�����Ȍ���ŏh��X�� ����
�ŏ��̃X����512Kbyte�z���ŏI���B
����́AProlog,lisp,Haskell,Ocaml,Erlang�Ȃǂ��o�����X�悭
�����悤�ɔz�����Đi�߂܂��B
����́AProlog,lisp,Haskell,Ocaml,Erlang�Ȃǂ��o�����X�悭
�����悤�ɔz�����Đi�߂܂��B
|
|
|
2 �F�f�t�H���g�̖����������F2009/11/02(��) 17:54:37
�O�X���̑�ނɎg�킹�Ă����������̂́A
C/C++�̏h��Еt���܂� 131���
http://pc12.2ch.net/test/read.cgi/tech/1255709298/
���� Java �̏h�肱���œ����܂� Part 68 ����
http://pc12.2ch.net/test/read.cgi/tech/1248012902/
Python �̏h�肱���œ����܂� Part 1
http://pc12.2ch.net/test/read.cgi/tech/1153585095/
Ruby�̏h�苳���Ă��������B2���ځ��v���O������
http://pc12.2ch.net/test/read.cgi/tech/1200175247/
BASIC�̏h��͂��O�ɂ܂��������v���O������
http://pc12.2ch.net/test/read.cgi/tech/1136788500/
C#,C���̏h��Еt���܂��B���v���O������
http://pc12.2ch.net/test/read.cgi/tech/1197620454/
�Ȃǂł����B
C/C++�̏h��Еt���܂� 131���
http://pc12.2ch.net/test/read.cgi/tech/1255709298/
���� Java �̏h�肱���œ����܂� Part 68 ����
http://pc12.2ch.net/test/read.cgi/tech/1248012902/
Python �̏h�肱���œ����܂� Part 1
http://pc12.2ch.net/test/read.cgi/tech/1153585095/
Ruby�̏h�苳���Ă��������B2���ځ��v���O������
http://pc12.2ch.net/test/read.cgi/tech/1200175247/
BASIC�̏h��͂��O�ɂ܂��������v���O������
http://pc12.2ch.net/test/read.cgi/tech/1136788500/
C#,C���̏h��Еt���܂��B���v���O������
http://pc12.2ch.net/test/read.cgi/tech/1197620454/
�Ȃǂł����B
3 �F�f�t�H���g�̖����������F2009/11/02(��) 20:29:28
http://pc12.2ch.net/test/read.cgi/tech/1255709298/507
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10044.txt
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10045.txt
# ��肪�Q����܂��B���ꂼ��Ⴄ�t�@�C���ɂ��Ă��炦���Ȃ�K���ł��B
# �X�������肢�v���܂��B
# <���1>
# �����ԃN���XCar�Ƀf�[�^�����o����o�������R�ɒlj�����
# �i�i���o�[��\���f�[�^�����o��lj�����B�R���\���f�[�^�����o��lj�����C
# �ړ��ɂ��R���c�ʂ̌v�Z�ɔR��f������C
# �^���N�e�ʂ�\���f�[�^�����o��lj�����C�����̂��߂̃����o����lj����铙�j�B
# �܂��lj��������̂��e�X�g�ł��� main�����쐬���C��o���邱�ƁB
# <���2>
# ���O�E�g���E�̏d�Ȃǂ������o�Ƃ��Ă��l�ԃN���X�����R�ɒ�`����B
# �쐬�����N���X���e�X�g�ł��� main�����쐬���C��o���邱�ƁB
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10044.txt
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10045.txt
# ��肪�Q����܂��B���ꂼ��Ⴄ�t�@�C���ɂ��Ă��炦���Ȃ�K���ł��B
# �X�������肢�v���܂��B
# <���1>
# �����ԃN���XCar�Ƀf�[�^�����o����o�������R�ɒlj�����
# �i�i���o�[��\���f�[�^�����o��lj�����B�R���\���f�[�^�����o��lj�����C
# �ړ��ɂ��R���c�ʂ̌v�Z�ɔR��f������C
# �^���N�e�ʂ�\���f�[�^�����o��lj�����C�����̂��߂̃����o����lj����铙�j�B
# �܂��lj��������̂��e�X�g�ł��� main�����쐬���C��o���邱�ƁB
# <���2>
# ���O�E�g���E�̏d�Ȃǂ������o�Ƃ��Ă��l�ԃN���X�����R�ɒ�`����B
# �쐬�����N���X���e�X�g�ł��� main�����쐬���C��o���邱�ƁB
4 �F�f�t�H���g�̖����������F2009/11/03(��) 02:05:41
http://pc12.2ch.net/test/read.cgi/tech/1255709298/509
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10047.txt
# �ۑ�Q
# �R���\�[�����͂����Z�p���̒l���v�Z���A���̓������R���\�[���o�͂���v���O�������쐬����B
# �Ȃ��A�b�v���O���~���O����Borland C++ Compiler�@5.5�@���g�p���邱�ƁB
#
# �Z�p���̍\���v�f�@�@�@�@�@�@�@�@�@�@�P�j�@���l�i�P�O�i���j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�j�@�l�����Z�q�i�����揜�@�{�|���^�j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�j�@���ʁi���A�E�j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�S�j�@�����i���j
#
# ���l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�������S���܂ŁA�������Q���܂łƂ���B
#
# �l�����Z�q�Ɗ��ʂƋL���@�D�揇�ʁ@�@�i�j���@���A�^�@���@�{�A�|�@���@��
#
#
# �G���[�\���@�@�@�@�@�@�@�@�@�@�@�@�@���Z�s�\�ȏꍇ�́A�G���[�\�������邱�ƁB
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��F�U+�R�����@�@�X�^�^�@�@�X-�T�j�@�@�W+�i�@
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10047.txt
# �ۑ�Q
# �R���\�[�����͂����Z�p���̒l���v�Z���A���̓������R���\�[���o�͂���v���O�������쐬����B
# �Ȃ��A�b�v���O���~���O����Borland C++ Compiler�@5.5�@���g�p���邱�ƁB
#
# �Z�p���̍\���v�f�@�@�@�@�@�@�@�@�@�@�P�j�@���l�i�P�O�i���j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�j�@�l�����Z�q�i�����揜�@�{�|���^�j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�j�@���ʁi���A�E�j
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�S�j�@�����i���j
#
# ���l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�������S���܂ŁA�������Q���܂łƂ���B
#
# �l�����Z�q�Ɗ��ʂƋL���@�D�揇�ʁ@�@�i�j���@���A�^�@���@�{�A�|�@���@��
#
#
# �G���[�\���@�@�@�@�@�@�@�@�@�@�@�@�@���Z�s�\�ȏꍇ�́A�G���[�\�������邱�ƁB
# �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��F�U+�R�����@�@�X�^�^�@�@�X-�T�j�@�@�W+�i�@
5 �F�f�t�H���g�̖����������F2009/11/03(��) 02:08:07
http://pc12.2ch.net/test/read.cgi/tech/1255709298/510
# [1] �v���O���~���O����
# [2] �������t�ɕ��ׂ��reverse(s) �������B
# ����ɂ��̊����g���āA���͂��s���Ƃɔ��]������v���O�������쐬����B�Ƃ������ł��B
# [1] �v���O���~���O����
# [2] �������t�ɕ��ׂ��reverse(s) �������B
# ����ɂ��̊����g���āA���͂��s���Ƃɔ��]������v���O�������쐬����B�Ƃ������ł��B
6 �F�f�t�H���g�̖����������F2009/11/03(��) 02:43:08
>>5
% Prolog
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,S1),
�@�@���](S1,S2),
�@�@atom_chars(S2,_���]���ꂽS).
���]([],[]).
���]([A|R1],R) :-
�@�@���](R,R2),
�@�@append(R2,[A],R).
���͂��s���Ƃɔ��]������(_���]���ꂽ���͍s�̂Ȃ��) :-
�@�@get_line(_�s),
�@�@���͂��s���Ƃɔ��]������(_�s,_���]���ꂽ���͍s�̂Ȃ��).
���͂��s���Ƃɔ��]������(end_of_file,[]) :- !.
���͂��s���Ƃɔ��]������(_�s,[_���]���ꂽ�s|R]) :-
�@�@'reverse(s)'(_�s,_���]���ꂽ�s),
�@�@get_line(_���̍s),
�@�@���͂��s���Ƃɔ��]������(_���̍s,R).
% Prolog
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,S1),
�@�@���](S1,S2),
�@�@atom_chars(S2,_���]���ꂽS).
���]([],[]).
���]([A|R1],R) :-
�@�@���](R,R2),
�@�@append(R2,[A],R).
���͂��s���Ƃɔ��]������(_���]���ꂽ���͍s�̂Ȃ��) :-
�@�@get_line(_�s),
�@�@���͂��s���Ƃɔ��]������(_�s,_���]���ꂽ���͍s�̂Ȃ��).
���͂��s���Ƃɔ��]������(end_of_file,[]) :- !.
���͂��s���Ƃɔ��]������(_�s,[_���]���ꂽ�s|R]) :-
�@�@'reverse(s)'(_�s,_���]���ꂽ�s),
�@�@get_line(_���̍s),
�@�@���͂��s���Ƃɔ��]������(_���̍s,R).
7 �F�f�t�H���g�̖����������F2009/11/03(��) 04:25:21
>>6 �Ԉ���Ă�!
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,S1),
�@�@���](S1,S2),
�@�@atom_chars(_���]���ꂽS,S2). ���������B
��������Chars��S*�ƕ\������̂́A���S�n�������BL�ɕς��悤�B(L��list��L)
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(L,L1),
�@�@���](L1,L2),
�@�@atom_chars(_���]���ꂽS,L2).
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,S1),
�@�@���](S1,S2),
�@�@atom_chars(_���]���ꂽS,S2). ���������B
��������Chars��S*�ƕ\������̂́A���S�n�������BL�ɕς��悤�B(L��list��L)
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(L,L1),
�@�@���](L1,L2),
�@�@atom_chars(_���]���ꂽS,L2).
8 �F�f�t�H���g�̖����������F2009/11/03(��) 04:35:38
>>8 �܂��܂��ԈႢ�B
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,L1),
�@�@���](L1,L2),
�@�@atom_chars(_���]���ꂽS,L2).
'reverse(s)'(S,_���]���ꂽS) :-
�@�@atom_chars(S,L1),
�@�@���](L1,L2),
�@�@atom_chars(_���]���ꂽS,L2).
9 �F�f�t�H���g�̖����������F2009/11/04(��) 09:52:48
% Prolog �ۑ��T�C�g nojiriko.asia ���̏�ō��T���܂ŃA�N�Z�X�ł��Ȃ����߁A
http://prolog.asia/html/prolog/
�ɃR�s�[�����܂����B�ꕔ�A�C���[�W�t�@�C����.txt�t�@�C���ɑ��݂��Ȃ����̂�����܂��B
http://prolog.asia/html/prolog/
�ɃR�s�[�����܂����B�ꕔ�A�C���[�W�t�@�C����.txt�t�@�C���ɑ��݂��Ȃ����̂�����܂��B
10 �F�f�t�H���g�̖����������F2009/11/04(��) 10:30:23
http://pc12.2ch.net/test/read.cgi/tech/1255709298/490
# [1] �v���O���~���O
# [2] double�^�̈�����2�����A�Q�̈����̐ς̐�Βl��Ԃ��A
# double�^�̖ߒl������ absmul() ���쐬������ŁA�����
# �m�F�̏o����v���O�����Ƃ��č쐬����B�Ƃ�������
#
# �W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g��S�ċ���
# �ɕύX���ďo�͂���v���O�������쐬����
# [1] �v���O���~���O
# [2] double�^�̈�����2�����A�Q�̈����̐ς̐�Βl��Ԃ��A
# double�^�̖ߒl������ absmul() ���쐬������ŁA�����
# �m�F�̏o����v���O�����Ƃ��č쐬����B�Ƃ�������
#
# �W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g��S�ċ���
# �ɕύX���ďo�͂���v���O�������쐬����
11 �F�f�t�H���g�̖����������F2009/11/04(��) 10:38:24
>>10
% Prolog ���(1)
absmul(_���������_��_1,_���������_��_2,_����) :-
�@�@Y is _���������_��_1 * _���������_��_2,
�@�@��Βl(Y,_����).
��Βl(X,X) :- X >= 0.0.
��Βl(Y,X) :- Y < 0.0,X is -1 * Y.
test_absmul :-
�@�@��̕��������_���܂�(_���������_��_1,_���������_��_2),
�@�@write('(1)��(2)�̐ς̐�Βl�Ƃ��Ă��Ȃ����l���铚��������Ă������� : '),
�@�@get_float(_���������_��_3),
�@�@absmul(_���������_��_1,_���������_��_2,_����),
�@�@test_absmul_�f�f(_����,_���������_��_3,_�f�f),
�@�@write_formatted('absmul���g�����v�Z�ł͉���%t ���Ȃ��̓�����%t�ł���\n',[_
���������_��_3,_����]),
�@�@write_formatted('�ӂ���%t!!\n',[_�f�f]).
��̕��������_���܂�(_���������_��_1,_���������_��_2) :-
�@�@write('���������_��(1) ������������ : '),
�@�@get_float(_���������_��_1),
�@�@write('���������_��(2) ������������ : '),
�@�@get_float(_���������_��_2).
test_absmul_�f�f(F,F,��v���Ă��܂�).
test_absmul_�f�f(F1,F2,��l�͈�v���܂���) :- \+(F1=F2).
% Prolog ���(1)
absmul(_���������_��_1,_���������_��_2,_����) :-
�@�@Y is _���������_��_1 * _���������_��_2,
�@�@��Βl(Y,_����).
��Βl(X,X) :- X >= 0.0.
��Βl(Y,X) :- Y < 0.0,X is -1 * Y.
test_absmul :-
�@�@��̕��������_���܂�(_���������_��_1,_���������_��_2),
�@�@write('(1)��(2)�̐ς̐�Βl�Ƃ��Ă��Ȃ����l���铚��������Ă������� : '),
�@�@get_float(_���������_��_3),
�@�@absmul(_���������_��_1,_���������_��_2,_����),
�@�@test_absmul_�f�f(_����,_���������_��_3,_�f�f),
�@�@write_formatted('absmul���g�����v�Z�ł͉���%t ���Ȃ��̓�����%t�ł���\n',[_
���������_��_3,_����]),
�@�@write_formatted('�ӂ���%t!!\n',[_�f�f]).
��̕��������_���܂�(_���������_��_1,_���������_��_2) :-
�@�@write('���������_��(1) ������������ : '),
�@�@get_float(_���������_��_1),
�@�@write('���������_��(2) ������������ : '),
�@�@get_float(_���������_��_2).
test_absmul_�f�f(F,F,��v���Ă��܂�).
test_absmul_�f�f(F1,F2,��l�͈�v���܂���) :- \+(F1=F2).
12 �F�f�t�H���g�̖����������F2009/11/04(��) 10:42:23
>>10
% Prolog ���(2)
�A���t�@�x�b�g(����).
�A���t�@�x�b�g(u).
�W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂��� :-
�@�@'stty raw',
�@�@get_char(A),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,''),
�@�@'stty -raw'.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(end_of_file,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(B),
�@�@write(' '),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(end_of_file,B) :-
�@�@\+(�A���t�@�x�b�g�Ƃ��đ��݂���(A)),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(B),
�@�@write(' '),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,''),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(A),
�@�@write(' '),
�@�@get_char(C),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(C,''),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@atom_concat(A,B,C),
�@�@get_char(D),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(D,C).
% Prolog ���(2)
�A���t�@�x�b�g(����).
�A���t�@�x�b�g(u).
�W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂��� :-
�@�@'stty raw',
�@�@get_char(A),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,''),
�@�@'stty -raw'.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(end_of_file,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(B),
�@�@write(' '),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(end_of_file,B) :-
�@�@\+(�A���t�@�x�b�g�Ƃ��đ��݂���(A)),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(B),
�@�@write(' '),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,''),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@�A���t�@�x�b�g�Ƃ��đ��݂���(A),
�@�@write(' '),
�@�@get_char(C),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(C,''),!.
�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(A,B) :-
�@�@atom_concat(A,B,C),
�@�@get_char(D),
�@�@�A���t�@�x�b�g��S�ċ����ɕύX���Ă��o�͂���(D,C).
13 �F�f�t�H���g�̖����������F2009/11/04(��) 15:11:44
http://pc12.2ch.net/test/read.cgi/tech/1255709298/554
# [1] ���ƒP���F C���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10056.txt
# ���
# input.bmp�Ƃ����r�b�g�}�b�v�t�@�C���i�F���͂Q�S�r�b�g�j���J���A
# ���̉摜�̐Ԃ̐��������̉摜�A�̐��������̉摜�A�̐��������̉摜�̎O��
# �t�@�C�����o�͂���v���O�����B
#
# �Ԃ̐����̉摜�t�@�C����(output_red.bmp�j
# �̐����̉摜�t�@�C����(output_blue.bmp�j
# �̐����̉摜�t�@�C����(output_green.bmp�j
# �摜�̃T�C�Y�ɂ��Ă͎��s���ɓ��͂����邱�ƂƂ���B�Ⴆ�Ainput.bmp
# ��200�~300�̉摜�ł������Ƃ��ɁA���s���Ɉȉ��̂悤�ɕ\�������͂���
# �uinput.bmp�̏c�͉��s�N�Z���ł����H�v�Q�O�O�Ɠ���
# �uinput.bmp�̉��͉��s�N�Z���ł����H�v�R�O�O�Ɠ���
#
# �ۑ�B������
# �t�@�C�����J���Ƃ��͊J�������ǂ����G���[�`�F�b�N���Ă���B
# �������ɗ̈���m�ۂ���imalloc)�����Ƃ��́A�m�ۂł������ǂ����G���[�`�F�b�N����
# �摜�t�@�C���̓y�C���g�Ƃ����\�t�g�������āAjpeg����r�b�g�}�b�v�i?��f������Q�S�r�b�g�j�ɕϊ��������̂Ƃ���B
# [1] ���ƒP���F C���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10056.txt
# ���
# input.bmp�Ƃ����r�b�g�}�b�v�t�@�C���i�F���͂Q�S�r�b�g�j���J���A
# ���̉摜�̐Ԃ̐��������̉摜�A�̐��������̉摜�A�̐��������̉摜�̎O��
# �t�@�C�����o�͂���v���O�����B
#
# �Ԃ̐����̉摜�t�@�C����(output_red.bmp�j
# �̐����̉摜�t�@�C����(output_blue.bmp�j
# �̐����̉摜�t�@�C����(output_green.bmp�j
# �摜�̃T�C�Y�ɂ��Ă͎��s���ɓ��͂����邱�ƂƂ���B�Ⴆ�Ainput.bmp
# ��200�~300�̉摜�ł������Ƃ��ɁA���s���Ɉȉ��̂悤�ɕ\�������͂���
# �uinput.bmp�̏c�͉��s�N�Z���ł����H�v�Q�O�O�Ɠ���
# �uinput.bmp�̉��͉��s�N�Z���ł����H�v�R�O�O�Ɠ���
#
# �ۑ�B������
# �t�@�C�����J���Ƃ��͊J�������ǂ����G���[�`�F�b�N���Ă���B
# �������ɗ̈���m�ۂ���imalloc)�����Ƃ��́A�m�ۂł������ǂ����G���[�`�F�b�N����
# �摜�t�@�C���̓y�C���g�Ƃ����\�t�g�������āAjpeg����r�b�g�}�b�v�i?��f������Q�S�r�b�g�j�ɕϊ��������̂Ƃ���B
14 �F�f�t�H���g�̖����������F2009/11/05(��) 02:08:06
http://pc12.2ch.net/test/read.cgi/tech/1255709298/561
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10060.txt
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10060.txt
15 �F�f�t�H���g�̖����������F2009/11/05(��) 02:09:22
http://pc12.2ch.net/test/read.cgi/tech/1255709298/562
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10061.txt
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10061.txt
16 �F�f�t�H���g�̖����������F2009/11/05(��) 02:10:20
http://pc12.2ch.net/test/read.cgi/tech/1255709298/563
# [1] ���ƒP���F�\�t�g�E�F�A�H�w
# [2] ��蕶(�܃R�[�h&�����N)�F
# (��/4) = tan^-1(1) = 1 - (1/3) + (1/5) - �c + (-1)^k * (1/(2k+1)) + �c
# �̌�����p���āA��n���܂ł̑������ߎ��ɂ��~���������߁A���̌덷�ƌv�Z���Ԃ𑪒肷��v���O�������쐬����B
# [1] ���ƒP���F�\�t�g�E�F�A�H�w
# [2] ��蕶(�܃R�[�h&�����N)�F
# (��/4) = tan^-1(1) = 1 - (1/3) + (1/5) - �c + (-1)^k * (1/(2k+1)) + �c
# �̌�����p���āA��n���܂ł̑������ߎ��ɂ��~���������߁A���̌덷�ƌv�Z���Ԃ𑪒肷��v���O�������쐬����B
17 �F�f�t�H���g�̖����������F2009/11/05(��) 02:15:23
http://pc12.2ch.net/test/read.cgi/tech/1255709298/564
# [1] ���ƒP���FC����
# [2] ��蕶
# ��蕶�P
# ���� n ����͂���� 'a' ���� n�ڂ܂ł̃A���t�@�x�b�g��S�ĕ\������v���O�������쐬����B (��Fn=6 �̎� abcdef��\��)
#
# ��蕶�Q
# ���� n ����͂����1����n �܂ł̊Ԃ� 3�̔{�����A
# 5�̔{���̂ǂ��炩�ł���悤�Ȑ��̘a��\������v���O���������B
# (��Fn=10 �̎� 3+5+6+9+10=33)
#
# ��蕶�R
# ���̃v���O������ (a)-(j)�̕�����for �����g���ď��������B #include<stdio.h> int main() { int a[10]; double sum,ave; sum=0; a[0]=1; a[1]=5; a[2]=7; a[3]=2; a[4]=4; a[5]=1; a[6]=9; a[7]=4; a[8]=20; a[9]=5; sum=sum+a[0];
# /* (a) ���� */ sum=sum+a[1]; /* (b) ���� */ sum=sum+a[2]; /* (c) ���� */ sum=sum+a[3]; /* (d) ���� */ sum=sum+a[4]; /* (e) ���� */ sum=sum+a[5]; /* (f) ���� */ sum=sum+a[6]; /* (g) ���� */ sum=sum+a[7];
# /* (h) ���� */ sum=sum+a[8]; /* (i) ���� */ sum=sum+a[9]; /* (j) ���� */ ave=sum/10; printf("���a�� %d �ł��B���ς� %d �ł��B\n",sum, ave); }
#
# ��蕶�S
# ������5���͂���ƁA�܂����̂܂ܕ\�����A���ɋt���ŕ\������v���O���������B
# ���s��F ������͂��ĉ������F 3 ������͂��ĉ������F 7 ������͂��ĉ������F1 ������͂��ĉ������F 2 ������͂��ĉ������F 5
# ���̂܂ܕ\�� 3 7 1 2 5 �t���ɕ\�� 5 2 1 7 3 �v���O�����̃e�L�X�g���R�s�[���ĉ��̃e�L�X�g���̓t�B�[���h�֏o�͌��ʂƋ��ɓ\��t���Ē�o���邱�ƁB
# [1] ���ƒP���FC����
# [2] ��蕶
# ��蕶�P
# ���� n ����͂���� 'a' ���� n�ڂ܂ł̃A���t�@�x�b�g��S�ĕ\������v���O�������쐬����B (��Fn=6 �̎� abcdef��\��)
#
# ��蕶�Q
# ���� n ����͂����1����n �܂ł̊Ԃ� 3�̔{�����A
# 5�̔{���̂ǂ��炩�ł���悤�Ȑ��̘a��\������v���O���������B
# (��Fn=10 �̎� 3+5+6+9+10=33)
#
# ��蕶�R
# ���̃v���O������ (a)-(j)�̕�����for �����g���ď��������B #include<stdio.h> int main() { int a[10]; double sum,ave; sum=0; a[0]=1; a[1]=5; a[2]=7; a[3]=2; a[4]=4; a[5]=1; a[6]=9; a[7]=4; a[8]=20; a[9]=5; sum=sum+a[0];
# /* (a) ���� */ sum=sum+a[1]; /* (b) ���� */ sum=sum+a[2]; /* (c) ���� */ sum=sum+a[3]; /* (d) ���� */ sum=sum+a[4]; /* (e) ���� */ sum=sum+a[5]; /* (f) ���� */ sum=sum+a[6]; /* (g) ���� */ sum=sum+a[7];
# /* (h) ���� */ sum=sum+a[8]; /* (i) ���� */ sum=sum+a[9]; /* (j) ���� */ ave=sum/10; printf("���a�� %d �ł��B���ς� %d �ł��B\n",sum, ave); }
#
# ��蕶�S
# ������5���͂���ƁA�܂����̂܂ܕ\�����A���ɋt���ŕ\������v���O���������B
# ���s��F ������͂��ĉ������F 3 ������͂��ĉ������F 7 ������͂��ĉ������F1 ������͂��ĉ������F 2 ������͂��ĉ������F 5
# ���̂܂ܕ\�� 3 7 1 2 5 �t���ɕ\�� 5 2 1 7 3 �v���O�����̃e�L�X�g���R�s�[���ĉ��̃e�L�X�g���̓t�B�[���h�֏o�͌��ʂƋ��ɓ\��t���Ē�o���邱�ƁB
18 �F�f�t�H���g�̖����������F2009/11/05(��) 02:17:18
http://pc12.2ch.net/test/read.cgi/tech/1255709298/565
# [1] ���ƒP���FC����v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10062.txt
# [1] ���ƒP���FC����v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10062.txt
19 �F�f�t�H���g�̖����������F2009/11/05(��) 04:22:57
http://pc12.2ch.net/test/read.cgi/tech/1255709298/566
# [1]���ƒP���@C������K
# [2]�R�}���h���C���Ŏw�肳�ꂽ�p�����ƋA�^�u�A���s�L��
# �݂̂���\�������e�L�X�g�t�@�C���Ɋ܂܂��P��̕p�x��
# �A���t�@�x�b�g���ɏo�͂���v���O�����B
# �P��Ƃ͉p�����݂̂ō\������Ă�����̂��w���B
# ��̒P�ꂪ�P�ꂽ���͕����P�ꂷ�ׂĂ����ꂽ���̂Ƃ���B
# �����P��Ƃ́A���̒P��̘A�����镔��������̂��Ƃł���B
# ���Ƃŏq�ׂ����d�n�b�V���e�[�u���𗘗p���邱�ƁB
# �s�̒����A�s�̑����A�P��̒����ɐ����͖������A�p�x��
# 32bit�����i�����t���j�Ő��͈̔͂ɕ\������̂Ƃ���B
# [1]���ƒP���@C������K
# [2]�R�}���h���C���Ŏw�肳�ꂽ�p�����ƋA�^�u�A���s�L��
# �݂̂���\�������e�L�X�g�t�@�C���Ɋ܂܂��P��̕p�x��
# �A���t�@�x�b�g���ɏo�͂���v���O�����B
# �P��Ƃ͉p�����݂̂ō\������Ă�����̂��w���B
# ��̒P�ꂪ�P�ꂽ���͕����P�ꂷ�ׂĂ����ꂽ���̂Ƃ���B
# �����P��Ƃ́A���̒P��̘A�����镔��������̂��Ƃł���B
# ���Ƃŏq�ׂ����d�n�b�V���e�[�u���𗘗p���邱�ƁB
# �s�̒����A�s�̑����A�P��̒����ɐ����͖������A�p�x��
# 32bit�����i�����t���j�Ő��͈̔͂ɕ\������̂Ƃ���B
20 �F�f�t�H���g�̖����������F2009/11/05(��) 15:22:49
http://pc12.2ch.net/test/read.cgi/tech/1255709298/569
# [1] ���ƒP���F�\�t�g�E�F�A�H�w
# [2] ��蕶(�܃R�[�h&�����N)�F
# �䐔�ߎ���p���āA������n�ɑ���@I = ��[1,2]ln(x)dx�@�̒l�����߂�v���O�������쐬���A�덷�����߂�B
# [1] ���ƒP���F�\�t�g�E�F�A�H�w
# [2] ��蕶(�܃R�[�h&�����N)�F
# �䐔�ߎ���p���āA������n�ɑ���@I = ��[1,2]ln(x)dx�@�̒l�����߂�v���O�������쐬���A�덷�����߂�B
21 �F�f�t�H���g�̖����������F2009/11/05(��) 19:22:00
>>19
Common Lisp
http://kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10072.txt
���d�n�b�V���e�[�u���̎g�������悭�킩��Ȃ��̂ŁA
���ʂ̃n�b�V���e�[�u���ł���Ă݂�
�����P����Ă����̂����܂����킩��Ȃ��̂����ǁA�Ⴆ��"word"�̕����P���
"w", "o", "r", "d", "wo", "or", "rd", "wor", "ord", "word"
�Ƃ������߂ł����ł����H
Common Lisp
http://kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10072.txt
���d�n�b�V���e�[�u���̎g�������悭�킩��Ȃ��̂ŁA
���ʂ̃n�b�V���e�[�u���ł���Ă݂�
�����P����Ă����̂����܂����킩��Ȃ��̂����ǁA�Ⴆ��"word"�̕����P���
"w", "o", "r", "d", "wo", "or", "rd", "wor", "ord", "word"
�Ƃ������߂ł����ł����H
22 �F�f�t�H���g�̖����������F2009/11/05(��) 21:30:29
>>21
���d�n�b�V���e�[�u���A�����P��Ƃ��ɕ�����܂���B
���ƎĂ݂����ł��ˁB
�����P��̉��߂͎�������ȊO�Ɏv�����Ȃ��B
���d�n�b�V���e�[�u���A�����P��Ƃ��ɕ�����܂���B
���ƎĂ݂����ł��ˁB
�����P��̉��߂͎�������ȊO�Ɏv�����Ȃ��B
23 �F�f�t�H���g�̖����������F2009/11/05(��) 23:02:33
>>20
;; Common Lisp
(defun trapezodial-rule-of-integration (fx min max ndivision)
(let ((tmp 0))
(do ((k 1 (+ k 1)))
((= k ndivision))
(incf tmp (funcall fx (+ min (* k (/ (- max min) ndivision))))))
(/ (* (- max min) (+ (/ (+ (funcall fx min) (funcall fx max)) 2) tmp)) ndivision)))
(defun main ()
(let (approximate true-value)
(setf approximate (trapezodial-rule-of-integration #'log 1 2 256)
true-value (- (* 2 (log 2)) 1))
(format t "�^�l: ~A~%�ߎ��l: ~A~%�덷: ~A~%" true-value approximate (- true-value approximate))))
;; Common Lisp
(defun trapezodial-rule-of-integration (fx min max ndivision)
(let ((tmp 0))
(do ((k 1 (+ k 1)))
((= k ndivision))
(incf tmp (funcall fx (+ min (* k (/ (- max min) ndivision))))))
(/ (* (- max min) (+ (/ (+ (funcall fx min) (funcall fx max)) 2) tmp)) ndivision)))
(defun main ()
(let (approximate true-value)
(setf approximate (trapezodial-rule-of-integration #'log 1 2 256)
true-value (- (* 2 (log 2)) 1))
(format t "�^�l: ~A~%�ߎ��l: ~A~%�덷: ~A~%" true-value approximate (- true-value approximate))))
24 �F�f�t�H���g�̖����������F2009/11/05(��) 23:46:15
>>18
;; Common Lisp
(defun merge (lst1 lst2 test-func)
(cond ((and (null lst1) (null lst2)) nil)
((null lst1) (cons (car lst2) (merge nil (cdr lst2) test-func)))
((null lst2) (cons (car lst1) (merge (cdr lst1) nil test-func)))
(t (if (funcall test-func (car lst1) (car lst2))
(cons (car lst1) (merge (cdr lst1) lst2 test-func))
(cons (car lst2) (merge lst1 (cdr lst2) test-func))))))
(defun merge-sort (lst test-func)
(cond ((> (length lst) 1)
(merge
(merge-sort (subseq lst 0 (floor (/ (length lst) 2))) test-func)
(merge-sort (subseq lst (floor (/ (length lst) 2))) test-func)
test-func))
(t lst)))
;; Common Lisp
(defun merge (lst1 lst2 test-func)
(cond ((and (null lst1) (null lst2)) nil)
((null lst1) (cons (car lst2) (merge nil (cdr lst2) test-func)))
((null lst2) (cons (car lst1) (merge (cdr lst1) nil test-func)))
(t (if (funcall test-func (car lst1) (car lst2))
(cons (car lst1) (merge (cdr lst1) lst2 test-func))
(cons (car lst2) (merge lst1 (cdr lst2) test-func))))))
(defun merge-sort (lst test-func)
(cond ((> (length lst) 1)
(merge
(merge-sort (subseq lst 0 (floor (/ (length lst) 2))) test-func)
(merge-sort (subseq lst (floor (/ (length lst) 2))) test-func)
test-func))
(t lst)))
25 �F�f�t�H���g�̖����������F2009/11/06(��) 02:56:56
http://pc12.2ch.net/test/read.cgi/tech/1255709298/598
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F 2�̐����l��1�̕������A�Ⴆ�u4+2�v�̂悤�ɓ��͂��A
# ���͂ɉ������l�����Z���s���Č��ʂ��o�͂���v���O�������쐬���Ȃ����B
# �������A�����̕����Ɏl�����Z�̋L���ȊO�̕��������͂��ꂽ���̂��Ƃ��l�����Ȃ����B
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F 2�̐����l��1�̕������A�Ⴆ�u4+2�v�̂悤�ɓ��͂��A
# ���͂ɉ������l�����Z���s���Č��ʂ��o�͂���v���O�������쐬���Ȃ����B
# �������A�����̕����Ɏl�����Z�̋L���ȊO�̕��������͂��ꂽ���̂��Ƃ��l�����Ȃ����B
26 �F�f�t�H���g�̖����������F2009/11/06(��) 07:19:57
>>25
% Prolog
���Ƃ�(_��������,N1,_���Z�q,N2,_����,_�f�f) :-
�@�@���������Ȃ��(_��������,_���������Ȃ�т̈�,R1),
�@�@���Z�q�����Ȃ��(R1,_���Z�q�����Ȃ��,R2),
�@�@���������Ȃ��(R2,_���������Ȃ�т̓�,R),
�@�@number_chars(N1,_���������Ȃ�т̈�),
�@�@number_chars(N2,_���������Ȃ�т̓�),
�@�@atom_chars(_��,_���Z�q�����Ȃ��).
�@�@���f�f(N1,_��,N2,_����,_�f�f).
���Z�q�����Ȃ��([],[],[]).
���Z�q�����Ȃ��([A|R],[],[A|R]) :- �l�����Z�q�ł͂Ȃ�(A),�����ł���(A).
���Z�q�����Ȃ��([A|R1],[A|R2],R) :- �l�����Z�q�ł͂Ȃ�(A),�����ł͂Ȃ�(A),���Z�q�����Ȃ��(R1,R2,R).
���Z�q�����Ȃ��([A|R1],[A|R2],R) :- �l�����Z�q�ł���(A),���Z�q�����Ȃ��(R1,R2,R).
���������Ȃ��([A|R],[],[A|R]) :- �����ł͂Ȃ�(A)..
���������Ȃ��([A|R],[A1|R2],R) :- �����ł���(A),���������Ȃ��(R1,R2,R).
���f�f(N1,_���Z�q,N2,_����,���Z�q���l�����Z�q�ł͂���܂���) :- \+(member(_���Z�q,[+,-,*,/])),!.
���f�f(N1,_���Z�q,N2,_����,����I��) :- integer(N1),integer(N2),member(_���Z�q,[+,-,*,/]),_�� =..[_���Z�q,N1,N2],_���� is _��.
�����ł���(A) :- member(A,['0','1','2','3','4','5','6','7','8','9']).
�����ł͂Ȃ�(A) :- \+(member(A,['0','1','2','3','4','5','6','7','8','9'])).
�l�����Z�q�ł���(A) :- member(A,['+','-','*','/']).
�l�����Z�q�ł͂Ȃ�(A) :- \+(member(A,['+','-','*','/'])).
% Prolog
���Ƃ�(_��������,N1,_���Z�q,N2,_����,_�f�f) :-
�@�@���������Ȃ��(_��������,_���������Ȃ�т̈�,R1),
�@�@���Z�q�����Ȃ��(R1,_���Z�q�����Ȃ��,R2),
�@�@���������Ȃ��(R2,_���������Ȃ�т̓�,R),
�@�@number_chars(N1,_���������Ȃ�т̈�),
�@�@number_chars(N2,_���������Ȃ�т̓�),
�@�@atom_chars(_��,_���Z�q�����Ȃ��).
�@�@���f�f(N1,_��,N2,_����,_�f�f).
���Z�q�����Ȃ��([],[],[]).
���Z�q�����Ȃ��([A|R],[],[A|R]) :- �l�����Z�q�ł͂Ȃ�(A),�����ł���(A).
���Z�q�����Ȃ��([A|R1],[A|R2],R) :- �l�����Z�q�ł͂Ȃ�(A),�����ł͂Ȃ�(A),���Z�q�����Ȃ��(R1,R2,R).
���Z�q�����Ȃ��([A|R1],[A|R2],R) :- �l�����Z�q�ł���(A),���Z�q�����Ȃ��(R1,R2,R).
���������Ȃ��([A|R],[],[A|R]) :- �����ł͂Ȃ�(A)..
���������Ȃ��([A|R],[A1|R2],R) :- �����ł���(A),���������Ȃ��(R1,R2,R).
���f�f(N1,_���Z�q,N2,_����,���Z�q���l�����Z�q�ł͂���܂���) :- \+(member(_���Z�q,[+,-,*,/])),!.
���f�f(N1,_���Z�q,N2,_����,����I��) :- integer(N1),integer(N2),member(_���Z�q,[+,-,*,/]),_�� =..[_���Z�q,N1,N2],_���� is _��.
�����ł���(A) :- member(A,['0','1','2','3','4','5','6','7','8','9']).
�����ł͂Ȃ�(A) :- \+(member(A,['0','1','2','3','4','5','6','7','8','9'])).
�l�����Z�q�ł���(A) :- member(A,['+','-','*','/']).
�l�����Z�q�ł͂Ȃ�(A) :- \+(member(A,['+','-','*','/'])).
27 �F�f�t�H���g�̖����������F2009/11/06(��) 08:37:32
>>16
% Prolog
func(K,X) :- X is (-1)^K * (1/(2*K+1)).
��(M,Pi) :- findsum(U,(for(0,K,M),func(M,U)),S),Pi is S * 4.
�v�Z���Ԃƌ덷(M,_�v�Z����,_�덷) :-
�@�@A is time,for(1,N,100),��(M,Pi),N=100,B is time,
�@�@_�덷 is Pi - pi,
�@�@_�v�Z���� is (B - A) / 100.
% Prolog
func(K,X) :- X is (-1)^K * (1/(2*K+1)).
��(M,Pi) :- findsum(U,(for(0,K,M),func(M,U)),S),Pi is S * 4.
�v�Z���Ԃƌ덷(M,_�v�Z����,_�덷) :-
�@�@A is time,for(1,N,100),��(M,Pi),N=100,B is time,
�@�@_�덷 is Pi - pi,
�@�@_�v�Z���� is (B - A) / 100.
28 �F�f�t�H���g�̖����������F2009/11/06(��) 09:39:04
>>18
% Prolog
�}�[�W�\�[�g(L,LX) :-
�Ȃ�т��ɕ�������(L,L1,L2),
�@�@�}�[�W�\�[�g(L1,L11),
�@�@�}�[�W�\�[�g(L2,L22),
�@�@��������(L11,L22,LX).
��������(L,[],L) :- !.
��������([],L,L) :- !.
��������([A|R1],[B|R2],[A|R3]) :-
�@�@A @< B,
�@�@��������(R1,[B|R2],R3).
��������([A|R1],[B|R2],[B|R3]) :-
�@�@A @>= B,
�@�@��������([A|R1],R2,R3).
�Ȃ�т��ɕ�������(L,L1,L2) :- �Ȃ�т��ɕ�������(L,L,[],[],L1,L2).
�Ȃ�т��ɕ�������(L,L0,LX,LY,LX,LY) :- append(LX,LY,L0),!.
�Ȃ�т��ɕ�������(L,L0,LX,LY,LX,[A|LY]) :- append(LX,[A|LY],L0),!.
�Ȃ�т��ɕ�������([A,B|R1],L0,LX,LY,L1,L2) :- �Ȃ�т��ɕ�������(R1,L0,[_|LX],[_|LY],L1,L2).
% Prolog
�}�[�W�\�[�g(L,LX) :-
�Ȃ�т��ɕ�������(L,L1,L2),
�@�@�}�[�W�\�[�g(L1,L11),
�@�@�}�[�W�\�[�g(L2,L22),
�@�@��������(L11,L22,LX).
��������(L,[],L) :- !.
��������([],L,L) :- !.
��������([A|R1],[B|R2],[A|R3]) :-
�@�@A @< B,
�@�@��������(R1,[B|R2],R3).
��������([A|R1],[B|R2],[B|R3]) :-
�@�@A @>= B,
�@�@��������([A|R1],R2,R3).
�Ȃ�т��ɕ�������(L,L1,L2) :- �Ȃ�т��ɕ�������(L,L,[],[],L1,L2).
�Ȃ�т��ɕ�������(L,L0,LX,LY,LX,LY) :- append(LX,LY,L0),!.
�Ȃ�т��ɕ�������(L,L0,LX,LY,LX,[A|LY]) :- append(LX,[A|LY],L0),!.
�Ȃ�т��ɕ�������([A,B|R1],L0,LX,LY,L1,L2) :- �Ȃ�т��ɕ�������(R1,L0,[_|LX],[_|LY],L1,L2).
29 �F�f�t�H���g�̖����������F2009/11/06(��) 11:06:37
>>14
% Prolog (BinaryDataModel��)
t2_14(File) :- get_lines(File,Lines),member(_�s,Lines),split(_�s,[','],L),�\���lj�(L),fail.
t2_14(_).
�����ԍ��N�_(-1).
�����ԍ��I�_(-1).
�\���lj�(L) :- �����ԍ��I�_(_�����ԍ��I�_),�\���lj�(L,_�����ԍ��I�_).
�\���lj�([A|R]) :- Random is random mod 9999,\+(index(Random,A,-1)),
�@�@assertz(index(Random,A,-1)),
�@�@length(R,Len),
�@�@assertz(num(Random,Len)),
�@�@attr��`(1,Len,Random,R),!.
�@�@retract(�����ԍ��I�_(_�����I�_�ԍ�)),
�@�@�\���lj�_2(_�����I�_�ԍ�,Random).
�\���lj�([A|R]) :- �\���lj�([A|R]).
�\���lj�_2(-1,Random) :- retract(�����ԍ��N�_(_�����N�_�ԍ�)),assertz(�����ԍ��N�_(Random)),assertz(�����ԍ��I�_(Random)),!.
�\���lj�_2(N,Random) :- assertz(�����ԍ��I�_(Random)),retract(index(N,W2,_)),assertz(index(N,W2,Random)),!.
attr��`(M,N,A,[]) :- M > N,!.
attr��`(M,N,A,[B|R]) :- assertz(attr(A,M,B)),M2 is M+1,attr��`(M2,N,A,R).
% Prolog (BinaryDataModel��)
t2_14(File) :- get_lines(File,Lines),member(_�s,Lines),split(_�s,[','],L),�\���lj�(L),fail.
t2_14(_).
�����ԍ��N�_(-1).
�����ԍ��I�_(-1).
�\���lj�(L) :- �����ԍ��I�_(_�����ԍ��I�_),�\���lj�(L,_�����ԍ��I�_).
�\���lj�([A|R]) :- Random is random mod 9999,\+(index(Random,A,-1)),
�@�@assertz(index(Random,A,-1)),
�@�@length(R,Len),
�@�@assertz(num(Random,Len)),
�@�@attr��`(1,Len,Random,R),!.
�@�@retract(�����ԍ��I�_(_�����I�_�ԍ�)),
�@�@�\���lj�_2(_�����I�_�ԍ�,Random).
�\���lj�([A|R]) :- �\���lj�([A|R]).
�\���lj�_2(-1,Random) :- retract(�����ԍ��N�_(_�����N�_�ԍ�)),assertz(�����ԍ��N�_(Random)),assertz(�����ԍ��I�_(Random)),!.
�\���lj�_2(N,Random) :- assertz(�����ԍ��I�_(Random)),retract(index(N,W2,_)),assertz(index(N,W2,Random)),!.
attr��`(M,N,A,[]) :- M > N,!.
attr��`(M,N,A,[B|R]) :- assertz(attr(A,M,B)),M2 is M+1,attr��`(M2,N,A,R).
30 �F�f�t�H���g�̖����������F2009/11/06(��) 11:10:27
>>29 ���Ă͂����Ȃ��Ƃ���ɉ��s�������Ă��܂����B
�\���lj�_2(-1,Random) :- retract(�����ԍ��N�_(_�����N�_�ԍ�)),assertz(�����ԍ��N�_(Random)),assertz(�����ԍ��I�_(Random)),!.
�\���lj�_2(N,Random) :- assertz(�����I�_,Random)),retract(index(N,W2,_)),assertz(index(N,W2,Random)),!.
�\���lj�_2(-1,Random) :- retract(�����ԍ��N�_(_�����N�_�ԍ�)),assertz(�����ԍ��N�_(Random)),assertz(�����ԍ��I�_(Random)),!.
�\���lj�_2(N,Random) :- assertz(�����I�_,Random)),retract(index(N,W2,_)),assertz(index(N,W2,Random)),!.
31 �F�f�t�H���g�̖����������F2009/11/06(��) 12:11:00
>>17 ��蕶1
:- op(600,xf,��).
'���� N ����͂���� a ���� N�ڂ܂ł̃A���t�@�x�b�g��S�ĕ\��'(N��) :-
�@�@for(1,M,N),put_code(96+M),M=N.
:- op(600,xf,��).
'���� N ����͂���� a ���� N�ڂ܂ł̃A���t�@�x�b�g��S�ĕ\��'(N��) :-
�@�@for(1,M,N),put_code(96+M),M=N.
32 �F�f�t�H���g�̖����������F2009/11/06(��) 12:20:33
>>17 ��蕶2
'���� N ����͂����1����N �܂ł̊Ԃ� 3�̔{�����A5�̔{���̂ǂ��炩�ł���悤�Ȑ��̘a��\��'(N) :-
�@�@findsum(U,(for(1,M,N),'3�̔{���ł��邩5�̔{��'(M)),Sum),
�@�@write_formatted('3��5�̔{���̍��v�� %t �ł�\n',[Sum]).
'3�̔{���ł��邩5�̔{��'(N) :- '3�̔{��(N),!.
'3�̔{���ł��邩5�̔{��'(N) :- '5�̔{��(N),!.
'3�̔{��'(N) :- 0 is N mod 3.
'5�̔{��'(N) :- 0 is N mod 5.
'���� N ����͂����1����N �܂ł̊Ԃ� 3�̔{�����A5�̔{���̂ǂ��炩�ł���悤�Ȑ��̘a��\��'(N) :-
�@�@findsum(U,(for(1,M,N),'3�̔{���ł��邩5�̔{��'(M)),Sum),
�@�@write_formatted('3��5�̔{���̍��v�� %t �ł�\n',[Sum]).
'3�̔{���ł��邩5�̔{��'(N) :- '3�̔{��(N),!.
'3�̔{���ł��邩5�̔{��'(N) :- '5�̔{��(N),!.
'3�̔{��'(N) :- 0 is N mod 3.
'5�̔{��'(N) :- 0 is N mod 5.
33 �F�f�t�H���g�̖����������F2009/11/06(��) 12:30:08
>>17 ��蕶4
% Prolog
'������5���͂���ƁA�܂����̂܂ܕ\�����A���ɋt���ŕ\������' :-
�@�@findall(_����,(for(1,N,5),write('������͂��ĉ������F'),get_integer(_����)),L),
�@�@concat_atom(L,' ',S1),
�@�@write_formatted('���͂��ꂽ�̂� %t �ł�\n',[S1]),
�@�@reverse(L,L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('�t���ɕ\������� %t �ƂȂ�܂�\n',[S2]).
% Prolog
'������5���͂���ƁA�܂����̂܂ܕ\�����A���ɋt���ŕ\������' :-
�@�@findall(_����,(for(1,N,5),write('������͂��ĉ������F'),get_integer(_����)),L),
�@�@concat_atom(L,' ',S1),
�@�@write_formatted('���͂��ꂽ�̂� %t �ł�\n',[S1]),
�@�@reverse(L,L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('�t���ɕ\������� %t �ƂȂ�܂�\n',[S2]).
34 �F�f�t�H���g�̖����������F2009/11/06(��) 15:32:45
http://pc12.2ch.net/test/read.cgi/tech/1248012902/454
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm 822.txt
#
# (1) ���͂��ꂽ���̐������f���ł��邩���肷��v���O�������쐬����B
# �������A�@�\�͈ȉ��̂悤�Ɏ���������̂Ƃ���B
# boolean �^�̖߂�l�������\�b�h isPrime �͈����ɐ��̐������Ƃ�A
# �f���Ȃ� true ��Ԃ��A�����łȂ��Ȃ� false ��Ԃ��B
# main ���\�b�h����AisPrime ���Ăяo���悤�ɂ���B
#
# (2)���͂��ꂽ���̐������f���ł��邩���肵�A�f���łȂ��ꍇ�͍ŏ��̑f������
# �o�͂���v���O�������쐬����B�������A�@�\�͈ȉ��̂悤�Ɏ���������̂Ƃ���B
# int �^�̖߂�l�������\�b�h minimumDivisor �͈����ɐ��̐������Ƃ�A
# �f���Ȃ�0 ��Ԃ��A�����łȂ��Ȃ�ŏ��̑f������Ԃ��B
# main ���\�b�h����AminimumDivisor ���Ăяo���A�߂�l�ɉ������o�͂����悤�ɂ���B
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm 822.txt
#
# (1) ���͂��ꂽ���̐������f���ł��邩���肷��v���O�������쐬����B
# �������A�@�\�͈ȉ��̂悤�Ɏ���������̂Ƃ���B
# boolean �^�̖߂�l�������\�b�h isPrime �͈����ɐ��̐������Ƃ�A
# �f���Ȃ� true ��Ԃ��A�����łȂ��Ȃ� false ��Ԃ��B
# main ���\�b�h����AisPrime ���Ăяo���悤�ɂ���B
#
# (2)���͂��ꂽ���̐������f���ł��邩���肵�A�f���łȂ��ꍇ�͍ŏ��̑f������
# �o�͂���v���O�������쐬����B�������A�@�\�͈ȉ��̂悤�Ɏ���������̂Ƃ���B
# int �^�̖߂�l�������\�b�h minimumDivisor �͈����ɐ��̐������Ƃ�A
# �f���Ȃ�0 ��Ԃ��A�����łȂ��Ȃ�ŏ��̑f������Ԃ��B
# main ���\�b�h����AminimumDivisor ���Ăяo���A�߂�l�ɉ������o�͂����悤�ɂ���B
35 �F�f�t�H���g�̖����������F2009/11/06(��) 17:08:41
>>34 (1)
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@isPrime_test(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
isPrime_test(N,true) :- isPrime(N).
isPrime_test(N,false) :- \+(isPrime(N)).
isPrime(1) :- !.
isPrime(N) :- for(2,M,N//2),0 is N mod M.
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@isPrime_test(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
isPrime_test(N,true) :- isPrime(N).
isPrime_test(N,false) :- \+(isPrime(N)).
isPrime(1) :- !.
isPrime(N) :- for(2,M,N//2),0 is N mod M.
36 �F�f�t�H���g�̖����������F2009/11/06(��) 17:14:22
>>35 ���܂���!! �t�������B�������܂��B
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@isPrime_test(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
isPrime_test(N,true) :- isPrime(N).
isPrime_test(N,false) :- \+(isPrime(N)).
isPrime(1) :- !.
isPrime(N) :- \+((for(2,M,N//2),0 is N mod M)).
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@isPrime_test(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
isPrime_test(N,true) :- isPrime(N).
isPrime_test(N,false) :- \+(isPrime(N)).
isPrime(1) :- !.
isPrime(N) :- \+((for(2,M,N//2),0 is N mod M)).
37 �F�f�t�H���g�̖����������F2009/11/06(��) 17:18:06
>>36 ���������
% �Ō�� ! �����Ēu���܂��傤�B
isPrime(1) :- !.
isPrime(N) :- \+((for(2,M,N//2),0 is N mod M)),!.
% �Ō�� ! �����Ēu���܂��傤�B
isPrime(1) :- !.
isPrime(N) :- \+((for(2,M,N//2),0 is N mod M)),!.
38 �F�f�t�H���g�̖����������F2009/11/06(��) 17:24:02
>>35 (2)
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@minimumDiviso(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
minimumDiviso(1,0) :- !.
minimumDiviso(N,M) :- for(2,M,N//2),0 is N mod M,!.
minimumDiviso(N,0).
% Prolog
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@minimumDiviso(N,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]).
minimumDiviso(1,0) :- !.
minimumDiviso(N,M) :- for(2,M,N//2),0 is N mod M,!.
minimumDiviso(N,0).
39 �F�f�t�H���g�̖����������F2009/11/06(��) 20:38:16
>>20
% Prolog �䐔�ߎ����ĕ�����Ȃ������`���ŁB
func(N,X) :- N2 is N,X is ln(N2).
t2_20_�덷(N,X1,X2,_�덷) :-
�@�@��`��(N,X1,X2,S),
�@�@_�덷 is S - (2 * log(2) -1).
��`��(N,X1,X2,S) :-
�@�@_�Ԋu is (X2 - X1) / N,
�@�@��`��(0,N,X1,_�Ԋu,S).
��`��(N,N,_,_,0.0) :- !.
��`��(J,N,X1,_�Ԋu,S) :-
�@�@func(X1 + _�Ԋu * J,U1),
�@�@func(X1 + _�Ԋu * (J + 1),U2),
�@�@S1 is (U1 + U2) * (1.0 / N) / 2.0,
�@�@J2 is J + 1,
�@�@��`��(J2,N,X1,_�Ԋu,S2),
�@�@S is S1 + S2.
% Prolog �䐔�ߎ����ĕ�����Ȃ������`���ŁB
func(N,X) :- N2 is N,X is ln(N2).
t2_20_�덷(N,X1,X2,_�덷) :-
�@�@��`��(N,X1,X2,S),
�@�@_�덷 is S - (2 * log(2) -1).
��`��(N,X1,X2,S) :-
�@�@_�Ԋu is (X2 - X1) / N,
�@�@��`��(0,N,X1,_�Ԋu,S).
��`��(N,N,_,_,0.0) :- !.
��`��(J,N,X1,_�Ԋu,S) :-
�@�@func(X1 + _�Ԋu * J,U1),
�@�@func(X1 + _�Ԋu * (J + 1),U2),
�@�@S1 is (U1 + U2) * (1.0 / N) / 2.0,
�@�@J2 is J + 1,
�@�@��`��(J2,N,X1,_�Ԋu,S2),
�@�@S is S1 + S2.
40 �F�f�t�H���g�̖����������F2009/11/07(�y) 06:49:00
>>19
% Prolog �n�b�V���Ƃ��ӎ������A���Prolog�炵���\����
:- dynamic(hash/2).
t2_19_�\�� :- listing(hash/2).
t2_19 :-
�@�@get_line(Line),
�@�@split(Line,[' ','\t','\n'],L),
�@�@member(_�P��,L),
�@�@sub_atom(_�P��,_,_,_,_�����P��),
�@�@\+(_�����P��=''),
�@�@t2_19_1(_�����P��),
�@�@fail.
t2_19.
t2_19_1(A) :- retract(hash(A,_�p�x)),_�p�x2 is _�p�x + 1,assertz(hash(A,_�p�x2)),!.
t2_19_1(A) :- assertz(hash(A,1)).
% Prolog �n�b�V���Ƃ��ӎ������A���Prolog�炵���\����
:- dynamic(hash/2).
t2_19_�\�� :- listing(hash/2).
t2_19 :-
�@�@get_line(Line),
�@�@split(Line,[' ','\t','\n'],L),
�@�@member(_�P��,L),
�@�@sub_atom(_�P��,_,_,_,_�����P��),
�@�@\+(_�����P��=''),
�@�@t2_19_1(_�����P��),
�@�@fail.
t2_19.
t2_19_1(A) :- retract(hash(A,_�p�x)),_�p�x2 is _�p�x + 1,assertz(hash(A,_�p�x2)),!.
t2_19_1(A) :- assertz(hash(A,1)).
41 �F�f�t�H���g�̖����������F2009/11/07(�y) 06:55:15
42 �F�f�t�H���g�̖����������F2009/11/07(�y) 06:57:50
>>3 �̂悤�ȃI�u�W�F�N�g�w���̉ۑ�͍���ESP�ŏ������炿����Ƒ҂��āB�����Y�ꂽ�E�E�E
43 �F�f�t�H���g�̖����������F2009/11/07(�y) 08:09:58
>>3
% ESP (���̈�)�@�Ȃ�������Ȃ����njp�����炯�B
class ���܂̂��� has
�@�@nature �l��,����;
�@�@attribute �ːЖ�:='�����x',�_�@,����;
�@�@:create(Class,_�_�@,_����,Obj) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�_�@:=_�_�@,Obj!����:=_����,Obj!�a����:='19490126';
instance
�@�@:�\��(Obj,_�_�@,_�\��) :- _�_�@@>=Obj!�_�@,�\��(Obj,_�_�@,_�\��);
local
�@�@�\��(Obj,'20091107','ESP�̂���');
end.
class �l�� has
�@�@nature �a��,���S,��`�q;
�@�@attribute �ːЖ�;
end.
class ���� has
�@�@attribute �g��,�̏d,���̖т̐F,�̖�,���̐F,���^,���;
end.
% ESP (���̈�)�@�Ȃ�������Ȃ����njp�����炯�B
class ���܂̂��� has
�@�@nature �l��,����;
�@�@attribute �ːЖ�:='�����x',�_�@,����;
�@�@:create(Class,_�_�@,_����,Obj) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�_�@:=_�_�@,Obj!����:=_����,Obj!�a����:='19490126';
instance
�@�@:�\��(Obj,_�_�@,_�\��) :- _�_�@@>=Obj!�_�@,�\��(Obj,_�_�@,_�\��);
local
�@�@�\��(Obj,'20091107','ESP�̂���');
end.
class �l�� has
�@�@nature �a��,���S,��`�q;
�@�@attribute �ːЖ�;
end.
class ���� has
�@�@attribute �g��,�̏d,���̖т̐F,�̖�,���̐F,���^,���;
end.
44 �F�f�t�H���g�̖����������F2009/11/07(�y) 08:11:47
>>3
% ESP (���̓�)
class �a�� has
�@�@attribute �a����,����,�����t�܂��͏��Y�w,�a���ɂ܂��G�s�\�[�h;
end.
class ���S has
�@�@attribute ���S����,�m�F��t,����,���S�Ɏ���o��,����,��݂̍菈;
end.
class ��`�q has
�@�@attribute ��`�q;
end.
% ESP (���̓�)
class �a�� has
�@�@attribute �a����,����,�����t�܂��͏��Y�w,�a���ɂ܂��G�s�\�[�h;
end.
class ���S has
�@�@attribute ���S����,�m�F��t,����,���S�Ɏ���o��,����,��݂̍菈;
end.
class ��`�q has
�@�@attribute ��`�q;
end.
45 �F�f�t�H���g�̖����������F2009/11/07(�y) 15:43:31
http://pc12.2ch.net/test/read.cgi/tech/1153585095/932
# ���łȂ�����n�̊K��(n!)�́C���̂悤�ɒ�`�����D
#
# n! = 1 �~ 2 �~ 3 �~ ... �~ n (n �� 1)
# 0! = 1
#
# ����n��^�����n!���v�Z���ĕԂ���fact(n)���`���C�����p����0!�`10!���v�Z���ĕ\������v���O�������쐬����D
#
# ���łȂ�����n�̊K��(n!)�́C���̂悤�ɒ�`�����D
#
# n! = 1 �~ 2 �~ 3 �~ ... �~ n (n �� 1)
# 0! = 1
#
# ����n��^�����n!���v�Z���ĕԂ���fact(n)���`���C�����p����0!�`10!���v�Z���ĕ\������v���O�������쐬����D
#
46 �F�f�t�H���g�̖����������F2009/11/07(�y) 15:51:56
>>45
% Prolog
'����n��^�����n!���v�Z���ĕԂ���fact(n)���`���C�����p����0!�`10!���v�Z���ĕ\������' :-
�@�@for(0,N,10),
�@�@fact(N,X),
�@�@write_formatted('n=%t,%t\n',[N,X]),
�@�@N=10.
fact(0,1).
fact(N,X) :- \+(N=0),N1 is N-1,fact(N1,Y),X is N * Y.
% Prolog
'����n��^�����n!���v�Z���ĕԂ���fact(n)���`���C�����p����0!�`10!���v�Z���ĕ\������' :-
�@�@for(0,N,10),
�@�@fact(N,X),
�@�@write_formatted('n=%t,%t\n',[N,X]),
�@�@N=10.
fact(0,1).
fact(N,X) :- \+(N=0),N1 is N-1,fact(N1,Y),X is N * Y.
47 �F�f�t�H���g�̖����������F2009/11/07(�y) 17:19:34
http://pc12.2ch.net/test/read.cgi/tech/1153585095/935
# �����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1������
��������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\����������`����
�D�l��Ԃ��K�v�͂Ȃ��D
#
# ���ɁC�L�[�{�[�h���當�����ǂݍ��݁C�ǂݍ�������������Ƃ��Ē�`���������Ăяo���悤�ɂ���D
#
# �����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1������
��������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\����������`����
�D�l��Ԃ��K�v�͂Ȃ��D
#
# ���ɁC�L�[�{�[�h���當�����ǂݍ��݁C�ǂݍ�������������Ƃ��Ē�`���������Ăяo���悤�ɂ���D
#
48 �F�f�t�H���g�̖����������F2009/11/07(�y) 17:43:43
>>47
% Prolog
'�����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1��������������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\������'(_������) :-
�@�@sub_atom(_������,0,M,1,_),
�@�@for(1,N,M),
�@�@sub_atom(_������,0,_,N,_��������),
�@�@write_formatted('%t\n',[_��������]),
�@�@N = M.
t2_47 :-
�@�@write('���������͂��Ă������� :\n'),
�@�@get_line(_������),
�@�@'�����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1��������������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\������'(_������).
% Prolog
'�����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1��������������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\������'(_������) :-
�@�@sub_atom(_������,0,M,1,_),
�@�@for(1,N,M),
�@�@sub_atom(_������,0,_,N,_��������),
�@�@write_formatted('%t\n',[_��������]),
�@�@N = M.
t2_47 :-
�@�@write('���������͂��Ă������� :\n'),
�@�@get_line(_������),
�@�@'�����Ƃ��ĉp��������Ȃ镶�����1�^���ČĂяo���ƁC���̑S�́C�Ō��1��������������́C�Ō��2��������������́C�c��1�����ɂȂ�܂ŕ\������'(_������).
49 �F�f�t�H���g�̖����������F2009/11/08(��) 04:39:22
http://pc12.2ch.net/test/read.cgi/tech/1255709298/615
# C++��10�i����2�i���ɕϊ�����v���O������z��g����
# ���Ԓʂ�ɕ\���ł���悤�ɂ���̂��Ăǂ������ł���
# C++��10�i����2�i���ɕϊ�����v���O������z��g����
# ���Ԓʂ�ɕ\���ł���悤�ɂ���̂��Ăǂ������ł���
50 �F�f�t�H���g�̖����������F2009/11/08(��) 04:40:56
>>49
% Prolog
t2_615 :-
�@�@write('10�i�����X�y�[�X�ŋ���ĉ������͂��Ă������� : '),
�@�@get_line(Line),
�@�@split(Line,[' '],L),
�@�@member(N,L),
�@�@��i��(N,L),
�@�@wrln(L),
�@�@fail.
t2_615.
��i��(_10�i��,L) :-
�@�@length(L,32),
�@�@��i��(_10�i��,[],X),
�@�@append(L1,X,L),
�@�@all(L1,0).
��i��(J,Y,[J|Y]) :- J < 2.
��i��(J,Y,X) :- J >= 2,J2 is J // 2,M is J mod 2,��i��(J2,[M|Y],X).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
wrln([]) :- !.
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
% Prolog
t2_615 :-
�@�@write('10�i�����X�y�[�X�ŋ���ĉ������͂��Ă������� : '),
�@�@get_line(Line),
�@�@split(Line,[' '],L),
�@�@member(N,L),
�@�@��i��(N,L),
�@�@wrln(L),
�@�@fail.
t2_615.
��i��(_10�i��,L) :-
�@�@length(L,32),
�@�@��i��(_10�i��,[],X),
�@�@append(L1,X,L),
�@�@all(L1,0).
��i��(J,Y,[J|Y]) :- J < 2.
��i��(J,Y,X) :- J >= 2,J2 is J // 2,M is J mod 2,��i��(J2,[M|Y],X).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
wrln([]) :- !.
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
51 �F�f�t�H���g�̖����������F2009/11/08(��) 04:57:45
>>50 �ԈႢ�B����
wrln([]) :- nl.
wrln([A|R]) :- write(A),wrln(R).
�ƒ������Awrln/1�͎g�킸�A
t2_615 :-
�@�@write('10�i�����X�y�[�X�ŋ���ĉ������͂��Ă������� : '),
�@�@get_line(Line),
�@�@split(Line,[' '],L),
�@�@member(N,L),
�@�@��i��(N,L),
�@�@atom_chars(A,L), /* �lj����� */
�@�@write_formatted('%t\n',[A]), /* ���ʂ�write_formatted/2 �� */
�@�@fail.
t2_615.
wrln([]) :- nl.
wrln([A|R]) :- write(A),wrln(R).
�ƒ������Awrln/1�͎g�킸�A
t2_615 :-
�@�@write('10�i�����X�y�[�X�ŋ���ĉ������͂��Ă������� : '),
�@�@get_line(Line),
�@�@split(Line,[' '],L),
�@�@member(N,L),
�@�@��i��(N,L),
�@�@atom_chars(A,L), /* �lj����� */
�@�@write_formatted('%t\n',[A]), /* ���ʂ�write_formatted/2 �� */
�@�@fail.
t2_615.
52 �F�f�t�H���g�̖����������F2009/11/08(��) 05:04:58
>>51 ����ɒ���
��i��/2�̑������͐����̃��X�g������Aatom_chars/2�͎g���Ȃ��B������atom�ƕʈ����B
concat_atom/2���g���悢���AISO�W���ł͂Ȃ�����A
>>51 �̑��Ă͎g�킸�A���Ă�wrln/1���̂��悢���낤�B
��i��/2�̑������͐����̃��X�g������Aatom_chars/2�͎g���Ȃ��B������atom�ƕʈ����B
concat_atom/2���g���悢���AISO�W���ł͂Ȃ�����A
>>51 �̑��Ă͎g�킸�A���Ă�wrln/1���̂��悢���낤�B
53 �F�f�t�H���g�̖����������F2009/11/08(��) 05:44:16
http://sum2cha.blogpico.com/archives/2017 ���X�ԍ�606
[1] ���ƒP���F �v���O���~���O
[2] ��蕶(�܃R�[�h&�����N)�F
�S����3�Ȃ̂ł���
�P�E �ȉ��̃v���O�������쐬
�E �ȉ��̐����0�`20�܂ŕ\��
�E ����͈ȉ��̒ʂ�Ƃ���
�E a[0] = 0.01, a[1] = 0.1, a[2] = 1.0
�E a[n+1] = a[n] + a[n-1] + a[n-2]
�E �v���O���������s�����a[0]�`a[20]�܂ł̒l�����s���ŕ\������邱��
[1] ���ƒP���F �v���O���~���O
[2] ��蕶(�܃R�[�h&�����N)�F
�S����3�Ȃ̂ł���
�P�E �ȉ��̃v���O�������쐬
�E �ȉ��̐����0�`20�܂ŕ\��
�E ����͈ȉ��̒ʂ�Ƃ���
�E a[0] = 0.01, a[1] = 0.1, a[2] = 1.0
�E a[n+1] = a[n] + a[n-1] + a[n-2]
�E �v���O���������s�����a[0]�`a[20]�܂ł̒l�����s���ŕ\������邱��
54 �F�f�t�H���g�̖����������F2009/11/08(��) 06:02:10
>>53 (����̓G���[�ƂȂ��)
% Prolog �ł�N+1�ł͒�`�͍���B����Ɉȉ��̃v���O�����ł�
% t2_53(M,Y) �̕����ŃG���[�ƂȂ�
t2_53 :-
�@�@findall(X,(for(0,N,20),t2_53(N,X)),L),
�@�@wrln(L).
t2_53(0,0.01).
t2_53(1,0.1).
t2_53(2,1.0).
t2_53(N,X) :-
M is N + 1,
�@�@N1 is N - 1,
�@�@N2 is N - 2,
�@�@t2_53(M,Y),
�@�@t2_53(N1,X1),
�@�@t2_53(N2,X1),
�@�@X is Y - X1 - X2.
%%%%%%%%%%%%%%%%%%%%
wrln([]).
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
% Prolog �ł�N+1�ł͒�`�͍���B����Ɉȉ��̃v���O�����ł�
% t2_53(M,Y) �̕����ŃG���[�ƂȂ�
t2_53 :-
�@�@findall(X,(for(0,N,20),t2_53(N,X)),L),
�@�@wrln(L).
t2_53(0,0.01).
t2_53(1,0.1).
t2_53(2,1.0).
t2_53(N,X) :-
M is N + 1,
�@�@N1 is N - 1,
�@�@N2 is N - 2,
�@�@t2_53(M,Y),
�@�@t2_53(N1,X1),
�@�@t2_53(N2,X1),
�@�@X is Y - X1 - X2.
%%%%%%%%%%%%%%%%%%%%
wrln([]).
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
55 �F�f�t�H���g�̖����������F2009/11/08(��) 06:05:07
>>53
% Prolog �d���Ȃ�����A�ȉ��Ƃ���B
t2_53 :-
�@�@findall(X,(for(0,N,20),t2_53(N,X)),L),
�@�@wrln(L).
t2_53(0,0.01).
t2_53(1,0.1).
t2_53(2,1.0).
t2_53(N,X) :-
�@�@N1 is N - 1,
�@�@N2 is N - 2,
�@�@N3 is N - 3,
�@�@t2_53(N1,X1),
�@�@t2_53(N2,X2),
�@�@t2_53(N3,X3),
�@�@X is X1 + X2 + X3.
%%%%%%%%%%%%%%%%%%%%
wrln([]).
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
% Prolog �d���Ȃ�����A�ȉ��Ƃ���B
t2_53 :-
�@�@findall(X,(for(0,N,20),t2_53(N,X)),L),
�@�@wrln(L).
t2_53(0,0.01).
t2_53(1,0.1).
t2_53(2,1.0).
t2_53(N,X) :-
�@�@N1 is N - 1,
�@�@N2 is N - 2,
�@�@N3 is N - 3,
�@�@t2_53(N1,X1),
�@�@t2_53(N2,X2),
�@�@t2_53(N3,X3),
�@�@X is X1 + X2 + X3.
%%%%%%%%%%%%%%%%%%%%
wrln([]).
wrln([A|R]) :- write_formatted('%t\n',[A]),wrln(R).
56 �F�f�t�H���g�̖����������F2009/11/08(��) 07:04:33
http://pc12.2ch.net/test/read.cgi/tech/1255709298/638
# [1] ���ƒP���F
# [2] ��蕶(�܃R�[�h&�����N)�F�\�P�b�g�ʐM��p�����`���b�g�̍쐬
# http://ime.nu/mikilab.doshisha.ac.jp/dia/research/report/2003/0714/006/report20030714006.html
# �ɂ���2.1�A2.2�̃N���C�A���g�A�T�[�o�̃v���O�����i�o����ΊȒP�ȉ�������肢���܂��j
# [1] ���ƒP���F
# [2] ��蕶(�܃R�[�h&�����N)�F�\�P�b�g�ʐM��p�����`���b�g�̍쐬
# http://ime.nu/mikilab.doshisha.ac.jp/dia/research/report/2003/0714/006/report20030714006.html
# �ɂ���2.1�A2.2�̃N���C�A���g�A�T�[�o�̃v���O�����i�o����ΊȒP�ȉ�������肢���܂��j
57 �F�f�t�H���g�̖����������F2009/11/08(��) 07:09:37
http://sum2cha.blogpico.com/archives/2017 ���X�ԍ�606
[1] ���ƒP���F �v���O���~���O
[2] ��蕶(�܃R�[�h&�����N)�F
# �R�D�ȉ��̃v���O�������쐬
# �R���R�}�X�̃}���o�c�Q�[���̃{�[�h���쐬
# �����Ɓ~�������݂�2�������W��̈ʒu�����
# ���͌�A����{�[�h��\������
# ���āA�悱�A�߂̂����ꂩ�Ɂ����~��3����
# ���_�Ńv���O�������I��
[1] ���ƒP���F �v���O���~���O
[2] ��蕶(�܃R�[�h&�����N)�F
# �R�D�ȉ��̃v���O�������쐬
# �R���R�}�X�̃}���o�c�Q�[���̃{�[�h���쐬
# �����Ɓ~�������݂�2�������W��̈ʒu�����
# ���͌�A����{�[�h��\������
# ���āA�悱�A�߂̂����ꂩ�Ɂ����~��3����
# ���_�Ńv���O�������I��
58 �F�f�t�H���g�̖����������F2009/11/08(��) 17:38:28
http://pc12.2ch.net/test/read.cgi/tech/1255709298/596
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̃A�h���X�̃v���O�����ɒlj����āA�_�C�N�X�g���@�̃v���O���������������Ă�������
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10070.txt
# �v���O�����Ɏg�p����f�[�^�t�@�C����
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10071.txt
# ���̃v���O�����ɁA�ȉ���2�`6�̏�����lj����ă_�C�N�X�g���̃v���O���������������Ă��������B
# 2�A���M�m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�ɂ��āA�ڑ������N�̒����𑗐M�m�[�h����̋����Ƃ���B
# 3�A���M�m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�̂����A�ŒZ�̋��������m�[�h���m��Ƃ���
# 4�A�m�肵���m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�ɂ��āA���M�m�[�h���炱�̊m��m�[�h���o�R���ē��B����o�H�̋������v�Z���A����܂ł̋������Z����X�V����
# 5�A�܂��m�肵�Ă��Ȃ��m�[�h�̂����A���M�m�[�h����̋������ŒZ�̃m�[�h���m��Ƃ���
# 6�A�S�Ẵm�[�h���m�肷��܂�4,5�̏������J��Ԃ��B
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̃A�h���X�̃v���O�����ɒlj����āA�_�C�N�X�g���@�̃v���O���������������Ă�������
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10070.txt
# �v���O�����Ɏg�p����f�[�^�t�@�C����
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10071.txt
# ���̃v���O�����ɁA�ȉ���2�`6�̏�����lj����ă_�C�N�X�g���̃v���O���������������Ă��������B
# 2�A���M�m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�ɂ��āA�ڑ������N�̒����𑗐M�m�[�h����̋����Ƃ���B
# 3�A���M�m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�̂����A�ŒZ�̋��������m�[�h���m��Ƃ���
# 4�A�m�肵���m�[�h�ɐڑ�����Ă���S�Ẵm�[�h�ɂ��āA���M�m�[�h���炱�̊m��m�[�h���o�R���ē��B����o�H�̋������v�Z���A����܂ł̋������Z����X�V����
# 5�A�܂��m�肵�Ă��Ȃ��m�[�h�̂����A���M�m�[�h����̋������ŒZ�̃m�[�h���m��Ƃ���
# 6�A�S�Ẵm�[�h���m�肷��܂�4,5�̏������J��Ԃ��B
59 �F�f�t�H���g�̖����������F2009/11/09(��) 02:30:15
http://pc12.2ch.net/test/read.cgi/tech/1255709298/651
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�
# 4���̐��̐��� n �����ׂċ����Ȃ���
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�
# 4���̐��̐��� n �����ׂċ����Ȃ���
60 �F�f�t�H���g�̖����������F2009/11/09(��) 02:33:33
http://pc12.2ch.net/test/read.cgi/tech/1248012902/461
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@�����@�z11��11��
# �y�@Ver�@ �z1.6.0_11
#
#
# �ۑ�ł�
# http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/825.zip
# �E�ۑ�
# �^����ꂽ�f�[�^�i�s��`�̃f�[�^�@�`.txt �x�N�g�����̃f�[�^�@b.txt�j�ɂ���
# pivot�I��t��Gauss�̏����@��p���ĘA���������`�������̉��������߂�
# �܂�����ꂽ���ɑ��ā@||�`���]��||�Q���v�Z����
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@�����@�z11��11��
# �y�@Ver�@ �z1.6.0_11
#
#
# �ۑ�ł�
# http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/825.zip
# �E�ۑ�
# �^����ꂽ�f�[�^�i�s��`�̃f�[�^�@�`.txt �x�N�g�����̃f�[�^�@b.txt�j�ɂ���
# pivot�I��t��Gauss�̏����@��p���ĘA���������`�������̉��������߂�
# �܂�����ꂽ���ɑ��ā@||�`���]��||�Q���v�Z����
61 �F�f�t�H���g�̖����������F2009/11/09(��) 03:55:38
>>59
% Prolog
'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n �����ׂċ�����'(L) :-
�@�@findall(N,'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n '(N),L).
'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n '(N) :-
�@�@�g����([0,1,2,3,4,5,6,7,8,9],2,[A,B]),
�@�@length(L,9),
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,0,0,L),
�@�@concat_atom(L,Atom),
�@�@atom_to_term(Atom,N1,_),
�@�@N is truncate(sqrt(N1)).
�@�@N >= 1000,N =< 9999,
�@�@U is N * N.
'�Q��ނ̐�����������Ȃ��Ȃ��'(_,_,1,1,[]) :- !.
'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,_,K,[A|R]) :-
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,1,K,R).
'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,K,_,[B|R]) :-
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,K,1,R).
% Prolog
'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n �����ׂċ�����'(L) :-
�@�@findall(N,'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n '(N),L).
'���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�4���̐��̐��� n '(N) :-
�@�@�g����([0,1,2,3,4,5,6,7,8,9],2,[A,B]),
�@�@length(L,9),
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,0,0,L),
�@�@concat_atom(L,Atom),
�@�@atom_to_term(Atom,N1,_),
�@�@N is truncate(sqrt(N1)).
�@�@N >= 1000,N =< 9999,
�@�@U is N * N.
'�Q��ނ̐�����������Ȃ��Ȃ��'(_,_,1,1,[]) :- !.
'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,_,K,[A|R]) :-
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,1,K,R).
'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,K,_,[B|R]) :-
�@�@'�Q��ނ̐�����������Ȃ��Ȃ��'(A,B,K,1,R).
62 �F�f�t�H���g�̖����������F2009/11/09(��) 04:24:18
63 �F�f�t�H���g�̖����������F2009/11/09(��) 04:56:03
http://pc12.2ch.net/test/read.cgi/tech/1255709298/657
# [1] ���ƒP���F �b����̃|�C���^�A�z��A�t�@�C���̖��ł�
# [2] ��蕶(�܃R�[�h&�����N)�F
# n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���v���O����������A
# ���s���ɂ����ēY�����Z�q�͗p�����A*(p+i)��*p++���ꂼ���p����p�^�[�������
# �������A���o�͏������t�@�C�������ɁA���o�̓t�@�C�����̓R�}���h���C���Ŏw�肷��
# [1] ���ƒP���F �b����̃|�C���^�A�z��A�t�@�C���̖��ł�
# [2] ��蕶(�܃R�[�h&�����N)�F
# n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���v���O����������A
# ���s���ɂ����ēY�����Z�q�͗p�����A*(p+i)��*p++���ꂼ���p����p�^�[�������
# �������A���o�͏������t�@�C�������ɁA���o�̓t�@�C�����̓R�}���h���C���Ŏw�肷��
64 �F�f�t�H���g�̖����������F2009/11/09(��) 05:06:17
>>63
% Prolog
'n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���'(N) :-
�@�@user_parameters([_���̓t�@�C��,_�o�̓t�@�C��]),
�@�@open(_���̓t�@�C��,read,Input),
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_)),Avg),
�@�@close(Input),
�@�@open(_�o�̓t�@�C��,write,Output),
�@�@write_formatted(Output,'���ϒl�� %t\n'),
�@�@close(Output),!.
% Prolog
'n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���'(N) :-
�@�@user_parameters([_���̓t�@�C��,_�o�̓t�@�C��]),
�@�@open(_���̓t�@�C��,read,Input),
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_)),Avg),
�@�@close(Input),
�@�@open(_�o�̓t�@�C��,write,Output),
�@�@write_formatted(Output,'���ϒl�� %t\n'),
�@�@close(Output),!.
65 �F�f�t�H���g�̖����������F2009/11/09(��) 05:07:54
>>65 ����
% Prolog
'n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���'(N) :-
�@�@user_parameters([_���̓t�@�C��,_�o�̓t�@�C��]),
�@�@open(_���̓t�@�C��,read,Input),
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_)),Avg),
�@�@close(Input),
�@�@open(_�o�̓t�@�C��,write,Output),
�@�@write_formatted(Output,'���ϒl�� %t\n',[Avg]), /* ���̍s���� */
�@�@close(Output),!.
% Prolog
'n���̃f�[�^��z��ɓ��͂����̕��ϒl���o�͂���'(N) :-
�@�@user_parameters([_���̓t�@�C��,_�o�̓t�@�C��]),
�@�@open(_���̓t�@�C��,read,Input),
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_)),Avg),
�@�@close(Input),
�@�@open(_�o�̓t�@�C��,write,Output),
�@�@write_formatted(Output,'���ϒl�� %t\n',[Avg]), /* ���̍s���� */
�@�@close(Output),!.
66 �F�f�t�H���g�̖����������F2009/11/09(��) 07:41:26
>>65 �����ꃖ�������B�ォ��l�s�ځA���ʕ����ЂƂ���Ȃ������B
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_))),Avg),
�@�@findavg(K,(for(1,M,N),get_line(Input,Line),(Line=end_of_file,!,fail;atom_to_term(Line,K,_))),Avg),
67 �F�f�t�H���g�̖����������F2009/11/09(��) 16:28:03
http://pc12.2ch.net/test/read.cgi/tech/1248012902/463
# �y�ۑ�z
# http://ime.nu/www51.tok2.com/home/rg550/cgi-bin/hosoku/img0047.zip
# �y�ۑ�1�z
# ���s��̂悤�ɃL�[�{�[�h���當�����ǂݍ��݁A�����^�̔z��Ɉꕶ���Âi�[
# ������A����(���Ԃ͂ǂ���ł����܂��܂���)�A�o�͂���v���O������
# �쐬���Ȃ����B
# �y�ۑ�2�z
# 0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t��
# �l�ŏo�͂���v���O�������쐬���Ȃ����B�܂��A100�̗����̕��ϒl�����킹��
# �o�͂��Ȃ����B
# �������A0����9 ���ꂼ��̌��𐔂��邽�߂̕ϐ��ɕK���z���p���Ă��������B
# (�o�����J�E���g�p�̕ϐ���10�p�ӂ��Ă͂����܂���B) �Ⴆ�A�o����
# �J�E���g�p�̔z�� count[] ��p�ӂ���ƁA count[0] ��0���o��������
# �i�[�����B����0��10��o�������ꍇ�Acount[0]=10�ƂȂ�B)
# �y�ۑ�z
# http://ime.nu/www51.tok2.com/home/rg550/cgi-bin/hosoku/img0047.zip
# �y�ۑ�1�z
# ���s��̂悤�ɃL�[�{�[�h���當�����ǂݍ��݁A�����^�̔z��Ɉꕶ���Âi�[
# ������A����(���Ԃ͂ǂ���ł����܂��܂���)�A�o�͂���v���O������
# �쐬���Ȃ����B
# �y�ۑ�2�z
# 0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t��
# �l�ŏo�͂���v���O�������쐬���Ȃ����B�܂��A100�̗����̕��ϒl�����킹��
# �o�͂��Ȃ����B
# �������A0����9 ���ꂼ��̌��𐔂��邽�߂̕ϐ��ɕK���z���p���Ă��������B
# (�o�����J�E���g�p�̕ϐ���10�p�ӂ��Ă͂����܂���B) �Ⴆ�A�o����
# �J�E���g�p�̔z�� count[] ��p�ӂ���ƁA count[0] ��0���o��������
# �i�[�����B����0��10��o�������ꍇ�Acount[0]=10�ƂȂ�B)
68 �F�f�t�H���g�̖����������F2009/11/09(��) 17:24:33
>>67
% Prolog �ۑ�1
'���s��̂悤�ɃL�[�{�[�h���當�����ǂݍ��݁A�����^�̔z��Ɉꕶ���Âi�[����
��A����(���Ԃ͂ǂ���ł����܂��܂���)�A�o�͂���' :-
�@�@get_chars(_�����Ȃ��),
�@�@sort(_�����Ȃ��,_���������Ȃ��),
�@�@atom_chars(_����������,_���������Ȃ��),
�@�@write_formatted('%t\n',[_����������]).
% Prolog �ۑ�1
'���s��̂悤�ɃL�[�{�[�h���當�����ǂݍ��݁A�����^�̔z��Ɉꕶ���Âi�[����
��A����(���Ԃ͂ǂ���ł����܂��܂���)�A�o�͂���' :-
�@�@get_chars(_�����Ȃ��),
�@�@sort(_�����Ȃ��,_���������Ȃ��),
�@�@atom_chars(_����������,_���������Ȃ��),
�@�@write_formatted('%t\n',[_����������]).
69 �F�f�t�H���g�̖����������F2009/11/09(��) 17:27:44
>>67
% Prolog �ۑ�2
'0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t�ƒl
�ŏo�͂���' :-
findall([N,0,[]],for(0,N,9),_�o�����J�E���g�p�Ȃ��),
'0����9�܂ł̐���������100��������'(1,L1),
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(L1,_�o�����J�E���g�p�Ȃ��).
'0����9�܂ł̐���������100��������'(N,[]) :- N > 100,!.
'0����9�܂ł̐���������100��������'(N,[A|R]) :-
A is random mod 10,
N2 is N + 1,
'0����9�܂ł̐���������100��������'(N2,R).
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([],L) :-
'�O���t�ƒl�ŏo��'(L),!.
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([N|R],L) :-
member([N,C,L1],L),
C2 is C + 1,
�Ȃ�т̒u��([N,C,L1],[N,C2,[_|L1]],L,L2),
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(R,L2).
�O���t�ƒl�ŏo��([]).
�O���t�ƒl�ŏo��([[N,C,L1]|R]) :-
all(L1,'*'),
write_formatted(' %t: %t %t\n',[N,L1,C]),
�O���t�ƒl�ŏo��(R).
% Prolog �ۑ�2
'0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t�ƒl
�ŏo�͂���' :-
findall([N,0,[]],for(0,N,9),_�o�����J�E���g�p�Ȃ��),
'0����9�܂ł̐���������100��������'(1,L1),
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(L1,_�o�����J�E���g�p�Ȃ��).
'0����9�܂ł̐���������100��������'(N,[]) :- N > 100,!.
'0����9�܂ł̐���������100��������'(N,[A|R]) :-
A is random mod 10,
N2 is N + 1,
'0����9�܂ł̐���������100��������'(N2,R).
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([],L) :-
'�O���t�ƒl�ŏo��'(L),!.
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([N|R],L) :-
member([N,C,L1],L),
C2 is C + 1,
�Ȃ�т̒u��([N,C,L1],[N,C2,[_|L1]],L,L2),
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(R,L2).
�O���t�ƒl�ŏo��([]).
�O���t�ƒl�ŏo��([[N,C,L1]|R]) :-
all(L1,'*'),
write_formatted(' %t: %t %t\n',[N,L1,C]),
�O���t�ƒl�ŏo��(R).
70 �F�f�t�H���g�̖����������F2009/11/09(��) 17:35:57
>>69 ��������
% Prolog �ۑ�2 (100�̗����̕��ϒl�͕\���s���̊W��A�ȗ����܂�)
'0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t�ƒl
�ŏo�͂���' :-
�@�@findall([N,0,[]],for(0,N,9),_�o�����J�E���g�p�Ȃ��),
�@�@'0����9�܂ł̐���������100��������'(1,L1),
�@�@'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(L1,_�o�����J�E���g�p�Ȃ��).
'0����9�܂ł̐���������100��������'(N,[]) :- N > 100,!.
'0����9�܂ł̐���������100��������'(N,[_������|R]) :-
�@�@_������ is random mod 10,
�@�@N2 is N + 1,
�@�@'0����9�܂ł̐���������100��������'(N2,R).
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([],L) :-
�@�@'�O���t�ƒl�ŏo��'(L),!.
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([N|R],L) :-
�@�@member([N,_�J�E���g,L1],L),
�@�@_�J�E���g2 is _�J�E���g + 1,
�@�@�Ȃ�т̒u��([N,_�J�E���g,L1],[N,_�J�E���g2,[_|L1]],L,L2),
�@�@'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(R,L2).
�O���t�ƒl�ŏo��([]).
�O���t�ƒl�ŏo��([[N,C,L]|R]) :-
�@�@all(L,'*'),
�@�@write_formatted(' %t: %t %t\n',[N,L,C]),
�@�@�O���t�ƒl�ŏo��(R).
% Prolog �ۑ�2 (100�̗����̕��ϒl�͕\���s���̊W��A�ȗ����܂�)
'0����9�܂ł̐���������100���������A���s��̂悤�ɂ��̏o�����z��_�O���t�ƒl
�ŏo�͂���' :-
�@�@findall([N,0,[]],for(0,N,9),_�o�����J�E���g�p�Ȃ��),
�@�@'0����9�܂ł̐���������100��������'(1,L1),
�@�@'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(L1,_�o�����J�E���g�p�Ȃ��).
'0����9�܂ł̐���������100��������'(N,[]) :- N > 100,!.
'0����9�܂ł̐���������100��������'(N,[_������|R]) :-
�@�@_������ is random mod 10,
�@�@N2 is N + 1,
�@�@'0����9�܂ł̐���������100��������'(N2,R).
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([],L) :-
�@�@'�O���t�ƒl�ŏo��'(L),!.
'���̏o�����z��_�O���t�ƒl�ŏo�͂���'([N|R],L) :-
�@�@member([N,_�J�E���g,L1],L),
�@�@_�J�E���g2 is _�J�E���g + 1,
�@�@�Ȃ�т̒u��([N,_�J�E���g,L1],[N,_�J�E���g2,[_|L1]],L,L2),
�@�@'���̏o�����z��_�O���t�ƒl�ŏo�͂���'(R,L2).
�O���t�ƒl�ŏo��([]).
�O���t�ƒl�ŏo��([[N,C,L]|R]) :-
�@�@all(L,'*'),
�@�@write_formatted(' %t: %t %t\n',[N,L,C]),
�@�@�O���t�ƒl�ŏo��(R).
71 �F�f�t�H���g�̖����������F2009/11/09(��) 17:59:38
http://pc12.2ch.net/test/read.cgi/tech/1248012902/464
# 0�`30�̐����̒����烉���_����5�d���Ȃ��őI�т�����ł���
# �ǂ�������炢���ł��傤���H
# �������������������������������
# 0�`30�̐����̒����烉���_����5�d���Ȃ��őI�т�����ł���
# �ǂ�������炢���ł��傤���H
# �������������������������������
72 �F�f�t�H���g�̖����������F2009/11/09(��) 18:08:00
>>71
% Prolog
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��' :-
�@�@length(L,5),
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L,[],X).
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'([],X,X).
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'([_|R1],Y,X) :-
�@�@N is random mod 31,
�@�@\+(member(N,Y)),
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(R1,[N|Y],X),!.
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L1,Y,X) :-
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L1,Y,X).
% Prolog
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��' :-
�@�@length(L,5),
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L,[],X).
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'([],X,X).
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'([_|R1],Y,X) :-
�@�@N is random mod 31,
�@�@\+(member(N,Y)),
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(R1,[N|Y],X),!.
'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L1,Y,X) :-
�@�@'0�`30�̐����̒����烉���_����5�d���Ȃ��őI��'(L1,Y,X).
73 �F�f�t�H���g�̖����������F2009/11/09(��) 18:35:25
http://pc12.2ch.net/test/read.cgi/tech/1255709298/694
# [1] ���ƒP���F�摜����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�@�u���[���n���̃A���S���Y����p���āA�E�C���h�E���ɐ�����`�悷��v���O�������쐬���Ȃ����B
# �@�@����̎d�l�͂Q�ʂ�̒�����I�тȂ����B�i�ǂ���ł��悢�j
#
# �@�@�d�l�P�i�}�E�X�̍��{�^���ƉE�{�^�����g�p����B������\���͂Ȃ��B�j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@ �����̎n�_���W�̎w��
# �@�@�}�E�X�̉E�{�^���N���b�N�@�@ �����̏I�_���W�̎w��y�ѐ����̕`��
#
# �@�@�d�l�Q�i�}�E�X�̍��{�^�������ő��삷��B������\������B�j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@�@�����̎n�_���W�̎w��A�y�ѐ����̕`��J�n
# �@�@�}�E�X�̈ړ��@�@�@�@�@�@�@�@�@�n�_���������₦�����Ƃ��ĕ`��B�i�Â������͏����j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@�@�����̏I�_���W�̊m��B������`��B
#
# �������A���C�u�����̓_��`�悷��API�����g���Đ������������ƁB����������API�����g���Ă͂Ȃ�Ȃ��B
# [1] ���ƒP���F�摜����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�@�u���[���n���̃A���S���Y����p���āA�E�C���h�E���ɐ�����`�悷��v���O�������쐬���Ȃ����B
# �@�@����̎d�l�͂Q�ʂ�̒�����I�тȂ����B�i�ǂ���ł��悢�j
#
# �@�@�d�l�P�i�}�E�X�̍��{�^���ƉE�{�^�����g�p����B������\���͂Ȃ��B�j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@ �����̎n�_���W�̎w��
# �@�@�}�E�X�̉E�{�^���N���b�N�@�@ �����̏I�_���W�̎w��y�ѐ����̕`��
#
# �@�@�d�l�Q�i�}�E�X�̍��{�^�������ő��삷��B������\������B�j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@�@�����̎n�_���W�̎w��A�y�ѐ����̕`��J�n
# �@�@�}�E�X�̈ړ��@�@�@�@�@�@�@�@�@�n�_���������₦�����Ƃ��ĕ`��B�i�Â������͏����j
# �@�@�}�E�X�̍��{�^���N���b�N�@�@�@�����̏I�_���W�̊m��B������`��B
#
# �������A���C�u�����̓_��`�悷��API�����g���Đ������������ƁB����������API�����g���Ă͂Ȃ�Ȃ��B
74 �F�f�t�H���g�̖����������F2009/11/09(��) 23:54:23
http://pc12.2ch.net/test/read.cgi/tech/1255709298/705
# [1] ���ƒP���F�f�[�^�\���ƃA���S���Y���v
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D
# �f�|�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\������v���O�������쐬
# ����D
# �������C���X�g�Ɋi�[����ہC���X�g�̍Ō�ɒlj�����悤�ɂ���D
# ��ia, b, c, - �Ə��ɓ��͂����Ƃ�a,b,c�Əo�͂����j
# [1] ���ƒP���F�f�[�^�\���ƃA���S���Y���v
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D
# �f�|�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\������v���O�������쐬
# ����D
# �������C���X�g�Ɋi�[����ہC���X�g�̍Ō�ɒlj�����悤�ɂ���D
# ��ia, b, c, - �Ə��ɓ��͂����Ƃ�a,b,c�Əo�͂����j
75 �F�f�t�H���g�̖����������F2009/11/09(��) 23:55:43
http://pc12.2ch.net/test/read.cgi/tech/1255709298/697
#
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10082.txt
# �v���O�����Ɏg�p����f�[�^�t�@�C����
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10071.txt
#
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10082.txt
# �v���O�����Ɏg�p����f�[�^�t�@�C����
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10071.txt
76 �F�f�t�H���g�̖����������F2009/11/10(��) 00:56:32
>>74
% Prolog
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��' :-
�@�@�V�����L���[�����(_�L���[),
�@�@rawmode,
�@�@get_char(_����),
�@�@'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����,_�L���[),
�@�@norawmode.
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'('-',_�L���[,_�L���[) :- !.
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����,_�L���[,_�L���[) :-
�@�@�L���[�ɗv�f��lj�����(_����,_�L���[,_�L���[_2),
�@�@get_char(_����_2),
�@�@'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����_2,_�L���[_2,_�L���[_4),
�@�@�L���[����v�f�����o��(_�v�f,_�L���[_3,_�L���[_4),
�@�@put_char(_�v�f).
�V�����L���[�����(X-X).
�L���[�͋�ł���(X-Y) :- X == Y.
�L���[�ɗv�f��lj�����(_�v�f,X-[_�v�f|Y],X-Y).
�L���[����v�f�����o��(_�v�f,[_�v�f|X]-Y,X-Y).
% Prolog
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��' :-
�@�@�V�����L���[�����(_�L���[),
�@�@rawmode,
�@�@get_char(_����),
�@�@'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����,_�L���[),
�@�@norawmode.
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'('-',_�L���[,_�L���[) :- !.
'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����,_�L���[,_�L���[) :-
�@�@�L���[�ɗv�f��lj�����(_����,_�L���[,_�L���[_2),
�@�@get_char(_����_2),
�@�@'���͂��ꂽ�������̃A���t�@�x�b�g���C���X�g��p���ď����i�[����D'�f�|'�f�����͂��ꂽ���ɕ����̓��͂��I�����C����܂łɊi�[���ꂽ�S�Ă̕�����\��'(_����_2,_�L���[_2,_�L���[_4),
�@�@�L���[����v�f�����o��(_�v�f,_�L���[_3,_�L���[_4),
�@�@put_char(_�v�f).
�V�����L���[�����(X-X).
�L���[�͋�ł���(X-Y) :- X == Y.
�L���[�ɗv�f��lj�����(_�v�f,X-[_�v�f|Y],X-Y).
�L���[����v�f�����o��(_�v�f,[_�v�f|X]-Y,X-Y).
77 �F�f�t�H���g�̖����������F2009/11/10(��) 01:14:45
<A HREF="http://nojiriko.asia/prolog/index.html">���̃f�B���N�g���̍���</A>
http://pc12.2ch.net/test/read.cgi/tech/1257481818/90
# �n�_
# x=cos(t)
# y=sin(t)
#
# �I�_
# x=cos(t+dt)
# y=sin(t+dt)
#
# �Ő���`���At=t+dt�ŋ^���~��`���Ă��܂��B
#
# �����`��ȉ~���A�C�ӂ̊p�x�ɌX����ɂ͂ǂ̂悤�ɂ���Ηǂ��̂ł��傤���H
#
http://pc12.2ch.net/test/read.cgi/tech/1257481818/90
# �n�_
# x=cos(t)
# y=sin(t)
#
# �I�_
# x=cos(t+dt)
# y=sin(t+dt)
#
# �Ő���`���At=t+dt�ŋ^���~��`���Ă��܂��B
#
# �����`��ȉ~���A�C�ӂ̊p�x�ɌX����ɂ͂ǂ̂悤�ɂ���Ηǂ��̂ł��傤���H
#
>>77
��s�ڂɃS�~�������Ă��܂����B�������Ă��������B
http://nojiriko.asia/prolog/ �T�C�g�͌̏ᒆ��12���ɕ������܂��B
����܂ł�
http://prolog.asia/html/prolog/ �T�C�g�ɂقƂ�ǂ��R�s�[���Ă���܂��B
��s�ڂɃS�~�������Ă��܂����B�������Ă��������B
http://nojiriko.asia/prolog/ �T�C�g�͌̏ᒆ��12���ɕ������܂��B
����܂ł�
http://prolog.asia/html/prolog/ �T�C�g�ɂقƂ�ǂ��R�s�[���Ă���܂��B
79 �F�f�t�H���g�̖����������F2009/11/10(��) 02:20:01
>>77
% Prolog
�^���~��`�� :-
�@�@�^���~���W���Ȃ�тɓ���(L),
�@�@�^���~��`��(L).
�^���~��`��([[X1,Y1],[X2,Y2]]) :- �����̕`��(X1,Y1,X2,Y2).
�^���~��`��([[X1,Y1],[X2,Y2]|R]) :-
�@�@�����̕`��(X1,Y1,X2,Y2),
�@�@�^���~��`��(R).
�^���~���W���Ȃ�тɓ���(L) :-
�@�@_2�� is 2 * pi,
�@�@_dt is _2�� / 100,
�@�@�^���~���W���Ȃ�тɓ���(0.0,_2��,_dt,L).
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,[]) :- _t_1 > _t_2,!.
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,[[X,Y]|R]) :-
�@�@X is cos(_t_1),
�@�@Y is sin(_t_1),
�@�@_t_3 is t_1 + _dt,
�@�@�^���~���W���Ȃ�тɓ���(_t_3,_t_2,R).
% Prolog
�^���~��`�� :-
�@�@�^���~���W���Ȃ�тɓ���(L),
�@�@�^���~��`��(L).
�^���~��`��([[X1,Y1],[X2,Y2]]) :- �����̕`��(X1,Y1,X2,Y2).
�^���~��`��([[X1,Y1],[X2,Y2]|R]) :-
�@�@�����̕`��(X1,Y1,X2,Y2),
�@�@�^���~��`��(R).
�^���~���W���Ȃ�тɓ���(L) :-
�@�@_2�� is 2 * pi,
�@�@_dt is _2�� / 100,
�@�@�^���~���W���Ȃ�тɓ���(0.0,_2��,_dt,L).
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,[]) :- _t_1 > _t_2,!.
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,[[X,Y]|R]) :-
�@�@X is cos(_t_1),
�@�@Y is sin(_t_1),
�@�@_t_3 is t_1 + _dt,
�@�@�^���~���W���Ȃ�тɓ���(_t_3,_t_2,R).
80 �F�f�t�H���g�̖����������F2009/11/10(��) 04:24:20
>>77
% Prolog (���a��1�ɌŒ�Ƃ����̂͂�����Ƌ����������)
�^���~��`��(_���a) :-
�@�@�^���~���W���Ȃ�тɓ���(_���a,L),
�@�@�^���~��`��(L).
�^���~��`��([[X1,Y1],[X2,Y2]]) :- �����̕`��(X1,Y1,X2,Y2).
�^���~��`��([[X1,Y1],[X2,Y2]|R]) :-
�@�@�����̕`��(X1,Y1,X2,Y2),
�@�@�^���~��`��(R).
�^���~���W���Ȃ�тɓ���(_���a,L) :-
�@�@_2�� is 2 * pi,
�@�@_dt is _2�� / 100,
�@�@�^���~���W���Ȃ�тɓ���(0.0,_2��,_dt,_���a,L).
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,_,[]) :- _t_1 > _t_2,!.
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,_���a,[[X,Y]|R]) :-
�@�@X is _���a * cos(_t_1),
�@�@Y is _���a * sin(_t_1),
�@�@_t_3 is t_1 + _dt,
�@�@�^���~���W���Ȃ�тɓ���(_t_3,_t_2,_dt,_���a,R). /* �����������܂��� *
% Prolog (���a��1�ɌŒ�Ƃ����̂͂�����Ƌ����������)
�^���~��`��(_���a) :-
�@�@�^���~���W���Ȃ�тɓ���(_���a,L),
�@�@�^���~��`��(L).
�^���~��`��([[X1,Y1],[X2,Y2]]) :- �����̕`��(X1,Y1,X2,Y2).
�^���~��`��([[X1,Y1],[X2,Y2]|R]) :-
�@�@�����̕`��(X1,Y1,X2,Y2),
�@�@�^���~��`��(R).
�^���~���W���Ȃ�тɓ���(_���a,L) :-
�@�@_2�� is 2 * pi,
�@�@_dt is _2�� / 100,
�@�@�^���~���W���Ȃ�тɓ���(0.0,_2��,_dt,_���a,L).
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,_,[]) :- _t_1 > _t_2,!.
�^���~���W���Ȃ�тɓ���(_t_1,_t_2,_dt,_���a,[[X,Y]|R]) :-
�@�@X is _���a * cos(_t_1),
�@�@Y is _���a * sin(_t_1),
�@�@_t_3 is t_1 + _dt,
�@�@�^���~���W���Ȃ�тɓ���(_t_3,_t_2,_dt,_���a,R). /* �����������܂��� *
81 �F�f�t�H���g�̖����������F2009/11/10(��) 04:29:43
http://pc12.2ch.net/test/read.cgi/tech/1255709298/719
# [1] ���ƒP���F�摜�����b�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F ��{�v���O���������Ɋe�������s��
# �@�@�@��{�v���O�����Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10083.txt
# �@�@�������e�F�@����摜�ɉ~�`�E���`��o��
# ���x�����O�A�k�ށE�c���̏������s��
# �������ʗ�͉摜�Q��
# �@�@�������ʗ�: http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10084.zip
# [1] ���ƒP���F�摜�����b�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F ��{�v���O���������Ɋe�������s��
# �@�@�@��{�v���O�����Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10083.txt
# �@�@�������e�F�@����摜�ɉ~�`�E���`��o��
# ���x�����O�A�k�ށE�c���̏������s��
# �������ʗ�͉摜�Q��
# �@�@�������ʗ�: http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10084.zip
82 �F�f�t�H���g�̖����������F2009/11/10(��) 04:52:17
>>75 �̖�蕶�͈ȉ��B (C�̃\�[�X��ǂ܂Ȃ��Ɖ�������Ă邩������Ȃ�)
# ���߂Čđ����N����܂łɊm���ł����ʐM��]���������B
# ���̃v���O�����ɒlj����āA�ȉ��̕��@�ŕ]�����s���v���O���������������Ă��������B
#
# 1�A�����_���ɑ���M�m�[�h�����肷��
# 2�A�^����ꂽ����M�m�[�h�Ԃ̌o�H�����肷��
# (a)���̌o�H��̑S�Ẵ����N�ɋe�ʂ�����ꍇ�A������1Mbps�������������A�u�m���ł����ʐM�v��1���₵�A�葱��1�ɖ߂�
# (b)���̌o�H��ɋe�ʂ̂Ȃ������N�����݂���ꍇ�A�đ��Ƃ��A���̎��_�܂ł́u�m���ł����ʐM�v���L�^���Ď葱��3�ɐi�ށB
# 3�A�S�����N�̋e�ʂ�������Ԃɖ߂��A�葱��1�ɖ߂�
# 4�A1�`3�̎葱����1000��s���A�u���߂Čđ����N����܂łɊm���ł����ʐM�v�̕��ς��Z�o����B
# ���߂Čđ����N����܂łɊm���ł����ʐM��]���������B
# ���̃v���O�����ɒlj����āA�ȉ��̕��@�ŕ]�����s���v���O���������������Ă��������B
#
# 1�A�����_���ɑ���M�m�[�h�����肷��
# 2�A�^����ꂽ����M�m�[�h�Ԃ̌o�H�����肷��
# (a)���̌o�H��̑S�Ẵ����N�ɋe�ʂ�����ꍇ�A������1Mbps�������������A�u�m���ł����ʐM�v��1���₵�A�葱��1�ɖ߂�
# (b)���̌o�H��ɋe�ʂ̂Ȃ������N�����݂���ꍇ�A�đ��Ƃ��A���̎��_�܂ł́u�m���ł����ʐM�v���L�^���Ď葱��3�ɐi�ށB
# 3�A�S�����N�̋e�ʂ�������Ԃɖ߂��A�葱��1�ɖ߂�
# 4�A1�`3�̎葱����1000��s���A�u���߂Čđ����N����܂łɊm���ł����ʐM�v�̕��ς��Z�o����B
83 �F�f�t�H���g�̖����������F2009/11/10(��) 05:52:50
http://pc12.2ch.net/test/read.cgi/tech/1200175247/704
# B��ɂP���߂��̐��l������A�����������͈̔�(�Ⴆ�P�O�O�`�P�O�P�Ȃ�)�ɓK�������l��
# �w�肵���Z���ɒ��o���A��������ꍇ�͂��̂����ɕ��ׂĒ��o����悤�ȃv���O��������肽���̂ł����A
# �ǂ̂悤�ɂ�����悢�ł��傤���H
# B��ɂP���߂��̐��l������A�����������͈̔�(�Ⴆ�P�O�O�`�P�O�P�Ȃ�)�ɓK�������l��
# �w�肵���Z���ɒ��o���A��������ꍇ�͂��̂����ɕ��ׂĒ��o����悤�ȃv���O��������肽���̂ł����A
# �ǂ̂悤�ɂ�����悢�ł��傤���H
84 �F�f�t�H���g�̖����������F2009/11/10(��) 06:23:33
>>83 �Ӗ��s���̂Ƃ��낪���邯�ǁA
% Prolog
t2_83(_���o�l�͈̓L�[�Ȃ��,_���o�Ȃ��) :-
�@�@'B��̐���'(B��),
�@�@���o�Ȃ�т̏�����(_�������o�Ȃ��),
�@�@t2_83(_���o�l�͈̓L�[�Ȃ��,B��,_�������o�Ȃ��,_���o�Ȃ��).
t2_83([],B��,X,X).
t2_83([[_�l�͈�|_�L�[]|R1],B��,_���o�Ȃ��,X) :-
�@�@'B��l���o'(B��,_�l�͈�,_�l�Ȃ��),
�@�@���o�Ȃ�т̍X�V(_�l�Ȃ��,_�L�[,_���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��),
�@�@t2_83(R,B��,_�X�V���ꂽ���o�Ȃ��,X).
'B��l���o'(B��,_�l����-_�l���,_�l�Ȃ��) :-
�@�@findall(_�l,(member(_�l,B��),_�l>=_�l����,_�l=<_�l���),_�l�Ȃ��).
���o�Ȃ�т̍X�V([],_,X,X).
���o�Ȃ�т̍X�V([_�l|R],_�L�[,_���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��) :-
�@�@list_nth(_�L�[,_���o�Ȃ��,L1),
�@�@append(L1,[_�l],L2),
�@�@�ʒu�w��ɂ��Ȃ�т̒u��(_�L�[,L2,_���o�Ȃ��,_�u�����ꂽ���o�Ȃ��),
�@�@���o�Ȃ�т̍X�V(R,_�L�[,_�u�����ꂽ���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��).
'B��̐���'(B��) :- findall(_�l,(for(1,N,10000),_�l is random mod 10000),B��).
���o�Ȃ�т̏�����([[],[],[],[],[],[],[],[],[],[]]).
% Prolog
t2_83(_���o�l�͈̓L�[�Ȃ��,_���o�Ȃ��) :-
�@�@'B��̐���'(B��),
�@�@���o�Ȃ�т̏�����(_�������o�Ȃ��),
�@�@t2_83(_���o�l�͈̓L�[�Ȃ��,B��,_�������o�Ȃ��,_���o�Ȃ��).
t2_83([],B��,X,X).
t2_83([[_�l�͈�|_�L�[]|R1],B��,_���o�Ȃ��,X) :-
�@�@'B��l���o'(B��,_�l�͈�,_�l�Ȃ��),
�@�@���o�Ȃ�т̍X�V(_�l�Ȃ��,_�L�[,_���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��),
�@�@t2_83(R,B��,_�X�V���ꂽ���o�Ȃ��,X).
'B��l���o'(B��,_�l����-_�l���,_�l�Ȃ��) :-
�@�@findall(_�l,(member(_�l,B��),_�l>=_�l����,_�l=<_�l���),_�l�Ȃ��).
���o�Ȃ�т̍X�V([],_,X,X).
���o�Ȃ�т̍X�V([_�l|R],_�L�[,_���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��) :-
�@�@list_nth(_�L�[,_���o�Ȃ��,L1),
�@�@append(L1,[_�l],L2),
�@�@�ʒu�w��ɂ��Ȃ�т̒u��(_�L�[,L2,_���o�Ȃ��,_�u�����ꂽ���o�Ȃ��),
�@�@���o�Ȃ�т̍X�V(R,_�L�[,_�u�����ꂽ���o�Ȃ��,_�X�V���ꂽ���o�Ȃ��).
'B��̐���'(B��) :- findall(_�l,(for(1,N,10000),_�l is random mod 10000),B��).
���o�Ȃ�т̏�����([[],[],[],[],[],[],[],[],[],[]]).
85 �F�f�t�H���g�̖����������F2009/11/10(��) 06:30:05
>>84
�s�������ɂ�����̂ŁA������ƃY�������Ă��邪�A�{����
�ʒu�w��ɂ��Ȃ�т̒u��/4 (���ꖢ��`!)�̏��̓J�E���g���Ȃ���ċA������
����Ƃ���B
�s�������ɂ�����̂ŁA������ƃY�������Ă��邪�A�{����
�ʒu�w��ɂ��Ȃ�т̒u��/4 (���ꖢ��`!)�̏��̓J�E���g���Ȃ���ċA������
����Ƃ���B
86 �F�f�t�H���g�̖����������F2009/11/10(��) 08:27:27
http://pc12.2ch.net/test/read.cgi/tech/1255709298/725
# [1] ���ƒP���F �A���S���Y��[I]
# [2] ��蕶(�܃R�[�h&�����N)�Fa,b,c,d,e��5�������A���t�@�x�b�g�Ƃ���
# �@�d���Ȃ�4�������ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āA
# �@ad,bd,de���܂܂Ȃ����̂�\������
# [3] ��
# �@[3.1] OS�F Linux
# �@[3.2] �R���p�C�����ƃo�[�W�����F gcc 3.4
# �@[3.3] ����F C
# [4] �����F 11��11��
# [5] ���̑��̐��� :
# [1] ���ƒP���F �A���S���Y��[I]
# [2] ��蕶(�܃R�[�h&�����N)�Fa,b,c,d,e��5�������A���t�@�x�b�g�Ƃ���
# �@�d���Ȃ�4�������ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āA
# �@ad,bd,de���܂܂Ȃ����̂�\������
# [3] ��
# �@[3.1] OS�F Linux
# �@[3.2] �R���p�C�����ƃo�[�W�����F gcc 3.4
# �@[3.3] ����F C
# [4] �����F 11��11��
# [5] ���̑��̐��� :
87 �F�f�t�H���g�̖����������F2009/11/10(��) 08:45:31
>>86
% Prolog
'a,b,c,d,e��5�������A���t�@�x�b�g�Ƃ��ďd���Ȃ�4�����ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āAad,bd,de���܂܂Ȃ����̂�\��' :-
�@�@����([a,b,c,d,e],4,L),
�@�@\+(append(_,[a,d|_],L)),
�@�@\+(append(_,[b,d|_],L)),
�@�@\+(append(_,[d,e|_],L)),
�@�@atom_chars(_��,L),
�@�@write_formatted('%t\n',[_��]),
�@�@fail.
'a,b,c,d,e��5�������A���t�@�x�b�g�Ƃ��ďd���Ȃ�4�����ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āAad,bd,de���܂܂Ȃ����̂�\��'.
% *** user: '����' / 3 ***
'����'(Y,0,[]).
����(Y,N,[A|X]) :-
�@�@del(A,Y,Z),
�@�@M is N - 1,
�@�@����(Z,M,X).
% *** user: del / 3 ***
del(A,[A|X],X).
del(A,[B|X],[B|Y]) :-
�@�@del(A,X,Y).
% Prolog
'a,b,c,d,e��5�������A���t�@�x�b�g�Ƃ��ďd���Ȃ�4�����ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āAad,bd,de���܂܂Ȃ����̂�\��' :-
�@�@����([a,b,c,d,e],4,L),
�@�@\+(append(_,[a,d|_],L)),
�@�@\+(append(_,[b,d|_],L)),
�@�@\+(append(_,[d,e|_],L)),
�@�@atom_chars(_��,L),
�@�@write_formatted('%t\n',[_��]),
�@�@fail.
'a,b,c,d,e��5�������A���t�@�x�b�g�Ƃ��ďd���Ȃ�4�����ō\�������S�Ă�word�̂Ȃ��ŕ���������Ƃ��āAad,bd,de���܂܂Ȃ����̂�\��'.
% *** user: '����' / 3 ***
'����'(Y,0,[]).
����(Y,N,[A|X]) :-
�@�@del(A,Y,Z),
�@�@M is N - 1,
�@�@����(Z,M,X).
% *** user: del / 3 ***
del(A,[A|X],X).
del(A,[B|X],[B|Y]) :-
�@�@del(A,X,Y).
88 �F�f�t�H���g�̖����������F2009/11/10(��) 11:32:34
http://pc12.2ch.net/test/read.cgi/tech/1255709298/733
# [1] ���ƒP���F���ƌ���
# [2] ��蕶�F�����Z�W�摜���K���}�����v���O���������
# [1] ���ƒP���F���ƌ���
# [2] ��蕶�F�����Z�W�摜���K���}�����v���O���������
89 �F�f�t�H���g�̖����������F2009/11/10(��) 11:46:10
>>89
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(C),
�@�@put_byte(C),
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output),
�@�@close(Output),
�@�@close(Input),!.
�K���}�(-1,_,_,_) :- !.
�K���}�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0
.5)),
�@�@put_byte(_����ꂽ�l),
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output,_�K���}�).
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(C),
�@�@put_byte(C),
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output),
�@�@close(Output),
�@�@close(Input),!.
�K���}�(-1,_,_,_) :- !.
�K���}�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0
.5)),
�@�@put_byte(_����ꂽ�l),
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output,_�K���}�).
90 �F�f�t�H���g�̖����������F2009/11/10(��) 11:50:09
>>89 ����
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(Input,C),�@�@ /* �����ӏ� */
�@�@put_byte(Output,C),�@�@/* �����ӏ� */
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output),
�@�@close(Output),
�@�@close(Input),!.
�K���}�(-1,_,_,_) :- !.
�K���}�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0.5)),
�@�@put_byte(Output,_����ꂽ�l),�@�@/* �����ӏ� */
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output,_�K���}�).
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(Input,C),�@�@ /* �����ӏ� */
�@�@put_byte(Output,C),�@�@/* �����ӏ� */
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output),
�@�@close(Output),
�@�@close(Input),!.
�K���}�(-1,_,_,_) :- !.
�K���}�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0.5)),
�@�@put_byte(Output,_����ꂽ�l),�@�@/* �����ӏ� */
�@�@get_byte(Input,C2),
�@�@�K���}�(C2,Input,Output,_�K���}�).
91 �F�f�t�H���g�̖����������F2009/11/10(��) 11:56:31
>>89 ���݂܂���B����ɒ����B�����������ɂȂ��Ă��܂����B�q�ꖼ��ς��܂��B
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(Input,C),
�@�@put_byte(Output,C),
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}��̈�(C2,Input,Output,_�K���}�),
�@�@close(Output),
�@�@close(Input),!.
�K���}��̈�(-1,_,_,_) :- !.
�K���}��̈�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0.5)),
�@�@put_byte(Output,_����ꂽ�l),
�@�@get_byte(Input,C2),
�@�@�K���}��̈�(C2,Input,Output,_�K���}�).
% Prolog
�K���}�(_�摜�t�@�C��,_Header�̒���,_�K���}�,_����ꂽ�摜�t�@�C��) :-
�@�@open(_�摜�t�@�C��,read,Input,[type(binary)]),
�@�@open(_����ꂽ�摜�t�B��,write,Output,[type(binary)]),
�@�@for(1,N,_Header�̒���),
�@�@get_byte(Input,C),
�@�@put_byte(Output,C),
�@�@N=_Header�̒���,
�@�@get_byte(Input,C2),
�@�@�K���}��̈�(C2,Input,Output,_�K���}�),
�@�@close(Output),
�@�@close(Input),!.
�K���}��̈�(-1,_,_,_) :- !.
�K���}��̈�(C,Input,Output,_�K���}�) :-
�@�@_����ꂽ�l is truncate(floor((( C / 255 ) ^ (1 / _�K���}�)) * 255 + 0.5)),
�@�@put_byte(Output,_����ꂽ�l),
�@�@get_byte(Input,C2),
�@�@�K���}��̈�(C2,Input,Output,_�K���}�).
92 �F�f�t�H���g�̖����������F2009/11/10(��) 13:17:35
http://pc12.2ch.net/test/read.cgi/tech/1255709298/651
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�
# 4���̐��̐��� n �����ׂċ����Ȃ���
# [1] ���ƒP���F �b���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̐���n�̂Q��̐��ɁA�Q��ނ̐�����������Ȃ�
# 4���̐��̐��� n �����ׂċ����Ȃ���
93 �F�f�t�H���g�̖����������F2009/11/10(��) 13:26:38
>>92 ���߂��>>59�Ɠ����������B���͖�肪�Ԉ���Ă����Ƃ����V���ߓo��B
http://pc12.2ch.net/test/read.cgi/tech/1255709298/752
# ���̐���n���Q�悵�ē�����4���̐����̂����A
# �Q��ނ̐�����������Ȃ����̂����ׂċ����Ȃ���
http://pc12.2ch.net/test/read.cgi/tech/1255709298/752
# ���̐���n���Q�悵�ē�����4���̐����̂����A
# �Q��ނ̐�����������Ȃ����̂����ׂċ����Ȃ���
94 �F�f�t�H���g�̖����������F2009/11/10(��) 14:33:27
>>93
% Prolog ���ꂾ�ƒP���ɂ��ׂ�2�悵�Ċm���߂���@�ōς�ł��܂��B
t2_93 :-
�@�@'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N),�@�@
�@�@write_formatted('%t\n',[N]),
�@�@fail.
t2_93.
'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N) :-
�@�@Max is trunscate(sqrt(9999)),
�@�@for(1,N,Max),
�@�@N1 is N * N,
�@�@number_chars(N1,L),
�@�@'2��ނ̐�����������Ȃ�'(L).
'2��ނ̐�����������Ȃ�'([A|R]) :- \+(R=[]),all(R,B),\+(B==A).
% Prolog ���ꂾ�ƒP���ɂ��ׂ�2�悵�Ċm���߂���@�ōς�ł��܂��B
t2_93 :-
�@�@'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N),�@�@
�@�@write_formatted('%t\n',[N]),
�@�@fail.
t2_93.
'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N) :-
�@�@Max is trunscate(sqrt(9999)),
�@�@for(1,N,Max),
�@�@N1 is N * N,
�@�@number_chars(N1,L),
�@�@'2��ނ̐�����������Ȃ�'(L).
'2��ނ̐�����������Ȃ�'([A|R]) :- \+(R=[]),all(R,B),\+(B==A).
95 �F�f�t�H���g�̖����������F2009/11/10(��) 14:55:07
>>93 �܂��܂�������B'2��ނ̐�����������Ȃ�'/1��ύX
% Prolog
t2_93 :-
�@�@'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N),�@�@
�@�@write_formatted('%t\n',[N]),
�@�@fail.
t2_93.
'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N) :-
�@�@Max is trunscate(sqrt(9999)),
�@�@for(1,N,Max),
�@�@N1 is N * N,
�@�@number_chars(N1,L),
�@�@'2��ނ̐�������������Ȃ�'(L).
'2��ނ̐�������������Ȃ�'([A|R]) :-
�@�@�Ȃ�т���폜(A,R,R1),
�@�@\+(R1=[]),
�@�@all(R1,_).
% *** user: '�Ȃ�т���폜' / 3 ***
�Ȃ�т���폜(_,[],[]) :- !.
�Ȃ�т���폜(_�폜����v�f,[_�폜����v�f|_�c��ΏۂȂ��],_�폜���ꂽ�Ȃ�
��) :-
�@�@�Ȃ�т���폜(_�폜����v�f,_�c��ΏۂȂ��,_�폜���ꂽ�Ȃ��),!.
�Ȃ�т���폜(_�폜����v�f,[_�v�f|_�c��ΏۂȂ��],[_�v�f|_�c��폜�Ȃ��])
:-
�@�@�Ȃ�т���폜(_�폜����v�f,_�c��ΏۂȂ��,_�c��폜�Ȃ��),!.
% Prolog
t2_93 :-
�@�@'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N),�@�@
�@�@write_formatted('%t\n',[N]),
�@�@fail.
t2_93.
'���̐���n���Q�悵�ē�����4���̐����̂����A�Q��ނ̐�����������Ȃ����̂����ׂċ�����'(N) :-
�@�@Max is trunscate(sqrt(9999)),
�@�@for(1,N,Max),
�@�@N1 is N * N,
�@�@number_chars(N1,L),
�@�@'2��ނ̐�������������Ȃ�'(L).
'2��ނ̐�������������Ȃ�'([A|R]) :-
�@�@�Ȃ�т���폜(A,R,R1),
�@�@\+(R1=[]),
�@�@all(R1,_).
% *** user: '�Ȃ�т���폜' / 3 ***
�Ȃ�т���폜(_,[],[]) :- !.
