CPU�A�[�L�e�N�`���ɂ��Č�� 9
�������O�炢�������A���\��AMD�[�EIntel�[�EGK�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�PS3���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
�y�ߋ��X���z
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3�@http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4�@http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5�@http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6�@http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7�@http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
http://cpu.jisakuita.net/
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�PS3���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
�y�ߋ��X���z
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3�@http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4�@http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5�@http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6�@http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7�@http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
http://cpu.jisakuita.net/
|
|
|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ Ɂ@�@�@�@�@ �p �l��@�@ �v���@�@�@�@�@�@�@�@�@�@ .,/���@�@�@.,� _,,y
�@�@�@�@.,v���v_�@�@�@�@�@�@�@�@ �l�@�@�@�@�@�@�l .|�@�@.ilށ@�@�@�@�@�@�@�@�@�@�@�@�s�@._�@�@ .,,l(�m^�
�@�@�@,i(�ʁ@ _,,,��vy�@�@�@�@�@ .,i�u�@�@�@�@�@�@.�t;�-v,|l���@�@�@�@�@�@�@�@�@ _,�m�|.�,.�'=,/��y�^
�@�@�@l�@�@,zll^ށ��@ ރ~�@�@�@�@.Ɂ@�@�@�@�@�@�@.il|���ll!�@�@�@�@�@�@�@�@�@�@ .���]�l �_ _����
�@�@�@�s�@il|���@�@�@�@ ̰v,_ .,i���@�@�@�@�@�@ ||�p�vrؤ�@�@�@�@�@�@�@�@�@�@�@�@�@�N'�].�M�@�@ �o
�@�@�@ �_�s �R�@�@�@�@�@.�li ._�N''�v,,_�@�@�@�@�@.�t���@ ���|�@,r���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �p
�@�@�@�@�@ �_�@,�r_�@�@�@ l�'�@�@�@ .ށ܁�-vzā@�@�@�@.�~Ɂ��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �l
�@�@�@�@�@�@ .�'=�~:���@ .�u�@�@�@�@�@ ./ .^�V�@�@�@�@ :�_ @�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�p
�@�@�@�@�@�@�@�@ ށ_�'�@�@�@.--�@�@,,�|�@�@�@ ��@�@�@ ރ~�p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ :�
�@�@�@�@�@�@�@�@�@�@ �^��,,,�N -�@�@ ''�N.���@�@�@:!.,�@�@�@@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �
�@�@�@�@�@�@�@�@�@�@�@�@�@ �k^�-v�,,,_,:�@�@�@�@ iށu�@�@�@�p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .,l�
�@�@�@�@�@�@�@�@�@�@�@�@�@ l!�@�@�@�@ .�L��'�v .,y�@�@�@�@�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ '��
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@�@,/ށ@.�~;.�L.�]�@�@�@ .�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �,
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@ Ɂ��@�R�@�@�@�@�@�@�k�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�
�@�@�@�@�@�@�@�@�@�@�@�@�@ �p�@�@�@�@�p�@�@�@�@�@���@�@�@ �p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o
�@�@�@�@�@�@�@�@�@�@�@�@�@ .|�@�@�@�@.Ё@�@�@�@ .<�@�@�@�@ �k�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �l
�@�@�@�@�@�@�@�@�@�@�@�@�@ .�o�@�@�@�@ �_,_�@�@ _�t��@�@�@ .�o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�p
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o�@�@�@�@�@�@�N^^�N���N'�-v-r�s�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �k
�@�@�@�@.,v���v_�@�@�@�@�@�@�@�@ �l�@�@�@�@�@�@�l .|�@�@.ilށ@�@�@�@�@�@�@�@�@�@�@�@�s�@._�@�@ .,,l(�m^�
�@�@�@,i(�ʁ@ _,,,��vy�@�@�@�@�@ .,i�u�@�@�@�@�@�@.�t;�-v,|l���@�@�@�@�@�@�@�@�@ _,�m�|.�,.�'=,/��y�^
�@�@�@l�@�@,zll^ށ��@ ރ~�@�@�@�@.Ɂ@�@�@�@�@�@�@.il|���ll!�@�@�@�@�@�@�@�@�@�@ .���]�l �_ _����
�@�@�@�s�@il|���@�@�@�@ ̰v,_ .,i���@�@�@�@�@�@ ||�p�vrؤ�@�@�@�@�@�@�@�@�@�@�@�@�@�N'�].�M�@�@ �o
�@�@�@ �_�s �R�@�@�@�@�@.�li ._�N''�v,,_�@�@�@�@�@.�t���@ ���|�@,r���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �p
�@�@�@�@�@ �_�@,�r_�@�@�@ l�'�@�@�@ .ށ܁�-vzā@�@�@�@.�~Ɂ��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �l
�@�@�@�@�@�@ .�'=�~:���@ .�u�@�@�@�@�@ ./ .^�V�@�@�@�@ :�_ @�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�p
�@�@�@�@�@�@�@�@ ށ_�'�@�@�@.--�@�@,,�|�@�@�@ ��@�@�@ ރ~�p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ :�
�@�@�@�@�@�@�@�@�@�@ �^��,,,�N -�@�@ ''�N.���@�@�@:!.,�@�@�@@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �
�@�@�@�@�@�@�@�@�@�@�@�@�@ �k^�-v�,,,_,:�@�@�@�@ iށu�@�@�@�p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .,l�
�@�@�@�@�@�@�@�@�@�@�@�@�@ l!�@�@�@�@ .�L��'�v .,y�@�@�@�@�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ '��
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@�@,/ށ@.�~;.�L.�]�@�@�@ .�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �,
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@ Ɂ��@�R�@�@�@�@�@�@�k�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�
�@�@�@�@�@�@�@�@�@�@�@�@�@ �p�@�@�@�@�p�@�@�@�@�@���@�@�@ �p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o
�@�@�@�@�@�@�@�@�@�@�@�@�@ .|�@�@�@�@.Ё@�@�@�@ .<�@�@�@�@ �k�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �l
�@�@�@�@�@�@�@�@�@�@�@�@�@ .�o�@�@�@�@ �_,_�@�@ _�t��@�@�@ .�o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�p
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o�@�@�@�@�@�@�N^^�N���N'�-v-r�s�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �k
( ߁��)
CPU�A�[�L�e�N�`���ɂ��Č�� 9
�͊ԈႢ
CPU�A�[�L�e�N�`���ɂ��Č�� 10
�͊ԈႢ
CPU�A�[�L�e�N�`���ɂ��Č�� 10
(�t��)��
�������肪�Ƃ�
��݂ɂȂ�܂�
��݂ɂȂ�܂�
���������A���̑O�ڂ̏I�Ղ́c
MAC�����ǂ����̽ڂŌ��ܔ����ė���
���肪�S�����ĺ��܂ŏ�荞��ł����̂���ϯ���B
MAC�����ǂ����̽ڂŌ��ܔ����ė���
���肪�S�����ĺ��܂ŏ�荞��ł����̂���ϯ���B
�O�X�����ł̋c�_�̑�������B
CPU������Ђ��p�\�R���{�̂̐�����Ђ������ꂪ�������Ƃ��������ۂ��ATV�R�}�[�V�������ɂ��Đ�������B
2008�N�̖{����Isaiah
�}���`�R�A�����\�t�g�E�F�A���̉��P�Ɍ����āA���������������Ă������B
���x�O�X����AMD���w�e���R�A�v���Z�b�T�𒊏ۉ�����\�t�g�E�F�A���C�����J������R���\�[�V�A����
�����グ�悤�Ƃ��Ă���Ƃ���EETimes�̋L�����Љ�����B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206501805
���x��AMicrosoft��Intel��UC Berkeley��Parallel Computing Lab���x������Ƃ����j���[�X���o�Ă������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206503988
�������}���`�R�A�Ή��t���[�����[�N�Ƃ����`�ł̎�����_���Ă���͗l���B
�@�@--------------------
�@�@The group believes developers could create a set of perhaps a dozen frameworks that understand the
�@�@intricacies of the hardware. The frameworks could be used to write modules that handle specific tasks
�@�@such as solving a matrix. New run time environments could dynamically schedule the modules across
�@�@available cores of various types.
�@�@--------------------
��̓I�ȃ^�[�Q�b�g��A���N�ȓ��Ɉ�ʓI�ɂȂ邱�Ƃ����炩�ȃL���b�V���A�[�L�e�N�`��������8-16�R�A��
SMP�V�X�e���Ƃ������Ƃ��B
���x�O�X����AMD���w�e���R�A�v���Z�b�T�𒊏ۉ�����\�t�g�E�F�A���C�����J������R���\�[�V�A����
�����グ�悤�Ƃ��Ă���Ƃ���EETimes�̋L�����Љ�����B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206501805
���x��AMicrosoft��Intel��UC Berkeley��Parallel Computing Lab���x������Ƃ����j���[�X���o�Ă������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206503988
�������}���`�R�A�Ή��t���[�����[�N�Ƃ����`�ł̎�����_���Ă���͗l���B
�@�@--------------------
�@�@The group believes developers could create a set of perhaps a dozen frameworks that understand the
�@�@intricacies of the hardware. The frameworks could be used to write modules that handle specific tasks
�@�@such as solving a matrix. New run time environments could dynamically schedule the modules across
�@�@available cores of various types.
�@�@--------------------
��̓I�ȃ^�[�Q�b�g��A���N�ȓ��Ɉ�ʓI�ɂȂ邱�Ƃ����炩�ȃL���b�V���A�[�L�e�N�`��������8-16�R�A��
SMP�V�X�e���Ƃ������Ƃ��B
12 �FMAC�I�^�������F2008/02/14(��) 18:30:06 ID:WmIF21ZD
��̘b�A�Ō�̈�߂�t�ŁA�������������̐��\�R�A�����w�e���R�A�����Ăނ��^�[�Q�b�g�Ƃ�������
���������B
���������B
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
UNIX��i5/OS�T�[�o�[�������uPOWER�V�X�e���Y�v��08�N�O���ɓ���--��IBM�̒S�����В�
http://itpro.nikkeibp.co.jp/article/Interview/20080211/293507/
> - ������POWER7�͂ǂ̂悤�ȃv���Z�T�ɂȂ�̂��H
>
> �@�܂�POWER6�𓊓���������ŁA�\������̂͑������邪�A�����Ă���
> ���̂�����BPOWER7�̃R�A���̓N�A�b�h�����������̂ɂȂ�B�܂�
> 1�R�A�Ŏ��s�ł���X���b�h�̐��������A�X�P�[���r���e�B���オ�邾�낤�B
> �����Ƃ��A��������16�R�A�܂ł͂����Ȃ����낤�B�R�A�P�̂̐��\������
> �������A�������[�ƃf�[�^������肷����o�̓o���h���Ƃ̃o�����X
> ���Ƃ�B
�}���`�R�A�A�}���`�X���b�h�A����IO��
http://itpro.nikkeibp.co.jp/article/Interview/20080211/293507/
> - ������POWER7�͂ǂ̂悤�ȃv���Z�T�ɂȂ�̂��H
>
> �@�܂�POWER6�𓊓���������ŁA�\������̂͑������邪�A�����Ă���
> ���̂�����BPOWER7�̃R�A���̓N�A�b�h�����������̂ɂȂ�B�܂�
> 1�R�A�Ŏ��s�ł���X���b�h�̐��������A�X�P�[���r���e�B���オ�邾�낤�B
> �����Ƃ��A��������16�R�A�܂ł͂����Ȃ����낤�B�R�A�P�̂̐��\������
> �������A�������[�ƃf�[�^������肷����o�̓o���h���Ƃ̃o�����X
> ���Ƃ�B
�}���`�R�A�A�}���`�X���b�h�A����IO��
�l�Ԃ̓V���A���ɂ��������𗝉��ł��Ȃ������B
�l�̓V���A���A����ǐK�y
�C���I�[�_���s���ƃ��b�`��H�̃C���p�N�g�����Ȃ�������
������Ă��ƂȂ̂��낤��Silverthorne��
������Ă��ƂȂ̂��낤��Silverthorne��
18 �FMAC�I�^��17 �����F2008/02/15(��) 23:58:38 ID:uien9vNs
>>17
���b�`�����ɂȂ�ꍇ�Ƃ����̂�A���\�X�e�[�W�̃X�[�p�[�p�C�v���C���\���ŋ��ɂ̓���N���b�N��
�Nj�����Ƃ������B
���b�`�����ɂȂ�ꍇ�Ƃ����̂�A���\�X�e�[�W�̃X�[�p�[�p�C�v���C���\���ŋ��ɂ̓���N���b�N��
�Nj�����Ƃ������B
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
20 �FMAC�I�^��19 �����F2008/02/16(�y) 00:55:21 ID:3jG331Ei
>>19
���̃J�L�R�~�ɂǂ�����肪���邷���H
���̃J�L�R�~�ɂǂ�����肪���邷���H
��T�����肩��CNET��Montalvo System�Ȃ��̃x���`���[���V����x86�v���Z�b�T���J�����Ă���
�炵���ƕĂ��邷�B(x86�݊��Ƃ햾�����Ă��Ȃ������ǁB�B�B)
http://www.news.com/Silent-start-up-readies-to-take-on-Intel-in-notebooks/2100-1006_3-6229304.html?tag=st.nl
http://www.news.com/The-secret-recipe-inside-Intels-latest-competitor/2100-1006_3-6230748.html
���lj��L�̂悤�Ȏ�����������ł�͗l�����ǁA���炩�̔��\������̂�A�����Ɛ�݂������B
�@�E�o���҂�d���A��v�Z�p�҂�x86�W�҂ł���
�@�@Vinod Dham: Intel -> NexGen -> AMD�Ɠn��������A�[�L�e�N�g
�@�@Matt Perry: ��Transmeta�d��
�@�@Peter Song: ��x86�݊��v���Z�b�T�̊J����
�@�@Greg Favor: NexGen -> AMD
�@�@Peter Glaskowsky: ��Microprocessor Report�ҏW��
�@�E�����d�̓v���Z�b�T���J�����Ă���炵��
�@�E�w�e���R�A�炵��
�R�[�h���[�t�B���O�����Ȃ��ˁB�B�B
�炵���ƕĂ��邷�B(x86�݊��Ƃ햾�����Ă��Ȃ������ǁB�B�B)
http://www.news.com/Silent-start-up-readies-to-take-on-Intel-in-notebooks/2100-1006_3-6229304.html?tag=st.nl
http://www.news.com/The-secret-recipe-inside-Intels-latest-competitor/2100-1006_3-6230748.html
���lj��L�̂悤�Ȏ�����������ł�͗l�����ǁA���炩�̔��\������̂�A�����Ɛ�݂������B
�@�E�o���҂�d���A��v�Z�p�҂�x86�W�҂ł���
�@�@Vinod Dham: Intel -> NexGen -> AMD�Ɠn��������A�[�L�e�N�g
�@�@Matt Perry: ��Transmeta�d��
�@�@Peter Song: ��x86�݊��v���Z�b�T�̊J����
�@�@Greg Favor: NexGen -> AMD
�@�@Peter Glaskowsky: ��Microprocessor Report�ҏW��
�@�E�����d�̓v���Z�b�T���J�����Ă���炵��
�@�E�w�e���R�A�炵��
�R�[�h���[�t�B���O�����Ȃ��ˁB�B�B
�R�[�h���[�t�B���O��������������ȁc
Crusoe�̖��Ă�
���x�̓������ш�������Ȃ��Ă邵�A�I���_�C�L���b�V�����傫���Ȃ��Ă邵�A
�O��肸���ƍ������\���o���Ȃ����Ǝv���B
�܂�Intel�����C�o�����炢��CPU���o���ė~��������
Crusoe�̖��Ă�
���x�̓������ш�������Ȃ��Ă邵�A�I���_�C�L���b�V�����傫���Ȃ��Ă邵�A
�O��肸���ƍ������\���o���Ȃ����Ǝv���B
�܂�Intel�����C�o�����炢��CPU���o���ė~��������
�ǂ�ȋƊE�ł����������A�Z�p�v�V�����ł��ɂȂ�ƁA�������肪�]���]���o�Ă����ˁB
x86CPU�����������ɂȂ����̂��ȁH
x86CPU�����������ɂȂ����̂��ȁH
PC�N���X�^�ʼn��x��TOP500�Ƀ����N���肵���V�X�e����[�����Ă���Linux Networx��SG�h�ɔ������ꂽ
�Ƃ̂��Ƃ��B
http://www.linuxnetworx.com/company_info/newsroom/press_releases/2008/february/momentum.html
http://www.itmedia.co.jp/news/articles/0802/16/news005.html
�Ƃ̂��Ƃ��B
http://www.linuxnetworx.com/company_info/newsroom/press_releases/2008/february/momentum.html
http://www.itmedia.co.jp/news/articles/0802/16/news005.html
>>24
CPU�ł��؍��E�����E�C���h�����肪�䓪���Ă���̂��ˁH
CPU�ł��؍��E�����E�C���h�����肪�䓪���Ă���̂��ˁH
�䓪����Ƃ����s���������̃u���N�X���낤
�؍��E��p�����CPU������悤�ɂȂ�Ƃ͎v��Ȃ�
�؍��E��p�����CPU������悤�ɂȂ�Ƃ͎v��Ȃ�
Wintel�Ƌ�����u�����Ǝ��s�ꂪ�Ȃ��ƕt�����Ă�������[�J�����������
���̈Ӗ��ł͑�pVIA�͌������Ă���ȁB
Intel���N�U�������Ċח��͎��Ԃ̖��Ƃ����C�����邪�B
Intel���N�U�������Ċח��͎��Ԃ̖��Ƃ����C�����邪�B
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
>>14
POWER6��POWER7�x�[�X��PC����CPU�𐫔\9���A�l�i1�����x�ŏo���ė~�����ȁB
>>26
������Pen��Pen2�̃R�s�[�炵�����lj��x���I���W�i��CPU���o���Ă�ˁB
�����A�����V�F�A�Ɛ肵���獡�̐��E�V�F�A�ȏゾ���獑�Y����鉿�l�͂���ȁB
�C���h�͍��̂Ƃ������ĂȂ��݂��������ǐl���Œ������炵������s����f�J�C���낤�ȁB
POWER6��POWER7�x�[�X��PC����CPU�𐫔\9���A�l�i1�����x�ŏo���ė~�����ȁB
>>26
������Pen��Pen2�̃R�s�[�炵�����lj��x���I���W�i��CPU���o���Ă�ˁB
�����A�����V�F�A�Ɛ肵���獡�̐��E�V�F�A�ȏゾ���獑�Y����鉿�l�͂���ȁB
�C���h�͍��̂Ƃ������ĂȂ��݂��������ǐl���Œ������炵������s����f�J�C���낤�ȁB
���ꂦ�AMAC�I�^��搶POWER7�l�^�̓X���[�������H
��������
��������
>>26
������x86�݊��ȃh���S���`�b�v�V���J���������ˁB
�ȑO����CPU�o�X�̃��C�Z���X��肪�傫�ȕǂɂȂ��Ă����ǁA���Ȃ烁����
�o�X��CPU�����ŁA�T�E�X�`�b�v���Ƃ�PCI-E�Őڑ�������[�}���^�C�����B
>>29
���x��Isaiah�́A���Ɏg���Â���Ă��@���A�ړI�ɉ������`�ōœK�̗p����
������CPU����ˁB
�ړI�̕�������₸��Ă邪�ASilverthorne�Ɛ��ݕ����o���邩�A���ʂ���
�Ԃ��邩�ŁA�ח����邩�ǂ��������܂�Ǝv���B
�����A�����됻���v���Z�X���P�������Ă�̂����Ƃ��s���Ȗ��ǁB
������x86�݊��ȃh���S���`�b�v�V���J���������ˁB
�ȑO����CPU�o�X�̃��C�Z���X��肪�傫�ȕǂɂȂ��Ă����ǁA���Ȃ烁����
�o�X��CPU�����ŁA�T�E�X�`�b�v���Ƃ�PCI-E�Őڑ�������[�}���^�C�����B
>>29
���x��Isaiah�́A���Ɏg���Â���Ă��@���A�ړI�ɉ������`�ōœK�̗p����
������CPU����ˁB
�ړI�̕�������₸��Ă邪�ASilverthorne�Ɛ��ݕ����o���邩�A���ʂ���
�Ԃ��邩�ŁA�ח����邩�ǂ��������܂�Ǝv���B
�����A�����됻���v���Z�X���P�������Ă�̂����Ƃ��s���Ȗ��ǁB
>���x��Isaiah�́A���Ɏg���Â���Ă��@���A�ړI�ɉ������`�ōœK�̗p����
>������CPU����ˁB
���ꂪ�ǂ����
�ނ���Silverthorne�͏o���̂��x������
2�N�O�Ȃ�ǂ�������������Ȃ���
>������CPU����ˁB
���ꂪ�ǂ����
�ނ���Silverthorne�͏o���̂��x������
2�N�O�Ȃ�ǂ�������������Ȃ���
�Ƃ�����Silverthorne�ɖ�������
>>27
PC Watch���
http://pc.watch.impress.co.jp/docs/article/991119/kaigai01.htm
>�����ЂƂ���B���V�A��MPU�A�[�L�e�N�gBoris Babaian���̉��Elbrus
>International�ł́AItanium������p�t�H�[�}���X�́uE2K�v�v���Z�b�T
>���J�����Ă��邪�A������g�����X���[�V�����\�t�g���g����x86�̃R�[�h
>��ϊ����Ď��s����B����MPU���AVLIW���C�N�Ȓ����ߌ�A�v���[�`�����
>�悤���B���Ђ́uE2K�v�̃y�[�W�ɊT�v������
��b�Ȋw�͂̍������V�A�Ȃ獂���\CPU���J���ł��邩�ȁB
PC Watch���
http://pc.watch.impress.co.jp/docs/article/991119/kaigai01.htm
>�����ЂƂ���B���V�A��MPU�A�[�L�e�N�gBoris Babaian���̉��Elbrus
>International�ł́AItanium������p�t�H�[�}���X�́uE2K�v�v���Z�b�T
>���J�����Ă��邪�A������g�����X���[�V�����\�t�g���g����x86�̃R�[�h
>��ϊ����Ď��s����B����MPU���AVLIW���C�N�Ȓ����ߌ�A�v���[�`�����
>�悤���B���Ђ́uE2K�v�̃y�[�W�ɊT�v������
��b�Ȋw�͂̍������V�A�Ȃ獂���\CPU���J���ł��邩�ȁB
37 �FMAC�I�^��36 �����F2008/02/16(�y) 22:29:46 ID:3jG331Ei
>>36
IPF�̌����W�������āAIntel��Elbrus���z���ς݂��B
http://www.intel.com/pressroom/kits/bios/bbabayan.htm
IPF�̌����W�������āAIntel��Elbrus���z���ς݂��B
http://www.intel.com/pressroom/kits/bios/bbabayan.htm
38 �F�R�E�L�́M�E,,�j�����������������F2008/02/16(�y) 22:47:48 ID:dEgHxPLu
���̂���Itanium�͂ς��Ƃ��Ȃ���
40 �F�R�E�L�́M�E,,�j�����������������F2008/02/16(�y) 23:35:29 ID:dEgHxPLu
Itanium�͐��\���M�����d��������B
�{���͐��\�ł�x86��2�{���Ői�����ă��[�h���Ă����\�肾�����̂�����
�{���͐��\�ł�x86��2�{���Ői�����ă��[�h���Ă����\�肾�����̂�����
�M�����d���Ƃ����ƁH
42 �F�R�E�L�́M�E,,�j�����������������F2008/02/16(�y) 23:44:20 ID:dEgHxPLu
3�n�ŏ璷�ɂ��đ������ňُ�n��藣���Ďc��2�n�ŘA���ғ��ł���Ƃ�
>>41
�݂������Ă�����
�݂������Ă�����
44 �F�R�E�L�́M�E,,�j�����������������F2008/02/17(��) 00:57:43 ID:eqN2t8U+
����Ȃ̂���������
http://ascii.jp/elem/000/000/029/29694/index-2.html
��Itanium 2�̓C���e���̃n�C�G���h����CPU�ł���AXeon�Ȃ�x86�n��CPU�Ɣ�r���āA�L���b�V���̃G���[������
�������I�ɐ藣���d�g�݁i�L���b�V���Z�[�t�e�N�m���W�[�j�ȂǁA�M���������コ���邳�܂��܂Ȏd�g�݂����B
http://ascii.jp/elem/000/000/029/29694/index-2.html
��Itanium 2�̓C���e���̃n�C�G���h����CPU�ł���AXeon�Ȃ�x86�n��CPU�Ɣ�r���āA�L���b�V���̃G���[������
�������I�ɐ藣���d�g�݁i�L���b�V���Z�[�t�e�N�m���W�[�j�ȂǁA�M���������コ���邳�܂��܂Ȏd�g�݂����B
CPU�P�̂ł͂Ȃ��C�V�X�e���S�̂�2W��Ȃ��Ƙb�ɂȂ�Ȃ��炵���ȁ�OLPC
46 �F�R�E�L�́M�E,,�j�����������������F2008/02/17(��) 04:40:26 ID:eqN2t8U+
DS�Ȃ݂̏���d�͐v���B
�|�P�R���Ȃ݂�v���������Ƃ��������
�d�r������50���ԂƂ��B
�����[�d���ƁA�J�o���ɓ�����ςȂ��Ƃ���
�G�Ȃ������������Â炢��
�d�r������50���ԂƂ��B
�����[�d���ƁA�J�o���ɓ�����ςȂ��Ƃ���
�G�Ȃ������������Â炢��
SUN��45nm�ȍ~�̐����p�[�g�i�[��TSMC�Ɍ��肵���������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206800071
�@�@------------------
�@�@The company is making gradual progress toward its goal of becoming a merchant chip provider.
�@�@The TSMC deal ultimately could assist in that effort.
�@�@[����]
�@�@In the future, Sun hopes TSMC will become a sales channel to provide Sparc cores to its
�@�@foundry customers.
�@�@------------------
�Ƃ������ƂŁASUN�v��Sparc�̊O�̂�g���s��ւ̐i�o���_���Ă���͗l���B
����Sparc��SUN�ƕx�m�ʈȊO�ɂ�TI��Ross Technology����s�̂̃`�b�v�������[�X����A
�g����������T�[�o�[�p�Ɏ���܂ŁA�l�X�ȕi�킪���݂��Ă������m���B�ŋ߂̐v�̃I�[�v��
�\�[�X����TSMC�����\�͂Ƃ������͂ȃo�b�N�A�b�v�ɂ��A�ċ����邷���ˁB�B�B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206800071
�@�@------------------
�@�@The company is making gradual progress toward its goal of becoming a merchant chip provider.
�@�@The TSMC deal ultimately could assist in that effort.
�@�@[����]
�@�@In the future, Sun hopes TSMC will become a sales channel to provide Sparc cores to its
�@�@foundry customers.
�@�@------------------
�Ƃ������ƂŁASUN�v��Sparc�̊O�̂�g���s��ւ̐i�o���_���Ă���͗l���B
����Sparc��SUN�ƕx�m�ʈȊO�ɂ�TI��Ross Technology����s�̂̃`�b�v�������[�X����A
�g����������T�[�o�[�p�Ɏ���܂ŁA�l�X�ȕi�킪���݂��Ă������m���B�ŋ߂̐v�̃I�[�v��
�\�[�X����TSMC�����\�͂Ƃ������͂ȃo�b�N�A�b�v�ɂ��A�ċ����邷���ˁB�B�B
�Ƃ���ōŋ߂�SUN��Sparc��A�R�A�Ԃ�L1���FPU�������L���Ă��邷�B
�t�@�u���X�ł��邽�߂������āA���ɍ�������N���b�N��v�ڕW�Ƃ��Ă��Ȃ����Ƃ��v���Ȃ��ǁA
�R�A�P�ʂǂ��납�A�p�C�v���C�����\�����郆�j�b�g�P�ʂł̍��x�ȃ��W�����[�v�����܂��@�\����
����͗l���B
���[�U�[��Ƃ��K�v�ɉ����Ď��s���j�b�g�̒lj���L1�L���b�V���̑I�����ł���Ƃ������Ƃ�
����A�w�e���Ȗ��߃Z�b�g�s�v�ŗp�r�ɉ������R�A���\���ł���Ƃ������ƂɂȂ邷�B
TSMC�̃o�b�N�A�b�v����ł�AAMD������̃w�e���R�A�^�A�N�Z�����[�^�헪���y���ɖʔ�������
�ɂ��Ȃ��Ȃ������ˁB�B�B
�t�@�u���X�ł��邽�߂������āA���ɍ�������N���b�N��v�ڕW�Ƃ��Ă��Ȃ����Ƃ��v���Ȃ��ǁA
�R�A�P�ʂǂ��납�A�p�C�v���C�����\�����郆�j�b�g�P�ʂł̍��x�ȃ��W�����[�v�����܂��@�\����
����͗l���B
���[�U�[��Ƃ��K�v�ɉ����Ď��s���j�b�g�̒lj���L1�L���b�V���̑I�����ł���Ƃ������Ƃ�
����A�w�e���Ȗ��߃Z�b�g�s�v�ŗp�r�ɉ������R�A���\���ł���Ƃ������ƂɂȂ邷�B
TSMC�̃o�b�N�A�b�v����ł�AAMD������̃w�e���R�A�^�A�N�Z�����[�^�헪���y���ɖʔ�������
�ɂ��Ȃ��Ȃ������ˁB�B�B
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�R�A�Ԃ�L1���L���ĉ���˂�H
53 �FMAC�I�^��52 �����F2008/02/20(��) 23:08:54 ID:BLWAYbSZ
>>52
���ꂷ�B
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
�@�@---------------------
�@�@�`�b�v�ʐς����܂葝���Ȃ������̂́A�L���b�V������������CPU�R�A�����L����\����
�@�@�̗p�������Ƃ��傫���B4��CPU�R�A���܂Ƃ߂��N���X�^�� 1�̒P�ʂƂ��A1�̃N���X�^����
�@�@1��1�����߃L���b�V��(32KB+8KB)��4��CPU�R�A�����L���A1��1���f�[�^�L���b�V��
�@�@(32KB) ��2��CPU�R�A�����L����B���������_���Z���j�b�g(FPU)���A�N���X�^����2��
�@�@CPU�R�A��1��FPU�����L����\���Ƃ����B
�@�@---------------------
���ꂷ�B
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
�@�@---------------------
�@�@�`�b�v�ʐς����܂葝���Ȃ������̂́A�L���b�V������������CPU�R�A�����L����\����
�@�@�̗p�������Ƃ��傫���B4��CPU�R�A���܂Ƃ߂��N���X�^�� 1�̒P�ʂƂ��A1�̃N���X�^����
�@�@1��1�����߃L���b�V��(32KB+8KB)��4��CPU�R�A�����L���A1��1���f�[�^�L���b�V��
�@�@(32KB) ��2��CPU�R�A�����L����B���������_���Z���j�b�g(FPU)���A�N���X�^����2��
�@�@CPU�R�A��1��FPU�����L����\���Ƃ����B
�@�@---------------------
�Ȃ�B
SMT�̊e�X���b�h�@�\�Ə]���R�A�ɒ��ԃ��C���[���������������ȁB
SMT�̊e�X���b�h�@�\�Ə]���R�A�ɒ��ԃ��C���[���������������ȁB
���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���ĉ���˂�H
���{SGI�A�uTesla�v���̗p����GPU�R���s���[�e�B���O�����\�����[�V����
http://journal.mycom.co.jp/news/2008/02/21/035/index.html
http://journal.mycom.co.jp/news/2008/02/21/035/index.html
����P�i��3D�Q�[���t�@���̂��߂́u������DirectX�v�u��
DirectX�͕���R���s���[�e�B���OAPI�ւƐi������
ttp://www.watch.impress.co.jp/game/docs/20080221/newdx.htm
DirectX�͕���R���s���[�e�B���OAPI�ւƐi������
ttp://www.watch.impress.co.jp/game/docs/20080221/newdx.htm
ISSCC��Rock�_����OpenSparc.net�ɃA�b�v����Ă邷�B
http://www.opensparc.net/publications/presentations/isscc-2008-a-third-generation-65nm-16-core-32-thread-plus-32-scout-thread-cmt.html
http://www.opensparc.net/publications/presentations/isscc-2008-a-third-generation-65nm-16-core-32-thread-plus-32-scout-thread-cmt.html
>>36
Babaian�̓\�A��Cray�ƌĂ�Ă��L���A�[�L�e�B�N�g��
Babaian�̓\�A��Cray�ƌĂ�Ă��L���A�[�L�e�B�N�g��
���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���ĉ���˂�H
�������̃T�C�g�̍��T�̋L���œǂ����ǁA
����� http://pr.fujitsu.com/jp/news/2008/02/15-2a.pdf
����� http://pr.fujitsu.com/jp/news/2008/02/19a.pdf
����ׂ�ƁA���͂⏤�px86�v���Z�b�T�ɂ�S�Ă��Ђꕚ������Ȃ��Ƃ����̂��[���ł��邷�B�B�B
http://www.geocities.jp/andosprocinfo/wadai08/20080223.htm
�@�@---------------------
�@�@JAXA��FX1�Ƃ���HX600���r����ƁC���҂Ƃ��ɃN���b�h�R�ACPU�� 4�ŁCCPU�`�b�v������
�@�@1�{��DDR InfiniBand�i2GB/s)�����Ă��܂��B�ő�̃��������ڗʂ�CPU�`�b�v������32GB��
�@�@�����ł��B�傫�ȈႢ�́CFX1��➑̂�5U�� 2.5�{�T�C�Y���傫���_�ƁCHX600��4�̃`�b�v��
�@�@HyperTransport�Ō���Ă���̂�16�R�A��SMP�ŁC���������S�̂ň�̋�ԂɂȂ�̂ɂ���
�@�@���āCFX1�ł�4�ɕ�����Ă���_�ł��B�܂��C����d�͂�FX1��2.2KW�ɑ��āCHX600��
�@�@780W�C�d�ʂ�70Kg�� 21Kg�ŁCFX1�̕����N���b�N��������Ƃ��C�M���x�������Ƃ�����
�@�@�����b�g�͂���Ƃ��Ă��C���������HX600�̕������͓I�ŁC���́C���̂Q�̃V�X�e�������
�@�@�K�v������̂��ǂ�������܂���B
�@�@---------------------
����� http://pr.fujitsu.com/jp/news/2008/02/15-2a.pdf
����� http://pr.fujitsu.com/jp/news/2008/02/19a.pdf
����ׂ�ƁA���͂⏤�px86�v���Z�b�T�ɂ�S�Ă��Ђꕚ������Ȃ��Ƃ����̂��[���ł��邷�B�B�B
http://www.geocities.jp/andosprocinfo/wadai08/20080223.htm
�@�@---------------------
�@�@JAXA��FX1�Ƃ���HX600���r����ƁC���҂Ƃ��ɃN���b�h�R�ACPU�� 4�ŁCCPU�`�b�v������
�@�@1�{��DDR InfiniBand�i2GB/s)�����Ă��܂��B�ő�̃��������ڗʂ�CPU�`�b�v������32GB��
�@�@�����ł��B�傫�ȈႢ�́CFX1��➑̂�5U�� 2.5�{�T�C�Y���傫���_�ƁCHX600��4�̃`�b�v��
�@�@HyperTransport�Ō���Ă���̂�16�R�A��SMP�ŁC���������S�̂ň�̋�ԂɂȂ�̂ɂ���
�@�@���āCFX1�ł�4�ɕ�����Ă���_�ł��B�܂��C����d�͂�FX1��2.2KW�ɑ��āCHX600��
�@�@780W�C�d�ʂ�70Kg�� 21Kg�ŁCFX1�̕����N���b�N��������Ƃ��C�M���x�������Ƃ�����
�@�@�����b�g�͂���Ƃ��Ă��C���������HX600�̕������͓I�ŁC���́C���̂Q�̃V�X�e�������
�@�@�K�v������̂��ǂ�������܂���B
�@�@---------------------
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
>>20
�����ŋC�t���Ă�������
�����ŋC�t���Ă�������
�R�s�y���������Ȃ��Ă�����ŃY�o���ƌ���������Ă��������B
���߃L���[����Ȃ����Z�p�C�v���C����ɂ�����Ă̂��������Ǝv����
�Ȃ̃o�b�t�@�ɂ����^�C���܂ŃX�e�[�g�ێ��Ƃ����Ă�̂��������
����JAXA�̃}�V�����č�������Ȃ��A�O����Ԉ���Ă�����
Pentium4���������Ƃ���SPARC64�Ȃ���
�Ȃ̃o�b�t�@�ɂ����^�C���܂ŃX�e�[�g�ێ��Ƃ����Ă�̂��������
����JAXA�̃}�V�����č�������Ȃ��A�O����Ԉ���Ă�����
Pentium4���������Ƃ���SPARC64�Ȃ���
�q��Z�\�Z�C���t�H���[���Ă邗
http://grape.mtk.nao.ac.jp/pub/people/makino/journal/journal-2008-02.html#24
> �A���u���O�͂Ƃ������A ��������Ƃ��ł͂���������� FX1 �̗ǂ��Ƃ����
> �����Ă������̂ł͂Ȃ����Ǝv��Ȃ����Ȃ������B 4�\�P�b�g Opteron ��
> ��ׂ�� B/F �� 3�{�ǂ��Ƃ��A���Ȃ��Ƃ��`�b�v���ł͓����������Ƃ�
> �܂��������ǂ����Ƃ�����̂ŁB
http://grape.mtk.nao.ac.jp/pub/people/makino/journal/journal-2008-02.html#24
> �A���u���O�͂Ƃ������A ��������Ƃ��ł͂���������� FX1 �̗ǂ��Ƃ����
> �����Ă������̂ł͂Ȃ����Ǝv��Ȃ����Ȃ������B 4�\�P�b�g Opteron ��
> ��ׂ�� B/F �� 3�{�ǂ��Ƃ��A���Ȃ��Ƃ��`�b�v���ł͓����������Ƃ�
> �܂��������ǂ����Ƃ�����̂ŁB
>>66
Pentium4�ő�K��SMP�g�߂ƁH��
Pentium4�ő�K��SMP�g�߂ƁH��
>>67 ����
�@�@--------------------
�@�@��ׂ�� B/F �� 3�{�ǂ��Ƃ��A
�@�@--------------------
�C�t���Ȃ����������ǁA>>62�̎d�l���Ɂu�������o���h���F40GB/s�v�Ƃ����L�q�����邷�ˁB�B�B
>>68 ����
�ł����x�̃V�X�e����N���X�^���B
�@�@--------------------
�@�@��ׂ�� B/F �� 3�{�ǂ��Ƃ��A
�@�@--------------------
�C�t���Ȃ����������ǁA>>62�̎d�l���Ɂu�������o���h���F40GB/s�v�Ƃ����L�q�����邷�ˁB�B�B
>>68 ����
�ł����x�̃V�X�e����N���X�^���B
128way SMP����4way/1n ode�ɕς����̂�
�O��̃o�X��������ĂȂ����Ă̂������������낤w
�O��̃o�X��������ĂȂ����Ă̂������������낤w
>>70
�����̃o�X��z�肵�Ă�H
�����̃o�X��z�肵�Ă�H
>>71
�o�X���[���A�v���Z�b�T�{�[�h�Ԃ̃N���X�o�[�X�C�b�`�H
�o�X���[���A�v���Z�b�T�{�[�h�Ԃ̃N���X�o�[�X�C�b�`�H
73 �FSocket774�F2008/02/26(��) 06:24:52 ID:FI7tKIM0
�Ƃ���ŃN���X�o�[�X�C�b�`���ĂȂ�Œx�₪�[���Ȃ́H
74 �FMAC�I�^��73 �����F2008/02/26(��) 07:11:44 ID:Qu9idi6X
RealWorldTech��David Wang����ISSCC2008 45nm CELL B.E.�̃��|�[�g���B
http://www.realworldtech.com/page.cfm?ArticleID=RWT022508002434
http://www.realworldtech.com/page.cfm?ArticleID=RWT022508002434
�A�[�L�e�N�`���I�ɂ�A�قڃN�A�h�R�APOWER6�ƌ����Ă��ǂ����C���t���[�������v���Z�b�T"z6"
���ڐ��i�����������o�Ă���Ƃ̂��Ƃ��B
http://searchdatacenter.techtarget.com/news/article/0,289142,sid80_gci1301967,00.html
�@�@-------------------
�@�@- a quad-core mainframe central processor previously called the z6;
�@�@-------------------
�v���Z�b�T�̕��̔��\�ł�A�S���f��z9�ɑ��ĂȂ��u6�v�ɖ߂�B�B�B�ƕ��c�������������m�����ǁA
���ǐ��i�Ƃ��Ă�"z10"�ɂȂ�͗l���B
���ڐ��i�����������o�Ă���Ƃ̂��Ƃ��B
http://searchdatacenter.techtarget.com/news/article/0,289142,sid80_gci1301967,00.html
�@�@-------------------
�@�@- a quad-core mainframe central processor previously called the z6;
�@�@-------------------
�v���Z�b�T�̕��̔��\�ł�A�S���f��z9�ɑ��ĂȂ��u6�v�ɖ߂�B�B�B�ƕ��c�������������m�����ǁA
���ǐ��i�Ƃ��Ă�"z10"�ɂȂ�͗l���B
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�}�N�I�^�o�����ɂ��\��t����͈̂��܂łɂ��Ă�����B
Mac�I�^���g�ɏ����Ă��炨����
���̕�����Ԃ��͂Ԃ���
���̕�����Ԃ��͂Ԃ���
���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���ĉ���˂�H
>>75�̑����ǁA�u���̌�̎��^�����ŁA32nm�����CELL�̃������R���g���[����ʂ̐V����
�������C���^�[�t�F�[�X�Ή��ɕύX����\��Ƃ����b���o���Ƃ̂��Ƃ��B
�@�@----------------------
�@�@BTW, I then asked the presenter - what about 32 nm? If you're I/O limited now, what are you
�@�@going to do at 32nm? (assuming there is such a 32 nm port). He gave a cryptic answer of
�@�@"Well, the XDR stuff may be fairly old by the time 32 nm is ready, so we may replace it with
�@�@something else."
�@�@----------------------
"something else"��XDR2�Ȃ̂��A�X�ɐ�i�I��Rambus�̋Z�p�Ȃ̂��A
http://www.rambus.com/jp/news/press_releases/2007/071128.html
Rambus�ƑS�R�W�Ȃ��̂���䂷�B
�������C���^�[�t�F�[�X�Ή��ɕύX����\��Ƃ����b���o���Ƃ̂��Ƃ��B
�@�@----------------------
�@�@BTW, I then asked the presenter - what about 32 nm? If you're I/O limited now, what are you
�@�@going to do at 32nm? (assuming there is such a 32 nm port). He gave a cryptic answer of
�@�@"Well, the XDR stuff may be fairly old by the time 32 nm is ready, so we may replace it with
�@�@something else."
�@�@----------------------
"something else"��XDR2�Ȃ̂��A�X�ɐ�i�I��Rambus�̋Z�p�Ȃ̂��A
http://www.rambus.com/jp/news/press_releases/2007/071128.html
Rambus�ƑS�R�W�Ȃ��̂���䂷�B
82 �FMAC�I�^��80 �����F2008/02/26(��) 23:48:49 ID:Qu9idi6X
>>80 ����
�@�@-----------------
�@�@���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���ĉ���˂�H
�@�@-----------------
�u���j�b�g�P�ʂł́i�R�A�̃J�X�^�}�C�Y���\�ȁj���x�ȃ��W�����[�v�v�Ƃ����Ӗ��ŏ�����������
����ɂ������������H
�@�@-----------------
�@�@���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���ĉ���˂�H
�@�@-----------------
�u���j�b�g�P�ʂł́i�R�A�̃J�X�^�}�C�Y���\�ȁj���x�ȃ��W�����[�v�v�Ƃ����Ӗ��ŏ�����������
����ɂ������������H
���j�b�g�P�ʂł̍��x�ȃ��W�����[�v���Ăǂ��������̂Ȃ̂������Ă�
84 �FMAC�I�^��80, 83 �����F2008/02/26(��) 23:52:23 ID:Qu9idi6X
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�����������������
�܂�������A������ȉ��ɂ��Ƃ�
���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
�C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
�܂�������A������ȉ��ɂ��Ƃ�
���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
�C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
87 �FMAC�I�^��86 �����F2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
ROB���C���e���p��ƌ������薽�߃L���[�ƌĂ肷��̂�A���E�L���Ƃ����ǂ�MAC�I�^������(��)
x86�p��ł������B�������邷�B
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
--
RS��ROB���ʕ��ł��邱�Ƃ�F�����Ă�悤�����B�B�B
843 ���O�F MAC�I�^��841 ���� [sage] ���e���F 2008/01/29(��) 20:28:46 ID:U+YuE5q6
>>841
���Ȃ������p���Ă���A
�@�@---------------
�@�@Also, each micro-op generated by the translator can represent functions to be performed �B�B�B
�@�@---------------
�̂����O�̃p���O���t�ɂ�A
�@�@---------------
�@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
�@�@initial implementation) and an optional ROM address.
�@�@---------------
�Ə����Ă���ǁA>>832��>>834��2�x���J��Ԃ��ď����Ă���
�@�@===============
�@�@x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops
�@�@===============
���ꉽ����(��)
���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
�s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
--
RS��ROB���ʕ��ł��邱�Ƃ�F�����Ă�悤�����B�B�B
843 ���O�F MAC�I�^��841 ���� [sage] ���e���F 2008/01/29(��) 20:28:46 ID:U+YuE5q6
>>841
���Ȃ������p���Ă���A
�@�@---------------
�@�@Also, each micro-op generated by the translator can represent functions to be performed �B�B�B
�@�@---------------
�̂����O�̃p���O���t�ɂ�A
�@�@---------------
�@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
�@�@initial implementation) and an optional ROM address.
�@�@---------------
�Ə����Ă���ǁA>>832��>>834��2�x���J��Ԃ��ď����Ă���
�@�@===============
�@�@x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops
�@�@===============
���ꉽ����(��)
���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
�s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
�����Ŗ��߃L���[=RS���ƔF�����Ă���̂Ȃ�A�܂��Ӗ����ʂ��邷���A
���߃L���[=ROB���ƔF�����Ă���̂Ȃ�A���Ȃ�[���ȃg���`���J�����B
858 ���O�F MAC�I�^ [sage] ���e���F 2008/01/30(��) 08:12:50 ID:X/E3HbLz
>>854 �c�q ����
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
���߃L���[=ROB���ƔF�����Ă���̂Ȃ�A���Ȃ�[���ȃg���`���J�����B
858 ���O�F MAC�I�^ [sage] ���e���F 2008/01/30(��) 08:12:50 ID:X/E3HbLz
>>854 �c�q ����
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
�������Ă������������ǁA���߃L���[=RS�Ƃ������Ƃł������ˁH
865 ���O�F MAC�I�^��859 ���� [sage] ���e���F 2008/01/31(��) 20:56:08 ID:0C6GGRXK
>>859
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
865 ���O�F MAC�I�^��859 ���� [sage] ���e���F 2008/01/31(��) 20:56:08 ID:0C6GGRXK
>>859
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���_�͂���ł����H
85 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 00:04:53 ID:TBIh/VLx
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
86 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 00:07:14 ID:TBIh/VLx
�����������������
�܂�������A������ȉ��ɂ��Ƃ�
���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
�C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
87 ���O�F MAC�I�^��86 ���� [sage] ���e���F 2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
85 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 00:04:53 ID:TBIh/VLx
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
86 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 00:07:14 ID:TBIh/VLx
�����������������
�܂�������A������ȉ��ɂ��Ƃ�
���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
�C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
87 ���O�F MAC�I�^��86 ���� [sage] ���e���F 2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
�{���ɁAROB�̂��Ƃ������������ǁA�ł����ˁH
87 ���O�F MAC�I�^��86 ���� [sage] ���e���F 2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
�O�X��858
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
87 ���O�F MAC�I�^��86 ���� [sage] ���e���F 2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
�O�X��858
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
94 �FMAC�I�^���ϑz �����F2008/02/27(��) 00:35:43 ID:0rj98mcp
MAC�I�^�͑O�X��858��865�ŁA���߃L���[��RS�Ȃ̂��AROB�Ȃ̂��A����ȊO�̂��̂Ȃ̂��A�ǂ���w���Ă��邷���H
96 �FMAC�I�^���ϑz �����F2008/02/27(��) 00:51:20 ID:0rj98mcp
>>95
����̈Ӗ��퉽�ƂȂ������ł��������ǁA
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
�̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
�o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
���Ȃ����g��OoOE�̎������l�X�Ȍ`�ł��邱�Ƃ�������Ă��Ȃ����������H
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/875
�@�@----------------------
�@�@���肪�����}���o���Ă��ꂽ�̂ʼn�����Ƃ��ƁA
�@�@��ԏ��Alpha 21264�̓��I�[�_�o�b�t�@����Ȃ��ă`�F�b�N�|�C���g�ŃC���I�[�_��Ԃ������e���Ă�B
�@�@�`�F�b�N�|�C���g�Ƃ����̂́A���̎��_�ł̃��W�X�^�}�b�v(�̃R�s�[)�Ȃ��ǁA�������^�C�v���ˁB
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@�O�Ԗڂ�ARM�ɂ��Ă͒m��Ȃ��̂ŁA
�@�@OoO Write back stage�Ƃ����̂�ROB�ɑ������邩�A�{����OoO commit����̂��͂킩��Ȃ����A
�@�@�ǂ���ɂ��施�߃L���[����issue���ɖ��߂���菜���Ȃ����R�͂Ȃ��Ȃ�B
�@�@----------------------
����̈Ӗ��퉽�ƂȂ������ł��������ǁA
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
�̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
�o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
���Ȃ����g��OoOE�̎������l�X�Ȍ`�ł��邱�Ƃ�������Ă��Ȃ����������H
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/875
�@�@----------------------
�@�@���肪�����}���o���Ă��ꂽ�̂ʼn�����Ƃ��ƁA
�@�@��ԏ��Alpha 21264�̓��I�[�_�o�b�t�@����Ȃ��ă`�F�b�N�|�C���g�ŃC���I�[�_��Ԃ������e���Ă�B
�@�@�`�F�b�N�|�C���g�Ƃ����̂́A���̎��_�ł̃��W�X�^�}�b�v(�̃R�s�[)�Ȃ��ǁA�������^�C�v���ˁB
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@�O�Ԗڂ�ARM�ɂ��Ă͒m��Ȃ��̂ŁA
�@�@OoO Write back stage�Ƃ����̂�ROB�ɑ������邩�A�{����OoO commit����̂��͂킩��Ȃ����A
�@�@�ǂ���ɂ��施�߃L���[����issue���ɖ��߂���菜���Ȃ����R�͂Ȃ��Ȃ�B
�@�@----------------------
97 �FMAC�I�^�������F2008/02/27(��) 00:53:12 ID:0rj98mcp
���^�C�A��OoO�Ŏ��s���Ȃ�����A�f�B�X�p�b�`���烊�^�C�A�܂�in-flight�Ȗ��߂̋L�^���c���Ă���
�K�v�����邷����A���ߊǗ����j�b�g�S�̂ōl���āu���^�C�A�܂ŃX���b�g���Ȃ��v�Ƃ����̂�
�����Șb���Ǝv�����B
�K�v�����邷����A���ߊǗ����j�b�g�S�̂ōl���āu���^�C�A�܂ŃX���b�g���Ȃ��v�Ƃ����̂�
�����Șb���Ǝv�����B
87 ���O�F MAC�I�^��86 ���� [sage] ���e���F 2008/02/27(��) 00:12:41 ID:0rj98mcp
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�́A�ǂ��������邷���ˁB�B�B
>>86
ROB�̂��Ƃ������������ǁB
OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
������ʂĂ���肷(��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�́A�ǂ��������邷���ˁB�B�B
99 �FMAC�I�^��98 �����F2008/02/27(��) 01:14:37 ID:0rj98mcp
�O�X��858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
���̖��߃L���[�Ƃ�ARS�����HROB�����H
�O�X��865
>�@ �@-------------------
>�@ �@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
>�@ �@-------------------
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���̖��߃L���[�Ƃ�ARS�����HROB�����H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
���̖��߃L���[�Ƃ�ARS�����HROB�����H
�O�X��865
>�@ �@-------------------
>�@ �@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
>�@ �@-------------------
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���̖��߃L���[�Ƃ�ARS�����HROB�����H
>>82
���[��A���ꂾ��
�@�ŋ߂�SUN��SPARC�́A�R�A�Ԃ�L1���FPU�������L���Ă���B
�@�R�A�P�ʂǂ��납�A�p�C�v���C�����\�����郆�j�b�g�P�ʂł�
�@�i�R�A�̃J�X�^�}�C�Y���\�ȁj���x�ȃ��W�����[�v��
�@���܂��@�\���Ă���͗l���B
���Ă��ƁH����ς�ǂ��킩��Ȃ��Ȃ�
�R�A�Ԃ�L1���FPU�������L�ł��邱�ƂƁA���j�b�g�P�ʂ�
�R�A�̃J�X�^�}�C�Y���\���Ă��Ƃ͓��l�Ȃ́H
���[��A���ꂾ��
�@�ŋ߂�SUN��SPARC�́A�R�A�Ԃ�L1���FPU�������L���Ă���B
�@�R�A�P�ʂǂ��납�A�p�C�v���C�����\�����郆�j�b�g�P�ʂł�
�@�i�R�A�̃J�X�^�}�C�Y���\�ȁj���x�ȃ��W�����[�v��
�@���܂��@�\���Ă���͗l���B
���Ă��ƁH����ς�ǂ��킩��Ȃ��Ȃ�
�R�A�Ԃ�L1���FPU�������L�ł��邱�ƂƁA���j�b�g�P�ʂ�
�R�A�̃J�X�^�}�C�Y���\���Ă��Ƃ͓��l�Ȃ́H
102 �FMAC�I�^��100 �����F2008/02/27(��) 01:23:45 ID:0rj98mcp
103 �FMAC�I�^��101 �����F2008/02/27(��) 01:26:05 ID:0rj98mcp
>>101
���l����Ȃ��̂�������Ȃ������ǁA������Niagara 1�ł�FPU�����L���ANiagara 2�ł�R�A���Ƃ�FPU
�������B�B�B�Ƃ������Ƃ�A�\���̎��R�x�������؋����Ǝv���邷�B
���l����Ȃ��̂�������Ȃ������ǁA������Niagara 1�ł�FPU�����L���ANiagara 2�ł�R�A���Ƃ�FPU
�������B�B�B�Ƃ������Ƃ�A�\���̎��R�x�������؋����Ǝv���邷�B
>>102
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
�������s�\�ȑg�ݍ��킹�������ł���̂́ARS��ROB�̂ǂ��炩�Е������Ȃ��ǁA�ǂ���H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
�������s�\�ȑg�ݍ��킹�������ł���̂́ARS��ROB�̂ǂ��炩�Е������Ȃ��ǁA�ǂ���H
>>102
�C�V���[���ꂽ���߂�Ax86�ł�RS�Ɏc�邷���H�c��Ȃ������H
�C�V���[���ꂽ���߂�Ax86�ł�RS�Ɏc�邷���H�c��Ȃ������H
�O�X��858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�����C�e���V���߂��肪�L���[�ɋ�����Ƃ������Ƃ́A�������Z���߂݂����ȃ��C�e���V�̒Z�����߂͋�����Ȃ��̂��ȁH
99 ���O�F MAC�I�^��98 ���� [sage] ���e���F 2008/02/27(��) 01:14:37 ID:0rj98mcp
>>98
�f�B�X�p�b�`-���^�C�A�Ԃɖ��߂��c��̂�x86�ŋ�̓I�ɉ������H�Ɛq�˂����ROB��
�����邾�����B
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�����C�e���V���߂��肪�L���[�ɋ�����Ƃ������Ƃ́A�������Z���߂݂����ȃ��C�e���V�̒Z�����߂͋�����Ȃ��̂��ȁH
99 ���O�F MAC�I�^��98 ���� [sage] ���e���F 2008/02/27(��) 01:14:37 ID:0rj98mcp
>>98
�f�B�X�p�b�`-���^�C�A�Ԃɖ��߂��c��̂�x86�ŋ�̓I�ɉ������H�Ɛq�˂����ROB��
�����邾�����B
����Ȃ銨�Ⴂ��˂����܂��
��
������떂�������߂�"�L���["���g�����
��
�ߋ��̔����Ƃ̖���������
��
����
����Ȋ����H
��
������떂�������߂�"�L���["���g�����
��
�ߋ��̔����Ƃ̖���������
��
����
����Ȋ����H
MAC�I�^�́A�����͂����̂�߂�
�^�C�g����URL�����ŏ\������
�^�C�g����URL�����ŏ\������
112 �FMAC�I�^���ϑz �����F2008/02/27(��) 08:29:52 ID:0rj98mcp
>>109
�@�@--------------
�@�@>>104��>>105��1�r�b�g�œ������鎿��Ȃ̂Ɂc
�@�@--------------
�����������Ă���Ȃ玄������K�v�햳�����A��ɂ���Ĕ]���ϑz�ʼn����g���f���Ȃ��Ƃ�
�l���Ă���̂Ȃ�A��������ɂ���K�v���������B
���ɘ_���I�ȍs�����Ǝv�������ǁB�B�B
�@�@--------------
�@�@>>104��>>105��1�r�b�g�œ������鎿��Ȃ̂Ɂc
�@�@--------------
�����������Ă���Ȃ玄������K�v�햳�����A��ɂ���Ĕ]���ϑz�ʼn����g���f���Ȃ��Ƃ�
�l���Ă���̂Ȃ�A��������ɂ���K�v���������B
���ɘ_���I�ȍs�����Ǝv�������ǁB�B�B
>>112
1�r�b�g�œ������鎿��ɁAMAC�I�^�������Ă���̂�����̂��y������(��)
1�r�b�g�œ������鎿��ɁAMAC�I�^�������Ă���̂�����̂��y������(��)
MAC�I�^��A�����Ƃ������̔����ɐӔC���������ق���������(��)
�R�e�����X������Ȃ�����A���������̂�肽����vip�ɂł��X�����ĂĂ���Ă����
MAC�I�^�����炩���ėV��ł���̂ł͂Ȃ��āA
���炩�ȊԈႢ��������悤�Ƃ��Ă���̂ŁA���������킯�ɂ������܂���
���炩�ȊԈႢ��������悤�Ƃ��Ă���̂ŁA���������킯�ɂ������܂���
Mac�I�^�A�Ƃ��Ƃ����ނ�
���Ƃ͎�����Blog�ł�낵����
���Ƃ͎�����Blog�ł�낵����
�ʂ�MAC�I�^�ɒp���������Ĉ��ނɂ������݂����킯�ł�Ȃ��āA
�����̊ԈႢ����������������������Ȃ��ˁB�B�B
�����̊ԈႢ����������������������Ȃ��ˁB�B�B
�x�m�ʂ̃T�C�g��JAXA��FX1�̌���������
�O���PRIMEPOWER��SMP�Ȃ̂�
�}���`�X���b�h��v���O���������Ȃ�
MPI�v���O�������������������
��p��FX1�ŁA1�m�[�h1�\�P�b�g�ɂ����̂́A���̂����Ȃ̂�
SMP�̃������ш�s���͐S�z����������
��������W���u�̃v���Z�b�T������
�����肭�����Ȃ������̂�
�����ɐ��\�łɂ��������������Ƃ���������
�x�N�g���X�p�R������PRIMEPOWER�̂Ƃ���
������@��ڍs���R�����܂�������Ă��Ȃ�
�x�m�ʂ̂����Ȃ肶��Ȃ��悤�ɂ����ƌ�����
�O���PRIMEPOWER��SMP�Ȃ̂�
�}���`�X���b�h��v���O���������Ȃ�
MPI�v���O�������������������
��p��FX1�ŁA1�m�[�h1�\�P�b�g�ɂ����̂́A���̂����Ȃ̂�
SMP�̃������ш�s���͐S�z����������
��������W���u�̃v���Z�b�T������
�����肭�����Ȃ������̂�
�����ɐ��\�łɂ��������������Ƃ���������
�x�N�g���X�p�R������PRIMEPOWER�̂Ƃ���
������@��ڍs���R�����܂�������Ă��Ȃ�
�x�m�ʂ̂����Ȃ肶��Ȃ��悤�ɂ����ƌ�����
����(>>76�Ƃ�)�ʂ�z10�����\���ꂽ���B
http://journal.mycom.co.jp/articles/2008/02/27/ibm/index.html
�ʔ����̂�A�v���Z�b�T"z6"��POWER6�łȂ��Ȃ��o�Ă��Ȃ�����MCM�p�b�P�[�W�ŏo���Ă������Ƃ��B
http://www.flickr.com/photos/21317126@N04/2290837631/in/set-72157603320138054/
�����A������ɊJ�����\�[�X�������MCM��POWER6��o�Ă��Ȃ��������B
http://journal.mycom.co.jp/articles/2008/02/27/ibm/index.html
�ʔ����̂�A�v���Z�b�T"z6"��POWER6�łȂ��Ȃ��o�Ă��Ȃ�����MCM�p�b�P�[�W�ŏo���Ă������Ƃ��B
http://www.flickr.com/photos/21317126@N04/2290837631/in/set-72157603320138054/
�����A������ɊJ�����\�[�X�������MCM��POWER6��o�Ă��Ȃ��������B
>>121
MAC�I�^����A������̉����肢���邷�B
104 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 01:28:16 ID:TBIh/VLx
>>102
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
�������s�\�ȑg�ݍ��킹�������ł���̂́ARS��ROB�̂ǂ��炩�Е������Ȃ��ǁA�ǂ���H
105 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 01:35:11 ID:TBIh/VLx
>>102
�C�V���[���ꂽ���߂�Ax86�ł�RS�Ɏc�邷���H�c��Ȃ������H
MAC�I�^����A������̉����肢���邷�B
104 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 01:28:16 ID:TBIh/VLx
>>102
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
�������s�\�ȑg�ݍ��킹�������ł���̂́ARS��ROB�̂ǂ��炩�Е������Ȃ��ǁA�ǂ���H
105 ���O�F Socket774 [sage] ���e���F 2008/02/27(��) 01:35:11 ID:TBIh/VLx
>>102
�C�V���[���ꂽ���߂�Ax86�ł�RS�Ɏc�邷���H�c��Ȃ������H
Z10�́A1�\�P�b�g�}�V���ł����疜����E���g����n�C�G���h������
�R�X�g�x�O�����āA���N���b�N&MCM�ɂ��邾��
System P�ł�MCM���Ȃ��Ȃ��łȂ����̂�
�����܂�Ƃ�����ˁH
Z10�ŏ�ʃ��f�����Ă����炭�炢�Ȃ낤��
���z�����^��1���ȏ�͂������낤
�R�X�g�x�O�����āA���N���b�N&MCM�ɂ��邾��
System P�ł�MCM���Ȃ��Ȃ��łȂ����̂�
�����܂�Ƃ�����ˁH
Z10�ŏ�ʃ��f�����Ă����炭�炢�Ȃ낤��
���z�����^��1���ȏ�͂������낤
����̓��C���t���[���Ȃ�ł����s��Ȃ��ƐM���Ă���
System Z�̑䐔�A�b�v�́A�x�m�ʂƂ���������q���Ƃ���������
�ق�Ƃ̐V�K���C���t���[�����[�U�[�Ȃ�Ă���܂��Ȃ�����A
���Ԃ�
�Ƃ���͎v������ł���
System Z�̑䐔�A�b�v�́A�x�m�ʂƂ���������q���Ƃ���������
�ق�Ƃ̐V�K���C���t���[�����[�U�[�Ȃ�Ă���܂��Ȃ�����A
���Ԃ�
�Ƃ���͎v������ł���
>>TBIh/VLx
���S�҂̉��ł��킩��悤�Ƀu���O���ĂĐ������Ă���
���S�҂̉��ł��킩��悤�Ƀu���O���ĂĐ������Ă���
>>126
�{���I�ɂ́AMAC�I�^��>>104��>>105�̎���ɓ������Ȃ������B
�ǂ������Ă��A�����̊ԈႢ��F�߂邱�ƂɂȂ邩��ˁB
������A>>96�̂悤�Ȍ�o�������Ă܂ł������ɂ͂��炩���B
�{���I�ɂ́AMAC�I�^��>>104��>>105�̎���ɓ������Ȃ������B
�ǂ������Ă��A�����̊ԈႢ��F�߂邱�ƂɂȂ邩��ˁB
������A>>96�̂悤�Ȍ�o�������Ă܂ł������ɂ͂��炩���B
http://nana2ch.hp.infoseek.co.jp/2ch2000.htm
���Ȃ�̕����������ŁA�����Ĕs�k��F�߂悤�Ƃ��Ȃ��B�Ԉ�����Ƃ��낪�������Ƃ��Ă��A�b����炵�ē����낤�Ƃ���B
���Ȃ�̕����������ŁA�����Ĕs�k��F�߂悤�Ƃ��Ȃ��B�Ԉ�����Ƃ��낪�������Ƃ��Ă��A�b����炵�ē����낤�Ƃ���B
���ᔻ���Ă�֓��l��
�֓��́g�ݓ����N�l�h�ɏ������Ă�킯��
�֓��̃e���r�ǂ́u�؍��l�̗��s�q�̓}�i�[�������v�ƌ�����������
���̔����������l��ԑg�~�������B
���̃e���r�ǂ͍ݓ� ���N ���a ���ł��ᔻ���܂��肾�����̖����Ȃ��B
���̃e���r�ǂ͓��a�s������݂̉��E���Nj����Ă܂���B
�֓��̃e���r�ǂł́u���a�v�Ƃ������t���̂��刵���̃w�^���B
�֓����čݓ� ���N ���a�ɗD�����s�s�ł���w
�֓��́g�ݓ����N�l�h�ɏ������Ă�킯��
�֓��̃e���r�ǂ́u�؍��l�̗��s�q�̓}�i�[�������v�ƌ�����������
���̔����������l��ԑg�~�������B
���̃e���r�ǂ͍ݓ� ���N ���a ���ł��ᔻ���܂��肾�����̖����Ȃ��B
���̃e���r�ǂ͓��a�s������݂̉��E���Nj����Ă܂���B
�֓��̃e���r�ǂł́u���a�v�Ƃ������t���̂��刵���̃w�^���B
�֓����čݓ� ���N ���a�ɗD�����s�s�ł���w
���ᔻ���Ă�֓��l��
�֓��́g�ݓ����N�l�h�ɏ������Ă�킯��
�֓��̃e���r�ǂ́u�؍��l�̗��s�q�̓}�i�[�������v�ƌ�����������
���̔����������l��ԑg�~�������B
���̃e���r�ǂ͍ݓ� ���N ���a ���ł��ᔻ���܂��肾�����̖����Ȃ��B
���̃e���r�ǂ͓��a�s������݂̉��E���Nj����Ă܂���B
�֓��̃e���r�ǂł́u���a�v�Ƃ������t���̂��刵���̃w�^���B
�֓����čݓ� ���N ���a�ɗD�����s�s�ł���w
�֓��́g�ݓ����N�l�h�ɏ������Ă�킯��
�֓��̃e���r�ǂ́u�؍��l�̗��s�q�̓}�i�[�������v�ƌ�����������
���̔����������l��ԑg�~�������B
���̃e���r�ǂ͍ݓ� ���N ���a ���ł��ᔻ���܂��肾�����̖����Ȃ��B
���̃e���r�ǂ͓��a�s������݂̉��E���Nj����Ă܂���B
�֓��̃e���r�ǂł́u���a�v�Ƃ������t���̂��刵���̃w�^���B
�֓����čݓ� ���N ���a�ɗD�����s�s�ł���w
MYCOM�Ɉ�������ISSCC���|�[�g���f�ڂ��Ă��邷�B
������A����ς菟��̒m�ꂽSPARC�̐V�^Rocks�̋L�����ƁB
http://journal.mycom.co.jp/articles/2008/03/02/isscc3/index.html
������A����ς菟��̒m�ꂽSPARC�̐V�^Rocks�̋L�����ƁB
http://journal.mycom.co.jp/articles/2008/03/02/isscc3/index.html
>>86
> ���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
> �C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
>>87
> >>86
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
>>96
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
> ���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
> �C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
>>87
> >>86
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
>>96
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�O�X��858
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
���ꂩ�炱�̃R�s�y����Ƃ��̓R�e����Ƃ��܂���
�O�X��865
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�����A�R�e�t���ĂȂ�
�X�}�\
�X�}�\
�X�p���t�B���^�n�̃A�{���@�\�~�����ˁB
���������̂�����Ɖ����������Ȃ��Ă����̂ł��ꂵ����
http://journal.mycom.co.jp/articles/2008/03/02/isscc1/001.html
>Opteron��HT��ʂ��ăA�h���X���u���[�h�L���X�g���ăX�k�[�v�����ŃL���b�V���R�q�[�����V������s���Ă���̂ɑ��āA
>Tukwila�̓f�B���N�g���x�[�X�̃L���b�V���R�q�[�����X������s���Ă���
����ǂ��Ⴄ�́H
>Opteron��HT��ʂ��ăA�h���X���u���[�h�L���X�g���ăX�k�[�v�����ŃL���b�V���R�q�[�����V������s���Ă���̂ɑ��āA
>Tukwila�̓f�B���N�g���x�[�X�̃L���b�V���R�q�[�����X������s���Ă���
����ǂ��Ⴄ�́H
141 �FMAC�I�^��140 �����F2008/03/02(��) 22:43:47 ID:Rb6z5yls
>>140
Opteron��S�Ẵv���Z�b�T�Ƀf�[�^���g�p�����ǂ������ڐq�˂ɂ����̂ɑ��āATukwila��
�ڎ��̈��ǂ݂ɂ����Ώ����f�ł���悤�ɂȂ��Ă���Ƃ����b���B
Opteron��S�Ẵv���Z�b�T�Ƀf�[�^���g�p�����ǂ������ڐq�˂ɂ����̂ɑ��āATukwila��
�ڎ��̈��ǂ݂ɂ����Ώ����f�ł���悤�ɂȂ��Ă���Ƃ����b���B
>>140
�L���b�V���u��ԁv���ێ����W�b�N���������i�z�[���G�[�W�F���g�j��ʂɒu���ďW���Ǘ�����
�L���b�V���u��ԁv���ێ����W�b�N���������i�z�[���G�[�W�F���g�j��ʂɒu���ďW���Ǘ�����
143 �F�ǂ��Ă������܂����F2008/03/04(��) 19:17:47 ID:jCJdsfie
>>134
���s���j�b�g�ɓ������Ȃ��Ŗ��߃L���[�ɕێ�����̂����E������
���߃L���[�̐[������32���߂��炢����H
���[�h���߂Ŗ��܂�Ƃ����肦�Ȃ�
���s���j�b�g�ɓ������Ȃ��Ŗ��߃L���[�ɕێ�����̂����E������
���߃L���[�̐[������32���߂��炢����H
���[�h���߂Ŗ��܂�Ƃ����肦�Ȃ�
��p���߂ł�������R�A�ԃp�C�v���C�����~�����B
�o�X�Ȃ�Ēʂ��Ă������I
�o�X�Ȃ�Ēʂ��Ă������I
�������]���̂ǂ���ӂɃp�C�v���C��������K�p�ł���̂��낤�H
�A�����J��R�A�����ړI��PS3��300�䒲�B��
http://gigazine.net/index.php?/news/comments/20080306_ps3_us_airforce/
http://gigazine.net/index.php?/news/comments/20080306_ps3_us_airforce/
z10
>>146
�X�[�p�[�R���s���[�^�����PS3--�Č����҂����H
http://japan.gamespot.com/news/story/0,3800076565,20359102,00.htm
������Y��Ȃ��ł�
�X�[�p�[�R���s���[�^�����PS3--�Č����҂����H
http://japan.gamespot.com/news/story/0,3800076565,20359102,00.htm
������Y��Ȃ��ł�
Victoria Falls��Niagara2���ڃT�[�o�[��A4-socket���f�����o��Ƃ̂��Ƃ��B
http://www.theregister.co.uk/2008/03/07/sun_victoria_falls/
�@�@-------------------
�@�@Sun will ship the two-socket T5140 and the two-socket T5240 servers. Later on, customers
�@�@will see the four-socket T5440 (Botaka) system as well.
�@�@-------------------
http://www.theregister.co.uk/2008/03/07/sun_victoria_falls/
�@�@-------------------
�@�@Sun will ship the two-socket T5140 and the two-socket T5240 servers. Later on, customers
�@�@will see the four-socket T5440 (Botaka) system as well.
