Intel Larrabee 1コア
Intelの将来は超マルチコアになるかもしれない Larrabee(ララビー) について語るスレです。
|
|
|
日本語でおk
関連記事
■インテル、次世代グラフィックチップ「Larrabee」の詳細を公開
ttp://japan.zdnet.com/news/hardware/story/0,2000056184,20378365,00.htm
■インテル、多コア型新チップ「Larrabee」の詳細を明らかに
ttp://japan.cnet.com/news/ent/story/0,2000056022,20378337,00.htm
■Intel、メニーコアプロセッサ「Larrabee」の概要を公開
ttp://www.itmedia.co.jp/news/articles/0808/05/news017.html
■インテルの「Larrabee」はやはりPentiumベースか
ttp://itpro.nikkeibp.co.jp/article/MAG/20080710/310551/
■インテル、次世代グラフィックチップ「Larrabee」の詳細を公開
ttp://japan.zdnet.com/news/hardware/story/0,2000056184,20378365,00.htm
■インテル、多コア型新チップ「Larrabee」の詳細を明らかに
ttp://japan.cnet.com/news/ent/story/0,2000056022,20378337,00.htm
■Intel、メニーコアプロセッサ「Larrabee」の概要を公開
ttp://www.itmedia.co.jp/news/articles/0808/05/news017.html
■インテルの「Larrabee」はやはりPentiumベースか
ttp://itpro.nikkeibp.co.jp/article/MAG/20080710/310551/
Intel740の再来ですね、わかります。
いや、違う。
Intelは遠い将来的にCPUにノース・サウス・グラフィック、全てを統合してしまうことを考えているらしい。
その件でnVIDIA(遠い将来においても多チップを維持する路線)と揉めて仲が悪く、
逆にIntelに同調していたATIとは緊密な関係だった、とか。
多分その「遠い将来」に向けての第1段階なんじゃないか。
今回は商業的に失敗したり、性能が悪くても簡単には撤退しない
といいですよね。(^^)
Intelは遠い将来的にCPUにノース・サウス・グラフィック、全てを統合してしまうことを考えているらしい。
その件でnVIDIA(遠い将来においても多チップを維持する路線)と揉めて仲が悪く、
逆にIntelに同調していたATIとは緊密な関係だった、とか。
多分その「遠い将来」に向けての第1段階なんじゃないか。
今回は商業的に失敗したり、性能が悪くても簡単には撤退しない
といいですよね。(^^)
サーバーとかはシングルスレッド性能不要なら
こちらの方が速いか?
同じダイサイズならね。
こちらの方が速いか?
同じダイサイズならね。
8 :(・∀・) チンポー!!:2008/08/05(火) 21:13:58 ID:jzSzy4sL
2005年に10GHz
http://pc.watch.impress.co.jp/docs/article/20010117/kaigai01.htm
2009年に100コア
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
http://pc.watch.impress.co.jp/docs/article/20010117/kaigai01.htm
2009年に100コア
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
9 :Socket774:2008/08/05(火) 22:05:09 ID:Jc4E9jgR
Superπやらせたら速そう
なんかナイアガラとか言う単語を連想したんだが
合言葉はLarrabee
12 :Socket774:2008/08/06(水) 00:23:02 ID:J5eKAzg6
イーチタイム
ララミー?
>>9
マルチスレッド版なんかあったか?
マルチスレッド版なんかあったか?
何コアでるか当てようぜ!
とりあえず32コア
17とか29とか微妙な数で頼む
シングルスレッド性能は1GHzで動く無印Pentium相当なんだろ?
apache位でしかまともなパフォーマンス出ないんじゃないの?
apache位でしかまともなパフォーマンス出ないんじゃないの?
MMX を忘れてるぞ
20 :Socket774:2008/08/08(金) 13:56:49 ID:+u2H1tU9
16コア@1GHzで512GFlopsらしい。
製品版は32コア@2GHzで2TFlopsくらいじゃね?
製品版は32コア@2GHzで2TFlopsくらいじゃね?
俺の脳は0.1Flops
>>12
ナイアガラ・トライアングル乙
ナイアガラ・トライアングル乙
無印Pentiumとの比較だとL1が命令、データともに8KBから32KBに増量。L2がオンダイで256KB追加だから、
元のキャッシュサイズが小さいから、結構性能にも効くんじゃね?
追加されたVPUが既存のSSE互換なら、アプリによってはかなり差がつくだろうし。
元のキャッシュサイズが小さいから、結構性能にも効くんじゃね?
追加されたVPUが既存のSSE互換なら、アプリによってはかなり差がつくだろうし。
グラボといえば熱も気になるところ
熱自体はよくわからないが、intelによれば10コアでダイサイズ、消費電力が
Core2Duo(多分Conroe)と同じくらいらしい。
32コア版で消費電力200Wくらいになるんじゃないだろうか?
消費電力とTDPは同じじゃないけど、TDPも200Wくらいが目安にはなるかと。
ついでに、48コアはダイサイズ的に無茶すぎるから出るかどうかわからないけど、消費電力からすると
PCI-Expressカードぎりぎりの300W以内には収まるっぽい。
Core2Duo(多分Conroe)と同じくらいらしい。
32コア版で消費電力200Wくらいになるんじゃないだろうか?
消費電力とTDPは同じじゃないけど、TDPも200Wくらいが目安にはなるかと。
ついでに、48コアはダイサイズ的に無茶すぎるから出るかどうかわからないけど、消費電力からすると
PCI-Expressカードぎりぎりの300W以内には収まるっぽい。
>>14
CUDA版が出るって話なかったっけ
CUDA版が出るって話なかったっけ
28 :,,・´∀`・,,)っ-○●◎:2008/08/09(土) 00:36:47 ID:PESzo0IS
>>23
論文読んだけど2issueでスカラ命令ユニットと512ビットのSIMDユニットが1個ずつ乗っかってる構成。
Vectorユニット側に命令発行ポートが2つついてて64/128/256bit SIMD命令を2つ同時発行できる
ような構成にでもなってない限り、たとえばSSEなら残り384ビットが遊ぶ。
ここまで特殊だと、SSEと互換を取る必然性すらない気がしてきた。
よくわからんが、FFT/AGM使えばPIの高速実装いけるんじゃないのか?
論文読んだけど2issueでスカラ命令ユニットと512ビットのSIMDユニットが1個ずつ乗っかってる構成。
Vectorユニット側に命令発行ポートが2つついてて64/128/256bit SIMD命令を2つ同時発行できる
ような構成にでもなってない限り、たとえばSSEなら残り384ビットが遊ぶ。
ここまで特殊だと、SSEと互換を取る必然性すらない気がしてきた。
よくわからんが、FFT/AGM使えばPIの高速実装いけるんじゃないのか?
29 :Socket774:2008/08/09(土) 23:10:21 ID:lF3I4yMI
で、そこまでコアを増やしたところでいつソフト側が対応してくれるの?
BeOSみたいなのなら、コアの数が増えればどんどん速くなってくれるだろうけどさ
BeOSみたいなのなら、コアの数が増えればどんどん速くなってくれるだろうけどさ
ソフトはOpenCLとかDX11に対応したものってことになるんじゃないかなぁ。
今からIntelが独自のAPIを押してくるとも考え辛いし。
Intel的にはLarrabeeが十分に競争力を持つまではむしろ
GPGPU的なソフトの普及は遅れてくれたほうが望ましいだろうけど。
今からIntelが独自のAPIを押してくるとも考え辛いし。
Intel的にはLarrabeeが十分に競争力を持つまではむしろ
GPGPU的なソフトの普及は遅れてくれたほうが望ましいだろうけど。
LarrabeeってGPUとしてはTBRになるんだってね
http://www.extremetech.com/article2/0,2845,2327047,00.asp
Kyro信者はIntelに忠誠を誓わなくてはな。
http://www.extremetech.com/article2/0,2845,2327047,00.asp
Kyro信者はIntelに忠誠を誓わなくてはな。
当面専用ソフトがないからGPUとして出しますよってことかね
でも普通のGPUとしてなら普通のGPUの方が性能いいだろうしな
ソフト資産がそろうまで待ちましょうかってことかな
でも普通のGPUとしてなら普通のGPUの方が性能いいだろうしな
ソフト資産がそろうまで待ちましょうかってことかな
>32
Intelの場合、SSEなどの新命令をでっちあげても普及速度凄いから
意外とソフト面の対応は速いんじゃないだろうか
Intelの場合、SSEなどの新命令をでっちあげても普及速度凄いから
意外とソフト面の対応は速いんじゃないだろうか
34 :,,・´∀`・,,)っ-○●◎:2008/08/11(月) 23:58:09 ID:y6R1bzbl
VEXエンコーディングを使うって説は結構有力みたいだなー。
もしそうならAVXのデコードにも容易に対応できる可能性が高い。
まあ512bitユニットで256ビットSIMD命令実行とか効率的にはベストではないが。
もしそうならAVXのデコードにも容易に対応できる可能性が高い。
まあ512bitユニットで256ビットSIMD命令実行とか効率的にはベストではないが。
Larrabeeは失敗確定
36 :Socket774:2008/08/12(火) 11:03:52 ID:agqfjhjA
失敗作でもいいから買ってみたい
i740みたいな事になるんじゃなかろうか
38 :Socket774:2008/08/20(水) 06:59:04 ID:v+mp/SJ0
待てばカイロの日和あり
どの程度のスペックになるんだ?
いきなりGTX280とタメ張るってことは無いだろうけど、
ミドル辺りに毛が生えた程度だろうか?
価格も気になるしな
いきなりGTX280とタメ張るってことは無いだろうけど、
ミドル辺りに毛が生えた程度だろうか?
価格も気になるしな
fusionの方が良いよ
あえて言おう
サザビーは出ないのか?
サザビーは出ないのか?
i486 8億コアとかatom 8億コアとか、そう言うアプローチはコンシューマじゃ
歓迎されないんじゃないの? まだi486 8億GHz とかのがパフォーマンス高そうだけど
http://pc11.2ch.net/test/read.cgi/jisaku/1211382565/
歓迎されないんじゃないの? まだi486 8億GHz とかのがパフォーマンス高そうだけど
http://pc11.2ch.net/test/read.cgi/jisaku/1211382565/
44 :,,・´∀`・,,)っ:2008/08/22(金) 00:44:21 ID:6R6YXCRn
光の速度知ってる?電子の移動速度はそれよりずっと遅い。何の制約もなしにクロックが引き上げ続けられるなら、
マルチコアへのシフトなんてそもそもありえないっつーの。
もはやパイプラインを細分化してももはやクロックはそれほどのびないし
細分化した分パイプラインハザードのペナルティ食らって効率が上がらない。
もはやマルチコアのほうが高いスケーラビリティが得られる。
GPUで肩代わりさせてきた処理分野におけるCPUの復権が当面の目的。
グラフィックプロセッシングはピクセル数分は並列化可能だから、
CPUのマルチコア化を推進する動機としては十分だからな。
マルチコアへのシフトなんてそもそもありえないっつーの。
もはやパイプラインを細分化してももはやクロックはそれほどのびないし
細分化した分パイプラインハザードのペナルティ食らって効率が上がらない。
もはやマルチコアのほうが高いスケーラビリティが得られる。
GPUで肩代わりさせてきた処理分野におけるCPUの復権が当面の目的。
グラフィックプロセッシングはピクセル数分は並列化可能だから、
CPUのマルチコア化を推進する動機としては十分だからな。
45 :Socket774:2008/08/22(金) 11:42:15 ID:R0oW3jif
偉そうなこと言う前に、そのどうしようもない日本語をどうにかしなさい
もはやぐだぐだって事ですね。
わかります。
わかります。
ララビーって純粋なGPU?
フュージョンみたいなCPU+GPU?
おせーて先生。
フュージョンみたいなCPU+GPU?
おせーて先生。
GPU用にテクスチャ関係の専用回路ある以外は、コア数が多いマルチコアCPU。
純粋なGPUでも、フュージョンみたいなCPU+GPUでもない。
純粋なGPUでも、フュージョンみたいなCPU+GPUでもない。
49 :Socket774:2008/08/22(金) 22:23:21 ID:QhHLsxeY
中途半端なゴミクズですね
わかります
わかります
グラフィック計算が得意なマルチコアCPU
CUDAより使いやすいなら使ってみたいな
GPGPUより速いことが条件だけど
CUDAより使いやすいなら使ってみたいな
GPGPUより速いことが条件だけど
x86コアのcellですね
HPC畑だけに好まれそう
HPC畑だけに好まれそう
動作デモもない。たとえ動作せずともシリコンもない。
どーゆーことよ?
どーゆーことよ?
273 :Socket774 [↓] :2008/08/22(金) 10:13:02 ID:jBeMNBWv
例えばH.264、VC-1等を再生する場合にも
larrabeeでは幾つかのCPU(?)を使い、デコードし多くの電力を消費するが
ATI,S3,nVIDIAでは再生専用の回路を使い低消費電力でこなす。
例えばATI,S3,nVIDIAのテッセレータは、単純な固定機能で高速に処理できるのに
larrabeeでは幾つかのCPU(?)コアを使わなければ、同等のパフォーマンスは得られない。
275 :Socket774 [↓] :2008/08/22(金) 15:14:06 ID:jBeMNBWv
大きな問題として、そのミドル並みのGPUがどの程度の規模で実現可能なのか
例えばGTX280並みの規模で9600GT程度のパフォーマンスだとしたら買うかね?
281 :Socket774 [↓] :2008/08/22(金) 21:16:03 ID:EMyXN76K
さて、フルプログラマブルなlarrabeeのパフォーマンスが如何ほどか
仮に製品版のlarrabeeのパフォーマンスを2Tflopsとしましょうか
これをGPUにおけるshaderのみならず、多くの固定機能としても割り振ることになるわけだが
つまりこれは、PS3でよくネタに使われるRSXの1.8Tflopsと同じ扱いになるわけだ
まぁ、テクスチャ関連は(どこまでかは知らないが)ハードで積むようだから
RSXより多少はマシなのかね?
282 :Socket774 [↓] :2008/08/22(金) 22:37:50 ID:HE0Mvwrz
コア16個で2GHz動作としても1TFlops。
283 :Socket774 [↓] :2008/08/22(金) 22:47:49 ID:EMyXN76K
2年後にトータル1tflopsか
とてもローエンドなGPUですね
6,000円位で買えるかな
例えばH.264、VC-1等を再生する場合にも
larrabeeでは幾つかのCPU(?)を使い、デコードし多くの電力を消費するが
ATI,S3,nVIDIAでは再生専用の回路を使い低消費電力でこなす。
例えばATI,S3,nVIDIAのテッセレータは、単純な固定機能で高速に処理できるのに
larrabeeでは幾つかのCPU(?)コアを使わなければ、同等のパフォーマンスは得られない。
275 :Socket774 [↓] :2008/08/22(金) 15:14:06 ID:jBeMNBWv
大きな問題として、そのミドル並みのGPUがどの程度の規模で実現可能なのか
例えばGTX280並みの規模で9600GT程度のパフォーマンスだとしたら買うかね?
281 :Socket774 [↓] :2008/08/22(金) 21:16:03 ID:EMyXN76K
さて、フルプログラマブルなlarrabeeのパフォーマンスが如何ほどか
仮に製品版のlarrabeeのパフォーマンスを2Tflopsとしましょうか
これをGPUにおけるshaderのみならず、多くの固定機能としても割り振ることになるわけだが
つまりこれは、PS3でよくネタに使われるRSXの1.8Tflopsと同じ扱いになるわけだ
まぁ、テクスチャ関連は(どこまでかは知らないが)ハードで積むようだから
RSXより多少はマシなのかね?
282 :Socket774 [↓] :2008/08/22(金) 22:37:50 ID:HE0Mvwrz
コア16個で2GHz動作としても1TFlops。
283 :Socket774 [↓] :2008/08/22(金) 22:47:49 ID:EMyXN76K
2年後にトータル1tflopsか
とてもローエンドなGPUですね
6,000円位で買えるかな
54 :,,・´∀`・,,)っ-○●◎:2008/08/23(土) 18:46:37 ID:rJ2nlBcm
ゲームやらないからビデオ性能なんて7600GT程度でも十分だが
汎用演算のスループットが欲しい俺にはその価格なら喜んで買うよ
汎用演算のスループットが欲しい俺にはその価格なら喜んで買うよ
汎用演算・・・、アニメ●ンコですね。わかります。
ギャグなんだが、
そのうちPCの価値ってストリームプロセッサをいかにたくさんつないだかっていう点だけが評価点だったりするんだろうか。
波形いじれるし、しぇーだもできるし、固定機能には負けるがそこはクロックとかでカバーっていう。
そのうちPCの価値ってストリームプロセッサをいかにたくさんつないだかっていう点だけが評価点だったりするんだろうか。
波形いじれるし、しぇーだもできるし、固定機能には負けるがそこはクロックとかでカバーっていう。
57 :,,・´∀`・,,)っ-○●◎:2008/08/23(土) 20:34:03 ID:rJ2nlBcm
そうなりつつある。
x86であることでいろいろ応用がきくしな。
リッチな8コアよりも性能的に尖った小さいx86コアで物量にものを言わせて
サービスをすべてコンテクストスイッチレスで動かすほうが
Windowsの動作も速い、なんてことも将来的にはありうる
x86であることでいろいろ応用がきくしな。
リッチな8コアよりも性能的に尖った小さいx86コアで物量にものを言わせて
サービスをすべてコンテクストスイッチレスで動かすほうが
Windowsの動作も速い、なんてことも将来的にはありうる
自作もおわるな〜。Orz
DOS時代みたく、どこのメモリを書き換えたら画面を更新する。
っていう系統のインターフェースだけ策定するとかには。。。ならんか。
出力系統はトリプルバッファリングできればそれ以上はほとんど必要ないしなぁ。
ハード単純化の傾向があるような無いような。。。メタ化!
DOS時代みたく、どこのメモリを書き換えたら画面を更新する。
っていう系統のインターフェースだけ策定するとかには。。。ならんか。
出力系統はトリプルバッファリングできればそれ以上はほとんど必要ないしなぁ。
ハード単純化の傾向があるような無いような。。。メタ化!
データマイニングとかに使うのが本命なんだろうけど、大規模データ処理を
行うのはGoogleとかのデータセンターであって、デスクトップではない。
デスクトップはもはやデータ表示装置(ブラウザ)でしかない方向にどんどん
向かっているという所からして、どうもこのプロセッサのマーケティング、
無理がある気がする。
Photosynthみたいのをご家庭で、というのは言えなくはないかもしれないけど、
その為に新規ボードを追加というのはちょっと無理。SSEやAVX内蔵プロセッサ
ならその売り方が出来るだろうけど…
行うのはGoogleとかのデータセンターであって、デスクトップではない。
デスクトップはもはやデータ表示装置(ブラウザ)でしかない方向にどんどん
向かっているという所からして、どうもこのプロセッサのマーケティング、
無理がある気がする。
Photosynthみたいのをご家庭で、というのは言えなくはないかもしれないけど、
その為に新規ボードを追加というのはちょっと無理。SSEやAVX内蔵プロセッサ
ならその売り方が出来るだろうけど…
>デスクトップはもはやデータ表示装置(ブラウザ)でしかない
動画が強力なブラウザだな Google Earth なんかを見ると
動画が強力なブラウザだな Google Earth なんかを見ると
頭脳放談 第99回 x86プロセッサをいっぱい並べたら何になる?
http://www.atmarkit.co.jp/fsys/zunouhoudan/099zunou/larrabee.html
http://www.atmarkit.co.jp/fsys/zunouhoudan/099zunou/larrabee.html
62 :,,・´∀`・,,)っ-○●◎:2008/08/29(金) 01:40:09 ID:XA+DpWi/
フェンスに完了スレはこっちでいいかね
DTMでは需要があるんではないかね。
111 :,,・´∀`・,, [↓] :2008/08/29(金) 19:06:12 ID:XA+DpWi/
Intel's Larrabee GPU Will Support Linux
http://www.phoronix.com/scan.php?page=news_item&px=NjYzOA
面白いことになったね
112 :Socket774 [↓] :2008/08/29(金) 19:24:32 ID:0dK6Hl59
?
Xの話じゃないの
Intel's Larrabee GPU Will Support Linux
http://www.phoronix.com/scan.php?page=news_item&px=NjYzOA
面白いことになったね
112 :Socket774 [↓] :2008/08/29(金) 19:24:32 ID:0dK6Hl59
?
Xの話じゃないの
65 :Socket774:2008/08/31(日) 14:12:14 ID:1sEe0nXS
普及の可能性があるとしたら、これ実はゲーム機ターゲットじゃないの?
先の将来性はありそうだが、当面使い道のないプロセッサに
アーキテクチャを普及させて、数をねじ込むとしたらコンソールが一番。
Intelも5年前は、Pentium 4しかなかったからPowerが席巻したが
これから数年後なら、面白いタイミングでもある。
もし可能性があるとしたら、MSだろうが
MSも自力でやろうとするとCellの二の舞になるから、Intelのコレは渡りに船だろう。
もちろんGPUは、別途ATIかNvidiaだろうがね。
今から数年後なら、飲めそうな範囲のコストでお互いの利益が一致する。
先の将来性はありそうだが、当面使い道のないプロセッサに
アーキテクチャを普及させて、数をねじ込むとしたらコンソールが一番。
Intelも5年前は、Pentium 4しかなかったからPowerが席巻したが
これから数年後なら、面白いタイミングでもある。
もし可能性があるとしたら、MSだろうが
MSも自力でやろうとするとCellの二の舞になるから、Intelのコレは渡りに船だろう。
もちろんGPUは、別途ATIかNvidiaだろうがね。
今から数年後なら、飲めそうな範囲のコストでお互いの利益が一致する。
ゲーム機にx86は要らないからな・・・
まあコスト次第だけど
MSの次世代機は、PowerとATIの組み合わせに、+Fusionの技術てトコで落ち着くんじゃ
まあコスト次第だけど
MSの次世代機は、PowerとATIの組み合わせに、+Fusionの技術てトコで落ち着くんじゃ
コンシューマの今世代の戦いはあと5年ほど持ちそうだなぁ。
以下冗談なんだけどさ、
CPUがAtomづある。でグラフィックがららびーにHDMIつけたやつ、
サウンドがららびーにジャックつけたやつ、
ネットワークがらら・・・。
ってかんじで、ららびーが全部メインメモリにつながってて、(IntelのなんとかViaってやつでもいいけどさ。
不要なユニットは別の用途につなげられるっていう、お馬鹿な設計でどこか出さないかねぇ。
多分現状でも3TFLOPS位出るような気がするんだけど。
以下冗談なんだけどさ、
CPUがAtomづある。でグラフィックがららびーにHDMIつけたやつ、
サウンドがららびーにジャックつけたやつ、
ネットワークがらら・・・。
ってかんじで、ららびーが全部メインメモリにつながってて、(IntelのなんとかViaってやつでもいいけどさ。
不要なユニットは別の用途につなげられるっていう、お馬鹿な設計でどこか出さないかねぇ。
多分現状でも3TFLOPS位出るような気がするんだけど。
>>59
ゲームまでも
10 :Socket774:2008/08/31(日) 20:24:37 ID:JpSgVC2q
ttp://jp.techcrunch.com/archives/20080709otoy-developing-server-side-3d-rendering-technology/
OTOYのサーバサイド・レンダリング技術
3Dの描画を従来のように個々のクライアントマシン(ユーザのパソコンなど)の上ではなく、ネットワークのサーバが行う。
「アプリケーションサービスとしてのゲーム(gaming as a service - GaaS)」とも呼ばれるこの技術を使うと、
もう、Xboxも要らない、Playstationも要らない、パソコンのパワーアップにお金をつぎ込む必要もない。
1台のモニタと少々の制御回路、そして受信と表示のためのソフトがあれば、
強力なサーバの大群から送られてくるコンテンツを楽しめる。
ゲームまでも
10 :Socket774:2008/08/31(日) 20:24:37 ID:JpSgVC2q
ttp://jp.techcrunch.com/archives/20080709otoy-developing-server-side-3d-rendering-technology/
OTOYのサーバサイド・レンダリング技術
3Dの描画を従来のように個々のクライアントマシン(ユーザのパソコンなど)の上ではなく、ネットワークのサーバが行う。
「アプリケーションサービスとしてのゲーム(gaming as a service - GaaS)」とも呼ばれるこの技術を使うと、
もう、Xboxも要らない、Playstationも要らない、パソコンのパワーアップにお金をつぎ込む必要もない。
1台のモニタと少々の制御回路、そして受信と表示のためのソフトがあれば、
強力なサーバの大群から送られてくるコンテンツを楽しめる。
ゲームの遠隔レンダリングはラグが大変なことになるから意味ないお。
ま、逆転の発想で、全員が同じレンダラファームにアクセスして遊ぶカジュアルゲームとか
10年ぐらいしたらあるかも知れないが。
ま、逆転の発想で、全員が同じレンダラファームにアクセスして遊ぶカジュアルゲームとか
10年ぐらいしたらあるかも知れないが。
15 :Socket774 [↓] :2008/08/31(日) 21:31:12 ID:JpSgVC2q
ttp://lucille.atso-net.jp/blog/?p=585
Larrabee paper review
まとめ
性能は微妙ですが、開発が既存のモデルをそのまま大体使えそうという利点は大きい.
Larrabee がいきなり既存の GPU を置き換えるとかリアルタイムレイトレプロセッサとして
使えるほどにはなれそうにありませんが(しかも実際に製品として出てくるにはあと
1,2 年かかることを考えると、さらに性能に疑問があります)、
たとえばオフラインレンダラの高速化などの、単なるプログラミングしやすい
演算アクセラレータとして使うにはいいかもしれません。
MUDA や lucille で Larrabee をサポートするのはどうするかなぁ… Intel の SDK の出来次第でしょうか.
‘08 末あたりにはシミュレータが提供されはじめるみたいなので、それから考えることにします.
ttp://lucille.atso-net.jp/blog/?p=585
Larrabee paper review
まとめ
性能は微妙ですが、開発が既存のモデルをそのまま大体使えそうという利点は大きい.
Larrabee がいきなり既存の GPU を置き換えるとかリアルタイムレイトレプロセッサとして
使えるほどにはなれそうにありませんが(しかも実際に製品として出てくるにはあと
1,2 年かかることを考えると、さらに性能に疑問があります)、
たとえばオフラインレンダラの高速化などの、単なるプログラミングしやすい
演算アクセラレータとして使うにはいいかもしれません。
MUDA や lucille で Larrabee をサポートするのはどうするかなぁ… Intel の SDK の出来次第でしょうか.
‘08 末あたりにはシミュレータが提供されはじめるみたいなので、それから考えることにします.
恐らくは、自身が開発してる物の方向性を信じるのはてのことなので当然かと
そういう人から見てもlarrabeeは微妙なんだね
そういう人から見てもlarrabeeは微妙なんだね
リアルタイムレイトレ面白いね。
結構動いてる。
ttp://slashdot.jp/~L.Entis/journal/449190
http://www.nicovideo.jp/watch/sm4413616
結構動いてる。
ttp://slashdot.jp/~L.Entis/journal/449190
http://www.nicovideo.jp/watch/sm4413616
NVIDIA Shows Interactive Ray Tracing on GPUs
http://www.hothardware.com/News/NVIDIA-Shows-Interactive-Ray-Tracing-on-GPUs/
この品質で1920x1080 30fps出るの??
http://www.hothardware.com/News/NVIDIA-Shows-Interactive-Ray-Tracing-on-GPUs/
この品質で1920x1080 30fps出るの??
nvのそのレイトレのデモ見たIntelは喜んだらしいよ
ショボイって
ショボイって
>>74
レイトレーシングだがポリゴンなのか。曲面の数式よりは負荷低いのかな
レイトレーシングだがポリゴンなのか。曲面の数式よりは負荷低いのかな
Intel リアルタイムレイトレーシングデモ
http://jp.youtube.com/watch?v=blfxI1cVOzU
http://www.youtube.com/watch?v=hIdvJONFOVU&feature=related
PS3 3台並列駆動でリアルタイムレイトレーシング(Cellによる描画)
http://www.youtube.com/watch?v=oLte5f34ya8&feature=related
http://jp.youtube.com/watch?v=blfxI1cVOzU
http://www.youtube.com/watch?v=hIdvJONFOVU&feature=related
PS3 3台並列駆動でリアルタイムレイトレーシング(Cellによる描画)
http://www.youtube.com/watch?v=oLte5f34ya8&feature=related
>>65
Intel needs a console deal to get Larrabee off the ground
http://www.theinquirer.net/gb/inquirer/news/2008/09/03/potential-console-deal-intel
新しいニュースだけどInquier曰く、Intelがホントに次世代Xbox向けに売り込んでるらしい。
CPUじゃなくてGPUだけど、次世代のLarrabeeをかなりのバーゲン価格にしてでも、
ゲームコンソールに採用させたいみたいだが…。
Intel needs a console deal to get Larrabee off the ground
http://www.theinquirer.net/gb/inquirer/news/2008/09/03/potential-console-deal-intel
新しいニュースだけどInquier曰く、Intelがホントに次世代Xbox向けに売り込んでるらしい。
CPUじゃなくてGPUだけど、次世代のLarrabeeをかなりのバーゲン価格にしてでも、
ゲームコンソールに採用させたいみたいだが…。
次世代Xboxが出る頃までに順当に進化した AMD Rxxx ベースのGPU
次世代Xboxが出る頃のプロセスに順調にシュリンクした Larrabee
Rxxx案を破棄するほどLarrabeeに魅力あるかなー
次世代Xboxが出る頃のプロセスに順調にシュリンクした Larrabee
Rxxx案を破棄するほどLarrabeeに魅力あるかなー
>>80
コスト抑えて完全互換できそうな可能性があるのって箱だけだよね
Wiiもエミュ出来るだろうしチップ乗っけても安いだろうけど
でも箱の完全互換はスゲー売りになるだろうしね
正直箱のゲームはもうみれる
コスト抑えて完全互換できそうな可能性があるのって箱だけだよね
Wiiもエミュ出来るだろうしチップ乗っけても安いだろうけど
でも箱の完全互換はスゲー売りになるだろうしね
正直箱のゲームはもうみれる
MSはXbox ngで、並列コードがx86で書けることには何の魅力を感じないと思うけどなー
Larabeeはパフォーマンスを抜きにすれば、GPUの終着駅まで行ってるな。
DirectXのバージョンが上がるごとに、GPUのプログラマビリティが少しずつ
広がっていってるが、最終的にはソフトレンダリング
ラスタライズGPU(nVIDIA、ATI) vs レイトレーシングGPU(Intel)
DirectXのバージョンが上がるごとに、GPUのプログラマビリティが少しずつ
広がっていってるが、最終的にはソフトレンダリング
ラスタライズGPU(nVIDIA、ATI) vs レイトレーシングGPU(Intel)
途中で書き込んでしまった。
まぁいいか。
まぁいいか。
486ベースにすればもっといっぱいコア積めたのに
87 :Socket774:2008/09/08(月) 07:45:12 ID:tNg+752J
IntelはLarabeeでゲームやらせるつもりなのか
HOT CHIPS 20 - Intelのグラフィックプロセサ「Larrabee」
ttp://journal.mycom.co.jp/articles/2008/09/06/hotchips5/001.html
適当に引用
>カナメは、32ビットの演算を16並列で実行するベクタユニット
>256ビット幅にしてNehalemの次世代のSandyBridgeで実装予定の
>AVX(Advanced Vector Extension)との機能の共通化をしないのは何故か
>256ビットから512ビットにするとかなり性能が上
>AVXは汎用的な計算処理を目指しているが、Larrabeeのベクタユニットは
>グラフィックス処理をメインに考えており、最適化のポイントが違う
ttp://journal.mycom.co.jp/articles/2008/09/06/hotchips5/001.html
適当に引用
>カナメは、32ビットの演算を16並列で実行するベクタユニット
>256ビット幅にしてNehalemの次世代のSandyBridgeで実装予定の
>AVX(Advanced Vector Extension)との機能の共通化をしないのは何故か
>256ビットから512ビットにするとかなり性能が上
>AVXは汎用的な計算処理を目指しているが、Larrabeeのベクタユニットは
>グラフィックス処理をメインに考えており、最適化のポイントが違う
>各コアは自分のL2キャッシュには高速でアクセスが出来
>リモートのキャッシュをアクセスする場合は、分散ディレクトリを参照して、
>目的のデータがあるL2キャッシュを判別してアクセスを行う
L2は総量全部フラットではないんだね
>リモートのキャッシュをアクセスする場合は、分散ディレクトリを参照して、
>目的のデータがあるL2キャッシュを判別してアクセスを行う
L2は総量全部フラットではないんだね
>Larrabeeでは各コアが自分のL2キャッシュに格納できる程度のサイズのタイルと呼ぶ
>フレームバッファの小領域を担当させるBinning Renderingという方式を用いる
PowerVR キター?
メモリコントローラには既存GUPほど広いバンド幅のものを積む気はなさそうだ
>フレームバッファの小領域を担当させるBinning Renderingという方式を用いる
PowerVR キター?
メモリコントローラには既存GUPほど広いバンド幅のものを積む気はなさそうだ
>Larrabeeの製品化は2009年の終わりから2010年の初めころと言われており、まだまだ先
>Intelが性能でNVIDIAやAMDに真っ向から対抗しようとするならば、
>16コアのリング2個をXringで接続した程度のチップを開発する必要がある
その頃には34コアCellも? 連投失礼
>Intelが性能でNVIDIAやAMDに真っ向から対抗しようとするならば、
>16コアのリング2個をXringで接続した程度のチップを開発する必要がある
その頃には34コアCellも? 連投失礼
>>87
CUDAはHPC分野で歓迎されてる
CUDAはHPC分野で歓迎されてる
CUDAは失敗が決定している
>>94
この動画何年前から存在すると思ってんのw
この動画何年前から存在すると思ってんのw
で、次世代らしき映像の片鱗なりが見られる映像はあるんでしょうか?
PCはまだまだ現世代でしかないし
つきぬけてんなこれって映像ないもんかしら
PCはまだまだ現世代でしかないし
つきぬけてんなこれって映像ないもんかしら
97 :Socket774:2008/09/09(火) 02:15:42 ID:ZEkNmK7V
は?
NVIDIAがPhysXをGeForceで動くようにしたみたいに、
IntelもHavokをLarrabeeで動くようにしてくれないかな?
IntelもHavokをLarrabeeで動くようにしてくれないかな?
よく考えたらDirectXのCPUでやっていたかなりの部分をララビーでやってくれるなら
CPUが頭打ちの今、普通の使い方でも結構存在価値があるような気がする
CPUが頭打ちの今、普通の使い方でも結構存在価値があるような気がする
CPUでネックになってるのはシングルパフォーマンスですので
意味ないですね
意味ないですね
101 :Socket774:2008/09/09(火) 11:21:02 ID:QkF/qIFL
所詮高クロック化した初代ペンチアムだからな、推して知るべし。
強化版SSEみたいのがのるんだよ?
LarrabeeがGPUとして駄目なのは火を見るより明らか。これは皆断言できるでしょう。
しかし多目的なアクセラレータとしては非常に期待感があるのは俺だけ?
サウンドエフェクトからエンコード、動画支援、セキュリティソフトの負荷軽減、起動、終了
X86コードが使えるから感がえ出したらきりが無いほど広がる。てかCPU要らなくね。
しかし多目的なアクセラレータとしては非常に期待感があるのは俺だけ?
サウンドエフェクトからエンコード、動画支援、セキュリティソフトの負荷軽減、起動、終了
X86コードが使えるから感がえ出したらきりが無いほど広がる。てかCPU要らなくね。
>>103
賛同!
大分前に俺もCPUの入れ替えになるもんだと思ってたんだが、
まー、メーカ的にはCPUも売りたいんだろうね。
>>67 の話もあるし。
まぁ、スパコンもスカラプロセッサとベクトルプロセッサを並搭するようになるみたいだから、
ここしばらくのトレンドなんでしょうなぁ。
賛同!
大分前に俺もCPUの入れ替えになるもんだと思ってたんだが、
まー、メーカ的にはCPUも売りたいんだろうね。
>>67 の話もあるし。
まぁ、スパコンもスカラプロセッサとベクトルプロセッサを並搭するようになるみたいだから、
ここしばらくのトレンドなんでしょうなぁ。
>>103
GPUにならない → ボリュームが出ない → 単価を安くできない → 普及しない
「多目的なアクセラレータ」を付けたとして、大多数のコンシューマPCユーザーに
とっての利点は現状ない。今後も >>59 のように、ますます無くなっていくよ。
次世代XBoxにでも採用されない限り、これはもう詰んでると思う。
個人的には欲しいけど、この世界、商売にならないものはあっという間に消えて
入手もできなくなるから、生きのこるか判らないものに投資できないんだよねー。
GPUにならない → ボリュームが出ない → 単価を安くできない → 普及しない
「多目的なアクセラレータ」を付けたとして、大多数のコンシューマPCユーザーに
とっての利点は現状ない。今後も >>59 のように、ますます無くなっていくよ。
次世代XBoxにでも採用されない限り、これはもう詰んでると思う。
個人的には欲しいけど、この世界、商売にならないものはあっという間に消えて
入手もできなくなるから、生きのこるか判らないものに投資できないんだよねー。
2D動画関連よりも重い処理の需要を何とかして掘り起こさないと、
何もせず放っておいたらCPUメーカーもDRAMメーカーみたいな
商売しか出来ない状況に追い込まれてしまうからIntelも必死なんだよ
何もせず放っておいたらCPUメーカーもDRAMメーカーみたいな
商売しか出来ない状況に追い込まれてしまうからIntelも必死なんだよ
>>106
まあそんなとこだね。
現状は、マルチコア化を進めているが、このままいくとコア単位性能でVIAに
追いつかれてしまう。Intelのプロセス優位が多くの場合無意味な状況が
まもなく来る。
日本メーカーがx86に再参入するには、絶好の機会だと思うんだけどね。
今ならVIAはもちろんAMDも数千億円で買える。
まあそんなとこだね。
現状は、マルチコア化を進めているが、このままいくとコア単位性能でVIAに
追いつかれてしまう。Intelのプロセス優位が多くの場合無意味な状況が
まもなく来る。
日本メーカーがx86に再参入するには、絶好の機会だと思うんだけどね。
今ならVIAはもちろんAMDも数千億円で買える。
108 :Socket774:2008/09/10(水) 18:51:11 ID:qy9WZRpH
開発者達はLarrabeeにやや懐疑的?
例えば,
「SSEの4×32ビットでさえ効率的に使うのは難しいのに16×32ビットのベクタ演算の効率が上げられるのか?」
という質問について太田氏は
「良質なツールの提供が重要になってくる」
オンボードVGAのドライバさえ満足に作れないIntelに出来るのか?
例えば,
「SSEの4×32ビットでさえ効率的に使うのは難しいのに16×32ビットのベクタ演算の効率が上げられるのか?」
という質問について太田氏は
「良質なツールの提供が重要になってくる」
オンボードVGAのドライバさえ満足に作れないIntelに出来るのか?
まぁVGAとしては普通のGPUの方が性能いいだろうしなぁ
よっぽどエンコとか他で一般的で性能が好ければいいけど
うーん、とりあえずエンコじゃGPGPUよりパフォーマンス発揮できそうだから
エンコ用API一杯出せばとりあえずPCゲーマーの何割かの人は取り込めるんじゃないかな
よっぽどエンコとか他で一般的で性能が好ければいいけど
うーん、とりあえずエンコじゃGPGPUよりパフォーマンス発揮できそうだから
エンコ用API一杯出せばとりあえずPCゲーマーの何割かの人は取り込めるんじゃないかな
サンプルボードは出るが、市場に量産品は出ない、に3ガバスかける。
DirectX 11のパフォーマンスはnVIDIAやATIに勝てないだろうけど、
永久にDirectXのバージョンアップに対応できるんじゃね?
永久にDirectXのバージョンアップに対応できるんじゃね?
ふとTILE64を思い出した。あれどうなったんだろう。
誘導
TILE64 part1
http://ghard.jisakuita.net/cell/1185631967.html 739-
TILE64 part2
http://ghard.jisakuita.net/cell/1188124579.html
TILE64 part1
http://ghard.jisakuita.net/cell/1185631967.html 739-
TILE64 part2
http://ghard.jisakuita.net/cell/1188124579.html
116 :Socket774:2008/09/11(木) 12:35:36 ID:KZaO4hp9
つか、なんで今更初代ペンティアムコアなの?
あれ、PPCにも負けてたんじゃなかったっけ?
あれ、PPCにも負けてたんじゃなかったっけ?
戻したのは考え方
それより新しいのはアウトオブオーダーで、1コア当たり・クロック当たりの
性能はあがるが、トランジスタ数当たりの効率はあがらない
積めるコア数がコアサイズに反比例するから、1コア当たりの
性能よりも、トランジスタ数当たりの性能が重視された
性能はあがるが、トランジスタ数当たりの効率はあがらない
積めるコア数がコアサイズに反比例するから、1コア当たりの
性能よりも、トランジスタ数当たりの性能が重視された
■ポラックの法則
CPUのダイサイズ2倍にしても性能は1.4倍にしかならない。
これを逆に応用して世代を戻した。
CPUのダイサイズ2倍にしても性能は1.4倍にしかならない。
これを逆に応用して世代を戻した。
「WinFastR PxVC1100」 SpursEngineを採用したPCI-Express ×1カード
ttp://www.leadtek.co.jp/news_release/ceatec2008.html
スレ違いだがあえて貼る
ttp://www.leadtek.co.jp/news_release/ceatec2008.html
スレ違いだがあえて貼る
121 :,,・´∀`・,,)っ:2008/09/11(木) 16:25:43 ID:mB6U7ole
x87はスタックマシン型の命令セットでアクティブレジスタは1本しかないから
レジスタリネーミング機構を備えないP5で浮動小数演算をやれば必ず依存関係が生じる。
このため、レイテンシ=スループットと、今日からすれば悪夢のような浮動小数演算性能。
たしかにこれではPPCに負けて当然。
新SIMD命令が中核だから別にx87が遅くても問題ない。
まあx87自体も4way FGMTでレイテンシ隠蔽できそうだが。
レジスタリネーミング機構を備えないP5で浮動小数演算をやれば必ず依存関係が生じる。
このため、レイテンシ=スループットと、今日からすれば悪夢のような浮動小数演算性能。
たしかにこれではPPCに負けて当然。
新SIMD命令が中核だから別にx87が遅くても問題ない。
まあx87自体も4way FGMTでレイテンシ隠蔽できそうだが。
122 :,,・´∀`・,,)っ:2008/09/11(木) 16:40:14 ID:mB6U7ole
VPUはコア毎1基だから、P5時代のU/Vみたいな非対称のデコードでも
VPU命令がどちらか片方でサイクル毎1マイクロ命令以上出力できればスループット的には問題ないことになる。
P5との違いは、デコード後はマイクロ命令はキューイングして汎用ALU/VPUの各演算ブロックにディスパッチするように見える。
このあたりはむしろP6ファミリーに近い。というよりはAtom?
VPU命令がどちらか片方でサイクル毎1マイクロ命令以上出力できればスループット的には問題ないことになる。
P5との違いは、デコード後はマイクロ命令はキューイングして汎用ALU/VPUの各演算ブロックにディスパッチするように見える。
このあたりはむしろP6ファミリーに近い。というよりはAtom?
専用メモリさえ積めば何とかなるし好感が持てる
UMAだったら死刑
UMAだったら死刑
>123
そうは言うがな大佐
こんなの普及させようと思ったら抱き合わせ販売しかなかろう
従来だったらノース内蔵にして低性能グラフィクスとしても使える
汎用アクセラレータ的位置付けでも行けただろうが
今後はそういうの無理となると、後はCPUにでも内蔵するしかない
やっぱ無理じゃね? このままだと普通にコケると思うよ
そうは言うがな大佐
こんなの普及させようと思ったら抱き合わせ販売しかなかろう
従来だったらノース内蔵にして低性能グラフィクスとしても使える
汎用アクセラレータ的位置付けでも行けただろうが
今後はそういうの無理となると、後はCPUにでも内蔵するしかない
やっぱ無理じゃね? このままだと普通にコケると思うよ
ララビーマンセー講演
[CEDEC 2008#12]Unreal Engineの生みの親Tim Sweeney氏が語る2012年から2020年にかけてのゲーム開発環境とは
http://www.4gamer.net/games/032/G003263/20080912053/
[CEDEC 2008#12]Unreal Engineの生みの親Tim Sweeney氏が語る2012年から2020年にかけてのゲーム開発環境とは
http://www.4gamer.net/games/032/G003263/20080912053/
UE3ってあの糞エンジンか
去年の売上上位のFPSって、Call OF Duty 4 , Orange Box , StalkerとかでUE勢でヒットしたのはBioShockくらいだったような。
ソフトウェアレンダリング信望者の意見としては妥当
信奉 信望
131 :Socket774:2008/09/15(月) 02:18:35 ID:LmpxhZ23
あげ
MPACTの亡霊が背後に見える
>132
intel的には正にソレ狙ってるんだし
亡霊つーよりむしろモロパクリ
intel的には正にソレ狙ってるんだし
亡霊つーよりむしろモロパクリ
ウマビー
ララビーララビーおやすみよ♪
ギザギザポリゴンの子守唄
900コアでいい
当時のままの386や486なら1チップに900コアは技術的には
可能だろうけど、マーケティング的に不可だろうな
可能だろうけど、マーケティング的に不可だろうな
ウマビー
141 :,,・´∀`・,,)っ-○◎●:2008/09/23(火) 20:12:55 ID:4mlWeJ+N
訳せません
これは年内に登場するのか?
2009半ばなら早いな 再来年頭かと思ってた
147 :Socket774:2008/10/06(月) 21:27:44 ID:0hSwGfF9
うーん。
いってることはPS3のcell ブロードバンドエンジンで行ってたこと
そのままなんだよなあ。
あれもcellにGPUやらせるっていってたし...
いってることはPS3のcell ブロードバンドエンジンで行ってたこと
そのままなんだよなあ。
あれもcellにGPUやらせるっていってたし...
149 :Socket774:2008/10/09(木) 16:01:43 ID:HHjjse95
ようするに、Intel版cellってことなんでしょ
ぜんぜん違うよーん
いっしょだよー
超低速で高レイテンンシのリングバスと
どうやって使うんだよっていう超無駄ワイドのSIMD
しかもセルのSPEのローカルストアみたいにメモリを各CPUで独立させず
コヒーレンシ処理するから、無駄な処理は増えて
さらに最初のは性能は512GFLOPSでまったく使えない。
超低速で高レイテンンシのリングバスと
どうやって使うんだよっていう超無駄ワイドのSIMD
しかもセルのSPEのローカルストアみたいにメモリを各CPUで独立させず
コヒーレンシ処理するから、無駄な処理は増えて
さらに最初のは性能は512GFLOPSでまったく使えない。
L2キャッシュのパーティションまたぎに速度は期待できないが、
明示的にコードを書かなくてもハードがやってくれる分だけ
Cellより楽、ってところか。
でもL2を高速ローカルメモリとして使いたい時には
やっぱりコーディングが必要と
明示的にコードを書かなくてもハードがやってくれる分だけ
Cellより楽、ってところか。
でもL2を高速ローカルメモリとして使いたい時には
やっぱりコーディングが必要と
大きな意味でプロセッサの設計に悩んでるんじゃないの
154 :Socket774:2008/10/09(木) 21:32:59 ID:HHjjse95
クロックが伸びないので、売りがないからでしょ
しかも、みんなで小馬鹿にしたcellが結構いいパフォーマンスだったりするからまねするしかないと
しかも、みんなで小馬鹿にしたcellが結構いいパフォーマンスだったりするからまねするしかないと
155 :,,・´∀`・,,)っ-○◎●:2008/10/10(金) 09:23:37 ID:VMFjn5J1
>>151
> 超低速で高レイテンンシのリングバスと
片方向512bit/secがどう低速なんだ?
64byteキャッシュラインを1エントリ分をシングルサイクル(スループット)で転送できる計算だ
暗にキャッシュラインはLoad/Storeユニットの幅と同じ64byte程度って示されてるが、
帯域そのものはL1と同程度であるといえる
> しかもセルのSPEのローカルストアみたいにメモリを各CPUで独立させず
> コヒーレンシ処理するから、無駄な処理は増えて
明示的に抑制するモードがあると書いてあったのでは?
そもそも、同じ理屈だとCore 2 Quadは反対側のダイ上のキャッシュに
アクセスするのに【FSBを経由】するからLarrabeeより更に酷い性能になることになるが。
そんなマルチスレッドプログラムは書く奴が馬鹿だよ
極力アドレスが被らないようにして同期・共有するアドレス空間アクセスの頻度は
最小限にするのは常識
> 超低速で高レイテンンシのリングバスと
片方向512bit/secがどう低速なんだ?
64byteキャッシュラインを1エントリ分をシングルサイクル(スループット)で転送できる計算だ
暗にキャッシュラインはLoad/Storeユニットの幅と同じ64byte程度って示されてるが、
帯域そのものはL1と同程度であるといえる
> しかもセルのSPEのローカルストアみたいにメモリを各CPUで独立させず
> コヒーレンシ処理するから、無駄な処理は増えて
明示的に抑制するモードがあると書いてあったのでは?