�Ȃ�т���폜(_�폜����v�f,[_�폜����v�f|_�c��ΏۂȂ��],_�폜���ꂽ�Ȃ�
��) :-
�@�@�Ȃ�т���폜(_�폜����v�f,_�c��ΏۂȂ��,_�폜���ꂽ�Ȃ��),!.
�Ȃ�т���폜(_�폜����v�f,[_�v�f|_�c��ΏۂȂ��],[_�v�f|_�c��폜�Ȃ��])
:-
�@�@�Ȃ�т���폜(_�폜����v�f,_�c��ΏۂȂ��,_�c��폜�Ȃ��),!.
96 �F�f�t�H���g�̖����������F2009/11/10(��) 16:34:41
http://sum2cha.blogpico.com/archives/2017 ���X�ԍ�182
# [1] ���ƒP���F�A���S���Y��
# [2] ��蕶�F���l���P����10�܂ŏo�͂���B�������A�T�܂ŏo�͂������_��
# ��x���s����
# [1] ���ƒP���F�A���S���Y��
# [2] ��蕶�F���l���P����10�܂ŏo�͂���B�������A�T�܂ŏo�͂������_��
# ��x���s����
97 �F�f�t�H���g�̖����������F2009/11/10(��) 16:40:22
>>96
% Prolog
'���l���P����10�܂ŏo�͂���B�������A�T�܂ŏo�͂������_�ň�x���s����' :-
�@�@for(1,N,10),
�@�@write(N),
�@�@'�������A�T�܂ŏo�͂������_�ň�x���s����'(N),
�@�@N = 10.
'�������A�T�܂ŏo�͂������_�ň�x���s����'(5) :- nl,!.
'�������A�T�܂ŏo�͂������_�ň�x���s����'(_).
% Prolog
'���l���P����10�܂ŏo�͂���B�������A�T�܂ŏo�͂������_�ň�x���s����' :-
�@�@for(1,N,10),
�@�@write(N),
�@�@'�������A�T�܂ŏo�͂������_�ň�x���s����'(N),
�@�@N = 10.
'�������A�T�܂ŏo�͂������_�ň�x���s����'(5) :- nl,!.
'�������A�T�܂ŏo�͂������_�ň�x���s����'(_).
98 �F�f�t�H���g�̖����������F2009/11/10(��) 16:43:31
99 �F�f�t�H���g�̖����������F2009/11/10(��) 16:54:59
>>96
% Prolog
t :- t(1).
t(N) :- N > 10,!.
t(5) :- write(5),nl,t(6),!.
t(N) :- write(N),N2 is N + 1,t(N2).
% Prolog
t :- t(1).
t(N) :- N > 10,!.
t(5) :- write(5),nl,t(6),!.
t(N) :- write(N),N2 is N + 1,t(N2).
100 �F�f�t�H���g�̖����������F2009/11/10(��) 17:00:33
>>96
% Prolog
t :- t(1).
t(N) :- N > 10.
t(5) :- write(5),nl,t(6).
t(N) :- N >= 1,N =< 10,\+(N=5),write(N),N2 is N + 1,t(N2).
% Prolog
t :- t(1).
t(N) :- N > 10.
t(5) :- write(5),nl,t(6).
t(N) :- N >= 1,N =< 10,\+(N=5),write(N),N2 is N + 1,t(N2).
101 �F�f�t�H���g�̖����������F2009/11/10(��) 18:07:23
http://sum2cha.blogpico.com/archives/2017 ���X�ԍ�297
# 3���傫���A���͂��ꂽ����̐������̑S�Ă̎��R������f���ɂ��āA
# 3�Ŋ�������͖̂������A3�Ŋ������]�肪1�̂��͉̂��Z���A
# �]�肪2�̂��̂͌��Z���č��v�����߂�
# 3���傫���A���͂��ꂽ����̐������̑S�Ă̎��R������f���ɂ��āA
# 3�Ŋ�������͖̂������A3�Ŋ������]�肪1�̂��͉̂��Z���A
# �]�肪2�̂��̂͌��Z���č��v�����߂�
102 �F�f�t�H���g�̖����������F2009/11/10(��) 18:30:24
>>101
% Prolog
'3���傫���A���͂��ꂽ����̐������̑S�Ă̎��R������f���ɂ��āA3�Ŋ�������͖̂������A3�Ŋ������]�肪1�̂��͉̂��Z���A�]�肪2�̂��̂͌��Z���č��v�����߂�'(_����l,_���v) :-
�@�@t2_101(4,_����l,_���v).
t2_101(N,_����l,0) :- N >= _����l,!.
t2_101(N,_����l,_���v) :-
�@�@\+(�f���ł���(N)),
�@�@2 N mod 3,
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v2),
�@�@_���v is _���v2 - N.
t2_101(N,_����l,_���v) :-
�@�@\+(�f���ł���(N)),
�@�@1 N mod 3,
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v2),
�@�@_���v is _���v2 + N.
t2_101(N,_����l,_���v) :-
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v).
�f���ł���(N) :- N2 is N // 2,for(2,M,N2),0 is N mod M,!,fail.
�f���ł���(_).
% Prolog
'3���傫���A���͂��ꂽ����̐������̑S�Ă̎��R������f���ɂ��āA3�Ŋ�������͖̂������A3�Ŋ������]�肪1�̂��͉̂��Z���A�]�肪2�̂��̂͌��Z���č��v�����߂�'(_����l,_���v) :-
�@�@t2_101(4,_����l,_���v).
t2_101(N,_����l,0) :- N >= _����l,!.
t2_101(N,_����l,_���v) :-
�@�@\+(�f���ł���(N)),
�@�@2 N mod 3,
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v2),
�@�@_���v is _���v2 - N.
t2_101(N,_����l,_���v) :-
�@�@\+(�f���ł���(N)),
�@�@1 N mod 3,
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v2),
�@�@_���v is _���v2 + N.
t2_101(N,_����l,_���v) :-
�@�@N2 is N + 1,
�@�@t2_101(N2,_����l,_���v).
�f���ł���(N) :- N2 is N // 2,for(2,M,N2),0 is N mod M,!,fail.
�f���ł���(_).
103 �F�f�t�H���g�̖����������F2009/11/14(�y) 05:23:04
104 �F�f�t�H���g�̖����������F2009/11/14(�y) 05:29:11
105 �F�f�t�H���g�̖����������F2009/11/17(��) 05:34:20
OCN�̃A�N�Z�X�������ɁAC/C++�̏h��X�����ǂ�ǂ�i��ł��܂��āA
�]���A�����Ȃ�����ǂ����Ȃ��Ȃ�܂����B����5�����͏Ȃ��܂��B
http://nojiriko.asia/prolog/index.html �ɂ͂��̊Ԃ̉�12��
���炢���ڂ��Ă���܂��B
�]���A�����Ȃ�����ǂ����Ȃ��Ȃ�܂����B����5�����͏Ȃ��܂��B
http://nojiriko.asia/prolog/index.html �ɂ͂��̊Ԃ̉�12��
���炢���ڂ��Ă���܂��B
106 �F�f�t�H���g�̖����������F2009/11/17(��) 06:08:28
>>105 12�ۑ�ǂ��납28�ۑ肠��悤�Ȃ̂ŁA�����N�������܂��B
c2-�̌�̔ԍ����e�h��X���̃��X�ԍ��ɂȂ�܂��B
<A HREF="http://nojiriko.asia/prolog/c2_713.html">c2-713:�J�G�T���Í��̕���</A>
<A HREF="http://nojiriko.asia/prolog/c2_817.html">c2-817:�؋��̒�z�ԍρB���N�ŕԍςł��邩</A>
<A HREF="http://nojiriko.asia/prolog/shiharaigaku.html"> :���[���̎x����</A>
<A HREF="http://nojiriko.asia/prolog/c2_821.html">c2-812:2�i����1�̕␔</A>
<A HREF="http://nojiriko.asia/prolog/c2_825.html">c2-825:1����20�܂ł�\������</A>
<A HREF="http://nojiriko.asia/prolog/c2_832.html">c2-832:�ő�l�ƒu�����邱�Ƃɂ���Đ���</A>
<A HREF="http://nojiriko.asia/prolog/c2_833.html">c2-833:�Ώ̍s��Ƃ�</A>
<A HREF="http://nojiriko.asia/prolog/c2_834.html">c2-834:������̌���</A>
<A HREF="http://nojiriko.asia/prolog/c2_836.html">c2-836:��̎���������</A>
<A HREF="http://nojiriko.asia/prolog/c2_840.html">c2-840:�O�[�E�`���L�E�p�[</A>
<A HREF="http://nojiriko.asia/prolog/c2_949.html">c2-949:���������̔F��</A>
<A HREF="http://nojiriko.asia/prolog/c2_950.html">c2-950:�P�|���h�͉��h����</A>
c2-�̌�̔ԍ����e�h��X���̃��X�ԍ��ɂȂ�܂��B
<A HREF="http://nojiriko.asia/prolog/c2_713.html">c2-713:�J�G�T���Í��̕���</A>
<A HREF="http://nojiriko.asia/prolog/c2_817.html">c2-817:�؋��̒�z�ԍρB���N�ŕԍςł��邩</A>
<A HREF="http://nojiriko.asia/prolog/shiharaigaku.html"> :���[���̎x����</A>
<A HREF="http://nojiriko.asia/prolog/c2_821.html">c2-812:2�i����1�̕␔</A>
<A HREF="http://nojiriko.asia/prolog/c2_825.html">c2-825:1����20�܂ł�\������</A>
<A HREF="http://nojiriko.asia/prolog/c2_832.html">c2-832:�ő�l�ƒu�����邱�Ƃɂ���Đ���</A>
<A HREF="http://nojiriko.asia/prolog/c2_833.html">c2-833:�Ώ̍s��Ƃ�</A>
<A HREF="http://nojiriko.asia/prolog/c2_834.html">c2-834:������̌���</A>
<A HREF="http://nojiriko.asia/prolog/c2_836.html">c2-836:��̎���������</A>
<A HREF="http://nojiriko.asia/prolog/c2_840.html">c2-840:�O�[�E�`���L�E�p�[</A>
<A HREF="http://nojiriko.asia/prolog/c2_949.html">c2-949:���������̔F��</A>
<A HREF="http://nojiriko.asia/prolog/c2_950.html">c2-950:�P�|���h�͉��h����</A>
107 �F�f�t�H���g�̖����������F2009/11/17(��) 06:11:39
<A HREF="http://nojiriko.asia/prolog/py954.html">py-954:1000�������������ׂ�
�́u3�܂���5�̔{���v�̍��v���v�Z���C���ʂ�\������v���O����</A>
<A HREF="http://nojiriko.asia/prolog/c2_956.html">c2-956:�����ꂽ�菇�ɏ]���ē��͂��ꂽ�l�̍ő�l��\������</A>
<A HREF="http://nojiriko.asia/prolog/c2_990.html">c2-990:�����̌l���ϓ_�ɂ��]��</A>
<A HREF="http://nojiriko.asia/prolog/c2_990_2.html">c2-990:�����̌l���ϓ_�ɂ��]��</A>
<A HREF="http://nojiriko.asia/prolog/py_964.html">py_964:�ꎞ�f�B���N�g��</A>
<A HREF="http://nojiriko.asia/prolog/py_972.html">py_972:�J��Ԃ�����</A>
<A HREF="http://nojiriko.asia/prolog/c132_42.html">c132-42:�J��Ԃ������Efindall/3,for/3,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_42.html">c132-43:����Ɋւ���C�����Prolog�̍���</A>
<A HREF="http://nojiriko.asia/prolog/c132_50.html">c132-50:�J��Ԃ������Ereverse,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_62.html">c132-62:�I��\���Ereverse,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_64.html">c132-64:�L�[�{�[�h����10�l���̐g������͂��A </A>
�́u3�܂���5�̔{���v�̍��v���v�Z���C���ʂ�\������v���O����</A>
<A HREF="http://nojiriko.asia/prolog/c2_956.html">c2-956:�����ꂽ�菇�ɏ]���ē��͂��ꂽ�l�̍ő�l��\������</A>
<A HREF="http://nojiriko.asia/prolog/c2_990.html">c2-990:�����̌l���ϓ_�ɂ��]��</A>
<A HREF="http://nojiriko.asia/prolog/c2_990_2.html">c2-990:�����̌l���ϓ_�ɂ��]��</A>
<A HREF="http://nojiriko.asia/prolog/py_964.html">py_964:�ꎞ�f�B���N�g��</A>
<A HREF="http://nojiriko.asia/prolog/py_972.html">py_972:�J��Ԃ�����</A>
<A HREF="http://nojiriko.asia/prolog/c132_42.html">c132-42:�J��Ԃ������Efindall/3,for/3,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_42.html">c132-43:����Ɋւ���C�����Prolog�̍���</A>
<A HREF="http://nojiriko.asia/prolog/c132_50.html">c132-50:�J��Ԃ������Ereverse,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_62.html">c132-62:�I��\���Ereverse,sub_atom/5</A>
<A HREF="http://nojiriko.asia/prolog/c132_64.html">c132-64:�L�[�{�[�h����10�l���̐g������͂��A </A>
108 �F�f�t�H���g�̖����������F2009/11/17(��) 06:13:35
<A HREF="http://nojiriko.asia/prolog/c132_68.html">c132-68:���Ȃ���IP�A�h���X��</A>
<A HREF="http://nojiriko.asia/prolog/c132_72.html">c132-72:�ꕶ�����A�����̕����\����������ƕ������Ƃ̗v���ʂ��ω�����</A>
<A HREF="http://nojiriko.asia/prolog/c132_74.html">c132-74:�s��ɒl�̊i�[�Ƃ��̓ǂݏo��</A>
<A HREF="http://nojiriko.asia/prolog/c132_76.html">c132-76:���͒��̃A���t�@�x�b�g�Ɛ����̏o���x��</A>
<A HREF="http://nojiriko.asia/prolog/c132_88.html">c132-88:�A���t�@�x�b�g��1���̕��������\��</A>
<A HREF="http://nojiriko.asia/prolog/c132_72.html">c132-72:�ꕶ�����A�����̕����\����������ƕ������Ƃ̗v���ʂ��ω�����</A>
<A HREF="http://nojiriko.asia/prolog/c132_74.html">c132-74:�s��ɒl�̊i�[�Ƃ��̓ǂݏo��</A>
<A HREF="http://nojiriko.asia/prolog/c132_76.html">c132-76:���͒��̃A���t�@�x�b�g�Ɛ����̏o���x��</A>
<A HREF="http://nojiriko.asia/prolog/c132_88.html">c132-88:�A���t�@�x�b�g��1���̕��������\��</A>
109 �F�f�t�H���g�̖����������F2009/11/17(��) 07:42:02
http://pc12.2ch.net/test/read.cgi/tech/1258158172/97
# struct meibo {char name[20];int eigo; int kokugo;}
# �݂����ȍ\���̂�meibo_t[]�Ƀ��[�v�łǂ�ǂ�f�[�^�����Đ��������̂ł����ǂ�����Ηǂ��ł����H
# int a= 0; meibo[a]=�݂����ɂ���ƃG���[���ł܂����A����[0]�ɂǂ�ǂ���������Ă�悤�ȋC�����܂�
# };
#
# struct meibo {char name[20];int eigo; int kokugo;}
# �݂����ȍ\���̂�meibo_t[]�Ƀ��[�v�łǂ�ǂ�f�[�^�����Đ��������̂ł����ǂ�����Ηǂ��ł����H
# int a= 0; meibo[a]=�݂����ɂ���ƃG���[���ł܂����A����[0]�ɂǂ�ǂ���������Ă�悤�ȋC�����܂�
# };
#
110 �F�f�t�H���g�̖����������F2009/11/17(��) 07:43:58
111 �F�f�t�H���g�̖����������F2009/11/17(��) 07:47:06
>>110 end_of_file��F��������̂�Y�ꂽ!
membo(L) :-
�@�@findall(L2,(get_line(Line),(Line=end_of_file,!,fail;split(Line,[','],L2))),L).
membo(L) :-
�@�@findall(L2,(get_line(Line),(Line=end_of_file,!,fail;split(Line,[','],L2))),L).
112 �F�f�t�H���g�̖����������F2009/11/17(��) 09:06:09
>>111 �܂��܂���ςȎ��s!! get_line/1�͔萫�ł͂Ȃ������Brepeat/1���K�v�B
membo(L) :-
�@�@findall(L2,(repeat,get_line(Line),(Line=end_of_file,!,fail;split(Line,[','],))),L).
membo(L) :-
�@�@findall(L2,(repeat,get_line(Line),(Line=end_of_file,!,fail;split(Line,[','],))),L).
113 �F�f�t�H���g�̖����������F2009/11/17(��) 09:53:06
���̏o��Ȃ̂ł����A���ꂾ���͍ڂ��Ă����܂��傤
http://pc12.2ch.net/test/read.cgi/tech/1258158172/81
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�F���J���Ɣ閧�������A�������g���Í����ƕ���
�����s���v���O�����������B�iRSA���j
# [4] �����F 2009/11/17���܂�
# �Í����ƕ������̎菇��
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10129.txt
#
http://pc12.2ch.net/test/read.cgi/tech/1258158172/81
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�F���J���Ɣ閧�������A�������g���Í����ƕ���
�����s���v���O�����������B�iRSA���j
# [4] �����F 2009/11/17���܂�
# �Í����ƕ������̎菇��
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10129.txt
#
114 �F�f�t�H���g�̖����������F2009/11/18(��) 05:49:29
http://pc12.2ch.net/test/read.cgi/tech/1258158172/123
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������GHIJKLMABCDERSTUVWFNOPQXYZ�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������v���O���������B
# ��F���͕�����CQ�ł������Ƃ�CDERSTUVWFNOPQ��\������B
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������GHIJKLMABCDERSTUVWFNOPQXYZ�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������v���O���������B
# ��F���͕�����CQ�ł������Ƃ�CDERSTUVWFNOPQ��\������B
115 �F�f�t�H���g�̖����������F2009/11/18(��) 05:55:10
http://pc12.2ch.net/test/read.cgi/tech/1258158172/118
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10132.txt
#
# �R���s���[�^�[�Ɋ�rand���g�p���ĂO�`�X�X�̐�������点�A
# �L�[�{�[�h��萔����͂��A
# �R���s���[�^�[�̍�������̕����傫����u�����Ƒ傫���ł��v�ƕ\�����A�ē���
# �R���s���[�^�[�̍�������̕�����������u�����Ə������ł��v�ƕ\�����A�ē���
# �R���s���[�^�[�̍�������ƈ�v����u������ł��v�ƕ\�����A�I��
# ���͎��ɂ́A����ڂ̃g���C�����\�����邱�ƁB
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10132.txt
#
# �R���s���[�^�[�Ɋ�rand���g�p���ĂO�`�X�X�̐�������点�A
# �L�[�{�[�h��萔����͂��A
# �R���s���[�^�[�̍�������̕����傫����u�����Ƒ傫���ł��v�ƕ\�����A�ē���
# �R���s���[�^�[�̍�������̕�����������u�����Ə������ł��v�ƕ\�����A�ē���
# �R���s���[�^�[�̍�������ƈ�v����u������ł��v�ƕ\�����A�I��
# ���͎��ɂ́A����ڂ̃g���C�����\�����邱�ƁB
116 �F�f�t�H���g�̖����������F2009/11/18(��) 05:57:11
http://pc12.2ch.net/test/read.cgi/tech/1258158172/132
# [1] ���ƒP���FC�������
# [2] ��蕶(�܃R�[�h&�����N)�Ftxt�t�@�C��������GUI�v���O���������Ȃ���
# [5] ���̑��̐����F�v�]�Ȃ̂ł����A�n�j�{�^���������ƃR�s�[���ł���悤�Ȃ��̂ɂȂ��Ă���Ƃ��肪�����ł��B
#
# [1] ���ƒP���FC�������
# [2] ��蕶(�܃R�[�h&�����N)�Ftxt�t�@�C��������GUI�v���O���������Ȃ���
# [5] ���̑��̐����F�v�]�Ȃ̂ł����A�n�j�{�^���������ƃR�s�[���ł���悤�Ȃ��̂ɂȂ��Ă���Ƃ��肪�����ł��B
#
117 �F�f�t�H���g�̖����������F2009/11/18(��) 06:27:12
>>114
% Prolog
������('GHIJKLMABCDERSTUVWFNOPQX').
��������͂��ꂽ��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶��������o���ĕ\��
����(_��P������,_��Q������,_�\�����镛������) :-
�@�@������(_������),
�@�@atom_chars(_������,Chars),
�@�@append(_,[_��P������|R1],Chars),
�@�@append(Chars2,[_��Q������|_],R1),
�@�@atom_chars(_�\�����镛������,Chars2),
�@�@write_formatted('%t\n',[_�\�����镛������]).
% Prolog
������('GHIJKLMABCDERSTUVWFNOPQX').
��������͂��ꂽ��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶��������o���ĕ\��
����(_��P������,_��Q������,_�\�����镛������) :-
�@�@������(_������),
�@�@atom_chars(_������,Chars),
�@�@append(_,[_��P������|R1],Chars),
�@�@append(Chars2,[_��Q������|_],R1),
�@�@atom_chars(_�\�����镛������,Chars2),
�@�@write_formatted('%t\n',[_�\�����镛������]).
118 �F�f�t�H���g�̖����������F2009/11/18(��) 06:57:34
119 �F�f�t�H���g�̖����������F2009/11/18(��) 07:10:05
>>114
python
input1 = 'C'
input2 = 'Q'
str = 'GHIJKLMABCDERSTUVWFNOPQXYZ'
print str[str.index('C'):str.index('Q')+1]
python
input1 = 'C'
input2 = 'Q'
str = 'GHIJKLMABCDERSTUVWFNOPQXYZ'
print str[str.index('C'):str.index('Q')+1]
120 �F�f�t�H���g�̖����������F2009/11/18(��) 07:25:48
>>115
python(�C���f���g��������������)
import random
x = random.randint(0,99)
y = -1
cnt = 0
while x != y:
if y < x:
print u'�����Ƒ傫���ł�'
elif y > x:
print u'�����Ə������ł�'
print u'���s�� : ' + unicode(cnt)
cnt += 1
y = input(u'Input your answer: ' )
print u'������ł� ' + unicode(x)
python(�C���f���g��������������)
import random
x = random.randint(0,99)
y = -1
cnt = 0
while x != y:
if y < x:
print u'�����Ƒ傫���ł�'
elif y > x:
print u'�����Ə������ł�'
print u'���s�� : ' + unicode(cnt)
cnt += 1
y = input(u'Input your answer: ' )
print u'������ł� ' + unicode(x)
121 �F�f�t�H���g�̖����������F2009/11/18(��) 07:28:18
122 �F�f�t�H���g�̖����������F2009/11/18(��) 07:53:23
>>116
python
from easygui import *
import sys,shutil
source = open('./src.dat','w')
source.write('test')
source.close()
r = msgbox(u'���ҁ[���܂����H','Copy',ok_button='OK')
if r != None:
shutil.copyfile('./src.dat','./dst.dat')
python
from easygui import *
import sys,shutil
source = open('./src.dat','w')
source.write('test')
source.close()
r = msgbox(u'���ҁ[���܂����H','Copy',ok_button='OK')
if r != None:
shutil.copyfile('./src.dat','./dst.dat')
123 �F�f�t�H���g�̖����������F2009/11/18(��) 08:06:50
>>114
% Prolog ���ۂɂ̓��C�u��������q��sub_atom/10���g���āA
% http://nojiriko.asia/prolog/t264_u.html
'2�̕����ɋ��܂ꂽ��������'(_������,_��ꕶ����,_�����,_��������) :-
�@�@sub_atom(_������,_,1,_,_,_��ꕶ����,_�c�蕶����,_,_,_),
�@�@sub_atom(_�c�蕶����,_,1,_,_��������,_�����,_,_,_,_).
% �\���͏ȗ������B
% Prolog ���ۂɂ̓��C�u��������q��sub_atom/10���g���āA
% http://nojiriko.asia/prolog/t264_u.html
'2�̕����ɋ��܂ꂽ��������'(_������,_��ꕶ����,_�����,_��������) :-
�@�@sub_atom(_������,_,1,_,_,_��ꕶ����,_�c�蕶����,_,_,_),
�@�@sub_atom(_�c�蕶����,_,1,_,_��������,_�����,_,_,_,_).
% �\���͏ȗ������B
124 �F�f�t�H���g�̖����������F2009/11/18(��) 11:22:26
http://pc12.2ch.net/test/read.cgi/tech/1258158172/141
# [1] ���ƒP���F�b����
# [2] ��蕶�F
# �����l�Ƃ��ē��͂��ꂽ����f������������v���O�������쐬����B
# �\���́A612 = 2^2*3^2*17�̂悤�ɂ���A�����2��2��~3��2��~17�Ƃ����Ӗ��ł�
��
#
# ���ʂɑS���~�ŕ\��������̂͂ł�����ł����A612 = 2^2*3^2*17��^�������A�`�̉���ƕ\������������킩��܂���ł����B
# ��낵�����˂������܂��B
#
# [1] ���ƒP���F�b����
# [2] ��蕶�F
# �����l�Ƃ��ē��͂��ꂽ����f������������v���O�������쐬����B
# �\���́A612 = 2^2*3^2*17�̂悤�ɂ���A�����2��2��~3��2��~17�Ƃ����Ӗ��ł�
��
#
# ���ʂɑS���~�ŕ\��������̂͂ł�����ł����A612 = 2^2*3^2*17��^�������A�`�̉���ƕ\������������킩��܂���ł����B
# ��낵�����˂������܂��B
#
125 �F�f�t�H���g�̖����������F2009/11/18(��) 11:37:36
http://pc12.2ch.net/test/read.cgi/tech/1258158172/140
#
# ���d�J��Ԃ������g���āCz=1-(x^2+y^2)��z=0���ʂƂ� �͂܂��̈�̑̐ς̋ߎ��l�����߂�D
#
# �ł��B��낵�����˂������܂��B
#
#
# ���d�J��Ԃ������g���āCz=1-(x^2+y^2)��z=0���ʂƂ� �͂܂��̈�̑̐ς̋ߎ��l�����߂�D
#
# �ł��B��낵�����˂������܂��B
#
126 �F�f�t�H���g�̖����������F2009/11/18(��) 13:03:21
>>124
% Prolog
�f��������\��(N) :- �f��������(N,X),write_formatted('%t = %t\n',[X]).
�f��������(N,X) :- �f��������(2,N,N,0,[],L),�f�����������\��(L,X).
�f��������(U,M,N,C,X,X) :- U >= N // 2,!.
�f��������(U,M,N,0,Y,X) :- member(J^_,Y),0 is U mod J,U2 is U + 2,�f��������(U2,N,N,0,Y,X),!.
�f��������(2,M,N,0,Y,X) :- \+(0 is M mod 2),�f��������(3,N,N,0,Y,X),!.
�f��������(2,M,N,C,Y,X) :- \+(0 is M mod 2),�f��������(3,N,N,0,[2^C|Y],X),!.
�f��������(U,M,N,0,Y,X) :- \+(U=2),\+(0 is M mod U),U2 is U + 2,�f��������(U2,N,N,0,Y,X),!.
�f��������(U,M,N,C,Y,X) :- \+(U=2),\+(0 is M mod U),U2 is U + 2,�f��������(U2,N,N,0,[U^C|Y],X),!.
�f��������(U,M,N,C,Y,X) :- 0 is M mod U,C2 is C + 1,M1 is M // U,�f��������(U,M1,N,C2,Y,X).
�f�����������\��([A],A) :- !.
�f�����������\��([A|R1],B * A) :- �f�����������\��(R1,B).
% Prolog
�f��������\��(N) :- �f��������(N,X),write_formatted('%t = %t\n',[X]).
�f��������(N,X) :- �f��������(2,N,N,0,[],L),�f�����������\��(L,X).
�f��������(U,M,N,C,X,X) :- U >= N // 2,!.
�f��������(U,M,N,0,Y,X) :- member(J^_,Y),0 is U mod J,U2 is U + 2,�f��������(U2,N,N,0,Y,X),!.
�f��������(2,M,N,0,Y,X) :- \+(0 is M mod 2),�f��������(3,N,N,0,Y,X),!.
�f��������(2,M,N,C,Y,X) :- \+(0 is M mod 2),�f��������(3,N,N,0,[2^C|Y],X),!.
�f��������(U,M,N,0,Y,X) :- \+(U=2),\+(0 is M mod U),U2 is U + 2,�f��������(U2,N,N,0,Y,X),!.
�f��������(U,M,N,C,Y,X) :- \+(U=2),\+(0 is M mod U),U2 is U + 2,�f��������(U2,N,N,0,[U^C|Y],X),!.
�f��������(U,M,N,C,Y,X) :- 0 is M mod U,C2 is C + 1,M1 is M // U,�f��������(U,M1,N,C2,Y,X).
�f�����������\��([A],A) :- !.
�f�����������\��([A|R1],B * A) :- �f�����������\��(R1,B).
127 �F�f�t�H���g�̖����������F2009/11/18(��) 14:02:25
128 �F�f�t�H���g�̖����������F2009/11/18(��) 14:05:40
>>127
% Prolog
�A�h���X���ɒlj�(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- assertz(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)).
�A�h���X������폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- retract(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)).
�A�h���X������d���폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :-
�@�@retract(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)),
�@�@write_formatted('%t\t%t\t%t\t\n',[_����,_�d�b�ԍ��Ȃ��,_�A�h���X]),
�@�@write('���̐߂��폜���܂��� y or n : '),get_line(Line),
�@�@�A�h���X������d���폜�̓�(_����,_�d�b�ԍ��Ȃ��,_�A�h���X).
�@�@fail.
�A�h���X������d���폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X).
�A�h���X������d���폜�̓�(y,_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- !.
�A�h���X������d���폜�̓�(y,_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :-
�@�@\+(Line = y),
�@�@asserta(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)),!.
�A�h���X����\��(_����) :-
�@�@�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X),
�@�@write_formatted('\n%t\t%t\t%t\t\n',[_����,_�d�b�ԍ��Ȃ��,_�A�h���X]).
% Prolog
�A�h���X���ɒlj�(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- assertz(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)).
�A�h���X������폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- retract(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)).
�A�h���X������d���폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :-
�@�@retract(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)),
�@�@write_formatted('%t\t%t\t%t\t\n',[_����,_�d�b�ԍ��Ȃ��,_�A�h���X]),
�@�@write('���̐߂��폜���܂��� y or n : '),get_line(Line),
�@�@�A�h���X������d���폜�̓�(_����,_�d�b�ԍ��Ȃ��,_�A�h���X).
�@�@fail.
�A�h���X������d���폜(_����,_�d�b�ԍ��Ȃ��,_�A�h���X).
�A�h���X������d���폜�̓�(y,_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :- !.
�A�h���X������d���폜�̓�(y,_����,_�d�b�ԍ��Ȃ��,_�A�h���X) :-
�@�@\+(Line = y),
�@�@asserta(�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X)),!.
�A�h���X����\��(_����) :-
�@�@�A�h���X��(_����,_�d�b�ԍ��Ȃ��,_�A�h���X),
�@�@write_formatted('\n%t\t%t\t%t\t\n',[_����,_�d�b�ԍ��Ȃ��,_�A�h���X]).
129 �F�f�t�H���g�̖����������F2009/11/18(��) 22:39:53
>>125
% Prolog
c132_125(_���ݐ�,_�̐ς̋ߎ��l) :-
�@�@_���� is 1 / _���ݐ�,
�@�@�f�ʐς̐ςݏグ(_����,0.0,L),
�@�@��`�̐ςݏグ(L,_����,_�̐ς̋ߎ��l).
�f�ʐς̐ςݏグ(_����,P,[]) :- P > 1.0,!.
�f�ʐς̐ςݏグ(_����,P,[U1|R]) :-
�@�@U1 is (sqrt((P-1.0) * (-1.0)) ^ 2) * pi,
�@�@P2 is P + _����,
�@�@�f�ʐς̐ςݏグ(_����,P2,R).
��`�̐ςݏグ([A,B],H,S) :- S is (A + B) / 2 * H,!.
��`�̐ςݏグ([A,B|R],H,S) :-
�@�@U is (A + B) / 2 * H,
�@�@��`�̐ςݏグ([B|R],H,S1),
�@�@S is S1 + U.
% Prolog
c132_125(_���ݐ�,_�̐ς̋ߎ��l) :-
�@�@_���� is 1 / _���ݐ�,
�@�@�f�ʐς̐ςݏグ(_����,0.0,L),
�@�@��`�̐ςݏグ(L,_����,_�̐ς̋ߎ��l).
�f�ʐς̐ςݏグ(_����,P,[]) :- P > 1.0,!.
�f�ʐς̐ςݏグ(_����,P,[U1|R]) :-
�@�@U1 is (sqrt((P-1.0) * (-1.0)) ^ 2) * pi,
�@�@P2 is P + _����,
�@�@�f�ʐς̐ςݏグ(_����,P2,R).
��`�̐ςݏグ([A,B],H,S) :- S is (A + B) / 2 * H,!.
��`�̐ςݏグ([A,B|R],H,S) :-
�@�@U is (A + B) / 2 * H,
�@�@��`�̐ςݏグ([B|R],H,S1),
�@�@S is S1 + U.
130 �F�f�t�H���g�̖����������F2009/11/19(��) 00:46:52
http://pc12.2ch.net/test/read.cgi/tech/1248012902/487
#�y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/834.txt
# [4] �T�����̃A���S���Y���ɂ��āC�ȉ��̖₢�ɓ�����
# (1) �傫�Ȏ҂��珇�Ƀf�[�^������ł���z���ΏۂƂ���C2 ���T���̃v
# ���O�����R�[�h�������D �v���O�����C���^�t�F�[�X(API) ��
# bsearch(int key)�Ƃ���D
#
# (2) �z���ΏۂƂ���ԕ��@��p���Ȃ����`�T���̃v���O�����������D�v��
# �O�����C���^�t�F�[�X(API)��lsearch(int key)�Ƃ���D
#
# (3) �z���ΏۂƂ���ԕ��@��p������`�T���̃v���O�����������D�������C
# �f�[�^�����t�ɂȂ邱�Ƃ͂Ȃ��Ɖ��肵�ėǂ��D�v���O�����C���^�t�F
# �[�X(API)��ssearch(int key)�Ƃ���D
#
# [5] �L���[��z��ŕ\�������Ƃ��C�f�[�^���L���[�ɑ}������insert(int i)
# �ƃf�[�^���L���[�����菜��remove()�̃v���O�����R�[�h�������D������
# �L���[�����t�ɂȂ邱�Ƃ͍l���Ȃ��Ă��ǂ��D�܂胊���O�L���[�ɂ���K�v
# �͂Ȃ��D
#
# [6] �A�����X�g�ŃX�^�b�N��\�������Ƃ��C�f�[�^���X�^�b�N�ɑ}������
# push(int i)�ƃf�[�^���X�^�b�N�����菜��pop()�̃v���O�����R�[�h����
# ���D�������X�^�b�N����̎���pop ���Ăꂽ�Ƃ��ɂ́C�G���[���b�Z�[�W��
# �o���悤�ɂ��邱�ƁD�i�A�����X�g���g���ƁC�����I�ɂ̓X�^�b�N�����t�ɂȂ�
# ���Ƃ͂Ȃ��̂ŁCpush �ɂ�����G���[���b�Z�[�W�͕s�v�j
#�y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/834.txt
# [4] �T�����̃A���S���Y���ɂ��āC�ȉ��̖₢�ɓ�����
# (1) �傫�Ȏ҂��珇�Ƀf�[�^������ł���z���ΏۂƂ���C2 ���T���̃v
# ���O�����R�[�h�������D �v���O�����C���^�t�F�[�X(API) ��
# bsearch(int key)�Ƃ���D
#
# (2) �z���ΏۂƂ���ԕ��@��p���Ȃ����`�T���̃v���O�����������D�v��
# �O�����C���^�t�F�[�X(API)��lsearch(int key)�Ƃ���D
#
# (3) �z���ΏۂƂ���ԕ��@��p������`�T���̃v���O�����������D�������C
# �f�[�^�����t�ɂȂ邱�Ƃ͂Ȃ��Ɖ��肵�ėǂ��D�v���O�����C���^�t�F
# �[�X(API)��ssearch(int key)�Ƃ���D
#
# [5] �L���[��z��ŕ\�������Ƃ��C�f�[�^���L���[�ɑ}������insert(int i)
# �ƃf�[�^���L���[�����菜��remove()�̃v���O�����R�[�h�������D������
# �L���[�����t�ɂȂ邱�Ƃ͍l���Ȃ��Ă��ǂ��D�܂胊���O�L���[�ɂ���K�v
# �͂Ȃ��D
#
# [6] �A�����X�g�ŃX�^�b�N��\�������Ƃ��C�f�[�^���X�^�b�N�ɑ}������
# push(int i)�ƃf�[�^���X�^�b�N�����菜��pop()�̃v���O�����R�[�h����
# ���D�������X�^�b�N����̎���pop ���Ăꂽ�Ƃ��ɂ́C�G���[���b�Z�[�W��
# �o���悤�ɂ��邱�ƁD�i�A�����X�g���g���ƁC�����I�ɂ̓X�^�b�N�����t�ɂȂ�
# ���Ƃ͂Ȃ��̂ŁCpush �ɂ�����G���[���b�Z�[�W�͕s�v�j
131 �F�f�t�H���g�̖����������F2009/11/19(��) 05:25:28
>>130
% Prolog
% [5]
insert(E,X-[E|Y],X-Y).
remove(E,[E|X]-Y,X-Y).
new(X-X).
empty(X-Y) :- X == Y.
% remove/3�͑g���q��Ƃ��đ��݂���B�����ł͕ʂɃ��[�U���o�^�\�Ƃ����B
% ?- remove([c,d],[a,b,c,d,e],X).
% X = [a,b,e]
% [6]
push(I,Stack,[I|Stack]).
pop(I,[I|Stack],Stack).
pop(I,[],[]) :- write('Error:stack empty!\n').
% Prolog
% [5]
insert(E,X-[E|Y],X-Y).
remove(E,[E|X]-Y,X-Y).
new(X-X).
empty(X-Y) :- X == Y.
% remove/3�͑g���q��Ƃ��đ��݂���B�����ł͕ʂɃ��[�U���o�^�\�Ƃ����B
% ?- remove([c,d],[a,b,c,d,e],X).
% X = [a,b,e]
% [6]
push(I,Stack,[I|Stack]).
pop(I,[I|Stack],Stack).
pop(I,[],[]) :- write('Error:stack empty!\n').
132 �F�f�t�H���g�̖����������F2009/11/19(��) 05:31:54
>>130
[4] Prolog�ɂ͔z�Ȃ����߁A���Ԉʒu�v�f��̂ɕK�������I��
���X�g����J��K�v������B���������āA���̖��̉��Ƃ��ĈӖ���
����v���O��������邱�Ƃ͂ł��Ȃ��B
[4] Prolog�ɂ͔z�Ȃ����߁A���Ԉʒu�v�f��̂ɕK�������I��
���X�g����J��K�v������B���������āA���̖��̉��Ƃ��ĈӖ���
����v���O��������邱�Ƃ͂ł��Ȃ��B
133 �F�f�t�H���g�̖����������F2009/11/19(��) 12:39:17
http://pc12.2ch.net/test/read.cgi/tech/1258158172/157
# [1] ���ƒP���F �A���S���Y��&�A�v���P�[�V����
# [2] ��蕶(�܃R�[�h&�����N)�F���|�\��csv�t�@�C���ō���Ă��܂��B
# �e�s�̏��́A
# �ڋq��,�O���J�z��,����������,�������㍂,���ߓ��t
# �ł���A���ߓ��t�ŏ����ɐ��Ă��āA���o�����璷�����͂���܂���B
# ����͖���P�������邽�߁A��l�̌ڋq����������Ȃ����Ƃɂ��܂��B
# ���čX�V�v���O�����̃o�O����A���錎�̑O���J�z����
# ���̑O���� �O���J�z��-����������+�������㍂ �ƕs�����ɂȂ��Ă��܂��܂����B
# �s�����ɂȂ����ȍ~�̏�������A
# ����ȑO�̏��̓����������A�������㍂�A���ߓ��t�ɂ��Ă͌�肪�Ȃ��Ƃ��āA
# 1) �s����������T��
# 2) ����ȑO�̂��ׂĂ̑O���J�z����S�̂���������悤�ɏ��������Ȃ����B
# �t�@�C���͈�U�ʂ̃t�@�C��(�Ⴆ��/tmp/xxxxxx)�ɐ��������̂�����A
# ���̌�A����csv�t�@�C���ɏ����߂��Ȃ����B
# [5] ���̑��̐����F ���t�Ȃǂ̎������͎��R�ɍH�v���Ă悢�B
# [1] ���ƒP���F �A���S���Y��&�A�v���P�[�V����
# [2] ��蕶(�܃R�[�h&�����N)�F���|�\��csv�t�@�C���ō���Ă��܂��B
# �e�s�̏��́A
# �ڋq��,�O���J�z��,����������,�������㍂,���ߓ��t
# �ł���A���ߓ��t�ŏ����ɐ��Ă��āA���o�����璷�����͂���܂���B
# ����͖���P�������邽�߁A��l�̌ڋq����������Ȃ����Ƃɂ��܂��B
# ���čX�V�v���O�����̃o�O����A���錎�̑O���J�z����
# ���̑O���� �O���J�z��-����������+�������㍂ �ƕs�����ɂȂ��Ă��܂��܂����B
# �s�����ɂȂ����ȍ~�̏�������A
# ����ȑO�̏��̓����������A�������㍂�A���ߓ��t�ɂ��Ă͌�肪�Ȃ��Ƃ��āA
# 1) �s����������T��
# 2) ����ȑO�̂��ׂĂ̑O���J�z����S�̂���������悤�ɏ��������Ȃ����B
# �t�@�C���͈�U�ʂ̃t�@�C��(�Ⴆ��/tmp/xxxxxx)�ɐ��������̂�����A
# ���̌�A����csv�t�@�C���ɏ����߂��Ȃ����B
# [5] ���̑��̐����F ���t�Ȃǂ̎������͎��R�ɍH�v���Ă悢�B
134 �F�f�t�H���g�̖����������F2009/11/19(��) 12:42:16
135 �F�f�t�H���g�̖����������F2009/11/19(��) 18:46:14
http://pc12.2ch.net/test/read.cgi/tech/1258320456/20
# ���鎩�R��n�ɂ��āCn�̖̂����Cn��菬�������̘̂a��n�ƈ�v����Ƃ��Cn�͊��S���ƌĂ��D
#
# ���Ƃ��C6�̖� 1, 2, 3, 6 �ł���C
#
# 6 = 1 + 2 + 3
#
# �Ȃ̂ŁC6�͊��S���ł���D
#
# 1000�ȉ��̂��ׂĂ̊��S����\������v���O�������쐬����D
#
# ���鎩�R��n�ɂ��āCn�̖̂����Cn��菬�������̘̂a��n�ƈ�v����Ƃ��Cn�͊��S���ƌĂ��D
#
# ���Ƃ��C6�̖� 1, 2, 3, 6 �ł���C
#
# 6 = 1 + 2 + 3
#
# �Ȃ̂ŁC6�͊��S���ł���D
#
# 1000�ȉ��̂��ׂĂ̊��S����\������v���O�������쐬����D
#
136 �F�f�t�H���g�̖����������F2009/11/19(��) 18:47:58
>>135
% Prolog
py2_20 :- for(1,N,1000),���S��(N),write_formatted('%t\n',[N]),N=1000,!.
py2_20.
���S��(N) :- findsum(M,(for(1,M,N),0 is N mod M,M < N),X),N is truncate(X).
% Prolog
py2_20 :- for(1,N,1000),���S��(N),write_formatted('%t\n',[N]),N=1000,!.
py2_20.
���S��(N) :- findsum(M,(for(1,M,N),0 is N mod M,M < N),X),N is truncate(X).
137 �F�f�t�H���g�̖����������F2009/11/19(��) 18:52:18
http://pc12.2ch.net/test/read.cgi/tech/1258158172/158
# [1] ���ƒP���F �v���O�������K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ����n��ǂݍ��݁A�ŊO���̒���n�̐����̂Ƃ�����܂����}���o�͂���v���O���������Ȃ����B
#
# [1] ���ƒP���F �v���O�������K
# [2] ��蕶(�܃R�[�h&�����N)�F
# ����n��ǂݍ��݁A�ŊO���̒���n�̐����̂Ƃ�����܂����}���o�͂���v���O���������Ȃ����B
#
138 �F�f�t�H���g�̖����������F2009/11/20(��) 05:40:49
http://pc12.2ch.net/test/read.cgi/tech/1258158172/168
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10137.txt
# [�ۑ�1-1]�@���`�T��
# �@�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A��������
# ���ʂ����ׂĕ\������v���O�������쐬���Ȃ���.�������A�z�� a ��1����30�܂ł̗�����100������
# ����Ƃ���.�܂��A���͂̑O�ɔz�� a �̓��e��10������ĕ\�����Ȃ���.
#
# [�ۑ�1-2]�@���`�T���i�ԕ��@�j
#�@�ԕ��@��p���ĉۑ�1-1�̃v���O��������������,�L�[�{�[�h����̓��͒l��1�`30�ȊO�̏ꍇ�A���邢��
# �z�� a �ɖړI�̃f�[�^�����݂��Ȃ��ꍇ�Ɂu������܂���ł����v�ƕ\������v���O�������쐬���Ȃ���.
# �������A�ړI�̃f�[�^�����݂���ꍇ��,�ŏ��Ɍ��������v�f�����\�������邱��.
#
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10137.txt
# [�ۑ�1-1]�@���`�T��
# �@�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A��������
# ���ʂ����ׂĕ\������v���O�������쐬���Ȃ���.�������A�z�� a ��1����30�܂ł̗�����100������
# ����Ƃ���.�܂��A���͂̑O�ɔz�� a �̓��e��10������ĕ\�����Ȃ���.
#
# [�ۑ�1-2]�@���`�T���i�ԕ��@�j
#�@�ԕ��@��p���ĉۑ�1-1�̃v���O��������������,�L�[�{�[�h����̓��͒l��1�`30�ȊO�̏ꍇ�A���邢��
# �z�� a �ɖړI�̃f�[�^�����݂��Ȃ��ꍇ�Ɂu������܂���ł����v�ƕ\������v���O�������쐬���Ȃ���.
# �������A�ړI�̃f�[�^�����݂���ꍇ��,�ŏ��Ɍ��������v�f�����\�������邱��.
#
139 �F�f�t�H���g�̖����������F2009/11/20(��) 05:45:33
http://pc12.2ch.net/test/read.cgi/tech/1258158172/172
# �_���̖��ł���
#
# 95�N�u�������N�ň�ԏo�����ǂ��v
# 96�N�u10�N��1�x�̈�i�v
# 97�N�u1976�N�ȗ��̕i���v
# 98�N�u10�N��1�x�̓�����N�v
# 99�N�u�i���͍�N���ǂ��v
# 00�N�u�o���͏�X�Ő\�����̖����d�オ��v
# 01�N�u����10�N�ōō��v
# 02�N�u�ߋ�10�N�ōō��ƌ���ꂽ01�N������o���h���v�u1995�N�ȗ��̏o���v
# 03�N�u100�N��1�x�̏o���v�u�ߔN�ɂȂ��ǂ��o���v
# 04�N�u���肪�������X�̏o���h���v
# 05�N�u�������N�ōō��v
# 06�N�u��N���l�ǂ��o���h���v
# 07�N�u�_�炩���ʎ������L���ŏ㎿�Ȗ��킢�v
# 08�N�u�L���ȉʎ����ƒ��悢�_�������a������
# 09�N�u�T�O�N�ɂP�x�̏o���h���v
#
# �ł�
# �_���̖��ł���
#
# 95�N�u�������N�ň�ԏo�����ǂ��v
# 96�N�u10�N��1�x�̈�i�v
# 97�N�u1976�N�ȗ��̕i���v
# 98�N�u10�N��1�x�̓�����N�v
# 99�N�u�i���͍�N���ǂ��v
# 00�N�u�o���͏�X�Ő\�����̖����d�オ��v
# 01�N�u����10�N�ōō��v
# 02�N�u�ߋ�10�N�ōō��ƌ���ꂽ01�N������o���h���v�u1995�N�ȗ��̏o���v
# 03�N�u100�N��1�x�̏o���v�u�ߔN�ɂȂ��ǂ��o���v
# 04�N�u���肪�������X�̏o���h���v
# 05�N�u�������N�ōō��v
# 06�N�u��N���l�ǂ��o���h���v
# 07�N�u�_�炩���ʎ������L���ŏ㎿�Ȗ��킢�v
# 08�N�u�L���ȉʎ����ƒ��悢�_�������a������
# 09�N�u�T�O�N�ɂP�x�̏o���h���v
#
# �ł�
140 �F�f�t�H���g�̖����������F2009/11/20(��) 05:52:14
http://pc12.2ch.net/test/read.cgi/tech/1248012902/493
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/840.txt
#
# ���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������B
# 36�i����{0�`9�CA�`Z}�̕������g�p���Ȃ�������Ȃ��B
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/840.txt
#
# ���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������B
# 36�i����{0�`9�CA�`Z}�̕������g�p���Ȃ�������Ȃ��B
141 �F�f�t�H���g�̖����������F2009/11/20(��) 05:55:02
http://pc12.2ch.net/test/read.cgi/tech/1258320456/30
# 1. ����n��^����ƁCn���f���̎���True���C�f���łȂ��Ƃ���False��Ԃ���prime(n) ���`����D
# 2. �� prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������v���O�����������D�������������\�����邱�ƁD
#
# Hint
#
# 1. �f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)�D
# 2. ����������ƁC2����n-1�܂ł̂�����ł�n�������Ȃ��ꍇ�Cn�͑f���ł���(�������Cn > 2�̏ꍇ)�D
# 3. �܂��́C2����n-1�܂ł̂����ꂩ1�ł�n������邱�Ƃ��ł���ꍇ�Cn�͑f���ł͂Ȃ�(����)�D
#
# 1. ����n��^����ƁCn���f���̎���True���C�f���łȂ��Ƃ���False��Ԃ���prime(n) ���`����D
# 2. �� prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������v���O�����������D�������������\�����邱�ƁD
#
# Hint
#
# 1. �f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)�D
# 2. ����������ƁC2����n-1�܂ł̂�����ł�n�������Ȃ��ꍇ�Cn�͑f���ł���(�������Cn > 2�̏ꍇ)�D
# 3. �܂��́C2����n-1�܂ł̂����ꂩ1�ł�n������邱�Ƃ��ł���ꍇ�Cn�͑f���ł͂Ȃ�(����)�D
#
142 �F�f�t�H���g�̖����������F2009/11/20(��) 06:30:50
>>139
% Prolog ��������ɂ���A���i�Kw �������̘_���I�ȉ�͂͂�������y���܂��Ă��������܂��B
�{�[�W�����E�k�[�{�[��搂�����('95�N','�������N�ň�ԏo�����ǂ�').
�{�[�W�����E�k�[�{�[��搂�����('96�N','10�N��1�x�̈�i').
�{�[�W�����E�k�[�{�[��搂�����('97�N','1976�N�ȗ��̕i��').
�{�[�W�����E�k�[�{�[��搂�����('98�N','10�N��1�x�̓�����N').
�{�[�W�����E�k�[�{�[��搂�����('99�N','�i���͍�N���ǂ�').
�{�[�W�����E�k�[�{�[��搂�����('00�N','�o���͏�X�Ő\�����̖����d�オ��').
�{�[�W�����E�k�[�{�[��搂�����('01�N','����10�N�ōō�').
�{�[�W�����E�k�[�{�[��搂�����('02�N','�ߋ�10�N�ōō��ƌ���ꂽ01�N������o���h��,1995�N�ȗ��̏o��').
�{�[�W�����E�k�[�{�[��搂�����('03�N','100�N��1�x�̏o��,�ߔN�ɂȂ��ǂ��o��').
�{�[�W�����E�k�[�{�[��搂�����('04�N','���肪�������X�̏o���h��').
�{�[�W�����E�k�[�{�[��搂�����('05�N','�������N�ōō�').
�{�[�W�����E�k�[�{�[��搂�����('06�N','��N���l�ǂ��o���h��').
�{�[�W�����E�k�[�{�[��搂�����('07�N','�_�炩���ʎ������L���ŏ㎿�Ȗ��킢').
�{�[�W�����E�k�[�{�[��搂�����('08�N','�L���ȉʎ����ƒ��悢�_�������a������').
�{�[�W�����E�k�[�{�[��搂�����('09�N','�T�O�N�ɂP�x�̏o���h��').
% Prolog ��������ɂ���A���i�Kw �������̘_���I�ȉ�͂͂�������y���܂��Ă��������܂��B
�{�[�W�����E�k�[�{�[��搂�����('95�N','�������N�ň�ԏo�����ǂ�').
�{�[�W�����E�k�[�{�[��搂�����('96�N','10�N��1�x�̈�i').
�{�[�W�����E�k�[�{�[��搂�����('97�N','1976�N�ȗ��̕i��').
�{�[�W�����E�k�[�{�[��搂�����('98�N','10�N��1�x�̓�����N').
�{�[�W�����E�k�[�{�[��搂�����('99�N','�i���͍�N���ǂ�').
�{�[�W�����E�k�[�{�[��搂�����('00�N','�o���͏�X�Ő\�����̖����d�オ��').
�{�[�W�����E�k�[�{�[��搂�����('01�N','����10�N�ōō�').
�{�[�W�����E�k�[�{�[��搂�����('02�N','�ߋ�10�N�ōō��ƌ���ꂽ01�N������o���h��,1995�N�ȗ��̏o��').
�{�[�W�����E�k�[�{�[��搂�����('03�N','100�N��1�x�̏o��,�ߔN�ɂȂ��ǂ��o��').
�{�[�W�����E�k�[�{�[��搂�����('04�N','���肪�������X�̏o���h��').
�{�[�W�����E�k�[�{�[��搂�����('05�N','�������N�ōō�').
�{�[�W�����E�k�[�{�[��搂�����('06�N','��N���l�ǂ��o���h��').
�{�[�W�����E�k�[�{�[��搂�����('07�N','�_�炩���ʎ������L���ŏ㎿�Ȗ��킢').
�{�[�W�����E�k�[�{�[��搂�����('08�N','�L���ȉʎ����ƒ��悢�_�������a������').
�{�[�W�����E�k�[�{�[��搂�����('09�N','�T�O�N�ɂP�x�̏o���h��').
143 �F�f�t�H���g�̖����������F2009/11/20(��) 07:30:38
>>142
% Prolog ���i�Kw ���Ƃ��E�E
�������N�ň�ԏo�����ǂ�(_�N�Y) :-
�@�@�o�����ǂ�(_�N�Y,_�o���),
�@�@�������N(_�N�Y,Term),
�@�@findall(_�o���2,(member(_�N�Y2,Term),�{�[�W�����E�k�[�{�[(_�N�Y2,_�o���2)),_�������N�̃{�[�W�����E�k�[�{�[�o����Ȃ��),
�@�@max(_�������N�̃{�[�W�����E�k�[�{�[�]���Ȃ��,_�o���).
% Prolog ���i�Kw ���Ƃ��E�E
�������N�ň�ԏo�����ǂ�(_�N�Y) :-
�@�@�o�����ǂ�(_�N�Y,_�o���),
�@�@�������N(_�N�Y,Term),
�@�@findall(_�o���2,(member(_�N�Y2,Term),�{�[�W�����E�k�[�{�[(_�N�Y2,_�o���2)),_�������N�̃{�[�W�����E�k�[�{�[�o����Ȃ��),
�@�@max(_�������N�̃{�[�W�����E�k�[�{�[�]���Ȃ��,_�o���).
144 �F�f�t�H���g�̖����������F2009/11/20(��) 07:50:07
>>143
% Prolog
�������N(_�N�Y,_�������N) :-
�@�@�N�����(_�N�Y,_�N),
�@�@��`�҂̔N��(_�N��),
�@�@���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,_���N),
�@�@_�N�_�N is _�N - _���N,
�@�@findall(_�N�Y2,(for(_�N�_�N,_�N2,_�N),concat_atom([_�N,�N],_�N�Y2)),_�������N).
�N�����(_�N�Y,_�N) :-
�@�@sub_atom(_�N�Y,S,_,_,�N),
�@�@sub_atom(_�N�Y,0,S,_,_�N2),
�@�@atom_to_term(_�N,_�N,_).
��`�҂̔N��(60).
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,3) :- _�N�� < 70.
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,5) :- _�N�� >= 70.
% Prolog
�������N(_�N�Y,_�������N) :-
�@�@�N�����(_�N�Y,_�N),
�@�@��`�҂̔N��(_�N��),
�@�@���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,_���N),
�@�@_�N�_�N is _�N - _���N,
�@�@findall(_�N�Y2,(for(_�N�_�N,_�N2,_�N),concat_atom([_�N,�N],_�N�Y2)),_�������N).
�N�����(_�N�Y,_�N) :-
�@�@sub_atom(_�N�Y,S,_,_,�N),
�@�@sub_atom(_�N�Y,0,S,_,_�N2),
�@�@atom_to_term(_�N,_�N,_).
��`�҂̔N��(60).
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,3) :- _�N�� < 70.
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,5) :- _�N�� >= 70.
145 �F�f�t�H���g�̖����������F2009/11/20(��) 10:42:39
>>141
% Prolog
prime(N,'True') :-
�@�@'�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N).
prime(N,'False') :-
�@�@\+('�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N)).
'�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N) :-
�@�@0 is N mod 1,
�@�@0 is N mod N,
�@�@\+((for(2,M,N-1),0 is N mod M)),
�@�@\+(N==1).
% Prolog
prime(N,'True') :-
�@�@'�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N).
prime(N,'False') :-
�@�@\+('�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N)).
'�f���Ƃ́C1�Ƃ��̐����g�݂̂�Ɏ����ł���(�������C1������)'(N) :-
�@�@0 is N mod 1,
�@�@0 is N mod N,
�@�@\+((for(2,M,N-1),0 is N mod M)),
�@�@\+(N==1).
146 �F�f�t�H���g�̖����������F2009/11/20(��) 10:47:29
>>141
% Prolog
'prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������' :-
�@�@for(1000,N,1),
�@�@prime(N,'True'),
�@�@write_formatted('%t\n',[N]),
�@�@N = 1.
'prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������'.
% Prolog
'prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������' :-
�@�@for(1000,N,1),
�@�@prime(N,'True'),
�@�@write_formatted('%t\n',[N]),
�@�@N = 1.
'prime(n) ���g�p���āC1000�ȉ��̑f�������ׂĕ\������'.
147 �F�f�t�H���g�̖����������F2009/11/20(��) 11:06:20
>>140
% Prolog ����͑O�X��875�Ɋ��o http://nojiriko.asia/prolog/t875.html
% �����ł͏�����������
http://nojiriko.asia/prolog/j68_493.html
% Prolog ����͑O�X��875�Ɋ��o http://nojiriko.asia/prolog/t875.html
% �����ł͏�����������
http://nojiriko.asia/prolog/j68_493.html
148 �F�f�t�H���g�̖����������F2009/11/20(��) 17:29:27
http://pc12.2ch.net/test/read.cgi/tech/1258158172/181
# [1] ���ƒP��:���𗘗p�����v���O����
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10144.txt
# �ۑ���e
# �G�߂�����܂����C�Ă̍��̓V�C�\��ł悭�u�s���w���v�Ƃ������t�������Ƃ�����Ǝv���܂��D
# �s���w���������Ə��������C�Q���邵���Ȃ�܂��D
# ���̕s���w���́C�C���i���m�ɂ͊����C���j�Ǝ��x�Ƃ���2�̐��l�ɂ�苁�߂��܂��D
# �C����t�i�x�j�C���x��h(��)�Ƃ���ƁC�ȉ��̎��ŕs���w�������߂��܂��D
# �s���w�� = 0.81�~ t + 0.01 �~ h �~ (0.99 �~ t - 14.3) + 46.3#
# ���̕s���w���ɂ��C���̕\�̂悤�Ȋ��o��悤�ł��D
# �s���w�� �`55 �`60 �`65 �`70 �`75 �`80 �`85 85�`
# [���]
# 2�̕��������_�^�idouble�^�j�̒l���u�C���i�x�j�v�Ɓu���x�i���j�v��\���l�Ƃ���2�̈����Ŏ��C
# �����̒l�ɂ���ċ��߂�ꂽ�s���w���̒l�idobule�^�j��߂�l�Ƃ������fukaishisuu�Ƃ��������ō쐬���悤�D
# ����ɁC����fukaishisuu���𗘗p���C�L�[�{�[�h����C���Ǝ��x�̒l����͂���ƁC
# �s���w���̒l�ɂ���đ̊����������t��\������v���O�������쐬���悤�D
# [1] ���ƒP��:���𗘗p�����v���O����
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10144.txt
# �ۑ���e
# �G�߂�����܂����C�Ă̍��̓V�C�\��ł悭�u�s���w���v�Ƃ������t�������Ƃ�����Ǝv���܂��D
# �s���w���������Ə��������C�Q���邵���Ȃ�܂��D
# ���̕s���w���́C�C���i���m�ɂ͊����C���j�Ǝ��x�Ƃ���2�̐��l�ɂ�苁�߂��܂��D
# �C����t�i�x�j�C���x��h(��)�Ƃ���ƁC�ȉ��̎��ŕs���w�������߂��܂��D
# �s���w�� = 0.81�~ t + 0.01 �~ h �~ (0.99 �~ t - 14.3) + 46.3#
# ���̕s���w���ɂ��C���̕\�̂悤�Ȋ��o��悤�ł��D
# �s���w�� �`55 �`60 �`65 �`70 �`75 �`80 �`85 85�`
# [���]
# 2�̕��������_�^�idouble�^�j�̒l���u�C���i�x�j�v�Ɓu���x�i���j�v��\���l�Ƃ���2�̈����Ŏ��C
# �����̒l�ɂ���ċ��߂�ꂽ�s���w���̒l�idobule�^�j��߂�l�Ƃ������fukaishisuu�Ƃ��������ō쐬���悤�D
# ����ɁC����fukaishisuu���𗘗p���C�L�[�{�[�h����C���Ǝ��x�̒l����͂���ƁC
# �s���w���̒l�ɂ���đ̊����������t��\������v���O�������쐬���悤�D
149 �F�f�t�H���g�̖����������F2009/11/20(��) 17:46:13
>>143 �ꃖ���Ԉ���Ă����B����
% Prolog
�������N(_�N�Y,_�������N) :-
�@�@�N�����(_�N�Y,_�N),
�@�@��`�҂̔N��(_�N��),
�@�@���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,_���N),
�@�@_�N�_�N is _�N - _���N,
�@�@findall(_�N�Y2,(for(_�N�_�N,_�N2,_�N),concat_atom([_�N2,�N],_�N�Y2)),_�������N).
�N�����(_�N�Y,_�N) :-
�@�@sub_atom(_�N�Y,S,_,_,�N),
�@�@sub_atom(_�N�Y,0,S,_,_�N2),
�@�@atom_to_term(_�N,_�N,_).
��`�҂̔N��(60).
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,3) :- _�N�� < 70.
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,5) :- _�N�� >= 70.
% Prolog
�������N(_�N�Y,_�������N) :-
�@�@�N�����(_�N�Y,_�N),
�@�@��`�҂̔N��(_�N��),
�@�@���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,_���N),
�@�@_�N�_�N is _�N - _���N,
�@�@findall(_�N�Y2,(for(_�N�_�N,_�N2,_�N),concat_atom([_�N2,�N],_�N�Y2)),_�������N).
�N�����(_�N�Y,_�N) :-
�@�@sub_atom(_�N�Y,S,_,_,�N),
�@�@sub_atom(_�N�Y,0,S,_,_�N2),
�@�@atom_to_term(_�N,_�N,_).
��`�҂̔N��(60).
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,3) :- _�N�� < 70.
���N�͒�`�҂̔N��ɂ���ĈقȂ�(_�N��,5) :- _�N�� >= 70.
150 �F�f�t�H���g�̖����������F2009/11/20(��) 19:08:56
>>148 ��s�厖�ȏ��������Ă���
# �s���w�� �`55 �`60 �`65 �`70 �`75 �`80�@ �`85�@�@�@ 85�`
# �@�̊� ���� ������ ���K ���K ���K ���s�� �s�� �s���ł��܂�Ȃ�
# �s���w�� �`55 �`60 �`65 �`70 �`75 �`80�@ �`85�@�@�@ 85�`
# �@�̊� ���� ������ ���K ���K ���K ���s�� �s�� �s���ł��܂�Ȃ�
151 �F�f�t�H���g�̖����������F2009/11/20(��) 20:26:11
>>148
% Prolog
�s���w���̊��\��(_�C��,_���x) :-
�@�@�s���w��(_�C��,_���x,_�s���w��),
�@�@�s���w���̊�(_�s���w��,_�̊�),
�@�@write_formatted('%t�ł�\n',[_�̊�]).
�s���w��(_�C��,_���x,_�s���w��) :-
�@�@_�s���w�� is truncate(0.81* _�C�� + 0.01 * _���x * (0.99 * _�C�� - 14.3) +
46.3).
�s���w���̊�(_�s���w��,������) :- _�s���w�� =< 55,!.
�s���w���̊�(_�s���w��,����) :- _�s���w�� =< 60,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 65,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 70,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 75,!.
�s���w���̊�(_�s���w��,���s��) :- _�s���w�� =< 80,!.
�s���w���̊�(_�s���w��,�s��) :- _�s���w�� =< 85,!.
�s���w���̊�(_�s���w��,�s���ł��܂�Ȃ�) :- _�s���w�� > 85.
% Prolog
�s���w���̊��\��(_�C��,_���x) :-
�@�@�s���w��(_�C��,_���x,_�s���w��),
�@�@�s���w���̊�(_�s���w��,_�̊�),
�@�@write_formatted('%t�ł�\n',[_�̊�]).
�s���w��(_�C��,_���x,_�s���w��) :-
�@�@_�s���w�� is truncate(0.81* _�C�� + 0.01 * _���x * (0.99 * _�C�� - 14.3) +
46.3).
�s���w���̊�(_�s���w��,������) :- _�s���w�� =< 55,!.
�s���w���̊�(_�s���w��,����) :- _�s���w�� =< 60,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 65,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 70,!.
�s���w���̊�(_�s���w��,���K) :- _�s���w�� =< 75,!.
�s���w���̊�(_�s���w��,���s��) :- _�s���w�� =< 80,!.
�s���w���̊�(_�s���w��,�s��) :- _�s���w�� =< 85,!.
�s���w���̊�(_�s���w��,�s���ł��܂�Ȃ�) :- _�s���w�� > 85.
152 �F�f�t�H���g�̖����������F2009/11/21(�y) 04:36:22
http://pc12.2ch.net/test/read.cgi/tech/1258158172/201
# [1] �A���S���Y��
# [2] ����͂���������̐����܂����͂��A���̐��������������͂��܂��B
# ���̒��ɘA����������ꍇ�A���̘A�����̌������߂ɓ��͂�����������������ʂ�\���B
# [1] �A���S���Y��
# [2] ����͂���������̐����܂����͂��A���̐��������������͂��܂��B
# ���̒��ɘA����������ꍇ�A���̘A�����̌������߂ɓ��͂�����������������ʂ�\���B
153 �F�f�t�H���g�̖����������F2009/11/21(�y) 05:20:06
154 �F�f�t�H���g�̖����������F2009/11/21(�y) 07:04:18
>>140
% Prolog �g�b�v���x�����������Ă����܂��B���͂������Ƃ����ꍇ�A
% ����͒�`�q��̈����Ƃ��ė^���邱�Ƃɂ��܂��BProlog�̓C���^�v���^�g�b�v�����
% �g�p��������O�ŁA�q��̂Ȃ��œ��͂����߂邱�Ƃ͂قƂ�ǂ���܂���B
% ����܂ŁAC����Ȃǂ̗l���ɏ]���Ă��܂������A���ꂩ��͏�L�̕��j�ł����܂��B
���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������
(_10�i��) :-
�@�@�m�i��(2,_10�i��,_2�i��������),
�@�@�m�i��(36,_10�i��,_36�i��������),
�@�@write_formatted('10�i�� %t �� 2�i���\���ł� %t 36�i���\���ł� %t �ƂȂ�܂�
\n',[_10�i��,_2�i��,_36�i��]).
% �m�i��/3�̒�`�� http://nojiriko.asia/prolog/j68_493.html �Q��
% Prolog �g�b�v���x�����������Ă����܂��B���͂������Ƃ����ꍇ�A
% ����͒�`�q��̈����Ƃ��ė^���邱�Ƃɂ��܂��BProlog�̓C���^�v���^�g�b�v�����
% �g�p��������O�ŁA�q��̂Ȃ��œ��͂����߂邱�Ƃ͂قƂ�ǂ���܂���B
% ����܂ŁAC����Ȃǂ̗l���ɏ]���Ă��܂������A���ꂩ��͏�L�̕��j�ł����܂��B
���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������
(_10�i��) :-
�@�@�m�i��(2,_10�i��,_2�i��������),
�@�@�m�i��(36,_10�i��,_36�i��������),
�@�@write_formatted('10�i�� %t �� 2�i���\���ł� %t 36�i���\���ł� %t �ƂȂ�܂�
\n',[_10�i��,_2�i��,_36�i��]).
% �m�i��/3�̒�`�� http://nojiriko.asia/prolog/j68_493.html �Q��
155 �F�f�t�H���g�̖����������F2009/11/21(�y) 07:07:33
>>154
% ���s�������Ă͂����Ȃ��Ƃ���ɓ����Ă��܂��܂����B
% ���������܂��B
���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������(_10�i��) :-
�@�@�m�i��(2,_10�i��,_2�i��������),
�@�@�m�i��(36,_10�i��,_36�i��������),
�@�@write_formatted('10�i�� %t �� 2�i���\���ł� %t 36�i���\���ł� %t �ƂȂ�܂�\n',[_10�i��,_2�i��,_36�i��]).
% �m�i��/3�̒�`�� http://nojiriko.asia/prolog/j68_493.html �Q��
% ���s�������Ă͂����Ȃ��Ƃ���ɓ����Ă��܂��܂����B
% ���������܂��B
���͂���10�i���̐�����\�����A10�i����2�i���ɁA10�i����36�i���ɕϊ����A�\������(_10�i��) :-
�@�@�m�i��(2,_10�i��,_2�i��������),
�@�@�m�i��(36,_10�i��,_36�i��������),
�@�@write_formatted('10�i�� %t �� 2�i���\���ł� %t 36�i���\���ł� %t �ƂȂ�܂�\n',[_10�i��,_2�i��,_36�i��]).
% �m�i��/3�̒�`�� http://nojiriko.asia/prolog/j68_493.html �Q��
156 �F�f�t�H���g�̖����������F2009/11/21(�y) 11:33:59
http://pc12.2ch.net/test/read.cgi/tech/1258158172/200
# [1] ���ƒP���F �R���s���[�^�A�[�L�e�N�`��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ȉ��̎d�l���������炽�����Q�[�����쐬����B
# �E ��x�Ɉ�ȏ�̕�������ʏ�ɕ\������
# �E ��莞�Ԉȓ��ɕ\�����ꂽ�����Ɠ����L�[�������ꂽ�瓾�_�Ƃ���
# �E �L�[���͂��t�����莞�Ԃ��߂����當������������
# �ȏ�̏��������J��Ԃ�
#
# [1] ���ƒP���F �R���s���[�^�A�[�L�e�N�`��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ȉ��̎d�l���������炽�����Q�[�����쐬����B
# �E ��x�Ɉ�ȏ�̕�������ʏ�ɕ\������
# �E ��莞�Ԉȓ��ɕ\�����ꂽ�����Ɠ����L�[�������ꂽ�瓾�_�Ƃ���
# �E �L�[���͂��t�����莞�Ԃ��߂����當������������
# �ȏ�̏��������J��Ԃ�
#
157 �F�f�t�H���g�̖����������F2009/11/21(�y) 12:29:05
158 �F�f�t�H���g�̖����������F2009/11/21(�y) 18:10:24
http://pc12.2ch.net/test/read.cgi/tech/1258158172/211
# [1] ���ƒP���F�v���O���~���O���K���
# [2] ��蕶�F
# #include <stdio.h>
#
# int main(void)
# {
# int t = 6;
#
# if(t >= 6 && t < 12){
# printf("%d���ł��B���͂悤�������܂��B\n",t);
# }else if (t >= 12 && t < 18) {
# printf("%d���ł��B����ɂ��́B\n",t);
# }else if (t >= 18 && t < 24) || (t >= 0 &&t < 6)){
# printf("%d���ł��B�����́B\n",t);
# }else {
# printf("%d���͎����͈̔͊O�ł��B\n",t);
# }
# return 0;
# }
# �����switch���ŏ����������v���O�������쐬���Ȃ����B
# �������Acase���̎g�p��4�������Ƃ���B
# [1] ���ƒP���F�v���O���~���O���K���
# [2] ��蕶�F
# #include <stdio.h>
#
# int main(void)
# {
# int t = 6;
#
# if(t >= 6 && t < 12){
# printf("%d���ł��B���͂悤�������܂��B\n",t);
# }else if (t >= 12 && t < 18) {
# printf("%d���ł��B����ɂ��́B\n",t);
# }else if (t >= 18 && t < 24) || (t >= 0 &&t < 6)){
# printf("%d���ł��B�����́B\n",t);
# }else {
# printf("%d���͎����͈̔͊O�ł��B\n",t);
# }
# return 0;
# }
# �����switch���ŏ����������v���O�������쐬���Ȃ����B
# �������Acase���̎g�p��4�������Ƃ���B
159 �F�f�t�H���g�̖����������F2009/11/21(�y) 18:13:24
>>158
% Prolog
switch�����g���ď����������������Z�߂�(T) :-
�@�@M is T // 6,
�@�@switch(M,(1:���͂悤�������܂�(T);2:����ɂ���(T);3:������(T))).
���͂悤�������܂�(T) :-
�@�@write_formatted('%t���ł��B���͂悤�������܂��B\n',[T]).
����ɂ���(T) :-
�@�@write_formatted('%t���ł��B����ɂ��́B\n',[T]).
������(T) :-
�@�@write_formatted('%t���ł��B�����́B\n',[T]).
switch(N,N:P) :-
�@�@call(P).
switch(N,(N:P;R)) :-
�@�@call(P).
switch(N,(A:P;R)) :-
�@�@\+(N=A),
�@�@switch(N,R).
% Prolog
switch�����g���ď����������������Z�߂�(T) :-
�@�@M is T // 6,
�@�@switch(M,(1:���͂悤�������܂�(T);2:����ɂ���(T);3:������(T))).
���͂悤�������܂�(T) :-
�@�@write_formatted('%t���ł��B���͂悤�������܂��B\n',[T]).
����ɂ���(T) :-
�@�@write_formatted('%t���ł��B����ɂ��́B\n',[T]).
������(T) :-
�@�@write_formatted('%t���ł��B�����́B\n',[T]).
switch(N,N:P) :-
�@�@call(P).
switch(N,(N:P;R)) :-
�@�@call(P).
switch(N,(A:P;R)) :-
�@�@\+(N=A),
�@�@switch(N,R).
160 �F�f�t�H���g�̖����������F2009/11/21(�y) 21:42:31
http://pc12.2ch.net/test/read.cgi/tech/1258158172/212
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# 3�s3��̎����s��A=�ma_ij�n��B�mb_ij�n�̐�AB���v�Z����B
# �������A��Z���ʂ̍s����mc_ij�n�Ƃ��Ď��̌v�Z���s�����̂Ƃ���B
# �s��̗v�f�ւ̓��͂́A��������邢�͏������q���������邱�ƁB
# c_ij=��a_ik�~b_kj (����k=0�ŁA2�܂łł�)
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# 3�s3��̎����s��A=�ma_ij�n��B�mb_ij�n�̐�AB���v�Z����B
# �������A��Z���ʂ̍s����mc_ij�n�Ƃ��Ď��̌v�Z���s�����̂Ƃ���B
# �s��̗v�f�ւ̓��͂́A��������邢�͏������q���������邱�ƁB
# c_ij=��a_ik�~b_kj (����k=0�ŁA2�܂łł�)
#
161 �F�f�t�H���g�̖����������F2009/11/21(�y) 21:43:43
>>160
% Prolog
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,for(1,N,3),length(L1,3),_�s��c),
�@�@findall(W,����([1,2,3],2,W),_����),
�@�@�|���Z(_����,_�s��a,_�s��b,_�s��c),
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
% Prolog
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,for(1,N,3),length(L1,3),_�s��c),
�@�@findall(W,����([1,2,3],2,W),_����),
�@�@�|���Z(_����,_�s��a,_�s��b,_�s��c),
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
162 �F�f�t�H���g�̖����������F2009/11/21(�y) 22:56:08
163 �F�f�t�H���g�̖����������F2009/11/22(��) 06:06:12
>>162
�����������I ����܂ł��ԈႦ���Ƃ��낪���������ȁE�E
�u�d������v�B
�d������(L,N,X) :- length(X,N),�d������(L,X).
�d������(L,[]).
�d������(L,[A|R]) :- member(A,L),�d������(L,R).
���`���Ă����B���̏�ŁB
�����������I ����܂ł��ԈႦ���Ƃ��낪���������ȁE�E
�u�d������v�B
�d������(L,N,X) :- length(X,N),�d������(L,X).
�d������(L,[]).
�d������(L,[A|R]) :- member(A,L),�d������(L,R).
���`���Ă����B���̏�ŁB
164 �F�f�t�H���g�̖����������F2009/11/22(��) 06:08:18
>>160 >>161����
% Prolog
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,for(1,N,3),length(L1,3),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�|���Z(_�d������,_�s��a,_�s��b,_�s��c),
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
% Prolog
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,for(1,N,3),length(L1,3),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�|���Z(_�d������,_�s��a,_�s��b,_�s��c),
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
165 �F�f�t�H���g�̖����������F2009/11/22(��) 06:23:30
http://pc12.2ch.net/test/read.cgi/tech/1258158172/221
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10149.txt
# ���C�����ɂ����āA�Q�̕�����
# �@��������2�{�����{���@�i����0�j
# �@��������2�{�����{���@�i����0�j
# �̌W�����A���A���A���A���A�����L�[�{�[�h������͂��A���̐��l�����Ɉ����Ƃ��ēn���B
# ���͂��̐��l��p���ĂQ�Ȑ��̌�_�̗L���ׁA���̌�_�̌���߂�l�Ƃ��ă��C�����ɓn��
# �i��_�������ꍇ�͂O�A��_���P�̏ꍇ�͂P�A��_���Q�̏ꍇ�͂Q�A��_�������ɑ��݂���ꍇ�́[�P��߂�l�ɂ���j�B
# �܂����́A������_���L�����݂���Ȃ�����̌�_�̍��W�l�����C�����ɓn���B
# ���C�����͊����瓾�������̏��āA��_�̌�����ʂɕ\�����A����ɂ�����_���L�����݂���Ȃ�����̍��W�l����ʂɕ\������B
# ���̂悤�ȃv���O�������쐬����B
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10149.txt
# ���C�����ɂ����āA�Q�̕�����
# �@��������2�{�����{���@�i����0�j
# �@��������2�{�����{���@�i����0�j
# �̌W�����A���A���A���A���A�����L�[�{�[�h������͂��A���̐��l�����Ɉ����Ƃ��ēn���B
# ���͂��̐��l��p���ĂQ�Ȑ��̌�_�̗L���ׁA���̌�_�̌���߂�l�Ƃ��ă��C�����ɓn��
# �i��_�������ꍇ�͂O�A��_���P�̏ꍇ�͂P�A��_���Q�̏ꍇ�͂Q�A��_�������ɑ��݂���ꍇ�́[�P��߂�l�ɂ���j�B
# �܂����́A������_���L�����݂���Ȃ�����̌�_�̍��W�l�����C�����ɓn���B
# ���C�����͊����瓾�������̏��āA��_�̌�����ʂɕ\�����A����ɂ�����_���L�����݂���Ȃ�����̍��W�l����ʂɕ\������B
# ���̂悤�ȃv���O�������쐬����B
166 �F�f�t�H���g�̖����������F2009/11/22(��) 07:10:26
>>165
% Prolog
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D > 0,
�@�@X is ((-1) * B + sqrt(D)) / (2 * A),
�@�@Y is _a * (X^2) + _b * X + _c.
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D > 0,
�@�@X is ((-1) * B - sqrt(D)) / (2 * A),
�@�@Y is _a * (X^2) + _b * X + _c.
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D = 0,
�@�@X is ((-1) * B / (2 * A)),
�@�@Y is _a * (X^2) + _b * X + _c.
% Prolog
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D > 0,
�@�@X is ((-1) * B + sqrt(D)) / (2 * A),
�@�@Y is _a * (X^2) + _b * X + _c.
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D > 0,
�@�@X is ((-1) * B - sqrt(D)) / (2 * A),
�@�@Y is _a * (X^2) + _b * X + _c.
��̕������̌�_(_a,_b,_c,_p,_q,_r,X,Y) :-
�@�@A is (_a - _p),
�@�@B is (-b - _q),
�@�@C is (_c - _r),
�@�@D is B^2 - 4 * A * C,
�@�@D = 0,
�@�@X is ((-1) * B / (2 * A)),
�@�@Y is _a * (X^2) + _b * X + _c.
167 �F�f�t�H���g�̖����������F2009/11/22(��) 12:35:58
http://pc12.2ch.net/test/read.cgi/tech/1258158172/224
# C++�ŁA�x�N�g���̉������s���v���O�����������Ă��������B
# #include <iostream>
# using namespace std;
# int main() {
#
# return 0;
# }
# ���́�cin�@�o�́�cout
# �z���for�ł��肢���܂��B
# C++�ŁA�x�N�g���̉������s���v���O�����������Ă��������B
# #include <iostream>
# using namespace std;
# int main() {
#
# return 0;
# }
# ���́�cin�@�o�́�cout
# �z���for�ł��肢���܂��B
168 �F�f�t�H���g�̖����������F2009/11/22(��) 12:37:12
169 �F�f�t�H���g�̖����������F2009/11/22(��) 18:54:01
http://pc12.2ch.net/test/read.cgi/tech/1258158172/236
# [1] C����v���O���~���O���K
# [2] �W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����v���O����
# �i�R�}���h���C���� 2 4 2 4 ��^�����ꍇ�^�u����͂�����3 7 10 17 20 27...�����ʒu��
# �Ȃ�悤�X�y�[�X��}������j
# ���͔͂��p�����Ɍ����ėǂ��B�܂��R�}���h���C������͐��̐�����\�����̂�
# �^������Ƃ��ėǂ�
# [1] C����v���O���~���O���K
# [2] �W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����v���O����
# �i�R�}���h���C���� 2 4 2 4 ��^�����ꍇ�^�u����͂�����3 7 10 17 20 27...�����ʒu��
# �Ȃ�悤�X�y�[�X��}������j
# ���͔͂��p�����Ɍ����ėǂ��B�܂��R�}���h���C������͐��̐�����\�����̂�
# �^������Ƃ��ėǂ�
170 �F�f�t�H���g�̖����������F2009/11/22(��) 19:15:18
>>169
% Prolog
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ����� :-
�@�@user_paramegers(L),
�@�@findall(N,(member(A,L),atom_to_term(A,N,_)),L2),
�@�@get_chars(Chars),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,Chars,X).
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([],_�^�u�X�g�b�v�T�C�N��,L2,L3) :-
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,L2,L3),!.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_,_,[],[]) :- !.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,['\t'|R2],L) :-
�@�@length(L2,N),
�@�@all(L2,' '),
�@�@append(L2,L3,L),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(R1,_�^�u�X�g�b�v�T�C�N��,R2,L3),!.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,[A|R2],[A|R3]) :-
�@�@\+(A='t'),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,R2,R3).
% Prolog
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ����� :-
�@�@user_paramegers(L),
�@�@findall(N,(member(A,L),atom_to_term(A,N,_)),L2),
�@�@get_chars(Chars),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,Chars,X).
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([],_�^�u�X�g�b�v�T�C�N��,L2,L3) :-
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,L2,L3),!.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_,_,[],[]) :- !.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,['\t'|R2],L) :-
�@�@length(L2,N),
�@�@all(L2,' '),
�@�@append(L2,L3,L),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(R1,_�^�u�X�g�b�v�T�C�N��,R2,L3),!.
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,[A|R2],[A|R3]) :-
�@�@\+(A='t'),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����([N|R1],_�^�u�X�g�b�v�T�C�N��,R2,R3).
171 �F�f�t�H���g�̖����������F2009/11/22(��) 19:22:13
>>170
% Prolog ���ꂾ�Ɖ����N����Ȃ�
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ����� :-
�@�@user_paramegers(L),
�@�@findall(N,(member(A,L),atom_to_term(A,N,_)),L2),
�@�@get_chars(Chars),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,Chars,X),
�@�@put_chars(X).
% Prolog ���ꂾ�Ɖ����N����Ȃ�
�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ����� :-
�@�@user_paramegers(L),
�@�@findall(N,(member(A,L),atom_to_term(A,N,_)),L2),
�@�@get_chars(Chars),
�@�@�W�����͂̕�����Ɋ܂܂��^�u���R�}���h���C���ŗ^�����T�C�N���̃^�u�X�g�b�v�ŃX�y�[�X�ɕϊ�����(_�^�u�X�g�b�v�T�C�N��,_�^�u�X�g�b�v�T�C�N��,Chars,X),
�@�@put_chars(X).
172 �F�f�t�H���g�̖����������F2009/11/22(��) 20:32:46
http://pc12.2ch.net/test/read.cgi/tech/1258158172/240
# [1] ���ƒP���F �v���O���~���O�_
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10150.txt
#
# ��Q(1)�������܂����B�Y��E������肢���܂��B
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10151.txt
# ��P
# �V�т̋��ɍ�����A�N�́A�T�����𗘗p���邱�Ƃɂ����B
# ����20�K�łP�O���~�肽�ꍇ�A�R�O����̗����͂�����ł��傤���H
# �����v�Z�ŋ��߂Ȃ����B
#
# ��Q
# �i�P�j�P�O���~��N���S���ŗa�������Ƃ��A�P�O�N��̌������v���v�Z�ŋ��߂�B
# �i�Q�j�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\������B
# [1] ���ƒP���F �v���O���~���O�_
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10150.txt
#
# ��Q(1)�������܂����B�Y��E������肢���܂��B
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10151.txt
# ��P
# �V�т̋��ɍ�����A�N�́A�T�����𗘗p���邱�Ƃɂ����B
# ����20�K�łP�O���~�肽�ꍇ�A�R�O����̗����͂�����ł��傤���H
# �����v�Z�ŋ��߂Ȃ����B
#
# ��Q
# �i�P�j�P�O���~��N���S���ŗa�������Ƃ��A�P�O�N��̌������v���v�Z�ŋ��߂�B
# �i�Q�j�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\������B
173 �F�f�t�H���g�̖����������F2009/11/23(��) 06:17:24
����20�K�Ƃ�(_����20�K) :- _����20�K is 20 / 100 / 100.
�N���S���Ƃ�(0.04).
����20�K�łP�O���~�肽�ꍇ�A�R�O����̗���(_30����̗���) :-
�@�@����20�K�Ƃ�(_����20�K),
�@�@_30����̗��� is _�a�� * _����20�K^30 - _�a��.
�P�O���~��N���S���ŗa�������Ƃ��A�P�O�N��̌������v(_10�N��̌������v) :-
�@�@�N���S���Ƃ�(_�N��4��),
�@�@_10�N��̌������v is 100000 * ( 1 + _�N��4��) ^ 10.
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\�� :- �O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(1,100000,0).
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N,_,_) :- N> 10,!.
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N,_�a���z,_�O�N�x�̗���) :-
�@�@�N���S���Ƃ�(_�N��4��),
�@�@_���N�̗��� is _�a���z * _�N��4��,
�@�@_���N�x�̗a���z is _�a���z * _�N��4��,
�@�@_�O�N�x�̗����Ƃ̍��z is _���N�x�̗��� - _�O�N�x�̗���,
�@�@write_formatted('%t�N�� �O�N�x�Ƃ̗������z�� %t �ł�\n',[N,_�O�N�x�̗����Ƃ̍��z]),
�@�@N2 is N + 1,
�@�@�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N2,_���N�x�̗a���z,_���N�x�̗���).
�N���S���Ƃ�(0.04).
����20�K�łP�O���~�肽�ꍇ�A�R�O����̗���(_30����̗���) :-
�@�@����20�K�Ƃ�(_����20�K),
�@�@_30����̗��� is _�a�� * _����20�K^30 - _�a��.
�P�O���~��N���S���ŗa�������Ƃ��A�P�O�N��̌������v(_10�N��̌������v) :-
�@�@�N���S���Ƃ�(_�N��4��),
�@�@_10�N��̌������v is 100000 * ( 1 + _�N��4��) ^ 10.
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\�� :- �O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(1,100000,0).
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N,_,_) :- N> 10,!.
�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N,_�a���z,_�O�N�x�̗���) :-
�@�@�N���S���Ƃ�(_�N��4��),
�@�@_���N�̗��� is _�a���z * _�N��4��,
�@�@_���N�x�̗a���z is _�a���z * _�N��4��,
�@�@_�O�N�x�̗����Ƃ̍��z is _���N�x�̗��� - _�O�N�x�̗���,
�@�@write_formatted('%t�N�� �O�N�x�Ƃ̗������z�� %t �ł�\n',[N,_�O�N�x�̗����Ƃ̍��z]),
�@�@N2 is N + 1,
�@�@�O�N�̗������ǂ̂��炢�������Ă䂭���A�O�N�x�̗����Ƃ̍��z��\��(N2,_���N�x�̗a���z,_���N�x�̗���).
174 �F�f�t�H���g�̖����������F2009/11/23(��) 08:21:38
http://pc12.2ch.net/test/read.cgi/tech/1200175247/745
# [1] ���ƒP���F�v���O���~���O����
#
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# �E��������Ca �Ȃ�� z�Cb �Ȃ�� y�Cc �Ȃ�� x �̂悤�ɁC���������啶�����A���t�@�x�b�g�̋t���̏o�������ɒu��������v���O���������Ȃ����D
# �E�����^����ꂽ�Ƃ��C�A���t�@�x�b�g��啶���C����������ʂ����ɏo���p�x���ɏ������ŕ��ׂ��������Ԃ��v���O���������Ȃ����D
#
# [1] ���ƒP���F�v���O���~���O����
#
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# �E��������Ca �Ȃ�� z�Cb �Ȃ�� y�Cc �Ȃ�� x �̂悤�ɁC���������啶�����A���t�@�x�b�g�̋t���̏o�������ɒu��������v���O���������Ȃ����D
# �E�����^����ꂽ�Ƃ��C�A���t�@�x�b�g��啶���C����������ʂ����ɏo���p�x���ɏ������ŕ��ׂ��������Ԃ��v���O���������Ȃ����D
#
175 �F�f�t�H���g�̖����������F2009/11/23(��) 08:26:10
>>174
% Prolog
��������Ca �Ȃ�� z�Cb �Ȃ�� y�Cc �Ȃ�� x �̂悤�ɁC���������啶�����A���t�@�x�b�g�̋t���̏o�������ɒu��������(_������,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ������) :-
�@�@atom_chars(_������,_�����Ȃ��),
�@�@�A���t�@�x�b�g�t���ϊ�(_�����Ȃ��,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ�����Ȃ��),
�@�@atom_chars(_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ������,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ�����Ȃ��).
�A���t�@�x�b�g�t���ϊ�([],[]).
�A���t�@�x�b�g�t���ϊ�([A|R1],[B|R2]) :-
�@�@�t���A���t�@�x�b�g�T��(A,B),
�@�@�A���t�@�x�b�g�t���ϊ�(R1,R2).
�t���A���t�@�x�b�g�T��(A,B) :-
�@�@�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(_,L1,L2),
�@�@append(L0,[A|_],L1),
�@�@length(L0,Len),
�@�@length(L3,Len),
�@�@append(L3,[B|_],L2).
�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z],[z,y,x,w,v,u,t,s,r,q,p,o,n,m,l,k,j,i,h,g,f,e,d,c,b,a]).
�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'],['Z','Y','X','W','V','U','T','S','R','Q','P','O','N','M','L','K','J','I','H','G','F','E','D','C','B','A']).
% Prolog
��������Ca �Ȃ�� z�Cb �Ȃ�� y�Cc �Ȃ�� x �̂悤�ɁC���������啶�����A���t�@�x�b�g�̋t���̏o�������ɒu��������(_������,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ������) :-
�@�@atom_chars(_������,_�����Ȃ��),
�@�@�A���t�@�x�b�g�t���ϊ�(_�����Ȃ��,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ�����Ȃ��),
�@�@atom_chars(_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ������,_�A���t�@�x�b�g�̋t���ɕϊ����ꂽ�����Ȃ��).
�A���t�@�x�b�g�t���ϊ�([],[]).
�A���t�@�x�b�g�t���ϊ�([A|R1],[B|R2]) :-
�@�@�t���A���t�@�x�b�g�T��(A,B),
�@�@�A���t�@�x�b�g�t���ϊ�(R1,R2).
�t���A���t�@�x�b�g�T��(A,B) :-
�@�@�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(_,L1,L2),
�@�@append(L0,[A|_],L1),
�@�@length(L0,Len),
�@�@length(L3,Len),
�@�@append(L3,[B|_],L2).
�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z],[z,y,x,w,v,u,t,s,r,q,p,o,n,m,l,k,j,i,h,g,f,e,d,c,b,a]).
�A���t�@�x�b�g�Ƌt���A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'],['Z','Y','X','W','V','U','T','S','R','Q','P','O','N','M','L','K','J','I','H','G','F','E','D','C','B','A']).
176 �F�f�t�H���g�̖����������F2009/11/23(��) 09:39:46
>>174
% Prolog ��蕶[2]
�����^����ꂽ�Ƃ��C�A���t�@�x�b�g��啶���C����������ʂ����ɏo���p�x���ɏ������ŕ��ׂ��������Ԃ�(_������,_�o���p�x���ɕ�������בւ���������) :-
�@�@atom_chars(_������,_�����Ȃ��),
�@�@�o���p�x���ɕ����Ȃ�т�ϊ�(_�����Ȃ��,[],_�o���p�x���ɕ��בւ��������Ȃ��),
�@�@atom_chars(_�o���p�x���ɕ��בւ��������Ȃ��,_�o���p�x���ɕ�������בւ���������).
�o���p�x���ɕ����Ȃ�т�ϊ�([],Y,X) :-
�@�@sort(Y,Z),
�@�@�o���p�x�Ȃ�т���t���ɕ����I��(Z,[],X).
�o���p�x���ɕ����Ȃ�т�ϊ�([C|R1],Y,X) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,Y,Z),
�@�@�o���p�x���ɕ����Ȃ�т�ϊ�(R1,Z,X).
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :- !.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C]|R1]) :- N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N,C]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
�o���p�x�Ȃ�т���t���ɕ����I��([],X,X) :- !.
�o���p�x�Ȃ�т���t���ɕ����I��([[N,C]|R1],Y,X) :-
�@�@�o���p�x�Ȃ�т���t���ɕ����I��(R1,[C|Y],X).
% Prolog ��蕶[2]
�����^����ꂽ�Ƃ��C�A���t�@�x�b�g��啶���C����������ʂ����ɏo���p�x���ɏ������ŕ��ׂ��������Ԃ�(_������,_�o���p�x���ɕ�������בւ���������) :-
�@�@atom_chars(_������,_�����Ȃ��),
�@�@�o���p�x���ɕ����Ȃ�т�ϊ�(_�����Ȃ��,[],_�o���p�x���ɕ��בւ��������Ȃ��),
�@�@atom_chars(_�o���p�x���ɕ��בւ��������Ȃ��,_�o���p�x���ɕ�������בւ���������).
�o���p�x���ɕ����Ȃ�т�ϊ�([],Y,X) :-
�@�@sort(Y,Z),
�@�@�o���p�x�Ȃ�т���t���ɕ����I��(Z,[],X).
�o���p�x���ɕ����Ȃ�т�ϊ�([C|R1],Y,X) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,Y,Z),
�@�@�o���p�x���ɕ����Ȃ�т�ϊ�(R1,Z,X).
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :- !.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C]|R1]) :- N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N,C]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
�o���p�x�Ȃ�т���t���ɕ����I��([],X,X) :- !.
�o���p�x�Ȃ�т���t���ɕ����I��([[N,C]|R1],Y,X) :-
�@�@�o���p�x�Ȃ�т���t���ɕ����I��(R1,[C|Y],X).
177 �F�f�t�H���g�̖����������F2009/11/23(��) 11:29:32
>>176
% �u�啶���E����������ʂ����Ɂv�������Ƃ����B�ǂ����������ȁE�E�E
% ���A��ρA�����̍ŏI�߂��܂������Ă����I C => C1
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :-
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C2]|R1]) :-
�@�@to_lower(C,C2),
�@�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
% �u�啶���E����������ʂ����Ɂv�������Ƃ����B�ǂ����������ȁE�E�E
% ���A��ρA�����̍ŏI�߂��܂������Ă����I C => C1
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :-
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C2]|R1]) :-
�@�@to_lower(C,C2),
�@�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
178 �F�f�t�H���g�̖����������F2009/11/23(��) 11:33:25
>>177
% ���߂Ɍ�肪�������B
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C2]) :- to_lower(C,C2),!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C2]|R1]) :-
�@�@to_lower(C,C2),
�@�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
% ���߂Ɍ�肪�������B
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C2]) :- to_lower(C,C2),!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C2]|R1]) :-
�@�@to_lower(C,C2),
�@�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
179 �F�f�t�H���g�̖����������F2009/11/23(��) 17:20:52
http://pc12.2ch.net/test/read.cgi/tech/1258158172/280
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶: http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10157.txt
#
# �ȉ��̂悤��ACII�R�[�h�\����ʂɕ\������v���O�������쐬�A�R���p�C���A
# ���s���Ȃ����B
# �������Afor����K���g�p���邱�ƁB�܂�ASCII�R�[�h0x7F�͐��䕶���ł���̂ŁA
# break���܂���continue�����g�p���ĉ�����邱�ƁB
#
# |0 1 2 3 4 5 6 7 8 9 A B C D E F
#---+--------------------------------
# 2 | ! " # $ % & ' ( ) * + , - . /
# 3 |0 1 2 3 4 5 6 7 8 9 : ; < = > ?
# 4 |@ A B C D E F G H I J K L M N O
# 5 |P Q R S T U V W X Y Z [ \ ] ^ _
# 6 |' a b c d e f g h i j k l m n o
# 7 |p q r s t u v w x y z { | } ~
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶: http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10157.txt
#
# �ȉ��̂悤��ACII�R�[�h�\����ʂɕ\������v���O�������쐬�A�R���p�C���A
# ���s���Ȃ����B
# �������Afor����K���g�p���邱�ƁB�܂�ASCII�R�[�h0x7F�͐��䕶���ł���̂ŁA
# break���܂���continue�����g�p���ĉ�����邱�ƁB
#
# |0 1 2 3 4 5 6 7 8 9 A B C D E F
#---+--------------------------------
# 2 | ! " # $ % & ' ( ) * + , - . /
# 3 |0 1 2 3 4 5 6 7 8 9 : ; < = > ?
# 4 |@ A B C D E F G H I J K L M N O
# 5 |P Q R S T U V W X Y Z [ \ ] ^ _
# 6 |' a b c d e f g h i j k l m n o
# 7 |p q r s t u v w x y z { | } ~
180 �F�f�t�H���g�̖����������F2009/11/23(��) 17:22:23
>>179
% Prolog
�����R�[�h�\�̍쐬 :-
�@�@write('�@|0 1 2 3 4 5 6 7 8 9 A B C D E F'\n'),
�@�@write('--+'),for(0,U2,16),write('--'),U2=16,nl,
�@�@for(2,N,7),
�@�@write_formatted('%t |',[N]),
�@�@for(0,M,15),
�@�@�\�����̕\��(N,M),
�@�@M = 15,
�@�@nl,
�@�@N = 7.
�\�����̕\��(7,15) :- !.
�\�����̕\��(N,M) :-
�@�@N >= 32,N =< 126,
�@�@Code is N * 16 + M,
�@�@char_code(A,Code),
�@�@write_formatted('%t ',[A]),!.
% Prolog
�����R�[�h�\�̍쐬 :-
�@�@write('�@|0 1 2 3 4 5 6 7 8 9 A B C D E F'\n'),
�@�@write('--+'),for(0,U2,16),write('--'),U2=16,nl,
�@�@for(2,N,7),
�@�@write_formatted('%t |',[N]),
�@�@for(0,M,15),
�@�@�\�����̕\��(N,M),
�@�@M = 15,
�@�@nl,
�@�@N = 7.
�\�����̕\��(7,15) :- !.
�\�����̕\��(N,M) :-
�@�@N >= 32,N =< 126,
�@�@Code is N * 16 + M,
�@�@char_code(A,Code),
�@�@write_formatted('%t ',[A]),!.
181 �F�f�t�H���g�̖����������F2009/11/23(��) 17:41:18
http://pc12.2ch.net/test/read.cgi/tech/1248012902/509
# �y�@�ۑ�@�zhttp://nojiriko.asia/jpeg/841.jpg
# �}�̗L���O���t�̍ŒZ�o�H�����߂�B
# �����l��MAX�ŃA���S���Y�������B
# �y�@�ۑ�@�zhttp://nojiriko.asia/jpeg/841.jpg
{kind=link}
# �}�̗L���O���t�̍ŒZ�o�H�����߂�B
# �����l��MAX�ŃA���S���Y�������B
182 �F�f�t�H���g�̖����������F2009/11/23(��) 18:45:55
http://pc12.2ch.net/test/read.cgi/tech/1258158172/283
# [1] ���ƒP���F C���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F �ȉ��̊|���Z�̕\���v���O�������쐬���Ȃ����B
# �@�@�@�@�P�@�Q�@�R�@�@�S�@�@�T�@�@�U�@�@�V�@�@�W�@�@�X�@�P�O
# �@�@�@�@�Q�@�S�@�U�@�@�W�@�P�O�@�P�Q�@�P�S�@�P�U�@�P�W�@�Q�O
# �@�@�@�@�R�@�U�@�X�@�P�Q�@�P�T�@�P�W�@�Q�P�@�Q�S�@�Q�V�@�R�O
# �@�@�@�@�E
# �@�@�@�@�E
# �@�@�@�@�E
# �@�@�@�P�O�E�E�E�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�P�O�O
# [1] ���ƒP���F C���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F �ȉ��̊|���Z�̕\���v���O�������쐬���Ȃ����B
# �@�@�@�@�P�@�Q�@�R�@�@�S�@�@�T�@�@�U�@�@�V�@�@�W�@�@�X�@�P�O
# �@�@�@�@�Q�@�S�@�U�@�@�W�@�P�O�@�P�Q�@�P�S�@�P�U�@�P�W�@�Q�O
# �@�@�@�@�R�@�U�@�X�@�P�Q�@�P�T�@�P�W�@�Q�P�@�Q�S�@�Q�V�@�R�O
# �@�@�@�@�E
# �@�@�@�@�E
# �@�@�@�@�E
# �@�@�@�P�O�E�E�E�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�P�O�O
183 �F�f�t�H���g�̖����������F2009/11/23(��) 19:08:04
>>182
% Prolog
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9],2,[M,N]),
�@�@S is M * N,
�@�@write_formatted('%3d',[S]),
�@�@N = 9,
�@�@nl,
�@�@fail.
���\��.
% Prolog
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9],2,[M,N]),
�@�@S is M * N,
�@�@write_formatted('%3d',[S]),
�@�@N = 9,
�@�@nl,
�@�@fail.
���\��.
184 �F�f�t�H���g�̖����������F2009/11/23(��) 19:11:41
>>183 ���͍D�݂܂��Awrite_fomatted/2�͈����Ɏ����\�ł��B
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9],2,[M,N]),
�@�@write_formatted('%3d',[M * N]),
�@�@N = 9,
�@�@nl,
�@�@fail.
���\��.
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9],2,[M,N]),
�@�@write_formatted('%3d',[M * N]),
�@�@N = 9,
�@�@nl,
�@�@fail.
���\��.
185 �F�f�t�H���g�̖����������F2009/11/23(��) 19:21:39
http://pc12.2ch.net/test/read.cgi/tech/1258158172/290
# [1] ���ƒP���F�v���O����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �s��ƃx�N�g���̊|���Z
# y=Ax (A(3*3�s��ȏ�)��x��K���ɏ�����)
#
# [1] ���ƒP���F�v���O����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �s��ƃx�N�g���̊|���Z
# y=Ax (A(3*3�s��ȏ�)��x��K���ɏ�����)
#
186 �F�f�t�H���g�̖����������F2009/11/23(��) 20:11:25
>>179
NB.J����
a=:(2 4$' |---+'),(3":,.2+i.6),.'|'
b=:'0123456789ABCEDF',:'-'
a,.b,6 16$(32+i.95){a.
|0123456789ABCEDF
---+----------------
2| !"#$%&'()*+,-./
3|0123456789:;<=>?
4|@ABCDEFGHIJKLMNO
5|PQRSTUVWXYZ[\]^_
6|`abcdefghijklmno
7|pqrstuvwxyz{|}~
NB.J����
a=:(2 4$' |---+'),(3":,.2+i.6),.'|'
b=:'0123456789ABCEDF',:'-'
a,.b,6 16$(32+i.95){a.
|0123456789ABCEDF
---+----------------
2| !"#$%&'()*+,-./
3|0123456789:;<=>?
4|@ABCDEFGHIJKLMNO
5|PQRSTUVWXYZ[\]^_
6|`abcdefghijklmno
7|pqrstuvwxyz{|}~
187 �F�f�t�H���g�̖����������F2009/11/23(��) 20:15:52
>>182
NB.J����
*/~>:i.10
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
NB.J����
*/~>:i.10
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
188 �F�f�t�H���g�̖����������F2009/11/24(��) 04:20:33
>>182
% Prolog >>187��������āA�Q�����łȂ����ƂɋC�Â���w�@����͋��łȂ��ĂȂ�Ă����̂��ȁH
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9,10],2,[M,N]),
�@�@S is M * N,
�@�@write_formatted('%3d',[S]),
�@�@N = 10,
�@�@nl,
�@�@fail.
���\��.
% Prolog >>187��������āA�Q�����łȂ����ƂɋC�Â���w�@����͋��łȂ��ĂȂ�Ă����̂��ȁH
���\�� :-
�@�@�d������([1,2,3,4,5,6,7,8,9,10],2,[M,N]),
�@�@S is M * N,
�@�@write_formatted('%3d',[S]),
�@�@N = 10,
�@�@nl,
�@�@fail.
���\��.
189 �F�f�t�H���g�̖����������F2009/11/24(��) 04:35:14
>>164
% �������Ԉ���Ă����B
% �ЂƂ�findall/3��findall/4�ɂȂ��Ă��܂��Ă���B�����ЂƂ́E�E�E.
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,(for(1,N,3),length(L1,3)),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�s��̊|���Z(_�d������,_�s��a,_�s��b,_�s��c).
% �������Ԉ���Ă����B
% �ЂƂ�findall/3��findall/4�ɂȂ��Ă��܂��Ă���B�����ЂƂ́E�E�E.
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,(for(1,N,3),length(L1,3)),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�s��̊|���Z(_�d������,_�s��a,_�s��b,_�s��c).
190 �F�f�t�H���g�̖����������F2009/11/24(��) 04:38:03
>>160
% Prolog ������ƊԈႢ���Ђǂ������̂ŏ��������B
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,(for(1,N,3),length(L1,3)),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�s��̊|���Z(_�d������,_�s��a,_�s��b,_�s��c).
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
% Prolog ������ƊԈႢ���Ђǂ������̂ŏ��������B
�s��̊|���Z(_�s��a,_�s��b,_�s��c) :-
�@�@findall(L1,(for(1,N,3),length(L1,3)),_�s��c),
�@�@findall(W,�d������([1,2,3],2,W),_�d������),
�@�@�s��̊|���Z(_�d������,_�s��a,_�s��b,_�s��c).
�s��̊|���Z([],_,_,_) :- !.
�s��̊|���Z([[I,J]|R1],_�s��a,_�s��b,_�s��c) :-
�@�@findsum(U,(�@ for(1,K,3),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��a,I,K,N1),
�@�@�@�@�@�@�@�@�@�s��v�f(_�s��b,K,J,N2),
�@�@�@�@�@�@�@�@�@U is N1 * N2),S),
�@�@�s��v�f(_�s��c,I,J,S),
�@�@�s��̊|���Z(R1,_�s��a,_�s��b,_�s��c).
�@
�s��v�f(_�s��,_�s,_��,_�l) :-
�@�@list_nth(_�s,_�s��,_�s�̒l�Ȃ��),
�@�@list_nth(_��,_�s�̒l�Ȃ��,_�l).
191 �F�f�t�H���g�̖����������F2009/11/24(��) 06:49:16
>>185
% Prolog
�ΏۂƂȂ�s��([[1,3,5],[2,8,12],[6,0,12]]).
�s��ƃx�N�g���̐�(_�x�N�g��,_�s��ƃx�N�g���̐�) :-
�@�@�ΏۂƂȂ�s��(_�s��),
�@�@�s��ƃx�N�g���̐�(_�s��,_�x�N�g��,_�s��ƃx�N�g���̐�).
�s��ƃx�N�g���̐�([],_�x�N�g��,[]).
�s��ƃx�N�g���̐�([_�s|R1],_�x�N�g��,[_�s2|R2]) :-
�@�@�s��ƃx�N�g���̐�(_�s,_�x�N�g��_�s2),
�@�@�s��ƃx�N�g���̐�(R1,_�x�N�g��,R2).
�s�ƃx�N�g���̐�([],[],[]).
�s�ƃx�N�g���̐�([A|R1],[B|R2],[C|R3]) :-
�@�@C is A * B,
�@�@�s�ƃx�N�g���̐�(R1,R2,R3).
% Prolog
�ΏۂƂȂ�s��([[1,3,5],[2,8,12],[6,0,12]]).
�s��ƃx�N�g���̐�(_�x�N�g��,_�s��ƃx�N�g���̐�) :-
�@�@�ΏۂƂȂ�s��(_�s��),
�@�@�s��ƃx�N�g���̐�(_�s��,_�x�N�g��,_�s��ƃx�N�g���̐�).
�s��ƃx�N�g���̐�([],_�x�N�g��,[]).
�s��ƃx�N�g���̐�([_�s|R1],_�x�N�g��,[_�s2|R2]) :-
�@�@�s��ƃx�N�g���̐�(_�s,_�x�N�g��_�s2),
�@�@�s��ƃx�N�g���̐�(R1,_�x�N�g��,R2).
�s�ƃx�N�g���̐�([],[],[]).
�s�ƃx�N�g���̐�([A|R1],[B|R2],[C|R3]) :-
�@�@C is A * B,
�@�@�s�ƃx�N�g���̐�(R1,R2,R3).
192 �F�f�t�H���g�̖����������F2009/11/24(��) 06:59:03
>>191 �܂��Ԉ���Ă����B�s�ƃx�N�g���̐�/3���s��ƃx�N�g���̐�/3�ɂȂ��Ă���Ƃ��낪����B
�ΏۂƂȂ�s��([[1,3,5],[2,8,12],[6,0,12]]).
�s��ƃx�N�g���̐�(_�x�N�g��,_�s��ƃx�N�g���̐�) :-
�@�@�ΏۂƂȂ�s��(_�s��),
�@�@�s��ƃx�N�g���̐�(_�s��,_�x�N�g��,_�s��ƃx�N�g���̐�).
�s��ƃx�N�g���̐�([],_�x�N�g��,[]).
�s��ƃx�N�g���̐�([_�s|R1],_�x�N�g��,[_�s2|R2]) :-
�@�@�s�ƃx�N�g���̐�(_�s,_�x�N�g��_�s2),
�@�@�s��ƃx�N�g���̐�(R1,_�x�N�g��,R2).
�s�ƃx�N�g���̐�([],[],[]).
�s�ƃx�N�g���̐�([A|R1],[B|R2],[C|R3]) :-
�@�@C is A * B,
�@�@�s�ƃx�N�g���̐�(R1,R2,R3).
�ΏۂƂȂ�s��([[1,3,5],[2,8,12],[6,0,12]]).
�s��ƃx�N�g���̐�(_�x�N�g��,_�s��ƃx�N�g���̐�) :-
�@�@�ΏۂƂȂ�s��(_�s��),
�@�@�s��ƃx�N�g���̐�(_�s��,_�x�N�g��,_�s��ƃx�N�g���̐�).
�s��ƃx�N�g���̐�([],_�x�N�g��,[]).
�s��ƃx�N�g���̐�([_�s|R1],_�x�N�g��,[_�s2|R2]) :-
�@�@�s�ƃx�N�g���̐�(_�s,_�x�N�g��_�s2),
�@�@�s��ƃx�N�g���̐�(R1,_�x�N�g��,R2).
�s�ƃx�N�g���̐�([],[],[]).
�s�ƃx�N�g���̐�([A|R1],[B|R2],[C|R3]) :-
�@�@C is A * B,
�@�@�s�ƃx�N�g���̐�(R1,R2,R3).
193 �F�f�t�H���g�̖����������F2009/11/24(��) 14:25:22
http://pc12.2ch.net/test/read.cgi/tech/1248012902/510
# �y �ۑ� �zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/842.txt
# (1)�w���̐�������͂��A�Y������w���̊w�Дԍ��A�w�N�A�Ȏ���\������B
# ���̃f�[�^�͊w���̊w�Дԍ��A���O�A���ȓ����A�Ȏ���z��lines�Ŋi�[�������̂ł��B
# String[] lines = { "0001, �R�c���Y,2,3,42", "0002, �c����Y,2,6,31", "0003, �֓��Ԏq,2,2,4" };
# split��equals���\�b�h�𗘗p����B���L���̓X�y�[�X�B
# ���� -n
# (2) (1)�𗘗p���Ċw���̖��O�̈ꕔ����͂��A�Y������w���̊w�Дԍ��A���O�A���ȓ�����\������B
# ���� -q
# (3) (1)�𗘗p���Ċe�w���̑S�Ẵf�[�^��Ȏ����ɕ\������B
# �y �ۑ� �zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/842.txt
# (1)�w���̐�������͂��A�Y������w���̊w�Дԍ��A�w�N�A�Ȏ���\������B
# ���̃f�[�^�͊w���̊w�Дԍ��A���O�A���ȓ����A�Ȏ���z��lines�Ŋi�[�������̂ł��B
# String[] lines = { "0001, �R�c���Y,2,3,42", "0002, �c����Y,2,6,31", "0003, �֓��Ԏq,2,2,4" };
# split��equals���\�b�h�𗘗p����B���L���̓X�y�[�X�B
# ���� -n
# (2) (1)�𗘗p���Ċw���̖��O�̈ꕔ����͂��A�Y������w���̊w�Дԍ��A���O�A���ȓ�����\������B
# ���� -q
# (3) (1)�𗘗p���Ċe�w���̑S�Ẵf�[�^��Ȏ����ɕ\������B
194 �F�f�t�H���g�̖����������F2009/11/24(��) 14:49:38
>>193
% Prolog
�w��('0001', �R�c���Y,2,3,42).
�w��('0002', �c����Y,2,6,31).
�w�Е�('0003', �֓��Ԏq,2,2,4).
�w���̐�������͂��A�Y������w���̊w�Дԍ��A�w�N�A�Ȏ���\��(_���O) :-
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]).
�w���̖��O�̈ꕔ����͂��A�Y������w���̊w�Дԍ��A���O�A���ȓ�����\��(_���O�̈ꕔ) :-
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@sub_atom(_���O,_,_,_,_���O�̈ꕔ),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O�̈ꕔ,_�w�Дԍ�,���O,_���ȓ���]).
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��' :-
�@�@findall([_�w�N,_�Ȏ�],�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),L1),
�@�@sort(L1,L2),
�@�@member([_�w�N,_�Ȏ�],L2),
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]),
�@�@fail.
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��'.
% Prolog
�w��('0001', �R�c���Y,2,3,42).
�w��('0002', �c����Y,2,6,31).
�w�Е�('0003', �֓��Ԏq,2,2,4).
�w���̐�������͂��A�Y������w���̊w�Дԍ��A�w�N�A�Ȏ���\��(_���O) :-
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]).
�w���̖��O�̈ꕔ����͂��A�Y������w���̊w�Дԍ��A���O�A���ȓ�����\��(_���O�̈ꕔ) :-
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@sub_atom(_���O,_,_,_,_���O�̈ꕔ),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O�̈ꕔ,_�w�Дԍ�,���O,_���ȓ���]).
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��' :-
�@�@findall([_�w�N,_�Ȏ�],�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),L1),
�@�@sort(L1,L2),
�@�@member([_�w�N,_�Ȏ�],L2),
�@�@�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]),
�@�@fail.
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��'.
195 �F�f�t�H���g�̖����������F2009/11/24(��) 15:28:19
>>194
% Prolog �����d�����A�ȉ��̏����̕�����ʓI�B
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��' :-
�@�@findall([_�w�N,_�Ȏ�,_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�],�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),L1),
�@�@sort(L1,L2),
�@�@member([_,_,_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�],L2),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]),
�@�@fail.
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��'.
% Prolog �����d�����A�ȉ��̏����̕�����ʓI�B
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��' :-
�@�@findall([_�w�N,_�Ȏ�,_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�],�w�Е�(_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�),L1),
�@�@sort(L1,L2),
�@�@member([_,_,_�w�Дԍ�,_���O,_���ȓ���,_�w�N,_�Ȏ�],L2),
�@�@write_formatted('%t,%t,%t,%t\n',[_���O,_�w�Дԍ�,�w�N,_�Ȏ�]),
�@�@fail.
'�e�w���̑S�Ẵf�[�^��Ȏ���(����)�ɕ\��'.
196 �F�f�t�H���g�̖����������F2009/11/24(��) 15:35:42
http://pc12.2ch.net/test/read.cgi/tech/1258158172/308
# �C�ӂ̂O�łȂ����R��n���L�[�{�[�h�œ��͂��A���͂�����������̏ꍇ�A
# ���̐����ɂR���|���ƂP�𑫂��܂��B���͂��������������̏ꍇ�A���̐������Q�Ŋ���܂��B
# �����ē���ꂽ�����ɓ��l�̑�������A�P�ɒB�������_�ŏI�����܂��B
# �����Ă��̑���������Ƃ��̑���ŏo���ő�l��\�����������B
# �C�ӂ̂O�łȂ����R��n���L�[�{�[�h�œ��͂��A���͂�����������̏ꍇ�A
# ���̐����ɂR���|���ƂP�𑫂��܂��B���͂��������������̏ꍇ�A���̐������Q�Ŋ���܂��B
# �����ē���ꂽ�����ɓ��l�̑�������A�P�ɒB�������_�ŏI�����܂��B
# �����Ă��̑���������Ƃ��̑���ŏo���ő�l��\�����������B
197 �F�f�t�H���g�̖����������F2009/11/24(��) 15:48:56
>>196
% Prolog
c132_308 :-
�@�@c132_308(N,0,_���삵����,N,_�ő�l),
�@�@write_formatted('%t,%t\n',[_���삵����,_�ő�l]).
c132_308(1,_���삵����,_���삵����,_�ő�l,_�ő�l) :-
�@�@\+(_���삵����=0),!.
c132_308(N,M,_���삵����,Max1,_�ő�l) :-
�@�@1 is N mod 2,
�@�@N2 is N * 3 + 1,
�@�@M2 is M + 1,
�@�@���݂̍ő�l��(N2,Max1,Max2),
�@�@c132_308(N2,M2,_���삵����,Max2,_�ő�l).
c132_308(N,M,_���삵����,Max1,_�ő�l) :-
�@�@0 is N mod 2,
�@�@N2 is N // 2,
�@�@M2 is M + 1,
�@�@���݂̍ő�l��(N2,Max1,Max2),
�@�@c132_308(N2,M2,_���삵����,Max2,_�ő�l).
���݂̍ő�l��(A,B,A) :- A >= B.
���݂̍ő�l��(A,B,B) :- A < B.
% Prolog
c132_308 :-
�@�@c132_308(N,0,_���삵����,N,_�ő�l),
�@�@write_formatted('%t,%t\n',[_���삵����,_�ő�l]).
c132_308(1,_���삵����,_���삵����,_�ő�l,_�ő�l) :-
�@�@\+(_���삵����=0),!.
c132_308(N,M,_���삵����,Max1,_�ő�l) :-
�@�@1 is N mod 2,
�@�@N2 is N * 3 + 1,
�@�@M2 is M + 1,
�@�@���݂̍ő�l��(N2,Max1,Max2),
�@�@c132_308(N2,M2,_���삵����,Max2,_�ő�l).
c132_308(N,M,_���삵����,Max1,_�ő�l) :-
�@�@0 is N mod 2,
�@�@N2 is N // 2,
�@�@M2 is M + 1,
�@�@���݂̍ő�l��(N2,Max1,Max2),
�@�@c132_308(N2,M2,_���삵����,Max2,_�ő�l).
���݂̍ő�l��(A,B,A) :- A >= B.
���݂̍ő�l��(A,B,B) :- A < B.
198 �F�f�t�H���g�̖����������F2009/11/24(��) 15:51:45
>>197 �����@�g�b�v���x�� ����ł� N �����͂ł��Ă��Ȃ�!
c132_308(N) :-
�@�@c132_308(N,0,_���삵����,N,_�ő�l),
�@�@write_formatted('%t,%t\n',[_���삵����,_�ő�l]).
c132_308(N) :-
�@�@c132_308(N,0,_���삵����,N,_�ő�l),
�@�@write_formatted('%t,%t\n',[_���삵����,_�ő�l]).