�@�@-------------------
�O�X��865
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�O�X��858
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�O�X��858
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
>>86
> ���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
> �C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
>>87
> >>86
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
>>96
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
> ���߃L���[=RS����́A�C�V���[���Ɏ�菜�������ǂ�
> �C���I�[�_�[��Ԃ̉ɕK�v�Ȃ��̂�ROB�Ɏc��
>>87
> >>86
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
>>96
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858�@(>>93�Q��)
> http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865�@(>>91�Q��)
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
���낻��ʂɃX�����ĂĂ����
�R�e�ɂ��Č�ꂶ��Ȃ�����A������
�R�e�ɂ��Č�ꂶ��Ȃ�����A������
�E�U�S�����R�e�t���Ă����Ζʓ|�����Ȃ��čςނ��ǂ˂�
�X���L�тĂ�Ǝv���Č���NGID�lj����Ă̂����[�`�������Ă�
�z���g������
�X���L�тĂ�Ǝv���Č���NGID�lj����Ă̂����[�`�������Ă�
�z���g������
�Ȃ����@�Ɓ@���炷�@��NG���[�h�ɂ��邩�B
�쐶������
�Ƃ킢���]���ϑz�ȂǂƎ���Ȃ��Ƃ������Ėق��Ă���킯�ɂ������Ȃ���
���f�������Đ\���킯�Ȃ��Ƃ�v�����AMAC�I�^������������܂Őh�����Ă�������
���f�������Đ\���킯�Ȃ��Ƃ�v�����AMAC�I�^������������܂Őh�����Ă�������
MAC�I�^�́A�����ȊԈႢ��������邱�Ƃ�A���̃X���ɂƂ��Ă��L�v���Ǝv�����B
����ˌ������Ă��炦��A�����I���Ǝv�����ǂˁB
����ˌ������Ă��炦��A�����I���Ǝv�����ǂˁB
>>145
���W�X�^�l�����i�w��j�R�A�ɑ���p�C�v���C��
���W�X�^�l�����i�w��j�R�A�ɑ���p�C�v���C��
�R�e�ɂ��Ă팟�����������A�̐S��MAC�I�^�����Ȃ��Ȃ��Ă��܂��ƍ���̂ŁA�~�߂邱�Ƃɂ������B
�X���^�C�Ń{�P
���ȃ��X�Ń��\�[�X�������ȋ�
�T���r�����J�X
���ȃ��X�Ń��\�[�X�������ȋ�
�T���r�����J�X
> �Ƃ킢���]���ϑz�ȂǂƎ���Ȃ��Ƃ������Ėق��Ă���킯�ɂ������Ȃ���
�����ŃX��������������Ă��˂��c
�����ŃX��������������Ă��˂��c
�l�ɕ����𗊂ނȂ�A����Ȃ�̌����ł��肢���邷(��)
>>161
���Ⴀ�AMAC�I�^��l�т����Ȃ��Ă��������ǁA�����̊ԈႢ�����������Ă����Ί��ق��邷
���Ⴀ�AMAC�I�^��l�т����Ȃ��Ă��������ǁA�����̊ԈႢ�����������Ă����Ί��ق��邷
MAC�I�^��CPU�A�[�L�e�N�`���̍��������𗝉������A�傫�ȊԈႢ���������炵�Ă��邷�B
�����̏Z�l�̃��x����MAC�I�^�ƌ\���S���̂悤�Ȃ̂ŁAMAC�I�^�̊ԈႢ�����������̂�A
�X���ɂƂ��Ă����ɗL�v���Ɗm�M���Ă邷�B
�����̏Z�l�̃��x����MAC�I�^�ƌ\���S���̂悤�Ȃ̂ŁAMAC�I�^�̊ԈႢ�����������̂�A
�X���ɂƂ��Ă����ɗL�v���Ɗm�M���Ă邷�B
�킽���ȊO�̏Z�l���AMAC�I�^�̊ԈႢ�����������������̂ł��\��Ȃ�����(��)
�ԈႢ���킩���Ă�Ȃ玩���ŃT�N���Ɛ���������������
����Ɠ������Ƃ��菑���ăX���r�炷�ȃN�Y
����Ɠ������Ƃ��菑���ăX���r�炷�ȃN�Y
>>166
�����퉽�x�������ŏ����Ă�MAC�I�^�ɔ]���ϑz��������Ă��邷�B
MAC�I�^���ꂵ�܂����>>96�݂����Ȃ̂������Ă���̂��B��̔�����(��)
��͂肱����{�l�̎�Œ������ė~�������B
���ƁA�����l���Ă��������ȂLj���Ȃ�����(��)
�����퉽�x�������ŏ����Ă�MAC�I�^�ɔ]���ϑz��������Ă��邷�B
MAC�I�^���ꂵ�܂����>>96�݂����Ȃ̂������Ă���̂��B��̔�����(��)
��͂肱����{�l�̎�Œ������ė~�������B
���ƁA�����l���Ă��������ȂLj���Ȃ�����(��)
>>166���A�������킩���Ă���̂Ȃ�A�����Ă����Ə����邷�B
�����łȂ��Ȃ�A�����Ő������w�K���ė~�������B
�����łȂ��Ȃ�A�����Ő������w�K���ė~�������B
��Transmeta��David Ditzel��Intel�ɓ��Ђ����Ƃ̂��Ƃ��B
http://www.theregister.co.uk/2008/03/08/ditzel_intel/
�@�@--------------------
�@�@Our sources reveal that Intel acquired Ditzel as a member of the Digital Enterprise Group (DEG),
�@�@which tackles both server and PC products. Ditzel will work with Stephen Pawlowski, an Intel senior
�@�@fellow and CTO of DEG.
�@�@--------------------
��Elbrus��Babaian�Ƌ��ɏ��p�ėpVLIW�v���Z�b�T�̎w���I�Z�p�҂�S��Intel�ɏW�܂������ƂɂȂ邷�B
http://www.theregister.co.uk/2008/03/08/ditzel_intel/
�@�@--------------------
�@�@Our sources reveal that Intel acquired Ditzel as a member of the Digital Enterprise Group (DEG),
�@�@which tackles both server and PC products. Ditzel will work with Stephen Pawlowski, an Intel senior
�@�@fellow and CTO of DEG.
�@�@--------------------
��Elbrus��Babaian�Ƌ��ɏ��p�ėpVLIW�v���Z�b�T�̎w���I�Z�p�҂�S��Intel�ɏW�܂������ƂɂȂ邷�B
>>166
> �ԈႢ���킩���Ă�Ȃ玩���ŃT�N���Ɛ���������������
�킽���퉽�x���u�����v�������Ă����̂ɁA�����炱��Ȃ��Ƃ������Ƃ��������ƁA
���Ȃ���MAC�I�^���̗����������킯�����B
> �ԈႢ���킩���Ă�Ȃ玩���ŃT�N���Ɛ���������������
�킽���퉽�x���u�����v�������Ă����̂ɁA�����炱��Ȃ��Ƃ������Ƃ��������ƁA
���Ȃ���MAC�I�^���̗����������킯�����B
>>169
��������PARROT����Ăق�����
��������PARROT����Ăق�����
>170
�u�ԈႢ�̂ق��v�����X�Ə����̂����������Č����Ă��
�����l�^�͈�x�ŏ\��
�u�ԈႢ�̂ق��v�����X�Ə����̂����������Č����Ă��
�����l�^�͈�x�ŏ\��
>>172
�u�����v�̂ق������X�����Ă���A�������Ă��炦�Ă��Ȃ��悤�Ŏc�O���B
�u�����v�̂ق������X�����Ă���A�������Ă��炦�Ă��Ȃ��悤�Ŏc�O���B
>173
�u�r�炵���܂������l�^�����Ă��v�Ǝv���Ă邾����������e���ĂȂ�����
�܂Ƃ��ȃ��C�^�[�⌤���҂ł����ԈႤ���Ƃ͂������A�������R�e���x�Ȃ�
�ԈႢ���炢�����ē�����O����B�Ȃɂ͂��Ⴂ�ł��N�Y
�u�r�炵���܂������l�^�����Ă��v�Ǝv���Ă邾����������e���ĂȂ�����
�܂Ƃ��ȃ��C�^�[�⌤���҂ł����ԈႤ���Ƃ͂������A�������R�e���x�Ȃ�
�ԈႢ���炢�����ē�����O����B�Ȃɂ͂��Ⴂ�ł��N�Y
>>174
�c�O�Ȃ���AMAC�I�^�̂킻���������x���̊ԈႢ�ł�Ȃ��A
CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
���ƁA���l��l�|���Ă��������Ƃ����Ȃ����B
�c�O�Ȃ���AMAC�I�^�̂킻���������x���̊ԈႢ�ł�Ȃ��A
CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
���ƁA���l��l�|���Ă��������Ƃ����Ȃ����B
�X�g�[�J�[�̃q�g��Ώۂɑ���ɂ���Ȃ��ƁA�Ƃ肠������������Ă��ꂽ�q�g�ɜ߂��ւ�邱�Ƃ�����
������A���u�������߂��B
>>175 ����
�@�@------------------
�@�@CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
�@�@------------------
���ɂ�A���Ȃ��̔]���ɏ���ɍ\�z���ꂽ�C���[�W�ɂ��������Ȃ����B
������������ȏd��Ȗ������Ȃ�A�w�E����q�g�����Ȃ��������ăR�g���ς��v��Ȃ������H
����a���L�́w�ڂ�������Q�����ɐ��`�������炷���߂ɐ_�ɑI�ꂽ���ʂȐl���x�Ă�
�v�����݂Ȃ��ˁB�B�B
������A���u�������߂��B
>>175 ����
�@�@------------------
�@�@CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
�@�@------------------
���ɂ�A���Ȃ��̔]���ɏ���ɍ\�z���ꂽ�C���[�W�ɂ��������Ȃ����B
������������ȏd��Ȗ������Ȃ�A�w�E����q�g�����Ȃ��������ăR�g���ς��v��Ȃ������H
����a���L�́w�ڂ�������Q�����ɐ��`�������炷���߂ɐ_�ɑI�ꂽ���ʂȐl���x�Ă�
�v�����݂Ȃ��ˁB�B�B
�������ꂪ�A�܂Ƃ��ȃ��C�^�[�⌤���҂ł��Ƃ��悤�Ȍ��ƍl�����Ă���̂Ȃ�A
�X���̃��x���̒ቺ�킩�Ȃ�[�����ƌ��킴��Ȃ����B
�v�X�����˂��B
�X���̃��x���̒ቺ�킩�Ȃ�[�����ƌ��킴��Ȃ����B
�v�X�����˂��B
>>176
�w�E���Ă��ꂽ�l��A�O�X���Ɉ�l�������邷�B
�w�E���Ă��ꂽ�l��A�O�X���Ɉ�l�������邷�B
179 �FMAC�I�^���⑫�F2008/03/09(��) 00:09:14 ID:lSXgkkSe
�v���Z�b�T���X�[�p�[�R���s���[�^�������X���b�h�ɂ�A�����w���ȃq�g������Ă���̂�
�ǂ�����b�Ȃ�ŁA�C�ɂ���ƕ������Ǝv�����B
���Ă�PowerPC�X���b�h��2�N�قǑO��Intel������X���b�h�Ȃ�āA�R�s�y�̊Ԃ�D���Ęb�肪
�����Ȃ�Ă̂����ʂ��������ƁB�B�B
�ǂ�����b�Ȃ�ŁA�C�ɂ���ƕ������Ǝv�����B
���Ă�PowerPC�X���b�h��2�N�قǑO��Intel������X���b�h�Ȃ�āA�R�s�y�̊Ԃ�D���Ęb�肪
�����Ȃ�Ă̂����ʂ��������ƁB�B�B
>>176
���Ȃ����A>>96�݂����Ȃ݂��Ƃ��Ȃ�������������Ă���Ƃ��������ƁA
�����̊ԈႢ�ɂ킻�������C�����Ă���悤�Ɏv���邷�B
�ԈႢ��f���ɒ��������ق����p�����Ȃ�����(��)
���Ȃ����A>>96�݂����Ȃ݂��Ƃ��Ȃ�������������Ă���Ƃ��������ƁA
�����̊ԈႢ�ɂ킻�������C�����Ă���悤�Ɏv���邷�B
�ԈႢ��f���ɒ��������ق����p�����Ȃ�����(��)
181 �FMAC�I�^��177 �����F2008/03/09(��) 00:13:03 ID:lSXgkkSe
>>177
�@�@---------------
�@�@�v�X�����˂��B
�@�@---------------
��킭�A�R�s�y�ȊO�̕��@�����肢���邷(��)
�@�@---------------
�@�@�v�X�����˂��B
�@�@---------------
��킭�A�R�s�y�ȊO�̕��@�����肢���邷(��)
�悭�l������AMAC�I�^�����ځ[�Ă���l�ɂ�W�Ȃ��b�ł��̂ŁA
�R�e�͂���ōs���̂��悳�������B
�ǂ��炪�{�l�����f�ɖ������Ƃ�Ȃ��Ǝv�����B
�R�e�͂���ōs���̂��悳�������B
�ǂ��炪�{�l�����f�ɖ������Ƃ�Ȃ��Ǝv�����B
>>176
OoO�v���Z�b�T�̃A�[�L�e�N�`����A���ۂ̂Ƃ��뗝������̂킩�Ȃ��ςȂ��̂Ȃ̂ŁA
MAC�I�^�݂����ɂ�����Ɨ����ł��Ă��Ȃ��A�}�`���A�������̂�Ȃ�̕s�v�c���Ȃ����B
�����Ƃ��A�_�ɑI��Ȃ��Ă�������ł�����x�̂��̂�����(��)
����ł��A�p�ꂪ������Ǝg���Ȃ���ɁARS��ROB�̋@�\�̋�ʂ�����ӂ�ŁA�������Ԉ���ė������Ă���̂̓q�h�C�Ǝv�������B
OoO�v���Z�b�T�̃A�[�L�e�N�`����A���ۂ̂Ƃ��뗝������̂킩�Ȃ��ςȂ��̂Ȃ̂ŁA
MAC�I�^�݂����ɂ�����Ɨ����ł��Ă��Ȃ��A�}�`���A�������̂�Ȃ�̕s�v�c���Ȃ����B
�����Ƃ��A�_�ɑI��Ȃ��Ă�������ł�����x�̂��̂�����(��)
����ł��A�p�ꂪ������Ǝg���Ȃ���ɁARS��ROB�̋@�\�̋�ʂ�����ӂ�ŁA�������Ԉ���ė������Ă���̂̓q�h�C�Ǝv�������B
������������x64��
AKIBA PC Hotline! HotHot REVIEW
http://pc.watch.impress.co.jp/docs/article/990326/hotrev03.htm
AKIBA PC Hotline! HotHot REVIEW
http://pc.watch.impress.co.jp/docs/article/990326/hotrev03.htm
�����A���s�������B
���W�X�^���l�[�~���O�ARS�AROB�̎O��OoO�v���Z�b�T�̒��j���Ȃ����̂��B
�����O��ʏ��C���I�[�_�v���Z�b�T�ɂ�Ȃ����̂��B
MAC�I�^�̗�����ARS�ɂ��Ă튮�S�ɊԈႢ�AROB�ɂ��Ă�����ĂĊw�K�����悤�����܂��ǂ�����������Ԃ��B
���W�X�^���l�[�~���O�ARS�AROB�̎O��OoO�v���Z�b�T�̒��j���Ȃ����̂��B
�����O��ʏ��C���I�[�_�v���Z�b�T�ɂ�Ȃ����̂��B
MAC�I�^�̗�����ARS�ɂ��Ă튮�S�ɊԈႢ�AROB�ɂ��Ă�����ĂĊw�K�����悤�����܂��ǂ�����������Ԃ��B
MAC�I�^��A
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
�Ƃ�
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�Ƃ��A�ꂵ�܂���ɂ����͂��Ȃ��Ƃ������Ă邷(��)�̂ŁA�Ӑ}����Ƃ��낪�킩��ɂ��������A
ROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^�o�b�t�@�A�Ƃ������̂������Ƀi���Z���X�Ȃ��̂��팾�킸�����Ȃ��B
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
�����ARS�̐����Ƃ��Ă��AROB�̐����Ƃ��Ă��A�v���Z�b�T���̂ǂ�ȃ��j�b�g�̐����Ƃ��Ă��A�Ԉ���Ă��邷�B
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
�Ƃ�
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�Ƃ��A�ꂵ�܂���ɂ����͂��Ȃ��Ƃ������Ă邷(��)�̂ŁA�Ӑ}����Ƃ��낪�킩��ɂ��������A
ROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^�o�b�t�@�A�Ƃ������̂������Ƀi���Z���X�Ȃ��̂��팾�킸�����Ȃ��B
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
�����ARS�̐����Ƃ��Ă��AROB�̐����Ƃ��Ă��A�v���Z�b�T���̂ǂ�ȃ��j�b�g�̐����Ƃ��Ă��A�Ԉ���Ă��邷�B
>>186
�ǂ����Ԉ���Ă��邩�A�������̂퉽���ɂ��Ă�A�O�X�����珑���Ă��Ă��邷���A
MAC�I�^�݂̂Ȃ炸�A�p�N�}���Ȃǂ̃X���Z�l�ɂ��Ȃ��Ȃ��������Ă��炦�Ȃ��Ďc�O���B
�\����ς��A������߂��ɑ����邷�B
�ǂ����Ԉ���Ă��邩�A�������̂퉽���ɂ��Ă�A�O�X�����珑���Ă��Ă��邷���A
MAC�I�^�݂̂Ȃ炸�A�p�N�}���Ȃǂ̃X���Z�l�ɂ��Ȃ��Ȃ��������Ă��炦�Ȃ��Ďc�O���B
�\����ς��A������߂��ɑ����邷�B
>>176
> �w�E����q�g�����Ȃ�����
�������x�ڂ��m��Ȃ����A���O���g�`�������тɖ���N����
���߂����Ȃ��Ɗ����Ďw�E���Ă��邾�낤�H
�T�C�����g�}�W�����e�B�����O�̌������Ƃł��v���Ă�̂��H��
�Ȓm���őI��I�ɏ�����đ��l��}���邻�̐l�i���A
ROM��ʂ肷����ɂ܂ŕs�����Â����Ă邱�Ƃ������������o����B
����ƁA���������Ă�ɂ��ւ�炸����ɎC�����Ă��邨�O
�̂ق������ɃX�g�[�J�[������B���l���Ȃ߂���悤�Ȑg������B
> �w�E����q�g�����Ȃ�����
�������x�ڂ��m��Ȃ����A���O���g�`�������тɖ���N����
���߂����Ȃ��Ɗ����Ďw�E���Ă��邾�낤�H
�T�C�����g�}�W�����e�B�����O�̌������Ƃł��v���Ă�̂��H��
�Ȓm���őI��I�ɏ�����đ��l��}���邻�̐l�i���A
ROM��ʂ肷����ɂ܂ŕs�����Â����Ă邱�Ƃ������������o����B
����ƁA���������Ă�ɂ��ւ�炸����ɎC�����Ă��邨�O
�̂ق������ɃX�g�[�J�[������B���l���Ȃ߂���悤�Ȑg������B
���v���Z�b�T���X�[�p�[�R���s���[�^�������X���b�h�ɂ�A�����w���ȃq�g������Ă���̂�
���ǂ�����b�Ȃ�ŁA�C�ɂ���ƕ������Ǝv�����B
�Ƃ肠���������Ȑl�ɂ���܂�B
���ǂ�����b�Ȃ�ŁA�C�ɂ���ƕ������Ǝv�����B
�Ƃ肠���������Ȑl�ɂ���܂�B
�����̂��ƌ����Ă��
�T�^�I��OoO�v���Z�b�T�ɂ��Ă̐����ł��B
�e���s���j�b�g��RS���܂Ƃ߂Ė��߃L���[�▽�߃E�B���h�E�Ƃ����܂��B
�t�F�b�`�������߂𗭂߂Ă������̂����߃L���[�Ƃ������肵�܂����A�Ӗ��I�ɍ�������悤�Ȃ��̂ł͂Ȃ��ł��傤�B
OoO�v���Z�b�T�ł́A�e���߂̓t�F�b�`�A�f�R�[�h�A���W�X�^���l�[���̃X�e�[�W���o�R���āA
�f�B�X�p�b�`�X�e�[�W�ŁA���߂̋@�\�ɑΉ��������s���j�b�g�̃��U�x�[�V�����X�e�[�V����(RS)�ɑ����܂��B
RS���̖��߂́A�I�y�����h�������܂ő҂�����܂��B
�I�y�����h�����������߂́A�������s���j�b�g�ɑ����܂��B������C�V���[�Ƃ����܂��B
�v���O�������Ő�s���閽�߂��A�I�y�����h�����킸�ɑ҂�����A�㑱�̖��߂���ɃC�V���[����邱�Ƃ�����܂��B
OoO�̗R���ł��B
�C�V���[���ꂽ���߂́A��������RS����폜����܂��B
���[�h�╂�������_���߂Ȃǂ̒����C�e���V���߂ł����Ă��A�I�y�����h�������Ă���������ɃC�V���[����܂��B
�����C�e���V���߂ɒ��ڂ��邢�͊ԐړI�Ɉˑ����閽�߂́A�I�y�����h�����킸�҂�����邱�Ƃ������ł��B
�f�B�X�p�b�`���C�V���[�����s�Ɩ�邱�Ƃ�����̂ŁA�ǂނƂ��͂�����Ƌ�ʂ��܂��傤�B
�e���s���j�b�g��RS���܂Ƃ߂Ė��߃L���[�▽�߃E�B���h�E�Ƃ����܂��B
�t�F�b�`�������߂𗭂߂Ă������̂����߃L���[�Ƃ������肵�܂����A�Ӗ��I�ɍ�������悤�Ȃ��̂ł͂Ȃ��ł��傤�B
OoO�v���Z�b�T�ł́A�e���߂̓t�F�b�`�A�f�R�[�h�A���W�X�^���l�[���̃X�e�[�W���o�R���āA
�f�B�X�p�b�`�X�e�[�W�ŁA���߂̋@�\�ɑΉ��������s���j�b�g�̃��U�x�[�V�����X�e�[�V����(RS)�ɑ����܂��B
RS���̖��߂́A�I�y�����h�������܂ő҂�����܂��B
�I�y�����h�����������߂́A�������s���j�b�g�ɑ����܂��B������C�V���[�Ƃ����܂��B
�v���O�������Ő�s���閽�߂��A�I�y�����h�����킸�ɑ҂�����A�㑱�̖��߂���ɃC�V���[����邱�Ƃ�����܂��B
OoO�̗R���ł��B
�C�V���[���ꂽ���߂́A��������RS����폜����܂��B
���[�h�╂�������_���߂Ȃǂ̒����C�e���V���߂ł����Ă��A�I�y�����h�������Ă���������ɃC�V���[����܂��B
�����C�e���V���߂ɒ��ڂ��邢�͊ԐړI�Ɉˑ����閽�߂́A�I�y�����h�����킸�҂�����邱�Ƃ������ł��B
�f�B�X�p�b�`���C�V���[�����s�Ɩ�邱�Ƃ�����̂ŁA�ǂނƂ��͂�����Ƌ�ʂ��܂��傤�B
ROB�̐����ł��B
ROB�͂��Ȃ�قȂ�������������̂ŁA��ԃV���v���Ȃ��̂̐��������܂��B
�f�B�X�p�b�`�X�e�[�W�ȑO�̂ǂ����ŁA���I�[�_�o�b�t�@(=ROB)�̃G���g���̊m�ۂ��s���܂��B
ROB�́A����\���~�X������A�N�Z�X��O�Ȃǂ̃C�x���g�����������ꍇ�ɁA
�v���Z�b�T��Ԃ��C���I�[�_��ԂɁA�܂�C�x���g�����������v���O�����n�_�܂Ŋ����߂����߂ɑ��݂��܂��B
ROB�̊e�G���g���́A�ꖽ�߂�ꕨ�����W�X�^�ɑΉ����邱�Ƃ������̂ł����A�����ɂ���ĈقȂ�܂��B
ROB�̊e�G���g���́A�o�͐惌�W�X�^��X�g�A�o�b�t�@�G���g���A��O���ȂǁA
�C���I�[�_��Ԃ̍X�V�ɕK�v�ȏ���ێ����Ă��܂��B
ROB�̃G���g���́A�v���O�������Ɋm�ۂ���A�������܂��B
ROB�̃G���g�����������A�v���Z�b�T��Ԃ��X�V����邱�Ƃ��A
���߂����^�C�A����A�Ƃ����܂��B�R�~�b�g����A�������Ӗ��ł��B
OoO���s�Ō㑱�̖��߂���Ɏ��s���I����Ă��Ă��A��s�̖��߂����^�C�A���Ă��Ȃ���A
�㑱�̖��߂̓��^�C�A���҂�����܂��B
����~�X���O����������ƁAROB�G���g���͖���������AOoO��Ԃ��j������܂��B
�y�[�W�t�H�[���g�Ȃǂ��N�����ꍇ�A�������ɗ�O���N���̂ł͂Ȃ��A��������Ή�����ROB�G���g���ɗ�O��������܂�܂��B
���̃G���g�����������鎞�ɁA��O�������������܂��B
ROB�͂��Ȃ�قȂ�������������̂ŁA��ԃV���v���Ȃ��̂̐��������܂��B
�f�B�X�p�b�`�X�e�[�W�ȑO�̂ǂ����ŁA���I�[�_�o�b�t�@(=ROB)�̃G���g���̊m�ۂ��s���܂��B
ROB�́A����\���~�X������A�N�Z�X��O�Ȃǂ̃C�x���g�����������ꍇ�ɁA
�v���Z�b�T��Ԃ��C���I�[�_��ԂɁA�܂�C�x���g�����������v���O�����n�_�܂Ŋ����߂����߂ɑ��݂��܂��B
ROB�̊e�G���g���́A�ꖽ�߂�ꕨ�����W�X�^�ɑΉ����邱�Ƃ������̂ł����A�����ɂ���ĈقȂ�܂��B
ROB�̊e�G���g���́A�o�͐惌�W�X�^��X�g�A�o�b�t�@�G���g���A��O���ȂǁA
�C���I�[�_��Ԃ̍X�V�ɕK�v�ȏ���ێ����Ă��܂��B
ROB�̃G���g���́A�v���O�������Ɋm�ۂ���A�������܂��B
ROB�̃G���g�����������A�v���Z�b�T��Ԃ��X�V����邱�Ƃ��A
���߂����^�C�A����A�Ƃ����܂��B�R�~�b�g����A�������Ӗ��ł��B
OoO���s�Ō㑱�̖��߂���Ɏ��s���I����Ă��Ă��A��s�̖��߂����^�C�A���Ă��Ȃ���A
�㑱�̖��߂̓��^�C�A���҂�����܂��B
����~�X���O����������ƁAROB�G���g���͖���������AOoO��Ԃ��j������܂��B
�y�[�W�t�H�[���g�Ȃǂ��N�����ꍇ�A�������ɗ�O���N���̂ł͂Ȃ��A��������Ή�����ROB�G���g���ɗ�O��������܂�܂��B
���̃G���g�����������鎞�ɁA��O�������������܂��B
�Ƃ����킯�ŁA���������Ƀg���`�L�Ȃ̂��������Ă��炦��Ƃ������B
���ɁA�L���[�ɋ����閽�߂ɂ��Ċ��S�Ɍ�����Ă���Ƃ���Ƃ��A�������ė~�������B
�O�X��858
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
�O�X��865
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���ɁA�L���[�ɋ����閽�߂ɂ��Ċ��S�Ɍ�����Ă���Ƃ���Ƃ��A�������ė~�������B
�O�X��858
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/858
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
> ���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
>
> �X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
> ���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
�O�X��865
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
����햾�炩��RS�̂��Ƃɂ��ď����Ă���Ƃ����v���Ȃ����B
> �Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
�����RS�ɂ��Ă�ԈႢ���B
�����邩�ǂ����͈ˑ��W�ɂ��̂ł����āA���ߎ��g�̃��C�e���V�Ƃ͖��W���B
ROB�ɂ��Ă��Ƃ��Ă��ԈႢ���B
���^�C�A����܂ł͂Ȃ��悭�������Ă邷�B�����C�e���V���߂��肪������Ȃ�Ă��Ƃ͂��肦�Ȃ����B
���������A����Ȑ����̃L���[��CPU���̂ǂ��ɂ��Ȃ����BMAC�I�^�̔]���L���[�����ˁB
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���炠��A�������ł�ROB�̘b�ɂȂ���������݂�������(��)
�ŁA�ꂵ�܂���ɂ���Ȃ��Ƃ������Ă邷�B
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
���̂�����ƑO�ɁA����Ȃ��Ƃ������Ėϑz�������Ă����ǂ�(��)
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
> �����ł��邱�ƂɈӖ������邷�B
����햾�炩��RS�̂��Ƃɂ��ď����Ă���Ƃ����v���Ȃ����B
> �Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
�����RS�ɂ��Ă�ԈႢ���B
�����邩�ǂ����͈ˑ��W�ɂ��̂ł����āA���ߎ��g�̃��C�e���V�Ƃ͖��W���B
ROB�ɂ��Ă��Ƃ��Ă��ԈႢ���B
���^�C�A����܂ł͂Ȃ��悭�������Ă邷�B�����C�e���V���߂��肪������Ȃ�Ă��Ƃ͂��肦�Ȃ����B
���������A����Ȑ����̃L���[��CPU���̂ǂ��ɂ��Ȃ����BMAC�I�^�̔]���L���[�����ˁB
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���炠��A�������ł�ROB�̘b�ɂȂ���������݂�������(��)
�ŁA�ꂵ�܂���ɂ���Ȃ��Ƃ������Ă邷�B
> �̒��ŁA�����āuOoO�̖��߃L���[�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^
> �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
���̂�����ƑO�ɁA����Ȃ��Ƃ������Ėϑz�������Ă����ǂ�(��)
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
RS�AROB�A���W�X�^���l�[����OoO���s����������CPU�A�[�L�e�N�`���̍������B
����RS�AROB�ɂ��đ�ԈႢ����������ɁA���ɂȂ��Ă��������Ȃ�MAC�I�^��A
CPU�A�[�L�e�N�`���ɂ��ĉ����������Ă��Ȃ��ƌ��킴��Ȃ����B
�f���āA�����҂�C�^�[�ł�����悤�Ȋ��Ⴂ��~�X�Ƃ��������x���̊ԈႢ�ł�Ȃ����B
��������ROB��x86�p��ƌ����Ă���悤�ł�B�B�B
MAC�I�^�����ɂ���R���������炩�������Ƃ퐄���Ēm��ׂ����B
���ہA���܂ł����R�������Ă�����܂�Ă������B
�����}�t���߂ł���A�킽���������܂ŔS�����Ȃ����������A�ߋ��ɂ���u���Ă��������A
�������ɍ���̊ԈႢ�킠�܂�ɂ��d��Ȃ̂ŁA���߂��킯�ɂ킢���Ȃ��������B
����RS�AROB�ɂ��đ�ԈႢ����������ɁA���ɂȂ��Ă��������Ȃ�MAC�I�^��A
CPU�A�[�L�e�N�`���ɂ��ĉ����������Ă��Ȃ��ƌ��킴��Ȃ����B
�f���āA�����҂�C�^�[�ł�����悤�Ȋ��Ⴂ��~�X�Ƃ��������x���̊ԈႢ�ł�Ȃ����B
��������ROB��x86�p��ƌ����Ă���悤�ł�B�B�B
MAC�I�^�����ɂ���R���������炩�������Ƃ퐄���Ēm��ׂ����B
���ہA���܂ł����R�������Ă�����܂�Ă������B
�����}�t���߂ł���A�킽���������܂ŔS�����Ȃ����������A�ߋ��ɂ���u���Ă��������A
�������ɍ���̊ԈႢ�킠�܂�ɂ��d��Ȃ̂ŁA���߂��킯�ɂ킢���Ȃ��������B
RS��ROB�ɂ��Ă̐������������Ȃ���A��������CPU�A�[�L�e�N�`���ɂ��Č�邱�ƂȂǕs�\���B
���̈Ӗ��ŁA�킽����X���^�C�ɒ����ɍs�����Ă������B
���Ȃ݂ɁAMAC�I�^�̊ԈႢ�푦���Ɏw�E���������]���ϑz��������܂��ĂˁB�B�B
859 ���O�F Socket774 [sage] ���e���F 2008/01/30(��) 14:05:46 ID:/JD5n/hb
>>858
> �t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
�H�HMAC�I�^�����ǂ��������������Ă���H
�����l���Ă���̂����������Ȃ����A���ꂱ���ǂ��ɂ��������L�q������H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���v���H
���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
��̓I�ɂ́A�L���b�V���~�X�������[�h���߂̌��ʂɈˑ����Ă��閽�ߌQ�Ƃ��B
�X���[�v�b�g���\������A���������_���߂��낤���������A�N�Z�X���߂��낤���A�ˑ����̂Ȃ�����͂ǂ�ǂ�o�Ă�����
868 ���O�F Socket774 [sage] ���e���F 2008/01/31(��) 23:32:50 ID:9700t1FF
>>865
������C���e���͊W�Ȃ�����c
�C�V���[����Ă��烊�^�C�A����܂ł̊Ԃ����߃L���[�Ɏc���Ăǂ��������B
���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
���̈Ӗ��ŁA�킽����X���^�C�ɒ����ɍs�����Ă������B
���Ȃ݂ɁAMAC�I�^�̊ԈႢ�푦���Ɏw�E���������]���ϑz��������܂��ĂˁB�B�B
859 ���O�F Socket774 [sage] ���e���F 2008/01/30(��) 14:05:46 ID:/JD5n/hb
>>858
> �t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
�H�HMAC�I�^�����ǂ��������������Ă���H
�����l���Ă���̂����������Ȃ����A���ꂱ���ǂ��ɂ��������L�q������H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���v���H
���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
��̓I�ɂ́A�L���b�V���~�X�������[�h���߂̌��ʂɈˑ����Ă��閽�ߌQ�Ƃ��B
�X���[�v�b�g���\������A���������_���߂��낤���������A�N�Z�X���߂��낤���A�ˑ����̂Ȃ�����͂ǂ�ǂ�o�Ă�����
868 ���O�F Socket774 [sage] ���e���F 2008/01/31(��) 23:32:50 ID:9700t1FF
>>865
������C���e���͊W�Ȃ�����c
�C�V���[����Ă��烊�^�C�A����܂ł̊Ԃ����߃L���[�Ɏc���Ăǂ��������B
���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
��ʂ��ˁ[����A�Ȃ������t�^�����
��ʂ��ˁ[�悤�ɂ��Ă邷�B
�����Ƒ���>>191��>>192�̂悤�ȉ���������������������A
MAC�I�^���g�������Ƃ��Ęb�����炻���Ƃ���̂��ڂɌ����邷����ˁB
�����Ƒ���>>191��>>192�̂悤�ȉ���������������������A
MAC�I�^���g�������Ƃ��Ęb�����炻���Ƃ���̂��ڂɌ����邷����ˁB
�E�U�C�̂�d�X���m���Ă邷���A�\����Ȃ��v���Ă����邷���A
�X���^�C�ɒ����ɍs�����Ă���ȏ�A���߂邱�Ƃ�Ȃ����B
�X���^�C�ɒ����ɍs�����Ă���ȏ�A���߂邱�Ƃ�Ȃ����B
>>176
> �@�@------------------
> �@�@CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
> �@�@------------------
> ���ɂ�A���Ȃ��̔]���ɏ���ɍ\�z���ꂽ�C���[�W�ɂ��������Ȃ����B
> ������������ȏd��Ȗ������Ȃ�A�w�E����q�g�����Ȃ��������ăR�g���ς��v��Ȃ������H
���ɂ��w�E����l���o�Ă�����AMAC�I�^�Ɏ����̊ԈႢ��F�߂����邱�Ƃ��ł��邩���m��Ȃ����B
(�ł��Ȃ������m��Ȃ������B�B�B)
MAC�I�^�������̊ԈႢ��F�ߒ���������A�킽�����R�s�y��A�����I��炷���Ƃ��ł��āA���������Ȃ��B
> �@�@------------------
> �@�@CPU�A�[�L�e�N�`���̍����ɂ��Ă̏d��Ȗ��������B
> �@�@------------------
> ���ɂ�A���Ȃ��̔]���ɏ���ɍ\�z���ꂽ�C���[�W�ɂ��������Ȃ����B
> ������������ȏd��Ȗ������Ȃ�A�w�E����q�g�����Ȃ��������ăR�g���ς��v��Ȃ������H
���ɂ��w�E����l���o�Ă�����AMAC�I�^�Ɏ����̊ԈႢ��F�߂����邱�Ƃ��ł��邩���m��Ȃ����B
(�ł��Ȃ������m��Ȃ������B�B�B)
MAC�I�^�������̊ԈႢ��F�ߒ���������A�킽�����R�s�y��A�����I��炷���Ƃ��ł��āA���������Ȃ��B
���[�̃E���R�����U���U������ɂ����̂�
�A��������炢��
�A��������炢��
�Ƃ������A����������悻�ł���
203 �FMAC�I�^���ϑz�̃q�g�F2008/03/09(��) 09:10:42 ID:lSXgkkSe
����Ƙb���q���肾�����̂ŁA���t���������邷�B
���̗����wROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ��x(>>96)�Ȃ�
���ǁA���߂��p�C�v���C�������ǂ̂悤�ɐi�ނ����l�����ꍇ�A
>>191
�@�@------------------
�@�@�f�B�X�p�b�`�X�e�[�W�ȑO�̂ǂ����ŁA���I�[�_�o�b�t�@(=ROB)�̃G���g���̊m�ۂ��s���܂��B
�@�@------------------
�Ƃ����K�v�����邷�B
�����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
�@�EROB�̋�
�@�E���l�[�����W�X�^�̋�
�@�ERS�̋�
�����āA���̒��ōł��J�����x���̂탊�^�C�A�܂ŋȂ�ROB�Ƃ������ƂɂȂ邷�B
RS�����Ă���Ή��ł��ł���ƍl���Ă��Ȃ������H
���̗����wROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ��x(>>96)�Ȃ�
���ǁA���߂��p�C�v���C�������ǂ̂悤�ɐi�ނ����l�����ꍇ�A
>>191
�@�@------------------
�@�@�f�B�X�p�b�`�X�e�[�W�ȑO�̂ǂ����ŁA���I�[�_�o�b�t�@(=ROB)�̃G���g���̊m�ۂ��s���܂��B
�@�@------------------
�Ƃ����K�v�����邷�B
�����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
�@�EROB�̋�
�@�E���l�[�����W�X�^�̋�
�@�ERS�̋�
�����āA���̒��ōł��J�����x���̂탊�^�C�A�܂ŋȂ�ROB�Ƃ������ƂɂȂ邷�B
RS�����Ă���Ή��ł��ł���ƍl���Ă��Ȃ������H
�悻����
���̃X���ł���
>>203
�ŏ��Ɋm�ۂ���A�Ō�ɉ�������̂�ROB�G���g�������A
�ʏ��RS�G���g��������ROB�G���g�����̂ق����������B
�p�C�v���C���̗��ꂩ�炢���Ă��ARS�ɋ��Ȃ��̂�ROB�G���g�����m�ۂ��Ȃ��Ƃ������Ƃ��ɂȂ����B
Issaiah�ł�AROB�G���g�����m�ۂ��Ă��烌�W�X�^���l�[�����s�Ȃ��邷�B
������RISC�ł�AROB�G���g���ƕ������W�X�^�퓯�������������āA���s���ē����Ɋm�ۂ���邷�B
ROB�G���g�����̖��߁E���W�X�^�ɑΉ�������v���Z�b�T�����邷���A
�����������̂ł�A�������W�X�^�ɑ��ď\���Ȑ���ROB�G���g�����m�ۂ���Ă��邷�̂ŁA
�������W�X�^�ɋ��Ȃ��Ă��AROB�G���g����m�ۂ��邱�Ƃ��\���B
������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
������A
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
ROB���g�ɋ��Ȃ���Ύ~�܂�̂퓖�R�Ƃ��āA���Ƃ̓��[�I�Ɍ����ĊԈႢ���B
���ɁARS�ɋ��Ȃ���AROB�G���g�����m�ۂ��Ă���f�B�X�p�b�`�X�e�[�W�Ŏ~�܂邾�����B
> �����āA���̒��ōł��J�����x���̂탊�^�C�A�܂ŋȂ�ROB�Ƃ������ƂɂȂ邷�B
���̎O�̃��j�b�g�̉���������r���Ăǂ������Ӗ������邷���B
> RS�����Ă���Ή��ł��ł���ƍl���Ă��Ȃ������H
�ǂ����炱��������Ȃ��o�Ă���̂��B�B�B
MAC�I�^�̔�Q�ϑz�͒ꂪ�m��Ȃ���(��)
�ŏ��Ɋm�ۂ���A�Ō�ɉ�������̂�ROB�G���g�������A
�ʏ��RS�G���g��������ROB�G���g�����̂ق����������B
�p�C�v���C���̗��ꂩ�炢���Ă��ARS�ɋ��Ȃ��̂�ROB�G���g�����m�ۂ��Ȃ��Ƃ������Ƃ��ɂȂ����B
Issaiah�ł�AROB�G���g�����m�ۂ��Ă��烌�W�X�^���l�[�����s�Ȃ��邷�B
������RISC�ł�AROB�G���g���ƕ������W�X�^�퓯�������������āA���s���ē����Ɋm�ۂ���邷�B
ROB�G���g�����̖��߁E���W�X�^�ɑΉ�������v���Z�b�T�����邷���A
�����������̂ł�A�������W�X�^�ɑ��ď\���Ȑ���ROB�G���g�����m�ۂ���Ă��邷�̂ŁA
�������W�X�^�ɋ��Ȃ��Ă��AROB�G���g����m�ۂ��邱�Ƃ��\���B
������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
������A
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
ROB���g�ɋ��Ȃ���Ύ~�܂�̂퓖�R�Ƃ��āA���Ƃ̓��[�I�Ɍ����ĊԈႢ���B
���ɁARS�ɋ��Ȃ���AROB�G���g�����m�ۂ��Ă���f�B�X�p�b�`�X�e�[�W�Ŏ~�܂邾�����B
> �����āA���̒��ōł��J�����x���̂탊�^�C�A�܂ŋȂ�ROB�Ƃ������ƂɂȂ邷�B
���̎O�̃��j�b�g�̉���������r���Ăǂ������Ӗ������邷���B
> RS�����Ă���Ή��ł��ł���ƍl���Ă��Ȃ������H
�ǂ����炱��������Ȃ��o�Ă���̂��B�B�B
MAC�I�^�̔�Q�ϑz�͒ꂪ�m��Ȃ���(��)
> ���̗����wROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ��x(>>96)�Ȃ�
�������������ǂ���������Ȃ��B
ROB��RS���܂߂Ĉꏏ�����ɏq�ׂāA>>203�݂����ȑ�R���������炷�ȊO�̂ǂ��������v�����邷���B
���Ȃ��킱��Ȃ��Ƃ������Ă�������ˁB
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
���ꂪ�A�u���̗����wROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ��x�v�ƁA�ǂ��������邷���B
�������������ǂ���������Ȃ��B
ROB��RS���܂߂Ĉꏏ�����ɏq�ׂāA>>203�݂����ȑ�R���������炷�ȊO�̂ǂ��������v�����邷���B
���Ȃ��킱��Ȃ��Ƃ������Ă�������ˁB
> ROB�̂��Ƃ������������ǁB
>
> OoOE�ŏ���d�͂��H�K�̖͂�肪�B�B�B�Ƃ����b�̒���RS���o�Ă���Ǝv�����ޖϑz�]�ɂ�
> ������ʂĂ���肷(��)
���ꂪ�A�u���̗����wROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ��x�v�ƁA�ǂ��������邷���B
209 �FMAC�I�^���ϑz�̃q�g�F2008/03/09(��) 18:32:18 ID:lSXgkkSe
>>206
�@�@------------------
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@------------------
�ł�A���ۂ̎�������������B
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@As an example, if one thread encounters multiple L2 cache misses, dependent instructions can back
�@�@up in the issue queues. This can inhibit the dispatching of additional groups, causing the second thread
�@�@to slow down. Resource-balancing logic detects the point at which a thread reaches a threshold of load
�@�@misses in the L2 cache and translation misses in the TLB. When this happens, thread performance is
�@�@throttled. Similarly, resource-balancing logic monitors the GCT to determine the number of entries each
�@�@thread is using. If the balancing logic detects that one thread is beginning to use too many GCT entries,
�@�@potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
�@�@===================
���ۂɖ�莋����Ă��đ�̎����Ⴊ����̂ɁA�w��Ȃ��x�Ɂw�n�����Ă���x����(��)
>>207
�w�f�B�X�p�b�`����Ă��烊�^�C�A����܂Ń��^�C�A����܂ŋȂ��L���[��RS��ROB�̂ǂ��炩�H�x�Ƃ���
�����,ROB���Ɠ������܂ł����ǁH(>>85-87�Q��)
�@�@------------------
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@------------------
�ł�A���ۂ̎�������������B
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@As an example, if one thread encounters multiple L2 cache misses, dependent instructions can back
�@�@up in the issue queues. This can inhibit the dispatching of additional groups, causing the second thread
�@�@to slow down. Resource-balancing logic detects the point at which a thread reaches a threshold of load
�@�@misses in the L2 cache and translation misses in the TLB. When this happens, thread performance is
�@�@throttled. Similarly, resource-balancing logic monitors the GCT to determine the number of entries each
�@�@thread is using. If the balancing logic detects that one thread is beginning to use too many GCT entries,
�@�@potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
�@�@===================
���ۂɖ�莋����Ă��đ�̎����Ⴊ����̂ɁA�w��Ȃ��x�Ɂw�n�����Ă���x����(��)
>>207
�w�f�B�X�p�b�`����Ă��烊�^�C�A����܂Ń��^�C�A����܂ŋȂ��L���[��RS��ROB�̂ǂ��炩�H�x�Ƃ���
�����,ROB���Ɠ������܂ł����ǁH(>>85-87�Q��)
>>209
GCT��ROB���Ƃ������Ƃ��A�悤�₭�������Ă��ꂽ�悤�ł��ꂵ����(��)
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
GCT��ROB���Ƃ������Ƃ��A�悤�₭�������Ă��ꂽ�悤�ł��ꂵ����(��)
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
{kind=link}
>>209
> If the balancing logic detects that one thread is beginning to use too many GCT entries,
> potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
����̂ǂ����A
>>206
> ������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�u�������W�X�^�ɋ��Ȃ��̂Łv�p�C�v���C�����~�߂邱�Ƃ̑�Ȃ̂��A�������ė~�������B
�킽���ɂ�ASMT�̃��[�h�o�����V���O�@�\�ɂ��������Ȃ������ǂˁB
> If the balancing logic detects that one thread is beginning to use too many GCT entries,
> potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
����̂ǂ����A
>>206
> ������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�u�������W�X�^�ɋ��Ȃ��̂Łv�p�C�v���C�����~�߂邱�Ƃ̑�Ȃ̂��A�������ė~�������B
�킽���ɂ�ASMT�̃��[�h�o�����V���O�@�\�ɂ��������Ȃ������ǂˁB
>>207
�w�f�B�X�p�b�`����Ă��烊�^�C�A����܂Ń��^�C�A����܂ŋȂ��L���[��RS��ROB�̂ǂ��炩�H�x�Ƃ���
�����,ROB���Ɠ������܂ł����ǁH(>>85-87�Q��)
�Ƃ������Ƃ�A
�O�X��865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
����̃L���[��AROB�ł������H
�w�f�B�X�p�b�`����Ă��烊�^�C�A����܂Ń��^�C�A����܂ŋȂ��L���[��RS��ROB�̂ǂ��炩�H�x�Ƃ���
�����,ROB���Ɠ������܂ł����ǁH(>>85-87�Q��)
�Ƃ������Ƃ�A
�O�X��865
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
����̃L���[��AROB�ł������H
>>209
> Similarly, resource-balancing logic monitors the GCT to determine the number of entries each
> thread is using. If the balancing logic detects that one thread is beginning to use too many GCT entries,
> potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
�ꉞ�A���{��ŗv�Ă����ƁA
(2way SMT��POWER5�ɂ�����)�A����̃X���b�h��GCT�G���g�����ʂɐ�L����悤�Ȃ��Ƃ�����ƁA
�����̃X���b�h���u���b�N���Ă��܂����Ƃ�����̂ŁA
���ו��U�@�\��GCT�G���g�����L���Ă���X���b�h���~�߂Ă��܂��A�Ƃ������ƁB
SMT�ɂ����ĕ��ו��U�̂��߂Ɂu����́v�X���b�h���~�߂��Ă��܂������̘b�ŁA
�����̃X���b�h�퓮�����܂܂��B
�܂�A�S�̂Ƃ��Ă�p�C�v���C���퓮�����܂܂ŁAROB�G���g���s���Ńp�C�v���C������~����悤�Ȃ��Ƃ�Ȃ����B
> Similarly, resource-balancing logic monitors the GCT to determine the number of entries each
> thread is using. If the balancing logic detects that one thread is beginning to use too many GCT entries,
> potentially blocking the other thread, it throttles back the thread that is using excessive GCT entries.
�ꉞ�A���{��ŗv�Ă����ƁA
(2way SMT��POWER5�ɂ�����)�A����̃X���b�h��GCT�G���g�����ʂɐ�L����悤�Ȃ��Ƃ�����ƁA
�����̃X���b�h���u���b�N���Ă��܂����Ƃ�����̂ŁA
���ו��U�@�\��GCT�G���g�����L���Ă���X���b�h���~�߂Ă��܂��A�Ƃ������ƁB
SMT�ɂ����ĕ��ו��U�̂��߂Ɂu����́v�X���b�h���~�߂��Ă��܂������̘b�ŁA
�����̃X���b�h�퓮�����܂܂��B
�܂�A�S�̂Ƃ��Ă�p�C�v���C���퓮�����܂܂ŁAROB�G���g���s���Ńp�C�v���C������~����悤�Ȃ��Ƃ�Ȃ����B
�f���ɁA�V���O���X���b�hCPU��ROB�G���g���s���������Ńp�C�v���C�����~�܂�悤�Ȏ�����T���Ă�������Ǝv�������A
�������Ȃ��̂͌�����͂����Ȃ��̂ŁA
�ꂵ�܂����SMT�̗�������o���Ă����ɑ���Ȃ����B
�����Ƃ�MAC�I�^�͌��ǂ̂Ƃ��뉽���������Ă��Ȃ��̂ŁA�g���`���J�������Ĕ��_�ɂ��Ȃ��Ă��Ȃ��킯����(��)
�������Ȃ��̂͌�����͂����Ȃ��̂ŁA
�ꂵ�܂����SMT�̗�������o���Ă����ɑ���Ȃ����B
�����Ƃ�MAC�I�^�͌��ǂ̂Ƃ��뉽���������Ă��Ȃ��̂ŁA�g���`���J�������Ĕ��_�ɂ��Ȃ��Ă��Ȃ��킯����(��)
>>192
�⑫�ł��B�ߕs���Ȃ������͓̂���B
�������W�X�^�̓C���I�[�_�[�Ɋm�ۂ���A���߂̃��^�C�A���ɃC���I�[�_�[�ɉ������܂��B
ROB�G���g�������l�ɃC���I�[�_�[�Ɋm�ۂ���A�C���I�[�_�[�ɉ������܂��B
�������ȈՉ����邽�߁A�������W�X�^��ROB�G���g������Έ�őΉ������邱�Ƃ������̂ł����A
�K�������������Ƃ͌���܂���B
Isaiah�̂悤�ɁAROB�G���g����������uop�����悤�ȃv���Z�b�T�ł́A
ROB�G���g���������̕������W�X�^�ɑΉ����邱�ƂɂȂ�܂��B
ROB�G���g���̊m�ۂ́A��p�C�v���C���X�e�[�W��ɂ͂���܂���B
���߂̃f�R�[�h��ł���A�Ƃ��Ɉˑ��W���Ȃ�ROB�G���g���̊m�ۂ����邱�Ƃ��ł��܂��B
ROB���̂͑傫�ȃ��j�b�g�ł����A�N���e�B�J���p�X��ɂ���킯�ł͂Ȃ��ŁA
���������\��̃l�b�N�ɂȂ邱�Ƃ�(���܂�)����܂���B
�⑫�ł��B�ߕs���Ȃ������͓̂���B
�������W�X�^�̓C���I�[�_�[�Ɋm�ۂ���A���߂̃��^�C�A���ɃC���I�[�_�[�ɉ������܂��B
ROB�G���g�������l�ɃC���I�[�_�[�Ɋm�ۂ���A�C���I�[�_�[�ɉ������܂��B
�������ȈՉ����邽�߁A�������W�X�^��ROB�G���g������Έ�őΉ������邱�Ƃ������̂ł����A
�K�������������Ƃ͌���܂���B
Isaiah�̂悤�ɁAROB�G���g����������uop�����悤�ȃv���Z�b�T�ł́A
ROB�G���g���������̕������W�X�^�ɑΉ����邱�ƂɂȂ�܂��B
ROB�G���g���̊m�ۂ́A��p�C�v���C���X�e�[�W��ɂ͂���܂���B
���߂̃f�R�[�h��ł���A�Ƃ��Ɉˑ��W���Ȃ�ROB�G���g���̊m�ۂ����邱�Ƃ��ł��܂��B
ROB���̂͑傫�ȃ��j�b�g�ł����A�N���e�B�J���p�X��ɂ���킯�ł͂Ȃ��ŁA
���������\��̃l�b�N�ɂȂ邱�Ƃ�(���܂�)����܂���B
>>203
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
ROB��C���t���C�g�Ȗ��߂����ׂĕ�����\���̂��B
RS��C���t���C�g�Ȗ��߂̈ꕔ�݂̂�ێ�����\���̂��B
���������āARS�ɋ�����̂�ROB�ɋ��Ȃ��悤�ȏ킠�肦�Ȃ����B
�܂�
> �@�ERS�̋�
���̏�����i���Z���X���B
�o������̂Ȃ�A����A�܂�RS�T�C�Y�̂ق���ROB�T�C�Y���傫�������T���Ă���������B
�������AROB�����������W�X�^�̂ق����N���e�B�J���ȃ��\�[�X���B
�������W�X�^��A��p�C�v���C����ɂ̂������Ă��鐫�\�I�ɃN���e�B�J���ȃ��\�[�X���B
�������W�X�^�ɋ�����̂ɁA��p�C�v���C������O�ꂽ�Ƃ���ɂ����Đ��\�I�ɗ]�T�̂���ROB�����t�ɂȂ��������߂�
��p�C�v���C�����~�܂�悤�ȃA�t�H�Ȑv�������킢�Ȃ����B
ROB�T�C�Y�ƕ������W�X�^�T�C�Y�������ł���悤�Ȏ����푶�݂��邷���A
��������CPU�ł�A
ROB�����t==�������W�X�^�����t
�Ȃ̂ŁA����
> �@�EROB�̋�
���̏������i���Z���X���B
�o������̂Ȃ�A����A�܂蕨�����W�X�^�ɋ�����̂�ROB�����t�̂��߂Ƀp�C�v���C�����~�܂�悤�Ȏ����T���Ă���������B
>>209��A���[�h�o�����T�[���X���b�h���~�߂�SMT�ŗL�̎����ŁA�S�R�W�Ȃ��b���B
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
ROB��C���t���C�g�Ȗ��߂����ׂĕ�����\���̂��B
RS��C���t���C�g�Ȗ��߂̈ꕔ�݂̂�ێ�����\���̂��B
���������āARS�ɋ�����̂�ROB�ɋ��Ȃ��悤�ȏ킠�肦�Ȃ����B
�܂�
> �@�ERS�̋�
���̏�����i���Z���X���B
�o������̂Ȃ�A����A�܂�RS�T�C�Y�̂ق���ROB�T�C�Y���傫�������T���Ă���������B
�������AROB�����������W�X�^�̂ق����N���e�B�J���ȃ��\�[�X���B
�������W�X�^��A��p�C�v���C����ɂ̂������Ă��鐫�\�I�ɃN���e�B�J���ȃ��\�[�X���B
�������W�X�^�ɋ�����̂ɁA��p�C�v���C������O�ꂽ�Ƃ���ɂ����Đ��\�I�ɗ]�T�̂���ROB�����t�ɂȂ��������߂�
��p�C�v���C�����~�܂�悤�ȃA�t�H�Ȑv�������킢�Ȃ����B
ROB�T�C�Y�ƕ������W�X�^�T�C�Y�������ł���悤�Ȏ����푶�݂��邷���A
��������CPU�ł�A
ROB�����t==�������W�X�^�����t
�Ȃ̂ŁA����
> �@�EROB�̋�
���̏������i���Z���X���B
�o������̂Ȃ�A����A�܂蕨�����W�X�^�ɋ�����̂�ROB�����t�̂��߂Ƀp�C�v���C�����~�܂�悤�Ȏ����T���Ă���������B
>>209��A���[�h�o�����T�[���X���b�h���~�߂�SMT�ŗL�̎����ŁA�S�R�W�Ȃ��b���B
��������>>209�̈��p���ɂ�A�������W�X�^�̃u�̎����łĂ��Ȃ����B
> �@�@------------------
> �@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> �@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
> �@�@------------------
MAC�I�^��A�Ӑ}�I�ɍŏ��̍s������Ĉ��p�����ۂ������A
���Ƃ̏������݂͂������B
> ������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
MAC�I�^��A�悭���������b�̂��炵�������邷���A����������ɂ��ė~�������̂��B
> �@�@------------------
> �@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> �@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
> �@�@------------------
MAC�I�^��A�Ӑ}�I�ɍŏ��̍s������Ĉ��p�����ۂ������A
���Ƃ̏������݂͂������B
> ������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
MAC�I�^��A�悭���������b�̂��炵�������邷���A����������ɂ��ė~�������̂��B
�Ƃ���ŁAROB��x86�p��Ƃ����̂�A�܂��������Ȃ������B
�O�X��
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
�O�X��
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
>>212
> �u�������W�X�^�ɋ��Ȃ��̂Łv�p�C�v���C�����~�߂邱�Ƃ̑�Ȃ̂��A�������ė~�������B
�u�������W�X�^�ɋ�����̂Ɂv�̊ԈႢ���B
> �u�������W�X�^�ɋ��Ȃ��̂Łv�p�C�v���C�����~�߂邱�Ƃ̑�Ȃ̂��A�������ė~�������B
�u�������W�X�^�ɋ�����̂Ɂv�̊ԈႢ���B
>>217
> ROB�����t==�������W�X�^�����t
> �Ȃ̂ŁA����
> > �@�EROB�̋�
> ���̏������i���Z���X���B
�������B
�i���Z���X�ȏ�����
> �@�E���l�[�����W�X�^�̋�
������̂ق����B
> ROB�����t==�������W�X�^�����t
> �Ȃ̂ŁA����
> > �@�EROB�̋�
> ���̏������i���Z���X���B
�������B
�i���Z���X�ȏ�����
> �@�E���l�[�����W�X�^�̋�
������̂ق����B
�۽�B��������Č���Ƶ����t���ʔ���[�ȁB
�Ƃ��Ă����ɂȂ邷�B�� �UMAC�� ��
�Ƃ��Ă����ɂȂ邷�B�� �UMAC�� ��
>>217
�⑫���B
>>203
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
�K�v�ȕ������W�X�^���m�ۂł��Ȃ��ꍇ�ɂ�A��p�C�v���C���킻���Ŏ~�܂邷�B
�������W�X�^��K�v�Ƃ��Ȃ����߂̏ꍇ��A�������W�X�^�ɋ��Ȃ��Ă��~�߂�K�v��Ȃ����B
ROB�G���g���̊m�ۂ�A��p�C�v���C���ƕ��s���čs���邷�B
���W�X�^���l�[����ROB�G���g���̊m�ۂɂ�ˑ��W���Ȃ�������A
�������W�X�^���m�ۂł��Ȃ��ꍇ�ł��AROB�G���g�����m�ۂ����u��v�Ŏ~�܂�悤�Ȏ��������肦�邷�B
�⑫���B
>>203
> �����ŏd�v�ȓ_��A�ȉ��̑S�Ă̏�������������Ȃ�����ROB�ւ̓o�^�̑O�Ŏ~�܂邱�Ƃ��B
> �@�EROB�̋�
> �@�E���l�[�����W�X�^�̋�
> �@�ERS�̋�
�K�v�ȕ������W�X�^���m�ۂł��Ȃ��ꍇ�ɂ�A��p�C�v���C���킻���Ŏ~�܂邷�B
�������W�X�^��K�v�Ƃ��Ȃ����߂̏ꍇ��A�������W�X�^�ɋ��Ȃ��Ă��~�߂�K�v��Ȃ����B
ROB�G���g���̊m�ۂ�A��p�C�v���C���ƕ��s���čs���邷�B
���W�X�^���l�[����ROB�G���g���̊m�ۂɂ�ˑ��W���Ȃ�������A
�������W�X�^���m�ۂł��Ȃ��ꍇ�ł��AROB�G���g�����m�ۂ����u��v�Ŏ~�܂�悤�Ȏ��������肦�邷�B
�����[��
���ʂ̓��{��ŗv�ď���
�Ȃɂӂ����ĂK�L��
���ʂ̓��{��ŗv�ď���
�Ȃɂӂ����ĂK�L��
�ǂ����ꍇ�ɂ��ꂪ���\����Ɋ�^�����邩
���������
���������
�S�`���S�`������Ă��P�̐��\�͓��ł�
���l��l���Ă��������Ƃ����Ȃ���(��)
2ch�ɔS�����ĂĂ��������Ƃ͈���Ȃ��
����
����
�i�@߄t߁j�߶�݁c �� 1jT1hkTg
�ʃR�A�̃��W�X�^�Q�Əo����悤�ɂȂ�����
�A�[�L�e�N�`���̌n�����͌݊����̎���ꂽ�V�����}�ɂȂ�ˁB
�A�[�L�e�N�`���̌n�����͌݊����̎���ꂽ�V�����}�ɂȂ�ˁB
>>230
TILE64�Ƃ����}���`�R�A�v���Z�b�T������Ȋ����ł��B
�����������̖�肪����̂ŁA���M���R�A����M���R�A�̓��ꃌ�W�X�^�ɒ��ڏ������ތ`�ɂȂ�܂����B
TILE64�Ƃ����}���`�R�A�v���Z�b�T������Ȋ����ł��B
�����������̖�肪����̂ŁA���M���R�A����M���R�A�̓��ꃌ�W�X�^�ɒ��ڏ������ތ`�ɂȂ�܂����B
���Ȃ݂�TILE64�́A1970�N���MIT�X�^�e�B�b�N�f�[�^�t���[�Ɏn�܂钷���n���̖���ł��B
ID���o���Ă݂����A ID:lSXgkkSe����ID:LDD2ACQC/ID:H29jm950�̂ق���
���������Ȃ��Ƃ������Ă���悤�Ɍ�����ȁB
���������Ȃ��Ƃ������Ă���悤�Ɍ�����ȁB
������in-order��SMT���đ����̃X���b�h�����C���������҂��ɓ������Ƃ����
���̕��̃��\�[�X�g���ĕ�����s�ł���킯�ł��Ȃ��̂�
�������������̂������ς�킩��Ȃ�
���̕��̃��\�[�X�g���ĕ�����s�ł���킯�ł��Ȃ��̂�
�������������̂������ς�킩��Ȃ�
>>234
��ʓI�ɂ͉��Z�퐔>>�V���O���X���b�hIPC�Ȃ̂ŁA�C���I�[�_�[�ł����X���b�h���疽�߂���������͈̂Ӗ�������܂��B
��ʓI�ɂ͉��Z�퐔>>�V���O���X���b�hIPC�Ȃ̂ŁA�C���I�[�_�[�ł����X���b�h���疽�߂���������͈̂Ӗ�������܂��B
�n�C�G���hPOWER6�T�[�o�[��Sysem i�̃��[�U�[�O���[�v��cCOMMON�ɍ��킹�āA�������ɂ����\�Ƃ̂��Ƃ��B
http://www.itjungle.com/tfh/tfh031008-story01.html
�@�@---------------------
�@�@So here are the two news items. First, the high-end of the Power6 server line, presumably to still be
�@�@called the System p 590 and 595 and the System i 595, are being launched at the beginning of April.
�@�@---------------------
���R�]���ʂ�MCM�ł𓋍ڂ��Ă���Ɨ\�z����邷�B>>121��z6 MCM�̂����Œx�ꂽ�Ƃ������������ǁA
�J���퓯���i�s�������͗l���B
http://www.itjungle.com/tfh/tfh031008-story01.html
�@�@---------------------
�@�@So here are the two news items. First, the high-end of the Power6 server line, presumably to still be
�@�@called the System p 590 and 595 and the System i 595, are being launched at the beginning of April.
�@�@---------------------
���R�]���ʂ�MCM�ł𓋍ڂ��Ă���Ɨ\�z����邷�B>>121��z6 MCM�̂����Œx�ꂽ�Ƃ������������ǁA
�J���퓯���i�s�������͗l���B
�ۈ�������Ă����_�Ȃ������B
���ɁA�����������˂Č������ꂷ�邱�Ƃ��ł��Ȃ��Ȃ����悤����(��)
���ɁA�����������˂Č������ꂷ�邱�Ƃ��ł��Ȃ��Ȃ����悤����(��)
�O�O���Ă�Ƃ��낾����������傢�҂�
�O�X��869
> ROB��x86�p��Ȃ��ǁB�B�B
�O�O��̂ɂ���ꂽ�������Ǝv���̂ŁA�Ƃ肠��������퐳�����̂����Ȃ̂������ė~�������B
����Ȃ��̂ɑ����ł��Ȃ��悤�ł�AMAC�I�^��CPU�A�[�L�e�N�`���ɂ��ĉ����������Ă��Ȃ��ƌ��킴��Ȃ����B
�������듚�����킸�����Ȃ��B
> ROB��x86�p��Ȃ��ǁB�B�B
�O�O��̂ɂ���ꂽ�������Ǝv���̂ŁA�Ƃ肠��������퐳�����̂����Ȃ̂������ė~�������B
����Ȃ��̂ɑ����ł��Ȃ��悤�ł�AMAC�I�^��CPU�A�[�L�e�N�`���ɂ��ĉ����������Ă��Ȃ��ƌ��킴��Ȃ����B
�������듚�����킸�����Ȃ��B
���W�X�^��Ax86�p��ł���
RS��Ax86�p��ł���
�L���b�V����A�ǂ��ł���
������������(��)
RS��Ax86�p��ł���
�L���b�V����A�ǂ��ł���
������������(��)
>>209
�̂悤�ȗ�������o���Ƃ�����݂�ƁA
����������MAC�I�^��APOWER5��Global Completion Table��ROB�����i���ƔF�߂������H
�F�߂��̂Ȃ�A����P�ĎӍ߂��ė~��������(��)
���邢��A�����܂�GCT��ROB�ł�Ȃ��Ǝ咣���邷���H
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
�̂悤�ȗ�������o���Ƃ�����݂�ƁA
����������MAC�I�^��APOWER5��Global Completion Table��ROB�����i���ƔF�߂������H
�F�߂��̂Ȃ�A����P�ĎӍ߂��ė~��������(��)
���邢��A�����܂�GCT��ROB�ł�Ȃ��Ǝ咣���邷���H
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
>>241
����������ł��锤���ˁB
����̓��e�̈Ӑ}�ɂ���yes/no�̎��������đ����ł��Ȃ��悤�ł�A
��͂�MAC�I�^�퉽�����������ɏ������炵�Ă������Ƃ̏؍��ɂȂ邷�B
����������ł��锤���ˁB
����̓��e�̈Ӑ}�ɂ���yes/no�̎��������đ����ł��Ȃ��悤�ł�A
��͂�MAC�I�^�퉽�����������ɏ������炵�Ă������Ƃ̏؍��ɂȂ邷�B
�O�X��885
> �X�ɖ��߂̗���̏�ŁuROB -> RS�v�ƂȂ��Ă��邷����AROB�������C�e���V�̖��߂ŋl�܂�A
> RS�ɖ��ߋ������邱�Ƃ���ł��Ȃ����B
> ���̕ӂ̎���Ƒ��A���POWER5�_����"Dynamic Resource Balancing"�̐߂ł��q�ׂ��Ă��邷�B
���߂̗��ꂪ�uROB->RS�v�ƂȂ��Ă���̂��A���POWER5�_���ɑ����ĉ�����Ă�������(��)
http://www.research.ibm.com/journal/rd/494/sinharoy.html
���̐}�����Ă������̂ŁA�Q�l�ɂ��Ă�������(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
> �X�ɖ��߂̗���̏�ŁuROB -> RS�v�ƂȂ��Ă��邷����AROB�������C�e���V�̖��߂ŋl�܂�A
> RS�ɖ��ߋ������邱�Ƃ���ł��Ȃ����B
> ���̕ӂ̎���Ƒ��A���POWER5�_����"Dynamic Resource Balancing"�̐߂ł��q�ׂ��Ă��邷�B
���߂̗��ꂪ�uROB->RS�v�ƂȂ��Ă���̂��A���POWER5�_���ɑ����ĉ�����Ă�������(��)
http://www.research.ibm.com/journal/rd/494/sinharoy.html
���̐}�����Ă������̂ŁA�Q�l�ɂ��Ă�������(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
�킽���ɂ�A"Group formation, instruction decode, dispatch"����Global completion table(=ROB)�ɗ���Ă��āA
GCT��Shared issue queues(=RS)�̊Ԃɂ�A���̗���������Ȃ����ˁB
GCT��Shared register mappers�Ԃɂ��A���̗���������Ȃ����B
�uROB->RS�v�̖��߂̗����A�ǂ����痈�����ˁB
��͂�MAC�I�^�̔]���t���[�����B
GCT��Shared issue queues(=RS)�̊Ԃɂ�A���̗���������Ȃ����ˁB
GCT��Shared register mappers�Ԃɂ��A���̗���������Ȃ����B
�uROB->RS�v�̖��߂̗����A�ǂ����痈�����ˁB
��͂�MAC�I�^�̔]���t���[�����B
����Ƃ�����������MAC�I�^��A
IBM���A�����āuGlobal completion table�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�Ƃł��咣���邷����(��)
IBM���A�����āuGlobal completion table�v�Ə������̂�AROB��RS���܂߂����ߊǗ��̂��߂̃L���[�^ �o�b�t�@���܂Ƃ߂ďq�ׂ����炷�B
�Ƃł��咣���邷����(��)
MAC�I�^��A���Ȃ��Ƃ�2000�N����CPU�W�̃X���ɏ풓���Ă����킯�����A
8�N�����Ă����̒��x�Ƃ������܂�����艽���������Ă��Ȃ����Ƃɂ�A���|����o���邷�B
�����̏��w����������w���ɂȂ鍠�����A�Ԉ�����m����A������ꂽ�܂܈���Ă��Ȃ����Ƃ�S����F�邷�B
8�N�����Ă����̒��x�Ƃ������܂�����艽���������Ă��Ȃ����Ƃɂ�A���|����o���邷�B
�����̏��w����������w���ɂȂ鍠�����A�Ԉ�����m����A������ꂽ�܂܈���Ă��Ȃ����Ƃ�S����F�邷�B
>>21�͒�
>>25�͒�
>>11�͗[��
>>121�͖�
>>18�͐[��
>>49�͖���
�ƁA�����ƌ��������ł��A�ۈ�����̃X���ɒ���t���Ă���l�q���f���邷�B
��̏������݂����Ȃ߂Ȃ̂�A�O�O��̂ɖZ�E����Ă��邩�炷���ˁB
�Ƃ肠�����A�����ł���ȒP�Ȏ�����o���Ƃ����̂ŁA���������ė~�������B
�������Ȃ��ăo�b�N���Ă���Ȃ�Ă��Ƃ͂Ȃ��Ǝv�������B
>>25�͒�
>>11�͗[��
>>121�͖�
>>18�͐[��
>>49�͖���
�ƁA�����ƌ��������ł��A�ۈ�����̃X���ɒ���t���Ă���l�q���f���邷�B
��̏������݂����Ȃ߂Ȃ̂�A�O�O��̂ɖZ�E����Ă��邩�炷���ˁB
�Ƃ肠�����A�����ł���ȒP�Ȏ�����o���Ƃ����̂ŁA���������ė~�������B
�������Ȃ��ăo�b�N���Ă���Ȃ�Ă��Ƃ͂Ȃ��Ǝv�������B
248 �F�ǂ��Ă������܂����F2008/03/11(��) 21:43:03 ID:6LaD4XAx
�̂Ƃ���ׂ��Mac���^�����킵���Ȃ�����
249 �F�ǂ��Ă������܂����F2008/03/11(��) 21:55:11 ID:6LaD4XAx
���܂�ď��߂Ĕ����������A�X�L�[��Pentium���W��
�������킩��₷��OoO�̐���������Ă�
�������킩��₷��OoO�̐���������Ă�
>>247
�o�b�N���Ȃ��悤�ɔO�������Ƃ����B
MAC�I�^�������ł���͂��̊ȒP�ȓ�̎����ȉ��̒ʂ肷�B
�EROB��x86�p�ꂩ�ۂ��H
�EPOWER5��GCT��ROB�������ۂ��H
CPU�A�[�L�e�N�`���ɂ��Ă���Ȃ�ɗ������Ă���l�ԂȂ�A�������ł��邷�B
�킽������̂ق��Ő������������̂ŁA������E���Ă��Ă���Ă����܂�Ȃ����B
�o�b�N���Ȃ��悤�ɔO�������Ƃ����B
MAC�I�^�������ł���͂��̊ȒP�ȓ�̎����ȉ��̒ʂ肷�B
�EROB��x86�p�ꂩ�ۂ��H
�EPOWER5��GCT��ROB�������ۂ��H
CPU�A�[�L�e�N�`���ɂ��Ă���Ȃ�ɗ������Ă���l�ԂȂ�A�������ł��邷�B
�킽������̂ق��Ő������������̂ŁA������E���Ă��Ă���Ă����܂�Ȃ����B
>>250
�����_�ł́AMAC�I�^��A�uROB��x86�p��Ȃ��ǁv�Ǝ咣���Ă��邷�B
�O�X��
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
�����_�ł́AMAC�I�^��A�uROB��x86�p��Ȃ��ǁv�Ǝ咣���Ă��邷�B
�O�X��
869 ���O�F MAC�I�^��868 ���� [sage] ���e���F 2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
>>250
�����_�ł�AMAC�I�^��A�uPOWER5��GCT��ROB�����ł���v�Ƃ����ӌ���ے肵�Ă邷�B
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
�����_�ł�AMAC�I�^��A�uPOWER5��GCT��ROB�����ł���v�Ƃ����ӌ���ے肵�Ă邷�B
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
>>250
���悤��MAC�I�^��A��x��ȉ��̓�̎���̓������q�ׂĂ���̂�����A(>>251��>>252)
������O�O�����肵�Ȃ��Ă��A�����ɓ���������������x�������ނ��B
> �EROB��x86�p�ꂩ�ۂ��H
> �EPOWER5��GCT��ROB�������ۂ��H
���悤��MAC�I�^��A��x��ȉ��̓�̎���̓������q�ׂĂ���̂�����A(>>251��>>252)
������O�O�����肵�Ȃ��Ă��A�����ɓ���������������x�������ނ��B
> �EROB��x86�p�ꂩ�ۂ��H
> �EPOWER5��GCT��ROB�������ۂ��H
MAC�I�^�펩���̎咣��������x�J�ւ������ނ����̂��Ƃ��B
���ꂷ��ł��Ȃ��̂�A�����m�△�������������Đg�������Ƃ�Ȃ��Ȃ������炷���ˁH
���ꂷ��ł��Ȃ��̂�A�����m�△�������������Đg�������Ƃ�Ȃ��Ȃ������炷���ˁH
�������Ȃ��̂�A�C�G�X�m�[�Ŏ��₳�ꂽ�̂ŁA�K���ŃO�O���ĒT�������Ă����L���Řb�����炷���Ƃ���ł��Ȃ����炷�ˁH
�uROB��x86�p��Ȃ��ǁv�uGCT��ROB�Ƃ���ɗ���ƌ��������ƌ����ׂ����v
�ƌ����Ȃ��̂�A�����Ă��܂��Βp�̏�h��ɂȂ邱�Ƃ��킩���Ă��邩�炷���H
�uROB��x86�p��ł�Ȃ����v�uGCT��ROB�������v
�ƌ����Ȃ��̂�A�����̌���F�߂邱�ƂɂȂ邩�炷���H
�O�O�����L���Ŏ�������点�Ȃ��̂�A�C�G�X�m�[�Őq�˂�ꂽ���炷���H
�ƌ����Ȃ��̂�A�����Ă��܂��Βp�̏�h��ɂȂ邱�Ƃ��킩���Ă��邩�炷���H
�uROB��x86�p��ł�Ȃ����v�uGCT��ROB�������v
�ƌ����Ȃ��̂�A�����̌���F�߂邱�ƂɂȂ邩�炷���H
�O�O�����L���Ŏ�������点�Ȃ��̂�A�C�G�X�m�[�Őq�˂�ꂽ���炷���H
�C�G�X�Ɠ����Ă��A�m�[�Ɠ����Ă��A��������炵�Ă��p�������A
����ȊO�ɁAMAC�I�^����A���Ȃ����ق��Ă��闝�R�킠����H
����ȊO�ɁAMAC�I�^����A���Ȃ����ق��Ă��闝�R�킠����H
�A���X�����Ɉ�ɂ܂Ƃ߂�B��������Ȃ番���Ă��������ǖ��Ӗ��ɕ�����ȁB
�K���ŃO�O���Ă邩��
������Ƒ҂��Ă����ĉ�����
������Ƒ҂��Ă����ĉ�����
�킽���̎����A������܂ł��Ȃ�������Ȃ�����ł�Ȃ�����B
�uROB��x86�p�ꂩ�H�v�Ƃ����̂�A�����ăg���r�A�ł�Ȃ����B
�Ԉ���Ċo����ƁA�u���W�X�^��x86�p��ł���v�u�L���b�V����x86�p��ł���v�ƌ������Ƃ��Ɠ����悤�Ȓp���������B
POWER5��GCT��A�u���b�N�}�ɂ��ڂ��Ă��Ă���Ȃ�̗ʂ̉�������Ă���d�v�ȃ��j�b�g���B
POWER5�̃A�[�L�e�N�`���𗝉����邽�߂ɂ�AGCT�����̃v���Z�b�T�̂ǂ̕����ɑ�������̂��A
�ǂ����Ă��������������Ȃ���Ȃ�Ȃ����B
>>258
ID��ARM
>>259
MAC�I�^���ԈႢ���������܂ł펀�ȂȂ����B
�uROB��x86�p�ꂩ�H�v�Ƃ����̂�A�����ăg���r�A�ł�Ȃ����B
�Ԉ���Ċo����ƁA�u���W�X�^��x86�p��ł���v�u�L���b�V����x86�p��ł���v�ƌ������Ƃ��Ɠ����悤�Ȓp���������B
POWER5��GCT��A�u���b�N�}�ɂ��ڂ��Ă��Ă���Ȃ�̗ʂ̉�������Ă���d�v�ȃ��j�b�g���B
POWER5�̃A�[�L�e�N�`���𗝉����邽�߂ɂ�AGCT�����̃v���Z�b�T�̂ǂ̕����ɑ�������̂��A
�ǂ����Ă��������������Ȃ���Ȃ�Ȃ����B
>>258
ID��ARM
>>259
MAC�I�^���ԈႢ���������܂ł펀�ȂȂ����B
ID:SEi8tyfB
GJ!