そもそも、同じ理屈だとCore 2 Quadは反対側のダイ上のキャッシュに
アクセスするのに【FSBを経由】するからLarrabeeより更に酷い性能になることになるが。
そんなマルチスレッドプログラムは書く奴が馬鹿だよ
極力アドレスが被らないようにして同期・共有するアドレス空間アクセスの頻度は
最小限にするのは常識
156 :,,・´∀`・,,)っ-○◎●:2008/10/10(金) 09:38:54 ID:VMFjn5J1
x86なので1バイト単位からの
SPE:16バイト単位の読み書きしかできない。
構造体アラインメントの問題がある。
命令間のレイテンシはなるべく小さくなるように設計されてるLarrabee(いつぞの資料によればL1ロードレイテンシが1)
に対し、SPEは非常にもっさり。同等の演算でもCore 2なんかの2倍のレイテンシを要する。
アンロールによりコードが伸びがち。
1コアあたり256KBのLS/L2でも全然効率が違うわけな。
メモリアドレッシングの効率は言うまでもないよな?
x86命令セット自体の強みはこれにあると言っても良い。
SPE:16バイト単位の読み書きしかできない。
構造体アラインメントの問題がある。
命令間のレイテンシはなるべく小さくなるように設計されてるLarrabee(いつぞの資料によればL1ロードレイテンシが1)
に対し、SPEは非常にもっさり。同等の演算でもCore 2なんかの2倍のレイテンシを要する。
アンロールによりコードが伸びがち。
1コアあたり256KBのLS/L2でも全然効率が違うわけな。
メモリアドレッシングの効率は言うまでもないよな?
x86命令セット自体の強みはこれにあると言っても良い。
157 :,,・´∀`・,,)っ-○◎●:2008/10/10(金) 09:39:37 ID:VMFjn5J1
↑訂正
Larrabeeはx86なので1バイト単位からのメモリアクセスが可能だが
SPEは16バイト単位の読み書きしかできない。
Larrabeeはx86なので1バイト単位からのメモリアクセスが可能だが
SPEは16バイト単位の読み書きしかできない。
512bit ringbusだと
ring bus自体の規模と消費電力も凄そうですね
ring bus自体の規模と消費電力も凄そうですね
3年後には解決
160 :,,・´∀`・,,)っ-○◎●:2008/10/10(金) 10:33:57 ID:VMFjn5J1
512bit/clkの間違いだ。氏ね俺
で、おまいらLarrabeeを何に使うんだ?
まさかGPUとして使うわけじゃないだろ?
まさかGPUとして使うわけじゃないだろ?
とりあえず、AV機器にでも使わせるんじゃね?
163 :,,・´∀`・,,)っ-○◎●:2008/10/10(金) 20:09:53 ID:VMFjn5J1
とりあえずリリースに先駆けてTMPGEncあたりが対応してくると思ってるが
普通に、CGのレンダリングに使う。
動的計画法のプログラムを載せて自分の研究に使う。
登場時点でx86の膨大なソフトウェア資産が使えるわけでもなし。
LarrabeeでWindowsを動かす!なんて誰も考えちゃおらんだろ。
CUDAやDirectX 11、OpenCLに比べて優位性を発揮できるもんかね?
「将来」メインストリームのCPUに命令が取り込まれるってだけじゃ厳しいと思うが。
LarrabeeでWindowsを動かす!なんて誰も考えちゃおらんだろ。
CUDAやDirectX 11、OpenCLに比べて優位性を発揮できるもんかね?
「将来」メインストリームのCPUに命令が取り込まれるってだけじゃ厳しいと思うが。
おいおい、中身はペンティアムだぜ・・
x86資産はそのまま使える。
x86資産はそのまま使える。
ペンティアム以降の命令を使ったx86資産は、そのままでは使えないだろ。
「ペンティアム以降の命令を使ったx86資産」を
わざわざLarrabeeのために書き換えるとも思えんし、
ペンティアムまでの命令を使った古いx86資産を
Larrabeeのために引っ張り出すとも思えんのだが。
「ペンティアム以降の命令を使ったx86資産」を
わざわざLarrabeeのために書き換えるとも思えんし、
ペンティアムまでの命令を使った古いx86資産を
Larrabeeのために引っ張り出すとも思えんのだが。
170 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 00:08:21 ID:ucUcLpmM
>>169
継承するコード資産は高級言語でいいじゃん。最適化なんてIntelコンパイラに任せておけよ。
Cellが何が駄目って、2005年の電撃的な発表以来、未だにIBM謹製のXL C/C++が「開発版」なんだぜ。
その意味じゃIntelは使い古したアーキテクチャの拡張故に地に足がついてる。
ちなみにLarrabeeはIntelの将来のCPUで搭載される命令を先行実装してるって言う意味では
過去の資産よりは「未来への資産」を重視してる。
AVXの更に先の世代ではLarrabeeのSIMD拡張は普通のCPUに搭載されることになる。
その点GPU屋なんかいい加減なもんだよ。世代毎にアーキがコロコロ変わるから、コンパイルし直さないと性能が出ない。
ソフト屋だってGPUメーカー1社あたりに何世代分も最適化コード吐いてられるほど暇じゃないんだぜ。
GPU(= Game Processing Unit)屋に任せてたらGPGPUはいつまでも流行らないって。
> CUDAやDirectX 11、OpenCLに比べて
逆に、どこがどう優位なんだ?
Game Processing(笑)にとらわれない汎用的な性能を追求すればLarrabeeが遙かに先を進んでるわけで。
何を追求するかの違いでしかない。その上でプロセスルールではIntelが最優位。
継承するコード資産は高級言語でいいじゃん。最適化なんてIntelコンパイラに任せておけよ。
Cellが何が駄目って、2005年の電撃的な発表以来、未だにIBM謹製のXL C/C++が「開発版」なんだぜ。
その意味じゃIntelは使い古したアーキテクチャの拡張故に地に足がついてる。
ちなみにLarrabeeはIntelの将来のCPUで搭載される命令を先行実装してるって言う意味では
過去の資産よりは「未来への資産」を重視してる。
AVXの更に先の世代ではLarrabeeのSIMD拡張は普通のCPUに搭載されることになる。
その点GPU屋なんかいい加減なもんだよ。世代毎にアーキがコロコロ変わるから、コンパイルし直さないと性能が出ない。
ソフト屋だってGPUメーカー1社あたりに何世代分も最適化コード吐いてられるほど暇じゃないんだぜ。
GPU(= Game Processing Unit)屋に任せてたらGPGPUはいつまでも流行らないって。
> CUDAやDirectX 11、OpenCLに比べて
逆に、どこがどう優位なんだ?
Game Processing(笑)にとらわれない汎用的な性能を追求すればLarrabeeが遙かに先を進んでるわけで。
何を追求するかの違いでしかない。その上でプロセスルールではIntelが最優位。
アドレス直に弄れる言語の資産は全滅だろ?
x86である価値ほとんど無いじゃん
x86である価値ほとんど無いじゃん
172 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 00:21:33 ID:ucUcLpmM
>アドレス直に弄れる言語の資産は全滅だろ?
FORTRANより後発のCが流行った理由って知ってる?
>x86である価値ほとんど無いじゃん
先見性の無い奴だな。猫も杓子もx86の時代はすぐそこだ。
x86 ISAは大規模・多様化するソフト開発におけるデファクトスタンダードになる。
http://headlines.yahoo.co.jp/hl?a=20081014-00000104-zdn_n-sci
FORTRANより後発のCが流行った理由って知ってる?
>x86である価値ほとんど無いじゃん
先見性の無い奴だな。猫も杓子もx86の時代はすぐそこだ。
x86 ISAは大規模・多様化するソフト開発におけるデファクトスタンダードになる。
http://headlines.yahoo.co.jp/hl?a=20081014-00000104-zdn_n-sci
Game Processing(笑)
であっても、とりあえず最初はそちら方面にフォーカスして宣伝しなきゃ
いけないっつーのがこれまたなんっつーか、あ〜ムニャムニャ
http://ascii.jp/elem/000/000/123/123347/02-04_o_.jpg
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
http://www.4gamer.net/games/021/G002195/
http://www.4gamer.net/games/032/G003263/20070919044/
http://www.4gamer.net/games/047/G004713/20080222012/
であっても、とりあえず最初はそちら方面にフォーカスして宣伝しなきゃ
いけないっつーのがこれまたなんっつーか、あ〜ムニャムニャ
http://ascii.jp/elem/000/000/123/123347/02-04_o_.jpg
{kind=link}
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
http://www.4gamer.net/games/021/G002195/
http://www.4gamer.net/games/032/G003263/20070919044/
http://www.4gamer.net/games/047/G004713/20080222012/
174 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 00:43:37 ID:ucUcLpmM
もちろんゲーム(笑)ですら勝機があるからでしょ。すぐに結果を出すのは無理とは思うが。
物理演算エンジンを買い取ったのもその一環。
GPUで出来ない演算をCPUにやらせてる以上はCPU-GPU間のデータ交換がボトルネックになる。
サーフェイス作ってブロック転送とかアホの子みたいなことをいちいちやってるのが今日のGPGPU。
ワンボードのGPUだけ(Intel的にはCPUだけ)で物理演算が完結するならそれに越したことはない。
1コアあたりのキャッシュが大きくて、SIMDだけでなくスカラ処理もそつなくこなせる
CPUを転用したようなアーキテクチャの方が有利だろうね
物理演算エンジンを買い取ったのもその一環。
GPUで出来ない演算をCPUにやらせてる以上はCPU-GPU間のデータ交換がボトルネックになる。
サーフェイス作ってブロック転送とかアホの子みたいなことをいちいちやってるのが今日のGPGPU。
ワンボードのGPUだけ(Intel的にはCPUだけ)で物理演算が完結するならそれに越したことはない。
1コアあたりのキャッシュが大きくて、SIMDだけでなくスカラ処理もそつなくこなせる
CPUを転用したようなアーキテクチャの方が有利だろうね
金融工学や分子構造や画像診断や地下資源探索じゃ見た目しょぼい。
ゲームだレイトレだ物理演算だぞと、インパクトのあるわかりやすさ重視でアピールして、
そっち系PCサイトやエンスージアストゲーマーを釣り上げた方が遥かに反応が良い。
ゲームだレイトレだ物理演算だぞと、インパクトのあるわかりやすさ重視でアピールして、
そっち系PCサイトやエンスージアストゲーマーを釣り上げた方が遥かに反応が良い。
コンパイルしなおすだけでマルチコア対応になるんだったら苦労しねーよ
ソースコード書き直しなんだからなじみのあるx86だとかはどうでもいい
ソースコード書き直しなんだからなじみのあるx86だとかはどうでもいい
素人でスマンがx86ってそんなに癌なの?
命令セットを刷新すると幸せになれる?
命令セットを刷新すると幸せになれる?
178 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 01:41:03 ID:ucUcLpmM
>コンパイルしなおすだけでマルチコア対応になるんだったら苦労しねーよ
まあもしIntelの謹製ツール使わずに開発しようってんなら本物のマゾだね。
マトリクス演算程度ならICC単体でも容易にベクトル化・スレッド化できるよ。
来年のICC11でAVXを使ったコードも吐くようになる予定。
Larrabee向けの開発ツールも来年ごろには出てくるんじゃね?
まあもしIntelの謹製ツール使わずに開発しようってんなら本物のマゾだね。
マトリクス演算程度ならICC単体でも容易にベクトル化・スレッド化できるよ。
来年のICC11でAVXを使ったコードも吐くようになる予定。
Larrabee向けの開発ツールも来年ごろには出てくるんじゃね?
179 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 02:08:41 ID:ucUcLpmM
>>177
PowerPC信奉の古いマカーをはじめRISC儲が盲目的に信じてきたことだな。
Appleがいまどっちにいるかを考えてみれ。
可変長命令フォーマットゆえに命令の切り出しのコストがかかるのは事実だよ。
1クロックに何命令も同時実行するようなプロセッサには切り出しに莫大なコストがかかる
逆にいうと1クロックあたり1〜2命令処理するんならそんなにコストはかからない。
x86は可変長とはいえ、ModRMフィールドさえ検出すれば命令の終端および次の命令の始端は簡単に求まる。
SIB+DISPの有無・長さがModRMを見るだけでわかるから。
それ以前にやらないといけないのは、imm8の有無の判定と、プリフィクスバイトの読み飛ばし。
まあ言ってみればこのプリフィクスバイトこそがx86の癌なんだが、Larrabeeではそんなに問題にならないはずだ。
AVXは、VEXエンコーディングによりModRMまでの長さを一定とすることでプリデコード処理を簡易化するが
Larrabeeでも512bit SIMD命令にはこのVEXフォーマットが使われる。
命令を切り出すためだけに場合によってプリフィクスバイトを読み捨てながらOpcodeバイト・ModRMバイトを
探索する羽目になるという、理不尽なしがらみから開放されるものだ。
PowerPC信奉の古いマカーをはじめRISC儲が盲目的に信じてきたことだな。
Appleがいまどっちにいるかを考えてみれ。
可変長命令フォーマットゆえに命令の切り出しのコストがかかるのは事実だよ。
1クロックに何命令も同時実行するようなプロセッサには切り出しに莫大なコストがかかる
逆にいうと1クロックあたり1〜2命令処理するんならそんなにコストはかからない。
x86は可変長とはいえ、ModRMフィールドさえ検出すれば命令の終端および次の命令の始端は簡単に求まる。
SIB+DISPの有無・長さがModRMを見るだけでわかるから。
それ以前にやらないといけないのは、imm8の有無の判定と、プリフィクスバイトの読み飛ばし。
まあ言ってみればこのプリフィクスバイトこそがx86の癌なんだが、Larrabeeではそんなに問題にならないはずだ。
AVXは、VEXエンコーディングによりModRMまでの長さを一定とすることでプリデコード処理を簡易化するが
Larrabeeでも512bit SIMD命令にはこのVEXフォーマットが使われる。
命令を切り出すためだけに場合によってプリフィクスバイトを読み捨てながらOpcodeバイト・ModRMバイトを
探索する羽目になるという、理不尽なしがらみから開放されるものだ。
181 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 02:53:42 ID:ucUcLpmM
・3バイト版VEXの場合
C4→ModRMの位置は4バイト目と仮定
→ペイロードのm-mmmmフィールドを参照し、0F3Aならimm8あり、0F38なら無し、0FならOpcodeバイトで判別
→0FのときもしVZEROUPPER/VZEROALLならOpcodeまでで終端
2バイト版VEXの場合
C5→ModRMの位置は3バイト目と仮定
→Opcodeバイトによりimm8の有無を判別。もしVZEROUPPER/VZEROALLならOpcodeまでで終端
32ビットモードの場合、LDS/LESと共存してるので多少判定コストが高くなるがたいしたことは無い
先頭バイトを見ただけでプリデコードアルゴリズムが決まってしまう、なんと合理的なことか。
ModRMバイトを見てSIB・DISPの有無・長さを判別するアルゴリズムは何十年物のノウハウがあるので
このへんは大して負担にはならないはず(つか、単純にテーブルルックアップで求まるだろ)
POWERにも最近は8バイト命令があったりするから必ずしもデコードは低コストではないよ
逆にさ、こんな変態命令フォーマット
(66|F3|F2) (REX) 0F (38|3A) Opcode ModRM (SIB) (disp8|disp32) (imm8)
も含め、最大6命令も同時に切り出しできるCore 2ってどんだけ力任せなんだよっていう。
C4→ModRMの位置は4バイト目と仮定
→ペイロードのm-mmmmフィールドを参照し、0F3Aならimm8あり、0F38なら無し、0FならOpcodeバイトで判別
→0FのときもしVZEROUPPER/VZEROALLならOpcodeまでで終端
2バイト版VEXの場合
C5→ModRMの位置は3バイト目と仮定
→Opcodeバイトによりimm8の有無を判別。もしVZEROUPPER/VZEROALLならOpcodeまでで終端
32ビットモードの場合、LDS/LESと共存してるので多少判定コストが高くなるがたいしたことは無い
先頭バイトを見ただけでプリデコードアルゴリズムが決まってしまう、なんと合理的なことか。
ModRMバイトを見てSIB・DISPの有無・長さを判別するアルゴリズムは何十年物のノウハウがあるので
このへんは大して負担にはならないはず(つか、単純にテーブルルックアップで求まるだろ)
POWERにも最近は8バイト命令があったりするから必ずしもデコードは低コストではないよ
逆にさ、こんな変態命令フォーマット
(66|F3|F2) (REX) 0F (38|3A) Opcode ModRM (SIB) (disp8|disp32) (imm8)
も含め、最大6命令も同時に切り出しできるCore 2ってどんだけ力任せなんだよっていう。
182 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 02:55:24 ID:ucUcLpmM
>>180
モノによる。Intelがドキュメント出してるけど、自動ベクトル化しやすいコードの作法ってのがあるから読んでおくといい。
モノによる。Intelがドキュメント出してるけど、自動ベクトル化しやすいコードの作法ってのがあるから読んでおくといい。
183 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 03:04:49 ID:ucUcLpmM
だろ?
現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
かつコア数増やしても全然スケールしない。
だからLarrabeeでもパフォーマンス出すためには書き直しが必要なのは目に見えてる。
x86であることはIntelの中の人の資産がいかせるってだけでしょ。
現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
かつコア数増やしても全然スケールしない。
だからLarrabeeでもパフォーマンス出すためには書き直しが必要なのは目に見えてる。
x86であることはIntelの中の人の資産がいかせるってだけでしょ。
185 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 03:19:37 ID:ucUcLpmM
中の人が生かせる
→十分じゃん
>現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
>かつコア数増やしても全然スケールしない。
逆に、なにを並列化しようとしてんの?
2コア4コア向けにでも分割処理の叩き台作っちゃえばあとは何コアだろうと簡単に応用できるもんだと思うけどな。
俺はOpenMPやらMPIなんて信用したこともないしする気もない。
ちなみに
http://www.intel.com/cd/software/products/asmo-na/eng/294797.htm
がCUDAやCALでも使えるなら、ぜひとも検討したいが。
→十分じゃん
>現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
>かつコア数増やしても全然スケールしない。
逆に、なにを並列化しようとしてんの?
2コア4コア向けにでも分割処理の叩き台作っちゃえばあとは何コアだろうと簡単に応用できるもんだと思うけどな。
俺はOpenMPやらMPIなんて信用したこともないしする気もない。
ちなみに
http://www.intel.com/cd/software/products/asmo-na/eng/294797.htm
がCUDAやCALでも使えるなら、ぜひとも検討したいが。
186 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 03:22:38 ID:ucUcLpmM
>>185
> 中の人が生かせる
> →十分じゃん
言いたいことは開発者の手元にあるx86のコード資産は生かせないということ
> >現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
> >かつコア数増やしても全然スケールしない。
>
> 逆に、なにを並列化しようとしてんの?
> 2コア4コア向けにでも分割処理の叩き台作っちゃえばあとは何コアだろうと簡単に応用できるもんだと思うけどな。
> 俺はOpenMPやらMPIなんて信用したこともないしする気もない。
アムダールの法則
これを乗り越えるためには根本的に設計見直す必要あり
> 中の人が生かせる
> →十分じゃん
言いたいことは開発者の手元にあるx86のコード資産は生かせないということ
> >現状Intelの並列化コンパイラ使ってもせいぜい10数%程度しかパフォーマンスは向上しない。
> >かつコア数増やしても全然スケールしない。
>
> 逆に、なにを並列化しようとしてんの?
> 2コア4コア向けにでも分割処理の叩き台作っちゃえばあとは何コアだろうと簡単に応用できるもんだと思うけどな。
> 俺はOpenMPやらMPIなんて信用したこともないしする気もない。
アムダールの法則
これを乗り越えるためには根本的に設計見直す必要あり
昔ベクトル化率向上による最適化に挑んでいたことがあるが
解法の選択まで戻らなければならないケースが多々あったな
解法の選択まで戻らなければならないケースが多々あったな
だめじゃん
190 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 07:37:27 ID:ucUcLpmM
>>187
で、Larrabeeは駄目でCUDAやCALは天国か?んなわきゃないよ。
そういう顧客には今のCoreファミリが最適なソリューションだ。
メニーコアのスケーラビリティは並列化問題に打ち勝った人へのご褒美さ。盆暗は求めちゃいけないんだ。
ああ大丈夫、馬鹿にも全にも使えるすべての開発者がフルに性能を発揮できるプロセッサに
なることなんて当のIntelだって目指してない。
普段はグラフィックプロセッシングというごく身近な課題さえこなしてくれてれば十分なわけだからね。
もちろん、過去のx86バイナリ資産やアセンブリコードの資産が使えなくとも批判される謂われも無い。
他はそれ以前の問題だから。
で、Larrabeeは駄目でCUDAやCALは天国か?んなわきゃないよ。
そういう顧客には今のCoreファミリが最適なソリューションだ。
メニーコアのスケーラビリティは並列化問題に打ち勝った人へのご褒美さ。盆暗は求めちゃいけないんだ。
ああ大丈夫、馬鹿にも全にも使えるすべての開発者がフルに性能を発揮できるプロセッサに
なることなんて当のIntelだって目指してない。
普段はグラフィックプロセッシングというごく身近な課題さえこなしてくれてれば十分なわけだからね。
もちろん、過去のx86バイナリ資産やアセンブリコードの資産が使えなくとも批判される謂われも無い。
他はそれ以前の問題だから。
誰もCUDAやCALが天国なんて書いてないだろ。
x86のコード資産がLarrabeeの利点にならないだけ。
Larrabee向けに書き換えるぐらいならC2D使ったほうが良い。
「未来への資産」なら、どう考えてもニッチのLarrabee向けに書き換えるより、
CPUに命令が実装されてからで十分。
CPUにどんな形で実装されるかわからんから、
CPU向けにコンパイルしなおさないと性能が出ない恐れがある。
x86のコード資産がLarrabeeの利点にならないだけ。
Larrabee向けに書き換えるぐらいならC2D使ったほうが良い。
「未来への資産」なら、どう考えてもニッチのLarrabee向けに書き換えるより、
CPUに命令が実装されてからで十分。
CPUにどんな形で実装されるかわからんから、
CPU向けにコンパイルしなおさないと性能が出ない恐れがある。
192 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 07:55:39 ID:ucUcLpmM
ならないことが何の問題が?
未来への資産ってだけでも十分だと思うけど。
未来への資産ってだけでも十分だと思うけど。
193 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 07:56:52 ID:ucUcLpmM
512ビット SIMD向けに並列化できるコードを書いておけばそれより小さい単位に落とし込むのは楽だぞ?
194 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 07:59:04 ID:ucUcLpmM
だからそういう考えの開発者にはGPGPUなんて使いこなせっこ無いからね
Intelだって自らのパラダイムに引き込む必要ない。
もっと世の中広いんだよ。己の狭い了見を押し付けないように。
Intelだって自らのパラダイムに引き込む必要ない。
もっと世の中広いんだよ。己の狭い了見を押し付けないように。
お前ら見えない奴と戦うな
197 :,,・´∀`・,,)っ-○◎●:2008/10/15(水) 08:10:11 ID:ucUcLpmM
> コンパイルし直さないと性能が出ないって言ってた、
は?
すべてのコンピューティングに通用するソリューションだと思ってるなら勘違いだし
通用させようという気はIntelすら持ち合わせてない。
エンコーディングやレンダリングといった並列度の高い仕事をやらせておけばいいのに
なにを火病ってるの?
君が使いこなせないからと言っても他に使いたい人はいるんだよ?
は?
すべてのコンピューティングに通用するソリューションだと思ってるなら勘違いだし
通用させようという気はIntelすら持ち合わせてない。
エンコーディングやレンダリングといった並列度の高い仕事をやらせておけばいいのに
なにを火病ってるの?
君が使いこなせないからと言っても他に使いたい人はいるんだよ?
製造業とは違ってソフトはデジタル信号の並びでしかなく簡単にコピーできるからね。
消費者が使うのは一握りの優れた人の作った優れたソフト。底辺プログラマーがマルチコアが難しかろうがトップがやれる以上、大勢には影響ない。
いうならば出口で淘汰されるか門前払いされるかの違いでしかなく、いずれにしても無能には用はない。
消費者が使うのは一握りの優れた人の作った優れたソフト。底辺プログラマーがマルチコアが難しかろうがトップがやれる以上、大勢には影響ない。
いうならば出口で淘汰されるか門前払いされるかの違いでしかなく、いずれにしても無能には用はない。
・将来のCPUに実装するLNIの露払い
・SandyBridgeで採用するring busの実験
にしかすぎないプロセッサに対してマジレス合戦すんな。
・SandyBridgeで採用するring busの実験
にしかすぎないプロセッサに対してマジレス合戦すんな。
200 :Socket774:2008/10/15(水) 14:02:28 ID:7FjXKPPE
のびてるから何か新しい情報出たのかと思ったら
ガッカリさすなやage
ガッカリさすなやage
GPGPUスレ落ちた?
日本のメーカーもプロセッサ開発を完全に放棄したわけではないようだが
PC向けとかは全然眼中にないみたいだな
ttp://journal.mycom.co.jp/news/2008/10/15/040/index.html
日本のメーカーもプロセッサ開発を完全に放棄したわけではないようだが
PC向けとかは全然眼中にないみたいだな
ttp://journal.mycom.co.jp/news/2008/10/15/040/index.html
利鞘の大きいPC向けはみんな作りたいと思ってるだろう。
でもインテルに対抗できないから誰も作ろうとしない。
一応NECはまだSX作ってるけどね。
でもインテルに対抗できないから誰も作ろうとしない。
一応NECはまだSX作ってるけどね。
>>170
,,・´∀`・,,)っ-○◎●よ、おまえ後藤だろ
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
Sunのメニーコアの話を聞いたとき初代ペンティアムをいっぱい並べるのを空想したが
まさか本当になるとは
Atomを128個並べるチップとかも可能じゃないか
,,・´∀`・,,)っ-○◎●よ、おまえ後藤だろ
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
Sunのメニーコアの話を聞いたとき初代ペンティアムをいっぱい並べるのを空想したが
まさか本当になるとは
Atomを128個並べるチップとかも可能じゃないか
また半強制新命令縛りで性能の底上げですか?
またAMDに追いつかれちゃって大慌てしそうな予感
206 :,,・´∀`・,,)っ-○◎●:2008/10/18(土) 13:20:56 ID:3i9EJ3i8
>>203
後藤は嘘を平気で言って訂正しないので嫌いです。馬鹿には支持されてるからたちが悪い。
後藤は嘘を平気で言って訂正しないので嫌いです。馬鹿には支持されてるからたちが悪い。
>>206
訂正されてないウソの例を幾つかよろ。
訂正されてないウソの例を幾つかよろ。
208 :,,・´∀`・,,)っ-○◎●:2008/10/18(土) 14:01:50 ID:3i9EJ3i8
「NehalemではStoreユニットはStore AddressとStore Dataに分かれた」
実際はPentium Pro時代からそういう構成です
記事をカンニングしたらしい安藤も同じ勘違いをしてる。
実際はPentium Pro時代からそういう構成です
記事をカンニングしたらしい安藤も同じ勘違いをしてる。
209 :,,・´∀`・,,)っ-○◎●:2008/10/18(土) 14:14:42 ID:3i9EJ3i8
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
>MMX Pentium以降のMMX/SSE系の拡張命令は、サポートしないと推測される。
>これは、同じ“巻き戻し型”CPUでも、Silverthorne系との大きな違いとなっている。
「推測」は書かなきゃ良いんだけどねぇ。
当たったためしがあったか?
で、後藤がこう思った理由はたぶん「デコーダが複雑になるから」だろ?
シングルサイクルでプリフィックスコードが大量に付いた命令をデコードすることを諦めさえすれば
別にSSEのサポートは困難ではないよ。
別にソフトエミュレーション(OSでトラップして実行)でもいいけど。
ちなみにIntelはLarrabeeにてStandard 64-bit Extensionをサポートすると明言してる。
Intelの64bit拡張のStandardとは、少なくともSSE3までのSIMD命令を含みます。
>MMX Pentium以降のMMX/SSE系の拡張命令は、サポートしないと推測される。
>これは、同じ“巻き戻し型”CPUでも、Silverthorne系との大きな違いとなっている。
「推測」は書かなきゃ良いんだけどねぇ。
当たったためしがあったか?
で、後藤がこう思った理由はたぶん「デコーダが複雑になるから」だろ?
シングルサイクルでプリフィックスコードが大量に付いた命令をデコードすることを諦めさえすれば
別にSSEのサポートは困難ではないよ。
別にソフトエミュレーション(OSでトラップして実行)でもいいけど。
ちなみにIntelはLarrabeeにてStandard 64-bit Extensionをサポートすると明言してる。
Intelの64bit拡張のStandardとは、少なくともSSE3までのSIMD命令を含みます。
210 :MACオタ>団子 さん:2008/10/18(土) 14:56:43 ID:8sSawSax
>>206
--------------------
後藤は嘘を平気で言って訂正しないので嫌いです。
--------------------
http://pc.watch.impress.co.jp/docs/2003/0602/kaigai01.htm
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
http://pc.watch.impress.co.jp/docs/2005/0621/kaigai192.htm
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
「後藤」「訂正」とかで沢山みつかるような気が。。。。
>>209
その推測わ、まだ間違いと確定していないす。
--------------------
「推測」は書かなきゃ良いんだけどねぇ。
当たったためしがあったか?
--------------------
Nehalemの命令帯域やら、Larrabeeのベクトル幅で大言壮語して恥をかいた誰かさんわ?
--------------------
後藤は嘘を平気で言って訂正しないので嫌いです。
--------------------
http://pc.watch.impress.co.jp/docs/2003/0602/kaigai01.htm
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
http://pc.watch.impress.co.jp/docs/2005/0621/kaigai192.htm
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
「後藤」「訂正」とかで沢山みつかるような気が。。。。
>>209
その推測わ、まだ間違いと確定していないす。
--------------------
「推測」は書かなきゃ良いんだけどねぇ。
当たったためしがあったか?
--------------------
Nehalemの命令帯域やら、Larrabeeのベクトル幅で大言壮語して恥をかいた誰かさんわ?
浮動小数演算のレイテンシが1のプロセッサがあると聞いた事があるんだけど誰か知らない?
212 :MACオタ>211 さん:2008/10/18(土) 15:12:13 ID:8sSawSax
>>211
当該コメントわ、依存命令へのフィードバック(デノーマル等の丸め処理無し)の話で、実例も
下記のように書いたかと思うす。未だに粘着しているということわ、内容が理解できなかったすか。。。
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/213
========================
213 名前:MACオタ>団子 さん 投稿日:2008/08/17(日) 16:46:04 ID:Zsenu7UF
>>207
------------------
スループット1をレイテンシ1だと思ってますなwwwww
------------------
古いコアデザインが回帰しているということで、PowerPC G4あたりのマニュアルでもどうぞ。
FMAをやるから加算のみでも1を乗ずる分余計にサイクルがかかるだけで、シングルステージ
で加算を行うす。
http://www.freescale.com/files/32bit/doc/ref_manual/MPC7410UM.pdf (Figure 6-3参照)
========================
当該コメントわ、依存命令へのフィードバック(デノーマル等の丸め処理無し)の話で、実例も
下記のように書いたかと思うす。未だに粘着しているということわ、内容が理解できなかったすか。。。
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/213
========================
213 名前:MACオタ>団子 さん 投稿日:2008/08/17(日) 16:46:04 ID:Zsenu7UF
>>207
------------------
スループット1をレイテンシ1だと思ってますなwwwww
------------------
古いコアデザインが回帰しているということで、PowerPC G4あたりのマニュアルでもどうぞ。
FMAをやるから加算のみでも1を乗ずる分余計にサイクルがかかるだけで、シングルステージ
で加算を行うす。
http://www.freescale.com/files/32bit/doc/ref_manual/MPC7410UM.pdf (Figure 6-3参照)
========================
213 :,,・´∀`・,,)っ:2008/10/18(土) 15:41:51 ID:zYJcwEab
>>210とか自作板一の恥晒しが何か言ってるよ
MACオタとダンゴが取っ組み合ってるスレかよ
「バカとキチガイの対決」ってヤツだ
216 :,,・´∀`・,,)っ:2008/10/18(土) 16:18:25 ID:zYJcwEab
>>212でまた無知蒙昧なMACオタが恥さらしてるな
AltiVecの積和算は乗算と一緒に加算値のデコードを平行して行い、IEEE754形式に正規化する前に加算を
畳み込んでるから乗算と加算を独立でやるより低レイテンシでできるだけで
FP加算の一連のサイクルそのもののレイテンシが短いわけではない。
現にG4もvfaddのレイテンシは4くらいだろ?
だんごやさんがたとえてあげる
朝のコンビニでパンを1つ買うためにレジに並ぶのとほぼ同等の手間で
パンと牛乳を一緒に持って並んで買うことはできるかもしれないが
それは牛乳を買うためのレジの待ち時間が短いことを意味しない。
AltiVecの積和算は乗算と一緒に加算値のデコードを平行して行い、IEEE754形式に正規化する前に加算を
畳み込んでるから乗算と加算を独立でやるより低レイテンシでできるだけで
FP加算の一連のサイクルそのもののレイテンシが短いわけではない。
現にG4もvfaddのレイテンシは4くらいだろ?
だんごやさんがたとえてあげる
朝のコンビニでパンを1つ買うためにレジに並ぶのとほぼ同等の手間で
パンと牛乳を一緒に持って並んで買うことはできるかもしれないが
それは牛乳を買うためのレジの待ち時間が短いことを意味しない。
217 :MACオタ>団子 さん:2008/10/18(土) 16:40:12 ID:8sSawSax
>>216
恥ずかしい間違いを取り繕うために、ソースも無い電波説を書き込むから恥を書くす。。。
-----------------
AltiVecの積和算
-----------------
>>213のリンク先を読めば判るようにスカラFPUの話題で、Altivecじゃ無いす。
そして、3段のステージの解説わFigure 6-3に「Multiply, Add, Round/Normalize」と明記されているす。
ちなみに、この当時のClassic PowerPCの解説わ沢山あるす。例えば
http://www-01.ibm.com/chips/techlib/techlib.nsf/techdocs/852569B20050FF7785256996007558C6/$file/cwg.pdf (p.105)
-----------------------
Figure 4-4 shows the floating-point pipeline. The execute stages have a multiply-add
structure: 1 cycle for multiply, 1 cycle for add, and one cycle for normalization.
-----------------------
恥ずかしい間違いを取り繕うために、ソースも無い電波説を書き込むから恥を書くす。。。
-----------------
AltiVecの積和算
-----------------
>>213のリンク先を読めば判るようにスカラFPUの話題で、Altivecじゃ無いす。
そして、3段のステージの解説わFigure 6-3に「Multiply, Add, Round/Normalize」と明記されているす。
ちなみに、この当時のClassic PowerPCの解説わ沢山あるす。例えば
http://www-01.ibm.com/chips/techlib/techlib.nsf/techdocs/852569B20050FF7785256996007558C6/$file/cwg.pdf (p.105)
-----------------------
Figure 4-4 shows the floating-point pipeline. The execute stages have a multiply-add
structure: 1 cycle for multiply, 1 cycle for add, and one cycle for normalization.
-----------------------
>>216
ちなみに、
-----------------
IEEE754形式に正規化する前に加算を畳み込んでるから
-----------------
この辺の話わ、正規化ステージ抜きに値を後続の命令にフィードバックできるという話と同じすから、
あなたの説の弁護になっていないことに気付くべきかと思うす。
ちなみに、
-----------------
IEEE754形式に正規化する前に加算を畳み込んでるから
-----------------
この辺の話わ、正規化ステージ抜きに値を後続の命令にフィードバックできるという話と同じすから、
あなたの説の弁護になっていないことに気付くべきかと思うす。
219 :,,・´∀`・,,)っ:2008/10/18(土) 16:57:51 ID:zYJcwEab
>>217-218
話にならんバカだな
1命令ごとに正規化をするのがx86の仕様でありIEEE754
指数部の大きい方に補正して24ビットの加算あるいは減算をするだけなら
1サイクルででできなくはないが
x86に限った話をすれば、SIMDレジスタには浮動小数以外のデータも投入する。
加算の後にたとえばビットマスク演算をやる可能性がある。
正規化を飛ばすこと自体無理。
だいたいにそういう正規化をサボる実装が廃れたのはIEEE754準拠でないと
使いものにならないと見なされるようになったからだろ。
いまやGPUですら754準拠
話にならんバカだな
1命令ごとに正規化をするのがx86の仕様でありIEEE754
指数部の大きい方に補正して24ビットの加算あるいは減算をするだけなら
1サイクルででできなくはないが
x86に限った話をすれば、SIMDレジスタには浮動小数以外のデータも投入する。
加算の後にたとえばビットマスク演算をやる可能性がある。
正規化を飛ばすこと自体無理。
だいたいにそういう正規化をサボる実装が廃れたのはIEEE754準拠でないと
使いものにならないと見なされるようになったからだろ。
いまやGPUですら754準拠
220 :MACオタ>団子 さん:2008/10/18(土) 17:31:29 ID:8sSawSax
>>219
また脳内インテルすか(笑) 現実に何度も裏切られているのに。。。
-----------------
1命令ごとに正規化をするのがx86の仕様でありIEEE754
-----------------
Larrabeeわ"fused" multiply-addをサポートするので、積と和の間で正規化わ諦めているす。
ちなみに"fused" multiply-addわ、IEEE754rで規格に追加予定す。
http://754r.ucbtest.org/drafts/archive/2006-10-04.pdf
=================
3.2.20 fusedMultiplyAdd: The operation fusedMultiplyAdd(x,y,z) computes (x × y ) + z as if
with unbounded range and precision, rounding only once to the destination format.
=================
また脳内インテルすか(笑) 現実に何度も裏切られているのに。。。
-----------------
1命令ごとに正規化をするのがx86の仕様でありIEEE754
-----------------
Larrabeeわ"fused" multiply-addをサポートするので、積と和の間で正規化わ諦めているす。
ちなみに"fused" multiply-addわ、IEEE754rで規格に追加予定す。
http://754r.ucbtest.org/drafts/archive/2006-10-04.pdf
=================
3.2.20 fusedMultiplyAdd: The operation fusedMultiplyAdd(x,y,z) computes (x × y ) + z as if
with unbounded range and precision, rounding only once to the destination format.
=================
一応、Larrabee論文より該当箇所を引用しておくす。
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
------------------------
The instruction set provides the standard arithmetic operations, including fused
multiply-add, and the standard logical operations, including instructions to extract
non-byte-aligned fields from pixels
------------------------
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
------------------------
The instruction set provides the standard arithmetic operations, including fused
multiply-add, and the standard logical operations, including instructions to extract
non-byte-aligned fields from pixels
------------------------
222 :,,・´∀`・,,)っ:2008/10/18(土) 17:41:01 ID:zYJcwEab
>>220
ま〜た詭弁か
FMAはFMAで1命令ですが(笑)
決して2命令とは言わないよ。
それ以前にSSE4.1の内積命令の時点で算・加算の中間結果に対する正規化の保証はなかったような
結局はパンと牛乳の話どおりなんだな。
ま〜た詭弁か
FMAはFMAで1命令ですが(笑)
決して2命令とは言わないよ。
それ以前にSSE4.1の内積命令の時点で算・加算の中間結果に対する正規化の保証はなかったような
結局はパンと牛乳の話どおりなんだな。
223 :MACオタ>団子 さん:2008/10/18(土) 17:57:15 ID:8sSawSax
>>222
----------------
SSE4.1の内積命令の時点で算・加算の中間結果に対する正規化の保証はなかったような
----------------
つまりIEEE754に準拠しないx86命令があるということで、現実を認めるのわ悪いことじゃ無いす。
----------------
SSE4.1の内積命令の時点で算・加算の中間結果に対する正規化の保証はなかったような
----------------
つまりIEEE754に準拠しないx86命令があるということで、現実を認めるのわ悪いことじゃ無いす。
224 :,,・´∀`・,,)っ:2008/10/18(土) 18:09:48 ID:zYJcwEab
規格準拠しないといけない部分は単体のMUL/ADDを実行すればいいだけだからな。
しかし結局加算「命令」のレイテンシ1の弁解になってないな
しかし結局加算「命令」のレイテンシ1の弁解になってないな
積和算の例で行くと正規化飛ばしてフォワーディングされてるのは加算ではなく
乗算のほうだ。
乗算のほうだ。
というか、積和算においてIEEE754正規形に丸めることなく
後続オペレーションにフォワーディングされるのは加算ではなく
乗算のほうな。
突っ込みできなくなるまでよく練ってからレスしろよ
っていうかレスするなMAC板の恥大王よ
○○スってあだ名は、公衆で見せることも憚られるような
恥ずかしい発言をするコテって見解でよろしいか?
後続オペレーションにフォワーディングされるのは加算ではなく
乗算のほうな。
突っ込みできなくなるまでよく練ってからレスしろよ
っていうかレスするなMAC板の恥大王よ
○○スってあだ名は、公衆で見せることも憚られるような
恥ずかしい発言をするコテって見解でよろしいか?
痴的クラスターさん、弾切れ?
まあこれ以上勉強しても無駄だろうけど、後学のために教えてあげよう。
P5世代までのx86の場合、80x87浮動小数演算の丸め動作仕様は模範的で
そのままIEEE754規格のモデルになったくらいだ。
むしろ高速化のためにIEEE非準拠の動作が加わったのはSSEになってからだよ。
rsqrtps/rsqrtssは有効精度が12ビットしかない とか色々。
これはAltiVecもそうだな。
世代が戻ったから規格に準拠しなくなるのはPowerPCみたいな亜流CPUくらいでは?w
P5世代までのx86の場合、80x87浮動小数演算の丸め動作仕様は模範的で
そのままIEEE754規格のモデルになったくらいだ。
むしろ高速化のためにIEEE非準拠の動作が加わったのはSSEになってからだよ。
rsqrtps/rsqrtssは有効精度が12ビットしかない とか色々。
これはAltiVecもそうだな。
世代が戻ったから規格に準拠しなくなるのはPowerPCみたいな亜流CPUくらいでは?w
恥の総合商社くんはWikipediaをソースにするの好きだろ?
x87の成り立ちは知っておこうよ
http://ja.wikipedia.org/wiki/Intel_8087
> 同社が8087を設計した当時、将来の浮動小数点形式の標準となることを目指していた。
> 実際、IEEE 754のx86向け実装の標準となることができた(厳密にはIEEE 754と8087/80287の
> 実装の間には非互換部分が存在する)。
x87の成り立ちは知っておこうよ
http://ja.wikipedia.org/wiki/Intel_8087
> 同社が8087を設計した当時、将来の浮動小数点形式の標準となることを目指していた。
> 実際、IEEE 754のx86向け実装の標準となることができた(厳密にはIEEE 754と8087/80287の
> 実装の間には非互換部分が存在する)。
ららびー何か面白そう
大昔、NEC98のスロットに挿すDOS/Vマシンボードって無かった?
アレみたいにららびーのボードだけでX86のOS動いちゃったりしないかな
大昔、NEC98のスロットに挿すDOS/Vマシンボードって無かった?
アレみたいにららびーのボードだけでX86のOS動いちゃったりしないかな
>230
残念ながら単独の製品としては出ずに
GPUとして抱き合わせ販売って話だったかと
残念ながら単独の製品としては出ずに
GPUとして抱き合わせ販売って話だったかと
232 :,,・´∀`・,,)っ:2008/10/18(土) 22:58:19 ID:zYJcwEab
GPU機能付きSIMDアクセラレータ
限定的で使いづらいがSIMDアクセラレータとしても使えるGPU
VAやIPS液晶のドットピッチの縮小が頭打ち気味だし
当分はゲームもGPGPUに頼った物理演算性能の向上に舵を切らざるを得ない。
限定的で使いづらいがSIMDアクセラレータとしても使えるGPU
VAやIPS液晶のドットピッチの縮小が頭打ち気味だし
当分はゲームもGPGPUに頼った物理演算性能の向上に舵を切らざるを得ない。
>>228
精度不足といえば3DNow!もあったな
午後こーだで三角関数の精度が13bitしかないから音質が下がる的な話
以前はGPUでも32bitFPUを24bitでケチったり、プレステCPUが固定小数点だったりな話もあったけど
精度不足といえば3DNow!もあったな
午後こーだで三角関数の精度が13bitしかないから音質が下がる的な話
以前はGPUでも32bitFPUを24bitでケチったり、プレステCPUが固定小数点だったりな話もあったけど
>>230
Xbox720に載ります
Xbox720に載ります
ららびぃでゲームよりもWCGで使ってみたい気もする
>>235
同意する。
同意する。
OS自身がメニーコアに対応するのはいつ頃ですか?
238 :MACオタ>団子 さん:2008/10/19(日) 10:29:57 ID:48cpWZLR
>>228
------------------
P5世代までのx86の場合、80x87浮動小数演算の丸め動作仕様は模範的で
そのままIEEE754規格のモデルになったくらいだ。
------------------
自慢気なところ非常に申し訳ないすけど、IntelとIEEE754の関係についてわこちらでもどうぞ。
http://www.intel.com/standards/floatingpoint.pdf
http://tiki.is.os-omicron.org/tiki.cgi?c=e&p=%C9%E2%C6%B0%BE%AE%BF%F4%C5%C0
-----------------------
W.Kahan 教授,Intel らが中心となって策定した.
Kahan氏は、HPの電卓や、Intel 8087の開発に携わった。8087のアーキテクチャは複雑になり
すぎたと後悔しているらしい。1989年にチューリング賞受賞。
-----------------------
出来レース。。。しかもドラフトの段階で8086を出してしまった性悪なところも(笑)
------------------
P5世代までのx86の場合、80x87浮動小数演算の丸め動作仕様は模範的で
そのままIEEE754規格のモデルになったくらいだ。
------------------
自慢気なところ非常に申し訳ないすけど、IntelとIEEE754の関係についてわこちらでもどうぞ。
http://www.intel.com/standards/floatingpoint.pdf
http://tiki.is.os-omicron.org/tiki.cgi?c=e&p=%C9%E2%C6%B0%BE%AE%BF%F4%C5%C0
-----------------------
W.Kahan 教授,Intel らが中心となって策定した.
Kahan氏は、HPの電卓や、Intel 8087の開発に携わった。8087のアーキテクチャは複雑になり
すぎたと後悔しているらしい。1989年にチューリング賞受賞。
-----------------------
出来レース。。。しかもドラフトの段階で8086を出してしまった性悪なところも(笑)
239 :,,・´∀`・,,)っ-○◎●:2008/10/19(日) 13:55:21 ID:cnb0JIoy
というか、恥の殿堂君はくんはとんでもない嘘をついたね。
PPC G3までに限ってもIEEE非準拠といわれてるのはFMAだけじゃん?Javaのドキュメント読んで気づいた。
あのね、加算まで終わってはじめてレジスタに書き出せる状態
中間結果を保持するのは「フォワーディングネットワーク」ではなくアキュムレータっていうんだよ。
フォワーディングネットワークに正規化されてない状態で流すだ?馬鹿もたいがいにしろ
先にも言ったけど
「MACヲタちょっとパン買ってこいや」命令で3分、
「MACヲタちょっとパンと牛乳を買ってこいや」命令を4分でこなしたとしても
「MACヲタちょっと牛乳買ってコイや」命令を1分でこなしたことにはならない
PPC G3までに限ってもIEEE非準拠といわれてるのはFMAだけじゃん?Javaのドキュメント読んで気づいた。
あのね、加算まで終わってはじめてレジスタに書き出せる状態
中間結果を保持するのは「フォワーディングネットワーク」ではなくアキュムレータっていうんだよ。
フォワーディングネットワークに正規化されてない状態で流すだ?馬鹿もたいがいにしろ
先にも言ったけど
「MACヲタちょっとパン買ってこいや」命令で3分、
「MACヲタちょっとパンと牛乳を買ってこいや」命令を4分でこなしたとしても
「MACヲタちょっと牛乳買ってコイや」命令を1分でこなしたことにはならない
240 :,,・´∀`・,,)っ-○◎●:2008/10/19(日) 18:49:16 ID:cnb0JIoy
pmaddwdは16ビット整数の積和算(内積)だが、他の整数乗算と同じ3クロックのレイテンシ
恥のデパート的解釈でいけばMMXの水平加算のレイテンシは0クロックということになる
恥のデパート的解釈でいけばMMXの水平加算のレイテンシは0クロックということになる
241 :,,・´∀`・,,)っ-○◎●:2008/10/19(日) 18:51:13 ID:cnb0JIoy
だんごやさんはヤマダ電機で5万円の商品を買ったら20%のポイントが還元されました。
頭の悪い人は言いました
「タダで1万円の商品をもらえるす」
頭の悪い人は言いました
「タダで1万円の商品をもらえるす」
1%引きじゃ何とも思わないが
レジで100人に1人タダと言われて大喜びするアホ日本人みたいなもんか
レジで100人に1人タダと言われて大喜びするアホ日本人みたいなもんか
ヤマダ電機の来店ポイントはホントにダダでばらまく
244 :,,・´∀`・,,)っ-○◎●:2008/10/19(日) 22:10:04 ID:cnb0JIoy
休みの日に500円引き券とかよく配ってるね。1万円以上の商品買わないと意味ないんだけど。
しかもその500円割引分はポイントの対象外になるし。
うまくできてるな。
しかもその500円割引分はポイントの対象外になるし。
うまくできてるな。
いや、来店ポイントは何も買わなくてももらえるの
買うと帰りにももらえる
買うと帰りにももらえる
http://dodgson.org/omo/t/?date=20060922
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.47.4979
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.47.4979
247 :,,・´∀`・,,)っ-●◎○:2008/10/24(金) 02:01:18 ID:JJ0keCsa
http://www.fudzilla.com/index.php?option=com_content&task=view&id=10089&Itemid=1
48コア
「少なくね?」・・・80コアだと思ってた馬鹿記者
いきなり48かよ!
16-32コアで順当に攻めると思ってた俺
48コア
「少なくね?」・・・80コアだと思ってた馬鹿記者
いきなり48かよ!
16-32コアで順当に攻めると思ってた俺
Nehalemですら8スレッド動くんじゃなかったっけ?
明確に差別化するためには48コアくらい必要ってことかな。
明確に差別化するためには48コアくらい必要ってことかな。
逆にLaraにHTは無いだろうな
NehaのHTの部分のDie面積だけでLaraのコア1こ作れそうだ
NehaのHTの部分のDie面積だけでLaraのコア1こ作れそうだ
>>250
Larrabeeは4Wayマルチスレッディングなので、1コア4スレッド。
Larrabeeは4Wayマルチスレッディングなので、1コア4スレッド。
252 :,,・´∀`・,,)っ-●◎○:2008/10/25(土) 14:45:05 ID:ixbtkhbG
HTそのものはたいした回路面積食わないよ。
FGMTなんて、ものすごく乱暴に言うなら単に各スレッドの命令ポインタから交互にフェッチしていくだけだし
レジスタファイルがスレッド数分だけ必要になる。
x86(の64bit拡張)は論理レジスタ本数は1種類あたり16本までなんで
コア全体で64本程度。
もちろんrax〜r15といった汎用レジスタやマスクレジスタ(詳細不明
ISAモデル上はFP/MMXユニットもあるはずだが多分普通は使う機会ないだろう。
FGMTなんて、ものすごく乱暴に言うなら単に各スレッドの命令ポインタから交互にフェッチしていくだけだし
レジスタファイルがスレッド数分だけ必要になる。
x86(の64bit拡張)は論理レジスタ本数は1種類あたり16本までなんで
コア全体で64本程度。
もちろんrax〜r15といった汎用レジスタやマスクレジスタ(詳細不明
ISAモデル上はFP/MMXユニットもあるはずだが多分普通は使う機会ないだろう。
( ゚Д゚)ウマー
そのうちラットの脳を使ったCPUが出る
>>255
ディスプレイにハラヘッタって、でかでかと出力されるんですね。わかります。
ディスプレイにハラヘッタって、でかでかと出力されるんですね。わかります。
そのくらいなら許せるが、
雌のラットの画像を勝手に探してきて催されたら切れる
雌のラットの画像を勝手に探してきて催されたら切れる
258 :Socket774:2008/11/01(土) 05:33:09 ID:U+dArlaF
LarrabeeコアはIA-32でIA-64では無いyo。
そりゃ、いまさら Itanium もなからうよw >>258
LarrabeeってPCIに刺すの?