199 �F�f�t�H���g�̖����������F2009/11/24(��) 16:36:16
http://pc12.2ch.net/test/read.cgi/tech/1258158172/314
# [1] ���ƒP���F �v���O���~���O
#
# [2] ��蕶(�܃R�[�h&�����N)�F
# ��`�I�A���S���Y�������TSP(����Z�[���X�}�����)�̋ߎ���@�̃v���O�����������B
# �������s�s���̐���5�`6���x�ŁA�s�s�Ԃ̋����͎��R�Ɍ��߂Ă悢�Ƃ���B
#
# [1] ���ƒP���F �v���O���~���O
#
# [2] ��蕶(�܃R�[�h&�����N)�F
# ��`�I�A���S���Y�������TSP(����Z�[���X�}�����)�̋ߎ���@�̃v���O�����������B
# �������s�s���̐���5�`6���x�ŁA�s�s�Ԃ̋����͎��R�Ɍ��߂Ă悢�Ƃ���B
#
200 �F�f�t�H���g�̖����������F2009/11/24(��) 16:51:02
# [1] ���ƒP���F C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ����Z�[���X�}������Nearest Addition�@�ʼn����v���O�������쐬����B
# Nearest Addition�@�Ƃ�
# (1)�P�̓s�s����Ȃ钷���O�̕����H�s���ЂƂ쐬����
# (2)���݂̕����H�s���S�Ă̓s�s���܂ނȂ�A���ꂪ��
# (3)�����łȂ��Ȃ�A�s�Ɋ܂܂��s�sj�Ƃs�Ɋ܂܂�Ȃ��s�sk�̑g�ݍ��킹�ŁA
# j��k�̊Ԃ̋����bjk(jk�͂b�̉E��)���ŏ��ɂ���悤�Ȃ��̂����߂�
# (4)(i,j)���s�Ɋ܂܂��p�X�Ƃ���Ƃ��A������Q�̃p�X(i,k)��(k,j)�Œu��������
# (5)�ȏ��(2)�`(4)���J��Ԃ�
# [2] ��蕶(�܃R�[�h&�����N)�F
# ����Z�[���X�}������Nearest Addition�@�ʼn����v���O�������쐬����B
# Nearest Addition�@�Ƃ�
# (1)�P�̓s�s����Ȃ钷���O�̕����H�s���ЂƂ쐬����
# (2)���݂̕����H�s���S�Ă̓s�s���܂ނȂ�A���ꂪ��
# (3)�����łȂ��Ȃ�A�s�Ɋ܂܂��s�sj�Ƃs�Ɋ܂܂�Ȃ��s�sk�̑g�ݍ��킹�ŁA
# j��k�̊Ԃ̋����bjk(jk�͂b�̉E��)���ŏ��ɂ���悤�Ȃ��̂����߂�
# (4)(i,j)���s�Ɋ܂܂��p�X�Ƃ���Ƃ��A������Q�̃p�X(i,k)��(k,j)�Œu��������
# (5)�ȏ��(2)�`(4)���J��Ԃ�
201 �F�f�t�H���g�̖����������F2009/11/24(��) 16:55:51
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# �^�C�s���O�v���O���������B
# �v���O�����̗���́A�p�P��P�s�P���P�O�������t�@�C�������A
# �P�D�e�L�X�g�t�@�C����������
# �Q�D�e�L�X�g�t�@�C���̂P�s�ڂ��\�������
# �R�D�^�C�s���O������i�~�X������Ƃ����P��^�C�s���O������j
# �S�D�P�s�ڂ��I���ƁA�Q�s�ڂ��\������A�܂��^�C�s���O������
# �T�D�P�O�₨�������A�����������Ԃƃ~�X�������o�͂����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �^�C�s���O�v���O���������B
# �v���O�����̗���́A�p�P��P�s�P���P�O�������t�@�C�������A
# �P�D�e�L�X�g�t�@�C����������
# �Q�D�e�L�X�g�t�@�C���̂P�s�ڂ��\�������
# �R�D�^�C�s���O������i�~�X������Ƃ����P��^�C�s���O������j
# �S�D�P�s�ڂ��I���ƁA�Q�s�ڂ��\������A�܂��^�C�s���O������
# �T�D�P�O�₨�������A�����������Ԃƃ~�X�������o�͂����
202 �F�f�t�H���g�̖����������F2009/11/24(��) 17:10:54
# [�P]���ƒP���@�v���O�������K
# [�Q]��蕶�F��s�Ɂu������v,�u������v,�u������v,�u�����v
# �Ƃ����ӂ���4�̑��������ꂼ��R���}�ŋ��ꂽ�t�@�C�����\���̂ɓǂݍ���
# �i�����܂ł͏o���܂����j�A����2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x�����߁A�W���o�͂ɏ����o���B
# �����ŒP��͏o���������ɕ��ׂ�B�܂��啶���͏������ɓǂݑւ��A��ʂ��Ȃ��B�܂��P��̂���a,the,by,for,in,on,of,to,with�͏��O���A�J�E���g���Ȃ��B
# [�Q]��蕶�F��s�Ɂu������v,�u������v,�u������v,�u�����v
# �Ƃ����ӂ���4�̑��������ꂼ��R���}�ŋ��ꂽ�t�@�C�����\���̂ɓǂݍ���
# �i�����܂ł͏o���܂����j�A����2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x�����߁A�W���o�͂ɏ����o���B
# �����ŒP��͏o���������ɕ��ׂ�B�܂��啶���͏������ɓǂݑւ��A��ʂ��Ȃ��B�܂��P��̂���a,the,by,for,in,on,of,to,with�͏��O���A�J�E���g���Ȃ��B
203 �F�f�t�H���g�̖����������F2009/11/24(��) 17:34:05
# [1] �ۑ�
# [2] ��蕶�F�����^�z�� str1[10] str2[10]��錾���A����ɍD����
# �@�@�@�@�@�@��������L�[�{�[�h������͂��A���ꂼ��̕�������
# �@�@�@�@�@�@�ɂP���������݂Ɏ��o���o�͂��Ȃ����B
# [2] ��蕶�F�����^�z�� str1[10] str2[10]��錾���A����ɍD����
# �@�@�@�@�@�@��������L�[�{�[�h������͂��A���ꂼ��̕�������
# �@�@�@�@�@�@�ɂP���������݂Ɏ��o���o�͂��Ȃ����B
204 �F�f�t�H���g�̖����������F2009/11/24(��) 17:36:00
>>203
% Prolog
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@sub_atom(Atom1,_,1,R,Char1),
�@�@sub_atom(Atom2,_,1,R,Char2),
�@�@(Char = Char1; Char = Char2).
% Prolog
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@sub_atom(Atom1,_,1,R,Char1),
�@�@sub_atom(Atom2,_,1,R,Char2),
�@�@(Char = Char1; Char = Char2).
205 �F�f�t�H���g�̖����������F2009/11/24(��) 17:53:59
http://pc12.2ch.net/test/read.cgi/tech/1258158172/316
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10165.txt
# �ۑ�P�A��rand()���g�p���ĂO�`�X�X�X�̐������P�O���A
# �@�@�@�@��ʂɕ\����������A�����i���l�̏��������j�ɕ\��������v���O����
# �@�@�@�@�i���s��j
#�@�@�@�@�V�T�U�A�W�R�U�A�Q�R�V�A�P�O�X�A�Q�X�O�A�U�S�V�A�Q�V�A�X�R�R�A�P�X�W�A�Q�R�X
# �@�@�@�@�Q�V�A�P�O�X�A�P�X�W�A�Q�R�V�A�Q�R�X�A�Q�X�O�A�U�S�V�A�V�T�U�A�W�R�U�A�X�R�R
#
# �ۑ�Q�A��rand()���g�p���ĂO�`�X�̐��������B������P�O�O����s���A�e���l�̏o����n[0]�`n[9]��
# �@�@�@�@�P�O�̔z��ɃZ�b�g�A�����p���Ď��̂悤�Ȗ_�O���t��\������v���O�������쐬����B
#�@�@�@�@�i���s��j
# �@�@�@�@0:***************
# 1:********
# 2:*************
# 3:***********
# 4:*******
# 5:*********
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10165.txt
# �ۑ�P�A��rand()���g�p���ĂO�`�X�X�X�̐������P�O���A
# �@�@�@�@��ʂɕ\����������A�����i���l�̏��������j�ɕ\��������v���O����
# �@�@�@�@�i���s��j
#�@�@�@�@�V�T�U�A�W�R�U�A�Q�R�V�A�P�O�X�A�Q�X�O�A�U�S�V�A�Q�V�A�X�R�R�A�P�X�W�A�Q�R�X
# �@�@�@�@�Q�V�A�P�O�X�A�P�X�W�A�Q�R�V�A�Q�R�X�A�Q�X�O�A�U�S�V�A�V�T�U�A�W�R�U�A�X�R�R
#
# �ۑ�Q�A��rand()���g�p���ĂO�`�X�̐��������B������P�O�O����s���A�e���l�̏o����n[0]�`n[9]��
# �@�@�@�@�P�O�̔z��ɃZ�b�g�A�����p���Ď��̂悤�Ȗ_�O���t��\������v���O�������쐬����B
#�@�@�@�@�i���s��j
# �@�@�@�@0:***************
# 1:********
# 2:*************
# 3:***********
# 4:*******
# 5:*********
206 �F�f�t�H���g�̖����������F2009/11/24(��) 18:08:38
>>205
% Prolog
'�O�`�X�X�X�̐������P�O���A��ʂɕ\����������A�����i���l�̏��������j�ɕ\��'(_���������Ȃ��) :-
�@�@findall(N,N is random mod 1000,L),
�@�@��������(L,[],_���������Ȃ��),
�Ȃ�т��s�o��(_��������Ȃ��).
��������([],X,X).
��������([A|R1],L,X) :- �}��(A,L,L1),��������(R1,L1,X).
�}��(A,[],[A]) :- !.
�}��(A,[B|R1],[A,B|R1]) :- A =< B,!.
�}��(A,[B|R1],[B|R2]) :-
�@�@�}��(A,R1,R2).
�Ȃ�т��s�o��([]).
�Ȃ�т��s�o��([A|R]) :-
�@�@write_formatted('%t\n',[A]),
�@�@�Ȃ�т��s�o��(R).
% Prolog
'�O�`�X�X�X�̐������P�O���A��ʂɕ\����������A�����i���l�̏��������j�ɕ\��'(_���������Ȃ��) :-
�@�@findall(N,N is random mod 1000,L),
�@�@��������(L,[],_���������Ȃ��),
�Ȃ�т��s�o��(_��������Ȃ��).
��������([],X,X).
��������([A|R1],L,X) :- �}��(A,L,L1),��������(R1,L1,X).
�}��(A,[],[A]) :- !.
�}��(A,[B|R1],[A,B|R1]) :- A =< B,!.
�}��(A,[B|R1],[B|R2]) :-
�@�@�}��(A,R1,R2).
�Ȃ�т��s�o��([]).
�Ȃ�т��s�o��([A|R]) :-
�@�@write_formatted('%t\n',[A]),
�@�@�Ȃ�т��s�o��(R).
207 �F�f�t�H���g�̖����������F2009/11/24(��) 18:14:19
http://pc12.2ch.net/test/read.cgi/tech/1258158172/321
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# �Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}������B
# �Ⴆ�A�����P�Q�R�S�T��AB�ł�=�R�̏ꍇ�A�P�Q�RAB�S�T�ƂȂ�B
# �i�P�j �z���p����B
# �i�Q�j���ƃ|�C���^�[��p���č��B
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# �Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}������B
# �Ⴆ�A�����P�Q�R�S�T��AB�ł�=�R�̏ꍇ�A�P�Q�RAB�S�T�ƂȂ�B
# �i�P�j �z���p����B
# �i�Q�j���ƃ|�C���^�[��p���č��B
208 �F�f�t�H���g�̖����������F2009/11/24(��) 18:20:18
>>207
% Prolog
'�Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}��'(S1,S2,S) :-
�@�@N1 is N - 1,
�@�@sub_atom(S1,0,N1,_,A1,A2,A3,_,_,_),
�@�@concat_atom([A1,S2,A2,A3],S).
% Prolog
'�Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}��'(S1,S2,S) :-
�@�@N1 is N - 1,
�@�@sub_atom(S1,0,N1,_,A1,A2,A3,_,_,_),
�@�@concat_atom([A1,S2,A2,A3],S).
209 �F�f�t�H���g�̖����������F2009/11/24(��) 18:25:05
>>208 �����Bsub_atom/10�̒���
% Prolog
'�Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}��'(S1,S2,S) :-
�@�@N1 is N - 1,
�@�@sub_atom(S1,0,N1,_,_,A2,A3,_,_,_),
�@�@concat_atom([A2,S2,A3],S).
% Prolog
'�Q�̕������S1��S2�̔z��ɓǂ݁AS1�̕�����̍ŏ����炎�ڂ�S2�̕������}��'(S1,S2,S) :-
�@�@N1 is N - 1,
�@�@sub_atom(S1,0,N1,_,_,A2,A3,_,_,_),
�@�@concat_atom([A2,S2,A3],S).
210 �F�f�t�H���g�̖����������F2009/11/24(��) 22:03:32
>>207
% Prolog
�ۑ�2 :-
�@�@�ۑ�2(100,[0,0,0,0,0,0,0,0,0,0],L),
�@�@�ۑ�2_�O���t(L).
�ۑ�2(0,L,L) :- !.
�ۑ�2(M,Y,L) :-
�@�@N is random mod 10,
N2 is N + 1,
�@�@'N�Ԗڗv�f���J�E���g�A�b�v'(1,N2,Y,Y1),
�@�@M1 is M - 1,
�@�@�ۑ�2(M1,Y1,L).
�ۑ�2_�O���t(L) :-
�@�@for(1,N,10),
�@�@N1 is N - 1,
�@�@list_nth(N,L,_�p�x),
�@�@findall('*',for(1,U,_�p�x),L2),
�@�@concat_atom([N1,':'|L2],S),
�@�@write_formatted('%t\n',[S]),
�@�@N = 10.
'N�Ԗڗv�f���J�E���g�A�b�v'(M,0,Y,Y1) :- 'N�Ԗڗv�f���J�E���g�A�b�v'(1,10,Y,Y1).
'N�Ԗڗv�f���J�E���g�A�b�v'(N,N,[A|R1],[B|R1]) :- B is A + 1,!.
'N�Ԗڗv�f���J�E���g�A�b�v'(M,N,[A|R1],[A|R2]) :- M2 is M + 1,'N�Ԗڗv�f���J�E���g�A�b�v'(M2,N,R1,R2).
% Prolog
�ۑ�2 :-
�@�@�ۑ�2(100,[0,0,0,0,0,0,0,0,0,0],L),
�@�@�ۑ�2_�O���t(L).
�ۑ�2(0,L,L) :- !.
�ۑ�2(M,Y,L) :-
�@�@N is random mod 10,
N2 is N + 1,
�@�@'N�Ԗڗv�f���J�E���g�A�b�v'(1,N2,Y,Y1),
�@�@M1 is M - 1,
�@�@�ۑ�2(M1,Y1,L).
�ۑ�2_�O���t(L) :-
�@�@for(1,N,10),
�@�@N1 is N - 1,
�@�@list_nth(N,L,_�p�x),
�@�@findall('*',for(1,U,_�p�x),L2),
�@�@concat_atom([N1,':'|L2],S),
�@�@write_formatted('%t\n',[S]),
�@�@N = 10.
'N�Ԗڗv�f���J�E���g�A�b�v'(M,0,Y,Y1) :- 'N�Ԗڗv�f���J�E���g�A�b�v'(1,10,Y,Y1).
'N�Ԗڗv�f���J�E���g�A�b�v'(N,N,[A|R1],[B|R1]) :- B is A + 1,!.
'N�Ԗڗv�f���J�E���g�A�b�v'(M,N,[A|R1],[A|R2]) :- M2 is M + 1,'N�Ԗڗv�f���J�E���g�A�b�v'(M2,N,R1,R2).
211 �F�f�t�H���g�̖����������F2009/11/24(��) 22:33:23
212 �F�f�t�H���g�̖����������F2009/11/24(��) 22:42:59
>>205
NB.J����
NB.
NB.�ۑ�1
(,:/:~)?10#100
63 92 51 92 39 15 43 89 36 69
15 36 39 43 51 63 69 89 92 92
NB.J����
NB.
NB.�ۑ�1
(,:/:~)?10#100
63 92 51 92 39 15 43 89 36 69
15 36 39 43 51 63 69 89 92 92
213 �F�f�t�H���g�̖����������F2009/11/24(��) 22:49:51
>>205
NB.J����
NB.
NB.�ۑ�2
load 'misc'
(":@[,':','*'#~])/"1>/:~nubcount ?100#10
0:*************
1:*************
2:*******
3:***************
4:***************
5:*****
6:*******
7:**********
8:******
9:*********
NB.J����
NB.
NB.�ۑ�2
load 'misc'
(":@[,':','*'#~])/"1>/:~nubcount ?100#10
0:*************
1:*************
2:*******
3:***************
4:***************
5:*****
6:*******
7:**********
8:******
9:*********
214 �F�f�t�H���g�̖����������F2009/11/25(��) 04:50:20
>>201
% Prolog
�e�L�X�g�t�@�C����ǂݍ���1�s�Â^�C�s���O���� :-
�@�@�e�L�X�g�t�@�C����������(_�e�L�X�g�t�@�C����),
�@�@get_lines(_�e�L�X�g�t�@�C����,Lines),
�@�@TimeA is time,
�@�@�^�C�s���O������(1,10,Lines,TimeB,0,_�~�X������),
�@�@_������������ is time - TimeA,
�@�@write_formatted('������������ %t�b, �~�X������ %t��\n',[_������������,_�~
�X������]),!.
�e�L�X�g�t�@�C����������(_�e�L�X�g�t�@�C����) :-
�@�@write('�e�L�X�g�t�@�C���������������� : '),
�@�@get_line(_�e�L�X�g�t�@�C����).
�^�C�s���O������(M,N,Lines,X,X) :-�@!.
�^�C�s���O������(M,N,[Line|R],Y,X) :-
�@�@write_formatted('%t:�@%t : ',[M,Line]),
�@�@get_line(Line),
�@�@M2 is M + 1,
�@�@�^�C�s���O������(M2,N,R,Y,X),!.
�^�C�s���O������(M,N,[Line|R],X) :-
�@�@Y2 is Y + 1,
�@�@�^�C�s���O������(M,N,[Line|R],Y2,X).
% Prolog
�e�L�X�g�t�@�C����ǂݍ���1�s�Â^�C�s���O���� :-
�@�@�e�L�X�g�t�@�C����������(_�e�L�X�g�t�@�C����),
�@�@get_lines(_�e�L�X�g�t�@�C����,Lines),
�@�@TimeA is time,
�@�@�^�C�s���O������(1,10,Lines,TimeB,0,_�~�X������),
�@�@_������������ is time - TimeA,
�@�@write_formatted('������������ %t�b, �~�X������ %t��\n',[_������������,_�~
�X������]),!.
�e�L�X�g�t�@�C����������(_�e�L�X�g�t�@�C����) :-
�@�@write('�e�L�X�g�t�@�C���������������� : '),
�@�@get_line(_�e�L�X�g�t�@�C����).
�^�C�s���O������(M,N,Lines,X,X) :-�@!.
�^�C�s���O������(M,N,[Line|R],Y,X) :-
�@�@write_formatted('%t:�@%t : ',[M,Line]),
�@�@get_line(Line),
�@�@M2 is M + 1,
�@�@�^�C�s���O������(M2,N,R,Y,X),!.
�^�C�s���O������(M,N,[Line|R],X) :-
�@�@Y2 is Y + 1,
�@�@�^�C�s���O������(M,N,[Line|R],Y2,X).
215 �F�f�t�H���g�̖����������F2009/11/25(��) 05:09:10
# http://codepad.org/JEzL3ZJ7 �͈ȉ��̃R�����g�t�������B������Q�l�Ƀi�b�v�U�b�N�v���O����������B
# /** �i�b�v�U�b�N�̌� */
# /** �i�b�v�U�b�N */
# /** �S�Ẵi�b�v�U�b�N�̑��d�� */
# /**
# * ���̃i�b�v�U�b�N���������@�B������������
# */
# /**
# * �i�b�v�U�b�N�̓��e��S�ĕ\������
#
# /**
# * �S�i�b�v�U�b�N�̑��d�ʂ��v�Z���Ccapacity�Ɋi�[����
# */
# /**
# * �i�b�v�U�b�N�ɓ���邱�Ƃ��ł���v�f
# * @author ���[���[
# *
# */
# /** �v�f��ID */
# /** �v�f�̏d���C�����_���Ɍ��� */
# /** �v�f�̉��l�C�����_���Ɍ��� */
# /**
# * ���̗v�f������������
# * @param givenId �v�f��ID
# */
# /** �i�b�v�U�b�N�̌� */
# /** �i�b�v�U�b�N */
# /** �S�Ẵi�b�v�U�b�N�̑��d�� */
# /**
# * ���̃i�b�v�U�b�N���������@�B������������
# */
# /**
# * �i�b�v�U�b�N�̓��e��S�ĕ\������
#
# /**
# * �S�i�b�v�U�b�N�̑��d�ʂ��v�Z���Ccapacity�Ɋi�[����
# */
# /**
# * �i�b�v�U�b�N�ɓ���邱�Ƃ��ł���v�f
# * @author ���[���[
# *
# */
# /** �v�f��ID */
# /** �v�f�̏d���C�����_���Ɍ��� */
# /** �v�f�̉��l�C�����_���Ɍ��� */
# /**
# * ���̗v�f������������
# * @param givenId �v�f��ID
# */
216 �F�f�t�H���g�̖����������F2009/11/25(��) 05:15:05
>>215 ��
http://pc12.2ch.net/test/read.cgi/tech/1248012902/512
http://pc12.2ch.net/test/read.cgi/tech/1248012902/515
����o�肳��Ă��܂��B
http://pc12.2ch.net/test/read.cgi/tech/1248012902/512
http://pc12.2ch.net/test/read.cgi/tech/1248012902/515
����o�肳��Ă��܂��B
217 �F�f�t�H���g�̖����������F2009/11/25(��) 05:18:56
218 �F�f�t�H���g�̖����������F2009/11/25(��) 06:31:01
http://pc12.2ch.net/test/read.cgi/tech/1258158172/330
# [1] ���ƒP���F�v���O����
# [2]��蕶
# ���̗v�̂Ńe�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�v���O����
# 1.�e�X�g�̓_������͂���K�C�_���X��p���Ď��̂悤�ɏo�́@�F�_���̓��� �I�������Fe���邢��E
# 2�Dfgets()��p���āA�e�X�g�̓_������Ƃ��ē���
# 3�D2�œ��͂���������'e'�܂���'E'�Ȃ�Ώ���2�`5�̏������I������6�̏������s��
# 4�D������œ��͂����_����int�^�ϐ��ɕϊ�(atoi���g�p����)
# 5�D4�ŕϊ�����int�^�̓_����0�_�ȏ�100�_�ȉ��Ȃ�A���ꂼ��̓_����̐l���𐔂���B
# 6�D5�̌��ʂ̕\��
# [1] ���ƒP���F�v���O����
# [2]��蕶
# ���̗v�̂Ńe�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�v���O����
# 1.�e�X�g�̓_������͂���K�C�_���X��p���Ď��̂悤�ɏo�́@�F�_���̓��� �I�������Fe���邢��E
# 2�Dfgets()��p���āA�e�X�g�̓_������Ƃ��ē���
# 3�D2�œ��͂���������'e'�܂���'E'�Ȃ�Ώ���2�`5�̏������I������6�̏������s��
# 4�D������œ��͂����_����int�^�ϐ��ɕϊ�(atoi���g�p����)
# 5�D4�ŕϊ�����int�^�̓_����0�_�ȏ�100�_�ȉ��Ȃ�A���ꂼ��̓_����̐l���𐔂���B
# 6�D5�̌��ʂ̕\��
219 �F�f�t�H���g�̖����������F2009/11/25(��) 06:52:14
>>218
% Prolog
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂� :-
�@�@write('�F�_���̓��� �I�������Fe���邢��E '),get_line(Line),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,[0,0,0,0,0,0,0,0,0,0],_10�_���Əo���p�x�Ȃ��),
�@�@for(1,N,10),
�@�@list_nth(N,_10�_���Əo���p�x�Ȃ��,M),
�@�@write_formatted('%t~%t�@%t�l\n',[(N-1) * 10,N * 10 - 1,M]),
�@�@N = 10.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(e,L,L) :- !.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�('E',L,L) :- !.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,L1,L) :-
�@�@atom_to_term(Line,N,_),N >= 0,N =< 100,
�@�@M is (N // 10) + 1,
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(N,L1,L2),
�@�@write('�F�_���̓��� �I�������Fe���邢��E '),get_line(Line2),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line2,L2,L).
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :- !.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C]|R1]) :-�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
% Prolog
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂� :-
�@�@write('�F�_���̓��� �I�������Fe���邢��E '),get_line(Line),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,[0,0,0,0,0,0,0,0,0,0],_10�_���Əo���p�x�Ȃ��),
�@�@for(1,N,10),
�@�@list_nth(N,_10�_���Əo���p�x�Ȃ��,M),
�@�@write_formatted('%t~%t�@%t�l\n',[(N-1) * 10,N * 10 - 1,M]),
�@�@N = 10.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(e,L,L) :- !.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�('E',L,L) :- !.
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,L1,L) :-
�@�@atom_to_term(Line,N,_),N >= 0,N =< 100,
�@�@M is (N // 10) + 1,
�@�@�o���p�x�Ȃ�т��J�E���g�A�b�v(N,L1,L2),
�@�@write('�F�_���̓��� �I�������Fe���邢��E '),get_line(Line2),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line2,L2,L).
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[],[1,C]) :- !.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C]|R1],[[N2,C]|R1]) :-�@N2 is N + 1,!.
�o���p�x�Ȃ�т��J�E���g�A�b�v(C,[[N,C1]|R1],[[N,C1]|R2]) :-�@�o���p�x�Ȃ�т��J�E���g�A�b�v(C,R1,R2).
220 �F�f�t�H���g�̖����������F2009/11/25(��) 07:28:13
http://pc12.2ch.net/test/read.cgi/tech/1258158172/328
# [1]�v���O���~���O����_
# [2]�v���O�����̐����ƃ��C�t�T�C�N���ɂ��Č���A�v���J���̎��ۂ܂���
# �_���� ����R�[�h���܂߂邱�ƁB
# [1]�v���O���~���O����_
# [2]�v���O�����̐����ƃ��C�t�T�C�N���ɂ��Č���A�v���J���̎��ۂ܂���
# �_���� ����R�[�h���܂߂邱�ƁB
221 �F�f�t�H���g�̖����������F2009/11/25(��) 07:38:49
>>53
NB. J����
0j2":,.(,[:+/_3{.])^:(18)0.01 0.1 1
0.01
0.10
1.00
1.11
2.21
4.32
7.64
14.17
26.13
47.94
88.24
162.31
298.49
549.04
1009.84
1857.37
3416.25
6283.46
11557.08
21256.79
39097.33
NB. J����
0j2":,.(,[:+/_3{.])^:(18)0.01 0.1 1
0.01
0.10
1.00
1.11
2.21
4.32
7.64
14.17
26.13
47.94
88.24
162.31
298.49
549.04
1009.84
1857.37
3416.25
6283.46
11557.08
21256.79
39097.33
222 �F�f�t�H���g�̖����������F2009/11/25(��) 11:38:40
http://pc12.2ch.net/test/read.cgi/tech/1258158172/337
# [1] ���ƒP���F�v���O����
# [2] ��蕶�F
# ��̒lx��y�̑傫�����̒l��Ԃ����`���}�N���͈ȉ��̂悤��
# ��`�ł���
# #define max(x,y) ((x) > (y) ? (x) : (y))
# ���̃}�N���𗘗p���āA�l�̒la,b,c,d�̒l�̍ő�l�����߂�
# max(max(a,b), max(c,d))
# �����
# max(max(max(a,b), c), d)
# ���ǂ̂悤�ɓW�J����邩���������A�l�@��������B
#
# [1] ���ƒP���F�v���O����
# [2] ��蕶�F
# ��̒lx��y�̑傫�����̒l��Ԃ����`���}�N���͈ȉ��̂悤��
# ��`�ł���
# #define max(x,y) ((x) > (y) ? (x) : (y))
# ���̃}�N���𗘗p���āA�l�̒la,b,c,d�̒l�̍ő�l�����߂�
# max(max(a,b), max(c,d))
# �����
# max(max(max(a,b), c), d)
# ���ǂ̂悤�ɓW�J����邩���������A�l�@��������B
#
223 �F�f�t�H���g�̖����������F2009/11/25(��) 11:39:48
http://pc12.2ch.net/test/read.cgi/tech/1258158172/338
# [1] ���ƒP���F�v���~���O��b
# [2] ��蕶(�܃R�[�h&�����N)�F5�̐����f�[�^���͂ɑ��鍇�v�v�Z�A���S���Y��
# �P�D�ϐ� s �� 0 ��ݒ肷��B
# �Q�D�ϐ� k �� 0 ��ݒ肷��B
# �R�D���� k < 5 �łȂ���A7.�֍s���B
# �S�D�����̓��͂�ϐ� a �Ɋi�[����B
# �T�D�ϐ� s �� �ϐ� a �������āA�ϐ� s �� �������B
# �U�D�ϐ� k �̓��e�� 1 �������₵�A3.�ɂ��ǂ�B
# �V�D�ϐ� s ���o�͕\������B
#
# [1] ���ƒP���F�v���~���O��b
# [2] ��蕶(�܃R�[�h&�����N)�F5�̐����f�[�^���͂ɑ��鍇�v�v�Z�A���S���Y��
# �P�D�ϐ� s �� 0 ��ݒ肷��B
# �Q�D�ϐ� k �� 0 ��ݒ肷��B
# �R�D���� k < 5 �łȂ���A7.�֍s���B
# �S�D�����̓��͂�ϐ� a �Ɋi�[����B
# �T�D�ϐ� s �� �ϐ� a �������āA�ϐ� s �� �������B
# �U�D�ϐ� k �̓��e�� 1 �������₵�A3.�ɂ��ǂ�B
# �V�D�ϐ� s ���o�͕\������B
#
224 �F�f�t�H���g�̖����������F2009/11/25(��) 11:40:54
http://pc12.2ch.net/test/read.cgi/tech/1258158172/339
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F5�l�̊w����3����(�������p)�̓_����
# �ǂݍ���ŁA2�����z���p���Ĉȉ��̏��������v���O�������쐬����B
# (1)�Ȗڕʂ̍ō��_�����߂�B
# (2)�e�w�N��3���Ȃ̕��ς����߂�B
# ������\�ɂ��ĕ\������B
#
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F5�l�̊w����3����(�������p)�̓_����
# �ǂݍ���ŁA2�����z���p���Ĉȉ��̏��������v���O�������쐬����B
# (1)�Ȗڕʂ̍ō��_�����߂�B
# (2)�e�w�N��3���Ȃ̕��ς����߂�B
# ������\�ɂ��ĕ\������B
#
225 �F�f�t�H���g�̖����������F2009/11/25(��) 13:41:27
226 �F�f�t�H���g�̖����������F2009/11/25(��) 13:51:25
>>223
% Prolog
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z' :-
�@�@'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(0,0,X),
write_formatted('%t',[X]).
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k,_s,_s) :- \+(_k < 5),!.
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k,_s,X) :-
�@�@get_integer(_a),
�@�@_s2 is _s + _a,
�@�@_k2 is _k + 1,
�@�@'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k2,_s2,X).
% Prolog
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z' :-
�@�@'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(0,0,X),
write_formatted('%t',[X]).
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k,_s,_s) :- \+(_k < 5),!.
'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k,_s,X) :-
�@�@get_integer(_a),
�@�@_s2 is _s + _a,
�@�@_k2 is _k + 1,
�@�@'5�̐����f�[�^���͂ɑ��鍇�v�v�Z'(_k2,_s2,X).
227 �F�f�t�H���g�̖����������F2009/11/25(��) 14:10:48
>>224
% Prolog
'5�l�̊w����3����(�������p)�̓_����ǂݍ���ŁA2�����z���p���āA�Ȗڕʍō��_
�A3���Ȃ̕��ς�\��' :-
�@�@findall(L,(for(1,N,5),get_line(Line),split(Line,[','],L)),_�w���̓��_�Ȃ��
),
�@�@�Ȗڕʍō��_(_�w�N�̓��_�Ȃ��,[_���ō��_,_���ō��_,_�p�ō��_]),
�@�@write('�Ȗڕʍō��_,��,��,�p\n'),
�@�@write_formatted(',%t,%t,%t\n',[_���ō��_,_���ō��_,_�p�ō��_]),
�@�@�ǂ�Ȋw�N�����邩(_�w���̓��_�Ȃ��,_�w�N�Ȃ��),
�@�@write('�w�N�ʁA�Ȗڕʕ��ϓ_\n'),
�@�@member(_�w�N,_�w�N�Ȃ��),
�@�@findavg([_��,_��,_�p],member([_�w�N,_��,_��_�p],_�w�N�̓��_�Ȃ��),[_������
,_������,_�p����]),
�@�@member([_�w�N,_������,_������,_�p����],_�e�w�N��3���Ȃ̕���),
�@�@write_formatted('%t,%t,%t,%t\n',[_�w�N,_������,_������,_�p����]),
�@�@fail.
'5�l�̊w����3����(�������p)�̓_����ǂݍ���ŁA2�����z���p���āA�Ȗڕʍō��_
�A3���Ȃ̕��ς�\��'.
�Ȗڕʍō��_(_�w�N�̓��_�Ȃ��,_�Ȗڕʍō��_) :-
�@�@�s��̓]�u(_�w�N�̓��_�Ȃ��,[_|L1]),
�@�@findall(Max,(member(L2,L1),max(L2,Max)),_�Ȗڕʍō��_).
�ǂ�Ȋw�N�����邩(_�w���̓��_�Ȃ��,_�w�N�Ȃ��) :-
�@�@findall(_�w�N,member(_�w�N,_�w�N�̓��_�Ȃ��),L),
�@�@sort(L,_�w�N�Ȃ��).
% Prolog
'5�l�̊w����3����(�������p)�̓_����ǂݍ���ŁA2�����z���p���āA�Ȗڕʍō��_
�A3���Ȃ̕��ς�\��' :-
�@�@findall(L,(for(1,N,5),get_line(Line),split(Line,[','],L)),_�w���̓��_�Ȃ��
),
�@�@�Ȗڕʍō��_(_�w�N�̓��_�Ȃ��,[_���ō��_,_���ō��_,_�p�ō��_]),
�@�@write('�Ȗڕʍō��_,��,��,�p\n'),
�@�@write_formatted(',%t,%t,%t\n',[_���ō��_,_���ō��_,_�p�ō��_]),
�@�@�ǂ�Ȋw�N�����邩(_�w���̓��_�Ȃ��,_�w�N�Ȃ��),
�@�@write('�w�N�ʁA�Ȗڕʕ��ϓ_\n'),
�@�@member(_�w�N,_�w�N�Ȃ��),
�@�@findavg([_��,_��,_�p],member([_�w�N,_��,_��_�p],_�w�N�̓��_�Ȃ��),[_������
,_������,_�p����]),
�@�@member([_�w�N,_������,_������,_�p����],_�e�w�N��3���Ȃ̕���),
�@�@write_formatted('%t,%t,%t,%t\n',[_�w�N,_������,_������,_�p����]),
�@�@fail.
'5�l�̊w����3����(�������p)�̓_����ǂݍ���ŁA2�����z���p���āA�Ȗڕʍō��_
�A3���Ȃ̕��ς�\��'.
�Ȗڕʍō��_(_�w�N�̓��_�Ȃ��,_�Ȗڕʍō��_) :-
�@�@�s��̓]�u(_�w�N�̓��_�Ȃ��,[_|L1]),
�@�@findall(Max,(member(L2,L1),max(L2,Max)),_�Ȗڕʍō��_).
�ǂ�Ȋw�N�����邩(_�w���̓��_�Ȃ��,_�w�N�Ȃ��) :-
�@�@findall(_�w�N,member(_�w�N,_�w�N�̓��_�Ȃ��),L),
�@�@sort(L,_�w�N�Ȃ��).
228 �F�f�t�H���g�̖����������F2009/11/25(��) 15:26:46
>>202
% Prolog
'2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x'(_�t�@�C��) :-
�@�@get_split_lines(_�t�@�C��,[','],L),
�@�@�o���p�x�����߂�(L,[],_�o���p�x�Ȃ��),
�@�@member([_�o���p�x,_�P��],_�o���p�x�Ȃ��),
�@�@write_formatted('%t,%t\n',[_�P��,_�o���p�x]),
�@�@fail.
'2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x'(_).
�o���p�x�����߂�([],X,X).
�o���p�x�����߂�([[_,W,_,_]|R],Y,X) :-
�@�@to_lower(W,W1),
�@�@\+(member(W1,[a,the,by,for,in,on,of,to,with])),
�@�@�o���p�x�̍X�V(W1,Y,Y2),
�@�@�o���p�x�����߂�(R,Y2,X).
�o���p�x�����߂�([[_,W,_,_]|R],Y,X) :-
�@�@to_lower(W,W1),
�@�@member(W1,[a,the,by,for,in,on,of,to,with]),
�@�@�o���p�x�����߂�(R,Y,X).
�o���p�x�̍X�V(W,[],[[1,W]]).
�o���p�x�̍X�V(W,[[S,W]|R],[[S2,W]|R]) :- S2 is S + 1,!.
�o���p�x�̍X�V(W,[L|R1],[L|R2]) :- �o���p�x�̍X�V(W,R1,R2).
% Prolog
'2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x'(_�t�@�C��) :-
�@�@get_split_lines(_�t�@�C��,[','],L),
�@�@�o���p�x�����߂�(L,[],_�o���p�x�Ȃ��),
�@�@member([_�o���p�x,_�P��],_�o���p�x�Ȃ��),
�@�@write_formatted('%t,%t\n',[_�P��,_�o���p�x]),
�@�@fail.
'2�Ԗڂ̑����Ɍ����S�Ă̑��قȂ�P��̏o���p�x'(_).
�o���p�x�����߂�([],X,X).
�o���p�x�����߂�([[_,W,_,_]|R],Y,X) :-
�@�@to_lower(W,W1),
�@�@\+(member(W1,[a,the,by,for,in,on,of,to,with])),
�@�@�o���p�x�̍X�V(W1,Y,Y2),
�@�@�o���p�x�����߂�(R,Y2,X).
�o���p�x�����߂�([[_,W,_,_]|R],Y,X) :-
�@�@to_lower(W,W1),
�@�@member(W1,[a,the,by,for,in,on,of,to,with]),
�@�@�o���p�x�����߂�(R,Y,X).
�o���p�x�̍X�V(W,[],[[1,W]]).
�o���p�x�̍X�V(W,[[S,W]|R],[[S2,W]|R]) :- S2 is S + 1,!.
�o���p�x�̍X�V(W,[L|R1],[L|R2]) :- �o���p�x�̍X�V(W,R1,R2).
229 �F�f�t�H���g�̖����������F2009/11/25(��) 16:32:05
http://pc12.2ch.net/test/read.cgi/tech/1258320456/43
# �����p�`��\������N���XPolygon���`���C�������̃C���X�^���X�����ĕ\������D���\�b�h�����s���Č��ʂ��������ƁD
#
# �E�ӂ̐���1�ӂ̒������A�g���r���[�g�Ƃ��Ď��� (�R���X�g���N�^�͈����Ƃ��ĕӂ̐���1�ӂ̒��������)
# �Eprint����Ǝ��̂悤�ɕ\�������
# [Polygon] �ӂ̐�: 5, �ӂ̒���: 100
# �E���͂̒�����Ԃ����\�b�h(perimeter)������ (�����Ȃ�)
#
# �����p�`��\������N���XPolygon���`���C�������̃C���X�^���X�����ĕ\������D���\�b�h�����s���Č��ʂ��������ƁD
#
# �E�ӂ̐���1�ӂ̒������A�g���r���[�g�Ƃ��Ď��� (�R���X�g���N�^�͈����Ƃ��ĕӂ̐���1�ӂ̒��������)
# �Eprint����Ǝ��̂悤�ɕ\�������
# [Polygon] �ӂ̐�: 5, �ӂ̒���: 100
# �E���͂̒�����Ԃ����\�b�h(perimeter)������ (�����Ȃ�)
#
230 �F�f�t�H���g�̖����������F2009/11/25(��) 16:44:19
>>229
% ESP
class Polygon has
�@�@:create(Class,Obj,_�ӂ̐�,_�ӂ̒���) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�ӂ̐� := _�ӂ̐�,
�@�@�@�@Obj!�ӂ̒��� := _�ӂ̒���;
instance
�@�@attribute �ӂ̐�,�ӂ̒���;
�@�@:perrimeter(OBJ,_���͂̒���) :-
�@�@�@�@_���͂̒��� := OBJ!�ӂ̒��� * OBJ!�ӂ̐�;
end.
% ESP
class Polygon has
�@�@:create(Class,Obj,_�ӂ̐�,_�ӂ̒���) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�ӂ̐� := _�ӂ̐�,
�@�@�@�@Obj!�ӂ̒��� := _�ӂ̒���;
instance
�@�@attribute �ӂ̐�,�ӂ̒���;
�@�@:perrimeter(OBJ,_���͂̒���) :-
�@�@�@�@_���͂̒��� := OBJ!�ӂ̒��� * OBJ!�ӂ̐�;
end.
231 �F�f�t�H���g�̖����������F2009/11/25(��) 16:54:53
>>224 �d�l�lj�
#
# �f�[�^�̓L�[�{�[�h����_������͂ŁB
# �\�́A
# �ԍ��b �@����@�@���w�@�@�p��@�@�b�ō��@�b�Œ�@�b����
# �@1 �b �@�@ �@�@ �b�@�@�@�b�@�@�@�b
# �@2 �b �@ �@ �@ �b�@�@�@�b�@�@�@�b
# �i���@���j
# �@5 �b �@ �@ �@ �b�@�@�@�b�@�@�@�b
# �@�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\
# �ō� �b
# �Œ� �b
# ���� �b
# �\�͂���Ȋ����ŁB
# �Œ�_�̕\�������肢���܂��B
#
# �f�[�^�̓L�[�{�[�h����_������͂ŁB
# �\�́A
# �ԍ��b �@����@�@���w�@�@�p��@�@�b�ō��@�b�Œ�@�b����
# �@1 �b �@�@ �@�@ �b�@�@�@�b�@�@�@�b
# �@2 �b �@ �@ �@ �b�@�@�@�b�@�@�@�b
# �i���@���j
# �@5 �b �@ �@ �@ �b�@�@�@�b�@�@�@�b
# �@�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\�\
# �ō� �b
# �Œ� �b
# ���� �b
# �\�͂���Ȋ����ŁB
# �Œ�_�̕\�������肢���܂��B
232 �F�f�t�H���g�̖����������F2009/11/25(��) 17:09:16
http://pc12.2ch.net/test/read.cgi/tech/1258158172/354
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10173.txt
# ���s���ʂ����̂悤�ɂȂ�悤�ɁA���̕\���Afor���̓�d���[�v��p���č쐬���Ȃ����B
#
# ***table of kuku ***
#
# | 1 2 3 4 5 6 7 8 9
# -----------------------------
# 1| 1 2 3 4 5 6 7 8 9
# 2| 2 4 6 8 10 12 14 16 18
# 3| 3 6 9 12 15 18 21 24 27
# 4| 4 8 12 16 20 24 28 32 36
# 5|
# �ȗ�
# |
# |
# 9| 9 18 27 36 45 54 63 72 81
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10173.txt
# ���s���ʂ����̂悤�ɂȂ�悤�ɁA���̕\���Afor���̓�d���[�v��p���č쐬���Ȃ����B
#
# ***table of kuku ***
#
# | 1 2 3 4 5 6 7 8 9
# -----------------------------
# 1| 1 2 3 4 5 6 7 8 9
# 2| 2 4 6 8 10 12 14 16 18
# 3| 3 6 9 12 15 18 21 24 27
# 4| 4 8 12 16 20 24 28 32 36
# 5|
# �ȗ�
# |
# |
# 9| 9 18 27 36 45 54 63 72 81
233 �F�f�t�H���g�̖����������F2009/11/25(��) 17:12:39
http://pc12.2ch.net/test/read.cgi/tech/1258158172/354
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10173.txt
# ���̂悤�Ɋe�O�Ԗڂ̗�v�f�Ƀe�X�g�̓_���������ݒ�ɂ��Ă���傫��
# �P�O�~�Q�̔z����B���̔z��̂P�Ԗڂ̗�v�f�ɓ_���̍��������珇�ʂ��i�[����v���O�������쐬���Ȃ����B
#
# �@ [0] [1]
# [0] 67
# [1] 43
# [2] 56
# [3] 97
# [4] 30
# [5] 88
# [6] 76
# [7] 55
# [8] 66
# [9] 78
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10173.txt
# ���̂悤�Ɋe�O�Ԗڂ̗�v�f�Ƀe�X�g�̓_���������ݒ�ɂ��Ă���傫��
# �P�O�~�Q�̔z����B���̔z��̂P�Ԗڂ̗�v�f�ɓ_���̍��������珇�ʂ��i�[����v���O�������쐬���Ȃ����B
#
# �@ [0] [1]
# [0] 67
# [1] 43
# [2] 56
# [3] 97
# [4] 30
# [5] 88
# [6] 76
# [7] 55
# [8] 66
# [9] 78
234 �F�f�t�H���g�̖����������F2009/11/25(��) 17:14:08
235 �F�f�t�H���g�̖����������F2009/11/25(��) 17:18:09
http://pc12.2ch.net/test/read.cgi/tech/1258158172/354
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10176.txt
# �������N�ȍ~�̐���N���S���̐��œ��͂���ƁA�a��œs�s��\������v���O�������쐬����B
# �������A�Q�̌��������N�͗����̔N��\�����邱�ƁB
#
# �i��A1989�N�����a64�N�A�������N�j
>>234 >233 �� http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10174.txt
�ł����B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �i�P�jhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10176.txt
# �������N�ȍ~�̐���N���S���̐��œ��͂���ƁA�a��œs�s��\������v���O�������쐬����B
# �������A�Q�̌��������N�͗����̔N��\�����邱�ƁB
#
# �i��A1989�N�����a64�N�A�������N�j
>>234 >233 �� http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10174.txt
�ł����B
236 �F�f�t�H���g�̖����������F2009/11/25(��) 17:54:37
>>235
% Prolog
�N������(����,1868,1912).
�N������(�吳,1912,1926).
�N������(���a,1926,1989).
�N������(����,1989,2009).
����a���(_����) :-
�@�@findall(_�a��,�����ȍ~�̐���a��ϊ�(_����,_�a��),L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t->%t\n',[S]).
�����ȍ~�̐���a��ϊ�(_����,_�a��) :-
�@�@�N������(_�N��,A,B),
�@�@_����>=A,
�@�@_����=<B,
�@�@N is _���� - A + 1,
�@�@�a��\��(_�N��,N,_�a��).
�a��\��(_�N��,1,_�a��) :- concat_atom([_�N��,���N],_�a��).
�a��\��(_�N��,N,_�a��) :- concat_atom([_�N��,N,�N],_�a��).
% Prolog
�N������(����,1868,1912).
�N������(�吳,1912,1926).
�N������(���a,1926,1989).
�N������(����,1989,2009).
����a���(_����) :-
�@�@findall(_�a��,�����ȍ~�̐���a��ϊ�(_����,_�a��),L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t->%t\n',[S]).
�����ȍ~�̐���a��ϊ�(_����,_�a��) :-
�@�@�N������(_�N��,A,B),
�@�@_����>=A,
�@�@_����=<B,
�@�@N is _���� - A + 1,
�@�@�a��\��(_�N��,N,_�a��).
�a��\��(_�N��,1,_�a��) :- concat_atom([_�N��,���N],_�a��).
�a��\��(_�N��,N,_�a��) :- concat_atom([_�N��,N,�N],_�a��).
237 �F�f�t�H���g�̖����������F2009/11/25(��) 17:56:20
>>236 �ꃖ���ԈႦ���B�����B
����a���(_����) :-
�@�@findall(_�a��,�����ȍ~�̐���a��ϊ�(_����,_�a��),L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t->%t\n',[_����,S]).
����a���(_����) :-
�@�@findall(_�a��,�����ȍ~�̐���a��ϊ�(_����,_�a��),L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t->%t\n',[_����,S]).
238 �F�f�t�H���g�̖����������F2009/11/25(��) 18:30:59
>>233
% Prolog
�z��([[67,_],[43,_],[56,_],[97,_],[30,_],[88,_],[76,_],[55,_],[66,_],[78,_]]).
�z��̂P�Ԗڂ̗�v�f�ɓ_���̍��������珇�ʂ��i�[����(L) :-
�@�@�z��(L),
�@�@���ʕt��(L,[],_���ʂȂ��),
�@�@���v�f�ɏ��ʂ��Z�b�g(L,_���ʂȂ��).
���ʕt��([],X,X).
���ʕt��([[A,_]|R1],Y1,X) :- �}��(A,Y1,Y2),���ʕt��(R1,Y2,X).
�}��(A,[],[A]).
�}��(A,[B|R],[A,B|R]) :- A > B,!.
�}��(A,[B|R1],[B|R2]) :- A =< B,�}��(A,R1,R2).
���v�f�ɏ��ʂ��Z�b�g([[A|V]|R],_���ʂȂ��) :-
�@�@list_nth(V,_���ʂȂ��,A),
�@�@���v�f�ɏ��ʂ��Z�b�g(R,_���ʂȂ��).
% Prolog
�z��([[67,_],[43,_],[56,_],[97,_],[30,_],[88,_],[76,_],[55,_],[66,_],[78,_]]).
�z��̂P�Ԗڂ̗�v�f�ɓ_���̍��������珇�ʂ��i�[����(L) :-
�@�@�z��(L),
�@�@���ʕt��(L,[],_���ʂȂ��),
�@�@���v�f�ɏ��ʂ��Z�b�g(L,_���ʂȂ��).
���ʕt��([],X,X).
���ʕt��([[A,_]|R1],Y1,X) :- �}��(A,Y1,Y2),���ʕt��(R1,Y2,X).
�}��(A,[],[A]).
�}��(A,[B|R],[A,B|R]) :- A > B,!.
�}��(A,[B|R1],[B|R2]) :- A =< B,�}��(A,R1,R2).
���v�f�ɏ��ʂ��Z�b�g([[A|V]|R],_���ʂȂ��) :-
�@�@list_nth(V,_���ʂȂ��,A),
�@�@���v�f�ɏ��ʂ��Z�b�g(R,_���ʂȂ��).
239 �F�f�t�H���g�̖����������F2009/11/25(��) 18:39:31
>>17
maxima
���1
f(x):= ([r:""],for i thru x do r:concat(r,ascii(96+i)),r)
���2
f(x):=sum(if(mod(i,3)=0 or mod(i,5)=0)then i else 0,i,1,x);
maxima
���1
f(x):= ([r:""],for i thru x do r:concat(r,ascii(96+i)),r)
���2
f(x):=sum(if(mod(i,3)=0 or mod(i,5)=0)then i else 0,i,1,x);
240 �F�f�t�H���g�̖����������F2009/11/25(��) 19:06:27
>>232
% Prolog
���\�� :-
�@�@write(' |'),
�@�@for(1,N,9),write_formatted('%2d ',[N]),N=9,nl,
�@�@for(1,M,30),write('-'),M=30,nl,
�@�@���\��(1,1).
���\��(9,10) :- nl,!.
���\��(M,10) :- nl,M2 is M + 1,���\��(M2,1).
���\��(M,1) :-
�@�@write_formatted('%t|%2d ',[M,M]),
�@�@���\��(M,2).
���\��(M,N) :-
�@�@write_formatted('%2d ',[M*N]),
�@�@N2 is N + 1,
�@�@���\��(M,N2).
% Prolog
���\�� :-
�@�@write(' |'),
�@�@for(1,N,9),write_formatted('%2d ',[N]),N=9,nl,
�@�@for(1,M,30),write('-'),M=30,nl,
�@�@���\��(1,1).
���\��(9,10) :- nl,!.
���\��(M,10) :- nl,M2 is M + 1,���\��(M2,1).
���\��(M,1) :-
�@�@write_formatted('%t|%2d ',[M,M]),
�@�@���\��(M,2).
���\��(M,N) :-
�@�@write_formatted('%2d ',[M*N]),
�@�@N2 is N + 1,
�@�@���\��(M,N2).
241 �F�f�t�H���g�̖����������F2009/11/25(��) 19:11:43
http://pc12.2ch.net/test/read.cgi/tech/1258158172/357
# [1] ���ƒP���F �f�[�^�\���ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10177.txt
# �P�Adata.dat����getc()��p���ăA���t�@�x�b�g���P�������ǂݍ��݁A�X�^�b�N��push-down����B
# �Q�A�X�^�b�N�̓��e��\�������print_stack_list(s)��print_stack_list.o�ɂ���B
# [1] ���ƒP���F �f�[�^�\���ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10177.txt
# �P�Adata.dat����getc()��p���ăA���t�@�x�b�g���P�������ǂݍ��݁A�X�^�b�N��push-down����B
# �Q�A�X�^�b�N�̓��e��\�������print_stack_list(s)��print_stack_list.o�ɂ���B
242 �F�f�t�H���g�̖����������F2009/11/25(��) 20:51:04
>>241
% Prolog
'data.dat����getc()��p���ăA���t�@�x�b�g���P�������ǂݍ��݁A�X�^�b�N��push-d
own����'(Stack1,Stack2) :-
�@�@see('data.dat'),
�@�@get_char(C),
�@�@'�X�^�b�N�ɑS������push-down����'(C,Stack1,Stack2),
seen.
'�X�^�b�N�ɑS������push-down����'(end_of_file,Stack,Stack) :-
'�X�^�b�N�ɑS������push-down����'(C,Stack,Stack2) :-
�@�@push(C,Stack,Stack1),
�@�@get_char(C2),
�@�@'�X�^�b�N�ɑS������push-down����'(C2,Stack1,Stack2).
push(C,Stack,[C|Stack]).
% Prolog
'data.dat����getc()��p���ăA���t�@�x�b�g���P�������ǂݍ��݁A�X�^�b�N��push-d
own����'(Stack1,Stack2) :-
�@�@see('data.dat'),
�@�@get_char(C),
�@�@'�X�^�b�N�ɑS������push-down����'(C,Stack1,Stack2),
seen.
'�X�^�b�N�ɑS������push-down����'(end_of_file,Stack,Stack) :-
'�X�^�b�N�ɑS������push-down����'(C,Stack,Stack2) :-
�@�@push(C,Stack,Stack1),
�@�@get_char(C2),
�@�@'�X�^�b�N�ɑS������push-down����'(C2,Stack1,Stack2).
push(C,Stack,[C|Stack]).
243 �F�f�t�H���g�̖����������F2009/11/25(��) 21:45:12
>>203
maxima
�Z��������̕��ɍ��킹�Ă��܂����A���������d�l�Ƃ������ƂŁB
f(a,b):=simplode(join(charlist(a),charlist(b)),"");
(%i4)f("123","asdfgh");
(%o4) 1a2s3d
(%i5)
maxima
�Z��������̕��ɍ��킹�Ă��܂����A���������d�l�Ƃ������ƂŁB
f(a,b):=simplode(join(charlist(a),charlist(b)),"");
(%i4)f("123","asdfgh");
(%o4) 1a2s3d
(%i5)
244 �F�f�t�H���g�̖����������F2009/11/26(��) 06:19:49
http://pc12.2ch.net/test/read.cgi/tech/1258158172/358
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.j
p/cgi-bin/joyful/img/10178.txt
# ���F���s���ʂ��ȉ��̒ʂ�ɂȂ�悤�Ƀv���O������lj����Ȃ����B
# ���݂̃f�[�^�F0/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F25
# 0 25
# ���݂̃f�[�^�F1/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F36
# 0 25
# 1 36
# ���݂̃f�[�^�F2/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F45
# 0 25
# 1 36
# 2 45
# ���݂̃f�[�^�F3/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F2
# �|�b�v�����f�[�^��45�ł��B
# 0 25
# 1 36
# ���݂̃f�[�^�F2/100
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.j
p/cgi-bin/joyful/img/10178.txt
# ���F���s���ʂ��ȉ��̒ʂ�ɂȂ�悤�Ƀv���O������lj����Ȃ����B
# ���݂̃f�[�^�F0/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F25
# 0 25
# ���݂̃f�[�^�F1/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F36
# 0 25
# 1 36
# ���݂̃f�[�^�F2/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F1
# �f�[�^�F45
# 0 25
# 1 36
# 2 45
# ���݂̃f�[�^�F3/100
# �i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F2
# �|�b�v�����f�[�^��45�ł��B
# 0 25
# 1 36
# ���݂̃f�[�^�F2/100
245 �F�f�t�H���g�̖����������F2009/11/26(��) 06:56:39
>>244
% Prolog
stack_size(100),
stack_operation(Stack1,Stack2) :- get_action(N),stack_operation(N,Stack1,Stack2).
stack_operation(0,Stack,Stack) :- !.
stack_operation(1,Stack1,Stack) :- write('�f�[�^ :'),get_integer(N),push(N,Stack,Stack2),print_stack_list(Stack2),get_action(N2),stack_operation(N2,Stack2,Stack).
stack_operation(2,Stack1,Stack) :- pop(A,Stack1,Stack2),write_formatted('�|�b�v�����f�[�^��%t�ł��B \n',[A]),print_stack_list(Stack2),get_action(N2),stack_operation(N2,Stack2,Stack).
get_action(N) :- write('�i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F'),get_integer(N).
push(A,Stack,[A|Stack]) :- stack_size(Max),length([A|Stack],Len),Len =< Max,!.
push(A,Stack,Stack) :- stack_size(Max),length(Stack,Max),write('�X�^�b�N���ő�T�C�Y���z���܂����B�v�b�V���ł��܂���!!\n'),!.
pop(A,[A|Stack],Stack).
pop(A,[],[]) :- write('�X�^�b�N�͋�ł�!!\n').
print_stack_list(Stack) :- stack_size(Max),print_stack_list(0,Max,Stack),write_formatted('���݂̃f�[�^ : %t/%t\n',[N,Max]),
print_stack_list(N,Max,[]) :- write('stack empty!\n'),!.
print_stack_list(N,Max,_) :- N > Max,write('�X�^�b�N�̍ő�T�C�Y�ɒB���܂���\n') :- !.
print_stack_list(N,Max,[A|R]) :- write_formatted('%t %t\n',[N,A]),N2 is N + 1,print_stack_list(N2,Max,R).
% Prolog
stack_size(100),
stack_operation(Stack1,Stack2) :- get_action(N),stack_operation(N,Stack1,Stack2).
stack_operation(0,Stack,Stack) :- !.
stack_operation(1,Stack1,Stack) :- write('�f�[�^ :'),get_integer(N),push(N,Stack,Stack2),print_stack_list(Stack2),get_action(N2),stack_operation(N2,Stack2,Stack).
stack_operation(2,Stack1,Stack) :- pop(A,Stack1,Stack2),write_formatted('�|�b�v�����f�[�^��%t�ł��B \n',[A]),print_stack_list(Stack2),get_action(N2),stack_operation(N2,Stack2,Stack).
get_action(N) :- write('�i�P�j�v�b�V���@�i�Q�j�|�b�v�@�i�O�j�I���F'),get_integer(N).
push(A,Stack,[A|Stack]) :- stack_size(Max),length([A|Stack],Len),Len =< Max,!.
push(A,Stack,Stack) :- stack_size(Max),length(Stack,Max),write('�X�^�b�N���ő�T�C�Y���z���܂����B�v�b�V���ł��܂���!!\n'),!.
pop(A,[A|Stack],Stack).
pop(A,[],[]) :- write('�X�^�b�N�͋�ł�!!\n').
print_stack_list(Stack) :- stack_size(Max),print_stack_list(0,Max,Stack),write_formatted('���݂̃f�[�^ : %t/%t\n',[N,Max]),
print_stack_list(N,Max,[]) :- write('stack empty!\n'),!.
print_stack_list(N,Max,_) :- N > Max,write('�X�^�b�N�̍ő�T�C�Y�ɒB���܂���\n') :- !.
print_stack_list(N,Max,[A|R]) :- write_formatted('%t %t\n',[N,A]),N2 is N + 1,print_stack_list(N2,Max,R).
246 �F�f�t�H���g�̖����������F2009/11/26(��) 06:58:55
>>245 ���s���Ă͂����Ȃ��Ƃ���ɉ��s�������Ă��܂��܂����B
stack_opration/3�ɏW�����Ă��܂�����A�����ēǂ�ł��������B
stack_opration/3�ɏW�����Ă��܂�����A�����ēǂ�ł��������B
247 �F�f�t�H���g�̖����������F2009/11/26(��) 07:06:20
248 �F�f�t�H���g�̖����������F2009/11/26(��) 07:10:53
http://pc12.2ch.net/test/read.cgi/tech/1258158172/365
# [1]���ƒP���F���pC���ꉉ�K
# [2]��蕶(�܃R�[�h&�����N)
# �W�����͂���P�����ȏ�̉p������'_'�ō\�������P���ǂݍ��݁A
# ���ꂼ��̒P�ꂪ����A���s�ڂ̉��ڂ̒P��ɏo����������P��A���t�@�x�b�g��
# �Ƀ��X�g��������쐬�v���O����
# �A���t�@�x�b�g���o�͂̌�o���p�x�i�o���������P�ꏇ�A�����ɂ��Ă̓A���t�@�x
# �b�g���j���ɂ��Ă����������ŏo��
# ���s�L���ƃ^�u�^�A���t�@�x�b�g�^����/ '_' /�����W�����͂���Ȃ��Ƃ��ėǂ��B
# ���͍s���A�P�꒷�A�퐔�A�P��ӂ�̏o���ɐ����͖����B
# �P��̑O��̋��͒P����\�����Ȃ������Ƃ���B�i�s���L�����܂ށj
# �����F �P�� (��) �ʒu�i�s�ԍ����Ⴂ���j���s
# �ʒu: 'L'�s�ԍ��i�P����J�n)-�s���P��ԍ��i�P����J�n)
# alpha (3��) L32-5 L66-4 L124-1
# beta (�Q��) L192-1 L276-3
#
# [1]���ƒP���F���pC���ꉉ�K
# [2]��蕶(�܃R�[�h&�����N)
# �W�����͂���P�����ȏ�̉p������'_'�ō\�������P���ǂݍ��݁A
# ���ꂼ��̒P�ꂪ����A���s�ڂ̉��ڂ̒P��ɏo����������P��A���t�@�x�b�g��
# �Ƀ��X�g��������쐬�v���O����
# �A���t�@�x�b�g���o�͂̌�o���p�x�i�o���������P�ꏇ�A�����ɂ��Ă̓A���t�@�x
# �b�g���j���ɂ��Ă����������ŏo��
# ���s�L���ƃ^�u�^�A���t�@�x�b�g�^����/ '_' /�����W�����͂���Ȃ��Ƃ��ėǂ��B
# ���͍s���A�P�꒷�A�퐔�A�P��ӂ�̏o���ɐ����͖����B
# �P��̑O��̋��͒P����\�����Ȃ������Ƃ���B�i�s���L�����܂ށj
# �����F �P�� (��) �ʒu�i�s�ԍ����Ⴂ���j���s
# �ʒu: 'L'�s�ԍ��i�P����J�n)-�s���P��ԍ��i�P����J�n)
# alpha (3��) L32-5 L66-4 L124-1
# beta (�Q��) L192-1 L276-3
#
249 �F�f�t�H���g�̖����������F2009/11/26(��) 07:52:19
>>248
% Prolog �����̍쐬�̂݁B�\���͎����X�ŁB
����������̍쐬(_�t�@�C��,_�����Ȃ��) :-
�@�@get_lines(_�t�@�C��,Lines),
�@�@�s�P�ʂɍ������쐬(1,Lines,[],_�����Ȃ��).
�s�P�ʂɍ������쐬(_�s�ԍ�,[],X,X).
�s�P�ʂɍ������쐬(_�s�ԍ�,[Line|R1],Y,X) :-
�@�@split(Line,[' ',',','\r','t'],_�P��Ȃ��),
�@�@�s�P�ʂɍ����ɒlj�(1,_�s�ԍ�,_�P��Ȃ��,Y,Y2),
�@�@_�s�ԍ�2 is _�s�ԍ� + 1,
�@�@�s�P�ʂɍ������쐬(_�s�ԍ�2,R1,Y2,X).
�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu,_�s�ԍ�,[],X,X).
�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu,_�s�ԍ�,[_�P��|R1],Y,X) :-
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,Y,Y2),
�@�@_�s�ł̑��Έʒu2 is _�s�ł̑��Έʒu + 1,
�@�@�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu2,_�s�ԍ�,R1,Y2,X).
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��,_�ʒu���Ȃ��,_�p�x]|R1],[[_�P��,_�X�V���ꂽ�ʒu���,_�p�x2]|R1]) :- !.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[_�P��,[_�s�ԍ�,_�s�ł̑��Έʒu],1],[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1]) :-
�@�@_�P�� @< _�P��2,!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R2]) :-
�@�@_�P�� @> _�P��2,
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,R1,R2).
% Prolog �����̍쐬�̂݁B�\���͎����X�ŁB
����������̍쐬(_�t�@�C��,_�����Ȃ��) :-
�@�@get_lines(_�t�@�C��,Lines),
�@�@�s�P�ʂɍ������쐬(1,Lines,[],_�����Ȃ��).
�s�P�ʂɍ������쐬(_�s�ԍ�,[],X,X).
�s�P�ʂɍ������쐬(_�s�ԍ�,[Line|R1],Y,X) :-
�@�@split(Line,[' ',',','\r','t'],_�P��Ȃ��),
�@�@�s�P�ʂɍ����ɒlj�(1,_�s�ԍ�,_�P��Ȃ��,Y,Y2),
�@�@_�s�ԍ�2 is _�s�ԍ� + 1,
�@�@�s�P�ʂɍ������쐬(_�s�ԍ�2,R1,Y2,X).
�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu,_�s�ԍ�,[],X,X).
�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu,_�s�ԍ�,[_�P��|R1],Y,X) :-
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,Y,Y2),
�@�@_�s�ł̑��Έʒu2 is _�s�ł̑��Έʒu + 1,
�@�@�s�P�ʂɍ����ɒlj�(_�s�ł̑��Έʒu2,_�s�ԍ�,R1,Y2,X).
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��,_�ʒu���Ȃ��,_�p�x]|R1],[[_�P��,_�X�V���ꂽ�ʒu���,_�p�x2]|R1]) :- !.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[_�P��,[_�s�ԍ�,_�s�ł̑��Έʒu],1],[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1]) :-
�@�@_�P�� @< _�P��2,!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R2]) :-
�@�@_�P�� @> _�P��2,
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,R1,R2).
250 �F�f�t�H���g�̖����������F2009/11/26(��) 07:57:33
>>249
% Prolog ���ߖڂ��������������B
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��,_�ʒu���Ȃ��,_�p�x]|R1],[[_�P��,_�X�V���ꂽ�ʒu���,_�p�x2]|R1]) :-
�@�@_�p�x2 is _�p�x + 1,
�@�@append(_�ʒu���Ȃ��,[_�s�ԍ�,_�s�ł̑��Έʒu],_�X�V���ꂽ�ʒu���),!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[_�P��,[_�s�ԍ�,_�s�ł̑��Έʒu],1],[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1]) :-
�@�@_�P�� @< _�P��2,!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R2]) :-
�@�@_�P�� @> _�P��2,
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,R1,R2).
% Prolog ���ߖڂ��������������B
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��,_�ʒu���Ȃ��,_�p�x]|R1],[[_�P��,_�X�V���ꂽ�ʒu���,_�p�x2]|R1]) :-
�@�@_�p�x2 is _�p�x + 1,
�@�@append(_�ʒu���Ȃ��,[_�s�ԍ�,_�s�ł̑��Έʒu],_�X�V���ꂽ�ʒu���),!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[_�P��,[_�s�ԍ�,_�s�ł̑��Έʒu],1],[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1]) :-
�@�@_�P�� @< _�P��2,!.
�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,[[_�P��1,_�ʒu���Ȃ��1,_�p�x1]|R1],[[�P��1,_�ʒu���Ȃ��1,_�p�x1]|R2]) :-
�@�@_�P�� @> _�P��2,
�@�@�����ɒlj�(_�P��,_�s�ԍ�,_�s�ł̑��Έʒu,R1,R2).
251 �F�f�t�H���g�̖����������F2009/11/26(��) 09:10:06
>>248
% Prolog
�����̑S�\��([]).
�����̑S�\��([[_�P��,_�ʒu���Ȃ��,�p�x]|R]) :-
�@�@findall(S,(member([A,B],_�ʒu���Ȃ��),concat_atom(['L',A,'-',B],S)),L),
�@�@concat_atom(L,' ',S2),
�@�@write_formatted('%t (%t) %t\n',[_�P��,�p�x,S2]),
�@�@�����̑S�\��(R).
�o���p�x�������S�\��(_�����Ȃ��) :-
�@�@findall([_�p�x|L],(member(L,_�����Ȃ��),last(L,_�p�x)),L1),
�@�@sort(L1,L2),
�@�@findall(L,member([_|L],L2),L3),
�@�@reverse(L3,L4),
�@�@�����̑S�\��(L3).
% Prolog
�����̑S�\��([]).
�����̑S�\��([[_�P��,_�ʒu���Ȃ��,�p�x]|R]) :-
�@�@findall(S,(member([A,B],_�ʒu���Ȃ��),concat_atom(['L',A,'-',B],S)),L),
�@�@concat_atom(L,' ',S2),
�@�@write_formatted('%t (%t) %t\n',[_�P��,�p�x,S2]),
�@�@�����̑S�\��(R).
�o���p�x�������S�\��(_�����Ȃ��) :-
�@�@findall([_�p�x|L],(member(L,_�����Ȃ��),last(L,_�p�x)),L1),
�@�@sort(L1,L2),
�@�@findall(L,member([_|L],L2),L3),
�@�@reverse(L3,L4),
�@�@�����̑S�\��(L3).
252 �F�f�t�H���g�̖����������F2009/11/26(��) 11:29:22
>>248
% Prolog
�����̕ی�(_����,_�ی�t�@�C��,_�����Ȃ��) :-
�@�@assertz(����(_����,_�����Ȃ��)),
�@�@tell(_�ی�t�@�C��),
�@�@listing(����),
�@�@told.
�����̒�`(_����,_�ی�t�@�C��,_�����Ȃ��) :-
�@�@reconsult(_�ی�t�@�C��),
�@�@����(_����,_�����Ȃ��).
% Prolog
�����̕ی�(_����,_�ی�t�@�C��,_�����Ȃ��) :-
�@�@assertz(����(_����,_�����Ȃ��)),
�@�@tell(_�ی�t�@�C��),
�@�@listing(����),
�@�@told.
�����̒�`(_����,_�ی�t�@�C��,_�����Ȃ��) :-
�@�@reconsult(_�ی�t�@�C��),
�@�@����(_����,_�����Ȃ��).
253 �F�f�t�H���g�̖����������F2009/11/26(��) 14:44:57
http://pc12.2ch.net/test/read.cgi/tech/1258320456/45
# Polygon���X�[�p�[�N���X�Ƃ��āC���O�p�`(Triangle)�C���l�p�`(Square)��\������N���X�����ꂼ���`����D
#
# �E�ӂ̒����݂̂������ɗ^���ăC���X�^���X������
# �E���g�̖ʐς��v�Z���Č��ʂ�Ԃ����\�b�harea()������
# ��3 = 1.73 �Ƃ��Ă悢
# ���C�����[�`���ł́C���ۂɃC���X�^���X�����C�e�C���X�^���X�ɂ��āC�C���X�^���X���g�C���͂̒����C�ʐς�3���ڂ�\������悤�ɂ���D
# Polygon���X�[�p�[�N���X�Ƃ��āC���O�p�`(Triangle)�C���l�p�`(Square)��\������N���X�����ꂼ���`����D
#
# �E�ӂ̒����݂̂������ɗ^���ăC���X�^���X������
# �E���g�̖ʐς��v�Z���Č��ʂ�Ԃ����\�b�harea()������
# ��3 = 1.73 �Ƃ��Ă悢
# ���C�����[�`���ł́C���ۂɃC���X�^���X�����C�e�C���X�^���X�ɂ��āC�C���X�^���X���g�C���͂̒����C�ʐς�3���ڂ�\������悤�ɂ���D
254 �F�f�t�H���g�̖����������F2009/11/26(��) 14:47:46
>>253
% ESP
class �����p�` has
�@�@:create(Class,Obj,_�ӂ̒���) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�ӂ̒��� := _�ӂ̒���;
instance
�@�@attibute �ӂ̒���,�p;
end.
class �O�p�` has
nature �����p�`;
�@�@attribute �p := 3;
instance
�@�@:area(Obj,_�ʐ�) :-
�@�@�@�@Obj!�ӂ̒��� * 1.73;
end.
class �l�p�` has
nature �����p�`;
�@�@attribute �p := 4;
instance
�@�@:area(Obj,_�ʐ�) :-
�@�@�@�@Obj!�ӂ̒��� * Obj!�ӂ̒���;
end.
% ESP
class �����p�` has
�@�@:create(Class,Obj,_�ӂ̒���) :-
�@�@�@�@:new(Class,Obj),
�@�@�@�@Obj!�ӂ̒��� := _�ӂ̒���;
instance
�@�@attibute �ӂ̒���,�p;
end.
class �O�p�` has
nature �����p�`;
�@�@attribute �p := 3;
instance
�@�@:area(Obj,_�ʐ�) :-
�@�@�@�@Obj!�ӂ̒��� * 1.73;
end.
class �l�p�` has
nature �����p�`;
�@�@attribute �p := 4;
instance
�@�@:area(Obj,_�ʐ�) :-
�@�@�@�@Obj!�ӂ̒��� * Obj!�ӂ̒���;
end.
255 �F�f�t�H���g�̖����������F2009/11/26(��) 15:22:19
http://pc12.2ch.net/test/read.cgi/tech/1170662552/284
# �ߋ��̊����𗘗p�����V�~�����[�V�����v���O�����B
# ��̓I�ɂ́A�f�[�^�Ƃ��ċ����̂���^�����̓����i���ʂɎn�l�A���l�A���l�A�I�l�A�o�����j
# ��10�N���I�[�v���I�t�B�X�̕\�v�Zcalc��yahoo�t�@�C�i���X������肵�܂����B
# �Ⴆ�A���̃f�[�^���g���ē���̓��ɂ��̊���1000�������A�ȍ~10�~�オ��Δ���
�A����l����
# 10�~������܂������A���̔��l���10�~������Δ��������i���̌����c�����Ȃ���
��܂Łj���A
# ���ꂼ��͔��l���10�~�オ��Ɣ���B
# ���������Ȃ��Ȃ�ƁA���l����P�����������Ƃ��납��܂��n�߂�B
# �Ƃ����悤�Ȃ��Ƃ��J��Ԃ��ƁA������̗��v�ł�����̔��l�̂�
# �ǂꂮ�炢�������ɂȂ�����Ԃ������ʂƂ��Ă������̂ł��B
#
# �ߋ��̊����𗘗p�����V�~�����[�V�����v���O�����B
# ��̓I�ɂ́A�f�[�^�Ƃ��ċ����̂���^�����̓����i���ʂɎn�l�A���l�A���l�A�I�l�A�o�����j
# ��10�N���I�[�v���I�t�B�X�̕\�v�Zcalc��yahoo�t�@�C�i���X������肵�܂����B
# �Ⴆ�A���̃f�[�^���g���ē���̓��ɂ��̊���1000�������A�ȍ~10�~�オ��Δ���
�A����l����
# 10�~������܂������A���̔��l���10�~������Δ��������i���̌����c�����Ȃ���
��܂Łj���A
# ���ꂼ��͔��l���10�~�オ��Ɣ���B
# ���������Ȃ��Ȃ�ƁA���l����P�����������Ƃ��납��܂��n�߂�B
# �Ƃ����悤�Ȃ��Ƃ��J��Ԃ��ƁA������̗��v�ł�����̔��l�̂�
# �ǂꂮ�炢�������ɂȂ�����Ԃ������ʂƂ��Ă������̂ł��B
#
256 �F�f�t�H���g�̖����������F2009/11/26(��) 17:19:32
http://pc12.2ch.net/test/read.cgi/tech/1258158172/368
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�P�`
# �R��int�^�����̍ŏ��l��Ԃ���
# int min3(int x,int y,int z)
# ���쐬����B�i�������A�W����min�͎g�p���Ȃ����ƁB�j
#
# �i���s��j
# �R�̐�������͂��Ă��������B
# �����P�F�P�T
# �����Q�F�R
# �����R�F�Q�R
# �ł��������l�͂R�ł��B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�P�`
# �R��int�^�����̍ŏ��l��Ԃ���
# int min3(int x,int y,int z)
# ���쐬����B�i�������A�W����min�͎g�p���Ȃ����ƁB�j
#
# �i���s��j
# �R�̐�������͂��Ă��������B
# �����P�F�P�T
# �����Q�F�R
# �����R�F�Q�R
# �ł��������l�͂R�ł��B
257 �F�f�t�H���g�̖����������F2009/11/26(��) 17:20:31
http://pc12.2ch.net/test/read.cgi/tech/1258158172/368
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�Q�`
# int�^�����̂S���Ԃ���
# int pow4(int x)
# ���쐬����B�i��������pow�͎g�p���Ȃ��j
#
# �i���s��j
# ��������͂��Ă��������F�T
# ���̂S��l�͂U�Q�T�ł��B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�Q�`
# int�^�����̂S���Ԃ���
# int pow4(int x)
# ���쐬����B�i��������pow�͎g�p���Ȃ��j
#
# �i���s��j
# ��������͂��Ă��������F�T
# ���̂S��l�͂U�Q�T�ł��B
258 �F�f�t�H���g�̖����������F2009/11/26(��) 17:21:28
http://pc12.2ch.net/test/read.cgi/tech/1258158172/368
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�R�`
# ��voold putstar(int n)���쐬���āA�����`��\������v���O�������쐬����B
#
# �i���s��j
# �����`�����܂��傤�B
# �����F�T
# �����F�R
# ����������
# ����������
# ����������
#
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�R�`
# ��voold putstar(int n)���쐬���āA�����`��\������v���O�������쐬����B
#
# �i���s��j
# �����`�����܂��傤�B
# �����F�T
# �����F�R
# ����������
# ����������
# ����������
#
259 �F�f�t�H���g�̖����������F2009/11/26(��) 18:05:57
http://pc12.2ch.net/test/read.cgi/tech/1258158172/368
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�S�`
# �����^�z��@str='ABCDEFG'�������ݒ肳��Ă���B����str�̃f�[�^���p�啶������A�p�������ɕϊ����Ȃ����B
#
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�S�`
# �����^�z��@str='ABCDEFG'�������ݒ肳��Ă���B����str�̃f�[�^���p�啶������A�p�������ɕϊ����Ȃ����B
#
260 �F�f�t�H���g�̖����������F2009/11/26(��) 18:08:58
http://pc12.2ch.net/test/read.cgi/tech/1258158172/368
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�T�`
# ���̗v�̂Ńe�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�v���O�������쐬���Ȃ����B
#
# �P�A�e�X�g�̓_������͂���K�C�_���X��p���Ď��̂悤�ɏo�͂��Ȃ����F�_������͂��Ȃ����A�I�������Fe���邢��E
# �Q�Afget()��p���āA�e�X�g�̓_������Ƃ��ē��͂��Ȃ���
# �R�A�P�œ��͂���������e���邢��E�ł���Ƃ��A�����Q�`�T�̏������I�����ĂU�̏������s���Ȃ���
# �S�A������œ��͂����_����int�^�ϐ��ɕϊ����Ȃ����iatoi���g�p���Ȃ����j
# �T�A�S�ŕϊ�����int�^�̓_�����O�_�ȏ�P�O�O�_�ȉ��Ȃ�A���̂��ꂼ��̓_����̐l���𐔂��Ȃ����B
# �U�C�T�̌��ʂ�\�����Ȃ����B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10180.txt
#
# �`�ۑ�T�`
# ���̗v�̂Ńe�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�v���O�������쐬���Ȃ����B
#
# �P�A�e�X�g�̓_������͂���K�C�_���X��p���Ď��̂悤�ɏo�͂��Ȃ����F�_������͂��Ȃ����A�I�������Fe���邢��E
# �Q�Afget()��p���āA�e�X�g�̓_������Ƃ��ē��͂��Ȃ���
# �R�A�P�œ��͂���������e���邢��E�ł���Ƃ��A�����Q�`�T�̏������I�����ĂU�̏������s���Ȃ���
# �S�A������œ��͂����_����int�^�ϐ��ɕϊ����Ȃ����iatoi���g�p���Ȃ����j
# �T�A�S�ŕϊ�����int�^�̓_�����O�_�ȏ�P�O�O�_�ȉ��Ȃ�A���̂��ꂼ��̓_����̐l���𐔂��Ȃ����B
# �U�C�T�̌��ʂ�\�����Ȃ����B
261 �F�f�t�H���g�̖����������F2009/11/26(��) 18:26:12
>>256
% Prolog
'�R�̐����̍ŏ��l��Ԃ�' :-
�@�@write('�R�̐�������͂��Ă��������B\n'),
�@�@'�R�̐�����'(1,[A|R]),
�@�@�ŏ��l��(A,R,_�ŏ��l),
�@�@write_formatted('�ł��������l��%t�ł��B\n',[_�ŏ��l]).
�ŏ��l��(A,[],A).
�ŏ��l��(A,[B|R],X) :- A =< B,�ŏ��l��(A,R,X).
�ŏ��l��(A,[B|R],X) :- A > B,�ŏ��l��(B,R,X).
'�R�̐�����'(N,[]) :- N > 3,!.
'�R�̐�����'(N,[_����|R]) :-
�@�@write('����%t�F',[N]),
�@�@get_integer(_����),
�@�@N2 is N + 1,
�@�@'�R�̐�����'(R).
% Prolog
'�R�̐����̍ŏ��l��Ԃ�' :-
�@�@write('�R�̐�������͂��Ă��������B\n'),
�@�@'�R�̐�����'(1,[A|R]),
�@�@�ŏ��l��(A,R,_�ŏ��l),
�@�@write_formatted('�ł��������l��%t�ł��B\n',[_�ŏ��l]).
�ŏ��l��(A,[],A).
�ŏ��l��(A,[B|R],X) :- A =< B,�ŏ��l��(A,R,X).
�ŏ��l��(A,[B|R],X) :- A > B,�ŏ��l��(B,R,X).
'�R�̐�����'(N,[]) :- N > 3,!.
'�R�̐�����'(N,[_����|R]) :-
�@�@write('����%t�F',[N]),
�@�@get_integer(_����),
�@�@N2 is N + 1,
�@�@'�R�̐�����'(R).
262 �F�f�t�H���g�̖����������F2009/11/26(��) 18:30:08
>>256
% Prolog 3�̐�����ɂ͈ȉ��̂���������B
'�R�̐�����'(L) :-
�@�@findall(_����,(for(1,N,3),write('����%t�F',[N]),get_integer(_����)),L).
% Prolog 3�̐�����ɂ͈ȉ��̂���������B
'�R�̐�����'(L) :-
�@�@findall(_����,(for(1,N,3),write('����%t�F',[N]),get_integer(_����)),L).
263 �F�f�t�H���g�̖����������F2009/11/26(��) 19:07:37
>>257
% Prolog 4����`�͈ȉ�����\�I�Ȃ��́B
pow4(X,Y) :- Y is X * X * X * X.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- Y is X ^ 4.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- pow4(4,X,Y).
pow4(1,X,X) :- !.
pow4(N,X,Y) :- N1 is N - 1,pow4(N1,X,Z),Y is X * Z.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- pow4(1,4,X,Y).
pow4(M,N,_,1) :- M > N,!.
pow4(M,N,X,Y) :- M1 is M + 1,pow4(M1,N,X,Z),Y is X * Z.
% Prolog 4����`�͈ȉ�����\�I�Ȃ��́B
pow4(X,Y) :- Y is X * X * X * X.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- Y is X ^ 4.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- pow4(4,X,Y).
pow4(1,X,X) :- !.
pow4(N,X,Y) :- N1 is N - 1,pow4(N1,X,Z),Y is X * Z.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
pow4(X,Y) :- pow4(1,4,X,Y).
pow4(M,N,_,1) :- M > N,!.
pow4(M,N,X,Y) :- M1 is M + 1,pow4(M1,N,X,Z),Y is X * Z.
264 �F�f�t�H���g�̖����������F2009/11/26(��) 19:20:17
>>263 4��̒�`�́@�ł��ˁB
pow4(M1,N,X,Z),Y is X * Z.
�ƍċA�̊O���ɉ��Z������̂�������ƋC�ɂȂ�܂��ˁB
pow4(X,Y) :- pow4(1,4,X,X,Y).
pow4(M,N,_,Y,Y) :- M > N,!.
pow4(M,N,X,Y1,Y) :- Y2 is X * Y1,M2 is M + 1,pow4(M2,N,X,Y2,Y).
�Ƃ���Β��ɓ���܂��B�����A���̎�̐�ǂݓI��@���킩��₷�����ǂ����B
pow4(M1,N,X,Z),Y is X * Z.
�ƍċA�̊O���ɉ��Z������̂�������ƋC�ɂȂ�܂��ˁB
pow4(X,Y) :- pow4(1,4,X,X,Y).
pow4(M,N,_,Y,Y) :- M > N,!.
pow4(M,N,X,Y1,Y) :- Y2 is X * Y1,M2 is M + 1,pow4(M2,N,X,Y2,Y).
�Ƃ���Β��ɓ���܂��B�����A���̎�̐�ǂݓI��@���킩��₷�����ǂ����B
265 �F�f�t�H���g�̖����������F2009/11/26(��) 19:30:04
>>258
% Prolog ����������Ȓ�`�����x���o�Ă��܂����Bfor/3���g���̂�
% ���܂�Prolog�I�Ȋ��������܂��A�g�����Ƃ͂���܂��B
�����`�����܂��傤 :-
�@�@write('���� :'),get_integer(_����),
�@�@write('���� :'),get_integer(_����),
�@�@for(1,M,_����),
�@�@for(1,N,_����),
�@�@write('*'),
�@�@N = _����,
�@�@nl,
�@�@M = _����.
% Prolog ����������Ȓ�`�����x���o�Ă��܂����Bfor/3���g���̂�
% ���܂�Prolog�I�Ȋ��������܂��A�g�����Ƃ͂���܂��B
�����`�����܂��傤 :-
�@�@write('���� :'),get_integer(_����),
�@�@write('���� :'),get_integer(_����),
�@�@for(1,M,_����),
�@�@for(1,N,_����),
�@�@write('*'),
�@�@N = _����,
�@�@nl,
�@�@M = _����.
266 �F�f�t�H���g�̖����������F2009/11/26(��) 20:28:08
>>259
% Prolog
str('ABCDEFG').
%%%%%%% ���ʂ͈ȉ��̒�`�ōς܂�%%%%%%%%%%%%
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@to_lower(Str1,Str2),
�@�@write_formatted('%t',[Str2]).
&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@atom_codes(Str1,Codes1),
�@�@findall(C,(member(A,Codes),C is A - 32),Codes2),
�@�@atom_codes(Str2,Codes2),
�@�@write_formatted('%t',[Str2]).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@atom_codes(Str1,Codes1),
�@�@�p�啶������A�p�������ɕϊ�(Codes1,Codes2),
�@�@atom_codes(Str2,Codes2),
�@�@write_formatted('%t',[Str2]).
�p�啶������A�p�������ɕϊ�([],[]).
�p�啶������A�p�������ɕϊ�([C1|R1],[C2|R2]) :- C2 is C1-32,�p�啶������A�p�������ɕϊ�(R1,R2)
% Prolog
str('ABCDEFG').
%%%%%%% ���ʂ͈ȉ��̒�`�ōς܂�%%%%%%%%%%%%
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@to_lower(Str1,Str2),
�@�@write_formatted('%t',[Str2]).
&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@atom_codes(Str1,Codes1),
�@�@findall(C,(member(A,Codes),C is A - 32),Codes2),
�@�@atom_codes(Str2,Codes2),
�@�@write_formatted('%t',[Str2]).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�p�啶������A�p�������ɕϊ� :-
�@�@str(Str1),
�@�@atom_codes(Str1,Codes1),
�@�@�p�啶������A�p�������ɕϊ�(Codes1,Codes2),
�@�@atom_codes(Str2,Codes2),
�@�@write_formatted('%t',[Str2]).
�p�啶������A�p�������ɕϊ�([],[]).
�p�啶������A�p�������ɕϊ�([C1|R1],[C2|R2]) :- C2 is C1-32,�p�啶������A�p�������ɕϊ�(R1,R2)
267 �F�f�t�H���g�̖����������F2009/11/26(��) 21:27:20
>>260
% Prolog
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂� :-
�@�@get_line(Line),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,[0,0,0,0,0,0,0,0,0,0,0],L),
�@�@���ꂼ��̓_����̐l�������l���邩�\��(L).
���ꂼ��̓_����̐l�������l���邩�\��(L) :-
�@�@append(L1,[M|L2],L),
�@�@length(L1,N),
�@�@write_formatted('%2d~%2d�_���%t�l�ł��B\n',[N*10,N*10+9,M]),
�@�@N = 9,
�@�@last(L,M11),
�@�@write_formatted('�@�@�@100�_��%t�l�ł��B\n',[M11]).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(e,L,L).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�('E',L,L).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,L1,L) :-
�@�@atom_to_term(Line,N,_),
�@�@�_����W�v�ɉ��Z(N,L1,L2),
�@�@get_line(Line2),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line2,L2,L).
�_����W�v�ɉ��Z(N,L1,L2) :-
�@�@N1 is N // 10,
�@�@length(L0,N1),
�@�@append(L0,[M|L3],L1),
�@�@M2 is M + 1,
�@�@append(L0,[M2|L3],L2).
% Prolog
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂� :-
�@�@get_line(Line),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,[0,0,0,0,0,0,0,0,0,0,0],L),
�@�@���ꂼ��̓_����̐l�������l���邩�\��(L).
���ꂼ��̓_����̐l�������l���邩�\��(L) :-
�@�@append(L1,[M|L2],L),
�@�@length(L1,N),
�@�@write_formatted('%2d~%2d�_���%t�l�ł��B\n',[N*10,N*10+9,M]),
�@�@N = 9,
�@�@last(L,M11),
�@�@write_formatted('�@�@�@100�_��%t�l�ł��B\n',[M11]).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(e,L,L).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�('E',L,L).
�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line,L1,L) :-
�@�@atom_to_term(Line,N,_),
�@�@�_����W�v�ɉ��Z(N,L1,L2),
�@�@get_line(Line2),
�@�@�e�X�g�̓_������͂��A���ꂼ��̓_����̐l�������l���邩���߂�(Line2,L2,L).
�_����W�v�ɉ��Z(N,L1,L2) :-
�@�@N1 is N // 10,
�@�@length(L0,N1),
�@�@append(L0,[M|L3],L1),
�@�@M2 is M + 1,
�@�@append(L0,[M2|L3],L2).
268 �F�f�t�H���g�̖����������F2009/11/27(��) 04:18:05
http://pc12.2ch.net/test/read.cgi/tech/1258158172/384
# [1] ���ƒP���F�q���[�}���C���^�[�t�F�C�X
# [2] ��蕶(�܃R�[�h&�����N)�F���Ȃ��Ƃ��ȉ��̉p������{�ꕪ�ɖ|��ł���v���O�������쐬����
# �@�@�@�@�@�@�@�@�@�@ 1.The boy beats a dog with a stick.
# 2.Every boy loves a dog .
# 3.The dog is loved by every boy.
# 4.The boy saw a girl with a telescope.
# 5.The boy saw a girl with a dog.
# 6.The boy cut a stick with a saw.
# [1] ���ƒP���F�q���[�}���C���^�[�t�F�C�X
# [2] ��蕶(�܃R�[�h&�����N)�F���Ȃ��Ƃ��ȉ��̉p������{�ꕪ�ɖ|��ł���v���O�������쐬����
# �@�@�@�@�@�@�@�@�@�@ 1.The boy beats a dog with a stick.
# 2.Every boy loves a dog .
# 3.The dog is loved by every boy.
# 4.The boy saw a girl with a telescope.
# 5.The boy saw a girl with a dog.
# 6.The boy cut a stick with a saw.
269 �F�f�t�H���g�̖����������F2009/11/27(��) 04:26:18
http://pc12.2ch.net/test/read.cgi/tech/1258158172/389
# [1] ���ƒP���FC������K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10187.txt
# �����P
# �@�C�ӂ̉�f�������摜���A�t�B���ϊ��i�ړ��C�g��k���C��]�C����f�j����v���O�������쐬����D
# �@�ϊ���̉摜�͉摜�t�@�C���Ƃ��ĕۑ����邱�ƁD
#
# �����Q
# �@���P�ō쐬�����v���O�����ɁC�t�A�t�B���ϊ����s���@�\��lj�����B
# �@�����āC�A�t�B���ϊ��C�t�A�t�B���ϊ��i�ŋߖT�@�j�C�t�A�t�B���ϊ��i���`��Ԗ@�j�ł̌��ʂɈႢ�����邱�Ƃ��m�F����D
#
# �@���t�A�t�B���ϊ��Ƃ́C�o�͉摜�̍��W�l�iX, Y�j�ɑ��ċt�ϊ����s�����ƂŁC���͉摜�̍��W�l�ix, y�j�����߂���̂ł���D
#
# �i���Ӂj
# �@�ϊ���̍��W�l���C�z��̃T�C�Y�i�c�Ɖ��j���z���邩�ǂ������m�F���C������ꍇ�͓K�ȗ�O�������s�����ƁD
#
# [1] ���ƒP���FC������K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10187.txt
# �����P
# �@�C�ӂ̉�f�������摜���A�t�B���ϊ��i�ړ��C�g��k���C��]�C����f�j����v���O�������쐬����D
# �@�ϊ���̉摜�͉摜�t�@�C���Ƃ��ĕۑ����邱�ƁD
#
# �����Q
# �@���P�ō쐬�����v���O�����ɁC�t�A�t�B���ϊ����s���@�\��lj�����B
# �@�����āC�A�t�B���ϊ��C�t�A�t�B���ϊ��i�ŋߖT�@�j�C�t�A�t�B���ϊ��i���`��Ԗ@�j�ł̌��ʂɈႢ�����邱�Ƃ��m�F����D
#
# �@���t�A�t�B���ϊ��Ƃ́C�o�͉摜�̍��W�l�iX, Y�j�ɑ��ċt�ϊ����s�����ƂŁC���͉摜�̍��W�l�ix, y�j�����߂���̂ł���D
#
# �i���Ӂj
# �@�ϊ���̍��W�l���C�z��̃T�C�Y�i�c�Ɖ��j���z���邩�ǂ������m�F���C������ꍇ�͓K�ȗ�O�������s�����ƁD
#
270 �F�f�t�H���g�̖����������F2009/11/27(��) 04:28:55
http://pc12.2ch.net/test/read.cgi/tech/1258158172/392
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �R�̎��R����ӂɂ����p�O�p�`��1000�o�͂���v���O�����������Ȃ����B
# �������A�R�̕� a, b, c �� a <= b <= c �Ƃ���B
# �܂��A�R�ӂ̔䗦���������̂̓J�E���g���Ȃ����ƂƂ���B
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# �R�̎��R����ӂɂ����p�O�p�`��1000�o�͂���v���O�����������Ȃ����B
# �������A�R�̕� a, b, c �� a <= b <= c �Ƃ���B
# �܂��A�R�ӂ̔䗦���������̂̓J�E���g���Ȃ����ƂƂ���B
271 �F�f�t�H���g�̖����������F2009/11/27(��) 04:35:15
http://pc12.2ch.net/test/read.cgi/tech/1258158172/407
# [1] ���ƒP���F C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�P�A������A��2�̐���(���ꂼ�� n, m �Ƃ���)����͂����
# n�����ڂ��� m���� *�ɕς���v���O�����������B
#
# ���s��
# �@�@��������͂��ĉ�����
# Toshidaigaku
# n����͂��ĉ�����
# 4
# m����͂��ĉ�����
# 2
# �o�͂�
# Tos**daigaku
#
# �ۑ�Q�A���������͂���ƁA�S�Ă̕��������̕����R�[�h�̕�����
# �ς��āA���ʂ�\������v���O�����������B
#
# ���s��
#
# ��������͂��ĉ�����
# Toshidaigaku
# �o�͂�
# Uptijebjhblv
# [1] ���ƒP���F C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�P�A������A��2�̐���(���ꂼ�� n, m �Ƃ���)����͂����
# n�����ڂ��� m���� *�ɕς���v���O�����������B
#
# ���s��
# �@�@��������͂��ĉ�����
# Toshidaigaku
# n����͂��ĉ�����
# 4
# m����͂��ĉ�����
# 2
# �o�͂�
# Tos**daigaku
#
# �ۑ�Q�A���������͂���ƁA�S�Ă̕��������̕����R�[�h�̕�����
# �ς��āA���ʂ�\������v���O�����������B
#
# ���s��
#
# ��������͂��ĉ�����
# Toshidaigaku
# �o�͂�
# Uptijebjhblv
272 �F�f�t�H���g�̖����������F2009/11/27(��) 04:38:13
http://pc12.2ch.net/test/read.cgi/tech/1258158172/408
# �ۑ�R�A���������͂���ƁA������
# a �̌��𐔂���v���O�����������B
#
# ���s��
#
# ��������͂��ĉ�����
# Toshidaigaku
# a��2�܂܂�Ă��܂�
#
# [5] ���̑��̐����F
# #include <stdio.h>
# int main()
# �X�^�[�g�ł��肢���܂��B
# �ۑ�R�A���������͂���ƁA������
# a �̌��𐔂���v���O�����������B
#
# ���s��
#
# ��������͂��ĉ�����
# Toshidaigaku
# a��2�܂܂�Ă��܂�
#
# [5] ���̑��̐����F
# #include <stdio.h>
# int main()
# �X�^�[�g�ł��肢���܂��B
273 �F�f�t�H���g�̖����������F2009/11/27(��) 04:57:22
http://pc12.2ch.net/test/read.cgi/tech/1248012902/527
# �y�@�ۑ�@�z http://ime.nu/www.dotup.org/uploda/www.dotup.org397919.txt.html
# �y�@�`�ԁ@�z1
# �y�@GUI�@ �z4
# �y�@�����@�z11/27�܂�
# �y�@Ver�@ �z1.6.0_16
#
# �ł���Γ���̉�������肢���܂�
# �p�^�[���ƍ��̖��ł��B
# string�^�̈������^���Ă��ꂪ�������̂��ǂ����肵�܂��B
# ��{�I�Ȃ��̂͏������̂ł����A�@�\�g����
# "you are a student" �� "You are Student"
# �̂悤�ɑ啶������������ʂ����ɓ������̂Ƃ��Ĕ��肳����̂��ۑ�ł�
# �y�@�ۑ�@�z http://ime.nu/www.dotup.org/uploda/www.dotup.org397919.txt.html
# �y�@�`�ԁ@�z1
# �y�@GUI�@ �z4
# �y�@�����@�z11/27�܂�
# �y�@Ver�@ �z1.6.0_16
#
# �ł���Γ���̉�������肢���܂�
# �p�^�[���ƍ��̖��ł��B
# string�^�̈������^���Ă��ꂪ�������̂��ǂ����肵�܂��B
# ��{�I�Ȃ��̂͏������̂ł����A�@�\�g����
# "you are a student" �� "You are Student"
# �̂悤�ɑ啶������������ʂ����ɓ������̂Ƃ��Ĕ��肳����̂��ۑ�ł�
274 �F�f�t�H���g�̖����������F2009/11/27(��) 06:59:59
http://pc12.2ch.net/test/read.cgi/tech/1258158172/425
# [1]�₳����C++�@���K
# [2]
# (1) int�l n,���char�|�C���^p�������Ɏ���char�|�C���^��߂�l�^�Ƃ����atos�����̎d�l�̂��Ƃɍ쐬
# p��NULL�łȂ��Ȃ���ꂪ�w���̈��delete[]�������NULL��Ԃ��Bp��NULL�̏ꍇ��p�ɂP�U�������̗̈�����蓖��,�w���̈��sprintf���ɂ��n�̂P�O�i������\�����������݂����Ԃ��B
# (2) �L�[�{�[�h���琳�̐��������͂����܂ŁA���͑��i������i�v�����v�g�j��\����
# ���͑҂����s���A���͂��ꂽ������int�Q�ƌ^����n�ɓ���Ė߂��input���쐬
# �}�j���s�����[�^��scanf���g�p���Ȃ����ƁB
# (3)8��int�ւ̎Q�ƈ���������sort�Ƃ������̂�void�����쐬
# ������݂Ă�����������Ȃ炻����܂߂��c��̈�����ΏۂƂ��Ȃ������̂��Ƃ�
# ���������������ɐ���B����Ώۂ̐�����s���ɋ��ŏo�͂���B
# ���̎�atos�����g�����ƁB�����L�q�Ƀ��[�v�i���[�v�����g������)�������Ă͂Ȃ�Ȃ��B
# (4) (1)~(3)�̊���p����main(void)�������s�����,����܂łɓ��͂��ꂽ���̐�����
# sort����p���ă\�[�g�^�\��������V����������input����p���ēǂݍ���
# ���Ƃ��W��J��Ԃ�����A���͂��ꂽ�W�̐��������̂�sort���ɂ��\������
# �悤�Ȃ��̂��쐬����Bfor����switch�����g�����ƁB�z����g��Ȃ����ƁB
# (5) (1)�`(4)�ɂ��Ă��ꂼ��Ɨ��Ƀe�X�g�����R�[�h���쐬���邱��
# [1]�₳����C++�@���K
# [2]
# (1) int�l n,���char�|�C���^p�������Ɏ���char�|�C���^��߂�l�^�Ƃ����atos�����̎d�l�̂��Ƃɍ쐬
# p��NULL�łȂ��Ȃ���ꂪ�w���̈��delete[]�������NULL��Ԃ��Bp��NULL�̏ꍇ��p�ɂP�U�������̗̈�����蓖��,�w���̈��sprintf���ɂ��n�̂P�O�i������\�����������݂����Ԃ��B
# (2) �L�[�{�[�h���琳�̐��������͂����܂ŁA���͑��i������i�v�����v�g�j��\����
# ���͑҂����s���A���͂��ꂽ������int�Q�ƌ^����n�ɓ���Ė߂��input���쐬
# �}�j���s�����[�^��scanf���g�p���Ȃ����ƁB
# (3)8��int�ւ̎Q�ƈ���������sort�Ƃ������̂�void�����쐬
# ������݂Ă�����������Ȃ炻����܂߂��c��̈�����ΏۂƂ��Ȃ������̂��Ƃ�
# ���������������ɐ���B����Ώۂ̐�����s���ɋ��ŏo�͂���B
# ���̎�atos�����g�����ƁB�����L�q�Ƀ��[�v�i���[�v�����g������)�������Ă͂Ȃ�Ȃ��B
# (4) (1)~(3)�̊���p����main(void)�������s�����,����܂łɓ��͂��ꂽ���̐�����
# sort����p���ă\�[�g�^�\��������V����������input����p���ēǂݍ���
# ���Ƃ��W��J��Ԃ�����A���͂��ꂽ�W�̐��������̂�sort���ɂ��\������
# �悤�Ȃ��̂��쐬����Bfor����switch�����g�����ƁB�z����g��Ȃ����ƁB
# (5) (1)�`(4)�ɂ��Ă��ꂼ��Ɨ��Ƀe�X�g�����R�[�h���쐬���邱��
275 �F�f�t�H���g�̖����������F2009/11/27(��) 07:13:02
>>270
% Prolog
'�R�̎��R����ӂɂ����p�O�p�`��1000�o��' :-
�@�@'�R�̎��R����ӂɂ����p�O�p�`'(1,1000,1,[],X),
�@�@member(L,X),
�@�@write_formatted('%t\n',[L]),
�@�@fail.
'�R�̎��R����ӂɂ����p�O�p�`��1000�o��'.
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,_,_,[]) :- M > Max,!.
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C,Y,[[A,B,C]|R]) :-
�@�@�����݂��Ȃ�(C,Y),
�@�@C1 is truncate(C ^ 2),
�@�@���R����2��(3,N,A,A1),
�@�@���R����2��(3,N,B,B1),
�@�@A =< B,
�@�@C1 is A1 + B1,
�@�@M2 is M + 1,C2 is C + 1,
�@�@'�R�̎��R����ӂɂ����p�O�p�`'(M2,Max,C2,[C|Y],R).
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C,Y,X) :- C2 is C + 1,'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C2,Y,X).
���R����2��(M,N,M,X) :- M =< N,X is truncate(M * M).
���R����2��(M1,N,M,X) :- M =< N,M2 is M1 + 1,���R����2��(M2,N,M,X).
�����݂��Ȃ�(A,L) :- \+((member(B,L),0 is A mod B)),!.
% Prolog
'�R�̎��R����ӂɂ����p�O�p�`��1000�o��' :-
�@�@'�R�̎��R����ӂɂ����p�O�p�`'(1,1000,1,[],X),
�@�@member(L,X),
�@�@write_formatted('%t\n',[L]),
�@�@fail.
'�R�̎��R����ӂɂ����p�O�p�`��1000�o��'.
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,_,_,[]) :- M > Max,!.
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C,Y,[[A,B,C]|R]) :-
�@�@�����݂��Ȃ�(C,Y),
�@�@C1 is truncate(C ^ 2),
�@�@���R����2��(3,N,A,A1),
�@�@���R����2��(3,N,B,B1),
�@�@A =< B,
�@�@C1 is A1 + B1,
�@�@M2 is M + 1,C2 is C + 1,
�@�@'�R�̎��R����ӂɂ����p�O�p�`'(M2,Max,C2,[C|Y],R).
'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C,Y,X) :- C2 is C + 1,'�R�̎��R����ӂɂ����p�O�p�`'(M,Max,C2,Y,X).
���R����2��(M,N,M,X) :- M =< N,X is truncate(M * M).
���R����2��(M1,N,M,X) :- M =< N,M2 is M1 + 1,���R����2��(M2,N,M,X).
�����݂��Ȃ�(A,L) :- \+((member(B,L),0 is A mod B)),!.
276 �F�f�t�H���g�̖����������F2009/11/27(��) 07:22:49
>>268
% Prolog (������)�@�ł��P���ɂ��Ȃ�B����Ȋ����ŁB
���p����(���N,boy).
���p����(�@��,beats).
���p����(�_,stick).
���p����(���ׂĂ�,Every).
���p����(����,saw).
���p����(��,dog).
���p����(������,loved).
���p����(���,cut).
���p����(�̂�����,saw).
:- module(���{��,[����/2,����/2,������/2]).
����([���N|R],R).
����([��|R],R).
����([�_|R],R).
����([����|R],R).
����([����|R],R).
����([������|R],R).
������([�ł�|R],R).
����([�@��|R],R).
:- module(�p��,[��/2,���/2,�q��/2,�ړI��/2,������/2,������/2,�O�u��/2,����/2,����/2]).
��(L,R) :- ���(L,R1),�q��(R1,R2),�ړI��(R2,R).
���(L,R) :- ������(L,R).
�E�E�E
% ����������A http://nojiriko.asia/prolog/c132_384.html �ɏ����Ă����܂��B
% Prolog (������)�@�ł��P���ɂ��Ȃ�B����Ȋ����ŁB
���p����(���N,boy).
���p����(�@��,beats).
���p����(�_,stick).
���p����(���ׂĂ�,Every).
���p����(����,saw).
���p����(��,dog).
���p����(������,loved).
���p����(���,cut).
���p����(�̂�����,saw).
:- module(���{��,[����/2,����/2,������/2]).
����([���N|R],R).
����([��|R],R).
����([�_|R],R).
����([����|R],R).
����([����|R],R).
����([������|R],R).
������([�ł�|R],R).
����([�@��|R],R).
:- module(�p��,[��/2,���/2,�q��/2,�ړI��/2,������/2,������/2,�O�u��/2,����/2,����/2]).
��(L,R) :- ���(L,R1),�q��(R1,R2),�ړI��(R2,R).
���(L,R) :- ������(L,R).
�E�E�E
% ����������A http://nojiriko.asia/prolog/c132_384.html �ɏ����Ă����܂��B
277 �F�f�t�H���g�̖����������F2009/11/27(��) 07:35:54
>>271
% Prolog
'�������2�̐���(���ꂼ�� n, m �Ƃ���)����͂����n�����ڂ���m����*�ɕς���'(_������,N,M,_�ϊ����ꂽ������) :-
�@�@sub_atom(_������,N - 1,M,R,_),
�@�@length(L,M),
�@�@all(L,*),
�@�@concat_atom(L,S),
�@�@sub_atom(_������,0,N,_,S1),
�@�@sub_atom(_������,N + M,R,_,S2),
�@�@concat_atom([S1,S,S2],_�ϊ����ꂽ������).
% Prolog
'�������2�̐���(���ꂼ�� n, m �Ƃ���)����͂����n�����ڂ���m����*�ɕς���'(_������,N,M,_�ϊ����ꂽ������) :-
�@�@sub_atom(_������,N - 1,M,R,_),
�@�@length(L,M),
�@�@all(L,*),
�@�@concat_atom(L,S),
�@�@sub_atom(_������,0,N,_,S1),
�@�@sub_atom(_������,N + M,R,_,S2),
�@�@concat_atom([S1,S,S2],_�ϊ����ꂽ������).
278 �F�f�t�H���g�̖����������F2009/11/27(��) 07:50:44
>>272
% Prolog
program :-
�@�@write('��������͂��ĉ�����\n'),
�@�@get_line(_������),
�@�@'���������͂���ƁA������ a �̌��𐔂���'(_������,N),
�@�@write_formatted('a��%t�܂܂�Ă��܂�\n',[N]).
'���������͂���ƁA������ a �̌��𐔂���'(_������,N) :-
�@�@findall(_,sub_atom(_������,_,1,_,a),L),
�@�@length(L,N).
% Prolog
program :-
�@�@write('��������͂��ĉ�����\n'),
�@�@get_line(_������),
�@�@'���������͂���ƁA������ a �̌��𐔂���'(_������,N),
�@�@write_formatted('a��%t�܂܂�Ă��܂�\n',[N]).
'���������͂���ƁA������ a �̌��𐔂���'(_������,N) :-
�@�@findall(_,sub_atom(_������,_,1,_,a),L),
�@�@length(L,N).
279 �F�f�t�H���g�̖����������F2009/11/27(��) 07:58:44
>>273
% Prolog
string�^�̈������^���đ啶������������ʂ������ꂪ�������̂��ǂ�����(_
������1,_������2,��������) :-
�@�@to_lower(_������1,_�����������ꂽ������),
�@�@to_lower(_������2,_�����������ꂽ������),!.
string�^�̈������^���đ啶������������ʂ������ꂪ�������̂��ǂ�����(_,
_,�������̂ł͂Ȃ�).
% Prolog
string�^�̈������^���đ啶������������ʂ������ꂪ�������̂��ǂ�����(_
������1,_������2,��������) :-
�@�@to_lower(_������1,_�����������ꂽ������),
�@�@to_lower(_������2,_�����������ꂽ������),!.
string�^�̈������^���đ啶������������ʂ������ꂪ�������̂��ǂ�����(_,
_,�������̂ł͂Ȃ�).
280 �F�f�t�H���g�̖����������F2009/11/27(��) 08:52:59
http://pc11.2ch.net/test/read.cgi/db/1252492296/290
# �E�e�[�u���f�[�^
# tblA
# pkey|value
# ----+-----
# 1�@�@|a
# 2�@�@|b
#
# tblB
# pkey|value
# ----+-----
# 1�@�@|c
#
# �E�~��������
# tblA
# pkey|value
# ----+-----
# 1�@�@|c
# 2�@�@|b
#
# �E���� ���e�[�u���Ƃ��Apkey����L�[�ł��B
# pkey�������ɁAtblA��value���AtblB��value�ŏ㏑���������̂ł����A
# �ǂ̗l�ɏ����̂���ʓI�Ȃ̂ł��傤���B
# �E�e�[�u���f�[�^
# tblA
# pkey|value
# ----+-----
# 1�@�@|a
# 2�@�@|b
#
# tblB
# pkey|value
# ----+-----
# 1�@�@|c
#
# �E�~��������
# tblA
# pkey|value
# ----+-----
# 1�@�@|c
# 2�@�@|b
#
# �E���� ���e�[�u���Ƃ��Apkey����L�[�ł��B
# pkey�������ɁAtblA��value���AtblB��value�ŏ㏑���������̂ł����A
# �ǂ̗l�ɏ����̂���ʓI�Ȃ̂ł��傤���B
281 �F�f�t�H���g�̖����������F2009/11/27(��) 09:22:57
>>280
% Prolog
tblA(1,a).
tblA(2,B).
tblB(1,c).
update(_�Ώۏq��/Arity1,_�L�[�ʒu1,_��u�����ʒu,_�u���w��q��/Arity2,_�L�[�ʒu2,_�u�����ʒu) :-
�@�@length(L1,Arity1),
�@�@length(L2,Arity2),
�@�@P1 =.. [_�Ώۏq��|L1],
�@�@P2 =.. [_�u���w��q��|L2],
�@�@list_nth(_�L�[�ʒu1,L1,A),
�@�@list_nth(_�L�[�ʒu2,L2,A),
�@�@list_nth(_�u�����ʒu,L2,B),
�@�@call(P2),
�@�@call(P1),
�@�@retract(P1),
�@�@�Ȃ�т̈ʒu�w��u��(_��u�����ʒu,B,L1,L3),
�@�@P3 =.. [_�Ώۏq��|L3],
�@�@asserta(P3).
% Prolog
tblA(1,a).
tblA(2,B).
tblB(1,c).
update(_�Ώۏq��/Arity1,_�L�[�ʒu1,_��u�����ʒu,_�u���w��q��/Arity2,_�L�[�ʒu2,_�u�����ʒu) :-
�@�@length(L1,Arity1),
�@�@length(L2,Arity2),
�@�@P1 =.. [_�Ώۏq��|L1],
�@�@P2 =.. [_�u���w��q��|L2],
�@�@list_nth(_�L�[�ʒu1,L1,A),
�@�@list_nth(_�L�[�ʒu2,L2,A),
�@�@list_nth(_�u�����ʒu,L2,B),
�@�@call(P2),
�@�@call(P1),
�@�@retract(P1),
�@�@�Ȃ�т̈ʒu�w��u��(_��u�����ʒu,B,L1,L3),
�@�@P3 =.. [_�Ώۏq��|L3],
�@�@asserta(P3).
282 �F�f�t�H���g�̖����������F2009/11/27(��) 19:03:46
283 �F�f�t�H���g�̖����������F2009/11/27(��) 19:35:56
http://pc12.2ch.net/test/read.cgi/tech/1258158172/430
# [1]C���ꉉ�K
# [2] �R�}���h���C���ŗ^����ꂽ������ǂݎ�肻�̑��a��Ԃ��������Ȃ����B
# �A���A��ł������łȂ������^����ꂽ�ꍇ�͂��̕������\�����A�v�Z�ł��Ȃ�
# ���Ƃ����b�Z�[�W�o�͂���B������64�r�b�g�����t�������͈̔͂Ƃ��^����ꂽ����
# ���͈̔͂Ɏ��܂�Ȃ��ꍇ��a�̌v�Z�̓r���ł����Ȃ�ꍇ���A�I�[�o�[�t���[����
# �|���b�Z�[�W�o�͂��邱�ƁB
# [1]C���ꉉ�K
# [2] �R�}���h���C���ŗ^����ꂽ������ǂݎ�肻�̑��a��Ԃ��������Ȃ����B
# �A���A��ł������łȂ������^����ꂽ�ꍇ�͂��̕������\�����A�v�Z�ł��Ȃ�
# ���Ƃ����b�Z�[�W�o�͂���B������64�r�b�g�����t�������͈̔͂Ƃ��^����ꂽ����
# ���͈̔͂Ɏ��܂�Ȃ��ꍇ��a�̌v�Z�̓r���ł����Ȃ�ꍇ���A�I�[�o�[�t���[����
# �|���b�Z�[�W�o�͂��邱�ƁB
284 �F�f�t�H���g�̖����������F2009/11/27(��) 19:48:45
http://pc12.2ch.net/test/read.cgi/tech/1248012902/539
# �y�@�ۑ�@�z�O�ڕ��׃Q�[�������i�ȉ��͎d�l�j
# �@�@�@�@�@�@�E��l�̑ΐ�҂����݂�O,X�̏ꏊ���}�E�X�ŃN���b�N����
# �@�@�@�@�@�@�E�}�E�X���N���b�N���ꂽ�Ƃ��A�ΐ�҂̃e�[�}�������Đ�����
# �@�@�@�@�@�@�E����O,X������ꏊ���w�肳�ꂽ��A��������
# �@�@�@�@�@�@�E���s�����肷��Ə��҂̃}�[�N�iXorO)��Ԃŕ`�悵�A�e�[�}����3��炷
# �@�@�@�@�@�@�E���s��������Ɠ��͂�����
# �y�@�`�ԁ@�z Applet
# �y�@GUI�@ �z �����Ȃ�
# �y�@�����@�z11�� 30��
# �y�@Ver�@ �z1.6.0_10
# �y�@�⑫�@�z�����łقڍ������ł���X���������ꍇ�Ƀe�[�}����3��Ȃ�܂���
# http://ime.nu/www.dotup.org/uploda/www.dotup.org401130.java.html
#
# ���ƍĕ`�悳����ƈȑO�ɕ`�悳����O��X�������Ă��܂��̂�
# paint���\�b�h�̒���super.paint(g)���g���ĂȂ���ł����A
# ����ł͂Ȃ����������x���Ȃ����̂ŁAupdate���\�b�h���g����
# ���̒���paint�ig�j�ڌĂяo���Ă܂�
# �y�@�ۑ�@�z�O�ڕ��׃Q�[�������i�ȉ��͎d�l�j
# �@�@�@�@�@�@�E��l�̑ΐ�҂����݂�O,X�̏ꏊ���}�E�X�ŃN���b�N����
# �@�@�@�@�@�@�E�}�E�X���N���b�N���ꂽ�Ƃ��A�ΐ�҂̃e�[�}�������Đ�����
# �@�@�@�@�@�@�E����O,X������ꏊ���w�肳�ꂽ��A��������
# �@�@�@�@�@�@�E���s�����肷��Ə��҂̃}�[�N�iXorO)��Ԃŕ`�悵�A�e�[�}����3��炷
# �@�@�@�@�@�@�E���s��������Ɠ��͂�����
# �y�@�`�ԁ@�z Applet
# �y�@GUI�@ �z �����Ȃ�
# �y�@�����@�z11�� 30��
# �y�@Ver�@ �z1.6.0_10
# �y�@�⑫�@�z�����łقڍ������ł���X���������ꍇ�Ƀe�[�}����3��Ȃ�܂���
# http://ime.nu/www.dotup.org/uploda/www.dotup.org401130.java.html
#
# ���ƍĕ`�悳����ƈȑO�ɕ`�悳����O��X�������Ă��܂��̂�
# paint���\�b�h�̒���super.paint(g)���g���ĂȂ���ł����A
# ����ł͂Ȃ����������x���Ȃ����̂ŁAupdate���\�b�h���g����
# ���̒���paint�ig�j�ڌĂяo���Ă܂�
285 �F�f�t�H���g�̖����������F2009/11/27(��) 20:35:48
http://pc12.2ch.net/test/read.cgi/tech/1258158172/432
# [1] ���ƒP���F�ɂȃ��V�W�܂�
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�ő�P�O���̐����� 10000 �ȉ��̐���������
# �@�^����ꂽ�Ƃ��A���̊e��������בւ��ďo����S
# �@�Ă̐��̒��ŁA���Ŋ����鐔�̑��������߂�B
#
# �@�v�Z��j s, d => ��
# �@�E 000, 1 => 1
# �@�E 1234567890, 1 => 3628800
# �@�E 123434, 2 => 90
#
# [1] ���ƒP���F�ɂȃ��V�W�܂�
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�ő�P�O���̐����� 10000 �ȉ��̐���������
# �@�^����ꂽ�Ƃ��A���̊e��������בւ��ďo����S
# �@�Ă̐��̒��ŁA���Ŋ����鐔�̑��������߂�B
#
# �@�v�Z��j s, d => ��
# �@�E 000, 1 => 1
# �@�E 1234567890, 1 => 3628800
# �@�E 123434, 2 => 90
#
286 �F�f�t�H���g�̖����������F2009/11/27(��) 21:25:00
>>255
% Prolog �V�~�����[�V�����̃G���W�������B�ڍׂ� http://nojiriko.asia/prolog/t2_255.html
�V�~�����[�V����([[_,_,_,_,_�O�I,_],[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�����̌_�@(_�O�I,_�n,_��,_��,_�I,_�_�@�Ȃ��),
����̃V�~�����[�V����(1,N,_�_�@�Ȃ��,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������).
�V�~�����[�V����([[_,_,_,_,_�O�I,_],[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�����̌_�@(_�O�I,_�n,_��,_��,_�I,_�_�@�Ȃ��),
����̃V�~�����[�V�����̓�(_�_�@�Ȃ��,_�����l1,_�����l2,_�����c��1,_�����c��2,_������1,_������2),
�V�~�����[�V����([[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
����̃V�~�����[�V����(M,M,[_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l,_�l,_�����c��1,_�����c��,_������1,_������).
����̃V�~�����[�V����(M,N,[_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l2,_�l,_�����c��1,_�����c��2,_������1,_������2),
M2 is M + 1,
����̃V�~�����[�V����(M2,N,R,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
����̃V�~�����[�V�����̓�([],_�����l,_�����l,_�����c��,_�����c��,_������,_������) :- !.
����̃V�~�����[�V�����̓�([_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l2,_�l,_�����c��1,_�����c��2,_������1,_������2),
����̃V�~�����[�V�����̓�(R,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
% Prolog �V�~�����[�V�����̃G���W�������B�ڍׂ� http://nojiriko.asia/prolog/t2_255.html
�V�~�����[�V����([[_,_,_,_,_�O�I,_],[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�����̌_�@(_�O�I,_�n,_��,_��,_�I,_�_�@�Ȃ��),
����̃V�~�����[�V����(1,N,_�_�@�Ȃ��,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������).
�V�~�����[�V����([[_,_,_,_,_�O�I,_],[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�����̌_�@(_�O�I,_�n,_��,_��,_�I,_�_�@�Ȃ��),
����̃V�~�����[�V�����̓�(_�_�@�Ȃ��,_�����l1,_�����l2,_�����c��1,_�����c��2,_������1,_������2),
�V�~�����[�V����([[_���t,_�n,_��,_��,_�I,_]|R],_���t,N,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
����̃V�~�����[�V����(M,M,[_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l,_�l,_�����c��1,_�����c��,_������1,_������).
����̃V�~�����[�V����(M,N,[_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l2,_�l,_�����c��1,_�����c��2,_������1,_������2),
M2 is M + 1,
����̃V�~�����[�V����(M2,N,R,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
����̃V�~�����[�V�����̓�([],_�����l,_�����l,_�����c��,_�����c��,_������,_������) :- !.
����̃V�~�����[�V�����̓�([_�l|R],_�����l1,_�����l,_�����c��1,_�����c��,_������1,_������) :-
�I�y(_�����l1,_�����l2,_�l,_�����c��1,_�����c��2,_������1,_������2),
����̃V�~�����[�V�����̓�(R,_�����l2,_�����l,_�����c��2,_�����c��,_������2,_������).
287 �F�f�t�H���g�̖����������F2009/11/27(��) 21:33:25
>>286 ����[���B
�����ǂ�ł����l�͂��Ȃ����낤����ǁA�ЂƂ��ƁB
�Ȃ��A����̃V�~�����[�V����/9 �Ƃ���Ƃ��������
����̃V�~�����[�V�����̓�/7 ������̂��A
���̈Ⴂ�͉����A���ꂼ��ǂ�ȓ��������Ă���̂��B
�����ǂ�ł����l�͂��Ȃ����낤����ǁA�ЂƂ��ƁB
�Ȃ��A����̃V�~�����[�V����/9 �Ƃ���Ƃ��������
����̃V�~�����[�V�����̓�/7 ������̂��A
���̈Ⴂ�͉����A���ꂼ��ǂ�ȓ��������Ă���̂��B
288 �F�f�t�H���g�̖����������F2009/11/28(�y) 05:32:52
http://pc12.2ch.net/test/read.cgi/tech/1258158172/438
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10181.txt
#
# �`�ۑ�P�`
# �ϐ�a,b,c�֒l��ǂݍ��݁A������ax2�iax�̓��j+bx+c=0�̉���o�͂���v���O�������쐬����B�������Aa=/0(a�m�b�g0)�̏ꍇ�̔��ʎ���D=b2-4ac�ŗ^��������̂Ƃ��A
# ���̌�����-b+-4ac/2a�ŗ^��������̂Ƃ���B�������ƂȂ�ꍇ�͂��Ƃ���x=3+5i,x=3-5i�̂悤�Ɏ������Ƌ��������킩��悤�ɏo�͂���B���ׂĂ̏ꍇ�������Ƃ����l����B
# ���[�g�̊���sqrt�����g���B���Ƃ���2.5�����߂�ꍇ�A
# double a;
# a=sqrt(2.5); /����2.5��a�ɑ����/
# �̂悤�ɏ����B�������Asqrt�́i�j���ɗ^�����鐔�i�ϐ����w��ł���j�͐��̎���(double�^�j�łȂ���Ȃ�Ȃ��B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10181.txt
#
# �`�ۑ�P�`
# �ϐ�a,b,c�֒l��ǂݍ��݁A������ax2�iax�̓��j+bx+c=0�̉���o�͂���v���O�������쐬����B�������Aa=/0(a�m�b�g0)�̏ꍇ�̔��ʎ���D=b2-4ac�ŗ^��������̂Ƃ��A
# ���̌�����-b+-4ac/2a�ŗ^��������̂Ƃ���B�������ƂȂ�ꍇ�͂��Ƃ���x=3+5i,x=3-5i�̂悤�Ɏ������Ƌ��������킩��悤�ɏo�͂���B���ׂĂ̏ꍇ�������Ƃ����l����B
# ���[�g�̊���sqrt�����g���B���Ƃ���2.5�����߂�ꍇ�A
# double a;
# a=sqrt(2.5); /����2.5��a�ɑ����/
# �̂悤�ɏ����B�������Asqrt�́i�j���ɗ^�����鐔�i�ϐ����w��ł���j�͐��̎���(double�^�j�łȂ���Ȃ�Ȃ��B
289 �F�f�t�H���g�̖����������F2009/11/28(�y) 05:34:14
http://pc12.2ch.net/test/read.cgi/tech/1258158172/438
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10181.txt
#
# �`�ۑ�Q�`
# �ϐ�������͂���ƁA�ȉ��̐}�̂悤�ȕ\�����s���v���O���������ꂼ��쐬����B�������A�}�͂����T�̏ꍇ�ł���B
# �P�̃v���O�����Ƃ��č쐬����B
#
# *
# �@�@�@�@***
# *****
# *******
# *********
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10181.txt
#
# �`�ۑ�Q�`
# �ϐ�������͂���ƁA�ȉ��̐}�̂悤�ȕ\�����s���v���O���������ꂼ��쐬����B�������A�}�͂����T�̏ꍇ�ł���B
# �P�̃v���O�����Ƃ��č쐬����B
#
# *
# �@�@�@�@***
# *****
# *******
# *********
290 �F�f�t�H���g�̖����������F2009/11/28(�y) 05:43:27
>>289
���݂܂���B�����܂����B�v����ɐ��́u�s���~�b�h�v�ł��B
���݂܂���B�����܂����B�v����ɐ��́u�s���~�b�h�v�ł��B
291 �F�f�t�H���g�̖����������F2009/11/28(�y) 06:23:36
>>203 (�Čf)
% Prolog
% sub_atom/5��ISO�W���̔萫�q��B
% �����ł́A�擪����ꕶ������肾���Ă��邪�A����͋K�i�ŕۏ����
% �����ł͂Ȃ��B�t���Ɏ��Ă��܂��Ă�����̌����悤���Ȃ��B
% ���݂̏����n�ł͂���œ����Ƃ����������B������I�ȃR�[�h��%%%�̂��ƂɁB
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@sub_atom(Atom1,_,1,R,Char1),
�@�@sub_atom(Atom2,_,1,R,Char2),
�@�@(Char = Char1; Char = Char2).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@atom_chars(Atom1,Chars1),
�@�@atom_chars(Atom2,Chars2),
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(Chars1,Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([Char|R],Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(Chars1,[Char|R],Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([_|R1],[_|R2],Char) :-
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(R1,R2,Char).