GJ!
���̃X���I�����
�o�J����l�ɑ����₪�����c
�����ƃ_���S������ĎO�l���B
�����A����
�����ƃ_���S������ĎO�l���B
�����A����
�l��l���Ă��������Ƃ����Ȃ����B
AMD������X���ɂ͌��ꂽ�݂��������������ɂ͗��Ȃ��悤���B
�悻�ł���N�Y��
�l��l���Ă��������Ƃ����Ȃ����B
�X���^�C�ɒ����ɍs�����Ă���̂ŁA�悻�ł��킯�ɂ킢���Ȃ����B
�X���^�C�ɒ����ɍs�����Ă���̂ŁA�悻�ł��킯�ɂ킢���Ȃ����B
NG���₷���悤�ɍs�����Ă�悤�����A�����ł���ĂĂ���
�����ŃI�i�j�[�����
blog�ł�����Ă��ł���
blog�ł�����Ă��ł���
�ړI����������A���_�ł���A���l�炵�߂邽�߂ł���A
�ǂ�Ȏ�i���̂��Ă��������B�Ƃ����킯�ł͂Ȃ���B
ID:SEi8tyfB������Ă��邱�Ƃ́A�ǂ�Ȑ������������ē��e���������낤���A
���ǂ̂Ƃ���r������B�r���̓X���[���폜�˗��ŁB
�ǂ�Ȏ�i���̂��Ă��������B�Ƃ����킯�ł͂Ȃ���B
ID:SEi8tyfB������Ă��邱�Ƃ́A�ǂ�Ȑ������������ē��e���������낤���A
���ǂ̂Ƃ���r������B�r���̓X���[���폜�˗��ŁB
���́@ID:SEi8tyfB�@�͕K�������r�炵�Ƃ͎v��Ȃ��B
���X�l�`�b�I�^����ɕs�K�v�ɐl��n���ɂ��������ŏ����Ă�̂������B
�����A�����X�ɂ��n���ē������Ƃ��J��Ԃ����A�Ȍ��ɂ͂��ׂ��B
���X�l�`�b�I�^����ɕs�K�v�ɐl��n���ɂ��������ŏ����Ă�̂������B
�����A�����X�ɂ��n���ē������Ƃ��J��Ԃ����A�Ȍ��ɂ͂��ׂ��B
�m���ɖ{MAC�I�^���UMAC�I�^���r�炵�Ȃ͎̂�������w
�{MAC�I�^�̑T�ⓚ&�\�[�X�R�s�֏��͕��͂�����ł����Ɏ}�t���߂ɓ������݉߂���
���������������킩��Ȃ��̂��肾�������ǁA�UMAC�I�^�̏������݂͓ǂ�łĉ���₷��w
�UMAC�I�^�͂����{MAC�I�^�̕��Ȃ��u���ĕ��ʂ�CPU�ɂ��Č���Ă���Ȃ����ȁB
�{MAC�I�^�̑T�ⓚ&�\�[�X�R�s�֏��͕��͂�����ł����Ɏ}�t���߂ɓ������݉߂���
���������������킩��Ȃ��̂��肾�������ǁA�UMAC�I�^�̏������݂͓ǂ�łĉ���₷��w
�UMAC�I�^�͂����{MAC�I�^�̕��Ȃ��u���ĕ��ʂ�CPU�ɂ��Č���Ă���Ȃ����ȁB
�ǂ��������ŁA���ʂɘb�̂ł���l�Ԃ����W�܂�悢�̂ɁB
���������̔��[�ƂȂ���Issaiah������
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�u���b�N�}�̉�������Ă݂�B
�����������Ă̒ʂ肾���ǁA�⑫���K�v�����Ȃ̂�
�ERename & allocate into Reservation Stations ���� ROB, MOB(=Memory Order Buffer), arch regs �ւ̃t���[
ROB�G���g���̓��W�X�^���l�[������݂̏���ێ����Ă���̂�
(ROB�G���g��������ɁA�������W�X�^����������ׂ���)
���������t���[���Ǝv���B
�������ǂ��Ȃ��Ă��邩�m��R���Ȃ����AROB�G���g���̊m�ێ��̂�FIQ�ƕ��s�����邱�Ƃ��\�ł͂���B
�EROB�̃u���b�N����OoO�u���b�N�ւ̃t���[
arch regs(x86���W�X�^)����ǂݏo�����f�[�^�̃t���[�B
�EOoO�u���b�N����ROB�u���b�N�ւ̃t���[
result forwarding network�o�R�ŁA���s���ʂ�ROB�G���g���ɏ������ރt���[�B
���߂̃��^�C�A���ɁAROB�G���g������arch regs�ɏ������݂��s����B1�y�[�W�O�́�����B
> Retirement means that the x86 registers are updated, memory changes are committed,
> x86 exceptions are taken, and so forth.
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�u���b�N�}�̉�������Ă݂�B
�����������Ă̒ʂ肾���ǁA�⑫���K�v�����Ȃ̂�
�ERename & allocate into Reservation Stations ���� ROB, MOB(=Memory Order Buffer), arch regs �ւ̃t���[
ROB�G���g���̓��W�X�^���l�[������݂̏���ێ����Ă���̂�
(ROB�G���g��������ɁA�������W�X�^����������ׂ���)
���������t���[���Ǝv���B
�������ǂ��Ȃ��Ă��邩�m��R���Ȃ����AROB�G���g���̊m�ێ��̂�FIQ�ƕ��s�����邱�Ƃ��\�ł͂���B
�EROB�̃u���b�N����OoO�u���b�N�ւ̃t���[
arch regs(x86���W�X�^)����ǂݏo�����f�[�^�̃t���[�B
�EOoO�u���b�N����ROB�u���b�N�ւ̃t���[
result forwarding network�o�R�ŁA���s���ʂ�ROB�G���g���ɏ������ރt���[�B
���߂̃��^�C�A���ɁAROB�G���g������arch regs�ɏ������݂��s����B1�y�[�W�O�́�����B
> Retirement means that the x86 registers are updated, memory changes are committed,
> x86 exceptions are taken, and so forth.
Isaiah�ł́Amicro-op(s)�ƌĂ����̂�
executable micro-op ���̂܂��s���j�b�g�Ŏ��s�ł������
fused micro-ops 0����3���߂�executable micro-ops��fuse��������
�Ɠ��ނ���̂ŁA�����micro-ops�Ə����Ă���ꍇ�ɂ́A�ǂ�����w���̂�������Ƌ�ʂ��邱�Ƃ��d�v�B
�łȂ���MA(��)
X86 INSTRUCTION TRANSLATION��
> The next stage translates the x86 instructions from the FIQ into micro-ops.
> Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the initial implementation)
> and an optional ROM address.
micro-ops�́A��ӏ��Ƃ�executable micro-ops�B
�����������̎��_�ł�fused micro-ops�͂܂��o�ė��Ă��Ȃ��B
> Also, each micro-op generated by the translator can represent functions to be performed by more than one execution unit.
> This combining of execution unit micro-ops into more powerful micro-ops is called micro-op fusion.
execution unit micro-ops == executable micro-ops�͂����̌��������B
����executable micro-ops��more powerful micro-ops��combining����̂���������Ă��Ȃ����A
> each micro-op generated by the translator(�ȉ���)
�Ƃ���̂ŁA�ϊ��킩��o�Ă������_�ł��ł�fused micro-ops���Ɠǂ߂�B
executable micro-op ���̂܂��s���j�b�g�Ŏ��s�ł������
fused micro-ops 0����3���߂�executable micro-ops��fuse��������
�Ɠ��ނ���̂ŁA�����micro-ops�Ə����Ă���ꍇ�ɂ́A�ǂ�����w���̂�������Ƌ�ʂ��邱�Ƃ��d�v�B
�łȂ���MA(��)
X86 INSTRUCTION TRANSLATION��
> The next stage translates the x86 instructions from the FIQ into micro-ops.
> Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the initial implementation)
> and an optional ROM address.
micro-ops�́A��ӏ��Ƃ�executable micro-ops�B
�����������̎��_�ł�fused micro-ops�͂܂��o�ė��Ă��Ȃ��B
> Also, each micro-op generated by the translator can represent functions to be performed by more than one execution unit.
> This combining of execution unit micro-ops into more powerful micro-ops is called micro-op fusion.
execution unit micro-ops == executable micro-ops�͂����̌��������B
����executable micro-ops��more powerful micro-ops��combining����̂���������Ă��Ȃ����A
> each micro-op generated by the translator(�ȉ���)
�Ƃ���̂ŁA�ϊ��킩��o�Ă������_�ł��ł�fused micro-ops���Ɠǂ߂�B
�ŁA�ϊ���ɂ����(�}�C�N���R�[�h���g��Ȃ�)x86���߂́A
�E��ɂ���1��fused micro-ops�ɕϊ�����邩�A�܂�x86���߂�fused micro-ops�͈�Έ�ɑΉ����Ă��邩
����肾�����킯�����A
�}�C�N���R�[�h���g��Ȃ�x86���߂́A���X3��executable micro-ops�ɕϊ�����邽�߁A
�킴�킴������fused micro-ops�ɕϊ�����K�v�����l���ɂ������ƁA
MICRO-OP RENAME��
> The translator and microcode subsystem can each produce three fused micro-ops
> (corresponding to up to three x86 instructions) each clock.
�ϊ���̃o���h����3 x86���߂Ȃ̂ŁA1��x86���߂�1��fused micro-ops�ɕϊ������Ƃ��傤�ǒނ荇�����ƁA
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
MICRO-OP RETIREMENT��
> Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
ROB�̃o���h����3 x86���߂ł���A
ROB�ɂ�fused micro-ops�̂܂܊i�[���ꃊ�^�C�A���邱�ƁAROB��x86�̃C���I�[�_�[��Ԃ��Ǘ����邱�Ƃ��v���A
�u�}�C�N���R�[�h���g��Ȃ�1��x86���߂́A�ϊ���ɂ����1��fused micro-ops�ɕϊ������v
�Ƃ����̂��A�������R�ȍl�������Ǝv���܂��B
�E��ɂ���1��fused micro-ops�ɕϊ�����邩�A�܂�x86���߂�fused micro-ops�͈�Έ�ɑΉ����Ă��邩
����肾�����킯�����A
�}�C�N���R�[�h���g��Ȃ�x86���߂́A���X3��executable micro-ops�ɕϊ�����邽�߁A
�킴�킴������fused micro-ops�ɕϊ�����K�v�����l���ɂ������ƁA
MICRO-OP RENAME��
> The translator and microcode subsystem can each produce three fused micro-ops
> (corresponding to up to three x86 instructions) each clock.
�ϊ���̃o���h����3 x86���߂Ȃ̂ŁA1��x86���߂�1��fused micro-ops�ɕϊ������Ƃ��傤�ǒނ荇�����ƁA
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
MICRO-OP RETIREMENT��
> Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
ROB�̃o���h����3 x86���߂ł���A
ROB�ɂ�fused micro-ops�̂܂܊i�[���ꃊ�^�C�A���邱�ƁAROB��x86�̃C���I�[�_�[��Ԃ��Ǘ����邱�Ƃ��v���A
�u�}�C�N���R�[�h���g��Ȃ�1��x86���߂́A�ϊ���ɂ����1��fused micro-ops�ɕϊ������v
�Ƃ����̂��A�������R�ȍl�������Ǝv���܂��B
>>208
��A�叕����ł��B
> �ŏI�I��queue��uop�o�͂ł�3 uop/cycle�ɗ��������?�܂����ς̘b�����ǁB
�����́A3 fused uop/cycle���Ǝv���̂ŁA
> 3��fused-uop�́Areorder buffer(ROB)�ւƈڂ���A�����ōő�6�̎��s�\uop�֓W�J�����B
���_�I�ɂ́A�����̍ő�6�̎��s�\uop�ւ̓W�J���������Ǝv���܂��B
�����Ƃ��Afused micro-ops������2�����̎��s�\uop���������Ȃ��̂ł���Η������܂��B
��A�叕����ł��B
> �ŏI�I��queue��uop�o�͂ł�3 uop/cycle�ɗ��������?�܂����ς̘b�����ǁB
�����́A3 fused uop/cycle���Ǝv���̂ŁA
> 3��fused-uop�́Areorder buffer(ROB)�ւƈڂ���A�����ōő�6�̎��s�\uop�֓W�J�����B
���_�I�ɂ́A�����̍ő�6�̎��s�\uop�ւ̓W�J���������Ǝv���܂��B
�����Ƃ��Afused micro-ops������2�����̎��s�\uop���������Ȃ��̂ł���Η������܂��B
����
>>276
> > Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
> ROB�̃o���h����3 x86���߂ł���A
ROB�̃o���h���́u3 fused micro-ops�v�ł���A
>>276
> > Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
> ROB�̃o���h����3 x86���߂ł���A
ROB�̃o���h���́u3 fused micro-ops�v�ł���A
���āA�ȏ�܂�����ŁA������x���̎咣�����肢���邷��MAC�I�^����
�O�X��
858 ���O�F MAC�I�^ [sage] ���e���F 2008/01/30(��) 08:12:50 ID:X/E3HbLz
>>854 �c�q ����
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
�O�X��
858 ���O�F MAC�I�^ [sage] ���e���F 2008/01/30(��) 08:12:50 ID:X/E3HbLz
>>854 �c�q ����
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
280 �FSocket774�F2008/03/13(��) 02:18:04 ID:VO25v4Yv
���킢�炵���l������̂��ȁB
MICRO-OP RENAME
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
> and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
�f���ɓǂ߂Afused micro-ops��ROB��place�����
�����Ă��̌�(and then)�A�ő�6��executable micro-ops�ɓW�J�����A�Ɠǂ߂܂��B
> The registers used in the executable micro-ops are mapped (renamed) into the larger internal set of registers
> and then placed in the seven micro-op "reservation stations" (RS) associated with the seven issue ports.
�f���ɓǂ߂Aexecutable micro-ops�Ŏg���Ă��郌�W�X�^�����l�[������āA
�����Ă��̌�(and then)�A7��RS��placce�����A�Ɠǂ߂܂��B
MAC�I�^�́A�O�X��843��
> ���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
> �悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
> �s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
�Ə����Ă��܂����A����͈Ӗ��̒ʂ�Ȃ��^��ł��B
�{���ɂ́Afused micro-ops��executable micro-ops�ɓW�J����āA���ꂼ���executable micro-ops��RS�ɕ��z�����Ə����Ă���̂ŁA
> RS�ōs����̂��H
�̓i���Z���X�����A
�����uROB��fused micro-ops������v�̂Ȃ�A�p�C�v���C���X�e�[�W�̈ꕔ�ƂȂ�͂��ł����A���������L�q�͂Ȃ��B
MICRO-OP RENAME
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
> and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
�f���ɓǂ߂Afused micro-ops��ROB��place�����
�����Ă��̌�(and then)�A�ő�6��executable micro-ops�ɓW�J�����A�Ɠǂ߂܂��B
> The registers used in the executable micro-ops are mapped (renamed) into the larger internal set of registers
> and then placed in the seven micro-op "reservation stations" (RS) associated with the seven issue ports.
�f���ɓǂ߂Aexecutable micro-ops�Ŏg���Ă��郌�W�X�^�����l�[������āA
�����Ă��̌�(and then)�A7��RS��placce�����A�Ɠǂ߂܂��B
MAC�I�^�́A�O�X��843��
> ���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
> �悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
> �s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
�Ə����Ă��܂����A����͈Ӗ��̒ʂ�Ȃ��^��ł��B
�{���ɂ́Afused micro-ops��executable micro-ops�ɓW�J����āA���ꂼ���executable micro-ops��RS�ɕ��z�����Ə����Ă���̂ŁA
> RS�ōs����̂��H
�̓i���Z���X�����A
�����uROB��fused micro-ops������v�̂Ȃ�A�p�C�v���C���X�e�[�W�̈ꕔ�ƂȂ�͂��ł����A���������L�q�͂Ȃ��B
281 �FSocket774�F2008/03/13(��) 02:19:09 ID:VO25v4Yv
�Ƃ���ŁA����ȋL�q�����邷�ˁB
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
> �m���Ă���悤�ɁAFusion(�Z��)�ƌĂ�ł���̂́A������RISC��uOPs��1��uOPs�ɗZ��������Ƃ����T�O���炾�B
> ������ACore MA�ł́A����uOPs�́uFused uOPs�v�ƌĂ�Ă���B�������A���Ԃ́A��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B
> �܂�ACISC���߂����Ȃ����Ƃ�Micro-OPs Fusion�̖{�����B
�u��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B�v
Core MA�ł������Ȃ�(��)
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
> �m���Ă���悤�ɁAFusion(�Z��)�ƌĂ�ł���̂́A������RISC��uOPs��1��uOPs�ɗZ��������Ƃ����T�O���炾�B
> ������ACore MA�ł́A����uOPs�́uFused uOPs�v�ƌĂ�Ă���B�������A���Ԃ́A��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B
> �܂�ACISC���߂����Ȃ����Ƃ�Micro-OPs Fusion�̖{�����B
�u��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B�v
Core MA�ł������Ȃ�(��)
Isaiah�̖��߂̗���́A���ǂ̂Ƃ���
FIQ���ϊ���܂��̓}�C�N���R�[�h��uop�L���[��ROB�����W�X�^���l�[����RS
�ƂȂ��Ă��܂��B
���̂����Afused uops��ێ�����̂́Auop�L���[��ROB�����ł����A
�O�X��992�̃p�N�}�����̌����ʂ�
> ��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
> ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
> �܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
ROB�ɂ͖��߂��̂��͓̂���܂���B
(�p�N�}������992�̏������݁u���́v�́A�܂��������������̂ł�)
�Ƃ����
�Efused uops��executable uops�ɕϊ�����p�C�v���C���X�e�[�W�͑��݂��Ȃ�
�̂�
�Efused ops�́A���C�������O�ƊȒP�ȃ��W�b�N��executable uops�ɕ����ł���ȒP�ȃt�H�[�}�b�g�ł���
���Ƃ���������܂��B
��������ƁAfused ops�͔�r�I�X�J�X�J�Ȗ��߃t�H�[�}�b�g�ɂȂ肻���ł���
�Efused uops��ێ�����̂�uop�L���[�̂�
�Ȃ̂ŁA�L���[�̃G���g�����ɂ����܂������G�ō����x��fused uops�t�H�[�}�b�g���̗p����K�v���͒Ⴂ�Ǝv���܂��B
���ǁA�O�X��845
> fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�́A�Ó��Ȑ������Ǝv���܂��B
�p�N�}���搶�A�����������H
�O�X��
986 ���O�F �p�N�}�� [sage] ���e���F 2008/02/13(��) 23:09:32 ID:6U5Xr+1Q
MAC�I�^��
�EROB��Intel�p��
�͊m���ɃC�^�C���A�S�������
�E ROB�ɂ�x86���߂�����
�E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
���̕ӂ̂܂����������邩��ȁB�ǂ�����ԈႢ�����������A�����ł�MAC�I�^�̕���x86���ӂ̎�����
�������Ă����̂ŏ����ƌ������Ƃɂ��悤�B
FIQ���ϊ���܂��̓}�C�N���R�[�h��uop�L���[��ROB�����W�X�^���l�[����RS
�ƂȂ��Ă��܂��B
���̂����Afused uops��ێ�����̂́Auop�L���[��ROB�����ł����A
�O�X��992�̃p�N�}�����̌����ʂ�
> ��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
> ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
> �܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
ROB�ɂ͖��߂��̂��͓̂���܂���B
(�p�N�}������992�̏������݁u���́v�́A�܂��������������̂ł�)
�Ƃ����
�Efused uops��executable uops�ɕϊ�����p�C�v���C���X�e�[�W�͑��݂��Ȃ�
�̂�
�Efused ops�́A���C�������O�ƊȒP�ȃ��W�b�N��executable uops�ɕ����ł���ȒP�ȃt�H�[�}�b�g�ł���
���Ƃ���������܂��B
��������ƁAfused ops�͔�r�I�X�J�X�J�Ȗ��߃t�H�[�}�b�g�ɂȂ肻���ł���
�Efused uops��ێ�����̂�uop�L���[�̂�
�Ȃ̂ŁA�L���[�̃G���g�����ɂ����܂������G�ō����x��fused uops�t�H�[�}�b�g���̗p����K�v���͒Ⴂ�Ǝv���܂��B
���ǁA�O�X��845
> fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�́A�Ó��Ȑ������Ǝv���܂��B
�p�N�}���搶�A�����������H
�O�X��
986 ���O�F �p�N�}�� [sage] ���e���F 2008/02/13(��) 23:09:32 ID:6U5Xr+1Q
MAC�I�^��
�EROB��Intel�p��
�͊m���ɃC�^�C���A�S�������
�E ROB�ɂ�x86���߂�����
�E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
���̕ӂ̂܂����������邩��ȁB�ǂ�����ԈႢ�����������A�����ł�MAC�I�^�̕���x86���ӂ̎�����
�������Ă����̂ŏ����ƌ������Ƃɂ��悤�B
>>282
�����ƁA�}�C�N���R�[�h���߂�3��fused uops�ł����ˁB
������24000���߂�����B
�����Ƃ�ROM�̓N���e�B�J�����\�[�X�ł͂Ȃ��Ǝv���܂��B
�̂���}�C�N�����߂̓X�J�X�J�łł����������B
�����ƁA�}�C�N���R�[�h���߂�3��fused uops�ł����ˁB
������24000���߂�����B
�����Ƃ�ROM�̓N���e�B�J�����\�[�X�ł͂Ȃ��Ǝv���܂��B
�̂���}�C�N�����߂̓X�J�X�J�łł����������B
WinChipC6�܂[�B
200MHz��i����Ȃ̂ɏ����A�{���ϊ����ʖ�����240MHz�쓮�ň��肵�Ă�����B
��p�t�@��������SANYO�ł��̂܂܂��ƔM�\���������ۂ����ǃO���X�h��Ȃ������璴����I
�����AIntel�̔�MMXODP������B���150MHz(����H180MHz���������ȁH)�Ƃ܂�Ȃ�Ė��͂Ȃ����B
���A���̃}�V����Pentium90MHz�Ńx�[�X�N���b�N�̕ύX�����PC-9821An�B
�������A�N�Z�X�����x������CPU�ł��܂����Ă���B
����H�̐S�̃A�[�L�e�N�`���͂悭�m����B���܂�B
200MHz��i����Ȃ̂ɏ����A�{���ϊ����ʖ�����240MHz�쓮�ň��肵�Ă�����B
��p�t�@��������SANYO�ł��̂܂܂��ƔM�\���������ۂ����ǃO���X�h��Ȃ������璴����I
�����AIntel�̔�MMXODP������B���150MHz(����H180MHz���������ȁH)�Ƃ܂�Ȃ�Ė��͂Ȃ����B
���A���̃}�V����Pentium90MHz�Ńx�[�X�N���b�N�̕ύX�����PC-9821An�B
�������A�N�Z�X�����x������CPU�ł��܂����Ă���B
����H�̐S�̃A�[�L�e�N�`���͂悭�m����B���܂�B
�{���͂������蓦���o�����̂��ȁH
�قƂڂ��߂�܂ł��Ȃ����肩�B
�قƂڂ��߂�܂ł��Ȃ����肩�B
�ʔ����������Ȃ��c
�Ԃ����Ⴏ�ǂ�����"�{��"����B
�ꐶ�����̕��ɂ͈������A��x���A���ɐ��_�Ӓ肵�Ă�����������ǂ��Ǝv���B
�Ԃ����Ⴏ�ǂ�����"�{��"����B
�ꐶ�����̕��ɂ͈������A��x���A���ɐ��_�Ӓ肵�Ă�����������ǂ��Ǝv���B
�l�i�͂Ƃ����������Ă�����e�͂ǂ���
�����Ō��邵���Ȃ��ȁA�f����ڽ�́B
ڽ������Լ�̘J�͂͏��Օi������B�
�����Ō��邵���Ȃ��ȁA�f����ڽ�́B
ڽ������Լ�̘J�͂͏��Օi������B�
288 �FSocket774�F2008/03/14(��) 04:04:50 ID:P7fagJMP
���ʂɌ������p����g����z���đ����\���͂���ʂ�����Ă���
Mail�̕ԐM���Ō����ɔ�Q������ǂ�łČ��ꂵ����
Mail�̕ԐM���Ō����ɔ�Q������ǂ�łČ��ꂵ����
���e�ɕ��傪�����Ȃ�����Ƃ����āA�l�i�U���ɑ���̂�ǂ����Ǝv�����B
���ނ̎ア�l��
�O�X��904
> ��̔]���ϑz�̃q�g����������(��)
> �������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
�Ƃ��邳���̂ŁA���p�ߏ�ɂȂ��Ă��܂������B
�O�X��904
> ��̔]���ϑz�̃q�g����������(��)
> �������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
�Ƃ��邳���̂ŁA���p�ߏ�ɂȂ��Ă��܂������B
>>288
���ӁB
���ӁB
��̂��Ȃ������퉽�̂��߂ɂ킽�������ď������邷���ˁB
�u�����o�Ă���ȁv�ƌĂяo���Ă���H
�����ɋꂵ�ނ��B
�u�����o�Ă���ȁv�ƌĂяo���Ă���H
�����ɋꂵ�ނ��B
>>288
>>291
����Ȃ��Ƃ��������ƁA���ȕٌ삹����Ȃ����B
�O�X��������킩��悤�ɁA���Ƃ��Ƃ킽������p�킠�܂肵�Ȃ����̂���������B
�X���̎�|����O���悤�ȓ��e��Ȃ�ׂ��T���ė~�������A�ƌ����Ă��������H(��)
>>291
����Ȃ��Ƃ��������ƁA���ȕٌ삹����Ȃ����B
�O�X��������킩��悤�ɁA���Ƃ��Ƃ킽������p�킠�܂肵�Ȃ����̂���������B
�X���̎�|����O���悤�ȓ��e��Ȃ�ׂ��T���ė~�������A�ƌ����Ă��������H(��)
�A���ȊO�͊T�˖��Ȃ��B�Z�p�I������������̂�����
���ׂȂ��Ƃɔ���������g�ɍ\���Ă�����B
�n���h����MAC�I�^�ɂ��Ă���̂�NG�w��̖ʂŗǂ���
MAC�I�^�����͗����ɃL�����B
���ׂȂ��Ƃɔ���������g�ɍ\���Ă�����B
�n���h����MAC�I�^�ɂ��Ă���̂�NG�w��̖ʂŗǂ���
MAC�I�^�����͗����ɃL�����B
����͂��ꂾ�A����MAC�I�^�Ƃ������Ƃ��ȁB
����͈��ނƂ������ƂŁB
����͈��ނƂ������ƂŁB
�P���̏u�Ԃ�ڌ����Ă�킯����
�۽��
���⏉����A�����`�����Z�p�ɖ��邢�J����
���������������傢�S�����̐l�i��Q�����悗
������ɂ�������B���S�Ƀl�^�ډ�������
���⏉����A�����`�����Z�p�ɖ��邢�J����
���������������傢�S�����̐l�i��Q�����悗
������ɂ�������B���S�Ƀl�^�ډ�������
�S�L�u�����A�V�_�J�O�����쏜�����悤�Ȋ��o
�Ȃ�Ƃ����▭�ȕ\���B
>>294
�T�˖��Ȃ��Ƃ����Ō�ɃL�����Ȃ�āA�������Ƃ����܂��˂�
�T�˖��Ȃ��Ƃ����Ō�ɃL�����Ȃ�āA�������Ƃ����܂��˂�
�ʂɃL�c���Ȃ�����
�ǂ����L�����Ƃ������o���玝�Ă��u����͎����̃L����������v�Ƃ����ق������邾�����낤��
�ǂ����L�����Ƃ������o���玝�Ă��u����͎����̃L����������v�Ƃ����ق������邾�����낤��
�r�炵�̊F����A�X���̎�|����O��铊�e��uMAC�I�^�v�̃R�e�ł��肢���邷�B
�̂�mac�݂������ȁB
�݂��MAC�I�^�ŏ����������L�����y�[�����{���B
�݂��MAC�I�^�ŏ����������L�����y�[�����{���B
����
�uMAC�I�^�v�̃R�e�ŃJ�L�R����ꍇ�� MAC�I�^�� (�`��A�`��) �ł��肢���邷�B
�悻�ł��
MAC�I�^�͋��L�R�e�n�����Ƃ������Ƃ�m��Ȃ����������B
���ꂾ�����w���Ȑl�����헝���ɋꂵ�ނ��B
���ꂾ�����w���Ȑl�����헝���ɋꂵ�ނ��B
���ɗ��������ł����E�E�E�H
MAC�I�^�̒m���̓g���r�A�̐�ł�w
OoO���s���ŏ��Ɏ��������}�V���A360/91�́A���ɍ������������ƂƁA�A�[�L�e�N�`����Ԃ̃T�|�[�g���Ȃ��݊����������Ă������߁A�����Ƃ�����Ȃ�����
������Ƌ������䂭���ʒm�����Ă�
Nehalem�X���ɂ͏o�v�����C�z�Ȃ̂ɂ������ɂ͗����A���B
����C���e�����肵��Transmeta�̋��{�XDavid R. Ditzel�́A
����OS�A���ꂩ��G�f�B�^�܂ł��ׂăn�[�h���������ɂ�CISC�}�V���ASYMBOL�v���W�F�N�g�ɎQ�����Ă����B
���̌�t����David A. Patterson�Ƌ��ɐ[�����Ȃ��ASPARC�v���W�F�N�g�𗧂��グ���B
����OS�A���ꂩ��G�f�B�^�܂ł��ׂăn�[�h���������ɂ�CISC�}�V���ASYMBOL�v���W�F�N�g�ɎQ�����Ă����B
���̌�t����David A. Patterson�Ƌ��ɐ[�����Ȃ��ASPARC�v���W�F�N�g�𗧂��グ���B
315 �F�R�E�L�́M�E,,�j�����������������F2008/03/18(��) 02:22:43 ID:Uja+Iq/H
�����A�f�B�c�F���������Ă悤�₭PARROT�������o���̂��B
NEC�Ɠ��H��A�ʔ������[�U�[��p����20Tbps�N���X�̌��ڑ��Z�p
http://pc.watch.impress.co.jp/docs/2008/0318/nec.htm
http://pc.watch.impress.co.jp/docs/2008/0318/nec.htm
���IBM�̎����悤�ȋL�����������ljؗ�ɃX���[�H
IBM�͂܂��v�f�Z�p�B
NEC�̂͋����v�Z�@�ɂ͎g���邾�낤�ȁB
NEC�̂͋����v�Z�@�ɂ͎g���邾�낤�ȁB
�j��ł���ȃA�[�L�e�N�`���Ƃ�����Rekursiv���J�������̂́A�L���ȍ����I�[�f�B�I���[�J�[��LINN�ł������B
Microsoft��Intel�A�R���V���[�}��������R���s���[�e�B���O��������ݗ�
http://pc.watch.impress.co.jp/docs/2008/0319/msintel.htm
http://pc.watch.impress.co.jp/docs/2008/0319/msintel.htm
�ւ��Ƃ��t�[���Ƃ��A�b�\�Ƃ������Ă����
�ւ�
�t�[��
324 �FSocket774�F2008/03/19(��) 22:41:42 ID:9y8WnOif
�A�b�\
���G�ȃA�h���b�V���O���[�h��W�X�^-�������ԉ��Z���߂Ȃ�CISC�炵������������Z8000�́A
�}�C�N���R�[�h���g�킸�n�[�h���C���[�h���W�b�N�Ŏ�������Ă���
�}�C�N���R�[�h���g�킸�n�[�h���C���[�h���W�b�N�Ŏ�������Ă���
�Ȃ��N�G�X�g����H
Nehalem�͂܂��
>>326
Isaiah�ɂ��ĉ�����Ă���
Isaiah�ɂ��ĉ�����Ă���
�g�����X�s���[�^�[�͂ǂ��Ȃ����H
�g�����X�s���[�^�́ACRC�̌v�Z���ꖽ�߂ōs���ȂǁA���ɕ��G�Ȗ��߂�����CISC�ł�����
�g�����X�s���[�^�̖��߃Z�b�g�̏ڍׂ������
ttp://www.transputer.net/iset/transbook.pdf
�^��_������Ή�����܂�
ttp://www.transputer.net/iset/transbook.pdf
�^��_������Ή�����܂�
���́A���E�ŏ���VLIW�ɂ��Ă̏��b�ł����H
Sun�A�`�b�v�Z�p�̌�����4400���h���̎������l��
ttp://www.itmedia.co.jp/enterprise/articles/0803/25/news064.html
�T���A�����\�E�����d�͂̌��z���`�b�v�J���𐄐i
�ߐڃ`�b�v�Ԃ����[�U�[�Ō��сu�}�N���`�b�v�v���J��
ttp://www.computerworld.jp/news/plf/101910.html
ttp://www.itmedia.co.jp/enterprise/articles/0803/25/news064.html
�T���A�����\�E�����d�͂̌��z���`�b�v�J���𐄐i
�ߐڃ`�b�v�Ԃ����[�U�[�Ō��сu�}�N���`�b�v�v���J��
ttp://www.computerworld.jp/news/plf/101910.html
�y���|�[�g�z������X�p�R���J���̐i����
ttp://journal.mycom.co.jp/articles/2008/03/29/supercomputer/index.html
ttp://journal.mycom.co.jp/articles/2008/03/29/supercomputer/index.html
627 ���O�FMAC�I�^��626 ����[sage] ���e���F2008/03/31(��) 00:35:01 ID:qfrBvVBg
>>626
���{�����邱�ƂŌ����ȐM�҂���B�ɂ�C�̓ł����ǁA���l��ߋ��̉����
�K���ɂ��܂����Ƃ������Ƃ�(��)
�����Ă�����e��>>175�̃����N��̒P�Ȃ��ǂ��B�B�B
�@�@-------------------------------
�@�@��QPI�́A���̓V���A���ł͂Ȃ�
�@�@-------------------------------
>>626
���{�����邱�ƂŌ����ȐM�҂���B�ɂ�C�̓ł����ǁA���l��ߋ��̉����
�K���ɂ��܂����Ƃ������Ƃ�(��)
�����Ă�����e��>>175�̃����N��̒P�Ȃ��ǂ��B�B�B
�@�@-------------------------------
�@�@��QPI�́A���̓V���A���ł͂Ȃ�
�@�@-------------------------------
����������A�Q�n�ɋA���Ă���Ȃ�����
�����͎���Ȃ���
�����͎���Ȃ���
http://softwareprojects.intel.com/avx/
Intel? AVX (Intel? Advanced Vector Extensions) is a 256 bit instruction set extension
to SSE and is designed for applications that are floating point intensive.
Intel? AVX (Intel? Advanced Vector Extensions) is a 256 bit instruction set extension
to SSE and is designed for applications that are floating point intensive.
MIPS�ЁA4�R�A�\�����\��
�v���Z�b�T�E�R�A�u1004K�v�\ (2008/04/02)
http://www.eetimes.jp/contents/200804/32925_1_20080402195900.cfm
�v���Z�b�T�E�R�A�u1004K�v�\ (2008/04/02)
http://www.eetimes.jp/contents/200804/32925_1_20080402195900.cfm
Hynix�ЁAGrandis�Ђ���
�uSTT-RAM�v�Z�p���� (2008/04/02)
http://www.eetimes.jp/contents/200804/32906_1_20080402174929.cfm
�uSTT-RAM�Z�p�́A������MRAM�Z�p�̌��E���鎟����̕s�������������[�Z�p���v
�uSTT-RAM�Z�p�͔����ɏ_��ɑΉ��ł���X�P�[���r���e�B������Ă���B���̂���
������i�߂邱�ƂŁA�_�C������̑f�q���x�����߂ăR�X�g���팸���邱�Ƃ��\��
�Ȃ�B����Ɍ��ݎ嗬�̃������[�E�`�b�v�Ɣ�ׂāA����d�͂��Ⴍ�A�ϋv���������A
�ǂݏo��/�������ݑ��x�������v
�uSTT-RAM�v�Z�p���� (2008/04/02)
http://www.eetimes.jp/contents/200804/32906_1_20080402174929.cfm
�uSTT-RAM�Z�p�́A������MRAM�Z�p�̌��E���鎟����̕s�������������[�Z�p���v
�uSTT-RAM�Z�p�͔����ɏ_��ɑΉ��ł���X�P�[���r���e�B������Ă���B���̂���
������i�߂邱�ƂŁA�_�C������̑f�q���x�����߂ăR�X�g���팸���邱�Ƃ��\��
�Ȃ�B����Ɍ��ݎ嗬�̃������[�E�`�b�v�Ɣ�ׂāA����d�͂��Ⴍ�A�ϋv���������A
�ǂݏo��/�������ݑ��x�������v
Silverthorne���Ă�����Pen4���ȓd�͂ɉ��ǂ���������CPU�Ȃ�ˁ[��
�Ă��Ɓ[�Ȏ��ʂ�����
�t�x�݂������܂ł�����A����܂ʼn䖝�䖝�B
����҂���̎����Y��Ȃ��ł��������B
����҂���H
SPARC64 VI+�̂��Ƃ�>����҂���
>>346
VII ������
VII ������
���ŁACell��SPE�𓋍ڂ����X�g���[�~���O�v���Z�b�T�uSpursEngine�v
http://pc.watch.impress.co.jp/docs/2008/0408/toshiba.htm
http://pc.watch.impress.co.jp/docs/2008/0408/toshiba.htm
350 �F�R�E�L�́M�E,,�j�����������������F2008/04/08(��) 14:21:01 ID:HaA4JWsP
�܂�Vista 64�ɑΉ����Ă���
�u�p�����p�v�Ȃ���������ƕ����Ă悗
�A�b�v�R���o�[�^�ɂ͗ǂ��Ǝv��
REGZA�ɓ��ڂ����̂����ꂩ��
REGZA�ɓ��ڂ����̂����ꂩ��
353 �F�R�E�L�́M�E,,�j�����������������F2008/04/08(��) 17:22:15 ID:HaA4JWsP
SD�\�[�X�̃A�b�v�X�P�[���ɂ͓������v�����肻������
>>349
GPU��H.264�f�R�[�h�x���͂܂���������B
�Ⴆ��UVD��Level 4.1����40Mbps�܂ł炵���B
http://pc11.2ch.net/test/read.cgi/jisaku/1192203200/567-
SpursEngine�̃f�R�[�_�͂ǂ�Level�܂őΉ����Ă�̂��C�ɂȂ�Ƃ���B
GPU��H.264�f�R�[�h�x���͂܂���������B
�Ⴆ��UVD��Level 4.1����40Mbps�܂ł炵���B
http://pc11.2ch.net/test/read.cgi/jisaku/1192203200/567-
SpursEngine�̃f�R�[�_�͂ǂ�Level�܂őΉ����Ă�̂��C�ɂȂ�Ƃ���B
355 �F�R�E�L�́M�E,,�j�����������������F2008/04/09(��) 19:29:53 ID:txUqHnlp
40Mbps����BD���x�Ȃ�\������Ȃ����B
40Gbps�ȍ����Ȃ��PCIe1.1(x16)�̏���ш敝�Ȃ�������ˁ[��
>>356
40Gbps���ăn�C�r�W�������x����k�ł��g������ˁ[�悗
40Gbps���ăn�C�r�W�������x����k�ł��g������ˁ[�悗
���Ђ�P�ʂ�����Ⴄ�B
�����R����cpu�ɑg�ݍ��ނ��Đ��\�I�ɂ͂ǂꂭ�炢������́H
amd�݂̂Ă�ƌ��I�ɏ㏸������Ă��Ƃ͂Ȃ������Ȃ��ǁA
�l�n�̐��\�㏸�������悤�Ȃ��̂Ȃ́H
amd�݂̂Ă�ƌ��I�ɏ㏸������Ă��Ƃ͂Ȃ������Ȃ��ǁA
�l�n�̐��\�㏸�������悤�Ȃ��̂Ȃ́H
>>359
> amd�݂̂Ă�ƌ��I�ɏ㏸������Ă��Ƃ͂Ȃ������Ȃ��ǁA
���܂�����̓������R���g���[�����O�t���ɂȂ��Ă���Athlon��
�g�������Ƃł�����̂��H
> amd�݂̂Ă�ƌ��I�ɏ㏸������Ă��Ƃ͂Ȃ������Ȃ��ǁA
���܂�����̓������R���g���[�����O�t���ɂȂ��Ă���Athlon��
�g�������Ƃł�����̂��H
http://www23.tomshardware.com/cpu_2006.html?modelx=33&model1=609&model2=694&chart=166
K8�̓}���`CPU�\�����ƃ��������C�e���V��������̂ŁA4CPU�ɍœK������Ă��Ȃ�
�����̃Q�[���n�x���`�Ŕ�r�����1���߂��������ꍇ������悤���ˁB
�������1CPU�̕��������B
���������C�e���V���d�v����Ȃ��̂��ƍ��͂��Ȃ����A���ʂ�����ꍇ�ƂȂ��ꍇ������Ƃ���
���ɓ��R�̌��_�ɂȂ邩�ƁB
�����intel���ƃ��������x�����Ƃ͑O����A�]�v��1CPU���Ɛ��\����͏�������������Ȃ��B
K8�̓}���`CPU�\�����ƃ��������C�e���V��������̂ŁA4CPU�ɍœK������Ă��Ȃ�
�����̃Q�[���n�x���`�Ŕ�r�����1���߂��������ꍇ������悤���ˁB
�������1CPU�̕��������B
���������C�e���V���d�v����Ȃ��̂��ƍ��͂��Ȃ����A���ʂ�����ꍇ�ƂȂ��ꍇ������Ƃ���
���ɓ��R�̌��_�ɂȂ邩�ƁB
�����intel���ƃ��������x�����Ƃ͑O����A�]�v��1CPU���Ɛ��\����͏�������������Ȃ��B
>>349
���{�C�ł��̃l�^PCI �J�[�h���q�b�g����Ƃ�
���̓��łł���v���ĂȂ��B
������ӂ̂o�b�ł��J��������������A�Ƃ����A�s�[���̈Ӗ������B
����͉Ɠd�g�ݍ��݁B
���{�C�ł��̃l�^PCI �J�[�h���q�b�g����Ƃ�
���̓��łł���v���ĂȂ��B
������ӂ̂o�b�ł��J��������������A�Ƃ����A�s�[���̈Ӗ������B
����͉Ɠd�g�ݍ��݁B
363 �F�R�E�L�́M�E,,�j�����������������F2008/04/12(�y) 17:52:19 ID:YgFI+RvI
�d�ʂ����l����H
�Ƃ肠����1���J�[�h�w����������
�Ƃ肠����1���J�[�h�w����������
364 �F�R�E�L�́M�E,,�j�����������������F2008/04/12(�y) 18:41:49 ID:YgFI+RvI
�X���h�ɂ��Ɩ@�l�݂̂Ōl�s�A��w�l�������Ƃ�
���肭�������ǂ����͒u���Ƃ���
�n���ɏ�����������L���Ă����܂��傤�Ƃ���������
��������Ȃ���
�n���ɏ�����������L���Ă����܂��傤�Ƃ���������
��������Ȃ���
IBM��Chartered��A32nm�v���Z�XHigh-K���^���Q�[�g�̕]���L�b�g���
http://pc.watch.impress.co.jp/docs/2008/0415/ibm.htm
http://pc.watch.impress.co.jp/docs/2008/0415/ibm.htm
�Ȃ��ǃn�t�j�E�����p���B
�n�t�j�E�����ǂ��������Ȃ�Ă̂�5�N�O���番�����Ă邱�ƁB
���̌��f�ł����͂��邯�ǁB
���^���Q�[�g�̕����d�v�B
���̌��f�ł����͂��邯�ǁB
���^���Q�[�g�̕����d�v�B
�v�����45nm�Ő�s����Intel�ɑ���A�A�h�o���e�[�W���L��̂��ǂ����A����B
�͂ӂ�
���f�̋[�l�����Ăǂ����낤
�͂ӂɂ��ނ���
���
��ł�ɂ��ނ���
�͂ӂɂ��ނ���
���
��ł�ɂ��ނ���
801�ƒ�g������ǂ����H
�m���������ɂ͂��łɌ��f��801�݂����ȃX�������������B
�m���������ɂ͂��łɌ��f��801�݂����ȃX�������������B
>>372
��̕��̌��f�͑��҂��������݂��ȕ��Ă������o�C�l����ł�(ww
��̕��̌��f�͑��҂��������݂��ȕ��Ă������o�C�l����ł�(ww
>>373
�V���������݂����Ȃ��킢���j�̎q���m�ł��ق���ł��ˁA������܂�
�V���������݂����Ȃ��킢���j�̎q���m�ł��ق���ł��ˁA������܂�
�L�����^�Ŏv���o���܂����B
�M�����Q�[��G���Q�[�ŁA�V�[�����ς��Ƃ��ɉ�ʂ��Ó]�����
�j���P���L�����^���f���Ĉނ���Ƃ����b���`���z������܂���ˁB
���̌n���̃Q�[���ɂ����ăt�F�[�h�A�E�g�͍�����Ȃ��Ĕ��ɂ���̂�
���[�U�[�t�����h���[�ł���A�ƌ����܂��傤�B�i�R
�M�����Q�[��G���Q�[�ŁA�V�[�����ς��Ƃ��ɉ�ʂ��Ó]�����
�j���P���L�����^���f���Ĉނ���Ƃ����b���`���z������܂���ˁB
���̌n���̃Q�[���ɂ����ăt�F�[�h�A�E�g�͍�����Ȃ��Ĕ��ɂ���̂�
���[�U�[�t�����h���[�ł���A�ƌ����܂��傤�B�i�R
>>372
��ł�ɂ��ނ���͂��ꂩ�A�Ȃ��Ȃ��������ɂ�������
��������Ⴄ�ƕ�������̂ɂƂ�ł��Ȃ��G�l���M�[���K�v
�������肷��킯��
��ł�ɂ��ނ���͂��ꂩ�A�Ȃ��Ȃ��������ɂ�������
��������Ⴄ�ƕ�������̂ɂƂ�ł��Ȃ��G�l���M�[���K�v
�������肷��킯��
PC/104 Embedded Consortium�A�uPCI/104-Express�v������F
http://pc.watch.impress.co.jp/docs/2008/0417/esc02.htm
http://pc.watch.impress.co.jp/docs/2008/0417/esc02.htm
�Ƃ����simplescalar�Ƃ͉��҂ŁA�g�����_�ĂȂ�ł���
>>379
CPU�̃V�~�����[�^�ŁA�����҂��������Ďg���܂��B
CPU�̃V�~�����[�^�ŁA�����҂��������Ďg���܂��B
simplescalar��C����Ńv���Z�b�T���L�q����Ă��āA���̃v���Z�b�T�̓�������낢��V�~�����[�V����
�ł��āA�X�[�p�[�X�P�[���Ƃ������Ō��߂���V�~�����[�^��
�����X�[�p�[�X�P�[�����ł���Ƃ��āA���ߊԂ̈ˑ��W�ɂ�鐫�\�ቺ��Ƃ��āA
�A�E�g�I�u�I�[�_�[�Ƃ����@���s�Ƃ��������simplescalar�͂��Ă������̂Ȃ�ł�����
�{�ƃT�C�g��PDF�݂Ă��C�}�C�`�킩��Ȃ��āc
�ł��āA�X�[�p�[�X�P�[���Ƃ������Ō��߂���V�~�����[�^��
�����X�[�p�[�X�P�[�����ł���Ƃ��āA���ߊԂ̈ˑ��W�ɂ�鐫�\�ቺ��Ƃ��āA
�A�E�g�I�u�I�[�_�[�Ƃ����@���s�Ƃ��������simplescalar�͂��Ă������̂Ȃ�ł�����
�{�ƃT�C�g��PDF�݂Ă��C�}�C�`�킩��Ȃ��āc
>>381
simplescaler�͕���\����OoO���s��2���x���L���b�V���܂Ŏ������Ă��邪
���̂܂܂Ŏg�����Ƃ͂܂��Ȃ�
�����҂������̃A�C�f�A���������ĕ]������̂Ɏg��
simplescaler�͕���\����OoO���s��2���x���L���b�V���܂Ŏ������Ă��邪
���̂܂܂Ŏg�����Ƃ͂܂��Ȃ�
�����҂������̃A�C�f�A���������ĕ]������̂Ɏg��
�Ƃ����킯�ŁA�N��ɂ͉��̂Ȃ�����
�p�Z�~�Ĕ���������?