少なくともオンボか、PCI-Eだろ
>>260
最初の製品はGPU兼用だから、マザーに乗るか、最近のトレンドでCPUに混載されるかのどっちかになると思う。
最初の製品はGPU兼用だから、マザーに乗るか、最近のトレンドでCPUに混載されるかのどっちかになると思う。
IntelのCPU選択すると漏れなくLarrabeeが付いてくる
外すは許されないという時代がもうすぐそこに迫ってる訳で・・・
外すは許されないという時代がもうすぐそこに迫ってる訳で・・・
いくらなんでもIntelの煽りを真に受けすぎ。
AVXでさえ当分先なのに、Larrabeeなんて
AVXでさえ当分先なのに、Larrabeeなんて
265 :,,・´∀`・,,)っ-●◎○:2008/11/01(土) 22:41:49 ID:sHed6bxe
Intelの予定ではララービは来年だぜ。
言葉足らずだった。
Larrabeeの機能がCPUに取り込まれる時期は、AVXより未来。
Larrabeeの機能がCPUに取り込まれる時期は、AVXより未来。
>>250-251
http://pc.watch.impress.co.jp/docs/2008/1031/kaigai474.htm
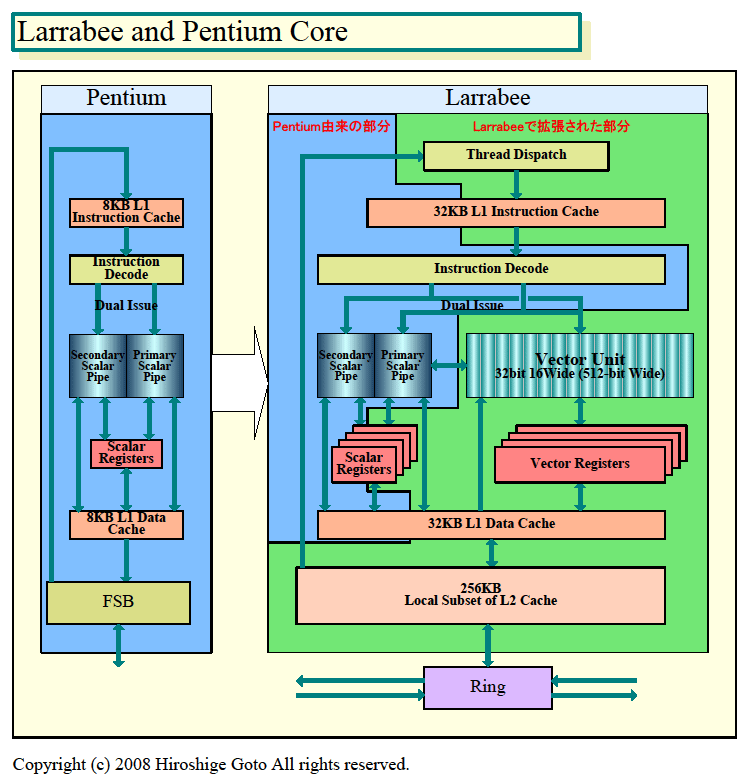
下の図は、LarrabeeのCPUコアをPentiumと比較したチャートだ。図の中で、ブルーの部分はPentiumに由来するユニット群、グリーンの部分はLarrabeeで新たに加えられたり拡張されたユニット群だ。
最大のポイントはLarrabee NIのベクタ命令に対応するベクタユニットとベクタレジスタが加えられたこと。実際にはスカラユニット側にも、ベクタロード/ストア命令やキャッシュ制御命令などのLarrabee NIのいくつかの新命令が追加されている。
スカラレジスタもマルチスレッディングのサポートのために4倍に拡張され、L1データキャッシュとL1命令キャッシュも、それぞれマルチスレッディングのために4倍のサイズとなった。レジスタ本数もマルチスレッディングのために拡張されているはずだ。
また、スレッドディスパッチャがL1命令キャッシュの前に追加された。PentiumではオンチップになかったL2キャッシュが内蔵され、FSBではなく、CPUコア内コミュニケーションのためのリングストップが加えられた。
http://pc.watch.impress.co.jp/docs/2008/1031/kaigai_01l.gif
http://pc.watch.impress.co.jp/docs/2008/1031/kaigai474.htm
下の図は、LarrabeeのCPUコアをPentiumと比較したチャートだ。図の中で、ブルーの部分はPentiumに由来するユニット群、グリーンの部分はLarrabeeで新たに加えられたり拡張されたユニット群だ。
最大のポイントはLarrabee NIのベクタ命令に対応するベクタユニットとベクタレジスタが加えられたこと。実際にはスカラユニット側にも、ベクタロード/ストア命令やキャッシュ制御命令などのLarrabee NIのいくつかの新命令が追加されている。
スカラレジスタもマルチスレッディングのサポートのために4倍に拡張され、L1データキャッシュとL1命令キャッシュも、それぞれマルチスレッディングのために4倍のサイズとなった。レジスタ本数もマルチスレッディングのために拡張されているはずだ。
また、スレッドディスパッチャがL1命令キャッシュの前に追加された。PentiumではオンチップになかったL2キャッシュが内蔵され、FSBではなく、CPUコア内コミュニケーションのためのリングストップが加えられた。
http://pc.watch.impress.co.jp/docs/2008/1031/kaigai_01l.gif
{kind=link}
> カラレジスタもマルチスレッディングのサポートのために4倍に拡張され
1コア4スレのHTはLarrabeeが初になるんだよな
i7もAtomも1コア2スレまで
技術的には16スレのHTでも可能らしいね
1コア4スレのHTはLarrabeeが初になるんだよな
i7もAtomも1コア2スレまで
技術的には16スレのHTでも可能らしいね
ララビーは出てみないことにはGPUとしては既存のものと対抗できるかわからんな
汎用的にはあんまりHTの数あげても意味ないでしょ
Larrabeeはグラフィクス用途だから4HTが最適となったと思われる
Larrabeeはグラフィクス用途だから4HTが最適となったと思われる
“Larrabee”に関して―“Larrabee”は2009年下半期登場他
ttp://northwood.blog60.fc2.com/blog-entry-2410.html
ttp://northwood.blog60.fc2.com/blog-entry-2410.html
メモリ帯域をセーブするLarrabeeアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1111/kaigai475.htm
http://pc.watch.impress.co.jp/docs/2008/1111/kaigai475.htm
274 :,,・´∀`・,,)っ-●◎○:2008/11/12(水) 07:20:08 ID:6J/ieuD2
考え方自体はIntelアーキテクチャらしいんだよね
Sandy Bridgeの先行実験を兼ねている
ATIもNVIDIAもキャッシュ少なすぎね?帯域ばっか増強しやがって。
Sandy Bridgeの先行実験を兼ねている
ATIもNVIDIAもキャッシュ少なすぎね?帯域ばっか増強しやがって。
そりゃ、Intelのキャッシュは豊富ですからw
誰がうまいことを言えと…
金持ち喧嘩せず
278 :Socket774:2008/11/12(水) 14:07:37 ID:S70hdx8D
>>252
次世代Itanium(Nehalemと共通チップセット)もHT対応だから
Atom、Core/Xeon、Itanium、LarrabeeインテルCPUが全部HT対応するね
Pen4ファンとしてこんな嬉しい事はない
次世代Itanium(Nehalemと共通チップセット)もHT対応だから
Atom、Core/Xeon、Itanium、LarrabeeインテルCPUが全部HT対応するね
Pen4ファンとしてこんな嬉しい事はない
279 :Socket774:2008/11/15(土) 00:36:26 ID:P6RnGXyn
IntelのDirectXやOpenGL記述能力の低さって本当に問題なのか?
ゲーム屋が直接Engine作ればいんじゃね。
Larrabeeがプログラマブルなため堕ちる効率
>
(負荷バランスによる専用ユニットの遊びの削減
+
DirectX層を跳ばしてゲーム屋がUnrealEngingeなどを書くことによる効率UP
+
Engineそのものをゲームごとに微調整することによる性能UP)
の可能性もあると思う。
Renderman用のフリーのシェーダーとかも結構あるんだし、
どっかの高校生がIntelより速くて安定したDirectXドライバ書いたり
するかも。
フリーで出して、スポンサーついて商業化、Intelが買収でフリーに戻る。
TANSTAAFLだからVIAとかAMDのクローンは弾かれる。
あと、サーバでSUNのNiagaraを食うってのもあるか。
ゲーム屋が直接Engine作ればいんじゃね。
Larrabeeがプログラマブルなため堕ちる効率
>
(負荷バランスによる専用ユニットの遊びの削減
+
DirectX層を跳ばしてゲーム屋がUnrealEngingeなどを書くことによる効率UP
+
Engineそのものをゲームごとに微調整することによる性能UP)
の可能性もあると思う。
Renderman用のフリーのシェーダーとかも結構あるんだし、
どっかの高校生がIntelより速くて安定したDirectXドライバ書いたり
するかも。
フリーで出して、スポンサーついて商業化、Intelが買収でフリーに戻る。
TANSTAAFLだからVIAとかAMDのクローンは弾かれる。
あと、サーバでSUNのNiagaraを食うってのもあるか。
280 :Socket774:2008/11/15(土) 01:26:06 ID:YrPhhYp+
VIAにLarrabee命令搭載NANO2をLarrabeeより早く出すことを期待したい。
AMDより先に3DNow!搭載Winchip2を出しちゃったチームが作ってるんだし。
AMDより先に3DNow!搭載Winchip2を出しちゃったチームが作ってるんだし。
281 :279:2008/11/15(土) 01:29:32 ID:YrPhhYp+
5行目の > は < だった。
mousou ha hodohodo ni
申し訳ない
君のLarrabeeは
深夜 コンビニエンスストアにたむろするような少年たちに
なすがままにされてしまった
君のLarrabeeは
深夜 コンビニエンスストアにたむろするような少年たちに
なすがままにされてしまった
NVIDIAを買収して現状のCPUコアとミドルクラスのGPUコアを1チップ化した方が良くね?
>>279
> IntelのDirectXやOpenGL記述能力の低さって本当に問題なのか?
> ゲーム屋が直接Engine作ればいんじゃね。
ドライバ開発をそんな投げっぱなしジャーマンなやり方にしたら
たとえハードウェアが勝っていても間違いなくGPUに負けるから。
そもそも、そのやり方はコンシューマーのゲーム屋が昔からやってきたことだが
開発の負担がでかくなりすぎてもうPS3の段階で破綻しつつある。
Intelが一切合切の情報公開を行えばLinuxコミュニティならドライバを
作ってくれるだろうが、その出来は今あるVGAのドライバと同じように
Windowsのものと比べてイマイチだろう。
まぁなんというか夢想乙。
> IntelのDirectXやOpenGL記述能力の低さって本当に問題なのか?
> ゲーム屋が直接Engine作ればいんじゃね。
ドライバ開発をそんな投げっぱなしジャーマンなやり方にしたら
たとえハードウェアが勝っていても間違いなくGPUに負けるから。
そもそも、そのやり方はコンシューマーのゲーム屋が昔からやってきたことだが
開発の負担がでかくなりすぎてもうPS3の段階で破綻しつつある。
Intelが一切合切の情報公開を行えばLinuxコミュニティならドライバを
作ってくれるだろうが、その出来は今あるVGAのドライバと同じように
Windowsのものと比べてイマイチだろう。
まぁなんというか夢想乙。
287 :,,・´∀`・,,)っ-●◎○:2008/11/15(土) 16:11:32 ID:0EXHNI7+
基本的にフレームワークはIntelが用意する。
あと、CUDAのプログラミングモデルよりはより柔軟なのは間違いない。
x86コア+512ビットSIMD改という構成は、NVIDIAのストリームマルチプロセッサと比べても
効率が悪いとは言えないし、とりあえず倍精度と整数では圧勝の可能性大。
NVIDIAの提供するスカラって、結局は、32ビット×8Way×4サイクルインターリーブ(=1024ビット単位)の
データレベル並列演算にすぎない。
Larrabeeの提供する「柔軟なSIMD」と比べてもかえって制約が多いくらい。
ぶっちゃけCUDAでやれることはLarrabeeでも殆どできる。
ATIのは、GPGPUってレベルじゃねーぞってことで。
あと、CUDAのプログラミングモデルよりはより柔軟なのは間違いない。
x86コア+512ビットSIMD改という構成は、NVIDIAのストリームマルチプロセッサと比べても
効率が悪いとは言えないし、とりあえず倍精度と整数では圧勝の可能性大。
NVIDIAの提供するスカラって、結局は、32ビット×8Way×4サイクルインターリーブ(=1024ビット単位)の
データレベル並列演算にすぎない。
Larrabeeの提供する「柔軟なSIMD」と比べてもかえって制約が多いくらい。
ぶっちゃけCUDAでやれることはLarrabeeでも殆どできる。
ATIのは、GPGPUってレベルじゃねーぞってことで。
やろうと思えばメインCPUをこなせるチップだしな〜
近い未来、ノートPCはこれになるんじゃないの?
近い未来、ノートPCはこれになるんじゃないの?
Larabee上で直接Winを動作させるまでには時間がかかるんじゃないか?
Larabeeにはまず仮想ホスト、ハイパーバイザに対応して欲しい。
そうすれば拡張カード形態の段階でも遊べるのでは
Larabeeにはまず仮想ホスト、ハイパーバイザに対応して欲しい。
そうすれば拡張カード形態の段階でも遊べるのでは
290 :Socket774:2008/11/17(月) 06:21:27 ID:v7xi6toO
>>285
PowerVRとPowerSGLは凋落しなかったよ
売れないまま終わったから
ああPowerSGL版バーチャロンよ永遠に
>>288
ユニファイドシェーダーをさらに発展させて
CPU担当のコアとGPU担当のコアをリアルタイムで増減させるとかね
PowerVRとPowerSGLは凋落しなかったよ
売れないまま終わったから
ああPowerSGL版バーチャロンよ永遠に
>>288
ユニファイドシェーダーをさらに発展させて
CPU担当のコアとGPU担当のコアをリアルタイムで増減させるとかね
どう考えても、このアーキだとタイルベースレンダリングが最適だと思うんだけど、どうなんだろ
PowerVRって既存のDirectX9cとか10.1との互換性バッチリなん?
根本的・仕様的に互換性取れないってんならキツイ
PowerVRって既存のDirectX9cとか10.1との互換性バッチリなん?
根本的・仕様的に互換性取れないってんならキツイ
少なくともKyroIIは9.0c下で動作するのは確認していたがw
S3のMeTaLのこともたまにでいいから思い出してあげてください
{kind=link}
GPUを過度に汎用にしたところで
それは無駄というもの
それは無駄というもの
いまだにGPUと決めつけて掛かる奴がいるとは・・・・
Tim Sweeneyも言ってるけど、最後の最後にはGPUなんてものはこの世から無くなる。
Tim Sweeneyも言ってるけど、最後の最後にはGPUなんてものはこの世から無くなる。
Tim Sweeneyがこの世から無くなる
298 :Socket774:2008/11/18(火) 18:42:55 ID:OKn45fE1
元々GPUなんて無かった
せっせとCPUたんがVRAMカキコしてたんだよ
せっせとCPUたんがVRAMカキコしてたんだよ
GPUが使われている理由は演算パワーだけじゃなくてメモリ帯域も大きな理由だろう。
MB上のモジュール形式のメモリに限られたコストで与えられる帯域はVGAカード上の
VRAMを超えられない。ハイエンドGPUはそう簡単にはなくならない。
MB上のモジュール形式のメモリに限られたコストで与えられる帯域はVGAカード上の
VRAMを超えられない。ハイエンドGPUはそう簡単にはなくならない。
>>296
すいませんが、今のマルチコアの進化してんだかしてないんだかって状況がまた以前のように
ズンズン性能が目に見えてあがるようにはなるんでしょうかね
最終的に近未来のCPUってララビーになるんでしょうか?
すいませんが、今のマルチコアの進化してんだかしてないんだかって状況がまた以前のように
ズンズン性能が目に見えてあがるようにはなるんでしょうかね
最終的に近未来のCPUってララビーになるんでしょうか?
ならん
もうパソコンなんて買い換えなくても10年は普通に持つ時代になってしまったしな
コアが32でも1でももう大した違いはない
コアが32でも1でももう大した違いはない
あ
304 :Socket774:2008/11/19(水) 10:48:04 ID:599mJRFR
でも将来的にはサー
ララビー見たいなのがGPUのメインになるよね
ゲームが主な目的だとしたら、今の所物量がまだまだぜんぜん足りないけど
物量が十分になった場合はソフトで書き書きした方がリアルになるってことで
そうなってくるとマルチコアの部分てGPUでやる方がよくなるってことは
CPUって進化おわってんじゃないだろうか
ってことはよ、結局ララビーみたいな形が次世代のCPUじゃなかんべか
ララビー見たいなのがGPUのメインになるよね
ゲームが主な目的だとしたら、今の所物量がまだまだぜんぜん足りないけど
物量が十分になった場合はソフトで書き書きした方がリアルになるってことで
そうなってくるとマルチコアの部分てGPUでやる方がよくなるってことは
CPUって進化おわってんじゃないだろうか
ってことはよ、結局ララビーみたいな形が次世代のCPUじゃなかんべか
んだんだ
コアやらGPUがどうこうよりも、演算チップとメモリの接続トポロジー、
L1キャッシュからHDDまで速度の違う記憶域の階層設計、
階層間のインターフェイスの設計の方が重要になる
L1キャッシュからHDDまで速度の違う記憶域の階層設計、
階層間のインターフェイスの設計の方が重要になる
じゃぁ、ビデオチップにCPUのっけりゃいいじゃん
メモリも載せればいいじゃん。
チップセットも載せようぜ!
電源も載せようぜ!!
あとSSD載せたら最強じゃね?
オレが載れば完成だ
TK-80か
315 :Socket774:2008/11/21(金) 10:26:35 ID:w9OiuSe8
uma-
316 :Socket774:2008/11/21(金) 11:09:46 ID:jg1NC/aQ
.,,-‐''"~~ ゙゙̄'''ー、,
.,/' ザ ル カ ウ ィ ヽ http://www.aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ | アラブ投資ファンド = ザルカウィ
|‐''/ \゙''ー|
| | | | A M D = 香田
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | //
.| ヽ、,,;;iiill|||||||||lllii;;, /.| 頭(CPU設計)と、体(工場)を分離する!
ヽ |'"~ー--‐~゙゙'''| /
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香 田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ んごっ!んごごうぅ…
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| /
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | ( んっごう!!!
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
.,/' ザ ル カ ウ ィ ヽ http://www.aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ | アラブ投資ファンド = ザルカウィ
|‐''/ \゙''ー|
| | | | A M D = 香田
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | //
.| ヽ、,,;;iiill|||||||||lllii;;, /.| 頭(CPU設計)と、体(工場)を分離する!
ヽ |'"~ー--‐~゙゙'''| /
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香 田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ んごっ!んごごうぅ…
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| /
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | ( んっごう!!!
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
>>316
グロ注意。切断動画。。。
グロ注意。切断動画。。。
318 :Socket774:2008/11/22(土) 20:04:53 ID:3VuTRHJ9
PowerVRは組み込みで大シェアだ。カーナビとか携帯電話に入ってる。
最新版はDirectX10サポートしてる。
タイルアーキテクチャで帯域節約型だからLarrabee用にIntelが提携・
買収しても不思議じゃない。
Atom用の次世代チップセットがPowerVRのIP買って造られてる。
最新版はDirectX10サポートしてる。
タイルアーキテクチャで帯域節約型だからLarrabee用にIntelが提携・
買収しても不思議じゃない。
Atom用の次世代チップセットがPowerVRのIP買って造られてる。
>PowerVR
IntelにとってPowerVRはxScale用に開発した2700Gで採用してたから
勝手知ったるところじゃないかと思はれ
IntelにとってPowerVRはxScale用に開発した2700Gで採用してたから
勝手知ったるところじゃないかと思はれ
いや、厳密には商用ソフトもあるからWAREZはあり得る
GPUとの違いが際立つLarrabeeキャッシュアーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/1125/kaigai477.htm
http://pc.watch.impress.co.jp/docs/2008/1125/kaigai477.htm
もしこれでGPU市場も制したら、CPU/マザー(チップセット)/SSD/GPUで4分野制覇か
ここまで独占させると後が怖いな
ここまで独占させると後が怖いな
SSD(NAND)はすぐに今ほど儲からなくなるかもしれないから
そうなったらDRAMみたいにあっさりやめるんじゃないか
そうなったらDRAMみたいにあっさりやめるんじゃないか
SSDのコントローラだけベンダーに売るって手もあるんじゃないかな。
チップセット以外で世代遅れのFabを使う製品が増えるのはIntelとしてはおいしいだろうし。
チップセット以外で世代遅れのFabを使う製品が増えるのはIntelとしてはおいしいだろうし。
326 :Socket774:2008/11/25(火) 17:13:36 ID:Ju9VWKtf
GPUは何れ遠からずCPUの一部に成るんだし、Intelが力を入れるのも仕方が無い
いづれはメモリもチップセットもSSDも混在してCPU一本でしょ。
最初はVGA機能はOFFにしてエンコーダーとして使うアニオタが買うんだろうな
,. -ー冖'⌒'ー-、
,ノ \
/ ,r‐へへく⌒'¬、 ヽ
{ノ へ.._、 ,,/~` 〉 } ,r=-、
/プ ̄`y'¨Y´ ̄ヽ―}j=く /,ミ=/
ノ /レ'>-〈_ュ`ー‐' リ,イ} 〃 /
/ _勺 イ;;∵r;==、、∴'∵; シ 〃 /
,/ └' ノ \ こ¨` ノ{ー--、〃__/
人__/ー┬ 个-、__,,.. ‐'´ 〃`ァーァー\
. / |/ |::::::|、 〃 /:::::/ ヽ
/ | |::::::|\、_________/' /:::::/〃
! l |::::::| ` ̄ ̄´ |::::::|/
ノ\ |::::::| |::::::|
,. -ー冖'⌒'ー-、
,ノ \
/ ,r‐へへく⌒'¬、 ヽ
{ノ へ.._、 ,,/~` 〉 } ,r=-、
/プ ̄`y'¨Y´ ̄ヽ―}j=く /,ミ=/
ノ /レ'>-〈_ュ`ー‐' リ,イ} 〃 /
/ _勺 イ;;∵r;==、、∴'∵; シ 〃 /
,/ └' ノ \ こ¨` ノ{ー--、〃__/
人__/ー┬ 个-、__,,.. ‐'´ 〃`ァーァー\
. / |/ |::::::|、 〃 /:::::/ ヽ
/ | |::::::|\、_________/' /:::::/〃
! l |::::::| ` ̄ ̄´ |::::::|/
ノ\ |::::::| |::::::|
330 :Socket774:2008/11/25(火) 18:53:29 ID:/zQCHNqf
マルチモニタ必須の人間はどうすりゃ良いんだよ
PCIにぶっさすADDカードでるかもよ?
信号スルーするだけのやつ。
信号スルーするだけのやつ。
いづれは我と一つになる…
まぁ、流れとしては今マルチコアの部分はGPGPUでなるべくGPUに仕事量を割り振るようにして
その割合が半分以上占めるようになったらララビーみたいなのがCPUとして使われることになるのかもな
その割合が半分以上占めるようになったらララビーみたいなのがCPUとして使われることになるのかもな
問題は、一般的な3Dパイプラインと処理のアルゴリズムがまったく異なるため、
3Dパイプラインを前提にしたアプリケーションとの間で、互換性の問題が生じやすいということにある。
これは、必ずしもPowerVRやタイリング・アーキテクチャ側の責任ばかりではないのだが、
マイノリティであるがゆえに、 PowerVR/タイリング・アーキテクチャ側が対応を迫られるのが実情だ。
DirectXにしても、結局は3Dパイプラインを前提に開発されているのである。
http://www.atmarkit.co.jp/misc/search/marker.php?query=%C5%F1%C2%C1&pg=www.atmarkit.co.jp/fpc/motoazabu/053_2002-02-22/graphics_mkt.html
Larrabeeはかつてないほどドライバ依存度の高いGPUとなる訳だが
はたしてまともに3Dゲームが動く物が出来るのだろうか。
3Dパイプラインを前提にしたアプリケーションとの間で、互換性の問題が生じやすいということにある。
これは、必ずしもPowerVRやタイリング・アーキテクチャ側の責任ばかりではないのだが、
マイノリティであるがゆえに、 PowerVR/タイリング・アーキテクチャ側が対応を迫られるのが実情だ。
DirectXにしても、結局は3Dパイプラインを前提に開発されているのである。
http://www.atmarkit.co.jp/misc/search/marker.php?query=%C5%F1%C2%C1&pg=www.atmarkit.co.jp/fpc/motoazabu/053_2002-02-22/graphics_mkt.html
Larrabeeはかつてないほどドライバ依存度の高いGPUとなる訳だが
はたしてまともに3Dゲームが動く物が出来るのだろうか。
動いたとしても古いゲームは軽視されるだろうな
そーいやXBOX360もタイリングだな。
339 :,,・´∀`・,,)っ-○◎●:2008/11/26(水) 22:55:21 ID:GrKYm10I
意味解らん。ソフト的にやるからある意味では旧い世代のGPUのエミュレーションもやりやすいだろう
ベンチサイトのグラフの長さで金出すかどうか決める
タイルレンダリングってPowerVRを思い出すな
342 :,,・´∀`・,,)っ-○◎●:2008/11/27(木) 00:00:16 ID:KVJ1xHPt
MSの中の人がCEDEC 2008についてレポートしてる
http://blogs.msdn.com/hiroyuk/archive/2008/09/12/8945797.aspx
> HWが20倍高速になっても、開発予算を2倍以上にすることはできないので、
> 生産性のために性能を犠牲にせざるを得ないし、そのために「すごい」
> ツールが必要になるでしょう。
これは同意してしまった。
http://blogs.msdn.com/hiroyuk/archive/2008/09/12/8945797.aspx
> HWが20倍高速になっても、開発予算を2倍以上にすることはできないので、
> 生産性のために性能を犠牲にせざるを得ないし、そのために「すごい」
> ツールが必要になるでしょう。
これは同意してしまった。
ワンチップにSLIやCrossFire形式で低性能コア60個詰め込んだみたいなもんだから
結果は小学生でも判る
結果は小学生でも判る
344 :,,・´∀`・,,)っ-○◎●:2008/11/27(木) 00:22:56 ID:KVJ1xHPt
GPUそのものがそういうもんだろ?
並列性のない処理には高クロックなスーパースカラコアのほうが有利。
並列性のない処理には高クロックなスーパースカラコアのほうが有利。
ソフトウェアレンダリングまんせー
SLIやCrossfireみたいな低速なバスに頼る方式で60個接続したら確かに厳しそうではある。
347 :,,・´∀`・,,)っ-●◎○:2008/11/27(木) 21:59:10 ID:KVJ1xHPt
512bit双方向のリングバスは超高速だと思うが
その低速なバスで同等の結果・性能を出そうってのがLarrabeeなんでしょ
デバイスドライバをオープンソースにしてくんないかなIntel
そしたら絶対にユーザー間でDX・ogl互換性と性能の競争原理が働いて凄い事になると思う
デバイスドライバをオープンソースにしてくんないかなIntel
そしたら絶対にユーザー間でDX・ogl互換性と性能の競争原理が働いて凄い事になると思う
まぁ、一般人にとってはエンコの救世主になるんじゃないかね
リングバスって時点で早くないと思うが
リングバスはチップの小型化や低消費電力化、発熱部分の分散
またそれらの2次的効果としてクロックを若干引き挙げられるって効果はあるが
反面、バス幅がどれだけあろうと遠いコアへのアクセスは時間がかかる
・・・と思ったが
リングバスはチップの小型化や低消費電力化、発熱部分の分散
またそれらの2次的効果としてクロックを若干引き挙げられるって効果はあるが
反面、バス幅がどれだけあろうと遠いコアへのアクセスは時間がかかる
・・・と思ったが
FSAAとかモーションブラーといったシーン単位の処理をどうするかってのがムズそう
あとレンダリングパイプラインの違いはドライバで吸収できるのか
KYROIIがある程度できてたみたいだし大丈夫なんかな
あとレンダリングパイプラインの違いはドライバで吸収できるのか
KYROIIがある程度できてたみたいだし大丈夫なんかな
352 :,,・´∀`・,,)っ-○◎●:2008/11/28(金) 00:12:40 ID:/NUP3hwi
512bit×双方向で2GHz駆動って相当速いけど?
バケツリレーする分には十分すぎるでしょ
NVIDIAやATIのストリームプロセッサはローカルメモリそのものがめちゃくちゃ少ない
バケツリレーする分には十分すぎるでしょ
NVIDIAやATIのストリームプロセッサはローカルメモリそのものがめちゃくちゃ少ない
256KBに納める必要があるのは…
・1タイル分のフレーム・Z・ステンシルの各種バッファ (一定)
・1タイル分の頂点データ (可変)
・1タイル分のピクセルに対応したテクスチャ (一定?)
フルプログラマブルだから、タイルの大きさも自由だし(128x128でも64x64でも32x16でも良い)、
ドライバ最適化し放題
・1タイル分のフレーム・Z・ステンシルの各種バッファ (一定)
・1タイル分の頂点データ (可変)
・1タイル分のピクセルに対応したテクスチャ (一定?)
フルプログラマブルだから、タイルの大きさも自由だし(128x128でも64x64でも32x16でも良い)、
ドライバ最適化し放題
リングバスはレイテンシが一定では無いから、一番遠い区画に対するレイテンシを常に想定しないといけない
…キャッシュコヒーレンシを確保する必要性って、あるのか?Intel w
…キャッシュコヒーレンシを確保する必要性って、あるのか?Intel w
355 :,,・´∀`・,,)っ-○◎●:2008/11/28(金) 00:49:37 ID:/NUP3hwi
コヒーレント制御無視する命令があるんでなかったっけ?
GPUアーキテクチャなんて高レイテンシ上等じゃないか。今更問題にならん。
GPUアーキテクチャなんて高レイテンシ上等じゃないか。今更問題にならん。
>>350
RADEON HD4xxxはリングバスの帯域の90%がテクスチャ転送の為に使われてて
無駄だったのでテクスチャ転送をクロスバにしたらチップ面積を食うリングバスが
不要になって性能がものすごく上がったんだよな。
RADEON HD4xxxはリングバスの帯域の90%がテクスチャ転送の為に使われてて
無駄だったのでテクスチャ転送をクロスバにしたらチップ面積を食うリングバスが
不要になって性能がものすごく上がったんだよな。
うん、レイテンシはどうでも良いw さらに帯域もどうでも良いw タイルアーキなら
ローカル2次キャッシュの量と速度ができる事と性能を決める
コヒーレンシにトランジスタ使うなら1コアでも多く積んでくれ、と思うがそうもいかんか
ローカル2次キャッシュの量と速度ができる事と性能を決める
コヒーレンシにトランジスタ使うなら1コアでも多く積んでくれ、と思うがそうもいかんか
512bit×双方向で2GHzといってもコア数(16〜48)からみると全然広くないよね
だからキャッシュてんこ盛りにしてタイルベースレンダリングにするんでしょ
まあ、GPU以外でも汎用的に使うことを考えると間違ってるとは思わないけどね
でも今のチップの電力消費はメモコンとキャッシュ
てんこ盛りキャッシュを高速駆動させて電力効率は悪化しないのかな
だからキャッシュてんこ盛りにしてタイルベースレンダリングにするんでしょ
まあ、GPU以外でも汎用的に使うことを考えると間違ってるとは思わないけどね
でも今のチップの電力消費はメモコンとキャッシュ
てんこ盛りキャッシュを高速駆動させて電力効率は悪化しないのかな
359 :,,・´∀`・,,)っ-○◎●:2008/11/28(金) 01:21:16 ID:/NUP3hwi
360 :,,・´∀`・,,)っ-○◎●:2008/11/28(金) 01:22:39 ID:/NUP3hwi
>>358
16コアで1リングとしてあとは外部バス(QPI?)接続じゃなかったっけ?
16コアで1リングとしてあとは外部バス(QPI?)接続じゃなかったっけ?
http://journal.mycom.co.jp/articles/2008/09/06/hotchips5/002.html
Xringでリング間をつなぐらしい。
Xringでリング間をつなぐらしい。
最初のカードはアニヲタのエンコ厨が買うんだから
TMPGとWinMEぐらい対応してりゃ十分でしょ。
一応VGAとしても使えるなら
ベンチ厨も買って速攻中古屋に持ってくかな?
TMPGとWinMEぐらい対応してりゃ十分でしょ。
一応VGAとしても使えるなら
ベンチ厨も買って速攻中古屋に持ってくかな?
エンコ用のカードも、東芝のSpursEngineを使った製品が出てるしな
それより安く売らない限り、見向きもされないだろう
それより安く売らない限り、見向きもされないだろう
取りとめも無く書いちゃう 性能的に必要性の無いコヒーレント制御入れたって事で思う事
Intelとしては将来にわたって「何を」保障してくれるだろうか?保障しようとしてるのだろうか?
仮に「命令セットとその実行結果」のみだとしたら、今までのx86のように、内部アーキは将来ガンガン変える可能性が
L1L2の容量が増えるかも・減るかもwしれない、レイテンシが短くなるかも・長くなるかもwしれない
リングバスやめてクロスバ・メッシュにするかもしれない、コア数が増えたり減ったりするかもしれない
PentiumコアからPenProやAtomに進化、もしくは486コアに先祖がえりするかもしれない
低速で面積の小さなトランジスタ全面に使ってクロックを下げるかもしれない
徹底的に「コア数を増やす」方向に投入テクノロジを振ろうとするつもりだとしたら、
1コアあたりの性能はより低く、クロックは低くなっていくはず
Intelとしては将来にわたって「何を」保障してくれるだろうか?保障しようとしてるのだろうか?
仮に「命令セットとその実行結果」のみだとしたら、今までのx86のように、内部アーキは将来ガンガン変える可能性が
L1L2の容量が増えるかも・減るかもwしれない、レイテンシが短くなるかも・長くなるかもwしれない
リングバスやめてクロスバ・メッシュにするかもしれない、コア数が増えたり減ったりするかもしれない
PentiumコアからPenProやAtomに進化、もしくは486コアに先祖がえりするかもしれない
低速で面積の小さなトランジスタ全面に使ってクロックを下げるかもしれない
徹底的に「コア数を増やす」方向に投入テクノロジを振ろうとするつもりだとしたら、
1コアあたりの性能はより低く、クロックは低くなっていくはず
>>366
CPUとの冗長性を保つ為にL2は256KBで固定だと思うよ
CPUとの冗長性を保つ為にL2は256KBで固定だと思うよ
それ以前に、Larrabeeに後継チップが出るという前提そのものが(;^ω^)
Larrabeeが売れるかどうかも怪しいのに
Larrabeeが売れるかどうかも怪しいのに
Larrabeeはスパコンで売れまくるよ
泥沼の安売り合戦な未来が見える
2万くらいなら遊びで買うんだけどなぁ
それ以上だと本気で元をとりにいかなきゃならん
Larrabeeの性能を引き出すには相当勉強しなきゃだめっぽいし、
是非安く売って欲しい
それ以上だと本気で元をとりにいかなきゃならん
Larrabeeの性能を引き出すには相当勉強しなきゃだめっぽいし、
是非安く売って欲しい
心配しなくても将来はソフトレンダになるからララビー的なGPUが主流になるでしょ
もっとも10年後位の話だろうけど
もっとも10年後位の話だろうけど
374 :Socket774:2008/11/29(土) 03:18:30 ID:dYF2/76o
2〜3万(TMPGの中の人がGETする補助金込み)で出るやろ
375 :,,・´∀`・,,)っ-●◎○:2008/11/29(土) 03:50:42 ID:d3UvztFy
Intel Compiler 11の価格に絶望した。
MKLなんて要らないからStandard Edition復活しろ。
MKLなんて要らないからStandard Edition復活しろ。
Larabeeみたいにメインメモリへの帯域が特別には太くないものは
スパコンのプロセッサとしては中途半端で、威力を発揮できる計算と
出来ない計算に分かれる。SX-9みたいな高コストだが
バケモノ的なものにも依然として需要はある。
ttp://journal.mycom.co.jp/photo/articles/2008/11/25/sx-9/images/016l.jpg
ttp://journal.mycom.co.jp/articles/2008/11/25/sx-9/index.html
スパコンのプロセッサとしては中途半端で、威力を発揮できる計算と
出来ない計算に分かれる。SX-9みたいな高コストだが
バケモノ的なものにも依然として需要はある。
ttp://journal.mycom.co.jp/photo/articles/2008/11/25/sx-9/images/016l.jpg
{kind=link}
ttp://journal.mycom.co.jp/articles/2008/11/25/sx-9/index.html
SpursEngine搭載カードは人柱が飛びついただけで終わった
あとは愚痴合戦
http://pc11.2ch.net/test/read.cgi/avi/1221058252/
http://pc11.2ch.net/test/read.cgi/avi/1225333897/
あとは愚痴合戦
http://pc11.2ch.net/test/read.cgi/avi/1221058252/
http://pc11.2ch.net/test/read.cgi/avi/1225333897/
WindowsMediaEncoderが対応したら
ネット生中継には便利なカードになるぞ
ネット生中継には便利なカードになるぞ
愚痴じゃなくてwktk状態みたいだが
なんか、「テクスチャユニット」ってのが物凄く気になるな…
フルプログラマブルじゃなかったの? テクスチャフェッチの手法に至るまでアルゴリズムを
コネコネできてこそ新しいレンダリング手法が生まれると思うのに
フルプログラマブルじゃなかったの? テクスチャフェッチの手法に至るまでアルゴリズムを
コネコネできてこそ新しいレンダリング手法が生まれると思うのに
>>380
使いたくないのなら使わなければいいだけじゃね
使いたくないのなら使わなければいいだけじゃね
PowerVRの場合、半透明ポリを後処理するのを除いて
基本1ピクセルにxテクセルって処理量が決まってるんだよね
Scatter-Gatherなんか使って、512bitレジスタにゴソっと1ピクセルに必要なテクセルを
バラバラのメインメモリアドレスから摘まんで持ってこれるんかね
基本1ピクセルにxテクセルって処理量が決まってるんだよね
Scatter-Gatherなんか使って、512bitレジスタにゴソっと1ピクセルに必要なテクセルを
バラバラのメインメモリアドレスから摘まんで持ってこれるんかね
384 :,,・´∀`・,,)っ-○◎●:2008/11/30(日) 00:40:54 ID:87fcriAM
> Scatter-Gatherなんか使って、512bitレジスタにゴソっと1ピクセルに必要なテクセルを
> バラバラのメインメモリアドレスから摘まんで持ってこれるんかね
ただ単にROPユニットの都合じゃないの?
> 全然バラバラのアドレスだと要素数分(16サイクル)確実にかかるだろうね。
NVidiaのハードだとテクスチャはスキャンライン順じゃなく、
ヒルベルト曲線順だかZ曲線順だと言われているよね。
キャッシュにヒットするので1ピクセルに対応するテクセルのアドレスが
全然バラバラってことはないとは思う。
だからなんだと言われたらそのとおりだが。
> バラバラのメインメモリアドレスから摘まんで持ってこれるんかね
ただ単にROPユニットの都合じゃないの?
> 全然バラバラのアドレスだと要素数分(16サイクル)確実にかかるだろうね。
NVidiaのハードだとテクスチャはスキャンライン順じゃなく、
ヒルベルト曲線順だかZ曲線順だと言われているよね。
キャッシュにヒットするので1ピクセルに対応するテクセルのアドレスが
全然バラバラってことはないとは思う。
だからなんだと言われたらそのとおりだが。
386 :Socket774:2008/12/02(火) 20:16:42 ID:6m1Si4XC
これって今買える唯一のPC用PowerVR?
デル、12.1型液晶ノート「Inspiron Mini 12」を最大35,000円値下げ
http://pc.watch.impress.co.jp/docs/2008/1202/dell.htm
>>377
ちょっと昔にあった
物理アクセラレーションカードみたいなもんで終わるかな
デル、12.1型液晶ノート「Inspiron Mini 12」を最大35,000円値下げ
http://pc.watch.impress.co.jp/docs/2008/1202/dell.htm
>>377
ちょっと昔にあった
物理アクセラレーションカードみたいなもんで終わるかな
AtomZシリーズを採用しているのは全部PowerVRだけど?
で?
他に有るのか?
他に有るのか?
PCだとSCHに載ってるのだけじゃないの?
製品名知らないがAV機器用のCanmoreもPowerVRだけど、これはPC用とはいえないしなー。
製品名知らないがAV機器用のCanmoreもPowerVRだけど、これはPC用とはいえないしなー。
PowerVRスレを復活させろ
391 :Socket774:2008/12/04(木) 05:51:26 ID:T4e0XCcM
( ゚Д゚)ウマー
>>377
東芝、SpursEngineイベント開催! あまりの人気に入場規制も
http://ascii.jp/elem/000/000/195/195266/
大盛況だった「SpursEngine」イベント――SDKの無償配布も告知
http://plusd.itmedia.co.jp/pcuser/articles/0812/08/news040.html
品薄になるほど好調な売れ行き
http://www.watch.impress.co.jp/akiba/hotline/20081206/etc_shopwatch.html
東芝、SpursEngineイベント開催! あまりの人気に入場規制も
http://ascii.jp/elem/000/000/195/195266/
大盛況だった「SpursEngine」イベント――SDKの無償配布も告知
http://plusd.itmedia.co.jp/pcuser/articles/0812/08/news040.html
品薄になるほど好調な売れ行き
http://www.watch.impress.co.jp/akiba/hotline/20081206/etc_shopwatch.html
誰もソフトを作らないSpursEngine
>>394
SpursEngineをWCGやSETIなんかに対応させれば面白いのにね
SpursEngineをWCGやSETIなんかに対応させれば面白いのにね
>395
負荷時でも10W、複数挿し可能らしいから、そういう用途には
向いてるかもしれないな。メジャーなクライアントバイナリ―は
東芝が用意すればいいのに
負荷時でも10W、複数挿し可能らしいから、そういう用途には
向いてるかもしれないな。メジャーなクライアントバイナリ―は
東芝が用意すればいいのに
東芝はコンシューマー商売下手だよね。
SSDとか気合い入ったの作らないし、
HD DVD失敗したならBDで行けばいいのにgdgdしてるし、
SpursEngineも最初からSDK付けておけばもっと盛り上がりそうなのに、
なんか何もかも中途半端な感じ。
SSDとか気合い入ったの作らないし、
HD DVD失敗したならBDで行けばいいのにgdgdしてるし、
SpursEngineも最初からSDK付けておけばもっと盛り上がりそうなのに、
なんか何もかも中途半端な感じ。
東芝は部品とサザエさんだけやってればいいって感じだ罠
SpursEngine使えばPS3のゲームがそのままPC上で動くとか
部品屋気性が抜けないんじゃ、東芝には期待できないな。
東芝の製品って昔から壊れやすい、安かろう悪かろうなイメージがあるんだよなぁ
一流企業のはずなのにやってることが二流
まあシャープもそうなんだが
一流企業のはずなのにやってることが二流
まあシャープもそうなんだが
部品といってもプログラマブルなものは最近はローレベルの
ソフト込みでアドバンテージがないと売れないんじゃないのかな
ソフト込みでアドバンテージがないと売れないんじゃないのかな
東芝はノーパソ全部HDDを廃止してさっさとSSDを広めろ
512bitのSIMDじゃなくって、512bit長のVLIWとかにはできなかったのかなあ
どうせJITはさむんなら、クルーソーみたいな構造が一番効率良いんじゃねの
どうせJITはさむんなら、クルーソーみたいな構造が一番効率良いんじゃねの
406 :,,・´∀`・,,)っ-●◎○:2008/12/12(金) 21:36:54 ID:LSddo0Nj
GPUを名乗ってはいるけどメニーコアx86だから。
ディスクリートGPUに収まる気など更々ない
ディスクリートGPUに収まる気など更々ない
うーんまあそういうコンセプトだよね、Intelだもんね
P5コアのかわりにEfficionだったらおもろいなとか思っただけw
P5コアのかわりにEfficionだったらおもろいなとか思っただけw
どこにも収まらなくて
あぼ〜ん
ですね
あぼ〜ん
ですね
PowerVRのライセンスを買ったのはLarrabee開発と関係あるの?
http://techreport.com/discussions.x/10549
2007年に発売される単体GPUカードにPowerVRの技術が使われるらしい(棒読み
2007年に発売される単体GPUカードにPowerVRの技術が使われるらしい(棒読み
411 :,,・´∀`・,,)っ-●◎○:2008/12/14(日) 03:51:30 ID:Dlzj/LNa
>>409
今のところ「全く」ない。Atom搭載MID向けだし。
ついでにAtom+Larrabeeも無いな。
やるくらいなら最初からLarrabeeだけにするでしょ
x86が土台なわけだし。
LarrabeeがGPUとして微妙って言われてるのは、プログラマブルでないモジュールまで
LarrabeeのGPUコアでまかなおうとしてるから。
普通の専用ハードウェアを搭載し、Larrabeeはプログラマブルシェーダ専用として積む
っていう可能性はあるんだけどね
これなら純粋なGPUとしてもNVIDIAと互角以上に戦える。
個人的にはPowerVRベースの固定ハード+x86メニーコアもいいと思うよ。
シェーダモデル的にはどうなるんだろ?
今のところ「全く」ない。Atom搭載MID向けだし。
ついでにAtom+Larrabeeも無いな。
やるくらいなら最初からLarrabeeだけにするでしょ
x86が土台なわけだし。
LarrabeeがGPUとして微妙って言われてるのは、プログラマブルでないモジュールまで
LarrabeeのGPUコアでまかなおうとしてるから。
普通の専用ハードウェアを搭載し、Larrabeeはプログラマブルシェーダ専用として積む
っていう可能性はあるんだけどね
これなら純粋なGPUとしてもNVIDIAと互角以上に戦える。
個人的にはPowerVRベースの固定ハード+x86メニーコアもいいと思うよ。
シェーダモデル的にはどうなるんだろ?
Larrabeeは3Dlabsの遺伝子が色濃く現れてるんだが
x86じゃなければ、万々歳だったのになぁ・・
P10->P20->P30(larrabee)って感じだ
ttp://www.beyond3d.com/images/reviews/3dlabsP10/progress-big.gif
x86じゃなければ、万々歳だったのになぁ・・
P10->P20->P30(larrabee)って感じだ
ttp://www.beyond3d.com/images/reviews/3dlabsP10/progress-big.gif
{kind=link}
現状のハイエンドGPUだと,低解像度ではピクセル数以上のポリゴン数を扱うことができそうだ。
パフォーマンスは兎も角、GPUとしてのドライバのクオリティに懸念を感じるな。Indelの場合。
特にDirectXのパイプラインとタイリング方式をどう折り合い付けるのか、とても不安。
特にDirectXのパイプラインとタイリング方式をどう折り合い付けるのか、とても不安。
そもそもさ、「専用ハードウェア」っていうのもさ、リングバス上に他のモジュールと同じように繋がってるんであれば、
結局は外部メモリへのメモリアクセスは全て共通の縛りになるわけで
要るかね?専用ハードウェア
結局は外部メモリへのメモリアクセスは全て共通の縛りになるわけで
要るかね?専用ハードウェア
あ、専用ハードウェアってのはテクスチャユニットの事
チップ外のメモリを触る場合、チップ内に専用ハードウェアがある事に意味なんてあるんかいな
チップ外のメモリを触る場合、チップ内に専用ハードウェアがある事に意味なんてあるんかいな
TMUは単なるメモリアクセスユニットじゃないよ
テクスチャに関する莫大な演算が行われる
演算能力だけならshaderなんて比較にならないほどに
へたすりゃ1ケタ違う
テクスチャに関する莫大な演算が行われる
演算能力だけならshaderなんて比較にならないほどに
へたすりゃ1ケタ違う
418 :,,・´∀`・,,)っ-○◎●:2008/12/15(月) 13:10:19 ID:7/5SpZFX
失敗作を引き合いに出してどうする
GMA系のVGAまだ開発続いてたのね
http://pc.watch.impress.co.jp/docs/2008/1215/ubiq235.htm
今後はララビーとPVRライセンス物だけでGMAはチーム解散と思ってたよん
http://pc.watch.impress.co.jp/docs/2008/1215/ubiq235.htm
今後はララビーとPVRライセンス物だけでGMAはチーム解散と思ってたよん
422 :,,・´∀`・,,)っ-●◎○:2008/12/15(月) 21:48:52 ID:7/5SpZFX
>>419
別にモノ自体は悪かないでしょ
固定ハードからシェーダへの過度期の製品だから叩かれただけで。
IntelだってPentium Proなしには今の技術はないんだぜ。
今現在は、シェーダ使わないけど性能要求大きい用途ってどんなのがある?