% Prolog
% sub_atom/5��ISO�W���̔萫�q��B
% �����ł́A�擪����ꕶ������肾���Ă��邪�A����͋K�i�ŕۏ����
% �����ł͂Ȃ��B�t���Ɏ��Ă��܂��Ă�����̌����悤���Ȃ��B
% ���݂̏����n�ł͂���œ����Ƃ����������B������I�ȃR�[�h��%%%�̂��ƂɁB
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@sub_atom(Atom1,_,1,R,Char1),
�@�@sub_atom(Atom2,_,1,R,Char2),
�@�@(Char = Char1; Char = Char2).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
���������ɂP���������݂Ɏ��o��(Atom1,Atom2,Char) :-
�@�@atom_chars(Atom1,Chars1),
�@�@atom_chars(Atom2,Chars2),
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(Chars1,Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([Char|R],Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(Chars1,[Char|R],Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([_|R1],[_|R2],Char) :-
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(R1,R2,Char).
292 �F�f�t�H���g�̖����������F2009/11/28(�y) 06:58:22
>>291
% �ȉ��̂悤�ɏ����l�������B�����ăX�}�[�g�����A��{�̂ǂ����
% ���X�g�̏������������炸�A�q��W�����̂�����Ŏ��͌����B
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([Char|R],Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([_|L1],L2,Char) :-
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(L2,L1,Char).
% �ȉ��̂悤�ɏ����l�������B�����ăX�}�[�g�����A��{�̂ǂ����
% ���X�g�̏������������炸�A�q��W�����̂�����Ŏ��͌����B
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([Char|R],Chars2,Char).
�����Ȃ�т��當�������ɂP���������݂Ɏ��o��([_|L1],L2,Char) :-
�@�@�����Ȃ�т��當�������ɂP���������݂Ɏ��o��(L2,L1,Char).
293 �F�f�t�H���g�̖����������F2009/11/28(�y) 07:43:30
>>288
% Prolog
:- op(250,xf,i).
�������̉�(0,B,C,X) :- X is (-1) * C / B.
�������̉�(A,B,C,X) :-
�@�@0.0 is B^2 - 4 * A * C,
�@�@X is ((-1) * B) / (2 * A).
�������̉�(A,B,C,X) :-
�@�@U is B^2 - 4 * A * C,
�@�@U > 0.0,
�@�@X is ((-1) * B) + sqrt(U)) / (2 * A).
�������̉�(A,B,C,X) :-
�@�@U is B^2 - 4 * A * C,
�@�@U > 0.0,
�@�@X is ((-1) * B) - sqrt(U)) / (2 * A).
�������̉�(A,B,C,(D+Ei)) :-
�@�@U is B^2 - 4 * A * C,
�@�@U < 0.0,
�@�@D is ((-1) * B) / (2 * A),
�@�@E is U / (2 * A).
�������̉�(A,B,C,(D-Ei)) :-
�@�@U is B^2 - 4 * A * C,
�@�@U < 0.0,
�@�@D is ((-1) * B) / (2 * A),
�@�@E is U / (2 * A).
% Prolog
:- op(250,xf,i).
�������̉�(0,B,C,X) :- X is (-1) * C / B.
�������̉�(A,B,C,X) :-
�@�@0.0 is B^2 - 4 * A * C,
�@�@X is ((-1) * B) / (2 * A).
�������̉�(A,B,C,X) :-
�@�@U is B^2 - 4 * A * C,
�@�@U > 0.0,
�@�@X is ((-1) * B) + sqrt(U)) / (2 * A).
�������̉�(A,B,C,X) :-
�@�@U is B^2 - 4 * A * C,
�@�@U > 0.0,
�@�@X is ((-1) * B) - sqrt(U)) / (2 * A).
�������̉�(A,B,C,(D+Ei)) :-
�@�@U is B^2 - 4 * A * C,
�@�@U < 0.0,
�@�@D is ((-1) * B) / (2 * A),
�@�@E is U / (2 * A).
�������̉�(A,B,C,(D-Ei)) :-
�@�@U is B^2 - 4 * A * C,
�@�@U < 0.0,
�@�@D is ((-1) * B) / (2 * A),
�@�@E is U / (2 * A).
294 �F�f�t�H���g�̖����������F2009/11/28(�y) 10:03:00
>>289
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),all(L1,' '),
�@�@�s���~�b�h(L1,[]).
�s���~�b�h([],HL).
�s���~�b�h([_|L1],HL) :-
�@�@append(L1,HL,L1,L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['*'|HL]).
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),all(L1,' '),
�@�@�s���~�b�h(L1,[]).
�s���~�b�h([],HL).
�s���~�b�h([_|L1],HL) :-
�@�@append(L1,HL,L1,L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['*'|HL]).
295 �F�f�t�H���g�̖����������F2009/11/28(�y) 10:07:27
>>294 �ԈႦ���B
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),
�@�@all(L1,' '),
�@�@�s���~�b�h(L1,[*]).
�s���~�b�h([],HL).
�s���~�b�h([A|L1],HL) :-
�@�@append([A|L1],HL,[A|L1],L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['**'|HL]).
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),
�@�@all(L1,' '),
�@�@�s���~�b�h(L1,[*]).
�s���~�b�h([],HL).
�s���~�b�h([A|L1],HL) :-
�@�@append([A|L1],HL,[A|L1],L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['**'|HL]).
296 �F�f�t�H���g�̖����������F2009/11/28(�y) 10:17:00
>>295 ����ς�Ⴄ�B�ӊO�Ƃ�₱�����B
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),
�@�@all(L1,' '),
�@�@�s���~�b�h(L1,[*]).
�s���~�b�h([],HL) :- concat_atom(HL,S),write_formatted('%t\n',[S]).
�s���~�b�h([_|L1],HL) :-
�@�@append(L1,HL,L1,L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['**'|HL]).
% Prolog
�s���~�b�h(N) :-
�@�@length(L1,N),
�@�@all(L1,' '),
�@�@�s���~�b�h(L1,[*]).
�s���~�b�h([],HL) :- concat_atom(HL,S),write_formatted('%t\n',[S]).
�s���~�b�h([_|L1],HL) :-
�@�@append(L1,HL,L1,L2),
�@�@concat_atom(L2,S),
�@�@write_formatted('%t\n',[S]),
�@�@�s���~�b�h(L1,['**'|HL]).
297 �F�f�t�H���g�̖����������F2009/11/28(�y) 10:35:08
>>296
���l���Z������length/2�ɉB������Ă��Ă����R�[�h�ł��ˁB�ł��������ɁA
length/2 + all/2 �Ƃ�
concat_atom/2 + write_formatted/2 �͂ЂƂ̃��[�e�B���e�B�q��ɓZ�߂�
���������Ǝv���܂���B���낻��B
���l���Z������length/2�ɉB������Ă��Ă����R�[�h�ł��ˁB�ł��������ɁA
length/2 + all/2 �Ƃ�
concat_atom/2 + write_formatted/2 �͂ЂƂ̃��[�e�B���e�B�q��ɓZ�߂�
���������Ǝv���܂���B���낻��B
298 �F�f�t�H���g�̖����������F2009/11/28(�y) 10:50:08
>>297
all/2 �� concat_atom/2 �͊��ɂ���ɓ�������ǁB�ł������A
�ėp�q��𑝂₳�Ȃ��Ƃ������A�����Ă��g��Ȃ��̂�Prolog�̃X�^�C�������ǁA
�������ɂ����܂ŕp�ɂɌ����ƂȂ�Ɓu���낻��v�����m��Ȃ��B
all/2 �� concat_atom/2 �͊��ɂ���ɓ�������ǁB�ł������A
�ėp�q��𑝂₳�Ȃ��Ƃ������A�����Ă��g��Ȃ��̂�Prolog�̃X�^�C�������ǁA
�������ɂ����܂ŕp�ɂɌ����ƂȂ�Ɓu���낻��v�����m��Ȃ��B
299 �F�f�t�H���g�̖����������F2009/11/28(�y) 12:06:05
>>283
% Prolog
���̓p�����[�^���Z(S) :-
�@�@user_parameters(L),
�@�@���̓p�����[�^���(L,0,S,����I��).
���̓p�����[�^���(_,_,_,_�f�f) :- \+(_�f�f=����I��),!.
���̓p�����[�^���([],S,S,����I��) :- !.
���̓p�����[�^���([A|R1],S1,S,����I��) :-
�@�@exception_handler(atom_to_term(A,N,_),error(E,I),error_message(E,I),fail),
�@�@���Z����(N,S1,S2,_�f�f2),
�@�@���̓p�����[�^���(R1,S2,S,_�f�f2).
���̓p�����[�^���([A|R1],S1,S,�ُ�I��) :-
�@�@write_formatted('���̓p�����[�^�̉�͒��ɃG���[���������܂����B:"%t" �������~���܂��B\n',[N]),!.
���Z����(N,S1,S2,����I��) :- integer(N),
�@�@exception_handler(S2 is S1 + N,error(E,I),error_message(E,I),fail),!.
���Z����(N,S1,S1,���Z�G���[) :- integer(N),!.
���Z����(N,S1,S1,���G���[) :- \+(integer(N)),
�@�@write_formatted('�p�����[�^�ɐ����ȊO�̗v�f������܂��� : %t\n',[N]),!.
error_message(E,I) :- write_formatted('%t,%t �G���[\n',[E,I]).
% Prolog
���̓p�����[�^���Z(S) :-
�@�@user_parameters(L),
�@�@���̓p�����[�^���(L,0,S,����I��).
���̓p�����[�^���(_,_,_,_�f�f) :- \+(_�f�f=����I��),!.
���̓p�����[�^���([],S,S,����I��) :- !.
���̓p�����[�^���([A|R1],S1,S,����I��) :-
�@�@exception_handler(atom_to_term(A,N,_),error(E,I),error_message(E,I),fail),
�@�@���Z����(N,S1,S2,_�f�f2),
�@�@���̓p�����[�^���(R1,S2,S,_�f�f2).
���̓p�����[�^���([A|R1],S1,S,�ُ�I��) :-
�@�@write_formatted('���̓p�����[�^�̉�͒��ɃG���[���������܂����B:"%t" �������~���܂��B\n',[N]),!.
���Z����(N,S1,S2,����I��) :- integer(N),
�@�@exception_handler(S2 is S1 + N,error(E,I),error_message(E,I),fail),!.
���Z����(N,S1,S1,���Z�G���[) :- integer(N),!.
���Z����(N,S1,S1,���G���[) :- \+(integer(N)),
�@�@write_formatted('�p�����[�^�ɐ����ȊO�̗v�f������܂��� : %t\n',[N]),!.
error_message(E,I) :- write_formatted('%t,%t �G���[\n',[E,I]).
300 �F�f�t�H���g�̖����������F2009/11/28(�y) 16:17:33
>>289
main = readLn >>= \n -> putStr $ unlines [replicate (n-i) ' ' ++ replicate (2*i-1) '*' | i <- [1..n]]
main = readLn >>= \n -> putStr $ unlines [replicate (n-i) ' ' ++ replicate (2*i-1) '*' | i <- [1..n]]
301 �F�f�t�H���g�̖����������F2009/11/28(�y) 16:39:48
>>288
import Data.Complex
solve2 :: RealFloat a => Complex a -> Complex a -> Complex a -> [Complex a]
solve2 0 b c = [c / b]
solve2 a b c = let d = b*b - 4*a*c
in [(-b + sqrt d) / (2*a), (-b - sqrt d) / (2*a)]
main = print $ solve2 1 1 1
import Data.Complex
solve2 :: RealFloat a => Complex a -> Complex a -> Complex a -> [Complex a]
solve2 0 b c = [c / b]
solve2 a b c = let d = b*b - 4*a*c
in [(-b + sqrt d) / (2*a), (-b - sqrt d) / (2*a)]
main = print $ solve2 1 1 1
302 �F�f�t�H���g�̖����������F2009/11/28(�y) 16:48:19
303 �F�f�t�H���g�̖����������F2009/11/28(�y) 17:57:58
>>285
% Prolog
'�ő�P�O���̐����� 10000 �ȉ��̐����������^����ꂽ�Ƃ��A���̊e��������בւ��ďo����S�Ă̐��̒��ŁA���Ŋ����鐔�̑��������߂�'(_�����Ȃ��,D,X) :-
�@�@length(_�����Ȃ��,Len),
�@�@Len =< 10,
�@�@D < 10000,
�@�@findall(Y,(�����Ȃ�т��珇��(_�����Ȃ��,Len,Y),0 is Y mod D),L),
�@�@sort(L,L2),
�@�@length(L2,X).
�����Ȃ�т��珇��(Y,0,0).
�����Ȃ�т��珇��(Y,N,X) :-
�@�@del(Z = Y - A),
�@�@M is N - 1,
�@�@�����Ȃ�т��珇��(Z,M,X2),
�@�@X is truncate(10^M*A+X2).
% Prolog
'�ő�P�O���̐����� 10000 �ȉ��̐����������^����ꂽ�Ƃ��A���̊e��������בւ��ďo����S�Ă̐��̒��ŁA���Ŋ����鐔�̑��������߂�'(_�����Ȃ��,D,X) :-
�@�@length(_�����Ȃ��,Len),
�@�@Len =< 10,
�@�@D < 10000,
�@�@findall(Y,(�����Ȃ�т��珇��(_�����Ȃ��,Len,Y),0 is Y mod D),L),
�@�@sort(L,L2),
�@�@length(L2,X).
�����Ȃ�т��珇��(Y,0,0).
�����Ȃ�т��珇��(Y,N,X) :-
�@�@del(Z = Y - A),
�@�@M is N - 1,
�@�@�����Ȃ�т��珇��(Z,M,X2),
�@�@X is truncate(10^M*A+X2).
304 �F�f�t�H���g�̖����������F2009/11/29(��) 03:34:10
http://pc12.2ch.net/test/read.cgi/tech/1258158172/451
# [1]�₳����C����
# [2]�@�S�̐���傫���̏��������ɕ��בւ���� Sort4(int *a,int *b.int *c,int *d)
# �i�Ăяo����a<=b<=c<=d�ƂȂ�j�����A���̊��𗘗p���ăL�[�{�[�h����S��
# �̐�����ǂݎ��A�傫�����ɏo�͂���v���O���������Ȃ����B
# Sort4���̒��ł̓��[�v���iwhile/do while/for)��p���Ȃ�����
#
# [1]�₳����C����
# [2]�@�S�̐���傫���̏��������ɕ��בւ���� Sort4(int *a,int *b.int *c,int *d)
# �i�Ăяo����a<=b<=c<=d�ƂȂ�j�����A���̊��𗘗p���ăL�[�{�[�h����S��
# �̐�����ǂݎ��A�傫�����ɏo�͂���v���O���������Ȃ����B
# Sort4���̒��ł̓��[�v���iwhile/do while/for)��p���Ȃ�����
#
305 �F�f�t�H���g�̖����������F2009/11/29(��) 03:37:27
http://pc12.2ch.net/test/read.cgi/tech/1258158172/458
# [1] ��b�v���O���~���O���K
#
# [2]99�����܂ł̕��������͂��C�A���t�@�x�b�g�̏������͑啶���ɁC�A���t�@�x�b�g�̑啶���͏������ɁC
# �܂��A���t�@�x�b�g�ȊO�̕����̓A�X�^���X�N�f*�f�ɕϊ�������������o�͂���v���O�������쐬����D
# 99�����ȉ��̕��������͂��Ă��������DabcABC123sDFgh#"x32YY=
#
# �ϊ����ꂽ�������ABCabc***SdfGH**X**yy*�ł��D
#
# �ǐL�F
# ���Ȃ݂ɂǂ����A�X�L�[�R�[�h���g���炵���ł��B
# �啶���̃R�[�h�ɂR�Q�𑫂��Ώ������̃R�[�h�ɂȂ�Ƃ������Ă܂����B
# ������g��Ȃ�������Ȃ��悤�ł��B
# ���ƃ��C�u�������͎g�p�s�ł��B
# ������Ƃ�������̏��߂Ăł��B
#
# [1] ��b�v���O���~���O���K
#
# [2]99�����܂ł̕��������͂��C�A���t�@�x�b�g�̏������͑啶���ɁC�A���t�@�x�b�g�̑啶���͏������ɁC
# �܂��A���t�@�x�b�g�ȊO�̕����̓A�X�^���X�N�f*�f�ɕϊ�������������o�͂���v���O�������쐬����D
# 99�����ȉ��̕��������͂��Ă��������DabcABC123sDFgh#"x32YY=
#
# �ϊ����ꂽ�������ABCabc***SdfGH**X**yy*�ł��D
#
# �ǐL�F
# ���Ȃ݂ɂǂ����A�X�L�[�R�[�h���g���炵���ł��B
# �啶���̃R�[�h�ɂR�Q�𑫂��Ώ������̃R�[�h�ɂȂ�Ƃ������Ă܂����B
# ������g��Ȃ�������Ȃ��悤�ł��B
# ���ƃ��C�u�������͎g�p�s�ł��B
# ������Ƃ�������̏��߂Ăł��B
#
306 �F�f�t�H���g�̖����������F2009/11/29(��) 04:00:01
>>285
NB. J����
f=:dyad def'+/0=y|~.".(i.!#x)A.x'
'000' f 1
1
'123434' f 2
90
'123456789' f 1
362880
'1234567890' f 1
|out of memory: f
| +/0=y|~.".(i.!#x) A.x
10����out of memory�ɂȂ��Ă��܂��܂��B(�g�p�����p�\�R���̃�������512MB)
�����ƃ�����������͎��s�ł���̂��ǂ����́A�킩��܂���B
NB. J����
f=:dyad def'+/0=y|~.".(i.!#x)A.x'
'000' f 1
1
'123434' f 2
90
'123456789' f 1
362880
'1234567890' f 1
|out of memory: f
| +/0=y|~.".(i.!#x) A.x
10����out of memory�ɂȂ��Ă��܂��܂��B(�g�p�����p�\�R���̃�������512MB)
�����ƃ�����������͎��s�ł���̂��ǂ����́A�킩��܂���B
307 �F�f�t�H���g�̖����������F2009/11/29(��) 04:08:43
>>305
% Prolog
'�A���t�@�x�b�g�̏������͑啶���ɃA���t�@�x�b�g�̑啶���͏������ɂ܂��A���t�@�x�b�g�ȊO�̕����̓A�X�^���X�N*�ɕϊ����ĕ\��' :-
�@�@write('99�����ȉ��̕��������͂��Ă�������. '),
�@�@get_line(Line),
�@�@atom_codes(Line,Codes),
�@�@length(Codes,_����),_���� =< 99,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(Codes,Codes2),
�@�@atom_codes(_�ϊ����ꂽ������,Codes2),
�@�@write_formatted('�ϊ����ꂽ�������%t�ł�\n',[_�ϊ����ꂽ������]).
�����R�[�h�ɂ�钼�ڕϊ�([],[]).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[Code2|R2]) :-
�@�@Code >= 65,Code =< 90,
�@�@Code2 is Code + 32,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[Code2|R2]) :-
�@�@Code >= 97,Code =< 122,
�@�@Code2 is Code - 32,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[42|R2]) :-
�@�@\+((Code >= 65,Code =< 90)),
�@�@\+((Code >= 97,Code =< 122)),
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
% Prolog
'�A���t�@�x�b�g�̏������͑啶���ɃA���t�@�x�b�g�̑啶���͏������ɂ܂��A���t�@�x�b�g�ȊO�̕����̓A�X�^���X�N*�ɕϊ����ĕ\��' :-
�@�@write('99�����ȉ��̕��������͂��Ă�������. '),
�@�@get_line(Line),
�@�@atom_codes(Line,Codes),
�@�@length(Codes,_����),_���� =< 99,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(Codes,Codes2),
�@�@atom_codes(_�ϊ����ꂽ������,Codes2),
�@�@write_formatted('�ϊ����ꂽ�������%t�ł�\n',[_�ϊ����ꂽ������]).
�����R�[�h�ɂ�钼�ڕϊ�([],[]).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[Code2|R2]) :-
�@�@Code >= 65,Code =< 90,
�@�@Code2 is Code + 32,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[Code2|R2]) :-
�@�@Code >= 97,Code =< 122,
�@�@Code2 is Code - 32,
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
�����R�[�h�ɂ�钼�ڕϊ�([Code|R1],[42|R2]) :-
�@�@\+((Code >= 65,Code =< 90)),
�@�@\+((Code >= 97,Code =< 122)),
�@�@�����R�[�h�ɂ�钼�ڕϊ�(R1,R2).
308 �F�f�t�H���g�̖����������F2009/11/29(��) 04:28:48
>>304
% Prolog
sort4(A,B,C,D,X1,X2,X3,X4) :-
�@�@����([A,B,C,D],4,[X1,X2,X3,X4]),
�@�@X1 >= X2,
�@�@X2 >= X3,
�@�@X3 >= X4,!.
% Prolog
sort4(A,B,C,D,X1,X2,X3,X4) :-
�@�@����([A,B,C,D],4,[X1,X2,X3,X4]),
�@�@X1 >= X2,
�@�@X2 >= X3,
�@�@X3 >= X4,!.
309 �F�f�t�H���g�̖����������F2009/11/29(��) 05:40:35
>>289
NB. J����
f=:monad def'''-*''(1!:2&2)@#~(,.<:@+:@(y&-))|.i.y'
f 5
----*
---***
--*****
-*******
*********
NB. J����
f=:monad def'''-*''(1!:2&2)@#~(,.<:@+:@(y&-))|.i.y'
f 5
----*
---***
--*****
-*******
*********
310 �F�f�t�H���g�̖����������F2009/11/29(��) 05:46:39
http://pc12.2ch.net/test/read.cgi/tech/1258158172/456
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10195.txt
#
# ����̓i�b�v�T�b�N���ɂ��čl���v���O�������쐬����BN�̉ו��������āA�X�̉ו��̏d����Wi�A�l�i��Pi�Ƃ���B�A��i��1����N�̐������Ӗ�����B
# �܂ɂ͍ő�W�̏d���܂œ������Ƃ���ƁA�ő�ł����番�����邱�Ƃ��ł��邩�H�Ƃ������B
# �f�[�^�t�@�C���́A�n�߂̈�s�ɉו��̌�N��������Ă���A���ɏd����������N�s��������Ă���B���̎��̍s����N�s���A���ꂼ��̉ו��̉��l��������Ă���Ƃ���B
# ���̃f�[�^�t�@�C���̏ꍇ�́A�R�̉ו�������A�d�݂͂P�O�A�Q�O�A�P�R�A��
# ���ꂼ��̒l�i�͂Q�R�A�Q�R�A�P�O�Ƃ�����\���B
# -------------------
# 3
# 10
# 20
# 13
# 23
# 23
# 10
# -------------------
# �ו��̏d�݂ƒl�i�͂Ƃ��ɁA�P����P�O�O�܂ł̗����ŗ^���邱�ƂƂ���B
# void_write_data_file(char*file,intN)�Ƃ��������ĂԂ�N���̃f�[�^�𗐐��Ő������A������ϐ�file�ɓ����Ă���
# �t�@�C�����̃t�@�C�����J���A�����Ƀf�[�^���L�^����Bvoid_read_data_file(char*file)�Ƃ��������ĂԂƁA������ϐ�file�ɂ���Ė��O���w�肳�ꂽ�t�@�C�����J���A���ϐ��̉ו��̏d�ݔz��W[]�ƒl�i�z��[]�Ƀf�[�^����͂���B
# [1] ���ƒP���F C++
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10195.txt
#
# ����̓i�b�v�T�b�N���ɂ��čl���v���O�������쐬����BN�̉ו��������āA�X�̉ו��̏d����Wi�A�l�i��Pi�Ƃ���B�A��i��1����N�̐������Ӗ�����B
# �܂ɂ͍ő�W�̏d���܂œ������Ƃ���ƁA�ő�ł����番�����邱�Ƃ��ł��邩�H�Ƃ������B
# �f�[�^�t�@�C���́A�n�߂̈�s�ɉו��̌�N��������Ă���A���ɏd����������N�s��������Ă���B���̎��̍s����N�s���A���ꂼ��̉ו��̉��l��������Ă���Ƃ���B
# ���̃f�[�^�t�@�C���̏ꍇ�́A�R�̉ו�������A�d�݂͂P�O�A�Q�O�A�P�R�A��
# ���ꂼ��̒l�i�͂Q�R�A�Q�R�A�P�O�Ƃ�����\���B
# -------------------
# 3
# 10
# 20
# 13
# 23
# 23
# 10
# -------------------
# �ו��̏d�݂ƒl�i�͂Ƃ��ɁA�P����P�O�O�܂ł̗����ŗ^���邱�ƂƂ���B
# void_write_data_file(char*file,intN)�Ƃ��������ĂԂ�N���̃f�[�^�𗐐��Ő������A������ϐ�file�ɓ����Ă���
# �t�@�C�����̃t�@�C�����J���A�����Ƀf�[�^���L�^����Bvoid_read_data_file(char*file)�Ƃ��������ĂԂƁA������ϐ�file�ɂ���Ė��O���w�肳�ꂽ�t�@�C�����J���A���ϐ��̉ו��̏d�ݔz��W[]�ƒl�i�z��[]�Ƀf�[�^����͂���B
311 �F�f�t�H���g�̖����������F2009/11/29(��) 05:54:22
312 �F�f�t�H���g�̖����������F2009/11/29(��) 06:47:48
>>310
% Prolog
�i�b�v�T�b�N���(_�t�@�C����,N,_���e�ő�d��,_�l�߂邱�Ƃ̂ł���ō����v���z) :-
�@�@�f�[�^�t�@�C���̓ǂݏo��(_�t�@�C����,N,_���i�Ȃ��,_�d���Ȃ��),
�@�@findall(M,for(1,M,N),_1����N�܂�),
�@�@findmax(_���v���i,�l�ߕ��̍쐬(N,_1����N�܂�,_���e�ő�d��,_�d���Ȃ��,_���i�Ȃ��,_���v���i),_�l�߂邱�Ƃ̂ł���ō����v���z).
�f�[�^�t�@�C���̓ǂݏo��(_�t�@�C����,N,_�d���Ȃ��,_���i�Ȃ��) :-
�@�@see(_�t�@�C����),get_integer(N),get_integers(L1),seen,
�@�@length(L2,N),length(L3,N),
�@�@append(_�d���Ȃ��,_���i�Ȃ��,L1),!.
�l�ߕ��̍쐬(N,_1����N�܂�,_���e�ő�d��,_�d���Ȃ��,_���i�Ȃ��,_���v���i) :-
�@�@for(1,M,N),
�@�@�g����(_1����N�܂�,M,L),
�@�@findsum(Wi,(member(A,L),list_nth(A,_�d���Ȃ��,Wi)),_���v�d��),
�@�@_���v�d�� =< _���e�ő�d��,
�@�@findsum(Pi,(member(A,L),list_nth(A,_���i�Ȃ��,Pi)),_���v���z).
get_integers(L) :-
�@�@findall(I,(get_line(Line),(Line=end_of_file,!,fail;atom_to_term(Line,I,_))),L),!.
% Prolog
�i�b�v�T�b�N���(_�t�@�C����,N,_���e�ő�d��,_�l�߂邱�Ƃ̂ł���ō����v���z) :-
�@�@�f�[�^�t�@�C���̓ǂݏo��(_�t�@�C����,N,_���i�Ȃ��,_�d���Ȃ��),
�@�@findall(M,for(1,M,N),_1����N�܂�),
�@�@findmax(_���v���i,�l�ߕ��̍쐬(N,_1����N�܂�,_���e�ő�d��,_�d���Ȃ��,_���i�Ȃ��,_���v���i),_�l�߂邱�Ƃ̂ł���ō����v���z).
�f�[�^�t�@�C���̓ǂݏo��(_�t�@�C����,N,_�d���Ȃ��,_���i�Ȃ��) :-
�@�@see(_�t�@�C����),get_integer(N),get_integers(L1),seen,
�@�@length(L2,N),length(L3,N),
�@�@append(_�d���Ȃ��,_���i�Ȃ��,L1),!.
�l�ߕ��̍쐬(N,_1����N�܂�,_���e�ő�d��,_�d���Ȃ��,_���i�Ȃ��,_���v���i) :-
�@�@for(1,M,N),
�@�@�g����(_1����N�܂�,M,L),
�@�@findsum(Wi,(member(A,L),list_nth(A,_�d���Ȃ��,Wi)),_���v�d��),
�@�@_���v�d�� =< _���e�ő�d��,
�@�@findsum(Pi,(member(A,L),list_nth(A,_���i�Ȃ��,Pi)),_���v���z).
get_integers(L) :-
�@�@findall(I,(get_line(Line),(Line=end_of_file,!,fail;atom_to_term(Line,I,_))),L),!.
313 �F�f�t�H���g�̖����������F2009/11/29(��) 09:01:30
314 �F�f�t�H���g�̖����������F2009/11/29(��) 10:37:37
http://pc12.2ch.net/test/read.cgi/tech/1258158172/475
# �y����e���v���z
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10196.txt
# ���͂��ꂽ1000�ȉ��̐�����f�����������āA���ʂ��o�͂���v���O�������쐬���Ȃ����B
# �f���������Ƃ́A���R����f������̐ς̌`�ɏ����\�����Ƃ������B
#
# ��:60=2*2*3*5 ���̂Ƃ�2�A3�A5��60�̑f�����ł���Ƃ����B
#
# ���R��N���f���������ł���Ƃ��AN��G^2�ƂȂ�f����G�����݂��邱�Ƃ����w�I�ɏؖ�����Ă���̂Ŏ��̂悤�ȃA���S���Y�����l�����B
# (1)�L�[�{�[�h������͂��ꂽ��n��1�ȉ��Ȃ�A�ē��͂�����B
# (2)k��2��������B
# (3)k�̓���m�Ƃ���B
# (4)n��m���r���An��m�ȏ�Ȃ�(�L�q�~�X��������Ȃ�n��m�����Ȃ�H)n��f�����Ƃ��ďo�͂��ďI������B
# (5)n��m��菬�������n��k�Ŋ���A��q�Ɨ]��r�����߂�B
# (6)�]��r��0�łȂ����(n��k�Ŋ����Ȃ����)�Ak�̒l��1���₵��(3)�ɖ߂�B
# (7)�]��r��0�Ȃ�(n��k�Ŋ������)�Ak��f�����Ƃ��ďo�͂���B
# (8)��q��1�Ȃ珈�����I������A�����łȂ����q��V����n�Ƃ���(5)�ɖ߂�B
# �y����e���v���z
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10196.txt
# ���͂��ꂽ1000�ȉ��̐�����f�����������āA���ʂ��o�͂���v���O�������쐬���Ȃ����B
# �f���������Ƃ́A���R����f������̐ς̌`�ɏ����\�����Ƃ������B
#
# ��:60=2*2*3*5 ���̂Ƃ�2�A3�A5��60�̑f�����ł���Ƃ����B
#
# ���R��N���f���������ł���Ƃ��AN��G^2�ƂȂ�f����G�����݂��邱�Ƃ����w�I�ɏؖ�����Ă���̂Ŏ��̂悤�ȃA���S���Y�����l�����B
# (1)�L�[�{�[�h������͂��ꂽ��n��1�ȉ��Ȃ�A�ē��͂�����B
# (2)k��2��������B
# (3)k�̓���m�Ƃ���B
# (4)n��m���r���An��m�ȏ�Ȃ�(�L�q�~�X��������Ȃ�n��m�����Ȃ�H)n��f�����Ƃ��ďo�͂��ďI������B
# (5)n��m��菬�������n��k�Ŋ���A��q�Ɨ]��r�����߂�B
# (6)�]��r��0�łȂ����(n��k�Ŋ����Ȃ����)�Ak�̒l��1���₵��(3)�ɖ߂�B
# (7)�]��r��0�Ȃ�(n��k�Ŋ������)�Ak��f�����Ƃ��ďo�͂���B
# (8)��q��1�Ȃ珈�����I������A�����łȂ����q��V����n�Ƃ���(5)�ɖ߂�B
315 �F�f�t�H���g�̖����������F2009/11/29(��) 10:40:15
http://pc12.2ch.net/test/read.cgi/tech/1258320456/47
# �y�@�ۑ�@�z�l�l�l����B�u���邽���v�̗��K�̈�Ƃ��āA
# �S�l���̒������ꕶ�����u��v�̎l����I��ŁA�O��I�ɗ��K���邱�Ƃ�
# ���܂����B�l���Ƃ́A
# �₷��͂ł˂Ȃ܂����̂�����ӂ��Ă����Ԃ��܂ł̂����݂�����
# ��ւނ��炵������ǂ̂��т����ɂЂƂ����݂��݂���݂���܂�
# ��܂��Ƃ͂ӂ䂼���т����܂��肯��ЂƂ߂�����������ʂƂ����ւ�
# ��܂��͂ɂ����̂������邵����݂͂Ȃ�������ւʂ��݂��Ȃ肯��
# ���[���́A
# 1) ��l�Q�[���ł���B
# 2) �l���̂Ȃ����疳��ׂɓ�I�ю����Ƒ���̎D�Ƃ���B
# 3) �ǂݎ�͎l���S���ǂݏグ��B���������ċ�D(���D���Ȃ�)���܂܂��B
# 4) �ꖇ��������_�ŏ����͂����A�c��̈ꖇ���������ƂƂ���B
#
# [���] �������g���Ă��ꂼ��̎����D�����߁A�����\�����܂��B
# ���ɁA�ǂݎD�̏��Ԃ����߂܂��B����͂��̒i�K�ł͕\�����܂���B
# ���A�ǂ݁A�����\�����A
# 1) ��D : �������ڂ܂œǂ܂�Ă��ꂪ�킩������
# 2) ����D : ����
# 3) �����D : ����
# ��\�����Ȃ����B������J��Ԃ��A���D���Ȃ��Ȃ�����Q�[���I�[�o�[�B
# 4) ��̃��[�h�ō��Ȃ���
# �@1) �ǂ܂ꂽ�D���l�Ƃ��L�����Ă���B
# �@2) �ǂ܂ꂽ�D�͖Y��Ă��܂��B
# ���ۂɂ͎��D�ɂ͉��̋傪������Ă��܂����A�����ł͈��S�̂����݂��������Ă�����̂Ƃ��܂��B
# �y�@�ۑ�@�z�l�l�l����B�u���邽���v�̗��K�̈�Ƃ��āA
# �S�l���̒������ꕶ�����u��v�̎l����I��ŁA�O��I�ɗ��K���邱�Ƃ�
# ���܂����B�l���Ƃ́A
# �₷��͂ł˂Ȃ܂����̂�����ӂ��Ă����Ԃ��܂ł̂����݂�����
# ��ւނ��炵������ǂ̂��т����ɂЂƂ����݂��݂���݂���܂�
# ��܂��Ƃ͂ӂ䂼���т����܂��肯��ЂƂ߂�����������ʂƂ����ւ�
# ��܂��͂ɂ����̂������邵����݂͂Ȃ�������ւʂ��݂��Ȃ肯��
# ���[���́A
# 1) ��l�Q�[���ł���B
# 2) �l���̂Ȃ����疳��ׂɓ�I�ю����Ƒ���̎D�Ƃ���B
# 3) �ǂݎ�͎l���S���ǂݏグ��B���������ċ�D(���D���Ȃ�)���܂܂��B
# 4) �ꖇ��������_�ŏ����͂����A�c��̈ꖇ���������ƂƂ���B
#
# [���] �������g���Ă��ꂼ��̎����D�����߁A�����\�����܂��B
# ���ɁA�ǂݎD�̏��Ԃ����߂܂��B����͂��̒i�K�ł͕\�����܂���B
# ���A�ǂ݁A�����\�����A
# 1) ��D : �������ڂ܂œǂ܂�Ă��ꂪ�킩������
# 2) ����D : ����
# 3) �����D : ����
# ��\�����Ȃ����B������J��Ԃ��A���D���Ȃ��Ȃ�����Q�[���I�[�o�[�B
# 4) ��̃��[�h�ō��Ȃ���
# �@1) �ǂ܂ꂽ�D���l�Ƃ��L�����Ă���B
# �@2) �ǂ܂ꂽ�D�͖Y��Ă��܂��B
# ���ۂɂ͎��D�ɂ͉��̋傪������Ă��܂����A�����ł͈��S�̂����݂��������Ă�����̂Ƃ��܂��B
316 �F�f�t�H���g�̖����������F2009/11/29(��) 10:58:48
>>182
�g�p����F�@R
write(sprintf("%4d",1:10%o%1:10),"",10)
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
�g�p����F�@R
write(sprintf("%4d",1:10%o%1:10),"",10)
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
317 �F�f�t�H���g�̖����������F2009/11/29(��) 11:30:26
>>314
NB. J����
f=:monad def';(,'' * ''&;)/<@":"0 q:y'
f 11111
41 * 271
f 11111111
11 * 73 * 101 * 137
NB. J����
f=:monad def';(,'' * ''&;)/<@":"0 q:y'
f 11111
41 * 271
f 11111111
11 * 73 * 101 * 137
318 �F�f�t�H���g�̖����������F2009/11/29(��) 12:28:54
http://pc12.2ch.net/test/read.cgi/tech/1258158172/486
# [1] ���ƒP���FC���ꉉ�K
# [2] ��蕶�F 1�`100�܂ł̐������J��Ԃ����͂��A�Ō��0����͂���Ƃ���܂ł�
# ���͂��ꂽ�l�̍��v�l��\������v���O�������쐬���Ȃ����B������
# 1�`100�ȊO�̐��������͂��ꂽ�Ƃ��́h�G���[�h�ƕ\��������B
#
# [1] ���ƒP���FC���ꉉ�K
# [2] ��蕶�F 1�`100�܂ł̐������J��Ԃ����͂��A�Ō��0����͂���Ƃ���܂ł�
# ���͂��ꂽ�l�̍��v�l��\������v���O�������쐬���Ȃ����B������
# 1�`100�ȊO�̐��������͂��ꂽ�Ƃ��́h�G���[�h�ƕ\��������B
#
319 �F�f�t�H���g�̖����������F2009/11/29(��) 13:42:13
>>17�@���2
�g�p����F�@R
f <- function (n) {
a <- 1:n
sum(a[a%%3==0|a%%5==0])
}
> f(10)
[1] 33
> f(2000)
[1] 933668
�g�p����F�@R
f <- function (n) {
a <- 1:n
sum(a[a%%3==0|a%%5==0])
}
> f(10)
[1] 33
> f(2000)
[1] 933668
320 �F�f�t�H���g�̖����������F2009/11/29(��) 18:06:47
>>17�@���1
�g�p����F�@R
f <- function (n) {substr("abcdefghijklmnopqrstuvwxyz",1,n)}
> f(6)
[1] "abcdef"
> f(30)
[1] "abcdefghijklmnopqrstuvwxyz"
�g�p����F�@R
f <- function (n) {substr("abcdefghijklmnopqrstuvwxyz",1,n)}
> f(6)
[1] "abcdef"
> f(30)
[1] "abcdefghijklmnopqrstuvwxyz"
321 �F�f�t�H���g�̖����������F2009/11/29(��) 18:47:28
http://pc12.2ch.net/test/read.cgi/tech/1258158172/497
# [1] ���ƒP���FC
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10200.txt
#
# �����ݒ肳�ꂽ������̏������t�ɕ��בւ���v���O�������쐬����B
# �������A���בւ��镔���͊��Ƃ��A������̒����͍ő�255�����Ƃ���
# [1] ���ƒP���FC
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10200.txt
#
# �����ݒ肳�ꂽ������̏������t�ɕ��בւ���v���O�������쐬����B
# �������A���בւ��镔���͊��Ƃ��A������̒����͍ő�255�����Ƃ���
322 �F�f�t�H���g�̖����������F2009/11/30(��) 05:04:32
http://pc12.2ch.net/test/read.cgi/tech/1248012902/549
# �ۑ�͒����čڂ����Ȃ�����
# <A HREF="http://nojiriko.asia/prolog/j68_549_kadai.html">�����ɃR�s�[�����Ă�
�܂���</A>
# �ۑ�͒����čڂ����Ȃ�����
# <A HREF="http://nojiriko.asia/prolog/j68_549_kadai.html">�����ɃR�s�[�����Ă�
�܂���</A>
323 �F�f�t�H���g�̖����������F2009/11/30(��) 05:07:01
324 �F�f�t�H���g�̖����������F2009/11/30(��) 06:05:17
>>318
% Prolog �ėp�q��̒�`�� http://nojiriko.asia/prolog/c132_486.html ���Q�Ƃ��Ă��������B
'1�`100�܂ł̐������J��Ԃ����͂��A�Ō��0����͂���Ƃ���܂łɓ��͂��ꂽ�l��
���v�l��\������'(_���v�l) :-
�@�@findsum(X,(repeat,get_integer(X),(X=0,!,fail;�͈͔͈̓`�F�b�N(X)),_���v�l),
�@�@write_formatted('���v��%t\n',[_���v�l]).
�����͈̓`�F�b�N(X):- X > 0,X =< 100.
�����͈̓`�F�b�N(X):- \+((X >0,X =<100)),write('�����͈̓G���[\n'),fail.
% Prolog �ėp�q��̒�`�� http://nojiriko.asia/prolog/c132_486.html ���Q�Ƃ��Ă��������B
'1�`100�܂ł̐������J��Ԃ����͂��A�Ō��0����͂���Ƃ���܂łɓ��͂��ꂽ�l��
���v�l��\������'(_���v�l) :-
�@�@findsum(X,(repeat,get_integer(X),(X=0,!,fail;�͈͔͈̓`�F�b�N(X)),_���v�l),
�@�@write_formatted('���v��%t\n',[_���v�l]).
�����͈̓`�F�b�N(X):- X > 0,X =< 100.
�����͈̓`�F�b�N(X):- \+((X >0,X =<100)),write('�����͈̓G���[\n'),fail.
325 �F�f�t�H���g�̖����������F2009/11/30(��) 06:16:26
>>321
% Prolog �����ݒ肳�ꂽ�Ƃ����Ƃ��낪�����BProlog���ƁE�E�E����
�����ݒ肳�ꂽ������̏������t�ɕ��בւ��� :-
�@�@retract('(����)�ݒ蕶����'(_������)),
�@�@������̔��](_������,_���]���ꂽ������),
�@�@asserta('(����)�ݒ蕶����'(_���]���ꂽ������)).
������̔��](_������,_���]���ꂽ������) :-
�@�@atom_chars(_������,Chars),
�@�@reverse(Chars,RChars),
�@�@atom_chars(_���]���ꂽ������,RChars).
% Prolog �����ݒ肳�ꂽ�Ƃ����Ƃ��낪�����BProlog���ƁE�E�E����
�����ݒ肳�ꂽ������̏������t�ɕ��בւ��� :-
�@�@retract('(����)�ݒ蕶����'(_������)),
�@�@������̔��](_������,_���]���ꂽ������),
�@�@asserta('(����)�ݒ蕶����'(_���]���ꂽ������)).
������̔��](_������,_���]���ꂽ������) :-
�@�@atom_chars(_������,Chars),
�@�@reverse(Chars,RChars),
�@�@atom_chars(_���]���ꂽ������,RChars).
326 �F�f�t�H���g�̖����������F2009/11/30(��) 07:12:49
>>321
�g�p����F�@�\�iBASIC
SUB reverse(a$)
LET b=LEN(a$)
LET c=INT(b/2)
FOR i = 1 TO c
LET t$=a$(i:i)
LET a$(i:i)=a$(b-i+1:b-i+1)
LET a$(b-i+1:b-i+1)=t$
LET c=5
NEXT I
END SUB
LET s$="12345"
CALL reverse(s$)
PRINT s$
END
���s����
54321
�g�p����F�@�\�iBASIC
SUB reverse(a$)
LET b=LEN(a$)
LET c=INT(b/2)
FOR i = 1 TO c
LET t$=a$(i:i)
LET a$(i:i)=a$(b-i+1:b-i+1)
LET a$(b-i+1:b-i+1)=t$
LET c=5
NEXT I
END SUB
LET s$="12345"
CALL reverse(s$)
PRINT s$
END
���s����
54321
327 �F�f�t�H���g�̖����������F2009/11/30(��) 07:42:12
>>318
�g�p����F�@�\�iBASIC
LET v=1
DO WHILE v<>0
INPUT v
IF 0<=v AND v<=100 THEN
LET s=s+v
ELSE
PRINT "�G���["
END IF
LOOP
PRINT s
END
���s����
? 1
? 2
? 200
�G���[
? 3
? 0
6
�g�p����F�@�\�iBASIC
LET v=1
DO WHILE v<>0
INPUT v
IF 0<=v AND v<=100 THEN
LET s=s+v
ELSE
PRINT "�G���["
END IF
LOOP
PRINT s
END
���s����
? 1
? 2
? 200
�G���[
? 3
? 0
6
328 �F�f�t�H���g�̖����������F2009/11/30(��) 12:23:26
>>318
�G���[�`�F�b�N����͈͂��܂��������B
�g�p����F�@�\�iBASIC
LET s=0
LET v=1
DO WHILE v<>0
INPUT v
IF 1<=v AND v<=100 THEN
LET s=s+v
ELSE
PRINT "�G���["
END IF
LOOP
PRINT s
END
���s����
? 1
? 2
? 200
�G���[
? 3
? 0
6
�G���[�`�F�b�N����͈͂��܂��������B
�g�p����F�@�\�iBASIC
LET s=0
LET v=1
DO WHILE v<>0
INPUT v
IF 1<=v AND v<=100 THEN
LET s=s+v
ELSE
PRINT "�G���["
END IF
LOOP
PRINT s
END
���s����
? 1
? 2
? 200
�G���[
? 3
? 0
6
329 �F�f�t�H���g�̖����������F2009/11/30(��) 12:26:27
>>17 �@���2
�g�p����F�@Arc
(def f (n)
(sum
[if (or (is (mod _ 3) 0) (is (mod _ 5) 0)) _ 0 ]
(range 1 n)))
arc> (f 20)
98
arc> (f 100000)
2333416668
arc>
�g�p����F�@Arc
(def f (n)
(sum
[if (or (is (mod _ 3) 0) (is (mod _ 5) 0)) _ 0 ]
(range 1 n)))
arc> (f 20)
98
arc> (f 100000)
2333416668
arc>
330 �F�f�t�H���g�̖����������F2009/11/30(��) 12:54:59
http://pc12.2ch.net/test/read.cgi/tech/1258158172/550
# [1] ���ƒP���F�@�v���O���~���O�U
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# 2�i����10�i���̑��ݕϊ��̃v���O���������B
# ������Ƃ��ĕϊ�(�v�Z)�����Ɠ��͕����Ƃ���B
# �����̐��A�������ϊ��ł���悤�ɂ���B
# ���͂�Scanf���g�p����B
#
# [1] ���ƒP���F�@�v���O���~���O�U
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# 2�i����10�i���̑��ݕϊ��̃v���O���������B
# ������Ƃ��ĕϊ�(�v�Z)�����Ɠ��͕����Ƃ���B
# �����̐��A�������ϊ��ł���悤�ɂ���B
# ���͂�Scanf���g�p����B
#
331 �F�f�t�H���g�̖����������F2009/11/30(��) 14:38:24
>>45
�g�p����F�@Arc
(def fact (n) (if (is n 0) 1 (apply * (range 1 n))))
arc> (for i 0 10 (prn (fact i)))
1
1
2
6
24
120
720
5040
40320
362880
3628800
nil
�g�p����F�@Arc
(def fact (n) (if (is n 0) 1 (apply * (range 1 n))))
arc> (for i 0 10 (prn (fact i)))
1
1
2
6
24
120
720
5040
40320
362880
3628800
nil
332 �F�f�t�H���g�̖����������F2009/11/30(��) 17:22:28
http://pc12.2ch.net/test/read.cgi/tech/1258158172/557
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10207.txt
# [���]
# �s���Ɨ������Ƃ��āA���̍s���Ɨ����A�X�^���X�N��\���������showwas
ter()���쐬����B
# ���͂͐��̐����������l����Ε��C�ł��B
#
# [����Ȃ�����]
# ���̃v���O��������???�̕���������܂���c
# �\���ł������݁A���̌Ăяo����v���g�^�C�v�錾�Ȃǂ��K���Ă��܂�
# ��낵�����肢�v���܂�
# [1] ���ƒP���F �v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10207.txt
# [���]
# �s���Ɨ������Ƃ��āA���̍s���Ɨ����A�X�^���X�N��\���������showwas
ter()���쐬����B
# ���͂͐��̐����������l����Ε��C�ł��B
#
# [����Ȃ�����]
# ���̃v���O��������???�̕���������܂���c
# �\���ł������݁A���̌Ăяo����v���g�^�C�v�錾�Ȃǂ��K���Ă��܂�
# ��낵�����肢�v���܂�
333 �F�f�t�H���g�̖����������F2009/11/30(��) 17:23:23
http://pc12.2ch.net/test/read.cgi/tech/1258158172/560
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�F
# int�^�����̂S���Ԃ���
# int pow4(int x)
# ���쐬����B�i��������pow�͎g�p���Ȃ��j
#
# �i���s��j
# ��������͂��Ă��������F�T
# ���̂S��l�͂U�Q�T�ł��B
#
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�F
# int�^�����̂S���Ԃ���
# int pow4(int x)
# ���쐬����B�i��������pow�͎g�p���Ȃ��j
#
# �i���s��j
# ��������͂��Ă��������F�T
# ���̂S��l�͂U�Q�T�ł��B
#
334 �F�f�t�H���g�̖����������F2009/11/30(��) 17:29:59
>>333
% Prolog ���o http://nojiriko.asia/prolog/c132_368_2.html
pow4 :-
�@�@get_inetger(N),
�@�@pow4(N,X),
�@�@write_formatted('����4��l��%t�ł��B\n',[X]).
pow4(N,X) :-
�@�@X is N * N * N * N.
% Prolog ���o http://nojiriko.asia/prolog/c132_368_2.html
pow4 :-
�@�@get_inetger(N),
�@�@pow4(N,X),
�@�@write_formatted('����4��l��%t�ł��B\n',[X]).
pow4(N,X) :-
�@�@X is N * N * N * N.
335 �F�f�t�H���g�̖����������F2009/11/30(��) 17:44:44
>>332
% Prolog
showwaster(M,N) :-
�@�@waster(M,N,L),
�@�@showwaster(L).
showwaster([]).
showwaster([L|R]) :-
�@�@writeAn(L),
�@�@showwaster(R).
waster(N1,N,M,[]) :- N1 > N,!.
waster(N1,N,M,[A|R]) :-
�@�@length(L,M),
�@�@all(L,*),
�@�@N2 is N1 + 1,
�@�@waster(N2,N,M,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeAn(_�Ȃ��) :-
�@�@concat_atom(_�Ȃ��,Atom),
�@�@write_formatted('%t\n',[Atom]).
% Prolog
showwaster(M,N) :-
�@�@waster(M,N,L),
�@�@showwaster(L).
showwaster([]).
showwaster([L|R]) :-
�@�@writeAn(L),
�@�@showwaster(R).
waster(N1,N,M,[]) :- N1 > N,!.
waster(N1,N,M,[A|R]) :-
�@�@length(L,M),
�@�@all(L,*),
�@�@N2 is N1 + 1,
�@�@waster(N2,N,M,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeAn(_�Ȃ��) :-
�@�@concat_atom(_�Ȃ��,Atom),
�@�@write_formatted('%t\n',[Atom]).
336 �F�f�t�H���g�̖����������F2009/11/30(��) 17:51:55
>>335 ����Ă����̂ŏ�������
% Prolog
showwaster(M,N) :-
�@�@waster(1,N,M,L), /* ��������� */
�@�@showwaster(L).
showwaster([]).
showwaster([L|R]) :-
�@�@writeAn(L),
�@�@showwaster(R).
waster(N1,N,M,[]) :- N1 > N,!.
waster(N1,N,M,[A|R]) :-
�@�@length(L,M),
�@�@all(L,*),
�@�@N2 is N1 + 1,
�@�@waster(N2,N,M,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeAn(_�Ȃ��) :-
�@�@concat_atom(_�Ȃ��,Atom),
�@�@write_formatted('%t\n',[Atom]).
% Prolog
showwaster(M,N) :-
�@�@waster(1,N,M,L), /* ��������� */
�@�@showwaster(L).
showwaster([]).
showwaster([L|R]) :-
�@�@writeAn(L),
�@�@showwaster(R).
waster(N1,N,M,[]) :- N1 > N,!.
waster(N1,N,M,[A|R]) :-
�@�@length(L,M),
�@�@all(L,*),
�@�@N2 is N1 + 1,
�@�@waster(N2,N,M,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeAn(_�Ȃ��) :-
�@�@concat_atom(_�Ȃ��,Atom),
�@�@write_formatted('%t\n',[Atom]).
337 �F�f�t�H���g�̖����������F2009/11/30(��) 20:19:03
338 �F�f�t�H���g�̖����������F2009/11/30(��) 20:21:22
>>258 >>332
�g�p����F�@maxima
showwaster(a,b):=(c:smake(b,"*"),for i thru a do print(c));
(%i1) showwaster(3,15);
***************
***************
***************
�g�p����F�@maxima
showwaster(a,b):=(c:smake(b,"*"),for i thru a do print(c));
(%i1) showwaster(3,15);
***************
***************
***************
339 �F�f�t�H���g�̖����������F2009/11/30(��) 20:28:07
http://pc12.2ch.net/test/read.cgi/tech/1258158172/565
#�@[1] ���ƒP���F�v���O���~���O���K
#�@[2] ��蕶(�܃R�[�h&�����N)�F
#�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10209.txt
# �ȉ��̎��s���ʂ����ɁA����[�~]�ƔN��[%]�Ɨa���N�x���L�[�{�[�h������͂����A
# �P�O�N�ԗa�������Ƃ��̖��N�x�̗����ƌ������v��\������v���O�������쐬�A�R���p�C���A���s���Ȃ����B
# �Ȃ��A�����͕����Ōv�Z���A���N�x�̗����̉~�P�ʖ����͐�̂Ă邱�ƁB
# ����[�~]����͂��Ă��������@: 3613 enter��
# �N��[%]����͂��Ă��������@ : 9.6�@enter��
# �a���N�x����͂��Ă��������@: 2009 enter��
# +-----------+------------+-----------+er��
# | �N�x�@ �@ |�@�@�����@�@|�@ �������v|
# +-----------+------------+-----------+
# |�@�@�@2009 |�@�@�@�@�@�@|�@�@�@3613 |
# |�@�@�@2010 |�@�@�@�@346 |�@�@�@3959 |
#�@�@�@�@�@�@�@�@<����>
# |�@�@�@2018 |�@�@�@�@721 |�@�@�@8238 |
# |�@�@�@2019 |�@�@�@�@790 |�@�@�@9028 |
# +-----------+------------+-----------+
#�@[1] ���ƒP���F�v���O���~���O���K
#�@[2] ��蕶(�܃R�[�h&�����N)�F
#�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10209.txt
# �ȉ��̎��s���ʂ����ɁA����[�~]�ƔN��[%]�Ɨa���N�x���L�[�{�[�h������͂����A
# �P�O�N�ԗa�������Ƃ��̖��N�x�̗����ƌ������v��\������v���O�������쐬�A�R���p�C���A���s���Ȃ����B
# �Ȃ��A�����͕����Ōv�Z���A���N�x�̗����̉~�P�ʖ����͐�̂Ă邱�ƁB
# ����[�~]����͂��Ă��������@: 3613 enter��
# �N��[%]����͂��Ă��������@ : 9.6�@enter��
# �a���N�x����͂��Ă��������@: 2009 enter��
# +-----------+------------+-----------+er��
# | �N�x�@ �@ |�@�@�����@�@|�@ �������v|
# +-----------+------------+-----------+
# |�@�@�@2009 |�@�@�@�@�@�@|�@�@�@3613 |
# |�@�@�@2010 |�@�@�@�@346 |�@�@�@3959 |
#�@�@�@�@�@�@�@�@<����>
# |�@�@�@2018 |�@�@�@�@721 |�@�@�@8238 |
# |�@�@�@2019 |�@�@�@�@790 |�@�@�@9028 |
# +-----------+------------+-----------+
340 �F�f�t�H���g�̖����������F2009/11/30(��) 20:55:10
341 �F�f�t�H���g�̖����������F2009/11/30(��) 20:56:40
>>258 >>332
�g�p����F�@Arc
(def showwaster (a b) (for i 1 a (for j 1 b (pr "*")) (prn) ))
arc> (showwaster 5 8)
********
********
********
********
********
nil
�g�p����F�@Arc
(def showwaster (a b) (for i 1 a (for j 1 b (pr "*")) (prn) ))
arc> (showwaster 5 8)
********
********
********
********
********
nil
342 �F�f�t�H���g�̖����������F2009/11/30(��) 21:41:02
>>305
-- Haskell
import Data.Char
main = getLine >>= putStrLn . map convert
convert c | isUpper c = toLower c
| isLower c = toUpper c
| otherwise = '*'
-- Haskell
import Data.Char
main = getLine >>= putStrLn . map convert
convert c | isUpper c = toLower c
| isLower c = toUpper c
| otherwise = '*'
343 �F�f�t�H���g�̖����������F2009/11/30(��) 21:42:51
>>314
-- Haskell
main = print $ factorize 60
factorize :: Integral a => a -> [a]
factorize = go 2
where
go k n | n < k*k = [n]
| r == 0 = k : go k q
| otherwise = go (k+1) n
where (q,r) = n `divMod` k
-- Haskell
main = print $ factorize 60
factorize :: Integral a => a -> [a]
factorize = go 2
where
go k n | n < k*k = [n]
| r == 0 = k : go k q
| otherwise = go (k+1) n
where (q,r) = n `divMod` k
344 �F�f�t�H���g�̖����������F2009/11/30(��) 21:47:02
345 �F�f�t�H���g�̖����������F2009/11/30(��) 21:47:19
>>318
-- Haskell
import Control.Monad.State
main = execStateT t318 0 >>= print
t318 :: StateT Int IO ()
t318 = do
n <- liftIO readLn
if n == 0
then return ()
else if 1 <= n && n <= 100
then modify (+n) >> t318
else error "error"
-- Haskell
import Control.Monad.State
main = execStateT t318 0 >>= print
t318 :: StateT Int IO ()
t318 = do
n <- liftIO readLn
if n == 0
then return ()
else if 1 <= n && n <= 100
then modify (+n) >> t318
else error "error"
346 �F�f�t�H���g�̖����������F2009/11/30(��) 21:51:12
>>258 >>332
�g�p����F�@�\�iBASIC
SUB showwaster(a,b)
PRINT REPEAT$(REPEAT$("*",b)&CHR$(10),a)
END SUB
CALL showwaster(5,3)
END
���s����
***
***
***
***
***
�g�p����F�@�\�iBASIC
SUB showwaster(a,b)
PRINT REPEAT$(REPEAT$("*",b)&CHR$(10),a)
END SUB
CALL showwaster(5,3)
END
���s����
***
***
***
***
***
347 �F�f�t�H���g�̖����������F2009/11/30(��) 22:09:01
>>322
-- Haskell
import System.Environment (getArgs)
newtype Point2D a = Point2D (a,a)
newtype Triangle a = Triangle (Point2D a,Point2D a)
main = do
argv <- getArgs
case argv of
[ax,ay,bx,by] -> let a = mkPoint2D (read ax) (read ay)
b = mkPoint2D (read bx) (read by)
in print $ getArea $ mkTriangle a b
_ -> putStrLn "usage: a.out ax ay bx by"
mkPoint2D = curry Point2D
mkTriangle = curry Triangle
getArea :: Fractional a => Triangle a -> a
getArea (Triangle (Point2D (ax,ay), Point2D (bx,by)))
= abs (ax*by - ay*bx) / 2
-- Haskell
import System.Environment (getArgs)
newtype Point2D a = Point2D (a,a)
newtype Triangle a = Triangle (Point2D a,Point2D a)
main = do
argv <- getArgs
case argv of
[ax,ay,bx,by] -> let a = mkPoint2D (read ax) (read ay)
b = mkPoint2D (read bx) (read by)
in print $ getArea $ mkTriangle a b
_ -> putStrLn "usage: a.out ax ay bx by"
mkPoint2D = curry Point2D
mkTriangle = curry Triangle
getArea :: Fractional a => Triangle a -> a
getArea (Triangle (Point2D (ax,ay), Point2D (bx,by)))
= abs (ax*by - ay*bx) / 2
348 �F�f�t�H���g�̖����������F2009/11/30(��) 22:23:14
>>339
% Prolog
'�P�O�N�ԗa�������Ƃ��̖��N�x�̗����ƌ������v��\��' :-
�@�@�Ñ��t����������('����[�~]����͂��Ă��������@: ',_����1),
�@�@�Ñ��t����������('�N��[%]����͂��Ă������� : ',_�N��),
�@�@�Ñ��t����������('�a���N�x����͂��Ă������� : ',_�a���N�x1),
�@�@write('+-----------+------------+-----------+\n'),
�@�@write('| �N�x�@ �@ |�@�@�����@�@|�@ �������v|\n').
�@�@write('+-----------+------------+-----------+\n'),
�@�@�������v�v�Z(_�a���N�x1,_�a���N�x,_�N��,0,_����1,_�������v),
�@�@�N�x���Ƃɕ\��(_�a���N�x1,_�a���N�x,_����,_�������v),
�@�@_�a���N�x is _�a���N�x1 + 10,
�@�@write('+-----------+------------+-----------+\n'),!.
�������v�v�Z(_�a���N�x,_�a���N�x,_�N��,_����,_����,_����).
�������v�v�Z(_�a���N�x1,_�a���N�x,_�N��,_,_����1,_����) :-
�@�@_����2 is truncate(_����1 * _�N�� / 100),
�@�@_����2 is _����1 + _����2,
�@�@_�a���N�x2 is _�a���N�x + 1,
�@�@�������v�v�Z(_�a���N�x2,_�a���N�x,_�N��,_����2,_����2,_�������v).
�N�x���Ƃɕ\��(_�a���N�x,_�a���N�x,_����,_�������v) :-
�@�@write_formatted('|�@�@�@%t |�@ |�@%8d |\n',[_�a���N�x,_�������v]),!.
�N�x���Ƃɕ\��(_,_�a���N�x,_����,_�������v) :-
�@�@write_formatted('|�@�@�@%t |�@%8d |�@%8d |\n',[_�a���N�x,_�������v]),!.
% Prolog
'�P�O�N�ԗa�������Ƃ��̖��N�x�̗����ƌ������v��\��' :-
�@�@�Ñ��t����������('����[�~]����͂��Ă��������@: ',_����1),
�@�@�Ñ��t����������('�N��[%]����͂��Ă������� : ',_�N��),
�@�@�Ñ��t����������('�a���N�x����͂��Ă������� : ',_�a���N�x1),
�@�@write('+-----------+------------+-----------+\n'),
�@�@write('| �N�x�@ �@ |�@�@�����@�@|�@ �������v|\n').
�@�@write('+-----------+------------+-----------+\n'),
�@�@�������v�v�Z(_�a���N�x1,_�a���N�x,_�N��,0,_����1,_�������v),
�@�@�N�x���Ƃɕ\��(_�a���N�x1,_�a���N�x,_����,_�������v),
�@�@_�a���N�x is _�a���N�x1 + 10,
�@�@write('+-----------+------------+-----------+\n'),!.
�������v�v�Z(_�a���N�x,_�a���N�x,_�N��,_����,_����,_����).
�������v�v�Z(_�a���N�x1,_�a���N�x,_�N��,_,_����1,_����) :-
�@�@_����2 is truncate(_����1 * _�N�� / 100),
�@�@_����2 is _����1 + _����2,
�@�@_�a���N�x2 is _�a���N�x + 1,
�@�@�������v�v�Z(_�a���N�x2,_�a���N�x,_�N��,_����2,_����2,_�������v).
�N�x���Ƃɕ\��(_�a���N�x,_�a���N�x,_����,_�������v) :-
�@�@write_formatted('|�@�@�@%t |�@ |�@%8d |\n',[_�a���N�x,_�������v]),!.
�N�x���Ƃɕ\��(_,_�a���N�x,_����,_�������v) :-
�@�@write_formatted('|�@�@�@%t |�@%8d |�@%8d |\n',[_�a���N�x,_�������v]),!.
349 �F�f�t�H���g�̖����������F2009/11/30(��) 23:02:04
>>305
�g�p����F�@�\�iBASIC
FUNCTION f$(s$)
FOR i=1 TO LEN(s$)
LET c=ORD(s$(i:i))
IF 65<=c AND c<=90 THEN
LET d=c+32
ELSEIF 97<=c AND c<=122 THEN
LET d=c-32
ELSE
LET d=42
END IF
LET s$(i:i)=CHR$(d)
NEXT I
LET f$=s$
END FUNCTION
PRINT f$("abcABC123sDFgh#""x32YY=")
END
���s����
ABCabc***SdfGH**X**yy*
�g�p����F�@�\�iBASIC
FUNCTION f$(s$)
FOR i=1 TO LEN(s$)
LET c=ORD(s$(i:i))
IF 65<=c AND c<=90 THEN
LET d=c+32
ELSEIF 97<=c AND c<=122 THEN
LET d=c-32
ELSE
LET d=42
END IF
LET s$(i:i)=CHR$(d)
NEXT I
LET f$=s$
END FUNCTION
PRINT f$("abcABC123sDFgh#""x32YY=")
END
���s����
ABCabc***SdfGH**X**yy*
350 �F�f�t�H���g�̖����������F2009/11/30(��) 23:12:34
>>339
ime.nu ���炢�����Ă���
-- Haskell
import Control.Arrow ((&&&), (>>>))
import Control.Applicative ((<*>))
import qualified System.IO.UTF8 as U
import System.IO (hFlush, stdout)
import Text.Printf (printf)
flush = hFlush stdout
main = do
U.putStr "����[�~]����͂��Ă�����: " >> flush
a <- readLn
U.putStr "�N��[%]����͂��Ă�������: " >> flush
b <- readLn
U.putStr "�a���N�x����͂��Ă�������: " >> flush
c <- readLn
putStrLn "+-----------+------------+-----------+"
U.putStrLn "| �N�x | ���� | �������v |"
putStrLn "+-----------+------------+-----------+"
mapM_ (\(x,(y,z)) -> putStrLn $ prettify x y z) $ zip [c,c+1..] $ take 11 $ t339 a b
putStrLn "+-----------+------------+-----------+"
where
prettify :: Int -> Int -> Int -> String
prettify = printf "|%11d|%12d|%11d|"
t339 init i = iterate (snd >>> interest i &&& ((+) <*> interest i)) (0,init)
interest :: (RealFrac a, Integral b) => a -> b -> b
interest d n = floor $ fromIntegral n * d/100
ime.nu ���炢�����Ă���
-- Haskell
import Control.Arrow ((&&&), (>>>))
import Control.Applicative ((<*>))
import qualified System.IO.UTF8 as U
import System.IO (hFlush, stdout)
import Text.Printf (printf)
flush = hFlush stdout
main = do
U.putStr "����[�~]����͂��Ă�����: " >> flush
a <- readLn
U.putStr "�N��[%]����͂��Ă�������: " >> flush
b <- readLn
U.putStr "�a���N�x����͂��Ă�������: " >> flush
c <- readLn
putStrLn "+-----------+------------+-----------+"
U.putStrLn "| �N�x | ���� | �������v |"
putStrLn "+-----------+------------+-----------+"
mapM_ (\(x,(y,z)) -> putStrLn $ prettify x y z) $ zip [c,c+1..] $ take 11 $ t339 a b
putStrLn "+-----------+------------+-----------+"
where
prettify :: Int -> Int -> Int -> String
prettify = printf "|%11d|%12d|%11d|"
t339 init i = iterate (snd >>> interest i &&& ((+) <*> interest i)) (0,init)
interest :: (RealFrac a, Integral b) => a -> b -> b
interest d n = floor $ fromIntegral n * d/100
351 �F�f�t�H���g�̖����������F2009/12/01(��) 00:06:02
>>339
�g�p����F�@�\�iBASIC
INPUT PROMPT "����[�~]����͂��Ă��������@:":����
INPUT PROMPT "�N��[%]����͂��Ă��������@ :":�N��
INPUT PROMPT "�a���N�x����͂��Ă��������@:":�a���N�x
LET ����=0
PRINT "+------------+------------+------------+"
PRINT "|�@�@�N�x�@�@|�@�@�����@�@|�@�������v�@|"
PRINT "+------------+------------+------------+"
PRINT USING "|############| |############|": �a���N�x,����
FOR i=1 TO 10
LET ����=INT(����*�N��/100)
LET ����=����+����
PRINT USING "|############|############|############|": �a���N�x+i,����,����
NEXT I
PRINT "+------------+------------+------------+"
END
�g�p����F�@�\�iBASIC
INPUT PROMPT "����[�~]����͂��Ă��������@:":����
INPUT PROMPT "�N��[%]����͂��Ă��������@ :":�N��
INPUT PROMPT "�a���N�x����͂��Ă��������@:":�a���N�x
LET ����=0
PRINT "+------------+------------+------------+"
PRINT "|�@�@�N�x�@�@|�@�@�����@�@|�@�������v�@|"
PRINT "+------------+------------+------------+"
PRINT USING "|############| |############|": �a���N�x,����
FOR i=1 TO 10
LET ����=INT(����*�N��/100)
LET ����=����+����
PRINT USING "|############|############|############|": �a���N�x+i,����,����
NEXT I
PRINT "+------------+------------+------------+"
END
352 �F�f�t�H���g�̖����������F2009/12/01(��) 01:00:03
ASP�ŋ���\������v���O����
For next��table�^�O���g�p����
�ǂȂ���������
For next��table�^�O���g�p����
�ǂȂ���������
353 �F�f�t�H���g�̖����������F2009/12/01(��) 02:49:06
Response.write "<table border=1>"
Response.write "<tr>"
Response.write "<td>"
For i=1 to 9
For j=1 to 9
A=j*i
Response.write A
Response.write "</td>"
Response.write "<td>"
Next
Response.write "</tr>"
Next
Response.write "</table>"
�e�[�u���ɏ�肭�����߂邱�Ƃ��ł��܂���B
�X�}�X�X�}�X�œ����ɔ[�߂Ă������@���������ł��B
Response.write "<tr>"
Response.write "<td>"
For i=1 to 9
For j=1 to 9
A=j*i
Response.write A
Response.write "</td>"
Response.write "<td>"
Next
Response.write "</tr>"
Next
Response.write "</table>"
�e�[�u���ɏ�肭�����߂邱�Ƃ��ł��܂���B
�X�}�X�X�}�X�œ����ɔ[�߂Ă������@���������ł��B
354 �F�f�t�H���g�̖����������F2009/12/01(��) 03:39:01
�ł����[�Basp�Ƃ������html���s���ł���orz
355 �F�f�t�H���g�̖����������F2009/12/01(��) 03:48:09
>>354
�ǂ��Ȃ����́H
�ǂ��Ȃ����́H
356 �F�f�t�H���g�̖����������F2009/12/01(��) 03:52:35
>>355
Response.write "<table border=1>"
For i=1 to 9
Response.write "<tr>"
For j=1 to 9
Response.write "<td>"
A=j*i
Response.write A
Response.write "</td>"
Next
Response.write "</tr>"
Next
Response.write "</table>"
��������ł������Ǝv���̂�����
�Ԉ���Ă���ȗ��ł�����w�E���Ăق�����
Response.write "<table border=1>"
For i=1 to 9
Response.write "<tr>"
For j=1 to 9
Response.write "<td>"
A=j*i
Response.write A
Response.write "</td>"
Next
Response.write "</tr>"
Next
Response.write "</table>"
��������ł������Ǝv���̂�����
�Ԉ���Ă���ȗ��ł�����w�E���Ăق�����
357 �F�f�t�H���g�̖����������F2009/12/01(��) 04:05:54
For�̊Ԃ�<td>���ЂƂ���B�����ł��ˁB
358 �F�f�t�H���g�̖����������F2009/12/01(��) 05:07:26
>>352 >>353
�劇��[]��<table></table>,������{}��<tr></tr>,
������()��<td></td>�Ƃ���͉��̂悤�Ɉ͂������݂����ł��B
���ƁA</td>��</tr>�͏ȗ��\�������ł��B
[
{(1)(2)(3)(4)(5)(6)(7)(8)(9)}
{(2)(4)(6)(8)(10)(12)(14)(16)(18)}
{(3)(6)(9)(12)(15)(18)(21)(24)(27)}
{(4)(8)(12)(16)(20)(24)(28)(32)(36)}
{(5)(10)(15)(20)(25)(30)(35)(40)(45)}
{(6)(12)(18)(24)(30)(36)(42)(48)(54)}
{(7)(14)(21)(28)(35)(42)(49)(56)(63)}
{(8)(16)(24)(32)(40)(48)(56)(64)(72)}
{(9)(18)(27)(36)(45)(54)(63)(72)(81)}
]
�劇��[]��<table></table>,������{}��<tr></tr>,
������()��<td></td>�Ƃ���͉��̂悤�Ɉ͂������݂����ł��B
���ƁA</td>��</tr>�͏ȗ��\�������ł��B
[
{(1)(2)(3)(4)(5)(6)(7)(8)(9)}
{(2)(4)(6)(8)(10)(12)(14)(16)(18)}
{(3)(6)(9)(12)(15)(18)(21)(24)(27)}
{(4)(8)(12)(16)(20)(24)(28)(32)(36)}
{(5)(10)(15)(20)(25)(30)(35)(40)(45)}
{(6)(12)(18)(24)(30)(36)(42)(48)(54)}
{(7)(14)(21)(28)(35)(42)(49)(56)(63)}
{(8)(16)(24)(32)(40)(48)(56)(64)(72)}
{(9)(18)(27)(36)(45)(54)(63)(72)(81)}
]
359 �F�f�t�H���g�̖����������F2009/12/01(��) 07:26:06
>>358
�����ł͕��^�O�̏ȗ��́A���܂芽�}����Ă��Ȃ��̂Œ��ӁB
�����ł͕��^�O�̏ȗ��́A���܂芽�}����Ă��Ȃ��̂Œ��ӁB
360 �F�f�t�H���g�̖����������F2009/12/01(��) 09:11:44
>>17 ���2
�g�p����F�@�\�iBASIC
FUNCTION f(n)
LET s=0
FOR i=1 TO n
IF MOD(i , 3 ) = 0 OR MOD(i , 5 ) = 0 THEN
LET s=s+i
END IF
NEXT I
LET f=s
END FUNCTION
PRINT f(500)
END
���s����
58418
�g�p����F�@�\�iBASIC
FUNCTION f(n)
LET s=0
FOR i=1 TO n
IF MOD(i , 3 ) = 0 OR MOD(i , 5 ) = 0 THEN
LET s=s+i
END IF
NEXT I
LET f=s
END FUNCTION
PRINT f(500)
END
���s����
58418
361 �F�f�t�H���g�̖����������F2009/12/01(��) 09:14:09
>>17 ���5
�g�p����F�@�\�iBASIC
DIM d(5)
FOR i=1 TO 5
INPUT PROMPT "������͂��ĉ������F":d(i)
NEXT I
PRINT "���̂܂ܕ\��"
FOR i=1 TO 5
PRINT d(i);
NEXT I
PRINT
PRINT "�t���ɕ\��"
FOR i=5 TO 1 STEP -1
PRINT d(i);
NEXT I
PRINT
END
���s����
������͂��ĉ������F10
������͂��ĉ������F11
������͂��ĉ������F12
������͂��ĉ������F13
������͂��ĉ������F14
���̂܂ܕ\��
10 11 12 13 14
�t���ɕ\��
14 13 12 11 10
�g�p����F�@�\�iBASIC
DIM d(5)
FOR i=1 TO 5
INPUT PROMPT "������͂��ĉ������F":d(i)
NEXT I
PRINT "���̂܂ܕ\��"
FOR i=1 TO 5
PRINT d(i);
NEXT I
PRINT "�t���ɕ\��"
FOR i=5 TO 1 STEP -1
PRINT d(i);
NEXT I
END
���s����
������͂��ĉ������F10
������͂��ĉ������F11
������͂��ĉ������F12
������͂��ĉ������F13
������͂��ĉ������F14
���̂܂ܕ\��
10 11 12 13 14
�t���ɕ\��
14 13 12 11 10
362 �F�f�t�H���g�̖����������F2009/12/01(��) 09:24:25
>>315
% Prolog �����Ȃ�̂Œ��j�����̂�
���݂̌��܂莚(_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�����̎茳�D�Ȃ��,_����̎茳�D�Ȃ��,_���܂莚�Ȃ��) :-
append(_�����̎�D�Ȃ��,_����̎�D�Ȃ��,_��D�Ƃ��đ��݂���D�Ȃ��),
���܂莚���f(_��D�Ƃ��đ��݂���D�Ȃ��,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_���܂莚�Ȃ��).
���܂莚���f([],_,[]) :- !.
���܂莚���f([_��D|R1],_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,[[_��D,Len,_���܂莚]|R2])
:-
�@�@�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,Len,_���܂莚),
�@�@���܂莚���f(R1,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,R2).
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,Len,_���܂莚) :-
�@�@findmax([Len,_���܂莚],
�@�@�@�@(�@ member(_�D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��),
�@�@�@�@�@�@\+(_�D=_��D),
�@�@�@�@�@�@�擪���狤�ʕ����̎��̕����܂�(1,_��D,_�D,_���܂莚,Len)),[Len,_���܂莚]),!.
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���([_���܂莚|_],_,[1,_���܂莚]).
�擪���狤�ʕ����̎��̕����܂�(N,[A|R1],[A|R2],[A|R3],Len) :-
�@�@N2 is N + 1,
�@�@�擪���狤�ʕ����̎��̕����܂�(R1,R2,R3,Len),!.
�擪���狤�ʕ����̎��̕����܂�(Len,[A|R1],_,[A],Len).
% Prolog �����Ȃ�̂Œ��j�����̂�
���݂̌��܂莚(_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�����̎茳�D�Ȃ��,_����̎茳�D�Ȃ��,_���܂莚�Ȃ��) :-
append(_�����̎�D�Ȃ��,_����̎�D�Ȃ��,_��D�Ƃ��đ��݂���D�Ȃ��),
���܂莚���f(_��D�Ƃ��đ��݂���D�Ȃ��,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_���܂莚�Ȃ��).
���܂莚���f([],_,[]) :- !.
���܂莚���f([_��D|R1],_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,[[_��D,Len,_���܂莚]|R2])
:-
�@�@�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,Len,_���܂莚),
�@�@���܂莚���f(R1,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,R2).
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,Len,_���܂莚) :-
�@�@findmax([Len,_���܂莚],
�@�@�@�@(�@ member(_�D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��),
�@�@�@�@�@�@\+(_�D=_��D),
�@�@�@�@�@�@�擪���狤�ʕ����̎��̕����܂�(1,_��D,_�D,_���܂莚,Len)),[Len,_���܂莚]),!.
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���([_���܂莚|_],_,[1,_���܂莚]).
�擪���狤�ʕ����̎��̕����܂�(N,[A|R1],[A|R2],[A|R3],Len) :-
�@�@N2 is N + 1,
�@�@�擪���狤�ʕ����̎��̕����܂�(R1,R2,R3,Len),!.
�擪���狤�ʕ����̎��̕����܂�(Len,[A|R1],_,[A],Len).
363 �F�f�t�H���g�̖����������F2009/12/01(��) 09:31:39
>>362 ��������
% Prolog �����Ȃ�̂Œ��j�����̂�
���݂̌��܂莚(_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�����̎茳�D�Ȃ��,_����̎茳�D�Ȃ��,_���܂莚�Ȃ��) :-
�@�@append(_�����̎�D�Ȃ��,_����̎�D�Ȃ��,_��D�Ƃ��đ��݂���D�Ȃ��),
�@�@���܂莚���f(_��D�Ƃ��đ��݂���D�Ȃ��,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_���܂莚�Ȃ��).
���܂莚���f([],_,[]) :- !.
���܂莚���f([_��D|R1],_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,[[_��D,_�ʒu,_���܂莚]|R2]) :-
�@�@�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�ʒu,_���܂莚),
�@�@���܂莚���f(R1,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,R2).
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�ʒu,_���܂莚) :-
�@�@findmax([_�ʒu,_���܂莚],
�@�@�@�@(�@ member(_�D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��),
�@�@�@�@�@�@\+(_�D=_��D),
�@�@�@�@�@�@�擪���狤�ʕ����̎��̕����܂�(1,_��D,_�D,_���܂莚,_�ʒu)),[_�ʒu,_���܂莚]),!.
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���([_���܂莚|_],_,[1,_���܂莚]).
�擪���狤�ʕ����̎��̕����܂�(N,[A|R1],[A|R2],[A|R3],Len) :-
�@�@N2 is N + 1,
�@�@�擪���狤�ʕ����̎��̕����܂�(R1,R2,R3,Len),!.
�擪���狤�ʕ����̎��̕����܂�(_�ʒu,[A|R1],_,[A],_�ʒu).
% Prolog �����Ȃ�̂Œ��j�����̂�
���݂̌��܂莚(_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�����̎茳�D�Ȃ��,_����̎茳�D�Ȃ��,_���܂莚�Ȃ��) :-
�@�@append(_�����̎�D�Ȃ��,_����̎�D�Ȃ��,_��D�Ƃ��đ��݂���D�Ȃ��),
�@�@���܂莚���f(_��D�Ƃ��đ��݂���D�Ȃ��,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_���܂莚�Ȃ��).
���܂莚���f([],_,[]) :- !.
���܂莚���f([_��D|R1],_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,[[_��D,_�ʒu,_���܂莚]|R2]) :-
�@�@�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�ʒu,_���܂莚),
�@�@���܂莚���f(R1,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,R2).
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���(_��D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��,_�ʒu,_���܂莚) :-
�@�@findmax([_�ʒu,_���܂莚],
�@�@�@�@(�@ member(_�D,_�܂��ǂ܂�Ă��Ȃ��D�Ȃ��),
�@�@�@�@�@�@\+(_�D=_��D),
�@�@�@�@�@�@�擪���狤�ʕ����̎��̕����܂�(1,_��D,_�D,_���܂莚,_�ʒu)),[_�ʒu,_���܂莚]),!.
�擪���狤�ʕ����̎��̕����܂łōŒ��̂���([_���܂莚|_],_,[1,_���܂莚]).
�擪���狤�ʕ����̎��̕����܂�(N,[A|R1],[A|R2],[A|R3],Len) :-
�@�@N2 is N + 1,
�@�@�擪���狤�ʕ����̎��̕����܂�(R1,R2,R3,Len),!.
�擪���狤�ʕ����̎��̕����܂�(_�ʒu,[A|R1],_,[A],_�ʒu).
364 �F�f�t�H���g�̖����������F2009/12/01(��) 09:34:16
>>45
�g�p����F�@�\�iBASIC
FUNCTION fact(n)
IF n=0 THEN
LET fact=0
ELSE
LET a=1
FOR i=1 TO n
LET a=a*i
NEXT I
LET fact=a
END IF
END FUNCTION
PRINT fact(15)
END
���s����
1307674368000
�g�p����F�@�\�iBASIC
FUNCTION fact(n)
IF n=0 THEN
LET fact=0
ELSE
LET a=1
FOR i=1 TO n
LET a=a*i
NEXT I
LET fact=a
END IF
END FUNCTION
PRINT fact(15)
END
���s����
1307674368000
365 �F�f�t�H���g�̖����������F2009/12/01(��) 09:46:21
���݂̌��܂莚�̔��f�͎��̓ǂݎD���ǂ܂��܂ł́u�ԁv�����A
��X���ׂĔ��f�������Ƃ͍l���ɂ����B
�ꖇ�ǂݏI��������_�ňꖇ�O�̒i�K�ɔ��C���������ĂƂ��������A
���R���낤���珑���������K�v�Ȃ悤���B
�ł����� http://nojiriko.asia/prolog/py2_47.html �ɏ����܂��B������Ƒ҂��āB
��X���ׂĔ��f�������Ƃ͍l���ɂ����B
�ꖇ�ǂݏI��������_�ňꖇ�O�̒i�K�ɔ��C���������ĂƂ��������A
���R���낤���珑���������K�v�Ȃ悤���B
�ł����� http://nojiriko.asia/prolog/py2_47.html �ɏ����܂��B������Ƒ҂��āB
366 �F�f�t�H���g�̖����������F2009/12/01(��) 14:52:51
>>207
�g�p����F�@�\�iBASIC
FUNCTION f$(a$,b$,n)
LET a$(n+1:n)=b$
LET f$=a$
END FUNCTION
PRINT f$("12345","AB",3)
END
���s����
123AB45
�g�p����F�@�\�iBASIC
FUNCTION f$(a$,b$,n)
LET a$(n+1:n)=b$
LET f$=a$
END FUNCTION
PRINT f$("12345","AB",3)
END
���s����
123AB45
367 �F�f�t�H���g�̖����������F2009/12/01(��) 15:20:33
>>365
�A�[�J�C�u�̕������Ă���������ǁA���̎�̂�́A�e��(�����ł͓ǂݎ�Ƃ������ƂɂȂ邯��)�A�T�[�o�[�ɂȂ��Ɩʔ����Ȃ��B
���̃v���O�������ƁA��������A�ꎚ������Ă���B���邢�́A���Z�҂�
�T�[�o�[�̃��[�h�Ŏ��̕�����҂��Ă���B
�����������ɍ��܂��H
�A�[�J�C�u�̕������Ă���������ǁA���̎�̂�́A�e��(�����ł͓ǂݎ�Ƃ������ƂɂȂ邯��)�A�T�[�o�[�ɂȂ��Ɩʔ����Ȃ��B
���̃v���O�������ƁA��������A�ꎚ������Ă���B���邢�́A���Z�҂�
�T�[�o�[�̃��[�h�Ŏ��̕�����҂��Ă���B
�����������ɍ��܂��H
368 �F�f�t�H���g�̖����������F2009/12/01(��) 16:32:50
>>367
�V�~�����[�V�����̈���z����ȁB�قƂ�ǃQ�[���B
�ʔ����������Ă݂邯�ǁB
���̑O�ɂ����������A�l�Ԃ̎v�l�ɋ߂Â��Ȃ�����ˁB
�V�~�����[�V�����̈���z����ȁB�قƂ�ǃQ�[���B
�ʔ����������Ă݂邯�ǁB
���̑O�ɂ����������A�l�Ԃ̎v�l�ɋ߂Â��Ȃ�����ˁB
370 �F�f�t�H���g�̖����������F2009/12/01(��) 17:25:54
<A HREF="http://nojiriko.asia/prolog/index.html">���̃f�B���N�g���̍���</A>
http://pc12.2ch.net/test/read.cgi/tech/1258158172/588
# [1] ���ƒP���FC�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10211.txt
#
# �ۑ�(1)
# 4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�����e���Œ�`���o�͂���v���O�����������B
#
# �ۑ�(2)
# �C�ӂ̐����ƌ�������͂��A�����ɊY�����鐮�����o�͂�������e���Œ�`�����ʂ��o�͂���v���O�����������B
# �Ⴆ�ΐ�����123456789�Ɠ��͂��A������5�Ƃ����ꍇ��5����5���o�͂�����B
#
# �ۑ�(3)
# �ۑ�(1)�̐�����z��`���Œ�`���A���l�ɍő�l�A�ŏ��l�A���ϒl���o�͂���v���O�����������B
# �i�]�͂�����Ε��U���l���Ă݂�j
http://pc12.2ch.net/test/read.cgi/tech/1258158172/588
# [1] ���ƒP���FC�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10211.txt
#
# �ۑ�(1)
# 4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�����e���Œ�`���o�͂���v���O�����������B
#
# �ۑ�(2)
# �C�ӂ̐����ƌ�������͂��A�����ɊY�����鐮�����o�͂�������e���Œ�`�����ʂ��o�͂���v���O�����������B
# �Ⴆ�ΐ�����123456789�Ɠ��͂��A������5�Ƃ����ꍇ��5����5���o�͂�����B
#
# �ۑ�(3)
# �ۑ�(1)�̐�����z��`���Œ�`���A���l�ɍő�l�A�ŏ��l�A���ϒl���o�͂���v���O�����������B
# �i�]�͂�����Ε��U���l���Ă݂�j
371 �F�f�t�H���g�̖����������F2009/12/01(��) 17:26:51
http://pc12.2ch.net/test/read.cgi/tech/1258158172/589
# [1]C�������
# [2] 3�̐���x,y,z����͂��A�����������Ƃ��āA�傫�����ɓ���ւ��ĕԂ���������B�������|�C���^�ϐ���p���邱�ƁB
# main���͐����̓��͂ƌ��ʂ̕\���݂̂ɂ���B
#
# [1]C�������
# [2] 3�̐���x,y,z����͂��A�����������Ƃ��āA�傫�����ɓ���ւ��ĕԂ���������B�������|�C���^�ϐ���p���邱�ƁB
# main���͐����̓��͂ƌ��ʂ̕\���݂̂ɂ���B
#
372 �F�f�t�H���g�̖����������F2009/12/01(��) 17:28:47
>>370 ��s�ڂ͊W����܂���B�������Ă��������B
373 �F�f�t�H���g�̖����������F2009/12/01(��) 17:41:44
>>370 �ۑ�(1)
% Prolog
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�' :-
�@�@'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_�ő�l,_�ŏ��l,_���ϒl),
�@�@write_formatted('�ő�l=%t,�ŏ��l=%t,���ϒl=%t\n',[_�ő�l,_�ŏ��l,_���ϒl]).
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@findall(N,(for(1,M,4),get_integer(N)),L),
�@�@max(L,_�ő�l),
�@�@min(L,_�ŏ��l),
�@�@avg(L,_���ϒl).
% Prolog
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�' :-
�@�@'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_�ő�l,_�ŏ��l,_���ϒl),
�@�@write_formatted('�ő�l=%t,�ŏ��l=%t,���ϒl=%t\n',[_�ő�l,_�ŏ��l,_���ϒl]).
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@findall(N,(for(1,M,4),get_integer(N)),L),
�@�@max(L,_�ő�l),
�@�@min(L,_�ŏ��l),
�@�@avg(L,_���ϒl).
374 �F�f�t�H���g�̖����������F2009/12/01(��) 17:51:37
>>370 �ۑ�(1)
% Prolog ����Ƃ��A���͂͊��̈����Ƃ��Ď��ׂ��Ȃ̂��낤���B
% Prolog�̏ꍇ�A�C���^�v���^������A
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_����1,_����2,_����3,_����4,_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@integer(_����1),integer(_����2),integer(_����3),integer(_����4),
�@�@max([_����1,_����2,_����3,_����4],_�ő�l),
�@�@min([_����1,_����2,_����3,_����4],_�ŏ��l),
�@�@avg([_����1,_����2,_����3,_����4],_���ϒl).
% �Ƃ�����������̂�������Ȃ��Bwrite_formatted/2�ŕW���o�͂ւ̈�Prolog�{���̃X�^�C���ł͂Ȃ��B
% Prolog ����Ƃ��A���͂͊��̈����Ƃ��Ď��ׂ��Ȃ̂��낤���B
% Prolog�̏ꍇ�A�C���^�v���^������A
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'(_����1,_����2,_����3,_����4,_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@integer(_����1),integer(_����2),integer(_����3),integer(_����4),
�@�@max([_����1,_����2,_����3,_����4],_�ő�l),
�@�@min([_����1,_����2,_����3,_����4],_�ŏ��l),
�@�@avg([_����1,_����2,_����3,_����4],_���ϒl).
% �Ƃ�����������̂�������Ȃ��Bwrite_formatted/2�ŕW���o�͂ւ̈�Prolog�{���̃X�^�C���ł͂Ȃ��B
375 �F�f�t�H���g�̖����������F2009/12/01(��) 18:06:02
>>370 �ۑ�(2)
% Prolog
�C�ӂ̐����ƌ�������͂��A�����ɊY�����鐮�����o�͂�������e���Œ�`�����ʂ��o��(_����������,_����,_����) :-
�@�@atom(_����������),
�@�@sub_atom(_����������,0,Len,0,_����������),
�@�@min([Len,_����],Min),
�@�@sub_atom(_����������,Len-Min,Min,_,_��������),
�@�@atom_to_term(_��������,_����,_),
�@�@integer(_����).
�@�@
% Prolog
�C�ӂ̐����ƌ�������͂��A�����ɊY�����鐮�����o�͂�������e���Œ�`�����ʂ��o��(_����������,_����,_����) :-
�@�@atom(_����������),
�@�@sub_atom(_����������,0,Len,0,_����������),
�@�@min([Len,_����],Min),
�@�@sub_atom(_����������,Len-Min,Min,_,_��������),
�@�@atom_to_term(_��������,_����,_),
�@�@integer(_����).
�@�@
376 �F�f�t�H���g�̖����������F2009/12/01(��) 18:07:55
>>370 �ۑ�(3)
% Prolog
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'([_����1,_����2,_����3,_����4],_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@integer(_����1),integer(_����2),integer(_����3),integer(_����4),
�@�@max([_����1,_����2,_����3,_����4],_�ő�l),
�@�@min([_����1,_����2,_����3,_����4],_�ŏ��l),
�@�@avg([_����1,_����2,_����3,_����4],_���ϒl).
% Prolog
'4�̐�������͂��A���̍ő�l�A�ŏ��l�A���ς����߂�'([_����1,_����2,_����3,_����4],_�ő�l,_�ŏ��l,_���ϒl) :-
�@�@integer(_����1),integer(_����2),integer(_����3),integer(_����4),
�@�@max([_����1,_����2,_����3,_����4],_�ő�l),
�@�@min([_����1,_����2,_����3,_����4],_�ŏ��l),
�@�@avg([_����1,_����2,_����3,_����4],_���ϒl).
377 �F�f�t�H���g�̖����������F2009/12/01(��) 18:08:56
>>370�@�ۑ�(1)
�g�p����F�@�\�iBASIC
DEF max4(a,b,c,d)=MAX(MAX(a,b),MAX(c,d))
DEF min4(a,b,c,d)=MIN(MIN(a,b),MIN(c,d))
DEF avg4(a,b,c,d)=(a+b+c+d)/4
LET a=31
LET b=41
LET c=59
LET d=26
PRINT max4(a,b,c,d);min4(a,b,c,d);avg4(a,b,c,d)
END
���s����
59 26 39.25
�g�p����F�@�\�iBASIC
DEF max4(a,b,c,d)=MAX(MAX(a,b),MAX(c,d))
DEF min4(a,b,c,d)=MIN(MIN(a,b),MIN(c,d))
DEF avg4(a,b,c,d)=(a+b+c+d)/4
LET a=31
LET b=41
LET c=59
LET d=26
PRINT max4(a,b,c,d);min4(a,b,c,d);avg4(a,b,c,d)
END
���s����
59 26 39.25
378 �F�f�t�H���g�̖����������F2009/12/01(��) 18:22:11
>>370�@�ۑ�(2)
�g�p����F�@�\�iBASIC
DEF f(n,d)=MOD(INT(n/10^(d-1)),10)
PRINT f(123456789,4)
END
���s����
6
�g�p����F�@�\�iBASIC
DEF f(n,d)=MOD(INT(n/10^(d-1)),10)
PRINT f(123456789,4)
END
���s����
6
379 �F�f�t�H���g�̖����������F2009/12/01(��) 18:24:48
>>371
% Prolog ���������v���O�����͂����ɊȒP�Ƀ\�[�X�����������ł��邩�Ɋ|�����Ă���B
% �����������ȒP�Ȃ�A����������`�͗L�͂��Ǝv���B
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,X,Y,Z) :-
�@�@X >= Y,Y >= Z.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,X,Z,Y) :-
�@�@X >= Z,Z >= Y.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Y,X,Z) :-
�@�@Y >= X,X >= Z.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Y,Z,X) :-
�@�@Y >= Z,Z >= X.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Z,X,Y) :-
�@�@Z >= X,X >= Y.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Z,Y,X) :-
�@�@Z >= Y,Y >= X.
% Prolog ���������v���O�����͂����ɊȒP�Ƀ\�[�X�����������ł��邩�Ɋ|�����Ă���B
% �����������ȒP�Ȃ�A����������`�͗L�͂��Ǝv���B
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,X,Y,Z) :-
�@�@X >= Y,Y >= Z.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,X,Z,Y) :-
�@�@X >= Z,Z >= Y.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Y,X,Z) :-
�@�@Y >= X,X >= Z.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Y,Z,X) :-
�@�@Y >= Z,Z >= X.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Z,X,Y) :-
�@�@Z >= X,X >= Y.
'3�̐���x,y,z�������Ƃ��āA�傫�����ɓ���ւ��ĕԂ�'(X,Y,Z,Z,Y,X) :-
�@�@Z >= Y,Y >= X.
380 �F�f�t�H���g�̖����������F2009/12/01(��) 18:44:24
381 �F�f�t�H���g�̖����������F2009/12/01(��) 19:01:46
382 �F�f�t�H���g�̖����������F2009/12/01(��) 19:13:16
http://pc12.2ch.net/test/read.cgi/tech/1258158172/590
# [1]C������K
# [2]�@���ʎZ�@SEND+MORE=MONEY�������v���O�����i�e���͐�����\���j
# 2�i������16�i���̏ꍇ�ɂ��āA�������鎞�͈���i�����������
# �\���B�A��������̏ꍇ���ŏ�ʌ��͂O�ł͂Ȃ����̂Ƃ���B
#
# [1]C������K
# [2]�@���ʎZ�@SEND+MORE=MONEY�������v���O�����i�e���͐�����\���j
# 2�i������16�i���̏ꍇ�ɂ��āA�������鎞�͈���i�����������
# �\���B�A��������̏ꍇ���ŏ�ʌ��͂O�ł͂Ȃ����̂Ƃ���B
#
383 �F�f�t�H���g�̖����������F2009/12/01(��) 19:16:16
>>382 �������o�Ă��܂����Bhttp://pc12.2ch.net/test/read.cgi/tech/1258158172/592http://pc12.2ch.net/test/read.cgi/tech/1258158172/590
# [1]C������K
# [2]�@���ʎZ�@SEND+MORE=MONEY�������v���O�����i�e���͐�����\���j
# 2�i������8�i���̏ꍇ�ɂ��āA�������鎞�͈���i�����������
# �\���B�A��������̏ꍇ���ŏ�ʌ��͂O�ł͂Ȃ����̂Ƃ���B
#
# [1]C������K
# [2]�@���ʎZ�@SEND+MORE=MONEY�������v���O�����i�e���͐�����\���j
# 2�i������8�i���̏ꍇ�ɂ��āA�������鎞�͈���i�����������
# �\���B�A��������̏ꍇ���ŏ�ʌ��͂O�ł͂Ȃ����̂Ƃ���B
#
384 �F�f�t�H���g�̖����������F2009/12/01(��) 19:29:19
>>370�@�ۑ�(2)
�g�p����F�@Arc
(def f(n d) (mod (trunc (/ n (expt 10 (- d 1)))) 10))
arc> (f 123456789 2)
8
�g�p����F�@Arc
(def f(n d) (mod (trunc (/ n (expt 10 (- d 1)))) 10))
arc> (f 123456789 2)
8
385 �F�f�t�H���g�̖����������F2009/12/01(��) 23:10:33
http://pc12.2ch.net/test/read.cgi/tech/1258158172/608
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10219.txt
# [�ۑ�1-1]�@���`�T��
# �@�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A��������
# ���ʂ����ׂĕ\������v���O�������쐬���Ȃ���.�������A�z�� a ��1����30�܂ł̗�����100������
# ����Ƃ���.�܂��A���͂̑O�ɔz�� a �̓��e��10������ĕ\�����Ȃ���.(�^���������g�p���邱�Ɓj
#
# [���s����]
# �z�� a �̓��e�͂��̒ʂ�ł�.
# 26 12 24 24 28 6 11 24 4 17 ���^�������Ȃ̂ō��̗�ƂȂ��B
# 15 19 11 16 29 28 20 22 5 19
# 1 8 5 25 5 13 4 4 30 7
# 16 26 19 9 20 16 15 30 9 24
#�@�@�@�@�@�@�@<����>
# 8 30 28 26 8 17 12 23 16 21
# 16 2 14 28 28 22 9 23 20 11
# 21 5 14 27 25 10 7 27 11 21
# 29 18 20 26 14 28 12 25 21 28
# 1�`30�܂ł̐�������͂��ĉ�����.
# 17
# a[9]�@�� 17 �Ɠ����l�ł�.
# a[65] �� 17 �Ɠ����l�ł�.
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10219.txt
# [�ۑ�1-1]�@���`�T��
# �@�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A��������
# ���ʂ����ׂĕ\������v���O�������쐬���Ȃ���.�������A�z�� a ��1����30�܂ł̗�����100������
# ����Ƃ���.�܂��A���͂̑O�ɔz�� a �̓��e��10������ĕ\�����Ȃ���.(�^���������g�p���邱�Ɓj
#
# [���s����]
# �z�� a �̓��e�͂��̒ʂ�ł�.
# 26 12 24 24 28 6 11 24 4 17 ���^�������Ȃ̂ō��̗�ƂȂ��B
# 15 19 11 16 29 28 20 22 5 19
# 1 8 5 25 5 13 4 4 30 7
# 16 26 19 9 20 16 15 30 9 24
#�@�@�@�@�@�@�@<����>
# 8 30 28 26 8 17 12 23 16 21
# 16 2 14 28 28 22 9 23 20 11
# 21 5 14 27 25 10 7 27 11 21
# 29 18 20 26 14 28 12 25 21 28
# 1�`30�܂ł̐�������͂��ĉ�����.
# 17
# a[9]�@�� 17 �Ɠ����l�ł�.
# a[65] �� 17 �Ɠ����l�ł�.
386 �F�f�t�H���g�̖����������F2009/12/01(��) 23:14:37
http://pc12.2ch.net/test/read.cgi/tech/1258158172/610
# ���
# A ����� B ���Q�[���őΐ킵���D�ΐ�� N ��ɂ킽���čs�����D�e��̑ΐ�ɂ����āC
# ��荂���_�����l�������l�����̉�̏��҂ƂȂ�D
# ���Ȃ킿�C�� i ��ڂ̑ΐ��
# A ����̓_���� B ����̓_�����傫����Α� i ��ڂ� A ����̏����C
# B ����̓_���� A ����̓_�����傫����� B ����̏����C
# ���_�̏ꍇ�͂ǂ���̏����ɂ��Ȃ�Ȃ��D
# N ��̑ΐ�ɂ����� A ����� B ����̓_�����^����ꂽ�Ƃ��C
# A ����� B �����ꂼ�ꉽ���������o�͂���v���O�������쐬����D
# ���
# A ����� B ���Q�[���őΐ킵���D�ΐ�� N ��ɂ킽���čs�����D�e��̑ΐ�ɂ����āC
# ��荂���_�����l�������l�����̉�̏��҂ƂȂ�D
# ���Ȃ킿�C�� i ��ڂ̑ΐ��
# A ����̓_���� B ����̓_�����傫����Α� i ��ڂ� A ����̏����C
# B ����̓_���� A ����̓_�����傫����� B ����̏����C
# ���_�̏ꍇ�͂ǂ���̏����ɂ��Ȃ�Ȃ��D
# N ��̑ΐ�ɂ����� A ����� B ����̓_�����^����ꂽ�Ƃ��C
# A ����� B �����ꂼ�ꉽ���������o�͂���v���O�������쐬����D
387 �F�f�t�H���g�̖����������F2009/12/01(��) 23:14:59
>>370�@�ۑ�(2)
�g�p����F�@Io
f:=method(n,d,n asString reverse at(d-1) asCharacter asNumber)
Io> f(12345,2)
==> 4
�g�p����F�@Io
f:=method(n,d,n asString reverse at(d-1) asCharacter asNumber)
Io> f(12345,2)
==> 4
388 �F�f�t�H���g�̖����������F2009/12/01(��) 23:27:30
http://pc12.2ch.net/test/read.cgi/tech/1258158172/604
# [1] ���ƒP���F
# ���_���r������۸��тł�
# �t�@�C�������s2�����Âǂݍ��݁A��̕����傫�����A��̕����傫�����A
# �J�E���g���Ă����܂��B�t�@�C����ǂݏI�������J�E���g�����������o�͂��܂��B
# [1] ���ƒP���F
# ���_���r������۸��тł�
# �t�@�C�������s2�����Âǂݍ��݁A��̕����傫�����A��̕����傫�����A
# �J�E���g���Ă����܂��B�t�@�C����ǂݏI�������J�E���g�����������o�͂��܂��B
389 �F�f�t�H���g�̖����������F2009/12/01(��) 23:40:01
http://pc12.2ch.net/test/read.cgi/tech/1258158172/611
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10222.txt
# �Q���̐�����͂���i�����A�Q���ȊO�̐�������͂�����A�ē��͂ƂȂ�j���쐬���A
# main���ł͓���ꂽ�Q���̒l�̂P�̈ʂƂP�O�̈ʂ̒l���|���Z�����l��\������v���O����
# ������m�F���邽�߂̓K��main�����쐬���邱�ƁB
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10222.txt
# �Q���̐�����͂���i�����A�Q���ȊO�̐�������͂�����A�ē��͂ƂȂ�j���쐬���A
# main���ł͓���ꂽ�Q���̒l�̂P�̈ʂƂP�O�̈ʂ̒l���|���Z�����l��\������v���O����
# ������m�F���邽�߂̓K��main�����쐬���邱�ƁB
390 �F�f�t�H���g�̖����������F2009/12/01(��) 23:58:53
>>389
% Prolog
program :-
�@�@�Q���̐�����͂���(N),
�@�@M is ((N // 10) * ( N mod 10)),
�@�@write_formatted('�Q���̒l %t �̂P�̈ʂƂP�O�̈ʂ̒l���|���Z�����l�� %t �ł�
\n',[N,M]).
�Q���̐�����͂���(N) :-
�@�@write('�Q���̐�����͂��Ă������� : '),
�@�@get_integer(N),
�@�@N >= 0,N =< 99.
�Q���̐�����͂���(N) :-
�@�@write_formatted('�Q���̐����܂���ł���\n�ē��� : '),
�@�@�Q���̐�����͂���(N).
% Prolog
program :-
�@�@�Q���̐�����͂���(N),
�@�@M is ((N // 10) * ( N mod 10)),
�@�@write_formatted('�Q���̒l %t �̂P�̈ʂƂP�O�̈ʂ̒l���|���Z�����l�� %t �ł�
\n',[N,M]).
�Q���̐�����͂���(N) :-
�@�@write('�Q���̐�����͂��Ă������� : '),
�@�@get_integer(N),
�@�@N >= 0,N =< 99.
�Q���̐�����͂���(N) :-
�@�@write_formatted('�Q���̐����܂���ł���\n�ē��� : '),
�@�@�Q���̐�����͂���(N).
391 �F�f�t�H���g�̖����������F2009/12/02(��) 00:05:54
>>370�@�ۑ�(2)
�g�p����F�@Xtal
ix:001>f:fun(n,d){a:n.to_s.split("").to_a; return a[a.size-d].to_i;}
ix:002>f(123456789,7).p;
3
�g�p����F�@Xtal
ix:001>f:fun(n,d){a:n.to_s.split("").to_a; return a[a.size-d].to_i;}
ix:002>f(123456789,7).p;
3
392 �F�f�t�H���g�̖����������F2009/12/02(��) 00:18:02
393 �F�f�t�H���g�̖����������F2009/12/02(��) 04:15:25
>>388 >>386���قƂ�Ǔ���B ��o���Ńf�[�^�t�H�[�}�b�g�� A : %d,B : %d �炵���B
% Prolog
program :-
�@�@user_parameters([_�t�@�C����]),
�@�@get_split_lines(_�t�@�C����,[':',' ',','],L),
�@�@�̂ǂ��炪�傫����(L,0,0,_�J�E���^A,_�J�E���^B),
�@�@write_formatted('A : %t,B : %t\n',[_�J�E���^A,_�J�E���^B]).
�̂ǂ��炪�傫����([],_�J�E���^A,_�J�E���^B,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@_��̕� > _��̕�,
�@�@A2 is A + 1,
�@�@�̂ǂ��炪�傫����(R1,A2,B,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@_��̕� < _��̕�,
�@�@�̂ǂ��炪�傫����(R1,A,B2,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@�̂ǂ��炪�傫����(R1,A,B,_�J�E���^A,_�J�E���^B).
% Prolog
program :-
�@�@user_parameters([_�t�@�C����]),
�@�@get_split_lines(_�t�@�C����,[':',' ',','],L),
�@�@�̂ǂ��炪�傫����(L,0,0,_�J�E���^A,_�J�E���^B),
�@�@write_formatted('A : %t,B : %t\n',[_�J�E���^A,_�J�E���^B]).
�̂ǂ��炪�傫����([],_�J�E���^A,_�J�E���^B,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@_��̕� > _��̕�,
�@�@A2 is A + 1,
�@�@�̂ǂ��炪�傫����(R1,A2,B,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@_��̕� < _��̕�,
�@�@�̂ǂ��炪�傫����(R1,A,B2,_�J�E���^A,_�J�E���^B).
�̂ǂ��炪�傫����([[_,_��̕�,_,_��̕�]|R1],A,B,_�J�E���^A,_�J�E���^B) :-
�@�@�̂ǂ��炪�傫����(R1,A,B,_�J�E���^A,_�J�E���^B).
394 �F�f�t�H���g�̖����������F2009/12/02(��) 05:40:49
>>114
�g�p����F�@J
f=:dyad def '(([}.[:i.[:>:])//:~x i.y){x'
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'CQ'
CDERSTUVWFNOPQ
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'AZ'
ABCDERSTUVWFNOPQXYZ
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'ZQ'
QXYZ
�g�p����F�@J
f=:dyad def '(([}.[:i.[:>:])//:~x i.y){x'
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'CQ'
CDERSTUVWFNOPQ
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'AZ'
ABCDERSTUVWFNOPQXYZ
'GHIJKLMABCDERSTUVWFNOPQXYZ' f 'ZQ'
QXYZ
395 �F�f�t�H���g�̖����������F2009/12/02(��) 05:41:30
>>389
;; Common Lisp
(defun mult()
(let ((num 0) n1 n10)
(do ()
((and (> num 9) (< num 100)))
(format t "2���̐�����͂��Ă�������~%> ")
(setf num (read)))
(setf n1 (mod num 10)
n10 (/ (- num n1) 10))
(format t "1�̈ʂ�10�̈ʂ̐� = ~A~%" (* n1 n10))))
;; Common Lisp
(defun mult()
(let ((num 0) n1 n10)
(do ()
((and (> num 9) (< num 100)))
(format t "2���̐�����͂��Ă�������~%> ")
(setf num (read)))
(setf n1 (mod num 10)
n10 (/ (- num n1) 10))
(format t "1�̈ʂ�10�̈ʂ̐� = ~A~%" (* n1 n10))))
396 �F�f�t�H���g�̖����������F2009/12/02(��) 06:01:11
>>385
% Prolog
'�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A�����������ʂ����ׂĕ\������' :-
�@�@'a ��1����30�܂ł̗�����100�����Ă���'(A),
�@�@'a �̓��e��10������ĕ\��'(A),
�@�@repeat,
�@�@write('�T�����鐮������͂��Ă�������(1~30) : '),
�@�@get_integer(N),
�@�@N >=1, N =< 30,!,
�@�@append(L1,[N|L2],A),
�@�@length(L1,_�ʒu),
�@�@write_formatted(' %t: %t\n',[N,_�ʒu+1]),
�@�@fail.
'�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A�����������ʂ����ׂĕ\������'.
'a ��1����30�܂ł̗�����100�����Ă���'(A) :-
�@�@findall(M,(for(1,N,100),M is ((random mod 30) + 1),A).
'a �̓��e��10������ĕ\��'(A) :-
�@�@'N�g'(10,A,L),
�@�@append(_,[L1|_],L),
�@�@write_formatted('%2d %2d %2d %2d %2d %2d %2d %2d %2d %2d\n',L1),
�@�@fail.
'a �̓��e��10������ĕ\��'(_).
% Prolog
'�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A�����������ʂ����ׂĕ\������' :-
�@�@'a ��1����30�܂ł̗�����100�����Ă���'(A),
�@�@'a �̓��e��10������ĕ\��'(A),
�@�@repeat,
�@�@write('�T�����鐮������͂��Ă�������(1~30) : '),
�@�@get_integer(N),
�@�@N >=1, N =< 30,!,
�@�@append(L1,[N|L2],A),
�@�@length(L1,_�ʒu),
�@�@write_formatted(' %t: %t\n',[N,_�ʒu+1]),
�@�@fail.
'�L�[�{�[�h����1����30�܂ł̐�������͂��A�z�� a �ɑ��ē��͒l�̐��`�T�����s���A�����������ʂ����ׂĕ\������'.
'a ��1����30�܂ł̗�����100�����Ă���'(A) :-
�@�@findall(M,(for(1,N,100),M is ((random mod 30) + 1),A).
'a �̓��e��10������ĕ\��'(A) :-
�@�@'N�g'(10,A,L),
�@�@append(_,[L1|_],L),
�@�@write_formatted('%2d %2d %2d %2d %2d %2d %2d %2d %2d %2d\n',L1),
�@�@fail.
'a �̓��e��10������ĕ\��'(_).
397 �F�f�t�H���g�̖����������F2009/12/02(��) 08:59:48
>>389
�g�p����F�@Xtal
input:fun(){n:0;
while(true){
print("2���̐�������́F");
n=stdin.get_s(2).to_i;
if(10<=n && n<=100)break;
}
return n;
}
n:input();
println(%f"1�̈ʂ�10�̈ʂ̐ς� %d * %d = %d"(n%10,n/10,n/10*(n%10)));
���s����
2���̐�������́F6
2���̐�������́F84
1�̈ʂ�10�̈ʂ̐ς� 4 * 8 = 32
�g�p����F�@Xtal
input:fun(){n:0;
while(true){
print("2���̐�������́F");
n=stdin.get_s(2).to_i;
if(10<=n && n<=100)break;
}
return n;
}
n:input();
println(%f"1�̈ʂ�10�̈ʂ̐ς� %d * %d = %d"(n%10,n/10,n/10*(n%10)));
���s����
2���̐�������́F6
2���̐�������́F84
1�̈ʂ�10�̈ʂ̐ς� 4 * 8 = 32
398 �F�f�t�H���g�̖����������F2009/12/02(��) 12:33:29
http://pc12.2ch.net/test/read.cgi/tech/1258320456/52
# �y�@�ۑ�@�z�a�̂ɂ��čl�@������B
# �� ...�@���ʐl��҂ق̉Y�̗[��͂₭������ق̐g��������� (���)
# ����͂��Ȃ蕡�G�Ȃ����ł��B
# �l���܂Ƃ́u�҂v�ł���A�u���v�ł��B�܂�������ł��B���̎p�Ɏ������ł��B
# ������͉Y�̔w�i�ł�����܂��B�Y�͗[��ł�����S�͕����u�҂��āv�����܂��B
# ���͂���܂���A�҂��Ă����ʐl�Ȃ̂ł��B�������̐l�Ȃ̂�����Ƃ����D�Ȃ̂�
# �����ł��B�Y�́u�Y�v�ł���Ɠ����ɐS�́u���v�ł���A���̐l(��)�̋C�������u��v�ȂӁA
# ����ł�����܂��B
# �u�Ă���v(�₢�Ă���̂��낤��)�Ƃ́A���ɏł���Đg���Ă��Ă���̂ł���A
# �₭������قƂ͑���(����)���z�ɂ��Ԃ��A�����A�Ă���A���ł��Ԃ���A�����
# �ς��A�Ăъ�������Ƃ����悤�ȁA�����@�̈��̒n���G�ł���A�g��������Ƃ���
# ���t�ɂ́u���v�������ł��܂܂�Ă��܂��B�����̉��͗[��̉Y�Ɏ��ۂɕY����
# ����̂�������܂���B
# �ȏ�̂悤�ȁA���̉̂Ɋ܂܂���Ƃ��ꂩ�炭��A�z���v���O�����ŕ\�����Ȃ����B
# �y�@�ۑ�@�z�a�̂ɂ��čl�@������B
# �� ...�@���ʐl��҂ق̉Y�̗[��͂₭������ق̐g��������� (���)
# ����͂��Ȃ蕡�G�Ȃ����ł��B
# �l���܂Ƃ́u�҂v�ł���A�u���v�ł��B�܂�������ł��B���̎p�Ɏ������ł��B
# ������͉Y�̔w�i�ł�����܂��B�Y�͗[��ł�����S�͕����u�҂��āv�����܂��B
# ���͂���܂���A�҂��Ă����ʐl�Ȃ̂ł��B�������̐l�Ȃ̂�����Ƃ����D�Ȃ̂�
# �����ł��B�Y�́u�Y�v�ł���Ɠ����ɐS�́u���v�ł���A���̐l(��)�̋C�������u��v�ȂӁA
# ����ł�����܂��B
# �u�Ă���v(�₢�Ă���̂��낤��)�Ƃ́A���ɏł���Đg���Ă��Ă���̂ł���A
# �₭������قƂ͑���(����)���z�ɂ��Ԃ��A�����A�Ă���A���ł��Ԃ���A�����
# �ς��A�Ăъ�������Ƃ����悤�ȁA�����@�̈��̒n���G�ł���A�g��������Ƃ���
# ���t�ɂ́u���v�������ł��܂܂�Ă��܂��B�����̉��͗[��̉Y�Ɏ��ۂɕY����
# ����̂�������܂���B
# �ȏ�̂悤�ȁA���̉̂Ɋ܂܂���Ƃ��ꂩ�炭��A�z���v���O�����ŕ\�����Ȃ����B
399 �F�f�t�H���g�̖����������F2009/12/02(��) 12:35:14
>>389
�g�p����F�@Io
input:=method(
f:=File standardInput
while(true,
write("number: ")
n:=f readLine asNumber
if(10<=n and n<=100,break(n))
))
x:=input
writeln(x%10," * ",(x/10)floor," = ",x%10 * (x/10)floor)
���s����
number: 34
4 * 3 = 12
�g�p����F�@Io
input:=method(
f:=File standardInput
while(true,
write("number: ")
n:=f readLine asNumber
if(10<=n and n<=100,break(n))
))
x:=input
writeln(x%10," * ",(x/10)floor," = ",x%10 * (x/10)floor)
���s����
number: 34
4 * 3 = 12
400 �F�f�t�H���g�̖����������F2009/12/02(��) 12:39:17
401 �F�f�t�H���g�̖����������F2009/12/02(��) 14:40:01
>>203
�g�p����F�@Io
f:=method(a,b,
s:=""
for(i,0,(a size) min(b size)-1,
s=s .. (a at(i)asCharacter) .. (b at(i)asCharacter)
)
s
)
Io> f("12345","asd")
==> 1a2s3d
�g�p����F�@Io
f:=method(a,b,
s:=""
for(i,0,(a size) min(b size)-1,
s=s .. (a at(i)asCharacter) .. (b at(i)asCharacter)
)
s
)
Io> f("12345","asd")
==> 1a2s3d
402 �F�f�t�H���g�̖����������F2009/12/02(��) 15:06:13
>>258 >>332
�g�p����F�@Io
showwaster:=method(a,b,a repeat("*"repeated(b)println))
Io> showwaster(6,6)
******
******
******
******
******
******
�g�p����F�@Io
showwaster:=method(a,b,a repeat("*"repeated(b)println))
Io> showwaster(6,6)
******
******
******
******
******
******
403 �F�f�t�H���g�̖����������F2009/12/02(��) 15:29:21
http://pc12.2ch.net/test/read.cgi/tech/1258158172/632
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10226.txt
#
# �v�f����no�ł���int�^�̔z��v2�̕��т��t���ɂ������̂�z��v1�Ɋi�[�����
# �@�@�@void intary_rcpy(int v1[], const int v2[],int no)
# ���쐬����
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10226.txt
#
# �v�f����no�ł���int�^�̔z��v2�̕��т��t���ɂ������̂�z��v1�Ɋi�[�����
# �@�@�@void intary_rcpy(int v1[], const int v2[],int no)
# ���쐬����
404 �F�f�t�H���g�̖����������F2009/12/02(��) 19:05:50
>>403
% Prolog
% Prolog�ɂ͌���v�f�Ƃ��Ĕz�Ȃ��A���X�g���g���B���X�g�ł��̖���\�����悤��
% ����ƁAno�̈���������B��������ΒP�Ȃ�reverse�����E�E�B
intary_rcpy(V1,V2,No) :-
�@�@length(V1,No),�@/* ���炩����No�v�f�̃��X�g������Ă��邪�قƂ�ǖ��Ӗ� */
�@�@intary_rcpy_1(V1,[],V2).
intary_rcpy_1(X,X,[]).
intary_rcpy_1(X,Y,[A|R]) :- intary_rcpy_1(X,[A|Y],R).
% Prolog
% Prolog�ɂ͌���v�f�Ƃ��Ĕz�Ȃ��A���X�g���g���B���X�g�ł��̖���\�����悤��
% ����ƁAno�̈���������B��������ΒP�Ȃ�reverse�����E�E�B
intary_rcpy(V1,V2,No) :-
�@�@length(V1,No),�@/* ���炩����No�v�f�̃��X�g������Ă��邪�قƂ�ǖ��Ӗ� */
�@�@intary_rcpy_1(V1,[],V2).
intary_rcpy_1(X,X,[]).
intary_rcpy_1(X,Y,[A|R]) :- intary_rcpy_1(X,[A|Y],R).
405 �F�f�t�H���g�̖����������F2009/12/02(��) 19:22:55
http://pc12.2ch.net/test/read.cgi/tech/1258158172/638
# �y����e���v���z
# [1] ���ƒP���F��w�̎���
# [2] ��蕶(�܃R�[�h&�����N)�F�����ɂ܂Ƃ߂ď����܂���
# �P�Foriginal�t�@�C������A�V�~�����[�V�����͈́i���l�j��ǂݎ��Ainserted�t�@�C���ɃR�s�[
# �Q�Fabsorbal�t�@�C������A�����q�̊e���q�̈ʒu�i���W�j��ǂݎ��
# �R�F�Q�̍��W�������_���ɔ������������i�����_���ɔ������������͈̔͂͂O�ȏ�original�t�@�C������ǂݍ��͈͂܂Łj�������s�ړ����Ainserted�t�@�C���ɏ�������
# �@�@�R�͓��͂��ꂽ����J��Ԃ�
# �S�F�R�̌��ʂ�inserted�t�@�C���ɏ��������A���̂���end���Q�����ݏI��
# �ȉ��̃R�[�h�ł̓V�~�����[�V�����͈͓͂ǂݎ��Ă��邪�����������ɔ��f����Ă��Ȃ�
# �܂��A�����q�̈ʒu�������ɂȂ��Ă��遨��������P������
# �y����e���v���z
# [1] ���ƒP���F��w�̎���
# [2] ��蕶(�܃R�[�h&�����N)�F�����ɂ܂Ƃ߂ď����܂���
# �P�Foriginal�t�@�C������A�V�~�����[�V�����͈́i���l�j��ǂݎ��Ainserted�t�@�C���ɃR�s�[
# �Q�Fabsorbal�t�@�C������A�����q�̊e���q�̈ʒu�i���W�j��ǂݎ��
# �R�F�Q�̍��W�������_���ɔ������������i�����_���ɔ������������͈̔͂͂O�ȏ�original�t�@�C������ǂݍ��͈͂܂Łj�������s�ړ����Ainserted�t�@�C���ɏ�������
# �@�@�R�͓��͂��ꂽ����J��Ԃ�
# �S�F�R�̌��ʂ�inserted�t�@�C���ɏ��������A���̂���end���Q�����ݏI��
# �ȉ��̃R�[�h�ł̓V�~�����[�V�����͈͓͂ǂݎ��Ă��邪�����������ɔ��f����Ă��Ȃ�
# �܂��A�����q�̈ʒu�������ɂȂ��Ă��遨��������P������
406 �F�f�t�H���g�̖����������F2009/12/02(��) 20:16:24
>>140
�g�p����F�@Io
f:=method(d,
write(d,"(base 10)\n",("".. d)toBase(2),"(base 2)\n",
("".. d)toBase(36)uppercase,"(base 36)\n")
)
Io> f(20)
20(base 10)
10100(base 2)
K(base 36)
�g�p����F�@Io
f:=method(d,
write(d,"(base 10)\n",("".. d)toBase(2),"(base 2)\n",
("".. d)toBase(36)uppercase,"(base 36)\n")
)
Io> f(20)
20(base 10)
10100(base 2)
K(base 36)
407 �F�f�t�H���g�̖����������F2009/12/02(��) 21:45:29
>>398
% Prolog ����͑�����ρB�؍\���ɂł��Z�߂�����̂��ȁB
��('���ʐl��҂ق̉Y�̗[��͂₭������ق̐g���������').
�̉�('���ʂЂƂ��܂ق̂���̂䂤�Ȃ��ɂ₭��������݂̂��������').
����(��,��).
����(_��,_�����I�Ȍ�) :-
sub_atom(_��,_,_,_,_�����I�Ȍ�),
\+(_�����I�Ȍ�==[]).
�A�z(����,�n���G).
�A�z(����,�z��).
�A�z(����,����).
�A�z(����,��).
�A�z(����,��).
�A�z(����,�D).
�A�z(����,�ς�).
�A�z(����,����).
�A�z(����,������).
�A�z(������,�C��).
�A�z(�Y,�C��).
�A�z(��,��).
�A�z(��,��).
% Prolog ����͑�����ρB�؍\���ɂł��Z�߂�����̂��ȁB
��('���ʐl��҂ق̉Y�̗[��͂₭������ق̐g���������').
�̉�('���ʂЂƂ��܂ق̂���̂䂤�Ȃ��ɂ₭��������݂̂��������').
����(��,��).
����(_��,_�����I�Ȍ�) :-
sub_atom(_��,_,_,_,_�����I�Ȍ�),
\+(_�����I�Ȍ�==[]).
�A�z(����,�n���G).
�A�z(����,�z��).
�A�z(����,����).
�A�z(����,��).
�A�z(����,��).
�A�z(����,�D).
�A�z(����,�ς�).
�A�z(����,����).
�A�z(����,������).
�A�z(������,�C��).
�A�z(�Y,�C��).
�A�z(��,��).
�A�z(��,��).
408 �F�f�t�H���g�̖����������F2009/12/02(��) 21:47:16
>>397 ��
�A�z(��,��).
�A�z(��,��).
�A�z(�g,��).
�A�z(�ł���,��).
�A�z(�ł���,�ł���).
�A�z(�ł���,�،͂炵).
�A�z(�،͂炵,�₵��).
�A�z(�،͂炵,�~).
�A�z(�Ă�,�ł���).
�A�z(�ł���,�l).
�A�z(��,�C).
�A�z(�C,��).
�A�z(��,��).
�A�z(��,�Y).
�A�z(��,��).
�A�z(��,��).
�A�z(��,��).
�A�z(�Y,��).
�A�z(�肢,��).
�A�z(��,�S).
�A�z(�肢,��).
�A�z(��,�w�M).
�A�z(��,��).
�A�z(��,��).
�A�z(�g,��).
�A�z(�ł���,��).
�A�z(�ł���,�ł���).
�A�z(�ł���,�،͂炵).
�A�z(�،͂炵,�₵��).
�A�z(�،͂炵,�~).
�A�z(�Ă�,�ł���).
�A�z(�ł���,�l).
�A�z(��,�C).
�A�z(�C,��).
�A�z(��,��).
�A�z(��,�Y).
�A�z(��,��).
�A�z(��,��).
�A�z(��,��).
�A�z(�Y,��).
�A�z(�肢,��).
�A�z(��,�S).
�A�z(�肢,��).
�A�z(��,�w�M).
409 �F�f�t�H���g�̖����������F2009/12/03(��) 03:38:49
410 �F�f�t�H���g�̖����������F2009/12/03(��) 03:43:23
http://pc12.2ch.net/test/read.cgi/tech/1258158172/664
# [1] C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���P�@unsigned int�^�̈�����1����, ���̒l��2�i���ň����
# �l�̂Ȃ���, print_bin() ���쐬��, ������m�F�ł���v��
# �O�����Ƃ��č쐬���� rep07.c �Ƃ��Ē�o����B
# ������, putchar() �ȊO�̃��C�u���������g�p���Ă͂Ȃ�
# �Ȃ��B
# [1] C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���P�@unsigned int�^�̈�����1����, ���̒l��2�i���ň����
# �l�̂Ȃ���, print_bin() ���쐬��, ������m�F�ł���v��
# �O�����Ƃ��č쐬���� rep07.c �Ƃ��Ē�o����B
# ������, putchar() �ȊO�̃��C�u���������g�p���Ă͂Ȃ�
# �Ȃ��B
411 �F�f�t�H���g�̖����������F2009/12/03(��) 03:44:43
http://pc12.2ch.net/test/read.cgi/tech/1258158172/664
# ���Q�@double�^�̔z���int�^�̈���������, double�^�̖ߒl������
# �����l����B��������double�^�̔z��̗v�f������������
# �^������Ƃ���, ��������double �^�̔z��Ɋi�[����Ă�
# ��l�̂����ő�̂��̂�ߒl�Ƃ��ĕԂ��� max_d_array() ��
# �쐬��, ����m�F�ł���v���O�����Ƃ��č쐬���� rep08.c ��
# ���Ē�o����B
# ������, max_d_array() �����ł͂����Ȃ�����Ă�ł͂�
# �炸, ����\���Ƃ��Ă� while()��, if()��, return���݂̂�
# �p���Ď������Ȃ���Ȃ�Ȃ��Bdo-while()��, for()��,
# switch-case��, goto��, ������(�O�����Z�q?:)�͎g���Ă͂Ȃ�
# �Ȃ��B�O�����Z�q�ȊO�̊e�퉉�Z�q�ƕϐ��͎��R�Ɏg���ėǂ��B
# ���Q�@double�^�̔z���int�^�̈���������, double�^�̖ߒl������
# �����l����B��������double�^�̔z��̗v�f������������
# �^������Ƃ���, ��������double �^�̔z��Ɋi�[����Ă�
# ��l�̂����ő�̂��̂�ߒl�Ƃ��ĕԂ��� max_d_array() ��
# �쐬��, ����m�F�ł���v���O�����Ƃ��č쐬���� rep08.c ��
# ���Ē�o����B
# ������, max_d_array() �����ł͂����Ȃ�����Ă�ł͂�
# �炸, ����\���Ƃ��Ă� while()��, if()��, return���݂̂�
# �p���Ď������Ȃ���Ȃ�Ȃ��Bdo-while()��, for()��,
# switch-case��, goto��, ������(�O�����Z�q?:)�͎g���Ă͂Ȃ�
# �Ȃ��B�O�����Z�q�ȊO�̊e�퉉�Z�q�ƕϐ��͎��R�Ɏg���ėǂ��B
412 �F�f�t�H���g�̖����������F2009/12/03(��) 03:45:49
http://pc12.2ch.net/test/read.cgi/tech/1258158172/664
# ���R
# �W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g�̕�����3������
# �炵�ĕW���o�͂ɏo�͂���V�[�U�[�Í����v���O�������쐬��
# �āArep09.c �Ƃ��Ē�o����B��̓I�ɂ�, �������ɑ��Ă�
# a -> d, b -> e, ..., w -> z, x -> a, y -> b, z -> c �Ȃ�
# �ϊ��ł���B�������啶���Ɋւ��Ă����l�̕ϊ�����������
# ����Ȃ�Ȃ��B
#
# ���R
# �W�����͂���̓��͂ɑ��āA�A���t�@�x�b�g�̕�����3������
# �炵�ĕW���o�͂ɏo�͂���V�[�U�[�Í����v���O�������쐬��
# �āArep09.c �Ƃ��Ē�o����B��̓I�ɂ�, �������ɑ��Ă�
# a -> d, b -> e, ..., w -> z, x -> a, y -> b, z -> c �Ȃ�
# �ϊ��ł���B�������啶���Ɋւ��Ă����l�̕ϊ�����������
# ����Ȃ�Ȃ��B
#
413 �F�f�t�H���g�̖����������F2009/12/03(��) 04:24:46
>>410
% Prolog
print_bin(N) :- N < 2,write(N).
print_bin(N) :- N >= 2,N2 is J // 2,M is N mod 2,print_bin(N2),write(M).
��i��(J,Y,[J|Y]) :- J < 2.
��i��(J,Y,X) :- J >= 2,J2 is J // 2,M is J mod 2,��i��(J2,[M|Y],X).
% Prolog
print_bin(N) :- N < 2,write(N).
print_bin(N) :- N >= 2,N2 is J // 2,M is N mod 2,print_bin(N2),write(M).
��i��(J,Y,[J|Y]) :- J < 2.
��i��(J,Y,X) :- J >= 2,J2 is J // 2,M is J mod 2,��i��(J2,[M|Y],X).
414 �F�f�t�H���g�̖����������F2009/12/03(��) 04:31:30
>>413 >>410 ���߂�B�Q�l�ɂ�����i��/3���c���Ă��܂����B����������āB
% Prolog
print_bin(N) :- N < 2,write(N).
print_bin(N) :- N >= 2,N2 is J // 2,M is N mod 2,print_bin(N2),write(M).
% Prolog
print_bin(N) :- N < 2,write(N).
print_bin(N) :- N >= 2,N2 is J // 2,M is N mod 2,print_bin(N2),write(M).
415 �F�f�t�H���g�̖����������F2009/12/03(��) 04:46:38
>>411
% Prolog
% ���X�g�v�f��N���z�������ɂ�fail�ɂ����A�����܂ł̍ő�l��Ԃ����ƂƂ���B
max_d_list(L,N,Max) :- max_d_list([D|R],N,D,Max).
max_d_list([],_,Max,Max) :- !.
max_d_list(_,0,Max,Max) :- !.
max_d_list([D|R],N,Max1,Max) :-
�@�@Max1 >= D,
�@�@N1 is N - 1,
�@�@max_d_list(R,N1,Max1,Max).
max_d_list([D|R],N,Max1,Max) :-
�@�@Max1 < D,
�@�@N1 is N - 1,
�@�@max_d_list(R,N1,D,Max).
% Prolog
% ���X�g�v�f��N���z�������ɂ�fail�ɂ����A�����܂ł̍ő�l��Ԃ����ƂƂ���B
max_d_list(L,N,Max) :- max_d_list([D|R],N,D,Max).
max_d_list([],_,Max,Max) :- !.
max_d_list(_,0,Max,Max) :- !.
max_d_list([D|R],N,Max1,Max) :-
�@�@Max1 >= D,
�@�@N1 is N - 1,
�@�@max_d_list(R,N1,Max1,Max).
max_d_list([D|R],N,Max1,Max) :-
�@�@Max1 < D,
�@�@N1 is N - 1,
�@�@max_d_list(R,N1,D,Max).
416 �F�f�t�H���g�̖����������F2009/12/03(��) 05:23:47
>>412
% Prolog
�A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
�A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N',
'O','P','Q','R','S','T','U','V','W','X','Y','Z']).
program :- rep03.
rep03 :- get_char(Char), �A���t�@�x�b�g�Ȃ�т̑I��(Char,L),rep03(Char,L).
rep03(end_of_file,_).
rep03(Char,L) :-
�@�@list_nth(N,L,Char),
�@�@�Ȃ�т̉�](������,3,L,L3),
�@�@list_nth(N,L3,A),
�@�@put_char(A),
�@�@get_char(Char2),
�@�@�A���t�@�x�b�g�Ȃ�т̑I��(Char2,L2),
�@�@rep03(Char2,L2).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= a,Char @=< z,�A���t�@�x�b�g(����
��,L).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= 'A',Char @=< 'Z',�A���t�@�x�b�g(
�啶��,L).
% Prolog
�A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
�A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N',
'O','P','Q','R','S','T','U','V','W','X','Y','Z']).
program :- rep03.
rep03 :- get_char(Char), �A���t�@�x�b�g�Ȃ�т̑I��(Char,L),rep03(Char,L).
rep03(end_of_file,_).
rep03(Char,L) :-
�@�@list_nth(N,L,Char),
�@�@�Ȃ�т̉�](������,3,L,L3),
�@�@list_nth(N,L3,A),
�@�@put_char(A),
�@�@get_char(Char2),
�@�@�A���t�@�x�b�g�Ȃ�т̑I��(Char2,L2),
�@�@rep03(Char2,L2).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= a,Char @=< z,�A���t�@�x�b�g(����
��,L).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= 'A',Char @=< 'Z',�A���t�@�x�b�g(
�啶��,L).
417 �F�f�t�H���g�̖����������F2009/12/03(��) 05:26:51
>>416 ���s�����s�����̂ŏ��������B
�A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
�A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']).
program :- rep03.
rep03 :- get_char(Char), �A���t�@�x�b�g�Ȃ�т̑I��(Char,L),rep03(Char,L).
rep03(end_of_file,_).
rep03(Char,L) :-
�@�@list_nth(N,L,Char),
�@�@�Ȃ�т̉�](������,3,L,L3),
�@�@list_nth(N,L3,A),
�@�@put_char(A),
�@�@get_char(Char2),
�@�@�A���t�@�x�b�g�Ȃ�т̑I��(Char2,L2),
�@�@rep03(Char2,L2).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= a,Char @=< z,�A���t�@�x�b�g(������,L).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= 'A',Char @=< 'Z',�A���t�@�x�b�g(�啶��,L).
�A���t�@�x�b�g(������,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
�A���t�@�x�b�g(�啶��,['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']).
program :- rep03.
rep03 :- get_char(Char), �A���t�@�x�b�g�Ȃ�т̑I��(Char,L),rep03(Char,L).
rep03(end_of_file,_).
rep03(Char,L) :-
�@�@list_nth(N,L,Char),
�@�@�Ȃ�т̉�](������,3,L,L3),
�@�@list_nth(N,L3,A),
�@�@put_char(A),
�@�@get_char(Char2),
�@�@�A���t�@�x�b�g�Ȃ�т̑I��(Char2,L2),
�@�@rep03(Char2,L2).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= a,Char @=< z,�A���t�@�x�b�g(������,L).
�A���t�@�x�b�g�Ȃ�т̑I��(Char,L) :- Char @>= 'A',Char @=< 'Z',�A���t�@�x�b�g(�啶��,L).
418 �F�f�t�H���g�̖����������F2009/12/03(��) 08:12:43
>>403
% Prolog
% Prolog�ɂ͌���v�f�Ƃ��Ĕz�Ȃ��A���X�g���g���B���X�g�ł��̖���\�����悤��
% ���ꂾ��V2�̗v�f�����z�����ꍇ��V1��No�őł���fail�Ƃ͂Ȃ�Ȃ��B
% �������No�ɖ����Ȃ��Ƃ�����������B
intary_rcpy(V1,V2,No) :-
�@�@intary_rcpy_1(V1,[],V2,No).
intary_rcpy_1(X,X,_,0) :- !.
intary_rcpy_1(X,X,[],_).
intary_rcpy_1(X,Y,[A|R],No) :- No1 is No - 1,intary_rcpy_1(X,[A|Y],R,No1).
% Prolog
% Prolog�ɂ͌���v�f�Ƃ��Ĕz�Ȃ��A���X�g���g���B���X�g�ł��̖���\�����悤��
% ���ꂾ��V2�̗v�f�����z�����ꍇ��V1��No�őł���fail�Ƃ͂Ȃ�Ȃ��B
% �������No�ɖ����Ȃ��Ƃ�����������B
intary_rcpy(V1,V2,No) :-
�@�@intary_rcpy_1(V1,[],V2,No).
intary_rcpy_1(X,X,_,0) :- !.
intary_rcpy_1(X,X,[],_).
intary_rcpy_1(X,Y,[A|R],No) :- No1 is No - 1,intary_rcpy_1(X,[A|Y],R,No1).
419 �F�f�t�H���g�̖����������F2009/12/03(��) 10:36:51
http://pc12.2ch.net/test/read.cgi/tech/1258158172/667
# [1] ���ƒP���FC++���K
# [2] ��蕶(�܃R�[�h&�����N)�F�����N���X2
# �����������N���X���쐬����B�N���X����Bunsu�B�f�[�^�����o��int�^��bunshi��bunbo��praivate�Ƃ���B
# �R���X�g���N�^�ɂ�菉�����������Ȃ��B�����l���w�肳��Ȃ������Ƃ��͏ȗ��������ł�bunshi,bunbo�Ƃ��P�ŏ��������邱�ƁB
# �܂�Bunsu�N���X�̐U�镑�����e�X�g����K��main�����쐬���邱�ƁB�P�t�@�C���ō쐬���Ă��������B
#
# �쐬�����
# �E�R���X�g���N�^
# �E���Z�q�̃I�[�o�[���[�h�ifriend���ō쐬���邱�Ɓj
# +, -, *, /, ==, != �̉��Z�q�ɂ��đ��d��`���s�Ȃ��B���Z���ʂ͖���B
# >>��<<�̃I�[�o�[���[�h�ifriend���ō쐬���邱�Ɓj
# �E<<Bunsu�N���X�̃I�u�W�F�N�g��cout�ŏo�͂���ƕ��q/����̌`���ŏo�͂���B
# [1] ���ƒP���FC++���K
# [2] ��蕶(�܃R�[�h&�����N)�F�����N���X2
# �����������N���X���쐬����B�N���X����Bunsu�B�f�[�^�����o��int�^��bunshi��bunbo��praivate�Ƃ���B
# �R���X�g���N�^�ɂ�菉�����������Ȃ��B�����l���w�肳��Ȃ������Ƃ��͏ȗ��������ł�bunshi,bunbo�Ƃ��P�ŏ��������邱�ƁB
# �܂�Bunsu�N���X�̐U�镑�����e�X�g����K��main�����쐬���邱�ƁB�P�t�@�C���ō쐬���Ă��������B
#
# �쐬�����
# �E�R���X�g���N�^
# �E���Z�q�̃I�[�o�[���[�h�ifriend���ō쐬���邱�Ɓj
# +, -, *, /, ==, != �̉��Z�q�ɂ��đ��d��`���s�Ȃ��B���Z���ʂ͖���B
# >>��<<�̃I�[�o�[���[�h�ifriend���ō쐬���邱�Ɓj
# �E<<Bunsu�N���X�̃I�u�W�F�N�g��cout�ŏo�͂���ƕ��q/����̌`���ŏo�͂���B
420 �F�f�t�H���g�̖����������F2009/12/03(��) 11:32:39
http://pc12.2ch.net/test/read.cgi/tech/1197620454/543
# �₢�P
# �E���z��array���g���ă��[�U�[�̃��O�C���y�[�W�����Ȃ����B
# �E���[�U�[���A�p�X���[�h�̃G���[���b�Z�[�W��\�������邱��
# �₢2
# �₢1�̃v���O���������p���āA�V�K���[�U�[�o�^�{�^�������Ȃ����Bkadai_06_02_01���[�U�[�o�^�͔z��𗘗p���邱��
# ���炩���߃��[�U�o�^�p�z���3���[�U�[���̖��O�ƃp�X���[�h���Z�b�g���Ă������ƁB
# ���[�U�[�o�^��10���܂łƂ���B10���[�U�[�����ꍇ�̓G���[��\�������Ȃ����B
# �܂�c��7�g��o�^����悢�B
# �v���O������for�Awhile�Ado while�̂ǂꂩ�ЂƂł悢�B
# ���[�U�[���̃G���[�̓t���O������ĕ\�����������ł��B�łȂ��ƒ����Ȃ�Ǝv���̂� �E�E�E�B
# �f�U�C���͍쐬�ς݂ł��B�C���[�W�����݂ɂ�����������܂���낵�����肢���܂��E�E�E�B
# sln�t�@�C���̖��O���t�H���_���ƈ���Ă��܂����C�ɂ��Ȃ��ł��������B
# �z����g��Ȃ����[�U�[�F�y�[�W������Ă݂��̂ł�������Q�l�ɂ��Ă���������� �Ǝv���܂��B
# �₢�P
# �E���z��array���g���ă��[�U�[�̃��O�C���y�[�W�����Ȃ����B
# �E���[�U�[���A�p�X���[�h�̃G���[���b�Z�[�W��\�������邱��
# �₢2
# �₢1�̃v���O���������p���āA�V�K���[�U�[�o�^�{�^�������Ȃ����Bkadai_06_02_01���[�U�[�o�^�͔z��𗘗p���邱��
# ���炩���߃��[�U�o�^�p�z���3���[�U�[���̖��O�ƃp�X���[�h���Z�b�g���Ă������ƁB
# ���[�U�[�o�^��10���܂łƂ���B10���[�U�[�����ꍇ�̓G���[��\�������Ȃ����B
# �܂�c��7�g��o�^����悢�B
# �v���O������for�Awhile�Ado while�̂ǂꂩ�ЂƂł悢�B
# ���[�U�[���̃G���[�̓t���O������ĕ\�����������ł��B�łȂ��ƒ����Ȃ�Ǝv���̂� �E�E�E�B
# �f�U�C���͍쐬�ς݂ł��B�C���[�W�����݂ɂ�����������܂���낵�����肢���܂��E�E�E�B
# sln�t�@�C���̖��O���t�H���_���ƈ���Ă��܂����C�ɂ��Ȃ��ł��������B
# �z����g��Ȃ����[�U�[�F�y�[�W������Ă݂��̂ł�������Q�l�ɂ��Ă���������� �Ǝv���܂��B
421 �F�f�t�H���g�̖����������F2009/12/03(��) 12:01:03
# [1] ���ƒP���Ffortran
# [2] ��蕶(�܃R�[�h&�����N)�F�z����g�킸�ɕ��ϒl�A���U�A�W������\������
# �f�[�^��n��n�̃f�[�^����͂��A���ϒl�A���U�A�W������W������B�Ȃ�n��5�ł���B
# dimension�Aif�Ago to���g���Ă͂����Ȃ��B
# [2] ��蕶(�܃R�[�h&�����N)�F�z����g�킸�ɕ��ϒl�A���U�A�W������\������
# �f�[�^��n��n�̃f�[�^����͂��A���ϒl�A���U�A�W������W������B�Ȃ�n��5�ł���B
# dimension�Aif�Ago to���g���Ă͂����Ȃ��B
422 �F�f�t�H���g�̖����������F2009/12/03(��) 13:41:06
>>421
% Prolog
�z����g�킸�ɕ��ϒl�A���U�A�W������\�� :-
�@�@write('�f�[�^�� : '),
�@�@get_integer(N),
�@�@write_formatted('%�̐���1��1�s�ŘA�����ē��͂��Ă������� : ',[N]),
�@�@get_line(Line),
�@�@atom_to_term(Line,X,_),
�@�@�z����g�킸�ɕ��ϒl�A���U�A�W������\��(1,N,X,0,_,Z).
�@�@_���U is Z / N,
�@�@_�W���� is sqrt(Z / (N - 1)),
write_formatted('���ϒl=%t,���U=%t,�W����=%t\n',[_���ϒl,_���U,_�W����]),!.
�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M,N,X,S,_����,0.0) :-
�@�@M > N,_���� is S / N,!.
�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M,N,X,S1,_����,Z) :-
�@�@get_line(Line2),
�@�@atom_to_term(line2,X2,_),
�@�@S2 is S1 + X,
�@�@M1 is M - 1,
�@�@�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M1,N,X2,S2,_����,Z2),
�@�@Z is (X - _����) ^ 2 + Z2.
% Prolog
�z����g�킸�ɕ��ϒl�A���U�A�W������\�� :-
�@�@write('�f�[�^�� : '),
�@�@get_integer(N),
�@�@write_formatted('%�̐���1��1�s�ŘA�����ē��͂��Ă������� : ',[N]),
�@�@get_line(Line),
�@�@atom_to_term(Line,X,_),
�@�@�z����g�킸�ɕ��ϒl�A���U�A�W������\��(1,N,X,0,_,Z).
�@�@_���U is Z / N,
�@�@_�W���� is sqrt(Z / (N - 1)),
write_formatted('���ϒl=%t,���U=%t,�W����=%t\n',[_���ϒl,_���U,_�W����]),!.
�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M,N,X,S,_����,0.0) :-
�@�@M > N,_���� is S / N,!.
�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M,N,X,S1,_����,Z) :-
�@�@get_line(Line2),
�@�@atom_to_term(line2,X2,_),
�@�@S2 is S1 + X,
�@�@M1 is M - 1,
�@�@�z����g�킸�ɕ��ϒl�A���U�A�W������\��(M1,N,X2,S2,_����,Z2),
�@�@Z is (X - _����) ^ 2 + Z2.
423 �F�f�t�H���g�̖����������F2009/12/03(��) 14:14:40
http://pc12.2ch.net/test/read.cgi/tech/1258158172/669
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶
# �������L�[�{�[�h������͂����A���͂��ꂽ���������߂ĉ�ʂɕ\������v���O���������Ȃ����B
# �������A���������߂�̂ɕW�����C�u���������g�p���Ȃ����ƁB�o�b�t�@�I�[�o�[�����Ȃǂ���������
# �s���ȓ��͍͂s���Ȃ����̂Ƃ���B
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶
# �������L�[�{�[�h������͂����A���͂��ꂽ���������߂ĉ�ʂɕ\������v���O���������Ȃ����B
# �������A���������߂�̂ɕW�����C�u���������g�p���Ȃ����ƁB�o�b�t�@�I�[�o�[�����Ȃǂ���������
# �s���ȓ��͍͂s���Ȃ����̂Ƃ���B
424 �F�f�t�H���g�̖����������F2009/12/03(��) 14:24:18
>>423
% Prolog
�������L�[�{�[�h������͂����A���͂��ꂽ���������߂ĉ�ʂɕ\������ :-
�@�@write('��������͂��Ă������� : '),
�@�@get_line(Line),
�@�@atom_chars(Line,Chars),
�@�@���͂��ꂽ���������߂�(Chars,N),
�@�@write_formatted('���͂��ꂽ������ %t �ł�\n',[N]).
���͂��ꂽ���������߂�([],0).
���͂��ꂽ���������߂�([_|R],N) :-
�@�@���͂��ꂽ���������߂�(R,N1),
�@�@N is N1 + 1.
% Prolog
�������L�[�{�[�h������͂����A���͂��ꂽ���������߂ĉ�ʂɕ\������ :-
�@�@write('��������͂��Ă������� : '),
�@�@get_line(Line),
�@�@atom_chars(Line,Chars),
�@�@���͂��ꂽ���������߂�(Chars,N),
�@�@write_formatted('���͂��ꂽ������ %t �ł�\n',[N]).
���͂��ꂽ���������߂�([],0).
���͂��ꂽ���������߂�([_|R],N) :-
�@�@���͂��ꂽ���������߂�(R,N1),
�@�@N is N1 + 1.
425 �F�f�t�H���g�̖����������F2009/12/03(��) 16:11:18
>>420
% Prolog
ttylogin :-
�@�@write('\nlogin: '),
�@�@get_line(_���[�U�[��),write('password: '),
�@�@system('stty -echo raw'),
�@�@get_char(X),put_char('*'),
�@�@�p�X���[�h��(X,Password),
�@�@���[�U�Ǘ�(_���[�U�[��,Password,_�f�f),
�@�@assertz(���O�C�����(_���[�U�[��,Password,_�f�f)),
�@�@�V�F��(_���[�U�[��,_�f�f),
�@�@ttylogin.
�p�X���[�h��('\r',[]) :- !.
�p�X���[�h��(C,[C|R]) :- get_char(C2),put_char('*'),�p�X���[�h��(C2,R).
���[�U�Ǘ�(_���[�U�[��,Password,ok) :-
�@�@concat_atom(Password,PasswordAtom),
�@�@�J�G�T����(17,PasswordAtom,_����),
�@�@user_password(_���[�U��,_����),!.
���[�U�Ǘ�(_���[�U�[��,Password,'UserPassword Error') :- user_passwork(_���[�U�[��,_),!.
���[�U�Ǘ�(_���[�U�[��,Password,S) :- concat_atom([���[�U�[��,_���[�U�[��,�͓o�^������܂���],S),!.
user_password(tama,'Jrslif').
�V�F��(_,S) :- \+(S==ok),!.
�V�F��(_,_) :- system.
% Prolog
ttylogin :-
�@�@write('\nlogin: '),
�@�@get_line(_���[�U�[��),write('password: '),
�@�@system('stty -echo raw'),
�@�@get_char(X),put_char('*'),
�@�@�p�X���[�h��(X,Password),
�@�@���[�U�Ǘ�(_���[�U�[��,Password,_�f�f),
�@�@assertz(���O�C�����(_���[�U�[��,Password,_�f�f)),
�@�@�V�F��(_���[�U�[��,_�f�f),
�@�@ttylogin.
�p�X���[�h��('\r',[]) :- !.
�p�X���[�h��(C,[C|R]) :- get_char(C2),put_char('*'),�p�X���[�h��(C2,R).
���[�U�Ǘ�(_���[�U�[��,Password,ok) :-
�@�@concat_atom(Password,PasswordAtom),
�@�@�J�G�T����(17,PasswordAtom,_����),
�@�@user_password(_���[�U��,_����),!.
���[�U�Ǘ�(_���[�U�[��,Password,'UserPassword Error') :- user_passwork(_���[�U�[��,_),!.
���[�U�Ǘ�(_���[�U�[��,Password,S) :- concat_atom([���[�U�[��,_���[�U�[��,�͓o�^������܂���],S),!.
user_password(tama,'Jrslif').
�V�F��(_,S) :- \+(S==ok),!.
�V�F��(_,_) :- system.
426 �F�f�t�H���g�̖����������F2009/12/03(��) 16:32:50
>>425
-raw�ɖ߂��̖Y�ꂽ�B
-raw�ɖ߂��̖Y�ꂽ�B
427 �F�f�t�H���g�̖����������F2009/12/03(��) 16:48:44
http://pc12.2ch.net/test/read.cgi/tech/1197620454/434
# ��蕶
# �����e�J�����@�ɂ��~����
# 1�~1�̐����`��1/4�~��p���ĉ~���������߂�v���O�������쐬������
# �Ȃ��A�W���A�y�ѐ����`��1/4�~�̐}�͈ȉ��̗l�ɂȂ�
# ��/4:1 = P : P + Q
# �� = 4P/P + Q = 4P/N
#�@�͉~�����AP�͉~�O�ɂ���_�̐��AN��P + Q�Ƃ���
# ��蕶
# �����e�J�����@�ɂ��~����
# 1�~1�̐����`��1/4�~��p���ĉ~���������߂�v���O�������쐬������
# �Ȃ��A�W���A�y�ѐ����`��1/4�~�̐}�͈ȉ��̗l�ɂȂ�
# ��/4:1 = P : P + Q
# �� = 4P/P + Q = 4P/N
#�@�͉~�����AP�͉~�O�ɂ���_�̐��AN��P + Q�Ƃ���
428 �F�f�t�H���g�̖����������F2009/12/03(��) 17:55:54
>>427
% Prolog
�����e�J�����@�ɂ��~���������߂�(N,Pi) :-
�@�@�����e�J�����@�ɂ��~���������߂�(0,N,0,H),
�@�@P is H / N,
�@�@Pi is 4 * Pi,
�@�@write_formatted('Pi = %t\n',[Pi]).
�����e�J�����@�ɂ��~���������߂�(M,N,H,H) :- M > N,!.
�����e�J�����@�ɂ��~���������߂�(M,N,H1,H) :-
�@�@X1 is (random mod 7717) / 7717,
�@�@Y1 is (random mod 7717) / 7717,
�@�@U is X * X + Y * Y,
�@�@'1�Ɏ��܂��Ă���J�E���g'(U,H1,H2),
�@�@M2 is M + 1,
�@�@�����e�J�����@�ɂ��~���������߂�(M,N,H2,H).
'1�Ɏ��܂��Ă���J�E���g'(U,H1,H2) :-
�@�@U < 1,
�@�@H2 is H1 + 1,!.
'1�Ɏ��܂��Ă���J�E���g'(U,H1,H1).
% Prolog
�����e�J�����@�ɂ��~���������߂�(N,Pi) :-
�@�@�����e�J�����@�ɂ��~���������߂�(0,N,0,H),
�@�@P is H / N,
�@�@Pi is 4 * Pi,
�@�@write_formatted('Pi = %t\n',[Pi]).
�����e�J�����@�ɂ��~���������߂�(M,N,H,H) :- M > N,!.
�����e�J�����@�ɂ��~���������߂�(M,N,H1,H) :-
�@�@X1 is (random mod 7717) / 7717,
�@�@Y1 is (random mod 7717) / 7717,
�@�@U is X * X + Y * Y,
�@�@'1�Ɏ��܂��Ă���J�E���g'(U,H1,H2),
�@�@M2 is M + 1,
�@�@�����e�J�����@�ɂ��~���������߂�(M,N,H2,H).
'1�Ɏ��܂��Ă���J�E���g'(U,H1,H2) :-
�@�@U < 1,
�@�@H2 is H1 + 1,!.
'1�Ɏ��܂��Ă���J�E���g'(U,H1,H1).
429 �F�f�t�H���g�̖����������F2009/12/03(��) 18:19:36
http://pc12.2ch.net/test/read.cgi/tech/1258158172/671
# [1] ���ƒP���F C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���Ƃ���y=sinx,y'=sinx+xcosx�����グ�Af'(x)=sinx+xcosx�̒l�𐔒l������
# ������@����v�Z����v���O�������쐬��
# ��͒l�Ɣ�r���Ă݂�B������h=0.1�Ƃ��A0��x���Ƃ���B
#
# [1] ���ƒP���F C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���Ƃ���y=sinx,y'=sinx+xcosx�����グ�Af'(x)=sinx+xcosx�̒l�𐔒l������
# ������@����v�Z����v���O�������쐬��
# ��͒l�Ɣ�r���Ă݂�B������h=0.1�Ƃ��A0��x���Ƃ���B
#
430 �F�f�t�H���g�̖����������F2009/12/03(��) 18:36:18
>>429
�g���Ă͌�����������肽���̂������ς�킩���B
�g���Ă͌�����������肽���̂������ς�킩���B
431 �F�f�t�H���g�̖����������F2009/12/03(��) 19:21:57
>>420
% Prolog �z��͂܂������g���Ă��Ȃ�����ǁAProlog�Ƃ��Ď��R�ȕ\���ŁB
adduser :-
�@�@write('username : '),get_line(_���[�U�[��),
�@�@rawmode,write('password : '),get_char(Char),put_char(*),
�@�@�p�X���[�h��(Char,Password),norawmode,
�@�@write('Retype Password : '),get_char(Char2),put_char(*),
�@�@�p�X���[�h��(Char2,Password2),
�@�@�p�X���[�h�͈�v����(Password,Password2),
�@�@��`�g�̌��E���z���Ă��Ȃ�,
�@�@���[�U�[�o�^(_���[�U�[��,Password),
�p�X���[�h�͈�v����(A,A) :- !.
�p�X���[�h�͈�v����(A,B) :- \+(A,B),write('�^�C�v���ꂽ�p�X���[�h�͈�v���܂���\n'),fail.
���[�U�[�o�^(_���[�U�[��,Password) :-
�@�@concat_atom(Password,PasswordAtom),
�@�@�J�G�T����(17,PasswordAtom,PasswordAtom2),
�@�@assertz(user_password(_���[�U-��,PasswordAtom2)).
��`�g�̌��E���z���Ă��Ȃ� :- ��`���̐�(user_password/2,N),N < 10,!.
��`�g�̌��E���z���Ă��Ȃ� :- write('�o�^���[�U�[��10���z���Ă��܂��B\n�o�^�ł��܂���B\n'),fail.
��`�߂̐�(Functor / Arity,N) :- functor(P,Functor,Arity),findsum(1,clause(P,_),F),N is truncate(F).
% Prolog �z��͂܂������g���Ă��Ȃ�����ǁAProlog�Ƃ��Ď��R�ȕ\���ŁB
adduser :-
�@�@write('username : '),get_line(_���[�U�[��),
�@�@rawmode,write('password : '),get_char(Char),put_char(*),
�@�@�p�X���[�h��(Char,Password),norawmode,
�@�@write('Retype Password : '),get_char(Char2),put_char(*),
�@�@�p�X���[�h��(Char2,Password2),
�@�@�p�X���[�h�͈�v����(Password,Password2),
�@�@��`�g�̌��E���z���Ă��Ȃ�,
�@�@���[�U�[�o�^(_���[�U�[��,Password),
�p�X���[�h�͈�v����(A,A) :- !.
�p�X���[�h�͈�v����(A,B) :- \+(A,B),write('�^�C�v���ꂽ�p�X���[�h�͈�v���܂���\n'),fail.
���[�U�[�o�^(_���[�U�[��,Password) :-
�@�@concat_atom(Password,PasswordAtom),
�@�@�J�G�T����(17,PasswordAtom,PasswordAtom2),
�@�@assertz(user_password(_���[�U-��,PasswordAtom2)).
��`�g�̌��E���z���Ă��Ȃ� :- ��`���̐�(user_password/2,N),N < 10,!.
��`�g�̌��E���z���Ă��Ȃ� :- write('�o�^���[�U�[��10���z���Ă��܂��B\n�o�^�ł��܂���B\n'),fail.
��`�߂̐�(Functor / Arity,N) :- functor(P,Functor,Arity),findsum(1,clause(P,_),F),N is truncate(F).
432 �F�f�t�H���g�̖����������F2009/12/04(��) 04:12:05
http://pc12.2ch.net/test/read.cgi/tech/1248012902/565
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/854.txt
# ���b�Z�[�W�̗���鏇�Ԃ͎��̂悤�ɂȂ�B
# �w���I�u�W�F�N�g(yamada)����
# 1)�����ւ̐��і₢���킹���b�Z�[�W(askScore("0001"))
# �����I�u�W�F�N�g(endo)����
# 2)���і₢���킹�̃��b�Z�[�W(searchScore("0001"))
# �������I�u�W�F�N�g(defaultOffice)����
# 3)���_�܂���-1��ԓ�
# �����I�u�W�F�N�g(endo)����
# 4)���_�܂���-1��ԓ�
#
# ���̏��ԂŃ��b�Z�[�W���������w���I�u�W�F�N�g�������I�u�W�F�N�g���o�R����
# �����̐��т�m�邱�Ƃ��ł���悤�ɂ��Ȃ����B
# �y�@�ۑ�@�zhttp://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/img/854.txt
# ���b�Z�[�W�̗���鏇�Ԃ͎��̂悤�ɂȂ�B
# �w���I�u�W�F�N�g(yamada)����
# 1)�����ւ̐��і₢���킹���b�Z�[�W(askScore("0001"))
# �����I�u�W�F�N�g(endo)����
# 2)���і₢���킹�̃��b�Z�[�W(searchScore("0001"))
# �������I�u�W�F�N�g(defaultOffice)����
# 3)���_�܂���-1��ԓ�
# �����I�u�W�F�N�g(endo)����
# 4)���_�܂���-1��ԓ�
#
# ���̏��ԂŃ��b�Z�[�W���������w���I�u�W�F�N�g�������I�u�W�F�N�g���o�R����
# �����̐��т�m�邱�Ƃ��ł���悤�ɂ��Ȃ����B
433 �F�f�t�H���g�̖����������F2009/12/04(��) 04:37:35
434 �F�f�t�H���g�̖����������F2009/12/04(��) 04:41:26
http://pc12.2ch.net/test/read.cgi/tech/1258158172/677
# [1] ���ƒP���F�v���O���~���O���K
# [2] �P�D�T���v���v���O�������Q�l�ɗ����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���ď��������ɕ\������v���O�������쐬����B
# �Q.�T���v���v���O�������Q�l�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���đ傫�����̂��珇�ɕ\������v���O�������쐬����B
# �R.�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂���������
# ���������ɕ\������v���O�������쐬����B�����͂P�O���͂�����v���O�����͏I������悤�ɂ��邱��.
# �S�D�O����P�܂ł�double�^�̐������Q�O�����ɂ���Đ������A���������ɕ\������v���O�������쐬����B
# �T�D�ȉ��̉p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ��ĕ\������v���O�������쐬����B���ׂĂ̂S�����̒P��ł��邱�Ƃ𗘗p���Ă��悢�B
#
# mane, malt, mama, mark, mare, maid, made, mach, many, mess, meat, neat, like, lime, limb
#
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10230.txt
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] �P�D�T���v���v���O�������Q�l�ɗ����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���ď��������ɕ\������v���O�������쐬����B
# �Q.�T���v���v���O�������Q�l�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���đ傫�����̂��珇�ɕ\������v���O�������쐬����B
# �R.�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂���������
# ���������ɕ\������v���O�������쐬����B�����͂P�O���͂�����v���O�����͏I������悤�ɂ��邱��.
# �S�D�O����P�܂ł�double�^�̐������Q�O�����ɂ���Đ������A���������ɕ\������v���O�������쐬����B
# �T�D�ȉ��̉p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ��ĕ\������v���O�������쐬����B���ׂĂ̂S�����̒P��ł��邱�Ƃ𗘗p���Ă��悢�B
#
# mane, malt, mama, mark, mare, maid, made, mach, many, mess, meat, neat, like, lime, limb
#
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10230.txt
#
435 �F�f�t�H���g�̖����������F2009/12/04(��) 04:46:12
http://pc12.2ch.net/test/read.cgi/tech/1258158172/688
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10234.txt
#
# ���X�g��p�����X�^�b�N�̊�{����
#
# ���X�g����p���ăX�^�b�N�̊�{������s���v���O�����������������B
# �}�̃v���O����������������B
# ���������L�̏��������B
#
# 1�F�@data.dat����getc()��p���ăA���t�@�x�b�g���ꕶ�����ǂݍ��݁A�X�^�b�N����push-down����B
#
# 2�F�@�X�^�b�N�̓��e��\��������@print_stack_list(s)�͕������Ă���̂ŁA�����R���p�C���ɂ��
# ���s�t�@�C�������B
# [1] ���ƒP���F
# �A���S���Y���ƃv���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10234.txt
#
# ���X�g��p�����X�^�b�N�̊�{����
#
# ���X�g����p���ăX�^�b�N�̊�{������s���v���O�����������������B
# �}�̃v���O����������������B
# ���������L�̏��������B
#
# 1�F�@data.dat����getc()��p���ăA���t�@�x�b�g���ꕶ�����ǂݍ��݁A�X�^�b�N����push-down����B
#
# 2�F�@�X�^�b�N�̓��e��\��������@print_stack_list(s)�͕������Ă���̂ŁA�����R���p�C���ɂ��
# ���s�t�@�C�������B
436 �F�f�t�H���g�̖����������F2009/12/04(��) 04:50:28
>>433
���̌�A
>684 ���O�F�f�t�H���g�̖��������� �F2009/12/04(��) 00:22:13
> >>683
> �� y=sinx,y'=sinx+xcosx
> �Q�̊�����Ȃ��Ȃ�A������Ė������ĂȂ������H
>685 ���O�F671 �F2009/12/04(��) 00:31:41
> >>684
> y'�͂���y�̎���������������Ȃ̂œ��ɖ����͂Ȃ��Ǝv����ł���
> ���������A������ӂ𗝉��ł��Ȃ������̂ł����ɏ������Ă��炢�܂����c
>686 ���O�F�f�t�H���g�̖��������� �F2009/12/04(��) 00:44:23
> y=xsinx�̊ԈႢ����Ȃ���ł���
�ƂȂ��Ă���B
���̌�A
>684 ���O�F�f�t�H���g�̖��������� �F2009/12/04(��) 00:22:13
> >>683
> �� y=sinx,y'=sinx+xcosx
> �Q�̊�����Ȃ��Ȃ�A������Ė������ĂȂ������H
>685 ���O�F671 �F2009/12/04(��) 00:31:41
> >>684
> y'�͂���y�̎���������������Ȃ̂œ��ɖ����͂Ȃ��Ǝv����ł���
> ���������A������ӂ𗝉��ł��Ȃ������̂ł����ɏ������Ă��炢�܂����c
>686 ���O�F�f�t�H���g�̖��������� �F2009/12/04(��) 00:44:23
> y=xsinx�̊ԈႢ����Ȃ���ł���
�ƂȂ��Ă���B
437 �F�f�t�H���g�̖����������F2009/12/04(��) 05:20:53
>>434
% Prolog
�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���ď��������ɕ\ �� :-
�@�@findall(M,(for(1,N,20),M is random),�����Ȃ��),
�@�@�o�u���\�[�g�ɂ���ď���������(_�����Ȃ��,_���������Ȃ��),
�@�@writeln(_���������Ȃ��).
�o�u���\�[�g�ɂ���ď���������(L1,L2) :-
�@�@���������܂�(L1,L3),
�@�@�o�u���\�[�g�ɂ���ď���������(L3,L2).
�o�u���\�[�g�ɂ���ď���������(L,L).
���������܂�([A,B|R],[B,A|R]) :-
�@�@A > B,!.
���������܂�([A,B|R1],[A|R2]) :-
�@�@A =< B,
�@�@���������܂�([B|R1],R2).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeln([]).
writeln([A|R]) :- write_formatted('%t\n',[A]),writeln(R).
% Prolog
�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���ď��������ɕ\ �� :-
�@�@findall(M,(for(1,N,20),M is random),�����Ȃ��),
�@�@�o�u���\�[�g�ɂ���ď���������(_�����Ȃ��,_���������Ȃ��),
�@�@writeln(_���������Ȃ��).
�o�u���\�[�g�ɂ���ď���������(L1,L2) :-
�@�@���������܂�(L1,L3),
�@�@�o�u���\�[�g�ɂ���ď���������(L3,L2).
�o�u���\�[�g�ɂ���ď���������(L,L).
���������܂�([A,B|R],[B,A|R]) :-
�@�@A > B,!.
���������܂�([A,B|R1],[A|R2]) :-
�@�@A =< B,
�@�@���������܂�([B|R1],R2).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
writeln([]).
writeln([A|R]) :- write_formatted('%t\n',[A]),writeln(R).
438 �F�f�t�H���g�̖����������F2009/12/04(��) 05:28:15
>>434
% Prolog
�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���đ傫�����ɕ\�� :-
�@�@findall(M,(for(1,N,20),M is random),�����Ȃ��),
�@�@�o�u���\�[�g�ɂ���đ傫������(_�����Ȃ��,_���������Ȃ��),
�@�@writeln(_���������Ȃ��).
�o�u���\�[�g�ɂ���đ傫������(L1,L2) :-
�@�@�傫�����̐������܂�(L1,L3),
�@�@�o�u���\�[�g�ɂ���đ傫������(L3,L2).
�o�u���\�[�g�ɂ���đ傫������(L,L).
�傫�����̐������܂�([A,B|R],[B,A|R]) :-
�@�@A < B,!.
�傫�����̐������܂�([A,B|R1],[A|R2]) :-
�@�@A >= B,
�@�@�傫�����̐������܂�([B|R1],R2).
% Prolog
�����ɂ���Đ��������Q�O�̐�����z��ɓ���A�o�u���\�[�g�ɂ���đ傫�����ɕ\�� :-
�@�@findall(M,(for(1,N,20),M is random),�����Ȃ��),
�@�@�o�u���\�[�g�ɂ���đ傫������(_�����Ȃ��,_���������Ȃ��),
�@�@writeln(_���������Ȃ��).
�o�u���\�[�g�ɂ���đ傫������(L1,L2) :-
�@�@�傫�����̐������܂�(L1,L3),
�@�@�o�u���\�[�g�ɂ���đ傫������(L3,L2).
�o�u���\�[�g�ɂ���đ傫������(L,L).
�傫�����̐������܂�([A,B|R],[B,A|R]) :-
�@�@A < B,!.
�傫�����̐������܂�([A,B|R1],[A|R2]) :-
�@�@A >= B,
�@�@�傫�����̐������܂�([B|R1],R2).
439 �F�f�t�H���g�̖����������F2009/12/04(��) 06:07:11
>>434
% Prolog
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������ :-
�@�@�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(10,[]).
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(0,_) :- !.
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(N,_���݂܂Ő��ꂽ�Ȃ��) :-
�@�@get_integer(_����),
�@�@������������Ȃ�тɑ}��(_����,_���݂܂Ő��ꂽ�Ȃ��,_���������Ȃ��),
�@�@concat_atom(_���������Ȃ��,' ',_������),
�@�@write_formatted('%t\n',[_������]),
�@�@N1 is N - 1,
�@�@�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(N1,_���������Ȃ��).
������������Ȃ�тɑ}��(N,[],[N]) :- !.
������������Ȃ�тɑ}��(N,[A|R],[N,A|R]) :- N < A,!.
������������Ȃ�тɑ}��(N,[A|R],[A|R]) :- N >= A,������������Ȃ�тɑ}��(N,R1,R2).
% Prolog
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������ :-
�@�@�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(10,[]).
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(0,_) :- !.
�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(N,_���݂܂Ő��ꂽ�Ȃ��) :-
�@�@get_integer(_����),
�@�@������������Ȃ�тɑ}��(_����,_���݂܂Ő��ꂽ�Ȃ��,_���������Ȃ��),
�@�@concat_atom(_���������Ȃ��,' ',_������),
�@�@write_formatted('%t\n',[_������]),
�@�@N1 is N - 1,
�@�@�L�[�{�[�h���玟�X�ɐ�������͂��A���͂̂��тɂ���܂łɓ��͂������������������ɕ\������(N1,_���������Ȃ��).
������������Ȃ�тɑ}��(N,[],[N]) :- !.
������������Ȃ�тɑ}��(N,[A|R],[N,A|R]) :- N < A,!.
������������Ȃ�тɑ}��(N,[A|R],[A|R]) :- N >= A,������������Ȃ�тɑ}��(N,R1,R2).
440 �F�f�t�H���g�̖����������F2009/12/04(��) 06:14:27
>>434
% Prolog
�O����P�܂ł�double�^�̐������Q�O�����ɂ���Đ������A���������ɕ\������ :-
�@�@findall(F,(for(1,N,20),F is (random mod 7717) / 7717),L1),
�@�@�o�u���\�[�g�ɂ���ď���������(L1,L2),
�@�@writeln(L2).
% Prolog
�O����P�܂ł�double�^�̐������Q�O�����ɂ���Đ������A���������ɕ\������ :-
�@�@findall(F,(for(1,N,20),F is (random mod 7717) / 7717),L1),
�@�@�o�u���\�[�g�ɂ���ď���������(L1,L2),
�@�@writeln(L2).
441 �F�f�t�H���g�̖����������F2009/12/04(��) 06:29:37
>>439 ��O�ߒ���
% R1 R2 �ł���ׂ��Ƃ��낪 R R �ɂȂ��Ă����B
������������Ȃ�тɑ}��(N,[],[N]) :- !.
������������Ȃ�тɑ}��(N,[A|R],[N,A|R]) :- N < A,!.
������������Ȃ�тɑ}��(N,[A|R1],[A|R2]) :- N >= A,������������Ȃ�тɑ}��(N,R1,R2).
% R1 R2 �ł���ׂ��Ƃ��낪 R R �ɂȂ��Ă����B
������������Ȃ�тɑ}��(N,[],[N]) :- !.
������������Ȃ�тɑ}��(N,[A|R],[N,A|R]) :- N < A,!.
������������Ȃ�тɑ}��(N,[A|R1],[A|R2]) :- N >= A,������������Ȃ�тɑ}��(N,R1,R2).
442 �F�f�t�H���g�̖����������F2009/12/04(��) 06:39:07
>>434
% Prolog
�p�P��Ȃ��([mane, malt, mama, mark, mare, maid, made, mach, many, mess, meat, neat, like, lime, limb]).
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ��ĕ\������' :-
�@�@�p�P��Ȃ��(L1),
�@�@'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'(L1,[],L2),
�@�@writeln(L2).
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'([],L,L) :- !.
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'([_�P��|R],L1,L2) :-
�@�@������������Ȃ�тɕ�����}��(_�P��,L1,L2),
�@�@'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'(R,L2,L).
������������Ȃ�тɕ�����}��(_������,[],[_������]) :- !.
������������Ȃ�тɕ�����}��(_������,[A|R],[_������,A|R]) :- _������ @< A,!.
������������Ȃ�тɕ�����}��(_������,[A|R1],[A|R2]) :- _������ @>= A,������������Ȃ�тɕ�����}��(_������,R1,R2).
% Prolog
�p�P��Ȃ��([mane, malt, mama, mark, mare, maid, made, mach, many, mess, meat, neat, like, lime, limb]).
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ��ĕ\������' :-
�@�@�p�P��Ȃ��(L1),
�@�@'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'(L1,[],L2),
�@�@writeln(L2).
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'([],L,L) :- !.
'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'([_�P��|R],L1,L2) :-
�@�@������������Ȃ�тɕ�����}��(_�P��,L1,L2),
�@�@'�p�P����������Ɂi�A���t�@�x�b�g���Ɂj�\�[�g�ɂ���ĕ��בւ���'(R,L2,L).
������������Ȃ�тɕ�����}��(_������,[],[_������]) :- !.
������������Ȃ�тɕ�����}��(_������,[A|R],[_������,A|R]) :- _������ @< A,!.
������������Ȃ�тɕ�����}��(_������,[A|R1],[A|R2]) :- _������ @>= A,������������Ȃ�тɕ�����}��(_������,R1,R2).
443 �F�f�t�H���g�̖����������F2009/12/04(��) 06:49:42
http://pc11.2ch.net/test/read.cgi/db/1081818145/493
#
# ����e�[�u���\����TBL-A�ATBL-B���̂Q������܂��B
# �e�[�u�����C�A�E�g�́A
# ����@�@�@int(8)
# �Ј��ԍ��@�@int(10)
# �\���@�@�@�@�@int(10�j
# ���Ƃ��܂��B
#
# TBL-A��TBL-B���r���A�ȉ��̂��Ƃ�SQL�ł�肽����ł����A�������������ł��傤���H
#
# (1)�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�
#
# (2)�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��
#
# (3)�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�
#
# (4)�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�
#
# ����e�[�u���\����TBL-A�ATBL-B���̂Q������܂��B
# �e�[�u�����C�A�E�g�́A
# ����@�@�@int(8)
# �Ј��ԍ��@�@int(10)
# �\���@�@�@�@�@int(10�j
# ���Ƃ��܂��B
#
# TBL-A��TBL-B���r���A�ȉ��̂��Ƃ�SQL�ł�肽����ł����A�������������ł��傤���H
#
# (1)�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�
#
# (2)�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��
#
# (3)�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�
#
# (4)�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�
444 �F�f�t�H���g�̖����������F2009/12/04(��) 07:24:49
>>435
% Prolog
stack(s,[]).
���X�g����p���ăX�^�b�N�̊�{������s�� :-
�@�@open('data.dat',read,Instrem),
�@�@get_char(Instream,C),
�@�@stack(s,L1),
�@�@���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C,L1,L2),
�@�@close(Instream),
�@�@save_stack(s,L2).
���X�g����p���ăX�^�b�N�̊�{������s��(Instream,end_of_file,L,L) :- !.
���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C,L1,L2) :-
�@�@push(C,L1,L3),
�@�@get_char(Instream,C2),
�@�@���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C2,L3,L2).
push(A,L,[A|L]).
save_stack(Stack,L) :- retract(stack(Stack,_)),assertz(stack(Stack,L)).
% Prolog
stack(s,[]).
���X�g����p���ăX�^�b�N�̊�{������s�� :-
�@�@open('data.dat',read,Instrem),
�@�@get_char(Instream,C),
�@�@stack(s,L1),
�@�@���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C,L1,L2),
�@�@close(Instream),
�@�@save_stack(s,L2).
���X�g����p���ăX�^�b�N�̊�{������s��(Instream,end_of_file,L,L) :- !.
���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C,L1,L2) :-
�@�@push(C,L1,L3),
�@�@get_char(Instream,C2),
�@�@���X�g����p���ăX�^�b�N�̊�{������s��(Instream,C2,L3,L2).
push(A,L,[A|L]).
save_stack(Stack,L) :- retract(stack(Stack,_)),assertz(stack(Stack,L)).
445 �F�f�t�H���g�̖����������F2009/12/04(��) 09:00:29
>>443
% Prolog (1)
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�'(_�Ј��ԍ�),!.
% Prolog (1)
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�'(_�Ј��ԍ�),!.
�Ј��\���Ǘ�(_�Ј��ԍ�) :- '�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�'(_�Ј��ԍ�),!.
446 �F�f�t�H���g�̖����������F2009/12/04(��) 09:03:51
>>443
% prolog (2)
'�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���,_�Ј��ԍ�,_�\��),
�@�@\+('TBL-B'(_,_�Ј��ԍ�,_)),
�@�@assertz('TBL-B'(_���,_�Ј��ԍ�,_�\��)).
'�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���A,_�Ј��ԍ�,_�\��A),
�@�@'TBL-B'(_���B,_�Ј��ԍ�,_�\��B),
�@�@_���A @> _���B,
�@�@retract('TBL-B'(_���B,_�Ј��ԍ�,_�\��B)),
�@�@assertz('TBL-B'(_���A,_�Ј��ԍ�,_�\��A)).
'�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���A,_�Ј��ԍ�,_�\��A),
�@�@'TBL-B'(_���B,_�Ј��ԍ�,_�\��B),
�@�@_���A @=< _���B.
'�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�'(_�Ј��ԍ�) :-
�@�@'TBL-B'(_,_�Ј��ԍ�,_),
�@�@\+('TBL-A'(_,_�Ј��ԍ�,_)).
% prolog (2)
'�Ј��ԍ���TBL-A�ɍ݂���TBL-B�ɖ����ꍇ-->TBL-B�ɊY�����R�[�h�lj�'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���,_�Ј��ԍ�,_�\��),
�@�@\+('TBL-B'(_,_�Ј��ԍ�,_)),
�@�@assertz('TBL-B'(_���,_�Ј��ԍ�,_�\��)).
'�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȍ~�̏ꍇ-->TBL-B�̊Y�����R�[�h��TBL-A�ŏ㏑��'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���A,_�Ј��ԍ�,_�\��A),
�@�@'TBL-B'(_���B,_�Ј��ԍ�,_�\��B),
�@�@_���A @> _���B,
�@�@retract('TBL-B'(_���B,_�Ј��ԍ�,_�\��B)),
�@�@assertz('TBL-B'(_���A,_�Ј��ԍ�,_�\��A)).
'�Ј��ԍ��������ɑ��݂��ATBL-A�̊����TBL-B�̊���ȑO�̏ꍇ-->�������Ȃ�'(_�Ј��ԍ�) :-
�@�@'TBL-A'(_���A,_�Ј��ԍ�,_�\��A),
�@�@'TBL-B'(_���B,_�Ј��ԍ�,_�\��B),
�@�@_���A @=< _���B.
'�Ј��ԍ���TBL-B�ɍ݂���TBL-A�ɖ����ꍇ-->�������Ȃ�'(_�Ј��ԍ�) :-
�@�@'TBL-B'(_,_�Ј��ԍ�,_),
�@�@\+('TBL-A'(_,_�Ј��ԍ�,_)).
447 �F�f�t�H���g�̖����������F2009/12/04(��) 09:33:57
>>445 >>446
Prolog�ȊO�̌���ł͂܂����ڂɂ�����Ȃ��\���̃v���O�����ł��ˁB
�d�l�̏����ɖ������Ȃ����Ƃ���̏����ł��B�������p�X���Ă����
�d�l�̕����ɂ��ꂼ��W���ł��܂�����A�����₷���Ȃ�܂��ˁB
Prolog�ȊO�̌���ł͂܂����ڂɂ�����Ȃ��\���̃v���O�����ł��ˁB
�d�l�̏����ɖ������Ȃ����Ƃ���̏����ł��B�������p�X���Ă����
�d�l�̕����ɂ��ꂼ��W���ł��܂�����A�����₷���Ȃ�܂��ˁB
448 �F�f�t�H���g�̖����������F2009/12/04(��) 10:32:31
>>436
�Ⴆ���O�����W�F�@�Ő��l��������v���O�����������āA
X��0.1���݂Œl�����߂āAsin(X) + X * cos(X) �̂��ꂼ��̒l��
��r����Ƃ����Ӗ��ł��傤�B
�Ⴆ���O�����W�F�@�Ő��l��������v���O�����������āA
X��0.1���݂Œl�����߂āAsin(X) + X * cos(X) �̂��ꂼ��̒l��
��r����Ƃ����Ӗ��ł��傤�B
449 �F�f�t�H���g�̖����������F2009/12/04(��) 13:11:39
http://pc12.2ch.net/test/read.cgi/tech/1258158172/689
# [1] ���ƒP���F
# �v���O���~���O��b���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# n�̒�����r�����o���Ƃ��̑g���킹�̐�nCr�����߂�����쐬����B
# �������A�ċA�͎g��Ȃ�����!(�J�Ԃ������g��)
# �G���[����(n<1�Ar<1�̏ꍇ�An<r�̏ꍇ)���l����B
#
# [1] ���ƒP���F
# �v���O���~���O��b���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# n�̒�����r�����o���Ƃ��̑g���킹�̐�nCr�����߂�����쐬����B
# �������A�ċA�͎g��Ȃ�����!(�J�Ԃ������g��)
# �G���[����(n<1�Ar<1�̏ꍇ�An<r�̏ꍇ)���l����B
#
450 �F�f�t�H���g�̖����������F2009/12/04(��) 13:20:33
>>449
% Prolog �O�ɂ���܂����ˁB������ƃC���`�L�L���R�[�h�ł��B
nCr(N,R,X) :-
�@�@Y is N-R+1,
�@�@findall(N1,for(N,N1,Y),L1),
�@�@findall(N2,for(R,N2,1),L2),
�@�@concat_atom(L1,'*',S1),
�@�@concat_atom(L2,'*',S2),
�@�@atom_to_term(S1,Term1,_),
�@�@atom_to_term(S2,Term2,_),
�@�@X is Term1 // Term2.
% Prolog �O�ɂ���܂����ˁB������ƃC���`�L�L���R�[�h�ł��B
nCr(N,R,X) :-
�@�@Y is N-R+1,
�@�@findall(N1,for(N,N1,Y),L1),
�@�@findall(N2,for(R,N2,1),L2),
�@�@concat_atom(L1,'*',S1),
�@�@concat_atom(L2,'*',S2),
�@�@atom_to_term(S1,Term1,_),
�@�@atom_to_term(S2,Term2,_),
�@�@X is Term1 // Term2.
451 �F�f�t�H���g�̖����������F2009/12/04(��) 13:39:26
http://pc12.2ch.net/test/read.cgi/tech/1258158172/690
# [1] ���ƒP���F
# �v���O���~���O��b
# [2] ��蕶(�܃R�[�h&�����N)�F
# �L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�v���O�������쐬����B
# �������A���a�����߂镔����main���ƕʂ̊�����邱�ƁB
#
# [1] ���ƒP���F
# �v���O���~���O��b
# [2] ��蕶(�܃R�[�h&�����N)�F
# �L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�v���O�������쐬����B
# �������A���a�����߂镔����main���ƕʂ̊�����邱�ƁB
#
452 �F�f�t�H���g�̖����������F2009/12/04(��) 13:41:56
>>451
% Prolog
program :-
�@�@user_paramebers([A]),
�@�@atom_to_term(A,N,_),
�@�@write('��s�ɃJ���}����%t�A%t�s�̕��������_������͂��Ă�������(���͏I����ctrl-d�����)\n',[N,N]),
�@�@'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a),
�@�@write_formatted('���a��%t�ł�\n',[_���a]).
'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a)�@:-
�@�@get_split_lines(user_input,[','],L),
�@�@findsum(S1,(member(Line,L),findsum(Line,S1)),_���a).
% Prolog
program :-
�@�@user_paramebers([A]),
�@�@atom_to_term(A,N,_),
�@�@write('��s�ɃJ���}����%t�A%t�s�̕��������_������͂��Ă�������(���͏I����ctrl-d�����)\n',[N,N]),
�@�@'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a),
�@�@write_formatted('���a��%t�ł�\n',[_���a]).
'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a)�@:-
�@�@get_split_lines(user_input,[','],L),
�@�@findsum(S1,(member(Line,L),findsum(Line,S1)),_���a).
453 �F�f�t�H���g�̖����������F2009/12/04(��) 13:43:51
>>452 user_parmebers�ɂȂ��Ă��܂����B���̓f�[�^���̃`�F�b�N������
% ���Ȃ����炩�Ȃ�̎蔲���ł��B
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@write('��s�ɃJ���}����%t�A%t�s�̕��������_������͂��Ă�������(���͏I����ctrl-d�����)\n',[N,N]),
�@�@'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a),
�@�@write_formatted('���a��%t�ł�\n',[_���a]).
'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a)�@:-
�@�@get_split_lines(user_input,[','],L),
�@�@findsum(S1,(member(Line,L),findsum(Line,S1)),_���a).
% ���Ȃ����炩�Ȃ�̎蔲���ł��B
program :-
�@�@user_parameters([A]),
�@�@atom_to_term(A,N,_),
�@�@write('��s�ɃJ���}����%t�A%t�s�̕��������_������͂��Ă�������(���͏I����ctrl-d�����)\n',[N,N]),
�@�@'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a),
�@�@write_formatted('���a��%t�ł�\n',[_���a]).
'�L�[�{�[�h��������z��a[N][N]�̊e�v�f�ɒl����͂��A���ׂĂ̗v�f�̑��a�����߂�'(_���a)�@:-
�@�@get_split_lines(user_input,[','],L),
�@�@findsum(S1,(member(Line,L),findsum(Line,S1)),_���a).
454 �F�f�t�H���g�̖����������F2009/12/04(��) 13:47:49
455 �F�f�t�H���g�̖����������F2009/12/04(��) 17:50:30
456 �F�f�t�H���g�̖����������F2009/12/04(��) 19:00:11
>>432
% Prolog�̓I�u�W�F�N�g�w������ł͂Ȃ��̂ŁA�悢�����͍��܂���B������
% Prolog�ł��̂悤�Ȃ��Ƃ��N���邽�߂ɂ͂��ꂼ�ꂪ�T�[�o�[�Ƃ��ċN�����Ă��āA
%%%%%%%%%%% �R�c �T�[�o�[ (���̏ꍇ�̓N���C�A���g�Ƃ���) %%%%%%%%%%%%%%%%
�搶(����,����).
�搶�ɐ��т�₢���킹��(����,_����) :-
�搶(����,_�搶),
_�搶 :: ����̐��т͉��_�ł��傤��(�R�c,_����).
%%%%%%%%%%% ���� �T�[�o�[�@%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����̐��т͉��_�ł��傤��(_���k,_����) :-
������ :: �W�͂���ł���(���і₢���킹,_�W),
_�W :: ���k�̐��т͉��_�ł��傤��(����,_���k,����,_����).
%%%%%%%%%% ������ �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�W�͂���ł���(���і₢���킹,defaultOffice).
%%%%%%%%%%% defaultOffice �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%
���k�̐��т͉��_�ł��傤��(_�搶,_���k,_�Ȗ�,_����) :-
���ѕ�(_���k,_�Ȗ�,_����),
concat_atom([_���k,��,_�Ȗ�,�̐��т�,_����,�_�ł�],_����).
���ѕ�(yamada,����,78).
���ѕ�(yamada,���w,57).
�̂悤�ȃ��b�Z�[�W�������s����K�v������܂��B
% Prolog�̓I�u�W�F�N�g�w������ł͂Ȃ��̂ŁA�悢�����͍��܂���B������
% Prolog�ł��̂悤�Ȃ��Ƃ��N���邽�߂ɂ͂��ꂼ�ꂪ�T�[�o�[�Ƃ��ċN�����Ă��āA
%%%%%%%%%%% �R�c �T�[�o�[ (���̏ꍇ�̓N���C�A���g�Ƃ���) %%%%%%%%%%%%%%%%
�搶(����,����).
�搶�ɐ��т�₢���킹��(����,_����) :-
�搶(����,_�搶),
_�搶 :: ����̐��т͉��_�ł��傤��(�R�c,_����).
%%%%%%%%%%% ���� �T�[�o�[�@%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����̐��т͉��_�ł��傤��(_���k,_����) :-
������ :: �W�͂���ł���(���і₢���킹,_�W),
_�W :: ���k�̐��т͉��_�ł��傤��(����,_���k,����,_����).
%%%%%%%%%% ������ �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�W�͂���ł���(���і₢���킹,defaultOffice).
%%%%%%%%%%% defaultOffice �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%
���k�̐��т͉��_�ł��傤��(_�搶,_���k,_�Ȗ�,_����) :-
���ѕ�(_���k,_�Ȗ�,_����),
concat_atom([_���k,��,_�Ȗ�,�̐��т�,_����,�_�ł�],_����).
���ѕ�(yamada,����,78).
���ѕ�(yamada,���w,57).
�̂悤�ȃ��b�Z�[�W�������s����K�v������܂��B
457 �F�f�t�H���g�̖����������F2009/12/04(��) 19:07:02
>>432 ��������
%%%%%%%%%%% �R�c �T�[�o�[ (���̏ꍇ�̓N���C�A���g�Ƃ���)%%%%%%%%%%%%%%%%%%%%%
�搶(����,����).
�搶�ɐ��т�₢���킹��(����,_����) :-
�@ �搶(����,_�搶),
�@ _�搶 :: ����̐��т͉��_�ł��傤��(�R�c,_����).
���b�Z�[�W��M(_����,_���b�Z�[�W) :- assertz(���b�Z�[�W(_����,_���b�Z�[�W)).
%%%%%%%%%%% ���� �T�[�o�[�@%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����̐��т͉��_�ł��傤��(_���k,_����) :-
�@�@������ :: �W�͂���ł���(���і₢���킹,_�W),
�@�@_�W :: ���k�̐��т͉��_�ł��傤��(����,_���k,����,_����).
%%%%%%%%%% ������ �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�W�͂���ł���(���і₢���킹,defaultOffice).
%%%%%%%%%%% defaultOffice �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%
���k�̐��т͉��_�ł��傤��(_�搶,_���k,_�Ȗ�,_����) :-
�@�@���ѕ�(_���k,_�Ȗ�,_����),
�@�@concat_atom([_���k,��,_�Ȗ�,�̐��т�,_����,�_�ł�],_����).
���ѕ�(yamada,����,78).
���ѕ�(yamada,���w,57).
%%%%%%%%%%% �R�c �T�[�o�[ (���̏ꍇ�̓N���C�A���g�Ƃ���)%%%%%%%%%%%%%%%%%%%%%
�搶(����,����).
�搶�ɐ��т�₢���킹��(����,_����) :-
�@ �搶(����,_�搶),
�@ _�搶 :: ����̐��т͉��_�ł��傤��(�R�c,_����).
���b�Z�[�W��M(_����,_���b�Z�[�W) :- assertz(���b�Z�[�W(_����,_���b�Z�[�W)).
%%%%%%%%%%% ���� �T�[�o�[�@%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����̐��т͉��_�ł��傤��(_���k,_����) :-
�@�@������ :: �W�͂���ł���(���і₢���킹,_�W),
�@�@_�W :: ���k�̐��т͉��_�ł��傤��(����,_���k,����,_����).
%%%%%%%%%% ������ �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�W�͂���ł���(���і₢���킹,defaultOffice).
%%%%%%%%%%% defaultOffice �T�[�o�[ %%%%%%%%%%%%%%%%%%%%%%%%%%%%
���k�̐��т͉��_�ł��傤��(_�搶,_���k,_�Ȗ�,_����) :-
�@�@���ѕ�(_���k,_�Ȗ�,_����),
�@�@concat_atom([_���k,��,_�Ȗ�,�̐��т�,_����,�_�ł�],_����).
���ѕ�(yamada,����,78).
���ѕ�(yamada,���w,57).
458 �F�f�t�H���g�̖����������F2009/12/04(��) 19:09:16
459 �F�f�t�H���g�̖����������F2009/12/04(��) 20:30:27
http://pc11.2ch.net/test/read.cgi/db/1252492296/307
#
# �Ɩ��e�[�u�� G_info
# �Ɩ�ID | �Ɩ��� |
# G0001 | �����v |
# G0002 | �~�~���� |
# G0003 | �����v |
#
# �Ɩ��S���e�[�u�� G_charge
# �Ɩ�ID | ���� | �Ј�ID
# G0001 | �Ǘ� | P101
# G0001 | ���� | P103
# G0001 | �v | P105
# G0002 | �Ǘ� | P102
# G0002 | ���� | P103
# G0002 | �v | P106
# G0003 | �Ǘ� | P101
# G0003 | ���� | P104
# G0003 | �v | P107
#
# ����ȃe�[�u���\���������Ƃ��āA
# �v = P101 ���� ���� = P103 �̒S���҂����Ɩ��������o���ɂ͂ǂ̂悤�ɂ�
#�@��Ηǂ��̂ł��傤���H
#
# �Ɩ��e�[�u�� G_info
# �Ɩ�ID | �Ɩ��� |
# G0001 | �����v |
# G0002 | �~�~���� |
# G0003 | �����v |
#
# �Ɩ��S���e�[�u�� G_charge
# �Ɩ�ID | ���� | �Ј�ID
# G0001 | �Ǘ� | P101
# G0001 | ���� | P103
# G0001 | �v | P105
# G0002 | �Ǘ� | P102
# G0002 | ���� | P103
# G0002 | �v | P106
# G0003 | �Ǘ� | P101
# G0003 | ���� | P104
# G0003 | �v | P107
#
# ����ȃe�[�u���\���������Ƃ��āA
# �v = P101 ���� ���� = P103 �̒S���҂����Ɩ��������o���ɂ͂ǂ̂悤�ɂ�
#�@��Ηǂ��̂ł��傤���H
460 �F�f�t�H���g�̖����������F2009/12/04(��) 20:37:39
461 �F�f�t�H���g�̖����������F2009/12/05(�y) 04:20:21
462 �F�f�t�H���g�̖����������F2009/12/05(�y) 04:40:17
% Prolog ���܂�
'>>459�̃e�[�u���\���t�@�C������e�[�u�������q��Ƃ��Ē�`����'(_�t�@�C��) :-
�@�@get_split_lines(_�t�@�C��,[' ','�b'],Lines),
�@�@��ȏ�̃e�[�u�����q��Ƃ��Ē�`(Lines).
��ȏ�̃e�[�u�����q��Ƃ��Ē�`(Lines) :-
�@�@append(_,[[A,B]|L2],Lines),
�@�@append([_|L3],[''|L4],L2),
�@�@sub_atom(A,_,_,_,_�e�[�u����,�e�[�u��,_,_,_,_),
�@�@�e�[�u�����q��Ƃ��Ē�`(_�e�[�u����,L3),
�@�@��ȏ�̃e�[�u�����q��Ƃ��Ē�`(L4).
��ȏ�̃e�[�u�����q��Ƃ��Ē�`(_).
�e�[�u�����q��Ƃ��Ē�`(_�e�[�u��,L) :-
�@�@member(L1,L),
�@�@P =.. [_�e�[�u��|L1],
�@�@assertz(P),
�@�@fail.
�e�[�u�����q��Ƃ��Ē�`(_,_).
'>>459�̃e�[�u���\���t�@�C������e�[�u�������q��Ƃ��Ē�`����'(_�t�@�C��) :-
�@�@get_split_lines(_�t�@�C��,[' ','�b'],Lines),
�@�@��ȏ�̃e�[�u�����q��Ƃ��Ē�`(Lines).
��ȏ�̃e�[�u�����q��Ƃ��Ē�`(Lines) :-
�@�@append(_,[[A,B]|L2],Lines),
�@�@append([_|L3],[''|L4],L2),
�@�@sub_atom(A,_,_,_,_�e�[�u����,�e�[�u��,_,_,_,_),
�@�@�e�[�u�����q��Ƃ��Ē�`(_�e�[�u����,L3),
�@�@��ȏ�̃e�[�u�����q��Ƃ��Ē�`(L4).
��ȏ�̃e�[�u�����q��Ƃ��Ē�`(_).
�e�[�u�����q��Ƃ��Ē�`(_�e�[�u��,L) :-
�@�@member(L1,L),
�@�@P =.. [_�e�[�u��|L1],
�@�@assertz(P),
�@�@fail.
�e�[�u�����q��Ƃ��Ē�`(_,_).
463 �F�f�t�H���g�̖����������F2009/12/05(�y) 05:27:18
http://pc12.2ch.net/test/read.cgi/tech/1235561034/658
# �ȉ���\������v���O�����������B
#
# -1
# ---3
# ------6
# ----------10
# ---------------15
# ---------------------21
# -------------------------25
# ---------------------------27
# ---------------------------27
# -------------------------25
# ---------------------21
# ---------------15
# ----------10
# ------6
# ---3
# -1
# �ȉ���\������v���O�����������B
#
# -1
# ---3
# ------6
# ----------10
# ---------------15
# ---------------------21
# -------------------------25
# ---------------------------27
# ---------------------------27
# -------------------------25
# ---------------------21
# ---------------15
# ----------10
# ------6
# ---3
# -1
464 �F�f�t�H���g�̖����������F2009/12/05(�y) 07:30:52
>>463
% Prolog
pro_658(Max,M) :- f1(0,Max,M,0).
f1(Max,Max,M,V) :- f2(Max,M,V).
f1(N,Max,M,V) :-
�@�@N =< Max,
�@�@V2 is V + N + 1,
�@�@'print-'(V2),
�@�@N2 is N + 1,
�@�@f1(N2,Max,M,V2),
�@�@'print-'(V2).
f2(N,M,_) :- N =< M,!.
f2(N,M,V) :-
�@�@V2 is V + N - M,
�@�@'print-'(V2),
�@�@N2 is N - M,
�@�@f2(N2,M,V2),
�@�@'print-'(V2).
'print-'(V) :- for(1,N,V),write(-),N=V,write_formatted('%t\n',[V]).
% Prolog
pro_658(Max,M) :- f1(0,Max,M,0).
f1(Max,Max,M,V) :- f2(Max,M,V).
f1(N,Max,M,V) :-
�@�@N =< Max,
�@�@V2 is V + N + 1,
�@�@'print-'(V2),
�@�@N2 is N + 1,
�@�@f1(N2,Max,M,V2),
�@�@'print-'(V2).
f2(N,M,_) :- N =< M,!.
f2(N,M,V) :-
�@�@V2 is V + N - M,
�@�@'print-'(V2),
�@�@N2 is N - M,
�@�@f2(N2,M,V2),
�@�@'print-'(V2).
'print-'(V) :- for(1,N,V),write(-),N=V,write_formatted('%t\n',[V]).
465 �F�f�t�H���g�̖����������F2009/12/05(�y) 09:53:55
466 �F�f�t�H���g�̖����������F2009/12/05(�y) 15:00:56
http://pc12.2ch.net/test/read.cgi/tech/1248012902/570
# 10�̒l�̍ő�l�����߂�v���O����
# 10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\������v���O�������쐬���Ȃ����Ƃ������̂ł��B
# ���s���ʂ̗�͈ȉ��̂悤�Ȋ����ł��B
# 1�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# 2�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# ��
# 10�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# ���̒��ň�Ԑg���������l�́���cm�ł��B
# �i���Ӂj
# 1�ő�l���L������ϐ���p�ӂ��A0�������Ă����B
# 2for����p���Ĉȉ��̏������\��J��Ԃ��B
# 2.1�u?�l�ڂ̐g���icm�j����͂��Ă��������v�ƕ\������
# 2.2�L�[�{�[�h����l����͂���B
# 2.3���͒l���L�����Ă���ő�l���傫�����ǂ�����if����p���Ĕ�r����B
# 2.3.1�傫���Ȃ�A���̒l���ő�l�Ƃ��đ������B
# 3 ���ʂ�\������
# 10�̒l�̍ő�l�����߂�v���O����
# 10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\������v���O�������쐬���Ȃ����Ƃ������̂ł��B
# ���s���ʂ̗�͈ȉ��̂悤�Ȋ����ł��B
# 1�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# 2�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# ��
# 10�l�ڂ̐g���icm�j����͂��Ă�������:�i���͑҂��j
# ���̒��ň�Ԑg���������l�́���cm�ł��B
# �i���Ӂj
# 1�ő�l���L������ϐ���p�ӂ��A0�������Ă����B
# 2for����p���Ĉȉ��̏������\��J��Ԃ��B
# 2.1�u?�l�ڂ̐g���icm�j����͂��Ă��������v�ƕ\������
# 2.2�L�[�{�[�h����l����͂���B
# 2.3���͒l���L�����Ă���ő�l���傫�����ǂ�����if����p���Ĕ�r����B
# 2.3.1�傫���Ȃ�A���̒l���ő�l�Ƃ��đ������B
# 3 ���ʂ�\������
467 �F�f�t�H���g�̖����������F2009/12/05(�y) 16:15:54
>>466
% Prolog
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��' :-
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[1]),
�@�@get_integer(I),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(1,I,M,X),
�@�@write_formatted('�ł����������g����%tcm�ł�\n',[X]).
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(10,I,M,M) :-
�@�@I =< M,!.
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(10,I,M,I) :-
�@�@I > M,!.
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N,I,M,X) :-
�@�@I =< M,
�@�@N2 is N + 1,
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[N2]),
�@�@get_integer(I2),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N2,I2,M,X).
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N,I,M,X) :-
�@�@I > M,
�@�@N2 is N + 1,
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[N2]),
�@�@get_integer(I2),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N2,I2,I,X).
% Prolog
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��' :-
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[1]),
�@�@get_integer(I),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(1,I,M,X),
�@�@write_formatted('�ł����������g����%tcm�ł�\n',[X]).
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(10,I,M,M) :-
�@�@I =< M,!.
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(10,I,M,I) :-
�@�@I > M,!.
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N,I,M,X) :-
�@�@I =< M,
�@�@N2 is N + 1,
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[N2]),
�@�@get_integer(I2),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N2,I2,M,X).
'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N,I,M,X) :-
�@�@I > M,
�@�@N2 is N + 1,
�@�@write_formatted('%�l�ڂ̐g������͂��Ă������� : ',[N2]),
�@�@get_integer(I2),
�@�@'10�l�̐g���f�[�^������cm�P�ʂœ��͂����Ƃ��A��ԑ傫�Ȑg���͉�cm����\��'(N2,I2,I,X).
468 �F�f�t�H���g�̖����������F2009/12/05(�y) 17:18:59
http://pc11.2ch.net/test/read.cgi/db/1252492296/314
# ���[�U�[�������̎��i�������Ă���Ƃ������肪���ȃe�[�u���\��������̂ł����A
# �u���i�P�܂��͎��i�Q�������Ă��郆�[�U�[�v�̌����͂ł���̂ł����A
# �u���i�P�Ǝ��i�Q�v�𗼕������Ă��郆�[�U�[�v�̌������ł��܂���B
#
# �e�[�u���\���͂���Ȋ����ł��B
#
# ���[�U�[�e�[�u��
# [���[�U�[ID�A���O]
# 001,�R�c
# 002,���
#
# ���i�e�[�u��
# [���[�U�[ID�A���i]
# 001,���i�P
# 001,���i�Q
# 002,���i�P
# ���[�U�[�������̎��i�������Ă���Ƃ������肪���ȃe�[�u���\��������̂ł����A
# �u���i�P�܂��͎��i�Q�������Ă��郆�[�U�[�v�̌����͂ł���̂ł����A
# �u���i�P�Ǝ��i�Q�v�𗼕������Ă��郆�[�U�[�v�̌������ł��܂���B
#
# �e�[�u���\���͂���Ȋ����ł��B
#
# ���[�U�[�e�[�u��
# [���[�U�[ID�A���O]
# 001,�R�c
# 002,���
#
# ���i�e�[�u��
# [���[�U�[ID�A���i]
# 001,���i�P
# 001,���i�Q
# 002,���i�P
469 �F�f�t�H���g�̖����������F2009/12/05(�y) 18:22:28
>>468
% Prolog
���[�U�[ID('001',�R�c).
���[�U�[ID('002',���).
���i('001',���i�P).
���i('001',���i�Q).
���i('002',���i�P).
'�u���i�P�Ǝ��i�Q�v�𗼕������Ă��郆�[�U�['(X) :-
�@�@setof(_���O,(���i(_���[�U�[ID,���i�P),���i(_���[�U�[ID,���i�Q),���[�U�[ID(_���[�U�[ID,_���O)),X).
% Prolog
���[�U�[ID('001',�R�c).
���[�U�[ID('002',���).
���i('001',���i�P).
���i('001',���i�Q).
���i('002',���i�P).
'�u���i�P�Ǝ��i�Q�v�𗼕������Ă��郆�[�U�['(X) :-
�@�@setof(_���O,(���i(_���[�U�[ID,���i�P),���i(_���[�U�[ID,���i�Q),���[�U�[ID(_���[�U�[ID,_���O)),X).
470 �F�f�t�H���g�̖����������F2009/12/06(��) 00:27:54
>>410
�g�p����F�@�\�iBASIC
SUB print_bin(n)
LET b$=""
IF n=0 THEN LET b$="0"
DO WHILE(n>0)
LET b$=STR$(MOD(n,2))&b$
LET n=INT(n/2)
LOOP
PRINT b$
END SUB
CALL print_bin(123456789)
PRINT BSTR$(123456789,2) !�g���݂̊��̏ꍇ
END
���s����
111010110111100110100010101
111010110111100110100010101
�g�p����F�@�\�iBASIC
SUB print_bin(n)
LET b$=""
IF n=0 THEN LET b$="0"
DO WHILE(n>0)
LET b$=STR$(MOD(n,2))&b$
LET n=INT(n/2)
LOOP
PRINT b$
END SUB
CALL print_bin(123456789)
PRINT BSTR$(123456789,2) !�g���݂̊��̏ꍇ
END
���s����
111010110111100110100010101
111010110111100110100010101
471 �F�f�t�H���g�̖����������F2009/12/06(��) 01:30:15
>>412
�g�p����F�@�\�iBASIC
LET t$="abcdefghijklmnopqrstuvvxyzabcABCDEFGHIJKLMNOPQRSTUVWXYZABC"
INPUT a$
LET s$=""
FOR i=1 TO LEN(a$)
LET b=POS(t$,a$(i:i))+3
LET s$=s$&t$(b:b)
NEXT I
PRINT s$
END
���s����
? aBcDeFgHiJkLmNoPqRsTuVwXyZ
dEfGhIjKlMnOpQrStUvWxYcAbC
�g�p����F�@�\�iBASIC
LET t$="abcdefghijklmnopqrstuvvxyzabcABCDEFGHIJKLMNOPQRSTUVWXYZABC"
INPUT a$
LET s$=""
FOR i=1 TO LEN(a$)
LET b=POS(t$,a$(i:i))+3
LET s$=s$&t$(b:b)
NEXT I
PRINT s$
END
���s����
? aBcDeFgHiJkLmNoPqRsTuVwXyZ
dEfGhIjKlMnOpQrStUvWxYcAbC
472 �F�f�t�H���g�̖����������F2009/12/06(��) 02:44:58
473 �F�f�t�H���g�̖����������F2009/12/06(��) 04:36:21
http://pc12.2ch.net/test/read.cgi/tech/1258158172/709
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10227.txt
#
# [�ۑ�P]
# �@100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\�����Ȃ���.�����
# �z��a�̃f�[�^����{�I��@�ɂ���ď����ɐ��A�����̔z��a���e��\�������Ȃ���.
# [�ۑ�Q]
# �@100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\�����Ȃ���.�����
# �z��a�̃f�[�^����{�I��@�ɂ���č~���ɐ��A�����̔z��a���e��\�������Ȃ���.
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10227.txt
#
# [�ۑ�P]
# �@100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\�����Ȃ���.�����
# �z��a�̃f�[�^����{�I��@�ɂ���ď����ɐ��A�����̔z��a���e��\�������Ȃ���.
# [�ۑ�Q]
# �@100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\�����Ȃ���.�����
# �z��a�̃f�[�^����{�I��@�ɂ���č~���ɐ��A�����̔z��a���e��\�������Ȃ���.
474 �F�f�t�H���g�̖����������F2009/12/06(��) 05:20:20
>>410
�g�p����F�@Io
g:=method(n,if(n<2,write(n),g((n/2)floor);write(n%2)))
print_bin:=method(n,g(n);writeln)
Io> print_bin(123456789)
111010110111100110100010101
==> nil
�g�p����F�@Io
g:=method(n,if(n<2,write(n),g((n/2)floor);write(n%2)))
print_bin:=method(n,g(n);writeln)
Io> print_bin(123456789)
111010110111100110100010101
==> nil
475 �F�f�t�H���g�̖����������F2009/12/06(��) 06:59:24
>>17�@���1
�g�p����F�@tcl
proc f {n} {string range " abcdefghijklmnopqrstuvwxyz" 1 $n}
% f 30
abcdefghijklmnopqrstuvwxyz
% f 7
abcdefg
�g�p����F�@tcl
proc f {n} {string range " abcdefghijklmnopqrstuvwxyz" 1 $n}
% f 30
abcdefghijklmnopqrstuvwxyz
% f 7
abcdefg
476 �F�f�t�H���g�̖����������F2009/12/06(��) 08:06:40
>>17�@���2
�g�p����F�@tcl
proc f {n} {
set s 0
for {set i 1} {$i<=$n} {incr i} {
if {[expr $i%3==0||$i%5==0]} {incr s $i}
}
puts $s
}
% f 10
33
% f 100
2418
�g�p����F�@tcl
proc f {n} {
set s 0
for {set i 1} {$i<=$n} {incr i} {
if {[expr $i%3==0||$i%5==0]} {incr s $i}
}
puts $s
}
% f 10
33
% f 100
2418
477 �F�f�t�H���g�̖����������F2009/12/06(��) 09:08:00
>>466
�g�p����F�@�\�iBASIC
LET h=0
FOR i=1 TO 10
INPUT PROMPT STR$(i)&"�l�ڂ̐g��(cm)����͂��Ă�������:":a
IF a>h THEN LET h=a
NEXT I
PRINT USING"���̒��ň�Ԑg���������l��###cm�ł��B": h
END
���s����
1�l�ڂ̐g��(cm)����͂��Ă�������:190
2�l�ڂ̐g��(cm)����͂��Ă�������:180
3�l�ڂ̐g��(cm)����͂��Ă�������:170
4�l�ڂ̐g��(cm)����͂��Ă�������:165
5�l�ڂ̐g��(cm)����͂��Ă�������:155
6�l�ڂ̐g��(cm)����͂��Ă�������:187
7�l�ڂ̐g��(cm)����͂��Ă�������:147
8�l�ڂ̐g��(cm)����͂��Ă�������:152
9�l�ڂ̐g��(cm)����͂��Ă�������:166
10�l�ڂ̐g��(cm)����͂��Ă�������:174
���̒��ň�Ԑg���������l��190cm�ł��B
�g�p����F�@�\�iBASIC
LET h=0
FOR i=1 TO 10
INPUT PROMPT STR$(i)&"�l�ڂ̐g��(cm)����͂��Ă�������:":a
IF a>h THEN LET h=a
NEXT I
PRINT USING"���̒��ň�Ԑg���������l��###cm�ł��B": h
END
���s����
1�l�ڂ̐g��(cm)����͂��Ă�������:190
2�l�ڂ̐g��(cm)����͂��Ă�������:180
3�l�ڂ̐g��(cm)����͂��Ă�������:170
4�l�ڂ̐g��(cm)����͂��Ă�������:165
5�l�ڂ̐g��(cm)����͂��Ă�������:155
6�l�ڂ̐g��(cm)����͂��Ă�������:187
7�l�ڂ̐g��(cm)����͂��Ă�������:147
8�l�ڂ̐g��(cm)����͂��Ă�������:152
9�l�ڂ̐g��(cm)����͂��Ă�������:166
10�l�ڂ̐g��(cm)����͂��Ă�������:174
���̒��ň�Ԑg���������l��190cm�ł��B
478 �F�f�t�H���g�̖����������F2009/12/06(��) 09:43:40
>>17�@���1
�g�p����F�@UWSC
print f(9)
print f(30)
FUNCTION f(n)
RESULT = copy("abcdefghijklmnopqrstuvwxyz",1,n)
FEND
���s����
abcdefghi
abcdefghijklmnopqrstuvwxyz
�g�p����F�@UWSC
print f(9)
print f(30)
FUNCTION f(n)
RESULT = copy("abcdefghijklmnopqrstuvwxyz",1,n)
FEND
���s����
abcdefghi
abcdefghijklmnopqrstuvwxyz
479 �F�f�t�H���g�̖����������F2009/12/06(��) 12:37:56
123456
12345
1234
123
12
1
12345
1234
123
12
1
480 �F�f�t�H���g�̖����������F2009/12/06(��) 12:45:48
>>47
����H�Ȃ������݂Ɏ��s�����̂ł�����x�B
�g�p����F�@�\�iBASIC
SUB f(s$)
LET b=LEN(s$)
FOR i=1 TO b
PRINT s$
LET s$=s$(1:b-i)
NEXT I
END SUB
CALL f("123456")
END
���s����
123456
12345
1234
123
12
1
����H�Ȃ������݂Ɏ��s�����̂ł�����x�B
�g�p����F�@�\�iBASIC
SUB f(s$)
LET b=LEN(s$)
FOR i=1 TO b
PRINT s$
LET s$=s$(1:b-i)
NEXT I
END SUB
CALL f("123456")
END
���s����
123456
12345
1234
123
12
1
481 �F�f�t�H���g�̖����������F2009/12/06(��) 16:23:31
>>17�@���1
�g�p����F�@�Ȃł���
��f(n)
�uabcdefghijklmnopqrstuvwxyz�v��1���� n ���������o���ĕ\���B
f(5)
���s����
abcde
�g�p����F�@�Ȃł���
��f(n)
�uabcdefghijklmnopqrstuvwxyz�v��1���� n ���������o���ĕ\���B
f(5)
���s����
abcde
482 �F�f�t�H���g�̖����������F2009/12/06(��) 17:42:45
>>481
�����˂��B
�����˂��B
483 �F�f�t�H���g�̖����������F2009/12/06(��) 17:52:52
http://pc12.2ch.net/test/read.cgi/tech/1258158172/735
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/1023
9.txt
#
# �P.
# ����[�~]�ƔN��[%]�Ɨa���N��[�N]���L�[�{�[�h������͂����A�����̌������v��\��
����
# �v���O����smp8-12.c���쐬�A�R���p�C���A���s���Ȃ����B
# (�ȉ��̎��s���ʂ��Q�Ƃɂ���)
# ���̍ہA�����A�N���A�a���N���������Ƃ��Č������v�����߂��clac_pandi()����
��
# ���p���邱�Ɓiclac_pandi�ł͉�ʕ\���s�Ƃ���j�B
# �Ȃ��A�����͕����Ōv�Z���A���N�x�̗����̉~�P�ʖ����͐؎̂Ă邱�ƁB
#
# ����[�~]����͂��Ă��������@: 3613 enter��
# �N��[%]����͂��Ă������� : 9.6 enter��
# �a���N�x����͂��Ă��������@: �Q�P enter��
# 3613�~��N��9.600000%��21�N�ԗa������ƁA24734�~�ɂȂ�܂��B
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/1023
9.txt
#
# �P.
# ����[�~]�ƔN��[%]�Ɨa���N��[�N]���L�[�{�[�h������͂����A�����̌������v��\��
����
# �v���O����smp8-12.c���쐬�A�R���p�C���A���s���Ȃ����B
# (�ȉ��̎��s���ʂ��Q�Ƃɂ���)
# ���̍ہA�����A�N���A�a���N���������Ƃ��Č������v�����߂��clac_pandi()����
��
# ���p���邱�Ɓiclac_pandi�ł͉�ʕ\���s�Ƃ���j�B
# �Ȃ��A�����͕����Ōv�Z���A���N�x�̗����̉~�P�ʖ����͐؎̂Ă邱�ƁB
#
# ����[�~]����͂��Ă��������@: 3613 enter��
# �N��[%]����͂��Ă������� : 9.6 enter��
# �a���N�x����͂��Ă��������@: �Q�P enter��
# 3613�~��N��9.600000%��21�N�ԗa������ƁA24734�~�ɂȂ�܂��B
484 �F�f�t�H���g�̖����������F2009/12/06(��) 17:53:57
http://pc12.2ch.net/test/read.cgi/tech/1258158172/735
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10239.txt
#
# 2.
# �������L�[�{�[�h������͂����A�p�啶���͉p�������ɕϊ����āA�p�������͉p�啶���ɕϊ����āA
# ���̑��̕����͂��̂܂o�͂���v���O�������쐬���Ȃ����B
# �������A�����̓��͂ɂ�getchar�����A�o�͂ɂ�putchar����K���g�p���邱�ƁB
# �܂��A�����̕ϊ��ɂ͕W�����C�u���������g�p�����A�����������Ƃ��鎩��̊�
# conv_letter()���쐬�A���p���邱��(conv_letter�ł͉�ʕ\���s�Ƃ���B�j
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10239.txt
#
# 2.
# �������L�[�{�[�h������͂����A�p�啶���͉p�������ɕϊ����āA�p�������͉p�啶���ɕϊ����āA
# ���̑��̕����͂��̂܂o�͂���v���O�������쐬���Ȃ����B
# �������A�����̓��͂ɂ�getchar�����A�o�͂ɂ�putchar����K���g�p���邱�ƁB
# �܂��A�����̕ϊ��ɂ͕W�����C�u���������g�p�����A�����������Ƃ��鎩��̊�
# conv_letter()���쐬�A���p���邱��(conv_letter�ł͉�ʕ\���s�Ƃ���B�j
#
485 �F�f�t�H���g�̖����������F2009/12/06(��) 17:55:50
http://pc12.2ch.net/test/read.cgi/tech/1258158172/735
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10239.txt
#
# �R.
# �Q�S�����̎��ԁA���A�b���L�[�{�[�h������͂����A�b���ɕϊ����ĉ�ʂɏo�͂���v���O������
# �쐬���Ȃ����B(�ȉ��̎��s���ʂ��Q�Ƃ̂��Ɓj�B���̍ہA���ԁA���A�b�������Ƃ��ĕb�������߂�
# ��clac_second()���쐬�A���p���邱��(clac second()�ł͉�ʕ\���s�Ƃ���B�j
# �Ȃ��A���̊��́A�s���Ȏ��ԁA���A�b���n���ꂽ�ہA�G���[�Ƃ���-1��Ԃ����ƂƂ���B
#
# ����(0�`23)����͂��Ă��������F96��
# ��(0�`59)����͂��Ă��������F36��
# �b(0�`59)����͂��Ă��������F13��
# �s���Ȏ��ԁA���A�܂��͕b�����͂���܂���
# ��
# ����(0�`23)����͂��Ă��������F16��
# ��(0�`59)����͂��Ă��������F36��
# �b(0�`59)����͂��Ă��������F13��
# �s���Ȏ��ԁA���A�܂��͕b�����͂���܂���
# 16����36��13�b��59773�b�ł��B
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶�F
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10239.txt
#
# �R.
# �Q�S�����̎��ԁA���A�b���L�[�{�[�h������͂����A�b���ɕϊ����ĉ�ʂɏo�͂���v���O������
# �쐬���Ȃ����B(�ȉ��̎��s���ʂ��Q�Ƃ̂��Ɓj�B���̍ہA���ԁA���A�b�������Ƃ��ĕb�������߂�
# ��clac_second()���쐬�A���p���邱��(clac second()�ł͉�ʕ\���s�Ƃ���B�j
# �Ȃ��A���̊��́A�s���Ȏ��ԁA���A�b���n���ꂽ�ہA�G���[�Ƃ���-1��Ԃ����ƂƂ���B
#
# ����(0�`23)����͂��Ă��������F96��
# ��(0�`59)����͂��Ă��������F36��
# �b(0�`59)����͂��Ă��������F13��
# �s���Ȏ��ԁA���A�܂��͕b�����͂���܂���
# ��
# ����(0�`23)����͂��Ă��������F16��
# ��(0�`59)����͂��Ă��������F36��
# �b(0�`59)����͂��Ă��������F13��
# �s���Ȏ��ԁA���A�܂��͕b�����͂���܂���
# 16����36��13�b��59773�b�ł��B
486 �F�f�t�H���g�̖����������F2009/12/06(��) 18:19:02
>>481
�Ȃł������Ȃ��B
�Ȃł������Ȃ��B
487 �F�f�t�H���g�̖����������F2009/12/06(��) 19:13:57
>>17�@���1
�g�p����F�@APL(A+)
$mode ascii
f n : 'abcdefghijklmnopqrstuvwxyz'[iota n min 26]
f 6
abcdef
f 30
abcdefghijklmnopqrstuvwxyz
�g�p����F�@APL(A+)
$mode ascii
f n : 'abcdefghijklmnopqrstuvwxyz'[iota n min 26]
f 6
abcdef
f 30
abcdefghijklmnopqrstuvwxyz
488 �F�f�t�H���g�̖����������F2009/12/06(��) 19:34:21
>>47
�g�p����F�@Io
f:=method(s,(b:=s size)repeat(i,writeln(s slice(0,b-i))))
Io> f("12345")
12345
1234
123
12
1
==> nil
�g�p����F�@Io
f:=method(s,(b:=s size)repeat(i,writeln(s slice(0,b-i))))
Io> f("12345")
12345
1234
123
12
1
==> nil
489 �F�f�t�H���g�̖����������F2009/12/06(��) 19:34:30
http://pc12.2ch.net/test/read.cgi/tech/1258158172/749
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10241.txt
# ���L�\���̌^�z������B
# �f�[�^�͓��͂��邱�ƁB
# �m�F�̂��ߊe�z��v�f��\�����邱�ƁB
# 20 40 10 50 30
# CD GH AB IJ EF
#
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10241.txt
# ���L�\���̌^�z������B
# �f�[�^�͓��͂��邱�ƁB
# �m�F�̂��ߊe�z��v�f��\�����邱�ƁB
# 20 40 10 50 30
# CD GH AB IJ EF
#
490 �F�f�t�H���g�̖����������F2009/12/07(��) 00:08:06
http://pc12.2ch.net/test/read.cgi/tech/1258158172/754
# [1] ���ƒP���FC
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���͂��ꂽ�f�[�^�����Ƃɔ��㖾�ׂ��쐬���ĕ\������B
# ���̓f�[�^�͏��i���Ƌ��z�ŁA�ő�Q�O���Ƃ��A^z�ŏI������B
# ���͂��ꂽ�f�[�^�͍\���̔z��ɋL�^���A
# ���͏I������z���W�v���č��v��\������B
# ���\���̃����o��
# ���i���Fchar�^�P�O��
# ���z�Flong�^
# �����s���ʁ�
# ^z
# ���i���@�@�@�@���z
# �߿�݁@�@�@248500
# �@�@�@�@�@3200
# ���ށ@�@�@�@120500
# ���ި��@�@314000
# ڲ���@�@�@65800
# ��װ�@�@�@�@79000
# ���v�@�@�@�@831000
#
# [1] ���ƒP���FC
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���͂��ꂽ�f�[�^�����Ƃɔ��㖾�ׂ��쐬���ĕ\������B
# ���̓f�[�^�͏��i���Ƌ��z�ŁA�ő�Q�O���Ƃ��A^z�ŏI������B
# ���͂��ꂽ�f�[�^�͍\���̔z��ɋL�^���A
# ���͏I������z���W�v���č��v��\������B
# ���\���̃����o��
# ���i���Fchar�^�P�O��
# ���z�Flong�^
# �����s���ʁ�
# ^z
# ���i���@�@�@�@���z
# �߿�݁@�@�@248500
# �@�@�@�@�@3200
# ���ށ@�@�@�@120500
# ���ި��@�@314000
# ڲ���@�@�@65800
# ��װ�@�@�@�@79000
# ���v�@�@�@�@831000
#
491 �F�f�t�H���g�̖����������F2009/12/07(��) 05:09:12
http://pc12.2ch.net/test/read.cgi/tech/1258158172/759
# [1] ���ƒP���FC���p
# [2] ��蕶(�܃R�[�h&�����N)�F�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10244.txt
#
# ��DeleteThreshold���쐬���AThreshold�i臒l�j�̒l��scanf�œǂݍ��݁A
# �w��a����d�̉p��Ɛ��w�̕��ϓ_��臒l���r���A
# 臒l�ȉ��̊w�������X�g����폜����v���O�������쐬����B
# ��DeleteThreshold���Ŋ�Print���g�p����B
# �܂��A��Print�̎��̍s�ɁA�`�l�폜�̏ꍇ�́u�`�l�폜���܂����v�Ɠ��͂���B
# �S���폜�̏ꍇ�́u�S���폜���܂����v��������͂���B
# [1] ���ƒP���FC���p
# [2] ��蕶(�܃R�[�h&�����N)�F�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10244.txt
#
# ��DeleteThreshold���쐬���AThreshold�i臒l�j�̒l��scanf�œǂݍ��݁A
# �w��a����d�̉p��Ɛ��w�̕��ϓ_��臒l���r���A
# 臒l�ȉ��̊w�������X�g����폜����v���O�������쐬����B
# ��DeleteThreshold���Ŋ�Print���g�p����B
# �܂��A��Print�̎��̍s�ɁA�`�l�폜�̏ꍇ�́u�`�l�폜���܂����v�Ɠ��͂���B
# �S���폜�̏ꍇ�́u�S���폜���܂����v��������͂���B
492 �F�f�t�H���g�̖����������F2009/12/07(��) 07:30:27
>>483
% Prolog
�������v(M,_����,_�ؓ���,_�������v) :-
�@�@�������v(1,M,_����,_�ؓ���,_�������v).
�������v(N,M,_����,_�������v,_�������v) :- N > M.
�������v(N,M,_����,_�������v1,_�������v) :-
�@�@N =< M,
�@�@_�������v2 is _�������v1 + floor(_�������v1 * _����),
�@�@N2 is N + 1,
�@�@�������v(N2,M,_����,_�������v2,_�������v).
% Prolog
�������v(M,_����,_�ؓ���,_�������v) :-
�@�@�������v(1,M,_����,_�ؓ���,_�������v).
�������v(N,M,_����,_�������v,_�������v) :- N > M.
�������v(N,M,_����,_�������v1,_�������v) :-
�@�@N =< M,
�@�@_�������v2 is _�������v1 + floor(_�������v1 * _����),
�@�@N2 is N + 1,
�@�@�������v(N2,M,_����,_�������v2,_�������v).
493 �F�f�t�H���g�̖����������F2009/12/07(��) 08:14:29
>>485
�g�p����F�@�\�iBASIC
FUNCTION calc_second(h,m,s)
IF (0<=h AND h<=23)AND(0<=m AND m <=59)AND(0<=s AND s<=59) THEN
LET calc_second=h*60*60+m*60+s
ELSE
LET calc_second=-1
END IF
END FUNCTION
INPUT PROMPT "����(0�`23)����͂��Ă��������F":h
INPUT PROMPT "��(0�`59)����͂��Ă��������F":m
INPUT PROMPT "�b(0�`59)����͂��Ă��������F":s
LET t=calc_second(h,m,s)
IF t=-1 THEN
PRINT "�s���Ȏ��ԁA���A�܂��͕b�����͂���܂����B"
ELSE
PRINT USING"##����##��##�b��#####�b�ł��B":h,m,s,t
END IF
END
���s����
����(0�`23)����͂��Ă��������F96
��(0�`59)����͂��Ă��������F36
�b(0�`59)����͂��Ă��������F13
�s���Ȏ��ԁA���A�܂��͕b�����͂���܂����B
����(0�`23)����͂��Ă��������F16
��(0�`59)����͂��Ă��������F36
�b(0�`59)����͂��Ă��������F13
16����36��13�b��59773�b�ł��B
�g�p����F�@�\�iBASIC
FUNCTION calc_second(h,m,s)
IF (0<=h AND h<=23)AND(0<=m AND m <=59)AND(0<=s AND s<=59) THEN
LET calc_second=h*60*60+m*60+s
ELSE
LET calc_second=-1
END IF
END FUNCTION
INPUT PROMPT "����(0�`23)����͂��Ă��������F":h
INPUT PROMPT "��(0�`59)����͂��Ă��������F":m
INPUT PROMPT "�b(0�`59)����͂��Ă��������F":s
LET t=calc_second(h,m,s)
IF t=-1 THEN
PRINT "�s���Ȏ��ԁA���A�܂��͕b�����͂���܂����B"
ELSE
PRINT USING"##����##��##�b��#####�b�ł��B":h,m,s,t
END IF
END
���s����
����(0�`23)����͂��Ă��������F96
��(0�`59)����͂��Ă��������F36
�b(0�`59)����͂��Ă��������F13
�s���Ȏ��ԁA���A�܂��͕b�����͂���܂����B
����(0�`23)����͂��Ă��������F16
��(0�`59)����͂��Ă��������F36
�b(0�`59)����͂��Ă��������F13
16����36��13�b��59773�b�ł��B
494 �F�f�t�H���g�̖����������F2009/12/07(��) 08:19:03
>>182
�g�p����F�@APL(A+)
$mode ascii
a := 1+iota 10
a *. a
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
�g�p����F�@APL(A+)
$mode ascii
a := 1+iota 10
a *. a
1 2 3 4 5 6 7 8 9 10
2 4 6 8 10 12 14 16 18 20
3 6 9 12 15 18 21 24 27 30
4 8 12 16 20 24 28 32 36 40
5 10 15 20 25 30 35 40 45 50
6 12 18 24 30 36 42 48 54 60
7 14 21 28 35 42 49 56 63 70
8 16 24 32 40 48 56 64 72 80
9 18 27 36 45 54 63 72 81 90
10 20 30 40 50 60 70 80 90 100
495 �F�f�t�H���g�̖����������F2009/12/07(��) 08:21:39
>>257 >>331
�g�p����F�@REBOL
>> pow4: func[n][n * n * n * n]
>> pow4(6)
== 1296
>> pow4(100)
== 100000000
>> pow4(500)
** Math Error: Math or number overflow
** Where: pow4
** Near: n * n * n
�g�p����F�@REBOL
>> pow4: func[n][n * n * n * n]
>> pow4(6)
== 1296
>> pow4(100)
== 100000000
>> pow4(500)
** Math Error: Math or number overflow
** Where: pow4
** Near: n * n * n
496 �F�f�t�H���g�̖����������F2009/12/07(��) 09:52:21
>>485
% Prolog
'�Q�S�����̎��ԁA���A�b���L�[�{�[�h������͂����A�b���ɕϊ����ĉ�ʂɏo�͂���':-
�@�@�Ñ��t����������('����(0�`23)����͂��Ă��������F',_����),
�@�@�Ñ��t����������('��(0�`59)����͂��Ă��������F',_��),
�@�@�Ñ��t����������('�b(0�`59)����͂��Ă��������F',_�b),
�@�@clac_second(_����,_��,_�b,_�f�f),
�@�@�ʎZ�b�\��(_����,_��,_�b,_�f�f).
clac_second(_����,_��,_�b,_�f�f) :-
�@�@_����>=0,_����=<23,
�@�@_��>=0,_��=<59,
�@�@_�b>=0,_�b=<59,
�@�@_�f�f is _���� * 60 * 60 + _�� * 60 + _�b,!.
clac_second(_����,_��,_�b,-1).
�ʎZ�b�\��(_,_,_,-1) :- write('�s���Ȏ��ԁA���A�܂��͕b�����͂���܂���\n'),!.
�ʎZ�b�\��(_����,_��,_�b,_�ʎZ�b) :-
�@�@write_formatted('%t����%t��%t�b��%t�b�ł�\n',[_����,_��,_�b,_�ʎZ�b]),!.
���t����������(_��,_����) :-
�@�@write(_��),
�@�@get_integer(_����),!.
% Prolog
'�Q�S�����̎��ԁA���A�b���L�[�{�[�h������͂����A�b���ɕϊ����ĉ�ʂɏo�͂���':-
�@�@�Ñ��t����������('����(0�`23)����͂��Ă��������F',_����),
�@�@�Ñ��t����������('��(0�`59)����͂��Ă��������F',_��),
�@�@�Ñ��t����������('�b(0�`59)����͂��Ă��������F',_�b),
�@�@clac_second(_����,_��,_�b,_�f�f),
�@�@�ʎZ�b�\��(_����,_��,_�b,_�f�f).
clac_second(_����,_��,_�b,_�f�f) :-
�@�@_����>=0,_����=<23,
�@�@_��>=0,_��=<59,
�@�@_�b>=0,_�b=<59,
�@�@_�f�f is _���� * 60 * 60 + _�� * 60 + _�b,!.
clac_second(_����,_��,_�b,-1).
�ʎZ�b�\��(_,_,_,-1) :- write('�s���Ȏ��ԁA���A�܂��͕b�����͂���܂���\n'),!.
�ʎZ�b�\��(_����,_��,_�b,_�ʎZ�b) :-
�@�@write_formatted('%t����%t��%t�b��%t�b�ł�\n',[_����,_��,_�b,_�ʎZ�b]),!.
���t����������(_��,_����) :-
�@�@write(_��),
�@�@get_integer(_����),!.
497 �F�f�t�H���g�̖����������F2009/12/07(��) 10:15:23
>>484
% Prolog
�������L�[�{�[�h������͂����A�p�啶���͉p�������ɕϊ����āA�p�������͉p�啶���ɕϊ����āA���̑��̕����͂��̂܂o�͂��� :-
�@�@get_char(C),
�@�@conv_letter(C,X),
�@�@put_char(C).
conv_letter(C1,C2) :-
�@�@�啶��(L1),
�@�@list_nth(N,L1,C1),
�@�@������(L2),
�@�@list_nth(N,L2,C2),!.
conv_letter(C1,C2) :-
�@�@������(L1),
�@�@list_nth(N,L1,C1),
�@�@�啶��(L2),
�@�@list_nth(N,L2,C2),!.
conv_letter(C,C).
�啶��(['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']).
������([a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
% Prolog
�������L�[�{�[�h������͂����A�p�啶���͉p�������ɕϊ����āA�p�������͉p�啶���ɕϊ����āA���̑��̕����͂��̂܂o�͂��� :-
�@�@get_char(C),
�@�@conv_letter(C,X),
�@�@put_char(C).
conv_letter(C1,C2) :-
�@�@�啶��(L1),
�@�@list_nth(N,L1,C1),
�@�@������(L2),
�@�@list_nth(N,L2,C2),!.
conv_letter(C1,C2) :-
�@�@������(L1),
�@�@list_nth(N,L1,C1),
�@�@�啶��(L2),
�@�@list_nth(N,L2,C2),!.
conv_letter(C,C).
�啶��(['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']).
������([a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z]).
498 �F�f�t�H���g�̖����������F2009/12/07(��) 10:50:34
>>47
�g�p����F�@J
smoutput\.'Hello, world!'
Hello, world!
ello, world!
llo, world!
lo, world!
o, world!
, world!
world!
world!
orld!
rld!
ld!
d!
!
�g�p����F�@J
smoutput\.'Hello, world!'
Hello, world!
ello, world!
llo, world!
lo, world!
o, world!
, world!
world!
world!
orld!
rld!
ld!
d!
!
499 �F�f�t�H���g�̖����������F2009/12/07(��) 11:02:14
>>490
% Prolog
���͂��ꂽ�f�[�^�����Ƃɔ��㖾�ׂ��쐬���ĕ\������ :-
�@�@����f�[�^�̎��W(_���W���ꂽ�f�[�^),
�@�@findsum(_���z,member([_,_���z],_���W���ꂽ�f�[�^),_���z���v),
�@�@write('���i���@�@ ���z\n'),
�@�@���ו\�̈��(_���W���ꂽ�f�[�^,_���z���v),!.
����f�[�^�̎��W(_���W���ꂽ�f�[�^) :-
�@�@write('���i���Ƌ��z���J���}�ŋ���ē��͂��Ă�������\n').
�@�@findall([A2,B],
�@�@�@�@�@ (�@�@for(1,N,10),get_line(Line),
�@�@�@�@�@�@�@�@(�@Line=end_of_file,!,fail;
�@�@�@�@�@�@�@�@�@ split(Line,[','],[A,B]),
�@�@�@�@�@�@�@�@�@ '10���̕�����'(A,A2))),_���W���ꂽ�f�[�^),!.
���ו\�̈��([],_���z���v) :- write_formatted('%10s %10d\n',[���z���v,_���z���v]).
���ו\�̈��([[_���i��,_���z]|R],_���z���v) :-
�@�@write_formatted('%10s %10d\n',[_���i��,_���z]),
�@�@���ו\�̈��(R,_���z���v).
'10���̕�����'(_������,_10���̕�����) :-
�@�@atom_chars(_������,Chars),
�@�@length(L,10),
�@�@apend(Chars,L1,L),
�@�@all(L1,' '),
�@�@atom_chars(_10���̕�����,L),!.
'10���̕�����'(_������,_10���̕�����) :- sub_atom(_������,0,10,_,_10���̕�����).
% Prolog
���͂��ꂽ�f�[�^�����Ƃɔ��㖾�ׂ��쐬���ĕ\������ :-
�@�@����f�[�^�̎��W(_���W���ꂽ�f�[�^),
�@�@findsum(_���z,member([_,_���z],_���W���ꂽ�f�[�^),_���z���v),
�@�@write('���i���@�@ ���z\n'),
�@�@���ו\�̈��(_���W���ꂽ�f�[�^,_���z���v),!.
����f�[�^�̎��W(_���W���ꂽ�f�[�^) :-
�@�@write('���i���Ƌ��z���J���}�ŋ���ē��͂��Ă�������\n').
�@�@findall([A2,B],
�@�@�@�@�@ (�@�@for(1,N,10),get_line(Line),
�@�@�@�@�@�@�@�@(�@Line=end_of_file,!,fail;
�@�@�@�@�@�@�@�@�@ split(Line,[','],[A,B]),
�@�@�@�@�@�@�@�@�@ '10���̕�����'(A,A2))),_���W���ꂽ�f�[�^),!.
���ו\�̈��([],_���z���v) :- write_formatted('%10s %10d\n',[���z���v,_���z���v]).
���ו\�̈��([[_���i��,_���z]|R],_���z���v) :-
�@�@write_formatted('%10s %10d\n',[_���i��,_���z]),
�@�@���ו\�̈��(R,_���z���v).
'10���̕�����'(_������,_10���̕�����) :-
�@�@atom_chars(_������,Chars),
�@�@length(L,10),
�@�@apend(Chars,L1,L),
�@�@all(L1,' '),
�@�@atom_chars(_10���̕�����,L),!.
'10���̕�����'(_������,_10���̕�����) :- sub_atom(_������,0,10,_,_10���̕�����).
500 �F�f�t�H���g�̖����������F2009/12/07(��) 11:09:31
>47
�g�p����F�@J
�ԈႦ�܂����B��납��������B
smoutput@|.\.|.'Hello, world!'
Hello, world!
Hello, world
Hello, worl
Hello, wor
Hello, wo
Hello, w
Hello,
Hello,
Hello
Hell
Hel
He
H
�g�p����F�@J
�ԈႦ�܂����B��납��������B
smoutput@|.\.|.'Hello, world!'
Hello, world!
Hello, world
Hello, worl
Hello, wor
Hello, wo
Hello, w
Hello,
Hello,
Hello
Hell
Hel
He
H
501 �F�f�t�H���g�̖����������F2009/12/07(��) 11:37:41
>>491
% Prolog
�p��(a,70).
�p��(b,79).
�p��(c,90).
�p��(d,69).
���w(a,80).
���w(b,63).
���w(c,55).
���w(d,80).
臒l�ȉ��̊w�������X�g����폜����(_�w�����X�g,_�����̊w�����X�g,_�폜���b�Z�[�W) :-
�@�@get_integer(_臒l),
�@�@findall([_�w��,_��Ȗڂ̕���],
�@�@�@�@(�@ member(_�w��,_�w�����X�g),�p��(_�w��,_�p��),���w(_�w��,_���w),
�@�@�@�@�@�@_��Ȗڂ̕��� is (_�p�� + _���w) / 2),_��Ȗڂ̕��ςȂ��),
�@�@findall(_�w��2,(member([_�w��2,_���ϓ_2],_��Ȗڂ̕��ςȂ��),_���ϓ_2 >= _臒l),_�����̊w���Ȃ��),
�@�@length(_�w���Ȃ��,Len1),
�@�@length(_�����̊w���Ȃ��,Len2),
�@�@�폜���b�Z�[�W(Len1,Len2,_�폜���b�Z�[�W).
�@
�폜���b�Z�[�W(Len,Len,'�S���폜���܂����B') :- !.
�폜���b�Z�[�W(Len1,Len2,_���b�Z�[�W) :- _�폜�l�� is Len2 - Len1,concat_atom([_�폜�l��,�l�폜���܂����B],_���b�Z�[�W).
臒l��ǂݍ���(_臒l) :-�@get_integer(_臒l).
% Prolog
�p��(a,70).
�p��(b,79).
�p��(c,90).
�p��(d,69).
���w(a,80).
���w(b,63).
���w(c,55).
���w(d,80).
臒l�ȉ��̊w�������X�g����폜����(_�w�����X�g,_�����̊w�����X�g,_�폜���b�Z�[�W) :-
�@�@get_integer(_臒l),
�@�@findall([_�w��,_��Ȗڂ̕���],
�@�@�@�@(�@ member(_�w��,_�w�����X�g),�p��(_�w��,_�p��),���w(_�w��,_���w),
�@�@�@�@�@�@_��Ȗڂ̕��� is (_�p�� + _���w) / 2),_��Ȗڂ̕��ςȂ��),
�@�@findall(_�w��2,(member([_�w��2,_���ϓ_2],_��Ȗڂ̕��ςȂ��),_���ϓ_2 >= _臒l),_�����̊w���Ȃ��),
�@�@length(_�w���Ȃ��,Len1),
�@�@length(_�����̊w���Ȃ��,Len2),
�@�@�폜���b�Z�[�W(Len1,Len2,_�폜���b�Z�[�W).
�@
�폜���b�Z�[�W(Len,Len,'�S���폜���܂����B') :- !.
�폜���b�Z�[�W(Len1,Len2,_���b�Z�[�W) :- _�폜�l�� is Len2 - Len1,concat_atom([_�폜�l��,�l�폜���܂����B],_���b�Z�[�W).
臒l��ǂݍ���(_臒l) :-�@get_integer(_臒l).
502 �F�f�t�H���g�̖����������F2009/12/07(��) 11:43:58
503 �F�f�t�H���g�̖����������F2009/12/07(��) 11:49:36
>>501
% Prolog ���������q���`�����̂�����A����ɒu�������Ă��������B
臒l�ȉ��̊w�������X�g����폜����(_�w�����X�g,_�����̊w�����X�g,_�폜���b�Z�[�W) :-
�@�@臒l��ǂݍ���(_臒l),
�@�@....
% Prolog ���������q���`�����̂�����A����ɒu�������Ă��������B
臒l�ȉ��̊w�������X�g����폜����(_�w�����X�g,_�����̊w�����X�g,_�폜���b�Z�[�W) :-
�@�@臒l��ǂݍ���(_臒l),
�@�@....
504 �F�f�t�H���g�̖����������F2009/12/07(��) 12:03:36
>>45
�g�p����F�@Io
fact:=method(n,a:=1;for(i,1,n,a=a*i);a)
Io> for(i,0,10,writeln(fact(i)))
1
1
2
6
24
120
720
5040
40320
362880
3628800
==> nil
�g�p����F�@Io
fact:=method(n,a:=1;for(i,1,n,a=a*i);a)
Io> for(i,0,10,writeln(fact(i)))
1
1
2
6
24
120
720
5040
40320
362880
3628800
==> nil
505 �F�f�t�H���g�̖����������F2009/12/07(��) 13:44:45
>>207
�g�p����F�@Io
f:=method(s1,s2,n,s1 asMutable atInsertSeq(n,s2))
Io> f("12345","AB",3)
==> 123AB45
�g�p����F�@Io
f:=method(s1,s2,n,s1 asMutable atInsertSeq(n,s2))
Io> f("12345","AB",3)
==> 123AB45
506 �F�f�t�H���g�̖����������F2009/12/07(��) 13:52:05
>>114
�g�p����F�@Io
f:=method(s1,s2,s1 .."GHIJKLMABCDERSTUVWFNOPQXYZ"between(s1,s2).. s2)
Io> f("C","Q")
==> CDERSTUVWFNOPQ
�g�p����F�@Io
f:=method(s1,s2,s1 .."GHIJKLMABCDERSTUVWFNOPQXYZ"between(s1,s2).. s2)
Io> f("C","Q")
==> CDERSTUVWFNOPQ
507 �F�f�t�H���g�̖����������F2009/12/07(��) 13:53:54
>>473
% Prolog
a([983,386,577,215,393,935,686,292,349,821,762,527,690,359,663,626,340,226,
872,236,711,468,367,529,882,630,162,923,767,335,429,802,622,958,969,967,893,
656,311,242,529,973,721,219,384,437,798,624,615,670,813,326,191,180,756,973,
762,870,896,581,205,325,384,727,336,405,746,229,113,957,424,595,982,145,714,
367,534,564,943,150,287,808,376,378,888,184,403,651,954,299,232,160,576,568,
839,812,926,586,994,939]).
'100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\��' :-
�@�@a(L),
�@�@member10(L1,L),
�@�@concat_atom(L1,' ',S),
�@�@write_formatted('%t\n',[S]),
�@�@fail.
'100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\��'.
member10(L1,L) :- length(L1,10),append(L1,L2,L).
member10(L1,L) :- length(L3,10),append(L3,L2,L),member10(L1,L2).
% Prolog
a([983,386,577,215,393,935,686,292,349,821,762,527,690,359,663,626,340,226,
872,236,711,468,367,529,882,630,162,923,767,335,429,802,622,958,969,967,893,
656,311,242,529,973,721,219,384,437,798,624,615,670,813,326,191,180,756,973,
762,870,896,581,205,325,384,727,336,405,746,229,113,957,424,595,982,145,714,
367,534,564,943,150,287,808,376,378,888,184,403,651,954,299,232,160,576,568,
839,812,926,586,994,939]).
'100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\��' :-
�@�@a(L),
�@�@member10(L1,L),
�@�@concat_atom(L1,' ',S),
�@�@write_formatted('%t\n',[S]),
�@�@fail.
'100����999�܂ł̗�����100�������z��a�̓��e��10���ɋ���ĕ\��'.
member10(L1,L) :- length(L1,10),append(L1,L2,L).
member10(L1,L) :- length(L3,10),append(L3,L2,L),member10(L1,L2).
508 �F�f�t�H���g�̖����������F2009/12/07(��) 13:59:35
>473 ��
% Prolog
�z��a�̃f�[�^����{�I��@�ɂ���ď����ɐ��A�����̔z��a���e��\�� :- a(L),��{�I��@(L,L2),write_formatted('%t\n',[L2]).
��{�I��@([A,B|R],L) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R],X,L2),
�@�@��{�I��@�̓�(A,X,L2,L).
��{�I��@([A,B|R],L) :-
�@�@A > B,
�@�@��{�I��@([B,A|R],L).
��{�I��@�̓�(A,B,L1,[A|L2]) :-
�@�@A =< B,
�@�@��{�I��@([B|L1],L2).
��{�I��@�̓�(A,B,L1,L) :-
�@�@A > B,
�@�@��{�I��@([B|L1],L).
�ŏ��Ɍ�������A��菬�������ƌ���(A,[],A,[]) :- !.
�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R],B,[A|R]) :- B > A,!.
�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R1],X,[B|R2]) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A��菬�������ƌ���(A,R1,X,R2).
% Prolog
�z��a�̃f�[�^����{�I��@�ɂ���ď����ɐ��A�����̔z��a���e��\�� :- a(L),��{�I��@(L,L2),write_formatted('%t\n',[L2]).
��{�I��@([A,B|R],L) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R],X,L2),
�@�@��{�I��@�̓�(A,X,L2,L).
��{�I��@([A,B|R],L) :-
�@�@A > B,
�@�@��{�I��@([B,A|R],L).
��{�I��@�̓�(A,B,L1,[A|L2]) :-
�@�@A =< B,
�@�@��{�I��@([B|L1],L2).
��{�I��@�̓�(A,B,L1,L) :-
�@�@A > B,
�@�@��{�I��@([B|L1],L).
�ŏ��Ɍ�������A��菬�������ƌ���(A,[],A,[]) :- !.
�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R],B,[A|R]) :- B > A,!.
�ŏ��Ɍ�������A��菬�������ƌ���(A,[B|R1],X,[B|R2]) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A��菬�������ƌ���(A,R1,X,R2).
509 �F�f�t�H���g�̖����������F2009/12/07(��) 14:12:25
>473 ��
% Prolog
�z��a�̃f�[�^����{�I��@�ɂ���č~���ɐ��A�����̔z��a���e��\�� :- a(L),
��{�I��@�~��(L,L2),write_formatted('%t\n',[L2]).
��{�I��@�~��([A,B|R],L) :-
�@�@A >= B,
�@�@�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R],X,L2),
�@�@��{�I��@�~���̓�(A,X,L2,L).
��{�I��@�~��([A,B|R],L) :-
�@�@A < B,
�@�@��{�I��@�~��([B,A|R],L).
��{�I��@�~���̓�(A,B,L1,[A|L2]) :-
�@�@A >= B,
�@�@��{�I��@�~��([B|L1],L2).
��{�I��@�~���̓�(A,B,L1,L) :-
�@�@A < B,
�@�@��{�I��@�~��([B|L1],L).
�ŏ��Ɍ�������A���傫�����ƌ���(A,[],A,[]) :- !.
�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R],B,[A|R]) :- B < A,!.
�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R1],X,[B|R2]) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A���傫�����ƌ���(A,R1,X,R2).
% Prolog
�z��a�̃f�[�^����{�I��@�ɂ���č~���ɐ��A�����̔z��a���e��\�� :- a(L),
��{�I��@�~��(L,L2),write_formatted('%t\n',[L2]).
��{�I��@�~��([A,B|R],L) :-
�@�@A >= B,
�@�@�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R],X,L2),
�@�@��{�I��@�~���̓�(A,X,L2,L).
��{�I��@�~��([A,B|R],L) :-
�@�@A < B,
�@�@��{�I��@�~��([B,A|R],L).
��{�I��@�~���̓�(A,B,L1,[A|L2]) :-
�@�@A >= B,
�@�@��{�I��@�~��([B|L1],L2).
��{�I��@�~���̓�(A,B,L1,L) :-
�@�@A < B,
�@�@��{�I��@�~��([B|L1],L).
�ŏ��Ɍ�������A���傫�����ƌ���(A,[],A,[]) :- !.
�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R],B,[A|R]) :- B < A,!.
�ŏ��Ɍ�������A���傫�����ƌ���(A,[B|R1],X,[B|R2]) :-
�@�@A =< B,
�@�@�ŏ��Ɍ�������A���傫�����ƌ���(A,R1,X,R2).
510 �F�f�t�H���g�̖����������F2009/12/07(��) 15:45:17
http://pc12.2ch.net/test/read.cgi/tech/1222224721/610
#
# ���������N����͂��āC����N��\������B
# �@�@�@�@�Ⴆ�C21�Ɠ��͂�����C�u����21�N�͐���2009�N�ł��v�ƕ\������B
# �i�q���g�F�����N�� a �Ƃ���ƁC����N��1988+a �j
#
# ���������N����͂��āC����N��\������B
# �@�@�@�@�Ⴆ�C21�Ɠ��͂�����C�u����21�N�͐���2009�N�ł��v�ƕ\������B
# �i�q���g�F�����N�� a �Ƃ���ƁC����N��1988+a �j
511 �F�f�t�H���g�̖����������F2009/12/07(��) 15:45:57
http://pc12.2ch.net/test/read.cgi/tech/1222224721/610
#
# �߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩
# ��\������B�i�q���g�F���̐��Ƒ��̐���ϐ��Ƃ��āC�߂̐��ƋT�̐��ɂ���
# �A�������������C����^���鎮�̒l��\��������悢�j
#
#
# �߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩
# ��\������B�i�q���g�F���̐��Ƒ��̐���ϐ��Ƃ��āC�߂̐��ƋT�̐��ɂ���
# �A�������������C����^���鎮�̒l��\��������悢�j
#
512 �F�f�t�H���g�̖����������F2009/12/07(��) 15:51:29
>>510
% Prolog
���������N����͂��āC����N��\�� :-
�@�@get_integer(_���������N),
�@�@_����N is 1988 + _���������N,
�@�@write_formatted('����%t�N�͐���%t�N�ł�\n',[_���������N,_����N]).
% Prolog
���������N����͂��āC����N��\�� :-
�@�@get_integer(_���������N),
�@�@_����N is 1988 + _���������N,
�@�@write_formatted('����%t�N�͐���%t�N�ł�\n',[_���������N,_����N]).
513 �F�f�t�H���g�̖����������F2009/12/07(��) 16:08:47
>>510
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@findall(N,for(0,N,_�߂ƋT�̓��̐��̍��v),L),
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%�C�A�T��%�C�B\n',[A,B]).
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@findall(N,for(0,N,_�߂ƋT�̓��̐��̍��v),L),
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%�C�A�T��%�C�B\n',[A,B]).
514 �F�f�t�H���g�̖����������F2009/12/07(��) 16:15:12
>>17�@���1
�g�p����F�@Xtal
f:fun(n)"abcdefghijklmnopqrstuvwxyz".split("").take(n).join("");
ix:005>f(8).p;
abcdefgh
ix:006>f(30).p;
abcdefghijklmnopqrstuvwxyz
�g�p����F�@Xtal
f:fun(n)"abcdefghijklmnopqrstuvwxyz".split("").take(n).join("");
ix:005>f(8).p;
abcdefgh
ix:006>f(30).p;
abcdefghijklmnopqrstuvwxyz
515 �F�f�t�H���g�̖����������F2009/12/07(��) 16:33:09
>>510
�g�p����F�@Xtal
f:fun(n)%f"����%d�N�́A����%d�N�ł��B"(n,1988+n);
ix:003>f(21).p;
����21�N�́A����2009�N�ł��B
�g�p����F�@Xtal
f:fun(n)%f"����%d�N�́A����%d�N�ł��B"(n,1988+n);
ix:003>f(21).p;
����21�N�́A����2009�N�ł��B
516 �F�f�t�H���g�̖����������F2009/12/07(��) 16:39:52
http://pc12.2ch.net/test/read.cgi/tech/1258158172/771
# [1] ���ƒP���FC���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F����ɑS�ċL�� http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10245.c
#
# ���
# graph.c�̊�print_graph_memory()���Q�l�ɁA�O���t�̘A���ł��邩�ۂ��̔�����s���v���O�������쐬����B
# �܂��͘A���ȏꍇ�́A��M�����ł��邩�ۂ��̔�����s���悤�ɂ���B
# sample5.dimacs�Asample6.dimacs�Asample7.dimacs��A������E��M�������肹��B
# [1] ���ƒP���FC���ꉉ�K
# [2] ��蕶(�܃R�[�h&�����N)�F����ɑS�ċL�� http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10245.c
#
# ���
# graph.c�̊�print_graph_memory()���Q�l�ɁA�O���t�̘A���ł��邩�ۂ��̔�����s���v���O�������쐬����B
# �܂��͘A���ȏꍇ�́A��M�����ł��邩�ۂ��̔�����s���悤�ɂ���B
# sample5.dimacs�Asample6.dimacs�Asample7.dimacs��A������E��M�������肹��B
517 �F�f�t�H���g�̖����������F2009/12/07(��) 16:51:46
http://pc11.2ch.net/test/read.cgi/db/1252492296/241
# SELECT �����S���R�[�h�̓���J��������A���������̂���@�͂���܂����H
#
# SELECT C FROM T
#
# �Ƃ�����Ƃ��� AAA�ABBB�ACCC �Ƃ������l�������鎞�AAAABBBCCC �̂悤�� 1�̒l���~�����ł��B
# ����ɂ����̊ԂɔC�ӂ̋�蕶�������� AAA:BBB:CCC �̂悤�Ȓl�邱�Ƃ͂ł���ł��傤���B
# SELECT �����S���R�[�h�̓���J��������A���������̂���@�͂���܂����H
#
# SELECT C FROM T
#
# �Ƃ�����Ƃ��� AAA�ABBB�ACCC �Ƃ������l�������鎞�AAAABBBCCC �̂悤�� 1�̒l���~�����ł��B
# ����ɂ����̊ԂɔC�ӂ̋�蕶�������� AAA:BBB:CCC �̂悤�Ȓl�邱�Ƃ͂ł���ł��傤���B
518 �F�f�t�H���g�̖����������F2009/12/07(��) 17:01:00
>>517
% Prolog
'SELECT�����S���R�[�h��N�ԖڃJ��������A���������̂�'(T/_�����̐�,N,_�A������������) :-
�@�@length(L,_�����̐�),
�@�@P =.. [T|L]),
�@�@findall(X,(call(P),list_nth(N,L,X)),_���Ȃ��),
�@�@concat_atom(_���Ȃ��,_�A������������).
% Prolog
'SELECT�����S���R�[�h��N�ԖڃJ��������A���������̂�'(T/_�����̐�,N,_�A������������) :-
�@�@length(L,_�����̐�),
�@�@P =.. [T|L]),
�@�@findall(X,(call(P),list_nth(N,L,X)),_���Ȃ��),
�@�@concat_atom(_���Ȃ��,_�A������������).
519 �F�f�t�H���g�̖����������F2009/12/07(��) 17:22:14
>>516
% Prolog
�L���O���t�ɉ����ē��B�\(A,B) :-
�@�@�L���O���t(A,B),!.
�L���O���t�ɉ����ē��B�\(A,B) :-
�@�@�L���O���t(A,C),
�@�@�L���O���t�ɉ����ē��B�\(C,B).
% Prolog
�L���O���t�ɉ����ē��B�\(A,B) :-
�@�@�L���O���t(A,B),!.
�L���O���t�ɉ����ē��B�\(A,B) :-
�@�@�L���O���t(A,C),
�@�@�L���O���t�ɉ����ē��B�\(C,B).
520 �F�f�t�H���g�̖����������F2009/12/07(��) 17:52:44
>>510
�g�p����F�@J
f=:monad def ' ''����'',(":y),''�N�́A����'',(":1988+y),''�N�ł��B'' '
f 10
����10�N�́A����1998�N�ł��B
�g�p����F�@J
f=:monad def ' ''����'',(":y),''�N�́A����'',(":1988+y),''�N�ł��B'' '
f 10
����10�N�́A����1998�N�ł��B
521 �F�f�t�H���g�̖����������F2009/12/07(��) 18:18:46
>>510
�g�p����F�@�\�iBASIC
SUB f(n)
PRINT "����";n;"�N�́A����";1988+n;"�N�ł��B"
END SUB
CALL f(15)
END
���s����
���� 15 �N�́A���� 2003 �N�ł��B
�g�p����F�@�\�iBASIC
SUB f(n)
PRINT "����";n;"�N�́A����";1988+n;"�N�ł��B"
END SUB
CALL f(15)
END
���s����
���� 15 �N�́A���� 2003 �N�ł��B
522 �F�f�t�H���g�̖����������F2009/12/07(��) 19:23:03
>>516
% Prolog
�L���O���t�ɉ����Ĉ�M����(A,_�o�H) :-
�@�@setof((B,C),�L���O���t(B,C),L),
�@�@length(L,Len),
�@�@�L���O���t�ɉ����Ĉ�M����(A,A,Len,[],_�o�H).
�L���O���t�ɉ����Ĉ�M����(A,A,Len,L,[]) :- length(L,Len),!.
�L���O���t�ɉ����Ĉ�M����(A,S,Len,L,[A|R]) :-
�@�@�L���O���t(A,B),
�@�@\+(member((A,B),L)),
�@�@�L���O���t�ɉ����Ĉ�M����(B,S,Len,[(A,B)|L],R).
% Prolog
�L���O���t�ɉ����Ĉ�M����(A,_�o�H) :-
�@�@setof((B,C),�L���O���t(B,C),L),
�@�@length(L,Len),
�@�@�L���O���t�ɉ����Ĉ�M����(A,A,Len,[],_�o�H).
�L���O���t�ɉ����Ĉ�M����(A,A,Len,L,[]) :- length(L,Len),!.
�L���O���t�ɉ����Ĉ�M����(A,S,Len,L,[A|R]) :-
�@�@�L���O���t(A,B),
�@�@\+(member((A,B),L)),
�@�@�L���O���t�ɉ����Ĉ�M����(B,S,Len,[(A,B)|L],R).
523 �F�f�t�H���g�̖����������F2009/12/07(��) 19:34:54
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߂̉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%�C�A�T��%�C�B\n',[A,B]).
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߂̉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%�C�A�T��%�C�B\n',[A,B]).
524 �F�f�t�H���g�̖����������F2009/12/07(��) 19:36:02
>>523 �S�~���c���Ă��܂����B
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߂̉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߂̉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
525 �F�f�t�H���g�̖����������F2009/12/07(��) 19:37:46
>>513 >>510 �ŏI�s�Ɍ�肪�������B
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@findall(N,for(0,N,_�߂ƋT�̓��̐��̍��v),L),
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%t�H�A�T��%t�C�B\n',[A,B]).
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@findall(N,for(0,N,_�߂ƋT�̓��̐��̍��v),L),
�@�@�d������(L,2,[A,B]),
�@�@_�߂ƋT�̓��̐��̍��v is A + B,
�@�@_�߂ƋT�̑��̐��̍��v is 2 * A + 4 * B,
�@�@write_formatted('�߂�%t�H�A�T��%t�C�B\n',[A,B]).
526 �F�f�t�H���g�̖����������F2009/12/07(��) 19:39:17
http://pc12.2ch.net/test/read.cgi/tech/1258158172/773
# [1] ���ƒP���F�v���O���~���O�
# [2] ��蕶(�܃R�[�h&�����N)�F �\���̂��g���ē�̕��f���̐ς����߂�
# [1] ���ƒP���F�v���O���~���O�
# [2] ��蕶(�܃R�[�h&�����N)�F �\���̂��g���ē�̕��f���̐ς����߂�
527 �F�f�t�H���g�̖����������F2009/12/07(��) 19:48:49
>>524 >>510 �܂��ԈႢ���������B
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
% ������������(�}�C�i�X���o�Ă���ƃG���[�ɂȂ邱�Ƃ�����)�s��̕ό`��
% http://nojiriko.asia/prolog/Gauss_gyoretsu_ni_henkei.html
% Prolog
�߂ƋT�̓��̐��̍��v�Ƒ��̐��̍��v����͂��āC �߂����H�C�T�����C���邩 :-
�@�@�Ñ��t����������('�߂ƋT�̓��̐����v : ',_�߂ƋT�̓��̐��̍��v),
�@�@�Ñ��t����������('�߂ƋT�̑��̐��̍��v : ',_�߂ƋT�̑��̐��̍��v),
�@�@�K�E�X�s��ɕό`([[1,1,_�߂ƋT�̓��̍��v],[2,4,_�߂ƋT�̑��̍��v]],L1),
�@�@����K�E�X�s��ɕό`(L1,[[_,_,_�߉��H],[_,_,_�T���C]]),
�@�@write_formatted('�߂�%t�H�A�T��%t�C\n',[_�߉��H,_�T���C]).
% ������������(�}�C�i�X���o�Ă���ƃG���[�ɂȂ邱�Ƃ�����)�s��̕ό`��
% http://nojiriko.asia/prolog/Gauss_gyoretsu_ni_henkei.html
528 �F�f�t�H���g�̖����������F2009/12/07(��) 21:00:15
>>511
�g�p����F�@J
f=:('�߂̐� = ',:'�T�̐� = '),.":@,.@%.&(1 1,:2 4)
f 3 8
�߂̐� = 2
�T�̐� = 1
f 20 64
�߂̐� = 8
�T�̐� = 12
�g�p����F�@J
f=:('�߂̐� = ',:'�T�̐� = '),.":@,.@%.&(1 1,:2 4)
f 3 8
�߂̐� = 2
�T�̐� = 1
f 20 64
�߂̐� = 8
�T�̐� = 12
529 �F�f�t�H���g�̖����������F2009/12/07(��) 21:49:03
>>495
REBOL�̃\�[�X�Ȃ�ď��߂Č����B���肪�Ƃ��B
REBOL�̃\�[�X�Ȃ�ď��߂Č����B���肪�Ƃ��B
530 �F�f�t�H���g�̖����������F2009/12/07(��) 22:06:20
>>511
�g�p����F�@maxima
f(x,y):=(matrix([1,1],[2,4])^^-1) . matrix([x],[y]);
g(x):=printf(true,"�߂̐� = ~a~%�T�̐� = ~a",x[1,1],x[2,1])
(%i40) g(f(3,8));
�߂̐� = 2
�T�̐� = 1
(%o40) false
(%i41) g(f(20,64));
�߂̐� = 8
�T�̐� = 12
(%o41) false
�g�p����F�@maxima
f(x,y):=(matrix([1,1],[2,4])^^-1) . matrix([x],[y]);
g(x):=printf(true,"�߂̐� = ~a~%�T�̐� = ~a",x[1,1],x[2,1])
(%i40) g(f(3,8));
�߂̐� = 2
�T�̐� = 1
(%o40) false
(%i41) g(f(20,64));
�߂̐� = 8
�T�̐� = 12
(%o41) false
531 �F�f�t�H���g�̖����������F2009/12/07(��) 23:56:11
>>47
�g�p����F�@maxima
f(s):=(b:slength(s),for i thru b do printf(true,"~a~%",substring(s,1,b-i+2)));
(%i68) f("maxima");
maxima
maxim
maxi
max
ma
m
(%o68) done
�g�p����F�@maxima
f(s):=(b:slength(s),for i thru b do printf(true,"~a~%",substring(s,1,b-i+2)));
(%i68) f("maxima");
maxima
maxim
maxi
max
ma
m
(%o68) done
532 �F�f�t�H���g�̖����������F2009/12/08(��) 05:03:21
>>174 ���2
�g�p����F�@J
f=:;@((]\:+/"1)@=<@#])@tolower
f 'aSddAdsAsfdaDfdfDF'
dddddddaaaaffffsss
f 'AAbbbCCccddDdd'
dddddccccbbbaa
�g�p����F�@J
f=:;@((]\:+/"1)@=<@#])@tolower
f 'aSddAdsAsfdaDfdfDF'
dddddddaaaaffffsss
f 'AAbbbCCccddDdd'
dddddccccbbbaa
533 �F�f�t�H���g�̖����������F2009/12/08(��) 06:32:31
>>17 ���1
�g�p����F�@REBOL
>> f: func[n][copy/part "abcdefghijklmnopqrstuvwxyz" n]
>> f 6
== "abcdef"
>> f 30
== "abcdefghijklmnopqrstuvwxyz"
�g�p����F�@REBOL
>> f: func[n][copy/part "abcdefghijklmnopqrstuvwxyz" n]
>> f 6
== "abcdef"
>> f 30
== "abcdefghijklmnopqrstuvwxyz"
534 �F�f�t�H���g�̖����������F2009/12/08(��) 08:22:54
>>489
% Prolog
%
% [[20,'CD'],[40,'GH'],[10,'AB'],[50,'IJ'],[30,'EF']]
%
prolog�ō\���̔z��ɋ߂����̂����m�F�̂��ߕ\������ :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@findall(A,member([A,_],L),L1),
�@�@concat_atom(L1,' ',S1),
�@�@write_formatted('%t\n',[S1]),
�@�@findall(B,member([B,_],L),L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('%t\n',[S2]).
prolog�ō\���̔z��ɋ߂����̂����(L) :-
�@�@get_split_lines(user_input,[','],L).
prolog�ō\���̔z��ɋ߂����̂����q��Ƃ��Ē�`����(_�\���̖�) :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),,
�@�@member(L1,L),
�@�@P =.. [_�\���̖�|L1],
�@�@assertz(P),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����q���`����(_).
% Prolog
%
% [[20,'CD'],[40,'GH'],[10,'AB'],[50,'IJ'],[30,'EF']]
%
prolog�ō\���̔z��ɋ߂����̂����m�F�̂��ߕ\������ :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@findall(A,member([A,_],L),L1),
�@�@concat_atom(L1,' ',S1),
�@�@write_formatted('%t\n',[S1]),
�@�@findall(B,member([B,_],L),L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('%t\n',[S2]).
prolog�ō\���̔z��ɋ߂����̂����(L) :-
�@�@get_split_lines(user_input,[','],L).
prolog�ō\���̔z��ɋ߂����̂����q��Ƃ��Ē�`����(_�\���̖�) :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),,
�@�@member(L1,L),
�@�@P =.. [_�\���̖�|L1],
�@�@assertz(P),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����q���`����(_).
535 �F�f�t�H���g�̖����������F2009/12/08(��) 08:40:55
>>489
% Prolog
%
% [[20,40,10,50,30],['CD','GH','AB','IJ','EF']]
%
% a([20,40,10,50,30],['CD','GH','AB','IJ','EF']).
prolog�ō\���̔z��ɋ߂����̂����m�F�̂��ߕ\������ :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@findall(L1,member(L1,L),L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('%t\n',[S2]),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����(L) :-
�@�@get_split_lines(user_input,[','],L).
prolog�ō\���̔z��ɋ߂����̂����q��Ƃ��Ē�`����(_�\���̖�) :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@member(L1,L),
�@�@P =.. [_�\���̖�,L1],
�@�@assertz(P),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����q���`����(_).
% Prolog
%
% [[20,40,10,50,30],['CD','GH','AB','IJ','EF']]
%
% a([20,40,10,50,30],['CD','GH','AB','IJ','EF']).
prolog�ō\���̔z��ɋ߂����̂����m�F�̂��ߕ\������ :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@findall(L1,member(L1,L),L2),
�@�@concat_atom(L2,' ',S2),
�@�@write_formatted('%t\n',[S2]),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����(L) :-
�@�@get_split_lines(user_input,[','],L).
prolog�ō\���̔z��ɋ߂����̂����q��Ƃ��Ē�`����(_�\���̖�) :-
�@�@prolog�ō\���̔z��ɋ߂����̂����(L),
�@�@member(L1,L),
�@�@P =.. [_�\���̖�,L1],
�@�@assertz(P),
�@�@fail.
prolog�ō\���̔z��ɋ߂����̂����q���`����(_).
536 �F�f�t�H���g�̖����������F2009/12/08(��) 08:42:36
537 �F�f�t�H���g�̖����������F2009/12/08(��) 09:19:03
>>526
% Prolog
:- op(350,xf,i).
���f���̐�(A + B i,C + D i,E + F i) :-
�@�@E is A * C - B * D,
�@�@F is A * D + B * C.
% Prolog
:- op(350,xf,i).
���f���̐�(A + B i,C + D i,E + F i) :-
�@�@E is A * C - B * D,
�@�@F is A * D + B * C.
538 �F�f�t�H���g�̖����������F2009/12/08(��) 09:23:46
>>17 ���2
�g�p����F�@REBOL
>> f: func [n] [s: 0 repeat i n [if (i // 5 = 0) or (i // 3 = 0) [s: s + i]] s ]
>> f 10
== 33
>> f 100
== 2418
�g�p����F�@REBOL
>> f: func [n] [s: 0 repeat i n [if (i // 5 = 0) or (i // 3 = 0) [s: s + i]] s ]
>> f 10
== 33
>> f 100
== 2418
539 �F�f�t�H���g�̖����������F2009/12/08(��) 09:58:49
http://pc12.2ch.net/test/read.cgi/tech/1258158172/778
# [1] ���ƒP���F�v���O���~���O���K�Q
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10246.txt
# �ۑ�2-1�̖�蕶�Ƃ��̃v���O���������Ɏ����Ƃ��܂��B
#
# [�ۑ�2-1]
# n���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���v���O�������쐬����B
# �Ȃ��A���s���ɂ����ēY�����Z�q��p���Ȃ����ƁB�܂��A*(p+i)�̌`��p���邱�ƁB
#
# [�ۑ�2-2]
# �ۑ�2-1�Ɠ����@�\�����v���O�������쐬����B�������A���o�͏������t�@�C�������ɕύX���A
# ���o�̓t�@�C���̓R�}���h���C���Ŏw�肷�邱�ƁB
#
# [1] ���ƒP���F�v���O���~���O���K�Q
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10246.txt
# �ۑ�2-1�̖�蕶�Ƃ��̃v���O���������Ɏ����Ƃ��܂��B
#
# [�ۑ�2-1]
# n���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���v���O�������쐬����B
# �Ȃ��A���s���ɂ����ēY�����Z�q��p���Ȃ����ƁB�܂��A*(p+i)�̌`��p���邱�ƁB
#
# [�ۑ�2-2]
# �ۑ�2-1�Ɠ����@�\�����v���O�������쐬����B�������A���o�͏������t�@�C�������ɕύX���A
# ���o�̓t�@�C���̓R�}���h���C���Ŏw�肷�邱�ƁB
#
540 �F�f�t�H���g�̖����������F2009/12/08(��) 10:08:00
>>539
% Prolog
'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���' :-
�@�@write('�f�[�^��:'),
�@�@get_integer(N),
�@�@findavg(I,(for(1,M,N),write_formatted('%t�Ԗ� �l:',[M]),get_integer(I)),_��
�ϒl),
�@�@write_formatted('����=%t\n',[_���ϒl]),!.
% Prolog
'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���' :-
�@�@write('�f�[�^��:'),
�@�@get_integer(N),
�@�@findavg(I,(for(1,M,N),write_formatted('%t�Ԗ� �l:',[M]),get_integer(I)),_��
�ϒl),
�@�@write_formatted('����=%t\n',[_���ϒl]),!.
541 �F�f�t�H���g�̖����������F2009/12/08(��) 10:14:57
>>539
% proloog
% �ۑ�2-2
program :-
�@�@user_parameters([_���̓t�@�C����,_�o�̓t�@�C����]),
�@�@see(_���̓t�@�C����),
�@�@tell(_�o�̓t�@�C����),
�@�@'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���',
�@�@told,
�@�@seen.
'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���' :-
�@�@get_integer(N),
�@�@findavg(I,(for(1,M,N),get_integer(I)),_���ϒl),
�@�@write_formatted('����=%t\n',[_���ϒl]),!.
% proloog
% �ۑ�2-2
program :-
�@�@user_parameters([_���̓t�@�C����,_�o�̓t�@�C����]),
�@�@see(_���̓t�@�C����),
�@�@tell(_�o�̓t�@�C����),
�@�@'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���',
�@�@told,
�@�@seen.
'N���̐����^�f�[�^��z��ɓ��͂��A���̕��ϒl���o�͂���' :-
�@�@get_integer(N),
�@�@findavg(I,(for(1,M,N),get_integer(I)),_���ϒl),
�@�@write_formatted('����=%t\n',[_���ϒl]),!.
542 �F�f�t�H���g�̖����������F2009/12/08(��) 12:23:08
>>17�@���2
�g�p����F�@�Ȃł���
��f(n)
�@s=0
�@i��1����n�܂ŌJ��Ԃ�
�@�@����(i%3=0)�܂���(i%5=0)�Ȃ��s=s+i
�@s��߂��B
f(10)��\��
f(100)��\��
���s����
33
2418
�g�p����F�@�Ȃł���
��f(n)
�@s=0
�@i��1����n�܂ŌJ��Ԃ�
�@�@����(i%3=0)�܂���(i%5=0)�Ȃ��s=s+i
�@s��߂��B
f(10)��\��
f(100)��\��
���s����
33
2418
543 �F�f�t�H���g�̖����������F2009/12/08(��) 13:47:15
>>370�@�ۑ�(2)
�g�p����F�@REBOL
>> f: func [n d] [mod (to-integer n / power 10 (d - 1)) 10]
>> f 123456789 4
== 6
�g�p����F�@REBOL
>> f: func [n d] [mod (to-integer n / power 10 (d - 1)) 10]
>> f 123456789 4
== 6
544 �F�f�t�H���g�̖����������F2009/12/08(��) 18:29:21
>>45
�g�p����F�@R
> fact <- function(n){if(n==0)1 else prod(1:n)}
> for(i in 0:10)cat(fact(i),"\n")
1
1
2
6
24
120
720
5040
40320
362880
3628800
�g�p����F�@R
> fact <- function(n){if(n==0)1 else prod(1:n)}
> for(i in 0:10)cat(fact(i),"\n")
1
1
2
6
24
120
720
5040
40320
362880
3628800
545 �F�f�t�H���g�̖����������F2009/12/08(��) 18:45:27
>>47
�g�p����F�@R
> f <- function(s){write(substring(s,1,(nchar(s)):1),"")}
> f("substring")
substring
substrin
substri
substr
subst
subs
sub
su
s
�g�p����F�@R
> f <- function(s){write(substring(s,1,(nchar(s)):1),"")}
> f("substring")
substring
substrin
substri
substr
subst
subs
sub
su
s
546 �F�f�t�H���g�̖����������F2009/12/08(��) 19:16:59
>>511
�g�p����F�@R
f <- function(x,y){
a <- matrix(c(1,2,1,4),2,2)
b <- matrix(c(x,y))
c <- solve(a) %*% b
cat("�߂̐� = ",c[1],"\n�T�̐� = ",c[2],"\n")
}
> f(3,8)
�߂̐� = 2
�T�̐� = 1
> f(10,24)
�߂̐� = 8
�T�̐� = 2
�g�p����F�@R
f <- function(x,y){
a <- matrix(c(1,2,1,4),2,2)
b <- matrix(c(x,y))
c <- solve(a) %*% b
cat("�߂̐� = ",c[1],"\n�T�̐� = ",c[2],"\n")
}
> f(3,8)
�߂̐� = 2
�T�̐� = 1
> f(10,24)
�߂̐� = 8
�T�̐� = 2
547 �F�f�t�H���g�̖����������F2009/12/08(��) 20:23:24
http://pc11.2ch.net/test/read.cgi/db/1252492296/321
#
# �X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏�������Ă������̂ł����A�ǂ̂悤�ɂ���悢�ł��傤���H
# �i������1�ʂȂǂ̏ꍇ�͎����Ɖ���8�l�����擾���܂��j
#
#
# �X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏�������Ă������̂ł����A�ǂ̂悤�ɂ���悢�ł��傤���H
# �i������1�ʂȂǂ̏ꍇ�͎����Ɖ���8�l�����擾���܂��j
#
548 �F�f�t�H���g�̖����������F2009/12/08(��) 20:27:26
>>547
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@for(5,N,1),
�@�@append(_,L,_,L3),
�@�@length(L,9),
�@�@member([_�X�R�A,_����],L),
�@�@�����̍ŗǂ̐Ȃ����(N,_����,L).
�����̍ŗǂ̐Ȃ����(N,_����,L) :-
�@�@list_nth(N,L,[_,_����]),!.
�����̍ŗǂ̐Ȃ����(N,_����,L) :-
�@�@M is 10 - N,
�@�@list_nth(M,L,[_,_����]),!.
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@for(5,N,1),
�@�@append(_,L,_,L3),
�@�@length(L,9),
�@�@member([_�X�R�A,_����],L),
�@�@�����̍ŗǂ̐Ȃ����(N,_����,L).
�����̍ŗǂ̐Ȃ����(N,_����,L) :-
�@�@list_nth(N,L,[_,_����]),!.
�����̍ŗǂ̐Ȃ����(N,_����,L) :-
�@�@M is 10 - N,
�@�@list_nth(M,L,[_,_����]),!.
549 �F�f�t�H���g�̖����������F2009/12/08(��) 20:32:27
>>511
�g�p����F�@�\�iBASIC
DATA 1,1,2,4
DIM a(2,2)
DIM b(2,1)
DIM c(2,1)
DIM g(2,2)
MAT READ a
MAT INPUT PROMPT "���̐�,���̐� : " :b
MAT g=INV(a)
MAT c=g*b
PRINT "�߂̐� = ";c(1,1)
PRINT "�T�̐� = ";c(2,1)
END
���s����
���̐�,���̐� : 100,360
�߂̐� = 20
�T�̐� = 80
�g�p����F�@�\�iBASIC
DATA 1,1,2,4
DIM a(2,2)
DIM b(2,1)
DIM c(2,1)
DIM g(2,2)
MAT READ a
MAT INPUT PROMPT "���̐�,���̐� : " :b
MAT g=INV(a)
MAT c=g*b
PRINT "�߂̐� = ";c(1,1)
PRINT "�T�̐� = ";c(2,1)
END
���s����
���̐�,���̐� : 100,360
�߂̐� = 20
�T�̐� = 80
550 �F�f�t�H���g�̖����������F2009/12/08(��) 22:24:28
>>547
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@append(L11,[[_�X�R�A,_����]|L12],L3),
�@�@�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L).
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L12,Len2),Len2 =< 4,
�@�@Len1 is 9 - Len2 - 1,length(L1,Len1),
�@�@append(_,L1,L11),
�@�@append(L1,[[_�X�R�A,����]|,L12],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L11,Len1),Len1 =< 4,
�@�@Len2 is 9 - Len1 - 1,length(L2,Len2),
�@�@append(L2,_,L12),
�@�@append(L11,[[_�X�R�A,_����]|L2],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L1,4),length(L2,4),
�@�@append(_,L1,L11),
�@�@append(L2,_,L12),
�@�@append(L1,[[_�X�R�A,_����]|L2],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@append(L11,[[_�X�R�A,_����]|L12],L).
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@append(L11,[[_�X�R�A,_����]|L12],L3),
�@�@�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L).
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L12,Len2),Len2 =< 4,
�@�@Len1 is 9 - Len2 - 1,length(L1,Len1),
�@�@append(_,L1,L11),
�@�@append(L1,[[_�X�R�A,����]|,L12],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L11,Len1),Len1 =< 4,
�@�@Len2 is 9 - Len1 - 1,length(L2,Len2),
�@�@append(L2,_,L12),
�@�@append(L11,[[_�X�R�A,_����]|L2],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@length(L1,4),length(L2,4),
�@�@append(_,L1,L11),
�@�@append(L2,_,L12),
�@�@append(L1,[[_�X�R�A,_����]|L2],L),!.
�����̍ŗǂ̐Ȃ����(L11,[_�X�R�A,_����],L12,L) :-
�@�@append(L11,[[_�X�R�A,_����]|L12],L).
551 �F�f�t�H���g�̖����������F2009/12/08(��) 22:28:58
552 �F�f�t�H���g�̖����������F2009/12/09(��) 04:40:26
http://pc12.2ch.net/test/read.cgi/tech/1258158172/810
# [1] �A���S���Y��
#
# [2] ���R���̐�����ɂ��邎�����傫�����Ə���������
# �����ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o�͂���B
# �܂�A(n-a,...,n+b,....n,....n+c,....,n-d)�Ƃ������ɂȂ��Ă���n��T���v���O�����ł��B
# [1] �A���S���Y��
#
# [2] ���R���̐�����ɂ��邎�����傫�����Ə���������
# �����ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o�͂���B
# �܂�A(n-a,...,n+b,....n,....n+c,....,n-d)�Ƃ������ɂȂ��Ă���n��T���v���O�����ł��B
553 �F�f�t�H���g�̖����������F2009/12/09(��) 04:52:17
>>552
% Prolog
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_���R���Ȃ��) :-
�@�@append(L1,[N|L2],_���R���Ȃ��),
�@�@findsum(1,(member(A,L1),A > N),1),
�@�@findsum(1,(member(B,L2),B < N),1),
�@�@write_formatted('%t\n',[N]).
% Prolog
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_���R���Ȃ��) :-
�@�@append(L1,[N|L2],_���R���Ȃ��),
�@�@findsum(1,(member(A,L1),A > N),1),
�@�@findsum(1,(member(B,L2),B < N),1),
�@�@write_formatted('%t\n',[N]).
554 �F�f�t�H���g�̖����������F2009/12/09(��) 05:24:08
http://pc12.2ch.net/test/read.cgi/tech/1258158172/784
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F �\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ����B
# �@�@��������ǂ��܂������Ȃ������̂�����ł��B
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10249.txt
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F �\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ����B
# �@�@��������ǂ��܂������Ȃ������̂�����ł��B
# �@�@http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10249.txt
#
555 �F�f�t�H���g�̖����������F2009/12/09(��) 05:29:49
>>554
% Prolog
�ԍ��E�����E�g��([[ 3,'��Y',180.0 ], [ 5,'��Y',175.5 ],[ 1,'�O�Y',180.0 ], [ 4,'�l�Y',175.5 ],[ 2,'�ܘY',169.9 ]]).
�\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ��� :-
�@�@retract(�ԍ��E�����E�g��(L)),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(L,[],L2),
�@�@assertz(�ԍ��E�����E�g��(L2)).
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([],L,L) :- !.
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([U|R1],L1,L) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,L1,L2),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(R1,L2,L).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([L],[L]).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� > _�g��1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� = _�g��1,
�@�@_�ԍ� < _�ԍ�1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[U|R1],[U|R2]) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],R1,R2).
% Prolog
�ԍ��E�����E�g��([[ 3,'��Y',180.0 ], [ 5,'��Y',175.5 ],[ 1,'�O�Y',180.0 ], [ 4,'�l�Y',175.5 ],[ 2,'�ܘY',169.9 ]]).
�\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ��� :-
�@�@retract(�ԍ��E�����E�g��(L)),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(L,[],L2),
�@�@assertz(�ԍ��E�����E�g��(L2)).
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([],L,L) :- !.
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([U|R1],L1,L) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,L1,L2),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(R1,L2,L).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([L],[L]).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� > _�g��1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� = _�g��1,
�@�@_�ԍ� < _�ԍ�1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[U|R1],[U|R2]) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],R1,R2).
556 �F�f�t�H���g�̖����������F2009/12/09(��) 05:35:51
>>555 >>554 �ԈႢ�B�^������̒P�ʐ߁B
% Prolog
�ԍ��E�����E�g��([[ 3,'��Y',180.0 ], [ 5,'��Y',175.5 ],[ 1,'�O�Y',180.0 ], [ 4,'�l�Y',175.5 ],[ 2,'�ܘY',169.9 ]]).
�\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ��� :-
�@�@retract(�ԍ��E�����E�g��(L)),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(L,[],L2),
�@�@assertz(�ԍ��E�����E�g��(L2)).
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([],L,L) :- !.
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([U|R1],L1,L) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,L1,L2),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(R1,L2,L).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,[U]) :- !.�@/* �C���ӏ��͂����ł� */
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� > _�g��1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� = _�g��1,
�@�@_�ԍ� < _�ԍ�1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[U|R1],[U|R2]) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],R1,R2).
% Prolog
�ԍ��E�����E�g��([[ 3,'��Y',180.0 ], [ 5,'��Y',175.5 ],[ 1,'�O�Y',180.0 ], [ 4,'�l�Y',175.5 ],[ 2,'�ܘY',169.9 ]]).
�\���̂�g�����ɕ��וς��Ȃ����B�g���������ꍇ�͔ԍ����Ⴂ���ɕ��ׂȂ��� :-
�@�@retract(�ԍ��E�����E�g��(L)),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(L,[],L2),
�@�@assertz(�ԍ��E�����E�g��(L2)).
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([],L,L) :- !.
�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������([U|R1],L1,L) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,L1,L2),
�@�@�g�����ɕ��וς���B�������g���������ꍇ�͔ԍ�����������(R1,L2,L).
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������(U,[U]) :- !.�@/* �C���ӏ��͂����ł� */
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� > _�g��1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[[_�ԍ�1,_����1,_�g��1]|R1],[[_�ԍ�,_����,_�g��],[_�ԍ�1,_����1,_�g��1]|R1]) :-
�@�@_�g�� = _�g��1,
�@�@_�ԍ� < _�ԍ�1,!.
�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],[U|R1],[U|R2]) :-
�@�@�g�����ɑ}�������������ꍇ�͔ԍ��̏�������([_�ԍ�,_����,_�g��],R1,R2).
557 �F�f�t�H���g�̖����������F2009/12/09(��) 05:39:37
>>552
�g�p����F�@J
���̒i��1�ɂȂ��Ă�����̂������̂���ł��B
f=:monad def 'y,:4=+/|:#@~.@>0 cutopen"1*-/~y'
f 10?100
88 20 14 3 43 66 18 28 59 31
0 0 0 0 1 0 0 0 0 0
f 10?100
11 76 40 72 83 64 59 66 22 42
0 0 1 1 0 1 1 0 0 0
�g�p����F�@J
���̒i��1�ɂȂ��Ă�����̂������̂���ł��B
f=:monad def 'y,:4=+/|:#@~.@>0 cutopen"1*-/~y'
f 10?100
88 20 14 3 43 66 18 28 59 31
0 0 0 0 1 0 0 0 0 0
f 10?100
11 76 40 72 83 64 59 66 22 42
0 0 1 1 0 1 1 0 0 0
558 �F�f�t�H���g�̖����������F2009/12/09(��) 11:47:50
>>547
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L).
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L) :-
�@�@length(L1,4),
�@�@length(L2,4),
�@�@append(L1,[[_�X�R�A,_����]|L2],L),
�@�@append(_,L,_,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L) :-
�@�@list_nth(N,L3,[_�X�R�A,_����]),
�@�@N < 4,
�@�@length(L,8),
�@�@append(L,_,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_,_,L3,L) :-
�@�@length(L,8),
�@�@append(_,L,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_,_,L,L).
% Prolog
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_����,L) :-
�@�@findall([_�X�R�A,_����],�X�R�A(_����,_�X�R�A),L1),
�@�@sort(L1,L2),
�@�@reverse(L2,L3),
�@�@�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L).
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L) :-
�@�@length(L1,4),
�@�@length(L2,4),
�@�@append(L1,[[_�X�R�A,_����]|L2],L),
�@�@append(_,L,_,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_�X�R�A,_����,L3,L) :-
�@�@list_nth(N,L3,[_�X�R�A,_����]),
�@�@N < 4,
�@�@length(L,8),
�@�@append(L,_,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_,_,L3,L) :-
�@�@length(L,8),
�@�@append(_,L,L3),!.
�X�R�A�����L���O�ŁA�����̏㉺4�l���܂߂�9�l���̏������(_,_,L,L).
559 �F�f�t�H���g�̖����������F2009/12/09(��) 12:05:20
>>558
sort/2 �̒���Areverse/2�̒���ł��ꂼ��ŏ���4�f�[�^�܂ł�
[_�X�R�A,_����]���o�����邩�ǂ�����������Ƃ������������͂Ȃ�B
sort/2 �̒���Areverse/2�̒���ł��ꂼ��ŏ���4�f�[�^�܂ł�
[_�X�R�A,_����]���o�����邩�ǂ�����������Ƃ������������͂Ȃ�B
560 �F�f�t�H���g�̖����������F2009/12/09(��) 14:31:44
>>552 ���̖��⑫�������ł��̂ŁA���ꕔ�ύX�B
% Prolog
% http://pc12.2ch.net/test/read.cgi/tech/1258158172/816
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_���R���Ȃ��) :-
�@�@append(L1,[N|L2],_���R���Ȃ��),
�@�@findsum(1,(member(A,L1),A > N),M1),M1 >= 1,
�@�@findsum(1,(member(B,L2),B < N),M2),M2 >= 1,
�@�@write_formatted('%t\n',[N]),
�@�@fail.
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_).
% Prolog
% http://pc12.2ch.net/test/read.cgi/tech/1258158172/816
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_���R���Ȃ��) :-
�@�@append(L1,[N|L2],_���R���Ȃ��),
�@�@findsum(1,(member(A,L1),A > N),M1),M1 >= 1,
�@�@findsum(1,(member(B,L2),B < N),M2),M2 >= 1,
�@�@write_formatted('%t\n',[N]),
�@�@fail.
���R���̐�����ɂ��邎�����傫�����Ə��������������ɂ�����n�̑O��ɂ��ꂼ��������ꍇ�A����n���o��(_).
561 �F�f�t�H���g�̖����������F2009/12/09(��) 15:12:43
http://pc11.2ch.net/test/read.cgi/db/1252492296/330
# ���e�[�u���f�[�^
# �EID�e�[�u�� �@�@# �E�}�X�^�[�e�[�u��
# 1, 2, 3 �@�@�@�@�@# 1, A
# 1, 2, 4 �@�@�@�@�@# 2, A
# 5, -1, -1 �@�@�@�@# 3, A
# -1, 1, 2 �@�@ �@�@# 4, B
# 2, -1, 5 �@�@ �@�@# -1, Z
#
# ����肽������
# �}�X�^�[�e�[�u�����Q�Ƃ���ID�e�[�u���̊eID�ɃN���X(A, B, Z)��U�蓖�āA
# �e���R�[�h������N���X�ɑ����邩�ۂ��肵�A����N���X�ɑ����郌�R�[�h
# �����N���X�t�Œ��o����B
# �����Łu����N���X�ɑ�����v�Ƃ́A�N���XA, B, Z����Ȃ�O���[�v�ɑ��āA
# Z�ȊO�̗v�f�����ނ������݂��Ȃ��ꍇ�ɁA�O���[�v�͂��̃N���X�ɑ�����ƒ�߂�B
# �ŏI�I�ɗ~�����f�[�^��
#
# 1, 2, 3, A
# 5, -1, -1, B
# -1, 1, 2, A
#
# �ƂȂ�܂��B��낵�����肢���܂��B
# ���e�[�u���f�[�^
# �EID�e�[�u�� �@�@# �E�}�X�^�[�e�[�u��
# 1, 2, 3 �@�@�@�@�@# 1, A
# 1, 2, 4 �@�@�@�@�@# 2, A
# 5, -1, -1 �@�@�@�@# 3, A
# -1, 1, 2 �@�@ �@�@# 4, B
# 2, -1, 5 �@�@ �@�@# -1, Z
#
# ����肽������
# �}�X�^�[�e�[�u�����Q�Ƃ���ID�e�[�u���̊eID�ɃN���X(A, B, Z)��U�蓖�āA
# �e���R�[�h������N���X�ɑ����邩�ۂ��肵�A����N���X�ɑ����郌�R�[�h
# �����N���X�t�Œ��o����B
# �����Łu����N���X�ɑ�����v�Ƃ́A�N���XA, B, Z����Ȃ�O���[�v�ɑ��āA
# Z�ȊO�̗v�f�����ނ������݂��Ȃ��ꍇ�ɁA�O���[�v�͂��̃N���X�ɑ�����ƒ�߂�B
# �ŏI�I�ɗ~�����f�[�^��
#
# 1, 2, 3, A
# 5, -1, -1, B
# -1, 1, 2, A
#
# �ƂȂ�܂��B��낵�����肢���܂��B
562 �F�f�t�H���g�̖����������F2009/12/09(��) 15:15:35
>>561
% Prolog
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�' :-
�@�@'ID'(Id_1,Id_2,Id_3),
�@�@�}�X�^�[(Id_1,_�N���X1),
�@�@�}�X�^�[(Id_2,_�N���X2),
�@�@�}�X�^�[(Id_3,_�N���X3),
�@�@setof(U,(member(U,[_�N���X1,_�N���X2,_�N���X3]),\+(U='Z')),[_�N���X]),
�@�@write_formatted('%t,%t,%t,%t\n',[Id_1,Id_2,Id_3,_�N���X]),
�@�@fail.
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�'.
% Prolog
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�' :-
�@�@'ID'(Id_1,Id_2,Id_3),
�@�@�}�X�^�[(Id_1,_�N���X1),
�@�@�}�X�^�[(Id_2,_�N���X2),
�@�@�}�X�^�[(Id_3,_�N���X3),
�@�@setof(U,(member(U,[_�N���X1,_�N���X2,_�N���X3]),\+(U='Z')),[_�N���X]),
�@�@write_formatted('%t,%t,%t,%t\n',[Id_1,Id_2,Id_3,_�N���X]),
�@�@fail.
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�'.
563 �F�f�t�H���g�̖����������F2009/12/09(��) 15:32:00
>>561�@���͌��̎���̍Ō�Ɉȉ��̕t�����������B�����������B
# ��ID�e�[�u���̗�=3�A�N���X��=3 �Ƃ����̂͑����Ă���K�v�͂Ȃ�
# ID��5��N���X��10��ނ���Ƃ����ꍇ�ł��K�p�\�ȉ����肢�������ł��B
http://pc11.2ch.net/test/read.cgi/db/1252492296/330
# ���ꂪ�\�ɂȂ�悤�ɕύX���Ȃ����B
# ��ID�e�[�u���̗�=3�A�N���X��=3 �Ƃ����̂͑����Ă���K�v�͂Ȃ�
# ID��5��N���X��10��ނ���Ƃ����ꍇ�ł��K�p�\�ȉ����肢�������ł��B
http://pc11.2ch.net/test/read.cgi/db/1252492296/330
# ���ꂪ�\�ɂȂ�悤�ɕύX���Ȃ����B
564 �F�f�t�H���g�̖����������F2009/12/09(��) 15:38:21
>>563
% Prolog �v��D�܂����ύX�ł͂Ȃ��B
% �q�� 'ID' ��1�����Ƃ��āA�f�[�^�����X�g�Ƃ��Ď��B
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�' :-
�@�@'ID'(L),
�@�@setof(U,(member(ID,L),�}�X�^�[(ID,U),\+(U='Z')),[_�N���X]),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t,%t\n',[S,_�N���X]),
�@�@fail.
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�'.
% Prolog �v��D�܂����ύX�ł͂Ȃ��B
% �q�� 'ID' ��1�����Ƃ��āA�f�[�^�����X�g�Ƃ��Ď��B
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�' :-
�@�@'ID'(L),
�@�@setof(U,(member(ID,L),�}�X�^�[(ID,U),\+(U='Z')),[_�N���X]),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t,%t\n',[S,_�N���X]),
�@�@fail.
'�N���XA, B, Z����Ȃ�O���[�v�ɑ��āAZ�ȊO�̗v�f�����ނ������݂��Ȃ�'.
565 �F�f�t�H���g�̖����������F2009/12/09(��) 15:51:57
>>552
�g�p����F�@�\�iBASIC
RANDOMIZE
LET N=10
DIM d(N)
FOR i=1 TO N
LET d(i)= INT(RND*100)
NEXT I
MAT PRINT d;
FOR i=3 TO N-2
LET lc1=0
LET lc2=0
FOR L=1 TO i-1
IF d(i)<d(L) THEN LET lc1=1
IF d(i)>d(L) THEN LET lc2=1
IF lc1+lc2=2 THEN BREAK
NEXT L
LET rc1=0
LET rc2=0
FOR R=i+1 TO N
IF d(i)<d(R) THEN LET rc1=1
IF d(i)>d(R) THEN LET rc2=1
IF rc1+rc2=2 THEN BREAK
NEXT R
IF lc1+lc2+rc1+rc2=4 THEN PRINT d(i);
NEXT I
END
���s����
95 26 34 5 55 45 99 65 44 1
34 55 45
�g�p����F�@�\�iBASIC
RANDOMIZE
LET N=10
DIM d(N)
FOR i=1 TO N
LET d(i)= INT(RND*100)
NEXT I
MAT PRINT d;
FOR i=3 TO N-2
LET lc1=0
LET lc2=0
FOR L=1 TO i-1
IF d(i)<d(L) THEN LET lc1=1
IF d(i)>d(L) THEN LET lc2=1
IF lc1+lc2=2 THEN BREAK
NEXT L
LET rc1=0
LET rc2=0
FOR R=i+1 TO N
IF d(i)<d(R) THEN LET rc1=1
IF d(i)>d(R) THEN LET rc2=1
IF rc1+rc2=2 THEN BREAK
NEXT R
IF lc1+lc2+rc1+rc2=4 THEN PRINT d(i);
NEXT I
END
���s����
95 26 34 5 55 45 99 65 44 1
34 55 45
566 �F�f�t�H���g�̖����������F2009/12/09(��) 17:58:06
>>370�@�ۑ�(2)
�g�p����F�@Yacas
In> f(n,d):=Mod(Div(n,10^(d-1)),10);
Out> True
In> f(123456789,2)
Out> 8
In> f(123456789,7)
Out> 3
�g�p����F�@Yacas
In> f(n,d):=Mod(Div(n,10^(d-1)),10);
Out> True
In> f(123456789,2)
Out> 8
In> f(123456789,7)
Out> 3
567 �F�f�t�H���g�̖����������F2009/12/09(��) 18:28:00
http://pc12.2ch.net/test/read.cgi/tech/1258158172/841
# [1] ���ƒP���F C���ꉉ�K��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10252.txt
#
# ���P�F
# ������(128��������)��ǂݍ��݁A���̒�����\������v���O�������쐬����B
# �������A������̑����ɂ́A�|�C���^�ϐ����g�p���邱�ƁB���������p���Ȃ����ƁB
#
# ���Q�F
# ���P�̓ǂݍ��ݕ������t�@�C�������ɕύX����B fgetc()�����g�p���邱�ƁB
# �R�}���h���C���Ƀt�@�C�������w��ł��邱�ƁB�������A�t�@�C�������w�肵�Ȃ��ꍇ�͕W�����͂Ƃ��邱�ƁB
# [1] ���ƒP���F C���ꉉ�K��
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10252.txt
#
# ���P�F
# ������(128��������)��ǂݍ��݁A���̒�����\������v���O�������쐬����B
# �������A������̑����ɂ́A�|�C���^�ϐ����g�p���邱�ƁB���������p���Ȃ����ƁB
#
# ���Q�F
# ���P�̓ǂݍ��ݕ������t�@�C�������ɕύX����B fgetc()�����g�p���邱�ƁB
# �R�}���h���C���Ƀt�@�C�������w��ł��邱�ƁB�������A�t�@�C�������w�肵�Ȃ��ꍇ�͕W�����͂Ƃ��邱�ƁB
568 �F�f�t�H���g�̖����������F2009/12/09(��) 18:29:49
>>567
% Prolog
'������(128��������)��ǂݍ��݁A���̒�����\������' :-
�@�@get_char(C),
�@�@'������(128��������)��ǂݍ���'(C,L),
�@�@length(L,N),
�@�@write_formatted('%t�����ł�\n',[N]).
'������(128��������)��ǂݍ���'('\n',[]) :- !.
'������(128��������)��ǂݍ���'(C,[C|R]) :-
�@�@get_char(C2),
�@�@'������(128��������)��ǂݍ���'(C2,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
program :-
�@�@user_parameters([_�t�@�C����]),
�@�@open(_�t�@�C����,read,Instream),
�@�@get_char(Instream,C),
�@�@'������(128��������)��ǂݍ���'(Instream,C,L),
�@�@length(L,N),
�@�@write_formatted('%t�����ł�\n',[N]),
�@�@close(Instream).
'������(128��������)��ǂݍ���'(_,'\n',[]) :- !.
'������(128��������)��ǂݍ���'(Instream,C,[C|R]) :-
�@�@get_char(Instream,C2),
�@�@'������(128��������)��ǂݍ���'(Instream,C2,R).
% Prolog
'������(128��������)��ǂݍ��݁A���̒�����\������' :-
�@�@get_char(C),
�@�@'������(128��������)��ǂݍ���'(C,L),
�@�@length(L,N),
�@�@write_formatted('%t�����ł�\n',[N]).
'������(128��������)��ǂݍ���'('\n',[]) :- !.
'������(128��������)��ǂݍ���'(C,[C|R]) :-
�@�@get_char(C2),
�@�@'������(128��������)��ǂݍ���'(C2,R).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
program :-
�@�@user_parameters([_�t�@�C����]),
�@�@open(_�t�@�C����,read,Instream),
�@�@get_char(Instream,C),
�@�@'������(128��������)��ǂݍ���'(Instream,C,L),
�@�@length(L,N),
�@�@write_formatted('%t�����ł�\n',[N]),
�@�@close(Instream).
'������(128��������)��ǂݍ���'(_,'\n',[]) :- !.
'������(128��������)��ǂݍ���'(Instream,C,[C|R]) :-
�@�@get_char(Instream,C2),
�@�@'������(128��������)��ǂݍ���'(Instream,C2,R).
569 �F�f�t�H���g�̖����������F2009/12/09(��) 18:34:13
>>17�@���1
�g�p����F�@Yacas
In> f(n):="abcdefghijklmnopqrstuvwxyz"[1 .. Min(n,26)]
Out> True
In> f(6)
Out> "abcdef"
In> f(30)
Out> "abcdefghijklmnopqrstuvwxyz"
�g�p����F�@Yacas
In> f(n):="abcdefghijklmnopqrstuvwxyz"[1 .. Min(n,26)]
Out> True
In> f(6)
Out> "abcdef"
In> f(30)
Out> "abcdefghijklmnopqrstuvwxyz"
570 �F�f�t�H���g�̖����������F2009/12/09(��) 18:48:40
>>17�@���2
�g�p����F�@Yacas
In> f(n):=Sum(i,1,n,If(Mod(i,3)=0 Or Mod(i,5)=0,i,0))
Out> True
In> f(10)
Out> 33
In> f(100)
Out> 2418
�g�p����F�@Yacas
In> f(n):=Sum(i,1,n,If(Mod(i,3)=0 Or Mod(i,5)=0,i,0))
Out> True
In> f(10)
Out> 33
In> f(100)
Out> 2418
571 �F�f�t�H���g�̖����������F2009/12/09(��) 20:12:52
>>511
�g�p����F�@Yacas
In> f(x,y):=Echo("{�߂̐�,�T�̐�} = ",SolveMatrix({{1,1},{2,4}},{x,y}))
Out> True
In> f(3,8)
{�߂̐�,�T�̐�} = {2,1}
Out> True
In> f(10,24)
{�߂̐�,�T�̐�} = {8,2}
Out> True
�g�p����F�@Yacas
In> f(x,y):=Echo("{�߂̐�,�T�̐�} = ",SolveMatrix({{1,1},{2,4}},{x,y}))
Out> True
In> f(3,8)
{�߂̐�,�T�̐�} = {2,1}
Out> True
In> f(10,24)
{�߂̐�,�T�̐�} = {8,2}
Out> True
572 �F�f�t�H���g�̖����������F2009/12/09(��) 21:22:41
http://pc12.2ch.net/test/read.cgi/tech/1258158172/858
# ../test/read.cgi/tech/1258158172/857
#
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F
# ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�D
# (a) ��Ԃ��P�O�������Ăǂ̋�Ԃɉ������邩�����߂�v���O�������쐬���Ȃ����D
# (b) ���������Ԃ�����������C����ɂ��̋�Ԃ��P�O�������Ăǂ̋�Ԃɉ������邩�����߂�Ƃ�����Ƃ��T��J��Ԃ��v���O�������쐬���Ȃ����D
#
# �i�⑫�j�Q���@
# �Q���@�Ƃ́C���Ԓl�̒藝�ɍ����������āC�����I�ɉ������Ƃ̂ł��Ȃ��������̉������߂���@�ł���D
# ���}�Ɏ����悤�ɁCx�̒l���������ω��������ꍇ�ɁC�ׂ荇�����f(x)�̒l�̕������قȂ��Ԃ����݂���ƁC���̕������̉��͂��̋�ԓ��ɑ��݂���D
# ��Ԃ����������߂Ă������Ƃɂ��C���̕������̋ߎ��������߂邱�Ƃ��ł���D�������̋ߎ���@�Ƃ��đ�\�I�Ȃ��̂ɂ͂Q���@�̑��ɁC�j���[�g���@������D
#
# ../test/read.cgi/tech/1258158172/857
#
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F
# ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�D
# (a) ��Ԃ��P�O�������Ăǂ̋�Ԃɉ������邩�����߂�v���O�������쐬���Ȃ����D
# (b) ���������Ԃ�����������C����ɂ��̋�Ԃ��P�O�������Ăǂ̋�Ԃɉ������邩�����߂�Ƃ�����Ƃ��T��J��Ԃ��v���O�������쐬���Ȃ����D
#
# �i�⑫�j�Q���@
# �Q���@�Ƃ́C���Ԓl�̒藝�ɍ����������āC�����I�ɉ������Ƃ̂ł��Ȃ��������̉������߂���@�ł���D
# ���}�Ɏ����悤�ɁCx�̒l���������ω��������ꍇ�ɁC�ׂ荇�����f(x)�̒l�̕������قȂ��Ԃ����݂���ƁC���̕������̉��͂��̋�ԓ��ɑ��݂���D
# ��Ԃ����������߂Ă������Ƃɂ��C���̕������̋ߎ��������߂邱�Ƃ��ł���D�������̋ߎ���@�Ƃ��đ�\�I�Ȃ��̂ɂ͂Q���@�̑��ɁC�j���[�g���@������D
#
573 �F�f�t�H���g�̖����������F2009/12/09(��) 21:23:58
http://pc12.2ch.net/test/read.cgi/tech/1258158172/859
#
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F ��y=x3+1�̔����Ȑ������߂�v���O�������쐬���Ȃ����D�v�Z�͈͂�0��x��2�Ƃ��C�Ԋu��0.1�Ƃ���D
#
#
#
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F ��y=x3+1�̔����Ȑ������߂�v���O�������쐬���Ȃ����D�v�Z�͈͂�0��x��2�Ƃ��C�Ԋu��0.1�Ƃ���D
#
#
574 �F�f�t�H���g�̖����������F2009/12/10(��) 04:23:15
http://pc12.2ch.net/test/read.cgi/tech/1258158172/862
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�@���X�g����
# �@ ���s���ʂ̂悤�ɃL�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[���A���͒l��
# �ԍ���t���ĕ\������v���O�������쐬���Ȃ���.���������͂̏I����Ctrl+d�ōs����悤�ɂ��邱�ƁB
# ���͂���l��������s��ƈقȂ�ꍇ�ɂ����������삷��悤�ɂ��邱��.
# �K��1�ȏ�̐��������͂����Ƃ���.
#
# [���s����]
# ���������Ԃɓ��͂��Ă�������.
# 5
# 10
# 15
# ���̓f�[�^�͈ȉ��̒ʂ�ł�.
# [1] 5
# [2] 10
# [3] 15
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�@���X�g����
# �@ ���s���ʂ̂悤�ɃL�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[���A���͒l��
# �ԍ���t���ĕ\������v���O�������쐬���Ȃ���.���������͂̏I����Ctrl+d�ōs����悤�ɂ��邱�ƁB
# ���͂���l��������s��ƈقȂ�ꍇ�ɂ����������삷��悤�ɂ��邱��.
# �K��1�ȏ�̐��������͂����Ƃ���.
#
# [���s����]
# ���������Ԃɓ��͂��Ă�������.
# 5
# 10
# 15
# ���̓f�[�^�͈ȉ��̒ʂ�ł�.
# [1] 5
# [2] 10
# [3] 15
575 �F�f�t�H���g�̖����������F2009/12/10(��) 04:27:37
http://pc12.2ch.net/test/read.cgi/tech/1258158172/863
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10253.txt
#
# �����P�]�P�@�����^�����i�r�b�g��̕\���j
# �@�����Ȃ�32bit��������͂��āA���̐���2�i�\������v���O�������쐬���Ȃ����B
# �����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������邱�ƁB
#
# [���s����]
# �����Ȃ�32bit��������͂��Ă�������.
# 987654321
# 987654321 ��2�i�\���� 0011 1010 1101 1110 0110 1000 1011 0001 �ł�.
# 0�̃r�b�g����15�C1�̃r�b�g����17�ł�.
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10253.txt
#
# �����P�]�P�@�����^�����i�r�b�g��̕\���j
# �@�����Ȃ�32bit��������͂��āA���̐���2�i�\������v���O�������쐬���Ȃ����B
# �����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������邱�ƁB
#
# [���s����]
# �����Ȃ�32bit��������͂��Ă�������.
# 987654321
# 987654321 ��2�i�\���� 0011 1010 1101 1110 0110 1000 1011 0001 �ł�.
# 0�̃r�b�g����15�C1�̃r�b�g����17�ł�.
576 �F�f�t�H���g�̖����������F2009/12/10(��) 04:32:17
http://pc12.2ch.net/test/read.cgi/tech/1258158172/863
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10253.txt
# �����P�]�Q
# �@�����Ȃ�32bit������2���͂��āA������2�i�\������v���O�������쐬���Ȃ����B
# ����ɁA���s��̂悤�Ƀr�b�g���](1�̕␔�\���`),�r�b�g�V�t�g(<<, >>), �r�b�g�_���ρi��),�r�b�g�_���a�i�b�j,
# �r�b�g�r���I�_���a�i�O�j��\�����Ȃ����B������2�i�\����4������邱��.
# �܂����P�]�P�ō쐬����2�i�\���̊����ė��p���邱�ƁB
# [���s����]
# �����Ȃ�32bit����2����͂��Ă�������.
# 987654321 123456789
# 987654321 ��2�i�\���� 0011 1010 1101 1110 0110 1000 1011 0001 ,
# 123456789 ��2�i�\���� 0000 0111 0101 1011 1100 1101 0001 0101 �ł�.
# �`987654321 ��2�i�\���� 1100 0101 0010 0001 10010111 0100 1110 ,
# �`123456789 ��2�i�\���� 1111 1000 1010 0100 0011 0010 1110 1010 �ł�.
# 987654321 << 1��2�i�\���� 0111 0101 1011 1100 1101 0001 0110 0010 ,
# 123456789 >> 1��2�i�\���� 0000 0011 1010 1101 1110 0110 1000 1010 �ł�.
# 987654321 & 123456879 ��2�i�\���� 0000 0010 0101 1010 0100 1000 0001 0001 �ł�
# 987654321 | 123456879 ��2�i�\���� 0011 1111 1101 1111 1110 1101 1011 0101 �ł�.
# 987654321 ^ 123456879 ��2�i�\���� 0011 1101 1000 0101 1010 0101 1010 0100 �ł�.
# [1] ���ƒP���FC����ƃA���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10253.txt
# �����P�]�Q
# �@�����Ȃ�32bit������2���͂��āA������2�i�\������v���O�������쐬���Ȃ����B
# ����ɁA���s��̂悤�Ƀr�b�g���](1�̕␔�\���`),�r�b�g�V�t�g(<<, >>), �r�b�g�_���ρi��),�r�b�g�_���a�i�b�j,
# �r�b�g�r���I�_���a�i�O�j��\�����Ȃ����B������2�i�\����4������邱��.
# �܂����P�]�P�ō쐬����2�i�\���̊����ė��p���邱�ƁB
# [���s����]
# �����Ȃ�32bit����2����͂��Ă�������.
# 987654321 123456789
# 987654321 ��2�i�\���� 0011 1010 1101 1110 0110 1000 1011 0001 ,
# 123456789 ��2�i�\���� 0000 0111 0101 1011 1100 1101 0001 0101 �ł�.
# �`987654321 ��2�i�\���� 1100 0101 0010 0001 10010111 0100 1110 ,
# �`123456789 ��2�i�\���� 1111 1000 1010 0100 0011 0010 1110 1010 �ł�.
# 987654321 << 1��2�i�\���� 0111 0101 1011 1100 1101 0001 0110 0010 ,
# 123456789 >> 1��2�i�\���� 0000 0011 1010 1101 1110 0110 1000 1010 �ł�.
# 987654321 & 123456879 ��2�i�\���� 0000 0010 0101 1010 0100 1000 0001 0001 �ł�
# 987654321 | 123456879 ��2�i�\���� 0011 1111 1101 1111 1110 1101 1011 0101 �ł�.
# 987654321 ^ 123456879 ��2�i�\���� 0011 1101 1000 0101 1010 0101 1010 0100 �ł�.
577 �F�f�t�H���g�̖����������F2009/12/10(��) 04:33:39
http://pc12.2ch.net/test/read.cgi/tech/1258158172/869
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������ABCDEFGHIJKLMN�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������v���O���������B �������W�����C�u�����͎g�p���Ȃ����ƁB
#
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������ABCDEFGHIJKLMN�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������v���O���������B �������W�����C�u�����͎g�p���Ȃ����ƁB
#
578 �F�f�t�H���g�̖����������F2009/12/10(��) 04:39:48
http://pc12.2ch.net/test/read.cgi/tech/1258158172/886
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
#
# �����K���1-6*
# 2��lnt�^�����la,b���C���ꂼ����w���|�C���^��p���ē���ւ���
# ��
# swap(int*a,lnt*b)
# ���쐬����.
# �@(���s��)
# �Q�̐�������͂��Ă��������D
# ����A:24
# ����B:25
# �����̒l���������܂����D
# ����A:25�ł��D
# ����B:24�ł��D
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
#
# �����K���1-6*
# 2��lnt�^�����la,b���C���ꂼ����w���|�C���^��p���ē���ւ���
# ��
# swap(int*a,lnt*b)
# ���쐬����.
# �@(���s��)
# �Q�̐�������͂��Ă��������D
# ����A:24
# ����B:25
# �����̒l���������܂����D
# ����A:25�ł��D
# ����B:24�ł��D
579 �F�f�t�H���g�̖����������F2009/12/10(��) 04:43:36
http://pc12.2ch.net/test/read.cgi/tech/1258158172/886
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
#
# �����K���1-7*
# 3��lnt�^�����l���C�����ɕ��ѕς�������쐬���C���s���ʂɂ��
# ���̊������������삷�邱�Ƃ��m�F����D(��̉ۑ�̊�swap���g�p����)
# �@(���s��)# �Q�̐�������͂��Ă��������D
# ����A:32
# ����B:48
# ����C:15
# �����̒l���������܂����D
# ����A:15
# ����B:32
# ����C:48
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
#
# �����K���1-7*
# 3��lnt�^�����l���C�����ɕ��ѕς�������쐬���C���s���ʂɂ��
# ���̊������������삷�邱�Ƃ��m�F����D(��̉ۑ�̊�swap���g�p����)
# �@(���s��)# �Q�̐�������͂��Ă��������D
# ����A:32
# ����B:48
# ����C:15
# �����̒l���������܂����D
# ����A:15
# ����B:32
# ����C:48
580 �F�f�t�H���g�̖����������F2009/12/10(��) 04:56:22
http://pc12.2ch.net/test/read.cgi/tech/1258158172/886
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
# �����K���1-9*
# 1�`10�܂ł̐����̘a�����߂�v���O�������|�C���^���g���ċ��߂�D(��
# �Ԃ�����C�\�ł���C���ς����߂�F������͔C�Ӊۑ�Ƃ���)�C
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
# �����K���1-9*
# 1�`10�܂ł̐����̘a�����߂�v���O�������|�C���^���g���ċ��߂�D(��
# �Ԃ�����C�\�ł���C���ς����߂�F������͔C�Ӊۑ�Ƃ���)�C
581 �F�f�t�H���g�̖����������F2009/12/10(��) 04:58:27
http://pc12.2ch.net/test/read.cgi/tech/1258158172/886
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
# �����K���1-10
# �傫��10�̐����^�z���p�ӂ��C�}�Q�̂悤�ɏ����ݒ肵�Ȃ����B����
# �z������ɒ��ׁA��̒l�̂݁C�ʂ̑傫��10�̐����^�z��ɑ������
# �����D�܂��C�z��̒��g�ƁC���i�[����������ʕ\�����Ȃ���.
#
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10254.txt
# �����K���1-10
# �傫��10�̐����^�z���p�ӂ��C�}�Q�̂悤�ɏ����ݒ肵�Ȃ����B����
# �z������ɒ��ׁA��̒l�̂݁C�ʂ̑傫��10�̐����^�z��ɑ������
# �����D�܂��C�z��̒��g�ƁC���i�[����������ʕ\�����Ȃ���.
582 �F�f�t�H���g�̖����������F2009/12/10(��) 07:55:15
>>573
% Prolog
f(X,Y) :- Y is X ^ 3 + 1.
'��y=x3+1�̔����Ȑ������߂�'(L) :-
�@�@'��y=x3+1�̔����Ȑ������߂�'(0,2,0,0.1,L).
'��y=x3+1�̔����Ȑ������߂�'(X1,XMax,Y1,_�Ԋu,[]) :- X1 >= XMax,!.
'��y=x3+1�̔����Ȑ������߂�'(X1,XMax,Y1,_�Ԋu,[[X,Z]|R]) :-
�@�@X is X1 + _�Ԋu,
�@�@f(X,Y),
�@�@Z is (Y-Y1) / _�Ԋu,
�@�@'��y=x3+1�̔����Ȑ������߂�'(X,XMax,Y,_�Ԋu,R).
% Prolog
f(X,Y) :- Y is X ^ 3 + 1.
'��y=x3+1�̔����Ȑ������߂�'(L) :-
�@�@'��y=x3+1�̔����Ȑ������߂�'(0,2,0,0.1,L).
'��y=x3+1�̔����Ȑ������߂�'(X1,XMax,Y1,_�Ԋu,[]) :- X1 >= XMax,!.
'��y=x3+1�̔����Ȑ������߂�'(X1,XMax,Y1,_�Ԋu,[[X,Z]|R]) :-
�@�@X is X1 + _�Ԋu,
�@�@f(X,Y),
�@�@Z is (Y-Y1) / _�Ԋu,
�@�@'��y=x3+1�̔����Ȑ������߂�'(X,XMax,Y,_�Ԋu,R).
583 �F�f�t�H���g�̖����������F2009/12/10(��) 08:00:37
>>572
% Prolog
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,X) :-
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,0,X,Y,X).
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,X,A,X) :-
�@�@abs((pi * X * X) - Y) < 0.01,!.
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z,A,X) :-
�@�@(pi * Z * Z) < Y,
�@�@Z2 is�@(P + Z) / 2,
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z2,Z,X),!.
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z,A,X) :-
�@�@Z2 is (A + Z) / 2,
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,Z,Z2,A,X).
% Prolog
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,X) :-
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,0,X,Y,X).
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,X,A,X) :-
�@�@abs((pi * X * X) - Y) < 0.01,!.
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z,A,X) :-
�@�@(pi * Z * Z) < Y,
�@�@Z2 is�@(P + Z) / 2,
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z2,Z,X),!.
ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,P,Z,A,X) :-
�@�@Z2 is (A + Z) / 2,
�@�@ycm2�̖ʐς�L����~�̔��ax���C�Q���@��p���ċߎ��������߂�(Y,Z,Z2,A,X).
584 �F�f�t�H���g�̖����������F2009/12/10(��) 08:15:11
>>574
% Prolog
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[���A���͒l�ɔԍ���t���ĕ\����
�� :-
�@�@write('���������Ԃɓ��͂��Ă�������. \n'),
�@�@�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����(L),
�@�@write('���̓f�[�^�͈ȉ��̒ʂ�ł�. \n'),
�@�@���͒l�ɔԍ���t���ĕ\������(1,L).
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����([]).
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����([N|R]) :-
�@�@get_integer(N),
�@�@�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����(R).
���͒l�ɔԍ���t���ĕ\������(1,[]).
���͒l�ɔԍ���t���ĕ\������(N,[A|R]) :-
�@�@write_formatted('[%t] %t\n',[N,A]),
�@�@N2 is N + 1,
�@�@���͒l�ɔԍ���t���ĕ\������(N2,R).
% Prolog
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[���A���͒l�ɔԍ���t���ĕ\����
�� :-
�@�@write('���������Ԃɓ��͂��Ă�������. \n'),
�@�@�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����(L),
�@�@write('���̓f�[�^�͈ȉ��̒ʂ�ł�. \n'),
�@�@���͒l�ɔԍ���t���ĕ\������(1,L).
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����([]).
�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����([N|R]) :-
�@�@get_integer(N),
�@�@�L�[�{�[�h������͂��Đ�������͏��Ƀ��X�g�Ɋi�[����(R).
���͒l�ɔԍ���t���ĕ\������(1,[]).
���͒l�ɔԍ���t���ĕ\������(N,[A|R]) :-
�@�@write_formatted('[%t] %t\n',[N,A]),
�@�@N2 is N + 1,
�@�@���͒l�ɔԍ���t���ĕ\������(N2,R).
585 �F�f�t�H���g�̖����������F2009/12/10(��) 08:51:45
>>577
% Prolog
������ABCDEFGHIJKLMN�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������ :-
�@�@atom_chars('ABCDEFGHIJKLMN',Chars),
�@�@write('���������͂��Ă������� :'),
�@�@get_line(_������),
�@�@sub_atom(_������,0,1,_,_��P����),
�@�@sub_atom(_������,1,1,_,_��Q����),
�@�@append(L1,[_��P����|L2],Chars),
�@�@��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,L1,L2,L),
�@�@concat_atom(L,_��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����),
�@�@write_formatted('��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����� %t �ł�\n',[_��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����]).
��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,L1,_,L) :-
�@�@append(_,[_��Q����|L],L1),!.
��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,_,L2,L) :-
�@�@append(L,[_��Q����|_],L2),!.
% Prolog
������ABCDEFGHIJKLMN�ɑ��ē��͂���������̑�P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶�����\������ :-
�@�@atom_chars('ABCDEFGHIJKLMN',Chars),
�@�@write('���������͂��Ă������� :'),
�@�@get_line(_������),
�@�@sub_atom(_������,0,1,_,_��P����),
�@�@sub_atom(_������,1,1,_,_��Q����),
�@�@append(L1,[_��P����|L2],Chars),
�@�@��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,L1,L2,L),
�@�@concat_atom(L,_��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����),
�@�@write_formatted('��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����� %t �ł�\n',[_��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����]).
��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,L1,_,L) :-
�@�@append(_,[_��Q����|L],L1),!.
��P�����ڂƑ�Q�����ڂ̊Ԃɂ��镶����(_��Q����,_,L2,L) :-
�@�@append(L,[_��Q����|_],L2),!.
586 �F�f�t�H���g�̖����������F2009/12/10(��) 10:34:09
>>575
% Prolog
�����Ȃ�32bit��������͂��āA���̐���2�i�\������B�����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������� :-
��i��(1234218219,L1),
'N�g'(4,L1,L2),
findall(B,(member(A,L2),concat_atom(A,B)),L3),
concat_atom(L3,' ',S),
write_formatted('%t��2�i�\����%t�ł�.\n',[N,S]),
count(member(0,L1),Count0),
count(member(1,L1),Count1),
write_formatted('0�̃r�b�g����%t�C1�̃r�b�g����%t�ł�.\n',[Count0,Count1]).
%�@��i��/2 'N�g'/3 count/2 �� http://nojiriko.asia/prolog/c132_863_1.html ���Q��
% Prolog
�����Ȃ�32bit��������͂��āA���̐���2�i�\������B�����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������� :-
��i��(1234218219,L1),
'N�g'(4,L1,L2),
findall(B,(member(A,L2),concat_atom(A,B)),L3),
concat_atom(L3,' ',S),
write_formatted('%t��2�i�\����%t�ł�.\n',[N,S]),
count(member(0,L1),Count0),
count(member(1,L1),Count1),
write_formatted('0�̃r�b�g����%t�C1�̃r�b�g����%t�ł�.\n',[Count0,Count1]).
%�@��i��/2 'N�g'/3 count/2 �� http://nojiriko.asia/prolog/c132_863_1.html ���Q��
587 �F�f�t�H���g�̖����������F2009/12/10(��) 10:38:41
>>586 (>>585) ����
% Prolog
�����Ȃ�32bit��������͂��āA���̐���2�i�\������B�����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������� :-
�@�@write('�����Ȃ�32bit��������͂��Ă�������. \n'),
�@�@get_integer(_�\�i��),
�@�@��i��(_�\�i��,L1),
�@�@'N�g'(4,L1,L2),
�@�@findall(B,(member(A,L2),concat_atom(A,B)),L3),
�@�@concat_atom(L3,' ',S),
�@�@write_formatted('%t��2�i�\����%t�ł�.\n',[N,S]),
�@�@count(member(0,L1),Count0),
�@�@count(member(1,L1),Count1),
�@�@write_formatted('0�̃r�b�g����%t�C1�̃r�b�g����%t�ł�.\n',[Count0,Count1]).
%�@��i��/2 'N�g'/3 count/2 �� http://nojiriko.asia/prolog/c132_863_1.html ���Q��
% Prolog
�����Ȃ�32bit��������͂��āA���̐���2�i�\������B�����0�̃r�b�g��1�̃r�b�g�̐����������Ȃ����B�������A2�i�\���͎��s��̂悤��4������� :-
�@�@write('�����Ȃ�32bit��������͂��Ă�������. \n'),
�@�@get_integer(_�\�i��),
�@�@��i��(_�\�i��,L1),
�@�@'N�g'(4,L1,L2),
�@�@findall(B,(member(A,L2),concat_atom(A,B)),L3),
�@�@concat_atom(L3,' ',S),
�@�@write_formatted('%t��2�i�\����%t�ł�.\n',[N,S]),
�@�@count(member(0,L1),Count0),
�@�@count(member(1,L1),Count1),
�@�@write_formatted('0�̃r�b�g����%t�C1�̃r�b�g����%t�ł�.\n',[Count0,Count1]).
%�@��i��/2 'N�g'/3 count/2 �� http://nojiriko.asia/prolog/c132_863_1.html ���Q��
588 �F�f�t�H���g�̖����������F2009/12/10(��) 12:41:27
http://pc12.2ch.net/test/read.cgi/tech/1248012902/584
# �y�@�ۑ�@�z http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm��857�ł�
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@GUI�@ �z�w��Ȃ�
# �y�@�����@�z12/11
# �y�@Ver�@ �z1.6.0_16
#
# ��낵�����肢���܂�
#
#
# �ȉ���2����ƔF���ł���悤�ȃv���O�������쐬����
# ?���擪�̒P��͕ϐ��Ƃ���
#
# '?x' :- �Ή�����v�f���啶���ł����Ă��������ł����Ă��悢.
# '?y' :- �啶���������̋�ʂ�����.
#
# �E?x is ?y and ?x name(?x)
# �ERose is rose and ?y name(Rose)
#
# �y�@�ۑ�@�z http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm��857�ł�
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@GUI�@ �z�w��Ȃ�
# �y�@�����@�z12/11
# �y�@Ver�@ �z1.6.0_16
#
# ��낵�����肢���܂�
#
#
# �ȉ���2����ƔF���ł���悤�ȃv���O�������쐬����
# ?���擪�̒P��͕ϐ��Ƃ���
#
# '?x' :- �Ή�����v�f���啶���ł����Ă��������ł����Ă��悢.
# '?y' :- �啶���������̋�ʂ�����.
#
# �E?x is ?y and ?x name(?x)
# �ERose is rose and ?y name(Rose)
#
589 �F�f�t�H���g�̖����������F2009/12/10(��) 12:45:34
>>588 �ԈႢ�܂����B�r���A���������������������Ă��܂����B
http://pc12.2ch.net/test/read.cgi/tech/1248012902/584
# �y�@�ۑ�@�z http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm��857�ł�
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@GUI�@ �z�w��Ȃ�
# �y�@�����@�z12/11
# �y�@Ver�@ �z1.6.0_16
#
# ��낵�����肢���܂�
#
#
# �ȉ���2����ƔF���ł���悤�ȃv���O�������쐬����
# ?���擪�̒P��͕ϐ��Ƃ���
#
# �E?x is ?y and ?x name(?x)
# �ERose is rose and ?y name(Rose)
#
http://pc12.2ch.net/test/read.cgi/tech/1248012902/584
# �y�@�ۑ�@�z http://ime.nu/rg550.hp.infoseek.co.jp/cgi-bin/joyful/main.htm��857�ł�
# �y�@�`�ԁ@�z1. Java�A�v���P�[�V����(main()�ŊJ�n)
# �y�@GUI�@ �z�w��Ȃ�
# �y�@�����@�z12/11
# �y�@Ver�@ �z1.6.0_16
#
# ��낵�����肢���܂�
#
#
# �ȉ���2����ƔF���ł���悤�ȃv���O�������쐬����
# ?���擪�̒P��͕ϐ��Ƃ���
#
# �E?x is ?y and ?x name(?x)
# �ERose is rose and ?y name(Rose)
#
590 �F�f�t�H���g�̖����������F2009/12/10(��) 12:58:28
http://pc12.2ch.net/test/read.cgi/tech/1258158172/890
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# sinx���e�C���[�W�J��n���ڂőł��������̂ɂ���
# x�ɂ��Ă�0����2�܂ł͈̔͂�0.05���݂ł������An�ɂ��Ă�n=1,2,3,4(���Ȃ킿�R���A�T���A�V���A�X���܂ł̓W�J)�ɂ��Čv�Z��
# x�@�@�@sinx�@�R���܂Ł@�E�E�E�E�E�X���܂�
# 0.0 �c
# 0.157�@�c
# �̂悤�Ȑ��\�������Ŏw�肵���t�@�C���ɏo�͂���v���O�������쐬���Ȃ����B
#
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# sinx���e�C���[�W�J��n���ڂőł��������̂ɂ���
# x�ɂ��Ă�0����2�܂ł͈̔͂�0.05���݂ł������An�ɂ��Ă�n=1,2,3,4(���Ȃ킿�R���A�T���A�V���A�X���܂ł̓W�J)�ɂ��Čv�Z��
# x�@�@�@sinx�@�R���܂Ł@�E�E�E�E�E�X���܂�
# 0.0 �c
# 0.157�@�c
# �̂悤�Ȑ��\�������Ŏw�肵���t�@�C���ɏo�͂���v���O�������쐬���Ȃ����B
#
591 �F�f�t�H���g�̖����������F2009/12/10(��) 13:50:47
>>576
% Prolog ����͊��S�Ɋ��o�ł��������ʂ��傫������ȑO�̂��̂��Q�Ƃ��Ă��������B
% �r�b�g���Z
http://nojiriko.asia/prolog/t855.html
% Prolog ����͊��S�Ɋ��o�ł��������ʂ��傫������ȑO�̂��̂��Q�Ƃ��Ă��������B
% �r�b�g���Z
http://nojiriko.asia/prolog/t855.html
592 �F�f�t�H���g�̖����������F2009/12/10(��) 14:53:47
http://pc12.2ch.net/test/read.cgi/tech/1258158172/904
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F ���鐮������͂��C���̖����ׂĂƖ̌���\������v���O�������쐬���Ȃ����D
#
# [1] ���ƒP���F for�Ƃ�while�Ƃ�
# [2] ��蕶(�܃R�[�h&�����N)�F ���鐮������͂��C���̖����ׂĂƖ̌���\������v���O�������쐬���Ȃ����D
#
593 �F�f�t�H���g�̖����������F2009/12/10(��) 14:59:47
>>592
% Prolog
���鐮������͂��C���̖����ׂĂƖ̌���\������ :-
�@�@get_integer(N),
�@�@count((for(1,M,N),0 is N mod M,write_formatted('%t ',[M])),Count),
�@�@write_formatted('\n�̌���%t�ł�\n',[Count]).
% count/2 �̒�`�� http://nojiriko.asia/prolog/c132_863_1.html �Q��
% Prolog
���鐮������͂��C���̖����ׂĂƖ̌���\������ :-
�@�@get_integer(N),
�@�@count((for(1,M,N),0 is N mod M,write_formatted('%t ',[M])),Count),
�@�@write_formatted('\n�̌���%t�ł�\n',[Count]).
% count/2 �̒�`�� http://nojiriko.asia/prolog/c132_863_1.html �Q��
594 �F�f�t�H���g�̖����������F2009/12/10(��) 15:03:56
http://pc12.2ch.net/test/read.cgi/tech/1258158172/907
# [2] ��蕶(�܃R�[�h&�����N)�F ���鐮������͂��C�����菬�����f�������ׂĕ\������v���O�������쐬���Ȃ����D
# [2] ��蕶(�܃R�[�h&�����N)�F ���鐮������͂��C�����菬�����f�������ׂĕ\������v���O�������쐬���Ȃ����D
595 �F�f�t�H���g�̖����������F2009/12/10(��) 15:22:53
>>594
% Prolog
���鐮������͂��C�����菬�����f�������ׂĕ\������ :-
�@�@write('��������͂��Ă������� : '),
�@�@get_integer(N),
�@�@N1 is N - 1,
�@�@�f������(N1,L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t��菬�������ׂĂ̑f���� %t �ł�\n',[N,S]).
% �f������/2 �� http://nojiriko.asia/prolog/t266.html �Q��
% Prolog
���鐮������͂��C�����菬�����f�������ׂĕ\������ :-
�@�@write('��������͂��Ă������� : '),
�@�@get_integer(N),
�@�@N1 is N - 1,
�@�@�f������(N1,L),
�@�@concat_atom(L,',',S),
�@�@write_formatted('%t��菬�������ׂĂ̑f���� %t �ł�\n',[N,S]).
% �f������/2 �� http://nojiriko.asia/prolog/t266.html �Q��
596 �F�f�t�H���g�̖����������F2009/12/10(��) 18:33:35
>>590
% Prolog
'sin(X)���e�C���[�W�J'(_�t�@�C����) :-
tell(_�t�@�C����),
�e�C���[�W�J(0.0),
told.
�e�C���[�W�J(F) :- F > 2 * pi,!.
�e�C���[�W�J(F) :- Y is sin(F),write_formatted('%3.1f %8.7f ',[F,Y]),fail.
�e�C���[�W�J(F) :-
for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
write('\n'),
F2 is F + pi * 0.05,
�e�C���[�W�J(F2).
? ?�@
�@�@for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
�@�@write('\n'),
�@�@F2 is F + pi * 0.05,
�@�@�e�C���[�W�J(F2).
�e�C���[�W�J(sin(X),N,Y) :-
�@�@findsum(Z,(for(0,M,N),�e�C���[�W�J�̓�(sin(X),M,Z)),Y).
�e�C���[�W�J�̓�(sin(X),N,Y) :-
�@�@U is 2 * N + 1,
�@�@�K��(U,U2),
�@�@Y is (((-1) ^ N) / U2) * (X ^ (2 * N + 1)).
% Prolog
'sin(X)���e�C���[�W�J'(_�t�@�C����) :-
tell(_�t�@�C����),
�e�C���[�W�J(0.0),
told.
�e�C���[�W�J(F) :- F > 2 * pi,!.
�e�C���[�W�J(F) :- Y is sin(F),write_formatted('%3.1f %8.7f ',[F,Y]),fail.
�e�C���[�W�J(F) :-
for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
write('\n'),
F2 is F + pi * 0.05,
�e�C���[�W�J(F2).
? ?�@
�@�@for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
�@�@write('\n'),
�@�@F2 is F + pi * 0.05,
�@�@�e�C���[�W�J(F2).
�e�C���[�W�J(sin(X),N,Y) :-
�@�@findsum(Z,(for(0,M,N),�e�C���[�W�J�̓�(sin(X),M,Z)),Y).
�e�C���[�W�J�̓�(sin(X),N,Y) :-
�@�@U is 2 * N + 1,
�@�@�K��(U,U2),
�@�@Y is (((-1) ^ N) / U2) * (X ^ (2 * N + 1)).
597 �F�f�t�H���g�̖����������F2009/12/10(��) 18:39:07
>>590 ��������
% Prolog �p��v�Z���I�[�o�[�t���[����̂��ȁBX = 2.0 �ӂ肩�炨�������Ȃ�B
'sin(X)���e�C���[�W�J'(_�t�@�C����) :-
�@�@tell(_�t�@�C����),
�@�@�e�C���[�W�J(0.0),
�@�@told.
�e�C���[�W�J(F) :- F > 2 * pi,!.
�e�C���[�W�J(F) :- Y is sin(F),write_formatted('%5.3f�@%8.7f ',[F,Y]),fail.
�e�C���[�W�J(F) :-
�@�@for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
�@�@write('\n'),
�@�@F2 is F + pi * 0.05,
�@�@�e�C���[�W�J(F2).
�e�C���[�W�J(sin(X),N,Y) :-
�@�@findsum(Z,(for(0,M,N),�e�C���[�W�J�̓�(sin(X),M,Z)),Y).
�e�C���[�W�J�̓�(sin(X),N,Y) :-
�@�@U is 2 * N + 1,
�@�@�K��(U,U2),
�@�@Y is (((-1) ^ N) / U2) * (X ^ (2 * N + 1)).
% Prolog �p��v�Z���I�[�o�[�t���[����̂��ȁBX = 2.0 �ӂ肩�炨�������Ȃ�B
'sin(X)���e�C���[�W�J'(_�t�@�C����) :-
�@�@tell(_�t�@�C����),
�@�@�e�C���[�W�J(0.0),
�@�@told.
�e�C���[�W�J(F) :- F > 2 * pi,!.
�e�C���[�W�J(F) :- Y is sin(F),write_formatted('%5.3f�@%8.7f ',[F,Y]),fail.
�e�C���[�W�J(F) :-
�@�@for(1,N,4),�e�C���[�W�J(sin(F),N,Y),write_formatted('%8.7f ',[Y]),N=4,
�@�@write('\n'),
�@�@F2 is F + pi * 0.05,
�@�@�e�C���[�W�J(F2).
�e�C���[�W�J(sin(X),N,Y) :-
�@�@findsum(Z,(for(0,M,N),�e�C���[�W�J�̓�(sin(X),M,Z)),Y).
�e�C���[�W�J�̓�(sin(X),N,Y) :-
�@�@U is 2 * N + 1,
�@�@�K��(U,U2),
�@�@Y is (((-1) ^ N) / U2) * (X ^ (2 * N + 1)).
598 �F�f�t�H���g�̖����������F2009/12/10(��) 21:05:37
>>589
% Prolog
'2����ƔF��'(_��1,_��2) :-
�@�@'SPLIT'(_��1,[' ','(',')'],L1),delete_space(L1,L11),
�@�@'SPLIT'(_��2,[' ','(',')'],L2),delete_space(L2,L22),
�@�@ �ϐ��u��(L11,L22,X,Y),
�@�@ X = Y.
delete_space(L1,L2) :- findall(A,(member(A,L1),\+(A=' ')),L2).
�ϐ��u��(L1,L2,VL1,VL2) :-
�@�@length(L1,Len),length(VL1,Len),length(VL2,Len),
�@�@append(L1,L2,L3),
�@�@�ϐ��u���̓�(X,L3,L4),
�@�@append(VL1,VL2,L4).
�ϐ��u���̓�(_,[],[]) :- !.
�ϐ��u���̓�(X,[A1|R1],[X|R2]) :-
�@�@\+(var(A1)),atom(A1),
�@�@sub_atom(A1,0,2,_,'?x'),
�@�@�ϐ��u���̓�(X,R1,R2),!.
�ϐ��u���̓�(X,[A1|R1],[_|R2]) :-
�@�@\+(var(A1)),atom(A1),
�@�@sub_atom(A1,0,2,_,'?y'),
�@�@�ϐ��u���̓�(X,R1,R2),!.
���u���̓�(X,[A|R1],[A|R2]) :- �ϐ��u���̓�(X,R1,R2),!.
% Prolog
'2����ƔF��'(_��1,_��2) :-
�@�@'SPLIT'(_��1,[' ','(',')'],L1),delete_space(L1,L11),
�@�@'SPLIT'(_��2,[' ','(',')'],L2),delete_space(L2,L22),
�@�@ �ϐ��u��(L11,L22,X,Y),
�@�@ X = Y.
delete_space(L1,L2) :- findall(A,(member(A,L1),\+(A=' ')),L2).
�ϐ��u��(L1,L2,VL1,VL2) :-
�@�@length(L1,Len),length(VL1,Len),length(VL2,Len),
�@�@append(L1,L2,L3),
�@�@�ϐ��u���̓�(X,L3,L4),
�@�@append(VL1,VL2,L4).
�ϐ��u���̓�(_,[],[]) :- !.
�ϐ��u���̓�(X,[A1|R1],[X|R2]) :-
�@�@\+(var(A1)),atom(A1),
�@�@sub_atom(A1,0,2,_,'?x'),
�@�@�ϐ��u���̓�(X,R1,R2),!.
�ϐ��u���̓�(X,[A1|R1],[_|R2]) :-
�@�@\+(var(A1)),atom(A1),
�@�@sub_atom(A1,0,2,_,'?y'),
�@�@�ϐ��u���̓�(X,R1,R2),!.
���u���̓�(X,[A|R1],[A|R2]) :- �ϐ��u���̓�(X,R1,R2),!.
599 �F�f�t�H���g�̖����������F2009/12/11(��) 03:59:19
600 �F�f�t�H���g�̖����������F2009/12/11(��) 04:16:03
601 �F�f�t�H���g�̖����������F2009/12/11(��) 04:41:50
>>580
% Prolog
% �|�C���^�[�]�X�Ƃ͉��̊W���Ȃ����A���p���₷�����a�̒�`�B
���a(_����,_�܂�,_���Ԗ�,_�܂łł�,_���a) :-
�@�@���a(_����,_�܂�,0,1,_���Ԗ�,_�܂łł�,_���a).
���a(M,N,X,Nth1,Nth,M,X) :- M > N,!,fail.
���a(M,N,Y,Nth,Nth,M,X) :- X is Y + M.
���a(M,N,Y,Nth1,Nth,Z,X) :-
�@�@M2 is M + 1,
�@�@Y2 is Y + M,
�@�@Nth2 is Nth1 + 1,
�@�@���a(M2,N,Y2,Nth2,Nth,Z,X).
% Prolog
% �|�C���^�[�]�X�Ƃ͉��̊W���Ȃ����A���p���₷�����a�̒�`�B
���a(_����,_�܂�,_���Ԗ�,_�܂łł�,_���a) :-
�@�@���a(_����,_�܂�,0,1,_���Ԗ�,_�܂łł�,_���a).
���a(M,N,X,Nth1,Nth,M,X) :- M > N,!,fail.
���a(M,N,Y,Nth,Nth,M,X) :- X is Y + M.
���a(M,N,Y,Nth1,Nth,Z,X) :-
�@�@M2 is M + 1,
�@�@Y2 is Y + M,
�@�@Nth2 is Nth1 + 1,
�@�@���a(M2,N,Y2,Nth2,Nth,Z,X).
602 �F�f�t�H���g�̖����������F2009/12/11(��) 12:02:10
>>599
�m����w ���������܂��BProlog�̕ϐ����g���Ƃ��܂������Ȃ��悤�ł��ˁB
>>600 �q�� 'SPLIT'/3 ��
http://nojiriko.asia/prolog/split_2.html ���Q�Ƃ��Ă��������B
�����ȃp�^�[������`����Ă��܂��B
�m����w ���������܂��BProlog�̕ϐ����g���Ƃ��܂������Ȃ��悤�ł��ˁB
>>600 �q�� 'SPLIT'/3 ��
http://nojiriko.asia/prolog/split_2.html ���Q�Ƃ��Ă��������B
�����ȃp�^�[������`����Ă��܂��B
603 �F�f�t�H���g�̖����������F2009/12/11(��) 15:37:00
http://pc12.2ch.net/test/read.cgi/tech/1258158172/949
# /* �I���W�i����calc */
# /* calc(���̓f�[�^�A�v�Z���ʂ̃A�h���X���i�[����|�C���^) */
# int calc(double input_data, double * data_ptr)
# {
# /*�|�C���^���g���āA�Ăяo�����̃f�[�^�i�[�ꏊ�ɒl��ݒ�@*/
# *data_ptr = input_data * 2;
# return0; /* ����I�� */
# }
#
# ��L�v���O�������Q�l�ɁA
# ��̓��̓f�[�^�̕ϐ�(�{���x�����^)
# double input_data1, input_data2;
# �ɑ��ẮA�l�����Z�i�{�A�|�A���A�^�j�̌��ʂ��A���ꂼ��
# double plus_data, minus_data, multiply_data, divide_data;
# �̂S�ϐ��ɐݒ肷��@�\�����A�I���W�i����calc���쐬����B
# �������Amain����ł�calc���̌Ăяo�����@�́A�ȉ��̂悤�ɂ��邱�ƁB
# calc(inpt_data1, input_data2, &plus_data, &minus_data, &multiply_data, _data);
# �Ō�ɁAmain����ŏ�L�S�ϐ��Ɋi�[���ꂽ�v�Z���ʂ���ʂɏo�͂���B
# �ȏ�̎d�l�̃v���O�������Acalc.c�Ƃ������O�ō쐬����B
# calc.c��Visual Studio�Ŏ��s���āA���s���ʂ�calc.c���̕����Ɂu�R�����g�s�v��
���ċL�ڂ��� �B
# /* �I���W�i����calc */
# /* calc(���̓f�[�^�A�v�Z���ʂ̃A�h���X���i�[����|�C���^) */
# int calc(double input_data, double * data_ptr)
# {
# /*�|�C���^���g���āA�Ăяo�����̃f�[�^�i�[�ꏊ�ɒl��ݒ�@*/
# *data_ptr = input_data * 2;
# return0; /* ����I�� */
# }
#
# ��L�v���O�������Q�l�ɁA
# ��̓��̓f�[�^�̕ϐ�(�{���x�����^)
# double input_data1, input_data2;
# �ɑ��ẮA�l�����Z�i�{�A�|�A���A�^�j�̌��ʂ��A���ꂼ��
# double plus_data, minus_data, multiply_data, divide_data;
# �̂S�ϐ��ɐݒ肷��@�\�����A�I���W�i����calc���쐬����B
# �������Amain����ł�calc���̌Ăяo�����@�́A�ȉ��̂悤�ɂ��邱�ƁB
# calc(inpt_data1, input_data2, &plus_data, &minus_data, &multiply_data, _data);
# �Ō�ɁAmain����ŏ�L�S�ϐ��Ɋi�[���ꂽ�v�Z���ʂ���ʂɏo�͂���B
# �ȏ�̎d�l�̃v���O�������Acalc.c�Ƃ������O�ō쐬����B
# calc.c��Visual Studio�Ŏ��s���āA���s���ʂ�calc.c���̕����Ɂu�R�����g�s�v��
���ċL�ڂ��� �B
604 �F�f�t�H���g�̖����������F2009/12/11(��) 15:47:01
>>603
% Prolog
program :-
�@�@user_parameters([Atom1,Atom2]),
�@�@atom_to_term(Atom1,Input_data1,_),
�@�@atom_to_term(Atom2,Input_data2,_),
�@�@calc(Input_data1,Input_data2,Plus_data,Minus_data,Multiply_data,Divide_data),
�@�@write_formatted('%t + %t = %t\n',[Input_data1,Input_data2,Plus_data]),
�@�@write_formatted('%t - %t = %t\n',[Input_data1,Input_data2,Minus_data]),
�@�@write_formatted('%t * %t = %t\n',[Input_data1,Input_data2,Multiply_data]),
�@�@write_formatted('%t / %t = %t\n',[Input_data1,Input_data2,Divide_data]).
calc(Input_data1,Input_data2,Plus_data,Minus_data,Multiply_data,Divide_data) :-
�@�@Plus_data is Input_data1 + Input_data2,
�@�@Minus_data is Input_data1 - Input_data2,
�@�@Multiply_data is Input_data1 * Input_data2,
�@�@Divide_data is Input_data1 / Input_data2.
% Prolog
program :-
�@�@user_parameters([Atom1,Atom2]),
�@�@atom_to_term(Atom1,Input_data1,_),
�@�@atom_to_term(Atom2,Input_data2,_),
�@�@calc(Input_data1,Input_data2,Plus_data,Minus_data,Multiply_data,Divide_data),
�@�@write_formatted('%t + %t = %t\n',[Input_data1,Input_data2,Plus_data]),
�@�@write_formatted('%t - %t = %t\n',[Input_data1,Input_data2,Minus_data]),
�@�@write_formatted('%t * %t = %t\n',[Input_data1,Input_data2,Multiply_data]),
�@�@write_formatted('%t / %t = %t\n',[Input_data1,Input_data2,Divide_data]).
calc(Input_data1,Input_data2,Plus_data,Minus_data,Multiply_data,Divide_data) :-
�@�@Plus_data is Input_data1 + Input_data2,
�@�@Minus_data is Input_data1 - Input_data2,
�@�@Multiply_data is Input_data1 * Input_data2,
�@�@Divide_data is Input_data1 / Input_data2.
605 �F�f�t�H���g�̖����������F2009/12/11(��) 17:03:38
http://pc12.2ch.net/test/read.cgi/tech/1258158172/966
# ���̂悤�Ɏx�������z�̌v�Z�����o�͂���悤�ɉ��̃v���O�������C�����Ă��������B
# menu0 650 1 650
# menu1 680 2 1360
# menu2 720 3 2160
# menu3 840 2 1680
# menu4 920 1 920
# menu5 980 0 0
# menu6 1080 0 0
# menu7 1280 1 1280
# goukei 10 6370
#
# ���j���[�ԍ����P�O��ł�����Ń��j���[���ꂼ��̌��ƍ��v���o�͂��銴���ł��B
# ���̂悤�Ɏx�������z�̌v�Z�����o�͂���悤�ɉ��̃v���O�������C�����Ă��������B
# menu0 650 1 650
# menu1 680 2 1360
# menu2 720 3 2160
# menu3 840 2 1680
# menu4 920 1 920
# menu5 980 0 0
# menu6 1080 0 0
# menu7 1280 1 1280
# goukei 10 6370
#
# ���j���[�ԍ����P�O��ł�����Ń��j���[���ꂼ��̌��ƍ��v���o�͂��銴���ł��B
606 �F�f�t�H���g�̖����������F2009/12/11(��) 17:27:52
>>605
% Prolog ����1
�P���\(menu0,650).
�P���\(menu1,680).
�P���\(menu2,720).
�P���\(menu3,840).
�P���\(menu4,920).
�P���\(menu5,980).
�P���\(menu6,1080).
�P���\(menu7,1280).
�x�������z�̌v�Z�����o�͂��� :-
�@�@length(L,10),
�@�@���j���[�ԍ��Ɛ��ʂ��P�O��ł�����(L),
�@�@�x�������z�̌v�Z�����o�͂���(L).
�x�������z�̌v�Z�����o�͂���(L) :-
�@�@�P���\(Menu,_�P��),
�@�@findsum(_����,member([Menu,_����],L),_���v����),
�@�@_���v���z is _���v���� * _�P��,
�@�@write_formatted('%t %t %t %t\n',[Menu,_�P��,_���v����,_���v���z]),
�@�@fail.
�x�������z�̌v�Z�����o�͂���(L) :-
�@�@findsum([_����,_���z],(�P���\(Menu,_�P��),member([Menu,_����],L),_���z is _���� * _�P��),[_���v����,_���v���z]),
�@�@write_formatted('gokei %5s %t %t\n',[Menu,' ',_���v����,_���v���z]).
% Prolog ����1
�P���\(menu0,650).
�P���\(menu1,680).
�P���\(menu2,720).
�P���\(menu3,840).
�P���\(menu4,920).
�P���\(menu5,980).
�P���\(menu6,1080).
�P���\(menu7,1280).
�x�������z�̌v�Z�����o�͂��� :-
�@�@length(L,10),
�@�@���j���[�ԍ��Ɛ��ʂ��P�O��ł�����(L),
�@�@�x�������z�̌v�Z�����o�͂���(L).
�x�������z�̌v�Z�����o�͂���(L) :-
�@�@�P���\(Menu,_�P��),
�@�@findsum(_����,member([Menu,_����],L),_���v����),
�@�@_���v���z is _���v���� * _�P��,
�@�@write_formatted('%t %t %t %t\n',[Menu,_�P��,_���v����,_���v���z]),
�@�@fail.
�x�������z�̌v�Z�����o�͂���(L) :-
�@�@findsum([_����,_���z],(�P���\(Menu,_�P��),member([Menu,_����],L),_���z is _���� * _�P��),[_���v����,_���v���z]),
�@�@write_formatted('gokei %5s %t %t\n',[Menu,' ',_���v����,_���v���z]).
607 �F�f�t�H���g�̖����������F2009/12/11(��) 17:29:14
>>605
% Prolog ����2
���j���[�ԍ��Ɛ��ʂ��P�O��ł�����([]).
���j���[�ԍ��Ɛ��ʂ��P�O��ł�����([L1|R]) :-
�@�@get_split_line([' ',','],L1),
�@�@���j���[�ԍ��Ɛ��ʂ��P�O��ł�����(R).
% Prolog ����2
���j���[�ԍ��Ɛ��ʂ��P�O��ł�����([]).
���j���[�ԍ��Ɛ��ʂ��P�O��ł�����([L1|R]) :-
�@�@get_split_line([' ',','],L1),
�@�@���j���[�ԍ��Ɛ��ʂ��P�O��ł�����(R).
608 �F�f�t�H���g�̖����������F2009/12/11(��) 18:01:35
http://science6.2ch.net/test/read.cgi/informatics/1155976582/70
# �P�F����O���tG�͂��̘A����������Ȃ�A�e�����͖B
# G�̒��_�̌������Ƃ���Ƃ��AF�̕ӂ̌��͂�����
#
# �Q�F�A���ȕ��ʃO���tG�ɂ����āA���_�̌������A�ӂ̌�����
# G�͕H���܂ނ��ӂ��P���������邱�ƂŕH���܂܂Ȃ��A���O���t�����
# �ŒႢ���̕ӂ���������悢��
# �h��Ȃ��Nj����Ă���
# �P�F����O���tG�͂��̘A����������Ȃ�A�e�����͖B
# G�̒��_�̌������Ƃ���Ƃ��AF�̕ӂ̌��͂�����
#
# �Q�F�A���ȕ��ʃO���tG�ɂ����āA���_�̌������A�ӂ̌�����
# G�͕H���܂ނ��ӂ��P���������邱�ƂŕH���܂܂Ȃ��A���O���t�����
# �ŒႢ���̕ӂ���������悢��
# �h��Ȃ��Nj����Ă���
609 �F�f�t�H���g�̖����������F2009/12/11(��) 18:36:02
http://pc12.2ch.net/test/read.cgi/tech/1245017721/12
# ���ۂ̖����ȒP�ɂ�������ł��B
#
# ����F
# �L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�֍s��
# �Ƃ������Ƃ�ڕW���z�܂ŌJ��Ԃ��A���B�����炻�̋����Ȃ��Ȃ�܂�
# �Ƃł���Q���A�Ȃ��Ȃ�����܂�����
#
# �L�����N�^��
# �@�@�E�o�C�g������@�F�@�莝�����P������
# �@�@�E��s�Œ���������@�F�@�莝�����O�ɂ��A�������P������
# �@�@�E�ƂŐQ��@�F�@�������P����
# �̏�Ԃ����܂��B
# ���z�̋��e�ʂ͂R�A�ڕW�����z�͂T�Ƃ��܂��B
#
# ���ۂ̖����ȒP�ɂ�������ł��B
#
# ����F
# �L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�֍s��
# �Ƃ������Ƃ�ڕW���z�܂ŌJ��Ԃ��A���B�����炻�̋����Ȃ��Ȃ�܂�
# �Ƃł���Q���A�Ȃ��Ȃ�����܂�����
#
# �L�����N�^��
# �@�@�E�o�C�g������@�F�@�莝�����P������
# �@�@�E��s�Œ���������@�F�@�莝�����O�ɂ��A�������P������
# �@�@�E�ƂŐQ��@�F�@�������P����
# �̏�Ԃ����܂��B
# ���z�̋��e�ʂ͂R�A�ڕW�����z�͂T�Ƃ��܂��B
#
610 �F�f�t�H���g�̖����������F2009/12/11(��) 19:42:33
http://pc12.2ch.net/test/read.cgi/tech/1258158172/975
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# ttp://kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10258.txt
#
# �\�P�̂悤�ɁC����R���e�X�g�Ɋւ���S�l�̂T�_���_�̃f�[�^������Ƃ��C�u�e�l�̓��_�̕��ς�
# ���߂�v�C�u���ϓ_���\�Q�̂悤�ȕ]�����s���v�C�u�f�[�^�╽�ϓ_�y�ѕ]����\������v�̂R�̃��[�U��`����p���Č��ʂ�\������B
#
# �\1
#
# http://fx.104ban.com/up/src/up10430.jpg
#
# �l����
# �f�[�^��No�Ɠ_����main ���̒��ŏ���������B�����Ċe�l�̓_���������Ƃ��ĕ��ϒl�����߂�
# ���[�U��`���C���ϒl�������Ƃ��ĕ]�������߂郆�[�U��`��,�f�[�^No�Ɠ_���ƕ��ϒl�ƕ]����
# �����Ƃ��ĕ\�����s�����[�U��`����ʁX�ɒ�`��,�����̃��[�U��`����main���̒��ŌĂ�
# �o���Č��ʂ�\������v���O�����Ƃ���B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
#
# ttp://kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10258.txt
#
# �\�P�̂悤�ɁC����R���e�X�g�Ɋւ���S�l�̂T�_���_�̃f�[�^������Ƃ��C�u�e�l�̓��_�̕��ς�
# ���߂�v�C�u���ϓ_���\�Q�̂悤�ȕ]�����s���v�C�u�f�[�^�╽�ϓ_�y�ѕ]����\������v�̂R�̃��[�U��`����p���Č��ʂ�\������B
#
# �\1
#
# http://fx.104ban.com/up/src/up10430.jpg
{kind=link}
#
# �l����
# �f�[�^��No�Ɠ_����main ���̒��ŏ���������B�����Ċe�l�̓_���������Ƃ��ĕ��ϒl�����߂�
# ���[�U��`���C���ϒl�������Ƃ��ĕ]�������߂郆�[�U��`��,�f�[�^No�Ɠ_���ƕ��ϒl�ƕ]����
# �����Ƃ��ĕ\�����s�����[�U��`����ʁX�ɒ�`��,�����̃��[�U��`����main���̒��ŌĂ�
# �o���Č��ʂ�\������v���O�����Ƃ���B
611 �F�f�t�H���g�̖����������F2009/12/11(��) 20:18:46
{kind=link}
612 �F�f�t�H���g�̖����������F2009/12/12(�y) 02:35:49
http://pc12.2ch.net/test/read.cgi/tech/1260532772/2
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10259.txt
#
# ��蕶���������߂����ɍڂ����܂���B[2]�̃����N���Q�Ƃ��Ă�������
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10259.txt
#
# ��蕶���������߂����ɍڂ����܂���B[2]�̃����N���Q�Ƃ��Ă�������
613 �F�f�t�H���g�̖����������F2009/12/12(�y) 02:40:13
http://pc12.2ch.net/test/read.cgi/tech/1136994325/977
# �^�[�~�i����Ńe�L�X�g��ҏW����v���O�������쐬����
# �ȉ��̃R�}���h���g����悤�ɂ��鎖
#
# i ���e�L�X�g�}��
# p ���P��̎�O�Ƀ|�C���^�ړ�
# d �����͂����������|�C���^�̌��̕���������
# c �����͂�����������|�C���^�̌�̕�����ɒu��������
# s ���|�C���^�̌�ɋ}��
# q ���I��
#
# �^�[�~�i����Ńe�L�X�g��ҏW����v���O�������쐬����
# �ȉ��̃R�}���h���g����悤�ɂ��鎖
#
# i ���e�L�X�g�}��
# p ���P��̎�O�Ƀ|�C���^�ړ�
# d �����͂����������|�C���^�̌��̕���������
# c �����͂�����������|�C���^�̌�̕�����ɒu��������
# s ���|�C���^�̌�ɋ}��
# q ���I��
#
614 �F�f�t�H���g�̖����������F2009/12/12(�y) 02:45:47
http://pc12.2ch.net/test/read.cgi/tech/1248012902/602
# �y�@�ۑ�@�z�����l�̖��O����͂��Ă���3���Ȃ̓_����S�������͂��A�e���Ȃ̕��ϓ_�ƁA�ō��_�Ǝ�����l�̖��O��\������B
# �y�@�ۑ�@�z�����l�̖��O����͂��Ă���3���Ȃ̓_����S�������͂��A�e���Ȃ̕��ϓ_�ƁA�ō��_�Ǝ�����l�̖��O��\������B
615 �F�f�t�H���g�̖����������F2009/12/12(�y) 04:10:37
http://pc12.2ch.net/test/read.cgi/tech/1260532772/5
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F 5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o����悤�ȃv���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# -----------------------------------------------
# ����F�H
# �Z���F�H
# ���ȁF�H
# �Љ�F�H
# �p��F�H
# ���v�_�́H�_�ł��B
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F 5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o����悤�ȃv���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# -----------------------------------------------
# ����F�H
# �Z���F�H
# ���ȁF�H
# �Љ�F�H
# �p��F�H
# ���v�_�́H�_�ł��B
616 �F�f�t�H���g�̖����������F2009/12/12(�y) 04:28:23
>>615
% Prolog
'5����'(����).
'5����'(�Z��).
'5����'(����).
'5����'(�Љ�).
'5����'(�p��).
'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o���ĕ\������' :-
�@�@'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o'(_���v�_),
�@�@write_formatted('���v�_��%t�_�ł�\n',[_���v�_]).
'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o'(_���v�_) :-
�@�@findsum(_�_��,('5����'(_����),���t����������('%t : ',[_����],_�_��)),_���v�_).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�Ñ��t����������(_�\���p�^�[��,_�Ñ����Ȃ��,_����) :-
�@�@write_formatted(_�\���p�^�[��,_�Ñ����Ȃ��),
�@�@get_integer(_����),!.
���t����������(_��,_����) :-
�@�@write(_��),
�@�@get_integer(_����),!.
% Prolog
'5����'(����).
'5����'(�Z��).
'5����'(����).
'5����'(�Љ�).
'5����'(�p��).
'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o���ĕ\������' :-
�@�@'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o'(_���v�_),
�@�@write_formatted('���v�_��%t�_�ł�\n',[_���v�_]).
'5���Ȃ̃e�X�g�̓_������͂��A�����̍��v�_���Z�o'(_���v�_) :-
�@�@findsum(_�_��,('5����'(_����),���t����������('%t : ',[_����],_�_��)),_���v�_).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
�Ñ��t����������(_�\���p�^�[��,_�Ñ����Ȃ��,_����) :-
�@�@write_formatted(_�\���p�^�[��,_�Ñ����Ȃ��),
�@�@get_integer(_����),!.
���t����������(_��,_����) :-
�@�@write(_��),
�@�@get_integer(_����),!.
617 �F�f�t�H���g�̖����������F2009/12/12(�y) 06:08:41
>>614->>616
���\�����Ŋy�����ˁB'3����'������E���w�E�p��ŁA'5����'��
����E�Z���E���ȁE�Љ�E�p��Ȃ̂��B���ꂪ�펯�H�@�ł͂Ȃ������B
����Ƃ��A���̏��w�Z�������ȁB���ǁA3���Ȃ̕��͎��t�����A
>>615 �����͎��s���ʂ́u��v���烊�o�[�X�G���W�j�A�����O���邱�Ƃɂ����B
�����������s���ʂ̗Ⴉ��d�l����₂���ԓx�����炵�Ă������̂��Ƃ����^��͎c��B
���\�����Ŋy�����ˁB'3����'������E���w�E�p��ŁA'5����'��
����E�Z���E���ȁE�Љ�E�p��Ȃ̂��B���ꂪ�펯�H�@�ł͂Ȃ������B
����Ƃ��A���̏��w�Z�������ȁB���ǁA3���Ȃ̕��͎��t�����A
>>615 �����͎��s���ʂ́u��v���烊�o�[�X�G���W�j�A�����O���邱�Ƃɂ����B
�����������s���ʂ̗Ⴉ��d�l����₂���ԓx�����炵�Ă������̂��Ƃ����^��͎c��B
618 �F�f�t�H���g�̖����������F2009/12/12(�y) 06:36:20
>>612 �̍ŏ��̉ۑ��
# ����{�ۑ� 1a (�Q���f�[�^�̐����ƕ\��)
# �Q���̐߂��i�[���邽�߂̃f�[�^�\���iTree �^�j���C���̂悤�ɒ�`����D
#
# typedef struct _tree {
# char node; /* �߂̃f�[�^ (1����) */
# struct _tree *left; /* ���̎q�ւ̃|�C���^ */
# struct _tree *right; /* �E�̎q�ւ̃|�C���^ */
# } Tree;
#
# �Q���̎}�Ɨt�̃f�[�^�����邽�߂̎��̂Q�̊������D
#
# Tree *branch(char x, Tree *l, Tree *r);
# �߂��i�[����L���̈���m��
# �߂��������i�߃f�[�^�� x�C���E�̎q�ւ̃|�C���^�� l, r �ɐݒ�j
# �������� Tree �^�f�[�^�ւ̃|�C���^��߂�l�Ƃ��ĕԂ�
#
# Tree *leaf(char x);
# �߂��i�[����L���̈���m��
# �߂��������i�߃f�[�^�� x�C���E�̎q�ւ̃|�C���^�� NULL �ɐݒ�j
# �������� Tree �^�f�[�^�ւ̃|�C���^��߂�l�Ƃ��ĕԂ�
# ����{�ۑ� 1a (�Q���f�[�^�̐����ƕ\��)
# �Q���̐߂��i�[���邽�߂̃f�[�^�\���iTree �^�j���C���̂悤�ɒ�`����D
#
# typedef struct _tree {
# char node; /* �߂̃f�[�^ (1����) */
# struct _tree *left; /* ���̎q�ւ̃|�C���^ */
# struct _tree *right; /* �E�̎q�ւ̃|�C���^ */
# } Tree;
#
# �Q���̎}�Ɨt�̃f�[�^�����邽�߂̎��̂Q�̊������D
#
# Tree *branch(char x, Tree *l, Tree *r);
# �߂��i�[����L���̈���m��
# �߂��������i�߃f�[�^�� x�C���E�̎q�ւ̃|�C���^�� l, r �ɐݒ�j
# �������� Tree �^�f�[�^�ւ̃|�C���^��߂�l�Ƃ��ĕԂ�
#
# Tree *leaf(char x);
# �߂��i�[����L���̈���m��
# �߂��������i�߃f�[�^�� x�C���E�̎q�ւ̃|�C���^�� NULL �ɐݒ�j
# �������� Tree �^�f�[�^�ւ̃|�C���^��߂�l�Ƃ��ĕԂ�
619 �F�f�t�H���g�̖����������F2009/12/12(�y) 06:37:51
���݂܂���B�̐S�ȕ�������Ă��܂����B���Ɠ�s�lj��ł��B
# �� branch() �� leaf() ���g���āC�Z�p����\���Q���̃f�[�^�����C
# �e�Q���̍��ւ̃|�C���^���CTree * �^�̕ϐ��Ɋi�[����D
# �� branch() �� leaf() ���g���āC�Z�p����\���Q���̃f�[�^�����C
# �e�Q���̍��ւ̃|�C���^���CTree * �^�̕ϐ��Ɋi�[����D
620 �F�f�t�H���g�̖����������F2009/12/12(�y) 06:38:59
>>612 ��Ԗڂ̉ۑ�ł��B
# ����{�ۑ� 1b (�Q���������ċA���̍쐬)
#
# �Q���́u�����v�����߂�� height() �����D
# �܂��C�\���Ȑ��̌����f�[�^�����C����̐�������������D
# ����{�ۑ� 1b (�Q���������ċA���̍쐬)
#
# �Q���́u�����v�����߂�� height() �����D
# �܂��C�\���Ȑ��̌����f�[�^�����C����̐�������������D
621 �F�f�t�H���g�̖����������F2009/12/12(�y) 07:34:47
622 �F�f�t�H���g�̖����������F2009/12/12(�y) 10:07:51
http://pc12.2ch.net/test/read.cgi/tech/1260532772/6
# ���T
# �p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\�������悤�ȃv���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# �A���t�@�x�b�g�̑啶������͂��ĉ������FA
# ��������a�ł��B
# ------------------------------------------------
# ���T
# �p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\�������悤�ȃv���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# �A���t�@�x�b�g�̑啶������͂��ĉ������FA
# ��������a�ł��B
# ------------------------------------------------
623 �F�f�t�H���g�̖����������F2009/12/12(�y) 10:13:26
>>622
% Prolog ���x�����x���J��Ԃ����ۑ�B�����ł́A�����ω����Ă݂悤�B
�啶���������̑Ή��\���`����(_�Ή��\�q�ꖼ) :-
�@�@abolish(_�Ή��\�q�ꖼ/2),
�@�@for(65,N,90),
�@�@N2 is N + 32,
�@�@char_code(_�啶��,N),
�@�@char_code(_������,N2),
�@�@P =.. [_�Ή��\�q�ꖼ,_�啶��,_������],
�@�@assertz(P),
�@�@N=90,!.
:- �啶���������̑Ή��\���`����('A,a...Z,z').
�p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\������� :-
�@�@write('�啶��������Ă������� :'),
�@�@rawmode,
�@�@get_char(C),
�@�@'A,a...Z,z'(CC,Cc),
�@�@put_char(Cc),
�@�@norawmode,
�@�@write_formatted('��������%t�ł��B\n',[Cc]).
% Prolog ���x�����x���J��Ԃ����ۑ�B�����ł́A�����ω����Ă݂悤�B
�啶���������̑Ή��\���`����(_�Ή��\�q�ꖼ) :-
�@�@abolish(_�Ή��\�q�ꖼ/2),
�@�@for(65,N,90),
�@�@N2 is N + 32,
�@�@char_code(_�啶��,N),
�@�@char_code(_������,N2),
�@�@P =.. [_�Ή��\�q�ꖼ,_�啶��,_������],
�@�@assertz(P),
�@�@N=90,!.
:- �啶���������̑Ή��\���`����('A,a...Z,z').
�p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\������� :-
�@�@write('�啶��������Ă������� :'),
�@�@rawmode,
�@�@get_char(C),
�@�@'A,a...Z,z'(CC,Cc),
�@�@put_char(Cc),
�@�@norawmode,
�@�@write_formatted('��������%t�ł��B\n',[Cc]).
624 �F�f�t�H���g�̖����������F2009/12/12(�y) 10:16:31
>>623 �r�[�ɊԈႦ���B �����B
�p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\������� :-
�@�@write('�啶��������Ă������� :'),
�@�@rawmode,
�@�@get_char(CC),
�@�@'A,a...Z,z'(CC,Cc),
�@�@put_char(Cc),
�@�@norawmode,
�@�@write_formatted('��������%t�ł��B\n',[Cc]).
�p���A���t�@�x�b�g�啶������͂���ƁA���̕����̏��������\������� :-
�@�@write('�啶��������Ă������� :'),
�@�@rawmode,
�@�@get_char(CC),
�@�@'A,a...Z,z'(CC,Cc),
�@�@put_char(Cc),
�@�@norawmode,
�@�@write_formatted('��������%t�ł��B\n',[Cc]).
625 �F�f�t�H���g�̖����������F2009/12/12(�y) 11:19:50
626 �F�f�t�H���g�̖����������F2009/12/12(�y) 11:37:32
http://pc12.2ch.net/test/read.cgi/tech/1260532772/10
# [1]�P���@����C����
# [2]���@�R���\�[������A�N���������b�ɑΉ����鐮�������ꂼ��ʂɕs�����͎��ɂ�
# �ē��͂𑣂��Ȃ���ǂݍ��݁A�����yyyymmddhhmmss�i���O���S���I��)�`���̎����\
# ���Ɖ��߂���B���̏������Q��s���Q�̎����\�����擾����B���ꂼ�ꂪ�������t�H�[
# �}�b�g���ǂ����ׁA���ɐ������ꍇ�́A���t���V�������̂̏���
# yyyy�Nmm��dd��hh��mm��ss�b�̏����ŏo�́j�����̎�������b�P�ʁA���P�ʁA���ԒP
# �ʁA���P�ʂŏo�͂���v���O�����i�����_��ʈȉ��l�̌ܓ��j
# �A���P�X�O�O�N�P���P���O���O���O�b�ȑO�̎����͗^�����Ȃ��Ƃ��ėǂ��B
# �܂��X�X�X�X�N�P�Q���R�P���Q�R���T�X���T�X�b�Ȍ�̎������^�����Ȃ��Ƃ���B
# ���邤�N�͂S�O�O�̔{�����P�O�O�̔{���łȂ��S�̔{���ȔN�ł���Ƃ��A�Q���̖���
# �ɂ��邤�����t�^�������̂Ƃ���B���ۂ̗�̌n�ł͕s����ɕt�^����邤�邤�b
# �͍l�����Ȃ��ėǂ����̂Ƃ��鐳�������t�łȂ��ꍇ�͂��̎|�o�͂������𒆎~����
# [1]�P���@����C����
# [2]���@�R���\�[������A�N���������b�ɑΉ����鐮�������ꂼ��ʂɕs�����͎��ɂ�
# �ē��͂𑣂��Ȃ���ǂݍ��݁A�����yyyymmddhhmmss�i���O���S���I��)�`���̎����\
# ���Ɖ��߂���B���̏������Q��s���Q�̎����\�����擾����B���ꂼ�ꂪ�������t�H�[
# �}�b�g���ǂ����ׁA���ɐ������ꍇ�́A���t���V�������̂̏���
# yyyy�Nmm��dd��hh��mm��ss�b�̏����ŏo�́j�����̎�������b�P�ʁA���P�ʁA���ԒP
# �ʁA���P�ʂŏo�͂���v���O�����i�����_��ʈȉ��l�̌ܓ��j
# �A���P�X�O�O�N�P���P���O���O���O�b�ȑO�̎����͗^�����Ȃ��Ƃ��ėǂ��B
# �܂��X�X�X�X�N�P�Q���R�P���Q�R���T�X���T�X�b�Ȍ�̎������^�����Ȃ��Ƃ���B
# ���邤�N�͂S�O�O�̔{�����P�O�O�̔{���łȂ��S�̔{���ȔN�ł���Ƃ��A�Q���̖���
# �ɂ��邤�����t�^�������̂Ƃ���B���ۂ̗�̌n�ł͕s����ɕt�^����邤�邤�b
# �͍l�����Ȃ��ėǂ����̂Ƃ��鐳�������t�łȂ��ꍇ�͂��̎|�o�͂������𒆎~����
627 �F�f�t�H���g�̖����������F2009/12/12(�y) 12:50:30
http://pc12.2ch.net/test/read.cgi/tech/1260532772/6
#
# ���S
# ���ʏ��2�_�ix1,y1�j�A�ix2,y2�j����͂��A�����2�_�Ԃ̋������Z�o����v���O�������쐬����BA�̕�������sqrt(A)�Ƃ������w���ŎZ�o�����iA�͈�����double�^�j�B
# ���w�����g�p����ꍇ�A<math.h>�Ƃ����t�@�C��������Ȃ���Ȃ�Ȃ��̂ŁA#include<stdio.h>��
# ���̍s��#include<math.h>�Ƃ������ߕ���t�������Ȃ���Ȃ�Ȃ��i2��include���j�B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# x1�F0
# y1�F0
# x2�F1
# y2�F1
# ����2�_�Ԃ̋�����1.414214�ł��B
#
# ���S
# ���ʏ��2�_�ix1,y1�j�A�ix2,y2�j����͂��A�����2�_�Ԃ̋������Z�o����v���O�������쐬����BA�̕�������sqrt(A)�Ƃ������w���ŎZ�o�����iA�͈�����double�^�j�B
# ���w�����g�p����ꍇ�A<math.h>�Ƃ����t�@�C��������Ȃ���Ȃ�Ȃ��̂ŁA#include<stdio.h>��
# ���̍s��#include<math.h>�Ƃ������ߕ���t�������Ȃ���Ȃ�Ȃ��i2��include���j�B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# x1�F0
# y1�F0
# x2�F1
# y2�F1
# ����2�_�Ԃ̋�����1.414214�ł��B
628 �F�f�t�H���g�̖����������F2009/12/12(�y) 12:52:18
>>627
% Prolog
'���ʏ��2�_�ix1,y1�j�A�ix2,y2�j����͂��A�����2�_�Ԃ̋������Z�o����' :-
�@�@'2�_�̍��W��'([x1,y1,x2,y2],[X1,Y1,X2,Y2]),
�@�@���ʏ��2�_�Ԃ̋���(X1,Y1,X2,Y2,_2�_�Ԃ̋���),
�@�@write_formatted('����2�_�Ԃ̋�����%t�ł��B\n',[_2�_�Ԃ̋���]).
'2�_�̍��W��'([],[]) :- !.
'2�_�̍��W��'([A|R1],[V|R2]) :-
�@�@concat_atom([A,' :'],S),
�@�@write(S),
�@�@get_line(Line),
�@�@atom_to_term(Line,V,_),
�@�@'2�_�̍��W��'(R1,R2).
���ʏ��2�_�Ԃ̋���(X1,Y1,X2,Y2,_2�_�Ԃ̋���) :-
�@�@_2�_�Ԃ̋��� is sqrt((X2-X1)^2 + (Y2-Y1)^2).
% Prolog
'���ʏ��2�_�ix1,y1�j�A�ix2,y2�j����͂��A�����2�_�Ԃ̋������Z�o����' :-
�@�@'2�_�̍��W��'([x1,y1,x2,y2],[X1,Y1,X2,Y2]),
�@�@���ʏ��2�_�Ԃ̋���(X1,Y1,X2,Y2,_2�_�Ԃ̋���),
�@�@write_formatted('����2�_�Ԃ̋�����%t�ł��B\n',[_2�_�Ԃ̋���]).
'2�_�̍��W��'([],[]) :- !.
'2�_�̍��W��'([A|R1],[V|R2]) :-
�@�@concat_atom([A,' :'],S),
�@�@write(S),
�@�@get_line(Line),
�@�@atom_to_term(Line,V,_),
�@�@'2�_�̍��W��'(R1,R2).
���ʏ��2�_�Ԃ̋���(X1,Y1,X2,Y2,_2�_�Ԃ̋���) :-
�@�@_2�_�Ԃ̋��� is sqrt((X2-X1)^2 + (Y2-Y1)^2).
629 �F�f�t�H���g�̖����������F2009/12/12(�y) 13:09:28
http://pc12.2ch.net/test/read.cgi/tech/1260532772/6
#
# ���Q
# ����X�icm�F�Z���`���[�g���j����͂���ƁAY(inch�F�C���`)�ɕϊ�����v���O�������쐬����B1�iinch�j��2.54�icm�j�Ƃ���B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# �����i�Z���`���[�g���œ��͂��ĉ������j�F2.54
# 2.54�icm�j�� 1.000�iinch�j�ł��B
#
# ���Q
# ����X�icm�F�Z���`���[�g���j����͂���ƁAY(inch�F�C���`)�ɕϊ�����v���O�������쐬����B1�iinch�j��2.54�icm�j�Ƃ���B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# �����i�Z���`���[�g���œ��͂��ĉ������j�F2.54
# 2.54�icm�j�� 1.000�iinch�j�ł��B
630 �F�f�t�H���g�̖����������F2009/12/12(�y) 13:10:35
>>629
% Prolog
'����X�icm�F�Z���`���[�g���j����͂���ƁAY(inch�F�C���`)�ɕϊ�����' :-
�@�@write('�����i�Z���`���[�g���œ��͂��ĉ������j�F'),
�@�@get_line(Line),
�@�@atom_to_term(Line,X,_),
�@�@�Z���`���[�g���E�C���`�ϊ�(X,Y),
�@�@write_formatted('%t (cm) �� %t (inch) �ł��B\n',[X,Y]).
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),
�@�@Y is X / 2.54.
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(Y)),
�@�@X is Y * 2.54.
% Prolog
'����X�icm�F�Z���`���[�g���j����͂���ƁAY(inch�F�C���`)�ɕϊ�����' :-
�@�@write('�����i�Z���`���[�g���œ��͂��ĉ������j�F'),
�@�@get_line(Line),
�@�@atom_to_term(Line,X,_),
�@�@�Z���`���[�g���E�C���`�ϊ�(X,Y),
�@�@write_formatted('%t (cm) �� %t (inch) �ł��B\n',[X,Y]).
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),
�@�@Y is X / 2.54.
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(Y)),
�@�@X is Y * 2.54.
631 �F�f�t�H���g�̖����������F2009/12/12(�y) 13:28:57
>>630 ����
% ! ���K�v�ł��ˁB
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),
�@�@Y is X / 2.54,!.
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(Y)),
�@�@X is Y * 2.54.
% ! ���K�v�ł��ˁB
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),
�@�@Y is X / 2.54,!.
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(Y)),
�@�@X is Y * 2.54.
632 �F�f�t�H���g�̖����������F2009/12/12(�y) 13:34:21
>>631
���̃J�b�g�Ȃ�ł���
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),!,
�@�@Y is X / 2.54.
�̈ʒu�ɓ����̂Ƃǂ��炪�������H�Ƃ��������ʂł����B
���̃J�b�g�Ȃ�ł���
�Z���`���[�g���E�C���`�ϊ�(X,Y) :-
�@�@\+(var(X)),!,
�@�@Y is X / 2.54.
�̈ʒu�ɓ����̂Ƃǂ��炪�������H�Ƃ��������ʂł����B
633 �F�f�t�H���g�̖����������F2009/12/12(�y) 13:48:41
>>632
�O���[���J�b�g�ƃ��b�h�J�b�g�Ƃ����悤�ȕ��ނ������āA
�m���uProlog�̋Z�|�v�Ȃǂɏڂ����������������Ǝv���܂��B
>>631 �̓O���[���J�b�g���ȁB���͎��͏ڂ����m��܂���B
�Y��܂����B��ʂ� ! ���Ō�ɏ������Ƃ������Ǝv���܂����A����́A
1) .. p(_) :- p1,!,p2,p3, .. p7.
2) .. p(_) :- p1,p2,p3, .. p7,!.
2) �̕������ʂȃo�b�N�g���b�N�����Ȃ��Ȃ邩��ł��B������p1����
p7���ǂ�Ȑ����̖ڕW�ł������Ƃ��Ă��A����p(_)�͌��萫�̏q���
���邱�Ƃ����m�ɂȂ�܂��B�V�X�e��(�����n)�Ƃ��̃\�[�X�̓ǂݎ��
���̂��Ƃ�`���邽�߂̃J�b�g���Ǝv���悢�ł��傤�B
�O���[���J�b�g�ƃ��b�h�J�b�g�Ƃ����悤�ȕ��ނ������āA
�m���uProlog�̋Z�|�v�Ȃǂɏڂ����������������Ǝv���܂��B
>>631 �̓O���[���J�b�g���ȁB���͎��͏ڂ����m��܂���B
�Y��܂����B��ʂ� ! ���Ō�ɏ������Ƃ������Ǝv���܂����A����́A
1) .. p(_) :- p1,!,p2,p3, .. p7.
2) .. p(_) :- p1,p2,p3, .. p7,!.
2) �̕������ʂȃo�b�N�g���b�N�����Ȃ��Ȃ邩��ł��B������p1����
p7���ǂ�Ȑ����̖ڕW�ł������Ƃ��Ă��A����p(_)�͌��萫�̏q���
���邱�Ƃ����m�ɂȂ�܂��B�V�X�e��(�����n)�Ƃ��̃\�[�X�̓ǂݎ��
���̂��Ƃ�`���邽�߂̃J�b�g���Ǝv���悢�ł��傤�B
634 �F�f�t�H���g�̖����������F2009/12/12(�y) 14:55:07
http://pc11.2ch.net/test/read.cgi/db/1252492296/344
# ID | NAME | DATA
# --+-------+-----
# 1 | tanaka | aa
# 2 | satou | bb
# 3 | suzuki | cc
#
# �Ⴆ����ȃe�[�u�����������Ƃ���
# ID��NAME�Ɋւ��ă}�b�`���郌�R�[�h��
# �擾����Ƃ�����
#
# WHERE ID = 1 AND NAME = 'tanaka'
#
# �Ƃ��܂����ǁA�}�b�`���O�̏�������������Ƃ�����
#
# WHERE (ID = 1 AND NAME = 'tanaka') OR (ID = 2 AND NAME = 'satou')
#
# ����Ȃӂ��ɒP���ɏ��������Ȃ��ł��傤���H
# �}�b�`���O�����̑ΏۗЂƂȂ�
#
# WHERE NAME in ('satou', 'suzuki')
#
# �Ƃł��܂����A������̏ꍇ�ɂ����������ӂ��ɂ܂Ƃ߂ď������@���Ȃ����Ǝv���܂��āE�E�E
# ID | NAME | DATA
# --+-------+-----
# 1 | tanaka | aa
# 2 | satou | bb
# 3 | suzuki | cc
#
# �Ⴆ����ȃe�[�u�����������Ƃ���
# ID��NAME�Ɋւ��ă}�b�`���郌�R�[�h��
# �擾����Ƃ�����
#
# WHERE ID = 1 AND NAME = 'tanaka'
#
# �Ƃ��܂����ǁA�}�b�`���O�̏�������������Ƃ�����
#
# WHERE (ID = 1 AND NAME = 'tanaka') OR (ID = 2 AND NAME = 'satou')
#
# ����Ȃӂ��ɒP���ɏ��������Ȃ��ł��傤���H
# �}�b�`���O�����̑ΏۗЂƂȂ�
#
# WHERE NAME in ('satou', 'suzuki')
#
# �Ƃł��܂����A������̏ꍇ�ɂ����������ӂ��ɂ܂Ƃ߂ď������@���Ȃ����Ǝv���܂��āE�E�E
635 �F�f�t�H���g�̖����������F2009/12/12(�y) 15:05:26
>>634
% Prolog
�e�[�u��(1,tanaka,aa).
�e�[�u��(2,satou,bb).
�e�[�u��(3,suzuki,cc).
?- �e�[�u��(1,takaka,Z);�e�[�u��(2,satou,Z).
?- findall([X,Y,Z],(member([X,Y],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z)),L).
% Prolog
�e�[�u��(1,tanaka,aa).
�e�[�u��(2,satou,bb).
�e�[�u��(3,suzuki,cc).
?- �e�[�u��(1,takaka,Z);�e�[�u��(2,satou,Z).
?- findall([X,Y,Z],(member([X,Y],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z)),L).
636 �F�f�t�H���g�̖����������F2009/12/12(�y) 16:29:09
637 �F�f�t�H���g�̖����������F2009/12/12(�y) 17:09:16
>>634
?- �e�[�u��(X,Y,Z),member([X,Y],[[1,tanaka],[2,satou]]).
?- member([X,Y],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z).
?- �e�[�u��(X,Y,Z),append(_,[[X,Y]|_],[[1,tanaka],[2,satou]]).
?- append(_,[[X,Y]|_],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z).
?- �e�[�u��(X,Y,Z),member([X,Y],[[1,tanaka],[2,satou]]).
?- member([X,Y],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z).
?- �e�[�u��(X,Y,Z),append(_,[[X,Y]|_],[[1,tanaka],[2,satou]]).
?- append(_,[[X,Y]|_],[[1,tanaka],[2,satou]]),�e�[�u��(X,Y,Z).
639 �F�f�t�H���g�̖����������F2009/12/12(�y) 17:32:42
640 �F�f�t�H���g�̖����������F2009/12/12(�y) 18:20:38
>>639
:- �啶���������̑Ή��\���`����('A,a...Z,z').�@�͂��̏�ɒ�`���ꂽ
�q�� �啶���������̑Ή��\���`����/1�@���C���^�v���^��consult���鎞��
���s���܂�(�����Ă��܂�)�B����ɂ���āA
'A,a...Z,z'('A',a).
'A,a...Z,z'('B',b).
<����>
'A,a...Z,z'('Z',z).
�Ƃ����ϊ��e�[�u������`���ꂽ���ƂɂȂ�܂��B��ʂ�Prolog�̃v���O���}��
���̂悤�ȋ�̓I�Ȓl�ɂ���`(�O���I�Ȓ�`)���D�ތX��������܂��B
�R�[�h��32�𑫂��ď�����������Ƃ����悤�ȃ��[�����q���Ɗ����A
�����������Ƃ͐�ɍς܂��Ă��܂����A�Ƃ����̂����̃v���O�����̎�|�ł��B
http://nojiriko.asia/prolog/t844.html �Ȃǂɂ��ɒ[�ȃR�[�h�������܂��B
�����ł̓\�[�X��ǂސl�̂��߂ɗ\�ߏ����ȃv���O����������ă\�[�X������
���܂��Ă��܂��B���̃R�[�h���L�[�{�[�h������͂���̂͂������ɉ����ł����A
�v���O�������ɓ������āA���o�I�ȃv���O�����R�[�h��p�ӂ��܂��B
�ǂ�����A�{�����s���Ɍv�Z�����ł��낤���ƂƗގ��̌v�Z��\�ߎ��s����
���܂��āA�v���O���}�ɂƂ��Ă��D�܂����Ɗ�����\�[�X�R�[�h������
����Ƃ����_�ŋ��ʂ��Ă��܂��B
:- �啶���������̑Ή��\���`����('A,a...Z,z').�@�͂��̏�ɒ�`���ꂽ
�q�� �啶���������̑Ή��\���`����/1�@���C���^�v���^��consult���鎞��
���s���܂�(�����Ă��܂�)�B����ɂ���āA
'A,a...Z,z'('A',a).
'A,a...Z,z'('B',b).
<����>
'A,a...Z,z'('Z',z).
�Ƃ����ϊ��e�[�u������`���ꂽ���ƂɂȂ�܂��B��ʂ�Prolog�̃v���O���}��
���̂悤�ȋ�̓I�Ȓl�ɂ���`(�O���I�Ȓ�`)���D�ތX��������܂��B
�R�[�h��32�𑫂��ď�����������Ƃ����悤�ȃ��[�����q���Ɗ����A
�����������Ƃ͐�ɍς܂��Ă��܂����A�Ƃ����̂����̃v���O�����̎�|�ł��B
http://nojiriko.asia/prolog/t844.html �Ȃǂɂ��ɒ[�ȃR�[�h�������܂��B
�����ł̓\�[�X��ǂސl�̂��߂ɗ\�ߏ����ȃv���O����������ă\�[�X������
���܂��Ă��܂��B���̃R�[�h���L�[�{�[�h������͂���̂͂������ɉ����ł����A
�v���O�������ɓ������āA���o�I�ȃv���O�����R�[�h��p�ӂ��܂��B
�ǂ�����A�{�����s���Ɍv�Z�����ł��낤���ƂƗގ��̌v�Z��\�ߎ��s����
���܂��āA�v���O���}�ɂƂ��Ă��D�܂����Ɗ�����\�[�X�R�[�h������
����Ƃ����_�ŋ��ʂ��Ă��܂��B
641 �F�f�t�H���g�̖����������F2009/12/12(�y) 18:29:49
http://pc12.2ch.net/test/read.cgi/tech/1260532772/32
# [1] ���ƒP���F �v���O���~���O�_
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̂`�E�a�̍s����`�~�a�̌v�Z�����āA���̌��ʂ�\������v���O�������쐬���Ȃ����B
#
#�@�`��[�T�@�R]�@�@�@�a��[�V�@�P�@�T�@�S]
#�@�@�@[�R�@�W]�@�@�@�@�@[�P�@�X�@�Q�@�W]
#�@�@�@[�P�@�U]
#�@�@�@[�X�@�P]
#
# ���̕\��)
#�@�@�@�@�@�@�@�@[38 32 31 44]
#�@�@�@�@�@�@�@�@[29 75 31 76]
#�@�@�@�@�@�@�@�@[13 55 17 52]
#�@�@�@�@�@�@�@�@[64 18 47 44]
# [1] ���ƒP���F �v���O���~���O�_
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���̂`�E�a�̍s����`�~�a�̌v�Z�����āA���̌��ʂ�\������v���O�������쐬���Ȃ����B
#
#�@�`��[�T�@�R]�@�@�@�a��[�V�@�P�@�T�@�S]
#�@�@�@[�R�@�W]�@�@�@�@�@[�P�@�X�@�Q�@�W]
#�@�@�@[�P�@�U]
#�@�@�@[�X�@�P]
#
# ���̕\��)
#�@�@�@�@�@�@�@�@[38 32 31 44]
#�@�@�@�@�@�@�@�@[29 75 31 76]
#�@�@�@�@�@�@�@�@[13 55 17 52]
#�@�@�@�@�@�@�@�@[64 18 47 44]
642 �F�f�t�H���g�̖����������F2009/12/12(�y) 18:51:20
>>641
% Prolog
'A'([[5,3],[3,8],[1,6],[9,1]]).
'B'([[7,1,5,4],[1,9,2,8]]).
�`�E�a�̍s����`�~�a�̌v�Z�����āA���̌��ʂ�\������ :-
'A'(_�s��A),
'B'(_�s��B),
�s��̐�(_�s��A,_�s��B,_�s��C),
�s��̕\��(_�s��C).
% �s��̐�/3,�s��̕\��/1 �̒�`�� http://nojiriko.asia/prolog/c133_32.html �Q��
% Prolog
'A'([[5,3],[3,8],[1,6],[9,1]]).
'B'([[7,1,5,4],[1,9,2,8]]).
�`�E�a�̍s����`�~�a�̌v�Z�����āA���̌��ʂ�\������ :-
'A'(_�s��A),
'B'(_�s��B),
�s��̐�(_�s��A,_�s��B,_�s��C),
�s��̕\��(_�s��C).
% �s��̐�/3,�s��̕\��/1 �̒�`�� http://nojiriko.asia/prolog/c133_32.html �Q��
643 �F�f�t�H���g�̖����������F2009/12/12(�y) 20:09:59
http://pc12.2ch.net/test/read.cgi/tech/1260532772/38
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10261.txt
#
# �ȉ��̃v���O�������쐬����B
# �v���O�����͓��t�E�x�����ǂ����E�o��̕��ށi���H�E���H�E�[�H�E�{�E�x���j�A
# �o��̋��z�E���������̖̂��O�����ɐq�ˁA�Q�ɂ���\���̂̔z��i�ő�Q�O���j�Ɋi�[����
# �Ō�ɔz��̃f�[�^���t�@�C���ɒNjL����B�A���œ��͂ł���悤�ɂ��A�������[�U��
# ���t�łO�N�Ɠ��͂���ƏI������悤�ɂ���B
#
# �c��̏��� http://nojiriko.asia/prolog/c133_38.html �ɍڂ��Ă����܂��B
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10261.txt
#
# �ȉ��̃v���O�������쐬����B
# �v���O�����͓��t�E�x�����ǂ����E�o��̕��ށi���H�E���H�E�[�H�E�{�E�x���j�A
# �o��̋��z�E���������̖̂��O�����ɐq�ˁA�Q�ɂ���\���̂̔z��i�ő�Q�O���j�Ɋi�[����
# �Ō�ɔz��̃f�[�^���t�@�C���ɒNjL����B�A���œ��͂ł���悤�ɂ��A�������[�U��
# ���t�łO�N�Ɠ��͂���ƏI������悤�ɂ���B
#
# �c��̏��� http://nojiriko.asia/prolog/c133_38.html �ɍڂ��Ă����܂��B
644 �F�f�t�H���g�̖����������F2009/12/12(�y) 21:15:45
>>643
# ���̖��ǂ����Ȃ�A���͂́A
# �x���̂Q�O�O�X�N�P�Q���P�P���ɒ��H�ŐH�p�����R�T�O�~ ����
# �x���̂Q�O�O�X�N�P�Q���P�P����Jump�Ƃ����{���Q�S�O�~ ������
# �̌`���ɂ��܂��傤�B���͍��ڂ̏o������������x���R�Ƃ������ƂŁB
# ���̖��ǂ����Ȃ�A���͂́A
# �x���̂Q�O�O�X�N�P�Q���P�P���ɒ��H�ŐH�p�����R�T�O�~ ����
# �x���̂Q�O�O�X�N�P�Q���P�P����Jump�Ƃ����{���Q�S�O�~ ������
# �̌`���ɂ��܂��傤�B���͍��ڂ̏o������������x���R�Ƃ������ƂŁB
645 �F�f�t�H���g�̖����������F2009/12/12(�y) 23:13:43
>>17 ���1
�g�p����F�@Axiom
f(n)=="abcdefghijklmnopqrstuvwxyz"(1..min(n,26))
(20) -> f(6)
(20) "abcdef"
(21) -> f(30)
(21) "abcdefghijklmnopqrstuvwxyz"
�g�p����F�@Axiom
f(n)=="abcdefghijklmnopqrstuvwxyz"(1..min(n,26))
(20) -> f(6)
(20) "abcdef"
(21) -> f(30)
(21) "abcdefghijklmnopqrstuvwxyz"
646 �F�f�t�H���g�̖����������F2009/12/12(�y) 23:15:07
>>17 ���2
�g�p����F�@Axiom
f(n)==reduce(+,[i for i in 1..n | rem(i,3)=0 or rem(i,5)=0])
(12) -> f(10)
(12) 33
(13) -> f(100)
(13) 2418
�g�p����F�@Axiom
f(n)==reduce(+,[i for i in 1..n | rem(i,3)=0 or rem(i,5)=0])
(12) -> f(10)
(12) 33
(13) -> f(100)
(13) 2418
647 �F�f�t�H���g�̖����������F2009/12/12(�y) 23:17:05
>>182
�g�p����F�@Axiom
print(matrix[[i*j for i in 1..10]for j in 1..10])
+1 2 3 4 5 6 7 8 9 10 +
| |
|2 4 6 8 10 12 14 16 18 20 |
| |
|3 6 9 12 15 18 21 24 27 30 |
| |
|4 8 12 16 20 24 28 32 36 40 |
| |
|5 10 15 20 25 30 35 40 45 50 |
| |
|6 12 18 24 30 36 42 48 54 60 |
| |
|7 14 21 28 35 42 49 56 63 70 |
| |
|8 16 24 32 40 48 56 64 72 80 |
| |
|9 18 27 36 45 54 63 72 81 90 |
| |
+10 20 30 40 50 60 70 80 90 100+
�g�p����F�@Axiom
print(matrix[[i*j for i in 1..10]for j in 1..10])
+1 2 3 4 5 6 7 8 9 10 +
| |
|2 4 6 8 10 12 14 16 18 20 |
| |
|3 6 9 12 15 18 21 24 27 30 |
| |
|4 8 12 16 20 24 28 32 36 40 |
| |
|5 10 15 20 25 30 35 40 45 50 |
| |
|6 12 18 24 30 36 42 48 54 60 |
| |
|7 14 21 28 35 42 49 56 63 70 |
| |
|8 16 24 32 40 48 56 64 72 80 |
| |
|9 18 27 36 45 54 63 72 81 90 |
| |
+10 20 30 40 50 60 70 80 90 100+
648 �F�f�t�H���g�̖����������F2009/12/12(�y) 23:18:08
>>45
�g�p����F�@Axiom
-> fact(n)==reduce(*,[i for i in 1..n])
-> for i in 0..10 repeat print(fact(i))
1
1
2
6
24
120
720
5040
40320
362880
3628800
�g�p����F�@Axiom
-> fact(n)==reduce(*,[i for i in 1..n])
-> for i in 0..10 repeat print(fact(i))
1
1
2
6
24
120
720
5040
40320
362880
3628800
649 �F�f�t�H���g�̖����������F2009/12/13(��) 01:00:04
>>575
�g�p����F�@J
f=:monad define
a=.(32#2)#:y
b=.(,' '&,)/_4[\1":a
c0=.+/0=a
c1=.32-c0
smoutput (":y),' ��2�i�\���� ',b,' �ł�.'
smoutput '0�̃r�b�g����',(":c0),',1�̃r�b�g����',(":c1),'�ł�.'
)
f 123456789
123456789 ��2�i�\���� 0000 0111 0101 1011 1100 1101 0001 0101 �ł�.
0�̃r�b�g����16,1�̃r�b�g����16�ł�.
�g�p����F�@J
f=:monad define
a=.(32#2)#:y
b=.(,' '&,)/_4[\1":a
c0=.+/0=a
c1=.32-c0
smoutput (":y),' ��2�i�\���� ',b,' �ł�.'
smoutput '0�̃r�b�g����',(":c0),',1�̃r�b�g����',(":c1),'�ł�.'
)
f 123456789
123456789 ��2�i�\���� 0000 0111 0101 1011 1100 1101 0001 0101 �ł�.
0�̃r�b�g����16,1�̃r�b�g����16�ł�.
650 �F�f�t�H���g�̖����������F2009/12/13(��) 01:50:16
>>575
�g�p����F�@J
f=:monad define
a=.>:I.0=y|~>:i.y
smoutput '�� = ',":a
smoutput '�̐� = ',":#a
)
f 12345
�� = 1 3 5 15 823 2469 4115 12345
�̐� = 8
�g�p����F�@J
f=:monad define
a=.>:I.0=y|~>:i.y
smoutput '�� = ',":a
smoutput '�̐� = ',":#a
)
f 12345
�� = 1 3 5 15 823 2469 4115 12345
�̐� = 8
651 �F�f�t�H���g�̖����������F2009/12/13(��) 01:56:21
652 �F�f�t�H���g�̖����������F2009/12/13(��) 03:35:51
653 �F�f�t�H���g�̖����������F2009/12/13(��) 03:37:42
>>629
�g�p����F�@J
f=:(,&'(cm) = ')@": , (,&'(inch)')@":@%&2.54
f 1
1(cm) = 0.393701(inch)
f 2.54
2.54(cm) = 1(inch)
f 49
49(cm) = 19.2913(inch)
�g�p����F�@J
f=:(,&'(cm) = ')@": , (,&'(inch)')@":@%&2.54
f 1
1(cm) = 0.393701(inch)
f 2.54
2.54(cm) = 1(inch)
f 49
49(cm) = 19.2913(inch)
654 �F�f�t�H���g�̖����������F2009/12/13(��) 03:56:56
http://pc12.2ch.net/test/read.cgi/tech/1260532772/67
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10263.txt
#
# �����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t
# �܂ł̓������v�Z���C���ʂ�\������v���O�������쐬�������D
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10263.txt
#
# �����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t
# �܂ł̓������v�Z���C���ʂ�\������v���O�������쐬�������D
655 �F�f�t�H���g�̖����������F2009/12/13(��) 04:53:52
>>643 >>644
% Prolog�@�ŏ��̓��͉�͕���(���������ׂ��ȉ�͂��K�v��������Ȃ�)
��͏㌮�ƂȂ錾�t([�x��,�N,��,��,�~,���H,�[�H,�{,��,��,��,��,��,���߂�,��,��,��]).
���͕��̉��(_��,_��͂������̗v�f) :-
��͏㌮�ƂȂ錾�t(_�����t�Ȃ��),
sPLIT(_��,_�����t�Ȃ��,L1),
�L�ӂȗv�f�̎��W(L1,_��͂������̗v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
member(_�o��̕���,[���H,�[�H,�{,�x��]),
\+(member(_�o��̕���,L1)),
�L�ӂȗv�f�̎��W(L,[_�o��̕���|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
member(X,[�N,��,��,�~],
\+(member([_,X],L1)),
append(_,[A,X|_],L),
'������?�������S�p�����͐����ɕϊ�����'(A,N),
�L�ӂȗv�f�̎��W(L,[[N,��]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
append(L0,[_�w����,��|R],L),
\+(member(_�w����,[�{,�[�H,���H,�x��])),
\+(member([�w����_�w����],L1)),
�L�ӂȗv�f�̎��W(L,[[�w����,_�w����]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(_,��͂������v�f,_��͂������v�f) :- !.
% Prolog�@�ŏ��̓��͉�͕���(���������ׂ��ȉ�͂��K�v��������Ȃ�)
��͏㌮�ƂȂ錾�t([�x��,�N,��,��,�~,���H,�[�H,�{,��,��,��,��,��,���߂�,��,��,��]).
���͕��̉��(_��,_��͂������̗v�f) :-
��͏㌮�ƂȂ錾�t(_�����t�Ȃ��),
sPLIT(_��,_�����t�Ȃ��,L1),
�L�ӂȗv�f�̎��W(L1,_��͂������̗v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
member(_�o��̕���,[���H,�[�H,�{,�x��]),
\+(member(_�o��̕���,L1)),
�L�ӂȗv�f�̎��W(L,[_�o��̕���|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
member(X,[�N,��,��,�~],
\+(member([_,X],L1)),
append(_,[A,X|_],L),
'������?�������S�p�����͐����ɕϊ�����'(A,N),
�L�ӂȗv�f�̎��W(L,[[N,��]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
append(L0,[_�w����,��|R],L),
\+(member(_�w����,[�{,�[�H,���H,�x��])),
\+(member([�w����_�w����],L1)),
�L�ӂȗv�f�̎��W(L,[[�w����,_�w����]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(_,��͂������v�f,_��͂������v�f) :- !.
656 �F�f�t�H���g�̖����������F2009/12/13(��) 04:56:33
>>655 ��������
��͏㌮�ƂȂ錾�t([�x��,�N,��,��,�~,���H,�[�H,�{,��,��,��,��,��,���߂�,��,��,
��]).
���͕��̉��(_��,_��͂������̗v�f) :-
�@�@��͏㌮�ƂȂ錾�t(_�����t�Ȃ��),
�@�@sPLIT(_��,_�����t�Ȃ��,L1),
�@�@�L�ӂȗv�f�̎��W(L1,_��͂������̗v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(_�o��̕���,[���H,�[�H,�{,�x��]),
�@�@\+(member(_�o��̕���,L1)),
�@�@�L�ӂȗv�f�̎��W(L,[_�o��̕���|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(X,[�N,��,��,�~],
�@�@\+(member([_,X],L1)),
�@�@append(_,[A,X|_],L),
�@�@'������?�������S�p�����͐����ɕϊ�����'(A,N),
�@�@�L�ӂȗv�f�̎��W(L,[[N,��]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@append(L0,[_�w����,��|R],L),
�@�@\+(member(_�w����,[�{,�[�H,���H,�x��])),
�@�@\+(member([�w����_�w����],L1)),
�@�@�L�ӂȗv�f�̎��W(L,[[�w����,_�w����]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(_,��͂������v�f,_��͂������v�f) :- !.
��͏㌮�ƂȂ錾�t([�x��,�N,��,��,�~,���H,�[�H,�{,��,��,��,��,��,���߂�,��,��,
��]).
���͕��̉��(_��,_��͂������̗v�f) :-
�@�@��͏㌮�ƂȂ錾�t(_�����t�Ȃ��),
�@�@sPLIT(_��,_�����t�Ȃ��,L1),
�@�@�L�ӂȗv�f�̎��W(L1,_��͂������̗v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(_�o��̕���,[���H,�[�H,�{,�x��]),
�@�@\+(member(_�o��̕���,L1)),
�@�@�L�ӂȗv�f�̎��W(L,[_�o��̕���|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(X,[�N,��,��,�~],
�@�@\+(member([_,X],L1)),
�@�@append(_,[A,X|_],L),
�@�@'������?�������S�p�����͐����ɕϊ�����'(A,N),
�@�@�L�ӂȗv�f�̎��W(L,[[N,��]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@append(L0,[_�w����,��|R],L),
�@�@\+(member(_�w����,[�{,�[�H,���H,�x��])),
�@�@\+(member([�w����_�w����],L1)),
�@�@�L�ӂȗv�f�̎��W(L,[[�w����,_�w����]|L1],_��͂������v�f),!.
�L�ӂȗv�f�̎��W(_,��͂������v�f,_��͂������v�f) :- !.
657 �F�f�t�H���g�̖����������F2009/12/13(��) 05:03:37
>>656�@�������܂��B�L�ӂȗv�f�̎��W�̑���`(��)
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(X,[�N,��,��,�~],
�@�@\+(member([X,_],L1)),
�@�@append(_,[A,X|_],L),
�@�@'������?�������S�p�����͐����ɕϊ�����'(A,N),
�@�@�L�ӂȗv�f�̎��W(L,[[X,N]|L1],_��͂������v�f),!.
�@�@�L�ӂȗv�f�̎��W(L,[[N,X]|L1],_��͂������v�f),!.
% ���ł͂Ȃ���X�łȂ��Ă͂����܂���B
�L�ӂȗv�f�̎��W(L,L1,_��͂������v�f) :-
�@�@member(X,[�N,��,��,�~],
�@�@\+(member([X,_],L1)),
�@�@append(_,[A,X|_],L),
�@�@'������?�������S�p�����͐����ɕϊ�����'(A,N),
�@�@�L�ӂȗv�f�̎��W(L,[[X,N]|L1],_��͂������v�f),!.
�@�@�L�ӂȗv�f�̎��W(L,[[N,X]|L1],_��͂������v�f),!.
% ���ł͂Ȃ���X�łȂ��Ă͂����܂���B
658 �F�f�t�H���g�̖����������F2009/12/13(��) 05:27:11
���ꔲ���Ă܂����B
http://pc12.2ch.net/test/read.cgi/tech/1260532772/6
���R
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����v���O�������쐬����B�]����Z�o���鉉�Z�q�́��ł��邪�A�����g��Ȃ����ƁB���s���ʂ̗���ȉ��Ɏ����B
http://pc12.2ch.net/test/read.cgi/tech/1260532772/6
���R
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����v���O�������쐬����B�]����Z�o���鉉�Z�q�́��ł��邪�A�����g��Ȃ����ƁB���s���ʂ̗���ȉ��Ɏ����B
659 �F�f�t�H���g�̖����������F2009/12/13(��) 05:32:40
>>658
% Prolog
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����(N,_�]��) :-
�@�@length(L,N),
�@�@'3�Ŋ��������Ɨ]����Z�o����'(L,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'([_,_,_|R],_�]��) :-
�@�@'3�Ŋ��������Ɨ]����Z�o����'(R,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'(L,_�]��) :- length(L,_�]��).
% Prolog
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����(N,_�]��) :-
�@�@length(L,N),
�@�@'3�Ŋ��������Ɨ]����Z�o����'(L,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'([_,_,_|R],_�]��) :-
�@�@'3�Ŋ��������Ɨ]����Z�o����'(R,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'(L,_�]��) :- length(L,_�]��).
660 �F�f�t�H���g�̖����������F2009/12/13(��) 05:39:41
>>659(>>658) �ς݂܂���B�����B
% Prolog
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����(X,_��,_�]��) :-
�@�@length(L,X),
�@�@'3�Ŋ��������Ɨ]����Z�o����'(L,[],_��,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'([_,_,_|R],L1,_��,_�]��) :-
�@�@'3�Ŋ��������Ɨ]����Z�o����'(R,[_|L1],_��,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'(L,L1,_��,_�]��) :- length(L1,_��),length(L,_�]��).
% Prolog
���鐮��X����͂������ɁA�����3�Ŋ��������Ɨ]����Z�o����(X,_��,_�]��) :-
�@�@length(L,X),
�@�@'3�Ŋ��������Ɨ]����Z�o����'(L,[],_��,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'([_,_,_|R],L1,_��,_�]��) :-
�@�@'3�Ŋ��������Ɨ]����Z�o����'(R,[_|L1],_��,_�]��).
'3�Ŋ��������Ɨ]����Z�o����'(L,L1,_��,_�]��) :- length(L1,_��),length(L,_�]��).
661 �F�f�t�H���g�̖����������F2009/12/13(��) 05:53:41
>>17 ���1
�g�p����F�@Scilab
-->function out=f(n)
--> out=part('abcdefghijkmnopqrstuvwxyz',1:n)
-->endfunction
-->f(6)
ans =
abcdef
-->f(30)
ans =
abcdefghijkmnopqrstuvwxyz
�g�p����F�@Scilab
-->function out=f(n)
--> out=part('abcdefghijkmnopqrstuvwxyz',1:n)
-->endfunction
-->f(6)
ans =
abcdef
-->f(30)
ans =
abcdefghijkmnopqrstuvwxyz
662 �F�f�t�H���g�̖����������F2009/12/13(��) 06:12:24
663 �F�f�t�H���g�̖����������F2009/12/13(��) 06:27:28
664 �F�f�t�H���g�̖����������F2009/12/13(��) 07:20:23
>>17 ���2
�g�p����F�@Scilab
function out=f(n)
s=0
for i=1:n
if modulo(i,3)==0 | modulo(i,5)==0 then
s=s+i
end
end
out=s
endfunction
-->f(10)
ans =
33.
-->f(100)
ans =
2418.
�g�p����F�@Scilab
function out=f(n)
s=0
for i=1:n
if modulo(i,3)==0 | modulo(i,5)==0 then
s=s+i
end
end
out=s
endfunction
-->f(10)
ans =
33.
-->f(100)
ans =
2418.
665 �F�f�t�H���g�̖����������F2009/12/13(��) 07:39:07
>>654
% Prolog (���̈�)
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��) :-
�@�@write('�����̓�����,�N,��,�� :'),
�@�@get_split_line([','],[_�����N�̌����̓�����,_�N,_��,_��]).
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t�܂ł̓������v�Z���C���ʂ�\������' :-
�@�@'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��),
�@�@�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(_����,_�����N�̌����̓�����),
�@�@���N�̐����(_����,_���N�̐���N),
�@�@_����N is _���N�̐���N + _�N - 1,
�@�@���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����),
�@�@write_formatted('���̔N�̌��U����̓�����%t���ł��B\n',[_����]).
���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����) :-
�@�@�N������O�������܂ł̓���(_����N,_��,_�O�������܂ł̓���),
�@�@_���� is _�O�������܂ł̓��� + _��.
�N������O�������܂ł̓���(_����N,_��,_�O�������܂ł̓���) :-
�@�@N is _�� - 1,
�@�@findsum(_����,(for(1,M,N),���̓���(_����N,_��,_����)),_�O�������܂ł̓���).
% Prolog (���̈�)
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��) :-
�@�@write('�����̓�����,�N,��,�� :'),
�@�@get_split_line([','],[_�����N�̌����̓�����,_�N,_��,_��]).
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t�܂ł̓������v�Z���C���ʂ�\������' :-
�@�@'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��),
�@�@�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(_����,_�����N�̌����̓�����),
�@�@���N�̐����(_����,_���N�̐���N),
�@�@_����N is _���N�̐���N + _�N - 1,
�@�@���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����),
�@�@write_formatted('���̔N�̌��U����̓�����%t���ł��B\n',[_����]).
���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����) :-
�@�@�N������O�������܂ł̓���(_����N,_��,_�O�������܂ł̓���),
�@�@_���� is _�O�������܂ł̓��� + _��.
�N������O�������܂ł̓���(_����N,_��,_�O�������܂ł̓���) :-
�@�@N is _�� - 1,
�@�@findsum(_����,(for(1,M,N),���̓���(_����N,_��,_����)),_�O�������܂ł̓���).
666 �F�f�t�H���g�̖����������F2009/12/13(��) 07:41:13
>>654
% Prolog�@(���̓�)
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(����,m).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(�吳,t).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(���a,s).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(����,h).
���N�̐����(����,1868).
���N�̐����(�吳,1912).
���N�̐����(�吳,1926).
���N�̐����(���a,1989).
���邤�N(_�N) :- 0 is _�N mod 400,!.
���邤�N(_�N) :- 0 is _�N mod 100,!,fail.
���邤�N(_�N) :- 0 is _�N mod 4,!.
���邤�N(_�N) :- \+(0 is _�N mod 4),fail.
���̓���(_,_��,31) :- member(_��,[1,3,5,7,8,10,12]).
���̓���(_,_��,30) :- member(_��,[4,6,8,10]).
���̓���(_�N,2,29) :- ���邤�N(_�N).
���̓���(_�N,2,28) :- \+(���邤�N(_�N)).
% Prolog�@(���̓�)
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(����,m).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(�吳,t).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(���a,s).
�����̓����������[�}���ϊ��������ɂ̍ŏ��̕���(����,h).
���N�̐����(����,1868).
���N�̐����(�吳,1912).
���N�̐����(�吳,1926).
���N�̐����(���a,1989).
���邤�N(_�N) :- 0 is _�N mod 400,!.
���邤�N(_�N) :- 0 is _�N mod 100,!,fail.
���邤�N(_�N) :- 0 is _�N mod 4,!.
���邤�N(_�N) :- \+(0 is _�N mod 4),fail.
���̓���(_,_��,31) :- member(_��,[1,3,5,7,8,10,12]).
���̓���(_,_��,30) :- member(_��,[4,6,8,10]).
���̓���(_�N,2,29) :- ���邤�N(_�N).
���̓���(_�N,2,28) :- \+(���邤�N(_�N)).
667 �F�f�t�H���g�̖����������F2009/12/13(��) 07:43:02
>>666 ����
% Prolog
���N�̐����(����,1868).
���N�̐����(�吳,1912).
���N�̐����(���a,1926).
���N�̐����(����,1989).
% Prolog
���N�̐����(����,1868).
���N�̐����(�吳,1912).
���N�̐����(���a,1926).
���N�̐����(����,1989).
668 �F�f�t�H���g�̖����������F2009/12/13(��) 07:46:59
>>665 ���� �̂�->��
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t�܂ł̓������v�Z���C���ʂ�\������' :-
�@�@'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��),
�@�@�����̓����������[�}���ϊ��������̍ŏ��̕���(_����,_�����N�̌����̓�����),
�@�@���N�̐����(_����,_���N�̐���N),
�@�@_����N is _���N�̐���N + _�N - 1,
�@�@���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����),
�@�@write_formatted('���̔N�̌��U����̓�����%t���ł��B\n',[_����]).
>>666 �����������@�̂�->��
�����̓����������[�}���ϊ��������̍ŏ��̕���(����,m).
�����̓����������[�}���ϊ��������̍ŏ��̕���(�吳,t).
�����̓����������[�}���ϊ��������̍ŏ��̕���(���a,s).
�����̓����������[�}���ϊ��������̍ŏ��̕���(����,h).
'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂����C���̔N�̌������炻�̓��t�܂ł̓������v�Z���C���ʂ�\������' :-
�@�@'�����N�̌����̓������C�N�C������ѓ��ŕ\�L���ꂽ���t����͂���'(_�����N�̌����̓�����,_�N,_��,_��),
�@�@�����̓����������[�}���ϊ��������̍ŏ��̕���(_����,_�����N�̌����̓�����),
�@�@���N�̐����(_����,_���N�̐���N),
�@�@_����N is _���N�̐���N + _�N - 1,
�@�@���̔N�̌������炻�̓��t�܂ł̓������v�Z����(_����N,_��,_��,_����),
�@�@write_formatted('���̔N�̌��U����̓�����%t���ł��B\n',[_����]).
>>666 �����������@�̂�->��
�����̓����������[�}���ϊ��������̍ŏ��̕���(����,m).
�����̓����������[�}���ϊ��������̍ŏ��̕���(�吳,t).
�����̓����������[�}���ϊ��������̍ŏ��̕���(���a,s).
�����̓����������[�}���ϊ��������̍ŏ��̕���(����,h).
669 �F�f�t�H���g�̖����������F2009/12/13(��) 08:13:23
670 �F�f�t�H���g�̖����������F2009/12/13(��) 10:06:58
>>257 >>331
�g�p����F�@MaTX
Func Integer pow4(n)
Integer n;
{
return n*n*n*n;
}
MaTX (6) pow4(77)
ans = 35153041
�g�p����F�@MaTX
Func Integer pow4(n)
Integer n;
{
return n*n*n*n;
}
MaTX (6) pow4(77)
ans = 35153041
671 �F�f�t�H���g�̖����������F2009/12/13(��) 10:16:14
>>17 ���1
�g�p����F�@MaTX
Func String f(n)
Integer n;
{
return "abcdefghijklmnopqrstuvwxyz"(1:min(n,26));
}
MaTX (20) f(6)
abcdef
MaTX (21) f(30)
abcdefghijklmnopqrstuvwxyz
�g�p����F�@MaTX
Func String f(n)
Integer n;
{
return "abcdefghijklmnopqrstuvwxyz"(1:min(n,26));
}
MaTX (20) f(6)
abcdef
MaTX (21) f(30)
abcdefghijklmnopqrstuvwxyz
672 �F�f�t�H���g�̖����������F2009/12/13(��) 12:17:34
>>17 ���2
�g�p����F�@MaTX
Func Real f(n)
Integer n;
{
a=[1:n];
return sum(a*((rem(a,3)==0) || (rem(a,5)==0)));
}
MaTX (72) f(10)
ans = 33
MaTX (73) f(100)
ans = 2418
�g�p����F�@MaTX
Func Real f(n)
Integer n;
{
a=[1:n];
return sum(a*((rem(a,3)==0) || (rem(a,5)==0)));
}
MaTX (72) f(10)
ans = 33
MaTX (73) f(100)
ans = 2418
673 �F�f�t�H���g�̖����������F2009/12/13(��) 16:54:18
>>17 ���2
�g�p����F�@Scilab
>664�@�ł�for�����g�������A������͔z����g����肩���B
����`���ʂ̕��@�����������̂ŁA������g���Ă݂��B
-->deff('[x]=f(n)','a=[1:n];x=sum(a(modulo(a,3)==0|modulo(a,5)==0))')
-->f(10)
ans =
33.
-->f(100)
ans =
2418.
�g�p����F�@Scilab
>664�@�ł�for�����g�������A������͔z����g����肩���B
����`���ʂ̕��@�����������̂ŁA������g���Ă݂��B
-->deff('[x]=f(n)','a=[1:n];x=sum(a(modulo(a,3)==0|modulo(a,5)==0))')
-->f(10)
ans =
33.
-->f(100)
ans =
2418.
674 �F�f�t�H���g�̖����������F2009/12/13(��) 19:05:06
>>592
�g�p����F�@Scilab
function f(n)
a=[1:n]
b=a(modulo(n,a)==0)
disp("�� = "+strcat(string(c)," "))
disp("�̐� = "+string(length(b)))
endfunction
-->f(30)
�� = 1 2 3 5 6 10 15 30
�̐� = 8
�g�p����F�@Scilab
function f(n)
a=[1:n]
b=a(modulo(n,a)==0)
disp("�� = "+strcat(string(c)," "))
disp("�̐� = "+string(length(b)))
endfunction
-->f(30)
�� = 1 2 3 5 6 10 15 30
�̐� = 8
675 �F�f�t�H���g�̖����������F2009/12/14(��) 00:18:50
676 �F�f�t�H���g�̖����������F2009/12/14(��) 05:52:40
677 �F�f�t�H���g�̖����������F2009/12/14(��) 06:20:31
http://pc12.2ch.net/test/read.cgi/tech/1260532772/83
# [1] ���ƒP���F C�v���O�������pA
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������̕W�����C�u���������g�p���A�w�肵���t�@�C���̒��ŁA������ōŏ��ɏo�Ă���P��ƍŌ�ɏo�Ă���P��A����ɍł������P����������\������B
# �������A���������̒P�ꂪ����ꍇ�ŏ��Ɍ�������ł����B
#
# �����ł̒P��Ƃ́A�X�y�[�X����s�A�^�u�ŋ��ꂽ������̂��Ƃł���B
# �������A�P��̒�����100�����ȓ��ƍl���Ă����B
#
# [1] ���ƒP���F C�v���O�������pA
# [2] ��蕶(�܃R�[�h&�����N)�F
# ������̕W�����C�u���������g�p���A�w�肵���t�@�C���̒��ŁA������ōŏ��ɏo�Ă���P��ƍŌ�ɏo�Ă���P��A����ɍł������P����������\������B
# �������A���������̒P�ꂪ����ꍇ�ŏ��Ɍ�������ł����B
#
# �����ł̒P��Ƃ́A�X�y�[�X����s�A�^�u�ŋ��ꂽ������̂��Ƃł���B
# �������A�P��̒�����100�����ȓ��ƍl���Ă����B
#
678 �F�f�t�H���g�̖����������F2009/12/14(��) 07:45:50
>>677
% Prolog
�w�肵���t�@�C���̒��ŁA������ōŏ��ɏo�Ă���P��ƍŌ�ɏo�Ă���P��A����ɍł������P����������\������(_�t�@�C��,_�ŏ��ɏo�Ă���P��,_�Ō�ɏo�Ă���P��,_�ł������P��) :-
�@�@get_lines(_�t�@�C��,Lines),
�@�@concat_atom(Lines,S),
�@�@split(S,[' ','\t','\n'],_�P��Ȃ��),
�@�@sort(_�P��Ȃ��,_���ꂽ�P��Ȃ��),
�@�@append([_�ŏ��ɏo�Ă���P��|_],[_�Ō�ɏo�Ă���P��],_���ꂽ�P��Ȃ��),
�@�@findmax(_����,(member(_�P��,_���ꂽ�P��Ȃ��),sub_atom(_�P��,_,_����,_,_�P��)),_�ł������P��).
% Prolog
�w�肵���t�@�C���̒��ŁA������ōŏ��ɏo�Ă���P��ƍŌ�ɏo�Ă���P��A����ɍł������P����������\������(_�t�@�C��,_�ŏ��ɏo�Ă���P��,_�Ō�ɏo�Ă���P��,_�ł������P��) :-
�@�@get_lines(_�t�@�C��,Lines),
�@�@concat_atom(Lines,S),
�@�@split(S,[' ','\t','\n'],_�P��Ȃ��),
�@�@sort(_�P��Ȃ��,_���ꂽ�P��Ȃ��),
�@�@append([_�ŏ��ɏo�Ă���P��|_],[_�Ō�ɏo�Ă���P��],_���ꂽ�P��Ȃ��),
�@�@findmax(_����,(member(_�P��,_���ꂽ�P��Ȃ��),sub_atom(_�P��,_,_����,_,_�P��)),_�ł������P��).
>>678
���ꂾ�ƁA�擪���啶���̒P�ꂪ��ɕ���ł��܂��̂��B���ƂŒ������܂��B
���ꂾ�ƁA�擪���啶���̒P�ꂪ��ɕ���ł��܂��̂��B���ƂŒ������܂��B
680 �F�f�t�H���g�̖����������F2009/12/14(��) 14:19:34
http://pc12.2ch.net/test/read.cgi/tech/1260532772/87
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������B
# �\���͑S����5�s�ɂȂ�B
#
# txt�t�@�C���̓��e
# Gunma
# 2016027
# 6363.16
# Saitama
# 7104222
# 3797.25
# Chiba
# 6108809
# 5156.60
# Tokyo
# 12790202
# 2187.58
# Kanagawa
# 8899545
# 2415.84
# [1] ���ƒP���F�v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F
# txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������B
# �\���͑S����5�s�ɂȂ�B
#
# txt�t�@�C���̓��e
# Gunma
# 2016027
# 6363.16
# Saitama
# 7104222
# 3797.25
# Chiba
# 6108809
# 5156.60
# Tokyo
# 12790202
# 2187.58
# Kanagawa
# 8899545
# 2415.84
681 �F�f�t�H���g�̖����������F2009/12/14(��) 14:32:54
http://pc12.2ch.net/test/read.cgi/tech/1260532772/95
# [1] ���ƒP���F�v�Z�@��{
# [2] ��蕶(�܃R�[�h&�����N)�F
# 1����10�܂ł̐�����2��̘a 1^2 + 2^2 + 3^2 + ... +8^2 + 9^2 + 10^2 �����߂�v���O����������Ă݂܂��傤�B
# �r���o�߂��\�����Ă��������B
# ��F1^2 + 2^2 =
# 1^2 + 2^2 + 3^2 =
# ....
#
# [1] ���ƒP���F�v�Z�@��{
# [2] ��蕶(�܃R�[�h&�����N)�F
# 1����10�܂ł̐�����2��̘a 1^2 + 2^2 + 3^2 + ... +8^2 + 9^2 + 10^2 �����߂�v���O����������Ă݂܂��傤�B
# �r���o�߂��\�����Ă��������B
# ��F1^2 + 2^2 =
# 1^2 + 2^2 + 3^2 =
# ....
#
682 �F�f�t�H���g�̖����������F2009/12/14(��) 15:03:18
>>678 (>>677)
% Prolog sort/2 �� ����������/2 �ɒu�������Ă��������B���̏�Œlj��B
����������([X|Xs],Ys) :- ����������(Xs,X,Littles,Bigs),����������(Littles,s),����������(Bigs,Bs),append(Ls,[X|Bs],Ys) .
����������([],[]).
% *** user: partition / 4 ***
����������([X|Xs],Y,[X|Ls],Bs) :- �������ɔ�r(X,Y,@<),����������(Xs,Y,Ls,Bs) .
����������([X|Xs],Y,[X|Ls],Bs) :- �������ɔ�r(X,Y,=),����������(Xs,Y,Ls,Bs) .
����������([X|Xs],Y,Ls,[X|Bs]) :- �������ɔ�r(X,Y,@<),����������(Xs,Y,Ls,Bs) .
����������([],Y,[],[]).
�������Ɍ���r(_��1,_��2,_��) :- atom_chars(_��1,Chars1),atom_chars(_��2,Chars2),�������ɔ�r(Chars1,Chars2,_��).
�������ɔ�r(L,L,=) :- !.
�������ɔ�r([],[_|_],@<) :- !.
�������ɔ�r([_|_],[],@>) :- !.
�������ɔ�r([A|R1],[A|R2],F) :- �������ɔ�r(R1,R2,Func),!.
�������ɔ�r([A|R1],[B|R2],@<) :- to_lower(A,U),to_lower(B,U),A <@ B,!.
�������ɔ�r([A|R1],[B|R2],@>) :- to_lower(A,U),to_lower(B,U),A @> B,!.
�������ɔ�r([A|R1],[B|R2],@<) :- \+((to_lower(A,U),to_lower(B,U))),A <@ B,!.
�������ɔ�r([A|R1],[B|R2],@>) :- \+((to_lower(A,U),to_lower(B,U))),A @> B,!.
% Prolog sort/2 �� ����������/2 �ɒu�������Ă��������B���̏�Œlj��B
����������([X|Xs],Ys) :- ����������(Xs,X,Littles,Bigs),����������(Littles,s),����������(Bigs,Bs),append(Ls,[X|Bs],Ys) .
����������([],[]).
% *** user: partition / 4 ***
����������([X|Xs],Y,[X|Ls],Bs) :- �������ɔ�r(X,Y,@<),����������(Xs,Y,Ls,Bs) .
����������([X|Xs],Y,[X|Ls],Bs) :- �������ɔ�r(X,Y,=),����������(Xs,Y,Ls,Bs) .
����������([X|Xs],Y,Ls,[X|Bs]) :- �������ɔ�r(X,Y,@<),����������(Xs,Y,Ls,Bs) .
����������([],Y,[],[]).
�������Ɍ���r(_��1,_��2,_��) :- atom_chars(_��1,Chars1),atom_chars(_��2,Chars2),�������ɔ�r(Chars1,Chars2,_��).
�������ɔ�r(L,L,=) :- !.
�������ɔ�r([],[_|_],@<) :- !.
�������ɔ�r([_|_],[],@>) :- !.
�������ɔ�r([A|R1],[A|R2],F) :- �������ɔ�r(R1,R2,Func),!.
�������ɔ�r([A|R1],[B|R2],@<) :- to_lower(A,U),to_lower(B,U),A <@ B,!.
�������ɔ�r([A|R1],[B|R2],@>) :- to_lower(A,U),to_lower(B,U),A @> B,!.
�������ɔ�r([A|R1],[B|R2],@<) :- \+((to_lower(A,U),to_lower(B,U))),A <@ B,!.
�������ɔ�r([A|R1],[B|R2],@>) :- \+((to_lower(A,U),to_lower(B,U))),A @> B,!.
683 �F�f�t�H���g�̖����������F2009/12/14(��) 15:16:51
>>680
% Prolog
txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������ :-
�@�@get_lines(_�t�@�C����,Lines),
�@�@'N�g'(3,Lines,_���Ȃ��),
�@�@member([_�s���{����,_�l��,_�ʐ�],_���Ȃ��),
�@�@write_formatted('%t %t %t\n',[_�s���{����,_�l��,_�ʐ�]),
�@�@fail.
txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������.
% Prolog
txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������ :-
�@�@get_lines(_�t�@�C����,Lines),
�@�@'N�g'(3,Lines,_���Ȃ��),
�@�@member([_�s���{����,_�l��,_�ʐ�],_���Ȃ��),
�@�@write_formatted('%t %t %t\n',[_�s���{����,_�l��,_�ʐ�]),
�@�@fail.
txt�t�@�C������f�[�^��ǂݍ��݁A�l�����ɕ��בւ��āA�s���{�����A�l���A�ʐς�1�s�ɕ\������.
684 �F�f�t�H���g�̖����������F2009/12/14(��) 15:46:04
>>681
% Prolog
'1����10�܂ł̐�����2��̘a��r���o�߂��\�����Ȃ��狁�߂�'(Sum) :-
�@�@'1����10�܂ł̐�����2��̘a'(1,10,0,Sum),
'1����10�܂ł̐�����2��̘a'(M,N,_,Sum,Sum) :- M > N,!.
'1����10�܂ł̐�����2��̘a'(M,N,L1,Sum1,Sum) :-
�@�@Sum2 is M ^ 2 + Sum1,
�@�@append(L,[M],L2),
�@�@�r���o�߂̕\��(L2,Sum2),
�@�@M2 is M + 1,
�@�@'1����10�܂ł̐�����2��̘a'(M2,N,L2,Sum2,Sum).
�r���o�߂̕\��([N],Sum) :- write_formatted('+ %t ^ 2 = %t\n',[Sum]),!.
�r���o�߂̕\��([N|R],Sum) :-
�@�@write_formatted('%t ^ 2 + ',[N]),
�@�@�r���o�߂̕\��(R,Sum).
% Prolog
'1����10�܂ł̐�����2��̘a��r���o�߂��\�����Ȃ��狁�߂�'(Sum) :-
�@�@'1����10�܂ł̐�����2��̘a'(1,10,0,Sum),
'1����10�܂ł̐�����2��̘a'(M,N,_,Sum,Sum) :- M > N,!.
'1����10�܂ł̐�����2��̘a'(M,N,L1,Sum1,Sum) :-
�@�@Sum2 is M ^ 2 + Sum1,
�@�@append(L,[M],L2),
�@�@�r���o�߂̕\��(L2,Sum2),
�@�@M2 is M + 1,
�@�@'1����10�܂ł̐�����2��̘a'(M2,N,L2,Sum2,Sum).
�r���o�߂̕\��([N],Sum) :- write_formatted('+ %t ^ 2 = %t\n',[Sum]),!.
�r���o�߂̕\��([N|R],Sum) :-
�@�@write_formatted('%t ^ 2 + ',[N]),
�@�@�r���o�߂̕\��(R,Sum).
685 �F�f�t�H���g�̖����������F2009/12/14(��) 16:21:12
http://pc12.2ch.net/test/read.cgi/tech/1260532772/104
# [1] ���ƒP���FC�v���O���~���O���K
# [2] ��蕶�F������f(x)=�bn�~?��n��{�bn-1�~?��(n-1)��{...�{�b1�~?
# �{�b0�~?�̂O��@�̎���n�Ƒ������̌W���bn,�bn-1,..,�b1,�b0�����ɓǂݍ��݁A
# �ϐ�?��0.0�A0.1�A0.2,�E�E�A0.9�A1.0�ɑ��鑽����f(x)�̒l���v�Z���Č��₷���`��
# [5] ���̑��̐����F�z��̖��ł��B for�\����K���g���A
# f(x)=((...((�bn?�{�bn-1)?�{�bn-2)...)?�{�b1)?�{�b0
# �ƒP���Ȍ����̗ǂ��v���O�����v�Z����悤�Ȃ��́B�܂�
# �@fx���bn
# �@fx��fx*?�{�bn-1�@�@�Ƃ����悤�ȑ�����Q�l�ɂ��čl���Ă݂�
# [1] ���ƒP���FC�v���O���~���O���K
# [2] ��蕶�F������f(x)=�bn�~?��n��{�bn-1�~?��(n-1)��{...�{�b1�~?
# �{�b0�~?�̂O��@�̎���n�Ƒ������̌W���bn,�bn-1,..,�b1,�b0�����ɓǂݍ��݁A
# �ϐ�?��0.0�A0.1�A0.2,�E�E�A0.9�A1.0�ɑ��鑽����f(x)�̒l���v�Z���Č��₷���`��
# [5] ���̑��̐����F�z��̖��ł��B for�\����K���g���A
# f(x)=((...((�bn?�{�bn-1)?�{�bn-2)...)?�{�b1)?�{�b0
# �ƒP���Ȍ����̗ǂ��v���O�����v�Z����悤�Ȃ��́B�܂�
# �@fx���bn
# �@fx��fx*?�{�bn-1�@�@�Ƃ����悤�ȑ�����Q�l�ɂ��čl���Ă݂�
686 �F�f�t�H���g�̖����������F2009/12/14(��) 16:30:23
>>681
�g�p����F�@�\�iBASIC
LET s=0
FOR i=1 TO 10
LET s=s+i*i
FOR j=2 TO i
PRINT STR$(j-1);"^2 + ";
NEXT J
PRINT STR$(i);"^2 =";s
NEXT I
END
���s����
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
�g�p����F�@�\�iBASIC
LET s=0
FOR i=1 TO 10
LET s=s+i*i
FOR j=2 TO i
PRINT STR$(j-1);"^2 + ";
NEXT J
PRINT STR$(i);"^2 =";s
NEXT I
END
���s����
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
687 �F�f�t�H���g�̖����������F2009/12/14(��) 18:30:19
>>681
�g�p����F�@J
;"1((>(,' + '&;)/&.><@,&'^2'@":"0&.><\>:i.10),.<' = '),.,.":&.>;/+/\*:>:i.10
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
�g�p����F�@J
;"1((>(,' + '&;)/&.><@,&'^2'@":"0&.><\>:i.10),.<' = '),.,.":&.>;/+/\*:>:i.10
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
688 �F�f�t�H���g�̖����������F2009/12/14(��) 18:44:14
http://pc12.2ch.net/test/read.cgi/tech/1260532772/112
# ���ƒP���F�A���S���Y���ƃf�[�^�\��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�|�[�J�[�Q�[���i�̈ꕔ�j��C����ɂč쐬����B
#
# �@�|�[�J�[�Q�[���i�̈ꕔ�j�͈ȉ��̏����������Ă��������B
#
# �@�@�@�J�[�h�̃V���b�t�����s���A�v���C���A�f�B�[���ɂ��ꂼ��5�����J�[�h��z��B
# �@�@�@�v���C���͔z��ꂽ�J�[�h�̒��������������̂�I���ł���悤�ɂ���B
# �@�@�@�f�B�[�����̑I�����[�`���̓_�~�[�̊��i���Ƃ��ΑS�������A�������Ȃ����j��p�ӂ���Ώ\���ł��B
# �@�@�@�v���C���A�f�B�[�����ꂼ��̖��肵�ď��s��\������B
#
# �@�\���A�J�[�h�̑I���͕W�����o�͂𗘗p���Ă��������B
#
# ���ƒP���F�A���S���Y���ƃf�[�^�\��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�|�[�J�[�Q�[���i�̈ꕔ�j��C����ɂč쐬����B
#
# �@�|�[�J�[�Q�[���i�̈ꕔ�j�͈ȉ��̏����������Ă��������B
#
# �@�@�@�J�[�h�̃V���b�t�����s���A�v���C���A�f�B�[���ɂ��ꂼ��5�����J�[�h��z��B
# �@�@�@�v���C���͔z��ꂽ�J�[�h�̒��������������̂�I���ł���悤�ɂ���B
# �@�@�@�f�B�[�����̑I�����[�`���̓_�~�[�̊��i���Ƃ��ΑS�������A�������Ȃ����j��p�ӂ���Ώ\���ł��B
# �@�@�@�v���C���A�f�B�[�����ꂼ��̖��肵�ď��s��\������B
#
# �@�\���A�J�[�h�̑I���͕W�����o�͂𗘗p���Ă��������B
#
689 �F�f�t�H���g�̖����������F2009/12/14(��) 19:07:33
>>688
% Prolog (���̈�)
�A��(2,3).
�A��(3,4).
�A��(4,5).
�A��(5,6).
�A��(6,7).
�A��(7,8).
�A��(8,9).
�A��(9,10).
�A��(10,'J').
�A��('J','Q').
�A��('Q','K').
�A��('K','A').
��('One Pair',[C1/A,C2/A,C3/B,C4/C,C5/D]) :- �قȂ�([A],[B,C,D]).
��('Two Pair',[C1/A,C2/A,C3/B,C4/B,C5/C]) :- �قȂ�([A,B],[C]).
��('Three Cards',[C1/A,C2/A,C3/A,C4/B,C5/C]) :- �قȂ�([A],[B,C]).
��('Four Cards',[C1/A,C2/A,C3/A,C4/A,C5/B]) :- �قȂ�([A],[B]).
��('Full House',[C1/A,C2/A,C3/A,C4/B,C5/B]) :- �قȂ�([A],[B]).
��('Flush',[C1/A,C1/B,C1/C,C1/D,C1/E]) :-
�@�@\+(��('Straight',[C1/A,C1/B,C1/C,C1/D,C1/E])).
��('Straight',[C1/A,C2/B,C3/C,C4/D,C5/E]) :-
�@�@�A��(A,B),�A��(B,C),�A��(C,D),�A��(D,E),
�@�@\+(��('Flush',[C1/A,C2/B,C3/C,C4/D,C5/E])).
% Prolog (���̈�)
�A��(2,3).
�A��(3,4).
�A��(4,5).
�A��(5,6).
�A��(6,7).
�A��(7,8).
�A��(8,9).
�A��(9,10).
�A��(10,'J').
�A��('J','Q').
�A��('Q','K').
�A��('K','A').
��('One Pair',[C1/A,C2/A,C3/B,C4/C,C5/D]) :- �قȂ�([A],[B,C,D]).
��('Two Pair',[C1/A,C2/A,C3/B,C4/B,C5/C]) :- �قȂ�([A,B],[C]).
��('Three Cards',[C1/A,C2/A,C3/A,C4/B,C5/C]) :- �قȂ�([A],[B,C]).
��('Four Cards',[C1/A,C2/A,C3/A,C4/A,C5/B]) :- �قȂ�([A],[B]).
��('Full House',[C1/A,C2/A,C3/A,C4/B,C5/B]) :- �قȂ�([A],[B]).
��('Flush',[C1/A,C1/B,C1/C,C1/D,C1/E]) :-
�@�@\+(��('Straight',[C1/A,C1/B,C1/C,C1/D,C1/E])).
��('Straight',[C1/A,C2/B,C3/C,C4/D,C5/E]) :-
�@�@�A��(A,B),�A��(B,C),�A��(C,D),�A��(D,E),
�@�@\+(��('Flush',[C1/A,C2/B,C3/C,C4/D,C5/E])).
690 �F�f�t�H���g�̖����������F2009/12/14(��) 20:13:19
http://pc11.2ch.net/test/read.cgi/db/1252492296/
# (idlist �e�[�u��)�@�@�@ (sales �e�[�u��)
# id�@ name�@ taxfree�@�@id�@ data�@ price
# 1�@�@A�@�@�@1�@�@�@�@�@ 1�@�@12/8�@ 3000
# 2�@�@B�@�@�@0�@�@�@�@�@ 1�@�@12/7�@ 2500
# 3�@�@C�@�@�@1�@�@�@�@�@ 2�@�@12/8�@ 2000
# 4�@�@D�@�@�@0�@�@�@�@�@ 2�@�@12/7�@ 2800
# 5�@�@E�@�@�@0�@�@�@�@�@ 3�@�@12/8�@�@150
# 6�@�@F�@�@�@1�@�@�@�@�@ 3�@�@12/7�@�@200
# �@�@�@�@�@�@�@�@�@�@�@�@6�@�@12/5�@�@500
#
# ��L2�̃e�[�u������A
# ���L�̌`���̂悤�ɁAidlist���� taxfree=1 �̂��̂��܂��\�����A
# �ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\���������ƍl��
�Ă��܂��B
#
# id�@ name�@ data�@ price
# 1�@�@A�@�@�@12/8�@ 3000
# 3�@�@C�@�@�@12/8�@ 150
# 6�@�@F�@�@�@12/5�@ 500
# (idlist �e�[�u��)�@�@�@ (sales �e�[�u��)
# id�@ name�@ taxfree�@�@id�@ data�@ price
# 1�@�@A�@�@�@1�@�@�@�@�@ 1�@�@12/8�@ 3000
# 2�@�@B�@�@�@0�@�@�@�@�@ 1�@�@12/7�@ 2500
# 3�@�@C�@�@�@1�@�@�@�@�@ 2�@�@12/8�@ 2000
# 4�@�@D�@�@�@0�@�@�@�@�@ 2�@�@12/7�@ 2800
# 5�@�@E�@�@�@0�@�@�@�@�@ 3�@�@12/8�@�@150
# 6�@�@F�@�@�@1�@�@�@�@�@ 3�@�@12/7�@�@200
# �@�@�@�@�@�@�@�@�@�@�@�@6�@�@12/5�@�@500
#
# ��L2�̃e�[�u������A
# ���L�̌`���̂悤�ɁAidlist���� taxfree=1 �̂��̂��܂��\�����A
# �ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\���������ƍl��
�Ă��܂��B
#
# id�@ name�@ data�@ price
# 1�@�@A�@�@�@12/8�@ 3000
# 3�@�@C�@�@�@12/8�@ 150
# 6�@�@F�@�@�@12/5�@ 500
692 �F�f�t�H���g�̖����������F2009/12/14(��) 20:26:06
>>690
% Prolog
'idlist���� taxfree=1 �̂��̂��܂��\�����A�ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\������' :-
�@�@write('id�@name�@date�@price\n'),
�@�@idlist(Id,Name,1),
�@�@findmax([Date,Id,Name,Price],sales(Id,Date,Price),[Date,Id,Name,Price]),
�@�@write_formatted('%2d�@%4s�@%t�@%4d\n',[Id,Name,Date,Price]),
�@�@fail.
'idlist���� taxfree=1 �̂��̂��܂��\�����A�ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\������'.
% Prolog
'idlist���� taxfree=1 �̂��̂��܂��\�����A�ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\������' :-
�@�@write('id�@name�@date�@price\n'),
�@�@idlist(Id,Name,1),
�@�@findmax([Date,Id,Name,Price],sales(Id,Date,Price),[Date,Id,Name,Price]),
�@�@write_formatted('%2d�@%4s�@%t�@%4d\n',[Id,Name,Date,Price]),
�@�@fail.
'idlist���� taxfree=1 �̂��̂��܂��\�����A�ŐV���t�̃f�[�^���A�ŐV���t�������ꍇ��ԋ߂����t�̃f�[�^��\������'.
693 �F�f�t�H���g�̖����������F2009/12/14(��) 20:33:28
http://pc12.2ch.net/test/read.cgi/tech/1260532772/94
# [1] ���ƒP���F �ʐM�v���g�R��
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10268.txt
# tcp��p����21�����钆����1�`3�̐�Server�AClient�Ŏ�荇���A
# �Ō��1����������������ƂȂ�Ύ��Q�[�������Ȃ����B
# server�Aclient�̏����A����юg�p����|�[�g�͎��R�Ɍ��߂č\��Ȃ��B
# [1] ���ƒP���F �ʐM�v���g�R��
# [2] ��蕶(�܃R�[�h&�����N)�F
# http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10268.txt
# tcp��p����21�����钆����1�`3�̐�Server�AClient�Ŏ�荇���A
# �Ō��1����������������ƂȂ�Ύ��Q�[�������Ȃ����B
# server�Aclient�̏����A����юg�p����|�[�g�͎��R�Ɍ��߂č\��Ȃ��B
694 �F�f�t�H���g�̖����������F2009/12/14(��) 22:00:12
http://pc12.2ch.net/test/read.cgi/tech/1260532772/125
# [1] �v�Z����
# [2]
# ����_�ɐÎ~���Ă����d�q���l����B�����ɒ����Ό������d���g�����˂��Ă����Ƃ��A�d
# �q�̉^���̗l�q���v�Z����B�~�Ό��̂Ƃ��͂ǂ����B����̗͖͂������Ă悢�B
#
# ��n�����߂���q���́A��C�̖��C���ď����Â�������B���̗l�q���v�Z����B�l
# �͎��ۂ̒l�����Ȃ��Ƃ��悢���A���C���n���̏d�͂��Ă܂��l�q�𐳂�
# �������������ł���킵�A����������B
#
# ��L���̍L���̔����d�ɂ������s���R���f���T�[�̎���̓d��i�d�ʁj���v�Z���A��
# ��������B���s���R���f���T�[�̓����ł͈�l�ȓd�ꂪ�ł��邱�Ƃ͂悭�m���Ă���B
# �������[�̓d��͂ǂ̂悤�ɂ���Ă���̂ł��낤���B
# (�R���f���T�[�����\���傫���ݒu�������^�̋��E���l����B���̒��ɃR���f���T�[�̋�
# �������A�Е��ɓd���������ċ��E�����̂悤�Ɏ�舵���悢�B)
# [1] �v�Z����
# [2]
# ����_�ɐÎ~���Ă����d�q���l����B�����ɒ����Ό������d���g�����˂��Ă����Ƃ��A�d
# �q�̉^���̗l�q���v�Z����B�~�Ό��̂Ƃ��͂ǂ����B����̗͖͂������Ă悢�B
#
# ��n�����߂���q���́A��C�̖��C���ď����Â�������B���̗l�q���v�Z����B�l
# �͎��ۂ̒l�����Ȃ��Ƃ��悢���A���C���n���̏d�͂��Ă܂��l�q�𐳂�
# �������������ł���킵�A����������B
#
# ��L���̍L���̔����d�ɂ������s���R���f���T�[�̎���̓d��i�d�ʁj���v�Z���A��
# ��������B���s���R���f���T�[�̓����ł͈�l�ȓd�ꂪ�ł��邱�Ƃ͂悭�m���Ă���B
# �������[�̓d��͂ǂ̂悤�ɂ���Ă���̂ł��낤���B
# (�R���f���T�[�����\���傫���ݒu�������^�̋��E���l����B���̒��ɃR���f���T�[�̋�
# �������A�Е��ɓd���������ċ��E�����̂悤�Ɏ�舵���悢�B)
695 �F�f�t�H���g�̖����������F2009/12/14(��) 22:07:24
http://pc12.2ch.net/test/read.cgi/tech/1260532772/126
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10269.txt
#
# �n�m�C�̓�
# �����𐔒l�łȂ�������ŕ\����悤�Ɏ�������B��F"A��","B��","C��"
#
% C����̃\�[�X�̈ꕔ��芷���Ƃ��Ă̏o��̂悤�ł����A
% �n�m�C�̓��̃v���O�����������Ƃ��܂��傤�B
# [1] ���ƒP���FC�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10269.txt
#
# �n�m�C�̓�
# �����𐔒l�łȂ�������ŕ\����悤�Ɏ�������B��F"A��","B��","C��"
#
% C����̃\�[�X�̈ꕔ��芷���Ƃ��Ă̏o��̂悤�ł����A
% �n�m�C�̓��̃v���O�����������Ƃ��܂��傤�B
696 �F�f�t�H���g�̖����������F2009/12/15(��) 05:50:53
697 �F�f�t�H���g�̖����������F2009/12/15(��) 06:00:36
>>17 ���2
�g�p����F�@Yorick
> func f(n){a=indgen(1:n);return sum(a*(a%3==0|a%5==0));}
> f(10)
33
> f(100)
2418
�g�p����F�@Yorick
> func f(n){a=indgen(1:n);return sum(a*(a%3==0|a%5==0));}
> f(10)
33
> f(100)
2418
698 �F�f�t�H���g�̖����������F2009/12/15(��) 06:29:25
>>693
% Prolog (�N���C�A���g ���̈�)
'�K��Client'(Host,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@host_addr(Server,Port),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@get_line(Input,Line),
�@�@write_formatted('%t\n',[Line]),
�@�@'�K��Client_1'(Input,Output,Line),
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
'�K��Client_1'(Input,Output,_��������) :-
�@�@get_line(Line),
�@�@'�K��Client_2'(Input,Output,Line,_��������).
'�K��Client_1'(_,_,_).
% Prolog (�N���C�A���g ���̈�)
'�K��Client'(Host,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@host_addr(Server,Port),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@get_line(Input,Line),
�@�@write_formatted('%t\n',[Line]),
�@�@'�K��Client_1'(Input,Output,Line),
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
'�K��Client_1'(Input,Output,_��������) :-
�@�@get_line(Line),
�@�@'�K��Client_2'(Input,Output,Line,_��������).
'�K��Client_1'(_,_,_).
699 �F�f�t�H���g�̖����������F2009/12/15(��) 06:31:05
>>693
% Prolog (�K���N���C�A���g ���̓�)
'�K��Client_2'(Input,Output,end_of_file,end_of_file) :- !.
'�K��Client_2'(Input,Output,_��������,_��������).
'�K��Client_2'(Input,Output,Line1,_��������) :-
�@�@atom_chars(_��������,Chars),
�@�@�������߂�(Chars,L),
�@�@atom_chars(_���̕����\��,L),
�@�@������𑗂�(_������̕����\��,Host,Socket,Input,Output),
�@�@get_line(Line2),
�@�@'�K��Client'(Input,Output,Line2,_��������).
�������߂�([A],[A]) :- !.
�������߂�([A,B],[A,B]) :- !.
�������߂�([A,B,C],[A,B,C]) :- !.
�������߂�([A,B,C,D],[A]) :- !.
�������߂�([_,_,_,_|R],X) :- �������߂�(R,X).
������𑗂�(_������̕����\��,Host,Input,Output) :-
�@�@write_formatted(Output,'%t\n',[_������̕����\��]),
�@�@flush_output(Output).
% Prolog (�K���N���C�A���g ���̓�)
'�K��Client_2'(Input,Output,end_of_file,end_of_file) :- !.
'�K��Client_2'(Input,Output,_��������,_��������).
'�K��Client_2'(Input,Output,Line1,_��������) :-
�@�@atom_chars(_��������,Chars),
�@�@�������߂�(Chars,L),
�@�@atom_chars(_���̕����\��,L),
�@�@������𑗂�(_������̕����\��,Host,Socket,Input,Output),
�@�@get_line(Line2),
�@�@'�K��Client'(Input,Output,Line2,_��������).
�������߂�([A],[A]) :- !.
�������߂�([A,B],[A,B]) :- !.
�������߂�([A,B,C],[A,B,C]) :- !.
�������߂�([A,B,C,D],[A]) :- !.
�������߂�([_,_,_,_|R],X) :- �������߂�(R,X).
������𑗂�(_������̕����\��,Host,Input,Output) :-
�@�@write_formatted(Output,'%t\n',[_������̕����\��]),
�@�@flush_output(Output).
700 �F�f�t�H���g�̖����������F2009/12/15(��) 06:43:41
>>698 (>>693) ��ԈႢ�B����!
'�K��Client'(Host,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@host_addr(Server,Port),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@get_line(Input,Line),
�@�@write_formatted('%t\n',[Line]),
�@�@'�K��Client_1'(Socket,Input,Output,Line).
'�K��Client_1'(_,Input,Output,_��������) :-
�@�@get_line(Line),
�@�@'�K��Client_2'(Input,Output,Line,_��������).
'�K��Client_1'(Socket,Input,Output,_) :-
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
'�K��Client'(Host,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@host_addr(Server,Port),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@get_line(Input,Line),
�@�@write_formatted('%t\n',[Line]),
�@�@'�K��Client_1'(Socket,Input,Output,Line).
'�K��Client_1'(_,Input,Output,_��������) :-
�@�@get_line(Line),
�@�@'�K��Client_2'(Input,Output,Line,_��������).
'�K��Client_1'(Socket,Input,Output,_) :-
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
701 �F�f�t�H���g�̖����������F2009/12/15(��) 06:51:12
>>17�@���1
�g�p����F�@Yorick
> func f(n){return strpart("abcdefghijklmnopqrstuvwxyz",1:n);}
> f(6)
"abcdef"
> f(30)
"abcdefghijklmnopqrstuvwxyz"
�g�p����F�@Yorick
> func f(n){return strpart("abcdefghijklmnopqrstuvwxyz",1:n);}
> f(6)
"abcdef"
> f(30)
"abcdefghijklmnopqrstuvwxyz"
702 �F�f�t�H���g�̖����������F2009/12/15(��) 06:51:57
>>699 (>>693)
% Prolog ������ԈႢ�����B�ŏI�߁B
'�K��Client_2'(Input,Output,end_of_file,end_of_file) :- !.
'�K��Client_2'(Input,Output,_��������,_��������).
'�K��Client_2'(Input,Output,Line1,_��������) :-
�@�@atom_chars(_��������,Chars),
�@�@�������߂�(Chars,L),
�@�@atom_chars(_���̕����\��,L),
�@�@������𑗂�(_������̕����\��,Host,Socket,Input,Output),
�@�@get_line(Line2),
�@�@'�K��Client_2'(Input,Output,Line2,_��������).
% Prolog ������ԈႢ�����B�ŏI�߁B
'�K��Client_2'(Input,Output,end_of_file,end_of_file) :- !.
'�K��Client_2'(Input,Output,_��������,_��������).
'�K��Client_2'(Input,Output,Line1,_��������) :-
�@�@atom_chars(_��������,Chars),
�@�@�������߂�(Chars,L),
�@�@atom_chars(_���̕����\��,L),
�@�@������𑗂�(_������̕����\��,Host,Socket,Input,Output),
�@�@get_line(Line2),
�@�@'�K��Client_2'(Input,Output,Line2,_��������).
703 �F�f�t�H���g�̖����������F2009/12/15(��) 07:51:50
>>698 (>>693)
% Prolog ������������B
'�K��Client'(Server,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@'�K��Client_1'(Socket,Input,Output,_��������).
% ���̒���get_line������K�v�͂Ȃ������B���ꂩ��_�������g�b�v���x���ɐڑ����Ă��Ȃ��������炻���������B
% Prolog ������������B
'�K��Client'(Server,Port,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@'�K��Client_1'(Socket,Input,Output,_��������).
% ���̒���get_line������K�v�͂Ȃ������B���ꂩ��_�������g�b�v���x���ɐڑ����Ă��Ȃ��������炻���������B
704 �F�f�t�H���g�̖����������F2009/12/15(��) 07:59:25
% Prolog ���菇�N���C�A���g�̈�ʌ^�������܂��B�q�ꖼ�ŗ^������ڕW�͓����(_�T�[�o����̎�M���,_�T�[�o�ւ̑��M���)
�N���C�A���g��ʌ^(Server,Port,_�q�ꖼ,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@�N���C�A���g��ʌ^_1(Input,Output,_�q�ꖼ,Line).
�N���C�A���g��ʌ^_1(_,Input,Output,_�q�ꖼ,_��������) :-
�@�@get_line(Line),
�@�@�N���C�A���g��ʌ^_2(Input,Output,Line,_�q�ꖼ,_��������).
�N���C�A���g��ʌ^_1(Socket,Input,Output,_,_) :-
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
�N���C�A���g��ʌ^_2(Input,Output,_,end_of_file,end_of_file) :- !.
�N���C�A���g��ʌ^_2(Input,Output,_,_��������,_��������).
�N���C�A���g��ʌ^_2(Input,Output,_�q�ꖼ,Line1,_��������) :-
�@�@functor(P,_�q�ꖼ,Arg),
�@�@arg(1,P,Line1),
�@�@arg(2,P,Message),
�@�@call(P),
�@�@write_formatted(Output,%t\n,[Message]),
�@�@flush_output(Output),
�@�@get_line(Line2),
�@�@�N���C�A���g��ʌ^_2(Input,Output,_�q�ꖼ,Line2,_��������).
�N���C�A���g��ʌ^(Server,Port,_�q�ꖼ,_��������) :-
�@�@socket(internet, stream, Socket),
�@�@socket_connect(Socket, Server : Port),
�@�@open(Socket,read,Input),
�@�@open(Socket,write,Output),
�@�@�N���C�A���g��ʌ^_1(Input,Output,_�q�ꖼ,Line).
�N���C�A���g��ʌ^_1(_,Input,Output,_�q�ꖼ,_��������) :-
�@�@get_line(Line),
�@�@�N���C�A���g��ʌ^_2(Input,Output,Line,_�q�ꖼ,_��������).
�N���C�A���g��ʌ^_1(Socket,Input,Output,_,_) :-
�@�@close(Input),
�@�@close(Output),
�@�@socket_shutdown(Socket),!.
�N���C�A���g��ʌ^_2(Input,Output,_,end_of_file,end_of_file) :- !.
�N���C�A���g��ʌ^_2(Input,Output,_,_��������,_��������).
�N���C�A���g��ʌ^_2(Input,Output,_�q�ꖼ,Line1,_��������) :-
�@�@functor(P,_�q�ꖼ,Arg),
�@�@arg(1,P,Line1),
�@�@arg(2,P,Message),
�@�@call(P),
�@�@write_formatted(Output,%t\n,[Message]),
�@�@flush_output(Output),
�@�@get_line(Line2),
�@�@�N���C�A���g��ʌ^_2(Input,Output,_�q�ꖼ,Line2,_��������).
705 �F�f�t�H���g�̖����������F2009/12/15(��) 08:22:04
>>704
% Prolog �Ⴆ�Έȉ��̂悤�ɐi�݂܂��B�����ł͈��̒ʐM���Ƃɒ�~�����Ă��܂��B
?- �N���C�A���g��ʌ^('192.9.168.2',10111,�K���Ƃ�Q�[��,X).
X = �ΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐ�;
X = �ΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐ�;
...
X = �ΐΐ�;
yes
?-
% Prolog �Ⴆ�Έȉ��̂悤�ɐi�݂܂��B�����ł͈��̒ʐM���Ƃɒ�~�����Ă��܂��B
?- �N���C�A���g��ʌ^('192.9.168.2',10111,�K���Ƃ�Q�[��,X).
X = �ΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐ�;
X = �ΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐΐ�;
...
X = �ΐΐ�;
yes
?-
706 �F�f�t�H���g�̖����������F2009/12/15(��) 09:33:39
http://pc12.2ch.net/test/read.cgi/tech/1257481818/43
# �A�z�z��𑽎����̂��̂Ƃ��Ĉ��������̂ł����A�ǂ̂悤�ɐ錾����悢�̂ł��傤���H
#
# typedef map<string, int> HogeMap;
# HogeMap pb;
# pb["test1"] = 10;
# pb["test2"] = 100;
#
# ���݂́��̂悤�ɐ錾���Ďg���Ă��܂����A
#
# pb["test1"][0] = 10;
# pb["test1"][1] = 20;
# pb["test2"][0] = 100;
# pb["test2"][1] = 200;
#
# �C���[�W�Ƃ��Ắ��̂悤�Ɉ��������̂ł��B������s�\�ł��傤���H
# �A�z�z��𑽎����̂��̂Ƃ��Ĉ��������̂ł����A�ǂ̂悤�ɐ錾����悢�̂ł��傤���H
#
# typedef map<string, int> HogeMap;
# HogeMap pb;
# pb["test1"] = 10;
# pb["test2"] = 100;
#
# ���݂́��̂悤�ɐ錾���Ďg���Ă��܂����A
#
# pb["test1"][0] = 10;
# pb["test1"][1] = 20;
# pb["test2"][0] = 100;
# pb["test2"][1] = 200;
#
# �C���[�W�Ƃ��Ắ��̂悤�Ɉ��������̂ł��B������s�\�ł��傤���H
707 �F�f�t�H���g�̖����������F2009/12/15(��) 09:35:09
708 �F�f�t�H���g�̖����������F2009/12/15(��) 09:40:31
http://pc12.2ch.net/test/read.cgi/tech/1254281104/887
# ����Ȃ̂ł���
#
# ���n�̋R��̕������ƕ���������f�[�^��������
# 10/10���A11/01���A12/20���Ƃ����悤�ɁA
# ������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ��
# ������������o���ɂ͂ǂ���������̂ł��傤���H
#
# �ǂ̋R��ł��\��Ȃ��̂ł����A���[�X���s����O���܂ŕ�����30���������R��̔n��
# �w�����Ă����ꍇ�̉������m��ɂ͂ǂ���������̂ł��傤���H
#
# ����Ȃ̂ł���
#
# ���n�̋R��̕������ƕ���������f�[�^��������
# 10/10���A11/01���A12/20���Ƃ����悤�ɁA
# ������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ��
# ������������o���ɂ͂ǂ���������̂ł��傤���H
#
# �ǂ̋R��ł��\��Ȃ��̂ł����A���[�X���s����O���܂ŕ�����30���������R��̔n��
# �w�����Ă����ꍇ�̉������m��ɂ͂ǂ���������̂ł��傤���H
#
709 �F�f�t�H���g�̖����������F2009/12/15(��) 11:04:22
>>708
% Prolog �d�ݕt��������Ă��Ȃ�����ȉ��̏ꍇ�łȂ��Ɖ����łȂ��B
:- op(250,xf,��).
:- op(250,xf,(%)).
�A�����E�A�������(�약�S��,10/10 ��,37 %,81 %).
�A�����E�A�������(�약�S��,11/1 ��,35 %,78 %).
�A�����E�A�������(�약�S��,12/20 ��,36 %,79 %).
�A�����E�A�������(���c��,10/10 ��,29 %,68 %).
�A�����E�A�������(���c��,11/1 ��,30 %,70 %).
�A�����E�A�������(���c��,12/20 ��,28 %,66 %).
�A�����E�A�������(�������Y,10/10 ��,17 %, 49 %).
�A�����E�A�������(�������Y,11/1 ��,27 %,66 %).
�A�����E�A�������(�������Y,12/20 ��,19 %,54 %).
'������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ�̕��������'(_�R��,_��/_�� ��,_�A������� %) :-
�@�@�A�����E�A�������(_�R��,_��/_�� ��,_�A���� %,_�A������� %),
�@�@_�A���� >= 30.
'������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ�̕��������'(_��/_�� ��,_�R��E�A�����Ȃ��) :-
�@�@findall([_�R��,_�A����],(�A�����E�A�������(_�R��,_��/_�� ��,_�A���� %,_�A������� %),_�A����>=30),_�R��E�A�����Ȃ��).
% Prolog �d�ݕt��������Ă��Ȃ�����ȉ��̏ꍇ�łȂ��Ɖ����łȂ��B
:- op(250,xf,��).
:- op(250,xf,(%)).
�A�����E�A�������(�약�S��,10/10 ��,37 %,81 %).
�A�����E�A�������(�약�S��,11/1 ��,35 %,78 %).
�A�����E�A�������(�약�S��,12/20 ��,36 %,79 %).
�A�����E�A�������(���c��,10/10 ��,29 %,68 %).
�A�����E�A�������(���c��,11/1 ��,30 %,70 %).
�A�����E�A�������(���c��,12/20 ��,28 %,66 %).
�A�����E�A�������(�������Y,10/10 ��,17 %, 49 %).
�A�����E�A�������(�������Y,11/1 ��,27 %,66 %).
�A�����E�A�������(�������Y,12/20 ��,19 %,54 %).
'������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ�̕��������'(_�R��,_��/_�� ��,_�A������� %) :-
�@�@�A�����E�A�������(_�R��,_��/_�� ��,_�A���� %,_�A������� %),
�@�@_�A���� >= 30.
'������t�܂łɕ�������30���ȏゾ�����R����w�������ꍇ�̕��������'(_��/_�� ��,_�R��E�A�����Ȃ��) :-
�@�@findall([_�R��,_�A����],(�A�����E�A�������(_�R��,_��/_�� ��,_�A���� %,_�A������� %),_�A����>=30),_�R��E�A�����Ȃ��).
710 �F�f�t�H���g�̖����������F2009/12/15(��) 11:30:43
http://pc12.2ch.net/test/read.cgi/tech/1260532772/158
# [1] ���ƒP���F�v�Z�@��{
# [2] ��蕶(�܃R�[�h&�����N)�F
# 1����500�܂ł̐�������A3�̔{����1�s��10���\������v���O���������B�������A��̐�����\�����錅����5���Ɏw�肷�邱�ƁB
#
# [1] ���ƒP���F�v�Z�@��{
# [2] ��蕶(�܃R�[�h&�����N)�F
# 1����500�܂ł̐�������A3�̔{����1�s��10���\������v���O���������B�������A��̐�����\�����錅����5���Ɏw�肷�邱�ƁB
#
711 �F�f�t�H���g�̖����������F2009/12/15(��) 11:36:04
>>710
% Prolog
'1����500�܂ł̐�������A3�̔{����1�s��10���\������' :-
�@�@findall(N,(for(1,N,500),0 is N mod 3),L),
�@�@'N�g'(10,L,L10),
�@�@concat_atom(L1,' ',S),
�@�@write_formatted('%t\n',[S]),
fail.
'1����500�܂ł̐�������A3�̔{����1�s��10���\������'.
% 'N�g'/2 �̒�`�� http://nojiriko.asia/prolog/c132_869_1.html ���Q�Ƃ��Ă�������
% Prolog
'1����500�܂ł̐�������A3�̔{����1�s��10���\������' :-
�@�@findall(N,(for(1,N,500),0 is N mod 3),L),
�@�@'N�g'(10,L,L10),
�@�@concat_atom(L1,' ',S),
�@�@write_formatted('%t\n',[S]),
fail.
'1����500�܂ł̐�������A3�̔{����1�s��10���\������'.
% 'N�g'/2 �̒�`�� http://nojiriko.asia/prolog/c132_869_1.html ���Q�Ƃ��Ă�������
712 �F�f�t�H���g�̖����������F2009/12/15(��) 11:48:58
>>592
�g�p����F�@Yorick
func f(n){
a=indgen(1:n)
b=a(where(n%a==0))
print,"yakusu = ",b
print,"yakusu no kazu = ",numberof(b)
}
> f,30
"yakusu = " [1,2,3,5,6,10,15,30]
"yakusu no kazu = " 8
�g�p����F�@Yorick
func f(n){
a=indgen(1:n)
b=a(where(n%a==0))
print,"yakusu = ",b
print,"yakusu no kazu = ",numberof(b)
}
> f,30
"yakusu = " [1,2,3,5,6,10,15,30]
"yakusu no kazu = " 8
713 �F�f�t�H���g�̖����������F2009/12/15(��) 11:59:31
>>592
�g�p����F�@J
_10,\5":"0>:I.0=3|>:i.500
3 6 9 12 15 18 21 24 27 30
33 36 39 42 45 48 51 54 57 60
63 66 69 72 75 78 81 84 87 90
93 96 99 102 105 108 111 114 117 120
123 126 129 132 135 138 141 144 147 150
153 156 159 162 165 168 171 174 177 180
183 186 189 192 195 198 201 204 207 210
213 216 219 222 225 228 231 234 237 240
243 246 249 252 255 258 261 264 267 270
273 276 279 282 285 288 291 294 297 300
303 306 309 312 315 318 321 324 327 330
333 336 339 342 345 348 351 354 357 360
363 366 369 372 375 378 381 384 387 390
393 396 399 402 405 408 411 414 417 420
423 426 429 432 435 438 441 444 447 450
453 456 459 462 465 468 471 474 477 480
483 486 489 492 495 498
�g�p����F�@J
_10,\5":"0>:I.0=3|>:i.500
3 6 9 12 15 18 21 24 27 30
33 36 39 42 45 48 51 54 57 60
63 66 69 72 75 78 81 84 87 90
93 96 99 102 105 108 111 114 117 120
123 126 129 132 135 138 141 144 147 150
153 156 159 162 165 168 171 174 177 180
183 186 189 192 195 198 201 204 207 210
213 216 219 222 225 228 231 234 237 240
243 246 249 252 255 258 261 264 267 270
273 276 279 282 285 288 291 294 297 300
303 306 309 312 315 318 321 324 327 330
333 336 339 342 345 348 351 354 357 360
363 366 369 372 375 378 381 384 387 390
393 396 399 402 405 408 411 414 417 420
423 426 429 432 435 438 441 444 447 450
453 456 459 462 465 468 471 474 477 480
483 486 489 492 495 498
714 �F�f�t�H���g�̖����������F2009/12/15(��) 12:02:58
>713
���[�B�܂����ԍ��A�ԈႦ�܂����B>>710 �ł��B
���[�B�܂����ԍ��A�ԈႦ�܂����B>>710 �ł��B
715 �F�f�t�H���g�̖����������F2009/12/15(��) 12:09:49
http://pc12.2ch.net/test/read.cgi/tech/1260532772/159
# [1] ���ƒP���F ���̂���̎��K���ɕK�v�ɂȂ�܂���
# [2] ��蕶(�܃R�[�h&�����N)�F
# �S�p�̓��{���JIS�R�[�h�ɕϊ��������ł��B
# �h�����������I�h�Ɠ��͂����Ƃ���
# 2422
# 2424
# 2426
# 2428
# 242A
# 3D2A
# �̂悤�ɕԂ��Ă����Ƃ��ꂵ���ł��B
#
# [1] ���ƒP���F ���̂���̎��K���ɕK�v�ɂȂ�܂���
# [2] ��蕶(�܃R�[�h&�����N)�F
# �S�p�̓��{���JIS�R�[�h�ɕϊ��������ł��B
# �h�����������I�h�Ɠ��͂����Ƃ���
# 2422
# 2424
# 2426
# 2428
# 242A
# 3D2A
# �̂悤�ɕԂ��Ă����Ƃ��ꂵ���ł��B
#
716 �F�f�t�H���g�̖����������F2009/12/15(��) 12:14:58
>>715
% Prolog
�S�p�̓��{���JIS�R�[�h�ɕϊ� :-
�@�@get_line(Line),
�@�@atom_chars(Line,Chars),
�@�@�S�p�̓��{���JIS�R�[�h�ɕϊ�(Chars).
�S�p�̓��{���JIS�R�[�h�ɕϊ�([]).
�S�p�̓��{���JIS�R�[�h�ɕϊ�([A|R]) :-
�@�@char_code(A,Code),
�@�@Jis_code is Code # truncate(2^15+2^7),
�@�@write_formatted('%x\n',[Jis_code]),
�@�@�S�p�̓��{���JIS�R�[�h�ɕϊ�(R).
% Prolog
�S�p�̓��{���JIS�R�[�h�ɕϊ� :-
�@�@get_line(Line),
�@�@atom_chars(Line,Chars),
�@�@�S�p�̓��{���JIS�R�[�h�ɕϊ�(Chars).
�S�p�̓��{���JIS�R�[�h�ɕϊ�([]).
�S�p�̓��{���JIS�R�[�h�ɕϊ�([A|R]) :-
�@�@char_code(A,Code),
�@�@Jis_code is Code # truncate(2^15+2^7),
�@�@write_formatted('%x\n',[Jis_code]),
�@�@�S�p�̓��{���JIS�R�[�h�ɕϊ�(R).
717 �F�f�t�H���g�̖����������F2009/12/15(��) 13:31:09
>>710
�g�p����F�@�\�iBASIC
FOR i=3 TO 500 STEP 3
PRINT USING "#####": i;
IF MOD(i,10)=0 THEN PRINT
NEXT I
PRINT
END
�g�p����F�@�\�iBASIC
FOR i=3 TO 500 STEP 3
PRINT USING "#####": i;
IF MOD(i,10)=0 THEN PRINT
NEXT I
END
718 �F�f�t�H���g�̖����������F2009/12/15(��) 14:29:08
>>658
�g�p����F�@maxima
f(n):=[a:fix(n/3),n-a*3];
(%i120) f(35);
(%o120) [11, 2]
(%i121) f(1234567);
(%o121) [411522, 1]
�g�p����F�@maxima
f(n):=[a:fix(n/3),n-a*3];
(%i120) f(35);
(%o120) [11, 2]
(%i121) f(1234567);
(%o121) [411522, 1]
719 �F�f�t�H���g�̖����������F2009/12/15(��) 15:10:35
720 �F�f�t�H���g�̖����������F2009/12/15(��) 15:15:59
>>711 (>>710) �悭������Ԉ���Ă܂����BL1->L10�ł��B
% ���ꂩ��http://nojiriko.asia/prolog/ �A�[�J�C�u�T�C�g�͌��ݒ�d���ŕ��ʂł��B
'1����500�܂ł̐�������A3�̔{����1�s��10���\������' :-
�@�@findall(N,(for(1,N,500),0 is N mod 3),L),
�@�@'N�g'(10,L,L10),
�@�@concat_atom(L10,' ',S),
�@�@write_formatted('%t\n',[S]),
fail.
'1����500�܂ł̐�������A3�̔{����1�s��10���\������'
% ���ꂩ��http://nojiriko.asia/prolog/ �A�[�J�C�u�T�C�g�͌��ݒ�d���ŕ��ʂł��B
'1����500�܂ł̐�������A3�̔{����1�s��10���\������' :-
�@�@findall(N,(for(1,N,500),0 is N mod 3),L),
�@�@'N�g'(10,L,L10),
�@�@concat_atom(L10,' ',S),
�@�@write_formatted('%t\n',[S]),
fail.
'1����500�܂ł̐�������A3�̔{����1�s��10���\������'
721 �F�f�t�H���g�̖����������F2009/12/15(��) 15:17:09
>>720
���ʂł� -> �s�ʂł�w
���ʂł� -> �s�ʂł�w
722 �F�f�t�H���g�̖����������F2009/12/15(��) 16:00:59
>>59
�g�p����F�@maxima
(%i176) f(n):=if length(unique(charlist(string(n*n))))=2 then true else false;
(%i177) for i:1000 thru 9999 do if f(i) then print(i);
1000
2000
3000
3114
�g�p����F�@maxima
(%i176) f(n):=if length(unique(charlist(string(n*n))))=2 then true else false;
(%i177) for i:1000 thru 9999 do if f(i) then print(i);
1000
2000
3000
3114
723 �F�f�t�H���g�̖����������F2009/12/15(��) 17:16:52
http://pc12.2ch.net/test/read.cgi/tech/1136788500/434
# �T�O�l�̃N���X�i�j�q�R�T�l�j����T�l�̈ψ��������_���ɑI�ԁB���̂Ƃ��I�ꂽ�ψ��̒��ɒj�R�l�A���Q�l������m����BASIC�ŋ��߂�B
#
# �T�O�l�̃N���X�i�j�q�R�T�l�j����T�l�̈ψ��������_���ɑI�ԁB���̂Ƃ��I�ꂽ�ψ��̒��ɒj�R�l�A���Q�l������m����BASIC�ŋ��߂�B
#
724 �F�f�t�H���g�̖����������F2009/12/15(��) 22:39:26
>>613
% Prolog (���̈�) ��肩������Ő\����Ȃ����BVT100�̃G�X�P�[�v�V�[�P���X�Ŏg�������Ȃ��́B
�J�[�\����Pl�s��ֈړ�(Pl) :- put_code(27),write_formatted('[%tA',[Pl]).
�J�[�\����Pl�s���ֈړ�(Pl) :- put_code(27),write_formatted('[%tB',[Pl]).
�J�[�\����Pc���E�ֈړ�(Pc) :- put_code(27),write_formatted('[%tC',[Pc]).
�J�[�\����Pc�����ֈړ�(Pc) :- put_code(27),write_formatted('[%tD',[Pc]).
�J�[�\�����ړ�(Pl,Pc) :- put_code(27),write_formatted('[%t;%tH',[Pl,Pc]).
�J�[�\�������ʂ̏I���܂ł����� :- put_code(27),write('[J').
��ʂ̎n�߂���J�[�\���܂ł����� :- put_code(27),write('[1J').
��ʑS�̂����� :- put_code(27),write('[2J').
�J�[�\������s�̏I���܂ł����� :- put_code(27),write('[K').
�s�S�̂����� :- put_code(27),write('[2K').
�s�̎n�߂���J�[�\���܂ł����� :- put_code(27),write('[1K').
% Prolog (���̈�) ��肩������Ő\����Ȃ����BVT100�̃G�X�P�[�v�V�[�P���X�Ŏg�������Ȃ��́B
�J�[�\����Pl�s��ֈړ�(Pl) :- put_code(27),write_formatted('[%tA',[Pl]).
�J�[�\����Pl�s���ֈړ�(Pl) :- put_code(27),write_formatted('[%tB',[Pl]).
�J�[�\����Pc���E�ֈړ�(Pc) :- put_code(27),write_formatted('[%tC',[Pc]).
�J�[�\����Pc�����ֈړ�(Pc) :- put_code(27),write_formatted('[%tD',[Pc]).
�J�[�\�����ړ�(Pl,Pc) :- put_code(27),write_formatted('[%t;%tH',[Pl,Pc]).
�J�[�\�������ʂ̏I���܂ł����� :- put_code(27),write('[J').
��ʂ̎n�߂���J�[�\���܂ł����� :- put_code(27),write('[1J').
��ʑS�̂����� :- put_code(27),write('[2J').
�J�[�\������s�̏I���܂ł����� :- put_code(27),write('[K').
�s�S�̂����� :- put_code(27),write('[2K').
�s�̎n�߂���J�[�\���܂ł����� :- put_code(27),write('[1K').
725 �F�f�t�H���g�̖����������F2009/12/16(��) 09:38:52
Prolog�����ȁE�E�E�E
�{���Ɏg���ĂȂ�����ȂȃJ���C�\�X
C����/C++�Ȃ疈���̂悤�ɏh�肪����̂�
�{���Ɏg���ĂȂ�����ȂȃJ���C�\�X
C����/C++�Ȃ疈���̂悤�ɏh�肪����̂�
726 �F�f�t�H���g�̖����������F2009/12/16(��) 10:00:03
Prolog�u���̏h����Ăǂ�Ȃ��̂ɂȂ�낤�B
�uProlog�̏h��Еt���܂��X���v���Ă���A�������݂��邩�ȁB
�uProlog�̏h��Еt���܂��X���v���Ă���A�������݂��邩�ȁB
727 �F�f�t�H���g�̖����������F2009/12/16(��) 10:02:07
728 �F�f�t�H���g�̖����������F2009/12/16(��) 10:22:33
729 �F�f�t�H���g�̖����������F2009/12/16(��) 10:36:41
>>681
�g�p����F�@Io
���[��A���s���ʂ��ȗ�������A�܂��܂��������B
s:=0;for(i,1,10,s=s+i*i;for(j,2,i,write(j-1,"^2 + "));writeln(i,"^2 = ",s))
�g�p����F�@Io
���[��A���s���ʂ��ȗ�������A�܂��܂��������B
s:=0;for(i,1,10,s=s+i*i;for(j,2,i,write(j-1,"^2 + "));writeln(i,"^2 = ",s))
730 �F�f�t�H���g�̖����������F2009/12/16(��) 11:22:24
>>45
�g�p����F�@maxima
(%i214) f(n):=apply("*",makelist(i,i,1,n));
(%i215) makelist(print(f(i)),i,0,10);
1
1
2
6
24
120
720
5040
40320
362880
3628800
�g�p����F�@maxima
(%i214) f(n):=apply("*",makelist(i,i,1,n));
(%i215) makelist(print(f(i)),i,0,10);
1
1
2
6
24
120
720
5040
40320
362880
3628800
731 �F�f�t�H���g�̖����������F2009/12/16(��) 12:43:15
http://pc12.2ch.net/test/read.cgi/tech/1260532772/169
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10273.txt
#
# ������ str1, str2���ꂼ��ɕ��������͂��Astr1��str1&' '&str2�̑�������āA
# str1�̓��e��\�������Ȃ����B
#
# str1?WAKARI
# str2?MASENN
# WAKARI MASENN
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10273.txt
#
# ������ str1, str2���ꂼ��ɕ��������͂��Astr1��str1&' '&str2�̑�������āA
# str1�̓��e��\�������Ȃ����B
#
# str1?WAKARI
# str2?MASENN
# WAKARI MASENN
732 �F�f�t�H���g�̖����������F2009/12/16(��) 12:45:24
http://pc12.2ch.net/test/read.cgi/tech/1260532772/170
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10274.txt
#
# ������str�̒��ɁA����c���܂܂�Ă�����i�܂܂�Ă��Ȃ���O�Ƃ���j
# ��Ԃ���
# int str_chnum(const char str[], int c) {/*�E�E�E�E*/}
# ���쐬����
# [1] ���ƒP���Fc����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10274.txt
#
# ������str�̒��ɁA����c���܂܂�Ă�����i�܂܂�Ă��Ȃ���O�Ƃ���j
# ��Ԃ���
# int str_chnum(const char str[], int c) {/*�E�E�E�E*/}
# ���쐬����
733 �F�f�t�H���g�̖����������F2009/12/16(��) 12:48:58
734 �F�f�t�H���g�̖����������F2009/12/16(��) 13:23:48
>>731
% Prolog ����͂ł��Ȃ�����A���̒��x
��s�����͂���ŘA������ :-
�@�@get_line(Str1),
�@�@get_line(Str2),
�@�@concat_atom([Str1,Str2],' ',Str),
�@�@write_formatted('%t\n',[Str]),
% Prolog ����͂ł��Ȃ�����A���̒��x
��s�����͂���ŘA������ :-
�@�@get_line(Str1),
�@�@get_line(Str2),
�@�@concat_atom([Str1,Str2],' ',Str),
�@�@write_formatted('%t\n',[Str]),
735 �F�f�t�H���g�̖����������F2009/12/16(��) 14:44:04
>>731
�g�p����F�@maxima
(%i216) f(s1,s2):=(s1:concat(s1," ",s2),print(s1));
(%i217) f("123","abc");
123 abc
�g�p����F�@maxima
(%i216) f(s1,s2):=(s1:concat(s1," ",s2),print(s1));
(%i217) f("123","abc");
123 abc
736 �F�f�t�H���g�̖����������F2009/12/16(��) 14:45:00
>>732
�g�p����F�@maxima
(%i257) str_chnum(s,c):=slength(s)-slength(ssubst("",c,s));
(%i258) str_chnum("123123111","1");
(%o258) 5
�g�p����F�@maxima
(%i257) str_chnum(s,c):=slength(s)-slength(ssubst("",c,s));
(%i258) str_chnum("123123111","1");
(%o258) 5
737 �F�f�t�H���g�̖����������F2009/12/16(��) 14:59:05
738 �F�f�t�H���g�̖����������F2009/12/16(��) 15:00:13
739 �F�f�t�H���g�̖����������F2009/12/16(��) 15:44:07
http://pc12.2ch.net/test/read.cgi/tech/1260532772/177
# [1] ���ƒP���F �R���s���[�^�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)
# �P�jf(x,y)=dy/dx=-4(x-1)y,y(0)=e^-2�̈�K�����������ɂ��ăI�C���[�̕��@�Ő��l�������߂�v���O�������쐬����B
# �Q�jdy/dx=f(x,y)=1-y,y(0)=0
# �@�@dy/dx=f(x,y)=y(1-y),y(0)=0.01
# �@�@dy/dx=f(x,y)=2yx,y(0)=1
# �̐��l�����I�C���[�@�ɂ���ċ��߂�B
#
# [1] ���ƒP���F �R���s���[�^�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)
# �P�jf(x,y)=dy/dx=-4(x-1)y,y(0)=e^-2�̈�K�����������ɂ��ăI�C���[�̕��@�Ő��l�������߂�v���O�������쐬����B
# �Q�jdy/dx=f(x,y)=1-y,y(0)=0
# �@�@dy/dx=f(x,y)=y(1-y),y(0)=0.01
# �@�@dy/dx=f(x,y)=2yx,y(0)=1
# �̐��l�����I�C���[�@�ɂ���ċ��߂�B
#
740 �F�f�t�H���g�̖����������F2009/12/16(��) 15:58:34
>>370�@�ۑ�(2)
�g�p����F�@maxima
(%i262) f(n,d):=(a:string(n),charat(a,slength(a)-d+1));
(%i263) f(123456789,4);
(%o263) 6
�g�p����F�@maxima
(%i262) f(n,d):=(a:string(n),charat(a,slength(a)-d+1));
(%i263) f(123456789,4);
(%o263) 6
741 �F�f�t�H���g�̖����������F2009/12/16(��) 17:22:43
>>731
�g�p����F�@Xtal
ix:001>str1:"123";
ix:002>str2:"abc";
ix:003>str1=str1~" "~str2;
ix:004>str1.p;
123 abc
�g�p����F�@Xtal
ix:001>str1:"123";
ix:002>str2:"abc";
ix:003>str1=str1~" "~str2;
ix:004>str1.p;
123 abc
742 �F�f�t�H���g�̖����������F2009/12/16(��) 17:23:36
>>732
�g�p����F�@Xtal
ix:008>str_chnum:fun(s,c)s.split("").to_a.select(|v|v==c).to_a.size;
ix:009>str_chnum("123123111","2").p;
2
�g�p����F�@Xtal
ix:008>str_chnum:fun(s,c)s.split("").to_a.select(|v|v==c).to_a.size;
ix:009>str_chnum("123123111","2").p;
2
743 �F�f�t�H���g�̖����������F2009/12/16(��) 18:00:06
>>731
�g�p����F�@Io
Io> str1:="123"
==> 123
Io> str2:="abc"
==> abc
Io> str1=str1 .. " " .. str2
==> 123 abc
Io> str1 println
123 abc
==> 123 abc
�g�p����F�@Io
Io> str1:="123"
==> 123
Io> str2:="abc"
==> abc
Io> str1=str1 .. " " .. str2
==> 123 abc
Io> str1 println
123 abc
==> 123 abc
744 �F�f�t�H���g�̖����������F2009/12/16(��) 18:01:01
>>732
�g�p����F�@Io
Io> f:=method(s,c,s size-(s asMutable removeSeq(c))size)
Io> f("123111","1")
==> 4
�g�p����F�@Io
Io> f:=method(s,c,s size-(s asMutable removeSeq(c))size)
Io> f("123111","1")
==> 4
745 �F�f�t�H���g�̖����������F2009/12/16(��) 19:40:37
>>731
�g�p����F�@Arc
arc> (= str1 "123")
"123"
arc> (= str2 "abc")
"abc"
arc> (= str1 (+ str1 " " str2))
"123 abc"
arc> (prn str1)
123 abc
"123 abc"
�g�p����F�@Arc
arc> (= str1 "123")
"123"
arc> (= str2 "abc")
"abc"
arc> (= str1 (+ str1 " " str2))
"123 abc"
arc> (prn str1)
123 abc
"123 abc"
746 �F�f�t�H���g�̖����������F2009/12/16(��) 19:41:30
>>732
�g�p����F�@Arc
;�g�ݍ��݊��̏ꍇ
arc> (count #\1 "123123111")
5
arc> (def str_chnum(s c) (- (len s) (len(rem c s))))
#<procedure: str_chnum>
arc> (str_chnum "123123111" #\1)
5
�g�p����F�@Arc
;�g�ݍ��݊��̏ꍇ
arc> (count #\1 "123123111")
5
arc> (def str_chnum(s c) (- (len s) (len(rem c s))))
#<procedure: str_chnum>
arc> (str_chnum "123123111" #\1)
5
747 �F�f�t�H���g�̖����������F2009/12/16(��) 20:28:07
http://pc12.2ch.net/test/read.cgi/tech/1260532772/179
# [1] ���ƒP���F�A���S���Y���̊�b
# [2] ��蕶�F�E�n�b�V�����ɂ��f�[�^�i�[��z���p���Ď�������v���O�����̍쐬
# �E���̓f�[�^�͎��R��
# �E�z��̗v�f���ƃn�b�V�����͔C��
# �E�d�������̓I�[�v���A�h���X�@��p����
#
# [1] ���ƒP���F�A���S���Y���̊�b
# [2] ��蕶�F�E�n�b�V�����ɂ��f�[�^�i�[��z���p���Ď�������v���O�����̍쐬
# �E���̓f�[�^�͎��R��
# �E�z��̗v�f���ƃn�b�V�����͔C��
# �E�d�������̓I�[�v���A�h���X�@��p����
#
748 �F�f�t�H���g�̖����������F2009/12/16(��) 21:15:40
>>731
�g�p����F�@R
> str1<-"123"
> str2<-"abc"
> str1<-paste(str1," ",str2,sep="")
> cat(str1,"\n")
123 abc
�g�p����F�@R
> str1<-"123"
> str2<-"abc"
> str1<-paste(str1," ",str2,sep="")
> cat(str1,"\n")
123 abc
749 �F�f�t�H���g�̖����������F2009/12/16(��) 21:16:51
>>732
�g�p����F�@R
> str_chnum<-function(s,c)nchar(s)-nchar(gsub(c,"",s))
> str_chnum("123123111","1")
[1] 5
�g�p����F�@R
> str_chnum<-function(s,c)nchar(s)-nchar(gsub(c,"",s))
> str_chnum("123123111","1")
[1] 5
750 �F�f�t�H���g�̖����������F2009/12/16(��) 21:56:50
>>681
�g�p����F�@R
> for(i in 1:10)cat(paste(1:i,"^2",sep="",collapse=" + "),"=",sum((1:i)^2),"\n")
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
�g�p����F�@R
> for(i in 1:10)cat(paste(1:i,"^2",sep="",collapse=" + "),"=",sum((1:i)^2),"\n")
1^2 = 1
1^2 + 2^2 = 5
1^2 + 2^2 + 3^2 = 14
1^2 + 2^2 + 3^2 + 4^2 = 30
1^2 + 2^2 + 3^2 + 4^2 + 5^2 = 55
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 = 91
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 = 140
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 = 204
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 = 285
1^2 + 2^2 + 3^2 + 4^2 + 5^2 + 6^2 + 7^2 + 8^2 + 9^2 + 10^2 = 385
751 �F�f�t�H���g�̖����������F2009/12/17(��) 04:56:45
http://pc12.2ch.net/test/read.cgi/tech/1260532772/191
# [1] ���ƒP���F�[�~���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10275.txt
# 1�T�Ԃ̔���グ�̍��v���v�Z������
# �ȉ��͋^���v���O���~���O�����p�����v���O�����ł���
# n = read();
# sum = 0;
# for i=1 to n{
# x=read(); sum =sum +x;
# }
# report(sum);
#
# ���̃v���O������sales.dat�Ƃ����t�@�C����ǂݍ��܂�C����̌`�ɒ������������Ȃ���
#
# �ǂݍ��܂���t�@�C���̓��e
# sales.dat
# 7
# 89231
# <����>
# 64489
# [1] ���ƒP���F�[�~���K
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10275.txt
# 1�T�Ԃ̔���グ�̍��v���v�Z������
# �ȉ��͋^���v���O���~���O�����p�����v���O�����ł���
# n = read();
# sum = 0;
# for i=1 to n{
# x=read(); sum =sum +x;
# }
# report(sum);
#
# ���̃v���O������sales.dat�Ƃ����t�@�C����ǂݍ��܂�C����̌`�ɒ������������Ȃ���
#
# �ǂݍ��܂���t�@�C���̓��e
# sales.dat
# 7
# 89231
# <����>
# 64489
752 �F�f�t�H���g�̖����������F2009/12/17(��) 05:07:18
>>751
% Prolog �{���͋[���v���O��������͂��ďq��ɕϊ�����v���O�����Ƃ������ˁB
% ���́A
1�T�Ԃ̔���グ�̍��v���v�Z������ :-
�@�@get_lines('sales.dat',Lines),
�@�@findsum(N,(member(A,Lines),atom_to_term(A,N,_)),Sum),
�@�@write_formatted('%t\n',[Sum]).
% Prolog �{���͋[���v���O��������͂��ďq��ɕϊ�����v���O�����Ƃ������ˁB
% ���́A
1�T�Ԃ̔���グ�̍��v���v�Z������ :-
�@�@get_lines('sales.dat',Lines),
�@�@findsum(N,(member(A,Lines),atom_to_term(A,N,_)),Sum),
�@�@write_formatted('%t\n',[Sum]).
753 �F�f�t�H���g�̖����������F2009/12/17(��) 06:46:51
754 �F�f�t�H���g�̖����������F2009/12/17(��) 07:33:55
755 �F�f�t�H���g�̖����������F2009/12/17(��) 07:34:58
http://pc12.2ch.net/test/read.cgi/tech/1260532772/194
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10277.txt
#
# �K�C�ۑ�2
# ����1����1�̓���������iAn={1 2 3 4 5 �E�E�En}�j�B���lX��Y����͂��āA
# ���̐���ɂ�����X������Y���܂ł̐���̘a���Z�o����v���O�������쐬����B
# ���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ��X������F1
# ��x���܂ŁF10
# ����1����1�̓�������ɂ����āA
# ��1�������10���܂ł̐���̘a��55�ł��B
# ------------------------------------------------
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10277.txt
#
# �K�C�ۑ�2
# ����1����1�̓���������iAn={1 2 3 4 5 �E�E�En}�j�B���lX��Y����͂��āA
# ���̐���ɂ�����X������Y���܂ł̐���̘a���Z�o����v���O�������쐬����B
# ���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ��X������F1
# ��x���܂ŁF10
# ����1����1�̓�������ɂ����āA
# ��1�������10���܂ł̐���̘a��55�ł��B
# ------------------------------------------------
756 �F�f�t�H���g�̖����������F2009/12/17(��) 07:36:52
http://pc12.2ch.net/test/read.cgi/tech/1260532772/194
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10277.txt
#
# ���W�ۑ�1
# �P�זE�����������ɂ�2����2�זE�ɂȂ�Ƃ���B1�C�����ȂȂ��Ƃ���ƁA
# �זE����1���C����͉̂����ڂɂȂ邩���Z�o����v���O�������쐬����B
# ���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# 15���ڂ�16384�̍זE���ɂȂ�܂��B
# ------------------------------------------------
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10277.txt
#
# ���W�ۑ�1
# �P�זE�����������ɂ�2����2�זE�ɂȂ�Ƃ���B1�C�����ȂȂ��Ƃ���ƁA
# �זE����1���C����͉̂����ڂɂȂ邩���Z�o����v���O�������쐬����B
# ���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# 15���ڂ�16384�̍זE���ɂȂ�܂��B
# ------------------------------------------------
757 �F�f�t�H���g�̖����������F2009/12/17(��) 08:00:19
>>726
Prolog�u���Əh��͂Ȃs���Ƃ��Ȃ��ȁB���Ȃ��Ƃ��ۓ����͂��Ȃ�����w
�S���̑�w��100�ȏ�Prolog�u�������邻��������A�������݂��炢�͂��肻��
�����ǁB
Prolog�u���Əh��͂Ȃs���Ƃ��Ȃ��ȁB���Ȃ��Ƃ��ۓ����͂��Ȃ�����w
�S���̑�w��100�ȏ�Prolog�u�������邻��������A�������݂��炢�͂��肻��
�����ǁB
758 �F�f�t�H���g�̖����������F2009/12/17(��) 09:04:08
>>755
�g�p����F�@J
g=:dyad def '+/x}.i.>:y'
f=:dyad define
smoutput '����1����1�̓�������ɂ����āA'
smoutput '��',(":x),'�������',(":y),'���܂ł̐���̘a��',(":x g y),'�ł��B'
)
2 f 9
����1����1�̓�������ɂ����āA
��2�������9���܂ł̐���̘a��44�ł��B
�g�p����F�@J
g=:dyad def '+/x}.i.>:y'
f=:dyad define
smoutput '����1����1�̓�������ɂ����āA'
smoutput '��',(":x),'�������',(":y),'���܂ł̐���̘a��',(":x g y),'�ł��B'
)
2 f 9
����1����1�̓�������ɂ����āA
��2�������9���܂ł̐���̘a��44�ł��B
759 �F�f�t�H���g�̖����������F2009/12/17(��) 09:17:43
>>756
�g�p����F�@J
f=:monad define
a=.2+<.2^.y
smoutput (":a),'���ڂ�',(":2^<:a),'�̍זE���ɂȂ�܂��B'
)
f 10000
15���ڂ�16384�̍זE���ɂȂ�܂��B
f 100000
18���ڂ�131072�̍זE���ɂȂ�܂��B
�g�p����F�@J
f=:monad define
a=.2+<.2^.y
smoutput (":a),'���ڂ�',(":2^<:a),'�̍זE���ɂȂ�܂��B'
)
f 10000
15���ڂ�16384�̍זE���ɂȂ�܂��B
f 100000
18���ڂ�131072�̍זE���ɂȂ�܂��B
760 �F�f�t�H���g�̖����������F2009/12/17(��) 11:49:04
>>755
�g�p����F�@maxima
f(a,b):=printf(true,"����1����1�̓�������ɂ����āA
��~d�������~d���܂ł̐���̘a��~d�ł��B
",a,b,sum(i,i,a,b));
(%i324) f(3,20);
����1����1�̓�������ɂ����āA
��3�������20���܂ł̐���̘a��207�ł��B
�g�p����F�@maxima
f(a,b):=printf(true,"����1����1�̓�������ɂ����āA
��~d�������~d���܂ł̐���̘a��~d�ł��B
",a,b,sum(i,i,a,b));
(%i324) f(3,20);
����1����1�̓�������ɂ����āA
��3�������20���܂ł̐���̘a��207�ł��B
761 �F�f�t�H���g�̖����������F2009/12/17(��) 12:10:06
>>756
�g�p����F�@maxima
f(n):=(a:fix(log(n)/log(2.0))+2,
printf(true,"~d���ڂ�~d�̍זE���ɂȂ�܂��B~%",a,2^(a-1)));
(%i329) f(1000);
11���ڂ�1024�̍זE���ɂȂ�܂��B
(%i330) f(10000);
15���ڂ�16384�̍זE���ɂȂ�܂��B
�g�p����F�@maxima
f(n):=(a:fix(log(n)/log(2.0))+2,
printf(true,"~d���ڂ�~d�̍זE���ɂȂ�܂��B~%",a,2^(a-1)));
(%i329) f(1000);
11���ڂ�1024�̍זE���ɂȂ�܂��B
(%i330) f(10000);
15���ڂ�16384�̍זE���ɂȂ�܂��B
762 �F�f�t�H���g�̖����������F2009/12/17(��) 13:48:11
763 �F�f�t�H���g�̖����������F2009/12/17(��) 13:48:54
>>732
�g�p����F�@Yorick
> func str_chnum(s,c){a=strchar(s);return sum(a==c);}
> str_chnum("123123111",'1')
5
�g�p����F�@Yorick
> func str_chnum(s,c){a=strchar(s);return sum(a==c);}
> str_chnum("123123111",'1')
5
764 �F�f�t�H���g�̖����������F2009/12/17(��) 17:29:31
>>755
% Prolog
����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����(X,Y,Sum) :-
�@�@findsum(N,for(X,N,Y),Sum).
% Prolog
����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����(X,Y,Sum) :-
�@�@findsum(N,for(X,N,Y),Sum).
765 �F�f�t�H���g�̖����������F2009/12/17(��) 17:39:58
>>756
% Prolog
�זE�����������ɂ�2����2�זE�ɂȂ�(N����,N����,_�����̍זE��,_�����̍זE��).
�זE�����������ɂ�2����2�זE�ɂȂ�(N1,_������,�����̍זE��,_�זE��) :-
�@�@N2 is N + 1,
�@�@_�����̍זE�� is _�����̍זE�� * 2,
�@�@�זE�����������ɂ�2����2�זE�ɂȂ�(N2,_������,_�����̍זE��,_�זE��).
?- �זE�����������ɂ�2����2�זE�ɂȂ�(1,_������,1,_�זE��),_�זE�� > 10000.
% Prolog
�זE�����������ɂ�2����2�זE�ɂȂ�(N����,N����,_�����̍זE��,_�����̍זE��).
�זE�����������ɂ�2����2�זE�ɂȂ�(N1,_������,�����̍זE��,_�זE��) :-
�@�@N2 is N + 1,
�@�@_�����̍זE�� is _�����̍זE�� * 2,
�@�@�זE�����������ɂ�2����2�זE�ɂȂ�(N2,_������,_�����̍זE��,_�זE��).
?- �זE�����������ɂ�2����2�זE�ɂȂ�(1,_������,1,_�זE��),_�זE�� > 10000.
766 �F�f�t�H���g�̖����������F2009/12/17(��) 17:50:52
>>755
% Prolog
:- op(250,xf,��).
'����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����'(X ��,Y ��,_����̘a) :-
�@�@findsum(N,for(X,N,Y),_����̘a).
% ����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����(X ��,Y ��,Sum) :-
% �@�@findsum(N,for(X,N,Y),Sum).
% �Ƃ���Ɓ@"����1����"�̂Ƃ����"��"�����ƌ�������SyntaxError�ɂȂ邩���m��Ȃ��B
% �V���O���N�H�[�c�ň͂߂��̂悤�Ȃ��Ƃ͋N����Ȃ��B
% Prolog
:- op(250,xf,��).
'����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����'(X ��,Y ��,_����̘a) :-
�@�@findsum(N,for(X,N,Y),_����̘a).
% ����1����1�̓�������ɂ�����X������Y���܂ł̐���̘a���Z�o����(X ��,Y ��,Sum) :-
% �@�@findsum(N,for(X,N,Y),Sum).
% �Ƃ���Ɓ@"����1����"�̂Ƃ����"��"�����ƌ�������SyntaxError�ɂȂ邩���m��Ȃ��B
% �V���O���N�H�[�c�ň͂߂��̂悤�Ȃ��Ƃ͋N����Ȃ��B
767 �F�f�t�H���g�̖����������F2009/12/17(��) 19:27:52
http://pc12.2ch.net/test/read.cgi/tech/1260532772/198
# [1] ���ƒP���F���v
# [2] ��蕶
# ���K���z�\���b����ł����Ă݂悤�B
# �搶���ŏ��̂�����Ƃ������Ă��ꂽ�B
# #include<stdio.h>
# #include<math.h>
# #include<stdilb.h>
#
# float normal_gauss_fn(float z)
# {
# return(exp(z*z/(-2.0))/sqrt(2.0*3.14));
# }
# [1] ���ƒP���F���v
# [2] ��蕶
# ���K���z�\���b����ł����Ă݂悤�B
# �搶���ŏ��̂�����Ƃ������Ă��ꂽ�B
# #include<stdio.h>
# #include<math.h>
# #include<stdilb.h>
#
# float normal_gauss_fn(float z)
# {
# return(exp(z*z/(-2.0))/sqrt(2.0*3.14));
# }
768 �F�f�t�H���g�̖����������F2009/12/17(��) 19:29:52
http://pc12.2ch.net/test/read.cgi/tech/1260532772/201
# [1] ���ƒP���F�摜������C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���������64�o�C�g�̃f�[�^������܂��B�����4x16�̍s��ł��B
# char buf[16][4] = { a0, b0, c0, d0, ... , a15, b15, c15, d15 };
#
# �g������p����xmm���W�X�^��4�������ēǍ��݂܂����B���̃C���[�W�͂����ł��B
# __m128i t0 = { a0 , b0 , c0 , d0 , ... , a3 , b3 , c3 , d3 };
# __m128i t1 = { a4 , b4 , c4 , d4 , ... , a7 , b7 , c7 , d7 };
# __m128i t2 = { a8 , b8 , c8 , d8 , ... , a11, b11, c11, d11 };
# __m128i t3 = { a12, b12, c12, d12, ... , a15, b15, c15, d15 };
#
# ��������16x4�̓]�u�s��܂��傤�B���e�̃C���[�W�͂����ł��B
# __m128i r0 = { a0, ... , a15 };
# __m128i r1 = { b0, ... , b15 };
# __m128i r2 = { c0, ... , c15 };
# __m128i r3 = { d0, ... , d15 };
#
# �ւ���
# r0 = _mm_set_epi8(buf[15][0], buf[14][0], ... , buf[0][0]);
# ���������x���v���O�����̓_���ł��Bxmm���W�X�^�̑���ŃJ�^��t���܂��傤�B
# [1] ���ƒP���F�摜������C����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���������64�o�C�g�̃f�[�^������܂��B�����4x16�̍s��ł��B
# char buf[16][4] = { a0, b0, c0, d0, ... , a15, b15, c15, d15 };
#
# �g������p����xmm���W�X�^��4�������ēǍ��݂܂����B���̃C���[�W�͂����ł��B
# __m128i t0 = { a0 , b0 , c0 , d0 , ... , a3 , b3 , c3 , d3 };
# __m128i t1 = { a4 , b4 , c4 , d4 , ... , a7 , b7 , c7 , d7 };
# __m128i t2 = { a8 , b8 , c8 , d8 , ... , a11, b11, c11, d11 };
# __m128i t3 = { a12, b12, c12, d12, ... , a15, b15, c15, d15 };
#
# ��������16x4�̓]�u�s��܂��傤�B���e�̃C���[�W�͂����ł��B
# __m128i r0 = { a0, ... , a15 };
# __m128i r1 = { b0, ... , b15 };
# __m128i r2 = { c0, ... , c15 };
# __m128i r3 = { d0, ... , d15 };
#
# �ւ���
# r0 = _mm_set_epi8(buf[15][0], buf[14][0], ... , buf[0][0]);
# ���������x���v���O�����̓_���ł��Bxmm���W�X�^�̑���ŃJ�^��t���܂��傤�B
769 �F�f�t�H���g�̖����������F2009/12/17(��) 22:33:58
http://pc12.2ch.net/test/read.cgi/tech/1260532772/206
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# �K�C�ۑ�1
# 3+6+9�{�E�{99�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������1683�ł��B
# ------------------------------------------------
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# �K�C�ۑ�1
# 3+6+9�{�E�{99�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������1683�ł��B
# ------------------------------------------------
770 �F�f�t�H���g�̖����������F2009/12/17(��) 22:37:14
http://pc12.2ch.net/test/read.cgi/tech/1260532772/206
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# �K�C�ۑ�Q
# 10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�v���O�������쐬����B
# for���ƃC���N�������g���Z�q�A���邢�̓f�N�������g���Z�q��p���Ȃ����B���s���ʂ�
# ����ȉ��Ɏ����B
# ------------------------------------------------
# 10000�ȉ��̐�����͂��ĉ������F1000
# 10000����10��Ђ����Ƃ��ł��܂��B
# ------------------------------------------------
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# �K�C�ۑ�Q
# 10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�v���O�������쐬����B
# for���ƃC���N�������g���Z�q�A���邢�̓f�N�������g���Z�q��p���Ȃ����B���s���ʂ�
# ����ȉ��Ɏ����B
# ------------------------------------------------
# 10000�ȉ��̐�����͂��ĉ������F1000
# 10000����10��Ђ����Ƃ��ł��܂��B
# ------------------------------------------------
771 �F�f�t�H���g�̖����������F2009/12/17(��) 22:39:51
http://pc12.2ch.net/test/read.cgi/tech/1260532772/206
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# ���W�ۑ�1
# 2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������-50�ł��B
# ------------------------------------------------
# �q���g�F��Ƃɕ�����ς��邱�Ƃ��l���Ă݂܂��傤�ia = -a�j
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# ���W�ۑ�1
# 2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������-50�ł��B
# ------------------------------------------------
# �q���g�F��Ƃɕ�����ς��邱�Ƃ��l���Ă݂܂��傤�ia = -a�j
772 �F�f�t�H���g�̖����������F2009/12/17(��) 22:43:17
http://pc12.2ch.net/test/read.cgi/tech/1260532772/206
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# ���W�ۑ�2
# �C�ӂ̐���X����͂���ƁA����X�̊K����Z�o�����v���O�������쐬����B
# �������A0����ѕ��̐�������͂���ƁA�u�l���s�K���ł��B�v�ƃ��b�Z�[�W���o��悤�ɂ���B
# �K���n!=1�~2�~�R�E�E�E�~���ŕ\�����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ��������͂��ĉ������F5
# 5�̊K���120�ł��B
# ------------------------------------------------
# �q���g�Fif���̒���for����while������ꍞ�ނ��Ƃ��ł��܂��B
# [1] ���ƒP���F �v���O���~���O�P
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10285.txt
#
# ���W�ۑ�2
# �C�ӂ̐���X����͂���ƁA����X�̊K����Z�o�����v���O�������쐬����B
# �������A0����ѕ��̐�������͂���ƁA�u�l���s�K���ł��B�v�ƃ��b�Z�[�W���o��悤�ɂ���B
# �K���n!=1�~2�~�R�E�E�E�~���ŕ\�����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ��������͂��ĉ������F5
# 5�̊K���120�ł��B
# ------------------------------------------------
# �q���g�Fif���̒���for����while������ꍞ�ނ��Ƃ��ł��܂��B
773 �F�f�t�H���g�̖����������F2009/12/17(��) 22:55:39
>>769
% Prolog
'3+6+9�{�E�{99�̌v�Z'(_���v) :-
�@�@'3+6+9�{�E�{99�̌v�Z'(3,_���v).
'3+6+9�{�E�{99�̌v�Z'(99,99) :- !.
'3+6+9�{�E�{99�̌v�Z'(N,Sum) :-
�@�@N3 is N + 3,
�@�@'3+6+9�{�E�{99�̌v�Z'(N3,Sum3),
�@�@Sum is Sum3 + N.
% Prolog
'3+6+9�{�E�{99�̌v�Z'(_���v) :-
�@�@'3+6+9�{�E�{99�̌v�Z'(3,_���v).
'3+6+9�{�E�{99�̌v�Z'(99,99) :- !.
'3+6+9�{�E�{99�̌v�Z'(N,Sum) :-
�@�@N3 is N + 3,
�@�@'3+6+9�{�E�{99�̌v�Z'(N3,Sum3),
�@�@Sum is Sum3 + N.
774 �F�f�t�H���g�̖����������F2009/12/17(��) 22:56:51
775 �F�f�t�H���g�̖����������F2009/12/17(��) 23:12:27
>>770
% Prolog
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�' :-
�@�@write('�C�ӂ̐�����͂��Ă������� :'),get_integer(N),
�@�@'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(10000,N,_��),
�@�@write_formatted('�������Ƃ̂ł����%t��ł��B\n',[_��]).
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M,N,0) :- M < N,!.
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M,N,_��) :-
�@�@M1 is M - N,
�@�@'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M1,N,_��1),
�@�@_�� is _��1 + 1.
% Prolog
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�' :-
�@�@write('�C�ӂ̐�����͂��Ă������� :'),get_integer(N),
�@�@'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(10000,N,_��),
�@�@write_formatted('�������Ƃ̂ł����%t��ł��B\n',[_��]).
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M,N,0) :- M < N,!.
'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M,N,_��) :-
�@�@M1 is M - N,
�@�@'10000�ȉ��̔C�ӂ̐�����͂��āA10000���炻�̐����������Ƃ̂ł���ׂ�'(M1,N,_��1),
�@�@_�� is _��1 + 1.
776 �F�f�t�H���g�̖����������F2009/12/17(��) 23:36:19
>>771
% Prolog
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_���v) :-
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z+'(1,2,_���v).
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_,100,-100) :-
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M,N,_���v) :-
�@�@M2 is M * -1,
�@�@N2 is N + 2,
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M2,N2,_���v2),
�@�@_���v is _���v2 + N * M.
�@
% Prolog
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_���v) :-
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z+'(1,2,_���v).
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_,100,-100) :-
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M,N,_���v) :-
�@�@M2 is M * -1,
�@�@N2 is N + 2,
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M2,N2,_���v2),
�@�@_���v is _���v2 + N * M.
�@
777 �F�f�t�H���g�̖����������F2009/12/17(��) 23:37:55
>>771 �����ꃖ��
% Prolog
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_���v) :-
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(1,2,_���v).
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_,100,-100) :-
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M,N,_���v) :-
�@�@M2 is M * -1,
�@�@N2 is N + 2,
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M2,N2,_���v2),
�@�@_���v is _���v2 + N * M.
% Prolog
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_���v) :-
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(1,2,_���v).
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(_,100,-100) :-
'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M,N,_���v) :-
�@�@M2 is M * -1,
�@�@N2 is N + 2,
�@�@'2�|4�{6�|8�E�E�E�E�E�|100�̌v�Z'(M2,N2,_���v2),
�@�@_���v is _���v2 + N * M.
778 �F�f�t�H���g�̖����������F2009/12/17(��) 23:43:24
779 �F�f�t�H���g�̖����������F2009/12/17(��) 23:46:51
http://pc12.2ch.net/test/read.cgi/tech/1260532772/209
# [1] ���ƒP���FC�v���O���~���O����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ܖڕ��ׂ̍쐬
# ��ɏI��������A�R���s���[�^�[�ɂ�钅��̐������̍쐬
# �T���v���v���O�����Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin
/joyful/img/10289.txt
#
# [1] ���ƒP���FC�v���O���~���O����
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ܖڕ��ׂ̍쐬
# ��ɏI��������A�R���s���[�^�[�ɂ�钅��̐������̍쐬
# �T���v���v���O�����Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin
/joyful/img/10289.txt
#
780 �F�f�t�H���g�̖����������F2009/12/17(��) 23:49:57
http://pc12.2ch.net/test/read.cgi/tech/1260532772/210
# �y����e���v���z
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10290.txt
#
# ���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g���������̂ł��B
#
# �i���O�j �i�_���j
# ����X�l�v 50
# ���̂ё� 0
# �o�ؐ��p�� 100
# ���c������ 20
# ���� 80
#
# �̂悤�ȃf�[�^��\�ߎ����Ă���Ƃ��āA���O�Ń\�[�g���������͂������������ɁA
# �_���Ń\�[�g����������0���珇�ɕ��ёւ��A��ʂɏo�͂��������̂ł����A
# ���������������������Ń\�[�g��������@�������炸�A
# ���O�Ɠ_�����ɓ��������@���v�������A��o�����ԋ߂ɂȂ��Ă��܂��܂����B
# �ǂ������肢���܂��B
#
# //�����Ń\�[�g�͖��������犿�����Ƃ͕ʂɕ\���������ɂЂ炪�ȂŖ��O�̃f�[�^�����Ă����̂ł��傤���H
# �y����e���v���z
# [1] ���ƒP���FC����
# [2] ��蕶(�܃R�[�h&�����N)�Fhttp://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10290.txt
#
# ���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g���������̂ł��B
#
# �i���O�j �i�_���j
# ����X�l�v 50
# ���̂ё� 0
# �o�ؐ��p�� 100
# ���c������ 20
# ���� 80
#
# �̂悤�ȃf�[�^��\�ߎ����Ă���Ƃ��āA���O�Ń\�[�g���������͂������������ɁA
# �_���Ń\�[�g����������0���珇�ɕ��ёւ��A��ʂɏo�͂��������̂ł����A
# ���������������������Ń\�[�g��������@�������炸�A
# ���O�Ɠ_�����ɓ��������@���v�������A��o�����ԋ߂ɂȂ��Ă��܂��܂����B
# �ǂ������肢���܂��B
#
# //�����Ń\�[�g�͖��������犿�����Ƃ͕ʂɕ\���������ɂЂ炪�ȂŖ��O�̃f�[�^�����Ă����̂ł��傤���H
781 �F�f�t�H���g�̖����������F2009/12/18(��) 00:17:53
782 �F�f�t�H���g�̖����������F2009/12/18(��) 02:17:22
783 �F�f�t�H���g�̖����������F2009/12/18(��) 02:26:34
784 �F�f�t�H���g�̖����������F2009/12/18(��) 05:08:57
http://pc12.2ch.net/test/read.cgi/tech/1260532772/216
# [1] ���ƒP���F �I�y���[�e�B���O�V�X�e��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�P�D �����Ƀt�@�C�������w�肷��ƁC���̃t�@�C���̃T�C�Y�ƃt�@�C���̎�ށi��ʃt�@�C���C�f
# �@�@�@�B���N�g���C�p�C�v���j�C�����čŏI�ύX������\������R�}���h�ifview �Ƃ������̂Ƃ���j����
# �@�@�@������D�������C�����ɂ́C�����̃t�@�C�����w��ł���悤�ɂ��邱�ƁD�܂��Cfstat �V�X�e��
# �@�@�@�R�[����p���邱�ƁD
#
# �@�@�@���s
# �@�@�@$ fview aaa.txt bbb.txt ccc.txt �c
# �@�@�@�q���g
# �@�@�@�t�@�C���̎�ނ́Cfstat �\���̃����o��st_mode �̏��4 �r�b�g�ŕ\�킳���D
# [1] ���ƒP���F �I�y���[�e�B���O�V�X�e��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�P�D �����Ƀt�@�C�������w�肷��ƁC���̃t�@�C���̃T�C�Y�ƃt�@�C���̎�ށi��ʃt�@�C���C�f
# �@�@�@�B���N�g���C�p�C�v���j�C�����čŏI�ύX������\������R�}���h�ifview �Ƃ������̂Ƃ���j����
# �@�@�@������D�������C�����ɂ́C�����̃t�@�C�����w��ł���悤�ɂ��邱�ƁD�܂��Cfstat �V�X�e��
# �@�@�@�R�[����p���邱�ƁD
#
# �@�@�@���s
# �@�@�@$ fview aaa.txt bbb.txt ccc.txt �c
# �@�@�@�q���g
# �@�@�@�t�@�C���̎�ނ́Cfstat �\���̃����o��st_mode �̏��4 �r�b�g�ŕ\�킳���D
785 �F�f�t�H���g�̖����������F2009/12/18(��) 05:10:42
http://pc12.2ch.net/test/read.cgi/tech/1260532772/216
# [1] ���ƒP���F �I�y���[�e�B���O�V�X�e��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�Q�D �����Ɏw�肵�������̃e�L�X�g�t�@�C���̓��e���������āC��̃t�@�C���ɂ܂Ƃ߂�R�}
# �@�@�@���h�icatfiles �Ƃ������̂Ƃ���j���쐬����D�������C�܂Ƃ߂����e���i�[����t�@�C�����́C
# �@�@�@�gconcat.txt�h�Ƃ��邱�ƁD�������Ccat �R�}���h��system ���̓����ŌĂԂ悤�ȍ\���͔F��
# �@�@�@�Ȃ��D�V�X�e���R�[���Ƃ��ẮCopen�Cclose�Cread�Cwrite ��p���邱�ƁD�܂��C�������Ă܂Ƃ�
# �@�@�@�����ʂ��i�[����t�@�C�������݂��Ȃ��ꍇ�ɂ́Ccreat �V�X�e���R�[����p���Đ������邱
# �@�@�@�ƁD
#
# �@�@�@���s
# �@�@�@$ catfiles aaa.txt bbb.txt ccc.txt �c
# [1] ���ƒP���F �I�y���[�e�B���O�V�X�e��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �@�Q�D �����Ɏw�肵�������̃e�L�X�g�t�@�C���̓��e���������āC��̃t�@�C���ɂ܂Ƃ߂�R�}
# �@�@�@���h�icatfiles �Ƃ������̂Ƃ���j���쐬����D�������C�܂Ƃ߂����e���i�[����t�@�C�����́C
# �@�@�@�gconcat.txt�h�Ƃ��邱�ƁD�������Ccat �R�}���h��system ���̓����ŌĂԂ悤�ȍ\���͔F��
# �@�@�@�Ȃ��D�V�X�e���R�[���Ƃ��ẮCopen�Cclose�Cread�Cwrite ��p���邱�ƁD�܂��C�������Ă܂Ƃ�
# �@�@�@�����ʂ��i�[����t�@�C�������݂��Ȃ��ꍇ�ɂ́Ccreat �V�X�e���R�[����p���Đ������邱
# �@�@�@�ƁD
#
# �@�@�@���s
# �@�@�@$ catfiles aaa.txt bbb.txt ccc.txt �c
786 �F�f�t�H���g�̖����������F2009/12/18(��) 06:05:59
>>780
% Prolog
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_����) :-
�@�@_���� = ���O,
�@�@findall([_�Ђ炪�Ȗ�,_���O,_�_��],(�f�[�^(_���O,_�_��),�����Ђ炪�ȕϊ�(_��
�O,_�Ђ炪�Ȗ�)),L),
�@�@sort(L,L1),
�@�@member([_,_���O2,_�_��2],L1),
�@�@write_formatted('%t %t\n',[_���O2,_�_��2]),
�@�@fail.
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_����) :-
�@�@_���� = �_��,
�@�@findall([_�_��,_���O],�f�[�^(_���O,_�_��),L),
�@�@sort(L,L1),
�@�@member([_�_��2,_���O2],L1),
�@�@write_formatted('%t %t\n',[_���O2,_�_��2]),
�@�@fail.
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_).
% Prolog
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_����) :-
�@�@_���� = ���O,
�@�@findall([_�Ђ炪�Ȗ�,_���O,_�_��],(�f�[�^(_���O,_�_��),�����Ђ炪�ȕϊ�(_��
�O,_�Ђ炪�Ȗ�)),L),
�@�@sort(L,L1),
�@�@member([_,_���O2,_�_��2],L1),
�@�@write_formatted('%t %t\n',[_���O2,_�_��2]),
�@�@fail.
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_����) :-
�@�@_���� = �_��,
�@�@findall([_�_��,_���O],�f�[�^(_���O,_�_��),L),
�@�@sort(L,L1),
�@�@member([_�_��2,_���O2],L1),
�@�@write_formatted('%t %t\n',[_���O2,_�_��2]),
�@�@fail.
���O�Ɠ_���̃f�[�^�������Ă��郊�X�g�\�����\�[�g����(_).
787 �F�f�t�H���g�̖����������F2009/12/18(��) 06:40:52
>>784
% Prolog
program :-
�@�@user_parameters(_�p�X���Ȃ��),
�@�@write('�p�X��,�T�C�Y,���,�ŏI�ύX����\n'),
�@�@�t�@�C������\������(_�p�X���Ȃ��),
�@�@halt.
�t�@�C������\������([]) :- !.
�t�@�C������\������([_�p�X��|R]) :-
�@�@�t�@�C������(_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����),
�@�@write_formatted('%t,%t,%t,%t,%t\n',[_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����]),
�@�@�t�@�C������\������(R).
�t�@�C������(_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����) :-
�@�@get_file_info(_�p�X��,[dev(Dev),ino(Ino),mode(Modes),nlink(Nlink),uid(Uid),uname(Uname),gid(Gid),gname(Gname),size(_�T�C�Y),atime(Atime),mtime(Mtime),ctime(_�ŏI�ύX����),blksize(Blksize),blocks(Blocks)]),
�@�@member(FI,Modes),
�@�@sub_atom(FI,0,2,_,if),
�@�@�t�@�C�����(FI,_���).
�t�@�C�����(ifblk,�u���b�N�t�@�C��).
�t�@�C�����(ifchr,�L�����N�^�t�@�C��).
�t�@�C�����(ififo,�p�C�v).
�t�@�C�����(ifreg,��ʃt�@�C��).
�t�@�C�����(ifdir,�f�B���N�g��).
�t�@�C�����(iflnk,�V���{���b�N�����N).
% Prolog
program :-
�@�@user_parameters(_�p�X���Ȃ��),
�@�@write('�p�X��,�T�C�Y,���,�ŏI�ύX����\n'),
�@�@�t�@�C������\������(_�p�X���Ȃ��),
�@�@halt.
�t�@�C������\������([]) :- !.
�t�@�C������\������([_�p�X��|R]) :-
�@�@�t�@�C������(_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����),
�@�@write_formatted('%t,%t,%t,%t,%t\n',[_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����]),
�@�@�t�@�C������\������(R).
�t�@�C������(_�p�X��,_�T�C�Y,_���,_�ŏI�ύX����) :-
�@�@get_file_info(_�p�X��,[dev(Dev),ino(Ino),mode(Modes),nlink(Nlink),uid(Uid),uname(Uname),gid(Gid),gname(Gname),size(_�T�C�Y),atime(Atime),mtime(Mtime),ctime(_�ŏI�ύX����),blksize(Blksize),blocks(Blocks)]),
�@�@member(FI,Modes),
�@�@sub_atom(FI,0,2,_,if),
�@�@�t�@�C�����(FI,_���).
�t�@�C�����(ifblk,�u���b�N�t�@�C��).
�t�@�C�����(ifchr,�L�����N�^�t�@�C��).
�t�@�C�����(ififo,�p�C�v).
�t�@�C�����(ifreg,��ʃt�@�C��).
�t�@�C�����(ifdir,�f�B���N�g��).
�t�@�C�����(iflnk,�V���{���b�N�����N).
788 �F�f�t�H���g�̖����������F2009/12/18(��) 06:54:46
>>785
% Prolog
program :-
�@�@user_parameters(_�p�X���Ȃ��),
�@�@open('concat.txt',write,Output1),
�@�@close(Output1),
�@�@open('concat.txt',append,Output),
�@�@�t�@�C��������������(Output,_�p�X���Ȃ��),
�@�@close(Output),
�@�@halt.
�t�@�C��������������(Output,[]) :- !.
�t�@�C��������������(Output,[_�p�X��|R]) :-
�@�@open(_�p�X��,read,Input),
�@�@get_char(C),
�@�@�ꕶ���Â���������(Input,Output,C),
�@�@close(Input),
�@�@�t�@�C��������������(Output,R).
�ꕶ���Â���������(_,_,end_of_file) :- !.
�ꕶ���Â���������(Input,Output,C) :-
�@�@put_char(Output,C),
�@�@get_char(Input,C2),
�@�@�ꕶ���Â���������(Input,Output,C2).
% Prolog
program :-
�@�@user_parameters(_�p�X���Ȃ��),
�@�@open('concat.txt',write,Output1),
�@�@close(Output1),
�@�@open('concat.txt',append,Output),
�@�@�t�@�C��������������(Output,_�p�X���Ȃ��),
�@�@close(Output),
�@�@halt.
�t�@�C��������������(Output,[]) :- !.
�t�@�C��������������(Output,[_�p�X��|R]) :-
�@�@open(_�p�X��,read,Input),
�@�@get_char(C),
�@�@�ꕶ���Â���������(Input,Output,C),
�@�@close(Input),
�@�@�t�@�C��������������(Output,R).
�ꕶ���Â���������(_,_,end_of_file) :- !.
�ꕶ���Â���������(Input,Output,C) :-
�@�@put_char(Output,C),
�@�@get_char(Input,C2),
�@�@�ꕶ���Â���������(Input,Output,C2).
789 �F�f�t�H���g�̖����������F2009/12/18(��) 06:58:38
790 �F�f�t�H���g�̖����������F2009/12/18(��) 07:00:54
791 �F�f�t�H���g�̖����������F2009/12/18(��) 07:13:13
792 �F�f�t�H���g�̖����������F2009/12/18(��) 07:13:56
793 �F�f�t�H���g�̖����������F2009/12/18(��) 07:39:17
794 �F�f�t�H���g�̖����������F2009/12/18(��) 07:40:04
795 �F�f�t�H���g�̖����������F2009/12/18(��) 10:50:57
796 �F�f�t�H���g�̖����������F2009/12/18(��) 11:25:59
http://pc12.2ch.net/test/read.cgi/tech/1260532772/226
# ��L���Q�l�ɁAmalloc����p���āA�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���A�C�ӂ̐l���̏������\�ȁA�v���O�������Amalloc.c�Ƃ������O�ō쐬����B
# malloc.c��Visual Studio�Ŏ��s���āi5���ȏ���́j�A���s���ʂ�malloc.c���̕����Ɂu�R�����g�s�v�Ƃ��ċL�ڂ���B�i�R�����g�s��lj�����A�r���h�\���Ċm�F�j
#
# ��L���Q�l�ɁAmalloc����p���āA�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���A�C�ӂ̐l���̏������\�ȁA�v���O�������Amalloc.c�Ƃ������O�ō쐬����B
# malloc.c��Visual Studio�Ŏ��s���āi5���ȏ���́j�A���s���ʂ�malloc.c���̕����Ɂu�R�����g�s�v�Ƃ��ċL�ڂ���B�i�R�����g�s��lj�����A�r���h�\���Ċm�F�j
#
797 �F�f�t�H���g�̖����������F2009/12/18(��) 11:28:33
>>796
% Prolog
% Prolog�ɂ�malloc()�͂������ɂȂ��Bassertz/2�ő�p����B
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂��� :-
�@�@get_line(Line),
�@�@�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line),
�@�@�w��(_����,_�w�Дԍ�,_�g��),
�@�@write_formatted('%t,%t,%t\n',[_����,_�w�Дԍ�,_�g��]),
�@�@fail.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(end_of_file) :- !.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line) :-
�@�@split(Line,[' '],[_����,_�w�Дԍ�,_�g��]),
�@�@assertz(�w��(_����,_�w�Дԍ�,_�g��)),
�@�@get_line(Line2),
�@�@�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line2).
% Prolog
% Prolog�ɂ�malloc()�͂������ɂȂ��Bassertz/2�ő�p����B
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂��� :-
�@�@get_line(Line),
�@�@�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line),
�@�@�w��(_����,_�w�Дԍ�,_�g��),
�@�@write_formatted('%t,%t,%t\n',[_����,_�w�Дԍ�,_�g��]),
�@�@fail.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(end_of_file) :- !.
�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line) :-
�@�@split(Line,[' '],[_����,_�w�Дԍ�,_�g��]),
�@�@assertz(�w��(_����,_�w�Дԍ�,_�g��)),
�@�@get_line(Line2),
�@�@�����A�w�Дԍ��A�g���̓��͂��s���A����ɁA���[�U����̓��͏I���w��������A�S�Ă̓��̓f�[�^����ʂɏo�͂���(Line2).
798 �F�f�t�H���g�̖����������F2009/12/18(��) 12:37:03
>>725
�ނ���prolog�̃R�[�h���߂邽�߂ɗ��Ă�ȉ���w
�ނ���prolog�̃R�[�h���߂邽�߂ɗ��Ă�ȉ���w
799 �F�f�t�H���g�̖����������F2009/12/18(��) 12:46:17
���̎������C�����̌��t�ŏؖ�����
�}������@�́C���ς̏ꍇ��N2/4��̔�r�Ɩ�N2/4��̔�����(�ړ�)���s���D�ň��̏ꍇ�́C���ꂼ�ꂻ��2�{�ɂȂ�
�}������@�́C���ς̏ꍇ��N2/4��̔�r�Ɩ�N2/4��̔�����(�ړ�)���s���D�ň��̏ꍇ�́C���ꂼ�ꂻ��2�{�ɂȂ�
800 �F�f�t�H���g�̖����������F2009/12/18(��) 13:01:31
>>786
% �����Ђ炪�ȕϊ�/2��Prolog�̏����n�Ƀ��C�u�����Ƃ��đ��݂���A�Ƃ����킯�ɂ͂����Ȃ��B
% ���͈ȉ��̂悤�ȃC���`�L�����Ďg���Ă���B
�����Ђ炪�ȕϊ�(_�����܂ݕ�����,_�Ђ炪�ȕ�����) :-
�@�@concat_atom(['echo "',_�����܂ݕ�����,'" | kakasi -JH'],S),
�@�@shs(S,_���[�}���܂ݕ�����Ȃ��),
�@�@_���[�}���܂ݕ�����Ȃ�� = [_�Ђ炪�ȕ�����|_] .
shs(S,L) :-
�@�@system(S,user_input,Input),
�@�@get_lines(Input,L),
�@�@close(Input).
% �����Ђ炪�ȕϊ�/2��Prolog�̏����n�Ƀ��C�u�����Ƃ��đ��݂���A�Ƃ����킯�ɂ͂����Ȃ��B
% ���͈ȉ��̂悤�ȃC���`�L�����Ďg���Ă���B
�����Ђ炪�ȕϊ�(_�����܂ݕ�����,_�Ђ炪�ȕ�����) :-
�@�@concat_atom(['echo "',_�����܂ݕ�����,'" | kakasi -JH'],S),
�@�@shs(S,_���[�}���܂ݕ�����Ȃ��),
�@�@_���[�}���܂ݕ�����Ȃ�� = [_�Ђ炪�ȕ�����|_] .
shs(S,L) :-
�@�@system(S,user_input,Input),
�@�@get_lines(Input,L),
�@�@close(Input).
801 �F�f�t�H���g�̖����������F2009/12/18(��) 13:28:21
802 �F�f�t�H���g�̖����������F2009/12/18(��) 13:29:46
803 �F�f�t�H���g�̖����������F2009/12/18(��) 14:30:25
804 �F�f�t�H���g�̖����������F2009/12/18(��) 14:31:16
>>771
�g�p����F�@Io
Io> s:=0;for(i,2,100,2,s=s+i*(-1)**(i/2+1))
==> -50
Io> s:=0;for(i,100,2,-2,s=i-s)
==> -50
Io> 2 toBy(100,2)asList reverseReduce(s,v,s-v)
==> -50
�g�p����F�@Io
Io> s:=0;for(i,2,100,2,s=s+i*(-1)**(i/2+1))
==> -50
Io> s:=0;for(i,100,2,-2,s=i-s)
==> -50
Io> 2 toBy(100,2)asList reverseReduce(s,v,s-v)
==> -50
805 �F�f�t�H���g�̖����������F2009/12/18(��) 14:35:45
>>771
% Prolog �����������X�g�\�L�͎v�������ۂ��Č����ȁB
:- op(200,xfx,(..)).
sum([A,B..C],X) :-
�@�@F is B - A,
�@�@D is (C // F) - 1,
�@�@findsum(U,(for(0,N,D),U is A + (N * F)),X).
% Prolog �����������X�g�\�L�͎v�������ۂ��Č����ȁB
:- op(200,xfx,(..)).
sum([A,B..C],X) :-
�@�@F is B - A,
�@�@D is (C // F) - 1,
�@�@findsum(U,(for(0,N,D),U is A + (N * F)),X).
% ���߂��N�ԈႦ���B
>>801
% Prolog �����������X�g�\�L�͎v�������ۂ��Č����ȁB
:- op(200,xfx,(..)).
sum([A,B..C],X) :-
�@�@F is B - A,
�@�@D is (C // F) - 1,
�@�@findsum(U,(for(0,N,D),U is A + (N * F)),X).
>>801
% Prolog �����������X�g�\�L�͎v�������ۂ��Č����ȁB
:- op(200,xfx,(..)).
sum([A,B..C],X) :-
�@�@F is B - A,
�@�@D is (C // F) - 1,
�@�@findsum(U,(for(0,N,D),U is A + (N * F)),X).
807 �F�f�t�H���g�̖����������F2009/12/18(��) 14:43:58
http://pc12.2ch.net/test/read.cgi/tech/1260532772/233
# [1] ���ƒP���Fif����for��
# [2] ��蕶(�܃R�[�h&�����N)�F�L�[�{�[�h����U�̐��l����͂��A
# �ő�l��\������v���O�������쐬
# ? �L�[�{�[�h������͂��鐔�l��F25 , 6 , 45, 18 , 57, 5
# [5] ���̑��̐����F
# ? for����p���ăL�[�{�[�h����l��ǂݍ��݂Ȃ���C
# ����܂łɓǂݍ��l�̍ő�lmax�Ɣ�r���C
# �����傫�����max�̒l���X�V����
# for(i=�H;i<=�H;�H){
# scanf(�H�H�H�H�H);
# if( �H > max) ???????;
# }
# [1] ���ƒP���Fif����for��
# [2] ��蕶(�܃R�[�h&�����N)�F�L�[�{�[�h����U�̐��l����͂��A
# �ő�l��\������v���O�������쐬
# ? �L�[�{�[�h������͂��鐔�l��F25 , 6 , 45, 18 , 57, 5
# [5] ���̑��̐����F
# ? for����p���ăL�[�{�[�h����l��ǂݍ��݂Ȃ���C
# ����܂łɓǂݍ��l�̍ő�lmax�Ɣ�r���C
# �����傫�����max�̒l���X�V����
# for(i=�H;i<=�H;�H){
# scanf(�H�H�H�H�H);
# if( �H > max) ???????;
# }
808 �F�f�t�H���g�̖����������F2009/12/18(��) 15:12:31
>>807
% Prolog �萫�̃I�y��rawmode�ł��܂��������͋^��B�����̂Ƃ���̃e�[�}�ł���append�^�ŏ����Ă݂�B
�ő�l��\������(Max) :-
�@�@rawmode,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N),
�@�@����܂ł̍ő�l��\������(N,N,Max).
�ő�l��\������(_) :- norawmode.
����܂ł̍ő�l��\������(N,Max,Max).�@/* �\������Ȃ炱�� */
����܂ł̍ő�l��\������(N,Max1,Max).
�@�@N >= Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@����܂ł̍ő�l��\������(N2,N,Max).
����܂ł̍ő�l��\������(N,Max1,Max).
�@�@N < Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@����܂ł̍ő�l��\������(N2,Max1,Max).
�����Ƃ��Ċm�肷��(32,0).
�����Ƃ��Ċm�肷��(10,0) :- !,fail.
�����Ƃ��Ċm�肷��(Code,N) :- \+(Code=10),\+(Code=32),
�@�@N1 is N - 48,
�@�@get_code(Code2),
�@�@�����Ƃ��Ċm�肷��(Code2,N2),
�@�@N is N2 * 10 + N1.
% Prolog �萫�̃I�y��rawmode�ł��܂��������͋^��B�����̂Ƃ���̃e�[�}�ł���append�^�ŏ����Ă݂�B
�ő�l��\������(Max) :-
�@�@rawmode,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N),
�@�@����܂ł̍ő�l��\������(N,N,Max).
�ő�l��\������(_) :- norawmode.
����܂ł̍ő�l��\������(N,Max,Max).�@/* �\������Ȃ炱�� */
����܂ł̍ő�l��\������(N,Max1,Max).
�@�@N >= Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@����܂ł̍ő�l��\������(N2,N,Max).
����܂ł̍ő�l��\������(N,Max1,Max).
�@�@N < Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@����܂ł̍ő�l��\������(N2,Max1,Max).
�����Ƃ��Ċm�肷��(32,0).
�����Ƃ��Ċm�肷��(10,0) :- !,fail.
�����Ƃ��Ċm�肷��(Code,N) :- \+(Code=10),\+(Code=32),
�@�@N1 is N - 48,
�@�@get_code(Code2),
�@�@�����Ƃ��Ċm�肷��(Code2,N2),
�@�@N is N2 * 10 + N1.
809 �F�f�t�H���g�̖����������F2009/12/18(��) 16:01:13
>>806
���̃��X�g�����̎w���������l�A�I���l�A�����l�Ȃ̂�
�������Ă��ꂾ�������l�A�����l�{�����l�A�I���l�Ȃ̂�
��ɂ��w���Ƃ��������ŁA������Ɩʔ����Ǝv���܂����B
���̃��X�g�����̎w���������l�A�I���l�A�����l�Ȃ̂�
�������Ă��ꂾ�������l�A�����l�{�����l�A�I���l�Ȃ̂�
��ɂ��w���Ƃ��������ŁA������Ɩʔ����Ǝv���܂����B
810 �F�f�t�H���g�̖����������F2009/12/18(��) 16:16:55
>>809
�v�����Ɗ�����̂��������Ǝv���̂ł����A�m���ɖʔ����ł��ˁB
�́X�AQBE�Ƃ����W���ꑰ�̗��^�̌��ꂠ���āA����͕\�v�Z�̂悤��
��`�̘g�ɂ�����������͂���Ƃ�����Ԃ���悤�Ƀf�[�^���\��
�����Ƃ������̂ł����B�v���O���~���O����̕��@�ɂ��z�ɂ��̂悤��
����Ԃɂ���@�Ƃ����̂������Ƃ����Ă����������m��Ȃ��B
�v�����Ɗ�����̂��������Ǝv���̂ł����A�m���ɖʔ����ł��ˁB
�́X�AQBE�Ƃ����W���ꑰ�̗��^�̌��ꂠ���āA����͕\�v�Z�̂悤��
��`�̘g�ɂ�����������͂���Ƃ�����Ԃ���悤�Ƀf�[�^���\��
�����Ƃ������̂ł����B�v���O���~���O����̕��@�ɂ��z�ɂ��̂悤��
����Ԃɂ���@�Ƃ����̂������Ƃ����Ă����������m��Ȃ��B
811 �F�f�t�H���g�̖����������F2009/12/18(��) 16:47:06
���Q�ҁF���c�ԍ]
���m���ݏZ�@26�@��
�a�����F1983�N8��29��
�ɓ�s�{����
���̓��F9��1��
���̎ԗ��F���F�̃G�b�Z
���̏Fhttp://www.pref.aichi.jp/police/koutsu/map/image/syousai/H21_36okazaki-12.gif
��Q�ҁF���с�������
���̎ԗ��ƌ���̎ʐ^
http://www.city.okazaki.aichi.jp/secure/2848/12.pdf
��ʐ^
http://up3.viploader.net/ippan/src/vlippan046402.jpg
���̏Fhttp://www.pref.aichi.jp/police/koutsu/map/image/syousai/H21_36okazaki-12.gif
���m���ݏZ�@26�@��
�a�����F1983�N8��29��
�ɓ�s�{����
���̓��F9��1��
���̎ԗ��F���F�̃G�b�Z
���̏Fhttp://www.pref.aichi.jp/police/koutsu/map/image/syousai/H21_36okazaki-12.gif
{kind=link}
��Q�ҁF���с�������
���̎ԗ��ƌ���̎ʐ^
http://www.city.okazaki.aichi.jp/secure/2848/12.pdf
��ʐ^
http://up3.viploader.net/ippan/src/vlippan046402.jpg
{kind=link}
���̏Fhttp://www.pref.aichi.jp/police/koutsu/map/image/syousai/H21_36okazaki-12.gif
812 �F�f�t�H���g�̖����������F2009/12/18(��) 19:42:41
>>808
�̎g�����ł����A
?- �ő�l��\������(Max).23
Max = 23;345
Max = 345;11
Max = 345;369
Max = 369;77
�Ƃ����悤�ɐi�ނ̂ł����A�u�L�[�{�[�h����U�̐��l���v��
�������q���`�ɑg�ݍ��܂�Ă��܂���ł����B�����g�ݍ���
���̂����ɏ����܂��B���e�ȏq��ɂ̓J�E���^��t�����Ȃ��ĂȂ�
�܂���B
�̎g�����ł����A
?- �ő�l��\������(Max).23
Max = 23;345
Max = 345;11
Max = 345;369
Max = 369;77
�Ƃ����悤�ɐi�ނ̂ł����A�u�L�[�{�[�h����U�̐��l���v��
�������q���`�ɑg�ݍ��܂�Ă��܂���ł����B�����g�ݍ���
���̂����ɏ����܂��B���e�ȏq��ɂ̓J�E���^��t�����Ȃ��ĂȂ�
�܂���B
813 �F�f�t�H���g�̖����������F2009/12/18(��) 19:54:56
>>807
% Prolog ���͐����͍ő�6�܂łɂȂ�܂����B��ϔ����Ȉʒu��
% �J�E���g6�����荞�݂܂����B�������Ɩ��ʂ�7�ڂ̓ǂݍ��݂�����邱�Ƃ��ł��܂��B
�ő�l��\������(Max) :-
�@�@rawmode,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N),
�@�@����܂ł̍ő�l��\������(1,N,N,Max).
�ő�l��\������(_) :- norawmode.
����܂ł̍ő�l��\������(_,N,Max,Max).�@/* �\������Ȃ炱�� */
����܂ł̍ő�l��\������(6,N,_,_) :- !,fail.
����܂ł̍ő�l��\������(M,N,Max1,Max).
�@�@N >= Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@M2 is M + 1,
�@�@����܂ł̍ő�l��\������(M2,N2,N,Max).
����܂ł̍ő�l��\������(M,N,Max1,Max).
�@�@N < Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@M2 is M + 1,
�@�@����܂ł̍ő�l��\������(M2,N2,Max1,Max).
% Prolog ���͐����͍ő�6�܂łɂȂ�܂����B��ϔ����Ȉʒu��
% �J�E���g6�����荞�݂܂����B�������Ɩ��ʂ�7�ڂ̓ǂݍ��݂�����邱�Ƃ��ł��܂��B
�ő�l��\������(Max) :-
�@�@rawmode,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N),
�@�@����܂ł̍ő�l��\������(1,N,N,Max).
�ő�l��\������(_) :- norawmode.
����܂ł̍ő�l��\������(_,N,Max,Max).�@/* �\������Ȃ炱�� */
����܂ł̍ő�l��\������(6,N,_,_) :- !,fail.
����܂ł̍ő�l��\������(M,N,Max1,Max).
�@�@N >= Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@M2 is M + 1,
�@�@����܂ł̍ő�l��\������(M2,N2,N,Max).
����܂ł̍ő�l��\������(M,N,Max1,Max).
�@�@N < Max1,
�@�@get_code(Code),
�@�@�����Ƃ��Ċm�肷��(Code,N2),
�@�@M2 is M + 1,
�@�@����܂ł̍ő�l��\������(M2,N2,Max1,Max).
814 �F�f�t�H���g�̖����������F2009/12/18(��) 23:21:53
815 �F�f�t�H���g�̖����������F2009/12/18(��) 23:22:43
816 �F�f�t�H���g�̖����������F2009/12/19(�y) 03:22:06
http://pc12.2ch.net/test/read.cgi/tech/1260532772/250
# [1] ���ƒP���FC���ꏉ���@�ϒ�����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���L�̂悤�Ȋ������B
# �@scanf��fgets��sscanf��g�ݍ��킹����
#
# �@int mscanf(int num , const char*str , const char*format, ...)
# �@num�F�ő啶�����@str:scanf�ł����Ƃ���̑����� format:scanf�ł����Ƃ���̑������ȍ~
# �@�߂�l��scanf�Ɠ����ɂ���B
# [1] ���ƒP���FC���ꏉ���@�ϒ�����
# [2] ��蕶(�܃R�[�h&�����N)�F
# ���L�̂悤�Ȋ������B
# �@scanf��fgets��sscanf��g�ݍ��킹����
#
# �@int mscanf(int num , const char*str , const char*format, ...)
# �@num�F�ő啶�����@str:scanf�ł����Ƃ���̑����� format:scanf�ł����Ƃ���̑������ȍ~
# �@�߂�l��scanf�Ɠ����ɂ���B
817 �F�f�t�H���g�̖����������F2009/12/19(�y) 04:04:42
# [1] ���ƒP���FProlog����
# [2] ��蕶(�܃R�[�h&�����N)�F �ȉ��̂悤�ȕs���S�Ȍ`���̏�^������
# ���Ƃ��������Ă���B���̏����t�@�C������ǂݎ��A���p���₷���q���
# ���Ď����I�ɒ�`�������B�t�@�C�����ƒ�`����q�ꖼ�������Ƃ��āA����
# ��͂��āA���𗘗p���Ղ�����q��������I�ɒ�`����q����`���Ȃ����B
#
# ���Q�ҁF�Ԗ��菬��
# ��ʌ��ݏZ�@21�@��
# �a�����F1988�N2��29��
# ����s���ؒ�
# ���̓��F7��31��
# ���̎ԗ��F���F�̃}�c�_�N�[�y
# ���̏Fhttp://www.pref.saitama.jp/police/
# ��Q�ҁF �������Y
# [2] ��蕶(�܃R�[�h&�����N)�F �ȉ��̂悤�ȕs���S�Ȍ`���̏�^������
# ���Ƃ��������Ă���B���̏����t�@�C������ǂݎ��A���p���₷���q���
# ���Ď����I�ɒ�`�������B�t�@�C�����ƒ�`����q�ꖼ�������Ƃ��āA����
# ��͂��āA���𗘗p���Ղ�����q��������I�ɒ�`����q����`���Ȃ����B
#
# ���Q�ҁF�Ԗ��菬��
# ��ʌ��ݏZ�@21�@��
# �a�����F1988�N2��29��
# ����s���ؒ�
# ���̓��F7��31��
# ���̎ԗ��F���F�̃}�c�_�N�[�y
# ���̏Fhttp://www.pref.saitama.jp/police/
# ��Q�ҁF �������Y
818 �F�f�t�H���g�̖����������F2009/12/19(�y) 05:37:38
http://pc12.2ch.net/test/read.cgi/tech/1260972593/39
# �t�H�[���̃e�L�X�g�{�b�N�X�ɓ��͂��ꂽ������(�p�����̂�)���擾���A1��������16�i���ɕϊ����A���̑��a���v�Z�������̂ł����ǂ����@�͂���܂����H
#
# �y��z
# �e�L�X�g�{�b�N�X��"12"�Ɠ��͂��ꂽ�Ƃ��A0x31 + 0x32���v�Z����0x63�Ƃ���B
#
# �܂��A3����16�i���ƂȂ������͉�2���̂ݎ擾���܂��B
# �擾����2����16�i���͊e���ɊY������p�������������͕�����Ŏ擾(���a��0x63�Ȃ��"6"��"3"�����ꂼ��擾)���܂��B
#
# �������GetBytes�ŕϊ���o�C�g�^�z��Ɋi�[���A
# BitConvert�ŘM��ȂǍl���܂�������肭�����܂���B
# �t�H�[���̃e�L�X�g�{�b�N�X�ɓ��͂��ꂽ������(�p�����̂�)���擾���A1��������16�i���ɕϊ����A���̑��a���v�Z�������̂ł����ǂ����@�͂���܂����H
#
# �y��z
# �e�L�X�g�{�b�N�X��"12"�Ɠ��͂��ꂽ�Ƃ��A0x31 + 0x32���v�Z����0x63�Ƃ���B
#
# �܂��A3����16�i���ƂȂ������͉�2���̂ݎ擾���܂��B
# �擾����2����16�i���͊e���ɊY������p�������������͕�����Ŏ擾(���a��0x63�Ȃ��"6"��"3"�����ꂼ��擾)���܂��B
#
# �������GetBytes�ŕϊ���o�C�g�^�z��Ɋi�[���A
# BitConvert�ŘM��ȂǍl���܂�������肭�����܂���B
819 �F�f�t�H���g�̖����������F2009/12/19(�y) 06:12:02
>>818
% Prolog
'16�i�A���t�@�x�b�g'(['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']).
'0..15'([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]).
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@mod is (M1+M2) mod 16,
�@�@char_code(C,Div),
�@�@char_code(D,Mod),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),!.
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
:- '16�i���Z���W�X�^�̐���'.
% Prolog
'16�i�A���t�@�x�b�g'(['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']).
'0..15'([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]).
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@mod is (M1+M2) mod 16,
�@�@char_code(C,Div),
�@�@char_code(D,Mod),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),!.
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
:- '16�i���Z���W�X�^�̐���'.
820 �F�f�t�H���g�̖����������F2009/12/19(�y) 06:18:08
>>819 �ԈႦ���B�������܂��Bmod->Mod�Ƃ��̌�̐��l->16�i�\�L�ϊ��̂Ƃ���ł��B
% Prolog
'16�i�A���t�@�x�b�g'(['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']).
'0..15'([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]).
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@Mod is (M1+M2) mod 16,
�@�@list_nth(N3,'0..15',Div),list_nth(N3,_16�i�A���t�@�x�b�g,C),
�@�@list_nth(N4,'0..15',Mod),list_nth(N4,_16�i�A���t�@�x�b�g,D),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),!.
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
:- '16�i���Z���W�X�^�̐���'.
% Prolog
'16�i�A���t�@�x�b�g'(['0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']).
'0..15'([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]).
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@Mod is (M1+M2) mod 16,
�@�@list_nth(N3,'0..15',Div),list_nth(N3,_16�i�A���t�@�x�b�g,C),
�@�@list_nth(N4,'0..15',Mod),list_nth(N4,_16�i�A���t�@�x�b�g,D),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),!.
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
:- '16�i���Z���W�X�^�̐���'.
821 �F�f�t�H���g�̖����������F2009/12/19(�y) 06:36:47
>>818
% Prolog ���ۂ̉��Z�����ł�
'16�i�����Ӗ���������m�̉��Z'(_������1,_������2,_�J��オ��,_16�i���Z���ꂽ������) :-
�@�@sub_atom(_������1,0,1,_,_������1_1),
�@�@sub_atom(_������2,0,1,_,_������2_1),
�@�@'16�i���Z���W�X�^'(_������1_1,_������2_1,_,_������3_1),
�@�@sub_atom(_������1,1,1,_,_������1_2),
�@�@sub_atom(_������2,1,1,_,_������2_2),
�@�@'16�i���Z���W�X�^'(_������1_2,_������2_2,_�J��オ��1,_������3_2),
�@�@'16�i���Z���W�X�^'(_�J��オ��1,_������3_1,_�J��オ��,_������4_1),
�@�@concat_atom([_������4_1,_������3_2],_16�i���Z���ꂽ������).
% Prolog ���ۂ̉��Z�����ł�
'16�i�����Ӗ���������m�̉��Z'(_������1,_������2,_�J��オ��,_16�i���Z���ꂽ������) :-
�@�@sub_atom(_������1,0,1,_,_������1_1),
�@�@sub_atom(_������2,0,1,_,_������2_1),
�@�@'16�i���Z���W�X�^'(_������1_1,_������2_1,_,_������3_1),
�@�@sub_atom(_������1,1,1,_,_������1_2),
�@�@sub_atom(_������2,1,1,_,_������2_2),
�@�@'16�i���Z���W�X�^'(_������1_2,_������2_2,_�J��オ��1,_������3_2),
�@�@'16�i���Z���W�X�^'(_�J��オ��1,_������3_1,_�J��オ��,_������4_1),
�@�@concat_atom([_������4_1,_������3_2],_16�i���Z���ꂽ������).
822 �F�f�t�H���g�̖����������F2009/12/19(�y) 06:39:53
823 �F�f�t�H���g�̖����������F2009/12/19(�y) 07:06:20
>>817
% Prolog �ςȏ������݂ɔ������Ă݂��̂́A���ꂪ�ł��T�^�I��Prolog�v���O���~���O�̃X�^�C��������B
':�̑O�̏������Ƃ��ďq����\������'(_�t�@�C����,_�q�ꖼ) :-
�@�@get_chars(_�t�@�C����,Chars),
�@�@concat_atom(Chars,S),
sPLIT(S,['\n',' ',':'],L1),
�@�@append(LX,['\n',_��,':'|LY],L1),
�@�@���ɑΉ�����������o��(LY,_���),
�@�@P =.. [_�q�ꖼ,_��,_���],
�@�@assertz(P),
�@�@fail.
':�̑O�̏������Ƃ��ďq����\������'(_,_).
���ɑΉ�����������o��([_,':'|_],_) :- !,fail.
���ɑΉ�����������o��([A|R],X) :-
member(A,[' ','\n']),
�@�@���ɑΉ�����������o��(R,X),!.
���ɑΉ�����������o��([A|R],A).
���ɑΉ�����������o��([_|R],A) :- ���ɑΉ�����������o��(R,A).
% Prolog �ςȏ������݂ɔ������Ă݂��̂́A���ꂪ�ł��T�^�I��Prolog�v���O���~���O�̃X�^�C��������B
':�̑O�̏������Ƃ��ďq����\������'(_�t�@�C����,_�q�ꖼ) :-
�@�@get_chars(_�t�@�C����,Chars),
�@�@concat_atom(Chars,S),
sPLIT(S,['\n',' ',':'],L1),
�@�@append(LX,['\n',_��,':'|LY],L1),
�@�@���ɑΉ�����������o��(LY,_���),
�@�@P =.. [_�q�ꖼ,_��,_���],
�@�@assertz(P),
�@�@fail.
':�̑O�̏������Ƃ��ďq����\������'(_,_).
���ɑΉ�����������o��([_,':'|_],_) :- !,fail.
���ɑΉ�����������o��([A|R],X) :-
member(A,[' ','\n']),
�@�@���ɑΉ�����������o��(R,X),!.
���ɑΉ�����������o��([A|R],A).
���ɑΉ�����������o��([_|R],A) :- ���ɑΉ�����������o��(R,A).
824 �F�f�t�H���g�̖����������F2009/12/19(�y) 07:36:28
825 �F�f�t�H���g�̖����������F2009/12/19(�y) 09:47:28
>>819->>821
�ɗ́A���[���������Ȃ��H
�f�[�^�x�[�X�ŏ������Ă�悤�Ɍ�����A�Ƃ����̂�Prolog�̃X�^�C���Ȃ�ł����H
�\�߁A�f�[�^�x�[�X�����邱�Ƃ��v���O���~���O�Ȃ̂��ƁH
�ɗ́A���[���������Ȃ��H
�f�[�^�x�[�X�ŏ������Ă�悤�Ɍ�����A�Ƃ����̂�Prolog�̃X�^�C���Ȃ�ł����H
�\�߁A�f�[�^�x�[�X�����邱�Ƃ��v���O���~���O�Ȃ̂��ƁH
826 �F�f�t�H���g�̖����������F2009/12/19(�y) 10:13:05
>>825
���[�[��B
�O���I�Ȓ�`���D�ށB�t���b�g�Ȓ�`���D�ށB���[���b�p�X�^�C����
�����̂ł��傤���B�����܂߂Ă��������v���O������ǂ��Ƃ���l��
�����ł��ˁB�D�܂�闝�R�́A
1) �萫�̏q��ɂ��Ղ��B
2) �o��������ۂ��₷���B
3) ��`����A�[�I�ɐV������`�������₷���B
����ȑO�ɁA�f�[�^�������ׂēI�Ȑ��E�ς̐l�������̂ł��傤���B
���[�[��B
�O���I�Ȓ�`���D�ށB�t���b�g�Ȓ�`���D�ށB���[���b�p�X�^�C����
�����̂ł��傤���B�����܂߂Ă��������v���O������ǂ��Ƃ���l��
�����ł��ˁB�D�܂�闝�R�́A
1) �萫�̏q��ɂ��Ղ��B
2) �o��������ۂ��₷���B
3) ��`����A�[�I�ɐV������`�������₷���B
����ȑO�ɁA�f�[�^�������ׂēI�Ȑ��E�ς̐l�������̂ł��傤���B
827 �F�f�t�H���g�̖����������F2009/12/19(�y) 12:15:29
>>818
�g�p����F�@Lua
function f(x)
s=0
for i=1,#x do s=s+x:byte(i) end
b=("%X"):format(s)
print(b:sub(#b-1))
end
> f("12")
63
> f("A123")
D7
�g�p����F�@Lua
function f(x)
s=0
for i=1,#x do s=s+x:byte(i) end
b=("%X"):format(s)
print(b:sub(#b-1))
end
> f("12")
63
> f("A123")
D7
828 �F�f�t�H���g�̖����������F2009/12/19(�y) 12:34:54
>>818
�g�p����F�@maxima
(%i439) f(s):=printf(true,"~X~%",mod(lsum(i,i,map(cint,charlist(s))),255));
(%i440) f("12");
63
(%i441) f("A123");
D7
�g�p����F�@maxima
(%i439) f(s):=printf(true,"~X~%",mod(lsum(i,i,map(cint,charlist(s))),255));
(%i440) f("12");
63
(%i441) f("A123");
D7
829 �F�f�t�H���g�̖����������F2009/12/19(�y) 12:50:38
>>818
�g�p����F�@Arc
arc> (def f(s) (coerce (mod (sum int (coerce s 'cons)) 255) 'string 16))
arc> (f "12")
"63"
arc> (f "A123")
"d7"
�g�p����F�@Arc
arc> (def f(s) (coerce (mod (sum int (coerce s 'cons)) 255) 'string 16))
arc> (f "12")
"63"
arc> (f "A123")
"d7"
830 �F�f�t�H���g�̖����������F2009/12/19(�y) 13:01:21
>>818
�g�p����F�@Io
Io> f:=method(a,s:=0;a foreach(v,s=s+v);(s%255)asString toBase(16))
Io> f("12")
==> 63
Io> f("A123")
==> d7
�g�p����F�@Io
Io> f:=method(a,s:=0;a foreach(v,s=s+v);(s%255)asString toBase(16))
Io> f("12")
==> 63
Io> f("A123")
==> d7
831 �F�f�t�H���g�̖����������F2009/12/19(�y) 14:00:23
>>818
�g�p����F�@Yorick
> func f(s){return swrite(format="%x",sum(strchar(s))%255);}
> f("12")
"63"
> f("A123")
"d7"
�g�p����F�@Yorick
> func f(s){return swrite(format="%x",sum(strchar(s))%255);}
> f("12")
"63"
> f("A123")
"d7"
832 �F�f�t�H���g�̖����������F2009/12/19(�y) 15:01:20
http://pc12.2ch.net/test/read.cgi/tech/1248012902/621
# http://ime.nu/www.dotup.org/uploda/www.dotup.org473124.zip
#
# 0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)��
# �݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������v���O�������쐬����B
# http://ime.nu/www.dotup.org/uploda/www.dotup.org473124.zip
#
# 0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)��
# �݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������v���O�������쐬����B
833 �F�f�t�H���g�̖����������F2009/12/19(�y) 16:44:33
>>832
% Prolog
'0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)�Ƃ݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������'(_�p�x) :-
�@�@findmax([W,U],(for(1,N,10),U is random mod 361,write_formatted('%t,',[U]),W is sin(U/180)),[Max,U2]),
�@�@write_formatted('\nsin(x)�ɍő�l��^�����̂�%t\n',[U2]).
% Prolog
'0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)�Ƃ݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������'(_�p�x) :-
�@�@findmax([W,U],(for(1,N,10),U is random mod 361,write_formatted('%t,',[U]),W is sin(U/180)),[Max,U2]),
�@�@write_formatted('\nsin(x)�ɍő�l��^�����̂�%t\n',[U2]).
834 �F�f�t�H���g�̖����������F2009/12/19(�y) 16:47:38
>>833 (>>832)
% Prolog �g�b�v���x���̈��������̂�Y��Ă����B
'0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)�Ƃ݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������' :-
�@�@findmax([W,U],(for(1,N,10),U is random mod 361,write_formatted('%t,',[U]),W is sin(U/180)),[Max,U2]),
�@�@write_formatted('\nsin(x)�ɍő�l��^�����̂�%t\n',[U2]).
% Prolog �g�b�v���x���̈��������̂�Y��Ă����B
'0����360�܂ł̐����������_����10���������A���̐������p�x(�ʓx�@)�Ƃ݂Ȃ����Ƃ��A����(sin)���ő�ƂȂ鐮����\������' :-
�@�@findmax([W,U],(for(1,N,10),U is random mod 361,write_formatted('%t,',[U]),W is sin(U/180)),[Max,U2]),
�@�@write_formatted('\nsin(x)�ɍő�l��^�����̂�%t\n',[U2]).
835 �F�f�t�H���g�̖����������F2009/12/19(�y) 17:15:58
>>832
�g�p����F�@J
]a=:?10#360
200 276 240 219 157 69 188 84 44 243
a/:|90-a
84 69 44 157 188 200 219 240 243 276
0{a/:|90-a
84
�g�p����F�@J
]a=:?10#360
200 276 240 219 157 69 188 84 44 243
a/:|90-a
84 69 44 157 188 200 219 240 243 276
0{a/:|90-a
84
836 �F�f�t�H���g�̖����������F2009/12/19(�y) 17:23:02
>>819
% Prolog ���������Ƃ�����r����fail�ɂȂ����B10-11�s�ځB'0..15' ���ԈႢ�B_0����15 �ł���
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@Mod is (M1+M2) mod 16,
�@�@list_nth(N3,_0����15,Div),list_nth(N3,_16�i�A���t�@�x�b�g,C),
�@�@list_nth(N4,_0����15,Mod),list_nth(N4,_16�i�A���t�@�x�b�g,D),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
% Prolog ���������Ƃ�����r����fail�ɂȂ����B10-11�s�ځB'0..15' ���ԈႢ�B_0����15 �ł���
'16�i���Z���W�X�^�̐���' :-
�@�@'16�i�A���t�@�x�b�g'(_16�i�A���t�@�x�b�g),
�@�@'0..15'(_0����15),
�@�@�d���g�ݍ��킹(_16�i�A���t�@�x�b�g,2,[A,B]),
�@�@list_nth(N1,_16�i�A���t�@�x�b�g,A),
�@�@list_nth(N1,_0����15,M1),
�@�@list_nth(N2,_16�i�A���t�@�x�b�g,B),
�@�@list_nth(N2,_0����15,M2),
�@�@Div is (M1+M2) // 16,
�@�@Mod is (M1+M2) mod 16,
�@�@list_nth(N3,_0����15,Div),list_nth(N3,_16�i�A���t�@�x�b�g,C),
�@�@list_nth(N4,_0����15,Mod),list_nth(N4,_16�i�A���t�@�x�b�g,D),
�@�@'16�i���Z���W�X�^��assertz'(A,B,C,D),
�@�@fail.
'16�i���Z���W�X�^�̐���'.
837 �F�f�t�H���g�̖����������F2009/12/19(�y) 17:31:20
>>819
% Prolog ����Ɉꃖ���G���[�����B
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
assertz('16�i���Z���W�X�^'(A,A,C,D)),!. /* A,B,C,D -> A,A,C,D */
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
assertz('16�i���Z���W�X�^'(A,B,C,D)),
assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
% Prolog ����Ɉꃖ���G���[�����B
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
assertz('16�i���Z���W�X�^'(A,A,C,D)),!. /* A,B,C,D -> A,A,C,D */
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
assertz('16�i���Z���W�X�^'(A,B,C,D)),
assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
838 �F�f�t�H���g�̖����������F2009/12/19(�y) 17:32:42
>>819�@���݂܂���B���������B
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,A,C,D)),!. /* A,B,C,D -> A,A,C,D */
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
'16�i���Z���W�X�^��assertz'(A,A,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,A,C,D)),!. /* A,B,C,D -> A,A,C,D */
'16�i���Z���W�X�^��assertz'(A,B,C,D) :-
�@�@assertz('16�i���Z���W�X�^'(A,B,C,D)),
�@�@assertz('16�i���Z���W�X�^'(B,A,C,D)),!.
839 �F�f�t�H���g�̖����������F2009/12/19(�y) 18:28:33
>>695
�g�p����F�@J
H=:i.@(,&2)`(({&0 2 1,0 2,{&1 0 2)@$:@<:)@.*
hanoi=:dyad def '(|:H y){x'
'ABC' hanoi 3
AACABBA
CBBCACC
'ABC' hanoi 5
AACABBAACCBCAACABBABCCBBAACABBA
CBBCACCBBAABCBBCACCABAACCBBCACC
�g�p����F�@J
H=:i.@(,&2)`(({&0 2 1,0 2,{&1 0 2)@$:@<:)@.*
hanoi=:dyad def '(|:H y){x'
'ABC' hanoi 3
AACABBA
CBBCACC
'ABC' hanoi 5
AACABBAACCBCAACABBABCCBBAACABBA
CBBCACCBBAABCBBCACCABAACCBBCACC
840 �F�f�t�H���g�̖����������F2009/12/20(��) 05:56:17
http://pc12.2ch.net/test/read.cgi/tech/1260532772/280
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# 0�`10�܂ł̐��̂����A�C�ӂ̐�����3��܂œ��͂��Đ����̐��Ă�A�����ăQ�[
�����쐬����B���Ă鐔��0�`10�܂ł̂������ł��\��Ȃ��B���s���ʂ̗���ȉ��Ɏ���
�B
# �����������ꍇ��
# 0�`10�܂ł̐�����͂��ĉ������B
# 5
# �����Ə��������ł��B
# ����2�킷�邱�Ƃ��ł��܂��B
# 1
# �����Ƒ傫�����ł��B
# ����1�킷�邱�Ƃ��ł��܂��B
# 3
# �吳���ł��B
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# 0�`10�܂ł̐��̂����A�C�ӂ̐�����3��܂œ��͂��Đ����̐��Ă�A�����ăQ�[
�����쐬����B���Ă鐔��0�`10�܂ł̂������ł��\��Ȃ��B���s���ʂ̗���ȉ��Ɏ���
�B
# �����������ꍇ��
# 0�`10�܂ł̐�����͂��ĉ������B
# 5
# �����Ə��������ł��B
# ����2�킷�邱�Ƃ��ł��܂��B
# 1
# �����Ƒ傫�����ł��B
# ����1�킷�邱�Ƃ��ł��܂��B
# 3
# �吳���ł��B
841 �F�f�t�H���g�̖����������F2009/12/20(��) 05:57:53
>>840 �̂Â��ł��B
# ��������Ȃ��ꍇ��
# 0�`10�܂ł̐�����͂��ĉ������B
# 5
# �����Ə��������ł��B
# ����2�킷�邱�Ƃ��ł��܂��B
# 1
# �����Ƒ傫�����ł��B
# ����1�킷�邱�Ƃ��ł��܂��B
# 4
# �����Ə��������ł��B
# ����0�킷�邱�Ƃ��ł��܂��B
# �c�O�I�I�s�����ł����B
# ��������Ȃ��ꍇ��
# 0�`10�܂ł̐�����͂��ĉ������B
# 5
# �����Ə��������ł��B
# ����2�킷�邱�Ƃ��ł��܂��B
# 1
# �����Ƒ傫�����ł��B
# ����1�킷�邱�Ƃ��ł��܂��B
# 4
# �����Ə��������ł��B
# ����0�킷�邱�Ƃ��ł��܂��B
# �c�O�I�I�s�����ł����B
842 �F�f�t�H���g�̖����������F2009/12/20(��) 06:01:15
http://pc12.2ch.net/test/read.cgi/tech/1260532772/280
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# �K�C�ۑ�3
# 0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������255.0�ł��B
# ------------------------------------------------
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# �K�C�ۑ�3
# 0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s���v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ������255.0�ł��B
# ------------------------------------------------
843 �F�f�t�H���g�̖����������F2009/12/20(��) 06:03:55
http://pc12.2ch.net/test/read.cgi/tech/1260532772/280
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# �K�C�ۑ�2
# �C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂����ꍇ�A�u���Z�ł��܂���v�ƕ\�������v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ���_�ł����H�F85
# �D�ł��B
# ------------------------------------------------
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
#
# �K�C�ۑ�2
# �C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂����ꍇ�A�u���Z�ł��܂���v�ƕ\�������v���O�������쐬����B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ���_�ł����H�F85
# �D�ł��B
# ------------------------------------------------
844 �F�f�t�H���g�̖����������F2009/12/20(��) 06:10:13
http://pc12.2ch.net/test/read.cgi/tech/1260532772/280
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
# �K�C�ۑ�1
# �C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����v���O�������쐬����B�~������3.141592654�Ƃ���B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ���a�́H�F5
# ���a5cm�̉~�̉~����15.707963cm�ł��B
# ------------------------------------------------
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10294.txt
# �K�C�ۑ�1
# �C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����v���O�������쐬����B�~������3.141592654�Ƃ���B���s���ʂ̗���ȉ��Ɏ����B
# ------------------------------------------------
# ���a�́H�F5
# ���a5cm�̉~�̉~����15.707963cm�ł��B
# ------------------------------------------------
845 �F�f�t�H���g�̖����������F2009/12/20(��) 06:55:03
>>844
% Prolog
:- op(700,xfx,��).
'�~������3.141592654�Ƃ���' :-
�@�@asserta((����`(��,_�l) :- _�l = 3.141592654)).
'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����' :-
�@�@write('���a�́H�F'),
�@�@get_line(Line),
�@�@atom_to_term(Line,_���a,_),
�@�@'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����'(_���a,_�~��),
�@�@write_formatted('���a%tcm�̉~�̉~����%tcm�ł��B \n',[_���a,_�~��]).
'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����'(_���a,_�~��) :-
�@�@_�~�� �� _���a * ��.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����`(_��,_�l) :- _�l is _��.
_�l �� _�� :- ����`(_��,_�l).
:- '�~������3.141592654�Ƃ���'.
% Prolog
:- op(700,xfx,��).
'�~������3.141592654�Ƃ���' :-
�@�@asserta((����`(��,_�l) :- _�l = 3.141592654)).
'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����' :-
�@�@write('���a�́H�F'),
�@�@get_line(Line),
�@�@atom_to_term(Line,_���a,_),
�@�@'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����'(_���a,_�~��),
�@�@write_formatted('���a%tcm�̉~�̉~����%tcm�ł��B \n',[_���a,_�~��]).
'�C�ӂ̒��a(cm)����͂������ɁA���̉~�����Z�o����'(_���a,_�~��) :-
�@�@_�~�� �� _���a * ��.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
����`(_��,_�l) :- _�l is _��.
_�l �� _�� :- ����`(_��,_�l).
:- '�~������3.141592654�Ƃ���'.
846 �F�f�t�H���g�̖����������F2009/12/20(��) 09:25:02
>>843
�g�p����F�@J
f=:(60 10 10 21#'�s��';'��';'��';'�D');@{~]
f 0 59 60 69 70 79 80 100
�s��
�s��
��
��
��
��
�D
�D
�g�p����F�@J
f=:(60 10 10 21#'�s��';'��';'��';'�D');@{~]
f 0 59 60 69 70 79 80 100
�s��
�s��
��
��
��
��
�D
�D
847 �F�f�t�H���g�̖����������F2009/12/20(��) 11:45:12
>>845 �����B
% Prolog ��/2�̒�`�ɕs��������܂����B
_�l �� _�� :-
�@�@functor(_��,_��,2),
�@�@arg(1,_��,_����1),
�@�@arg(2,_��,_����2),
�@�@_�l1 �� _����1,
�@�@_�l2 �� _����2,
�@�@_��2 =..[_��,_�l1,_�l2],
�@�@_�l �� _��2.
_�l �� _�� :-
�@�@functor(_��,_��,1),
�@�@arg(1,_��,_����1),
�@�@_�l1 �� _����1,
�@�@_��1 =..[_��,_����1],
�@�@_�l �� _��1.
_�l �� _�� :- ����`(_��,_�l).
% Prolog ��/2�̒�`�ɕs��������܂����B
_�l �� _�� :-
�@�@functor(_��,_��,2),
�@�@arg(1,_��,_����1),
�@�@arg(2,_��,_����2),
�@�@_�l1 �� _����1,
�@�@_�l2 �� _����2,
�@�@_��2 =..[_��,_�l1,_�l2],
�@�@_�l �� _��2.
_�l �� _�� :-
�@�@functor(_��,_��,1),
�@�@arg(1,_��,_����1),
�@�@_�l1 �� _����1,
�@�@_��1 =..[_��,_����1],
�@�@_�l �� _��1.
_�l �� _�� :- ����`(_��,_�l).
848 �F�f�t�H���g�̖����������F2009/12/20(��) 11:57:34
>>845 �܂��܂������B
% Prolog >>847���ƒ�~���܂���ˁB
_�l �� _�� :-
�@�@functor(_��,_��,2),
�@�@arg(1,_��,_����1),
�@�@arg(2,_��,_����2),
�@�@_�l1 �� _����1,
�@�@_�l2 �� _����2,
�@�@_��2 =..[_��,_�l1,_�l2],
�@�@����`(_��2,_�l).
_�l �� _�� :-
�@�@functor(_��,_��,1),
�@�@arg(1,_��,_����1),
�@�@_�l1 �� _����1,
�@�@_��1 =..[_��,_����1],
�@�@����`(_��1,_�l).
_�l �� _�� :- ����`(_��,_�l).
% Prolog >>847���ƒ�~���܂���ˁB
_�l �� _�� :-
�@�@functor(_��,_��,2),
�@�@arg(1,_��,_����1),
�@�@arg(2,_��,_����2),
�@�@_�l1 �� _����1,
�@�@_�l2 �� _����2,
�@�@_��2 =..[_��,_�l1,_�l2],
�@�@����`(_��2,_�l).
_�l �� _�� :-
�@�@functor(_��,_��,1),
�@�@arg(1,_��,_����1),
�@�@_�l1 �� _����1,
�@�@_��1 =..[_��,_����1],
�@�@����`(_��1,_�l).
_�l �� _�� :- ����`(_��,_�l).
849 �F�f�t�H���g�̖����������F2009/12/20(��) 12:19:17
850 �F�f�t�H���g�̖����������F2009/12/20(��) 16:35:13
>>843
�g�p����F�@R
f <- function(n){
a[0:59]<-"�s��"
a[60:69]<-"��"
a[70:79]<-"��"
a[80:100]<-"�D"
a[n]
}
> f(55)
[1] "�s��"
�g�p����F�@R
f <- function(n){
a[0:59]<-"�s��"
a[60:69]<-"��"
a[70:79]<-"��"
a[80:100]<-"�D"
a[n]
}
> f(55)
[1] "�s��"
851 �F�f�t�H���g�̖����������F2009/12/20(��) 16:48:31
>>849
>>844�̎d�l����~�����v�Z����q��̒�`��
�~��(_���a,_�~��) :- _�~�� is _���a * 3.141592654.
�ł悢�B>>845�́u�~������3.141592654�Ƃ���B�v�Ƃ����ꕶ�ɍS������`�ł��ˁB
�d�l�̕��͂ɉ����Ăł��邾�����ʂ𗎂Ƃ��Ȃ��悤�ɒ�`���Ă����ƁA�����
�������ȂƂ����̂�>>845�ŁA�P�Ȃ���ł��ˁB���̂悤�Ƀv���O�����\�����g�U
���Ă������Ƃ�]���ĎU���I�v���O���~���O�ƁuProlog�ł܂�����X���v�ł͕\��
���܂����B�d�l�̕��́A�~�߂�l�̌��ꊴ�o�ɂ���ăv���O�����\�����ω���
�܂�����B
>>844�̎d�l����~�����v�Z����q��̒�`��
�~��(_���a,_�~��) :- _�~�� is _���a * 3.141592654.
�ł悢�B>>845�́u�~������3.141592654�Ƃ���B�v�Ƃ����ꕶ�ɍS������`�ł��ˁB
�d�l�̕��͂ɉ����Ăł��邾�����ʂ𗎂Ƃ��Ȃ��悤�ɒ�`���Ă����ƁA�����
�������ȂƂ����̂�>>845�ŁA�P�Ȃ���ł��ˁB���̂悤�Ƀv���O�����\�����g�U
���Ă������Ƃ�]���ĎU���I�v���O���~���O�ƁuProlog�ł܂�����X���v�ł͕\��
���܂����B�d�l�̕��́A�~�߂�l�̌��ꊴ�o�ɂ���ăv���O�����\�����ω���
�܂�����B
852 �F�f�t�H���g�̖����������F2009/12/20(��) 20:05:13
>>844
�g�p����F�@J
J�ɂ̓G���W�j�A�����O�\�L�݂����ɂ�����pi�̃��e�����\�L������B
1p2 �� 1*pi^2 ��\���B�܂��A o. ��P�����Z�q�Ƃ��Ďg����pi�̔{����Ԃ��B
5p1
15.708
f=:o.
f 5
15.708
�g�p����F�@J
J�ɂ̓G���W�j�A�����O�\�L�݂����ɂ�����pi�̃��e�����\�L������B
1p2 �� 1*pi^2 ��\���B�܂��A o. ��P�����Z�q�Ƃ��Ďg����pi�̔{����Ԃ��B
5p1
15.708
f=:o.
f 5
15.708
853 �F�f�t�H���g�̖����������F2009/12/20(��) 22:12:32
>>840
% Prolog
'0�`10�܂ł̐��̂����A�C�ӂ̐�����3��܂œ��͂��Đ����̐��Ă�A�����ăQ�[��' :-
�@�@_���� is random mod 11,
�@�@���̓���(_��),
�@�@'3��܂œ��͂��Đ����̐��Ă�'(3,_��,_����).
'3��܂œ��͂��Đ����̐��Ă�'(_,_��,_��) :-
�@�@write('�吳��!!!\n'),!.
'3��܂œ��͂��Đ����̐��Ă�'(1,_��1,_����) :-
�@�@write('�c�O�I�I�s�����ł����B\n'),!.
'3��܂œ��͂��Đ����̐��Ă�'(N,_��1,_����) :-
�@�@�f�f(_��1,_����,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]),
�@�@N1 is N - 1,
�@�@write_formatted('����%t�킷�邱�Ƃ��ł��܂��B\n',[N1]),
�@�@���̓���(_��2),
�@�@'3��܂œ��͂��Đ����̐��Ă�'(N1,_��2,_����),!.
�f�f(_��,_����,'�����Ƒ傫�����ł��B\n') :- _�� < _����,!.
�f�f(_��,_����,'�����Ə��������ł��B\n') :- _�� > _����,!.
���̓���(_��) :- repeat,write('0�`10�܂ł̐�����͂��ĉ������B\n'),get_integer(_��),_�� >= 0, _�� =< 10,!.
% Prolog
'0�`10�܂ł̐��̂����A�C�ӂ̐�����3��܂œ��͂��Đ����̐��Ă�A�����ăQ�[��' :-
�@�@_���� is random mod 11,
�@�@���̓���(_��),
�@�@'3��܂œ��͂��Đ����̐��Ă�'(3,_��,_����).
'3��܂œ��͂��Đ����̐��Ă�'(_,_��,_��) :-
�@�@write('�吳��!!!\n'),!.
'3��܂œ��͂��Đ����̐��Ă�'(1,_��1,_����) :-
�@�@write('�c�O�I�I�s�����ł����B\n'),!.
'3��܂œ��͂��Đ����̐��Ă�'(N,_��1,_����) :-
�@�@�f�f(_��1,_����,_�f�f),
�@�@write_formatted('%t\n',[_�f�f]),
�@�@N1 is N - 1,
�@�@write_formatted('����%t�킷�邱�Ƃ��ł��܂��B\n',[N1]),
�@�@���̓���(_��2),
�@�@'3��܂œ��͂��Đ����̐��Ă�'(N1,_��2,_����),!.
�f�f(_��,_����,'�����Ƒ傫�����ł��B\n') :- _�� < _����,!.
�f�f(_��,_����,'�����Ə��������ł��B\n') :- _�� > _����,!.
���̓���(_��) :- repeat,write('0�`10�܂ł̐�����͂��ĉ������B\n'),get_integer(_��),_�� >= 0, _�� =< 10,!.
854 �F�f�t�H���g�̖����������F2009/12/20(��) 22:34:31
>>842
% Prolog
'0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s��' :-
�@�@findsum(V,(for(1,N,50),V is N * 0.2),Sum),
�@�@write_formatted('%t\n',[Sum]).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
'0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s��' :-
�@�@��������̗v(0.2, 50.0, 0.2, 0.0, Sum),
�@�@write_formatted('%t\n',[Sum]).
��������̗v(V1,Max,_,Sum,Sum) :- V1 > Max,!.
��������̗v(V1,Max,V,Sum1,Sum) :-
�@�@Sum2 is Sum1 + V1,
�@�@V2 is V1 + V,
�@�@��������̗v(V2,Max,Sum2,Sum).
% Prolog
'0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s��' :-
�@�@findsum(V,(for(1,N,50),V is N * 0.2),Sum),
�@�@write_formatted('%t\n',[Sum]).
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
'0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s��' :-
�@�@��������̗v(0.2, 50.0, 0.2, 0.0, Sum),
�@�@write_formatted('%t\n',[Sum]).
��������̗v(V1,Max,_,Sum,Sum) :- V1 > Max,!.
��������̗v(V1,Max,V,Sum1,Sum) :-
�@�@Sum2 is Sum1 + V1,
�@�@V2 is V1 + V,
�@�@��������̗v(V2,Max,Sum2,Sum).
855 �F�f�t�H���g�̖����������F2009/12/20(��) 22:58:55
http://pc12.2ch.net/test/read.cgi/tech/1260532772/309
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2a�i�����̓ǂݍ��݂ƕ\���j
#
# �ۑ� 2a �� 2b �ł́C�Z�p����ǂ݁C�\�����C�l�����߂�v���O���������D
#
# ����ꂽ���ԓ��Ő��������̖{�������������悭�w�Ԃ��߂ɁC
# ���͂ł���Z�p���̍\�����C���� BNF �Œ�߂���̂Ɍ���D
#
# �萔 ::= 0 | 1 | �c | 9
# �ϐ� ::= a | b | �c | z | A | B | �c | Z
# �Z�p�� ::= �萔
# | �ϐ�
# | (�Z�p��+�Z�p��)
# | (�Z�p��*�Z�p��)
#
# �܂�C�P���̒萔��P�����̕ϐ��̘a��ς���Ȃ鎮�����͂ł���D
#
# ���͂��ꂽ�Z�p����ǂݍ��݁C�Q���f�[�^�Ƃ��Ċi�[���C���̃f�[�^�����Ƃ�
# ���͂Ɠ����Z�p����\������C�Ƃ��������i���}�j���J��Ԃ��v���O���������D
#
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2a�i�����̓ǂݍ��݂ƕ\���j
#
# �ۑ� 2a �� 2b �ł́C�Z�p����ǂ݁C�\�����C�l�����߂�v���O���������D
#
# ����ꂽ���ԓ��Ő��������̖{�������������悭�w�Ԃ��߂ɁC
# ���͂ł���Z�p���̍\�����C���� BNF �Œ�߂���̂Ɍ���D
#
# �萔 ::= 0 | 1 | �c | 9
# �ϐ� ::= a | b | �c | z | A | B | �c | Z
# �Z�p�� ::= �萔
# | �ϐ�
# | (�Z�p��+�Z�p��)
# | (�Z�p��*�Z�p��)
#
# �܂�C�P���̒萔��P�����̕ϐ��̘a��ς���Ȃ鎮�����͂ł���D
#
# ���͂��ꂽ�Z�p����ǂݍ��݁C�Q���f�[�^�Ƃ��Ċi�[���C���̃f�[�^�����Ƃ�
# ���͂Ɠ����Z�p����\������C�Ƃ��������i���}�j���J��Ԃ��v���O���������D
#
856 �F�f�t�H���g�̖����������F2009/12/20(��) 23:01:43
http://pc12.2ch.net/test/read.cgi/tech/1260532772/309
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2b�i�����̒l�̌v�Z�j
#
# �ۑ� 2a �̃v���O�����ɁC�Z�p���̒l���v�Z���ĕ\������@�\��lj�����D
# �������C�ϐ��̒l�͑S�ĂP�ł���Ƃ��āC���̒l�����߂邱�ƁD
#
# �Ⴆ�C���͂� (2*3) �� (x+(y+z)) �̏ꍇ�C���̂悤�ȏo�͂�����悢�D
# show: �ɑ����ē��͂��ꂽ�Z�p�����Ceval: �ɑ����ĎZ�p���̒l��\�����Ă���D
#
# (2*3) ������
# show: (2*3)
# eval: 6
#
# (x+(y+z)) ������
# show: (x+(y+z))
# eval: 3
#
# �܂��C�Z�p���̒l�����߂�� eval_exp()�iexp.c �ɂ���j������������D
# �\���Ȑ��̌����f�[�^���g���ē���̐��������m���߂�D
#
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2b�i�����̒l�̌v�Z�j
#
# �ۑ� 2a �̃v���O�����ɁC�Z�p���̒l���v�Z���ĕ\������@�\��lj�����D
# �������C�ϐ��̒l�͑S�ĂP�ł���Ƃ��āC���̒l�����߂邱�ƁD
#
# �Ⴆ�C���͂� (2*3) �� (x+(y+z)) �̏ꍇ�C���̂悤�ȏo�͂�����悢�D
# show: �ɑ����ē��͂��ꂽ�Z�p�����Ceval: �ɑ����ĎZ�p���̒l��\�����Ă���D
#
# (2*3) ������
# show: (2*3)
# eval: 6
#
# (x+(y+z)) ������
# show: (x+(y+z))
# eval: 3
#
# �܂��C�Z�p���̒l�����߂�� eval_exp()�iexp.c �ɂ���j������������D
# �\���Ȑ��̌����f�[�^���g���ē���̐��������m���߂�D
#
857 �F�f�t�H���g�̖����������F2009/12/20(��) 23:08:29
http://pc12.2ch.net/test/read.cgi/tech/1260532772/309
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2c�i�����f�[�^�̊�{����j
# �Z�p���̒l��ς����Ɋ��ʂ������蒼���ȒP�Ȏ��ό`���l����D�Ⴆ�C��
# (1+(2+3))
# (a*(b*c))
# ((i*x)+((j*y)+(k*z)))
# �̊��ʂ����ɂ����蒼���ƁC���ꂼ��C���̎��ɂȂ�D
# ((1+2)+3)
# ((a*b)*c)
# (((i*x)+(j*y))+(k*z))
# ���ʂ����ɂ����蒼���� (�`+(�a+�b)) �� (�`*(�a*�b)) �̌`�̎Z�p����
# ((�`+�a)+�b) �� ((�`*�a)*�b) �̌`�ɂ��鎮�ό`�́C���ɑΉ������
# �u���ɓ]��v����ό`�Ƒ�������i���}�j�D
#
# http://www.cs.info.mie-u.ac.jp/~toshi/lectures/tree/exp012.png�@���@http://www.cs.info.mie-u.ac.jp/~toshi/lectures/tree/exp013.png
#
# ���̑�������s����� rotate_left_exp()�iexp.c �ɂ���j������������D
# ���̊����g���C�\�ȏꍇ�ɂ����Z�p���̊��ʂ����ɂ����蒼����
# assoc_left() �� ex2.c �ɍ���ē���m�F����D
# [1] ���ƒP���F �v���O���~���O���K
# [2] ��蕶(�܃R�[�h&�����N)�F http://ime.nu/kansai2channeler.hp.infoseek.co.jp/cgi-bin/joyful/img/10297.txt
# ����{�ۑ� 2c�i�����f�[�^�̊�{����j
# �Z�p���̒l��ς����Ɋ��ʂ������蒼���ȒP�Ȏ��ό`���l����D�Ⴆ�C��
# (1+(2+3))
# (a*(b*c))
# ((i*x)+((j*y)+(k*z)))
# �̊��ʂ����ɂ����蒼���ƁC���ꂼ��C���̎��ɂȂ�D
# ((1+2)+3)
# ((a*b)*c)
# (((i*x)+(j*y))+(k*z))
# ���ʂ����ɂ����蒼���� (�`+(�a+�b)) �� (�`*(�a*�b)) �̌`�̎Z�p����
# ((�`+�a)+�b) �� ((�`*�a)*�b) �̌`�ɂ��鎮�ό`�́C���ɑΉ������
# �u���ɓ]��v����ό`�Ƒ�������i���}�j�D
#
# http://www.cs.info.mie-u.ac.jp/~toshi/lectures/tree/exp012.png�@���@http://www.cs.info.mie-u.ac.jp/~toshi/lectures/tree/exp013.png
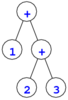{kind=link}
{kind=link}
#
# ���̑�������s����� rotate_left_exp()�iexp.c �ɂ���j������������D
# ���̊����g���C�\�ȏꍇ�ɂ����Z�p���̊��ʂ����ɂ����蒼����
# assoc_left() �� ex2.c �ɍ���ē���m�F����D
858 �F�f�t�H���g�̖����������F2009/12/21(��) 04:15:39
http://pc12.2ch.net/test/read.cgi/tech/1260532772/310
# [1] ���ƒP���F�A���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�@���i�ċA�j�ő����
# �@�L�[�{�[�h���玩�R����2���͂��A�����̍ő���ƍŏ����{����\������v���O�������쐬���Ȃ����B
# �������A�ő���̌v�Z�͊��i�ċA�j��p���邱�ƁB�ő�����v�Z������̖��O��gcd�Ƃ��邱�ƁB
#
# ���s����
# ���R����2���͂��ĉ�����.
# 3243�@6578
# 3243��6578�̍ő���͂Q�R,�ŏ����{���� 927498 �ł��B
# [1] ���ƒP���F�A���S���Y��
# [2] ��蕶(�܃R�[�h&�����N)�F
# �ۑ�@���i�ċA�j�ő����
# �@�L�[�{�[�h���玩�R����2���͂��A�����̍ő���ƍŏ����{����\������v���O�������쐬���Ȃ����B
# �������A�ő���̌v�Z�͊��i�ċA�j��p���邱�ƁB�ő�����v�Z������̖��O��gcd�Ƃ��邱�ƁB
#
# ���s����
# ���R����2���͂��ĉ�����.
# 3243�@6578
# 3243��6578�̍ő���͂Q�R,�ŏ����{���� 927498 �ł��B
859 �F�f�t�H���g�̖����������F2009/12/21(��) 04:21:24
http://pc12.2ch.net/test/read.cgi/tech/1248012902/632
# �y�@�ۑ�@�z
# ����(string)�A�ӂ肪��(string)�A�g�єԍ�(string)�A���[���A�h���X(string)
# ���t�B�[���h�Ƃ��Ď��N���XAddressBook���`����B
# �N���X���ɁA�ӂ肪�ȂŎ������ɕ��בւ��邽�߂�compareTo���`����B
# �O����,TelNoSort�Ƃ����A�d�b�ԍ�(������)���������ɕ��ѕς��邽�߂̃��\�b�h��
# �쐬����B
# ���C���E�v���O�����ŁAAddressBook�N���X�̔z��(ArrayList)���`���A
# �ȉ��̓���������Ȃ��v���O���������B
# �R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������B
# �E�z��ɑ�����ꂽ�f�[�^���ӂ肪�ȏ��ɁA���₷���o�͂���B
# �E�z��ɑ�����ꂽ�f�[�^��d�b�ԍ����ɁA���₷���o�͂���B
# ���́A�o�͂ɂ́Afor�����g�����ƁB
# �y�@�ۑ�@�z
# ����(string)�A�ӂ肪��(string)�A�g�єԍ�(string)�A���[���A�h���X(string)
# ���t�B�[���h�Ƃ��Ď��N���XAddressBook���`����B
# �N���X���ɁA�ӂ肪�ȂŎ������ɕ��בւ��邽�߂�compareTo���`����B
# �O����,TelNoSort�Ƃ����A�d�b�ԍ�(������)���������ɕ��ѕς��邽�߂̃��\�b�h��
# �쐬����B
# ���C���E�v���O�����ŁAAddressBook�N���X�̔z��(ArrayList)���`���A
# �ȉ��̓���������Ȃ��v���O���������B
# �R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������B
# �E�z��ɑ�����ꂽ�f�[�^���ӂ肪�ȏ��ɁA���₷���o�͂���B
# �E�z��ɑ�����ꂽ�f�[�^��d�b�ԍ����ɁA���₷���o�͂���B
# ���́A�o�͂ɂ́Afor�����g�����ƁB
860 �F�f�t�H���g�̖����������F2009/12/21(��) 05:11:19
#�y�@�ۑ�@�z
#�u0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s���v���O�������쐬����B�v��
# �����ۑ蕶���^����ꂽ�Ƃ���B
# ���̕����A�������� 0.2,0.4,0.6...10.0�̘a���v�Z����ۑ�ł���ƔF������
# ���Ƃ��ł���ŏ����̃v���O�����������B
#�u0.2+0.4+0.6+�E�E�E�E�E+10.0�̌v�Z���s���v���O�������쐬����B�v��
# �����ۑ蕶���^����ꂽ�Ƃ���B
# ���̕����A�������� 0.2,0.4,0.6...10.0�̘a���v�Z����ۑ�ł���ƔF������
# ���Ƃ��ł���ŏ����̃v���O�����������B
861 �F�f�t�H���g�̖����������F2009/12/21(��) 06:32:44
http://pc12.2ch.net/test/read.cgi/tech/1260532772/330
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# �L�[�{�[�h���琔����͂Ƃ��Ď��A���̌�����int�^�f�[�^���L�[�{�[�h������A
#�@�����̍ő�l����ʂɏo�͂���v���O������calloc��p���ď����B
# [1] ���ƒP���F�v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F
# �L�[�{�[�h���琔����͂Ƃ��Ď��A���̌�����int�^�f�[�^���L�[�{�[�h������A
#�@�����̍ő�l����ʂɏo�͂���v���O������calloc��p���ď����B
862 �F�f�t�H���g�̖����������F2009/12/21(��) 07:06:58
>>843
% Prolog
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v
�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂�����
���A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_�� �� _�_�� �ł���� _�f�f,
�@�@write_formatted('%t\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł��B'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
% Prolog
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v
�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂�����
���A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_�� �� _�_�� �ł���� _�f�f,
�@�@write_formatted('%t\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł��B'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
863 �F�f�t�H���g�̖����������F2009/12/21(��) 07:11:28
>>843 �����B
% Prolog�@�g�b�v�̏q�ꖼ���s�K�ȂƂ���ʼn��s���Ă��܂����B
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂����ꍇ�A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_�� �� _�_�� �ł���� _�f�f,
�@�@write_formatted('%t�B\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł�'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
% Prolog�@�g�b�v�̏q�ꖼ���s�K�ȂƂ���ʼn��s���Ă��܂����B
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂����ꍇ�A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_�� �� _�_�� �ł���� _�f�f,
�@�@write_formatted('%t�B\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł�'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
864 �F�f�t�H���g�̖����������F2009/12/21(��) 12:32:35
>>863 �ꃖ���Ԉ���Ă��B�u�_�ł���v�Ƃ����I�y���[�^�łȂ��Ă͂����Ȃ��B
���̓_�� �� _�_�� �ł���� _�f�f, -> ���̓_�� �� _�_�� �_�ł���� _�f�f,
���̓_�� �� _�_�� �ł���� _�f�f, -> ���̓_�� �� _�_�� �_�ł���� _�f�f,
865 �F�f�t�H���g�̖����������F2009/12/21(��) 15:08:10
>>843 ���������܂��Bvi�̕\�����ƑS�p�̑O��̃X�y�[�X���������Ă���̂��悭�킩��Ȃ��B
% Prolog
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v
�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂�����
���A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_���� _�_�� �_�ł���� _�f�f,
�@�@write_formatted('%t\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł��B'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
% Prolog
:- op(600,fx,���̓_����).
:- op(550,xfx,�_�ł����).
:- op(500,xfx,�`).
'�C�ӂ̓_������͂��A���̓_����0�`59�_�ł���u�s�v�A60�`69�_�ł���u�v
�A70�`79�_�ł���u�ǁv�A80�`100�_�ł���u�D�v�A�����ȊO�̓_������͂�����
���A�u���Z�ł��܂���v�ƕ\������' :-
�@�@�C�ӂ̓_������͂�(_�_��),
�@�@���̓_���� _�_�� �_�ł���� _�f�f,
�@�@write_formatted('%t\n',[_�f�f]).
�C�ӂ̓_������͂�(_�_��) :- write('���_�ł����H '),get_integer(_�_��).
���̓_���� _�_�� �_�ł���� _�f�f :-
�@�@���̓_���� _�����`_��� �_�ł���� _�f�f1,
�@�@_�_��>=_����,
�@�@_�_��=<_���,
�@�@concat_atom([_�f�f1,'�ł��B'],_�f�f),!.
���̓_���� _ �_�ł���� ���Z�ł��܂���.
���̓_���� 0�`59 �_�ł���� �s��.
���̓_���� 60�`69 �_�ł���� ��.
���̓_���� 70�`79 �_�ł���� ��.
���̓_���� 80�`100 �_�ł���� �D.
866 �F�f�t�H���g�̖����������F2009/12/21(��) 18:14:05
>>859
% Prolog (���̈�) ��ɂ���ăI�u�W�F�N�g�w���ɂ͂Ȃ�܂���B
'�R�l���̃f�[�^���L�[�{�[�h������͂��A�ӂ肪�ȏ��ɁA���₷���o�͂��� :-
�@�@'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(3,_�f�[�^�Ȃ��),
�@�@���ʒu�w�菸������([2],_�f�[�^�Ȃ��,_�����Ȃ��),
�@�@���₷���o�͂���(_�����Ȃ��).
�@
'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(0,[]) :- !.
'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(N,[[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]|R]) :-
�@�@get_line(Line),
�@�@split(Line,[','],[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]),
�@�@N1 is N - 1,
�@�@'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(N1,R).
���₷���o�͂���([]) :- !.
���₷���o�͂���([[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]|R]) :-
�@�@write_formatted('%20s,%20s,%12s,%30s\n',[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]),
�@�@���₷���o�͂���(R).
% Prolog (���̈�) ��ɂ���ăI�u�W�F�N�g�w���ɂ͂Ȃ�܂���B
'�R�l���̃f�[�^���L�[�{�[�h������͂��A�ӂ肪�ȏ��ɁA���₷���o�͂��� :-
�@�@'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(3,_�f�[�^�Ȃ��),
�@�@���ʒu�w�菸������([2],_�f�[�^�Ȃ��,_�����Ȃ��),
�@�@���₷���o�͂���(_�����Ȃ��).
�@
'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(0,[]) :- !.
'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(N,[[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]|R]) :-
�@�@get_line(Line),
�@�@split(Line,[','],[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]),
�@�@N1 is N - 1,
�@�@'�R�l���̃f�[�^���L�[�{�[�h������͂��A���X�g�ɑ������'(N1,R).
���₷���o�͂���([]) :- !.
���₷���o�͂���([[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]|R]) :-
�@�@write_formatted('%20s,%20s,%12s,%30s\n',[_����,_�ӂ肪��,_�g�єԍ�,_���[���A�h���X]),
�@�@���₷���o�͂���(R).
867 �F�f�t�H���g�̖����������F2009/12/21(��) 18:16:11
>>859
% Prolog (���̓�)
���ʒu�w�菸������(_���̈ʒu�Ȃ��,_�ΏۂȂ��,_�����Ȃ��) :-
�@�@�����̕t��(_���̈ʒu�Ȃ��,_�ΏۂȂ��,_����t�������Ȃ��),
�@�@sort(_����t�������Ȃ��,_����t�����Đ����Ȃ��),
�@�@length(_���̈ʒu�Ȃ��,Len),
�@�@�����̏���(Len,_����t�����Đ����Ȃ��,_�����Ȃ��).
�����̕t��([],_�ΏۂȂ��,_�ΏۂȂ��) :- !.
�����̕t��([_���̈ʒu|R1],_�ΏۂȂ��,[_��|R2]) :-
�@�@list_nth(_���̈ʒu,_�ΏۂȂ��,_��),
�@�@�����̕t��(R1,_�ΏۂȂ��,R2).
�����̍폜(_���̍��ڐ�,[],[]) :- !.
�����̍폜(_���̍��ڐ�,[L1|R1],[L2|R2]) :-
�@�@�擪����n�v�f(_���̍��ڐ�,L1,_,L2),
�@�@�����̍폜(_���̍��ڐ�,R1,R2).
�擪����n�v�f(0,L,[],L) :- !.
�擪����n�v�f(N,[A|R1],[A|R2],R3) :-
�@�@M is N - 1,
�@�@�擪����n�v�f(M,R1,R2,R3).
% Prolog (���̓�)
���ʒu�w�菸������(_���̈ʒu�Ȃ��,_�ΏۂȂ��,_�����Ȃ��) :-
�@�@�����̕t��(_���̈ʒu�Ȃ��,_�ΏۂȂ��,_����t�������Ȃ��),
�@�@sort(_����t�������Ȃ��,_����t�����Đ����Ȃ��),
�@�@length(_���̈ʒu�Ȃ��,Len),
�@�@�����̏���(Len,_����t�����Đ����Ȃ��,_�����Ȃ��).
�����̕t��([],_�ΏۂȂ��,_�ΏۂȂ��) :- !.
�����̕t��([_���̈ʒu|R1],_�ΏۂȂ��,[_��|R2]) :-
�@�@list_nth(_���̈ʒu,_�ΏۂȂ��,_��),
�@�@�����̕t��(R1,_�ΏۂȂ��,R2).
�����̍폜(_���̍��ڐ�,[],[]) :- !.
�����̍폜(_���̍��ڐ�,[L1|R1],[L2|R2]) :-
�@�@�擪����n�v�f(_���̍��ڐ�,L1,_,L2),
�@�@�����̍폜(_���̍��ڐ�,R1,R2).
�擪����n�v�f(0,L,[],L) :- !.
�擪����n�v�f(N,[A|R1],[A|R2],R3) :-
�@�@M is N - 1,
�@�@�擪����n�v�f(M,R1,R2,R3).
868 �F�f�t�H���g�̖����������F2009/12/21(��) 18:27:10
>>861
% Prolog
�L�[�{�[�h���琔����͂Ƃ��Ď��A���̌�����int�^�f�[�^���L�[�{�[�h������A�����̍ő�l����ʂɏo�͂��� :-
�@�@�L�[�{�[�h���琔����͂Ƃ��Ď��(_��),
�@�@_�� is truncate(_��),
�@�@findall(_�f�[�^,(for(1,N,_��),get_integer(_�f�[�^)),_�f�[�^�Ȃ��),
�@�@max(_�f�[�^�Ȃ��,_�ő�l),
�@�@write_formatted('���͂��ꂽ�f�[�^�̍ő�l��%t�ł�\n',[_�ő�l]).
�L�[�{�[�h���琔����͂Ƃ��Ď��(_��) :-
�@�@repeat,
�@�@get_line(Line),
�@�@atom_to_term(Line,_��,_),
�@�@number(_��),!.
% Prolog
�L�[�{�[�h���琔����͂Ƃ��Ď��A���̌�����int�^�f�[�^���L�[�{�[�h������A�����̍ő�l����ʂɏo�͂��� :-
�@�@�L�[�{�[�h���琔����͂Ƃ��Ď��(_��),
�@�@_�� is truncate(_��),
�@�@findall(_�f�[�^,(for(1,N,_��),get_integer(_�f�[�^)),_�f�[�^�Ȃ��),
�@�@max(_�f�[�^�Ȃ��,_�ő�l),
�@�@write_formatted('���͂��ꂽ�f�[�^�̍ő�l��%t�ł�\n',[_�ő�l]).
�L�[�{�[�h���琔����͂Ƃ��Ď��(_��) :-
�@�@repeat,
�@�@get_line(Line),
�@�@atom_to_term(Line,_��,_),
�@�@number(_��),!.
869 �F�f�t�H���g�̖����������F2009/12/21(��) 20:44:37
>>609
% Prolog �ǂ������łǂ������Ȃ̂��킩��Ȃ��Ȃ��Ă��܂����B
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z1,_���z2,_����1,_����2) :-
���z�������ς��ɂȂ�����(_���z1),
��s�Œ���������(_���z1,_���z2,_����1,_����2),!.
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z1,_���z2,_����1,_����2) :-
�L�����N�^���o�C�g������(_����1,_����3),
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z3,_���z2,_����1,_����2).
�L�����N�^���o�C�g������(_����1,_����2) :- _����2 is _���� + 1.
���z�������ς��ɂȂ�����(_���z) :- �����ς��ɂȂ�����(_���z).
�����ς��ɂȂ�����(_���z) :- ���z�̋��e��(_���z�̋��e��), _���z >= _���z�̋��e��,!.
��s�Œ���������(_���z1,_���z2,_����1,_����2) :- �莝�����O�ɂ�(_���z1,_���z2),�������P������(_����1,_����2).
�莝�����O�ɂ�(_���z1,_���z2) :- _���z2 = 0.
�������P������(_����1,_����2) :- _����2 is _����1 + 1.
% Prolog �ǂ������łǂ������Ȃ̂��킩��Ȃ��Ȃ��Ă��܂����B
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z1,_���z2,_����1,_����2) :-
���z�������ς��ɂȂ�����(_���z1),
��s�Œ���������(_���z1,_���z2,_����1,_����2),!.
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z1,_���z2,_����1,_����2) :-
�L�����N�^���o�C�g������(_����1,_����3),
�L�����N�^���o�C�g�����č��z�������ς��ɂȂ������s�ւ���(_���z3,_���z2,_����1,_����2).
�L�����N�^���o�C�g������(_����1,_����2) :- _����2 is _���� + 1.
���z�������ς��ɂȂ�����(_���z) :- �����ς��ɂȂ�����(_���z).
�����ς��ɂȂ�����(_���z) :- ���z�̋��e��(_���z�̋��e��), _���z >= _���z�̋��e��,!.
��s�Œ���������(_���z1,_���z2,_����1,_����2) :- �莝�����O�ɂ�(_���z1,_���z2),�������P������(_����1,_����2).
�莝�����O�ɂ�(_���z1,_���z2) :- _���z2 = 0.
�������P������(_����1,_����2) :- _����2 is _����1 + 1.
870 �F�f�t�H���g�̖����������F2009/12/21(��) 20:48:11
>>609
% Prolog (���̓�)
�ڕW���z�܂ŌJ��Ԃ��A���B�����炻�̋����Ȃ��Ȃ�܂�(_�ڕW���z,_����1,_����2) :-
�@�@�ڕW���z�ɓ��B����(_����1,_�ڕW���z),
�@�@���̋����Ȃ��Ȃ�܂ʼnƂŐQ��(_����1,_����2).
�@
���̋����Ȃ��Ȃ�܂�(_����1,0) :- _����1 =< 0,!.
���̋����Ȃ��Ȃ�܂�(_����1,_����2) :-
�@�@�ƂŐQ��(_����1,_����3),
�@�@���̋����Ȃ��Ȃ�܂�(_�a��3,_�a��2).
�ƂŐQ��(_����1,_����2) :- �������P����(_����1,_����2).
�������P����(_����1,_����2) :- _����2 is _����1 - 1.
�莝�����O�ɂ��A�������P������(_���z1,_���z2,_����1,_����2) :- _���z2 = 0,_����2 is _����1 + 1.
���z�̋��e�ʂ͂R(_���z�̋��e��) :- ���z�̋��e��(_���z�̋��e��).
���z�̋��e��(3).
�ڕW�����z�͂T(_�ڕW�����z) :- �ڕW�����z(_�ڕW�����z).
�ڕW�����z(5).
% Prolog (���̓�)
�ڕW���z�܂ŌJ��Ԃ��A���B�����炻�̋����Ȃ��Ȃ�܂�(_�ڕW���z,_����1,_����2) :-
�@�@�ڕW���z�ɓ��B����(_����1,_�ڕW���z),
�@�@���̋����Ȃ��Ȃ�܂ʼnƂŐQ��(_����1,_����2).
�@
���̋����Ȃ��Ȃ�܂�(_����1,0) :- _����1 =< 0,!.
���̋����Ȃ��Ȃ�܂�(_����1,_����2) :-
�@�@�ƂŐQ��(_����1,_����3),
�@�@���̋����Ȃ��Ȃ�܂�(_�a��3,_�a��2).
�ƂŐQ��(_����1,_����2) :- �������P����(_����1,_����2).
�������P����(_����1,_����2) :- _����2 is _����1 - 1.
�莝�����O�ɂ��A�������P������(_���z1,_���z2,_����1,_����2) :- _���z2 = 0,_����2 is _����1 + 1.
���z�̋��e�ʂ͂R(_���z�̋��e��) :- ���z�̋��e��(_���z�̋��e��).
���z�̋��e��(3).
�ڕW�����z�͂T(_�ڕW�����z) :- �ڕW�����z(_�ڕW�����z).
�ڕW�����z(5).
871 �F�f�t�H���g�̖����������F2009/12/22(��) 06:25:50
���X�Y�����Ă�Ƃ���͂��邯�ǁA���i�͂���łł�������A��̓Q�[����main������
�g�ݗ��Ă�B���̃Q�[�����ƁAmember�^�̔萫�̏q����g�b�v�ɂ����Ă��āA
�X�e�b�p�[�̓����������āA���x�A���z�̒��g�ƁA�����������Ŗ߂��悤�ɂ���B
���̊Ԃ̓���(�Ⴆ�ΐQ��)�������ɖ߂�悤�ɂł���Ζ{���͂悢�B
�g�ݗ��Ă�B���̃Q�[�����ƁAmember�^�̔萫�̏q����g�b�v�ɂ����Ă��āA
�X�e�b�p�[�̓����������āA���x�A���z�̒��g�ƁA�����������Ŗ߂��悤�ɂ���B
���̊Ԃ̓���(�Ⴆ�ΐQ��)�������ɖ߂�悤�ɂł���Ζ{���͂悢�B
872 �F�f�t�H���g�̖����������F2009/12/22(��) 07:29:29
873 �F�f�t�H���g�̖����������F2009/12/22(��) 08:19:17
����M���̖�]�݂����ȃQ�[���Ȃ̂��ƁB
http://pc12.2ch.net/test/read.cgi/tech/1260532772/365
# [1] ���ƒP���F�����v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F�}�C���X�C�[�p�[������Ă��������B
# �E�c�̗��ABC...�ŁA���̗��123...�ŕ\�����A���W���J��Ԃ����͂���
# �E�e�̑傫���͎��R�ł���i��Փx���Ƃɑ傫����I�ׂ铙�v�H�v�j
# �E�n���̈ʒu�͖����_���ł��邱��
# �E�w��i���́j�������W�ɂ͎��͂̒n���̐���\��������
# �E�n���̂�����W����͂��邩�A�S�Ă̈��u����͂��邱�ƂŃN���A�Ƃ���
# �E���̑��A�H�v����������Ɖ��_
# [1] ���ƒP���F�����v���O���~���O
# [2] ��蕶(�܃R�[�h&�����N)�F�}�C���X�C�[�p�[������Ă��������B
# �E�c�̗��ABC...�ŁA���̗��123...�ŕ\�����A���W���J��Ԃ����͂���
# �E�e�̑傫���͎��R�ł���i��Փx���Ƃɑ傫����I�ׂ铙�v�H�v�j
# �E�n���̈ʒu�͖����_���ł��邱��
# �E�w��i���́j�������W�ɂ͎��͂̒n���̐���\��������
# �E�n���̂�����W����͂��邩�A�S�Ă̈��u����͂��邱�ƂŃN���A�Ƃ���
# �E���̑��A�H�v����������Ɖ��_