��Apple�������d�̓v���Z�b�T�̕�PA Semi������ - ��Forbes��
��Apple���v���Z�b�T���[�J�[�̕�PA Semi�������ƁA�o�ώ��̕�Forbes�i�I�����C���Łj��4��23���t���̋L����
�Ă���B�����ɑ���Apple���������̎�����F�߂��Ƃ����B�������z���̏ڍׂɂ��Ă̓R�����g���Ă��Ȃ����A
�����̕ɂ��Δ������z��2��7800���h���ŁA�S�z�L���b�V���ɂ�������Ƃ����BPA Semi��Alpha��StrongARM��
�v�ȂǂŒm����Dan Dobberpuhl����������t�@�u���X�̃v���Z�b�T���[�J�[�B��ɒ����d�̓v���Z�b�T�̐v��
���݂Ƃ��Ă���APWRficient�Ȃǂ̐��i������BApple�ł͓��Ђ̋Z�p��iPhone��iPod�Ȃǂ̌g�ы@��ɉ��p������̂Ƃ݂���B
http://journal.mycom.co.jp/news/2008/04/24/001/index.html
�T���X���Ƃ̊W����肭�����ĂȂ��̂��ȁH
��Apple���v���Z�b�T���[�J�[�̕�PA Semi�������ƁA�o�ώ��̕�Forbes�i�I�����C���Łj��4��23���t���̋L����
�Ă���B�����ɑ���Apple���������̎�����F�߂��Ƃ����B�������z���̏ڍׂɂ��Ă̓R�����g���Ă��Ȃ����A
�����̕ɂ��Δ������z��2��7800���h���ŁA�S�z�L���b�V���ɂ�������Ƃ����BPA Semi��Alpha��StrongARM��
�v�ȂǂŒm����Dan Dobberpuhl����������t�@�u���X�̃v���Z�b�T���[�J�[�B��ɒ����d�̓v���Z�b�T�̐v��
���݂Ƃ��Ă���APWRficient�Ȃǂ̐��i������BApple�ł͓��Ђ̋Z�p��iPhone��iPod�Ȃǂ̌g�ы@��ɉ��p������̂Ƃ݂���B
http://journal.mycom.co.jp/news/2008/04/24/001/index.html
�T���X���Ƃ̊W����肭�����ĂȂ��̂��ȁH
386 �FMAC�I�^��385 �����F2008/04/24(��) 08:01:32 ID:6wAULpVv
>>385
���̘b�ɂ�A���ɋ����������Ă��܂����B
���̘b�ɂ�A���ɋ����������Ă��܂����B
388 �F�R�E�L�́M�E,,�j�����������������F2008/04/24(��) 09:33:25 ID:HKQnbFfP
��͂�PPC Mac������
iPhone�p����˂���
���܂���PowerPC��MAC�Ȃ�ďo�������Ĕ���Ȃ�����
Windows�݊��@�Ƃ��Ă����g���ĂȂ�����
���܂���PowerPC��MAC�Ȃ�ďo�������Ĕ���Ȃ�����
Windows�݊��@�Ƃ��Ă����g���ĂȂ�����
Xserve�̔h���i�ɍ̗p
391 �F�R�E�L�́M�E,,�j�����������������F2008/04/24(��) 13:29:19 ID:HKQnbFfP
�ނ���C�V����������@�ō̗p������̂��Ǝv���Ă����B
Atom�g������
�Ȃ��GPU�̂ق���CPU���G���R�[�h����r�ɂȂ�Ȃ����炢�����̂ł����H
�����Ƃ���������
>>385
����ς�POWER���Ꮴ���������̂���
����ς�POWER���Ꮴ���������̂���
�������A���ɂ����POWER���̂Ă�Apple�ɔ�����Ƃ͂Ȃ�
����Ȃ�����
����Ȃ�����
POWER�n��S�Ĉꊇ��ōl���Ă�悤�Ȕ����̓A�z�Ƃ���
���[��A�m����Apple��PowerPC�̘b�́A���̌��Ƃ͊W�Ȃ���������
�Ƃɂ���PWRficient���Ȃ��Ȃ����Ⴄ�̂͂ƂĂ��߂���
�Ƃɂ���PWRficient���Ȃ��Ȃ����Ⴄ�̂͂ƂĂ��߂���
>>395
POWER�����珤�����������Ƃ����킯�ł͂Ȃ��炵��
Montalvo Systems is no more
http://www.cnet.com/8301-13512_1-9928711-23.html
POWER�����珤�����������Ƃ����킯�ł͂Ȃ��炵��
Montalvo Systems is no more
http://www.cnet.com/8301-13512_1-9928711-23.html
���łɂ��������\���Ƃ���
Glaskowsky����ɂ�Apple�������������̂��ǂ߂Ȃ��炵��
Apple's peculiar purchase-- the six Ps of PA Semi
http://www.cnet.com/8301-13512_1-9928659-23.html
�A�����܂�
Glaskowsky����ɂ�Apple�������������̂��ǂ߂Ȃ��炵��
Apple's peculiar purchase-- the six Ps of PA Semi
http://www.cnet.com/8301-13512_1-9928659-23.html
�A�����܂�
�X���`���������ǁA
����ϗ\�z�̒ʂ� iPhone �Ƃ��̕�������Ȃ��́H
iPhone �� OS X �n�������Ǝv�����ǁADarwin ���� x86 �� PowerPC �݂̂���Ȃ��ł����B
http://www.opensource.apple.com/darwinsource/
�P���ɁuARM �Ή���߂����ĉ������v���Ă��Ƃ��Ǝv�������ǁB
���ƁAPowerPC �Ȃ琫�\�I�ɂ� AppleTV �Ƃ��ANEC �݂��� XServe �̃X�g���[�W����Ƃ�
�Ɏg���邩�� (����܂�ǂ��A�C�f�A�ɂ͌����Ȃ����ǂ�)
����ϗ\�z�̒ʂ� iPhone �Ƃ��̕�������Ȃ��́H
iPhone �� OS X �n�������Ǝv�����ǁADarwin ���� x86 �� PowerPC �݂̂���Ȃ��ł����B
http://www.opensource.apple.com/darwinsource/
�P���ɁuARM �Ή���߂����ĉ������v���Ă��Ƃ��Ǝv�������ǁB
���ƁAPowerPC �Ȃ琫�\�I�ɂ� AppleTV �Ƃ��ANEC �݂��� XServe �̃X�g���[�W����Ƃ�
�Ɏg���邩�� (����܂�ǂ��A�C�f�A�ɂ͌����Ȃ����ǂ�)
�C���e���ł�k�炵���B
Jobs Still Hearts Intel
http://blogs.wsj.com/biztech/2008/04/24/jobs-still-hearts-intel/?mod=WSJBlog
Jobs Still Hearts Intel
http://blogs.wsj.com/biztech/2008/04/24/jobs-still-hearts-intel/?mod=WSJBlog
403 �FSocket774�F2008/04/29(��) 18:23:52 ID:iip1OQid
age
Intel������Xscale�g���Ă�����Intel����Ȃ��Ȃ�g�����ꂽPowerPC���B
������Ăǂ�ȃu�����h�M���悗
������Ăǂ�ȃu�����h�M���悗
Intel��Cray�A�X�[�p�[�R���s���[�^����ŋ���
http://pc.watch.impress.co.jp/docs/2008/0430/intelcray.htm
http://pc.watch.impress.co.jp/docs/2008/0430/intelcray.htm
TSMC�A65nm�v���Z�X�̗ʎY�������ɐi��
�`2008�N�㔼�ɂ�45nm�֖{�i�ڍs
http://pc.watch.impress.co.jp/docs/2008/0430/tsmc.htm
�`2008�N�㔼�ɂ�45nm�֖{�i�ڍs
http://pc.watch.impress.co.jp/docs/2008/0430/tsmc.htm
>>404
iPhone �� Samsung 339S0030 ARM �Ȃ��ǁH
ttp://ja.wikipedia.org/wiki/IPhone
ttp://journal.mycom.co.jp/articles/2007/07/19/InsideiPhone/003.html
��Xscale ���H���Ă����\�͂��������ǂˁc
iPhone �� Samsung 339S0030 ARM �Ȃ��ǁH
ttp://ja.wikipedia.org/wiki/IPhone
ttp://journal.mycom.co.jp/articles/2007/07/19/InsideiPhone/003.html
��Xscale ���H���Ă����\�͂��������ǂˁc
>>408
�b����PIC�V���[�Y�A��N11����32bit�g������PIC32�\�������A
�b�����ŋ������̂�MIPS32�R�A�𓋍ڂ������ƁB
�ց[�A�ӊO�ȂƂ����MIPS���������Ă�Ȃ��B�܂������ŏ���������A���낤���ǁB
�b����PIC�V���[�Y�A��N11����32bit�g������PIC32�\�������A
�b�����ŋ������̂�MIPS32�R�A�𓋍ڂ������ƁB
�ց[�A�ӊO�ȂƂ����MIPS���������Ă�Ȃ��B�܂������ŏ���������A���낤���ǁB
intel Mac�ɂ�PowerPC�𖼗_CPU�Ƃ��ē��ڂ��悤
> �c�c������PowerPC�������牽�ɁH
�Q�[���@
�܂��A��k�����B
�Q�[���@
�܂��A��k�����B
Pippin�̂��Ƃ����[�I�I�I
���܂ɂ�PA-RISC�̂��Ƃ��v���o���āB
>>414
���������������Ȃ��Ȃ����������łȂ�
���������������Ȃ��Ȃ����������łȂ�
�m����EGI��EFI���̗p���������Ԃ��A�N���V�b�N�J�[�Ƃ��ă��X�g�A���ێ�
���悤�Ƃ��Ă��A�d�q���䕔�����ǂ��ɂ��Ȃ�Ȃ�����A���̍��̃t�@�[��
�����z�ŃG�~�����[�g�\�Ȃ珕�����Ȃ��B
COOL Chips XI - ���H�̓n�[�h�ȃ\�t�g�ƃ\�t�g�ȃn�[�h�̓������s�v
http://journal.mycom.co.jp/articles/2008/05/02/coolchips4/index.html
���́A�\�t�g�̋K�͂����債�A��蒼�����Ƃ����ɓ���Ȃ��Ă��Ă���_�ŁA���R�A�\�t�g���\�t�g��
�ϐ���ۂw�͂͏d�v�ł��邪�A���z���Ȃǂ̋Z�p���g���āA�ς����Ȃ��n�[�h�ȃ\�t�g��V�����n�[�h
�œ��������Ƃ��d�v�Ǝ咣�����B�����āA�}���`�R�A���ɂ��d�͂̑�����}���č������\���������āA�Â�
�\�t�g�̉��z���s���\�ɂ��A�X�ɃR�A���𑝂₵�Đ��\�����シ��Ƃ������ł���B
���悤�Ƃ��Ă��A�d�q���䕔�����ǂ��ɂ��Ȃ�Ȃ�����A���̍��̃t�@�[��
�����z�ŃG�~�����[�g�\�Ȃ珕�����Ȃ��B
COOL Chips XI - ���H�̓n�[�h�ȃ\�t�g�ƃ\�t�g�ȃn�[�h�̓������s�v
http://journal.mycom.co.jp/articles/2008/05/02/coolchips4/index.html
���́A�\�t�g�̋K�͂����債�A��蒼�����Ƃ����ɓ���Ȃ��Ă��Ă���_�ŁA���R�A�\�t�g���\�t�g��
�ϐ���ۂw�͂͏d�v�ł��邪�A���z���Ȃǂ̋Z�p���g���āA�ς����Ȃ��n�[�h�ȃ\�t�g��V�����n�[�h
�œ��������Ƃ��d�v�Ǝ咣�����B�����āA�}���`�R�A���ɂ��d�͂̑�����}���č������\���������āA�Â�
�\�t�g�̉��z���s���\�ɂ��A�X�ɃR�A���𑝂₵�Đ��\�����シ��Ƃ������ł���B
����������Precision Architecture�ɂ��������Z�O�����g����������
�Z�O�����g���Ĕ��������
�Z�O�����g���Ĕ��������
8086�̃}�j���A���ɂ�����ʂ�A�������ی����P�[�V�����̑ΏۂƂȂ�_���I�ȃ������̈ꂩ���܂肪�Z�O�����g�Ȃ̂ɁA
���w�ȃ}�C�R���~�̓A�h���X��Ԃ��g�����邽�߂̃Q�^�Ƃ��������ł��Ȃ�������
���w�ȃ}�C�R���~�̓A�h���X��Ԃ��g�����邽�߂̃Q�^�Ƃ��������ł��Ȃ�������
�����80386�Ȃ炻������8086����P�Z�O�����g�����������Ď��p�ɂȂ��
�g�������Ԉ���Ă��܂���
6809�����[�N�X�e�[�V�����Ɏg������͂��Ȃ��̂�(Mac�͊낤�������Ȃ肩���܂�����)�A
8086������ɉߑ�]�����Ē@���Ă��܂���
6809�����[�N�X�e�[�V�����Ɏg������͂��Ȃ��̂�(Mac�͊낤�������Ȃ肩���܂�����)�A
8086������ɉߑ�]�����Ē@���Ă��܂���
���[�N�X�e�[�V�����ǂ��납9801��640x400/16�F�̃O���t�B�b�N���������Ƃ���
����������
���̂��߂�VRAM���p�b�N�h�s�N�Z���ł͂Ȃ��Z�O�����g���Ƃ̃v���[���\���ɂ��Ȃ�����Ȃ��
����������
���̂��߂�VRAM���p�b�N�h�s�N�Z���ł͂Ȃ��Z�O�����g���Ƃ̃v���[���\���ɂ��Ȃ�����Ȃ��
98��640*400 16�F���o�������̂Ƃ���
���F���𑜓x����ˁH
�Z�O�����g�A�[�L�e�N�`���̈ꕔ�̃~�j�R���Ƃ�
���C���t���[����64�`256kB�Z�O�����g��
64kB���ē������Ƃ���Ȃɋ�����Ԃ���Ȃ������̂ł́H�Ǝv��
���܂����286�ŃZ�O�����g�T�C�Y�̊g���������낤��
���F���𑜓x����ˁH
�Z�O�����g�A�[�L�e�N�`���̈ꕔ�̃~�j�R���Ƃ�
���C���t���[����64�`256kB�Z�O�����g��
64kB���ē������Ƃ���Ȃɋ�����Ԃ���Ȃ������̂ł́H�Ǝv��
���܂����286�ŃZ�O�����g�T�C�Y�̊g���������낤��
8086�̘_���A�h���X��Ԃ�16bit�ł�
�}�j���A���ɂ������Ă���܂�
�}�j���A���ɂ������Ă���܂�
>>422
�������ĉ��N��z�肵�Ă邩�m���1982�`83�N������ł�
64KB�̓p�\�R���̐��E�ł��e������������B
1984�N�ɏo������MB-S1�m���Ă邩�H
�������ĉ��N��z�肵�Ă邩�m���1982�`83�N������ł�
64KB�̓p�\�R���̐��E�ł��e������������B
1984�N�ɏo������MB-S1�m���Ă邩�H
�����͂Ƃ������A���������A�v���P�[�V������ΏۂƂ�������
���APIC�̃A�h���X��Ԃ�32�r�b�g�Ȃ��̂ŋ����ƒ@���l�͂��Ȃ�
����Ɠ����ł�
���݂��ƂȂ�IBM��NEC�Ɍ����ׂ��ŁA�C���e���̐ӔC�ł͂Ȃ��ł��傤
���APIC�̃A�h���X��Ԃ�32�r�b�g�Ȃ��̂ŋ����ƒ@���l�͂��Ȃ�
����Ɠ����ł�
���݂��ƂȂ�IBM��NEC�Ɍ����ׂ��ŁA�C���e���̐ӔC�ł͂Ȃ��ł��傤
>>426
�ŁH�@1982�`1983�N�����ł�64KB�͓��{�̃p�\�R���p�r�ł͂��ł�
�傫�ȃl�b�N�ɂȂ��Ă����Ƃ������Ƃ͎^���������������ȁB
�ŁH�@1982�`1983�N�����ł�64KB�͓��{�̃p�\�R���p�r�ł͂��ł�
�傫�ȃl�b�N�ɂȂ��Ă����Ƃ������Ƃ͎^���������������ȁB
����ȍ��x�ȍŐ�[�̂��̂̓G���C�F����ɍl���Ă���������
����Ă킩��₷���Ȃ����Ƃ���Ńv���O���}����ɕ���������
�v���O�����������y�ɂ��Ă���������ō��̍K���ł�
����Ă킩��₷���Ȃ����Ƃ���Ńv���O���}����ɕ���������
�v���O�����������y�ɂ��Ă���������ō��̍K���ł�
>>427
�������^�����܂���
���̏Ńp�\�R����8086���̗p����NEC��IBM�̓A�z�A
������C���e���Ɍ�����}�C�R���~�͂����ƃA�z�Ƃ��������ł�
�������^�����܂���
���̏Ńp�\�R����8086���̗p����NEC��IBM�̓A�z�A
������C���e���Ɍ�����}�C�R���~�͂����ƃA�z�Ƃ��������ł�
�ǂ����Ă킩��Ȃ��̂��ȁ[
8086�Ȃ�Ă��傹��8080�ŁA�C���e�������̂���ō���Ă���̂ɁA
���ꂪ����Ȃ����ꂪ����Ȃ����āA�}�C�R���V��͌����Ⴂ�̕s���������Ƃ�
8086�Ȃ�Ă��傹��8080�ŁA�C���e�������̂���ō���Ă���̂ɁA
���ꂪ����Ȃ����ꂪ����Ȃ����āA�}�C�R���V��͌����Ⴂ�̕s���������Ƃ�
>>429
����IBM-PC��PC-9801�̎��_�ł͑��ɑI�����͂Ȃ���������B
MC68000�͍����������B
����80386���o�����8086�݊��Ƃ��Ă��̌�P�O�N���g�����������Ƃ��ȁB
����IBM-PC��PC-9801�̎��_�ł͑��ɑI�����͂Ȃ���������B
MC68000�͍����������B
����80386���o�����8086�݊��Ƃ��Ă��̌�P�O�N���g�����������Ƃ��ȁB
������̎g���Ă���p�\�R�����R���s���[�^�̂��ׂĂƎv���Ă���̂���
���w���Ă��킢��
���w���Ă��킢��
68000�������̂̓��g���[���̐ӔC�ł�
���ۃr�W�l�X�`�����X�����킯����
�C���e�����撣����8086�����������āA�Ȃ��@����Ȃ���Ȃ�Ȃ�
�t���݂������Ƃ�
���ۃr�W�l�X�`�����X�����킯����
�C���e�����撣����8086�����������āA�Ȃ��@����Ȃ���Ȃ�Ȃ�
�t���݂������Ƃ�
�����Ȓ��̋������A���ӔC�ȃ}�X�R�~�ɂ���ăX�[�p�[�O�Ǝ����グ��ꂽ�悤�Ȃ���
�̗������܂�������Ƃ����āA������ӂ߂�̂͋؈Ⴂ
�}�X�R�~��ӂ߂�ׂ�
8086�̕]���Ƃ����_�ł́A����͌N���肾���ԒႭ�]�����Ă����A���Ԃ�
�̗������܂�������Ƃ����āA������ӂ߂�̂͋؈Ⴂ
�}�X�R�~��ӂ߂�ׂ�
8086�̕]���Ƃ����_�ł́A����͌N���肾���ԒႭ�]�����Ă����A���Ԃ�
�ǂ��������o�X�̓����Ɉ����������āA���or�ڍ�����A�ɂP�O�O���y���J�B
�pARM�Ђ�A�����チ�����[�C���^�[�t�F�[�X��
�K�i����Ɍ������[�L���O�O���[�v��n��
http://www.ednjapan.com/content/l_news/2008/05/u0o6860000004sp8.html
SPMT�́A���DRAM�`�b�v���^�[�Q�b�g�Ƃ����V�����������[�A�[�L�e�N�`���ŁA���݂̃������[�Ŏ嗬��
�Ȃ��Ă���p�������C���^�[�t�F�[�X�̑���ɁA�V���A���C���^�[�t�F�[�X��p����B����ɂ��A�d�r
�����̉����A����d�͂̍팸�A�[�q���̍팸�Ȃǂ������ł���Ƃ����B
�pARM�Ђ�A�����チ�����[�C���^�[�t�F�[�X��
�K�i����Ɍ������[�L���O�O���[�v��n��
http://www.ednjapan.com/content/l_news/2008/05/u0o6860000004sp8.html
SPMT�́A���DRAM�`�b�v���^�[�Q�b�g�Ƃ����V�����������[�A�[�L�e�N�`���ŁA���݂̃������[�Ŏ嗬��
�Ȃ��Ă���p�������C���^�[�t�F�[�X�̑���ɁA�V���A���C���^�[�t�F�[�X��p����B����ɂ��A�d�r
�����̉����A����d�͂̍팸�A�[�q���̍팸�Ȃǂ������ł���Ƃ����B
���q�����x���ɂȂ��������̌��E�ɁA������ƌ����������Ă������Ď��Ȃ̂��ȁH
��R�A�R���f���T�A�C���_�N�^�Ɏ���
�u��4�̎f�q�v��HP�Ђ����� (2008/05/02)
http://www.eetimes.jp/contents/200805/34206_1_20080502150844.cfm
Chua����1971�N�ɔ��\�����_���̒��ŁA��R�ƃR���f���T�A�C���_�N�^�ɑ�����4�̉�H�v�f��
���݂��邱�Ƃ𐔊w�I�ɐ��肵���B���̑f�q���̓������X�^�ƌĂB��R�l��ω�������
���ƂŁA���̑f�q��ʉ߂���d���̕ω����u�������[�i�L���j�v�������������Ă��邩�炾�B
����HP�Ђ����������������X�^�́A��_���`�^���iTiO2�j�̔����𗘗p���č쐬����Ă���A
�d�����ʉ߂���ƒ�R�l���ω�����B
�u���̐V���ȉ�H�f�q�́A�d�q��H�����ݕ����鐔�����̉ۑ�����������i�ɂȂ邾�낤�B
�������X�^�͌`����������������قǁA���������シ�邩�炾�v��Chua���͌����B
�u�������X�^�́A�����ɂ�郊�[�N�d���̑��傪���ɂȂ��Ă���g�����W�X�^�Ƃ͈قȂ�A
������i�߂Ă����ʂȏ���d�͂ɂ�锭�M�̖��͐����Ȃ��B�]���ă������X�^���g���A
�`�ɂ߂ď������i�m�X�P�[���̉�H���쐬�ł���悤�ɂȂ邾�낤�v�i�����j�B
��R�A�R���f���T�A�C���_�N�^�Ɏ���
�u��4�̎f�q�v��HP�Ђ����� (2008/05/02)
http://www.eetimes.jp/contents/200805/34206_1_20080502150844.cfm
Chua����1971�N�ɔ��\�����_���̒��ŁA��R�ƃR���f���T�A�C���_�N�^�ɑ�����4�̉�H�v�f��
���݂��邱�Ƃ𐔊w�I�ɐ��肵���B���̑f�q���̓������X�^�ƌĂB��R�l��ω�������
���ƂŁA���̑f�q��ʉ߂���d���̕ω����u�������[�i�L���j�v�������������Ă��邩�炾�B
����HP�Ђ����������������X�^�́A��_���`�^���iTiO2�j�̔����𗘗p���č쐬����Ă���A
�d�����ʉ߂���ƒ�R�l���ω�����B
�u���̐V���ȉ�H�f�q�́A�d�q��H�����ݕ����鐔�����̉ۑ�����������i�ɂȂ邾�낤�B
�������X�^�͌`����������������قǁA���������シ�邩�炾�v��Chua���͌����B
�u�������X�^�́A�����ɂ�郊�[�N�d���̑��傪���ɂȂ��Ă���g�����W�X�^�Ƃ͈قȂ�A
������i�߂Ă����ʂȏ���d�͂ɂ�锭�M�̖��͐����Ȃ��B�]���ă������X�^���g���A
�`�ɂ߂ď������i�m�X�P�[���̉�H���쐬�ł���悤�ɂȂ邾�낤�v�i�����j�B
>>436
�ق������A���ȏ�����������������̗��_���ؖ����ꂽ���Ď����`�B
�������͂������̂��`�A�t�H�b�t�H�b�t�H�b�t�H�b�t�H�b�B
�u����܂ł́A�d���Ɠd�ׂƂ���2�̕����ʂ̊W���Ɋ�Â��ēd�q��H���_���\�z���Ă������A
����͌�肾�����B�d�q��H���_�������Ƃ��Ă����̂́A�g�ݍ��킹��ׂ������ʂ������Ɠd�ׂ�
����Ƃ������Ƃ��v��Chua���͎咣����B�u���̏́A�w�A���X�g�e���X�̉^���_�x�Ɏ��Ă���B
�Ñ�M���V���̓N�w�҂ł���A���X�g�e���X�́A�͂͑��x�ɔ�Ⴗ��Ƃ������A�㐢�ɂȂ��Ă��ꂪ
���ł��邱�Ƃ����炩�ɂȂ����B�A�C�U�b�N�E�j���[�g�����A���X�g�e���X�̉^���_�͌����
�����ʂɊ�Â��Ă���Ǝw�E����܂ŁA2000�N���̊ԁA�l�X�͂���𐳂����Ǝv������ł����̂�
����B�j���[�g���́A�͉͂����x�ɔ�Ⴗ��Ǝw�E�����B�����x�Ƃ́A���Ȃ킿���x�̕ω����ł���B
����͂܂��Ɍ��݂̓d�q��H���_�Ɠ������B�d�q��H���_�̋��ȏ��͂���܂ŁA���܂̍���Ȃ�
���ۂ��O���ƕٖ����Ȃ���A�d���Ɠd�ׂƂ���������g�ݍ��킹�̕����ʂ̊W���Ɋ�Â��Ę_���Ă����B
���ȏ����`����ׂ��������̂́A�����Ɠd�ׂ̊W�Ɋ�Â���H���_�ł���v�i�����j�B
�ق������A���ȏ�����������������̗��_���ؖ����ꂽ���Ď����`�B
�������͂������̂��`�A�t�H�b�t�H�b�t�H�b�t�H�b�t�H�b�B
�u����܂ł́A�d���Ɠd�ׂƂ���2�̕����ʂ̊W���Ɋ�Â��ēd�q��H���_���\�z���Ă������A
����͌�肾�����B�d�q��H���_�������Ƃ��Ă����̂́A�g�ݍ��킹��ׂ������ʂ������Ɠd�ׂ�
����Ƃ������Ƃ��v��Chua���͎咣����B�u���̏́A�w�A���X�g�e���X�̉^���_�x�Ɏ��Ă���B
�Ñ�M���V���̓N�w�҂ł���A���X�g�e���X�́A�͂͑��x�ɔ�Ⴗ��Ƃ������A�㐢�ɂȂ��Ă��ꂪ
���ł��邱�Ƃ����炩�ɂȂ����B�A�C�U�b�N�E�j���[�g�����A���X�g�e���X�̉^���_�͌����
�����ʂɊ�Â��Ă���Ǝw�E����܂ŁA2000�N���̊ԁA�l�X�͂���𐳂����Ǝv������ł����̂�
����B�j���[�g���́A�͉͂����x�ɔ�Ⴗ��Ǝw�E�����B�����x�Ƃ́A���Ȃ킿���x�̕ω����ł���B
����͂܂��Ɍ��݂̓d�q��H���_�Ɠ������B�d�q��H���_�̋��ȏ��͂���܂ŁA���܂̍���Ȃ�
���ۂ��O���ƕٖ����Ȃ���A�d���Ɠd�ׂƂ���������g�ݍ��킹�̕����ʂ̊W���Ɋ�Â��Ę_���Ă����B
���ȏ����`����ׂ��������̂́A�����Ɠd�ׂ̊W�Ɋ�Â���H���_�ł���v�i�����j�B
>>436
����Ń`�^�����ꂪ�E�v����̂��ȁH
�g�o�������Ɛ肷��ƊȒP�ɂ͂����Ȃ��C�����邪�A����i�`�q�n�B
�������X�^�̓��쌴���́A�q�X�e���V�X���ۂɂ���B�u�I���v����u�I�t�v�A�������́u�I�t�v����
�u�I���v�Ƃ�����ɁA�����Ԃ������1�̏�Ԃɐ�ւ��ۂɁA�ω����x�������BChua����
Williams���ɂ��A�q�X�e���V�X���ۂ͎�H�̊�{�I�ȓ����ł���ɂ�������炸�A�d����H
���_�ɂ����Ă͗�O�Ƃ��Ĉ����Ă����Ƃ����B�u�q�X�e���V�X���ۂ́A��4�̎f�q�A���Ȃ킿
�������X�^�̑��݂��ؖ�������̂ł���BWilliams���́A���̌��ۂ��]���̗��_�Ő����ł��Ȃ�����
�ɒ��ڂ��A���������Ƃ�������͂����ƋC�t�����̂��v�iChua���j�B
�@�Ⴆ�A��_���`�^���Ɏ_�f���߂Â���ƁA��R�l���ω�����Ƃ������ۂ��̂��̂͂���܂ł�
�m���Ă����B���̌��ۂ𗘗p�����̂���_���`�^���_�f�Z���T�[�ł���B�������A���̂悤�Ȍ���
���Ȃ�������̂��͐����ł��Ȃ������B�u�q�X�e���V�X���ۂ������Ă��邱�Ƃ́A�����J�[�u�𑪒�
���邱�ƂŊm�F����Ă����B����������������������邱�Ƃ��ł��Ȃ������̂ŁA�ł��ȒP�ȉ��p��
����Z���T�[�����쐬�ł��Ȃ������v��Chua���͌����B�u������HP�Ђ̐��ʂɂ���č��A���̌�����
���炩�ɂȂ����B�]���āA�q�X�e���V�X���ۂ𗘗p���Ă��܂��܂ȃ^�C�v�̐V������H��v�ł���
�悤�ɂȂ�v�i�����j�B
�@�������X�^�́A�������[���������������`�̒�R��Ƃ��ĐU�镑���BChua����Williams���ɂ��A
���^�ŃG�l���M�����̍����������[�E�`�b�v�����������i�ɂȂ�Ƃ���B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
����Ƀ������[�E�`�b�v�ɂƂǂ܂炸�A���Ă͑z�����炳��Ȃ������悤�ȐV�����`�b�v����������
�\������߂�Ǝ咣����B
����Ń`�^�����ꂪ�E�v����̂��ȁH
�g�o�������Ɛ肷��ƊȒP�ɂ͂����Ȃ��C�����邪�A����i�`�q�n�B
�������X�^�̓��쌴���́A�q�X�e���V�X���ۂɂ���B�u�I���v����u�I�t�v�A�������́u�I�t�v����
�u�I���v�Ƃ�����ɁA�����Ԃ������1�̏�Ԃɐ�ւ��ۂɁA�ω����x�������BChua����
Williams���ɂ��A�q�X�e���V�X���ۂ͎�H�̊�{�I�ȓ����ł���ɂ�������炸�A�d����H
���_�ɂ����Ă͗�O�Ƃ��Ĉ����Ă����Ƃ����B�u�q�X�e���V�X���ۂ́A��4�̎f�q�A���Ȃ킿
�������X�^�̑��݂��ؖ�������̂ł���BWilliams���́A���̌��ۂ��]���̗��_�Ő����ł��Ȃ�����
�ɒ��ڂ��A���������Ƃ�������͂����ƋC�t�����̂��v�iChua���j�B
�@�Ⴆ�A��_���`�^���Ɏ_�f���߂Â���ƁA��R�l���ω�����Ƃ������ۂ��̂��̂͂���܂ł�
�m���Ă����B���̌��ۂ𗘗p�����̂���_���`�^���_�f�Z���T�[�ł���B�������A���̂悤�Ȍ���
���Ȃ�������̂��͐����ł��Ȃ������B�u�q�X�e���V�X���ۂ������Ă��邱�Ƃ́A�����J�[�u�𑪒�
���邱�ƂŊm�F����Ă����B����������������������邱�Ƃ��ł��Ȃ������̂ŁA�ł��ȒP�ȉ��p��
����Z���T�[�����쐬�ł��Ȃ������v��Chua���͌����B�u������HP�Ђ̐��ʂɂ���č��A���̌�����
���炩�ɂȂ����B�]���āA�q�X�e���V�X���ۂ𗘗p���Ă��܂��܂ȃ^�C�v�̐V������H��v�ł���
�悤�ɂȂ�v�i�����j�B
�@�������X�^�́A�������[���������������`�̒�R��Ƃ��ĐU�镑���BChua����Williams���ɂ��A
���^�ŃG�l���M�����̍����������[�E�`�b�v�����������i�ɂȂ�Ƃ���B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
����Ƀ������[�E�`�b�v�ɂƂǂ܂炸�A���Ă͑z�����炳��Ȃ������悤�ȐV�����`�b�v����������
�\������߂�Ǝ咣����B
>>436
����̂g�o�̔��\�ɁA�v�������胏�N�e�J�o�������ł��B
�@Chua�����\�����Ă����ʂ�AHP�Ђ͂��łɁA�N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â��V�����^�C�v��
�`�b�v���������Ă���B����͒P�Ȃ郁�����[�E�`�b�v������̂��B�u�쐬�����������X�^�́A�傫�ȓd��
��Z���Ԃň������A�f�W�^���f�q�̂悤�ɐU�镑���B�������A�����ȓd�����Ԃ����Ĉ������A�A�i���O
�f�q�̂悤�ȋ����������v��Williams���͌����B�u���Ђ͂��łɁA�N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â�
�f�W�^�����������ƃA�i���O���������̗����ɂ��āA�V���ȃ^�C�v�̉�H�̐v��i�߂Ă���B�A�i���O��������
�ł́A�l�Ԃ̔]���ɂ���V�i�v�X�ɋ߂��d�g�݂œ��삷���H�������������B���Ȃ킿�A�������ʂ̉������傫��
�����������̔�r�Ɋ�Â����f�ɂ���ăR���g���[���@�\�����s����A�j���[�����̂悤�ȃA�i���O�v�Z�@�ł���v
�i�����j�B
�@HP�Ђ́A2008�N�̌㔼�ȍ~�A�������X�^��K�p�����N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â����܂��܂�
�^�C�v�̃`�b�v�ɂ��āA�����ڍׂ����\����Ƃ����B
�u�������X�^�́A�P�Ɋ����̃������[�E�`�b�v��u��������Z�p�ł͂Ȃ��B����܂ł͒N���l�������Ȃ������悤�ȁA
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
������^�C�v�̐V�����`�b�v�����o�����߂Ɏg���邾�낤�v
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
��Williams���͏q�ׂĂ���B
����̂g�o�̔��\�ɁA�v�������胏�N�e�J�o�������ł��B
�@Chua�����\�����Ă����ʂ�AHP�Ђ͂��łɁA�N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â��V�����^�C�v��
�`�b�v���������Ă���B����͒P�Ȃ郁�����[�E�`�b�v������̂��B�u�쐬�����������X�^�́A�傫�ȓd��
��Z���Ԃň������A�f�W�^���f�q�̂悤�ɐU�镑���B�������A�����ȓd�����Ԃ����Ĉ������A�A�i���O
�f�q�̂悤�ȋ����������v��Williams���͌����B�u���Ђ͂��łɁA�N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â�
�f�W�^�����������ƃA�i���O���������̗����ɂ��āA�V���ȃ^�C�v�̉�H�̐v��i�߂Ă���B�A�i���O��������
�ł́A�l�Ԃ̔]���ɂ���V�i�v�X�ɋ߂��d�g�݂œ��삷���H�������������B���Ȃ킿�A�������ʂ̉������傫��
�����������̔�r�Ɋ�Â����f�ɂ���ăR���g���[���@�\�����s����A�j���[�����̂悤�ȃA�i���O�v�Z�@�ł���v
�i�����j�B
�@HP�Ђ́A2008�N�̌㔼�ȍ~�A�������X�^��K�p�����N���X�o�[�E�X�C�b�`�E�A�[�L�e�N�`���Ɋ�Â����܂��܂�
�^�C�v�̃`�b�v�ɂ��āA�����ڍׂ����\����Ƃ����B
�u�������X�^�́A�P�Ɋ����̃������[�E�`�b�v��u��������Z�p�ł͂Ȃ��B����܂ł͒N���l�������Ȃ������悤�ȁA
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
������^�C�v�̐V�����`�b�v�����o�����߂Ɏg���邾�낤�v
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
��Williams���͏q�ׂĂ���B
�ƂĂ������[���b��Ȃ��A�X��������ˁH
�ނ������
�w�E���邾�����ƃA���Ȃ�œK���ȃX���T���Ă���
�y�h�s�zHP���A��4�̉�H�f�q�wmemristor�x�����߂Ď��ۂɍ쐬
http://news24.2ch.net/test/read.cgi/scienceplus/1209701117/
�y�h�s�zHP���A��4�̉�H�f�q�wmemristor�x�����߂Ď��ۂɍ쐬
http://news24.2ch.net/test/read.cgi/scienceplus/1209701117/
443 �F�R�E�L�́M�E,,�j�����������������F2008/05/02(��) 20:45:52 ID:IrPNpGgC
�挎�̃l�^�����ǂ���Ȃ̂�����ˁB
�܂����p���ɂ͂قlj����̂��낤���ȁB
http://sankei.jp.msn.com/economy/it/080412/its0804121306001-n1.htm
�܂����p���ɂ͂قlj����̂��낤���ȁB
http://sankei.jp.msn.com/economy/it/080412/its0804121306001-n1.htm
>>436
�������A����}�W�Ő����Ȃ���?
wiki�ɂ��A
d��m = MdQ
�����āB
�d��Q�͓d��i�̎��Ԑϕ�������P���Șb�A�ߋ��ɗ����������d���̗ʂ����A
������ω���������B���R�����̂���߂�Εۑ�(�L���f�q)�ɂ��g����B
�������قǓ������悭�Ȃ�炵�����A�ł����������X�^�f�q���ł��Ȃ����Ȃ��B
����Ńp���[�n�̑f�q�Ƃ���������d�C�v�̏펯���Ђ����肩����c�B
�j���[�������C�N�ȑf�q���ȒP�ɂ����Ƃ����̂��[���B�قƂ�ǂ��̂܂܂����B
�������A����}�W�Ő����Ȃ���?
wiki�ɂ��A
d��m = MdQ
�����āB
�d��Q�͓d��i�̎��Ԑϕ�������P���Șb�A�ߋ��ɗ����������d���̗ʂ����A
������ω���������B���R�����̂���߂�Εۑ�(�L���f�q)�ɂ��g����B
�������قǓ������悭�Ȃ�炵�����A�ł����������X�^�f�q���ł��Ȃ����Ȃ��B
����Ńp���[�n�̑f�q�Ƃ���������d�C�v�̏펯���Ђ����肩����c�B
�j���[�������C�N�ȑf�q���ȒP�ɂ����Ƃ����̂��[���B�قƂ�ǂ��̂܂܂����B
���R�d�����t�ɗ����Ύ����͊�ɖ߂��Ă����B�����������y�����B
�����A�������X�^���X���̑傫���f�q����Ȃ��Ɠd���ʂ������K�v�ɐ������Ⴄ����
��̓I�ɂǂꂭ��̃������X�^���X�������z�I�ȓ����œ�����̂��͓�B
>�d�q��H���_�̋��ȏ��͂���܂ŁA���܂̍���Ȃ�
>���ۂ��O���ƕٖ����Ȃ���A�d���Ɠd�ׂƂ���������g�ݍ��킹�̕����ʂ̊W���Ɋ�Â��Ę_���Ă����B
>���ȏ����`����ׂ��������̂́A�����Ɠd�ׂ̊W�Ɋ�Â���H���_�ł���
����������H���_���Ď��C�̍l���͔r���������̂Ȃ킯�ŁA���̐����͑傰���B
���C�������ƍl����Ƃ��͉�H���_�͂��������g��Ȃ��B
EETimes�̋L���́u�d�ׁv���u�d���v�Ƃ�݂������ق������(���{�l?)�ɂ͗������₷���B
�����A�������X�^���X���̑傫���f�q����Ȃ��Ɠd���ʂ������K�v�ɐ������Ⴄ����
��̓I�ɂǂꂭ��̃������X�^���X�������z�I�ȓ����œ�����̂��͓�B
>�d�q��H���_�̋��ȏ��͂���܂ŁA���܂̍���Ȃ�
>���ۂ��O���ƕٖ����Ȃ���A�d���Ɠd�ׂƂ���������g�ݍ��킹�̕����ʂ̊W���Ɋ�Â��Ę_���Ă����B
>���ȏ����`����ׂ��������̂́A�����Ɠd�ׂ̊W�Ɋ�Â���H���_�ł���
����������H���_���Ď��C�̍l���͔r���������̂Ȃ킯�ŁA���̐����͑傰���B
���C�������ƍl����Ƃ��͉�H���_�͂��������g��Ȃ��B
EETimes�̋L���́u�d�ׁv���u�d���v�Ƃ�݂������ق������(���{�l?)�ɂ͗������₷���B
�X�s���g���j�N�X�ł�������
���Ȃ݂ɒ��T���X�����A>>191�ȍ~�ʼn������Ă���OOO�̉����
���Ȃ萳�m����B���̕ӂ�Web�L����肩�Ȃ�ڍׂŐ��m�����A
���ꂪ�X���[����邠���肱�̃X���̌��E���������B
�S���N������ׂ��B
���Ȃ萳�m����B���̕ӂ�Web�L����肩�Ȃ�ڍׂŐ��m�����A
���ꂪ�X���[����邠���肱�̃X���̌��E���������B
�S���N������ׂ��B
�X���̌��E�Ƃ�����蓽���f���̌��E���ȁB
�؋��\�[�X�Ȃ��Ō������Ȃ��̓����f���ł܂��߂ɉ��������Ă�
�M�p���ăC�C���ǂ������f�ł��Ȃ����疳�Ӗ��ȂB
�؋��\�[�X�Ȃ��Ō������Ȃ��̓����f���ł܂��߂ɉ��������Ă�
�M�p���ăC�C���ǂ������f�ł��Ȃ����疳�Ӗ��ȂB
CPU�A�[�L�e�N�`���ɂ��Č��X���ł����ė�������X������Ȃ����炗
�[�����^�̑��肵�Ă��Ȃ�ăX���[�����Ɍ��܂��Ă邾��
ID:H29jm950�̃��X�̓��e�Ɋւ��Ă͐��m����MAC�I�^�̃}�l��
�������\���̂͂��������Ȃ��̂��Ƃ������ꂾ�����悤�ȋC������
�������\���̂͂��������Ȃ��̂��Ƃ������ꂾ�����悤�ȋC������
>>445
�����������̃\�[�X���ǂB�d���ł͂Ȃ��d�ׂƏ����Ă���̂́A
����쐬�����������X�^�����̂���������������Ȃ����������B
1971�N�ɏo�����_���Ń������X�^�Ƃ��������ゾ���̊��㗝�_�̑f�q�������āA
����쐬�����f�q������ɊY��������́B
�������̐������������̂�������Ȃ��̂ŕ��y�ɂ̂����Ƃ��ē����̓R���s���[�^�W�̉��p�����C��?
��H���_��������ʂ̋��ȏ���RLC�ƕ���Ń��C���ň������e����Ȃ��\���B
�ł����y������Љ�炢�͂��ꂻ���B
�f�q�����ꎩ�̂ŋL����p�������Ă���Ă̂��ʔ����B
�����������̃\�[�X���ǂB�d���ł͂Ȃ��d�ׂƏ����Ă���̂́A
����쐬�����������X�^�����̂���������������Ȃ����������B
1971�N�ɏo�����_���Ń������X�^�Ƃ��������ゾ���̊��㗝�_�̑f�q�������āA
����쐬�����f�q������ɊY��������́B
�������̐������������̂�������Ȃ��̂ŕ��y�ɂ̂����Ƃ��ē����̓R���s���[�^�W�̉��p�����C��?
��H���_��������ʂ̋��ȏ���RLC�ƕ���Ń��C���ň������e����Ȃ��\���B
�ł����y������Љ�炢�͂��ꂻ���B
�f�q�����ꎩ�̂ŋL����p�������Ă���Ă̂��ʔ����B
�X���Ⴂ�Ȃ̂ł���ōŌ�B�܂��܂��F����ύX�B
>�u����܂ł́A�d���Ɠd�ׂƂ���2�̕����ʂ̊W���Ɋ�Â��ēd�q��H���_���\�z���Ă������A
>����͌�肾�����B�d�q��H���_�������Ƃ��Ă����̂́A�g�ݍ��킹��ׂ������ʂ������Ɠd�ׂ�
>����Ƃ������Ƃ��v��Chua���͎咣����B
Chua���������Ă���͉̂�H���_�Ɏ�����m��g�ݓ���邱�Ƃ�(?)
http://en.wikipedia.org/wiki/Circuit_element
������wiki�̐������݂�Ǝ�����g�ݓ���Ă��m���Ɉ�ѐ��������ĐV�N���B
��H���_�ł��d���͎����̎��ԕω��ōl����ƁB
>�u����܂ł́A�d���Ɠd�ׂƂ���2�̕����ʂ̊W���Ɋ�Â��ēd�q��H���_���\�z���Ă������A
>����͌�肾�����B�d�q��H���_�������Ƃ��Ă����̂́A�g�ݍ��킹��ׂ������ʂ������Ɠd�ׂ�
>����Ƃ������Ƃ��v��Chua���͎咣����B
Chua���������Ă���͉̂�H���_�Ɏ�����m��g�ݓ���邱�Ƃ�(?)
http://en.wikipedia.org/wiki/Circuit_element
������wiki�̐������݂�Ǝ�����g�ݓ���Ă��m���Ɉ�ѐ��������ĐV�N���B
��H���_�ł��d���͎����̎��ԕω��ōl����ƁB
�ǂ��ɂ��킩���
�������X�^�͗��ꍞ��ł����d�ׂ𗭂߂���ł��邮��Ƃ�����Ƃ��H
�������X�^�͗��ꍞ��ł����d�ׂ𗭂߂���ł��邮��Ƃ�����Ƃ��H
����Ȃ�QFP�Ƃ��傱���Ǝ��Ƃ��
���d���ł��Ȃ���ł����͍̂������Ȃ�������
���d���ł��Ȃ���ł����͍̂������Ȃ�������
���������L����R�C����������āA�Е��͗��߂��d�ׂ����邮��A�����Е��̒�R�l���ς����ĂƂ����ȁH
�U��
�y�h�s�zHP���A��4�̉�H�f�q�wmemristor�x�����߂Ď��ۂɍ쐬
http://news24.2ch.net/test/read.cgi/scienceplus/1209701117/
�y�h�s�zHP���A��4�̉�H�f�q�wmemristor�x�����߂Ď��ۂɍ쐬
http://news24.2ch.net/test/read.cgi/scienceplus/1209701117/
>>440-441
�m���Ɏ�����CPU�Ƃ�����ɂ͂����A�������X�^��CPU�A�[�L�e�B�N�`���ɂ܂�
�ւ��ɂ́A����������ɂȂ邾�낤�ˁB
�ł������ɂ�鍂���\�����A���q�����x���ɂȂ��Ă���22nm�ȍ~�������Ȃ�����
�ł́A���̃f�W�^������̃g�����W�X�^�ɂ��_����H�ł͂Ȃ��u���[�N�X���[��
�K�v�����A�������X�^�ɂ��ꂪ���ҏo����B
�Ȃɂ��돬���̋Z�p��ޗ��A�H���̘b����Ȃ��āA�d�C��H���_�̍��{��������
�����̘b������A���ꂩ��ǂꂾ���e�����傫���L���邪������Ȃ��������B
���S�Ȗϑz�����ǁA�Ⴆ�Ε����̃t���b�v�t���b�v��H���P�f�q�Ŏ����A�Ȃ��
����A���������_���Z�Ȃ��A�i���O��H�ō������s�A�Ȃ�Ď����L��̂����H
�m���Ɏ�����CPU�Ƃ�����ɂ͂����A�������X�^��CPU�A�[�L�e�B�N�`���ɂ܂�
�ւ��ɂ́A����������ɂȂ邾�낤�ˁB
�ł������ɂ�鍂���\�����A���q�����x���ɂȂ��Ă���22nm�ȍ~�������Ȃ�����
�ł́A���̃f�W�^������̃g�����W�X�^�ɂ��_����H�ł͂Ȃ��u���[�N�X���[��
�K�v�����A�������X�^�ɂ��ꂪ���ҏo����B
�Ȃɂ��돬���̋Z�p��ޗ��A�H���̘b����Ȃ��āA�d�C��H���_�̍��{��������
�����̘b������A���ꂩ��ǂꂾ���e�����傫���L���邪������Ȃ��������B
���S�Ȗϑz�����ǁA�Ⴆ�Ε����̃t���b�v�t���b�v��H���P�f�q�Ŏ����A�Ȃ��
����A���������_���Z�Ȃ��A�i���O��H�ō������s�A�Ȃ�Ď����L��̂����H
>>452
�܂��`������i�K�ł̓j���[�g���͊w���ŁA�ʎq�͊w�͋����Ȃ��l�ȃ����W�����B
�܂��`������i�K�ł̓j���[�g���͊w���ŁA�ʎq�͊w�͋����Ȃ��l�ȃ����W�����B
�_�f��E�̈ړ��x���d�q�̈ړ��x������Ƃ͎v���Ȃ�����
FF�̒u���������Ă̂͂Ȃ����낤��
FF�̒u���������Ă̂͂Ȃ����낤��
461 �FMAC�I�^���o�N�}�� �����F2008/05/06(��) 13:14:15 ID:VeL5EoZJ
>>447-448
�@�@----------------
�@�@>>191�ȍ~�ʼn������Ă���OOO�̉���͂��Ȃ萳�m����B
�@�@----------------
���������Ƃɐ������m�����g���ĊԈ�����咣�����Ă�̂����胂�m���BIsaiah��ROB��x86���߂��̂���
���i�[�����Ƃ����ނ̖ό��팾���ɋy���A�Ⴆ��>>206�̃g���f�����ɂ�˂����݂�����ׂ�����
�v�����B
>>206
�@�@=================
�@�@������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@=================
�@�@----------------
�@�@>>191�ȍ~�ʼn������Ă���OOO�̉���͂��Ȃ萳�m����B
�@�@----------------
���������Ƃɐ������m�����g���ĊԈ�����咣�����Ă�̂����胂�m���BIsaiah��ROB��x86���߂��̂���
���i�[�����Ƃ����ނ̖ό��팾���ɋy���A�Ⴆ��>>206�̃g���f�����ɂ�˂����݂�����ׂ�����
�v�����B
>>206
�@�@=================
�@�@������ɂ���A�ǂ�ȃv���Z�b�T�ł��������W�X�^�ɑ��ď\���ȃG���g����������ROB������Ă��邷�B
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@=================
462 �FMAC�I�^�������F2008/05/06(��) 13:18:01 ID:VeL5EoZJ
�ǂ�������������A>>209��PowerPC ISA�n�ł̂̎����������������ǁA���傤��x86��OoOE�œK����
�ւ��鎑�����������̂ŏ����Ă������B
http://jp.xlsoft.com/documents/intel/seminar/4_Core2_perf_counters_J.pdf
������"RESOURCE_STALLS.ROB_FULL"�ƕ��ނ���Ă���̂�ROB�̋҂��ɂ��X�g�[�����B
���Ȃ݂ɂ��̕����ł�ROB��x86�p��Ȃ̂��ӎ����āA�ėp�̗p����g���Ă��������L�q�����Ă��邷�B
�@�@=================
�@�@.���s�X�g�[��
�@�@�@- ���͂�X�R�A�{�[�h�҂��AL2�~�X�ABW�ADTLB�A���̑�
�@�@=================
�w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
�@�@
������ɂ���~�[����ł����ȏ��I�������ʂ����Ƃ�\�Ȗ�ŁA�����f���ŃJ�L�R�~�̐M���x��
�]������̂����Ƃ������Ƃ��Ǝv�����B�M���x�Ȃ�Ē������ƋL����ǂݑ����āA���l�̒m����
��g���čs��ꂽ�\�z���A�ǂ̒��x���Ă�����������邵��������Ȃ������ˁH
�����g��A���̕��@�ŕ��ꃋ�[�}�[�T�C�g�̕]�����s���Ă��邷�B10�N�߂��Œ�n���h�����g���Ă���
�̂��A���ꂪ���R���B
�ւ��鎑�����������̂ŏ����Ă������B
http://jp.xlsoft.com/documents/intel/seminar/4_Core2_perf_counters_J.pdf
������"RESOURCE_STALLS.ROB_FULL"�ƕ��ނ���Ă���̂�ROB�̋҂��ɂ��X�g�[�����B
���Ȃ݂ɂ��̕����ł�ROB��x86�p��Ȃ̂��ӎ����āA�ėp�̗p����g���Ă��������L�q�����Ă��邷�B
�@�@=================
�@�@.���s�X�g�[��
�@�@�@- ���͂�X�R�A�{�[�h�҂��AL2�~�X�ABW�ADTLB�A���̑�
�@�@=================
�w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
�@�@
������ɂ���~�[����ł����ȏ��I�������ʂ����Ƃ�\�Ȗ�ŁA�����f���ŃJ�L�R�~�̐M���x��
�]������̂����Ƃ������Ƃ��Ǝv�����B�M���x�Ȃ�Ē������ƋL����ǂݑ����āA���l�̒m����
��g���čs��ꂽ�\�z���A�ǂ̒��x���Ă�����������邵��������Ȃ������ˁH
�����g��A���̕��@�ŕ��ꃋ�[�}�[�T�C�g�̕]�����s���Ă��邷�B10�N�߂��Œ�n���h�����g���Ă���
�̂��A���ꂪ���R���B
�����������Ƃ��
http://www.cs.utexas.edu/users/dburger/teaching/cs395t-s08/papers/3_smith.pdf
�܁AMAC�I�^�͂��̘_���ł��ǂ�ŏ����͂�������ƁB
�܁AMAC�I�^�͂��̘_���ł��ǂ�ŏ����͂�������ƁB
465 �FMAC�I�^���o�N�}�� �����F2008/05/06(��) 14:31:43 ID:VeL5EoZJ
>>464
�o�^���W�ł���Hyperthreading�����A�p��Ƃ��Ďg�p���Ă���_����L�邷���ǁH
http://www.google.com/search?q=Hyperthreading+filetype%3Apdf+site%3A.edu
���j�I�o�܂�ʂɂ��āA�Ⴆ��TLB��L2�L���b�V���Ƃ����p������Ђ̃}�j���A���Ŏg�p���Ȃ��v��
�Z�b�T�x���_��F���ƌ����ėǂ������ǁA�Ǖ��ɂ���ROB�Ƃ����ď̂��g���Ă���̂�x86�x���_������
�����B
���̓_�ɔ��_�ł��鎑��������ΏЉ�����肢���邷�B
�o�^���W�ł���Hyperthreading�����A�p��Ƃ��Ďg�p���Ă���_����L�邷���ǁH
http://www.google.com/search?q=Hyperthreading+filetype%3Apdf+site%3A.edu
���j�I�o�܂�ʂɂ��āA�Ⴆ��TLB��L2�L���b�V���Ƃ����p������Ђ̃}�j���A���Ŏg�p���Ȃ��v��
�Z�b�T�x���_��F���ƌ����ėǂ������ǁA�Ǖ��ɂ���ROB�Ƃ����ď̂��g���Ă���̂�x86�x���_������
�����B
���̓_�ɔ��_�ł��鎑��������ΏЉ�����肢���邷�B
>>465
http://www.freescale.com/files/32bit/doc/app_note/AN2808.pdf?fpsp=1&WT_TYPE=Application%20Notes&WT_VENDOR=FREESCALE&WT_FILE_FORMAT=pdf&WT_ASSET=Documentation
PowerPC750 (page3) Reorder Buffer 6 entries
http://www.via.com.tw/en/downloads/whitepapers/processors/WP080124Isaiah-architecture-brief.pdf
VIA Isaiah
http://www.freescale.com/files/32bit/doc/app_note/AN2808.pdf?fpsp=1&WT_TYPE=Application%20Notes&WT_VENDOR=FREESCALE&WT_FILE_FORMAT=pdf&WT_ASSET=Documentation
PowerPC750 (page3) Reorder Buffer 6 entries
http://www.via.com.tw/en/downloads/whitepapers/processors/WP080124Isaiah-architecture-brief.pdf
VIA Isaiah
>>464
��Reorder Buffer�̍ŏ��̘_��(�̂͂�)�ŁA
1985�N���m�Ȃ̂ŁAP6��10�N���O�ŁAx86��OOO����͓��R�W�Ȃ��B
�_���ɏ����Ă���Ƃ���A���Ƃ���Reorder Buffer��Out Of Order Completion�̃v���Z�b�T��
"���m�Ȋ��荞��/��O"���������邽�߂̂���(���͊g�������Register Renaming�Ȃǂ̂��߂Ɏg��ꂽ�������)�B
ROB�ȊO�ɂ����A��������Ԃ�s�x�e�[�u���ɋL������Check point����������B
http://www.arch.ce.hiroshima-cu.ac.jp/~kitamura/public/architecture_2006_07.pdf
��Reorder Buffer�̍ŏ��̘_��(�̂͂�)�ŁA
1985�N���m�Ȃ̂ŁAP6��10�N���O�ŁAx86��OOO����͓��R�W�Ȃ��B
�_���ɏ����Ă���Ƃ���A���Ƃ���Reorder Buffer��Out Of Order Completion�̃v���Z�b�T��
"���m�Ȋ��荞��/��O"���������邽�߂̂���(���͊g�������Register Renaming�Ȃǂ̂��߂Ɏg��ꂽ�������)�B
ROB�ȊO�ɂ����A��������Ԃ�s�x�e�[�u���ɋL������Check point����������B
http://www.arch.ce.hiroshima-cu.ac.jp/~kitamura/public/architecture_2006_07.pdf
�W�Ȃ��v����������
���ƂȂ��Ă͊��荞�ݏ�����p�R�v���Z�b�T�i�Ƃ����Ă��h�r�`�̓��C���ƈꏏ�����Ǐ������Ēx���j�ڂ�����悤�Ȋ�K�X
���ƂȂ��Ă͊��荞�ݏ�����p�R�v���Z�b�T�i�Ƃ����Ă��h�r�`�̓��C���ƈꏏ�����Ǐ������Ēx���j�ڂ�����悤�Ȋ�K�X
>>462
���݂܂���
>�w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
������MAC�I�^�ł��A�܂�������Ȃ��Ƃ������o���Ƃ͎v���Ă����܂���ł���
���X���̃e���v���ɂ��Ă������ł����H
>>465
�Ǖ�������̂͂�����ƁA��
�l�K�e�B�u�Ȉӌ��������ƒ��ׂĂق����ł�����
���݂܂���
>�w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
������MAC�I�^�ł��A�܂�������Ȃ��Ƃ������o���Ƃ͎v���Ă����܂���ł���
���X���̃e���v���ɂ��Ă������ł����H
>>465
�Ǖ�������̂͂�����ƁA��
�l�K�e�B�u�Ȉӌ��������ƒ��ׂĂق����ł�����
>>462
> �w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
����푽���A���܂ł�MAC�I�^�̔����̒��ł��ł��p�������̂��B
�܂����Ƃ͎v�����ǁA�{���Ɂu�X�R�A�{�[�h��ROB�̂��Ƃ��w�����v�Ǝv���Ă��ł����H
���傤���Ȃ����ƂŃX��������������Ȃ��̂ŁA���������ɒ������Ă��炦����ꂵ������
> �w�X�R�A�{�[�h�x��ROB�̂��Ƃ��w�����B
����푽���A���܂ł�MAC�I�^�̔����̒��ł��ł��p�������̂��B
�܂����Ƃ͎v�����ǁA�{���Ɂu�X�R�A�{�[�h��ROB�̂��Ƃ��w�����v�Ǝv���Ă��ł����H
���傤���Ȃ����ƂŃX��������������Ȃ��̂ŁA���������ɒ������Ă��炦����ꂵ������
>>461
http://ja.wikipedia.org/wiki/%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF%E3%83%BB%E3%83%AA%E3%83%8D%E3%83%BC%E3%83%9F%E3%83%B3%E3%82%B0
�����ǂ�ł����Ă�������
�����ł��Ȃ��Ƃ���͎��₵�Ă����Γ����܂�
����ȏ�X�����r�炷�O�ɁA���˂�����
http://ja.wikipedia.org/wiki/%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF%E3%83%BB%E3%83%AA%E3%83%8D%E3%83%BC%E3%83%9F%E3%83%B3%E3%82%B0
�����ǂ�ł����Ă�������
�����ł��Ȃ��Ƃ���͎��₵�Ă����Γ����܂�
����ȏ�X�����r�炷�O�ɁA���˂�����
473 �FMAC�I�^���o�N�}�� �����F2008/05/06(��) 23:14:16 ID:VeL5EoZJ
>>466
�\����Ȃ������ǁA��̔S���̃q�g���o�Ă����̂Ŏ�Z�ɍς܂����B
�p��Ƃ��Ă�"reorder buffer"��x86�p��Ƃ��Ă�ROB�킿�ƈႤ���Ǝv�����B
�܂��APowerPC�Ɋւ��Ĉꎞ��(��̓I�ɂ�IBM microelectronics���A�[�L�e�N�`�����哱���Ă���
Somerset������)�Ɋ��Ɩ������"reorder buffer"�Ƃ����p����g���Ă���̂�AIBM microelectronics
���̂�x86�x���_�ł����������炾�Ǝv���邷�B
POWER�̃O���[�v��̂���"completion buffer"�̗p����g���Ă��邵�A>>466�̃����N���7447A
�̃u���b�N�}�ɂ�����悤��Motorola SPS(=Freescale)������PowerPC��"completion buffer"���B
Isaiah�����̈��p�������헝�������˂邷���ǁA�������x86���BVIA���l��x86�x���_�ł���AMD��
�Z�p������ROB�Ƃ������̂��g���Ă��邷�B
�\����Ȃ������ǁA��̔S���̃q�g���o�Ă����̂Ŏ�Z�ɍς܂����B
�p��Ƃ��Ă�"reorder buffer"��x86�p��Ƃ��Ă�ROB�킿�ƈႤ���Ǝv�����B
�܂��APowerPC�Ɋւ��Ĉꎞ��(��̓I�ɂ�IBM microelectronics���A�[�L�e�N�`�����哱���Ă���
Somerset������)�Ɋ��Ɩ������"reorder buffer"�Ƃ����p����g���Ă���̂�AIBM microelectronics
���̂�x86�x���_�ł����������炾�Ǝv���邷�B
POWER�̃O���[�v��̂���"completion buffer"�̗p����g���Ă��邵�A>>466�̃����N���7447A
�̃u���b�N�}�ɂ�����悤��Motorola SPS(=Freescale)������PowerPC��"completion buffer"���B
Isaiah�����̈��p�������헝�������˂邷���ǁA�������x86���BVIA���l��x86�x���_�ł���AMD��
�Z�p������ROB�Ƃ������̂��g���Ă��邷�B
�Ƃ���ŊF����l�^�{��wikipedia�Ȃ��H
>>472�̓��{���wikipedia��p��ł̈����ʂ�����(���̂�����}���폜����Ă���)�A>>464��
�_�����p���wikipedia�̎Q�l�������ˁB�B�B
http://en.wikipedia.org/wiki/Register_renaming
>>472�̓��{���wikipedia��p��ł̈����ʂ�����(���̂�����}���폜����Ă���)�A>>464��
�_�����p���wikipedia�̎Q�l�������ˁB�B�B
http://en.wikipedia.org/wiki/Register_renaming
475 �FMAC�I�^���⑫�F2008/05/06(��) 23:42:09 ID:VeL5EoZJ
���Ȃ݂ɂ��̉p���wikipedia�A�Ȃ�x86�p�ꂪOoO�֘A�ōL���g���Ă��邩�Ƃ������������Ă��邷�B
�@�@-------------------
�@�@The P6 "microarchitecture" was the first Intel based processors that implemented both
�@�@out-of-order execution and register renaming.
�@�@-------------------
���p�v���Z�b�T����SMT����������HyperThreading�Ɨǂ���������ƁB�B�B
�@�@-------------------
�@�@The P6 "microarchitecture" was the first Intel based processors that implemented both
�@�@out-of-order execution and register renaming.
�@�@-------------------
���p�v���Z�b�T����SMT����������HyperThreading�Ɨǂ���������ƁB�B�B
MAC�I�^�������߂��ȁB�p����ǂ߂Ȃ��݂��������B
�ނ���_�����ᖳ�����������������̂���
>>473
> �p��Ƃ��Ă�"reorder buffer"��x86�p��Ƃ��Ă�ROB�킿�ƈႤ���Ǝv�����B
MAC�I�^�̔]���ł͂ǂ��Ⴄ���������ė~�����Ƃ���A�Ǝv�������ǁA�ǂ����ł�������
�Ƃ���ŁAJim Smith�̘_���͖����ł����ˁc
> �p��Ƃ��Ă�"reorder buffer"��x86�p��Ƃ��Ă�ROB�킿�ƈႤ���Ǝv�����B
MAC�I�^�̔]���ł͂ǂ��Ⴄ���������ė~�����Ƃ���A�Ǝv�������ǁA�ǂ����ł�������
�Ƃ���ŁAJim Smith�̘_���͖����ł����ˁc
>>475
���A����łȂ�Łux86�p�ꂪOoO�֘A�ōL���g���Ă��邩�Ƃ��������v�ɂȂ�́H
�uP6�}�C�N���A�[�L�e�N�`����OoO�ƃ��W�X�^���l�[�~���O�𗼕����������ŏ���Intel�̃v���Z�b�T�ł���v
�Ƃ��ēǂ߂Ȃ��悤��
���A����łȂ�Łux86�p�ꂪOoO�֘A�ōL���g���Ă��邩�Ƃ��������v�ɂȂ�́H
�uP6�}�C�N���A�[�L�e�N�`����OoO�ƃ��W�X�^���l�[�~���O�𗼕����������ŏ���Intel�̃v���Z�b�T�ł���v
�Ƃ��ēǂ߂Ȃ��悤��
480 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 12:15:48 ID:zZWj2lGD
OoO��Intel�p��FDynamic Execution
>>473
�����ƁA���̊Ԃ�Completion table��ROB���ƔF�߂�悤�ɂȂ��������H
"SPARC64" "reorder buffer"�ŃO�O���ieee explore�̋L�����Ђ������邷
�L���L���Ȃ̂Ŗ{���͓ǂ߂Ȃ��l�����邩�Ǝv�������A�ǂ߂�l�͂ǂ���
�����ƁA���̊Ԃ�Completion table��ROB���ƔF�߂�悤�ɂȂ��������H
"SPARC64" "reorder buffer"�ŃO�O���ieee explore�̋L�����Ђ������邷
�L���L���Ȃ̂Ŗ{���͓ǂ߂Ȃ��l�����邩�Ǝv�������A�ǂ߂�l�͂ǂ���
"PA-8000" "reorder buffer"�ŃO�O��ƁA�o���o���
�Ƃ肠���������PA-8000�̃f�U�C�i�[�̋L����
ttp://csdl2.computer.org/persagen/DLAbsToc.jsp?resourcePath=/dl/mags/mi/&toc=comp/mags/mi/1997/02/m2toc.xml&DOI=10.1109/40.592310
>>473
���̊Ԃɂ�猾���Ă邱�Ƃ������ɂȂ�MAC�I�^�̔]���X���S�z�ɂȂ��Ă����̂ŁA�O�̃��X�����Ă�����(��)
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
�Ƃ肠���������PA-8000�̃f�U�C�i�[�̋L����
ttp://csdl2.computer.org/persagen/DLAbsToc.jsp?resourcePath=/dl/mags/mi/&toc=comp/mags/mi/1997/02/m2toc.xml&DOI=10.1109/40.592310
>>473
���̊Ԃɂ�猾���Ă邱�Ƃ������ɂȂ�MAC�I�^�̔]���X���S�z�ɂȂ��Ă����̂ŁA�O�̃��X�����Ă�����(��)
�O�X��
877 ���O�F MAC�I�^��875 ���� [sage] ���e���F 2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
�����������Ƃ��
MAC�I�^�ɂ��Č��X���͂����ł���
485 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 20:55:26 ID:zZWj2lGD
�܂������MMX Pentium�̎��_�ł���Ϙa�Z�iPMADDWD�j�������ς݂Ȃ��Ƃ���m��Ȃ��q�Ȃ��
���͊W�Ȃ����Ȃ������悤�ȁc
Did Apple invest in P.A. Semi prior to acquisition?
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=207501926
Did Apple invest in P.A. Semi prior to acquisition?
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=207501926
�܂�����A���߂������Ē��ׂĂ��̃U�}���c
�����Œc�q����̃��X�ŃX�����������܂�]�X�����Ƃ��ЂƂ܂�����������
489 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 07:49:54 ID:QQwu9ZkE
>>488�����ځ[��ł�߂Ȃ�
��������MAC�I�^�̓C���I�[�_�[�ł�SMT�������ł��Ȃ��Ȃ�Č����Ă����Ƃ���������
�������Ă�����璿�����P�Ă������A�}���Ƃ��ǂ��Ȃ��Ă�����
�������Ă�����璿�����P�Ă������A�}���Ƃ��ǂ��Ȃ��Ă�����
���[���A�s�������W�b�N�Z�p���J�� - �ҋ@���̏���d�͂��[����
http://journal.mycom.co.jp/news/2008/05/08/017/index.html
��L�͉��L�̍�N�������Ă��̂��A�ʎY���ɖڏ�����������A
�������\�������Ă������ȁH
�yCEATEC�z���[�����s������CPU�������C����d�͂�1�P�^�팸
http://techon.nikkeibp.co.jp/article/NEWS/20071002/140085/
http://journal.mycom.co.jp/news/2008/05/08/017/index.html
��L�͉��L�̍�N�������Ă��̂��A�ʎY���ɖڏ�����������A
�������\�������Ă������ȁH
�yCEATEC�z���[�����s������CPU�������C����d�͂�1�P�^�팸
http://techon.nikkeibp.co.jp/article/NEWS/20071002/140085/
492 �FMAC�I�^��490 �����F2008/05/08(��) 18:40:27 ID:UrOM/xel
>>490
�@�@------------------
�@�@�������Ă�����璿�����P�Ă������A
�@�@------------------
����̂��Ƃ��Ǝv�������ǁA���l�ɒ�������ēP�Ă�悤�Ȃ��Ƃ폑���ĂȂ����B
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/818-
�@�@------------------
�@�@818 ���O�FMAC�I�^ ���e���F2007/02/24(�y) 23:01:08 ID:GU07UDeW
�@�@�@�@[����]
�@�@�@�@issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�@�@------------------
���Ȃ݂�POWER6��SMT�Ɋւ��Ă�A���̌�̏��ŃO���[�v�����̒i�K�ňقȂ�X���b�h��
���߂�O���[�v�ɍ����ē����Ƃ���issue queue (=reservation station)���g�p���Ȃ��Ɠ���
SMT�ƒm���Ă͂��߂Ĕ[���������B
�@�@------------------
�@�@�������Ă�����璿�����P�Ă������A
�@�@------------------
����̂��Ƃ��Ǝv�������ǁA���l�ɒ�������ēP�Ă�悤�Ȃ��Ƃ폑���ĂȂ����B
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/818-
�@�@------------------
�@�@818 ���O�FMAC�I�^ ���e���F2007/02/24(�y) 23:01:08 ID:GU07UDeW
�@�@�@�@[����]
�@�@�@�@issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�@�@------------------
���Ȃ݂�POWER6��SMT�Ɋւ��Ă�A���̌�̏��ŃO���[�v�����̒i�K�ňقȂ�X���b�h��
���߂�O���[�v�ɍ����ē����Ƃ���issue queue (=reservation station)���g�p���Ȃ��Ɠ���
SMT�ƒm���Ă͂��߂Ĕ[���������B
493 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 18:55:20 ID:QQwu9ZkE
�Ϙa�Z�̊��Ⴂ�̒����܂��[�H
494 �FMAC�I�^���c�q �����F2008/05/08(��) 18:58:04 ID:UrOM/xel
495 �FMAC�I�^��493 �����F2008/05/08(��) 19:02:31 ID:UrOM/xel
>>493
�@�@-------------
�@�@�Ϙa�Z�̊��Ⴂ�̒����܂��[�H
�@�@-------------
���Ⴂ���Ă̂햳�������������ǁH
�Ƃ���ŁA�����Řb��ɂȂ���"fused multiply-add"���Ă̂햽�߂̘b����Ȃ��ĉ��Z���j�b�g��
�����̘b���B�c�q���m�X�S�����Ⴂ�����ĈВ����Ă�悤�ȋC���B�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/23-24
������ł�������������"fused"�̈Ӗ��ׂ邱�Ƃ������߂��邷�B
�@�@-------------
�@�@�Ϙa�Z�̊��Ⴂ�̒����܂��[�H
�@�@-------------
���Ⴂ���Ă̂햳�������������ǁH
�Ƃ���ŁA�����Řb��ɂȂ���"fused multiply-add"���Ă̂햽�߂̘b����Ȃ��ĉ��Z���j�b�g��
�����̘b���B�c�q���m�X�S�����Ⴂ�����ĈВ����Ă�悤�ȋC���B�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1209908499/23-24
������ł�������������"fused"�̈Ӗ��ׂ邱�Ƃ������߂��邷�B
496 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 19:20:13 ID:QQwu9ZkE
pmaddwd��fused����Ȃ��炵��������������
497 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 19:21:42 ID:QQwu9ZkE
�܂������pmulhw/pmullw�Ɠ������C�e���V�E�X���[�v�b�g�Ŏ��s�ł���̂Ƀ}�N�����߂��������Ɗ��Ⴂ���Ă�̂��낤���H
>>492
> ���Ȃ݂�POWER6��SMT�Ɋւ��Ă�A���̌�̏��ŃO���[�v�����̒i�K�ňقȂ�X���b�h��
> ���߂�O���[�v�ɍ����ē����Ƃ���issue queue (=reservation station)���g�p���Ȃ��Ɠ���
> SMT�ƒm���Ă͂��߂Ĕ[���������B
�Ɠ�(�}��)
�����A����ς�܂�SMT�𗝉����Ă˂��悱����
������ƈ��S������
> ���Ȃ݂�POWER6��SMT�Ɋւ��Ă�A���̌�̏��ŃO���[�v�����̒i�K�ňقȂ�X���b�h��
> ���߂�O���[�v�ɍ����ē����Ƃ���issue queue (=reservation station)���g�p���Ȃ��Ɠ���
> SMT�ƒm���Ă͂��߂Ĕ[���������B
�Ɠ�(�}��)
�����A����ς�܂�SMT�𗝉����Ă˂��悱����
������ƈ��S������
499 �FMAC�I�^���c�q �����F2008/05/08(��) 19:36:06 ID:UrOM/xel
>>496
�������Z�Ɂw�ۂ߁x�햳������B
�������Z�Ɂw�ۂ߁x�햳������B
500 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 19:37:36 ID:QQwu9ZkE
�́HARM��FMA���������Z����
>>497
33 ���O�FMAC�I�^��30 ����[sage] ���e���F2008/05/06(��) 23:53:21 ID:VeL5EoZJ
>>30
�@�@------------------
�@�@PPC�͐Ϙa���߂����������ǃp�C�v���C�����ĂȂ���������
�@�@���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�@�@------------------
�p�C�v���C��������"fused" multiply-add���ᖳ���Ȃ邷���ǁB�B�B
�܂�PPC�햽�߃Z�b�g�ł����ē����A�[�L�e�N�`����K�肵�Ȃ�������A�ǂ�PowerPC�̂��Ƃ�
�����Ă���̂��m��Ȃ������ǁAG3�Ȃ�fadd�̃��C�e���V1�Afmadd�̃��C�e���V2���B
http://www.freescale.com/files/32bit/doc/ref_manual/MPC750UM.pdf (p.270�Q��)
33 ���O�FMAC�I�^��30 ����[sage] ���e���F2008/05/06(��) 23:53:21 ID:VeL5EoZJ
>>30
�@�@------------------
�@�@PPC�͐Ϙa���߂����������ǃp�C�v���C�����ĂȂ���������
�@�@���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�@�@------------------
�p�C�v���C��������"fused" multiply-add���ᖳ���Ȃ邷���ǁB�B�B
�܂�PPC�햽�߃Z�b�g�ł����ē����A�[�L�e�N�`����K�肵�Ȃ�������A�ǂ�PowerPC�̂��Ƃ�
�����Ă���̂��m��Ȃ������ǁAG3�Ȃ�fadd�̃��C�e���V1�Afmadd�̃��C�e���V2���B
http://www.freescale.com/files/32bit/doc/ref_manual/MPC750UM.pdf (p.270�Q��)
502 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 19:38:47 ID:QQwu9ZkE
>>23
�Ϙa���Z���j�b�g��x86�ȊO�Ȃ�ARM��g������PowerPC�ł����ڂ��Ă���̂ŁA�S�R�w��i�I�x
���ᖳ�����B
�EARM http://www.arm.com/products/CPUs/arch-simd.html
�@�@---------------------
�@�@ARMv6 SIMD Features:
�@�@�@[����]
�@�@�@- Dual 16x16 multiply-add/subtract
�@�@---------------------
�E�g������PowerPC http://www-306.ibm.com/chips/micronews/vol7_no4/mn_vol7_no4_fnl.pdf (p.27-29)
�@�@---------------------
�@�@Operation�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Cycle count latency/throughput
�@�@Floating (negative) multiply-add/subtract�@�@�@�@�@�@5/1
�@�@---------------------
ARMv6�̐������Z�ɂ͊ۂ߂�����炵���ȁB
�Ϙa���Z���j�b�g��x86�ȊO�Ȃ�ARM��g������PowerPC�ł����ڂ��Ă���̂ŁA�S�R�w��i�I�x
���ᖳ�����B
�EARM http://www.arm.com/products/CPUs/arch-simd.html
�@�@---------------------
�@�@ARMv6 SIMD Features:
�@�@�@[����]
�@�@�@- Dual 16x16 multiply-add/subtract
�@�@---------------------
�E�g������PowerPC http://www-306.ibm.com/chips/micronews/vol7_no4/mn_vol7_no4_fnl.pdf (p.27-29)
�@�@---------------------
�@�@Operation�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Cycle count latency/throughput
�@�@Floating (negative) multiply-add/subtract�@�@�@�@�@�@5/1
�@�@---------------------
ARMv6�̐������Z�ɂ͊ۂ߂�����炵���ȁB
503 �FMAC�I�^���c�q �����F2008/05/08(��) 19:42:34 ID:UrOM/xel
>>500
�@�@----------------
�@�@ARM��FMA���������Z����
�@�@----------------
NEON��P���x���������_���T�|�[�g���Ă��Ŋ��Ⴂ�������B
���̕ӂ̘bAMD������X���ŏ��������Ɍ������Ȃ������̂ŁA���łɃ\�[�X�����肢���邷�B
�@�@----------------
�@�@ARM��FMA���������Z����
�@�@----------------
NEON��P���x���������_���T�|�[�g���Ă��Ŋ��Ⴂ�������B
���̕ӂ̘bAMD������X���ŏ��������Ɍ������Ȃ������̂ŁA���łɃ\�[�X�����肢���邷�B
�������Z�Ƃ������A�Œ菬���_���Z�Ȃ�ۂ߂����邾���l
�܂��ARS���g��Ȃ��}�V����SMT��Ɠ��Ƃ��������܂����[���h�ł͊ۂ߂��s�v�Ȃ̂���
�܂��ARS���g��Ȃ��}�V����SMT��Ɠ��Ƃ��������܂����[���h�ł͊ۂ߂��s�v�Ȃ̂���
�܂�����ȊO�͕����Ă���Ǝv�����ǁA
SMT�Ƃ����̂̓f�B�X�p�b�`�X�e�[�W�̎�O�܂ł��X���b�h���ɗp�ӂ��āA����ȍ~�̎��s�n���X���b�h�Ԃŋ��L������̂ł�
�C���I�[�_�[�}�V����SMT�́A�Ⴆ�Γ�̃X���b�h�̐擪���߂���A���ꂼ����s�\�Ȗ��߂�(�\�Ȃ�)�����Ƀf�B�X�p�b�`���Ď��s���܂�
�A�E�g�I�u�I�[�_�[�}�V����SMT�́A��̃X���b�h�̐擪���߂��珇��RS�Ƀf�B�X�p�b�`���āA�C�V���[�X�e�[�W�Ŏ��s�\�Ȗ��߂��C�V���[���܂�
�ǂ�����X���b�h�̗D��x���Ǘ����郍�W�b�N�͕K�v�ł�
SMT�Ƃ����̂̓f�B�X�p�b�`�X�e�[�W�̎�O�܂ł��X���b�h���ɗp�ӂ��āA����ȍ~�̎��s�n���X���b�h�Ԃŋ��L������̂ł�
�C���I�[�_�[�}�V����SMT�́A�Ⴆ�Γ�̃X���b�h�̐擪���߂���A���ꂼ����s�\�Ȗ��߂�(�\�Ȃ�)�����Ƀf�B�X�p�b�`���Ď��s���܂�
�A�E�g�I�u�I�[�_�[�}�V����SMT�́A��̃X���b�h�̐擪���߂��珇��RS�Ƀf�B�X�p�b�`���āA�C�V���[�X�e�[�W�Ŏ��s�\�Ȗ��߂��C�V���[���܂�
�ǂ�����X���b�h�̗D��x���Ǘ����郍�W�b�N�͕K�v�ł�
506 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 19:54:47 ID:QQwu9ZkE
Cell��PPE�͂�����Symmetric-FGMT�����ǂ�
508 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 20:03:50 ID:QQwu9ZkE
SMT�́A�����̃X���b�h���狟�����ꂽ���߂�(�\�Ȃ�)�����Ɏ��s������̂������܂�
�Â�Denelcor HEP��CDC6600��PP��SMT�ł͂���܂���
������FGMT�ɕ��ނ����ł��傤
�Â�Denelcor HEP��CDC6600��PP��SMT�ł͂���܂���
������FGMT�ɕ��ނ����ł��傤
�������H
90nm��C7��30mm2������
�債�ď�������ł��Ȃ�
90nm��C7��30mm2������
�債�ď�������ł��Ȃ�
511 �FMAC�I�^��505 �����F2008/05/08(��) 22:37:06 ID:UrOM/xel
>>505
�V�����ڂ̋Z�p������A������g���f�����Ƃ܂Ō�����E�C�햳�������ǁACELL PPE��Atom��
FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
CELL PPE: http://www.research.ibm.com/journal/rd/515/chen2.gif
Atom: http://images.anandtech.com/reviews/cpu/intel/silverthorne/blockdiag.jpg
�ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
�V�����ڂ̋Z�p������A������g���f�����Ƃ܂Ō�����E�C�햳�������ǁACELL PPE��Atom��
FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
CELL PPE: http://www.research.ibm.com/journal/rd/515/chen2.gif
{kind=link}
Atom: http://images.anandtech.com/reviews/cpu/intel/silverthorne/blockdiag.jpg
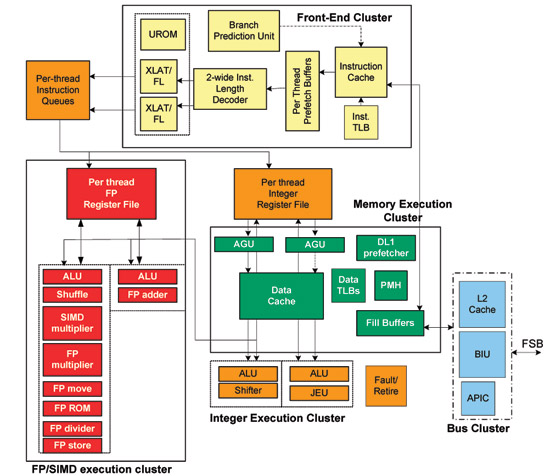{kind=link}
�ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
>>511
> CELL PPE��Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B (�}��)
> �ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
�����SMT���ƌ����Ă邾��
>>505
> SMT�Ƃ����̂̓f�B�X�p�b�`�X�e�[�W�̎�O�܂ł��X���b�h���ɗp�ӂ��āA����ȍ~�̎��s�n���X���b�h�Ԃŋ��L������̂ł�
�����̔]������������̂͊��ق��Ă�邯�ǁA���l�̔�����s�����Ȃ��ł����
���ނ�A�ȁH
> CELL PPE��Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B (�}��)
> �ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
�����SMT���ƌ����Ă邾��
>>505
> SMT�Ƃ����̂̓f�B�X�p�b�`�X�e�[�W�̎�O�܂ł��X���b�h���ɗp�ӂ��āA����ȍ~�̎��s�n���X���b�h�Ԃŋ��L������̂ł�
�����̔]������������̂͊��ق��Ă�邯�ǁA���l�̔�����s�����Ȃ��ł����
���ނ�A�ȁH
���ꂪFGMT����
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai_17.jpg
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai01_06l.gif
FGMT���Ă������ȁ[
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai_17.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai01_06l.gif
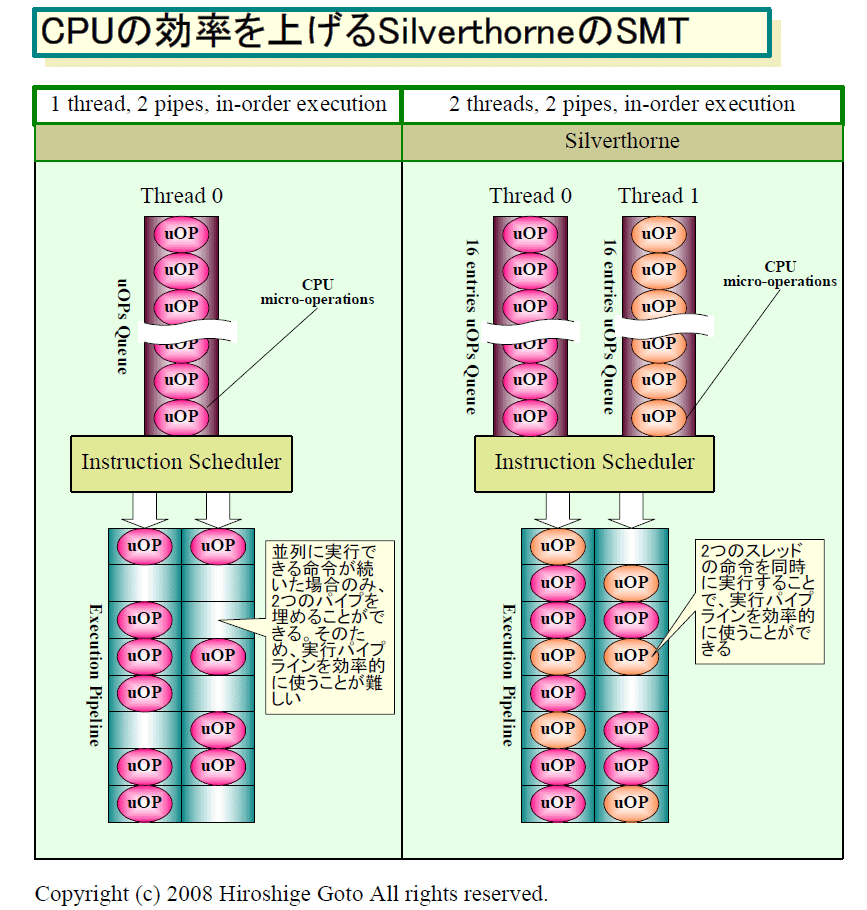{kind=link}
FGMT���Ă������ȁ[
514 �FMAC�I�^��512 �����F2008/05/08(��) 22:49:50 ID:UrOM/xel
>>512
�@�@-----------------
�@�@�����SMT���ƌ����Ă邾��
�@�@-----------------
�㓡���ɂł����[���𑗂��Ă݂�Ɨǂ����Ǝv�����B������Q�҂푽������(��)
http://pc.watch.impress.co.jp/docs/2005/0713/kaigai198.htm
�@�@=================
�@�@����ɑ��āAFine-Grained Multithreading�́A�����T�C�N���ɕ����X���b�h�̖��߂͓������s
�@�@�ł��Ȃ��B1�T�C�N���P�ʂŃX���b�h���ւ��Ď��s�ł���BCell�v���Z�b�T��PPE(Power
�@�@Processor Element)�Ȃǂ̃}���`�X���b�f�B���O�����̕������B
�@�@=================
�@�@-----------------
�@�@�����SMT���ƌ����Ă邾��
�@�@-----------------
�㓡���ɂł����[���𑗂��Ă݂�Ɨǂ����Ǝv�����B������Q�҂푽������(��)
http://pc.watch.impress.co.jp/docs/2005/0713/kaigai198.htm
�@�@=================
�@�@����ɑ��āAFine-Grained Multithreading�́A�����T�C�N���ɕ����X���b�h�̖��߂͓������s
�@�@�ł��Ȃ��B1�T�C�N���P�ʂŃX���b�h���ւ��Ď��s�ł���BCell�v���Z�b�T��PPE(Power
�@�@Processor Element)�Ȃǂ̃}���`�X���b�f�B���O�����̕������B
�@�@=================
516 �FMAC�I�^��515 �����F2008/05/08(��) 22:55:25 ID:UrOM/xel
>>515
�@�@-----------------
�@�@�����̌�����\�����Ă���旊�ނ�A�ق��
�@�@-----------------
�p��Ɉُ�ɂ������ƁA�L�`�K�C�S������݂����ɂȂ�B�B�B�Ƃ����̂�������(��)
�w�p��̂����������x�핅�ꃋ�[�}�[�f����w�W�Ƃ��Ė��ɗ������ǁB�B�B
�@�@-----------------
�@�@�����̌�����\�����Ă���旊�ނ�A�ق��
�@�@-----------------
�p��Ɉُ�ɂ������ƁA�L�`�K�C�S������݂����ɂȂ�B�B�B�Ƃ����̂�������(��)
�w�p��̂����������x�핅�ꃋ�[�}�[�f����w�W�Ƃ��Ė��ɗ������ǁB�B�B
MAC�I�^�͕��ꃋ�[�}�[�̕M���A�ƁB
>>512
������Ƃ܂Ă��̃N�\�{�P
PPE�̂ق���Cycle-alternating dual-instruction dispatch���ď����Ă邶��ˁ[��
���̉���Dual-instruction dependency checking�����邵�A
��ʓI�ȃC���I�[�_�[�v���Z�b�T�ł�Dual-instruction stall and issue�܂ł��f�B�X�p�b�`�X�e�[�W��������
���ꂪ�؋��ɂ����ŃX�g�[�����邶��ˁ[��
PPE��FGMT�����ASMT��Atom�Ƃ͑S�R�Ⴄ����˂���
���ɂ��������ĂȂ�����PPE��Atom��Ɍ������
������Ƃ܂Ă��̃N�\�{�P
PPE�̂ق���Cycle-alternating dual-instruction dispatch���ď����Ă邶��ˁ[��
���̉���Dual-instruction dependency checking�����邵�A
��ʓI�ȃC���I�[�_�[�v���Z�b�T�ł�Dual-instruction stall and issue�܂ł��f�B�X�p�b�`�X�e�[�W��������
���ꂪ�؋��ɂ����ŃX�g�[�����邶��ˁ[��
PPE��FGMT�����ASMT��Atom�Ƃ͑S�R�Ⴄ����˂���
���ɂ��������ĂȂ�����PPE��Atom��Ɍ������
Jim Smith�̘_����Reorder Buffer�Ƃ����p�ꂪ�o�Ă���̂��ǂ����������
ROB��x86�p�ꂶ��Ȃ��̂��ˁH
���O�̏h��͂����ς������A�������ƕЕt����
ROB��x86�p�ꂶ��Ȃ��̂��ˁH
���O�̏h��͂����ς������A�������ƕЕt����
�����ȑO��ATOM��FGMT���Ɗ��Ⴂ���Ă�
FGMT���Ȃ�Ȃ̂����������킩���ĂȂ��\�������邪
FGMT���Ȃ�Ȃ̂����������킩���ĂȂ��\�������邪
>>516
�p��ɂ������Ȃ�������̂��ǂ����Ǝv���̂�
POWER5��Global completion buffer�����v���Z�b�T��ROB�����i���Ƃ������Ƃ��A�F�߂Ă��ꂽ�̂��ǂ����A�Ԏ����~�����ł�����
�p��ɂ������Ȃ�������̂��ǂ����Ǝv���̂�
POWER5��Global completion buffer�����v���Z�b�T��ROB�����i���Ƃ������Ƃ��A�F�߂Ă��ꂽ�̂��ǂ����A�Ԏ����~�����ł�����
��掂����̃l�^�Ƃ��Ă�SMT���ދc�_��ʂɂ��āAIBM�̘_���ɂ�PPE��SMT�Ǝ咣���Ă���
���m�푶�݂��邷�B�m���ȑO�ɂ����p�������ƁB�B�B
http://www.research.ibm.com/journal/rd/494/kahle.html
�@�@----------------------
�@�@The processor provides two simultaneous threads of execution within the processor and can be
�@�@viewed as a two-way multiprocessor with shared dataflow.