別にモノ自体は悪かないでしょ
固定ハードからシェーダへの過度期の製品だから叩かれただけで。
IntelだってPentium Proなしには今の技術はないんだぜ。
今現在は、シェーダ使わないけど性能要求大きい用途ってどんなのがある?
fxの失敗でnvは旧来の手法に戻したのよ
(そして、ATIと同様の構造になる)
それが6,7,8シリーズの系譜だ
逆に3dlabsは更に汎用化を推し進めたが
(そして、ATIと同様の構造になる)
それが6,7,8シリーズの系譜だ
逆に3dlabsは更に汎用化を推し進めたが
あとDX10以降はshaderが必須だから
shader使わないってのは単にテクスチャべたべた張り付けるしかないだろうな
フィルターかけて
そんな場合でもTMUの処理能力が高くなきゃ遅いし
PS3の1.8Tflops(わら)のほとんどはTMUだったりする
shader使わないってのは単にテクスチャべたべた張り付けるしかないだろうな
フィルターかけて
そんな場合でもTMUの処理能力が高くなきゃ遅いし
PS3の1.8Tflops(わら)のほとんどはTMUだったりする
AMD,Open CL 1.0サポートを表明。2009年のSDK配布開始を予告
http://www.4gamer.net/games/080/G008082/20081215051/
http://www.4gamer.net/games/080/G008082/20081215051/
http://lucille.atso-net.jp/blog/?p=585
テクスチャ処理は機能が決まっているわりに演算量が多い処理なので HW で提供というのは正しい判断です。
Aniso filtering とか SW でやったらベラボーに時間がかかるしね.
ただ、演算コアから HW テクスチャユニットを使うには L2 を介して
texturing コマンド(か特殊メモりアドレスへのアクセス?)を発行しないといけないので、
テクスチャリングのレイテンシがでかそうなのが気になりますね。
スレッディングとかで隠蔽はできますが、テクスチャリングのパフォーマンスを出すには
そのようなプログラミングが明示的に必要になりそうです.
テクスチャ処理は機能が決まっているわりに演算量が多い処理なので HW で提供というのは正しい判断です。
Aniso filtering とか SW でやったらベラボーに時間がかかるしね.
ただ、演算コアから HW テクスチャユニットを使うには L2 を介して
texturing コマンド(か特殊メモりアドレスへのアクセス?)を発行しないといけないので、
テクスチャリングのレイテンシがでかそうなのが気になりますね。
スレッディングとかで隠蔽はできますが、テクスチャリングのパフォーマンスを出すには
そのようなプログラミングが明示的に必要になりそうです.
Intelヒルズボロが開発するCPUアーキテクチャの方向性
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
ウマビー
で、これって出たばっかりだとあんまり意味ないんだろうなぁ
3年は待たないとまともなソフトがでそろわなさそうだ
GPUとして使うにも、普通の奴の方が当分よさそうだし
3年は待たないとまともなソフトがでそろわなさそうだ
GPUとして使うにも、普通の奴の方が当分よさそうだし
多コア時代へ向けて内部バスの習作ついでに間抜けなアーリマから幾らか小遣い銭を巻き上げるのが目的
TMPGEncあたりは真っ先に対応ソフトリリースしそうだけどな
もうエンコなんてしねえよ
434 :Socket774:2008/12/23(火) 11:09:46 ID:YheX+wNy
ウンコ
ハードがなければソフトも組みようがないし
436 :,,・´∀`・,,)っ-●◎○:2008/12/23(火) 15:39:24 ID:ScZ+x1f2
仕様をある程度見込んで簡易アセンブラ作ってる俺様に謝れ!誤れ!
438 :,,・´∀`・,,)っ-○◎●:2008/12/23(火) 20:45:03 ID:ScZ+x1f2
ネイティブ触るのに「ICC Professional買え」って言われるとたまらん。
GNU binutilsが対応してくれないとな
GNU binutilsが対応してくれないとな
今後十年でGPUが無くなりそうな気配
440 :Socket774:2008/12/26(金) 09:41:56 ID:yhU6xDqK
もう援交なんてしねえよ
442 :,,・´∀`・,,)っ-●◎○:2008/12/26(金) 17:58:18 ID:H8ta8NrL
なくなりはしないよ。どうせそんなに大容量積めないし。
L4キャッシュくらいに使うかどうかってところ。
L4キャッシュくらいに使うかどうかってところ。
激安機やUMPCがほんとに1チップPCになるだけじゃね?
今のオンボがPowerVRだよ
結局DRAM混載ものは8MB止まりだったな
そのDRAMの使い道が中途半端だからでしょ
OSの方で、全部をまとめて仮想メモリとして扱えるようにすればいいのかな?
OSの方で、全部をまとめて仮想メモリとして扱えるようにすればいいのかな?
なんでedramって何百メガの大容量のせたり、接続したりできないの?
連投ごめん。載せるのはダイがでかくなるから無理だね。
でもなんで大容量をMCMできないの?
でもなんで大容量をMCMできないの?
449 :Socket774:2009/01/01(木) 22:46:43 ID:5G30f2J0
未だやる必要がないんだよオンダイキャッシュで十分性能が出てるから
あとMCMは実は結構高い
投入時期は違うもののHarpertownとNehalem-EPのコストは同じ位なんて話もある
あとMCMは実は結構高い
投入時期は違うもののHarpertownとNehalem-EPのコストは同じ位なんて話もある
サンクス。やっぱりあまり意味が無いって言うのが一番なんですかね。
横レスだが、VIAのツインコアが全然出ないのはそれが理由か。
間に合わせのやっつけで作っても
意味ないって熟知してるからだよ
意味ないって熟知してるからだよ
( ゚Д゚)ウマービ
これって装着したらタスクマネージャーのCPU数が凄いことになったりすんのかな
455 :,,・´∀`・,,)っ-○◎●:2009/01/08(木) 16:02:51 ID:Een5kEL3
ないない
LarrabeeはLarrabeeで、PCのOSとは別のマイクロOSが動くらしい。
ただ、Xeonソケットに刺さる「メニーコアCPU」としてのLarrabeeも計画されてるとか、ないとか。
LarrabeeはLarrabeeで、PCのOSとは別のマイクロOSが動くらしい。
ただ、Xeonソケットに刺さる「メニーコアCPU」としてのLarrabeeも計画されてるとか、ないとか。
LarrabeeをSocket Bに挿せるようにしただけじゃHPCではアプリを選ぶだろうな。
コードネームがkeiferだった頃はメモリバンド幅FBD8chで100GB/sとかだったけど。
でもデュアルソケットでWestmereとLarrabeeを混在させられるなら普通にWS向けでも売れそうだな。
GPU向けのLarrabeeと違ってECCメモリが使えるからCUDAは完全に死亡する予感。
サーバー向けではOpteronとXeonが窮地に立つ。
今のx86サーバーの用途って半分以上がWebサーバーやmailサーバーだからなー。
Niagaraの性能見る限りこの分野じゃLarrabee大爆発だろ。Niagaraはぶったくり価格だから助かってるが。。。
コードネームがkeiferだった頃はメモリバンド幅FBD8chで100GB/sとかだったけど。
でもデュアルソケットでWestmereとLarrabeeを混在させられるなら普通にWS向けでも売れそうだな。
GPU向けのLarrabeeと違ってECCメモリが使えるからCUDAは完全に死亡する予感。
サーバー向けではOpteronとXeonが窮地に立つ。
今のx86サーバーの用途って半分以上がWebサーバーやmailサーバーだからなー。
Niagaraの性能見る限りこの分野じゃLarrabee大爆発だろ。Niagaraはぶったくり価格だから助かってるが。。。
なんでECCメモリ次第なのか全然分からないオレガイル
つかLarrabeeで
広く言えば計算エンジンというかアクセラレータみたいな物で
server組むアフォってこの世に居るのか。
オレの全然ワカラン世界だ。
広く言えば計算エンジンというかアクセラレータみたいな物で
server組むアフォってこの世に居るのか。
オレの全然ワカラン世界だ。
459 :,,・´∀`・,,)っ-○◎●:2009/01/09(金) 06:32:25 ID:8hHbNwdi
どっちかというとAtomのメニーコアに期待したい。
メニーコア向けに作られてた
どっちかというと旧KaiferってAtomとの共通設計じゃないかと思うんだが
4GHz 32コアで1TFLOPS(SP)だから丁度一致する
メニーコア向けに作られてた
どっちかというと旧KaiferってAtomとの共通設計じゃないかと思うんだが
4GHz 32コアで1TFLOPS(SP)だから丁度一致する
>>457-458
>なんでECCメモリ次第なのか全然分からない
HPCでも信頼性って大事なんですよ。
例えばロスアラモス研がやってる核兵器の安全性検証とかで計算結果が間違っていたらえらいことになる。
これは極端な例にしてもお金を沢山出して買ったマシンの計算結果が信頼できないなんて問題でしょ。
初期のLarrabeeでECCメモリが使えない点はディスアドバンテージだとIntel自身も認めている。
http://www.hpcwire.com/blogs/Larrabee-for-HPC-Not-So-Fast-36336839.html
>つかLarrabeeで
>広く言えば計算エンジンというかアクセラレータみたいな物で
>server組む
Xeonソケットに刺さる(>>455) LarrabeeをSocket Bに挿せる(>>456) Niagara(>>456)
と書いてあるわけだが。
CELLがPS3だけではなくPCI-Expressを利用してアクセラレータボードを出してるのと逆パターンだよ。
わからないならNiagara Sunでググれ。
>なんでECCメモリ次第なのか全然分からない
HPCでも信頼性って大事なんですよ。
例えばロスアラモス研がやってる核兵器の安全性検証とかで計算結果が間違っていたらえらいことになる。
これは極端な例にしてもお金を沢山出して買ったマシンの計算結果が信頼できないなんて問題でしょ。
初期のLarrabeeでECCメモリが使えない点はディスアドバンテージだとIntel自身も認めている。
http://www.hpcwire.com/blogs/Larrabee-for-HPC-Not-So-Fast-36336839.html
>つかLarrabeeで
>広く言えば計算エンジンというかアクセラレータみたいな物で
>server組む
Xeonソケットに刺さる(>>455) LarrabeeをSocket Bに挿せる(>>456) Niagara(>>456)
と書いてあるわけだが。
CELLがPS3だけではなくPCI-Expressを利用してアクセラレータボードを出してるのと逆パターンだよ。
わからないならNiagara Sunでググれ。
混在させるのならx86よりも、尖がったもの同士、
NiagaraタイプとCell、Larrabeeタイプの方が面白そう。
面白さは趣味的なもので、実用性はどうなっても知らないが
NiagaraタイプとCell、Larrabeeタイプの方が面白そう。
面白さは趣味的なもので、実用性はどうなっても知らないが
462 :Socket774:2009/01/11(日) 10:37:50 ID:OWGbygpA
似たもの同志を組合せてどうするんだ?
異なるものや補完しあうものを組合せるほうが性能出しやすいし面白いと思うが
異なるものや補完しあうものを組合せるほうが性能出しやすいし面白いと思うが
463 :,,・´∀`・,,)っ-○○◎:2009/01/11(日) 12:19:48 ID:WBW6NGHY
AMDが万能型のCPU+尖った設計のGPUのあわせ技で市場をねらう戦略だね。
x86資産を持たないNVIDIAがプログラマビリティ重視してるのと対象的。
x86資産を持たないNVIDIAがプログラマビリティ重視してるのと対象的。
464 :MACオタ>団子 さん:2009/01/11(日) 12:33:25 ID:zIHSxZkM
>>463
AMDのChuck MooreのCELL/B.E.批判を合わせて聞くと面白いかもしれませんよ。
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/ (講演ビデオのリンク付)
AMDのChuck MooreのCELL/B.E.批判を合わせて聞くと面白いかもしれませんよ。
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/ (講演ビデオのリンク付)
465 :,,・´∀`・,,)っ-○◎●:2009/01/11(日) 16:05:36 ID:uJrTAOif
お前の引用はいつも面白くない
既に紫になってるものばっかし
既に紫になってるものばっかし
466 :MACオタ>団子 さん:2009/01/11(日) 16:18:34 ID:zIHSxZkM
>>465
いつもご愛読いただいているようですね(笑)
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/766
--------------------
766 名前:MACオタ 投稿日:2008/06/07(土) 14:25:51 ID:0SS3idWO
AMDのシニアフェロー、Charles Mooreのスタンフォード大学での講演をThe Registerが伝えているす。
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/
--------------------
いつもご愛読いただいているようですね(笑)
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/766
--------------------
766 名前:MACオタ 投稿日:2008/06/07(土) 14:25:51 ID:0SS3idWO
AMDのシニアフェロー、Charles Mooreのスタンフォード大学での講演をThe Registerが伝えているす。
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/
--------------------
467 :,,・´∀`・,,)っ-○◎●:2009/01/11(日) 16:22:55 ID:uJrTAOif
自意識過剰だな
theregisterはRSS登録してるからお前の紹介は要らんと言ってるのだ
theregisterはRSS登録してるからお前の紹介は要らんと言ってるのだ
468 :MACオタ>団子 さん:2009/01/11(日) 16:31:25 ID:zIHSxZkM
>>467
---------------
theregisterはRSS登録してるから
---------------
見栄を張らなくても良いですよ。団子さんがいつも引用するのは、後藤記事や北森瓦版とか
なのは、皆知ってますから(笑)
---------------
theregisterはRSS登録してるから
---------------
見栄を張らなくても良いですよ。団子さんがいつも引用するのは、後藤記事や北森瓦版とか
なのは、皆知ってますから(笑)
469 :,,・´∀`・,,)っ-○◎●:2009/01/11(日) 16:35:35 ID:uJrTAOif
中身のないコピペは要らないって言ってるんだよ
次なんか言ったらお前もあぼーんフィルタに入れる
次なんか言ったらお前もあぼーんフィルタに入れる
>>468
ワロタw
ワロタw
471 :,,・´∀`・,,)っ-●◎○:2009/01/11(日) 23:17:50 ID:uJrTAOif
コピペが芸風だからそれが価値だと思ってるんだね。手に負えないよ。
AMDが中途半端な存在であるCellを馬鹿にしてるのは当の昔から知ってること。
自慢げにコピペ爆撃。いつもの。
己の浅はかさを知れってことよ。
AMDが中途半端な存在であるCellを馬鹿にしてるのは当の昔から知ってること。
自慢げにコピペ爆撃。いつもの。
己の浅はかさを知れってことよ。
( ・∀・) マチクタビレター
もうそろそろ発表があってもいいんじゃない?
発売中止の
もうそろそろ発表があってもいいんじゃない?
発売中止の
473 :Socket774:2009/01/12(月) 15:21:52 ID:7ymE2zcS
AMDへの投資中止を、アラブ投資ファンドが発表するほうが先だよ。アラブ人は石油収入ガタ落ち・・・
.,,-‐''"~~ ゙゙̄'''ー、,
.,/' ザ ル カ ウ ィ ヽ http://aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ | アラブ投資ファンド = ザルカウィ
|‐''/ \゙''ー|
| | | | A M D = 香田
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | //
.| ヽ、,,;;iiill|||||||||lllii;;, /.| 頭(CPU設計)と、体(工場)を分離する!
ヽ |'"~ー--‐~゙゙'''| /
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香 田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| / んっごう!!
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | (
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
.,,-‐''"~~ ゙゙̄'''ー、,
.,/' ザ ル カ ウ ィ ヽ http://aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ | アラブ投資ファンド = ザルカウィ
|‐''/ \゙''ー|
| | | | A M D = 香田
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | //
.| ヽ、,,;;iiill|||||||||lllii;;, /.| 頭(CPU設計)と、体(工場)を分離する!
ヽ |'"~ー--‐~゙゙'''| /
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香 田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| / んっごう!!
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | (
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
ことしじゃないか
もうそろそろ32コアCPUの話も出ていいころじゃまいかw
今は一部の鯖用が6コアであとは4コアだぞw
もうそろそろ32コアCPUの話も出ていいころじゃまいかw
今は一部の鯖用が6コアであとは4コアだぞw
475 :,,・´∀`・,,)っ-○◎○:2009/01/12(月) 17:12:34 ID:nJjDJ95S
LarrabeeのSIMDユニットはGPUに特化したものだから
HPCじゃない鯖用としては不向きじゃないかな。
鯖向けとしてはAtomのほうが無駄がないと思う。
もともとメニーコア向けに設計されてたという情報もあるくらいだし。
というわけで、こういうXeonを希望。x64・仮想化・省電力ステート全部Enableで。
[Atom][Atom] [Atom][Atom]
| | | |
[L2 512KB] [L2 512KB]
| |
[L3 4-16MB/DDR3/QPI]
| |
[L2 512KB] [L2 512KB]
| | | |
[Atom][Atom] [Atom][Atom]
HPCじゃない鯖用としては不向きじゃないかな。
鯖向けとしてはAtomのほうが無駄がないと思う。
もともとメニーコア向けに設計されてたという情報もあるくらいだし。
というわけで、こういうXeonを希望。x64・仮想化・省電力ステート全部Enableで。
[Atom][Atom] [Atom][Atom]
| | | |
[L2 512KB] [L2 512KB]
| |
[L3 4-16MB/DDR3/QPI]
| |
[L2 512KB] [L2 512KB]
| | | |
[Atom][Atom] [Atom][Atom]
476 :Socket774:2009/01/12(月) 17:49:32 ID:SdaaSntk
ATOMベースというだけでやだーという人がいっぱいいる予感
477 :,,・´∀`・,,)っ-○◎●:2009/01/12(月) 18:23:38 ID:nJjDJ95S
じゃあLarrabeeがいいの?違うだろ?
具体的に言うよ。Larrabeeは512bitユニット×1だ。
スカラユニットはAtomよりしょぼいし、Dual issueできる命令の組み合わせもAtomより更に厳しい。
Atomは128bit SIMD/FP×2だから、従来x86のスカラ〜SSE命令までの性能に限れば
Atomのほうが倍くらいは速い筈。
(ちょっと驚いたんだけど、少なくとも整数に限ってはSSEの性能は用途によれば倍の
クロックのCell SPEをも圧倒する)
Atomに採用されてるBonnelアーキテクチャは正統なx86メニーコア向けプロジェクトの成果物。
Larrabee強引な言い方をすればGPUシェーダにPentium由来のスカラユニットとデコーダをくっつけたもの。
設計ポリシーが全然違う。
具体的に言うよ。Larrabeeは512bitユニット×1だ。
スカラユニットはAtomよりしょぼいし、Dual issueできる命令の組み合わせもAtomより更に厳しい。
Atomは128bit SIMD/FP×2だから、従来x86のスカラ〜SSE命令までの性能に限れば
Atomのほうが倍くらいは速い筈。
(ちょっと驚いたんだけど、少なくとも整数に限ってはSSEの性能は用途によれば倍の
クロックのCell SPEをも圧倒する)
Atomに採用されてるBonnelアーキテクチャは正統なx86メニーコア向けプロジェクトの成果物。
Larrabee強引な言い方をすればGPUシェーダにPentium由来のスカラユニットとデコーダをくっつけたもの。
設計ポリシーが全然違う。
>>475
それなんてNiagara?
それなんてNiagara?
L4キャッシュはバス幅広げないかぎり、無理があるよな。
64→128ビットx86の時代なら(ry
64→128ビットx86の時代なら(ry
そりゃそうだろな。
HTx4が有効に働く場合はかなり限られてると思う。
HTx4が有効に働く場合はかなり限られてると思う。
>>462
>461のはそれぞれ別の方向へ向かってて似てないんじゃないか?
>461のはそれぞれ別の方向へ向かってて似てないんじゃないか?
×32ビット構成1GビットXDR DRAMを製品化
http://www.elpida.com/ja/news/2009/01-20.html
http://www.elpida.com/ja/news/2009/01-20.html
Larrabeeは時代的にまだ早すぎるんだよな。
いまだにソフトはマルチコア対応が遅れている。
4コアあってもエンコで4コア使うアプリでCPUを100%占有すら
してくれない。
4コアそれぞれ、50%程度なのには笑ったw。
XVID複数コア指定しても25%程度、これじゃシングルコアと同じ。
nehalemにしても、高速なのは通常命令よりSSEなわけで、
SSEに最適化しないとnahalemの恩恵は薄い。
Larrabeeが来ても新命令や、SSEにすら最適化が遅れている。
通常命令であっても、コア性能がPen3並みに落ちるわけで、
ほとんどのアプリが遅くなる予感。
いまだにソフトはマルチコア対応が遅れている。
4コアあってもエンコで4コア使うアプリでCPUを100%占有すら
してくれない。
4コアそれぞれ、50%程度なのには笑ったw。
XVID複数コア指定しても25%程度、これじゃシングルコアと同じ。
nehalemにしても、高速なのは通常命令よりSSEなわけで、
SSEに最適化しないとnahalemの恩恵は薄い。
Larrabeeが来ても新命令や、SSEにすら最適化が遅れている。
通常命令であっても、コア性能がPen3並みに落ちるわけで、
ほとんどのアプリが遅くなる予感。
遅くなるって何と比べてるんだ
>>484
なんか滅茶苦茶理論だなwww
なんか滅茶苦茶理論だなwww
遅くなろうがなるまいが、もはやこの道しか残されていないのだ。
>>484
「PenDが否定されたのはSSE3に対応したソフトがエンコードくらいだったから」並の暴論だなw
新命令ばかり使う特殊な状況だけ速いCPUとか、組込用以外ではいらない子
PadLockで暗号化通信だけは異常に速いVIA系のCPUとか
「PenDが否定されたのはSSE3に対応したソフトがエンコードくらいだったから」並の暴論だなw
新命令ばかり使う特殊な状況だけ速いCPUとか、組込用以外ではいらない子
PadLockで暗号化通信だけは異常に速いVIA系のCPUとか
いや、つーか、Windowsでも走らせると思ってんのかっつーか
490 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 17:14:17 ID:Ppfr+k5r
GeForce8は大幅なアーキテクチャの変更を行った結果、旧来タイトルはGeForce7より性能低下したよね。
新アーキテクチャを生かした「圧倒的な表現力」を誇るフラグシップタイトルによって、移行を促進した。
それがロストプラネットだったり、今のCrysisだったりしたわけだ。
IntelにとってはそのフラグシップタイトルがFarcry2やQuake 4。Larrabeeを売り込むためのタイトルだ。
Intelがデモした次元でのGPUでの物理演算やリアルタイムレイトレーシングは、現行のNVIDIA・ATIの
アーキテクチャはボトルネックが多い。
MSにもWindows 7を販促するための材料が必要だ。DX10.xは新OSを売る要素としては弱すぎた。
革新的なゲームが必要だった。MSがWindows 7を予定より早めた理由。まさにそれが革新的なGPUの登場だ。
NVIDIAはLarrabee対抗のために一気に55nmから40nmにスキップし、Compute Capabilityを刷新したGT300を投入する。
ATIは、RV770を40nmにシュリンクしコアを増やしただけのRV870を投入し、守りのターンに入る。
新アーキテクチャを生かした「圧倒的な表現力」を誇るフラグシップタイトルによって、移行を促進した。
それがロストプラネットだったり、今のCrysisだったりしたわけだ。
IntelにとってはそのフラグシップタイトルがFarcry2やQuake 4。Larrabeeを売り込むためのタイトルだ。
Intelがデモした次元でのGPUでの物理演算やリアルタイムレイトレーシングは、現行のNVIDIA・ATIの
アーキテクチャはボトルネックが多い。
MSにもWindows 7を販促するための材料が必要だ。DX10.xは新OSを売る要素としては弱すぎた。
革新的なゲームが必要だった。MSがWindows 7を予定より早めた理由。まさにそれが革新的なGPUの登場だ。
NVIDIAはLarrabee対抗のために一気に55nmから40nmにスキップし、Compute Capabilityを刷新したGT300を投入する。
ATIは、RV770を40nmにシュリンクしコアを増やしただけのRV870を投入し、守りのターンに入る。
491 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 17:40:05 ID:Ppfr+k5r
リアルタイムレイトレーシングは低解像度なら実用域に達してるようだね。
http://www.4gamer.net/games/047/G004713/20080222012/
> IntelにとってはそのフラグシップタイトルがFarcry2やQuake 4。
とはいったけどこれがそのまんま出るわけじゃないか。現行マルチコアCPUでも十分できるレベルでの「デモ」だし
http://www.4gamer.net/games/047/G004713/20080222012/
> IntelにとってはそのフラグシップタイトルがFarcry2やQuake 4。
とはいったけどこれがそのまんま出るわけじゃないか。現行マルチコアCPUでも十分できるレベルでの「デモ」だし
性能以前にそもそも過去のゲームが正しく動くかどうかが問題だろ
493 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 18:11:22 ID:Ppfr+k5r
過去のゲーム?w
いまだにBF1942以前のゲームとかやってる人?
性能的にはほどほどには動くんじゃないの?
120fpsとか240fpsとか出ないとだめな人?
新規のゲームが売れる→OS・ハードが売れる
MSとIntelの思惑は一致してるんだよ。
いまだにBF1942以前のゲームとかやってる人?
性能的にはほどほどには動くんじゃないの?
120fpsとか240fpsとか出ないとだめな人?
新規のゲームが売れる→OS・ハードが売れる
MSとIntelの思惑は一致してるんだよ。
ミッドシップで大荷物を運んだりダンプカーで峠を攻めたりしたいのか?
GPUとして市場に割り込むなら過去のソフトとの互換性が必要で
不具合なく動くかどうかが問題だと言ってるんだよ
そこに何の不安も感じないんなら言うことないわ
不具合なく動くかどうかが問題だと言ってるんだよ
そこに何の不安も感じないんなら言うことないわ
いまだにGPUだと思ってるのか。アフォが。
497 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 18:47:51 ID:Ppfr+k5r
>>495
過去のソフト?
言っちゃ悪いけど過去のゲームが動く程度の需要じゃ金が動かないんだよ。
PCゲーム市場をリードしてきたのは、マシン丸ごと買い換えないといけないような
劇的な表現力の変化を伴う新しいゲームだ。
古いゲームは古いマシンでやればいいじゃない?
リアルタイムレイトレーシングは、簡素なものならPS3のキルゾーン2でもSPEを駆使してやってたりするし
ゲーム業界はそっち方面に可能性を見出してる。
Larrabeeが256KB/Coreの共有キャッシュを持つのと同様に、NVIDIAもGT300アーキテクチャでは
ローカルメモリを増やす方向に向かってる。高速なレイトレーシングにはある程度の容量の
データキャッシュが欠かせない。
少なくともラスタグラフィック用のGPU(要するに今のATIのGPUアーキ)に未来はない。
過去のソフト?
言っちゃ悪いけど過去のゲームが動く程度の需要じゃ金が動かないんだよ。
PCゲーム市場をリードしてきたのは、マシン丸ごと買い換えないといけないような
劇的な表現力の変化を伴う新しいゲームだ。
古いゲームは古いマシンでやればいいじゃない?
リアルタイムレイトレーシングは、簡素なものならPS3のキルゾーン2でもSPEを駆使してやってたりするし
ゲーム業界はそっち方面に可能性を見出してる。
Larrabeeが256KB/Coreの共有キャッシュを持つのと同様に、NVIDIAもGT300アーキテクチャでは
ローカルメモリを増やす方向に向かってる。高速なレイトレーシングにはある程度の容量の
データキャッシュが欠かせない。
少なくともラスタグラフィック用のGPU(要するに今のATIのGPUアーキ)に未来はない。
498 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 18:52:31 ID:Ppfr+k5r
ゲーム市場はオンボード(=GMA)でもできるレベルのliteなオンラインゲームと
enthusiast向けのハイエンドゲームに二極化する。
てか、すでにそうなってる。
enthusiast向けのハイエンドゲームに二極化する。
てか、すでにそうなってる。
499 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 19:48:53 ID:Ppfr+k5r
互換性の保障についてだけど
Direct X 11が過去のソフトとの充分な互換性を確保しており、なおかつハードウェアがWHQL準拠であれば
古いソフトとの互換性も暗黙に保障できるといっていいんじゃないの?
ATIとNVIDIAはアーキテクチャがまったく別物だけど、DirectXが違いを吸収してくれてるように
Larrabeeも透過的に扱われるだろうよ。
DX11で何が変わるって、Direct 3Dのシェーダモデルが5.0になり、あとDirect 2DというAPIが加わる。
基本的に9.0cまでの上位互換だよ。
ちなみに、AMD/ATIもGPUでのリアルタイムレイトレーシングのデモをやってるが基本的に方法が違う。
・トレース結果をキャッシュに保持することで値を再利用性を高める(Intel)
→演算ユニットが相対的に少ないので、キャッシュを生かして計算済み結果を再利用したほうが効率がいい
演算回数が減るので電力効率に優れるが、演算回数重視の旧来ゲームでは不利。
・従来GPUの特徴である馬鹿みたいに多い演算機で、都度都度再計算する(AMD)
→計算済み結果をメモリからとってくるのは時間がかかるので再計算したほうが速い。
値再利用を前提としたキャッシュアーキテクチャよりも電力効率では不利だが
旧来(ラスタグラフィック)のパイプライン構造をそのまま生かせるので、
短期的にはつぶしがきく。過渡期には強いかもしれない。
ダイサイズの制約の中で、演算ユニットをとるか、キャッシュをとるか。
レイトレーシングへの移行が進めばLarrabeeのようなGPUのほうが優位になるが
短期的にはどう転ぶかわからないといったことろ。
低解像度であればローエンドのCPUによるソフトレンダだけでも充分フレームレートを確保できる方法だし
ワイドなSIMDユニットを備えるLarrabeeならより高解像度でもこなせる。
レイトレベースへの移行の前段階はすでにクリアされてる。
x86を選ばないメリット?そんなものはない。
SIMDのベクトル長が増えるとx86でのデコーダの負担は相対的に小さくなる。
マルチコア化が進めば高解像度でもCPUだけでレンダリングできるようになる。
そうなればディスクリートGPU自体不要になる。
CPUでLarrabeeのSIMD命令を実行する将来のために、むしろx86である必要があるわけだ。
Direct X 11が過去のソフトとの充分な互換性を確保しており、なおかつハードウェアがWHQL準拠であれば
古いソフトとの互換性も暗黙に保障できるといっていいんじゃないの?
ATIとNVIDIAはアーキテクチャがまったく別物だけど、DirectXが違いを吸収してくれてるように
Larrabeeも透過的に扱われるだろうよ。
DX11で何が変わるって、Direct 3Dのシェーダモデルが5.0になり、あとDirect 2DというAPIが加わる。
基本的に9.0cまでの上位互換だよ。
ちなみに、AMD/ATIもGPUでのリアルタイムレイトレーシングのデモをやってるが基本的に方法が違う。
・トレース結果をキャッシュに保持することで値を再利用性を高める(Intel)
→演算ユニットが相対的に少ないので、キャッシュを生かして計算済み結果を再利用したほうが効率がいい
演算回数が減るので電力効率に優れるが、演算回数重視の旧来ゲームでは不利。
・従来GPUの特徴である馬鹿みたいに多い演算機で、都度都度再計算する(AMD)
→計算済み結果をメモリからとってくるのは時間がかかるので再計算したほうが速い。
値再利用を前提としたキャッシュアーキテクチャよりも電力効率では不利だが
旧来(ラスタグラフィック)のパイプライン構造をそのまま生かせるので、
短期的にはつぶしがきく。過渡期には強いかもしれない。
ダイサイズの制約の中で、演算ユニットをとるか、キャッシュをとるか。
レイトレーシングへの移行が進めばLarrabeeのようなGPUのほうが優位になるが
短期的にはどう転ぶかわからないといったことろ。
低解像度であればローエンドのCPUによるソフトレンダだけでも充分フレームレートを確保できる方法だし
ワイドなSIMDユニットを備えるLarrabeeならより高解像度でもこなせる。
レイトレベースへの移行の前段階はすでにクリアされてる。
x86を選ばないメリット?そんなものはない。
SIMDのベクトル長が増えるとx86でのデコーダの負担は相対的に小さくなる。
マルチコア化が進めば高解像度でもCPUだけでレンダリングできるようになる。
そうなればディスクリートGPU自体不要になる。
CPUでLarrabeeのSIMD命令を実行する将来のために、むしろx86である必要があるわけだ。
思考実験的に、Intel以外の路線がうまくいくケースってのも想定してみると面白そうだけど
OSってインオーダーでもアウトオブオーダー効率性関係なし?
それともあるの?
それともあるの?
x86 GPU(笑)
>>499
>ATIとNVIDIAはアーキテクチャがまったく別物だけど、DirectXが違いを吸収してくれてるように
>Larrabeeも透過的に扱われるだろうよ。
その透過的ってやつをインテルが本気でやる気があるのかってこと。
透過的である以上LarrabeeもレイトレじゃなくてZバッファを前提にした従来型の
GPUとして動作する必要があるけどレイトレのアピールばかりしてるのを見てると
インテルとしてはそれはやりたくないんじゃないのと思えるんだよ。
まぁ、もう三度目だし通じそうにないね。
>ATIとNVIDIAはアーキテクチャがまったく別物だけど、DirectXが違いを吸収してくれてるように
>Larrabeeも透過的に扱われるだろうよ。
その透過的ってやつをインテルが本気でやる気があるのかってこと。
透過的である以上LarrabeeもレイトレじゃなくてZバッファを前提にした従来型の
GPUとして動作する必要があるけどレイトレのアピールばかりしてるのを見てると
インテルとしてはそれはやりたくないんじゃないのと思えるんだよ。
まぁ、もう三度目だし通じそうにないね。
504 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 20:46:37 ID:Ppfr+k5r
>>500
AMDも将来のことは見据えてるよ。
AMDとしてはFusionが最適解になるかもしれない。
GPUからアクセスできる高速なメモリが確保できるからね。
CPUのキャッシュメモリを一部だけでもGPUに開放すれば、簡易的ではあるが
それほどレイテンシの大きくないレイトレースキャッシュになりうる。
AMDは、Fusionは将来的にはx86のコードシーケンスからGPUにアクセスできるできるようにする
といっている。そのためには、よりワイドなSIMD命令をサポートする必要がある。
後手に回る限りはIntelとの互換性もある程度確保しなければならない。
それって出来上がるものは結局、「AMD版Larrabee」なんじゃないの?
一番つぶしがきかないのが自前のx86アーキを持たないNVIDIAだ。
AMDも将来のことは見据えてるよ。
AMDとしてはFusionが最適解になるかもしれない。
GPUからアクセスできる高速なメモリが確保できるからね。
CPUのキャッシュメモリを一部だけでもGPUに開放すれば、簡易的ではあるが
それほどレイテンシの大きくないレイトレースキャッシュになりうる。
AMDは、Fusionは将来的にはx86のコードシーケンスからGPUにアクセスできるできるようにする
といっている。そのためには、よりワイドなSIMD命令をサポートする必要がある。
後手に回る限りはIntelとの互換性もある程度確保しなければならない。
それって出来上がるものは結局、「AMD版Larrabee」なんじゃないの?
一番つぶしがきかないのが自前のx86アーキを持たないNVIDIAだ。
505 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 20:50:22 ID:Ppfr+k5r
>>503
性能的には相対的に不利だろうけど機能は提供するだろうよ。旧来機能はソフト的にやればなんでもできるだろ。
たとえば8800GTXは7600GTより遅いことがあったけどそれが何の問題がある?
Windows 7はCPUでソフトGPUをやる機能もあるの知ってる?
IntelとMSはマルチコアの活用について共同出資の研究所を作って協業してる。
性能的には相対的に不利だろうけど機能は提供するだろうよ。旧来機能はソフト的にやればなんでもできるだろ。
たとえば8800GTXは7600GTより遅いことがあったけどそれが何の問題がある?
Windows 7はCPUでソフトGPUをやる機能もあるの知ってる?
IntelとMSはマルチコアの活用について共同出資の研究所を作って協業してる。
83PSのろすぷらが新アーキテクチャを生かした「圧倒的な表現力」
(笑)
あ、あとIntel以外はGPUにx86は使えないと思うよ
VIAとすったもんだやったとき、S3には使わせないってのが条件だったし
(笑)
あ、あとIntel以外はGPUにx86は使えないと思うよ
VIAとすったもんだやったとき、S3には使わせないってのが条件だったし
507 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 20:57:11 ID:Ppfr+k5r
http://slashdot.jp/it/article.pl?sid=08/12/01/0914219
x86(MMX/SSEはあれば速いが必須ではない)で、Direct X10のすべての機能を提供できるのに
Larrabeeで提供できない理由がどこにあるの?
x86(MMX/SSEはあれば速いが必須ではない)で、Direct X10のすべての機能を提供できるのに
Larrabeeで提供できない理由がどこにあるの?
508 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 21:04:07 ID:Ppfr+k5r
>>506
CPUでGPU代替やるのにもx86 ISAを使えないの?ww
Windows WARPはIntel CPU以外でも使える技術だけど。もちろんAMDでもVIAでも。
CPUレンダリングエンジンとSIMDユニットの強力なx86を組み合わせれば、GPUと同じことになるじゃない。
IntelにとってはそれがLarrabeeであり、AMDにとってはFusion(の最終構想)
CPUでGPU代替やるのにもx86 ISAを使えないの?ww
Windows WARPはIntel CPU以外でも使える技術だけど。もちろんAMDでもVIAでも。
CPUレンダリングエンジンとSIMDユニットの強力なx86を組み合わせれば、GPUと同じことになるじゃない。
IntelにとってはそれがLarrabeeであり、AMDにとってはFusion(の最終構想)
corei7でintelおんぼ以下(crysisロー設定)のえみゅでどうしろと
>>507
インテルは今でもオンボを作ってるしあるしそりゃある程度は動く物を
作れるだろうよ。でも、その動作は信頼されてなくてサポート対象から
外されたり、動かしたかったらグラボを買え、と言われる。
そんな現状を変える気があるの?ってことなんだけどなぁ。
インテルは今でもオンボを作ってるしあるしそりゃある程度は動く物を
作れるだろうよ。でも、その動作は信頼されてなくてサポート対象から
外されたり、動かしたかったらグラボを買え、と言われる。
そんな現状を変える気があるの?ってことなんだけどなぁ。
511 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 21:35:16 ID:Ppfr+k5r
>でも、その動作は信頼されてなくてサポート対象から
>外されたり、動かしたかったらグラボを買え、と言われる。
それ機能じゃなくて性能不足の問題じゃないの?
メモリ共有だからフレーム脱落したり帯域とりあったりするんだよ。
安定性に関してなら、バグだらけのベータ版ドライバを好き好んで試す人が多いのは
GeForceエンスージアニストの不思議な性質
>外されたり、動かしたかったらグラボを買え、と言われる。
それ機能じゃなくて性能不足の問題じゃないの?
メモリ共有だからフレーム脱落したり帯域とりあったりするんだよ。
安定性に関してなら、バグだらけのベータ版ドライバを好き好んで試す人が多いのは
GeForceエンスージアニストの不思議な性質
513 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 22:38:12 ID:Ppfr+k5r
要はWPFのC++版じゃねーのかと思ったけどあらかた当たってるらしいな
PowerVRってDirectXの互換性低かったよな
同様のタイリングを行うLRBの互換性に不安を持つのは当然だろう
同様のタイリングを行うLRBの互換性に不安を持つのは当然だろう
515 :,,・´∀`・,,)っ-●◎○:2009/01/25(日) 23:11:14 ID:Ppfr+k5r
PowerVRとは実現できるタイルの規模がぜんぜん違う。
規模が違うとどうして問題ないんだ?
>>499
デコーダの負担は減るけど、メモリアクセス効率は悪化しないか?
その点だけならメモリバスに合わせたバイト長のVLIWにしといて、きっちりプリフェッチ分送れるAMDの方が
電力効率は上がる気がするけど
デコーダの負担は減るけど、メモリアクセス効率は悪化しないか?
その点だけならメモリバスに合わせたバイト長のVLIWにしといて、きっちりプリフェッチ分送れるAMDの方が
電力効率は上がる気がするけど
518 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 01:37:18 ID:6xSNexGJ
VLIWは命令長がでかい。
半分以上NOPでスロットが埋まってても固定命令サイズ食っちゃうからその意味では
効率が悪い。
っていうか、IntelのVLIWで成功したものってどんだけあったっけ?Itaniumといいi860といい・・・
でもGMA(笑)もVLIWだっけ。
LarrabeeのSIMD命令はAVXと同じVEXエンコーディングによって命令長の推定をしやすい形にしてるから
その辺の負担は軽いと認識してる。
半分以上NOPでスロットが埋まってても固定命令サイズ食っちゃうからその意味では
効率が悪い。
っていうか、IntelのVLIWで成功したものってどんだけあったっけ?Itaniumといいi860といい・・・
でもGMA(笑)もVLIWだっけ。
LarrabeeのSIMD命令はAVXと同じVEXエンコーディングによって命令長の推定をしやすい形にしてるから
その辺の負担は軽いと認識してる。
Itaniumはそれなりに成果だしてなかったっけ?
回路規模が糞だけどネイティブx64の性能はまあまあだったような
かつてのAMD妨害工作用命令挿入みたいに、ガチガチにVLIWで最適化するコンパイラ出すとか。。。無いか(笑)
AVX系の再整理された命令使うのは良いんだけど、x87みたいに命令分離した方が得策じゃない?
旧来のx86コードをLarrabeeシリーズ上で動かせるようにするのは、Itaniumにx86エミュ載せるような愚考だと思うんだけどなぁ…
(初期のLarrabeeはGPU専用で、将来対応しそうだという話でね)
回路規模が糞だけどネイティブx64の性能はまあまあだったような
かつてのAMD妨害工作用命令挿入みたいに、ガチガチにVLIWで最適化するコンパイラ出すとか。。。無いか(笑)
AVX系の再整理された命令使うのは良いんだけど、x87みたいに命令分離した方が得策じゃない?
旧来のx86コードをLarrabeeシリーズ上で動かせるようにするのは、Itaniumにx86エミュ載せるような愚考だと思うんだけどなぁ…
(初期のLarrabeeはGPU専用で、将来対応しそうだという話でね)
Larrabeeの死角はメモリバンド幅じゃないのかな。メモリインターフェイスは
まだ詳細不明だがIntelは大バンド幅を与える気は全然なさげ。
アプリのバンド幅需要次第ではLarabee大成功ってなるのかもしれないが
まだ詳細不明だがIntelは大バンド幅を与える気は全然なさげ。
アプリのバンド幅需要次第ではLarabee大成功ってなるのかもしれないが
SIMD特化型CPUでメモリへの要求が少ないってマトモに使われてないって事じゃ?
ゲームのトレンドが局所性でどうにかなるアプリに向かうかどうかって話になるんだろうか
HPCはどうしても帯域欲しいですって話が出てきそうだけどその辺は棲み分けるのかな
HPCはどうしても帯域欲しいですって話が出てきそうだけどその辺は棲み分けるのかな
523 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 15:49:21 ID:6xSNexGJ
>>519
あのさ、x86だからWordやExcelが実用的な性能で動かないといけないとか勘違いしてない?
まあ、そこそこ実用的な性能で動く必要があるとして、Atomといういい例があるじゃん。
x86からアウトオブオーダを取っ払い、2issueに命令帯域を削ぎ落とし、その代わりにHTをサポート。
SSEは倍精度を除いてPentium Mをしのぐほどの性能を誇りながら、トランジスタ数は劇的に減ってるんだ。
それよりさらにワイドなSIMDユニットを搭載し、代わりにx86スカラ性能をさらに諦めるという
極端なことをやるのがLarrabeeだ。
Larrabeeのx86エンジンはAtomより更にシンプルになることが知られている。
具体的にはPentiumのときのU/Vデコーダに近いような制約が復活する。
Atomはまだ主役はSSEじゃなくてスカラ命令だから、そこそこ性能が悪くならない程度には
トランジスタを割いてる。LarrabeeはSIMDが主役で従来x86命令(スカラ)は脇役になる。
実用上、添字やビットマスク、アドレス計算、分岐なんかを担当する程度の使い方しか要求されない。
別にWebブラウズしたりメールしたり表計算したりするわけじゃないんだから、利用頻度の低い
命令なんかは遅くてもかまわないわけで、そういうのはマイクロコードで提供したっていい。
基本的に滅多に使わないんだからさ。
>>520
メモリ周りってGPUにおいて最も電気食らいな場所のひとつジャン。
パラダイムシフトが完了すれば、今ほどのメモリ帯域は必要なくなるよ。
ディスクリートGPU自体不要になる。
CPUベースのレイトレーシングの課題は充分なコア数が確保できてないこと。
そこでレイトレーシングに特化した「メニーコアCPU」を先行投入する必要がある。
LarrabeeはディスクリートGPUからメニーコアCPUへの橋渡し以上の意味は無い。
過渡期の実装である以上は従来GPUと同程度の機能は提供しないといけないわけで
必然的にメモリ帯域は確保してくることになるでしょ。
すでにGDDR5ってうわさが出てるけど。
あのさ、x86だからWordやExcelが実用的な性能で動かないといけないとか勘違いしてない?
まあ、そこそこ実用的な性能で動く必要があるとして、Atomといういい例があるじゃん。
x86からアウトオブオーダを取っ払い、2issueに命令帯域を削ぎ落とし、その代わりにHTをサポート。
SSEは倍精度を除いてPentium Mをしのぐほどの性能を誇りながら、トランジスタ数は劇的に減ってるんだ。
それよりさらにワイドなSIMDユニットを搭載し、代わりにx86スカラ性能をさらに諦めるという
極端なことをやるのがLarrabeeだ。
Larrabeeのx86エンジンはAtomより更にシンプルになることが知られている。
具体的にはPentiumのときのU/Vデコーダに近いような制約が復活する。
Atomはまだ主役はSSEじゃなくてスカラ命令だから、そこそこ性能が悪くならない程度には
トランジスタを割いてる。LarrabeeはSIMDが主役で従来x86命令(スカラ)は脇役になる。
実用上、添字やビットマスク、アドレス計算、分岐なんかを担当する程度の使い方しか要求されない。
別にWebブラウズしたりメールしたり表計算したりするわけじゃないんだから、利用頻度の低い
命令なんかは遅くてもかまわないわけで、そういうのはマイクロコードで提供したっていい。
基本的に滅多に使わないんだからさ。
>>520
メモリ周りってGPUにおいて最も電気食らいな場所のひとつジャン。
パラダイムシフトが完了すれば、今ほどのメモリ帯域は必要なくなるよ。
ディスクリートGPU自体不要になる。
CPUベースのレイトレーシングの課題は充分なコア数が確保できてないこと。
そこでレイトレーシングに特化した「メニーコアCPU」を先行投入する必要がある。
LarrabeeはディスクリートGPUからメニーコアCPUへの橋渡し以上の意味は無い。
過渡期の実装である以上は従来GPUと同程度の機能は提供しないといけないわけで
必然的にメモリ帯域は確保してくることになるでしょ。
すでにGDDR5ってうわさが出てるけど。
524 :Socket774:2009/01/26(月) 17:56:42 ID:iBABzCWH
525 :Socket774:2009/01/26(月) 18:37:29 ID:0OP5DBFd
つ VMware6.5
526 :Socket774:2009/01/26(月) 20:23:06 ID:iBABzCWH
無料でね。
http://isdlibrary.intel-dispatch.com/vc/2224/VA2_QuakeWars_NOcovers_final.pdf
http://www.youtube.com/v/mtHDSG2wNho
http://www.youtube.com/v/mtHDSG2wNho
うんこすぎる
529 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 21:12:30 ID:6xSNexGJ
やっぱ細かいところはテクスチャの素材次第だな。
世代遅れのゲームでも水や金属のような反射物の表現はレイトレーシングに置き換えるだけで
圧倒的にリアルになるがくすんだオブジェクトはテクスチャの地が出て違和感が生じる。
テクスチャに影を焼きこんだりとかアホな工程が減るだけでも、開発工数・表現力ともにメリットはある
世代遅れのゲームでも水や金属のような反射物の表現はレイトレーシングに置き換えるだけで
圧倒的にリアルになるがくすんだオブジェクトはテクスチャの地が出て違和感が生じる。
テクスチャに影を焼きこんだりとかアホな工程が減るだけでも、開発工数・表現力ともにメリットはある
>メモリ周りってGPUにおいて最も電気食らいな場所のひとつジャン。
>パラダイムシフトが完了すれば、今ほどのメモリ帯域は必要なくなるよ。
こんなの初耳だけどどなたかソース出せますかね。レイトレで必要な帯域は
増えることはあっても減ることはないと思うんだけど。
>パラダイムシフトが完了すれば、今ほどのメモリ帯域は必要なくなるよ。
こんなの初耳だけどどなたかソース出せますかね。レイトレで必要な帯域は
増えることはあっても減ることはないと思うんだけど。
狭いメモリ帯域でも演算機は必要、となるためには、演算量>帯域、
そうなるケースは”遠く”へ送受しないローカルなデータを
何度も処理するケース。
当然のことながらそういう処理へ帰結できる課題もあるけど、
できない課題もいっぱいある。できない課題が減る見込みだというなら
根拠はなんだろうな
そうなるケースは”遠く”へ送受しないローカルなデータを
何度も処理するケース。
当然のことながらそういう処理へ帰結できる課題もあるけど、
できない課題もいっぱいある。できない課題が減る見込みだというなら
根拠はなんだろうな
Intel自身は今後RMS(認識・抽出・合成)が重要と言っていて
こいつらは皆データ大量
こいつらは皆データ大量
533 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:02:57 ID:6xSNexGJ
>>530
論文くらい嫁よ
レイトレーシングは、トレースした値をキャッシュして再利用することで性能を稼げるんだよ。
モバイル用のCeleronでも実用レベルの描画ができるのは、余裕のあるL2キャッシュによって
FSBの帯域をセーブすることができるから。
論文くらい嫁よ
レイトレーシングは、トレースした値をキャッシュして再利用することで性能を稼げるんだよ。
モバイル用のCeleronでも実用レベルの描画ができるのは、余裕のあるL2キャッシュによって
FSBの帯域をセーブすることができるから。
534 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:05:28 ID:6xSNexGJ
>>532
Core i7の広帯域インターコネクトに答えがあるだろ
Core i7の広帯域インターコネクトに答えがあるだろ
>>533
嫁というならURLを出してくれ
嫁というならURLを出してくれ
536 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:11:21 ID:6xSNexGJ
リアルタイムレイトレーシングシステム の設計と評価
www.archi.is.tohoku.ac.jp/people/simakura/3dcgiram/unit/021118.pdf
> メモリバンド幅を高く保つ
> キャッシュサイズを大きくする
Intel CPUの路線にジャストフィットだろ?
www.archi.is.tohoku.ac.jp/people/simakura/3dcgiram/unit/021118.pdf
> メモリバンド幅を高く保つ
> キャッシュサイズを大きくする
Intel CPUの路線にジャストフィットだろ?
537 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 22:13:05 ID:6xSNexGJ
GPUはバンド幅はあってもキャッシュが無い
>>536
これは別に現存のGPUと比較したわけでもないのに、なんでこれから
必要バンド幅が減るなんて結論が出るんだ?