�@�@----------------------
Intel��Atom��SMT�ƌ��̂��Ă��邵�A�p��Ƃ��č��ケ���炪�嗬�ɂȂ�\�����傫�����B
���m�푶�݂��邷�B�m���ȑO�ɂ����p�������ƁB�B�B
http://www.research.ibm.com/journal/rd/494/kahle.html
�@�@----------------------
�@�@The processor provides two simultaneous threads of execution within the processor and can be
�@�@viewed as a two-way multiprocessor with shared dataflow.
�@�@----------------------
Intel��Atom��SMT�ƌ��̂��Ă��邵�A�p��Ƃ��č��ケ���炪�嗬�ɂȂ�\�����傫�����B
FGMT���L�`��SMT�ƌď̂���̂͂܂����肾��
Atom��FGMT�ƌĂԂ̂͂��肦��
Atom��FGMT�ƌĂԂ̂͂��肦��
���ǁA���������Ɉ��p���邾���Ŏ����̓��ōl���邱�Ƃ͏o���Ȃ��Ƃ������Ƃ��B
>>522
���̘_��(�Ƃ��ɂ��̈��p����)��ǂ�ŁAIBM��PPE��SMT�Ǝ咣���Ă���Ɩ{�C�Ŏv���Ă���̂Ȃ�A����ς�]���X�����Ă���Ƃ����c
���̘_��(�Ƃ��ɂ��̈��p����)��ǂ�ŁAIBM��PPE��SMT�Ǝ咣���Ă���Ɩ{�C�Ŏv���Ă���̂Ȃ�A����ς�]���X�����Ă���Ƃ����c
�ʂɗ�������K�v����Ȃ��Ǝv���̂���
Atom��FGMT�ł͂Ȃ���FGMT�Ƃ͒N���Ă�ł��Ȃ��̂�����
Atom��FGMT�ł͂Ȃ���FGMT�Ƃ͒N���Ă�ł��Ȃ��̂�����
�܂�����`���ɂ܂���y�[�W
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
>>525
MAC�I�^�������Ă���̂�IBM��PPE���uSMT�ƌď̂��Ă���v����
MAC�I�^�������Ă���̂�IBM��PPE���uSMT�ƌď̂��Ă���v����
��ʓI�ɂ́AFGMT�́A1�T�C�N���Ȃ������T�C�N�����ɖ��߂���������X���b�h���ւ���^�C�v�̂��̂������܂�
�����X���b�h����u�����Ɂv���߂̋������ł��Ȃ��̂�SMT�Ƃ̈Ⴂ�ł�
�Ȃ̂ŁA>>511��PPE�̃u���b�N�}���猩�邩����APPE��FGMT�ł����āASMT�ł͂���܂���
�O��͕s�]�������̂ŁA�܂����܂��ʔ������Ƃ������܂ň������݂܂�
�����X���b�h����u�����Ɂv���߂̋������ł��Ȃ��̂�SMT�Ƃ̈Ⴂ�ł�
�Ȃ̂ŁA>>511��PPE�̃u���b�N�}���猩�邩����APPE��FGMT�ł����āASMT�ł͂���܂���
�O��͕s�]�������̂ŁA�܂����܂��ʔ������Ƃ������܂ň������݂܂�
>>528
�ǂ����ɂ���AIBM��PPE��SMT�ƍl���ĂȂ��ł��傤
SMT�Ȃ炱���Ȃ�͂�
The processor provides two threads of *simultaneous execution* within the processor and...
�ǂ����ɂ���AIBM��PPE��SMT�ƍl���ĂȂ��ł��傤
SMT�Ȃ炱���Ȃ�͂�
The processor provides two threads of *simultaneous execution* within the processor and...
>>529
>��ʓI�ɂ́AFGMT�́A1�T�C�N���Ȃ������T�C�N�����ɖ��߂���������X���b�h���ւ���^�C�v�̂��̂������܂�
MAC�I�^�̒�`����FGMT�͂����ł͂Ȃ��悤�Ȃ̂ł���������b���������܂���
>��ʓI�ɂ́AFGMT�́A1�T�C�N���Ȃ������T�C�N�����ɖ��߂���������X���b�h���ւ���^�C�v�̂��̂������܂�
MAC�I�^�̒�`����FGMT�͂����ł͂Ȃ��悤�Ȃ̂ł���������b���������܂���
>>531
������
�܂��������܂Ńo�J���Ƃ͎v���܂���ł���
>>530�̕⑫
�܂��̈��p���́A�v���Z�b�T�͓�̃X���b�h��������ɕ����Ă���A���炢�̈Ӗ��ł�
�����Ɏ��s����Ƃ͏����Ă��Ȃ�
���܂�
Coarse Grain MT�́A�L���b�V���~�X�Ȃǂ̃C�x���g���N�����ꍇ�ɃX���b�h�X�C�b�`�����܂�
�C�x���g���N���Ă��瑼�X���b�h�̃t�F�b�`���n�߂�̂Ńo�u�����������܂�
������
�܂��������܂Ńo�J���Ƃ͎v���܂���ł���
>>530�̕⑫
�܂��̈��p���́A�v���Z�b�T�͓�̃X���b�h��������ɕ����Ă���A���炢�̈Ӗ��ł�
�����Ɏ��s����Ƃ͏����Ă��Ȃ�
���܂�
Coarse Grain MT�́A�L���b�V���~�X�Ȃǂ̃C�x���g���N�����ꍇ�ɃX���b�h�X�C�b�`�����܂�
�C�x���g���N���Ă��瑼�X���b�h�̃t�F�b�`���n�߂�̂Ńo�u�����������܂�
�]�k
�o�b�N�G���h��OoO���ƁA�t�����g�G���h�̍\���ɂ�����炸�A�����X���b�h�̖��߂��Ɏ��s���Ă��܂�
����ł͕��ނƂ��Ă͓s��������
����Ń��_���ȕ��ނł́A�t�����g�G���h�̍\���ɂ���ĕ��ނ���悤�ɂȂ�܂���
�o�b�N�G���h��OoO���ƁA�t�����g�G���h�̍\���ɂ�����炸�A�����X���b�h�̖��߂��Ɏ��s���Ă��܂�
����ł͕��ނƂ��Ă͓s��������
����Ń��_���ȕ��ނł́A�t�����g�G���h�̍\���ɂ���ĕ��ނ���悤�ɂȂ�܂���
>>508
Atom�R�A�̉ł���̓����r�[�Ɍ��܂��Ă܂��̂ł��S�z�Ȃ��B
Atom�R�A�̉ł���̓����r�[�Ɍ��܂��Ă܂��̂ł��S�z�Ȃ��B
�ҋ@���̏���d�͂��[�����I
���[�������E�ŏ��߂ĕs�������W�b�N�Z�p���J��
http://www.rohm.co.jp/news/080508a.html
> ���[���́A����̋��U�d�̂ɂ��s�������W�b�N�Z�p�����p�����J�X�^��LSI�ɂ���
> ���q�l�ւ̒�Ċ�����i�߁A1�N���ڕW�ɗʎY�����߂��������ƍl���Ă��܂��B
���[�������E�ŏ��߂ĕs�������W�b�N�Z�p���J��
http://www.rohm.co.jp/news/080508a.html
> ���[���́A����̋��U�d�̂ɂ��s�������W�b�N�Z�p�����p�����J�X�^��LSI�ɂ���
> ���q�l�ւ̒�Ċ�����i�߁A1�N���ڕW�ɗʎY�����߂��������ƍl���Ă��܂��B
���͂悤�������܂�
�܂������^�ɂ�����lj�
New! �E�������Z�Ɂw�ۂ߁x�햳������B (�Œ菬���_����m��Ȃ��I)
.>>499
>
>>504
> �������Z�Ƃ������A�Œ菬���_���Z�Ȃ�ۂ߂����邾���l
����ɂ������Ăق�������
>>465
> ���j�I�o�܂�ʂɂ��āA�Ⴆ��TLB��L2�L���b�V���Ƃ����p������Ђ̃}�j���A���Ŏg�p���Ȃ��v��
> �Z�b�T�x���_��F���ƌ����ėǂ������ǁA�Ǖ��ɂ���ROB�Ƃ����ď̂��g���Ă���̂�x86�x���_������
> �����B
ROB��TLB��L���b�V���Ɠ������炢�Ɉ�ʓI�ȗp��ŁAHP���x�m�ʂ����Ђ̃v���Z�b�T�Ŏg�p���Ă��邵�A
�A�J�f�~�b�N�Ș_���ł��AP6�o��͂邩�ȑO���炲�����R�Ɏg���Ă���
�Ƃ����̂��펯�l�̎咣�ł����A
(IBM�̓��������X�g���[�W�ƌĂт�����悤�ȉ�ЂȂ̂ŁA��O���̗�O�ƌ����Ă悢����)
>>516
> �p��Ɉُ�ɂ������ƁA�L�`�K�C�S������݂����ɂȂ�B�B�B�Ƃ����̂�������(��)
��������ROB��x86�p�ꂾ�Ɠ�Ȃ������܂����A�p��Ɉُ�ɂ���������������l�҂��Ƃ����̂����̃X���S���̋��ʌ����ł���
����͂Ƃ������AROB��x86�p�ꂾ�Ƃ������ʗp��͉��ɂȂ�̂��ȁH
IBM�p��ł͉��ɂȂ�̂��ȁH
���������ˁH
�܂������^�ɂ�����lj�
New! �E�������Z�Ɂw�ۂ߁x�햳������B (�Œ菬���_����m��Ȃ��I)
.>>499
>
>>504
> �������Z�Ƃ������A�Œ菬���_���Z�Ȃ�ۂ߂����邾���l
����ɂ������Ăق�������
>>465
> ���j�I�o�܂�ʂɂ��āA�Ⴆ��TLB��L2�L���b�V���Ƃ����p������Ђ̃}�j���A���Ŏg�p���Ȃ��v��
> �Z�b�T�x���_��F���ƌ����ėǂ������ǁA�Ǖ��ɂ���ROB�Ƃ����ď̂��g���Ă���̂�x86�x���_������
> �����B
ROB��TLB��L���b�V���Ɠ������炢�Ɉ�ʓI�ȗp��ŁAHP���x�m�ʂ����Ђ̃v���Z�b�T�Ŏg�p���Ă��邵�A
�A�J�f�~�b�N�Ș_���ł��AP6�o��͂邩�ȑO���炲�����R�Ɏg���Ă���
�Ƃ����̂��펯�l�̎咣�ł����A
(IBM�̓��������X�g���[�W�ƌĂт�����悤�ȉ�ЂȂ̂ŁA��O���̗�O�ƌ����Ă悢����)
>>516
> �p��Ɉُ�ɂ������ƁA�L�`�K�C�S������݂����ɂȂ�B�B�B�Ƃ����̂�������(��)
��������ROB��x86�p�ꂾ�Ɠ�Ȃ������܂����A�p��Ɉُ�ɂ���������������l�҂��Ƃ����̂����̃X���S���̋��ʌ����ł���
����͂Ƃ������AROB��x86�p�ꂾ�Ƃ������ʗp��͉��ɂȂ�̂��ȁH
IBM�p��ł͉��ɂȂ�̂��ȁH
���������ˁH
> �p��Ɉُ�ɂ������ƁA�L�`�K�C�S������݂����ɂȂ�B�B�B�Ƃ����̂�������(��)
�m���ɂ܂�����ƌ����A������Ƃ����p��̎g������
���X�ɗg������肵�܂�����l�҂��Ɖ����F�����Ă�w
�m���ɂ܂�����ƌ����A������Ƃ����p��̎g������
���X�ɗg������肵�܂�����l�҂��Ɖ����F�����Ă�w
538 �F,,�E�L�́M�E,,�j��-�������F2008/05/09(��) 19:24:25 ID:/IFgkn/u
�Œ菬�����Č����������ɂ���ʌ������߂���̂ɂ͊ۂ߂͑��݂���
��Fpmulhsw/pmulhrsw
��Fpmulhsw/pmulhrsw
���[�A����ł܂���������MAC�I�^�̗E�p�����邱�Ƃ͏o����ȁB
���������ŋ߂ɂȂ��ĕ������Ă����̂ɁB
���������ŋ߂ɂȂ��ĕ������Ă����̂ɁB
�܂�����͖łт��A���x�����đh�邳
�ċx�ɂ܂ŕK����wikipedia�ׂĂ܂��̂ŁA�������
>>540
����Ȃ���?�@���˂�
����Ȃ���?�@���˂�
�o���X�I
��w�Ҙ_�ɕ�����
>>348��SpursEngine����PC�o�����
ttp://gigazine.net/index.php?/news/comments/20080512_cell_qosmio_g40/
ttp://gigazine.net/index.php?/news/comments/20080512_cell_qosmio_g40/
NEC�A�u�n���V�~�����[�^�����V�X�e���v���J��
http://pc.watch.impress.co.jp/docs/2008/0512/nec.htm
http://pc.watch.impress.co.jp/docs/2008/0512/nec.htm
547 �F,,�E�L�́M�E,,�j��-�������F2008/05/12(��) 22:57:40 ID:9L/NVF09
>>545
�܂�Cell�v���O���~���O��肽���Ȃ�PS3 40GB�����������������ǂ�
�܂�Cell�v���O���~���O��肽���Ȃ�PS3 40GB�����������������ǂ�
Cell�v���O���~���O����H.264�G���R�[�_/�f�R�[�_�M��̕����ʔ���������ˁH
���[�U�[�v���O��������G���悤�ɂȂ��Ă�̂��킩��ǁA
�G�ꂽ��Cell�ƍ��킹�ăt��HD��������A���^�C���ʼn�͂�����F��������
3D���f�����č\��������AR������etc.�o������
���[�U�[�v���O��������G���悤�ɂȂ��Ă�̂��킩��ǁA
�G�ꂽ��Cell�ƍ��킹�ăt��HD��������A���^�C���ʼn�͂�����F��������
3D���f�����č\��������AR������etc.�o������
�@ ,j;;;;;j,. ---�� �M �@�\--�]�_ l;;;;;; �@�@ ���͂�PC���������
�@�o;;;;;;�T T�i� i �@ �@f'�j�@�@ !i;;;;;�@�@ �������������ł��ł���
�@ �S;;;ʁ@�@�@�@Ɂ@�@�@�@�@�@�@.::!l�;;r�
�@�@ `Z;i�@�@�@�q.,_..,.�@�@�@�@�@�@�;;;;;;;;>
�@ �@,;��ʁA�@�_,.�-�_',. �@ �@,���: Y;;f �@�@ ����Ȃӂ��ɍl���Ă���������
�@�@ ~''���R �@ �M��L �@�@ r'�L:::.�@`!�@�@�@���ɂ�����܂���
�@�o;;;;;;�T T�i� i �@ �@f'�j�@�@ !i;;;;;�@�@ �������������ł��ł���
�@ �S;;;ʁ@�@�@�@Ɂ@�@�@�@�@�@�@.::!l�;;r�
�@�@ `Z;i�@�@�@�q.,_..,.�@�@�@�@�@�@�;;;;;;;;>
�@ �@,;��ʁA�@�_,.�-�_',. �@ �@,���: Y;;f �@�@ ����Ȃӂ��ɍl���Ă���������
�@�@ ~''���R �@ �M��L �@�@ r'�L:::.�@`!�@�@�@���ɂ�����܂���
���s�Ȃ̂��ȁH���x�͊g���{���x�Ή���Cell�������ȁB
ttp://pc.watch.impress.co.jp/docs/2008/0514/ibm.htm
ttp://pc.watch.impress.co.jp/docs/2008/0514/ibm.htm
551 �FMAC�I�^��550 �����F2008/05/14(��) 22:17:05 ID:P5vaqc22
>>550
Road Runner�Ɏg��CELL�u���[�h�T�[�o�[�Ȃ�ŁA���i���܂Ŋ܂߂ĈȑO����m���Ă������m���B
http://www.lanl.gov/orgs/hpc/roadrunner/rrinfo/RR%20webPDFs/Roadrunner%20System%20Overview%20Oct%2017,%202007%20(LAUR).pdf
Road Runner�Ɏg��CELL�u���[�h�T�[�o�[�Ȃ�ŁA���i���܂Ŋ܂߂ĈȑO����m���Ă������m���B
http://www.lanl.gov/orgs/hpc/roadrunner/rrinfo/RR%20webPDFs/Roadrunner%20System%20Overview%20Oct%2017,%202007%20(LAUR).pdf
552 �F,,�E�L�́M�E,,�j��-�������F2008/05/14(��) 22:19:53 ID:oBjLiF0C
����Enhanced Broadband Engine�������������B
FPU�͒P���x�Ϙa�~4��p�ŁA�{���x���}�N�����߂݂����Ȍ`�Ŏ������Ă��̂�{���x�Ϙa�~2���ŏ����ł���悤�ɂ�������
FPU�͒P���x�Ϙa�~4��p�ŁA�{���x���}�N�����߂݂����Ȍ`�Ŏ������Ă��̂�{���x�Ϙa�~2���ŏ����ł���悤�ɂ�������
���ŏ��\�����i��138��6,000�~�B
�@�@( ߄t� )
�@�@( ߄t� )
�܂��AMacIIfx���炢�̒l�i���Ă��Ƃ�
RoadRunner�͏����ɐi��ł���݂������ˁB
���E�ŏ���1PFLOS�X�p�R��CPU��CELL�������Ȃ̂��ȁB
���E�ŏ���1PFLOS�X�p�R��CPU��CELL�������Ȃ̂��ȁB
�f���A���v���Z�b�T�ł܂��ɍő��I Skulltrail�v���b�g�t�H�[�����ڃ��f���z
�p�[�\�i���R���s���[�^�Ƃ��Ă͕����ʂ�ō��A�ő��\���ƌĂׂ鎊���̈�i�B
�Ɍ��܂Ő��\��Njy���������ɂ������߂̃G�N�X�g���[���E�n�C�G���hPC�ł��B
��Prime Galleria XS -Skulltrail- ���^�C�v �y�ō��z \399,800
��Prime Galleria XS -Skulltrail- ���^�C�v �y�ō��z\1,339,800
http://djmail.dospara.co.jp/tr/56cz4x6915907119
�p�[�\�i���R���s���[�^�Ƃ��Ă͕����ʂ�ō��A�ő��\���ƌĂׂ鎊���̈�i�B
�Ɍ��܂Ő��\��Njy���������ɂ������߂̃G�N�X�g���[���E�n�C�G���hPC�ł��B
��Prime Galleria XS -Skulltrail- ���^�C�v �y�ō��z \399,800
��Prime Galleria XS -Skulltrail- ���^�C�v �y�ō��z\1,339,800
http://djmail.dospara.co.jp/tr/56cz4x6915907119
>>552
���̉��ǂł����[�J����������512KB�ňꏏ�݂��������APS4�p����Ȃ���PS3�U�p�������
�����������Ď����ȁH
�{���x�Ȃ�ĕ��ʂ̃Q�[���ł͖w�ǎg���ĂȂ����낤����A���x�A�b�v�ɂ��݊�����
�����A�w�ǖ������낤���B
���̉��ǂł����[�J����������512KB�ňꏏ�݂��������APS4�p����Ȃ���PS3�U�p�������
�����������Ď����ȁH
�{���x�Ȃ�ĕ��ʂ̃Q�[���ł͖w�ǎg���ĂȂ����낤����A���x�A�b�v�ɂ��݊�����
�����A�w�ǖ������낤���B
CELL��256k�̃L���b�V���ɋ��L��8MLS���������������
�g�����W�X�^��8�������邯��65�i�m�O��Ȃ�\������
�g�����W�X�^��8�������邯��65�i�m�O��Ȃ�\������
560 �F,,�E�L�́M�E,,�j��-�������F2008/05/17(�y) 07:32:06 ID:eL4VBrau
Power �~ Cell �Ƃ����Ă�낤��
PPE��OoO��Power�R�A�ɒu��������Ă��肷��̂��H
PPE��OoO��Power�R�A�ɒu��������Ă��肷��̂��H
561 �FMAC�I�^���c�q �����F2008/05/17(�y) 10:50:02 ID:tl5HJ+lJ
>>560
CELL BE�Ɋւ��Ă�A������`�b�v�̖��O�����J����Ă��邷�B
����SPE x 32 + PPE x 2��"PowerXCell 32ii"���ˁB
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/ibm.pdf
������\�t�g�I�Ȍ݊����ێ��̂��߂ɃR�A�𑝂₵�����邾�����ƁB�B�B
���ꂪCELL�̃R���Z�v�g�ł����邷�B
CELL BE�Ɋւ��Ă�A������`�b�v�̖��O�����J����Ă��邷�B
����SPE x 32 + PPE x 2��"PowerXCell 32ii"���ˁB
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/ibm.pdf
������\�t�g�I�Ȍ݊����ێ��̂��߂ɃR�A�𑝂₵�����邾�����ƁB�B�B
���ꂪCELL�̃R���Z�v�g�ł����邷�B
527 ���O�FSocket774[sage] ���e���F2008/05/08(��) 23:18:13 ID:+V0bLI1h
�܂�����`���ɂ܂���y�[�W
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
����or���_�܂��[�H
�܂�����`���ɂ܂���y�[�W
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
����or���_�܂��[�H
VIA�̎���������pDigitimes���`���Ă��邷�B
�����L�����L���T�C�g�Ɉڂ����Ƃ���Ȃ̂ŁA�O���]�ڂ��Ă������B
http://www.digitimes.com/mobos/a20080515PD214.html
�@�@----------------------
�@�@�wVIA to adopt 45nm process and launch dual-core CPU by the end of 2009�x
�@�@ Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 15 May 2008]
�@�@Taiwan-based VIA Technologies is planning to adopt a 45nm process for the manufacture of
�@�@its processors, and expects to launch dual-core CPUs by the end of 2009, according to sources
�@�@at the company.
�@�@VIA has also revealed more details of its initial-launch Isaiah-based processor, which will
�@�@feature a core frequency of 2GHz, a V4 Bus speed from 800-1333MHz, and two 64KB L1
�@�@cache and 1MB L2 cache pairs with 16-way associatively. The CPU will be manufactured
�@�@by Fujitsu adopting a 65nm process. The CPU is pin compatible with the company's C7
�@�@processors.
�@�@VIA has forecast CPU shipments in 2008 to double or even triple on year, with shipments in
�@�@the first half of 2008 to equal total shipments in 2007.
�@�@----------------------
�ȑO�̃����[�X�ł�"Twin-core"�ƌĂ�MCM���J�����Ă���VIA�����ǁA�ϋɓI��45nm�v���Z�X��
�O�i����Ƃ���ƁA�l�C�e�B�u�}���`�R�A���J�����Ȃ̂�������Ȃ����B
�����L�����L���T�C�g�Ɉڂ����Ƃ���Ȃ̂ŁA�O���]�ڂ��Ă������B
http://www.digitimes.com/mobos/a20080515PD214.html
�@�@----------------------
�@�@�wVIA to adopt 45nm process and launch dual-core CPU by the end of 2009�x
�@�@ Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 15 May 2008]
�@�@Taiwan-based VIA Technologies is planning to adopt a 45nm process for the manufacture of
�@�@its processors, and expects to launch dual-core CPUs by the end of 2009, according to sources
�@�@at the company.
�@�@VIA has also revealed more details of its initial-launch Isaiah-based processor, which will
�@�@feature a core frequency of 2GHz, a V4 Bus speed from 800-1333MHz, and two 64KB L1
�@�@cache and 1MB L2 cache pairs with 16-way associatively. The CPU will be manufactured
�@�@by Fujitsu adopting a 65nm process. The CPU is pin compatible with the company's C7
�@�@processors.
�@�@VIA has forecast CPU shipments in 2008 to double or even triple on year, with shipments in
�@�@the first half of 2008 to equal total shipments in 2007.
�@�@----------------------
�ȑO�̃����[�X�ł�"Twin-core"�ƌĂ�MCM���J�����Ă���VIA�����ǁA�ϋɓI��45nm�v���Z�X��
�O�i����Ƃ���ƁA�l�C�e�B�u�}���`�R�A���J�����Ȃ̂�������Ȃ����B
564 �FMAC�I�^��562 �����F2008/05/17(�y) 11:00:43 ID:tl5HJ+lJ
���܂��܃q�}�Ȃ̂��ATheINQ��Charlie "Groo" Demerjian��RealWorldTech�f���ɐF�X
�ʔ����b�������Ă��邷�B
���̃X���b�h�W�ł�A���̃e�[�}���ʔ����Ǝv���̂�Groo�̏������݂����ł����o���ēǂ��
�݂�Ɨǂ����Ǝv�����B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=90000&threadid=90000&roomid=2
�@�EGPGPU�펀��ł���
�@�E��v�Q�[���R���\�[���x���_�͎�����̃R���Z�v�g�����Ɍ��肵�Ă���B
�@�@- Sony��PS4�̎d�l����N���Ɍ����
�@�@- CPU, GPU���̎�v���i�ɂ킻�ꂼ��5�̑I����������炵���B
�@�@�@CPU: AMD, Intel, IBM, Sony, Freescale, TI, Sun, (+ ��̃x���`���[���)
�@�@�@GPU: AMD, Nvidia, IBM, S3, PowerVR, XGI, Matrox, Intel, (+ ��̃x���`���[���)
�ʔ����b�������Ă��邷�B
���̃X���b�h�W�ł�A���̃e�[�}���ʔ����Ǝv���̂�Groo�̏������݂����ł����o���ēǂ��
�݂�Ɨǂ����Ǝv�����B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=90000&threadid=90000&roomid=2
�@�EGPGPU�펀��ł���
�@�E��v�Q�[���R���\�[���x���_�͎�����̃R���Z�v�g�����Ɍ��肵�Ă���B
�@�@- Sony��PS4�̎d�l����N���Ɍ����
�@�@- CPU, GPU���̎�v���i�ɂ킻�ꂼ��5�̑I����������炵���B
�@�@�@CPU: AMD, Intel, IBM, Sony, Freescale, TI, Sun, (+ ��̃x���`���[���)
�@�@�@GPU: AMD, Nvidia, IBM, S3, PowerVR, XGI, Matrox, Intel, (+ ��̃x���`���[���)
>>564
�ց[�A4�̂����ǂꂪ�����łǂꂪ�R�Ȃ̂������Ă��炢�����ˁB
�ց[�A4�̂����ǂꂪ�����łǂꂪ�R�Ȃ̂������Ă��炢�����ˁB
567 �FMAC�I�^��566 �����F2008/05/17(�y) 11:35:30 ID:tl5HJ+lJ
>>566
���Ȃ��Ƃ�1�Ԗڂ�2�Ԗڂ�_���I�ɂ��������Ă��邩�Ǝv�����B
ROB��x86�p�ꂾ����w�����x�̋@�\�ɕʂ̃l�[�~���O���g�p�������B�B�B
���Ȃ��Ƃ�1�Ԗڂ�2�Ԗڂ�_���I�ɂ��������Ă��邩�Ǝv�����B
ROB��x86�p�ꂾ����w�����x�̋@�\�ɕʂ̃l�[�~���O���g�p�������B�B�B
MAC�I�^���Ă܂�ROB��x86�p�ꂾ���Č�������c�B
���̃X�����ςĂ�����ƁE�����҂������Ƃ�����
������Ă���Ǝv������قǂقǂɂ��Ē��������ق����������B
���̃X�����ςĂ�����ƁE�����҂������Ƃ�����
������Ă���Ǝv������قǂقǂɂ��Ē��������ق����������B
>Atom��FGMT
����͂����炩�ɊԈႢ�Ȃ��炳�����ƒ��������
����͂����炩�ɊԈႢ�Ȃ��炳�����ƒ��������
>>567
����A���@�I�ɂ��ʂɖ������ĂȂ��ł���B
ROB��x86�p��ł��낤�ƈ�ʗp��ł��낤�ƁAGCT�Ƃ����ʂ̃l�[�~���O���g�p���邱�Ƃɖ�肪����Ƃ͎v����B
�P�Ȃ錾�����������B
�����MAC�I�^�͋@�\�I��
ROB��GCT
�ƑO�X���Ō����Ă���ł���H
��������A������������(����Ȃ��Ǝv������)���w�E�͏o���Ȃ���B
�����w�E����Ȃ�O����P�Ȃ��ƂˁB
(ROB��GCT���ʋ@�\�Ȃ�ʂ̃l�[�~���O���g�p����͓̂�����O�Ƃ������Ƃ�)
����A���@�I�ɂ��ʂɖ������ĂȂ��ł���B
ROB��x86�p��ł��낤�ƈ�ʗp��ł��낤�ƁAGCT�Ƃ����ʂ̃l�[�~���O���g�p���邱�Ƃɖ�肪����Ƃ͎v����B
�P�Ȃ錾�����������B
�����MAC�I�^�͋@�\�I��
ROB��GCT
�ƑO�X���Ō����Ă���ł���H
��������A������������(����Ȃ��Ǝv������)���w�E�͏o���Ȃ���B
�����w�E����Ȃ�O����P�Ȃ��ƂˁB
(ROB��GCT���ʋ@�\�Ȃ�ʂ̃l�[�~���O���g�p����͓̂�����O�Ƃ������Ƃ�)
Out Of Order���s�͊e�A�[�L�e�N�`���Ŏ������܂��܂�������A
�ď̂����[�J�[�Ǝ��̂��̂������̂͊m���B
�����AROB��x86�p��Ƃ����͖̂��炩�ȊԈႢ�B
���ʂ�Intel�Ƃ͂Ȃ��W�̂Ȃ��_���ł��g���Ă��邵�A
���Ƃ��Ƃ͑�^�R���s���[�^���ʂ̌������琶�܂ꂽ���̂��B
�v��MAC�I�^��OOO���悭�������Ă��Ȃ����Ă����B
�����炱��Ȗό������܂��B
�p��̒�`�������g���ɂ����Ɨ������悤�B
�ď̂����[�J�[�Ǝ��̂��̂������̂͊m���B
�����AROB��x86�p��Ƃ����͖̂��炩�ȊԈႢ�B
���ʂ�Intel�Ƃ͂Ȃ��W�̂Ȃ��_���ł��g���Ă��邵�A
���Ƃ��Ƃ͑�^�R���s���[�^���ʂ̌������琶�܂ꂽ���̂��B
�v��MAC�I�^��OOO���悭�������Ă��Ȃ����Ă����B
�����炱��Ȗό������܂��B
�p��̒�`�������g���ɂ����Ɨ������悤�B
>�v��MAC�I�^��OOO���悭�������Ă��Ȃ����Ă����B
�W�Ȃ��ȁB
�v��MAC�I�^���l�̎w�E�ɂ܂���������݂��Ȃ��L�`�K�C���Ă������B
�W�Ȃ��ȁB
�v��MAC�I�^���l�̎w�E�ɂ܂���������݂��Ȃ��L�`�K�C���Ă������B
����A�l�̎w�E�Ɏ���݂��Ȃ����Ă̂����邪�AOOO�̗����͊W����Ǝv����`�B
OOO�̓�����ڂ����m�낤�ƒ��ׂĂ����A
Reorder Buffer�Ƃ������t�ɂ͕��ʑ�������B������x86�p�ꂾ�Ȃ�Ĕ��z�͏o�Ă��Ȃ��B
�e�Ђ�Reorder Buffer�ɑ�������@�\���Ȃ�ƌĂ�ł��邩���킩��悤�ɂȂ�B
��ɗp�ꂩ����邩�炱��Ȃ��ƂɂȂ�B
OOO�̓�����ڂ����m�낤�ƒ��ׂĂ����A
Reorder Buffer�Ƃ������t�ɂ͕��ʑ�������B������x86�p�ꂾ�Ȃ�Ĕ��z�͏o�Ă��Ȃ��B
�e�Ђ�Reorder Buffer�ɑ�������@�\���Ȃ�ƌĂ�ł��邩���킩��悤�ɂȂ�B
��ɗp�ꂩ����邩�炱��Ȃ��ƂɂȂ�B
>>573
�W�Ȃ��B
�ǂ������ǂ�ł������ɓs���̂��������ȊO�̓i�`�������ɓǂݔ����B
�l�̎w�E�ɂ܂���������݂��Ȃ��̂��������ƁB
�W�Ȃ��B
�ǂ������ǂ�ł������ɓs���̂��������ȊO�̓i�`�������ɓǂݔ����B
�l�̎w�E�ɂ܂���������݂��Ȃ��̂��������ƁB
575 �FMAC�I�^�F2008/05/17(�y) 17:59:55 ID:tl5HJ+lJ
�C�����Ƃ��̃X���b�h���݂����Ȃ�ŁA�v���Ԃ��age�Ă������B
�����̈�����Ύ��́u�ŋ߂̘b��v�ł�QS22 & Roadrunner�̘b������グ�Ă��邷�B
http://www.geocities.jp/andosprocinfo/wadai08/20080517.htm
�����l�^�{���Â��悤�ŁA��Ԉ���Ă��镔����������̂ŕ⑫���Ă������B
�@�@----------------------
�@�@IBM�͂���CELL�v���Z�T��PowerXCell 8i�Ɩ��Â��Ă��܂��B����PowerPoint��Excel��A�z����
�@�@MicroSoft���當�傪�������ł����CTM�}�[�N�����Ă��܂��B"8"��8�R�A�ł��傤���C"i"��
�@�@���ł��傤�ˁB
�@�@----------------------
�����A���̖�����c�q����́wPower �~ Cell �Ƃ����Ă�낤�� �x(>>560)�����肾�Ǝv���邷�B
������ƂȂ�"PowerXCell 32ii"(>>562)�̖��O���猩�Ă�������SPE�̐��Ai�̐���PPE�̐��Ƃ���
���j�̗l���B
�@�@----------------------
�@�@Road Runner�Ɋւ��ẮC2006�N9��9���̘b��ŏЉ�Ă��܂����C���X�A�����X��������Web
�@�@�Ɏ��������J����Ă��܂��B����ɂ��ƁCLS21�@1.8GHz�f���A���R�AOpteron x2 �u���[�h��2��
�@�@��QS22�u���[�h��InfiniBabd�Œ������ꂽ���̂��v�Z�m�[�h
�@�@----------------------
�ŐV�̎����킱�ꂷ�Bhttp://www.lanl.gov/orgs/hpc/roadrunner/pdfs/Roadrunner-tutorial-session-1-web1.pdf
Opteron�u���[�h(LS21)��CELL�u���[�h(QS22)�Ԃ̃C���^�R�l�N�g��Infiniband�ł햳���APCIe��
���ڎg���Ă��邷�B(p.8�Ȃ�)
�����̈�����Ύ��́u�ŋ߂̘b��v�ł�QS22 & Roadrunner�̘b������グ�Ă��邷�B
http://www.geocities.jp/andosprocinfo/wadai08/20080517.htm
�����l�^�{���Â��悤�ŁA��Ԉ���Ă��镔����������̂ŕ⑫���Ă������B
�@�@----------------------
�@�@IBM�͂���CELL�v���Z�T��PowerXCell 8i�Ɩ��Â��Ă��܂��B����PowerPoint��Excel��A�z����
�@�@MicroSoft���當�傪�������ł����CTM�}�[�N�����Ă��܂��B"8"��8�R�A�ł��傤���C"i"��
�@�@���ł��傤�ˁB
�@�@----------------------
�����A���̖�����c�q����́wPower �~ Cell �Ƃ����Ă�낤�� �x(>>560)�����肾�Ǝv���邷�B
������ƂȂ�"PowerXCell 32ii"(>>562)�̖��O���猩�Ă�������SPE�̐��Ai�̐���PPE�̐��Ƃ���
���j�̗l���B
�@�@----------------------
�@�@Road Runner�Ɋւ��ẮC2006�N9��9���̘b��ŏЉ�Ă��܂����C���X�A�����X��������Web
�@�@�Ɏ��������J����Ă��܂��B����ɂ��ƁCLS21�@1.8GHz�f���A���R�AOpteron x2 �u���[�h��2��
�@�@��QS22�u���[�h��InfiniBabd�Œ������ꂽ���̂��v�Z�m�[�h
�@�@----------------------
�ŐV�̎����킱�ꂷ�Bhttp://www.lanl.gov/orgs/hpc/roadrunner/pdfs/Roadrunner-tutorial-session-1-web1.pdf
Opteron�u���[�h(LS21)��CELL�u���[�h(QS22)�Ԃ̃C���^�R�l�N�g��Infiniband�ł햳���APCIe��
���ڎg���Ă��邷�B(p.8�Ȃ�)
576 �FMAC�I�^�������F2008/05/17(�y) 18:02:12 ID:tl5HJ+lJ
��̍Ō�̍s�A�������B
�@�@(p.8�Ȃ�) -> (p.17�Ȃ�)
�@�@(p.8�Ȃ�) -> (p.17�Ȃ�)
��P.A. Semi��PWRficient�`�b�v��AApple���狟�����������邱�Ƃ����܂����炵�����B
http://www.theregister.co.uk/2008/05/16/pasemi_apple_support/
�@�@-------------------
�@�@PA Semi's staff has started notifying a limited set of customers that the company's existing
�@�@dual-core processor will enjoy long-term support. Apple will employ a number of old PA Semi
�@�@staffers just for this task, which is good news for folks making missiles, mine-sweeping gear
�@�@and storage boxes.
�@�@-------------------
http://www.theregister.co.uk/2008/05/16/pasemi_apple_support/
�@�@-------------------
�@�@PA Semi's staff has started notifying a limited set of customers that the company's existing
�@�@dual-core processor will enjoy long-term support. Apple will employ a number of old PA Semi
�@�@staffers just for this task, which is good news for folks making missiles, mine-sweeping gear
�@�@and storage boxes.
�@�@-------------------
���ꂾ���@����Ĕ��_��o���Ȃ��̂�
�������Ⴀ���Ⴀ�Ɠo�ꂷ��MAC�I�^�̒p�m�炸�Ԃ�ɂ�
����Ă��̂������Ȃ���
�������Ⴀ���Ⴀ�Ɠo�ꂷ��MAC�I�^�̒p�m�炸�Ԃ�ɂ�
����Ă��̂������Ȃ���
�@�@�@�@�@�@ �^ �_�@�@�^�_�@���
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��ROB��x86�p��Ȃ��ǁB�B�B
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��ROB��x86�p��Ȃ��ǁB�B�B
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
����Ȃ�ł�����?�����ł���?
LLVM��RISC�ɔ�����܂���?
LLVM��RISC�ɔ�����܂���?
582 �F,,�E�L�́M�E,,�j��-�������F2008/05/20(��) 12:43:14 ID:cExqQ2qV
���z�}�V���̓n�[�h�E�F�A�ł����H
�G�ɕ`�����݂͖݂ł���?
Takwila���ڐ��i�허�N�ɂȂ�Ƃ��BPOWER6+�ƂԂ��邱�ƂɂȂ邷���ˁB�B�B
http://www.pcworld.com/businesscenter/article/146043/tukwila_itanium_servers_due_early_next_year_intel_said.html
�@�@--------------------
�@�@Intel will start shipping a quad-core version of its Itanium processor to system vendors in
�@�@about six months, with the first servers based on the chip due in early 2009, Intel said Monday.
�@�@--------------------
http://www.pcworld.com/businesscenter/article/146043/tukwila_itanium_servers_due_early_next_year_intel_said.html
�@�@--------------------
�@�@Intel will start shipping a quad-core version of its Itanium processor to system vendors in
�@�@about six months, with the first servers based on the chip due in early 2009, Intel said Monday.
�@�@--------------------
cnet blog�̏���ǁAVIA isaiah�퍡�����ɔ��\�����Ƃ̂��Ƃ��B
http://news.cnet.com/8301-10784_3-9945568-7.html
�@�@---------------------
�@�@Is the end of the Intel-AMD duopoly nigh? Via Technologies is hoping this may be the
�@�@case when it announces the "Isaiah" processor later this month.
�@�@---------------------
http://news.cnet.com/8301-10784_3-9945568-7.html
�@�@---------------------
�@�@Is the end of the Intel-AMD duopoly nigh? Via Technologies is hoping this may be the
�@�@case when it announces the "Isaiah" processor later this month.
�@�@---------------------
�������Ă��Ƃ���10���Ȃ�����
�Q�����Ȃ��Ƃ������\������Computex�ɂ��o�W����悤����
���邢��Atom�ɂ��Ԃ��ė��邩���H
ttp://www.viatech.co.jp/jp/company/events/computex2008/
�X���[������肢������������ Computex 2008 �� VIA �ɂ��z����
>�ȓd�͂̃��o�C���R���s���[�e�B���O�ɂ�����V�����閾���������������A
>VIA�̓G�L�T�C�e�B���O�ȐV�����v���b�g�z�[���Z�p����є�ނ̂Ȃ����b�g�������
>�p�t�H�[�}���X�ɂ����郊�[�_�[�V�b�v��Computex 2008�ɂ����Ė��炩�ɂ��܂��B
�܂��A�N���ɂ͎�ɏo����H
�Q�����Ȃ��Ƃ������\������Computex�ɂ��o�W����悤����
���邢��Atom�ɂ��Ԃ��ė��邩���H
ttp://www.viatech.co.jp/jp/company/events/computex2008/
�X���[������肢������������ Computex 2008 �� VIA �ɂ��z����
>�ȓd�͂̃��o�C���R���s���[�e�B���O�ɂ�����V�����閾���������������A
>VIA�̓G�L�T�C�e�B���O�ȐV�����v���b�g�z�[���Z�p����є�ނ̂Ȃ����b�g�������
>�p�t�H�[�}���X�ɂ����郊�[�_�[�V�b�v��Computex 2008�ɂ����Ė��炩�ɂ��܂��B
�܂��A�N���ɂ͎�ɏo����H
�@�@�@�@�@�@ �^ �_�@�@�^�_�@���
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�܂�����A
�j���[�X�ɓO���āA���O�ƏZ�l�̋L���𗬂��C���ˁB
�j���[�X�ɓO���āA���O�ƏZ�l�̋L���𗬂��C���ˁB
���݂ɑ匴�����ł�VTF2008��1���ɒZ�k����邪�J�Â���Ƃ̎�
590 �FMAC�I�^��588 �����F2008/05/21(��) 23:28:58 ID:30NFPtNr
>>588
���������ނ̕ςȒm�������̃q�g��A����ɂ��Ȃ��Ƃ����b��(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/832
�@�@---------------------
�@�@ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
�@�@---------------------
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/206
�@�@------------------
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@------------------
���������ނ̕ςȒm�������̃q�g��A����ɂ��Ȃ��Ƃ����b��(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/832
�@�@---------------------
�@�@ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
�@�@---------------------
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/206
�@�@------------------
�@�@�Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
�@�@����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
�@�@------------------
�����A�Ȃ���Ȃ���������������Ĕ��_���Ă����܂����A���ɔ����������Ă���I
�@�@�@�@�@�@ �^ �_�@�@�^�_�@���
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
.�@�@�@�@�@�^�@�i�[�j �@�i�[�j�_�@�@�@�@�@�@
�@�@�@�@�^�@�@ �܁i__�l__�j�� �_�@�@�@�@��issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�@�@�@�@|�@�@ �@�@�@|r��-|�@�@�@�@| �@�@�@
�@�@�@�@ �_�@�@�@�@ `�['�L�@�@ �^ �@�@�@�@
�@�@�@�@�m�@�@�@�@�@�@�@�@�@�@ �@�_
�@ �^�L�@�@�@�@�@�@�@�@�@�@�@�@ �@�@�R �@ �@ �@ �@ �@ �@ �@
�@|�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�_
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-�. �@ �@
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�@ �@�@�@�@ �@�@�@�Q�Q�Q_
�@�@�@�@�@�@�@ �^_�m �@�R�_�_
�@Ё@Ё@Ё@�@o�(�i���j) (�i���j)�o�@�@�@�@�@�@Ё@Ё@�
/��)��)��. ::::::�܁i__�l__�j��:::�_�@�@�@/��)��)��)
|�@/�@/�@/�@�@�@�@�@|r��-|�@�@�@�@|�@(��)/�@/ / /�^�@�@�@�����������������@
|�@:::::::::::(��)�@�@�@�@|�@|�@ |�@�@ �^ �@�T�@�@:::::::::::/
|�@�@�@�@�@�m�@�@ �@�@|�@|�@ |�@ �@�_�@�@/�@�@�j�@�@/
�R�@�@�@�@/�@�@�@�@�@`�['�L �@ �@ �@�R /�@�@�@�@�^�@�@�@�@�@�o
�@|�@�@�@�@|�@�@ l||l�@���l l||l �@�@�@�@ l||l ���l l||l�@�@�o�@�@�@��
�@�R�@�@�@ -��''''''"~~�M`'�[--��@�@�@-��'''''''�[-��@�@�@�@��
�@�@�R �Q�Q�Q�Q(��)(��)��)�@)�@�@(�܁Q(��)��)��))
�����肳�A�܂�����
�܂�> issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�܂�> Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
����̍����𑁂������Ă��Ă������
�܂�> issue queue������OoOE�@�\�������Ȃ��v���Z�b�T��SMT���Ď�������Ӗ������邷��(��)
�܂�> Atom��FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
����̍����𑁂������Ă��Ă������
�Ƃ肠�����ł���AA�����͂�߂Ă���B
>>594
MAC�I�^��ǂ��o���̂ɋ��͂��Ă��ꂽ��
MAC�I�^��ǂ��o���̂ɋ��͂��Ă��ꂽ��
���X������ł��
593�̂悤�Ȋ����̃��X�Ȃ炢�����A�ł���AA�△�ʃR�s�y�݂����Ȃ̂Ń��O�����̂͊��ق�
593�̂悤�Ȋ����̃��X�Ȃ炢�����A�ł���AA�△�ʃR�s�y�݂����Ȃ̂Ń��O�����̂͊��ق�
NCSA����Blue Waters�̎d�l�̈ꕔ�Ƃ��ĘR��Ă���POWER7/PERCS�̎d�l���B
http://www.ncsa.edu/BlueWaters/prac-solicit-080304.pdf
�@�@-------------------------
�@�@- The Power7 is based on advanced multicore processor technology.
�@�@- More than 200,000 cores will be available to applications running on the system.
�@�@- Blue Waters will be capable of optimized simultaneous multithreading (SMT) and has
�@�@�@vector multimedia extension (VMX) capability.
�@�@- The cache architecture will feature multiple levels of cache (private L1 and L2 caches
�@�@�@for each core and an L3 shared cache).
�@�@-------------------------
���Ȃ��Ƃ����C���R�A��POWER6�P���Ă������Ȋ������B
http://www.ncsa.edu/BlueWaters/prac-solicit-080304.pdf
�@�@-------------------------
�@�@- The Power7 is based on advanced multicore processor technology.
�@�@- More than 200,000 cores will be available to applications running on the system.
�@�@- Blue Waters will be capable of optimized simultaneous multithreading (SMT) and has
�@�@�@vector multimedia extension (VMX) capability.
�@�@- The cache architecture will feature multiple levels of cache (private L1 and L2 caches
�@�@�@for each core and an L3 shared cache).
�@�@-------------------------
���Ȃ��Ƃ����C���R�A��POWER6�P���Ă������Ȋ������B
CELL/B.E.�̃A�[�L�e�N�gPeter Hofstee���ŋ߂̍u���Ō����CELL�̏����v�悷�B
http://www.csm.ornl.gov/workshops/HPA/documents/1-arch/doe_dod_112907_hofstee.pdf (p.12�Q��)
�@�@------------------
�@�@�EIntegrate the equivalent of a RoadRunnernode on a chip
�@�@�@- Leverage Power 7 technology
�@�@�@- Allows a 10PFlop system of reasonable size
�@�@�@- Improved SPE . main core latency and bandwidth
�@�@�@- Improved cross-system latencies
�@�@------------------
����3�Ԗڂ�����ASPE�̃R�A�d�l�Ɏ������C���X�Ȃ̂�ӊO���B
http://www.csm.ornl.gov/workshops/HPA/documents/1-arch/doe_dod_112907_hofstee.pdf (p.12�Q��)
�@�@------------------
�@�@�EIntegrate the equivalent of a RoadRunnernode on a chip
�@�@�@- Leverage Power 7 technology
�@�@�@- Allows a 10PFlop system of reasonable size
�@�@�@- Improved SPE . main core latency and bandwidth
�@�@�@- Improved cross-system latencies
�@�@------------------
����3�Ԗڂ�����ASPE�̃R�A�d�l�Ɏ������C���X�Ȃ̂�ӊO���B
�[���j���[�X���������Ă��Ă���������Ȃ��H
�]�v�Ȃ��ƌ����n�߂���m���̂���l���Nj����Ă����������B
�]�v�Ȃ��ƌ����n�߂���m���̂���l���Nj����Ă����������B
>>598,599
527 ���O�FSocket774[sage] ���e���F2008/05/08(��) 23:18:13 ID:+V0bLI1h
�܂�����`���ɂ܂���y�[�W
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
���̂Ƃ���S��������������ē����Ă��B
�ÎQ������M�p����ƌ����Ă����ꂶ�ᖳ���Șb�B
���������ɂ͐����͂������t���Ȃ��ƂˁB
���̂܂܂���j���[�X���\�肷�邾���̑��݂ɂȂ����Ⴄ��[�B
527 ���O�FSocket774[sage] ���e���F2008/05/08(��) 23:18:13 ID:+V0bLI1h
�܂�����`���ɂ܂���y�[�W
�EROB��x86�p��
�EPOWER5��Global completion table�͑��v���Z�b�T��ROB�����ł͂Ȃ�
�E�C���I�[�_�[�v���Z�b�T��SMT�͈Ӗ����Ȃ�
�EAtom��FGMT
���̂Ƃ���S��������������ē����Ă��B
�ÎQ������M�p����ƌ����Ă����ꂶ�ᖳ���Șb�B
���������ɂ͐����͂������t���Ȃ��ƂˁB
���̂܂܂���j���[�X���\�肷�邾���̑��݂ɂȂ����Ⴄ��[�B
>>590
> ���������ނ̕ςȒm�������̃q�g��A����ɂ��Ȃ��Ƃ����b��(��)
�����̒m���ł͑R�ł��Ȃ��ƔF�߂�킯�ł���
�����Ƃ�
> ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
ROB��1�G���g����1uop������Isaiah��
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
��p�C�v���C����ROB�G���g���m�ۃX�e�[�W�����݂���v���Z�b�T��T���Ă����Ƃ����̂́A
������P�̖������ɕC�G����Ǝv�����ǂ�www
> ���������ނ̕ςȒm�������̃q�g��A����ɂ��Ȃ��Ƃ����b��(��)
�����̒m���ł͑R�ł��Ȃ��ƔF�߂�킯�ł���
�����Ƃ�
> ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
ROB��1�G���g����1uop������Isaiah��
> �Ȃ��Ȃ�AROB�G���g���̊m�ۂ퉉�Z�p�C�v���C���̈ꕔ�ł�Ȃ��̂ŁA
> ����ȂƂ��낪�l�b�N�ɂȂ��ăp�C�v���C�����~�߂�̂�n�����Ă��邩�炷�B
��p�C�v���C����ROB�G���g���m�ۃX�e�[�W�����݂���v���Z�b�T��T���Ă����Ƃ����̂́A
������P�̖������ɕC�G����Ǝv�����ǂ�www
�ߋ��L�����甭�@���Ă݂�
���̑O��͂Ȃ��Ȃ��y������b�������Ă���
CPU�A�[�L�e�N�`���ɂ��Č�� 6
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/860
870 ���O�F MAC�I�^��865 ���� [sage] ���e���F 2007/02/25(��) 01:28:26 ID:Y7sl0DIy
>>865
�n���ɂ���̂������R�����ǁA�b��₷�����邽�߂�issue queue (x86�̏ꍇreorder buffer)
�����菜�����Ƃ��ł���̂�completion�Ȃ�retire�Ȃ�Ƃ��Ă����Ƃ����̂ŗǂ������H
�������ɂ��v��AA�\�肽���Ȃ��ww
���̑O��͂Ȃ��Ȃ��y������b�������Ă���
CPU�A�[�L�e�N�`���ɂ��Č�� 6
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/860
870 ���O�F MAC�I�^��865 ���� [sage] ���e���F 2007/02/25(��) 01:28:26 ID:Y7sl0DIy
>>865
�n���ɂ���̂������R�����ǁA�b��₷�����邽�߂�issue queue (x86�̏ꍇreorder buffer)
�����菜�����Ƃ��ł���̂�completion�Ȃ�retire�Ȃ�Ƃ��Ă����Ƃ����̂ŗǂ������H
�������ɂ��v��AA�\�肽���Ȃ��ww
�ߋ��X���̂��̂�����������[�����Ƃ肪��������
CPU�A�[�L�e�N�`���ɂ��Č�� 6
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/870
870 ���O�F MAC�I�^��865 ���� [sage] ���e���F 2007/02/25(��) 01:28:26 ID:Y7sl0DIy
>>865
�n���ɂ���̂������R�����ǁA�b��₷�����邽�߂�issue queue (x86�̏ꍇreorder buffer)
�����菜�����Ƃ��ł���̂�completion�Ȃ�retire�Ȃ�Ƃ��Ă����Ƃ����̂ŗǂ������H
�������ɂ��v��AA�\�肽���Ȃ��www
CPU�A�[�L�e�N�`���ɂ��Č�� 6
http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/870
870 ���O�F MAC�I�^��865 ���� [sage] ���e���F 2007/02/25(��) 01:28:26 ID:Y7sl0DIy
>>865
�n���ɂ���̂������R�����ǁA�b��₷�����邽�߂�issue queue (x86�̏ꍇreorder buffer)
�����菜�����Ƃ��ł���̂�completion�Ȃ�retire�Ȃ�Ƃ��Ă����Ƃ����̂ŗǂ������H
�������ɂ��v��AA�\�肽���Ȃ��www
�X�}���c
�܂���SMT�������E���Ă���
829 ���O�F MAC�I�^���c�q ���� [sage] ���e���F 2007/02/25(��) 00:19:40 ID:Y7sl0DIy
>>826
���߃L���[���X���b�h�ŋ��L����SMT�ł�A�ЂƂ̃X���b�h�̖��߂��X�g�[������ƑS��
�~�܂邷�B������in-order�Ń}���`�X���b�h����������ꍇ��PPE��Niagara�̂悤�ɋ����I��
��T�C�N�����ƂɃR���e�L�X�g���ւ���FGMT(Fine-grain multithreading)���g�����B
�܂���SMT�������E���Ă���
829 ���O�F MAC�I�^���c�q ���� [sage] ���e���F 2007/02/25(��) 00:19:40 ID:Y7sl0DIy
>>826
���߃L���[���X���b�h�ŋ��L����SMT�ł�A�ЂƂ̃X���b�h�̖��߂��X�g�[������ƑS��
�~�܂邷�B������in-order�Ń}���`�X���b�h����������ꍇ��PPE��Niagara�̂悤�ɋ����I��
��T�C�N�����ƂɃR���e�L�X�g���ւ���FGMT(Fine-grain multithreading)���g�����B
>�ЂƂ̃X���b�h�̖��߂��X�g�[������ƑS���~�܂邷�B
���₻��SMT�̈Ӗ��Ȃ����E�E�E
���₻��SMT�̈Ӗ��Ȃ����E�E�E
MAC�I�^�������Ă̂�CPU�A�[�L�e�N�`���ɂ��Č��̂�
�X����2�������Ă���B�͂����肢���Ă�����
�X����2�������Ă���B�͂����肢���Ă�����
MAC�I�^���g�ŃX�����Ă��ׂ�����
����͈琬�Q�[���Ȃ���A���̉ߒ��Ŋw�Ԃ��̂�����̂ł͂Ȃ���
http://pc11.2ch.net/test/read.cgi/mac/1190013206/
����̒��ɐV�����X�����Ă邭�炢�Ȃ炱����d�����ق����B
����̒��ɐV�����X�����Ă邭�炢�Ȃ炱����d�����ق����B
�X���[�ł������낤
�[���������Ă���͍r�����R����
�ł��Ȃ��Ȃ甼�N�Ƃ��킸���X��ROM���Ă�
�[���������Ă���͍r�����R����
�ł��Ȃ��Ȃ甼�N�Ƃ��킸���X��ROM���Ă�
http://pc.watch.impress.co.jp/docs/2008/0523/kaigai441.htm
X86�v���Z�b�T�ɂƂ��Ă͂��܂肢���b�Ƃ͂�����������
���߂ŃR�[�_�`�����̂ĂȂ�����A�M�̋Ǐ��W���͔���������Ă��Ƃ�
��͂�Intel�͂ǂ�����x86�̂Ă邱�ƂɂȂ��Ȃ����낤����
�f�R�[�_���\�t�g���Ɏ����Ă����ق����i�v����ɃG�~�����[�^�[�j�͂邩�ɃG���K���g��
X86�v���Z�b�T�ɂƂ��Ă͂��܂肢���b�Ƃ͂�����������
���߂ŃR�[�_�`�����̂ĂȂ�����A�M�̋Ǐ��W���͔���������Ă��Ƃ�
��͂�Intel�͂ǂ�����x86�̂Ă邱�ƂɂȂ��Ȃ����낤����
�f�R�[�_���\�t�g���Ɏ����Ă����ق����i�v����ɃG�~�����[�^�[�j�͂邩�ɃG���K���g��
133 �FSocket774 �F2008/05/24(�y) 00:47:16 ID:VXSRm/5a
http://www.dennobaio.jp/51CE0101G1600167.html
�^�ԁFCrusoe TM5800 x100�Z�b�g
�d�l�F800MHz/FSB 133MHz
�����F[�o���N][54]
\4,999
http://www.dennobaio.jp/51CE0101G1600167.html
�^�ԁFCrusoe TM5800 x100�Z�b�g
�d�l�F800MHz/FSB 133MHz
�����F[�o���N][54]
\4,999
>>612
>�f�R�[�_���\�t�g���Ɏ����Ă����ق����i�v����ɃG�~�����[�^�[�j�͂邩�ɃG���K���g��
Itanium�ł͎��s�������B
���݂̂悤�Ƀg�����W�X�^���ɗ]�T��������
�����\�͂��グ����Ȃ�����ł���Ƃł��H
>�f�R�[�_���\�t�g���Ɏ����Ă����ق����i�v����ɃG�~�����[�^�[�j�͂邩�ɃG���K���g��
Itanium�ł͎��s�������B
���݂̂悤�Ƀg�����W�X�^���ɗ]�T��������
�����\�͂��グ����Ȃ�����ł���Ƃł��H
���O�ɂ܂邲�ƃR���p�C�����Ă̂���Ή�������Ȃ��낤���ȁc�c
�܂��A�^�C�v���C�^�[��QWERTY�z��݂����ɁA����Ɛl�Ԃ̋r���Ђ��ς�Ȃ���
x86�͑�����������悤�ȋC�����Ȃ��ł��Ȃ�
�܂��A�^�C�v���C�^�[��QWERTY�z��݂����ɁA����Ɛl�Ԃ̋r���Ђ��ς�Ȃ���
x86�͑�����������悤�ȋC�����Ȃ��ł��Ȃ�
banias�̍���CISC�}���Z�[���Ă�����
�܂����̂����h��߂����肵�Ă�
�܂����̂����h��߂����肵�Ă�
617 �F,,�E�L�́M�E,,�j��-�������F2008/05/24(�y) 09:22:53 ID:PnwyODGk
Phenom��32B�t�F�b�`�ɂ��Ă�Core 2�ɏ��ĂȂ��㔚�M�ŃN���b�N���オ��Ȃ��̂��A�t�����g�G���h�̕��S�̏d���̂ł����H
AVX���Ăǂ��ȂˁB
VEX(3byte) OP ModRM SIB disp32 imm8��11�o�C�g
�łȂ��Ƃ�3���W�X�^���߂��g����5�`6�o�C�g�H���킯���B
16byte�t�F�b�`�̂܂܂���A3���ߓ������s����悤�ȃL���p�͂ǂ��l�������ĂȂ��B
vaddps xmm1, xmm2, xmm3��
movaps xmm1, xmm3 + addps xmm1, xmm2��
��������Ď��s�����Ƃ��Ă�����s�v�c�͂Ȃ���
AVX���Ăǂ��ȂˁB
VEX(3byte) OP ModRM SIB disp32 imm8��11�o�C�g
�łȂ��Ƃ�3���W�X�^���߂��g����5�`6�o�C�g�H���킯���B
16byte�t�F�b�`�̂܂܂���A3���ߓ������s����悤�ȃL���p�͂ǂ��l�������ĂȂ��B
vaddps xmm1, xmm2, xmm3��
movaps xmm1, xmm3 + addps xmm1, xmm2��
��������Ď��s�����Ƃ��Ă�����s�v�c�͂Ȃ���
AVX�͂����܂�PARROT�ɔ����Ă̖��߂Ȃ�łˁ[�́H
�����IntelCPU�Ƃ̑����͂���Ȃɍl����ł�������łȂ��낤��
�����IntelCPU�Ƃ̑����͂���Ȃɍl����ł�������łȂ��낤��
619 �F,,�E�L�́M�E,,�j��-�������F2008/05/24(�y) 10:22:27 ID:PnwyODGk
MXCSR�̏�Ԃɂ����2byte Opcode�̈�i��87�EMMX�ESSE1�Ȃǁj��ǂݑւ���Ƃ������
1�o�C�g���炢�͏��Ȃ��Ƃ��ߖ�ł���Ǝv�����ȁB
�܂��݊����̖�������낤���B
1�o�C�g���炢�͏��Ȃ��Ƃ��ߖ�ł���Ǝv�����ȁB
�܂��݊����̖�������낤���B
>>613
\4,999 �����������܂���
\4,999 �����������܂���
>>614
Mac��68k��PPC�G�~�����[�^�[�͍����\�ŗL������������
�\�t�g�E�F�A�̉��ʑw�ł��������Ȃ�y�i���e�B�����̂Ԃ�ւ��ł�
Mac��68k��PPC�G�~�����[�^�[�͍����\�ŗL������������
�\�t�g�E�F�A�̉��ʑw�ł��������Ȃ�y�i���e�B�����̂Ԃ�ւ��ł�
>>612
���̐�s���l�܂邱�Ƃ������Ă��C�e�n�X�̎�@��������邱�Ƃ�
�Ŕj���邱�Ƃ��\���Ă��Ƃ��B
�ʂ����Ă����܂Ńv���Z�X�Z�p�̊v�V���ǂ��t�����B
���̐�s���l�܂邱�Ƃ������Ă��C�e�n�X�̎�@��������邱�Ƃ�
�Ŕj���邱�Ƃ��\���Ă��Ƃ��B
�ʂ����Ă����܂Ńv���Z�X�Z�p�̊v�V���ǂ��t�����B
FX!32�͈�x�l�C�e�B�u�ɕϊ�������L���b�V������Ă��͂�����
>>621
�i���̎~�܂��Ă��܂���68k���v���Z�b�T��
�o�ꎞ����68k��舳�|�I�ɍ����\��PPC��̃G�~�����^�����͂ꂽ
�Ƃ��������̂���
����ł�68040�̂ق���PPC601+�G�~����葬�������̂ŁA�n�C�G���h�͂��炭�u���������Ȃ��������炢��
�i���̎~�܂��Ă��܂���68k���v���Z�b�T��
�o�ꎞ����68k��舳�|�I�ɍ����\��PPC��̃G�~�����^�����͂ꂽ
�Ƃ��������̂���
����ł�68040�̂ق���PPC601+�G�~����葬�������̂ŁA�n�C�G���h�͂��炭�u���������Ȃ��������炢��
>625
�܂������Ȃ��A�G�~�����g�������͊Ԃɍ��킹��̂���ړI��
���x���͌����������ɒu�������̂���������x���������ȁc�c
9500�����肩��̗p���ꂽ�V�G�~���Ō��I�ɐ��\���オ������
�����\�ŕ]��������(?)�̂́A�������̂ق�����Ȃ����ƁB
���ƁAOS���̑��\�t�g�������X�ɂ����ǐ�ւ��Ă��������Ă̂�������
Alpha�ɂ���crusoe�ɂ���A�ǂ�ǂ�l�C�e�B�u�������オ���Ă�����
�G�~���̃I�[�o�[�w�b�h�����ɂȂ�Ȃ����炢�����Ȃ��Ă������͂�
Intel�����ɂ��������g����G�~���ƁA����I�V�A�[�L�e�N�`���ւ̈ڍs������
�����悤�ȓW�J���܂��Ă����Ȃ����c�c
���čl�����낤�˂��A�C���e���̐l��w
�܂������Ȃ��A�G�~�����g�������͊Ԃɍ��킹��̂���ړI��
���x���͌����������ɒu�������̂���������x���������ȁc�c
9500�����肩��̗p���ꂽ�V�G�~���Ō��I�ɐ��\���オ������
�����\�ŕ]��������(?)�̂́A�������̂ق�����Ȃ����ƁB
���ƁAOS���̑��\�t�g�������X�ɂ����ǐ�ւ��Ă��������Ă̂�������
Alpha�ɂ���crusoe�ɂ���A�ǂ�ǂ�l�C�e�B�u�������オ���Ă�����
�G�~���̃I�[�o�[�w�b�h�����ɂȂ�Ȃ����炢�����Ȃ��Ă������͂�
Intel�����ɂ��������g����G�~���ƁA����I�V�A�[�L�e�N�`���ւ̈ڍs������
�����悤�ȓW�J���܂��Ă����Ȃ����c�c
���čl�����낤�˂��A�C���e���̐l��w
Itanium��x86���G�~���ɂȂ����̂�2�̓r�����炾����Ax86���\�����܂����ł��A
IA-64�̐��\�����|�I�Ȃ�u������������čl������ˁB
IA-64�̐��\�����|�I�Ȃ�u������������čl������ˁB
628 �F,,�E�L�́M�E,,�j��-�������F2008/05/24(�y) 21:35:17 ID:/FK0JNgE
���̋t��������ɂȂ��Ă����ȁB
x86�Ő��\���o���Ȃ��Ȃ�Ȃ�V�A�[�L�e�N�`�����K�v�Ƃ����̂���`������������
�̐S��ia64�͑傢�ɒx��܂����Ă邵x86�͂܂������邵
IE32EL��Itanium 2�͊撣���Ă悤�₭���N���b�N��NetBurst Xeon�Ɠ�����
�������}���`�R�A�EHT���ł�1�X���b�h�������s�ł��Ȃ��i���͒m��j�Ƃ��ˁB
x86�Ő��\���o���Ȃ��Ȃ�Ȃ�V�A�[�L�e�N�`�����K�v�Ƃ����̂���`������������
�̐S��ia64�͑傢�ɒx��܂����Ă邵x86�͂܂������邵
IE32EL��Itanium 2�͊撣���Ă悤�₭���N���b�N��NetBurst Xeon�Ɠ�����
�������}���`�R�A�EHT���ł�1�X���b�h�������s�ł��Ȃ��i���͒m��j�Ƃ��ˁB
x86���܂���������Ă̂́A���m�̑P���������Ă������͋���������ꂽ���Ă���������Ȃ�
Alpha���낤��68���낤���A���z��������፡�ł��őO���ɂ����ˁH
Alpha���낤��68���낤���A���z��������፡�ł��őO���ɂ����ˁH
���ꂾ�����b�`��POWER�̐��\���l����ɁA�g���g�����炢���ւ̎R
���������samsung��alpha�������Ă��܂��Ɩʔ����̂���
>>630
SpecCPU2006�̃x���`�������APower6��Core2��6750/6850���炢��
�����Ȃ̂�����ƍ������ɂ͂����������\����Ȃ��ȂƎv���B
10�i�����Z�@�\������̂��l�����Ă��R�X�g�p�t�H�[�}���X���ǂ��Ƃ�
�����Ȃ��B
SpecCPU2006�̃x���`�������APower6��Core2��6750/6850���炢��
�����Ȃ̂�����ƍ������ɂ͂����������\����Ȃ��ȂƎv���B
10�i�����Z�@�\������̂��l�����Ă��R�X�g�p�t�H�[�}���X���ǂ��Ƃ�
�����Ȃ��B
RISC���o�ꂵ������CISC(x86)�ł͐��\���オ���ł��ɂȂ�RISC�ɑR�ł��Ȃ�
�Ƃ����_���������炵�����ǁA���������_�������Ă��l��������x86��RISC��
��@����荞�������RISC���ɖ��ߕϊ�������Ƃ��̗\�����炢�ł��Ȃ�����
�̂���?
����Ƃ���L�̂悤�Ȏ�i��x86���g���Ă�RISC�ɏ��ĂȂ����낤�Ƃ����\��
�������̂�?�@
�Ƃ����_���������炵�����ǁA���������_�������Ă��l��������x86��RISC��
��@����荞�������RISC���ɖ��ߕϊ�������Ƃ��̗\�����炢�ł��Ȃ�����
�̂���?
����Ƃ���L�̂悤�Ȏ�i��x86���g���Ă�RISC�ɏ��ĂȂ����낤�Ƃ����\��
�������̂�?�@
>>633
CISC->RISC�ϊ��̍ŏ��̘_����
ttp://www.cs.clemson.edu/~mark/hps.html
�ɂ���ʂ�1986�N�Ŕ����Ȏ����Ȃ��ǁA
�}�[�P�e�B���O�I�_���́u���ߕϊ��̃I�[�o�[�w�b�h�͏�ɑ��݂��邩��RISC�L���v������
PentiumPro��RISC�ɐ�삯��OoO�����������̂͂������ɋ����������悤����
CISC->RISC�ϊ��̍ŏ��̘_����
ttp://www.cs.clemson.edu/~mark/hps.html
�ɂ���ʂ�1986�N�Ŕ����Ȏ����Ȃ��ǁA
�}�[�P�e�B���O�I�_���́u���ߕϊ��̃I�[�o�[�w�b�h�͏�ɑ��݂��邩��RISC�L���v������
PentiumPro��RISC�ɐ�삯��OoO�����������̂͂������ɋ����������悤����
�����ƁA�x���Ƃ͂���K5��OoO������������
Nx586��OoO������
ttp://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_1260_1272,00.html
����͓������߃Z�b�g��RISC86���_�C���N�g�Ɏ��s�ł���
�ȂAx86���������ww
ttp://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_1260_1272,00.html
����͓������߃Z�b�g��RISC86���_�C���N�g�Ɏ��s�ł���
�ȂAx86���������ww
�Ȃ�Ńl�C�e�B�uRISC���͓������݂������낤��
������Ƌ^��
������Ƌ^��
���W�X�^�������OoO�͂��̎��_�ł͕s�v��������ˁH
����OoO�́A�\�Ȍ��胁�����A�N�Z�X�𑁂����s���ăL���b�V���~�X�����炷���߂ɂ����ŁA
�t�ˑ��ɂ��X�g�[���̉����̂��߂�����������OoO�Ƃ͈Ӗ��������ς���Ă��܂���
����OoO�́A�\�Ȍ��胁�����A�N�Z�X�𑁂����s���ăL���b�V���~�X�����炷���߂ɂ����ŁA
�t�ˑ��ɂ��X�g�[���̉����̂��߂�����������OoO�Ƃ͈Ӗ��������ς���Ă��܂���
639 �FSocket774�F2008/05/25(��) 04:12:42 ID:sylakmaM
>>633
�q�h�r�b�̓f�R�[�_�[���v��Ȃ��A���Ă̂��傫��
�f�T����32����64�̕p�ɂȍs�����̂����Ńf�R�[�_�[���K�v�ɂȂ����̂����M�̌�����1�Ȃ��B
���Ƃh�`�|�U�S�͏����ȎI�p�`�b�v�ŃR���V���[�}�[�ɂ͐�Ζ���
>>637
���̘_���A���ĂƂ�����
�Ƃɂ������o���ď�ɍŐV�v���Z�X�`�b�v�𓊓���������Ƃ��������胂�f���ł�86�͐����c���Ă�������B
�Ђ邪�����Ăo���������o�b�͂`���������ƃQ�[���@�����Ȃ�����A�J����p���̂��̂��������Ȃ��Ƃ����W�����}�ɂȂ���
�����A���ɓ������v�Ȃ��{�v�̗e�Ղ��ło���������̂ق������낢����₷���͎̂�������
�q�h�r�b�̓f�R�[�_�[���v��Ȃ��A���Ă̂��傫��
�f�T����32����64�̕p�ɂȍs�����̂����Ńf�R�[�_�[���K�v�ɂȂ����̂����M�̌�����1�Ȃ��B
���Ƃh�`�|�U�S�͏����ȎI�p�`�b�v�ŃR���V���[�}�[�ɂ͐�Ζ���
>>637
���̘_���A���ĂƂ�����
�Ƃɂ������o���ď�ɍŐV�v���Z�X�`�b�v�𓊓���������Ƃ��������胂�f���ł�86�͐����c���Ă�������B
�Ђ邪�����Ăo���������o�b�͂`���������ƃQ�[���@�����Ȃ�����A�J����p���̂��̂��������Ȃ��Ƃ����W�����}�ɂȂ���
�����A���ɓ������v�Ȃ��{�v�̗e�Ղ��ło���������̂ق������낢����₷���͎̂�������
640 �FSocket774�F2008/05/25(��) 04:17:00 ID:sylakmaM
�������A�h����������x86���ǂ��������Ȃ낤��
�w�e���W�j�A�X�}���`�R�A���Ă����ɂ����āA��86�ƐV�A�[�L�e�N�`���̃n�C�u���b�h�`�b�v�ɂ���̂��Ƃ��v���邪
�l�I�ɂ͂`����������������悤�ȃ\�t�g�E�F�A�G�~�����[�^�����������ق����G���K���g���������Ǝv��
���肷��ƁA��86���̂̃y�i���e�B�ƁA�V�A�[�L�e�N�`���{�G�~�����[�^�̃y�i���e�B���肠����������Ȃ��Ǝv���Ă݂�
�w�e���W�j�A�X�}���`�R�A���Ă����ɂ����āA��86�ƐV�A�[�L�e�N�`���̃n�C�u���b�h�`�b�v�ɂ���̂��Ƃ��v���邪
�l�I�ɂ͂`����������������悤�ȃ\�t�g�E�F�A�G�~�����[�^�����������ق����G���K���g���������Ǝv��
���肷��ƁA��86���̂̃y�i���e�B�ƁA�V�A�[�L�e�N�`���{�G�~�����[�^�̃y�i���e�B���肠����������Ȃ��Ǝv���Ă݂�
641 �FSocket774�F2008/05/25(��) 04:19:15 ID:sylakmaM
�E�E�E���A������
�d�e�h�y�����āA�n�r�ƃn�[�h�̊Ԃ̂d�e�h�w�ɂ�86�G�~�����[�^�[����������A
���Ď�͎g���Ȃ�����
���������Ȃ�A�Ȃ�łh�����������d�e�h�y�����悤�Ƃ��Ă邩������C������
�d�e�h�y�����āA�n�r�ƃn�[�h�̊Ԃ̂d�e�h�w�ɂ�86�G�~�����[�^�[����������A
���Ď�͎g���Ȃ�����
���������Ȃ�A�Ȃ�łh�����������d�e�h�y�����悤�Ƃ��Ă邩������C������
>>639
�Ƃ͂���x86�̓t�����g�G���h���ʓ|�Ȃ����ŁA����ȊO��RISC�ƕς���
�t��uop�̐v�̎��R�x�Ȃ�Ă��̂����邼
POWER�̂ق����y���Ƃ͎v���Ȃ�
�t�����g�G���h�ȊO�ɂǂ������Ƃ��낪�y�Ȃ̂������Ă݂Ăق���
���낢��Ƃ�������ɂ�4,5�قNj����Ă���
�Ƃ͂���x86�̓t�����g�G���h���ʓ|�Ȃ����ŁA����ȊO��RISC�ƕς���
�t��uop�̐v�̎��R�x�Ȃ�Ă��̂����邼
POWER�̂ق����y���Ƃ͎v���Ȃ�
�t�����g�G���h�ȊO�ɂǂ������Ƃ��낪�y�Ȃ̂������Ă݂Ăق���
���낢��Ƃ�������ɂ�4,5�قNj����Ă���
>>640
x86�̏ꍇOP�R�[�h���X�p�Q�b�e�B�ɂȂ��Ă邾��������
�]���R�[�h���������ǒx����AAVX�Ń��R���p�C������ΐ��\�o���A
���đΉ������ŏ\������B
x86�̏ꍇOP�R�[�h���X�p�Q�b�e�B�ɂȂ��Ă邾��������
�]���R�[�h���������ǒx����AAVX�Ń��R���p�C������ΐ��\�o���A
���đΉ������ŏ\������B
�����������̃v���Z�b�T�̃{�g���l�b�N��
�E����\���~�X
�E�L���b�V���~�X
�Ȃ���A���s��ISA��x86�ł���POWER�ł���A�������Đ��\�ɂ͊W�Ȃ�����
�ނ���ISA�̌����́A�����̃~�X�ɑ��ėǂ��q���g��^��������ōs���Ă�
�E����\���~�X
�E�L���b�V���~�X
�Ȃ���A���s��ISA��x86�ł���POWER�ł���A�������Đ��\�ɂ͊W�Ȃ�����
�ނ���ISA�̌����́A�����̃~�X�ɑ��ėǂ��q���g��^��������ōs���Ă�
646 �FSocket774�F2008/05/25(��) 04:35:05 ID:sylakmaM
>>642
�o���������̏ꍇ�A�o�o�b���߂ڎ��s�o����A���Ďq�Ǝ��̂������b�g����
�N���b�N�A�b�v��M�����A���\����̏�Q�ƂȂ�z�b�g�X�|�b�g�U�����ė}������A���Ă��Ƃ���
��86�݂����Ƀf�R�[�_�[�Ȃǂ���g����K�v���Ȃ��̂ŔM�U�����₷���A
�͂��߂���64�a�����ƃ}���`�R�A�����z�肳��Ă�̂ŁA�v�̏�Q�����Ȃ����ď�����
��₱�������Ƃ��g�����W�X�^�Ė�������������ƁA�������z�b�g�X�|�b�g�����Ă��܂��B
�c����ł��f�T�̃f�R�[�_�[�\���͂܂����Ƃ����������B
���ꂾ�Ƃo���������̗��_���ۂ��ƒׂ��悤�Ȃ���
>>643
�V�h�r�`�Ɋ��҂����Ⴄ�̂��A��86�̕��G����ȍ\�������Đ�]���Ă邩��ŁE�E�E
�o���������̏ꍇ�A�o�o�b���߂ڎ��s�o����A���Ďq�Ǝ��̂������b�g����
�N���b�N�A�b�v��M�����A���\����̏�Q�ƂȂ�z�b�g�X�|�b�g�U�����ė}������A���Ă��Ƃ���
��86�݂����Ƀf�R�[�_�[�Ȃǂ���g����K�v���Ȃ��̂ŔM�U�����₷���A
�͂��߂���64�a�����ƃ}���`�R�A�����z�肳��Ă�̂ŁA�v�̏�Q�����Ȃ����ď�����
��₱�������Ƃ��g�����W�X�^�Ė�������������ƁA�������z�b�g�X�|�b�g�����Ă��܂��B
�c����ł��f�T�̃f�R�[�_�[�\���͂܂����Ƃ����������B
���ꂾ�Ƃo���������̗��_���ۂ��ƒׂ��悤�Ȃ���
>>643
�V�h�r�`�Ɋ��҂����Ⴄ�̂��A��86�̕��G����ȍ\�������Đ�]���Ă邩��ŁE�E�E
>>645
�f�R�[�_�l�b�N�͓d�͐��\�ւ̉e���͑傫��������
�f�R�[�_�l�b�N�͓d�͐��\�ւ̉e���͑傫��������
648 �FSocket774�F2008/05/25(��) 04:41:36 ID:sylakmaM
>>644
�]���̂�86�R�[�h�͂��͂₻�̂܂܂ɂ��邵���Ȃ���łȂ��H
�h����������l�r�A�k�����������������߂������A���������Ȃ���́A�i���ɂ`�u�w�ɃR���p�C������
����Ȃ�A�Ƃ肠�����l�r�ɐV�A�[�L�e�N�`���pWindows�ƃG�~�����[�^�[��p�ӂ����ق����܂�����
����ŁA�]���̂b�o�t���ڎ��s�Ɠ������x���̑��x�i���o���������l�������x�j���o������ނ˖��ɂ͂Ȃ�Ȃ�����
�]���̂�86�R�[�h�͂��͂₻�̂܂܂ɂ��邵���Ȃ���łȂ��H
�h����������l�r�A�k�����������������߂������A���������Ȃ���́A�i���ɂ`�u�w�ɃR���p�C������
����Ȃ�A�Ƃ肠�����l�r�ɐV�A�[�L�e�N�`���pWindows�ƃG�~�����[�^�[��p�ӂ����ق����܂�����
����ŁA�]���̂b�o�t���ڎ��s�Ɠ������x���̑��x�i���o���������l�������x�j���o������ނ˖��ɂ͂Ȃ�Ȃ�����
���X��age��ȁI�E���R�Q�n�~��
>>646
���܂�
�����Ƃ��C���[�W�ł��Ȃ�
> �N���b�N�A�b�v��M�����A���\����̏�Q�ƂȂ�z�b�g�X�|�b�g�U�����ė}������A���Ă��Ƃ���
���݂ǂ��ɂǂ������z�b�g�X�|�b�g��������(�z���ł������ł�)�APOWER�Ȃ�Ȃ������ł���̂��Ƃ����̂��킩��܂���B
> ��86�݂����Ƀf�R�[�_�[�Ȃǂ���g����K�v���Ȃ��̂ŔM�U�����₷���A
> �͂��߂���64�a�����ƃ}���`�R�A�����z�肳��Ă�̂ŁA�v�̏�Q�����Ȃ����ď�����
> ��₱�������Ƃ��g�����W�X�^�Ė�������������ƁA�������z�b�g�X�|�b�g�����Ă��܂��B
�t�����g�G���h�̖��_�ȊO�������ė~�����̂ł����APOWER���ŏ���32bit�������������A
��������64bit����}���`�R�A���Łu��̓I�ɂǂ��ɂǂꂭ�炢�v�v�̏�Q������̂��A�����Ƃ��킩��Ȃ��B
(�ǂ����Ƃǂ������q�����C���[���V���ȃN���e�B�J���p�X�ɂȂ��Ă��܂��Ƃ��A������������������Ƃ悭�킩�����)
���܂�
�����Ƃ��C���[�W�ł��Ȃ�
> �N���b�N�A�b�v��M�����A���\����̏�Q�ƂȂ�z�b�g�X�|�b�g�U�����ė}������A���Ă��Ƃ���
���݂ǂ��ɂǂ������z�b�g�X�|�b�g��������(�z���ł������ł�)�APOWER�Ȃ�Ȃ������ł���̂��Ƃ����̂��킩��܂���B
> ��86�݂����Ƀf�R�[�_�[�Ȃǂ���g����K�v���Ȃ��̂ŔM�U�����₷���A
> �͂��߂���64�a�����ƃ}���`�R�A�����z�肳��Ă�̂ŁA�v�̏�Q�����Ȃ����ď�����
> ��₱�������Ƃ��g�����W�X�^�Ė�������������ƁA�������z�b�g�X�|�b�g�����Ă��܂��B
�t�����g�G���h�̖��_�ȊO�������ė~�����̂ł����APOWER���ŏ���32bit�������������A
��������64bit����}���`�R�A���Łu��̓I�ɂǂ��ɂǂꂭ�炢�v�v�̏�Q������̂��A�����Ƃ��킩��Ȃ��B
(�ǂ����Ƃǂ������q�����C���[���V���ȃN���e�B�J���p�X�ɂȂ��Ă��܂��Ƃ��A������������������Ƃ悭�킩�����)
>>648
>�h����������l�r�A�k�����������������߂������A���������Ȃ���́A�i���ɂ`�u�w�ɃR���p�C������
����Ȑ̂̃R�[�h���x�������Ăǂ��ł����������
�ǂ���256bit SIMD�ɏ��������Ȃ��ᐫ�\�͏o�Ȃ�
>�h����������l�r�A�k�����������������߂������A���������Ȃ���́A�i���ɂ`�u�w�ɃR���p�C������
����Ȑ̂̃R�[�h���x�������Ăǂ��ł����������
�ǂ���256bit SIMD�ɏ��������Ȃ��ᐫ�\�͏o�Ȃ�
�q���g
�S�p
�S�p
����̊��҂��Ă��铚�́A�Ⴆ����Ȋ�����
�uPOWER��x86�̂悤�ȑ�H�炢�̃f�R�[�_���s�v�Ȃ̂ŁA
�o�b�N�G���h���C���I�[�_�[�ɂ��ăN���b�N���グ��Ƃ������j��I�Ԃ����̎��R�x������v
�����܂ŗႾ����ȁA�����
�uPOWER��x86�̂悤�ȑ�H�炢�̃f�R�[�_���s�v�Ȃ̂ŁA
�o�b�N�G���h���C���I�[�_�[�ɂ��ăN���b�N���グ��Ƃ������j��I�Ԃ����̎��R�x������v
�����܂ŗႾ����ȁA�����
657 �F,,�E�L�́M�E,,�j��-�������F2008/05/25(��) 10:42:08 ID:XtBgO14+
�C���I�[�_�ɂ�����x86���ȓd�͂ɂȂ�܂����Ƃ�
Atom���Ă����炭G4�ɋ߂����x�̐��\�����Ȃ����Ǝv���B
����x���`�}�[�N�X�R�A��������ł̐���������
��������G4�}�V�������Ă邩���
Atom���Ă����炭G4�ɋ߂����x�̐��\�����Ȃ����Ǝv���B
����x���`�}�[�N�X�R�A��������ł̐���������
��������G4�}�V�������Ă邩���
�o�b�N�G���h��x86�ł��C���I�[�_�[���ŏȓd�͂ɂȂ邾�낤���A
�t�����g�G���h����H�炢���ƃN���b�N������܂�グ����
�t�����g�G���h����H�炢���ƃN���b�N������܂�グ����
��̂ǂ̃v���Z�T���^�[�Q�b�g�Ƀp�t�H�[�}���X�`���[�j���O��������̂��Y��PG�������o�������B
G4���A�������肪�ݑ��ő��Ђ��ς��Ă�����
DDR3�Ƃ��ɑΉ������Ă��A���ł��ʗp���鐫�\�����Ȃ����˂�
�Ƃ������AFSB100MHz�Ŏg���Ă�[email protected]��133��Mac�ɐςݑւ�����
���ꂾ����1���قǐ��\�オ��������Ȃ��c�c����ł�core2��1.8�̔����قǂ�����
DDR3�Ƃ��ɑΉ������Ă��A���ł��ʗp���鐫�\�����Ȃ����˂�
�Ƃ������AFSB100MHz�Ŏg���Ă�[email protected]��133��Mac�ɐςݑւ�����
���ꂾ����1���قǐ��\�オ��������Ȃ��c�c����ł�core2��1.8�̔����قǂ�����
>661
�o�b�N�T�C�h�L���b�V���������Ă�̂����Ԃ��ԑ傫�Ȍ����ŁA603�܂ł�G3�ȍ~�͂܂�ŕʕ�
��3�Ƃ̑̊�����OS���Ⴄ��łȂ�Ƃ��B
���������3�ɂ�RIMM�d�l�̂����������
FSB�ς��Ȃ�����Ӗ��Ȃ������낤��
�o�b�N�T�C�h�L���b�V���������Ă�̂����Ԃ��ԑ傫�Ȍ����ŁA603�܂ł�G3�ȍ~�͂܂�ŕʕ�
��3�Ƃ̑̊�����OS���Ⴄ��łȂ�Ƃ��B
���������3�ɂ�RIMM�d�l�̂����������
FSB�ς��Ȃ�����Ӗ��Ȃ������낤��
gcc�ŃR���p�C������SPECint/fp_2000
���点��ƁA500(1GHz)���炢�s������
pen3�Ɠ���������ȏ�ɑ����Ǝv����
G4�̘b����
G5���L���b�V��1MB�ł͌��\����
���点��ƁA500(1GHz)���炢�s������
pen3�Ɠ���������ȏ�ɑ����Ǝv����
G4�̘b����
G5���L���b�V��1MB�ł͌��\����
>>657
�C���I�[�_�ł̐��\�����A�A�[�L�e�N�`���̗D�����ɂł���̂�����Ȃ�
Atom�͐��\��������x�̂ĂĂ邩��C���I�[�_���Ƃꂽ��
���ꂪ���C���X�g���[���ł����邩�Ƃ����ƁAIntel���ق̋Z�p�͂������Ă��Ă����������Ă��Ƃ���
�C���I�[�_�ł̐��\�����A�A�[�L�e�N�`���̗D�����ɂł���̂�����Ȃ�
Atom�͐��\��������x�̂ĂĂ邩��C���I�[�_���Ƃꂽ��
���ꂪ���C���X�g���[���ł����邩�Ƃ����ƁAIntel���ق̋Z�p�͂������Ă��Ă����������Ă��Ƃ���
���C���X�g���[���ŃC���I�[�_�̃v���Z�b�T�Ȃ�����Intel���ق̋Z�p�͂��Ȃɂ��Ȃ�����
668 �F,,�E�L�́M�E,,�j��-�������F2008/05/26(��) 00:22:02 ID:SnuHi8tY
Itanium�͈ꉞ�C���I�[�_��VLIW�A�[�L�e�N�`��
���m�Ɍ�����EPIC���Č����炵�����B
���m�Ɍ�����EPIC���Č����炵�����B
Sparc���ăC���I�[�_�[����Ȃ�����?(Sparc64�͈Ⴄ�݂�������)
�����ARock��OoO��
�����[�X�͂܂�����
�����[�X�͂܂�����
R1���ď���SPARC64�̂��Ƃ���ˁH
isaiah + nVidia GPU�̃V�X�e�������T���\���ꂻ�����B
http://news.cnet.com/8301-13924_3-9951669-64.html
�@�@---------------------
�@�@Via will provide the central processing unit and motherboard, plus the core logic (chipset)
�@�@solution, while Nvidia will provide the graphics processing unit, said Drew Henry, general
�@�@manager of Nvidia's platform products division.
�@�@Nvidia will offer standalone "discrete" graphics for both notebook and desktop platforms
�@�@using the Isaiah chip, Henry said.
�@�@---------------------
isaiah + VIA chipaset + nVidia GPU�Ƃ̂��Ƃ��B
http://news.cnet.com/8301-13924_3-9951669-64.html
�@�@---------------------
�@�@Via will provide the central processing unit and motherboard, plus the core logic (chipset)
�@�@solution, while Nvidia will provide the graphics processing unit, said Drew Henry, general
�@�@manager of Nvidia's platform products division.
�@�@Nvidia will offer standalone "discrete" graphics for both notebook and desktop platforms
�@�@using the Isaiah chip, Henry said.
�@�@---------------------
isaiah + VIA chipaset + nVidia GPU�Ƃ̂��Ƃ��B
�ŁA�������NVIDIA��ARM11�R�A��SoC�ɐi�o�Ƃ����b�肷�B
http://www.theinquirer.net/gb/inquirer/news/2008/05/24/nvidia-two-cpu-lines
�@�@�ETegra APX 2500
�@�@�@- die size 144mm^2
�@�@�@- OpenGL ES 2.0
�@�@�@- 720p�f����14MBps�ŃG���R�[�h/�f�R�[�h
�@�@�ECSX 600/650
�@�@�@- �_�C�X�^�b�L���O��256KB L2�ڑ�
�@�@�@- 700-800MHz
�@�@�@- 1080p�f����24FPS��
�@�@�@- 3W
��̃j���[�X�ƍ��킹�ă��o�C����LPIA�ƒ����d��SoC���ʂŃJ�o�[����Ӑ}�̗l���B
http://www.theinquirer.net/gb/inquirer/news/2008/05/24/nvidia-two-cpu-lines
�@�@�ETegra APX 2500
�@�@�@- die size 144mm^2
�@�@�@- OpenGL ES 2.0
�@�@�@- 720p�f����14MBps�ŃG���R�[�h/�f�R�[�h
�@�@�ECSX 600/650
�@�@�@- �_�C�X�^�b�L���O��256KB L2�ڑ�
�@�@�@- 700-800MHz
�@�@�@- 1080p�f����24FPS��
�@�@�@- 3W
��̃j���[�X�ƍ��킹�ă��o�C����LPIA�ƒ����d��SoC���ʂŃJ�o�[����Ӑ}�̗l���B
ttp://www.dailytech.com/NVIDIA+Promises+Powerful+Sub45+Processing+Platform+to+Counter+Intel/article11452.htm
�i�摜�͍����ł��j
���������̍���Ă����Č��ǃ`�b�v�Z�b�g�͖����������̂��H
�P�̂��Ă��Ƃ�MXM�ł̒��A��Ȃ�Chrome4300e�̂ق���������
ttp://pc.watch.impress.co.jp/docs/2008/0421/esc04_23.jpg
��������Ȃ�
�i�摜�͍����ł��j
���������̍���Ă����Č��ǃ`�b�v�Z�b�g�͖����������̂��H
�P�̂��Ă��Ƃ�MXM�ł̒��A��Ȃ�Chrome4300e�̂ق���������
ttp://pc.watch.impress.co.jp/docs/2008/0421/esc04_23.jpg
{kind=link}
��������Ȃ�
Isaiah��Chrome400���Ɨ���CS200��
CS200A����Ȃ����A�^�[�Q�b�g�I��
��HA���t���Ɖ����Ⴄ�́H
CS200�̓n�C�p�t�H�[�}���X����
CS200A�͏ȓd�͌���
CS200A�͏ȓd�͌���
�����Ȃ@���肪��
>>673
�܊pIntel���T���ėǂ��`�����X�Ȃ̂ɁA�����r���[����Ȃ���nVidia��
GPU�����`�b�v�Z�b�g�ōs���ĂȂ��̂͒ɂ��ȁB
Intel���uCentrino 2�v�������B�����̓O���t�B�b�N�X�ƃ��C�����X
http://www.itmedia.co.jp/news/articles/0805/28/news030.html
�܊pIntel���T���ėǂ��`�����X�Ȃ̂ɁA�����r���[����Ȃ���nVidia��
GPU�����`�b�v�Z�b�g�ōs���ĂȂ��̂͒ɂ��ȁB
Intel���uCentrino 2�v�������B�����̓O���t�B�b�N�X�ƃ��C�����X
http://www.itmedia.co.jp/news/articles/0805/28/news030.html
Windows��POWER6�ɈڐA����Ƃ����\���o����Ă���Ƃ��B�B�B
http://www.itjungle.com/tfh/tfh052708-story07.html
�@�@----------------------
�@�@According to one telling of the rumor, Mark Shearer, the former general manager of the
�@�@former System i division and now vice president of marketing and offerings for IBM's
�@�@Business Systems division, told people at COMMON Europe that Windows on Power
�@�@was in the works.
�@�@----------------------
http://www.itjungle.com/tfh/tfh052708-story07.html
�@�@----------------------
�@�@According to one telling of the rumor, Mark Shearer, the former general manager of the
�@�@former System i division and now vice president of marketing and offerings for IBM's
�@�@Business Systems division, told people at COMMON Europe that Windows on Power
�@�@was in the works.
�@�@----------------------
�N���E�h�ׂ̈̎���DC�ɂł��g��������
684 �FMAC�I�^��530 �����F2008/05/28(��) 19:07:00 ID:9GlKuR7m
>>530
�@�@------------------
�@�@�ǂ����ɂ���AIBM��PPE��SMT�ƍl���ĂȂ��ł��傤
�@�@------------------
�Â��b�肷���ǁA�ӂƎv���o���Č������Ă݂����B
http://publib.boulder.ibm.com/infocenter/ieduasst/stgv1r0/topic/com.ibm.iea.cbe/cbe/1.0/Overview/L1T1H1_10_CellArchitecture.pdf
�@�@====================
�@�@PPE handles operationg system and control tasks
�@�@�@- 64-bit Power Architecture with VMX
�@�@�@- In-order, 2-way hardware simultaneous multi-threading (SMT)
�@�@�@- Coherent Load/Store with 32KB I & D L1 and 512KB L2
�@�@====================
http://www-03.ibm.com/technology/cell/pdf/PowerXCell_PB_7May2008_pub.pdf
�@�@====================
�@�@�E64-Bit Power Processor Element
�@�@�@- Dual-instruction issue; two threads, simultaneous multithreading (SMT)
�@�@====================
�@�@------------------
�@�@�ǂ����ɂ���AIBM��PPE��SMT�ƍl���ĂȂ��ł��傤
�@�@------------------
�Â��b�肷���ǁA�ӂƎv���o���Č������Ă݂����B
http://publib.boulder.ibm.com/infocenter/ieduasst/stgv1r0/topic/com.ibm.iea.cbe/cbe/1.0/Overview/L1T1H1_10_CellArchitecture.pdf
�@�@====================
�@�@PPE handles operationg system and control tasks
�@�@�@- 64-bit Power Architecture with VMX
�@�@�@- In-order, 2-way hardware simultaneous multi-threading (SMT)
�@�@�@- Coherent Load/Store with 32KB I & D L1 and 512KB L2
�@�@====================
http://www-03.ibm.com/technology/cell/pdf/PowerXCell_PB_7May2008_pub.pdf
�@�@====================
�@�@�E64-Bit Power Processor Element
�@�@�@- Dual-instruction issue; two threads, simultaneous multithreading (SMT)
�@�@====================
685 �F,,�E�L�́M�E,,�j��-�������F2008/05/28(��) 19:07:35 ID:5K2oxvdm
�r�b�O�G���f�B�A���}�V������NT�J�[�l���̈ڐA���і�����Ȃ����������H
����360����������
����360����������
686 �FMAC�I�^���⑫�F2008/05/28(��) 19:10:20 ID:9GlKuR7m
���Ȃ݂Ɍ�҂̕�����V�^CELL/BE�A"PowerXCell 8i"�̏ڂ����Љ�Ȃ̂ŁA�K�ǂ��Ǝv�����B
����PPE��FGMT�ƌ��������̂�SMT�ƌ��������̂��ǂ����ȂH
������Atom�́H
�ǂ̃��x����simultaneous�ƌ����Ă���̂��H
�F�X�^�O���s���Ȃ��B
������Atom�́H
�ǂ̃��x����simultaneous�ƌ����Ă���̂��H
�F�X�^�O���s���Ȃ��B
688 �FMAC�I�^��683 �����F2008/05/28(��) 19:43:24 ID:9GlKuR7m
>>683
���ɔ����ς݂�x86 linux�G�~�����[�^"PowerVM Lx86��Windows�łȂ炠�肻���Șb���B
PowerVM Lx86��Transitive��QuickTransit���g���Ă��邷���ǁAAPI�R�[����O���t�B�b�N
�@�\���d�_�I�Ƀl�C�e�B�u������Ƃ���PowerMac��x86�G�~���ɋ߂���@������Ă��邷�B
�������Microsoft�̋��͂����ŊJ������A���������̐��\���o���Ȃ������ˁB�B�B
http://journal.mycom.co.jp/articles/2004/09/30/transitive/
���ɔ����ς݂�x86 linux�G�~�����[�^"PowerVM Lx86��Windows�łȂ炠�肻���Șb���B
PowerVM Lx86��Transitive��QuickTransit���g���Ă��邷���ǁAAPI�R�[����O���t�B�b�N
�@�\���d�_�I�Ƀl�C�e�B�u������Ƃ���PowerMac��x86�G�~���ɋ߂���@������Ă��邷�B
�������Microsoft�̋��͂����ŊJ������A���������̐��\���o���Ȃ������ˁB�B�B
http://journal.mycom.co.jp/articles/2004/09/30/transitive/
689 �FMAC�I�^�������F2008/05/28(��) 19:46:02 ID:9GlKuR7m
���x86��68k���ԈႦ�����B
�@��: PowerMac��x86�G�~��
�@��: PowerMac��68k�G�~��
�@��: PowerMac��x86�G�~��
�@��: PowerMac��68k�G�~��
PowerPC��NT4���v���o�����B
�Ƃ���ŏT���ɐ���オ���Ă����f�R�[�_�̘b�肷���ǁA���̎v���Ƃ�������������B
�@��{�I��RISC��VLIW�̎u����A�w�R���p�C�����G/�n�[�h�E�F�A�P���x�Ƃ������m���B
���������Ӗ��ł�OoOE�Ȃ�RISC�̖{������O��Ă���ƌ������ŁA�V�v��RISC�v���Z�b�T
���C���I�[�_�[�ɉ�A������AIPF����łɃC���I�[�_�[�v��ۂ��Ă���̂��[�����邷�B
�@���̕ӂ܂����POWER6����ɖʔ����v�ŁA�C���I�[�_�[+SMT�̖��߃t���[��9�{�̉��Z
�p�C�v���C���ɍ��킹�Ăŕ���ɋl�ߒ����Ď��s����Ƃ����\���ŁA�}���`�X���b�h�����ꂽVLIW��
���邱�Ƃ��ł����Ȃ����Ǝv�����B
http://www.research.ibm.com/journal/rd/516/le.html
�@PowerPC ISA�����s����VLIW�v���Z�b�T�Ƃ����T�O��90�N��Ɍ������ꂽDAISY
(http://www.research.ibm.com/daisy/)���̂��̂��B���݃T�[�o�[����POWER�̒��ڂ̋�������
��IPF�ł���ȏ�AIBM����wVLIW�x�Ƃ������t���o�Ă���Ƃ�v���Ȃ������ǁA�������ʂ퐶�������
����悤�Ɍ����邷�B
�@VLIW�̏h���Ƃ��ėD�G�ȃR���p�C�����K�{�ƂȂ���ǁA�t�Ɍ����Ζډ��̂Ƃ���SPEC CPU
2006�ł�Intel Core�A�[�L�e�N�`���ɑ��Ė��m�ȗD�ʂ������Ă��Ȃ�POWER6(�Ƃ��̌�p�i)��
�V�R���p�C���ő���i�Ƃ�����������҂ł���̂�������Ȃ����B
�@��{�I��RISC��VLIW�̎u����A�w�R���p�C�����G/�n�[�h�E�F�A�P���x�Ƃ������m���B
���������Ӗ��ł�OoOE�Ȃ�RISC�̖{������O��Ă���ƌ������ŁA�V�v��RISC�v���Z�b�T
���C���I�[�_�[�ɉ�A������AIPF����łɃC���I�[�_�[�v��ۂ��Ă���̂��[�����邷�B
�@���̕ӂ܂����POWER6����ɖʔ����v�ŁA�C���I�[�_�[+SMT�̖��߃t���[��9�{�̉��Z
�p�C�v���C���ɍ��킹�Ăŕ���ɋl�ߒ����Ď��s����Ƃ����\���ŁA�}���`�X���b�h�����ꂽVLIW��
���邱�Ƃ��ł����Ȃ����Ǝv�����B
http://www.research.ibm.com/journal/rd/516/le.html
�@PowerPC ISA�����s����VLIW�v���Z�b�T�Ƃ����T�O��90�N��Ɍ������ꂽDAISY
(http://www.research.ibm.com/daisy/)���̂��̂��B���݃T�[�o�[����POWER�̒��ڂ̋�������
��IPF�ł���ȏ�AIBM����wVLIW�x�Ƃ������t���o�Ă���Ƃ�v���Ȃ������ǁA�������ʂ퐶�������
����悤�Ɍ����邷�B
�@VLIW�̏h���Ƃ��ėD�G�ȃR���p�C�����K�{�ƂȂ���ǁA�t�Ɍ����Ζډ��̂Ƃ���SPEC CPU
2006�ł�Intel Core�A�[�L�e�N�`���ɑ��Ė��m�ȗD�ʂ������Ă��Ȃ�POWER6(�Ƃ��̌�p�i)��
�V�R���p�C���ő���i�Ƃ�����������҂ł���̂�������Ȃ����B
>>684
���T�[�`����Ȃ��l�́A���܁ASMT�Ƃ����p��̎g�p���@�Ɋւ��ĂЂǂ�
���ڒ��B�w�p�p��I�ɂ́Aatom��SMT�Ő������Ǝv����B�㓡������
�}��M����Ȃ�A2�̃X���b�h����f�B�X�p�b�`����Ă���4�̖���
�̒���2��issue�|�C���g�őI������issue�ł��H
���ƌ����āA�����X���b�h����̃f�B�X�p�b�`��cycle by cycle������
FGMT���A�ƌ�����Ƃ���͂���Ŏv���Y�ނƂ���ł͂���BPPU�ɂ���
���A���̎�����20�y�[�W�̐}�������FP�p�C�v���Ɨ�����queue��������
�邩��A������cycle by cycle�Ȑ����͗�����ˁB
���T�[�`����Ȃ��l�́A���܁ASMT�Ƃ����p��̎g�p���@�Ɋւ��ĂЂǂ�
���ڒ��B�w�p�p��I�ɂ́Aatom��SMT�Ő������Ǝv����B�㓡������
�}��M����Ȃ�A2�̃X���b�h����f�B�X�p�b�`����Ă���4�̖���
�̒���2��issue�|�C���g�őI������issue�ł��H
���ƌ����āA�����X���b�h����̃f�B�X�p�b�`��cycle by cycle������
FGMT���A�ƌ�����Ƃ���͂���Ŏv���Y�ނƂ���ł͂���BPPU�ɂ���
���A���̎�����20�y�[�W�̐}�������FP�p�C�v���Ɨ�����queue��������
�邩��A������cycle by cycle�Ȑ����͗�����ˁB
693 �FMAC�I�^��692 �����F2008/05/28(��) 23:09:44 ID:9GlKuR7m
>>692
�@�@--------------------
�@�@���T�[�`����Ȃ��l�́A���܁ASMT�Ƃ����p��̎g�p���@�Ɋւ��ĂЂǂ����ڒ��B
�@�@--------------------
http://domino.research.ibm.com/comm/research_projects.nsf/pages/multicore.index.html
�@�@====================
�@�@- Cell B.E. - released in 2005, Cell B.E. is the first heterogeneous multicore solution
�@�@�@with 1 Power Architecture CPU (including 2-way SMT) and 8 Synergistic Processor
�@�@�@CPUs, for a total of 9 cores and 10 threads per chip.
�@�@====================
���T�[�`����Ȃ��B�B�B����(��)
�@�@--------------------
�@�@���T�[�`����Ȃ��l�́A���܁ASMT�Ƃ����p��̎g�p���@�Ɋւ��ĂЂǂ����ڒ��B
�@�@--------------------
http://domino.research.ibm.com/comm/research_projects.nsf/pages/multicore.index.html
�@�@====================
�@�@- Cell B.E. - released in 2005, Cell B.E. is the first heterogeneous multicore solution
�@�@�@with 1 Power Architecture CPU (including 2-way SMT) and 8 Synergistic Processor
�@�@�@CPUs, for a total of 9 cores and 10 threads per chip.
�@�@====================
���T�[�`����Ȃ��B�B�B����(��)
MacOS9���ڐA�Ȃ�킩�邯�ǂȁB
OSX�͕������B
OSX�͕������B
OS�Ƃ�����AOSX��MacOS9���i�i�ɂ����Ǝv�����˂�
����Ƃ��Ă�MacOS9�̂ق����G�Ȉ����ɂ��ς��ĕ֗�������
����Ƃ��Ă�MacOS9�̂ق����G�Ȉ����ɂ��ς��ĕ֗�������
>>693
�܂��������ǂˁB��[����ɁA�v�Z�@�A�[�L�e�N�`���Ɋւ���w�p�I
�Ȕ��\�Ƃ��������ȊO�ł́ASMT��FGMT�̍��Ƃ����̂͌��\�K���Ɉ����
�Ă��邵�A���O�I�ɂ�PPU��FGMT�Ȃ̂��H�Ɩ����Ƃ�����ƈ���������
�Ȃ����Ă̂����������킯���B
�ł��Aatom��SMT�ł����Ǝv����B
�܂��������ǂˁB��[����ɁA�v�Z�@�A�[�L�e�N�`���Ɋւ���w�p�I
�Ȕ��\�Ƃ��������ȊO�ł́ASMT��FGMT�̍��Ƃ����̂͌��\�K���Ɉ����
�Ă��邵�A���O�I�ɂ�PPU��FGMT�Ȃ̂��H�Ɩ����Ƃ�����ƈ���������
�Ȃ����Ă̂����������킯���B
�ł��Aatom��SMT�ł����Ǝv����B
IBM�̃Z�[���X�g�[�N�͗�������
���T�[�`�̐l�̈ӌ�
ttp://eceweb.uccs.edu/wang/ECE4480-s2008/Ch9_CMPSMT.ppt
Multiprocessor on a Chip &
Simultaneous Multi-threads
[Adapted from Computer Organization and Design, Patterson & Hennessy, (c) 2005]
��SMT�̏�
# The PPE is strangely similar to one of the Xenon cores
* Almost identical, really. Slight ISA differences, and fine-grained MT instead of real SMT
�ł��Aatom��SMT�ł����Ǝv����B
���T�[�`�̐l�̈ӌ�
ttp://eceweb.uccs.edu/wang/ECE4480-s2008/Ch9_CMPSMT.ppt
Multiprocessor on a Chip &
Simultaneous Multi-threads
[Adapted from Computer Organization and Design, Patterson & Hennessy, (c) 2005]
��SMT�̏�
# The PPE is strangely similar to one of the Xenon cores
* Almost identical, really. Slight ISA differences, and fine-grained MT instead of real SMT
�ł��Aatom��SMT�ł����Ǝv����B
699 �FMAC�I�^��698 �����F2008/05/29(��) 01:47:06 ID:hZstmRxS
>>698
���T�[�`�����Ȃ��m��Ȃ������ǁA���̃q�g�P�ɊԈႦ�Ă��邷(��)
�@�@-----------------
�@�@Slight ISA differences, and fine-grained MT instead of real SMT
�@�@-----------------
xbox360��Xenon��PPE�Ɠ����p�C�v���C���\��������APPE��FGMT�ɕ��ނ���Ȃ瓯����FGMT���B
http://www.hotchips.org/archives/hc17/3_Tue/HC17.S8/HC17.S8T4.pdf (p.6�Q��)
�@�@=================
�@�@- 2 symmetric fine grain hardware threads
�@�@=================
���T�[�`�����Ȃ��m��Ȃ������ǁA���̃q�g�P�ɊԈႦ�Ă��邷(��)
�@�@-----------------
�@�@Slight ISA differences, and fine-grained MT instead of real SMT
�@�@-----------------
xbox360��Xenon��PPE�Ɠ����p�C�v���C���\��������APPE��FGMT�ɕ��ނ���Ȃ瓯����FGMT���B
http://www.hotchips.org/archives/hc17/3_Tue/HC17.S8/HC17.S8T4.pdf (p.6�Q��)
�@�@=================
�@�@- 2 symmetric fine grain hardware threads
�@�@=================
>>691
�܂���daisy(�₻��ȑO)�̘_����ǂ��Ƃ��Ȃ��A����ǂ�ł��Ă��������Ă��Ȃ����Ƃ͋����ɂ͂��������܂��A
��������VLIW�����Ȃ̂��悭�킩���Ă��Ȃ��悤�ł�
����ς�p�ꂩ������Ă���݂����ł���
�ł��Aatom��SMT�ł����Ǝv����B
�܂���daisy(�₻��ȑO)�̘_����ǂ��Ƃ��Ȃ��A����ǂ�ł��Ă��������Ă��Ȃ����Ƃ͋����ɂ͂��������܂��A
��������VLIW�����Ȃ̂��悭�킩���Ă��Ȃ��悤�ł�
����ς�p�ꂩ������Ă���݂����ł���
�ł��Aatom��SMT�ł����Ǝv����B
701 �FMAC�I�^��700 �����F2008/05/29(��) 02:06:08 ID:hZstmRxS
>>699
�܂��ACell�قǎ����̂Ȃ�Xenon�ɂ��Ă͂Ƃ������A
���R���R������̂�PPE���킴�킴FGMT�Ă�肵�Ă邾�낤�B
ppt�ɂ́A��(�Ƃ������A�p�^�l�l)���AFGMT��SMT���ǂ���ʂ��Ă��邩�����Ă��邵
ttp://www.research.ibm.com/journal/rd/515/chen.pdf
��Figure 2��Cycle-alternating dual-instruction dispatch���A�ǂ���ɍ��v���邩�͔n���ł��킩�邾�낤�B
>>701
�p����ӂ�܂킵�ė��������C�ɂȂ��Ă�̂͂����̂܂������
�ł��Aatom��SMT�ł����Ǝv����B
�܂��ACell�قǎ����̂Ȃ�Xenon�ɂ��Ă͂Ƃ������A
���R���R������̂�PPE���킴�킴FGMT�Ă�肵�Ă邾�낤�B
ppt�ɂ́A��(�Ƃ������A�p�^�l�l)���AFGMT��SMT���ǂ���ʂ��Ă��邩�����Ă��邵
ttp://www.research.ibm.com/journal/rd/515/chen.pdf
��Figure 2��Cycle-alternating dual-instruction dispatch���A�ǂ���ɍ��v���邩�͔n���ł��킩�邾�낤�B
>>701
�p����ӂ�܂킵�ė��������C�ɂȂ��Ă�̂͂����̂܂������
�ł��Aatom��SMT�ł����Ǝv����B
�m����DAISY�̎�v�Ȑ��ʂł���"tree based VLIW"�Ƃ������c��Itanium�̃v���f�B�P�[�V����
�Ɠ������p��_�������m�̗l������A�s�K�v�Ȍv�Z��s��Ȃ��Ƃ�������̒����d�͉��̗���
�ɔ����Ă��邷�B
http://www.research.ibm.com/daisy/manual-small.html
������ [DAISY] - [predication] + [(load/branch) lookahead] �Ǝv���ƁA�ĊO���Ă���Ƃ���������
�v�����B
�Ɠ������p��_�������m�̗l������A�s�K�v�Ȍv�Z��s��Ȃ��Ƃ�������̒����d�͉��̗���
�ɔ����Ă��邷�B
http://www.research.ibm.com/daisy/manual-small.html
������ [DAISY] - [predication] + [(load/branch) lookahead] �Ǝv���ƁA�ĊO���Ă���Ƃ���������
�v�����B
704 �FMAC�I�^��702 �����F2008/05/29(��) 02:30:02 ID:hZstmRxS
>>702
�ǂ��Ɋ��S�������A�����ς藝���ł��Ȃ������ǁA
�@�@--------------------
�@�@ppt�ɂ́A��(�Ƃ������A�p�^�l�l)���AFGMT��SMT���ǂ���ʂ��Ă��邩�����Ă��邵
�@�@--------------------
���Ȃ����}�[�P�e�B���O�D����Ȃ�IBM�̔��\�����l�̐}�Ń}���`�X���b�h��@�̕��ނ�
������Ă��邷�B
http://www.hotchips.org/archives/hc15/3_Tue/11.ibm.pdf (p.6�Q��)
�ǂ��Ɋ��S�������A�����ς藝���ł��Ȃ������ǁA
�@�@--------------------
�@�@ppt�ɂ́A��(�Ƃ������A�p�^�l�l)���AFGMT��SMT���ǂ���ʂ��Ă��邩�����Ă��邵
�@�@--------------------
���Ȃ����}�[�P�e�B���O�D����Ȃ�IBM�̔��\�����l�̐}�Ń}���`�X���b�h��@�̕��ނ�
������Ă��邷�B
http://www.hotchips.org/archives/hc15/3_Tue/11.ibm.pdf (p.6�Q��)
>>703
�͂��͂�
�p����ӂ�܂킷�̂͊y������
> ������ [DAISY] - [predication] + [(load/branch) lookahead] �Ǝv���ƁA�ĊO���Ă���Ƃ���������
�v�����B
�C���J�ƃT�����炢�ɂ͎��Ă��邩����w
�Ƃ��ɏ��߂ăC���J�������l�ɂ͋�ʂ��Ȃ�������ww
>>704
> http://www.hotchips.org/archives/hc15/3_Tue/11.ibm.pdf (p.6�Q��)
PPE������4�̐}�̊Y�����邩�A���̐l�͗������Ă��܂�w
�ł��Aatom��SMT�ł����Ǝv����B
�͂��͂�
�p����ӂ�܂킷�̂͊y������
> ������ [DAISY] - [predication] + [(load/branch) lookahead] �Ǝv���ƁA�ĊO���Ă���Ƃ���������
�v�����B
�C���J�ƃT�����炢�ɂ͎��Ă��邩����w
�Ƃ��ɏ��߂ăC���J�������l�ɂ͋�ʂ��Ȃ�������ww
>>704
> http://www.hotchips.org/archives/hc15/3_Tue/11.ibm.pdf (p.6�Q��)
PPE������4�̐}�̊Y�����邩�A���̐l�͗������Ă��܂�w
�ł��Aatom��SMT�ł����Ǝv����B
�܂�����͊w���Ȃ��Đ��i�ƌ㓡�����̋L�������m��Ȃ�����A
�����ł��������̂�������Ɩ�����֘A�Â��čl�����Ⴄ��ˁB
�ł��Aatom��SMT�ł����Ǝv����B
�����ł��������̂�������Ɩ�����֘A�Â��čl�����Ⴄ��ˁB
�ł��Aatom��SMT�ł����Ǝv����B
��n�O VS ��n�O
���O��̎�i�ƖړI�͕ʃX���ł��肢������
���O��̎�i�ƖړI�͕ʃX���ł��肢������
�����A�X�����Ă�������ŁA�����ɗ��ĂĂ����
�I�^���c�_���瓦���Ă����ʃX�����ĂĂ��Ӗ��Ȃ��B
�����ł�����B
CPU�̘b�͂��Ă�킯�����B
�����ł�����B
CPU�̘b�͂��Ă�킯�����B
710 �FMAC�I�^��709 �����F2008/05/29(��) 07:51:08 ID:hZstmRxS
>>709
�@�@------------------
�@�@�I�^���c�_���瓦���Ă�
�@�@------------------
���������ނ̃q�g�B����ɋc�_�����藧��������@�������ė~�������m���B
�@�E��̓I�Ȏw�E�����ɁA�Ґ����˂Ŕ�� (>>700�Ƃ�)
�@�E���p�\�[�X��ԈႢ (>>698-699)
�@�E�w�E����Ă������̐����������� (>>702)
�@�@------------------
�@�@�I�^���c�_���瓦���Ă�
�@�@------------------
���������ނ̃q�g�B����ɋc�_�����藧��������@�������ė~�������m���B
�@�E��̓I�Ȏw�E�����ɁA�Ґ����˂Ŕ�� (>>700�Ƃ�)
�@�E���p�\�[�X��ԈႢ (>>698-699)
�@�E�w�E����Ă������̐����������� (>>702)
�Ƃ肠�����_�����Ă����B
�I�^��PPE��FGMT�ƌ�������(>>511)�̂�SMT�ƌ�������(>>684)�̂��H
����Ƃ�FGMT����SMT�ł���ƌ��������̂��H(���̏ꍇ�͍L�`��SMT�ƂȂ肻������)
���l��Atom��FGMT���ƌ����Ă���(>>511)���A���̌�F��Ȑl���炻���SMT����Ɠ˂����܂�Ă���B
����Ɋւ��Ē�������C�͂���̂��H
��������C�������Ȃ�Atom��FGMT�ł���Ƃ����������o���Ă���B
�I�^��PPE��FGMT�ƌ�������(>>511)�̂�SMT�ƌ�������(>>684)�̂��H
����Ƃ�FGMT����SMT�ł���ƌ��������̂��H(���̏ꍇ�͍L�`��SMT�ƂȂ肻������)
���l��Atom��FGMT���ƌ����Ă���(>>511)���A���̌�F��Ȑl���炻���SMT����Ɠ˂����܂�Ă���B
����Ɋւ��Ē�������C�͂���̂��H
��������C�������Ȃ�Atom��FGMT�ł���Ƃ����������o���Ă���B
>>707
�V�X���}�_�[�H
>>691
> �C���I�[�_�[+SMT�̖��߃t���[��9�{�̉��Z
> �p�C�v���C���ɍ��킹�Ăŕ���ɋl�ߒ����Ď��s����Ƃ����\���ŁA�}���`�X���b�h�����ꂽVLIW��
> ���邱�Ƃ��ł����Ȃ����Ǝv�����B
�C���I�[�_�[��POWER6�ƌ����ǂ����I�ɖ��߂̈ˑ��W���`�F�b�N���Ă���̂ŁA
���ꂪVLIW�Ɍ�����̂͂܂�����������A
�܂�������ɓǂ�ł��炤���߂̃��X�ł��Ȃ��̂ŁA����Ȃ��������I�ȉ��������̂����ق炵������
����������A�܂������
> �@�E���p�\�[�X��ԈႢ (>>698-699)
Xenon�ɂ��Ă͂Ƃ������APPE�ɂ��Ă͊Ԉ���Ă͂��Ȃ���
�����ĐX�������Ȃ܂������ɂ͋C�ɂ���Ȃ���������Ȃ���
�Ƃ����Xenon��PPE�̃t�����g�G���h�����S�ɓ���̂��̂Ƃ����͂�����Ƃ����؋���MS��IBM����o�Ă���̂��ȁH
> �@�E�w�E����Ă������̐����������� (>>702)
�܂��Ɍ�����Ƃ͂͂Ȃ͂����h�ł͂��邪�A
>>705��4�}�̂ǂ��Cell PPE�����ނ���邩�́A�܂������͓������邩�ȁH�������Ȃ��Ă������ǁB
�ł��Aatom��SMT�ł����Ǝv����B
�V�X���}�_�[�H
>>691
> �C���I�[�_�[+SMT�̖��߃t���[��9�{�̉��Z
> �p�C�v���C���ɍ��킹�Ăŕ���ɋl�ߒ����Ď��s����Ƃ����\���ŁA�}���`�X���b�h�����ꂽVLIW��
> ���邱�Ƃ��ł����Ȃ����Ǝv�����B
�C���I�[�_�[��POWER6�ƌ����ǂ����I�ɖ��߂̈ˑ��W���`�F�b�N���Ă���̂ŁA
���ꂪVLIW�Ɍ�����̂͂܂�����������A
�܂�������ɓǂ�ł��炤���߂̃��X�ł��Ȃ��̂ŁA����Ȃ��������I�ȉ��������̂����ق炵������
����������A�܂������
> �@�E���p�\�[�X��ԈႢ (>>698-699)
Xenon�ɂ��Ă͂Ƃ������APPE�ɂ��Ă͊Ԉ���Ă͂��Ȃ���
�����ĐX�������Ȃ܂������ɂ͋C�ɂ���Ȃ���������Ȃ���
�Ƃ����Xenon��PPE�̃t�����g�G���h�����S�ɓ���̂��̂Ƃ����͂�����Ƃ����؋���MS��IBM����o�Ă���̂��ȁH
> �@�E�w�E����Ă������̐����������� (>>702)
�܂��Ɍ�����Ƃ͂͂Ȃ͂����h�ł͂��邪�A
>>705��4�}�̂ǂ��Cell PPE�����ނ���邩�́A�܂������͓������邩�ȁH�������Ȃ��Ă������ǁB
�ł��Aatom��SMT�ł����Ǝv����B
atom�̐���ALU����Execute�X�e�[�W��1���Ď��̓X���[�v�b�g1�A���C�e���V1����ˁB
inorder�̓R���p�C���̍œK���̉e�����₷���Ƃ͂����A
�V���O���X���b�h�ł�IPC1�͊m�ۂł��Ă��������̐��\���ł�C���������
���܂茋�ʂ��U���Ȃ��͓̂���ȃX�g�[���Ƃ�����̂��ˁH
PPE�̓L���b�V���~�X����ƃp�C�v���C���t���b�V�����邯��atom�������Ȃ낤���B
inorder�̓R���p�C���̍œK���̉e�����₷���Ƃ͂����A
�V���O���X���b�h�ł�IPC1�͊m�ۂł��Ă��������̐��\���ł�C���������
���܂茋�ʂ��U���Ȃ��͓̂���ȃX�g�[���Ƃ�����̂��ˁH
PPE�̓L���b�V���~�X����ƃp�C�v���C���t���b�V�����邯��atom�������Ȃ낤���B
714 �F,,�E�L�́M�E,,�j��-�������F2008/05/29(��) 22:53:01 ID:iBzJDYL/
NetBurst������Ȋ����������ȁB
L2�̃��C�e���V���p�C�v���C���n�U�[�h�̃N���b�N���ƈ�v���Ă�̂����̂������B
L2�̃��C�e���V���p�C�v���C���n�U�[�h�̃N���b�N���ƈ�v���Ă�̂����̂������B
���������ł�����Ă��邷���ǁA���O�̏��ʂ�isaiah���炽��VIA "nano"�����\���ꂽ���B
http://www.via.com.tw/en/downloads/whitepapers/processors/WP080529VIA_Nano.pdf
http://www.via.com.tw/en/downloads/whitepapers/processors/WP080529VIA_Nano.pdf
���ł�>>563�ň��p����Digitimes�L���̑����IDG���`���Ă��邷�B
http://www.pcworld.com/businesscenter/article/146417/via_plans_dualcore_nano_processor_shift_to_45nm.html
�@�@------------------
�@�@Via expects to release a dual-core version of its Nano processor next year and shift
�@�@production of the new chips to a more advanced 45-nanometer process.
�@�@------------------
45nm�Ńf���A���R�A�Ƃ����̂�Anano�̂��Ƃ��������B�ӗ~�I�ɊJ���i�߂Ă���l���B
http://www.pcworld.com/businesscenter/article/146417/via_plans_dualcore_nano_processor_shift_to_45nm.html
�@�@------------------
�@�@Via expects to release a dual-core version of its Nano processor next year and shift
�@�@production of the new chips to a more advanced 45-nanometer process.
�@�@------------------
45nm�Ńf���A���R�A�Ƃ����̂�Anano�̂��Ƃ��������B�ӗ~�I�ɊJ���i�߂Ă���l���B
�������Z�p�I�b�肶��Ȃ������ǁAItanium�̏o�א��Ɋւ��鋻���[����������̂ŏ����Ă������B
http://www.itjungle.com/two/two052808-story02.html
�@�@-----------------------
�@�@Through 2007, over 184,000 Itanium-based machines have shipped worldwide, with aggregate
�@�@revenues up 30.8 percent and shipments up 36.3 percent compared to 2006's Itanium sales
�@�@and shipments, according to IDC.
�@�@-----------------------
http://www.itjungle.com/two/two052808-story02.html
�@�@-----------------------
�@�@Through 2007, over 184,000 Itanium-based machines have shipped worldwide, with aggregate
�@�@revenues up 30.8 percent and shipments up 36.3 percent compared to 2006's Itanium sales
�@�@and shipments, according to IDC.
�@�@-----------------------
���ǃX���[����I�^�B
�������ƌ��킸���ĉ��ƌ����̂��B
�������ƌ��킸���ĉ��ƌ����̂��B
�܂�����L��̃A�[�L�e�N�`���X����
�����̃A�[�L�e�N�`���X���ɂ킯�Ă�������B
�܂�����͂������N�A�ǂ��̃X���ɂ����Ⴕ���łĂ��邩��ȁB
�����̏������݂Ɏ��M������̂Ȃ�A
���g�̐�p�X�������Ăđ������|���Č����Ăق������̂��B
�����̃A�[�L�e�N�`���X���ɂ킯�Ă�������B
�܂�����͂������N�A�ǂ��̃X���ɂ����Ⴕ���łĂ��邩��ȁB
�����̏������݂Ɏ��M������̂Ȃ�A
���g�̐�p�X�������Ăđ������|���Č����Ăق������̂��B
CS200A����1,8GHz�o�Ȃ��C������
>>713
�v���t�F�b�`�╪��\�����T���ڂƂ������ˁB
�������A[�e���r] - [�u���E����] + [�R���v���b�T�[�A��] �Ǝv���ƁA�①�ɂƈĊO���Ă���Ƃ��������Ǝv�����B
�ł��Aatom��SMT�ł����Ǝv����B
�v���t�F�b�`�╪��\�����T���ڂƂ������ˁB
�������A[�e���r] - [�u���E����] + [�R���v���b�T�[�A��] �Ǝv���ƁA�①�ɂƈĊO���Ă���Ƃ��������Ǝv�����B
�ł��Aatom��SMT�ł����Ǝv����B
���ځ[��p���C�����ɂݓ���
�ǂ��ł��������A�͂₭�X�����ĂĂ����
���ꗧ�Ă��Ȃ���
atom��SMT�����ǂ�
���ꗧ�Ă��Ȃ���
atom��SMT�����ǂ�
�Ƃ���ŁAMAC�I�^�Ƃ͗��ĂĂ��ꂽ��ʃX���ł�邯��
�݂�Ȃ������̃X���ł͉����������́H
�قƂ�ǂ̃��X���A�܂��Ɠ����x���ȉ��̖ό��Ȃ���
����ɂ��Ă͂������ł���Ă����́H
�݂�Ȃ������̃X���ł͉����������́H
�قƂ�ǂ̃��X���A�܂��Ɠ����x���ȉ��̖ό��Ȃ���
����ɂ��Ă͂������ł���Ă����́H
>>724
��肽�������Ă�����B
Mac�I�^�͒m�������[�ȏ�ɒ�������C�Ȃ��ԓx����������@����Ă��ł����āA
�ԓx�ǂ��Ēm�����[�ȓz�ɓ����悤�ȑΉ�������>>724���@�����Ǝv�����ǁB
��肽�������Ă�����B
Mac�I�^�͒m�������[�ȏ�ɒ�������C�Ȃ��ԓx����������@����Ă��ł����āA
�ԓx�ǂ��Ēm�����[�ȓz�ɓ����悤�ȑΉ�������>>724���@�����Ǝv�����ǁB
��MAC�I�^�������̃u���O�ł��Ⴂ���b����Ȃ���?
��C��߂Ȃ�MAC�I�^���A�����ŃR�s�y���܂��邩�牽�����Ă����ʂ���
�����̓s���̗ǂ����ԂɃl�^�������āA�m�����x�����Ⴛ���Ȃ�������Ă̓`�N�`�N�U�߂�
����ȊO�ɂ͋������Ȃ����Ă̂��}�R����̓O�ꂵ���X�^�C��������A
�u���O�̂悤�ɍ��𐘂��ăf�B�t�F���X�����Ȃ��Ⴂ���Ȃ��悤�ȏꏊ�Ɉڂ�͂����Ȃ���ŁB
�ł�����̓}�R����Ɍ��������ł͂Ȃ����A�����ł�����ˁH
����ȊO�ɂ͋������Ȃ����Ă̂��}�R����̓O�ꂵ���X�^�C��������A
�u���O�̂悤�ɍ��𐘂��ăf�B�t�F���X�����Ȃ��Ⴂ���Ȃ��悤�ȏꏊ�Ɉڂ�͂����Ȃ���ŁB
�ł�����̓}�R����Ɍ��������ł͂Ȃ����A�����ł�����ˁH
729 �F,,�E�L�́M�E,,�j��-�������F2008/05/30(��) 21:05:52 ID:bAPgk5Zh
���̂��Ƃ�
�͂��͂��X�����������܂�������܂�B�X�s�[�h�Љ�
�������A�������A���Ղ��������I
�Q�l�܂ł�Atom/1.6GHz��Nano/1.8GHz��Windows Experience Index�̔�r���B
��Atom: 2.9 (�\�[�X: http://journal.mycom.co.jp/articles/2008/04/02/idf03/)
�@�@http://journal.mycom.co.jp/photo/articles/2008/04/02/idf03/images/013l.jpg
��Nano: 3.3 (�\�[�X: http://www.hkepc.com/?id=1227&fs=c1h)
�@�@http://www.hkepc.com/database/images/thumbs/320x240.2008052919372949251080825.jpg
��Atom: 2.9 (�\�[�X: http://journal.mycom.co.jp/articles/2008/04/02/idf03/)
�@�@http://journal.mycom.co.jp/photo/articles/2008/04/02/idf03/images/013l.jpg
{kind=link}
��Nano: 3.3 (�\�[�X: http://www.hkepc.com/?id=1227&fs=c1h)
�@�@http://www.hkepc.com/database/images/thumbs/320x240.2008052919372949251080825.jpg
{kind=link}
�ǂ������\���Ȃ̂��킩���
nano�̕���graphics�̍��ڂ�5.9�A5.7�Ȃ̂��C�ɂȂ�
��������VX800���ᖳ���Ƃ͎v����
C7 1.5GHz�� 2.0
atom 1.6GHz(HT)��2.9
nano 1.8GHz��3.3��
nano�̕���graphics�̍��ڂ�5.9�A5.7�Ȃ̂��C�ɂȂ�
��������VX800���ᖳ���Ƃ͎v����
C7 1.5GHz�� 2.0
atom 1.6GHz(HT)��2.9
nano 1.8GHz��3.3��
�f�X�N�g�b�v��RISC���u�C�u�C���킹���̂́A��������386����Pentium���炢
�܂ł��B
P6�o��ȍ~�͐��f���ɁB
�܂ł��B
P6�o��ȍ~�͐��f���ɁB
G3�o�ꓖ����2�{����������Y�ꂿ�Ⴂ���Ȃ���
2�{�̓A���Ƃ��Ă��A���x�I�D�ʂ͊m���ɂ�����
2�{�̓A���Ƃ��Ă��A���x�I�D�ʂ͊m���ɂ�����
http://pc.watch.impress.co.jp/docs/2008/0602/kaigai442.htm
>���̂��Ƃ́ANehalem�A�[�L�e�N�`���́A���C���X�g���[��PC�ɐZ�����n�߂�܂ł�3�l����������A
>���C���X�g���[���f�X�N�g�b�v��u��������ɂ�1�N�ȏォ���邱�Ƃ��Ӗ�����B
>���C���X�g���[���f�X�N�g�b�vCPU����C�ɒu���������ACore Microarchitecture(Core MA)�̃P�[�X�Ƃ͑傫���قȂ�B
>Intel��Mobility Group�́A���݊J�����Ă���uSandy Bridge(�T���f�B�u���b�W)�v��2010�N���Ƀ����[�X����\�肾�B
>Sandy Bridge��Mobility Group���哱���ĊJ�����Ă��邽�߁ADigital Enterprise Group�哱�ŊJ������Nehalem�ƈقȂ�A
>�ŏ��̃o�[�W�������烂�o�C���ɓK�p�ł���ƌ�����B�����ASandy Bridge���X�P�W���[���ʂ�ɏo��Ȃ�A
>���o�C���ł�Nehalem�t�@�~���́A1�N�����x�̒Z���ŏI���\��������B
��d���I>>>>>>>>>�f�X�N�g�b�v>>�m�[�g��������H
>���̂��Ƃ́ANehalem�A�[�L�e�N�`���́A���C���X�g���[��PC�ɐZ�����n�߂�܂ł�3�l����������A
>���C���X�g���[���f�X�N�g�b�v��u��������ɂ�1�N�ȏォ���邱�Ƃ��Ӗ�����B
>���C���X�g���[���f�X�N�g�b�vCPU����C�ɒu���������ACore Microarchitecture(Core MA)�̃P�[�X�Ƃ͑傫���قȂ�B
>Intel��Mobility Group�́A���݊J�����Ă���uSandy Bridge(�T���f�B�u���b�W)�v��2010�N���Ƀ����[�X����\�肾�B
>Sandy Bridge��Mobility Group���哱���ĊJ�����Ă��邽�߁ADigital Enterprise Group�哱�ŊJ������Nehalem�ƈقȂ�A
>�ŏ��̃o�[�W�������烂�o�C���ɓK�p�ł���ƌ�����B�����ASandy Bridge���X�P�W���[���ʂ�ɏo��Ȃ�A
>���o�C���ł�Nehalem�t�@�~���́A1�N�����x�̒Z���ŏI���\��������B
��d���I>>>>>>>>>�f�X�N�g�b�v>>�m�[�g��������H
�̂Ƃ����������ʂ�Ƃ������C���ꂪ���ʂ̃C���e���̂������ƁB
Nehalem����ʌ����ɍ~��Ă���̂�32nm�܂ő҂��Ȃ��Ƃ����Ȃ��Ȃ邩���m����
09�N�㔼���āA�����32nm�̐��Y�����グ�Ƃ��Ԃ��Ă邶���
�ւ�����ƁA�f�X�N�g�b�v��45nm�͏��������o���āA������32nm�Ɉڍs�����łȂ��́H
09�N�㔼���āA�����32nm�̐��Y�����グ�Ƃ��Ԃ��Ă邶���
�ւ�����ƁA�f�X�N�g�b�v��45nm�͏��������o���āA������32nm�Ɉڍs�����łȂ��́H
Legit Reviews��Centaur Technologies�������K��L���B
http://www.legitreviews.com/article/719/1/
����i��Nano�Ɠ��쌟�ؒ��̗l�q�����Ď��邷�B
���������̋K�͂���A���\����ʎY�܂ł̊��Ԃ������̂퓖����O���ˁB�B�B
http://www.legitreviews.com/article/719/1/
����i��Nano�Ɠ��쌟�ؒ��̗l�q�����Ď��邷�B
���������̋K�͂���A���\����ʎY�܂ł̊��Ԃ������̂퓖����O���ˁB�B�B
11x11�̃p�b�P�[�W��eden-n��NanoBGA�i15x15)���X�ɏ������̂�
�inanoBGA2��22x22)
nano���ƃM���M������
ttp://www.viatech.co.jp/jp/downloads/presentations/processors/pb_via-isaiah_080124.pdf
11x11��C7���ȂƂ��v�������A��������nano�����p�b�P�[�W�������̂�
�ŁAnano�𓋍ڂ���Mobile-ITX�����̂����o���
�inanoBGA2��22x22)
nano���ƃM���M������
ttp://www.viatech.co.jp/jp/downloads/presentations/processors/pb_via-isaiah_080124.pdf
11x11��C7���ȂƂ��v�������A��������nano�����p�b�P�[�W�������̂�
�ŁAnano�𓋍ڂ���Mobile-ITX�����̂����o���
�yCOMPUTEX�zNVIDIA��Intel��Atom�R�i�C�u���揈���\�͂�10�{�C����d�͂�1/10�v
http://techon.nikkeibp.co.jp/article/NEWS/20080603/152751/
x86 vs. ARM �͂��܂����H
http://techon.nikkeibp.co.jp/article/NEWS/20080603/152751/
x86 vs. ARM �͂��܂����H
742 �F,,�E�L�́M�E,,�j��-�������F2008/06/03(��) 18:26:09 ID:g39CiaOC
Intel��Xscale���߂�������
ASUS�Ƃ��̃~�j�m�[�g���ăl�b�g�ƃ��[�����ł���������낤���ăR���Z�v�g�������Ǝv������
�킴�킴x86�̗p���Ă��̂͑����Ƃ��ꂷ��͕s������������H
�킴�킴x86�̗p���Ă��̂͑����Ƃ��ꂷ��͕s������������H
XP���������������낤
IE����FireFox�ɂȂ��������Ńp�j�b�N�ɂȂ�悤�Ȉ�ʐl����ɂ�
����OS���Ɣ���Â炢����ȁc�c
IE����FireFox�ɂȂ��������Ńp�j�b�N�ɂȂ�悤�Ȉ�ʐl����ɂ�
����OS���Ɣ���Â炢����ȁc�c
TSMC��45nm�̃n�[�t�m�[�h�A40nm�v���Z�X���J�n����Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208401660
�@�@-----------------------
�@�@TSMC has moved into production at both the 45- and 40-nm nodes. In March, TSMC unveiled
�@�@its 40-nm process. The process is an interim, "half node" step toward the 32-nm process node,
�@�@which TSMC expects to ramp starting late next year.
�@�@-----------------------
�����Ă���ʂ�32nm�����N���ɂ�n�߂�\��炵�����B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208401660
�@�@-----------------------
�@�@TSMC has moved into production at both the 45- and 40-nm nodes. In March, TSMC unveiled
�@�@its 40-nm process. The process is an interim, "half node" step toward the 32-nm process node,
�@�@which TSMC expects to ramp starting late next year.