むしろ、オブジェクトの検索だけで節約しなければならないほど莫大な
帯域が必要なように思えるが。
これは別に現存のGPUと比較したわけでもないのに、なんでこれから
必要バンド幅が減るなんて結論が出るんだ?
むしろ、オブジェクトの検索だけで節約しなければならないほど莫大な
帯域が必要なように思えるが。
539 :,,・´∀`・,,)っ-●◎○:2009/01/26(月) 23:16:31 ID:6xSNexGJ
キャッシュの増量の活用により演算ユニットあたりの必要メモリ帯域は既存のGPUより減る。
あくまで相対的なものだ。
あくまで相対的なものだ。
540 :Socket774:2009/01/26(月) 23:44:19 ID:0OP5DBFd
>>526
無料だよ
無料だよ
>>539
いや、今のGPUにもキャッシュはあるし・・・なんかそこから話がおかしいかと
いや、今のGPUにもキャッシュはあるし・・・なんかそこから話がおかしいかと
542 :,,・´∀`・,,)っ-○◎●:2009/01/27(火) 00:10:44 ID:lGkwqIrZ
知ってるよ、ダイ全体で数十〜数百KBだろ?
全然足りねーよ。
全然足りねーよ。
ループしてるぞ
545 :,,・´∀`・,,)っ-○◎●:2009/01/27(火) 00:54:26 ID:lGkwqIrZ
キャッシュ容量が性能に与える影響は俺が引用したグラフを見ればわかるだろ。
わからんならもうええわ
わからんならもうええわ
546 :,,・´∀`・,,)っ-○◎●:2009/01/27(火) 00:55:51 ID:lGkwqIrZ
>>543
CPUでいいからこそ、x86ベースで後腐れ無くCPUに統合できるLarrabeeなんだよ。
CPUでいいからこそ、x86ベースで後腐れ無くCPUに統合できるLarrabeeなんだよ。
>>523
言いたかったのは複雑でボトルネックになりやすいx86デコーダを、
スループット重視のマルチコアCPUにn個分載せたら無駄にならない?って意味だったんだけど
ハードワイヤーじゃなくてマイクロコードにしとけば良い話ではあるね
それはそうとLarrabeeの内部設計って、CPUとの連携には向いてないんじゃ?
n個のコアのキャッシュコヒーレンシは高速な内部バスに留まるうちはいいけど、
CPUと組み合わせたらオフチップでP2Pなバスに載せるわけで、メインCPUの命令とかと同期する時に破綻する気がするんだけど・・・
言いたかったのは複雑でボトルネックになりやすいx86デコーダを、
スループット重視のマルチコアCPUにn個分載せたら無駄にならない?って意味だったんだけど
ハードワイヤーじゃなくてマイクロコードにしとけば良い話ではあるね
それはそうとLarrabeeの内部設計って、CPUとの連携には向いてないんじゃ?
n個のコアのキャッシュコヒーレンシは高速な内部バスに留まるうちはいいけど、
CPUと組み合わせたらオフチップでP2Pなバスに載せるわけで、メインCPUの命令とかと同期する時に破綻する気がするんだけど・・・
548 :,,・´∀`・,,)っ-○◎●:2009/01/27(火) 01:23:22 ID:lGkwqIrZ
>>547
LarrabeeのSIMDユニットは1基で単精度積和算16並列に行えるから
NVIDIAのシェーダに換算すると16SPに相当する。
LarrabeeそのものはホストCPUのメモリ空間と独立なモデルを採るらしい
Larrabee自体のCPUへの統合は、単にいまのCore MAの後継CPUに
Larrabee互換SIMDユニットと命令を搭載するだけで終わる話なので、そのものが載るとは思わない。
どのみち何年も先の話になるが・・・
LarrabeeのSIMDユニットは1基で単精度積和算16並列に行えるから
NVIDIAのシェーダに換算すると16SPに相当する。
LarrabeeそのものはホストCPUのメモリ空間と独立なモデルを採るらしい
Larrabee自体のCPUへの統合は、単にいまのCore MAの後継CPUに
Larrabee互換SIMDユニットと命令を搭載するだけで終わる話なので、そのものが載るとは思わない。
どのみち何年も先の話になるが・・・
549 :Socket774:2009/01/27(火) 02:45:49 ID:OYWGC152
550 :Socket774:2009/01/27(火) 03:13:31 ID:2P6nau0v
そんなのしららびー
SSE4とか128ビット並列処理だけど
32ビット4コアあるんだから一緒じゃないかと思ってしまうわけで
SSEなんて無駄機能減らして単純化すれば発熱も消費電力も低くなるから高速動作も出来る
というわけで作ったのがlarrabee
32ビット4コアあるんだから一緒じゃないかと思ってしまうわけで
SSEなんて無駄機能減らして単純化すれば発熱も消費電力も低くなるから高速動作も出来る
というわけで作ったのがlarrabee
552 :,,・´∀`・,,)っ-○◎●:2009/01/27(火) 03:49:11 ID:lGkwqIrZ
ねーよ
SSEよりもっと強力なSIMDユニット載せてその代わりCPUより低クロック(2GHz前後)で動作する。
Atom同様に(Atom以上に)シンプルなインオーダパイプラインだから比較的低消費電力。
SSEよりもっと強力なSIMDユニット載せてその代わりCPUより低クロック(2GHz前後)で動作する。
Atom同様に(Atom以上に)シンプルなインオーダパイプラインだから比較的低消費電力。
{kind=link}
larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
555 :,,・´∀`・,,)っ-●◎○:2009/01/27(火) 19:45:09 ID:lGkwqIrZ
貴重なPCIe x16を勝手に占有してなおかつ交換できないって何の拷問ですか
HavendaleのGPU部分てlarrabeeなの?
それとも過去の糞GPUなの?
ロードマップ見るとnahalemの位置になっているし今年末て予定に
なっているからHavendaleチップ内の別コアGPUの詳細がない以上
larrabeeなGPUと思うのがユーザーの気持ち。
それとも過去の糞GPUなの?
ロードマップ見るとnahalemの位置になっているし今年末て予定に
なっているからHavendaleチップ内の別コアGPUの詳細がない以上
larrabeeなGPUと思うのがユーザーの気持ち。
larrabeeも初発は糞だと予想されてるけど
Lynnfieldはx16+x8で外部接続
Havendaleはx1で外部接続
ごみだなw
しかもOC不可能w
Lynnfieldはx16+x8で外部接続
Havendaleはx1で外部接続
ごみだなw
しかもOC不可能w
>>552
比較的低消費電力ってのは、さすがに都合よく解釈しすぎじゃない?
GPGPUがまだHPCみたいな付加価値高い所がメインだから、130Wクラス当たりを出しそうな気がするけど
競合のTeslaは≒300W近いから、下手すればItanium並のが来ると思うし
比較的低消費電力ってのは、さすがに都合よく解釈しすぎじゃない?
GPGPUがまだHPCみたいな付加価値高い所がメインだから、130Wクラス当たりを出しそうな気がするけど
競合のTeslaは≒300W近いから、下手すればItanium並のが来ると思うし
>>556
常識的に考えてLarrabee載せる訳ないだろ。
常識的に考えてLarrabee載せる訳ないだろ。
560 :,,・´∀`・,,)っ-○◎●:2009/01/28(水) 02:48:26 ID:B/HeJ7ke
>>558
x86だから電力効率で相対的に不利ということは断じてないってことを言いたかった。
当然補助電源で賄いきれるだけ(300W)のTDP枠はめいっぱい使うでしょ。
それが48コア(NVIDIA換算768SP)とか言われてるわけだが。
x86だから電力効率で相対的に不利ということは断じてないってことを言いたかった。
当然補助電源で賄いきれるだけ(300W)のTDP枠はめいっぱい使うでしょ。
それが48コア(NVIDIA換算768SP)とか言われてるわけだが。
GMA500だろ
たぶんアイドル時の省電力とか何にもやってないんだろうな
もしかしたらhavendaleのようなGPU内臓タイプは必要な時意外はPCIEのグラボの電源を切るなんてことが出来るのかも
>>562
それ、いわゆるPowerVRのライセンス品なんだけど、上のグレードにしないとパワーでないよ。シャレではなく。
それ、いわゆるPowerVRのライセンス品なんだけど、上のグレードにしないとパワーでないよ。シャレではなく。
>>561-562
GMA950かそのマイナーアップデートと考えるのが普通だと思うがな。
GMA950かそのマイナーアップデートと考えるのが普通だと思うがな。
567 :,,・´∀`・,,)っ-○◎●:2009/01/28(水) 21:54:49 ID:B/HeJ7ke
G35はGMA X3000だったからGMA X5000くらいじゃね?
なんで世代が退行するんだよ
なんで世代が退行するんだよ
havendaleと同じタイミングでLarrabeeがでるのは
ロードマップで決まっている、
havendaleに実装されないとしたら、Larrabeeというコードネームの
CPUがでるってこと?
>>554 :Socket774:2009/01/27(火) 13:25:05 ID:YSQOzIza
> larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
Larrabeeが周辺コアだとすれば、コプロってことでしょ。
それならCPUロードマップには乗せずチップセットのロードマップ上の話に
なるだろう。
かなり今年末初リリースという話が延期されていないのならば、
何かしら名前があると思う。Larrabeeチップセットか
Larrabee内蔵CPUと考えるのが妥当って話。
Larrabeeはx86命令で動くGPUという意味で作られたはずなので
PCI-e x16経由でつながるGPUという考え方もできる。
この辺てどうなのよ?
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai_3l.gif
この図だとWestmere(2010年)の前に位置している。
ロードマップで決まっている、
havendaleに実装されないとしたら、Larrabeeというコードネームの
CPUがでるってこと?
>>554 :Socket774:2009/01/27(火) 13:25:05 ID:YSQOzIza
> larrabeeはただのチップだからマザーメーカーが勝手に乗せようと思えば乗せられる
Larrabeeが周辺コアだとすれば、コプロってことでしょ。
それならCPUロードマップには乗せずチップセットのロードマップ上の話に
なるだろう。
かなり今年末初リリースという話が延期されていないのならば、
何かしら名前があると思う。Larrabeeチップセットか
Larrabee内蔵CPUと考えるのが妥当って話。
Larrabeeはx86命令で動くGPUという意味で作られたはずなので
PCI-e x16経由でつながるGPUという考え方もできる。
この辺てどうなのよ?
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai_3l.gif
{kind=link}
この図だとWestmere(2010年)の前に位置している。
{kind=link}
570 :,,・´∀`・,,)っ-○◎●:2009/01/28(水) 23:37:19 ID:B/HeJ7ke
>>568
http://media.arstechnica.com/news.media/larrabee-pci.gif
少なくとも今後数年内はGMAはX4500HDの直接の進化版になるから安心汁
しかしダイサイズありえねー
http://media.arstechnica.com/news.media/larrabee-pci.gif
{kind=link}
少なくとも今後数年内はGMAはX4500HDの直接の進化版になるから安心汁
しかしダイサイズありえねー
それ俺がペイントで落書きした絵
元ネタはIntelのプレゼン資料だよ。
2006年のものだから確度は微妙だけど。
2006年のものだから確度は微妙だけど。
ほほう
>Among several topics, came up the most interesting one, visual
>computing and Intel's plans on it. 'Larrabee' strikes as a buzzword.
> It is the codename of Intel's upcoming graphics processor (GPU)
>architecture with which it plans to take on established players
>such as NVIDIA and AMD among others.
>What's unique (so far) about Larrabee is that it's entirely made
> up of x86 processing cores. The Larrabee is likely to have 32 x86
> processing cores. Here's a surprise: These processing cores are
> based on the design of Pentuim P54C, a 13+ year old x86 processor.
> This processor will be miniaturised to the 45nm fabrication process,
> they will be assisted by a 512-bit SIMD unit and these cores will
> support 64-bit address. Gelsinger says that 32 of these cores
> clocked at 2.00 GHz could belt out 2 TFLOPs of raw computational
> power. That's close to that of the upcoming AMD R700. Heise also
> reports that this GPU could have a TDP of as much as 300W (peak).
512bit SIM /32core /2TFlops/ 300W 単語拾っただけでもすごいかんじ、
>computing and Intel's plans on it. 'Larrabee' strikes as a buzzword.
> It is the codename of Intel's upcoming graphics processor (GPU)
>architecture with which it plans to take on established players
>such as NVIDIA and AMD among others.
>What's unique (so far) about Larrabee is that it's entirely made
> up of x86 processing cores. The Larrabee is likely to have 32 x86
> processing cores. Here's a surprise: These processing cores are
> based on the design of Pentuim P54C, a 13+ year old x86 processor.
> This processor will be miniaturised to the 45nm fabrication process,
> they will be assisted by a 512-bit SIMD unit and these cores will
> support 64-bit address. Gelsinger says that 32 of these cores
> clocked at 2.00 GHz could belt out 2 TFLOPs of raw computational
> power. That's close to that of the upcoming AMD R700. Heise also
> reports that this GPU could have a TDP of as much as 300W (peak).
512bit SIM /32core /2TFlops/ 300W 単語拾っただけでもすごいかんじ、
4枚挿しで火をふきます
クソでけぇww
インテルとドリームワークス、スーパーボウルのCMで協力
DreamWorksは、「Larrabee」を3D映像に利用する準備を進めており、
両社は米国時間2月1日に開催されるスーパーボウルのテレビ中継で
流れるCMで、この3D技術による3月公開予定のアニメ映画の予告編を流す。
http://japan.cnet.com/news/media/story/0,2000056023,20387350,00.htm
DreamWorksは、「Larrabee」を3D映像に利用する準備を進めており、
両社は米国時間2月1日に開催されるスーパーボウルのテレビ中継で
流れるCMで、この3D技術による3月公開予定のアニメ映画の予告編を流す。
http://japan.cnet.com/news/media/story/0,2000056023,20387350,00.htm
まぁ、CG用のワークステーションとしては今のところコストパフォーマンス抜群だろうな
ウマビー
582 :,,・´∀`・,,)っ-●◎○:2009/02/05(木) 06:07:55 ID:orEX+PM1
Intelが何のためにNVIDIAから大量に人材引き抜いてると思う?
GPU各社のカスの寄集めを作るため
GPU各社のオチコボレを集めて
糟のごった煮寒天を作るため
糟のごった煮寒天を作るため
i740の悪夢再び?
586 :Socket774:2009/02/05(木) 11:55:06 ID:ts8+uk2a
i740はVRAMを出し惜しみしてた
VGA屋に不良在庫を抱えさせる功績があったインテル最高傑作
VGA屋に不良在庫を抱えさせる功績があったインテル最高傑作
587 :Socket774:2009/02/05(木) 13:10:55 ID:mVTOPVQu
Intelさまがんばってくださいいいいいいいいいいいいい!
今のNvidiaとかATIの電力食いまくり熱だしまくりの糞板を市場から廃滅してください!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
今のNvidiaとかATIの電力食いまくり熱だしまくりの糞板を市場から廃滅してください!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
そんな志の低いことをIntelがわざわざするわけ無いだろ。
10年先を見よ。
10年先を見よ。
そんなkotoは無駄
590 :Socket774:2009/02/05(木) 19:15:27 ID:5sIqebny
IntelにとってGPUなんて片手間のしごとだろ
本気でやるわけないじゃん
本気でやるわけないじゃん
591 :,,・´∀`・,,)っ-○◎●:2009/02/05(木) 19:30:27 ID:orEX+PM1
Intelに本気を感じた。
敢えて言おう。CtはCUDAよりよっぽどマシな言語処理系だ。
敢えて言おう。CtはCUDAよりよっぽどマシな言語処理系だ。
C#と同じで、Googleで検索しにくい名前はイカン。
CUDAよりよっぽどマシくらいで盛り上がられると、とりあえず落ち着けとは思うなw
>>591
Ctってもう触れるのん?
Ctってもう触れるのん?
137 :Socket774 [sage] :2008/09/12(金) 17:15:22 ID:pCJ2/Iuy
あとLarrabeeもintel自身でさえCtではなくDX11、OpneCLにご執心
なぜならスタンダードだから
461 :Socket774 [sage] :2008/11/01(土) 00:36:29 ID:U3KlK9XI
Streaming言語の方言wによる囲い込み大作戦でどのベンダーも必死乙状態だが
無料で使えるくらいにしないと普及しないってば…
特にCt。
462 :Socket774 [sage] :2008/11/01(土) 06:34:45 ID:6TR6R6aV
http://www.intel.co.jp/jp/business/glossary/6365.htm
IntelはCtを普及させる気がないのか・・・
647 :Socket774 [sage] :2008/12/10(水) 22:33:45 ID:jqwBhgIw
OpenCLってメニーコアでソフトウェアレンダリングエンジンを書くのが主な目的なのかな。
Specification見たらそんな気がした。
結局一番得しそうなのはIntelかな。大学にエンジン書かせてそのままLarrabeeに持ってくっていう
あとLarrabeeもintel自身でさえCtではなくDX11、OpneCLにご執心
なぜならスタンダードだから
461 :Socket774 [sage] :2008/11/01(土) 00:36:29 ID:U3KlK9XI
Streaming言語の方言wによる囲い込み大作戦でどのベンダーも必死乙状態だが
無料で使えるくらいにしないと普及しないってば…
特にCt。
462 :Socket774 [sage] :2008/11/01(土) 06:34:45 ID:6TR6R6aV
http://www.intel.co.jp/jp/business/glossary/6365.htm
IntelはCtを普及させる気がないのか・・・
647 :Socket774 [sage] :2008/12/10(水) 22:33:45 ID:jqwBhgIw
OpenCLってメニーコアでソフトウェアレンダリングエンジンを書くのが主な目的なのかな。
Specification見たらそんな気がした。
結局一番得しそうなのはIntelかな。大学にエンジン書かせてそのままLarrabeeに持ってくっていう
597 :,,・´∀`・,,)っ-●◎○:2009/02/06(金) 02:06:02 ID:36Q+eCpY
コーディングスタイル
http://cache-www.intel.com/cd/00/00/40/73/407336_407336.pdf
この資料の15ページ参照
さて後藤が説明してた汎用IAと IA++の混成までIntel公式の資料に出てきてしまったぞ
CUDAがまともじゃないってのは、ベクトル演算に特化しすぎてスカラで済む演算まで
無駄に並列演算してるから。このへんはハードの問題といえるかもしれない。
たとえば配列の添字あるいはポインタ算出。
Larrabeeのようなx86スカラ+ワイドSIMDなら、配列に対する連続したアドレスの算出なんて
スカラ側の演算1〜2回程度で済む。(REX+)ModRM+SIB+DISPで表現可能であれば
一般のオペレーションのメモリアドレッシングモードに組み込んでしまうことができる。
で、不連続なデータにアクセスする必要があるときだけGatherオペレーションを使えばいい。
対して、CUDAはデータが連続・不連続かにかかわらずアドレス算出を1ワープ32スレッドそれぞれ
独立でやるような感じ。これで電力効率良いわけが無い。
逆説的だけど、レジスタが大量にあるのは、ロード・ストア周りの実装の非効率さを隠蔽する目的もあると思われる。
http://cache-www.intel.com/cd/00/00/40/73/407336_407336.pdf
この資料の15ページ参照
さて後藤が説明してた汎用IAと IA++の混成までIntel公式の資料に出てきてしまったぞ
CUDAがまともじゃないってのは、ベクトル演算に特化しすぎてスカラで済む演算まで
無駄に並列演算してるから。このへんはハードの問題といえるかもしれない。
たとえば配列の添字あるいはポインタ算出。
Larrabeeのようなx86スカラ+ワイドSIMDなら、配列に対する連続したアドレスの算出なんて
スカラ側の演算1〜2回程度で済む。(REX+)ModRM+SIB+DISPで表現可能であれば
一般のオペレーションのメモリアドレッシングモードに組み込んでしまうことができる。
で、不連続なデータにアクセスする必要があるときだけGatherオペレーションを使えばいい。
対して、CUDAはデータが連続・不連続かにかかわらずアドレス算出を1ワープ32スレッドそれぞれ
独立でやるような感じ。これで電力効率良いわけが無い。
逆説的だけど、レジスタが大量にあるのは、ロード・ストア周りの実装の非効率さを隠蔽する目的もあると思われる。
>>582
Intelが狙ってるのはGPGPU(というより、単一の超並列演算器)であって
グラフィックに特化する事を狙ってるわけじゃないでしょ
あっちの映像処理の世界はシェーディングとかの演算に加えて、データ自体のスループットが結構重要
Intelが狙ってるのはGPGPU(というより、単一の超並列演算器)であって
グラフィックに特化する事を狙ってるわけじゃないでしょ
あっちの映像処理の世界はシェーディングとかの演算に加えて、データ自体のスループットが結構重要
599 :,,・´∀`・,,)っ-●◎○:2009/02/06(金) 02:15:56 ID:36Q+eCpY
確かにIntelがNVIDIAほどラスタグラフィックを本気でやってるようには見えん。
目先のベクタグラフィック志向重視、的な。
ん?DreamworksのMonsters VS Aliensは全編レイトレ?
目先のベクタグラフィック志向重視、的な。
ん?DreamworksのMonsters VS Aliensは全編レイトレ?
というかCGは基本的にレイトレ+光散乱シミュレーションですwww
その前のモデリングとかプレビューが結構コンサバティブで、OpenGLの固定だったり
テクスチャの解像度が4kx4kとか良くあるけど、LarrabeeのL2キャッシュは512KBくらい?
その前のモデリングとかプレビューが結構コンサバティブで、OpenGLの固定だったり
テクスチャの解像度が4kx4kとか良くあるけど、LarrabeeのL2キャッシュは512KBくらい?
601 :,,・´∀`・,,)っ-●◎○:2009/02/06(金) 07:50:39 ID:36Q+eCpY
256KB/Coreの共有キャッシュのはずだけど。
16コアで4MBだね。
DreamworksのレンダリングファームはHarpertown→Gainestown→Gainestown+Larrabeeの移行プランじゃなかったっけ?
もうLarrabeeのサンプルはDreamworksで評価されてるようだが
16コアで4MBだね。
DreamworksのレンダリングファームはHarpertown→Gainestown→Gainestown+Larrabeeの移行プランじゃなかったっけ?
もうLarrabeeのサンプルはDreamworksで評価されてるようだが
>>597
いや、その辺は既にみんな織り込み済みだろ?
そうじゃない奴がレスすることもあるが、そういうのは放置でいいし、今更盛り上がるような
ことじゃなくノーサプライズだと思うけどなぁ
Larrabeeは面白いと思うし、だから俺もここをちょくちょく見てるわけだけど、今はもう少し
冷静でいた方がいろいろと話しやすいと思うんだけどね
いや、その辺は既にみんな織り込み済みだろ?
そうじゃない奴がレスすることもあるが、そういうのは放置でいいし、今更盛り上がるような
ことじゃなくノーサプライズだと思うけどなぁ
Larrabeeは面白いと思うし、だから俺もここをちょくちょく見てるわけだけど、今はもう少し
冷静でいた方がいろいろと話しやすいと思うんだけどね
603 :,,・´∀`・,,)っ-●◎○:2009/02/06(金) 08:22:25 ID:36Q+eCpY
いずれにしてもすべてが明らかになるのは例の映画公開後になると思われる
http://techresearch.intel.com/UserFiles/en-us/File/terascale/Whitepaper-Ct.pdf
シンタックスが>>597の資料とだいぶ違うな。
AVXの仕様すらコロコロ変わるからたまりませんわ。
http://techresearch.intel.com/UserFiles/en-us/File/terascale/Whitepaper-Ct.pdf
シンタックスが>>597の資料とだいぶ違うな。
AVXの仕様すらコロコロ変わるからたまりませんわ。
OpenCLだったらクアッドCPUで動かした方がGTX280ですら早い
世間で4倍早いだの言ってるのは
SSE最適化もマルチコア化もされてないプログラムと比較してるだけ
SSE最適化もマルチコア化もされてないプログラムと比較してるだけ
なにが?
チョーヨンピル
>>604
日本語でOK
日本語でOK
609 :Socket774:2009/02/07(土) 20:10:13 ID:JQaZjmK2
3倍早いのは赤いだけなんですね
>>601
今はまだOpteronだよ
65nm Phenomコアがコケたせいで、愛想つかしたからIntelに変えたって話
向こうは学生が大手のレンダリングクラスタを借りられるとかあるから、
将来の顧客をつかむ為にも重要な販売先だったんだけど、何やってんだか
DreamWorksはLinuxでクラスタ組んでるはずなんだけど、
ICCにマネージドコードかなんか吐かせるのかな?
OpenCLも上がってないし、最初から裸のバイナリを出力するとは思えないけど
今はまだOpteronだよ
65nm Phenomコアがコケたせいで、愛想つかしたからIntelに変えたって話
向こうは学生が大手のレンダリングクラスタを借りられるとかあるから、
将来の顧客をつかむ為にも重要な販売先だったんだけど、何やってんだか
DreamWorksはLinuxでクラスタ組んでるはずなんだけど、
ICCにマネージドコードかなんか吐かせるのかな?
OpenCLも上がってないし、最初から裸のバイナリを出力するとは思えないけど
611 :Socket774:2009/02/08(日) 01:05:35 ID:/s/L5Uam
3Dアプリもオリジナルだったよね
613 :,,・´∀`・,,)っ-○◎●:2009/02/08(日) 07:17:29 ID:bDqzIbh7
Larrabeeの情報のまとめサイトとしては一番いいかな
Intelの中の人もチェックしてるからそれなりに確度は高い情報が
PowerVRと同じタイルレンダだから互換性が低いのではって意見があったけど
PowerVRのタイルのサイズが桁違いだから、パフォーマンス面ではそんなに問題ないのではないかと。
それでなくともラスタグラフィックの性能は飽和状態で、GPU上で物理演算やAIを動かそうとしてる
現状では、将来的にもGPU本来の機能に特化するのが最適とは限らない。
Intelの中の人もチェックしてるからそれなりに確度は高い情報が
PowerVRと同じタイルレンダだから互換性が低いのではって意見があったけど
PowerVRのタイルのサイズが桁違いだから、パフォーマンス面ではそんなに問題ないのではないかと。
それでなくともラスタグラフィックの性能は飽和状態で、GPU上で物理演算やAIを動かそうとしてる
現状では、将来的にもGPU本来の機能に特化するのが最適とは限らない。
タイルであることが問題でサイズは関係ないかと
615 :,,・´∀`・,,)っ-○◎●:2009/02/08(日) 13:42:17 ID:bDqzIbh7
単にキャッシュのローカリティを生かしたタイルレンダが一番性能が出るから手法として使ってるだけでしょ
ソフト的にやってるわけだから、タイルという手法だけに縛られる訳ではない。
必要ならレンダリング方法を変えることも出来る。
性能はともかくドライバ次第で永久的にDirectXの仕様を満たし続けることができる。
PVRのDX9との互換性が問題になる云々はハード的に融通がきかなかったからでしょ
単純にDX9のグラフィックパイプラインに必要な機能が足りてなかった。
ソフト的にやってるわけだから、タイルという手法だけに縛られる訳ではない。
必要ならレンダリング方法を変えることも出来る。
性能はともかくドライバ次第で永久的にDirectXの仕様を満たし続けることができる。
PVRのDX9との互換性が問題になる云々はハード的に融通がきかなかったからでしょ
単純にDX9のグラフィックパイプラインに必要な機能が足りてなかった。
616 :,,・´∀`・,,)っ-○◎●:2009/02/08(日) 17:52:33 ID:bDqzIbh7
PowerVRは具体的にはZバッファがない。メモリがないだけでなくZテストもない。
タイルレンダだからZバッファが不要というわけだ。
Larrabeeは別にZバッファを前提としたレンダリングができないわけじゃない。
(というか、Zバッファの効果についてSIGGRAPHで具体的なパフォーマンスも示している)
捨てピクセルが発生せずメモりトラフィックをセーブすることができるからラスタレンダリングの
代替手段としてタイルレンダを提案してるくらいで、別に従来のレンダリング方法が使えないわけではない。
他に、タイルレンダ方式だとアルファブレンドのパフォーマンスが出ないなんて言いがかりもあったかな。
PowerVRの問題であって、Larrabeeのハードウェア機能的にアルファブレンドが遅い理由はどこにもない。
(MMXでアルファブレンド爆速なんて売り文句もありました。Intelのサイトに行けばその手のコードはうざいほどゲットできます。)
Larrabee上では特権モードで動くOSが動いて自分でタスク管理をやるらしい。
GPU機能は「Larrabee OS」で動くアプリケーションだ。
面白いことに、Cell GPUにCell OSと、Cellの初期構想をLarrabeeではほとんど実現してる。
タイルレンダだからZバッファが不要というわけだ。
Larrabeeは別にZバッファを前提としたレンダリングができないわけじゃない。
(というか、Zバッファの効果についてSIGGRAPHで具体的なパフォーマンスも示している)
捨てピクセルが発生せずメモりトラフィックをセーブすることができるからラスタレンダリングの
代替手段としてタイルレンダを提案してるくらいで、別に従来のレンダリング方法が使えないわけではない。
他に、タイルレンダ方式だとアルファブレンドのパフォーマンスが出ないなんて言いがかりもあったかな。
PowerVRの問題であって、Larrabeeのハードウェア機能的にアルファブレンドが遅い理由はどこにもない。
(MMXでアルファブレンド爆速なんて売り文句もありました。Intelのサイトに行けばその手のコードはうざいほどゲットできます。)
Larrabee上では特権モードで動くOSが動いて自分でタスク管理をやるらしい。
GPU機能は「Larrabee OS」で動くアプリケーションだ。
面白いことに、Cell GPUにCell OSと、Cellの初期構想をLarrabeeではほとんど実現してる。
まるっきり3dlabsの構想だね
618 :Socket774:2009/02/08(日) 20:25:03 ID:wNRWsz1L
従来のCPUビジネスじゃそろそろ限界+不況なんで
ATOMで堅いところを押さえて、LarrabeeでGPU屋なわばりを分捕ろうと言う作戦かい
さすがIntel様だ
ATOMで堅いところを押さえて、LarrabeeでGPU屋なわばりを分捕ろうと言う作戦かい
さすがIntel様だ
620 :MACオタ>619 さん:2009/02/08(日) 21:53:55 ID:DgOAOAJ2
>>619
Larrabeeのドライバ開発チームは新規に集められたスタッフで構成されていると信じられています。
http://www.theinquirer.net/inquirer/news/182/1046182/intel-hunts-for-graphics-driver-expert
------------------
The wording of the job post, which you can see here, certainly makes it sound like Intel
means business when it comes to Larrabee.
------------------
Larrabeeのドライバ開発チームは新規に集められたスタッフで構成されていると信じられています。
http://www.theinquirer.net/inquirer/news/182/1046182/intel-hunts-for-graphics-driver-expert
------------------
The wording of the job post, which you can see here, certainly makes it sound like Intel
means business when it comes to Larrabee.
------------------
MODドライバがたくさん出回るんだろうなw
今のPowerVRはZバッファあるだろ
>>618
CPU屋とGPU屋は激突コースが確定してるから仕方ない
GPU屋もCPUの領域を取りに行ってるから、何もしなきゃ「CPUはAtomだけよろしく」という
ことになる
まぁ俺らはどっちに転んでも構わないが
CPU屋とGPU屋は激突コースが確定してるから仕方ない
GPU屋もCPUの領域を取りに行ってるから、何もしなきゃ「CPUはAtomだけよろしく」という
ことになる
まぁ俺らはどっちに転んでも構わないが
624 :,,・´∀`・,,)っ-○◎●:2009/02/08(日) 22:55:06 ID:bDqzIbh7
>>607
メッコールかw
メッコールかw
FF11の描画エンジンはかなり古いから参考にならん
627 :Socket774:2009/02/09(月) 12:46:32 ID:qV5SwvIB
Playstation 4のGPUはLarrabee?
http://www.theinquirer.net/inquirer/news/851/1050851/intel-design-playstation-gpu
http://www.theinquirer.net/inquirer/news/851/1050851/intel-design-playstation-gpu
628 :Socket774:2009/02/09(月) 14:39:42 ID:1nm+xbUi
>>627
そのまえにソニーが死にます
そのまえにソニーが死にます
Larrabeeも死にます。
何ヶ月か前に次期XBOXに売り込み中という記事があったな。
Larrabeeのドライバをマイクロソフトに書いてもらって一石二鳥という話だったが。
Larrabeeのドライバをマイクロソフトに書いてもらって一石二鳥という話だったが。
黙って待ていても欲しい買い手が来るx86CPUと違って
Larrabeeは売り込み大変そうだな
Larrabeeは売り込み大変そうだな
その黙っていれば売れる状態にまでしたのがIntelだからな
見方を変えればLarrabeeは既存の市場を守るための施策の一つであって
IntelはCPUを売るためなら何でもやるということの現われだな
コンパイラやライブラリはもとよりフラッシュメモリなんかもそうだし
果てはボランティアとかもやってるしな
言うまでもなくこれらは不採算部門
これでリストラとか言い出さなければ模範的な大企業なんだがな
見方を変えればLarrabeeは既存の市場を守るための施策の一つであって
IntelはCPUを売るためなら何でもやるということの現われだな
コンパイラやライブラリはもとよりフラッシュメモリなんかもそうだし
果てはボランティアとかもやってるしな
言うまでもなくこれらは不採算部門
これでリストラとか言い出さなければ模範的な大企業なんだがな
TSMC's 40nm problem revealed
ttp://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
TSMCの40nmプロセスはリーク電流のせいで消費電力がほとんど下がらないらしい。
微細化によってダイサイズは小さく(安く)なるが、もうすでに300Wの限界ギリギリまで枠を使っているので、
消費電力が下がらないとシェーダーを増やしたり出来ないので性能を上げられない。
んで、TSMCがHK/MGを採用する28nmプロセスはIntelの32nmプロセスより若干遅れて提供を開始する予定。
そのプロセスで製造される各社のVGAは、これまでの例から、1年以上後の2011年の春頃に登場するだろう。
そんなわけで、TSMCが消費電力の壁にぶつかっているので、2009〜2010年の間はGPGPUの性能向上は鈍化すると思われる。
明らかに時流はLarrabeeに味方している。
ttp://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
TSMCの40nmプロセスはリーク電流のせいで消費電力がほとんど下がらないらしい。
微細化によってダイサイズは小さく(安く)なるが、もうすでに300Wの限界ギリギリまで枠を使っているので、
消費電力が下がらないとシェーダーを増やしたり出来ないので性能を上げられない。
んで、TSMCがHK/MGを採用する28nmプロセスはIntelの32nmプロセスより若干遅れて提供を開始する予定。
そのプロセスで製造される各社のVGAは、これまでの例から、1年以上後の2011年の春頃に登場するだろう。
そんなわけで、TSMCが消費電力の壁にぶつかっているので、2009〜2010年の間はGPGPUの性能向上は鈍化すると思われる。
明らかに時流はLarrabeeに味方している。
sonyカワイソス…
まず3DMARK系が動かないとね
動かないと思う根拠が知りたいね
性能の指標だからね
動くなら何も言うまい
動くなら何も言うまい
INTELはLarrabeeを売り込みたいからってベンチマークに細工とかしてきそうだなぁ
3Dゲーム用として使うよりは、HD画像処理のアクセラレータや
WCGやSETIなんかに活用出来れば面白いんだが
WCGやSETIなんかに活用出来れば面白いんだが
いちいちSPEエミュさせんでも、元々x86なんだから
ソースにちょっと手を加えるだけでいけそうな気もするんだがな
ソースにちょっと手を加えるだけでいけそうな気もするんだがな
独占とか言って叩くのは個人の自由だが、WindowsはLinuxみたいな糞よりは遥かにクオリティが高いからな
時と場合を選んで言葉を使わないと、派遣切りとか言って大企業を執拗に叩く割に、
中間マージンで搾取しまくりの現代の奴隷商人である派遣会社を一切批判しないメディアのような卑劣さが漂う
時と場合を選んで言葉を使わないと、派遣切りとか言って大企業を執拗に叩く割に、
中間マージンで搾取しまくりの現代の奴隷商人である派遣会社を一切批判しないメディアのような卑劣さが漂う
もしもSPEいらなくなるならCellの価値はなくなるよなあ
PS4は開発に金かけられないだろうから
Cell拡張と後はインテル外注かの2択くらいしかないだろうし
>>645ご自身のことですね。わかります
PS4は開発に金かけられないだろうから
Cell拡張と後はインテル外注かの2択くらいしかないだろうし
>>645ご自身のことですね。わかります
647 :,,・´∀`・,,)っ-●◎○:2009/02/10(火) 01:33:14 ID:AwU8IVoV
PS3互換にする必要も無い気がするんだけど。
あれだけ売れたPS2の互換だって切り捨てた会社だぜ?
Cellそのものがいらない子だ。
SPEによるシェーダ代替とか物理演算とかはGPUが貧弱という前提が必要だが
PS3の路線の延長としてGPUにLarrabeeを採用するとすれば、ぶっちゃけCPU要らなくなるんじゃね?
あれだけ売れたPS2の互換だって切り捨てた会社だぜ?
Cellそのものがいらない子だ。
SPEによるシェーダ代替とか物理演算とかはGPUが貧弱という前提が必要だが
PS3の路線の延長としてGPUにLarrabeeを採用するとすれば、ぶっちゃけCPU要らなくなるんじゃね?
PS4のグラフィックはレイトレです、とかならいい選択かもれないがPS3の失敗と
クタの退任で保守的になっているSCEがそこまでやるかねえ。ユーザーの求める物が
はたして革新的なグラフィックなのか怪しくなっている現在、Cell拡張とnVIDIAが
一番低リスクな気がするが、あるいはディスカウントがよっぽど大きいのか。
クタの退任で保守的になっているSCEがそこまでやるかねえ。ユーザーの求める物が
はたして革新的なグラフィックなのか怪しくなっている現在、Cell拡張とnVIDIAが
一番低リスクな気がするが、あるいはディスカウントがよっぽど大きいのか。
649 :,,・´∀`・,,)っ-○◎●:2009/02/10(火) 12:37:28 ID:AwU8IVoV
困ったことに、どれを選んでもCellは持て余すんだよね。
RSXが劣化GeForce 7で頂点シェーダが貧弱だったからSPUで機能代替するメリットがあったが、
GeForce8以降だと機能が被る。
物理演算だってGeForceならPhysXがある。LarrabeeにはHavokがある。
CellそのものをGPUにしてしまうくらいなら活用のしようもあるのだが、
そっちのほうが現実性ないだろ?
諫早工場を「あそに売ると」やっちゃったから、もはやCellにこだわり続ける理由もない。
PS2までうまくいってたPS事業を傾かせる元凶となったアーキテクチャだし
引き延ばすメリットもないだろ。
RSXが劣化GeForce 7で頂点シェーダが貧弱だったからSPUで機能代替するメリットがあったが、
GeForce8以降だと機能が被る。
物理演算だってGeForceならPhysXがある。LarrabeeにはHavokがある。
CellそのものをGPUにしてしまうくらいなら活用のしようもあるのだが、
そっちのほうが現実性ないだろ?
諫早工場を「あそに売ると」やっちゃったから、もはやCellにこだわり続ける理由もない。
PS2までうまくいってたPS事業を傾かせる元凶となったアーキテクチャだし
引き延ばすメリットもないだろ。
>>635
ララビーとは関係ないけどTFCが付け入る隙は生まれたわけだね
ララビーとは関係ないけどTFCが付け入る隙は生まれたわけだね
651 :,,・´∀`・,,)っ-○◎●:2009/02/10(火) 12:55:52 ID:AwU8IVoV
TSMCがHKMG採用までにRadeonが作れる設備が作れるならNVIDIAだけが置いてけぼり喰らうわけだが
とりあえず当面はAMDも残念なことになる。
それ以降に関しては、TFCがNVIDIAのGPUを製造するシナリオも当然あると思う。
とりあえず当面はAMDも残念なことになる。
それ以降に関しては、TFCがNVIDIAのGPUを製造するシナリオも当然あると思う。
653 :Socket774:2009/02/11(水) 11:20:45 ID:97Wmy7f9
>652 むしろCellはコア数増やして全部Cellでやればいいよ
いやむしろ全部Larrabeeでネットやろうぜ
いやむしろ全部Larrabeeでネットやろうぜ
654 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 12:01:16 ID:pGz2zkVB
PS3のCellってもともとGPUの処理もまかなう予定だったそうだけど、
具体的にどんなレンダリング方法を試みようとしてたのか、ハッキリ言ってこれは向いてるってものがない。
MSの人も指摘するとおり計画が破綻してNVIDIAに頼ったというのが事実。
リングバスはもともとソフト的にグラフィックパイプラインをやる上では重要な位置づけで
たとえばレイトレーシングなら6つのプロセッサをリングバスで接続すればバケツリレーで
処理ができる。
でも実際にやろうとしてみると逆にLSがボトルネックになる。
たとえばレイトレだと、共有メモリが絶対的に優れてると絶対的なことはいえないのだが、
独立メモリであるLSは、Larrabeeみたいな共有キャッシュよりあまり効率が良くない。
他のSPE上のLSの○○番目のデータをとってくるにしてもいちいちDMAコマンドを発行して
ブロック単位でまとめて転送してくるしかない。
結果としてはデータを重複して持つことになってしまう。
その上128KB〜1MBというアーキテクチャ上の制限もあるから拡張の余地があまりない。
レイトレーシングパイプラインのキャッシュメモリは共有分散型でトータル数MBが一番妥当なんだよね
Larrabeeはx86アーキテクチャの延長でCellのやろうとしてできなかったことを試みてるんだよね。
更に言うと、SPUの命令Opcode空間は最初の実装の次点で9割以上使ってしまってる。
SPEはまっさらからコード体系を再設計するとかしない限り、たとえば256ビットとか512ビットとかの
SIMDには対応できない。
んで、コアを増やすくらいしか根本的にスループットを引き上げる方法がない。
いまだに数千〜数万命令の拡張の余地がある命令セットってx86くらいしかない。
具体的にどんなレンダリング方法を試みようとしてたのか、ハッキリ言ってこれは向いてるってものがない。
MSの人も指摘するとおり計画が破綻してNVIDIAに頼ったというのが事実。
リングバスはもともとソフト的にグラフィックパイプラインをやる上では重要な位置づけで
たとえばレイトレーシングなら6つのプロセッサをリングバスで接続すればバケツリレーで
処理ができる。
でも実際にやろうとしてみると逆にLSがボトルネックになる。
たとえばレイトレだと、共有メモリが絶対的に優れてると絶対的なことはいえないのだが、
独立メモリであるLSは、Larrabeeみたいな共有キャッシュよりあまり効率が良くない。
他のSPE上のLSの○○番目のデータをとってくるにしてもいちいちDMAコマンドを発行して
ブロック単位でまとめて転送してくるしかない。
結果としてはデータを重複して持つことになってしまう。
その上128KB〜1MBというアーキテクチャ上の制限もあるから拡張の余地があまりない。
レイトレーシングパイプラインのキャッシュメモリは共有分散型でトータル数MBが一番妥当なんだよね
Larrabeeはx86アーキテクチャの延長でCellのやろうとしてできなかったことを試みてるんだよね。
更に言うと、SPUの命令Opcode空間は最初の実装の次点で9割以上使ってしまってる。
SPEはまっさらからコード体系を再設計するとかしない限り、たとえば256ビットとか512ビットとかの
SIMDには対応できない。
んで、コアを増やすくらいしか根本的にスループットを引き上げる方法がない。
いまだに数千〜数万命令の拡張の余地がある命令セットってx86くらいしかない。
,__ http://japanese.engadget.com/images/2006/06/kutaragi.jpg
r勹ー−、 \
/シ_ -__ ヽハ , -――――-、_ 在りし日のクタ
{ソ_,= 、 ´` }_」! / //_;'┐
{j ゝ - ,ヽ ィ } / __ __ __ //r_‐、〉'
{ 〈 '  ̄ _ rノ / /┘_〈 _‐/ //r'‐、/ 今ほど落ちぶれるとは夢にも
ヽ r、´ リ / / ̄7、 }
___ __>-- 、 }ヘ ___/ / / /
/´ \ \ \八/\}\ / / /} 〈
| \ \ \ \〉l / / /タュュ」\
| \ \ | |} | く ̄ ̄/⌒二二)../}/ `ー―〉
| ヽ ヽ}__j_ >'チ  ̄`ー' / /
| , イ´ ̄ ̄ ̄ |_____./ /
\ ∨ | / /
}\ / l / /
| \_______ cccc/ |\' /
. / C/ i ̄ l ヽ.___/
{kind=link}
r勹ー−、 \
/シ_ -__ ヽハ , -――――-、_ 在りし日のクタ
{ソ_,= 、 ´` }_」! / //_;'┐
{j ゝ - ,ヽ ィ } / __ __ __ //r_‐、〉'
{ 〈 '  ̄ _ rノ / /┘_〈 _‐/ //r'‐、/ 今ほど落ちぶれるとは夢にも
ヽ r、´ リ / / ̄7、 }
___ __>-- 、 }ヘ ___/ / / /
/´ \ \ \八/\}\ / / /} 〈
| \ \ \ \〉l / / /タュュ」\
| \ \ | |} | く ̄ ̄/⌒二二)../}/ `ー―〉
| ヽ ヽ}__j_ >'チ  ̄`ー' / /
| , イ´ ̄ ̄ ̄ |_____./ /
\ ∨ | / /
}\ / l / /
| \_______ cccc/ |\' /
. / C/ i ̄ l ヽ.___/
656 :MACオタ>団子 さん:2009/02/11(水) 14:37:10 ID:VQG9IPsT
>>654
-------------------
SPEはまっさらからコード体系を再設計するとかしない限り、たとえば256ビットとか
512ビットとかの SIMDには対応できない。
-------------------
レジスタ数を減らした拡張命令セットが定義可能なことは確認済みです。
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/74
====================
現ISAとの互換性を保ちつつ、専用命令で『大幅な性能向上』を得るための最も単純な解決策わ
ベクトルレジスタを連結して128個の128-bit幅VRFを256-bit幅 x 64又わ512-bit幅 x 32として
扱うことす。
====================
命令エンコードの詳細については、当該投稿をどうぞ。
-------------------
SPEはまっさらからコード体系を再設計するとかしない限り、たとえば256ビットとか
512ビットとかの SIMDには対応できない。
-------------------
レジスタ数を減らした拡張命令セットが定義可能なことは確認済みです。
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/74
====================
現ISAとの互換性を保ちつつ、専用命令で『大幅な性能向上』を得るための最も単純な解決策わ
ベクトルレジスタを連結して128個の128-bit幅VRFを256-bit幅 x 64又わ512-bit幅 x 32として
扱うことす。
====================
命令エンコードの詳細については、当該投稿をどうぞ。
657 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 15:03:07 ID:pGz2zkVB
Opcodeにあといくつ空きがあるか調べてみればわかることだ
どっちにしろ既存命令潰さないと無理だけどねwww
馬鹿だからわかんないだろうけど
どっちにしろ既存命令潰さないと無理だけどねwww
馬鹿だからわかんないだろうけど
658 :MACオタ>団子 さん:2009/02/11(水) 15:09:52 ID:VQG9IPsT
660 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 15:13:58 ID:pGz2zkVB
4レジスタ命令と2レジスタ+ハーフワード即値命令で殆ど食いつぶしてるんですが。
661 :MACオタ>団子 さん:2009/02/11(水) 15:16:31 ID:VQG9IPsT
>>660
いつものように知ったか振りが止まらないようですが、
------------------
4レジスタ命令と2レジスタ+ハーフワード即値命令で殆ど食いつぶしてるんですが。
------------------
>>659の感想はいかがですか(笑)
いつものように知ったか振りが止まらないようですが、
------------------
4レジスタ命令と2レジスタ+ハーフワード即値命令で殆ど食いつぶしてるんですが。
------------------
>>659の感想はいかがですか(笑)
662 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 15:31:07 ID:pGz2zkVB
倍精度積和やキャリー/ボロー処理が第一ソースオペランドを破壊してるんですが
それをOpcodeに余裕があるって言うんですか?
x86ってアドレッシングモードの即値・スケール値込みだと最大7オペランドくらいになる。
当たり前のように使えるModRM+SIB+DISPによるアドレッシングモードだが
実は性能を引き上げる上で大きく寄与していた。
Cellの命令セット触ってみて、なぜRISCの時代が終わったのか分かったよ
それをOpcodeに余裕があるって言うんですか?
x86ってアドレッシングモードの即値・スケール値込みだと最大7オペランドくらいになる。
当たり前のように使えるModRM+SIB+DISPによるアドレッシングモードだが
実は性能を引き上げる上で大きく寄与していた。
Cellの命令セット触ってみて、なぜRISCの時代が終わったのか分かったよ
663 :MACオタ>団子 さん:2009/02/11(水) 15:34:56 ID:VQG9IPsT
>>662
-------------------
倍精度積和やキャリー/ボロー処理が第一ソースオペランドを破壊してるんですが
それをOpcodeに余裕があるって言うんですか?
-------------------
それは命令仕様の問題で、op-codeの余裕とどういった関係があるのでしょうか(笑)
-------------------
倍精度積和やキャリー/ボロー処理が第一ソースオペランドを破壊してるんですが
それをOpcodeに余裕があるって言うんですか?
-------------------
それは命令仕様の問題で、op-codeの余裕とどういった関係があるのでしょうか(笑)
もうMACオタはNGするとか言ってなかったっけ?