�@�@-----------------------
�����Ă���ʂ�32nm�����N���ɂ�n�߂�\��炵�����B
>>743
�V�X�e�����\��V�X�e�����i��CPU�����ł͌��܂�Ȃ��A�Ƃ��������ƁB
ARM11�����Ă����\��Ȃ����낤���ǁA���Ⴀ�`�b�v�Z�b�g�͂ǂ������?�Ƃ������ɂȂ��ŁA
HT�Ή��R�A�����AMD�����`�b�v�Z�b�g���p���ቿ�i�I�ȃ����b�g�Ȃ�Ė������낤���B
�V�X�e�����\��V�X�e�����i��CPU�����ł͌��܂�Ȃ��A�Ƃ��������ƁB
ARM11�����Ă����\��Ȃ����낤���ǁA���Ⴀ�`�b�v�Z�b�g�͂ǂ������?�Ƃ������ɂȂ��ŁA
HT�Ή��R�A�����AMD�����`�b�v�Z�b�g���p���ቿ�i�I�ȃ����b�g�Ȃ�Ė������낤���B
>>746
�v���b�g�t�H�[���̖����������̂��A�]����SoC���i���ƍ��x��CPU����͂Ȋ����H
�Ă��Ƃ�Tegra��PC�ɂ��g���郌�x����CPU�ł���SoC���ĂƂ��낪�L���Ȃ킯��
�v���b�g�t�H�[���̖����������̂��A�]����SoC���i���ƍ��x��CPU����͂Ȋ����H
�Ă��Ƃ�Tegra��PC�ɂ��g���郌�x����CPU�ł���SoC���ĂƂ��낪�L���Ȃ킯��
748 �FSocket774�F2008/06/05(��) 09:42:33 ID:DzQAQzY8
ttp://pc.nikkeibp.co.jp/article/news/20080604/1004167/?SS=pco_imgview&FD=-650025167
E7200�̖�1/6
ttp://pc.nikkeibp.co.jp/article/news/20080604/1004167/?SS=pco_imgview&FD=-648178125
E7200�̔�����肿����Ƒ���
�E�E�E�E
E7200�̖�1/6
ttp://pc.nikkeibp.co.jp/article/news/20080604/1004167/?SS=pco_imgview&FD=-648178125
E7200�̔�����肿����Ƒ���
�E�E�E�E
�P����DMIPS�������Ă����傤���Ȃ����ǁAARM11��1.2 MIPS/MHz�炵���̂ŁA
800MHz��Tegra����960DMIPS���炢���낤�B
Pen!!!��1GHz��2000��̂悤�Ȃ̂ŁATegra��ARM11�̐��\��Pen!!!�⏉��Athlon��500MHz���炢
�̐��\���낤���B
PC�Ƃ��Ďg���ɂ�CPU�P�̂ł͂܂���͂���Ȃ����ȁB
�̂�GPU�̕�������NVIDIA�I�ɂ͖���肾�낤���ǁB
800MHz��Tegra����960DMIPS���炢���낤�B
Pen!!!��1GHz��2000��̂悤�Ȃ̂ŁATegra��ARM11�̐��\��Pen!!!�⏉��Athlon��500MHz���炢
�̐��\���낤���B
PC�Ƃ��Ďg���ɂ�CPU�P�̂ł͂܂���͂���Ȃ����ȁB
�̂�GPU�̕�������NVIDIA�I�ɂ͖���肾�낤���ǁB
�������l�b�g��p�Ɏg���Ă�G4@1GHz�i����������3/1GHz�����j�ŁA����͂�����˂�
�ł��A�d�������i�摜�A����n�j���ŐV��GPU�ɔC������Ƃ��A�g�ы@��ʼn�ʋ����Ƃ��Ȃ�
�ĊO�����邩�������c�c����ȊO�̃T�C�g�߂���Ƃ��Ȃ�233MHz�ł�����Ă�����
�ł��A�d�������i�摜�A����n�j���ŐV��GPU�ɔC������Ƃ��A�g�ы@��ʼn�ʋ����Ƃ��Ȃ�
�ĊO�����邩�������c�c����ȊO�̃T�C�g�߂���Ƃ��Ȃ�233MHz�ł�����Ă�����
>>747
����ACPU�ȊO���ʖڂȂ�B
EMONE�݂�����Geforce�ς߂�����x�O���t�B�b�N���͂Ȃ�Ƃ��Ȃ邯�ǁA
CE�n�ŃA�N�Z�����[�V���������O���t�B�b�N�����Ă�SoC�Ȃ�āc
����ł�����R�[�f�b�N�Ƃ�HDD�C���^�[�t�F�C�X�́c
EMONE�A���ۂ̃R�X�g��EeePC��ׂ�Ƃǂ��������Ȃ̂��c(w
����ACPU�ȊO���ʖڂȂ�B
EMONE�݂�����Geforce�ς߂�����x�O���t�B�b�N���͂Ȃ�Ƃ��Ȃ邯�ǁA
CE�n�ŃA�N�Z�����[�V���������O���t�B�b�N�����Ă�SoC�Ȃ�āc
����ł�����R�[�f�b�N�Ƃ�HDD�C���^�[�t�F�C�X�́c
EMONE�A���ۂ̃R�X�g��EeePC��ׂ�Ƃǂ��������Ȃ̂��c(w
�z���C�g�y�[�p�[: �x�m��SPARC64VII�v���Z�b�T
http://img.jp.fujitsu.com/downloads/jp/jhpc/sparc64vii-wpj.pdf
SPARC64VII��VMT����Ȃ���SMT�Ȃ�
http://img.jp.fujitsu.com/downloads/jp/jhpc/sparc64vii-wpj.pdf
SPARC64VII��VMT����Ȃ���SMT�Ȃ�
>>752
�ʔ����������Љ�������Ċ��ӂ��邷�B
�ʔ����������Љ�������Ċ��ӂ��邷�B
�Ȃɂ��̗���
���N�̍����AIBM��Through-Silicon Vias�ɂ��3D�_�C�X�^�b�N�̔��\�������̂��o���Ă���q�g��
�����Ǝv�����Bhttp://www-03.ibm.com/press/us/en/pressrelease/21350.wss
�����\�`�b�v������3D�_�C�X�^�b�N�̍ő�̖�肪��p�ɂ���̂����m�̘b�肷���ǁAIBM��
�d�˂��_�C�Ԃ𐅗₷��Z�p�\�������B
http://www-03.ibm.com/press/us/en/pressrelease/24385.wss
�@�@------------------------
�@�@Brunschwiler and his team piped water into cooling structures as thin as a human hair
�@�@(50 microns) between the individual chip layers in order to remove heat efficiently at
�@�@the source. Using the superior thermophysical qualities of water, scientists were able to
�@�@demonstrate a cooling performance of up to 180 W/cm2 per layer for a stack with a typical
�@�@footprint of 4 cm2
�@�@------------------------
�����Ǝv�����Bhttp://www-03.ibm.com/press/us/en/pressrelease/21350.wss
�����\�`�b�v������3D�_�C�X�^�b�N�̍ő�̖�肪��p�ɂ���̂����m�̘b�肷���ǁAIBM��
�d�˂��_�C�Ԃ𐅗₷��Z�p�\�������B
http://www-03.ibm.com/press/us/en/pressrelease/24385.wss
�@�@------------------------
�@�@Brunschwiler and his team piped water into cooling structures as thin as a human hair
�@�@(50 microns) between the individual chip layers in order to remove heat efficiently at
�@�@the source. Using the superior thermophysical qualities of water, scientists were able to
�@�@demonstrate a cooling performance of up to 180 W/cm2 per layer for a stack with a typical
�@�@footprint of 4 cm2
�@�@------------------------
��̔��\�ƕʂɁAIBM�ƃW���[�W�A�H�ȑ�w��3D�_�C�X�^�b�L���O�`�b�v�Ƀ}�C�N���`�����l����
���荞�q�[�g�V���N������Ƃ����_�����\�������Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208402305
�@�@-----------------------
�@�@With the technology, a microchanneled cooled processor at 3-GHz can operate at 83 Watts
�@�@in 47 degree Celsius conditions, according to the paper. In comparison, an air cooled processor
�@�@at 3-GHz operates at 102 Watts in 88 degree Celsius conditions, according to the paper.
�@�@-----------------------
���荞�q�[�g�V���N������Ƃ����_�����\�������Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208402305
�@�@-----------------------
�@�@With the technology, a microchanneled cooled processor at 3-GHz can operate at 83 Watts
�@�@in 47 degree Celsius conditions, according to the paper. In comparison, an air cooled processor
�@�@at 3-GHz operates at 102 Watts in 88 degree Celsius conditions, according to the paper.
�@�@-----------------------
���łɃy���`�F�f�q����肱�߂悗
�C���e���������O���猤�����Ă����ǂ��̂ɂȂ�̂��B
>>757
�y���`�F�f�q����̔��M�͉����Ɏ����Ă����悗
�y���`�F�f�q����̔��M�͉����Ɏ����Ă����悗
PC Perspective��Mini-ITX 2.0�Ɋւ���VIA��NVIDIA�̋�����Ŏd���ꂽatom��nano��
��r�x���`�}�[�N���ʂ��f�ڂ��Ă��邷�B
http://www.pcper.com/article.php?aid=572
PCMark Vantage, Sandra XIIc, 3Dmark 2006, SuperPI���X�B��̓I�ȃv���Z�b�T�̖��́^�i��
��x���`���ʂ̐��l�햾�炩�ɂ���Ă��Ȃ����̂́A
�@Other Mainstream CPU -> atom
���Ă��Ƃ炵�����B
���ł�Mini-ITX 2.0���\���̃v���[��������VIA�T�C�g���B(��L�̎�����܂܂�Ă��Ȃ���)
http://www.via.com.tw/en/downloads/presentations/events/computex08/VIA_PressConf_Mini-ITX2-0_080605.pdf
��r�x���`�}�[�N���ʂ��f�ڂ��Ă��邷�B
http://www.pcper.com/article.php?aid=572
PCMark Vantage, Sandra XIIc, 3Dmark 2006, SuperPI���X�B��̓I�ȃv���Z�b�T�̖��́^�i��
��x���`���ʂ̐��l�햾�炩�ɂ���Ă��Ȃ����̂́A
�@Other Mainstream CPU -> atom
���Ă��Ƃ炵�����B
���ł�Mini-ITX 2.0���\���̃v���[��������VIA�T�C�g���B(��L�̎�����܂܂�Ă��Ȃ���)
http://www.via.com.tw/en/downloads/presentations/events/computex08/VIA_PressConf_Mini-ITX2-0_080605.pdf
ttp://pc.watch.impress.co.jp/docs/2008/0606/comp17.htm
>Nano�v���Z�b�T�Ƌ������А��i�Ƃ̔�r�B�������А��i�Ƃ�Merom�R�A��Core 2 Solo�Ƃ̂��Ƃ����A�N���b�N�Ȃǂ͕s��
���������Ƒ���Merom-L���Ă��ƂɂȂ��Ă邪
ttp://pc.watch.impress.co.jp/docs/2008/0529/via.htm
�����̈�ԉ���office bench�����ǂ��̊G���炷���
�N���b�N������i�̐����j�p�t�H�[�}���X��Merom-L�Ɠ�����
>>761�̋L���̋^��_��
atom���͂����ă��C���X�g���[���Ȃ̂�
atom���Ƃ���VIA���ǂ�����Ă���\�O�Ɏ�ɓ����ꂽ�̂�
>Nano�v���Z�b�T�Ƌ������А��i�Ƃ̔�r�B�������А��i�Ƃ�Merom�R�A��Core 2 Solo�Ƃ̂��Ƃ����A�N���b�N�Ȃǂ͕s��
���������Ƒ���Merom-L���Ă��ƂɂȂ��Ă邪
ttp://pc.watch.impress.co.jp/docs/2008/0529/via.htm
�����̈�ԉ���office bench�����ǂ��̊G���炷���
�N���b�N������i�̐����j�p�t�H�[�}���X��Merom-L�Ɠ�����
>>761�̋L���̋^��_��
atom���͂����ă��C���X�g���[���Ȃ̂�
atom���Ƃ���VIA���ǂ�����Ă���\�O�Ɏ�ɓ����ꂽ�̂�
�ł��ASuperPI��3�{�߂��������Ă邩��AAtom�̕����������藈��C�����邯�ǁB
�Ƃ���ŁA�}���K�̂ق���Atom���Ă̂͂���܂������Ӗ�����Ȃ�����AstroBoy�ɂȂ������ĕ�������
CPU��Atom�ł����낤���H
CPU��Atom�ł����낤���H
> �p�ꌗ�ł́uAstro Boy�v�i����Ɓu�F�����N�v�j�̃^�C�g���ɉ��߂�ꂽ�B
> ��˂͐��O�A�u�A�g���v���u���Ȃ�v���Ӗ�����X�����O�ł��邽�߉���������
> �������Ă����B�A���A�A�����J�ɂ̓A�j���[�V������i�́uAtom Ant�i���̓A���g�j�v�A
> �A�����J���R�~�b�N�́uThe Mighty Atom�v�uThe Atom�v�A�L���v�e���E�}�[�x����
> �G�L�����N�^�[�Ƃ��āuMr.Atom�v�����݂��邱�Ƃ���A����Ɉق������������
> ����B�p���Wikipedia�ł́A�A�j����1���NBC�e���r���A�������ۂɁA����
> DC�R�~�b�N�X�������i"Mighty Atom"�j�̃q�[���[�R�~�b�N�����s���Ă������߂�
> �L�ڂ���Ă���B
�o�T: �t���[�S�Ȏ��T�w�E�B�L�y�f�B�A�iWikipedia�j�x
> ��˂͐��O�A�u�A�g���v���u���Ȃ�v���Ӗ�����X�����O�ł��邽�߉���������
> �������Ă����B�A���A�A�����J�ɂ̓A�j���[�V������i�́uAtom Ant�i���̓A���g�j�v�A
> �A�����J���R�~�b�N�́uThe Mighty Atom�v�uThe Atom�v�A�L���v�e���E�}�[�x����
> �G�L�����N�^�[�Ƃ��āuMr.Atom�v�����݂��邱�Ƃ���A����Ɉق������������
> ����B�p���Wikipedia�ł́A�A�j����1���NBC�e���r���A�������ۂɁA����
> DC�R�~�b�N�X�������i"Mighty Atom"�j�̃q�[���[�R�~�b�N�����s���Ă������߂�
> �L�ڂ���Ă���B
�o�T: �t���[�S�Ȏ��T�w�E�B�L�y�f�B�A�iWikipedia�j�x
AMD�̃V�j�A�t�F���[�ACharles Moore�̃X�^���t�H�[�h��w�ł̍u����The Register���`���Ă��邷�B
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/
���g��"x86 everywhere"���"GPGPU�}���Z�["�Ȃ�Ęb�Ȃ��ǁA�I�O���CELL BE�ᔻ��
�������炵�����B
�v����ɃA���_�[���̖@���I�ɍl����ƁA�^�X�N���蓖�Ă��s��PPE�������i�K�ɂȂ�̂ŁA
PPE�̐��\���w�{��CELL BE��_���ƁBOpteron�𐧌�Ɏg��Fusion��������������(��)
�Q�l�܂ł�CELL BE�̃v���O���~���O���f���Ɋւ��鎑����R���Ƃ��B�w�W���u�E�L���[���f���x��
CELL�v���O���~���O�̑S�ĂƎv������ł���悤���ˁB
http://watch.impress.co.jp/game/docs/20050316/ps3.htm
AMD�̎�����������Ƀs���g���O�ꂽ�o���ɂȂ肻���Ȋ������B
���Y�u����E�F�u�L���X�g����Ă��邷�BCELL�̘b���26�������肩��B
http://stanford-online.stanford.edu/courses/ee380/080604-ee380-300.asx
http://www.theregister.co.uk/2008/06/06/moore_cell_amd/
���g��"x86 everywhere"���"GPGPU�}���Z�["�Ȃ�Ęb�Ȃ��ǁA�I�O���CELL BE�ᔻ��
�������炵�����B
�v����ɃA���_�[���̖@���I�ɍl����ƁA�^�X�N���蓖�Ă��s��PPE�������i�K�ɂȂ�̂ŁA
PPE�̐��\���w�{��CELL BE��_���ƁBOpteron�𐧌�Ɏg��Fusion��������������(��)
�Q�l�܂ł�CELL BE�̃v���O���~���O���f���Ɋւ��鎑����R���Ƃ��B�w�W���u�E�L���[���f���x��
CELL�v���O���~���O�̑S�ĂƎv������ł���悤���ˁB
http://watch.impress.co.jp/game/docs/20050316/ps3.htm
AMD�̎�����������Ƀs���g���O�ꂽ�o���ɂȂ肻���Ȋ������B
���Y�u����E�F�u�L���X�g����Ă��邷�BCELL�̘b���26�������肩��B
http://stanford-online.stanford.edu/courses/ee380/080604-ee380-300.asx
���̂Ƃ���A�W���u�E�L���[���f�����قƂ�ǂ����ǂ�
���ꂪ����ڂ��Ȃ�CELL�̏�����������
���ς�炸MAC�I�^�͘e���Â��˂�w
���ꂪ����ڂ��Ȃ�CELL�̏�����������
���ς�炸MAC�I�^�͘e���Â��˂�w
�������Ă��������Ȃ��Ă���������t���[�W�����������Əo���Ă����
769 �F,,�E�L�́M�E,,�j��-�������F2008/06/07(�y) 20:32:11 ID:eIHMW9R8
�X�J�����Z���܂Ƃ��ɂł���̂�PPE�����Ȃ����_�Łi����
�x�N�g���ƃX�J�����o�����X�悭���p�t�H�[�}���X�Ȃ̂������\�ł�����
Cell�͂����܂ł������ł����Ȃ��B
Nehalem�ŕ������Ƀt�H�[�J�X����Intel�̕��������Ă̂͐������Ǝv���Ă���B
�x�N�g���ƃX�J�����o�����X�悭���p�t�H�[�}���X�Ȃ̂������\�ł�����
Cell�͂����܂ł������ł����Ȃ��B
Nehalem�ŕ������Ƀt�H�[�J�X����Intel�̕��������Ă̂͐������Ǝv���Ă���B
Nehalem�ŕ������Ƀt�H�[�J�X����Intel�̕��������Ă̂͐������Ǝv���Ă���B
������ƑO�܂łقƂ�ǖ��ɗ����Ȃ��Ƃ����Ă�������
������ƑO�܂łقƂ�ǖ��ɗ����Ȃ��Ƃ����Ă�������
771 �F,,�E�L�́M�E,,�j��-�������F2008/06/07(�y) 23:04:14 ID:eIHMW9R8
�����A���ɗ����Ȃ��p�r�ł͑S�����ɗ����Ȃ���B
�e�L�X�g�������������Ɗ������p�r�ɂ͂������������B
�e�L�X�g�������������Ɗ������p�r�ɂ͂������������B
772 �F,,�E�L�́M�E,,�j��-�������F2008/06/07(�y) 23:26:27 ID:eIHMW9R8
���ƂˁA��������1�`2�o�C�g�P�ʂʼnϒ��̃f�[�^��������̂��Ė{��SIMD�Ȃ���s�����Ȃ�B
�t�ɁA����ȕ�������������߂̊g�����o���邭�炢�AIntel��SIMD�g���ɂ͏_��������B
�ėp���W�X�^��SIMD���W�X�^�̃f�[�^���������������ˁB
PPC/AltiVec����Vector���W�X�^�̒��g��16�o�C�g�A���C�������g���ꂽ�̈�ɃX�g�A���Ȃ��Ɣėp���W�X�^�ɓǂݏo���Ȃ��B
�}�k�P�Ȏ������Ǝv��ˁH
�t�ɁA����ȕ�������������߂̊g�����o���邭�炢�AIntel��SIMD�g���ɂ͏_��������B
�ėp���W�X�^��SIMD���W�X�^�̃f�[�^���������������ˁB
PPC/AltiVec����Vector���W�X�^�̒��g��16�o�C�g�A���C�������g���ꂽ�̈�ɃX�g�A���Ȃ��Ɣėp���W�X�^�ɓǂݏo���Ȃ��B
�}�k�P�Ȏ������Ǝv��ˁH
773 �FMAC�I�^���c�q �����F2008/06/07(�y) 23:55:42 ID:0SS3idWO
>>772
�f�[�^�A���C�����g�Ɋւ���y�i���e�B�̌y����A����1�N�قǂ̐V�����v�Ŏ������ꂽ�d�l
������A2005�N���\�̃v���Z�b�T�Ɣ�r����̂�ԈႢ���B
���ƕ�������ăx�N�g�����̂��̂����ǁB�B�B
�f�[�^�A���C�����g�Ɋւ���y�i���e�B�̌y����A����1�N�قǂ̐V�����v�Ŏ������ꂽ�d�l
������A2005�N���\�̃v���Z�b�T�Ɣ�r����̂�ԈႢ���B
���ƕ�������ăx�N�g�����̂��̂����ǁB�B�B
MAC�I�^�̓v���O�����ł��Ȃ�����R�����g���Ȃ��Ⴂ���̂�
�}�R����ɂ�D/A/N/G/O�̘b����ʂ��Ȃ���
���܂�Ƀg���`���J���ȃ��X���Ԃ��Ă��Ēc�q���т����肵�Ă�Ǝv���
777 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 06:26:44 ID:BO9+awkb
�͂��H
MMX���\��������movd eax,mm0�Ƃ��ł������A���C�������g�̐���Ȃ�ĂȂ������ˁB
�A���C�������g�̐���Ȃ��SSE�������������̂ŁA����ł���movups�g���Ώ��X�x�����炢�ōς�ł��B
�iFPU�Ƃ̐�ւ����K�v�Ȃ̂͒ɂ��d�l���������j
AltiVec�Ƃ�SPE�͕������Ȃɂ�������B
���Ƃ��ΐ��K�\���G���W���Ƃ����������Ƃ��Ȃ��B
branch���߂��g���ɂ���AltiVec��SIMD���W�X�^����GPR�ɓ]�����邾���ŃX�g�A�E���[�h��6����8������炤����B���蓾�Ȃ��B
�����ƒP���Ȃ̂ł�������Bstrcmp�Ƃ�strstr�̎�������H
SSE4.2�ł͂ق�̐����߂Ŏ����ł����BASCII�����C�h�������ˁB
4.1��ptest�Ń_�C���N�g�ɕ�������t���O�����ł���悤�ɂȂ�������
MMX���\��������movd eax,mm0�Ƃ��ł������A���C�������g�̐���Ȃ�ĂȂ������ˁB
�A���C�������g�̐���Ȃ��SSE�������������̂ŁA����ł���movups�g���Ώ��X�x�����炢�ōς�ł��B
�iFPU�Ƃ̐�ւ����K�v�Ȃ̂͒ɂ��d�l���������j
AltiVec�Ƃ�SPE�͕������Ȃɂ�������B
���Ƃ��ΐ��K�\���G���W���Ƃ����������Ƃ��Ȃ��B
branch���߂��g���ɂ���AltiVec��SIMD���W�X�^����GPR�ɓ]�����邾���ŃX�g�A�E���[�h��6����8������炤����B���蓾�Ȃ��B
�����ƒP���Ȃ̂ł�������Bstrcmp�Ƃ�strstr�̎�������H
SSE4.2�ł͂ق�̐����߂Ŏ����ł����BASCII�����C�h�������ˁB
4.1��ptest�Ń_�C���N�g�ɕ�������t���O�����ł���悤�ɂȂ�������
778 �FMAC�I�^���c�q �����F2008/06/08(��) 09:12:28 ID:Ny6L4ngI
>>777
CELL��1-byte�f�[�^�ɑ���@�\������Ă����ŕ�����Ɋւ�������s������
����ނɂ������Ǝv�����B
�@�@------------------
�@�@strcmp�Ƃ�strstr�̎�������H
�@�@------------------
http://www.freevec.org/functions?page=1
���ƁA���ߐ��Ō���Ă�RISC����(��)
CELL��1-byte�f�[�^�ɑ���@�\������Ă����ŕ�����Ɋւ�������s������
����ނɂ������Ǝv�����B
�@�@------------------
�@�@strcmp�Ƃ�strstr�̎�������H
�@�@------------------
http://www.freevec.org/functions?page=1
���ƁA���ߐ��Ō���Ă�RISC����(��)
�{��ɖ߂��>>766��Chuck Moore�u���̖���A
�@�@�w���O�Ń^�X�N�����I/O���s����PE�x vs. �w�P�Ȃ�A�N�Z�����[�^�x
�Ƃ����v��̃g���[�h�I�t�����āA�^�X�N����p�v���Z�b�T�̐��\�݂̂�CMP�̌�������낤
�Ƃ��Ă��邱�Ƃ��B���͂Ȃ̂ɉz�������Ƃ햳�������ǁA���ߐ���Ƀ��\�[�X���₷���Ă̂�
OoOE�Ɠ���������Ȃ����ƁB�B�B
�����{���ɒ@�������̂�CELL B.E.����Ȃ��āA���l��PE��x86�݊���ɂ��Ă���intel�̐v��
�Ǝv�����B
���ꂩ��>>773�Łw��������ăx�N�g�����̂��̂����ǁB�B�B�x�Ə�������R�����g�����������ǁA
�����̏o���s�o����Ƃ������A�̂��當�����r��SIMD�̉��p����Ƃ��ċ������Ă��郂�m���B
�Ⴆ�� http://www.freescale.com/files/32bit/doc/fact_sheet/ALTIVECWP.pdf(���͂�1999�N�����Ɠ�����)
�@�@------------------------
�@�@In addition to accelerating next-generation applications, AltiVec technology can, through its
�@�@wide datapaths and wide field operations, also accelerate many time-consuming traditional
�@�@computing and embedded processing operations such as memory copies, string compares
�@�@and page clears.
�@�@------------------------
�@�@�w���O�Ń^�X�N�����I/O���s����PE�x vs. �w�P�Ȃ�A�N�Z�����[�^�x
�Ƃ����v��̃g���[�h�I�t�����āA�^�X�N����p�v���Z�b�T�̐��\�݂̂�CMP�̌�������낤
�Ƃ��Ă��邱�Ƃ��B���͂Ȃ̂ɉz�������Ƃ햳�������ǁA���ߐ���Ƀ��\�[�X���₷���Ă̂�
OoOE�Ɠ���������Ȃ����ƁB�B�B
�����{���ɒ@�������̂�CELL B.E.����Ȃ��āA���l��PE��x86�݊���ɂ��Ă���intel�̐v��
�Ǝv�����B
���ꂩ��>>773�Łw��������ăx�N�g�����̂��̂����ǁB�B�B�x�Ə�������R�����g�����������ǁA
�����̏o���s�o����Ƃ������A�̂��當�����r��SIMD�̉��p����Ƃ��ċ������Ă��郂�m���B
�Ⴆ�� http://www.freescale.com/files/32bit/doc/fact_sheet/ALTIVECWP.pdf(���͂�1999�N�����Ɠ�����)
�@�@------------------------
�@�@In addition to accelerating next-generation applications, AltiVec technology can, through its
�@�@wide datapaths and wide field operations, also accelerate many time-consuming traditional
�@�@computing and embedded processing operations such as memory copies, string compares
�@�@and page clears.
�@�@------------------------
780 �FSocket774�F2008/06/08(��) 10:28:46 ID:ztyeFprC
�l�g�o�̃�OPS�����̂܂ܖ��߃Z�b�g�ɂ���RISC�������ǂ̂��炢��
�p�t�H�[�}���X���o���?
�p�t�H�[�}���X���o���?
���K�\���̘b�������當�����r�͑z�肳��Ă������Ď������ɕԂ��ꂽ�c�q�ɓ�������Ȃ��Ă����B
128bitSIMD��glibc��2�{�����x���ᕳ�����Ă����̂�����Ȃ��APPE�̂悤�Ȕėp�R�A��
�^�X�N���䂵�����Ȃ��Ă����A���S���Y���Ȃ�đ�������ȗႾ�Ƃ������Ƃ��m��Ȃ�MAC���^��
�܂�1,2�T�Ԑ����ė���ׂ����Ǝv����B
128bitSIMD��glibc��2�{�����x���ᕳ�����Ă����̂�����Ȃ��APPE�̂悤�Ȕėp�R�A��
�^�X�N���䂵�����Ȃ��Ă����A���S���Y���Ȃ�đ�������ȗႾ�Ƃ������Ƃ��m��Ȃ�MAC���^��
�܂�1,2�T�Ԑ����ė���ׂ����Ǝv����B
�v���O�������������ƂȂ��l�̋Y���̓X���[���ׂ��B
783 �F�R�E�L�́M�E,,�j�����������������F2008/06/08(��) 11:34:00 ID:Z/4VyrV5
����m���Ă邯�ǒx����BPPE��G4�Ŋm�F�ς݁B
����SSE2��p����strlen�̎����T���v���u���Ă邯��
�w�ǂ�CPU�ŕW�����̔{�ȏ�̃X���[�v�b�g������ꂽ�B
SSE4.2�Ȃ炱����x�����Ƃ͂Ȃ��Ǝv����B
����SSE2��p����strlen�̎����T���v���u���Ă邯��
�w�ǂ�CPU�ŕW�����̔{�ȏ�̃X���[�v�b�g������ꂽ�B
SSE4.2�Ȃ炱����x�����Ƃ͂Ȃ��Ǝv����B
784 �F�R�E�L�́M�E,,�j�����������������F2008/06/08(��) 11:35:42 ID:Z/4VyrV5
����m���Ă邯�ǒx����BPPE��G4�Ŋm�F�ς݁B
����SSE2��p����strlen�̎����T���v���u���Ă邯��
�w�ǂ�CPU�ŕW�����̔{�ȏ�̃X���[�v�b�g������ꂽ�B
SSE4.2�Ȃ炱����x�����Ƃ͂Ȃ��Ǝv����B
����SSE2��p����strlen�̎����T���v���u���Ă邯��
�w�ǂ�CPU�ŕW�����̔{�ȏ�̃X���[�v�b�g������ꂽ�B
SSE4.2�Ȃ炱����x�����Ƃ͂Ȃ��Ǝv����B
785 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 12:31:32 ID:BO9+awkb
pcmp*��pmovmskb��test
������Wolfdale�ł͊e1���߁�1��Op�őΉ����Ă��
���C�e���V���Z������������5�N���b�N
�������pcmp*��ptest�ł������B
Nehalem��SSE4.2�̔���ł���ő�16�~16byte�̔�r�ɂ���
1�N���b�N�ŏo����Ƃ͗��Ɏv���A���Ȃ��Ƃ��n�[�h�E�F�A�x���̕���
�\�t�g�ł����͑����Ȃ�Ǝv����
AltiVec�ɂ�pmovmskb�����̖��߂��Ȃ���ˁi����ɂ�SPE�ɂ͂���j
�r�b�g�J�E���g���݂����Ƀ\�t�g�ł�肭�肵�ďk�邵���Ȃ��B
�Ƃ�����SIMD���W�X�^�Ɣėp���W�X�^�̒��g�̃f�[�^���������閽�߂��̂��̂��Ȃ��B
������Wolfdale�ł͊e1���߁�1��Op�őΉ����Ă��
���C�e���V���Z������������5�N���b�N
�������pcmp*��ptest�ł������B
Nehalem��SSE4.2�̔���ł���ő�16�~16byte�̔�r�ɂ���
1�N���b�N�ŏo����Ƃ͗��Ɏv���A���Ȃ��Ƃ��n�[�h�E�F�A�x���̕���
�\�t�g�ł����͑����Ȃ�Ǝv����
AltiVec�ɂ�pmovmskb�����̖��߂��Ȃ���ˁi����ɂ�SPE�ɂ͂���j
�r�b�g�J�E���g���݂����Ƀ\�t�g�ł�肭�肵�ďk�邵���Ȃ��B
�Ƃ�����SIMD���W�X�^�Ɣėp���W�X�^�̒��g�̃f�[�^���������閽�߂��̂��̂��Ȃ��B
�����CPU�n�X���̃R�e�n���͂Ȃ��S��Intel�M�҂�
�Ȃ��݂�Ȃ��݂�Ȕ��ʼn������悤��
�������ۂ�����ɁA���̑S�Ă̗�����
IntelCPU�������グ�邱�Ƃɂ����g���̂�
�Ȃ��݂�Ȃ��݂�Ȕ��ʼn������悤��
�������ۂ�����ɁA���̑S�Ă̗�����
IntelCPU�������グ�邱�Ƃɂ����g���̂�
>>786
�Ȃ��Intel CPU�������グ�Ă���̂������Ă�낤��??
2ch�̎���ŃA�[�L�e�N�`���̋c�_�����Ă���l�́A
RISC vs x86�̎��ォ�炻��ȑO����CPU�̐i�������Ă��Ă���l�ƁA
����ł܂�Intel x86���肫�ŁA����ɑ���R�n�A�Ƃ������������Ă���l��2�ʂ肪����B
�O�҂́Ax86�������܂ŕ��y����Ɏ������o�܂�������x�����Ō��Ă������A
Intel�Ɛ�ł͂Ȃ�������m���Ă���BIntel���i���Ɏs����x�z���Ă���Ƃ�
�v���ĂȂ��B
��҂̐l�����́Ax86�ȊO�͖w�Ǎl�����Ȃ��AIntel�ȊO�̂��̂��������
���������ĉߏ�Ɏ����グ�鐫��������B
�m���̂�����̂��AIntel CPU�������グ�Ă����ł͂Ȃ��āA
���������Ă��܂���B�����������������グ�����͂Ȃ��B
�����ے�h�̊ԈႢ���w�E���Ă������炻���Ȃ�B
����͉��x�������Ă���ǁA�Ȃ��Ȃ���������Ȃ���ȁB
�Ȃ��Intel CPU�������グ�Ă���̂������Ă�낤��??
2ch�̎���ŃA�[�L�e�N�`���̋c�_�����Ă���l�́A
RISC vs x86�̎��ォ�炻��ȑO����CPU�̐i�������Ă��Ă���l�ƁA
����ł܂�Intel x86���肫�ŁA����ɑ���R�n�A�Ƃ������������Ă���l��2�ʂ肪����B
�O�҂́Ax86�������܂ŕ��y����Ɏ������o�܂�������x�����Ō��Ă������A
Intel�Ɛ�ł͂Ȃ�������m���Ă���BIntel���i���Ɏs����x�z���Ă���Ƃ�
�v���ĂȂ��B
��҂̐l�����́Ax86�ȊO�͖w�Ǎl�����Ȃ��AIntel�ȊO�̂��̂��������
���������ĉߏ�Ɏ����グ�鐫��������B
�m���̂�����̂��AIntel CPU�������グ�Ă����ł͂Ȃ��āA
���������Ă��܂���B�����������������グ�����͂Ȃ��B
�����ے�h�̊ԈႢ���w�E���Ă������炻���Ȃ�B
����͉��x�������Ă���ǁA�Ȃ��Ȃ���������Ȃ���ȁB
�{���ɗD�ꂽ�v�̐��i���ł�ΒN�����Ă����ƔF�߂�ł��傤�B
�P���ȃ��[�J�[�M��vs�A���`�_�ɂ݂��Ă��܂��ЂƂ́A
�Z�p�I�Ȗ{���̖ʔ����ɋC�����ĂȂ���������B
�P���ȃ��[�J�[�M��vs�A���`�_�ɂ݂��Ă��܂��ЂƂ́A
�Z�p�I�Ȗ{���̖ʔ����ɋC�����ĂȂ���������B
>>787
����A�ʂɂǂ�CPU�������グ�����A�Ƃ��Ȃ����āB
������o�J�ɂ��������Ȃ���A���̔̃R�e�́B
�Ă�����������`���̒Ⴂ�����Ō����Ă����̎���
�Z�p�ғI�v�l����Ȃ������Ƃ������E�E
���{�b�g�A�j�����Ăǂ�������������
����Ă�o�J�I�^�ƕς��Ȃ����낤w
���ۂɂ̓W�����P���݂����Ȃ���ŁA�����͂��������D��Ă邯��
�����͂��������E�E�Ƃ����Ɍ������Ȃ��āA�������ʔ����̂ɁE�E�B
������x�킩���Ă�z�Ȃ炻��Ȃ����肫���Ă邱�Ƃ��낤�B
�ނ��D����CPU�Ƃ��������Ŏ����Ă��Ă���������
�Ȃ����̃R�e�͂�����������������������肶��Ȃ���˂��B
����A�ʂɂǂ�CPU�������グ�����A�Ƃ��Ȃ����āB
������o�J�ɂ��������Ȃ���A���̔̃R�e�́B
�Ă�����������`���̒Ⴂ�����Ō����Ă����̎���
�Z�p�ғI�v�l����Ȃ������Ƃ������E�E
���{�b�g�A�j�����Ăǂ�������������
����Ă�o�J�I�^�ƕς��Ȃ����낤w
���ۂɂ̓W�����P���݂����Ȃ���ŁA�����͂��������D��Ă邯��
�����͂��������E�E�Ƃ����Ɍ������Ȃ��āA�������ʔ����̂ɁE�E�B
������x�킩���Ă�z�Ȃ炻��Ȃ����肫���Ă邱�Ƃ��낤�B
�ނ��D����CPU�Ƃ��������Ŏ����Ă��Ă���������
�Ȃ����̃R�e�͂�����������������������肶��Ȃ���˂��B
> �P���ȃ��[�J�[�M��vs�A���`�_�ɂ݂��Ă��܂��ЂƂ́A
��������Ȃ��q�ϓI���_�ɗ��������͂��Č����͓̂ǂ߂Δ����B
��������Ȃ��q�ϓI���_�ɗ��������͂��Č����͓̂ǂ߂Δ����B
�N��͂܂�ł킩���ĂȂ��B
��́A�������������������ĉ��ł���?w
��́A�������������������ĉ��ł���?w
>>788
�_���̓W�J���ǂ������ł��Ȃ�
�_���̓W�J���ǂ������ł��Ȃ�
�N��̖ڂɃt�B���^���������Ă邾���B
�R���s���[�^�Ȋw��R���s���[�^�j�ł��w��ŁA
�Z�p�I�ȃv���O�����ł�����Ă݂�����B
����̃R�e�͒P�ɋZ�p�l�^���D���Ȃ����ŁA
���ꂪ���ɂȂ��Ă��Ƃ͎��Ȍ����~�œ˂������Ă��邾��w
�N��ɂ͎����������Ȃ��������ē����悤��Intel CPU��
�����グ�Ă���悤�Ɍ����邾�낤�B
�R���s���[�^�Ȋw��R���s���[�^�j�ł��w��ŁA
�Z�p�I�ȃv���O�����ł�����Ă݂�����B
����̃R�e�͒P�ɋZ�p�l�^���D���Ȃ����ŁA
���ꂪ���ɂȂ��Ă��Ƃ͎��Ȍ����~�œ˂������Ă��邾��w
�N��ɂ͎����������Ȃ��������ē����悤��Intel CPU��
�����グ�Ă���悤�Ɍ����邾�낤�B
���Ȃ݂ɉ���AMD������CPU�X�����ŏ��ɗ��Ă����{�l�����ǁA
MAC�I�^�����X��AMD�~������������͉̂ߋ����ꂩ��B
Intel vs AMD �M�Ҙ_�ł͂Ȃ��āA����Ȃ鎩�Ȍ����̐���̉ʂāB
�����ŃR�e������Ĕ��_���Ă݂�A
�{���̎咣�������ʂ�������킩����?
�R�e���đ�T�A�{���咣�⏑�����݂̐��i���䂪��ł������Ȃ�B
�����Ȃ�ł���Ȃ��Ƃ����Ă��c�B
MAC�I�^�����X��AMD�~������������͉̂ߋ����ꂩ��B
Intel vs AMD �M�Ҙ_�ł͂Ȃ��āA����Ȃ鎩�Ȍ����̐���̉ʂāB
�����ŃR�e������Ĕ��_���Ă݂�A
�{���̎咣�������ʂ�������킩����?
�R�e���đ�T�A�{���咣�⏑�����݂̐��i���䂪��ł������Ȃ�B
�����Ȃ�ł���Ȃ��Ƃ����Ă��c�B
���i���c��ł邩��R�e����Ă�Ƃ����̂������
���A�����ᑊ��ɂ���Ȃ����炾�낤
���A�����ᑊ��ɂ���Ȃ����炾�낤
797 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 17:56:35 ID:BO9+awkb
Intel��NetBurst�݂����ȃN�\�A�[�L�e�N�`�������Ă���PPC+AltiVec�����グ�Ă��B
���ƁACrusoe�̂ق���ULV Pen3����Ƃ����C�Ŏ���ɐ������Ă��B�̂́B
���ƁACrusoe�̂ق���ULV Pen3����Ƃ����C�Ŏ���ɐ������Ă��B�̂́B
nano��Core2����
799 �FMAC�I�^���c�q �����F2008/06/08(��) 19:19:14 ID:Ny6L4ngI
>>785
�@�@--------------------
�@�@���Ȃ��Ƃ��n�[�h�E�F�A�x���̕��̓\�t�g�ł����͑����Ȃ�Ǝv����
�@�@--------------------
���[�W�R�A vs. �X���[���R�A�̃g���[�h�I�t�̔��e�̘b�Ȃ̂ŁA�������������ۂ���c�_�̗]�n��
���邩�Ǝv�����BPOWER�̏ꍇ�ACELL�̂悤�ɐ�p�@�\��R�v���Z�b�T�Ŏ�������I�v�V������
DFP�̎���̂悤��ISA���g������I�v�V�������I���ł���ŁA���݂̎������I������Ă���
������B
�R�[�h�T�C�Y�ƃ������e�ʂ̏������l���Ă��A�o�C�g�A���C�����g�̐���������_�Ŋɂ߂邱�Ƃ�
�����ɉЍ����c���Ȃ����ǂ����^��ȋC�����邷�B
>>797
�@�@--------------------
�@�@Intel��NetBurst�݂����ȃN�\�A�[�L�e�N�`�������Ă���
�@�@--------------------
Pentium4��SPEC CPU�x���`�}�[�N�œ����̃n�C�G���hRISC���R�U�炵���̂펖�����B����s����
������Ƃ��������ŃN�\�Ă����Ă̂�������ƁB�B�B
�@�@--------------------
�@�@���Ȃ��Ƃ��n�[�h�E�F�A�x���̕��̓\�t�g�ł����͑����Ȃ�Ǝv����
�@�@--------------------
���[�W�R�A vs. �X���[���R�A�̃g���[�h�I�t�̔��e�̘b�Ȃ̂ŁA�������������ۂ���c�_�̗]�n��
���邩�Ǝv�����BPOWER�̏ꍇ�ACELL�̂悤�ɐ�p�@�\��R�v���Z�b�T�Ŏ�������I�v�V������
DFP�̎���̂悤��ISA���g������I�v�V�������I���ł���ŁA���݂̎������I������Ă���
������B
�R�[�h�T�C�Y�ƃ������e�ʂ̏������l���Ă��A�o�C�g�A���C�����g�̐���������_�Ŋɂ߂邱�Ƃ�
�����ɉЍ����c���Ȃ����ǂ����^��ȋC�����邷�B
>>797
�@�@--------------------
�@�@Intel��NetBurst�݂����ȃN�\�A�[�L�e�N�`�������Ă���
�@�@--------------------
Pentium4��SPEC CPU�x���`�}�[�N�œ����̃n�C�G���hRISC���R�U�炵���̂펖�����B����s����
������Ƃ��������ŃN�\�Ă����Ă̂�������ƁB�B�B
800 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 19:27:01 ID:BO9+awkb
���R�[�h�T�C�Y�ƃ������e�ʂ̏������l���Ă��A�o�C�g�A���C�����g�̐���������_�Ŋɂ߂邱�Ƃ�
�������ɉЍ����c���Ȃ����ǂ����^��ȋC�����邷�B
2��̃��[�hor�X�g�A�{permute�ƌ��������_�Ŗ����̂Ȃ������Ŏ�����������Ȃ���͂Ȃ��ˁB
�ނ���XMM�̃��[�h�E�X�g�A�ȊO�A���C�������g����̂Ȃ�CPU�Ƃ���30�N�A���݂Ɏ����Ă鎖������ڂ�w���邱�Ƃ̂ق�������������B
�������ɉЍ����c���Ȃ����ǂ����^��ȋC�����邷�B
2��̃��[�hor�X�g�A�{permute�ƌ��������_�Ŗ����̂Ȃ������Ŏ�����������Ȃ���͂Ȃ��ˁB
�ނ���XMM�̃��[�h�E�X�g�A�ȊO�A���C�������g����̂Ȃ�CPU�Ƃ���30�N�A���݂Ɏ����Ă鎖������ڂ�w���邱�Ƃ̂ق�������������B
Compaq����������������AAlphaAXP�̍ŋ��`���͑����Ă����̂��낤���c�B
Compaq�ɂ��DEC�����A�ɒ����B
�����21264��1�N�ȏ�x�ꂽ�ƋL�����Ă�B
�����21264��1�N�ȏ�x�ꂽ�ƋL�����Ă�B
803 �FMAC�I�^���c�q �����F2008/06/08(��) 19:45:00 ID:Ny6L4ngI
>>800
�@�@----------------
�@�@XMM�̃��[�h�E�X�g�A�ȊO
�@�@----------------
SIMD�̘b�����Ă���̂ɁA�Ȃ�XMM�����O�ł����Ⴄ�����HMMX�̃��[�h�����FPR������
�V�K�ɐ�����lj����闝�R�������̂�A������O���ƁB�B�B
�@�@----------------
�@�@XMM�̃��[�h�E�X�g�A�ȊO
�@�@----------------
SIMD�̘b�����Ă���̂ɁA�Ȃ�XMM�����O�ł����Ⴄ�����HMMX�̃��[�h�����FPR������
�V�K�ɐ�����lj����闝�R�������̂�A������O���ƁB�B�B
804 �FMAC�I�^��801 �����F2008/06/08(��) 19:47:06 ID:Ny6L4ngI
>>801-802
�n�C�G���hAlpha���x�ꂽ���R��IBM�ɐ����ϑ�������������炷�BPA-RISC�������B
���Ȃ��Ƃ������_�܂ł�A���O�̍H��������đ�Ȃ��Ƃ��������B
�n�C�G���hAlpha���x�ꂽ���R��IBM�ɐ����ϑ�������������炷�BPA-RISC�������B
���Ȃ��Ƃ������_�܂ł�A���O�̍H��������đ�Ȃ��Ƃ��������B
�܂������̂�
806 �FMAC�I�^���⑫�F2008/06/08(��) 19:54:00 ID:Ny6L4ngI
�Q�l�������B
http://www.my-esm.com/digest/story/OEG20000522S0057
http://www.theinquirer.net/en/inquirer/news/2003/10/27/hp-blames-ibm-micro-for-alpha-ev79-death
http://www.my-esm.com/digest/story/OEG20000522S0057
http://www.theinquirer.net/en/inquirer/news/2003/10/27/hp-blames-ibm-micro-for-alpha-ev79-death
807 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 21:09:41 ID:BO9+awkb
Phenom�ł�movdqa��A�h���b�V���O���[�h�ł�XMM�̃A���C�������g���Ȃ��Ȃ��Ă邪�ȁB
SandyBridge�ł��Ȃ��Ȃ�\��B�i256bit SIMD�ł͐������j
SandyBridge�ł��Ȃ��Ȃ�\��B�i256bit SIMD�ł͐������j
>>786
>�����CPU�n�X���̃R�e�n���͂Ȃ��S��Intel�M�҂�
�Q�l�������˂�����H��
�͂邩�͉̂����R�e�n������������
�܂��v���O�����g�ޓz��AMD���Intel���ɂȂ�ł���BAMD��CPU�͋�����
�R�[�h�𑬂�����̂����Ŗʔ������Ȃ��B
>�����CPU�n�X���̃R�e�n���͂Ȃ��S��Intel�M�҂�
�Q�l�������˂�����H��
�͂邩�͉̂����R�e�n������������
�܂��v���O�����g�ޓz��AMD���Intel���ɂȂ�ł���BAMD��CPU�͋�����
�R�[�h�𑬂�����̂����Ŗʔ������Ȃ��B
>>795
>�R�e���đ�T�A�{���咣�⏑�����݂̐��i���䂪��ł������Ȃ�B
��������B���i�c��ł�z��������ł̓R�e�Ȃ�Ă��Ȃ����炾�悗
�f�����b�g�����Ȃ��B
>�R�e���đ�T�A�{���咣�⏑�����݂̐��i���䂪��ł������Ȃ�B
��������B���i�c��ł�z��������ł̓R�e�Ȃ�Ă��Ȃ����炾�悗
�f�����b�g�����Ȃ��B
810 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 21:39:56 ID:BO9+awkb
�܁A���͂��̃R�e���̂܂�܂ő��̔Ŕn���݂����ɓ�ꍇ���Ă��肷�邪�ȁB
811 �FMAC�I�^���c�q �����F2008/06/08(��) 21:51:57 ID:Ny6L4ngI
>>807
�@�@-----------------
�@�@Phenom�ł�movdqa��A�h���b�V���O���[�h�ł�XMM�̃A���C�������g���Ȃ��Ȃ��Ă邪�ȁB
�@�@-----------------
AMD�I�ɂ���P�Ƃ������v��̐؎��ȗ��R�����邷��B
http://pc11.2ch.net/test/read.cgi/jisaku/1172183431/652
�@�@=================
�@�@652 ���O�FMAC�I�^ ���e���F2007/03/19(��) 23:07:04 ID:Qs8c3R9z
�@�@�@�@GDC��AMD��SSE128�Ή��̍œK���ɂ��ču�������X���C�h���B
�@�@�@�@http://developer.amd.com/assets/GDC2007_Multicore_JB.pdf
�@�@�@�@�ڂ����R�����g��c�q����ɂł����肢�����������ǁA�u�L���b�V�������Ȃ�����R���p�C���I�v�V����
�@�@�@�@��"���x�D��"���"�T�C�Y�D��ɂ��Ăˁv�Ƃ��A�u�~�X�A���C�����g�f�[�^�̓ǂݍ��݂ɑΉ����Ă�
�@�@�@�@����A�A���C�����g�p�ɖ��ʂȃp�f�B���O����ꂽ�f�[�^�\���̓����āv�Ƃ��A�����ɉЍ����c��
�@�@�@�@�����Ȃ��Ƃ������Ă��邷�B�B�B
�@�@=================
�@�@-----------------
�@�@Phenom�ł�movdqa��A�h���b�V���O���[�h�ł�XMM�̃A���C�������g���Ȃ��Ȃ��Ă邪�ȁB
�@�@-----------------
AMD�I�ɂ���P�Ƃ������v��̐؎��ȗ��R�����邷��B
http://pc11.2ch.net/test/read.cgi/jisaku/1172183431/652
�@�@=================
�@�@652 ���O�FMAC�I�^ ���e���F2007/03/19(��) 23:07:04 ID:Qs8c3R9z
�@�@�@�@GDC��AMD��SSE128�Ή��̍œK���ɂ��ču�������X���C�h���B
�@�@�@�@http://developer.amd.com/assets/GDC2007_Multicore_JB.pdf
�@�@�@�@�ڂ����R�����g��c�q����ɂł����肢�����������ǁA�u�L���b�V�������Ȃ�����R���p�C���I�v�V����
�@�@�@�@��"���x�D��"���"�T�C�Y�D��ɂ��Ăˁv�Ƃ��A�u�~�X�A���C�����g�f�[�^�̓ǂݍ��݂ɑΉ����Ă�
�@�@�@�@����A�A���C�����g�p�ɖ��ʂȃp�f�B���O����ꂽ�f�[�^�\���̓����āv�Ƃ��A�����ɉЍ����c��
�@�@�@�@�����Ȃ��Ƃ������Ă��邷�B�B�B
�@�@=================
812 �FMAC�I�^�������F2008/06/08(��) 21:57:03 ID:Ny6L4ngI
�ł��ǂݒ����Ă݂�ƁA���j�C�R�A����ɂ�A�L���b�V����LS���P�`�邱�Ƃ��d�v�ɂȂ��āA
�A���C�����g�̂��߂̃p�f�B���O�Ȃ�Ę_�O�B�B�B�Ȃ�Ă��ƂɂȂ邩������Ȃ����B
�A���C�����g�̂��߂̃p�f�B���O�Ȃ�Ę_�O�B�B�B�Ȃ�Ă��ƂɂȂ邩������Ȃ����B
813 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 22:09:08 ID:BO9+awkb
>>808
�m����Intel�̂ق��������ŃR�[�h�g�ޕ��ɂ͐��\�o���₷���B
������l��������Ǝv������
����Pen4�����͑匙����������B
����SSE2��������Ȃ���MMX���x������������ȁB
�i�Ȃ܂�PenM�⏉��Athlon64�܂ł�64bit SIMD�̕��������������j
�f�[�^�L���b�V�����������ĂȂ��Ȃ����\�łȂ����A�₽��}�V�����邳�����A�����Ŏd���Ȃ������B
�����Pen4�Ɠ�����IA-64�����݂��Ă����Ǝ��̂���86�ւ̍ő�̎��ȃl�K�L�����������Ǝv���Ă�B
�܁ACell�ɂ��Ă�Itanium�ɂ��Ă����z�����͗��h��������ȁB
�b�͖߂邪�A�z���g��Phenom�����āA��p�ɃR�[�h�g��ł��A���N���b�N��Core 2���
�����ԑ����P�[�X�����Ă���B
32byte ���߃t�F�b�`������x64�̐V���߂�SSE*��ϋɊ��p���ď��߂ĈӖ���������̂�����
�K�������Â��R�[�h�ł��������v�ɂ��Ă�킯�ł͂Ȃ��B
�ނ��덡�̂Ƃ����AMD���Intel�̂ق����ێ�I���Ǝv���Ă���B
�ǂ����������v�V�I������NetBurst���̂ĂāA�C�X���G���哱��P6�A�[�L�̊g�����J��Ԃ��Ă�B
�܂����ꂾ��P6���悭�ł����A�[�L�e�N�`�����������Ă��ƂȂ��ǁB
���X����A�[�L��AVX�͂܂��v�V�I�����ǁA3�I�y�����h�g���Ȃ�AMD��SSE5�̔��\�̂ق���
��s���Ă邵�AFMA�Ȃɂ��Ă�AMD��SSE5�����čQ�ĂĒlj�������Ȃ����Ǝv���Ă�B
�j�[���j�b�N����@�\���������肻�̂܂܁i�������h���������̂ق����I�y�����h�w��̋@�\���͏�j����
Sandy Bridge�ɂ͊Ԃɍ��킸���̃A�[�L�ł̊g���\��ɂȂ��Ă�Ƃ���ȂˁB
���ƁAVEX�̊g�����@���́AAMD64��LDS,LES��ׂ��Ă���ĂȂ��Ⴀ�肦�����B
�m����Intel�̂ق��������ŃR�[�h�g�ޕ��ɂ͐��\�o���₷���B
������l��������Ǝv������
����Pen4�����͑匙����������B
����SSE2��������Ȃ���MMX���x������������ȁB
�i�Ȃ܂�PenM�⏉��Athlon64�܂ł�64bit SIMD�̕��������������j
�f�[�^�L���b�V�����������ĂȂ��Ȃ����\�łȂ����A�₽��}�V�����邳�����A�����Ŏd���Ȃ������B
�����Pen4�Ɠ�����IA-64�����݂��Ă����Ǝ��̂���86�ւ̍ő�̎��ȃl�K�L�����������Ǝv���Ă�B
�܁ACell�ɂ��Ă�Itanium�ɂ��Ă����z�����͗��h��������ȁB
�b�͖߂邪�A�z���g��Phenom�����āA��p�ɃR�[�h�g��ł��A���N���b�N��Core 2���
�����ԑ����P�[�X�����Ă���B
32byte ���߃t�F�b�`������x64�̐V���߂�SSE*��ϋɊ��p���ď��߂ĈӖ���������̂�����
�K�������Â��R�[�h�ł��������v�ɂ��Ă�킯�ł͂Ȃ��B
�ނ��덡�̂Ƃ����AMD���Intel�̂ق����ێ�I���Ǝv���Ă���B
�ǂ����������v�V�I������NetBurst���̂ĂāA�C�X���G���哱��P6�A�[�L�̊g�����J��Ԃ��Ă�B
�܂����ꂾ��P6���悭�ł����A�[�L�e�N�`�����������Ă��ƂȂ��ǁB
���X����A�[�L��AVX�͂܂��v�V�I�����ǁA3�I�y�����h�g���Ȃ�AMD��SSE5�̔��\�̂ق���
��s���Ă邵�AFMA�Ȃɂ��Ă�AMD��SSE5�����čQ�ĂĒlj�������Ȃ����Ǝv���Ă�B
�j�[���j�b�N����@�\���������肻�̂܂܁i�������h���������̂ق����I�y�����h�w��̋@�\���͏�j����
Sandy Bridge�ɂ͊Ԃɍ��킸���̃A�[�L�ł̊g���\��ɂȂ��Ă�Ƃ���ȂˁB
���ƁAVEX�̊g�����@���́AAMD64��LDS,LES��ׂ��Ă���ĂȂ��Ⴀ�肦�����B
�����͐Ⴉ�H
P6�̊g���Ȃ킯�Ȃ�����
�p�C�v���C���i�����S�R�Ⴄ��
�p�C�v���C���i�����S�R�Ⴄ��
nano�ŋ�
817 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 22:39:40 ID:BO9+awkb
>>815
��Family 6����
�p�C�v���C���i�����A�[�L�e�N�`���敪�̈Ⴂ���čl����Ȃ�
PPC�̏���G4�Ɩ���mini��G4����S�R�ʕ�����
Willamette/Northwood��20�i HT��Northwood��21�i�APrescott��31�i�ɂȂ���NetBurst�A�[�L�͉��҂����Ď��ɂȂ�B
��Family 6����
�p�C�v���C���i�����A�[�L�e�N�`���敪�̈Ⴂ���čl����Ȃ�
PPC�̏���G4�Ɩ���mini��G4����S�R�ʕ�����
Willamette/Northwood��20�i HT��Northwood��21�i�APrescott��31�i�ɂȂ���NetBurst�A�[�L�͉��҂����Ď��ɂȂ�B
>>817
�܂Ƃ��ɑ��肷��Ȃ�c
�N���b�N���オ�������{�p�C�v���C����������͓̂�����O���Ď���������Ȃ��z��
�܂��v���X�R�͂ǂ����Ǝv�����c
�܂Ƃ��ɑ��肷��Ȃ�c
�N���b�N���オ�������{�p�C�v���C����������͓̂�����O���Ď���������Ȃ��z��
�܂��v���X�R�͂ǂ����Ǝv�����c
819 �FMAC�I�^���c�q �����F2008/06/08(��) 22:48:26 ID:Ny6L4ngI
>>817
�@�@------------------
�@�@PPC�̏���G4�Ɩ���mini��G4����S�R�ʕ�����
�@�@------------------
G4��G4+�Ɋւ��Ă�A�p�C�v���C���i���ǂ��납���Z��̐��܂ňႤ��őS�R�ʕ����B
�@�@------------------
�@�@PPC�̏���G4�Ɩ���mini��G4����S�R�ʕ�����
�@�@------------------
G4��G4+�Ɋւ��Ă�A�p�C�v���C���i���ǂ��납���Z��̐��܂ňႤ��őS�R�ʕ����B
�p�C�v���C���i�����ς������ʕ�����
���ƁAfamily6�Ƃ�CPUID�̓A�[�L�e�N�`���ƊW�Ȃ���
���ڂɂ�
���ƁAfamily6�Ƃ�CPUID�̓A�[�L�e�N�`���ƊW�Ȃ���
���ڂɂ�
P6�̊g���łȂ��S���̐V�A�[�L�e�N�`���̊��ɂ͊J�����Ԃ��L�蓾�Ȃ��قǑ���������
822 �F,,�E�L�́M�E,,�j��-�������F2008/06/08(��) 23:40:25 ID:BO9+awkb
Atom��Family=6��������Ă邪OoO�̗L����P6�A�[�L�̗p���ɂ͊܂܂�Ȃ��悤��
823 �FSocket774�F2008/06/08(��) 23:41:19 ID:f8j7B+i0
RISC��CISC�̐킢�������Ă邩�炱���AX86�A�[�L�e�N�`���̌��E�������Ă�����
�����ł�����ǂ�
CPU�R�A���ɂ�����M�݂̕����݂̍ő�̖��Ƃ���Ȃ�A
x86���߂��f�R�[�_�[�g���ă�OPs�ɕ������Ď��s���Ă�A
����Intel�̂������́A���E�ɗ��Ă���Ď����w���Ă�킯������B
���A�R�A���ň�Ԕ��M���Ă�̂̓f�R�[�_�[�Ȃ�ˁB
������A�v���O�����R�[�h�ڎ��s�ł���PowerPC�iG5�����j��A
Atom�������������Ƃ����̂��킩��
�����ł�����ǂ�
CPU�R�A���ɂ�����M�݂̕����݂̍ő�̖��Ƃ���Ȃ�A
x86���߂��f�R�[�_�[�g���ă�OPs�ɕ������Ď��s���Ă�A
����Intel�̂������́A���E�ɗ��Ă���Ď����w���Ă�킯������B
���A�R�A���ň�Ԕ��M���Ă�̂̓f�R�[�_�[�Ȃ�ˁB
������A�v���O�����R�[�h�ڎ��s�ł���PowerPC�iG5�����j��A
Atom�������������Ƃ����̂��킩��
�́H
> ���A�R�A���ň�Ԕ��M���Ă�̂̓f�R�[�_�[�Ȃ�ˁB
�܂��ŁH
�܂��ŁH
�M���Ȃ��Ă�����ŗ�₹�Α��v���낤
�h���C�A�C�X��p�p�́u���ˁv�t���}�U�[��������
ttp://www.watch.impress.co.jp/akiba/hotline/20080607/etc_foxconn.html
�h���C�A�C�X��p�p�́u���ˁv�t���}�U�[��������
ttp://www.watch.impress.co.jp/akiba/hotline/20080607/etc_foxconn.html
827 �F,,�E�L�́M�E,,�j��-�������F2008/06/09(��) 00:04:14 ID:BO9+awkb
Pen3��PenM ��OPs Fusion�lj��@K6��K7�ɕC�G����ύX
PenM��Core2�@x64�Ή��@�@�@�@�@�@�@K7��K8�̃R�A�̊g���̃L��
�@�@�@�@�@�@�@�@�@�@SSE�@2�{���@�@�@�@K8��K10�̃R�A�g���̃L��
Core2��Core3(Nehalem) �@�@�@�@�@������AMD�D�ʂ��g��
�����S������Ă��uFamily=6�v�𑱂��Ă���
AMD�Ȃ�Ă�������イFamily���V����̂ɁB
�܂��AAMD�̃p�C�v���C���\�����݂��K10�܂ł�K7�̃}�C�i�[�`�F���W�ƌ����Ȃ����Ȃ��B
PenM��Core2�@x64�Ή��@�@�@�@�@�@�@K7��K8�̃R�A�̊g���̃L��
�@�@�@�@�@�@�@�@�@�@SSE�@2�{���@�@�@�@K8��K10�̃R�A�g���̃L��
Core2��Core3(Nehalem) �@�@�@�@�@������AMD�D�ʂ��g��
�����S������Ă��uFamily=6�v�𑱂��Ă���
AMD�Ȃ�Ă�������イFamily���V����̂ɁB
�܂��AAMD�̃p�C�v���C���\�����݂��K10�܂ł�K7�̃}�C�i�[�`�F���W�ƌ����Ȃ����Ȃ��B
828 �F,,�E�L�́M�E,,�j��-�������F2008/06/09(��) 00:11:41 ID:NGwLmfjY
>>823
Atom�̓f�R�[�_�̓t���Z�b�g�ς�ł�B
SSE��128bit�t���������B
Atom��������̂�Dynamic Execution(OoO)
���_��CPU�A�[�L�ň�Ԕ��M����̂�OoO�E���W�X�^���l�[�~���O�@�\���B
�������t�����g�G���h������Ȃ�ɔM���炵���B
���������Ƃ͈�T�Ɍ����Ȃ��̂Ō��ʘ_�����ǁA���߃t�F�b�`��32�o�C�g�Ɋg����
�{�g���l�b�N�������͂�����Phenom�̓N���b�N���オ��Ȃ���M����ŁA
���ʓI��Core 2���ᐫ�\�ɂȂ��Ă��܂����B
Intel������P6�����LCP�X�g�[���̎d�l�����X���������Ă���32byte�t�F�b�`�̗̍p��
������܂Ō��������̂��Ӗ��͂���悤���B
Atom�̓f�R�[�_�̓t���Z�b�g�ς�ł�B
SSE��128bit�t���������B
Atom��������̂�Dynamic Execution(OoO)
���_��CPU�A�[�L�ň�Ԕ��M����̂�OoO�E���W�X�^���l�[�~���O�@�\���B
�������t�����g�G���h������Ȃ�ɔM���炵���B
���������Ƃ͈�T�Ɍ����Ȃ��̂Ō��ʘ_�����ǁA���߃t�F�b�`��32�o�C�g�Ɋg����
�{�g���l�b�N�������͂�����Phenom�̓N���b�N���オ��Ȃ���M����ŁA
���ʓI��Core 2���ᐫ�\�ɂȂ��Ă��܂����B
Intel������P6�����LCP�X�g�[���̎d�l�����X���������Ă���32byte�t�F�b�`�̗̍p��
������܂Ō��������̂��Ӗ��͂���悤���B
�����͐~�[�������݂̃I���p���[�h���ȁB
�������ꂪ����
�₽���Family=6�ɂ�������Ă�悤�����ǁA
intel���S�R��������R�ŕ�ID��U���Ă�
�����咣�ŐV�A�[�L�Ɛ�������m��������ė~�����ł��A�c�q��y�B
intel���S�R��������R�ŕ�ID��U���Ă�
�����咣�ŐV�A�[�L�Ɛ�������m��������ė~�����ł��A�c�q��y�B
832 �F�R�E�L�́M�E,,�j�����������������F2008/06/09(��) 01:48:36 ID:NGwLmfjY
������}�[�L�e�N�`����FamilyID�͈�v���郂������Ȃ���B
���Ƃ���AMD
K6��Family=5
K7��Family=6
K8��NetBurst�Ɠ���Family=15
����FamilyID�͋Z�p�I�Ȗ{�����܂�ł�Ǝv���B
�ŁA�z���g�̘b�ANehalem�́uPentium 8�v���Ă����Ă����������邩��
Family=8�ɂȂ�Ǝv���Ă���B
����Family�ς���@�����Ƃ����SandyBridge���ȁH
�����A�c�O�Ȃ��Ƃ�Ext.Model�l�ɂ͂܂��]�T������悤�Ȃ�ˁB
�����܂�6�ɂ�����葱�����Ђ��Ă������������Ǝv����B
�Ȃ�ɂ���x64�T�|�[�g�����������S���̃g�����W�X�^�̒lj��ōςފg���ƌ����Ă̂�����Ђ�����ˁB
����قǑ傫�Ȋg��������Family��ς��Ȃ��͈̂Â�AMD��K7�ȍ~�̊g���ɑ���l�K�L������
�Ӗ�������Ǝv���Ă���B
���Ƃ���AMD
K6��Family=5
K7��Family=6
K8��NetBurst�Ɠ���Family=15
����FamilyID�͋Z�p�I�Ȗ{�����܂�ł�Ǝv���B
�ŁA�z���g�̘b�ANehalem�́uPentium 8�v���Ă����Ă����������邩��
Family=8�ɂȂ�Ǝv���Ă���B
����Family�ς���@�����Ƃ����SandyBridge���ȁH
�����A�c�O�Ȃ��Ƃ�Ext.Model�l�ɂ͂܂��]�T������悤�Ȃ�ˁB
�����܂�6�ɂ�����葱�����Ђ��Ă������������Ǝv����B
�Ȃ�ɂ���x64�T�|�[�g�����������S���̃g�����W�X�^�̒lj��ōςފg���ƌ����Ă̂�����Ђ�����ˁB
����قǑ傫�Ȋg��������Family��ς��Ȃ��͈̂Â�AMD��K7�ȍ~�̊g���ɑ���l�K�L������
�Ӗ�������Ǝv���Ă���B
�}�t���߂ɂ��������������
���ہAF15��F15E�݂����Ȃ��Ǝv����
�����Ԃ���ǂ��ꂽ���A�x�[�X�ƂȂ���̂�����킯����
���ہAF15��F15E�݂����Ȃ��Ǝv����
�����Ԃ���ǂ��ꂽ���A�x�[�X�ƂȂ���̂�����킯����
>>828
Atom�͂��W�U���߂��f�R�[�_�Ń�OP���ɂ������ڎ��s���邱�Ƃŏȓd�͉��E�ᔭ�M�����Ă�Ƃ��������Ă܂���
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
�M�݉̕������{�������邽�߂ɂƂ�ꂽ��@���ƌĂL���������Ă܂�
Atom�͂��W�U���߂��f�R�[�_�Ń�OP���ɂ������ڎ��s���邱�Ƃŏȓd�͉��E�ᔭ�M�����Ă�Ƃ��������Ă܂���
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
�M�݉̕������{�������邽�߂ɂƂ�ꂽ��@���ƌĂL���������Ă܂�
x86�ڎ��s�āc
Cyrix3���Ōゾ�������B
x86�Ɍ��炸PowerPCG5�ł�������͕ʖ��߂ɂȂ��Ă��肵�܂���
�ǂ������Ƃ��낪�������̏�Q�ɂȂ��ł���H
�ǂ������Ƃ��낪�������̏�Q�ɂȂ��ł���H
838 �F,,�E�L�́M�E,,�j��-�������F2008/06/09(��) 11:44:44 ID:NGwLmfjY
L1���[�h���X�e�[�W�ɉ������Ă邵�A����Ӗ�����add eax, [mem]�Ƃ�
�_�C���N�g�Ɂi���������Ɂj���s�ł���낤�ˁB
���ɏ��Z�Ƃ����z�������̂܂��s�ł���悤�ɂ͎v���Ȃ����E�E�E
�_�C���N�g�Ɂi���������Ɂj���s�ł���낤�ˁB
���ɏ��Z�Ƃ����z�������̂܂��s�ł���悤�ɂ͎v���Ȃ����E�E�E
������Ƃ��u�˂��܂��B
���قͽ���ݸދZ�p���������Ă��܂����H
�j���[�X�L�����v���X�����[�X�݂������狳���Ă�������
���قͽ���ݸދZ�p���������Ă��܂����H
�j���[�X�L�����v���X�����[�X�݂������狳���Ă�������
�O�O����������肻���Ȃ��̂���
http://ascii24.com/news/i/topi/article/2005/04/07/655259-002.html
http://journal.mycom.co.jp/articles/2006/10/12/idf1/001.html
http://journal.mycom.co.jp/articles/2007/01/08/micro2/003.html
http://ascii24.com/news/i/topi/article/2005/04/07/655259-002.html
http://journal.mycom.co.jp/articles/2006/10/12/idf1/001.html
http://journal.mycom.co.jp/articles/2007/01/08/micro2/003.html
�n�[�h�R�[�f�B���O�̃R�X�g���ƃ��W�X�^���l�[���ӂ肩�ȃV���v�����߂Ȃ͂���RISC�̃}�C�N���R�[�h�̗̍p���R��
>>840
�������I�ǂ��������I
�������I�ǂ��������I
NYTimes��CELL BE+Opteron�̃n�C�u���b�h�N���X�^"Roadrunner"�ɂ��y�^�t���b�v�X
�˔j���X�N�[�v���Ă�悤���B
�l�^����{���t�ōX�V���ꂽNetlib��Linpack�����L���O���B
http://www.netlib.org/benchmark/performance.pdf
�@�@------------------------
�@�@Computer:
�@�@�@IBM BladeCenter cluster of 3060 nodes dual socket 1.8 GHz
�@�@Opteron (dual core) LS21 blades plus 6120 nodes dual socket
�@�@3.2 GHz PowerXCell 8i (8 SPU + 1 PPU cores) QS22 blades
�@�@w/InfiniBand
�@�@Numbers of Procs/Cores: 122400
�@�@Rmax: 1026000 [GFlops]
�@�@Rpeak: 1375776 [GFlops]
�@�@------------------------
���� 74.5%��ėp�C���^�R�l�N�g���g�p�����V�X�e���Ƃ��Ă�D�G���Ǝv�����B
���Ȃ݂Ɍ��݂�2�ʂ�BlueGene/L��478.2TFlops���B
�˔j���X�N�[�v���Ă�悤���B
�l�^����{���t�ōX�V���ꂽNetlib��Linpack�����L���O���B
http://www.netlib.org/benchmark/performance.pdf
�@�@------------------------
�@�@Computer:
�@�@�@IBM BladeCenter cluster of 3060 nodes dual socket 1.8 GHz
�@�@Opteron (dual core) LS21 blades plus 6120 nodes dual socket
�@�@3.2 GHz PowerXCell 8i (8 SPU + 1 PPU cores) QS22 blades
�@�@w/InfiniBand
�@�@Numbers of Procs/Cores: 122400
�@�@Rmax: 1026000 [GFlops]
�@�@Rpeak: 1375776 [GFlops]
�@�@------------------------
���� 74.5%��ėp�C���^�R�l�N�g���g�p�����V�X�e���Ƃ��Ă�D�G���Ǝv�����B
���Ȃ݂Ɍ��݂�2�ʂ�BlueGene/L��478.2TFlops���B
>>843
���@�肷���[
���@�肷���[
ITJungle�ɂ���POWER6���ڂ̃��[�G���h�T�[�o�[(�ƌ����Ă�$18K�B�B�B)�APower 520��
�o�Ă���Ƃ̂��Ƃ��B�܂��A6GHz�ɍ���������POWER6+�����N�̖����痈�N�����ɓo��
�Ƃ̂��Ƃ��B
http://www.itjungle.com/tfh/tfh060908-story01.html
�@�@----------------------
�@�@so I have been told, allow it to ramp up the clock speeds to 6 GHz and higher on the
�@�@Power6+ chips, which is another 20 percent higher than the top-end 5 GHz clock speed
�@�@on the Power6 chips used in the Power 595 and probably to be deployed in other Power
�@�@Systems machines either later this year or early next. (My guess is early next.)