665 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 15:47:43 ID:pGz2zkVB
命令セットマニュアルよく見たら16ビット即値とるオペレーションってソース破壊型か。
道理でoriによるコピーが増えるわけだ。クソ過ぎる。
優位に導く余裕が無いだけでも万死に値する。
道理でoriによるコピーが増えるわけだ。クソ過ぎる。
優位に導く余裕が無いだけでも万死に値する。
団子は決して自分の間違いを認めない
667 :Socket774:2009/02/11(水) 16:01:27 ID:6DH38jjR
似たようなもんだろ
668 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 16:22:00 ID:pGz2zkVB
>>666
俺は4オペランドにすべき命令がソース破壊になってると言う観点から余裕が無いと言ってるわけだが。
256bit×64本でも512bit×32本みたいなけちな拡張方法自体発想に無いし思いつくのを賢いとも思わない。
レジスタ本数やオペランド数に制限を入れないと拡張できないのを余裕とは言わない。
x86の論理レジスタは汎用レジスタ16本+SIMD16本+αだが、Larrabeeではそれが4スレッド
物理的には1コアあたりSIMDレジスタは64本(テンポラルを入れるとそれ以上)備えてることになる
VEXエンコーディングはレジスタ間オペレーションだけでも5レジスタオペランドまで対応できるフォーマットだ。
たとえばSIMDレジスタの本数を32本や64本なんて拡張だってOpcode空間の余裕的には可能だ
俺は4オペランドにすべき命令がソース破壊になってると言う観点から余裕が無いと言ってるわけだが。
256bit×64本でも512bit×32本みたいなけちな拡張方法自体発想に無いし思いつくのを賢いとも思わない。
レジスタ本数やオペランド数に制限を入れないと拡張できないのを余裕とは言わない。
x86の論理レジスタは汎用レジスタ16本+SIMD16本+αだが、Larrabeeではそれが4スレッド
物理的には1コアあたりSIMDレジスタは64本(テンポラルを入れるとそれ以上)備えてることになる
VEXエンコーディングはレジスタ間オペレーションだけでも5レジスタオペランドまで対応できるフォーマットだ。
たとえばSIMDレジスタの本数を32本や64本なんて拡張だってOpcode空間の余裕的には可能だ
669 :MACオタ>団子 さん:2009/02/11(水) 16:31:21 ID:VQG9IPsT
>>668
----------------
俺は4オペランドにすべき命令がソース破壊になってると言う観点から余裕が無いと
言ってるわけだが。
----------------
『ぼくの考えたスゴい命令セット』の話はご自身のホームページでどうぞ(笑)
拡張以前に最初からSPE ISAで倍精度積和演算等は結果を上書きする3引数命令です。
----------------
俺は4オペランドにすべき命令がソース破壊になってると言う観点から余裕が無いと
言ってるわけだが。
----------------
『ぼくの考えたスゴい命令セット』の話はご自身のホームページでどうぞ(笑)
拡張以前に最初からSPE ISAで倍精度積和演算等は結果を上書きする3引数命令です。
670 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 16:48:11 ID:pGz2zkVB
この結果レジスタ指定に必要な命令フィールドわ、以下のように減少するす。
4引数: 28-bit -> 24-bit (256-bit幅), 20-bit (512-bit幅)
3引数: 21-bit -> 18-bit (256-bit幅), 15-bit (512-bit幅)
そして4-引数命令を8-bitフォーマット(256-bit幅の場合)又わ11-bitフォーマット(512-bit幅の場合)
に割り当てることが可能になるす。
>>73に書いた通り、8-bit Op-codeも4引数命令を割り当てる程度にわ空いているすから、
このやりかたわ、論理的にわ可能ということす。
的中するかどうかわ、数年後ということで。。。
↑ぼくの考えたすごい命令セット(笑)
4引数: 28-bit -> 24-bit (256-bit幅), 20-bit (512-bit幅)
3引数: 21-bit -> 18-bit (256-bit幅), 15-bit (512-bit幅)
そして4-引数命令を8-bitフォーマット(256-bit幅の場合)又わ11-bitフォーマット(512-bit幅の場合)
に割り当てることが可能になるす。
>>73に書いた通り、8-bit Op-codeも4引数命令を割り当てる程度にわ空いているすから、
このやりかたわ、論理的にわ可能ということす。
的中するかどうかわ、数年後ということで。。。
↑ぼくの考えたすごい命令セット(笑)
671 :MACオタ>団子 さん:2009/02/11(水) 16:59:33 ID:VQG9IPsT
>>670
私流の『ぼくが考えたスゴい命令セット』は昔のCELLスレッドにあります。
誰かさんの妄想と違って、op-codeの空きを数えるくらいのことはしてますので、そちらをよろしく(笑)
http://game10.2ch.net/test/read.cgi/ghard/1129650583/
465-466, 522, 531-532, 575あたりでしょうか。
私流の『ぼくが考えたスゴい命令セット』は昔のCELLスレッドにあります。
誰かさんの妄想と違って、op-codeの空きを数えるくらいのことはしてますので、そちらをよろしく(笑)
http://game10.2ch.net/test/read.cgi/ghard/1129650583/
465-466, 522, 531-532, 575あたりでしょうか。
団子さんの主張する『俺は4オペランドにすべき命令』(>>668参照)ですが、IBMの最新のPPC ISAの
拡張"VSX"では積和演算は3引数に変更されています。
http://www.power.org/resources/downloads/PowerISA_V2.06_PUBLIC.pdf
団子さんのアイデアはIntelのアーキテクトにもIBMのアーキテクトにも却下されてしまったようですね(笑)
拡張"VSX"では積和演算は3引数に変更されています。
http://www.power.org/resources/downloads/PowerISA_V2.06_PUBLIC.pdf
団子さんのアイデアはIntelのアーキテクトにもIBMのアーキテクトにも却下されてしまったようですね(笑)
673 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 17:10:42 ID:pGz2zkVB
変位ゼロ指定でバイトシフト命令(Oddパイプ側)を使えばEvenパイプ使わずに別のレジスタに値退避できるので
倍精度拡張版Cellが実効性能半分ってわけでもない。
もっともこの程度の最適化は、Oddパイプ側に空きがあればコンパイラが自分で行うけど。
LINPACKがハッタリ以外のなんでもないことだけはわかった。
倍精度拡張版Cellが実効性能半分ってわけでもない。
もっともこの程度の最適化は、Oddパイプ側に空きがあればコンパイラが自分で行うけど。
LINPACKがハッタリ以外のなんでもないことだけはわかった。
674 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 17:42:34 ID:pGz2zkVB
そもそも論理レジスタ本数がそれほど多くない命令セットでは同じ論理レジスタを繰り返し
再利用する頻度が高いので、4オペランドにすることでのメリットも決して大きくは無い。
レジスタ128本の命令セットでそれをやるのは、どうかと思うけど(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)
そして誰も見向きもしなくなったころにSSEのまねごとをするVSX(笑)
破壊する加算値か乗算値のどっちのレジスタを破壊するか選べる時点でAMDのSSE5もIntelのFMAも
SPU(笑)よりだいぶマシな仕様だ。
破壊しない2つのオペランドのうちどちらかをメモリアドレッシングするかを指定できることができる
(μOPsドメイン数の削減)というわけでx86ならではの利点は充分ある。
再利用する頻度が高いので、4オペランドにすることでのメリットも決して大きくは無い。
レジスタ128本の命令セットでそれをやるのは、どうかと思うけど(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)
そして誰も見向きもしなくなったころにSSEのまねごとをするVSX(笑)
破壊する加算値か乗算値のどっちのレジスタを破壊するか選べる時点でAMDのSSE5もIntelのFMAも
SPU(笑)よりだいぶマシな仕様だ。
破壊しない2つのオペランドのうちどちらかをメモリアドレッシングするかを指定できることができる
(μOPsドメイン数の削減)というわけでx86ならではの利点は充分ある。
675 :MACオタ>団子 さん:2009/02/11(水) 17:45:59 ID:VQG9IPsT
>>674
-----------------
(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)
-----------------
精神的に追い詰められてきたっぽいので、これ以上追求するのはヤメておきましょう…
-----------------
(笑)(笑)(笑)(笑)(笑)(笑)(笑)(笑)
-----------------
精神的に追い詰められてきたっぽいので、これ以上追求するのはヤメておきましょう…
676 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 17:54:13 ID:pGz2zkVB
そもそもレジスタ破壊しない方法使いたければvmulps+vaddpsでいいわけで。
どうせ並列実行できるんだし。
それはさておきCellスレ45のx86がLINPACKの性能が低いから嫌われてる云々は言いがかりだな。
乗算と加算を同時発行すればいいじゃん。128bit SIMD乗算器+加算器があるんだから。
まあ事実、現時点でTOP500の7割をIntelアーキが掌握してるが。
どうせ並列実行できるんだし。
それはさておきCellスレ45のx86がLINPACKの性能が低いから嫌われてる云々は言いがかりだな。
乗算と加算を同時発行すればいいじゃん。128bit SIMD乗算器+加算器があるんだから。
まあ事実、現時点でTOP500の7割をIntelアーキが掌握してるが。
677 :MACオタ>団子 さん:2009/02/11(水) 19:07:48 ID:VQG9IPsT
>>676
----------------
LINPACKの性能が低いから嫌われてる云々は言いがかりだな。
----------------
日付に注意しましょう。2005年に Core Microarchitecture の製品は存在しませんでした。
http://game10.2ch.net/test/read.cgi/ghard/1129650583/401
================
401 名前:MACオタ>>396 さん 投稿日:2005/10/29(土) 20:35:39 ID:9u6jOne9
================
----------------
LINPACKの性能が低いから嫌われてる云々は言いがかりだな。
----------------
日付に注意しましょう。2005年に Core Microarchitecture の製品は存在しませんでした。
http://game10.2ch.net/test/read.cgi/ghard/1129650583/401
================
401 名前:MACオタ>>396 さん 投稿日:2005/10/29(土) 20:35:39 ID:9u6jOne9
================
678 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 19:09:53 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
因果関係がおかしいと言ってるのだ。
Core MAはFMAをサポートしていない
>性能が劣るという理由で選択から外れたりすることがあるす。
因果関係がおかしいと言ってるのだ。
Core MAはFMAをサポートしていない
679 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 19:28:56 ID:pGz2zkVB
まさか128ビット加算・乗算共有×1だと思ってたのか?
結局x86が命令セット上のSIMDベクトル長が実装の2倍確保してきた歴史知らないんだな。
道理でSandy Bridgeに本物の256bitのSIMDユニットが載るなんて勘違いするわけだ。
結局x86が命令セット上のSIMDベクトル長が実装の2倍確保してきた歴史知らないんだな。
道理でSandy Bridgeに本物の256bitのSIMDユニットが載るなんて勘違いするわけだ。
680 :MACオタ>団子 さん:2009/02/11(水) 19:47:40 ID:VQG9IPsT
>>679
面倒なので、Intelの方の回答をそのまま引用します。
http://software.intel.com/en-us/forums/intel-math-kernel-library/topic/52010/
---------------------
Ideally, Core 2 Duo could issue both a parallel floating point multiply and an add on the
same clock cycle, so peak flops would be 4/cycle, per core, even in double precision.
---------------------
前世代のアーキテクチャと比較するなら、これでも。
http://msacs.kennesaw.edu/grid/status-report/grid-status-20061011/howto-peakglfops.txt
面倒なので、Intelの方の回答をそのまま引用します。
http://software.intel.com/en-us/forums/intel-math-kernel-library/topic/52010/
---------------------
Ideally, Core 2 Duo could issue both a parallel floating point multiply and an add on the
same clock cycle, so peak flops would be 4/cycle, per core, even in double precision.
---------------------
前世代のアーキテクチャと比較するなら、これでも。
http://msacs.kennesaw.edu/grid/status-report/grid-status-20061011/howto-peakglfops.txt
>>679
別のIntelの方のもう少し親切な解説。Sandy Bridgeについての言及もあります。
http://software.intel.com/en-us/forums/intel-avx-and-cpu-instructions/topic/59294/reply/65657/
---------------------
Upcoming products based on Sandy Bridge microarchitecture will once again double
peak FP operations throughput by introducing 256-bit AVX instruction set, supported
by microarchitecture capability to start 1 256-bit FP MUL and 1 256-bit FP ADD
operations per cycle (16 SP or 8 DP FLOPS).
---------------------
別のIntelの方のもう少し親切な解説。Sandy Bridgeについての言及もあります。
http://software.intel.com/en-us/forums/intel-avx-and-cpu-instructions/topic/59294/reply/65657/
---------------------
Upcoming products based on Sandy Bridge microarchitecture will once again double
peak FP operations throughput by introducing 256-bit AVX instruction set, supported
by microarchitecture capability to start 1 256-bit FP MUL and 1 256-bit FP ADD
operations per cycle (16 SP or 8 DP FLOPS).
---------------------
682 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 20:16:34 ID:pGz2zkVB
もちろん読んでるよ。
Loadも同じく256ビット/clkのサイクルを実現す
しかし
Upcoming Intel(R) 64 Instruction Set Architecture Extensions
- Intel(R) Advanced Vector Extensions (Intel(R) AVX)
https://intel.wingateweb.com/SHchina/published/NGMS002/SP_NGMS002_100r_eng.pdf
「2nd load port」に注目。Loadは128ビット×2に分解して実行してるのだよ。
ユニット数を増やせば本物の256bit実行ユニットなんて乗せる必要ないんだよ。
Loadも同じく256ビット/clkのサイクルを実現す
しかし
Upcoming Intel(R) 64 Instruction Set Architecture Extensions
- Intel(R) Advanced Vector Extensions (Intel(R) AVX)
https://intel.wingateweb.com/SHchina/published/NGMS002/SP_NGMS002_100r_eng.pdf
「2nd load port」に注目。Loadは128ビット×2に分解して実行してるのだよ。
ユニット数を増やせば本物の256bit実行ユニットなんて乗せる必要ないんだよ。
また団子がフルボッコにされてるのか
何度目だよこの流れ
何度目だよこの流れ
684 :MACオタ>団子 さん:2009/02/11(水) 20:21:37 ID:VQG9IPsT
>>682
--------------
もちろん読んでるよ
--------------
それでは2005年の時点でx86勢は 2 DP Flop/Cycle でスペック上PowerPCやCELL/B.E.に劣っていた
ことは認めるということでよろしいですね。
謝罪しろとは言いませんが、>>676のような言いがかりは勘弁してください。
--------------
もちろん読んでるよ
--------------
それでは2005年の時点でx86勢は 2 DP Flop/Cycle でスペック上PowerPCやCELL/B.E.に劣っていた
ことは認めるということでよろしいですね。
謝罪しろとは言いませんが、>>676のような言いがかりは勘弁してください。
685 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 20:52:35 ID:pGz2zkVB
いいえ、積和算を実装してないのと因果関係がありません。
686 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 20:54:24 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
積和命令を持たない結果性能が劣ると主張したのは誰だよ?
>性能が劣るという理由で選択から外れたりすることがあるす。
積和命令を持たない結果性能が劣ると主張したのは誰だよ?
687 :MACオタ>団子 さん:2009/02/11(水) 20:58:10 ID:VQG9IPsT
>>686
あなたの脳内では 2Flop/cycle は 4Flop/cycleより優れているのですか(笑)
(>>680の下のリンクより)
----------------
2 - AMD Opteron
2 - Intel P4 and Xeon versions < Woodcrest
4 - Intel Woodcrest
4 - PowerPC
----------------
あなたの脳内では 2Flop/cycle は 4Flop/cycleより優れているのですか(笑)
(>>680の下のリンクより)
----------------
2 - AMD Opteron
2 - Intel P4 and Xeon versions < Woodcrest
4 - Intel Woodcrest
4 - PowerPC
----------------
688 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 21:12:40 ID:pGz2zkVB
積和命令を持たないこととLINPACKのピーク性能に因果関係があると主張してるのはお前だ
ごまかすな。
ごまかすな。
689 :MACオタ>団子 さん:2009/02/11(水) 21:19:27 ID:VQG9IPsT
>>688
------------------
積和命令を持たないこととLINPACKのピーク性能に因果関係がある
------------------
ピーク性能の計算式も>>680の下のリンクに書いてあるのですが…
------------------
積和命令を持たないこととLINPACKのピーク性能に因果関係がある
------------------
ピーク性能の計算式も>>680の下のリンクに書いてあるのですが…
690 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 21:23:24 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
これはお前の言葉だよ。
>性能が劣るという理由で選択から外れたりすることがあるす。
これはお前の言葉だよ。
積和算器といえば
GPUでもっともshaderの実行効率の高いS3 Chrome400,500は積和算器がない
GPUでもっともshaderの実行効率の高いS3 Chrome400,500は積和算器がない
692 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 21:28:39 ID:pGz2zkVB
Upcoming products based on Sandy Bridge microarchitecture will once again double
peak FP operations throughput by introducing 256-bit AVX instruction set, supported
by microarchitecture capability to start 1 256-bit FP MUL and 1 256-bit FP ADD
operations per cycle (16 SP or 8 DP FLOPS).
↑これどこに256ビットSIMDユニットが乗っかってるって読めるの?
Core MAの実装は「128bit EUs」と明言してる。逆に言うと・・・
言語能力のない人間の詭弁は呆れる
peak FP operations throughput by introducing 256-bit AVX instruction set, supported
by microarchitecture capability to start 1 256-bit FP MUL and 1 256-bit FP ADD
operations per cycle (16 SP or 8 DP FLOPS).
↑これどこに256ビットSIMDユニットが乗っかってるって読めるの?
Core MAの実装は「128bit EUs」と明言してる。逆に言うと・・・
言語能力のない人間の詭弁は呆れる
693 :MACオタ>団子 さん:2009/02/11(水) 21:47:50 ID:VQG9IPsT
>>680
いい加減面倒なので、Top500のサイトに行って、自分でピーク性能の計算式を確認してください。
Rpeak = [コア数] x [(V)FPU数] x [SIMD幅] x [命令並列性(積和命令がある場合2)] x [クロック] ÷ [スループット(cycle)]
http://www.top500.org/
以後、「団子さんはプロセッサのピーク性能の計算式を知らなかった」ということで、
この辺のリンクを貼らせていただきます。
いい加減面倒なので、Top500のサイトに行って、自分でピーク性能の計算式を確認してください。
Rpeak = [コア数] x [(V)FPU数] x [SIMD幅] x [命令並列性(積和命令がある場合2)] x [クロック] ÷ [スループット(cycle)]
http://www.top500.org/
以後、「団子さんはプロセッサのピーク性能の計算式を知らなかった」ということで、
この辺のリンクを貼らせていただきます。
694 :,,・´∀`・,,)っ-●◎○:2009/02/11(水) 21:50:06 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
どこに因果関係があるの?
>性能が劣るという理由で選択から外れたりすることがあるす。
どこに因果関係があるの?
テスト
団子さんはコピペに励んでいるようですが、実際に積和命令の有無が採用に影響した例は
バージニア工科大学のPower Mac G5クラスタがあります。
http://www.macdevcenter.com/pub/a/mac/2003/10/29/osxcon_g5cluster.html
----------------------
Each is capable of a fused, multiple-add operation per cycle, so you get 2 flops per cycle.
This means that 2GHz corresponds to 8 GFlops, so each dual G5 can deliver a peak of 16
GFlops of double-precision performance. That is more than a modern Cray node.
----------------------
バージニア工科大学のPower Mac G5クラスタがあります。
http://www.macdevcenter.com/pub/a/mac/2003/10/29/osxcon_g5cluster.html
----------------------
Each is capable of a fused, multiple-add operation per cycle, so you get 2 flops per cycle.
This means that 2GHz corresponds to 8 GFlops, so each dual G5 can deliver a peak of 16
GFlops of double-precision performance. That is more than a modern Cray node.
----------------------
ついでですから、団子さんの愚行も記録に残しておきましょう。
http://pc11.2ch.net/test/read.cgi/jisaku/1233047752/758
----------------
758 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 21:37:42 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
----------------
以下、内容が同じなのでリンクのみ
http://pc11.2ch.net/test/read.cgi/jisaku/1231688064/609
http://pc11.2ch.net/test/read.cgi/mac/1193441533/445
他にも貼っているかどうか、あとで必死チェッカーで見てみようかと(笑)
http://pc11.2ch.net/test/read.cgi/jisaku/1233047752/758
----------------
758 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 21:37:42 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
----------------
以下、内容が同じなのでリンクのみ
http://pc11.2ch.net/test/read.cgi/jisaku/1231688064/609
http://pc11.2ch.net/test/read.cgi/mac/1193441533/445
他にも貼っているかどうか、あとで必死チェッカーで見てみようかと(笑)
698 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 22:51:46 ID:pGz2zkVB
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
どこに因果関係があるの?
>性能が劣るという理由で選択から外れたりすることがあるす。
どこに因果関係があるの?
699 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 22:52:34 ID:pGz2zkVB
700 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 22:53:44 ID:pGz2zkVB
ユニット構成も知らずに積和【命令】が性能を左右すると思い込んでるお馬鹿さん
701 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 23:11:09 ID:pGz2zkVB
Core 2までのSSEがそんなに速くなかったのは、128ビットSIMDに対して、ユニット側は64bit FADD + FMULで
それぞれ2サイクルかけて実行してたからです。
どっかの馬鹿が言うように【積和算がないからではありません】
それぞれ2サイクルかけて実行してたからです。
どっかの馬鹿が言うように【積和算がないからではありません】
702 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 23:12:28 ID:pGz2zkVB
しかしCell 45は珍発言の宝庫だな。
>>697の続きですが、ゲハまで貼りに行った様で…
http://dubai.2ch.net/test/read.cgi/ghard/1234159396/916
-----------------------
916 名前:,,・´∀`・,,)っ-●◎○ 投稿日:2009/02/11(水) 21:58:49 ID:/lCqDwXB0
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
-----------------------
新・mac板からゲハまで満遍なく… 英文資料は読まなくても、こういうドーでも良いことはまめ
なんですね(笑)
http://dubai.2ch.net/test/read.cgi/ghard/1234159396/916
-----------------------
916 名前:,,・´∀`・,,)っ-●◎○ 投稿日:2009/02/11(水) 21:58:49 ID:/lCqDwXB0
>例えばx86 ISAわ、浮動小数点の積和演算命令を持たないすけど、この結果HPC分野でわLinpackでのピーク
>性能が劣るという理由で選択から外れたりすることがあるす。
-----------------------
新・mac板からゲハまで満遍なく… 英文資料は読まなくても、こういうドーでも良いことはまめ
なんですね(笑)
704 :,,・´∀`・,,)っ-○◎●:2009/02/11(水) 23:48:19 ID:pGz2zkVB
どうでもよくないよ。積和演算のレイテンシ1さん
同じく>>697の続きです。必死チェッカーに感謝(笑)
http://pc11.2ch.net/test/read.cgi/mac/1214461149/143
それにしても、いい歳してコピペ荒らしとは親が泣いていそうな気が…
http://pc11.2ch.net/test/read.cgi/mac/1214461149/143
それにしても、いい歳してコピペ荒らしとは親が泣いていそうな気が…
707 :,,・´∀`・,,)っ-●◎○:2009/02/12(木) 04:11:06 ID:2yxR3oAR
要するにそれがSPAMヲタくんの巡回コースなんだよね
それ以外の板もくまなく探して見つけてごらんwww
他のパターンのコピペもやってあげてるから
それ以外の板もくまなく探して見つけてごらんwww
他のパターンのコピペもやってあげてるから
708 :MACオタ>団子 さん:2009/02/12(木) 06:29:57 ID:AxJ9pFD9
>>707
----------------
他のパターンのコピペもやってあげてるから
----------------
いや、いい大人に荒らし行為を告白されても困るのですが…
なんだか団子さんの親御さんのご苦労を考えると、こっちの方が泣けてきました。
----------------
他のパターンのコピペもやってあげてるから
----------------
いや、いい大人に荒らし行為を告白されても困るのですが…
なんだか団子さんの親御さんのご苦労を考えると、こっちの方が泣けてきました。
709 :,,・´∀`・,,)っ-●◎○:2009/02/12(木) 07:44:25 ID:2yxR3oAR
>荒らし
日記に書けばいいような海外記事のコピペを空気を読まずに次々と掲示板に投稿する行為のことですね。わかります
日記に書けばいいような海外記事のコピペを空気を読まずに次々と掲示板に投稿する行為のことですね。わかります
710 :,,・´∀`・,,)っ-●◎○:2009/02/12(木) 07:44:49 ID:2yxR3oAR
>他のパターンのコピペもやってあげてるから
これはSPAMヲタくんのことだよ
これはSPAMヲタくんのことだよ
お前らの取っ組み合いするためのスレじゃねぇんだよ
もっとやれ
MACオタは低レベルだから無視するとか言いながら
我慢できずにこの有様だからな。団子の人間性はその程度ということ
我慢できずにこの有様だからな。団子の人間性はその程度ということ
714 :,,・´∀`・,,)っ-○◎●:2009/02/12(木) 21:18:15 ID:2yxR3oAR
「〜す」の芸風を更正されたのは誰の功績と心得る?w
まあ俺じゃないと思うけど
まあ俺じゃないと思うけど
どっちも同じ土俵で掛け合い漫才やってんだから当然同レベル
716 :Socket774:2009/02/13(金) 16:57:52 ID:t6J79Gy+
.,,-‐''"~~ ゙゙̄'''ー、,
.,/' ザルカウイ ヽ http://aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ |
|‐''/ \゙''ー|
| | | |
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | // 陸自撤退の要求を日本が断ったから
.| ヽ、,,;;iiill|||||||||lllii;;, /.|
ヽ |'"~ー--‐~゙゙'''| / 香田は、んっごうの刑!
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| / んっごう!!
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | (
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
.,/' ザルカウイ ヽ http://aliennationreport.com/SHOSEIKODA.wmv
,,i´ ヽ
| _,,,;---‐‐‐---、,____ |
|‐''/ \゙''ー|
| | | |
( ./ ,;;iiilllllllliii;;,,;;iiillllllllii;;,, | )
.| | ≪・≫/| | ≪・≫ .| /
| |\ ~~// | ~~~ /| /
| | | ./ .L;....;J ヽ | // 陸自撤退の要求を日本が断ったから
.| ヽ、,,;;iiill|||||||||lllii;;, /.|
ヽ |'"~ー--‐~゙゙'''| / 香田は、んっごうの刑!
| ゙'''ー----‐''" |
___/\ r'" ̄`⌒'"⌒`⌒⌒'ー、_
/ | \__.r' 香田 ヽ
( `ゝ
(;;;;;;;;;;;;;;;;;人_(\!((^i_/ヽ、::*::: }
| /*-'' ̄ :;; ̄''- i リ
| ソr《;,・;》、i r《;,・;》、 | . |
リ i ;;;;;; | :::: | |
} <ヘ :;;;;; ノ ::: /;; > i
ゴリッ | |:::l:;;;;;;;*`;;ー;;`ヽ: l::::| |
⌒⌒ヽ 彡`';:; ヽ:::;;; l l===ュヽ ::/ リノ
、 ) ̄} ̄ ̄ ̄ ̄ ̄ヾ ;; |、'^Y^',,|:::/| / んっごう!!
、_人_,ノ⌒)}─┐ .,,;:':;}#;\∬;;;-'/ | (
_,,ノ´ └───;イ;゚;'∬:∬ j,/
r‐'´ ブチッ…ブチブチ…','/;;∬∬∬ \
718 :,,・´∀`・,,)っ-●◎○:2009/02/13(金) 18:43:00 ID:2KWocYVQ
MACヲタは自分がどれだけあほなこと言ってるかわかってないからね
CISCは基本的に命令とALUの実装が1:1対応してるとは限らないわけで
演算命令のスループットが命令よりもALUの実装に縛られることも理解してない
CISCは基本的に命令とALUの実装が1:1対応してるとは限らないわけで
演算命令のスループットが命令よりもALUの実装に縛られることも理解してない
MACオタなんて揚げ足取りしかしてないんだから相手にするなよw
どっちも糞だが、今回は先に黙ったMACオタが若干マシだな
(・w・)
/\ /\ /\
.. __ __ ___/\/ \/ \/ \/ |_
. .. / __| ヽ \
/ / \ ' / MACオタッ!
| |=- 廾、 l \ おまえの命がけの自演ッ!
| T. '’".;:::"’ '.| / /
ヽ{ ,.'-_-'、 レ/  ̄|/\/\ /\ /\
. !:ト、.-三- ,ノト、 _/\/ \/ \/
,ノ´f ヽ;;;;;;: ノ!ヽ\._ \
/ノ !|`ヽ三イ ヽノノ `'ー-、._ / このリバ原は
/ r'/ | /::|,二ニ‐'´イ -‐''" /´{ \ 敬意を表するッ!
{ V ヽ.V/,. -‐''"´ i / |/
ヽ { r‐、___ i / ∩  ̄| /\/\ /\ /\
} .ゝ二=、ヒ_ソ‐-、 i__,. '| r‐、 U \/
. | 〉 ,. -',二、ヽ. `ニ二i___ |:| l| |
|'}:} ,/|毒|\丶 i ,::'| 'ー' {
|ノノ |,ノ:::::|ト、 \ヽ ! i }`i´ r|
|_>'ィ毒::::ノ 丶 ハ し-' | ! | |
┌≦:::::::::::::/ lハ | ) U
/ィf冬::::::イ |::.. j: }lハ. |∩ '゙}
.. __ __ ___/\/ \/ \/ \/ |_
. .. / __| ヽ \
/ / \ ' / MACオタッ!
| |=- 廾、 l \ おまえの命がけの自演ッ!
| T. '’".;:::"’ '.| / /
ヽ{ ,.'-_-'、 レ/  ̄|/\/\ /\ /\
. !:ト、.-三- ,ノト、 _/\/ \/ \/
,ノ´f ヽ;;;;;;: ノ!ヽ\._ \
/ノ !|`ヽ三イ ヽノノ `'ー-、._ / このリバ原は
/ r'/ | /::|,二ニ‐'´イ -‐''" /´{ \ 敬意を表するッ!
{ V ヽ.V/,. -‐''"´ i / |/
ヽ { r‐、___ i / ∩  ̄| /\/\ /\ /\
} .ゝ二=、ヒ_ソ‐-、 i__,. '| r‐、 U \/
. | 〉 ,. -',二、ヽ. `ニ二i___ |:| l| |
|'}:} ,/|毒|\丶 i ,::'| 'ー' {
|ノノ |,ノ:::::|ト、 \ヽ ! i }`i´ r|
|_>'ィ毒::::ノ 丶 ハ し-' | ! | |
┌≦:::::::::::::/ lハ | ) U
/ィf冬::::::イ |::.. j: }lハ. |∩ '゙}
723 :,,・´∀`・,,)っ-○◎●:2009/02/20(金) 18:09:12 ID:ntaPO4iU
45nm Core 2で内積命令をサポートし1命令で7SPあるいは3DP分実行できるようになっても
ピーク浮動小数演算性能は従来と全く変わらなかったわけですが。
積和算(笑)
ピーク浮動小数演算性能は従来と全く変わらなかったわけですが。
積和算(笑)
724 :,,・´∀`・,,)っ-○◎●:2009/02/20(金) 18:11:44 ID:ntaPO4iU
あとコレは吹いたwww
8800GTとGTXが同じだと思ったらしい。
Phenom X3とX4程度には違うわけだが。
481 名前:MACオタ>480 さん[sage] 投稿日:2009/02/15(日) 11:58:49 ID:xwekogcK0
>>480
-------------------
いまだに2600 HDや8800GTなんぞで「次世代グラフィック」なんて
-------------------
ゲームに使うわけじゃあるまいし、8800って優秀ですよ。
http://www.unitcom.co.jp/gpgpu/bench_mark.html
484 名前:名称未設定[] 投稿日:2009/02/15(日) 12:28:54 ID:ETGNZoa80
>>481
おまえはPowerPCだけ粘着してろよ。>>473の宿題はまだか?w
だいいち、純正カードは8800GTXじゃなくて無印GTだろ。違うカードのベンチ結果
持ち出して寝ぼけてるのか?しかも現行カードの2/3程度の処理能力しか
ないもののどこが優秀なんだ、このアホウが。
8800GTとGTXが同じだと思ったらしい。
Phenom X3とX4程度には違うわけだが。
481 名前:MACオタ>480 さん[sage] 投稿日:2009/02/15(日) 11:58:49 ID:xwekogcK0
>>480
-------------------
いまだに2600 HDや8800GTなんぞで「次世代グラフィック」なんて
-------------------
ゲームに使うわけじゃあるまいし、8800って優秀ですよ。
http://www.unitcom.co.jp/gpgpu/bench_mark.html
484 名前:名称未設定[] 投稿日:2009/02/15(日) 12:28:54 ID:ETGNZoa80
>>481
おまえはPowerPCだけ粘着してろよ。>>473の宿題はまだか?w
だいいち、純正カードは8800GTXじゃなくて無印GTだろ。違うカードのベンチ結果
持ち出して寝ぼけてるのか?しかも現行カードの2/3程度の処理能力しか
ないもののどこが優秀なんだ、このアホウが。
お前らの取っ組み合いするためのスレじゃねぇんだよ
726 :,,・´∀`・,,)っ-○◎●:2009/02/23(月) 00:40:25 ID:L2fCH4hI
What Is the Intel/nVidia Skirmish Really About?
http://www.internetnews.com/hardware/article.php/3804911/What+Is+the+IntelnVidia+Skirmish+Really+About.htm
http://www.internetnews.com/hardware/article.php/3804911/What+Is+the+IntelnVidia+Skirmish+Really+About.htm
>>726
斜め読み
NVIDIA「我々のチップセットはIntelより優れたグラフィックス処理能力を有している。Intelは消費者から選択肢を奪おうとしている。」
Intel「これは知的財産権の問題だ。われわれはNVIDIAとライセンスに関する交渉を一年間にわたって行ってきたがそれは実らなかった。」
斜め読み
NVIDIA「我々のチップセットはIntelより優れたグラフィックス処理能力を有している。Intelは消費者から選択肢を奪おうとしている。」
Intel「これは知的財産権の問題だ。われわれはNVIDIAとライセンスに関する交渉を一年間にわたって行ってきたがそれは実らなかった。」
2007年のNVIDIAにおいて、チップセットビジネスは6.61億ドルの売り上げを誇り全体の21%を占める。
とあるが、これが殆ど消えるとなると痛いだろうな。
まあでもこの提訴はどう考えてもIntelに分があると思います。
たらればで言えばあの時素直に買収されておけばよかったんだよなぁ。
AMDがATIを買った直後。一番自分を高く売れる時期だったんじゃないの。
あの時は時価総額100億ドルを超えていたと記憶しているが。
寝る。
とあるが、これが殆ど消えるとなると痛いだろうな。
まあでもこの提訴はどう考えてもIntelに分があると思います。
たらればで言えばあの時素直に買収されておけばよかったんだよなぁ。
AMDがATIを買った直後。一番自分を高く売れる時期だったんじゃないの。
あの時は時価総額100億ドルを超えていたと記憶しているが。
寝る。
○ 高すぎてどこも手を出さなかった時期
/\ /\ /\
.. __ __ ___/\/ \/ \/ \/ |_
. .. / __| ヽ \
/ / \ ' / ,,・´∀`・,,)っ-○◎●ッ!
| |=- 廾、 l \ おまえのレス連投粘着する勇気ッ!
| T. '’".;:::"’ '.| / /
ヽ{ ,.'-_-'、 レ/  ̄|/\/\ /\ /\
. !:ト、.-三- ,ノト、 _/\/ \/ \/
,ノ´f ヽ;;;;;;: ノ!ヽ\._ \
/ノ !|`ヽ三イ ヽノノ `'ー-、._ / この川原亮俊は
/ r'/ | /::|,二ニ‐'´イ -‐''" /´{ \ 敬意を表するッ!
{ V ヽ.V/,. -‐''"´ i / |/
ヽ { r‐、___ i / ∩  ̄| /\/\ /\ /\
} .ゝ二=、ヒ_ソ‐-、 i__,. '| r‐、 U \/
. | 〉 ,. -',二、ヽ. `ニ二i___ |:| l| |
|'}:} ,/|毒|\丶 i ,::'| 'ー' {
|ノノ |,ノ:::::|ト、 \ヽ ! i }`i´ r|
|_>'ィ毒::::ノ 丶 ハ し-' | ! | |
┌≦:::::::::::::/ lハ | ) U
/ィf冬::::::イ |::.. j: }lハ. |∩ '゙}
.. __ __ ___/\/ \/ \/ \/ |_
. .. / __| ヽ \
/ / \ ' / ,,・´∀`・,,)っ-○◎●ッ!
| |=- 廾、 l \ おまえのレス連投粘着する勇気ッ!
| T. '’".;:::"’ '.| / /
ヽ{ ,.'-_-'、 レ/  ̄|/\/\ /\ /\
. !:ト、.-三- ,ノト、 _/\/ \/ \/
,ノ´f ヽ;;;;;;: ノ!ヽ\._ \
/ノ !|`ヽ三イ ヽノノ `'ー-、._ / この川原亮俊は
/ r'/ | /::|,二ニ‐'´イ -‐''" /´{ \ 敬意を表するッ!
{ V ヽ.V/,. -‐''"´ i / |/
ヽ { r‐、___ i / ∩  ̄| /\/\ /\ /\
} .ゝ二=、ヒ_ソ‐-、 i__,. '| r‐、 U \/
. | 〉 ,. -',二、ヽ. `ニ二i___ |:| l| |
|'}:} ,/|毒|\丶 i ,::'| 'ー' {
|ノノ |,ノ:::::|ト、 \ヽ ! i }`i´ r|
|_>'ィ毒::::ノ 丶 ハ し-' | ! | |
┌≦:::::::::::::/ lハ | ) U
/ィf冬::::::イ |::.. j: }lハ. |∩ '゙}
VIAが安く買ってくれますよ
>>726
斜め読み
NVIDIA「我々のチップセットはIntelより優れたグラフィックス処理能力を有しているニダ。Intelは消費者から選択肢を奪おうとしているニダ。」
Intel「これは知的財産権の問題だ。われわれはNVIDIAとライセンスに関する交渉を一年間にわたって行ってきたがそれは実らなかった。」
斜め読み
NVIDIA「我々のチップセットはIntelより優れたグラフィックス処理能力を有しているニダ。Intelは消費者から選択肢を奪おうとしているニダ。」
Intel「これは知的財産権の問題だ。われわれはNVIDIAとライセンスに関する交渉を一年間にわたって行ってきたがそれは実らなかった。」
つまんね
それじゃ根本的な争点(最初っからまとまらない)
元々Intelはチップセット込みでCPUの販売価格を設定している
ノースブリッジにはメモリコントローラも含めた原価が設定されており、これがi7だとCPUに内臓されることになった
Intelはその価格をX58チップセットに上乗せすることでチップセット+CPUでの販売価格維持を想定していると推測される
そのことでNVIDIAへのライセンス料がメモリコントローラ分だけ上乗せされることとなる
NVIDIAとしてはそれを認めるわけにはいかないというのが争点だ
AMDのCPUだと内臓メモリコントローラの原価はCPU価格に上乗せされている、
これは元々チップセットを作ってなかったのだから当然であり今更である
しかしNVIDIAからすればAMD系のチップセットだとメモコン有無に拘らずライセンス料は不要であり、
Intel系だとメモコン有無によりライセンス料が違ってくる、よって認められないとの主張だろう
元々Intelはチップセット込みでCPUの販売価格を設定している
ノースブリッジにはメモリコントローラも含めた原価が設定されており、これがi7だとCPUに内臓されることになった
Intelはその価格をX58チップセットに上乗せすることでチップセット+CPUでの販売価格維持を想定していると推測される
そのことでNVIDIAへのライセンス料がメモリコントローラ分だけ上乗せされることとなる
NVIDIAとしてはそれを認めるわけにはいかないというのが争点だ
AMDのCPUだと内臓メモリコントローラの原価はCPU価格に上乗せされている、
これは元々チップセットを作ってなかったのだから当然であり今更である
しかしNVIDIAからすればAMD系のチップセットだとメモコン有無に拘らずライセンス料は不要であり、
Intel系だとメモコン有無によりライセンス料が違ってくる、よって認められないとの主張だろう
つまんね
736 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 03:59:59 ID:0qtj8Ebf
それが本当だとしてソニーは単にアホなのか
それとも全分野壊滅状態が故に自棄になっているのか
分かりかねないわー
それとも全分野壊滅状態が故に自棄になっているのか
分かりかねないわー
分かるなら教えてくれよ
必要なのは、PS4じゃなくて、PS2.5だと思うんだ
>>739
それをやるには、もうすでに3年遅い。
もうPS3出しちまって随分経つのに、今さらPS4をSD機や低性能機で
出すわけにはいかんだろ。
GameCube -> Wii みたいに、名前すっぱり変えて新機軸の据え置きコンソール
やるなら兎も角(それはソニーには出来ないだろうし)。
Cellも捨てるに捨てられず、GPUは外から調達せざるを得ず、nVidiaはもう相手にしたくない。
つーわけで、Cell+ララ搭載機が$399位でばらまけるようになる時期が来るまで待って、
その構成で出してくると予想。
でもその時期にはMS機がすでにハイエンド次世代機を席巻してて今度も苦戦しそうだが。
それをやるには、もうすでに3年遅い。
もうPS3出しちまって随分経つのに、今さらPS4をSD機や低性能機で
出すわけにはいかんだろ。
GameCube -> Wii みたいに、名前すっぱり変えて新機軸の据え置きコンソール
やるなら兎も角(それはソニーには出来ないだろうし)。
Cellも捨てるに捨てられず、GPUは外から調達せざるを得ず、nVidiaはもう相手にしたくない。
つーわけで、Cell+ララ搭載機が$399位でばらまけるようになる時期が来るまで待って、
その構成で出してくると予想。
でもその時期にはMS機がすでにハイエンド次世代機を席巻してて今度も苦戦しそうだが。
それCell積まないほうがいいんじゃ
プライドと互換性、どちらも捨てられないだろうから。
nVidia GPU載せずでのPS3ソフト互換性は、360のような個別ソフト用パッチでいけるんでない?
互換機能使ってみんなやりたがるPS3用ソフトなんてどうせ極少数だし。
nVidia GPU載せずでのPS3ソフト互換性は、360のような個別ソフト用パッチでいけるんでない?
互換機能使ってみんなやりたがるPS3用ソフトなんてどうせ極少数だし。
743 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 19:38:09 ID:0qtj8Ebf
PS3のPS2互換ですら1年で切り捨てたのに今更PS3互換に拘る理由が思い当たらない。
むしろ併売すればいいじゃん。「10年戦える」って言ってるんだし。
あるいは上位エディションに超解像支援の名目でPS3互換ハード載っけて通常版はPS3互換無し程度で。
むしろ併売すればいいじゃん。「10年戦える」って言ってるんだし。
あるいは上位エディションに超解像支援の名目でPS3互換ハード載っけて通常版はPS3互換無し程度で。
RSXをLarrabeeにすげかえて、RSXをエミュレートさせるとか
ていうか仮にPS3→PS4でCellのSPE数を増やしたら互換って取れるもんなの?
リングバスのレイテンシ変わったら動かないソフトばっかなんじゃね
ていうか仮にPS3→PS4でCellのSPE数を増やしたら互換って取れるもんなの?
リングバスのレイテンシ変わったら動かないソフトばっかなんじゃね
あとGDDR3とGDDR5って互換取れるんだっけ
GCとWiiでSDRAMとGDDR3の互換取れてたからいけるんかね
GCとWiiでSDRAMとGDDR3の互換取れてたからいけるんかね
746 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 19:56:39 ID:0qtj8Ebf
Wiiは24MBのSDRAM+GDDR3 64MBでゲームキューブのソフトを動かすときはSDRAMだけを使う。
CPUやGPUのクロックもおとしてGC互換というかそのものになる
CPUやGPUのクロックもおとしてGC互換というかそのものになる
あ、いや外付けのSDR-SDRAMとDDR2-SDRAMって互換取れるんだなって
GCは1T-SRAM24MB+SDR-SDRAM16MB
Wiiは1T-SRAM24MB+GDDR3-SDRAM64MBだもんでさ
GCは1T-SRAM24MB+SDR-SDRAM16MB
Wiiは1T-SRAM24MB+GDDR3-SDRAM64MBだもんでさ
748 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 20:11:27 ID:0qtj8Ebf
そっちか。
メモリプロトコルを直接ソフトで触る訳じゃないんだしそのへんは大丈夫なんじゃね?
シビアにタイミングを要求するような作り込みをしてないってのもあるだろうけど。
つーかさ、Larrabeeを採用するとしたらそれだけでCellに拘る理由が消えるんだが。
DX10世代ではGPU側でやってる仕事をPS3ではCPU(SPE)でやってるわけで
GPU側がリッチになってしまうと、Cellは要らない子になってしまうんじゃね?
しかもLarrabeeはCPUそのもののジョブもこなせるときた。
整数スカラ演算やらせたらSPEより速い可能性もある。
(実際シングルスレッドのベンチでAtom 1.6GHz>SPE 3.2GHzを確認してる)
メモリプロトコルを直接ソフトで触る訳じゃないんだしそのへんは大丈夫なんじゃね?
シビアにタイミングを要求するような作り込みをしてないってのもあるだろうけど。
つーかさ、Larrabeeを採用するとしたらそれだけでCellに拘る理由が消えるんだが。
DX10世代ではGPU側でやってる仕事をPS3ではCPU(SPE)でやってるわけで
GPU側がリッチになってしまうと、Cellは要らない子になってしまうんじゃね?
しかもLarrabeeはCPUそのもののジョブもこなせるときた。
整数スカラ演算やらせたらSPEより速い可能性もある。
(実際シングルスレッドのベンチでAtom 1.6GHz>SPE 3.2GHzを確認してる)
http://japanese.engadget.com/2009/02/25/ps3-janco-rumor/
アナリスト:PS3値下げは秒読み段階、ブルーレイなしモデルも検討
PS4?(wara)
アナリスト:PS3値下げは秒読み段階、ブルーレイなしモデルも検討
PS4?(wara)
またヒッキーかw
751 :,,・´∀`・,,)っ-○◎●:2009/02/26(木) 22:45:41 ID:0qtj8Ebf
Fab売り払った時点で、Cell捨ててるも同然じゃねーの?
>>748
まぁ理性的に考えればそのとおり。
もっと理性的になるとコストばかりかかってリスク高杉な据え置き機なんて
もうPS3をだらだらと引き延ばしてそのままでフェードアウトさせて、
携帯機にリソースを一本化するだろうけど。
それはともかく、久夛良木も晴れて大学に逃げたようだし、
確かにCellに対する無駄なプライドもそろそろ捨てられるかもしれない。
まぁ理性的に考えればそのとおり。
もっと理性的になるとコストばかりかかってリスク高杉な据え置き機なんて
もうPS3をだらだらと引き延ばしてそのままでフェードアウトさせて、
携帯機にリソースを一本化するだろうけど。
それはともかく、久夛良木も晴れて大学に逃げたようだし、
確かにCellに対する無駄なプライドもそろそろ捨てられるかもしれない。
>>749
あんな莫大な棚卸資産抱えた状態で値下げなんてしたらマジで死ぬ
あんな莫大な棚卸資産抱えた状態で値下げなんてしたらマジで死ぬ
約2000億
756 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 07:02:07 ID:TrruVJm2
>>753
どうせ捌けない在庫なんてため込んでても仕方ないじゃん。
棚卸資産としてストックしておけば決算上大赤字にはならないけどキャッシュフローは悪くなるばかり。
んで、今のソニーにとって必要なのは現金。
値下げしたぶん赤字を計上するだろうがが、現金化が最優先だろう。
どうせ捌けない在庫なんてため込んでても仕方ないじゃん。
棚卸資産としてストックしておけば決算上大赤字にはならないけどキャッシュフローは悪くなるばかり。
んで、今のソニーにとって必要なのは現金。
値下げしたぶん赤字を計上するだろうがが、現金化が最優先だろう。
末期のセガのDC投売りの再来来いやー。
ttp://www.z-z-z.jp/BLOG/log/eid264.html
ただ、Larabeeは、第一世代のものは、ATIやNVIDIAのハイエンドGPUには全く及ばないパフォーマンスといわれている。
テクスチャユニットに負荷がかかるとリングバスがパンクして思ったほどパフォーマンスがでないらしい。
なので、PS4に載せるとしても世代を更新させたものじゃないと、また、今回のPS3みたいにあとでケチがつくので注意したいところ。
ただ、Larabeeは、第一世代のものは、ATIやNVIDIAのハイエンドGPUには全く及ばないパフォーマンスといわれている。
テクスチャユニットに負荷がかかるとリングバスがパンクして思ったほどパフォーマンスがでないらしい。
なので、PS4に載せるとしても世代を更新させたものじゃないと、また、今回のPS3みたいにあとでケチがつくので注意したいところ。
759 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 20:23:51 ID:TrruVJm2
第1世代(45nm)は良くてHPC向け、そのものがキャンセルっぽいですよ。
ディスクリートGPUとしてはいま32nmを前提に動いてるし。
ディスクリートGPUとしてはいま32nmを前提に動いてるし。
単に力技なら期待薄だな
761 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 20:33:08 ID:TrruVJm2
GPGPUなんて数に頼った力技以外のなんでもないけどね。
IntelにとってはGPU機能をアプリケーションの一つとするx86ベースの汎用メニーコアプロセッサだし。
方向性としてCellに近いんじゃないの?
IntelにとってはGPU機能をアプリケーションの一つとするx86ベースの汎用メニーコアプロセッサだし。
方向性としてCellに近いんじゃないの?
という言い訳は、一般人は知ったこっちゃない
こんな話が出ているのに何故>>758のようなことが言えるのだろうか?
http://pc11.2ch.net/test/read.cgi/jisaku/1233047752/837
837 名前:MACオタ[sage] 投稿日:2009/02/17(火) 07:08:35 ID:wxwJlR0d
誰かLarrabeeが既に一部顧客の下でCG制作に使われているとか大騒ぎしていたような
気がしますが、まだ実物のチップが存在しないという話が出てきました。
TheINQのCharlie "Groo" Demerjian氏がRWT掲示板へ次のような投稿をしています。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
--------------
>didn't inq had an article a few weeks back that lbr test silicon was already out?
Not that I am aware of, but I might have missed it due to the extreme suckiness of our new engine.
That said, it was not taped out as of Oct 1, and the Taiwanese were expecting silicon in January.
That didn't happen either, but the boards have been done since summer, I have seen some.
Basically, it is 6+ months late so far and counting.
--------------
予定より半年遅れているそうで…
http://pc11.2ch.net/test/read.cgi/jisaku/1233047752/837
837 名前:MACオタ[sage] 投稿日:2009/02/17(火) 07:08:35 ID:wxwJlR0d
誰かLarrabeeが既に一部顧客の下でCG制作に使われているとか大騒ぎしていたような
気がしますが、まだ実物のチップが存在しないという話が出てきました。
TheINQのCharlie "Groo" Demerjian氏がRWT掲示板へ次のような投稿をしています。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
--------------
>didn't inq had an article a few weeks back that lbr test silicon was already out?
Not that I am aware of, but I might have missed it due to the extreme suckiness of our new engine.