�@�@----------------------
Tukwila�ɑ��鏀���햜�[�̗l���B(>>584�Q��)
�o�Ă���Ƃ̂��Ƃ��B�܂��A6GHz�ɍ���������POWER6+�����N�̖����痈�N�����ɓo��
�Ƃ̂��Ƃ��B
http://www.itjungle.com/tfh/tfh060908-story01.html
�@�@----------------------
�@�@so I have been told, allow it to ramp up the clock speeds to 6 GHz and higher on the
�@�@Power6+ chips, which is another 20 percent higher than the top-end 5 GHz clock speed
�@�@on the Power6 chips used in the Power 595 and probably to be deployed in other Power
�@�@Systems machines either later this year or early next. (My guess is early next.)
�@�@----------------------
Tukwila�ɑ��鏀���햜�[�̗l���B(>>584�Q��)
>>843
�ւ��[�AHPC�ł���1PFLOPS���B�ł����B���U���߭�èݸނł͈ꑫ���FAH��1PFLOPS�z�����Ă��܂����A
�ǂ����CellB.E.�������͂ɂȂ����̂��ʔ����ł��ˁB
�ւ��[�AHPC�ł���1PFLOPS���B�ł����B���U���߭�èݸނł͈ꑫ���FAH��1PFLOPS�z�����Ă��܂����A
�ǂ����CellB.E.�������͂ɂȂ����̂��ʔ����ł��ˁB
���߂łƂ��������܂�
POWER��������
>>847
���̊g���q�� WebSphere �H
���̊g���q�� WebSphere �H
>>843
���ɂ�QS22�P�̂̌���(170GF/217GF�A78.4%)��
QS22�N���X�^(�~84)�̌���(11TF/18TF�A60.7%)
�������L���O�ɍڂ��Ă�ˁB
�P����CELL�݂̂ŃN���X�^�g�ނƌ����������Ȃ��Ă�̂�
PPE������ڂ�����H
���ɂ�QS22�P�̂̌���(170GF/217GF�A78.4%)��
QS22�N���X�^(�~84)�̌���(11TF/18TF�A60.7%)
�������L���O�ɍڂ��Ă�ˁB
�P����CELL�݂̂ŃN���X�^�g�ނƌ����������Ȃ��Ă�̂�
PPE������ڂ�����H
�܂��킩���Ă�Ǝv�����A���p�v���Z�b�T�Ȃǂ������ڂ���� ���Y�p����R�X�g���l�b�N�ɂȂ邩���
853 �FMAC�I�^��851 �����F2008/06/11(��) 12:28:55 ID:2AW4op/U
>>851
�@�@------------------
�@�@PPE������ڂ�����H
�@�@------------------
�^�U�̒���m��Ȃ������ǁA���������b��ǂ��B
http://pc11.2ch.net/test/read.cgi/tech/1183091522/924
�@�@==================
�@�@����IBM��Cell�̃Z�~�i�[�����ɍs���Ă����B
�@�@�����Ń��[�h�����i�[�̘b�������āA�ʔ��������B
�@�@�������̂��A���[�h�����i�[�̓I�v�e������Cell�̍��ڂŁA
�@�@Cell�����ō\�z�����V�X�e�����A���\����͈����Ȃ邻�����B
�@�@==================
�@�@------------------
�@�@PPE������ڂ�����H
�@�@------------------
�^�U�̒���m��Ȃ������ǁA���������b��ǂ��B
http://pc11.2ch.net/test/read.cgi/tech/1183091522/924
�@�@==================
�@�@����IBM��Cell�̃Z�~�i�[�����ɍs���Ă����B
�@�@�����Ń��[�h�����i�[�̘b�������āA�ʔ��������B
�@�@�������̂��A���[�h�����i�[�̓I�v�e������Cell�̍��ڂŁA
�@�@Cell�����ō\�z�����V�X�e�����A���\����͈����Ȃ邻�����B
�@�@==================
POWER6/5GHz���ڂ�POWER 595��TPC-C�łԂ�������̃g�b�v�̐��т��L�^����
�Ƃ̂��Ƃ��B
http://www.tpc.org/tpcc/results/tpcc_perf_results.asp
�@IBM POWER595: 6085166tpmC (POWER6/5GHz, 32-sockets/64-cores/128-threads)
�@HP Superdome: 4092799tpmC (Montecito/1.6GHz, 64-sockets/128-cores/256-threads)
�@IBM p5-595: 4033378tpmC (POWER5/2.3GHz, 32-sockets/64-cores/128-threads)
�Ƃ̂��Ƃ��B
http://www.tpc.org/tpcc/results/tpcc_perf_results.asp
�@IBM POWER595: 6085166tpmC (POWER6/5GHz, 32-sockets/64-cores/128-threads)
�@HP Superdome: 4092799tpmC (Montecito/1.6GHz, 64-sockets/128-cores/256-threads)
�@IBM p5-595: 4033378tpmC (POWER5/2.3GHz, 32-sockets/64-cores/128-threads)
���߂łƂ��������܂�
���߂łƂ��������܂�
POWERMac�������ƕ��������끄�Â�
�{���ŃN���V�b�N�R�J�E�R�[���������������݂����ɃA�����J�̃}�J�[���s���^�������邵���Ȃ��悤����w
NYTimes�̃u���O�ŁAJobs��P.A. Semi�̔�����iPhone�p�`�b�v�̊J���̂��߂�
������ƕĂ��邷�B
http://bits.blogs.nytimes.com/2008/06/10/apple-in-parallel-turning-the-pc-world-upside-down/
�@�@------------------------
�@�@�gPA Semi is going to do system-on-chips for iPhones and iPods,�h he said.
�@�@------------------------
������ƕĂ��邷�B
http://bits.blogs.nytimes.com/2008/06/10/apple-in-parallel-turning-the-pc-world-upside-down/
�@�@------------------------
�@�@�gPA Semi is going to do system-on-chips for iPhones and iPods,�h he said.
�@�@------------------------
ID:6yjcx4nk
�E�E�����܂ŘI���ɃR�e�{�l�̖������i�삳���ƈ�����w
�E�E�����܂ŘI���ɃR�e�{�l�̖������i�삳���ƈ�����w
>>832
FamilyID=6����15�ɔ�̂́AFamilyID������3bit�����݂Ȃ��A�zOS��̂����ŁA�����7�`14�͎g���Ȃ��Ǝv���܂��B
����Ӗ��Z�p�I�Ȗ{���ɂ͈Ⴂ�Ȃ�w
FamilyID=6����15�ɔ�̂́AFamilyID������3bit�����݂Ȃ��A�zOS��̂����ŁA�����7�`14�͎g���Ȃ��Ǝv���܂��B
����Ӗ��Z�p�I�Ȗ{���ɂ͈Ⴂ�Ȃ�w
>>861
Ext.Model�����Ȃ�������Penryn��Pen3�ƌ�F�����Đ���ɓ����Ȃ��A�z�A�v���������Ă���
��̓I�ɂ͎ʐ^���̂��Ƃ�����
Ext.Model�����Ȃ�������Penryn��Pen3�ƌ�F�����Đ���ɓ����Ȃ��A�z�A�v���������Ă���
��̓I�ɂ͎ʐ^���̂��Ƃ�����
POWERMac�̕���������C�Ȃ��Ȃ玀�˂恄��
�J�i�_�̌����@�ւ�Niagara 2�x�[�X�̃N���X�^�����݂���Ƃ̂��Ƃ��B
�Ȃ�ł����I�ȃ������𗣎U�I�ɃA�N�Z�X����p�r���Ƒ����Ƃ��B
http://www.hpcwire.com/blogs/19804214.html
http://www.rz.rwth-aachen.de/ca/k/raw/lang/de/
�@�@---------------------
�@�@It turns out the the UltraSPARC T2 processor is ideally suited for scalable applications
�@�@which consume a high memory bandwidth, former vector codes falling into this category.
�@�@This has been shown by our sparse matrix vector multiplication case study, which is a
�@�@compute intense kernel of many PDE solvers, and some of our application benchmarks.
�@�@---------------------
�Ȃ�ł����I�ȃ������𗣎U�I�ɃA�N�Z�X����p�r���Ƒ����Ƃ��B
http://www.hpcwire.com/blogs/19804214.html
http://www.rz.rwth-aachen.de/ca/k/raw/lang/de/
�@�@---------------------
�@�@It turns out the the UltraSPARC T2 processor is ideally suited for scalable applications
�@�@which consume a high memory bandwidth, former vector codes falling into this category.
�@�@This has been shown by our sparse matrix vector multiplication case study, which is a
�@�@compute intense kernel of many PDE solvers, and some of our application benchmarks.
�@�@---------------------
�ւ�
>866
����Ȃ�
�n�C�p�[�J�[�h�Ƃ��܂Œׂ��Ȃ��Ă悳�����Ȃ���Ȃ̂�
����Ȃ�
�n�C�p�[�J�[�h�Ƃ��܂Œׂ��Ȃ��Ă悳�����Ȃ���Ȃ̂�
�A�����I�������Ƃ������X�J���[�ȍ~��F�߂ĂȂ���������B
>>867
�A�g�L���\���������ɂ́A�X�J���[��HyperCard�̌����������Ă�炵���B
>>867
�A�g�L���\���������ɂ́A�X�J���[��HyperCard�̌����������Ă�炵���B
�܂��͂ǂꂾ�����m�����炯�o���C�����ނ̂��
�a�s���Z�Ƃ͂��邪�A�����_���A�N�Z�X����Ƃ͌�����
�ނ���эs��ŘA���I�Ƀ������A�N�Z�X���邱�Ƃ̂ق���������
�a�s���Z�Ƃ͂��邪�A�����_���A�N�Z�X����Ƃ͌�����
�ނ���эs��ŘA���I�Ƀ������A�N�Z�X���邱�Ƃ̂ق���������
��������AMD���ʔ����Ȃ̂����Ă��̂ɍ����C�t������
ttp://developer.amd.com/cpu/Libraries/sseplus/Pages/default.aspx
ttp://developer.amd.com/cpu/Libraries/sseplus/Pages/default.aspx
872 �F,,�E�L�́M�E,,�j��-�������F2008/06/13(��) 22:34:34 ID:p7oDIxgh
SSSE3/SSE4.1���g����SSE4A/SSE5�G�~�����[�V�����̎������Ȃ��ȁB
����܂�g���Ȃ��T���v�����B
����܂�g���Ȃ��T���v�����B
Yellow Dog Linux��Terra Soft���f���A��PowerPC 970MP�̃��[�N�X�e�[�V����������Ƃ̂��Ƃ��B
http://terrasoftsolutions.com/products/powerstation/
��������AIBM��IntelliStation 185�Ȃ�Ȃ������B�B�B
http://www-03.ibm.com/systems/intellistation/power/hardware/185/index.html
�F����ʂɂ��āA���l�i$1,850�Ƃ̂��Ƃ�����A���Ǝ�y�ɓ���\��PowerPC Linux�̃v���b�g
�t�H�[���ł킠�邷�B
http://terrasoftsolutions.com/products/powerstation/
��������AIBM��IntelliStation 185�Ȃ�Ȃ������B�B�B
http://www-03.ibm.com/systems/intellistation/power/hardware/185/index.html
�F����ʂɂ��āA���l�i$1,850�Ƃ̂��Ƃ�����A���Ǝ�y�ɓ���\��PowerPC Linux�̃v���b�g
�t�H�[���ł킠�邷�B
874 �FMAC�I�^���⑫�F2008/06/15(��) 22:26:25 ID:fvrvWeGO
�y���������Ă݂�ƁAPowre Mac G5 2.5GHz Quad�̒��É��i��$1,500�ʂ̂悤���B
IBM���A�����Ƒ������������g�̂�����Ă����Ηǂ��������m�����ǁB�B�B
IBM���A�����Ƒ������������g�̂�����Ă����Ηǂ��������m�����ǁB�B�B
875 �F,,�E�L�́M�E,,�j��-�������F2008/06/15(��) 23:33:37 ID:5bcntWF7
���f���A��PowerPC 970MP�̃��[�N�X�e�[�V����
��������970MP�{PS3�N���X�^�̐e�@�̒P�̔���ł��������ł���
��������970MP�{PS3�N���X�^�̐e�@�̒P�̔���ł��������ł���
876 �F,,�E�L�́M�E,,�j��-�������F2008/06/15(��) 23:37:09 ID:5bcntWF7
�����Ǝ�y�ɓ���\��PowerPC Linux�̃v���b�g
���t�H�[���ł킠�邷�B
�����APS3�A�̂�Mac�͎�y�ɓ��荢��ł��������ł���
���t�H�[���ł킠�邷�B
�����APS3�A�̂�Mac�͎�y�ɓ��荢��ł��������ł���
�ԍڗp�}�C�R���ւ̕��y�g���_��ARM�R�A
http://pc.watch.impress.co.jp/docs/2008/0616/arm.htm
http://pc.watch.impress.co.jp/docs/2008/0616/arm.htm
878 �FMAC�I�^���c�q �����F2008/06/16(��) 08:03:14 ID:fqpP/Io+
>>876
�@�@--------------------
�@�@�����APS3�A�̂�Mac�͎�y�ɓ��荢��ł��������ł���
�@�@--------------------
����: �ᐫ�\�B�V�^��ARM�ڍs
PS3: ���������Ȃ��BHypervisor�̐����BPPE��ᐫ�\
PowerMac: ���Îs��̂�
�@�@--------------------
�@�@�����APS3�A�̂�Mac�͎�y�ɓ��荢��ł��������ł���
�@�@--------------------
����: �ᐫ�\�B�V�^��ARM�ڍs
PS3: ���������Ȃ��BHypervisor�̐����BPPE��ᐫ�\
PowerMac: ���Îs��̂�
�ɂȂ��Ƃ���
880 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 11:52:56 ID:529taapO
970MP���̒ᐫ�\���B�B�B
881 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 12:03:28 ID:529taapO
���Â�PPC�}�b�N�Ȃ�\�t�}�b�v�ɂ�����ł�����ˁB
����s���������낤���ǁB
����s���������낤���ǁB
�Ō�̍ԁADTP�����A�悤�₭Classic������ڍs���n�߂����ȁB
Old PPC Mac������Ŋm�ۂ���A�������낻�댸���Ă����B
�Ƃ͂������̂́A�����̒����o�ŎЂ��ҏW���ɂ���Ă�
�͖�����OS9+Illustrator8+QuarkXPress3.3�������������肷�邪��
Old PPC Mac������Ŋm�ۂ���A�������낻�댸���Ă����B
�Ƃ͂������̂́A�����̒����o�ŎЂ��ҏW���ɂ���Ă�
�͖�����OS9+Illustrator8+QuarkXPress3.3�������������肷�邪��
883 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 20:20:08 ID:529taapO
Leopard��classic�����؎̂Ă�Apple�̂����f�ł��̂ŁB
�Ƃ������ALinux��1400�h��������PPC�}�V���Ȃ�Ċ����đI�ԗ��R���āA�M�҈ȊO�ɂ͂Ȃ���ˁB
���ƂȂ����ᐫ�\������Flash����Đ��ł��Ȃ���
�ۂ��Ɣ����Ă�1000�h����Core 2 Quad�̂ق�������ۂǐ��\�������B
�Ƃ������ALinux��1400�h��������PPC�}�V���Ȃ�Ċ����đI�ԗ��R���āA�M�҈ȊO�ɂ͂Ȃ���ˁB
���ƂȂ����ᐫ�\������Flash����Đ��ł��Ȃ���
�ۂ��Ɣ����Ă�1000�h����Core 2 Quad�̂ق�������ۂǐ��\�������B
884 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 20:35:16 ID:529taapO
������1850�h�����B
20�����炢���ȁB
�E�E�E�_�O
20�����炢���ȁB
�E�E�E�_�O
885 �FMAC�I�^���c�q �����F2008/06/16(��) 21:35:34 ID:fqpP/Io+
>>884
���ł��@�������N���Ȃ̂�������Ȃ������ǁA
�@�E2-socket
�@�EECC DIMM�T�|�[�g
�@�E8-DIMM Slots
�@�ESAS RAID�R���g���[������
�@�EPCI-X�X���b�g�t
���Ă̂�ANetburst Xeon�ł�����Ȓl�i���B
http://www.asaservers.com/config.asp?config_id=7044A%2D8
���ł��@�������N���Ȃ̂�������Ȃ������ǁA
�@�E2-socket
�@�EECC DIMM�T�|�[�g
�@�E8-DIMM Slots
�@�ESAS RAID�R���g���[������
�@�EPCI-X�X���b�g�t
���Ă̂�ANetburst Xeon�ł�����Ȓl�i���B
http://www.asaservers.com/config.asp?config_id=7044A%2D8
�Ă�Hot Chips 20�̃v���O���������J����Ă��邷�B
�߂ڂ������\��A����Ȋ������B
������ (8/25) http://www.hotchips.org/hc20/program/conference_day_one.htm
�@�EPower-Performance Comparison of POWER5 &POWER6 Microprocessors (IBM)
�@�ESpursEngine - Cell Derivative High-Perf Stream Proc. for Media Acceleration (����)
�@�EAMD mediaDSP: A Programmable Multicore Video Processor Platform (AMD)
�@�EPowerXCell 8i: A Cell Broadband Engine Architecture for Supercomputing (IBM)
������� (8/26) http://www.hotchips.org/hc20/program/conference_day_two.htm
�@�E Inside Intel�fs Next Generation Nehalem Microarchitecture (Intel)
�@�ENVIDIA G100: TeraFLOPS Visual Computing (NVIDIA)
�@�ELarrabee: A Many-Core x86 Architecture for Visual Computing (Intel)
�@�ETukwila: A Quad-Core Intel(R) Itanium(R) Processor (Intel)
�@�ESPARC64VII: Fujitsu�fs Next Generation Quad-Core Processor (�x�m��)
�@�ERock: A 3rd Gen 65nm, 16-Core, 32+32 Scout Threads CMT SPARC Proc. (SUN)
�߂ڂ������\��A����Ȋ������B
������ (8/25) http://www.hotchips.org/hc20/program/conference_day_one.htm
�@�EPower-Performance Comparison of POWER5 &POWER6 Microprocessors (IBM)
�@�ESpursEngine - Cell Derivative High-Perf Stream Proc. for Media Acceleration (����)
�@�EAMD mediaDSP: A Programmable Multicore Video Processor Platform (AMD)
�@�EPowerXCell 8i: A Cell Broadband Engine Architecture for Supercomputing (IBM)
������� (8/26) http://www.hotchips.org/hc20/program/conference_day_two.htm
�@�E Inside Intel�fs Next Generation Nehalem Microarchitecture (Intel)
�@�ENVIDIA G100: TeraFLOPS Visual Computing (NVIDIA)
�@�ELarrabee: A Many-Core x86 Architecture for Visual Computing (Intel)
�@�ETukwila: A Quad-Core Intel(R) Itanium(R) Processor (Intel)
�@�ESPARC64VII: Fujitsu�fs Next Generation Quad-Core Processor (�x�m��)
�@�ERock: A 3rd Gen 65nm, 16-Core, 32+32 Scout Threads CMT SPARC Proc. (SUN)
887 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 21:45:27 ID:529taapO
���E�f���A���\�P�b�g
970���Ƃ��̋��ш�FSB�Ńf���A���\�P�b�g�Ȃ��Core 2 Quad�̂ق����}�V�ł���
���EECC DIMM�T�|�[�g
i3000/3100�v���b�g�t�H�[���őΉ����Ă��
���E8-DIMM Slots
�������Ƃ���ECC��8�����}������S�R���育�뉿�i����Ȃ��Ȃ��
���ESAS RAID�R���g���[������
�����i3000/3100�v���b�g�t�H�[���őΉ����Ă��
���EPCI-X�X���b�g�t
���X���Ɏg���́H
970���Ƃ��̋��ш�FSB�Ńf���A���\�P�b�g�Ȃ��Core 2 Quad�̂ق����}�V�ł���
���EECC DIMM�T�|�[�g
i3000/3100�v���b�g�t�H�[���őΉ����Ă��
���E8-DIMM Slots
�������Ƃ���ECC��8�����}������S�R���育�뉿�i����Ȃ��Ȃ��
���ESAS RAID�R���g���[������
�����i3000/3100�v���b�g�t�H�[���őΉ����Ă��
���EPCI-X�X���b�g�t
���X���Ɏg���́H
���ʂ̃f�X�N�g�b�v���̒l�i�Ń��[�N�X�e�[�V������
���邱�ƂɒN���������Ȃ��A�Ă��Ƃ��{��
���邱�ƂɒN���������Ȃ��A�Ă��Ƃ��{��
889 �FMAC�I�^���c�q �����F2008/06/16(��) 21:49:49 ID:fqpP/Io+
>>887
����i3000/3100�̂������V�X�e����$1,000���Ă邷��(��)
(>>883�Q��)
�@�@------------------------
�@�@�ۂ��Ɣ����Ă�1000�h����Core 2 Quad�̂ق�������ۂǐ��\�������B
�@�@------------------------
����i3000/3100�̂������V�X�e����$1,000���Ă邷��(��)
(>>883�Q��)
�@�@------------------------
�@�@�ۂ��Ɣ����Ă�1000�h����Core 2 Quad�̂ق�������ۂǐ��\�������B
�@�@------------------------
Multicore Video Processor Platform�H�H
891 �FMAC�I�^��890 �����F2008/06/16(��) 21:54:16 ID:fqpP/Io+
>>890
ATI�̕����Ǝv���邷�B
ATI�̕����Ǝv���邷�B
892 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 21:54:45 ID:529taapO
����A�������ŏ��\���Ȃ�]�T��10�����
http://h50157.www5.hp.com/is-bin/INTERSHOP.enfinity/eCS/Store/ja/-/JPY/BrowseCatalogForBusiness-Start?CategoryName=SERI:388
��BTO�ŃN�A�b�h�R�AXeon�I�Ԃ��Celeron�Ŕ����ă��e�[���i�Ɍ��������ق��������B
http://h50157.www5.hp.com/is-bin/INTERSHOP.enfinity/eCS/Store/ja/-/JPY/BrowseCatalogForBusiness-Start?CategoryName=SERI:388
��BTO�ŃN�A�b�h�R�AXeon�I�Ԃ��Celeron�Ŕ����ă��e�[���i�Ɍ��������ق��������B
893 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 22:03:42 ID:529taapO
�Ƃ������AXeon(Core 2)������PPC970�Ȃ̂̓W���u�Y����F�߂Ă鎖�������B
�́ASun����UltraSPARC IIe���ڂ̌������[�N�X�e�[�V�������o�Ă����Ƃ��͊��삵�����B
�A�����AJava�̃p�t�H�[�}���X��r�����琔������Celeron Windows 2000�@�̂ق���
�����Ƃ������Ȃ����ʂ������B
970MP�����F���ƂȂ��Ă͋������CPU������
�������x���`�������Celeron Dualcore�ɂ��������Ȃ��́H
�́ASun����UltraSPARC IIe���ڂ̌������[�N�X�e�[�V�������o�Ă����Ƃ��͊��삵�����B
�A�����AJava�̃p�t�H�[�}���X��r�����琔������Celeron Windows 2000�@�̂ق���
�����Ƃ������Ȃ����ʂ������B
970MP�����F���ƂȂ��Ă͋������CPU������
�������x���`�������Celeron Dualcore�ɂ��������Ȃ��́H
894 �FMAC�I�^���c�q �����F2008/06/16(��) 22:04:42 ID:fqpP/Io+
>>892
�@�@----------------------
�@�@��BTO�ŃN�A�b�h�R�AXeon�I�Ԃ��Celeron�Ŕ����ă��e�[���i�Ɍ��������ق��������B
�@�@----------------------
(��)
���ꂩ��A�ŏ��\������SAS�햳�����B
�}�U�[�{�[�h��PCIe x16�X���b�g���������ˁB�������������܂��傤�B
�@�@----------------------
�@�@��BTO�ŃN�A�b�h�R�AXeon�I�Ԃ��Celeron�Ŕ����ă��e�[���i�Ɍ��������ق��������B
�@�@----------------------
(��)
���ꂩ��A�ŏ��\������SAS�햳�����B
�}�U�[�{�[�h��PCIe x16�X���b�g���������ˁB�������������܂��傤�B
895 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 22:18:07 ID:529taapO
SAS���݂ł��������������ǂˁB�܂�������B
�ǂ����ɂ���GNU/Linux�݂����ȃI�[�v���\�[�X�̊������傤�т킴�킴Core 2/Xeon��胏�b�g�E�p�t�H�[�}���X��
����PPC�ȂŎg�������b�g�̂���l�ԂȂǂ��ɂ����Ȃ��ł���B
PPC�M�҂̉ߋ��̉h���ւ̎����͂������ˁB
�ǂ����ɂ���GNU/Linux�݂����ȃI�[�v���\�[�X�̊������傤�т킴�킴Core 2/Xeon��胏�b�g�E�p�t�H�[�}���X��
����PPC�ȂŎg�������b�g�̂���l�ԂȂǂ��ɂ����Ȃ��ł���B
PPC�M�҂̉ߋ��̉h���ւ̎����͂������ˁB
896 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 22:24:59 ID:529taapO
�Ƃ�����Linux���[�U�[�ɂƂ��Ă�x86�̃R�[�h���Y���g���Ȃ����Ƃ̂ق���SAS�̗L�����d��Ȗ�肾�ȁB
GNU/Linux�c�[���Q�E�G��PPC�ŗL���Y�Ȃ�ĂقڊF��������86��p�̃R�[�h���Y�͕���قǂ���B
PPC970��I�Ԃ��Ǝ��̂��f�����b�g�Ȃ�B
GNU/Linux�c�[���Q�E�G��PPC�ŗL���Y�Ȃ�ĂقڊF��������86��p�̃R�[�h���Y�͕���قǂ���B
PPC970��I�Ԃ��Ǝ��̂��f�����b�g�Ȃ�B
��������Power6�Ă���ς胏�[�N�X�e�[�V��������ɂ͕s�����ȃv���Z�b�T�ɂȂ����́H
898 �FMAC�I�^��897 �����F2008/06/16(��) 22:46:33 ID:fqpP/Io+
>>897
�����s�����ȑO��CAD�𒆐S�Ƃ���EWS�s���x86������肵���͗l���B
POWER5����Intellipower�̌�p�@���o�Ȃ��Ƃ��������ƁAIBM�����߂���ł�H
�����s�����ȑO��CAD�𒆐S�Ƃ���EWS�s���x86������肵���͗l���B
POWER5����Intellipower�̌�p�@���o�Ȃ��Ƃ��������ƁAIBM�����߂���ł�H
899 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 22:57:59 ID:529taapO
�Ƃ������ˁALinux�g���̂�SAS��ECC���K�v����Ȃ���ˁB
�g��Ȃ��Ƃ����I�v�V�������I�ׂāA10���ȉ��ɗ��Ƃ��邩�H
�ł��ˁ[�Ȃ炨�荠�ł��Ȃ�ł��Ȃ��B
PPC���D���ȓz�ɂ������l���Ȃ���
�g��Ȃ��Ƃ����I�v�V�������I�ׂāA10���ȉ��ɗ��Ƃ��邩�H
�ł��ˁ[�Ȃ炨�荠�ł��Ȃ�ł��Ȃ��B
PPC���D���ȓz�ɂ������l���Ȃ���
900 �FMAC�I�^���c�q �����F2008/06/16(��) 23:27:18 ID:fqpP/Io+
>>899
�d�l����Ȃ��Ȃ�A���Â�PowerMac�ł�PS3�ł�xbox360�ł������ł��ǂ���ł�(��)
�d�l����Ȃ��Ȃ�A���Â�PowerMac�ł�PS3�ł�xbox360�ł������ł��ǂ���ł�(��)
�܂�����Ȃ��b��ʂɂ��āAPPC Linux�g��̕K�v���ɔ����Ă���̂�IBM�Ȗ���A
�ǂ���Intellipower����o����Ȃ�����Ƒ������ׂ����������A���ꂩ��n�߂�Ȃ�POWER4�R�A
�Ȃ�đO���I�̈╨����Ȃ����m�𓊓����ׂ����Ǝv�����B
�ǂ���Intellipower����o����Ȃ�����Ƒ������ׂ����������A���ꂩ��n�߂�Ȃ�POWER4�R�A
�Ȃ�đO���I�̈╨����Ȃ����m�𓊓����ׂ����Ǝv�����B
G5��̂ĂȂ�Ẩ�C���c��v������B
x86�Ȃ�POWER�ŕЎ�ԂɃG�~�����Ă����肪���邾��B
904 �F,,�E�L�́M�E,,�j��-�������F2008/06/17(��) 07:14:01 ID:WRDwzsBB
x86���PPC�G�~������Ă����肪����Ǝv�����́A�n�Q����
G3�̂���́Ax86�R�[�h�̓G�~���ł������Č����Ă���
���ꂪ������R�l�N�e�B�b�N�X��MS�ɔ������ꂿ����āc�c
���ꂪ������R�l�N�e�B�b�N�X��MS�ɔ������ꂿ����āc�c
Freesacle���ő�8-core��e500mc�R�A(Book-E PPC��)���W�ς���SoC�A"QorIQ P4080"�\�������B
http://media.freescale.com/phoenix.zhtml?c=196520&p=irol-newsArticle&ID=1165848
http://www.freescale.com/files/netcomm/doc/fact_sheet/QorIQ_P4080.pdf
�@�E45nm�v���Z�X
�@�Eup to 8 e500mc/1.5GHz�R�A
�@�E�Ɨ�L1 I 32KB + D 32KB, �Ɨ�L2 128KB, ���LL3 2MB
�@�EDDR2/DDR3�������R���g���[�� x 2
�@�EPCIe x 3, Serial RapidIO x 2, 10GbE x 2, GbE x 8
�@�E�Í�������уp�^�[���}�b�`�p�A�N�Z�����[�^
�@�Emid-2009�T���v�����O�J�n
http://media.freescale.com/phoenix.zhtml?c=196520&p=irol-newsArticle&ID=1165848
http://www.freescale.com/files/netcomm/doc/fact_sheet/QorIQ_P4080.pdf
�@�E45nm�v���Z�X
�@�Eup to 8 e500mc/1.5GHz�R�A
�@�E�Ɨ�L1 I 32KB + D 32KB, �Ɨ�L2 128KB, ���LL3 2MB
�@�EDDR2/DDR3�������R���g���[�� x 2
�@�EPCIe x 3, Serial RapidIO x 2, 10GbE x 2, GbE x 8
�@�E�Í�������уp�^�[���}�b�`�p�A�N�Z�����[�^
�@�Emid-2009�T���v�����O�J�n
907 �FMAC�I�^���⑫�F2008/06/18(��) 00:35:17 ID:g8Utdww1
�@�E30W �ȉ�
�Ƃ����̂������Y�ꂽ���B
�Ƃ����̂������Y�ꂽ���B
Top500���\
http://www.top500.org/list/2008/06/100
RoadRunner�̓d�͌����X�Q�[�B
BlueGene/P���ǂ��Ȃ���B
�ł��d�͌����̗ǂ��X�p�R���͂���܂�
324�ʂ�QS22CELL�N���X�^�ɂȂ����悤�ł��B
http://www.top500.org/list/2008/06/100
RoadRunner�̓d�͌����X�Q�[�B
BlueGene/P���ǂ��Ȃ���B
�ł��d�͌����̗ǂ��X�p�R���͂���܂�
324�ʂ�QS22CELL�N���X�^�ɂȂ����悤�ł��B
IBM�i���A�����J�j�l�A���̔{���x�ɍœK�����ꂽ�v���Z�b�T��
���ƂȂ����v���Z�b�T�ɖ^���{��Ƃ������������牭�~�̔������炢��Ԃ��ĉ����� ����
���ƂȂ����v���Z�b�T�ɖ^���{��Ƃ������������牭�~�̔������炢��Ԃ��ĉ����� ����
910 �F,,�E�L�́M�E,,�j��-�������F2008/06/18(��) 20:50:39 ID:k35grsI0
���{��Ƃ���Ȃ��ĎY�����Ɗ؍��̎��{�̓�������Ƃł��̂ŁB
���\�d�͔�Ȃ�AGRAPE DR���D�҂�����
��Ŏn�߂�Top500������Ȃɉe���͂����Ȃ�āA�h���K�����ߍ��Ȃ���
��Ŏn�߂�Top500������Ȃɉe���͂����Ȃ�āA�h���K�����ߍ��Ȃ���
���O�̃}�V�� �N���X�^�� �����ăs�[�N�͑���
�A�v�����\�o���ʊԂ� �x���`��Top500����߂�
�������ăN���X�^�� ���̉A�Ɏ��𐾂�
�x�N�g���@ ������� �䓙�̓N���X�^���
�A�v�����\�o���ʊԂ� �x���`��Top500����߂�
�������ăN���X�^�� ���̉A�Ɏ��𐾂�
�x�N�g���@ ������� �䓙�̓N���X�^���
IBM�uRoadrunner�v��1Peta FLOPS���ŃX�p�R��1�ʂ�
�`�������͓���/�}�g��/����̃V�X�e�������o��
http://pc.watch.impress.co.jp/docs/2008/0619/top500.htm
�`�������͓���/�}�g��/����̃V�X�e�������o��
http://pc.watch.impress.co.jp/docs/2008/0619/top500.htm
����������A���ꎟ�������̉������߂鑬�x�������惉���L���O����߂���ǂ����B
�E�E�E�E�ƃ�104�����̑����Ŕ���CPU�����߂Ă��鉴�l�������Ă��A���̐����͂��Ȃ��ł��ˁB
�E�E�E�E�ƃ�104�����̑����Ŕ���CPU�����߂Ă��鉴�l�������Ă��A���̐����͂��Ȃ��ł��ˁB
>>911
GRAPE�̐V������̓x���`���点���邩��ڂ�\��������Ƃ͕����Ă��邪�A
����œd�͌��������Ȃ邩�͌��ǂ킩���Ǝv���B
���̃����L���O���߂�x���`�Ō����o���邩����肾���B
GRAPE�̐V������̓x���`���点���邩��ڂ�\��������Ƃ͕����Ă��邪�A
����œd�͌��������Ȃ邩�͌��ǂ킩���Ǝv���B
���̃����L���O���߂�x���`�Ō����o���邩����肾���B
Top500�͊��ɖ��Ӗ���ʂ�z���āg�Q�h�ł����Ȃ����ǂȁB
IBM���₽��ƍS��͔̂n�������炩�B
IBM���₽��ƍS��͔̂n�������炩�B
��ł܂�����top500�����ɁA�^�u���K�[��^�G�R�m�~�X�g�������Ƃ��炵�����͂ŁA
�����X�p�R���ᔻ�_��W�J����̂��Ǝv���ƋC���œ���B
�����X�p�R���ᔻ�_��W�J����̂��Ǝv���ƋC���œ���B
CFD��Top500����������
IBM�O���[�v�A32nm��High-k/���^���Q�[�g�Z�p�����\
http://pc.watch.impress.co.jp/docs/2008/0620/vlsi01.htm
http://pc.watch.impress.co.jp/docs/2008/0620/vlsi01.htm
�C���e�������ĕ����ĂȂ�����I
IMEC�A32nm High-k/���^���Q�[�g�v���Z�X��
���Ǎ�\
http://www.ednjapan.com/content/l_news/2008/06/u0o686000000dbv5.html
IMEC�A32nm High-k/���^���Q�[�g�v���Z�X��
���Ǎ�\
http://www.ednjapan.com/content/l_news/2008/06/u0o686000000dbv5.html
�O�\�������Ɨ���t�]�����E�E�E�̂��H
922 �FMAC�I�^��920 �����F2008/06/20(��) 17:27:04 ID:VL2Havpu
>>921
���ۂɗʎY���Ă���Intel�̐�s��h�邪�Ȃ����ƁB
���ۂɗʎY���Ă���Intel�̐�s��h�邪�Ȃ����ƁB
6/10�ɊJ�Â��ꂽIBM��CELL�Z�~�i�[�̃v���[�����������J����Ă��邷�B
http://www-06.ibm.com/jp/solutions/deepcomputing/events/cell.html
Roadrunner�̃^�C�����[�ȃl�^�����邷�B�������䂩���l�^��A���̕ӁB
�uCell/B.E.��Supercomputer�ւ̓W�J�v
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_HPC_Japan_Cell_Seminar_A4.pdf
Roadrunner�̉�������S�B
�@- PowerXCell8i��Performance per Watt��A1.1GFlops(DP)/Watt (�܂����d�͂�97W)
�@- Roadrunner�ɂ�����Opteron��MPI�ʐM��p(p.29)
�@- Cell�P�̂��Cell + Opteron��x���Ȃ� (p.47)
�uIBM BladeCenter QS21�����IBM SDK for Multicore 3.0�̂��Љ�v
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/argo_graphics.pdf
�@- ������CELL�Ŗ��߃Z�b�g�Ɏ������H(p.10)
�@�@----------------------------
�@�@2010�N1H�ڕW
�@�@BladeCenter QS2Z
�@�@- First CBEA teraflops�v���Z�b�T
�@�@- 2 PPE + 32 eSPE
�@�@- Powre Architecture compliant�@�@�@�@�@<--- �R��
�@�@- SP: �`2TFLOPS (�u���[�h������)
�@�@- DP: �`1TFLOPS (�u���[�h������)
�@�@- �����チ�����E�e�N�m���W�[
�@�@----------------------------
http://www-06.ibm.com/jp/solutions/deepcomputing/events/cell.html
Roadrunner�̃^�C�����[�ȃl�^�����邷�B�������䂩���l�^��A���̕ӁB
�uCell/B.E.��Supercomputer�ւ̓W�J�v
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_HPC_Japan_Cell_Seminar_A4.pdf
Roadrunner�̉�������S�B
�@- PowerXCell8i��Performance per Watt��A1.1GFlops(DP)/Watt (�܂����d�͂�97W)
�@- Roadrunner�ɂ�����Opteron��MPI�ʐM��p(p.29)
�@- Cell�P�̂��Cell + Opteron��x���Ȃ� (p.47)
�uIBM BladeCenter QS21�����IBM SDK for Multicore 3.0�̂��Љ�v
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/argo_graphics.pdf
�@- ������CELL�Ŗ��߃Z�b�g�Ɏ������H(p.10)
�@�@----------------------------
�@�@2010�N1H�ڕW
�@�@BladeCenter QS2Z
�@�@- First CBEA teraflops�v���Z�b�T
�@�@- 2 PPE + 32 eSPE
�@�@- Powre Architecture compliant�@�@�@�@�@<--- �R��
�@�@- SP: �`2TFLOPS (�u���[�h������)
�@�@- DP: �`1TFLOPS (�u���[�h������)
�@�@- �����チ�����E�e�N�m���W�[
�@�@----------------------------
���������A��̎�����>>853�œ]�ڂ����b�̐M�ߐ���m�肷�B�Q�����˂�\�[�X��
�̂Ă����̂��ᖳ���Ƃ������ƂŁB�B�B
�̂Ă����̂��ᖳ���Ƃ������ƂŁB�B�B
926 �FMAC�I�^��925 �����F2008/06/21(�y) 19:41:53 ID:QtBsYZWJ
>>925
�����e�̃q�g����ۂɍu�������ď����Ă��邷����A�v���[�����������Ă��邾���̉�X���
���\�҂̈Ӑ}��ǂ��`���Ă���Ǝv�����B
���ۂ�p.24�����Ă��AOpteron�Ƃ̃n�C�u���b�h�^��I���������R�Ƃ���
�u�V�����A�[�L�e�N�`���ւ̒���v���u�w�e���W�j�A�X�V�X�e���ł̕W���̊m���ƃ��[�_�[�V�b�v�v
���Ƃ����A����ڗD��̑I�����������Ƃ�����Ă��邷�B
�����e�̃q�g����ۂɍu�������ď����Ă��邷����A�v���[�����������Ă��邾���̉�X���
���\�҂̈Ӑ}��ǂ��`���Ă���Ǝv�����B
���ۂ�p.24�����Ă��AOpteron�Ƃ̃n�C�u���b�h�^��I���������R�Ƃ���
�u�V�����A�[�L�e�N�`���ւ̒���v���u�w�e���W�j�A�X�V�X�e���ł̕W���̊m���ƃ��[�_�[�V�b�v�v
���Ƃ����A����ڗD��̑I�����������Ƃ�����Ă��邷�B
>>926
�����e�₨�O�̂悤�Ȕn���ƈꏏ�ɂ��Ȃ��ł���B
����̓R�[�h��Hybrid node�����Ă��A���܂�����������Ă��܂���A�Ƃ��������Ȃ�
�f�[�^������ʐM�������ŁA������x������������͓̂��R
Cell�����ō\�z�����V�X�e�������݂��Ȃ�
�����e�₨�O�̂悤�Ȕn���ƈꏏ�ɂ��Ȃ��ł���B
����̓R�[�h��Hybrid node�����Ă��A���܂�����������Ă��܂���A�Ƃ��������Ȃ�
�f�[�^������ʐM�������ŁA������x������������͓̂��R
Cell�����ō\�z�����V�X�e�������݂��Ȃ�
928 �FMAC�I�^��927 �����F2008/06/21(�y) 21:30:00 ID:QtBsYZWJ
>>927
���l��n����������q�g���āA�ǂ����ĐԂ��p�������������炩�ȏ������݂����邷����(��)
�@�@------------------
�@�@Cell�����ō\�z�����V�X�e�������݂��Ȃ�
�@�@------------------
http://www.top500.org/system/9425
http://www.top500.org/system/9563
���ł�
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_HPC_Japan_Cell_Seminar_A4.pdf
�@�@===================
�@�@- Black letters are measured, brown letters are projected. (P.45)
�@�@===================
Milago�R�[�h��Hybrid�̕������\���オ���Ă���̂������Ȃ��悤���ˁB���Ȃ��̘_�@�ł�
�@�@-------------------
�@�@�f�[�^������ʐM�������ŁA������x������������͓̂��R
�@�@-------------------
��������Ȃ������H
���l��n����������q�g���āA�ǂ����ĐԂ��p�������������炩�ȏ������݂����邷����(��)
�@�@------------------
�@�@Cell�����ō\�z�����V�X�e�������݂��Ȃ�
�@�@------------------
http://www.top500.org/system/9425
http://www.top500.org/system/9563
���ł�
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_HPC_Japan_Cell_Seminar_A4.pdf
�@�@===================
�@�@- Black letters are measured, brown letters are projected. (P.45)
�@�@===================
Milago�R�[�h��Hybrid�̕������\���オ���Ă���̂������Ȃ��悤���ˁB���Ȃ��̘_�@�ł�
�@�@-------------------
�@�@�f�[�^������ʐM�������ŁA������x������������͓̂��R
�@�@-------------------
��������Ȃ������H
�ǂ������o�J�Ƃ��m�肽���킯����Ȃ�����A����������Ԃ����邭�炢�Ȃ�
���������ڍׂɏ����Ă���
���������ڍׂɏ����Ă���
930 �FMAC�I�^��929 �����F2008/06/21(�y) 21:55:31 ID:QtBsYZWJ
>>929
���ɂ�>>923-924�̃����N��Ƃ��̉���ŏ\�������ǁA��������Ȃ����Ƃ�����Ȃ��̓I��
����������A�N�����Ă����Ǝv�����B
�@�@
���ɂ�>>923-924�̃����N��Ƃ��̉���ŏ\�������ǁA��������Ȃ����Ƃ�����Ȃ��̓I��
����������A�N�����Ă����Ǝv�����B
�@�@
�������ǁA���X�����Ă�l��MAC�I�^�u���X�������ĂĂ�����
>930
�����Ƃ������Ȃ��Č����Ă�́B�ǂ�łĂ����Ƃ���������������
�����Ƃ������Ȃ��Č����Ă�́B�ǂ�łĂ����Ƃ���������������
VLSI Symposia��IBM�Ɠ��ł��o���N�V���R�������Ɍ������ʂ̈قȂ�w��\�肠�킹��
"Direct Silicon Bonding"�ɂ��CMOS�̐��\����Ɋւ��锭�\���s�����Ƃ̂��Ƃ��B
http://hosted-communications.tmcnet.com/topics/broadband-comm/articles/31951-toshiba-ibm-team-develop-high-performance-cmos-fet.htm
�@�@----------------------
�@�@DSB can achieve a 30 percent performance boost for CMOS as high-k dielectrics and metal
�@�@gates but is simpler to implement, according to Toshiba and IBM.
�@�@----------------------
SOI�Ɨǂ������E�F�n�����@�ɂȂ�Ǝv��������A�o���N�V���R���ł��R�X�g�����b�g������̂��䂷���ǁA
Spurs Engine�̐��\����ɂł��𗧂̂�������Ȃ����B
"Direct Silicon Bonding"�ɂ��CMOS�̐��\����Ɋւ��锭�\���s�����Ƃ̂��Ƃ��B
http://hosted-communications.tmcnet.com/topics/broadband-comm/articles/31951-toshiba-ibm-team-develop-high-performance-cmos-fet.htm
�@�@----------------------
�@�@DSB can achieve a 30 percent performance boost for CMOS as high-k dielectrics and metal
�@�@gates but is simpler to implement, according to Toshiba and IBM.
�@�@----------------------
SOI�Ɨǂ������E�F�n�����@�ɂȂ�Ǝv��������A�o���N�V���R���ł��R�X�g�����b�g������̂��䂷���ǁA
Spurs Engine�̐��\����ɂł��𗧂̂�������Ȃ����B
935 �FMAC�I�^��933 �����F2008/06/21(�y) 22:59:11 ID:QtBsYZWJ
>>933
�����l(measured)�̔�r��A���̂�����������B
����ȑO��"Cell Only"��"Hybrid"�̔�r�ŁAOpteron�Ƃ�Hybrid�������\�ȗ�������Ȃ��ǁB�B�B
�����l(measured)�̔�r��A���̂�����������B
����ȑO��"Cell Only"��"Hybrid"�̔�r�ŁAOpteron�Ƃ�Hybrid�������\�ȗ�������Ȃ��ǁB�B�B
937 �FMAC�I�^��936 �����F2008/06/21(�y) 23:31:07 ID:QtBsYZWJ
>>936
MYCOM�̕����}�������ėǂ����ˁB
MYCOM�̕����}�������ėǂ����ˁB
�b��߂���Roadrunner�Ή��\�t�g�J�����̃x���`�}�[�N�̘b��A���T�T���Ă݂���
"Cell only"�̕���CELL�ɂ��z�b�g�R�[�h���̌v�Z���ԁA"Hybrid"�̕���V���O���m�[�h�ł�
���ʑS�̂��������B�ŁAMilagro�̃R�������A�B
�\�[�X��ALLNL��J.A. Turner���̃R���B�Y���̃y�[�W��p.55���B
http://www.lanl.gov/orgs/hpc/roadrunner/pdfs/Turner%20-%20RR%20Apps,%20Programming,%20&%20Results/RR_Seminar_Apps_Results_Programming.pdf
"Cell only"�̕���(kernels)�Ƃ������߂������Ă��邷�B
>>927 ����́A
�@�@------------------------
�@�@����̓R�[�h��Hybrid node�����Ă��A���܂�����������Ă��܂���A�Ƃ��������Ȃ�
�@�@------------------------
�Ă̂퓖���肷�B
�����Ap.57�������Opteron��PPE���Ăǂ��炩�Е��ɂ������ׂ�������Ȃ��悤�Ŗ{����
�n�C�u���b�h�ɂ���Ӗ�������̂���^�₷�BTop500�ɓo�^���ꂽCELL�݂̂̃N���X�^�̂���
http://www.top500.org/system/9425
�̕���AIBM�Г��̃��m������AIBM�̃q�g��m���Ă���\�����������B
6/10�̓��{IBM�̃Z�~�i�[�Ŏ��ۂɍu���҂��������������A���ЎQ���҂̕��ɂ��������������m���B
"Cell only"�̕���CELL�ɂ��z�b�g�R�[�h���̌v�Z���ԁA"Hybrid"�̕���V���O���m�[�h�ł�
���ʑS�̂��������B�ŁAMilagro�̃R�������A�B
�\�[�X��ALLNL��J.A. Turner���̃R���B�Y���̃y�[�W��p.55���B
http://www.lanl.gov/orgs/hpc/roadrunner/pdfs/Turner%20-%20RR%20Apps,%20Programming,%20&%20Results/RR_Seminar_Apps_Results_Programming.pdf
"Cell only"�̕���(kernels)�Ƃ������߂������Ă��邷�B
>>927 ����́A
�@�@------------------------
�@�@����̓R�[�h��Hybrid node�����Ă��A���܂�����������Ă��܂���A�Ƃ��������Ȃ�
�@�@------------------------
�Ă̂퓖���肷�B
�����Ap.57�������Opteron��PPE���Ăǂ��炩�Е��ɂ������ׂ�������Ȃ��悤�Ŗ{����
�n�C�u���b�h�ɂ���Ӗ�������̂���^�₷�BTop500�ɓo�^���ꂽCELL�݂̂̃N���X�^�̂���
http://www.top500.org/system/9425
�̕���AIBM�Г��̃��m������AIBM�̃q�g��m���Ă���\�����������B
6/10�̓��{IBM�̃Z�~�i�[�Ŏ��ۂɍu���҂��������������A���ЎQ���҂̕��ɂ��������������m���B
6/10�̃Z�~�i�[�����A���������@���Ă����玟����CELL�ɂ��Č��y�����ʂ̂����������B
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_Strat_JHC_Japan.pdf
�@�E�]���^Cell/B.E.��2009�N��45nm�v���Z�X��
�@�E�ȑO�̃��[�h�}�b�v�ɂ�����2*PPE + 32*SPE��"PowerXCell 32ii"��L�����Z���B�����
�@�@4*PPE + 32*SPE��"PowerXCell 32iv"�ցB
�@�EPowerXCell 32iv�̐����PPE�Ɏ������ -> PPE' ��
�@�E������SPE��"eSPE"�ɐi��
�@�E�N���b�N���グ��A�`3.8GHz
�@�E���̑�PowerXCell 32iv����̓�����A���L�̒ʂ�
�@�@- 100% backward compatible
�@�@- PPE���\��啝����
�@�@- SPE��V���ߒlj��ȊO�팻��� (�V���߃Z�b�g���g�p����\�t�g��啝�ɐ��\����)
�@�@- SPE�Ԃ̒ʐM���C�e���V�팸
�@�@- More on-chip memory (LS���ʂ��H)
�@�@- ���C���������A�N�Z�X�̑�敝�����ƃ��C�e���V�팸
http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_Strat_JHC_Japan.pdf
�@�E�]���^Cell/B.E.��2009�N��45nm�v���Z�X��
�@�E�ȑO�̃��[�h�}�b�v�ɂ�����2*PPE + 32*SPE��"PowerXCell 32ii"��L�����Z���B�����
�@�@4*PPE + 32*SPE��"PowerXCell 32iv"�ցB
�@�EPowerXCell 32iv�̐����PPE�Ɏ������ -> PPE' ��
�@�E������SPE��"eSPE"�ɐi��
�@�E�N���b�N���グ��A�`3.8GHz
�@�E���̑�PowerXCell 32iv����̓�����A���L�̒ʂ�
�@�@- 100% backward compatible
�@�@- PPE���\��啝����
�@�@- SPE��V���ߒlj��ȊO�팻��� (�V���߃Z�b�g���g�p����\�t�g��啝�ɐ��\����)
�@�@- SPE�Ԃ̒ʐM���C�e���V�팸
�@�@- More on-chip memory (LS���ʂ��H)
�@�@- ���C���������A�N�Z�X�̑�敝�����ƃ��C�e���V�팸
940 �FMAC�I�^���⑫�F2008/06/22(��) 00:32:55 ID:7EkjfsSX
�����Șb�A���߃R�[�h�ɑS���]�T������SPE ISA���ǂ����ς���̂�����ɋ����[�����B
�Ȃ�ƂȂ��u�݊����[�h�v�Ɓu�V���߃��[�h�v���ւ���ISA�̃��Z�b�g�����悤�ȋC������
�����ǁA�������SPE ISA���D���ɂȂ�Ȃ����̊�]�ɉ߂��Ȃ������ˁB�B�B
�Ȃ�ƂȂ��u�݊����[�h�v�Ɓu�V���߃��[�h�v���ւ���ISA�̃��Z�b�g�����悤�ȋC������
�����ǁA�������SPE ISA���D���ɂȂ�Ȃ����̊�]�ɉ߂��Ȃ������ˁB�B�B
941 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 07:26:59 ID:YpuPayhY
�X�C�[�c�i�j�݂����ȁu��v�̎g�������߂�������
MAC�I�^���ĕ��������p�ɂɏ������݂��Ă�̂ȁB
�l�����\�������
�q�싳����ARoadrunner(�Ƃ������CELL B.E.)�ɂ��܂芴�����Ȃ������͗l���B
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note062.html
�@�@---------------------
�@�@BG/P ��葁���g�݂����Đ��\���o�����A�Ƃ����̂͑f���炵�����Ƃł����ACELL �Ƃ��������
�@�@�`�b�v�Ɋւ������A�{���x�ł����\���ꂽ�u�Ԃł��錻�݂� x86 �`�b�v�ɔ�ׂ����i�����b�g��
�@�@�w�ǂȂ��킯�ŁA����̔��W�����邩�ǂ����Ƃ����ϓ_�ł͋ɂ߂Č������ł��傤�B
�@�@---------------------
IBM��CELL�u���[�h�AQS22�������Ȃ̂펖�������炱����d�������������B�B�B
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note062.html
�@�@---------------------
�@�@BG/P ��葁���g�݂����Đ��\���o�����A�Ƃ����̂͑f���炵�����Ƃł����ACELL �Ƃ��������
�@�@�`�b�v�Ɋւ������A�{���x�ł����\���ꂽ�u�Ԃł��錻�݂� x86 �`�b�v�ɔ�ׂ����i�����b�g��
�@�@�w�ǂȂ��킯�ŁA����̔��W�����邩�ǂ����Ƃ����ϓ_�ł͋ɂ߂Č������ł��傤�B
�@�@---------------------
IBM��CELL�u���[�h�AQS22�������Ȃ̂펖�������炱����d�������������B�B�B
>>945
�v���b�g�t�H�[���̊J���͑��x�������Ȃ�ɂȂ��Ă��錻���
��������i�̈�������ɂ����E�����邩��J����y�C�ł��邩����肾���B
wintel�����intel�̒z�����}�[�W���i�R�l�Ǝ����I�j�͂܂��ł���
�v���b�g�t�H�[���̊J���͑��x�������Ȃ�ɂȂ��Ă��錻���
��������i�̈�������ɂ����E�����邩��J����y�C�ł��邩����肾���B
wintel�����intel�̒z�����}�[�W���i�R�l�Ǝ����I�j�͂܂��ł���
PowerXCell 8iMac�����o������
��IBM�̒��̐l�͍l���Ă���킯�ł��ˁB
��IBM�̒��̐l�͍l���Ă���킯�ł��ˁB
������̃O�_�O�_(>>873-901)�݂����ɂȂ�Ȃ��悤�ɁAIBM�ɂ�CELL B.E.�̊g�̂ɐs�͂���
�~�������m���B�����������ł�撣���Ă��邷����B�B�B
http://www.toshiba.co.jp/about/press/2008_04/pr_j0801.htm
http://www.tgdaily.com/content/view/37845/135/
http://journal.mycom.co.jp/articles/2008/06/07/computex13/index.html
http://japanese.engadget.com/2008/06/16/qosmio-g55-spursengine/
�~�������m���B�����������ł�撣���Ă��邷����B�B�B
http://www.toshiba.co.jp/about/press/2008_04/pr_j0801.htm
http://www.tgdaily.com/content/view/37845/135/
http://journal.mycom.co.jp/articles/2008/06/07/computex13/index.html
http://japanese.engadget.com/2008/06/16/qosmio-g55-spursengine/
PS4�̂ق����Vcell�̗p�͂��邾�낤����
PS3�ł���A���ꂩ�畁�y���ĂƂ�������c�c
PS3�ł���A���ꂩ�畁�y���ĂƂ�������c�c
950 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 13:21:25 ID:YpuPayhY
PS4�͖�����ˁH
�\�j�[�̋Ɛѐ�����ŕ��䂳��Ă��炵�����A���悢��A�����ƁB
SCE���ׂꂽ��Cell�̌����W�ǂ��Ȃ�낤�ȁB
�y�[�p�[�����[�X�ɏI��������j�[�R�A���i�Q���\����������
Cell�͂܂��}�V�ȕ����B
�\�j�[�̋Ɛѐ�����ŕ��䂳��Ă��炵�����A���悢��A�����ƁB
SCE���ׂꂽ��Cell�̌����W�ǂ��Ȃ�낤�ȁB
�y�[�p�[�����[�X�ɏI��������j�[�R�A���i�Q���\����������
Cell�͂܂��}�V�ȕ����B
951 �FMAC�I�^���c�q �����F2008/06/22(��) 13:31:09 ID:7EkjfsSX
>>950
�@�@--------------
�@�@Cell�͂܂��}�V�ȕ����B
�@�@--------------
���낻�낢�܂܂�CELL B.E.��@���Ă����̂��p���������Ȃ��Ă��������H
�@�@--------------
�@�@Cell�͂܂��}�V�ȕ����B
�@�@--------------
���낻�낢�܂܂�CELL B.E.��@���Ă����̂��p���������Ȃ��Ă��������H
952 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 13:33:13 ID:YpuPayhY
�p���������̂͂��܂���
>>945
�}�L�[�m�͂悭CELL����Ȃ��ăN���b�h�g���A
�ǂ������Ƃ������Ă邯�ǁA����d�͂͑S��
�ᒆ�ɂȂ��ȁB
Top500�̃N���b�h�N���X�^�̓d�͐��\�䌩��ƁA
Roadrunner��BlueGene/P�ɏ����ł���Ƃ�
�v���Ȃ����ǁB
CO2�팸������邱�̂������A�d�͐H������
������Ⴉ�܂�ˁ[�A�Ƃ����p���͑�w�����Ƃ���
����Ȃ̂��B
�}�L�[�m�͂悭CELL����Ȃ��ăN���b�h�g���A
�ǂ������Ƃ������Ă邯�ǁA����d�͂͑S��
�ᒆ�ɂȂ��ȁB
Top500�̃N���b�h�N���X�^�̓d�͐��\�䌩��ƁA
Roadrunner��BlueGene/P�ɏ����ł���Ƃ�
�v���Ȃ����ǁB
CO2�팸������邱�̂������A�d�͐H������
������Ⴉ�܂�ˁ[�A�Ƃ����p���͑�w�����Ƃ���
����Ȃ̂��B
954 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 13:59:27 ID:YpuPayhY
x86�R�[�h���Y�����Ȃ�CPU�������đI�Ԃقǂ̑傫�ȍ��ł��Ȃ���ˁH
�������Intel�v���Z�b�T����ԑI��Ă�킯�ŁB
���FCell�Ȃ��SIMD�����^�C���I�[�_�R�A�̏W���̂����H
x86�Ɣ�ׂ���ėp�����_�D�̍����B
�������Intel�v���Z�b�T����ԑI��Ă�킯�ŁB
���FCell�Ȃ��SIMD�����^�C���I�[�_�R�A�̏W���̂����H
x86�Ɣ�ׂ���ėp�����_�D�̍����B
Cell�����߂ă������A�N�Z�X�������X�^�X�y�b�N�������琶���c�铹����������������Ȃ��̂ɂ˂�
956 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 14:08:44 ID:YpuPayhY
�����������Z�̘_���s�[�N���\�������g�[�^�����\�����߂�Ȃ�ăg���f���_��
��ʂ̒��w�������ɂ��Ă���
��ʂ̒��w�������ɂ��Ă���
VIA���f���A���R�A"nano"�̐����ɂ���TSMC�ƌ�����Digitimes���Ă��邷�B
http://www.digitimes.com/mobos/a20080618PB202.html
�@�@--------------------------
�@�@TSMC in talks to manufacture CPUs for VIA, says paper
�@�@EDN, June 18; Joseph Tsai, DIGITIMES [Wednesday 18 June 2008]
�@�@�@Taiwan Semiconductor Manufacturing Company (TSMC) recently held discussions
�@�@with VIA Technologies over the mass production of the company's upcoming dual-core
�@�@and 45nm Nano (Isaiah) CPUs in the first half of 2009, according to a Chinese-language
�@�@Economic Daily News (EDN) report.
�@�@�@VIA commented that the company is considering criteria including quotes, manufacturer's
�@�@technological capability and service to decide where to place its orders. Meanwhile TSMC
�@�@refused to comment regard specific clients, added the paper.
�@�@--------------------------
http://www.digitimes.com/mobos/a20080618PB202.html
�@�@--------------------------
�@�@TSMC in talks to manufacture CPUs for VIA, says paper
�@�@EDN, June 18; Joseph Tsai, DIGITIMES [Wednesday 18 June 2008]
�@�@�@Taiwan Semiconductor Manufacturing Company (TSMC) recently held discussions
�@�@with VIA Technologies over the mass production of the company's upcoming dual-core
�@�@and 45nm Nano (Isaiah) CPUs in the first half of 2009, according to a Chinese-language
�@�@Economic Daily News (EDN) report.
�@�@�@VIA commented that the company is considering criteria including quotes, manufacturer's
�@�@technological capability and service to decide where to place its orders. Meanwhile TSMC
�@�@refused to comment regard specific clients, added the paper.
�@�@--------------------------
>>956
����Cell�P�R�A�̃s�[�N�������Z���\�Ŋ��łȂ������������H
����Cell�P�R�A�̃s�[�N�������Z���\�Ŋ��łȂ������������H
�����������Ƃł���B
557 ���O�F�R�E�L�́M�E,,�j���������������� ���e���F2008/06/16(��) 23:28:21 ID:529taapO
�������Z�~�̉��I�ɂ͍�����͂ǂ���N�Y
557 ���O�F�R�E�L�́M�E,,�j���������������� ���e���F2008/06/16(��) 23:28:21 ID:529taapO
�������Z�~�̉��I�ɂ͍�����͂ǂ���N�Y
���`���`��`��������IBM�ސ�CellMac���o����(ry
HPC�s�ꂪ�����Ɋg�債�Ă������ʂ�������Ƃ͌����A
�����̃v���Z�b�T�����˂��i�ޕ��������_���Z�C���t���͂ǁ[�Ȃ邱�Ƃ��B
�����̃v���Z�b�T�����˂��i�ޕ��������_���Z�C���t���͂ǁ[�Ȃ邱�Ƃ��B
962 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 22:12:56 ID:YpuPayhY
�yVLSI 2008���|�[�g�z
HDTV�M�������`�b�v�̕�������
http://pc.watch.impress.co.jp/docs/2008/0623/vlsi03.htm
HDTV�M�������`�b�v�̕�������
http://pc.watch.impress.co.jp/docs/2008/0623/vlsi03.htm
964 �FSocket774�F2008/06/23(��) 00:25:29 ID:28lMjoHC
���{IBM�ACell�̔{���x���������_���Z��
5�{�ɋ��������uPowerXCell 8i�v
BladeCenter QS22
5��14�� ���\
http://pc.watch.impress.co.jp/docs/2008/0514/ibm.htm
5�{�ɋ��������uPowerXCell 8i�v
BladeCenter QS22
5��14�� ���\
http://pc.watch.impress.co.jp/docs/2008/0514/ibm.htm
���X��age��Ƃ́E�E�E
����Ȃɍ폜�˗����o���ė~�����̂���
����Ȃɍ폜�˗����o���ė~�����̂���
966 �FSocket774�F2008/06/23(��) 16:54:03 ID:DkMF2FS1
�����Ď���폜�˗����o���Ȃ�>>965�ł�����
���ǃn�t�j�E���Ɉˑ����BIntel�Ǝ������D�ɂȂ�����A�ǂ��������Ȃ̂��B
NEC�G����45/40nm�g�����W�X�^�̐V�Z�p���J���A
臒l�d���̐���Ƀn�t�j�E���𗘗p
[issued: 2008.06.23]
http://www.ednjapan.com/content/l_news/2008/06/u0o686000000dww7.html
NEC�G����45/40nm�g�����W�X�^�̐V�Z�p���J���A
臒l�d���̐���Ƀn�t�j�E���𗘗p
[issued: 2008.06.23]
http://www.ednjapan.com/content/l_news/2008/06/u0o686000000dww7.html
���������Z�p���ƁA�������D�ɖ��W�����牿�l��������Ȃ��B
VLSI 2008�z
���ł�FinFET�ŐV�m���A
�c�ݍœK���ō���/��d�͉� (2008/06/23)
http://www.eetimes.jp/contents/200806/35965_1_20080623162712.cfm
VLSI 2008�z
���ł�FinFET�ŐV�m���A
�c�ݍœK���ō���/��d�͉� (2008/06/23)
http://www.eetimes.jp/contents/200806/35965_1_20080623162712.cfm
�����̂̓��A���^���̌ł܂�B
Hf���炢�Ŏ����Ƃ������Ă����B
Hf���炢�Ŏ����Ƃ������Ă����B
���������͂��Č��ʂɍH������݂��邮�炢�̖����������ė~�����B
���̓y�n�̌������̗��݂ŐV���ȗ������������鈫���B
>>945
�q��搶�A���낻��GRAPE-DR�̐V�l�^�o���Ă���Ȃ����ȁc
�q��搶�A���낻��GRAPE-DR�̐V�l�^�o���Ă���Ȃ����ȁc
TheRegister��Niagara3�X�N�[�v���B
http://www.theregister.co.uk/2008/06/23/sun_niagara_k2/
�@�@---------------------
�@�@By late 2009, the server maker should deliver a third major revision of its Niagara processor
�@�@which will have 16 cores and an astonishing 16 threads per core, The Register has learned.
�@�@---------------------
�R�����g��Ashlee Vance�L�҂����Ă�����e�����A�N���b�N�퐘���u���Ƃ̂��Ƃ��B
http://www.theregister.co.uk/2008/06/23/sun_niagara_k2/
�@�@---------------------
�@�@By late 2009, the server maker should deliver a third major revision of its Niagara processor
�@�@which will have 16 cores and an astonishing 16 threads per core, The Register has learned.
�@�@---------------------
�R�����g��Ashlee Vance�L�҂����Ă�����e�����A�N���b�N�퐘���u���Ƃ̂��Ƃ��B
�N���b�N�����u����16�X���b�h���ĉ��Z��܂����₷�H
�ł��R�A���{�����Ȃ�
�ł��R�A���{�����Ȃ�
http://www.c0t0d0s0.org/archives/4544-Rumours-about-KT.html
> Ashlee doesn�Lt know half
����Ȃ��ƌ����Ă܂�����
> Ashlee doesn�Lt know half
����Ȃ��ƌ����Ă܂�����
AS/400��20���N�L�O����݂Ŋ���̋L�����o�Ă��邷���ǁA���̋L���̒���Frank Soltis��
POWER7�ɂ��Č�����Ƃ����b���o�Ă��邷�B
http://www.itjungle.com/tfh/tfh062308-story01.html
�@�E2010���o��
�@�E�}���`�R�A��(4-core?)
�@�E�ߋ��̃��C���t���[����IOP�̂悤�Ȑ�p�@�\�̃R�A�����n�C�u���b�h�\��
�@�E�R�A������̃X���b�h����A����قǑ��₳�Ȃ� (�ނ���2-thread�̂܂�?)
POWER7�ɂ��Č�����Ƃ����b���o�Ă��邷�B
http://www.itjungle.com/tfh/tfh062308-story01.html
�@�E2010���o��
�@�E�}���`�R�A��(4-core?)
�@�E�ߋ��̃��C���t���[����IOP�̂悤�Ȑ�p�@�\�̃R�A�����n�C�u���b�h�\��
�@�E�R�A������̃X���b�h����A����قǑ��₳�Ȃ� (�ނ���2-thread�̂܂�?)
>>967
High-K�Q�[�g�≏�ŁA�d�����̕]���������ƏI����Ă�̂���HfSiON�̑��ɂ���̂��ƁB
��Hf�n�ł�R&D�ł�NEC�G���͐��҂Ȃ̂����B
High-K�Q�[�g�≏�ŁA�d�����̕]���������ƏI����Ă�̂���HfSiON�̑��ɂ���̂��ƁB
��Hf�n�ł�R&D�ł�NEC�G���͐��҂Ȃ̂����B
NEC�ALSI�̉��x���z���ڍׂɑ���ł���Z�p���J��
http://pc.watch.impress.co.jp/docs/2008/0627/nec.htm
http://pc.watch.impress.co.jp/docs/2008/0627/nec.htm
���l�T�X��������v���Z�b�T���J���A
�摜���������Ő��\��17GOPS (2008/06/30)
http://www.eetimes.jp/contents/200806/36045_1_20080630130152.cfm
�摜���������Ő��\��17GOPS (2008/06/30)
http://www.eetimes.jp/contents/200806/36045_1_20080630130152.cfm
�Ӂ[��c
OSCAR�Ƃ����o���Ă���݂��������A����͌J��Ԃ��Ƃ������Ȃ�Ƃ������A
�������s���A�܂��J��Ԃ����낤�ȁB
����AIntel��2006�ɔ��\����80core�̕ςȂ̂�Inspire����č��n�߂���0.5�J�m�b�T��
OSCAR�Ƃ����o���Ă���݂��������A����͌J��Ԃ��Ƃ������Ȃ�Ƃ������A
�������s���A�܂��J��Ԃ����낤�ȁB
����AIntel��2006�ɔ��\����80core�̕ςȂ̂�Inspire����č��n�߂���0.5�J�m�b�T��
�Ȃ��SH-2�Ȃ낤�ȁB�ʂɈ����Ƃ������Ƃ͖������B
���l�T�X�����AOS�������K�v�Ȃ����ASH-2A�̓��A���^�C�������Ɍ����Ă�炵�����B
������ӂōi�荞�߂�SH-3��4��g�ѓd�b�������K���Ă��ƂȂ�Ȃ��H
������ӂōi�荞�߂�SH-3��4��g�ѓd�b�������K���Ă��ƂȂ�Ȃ��H
�������o�X�́H
������2�r�b�gSIMD����
���̎�͂�قǎ��v������̂�
���̎�͂�قǎ��v������̂�
���̎�̂��̂��āA���������������悪���܂��Ă�Ǝv�����ǁB
���̕ӂ̈�A�̃V���[�Y�̓��l�̓��ӕ���ł���B
http://www.google.co.jp/search?as_q=%E3%83%AB%E3%83%8D%E3%82%B5%E3%82%B9&as_oq=%E3%82%AB%E3%83%A1%E3%83%A9+%E3%83%86%E3%83%AC%E3%83%93
���̕ӂ̈�A�̃V���[�Y�̓��l�̓��ӕ���ł���B
http://www.google.co.jp/search?as_q=%E3%83%AB%E3%83%8D%E3%82%B5%E3%82%B9&as_oq=%E3%82%AB%E3%83%A1%E3%83%A9+%E3%83%86%E3%83%AC%E3%83%93
�g�ݍ��݉摜�����Ƃ����͕̂����邪
�Ȃ�2bit SIMD�Ȃ̂��ȁA���[�̂�
�����̐l�̋^�₾��
�A���S���Y���Ƃ�����S���킩��Ȃ�����
����way SIMD���ĉ����_���Ȃ́H
���҂̓o�ꂫ�ڂ��
�Ȃ�2bit SIMD�Ȃ̂��ȁA���[�̂�
�����̐l�̋^�₾��
�A���S���Y���Ƃ�����S���킩��Ȃ�����
����way SIMD���ĉ����_���Ȃ́H
���҂̓o�ꂫ�ڂ��
>>987
�O�b�h�C���[MPP�ȗ��̓`���Ȃ̂ł�
�O�b�h�C���[MPP�ȗ��̓`���Ȃ̂ł�
�j��������������
990
992 �FSocket774�F2008/07/02(��) 13:50:06 ID:Lj0gzj+C
���X���C���l
SIMD���̂��̂�����
MAC�I�^�͂����ɋA��ł���܂����B
���Ƃ��Ƒ�(PPC�X��)���Ȃ��Ȃ������玩��ɗ��������B
996get
����
���߂���
1000
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/