That said, it was not taped out as of Oct 1, and the Taiwanese were expecting silicon in January.
That didn't happen either, but the boards have been done since summer, I have seen some.
Basically, it is 6+ months late so far and counting.
--------------
予定より半年遅れているそうで…
> ただ、1つだけいえそうなのは、PS4世代では、レンダリングパイプラインが
> ソフトウェアに回帰するんじゃないかということ。
じゃぁCellかLarabeeしかないな。
MS+AMD組のリークや予測が出てこないがどうなるんだろうな。
> ソフトウェアに回帰するんじゃないかということ。
じゃぁCellかLarabeeしかないな。
MS+AMD組のリークや予測が出てこないがどうなるんだろうな。
765 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:12:05 ID:TrruVJm2
固定機能プロセッサで出来ることを汎用プロセッサでやると電力効率は悪くなる。
じゃあ、固定機能プロセッサで出来なかったり逆に効率が悪かったりすることをこなす場合に
そこでフルプログラマブルなGPU(=メニーコアCPU)の出番なわけだ。
どこまでプログラマビリティが求められるか、どこまでがCPUの取り分になるか?
ゲーム機でもGPGPU性能のニーズは高まりつつあるからね。
爆発とかのエフェクトに対してきめ細かな衝突判定をしたいとかさ。
とりあえずPPU+SPU+GPUは最悪な組み合わせだと言ってる。
「汎用的なグラフィックプロセッシング」の分野はモダンなGPUだけでやれるようになってしまったので
SPUを持て余す。
PS2時代のGSみたいなメモリ転送に特化した独自GPUと連携してEIBで繋がれた複数のSPEを用いて
バケツリレーでグラフィックパイプラインを組むくらいでないと活用のしようがない。
んで、それって効率いいの?って話になるわけで。
新たにCellベースのGPUを作るより曲がりなりにもGPUとしてチューンされてるLarrabee使った方が
開発コストかからないんじゃないかってのが今の風向き。
じゃあ、固定機能プロセッサで出来なかったり逆に効率が悪かったりすることをこなす場合に
そこでフルプログラマブルなGPU(=メニーコアCPU)の出番なわけだ。
どこまでプログラマビリティが求められるか、どこまでがCPUの取り分になるか?
ゲーム機でもGPGPU性能のニーズは高まりつつあるからね。
爆発とかのエフェクトに対してきめ細かな衝突判定をしたいとかさ。
とりあえずPPU+SPU+GPUは最悪な組み合わせだと言ってる。
「汎用的なグラフィックプロセッシング」の分野はモダンなGPUだけでやれるようになってしまったので
SPUを持て余す。
PS2時代のGSみたいなメモリ転送に特化した独自GPUと連携してEIBで繋がれた複数のSPEを用いて
バケツリレーでグラフィックパイプラインを組むくらいでないと活用のしようがない。
んで、それって効率いいの?って話になるわけで。
新たにCellベースのGPUを作るより曲がりなりにもGPUとしてチューンされてるLarrabee使った方が
開発コストかからないんじゃないかってのが今の風向き。
766 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:13:13 ID:TrruVJm2
>>763
Demerjianは嘘記事も平気で書くでたらめ記者だけどwwww
Demerjianは嘘記事も平気で書くでたらめ記者だけどwwww
ただしItaniumに限る。
はたしてPS4なんて出す気あるのかって
769 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:22:09 ID:TrruVJm2
>>767
「デマーじゃん」って言うくらいですから。
ちょっと前だとPenrynにHTが搭載されてるなんて大嘘もついてた。
彼は確たる情報網など持ってない。基本でっちあげ。
ゴシップの記者なんて5割でも当たればいい世界だからね。
「デマーじゃん」って言うくらいですから。
ちょっと前だとPenrynにHTが搭載されてるなんて大嘘もついてた。
彼は確たる情報網など持ってない。基本でっちあげ。
ゴシップの記者なんて5割でも当たればいい世界だからね。
770 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:23:52 ID:TrruVJm2
あと、彼によれば2006年夏くらいまでPS3も2008年くらい登場ということにされてましたよ。
プログラマー泣かせか…>Larrabee
初めて並列化なんかしようとした時はどっちにしろ泣くんだよ。
アーキテクチャやツールサポートによって
目から涙がこぼれる位か、号泣するかの差はあるだろうが。
アーキテクチャやツールサポートによって
目から涙がこぼれる位か、号泣するかの差はあるだろうが。
>>769-770
確かにGrooは間違った記事を書くことも多いがちゃんとした情報網を持っていると思うよ。
HOT CHIPSとかISSCCにまめに参加して直接開発者に話を聞いたりもしているみたいだしね。
海外の後藤だと俺は考えている。・・・まあINQ記者の話なんかどうでもいい。
報道は4亀の本間だが、2010年後半にずれ込んだという話も出てきて、>>763と符合している。
確度はそこそこあるのではないの。 >>Larrabeeシリコン不在説
>>771
「攻撃や追尾のパターンがミエミエの伝説のモンスターとか、NPCをすり抜ける落石とか、
見た目は派手だけど動きが嘘臭いゲームを作っても何時かは売れなくなる気がする・・・」
っていうのが開発者側にあるから、LarrabeeとかGPGPUに注目が集まっているんじゃないの?
確かにGrooは間違った記事を書くことも多いがちゃんとした情報網を持っていると思うよ。
HOT CHIPSとかISSCCにまめに参加して直接開発者に話を聞いたりもしているみたいだしね。
海外の後藤だと俺は考えている。・・・まあINQ記者の話なんかどうでもいい。
報道は4亀の本間だが、2010年後半にずれ込んだという話も出てきて、>>763と符合している。
確度はそこそこあるのではないの。 >>Larrabeeシリコン不在説
>>771
「攻撃や追尾のパターンがミエミエの伝説のモンスターとか、NPCをすり抜ける落石とか、
見た目は派手だけど動きが嘘臭いゲームを作っても何時かは売れなくなる気がする・・・」
っていうのが開発者側にあるから、LarrabeeとかGPGPUに注目が集まっているんじゃないの?
x 2010年後半にずれ込んだという話も出てきて、
○ 投入が2010年後半にずれ込んだという話も出てきて、
○ 投入が2010年後半にずれ込んだという話も出てきて、
バリデーションにかかる時間を考えると
半年遅れ+12〜15ヶ月
で市場投入は必然的に2010年後半
半年遅れ+12〜15ヶ月
で市場投入は必然的に2010年後半
776 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:51:07 ID:TrruVJm2
32nmに移行込みでやってるから結果的には前倒しになるんじゃないの?
777 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 21:52:56 ID:TrruVJm2
てな話は去年くらいからあったようで
http://gpucafe.com/2008/07/larrabee-could-come-on-32nm/
http://gpucafe.com/2008/07/larrabee-could-come-on-32nm/
このPentiumベースの最初のメニーコアアーキテクチャプロセッサ「Larrabee(TM)」は、
インテルによって設計、製造、販売される予定で、量産出荷は2009年になる見込みです。
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
インテル コーポレーション(本社:米国カリフォルニア州サンタクララ)は、本日、
「Larrabee(TM) プロセッサ」の生産スケジュールの変更を顧客に連絡したと発表しました。
連絡された最新の生産スケジュールによると、同プロセッサのサンプル出荷は2009年に、
また、当初2009年に予定されていた量産出荷は、2010年後半に予定されています。
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
米Intel社は,「Larrabee(ララビ)」を搭載した実機を使ったデモを初公開した。
2009年9月22日から米国サンフランシスコで開催中のパソコン関連の
技術者向け会議「IDF(Intel Developer Forum) Fall 2009」の基調講演で,
社長兼CEOのPaul Otellini氏自らが,デモを披露した。
Larrabeeは,すでに特定メーカ向けのサンプル出荷が始まっているもよう。
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
という夢を見た。
インテルによって設計、製造、販売される予定で、量産出荷は2009年になる見込みです。
http://www.intel.co.jp/jp/intel/pr/press/jointhp.htm
インテル コーポレーション(本社:米国カリフォルニア州サンタクララ)は、本日、
「Larrabee(TM) プロセッサ」の生産スケジュールの変更を顧客に連絡したと発表しました。
連絡された最新の生産スケジュールによると、同プロセッサのサンプル出荷は2009年に、
また、当初2009年に予定されていた量産出荷は、2010年後半に予定されています。
http://www.intel.co.jp/jp/intel/pr/press98/980601.htm
米Intel社は,「Larrabee(ララビ)」を搭載した実機を使ったデモを初公開した。
2009年9月22日から米国サンフランシスコで開催中のパソコン関連の
技術者向け会議「IDF(Intel Developer Forum) Fall 2009」の基調講演で,
社長兼CEOのPaul Otellini氏自らが,デモを披露した。
Larrabeeは,すでに特定メーカ向けのサンプル出荷が始まっているもよう。
http://techon.nikkeibp.co.jp/article/NEWS/20080118/145725/
という夢を見た。
出る出る言っといて結局全然出なくて、全く実用にはならないのは、
ホログラフィックディスクやFEDを髣髴とさせるな
ホログラフィックディスクやFEDを髣髴とさせるな
780 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 22:19:57 ID:TrruVJm2
45nmでの量産をキャンセルしたくらいしか実害出てないけどな。
Itaniumと違ってGMAがシェア取ってるのが強みかねー。
GMAをCPUに同梱しただけでNVIDIAは大打撃だ。 >>726
GMAをCPUに同梱しただけでNVIDIAは大打撃だ。 >>726
945 :,,・´∀`・,,)っ-○◎● [sage] :2009/01/21(水) 20:07:18 ID:fTz/hcND
>>938
最新である必要あるか?
仮想敵となるGeForceのハイエンドGT300シリーズは40nmとはいえ多寡がASICだ。
それより下は55nm。
ハイエンド〜アッパーミドル向けの生産は32nmのWestmereに移行するのはQ4頃だけど
そのとき既に45nmは減価償却を済ませ、残りは昇華試合だよ。
Larrabeeが出るのも同時期。つまりCeleronの立ち位置。
元来のCeleronのローエンド価格帯のCPUはよりダイの小さいAtomで賄えるようになったから
ある程度はダイサイズの大きい製品を作るだけの製造キャパの余裕ができる。
数千円のCeleron作るよりは数万円のGPU作った方がいいだろ?
歩留まり?心配ない。
冗長構成にしておけば1コア2コア死んでも製品にはなるし、全部使えなければキーホルダーにすればいい。
AMDを見習え。
>>938
最新である必要あるか?
仮想敵となるGeForceのハイエンドGT300シリーズは40nmとはいえ多寡がASICだ。
それより下は55nm。
ハイエンド〜アッパーミドル向けの生産は32nmのWestmereに移行するのはQ4頃だけど
そのとき既に45nmは減価償却を済ませ、残りは昇華試合だよ。
Larrabeeが出るのも同時期。つまりCeleronの立ち位置。
元来のCeleronのローエンド価格帯のCPUはよりダイの小さいAtomで賄えるようになったから
ある程度はダイサイズの大きい製品を作るだけの製造キャパの余裕ができる。
数千円のCeleron作るよりは数万円のGPU作った方がいいだろ?
歩留まり?心配ない。
冗長構成にしておけば1コア2コア死んでも製品にはなるし、全部使えなければキーホルダーにすればいい。
AMDを見習え。
赤字予測の影響かはわからんが、32nmプロセスにおけるIntelの戦略に大変更があったのは確定的に明らか。
ttp://pc.watch.impress.co.jp/docs/2009/0212/hot597.htm
1/21ってえとIntelの4Q08決算の少し後だな。
そのときのプレスリリースによると1Q09のR&Dは直前期比で微減、通年ではほぼフラットって話だったからコンサバティブな予測になっても仕方がない。
ttp://pc.watch.impress.co.jp/docs/2009/0212/hot597.htm
1/21ってえとIntelの4Q08決算の少し後だな。
そのときのプレスリリースによると1Q09のR&Dは直前期比で微減、通年ではほぼフラットって話だったからコンサバティブな予測になっても仕方がない。
785 :,,・´∀`・,,)っ-○◎●:2009/02/27(金) 23:07:44 ID:TrruVJm2
>>782
ところが、45nmを残さないんだよね。
45nmはイスラエルのFab28を残して閉鎖あるいは32nm転換する方針になったらしい。
Fab1つ当たりの生産量が結構あるらしいので。
2010年に出るなら逆に32nmへの移行が早まった形だよ。
Havendaleの例と同じだな
ところが、45nmを残さないんだよね。
45nmはイスラエルのFab28を残して閉鎖あるいは32nm転換する方針になったらしい。
Fab1つ当たりの生産量が結構あるらしいので。
2010年に出るなら逆に32nmへの移行が早まった形だよ。
Havendaleの例と同じだな
並列化プログラム・マルチスレドって同期にコストかかりすぎるんだよなぁ…エミュレータとか書けない
1秒間に33868800回同期したいのに
1秒間に33868800回同期したいのに
>>786
同期回数を極力減らす方向で設計しないとダメだろ・・・(言うまでも無く)
同期回数を極力減らす方向で設計しないとダメだろ・・・(言うまでも無く)
788 :,,・´∀`・,,)っ-○◎●:2009/02/28(土) 00:59:01 ID:aHJb2TRX
> 1秒間に33868800回同期したい
この言い回し最高www
なんかの歌詞かとオモタ
結局のところ1スレッドを2スレッドにするまでが一番困難なんだよね。
2コアを100スレッドにする程度ならそんなに考え方を変えなくていい
この言い回し最高www
なんかの歌詞かとオモタ
結局のところ1スレッドを2スレッドにするまでが一番困難なんだよね。
2コアを100スレッドにする程度ならそんなに考え方を変えなくていい
Pentium4の最大の功績は、HyperThreadingでソフトウェア側の準備期間を長くしたことかもね。
あれで2年はスタート地点を前倒ししたんじゃないか。
あれで2年はスタート地点を前倒ししたんじゃないか。
いや、言い回しっていうか…エミュレータプログラムはそういうモノなんですけどね
1秒間に60回同期すればいいゲームプログラムはほんとラクだと思う
ID:jRzQsEA0 = 小学生
レジスタなんてひとつもないプロセッサにして欲しいのになぁ
スレッドスイッチのコストがゼロならいいのに
スレッドスイッチのコストがゼロならいいのに
794 :,,・´∀`・,,)っ-○◎●:2009/02/28(土) 01:32:56 ID:aHJb2TRX
逆に考えるんだ。
マルチコア化が加速すれば1コアあたりのコンテクストスイッチ頻度が減ると。
マルチコア化が加速すれば1コアあたりのコンテクストスイッチ頻度が減ると。
795 :,,・´∀`・,,)っ-○◎●:2009/02/28(土) 01:36:06 ID:aHJb2TRX
>>790
いや、1万年と2千年前から〜のノリかと思ったんだ
いや、1万年と2千年前から〜のノリかと思ったんだ
796 :,,・´∀`・,,)っ-○◎●:2009/02/28(土) 01:37:29 ID:aHJb2TRX
何かと思ったらプレステエミュか。
798 :,,・´∀`・,,)っ-○◎●:2009/02/28(土) 03:28:31 ID:aHJb2TRX
ttp://www.dailytech.com/Intels+CEO+Paul+Otellini+Talks+Tech+Strategy+and+Future+Directions+Part+1/article14416.htm
ttp://www.dailytech.com/Intels+CEO+Paul+Otellini+Talks+Tech+Strategy+and+Future+Directions+Part+2/article14420.htm
【ここ注目】
> ・一部製造リソースをTIやSonyといった主要な顧客に回すかも知れない。
PS4も現実味帯びてきたな
ttp://www.dailytech.com/Intels+CEO+Paul+Otellini+Talks+Tech+Strategy+and+Future+Directions+Part+2/article14420.htm
【ここ注目】
> ・一部製造リソースをTIやSonyといった主要な顧客に回すかも知れない。
PS4も現実味帯びてきたな
結局Larrabeeはいつ出る予定なの?
早くて2010年後半というのは間違いないわけね?
早くて2010年後半というのは間違いないわけね?
800 :Socket774:2009/02/28(土) 07:03:59 ID:Iy1xTODl
Intel + MS + Sony連合結成
NVIDIA完全にオワタ
NVIDIA完全にオワタ
Adee ageri delosta di osa. Horela queded pear voxero.
802 :MACオタ>773 さん:2009/02/28(土) 10:25:05 ID:YGD41iQJ
>>773
-------------------
海外の後藤だと俺は考えている。
-------------------
それはCarlieに失礼ではないでしょうか?しょせん後藤氏は、
・技術的素養なし
・取材費は雑誌社持ち
・インタビューで仕入れたネタ以外何も無し
ですが、Carlieは映画に出てくる新聞記者並みに取材してますよ。もちろん最近の代表先はコレ。
http://www.theinquirer.net/inquirer/news/052/1050052/nvidia-chips-show-underfill-problems
「ペンは剣より強し」という言葉をこの現代で繰り返すことになるとは思いませんでした。
-------------------
海外の後藤だと俺は考えている。
-------------------
それはCarlieに失礼ではないでしょうか?しょせん後藤氏は、
・技術的素養なし
・取材費は雑誌社持ち
・インタビューで仕入れたネタ以外何も無し
ですが、Carlieは映画に出てくる新聞記者並みに取材してますよ。もちろん最近の代表先はコレ。
http://www.theinquirer.net/inquirer/news/052/1050052/nvidia-chips-show-underfill-problems
「ペンは剣より強し」という言葉をこの現代で繰り返すことになるとは思いませんでした。
803 :Socket774:2009/02/28(土) 11:23:50 ID:nw5lYZma
東芝の諫早はどうなっちゃうの?エロイひとおしえて
805 :MACオタ>804 さん:2009/02/28(土) 14:25:18 ID:YGD41iQJ
>>804
配線層の断面写真程度なら、取材費があって、そこそこの大学や研究所にツテがあるなら
撮影はできます。
言語の問題とは思えませんが…
後藤氏に関しては、そもそも業界のツテと英語が出来るというのが唯一の取り得のような気が.…
結局その『ツテ』もジャーナリズムとはとても呼べない広報レベルに過ぎないということで。
配線層の断面写真程度なら、取材費があって、そこそこの大学や研究所にツテがあるなら
撮影はできます。
言語の問題とは思えませんが…
後藤氏に関しては、そもそも業界のツテと英語が出来るというのが唯一の取り得のような気が.…
結局その『ツテ』もジャーナリズムとはとても呼べない広報レベルに過ぎないということで。
806 :,,・´∀`・,,)っ-●◎○:2009/02/28(土) 15:19:29 ID:aHJb2TRX
情報網(笑)
グランツーリスモ5のデモがPC上で動いてるとか
iPhoneにAtom採用とか
妄想記事を書くのが素養(笑)
グランツーリスモ5のデモがPC上で動いてるとか
iPhoneにAtom採用とか
妄想記事を書くのが素養(笑)
後藤もDemerjianもおまえらよりはマシさ
808 :,,・´∀`・,,)っ-●◎○:2009/02/28(土) 15:34:05 ID:aHJb2TRX
息を吐くように嘘をつく典型的ゴシップ記者じゃん
809 :,,・´∀`・,,)っ-●◎○:2009/02/28(土) 15:37:48 ID:aHJb2TRX
ペンは剣より強しの意味を調べた方がいいんじゃね
>>804
それがハンデになるようじゃただの無能者だな。いや、言うまでもなかったか
それがハンデになるようじゃただの無能者だな。いや、言うまでもなかったか
ハンデはハンデだろ
813 :,,・´∀`・,,)っ-○◎●:2009/03/05(木) 03:49:25 ID:4eF+/58k
突っ込みどころが多すぎてどこから突っ込んで良いか逆に迷う、本日の後藤の主観記事
http://pc.watch.impress.co.jp/docs/2009/0305/kaigai493.htm
> Cell B.E.は、4-wideの短いベクタエンジンを実装しながら、スカラ命令も実行できる、
> 汎用性の高いCPUコア「SPU(Synergistic Processor Unit)」を採用した。ストリームプロセッシングでは
> 有効ではないキャッシュアーキテクチャは取らず、各CPUコアのメモリ空間はそれぞれ独立している。
スカラ命令が実行できる?
基本SIMD命令しかサポートしてなくて、プリファードスロット(ベクトルの第1要素)をスカラと
見なしてやるしかないんだけど
> Cell B.E.と比べると、Larrabeeの方がよりデータ並列に振っている。
> ベクタを長くしてデータ並列を強めると、コントロールフローのムダが大きくなる。
【また】やっちまったなwww
受け売りだけやってればいいのに><
x86でXMMレジスタ上で浮動小数を扱う場合、たとえば単精度のスカラ加算を行うとする。
128bit等速のSIMDユニットを搭載してる最近のCPUではaddssでもaddpsでも同一レイテンシ・
スループットなのでどっちでもいいのだが、前者はプリファードな32bitのみ作用する。
最近のIntel CPUは、スカラ演算命令を処理する場合、残った96ビット分の捨てデータ分は供給を止めて
電力カットするような最適化をやってます。
65nmのCore MAあたりで既に実装されてた機構ですが、より消費電力重視のAtomでは言わずもがな、です。
その点でいくと128ビットSIMDとは別個にスカラ専用の同等命令を備えないCellのほうが分が悪いわけです。
ベクトル長のことを言い出したら、GeForce 8以降は1024ビットのSIMD相当(32 Thread/SM)なわけで、
「ベターGPGPU」として使う分には512ビットって別に長くもないわけですが。
CPU用にはもっと並列度の低いSIMDで十分だって言うなら、別にLarrabeeじゃないIntelプロセッサだって
いいわけで、Core MAでも良いのでは?
GPUだと言ったりCPUだと言ったり大変ですな。Cellはどっちにも使えませんが。
http://pc.watch.impress.co.jp/docs/2009/0305/kaigai493.htm
> Cell B.E.は、4-wideの短いベクタエンジンを実装しながら、スカラ命令も実行できる、
> 汎用性の高いCPUコア「SPU(Synergistic Processor Unit)」を採用した。ストリームプロセッシングでは
> 有効ではないキャッシュアーキテクチャは取らず、各CPUコアのメモリ空間はそれぞれ独立している。
スカラ命令が実行できる?
基本SIMD命令しかサポートしてなくて、プリファードスロット(ベクトルの第1要素)をスカラと
見なしてやるしかないんだけど
> Cell B.E.と比べると、Larrabeeの方がよりデータ並列に振っている。
> ベクタを長くしてデータ並列を強めると、コントロールフローのムダが大きくなる。
【また】やっちまったなwww
受け売りだけやってればいいのに><
x86でXMMレジスタ上で浮動小数を扱う場合、たとえば単精度のスカラ加算を行うとする。
128bit等速のSIMDユニットを搭載してる最近のCPUではaddssでもaddpsでも同一レイテンシ・
スループットなのでどっちでもいいのだが、前者はプリファードな32bitのみ作用する。
最近のIntel CPUは、スカラ演算命令を処理する場合、残った96ビット分の捨てデータ分は供給を止めて
電力カットするような最適化をやってます。
65nmのCore MAあたりで既に実装されてた機構ですが、より消費電力重視のAtomでは言わずもがな、です。
その点でいくと128ビットSIMDとは別個にスカラ専用の同等命令を備えないCellのほうが分が悪いわけです。
ベクトル長のことを言い出したら、GeForce 8以降は1024ビットのSIMD相当(32 Thread/SM)なわけで、
「ベターGPGPU」として使う分には512ビットって別に長くもないわけですが。
CPU用にはもっと並列度の低いSIMDで十分だって言うなら、別にLarrabeeじゃないIntelプロセッサだって
いいわけで、Core MAでも良いのでは?
GPUだと言ったりCPUだと言ったり大変ですな。Cellはどっちにも使えませんが。
814 :,,・´∀`・,,)っ-○◎●:2009/03/05(木) 04:40:46 ID:4eF+/58k
> しかしLarrabeeでは、ユニプロセッサの整数演算パフォーマンスに疑問符がついている。
(ry
> In-Order実行で2命令発行のP54Cコアは、2GHz台で走らせても、それほど高いスカラ
> 演算性能を発揮できないはずだ。同じIn- Order実行2命令発行でも、より洗練された
> Atom系(Bonnell:ボンネル)アーキテクチャのCPUコアと比べて、同クロック時の性能が
> 高いとは考えにくい。
ここは概ね同意なんだが、後藤は自分の記事でAtomは80486ベースだと説明してるよね。
そのレベルではLarrabeeもP54Cに手を入れてくる可能性は高い。
Atomのデコーダは貧弱で、一度デコードしてプリデコードタグがついたものでないと
ハードワイヤードでデコードできない。
命令フェッチ帯域も8byte/clkと狭い(P5以降は16byte/clk)。
性能よりも電力を抑える方向に最適化した結果だと思われる。
逆に、一度デコーダを通ってプリデコードタグがついた命令だと、再デコード時には最大2並列
(命令フェッチ帯域が間に合う範囲内で)デコードできる。
タグが付いた命令に対してならペアリング制限の厳しいP5よりはデコード効率はよくなることもある。
その辺のバランスも含めてなので、Atomのほうが洗練されてるかどうかは実物が出るまでは
判断しづらい。
LarrabeeがP54Cのそれよりはデコーダは強化されてると断言できる資料は既に出てる。
去年8月時点でのLarrabeeの論文の時点でpopcntやlzcnt(AMDのそれと互換かは不明)も
搭載してることが明言されてる。その程度にはスカラ性能も強化するってことだ。
P54Cまでだとプリフィクスや2バイトOpcodeのエスケープバイトを1バイト噛ませるだけで
1クロックストールし、P55C以降はMMX対応のために1バイトまでのプリフィクスまたは
エスケープならストールなしに噛ませることができるようになった。
Larrabeeは64ビット拡張をサポートするので対応すべき2バイトOpcode命令も増えるし
REXプリフィクスも載っかる。
AVX以降の共通の命令セット基盤となるVEXは3〜4バイトOpcode相当なので、その辺までは
耐えられる設計にしないといけない。逆にいうとスカラとベクタ共通の命令の受け入れ口である
デコード段がネックになっていてはVPUにすら命令供給が間に合わない。
(ry
> In-Order実行で2命令発行のP54Cコアは、2GHz台で走らせても、それほど高いスカラ
> 演算性能を発揮できないはずだ。同じIn- Order実行2命令発行でも、より洗練された
> Atom系(Bonnell:ボンネル)アーキテクチャのCPUコアと比べて、同クロック時の性能が
> 高いとは考えにくい。
ここは概ね同意なんだが、後藤は自分の記事でAtomは80486ベースだと説明してるよね。
そのレベルではLarrabeeもP54Cに手を入れてくる可能性は高い。
Atomのデコーダは貧弱で、一度デコードしてプリデコードタグがついたものでないと
ハードワイヤードでデコードできない。
命令フェッチ帯域も8byte/clkと狭い(P5以降は16byte/clk)。
性能よりも電力を抑える方向に最適化した結果だと思われる。
逆に、一度デコーダを通ってプリデコードタグがついた命令だと、再デコード時には最大2並列
(命令フェッチ帯域が間に合う範囲内で)デコードできる。
タグが付いた命令に対してならペアリング制限の厳しいP5よりはデコード効率はよくなることもある。
その辺のバランスも含めてなので、Atomのほうが洗練されてるかどうかは実物が出るまでは
判断しづらい。
LarrabeeがP54Cのそれよりはデコーダは強化されてると断言できる資料は既に出てる。
去年8月時点でのLarrabeeの論文の時点でpopcntやlzcnt(AMDのそれと互換かは不明)も
搭載してることが明言されてる。その程度にはスカラ性能も強化するってことだ。
P54Cまでだとプリフィクスや2バイトOpcodeのエスケープバイトを1バイト噛ませるだけで
1クロックストールし、P55C以降はMMX対応のために1バイトまでのプリフィクスまたは
エスケープならストールなしに噛ませることができるようになった。
Larrabeeは64ビット拡張をサポートするので対応すべき2バイトOpcode命令も増えるし
REXプリフィクスも載っかる。
AVX以降の共通の命令セット基盤となるVEXは3〜4バイトOpcode相当なので、その辺までは
耐えられる設計にしないといけない。逆にいうとスカラとベクタ共通の命令の受け入れ口である
デコード段がネックになっていてはVPUにすら命令供給が間に合わない。
815 :Socket774:2009/03/05(木) 12:35:28 ID:o0ayirSp
どうでもいいじゃん、どうせ失敗作なんだし
Larrabeeなんていつ出るんだよ
いつまで経っても出ないんだろどうせ
いつまで経っても出ないんだろどうせ
GK参上かよ
LarrabeeってCGのどっかとスパコンのどっか既に契約取ってなかったっけ?
820 :Socket774:2009/03/05(木) 21:20:24 ID:3UG3KZdF
ララビーよりビラビラのが好きだな
821 :MACオタ>団子 さん:2009/03/06(金) 22:57:53 ID:tdZ7wEZi
>>813-814
IBM自身がSIMDレジスタのみでスカラの処理も行えることを自慢していますから、
そういう文句の付け方をしても、世間も後藤氏も受け入れてくれないと思いますよ。
http://www.research.ibm.com/cell/cell_compilation.html
---------------------
A key innovation in the Synergistic Processor Architecture is the use of scalar
layering to map scalar computation on a pervasively data parallel architecture
as implemented by the SPU.
---------------------
IBM自身がSIMDレジスタのみでスカラの処理も行えることを自慢していますから、
そういう文句の付け方をしても、世間も後藤氏も受け入れてくれないと思いますよ。
http://www.research.ibm.com/cell/cell_compilation.html
---------------------
A key innovation in the Synergistic Processor Architecture is the use of scalar
layering to map scalar computation on a pervasively data parallel architecture
as implemented by the SPU.
---------------------
822 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 00:20:51 ID:YnyN6ZrM
理解力がないな。むしろ学が無いな
128ビット全ベクトル操作して1要素分の結果だけを使うのをスカラ処理って言っていいなら
この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
誤答の今回の詭弁「コントロールフローのムダ」について
もうちっとフォローしとこうか。
必要なのは32ビットだけであっても、128bitのSIMD演算しか使えないから、残りの96ビット分、
捨てられるデータがALUに投入され、演算処理が行われ、デスティネーションレジスタに吐き出される。
これは明らかに「ムダ」なんだよ。
さて、IntelのCPUでは、SSEはもちろんAVXでも相変わらず、スカラ演算専用命令がサポートされます。
理由はもちろん、「コントロールフローのムダ」(笑)を省くためです。
結局無駄が生じるかどうかは、ベクトル長ではなく、サポートするインストラクションによって決まる
ものであって、全エレメントきれいに埋められないのであれば、よりデータフローの小さい命令を
明示的に使うことで、無駄は省けるわけだ。
256ビットで大きすぎるなら128ビット、それでもまだ粒度が必要ならスカラですよ。
その点において常に128ビット単位でしか演算できない上に命令間のレイテンシすら他のCPUと比べても
大きい、「コントロールフローのムダ」の塊のCellを引き合いに出すのはお門違いなわけで。
128ビット全ベクトル操作して1要素分の結果だけを使うのをスカラ処理って言っていいなら
この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
誤答の今回の詭弁「コントロールフローのムダ」について
もうちっとフォローしとこうか。
必要なのは32ビットだけであっても、128bitのSIMD演算しか使えないから、残りの96ビット分、
捨てられるデータがALUに投入され、演算処理が行われ、デスティネーションレジスタに吐き出される。
これは明らかに「ムダ」なんだよ。
さて、IntelのCPUでは、SSEはもちろんAVXでも相変わらず、スカラ演算専用命令がサポートされます。
理由はもちろん、「コントロールフローのムダ」(笑)を省くためです。
結局無駄が生じるかどうかは、ベクトル長ではなく、サポートするインストラクションによって決まる
ものであって、全エレメントきれいに埋められないのであれば、よりデータフローの小さい命令を
明示的に使うことで、無駄は省けるわけだ。
256ビットで大きすぎるなら128ビット、それでもまだ粒度が必要ならスカラですよ。
その点において常に128ビット単位でしか演算できない上に命令間のレイテンシすら他のCPUと比べても
大きい、「コントロールフローのムダ」の塊のCellを引き合いに出すのはお門違いなわけで。
また始まったよ
死ねばいいのに
死ねばいいのに
でもこの人詳しいなあ
感心する
感心する
825 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 09:13:15 ID:YnyN6ZrM
http://pc.watch.impress.co.jp/docs/2009/0305/kaigai08.pdf
このへんの図って本人解って書いてるのかってたびたび思うんだけど
IBMのマニュアルにまったく同じダイアグラムが書いてあるんだよね。
まあそのまま転載すれば権利問題でうるさいから自分で頑張って手作業で描きました
ってところなんだろうけど、理解して書いてるのか、最近の言動見てると怪しい
このへんの図って本人解って書いてるのかってたびたび思うんだけど
IBMのマニュアルにまったく同じダイアグラムが書いてあるんだよね。
まあそのまま転載すれば権利問題でうるさいから自分で頑張って手作業で描きました
ってところなんだろうけど、理解して書いてるのか、最近の言動見てると怪しい
826 :MACオタ>団子 さん:2009/03/07(土) 12:03:30 ID:8ZlVP1MY
>>822
-----------------
この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
-----------------
自慢しているのはIBMなんですから、文句を言う先は別だ…という話です。
それともおなじクレームを英語で書くのは無理でしたか(笑)
-----------------
この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
-----------------
自慢しているのはIBMなんですから、文句を言う先は別だ…という話です。
それともおなじクレームを英語で書くのは無理でしたか(笑)
827 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 12:15:31 ID:YnyN6ZrM
IBM自体は何もおかしなことは言ってないよ。
スカラ「命令」なんていってるのは誤答だけだし。
ちなみに別に英語で聞く必要もないね。
土居さんあたりにでも聞けばいいと思うよ
スカラ「命令」なんていってるのは誤答だけだし。
ちなみに別に英語で聞く必要もないね。
土居さんあたりにでも聞けばいいと思うよ
828 :MACオタ>団子 さん:2009/03/07(土) 12:31:44 ID:8ZlVP1MY
>>827
------------------
ちなみに別に英語で聞く必要もないね。
土居さんあたりにでも聞けばいいと思うよ
------------------
論文のトップネームに価値があるように、この世界には『文責』という概念があるのですよ。
>>821のリンク先の文章の場合、連絡先が書いてあるMichael Gschwind氏に質問するのが
正当というものです。
大物ですので、もし相手をしてもらえればよい経験になると思いますよ。
http://domino.watson.ibm.com/comm/pr.nsf/pages/bio.gschwind.html
------------------
ちなみに別に英語で聞く必要もないね。
土居さんあたりにでも聞けばいいと思うよ
------------------
論文のトップネームに価値があるように、この世界には『文責』という概念があるのですよ。
>>821のリンク先の文章の場合、連絡先が書いてあるMichael Gschwind氏に質問するのが
正当というものです。
大物ですので、もし相手をしてもらえればよい経験になると思いますよ。
http://domino.watson.ibm.com/comm/pr.nsf/pages/bio.gschwind.html
829 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 12:38:28 ID:YnyN6ZrM
くどいようだが【何も間違ったことは言ってないぜ】
曲解してるのはお前と五等だけだよ。
いかくさい。あっち池。しっし
曲解してるのはお前と五等だけだよ。
いかくさい。あっち池。しっし
MACオタは相変わらず揚げ足取りみたいな事しかしないなぁ
831 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 12:43:10 ID:YnyN6ZrM
Michael Gschwindが、Scaler Instructionなんて言ったのか?
高級言語レベルでの話程度しかしてないようだが?
命令レベルの話をしてると思うならお前の曲解だ。言いがかりだ。Michael Gschwindの名前を盾にした詭弁だ。
高級言語レベルでの話程度しかしてないようだが?
命令レベルの話をしてると思うならお前の曲解だ。言いがかりだ。Michael Gschwindの名前を盾にした詭弁だ。
832 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 12:43:41 ID:YnyN6ZrM
>>830
馬鹿だから仕方ない
馬鹿だから仕方ない
揚げ足取りするのはどっちも得意だけどね
834 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 13:20:07 ID:YnyN6ZrM
"scalar layering"
って、高級言語レベルのスカラ演算を、高級言語のコンパイラが、プリファードスロットを用い
残りの要素スカスカのSIMD命令のシーケンスに展開しますよ的な、当たり前の話で、
別に技術的に見所の有る話ではない。
ネイティブ命令セットレベル・アーキテクチャレベルでどうこうするって話じゃないよ。
その「ハード支援なきスカラ・レイヤリング」の結果が、ロード・ストアがクソ遅いという
現実だったり、常に128ビットのデータフローが発生するけど電力効率的にどうよ?
って話しなわけ。
って、高級言語レベルのスカラ演算を、高級言語のコンパイラが、プリファードスロットを用い
残りの要素スカスカのSIMD命令のシーケンスに展開しますよ的な、当たり前の話で、
別に技術的に見所の有る話ではない。
ネイティブ命令セットレベル・アーキテクチャレベルでどうこうするって話じゃないよ。
その「ハード支援なきスカラ・レイヤリング」の結果が、ロード・ストアがクソ遅いという
現実だったり、常に128ビットのデータフローが発生するけど電力効率的にどうよ?
って話しなわけ。
835 :MACオタ>団子 さん:2009/03/07(土) 15:16:20 ID:8ZlVP1MY
>>834
--------------------
別に技術的に見所の有る話ではない。
--------------------
だから、>>821のリンク先で"A key innovation in the Synergistic Processor Architecture"と
主張しているGschwind氏へ文句はどうぞ(笑)
エラいヒトや外人に文句をつけられないヘタレと自認してるなら構わないですよ。
英語で文章が書けないのは責められるような過誤ではありませんし(笑)
--------------------
別に技術的に見所の有る話ではない。
--------------------
だから、>>821のリンク先で"A key innovation in the Synergistic Processor Architecture"と
主張しているGschwind氏へ文句はどうぞ(笑)
エラいヒトや外人に文句をつけられないヘタレと自認してるなら構わないですよ。
英語で文章が書けないのは責められるような過誤ではありませんし(笑)
836 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 15:18:15 ID:YnyN6ZrM
そんなに英語が自慢なら俺へのレスは全て英語で書いてくれ。
日本語もどきを喋られるのは目障りでしょうがない。
日本語もどきを喋られるのは目障りでしょうがない。
837 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 15:30:29 ID:YnyN6ZrM
So, please call me "dumpling". OK?
innovation(笑)云々は所詮は主観的なものでしかないので好きに言わせておけって感じだが
後藤のCellのSPEにスカラ【命令】が存在するとの主張は、客観的事実に反する。
innovation(笑)云々は所詮は主観的なものでしかないので好きに言わせておけって感じだが
後藤のCellのSPEにスカラ【命令】が存在するとの主張は、客観的事実に反する。
今回に限っては団子支持。MACオタは見苦しい。
そうでもない
面と向かったケンカから逃げるいつもの団子が見られただけw
面と向かったケンカから逃げるいつもの団子が見られただけw
限るなよ
841 :,,・´∀`・,,)っ-○◎●:2009/03/07(土) 17:14:07 ID:YnyN6ZrM
喧嘩にすらなってねーけど。敗走したのは負け犬
冷静に読んでくれればわかるが俺にはMichael Gschwindに文句を言う理由は微塵もないわけで
自分がやりもしないことを他人に要求するのは言い出しっぺの法則通りだな。
冷静に読んでくれればわかるが俺にはMichael Gschwindに文句を言う理由は微塵もないわけで
自分がやりもしないことを他人に要求するのは言い出しっぺの法則通りだな。
よーわからん。
>>821
> A key innovation in the Synergistic Processor Architecture is the use of scalar
> layering to map scalar computation on a pervasively data parallel architecture
> as implemented by the SPU.
に
>>822
> 128ビット全ベクトル操作して1要素分の結果だけを使うのをスカラ処理って言っていいなら
> この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
は的確なつっこみじゃないの?
なんでそれを取り下げるんだ?
それともSPUをスカラプロセッサとして認めちゃうわけ?
>>821
> A key innovation in the Synergistic Processor Architecture is the use of scalar
> layering to map scalar computation on a pervasively data parallel architecture
> as implemented by the SPU.
に
>>822
> 128ビット全ベクトル操作して1要素分の結果だけを使うのをスカラ処理って言っていいなら
> この世のベクトルプロセッサは全てスカラプロセッサだな(笑)
は的確なつっこみじゃないの?
なんでそれを取り下げるんだ?
それともSPUをスカラプロセッサとして認めちゃうわけ?
843 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 18:54:13 ID:YnyN6ZrM
いいや。
スカラ演算を自動的にベクトル化するなら実用性はあるけど、第一要素以外使わないベクトル化が
イノベーションなんてギャグの範疇でしょ
そのたった2行で笑い飛ばせるような内容にわざわざ長文メールなんて送る価値は無いよ。
所詮その程度だし
俺は後藤は大衆に影響力のある記事を書ける人間と評価してます。
評価してるからこそ挑む価値があるのです。
そもそも今回のは動機が>>815だし、突っ込みどころが満載すぎた。
スカラ演算を自動的にベクトル化するなら実用性はあるけど、第一要素以外使わないベクトル化が
イノベーションなんてギャグの範疇でしょ
そのたった2行で笑い飛ばせるような内容にわざわざ長文メールなんて送る価値は無いよ。
所詮その程度だし
俺は後藤は大衆に影響力のある記事を書ける人間と評価してます。
評価してるからこそ挑む価値があるのです。
そもそも今回のは動機が>>815だし、突っ込みどころが満載すぎた。
844 :,,・´∀`・,,)っ-●◎○:2009/03/07(土) 19:14:18 ID:YnyN6ZrM
いやしかし、その発想でいいならほとんどの整数演算をSSE化できるわwww
max/minや簡単な比較・選択命令ならx86スカラよりは若干速くなりそうだけどな
max/minや簡単な比較・選択命令ならx86スカラよりは若干速くなりそうだけどな
845 :MACオタ>団子 さん:2009/03/07(土) 23:31:12 ID:8ZlVP1MY
>>837
こんなことのたtめに一生懸命辞書を引いたんですか…
----------------
So, please call me "dumpling". OK?
----------------
英語的にヘタレは "chicken" かと…
>>844
-------------------
その発想でいいならほとんどの整数演算をSSE化できるわwww
-------------------
"Scalar Layering"のポイントは、そのやり方でレジスタファイルや演算ユニットを節約する
という点にあります。旧来のユニットを残してしまっては意味がありません。
こんなことのたtめに一生懸命辞書を引いたんですか…
----------------
So, please call me "dumpling". OK?
----------------
英語的にヘタレは "chicken" かと…
>>844
-------------------
その発想でいいならほとんどの整数演算をSSE化できるわwww
-------------------
"Scalar Layering"のポイントは、そのやり方でレジスタファイルや演算ユニットを節約する
という点にあります。旧来のユニットを残してしまっては意味がありません。
それって石から見ると普通の演算と節約された演算はどうやって見分けるん
847 :,,・´∀`・,,)っ-●◎○:2009/03/08(日) 06:26:56 ID:gjoXnm+H
>>845
No no no no no no
"Dango" means japanese dumpling. OK?
It is commonly said that the chicken forgets everything when walking 3 steps.
However, you are more foolish from the chicken.
There seems to be in your brains the nest food by the maggot.
>>846
32ビットのレジスタを128本積んだとしてもレジスタファイルの規模はそんなに増えないね。
むしろ単一のスカラ値のためにわざわざ128ビット割り当てるのは
スカラ値のロード・ストアのためにわざわざpermuteパターンを別のレジスタにロードしておかないといけない。
コード効率とか、電力効率とか考えれば明らかにミス設計。
ARMのNEONでは128bitのSIMDレジスタ16本を32本の64ビットレジスタとしても使えるね
「効率」を語るならこれくらいはやるべきだな。
No no no no no no
"Dango" means japanese dumpling. OK?
It is commonly said that the chicken forgets everything when walking 3 steps.
However, you are more foolish from the chicken.
There seems to be in your brains the nest food by the maggot.
>>846
32ビットのレジスタを128本積んだとしてもレジスタファイルの規模はそんなに増えないね。
むしろ単一のスカラ値のためにわざわざ128ビット割り当てるのは
スカラ値のロード・ストアのためにわざわざpermuteパターンを別のレジスタにロードしておかないといけない。
コード効率とか、電力効率とか考えれば明らかにミス設計。
ARMのNEONでは128bitのSIMDレジスタ16本を32本の64ビットレジスタとしても使えるね
「効率」を語るならこれくらいはやるべきだな。
848 :,,・´∀`・,,)っ-●◎○:2009/03/08(日) 08:14:33 ID:gjoXnm+H
っと、ハードから見た「見分け」だったかな。
できないよ。だから常に128ビットのデータフローが発生するって言ってるの。
てか、CellのSPEってあからさまに1コアをPowerPC未満のトランジスタ数で実装することしか
考えてないでしょ。コアサイズを削ってSIMDとマルチコアに賭ける理想主義。
多コア化によるスケーラビリティの向上に行き詰ったらその時点で終了なアーキテクチャ。
その意味でLarrabeeは現実主義なんだよね。
1コアあたりのトランジスタ数をリッチに割り振ったCore系列のアーキテクチャにも
Larrabeeの命令セットは実装できる。
ムーアの法則がもたらす進化を、コア数を増やす以外の方向に割り振れる。
ModRM+SIB+DISPによるアドレッシングって直列方向のコード密度を高める点で
かなりパフォーマンスに寄与してる。
できないよ。だから常に128ビットのデータフローが発生するって言ってるの。
てか、CellのSPEってあからさまに1コアをPowerPC未満のトランジスタ数で実装することしか
考えてないでしょ。コアサイズを削ってSIMDとマルチコアに賭ける理想主義。
多コア化によるスケーラビリティの向上に行き詰ったらその時点で終了なアーキテクチャ。
その意味でLarrabeeは現実主義なんだよね。
1コアあたりのトランジスタ数をリッチに割り振ったCore系列のアーキテクチャにも
Larrabeeの命令セットは実装できる。
ムーアの法則がもたらす進化を、コア数を増やす以外の方向に割り振れる。
ModRM+SIB+DISPによるアドレッシングって直列方向のコード密度を高める点で
かなりパフォーマンスに寄与してる。
>>847
英語は割とダメダメみたいだな。ま、実にどうでもいい事だが
英語は割とダメダメみたいだな。ま、実にどうでもいい事だが
そういうのは英語で言うと説得力が出るんじゃね
851 :,,・´∀`・,,)っ-●◎○:2009/03/10(火) 06:11:01 ID:ytZsUmnX
俗に鶏は3歩歩くと全てを忘れるなどと言われますが
あなたは鶏よりもっと馬鹿です。
頭に蛆虫沸いてるんじゃないの。
あなたは鶏よりもっと馬鹿です。
頭に蛆虫沸いてるんじゃないの。
852 :,,・´∀`・,,)っ-●◎○:2009/03/10(火) 06:26:06 ID:ytZsUmnX
ところで闘鶏は英語でchicken fightだけど
あの勇ましさ見たらとても臆病者に形容できないと思うけどね。
brave fightくらいにしといてほしいね。
臆病者って2chでしか自己顕示できないどっかのおじさんのことだけどね。
あの勇ましさ見たらとても臆病者に形容できないと思うけどね。
brave fightくらいにしといてほしいね。
臆病者って2chでしか自己顕示できないどっかのおじさんのことだけどね。
853 :,,・´∀`・,,)っ-●◎○:2009/03/10(火) 06:38:53 ID:ytZsUmnX
Wikipediaで由来調べてみました。
> チキンの由来は、寒いときや何か恐怖を感じたとき、ヒトの皮膚は体温を維持するために鳥肌がたつ。
> このときの様態がニワトリの羽根をむしった状態と同様であることや、鳥類が周囲に気を配り
> キョロキョロしていることなどから、四六時中まわりの目を気にして動向を伺うことで自らの
> 安寧を保とうとする臆病者として表現される。
なるほど、後半は誰かさんそっくりですね
いい音楽やいい映画で鳥肌立つのはどういう生理現象なんでしょうかね。
> チキンの由来は、寒いときや何か恐怖を感じたとき、ヒトの皮膚は体温を維持するために鳥肌がたつ。
> このときの様態がニワトリの羽根をむしった状態と同様であることや、鳥類が周囲に気を配り
> キョロキョロしていることなどから、四六時中まわりの目を気にして動向を伺うことで自らの
> 安寧を保とうとする臆病者として表現される。
なるほど、後半は誰かさんそっくりですね
いい音楽やいい映画で鳥肌立つのはどういう生理現象なんでしょうかね。
臆病者って2chでしか自己顕示できないどっかのおじさんのことだけどね。
,,・´∀`・,,)っ-●◎○
の事ですね?分かります
,,・´∀`・,,)っ-●◎○
の事ですね?分かります
せめてLarrabeeに関係ある話をしろよ
団子の大人気無さはMACオタの鬱陶しさ以上に迷惑だわ
弱い犬ほどよくわめくらしいから仕方ない
よくわからんけどLarrabeeってすげーの?
Larrabeeこそ人類の希望。
人類の中でもソフトウェア工学者にとって
バッドノウハウを発掘し高尚な学問にまで昇華させる機会を作ってくれる希望だね
バッドノウハウを発掘し高尚な学問にまで昇華させる機会を作ってくれる希望だね
861 :,,・´∀`・,,)っ-●◎○:2009/03/11(水) 01:49:41 ID:OBmodYVu
確かにCellもCUDAも希望に満ち溢れてたね
CUDAは成功してるじゃん
863 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 02:44:04 ID:OBmodYVu
成功(笑)
さっぱりビジネスで使われてないじゃん。
Cellにはまだ専業ベンチャー企業がいるが、CUDAはそれ以下だよ。
Tesla(笑)
寄附講座設けて大学で講義したりやってる程度にはアカデミックな世界では動きはあるが
それすらx86の既得権と比較すれば閑古鳥が鳴くレベルだよ。
さっぱりビジネスで使われてないじゃん。
Cellにはまだ専業ベンチャー企業がいるが、CUDAはそれ以下だよ。
Tesla(笑)
寄附講座設けて大学で講義したりやってる程度にはアカデミックな世界では動きはあるが
それすらx86の既得権と比較すれば閑古鳥が鳴くレベルだよ。
新しい技術が浸透するのには時間がかかるんだよ
今は使われだした時期
少なくともLarrabeeよりはだいぶ期待が持てる
今は使われだした時期
少なくともLarrabeeよりはだいぶ期待が持てる
865 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 03:05:44 ID:OBmodYVu
残念だが世の大半の開発者はCやC++より柔軟性の低い言語を覚えてまでGPUを使いたがらない。
CellですらC/C++が使えるのに変態独自言語しか使えない時点で終わってるよ。
CellですらC/C++が使えるのに変態独自言語しか使えない時点で終わってるよ。
866 :Socket774:2009/03/11(水) 03:07:50 ID:dK4wZYTf
なんかLinux信者みたいだな
常識的に考えればNVIDIAにIntelを上回る開発環境を整えられるはずがない
まあ期待するのは個人の勝手なんだがw
常識的に考えればNVIDIAにIntelを上回る開発環境を整えられるはずがない
まあ期待するのは個人の勝手なんだがw
ゲーマーにそっぽ向かれるような性能だと出だしでコケるよね
45nmスキップして32nmで力技で持っていくみたいな話もあるけど大丈夫?
45nmスキップして32nmで力技で持っていくみたいな話もあるけど大丈夫?
868 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 03:47:24 ID:OBmodYVu
そもそもディスクリートGPU自体が縮退産業。
Intelにとっては将来のメニーコア向けの実験、兼、HPCでのCell駆除のためのカード以外のなんでもない。
ゲーマー(笑)だけで需要満たせるならNもAもGPGPUなんてやってない。
Intelにとっては将来のメニーコア向けの実験、兼、HPCでのCell駆除のためのカード以外のなんでもない。
ゲーマー(笑)だけで需要満たせるならNもAもGPGPUなんてやってない。
実験(笑)じゃnVidiaには勝てないな
そうこうしてるうちに着々とCUDAが浸透して
終了だろうw
そうこうしてるうちに着々とCUDAが浸透して
終了だろうw
870 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 04:05:10 ID:OBmodYVu
無理だね。市場そのものがないじゃんw
登場から2年もかけて芽が出ないものは終わる
Intelは現時点でGMAだけで5割以上のシェアとってる上に、IGP相当のGPUコアが
CPUに統合されることで、2012年までにIGPの市場は消滅する。
自動的にIntelのGPUが市場の7〜8割がたを占めるようになる。
Larrabeeが真に意味を持つようになるのはGPU統合CPUの次のステップだね。
そして、x86を持ってないのがNVIDIA(笑)
売上げの20%を占めるIGPの市場をそっくりそのまま失う。
あとは年々縮小するディスクリートGPU市場でがんばって下さいとしか。
ゲームもPC専門でやる企業は既にいないし、
出るタイトルコンシューマゲーム機のおまけに成り下がる。てか、今既にそうなってる。
登場から2年もかけて芽が出ないものは終わる
Intelは現時点でGMAだけで5割以上のシェアとってる上に、IGP相当のGPUコアが
CPUに統合されることで、2012年までにIGPの市場は消滅する。
自動的にIntelのGPUが市場の7〜8割がたを占めるようになる。
Larrabeeが真に意味を持つようになるのはGPU統合CPUの次のステップだね。
そして、x86を持ってないのがNVIDIA(笑)
売上げの20%を占めるIGPの市場をそっくりそのまま失う。
あとは年々縮小するディスクリートGPU市場でがんばって下さいとしか。
ゲームもPC専門でやる企業は既にいないし、
出るタイトルコンシューマゲーム機のおまけに成り下がる。てか、今既にそうなってる。
871 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 04:24:33 ID:OBmodYVu
実際問題CUDAの性能は酷いよ
1SPあたり4スレッド単位で演算をインターリーブするので
シェーダコアが1.2GHz動作ならシングルスレッド・スカラ性能は最高でも300MHz相当
ベクタ演算ユニットの小回りのきかなさを加味するとそれ以下。
Larrabeeのクロックレンジは2GHz前後で、x86スカラコアを備えるので
まあそれ相応の性能だな。
1SPあたり4スレッド単位で演算をインターリーブするので
シェーダコアが1.2GHz動作ならシングルスレッド・スカラ性能は最高でも300MHz相当
ベクタ演算ユニットの小回りのきかなさを加味するとそれ以下。
Larrabeeのクロックレンジは2GHz前後で、x86スカラコアを備えるので
まあそれ相応の性能だな。
larrabee(笑)
CUDAって出てからTMPGEncのフィルタの処理くらいしか見てないな
それも画質落ちるし大して早くないし
x86のLarrabeeならエンコに使われたりもしやすいのかい
それも画質落ちるし大して早くないし
x86のLarrabeeならエンコに使われたりもしやすいのかい
ふとおもったが、OPENCLの展望はどうなんだろうねぇ。
875 :,,・´∀`・,,)っ-○◎●:2009/03/11(水) 07:26:46 ID:OBmodYVu
>>873
そりゃソフト次第だろうよ。
OSが動かせるくらい柔軟性があるLarrabeeなら、早いか遅いかは別にして
CPU同等の品質を維持することは理屈の上ではできるね。
逆に劣化させるのは簡単だが
GPUは劣化させなきゃ速いといえるだけの性能が出せないほど
メモリの制約がきつかったりするのは確かだと思うよ。
「GP」GPUなんてそもそも実用性がないんだよ。
汎用を捨ててラスタグラフィック処理に特化してるものに汎用性を期待する方が間違い。
誤差の考え方も違う。
0.001%の演算誤差程度なら見た目に関係ないからケンチャナヨなのがGPU畑の考えなら
SIMD命令でIEEEの浮動小数丸め全サポートしてるのがCPU畑のIntel。
比較するまでもない。
>>874
Intelは支持してるよ。競合他社の言語以外は全部サポートだ。
ただ、「GPGPU版のJava」的なものを期待してるならそれは期待外れだ。
C, C++がベンダレベルで別々の実装である以上に、細かい仕様は処理系依存
MSが不支持だからWindowsでデファクトスタンダードが存在しないことになるんだ。
で、各ベンダー毎に互換性のない実装を出すことになる。
意味ないんだよ。
意味ないからこそ、NVIDIAはCUDA、ATIはATI Streamの独自処理系の開発を辞めない。
最適化したCのコードが普通のCPU向けのコードと全然互換性がなかったりするけど
逆に互換性を維持しようとしたらたらCPUより遅くなるオチが待ってると思う。Cellがそうだし。
尖ったプロセッサの宿命として、尖ったところを丸めたら、最大公約数の性能しか出なくなる。
コンパイラがよっぽど賢くない限りね。
そりゃソフト次第だろうよ。
OSが動かせるくらい柔軟性があるLarrabeeなら、早いか遅いかは別にして
CPU同等の品質を維持することは理屈の上ではできるね。
逆に劣化させるのは簡単だが
GPUは劣化させなきゃ速いといえるだけの性能が出せないほど
メモリの制約がきつかったりするのは確かだと思うよ。
「GP」GPUなんてそもそも実用性がないんだよ。
汎用を捨ててラスタグラフィック処理に特化してるものに汎用性を期待する方が間違い。
誤差の考え方も違う。
0.001%の演算誤差程度なら見た目に関係ないからケンチャナヨなのがGPU畑の考えなら
SIMD命令でIEEEの浮動小数丸め全サポートしてるのがCPU畑のIntel。
比較するまでもない。
>>874
Intelは支持してるよ。競合他社の言語以外は全部サポートだ。
ただ、「GPGPU版のJava」的なものを期待してるならそれは期待外れだ。
C, C++がベンダレベルで別々の実装である以上に、細かい仕様は処理系依存
MSが不支持だからWindowsでデファクトスタンダードが存在しないことになるんだ。
で、各ベンダー毎に互換性のない実装を出すことになる。
意味ないんだよ。
意味ないからこそ、NVIDIAはCUDA、ATIはATI Streamの独自処理系の開発を辞めない。
最適化したCのコードが普通のCPU向けのコードと全然互換性がなかったりするけど
逆に互換性を維持しようとしたらたらCPUより遅くなるオチが待ってると思う。Cellがそうだし。
尖ったプロセッサの宿命として、尖ったところを丸めたら、最大公約数の性能しか出なくなる。
コンパイラがよっぽど賢くない限りね。
876 :Socket774:2009/03/11(水) 07:29:37 ID:9BMlgJZv
ぽしゃるだろ
ネイティブサポートの方が期待薄
実数演算の精度って、ちょっと手抜きすると露骨に画質落ちるとこがあるんだよな
特にDCTとかはかなり精度が重要なんだが、単精度とか平気で使われてて困る
H.264で実数演算やめたのは地味にかなり大きい
特にDCTとかはかなり精度が重要なんだが、単精度とか平気で使われてて困る
H.264で実数演算やめたのは地味にかなり大きい
PC以外で流行って、7〜8年後に気がついたらPCでもみんな使ってたって感じ?
団子は見てて嫌悪感しか感じさせない男だな
大人気ないとかそういうレベルじゃないわ
大人気ないとかそういうレベルじゃないわ
881 :,,・´∀`・,,)っ-○◎●:2009/03/12(木) 19:08:29 ID:FJ1MmSU9
じゃあ君が俺に好感持たせてくれよ
とりあえずたるさんに喧嘩売ってきた(ってのは昨日の話)
あとCtのメリット云々を書いてみた
暇だったらゆっくり読んでってね!!
とりあえずたるさんに喧嘩売ってきた(ってのは昨日の話)
あとCtのメリット云々を書いてみた
暇だったらゆっくり読んでってね!!
読んだけどだらだら長すぎ論理が飛躍しすぎ。
細かく指摘してやろうかと思ったけどたぶんファビョルからやめた。
細かく指摘してやろうかと思ったけどたぶんファビョルからやめた。
おお
やってくれた
これで次回以降のたるさんの視点が切り替わるはず
やってくれた
これで次回以降のたるさんの視点が切り替わるはず
884 :,,・´∀`・,,)っ-○◎●:2009/03/13(金) 00:45:17 ID:2n3V2MSp
先進的なフレームワーク、コンパイラを前提として
現物が出てくるまでは最強を夢見れる。
現物が出てくるまでは最強を夢見れる。
886 :,,・´∀`・,,)っ-○◎●:2009/03/13(金) 01:05:45 ID:2n3V2MSp
Parralel Studio、現物出てるけどどう思った?
VS2010 CTPのマルチスレッド機能、これは傑作だわ。
ちなみにLarrabee開発もアドインで対応するらしいよ。
VS2010 CTPのマルチスレッド機能、これは傑作だわ。
ちなみにLarrabee開発もアドインで対応するらしいよ。
アドインで対応って言うか、Parralel StudioはVisual Studio必須なんじゃ?
888 :Socket774:2009/03/14(土) 12:34:08 ID:kU8Q4ioO
>>865
数値計算業界に限って言えば
単純なコードで長時間の計算を行うわけで、
CellやCUDAのアプローチは正解
そしてハードが5年以上固定のゲームもそういえる部分がある。
最初からスパコンとゲーム専用につくられ、
PS3やロードランナーにのったと。
CUDAは倍精度が微妙すぎて数値計算に使えないが
数値計算業界に限って言えば
単純なコードで長時間の計算を行うわけで、
CellやCUDAのアプローチは正解
そしてハードが5年以上固定のゲームもそういえる部分がある。
最初からスパコンとゲーム専用につくられ、
PS3やロードランナーにのったと。
CUDAは倍精度が微妙すぎて数値計算に使えないが
MixiのCUDAフォーラム覗いたら団子がいてびびったw
こわいお(´;ω;`)
こわいお(´;ω;`)
!
| 丶 _ .,! ヽ
> ``‐.`ヽ、 .|、 |
゙'. ,ト `i、 `i、 .、″
| .,.:/"" ゙‐,. ` /
` .,-''ヽ"` ヽ,,,、 !
、,、‐'゙l‐、 .丿 : ':、
、/ヽヽ‐ヽ、;,,,,,,,,,-.ッ:''` .,"-、
,r"ツぃ丶 `````` ../ `i、
,.イ:、ヽ/ー`-、-ヽヽヽ、−´ .l゙`-、
_,,l゙-:ヽ,;、、 、、丶 ゙i、,,、
,<_ l_ヽ冫`'`-、;,,,、、、、.............,,,,、.-`": │ `i、
、、::|、、、ヽ,、、. ```: : : ``` 、.、'` .|丶、
.l","ヽ、,"、,"'、ぃ、、,、、、、.、、、.、、、_、.,,.ヽ´ l゙ ゙).._
,、':゙l:、、`:ヽ、`:、 : `"```¬――'''"`゙^` : ..、丶 .l゙ `ヽ
,i´.、ヽ".、".、"'ヽヽ;,:、........、 、、...,,,、−‘` 、‐ |゙゙:‐,
,.-l,i´.、".`ヽ,,,.".` `゙゙'"`'-ー"``"``r-ー`'": _.‐′ 丿 ,!
j".、'ヽ,".、".、"`''`ー、._、、、 、._,、..-‐:'''′ .、,:" 丿
゙l,"`"`''ヽヽ"`"` ```゙'''"ヽ∠、、、、ぃ-`''''": ` 、._./` ._/`
`'i`ヽヽヽ`''ーi、、、: : 、.,-‐'` 、/`
``ヽン'`"` : `~``―ヽ::,,,,,,,,,,.....................,,,,.ー'``^ ,、‐'"`
`"'゙―-、,,,,..、、 : ..,、ー'"'`
: `‘"`―---------‐ヽ``"''''''"
| 丶 _ .,! ヽ
> ``‐.`ヽ、 .|、 |
゙'. ,ト `i、 `i、 .、″
| .,.:/"" ゙‐,. ` /
` .,-''ヽ"` ヽ,,,、 !
、,、‐'゙l‐、 .丿 : ':、
、/ヽヽ‐ヽ、;,,,,,,,,,-.ッ:''` .,"-、
,r"ツぃ丶 `````` ../ `i、
,.イ:、ヽ/ー`-、-ヽヽヽ、−´ .l゙`-、
_,,l゙-:ヽ,;、、 、、丶 ゙i、,,、
,<_ l_ヽ冫`'`-、;,,,、、、、.............,,,,、.-`": │ `i、
、、::|、、、ヽ,、、. ```: : : ``` 、.、'` .|丶、
.l","ヽ、,"、,"'、ぃ、、,、、、、.、、、.、、、_、.,,.ヽ´ l゙ ゙).._
,、':゙l:、、`:ヽ、`:、 : `"```¬――'''"`゙^` : ..、丶 .l゙ `ヽ
,i´.、ヽ".、".、"'ヽヽ;,:、........、 、、...,,,、−‘` 、‐ |゙゙:‐,
,.-l,i´.、".`ヽ,,,.".` `゙゙'"`'-ー"``"``r-ー`'": _.‐′ 丿 ,!
j".、'ヽ,".、".、"`''`ー、._、、、 、._,、..-‐:'''′ .、,:" 丿
゙l,"`"`''ヽヽ"`"` ```゙'''"ヽ∠、、、、ぃ-`''''": ` 、._./` ._/`
`'i`ヽヽヽ`''ーi、、、: : 、.,-‐'` 、/`
``ヽン'`"` : `~``―ヽ::,,,,,,,,,,.....................,,,,.ー'``^ ,、‐'"`
`"'゙―-、,,,,..、、 : ..,、ー'"'`
: `‘"`―---------‐ヽ``"''''''"
URL晒してごらんよ889
mixi内のURL晒してどうすんだよw
誰かに招待してもらえ
誰かに招待してもらえ
ハァ?
今時mixi入ってない奴情弱いるの?
団子の恥晒し文章見に行くだけさ
今時mixi入ってない奴情弱いるの?
団子の恥晒し文章見に行くだけさ
mixiのmの字もわからない俺が来ましたよ
団子で検索するかCUDAフォーラムに行けばいいだろ
ちょっとは頭使えよw
ちょっとは頭使えよw
めんどくせーんだよカス
さっさと晒せ
URL程度もコピペできないのか(笑)
さっさと晒せ
URL程度もコピペできないのか(笑)
気にくわんなお前の態度はw
ググレカスだぼけw
ググレカスだぼけw
mixiwwwwwwwwwwwww
負けず嫌いのヘタレ小僧は本当に役に立たないな
あぼーんでいいわこんなゴミ
あぼーんでいいわこんなゴミ
グーグルで検索できると思い込んでる知能の低さに爆笑したけどまぁいいや消えてるし
教えて君に対する決まり文句にマジレスしてる馬鹿に爆笑www
ちょっと頭の弱い子なんだ。
そっとしておいてやれw
そっとしておいてやれw
903 :,,・´∀`・,,)っ-○◎●:2009/03/15(日) 00:42:13 ID:vQeMusDN
たるさんがあっさり主張曲がってますけどどう思った?
904 :,,・´∀`・,,)っ-○◎●:2009/03/15(日) 00:43:48 ID:vQeMusDN
906 :,,・´∀`・,,)っ-○◎●:2009/03/15(日) 01:16:32 ID:vQeMusDN
でっち上げの知識でゴリ押しして他人は説得できませんよ
公開してないけど数回メールのやりとりがありました
公開してないけど数回メールのやりとりがありました
>>903
次回以降に期待したいと思った
次回以降に期待したいと思った
たるさんの正直さを少しは見習えよ。
ここの奴らは自分の間違いを認めなさすぎ。
ここの奴らは自分の間違いを認めなさすぎ。
すまん誤爆
あれ!誤爆してない!
メモリのところもひどい妄想だな。
マルチコアが(笑)ってのは事実だと思うが
Larrabeeなんて流行るわけないよ
そもそもパフォーマンスが悪すぎ
IGP相当のGPUがCPUに統合されるなんて言ってるけど、
結局、パフォーマンスが悪いからオンボードのVGAと
同じ扱いだろうねw
そもそもパフォーマンスが悪すぎ
IGP相当のGPUがCPUに統合されるなんて言ってるけど、
結局、パフォーマンスが悪いからオンボードのVGAと
同じ扱いだろうねw
でも今後描画以外の使用目的が拡大していくと、
対応が限定されるGPGPUはシカトされる危険性があるよ。
これ以上FPS上がってどうすんの状態の描画のみのハイパフォーマンスより、
大勢はトータルパフォーマンスをとるだろうから。
対応が限定されるGPGPUはシカトされる危険性があるよ。
これ以上FPS上がってどうすんの状態の描画のみのハイパフォーマンスより、
大勢はトータルパフォーマンスをとるだろうから。
製造技術の優位と、コア数の増大で性能がリニアに向上するのを利用して、既存のGPU相手にはごり押しするんじゃね。
TSMCの40nmプロセスはリーク電流が多すぎて大変らしくて、RV770の後継のRV790は55nmのままみたいだし。
TSMCの40nmプロセスはリーク電流が多すぎて大変らしくて、RV770の後継のRV790は55nmのままみたいだし。
916 :,,・´∀`・,,)っ-○◎●:2009/03/17(火) 20:54:25 ID:pnCjU0P4
Ctの仮想マシンの仕様だけど
__ __ n _____
| | / / / / / |
| |. / / /⌒ヽ/ / / ̄ ̄|. l
| | / / ( ^ω^ ) / /. / /
| | / / ノ/ / ノ /  ̄ ̄ /
| |. / / // / ノ / / ̄ ̄ ̄
| |/ / ⊂( し'./ / /
|. / | ノ' / /
| /. し' ./ /
 ̄ ̄ ̄  ̄ ̄
っていうレイヤーで、1024ビットのSIMD命令セットがサポートされる模様
SIMD命令数は75命令とか
Ctは113命令になってるが、こいつは組み込み関数(演算子)の数だな。
__ __ n _____
| | / / / / / |
| |. / / /⌒ヽ/ / / ̄ ̄|. l
| | / / ( ^ω^ ) / /. / /
| | / / ノ/ / ノ /  ̄ ̄ /
| |. / / // / ノ / / ̄ ̄ ̄
| |/ / ⊂( し'./ / /
|. / | ノ' / /
| /. し' ./ /
 ̄ ̄ ̄  ̄ ̄
っていうレイヤーで、1024ビットのSIMD命令セットがサポートされる模様
SIMD命令数は75命令とか
Ctは113命令になってるが、こいつは組み込み関数(演算子)の数だな。
917 :,,・´∀`・,,)っ-○◎●:2009/03/17(火) 20:55:25 ID:pnCjU0P4
{kind=link}
918 :,,・´∀`・,,)っ-○◎●:2009/03/18(水) 22:20:11 ID:ZwrNmytX
レイトレーシングを20倍高速化する方法、Caustic Graphics社が開発
http://japanese.engadget.com/2009/03/17/20-caustic-graphics/
こういうインチキ何度も見た気が・・・気のせいか?
http://japanese.engadget.com/2009/03/17/20-caustic-graphics/
こういうインチキ何度も見た気が・・・気のせいか?
>>916
おまえこのAAはコピペミスなのか?
おまえこのAAはコピペミスなのか?
Larrabeeコアって高クロック化に向いてなさそう
Cellのはテストで5GHzとかだろ?どうすんの?
Cellのはテストで5GHzとかだろ?どうすんの?
別に
922 :,,・´∀`・,,)っ-○◎●:2009/03/19(木) 22:19:02 ID:0VmCb7sP
>>920
Cellはクロック上げてもどうしようもないと思うよ。
命令自体のレイテンシがでかすぎて、3.2GHzとはいっても
アンロールしまくって実質1024ビット×400MHz相当で使う必要があるし
どっちかというとクロック落として良いから小回りを効くようにした方がいい。
額面性能と実効性能の差が酷い。
Cellはクロック上げてもどうしようもないと思うよ。
命令自体のレイテンシがでかすぎて、3.2GHzとはいっても
アンロールしまくって実質1024ビット×400MHz相当で使う必要があるし
どっちかというとクロック落として良いから小回りを効くようにした方がいい。
額面性能と実効性能の差が酷い。
小回りよくしたコア何十個も積んでどうすんの?
924 :,,・´∀`・,,)っ-○◎●:2009/03/19(木) 22:38:45 ID:0VmCb7sP
Cellのことだな。
よくわかってるじゃないか。
よくわかってるじゃないか。
925 :,,・´∀`・,,)っ-○◎●:2009/03/19(木) 22:59:20 ID:0VmCb7sP
コアを何十も積むという発想から脱却した方がいいよ。
単精度1TFLOPSを実現するのにCellなら4GHzのコアを32個積む必要があるが
Larrabeeなら2GHzで16コアで済むんだ。
1コアあたりの性能を上げるのにクロックだけを上げるってのは
最早得策じゃないんだよ。
単精度1TFLOPSを実現するのにCellなら4GHzのコアを32個積む必要があるが
Larrabeeなら2GHzで16コアで済むんだ。
1コアあたりの性能を上げるのにクロックだけを上げるってのは
最早得策じゃないんだよ。
ララビーはどんなにコア増やしてもオーバーヘッドが発生しない魔法のアーキテクチャなんですよね^^
あははは^^
あははは^^
927 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 00:18:04 ID:d6W2fX25
いいや、オーバーヘッドはあるよ。
だからこそ1コアあたりの性能を引き上げることも有る程度必要になる。
だが、そのためにクロックをひたすら上げるってのは愚か過ぎる。
だからこそ1コアあたりの性能を引き上げることも有る程度必要になる。
だが、そのためにクロックをひたすら上げるってのは愚か過ぎる。
{kind=link}
シミュレート値
930 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 00:50:21 ID:d6W2fX25
タイルレンダの本質が見えてる人には理屈はわかるんだろうけどね。
2GHzのGPUとしては高クロックなコア、たかだか10クロックの低レイテンシなL2キャッシュ・・・
2GHzのGPUとしては高クロックなコア、たかだか10クロックの低レイテンシなL2キャッシュ・・・
http://a96sj096.cocolog-nifty.com/weblog/2008/02/nehalemshanghai_7fb6.html
これのことか?
何でIntelがAMDが(当時)開発中のCPUのシムを出来るんだ?www
Sunのwebでのリークだとすると、時期的に初期ESでの実測と
考えるのが妥当だろ。JK
これのことか?
何でIntelがAMDが(当時)開発中のCPUのシムを出来るんだ?www
Sunのwebでのリークだとすると、時期的に初期ESでの実測と
考えるのが妥当だろ。JK
てか、1世代目はすでに失敗作っつてんじゃん
それにタイル処理でリニアにパフォーマンスが上がるのは頂点処理を無視した場合
それにタイル処理でリニアにパフォーマンスが上がるのは頂点処理を無視した場合
934 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 10:13:04 ID:d6W2fX25
>てか、1世代目はすでに失敗作っつてんじゃん
ソース
ソース
935 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 10:15:35 ID:d6W2fX25
つーか、頂点処理こそ1〜2コアをVertex Shaderとして使えば充分なような。
ttp://www.z-z-z.jp/BLOG/log/eid264.html
ただ、Larabeeは、第一世代のものは、ATIやNVIDIAのハイエンドGPUには全く及ばないパフォーマンスといわれている。
テクスチャユニットに負荷がかかるとリングバスがパンクして思ったほどパフォーマンスがでないらしい。
頂点処理もDX11世代からはテッセレータが加わり扱うデータ量は膨大になる
高次サーフェス何かがようやく使えるかもしれないね
atiの場合専用固定ユニットでテッセレータを搭載し高速に処理っていうが
汎用プロセッサならどうなんかね
ただ、Larabeeは、第一世代のものは、ATIやNVIDIAのハイエンドGPUには全く及ばないパフォーマンスといわれている。
テクスチャユニットに負荷がかかるとリングバスがパンクして思ったほどパフォーマンスがでないらしい。
頂点処理もDX11世代からはテッセレータが加わり扱うデータ量は膨大になる
高次サーフェス何かがようやく使えるかもしれないね
atiの場合専用固定ユニットでテッセレータを搭載し高速に処理っていうが
汎用プロセッサならどうなんかね
>>936
>>758-
>>758-
ラデもリングバス止めてからパフォーマンスがよくなったからな。
939 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 14:31:45 ID:d6W2fX25
リングバスがネックってのはどっからの推測だろうね?
旧Radeonの弱点を言ってるようにしか見えないんだが。
ATIのはたかだか700MHz前後動作のコアだろ。
Larrabeeは上り下り計1024ビットのリングバスって点では旧Radeon HDと同じだが
2GHz前後のクロック数なら物理的な帯域はその約3倍あるわけだが。
旧Radeonの弱点を言ってるようにしか見えないんだが。
ATIのはたかだか700MHz前後動作のコアだろ。
Larrabeeは上り下り計1024ビットのリングバスって点では旧Radeon HDと同じだが
2GHz前後のクロック数なら物理的な帯域はその約3倍あるわけだが。
性能は?
クロックドメインが同じとは限らないし
仮に同じでも縛熱ジャン
仮に同じでも縛熱ジャン
942 :,,・´∀`・,,)っ-●◎○:2009/03/20(金) 15:17:52 ID:d6W2fX25
いいや、キャッシュライン1つを1クロックで転送できると言ってるからコアクロックと同一だろう
それでも大丈夫、Cellの3.2GHzよりは低クロックだから
むしろクロスバーのほうが熱源になるんだが。
それでも大丈夫、Cellの3.2GHzよりは低クロックだから
むしろクロスバーのほうが熱源になるんだが。
一番電力食うのはxbarだがな
meshや階層型のringは省電力
meshや階層型のringは省電力
被ったw
原則はそうでも設計によって変わってくるから一概には言えんでしょ。
RADEONだってテクスチャキャッシュの構成を変えて省電力化したんだし。
RADEONだってテクスチャキャッシュの構成を変えて省電力化したんだし。
ATIの場合RV670->RV770で製造プロセス同じで
演算ユニット大幅増設にもかかわらず
さほど熱、電力共に変わりなかった
替ったのは、リングバスくらいで
演算ユニット大幅増設にもかかわらず
さほど熱、電力共に変わりなかった
替ったのは、リングバスくらいで
ちなみにR600(512(1024)bit)からRV670(256(512)bit)に変更した分で1.1億トランジスタ削減してる
948 :,,・´∀`・,,)っ-○◎●:2009/03/20(金) 19:29:12 ID:d6W2fX25
しらんがな
単純計算だけど
512bit×2GHz=1Tbits/s
512bit×800MHz≒0.41Tbits/sec
ま、それでなくとも、256KB/coreのキャッシュを駆使してタイリングするのと
少量のスクラッチパッドメモリでやりくりするのと
リングバスの負荷のかかりかたが同じとは限らない
善爺はどこの情報根拠にしてるんだろうな
単純計算だけど
512bit×2GHz=1Tbits/s
512bit×800MHz≒0.41Tbits/sec
ま、それでなくとも、256KB/coreのキャッシュを駆使してタイリングするのと
少量のスクラッチパッドメモリでやりくりするのと
リングバスの負荷のかかりかたが同じとは限らない
善爺はどこの情報根拠にしてるんだろうな
larrabeeには期待してる
3dlabsのGPUとして
ただ、フルプログラマブルのGPUってのは他所もやってきそうだが次世代で
x86じゃないだけで
3dlabsのGPUとして
ただ、フルプログラマブルのGPUってのは他所もやってきそうだが次世代で
x86じゃないだけで
スーパーコンピュータはどうなるのか
ttp://journal.mycom.co.jp/articles/2009/03/02/jointicfs/001.html
>ベクトルSMPやスカラSMP方式での高性能の実現は、電力と
>ネットワークバンド幅の点で限界となる。このため、超低消費電力技術を
>駆使した超並列方式と演算アクセラレータの組み合わせが有望
CellやLarrabeeはこの分類方法ではどちらに入るのか
ttp://journal.mycom.co.jp/articles/2009/03/02/jointicfs/001.html
>ベクトルSMPやスカラSMP方式での高性能の実現は、電力と
>ネットワークバンド幅の点で限界となる。このため、超低消費電力技術を
>駆使した超並列方式と演算アクセラレータの組み合わせが有望
CellやLarrabeeはこの分類方法ではどちらに入るのか
両方超並列方式じゃねぇの
952 :,,・´∀`・,,)っ-○◎●:2009/03/20(金) 23:27:03 ID:d6W2fX25
SIMD拡張命令のベクトル長が大きくなってもスーパースカラはスーパースカラだぜ。
Larrabeeでも変わらない。
x86由来のスカラレジスタによるメモリアドレッシングはLarrabeeの最大の武器になる予定。
Larrabeeでも変わらない。
x86由来のスカラレジスタによるメモリアドレッシングはLarrabeeの最大の武器になる予定。
結局、ララビの製品版は何時なんだよw
物が出ないと俺のようなど素人には分からん。
今年末には出るって話しだったが…。
物が出ないと俺のようなど素人には分からん。
今年末には出るって話しだったが…。
ララビーのシミュレータとかってないのん?
団子さんとか密かに自作してないすか?
団子さんとか密かに自作してないすか?
955 :,,・´∀`・,,)っ-○◎●:2009/03/21(土) 16:39:56 ID:wJ2vA02m
んなもんないよ。
演算ユニット構成から命令のスループットを推測するくらいしかできてねぇ。
そもそもLarrabeeはCellのようにハードウェアありきの代物ではなくて
Ct/VIPやSTMなどのマルチスレッド支援ソフトウェアの動作プラットフォームの1形態と
解釈しております。
演算ユニット構成から命令のスループットを推測するくらいしかできてねぇ。
そもそもLarrabeeはCellのようにハードウェアありきの代物ではなくて
Ct/VIPやSTMなどのマルチスレッド支援ソフトウェアの動作プラットフォームの1形態と
解釈しております。
出ても用途がないからさ
CUDAやろうとゲフォ買ったけど何作ろうかなって考えてるだけ
CUDAやろうとゲフォ買ったけど何作ろうかなって考えてるだけ
957 :,,・´∀`・,,)っ-○◎●:2009/03/25(水) 20:42:58 ID:lnL5FONc
なにその俺
http://software.intel.com/en-us/articles/prototype-primitives-guide/
Prototype Primitives Guide
This .inl file provides a C++-implementation of the Larrabee new instructions.
LNIのC Intrinsics仕様公開
http://software.intel.com/en-us/articles/prototype-primitives-guide/
Prototype Primitives Guide
This .inl file provides a C++-implementation of the Larrabee new instructions.
LNIのC Intrinsics仕様公開
何ぞこれ
Real-time ray tracing gets an airing
ttp://www.theinquirer.net/inquirer/news/516/1051516/real-ray-tracing-airing
Real-time ray tracing gets an airing
ttp://www.theinquirer.net/inquirer/news/516/1051516/real-ray-tracing-airing
何この幼稚園児w
まだ40弱も残ってるのに・・・
963 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 01:14:30 ID:D0rPPE4r
MACオタが発狂でもしない限りあと1週間は埋まらないぞ
スレの速度見てから立てろよアホか
失速し始めたのはここ最近の話
今北。
スレ軽く流し読みしたけど、第一世代はキャンセルで、
製造プロセスを小さくしたのを1年遅れぐらいで出して、
それは3D表示はいまいちだけど、
GPGPU用としてなら、まあまあ期待できる性能ってことでOK?
スレ軽く流し読みしたけど、第一世代はキャンセルで、
製造プロセスを小さくしたのを1年遅れぐらいで出して、
それは3D表示はいまいちだけど、
GPGPU用としてなら、まあまあ期待できる性能ってことでOK?
GDC 2009のスライドが見つからない
http://www.pcper.com/article.php?aid=683
http://news.cnet.com/8301-13924_3-10204911-64.html
http://www.pcper.com/article.php?aid=683
http://news.cnet.com/8301-13924_3-10204911-64.html
969 :MACオタ>968 さん:2009/03/28(土) 11:26:34 ID:cu35dzXH
>>968
ベクトルレジスタが32個になってますね。既出の情報でしたっけ?
http://bto.cnet.com/i/bto/20090326/larrabee.png
またもや団子さんの推測は破綻したんでしょうか。
>>674
=====================
674 名前:,,・´∀`・,,)っ-●◎○ 投稿日:2009/02/11(水) 17:42:34 ID:pGz2zkVB
そもそも論理レジスタ本数がそれほど多くない命令セットでは同じ論理レジスタを繰り返し
再利用する頻度が高いので、4オペランドにすることでのメリットも決して大きくは無い。
=====================
Intelはレジスタ本数をPowerPC並に増やしたけれど、積和命令は引数破壊形式にした…と(笑)
ベクトルレジスタが32個になってますね。既出の情報でしたっけ?
http://bto.cnet.com/i/bto/20090326/larrabee.png
{kind=link}
またもや団子さんの推測は破綻したんでしょうか。
>>674
=====================
674 名前:,,・´∀`・,,)っ-●◎○ 投稿日:2009/02/11(水) 17:42:34 ID:pGz2zkVB
そもそも論理レジスタ本数がそれほど多くない命令セットでは同じ論理レジスタを繰り返し
再利用する頻度が高いので、4オペランドにすることでのメリットも決して大きくは無い。
=====================
Intelはレジスタ本数をPowerPC並に増やしたけれど、積和命令は引数破壊形式にした…と(笑)
>GDC 2009のスライドが見つからない
26日までのは出てるけど
月曜には出るんじゃないか
26日までのは出てるけど
月曜には出るんじゃないか
972 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 12:57:16 ID:D0rPPE4r
期待にこたえて発狂してくれると思ってましたよww
>Intelはレジスタ本数をPowerPC並に増やしたけれど、積和命令は引数破壊形式にした…と(笑)
まあ馬鹿にはそう見えるんでしょうね。
そういえばSIMDレジスタが32本しか使えないPowerPCのほうにはdestructiveなFMAは無かったね。
倍精度のSIMD演算すらできなかったけど。
倍精度FMAを持つCPUアーキテクチャとその演算対象レジスタの本数です
Bulldozer(笑) SSE5 XMMレジスタ 16本
Haswell XMM/YMMレジスタ 16本
Larrabee Vectorレジスタ 32本
POWER7 VSXレジスタ 64本
SPU 汎用レジスタ 128本
きっと32以上の数も数えられない子なんでしょうね。
でさ、もしさ、mask演算が第一ソースオペランドとデスティネーションオペランドが独立してて
5オペランドだってみ?省電力技術になり得なくね?
同一だからこそ、maskのビットが0のエレメントに対して純粋に「演算をしない」ようにできる。
つまりバスパワーの制御により電力の節約ができる技術なんだ。
電力効率の観点からすればアリだろ。
ま、一つ質問しようか?
vfmadd132pdとvfmadd231pdそしてvfmadd233pdは破壊される対象のオペランドは同じですか?
それとも違いますか?
もう一つ聞くと、vfmadd233pd v1, v2, v3は破壊型の命令だと思いますか?
あー、レジスタが128本もあるのに、加算値か乗算値かのどっちを破壊するかすら選べない
お馬鹿なアーキテクチャがあるらしいですよ。
pa-goodbye(笑)
>Intelはレジスタ本数をPowerPC並に増やしたけれど、積和命令は引数破壊形式にした…と(笑)
まあ馬鹿にはそう見えるんでしょうね。
そういえばSIMDレジスタが32本しか使えないPowerPCのほうにはdestructiveなFMAは無かったね。
倍精度のSIMD演算すらできなかったけど。
倍精度FMAを持つCPUアーキテクチャとその演算対象レジスタの本数です
Bulldozer(笑) SSE5 XMMレジスタ 16本
Haswell XMM/YMMレジスタ 16本
Larrabee Vectorレジスタ 32本
POWER7 VSXレジスタ 64本
SPU 汎用レジスタ 128本
きっと32以上の数も数えられない子なんでしょうね。
でさ、もしさ、mask演算が第一ソースオペランドとデスティネーションオペランドが独立してて
5オペランドだってみ?省電力技術になり得なくね?
同一だからこそ、maskのビットが0のエレメントに対して純粋に「演算をしない」ようにできる。
つまりバスパワーの制御により電力の節約ができる技術なんだ。
電力効率の観点からすればアリだろ。
ま、一つ質問しようか?
vfmadd132pdとvfmadd231pdそしてvfmadd233pdは破壊される対象のオペランドは同じですか?
それとも違いますか?
もう一つ聞くと、vfmadd233pd v1, v2, v3は破壊型の命令だと思いますか?
あー、レジスタが128本もあるのに、加算値か乗算値かのどっちを破壊するかすら選べない
お馬鹿なアーキテクチャがあるらしいですよ。
pa-goodbye(笑)
973 :MACオタ>971 さん:2009/03/28(土) 12:58:36 ID:cu35dzXH
974 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:04:06 ID:D0rPPE4r
俺の預言を思い出してくれwww
> たとえばSIMDレジスタの本数を32本や64本なんて拡張だってOpcode空間の余裕的には可能だ
たとえばこれが「4バイトVEX」でも必要になる技術だと思うかね?
> たとえばSIMDレジスタの本数を32本や64本なんて拡張だってOpcode空間の余裕的には可能だ
たとえばこれが「4バイトVEX」でも必要になる技術だと思うかね?
975 :MACオタ>団子 さん:2009/03/28(土) 13:08:39 ID:cu35dzXH
>>974
-------------
俺の預言
-------------
誰かの受け売りだったって意味ですか?
http://ja.wikipedia.org/wiki/%E9%A0%90%E8%A8%80%E8%80%85
=============
「預言者」を「神の代弁者」、「予言者」を「未来を語る人」の意味に用いている。
=============
-------------
俺の預言
-------------
誰かの受け売りだったって意味ですか?
http://ja.wikipedia.org/wiki/%E9%A0%90%E8%A8%80%E8%80%85
=============
「預言者」を「神の代弁者」、「予言者」を「未来を語る人」の意味に用いている。
=============
976 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:09:51 ID:D0rPPE4r
神、いわゆるゴッド
AVXのマニュアルで、FMAが4オペランドから3オペランドになってたけど
LRBniに合わせたのかな?
LRBniに合わせたのかな?
978 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:16:00 ID:D0rPPE4r
979 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:18:07 ID:D0rPPE4r
>>977
そっちのほうが自然ですな。
imm8を第4オペランドと解釈することができるのに敢えてそれをやった、と。
まあ、Opcodeも0F 38のほうに移ったんで、元の4オペランド仕様のほうを復活しても
破壊型とも共存できるわけですが
そっちのほうが自然ですな。
imm8を第4オペランドと解釈することができるのに敢えてそれをやった、と。
まあ、Opcodeも0F 38のほうに移ったんで、元の4オペランド仕様のほうを復活しても
破壊型とも共存できるわけですが
980 :MACオタ>977 さん:2009/03/28(土) 13:21:09 ID:cu35dzXH
>>977
AVXの方は1月半ばに3引数に変更されています。
http://aceshardware.freeforums.org/intel-avx-kills-amd-sse5-t538-30.html#9509
AVXの方は1月半ばに3引数に変更されています。
http://aceshardware.freeforums.org/intel-avx-kills-amd-sse5-t538-30.html#9509
981 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:22:44 ID:D0rPPE4r
いいえ、去年12月の第4版の時点です
982 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:27:34 ID:D0rPPE4r
http://dango.chu.jp/tripper/20090107.html
俺が7日の時点でねたにしてるのに中旬なわけがないだろう
どうやらMASK用のオペランドを確保する方法まで預言してた気がします
俺が7日の時点でねたにしてるのに中旬なわけがないだろう
どうやらMASK用のオペランドを確保する方法まで預言してた気がします
983 :MACオタ>団子 さん:2009/03/28(土) 13:36:14 ID:cu35dzXH
>>981
公開は一月に入ってからのようですが?
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/587
---------------------
587 名前:Socket774 投稿日:2009/01/06(火) 20:43:07 ID:IMwYnYnn
AVX Program Reference 更新
ttp://software.intel.com/file/8418
vpermil2ps/vpermil2pdが消えた
FMAが3オペランドになった
---------------------
リンク先のrev4仕様書のファイル更新日も2008/12/29です。
公開は一月に入ってからのようですが?
http://pc11.2ch.net/test/read.cgi/jisaku/1228400588/587
---------------------
587 名前:Socket774 投稿日:2009/01/06(火) 20:43:07 ID:IMwYnYnn
AVX Program Reference 更新
ttp://software.intel.com/file/8418
vpermil2ps/vpermil2pdが消えた
FMAが3オペランドになった
---------------------
リンク先のrev4仕様書のファイル更新日も2008/12/29です。
984 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:40:10 ID:D0rPPE4r
>>983
そいつの発見が7日なだけ。
PDFの中身見ればわかるがドキュメントの仕様変更したのは12月とある。
それでも彼が発見したのも現地時間ではまだ1月6日なわけで
少なくとも「1月半ば」なわけがないわな
どうせbinutilsのパッチで気づいたクチだろw
そいつの発見が7日なだけ。
PDFの中身見ればわかるがドキュメントの仕様変更したのは12月とある。
それでも彼が発見したのも現地時間ではまだ1月6日なわけで
少なくとも「1月半ば」なわけがないわな
どうせbinutilsのパッチで気づいたクチだろw
985 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:41:53 ID:D0rPPE4r
元の4オペランドの空間はちゃんと残ってるのも注目
986 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:46:51 ID:D0rPPE4r
でまかせニュースサイトばっかし見てないで、各社、たとえば
IntelとAMDくらいはニュース購読しておきなさいよ。
IntelとAMDくらいはニュース購読しておきなさいよ。
987 :MACオタ>団子 さん:2009/03/28(土) 13:54:13 ID:cu35dzXH
>>986
つまらないところでケチをつけられましたが、『1月半ばには』ということで一文字付け加えて
納得してもらえますか?元々>>980はそういった意図で書かれていますし。
-----------------
IntelとAMDくらいはニュース購読
-----------------
自信ありげな割に、そのニュースそのものの文面を貼れないのは何故ですか(笑)
つまらないところでケチをつけられましたが、『1月半ばには』ということで一文字付け加えて
納得してもらえますか?元々>>980はそういった意図で書かれていますし。
-----------------
IntelとAMDくらいはニュース購読
-----------------
自信ありげな割に、そのニュースそのものの文面を貼れないのは何故ですか(笑)
988 :,,・´∀`・,,)っ-●◎○:2009/03/28(土) 13:57:56 ID:D0rPPE4r
なんだ、その程度がw
ソフト開発に縁が無い人間なんだね
ソフト開発に縁が無い人間なんだね
989 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 14:06:15 ID:D0rPPE4r
http://feeds.feedburner.com/IntelSoftwareNetworkBlog
http://feeds.feedburner.com/ISNMain
この辺ならRSSリーダーに登録すれば無料で読めるだろ
Larrabeeのプロトタイプ関数の記事も23日付けで配信されてたぞ
あとこれも
http://amd-member.com/newsletters/DevCentral/0309.html
http://feeds.feedburner.com/ISNMain
この辺ならRSSリーダーに登録すれば無料で読めるだろ
Larrabeeのプロトタイプ関数の記事も23日付けで配信されてたぞ
あとこれも
http://amd-member.com/newsletters/DevCentral/0309.html
990 :MACオタ>団子 さん:2009/03/28(土) 14:09:49 ID:cu35dzXH
>>988
常々言ってますように、ただのヲタクですので(笑)
http://piza.2ch.net/log/mac/kako/947/947822478.html
--------------------
24 名前: MACオタ>23 さん 投稿日: 2000/01/21(金) 17:14
ちっとも実利的な役に立たないのがヲタクってものす。
--------------------
常々言ってますように、ただのヲタクですので(笑)
http://piza.2ch.net/log/mac/kako/947/947822478.html
--------------------
24 名前: MACオタ>23 さん 投稿日: 2000/01/21(金) 17:14
ちっとも実利的な役に立たないのがヲタクってものす。
--------------------
991 :MACオタ>団子 さん:2009/03/28(土) 14:14:55 ID:cu35dzXH
>>989
せっかく教えていただいて失礼なんですが、当の情報をペタリと貼れば>>981の段階で
話はすっきり片付くと思うのですが?という意味です。
ちなみに>>981の内容はそっくりそのまま>>980のリンク先に書いてあります。
-------------------
The latest version (319433-004) lists the SSE5-like ...
-------------------
せっかく教えていただいて失礼なんですが、当の情報をペタリと貼れば>>981の段階で
話はすっきり片付くと思うのですが?という意味です。
ちなみに>>981の内容はそっくりそのまま>>980のリンク先に書いてあります。
-------------------
The latest version (319433-004) lists the SSE5-like ...
-------------------
992 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 14:20:53 ID:D0rPPE4r
AVXのvpblendvb/vblendvps/vblendvpdだけはimm8を第4オペランドとして使う仕様が残ってるがこれは何故か?
おそらく、FMAはSimple Decoderでデコードできないとスループット的にまずいと考えたのでは
おそらく、FMAはSimple Decoderでデコードできないとスループット的にまずいと考えたのでは
993 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 14:41:20 ID:D0rPPE4r
というのも
imm8をレジスタオペランドとして解釈するにはデコーダに大幅な拡張が必要になるだろうからね
マイクロコードでのデコードだけにとどめた方が賢明と解釈したのかも知れない。
レガシーSSEからAVXに移行が進めばSimple DecoderからレガシーSSEのデコードロジックを
外しても問題なくなるだろ?(今度はマイクロコードでのみデコードできるようになる)
IntelはAVXでレガシーSSEにソフトエミュレーションで実現する方法にも言及してるが、
SSEのデコードロジックを廃止するのは既定路線らしい。
んで、廃止にした分シンプルデコーダの方にロジックを追加する余地が出てくる
もちろんimm8をレジスタオペランドとして解釈するアルゴリズムもね。
そのときまではVPERMIL2P{S,D}や4オペランドFMAはお預けだろう。
にしてもAMDのエンコーディングは変態仕様すぎないか
SIBとDISPの間にDREXを突っ込んだり、SSE4Aでimm8を2つとったり・・・
どっちもLarrabeeとは関係なかったな。
imm8をレジスタオペランドとして解釈するにはデコーダに大幅な拡張が必要になるだろうからね
マイクロコードでのデコードだけにとどめた方が賢明と解釈したのかも知れない。
レガシーSSEからAVXに移行が進めばSimple DecoderからレガシーSSEのデコードロジックを
外しても問題なくなるだろ?(今度はマイクロコードでのみデコードできるようになる)
IntelはAVXでレガシーSSEにソフトエミュレーションで実現する方法にも言及してるが、
SSEのデコードロジックを廃止するのは既定路線らしい。
んで、廃止にした分シンプルデコーダの方にロジックを追加する余地が出てくる
もちろんimm8をレジスタオペランドとして解釈するアルゴリズムもね。
そのときまではVPERMIL2P{S,D}や4オペランドFMAはお預けだろう。
にしてもAMDのエンコーディングは変態仕様すぎないか
SIBとDISPの間にDREXを突っ込んだり、SSE4Aでimm8を2つとったり・・・
どっちもLarrabeeとは関係なかったな。
994 :MACオタ>団子 さん:2009/03/28(土) 14:48:19 ID:cu35dzXH
>>993
------------------
IntelはAVXでレガシーSSEにソフトエミュレーションで実現する方法にも言及してるが、
------------------
ここはLarrabeeに関係あるのでは?
LRB ISAを見ると、私にはどうしてもSSEをネイティブサポートするとは思えないのですが?
------------------
IntelはAVXでレガシーSSEにソフトエミュレーションで実現する方法にも言及してるが、
------------------
ここはLarrabeeに関係あるのでは?
LRB ISAを見ると、私にはどうしてもSSEをネイティブサポートするとは思えないのですが?
995 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 14:53:33 ID:D0rPPE4r
やったとしてマイクロコードでのデコードになるだろうね
前置バイトの長さが不定のSSE*を、出来たとして実用的なスループットでデコード出来る保証はないし
する必要もない。
どうせ動かすのはWindowsでもLinuxでもなく"Larrabee OS"だから既存アプリは再コンパイル必須だし。
しかしその先のシナリオはわからない。
前置バイトの長さが不定のSSE*を、出来たとして実用的なスループットでデコード出来る保証はないし
する必要もない。
どうせ動かすのはWindowsでもLinuxでもなく"Larrabee OS"だから既存アプリは再コンパイル必須だし。
しかしその先のシナリオはわからない。
NG宣言したならNGしろよ団子
NGはヲタとの交渉材料だよ
998 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 16:26:32 ID:D0rPPE4r
埋めなきゃ仕方ないだろ
999 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 16:27:31 ID:D0rPPE4r
A += B*C;
くらいはSPEの倍精度でも選べても良かったな
くらいはSPEの倍精度でも選べても良かったな
1000 :,,・´∀`・,,)っ-○◎●:2009/03/28(土) 16:28:04 ID:D0rPPE4r
1000貰っておく
1001 :1001: