CPU�A�[�L�e�N�`���ɂ��Č�� 9
���O�炢�������A���\��AMD�[�EIntel�[�EGK�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�PS3���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� �W
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
�y�ߋ��X���z
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3�@http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4�@http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5�@http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6�@http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7�@http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
http://cpu.jisakuita.net/
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�PS3���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� �W
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
�y�ߋ��X���z
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3�@http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4�@http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5�@http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6�@http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7�@http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
http://cpu.jisakuita.net/
|
|
|
2get
>>1�@��
4 �FSocket774�F2007/08/12(��) 13:24:51 ID:UqXNArOR
�@�@�@�@�@ �^�@�@�@�@�@�_
�@�@�@�@�@�^�@�@�^�P�܁P�_
�@�@�@�@ /�@�@ / �܁@�@�܁@�b�@�@�@|�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�b�@�^�@ (�E)�@�@(�E) �b�@�@�@| �Ă߁[�Ȃ悱�̕��X���́I�I
�@ �^�܁@ (6�@�@�@�@�@�@ �b�@�@�@| �Ă߁[�͐��_��Q�ł�����̂��H
�@�i�@�@�b�@�@�^ �Q�Q�Q �@�b �@���@���Ƃ�������S���@�@�@�@�@�@�I
�@�@�|�@�_�@�@�@�_�Q/�@ �^ �@�@�@�_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@// �@,,r'�L�܁R�Q�Q_�^�@�@�@�@�@,�B
�@�@ �^�@�@�@�@�R�@�@�@�@�@�@ ri/ �c
�@ /�@�@ i�@�@�@�@�g�A�@�@�@__,,,��)�^ �@�@�@�@�@�@�@�� �@�@�@�@�@�@�@�@�@�@
�@|�@�@�@ !�@�@ �@ �j�MY'''"�@�R,,�^ �@�@�@�@ �^�P�P�P�P�_�@�@�@�@�@�@�@�@
�@ ! l�@ �@|�@�@�@��,,�@�@�@,,,�B'"�@�@�@�@�@�@/.�@�@�@�@�@�@�@�@ �_�@
�@ �R�R �@�T�@�@�@ !�P!~�`�A �@�@�@�@�@�@/ �@�@�@�@�@�@�@�@�@ �b�@�@�@�@
�@�@�R�@�@�^�P""'''�܁P"^'''''�[--�A :::|||||||||||||||||||||||||||||||||�@
�@�@Y'�L�@�@�@�@�@�@�@�@�@�@�^�@�@�@ """''''�`--�A|||||||||||||||||�j�@
�@�@�@�i�@�@�@�@�@�@���@�@,,;;''�@�@....::::::::::: ::::r''''""�P""�R �@ �b
�@�@ �T �@�@�[--�A,,,,,___�@�@�@ �@�@::: ::,,,,,�[�M''''''��''�[�C�@ .�^
�@�@�@�@�@�R�@�@�@�@�@�@�_�@�P""'''""�P�@�@�@�_�Q�Q�Q_�^-�A
�@�@�@�@�@�R�@�@�@�@�@�@ �R �@::::::::::::::::::::�@�^ �@�@�@ �@�@�@�@�@�M�R
�@�@�@�@�@�@�R�@�@���@�@�@�j�@�@�@�@�@�@ /�@�@�@�@�m�@�@�@�T�@�R�@,�r
�@�@�@�@�@�@�@�T�@�@�@ �@�@!�@�@�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@!�@�@�@�@�@| �@�@�@�@�@/�@�@�@�l�@�@�@�@�@�R�@�@�@�R
�@�@�@�@�@�@�@�@| �@�@�@�@,;;}�@�@�@ �@ !�[-�A/�@�@�R�@�Q,,,-�['''''--�w
�@�@�@�@�@ �@ �@ |�m�@�@�@�@| �@�@�@ �@|�@�@/�@�@�@�@Y�@�@�@�@�@�@�@�@�R
�@�@�@�@�@�@�@�@ {�@�@�@�@�@| �@�@ �@ | �@ ���@�@�@ �@ �j�@�@>>1 �@�@�@ �R
�@�@�@�@�@�^�@�@�^�P�܁P�_
�@�@�@�@ /�@�@ / �܁@�@�܁@�b�@�@�@|�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@�b�@�^�@ (�E)�@�@(�E) �b�@�@�@| �Ă߁[�Ȃ悱�̕��X���́I�I
�@ �^�܁@ (6�@�@�@�@�@�@ �b�@�@�@| �Ă߁[�͐��_��Q�ł�����̂��H
�@�i�@�@�b�@�@�^ �Q�Q�Q �@�b �@���@���Ƃ�������S���@�@�@�@�@�@�I
�@�@�|�@�_�@�@�@�_�Q/�@ �^ �@�@�@�_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@// �@,,r'�L�܁R�Q�Q_�^�@�@�@�@�@,�B
�@�@ �^�@�@�@�@�R�@�@�@�@�@�@ ri/ �c
�@ /�@�@ i�@�@�@�@�g�A�@�@�@__,,,��)�^ �@�@�@�@�@�@�@�� �@�@�@�@�@�@�@�@�@�@
�@|�@�@�@ !�@�@ �@ �j�MY'''"�@�R,,�^ �@�@�@�@ �^�P�P�P�P�_�@�@�@�@�@�@�@�@
�@ ! l�@ �@|�@�@�@��,,�@�@�@,,,�B'"�@�@�@�@�@�@/.�@�@�@�@�@�@�@�@ �_�@
�@ �R�R �@�T�@�@�@ !�P!~�`�A �@�@�@�@�@�@/ �@�@�@�@�@�@�@�@�@ �b�@�@�@�@
�@�@�R�@�@�^�P""'''�܁P"^'''''�[--�A :::|||||||||||||||||||||||||||||||||�@
�@�@Y'�L�@�@�@�@�@�@�@�@�@�@�^�@�@�@ """''''�`--�A|||||||||||||||||�j�@
�@�@�@�i�@�@�@�@�@�@���@�@,,;;''�@�@....::::::::::: ::::r''''""�P""�R �@ �b
�@�@ �T �@�@�[--�A,,,,,___�@�@�@ �@�@::: ::,,,,,�[�M''''''��''�[�C�@ .�^
�@�@�@�@�@�R�@�@�@�@�@�@�_�@�P""'''""�P�@�@�@�_�Q�Q�Q_�^-�A
�@�@�@�@�@�R�@�@�@�@�@�@ �R �@::::::::::::::::::::�@�^ �@�@�@ �@�@�@�@�@�M�R
�@�@�@�@�@�@�R�@�@���@�@�@�j�@�@�@�@�@�@ /�@�@�@�@�m�@�@�@�T�@�R�@,�r
�@�@�@�@�@�@�@�T�@�@�@ �@�@!�@�@�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@�@�@�@�@!�@�@�@�@�@| �@�@�@�@�@/�@�@�@�l�@�@�@�@�@�R�@�@�@�R
�@�@�@�@�@�@�@�@| �@�@�@�@,;;}�@�@�@ �@ !�[-�A/�@�@�R�@�Q,,,-�['''''--�w
�@�@�@�@�@ �@ �@ |�m�@�@�@�@| �@�@�@ �@|�@�@/�@�@�@�@Y�@�@�@�@�@�@�@�@�R
�@�@�@�@�@�@�@�@ {�@�@�@�@�@| �@�@ �@ | �@ ���@�@�@ �@ �j�@�@>>1 �@�@�@ �R
10+10���ǂ������20�ƎZ�o�����ł����H
100/3���ǂ������33.33333�ƎZ�o�����ł����H
144����ǂ������12�ƎZ�o�����ł����H
100/3���ǂ������33.33333�ƎZ�o�����ł����H
144����ǂ������12�ƎZ�o�����ł����H
53. ������A�y�^�X�P�[���AT2K (2007/8/12)
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note054.html
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note054.html
����������������
http://rblog-tech.japan.cnet.com/petaflops/2007/08/blue_genel_4f40.html#comment-2124765
> �\�V����A�f���炵����A�̍l�@�ł��ˁB�����������Ă���܂��B
�J�߂�l������Ȃ�
> �\�V����A�f���炵����A�̍l�@�ł��ˁB�����������Ă���܂��B
�J�߂�l������Ȃ�
>>8
����Ȃ����̂�Ȃ��ł�
����Ȃ����̂�Ȃ��ł�
�x�N�g���͏@��������ȁB
�ςȔS�������Ĉȗ����̃X�����܂�Ȃ��Ȃ����B
�ςȔS�������Ĉȗ����̃X�����܂�Ȃ��Ȃ����B
AMD������X���b�h�ɏ��������̓�̃l�^�B�������������������ǁA������̕��X��
�����Ȃ������H
������1
Hynics��Innovative Silicon����Z-RAM�̃��C�Z���X���āA
�ėpDRAM������\��Ƃ̂��Ƃ��B
http://www.dailytech.com/Hynix+Licenses+ISi+ZRAM+Technology+for+Future+DRAM+Chips/article8395.htm
������2
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~118952,00.html
http://developer.amd.com/LWP
"real time compiler"�ɂ��}���`�^�w�e���R�A�̉��p �Ƃ����H�����m����AMD�����Ői��
���Ă���͗l���B
�Ƃ팾���C�Ȃ�ƂȂ����ЊJ���Ɏ��s������ŊJ�����\�[�X���邽�߂Ɍ��J �����悤�ȓ�����
���邷�B
��������������ăg���f���Ȃ��Z�L�����e�B�z�[���ɂȂ�悤�ȋC������̂� ���̊��Ⴂ�����ˁB�B�B
�����Ȃ������H
������1
Hynics��Innovative Silicon����Z-RAM�̃��C�Z���X���āA
�ėpDRAM������\��Ƃ̂��Ƃ��B
http://www.dailytech.com/Hynix+Licenses+ISi+ZRAM+Technology+for+Future+DRAM+Chips/article8395.htm
������2
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~118952,00.html
http://developer.amd.com/LWP
"real time compiler"�ɂ��}���`�^�w�e���R�A�̉��p �Ƃ����H�����m����AMD�����Ői��
���Ă���͗l���B
�Ƃ팾���C�Ȃ�ƂȂ����ЊJ���Ɏ��s������ŊJ�����\�[�X���邽�߂Ɍ��J �����悤�ȓ�����
���邷�B
��������������ăg���f���Ȃ��Z�L�����e�B�z�[���ɂȂ�悤�ȋC������̂� ���̊��Ⴂ�����ˁB�B�B
12 �FMAC�I�^�������F2007/08/16(��) 02:25:14 ID:fFpXOPzy
�O�҂ɂ��Ă�A���܂�CMOS�Ƃ�ʂ̓���ȃv���Z�X���K�v������DRAM���_����H�Ɠ���
�v���Z�X�Ő����ł���Ƃ����̂�AZ-RAM���̂��̂̓����ȏ�ɋ����[�����Ǝv�����B
CMOS�̍Ő�[�v���Z�X�̎s�ꂪ�L����A�������u�̃R�X�g�������Ȃ��āA�v���Z�b�T���ʂł�
Intel�̑R�n�������\���������Ă����Ȃ������ˁH
�����ɖڂ������̂��؍���Ƃ�Hynics�Ƃ����̂��������Ƃ��낷�B
��҂ɂ��Ă�AMD�̃q�g�����̃C���^�r���[�L���ŏq�ׂĂ���悤��
http://www.hwupgrade.com/articles/cpu/38/the-technological-future-of-amd-an-interview-with-giuseppe-amato_index.html
Fusion�ł�Transmeta��CodeMorphing�̂悤�Ȏd�g�݂Ŋe�R�A�Ɏd����U�蕪����"real time compiler"
���������Ă���Ƃ����b�ƊW���[���͗l���B
"Reverse-HT"�̕��ꃋ�[�}�[���A���̕ӂ��\�[�X�����������ˁB�B�B
�v���Z�X�Ő����ł���Ƃ����̂�AZ-RAM���̂��̂̓����ȏ�ɋ����[�����Ǝv�����B
CMOS�̍Ő�[�v���Z�X�̎s�ꂪ�L����A�������u�̃R�X�g�������Ȃ��āA�v���Z�b�T���ʂł�
Intel�̑R�n�������\���������Ă����Ȃ������ˁH
�����ɖڂ������̂��؍���Ƃ�Hynics�Ƃ����̂��������Ƃ��낷�B
��҂ɂ��Ă�AMD�̃q�g�����̃C���^�r���[�L���ŏq�ׂĂ���悤��
http://www.hwupgrade.com/articles/cpu/38/the-technological-future-of-amd-an-interview-with-giuseppe-amato_index.html
Fusion�ł�Transmeta��CodeMorphing�̂悤�Ȏd�g�݂Ŋe�R�A�Ɏd����U�蕪����"real time compiler"
���������Ă���Ƃ����b�ƊW���[���͗l���B
"Reverse-HT"�̕��ꃋ�[�}�[���A���̕ӂ��\�[�X�����������ˁB�B�B
�@
>>12
Z-RAM�̐����v���Z�X�����ʂ̘_����H�Ɠ����ōςނ��Ă̂́A�]����DRAM��
�u�������ōl�����ꍇ�A���܂胁���b�g�͖������ƁB
�]����DRAM�̐����K�͂�����Ȃ̂ŁA���ꎩ�̂ŋK�̓����b�g�͊������Ă邵�B
�܂�DRAM�����Y�ߏ�ɂȂ������ɁA���Y���C����]�p�\�Ƃ����ی��ɂ͂Ȃ�
���ǁB
�����A�]����DRAM�ł͔����ɂ��L���p�V�^�̗e�ʊm�ۂ�����ɂȂ����̂ƁA
���炭�������o�X�������ɂ�背�C�e���V����̉e�����������Ȃ��Ă��āAZ-RAM
�Ȃ炻��炪���P�\������A�Ƃ������R�Ȃ̂ł��傤�ˁB
�����A������K�͂̃����b�g��SOI���A������x�������B�\�ȃ��x���ɂ܂�
�����Ă����Ȃ��ƁA�]����DRAM��A���ɉ����Ԃ���Ă��܂��\���͗L�肻��
�ł����B
Z-RAM�̐����v���Z�X�����ʂ̘_����H�Ɠ����ōςނ��Ă̂́A�]����DRAM��
�u�������ōl�����ꍇ�A���܂胁���b�g�͖������ƁB
�]����DRAM�̐����K�͂�����Ȃ̂ŁA���ꎩ�̂ŋK�̓����b�g�͊������Ă邵�B
�܂�DRAM�����Y�ߏ�ɂȂ������ɁA���Y���C����]�p�\�Ƃ����ی��ɂ͂Ȃ�
���ǁB
�����A�]����DRAM�ł͔����ɂ��L���p�V�^�̗e�ʊm�ۂ�����ɂȂ����̂ƁA
���炭�������o�X�������ɂ�背�C�e���V����̉e�����������Ȃ��Ă��āAZ-RAM
�Ȃ炻��炪���P�\������A�Ƃ������R�Ȃ̂ł��傤�ˁB
�����A������K�͂̃����b�g��SOI���A������x�������B�\�ȃ��x���ɂ܂�
�����Ă����Ȃ��ƁA�]����DRAM��A���ɉ����Ԃ���Ă��܂��\���͗L�肻��
�ł����B
SUN��Hot Chips 19�Ŗ����`�b�v�ԃC���^�R�l�N�g "Proximity Technology"�̃f�����s���Ƃ̂��Ƃ��B
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=201800931
�@�@--------------------
�@�@Sun will show at Hot Chips a four-port, 10 Gbit/second Ethernet switch based on a new
�@�@package that uses Proximity to link seven chips in a multi-chip module.
�@�@--------------------
�L�����ɂ����y�����邷����"proximity technology"��č��̃X�[�p�[�R���s���[�^�J���v���W�F�N�g
HPCS��SUN��Ẵv���W�F�N�g�Ƃ��ĊJ������Ă������m���B
http://research.sun.com/spotlight/2004-09-20.feature-proximity.html
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=201800931
�@�@--------------------
�@�@Sun will show at Hot Chips a four-port, 10 Gbit/second Ethernet switch based on a new
�@�@package that uses Proximity to link seven chips in a multi-chip module.
�@�@--------------------
�L�����ɂ����y�����邷����"proximity technology"��č��̃X�[�p�[�R���s���[�^�J���v���W�F�N�g
HPCS��SUN��Ẵv���W�F�N�g�Ƃ��ĊJ������Ă������m���B
http://research.sun.com/spotlight/2004-09-20.feature-proximity.html
��������14�����X���Ă��ꂽ�̂ɁA�������̘b�������Ⴄ��
17 �FMAC�I�^��16 �����F2007/08/19(��) 23:10:08 ID:Vz82tuLJ
Z-RAM�ɂ��Ă�Hynics���AMD�̕�����Ƀ��C�Z���X�Ă邩��Ȃ�
����2�ɂ��Ă͂悭�킩���
����2�ɂ��Ă͂悭�킩���
�I�^��Hynix����Ȃ���Hynics�Ə������Ƃɉ����Ӗ��͂���̂��H
�ق�Ƃ�Hynix����
�������������� orz
�������������� orz
Tilera�A�f���A���R�AXeon���10�{������64�R�ACPU�uTILE64�v
http://pc.watch.impress.co.jp/docs/2007/0821/tilera.htm
http://pc.watch.impress.co.jp/docs/2007/0821/tilera.htm
>>21
http://www.tilera.com/products/processors.php
�b�H 3-way VLIW pipeline for instruction level parallelism
�b�H 5 Mbytes of on-chip Cache
VLIW���Ⴀ�A�ǂ����Ă�x86�݊��Ƃ͎v����ȁB
�������A�TMB�̃L���b�V�����ڂ��Ă���āA��̃_�C�T�C�Y�͂ǂ����낤�Ȃ��B
�b�H Four DDR2 memory controllers with optional ECC
�b�H Two 10GbE XAUI MAC/PHY interfaces
�b�H Two 4-lane 10Gbps PCI-e MAC/PHY interfaces
�b�H Two GbE MAC interfaces
DDR2�������R���g���[�� x4�APCI-Ex4 x2�AGbE x2�A���������Ă邵�B
���悢��h���S��III��x86�݊��ŏo���Ȃ��ƁA�����s�ꂪ�����]�n��
�����Ȃ肻���ł��ˁB
http://www.tilera.com/products/processors.php
�b�H 3-way VLIW pipeline for instruction level parallelism
�b�H 5 Mbytes of on-chip Cache
VLIW���Ⴀ�A�ǂ����Ă�x86�݊��Ƃ͎v����ȁB
�������A�TMB�̃L���b�V�����ڂ��Ă���āA��̃_�C�T�C�Y�͂ǂ����낤�Ȃ��B
�b�H Four DDR2 memory controllers with optional ECC
�b�H Two 10GbE XAUI MAC/PHY interfaces
�b�H Two 4-lane 10Gbps PCI-e MAC/PHY interfaces
�b�H Two GbE MAC interfaces
DDR2�������R���g���[�� x4�APCI-Ex4 x2�AGbE x2�A���������Ă邵�B
���悢��h���S��III��x86�݊��ŏo���Ȃ��ƁA�����s�ꂪ�����]�n��
�����Ȃ肻���ł��ˁB
>>22
�������ACPU�ԒʐM�͂���������10GbE XAUI �ł�����Ď����ȁH
�C�[�T�l�b�g���Ⴀ�I�[�o�[�w�b�h���傫������C�����邯�ǁA�ėp����
�������҂��Ղ����烂�[�}���^�C���H
�b�E Flexible I/O interface
�T�E�X�Ƃ̐ڑ��ɂ͏�L��i/o���g����Ǝv�����ǁB
http://www.tilera.com/pdf/ProBrief_Tile64_Web.pdf
�bPart Number�@�@�@�@Number�@�@�@�@Memory�@�@�@�@I/O�@�@�@�@�@�@�@�@�@�@�@�@�@Frequency �@�@�@�@�@Operating
�b�@�@�@�@�@�@�@�@�@of Tiles�@�@�@�@�@�@�@�@�@�@Interfaces�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Temperature
�b
�bTLR26420 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26420 BG-xI�@�@�@64�@�@�@�@�@2 DDR2�@�@�@�@2 PCI-e , 2 GbE�@�@�@�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bTLR26440 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26440 BG-xI�@�@�@64�@�@�@�@�@4 DDR2�@�@�@�@1 XAUI, 1 PCI-e, 2 GbE�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bTLR26480 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26480 BG-xI�@�@�@64�@�@�@�@�@4 DDR2�@�@�@�@2 XAUI, 2 PCI-e, 2 GbE�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bx = Frequency code: 6=600MHz, 7=750MHZ, 9=900MHz
���Ə�L������ƁA�Ή��V�X�e���Ƃ��Ă�
TLR26420�@�F�@Single
TLR26440�@�F�@Dual
TLR26480�@�F�@Multi(�S�j
�Ƃ����ӂ�ł��傤���B
�������ACPU�ԒʐM�͂���������10GbE XAUI �ł�����Ď����ȁH
�C�[�T�l�b�g���Ⴀ�I�[�o�[�w�b�h���傫������C�����邯�ǁA�ėp����
�������҂��Ղ����烂�[�}���^�C���H
�b�E Flexible I/O interface
�T�E�X�Ƃ̐ڑ��ɂ͏�L��i/o���g����Ǝv�����ǁB
http://www.tilera.com/pdf/ProBrief_Tile64_Web.pdf
�bPart Number�@�@�@�@Number�@�@�@�@Memory�@�@�@�@I/O�@�@�@�@�@�@�@�@�@�@�@�@�@Frequency �@�@�@�@�@Operating
�b�@�@�@�@�@�@�@�@�@of Tiles�@�@�@�@�@�@�@�@�@�@Interfaces�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Temperature
�b
�bTLR26420 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26420 BG-xI�@�@�@64�@�@�@�@�@2 DDR2�@�@�@�@2 PCI-e , 2 GbE�@�@�@�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bTLR26440 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26440 BG-xI�@�@�@64�@�@�@�@�@4 DDR2�@�@�@�@1 XAUI, 1 PCI-e, 2 GbE�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bTLR26480 BG-xC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Commercial
�bTLR26480 BG-xI�@�@�@64�@�@�@�@�@4 DDR2�@�@�@�@2 XAUI, 2 PCI-e, 2 GbE�@�@�@600 MHz - 900 MHz�@�@�@Industrial
�b
�bx = Frequency code: 6=600MHz, 7=750MHZ, 9=900MHz
���Ə�L������ƁA�Ή��V�X�e���Ƃ��Ă�
TLR26420�@�F�@Single
TLR26440�@�F�@Dual
TLR26480�@�F�@Multi(�S�j
�Ƃ����ӂ�ł��傤���B
>>23
pdf���ڂ����ǂ�łȂ�����ʖڂ����A�ԍ��̉��Q���� 20�A40�A80�A�ɂȂ��Ă�
�����炷��ƁA���L�̕������������ȋC�����Ă��܂����B
TLR26420�@�F�@Dual
TLR26440�@�F�@Quad
TLR26480�@�F�@Octet
���������Ȃ�ƁACPU�ԒʐM�ɂ�PCI-e��XAUI�����݂��Ďg�����Ęb��
�Ȃ肻���ł����A������������GbE�܂ō��݂�����̂��H
pdf���ڂ����ǂ�łȂ�����ʖڂ����A�ԍ��̉��Q���� 20�A40�A80�A�ɂȂ��Ă�
�����炷��ƁA���L�̕������������ȋC�����Ă��܂����B
TLR26420�@�F�@Dual
TLR26440�@�F�@Quad
TLR26480�@�F�@Octet
���������Ȃ�ƁACPU�ԒʐM�ɂ�PCI-e��XAUI�����݂��Ďg�����Ęb��
�Ȃ肻���ł����A������������GbE�܂ō��݂�����̂��H
25 �FSocket774�F2007/08/21(��) 23:02:40 ID:oQvhQauX
�����̗��c(�h���S��)�̌��s�^�C�v��PEN4�N���X�̐��\������ƌ�����
�ق�ƂȂ́H�����̋Z�p�ł����܂ł̃A�[�L�e�N�`����v�ł���Ƃ�
�v���Ȃ��B
�ق�ƂȂ́H�����̋Z�p�ł����܂ł̃A�[�L�e�N�`����v�ł���Ƃ�
�v���Ȃ��B
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04_02.jpg
http://download.intel.com/jp/developer/jpdoc/IXP23XX-network-processors-0205_j.pdf
http://www.hkepc.com/bbs/attachment.php?aid=492035
Tilera�͂��̎s��Ő키�̂��H���i�����͓I�ɂ��т����[
{kind=link}
http://download.intel.com/jp/developer/jpdoc/IXP23XX-network-processors-0205_j.pdf
http://www.hkepc.com/bbs/attachment.php?aid=492035
Tilera�͂��̎s��Ő키�̂��H���i�����͓I�ɂ��т����[
MIT��Anant Agarwal����1996�N�ɊJ���������b�V���\���}���`�R�A�E�A�[�L�e�N�`�����x�[�X�ɁC�v���Z�T���������Ă����B
�����̌����v���W�F�N�g�uRaw�v�͕č��h���ȍ��������v��ǁiDARPA�j�ƑS�ĉȊw���c�iNSF�j���琔�S���h���̎����������C
2002�N�ɓ��A�[�L�e�N�`���E�x�[�X���̎���}���`�R�A�E�v���Z�T�Ɗ֘A�\�t�g�E�G�A���J�������B
TILE64�́C�}���`�R�A�E�v���Z�T���i�n��uTile Processor�v�Ƃ��đ��e�̐��i�B
���b�V���\���A�[�L�e�N�`�����̗p���Ă��邽�߁C�����i�n��̃v���Z�T�͓��ڃR�A���𐔐�܂ő��₷���Ƃ��\�Ƃ����B
��ʓI�ȃ}���`�R�A�E�v���Z�T�̓R�A�Ԃ̐ڑ����W����̂ŁC����肷��f�[�^���������1�J���ɏW�����C��X���[�Y�ɗ���Ȃ��Ȃ�Ƃ����B
����ɑ�iMesh�́C�e�R�A�ɒʐM�p�X�C�b�`��݂��C�R�A���m�����ڃf�[�^�������ł���悤2�����I�ɔz�������B
����ɂ��C�f�[�^�ш敝���g�債�C�R�A�Ԃ̐ڑ��������Z���Ȃ邤���C
�ړI�ɍ��킹�ăR�A�̐����������邱�Ƃ��ł���B
TILE64�ɓ��ڂ���64�̃R�A�́C��������ėp�̃v���O�����\�ȉ��Z�R�A�ŁC
�R�A���Ƃ�Linux�Ȃǂ�OS��Ɨ����ē�������B
�e�R�A�Ƀ��x��1�iL1�j�^L2�L���b�V���E�������[�𓋍ڂ��CL3�L���b�V�������U���Đ݂����B
Tilera�́C���v���Z�T�p�̊J�����uMulticore Development Environment�iMDE�j�v���p�ӂ��C
Eclipse�x�[�X�̓����J�����iIDE�j�CANSI�W��C�R���p�C���C�V�~�����[�V�����p���f���C�R�}���h���C���p�C���^�t�F�[�X�C�f�o�b�O�^�v���t�@�C���p�c�[���C�e�탉�C�u���������B
����10�Јȏオ���v���Z�T�̗̍p�����߂��Ƃ����B
�����̌����v���W�F�N�g�uRaw�v�͕č��h���ȍ��������v��ǁiDARPA�j�ƑS�ĉȊw���c�iNSF�j���琔�S���h���̎����������C
2002�N�ɓ��A�[�L�e�N�`���E�x�[�X���̎���}���`�R�A�E�v���Z�T�Ɗ֘A�\�t�g�E�G�A���J�������B
TILE64�́C�}���`�R�A�E�v���Z�T���i�n��uTile Processor�v�Ƃ��đ��e�̐��i�B
���b�V���\���A�[�L�e�N�`�����̗p���Ă��邽�߁C�����i�n��̃v���Z�T�͓��ڃR�A���𐔐�܂ő��₷���Ƃ��\�Ƃ����B
��ʓI�ȃ}���`�R�A�E�v���Z�T�̓R�A�Ԃ̐ڑ����W����̂ŁC����肷��f�[�^���������1�J���ɏW�����C��X���[�Y�ɗ���Ȃ��Ȃ�Ƃ����B
����ɑ�iMesh�́C�e�R�A�ɒʐM�p�X�C�b�`��݂��C�R�A���m�����ڃf�[�^�������ł���悤2�����I�ɔz�������B
����ɂ��C�f�[�^�ш敝���g�債�C�R�A�Ԃ̐ڑ��������Z���Ȃ邤���C
�ړI�ɍ��킹�ăR�A�̐����������邱�Ƃ��ł���B
TILE64�ɓ��ڂ���64�̃R�A�́C��������ėp�̃v���O�����\�ȉ��Z�R�A�ŁC
�R�A���Ƃ�Linux�Ȃǂ�OS��Ɨ����ē�������B
�e�R�A�Ƀ��x��1�iL1�j�^L2�L���b�V���E�������[�𓋍ڂ��CL3�L���b�V�������U���Đ݂����B
Tilera�́C���v���Z�T�p�̊J�����uMulticore Development Environment�iMDE�j�v���p�ӂ��C
Eclipse�x�[�X�̓����J�����iIDE�j�CANSI�W��C�R���p�C���C�V�~�����[�V�����p���f���C�R�}���h���C���p�C���^�t�F�[�X�C�f�o�b�O�^�v���t�@�C���p�c�[���C�e�탉�C�u���������B
����10�Јȏオ���v���Z�T�̗̍p�����߂��Ƃ����B
>>25
�A�[�L�e�N�`���̗D�z���s�[�N���\�����Ō��܂�̂Ȃ�A�ʂɂ��������͂Ȃ��Ǝv�����ǁB
�����v���Z�X������Pentium4�����̍��Ƃ�3�`4����Ⴄ���B
�A�[�L�e�N�`���̗D�z���s�[�N���\�����Ō��܂�̂Ȃ�A�ʂɂ��������͂Ȃ��Ǝv�����ǁB
�����v���Z�X������Pentium4�����̍��Ƃ�3�`4����Ⴄ���B
29 �FSocket774�F2007/08/22(��) 07:47:30 ID:B9W5RcmE
�h���S���̑�ꐢ���MIPS�̃p�N��
���������c�Ə����Ă���͊��c���Ɠ˂����܂ꂽ�̂��v���o�����B
31 �FSocket774�F2007/08/22(��) 10:01:18 ID:UrcINMKJ
TILE64�͐��\����������ƁA
���ʂɃg�b�v�ɏ��o�������Ȃ̂����A
���҂̈ӌ��͈Ⴄ�̂�?
���ʂɃg�b�v�ɏ��o�������Ȃ̂����A
���҂̈ӌ��͈Ⴄ�̂�?
�N���[�\�[�݂���x86�Ɍ��������Ă��C�������肵�����̂ɂȂ�̂��I�`��
�X�̃R�A�̐��\���s�����ȋC������B
�d�A���R�AXeon��10�{���ĕ\�����Ȃɂ����B
�܂����l�g�o�Ɣ�ׂĂȂ��ł��傤�ˁA�ƁB
�d�A���R�AXeon��10�{���ĕ\�����Ȃɂ����B
�܂����l�g�o�Ɣ�ׂĂȂ��ł��傤�ˁA�ƁB
TheInquirer��SPECViewPerf 10�������̃��r�W������Mac OS X��Linux���T�|�[�g����Ɠ`���Ă��邷�B
http://www.theinquirer.net/default.aspx?article=41854
�@�@-------------------
�@�@The future of this benchmark is going multi-platform, since development group is
�@�@pushing to release binaries for Linux and Mac OS X.�@�@
�@�@-------------------
http://www.theinquirer.net/default.aspx?article=41854
�@�@-------------------
�@�@The future of this benchmark is going multi-platform, since development group is
�@�@pushing to release binaries for Linux and Mac OS X.�@�@
�@�@-------------------
SUN�������T�[�o�[��SPARC�ł���Rock��Transactional Memory���������Ƃ̂��Ƃ��B
http://www.theregister.co.uk/2007/08/21/sun_transactional_memory_rock/
�@�@--------------------
�@�@Hot Chips Hoping to improve the state of server software, Sun Microsystems has
�@�@confirmed that it will include support for transactional memory with the first generation
�@�@of its Rock processors due out in the second half of next year.
�@�@--------------------
SUN��web site��Transactional Memory�̃y�[�W���B
http://research.sun.com/spotlight/2007/2007-08-13_transactional_memory.html
http://www.theregister.co.uk/2007/08/21/sun_transactional_memory_rock/
�@�@--------------------
�@�@Hot Chips Hoping to improve the state of server software, Sun Microsystems has
�@�@confirmed that it will include support for transactional memory with the first generation
�@�@of its Rock processors due out in the second half of next year.
�@�@--------------------
SUN��web site��Transactional Memory�̃y�[�W���B
http://research.sun.com/spotlight/2007/2007-08-13_transactional_memory.html
���\���������GRAPE-DR���g�b�v����l�[�́H
>>36
TESLA����ˁH�@FPU�P���x������
TESLA����ˁH�@FPU�P���x������
Rock�̑O��Victoria Falls������
Sun eyes 256-threaded server
http://www.vnunet.com/vnunet/news/2197040/sun-eyes-256-threaded-server
Sun eyes 256-threaded server
http://www.vnunet.com/vnunet/news/2197040/sun-eyes-256-threaded-server
39 �F�E�́E�j��-�������F2007/08/22(��) 23:25:29 ID:R6eTdDzS
192GOPS���S��FP���Z���Ɖ��肵�Ă�192GFLOPS�ɂ����Ȃ�Ȃ��̂�
�Ƃ肠����Cell���FP���\�����Ȃ�Ă��Ƃ͂Ȃ��Ǝv���܂�
�Ƃ肠����Cell���FP���\�����Ȃ�Ă��Ƃ͂Ȃ��Ǝv���܂�
�Ȃ��Cell���g���Ă��������
41 �F�E�́E�j��-�������F2007/08/23(��) 01:34:03 ID:DMryZBLn
�Ƃ�ł��Ȃ�
����������D���ł�
����������D���ł�
�܂��͑O�t�����Ă��Ƃ�
Hot Chips 19 - ������v���Z�b�T�Z�p�����\��
http://journal.mycom.co.jp/articles/2007/08/22/hotchips/index.html
Hot Chips 19 - ������v���Z�b�T�Z�p�����\��
http://journal.mycom.co.jp/articles/2007/08/22/hotchips/index.html
ttp://news21.2ch.net/test/read.cgi/bizplus/1186008715/
������A�K�����Ȃ��Ă���B
�ςȃn�[�h����Ă݂܂������Ǔ�������̌����݂Ȃ�����
����A���O�甄��鉞�p�l������Ă��܂���c�t����B
�ŁA������4K�corz
������A�K�����Ȃ��Ă���B
�ςȃn�[�h����Ă݂܂������Ǔ�������̌����݂Ȃ�����
����A���O�甄��鉞�p�l������Ă��܂���c�t����B
�ŁA������4K�corz
44 �FMAC�I�^��43 �����F2007/08/24(��) 08:24:42 ID:H3TGp+bh
>>43
�@�@-------------------
�@�@������A�K�����Ȃ��Ă���B
�@�@-------------------
�����CELL B.E.��@���Ȃ���Ύ���ł��܂��A���Ȃ��̂��Ƃ���(��)
�w�����[�����h��w��CELL/B.E.���p�̂��߂̃}���`�R�A�X�[�p�[�R���s���[�^�Z���^�[��ݗ��x
http://money.cnn.com/news/newsfeeds/articles/marketwire/0294298.htm
�@�@---------------------
�@�@The MCC will bring to UMBC a high-performance computational test laboratory based on
�@�@the Cell Broadband Engine (Cell/B.E.), jointly developed by IBM, Sony Corp., Sony Computer
�@�@Entertainment Inc. (SCE) and Toshiba Corp.
�@�@---------------------
�@�@-------------------
�@�@������A�K�����Ȃ��Ă���B
�@�@-------------------
�����CELL B.E.��@���Ȃ���Ύ���ł��܂��A���Ȃ��̂��Ƃ���(��)
�w�����[�����h��w��CELL/B.E.���p�̂��߂̃}���`�R�A�X�[�p�[�R���s���[�^�Z���^�[��ݗ��x
http://money.cnn.com/news/newsfeeds/articles/marketwire/0294298.htm
�@�@---------------------
�@�@The MCC will bring to UMBC a high-performance computational test laboratory based on
�@�@the Cell Broadband Engine (Cell/B.E.), jointly developed by IBM, Sony Corp., Sony Computer
�@�@Entertainment Inc. (SCE) and Toshiba Corp.
�@�@---------------------
�X�p�R���p�r�Ȃ�R�X�g�Ȃ�čl�����ɍςނ�
��������x�N�g���@�͂Ȃ��
>>44
���p������邱�Ƃ͂����ւ�ǂ����Ƃ����A���̑O�Ɏs��ɓ������Ă��܂��̂͏��������ׂ��ׂ��ȁB
�e���X�P�[���v���W�F�N�g�Ƃ��ɖc��ȋ����g���A����i�������s��ւ̓����͂܂��A�Ȗ^�Ђ̓G�����B
���p������邱�Ƃ͂����ւ�ǂ����Ƃ����A���̑O�Ɏs��ɓ������Ă��܂��̂͏��������ׂ��ׂ��ȁB
�e���X�P�[���v���W�F�N�g�Ƃ��ɖc��ȋ����g���A����i�������s��ւ̓����͂܂��A�Ȗ^�Ђ̓G�����B
����d��1W��86�n�}�C�N���v���Z�T�C��pVIA�Ђ��J��
http://techon.nikkeibp.co.jp/article/NEWS/20070824/138239/
Silverthorne�̘I�����H
http://techon.nikkeibp.co.jp/article/NEWS/20070824/138239/
Silverthorne�̘I�����H
�X�p�R���̉��p���Ă��������l�^����
����ł�����ɂ�Ȃ��Ԏ����]�ԑ��Ə�ԁB
��K�͉�͉]�X�ś��������˂Ă���Ƃ��X�b�Ƃ��\�Z�Ƃ��ĕςȂ��̂������܂���
����Ȃ��������t�ł����ĉ����ǂ����p�����H���Ă��������܂���
�������ƂƂ��ďI����Ă��B
����ł�����ɂ�Ȃ��Ԏ����]�ԑ��Ə�ԁB
��K�͉�͉]�X�ś��������˂Ă���Ƃ��X�b�Ƃ��\�Z�Ƃ��ĕςȂ��̂������܂���
����Ȃ��������t�ł����ĉ����ǂ����p�����H���Ă��������܂���
�������ƂƂ��ďI����Ă��B
51 �F�E�́E�j��-�������F2007/08/25(�y) 02:00:29 ID:ka21+Mjl
�Ȃ���TILE64���D�������ȁB
Amazon�Ŏ��̏��Д��������Ǝv�����獂����B
Amazon�Ŏ��̏��Д��������Ǝv�����獂����B
���������l���ăR���s���[�^�̃X�y�b�N�����������Ă��Ȃ��낤��
53 �F�E�́E�j��-�������F2007/08/25(�y) 02:08:31 ID:ka21+Mjl
�J�^���O�X�y�b�N���������TILE��Cell��FP���\���m���ɒႢ��B
�������\�ƒ����d�̖͂ʂ�TILE�͗D�G�Ƃ����Ă�B
�������\�ƒ����d�̖͂ʂ�TILE�͗D�G�Ƃ����Ă�B
Cell��GRAPE�Ɣ�r�������Ă��傤���Ȃ�
���������債�Ė��ɗ����Ȃ�����
���������債�Ė��ɗ����Ȃ�����
55 �F�E�́E�j��-�������F2007/08/25(�y) 02:12:16 ID:ka21+Mjl
�g�ݍ��݂̃l�b�g���[�N�@������ɂ͍ŗǁB
����̃G���R�[�h��点�Ă��D�G�B
���i���育���DSP�̑�ւɂȂ肤��B
�Ȃɂ��s���H
FPGA�\�����[�V�����Ƃ��m��Ȃ��l�Ȃ́H
����̃G���R�[�h��点�Ă��D�G�B
���i���育���DSP�̑�ւɂȂ肤��B
�Ȃɂ��s���H
FPGA�\�����[�V�����Ƃ��m��Ȃ��l�Ȃ́H
FPU�ς�ł�́H
�yHOT CHIPS�zIntel�Ђ��Í���������H���W�ς���SoC�uTolapai�v�𖾂炩��
http://techon.nikkeibp.co.jp/article/NEWS/20070824/138169/
07�NQ2�̃T�[�o�s��Ax86���ő吨�͂ɁA�����IT�o�u���ȗ��̐���
http://journal.mycom.co.jp/news/2007/08/24/010/index.html
http://techon.nikkeibp.co.jp/article/NEWS/20070824/138169/
07�NQ2�̃T�[�o�s��Ax86���ő吨�͂ɁA�����IT�o�u���ȗ��̐���
http://journal.mycom.co.jp/news/2007/08/24/010/index.html
DSP�̑���ɂ킴�킴Cell�A�fRAPE�����o���n����
�����炢����
�����炢����
59 �F�E�́E�j��-�������F2007/08/25(�y) 02:17:30 ID:ka21+Mjl
>>58
�́H���Ԃł����M�l�́B
DSP��։]�X�Ɋւ��ĉ���Cell��GRAPE�͈�x�����������ɏo���ĂȂ����H
Intel��80�R�A�̎��샂�f���ɂ����郁�b�V���\�������āA���̘_�������ɂȂ��Ă�킯�ŁB
�́H���Ԃł����M�l�́B
DSP��։]�X�Ɋւ��ĉ���Cell��GRAPE�͈�x�����������ɏo���ĂȂ����H
Intel��80�R�A�̎��샂�f���ɂ����郁�b�V���\�������āA���̘_�������ɂȂ��Ă�킯�ŁB
�t�@�r�����ĂȂ��ŃI�V�b�R���ĐQ�Ȃ���
PC�p�̉�������\�t�g�uRT-IR01�v�APS3���O�t��DSP�{�b�N�X�Ƃ��ė��p
http://news21.2ch.net/test/read.cgi/bizplus/1187662411/
http://news21.2ch.net/test/read.cgi/bizplus/1187662411/
�ց[�A�{�b�N�X�Ƃ��ĂȂ琔���~������������čl����
�s�u�Ō����邵
�s�u�Ō����邵
63 �F�E�́E�j��-�������F2007/08/25(�y) 02:22:43 ID:ka21+Mjl
>>56
�_�C�T�C�Y����T�Z����FPU�͐ς�łȂ��B
��������H.264�͐����x�[�X������FPU�͗v��Ȃ��B
32�r�b�g�������j�b�g��3���x�ł��傤�B
�����A10�i�ȉ��̃C���I�[�_�p�C�v���C����VLIW������
�p�C�v���C���͂����낵���P���ōςށB
�_�C�T�C�Y����T�Z����FPU�͐ς�łȂ��B
��������H.264�͐����x�[�X������FPU�͗v��Ȃ��B
32�r�b�g�������j�b�g��3���x�ł��傤�B
�����A10�i�ȉ��̃C���I�[�_�p�C�v���C����VLIW������
�p�C�v���C���͂����낵���P���ōςށB
�ց[�A�ց[�A�����Ƃ͕������Ă��S����
65 �F�E�́E�j��-�������F2007/08/25(�y) 02:25:47 ID:ka21+Mjl
���̎ア�q�͖����̕�����
NGID�F5GX2ByhC
NGID�F5GX2ByhC
�ǂ������o�J
�c�q��Y��"�Ԃ����"�h�ȂȁB
68 �F�E�́E�j��-�������F2007/08/25(�y) 02:28:25 ID:ka21+Mjl
>>67
�����u��������v�h�����́B
�����u��������v�h�����́B
�ł������ӂ�NGID
���ĐQ�邩�B
���ĐQ�邩�B
>>42
�o�[�i�[�r���W���Đ��͌v�Z�@�������̂��I�m��Ȃ������`�B
�o�[�i�[�r���W���Đ��͌v�Z�@�������̂��I�m��Ȃ������`�B
>>44 �̘b�̏ڕ��EETimes���`���Ă��邷�B
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=201802222
�@�@-----------------------
�@�@Next month, IBM will deliver 24 Cell Broadband Engines (BE) for the UMBC Multicore Computing Center.
�@�@Based on the same Cell processor that powers Sony's Playstation 3, the system will include a dozen IBM
�@�@BladeCenter QS20s, each with dual 3.2-GHz Cell Broadband Engines. The 24 processors will be connected by
�@�@Gigabit Ethernet and 20-Gbit/second Infiniband links.
�@�@-----------------------
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=201802222
�@�@-----------------------
�@�@Next month, IBM will deliver 24 Cell Broadband Engines (BE) for the UMBC Multicore Computing Center.
�@�@Based on the same Cell processor that powers Sony's Playstation 3, the system will include a dozen IBM
�@�@BladeCenter QS20s, each with dual 3.2-GHz Cell Broadband Engines. The 24 processors will be connected by
�@�@Gigabit Ethernet and 20-Gbit/second Infiniband links.
�@�@-----------------------
73 �FSocket774�F2007/08/27(��) 21:34:14 ID:03mnI2r/
itanium2�@�͂�����Ȃ��ȃ��������ˁB
�����\�[�_�B�ŏ����番�����Ă������ƁB
�ȁ[��Č������炷�ƁA�܂����֏L�����m������ŐH�ׂĂ܂��������H
�Ƃ��t�@�r���肻���ł�����
�ȁ[��Č������炷�ƁA�܂����֏L�����m������ŐH�ׂĂ܂��������H
�Ƃ��t�@�r���肻���ł�����
75 �F�E�́E�j��-�������F2007/08/28(��) 00:10:02 ID:b+i2NWa7
����Clovertown�ł����B�B�B
�����ނ��c
�_�{�n�[�ɐH��
�_�{�n�[�ɐH��
77 �F�E�́E�j��-�������F2007/08/28(��) 00:15:07 ID:b+i2NWa7
���₳��
�����炵�����ƁB
�C�C�q������I�V�b�R���ĐQ�悤�ˁB
�C�C�q������I�V�b�R���ĐQ�悤�ˁB
�ŏ�����킩���Ă�������
���̗ނ̑䎌��f���z�Ɍ�����
���̗ނ̑䎌��f���z�Ɍ�����
����
���g�̖������肢���
Hot Chips 19 - IBM��POWER6�A���͂�RAS��SMP�L���b�V���R�q�[�����X������
http://journal.mycom.co.jp/articles/2007/08/30/hotchips01/index.html
RAS��SPARC64�ȏォ��
http://journal.mycom.co.jp/articles/2007/08/30/hotchips01/index.html
RAS��SPARC64�ȏォ��
84 �FSocket774�F2007/09/01(�y) 23:02:53 ID:OKJoDMuE
>>83
> �S�̂ɋ����悤�Ȗ��߂͂Ȃ��C������ʓI�Ȗ��߂�3�A�h���X���߂ɂ��ĒW�X�ƒlj����������ł��B�����̖��߂͂��Ȃ蒷���Ȃ�̂ŁC1�T�C�N����1���߂����f�R�[�h�ł��Ȃ��Ǝv���܂��B
���܂��A���C������Ă���A�Œ蒷�̖��߂Ȃ瓊�@�I�Ƀf�R�[�h���đS�ROK
> �S�̂ɋ����悤�Ȗ��߂͂Ȃ��C������ʓI�Ȗ��߂�3�A�h���X���߂ɂ��ĒW�X�ƒlj����������ł��B�����̖��߂͂��Ȃ蒷���Ȃ�̂ŁC1�T�C�N����1���߂����f�R�[�h�ł��Ȃ��Ǝv���܂��B
���܂��A���C������Ă���A�Œ蒷�̖��߂Ȃ瓊�@�I�Ƀf�R�[�h���đS�ROK
>>63
FP�ς�łȂ��̂͐����A�p�C�v�����̕��G�x��L1�~�X�̃n���h�����O�̎d��
�ɂ��ˑ�����ȁA�ł��N�͐��i�j�]���Ă邩��Θb�͂������Ȃ��ȁB
FP�ς�łȂ��̂͐����A�p�C�v�����̕��G�x��L1�~�X�̃n���h�����O�̎d��
�ɂ��ˑ�����ȁA�ł��N�͐��i�j�]���Ă邩��Θb�͂������Ȃ��ȁB
86 �F�E�́E�j��-�������F2007/09/02(��) 19:33:02 ID:QJfCIja5
Tilera����ē��̃��[��������B
VIA�̈ȑO��
ttp://journal.mycom.co.jp/articles/2004/10/07/fpf1/index.html
���\����CPU�����N�ɂ͏o��͗l
����2�{���������_4�{�ƁA�܂��������ɑ����Ȃ�݂���
�܂�VIA���Ԃ����邩��ǂ��Ȃ邩�������
ttp://journal.mycom.co.jp/articles/2004/10/07/fpf1/index.html
���\����CPU�����N�ɂ͏o��͗l
����2�{���������_4�{�ƁA�܂��������ɑ����Ȃ�݂���
�܂�VIA���Ԃ����邩��ǂ��Ȃ邩�������
88 �FSocket774�F2007/09/07(��) 02:01:42 ID:XavJ3Nyt
���_��
�c�q�݂͂�Ȃ̌�����
���Ⴀ�A���܂���ނȂ�������
�Ȃ̖��ɗ������݁Bage�Ƃ����B
�c�q�݂͂�Ȃ̌�����
���Ⴀ�A���܂���ނȂ�������
�Ȃ̖��ɗ������݁Bage�Ƃ����B
LSI��Tarari��������B
ttp://www.tarari.com/news_pr_details.asp?ID=104
ttp://www.tarari.com/news_pr_details.asp?ID=104
TSMC�APC�p����45nm���i��2008�N�����ɓ���
http://pc.watch.impress.co.jp/docs/2007/0910/tsmc.htm
http://pc.watch.impress.co.jp/docs/2007/0910/tsmc.htm
�����I��R700���ۂ��Ȃ�
92 �FSocket774�F2007/09/10(��) 19:11:44 ID:J2sdk250
�m��GPU��CPU�͑S�R�v���Z�X���Ⴄ���Ęb���L�����C���B
Hot Chips 19 - IBM�̐V�v�̃��C���t���[���v���Z�T�uz6�v
http://journal.mycom.co.jp/articles/2007/09/11/hotchips1/index.html
�܂��ɉ�����������
http://journal.mycom.co.jp/articles/2007/09/11/hotchips1/index.html
�܂��ɉ�����������
���������̂œ���Mac�������������Ȃ�
POWER6�ł���Ȃ��̂ɁC�g���߃Z�b�g��p�r���قȂ�̂ŁA
�`�b�v�S�̂̃}�C�N���A�[�L�e�N�`���Ƃ��Ă͕ʕ��ƂȂ��Ă���B�h
�ł́C�]�v���肦�Ȃ������B
�`�b�v�S�̂̃}�C�N���A�[�L�e�N�`���Ƃ��Ă͕ʕ��ƂȂ��Ă���B�h
�ł́C�]�v���肦�Ȃ������B
���������Ă��������炢�������悤w
��낤�����Ă̂Ȃ猻���Ƃ̑Ë������邯�ǂ��c�c
��낤�����Ă̂Ȃ猻���Ƃ̑Ë������邯�ǂ��c�c
Hot Chips 19 - Sun�̒��}���`�X���b�h�V�X�e���p�v���Z�T�uVictoria Falls�v
http://journal.mycom.co.jp/articles/2007/09/11/hotchips2/index.html
���̒��̗����ς��邩���m��Ȃ��`�b�v�A�ƌ�������J�߂�����
http://journal.mycom.co.jp/articles/2007/09/11/hotchips2/index.html
���̒��̗����ς��邩���m��Ȃ��`�b�v�A�ƌ�������J�߂�����
System/360����n�܂���zSeries�ɂ�����܂őS�ĉ�����
�~�b�V�����N���e�B�J���Ȋ���n�ł͎���IBM�����I�ׂȂ�
�Ƃ����Ȃ��A�E�`�̉�Ђ̃o�b�N�G���h��IA64
�~�b�V�����N���e�B�J���Ȋ���n�ł͎���IBM�����I�ׂȂ�
�Ƃ����Ȃ��A�E�`�̉�Ђ̃o�b�N�G���h��IA64
100 �FSocket774�F2007/09/12(��) 22:59:57 ID:3IxTZPU/
>>99
IA-64�c���C�̓�
IA-64�c���C�̓�
>�~�b�V�����N���e�B�J���Ȋ���n�ł͎���IBM�����I�ׂȂ�
IA64(����Ȃ��Ă���������)�ʼnߋ��ɖ�肪�L�����Ȃ�N���Ă�
IA64(����Ȃ��Ă���������)�ʼnߋ��ɖ�肪�L�����Ȃ�N���Ă�
102 �FSocket774�F2007/09/13(��) 00:47:37 ID:9MYOIqRe
�~��IBM�ƕ����ĘA�z�������
IBM��Power��PPC��PPC Mac����݂̂��߂ɑ���PPC��MAC����ĸ��(���܂ł����Ⴂ�̉�)
��̏ꍇ:
�@�@IBM��System360���c390
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����̕ӂ�Power�Ɏ嗬�͈ڂ����Ǝv���Ă���
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�cz4��z6�c�܂������Ă��̂�
�������A��͂�����Ƃ������ǂ�����A�I�Ȃ��籯���
IBM��Power��PPC��PPC Mac����݂̂��߂ɑ���PPC��MAC����ĸ��(���܂ł����Ⴂ�̉�)
��̏ꍇ:
�@�@IBM��System360���c390
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����̕ӂ�Power�Ɏ嗬�͈ڂ����Ǝv���Ă���
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�cz4��z6�c�܂������Ă��̂�
�������A��͂�����Ƃ������ǂ�����A�I�Ȃ��籯���
IBM��HAL���R���s���[�^�̔��������ǂȉ���
IBM��HAL��PCG
>IBM�ƕ����ĘA�z�������
�V���`�j���̗v�ǃV���[�Y�̃C�r���_�ȉ��͂��Ȃ�ْ̈[�B
�V���`�j���̗v�ǃV���[�Y�̃C�r���_�ȉ��͂��Ȃ�ْ̈[�B
�n�[�h��s�C�Ƃ�����PG�u������̃��[�J���������B
PeroGuri
�n��A���ہA���Ђł�IA64�̗p�������Ă��
>>98
�����̒��̗����ς��邩������Ȃ�
Niagara��Cell���o�鎞�ɂ������Z���t��������
>>98
�����̒��̗����ς��邩������Ȃ�
Niagara��Cell���o�鎞�ɂ������Z���t��������
�uReinventing Computing�v - �X�p�R���E�̋��l�EBurton Smith���m
http://journal.mycom.co.jp/articles/2007/09/12/rc/
Functional Programming �� Transaction Processing �ł���
http://journal.mycom.co.jp/articles/2007/09/12/rc/
Functional Programming �� Transaction Processing �ł���
110 �FSocket774�F2007/09/14(��) 01:10:16 ID:nXNkYHbV
Transaction Processing�͒m��Ȃ���
Functional Programming�Ő��\�o���̂͒P���ɍl�����
��ؓꂶ��s���Ȃ����B��{�����I������B
�������߂₷�����ĈӖ����ȁB
Functional Programming�Ő��\�o���̂͒P���ɍl�����
��ؓꂶ��s���Ȃ����B��{�����I������B
�������߂₷�����ĈӖ����ȁB
111 �FSocket774�F2007/09/14(��) 01:12:39 ID:nXNkYHbV
�Ƃ������AFunctional Programming�͐��\����̂��߂�
�̗p�����Ȃ����(����)�B
�����s���Ă���Java����OOp��荂�����Y�������܂݂Ȃ��B
���������Ă����̂̐l�Ȃ̂��A�悤�킩���B
�̗p�����Ȃ����(����)�B
�����s���Ă���Java����OOp��荂�����Y�������܂݂Ȃ��B
���������Ă����̂̐l�Ȃ̂��A�悤�킩���B
112 �FSocket774�F2007/09/14(��) 05:21:50 ID:bQXeHBTt
�f�[�^�t���[�̐̂�����^�����HPC�Ɍ����Ă���ƌ����Ă���
��{�����I�A�Ƃ��������\�[�X�̉���̃^�C�~���O���킩��Ȃ��̂��ő�̃l�b�N������
����͖����I�ȓ����R�[�h�������Ȃ��Ă������Ƃ������_�ƕ\����̂Ȃ̂łȂ��Ȃ����܂�������
��{�����I�A�Ƃ��������\�[�X�̉���̃^�C�~���O���킩��Ȃ��̂��ő�̃l�b�N������
����͖����I�ȓ����R�[�h�������Ȃ��Ă������Ƃ������_�ƕ\����̂Ȃ̂łȂ��Ȃ����܂�������
���{�_�̐̂��狤�Y��`�͐l�ނɌ����Ă�Ƃ��H
������C or FORTRAN + MPI��compiler (hardware) friendly��
�R�[�h�����Ă�킯�����B
������C or FORTRAN + MPI��compiler (hardware) friendly��
�R�[�h�����Ă�킯�����B
114 �FSocket774�F2007/09/14(��) 12:21:44 ID:bQXeHBTt
�z��Ɗ��^����͑������������������������
SISAL�͑����g���Ă����̂��������
SISAL�͑����g���Ă����̂��������
������A10PFLOPS���̃X�p�R����2012�N�Ɋ���
http://pc.watch.impress.co.jp/docs/2007/0914/riken.htm
http://pc.watch.impress.co.jp/docs/2007/0914/riken.htm
IBM holds 128-thread 'Q7' variant of Power7
http://www.theregister.co.uk/2007/09/13/ibm_q7_chip/
Niagara�R�����H
http://www.theregister.co.uk/2007/09/13/ibm_q7_chip/
Niagara�R�����H
117 �FSocket774�F2007/09/14(��) 21:58:51 ID:PZZ7Qp+c
>>115
���킶��Y�ؐL���Ă���悤��k(ry
���킶��Y�ؐL���Ă���悤��k(ry
2012�N��45nm���ăA�z��
�܂��ғ�����̂�2010�N�̂悤����
120 �FSocket774�F2007/09/15(�y) 01:17:58 ID:zfK7cFi1
�����Ɠ����o�������ɂ́A�R�A������̐��\���O���ȃR���f�e�B�[���i�̐����̈�A
�ł�MP������������LINPACK�Ȃ瑬������iT^T�j�Ƃ������Ȃ���A
�w�ǎ��p�I���ɗ��ĂȂ����ɁA��Ђ݂����Ș_�������U�炩����
�܂����Ɨ\�Z�����ꗬ���v���W�F�N�g�ł����グ�ē�����c
�����̃p�^�[���Ȃ낤�ȁB
�ł�MP������������LINPACK�Ȃ瑬������iT^T�j�Ƃ������Ȃ���A
�w�ǎ��p�I���ɗ��ĂȂ����ɁA��Ђ݂����Ș_�������U�炩����
�܂����Ɨ\�Z�����ꗬ���v���W�F�N�g�ł����グ�ē�����c
�����̃p�^�[���Ȃ낤�ȁB
�������Ȃ�PC Watch������ȃl�^�ŋL�������̂��B
���ẮA���o�݂����ɋ�������Đ�`�L�����������B
���ẮA���o�݂����ɋ�������Đ�`�L�����������B
1 �{�{��(���m��) 2007/09/15(�y) 04:45:03 ID:PszHDssB0 BE:1168387889-PLT(23707) �|�C���g���T
1 ���O�F�炢��_��)�m ��RIDEONxuoc [��������sage] ���e���F2007/09/15(�y) 04:20:44 ID:yGgzjDVT0
80 ���O�F�݂肠��� ��HoEz2Szyyw [sage] ���e���F2007/09/15(�y) 03:53:29 ID:44VPMvakO
���o��ʂŃ\�j�[�����̎��Ɣ��p�L�^�R��
���ǃZ����PS3������������������
6 ���O�F����������K������[sage] ���e���F2007/09/15(�y) 04:24:51 ID:2ElB0gmr0
http://up2.viploader.net/upphp/src/vlphp068974.jpg
���o����
1 ���O�F�炢��_��)�m ��RIDEONxuoc [��������sage] ���e���F2007/09/15(�y) 04:20:44 ID:yGgzjDVT0
80 ���O�F�݂肠��� ��HoEz2Szyyw [sage] ���e���F2007/09/15(�y) 03:53:29 ID:44VPMvakO
���o��ʂŃ\�j�[�����̎��Ɣ��p�L�^�R��
���ǃZ����PS3������������������
6 ���O�F����������K������[sage] ���e���F2007/09/15(�y) 04:24:51 ID:2ElB0gmr0
http://up2.viploader.net/upphp/src/vlphp068974.jpg
{kind=link}
���o����
399 �F����������K������ [] �F2007/09/15(�y) 05:33:22 ID:FTvCyqJD0
�\�j�[Cell�P�ށi���o�V���j
http://up2.viploader.net/pic/src/viploader479527.jpg
422 �F����������K������ [sage] �F2007/09/15(�y) 05:45:27 ID:FTvCyqJD0
3��
http://up2.viploader.net/upphp/src/vlphp068990.jpg
419 �F����������K������ [sage] �F2007/09/15(�y) 05:43:36 ID:2ElB0gmr0
http://up2.viploader.net/upphp/src/vlphp068989.jpg
13��
�\�j�[Cell�P�ށi���o�V���j
http://up2.viploader.net/pic/src/viploader479527.jpg
{kind=link}
422 �F����������K������ [sage] �F2007/09/15(�y) 05:45:27 ID:FTvCyqJD0
3��
http://up2.viploader.net/upphp/src/vlphp068990.jpg
{kind=link}
419 �F����������K������ [sage] �F2007/09/15(�y) 05:43:36 ID:2ElB0gmr0
http://up2.viploader.net/upphp/src/vlphp068989.jpg
{kind=link}
13��
124 �F�E�́E�j�����������F2007/09/15(�y) 07:51:58 ID:FpKKBuDw
��������
GK�ܖڂ�������������������������
GK�ܖڂ�������������������������
���݂܂���A�����炿����ƃR�s�y���܂�
�W���}�Ȃ炠�ځ[�Ƃ���
�Â�����Ԉ���Ă�ӏ��̂����݂͂Ȃ���
�W���}�Ȃ炠�ځ[�Ƃ���
�Â�����Ԉ���Ă�ӏ��̂����݂͂Ȃ���
470 �F�ԑg�̓r���ł����������ł� �F05/02/08 16:29:26 ID:ALl8FbKN
Cell�̂���APowerPC�̃R�A��8����̂������[�Ǝv������A����1����ˁ[���悗
������8�̃R�A���ċL�ڂ���Ă邯�ǁA����P�Ȃ�MMX�̂悤��SIMD���ߗp���W�X�^�[�̎�����H
�����}���`�R�A�Ȃ̂��Ə��ꎞ�Ԗ₢�l�߂������E�E�E�E
���W�X�^�[�́y�R�A�z�Ƃ͌����
����Ȃ���R�A�Ƃ����Ȃ�MMXPentium�ł��}���`�R�A���@�ޫ�!!
Cell�̃_�C�A�O�����@http://pc.watch.impress.co.jp/docs/2005/0208/kaigai01l.gif
473 �F�ԑg�̓r���ł����������ł� �F05/02/08 16:31:51 ID:KG2wmUsF
>>470
�ǂ��Ƀ��W�X�^�Ə����Ă���
474 �F�ԑg�̓r���ł����������ł� �F05/02/08 16:34:06 ID:ALl8FbKN
>>473
>Cell�̒���8���ڂ���Ă���SPE�́A�����̃f�[�^�ɑ���1���߂œ����������ɍs�Ȃ����Ƃ��ł���SIMD�^�v���Z�b�T���B
>X86�nCPU��SSE���j�b�g���Ɨ������v���Z�b�T�ɂȂ����ƍl���Ă������B
>SSE�Ɠ��l�ɁA32bit�̒P���x���������_�f�[�^4����f�[�^4��1���߂œ����ɏ����ł���B
http://pc.watch.impress.co.jp/docs/2005/0208/kaigai153.htm
�P�Ȃ郌�W�X�^�ł���
139 �FSocket774 [sage] �F05/02/09(��) 06:14:51 ID:cnHOdkPn
227 :Socket774 : 04/11/30 07:41:07 ID:84EYjZr6
>>225-226
cell���Ăǂ�ȃA�[�L�e�N�`���ȂȁH
�Ȃ�IBM��Power�v���Z�b�T�Ƀx�N�g�����j�b�g���R�v���Z�b�T�Ƃ��ĕ���
�Ȃ��������̈����c
���ǂ��ꂻ���X���̗\�z�ʂ�B�ނ����B
Cell�̂���APowerPC�̃R�A��8����̂������[�Ǝv������A����1����ˁ[���悗
������8�̃R�A���ċL�ڂ���Ă邯�ǁA����P�Ȃ�MMX�̂悤��SIMD���ߗp���W�X�^�[�̎�����H
�����}���`�R�A�Ȃ̂��Ə��ꎞ�Ԗ₢�l�߂������E�E�E�E
���W�X�^�[�́y�R�A�z�Ƃ͌����
����Ȃ���R�A�Ƃ����Ȃ�MMXPentium�ł��}���`�R�A���@�ޫ�!!
Cell�̃_�C�A�O�����@http://pc.watch.impress.co.jp/docs/2005/0208/kaigai01l.gif
{kind=link}
473 �F�ԑg�̓r���ł����������ł� �F05/02/08 16:31:51 ID:KG2wmUsF
>>470
�ǂ��Ƀ��W�X�^�Ə����Ă���
474 �F�ԑg�̓r���ł����������ł� �F05/02/08 16:34:06 ID:ALl8FbKN
>>473
>Cell�̒���8���ڂ���Ă���SPE�́A�����̃f�[�^�ɑ���1���߂œ����������ɍs�Ȃ����Ƃ��ł���SIMD�^�v���Z�b�T���B
>X86�nCPU��SSE���j�b�g���Ɨ������v���Z�b�T�ɂȂ����ƍl���Ă������B
>SSE�Ɠ��l�ɁA32bit�̒P���x���������_�f�[�^4����f�[�^4��1���߂œ����ɏ����ł���B
http://pc.watch.impress.co.jp/docs/2005/0208/kaigai153.htm
�P�Ȃ郌�W�X�^�ł���
139 �FSocket774 [sage] �F05/02/09(��) 06:14:51 ID:cnHOdkPn
227 :Socket774 : 04/11/30 07:41:07 ID:84EYjZr6
>>225-226
cell���Ăǂ�ȃA�[�L�e�N�`���ȂȁH
�Ȃ�IBM��Power�v���Z�b�T�Ƀx�N�g�����j�b�g���R�v���Z�b�T�Ƃ��ĕ���
�Ȃ��������̈����c
���ǂ��ꂻ���X���̗\�z�ʂ�B�ނ����B
149 �FSocket774 [sage] �F05/02/09(��) 12:52:27 ID:Giwitjc4
�e���Z���̓�����PPE�ł������iSPE����eSPE�ɑ��Ē��₷��@�\�������j
G5�̃x�N�^���Z����ӏ����A���O�͖Y�ꂽ���A�_�C�̏�Ƀx���b�ƕ��ׂ������B
�܂��m���ɔėp�^CPU�ł���P4��Athlon�Ɣ�r����
�X�g���[�~���O�^�̏�������点��ᑬ���낤��
����ȍ\�����Ă�Γ�����O����Ǝv���B
173 �FSocket774 [sage] �F05/02/09(��) 22:04:18 ID:dnpQ+B8a
>>167
>Cell�̊e�v���Z�b�T�G�������g�A
>PPE��SPE�͂ǂ���������̃n�C�G���h�v���Z�b�T�����\�����ȑf������Ă���B
>���G�ȃX�P�W���[�����O���s�Ȃ�Ȃ����ƂŁA
>���_��CPU���d�����Ă��錴���ł��鐧��n�������ȑf�����Ă���B
Cell�̐��̂��Y�o���������ȁ@�������㓡�B
�v����ɍ�����CPU�����鍂�x�ȃX�P�W���[�����O�͕s�\�B
���߈ˑ��W�������X�g���[�~���O�f�[�^��
�����Ђ����珈������v���Z�b�T���ƁB
252 �FSocket774 [sage] �F05/02/10(��) 23:33:13 ID:M4eOQpwm
ttp://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765505.jpg.html
���ꌩ���SPE��L2�L���b�V����������
�̐S��PPC������1/10���x����������ˁB
��̂ǂꂾ���Q�[���p�Ƃ��Ċ�����ċ@�\���܂������̂��B
���Ɏ��@���Q�M�K�O��œ��삷��Ƃ���
���N���b�N��G5�ӂ�Ɣ�r�������i�ǂ��납
�Q�`�R�i�͐��\�Ⴛ���B
�e���Z���̓�����PPE�ł������iSPE����eSPE�ɑ��Ē��₷��@�\�������j
G5�̃x�N�^���Z����ӏ����A���O�͖Y�ꂽ���A�_�C�̏�Ƀx���b�ƕ��ׂ������B
�܂��m���ɔėp�^CPU�ł���P4��Athlon�Ɣ�r����
�X�g���[�~���O�^�̏�������点��ᑬ���낤��
����ȍ\�����Ă�Γ�����O����Ǝv���B
173 �FSocket774 [sage] �F05/02/09(��) 22:04:18 ID:dnpQ+B8a
>>167
>Cell�̊e�v���Z�b�T�G�������g�A
>PPE��SPE�͂ǂ���������̃n�C�G���h�v���Z�b�T�����\�����ȑf������Ă���B
>���G�ȃX�P�W���[�����O���s�Ȃ�Ȃ����ƂŁA
>���_��CPU���d�����Ă��錴���ł��鐧��n�������ȑf�����Ă���B
Cell�̐��̂��Y�o���������ȁ@�������㓡�B
�v����ɍ�����CPU�����鍂�x�ȃX�P�W���[�����O�͕s�\�B
���߈ˑ��W�������X�g���[�~���O�f�[�^��
�����Ђ����珈������v���Z�b�T���ƁB
252 �FSocket774 [sage] �F05/02/10(��) 23:33:13 ID:M4eOQpwm
ttp://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765505.jpg.html
{kind=link}
���ꌩ���SPE��L2�L���b�V����������
�̐S��PPC������1/10���x����������ˁB
��̂ǂꂾ���Q�[���p�Ƃ��Ċ�����ċ@�\���܂������̂��B
���Ɏ��@���Q�M�K�O��œ��삷��Ƃ���
���N���b�N��G5�ӂ�Ɣ�r�������i�ǂ��납
�Q�`�R�i�͐��\�Ⴛ���B
256 �FSocket774 [sage] �F05/02/10(��) 23:56:45 ID:Dj/pe3BU
SIMD���Z���j�b�g���W�ς��A�R�C�c��������I�ɉƂ���
��ԑ厖�ȕ�����OS�ƃR���p�C���Ɋۓ��������̂͂ǂ���H�Ǝv���B
�W���郆�j�b�g�Ԃ̍��x�ȃX�P�W���[�����O��Cell���g�ł͂����ȁB
�ςȏ�����������\�������Ă��Ă��A�V�X�e���S�̂̃p�t�H�[�}���X�͏オ��Ȃ��Ǝv�����B
257 �FSocket774 [sage] �F05/02/11(��) 00:01:09 ID:JV0N5HE3
�ł����ꂾ��ASIMD���Ă��̐��\�g���邽�߂ɂ́A�R���p�C���̍œK�����\��
���邱�ƂȂ���A�R�[�h�����l�Ԃ̕��ł�����Ȃ��SIMD���������悤�ȃR�[�f�B���O��
���Ȃ��Ƃ����Ȃ���ŁA����Ȃ�SIMD���j�b�g�ς�ł��������������悤�ȏ�
�Ȃ�̂��r���^�₾�B�܂��č���A�E�l�I�ȃR�[�h�͔����āA�Ȃ邾���ėp�I�ȃR�[�h��
�����܂��傤�Ƃ���������Ă������オ�v���O���}�̒��S�ƂȂ���鎞��Ȃ̂ɁB
259 �FSocket774 [sage] �F05/02/11(��) 01:12:54 ID:CJqP/Dzy
>>252
�E�`�玩��Z�l�����i����e����ł�CPU�Ƃ�
�S���َ��Ȃ��̂��ˁB
�_�C�̂قƂ�ǂ��x�N�^���Z���j�b�g�Ŗ��܂��Ă�B
�X�g���[�~���O�n�����ɓ��������A�Ƃ����Ε������͂悢��
���̂��߂̑㏞�͑傫����A���ꂶ��B
266 �FSocket774 [sage] �F05/02/11(��) 07:57:16 ID:aXKmDlMO
SSE2�݂����Ȃ̂��������Ă�����o����͔̂���������������B
��������SIMD���Z���������\�͑債�����Ƃ͂Ȃ��������B
�܂��Q�[���@�p��CPU������X�y�b�N�]�X�͂��܂��肶��Ȃ���������Ȃ����ǁB
321 �FSocket774 [sage] �F05/02/13(��) 13:39:22 ID:siC1TrqZ
���ǂ�PowerPC+DSP�W���B�p���[�͂��肻�������ǂˁB
SIMD���Z���j�b�g���W�ς��A�R�C�c��������I�ɉƂ���
��ԑ厖�ȕ�����OS�ƃR���p�C���Ɋۓ��������̂͂ǂ���H�Ǝv���B
�W���郆�j�b�g�Ԃ̍��x�ȃX�P�W���[�����O��Cell���g�ł͂����ȁB
�ςȏ�����������\�������Ă��Ă��A�V�X�e���S�̂̃p�t�H�[�}���X�͏オ��Ȃ��Ǝv�����B
257 �FSocket774 [sage] �F05/02/11(��) 00:01:09 ID:JV0N5HE3
�ł����ꂾ��ASIMD���Ă��̐��\�g���邽�߂ɂ́A�R���p�C���̍œK�����\��
���邱�ƂȂ���A�R�[�h�����l�Ԃ̕��ł�����Ȃ��SIMD���������悤�ȃR�[�f�B���O��
���Ȃ��Ƃ����Ȃ���ŁA����Ȃ�SIMD���j�b�g�ς�ł��������������悤�ȏ�
�Ȃ�̂��r���^�₾�B�܂��č���A�E�l�I�ȃR�[�h�͔����āA�Ȃ邾���ėp�I�ȃR�[�h��
�����܂��傤�Ƃ���������Ă������オ�v���O���}�̒��S�ƂȂ���鎞��Ȃ̂ɁB
259 �FSocket774 [sage] �F05/02/11(��) 01:12:54 ID:CJqP/Dzy
>>252
�E�`�玩��Z�l�����i����e����ł�CPU�Ƃ�
�S���َ��Ȃ��̂��ˁB
�_�C�̂قƂ�ǂ��x�N�^���Z���j�b�g�Ŗ��܂��Ă�B
�X�g���[�~���O�n�����ɓ��������A�Ƃ����Ε������͂悢��
���̂��߂̑㏞�͑傫����A���ꂶ��B
266 �FSocket774 [sage] �F05/02/11(��) 07:57:16 ID:aXKmDlMO
SSE2�݂����Ȃ̂��������Ă�����o����͔̂���������������B
��������SIMD���Z���������\�͑債�����Ƃ͂Ȃ��������B
�܂��Q�[���@�p��CPU������X�y�b�N�]�X�͂��܂��肶��Ȃ���������Ȃ����ǁB
321 �FSocket774 [sage] �F05/02/13(��) 13:39:22 ID:siC1TrqZ
���ǂ�PowerPC+DSP�W���B�p���[�͂��肻�������ǂˁB
407 �FSocket774 [sage] �F05/02/25(��) 09:24:27 ID:VBde/PuJ
>>404
���ȁcCell���܂Ƃ��ɏ�肱�Ȃ���_�v���O���}�͂���������Ȃ����낤
�~�[���������R�[�h�ł������ł���R���p�C���ł������Ȃ�b�͂܂��Ⴄ���낤���ǁc
PS2�������������ς�炸SCE�͊J���҂̕�����������͂Ȃ��炵����
528 �FSocket774 [sage] �F05/03/13(��) 19:43:06 ID:YWmUEOA/
�����Ƃ��v���O���}�̊Ԃł͐������Z���x�������ŁA���[�`���̎��s
�ɂ͌����ĂȂ����Ă����̂͒��������ˁB
���炩��Athlon64��Pentium-M�̕����L�����Ƃ������Ƃ�FA�B
������s�͖{�����ɑ��ā�{�����_�l������A������200GFLOPS����
�������Ƃ������Ă��܂������̌�����˂�����L�����y�[���B
�㓡�Ƃ����ꂭ�炢�̂��ƕ������Ăĕ���ō��v�Ȃ�FLOPS�Ƃ��A�āB
���������������x���̐��i�ł����Ȃ���B
�A�[�L�e�N�`����Power�n�ł��݊��i������ˁB
���Ǖ��������g������T���n�̊w�p�v�Z�ɖ������Ă�l��Cell���S�R
�����ĂȂ��������Ă邵�A�������ۂ��g���[�X������W�v�Z������
�w�p�v�Z�Ǝv���Ă�A�Ȋw�����Ⴂ�����T�����[�}���Ƃ��w���𖾂炩��
�^�[�Q�b�g�ɂ����L�������n�̃y�[�W���J��L���Ă�B
�����������āA���W���[��2��5��20�{���炢�̒������q�b�^�[������
�I����L�����v���ɖJ�߂�����X�|�[�c���ƑS���ς����B
625 �FSocket774 [] �F05/03/15(��) 01:53:47 ID:69HoDsHb
IBM�́A�}�C�N���\�t�g�Ƀ��m�W�j�A�X�}���`�R�A���̗p������
�\�j�[�Ƀw�e���W�j�A�X���̗p������킯���B
�O�҂�MS���ϑ��̎��А���������A�`���͂�����
POWER4�̃m�E�n�E�𗬗p
��҂́A���s���Ă��\�j�[���_���[�W��H�炤����������`�����܂���
��ŏ����҂��ǂ����ł�IBM�͗��v��ƁE�E�E�E
>>404
���ȁcCell���܂Ƃ��ɏ�肱�Ȃ���_�v���O���}�͂���������Ȃ����낤
�~�[���������R�[�h�ł������ł���R���p�C���ł������Ȃ�b�͂܂��Ⴄ���낤���ǁc
PS2�������������ς�炸SCE�͊J���҂̕�����������͂Ȃ��炵����
528 �FSocket774 [sage] �F05/03/13(��) 19:43:06 ID:YWmUEOA/
�����Ƃ��v���O���}�̊Ԃł͐������Z���x�������ŁA���[�`���̎��s
�ɂ͌����ĂȂ����Ă����̂͒��������ˁB
���炩��Athlon64��Pentium-M�̕����L�����Ƃ������Ƃ�FA�B
������s�͖{�����ɑ��ā�{�����_�l������A������200GFLOPS����
�������Ƃ������Ă��܂������̌�����˂�����L�����y�[���B
�㓡�Ƃ����ꂭ�炢�̂��ƕ������Ăĕ���ō��v�Ȃ�FLOPS�Ƃ��A�āB
���������������x���̐��i�ł����Ȃ���B
�A�[�L�e�N�`����Power�n�ł��݊��i������ˁB
���Ǖ��������g������T���n�̊w�p�v�Z�ɖ������Ă�l��Cell���S�R
�����ĂȂ��������Ă邵�A�������ۂ��g���[�X������W�v�Z������
�w�p�v�Z�Ǝv���Ă�A�Ȋw�����Ⴂ�����T�����[�}���Ƃ��w���𖾂炩��
�^�[�Q�b�g�ɂ����L�������n�̃y�[�W���J��L���Ă�B
�����������āA���W���[��2��5��20�{���炢�̒������q�b�^�[������
�I����L�����v���ɖJ�߂�����X�|�[�c���ƑS���ς����B
625 �FSocket774 [] �F05/03/15(��) 01:53:47 ID:69HoDsHb
IBM�́A�}�C�N���\�t�g�Ƀ��m�W�j�A�X�}���`�R�A���̗p������
�\�j�[�Ƀw�e���W�j�A�X���̗p������킯���B
�O�҂�MS���ϑ��̎��А���������A�`���͂�����
POWER4�̃m�E�n�E�𗬗p
��҂́A���s���Ă��\�j�[���_���[�W��H�炤����������`�����܂���
��ŏ����҂��ǂ����ł�IBM�͗��v��ƁE�E�E�E
>>126-129
����������������
����������������
�y��Ɓz�\�j�[�APS�R�̐S�����u�Z���v�Ȃǂ��܂ށw��[�����́x�̐��Y�P�ށc���ł�1000���~�Ŕ��p
http://news22.2ch.net/test/read.cgi/newsplus/1189808312/
http://news22.2ch.net/test/read.cgi/newsplus/1189808312/
�܂��O�̂Ɏ��s�ł����BIBM�������ȁB
GK��
PS3�̎��s�͖��炩�����ȁB
������@�łԂ�������ʼn��ʂƂ����E�E�E�B
������@�łԂ�������ʼn��ʂƂ����E�E�E�B
PC Watch�����ǁA���������čL�����������炢������A
���������Ȃ��B������l����Ɠ��{�ɂ̓��[�J�[�̉e�������ɁA
���R�ɏ����悤�Ȓc�͖̂������Ă��Ƃ��B
�܂��C�O�̂��ǂ��܂ŐM�p�ł��邩�͒m��Ȃ����A
���Ȃ��Ƃ����{���͐M�p�ł���ȁB
���������Ȃ��B������l����Ɠ��{�ɂ̓��[�J�[�̉e�������ɁA
���R�ɏ����悤�Ȓc�͖̂������Ă��Ƃ��B
�܂��C�O�̂��ǂ��܂ŐM�p�ł��邩�͒m��Ȃ����A
���Ȃ��Ƃ����{���͐M�p�ł���ȁB
sony�̌��Z����PS3�̃R�X�g���v�Z����Ζ��炩�Ȃ悤�ɁACELL/B.E.���̕��偨�Q�[������
�ɔ̔�����Ƃ����`���ŁA���v�̕t���ւ������Ă����͗l���B�ŁA�����̕���퍕���A�Q�[����Ԏ���(��)
���������Ӗ��ł�ASCEI�����ڃt�@�u�����L���Ă�������ƈ���āA�Q�[������ɓ����̃����b�g��
���������悤�Ɏv���邷�B
�ɔ̔�����Ƃ����`���ŁA���v�̕t���ւ������Ă����͗l���B�ŁA�����̕���퍕���A�Q�[����Ԏ���(��)
���������Ӗ��ł�ASCEI�����ڃt�@�u�����L���Ă�������ƈ���āA�Q�[������ɓ����̃����b�g��
���������悤�Ɏv���邷�B
Freescale Technology Forum Japan�Ō��J���ꂽBook-E PowerPC 32-way��SoC���B
http://pc.watch.impress.co.jp/docs/2007/0914/freescale.htm
http://pc.watch.impress.co.jp/docs/2007/0914/freescale_21.jpg
�@�@--------------------
�@�@Power�A�[�L�e�N�`����CPU�R�A���ő��32�Ɛ����������ł���g�ݍ��ݗp�v���b�g�t�H�[��(SoC)��
�@�@�Љ���BCPU�R�A�̓�����g���͍ő�1.5GHz�ƍ����B�o�X�ł͂Ȃ��A�X�C�b�`�h�E�t�@�u���b�N�ɂ����
�@�@�eCPU�R�A�������ɐڑ�����B
�@�@--------------------
����IBM�̔����̕����PowerPC�S���d��������Lisa Su��CTO�Ƃ��ĉ������Ă��邱�Ƃł�����A
Freescale�̓������ڂ헣���Ȃ����Ǝv�����B
http://pc.watch.impress.co.jp/docs/2007/0914/freescale.htm
http://pc.watch.impress.co.jp/docs/2007/0914/freescale_21.jpg
{kind=link}
�@�@--------------------
�@�@Power�A�[�L�e�N�`����CPU�R�A���ő��32�Ɛ����������ł���g�ݍ��ݗp�v���b�g�t�H�[��(SoC)��
�@�@�Љ���BCPU�R�A�̓�����g���͍ő�1.5GHz�ƍ����B�o�X�ł͂Ȃ��A�X�C�b�`�h�E�t�@�u���b�N�ɂ����
�@�@�eCPU�R�A�������ɐڑ�����B
�@�@--------------------
����IBM�̔����̕����PowerPC�S���d��������Lisa Su��CTO�Ƃ��ĉ������Ă��邱�Ƃł�����A
Freescale�̓������ڂ헣���Ȃ����Ǝv�����B
Q7�ɂ��ĉ����m��Ȃ����H
>>131
�Ɠd���[�J�����O��Fab��CPU���̂��Ăǂ���H�Ǝv���Ă����B
�Ɠd�p�̃V�X�e������ƃG���R/�f�R�`�b�v��������
��������������������B
�܂����R�̌��ʂ��ƁB
�l�^�Ƃ��Ă͏\���y���߂����烈�V�Ƃ��܂��傤�B
�Ɠd���[�J�����O��Fab��CPU���̂��Ăǂ���H�Ǝv���Ă����B
�Ɠd�p�̃V�X�e������ƃG���R/�f�R�`�b�v��������
��������������������B
�܂����R�̌��ʂ��ƁB
�l�^�Ƃ��Ă͏\���y���߂����烈�V�Ƃ��܂��傤�B
���o���āA�ŏ��������ă��C�V�����Ƃ��āA�X���ƒ@���Ĕᔻ�L���B
�o�u���o�ς̎��������A�D���ɂȂ�Ȱ�ȁB
�o�u���o�ς̎��������A�D���ɂȂ�Ȱ�ȁB
141 �FMAC�I�^��138 �����F2007/09/15(�y) 13:40:37 ID:bs69mZxc
>>138
"Q7"�l�^��A����TheRegs�̋L�����������B
"Q7"�l�^��A����TheRegs�̋L�����������B
����͎c�O
��������ɂ���������҂��Ƃ���
��������ɂ���������҂��Ƃ���
143 �F�E�́E�j�����������F2007/09/15(�y) 20:32:51 ID:FpKKBuDw
�������PS3�s�k�錾�ł��傱��B
���ɖׂ��錩���݂�����Ȃ�A5000��������Fab����������1000���Ŕ���悤�ȕK�v�͖����B
�Ȃɂ�蔄�p�v��PS3�̃J�c����ɂ͎g��Ȃ��B
���ɖׂ��錩���݂�����Ȃ�A5000��������Fab����������1000���Ŕ���悤�ȕK�v�͖����B
�Ȃɂ�蔄�p�v��PS3�̃J�c����ɂ͎g��Ȃ��B
�V�v���Z�X��Cell�͎��А��Y���Ȃ��Ƃ���
�����ƑO�̔��\�̒i�K�ł��炩�������Ă��B
���傤�ǂ��O����PS3�����Ă͂��Ⴂ�ł����̂��b�����B
�����ƑO�̔��\�̒i�K�ł��炩�������Ă��B
���傤�ǂ��O����PS3�����Ă͂��Ⴂ�ł����̂��b�����B
>�Ɠd���[�J�����O��Fab��CPU���̂��Ăǂ���H�Ǝv���Ă����B
�Ɠd�����낤��
��������悪�O���l���L��̂ł����
���ЍH��ō�����������オ��B
��������悪�O���l���L��A�̘b�����B
�Ɠd�����낤��
��������悪�O���l���L��̂ł����
���ЍH��ō�����������オ��B
��������悪�O���l���L��A�̘b�����B
146 �FMAC�I�^��139 �����F2007/09/15(�y) 23:14:28 ID:bs69mZxc
>>139
�@�@-----------------
�@�@�Ɠd���[�J�����O��Fab��CPU���̂��Ăǂ���H�Ǝv���Ă����B
�@�@-----------------
���Ȃ��������v���̂�A���肷(��)
http://www.watch.impress.co.jp/av/docs/20070619/pana.htm
�@�@-----------------
�@�@�Ɠd���[�J�����O��Fab��CPU���̂��Ăǂ���H�Ǝv���Ă����B
�@�@-----------------
���Ȃ��������v���̂�A���肷(��)
http://www.watch.impress.co.jp/av/docs/20070619/pana.htm
�����͊撣���Ă���
�ł��A���Ɖ����㎝��
�ł��A���Ɖ����㎝��
148 �F�E�́E�j�����������F2007/09/16(��) 01:42:24 ID:XnRK1xQh
�\�j�[�͉Ɠd���[�J�[�ł���O�ɐ��E�ɖ���A�˂�i���j�����̃��[�J�[����
149 �F�E�́E�j�����������F2007/09/16(��) 01:43:54 ID:XnRK1xQh
�ނ���A�Ɠd���[�J�[���ߋ�Ɠ����s��Łu�Q�[���@�v�o���Ă�̂��Ăǂ���H���ĂȘb�ɂȂ邵�B
���^�N�̌o�c�ᔻ�ȂS���N�����B
�I�V�b�R���ĐQ�Ȃ������Ă��������Ă�ł���B
�I�V�b�R���ĐQ�Ȃ������Ă��������Ă�ł���B
�N���o�c�ᔻ���Ă������H
�i���Œނ�邩�ȁA�킴�킴��ID��
�u�\�j�[�̔����̐��Y�ݔ��̔��p�v�͌��̖͗l
http://www.itmedia.co.jp/news/articles/0709/15/news019.html
http://www.itmedia.co.jp/news/articles/0709/15/news019.html
�܂����o�̔���L���������H��
�����ō��B
�����ō��B
155 �F�E�́E�j�����������F2007/09/16(��) 02:18:53 ID:XnRK1xQh
�X���ƊW�Ȃ����ǂ��A���u�ނ�v�Ƃ��u�ނ�t�v���Ă����̂́A
�@�ނ�t ���@�@�@ �@
. �@�@�@�@�@�@�@�@ �@ �^|�@����
�@�@�@�@�@���@�@�^�@ |
.�@�@�@�@�iV�R�^ �@ �@|
�@�@�@ �����@�@�@�@�@|
�'�":"''"''':'';;':,':;.:.,.,�Q_|�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@�@�@ �@ �@ |
�@�@�a�i�^���a�j��.���@>�++<�@�`
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�̑g�ݍ��킹���Ǝv���Ă����ǁA
�ŋߎ��̒ނ�t���_�C���N�g�Ŏ����̖{�����U������āu�ނꂽ�I�v�Ƃ�
�����Ă�̑�����ˁB
�@����́A�ǂ������Ƃ����ƁA
�@�@�@ �@ �@ �@ ,�`�`�`�`�`�` �A
|�_�@�@�@�@�@�i�@�ނꂽ��`�E�E�E�j
|�@ �_�@�@�@�@�M�`�`�`v�`�`�`�L
���@�@ �_
�'�":"''"''':'';;':,':;.:.,.,�@ �R���m
�@�@�@�@�@�@�@�@�@ ~~~~~|~~~~~~~�P�P�P�P�P�P�P
�@�@ �@ �@ �@ �@ �@ �@ �@ �g>�++<
�@�@�@�@�@�@�@ �@ �@ �@ �m�j
���Ǝv�����ǁA�ǂ���H
�@�ނ�t ���@�@�@ �@
. �@�@�@�@�@�@�@�@ �@ �^|�@����
�@�@�@�@�@���@�@�^�@ |
.�@�@�@�@�iV�R�^ �@ �@|
�@�@�@ �����@�@�@�@�@|
�'�":"''"''':'';;':,':;.:.,.,�Q_|�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@�@�@ �@ �@ |
�@�@�a�i�^���a�j��.���@>�++<�@�`
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�̑g�ݍ��킹���Ǝv���Ă����ǁA
�ŋߎ��̒ނ�t���_�C���N�g�Ŏ����̖{�����U������āu�ނꂽ�I�v�Ƃ�
�����Ă�̑�����ˁB
�@����́A�ǂ������Ƃ����ƁA
�@�@�@ �@ �@ �@ ,�`�`�`�`�`�` �A
|�_�@�@�@�@�@�i�@�ނꂽ��`�E�E�E�j
|�@ �_�@�@�@�@�M�`�`�`v�`�`�`�L
���@�@ �_
�'�":"''"''':'';;':,':;.:.,.,�@ �R���m
�@�@�@�@�@�@�@�@�@ ~~~~~|~~~~~~~�P�P�P�P�P�P�P
�@�@ �@ �@ �@ �@ �@ �@ �@ �g>�++<
�@�@�@�@�@�@�@ �@ �@ �@ �m�j
���Ǝv�����ǁA�ǂ���H
��������ʂ����ϔ����B�����̂��Ƃ����ǂ��B
�ł��̂Ȃ��Ƃ���ɉ��͗����Ȃ���ˁB
�ł��̂Ȃ��Ƃ���ɉ��͗����Ȃ���ˁB
157 �F�E�́E�j�����������F2007/09/16(��) 02:25:18 ID:XnRK1xQh
>>153
�́[�H
����Ȃ���̈�Ɍ��܂��Ă邾��B�Ȃ�ŘA�x�͂��߂ɔ��\���������Ǝv���Ă�́B
Cell���ƓP�ނɑ��Ċ���̎x���邽�߂̉��o�̈�B
>>154
�e��GK��������������
�́[�H
����Ȃ���̈�Ɍ��܂��Ă邾��B�Ȃ�ŘA�x�͂��߂ɔ��\���������Ǝv���Ă�́B
Cell���ƓP�ނɑ��Ċ���̎x���邽�߂̉��o�̈�B
>>154
�e��GK��������������
�Ƃ������őS�Ċ؍��N����
160 �F�E�́E�j�����������F2007/09/16(��) 02:30:58 ID:XnRK1xQh
���ꂪ���o�̔���L���Ȃ�
NHK�����o�ɏ悶�Ĕ�������ƂɂȂ��
NHK�����o�ɏ悶�Ĕ�������ƂɂȂ��
161 �F�E�́E�j�����������F2007/09/16(��) 02:33:06 ID:XnRK1xQh
Q �\�j�[�����ł��ے肵�Ă��邼
�@https://www.release.tdnet.info/inbs/I_main_00.html
A �����ے肵���̂ł����āA���̂悤�ȗ\��͖����Ɣے肵���킯�ł͂���܂���B
�@�ł���i�K�ł͂Ȃ��Ƃ��������ŁA�v��̍ŏI�i�K�Ƃ������Ƃ͏\������܂��B
�@�ގ��̗�E�E�E�E
�@2007�N7��25��
�@�ɐ��OIR�@�u���ЂƂ��ĉ������肵�������͂������܂���v
�@http://www.isetan.co.jp/icm2/jsp/isetan/financial/news_pdf/070725_news.pdf
�@
�@2007�N8��23��
�@������Јɐ��O�Ɗ�����ЎO�z�Ƃ̋���������Аݗ��ɂ��o�c�����Ɋւ��邨�m�点
�@http://www.isetan.co.jp/icm2/jsp/isetan/financial/news_pdf/070823_news_japanese.pdf
Q �ł��A����ł͂Ȃ���ł���
A ���̌v�悪�ڍ�����ƁA�ނ������ł��B
�@�L��]��ɂ̂��߂Ɏ~�܂��Ă��郉�C�������邱�Ƃ͑z���ɓ����܂���B�ɂ�
�@������炸�A�H����ێ����l����������邽�߂ɐԎ��𐂂ꗬ�����ƂɂȂ�܂��B
�@https://www.release.tdnet.info/inbs/I_main_00.html
A �����ے肵���̂ł����āA���̂悤�ȗ\��͖����Ɣے肵���킯�ł͂���܂���B
�@�ł���i�K�ł͂Ȃ��Ƃ��������ŁA�v��̍ŏI�i�K�Ƃ������Ƃ͏\������܂��B
�@�ގ��̗�E�E�E�E
�@2007�N7��25��
�@�ɐ��OIR�@�u���ЂƂ��ĉ������肵�������͂������܂���v
�@http://www.isetan.co.jp/icm2/jsp/isetan/financial/news_pdf/070725_news.pdf
�@
�@2007�N8��23��
�@������Јɐ��O�Ɗ�����ЎO�z�Ƃ̋���������Аݗ��ɂ��o�c�����Ɋւ��邨�m�点
�@http://www.isetan.co.jp/icm2/jsp/isetan/financial/news_pdf/070823_news_japanese.pdf
Q �ł��A����ł͂Ȃ���ł���
A ���̌v�悪�ڍ�����ƁA�ނ������ł��B
�@�L��]��ɂ̂��߂Ɏ~�܂��Ă��郉�C�������邱�Ƃ͑z���ɓ����܂���B�ɂ�
�@������炸�A�H����ێ����l����������邽�߂ɐԎ��𐂂ꗬ�����ƂɂȂ�܂��B
����ȑO��>>153�̋L���̓��e�������Ƃ�߁B
���ł����Ƃ����P��n�̃j���[�X�ł͂Ȃ��A
>>153�ɂ́ASONY�Ɠ��ł�{���肵���o���͖��������}
�ƌ����ɔے肵�܂���
�Ƃ����j���[�X�Ȃ��������B
���ł����Ƃ����P��n�̃j���[�X�ł͂Ȃ��A
>>153�ɂ́ASONY�Ɠ��ł�{���肵���o���͖��������}
�ƌ����ɔے肵�܂���
�Ƃ����j���[�X�Ȃ��������B
���A�����Ńt�H���[�������B
>>157
�`���R�ɐH�����Ȃ�A�_�{�n�[���B
�`���R�ɐH�����Ȃ�A�_�{�n�[���B
>>146
>H.264/MPEG-4 AVC��VC-1�A
>MPEG-2�Ȃǂ̃R�[�f�b�N�𓋍ڂ���1�`�b�v�̃V�X�e��LSI
�Ɠd����ASIC��
CPU�ƌĂԂ̂͂��O�̏��肷����
�Ԉ���Ă邷
>H.264/MPEG-4 AVC��VC-1�A
>MPEG-2�Ȃǂ̃R�[�f�b�N�𓋍ڂ���1�`�b�v�̃V�X�e��LSI
�Ɠd����ASIC��
CPU�ƌĂԂ̂͂��O�̏��肷����
�Ԉ���Ă邷
>>139�����Ɠǂ�ł�H
>>165
�L���{���ɂ����邯��
���Z�L���A�����ɂ��Ή�����Ǝ��̃}���`�v���Z�b�T�Z�p���̗p
�ꉞCPU���ڂ��Ă���ǁA�ڍוs�������B
�T�v�̃_�C�ʐ^������ACPU����߂Ă���ʐς͋������ǁB
�L���{���ɂ����邯��
���Z�L���A�����ɂ��Ή�����Ǝ��̃}���`�v���Z�b�T�Z�p���̗p
�ꉞCPU���ڂ��Ă���ǁA�ڍוs�������B
�T�v�̃_�C�ʐ^������ACPU����߂Ă���ʐς͋������ǁB
168 �F�E�́E�j�����������F2007/09/16(��) 12:06:28 ID:XnRK1xQh
�Y�o�F�Ő�[�����̂̐ݔ��A�\�j�[�����ł֔��p����
http://www.sankei.co.jp/keizai/sangyo/070915/sng070915001.htm
�����F�\�j�[�F�Ő�[�����̂̐��Y�ݔ��A���ł֔��p����
http://www.mainichi-msn.co.jp/keizai/kigyou/news/20070916k0000m020029000c.html
�ǔ��F�\�j�[�A���łɐ�[�����̐ݔ����p�ցc�l�o�t���Y����P��
http://www.yomiuri.co.jp/atmoney/news/20070915i304.htm
�����F�\�j�[�A�o�r�R�́u�Z���v���Y�P�ށ@���łɔ��p��
http://www.asahi.com/business/update/0915/TKY200709150062.html
���o�F�\�j�[�A��[�����̂̐��Y�P�ށE���ł�1000���~�Ŕ��p
http://www.nikkei.co.jp/news/sangyo/20070915AT1D1406014092007.html
�����F�\�j�[���Ő�[�����̐��Y����P�ށ@�Q�[���@�p�ݔ����p�ց@���łƌ���
http://www.chunichi.co.jp/article/economics/news/CK2007091502049093.html
TBS�F�\�j�[�A�����̐ݔ��𓌎łɔ��p��
http://www.nicovideo.jp/watch/sm1064823
http://www.sankei.co.jp/keizai/sangyo/070915/sng070915001.htm
�����F�\�j�[�F�Ő�[�����̂̐��Y�ݔ��A���ł֔��p����
http://www.mainichi-msn.co.jp/keizai/kigyou/news/20070916k0000m020029000c.html
�ǔ��F�\�j�[�A���łɐ�[�����̐ݔ����p�ցc�l�o�t���Y����P��
http://www.yomiuri.co.jp/atmoney/news/20070915i304.htm
�����F�\�j�[�A�o�r�R�́u�Z���v���Y�P�ށ@���łɔ��p��
http://www.asahi.com/business/update/0915/TKY200709150062.html
���o�F�\�j�[�A��[�����̂̐��Y�P�ށE���ł�1000���~�Ŕ��p
http://www.nikkei.co.jp/news/sangyo/20070915AT1D1406014092007.html
�����F�\�j�[���Ő�[�����̐��Y����P�ށ@�Q�[���@�p�ݔ����p�ց@���łƌ���
http://www.chunichi.co.jp/article/economics/news/CK2007091502049093.html
TBS�F�\�j�[�A�����̐ݔ��𓌎łɔ��p��
http://www.nicovideo.jp/watch/sm1064823
���ɐl
�܂��A����ȂƂ��ʼn��X���l�^����Ȃ����
�������ǂ�����Ă�̂�����Ƌ������Ђɂ�镗�]�Ɏv����
�y���r���[�z
���p���₷���Ȃ����_�C�i�~�b�N���R���t�B�M�����u���v���Z�b�T�Z�p
http://journal.mycom.co.jp/articles/2007/09/14/drp/index.html
���p���₷���Ȃ����_�C�i�~�b�N���R���t�B�M�����u���v���Z�b�T�Z�p
http://journal.mycom.co.jp/articles/2007/09/14/drp/index.html
http://www.starc.jp/download/sympo2007/11_yoshimori.pdf
SoP (Sea of Processor) ������
�u�g�ݍ��ݗp�r�ł͎哱���������]�n���c���Ă���v���Ăق�Ƃ���
SoP (Sea of Processor) ������
�u�g�ݍ��ݗp�r�ł͎哱���������]�n���c���Ă���v���Ăق�Ƃ���
�����Ȃ�Intel�ȊO�͕Ӌ����������c���Ă��Ȃ��̂�����
������j�b�`�s��Ƃ�����
������j�b�`�s��Ƃ�����
�����ƁA�܂�I�͂��C���݂���
90�N��O���̂悤�ɌX���ċ��������Ȃ�O�Ɋ撣��������
ϼ�
90�N��O���̂悤�ɌX���ċ��������Ȃ�O�Ɋ撣��������
ϼ�
�C���e���A32nm�v���Z�b�T��2009�N�Ɏs�����
http://www.computerworld.jp/news/plf/79409.html
http://www.computerworld.jp/news/plf/79409.html
�����������ȃC���e��
�ق��ق��Ɣ����̂�1000���N���X�̐ݔ��������ł���̂���
����Intel��IBM���炢�����Ȃ��C������
����Intel��IBM���炢�����Ȃ��C������
IBM�������̂ɁA����Ȃɏo���Ȃ��̂ł�
��������Ȃ�Intel��IBM����Ȃ���Intel��TSMC�ȋC������
>>180
TSMC�̓v���Z�X�E�����ɐ�Ă邪
architecture�͑������B�����Ɗ������������B
>>178
5000�������^�Ђ̗���́c
TSMC�̓v���Z�X�E�����ɐ�Ă邪
architecture�͑������B�����Ɗ������������B
>>178
5000�������^�Ђ̗���́c
���炩��>>181�̑��Ƃ���
�Ј���
0.35�~�N�����͉��N���g���Â����̂ɁA45nm�͂����X�V�Ȃ̂��B
Nehelem�̃_�C�ʐ^���o����Ă��邱�Ƃ�A���m���Ǝv���邷�B
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388_13.jpg
���ڂ�A�L���b�V����I/O�ɑ���R�A�ʐς̊����̑傫�����Ǝv�����B���ƕ��������Ⴄ�����ǁA
�q�쎁�̃}�C�N���A�[�L�e�N�`���̐i���Ɋւ��錩����I�m�����������ˁB�B�B
http://jun.artcompsci.org/articles/future_sc/note015.html
�@�@---------------------
�@�@�@�����Ƃ��A�}�C�N���v���Z�b�T�̏ꍇ�A�������g�����W�X�^�́A�N���b�N���グ�邱�ƁA�傫�ȃL���b�V��
�@�@�����邱�Ƃő����ł��������A�N�Z�X�����炷���ƁA���Ɏg���Ă���킯�őS�����Ӗ��Ƃ����킯��
�@�@�͂Ȃ��̂ł����A�ł��L���Ȏg���������H�Ƃ����Ƃ܂��K�����������ł͂Ȃ����ȁA�Ƃ����C�����܂��B
�@�@�@��������Ă݂�ƁA�L���g����v�Z�@�A�[�L�e�N�`�������߂Ă���̂́A��r�I�P���ȋZ�p�I�v
�@�@���ƁA����ɓK�����A�[�L�e�N�`�����łĂ���܂ł̎��Ԓx�ꂾ�A�Ƃ�����悤�Ɏv���܂��B Cray ��
�@�@�x�N�g���A�[�L�e�N�`�����Ai860 �ł̃V���O���`�b�v�������p�C�v���C���v���Z�b�T���A�Z�p�I�ɂ���
�@�@���L���ɂȂ���������� 5-10 �N�x��Č���Ă��܂��B1995�N�ȍ~�� CMOS VLSI �̋Z�p�g�����h
�@�@�ɓK�������A�[�L�e�N�`���͂܂�����Ă��Ȃ��A�Ƃ������Ƃł��傤�B
�@�@---------------------
Intel���g�����W�X�^�̎g�����Ɋւ���u���[�N�X���[�Ɏ������̂��Ƃ���Ƌ����[���b���B
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388_13.jpg
{kind=link}
���ڂ�A�L���b�V����I/O�ɑ���R�A�ʐς̊����̑傫�����Ǝv�����B���ƕ��������Ⴄ�����ǁA
�q�쎁�̃}�C�N���A�[�L�e�N�`���̐i���Ɋւ��錩����I�m�����������ˁB�B�B
http://jun.artcompsci.org/articles/future_sc/note015.html
�@�@---------------------
�@�@�@�����Ƃ��A�}�C�N���v���Z�b�T�̏ꍇ�A�������g�����W�X�^�́A�N���b�N���グ�邱�ƁA�傫�ȃL���b�V��
�@�@�����邱�Ƃő����ł��������A�N�Z�X�����炷���ƁA���Ɏg���Ă���킯�őS�����Ӗ��Ƃ����킯��
�@�@�͂Ȃ��̂ł����A�ł��L���Ȏg���������H�Ƃ����Ƃ܂��K�����������ł͂Ȃ����ȁA�Ƃ����C�����܂��B
�@�@�@��������Ă݂�ƁA�L���g����v�Z�@�A�[�L�e�N�`�������߂Ă���̂́A��r�I�P���ȋZ�p�I�v
�@�@���ƁA����ɓK�����A�[�L�e�N�`�����łĂ���܂ł̎��Ԓx�ꂾ�A�Ƃ�����悤�Ɏv���܂��B Cray ��
�@�@�x�N�g���A�[�L�e�N�`�����Ai860 �ł̃V���O���`�b�v�������p�C�v���C���v���Z�b�T���A�Z�p�I�ɂ���
�@�@���L���ɂȂ���������� 5-10 �N�x��Č���Ă��܂��B1995�N�ȍ~�� CMOS VLSI �̋Z�p�g�����h
�@�@�ɓK�������A�[�L�e�N�`���͂܂�����Ă��Ȃ��A�Ƃ������Ƃł��傤�B
�@�@---------------------
Intel���g�����W�X�^�̎g�����Ɋւ���u���[�N�X���[�Ɏ������̂��Ƃ���Ƌ����[���b���B
���ŁACell�̋Z�p��p�����}���`�R�A�f�������G���W��
�|HD�f���̍����ϊ��Ȃǂɉ��p�\�ȁuSpursEngine�v
http://www.watch.impress.co.jp/av/docs/20070920/toshiba.htm
�|HD�f���̍����ϊ��Ȃǂɉ��p�\�ȁuSpursEngine�v
http://www.watch.impress.co.jp/av/docs/20070920/toshiba.htm
188 �FSocket774�F2007/09/20(��) 23:57:18 ID:9uX0QpXQ
>186
���E�Ŕ��]���Ă�̂ō����Ō����A�R�A�̍��オ�������Z��ʼnE�オL1�L���b�V���A����SSE�̃��W�X�^�����Z��Ɍ����邯�ǁA�ǂ����낤�H
���E�Ŕ��]���Ă�̂ō����Ō����A�R�A�̍��オ�������Z��ʼnE�オL1�L���b�V���A����SSE�̃��W�X�^�����Z��Ɍ����邯�ǁA�ǂ����낤�H
L1����L2�̋߂��ɂ��鎖����������Nehalem�̓R�A���t�ɕt���Ă�l�Ɍ������
�Ȃ�Core2�Ɣ�ׂăL���b�V���̊������啝�ɏk�������悤��
191 �F�E�́E�j�����������F2007/09/23(��) 01:56:18 ID:rbQjQyuw
���Ȃ݂�Penryn12M��Nehalem8M
�_�C�T�C�Y��Nehalem�̂ق����傫���B
Core 2�t�@�~���̑�e�ʃL���b�V���͑����̎コ��₤�Ӗ����傫����������
Core 3����ł͌����Ă��s�v�c�͖����ł���B
�_�C�T�C�Y��Nehalem�̂ق����傫���B
Core 2�t�@�~���̑�e�ʃL���b�V���͑����̎コ��₤�Ӗ����傫����������
Core 3����ł͌����Ă��s�v�c�͖����ł���B
�����R����QP�ŃL���b�V���ɂ���6�`8MB���ʂ����
Shanghai��L3��6MB������Α��e�ʂ�8MB�ɂȂ���Nehalem�Ɠ����ɂȂ��ȁB
��������Nehalem�Ɋւ��銴�z���B
http://www.geocities.jp/andosprocinfo/wadai07/20070922.htm
�@�@---------------------
�@�@�R�A�̏ڍׂ͕s���ł����C2�X���b�h��SMT���T�|�[�g����ƌ����Ă��܂��B�Ȃ��C�ȑO��Hyper-
�@�@Thread�ł͖����C�w��/�ƊE�W����Simultaneous Multi-Thread�ɗp���ύX�����̂����s���ł��B
�@�@---------------------
�ȑO������������C���e����"markitecture"��ᔻ���Ă���̂�m���Ă��邷���ǁAPen4��Hyper-
Threading�����p�v���Z�b�T�ɂ�����ŏ���SMT�̎����������̂펖�����B�����ƌ��݂�"SMT"�Ƃ���
�p��̈�ʓI�ȔF�����r����A����������悤�Șb���ᖳ���Ǝv���邷�B
�@�@---------------------
�@�@����̔��\�ł́C��������DDR3��3�`���l���T�|�[�g�ƂȂ��Ă��܂����C3��17���̘b��ŏЉ
�@�@��The Inquirer�̋L���ł́C�����Volume�p��Thurley�ŁC�n�C�G���h�T�[�o�p��4+1�`���l����
�@�@FB-DIMM���T�|�[�g�ƂȂ��Ă��܂��B
�@�@---------------------
���Ȃ݂ɁA�������̂�����̘b���{���Ȃ�Nehalem��n�C�G���h�v���Z�b�T�ɂ����郂�W�����[�v��
�听����ƂȂ邩�Ǝv�����B
http://www.geocities.jp/andosprocinfo/wadai07/20070922.htm
�@�@---------------------
�@�@�R�A�̏ڍׂ͕s���ł����C2�X���b�h��SMT���T�|�[�g����ƌ����Ă��܂��B�Ȃ��C�ȑO��Hyper-
�@�@Thread�ł͖����C�w��/�ƊE�W����Simultaneous Multi-Thread�ɗp���ύX�����̂����s���ł��B
�@�@---------------------
�ȑO������������C���e����"markitecture"��ᔻ���Ă���̂�m���Ă��邷���ǁAPen4��Hyper-
Threading�����p�v���Z�b�T�ɂ�����ŏ���SMT�̎����������̂펖�����B�����ƌ��݂�"SMT"�Ƃ���
�p��̈�ʓI�ȔF�����r����A����������悤�Șb���ᖳ���Ǝv���邷�B
�@�@---------------------
�@�@����̔��\�ł́C��������DDR3��3�`���l���T�|�[�g�ƂȂ��Ă��܂����C3��17���̘b��ŏЉ
�@�@��The Inquirer�̋L���ł́C�����Volume�p��Thurley�ŁC�n�C�G���h�T�[�o�p��4+1�`���l����
�@�@FB-DIMM���T�|�[�g�ƂȂ��Ă��܂��B
�@�@---------------------
���Ȃ݂ɁA�������̂�����̘b���{���Ȃ�Nehalem��n�C�G���h�v���Z�b�T�ɂ����郂�W�����[�v��
�听����ƂȂ邩�Ǝv�����B
195 �F�E�́E�j�����������F2007/09/23(��) 11:48:58 ID:rbQjQyuw
�P�DNetBurst�������j�ɂ�����
�Q�DHyper-Threading���̂͌�ł������̏o�����Ƃ��Ɏg���\��
�R�D�����[�X����Ƃ��ɂ͖��̎g����
�Q�DHyper-Threading���̂͌�ł������̏o�����Ƃ��Ɏg���\��
�R�D�����[�X����Ƃ��ɂ͖��̎g����
196 �FMAC�I�^�������F2007/09/23(��) 11:49:56 ID:IrcE33RW
�@�@-----------------------
�@�@[Tylersburg�̃C���^�R�l�N�g�\���ɂ���]
�@�@CPU����IO�ւ̃p�X��1�{�����Ȃ��ƁC�ǂ����Ńp�X�����ƁC�d�v�ȃf�[�^��������f�B�X�N��
�@�@�����Ȃ��Ȃ��Ă��܂����肷��̂ŁC�n�C�G���h�̃T�[�o�ł�2��CPU���瓯���IO�ɐڑ��ł���
�@�@�\�����̂�̂���ʓI�ł����C����Tylersburg��IO�n�u�̃��x���ł��ꂪ�o����Ƃ����_�ŁC
�@�@AMD�̃`�b�v�Z�b�g���D��Ă��܂��B
�@�@-----------------------
���C���t���[���N���X��RAS�����蕨��SPARC64�̃A�[�L�e�N�g�Ƃ��āA�����������z�ɂȂ�Ƃ�v��
�����ǁA�������Tylersburg�̐��i�Z�O�����g����l���āA�v���Z�b�T�����̃������ɑ���I/O�����
DMA���\���l�����Ă̂��Ƃ��Ǝv���邷�B(�����r�f�I���X)
Intel I/OAT (http://www.intel.com/technology/ioacceleration/index.htm)�̂悤��Intel��I/O�Ɋւ���
�v���Z�b�T�����f�[�^�̃R�s�[���팸���邱�ƂŌ������グ�邱�Ƃɒ��͂��Ă��邷�B
�@�@[Tylersburg�̃C���^�R�l�N�g�\���ɂ���]
�@�@CPU����IO�ւ̃p�X��1�{�����Ȃ��ƁC�ǂ����Ńp�X�����ƁC�d�v�ȃf�[�^��������f�B�X�N��
�@�@�����Ȃ��Ȃ��Ă��܂����肷��̂ŁC�n�C�G���h�̃T�[�o�ł�2��CPU���瓯���IO�ɐڑ��ł���
�@�@�\�����̂�̂���ʓI�ł����C����Tylersburg��IO�n�u�̃��x���ł��ꂪ�o����Ƃ����_�ŁC
�@�@AMD�̃`�b�v�Z�b�g���D��Ă��܂��B
�@�@-----------------------
���C���t���[���N���X��RAS�����蕨��SPARC64�̃A�[�L�e�N�g�Ƃ��āA�����������z�ɂȂ�Ƃ�v��
�����ǁA�������Tylersburg�̐��i�Z�O�����g����l���āA�v���Z�b�T�����̃������ɑ���I/O�����
DMA���\���l�����Ă̂��Ƃ��Ǝv���邷�B(�����r�f�I���X)
Intel I/OAT (http://www.intel.com/technology/ioacceleration/index.htm)�̂悤��Intel��I/O�Ɋւ���
�v���Z�b�T�����f�[�^�̃R�s�[���팸���邱�ƂŌ������グ�邱�Ƃɒ��͂��Ă��邷�B
197 �FMAC�I�^���c�q �����F2007/09/23(��) 11:57:14 ID:IrcE33RW
>>195
�@�@------------------
�@�@�R�D�����[�X����Ƃ��ɂ͖��̎g����
�@�@------------------
���܂܂�"xxx Technology"�Ɩ��ł������m��A���ׂĂ��������������L�肻���Șb���B
��������HTT��"Jackson Technology"���������B
���Ȃ݂�Intel��Montecito��SoEMT��"HyperThreading"�Ɩ��ł��Ă��邷�����ʂ����邽�߂�
��剻������IDF�ł�SMT�ƌĂ�ł����Ƃ����\������ԑ傫�����Ǝv�����B
�}�[�P�e�B���O�Ƃ��Ă�HyperThreading�Ƃ�HyperThreading2�Ƃ���肻�����B
�@�@------------------
�@�@�R�D�����[�X����Ƃ��ɂ͖��̎g����
�@�@------------------
���܂܂�"xxx Technology"�Ɩ��ł������m��A���ׂĂ��������������L�肻���Șb���B
��������HTT��"Jackson Technology"���������B
���Ȃ݂�Intel��Montecito��SoEMT��"HyperThreading"�Ɩ��ł��Ă��邷�����ʂ����邽�߂�
��剻������IDF�ł�SMT�ƌĂ�ł����Ƃ����\������ԑ傫�����Ǝv�����B
�}�[�P�e�B���O�Ƃ��Ă�HyperThreading�Ƃ�HyperThreading2�Ƃ���肻�����B
199 �F�E�́E�j�����������F2007/09/23(��) 12:06:55 ID:rbQjQyuw
�g���[�X�L���b�V�����g���Ƃ������͂Ȃ����A����ς蒀���f�R�[�h���B
Cell��PPE�݂����ȏ����ȃR�A�ł�����݂Ƀt�F�b�`���Ă��������R�X�g�͂���Ȃɂ�����Ȃ��Ƃ͎v����
�ǂ����������ŐU�蕪����̂�����H���X�Œ肶��Ȃ��Ƃ͎v�����B
�f�l�l�������ǁA�p�C�v���C���̒��Ƀv���t�@�C���������ăt�F�b�`���j�b�g�Ƀt�B�[�h�o�b�N����Ƃ��B
Cell��PPE�݂����ȏ����ȃR�A�ł�����݂Ƀt�F�b�`���Ă��������R�X�g�͂���Ȃɂ�����Ȃ��Ƃ͎v����
�ǂ����������ŐU�蕪����̂�����H���X�Œ肶��Ȃ��Ƃ͎v�����B
�f�l�l�������ǁA�p�C�v���C���̒��Ƀv���t�@�C���������ăt�F�b�`���j�b�g�Ƀt�B�[�h�o�b�N����Ƃ��B
200 �F�E�́E�j�����������F2007/09/23(��) 12:28:37 ID:rbQjQyuw
��SMT�̎������@�̌���
>>186�̌�A�����ƃ}�V��Nehalem�摜��T���Ă��������ǁA�����̂�>>186�̃����N��̃X���C�h��
�ʐ^�����ɂ������z���B
�@�E�܂������[���̂�ABarcelona�̃��C�A�E�g�Ƃ̗ގ������B
�@�@(http://img62.imageshack.us/img62/6079/dieoi4.jpg �Q��)
�@�@�@���ɒ����ɂɃm�[�X�u���b�W��z�u���A���ɍŏI���x���̃L���b�V���A���E��I/O�A��Ƀ������C���^�[
�@�@�t�F�[�X�B�B�B�Ƃ��������C�A�E�g�Ɍ����邷�B
�@�@�@���ӑ��̃R�A��NB���牓���Ȃ邷����A�R�A�ׂ̗�NB��z�u����Ƃ������@���A�d��������
�@�@���߂ɁA���̔z�u���s�����ǂ��̂��Ǝv���邷�B
�@�EL1��L2�����ɉ���
�@�@�����Ƃ���A4����ł�R�A�̏��L1������A���ɕ���ł���L���b�V�����琏���������BBarcelona��
�@�@L3��L1���猩��Ɖ����ă��C�e���V���傫�����B����Nehalem�̍ŏI���x���̃L���b�V����L3�Ȃ̂��A
�@�@L2���璼�ڃf�[�^��ǂݍ��ދ@�\������Ƃ��A�����\�z�O�̂�����������悤�ȋC�����邷�B
�ʐ^�����ɂ������z���B
�@�E�܂������[���̂�ABarcelona�̃��C�A�E�g�Ƃ̗ގ������B
�@�@(http://img62.imageshack.us/img62/6079/dieoi4.jpg �Q��)
{kind=link}
�@�@�@���ɒ����ɂɃm�[�X�u���b�W��z�u���A���ɍŏI���x���̃L���b�V���A���E��I/O�A��Ƀ������C���^�[
�@�@�t�F�[�X�B�B�B�Ƃ��������C�A�E�g�Ɍ����邷�B
�@�@�@���ӑ��̃R�A��NB���牓���Ȃ邷����A�R�A�ׂ̗�NB��z�u����Ƃ������@���A�d��������
�@�@���߂ɁA���̔z�u���s�����ǂ��̂��Ǝv���邷�B
�@�EL1��L2�����ɉ���
�@�@�����Ƃ���A4����ł�R�A�̏��L1������A���ɕ���ł���L���b�V�����琏���������BBarcelona��
�@�@L3��L1���猩��Ɖ����ă��C�e���V���傫�����B����Nehalem�̍ŏI���x���̃L���b�V����L3�Ȃ̂��A
�@�@L2���璼�ڃf�[�^��ǂݍ��ދ@�\������Ƃ��A�����\�z�O�̂�����������悤�ȋC�����邷�B
202 �F�E�́E�j�����������F2007/09/23(��) 12:48:41 ID:rbQjQyuw
�q���g�Fmovntdqa����L2�ȉ�����16�o�C�g���_�C���N�g�ɓǂޖ��߂���ȁH
203 �FMAC�I�^���c�q �����F2007/09/23(��) 13:03:15 ID:IrcE33RW
>>202
������->���W�X�^�̓]�����߂�A�}���`���f�B�AISA�������A�[�L�e�N�`���œ��ɒ��������߂���Ȃ����B
>>201�ŏ������b��A������������L2�q�b�g�����ꍇ�Ƀf�[�^�p�X�����ʂȈ�������(�Ⴆ�A
���s���j�b�g�̓��͂Ƃ��Ē��ڎg�p�����)�\�����l���Ă��邷���ǁB�B�B
������->���W�X�^�̓]�����߂�A�}���`���f�B�AISA�������A�[�L�e�N�`���œ��ɒ��������߂���Ȃ����B
>>201�ŏ������b��A������������L2�q�b�g�����ꍇ�Ƀf�[�^�p�X�����ʂȈ�������(�Ⴆ�A
���s���j�b�g�̓��͂Ƃ��Ē��ڎg�p�����)�\�����l���Ă��邷���ǁB�B�B
204 �FMAC�I�^@�⑫�F2007/09/23(��) 13:09:12 ID:IrcE33RW
POWER6�ł����[�h�^�X�g�A�L���[�ɑ��݂���f�[�^��A���W�X�^������ɂ��̂܂܉��Z��̓��͂�
���Ďg����炵��������AL2�������Ȃ������Ƃ̑㏞�Ƃ��ĊԂ̃o�b�t�@���e�ʉ����A���@�\������
�Ƃ����̂�\�������邩�Ǝv�����B
���Ďg����炵��������AL2�������Ȃ������Ƃ̑㏞�Ƃ��ĊԂ̃o�b�t�@���e�ʉ����A���@�\������
�Ƃ����̂�\�������邩�Ǝv�����B
205 �F�E�́E�j�����������F2007/09/23(��) 13:09:20 ID:rbQjQyuw
�䗦����v�Z���Ă݂Ă���
http://www.dvhardware.net/news/intel_penryn_45nm_die.jpg
AMD�݂̂�����L1��L2�ɓ����ɗv����������悤�Ȑv�����킩���ˁB
���ƁA���L���Ă郉�C����L2�ɂ����u���Ȃ��Ƃ�
http://www.dvhardware.net/news/intel_penryn_45nm_die.jpg
{kind=link}
AMD�݂̂�����L1��L2�ɓ����ɗv����������悤�Ȑv�����킩���ˁB
���ƁA���L���Ă郉�C����L2�ɂ����u���Ȃ��Ƃ�
206 �F�E�́E�j�����������F2007/09/23(��) 13:21:30 ID:rbQjQyuw
SSE4�̃p�t�H�[�}���X�ɂ��čڂ��Ă邯��
http://softwarecommunity.intel.com/articles/eng/1248.htm
http://softwarecommunity.intel.com/articles/eng/1246.htm
���Ă���A�R�[�f�b�N����ȊO�Ȃ��܂����p�@���v�����Ȃ����B
http://softwarecommunity.intel.com/articles/eng/1248.htm
http://softwarecommunity.intel.com/articles/eng/1246.htm
���Ă���A�R�[�f�b�N����ȊO�Ȃ��܂����p�@���v�����Ȃ����B
> �ȑO��Hyper-Thread�ł͖����C�w��/�ƊE�W����Simultaneous Multi-Thread�ɗp���ύX
HT�Ə�����Hyper-Transport�ƕ���킵������c�Ƃ������Ă݂�Ă���
HT�Ə�����Hyper-Transport�ƕ���킵������c�Ƃ������Ă݂�Ă���
208 �F�E�́E�j�����������F2007/09/23(��) 15:11:58 ID:rbQjQyuw
SSE5�̌������邵�AAMD�͈Ӑ}�I�ɕ���킵�����O�t���Ă��Ă�Ɍ��܂��Ă邾�낤
209 �FMAC�I�^���c�q �����F2007/09/23(��) 15:29:31 ID:IrcE33RW
>>206
�@�@----------------
�@�@�R�[�f�b�N����ȊO�Ȃ��܂����p�@
�@�@----------------
����e�[�u���Q�ƂƂ��ǂ������H�������A���S���Y�����ǂ�����m�������Ƃ��ᖳ�������ǁB�B�B
�@�@----------------
�@�@�R�[�f�b�N����ȊO�Ȃ��܂����p�@
�@�@----------------
����e�[�u���Q�ƂƂ��ǂ������H�������A���S���Y�����ǂ�����m�������Ƃ��ᖳ�������ǁB�B�B
210 �F�E�́E�j�����������F2007/09/23(��) 15:35:03 ID:rbQjQyuw
>>209���ꂾ�I
http://www.geocities.com/tk2001b/utripper/
���̃\�t�g��UFC-Crypt��SSE�ōĎ������Ă邯�ǁA������movntdqa�g���Α����ł��邩�������B
http://www.geocities.com/tk2001b/utripper/
���̃\�t�g��UFC-Crypt��SSE�ōĎ������Ă邯�ǁA������movntdqa�g���Α����ł��邩�������B
>>195
Ultra-Threading�Ƃ��Ȃʂ̖��O�l����Ǝv���
Ultra-Threading�Ƃ��Ȃʂ̖��O�l����Ǝv���
>>211
GPU���g���Ă��悤��
GPU���g���Ă��悤��
�O�[�����������
214 �FSocket774�F2007/09/24(��) 07:11:16 ID:iXMqxaXb
PS3 Cell��6.21Ghz�܂�OC�������I�I
http://www.youtube.com/watch?v=77W5at3TbWM
http://www.youtube.com/watch?v=77W5at3TbWM
215 �F�E�́E�j�����������F2007/09/24(��) 07:13:04 ID:RlQx0MtY
ּ�����ˁ[��
216 �FSocket774�F2007/09/24(��) 10:05:54 ID:J8+ZfhMM
���ɍ�����GUP��SIMM�n�̈ꕔ����������@�\���t������邩��CPU�ł�SIMM�n�̐��\�͕s�v���Ƃ���
�A�t�H�Ȉӌ�������̂ɂ͋��������B
���������A�����R�X�g���l���Ă����҂͕ʂ̉��l�����B
3�c���\��Nj�����ꕔ�̃Q�[���I�^�N�ׂ̈����ɍ�����GPU�����݂��Ă���Ƃ����������
��ʗ��p�҂ɂ͖w�lj��̖���������GPU��K�{�Ƃ��邩�̂悤�Ș_���̓o�J�炵��������������B
�����āAGPU���̂��̂�����ɂ�荂����d�́������M�ł���̂Ȃ�Ώ��X�A����Ȑl�����ׂ̈ɑ��݂��A
��ʗ��p�҂ɂ͉��������݂ł��葱���Ă��ė~�����B
���̈Ӗ��ɂ����Ă�CPU�ł�SIMM�n�\�͂�GPU�̂���Ƃ͕ʉ��l�ł��蓯��Ɉ������̂ł͂Ȃ��ƌ�����B
�A�t�H�Ȉӌ�������̂ɂ͋��������B
���������A�����R�X�g���l���Ă����҂͕ʂ̉��l�����B
3�c���\��Nj�����ꕔ�̃Q�[���I�^�N�ׂ̈����ɍ�����GPU�����݂��Ă���Ƃ����������
��ʗ��p�҂ɂ͖w�lj��̖���������GPU��K�{�Ƃ��邩�̂悤�Ș_���̓o�J�炵��������������B
�����āAGPU���̂��̂�����ɂ�荂����d�́������M�ł���̂Ȃ�Ώ��X�A����Ȑl�����ׂ̈ɑ��݂��A
��ʗ��p�҂ɂ͉��������݂ł��葱���Ă��ė~�����B
���̈Ӗ��ɂ����Ă�CPU�ł�SIMM�n�\�͂�GPU�̂���Ƃ͕ʉ��l�ł��蓯��Ɉ������̂ł͂Ȃ��ƌ�����B
>3�c���\��Nj�����ꕔ�̃Q�[���I�^�N�ׂ̈����ɍ�����GPU�����݂��Ă���Ƃ����������
�Z�p�͂��֎����邽�߂���Ȃ���>������GPU
�Q�[�����^�N�����āA�啔���̍���t�̓~�h����������Ȃ���
�Z�p�͂��֎����邽�߂���Ȃ���>������GPU
�Q�[�����^�N�����āA�啔���̍���t�̓~�h����������Ȃ���
SIMM�n���ĉ��H
219 �FMAC�I�^��217 �����F2007/09/24(��) 12:14:58 ID:YP6AWiRE
>>217
>>216���Ă�����w�G���R�s�y�x�Ƃ������c�Ȃ�ŁA����ɂ��Ȃ��ق����ǂ����Ǝv�����B
http://pc11.2ch.net/test/read.cgi/jisaku/1186625438/523 �Ƃ��B
>>216���Ă�����w�G���R�s�y�x�Ƃ������c�Ȃ�ŁA����ɂ��Ȃ��ق����ǂ����Ǝv�����B
http://pc11.2ch.net/test/read.cgi/jisaku/1186625438/523 �Ƃ��B
220 �FMAC�I�^���⑫�F2007/09/24(��) 12:16:37 ID:YP6AWiRE
���������3�N�ȏ�O���瑶�݂���݂������B
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
���Ȃ݂ɂ�������X���Ŗ\��Ă遜�͌��c���������̘^��
>>221
�}�W���悗����������
�}�W���悗����������
223 �FMAC�I�^��222 �����F2007/09/24(��) 15:09:06 ID:YP6AWiRE
>>222
���̂��������A����������\�킸�F�肵�ĉ���Ă��邷����A���l�ɕ����������ǂ����Ǝv�����B
�������x���肪�����F����Ă��邱�Ƃ��(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1189440665/291
�@�@-----------------------
�@�@291 ���O�FSocket774 ���e���F2007/09/16(��) 18:46:10 ID:gHqDu/Oe
�@�@�@�@MAC�I�^��`���|�R�l�i�����F�G���j�ɈႢ�˂������B
�@�@-----------------------
���̂��������A����������\�킸�F�肵�ĉ���Ă��邷����A���l�ɕ����������ǂ����Ǝv�����B
�������x���肪�����F����Ă��邱�Ƃ��(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1189440665/291
�@�@-----------------------
�@�@291 ���O�FSocket774 ���e���F2007/09/16(��) 18:46:10 ID:gHqDu/Oe
�@�@�@�@MAC�I�^��`���|�R�l�i�����F�G���j�ɈႢ�˂������B
�@�@-----------------------
���Ɨ]�k�����ǁAPS3�̔ᔻ�{�̍�҂��Q�n�̃X���b�h�Ɍ���ċ��Ԃ��N�����炵�����B
�Q�����˂�̈����`�����܂����(��)
���̖{�@http://ktane.moe-nifty.com/sizuma_drive/2007/09/3_4f7d.html
���̃X���b�h
http://megalodon.jp/?url=http://ex23.2ch.net/test/read.cgi/ghard/1190543935/&date=20070924143554
�����f���Ŏ��������n�߂�y���j�ł��鎖��̒lj��Ƃ������ƂŁB�B�B
�Q�����˂�̈����`�����܂����(��)
���̖{�@http://ktane.moe-nifty.com/sizuma_drive/2007/09/3_4f7d.html
���̃X���b�h
http://megalodon.jp/?url=http://ex23.2ch.net/test/read.cgi/ghard/1190543935/&date=20070924143554
�����f���Ŏ��������n�߂�y���j�ł��鎖��̒lj��Ƃ������ƂŁB�B�B
226 �FMAC�I�^���⑫�F2007/09/24(��) 16:09:14 ID:YP6AWiRE
�K���`�F�b�J�[�̋L�^
http://hissi.dyndns.ws/read.php/ghard/20070924/ZUR4cFptWVAw.html
�@�@--------------------
�@�@�ڂ��B
�@�@�Q�����˂�͉����q�}�Ȏ��Ƃ��ɂ悭���Ă���
�@�@�q�b�L�[�~�[�̐��ԂȂ��c�����Ă�����肾����
�@�@�����������̓b��C���Ȃ�Ƃ����Ȃ��ƂQ�����˂�͏I���
�@�@�������E�Ƌ��\���E�̔��f���t���Ȃ��v�A�`�����̗��܂��ɂȂ��Ă���
�@�@���������荇���Ƃ͑��̍��l�b�g�̍�����n�荇���Ă�����
�@�@�{�C�o���ĘA����|�����Ă��ǂ���������
�@�@���܂�Ƀ��x�����Ⴗ���Ĕ����̎���ɂ߂Ă��܂�
�@�@�l�`�P�b�g�Ƃ������t���g������͖������i�l�`�P�b�g���Č��t�匙�������j
�@�@���������Љ�l�Ƃ��Ă̍Œ���}�i�[���w��ŏ�������ŗ~����
�@�@�ʂɋƊE�l�������珔��������Čh���Ƃ������������������Ă��Ȃ�
�@�@�����Œ���A�l�̘b�����炢�̑ԓx�͎����ė~����
�@�@����͂Q�����˂�̖�肶��Ȃ����̓��{�S�̖̂�肾�Ǝv��
�@�@���낻�낱�̍��͗ՊE�_�����Ă���C������
�@�@���̃X���b�h�ł̉��̓Ƃ茾�͒N���m���邱�ƂȂ�dat�ɗ����邾�낤����
�@�@���N��ł���������d�q�̊C�ɏ���ĒN����l�ł��ǎ�����l�̖ڂɗ��܂��ė~����
�@�@���C�^�[�ҋƂ̂�������̓Ƃ茾�ł���
�@�@--------------------
http://hissi.dyndns.ws/read.php/ghard/20070924/ZUR4cFptWVAw.html
�@�@--------------------
�@�@�ڂ��B
�@�@�Q�����˂�͉����q�}�Ȏ��Ƃ��ɂ悭���Ă���
�@�@�q�b�L�[�~�[�̐��ԂȂ��c�����Ă�����肾����
�@�@�����������̓b��C���Ȃ�Ƃ����Ȃ��ƂQ�����˂�͏I���
�@�@�������E�Ƌ��\���E�̔��f���t���Ȃ��v�A�`�����̗��܂��ɂȂ��Ă���
�@�@���������荇���Ƃ͑��̍��l�b�g�̍�����n�荇���Ă�����
�@�@�{�C�o���ĘA����|�����Ă��ǂ���������
�@�@���܂�Ƀ��x�����Ⴗ���Ĕ����̎���ɂ߂Ă��܂�
�@�@�l�`�P�b�g�Ƃ������t���g������͖������i�l�`�P�b�g���Č��t�匙�������j
�@�@���������Љ�l�Ƃ��Ă̍Œ���}�i�[���w��ŏ�������ŗ~����
�@�@�ʂɋƊE�l�������珔��������Čh���Ƃ������������������Ă��Ȃ�
�@�@�����Œ���A�l�̘b�����炢�̑ԓx�͎����ė~����
�@�@����͂Q�����˂�̖�肶��Ȃ����̓��{�S�̖̂�肾�Ǝv��
�@�@���낻�낱�̍��͗ՊE�_�����Ă���C������
�@�@���̃X���b�h�ł̉��̓Ƃ茾�͒N���m���邱�ƂȂ�dat�ɗ����邾�낤����
�@�@���N��ł���������d�q�̊C�ɏ���ĒN����l�ł��ǎ�����l�̖ڂɗ��܂��ė~����
�@�@���C�^�[�ҋƂ̂�������̓Ƃ茾�ł���
�@�@--------------------
228 �F�E�́E�j�����������F2007/09/24(��) 18:03:45 ID:RlQx0MtY
������������������������������������������������������������������
�܂��A�ǂ����ɂ���Q�n�̗���̓I�J�V�C��
�܂��A�ǂ����ɂ���Q�n�̗���̓I�J�V�C��
229 �FMAC�I�^���c�q �����F2007/09/24(��) 18:17:14 ID:YP6AWiRE
>>228
�@�@------------------
�@�@�܂��A�ǂ����ɂ���Q�n�̗���̓I�J�V�C��
�@�@------------------
�ʂɃQ�n�̖��Ƃ������A�����f���̎g����������Ȃ����o�J������Ƃ��������̘b���B
�c�q������������g�Ɋւ��鍡�܂ł̃J�L�R�~���l�������������ǂ����ƁB�B�B
���łɍ���̌���A�w��M�̕��ɂ��ǂ����ʋ��t�������Ǝv�����B
�@�@------------------
�@�@�܂��A�ǂ����ɂ���Q�n�̗���̓I�J�V�C��
�@�@------------------
�ʂɃQ�n�̖��Ƃ������A�����f���̎g����������Ȃ����o�J������Ƃ��������̘b���B
�c�q������������g�Ɋւ��鍡�܂ł̃J�L�R�~���l�������������ǂ����ƁB�B�B
���łɍ���̌���A�w��M�̕��ɂ��ǂ����ʋ��t�������Ǝv�����B
230 �F�E�́E�j�����������F2007/09/24(��) 18:19:39 ID:RlQx0MtY
������G�h�E�B���M�̐l�M���Ă��
231 �F�E�́E�j�����������F2007/09/24(��) 18:28:58 ID:RlQx0MtY
�������A���y��`�z�͂ˁ[���
����Ȃ�ł������������Ƃ܂��
����Ȃ�ł������������Ƃ܂��
232 �FMAC�I�^�F2007/09/24(��) 20:38:43 ID:YP6AWiRE
������>>225-226�ŖO�����炸�A�Ώ�����}���čX�ɕ挊���@����邷�ˁB
�������������̉Ύ���ɂȂ��Ă��邷�B
http://ex23.2ch.net/test/read.cgi/ghard/1190615019/
http://ex23.2ch.net/test/read.cgi/ghard/1190632555/
�������������̉Ύ���ɂȂ��Ă��邷�B
http://ex23.2ch.net/test/read.cgi/ghard/1190615019/
http://ex23.2ch.net/test/read.cgi/ghard/1190632555/
233 �F�E�́E�j�����������F2007/09/24(��) 20:42:51 ID:RlQx0MtY
���������Ȃ��̖{
TM2���쓮����悤�ȉ��x�ɂȂ������_�łǂ���������ĂĂ����������Ȃ��ƍl���邪�ȉ���
http://tmp6.2ch.net/test/read.cgi/mog2/1190155780/683
http://tmp6.2ch.net/test/read.cgi/mog2/1190155780/683
http://tmp6.2ch.net/test/read.cgi/mog2/1190155780/686
http://tmp6.2ch.net/test/read.cgi/mog2/1190155780/689
�܂��܂���p�����Ă܂��ˁB
���x�ς��Ă�OC�ɂ��G���[�͉����ł��Ȃ������ł���
http://tmp6.2ch.net/test/read.cgi/mog2/1190155780/689
�܂��܂���p�����Ă܂��ˁB
���x�ς��Ă�OC�ɂ��G���[�͉����ł��Ȃ������ł���
237 �F�E�́E�j�����������F2007/09/24(��) 21:32:06 ID:RlQx0MtY
�F�{���ځ[��
�c�q�p��W
���ځ[���Ȃ�Ȃ����瓦���o�����ƁB
���ځ[���Ȃ�Ȃ����瓦���o�����ƁB
239 �F�E�́E�j�����������F2007/09/24(��) 21:34:54 ID:RlQx0MtY
�F�{�X�^���h�A����FF4�n
234 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
235 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
236 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
237 ���O�F�E�́E�j����������[sage] ���e���F2007/09/24(��) 21:32:06 ID:RlQx0MtY
�F�{���ځ[��
238 ���O�FSocket774[sage] ���e���F2007/09/24(��) 21:33:27 ID:2k8jlADu
�c�q�p��W
���ځ[���Ȃ�Ȃ����瓦���o�����ƁB
234 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
235 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
236 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
237 ���O�F�E�́E�j����������[sage] ���e���F2007/09/24(��) 21:32:06 ID:RlQx0MtY
�F�{���ځ[��
238 ���O�FSocket774[sage] ���e���F2007/09/24(��) 21:33:27 ID:2k8jlADu
�c�q�p��W
���ځ[���Ȃ�Ȃ����瓦���o�����ƁB
�c�q���S�����͗l�B�`�[���B
241 �F�E�́E�j�����������F2007/09/24(��) 22:01:48 ID:RlQx0MtY
�����W�[�p���������Ȃ����Ă��
242 �F���\�\�\���i�E�`�E�F2007/09/24(��) 22:03:17 ID:XXbpUa2q
�t���܃_���S
243 �F�E�́E�j�����������F2007/09/24(��) 22:04:08 ID:RlQx0MtY
�n���ҁA����̓o�[���̂悤�Ȃ��̂�
������˂��c
245 �F�R�M�́L>��-{}@{}@{}@ ��7idzB6JMx. �F2007/09/25(��) 03:43:34 ID:aK9ekaBY
A�����������ȁB
�̂�vs�X���ɂ��������̂ɁB
�̂�vs�X���ɂ��������̂ɁB
���ł��uSpursEngine�v����Qosmio��W��
http://pc.watch.impress.co.jp/docs/2007/1002/ceatec01.htm
http://pc.watch.impress.co.jp/docs/2007/1002/ceatec01.htm
���[�����s������CPU�������C����d�͂�1�P�^�팸
http://techon.nikkeibp.co.jp/article/NEWS/20071002/140085/
http://techon.nikkeibp.co.jp/article/NEWS/20071002/140085/
249 �F�E�́E�j�����������F2007/10/03(��) 01:05:35 ID:UgwGfELV
>>248
�ʔ����A�C�f�A���Ȃ��B
�������W�X�^��s�������ɂ��鎖�ŁACPU��halt��Ԃ�w�Ǔd��off�ɏo����
����A����ŏȓd�͉�������Ď����BIntel�����肪���i�K���̃X�e�[�g��
�p�ӂ��Ďl�ꔪ�ꂵ�Ă鎖���A�v��������P�����o����B
����x86�Ɏg���ɂ̓��W�X�^��������Ȃ��ċ���ȓ����L���b�V�����ǂ�����
�����ۑ肾�ȁB���z�I�ɂ̓L���b�V�����S�ĕs�����ɏo����Ηǂ����A�ʖ�
�Ȃ�X�e�[�g���Q�i�K�ɂ���K�v���L�邵�B
�ʔ����A�C�f�A���Ȃ��B
�������W�X�^��s�������ɂ��鎖�ŁACPU��halt��Ԃ�w�Ǔd��off�ɏo����
����A����ŏȓd�͉�������Ď����BIntel�����肪���i�K���̃X�e�[�g��
�p�ӂ��Ďl�ꔪ�ꂵ�Ă鎖���A�v��������P�����o����B
����x86�Ɏg���ɂ̓��W�X�^��������Ȃ��ċ���ȓ����L���b�V�����ǂ�����
�����ۑ肾�ȁB���z�I�ɂ̓L���b�V�����S�ĕs�����ɏo����Ηǂ����A�ʖ�
�Ȃ�X�e�[�g���Q�i�K�ɂ���K�v���L�邵�B
>>249
PS3�Ɠ����ŁA�ǂꂾ���g���Ղ����C�u������h���C�o���A���ł��p�ӏo���邩
�ǂ����ɂ������Ă�C���B
���p�҂ɂƂ��Ă݂�A�摜�������ҏW�p�̊����̊g���J�[�h�̗ނƁA�p�r�I
�ɂ͕ς�Ȃ��̂����B
PS3�Ɠ����ŁA�ǂꂾ���g���Ղ����C�u������h���C�o���A���ł��p�ӏo���邩
�ǂ����ɂ������Ă�C���B
���p�҂ɂƂ��Ă݂�A�摜�������ҏW�p�̊����̊g���J�[�h�̗ނƁA�p�r�I
�ɂ͕ς�Ȃ��̂����B
>>249
���܂ł̗Ⴉ�猾���Ĉ�ʌ���PC�̂��܂��̃A�N�Z�T���[�I�\�t�g�͎Г��Ń\�t�g�g�߂�z�ɂ�点��
����ȏ�̃V�X�e���ɐ[���������\�t�g�╡�G�ȃA�v���P�[�V�����͊O���������Ǝv���B
���܂ł̗Ⴉ�猾���Ĉ�ʌ���PC�̂��܂��̃A�N�Z�T���[�I�\�t�g�͎Г��Ń\�t�g�g�߂�z�ɂ�点��
����ȏ�̃V�X�e���ɐ[���������\�t�g�╡�G�ȃA�v���P�[�V�����͊O���������Ǝv���B
253 �FSocket774�F2007/10/04(��) 07:02:44 ID:G7jGpLHn
>>188
������SSE�̃��W�X�^�����Z��Ɍ�����
����L2�Ȃ�Ȃ��낤���i���̂悤�Ɍ����Ȃ����c�j
L1-L2�������Ƃ�L3�͂ǂ��H�Ƃ��₽��f�J���ˁH�Ƃ�����������c
������SSE�̃��W�X�^�����Z��Ɍ�����
����L2�Ȃ�Ȃ��낤���i���̂悤�Ɍ����Ȃ����c�j
L1-L2�������Ƃ�L3�͂ǂ��H�Ƃ��₽��f�J���ˁH�Ƃ�����������c
255 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 02:23:36 ID:ciMKYx9v
L2���牓���̂�L1 Inst�ʼn��̂�L1 Data�����l
����Ȃ��Ƃǂ��ł��������絼�����ĐQ��揬�m
����ID�ɂĂǂ��ł��������ƁA�ꌾ�ް��
258 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 03:18:35 ID:ciMKYx9v
�A�z
�ǂ��T������
�c�q���ăz���H
261 �FMAC�I�^���c�q �����F2007/10/06(�y) 16:30:38 ID:CLRn0sLW
>>255
�Ȃ����Ȃ������ɑ���������(��)
����킻��Ƃ��āANehelem�̍��i���摜���o����Ă�̂Ȃ烊���N�������ė~�������B
�@�@-----------------------
�@�@L2���牓���̂�L1 Inst�ʼn��̂�L1 Data�����l
�@�@-----------------------
���x�������Ă���悤�ɁA�_�C�ʐ^�Ō��Ă���̂�w�z���p�^�[���x�ł�����SRAM�A���C�̂悤��
�i�q��ɃL���C�ɕ��ԃu���b�N��A�ȒP�ɔ��ʂł��邷�B
�ŁA�R�A�̉����̃u���b�N�ɂ�32-64KB��SRAM�A���C�ɑ������镔���팩������Ȃ������ǁA
����"L1 data"���Ăǂ�̂��Ƃ����H
�Ȃ����Ȃ������ɑ���������(��)
����킻��Ƃ��āANehelem�̍��i���摜���o����Ă�̂Ȃ烊���N�������ė~�������B
�@�@-----------------------
�@�@L2���牓���̂�L1 Inst�ʼn��̂�L1 Data�����l
�@�@-----------------------
���x�������Ă���悤�ɁA�_�C�ʐ^�Ō��Ă���̂�w�z���p�^�[���x�ł�����SRAM�A���C�̂悤��
�i�q��ɃL���C�ɕ��ԃu���b�N��A�ȒP�ɔ��ʂł��邷�B
�ŁA�R�A�̉����̃u���b�N�ɂ�32-64KB��SRAM�A���C�ɑ������镔���팩������Ȃ������ǁA
����"L1 data"���Ăǂ�̂��Ƃ����H
��������L1��L2�͋߂��Ƃ���ɂ���͂��Ƃ������肩�炵�Ă܂������Ă���̂�
�N�B�͂悭�����̂̃v���ł������̂Ƀ_�C���݂Ă����܂Œ��X�c�_�ł���ȁB
�N�B�͂悭�����̂̃v���ł������̂Ƀ_�C���݂Ă����܂Œ��X�c�_�ł���ȁB
263 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 16:39:50 ID:ciMKYx9v
���W�X�^���āA�ėp�EFP/SIMD�e128�{���x�����Ă���������3KB���x�����
SRAM�ƒP����r�͏o���Ȃ�����
SRAM�ƒP����r�͏o���Ȃ�����
264 �FMAC�I�^��262 �����F2007/10/06(�y) 16:58:27 ID:CLRn0sLW
>>262
�@�@-------------------
�@�@��������L1��L2�͋߂��Ƃ���ɂ���͂��Ƃ������肩�炵�Ă܂������Ă���
�@�@-------------------
�f�[�^�t���[�ɍ��킹����H�z�u�̏d�v���ɂ��Ă�A����Ƃ�(��)
http://www.ece.ucdavis.edu/~yanzi/esscirc06_submit.pdf
�@�@-------------------
�@�@��������L1��L2�͋߂��Ƃ���ɂ���͂��Ƃ������肩�炵�Ă܂������Ă���
�@�@-------------------
�f�[�^�t���[�ɍ��킹����H�z�u�̏d�v���ɂ��Ă�A����Ƃ�(��)
http://www.ece.ucdavis.edu/~yanzi/esscirc06_submit.pdf
>>264
�Ȃ�Ńs���g�̂��ꂽ�\�[�X�������Ă��邩�Ȃ��B
�Ȃ�ł��\�[�X��悢�Ƃ����킯�ł͂Ȃ��B
�����̃v���Z�b�T�̃_�C�ʐ^���݂Ă�����
L1��ALU�͋߂��ʒu�ɂ��邪�AL1��L2�͕K�������߂��ʒu�ɂ͖����B
�������ꂾ���B
�Ȃ�Ńs���g�̂��ꂽ�\�[�X�������Ă��邩�Ȃ��B
�Ȃ�ł��\�[�X��悢�Ƃ����킯�ł͂Ȃ��B
�����̃v���Z�b�T�̃_�C�ʐ^���݂Ă�����
L1��ALU�͋߂��ʒu�ɂ��邪�AL1��L2�͕K�������߂��ʒu�ɂ͖����B
�������ꂾ���B
L1�͂������Data�̕��ˁB
267 �FMAC�I�^��265 �����F2007/10/06(�y) 18:27:24 ID:CLRn0sLW
>>265
�@�@-----------------
�@�@�����̃v���Z�b�T�̃_�C�ʐ^���݂Ă�����
�@�@L1��ALU�͋߂��ʒu�ɂ��邪�AL1��L2�͕K�������߂��ʒu�ɂ͖����B
�@�@�������ꂾ���B
�@�@-----------------
�������ۂ���(��)
�z�����푬�x�ɉe������̂ŁA�f�[�^�t���[�ɍ��킹�ă��C�A�E�g����̂핁�ʂ̘b���B
����L���Ȃ�A����Ȃ�Ƃ��B
http://journal.mycom.co.jp/column/architecture/027/index.html
�@�@-----------------
�@�@�����̃v���Z�b�T�̃_�C�ʐ^���݂Ă�����
�@�@L1��ALU�͋߂��ʒu�ɂ��邪�AL1��L2�͕K�������߂��ʒu�ɂ͖����B
�@�@�������ꂾ���B
�@�@-----------------
�������ۂ���(��)
�z�����푬�x�ɉe������̂ŁA�f�[�^�t���[�ɍ��킹�ă��C�A�E�g����̂핁�ʂ̘b���B
����L���Ȃ�A����Ȃ�Ƃ��B
http://journal.mycom.co.jp/column/architecture/027/index.html
��ۂł��Ȃ�ł��Ȃ�����B�ǂ̕����̒x�����ŏ��ɂ���ׂ����̑I���̌��ʁA
����L1��L2�͕K�������߂��킯�ł͂Ȃ��Ƃ������������邾���ł����B
MAC�I�^�݂����ȗ��R�������ĂȂ��\�[�X�\�蓦����Y�Ͳ�ȁB
����L1��L2�͕K�������߂��킯�ł͂Ȃ��Ƃ������������邾���ł����B
MAC�I�^�݂����ȗ��R�������ĂȂ��\�[�X�\�蓦����Y�Ͳ�ȁB
Merom��Montecito�Ɣ�ׂ�Ƌ߂��Ƃ͌����Ȃ����c
http://img.presence-pc.com/dossiers/quadcore/quadcoredie.jpg
���ǂ̕����̒x�����ŏ��ɂ���ׂ����̑I���̌���
���ꂪ�S�Ă���ˁ`
��������Nehalem�ɂ��Ă͂قƂ�lj����킩���ĂȂ���
�ʐ^�������ĎQ�l�ɂȂ�Ȃ�
http://img.presence-pc.com/dossiers/quadcore/quadcoredie.jpg
{kind=link}
���ǂ̕����̒x�����ŏ��ɂ���ׂ����̑I���̌���
���ꂪ�S�Ă���ˁ`
��������Nehalem�ɂ��Ă͂قƂ�lj����킩���ĂȂ���
�ʐ^�������ĎQ�l�ɂȂ�Ȃ�
{kind=link}
271 �FMAC�I�^��269-270 �����F2007/10/06(�y) 19:45:49 ID:CLRn0sLW
>>269-270
�P�Ȃ鎩���Ƃ��I�i�j�[���ᖳ���Ȃ�A�����N��̎ʐ^�ɉ�����K�v���Ǝv�����B
�����������c�B�@
http://www-03.ibm.com/chips/photolibrary/photo10.nsf/WebViewNumber/906FCACC31275D0400256FDB00694A09
���Ȃ݂ɁA����>>265��
�@�@-----------------
�@�@L1��ALU�͋߂��ʒu�ɂ��邪�A
�@�@-----------------
���R���ς������ďؖ�����(��)
ALU��"Arithmetric and Logic Unit"���Ĕ����Č����Ă���đO���ǁB
http://e-words.jp/w/ALU.html
�P�Ȃ鎩���Ƃ��I�i�j�[���ᖳ���Ȃ�A�����N��̎ʐ^�ɉ�����K�v���Ǝv�����B
�����������c�B�@
http://www-03.ibm.com/chips/photolibrary/photo10.nsf/WebViewNumber/906FCACC31275D0400256FDB00694A09
���Ȃ݂ɁA����>>265��
�@�@-----------------
�@�@L1��ALU�͋߂��ʒu�ɂ��邪�A
�@�@-----------------
���R���ς������ďؖ�����(��)
ALU��"Arithmetric and Logic Unit"���Ĕ����Č����Ă���đO���ǁB
http://e-words.jp/w/ALU.html
272 �F���다�L ��W/mVP3FtOs �F2007/10/06(�y) 20:01:34 ID:IrjNIWPw
�����z�����푬�x�ɉe������̂ŁA�f�[�^�t���[�ɍ��킹�ă��C�A�E�g����̂핁�ʂ̘b���B
�Ȃ�A
����L1��ALU�͋߂��ʒu�ɂ��邪�A
�ɂȂ�̂����R����ˁ[��?
�Ȃ�A
����L1��ALU�͋߂��ʒu�ɂ��邪�A
�ɂȂ�̂����R����ˁ[��?
273 �FMAC�I�^�����다�L �����F2007/10/06(�y) 20:03:45 ID:CLRn0sLW
>>272
LSU (Load/Store Unit)���߂���Ζ��Ȃ����B
LSU (Load/Store Unit)���߂���Ζ��Ȃ����B
>>271
�������N��̎ʐ^�ɉ�����K�v
�ȒP�ɂ킩���Ȃ������́H
�����x�������Ă���悤�ɁA�_�C�ʐ^�Ō��Ă���̂�w�z���p�^�[���x�ł�����SRAM�A���C�̂悤��
���i�q��ɃL���C�ɕ��ԃu���b�N��A�ȒP�ɔ��ʂł��邷�B
�������N��̎ʐ^�ɉ�����K�v
�ȒP�ɂ킩���Ȃ������́H
�����x�������Ă���悤�ɁA�_�C�ʐ^�Ō��Ă���̂�w�z���p�^�[���x�ł�����SRAM�A���C�̂悤��
���i�q��ɃL���C�ɕ��ԃu���b�N��A�ȒP�ɔ��ʂł��邷�B
275 �FMAC�I�^��274 �����F2007/10/06(�y) 20:54:52 ID:CLRn0sLW
277 �FMAC�I�^��276 �����F2007/10/06(�y) 21:12:20 ID:CLRn0sLW
>>276
Merom��Montecito���ᐏ���X�P�[�����Ⴄ�����ǁB�B�B
Merom��Montecito���ᐏ���X�P�[�����Ⴄ�����ǁB�B�B
278 �FMAC�I�^��276 �����F2007/10/06(�y) 21:23:38 ID:CLRn0sLW
>>276
�@�@------------------------
�@�@Merom��Montecito�Ɣ�ׂ��L2(L2D)��L1D���߂��Ƃ͌����Ȃ����c
�@�@------------------------
���̐}������ƊԈ���Ă�Ǝv�������ǁB�B�B
http://content.answers.com/main/content/wp/en/0/08/Montecito_micrograph.jpg
�@�@------------------------
�@�@Merom��Montecito�Ɣ�ׂ��L2(L2D)��L1D���߂��Ƃ͌����Ȃ����c
�@�@------------------------
���̐}������ƊԈ���Ă�Ǝv�������ǁB�B�B
http://content.answers.com/main/content/wp/en/0/08/Montecito_micrograph.jpg
{kind=link}
279 �FMAC�I�^���⑫�F2007/10/06(�y) 21:31:55 ID:CLRn0sLW
��̃����N��̐}�̌��T��Intel��ISSCC�̘_���Ƃ̂��Ƃ����ǁAIntel�I�ȃ������K�w���ʂ�
��`�ƈقȂ�悤�ŁA
�@L1 -> L0
�@L2 -> L1
�@L3 -> L2
�ƂȂ��Ă��邷�B���������Ĉ�ԑ�ʐς�SRAM�A���C(�ʏ�L3�ɕ��ނ����)��"12MB L2 Cache"
�ƕ\�L����Ă��邷�B
��`�ƈقȂ�悤�ŁA
�@L1 -> L0
�@L2 -> L1
�@L3 -> L2
�ƂȂ��Ă��邷�B���������Ĉ�ԑ�ʐς�SRAM�A���C(�ʏ�L3�ɕ��ނ����)��"12MB L2 Cache"
�ƕ\�L����Ă��邷�B
Itanium��L1$(16KB + 16KB)��Intel��L0$�ƌĂ�ł����̂͌��\�̘̂b�ōŋ߂̍œK���K�C�h(�ܘ_Montecito�ł�)���ł͂�������L1�ƋL�q����Ă���킯����
�܂������g������肾�ȁA�Ƃ�
�܂������g������肾�ȁA�Ƃ�
281 �FMAC�I�^��280 �����F2007/10/06(�y) 22:12:59 ID:CLRn0sLW
>>280
>>279��}�̉���������������B����Δ���悤�ɁA256KB L2D (L1D)��16KB L1D (L0D)��A
�ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ����B
>>279��}�̉���������������B����Δ���悤�ɁA256KB L2D (L1D)��16KB L1D (L0D)��A
�ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ����B
282 �FMAC�I�^���⑫�F2007/10/06(�y) 22:14:30 ID:CLRn0sLW
{kind=link}
MAC�I�^����̂��Ƃ������S�D��̔��_�Řb������Ă��Ă���悤�����A
L1-L2�̋����]�X�̘b�͑҂��������Ă��ƂŏI���B
L1-L2�̋����]�X�̘b�͑҂��������Ă��ƂŏI���B
>>281-282
���ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ�
Nehalem��L2��L1�̋����������Ƃ������_�����邯�ǁA�����́H�i��
���ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ�
Nehalem��L2��L1�̋����������Ƃ������_�����邯�ǁA�����́H�i��
285 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 22:52:25 ID:ciMKYx9v
>>270
Itanium�̃��X�g���x���L���b�V����L3�ł�
Itanium�̃��X�g���x���L���b�V����L3�ł�
286 �FMAC�I�^��284 �����F2007/10/06(�y) 22:55:11 ID:CLRn0sLW
>>284
�@�@------------------
�@�@Nehalem��L2��L1�̋����������Ƃ������_�����邯�ǁA�����́H�i��
�@�@------------------
���Ă���̂�A���Ȃ��̓����Ǝv�����B�����ʂ�Ƃ������ƂŁB
Penryn �_�C�ʐ^ http://download.intel.com/pressroom/kits/45nm/Penryn%20Die%20Photo_300.jpg
Nehalem >>186�����N��
�@�@------------------
�@�@Nehalem��L2��L1�̋����������Ƃ������_�����邯�ǁA�����́H�i��
�@�@------------------
���Ă���̂�A���Ȃ��̓����Ǝv�����B�����ʂ�Ƃ������ƂŁB
Penryn �_�C�ʐ^ http://download.intel.com/pressroom/kits/45nm/Penryn%20Die%20Photo_300.jpg
{kind=link}
Nehalem >>186�����N��
��: ���Ă���̂�A���̓����Ǝv�����B
typo??
typo??
> >>279��}�̉���������������B����Δ���悤�ɁA256KB L2D (L1D)��16KB L1D (L0D)��A
> �ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ����B
MAC�I�^�̎��_�ł́AL0��L1�͋߂��Ȃ���Ȃ�Ȃ��͂�����??
> �ׂ荇���Ă�����̂́A�����ċ�����߂��Ȃ����B
MAC�I�^�̎��_�ł́AL0��L1�͋߂��Ȃ���Ȃ�Ȃ��͂�����??
290 �FMAC�I�^��288 �����F2007/10/06(�y) 23:08:58 ID:CLRn0sLW
�J�L�R�Ƃ������Ȃ��������߂�������������
http://chip-architect.com/news/K8L_floorplan.jpg
������݂��LSU��ALU�ɋ߂��K�v������Ȃ��悤���ȁB
���܂œ\��ꂽ�_�C�ʐ^�����ׂČ�����ŁAL1��L2�͋߂��Ȃ��Ⴂ���Ȃ��Ȃ��
������M���Ă���z�͂������Ȃ�㩁B
{kind=link}
������݂��LSU��ALU�ɋ߂��K�v������Ȃ��悤���ȁB
���܂œ\��ꂽ�_�C�ʐ^�����ׂČ�����ŁAL1��L2�͋߂��Ȃ��Ⴂ���Ȃ��Ȃ��
������M���Ă���z�͂������Ȃ�㩁B
293 �FMAC�I�^��292 �����F2007/10/06(�y) 23:32:35 ID:CLRn0sLW
>>292
chip-architect�̏���Ǝ���͂Ȃ̂Ō����̏�ᖳ�����B
�����A����Ƃ��Č��ʓI��K8��L1�����ɒx���̂펖�����B
http://www.techreport.com/articles.x/13224/3
chip-architect�̏���Ǝ���͂Ȃ̂Ō����̏�ᖳ�����B
�����A����Ƃ��Č��ʓI��K8��L1�����ɒx���̂펖�����B
http://www.techreport.com/articles.x/13224/3
��������chip-architect�͂��܂�M�p���Ė������A
���̃X����MAC�I�^�̉�͂͂����ƐM�p���ĂȂ����B
����PPC970FX���炠�܂�߂��Ƃ͂����Ȃ��ˁB
���̃X����MAC�I�^�̉�͂͂����ƐM�p���ĂȂ����B
����PPC970FX���炠�܂�߂��Ƃ͂����Ȃ��ˁB
295 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 23:36:44 ID:ciMKYx9v
>>292
�m���ɂȂ���BL1�̃��C�e���V���͍Œ�ł���ɓǂݎn�߂邩��ˁB
�m���ɂȂ���BL1�̃��C�e���V���͍Œ�ł���ɓǂݎn�߂邩��ˁB
{kind=link}
297 �FMAC�I�^��294 �����F2007/10/06(�y) 23:43:20 ID:CLRn0sLW
>>294
�@�@---------------
�@�@��������chip-architect�͂��܂�M�p���Ė������A
�@�@---------------
Hans de Vries���̘b��AAcesHardware��RealWorldTech�̌f���ł����Γǂ߂邷���ǁA
�M���ł���l�����Ǝv�����B
�@�@---------------
�@�@��������chip-architect�͂��܂�M�p���Ė������A
�@�@---------------
Hans de Vries���̘b��AAcesHardware��RealWorldTech�̌f���ł����Γǂ߂邷���ǁA
�M���ł���l�����Ǝv�����B
298 �FMAC�I�^��296 �����F2007/10/06(�y) 23:44:55 ID:CLRn0sLW
�������AIntel�̌����T�C�g��NetBurst�̃v���b�g��chip-architect�̃_�C���͂Ƃ�
��r����ƌ��\�Ⴄ�ȁB
��r����ƌ��\�Ⴄ�ȁB
http://www.chip-architect.com/news/Northwood_130nm_die_text_1600x1200.jpg
http://www.activewin.com/reviews/hardware/processors/intel/p428ghz/cpuarch.shtml
���̃����N��̂�Intel�̌����T�C�g�̃v���b�g�����̂܂܂͂��Ă���L���B
��̂Ɣ�r����Ƒ�͍̂����Ă��邪�ADynamic Execution��Hiperpipeline��
�����̑Ή������܂����B�ʂ�Intel�����̕����������Ƃ�������͂Ȃ����ǂˁB
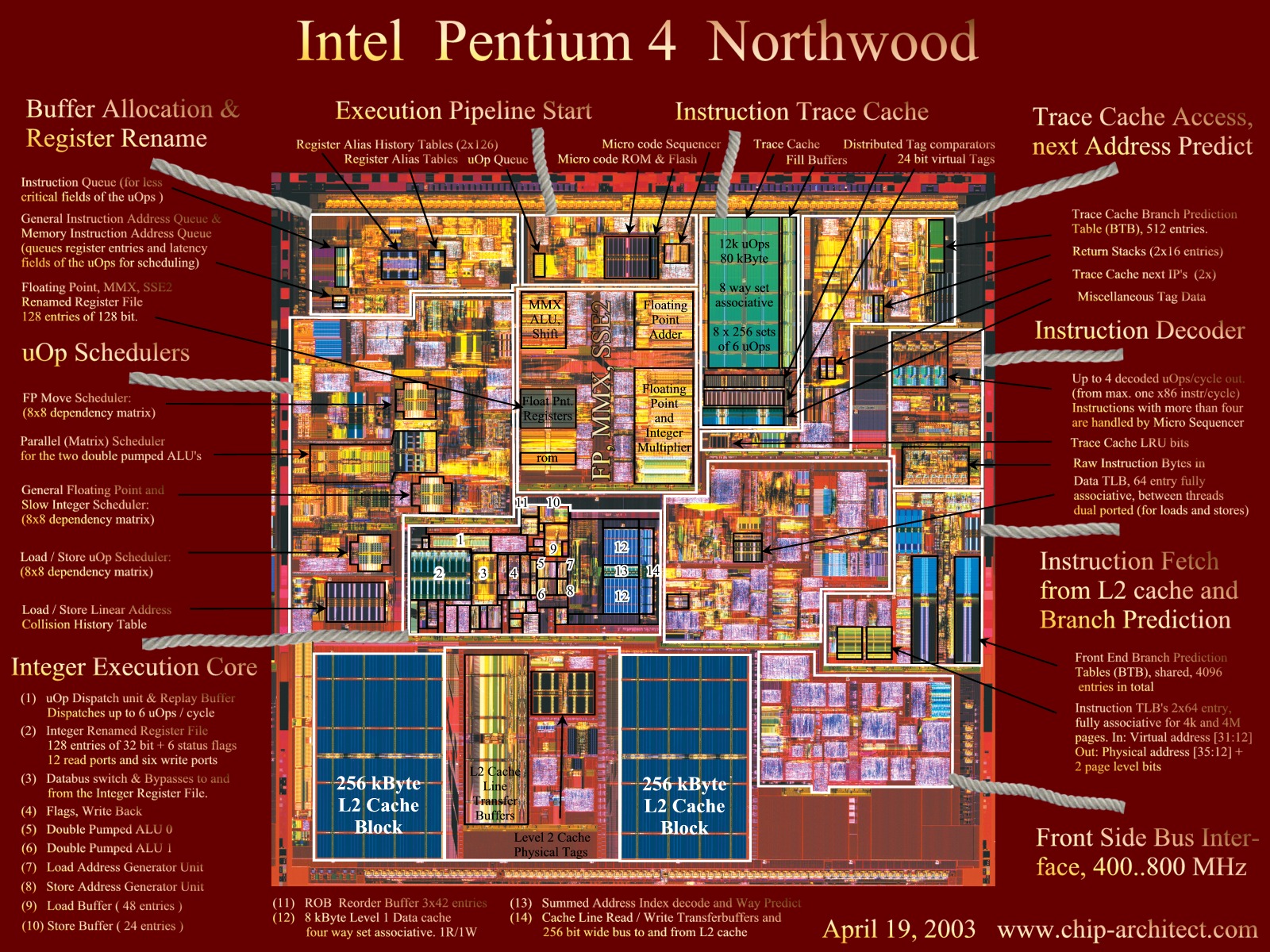{kind=link}
http://www.activewin.com/reviews/hardware/processors/intel/p428ghz/cpuarch.shtml
���̃����N��̂�Intel�̌����T�C�g�̃v���b�g�����̂܂܂͂��Ă���L���B
��̂Ɣ�r����Ƒ�͍̂����Ă��邪�ADynamic Execution��Hiperpipeline��
�����̑Ή������܂����B�ʂ�Intel�����̕����������Ƃ�������͂Ȃ����ǂˁB
���Ȃ݂�Willamette��Northwood�̔�r�ɂȂ����Ⴄ���ǁA���҂�
����قǃ��C�A�E�g�ɈႢ�͂Ȃ��̂ŁB
����قǃ��C�A�E�g�ɈႢ�͂Ȃ��̂ŁB
302 �FMAC�I�^��300 �����F2007/10/07(��) 00:24:15 ID:00wOqcSE
>>300-301
���ɂ��������Ȃ������ǁB�B�B
���̃����N�̉���}�ƃ_�C�ʐ^��90����]���Ă��邵�Achip-archtect�̐}��X��90������Ă��邷�̂�
���邷���H
���ɂ��������Ȃ������ǁB�B�B
���̃����N�̉���}�ƃ_�C�ʐ^��90����]���Ă��邵�Achip-archtect�̐}��X��90������Ă��邷�̂�
���邷���H
intel��M������M���Ȃ��������ς��ȁB
�_�C�ʐ^���^���Ă݂Ă͂ǂ���B
�_�C�ʐ^���^���Ă݂Ă͂ǂ���B
304 �FSocket774�F2007/10/07(��) 07:11:52 ID:rCkFIHmk
�ǂ��炩�Ƃ����ƃ��C�A�E�g�̐���̂ق����L�c����
305 �FSocket774�F2007/10/07(��) 12:38:25 ID:inyx0RFJ
����
���Z�@�Ƃ��̂����݂���b�������H
���Z�@�Ƃ��̂����݂���b�������H
306 �FMAC�I�^��305 �����F2007/10/07(��) 12:47:54 ID:00wOqcSE
MAC�I�^�@= �����̓ǂ�ŗ����ł��Ȃ��\�[�X�����������Ă��Ēm������
�v���O�����J�E���^���ă��W�X�^��adder�ŃC���N�������g���Ă�킯����ˁ[���
�f�G�ȑf�G�ȃn�[�h�̂��b���̎n�܂�ł�
�f�G�ȑf�G�ȃn�[�h�̂��b���̎n�܂�ł�
���낻��ǂ����̃T�C�g�ւ̃����N�����ɂ����i�s�͂������B
�������˂āA>>305, >>308�̗���L�{���B
��������mycom�̂�͂��܂����ǂ݂ɂ������B���ʂœǂ߂�Ȃ�ʂ����A
Web�ŕ��ʂɓǂ߂�e�L�X�g�̃��x���̌��E�������Ă�Ƃ���㩁B
�������˂āA>>305, >>308�̗���L�{���B
��������mycom�̂�͂��܂����ǂ݂ɂ������B���ʂœǂ߂�Ȃ�ʂ����A
Web�ŕ��ʂɓǂ߂�e�L�X�g�̃��x���̌��E�������Ă�Ƃ���㩁B
310 �FMAC�I�^��309 �����F2007/10/08(��) 00:49:37 ID:npbht7O+
>>309
�܂Ƃ��ȉȊw������Ă���Ȃ�A�}���Ȃ��������Ȃ��������Ȃ��̕��������ł�����������
����Ȃ�Ă��Ƃ��A�ǂꂾ������z���ł��锤���B
�Ȋw��Z�p��SF�������ᖳ������(��)
�܂Ƃ��ȉȊw������Ă���Ȃ�A�}���Ȃ��������Ȃ��������Ȃ��̕��������ł�����������
����Ȃ�Ă��Ƃ��A�ǂꂾ������z���ł��锤���B
�Ȋw��Z�p��SF�������ᖳ������(��)
�P��PC��ʂŕ��ʂɓǂ߂镶�͂���Ȃ��ȂƂ��������������ǁc�B
�Ƃ��҂ȃ��X�������ȁB
���̃X���͎���̒��łَ͈��B�����N�\��͑��ɑ�R���邵�A
���_�ɂ��������b���݂����B
http://cpu.jisakuita.net/architecture/1082357989.html
�Ƃ��҂ȃ��X�������ȁB
���̃X���͎���̒��łَ͈��B�����N�\��͑��ɑ�R���邵�A
���_�ɂ��������b���݂����B
http://cpu.jisakuita.net/architecture/1082357989.html
312 �FMAC�I�^���f�l �����F2007/10/08(��) 01:12:28 ID:npbht7O+
>>311
����A�Q�l�����̃����N�����A���͂̂݁A���e�̐^�U���s���ȓ����f���ʼn����w�ׂ�Ǝv������ł��邷���H
����A�Q�l�����̃����N�����A���͂̂݁A���e�̐^�U���s���ȓ����f���ʼn����w�ׂ�Ǝv������ł��邷���H
�����AMAC�I�^�͕��n���Ǝv���B�������݂��痝�n/�G���W�j�A�ɑ���
�R���v���b�N�X���ɂ��ݏo�Ă���ˁB
�R���s���[�^�A�[�L�e�N�`���͍H�w����̒��ł͐��w�̊����ʂ������ɏ��Ȃ�����ł���B
��ʓI�l�@�Ƃ����Ă����w�I�ɂ͓���Ȃ���ˁB�T�O�I�Șb�����S�B
����ɍH�w��i�J���ɂ����鐔���̋�g�͖ړI��B�����邽�߂̎�i��1�ł����āA
������������Ă�킯����Ȃ���B�T�O�I�A�����I�������厖�Ȃ��ǁB
�R���v���b�N�X���ɂ��ݏo�Ă���ˁB
�R���s���[�^�A�[�L�e�N�`���͍H�w����̒��ł͐��w�̊����ʂ������ɏ��Ȃ�����ł���B
��ʓI�l�@�Ƃ����Ă����w�I�ɂ͓���Ȃ���ˁB�T�O�I�Șb�����S�B
����ɍH�w��i�J���ɂ����鐔���̋�g�͖ړI��B�����邽�߂̎�i��1�ł����āA
������������Ă�킯����Ȃ���B�T�O�I�A�����I�������厖�Ȃ��ǁB
���Ȃ݂Ɏ��̓R���s���[�^�Ɋւ��Ă͑f�l�����ǁA�d���͊J���n�B
�����ˁA���Z�p��\�t�g�E�F�A�H�w�ȑO�̘b�B
�ŏ��\���̃R���s���[�^�[��CPU���̂��̂̊�{�\�����������ׂ��B
��发�ǂ���H�ڂɂȂ邯�ǂˁB���̑O�ɐ��w(���ɐ����A�_�����Z�̕���)���ł��Ȃ��Ƙb�ɂ��Ȃ�Ȃ��B
�ŏ��\���̃R���s���[�^�[��CPU���̂��̂̊�{�\�����������ׂ��B
��发�ǂ���H�ڂɂȂ邯�ǂˁB���̑O�ɐ��w(���ɐ����A�_�����Z�̕���)���ł��Ȃ��Ƙb�ɂ��Ȃ�Ȃ��B
316 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 01:41:13 ID:wd4n7JNm
�ÏL���{�����ǃy�^�[�\�����w�l�V�[��
�������̋L���͂��Ƃŏ��Љ����ꂻ������ˁB
�]���āA���͂��܂�ǂދC�͖����B���Ȃ݂Ƀw�l�p�^�͉��N���O�ɓǂB
�w�l�p�^�́ARISC~�X�[�p�[�X�J���̘b�܂ł͂������ǁA�ł�������Ă邯�Ǎŋ߂̘b��͂��߁B
�A�E�g�I�u�I�[�_�[�ȍ~�Ȃ瑼�ɂ����Ƃ����{������B���荞�݂�I/O�Ȃǂǂ낢�������ア�B
�]���āA���͂��܂�ǂދC�͖����B���Ȃ݂Ƀw�l�p�^�͉��N���O�ɓǂB
�w�l�p�^�́ARISC~�X�[�p�[�X�J���̘b�܂ł͂������ǁA�ł�������Ă邯�Ǎŋ߂̘b��͂��߁B
�A�E�g�I�u�I�[�_�[�ȍ~�Ȃ瑼�ɂ����Ƃ����{������B���荞�݂�I/O�Ȃǂǂ낢�������ア�B
���܂�B�{���̓X���̗����߂����Ƃ��Ď��݂������ŁA���̂��߂Ƃ����̂͂��Ȃ�͂�����w
���̃X���͉��݂�����CQ�o�Ń��x���̐~�[���G�k����Ƃ��낾��
���܂茨�I�͂炸�ɂ�������
���܂茨�I�͂炸�ɂ�������
320 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 01:56:09 ID:wd4n7JNm
x86�A�Z���u���Ȃ�Pentium�}�V������傪���ʂ������B
IA�́uIntel�A�[�L�e�N�`���`�v�ȏ�̖{�͂Ȃ��ȁB
�ǂ����g�тł���PDF�r���[�A�o���Ȃ����ȁB�������
�d�Ԃ̒��œǂ݂����B
IA�́uIntel�A�[�L�e�N�`���`�v�ȏ�̖{�͂Ȃ��ȁB
�ǂ����g�тł���PDF�r���[�A�o���Ȃ����ȁB�������
�d�Ԃ̒��œǂ݂����B
321 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 01:56:40 ID:wd4n7JNm
>>319
CQ�o�ł̃��b�N�͂Ȃɂ��ɖ��ʂ�������
CQ�o�ł̃��b�N�͂Ȃɂ��ɖ��ʂ�������
�A�Z���u����architecture��
����܂�W�Ȃ�
�����܂��Ƃ�ł����������
����܂�W�Ȃ�
�����܂��Ƃ�ł����������
��������āA���܂���ǂނƂ��˂�
324 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 04:46:35 ID:wd4n7JNm
�܂�ISA�ƃ}�C�N���A�[�L���Ⴂ�����邩��Ȃ�
�ł����߃Z�b�g��m�炸�ɉ��ł���ȉ�H������́H�Ȃ�ċ^��͉������Ȃ�
�ł����߃Z�b�g��m�炸�ɉ��ł���ȉ�H������́H�Ȃ�ċ^��͉������Ȃ�
>>310
�Ƃ肠�������܂��͌�L.R.�t�H���[�h�Ɏӂ�B
�Ƃ肠�������܂��͌�L.R.�t�H���[�h�Ɏӂ�B
326 �FMAC�I�^��325 �����F2007/10/08(��) 07:40:40 ID:npbht7O+
>>325
���̗���ǂ�ŕ������������C�ɂȂ��Ă���Ȃ������B
���̗���ǂ�ŕ������������C�ɂȂ��Ă���Ȃ������B
����Ȕ��z�����o�Ă��Ȃ��f�G�ȓ��ɕ�R��
>>323
�Ó��B���ƂȂ��Ă̓w�l�p�^�͌Â��A�k���C�A�璷��3���q������Ă�B
�}���₽�瑽���āA1�y�[�W�̏��ʂ����Ȃ��̂��l�I�ɃA�E�g�B
C��A�Z���u�����Ƃ肠�����������Ƃ����\�t�g�n�̓���҂�
�ǂނɂ͂������ǂˁB�����ʂ̘b���ア��B
�Ó��B���ƂȂ��Ă̓w�l�p�^�͌Â��A�k���C�A�璷��3���q������Ă�B
�}���₽�瑽���āA1�y�[�W�̏��ʂ����Ȃ��̂��l�I�ɃA�E�g�B
C��A�Z���u�����Ƃ肠�����������Ƃ����\�t�g�n�̓���҂�
�ǂނɂ͂������ǂˁB�����ʂ̘b���ア��B
329 �FMAC�I�^��328 �����F2007/10/08(��) 13:52:23 ID:npbht7O+
>>328
���ȏ����Â��̂�A������O���Ǝv�������ǁB�B�B
���ȏ����Â��̂�A������O���Ǝv�������ǁB�B�B
>>329
���ȏ��ɂ���b�ɂēO���ČÂ��b�肵�������ĂȂ����̂ƁA���p���ʂ̍ŋ߂�
�b��������������̂�����B
�܂��A��w�̋��ȏ��������ɓǔj���Ă��Ƃ̂Ȃ���̑z���͂ǂ��ł��������B
���ȏ��ɂ���b�ɂēO���ČÂ��b�肵�������ĂȂ����̂ƁA���p���ʂ̍ŋ߂�
�b��������������̂�����B
�܂��A��w�̋��ȏ��������ɓǔj���Ă��Ƃ̂Ȃ���̑z���͂ǂ��ł��������B
331 �FMAC�I�^��330 �����F2007/10/08(��) 14:00:47 ID:npbht7O+
>>330
�@�@-----------------
�@�@���p���ʂ̍ŋ߂̘b��������������̂�����B
�@�@-----------------
�����̃q�g�������̖{����Ă邾���̂悤�ȁB�B�B
�@�@-----------------
�@�@���p���ʂ̍ŋ߂̘b��������������̂�����B
�@�@-----------------
�����̃q�g�������̖{����Ă邾���̂悤�ȁB�B�B
�R���s���[�^�̒�x���̕����𗝉���������Ȃ�
8bit�Ƃ�16bit�}�V�����������{���������낤��
��������2007�N�A���̎�̖{�����Ȃ��̂��l�b�N
�ŋ�MS-DOS�݊�OS�ɐG��邱�Ƃ�������
DOS�̏��S�Ҍ�������{�T��������
�����Ö{�����Ȃ����
8bit�Ƃ�16bit�}�V�����������{���������낤��
��������2007�N�A���̎�̖{�����Ȃ��̂��l�b�N
�ŋ�MS-DOS�݊�OS�ɐG��邱�Ƃ�������
DOS�̏��S�Ҍ�������{�T��������
�����Ö{�����Ȃ����
�Ⴆ�ŋ߂�cpu�̃��W�X�^�Ԑڕ����݂�����
�킩��₷��������F����CPU���J�j�Y���Ƃ�������
����A��勳��͎ĂȂ����ǂ�
��w�̃e�L�X�g�Ƃ���������Ȃ��́H
�킩��₷��������F����CPU���J�j�Y���Ƃ�������
����A��勳��͎ĂȂ����ǂ�
��w�̃e�L�X�g�Ƃ���������Ȃ��́H
334 �FMAC�I�^��333 �����F2007/10/08(��) 14:12:52 ID:npbht7O+
>>333
�����������ŐV�̘b��_����ǂނ���B
�{�����J����Ă��Ȃ��_�����A��w�̎��Ɗ֘A�̃����N�����X�ł��ǂ߂�悤�Ɍ��J����Ă�����
����̂�A�����������R���B
�����������ŐV�̘b��_����ǂނ���B
�{�����J����Ă��Ȃ��_�����A��w�̎��Ɗ֘A�̃����N�����X�ł��ǂ߂�悤�Ɍ��J����Ă�����
����̂�A�����������R���B
�L���ł̓o�^�K�v�����ǁAIEEE�Ƃ����{����w��ɓo�^����Ă�_����������
�o�^���ČĂ��Ƃˁ[����
�o�^���ČĂ��Ƃˁ[����
>>332
>8bit�Ƃ�16bit�}�V�����������{���������낤��
�n�[�h�n�̏ꍇ�̓f�W�^����H�̊�b�͂���Ƃ��āAHDL��8/16bit���炢�̊ȒP�Ȑv��
�ł���悤�ɂȂ��Ă��炩�A���Ȃ��Ƃ����s���Ă���ˁA�R���s���[�^�A�[�L�e�N�`���́B
�f�W�^����H�`HDL�`CMOS VLSI�v�`�R���s���[�^�A�[�L�e�N�`��
�̋��n������肭�����ĂȂ��C������B
���낢����ł��f�ГI�ɂȂ����Ⴄ�B
���̓_�A�\�t�g�E�G�A/�v���O���~���O�͏��Ђ��L�x�ł����܂����B
>8bit�Ƃ�16bit�}�V�����������{���������낤��
�n�[�h�n�̏ꍇ�̓f�W�^����H�̊�b�͂���Ƃ��āAHDL��8/16bit���炢�̊ȒP�Ȑv��
�ł���悤�ɂȂ��Ă��炩�A���Ȃ��Ƃ����s���Ă���ˁA�R���s���[�^�A�[�L�e�N�`���́B
�f�W�^����H�`HDL�`CMOS VLSI�v�`�R���s���[�^�A�[�L�e�N�`��
�̋��n������肭�����ĂȂ��C������B
���낢����ł��f�ГI�ɂȂ����Ⴄ�B
���̓_�A�\�t�g�E�G�A/�v���O���~���O�͏��Ђ��L�x�ł����܂����B
337 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 17:52:50 ID:wd4n7JNm
�\�t�g�Ȃ�Lion's Commentary�Ƃ��^�l���o�E���{������͌Â��H
���ł������{���Ǝv������
���ł������{���Ǝv������
>>335
�_���͕��ʂ͒��҂Ɍ����^�_�ő����Ă��炦���
�_���͕��ʂ͒��҂Ɍ����^�_�ő����Ă��炦���
339 �F�R�E�L�́M�E,,�j�����������������F2007/10/09(��) 02:13:07 ID:nlVpVMg0
Agner����x86�A�[�L��͂͂������Ƃ������B
>>337
���܂�ɂ��Â��B
���܂�ɂ��Â��B
�c�q�̓X�g���X�c�[���Ȃ���ĂȂ����(�L�E�ցE)
>>334
�ǂ��ł��������A���J����Ă��Ȃ����̂͘_���Ƃ͌ĂȂ�
�ǂ��ł��������A���J����Ă��Ȃ����̂͘_���Ƃ͌ĂȂ�
>>332
����Ȃ�ŕςȃN�Z�t�������ׂ̃w�l�p�^���Ǝv���̂����c
����Ȃ�ŕςȃN�Z�t�������ׂ̃w�l�p�^���Ǝv���̂����c
344 �FMAC�I�^��342 �����F2007/10/09(��) 08:51:08 ID:FADSsF6t
>>342
���Ɂw�����x��t���Ƃ��ė~�������B
���Ɂw�����x��t���Ƃ��ė~�������B
>>343
�w�l�p�^�{��8bit/16bit�̉���͌݊����������B
�č��͂ǂ�������Ȃ����A�f�W�^����H���K�����Ă̂���A
�w�l�p�^�����ȏ��ɂ����Ȃ�A�[�L�e�N�`���̍u�`���������肷��̂�
���{�̑�w�̃J���L�������������肷��B
�w�l�p�^�{��RISC�A�[�L�e�N�`���ɂ͋������A
���n�I��CPU�̊�b�͏����ĂȂ��B
�w�l�p�^�{��8bit/16bit�̉���͌݊����������B
�č��͂ǂ�������Ȃ����A�f�W�^����H���K�����Ă̂���A
�w�l�p�^�����ȏ��ɂ����Ȃ�A�[�L�e�N�`���̍u�`���������肷��̂�
���{�̑�w�̃J���L�������������肷��B
�w�l�p�^�{��RISC�A�[�L�e�N�`���ɂ͋������A
���n�I��CPU�̊�b�͏����ĂȂ��B
PDP�Ȃ�360�Ȃ�VAX�Ȃ�68000�A������������Z80�ł������A
CPU�̊�b��m�������
�w�l�p�^�߂�Sparc��MIPS�̒���pipeline�Ɏv�������炷
���ꂪ90�N��A���ꂩ����Ɉꐢ�I�B
������Â��Ə�ŏ������̂ɁAʹނ�
CPU�̊�b��m�������
�w�l�p�^�߂�Sparc��MIPS�̒���pipeline�Ɏv�������炷
���ꂪ90�N��A���ꂩ����Ɉꐢ�I�B
������Â��Ə�ŏ������̂ɁAʹނ�
��������ŏ���Sparc��87�N�x�m��gatearray
R2000,MIPS-X��'80�N�㖖��
R2000,MIPS-X��'80�N�㖖��
�ꐢ�I��
�܂�21���I�̋��ȏ���CPU�̑n�肩�����A�ƁB
�@�@(�@߄t�)�@���ȏ��͉����������ȁI�H�c�ƁB
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�@�@(�@߄t�)�@�c�c�c
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�@�@( ߄t� )
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�@�@(�@߄t�)�@�c�c�c
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�@�@( ߄t� )
�Q(__��/�P�P�P/�Q
�@�@�_/�@�@�@�@ /
�@�@�@�@�P�P�P
�����������
352 �F�R�E�L�́M�E,,�j�����������������F2007/10/11(��) 01:40:47 ID:k28Q6TG1
�K���ɉ��̈Ӗ�������́H
�����V����̎����V�X�e���̘b�肷�B
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note055.html
�@�@---------------
�@�@���D�����̂� NEC �ŁA�V�X�e���� NEC SX �̎����V�X�e��(�����\)�� Cray�� XT4, NEC �̂�
�@�@�v���d�l�� 1.6 Tflops �ȏ�AXT4 �̓N���C�W���p���̎����ɂ��� 824 �m�[�h�A 29 Tflops �̃V�X
�@�@�e���ł�(�\���m�[�h�܂�)�B
�@�@[����]
�@�@�����V����̃X�[�p�[�R���s���[�^�[�V�X�e�����A SX/XT4 �̑��� GRAPE-DR ���������p�V�X
�@�@�e���Ƃ��ē������A�s�[�N���\��s�[�N���\�ł̉��i���\��Ɋւ��Ă͂�����̂ق����ǂ����̂�
�@�@�Ȃ�܂��B
�@�@---------------
http://grape.mtk.nao.ac.jp/~makino/articles/future_sc/note055.html
�@�@---------------
�@�@���D�����̂� NEC �ŁA�V�X�e���� NEC SX �̎����V�X�e��(�����\)�� Cray�� XT4, NEC �̂�
�@�@�v���d�l�� 1.6 Tflops �ȏ�AXT4 �̓N���C�W���p���̎����ɂ��� 824 �m�[�h�A 29 Tflops �̃V�X
�@�@�e���ł�(�\���m�[�h�܂�)�B
�@�@[����]
�@�@�����V����̃X�[�p�[�R���s���[�^�[�V�X�e�����A SX/XT4 �̑��� GRAPE-DR ���������p�V�X
�@�@�e���Ƃ��ē������A�s�[�N���\��s�[�N���\�ł̉��i���\��Ɋւ��Ă͂�����̂ق����ǂ����̂�
�@�@�Ȃ�܂��B
�@�@---------------
�Ƃ���ł����ƋC�ɂȂ��Ă����̂����A
>>1��
>�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
>CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
����2�s�͂Ȃ�Ȃ�?
>>1��
>�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
>CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
����2�s�͂Ȃ�Ȃ�?
356 �F�R�E�L�́M�E,,�j�����������������F2007/10/13(�y) 19:13:04 ID:vm3oX+/R
>>354
�܂��s�[�N���\��
�܂��s�[�N���\��
357 �FMAC�I�^���c�q �����F2007/10/13(�y) 19:16:18 ID:oZktu19s
>>356
�����N��̓��e��ǂ܂Ȃ��K���Ȃ��B�B�B
�@�@----------------------
�@�@�����V����̗v���d�l�͓���E�}�g�E����̂悤�ȐV�K�J����v��������̂ł͂���܂���B
�@�@���B�͗v���d�l���e�Ђ̃X�J������V�X�e���� PC �N���X�^�ɃC���t�B�j�o���h�l�b�g���[�N��
�@�@�������̂Ŏd�l�������Ƃ��ł���悤�ɐv���Ă��܂��B���̑���A���ۂɃ��[�U�[��
�@�@�v���O�����Ő��\���ł邱�Ƃ������ĉ������A�Ƃ����v���������킯�ł��B
�@�@----------------------
�����N��̓��e��ǂ܂Ȃ��K���Ȃ��B�B�B
�@�@----------------------
�@�@�����V����̗v���d�l�͓���E�}�g�E����̂悤�ȐV�K�J����v��������̂ł͂���܂���B
�@�@���B�͗v���d�l���e�Ђ̃X�J������V�X�e���� PC �N���X�^�ɃC���t�B�j�o���h�l�b�g���[�N��
�@�@�������̂Ŏd�l�������Ƃ��ł���悤�ɐv���Ă��܂��B���̑���A���ۂɃ��[�U�[��
�@�@�v���O�����Ő��\���ł邱�Ƃ������ĉ������A�Ƃ����v���������킯�ł��B
�@�@----------------------
358 �F�R�E�L�́M�E,,�j�����������������F2007/10/13(�y) 21:44:52 ID:vm3oX+/R
�ǂ�łȂ���
>2��ނɂ���Ȃ炻���������_�ŃA�[�L�e�N�`���̍Č���������ׂ��ł��傤�B
�����͓��ӂł��邪�A�ǂ�ł����[�U���g����ƍ�����̗��ɂڂ낪�o�邗
�����͓��ӂł��邪�A�ǂ�ł����[�U���g����ƍ�����̗��ɂڂ낪�o�邗
���ۂɃ��[�U�[�̃v���O�����Ő��\���ł邱�Ƃ���������̂͌��\�����A
���[�J�[�����ꂱ���ԉɂ����Ă悤�₭�����Ȃ����̂ł�
��ԉɉɂ������镪�{���]�|�ɂȂ肩�˂Ȃ��B
�K�p����A�v���̐��\�����[�U�T�C�h�ł��v���ȒP�ɏo���邱�Ƃ������
��������ƓK���͈͂ɕ��E�]�T������M����������
�\�t�g������ł��g����ł��g���₷���Ȃ��Ă͂Ȃ�Ȃ��Ƃ����
���[�J�[�����ꂱ���ԉɂ����Ă悤�₭�����Ȃ����̂ł�
��ԉɉɂ������镪�{���]�|�ɂȂ肩�˂Ȃ��B
�K�p����A�v���̐��\�����[�U�T�C�h�ł��v���ȒP�ɏo���邱�Ƃ������
��������ƓK���͈͂ɕ��E�]�T������M����������
�\�t�g������ł��g����ł��g���₷���Ȃ��Ă͂Ȃ�Ȃ��Ƃ����
361 �F�R�E�L�́M�E,,�j�����������������F2007/10/13(�y) 22:47:57 ID:vm3oX+/R
>>360
PS3��n���ɂ���ȁI
PS3��n���ɂ���ȁI
>>358
��C���ǂ߂�悤�ɂȂ�Ƃ����ˁB
��C���ǂ߂�悤�ɂȂ�Ƃ����ˁB
>>357
��C��ǂ܂Ȃ��K���Ȃ��B�B�B
��C��ǂ܂Ȃ��K���Ȃ��B�B�B
364 �F�R�E�L�́M�E,,�j�����������������F2007/10/14(��) 01:52:15 ID:D9ZR/d+v
2�Ԑ����܂��
���ŁuSpursEngine�v�Ɍ���PC�̉\��
http://pc.watch.impress.co.jp/docs/2007/1015/mobile395.htm
http://pc.watch.impress.co.jp/docs/2007/1015/mobile395.htm
ARM�A�}���`�R�A�̍����\/��d�͑g����CPU
�uCortex-A9�v
http://pc.watch.impress.co.jp/docs/2007/1015/arm.htm
�uCortex-A9�v
http://pc.watch.impress.co.jp/docs/2007/1015/arm.htm
>>366
�n�b�L���Ƃ͕�����A1�`�S�̃R�A��I���o������Ď����ȁH
�n�b�L���Ƃ͕�����A1�`�S�̃R�A��I���o������Ď����ȁH
368 �F�ǂ��Ă������܂����F2007/10/15(��) 20:20:13 ID:uH0FfAq4
arm�̃}���`�R�A���Đ���Drystome MIPS����H
Intel��AMD��2�����炢�Ⴄ��ˁH
���\�����W���܂������Ⴄ�����r�̑ΏۂɂȂ�Ȃ���ˁH
�Ƃ͂����Ă��A1000MIPS��Pentitm66MHz��10�{
����������ɂȂ�����Ȃ�
Intel��AMD��2�����炢�Ⴄ��ˁH
���\�����W���܂������Ⴄ�����r�̑ΏۂɂȂ�Ȃ���ˁH
�Ƃ͂����Ă��A1000MIPS��Pentitm66MHz��10�{
����������ɂȂ�����Ȃ�
Pentitm
2010�N���ɂ��ARM�̐헪�ƐVCPU�R�A
http://pc.watch.impress.co.jp/docs/2007/1018/arm.htm
http://pc.watch.impress.co.jp/docs/2007/1018/arm.htm
2010�N���ɂ��ARM�̐헪�ƐVCPU�R�A
http://pc.watch.impress.co.jp/docs/2007/1018/arm.htm
http://pc.watch.impress.co.jp/docs/2007/1018/arm.htm
http://pc.watch.impress.co.jp/docs/2007/1018/ubiq203.htm
Intel�̑g�ݍ������p��Silverthorne�́ATDP1W��̂�1GHz����͗l�B
ARM�̋L����DMIPS�l�̔�r�O���t���Q�l�ɂ���ƁASilverthorne�̐��\��PenM�����Ȃ�A
Cortex-A8 1GHz��Silverthorne0.9GHz��TDP�ADMIPS�l�Ƃ��Ɍ݊p���ۂ��ȁB
Silverthorne�̕��̓`�b�v�Z�b�g��TDP��2.5W��A�C�h������100mW�Ƃ܂��܂���葽�����ǁB
Intel�̑g�ݍ������p��Silverthorne�́ATDP1W��̂�1GHz����͗l�B
ARM�̋L����DMIPS�l�̔�r�O���t���Q�l�ɂ���ƁASilverthorne�̐��\��PenM�����Ȃ�A
Cortex-A8 1GHz��Silverthorne0.9GHz��TDP�ADMIPS�l�Ƃ��Ɍ݊p���ۂ��ȁB
Silverthorne�̕��̓`�b�v�Z�b�g��TDP��2.5W��A�C�h������100mW�Ƃ܂��܂���葽�����ǁB
>>370-371
OoO�̗p�ɋ������c����
OoO�̗p�ɋ������c����
�܂������Moorestown�܂ł̖���
>>372
�{����Silverthone���d�͐��\���Cortex-A�V���[�Y�Ƃ͂���ARM v7�Ɠ�����������A
����ARM�̖��߃Z�b�g�̉��l���ĉ��Ȃ́H�Ƃ͎v���ȁB
�܁[�ASilverthone��45nm�����ǁA�����v���Z�X��肻�̐��\�̃v���Z�b�T����ɓ��邱�Ƃ��厖�����B
�{����Silverthone���d�͐��\���Cortex-A�V���[�Y�Ƃ͂���ARM v7�Ɠ�����������A
����ARM�̖��߃Z�b�g�̉��l���ĉ��Ȃ́H�Ƃ͎v���ȁB
�܁[�ASilverthone��45nm�����ǁA�����v���Z�X��肻�̐��\�̃v���Z�b�T����ɓ��邱�Ƃ��厖�����B
>>375
ARM�̉��l�́A�l�i��ASIC�������邩�A���낤�B
ARM�̉��l�́A�l�i��ASIC�������邩�A���낤�B
��89�� �u�s�����v���Z�b�T�v���ĉ����������́H
http://www.atmarkit.co.jp/fsys/zunouhoudan/089zunou/framcpu.html
http://www.atmarkit.co.jp/fsys/zunouhoudan/089zunou/framcpu.html
ARM�͎��M���X
http://japan.cnet.com/interview/story/0,2000055954,20352144-2,00.htm
�\�\�s��V�F�A���ێ��ł��Ă��闝�R�͂Ȃ�ł��傤�B
�@�킪�Ђ̃G�R�V�X�e�������̗��R�ł��B
���i�����A���̐��i�ɍœK�ȃ��[�U�̌������K�v������܂��B
1�̊�Ƃł�����s�����Ƃ͂ł��܂���B
�䂪�Ђ̃G�R�V�X�e���ɂ�400�ȏ�̊�Ƃ�����܂��B
���̊�Ƃł͂����͂����܂���B
http://japan.cnet.com/interview/story/0,2000055954,20352144-2,00.htm
�\�\�s��V�F�A���ێ��ł��Ă��闝�R�͂Ȃ�ł��傤�B
�@�킪�Ђ̃G�R�V�X�e�������̗��R�ł��B
���i�����A���̐��i�ɍœK�ȃ��[�U�̌������K�v������܂��B
1�̊�Ƃł�����s�����Ƃ͂ł��܂���B
�䂪�Ђ̃G�R�V�X�e���ɂ�400�ȏ�̊�Ƃ�����܂��B
���̊�Ƃł͂����͂����܂���B
>>378
�R��IT�W���Ă�Ƃǂ����Ђ����������
�G�R�V�X�e�����Č��t�͂��̂܂����Ȃ��ŗ~������
���߂Ē���Ő��Ԍn
���ǂ͗v�����3rd-party�������Ɩׂ������Ă����܂�����Ă��������
�R��IT�W���Ă�Ƃǂ����Ђ����������
�G�R�V�X�e�����Č��t�͂��̂܂����Ȃ��ŗ~������
���߂Ē���Ő��Ԍn
���ǂ͗v�����3rd-party�������Ɩׂ������Ă����܂�����Ă��������
�u���[�h�R���AHSUPA�Ή��V���O���`�b�v�ȂǍ����\���i���f��
http://k-tai.impress.co.jp/cda/article/news_toppage/36802.html
�b65nm�v���Z�X�Œ�R�X�g�A�����d�͂��������Ȃ���AHSUPA/HSDPA��EDGE�ɑΉ����ABluetooth�A
�bFM���W�I���T�|�[�g����B
�b�f���A���R�ACPU�ɂ�ARM 11���̗p����AOS��Symbian OS�AWindows Mobile�ALinux���T�|�[�g�����B
�b�p�b�P�[�W�T�C�Y��12�~12mm�B
Silverthorne���g�ђ[���őR����ׂɂ́A�v���Z�X���Q���キ�炢��s���Ȃ��Ɩ���JARO�B
http://k-tai.impress.co.jp/cda/article/news_toppage/36802.html
�b65nm�v���Z�X�Œ�R�X�g�A�����d�͂��������Ȃ���AHSUPA/HSDPA��EDGE�ɑΉ����ABluetooth�A
�bFM���W�I���T�|�[�g����B
�b�f���A���R�ACPU�ɂ�ARM 11���̗p����AOS��Symbian OS�AWindows Mobile�ALinux���T�|�[�g�����B
�b�p�b�P�[�W�T�C�Y��12�~12mm�B
Silverthorne���g�ђ[���őR����ׂɂ́A�v���Z�X���Q���キ�炢��s���Ȃ��Ɩ���JARO�B
�iEmbedded�ECE�ł͂Ȃ��j�t���X�y�b�N��XP/Vista������UMPC�EMID��
�]���ǂ���̌g�ѓd�b�E�X�}�[�g�t�H���ƂŏZ�ݕ����邨
�]���ǂ���̌g�ѓd�b�E�X�}�[�g�t�H���ƂŏZ�ݕ����邨
UMPC��FPS�Ƃ��o�����炷���������Ȃ�
99% DOOM��������t���o����
ttp://ratkun.at.webry.info/200705/article_3.html
>�������x�����߂�̂́A�̂������N���b�N���[�g�Ȃ̂ł���B
>�������x�����߂�̂́A�̂������N���b�N���[�g�Ȃ̂ł���B
���b�g�N���킢����
���b�g�N��������������������������������
387 �FSocket774�F2007/10/20(�y) 13:19:58 ID:mKGGm2PA
�����ア�̂����邪�A�킴�Ƃ��낤�ˁB
�v�̓N���b�N�T�C�g������A�l���W�߂�̂��ړI�B
�v�̓N���b�N�T�C�g������A�l���W�߂�̂��ړI�B
388 �F�R�E�L�́M�E,,�j�����������������F2007/10/21(��) 02:04:08 ID:Sx9CwrnQ
�l�W�߂�454�q�b�g�Ƃ�����������
���̃X���b�h���ŋߘb�肪�₵���̂�IBM���Ĉȍ~�Ɍ���Ă���POWER6, 6+, 7�̃��[�h�}�b�v�ɂ��ď���
�����������B
2010��PERCS�̂���I�ڂ��߂��Ȃ������ƂŁA�ŋ߂�IBM��POWER���[�h�}�b�v�ɂ�POWER7�܂Ŏ������
�悤�ɂȂ��Ă������B���̒��Ŗ��炩�ɂȂ��Ă������Ƃ�A����2�_���B
�@�E�N���b�N�̏㏸��POWER6�ň�U�X�g�b�v�B�Ȍ�Ђ�����R�A�������ɐi�ޗ\��
�@�EPOWER7��"Advanced Hybrid Core Design"�Ə̂���w�e���R�A (or �A�N�Z�����[�^)�\���ɂȂ�ƕ\��
�O�҂�O�̃X���b�h�ŏ������b�����t��������Ƃ����b�����ǁA
(http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/850-856 �Q��)
POWER6+�ŃR�A��2�{�APOWER7�ł܂�2�{�Ƃ������Ƃ��B�������N���b�N�̕���POWER6-7�����"4+ GHz"
�Ƃ���Ă��邷�B
�����̂�����p�ɎQ�l������2�قNj����Ă������B
http://www.ibm.com/ru/events/presentations/ibmday/mozgovoy.pdf
http://www-05.ibm.com/dk/news/events/systemiconference/pdf/Erik_Rex_POWER6.pdf
�㓡�L����Intel�̃T�[�o�[�v���Z�b�T���}���`�R�A��簐i���Ă���b�������Ă��邷���ǁA���̕ӂ�Sun Niagara
��POWER�̂����������[�h�}�b�v�ɑR���Ă���Ƃ������Ƃ��B
�����������B
2010��PERCS�̂���I�ڂ��߂��Ȃ������ƂŁA�ŋ߂�IBM��POWER���[�h�}�b�v�ɂ�POWER7�܂Ŏ������
�悤�ɂȂ��Ă������B���̒��Ŗ��炩�ɂȂ��Ă������Ƃ�A����2�_���B
�@�E�N���b�N�̏㏸��POWER6�ň�U�X�g�b�v�B�Ȍ�Ђ�����R�A�������ɐi�ޗ\��
�@�EPOWER7��"Advanced Hybrid Core Design"�Ə̂���w�e���R�A (or �A�N�Z�����[�^)�\���ɂȂ�ƕ\��
�O�҂�O�̃X���b�h�ŏ������b�����t��������Ƃ����b�����ǁA
(http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/850-856 �Q��)
POWER6+�ŃR�A��2�{�APOWER7�ł܂�2�{�Ƃ������Ƃ��B�������N���b�N�̕���POWER6-7�����"4+ GHz"
�Ƃ���Ă��邷�B
�����̂�����p�ɎQ�l������2�قNj����Ă������B
http://www.ibm.com/ru/events/presentations/ibmday/mozgovoy.pdf
http://www-05.ibm.com/dk/news/events/systemiconference/pdf/Erik_Rex_POWER6.pdf
�㓡�L����Intel�̃T�[�o�[�v���Z�b�T���}���`�R�A��簐i���Ă���b�������Ă��邷���ǁA���̕ӂ�Sun Niagara
��POWER�̂����������[�h�}�b�v�ɑR���Ă���Ƃ������Ƃ��B
���������A�q�쎁�������Ă����u�����\�̐V�^SX�v(>>354�Q��)�����\���ꂽ�����ǁA�x�N�g���}�j�A
�̊F�����A������邱�Ƃ햳�������H
http://www.nec.co.jp/press/ja/0710/2501.html
�@�@---------------------
�@�@NEC�́A���E���̒P��R�A������102.4�M�K�t���b�v�X(GFLOPS:1�b�Ԃ�10����̕��������_���Z
�@�@���\)�����������V�K�J��CPU�̓��ڂȂǂɂ��A�ő�x�N�g�����\��839�e���t���b�v�X(TFLOPS:
�@�@1�b�Ԃ�1����̕��������_���Z���\)�ƂȂ�A�x�N�g���^�Ƃ��ẮA���E�ō����̃X�[�p�[�R��
�@�@�s���[�^�uSX�V���[�Y ���f��SX-9�v�i�����A�{����萢�E�����ɔ̔��������J�n�������܂����B
�@�@---------------------
�̊F�����A������邱�Ƃ햳�������H
http://www.nec.co.jp/press/ja/0710/2501.html
�@�@---------------------
�@�@NEC�́A���E���̒P��R�A������102.4�M�K�t���b�v�X(GFLOPS:1�b�Ԃ�10����̕��������_���Z
�@�@���\)�����������V�K�J��CPU�̓��ڂȂǂɂ��A�ő�x�N�g�����\��839�e���t���b�v�X(TFLOPS:
�@�@1�b�Ԃ�1����̕��������_���Z���\)�ƂȂ�A�x�N�g���^�Ƃ��ẮA���E�ō����̃X�[�p�[�R��
�@�@�s���[�^�uSX�V���[�Y ���f��SX-9�v�i�����A�{����萢�E�����ɔ̔��������J�n�������܂����B
�@�@---------------------
���̕��A�ǂ���
392 �FSocket774�F2007/10/28(��) 03:57:18 ID:rHwytf3M
SX�X�Ȃ�Ă̂��o���킯������܂��܂��x�N�g���͏I���Ȃ����Ď�����H
SX10��1P��_���낤�Ȃ��c
�}�j�A����Ȃ�����
�p���͗͂Ȃ�
�Ƃ����������җ��v
����ł��Ԏ��Ȃ낤��
�p���͗͂Ȃ�
�Ƃ����������җ��v
����ł��Ԏ��Ȃ낤��
�u���v�Ƃ��u�v�V�v�Ƃ��u�ɂ��v��������
���n�]�����
���n�]�����
�l�n�[�����̃A�[�L�e�N�`�����g���� LGA775 CPU ���ďo�Ȃ���ł��H
�l�n�[�������ă������R���g���[���[��������邻���ł����A
LGA775�p�ɕ����o���Ȃ���ł����H
�l�n�[�������ă������R���g���[���[��������邻���ł����A
LGA775�p�ɕ����o���Ȃ���ł����H
397 �F�R�E�L�́M�E,,�j�����������������F2007/10/28(��) 05:16:45 ID:IFnrUqo9
LGA775�̌�p��LGA715�ł�
>>395
�u�ɂ��v�͂Ƃ������A�u���v�Ƃ��u�v�V�v�̓}�[�P�e�B���O�p�ꂾ��B
�ǂ��������Č����ƁA�����킩���ĂȂ����n���������Ȍ��t�B
�u�ɂ��v�͂Ƃ������A�u���v�Ƃ��u�v�V�v�̓}�[�P�e�B���O�p�ꂾ��B
�ǂ��������Č����ƁA�����킩���ĂȂ����n���������Ȍ��t�B
Super�AInnovation��������
���n�I���ǂ����킩��A�R���s���[�e�B���O�Ȋ����Ȃ�
�����j�A
���p�C�v���C��
���R���s���[�^
�ȂV�N�ȋ�����W
���n�I���ǂ����킩��A�R���s���[�e�B���O�Ȋ����Ȃ�
�����j�A
���p�C�v���C��
���R���s���[�^
�ȂV�N�ȋ�����W
�����܂ł����ƁA�ő��A
�@����obsolete
�@����obsolete
��������niagara2�͑����݂�������
�����ɂ͉��Ȃ�����
�����ɂ͉��Ȃ�����
SPECweb��Tigerton��葬������SPECjbb��Clovertown���x�������
�����ł��V���O���X���b�h���\���K�v�ȗp�r�ɂȂ�Ƒʖڑʖ�
�����ł��V���O���X���b�h���\���K�v�ȗp�r�ɂȂ�Ƒʖڑʖ�
404 �F�R�E�L�́M�E,,�j�����������������F2007/10/29(��) 07:00:00 ID:vjmDbN68
Java���Č��ǎ����X���b�h�����݂����Ȏ����ʖڂȂ�
>>389�̑��������ǁA2010�N���܂ł̃��[�h�}�b�v������ׂ�ƕ�������2�ɕ����ꂽ�悤��
�����邷�B
���V���O���X���b�h�d���̐V�K���[�W�R�A�J��->��(�X)����v���Z�X�ő�K�̓}���`�R�A��
�@IBM (POWER6�R�A x2@2007 -> POWER7�R�A x8@2010)
�@Intel x86 (Nehalem�R�A x4@2008 -> Nehalem x8@2009)
����(��)����R�A�K�͂Ń}���`�R�A��
�@Intel IPF (Tukwila�R�A x4@2008 -> Poulson/Kitson many-core@2009-)
�@SUN (US-II�R�A x 8@2007 -> Rock�R�A x 16@2008?)
�@AMD (K8L�R�A x 4@2007 -> Bulldoser�R�A x 16@2010)
�e�`�b�v�̃g�����W�X�^���Ȃǂ̏�o�������������ו��������̂�������Ȃ������ǁA
���Ԉ���ĂȂ��Ǝv�����B
�����邷�B
���V���O���X���b�h�d���̐V�K���[�W�R�A�J��->��(�X)����v���Z�X�ő�K�̓}���`�R�A��
�@IBM (POWER6�R�A x2@2007 -> POWER7�R�A x8@2010)
�@Intel x86 (Nehalem�R�A x4@2008 -> Nehalem x8@2009)
����(��)����R�A�K�͂Ń}���`�R�A��
�@Intel IPF (Tukwila�R�A x4@2008 -> Poulson/Kitson many-core@2009-)
�@SUN (US-II�R�A x 8@2007 -> Rock�R�A x 16@2008?)
�@AMD (K8L�R�A x 4@2007 -> Bulldoser�R�A x 16@2010)
�e�`�b�v�̃g�����W�X�^���Ȃǂ̏�o�������������ו��������̂�������Ȃ������ǁA
���Ԉ���ĂȂ��Ǝv�����B
>>404
�ւ��`�A�����Ȃ́c�H
��낵����A���̂��Ƃɂ��ĉ�����Ă���Q�l�����������ł����炲�����肢�܂��B
(URL �ł� ��k)
����ƁA���̓_���}�C�N���v���Z�b�T�̐v�̂ǂ����������Ɋւ���Ă���̂����m�肽���B
�ւ��`�A�����Ȃ́c�H
��낵����A���̂��Ƃɂ��ĉ�����Ă���Q�l�����������ł����炲�����肢�܂��B
(URL �ł� ��k)
����ƁA���̓_���}�C�N���v���Z�b�T�̐v�̂ǂ����������Ɋւ���Ă���̂����m�肽���B
>>405
Poulson��32nm��6����10�R�A�ƌ����Ă��邩��"�V�K���[�W�R�A"�ɓ������Ȃ���
Kittson�͂܂��A�[�L�e�N�`������܂��ĂȂ����낤����ǂ���Ƃ������Ȃ��͂�
����many-core���e�Ɩڂ���Ă���Larrabee�̂��Ƃ��Y��Ȃ��ł�������
Poulson��32nm��6����10�R�A�ƌ����Ă��邩��"�V�K���[�W�R�A"�ɓ������Ȃ���
Kittson�͂܂��A�[�L�e�N�`������܂��ĂȂ����낤����ǂ���Ƃ������Ȃ��͂�
����many-core���e�Ɩڂ���Ă���Larrabee�̂��Ƃ��Y��Ȃ��ł�������
�C���e���A�uItanium�v�v���Z�b�T�̒P��R�A������̃p�t�H�[�}���X������v��
http://japan.cnet.com/news/ent/story/0,2000056022,20357972,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20357972,00.htm
409 �FMAC�I�^��407 �����F2007/10/29(��) 19:18:59 ID:WHdYQayy
>>407
Poulson�܂ő҂ƃT�[�o�[�v���Z�b�T�̃}���`�R�A���̒����Ɏ��c������
�Ȃ������ˁH���̂Ƃ���CTukwila�̃I���W�i���v�����Ɖ\���ꂽ16-core�N���X��
���j�C�R�A���Ă̂�Poulson�ɂȂ��Ȃ����Ƃ����������Ă��邷�B
http://news.zdnet.com/2100-9584-5984747.html
�@�@----------------------
�@�@An ambitious future-generation product code-named Tanglewood had been
�@�@planned with as many as 16 processing cores, according to a source
�@�@familiar with the plan and a document about the chip seen by CNET
�@�@News.com. But in December 2003, Intel announced the model would be
�@�@called Tukwila instead--quietly moving to a more conventional design
�@�@that had four or more cores, slated for release in 2007.
�@�@----------------------
Poulson�܂ő҂ƃT�[�o�[�v���Z�b�T�̃}���`�R�A���̒����Ɏ��c������
�Ȃ������ˁH���̂Ƃ���CTukwila�̃I���W�i���v�����Ɖ\���ꂽ16-core�N���X��
���j�C�R�A���Ă̂�Poulson�ɂȂ��Ȃ����Ƃ����������Ă��邷�B
http://news.zdnet.com/2100-9584-5984747.html
�@�@----------------------
�@�@An ambitious future-generation product code-named Tanglewood had been
�@�@planned with as many as 16 processing cores, according to a source
�@�@familiar with the plan and a document about the chip seen by CNET
�@�@News.com. But in December 2003, Intel announced the model would be
�@�@called Tukwila instead--quietly moving to a more conventional design
�@�@that had four or more cores, slated for release in 2007.
�@�@----------------------
>>409
>>408���\���Ă��ꂽ����
Itanium��POWER��SPARC64���ˑR�Ƃ��ăV���O���X���b�h���\��RAS�@�\�d����
�X���[�v�b�g���d������Ȃ�64S�Ƃ�32S�Ƃ��̍��؎d�l���Ă˂��ĕ��j�Ɍ�����
Poulson�͂ˁ[�ŋ߂ɂȂ���Intel�̃A�[�L�e�N�g���P����(�{�X�Q�[����)�R�A�𑝂₷�킯����Ȃ��Ƃ������Ă邵
16�R�A�ȏ���Ă̂͂��肦�Ȃ��Ǝv���
>>408���\���Ă��ꂽ����
Itanium��POWER��SPARC64���ˑR�Ƃ��ăV���O���X���b�h���\��RAS�@�\�d����
�X���[�v�b�g���d������Ȃ�64S�Ƃ�32S�Ƃ��̍��؎d�l���Ă˂��ĕ��j�Ɍ�����
Poulson�͂ˁ[�ŋ߂ɂȂ���Intel�̃A�[�L�e�N�g���P����(�{�X�Q�[����)�R�A�𑝂₷�킯����Ȃ��Ƃ������Ă邵
16�R�A�ȏ���Ă̂͂��肦�Ȃ��Ǝv���
411 �FMAC�I�^��410 �����F2007/10/30(��) 00:47:27 ID:q9aAt3ws
>>410
�@�@--------------
�@�@>>408���\���Ă��ꂽ����
�@�@--------------
���̋L���AMontecito -> Tukwila�̕ύX���V���O���X���b�h���\����̗�Ƃ��ċ����Ă��邷���ǁB�B�B
�@�@==============
�@�@McNairy���́AMontecito����uTukwila�v�ւ̎��̈ڍs�ł́A�P��R�A�v���Z�b�T�ɂ�����u�V���O��
�@�@�X�g���[���̃p�t�H�[�}���X�v�̌��オ���҂ł���ƌ��B
�@�@==============
Tukwila�̃_�C�ʐ^��ŋߌ��J���ꂽ�����ǁA�R�A���̂�Montecito�Ƃقړ������B
Tukwila: http://www.theinquirer.net/gb/inquirer/news/2007/10/17/idf-taiwan-itanium-news
Montecito: http://en.wikipedia.org/wiki/Image:Montecito_micrograph.jpg
�܂�Poulson�������Ȃ郂�m����lj����҂������ǁA�T�[�o�[�����v���Z�b�T�ɂ����郁�j�C�R�A��A
�т����肷��قǑ����L�܂�Ǝv�����B
�@�@--------------
�@�@>>408���\���Ă��ꂽ����
�@�@--------------
���̋L���AMontecito -> Tukwila�̕ύX���V���O���X���b�h���\����̗�Ƃ��ċ����Ă��邷���ǁB�B�B
�@�@==============
�@�@McNairy���́AMontecito����uTukwila�v�ւ̎��̈ڍs�ł́A�P��R�A�v���Z�b�T�ɂ�����u�V���O��
�@�@�X�g���[���̃p�t�H�[�}���X�v�̌��オ���҂ł���ƌ��B
�@�@==============
Tukwila�̃_�C�ʐ^��ŋߌ��J���ꂽ�����ǁA�R�A���̂�Montecito�Ƃقړ������B
Tukwila: http://www.theinquirer.net/gb/inquirer/news/2007/10/17/idf-taiwan-itanium-news
Montecito: http://en.wikipedia.org/wiki/Image:Montecito_micrograph.jpg
{kind=link}
�܂�Poulson�������Ȃ郂�m����lj����҂������ǁA�T�[�o�[�����v���Z�b�T�ɂ����郁�j�C�R�A��A
�т����肷��قǑ����L�܂�Ǝv�����B
412 �FMAC�I�^���⑫�F2007/10/30(��) 00:55:49 ID:q9aAt3ws
Nehalem�̑�K�͂ȃR�A�g���̉e�ɉB�ꂪ�������ǁA�ŋ߂�Intel���X���[���R�A�ɂ��d�͌�����
����ɂ��Č�葱���Ă��邱�Ƃ����ɒu���Ă����������ǂ��������B
http://journal.mycom.co.jp/articles/2006/10/12/idf1/013.html
����ɂ��Č�葱���Ă��邱�Ƃ����ɒu���Ă����������ǂ��������B
http://journal.mycom.co.jp/articles/2006/10/12/idf1/013.html
���ƋZ�p�I�\�����������Ă͂����Ȃ�
414 �F�R�E�L�́M�E,,�j�����������������F2007/10/30(��) 06:05:26 ID:EJ1D+fUx
>>406
��Ȃ���Ȃ���B
���������ɗB���Java���������Ŏ����I�ȃX���b�h�����T�|�[�g���ĂȂ��킯�ŁB
���z��茻���͌��������Ă������Ƃ���Ȃ��́B
��������I�ȃ}���`�X���b�h���͉\�B
��Ȃ���Ȃ���B
���������ɗB���Java���������Ŏ����I�ȃX���b�h�����T�|�[�g���ĂȂ��킯�ŁB
���z��茻���͌��������Ă������Ƃ���Ȃ��́B
��������I�ȃ}���`�X���b�h���͉\�B
�������Ƀr�b�g�V���A���v���Z�b�T�𑽐����������āA
�����SIMD�œ��������Ă̂͂ǂ����낤?
�Ⴆ�ASRAM�ɋ߂����x�œ���eDRAM��
10000���炢�̃r�b�g�V���A�����Z�������
(eDRAM�`�b�v���~10000)bit�@SIMD�œ��삷���
�����āA����e�c�q�`�l�Z�b�g�ƃ�������1024bit�@1.5Hz�̃o�X�Őڑ�
1�@eDRAM=10000bit�@SIMD
eDRAM1��=16MB
1DIMM=16�@eDRAM
1�V�X�e��=32�@DIMM
5120000bit�@SIMD,�@8GB�@���C��������
�����128GB���炢��Solid�@State�@Disk��
�Ȃ�Ă̂��������炢�����ĂȂ�?
���C��CPU��POWER6���t�����f��p��8Ghz���炢?
�����SIMD�œ��������Ă̂͂ǂ����낤?
�Ⴆ�ASRAM�ɋ߂����x�œ���eDRAM��
10000���炢�̃r�b�g�V���A�����Z�������
(eDRAM�`�b�v���~10000)bit�@SIMD�œ��삷���
�����āA����e�c�q�`�l�Z�b�g�ƃ�������1024bit�@1.5Hz�̃o�X�Őڑ�
1�@eDRAM=10000bit�@SIMD
eDRAM1��=16MB
1DIMM=16�@eDRAM
1�V�X�e��=32�@DIMM
5120000bit�@SIMD,�@8GB�@���C��������
�����128GB���炢��Solid�@State�@Disk��
�Ȃ�Ă̂��������炢�����ĂȂ�?
���C��CPU��POWER6���t�����f��p��8Ghz���炢?
416 �FSocket774�F2007/10/30(��) 22:57:15 ID:WkJW4PBE
2���L���b�V���Ȃ�ėv��Ȃ�����A�S�ʂ�1���L���b�V���ɂ����������I�ɑ���
>>416
���ꂷ��ƃN���b�N���������Ȃ�
���ꂷ��ƃN���b�N���������Ȃ�
>>415
3.2GHz�œ���SRAM��SIMD�R�A���ē������Ƃ������̂͌������Ƃ���܂��B
���_�l�͐�����ł����A�ϑԉ߂��Ĉꕔ�̃g�b�v�K���ȊO���\�������o���Ă܂���B
3.2GHz�œ���SRAM��SIMD�R�A���ē������Ƃ������̂͌������Ƃ���܂��B
���_�l�͐�����ł����A�ϑԉ߂��Ĉꕔ�̃g�b�v�K���ȊO���\�������o���Ă܂���B
���r�E�X1�͂������Ȃ�
420 �FSocket774�F2007/10/30(��) 23:16:35 ID:WkJW4PBE
�ʂ�5GHz��10GHz���_���Ă��Ȃ�����
PA-RISC,Power2,R8000(FPU�͈ꎟ�L���b�V���ɃA�N�Z�X�����A�L���b�V���ɂ̂݃A�N�Z�X)�Ȃ�
�S����N���b�N
�S����N���b�N
422 �FSocket774�F2007/10/30(��) 23:42:26 ID:WkJW4PBE
130�ɂ̎��_��1GHz�N���X�Ȃ�x���Ȃ�����
423 �F�R�E�L�́M�E,,�j�����������������F2007/10/30(��) 23:59:58 ID:EJ1D+fUx
>>416
�L���b�V���e�ʂ�傫������ƃ��C�e���V�����ɂȂ�B
������K�w�\�����厖�Ȃ́B
SPE��LS�݂����ɂ��ꂻ�̂��̂��S��������Ԃɂ��Ă��܂��Η��_�ア����ł��傫���o����
�L���b�V���e�ʂ�傫������ƃ��C�e���V�����ɂȂ�B
������K�w�\�����厖�Ȃ́B
SPE��LS�݂����ɂ��ꂻ�̂��̂��S��������Ԃɂ��Ă��܂��Η��_�ア����ł��傫���o����
���ʃL���b�V���e�ʂ�傫��������q�b�g�����オ����
���C�e���V��H�炢�ɂ����Ȃ邾������
�s�Ԃ��J����Ɠ˂����܂�₷�����A�܂ǁ[�ł��ǂ����B
���C�e���V��H�炢�ɂ����Ȃ邾������
�s�Ԃ��J����Ɠ˂����܂�₷�����A�܂ǁ[�ł��ǂ����B
���ӂ����͂��Ă����APower4,5,5+��L2���肾������
426 �F�R�E�L�́M�E,,�j�����������������F2007/10/31(��) 00:21:45 ID:z0sDZHjL
>>424
������������
�L���b�V���̃G���g������������L���b�V���ɖړI�̃A�h���X�����݂��邩
�m�F�����鏈���̗ʂ��������
������������
�L���b�V���̃G���g������������L���b�V���ɖړI�̃A�h���X�����݂��邩
�m�F�����鏈���̗ʂ��������
427 �F�R�E�L�́M�E,,�j�����������������F2007/10/31(��) 00:23:44 ID:z0sDZHjL
�����A�ނ���z���x���̖�������
������
�}�X�~���ăl���⏬�m
�L���b�V�����̂̃��C�e���V�ƃ������܂Ŋ܂߂������I�ȃ��C�e���V�Ƃŋc�_���H������Ă�B
431 �F�R�E�L�́M�E,,�j�����������������F2007/10/31(��) 00:30:59 ID:z0sDZHjL
�L���b�V���e�ʂ�{�ɂ���ƃ��C�e���V��1��������Čo������m��Ȃ��ȃK�L��
433 �F�R�E�L�́M�E,,�j�����������������F2007/10/31(��) 00:37:24 ID:z0sDZHjL
�����m�炸�ɒp������������������
�������A�N�Z�X�ɋǏ���������Ώ������Ă��q�b�g���C�e���V�̒Z���L���b�V���̂ق����L��
�������A�N�Z�X�ɋǏ���������Ώ������Ă��q�b�g���C�e���V�̒Z���L���b�V���̂ق����L��
���̒Ⴂ�R���̑���Ȃ���
>>431
�Ă��Ƃ͔����ɂ���ƃ��C�e���V���P����Ƃ������Ƃ����w
�Ă��Ƃ͔����ɂ���ƃ��C�e���V���P����Ƃ������Ƃ����w
Penryn��L2���������ǃ��C�e���V�����Ȃ����炵����
�E�F�f�B���O�s�[�`��
�Ƃ��Ă����@���ȂȂ߂���I
�Ƃ��Ă����@���ȂȂ߂���I
�C���e���A�R�A���x���̃G���[���o�@�\�𓋍ڂ����uItanium 9100�v
�`�~�b�V�����N���e�B�J������ł̗̍p��
http://pc.watch.impress.co.jp/docs/2007/1031/intel.htm
�`�~�b�V�����N���e�B�J������ł̗̍p��
http://pc.watch.impress.co.jp/docs/2007/1031/intel.htm
�~�b�V�����N���e�B�J���Ȃ�ėp�ꂪ���悢��O�ʂɏo�Ă����
���Ⴀ�A���܂Ń~�b�V���������ʼn�����Ă��́H�Ƌ^�������Ȃ�B
�X�ɁA�Ŏ��̃l�^�́H�Ƃ������A�l�^�ꊴ�������B
�o�J�R�s�[�ɂ܂����X������邢����
���Ⴀ�A���܂Ń~�b�V���������ʼn�����Ă��́H�Ƌ^�������Ȃ�B
�X�ɁA�Ŏ��̃l�^�́H�Ƃ������A�l�^�ꊴ�������B
�o�J�R�s�[�ɂ܂����X������邢����
�����������[�A�z
441 �F�R�E�L�́M�E,,�j�����������������F2007/11/01(��) 21:33:38 ID:toPrRZ3M
>>435
���������v�Ȃ�A��������Ȃ��́B
���Ȃ݂�Northwood�i130nm�j��8Way�Z�b�g�A�\�V�G�C�e�B�u�Ń��C�e���V2���������Ă���B
�T�C�Y��8KB�B
���̓����ɂ��Ă��̍��N���b�N�v�ł��̃��C�e���V��L2�����Ȃ����肠�蓾�Ȃ��ł���
Prescott��16KB�Ń��C�e���V4�ɒቺ���Ă邯�ǁA�X�Ȃ鍂�N���b�N����_�����v�������i�ߋ��`�j����
�܂������ȂƂ��낾�낤�B
L2�̏ꍇ������
Banias(1MB) 8 ��Dothan(2MB) 9
����Prescott��1MB��31��2MB��32�����������ȁB
>>436
1.5�{���āA��Ԍ��ʂłɂ�����Ȃ����Ǝv���B�ǂ����Ȃ�2�{�ɂ��Ȃ��ƁB
���ꎩ��Nehalem�̐��\�����̂��߂̃f�`���[���ȋC�������B
Yonah�����v���Εs���Ƀ��C�e���V�����Ȃ��Ă��B4MB��Core 2 Duo�ƃ��C�e���V���������B
���������v�Ȃ�A��������Ȃ��́B
���Ȃ݂�Northwood�i130nm�j��8Way�Z�b�g�A�\�V�G�C�e�B�u�Ń��C�e���V2���������Ă���B
�T�C�Y��8KB�B
���̓����ɂ��Ă��̍��N���b�N�v�ł��̃��C�e���V��L2�����Ȃ����肠�蓾�Ȃ��ł���
Prescott��16KB�Ń��C�e���V4�ɒቺ���Ă邯�ǁA�X�Ȃ鍂�N���b�N����_�����v�������i�ߋ��`�j����
�܂������ȂƂ��낾�낤�B
L2�̏ꍇ������
Banias(1MB) 8 ��Dothan(2MB) 9
����Prescott��1MB��31��2MB��32�����������ȁB
>>436
1.5�{���āA��Ԍ��ʂłɂ�����Ȃ����Ǝv���B�ǂ����Ȃ�2�{�ɂ��Ȃ��ƁB
���ꎩ��Nehalem�̐��\�����̂��߂̃f�`���[���ȋC�������B
Yonah�����v���Εs���Ƀ��C�e���V�����Ȃ��Ă��B4MB��Core 2 Duo�ƃ��C�e���V���������B
442 �F�R�E�L�́M�E,,�j�����������������F2007/11/01(��) 21:36:09 ID:toPrRZ3M
���܂���Northwood��L1��4Way��Prescott��8Way��
CPU�̓������`�b�v
Itanium��CPU����Ȃ����Z���j�b�g�Ă�SRAM
�����͒c�q�����������_�͂��Ă��W
�����͒c�q�����������_�͂��Ă��W
445 �FSocket774�F2007/11/02(��) 05:50:06 ID:GHQjo1e6
���Ⴀ4KB�Ȃ烌�C�e���V1�ŁA2KB�Ȃ�0�Ȃ�ł���������
447 �FSocket774�F2007/11/02(��) 08:00:36 ID:GHQjo1e6
���Ⴀ�ABanias��L2�̕����v�����ǂ����Ď�����
���̃o�J�͂��܂ő�������肾�H
449 �FSocket774�F2007/11/02(��) 08:23:11 ID:GHQjo1e6
���L���b�V���̃G���g������������L���b�V���ɖړI�̃A�h���X�����݂��邩
���m�F�����鏈���̗ʂ��������
�܂肳���ARAID�݂����ɓ������e��L1�L���b�V�������Ɍq���Ηǂ���
�Ⴆ��64KB��L1�L���b�V��������CPU�Ȃ�A
L1��4������Γ��ꎞ�ԂŁA4�{�̗ʂ�L1�L���b�V���ɃA�N�Z�X�o���鎖�Ȃ��
���m�F�����鏈���̗ʂ��������
�܂肳���ARAID�݂����ɓ������e��L1�L���b�V�������Ɍq���Ηǂ���
�Ⴆ��64KB��L1�L���b�V��������CPU�Ȃ�A
L1��4������Γ��ꎞ�ԂŁA4�{�̗ʂ�L1�L���b�V���ɃA�N�Z�X�o���鎖�Ȃ��
�Ȃ�Ƃ������ʐv
>>449
�ʐς��ł����Ȃ���̕��z���������Ȃ�̂Ń��C�e���V�������Ȃ�B
�ʐς��ł����Ȃ���̕��z���������Ȃ�̂Ń��C�e���V�������Ȃ�B
>>449
�����AAMD��Intel����������Ă��B���̋Z�p�ŏo����͈͂łˁB
�����AAMD��Intel����������Ă��B���̋Z�p�ŏo����͈͂łˁB
���▢���\���L���b�V���Ȃ�Ă������Ȃ�
�K�v�ɂȂ�O�ɏ���Ƀ��W�X�^�ɏ������܂ꂽ�獢�邾��H
�����烌�C�e���V��0�������Ȃ��悤�ɃL���b�V�����₵�Ă��
�K�v�ɂȂ�O�ɏ���Ƀ��W�X�^�ɏ������܂ꂽ�獢�邾��H
�����烌�C�e���V��0�������Ȃ��悤�ɃL���b�V�����₵�Ă��
455 �FSocket774�F2007/11/02(��) 20:24:07 ID:Z0BoiabA
UltraSPARC T2
8�̃R�A��64�̃X���b�h
�C���e���̂͂邩����s���ĂȂ����H
http://jp.sun.com/products/processors/
8�̃R�A��64�̃X���b�h
�C���e���̂͂邩����s���ĂȂ����H
http://jp.sun.com/products/processors/
�����O�Ɏ����Ŏ����^�R
�����Ŏ����Ȃ��Ă��l�ɕ�����̂��Q��������N�Y
�}�}�ɂ��������˂����Ĕ���
http://online.plathome.co.jp/detail.html?scd=11811710
http://online.plathome.co.jp/detail.html?scd=11811710
���삷������ƈ��オ�肾��
��������
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
459 �FSocket774 �F2007/11/02(��) 21:03:59 ID:Z0BoiabA
���삷������ƈ��オ�肾��
461 �F�R�E�L�́M�E,,�j�����������������F2007/11/02(��) 21:26:21 ID:Tl0apWDx
�ėp���W�X�^������128�{�Ƃ������ŋ߂�CPU���āB
���W�X�^�t�@�C���̍��v�T�C�Y2KB���炢�z���Ă��Ȃ���
����Ȃ��C�e���V1�Ń��[�h�E���C�g�ł���Ώ\�����B
���W�X�^�t�@�C���̍��v�T�C�Y2KB���炢�z���Ă��Ȃ���
����Ȃ��C�e���V1�Ń��[�h�E���C�g�ł���Ώ\�����B
�ǂ��P���ȃA�v���g���Ă�
�ŋ߂̂̓��W�X�^�t�@�C���̃��C�e���V��1����Ȃ����ǂ�
464 �F�R�E�L�́M�E,,�j�����������������F2007/11/03(�y) 08:10:13 ID:Nka81Lvh
Core 2�͎Q�ƃ��W�X�^����4�{�ȏ�ɑ�����Ɛ��\�ቺ���邵�ȁB
�����A�L�������[�^��3�{�����Ȃ���Ȃ��̂���
�����A�L�������[�^��3�{�����Ȃ���Ȃ��̂���
�����������[�A�z
466 �F�R�E�L�́M�E,,�j�����������������F2007/11/03(�y) 11:13:21 ID:Nka81Lvh
�����������[�A�z
>>466
����A����ς肨�O���킩���ĂȂ�
����A����ς肨�O���킩���ĂȂ�
468 �F�R�E�L�́M�E,,�j�����������������F2007/11/03(�y) 20:34:16 ID:Nka81Lvh
�Ȃ��W�X�^���[�h�X�g�[���̖��m��Ȃ��̂�
SPECfp_base_rate2006 ��r
http://japan.cnet.com/blog/kichi/2007/11/03/entry_25000980/
http://japan.cnet.com/blog/kichi/2007/11/03/entry_25000980/
471 �FSocket774�F2007/11/04(��) 10:16:49 ID:cbJqMQVE
X86�A�[�L�e�N�`����,CISC��RISC���ߕϊ��Ƃ�����@�ɂ�萶���c��
���Ƃ��ł������A���ꂪ��肭�����Ȃ�������IA-64���f�X�N�g�b�v
�Ŏg���Ă��̂��ȁH
(�{��IA-64���̂�x86�̌㊘�Ƃ��ĊJ������Ă��B�j
Intel AMD Nexgen ��x86���[�J�[��Cisc��Risc���ߕϊ��̎�@��
�ڍ����A�Ȃ�Ƃ�Cisc�ł���x86���߂̂܂܍����������@������
(Cyrix�͂��̎�@�������)
�������A���\���オ���ł��ƂȂ�intel��IA-64���f�X�N�g�b�v��
�g�傳���邽�ߖ{��������B
AMD�͂��߂Ƃ���x86�݊����[�J�[���Ǝ��A�[�L�e�N�`����͍�����
���A�V�����J�����̃T�|�[�g��intel�ɍ����������A
���ʁA�s���IA-64 Intel�̓Ɛ�s��ɂȂ��Ă��\���������������B
���Ƃ��ł������A���ꂪ��肭�����Ȃ�������IA-64���f�X�N�g�b�v
�Ŏg���Ă��̂��ȁH
(�{��IA-64���̂�x86�̌㊘�Ƃ��ĊJ������Ă��B�j
Intel AMD Nexgen ��x86���[�J�[��Cisc��Risc���ߕϊ��̎�@��
�ڍ����A�Ȃ�Ƃ�Cisc�ł���x86���߂̂܂܍����������@������
(Cyrix�͂��̎�@�������)
�������A���\���オ���ł��ƂȂ�intel��IA-64���f�X�N�g�b�v��
�g�傳���邽�ߖ{��������B
AMD�͂��߂Ƃ���x86�݊����[�J�[���Ǝ��A�[�L�e�N�`����͍�����
���A�V�����J�����̃T�|�[�g��intel�ɍ����������A
���ʁA�s���IA-64 Intel�̓Ɛ�s��ɂȂ��Ă��\���������������B
472 �FSocket774�F2007/11/04(��) 10:20:24 ID:cbJqMQVE
>>471
AMD��HP����IA-64�̃��C�Z���X����IA-64�݊�CPU�o���Ă��\��������ȁB
(IA-64�̌�����Intel��HP�łǂ��Ȃ��Ă��̂��͒m��Ȃ���)
AMD��HP����IA-64�̃��C�Z���X����IA-64�݊�CPU�o���Ă��\��������ȁB
(IA-64�̌�����Intel��HP�łǂ��Ȃ��Ă��̂��͒m��Ȃ���)
1:Alpha�n���̂܂܋������Ă���
2:IBM�����낵���C�C�L�ɂȂ��Ă���
3:ARM���e��������AmigaOS����vOS�ɐ����Ă���
2:IBM�����낵���C�C�L�ɂȂ��Ă���
3:ARM���e��������AmigaOS����vOS�ɐ����Ă���
>>473
DEC�̋K�͂��炵��1�͖����Ǝv���B
�\���Ƃ��Ă�2���ȁBPrep(PowerPC Refarence Plathome)��PC�̎�͂�
�Ȃ��Ă��\���������B
DEC�̋K�͂��炵��1�͖����Ǝv���B
�\���Ƃ��Ă�2���ȁBPrep(PowerPC Refarence Plathome)��PC�̎�͂�
�Ȃ��Ă��\���������B
>>471
���Ƃ�IA-64CPU��IA-32�삳����\�͂��A������P6�݂����Ƀ��b�T��������
����A�����ɏ���d�͂��f�X�N�g�b�v�����Ƃ͌����Ȃ����炢�傫������A�`�b�v
�Z�b�g�̋��p�����x�ꂽ�i���܂��ɏo���ĂȂ��j���A�����A���̗v���������B
���Ƃ�IA-64CPU��IA-32�삳����\�͂��A������P6�݂����Ƀ��b�T��������
����A�����ɏ���d�͂��f�X�N�g�b�v�����Ƃ͌����Ȃ����炢�傫������A�`�b�v
�Z�b�g�̋��p�����x�ꂽ�i���܂��ɏo���ĂȂ��j���A�����A���̗v���������B
IA-64���j�b�`�ɂȂ��Ă�ő�̗v���͊J���x���œ����\�肩��2�N�x��āA�o���琫�\�͎���x�ꂾ�Ǝv�����B
�����\��ʂ�o�Ă���APOWER�ȊO��RISC�s��S���H���Ă��͂������Ax86-64�̎������o��܂ł̊Ԃ�
�\�t�g�E�F�A���Y��~�ςł��āAx86��p��64bit��IA-64�Ƃ����������Ă����\������������Ȃ����ƁB
�����\��ʂ�o�Ă���APOWER�ȊO��RISC�s��S���H���Ă��͂������Ax86-64�̎������o��܂ł̊Ԃ�
�\�t�g�E�F�A���Y��~�ςł��āAx86��p��64bit��IA-64�Ƃ����������Ă����\������������Ȃ����ƁB
>>471
������ƃO�O������MMXpentium�̃v���Z�X��0.35��200MHz���炢�܂ŏo�Ă����͂��B
�ꐢ��ŃN���b�N��1.4�{�ɂȂ�ƌ����Ă��邱�Ƃ���65nm�Ȃ�5����ł����炭1.1GHz���炢�s���Ă����B
�p�C�v���C���̉��ǂ��s���Ȃ���͂Ȃ��̂ł����Ƒ������낤���A�悤�₭�ŏ���PentiumM�ɒǂ������炢���B
�c�c�܂�����ȃe�L�g�[�Ȍv�Z���Ă��Ȃ�̈Ӗ����Ȃ����B
������ƃO�O������MMXpentium�̃v���Z�X��0.35��200MHz���炢�܂ŏo�Ă����͂��B
�ꐢ��ŃN���b�N��1.4�{�ɂȂ�ƌ����Ă��邱�Ƃ���65nm�Ȃ�5����ł����炭1.1GHz���炢�s���Ă����B
�p�C�v���C���̉��ǂ��s���Ȃ���͂Ȃ��̂ł����Ƒ������낤���A�悤�₭�ŏ���PentiumM�ɒǂ������炢���B
�c�c�܂�����ȃe�L�g�[�Ȍv�Z���Ă��Ȃ�̈Ӗ����Ȃ����B
Itanium��2�N�����o�Ă��A����܂茻�݂ƕϊ��Ȃ��Ǝv��
���_���������ƁAVLIW�ŃA�E�g��I�u��I�[�_�[��X�[�p�[�X�J�����
�����`�b�v�����͖̂����������킯��
�n�߂�X86�Ȃ݂̒l�i��RISC�����|���鐫�\���Ęb������������
���ۂ́B�B�B
���_���������ƁAVLIW�ŃA�E�g��I�u��I�[�_�[��X�[�p�[�X�J�����
�����`�b�v�����͖̂����������킯��
�n�߂�X86�Ȃ݂̒l�i��RISC�����|���鐫�\���Ęb������������
���ۂ́B�B�B
Itanium�̃N���b�N������̐��\��
�����Pentium3�Ȃ�
Itanium2��Alpha21264�Ȃ�
����Ŋ����̃A�[�L�e�B�N�`���𓑑��Ƃ��ϑz
�����Pentium3�Ȃ�
Itanium2��Alpha21264�Ȃ�
����Ŋ����̃A�[�L�e�B�N�`���𓑑��Ƃ��ϑz
��������ƃA�v����loop�Ɉ˂��Đ��\�Ƀ����������Ăˁc
L3�̂������������Č����Ă��镨�ł͂܂��܂��̌������ȁc
�u���\�v�����Ŏs����Ђ�����Ԃ��̂Ȃ�A���{�ȏ�̍������Ȃ��Ă͖������Ǝv���B
�Ȃ̂Ƀh���O���̔w��ׁB�������e�̌ł�(����̃\�t�g�s��Ȃǂ̐���̍L����)��
���ڂ����炯�A�ǂ��Ő����c���ƁB
L3�̂������������Č����Ă��镨�ł͂܂��܂��̌������ȁc
�u���\�v�����Ŏs����Ђ�����Ԃ��̂Ȃ�A���{�ȏ�̍������Ȃ��Ă͖������Ǝv���B
�Ȃ̂Ƀh���O���̔w��ׁB�������e�̌ł�(����̃\�t�g�s��Ȃǂ̐���̍L����)��
���ڂ����炯�A�ǂ��Ő����c���ƁB
���㐔�N�̃��[�h�}�b�v��Itanium���Xeon�̕������\�͈��|�I�ɏ�B
Itanium�̓j�b�`�����~�܂�Ȃ����낤�B
Itanium�̓j�b�`�����~�܂�Ȃ����낤�B
2�N�������Ă��A���\�ŐH���͖������낤�ˁB�����o��O��Itanium�ɃR�~�b�g���Ă郁���o�[�͑�����������A
�n�C�G���h�T�[�o�̃V�F�A�ō��݂����ɐ������͂����茾���Ȃ��݂����ȏ�Ȃ����Ƃɂ͂Ȃ�Ȃ�����
�\���͂����Ȃ����낤���B���ۂ͂قƂ�Ǔ�����ꂽ����w
CPU�P�̂��炷��ƁAXeonDP�̕����i���������ǁAMP�̕���Tukwila�����[�h�}�b�v�ʂ�o��A
���̂Ƃ��͂܂�CoreMA��Dunnington������܂��Ȃ�Ƃ��Ȃ��Ȃ����낤���B
MP��Nehalem�ɂȂ�Ƃ��́A32nm��Poulson�����B
���[�h�}�b�v�ʂ�Itanium���J������邩����Ԃ��₵�����B
�n�C�G���h�T�[�o�̃V�F�A�ō��݂����ɐ������͂����茾���Ȃ��݂����ȏ�Ȃ����Ƃɂ͂Ȃ�Ȃ�����
�\���͂����Ȃ����낤���B���ۂ͂قƂ�Ǔ�����ꂽ����w
CPU�P�̂��炷��ƁAXeonDP�̕����i���������ǁAMP�̕���Tukwila�����[�h�}�b�v�ʂ�o��A
���̂Ƃ��͂܂�CoreMA��Dunnington������܂��Ȃ�Ƃ��Ȃ��Ȃ����낤���B
MP��Nehalem�ɂȂ�Ƃ��́A32nm��Poulson�����B
���[�h�}�b�v�ʂ�Itanium���J������邩����Ԃ��₵�����B
�ł����{�Ŕ���Ă��ł���H>Itanium
�� 64bit�B
�����Z�h���\�����APC�͉͓��O�ゾ������܂����A�ɘ_���Ĉ������I���`���B
����ɑf�l�����EPIC�֖����������̂�����������肾�����B
�����Z�h���\�����APC�͉͓��O�ゾ������܂����A�ɘ_���Ĉ������I���`���B
����ɑf�l�����EPIC�֖����������̂�����������肾�����B
Itanium�̓n�C�G���h�T�[�o�`���C���t���[���̉��̕��Ƃ����▭�ȂƂ����˂���
�I�[�v�����̔g�ɏ��p�����X�ɍ���System z�̒u���������˂炤
�I�[�v�����̔g�ɏ��p�����X�ɍ���System z�̒u���������˂炤
489 �F�R�E�L�́M�E,,�j�����������������F2007/11/04(��) 21:01:35 ID:+x2Fr5PY
Itanium��OoO�̗p����ΐ��\���̐��\����͌����߂�Ƃ����\�������������A
OoO���m�肷���EPIC�A�[�L�e�N�`���̑��݈Ӌ`���E�E�E
OoO���m�肷���EPIC�A�[�L�e�N�`���̑��݈Ӌ`���E�E�E
Itanium��ooo&15stage�O��̃p�C�v���C������
�����[�����A�C�f�B�A���Ǝv��
CoreMA�̔䂶��Ȃ������ɂȂ��
���т�1.5�{�̑����͒B���ł���
�L���b�V�������̃g�����W�X�^���S�z��������Ȃ�����
�܂�1��������Ȃ����낤����]�T
��p���`�b�v������p�C�v�Ƃ��C�I������p�Ƃ��ł�������Ԃ���
�����[�����A�C�f�B�A���Ǝv��
CoreMA�̔䂶��Ȃ������ɂȂ��
���т�1.5�{�̑����͒B���ł���
�L���b�V�������̃g�����W�X�^���S�z��������Ȃ�����
�܂�1��������Ȃ����낤����]�T
��p���`�b�v������p�C�v�Ƃ��C�I������p�Ƃ��ł�������Ԃ���
>>489
�悭�����������X���邯��EPIC + OoO�̓g�����W�X�^������d�͂��������\��OoO��菭�Ȃ��čς�
���̎�̐i���I�ȃ}�C�N���A�[�L�e�N�`�����̗p����Ȃ��̂̓n�C�G���h�T�[�o�[�����Œ蒅������������炾��
Niagara��SPARC64��UltraSPARC IV��u���������Ȃ��̂Ɠ���
�Ă��A�������ꂽItanium���S��HP�̃f�U�C���Ȃ̂�Intel��Itanium�ɑ���S�̔����������Ă邾��
�{���ɂ��C������Ȃ�f�X�N�g�b�v��WS�����̐v�Ő��i���o��
L3�ڂɂ���Ƃ��p�b�P�[�W�T�C�Y������������Ƃ��o�X����64bit�ɂ���Ƃ��Ő�[�̃v���Z�X���[�����̗p����Ƃ���邱�Ƃ͑�R����
���[��[�S�����킹���̂�x64�̑��݂ł���A����ς�Merced�̒x���͑傫������
�悭�����������X���邯��EPIC + OoO�̓g�����W�X�^������d�͂��������\��OoO��菭�Ȃ��čς�
���̎�̐i���I�ȃ}�C�N���A�[�L�e�N�`�����̗p����Ȃ��̂̓n�C�G���h�T�[�o�[�����Œ蒅������������炾��
Niagara��SPARC64��UltraSPARC IV��u���������Ȃ��̂Ɠ���
�Ă��A�������ꂽItanium���S��HP�̃f�U�C���Ȃ̂�Intel��Itanium�ɑ���S�̔����������Ă邾��
�{���ɂ��C������Ȃ�f�X�N�g�b�v��WS�����̐v�Ő��i���o��
L3�ڂɂ���Ƃ��p�b�P�[�W�T�C�Y������������Ƃ��o�X����64bit�ɂ���Ƃ��Ő�[�̃v���Z�X���[�����̗p����Ƃ���邱�Ƃ͑�R����
���[��[�S�����킹���̂�x64�̑��݂ł���A����ς�Merced�̒x���͑傫������
�s�ꐫ���Ȃ��̂͂悭�킩������B
�ϑz���邮�炢������邱�Ƃ͂Ȃ��ȁB
�ϑz���邮�炢������邱�Ƃ͂Ȃ��ȁB
http://www.itmedia.co.jp/enterprise/articles/0711/02/news040.html
��Ԕ���Ă�����{�s���Itanium�̃V�F�A��24%�B
�̔����z��POWER�ASPARC�������Ă��Ă��AIntel��CPU��������蕪�Ȃ����B
Tukwila�ɂȂ�A������BoxboroMC�ɂ܂��Ȃ肻���Ȃ̂ŁA������蕪�����邾�낤���ǁA
Intel���炵����ׂ��̏��Ȃ��s�ꂾ�낤�ˁB
��Ԕ���Ă�����{�s���Itanium�̃V�F�A��24%�B
�̔����z��POWER�ASPARC�������Ă��Ă��AIntel��CPU��������蕪�Ȃ����B
Tukwila�ɂȂ�A������BoxboroMC�ɂ܂��Ȃ肻���Ȃ̂ŁA������蕪�����邾�낤���ǁA
Intel���炵����ׂ��̏��Ȃ��s�ꂾ�낤�ˁB
>>491
> >>489
> �悭�����������X���邯��EPIC + OoO�̓g�����W�X�^������d�͂��������\��OoO��菭�Ȃ��čς�
�ق�܂����ȁBEPIC���ڎw���Ă�����̖ړI��^�����ے肾�ȁB
> L3�ڂɂ���Ƃ��p�b�P�[�W�T�C�Y������������Ƃ��o�X����64bit�ɂ���Ƃ��Ő�[�̃v���Z�X���[�����̗p����Ƃ���邱�Ƃ͑�R����
> >>489
> �悭�����������X���邯��EPIC + OoO�̓g�����W�X�^������d�͂��������\��OoO��菭�Ȃ��čς�
�ق�܂����ȁBEPIC���ڎw���Ă�����̖ړI��^�����ے肾�ȁB
> L3�ڂɂ���Ƃ��p�b�P�[�W�T�C�Y������������Ƃ��o�X����64bit�ɂ���Ƃ��Ő�[�̃v���Z�X���[�����̗p����Ƃ���邱�Ƃ͑�R����
����IA-84�g���Ă����v�����̂́A�R���������x���܂�(�\�t�g�܂�)�̂�
�㉽�N�����邩���J�����A�Ƃ�����ہB
SGI�݂���HPC����(�v����ɐM�����قǂقǂŲ�YO�A�\�t�g��ȁA�P����program���삷������)
���ʂɓ�����������������̂́A���̕���Ɍ����݂����邩��ł͂Ȃ�����̍ȂƎv�����B
�㉽�N�����邩���J�����A�Ƃ�����ہB
SGI�݂���HPC����(�v����ɐM�����قǂقǂŲ�YO�A�\�t�g��ȁA�P����program���삷������)
���ʂɓ�����������������̂́A���̕���Ɍ����݂����邩��ł͂Ȃ�����̍ȂƎv�����B
IA-84�ɂ��Ă��킵��
����A�@���Ă悗
��i��84bit�A�[�L�e�N�`���Ɋ���
VLIW��OoO�͑������ł�(EPIC����)�C�^��OoO�t������������v���Z�b�T�ɂȂ�\�������ˁH
�����E���z���W�X�^�̎������������ɂ͂Ȃ肻��������
�����E���z���W�X�^�̎������������ɂ͂Ȃ肻��������
���ɕ������W�X�^512�{�ɂȂ�Ƃ��Ă�
�ꎟ�L���b�V�����ł������炢�ł��ނ�
21464�̃��W�X�^��512�{�ŃT�C�Y���ꎟ�L���b�V����菬�������炢������
���W�X�^�A�N�Z�X��3�X�e�[�W��
4�X�e�[�W�̃v���X�R���̓}�V��������
�ꎟ�L���b�V�����ł������炢�ł��ނ�
21464�̃��W�X�^��512�{�ŃT�C�Y���ꎟ�L���b�V����菬�������炢������
���W�X�^�A�N�Z�X��3�X�e�[�W��
4�X�e�[�W�̃v���X�R���̓}�V��������
>>499
���W�X�^���l�[���Ȃ���OoO�ł����킯����
���W�X�^���l�[���Ȃ���OoO�ł����킯����
Itanium�̕��������_���W�X�^��80bit������?
�ɂ��������Ȃ�
�ɂ��������Ȃ�
82 bit
�� bit
�l�X�̂��i����
�������Ȃ��VLIW(or EPIC)���Ăǂ����������N���b�N��߂Ȃ́H
�X�[�p�[�X�J�������N���b�N�����ɂ����̂Ǝ��Ă�C���B
���炭����ɓ������삷���H�K�͂��傫���āA���m�ɓ��������̂�����
�ɂȂ邹���ł́H
���炭����ɓ������삷���H�K�͂��傫���āA���m�ɓ��������̂�����
�ɂȂ邹���ł́H
��C�e���V�ő�e�ʂ̃L���b�V�������R�̈����Ȃ�����
�ł�Montecito�̃N���b�N���Ⴂ�̂�Foxton�Ńg���u��������
�_���ɂ�2GHz�ȏ�ł̓�����\�Ƃ͂����菑���Ă��邵
Montvale�̃N���b�N���Ⴂ�̂͗�ɂ����Intel����x86�������ă��\�[�X���Ȃ��������炗
http://www.intel.com/pressroom/archive/releases/20040907corp_a.htm
>An enhanced Itanium 2 dual-core processor, codenamed "Montvale,"
> will be the first Itanium processor based on the 65 nm process technology, and is planned after Montecito.
�ł�Montecito�̃N���b�N���Ⴂ�̂�Foxton�Ńg���u��������
�_���ɂ�2GHz�ȏ�ł̓�����\�Ƃ͂����菑���Ă��邵
Montvale�̃N���b�N���Ⴂ�̂͗�ɂ����Intel����x86�������ă��\�[�X���Ȃ��������炗
http://www.intel.com/pressroom/archive/releases/20040907corp_a.htm
>An enhanced Itanium 2 dual-core processor, codenamed "Montvale,"
> will be the first Itanium processor based on the 65 nm process technology, and is planned after Montecito.
�p�C�v���C���̓J���P�[�ˁ[��ˁ[�́H
VLIW���ĂΏ]���d�l�ȃp�C�v���C�����̎����Փ˂��u���b�N�P�ʂʼn������d�g��
���ߒ����z�����p�C�v���C����p�ӂ��邭�炢�Ȃ�T���ɖ��ߒ��𑝂₷���
VLIW���ĂΏ]���d�l�ȃp�C�v���C�����̎����Փ˂��u���b�N�P�ʂʼn������d�g��
���ߒ����z�����p�C�v���C����p�ӂ��邭�炢�Ȃ�T���ɖ��ߒ��𑝂₷���
�N���b�N���x���̂�Itanium�ŗL�̖�肾��
Cell��SPE��VLIW�������N���b�N����
Cell��SPE��VLIW�������N���b�N����
��ȃ��\�[�X�P�`��܂���������
�ꏏ�ɂ���Ă��ȁ[
�ꏏ�ɂ���Ă��ȁ[
514 �F�R�E�L�́M�E,,�j�����������������F2007/11/08(��) 00:20:08 ID:gKJkQGuD
>>511
SPE��SIMD�̃X�[�p�[�X�P�[���i�A�E�g�I�u�I�[�_�Ȃ��j
SPE��SIMD�̃X�[�p�[�X�P�[���i�A�E�g�I�u�I�[�_�Ȃ��j
SIMD��VLI�v�̓��C�����Ⴄ�C�������
>>514
�����A����������
�X�[�p�[�X�J���ɂ��邩VLIW�ɂ��邩�Ń��������
�܂��A���N���b�N��VLIW�Ȃ�C���e����TFLOPS�`�b�v�Ƃ�
�����A����������
�X�[�p�[�X�J���ɂ��邩VLIW�ɂ��邩�Ń��������
�܂��A���N���b�N��VLIW�Ȃ�C���e����TFLOPS�`�b�v�Ƃ�
�������i�삵�Ă����͖��炩�ɍH���
�ǂ��݂Ă��i�삵�悤���Ȃ��ł��医��
�ǂ��݂Ă��i�삵�悤���Ȃ��ł��医��
�Ƒf�l���\���Ă���܂�
��������������x����Ă͂�����炻��Ȃ�̃����b�g�����B
CLOVERTOWN�ŏ\������˂��́H�@�ƁA�f�l�͎v���Ă��܂����B
CLOVERTOWN�ŏ\������˂��́H�@�ƁA�f�l�͎v���Ă��܂����B
�Ƃ������A�ǂ������Ƃ��������́H
x86���Ă킯����Ȃ�����\�t�g�̌݊����͂Ȃ��킯��
�i��������ɂ��Ă�x86�́A�������������̂��C���e������o�Ă�̂Ŗ��Ӗ��j
�f�l�ɂ͂����ς�킩���̂ŋ����Ă���
x86���Ă킯����Ȃ�����\�t�g�̌݊����͂Ȃ��킯��
�i��������ɂ��Ă�x86�́A�������������̂��C���e������o�Ă�̂Ŗ��Ӗ��j
�f�l�ɂ͂����ς�킩���̂ŋ����Ă���
http://www.itmedia.co.jp/enterprise/articles/0602/20/news007.html
http://www.itmedia.co.jp/enterprise/articles/0610/31/news001.html
http://www.itmedia.co.jp/enterprise/articles/0611/13/news003.html
http://www.itmedia.co.jp/enterprise/articles/0610/31/news001.html
http://www.itmedia.co.jp/enterprise/articles/0611/13/news003.html
���POWER6�u���[�h�A���ɓo�ꂷ�B
http://www-06.ibm.com/jp/press/20071107002.html
�@�E4GHz dual-core x 2-socket
�@�EL3�Ȃ�
�@�E2GB������
�@�E��L�̍ŏ��\����\932,505(�ō�)
���i�I�ɂ�x86�ɕ����ĂȂ����B�����Ƃ����\�̕���AL3�L���4.7GHz��p570�Ɣ�ׂ�Ƃ����������B
http://www-03.ibm.com/systems/bladecenter/js22e/perfdata.html
�@�ESPECint2006_rate (4-core): 84.7(peak)/77.2(base)
�@�ESPECfp2006_rate( (4-core): 75.0(peak)/65.7(base)
[�Q�l]
�@��p570 (POWER6/4.7GHz, L3�L��)
�@�ESPECint2006_rate (4-core): 118(peak)/105(base)
�@�ESPECfp2006_rate( (4-core): 115(peak)/97.5(base)
�@��BladeCenter HS21 Xeon 5160/3GHz
�@�ESPECint2006_rate (4-core): 52.9(base)
�@�ESPECfp2006_rate( (4-core): 41.4(base)
�@��BladeCenter HS21 Xeon X5355/3GHz
�@�ESPECint2006_rate (8-core): 96.0(peak)/89.9(base)
�@�ESPECfp2006_rate( (8-core): 56.8(base)
http://www-06.ibm.com/jp/press/20071107002.html
�@�E4GHz dual-core x 2-socket
�@�EL3�Ȃ�
�@�E2GB������
�@�E��L�̍ŏ��\����\932,505(�ō�)
���i�I�ɂ�x86�ɕ����ĂȂ����B�����Ƃ����\�̕���AL3�L���4.7GHz��p570�Ɣ�ׂ�Ƃ����������B
http://www-03.ibm.com/systems/bladecenter/js22e/perfdata.html
�@�ESPECint2006_rate (4-core): 84.7(peak)/77.2(base)
�@�ESPECfp2006_rate( (4-core): 75.0(peak)/65.7(base)
[�Q�l]
�@��p570 (POWER6/4.7GHz, L3�L��)
�@�ESPECint2006_rate (4-core): 118(peak)/105(base)
�@�ESPECfp2006_rate( (4-core): 115(peak)/97.5(base)
�@��BladeCenter HS21 Xeon 5160/3GHz
�@�ESPECint2006_rate (4-core): 52.9(base)
�@�ESPECfp2006_rate( (4-core): 41.4(base)
�@��BladeCenter HS21 Xeon X5355/3GHz
�@�ESPECint2006_rate (8-core): 96.0(peak)/89.9(base)
�@�ESPECfp2006_rate( (8-core): 56.8(base)
524 �FMAC�I�^�������F2007/11/08(��) 21:29:08 ID:r2d0s3P9
�咆�K�̓V�X�e���J���ł́A�V�X�e���J�����ɂ����郊�X�N��R�X�g�̔����́A
�V�X�e���̊��i�K�ƃe�X�g�i�K�ɂ�������̂��唼���߁A
zSeries�EIA64�V�X�e����x86�V�X�e���̉��i���́A�V�X�e���̊�楗��ĥ
�R�[�f�B���O�ɂ������p�����r���Ă������ł�����x�̍������Ȃ�
�V�X�e���̊��i�K�ƃe�X�g�i�K�ɂ�������̂��唼���߁A
zSeries�EIA64�V�X�e����x86�V�X�e���̉��i���́A�V�X�e���̊�楗��ĥ
�R�[�f�B���O�ɂ������p�����r���Ă������ł�����x�̍������Ȃ�
�����Aita�@��DQN�~�[
System z���ᔻ���Ă݂�悗��
�[���A��i�����������
System z���ᔻ���Ă݂�悗��
�[���A��i�����������
system z�������I���\��������
�_�E���T�C�W���O(����)�̗���ɂ͋t�炦�Ȃ�
��������z990�Ƃ��̃p�C�v���C���͕��G��CISC���߂ȍœK�����ꂽ���̂�����(byIBM�Ȃ�Ƃ��W���[�i��)����
system z�͂ǂ��ȂH
�N���b�N��������������ARISC�I�ɂȂ��Ă�C������
�_�E���T�C�W���O(����)�̗���ɂ͋t�炦�Ȃ�
��������z990�Ƃ��̃p�C�v���C���͕��G��CISC���߂ȍœK�����ꂽ���̂�����(byIBM�Ȃ�Ƃ��W���[�i��)����
system z�͂ǂ��ȂH
�N���b�N��������������ARISC�I�ɂȂ��Ă�C������
Power6�Ƃ����C���t���[�����x���̃G���[������X86�ł��Ƃ����
3�d�����b�N�X�e�b�v���K�v�Ȃ�Ŗ���������
�X�g���^�X�����������}�V������Ă邯��
3�d�����b�N�X�e�b�v���K�v�Ȃ�Ŗ���������
�X�g���^�X�����������}�V������Ă邯��
530 �FMAC�I�^��527-528 �����F2007/11/08(��) 22:01:49 ID:r2d0s3P9
>>527-528
IPF���Ȃ������A���������ǁASystem z�̍ŐVCPU "z6"��POWER6�R�A�Ɠ����p�C�v���C���\����
�Ő�[�l�C�e�B�u�E�N�A�h�R�A�v���Z�b�T�Ȃ��ǁB�B�B
http://journal.mycom.co.jp/articles/2007/09/11/hotchips1/index.html
�@�@-------------------
�@�@POWER6�Ƃ͌Z��̊W�ŁA���W�b�N�̍\���v�f�ƂȂ郉�b�`�A���W�X�^�t�@�C����SRAM�}�N���Ȃ�
�@�@�����p���Ă���A�����╂�������_���Z��A�������R���g���[���Ȃǂ��v�̑啔���������ł����
�@�@�����B�������A���߃Z�b�g��p�r���قȂ�̂ŁA�`�b�v�S�̂̃}�C�N���A�[�L�e�N�`���Ƃ��Ă͕ʕ���
�@�@�Ȃ��Ă���B
�@�@z6��POWER6�Ɠ���65nm SOI CMOS�v���Z�X�ō���Ă��邪�APOWER6���f���A���R�A�ł���
�@�@�̂ɑ��āAz6�̓N���b�h�R�A�ł���A���\�ʐ^�ł݂�ƁA�`�b�v�ʐ^�ł݂�� POWER6��1.5�{����
�@�@���̃T�C�Y�ŁA21.7mm�~20.0mm�Ƃ�������ȃ`�b�v�ł���B�e�R�A��64KB��1�����߃L���b�V���A
�@�@128KB��1 ���f�[�^�L���b�V����3MB��2���L���b�V���������Ă���B�`�b�v�S�̂̃g�����W�X�^����
�@�@991M�ŁA���z������6km�ɒB����Ƃ����B
�@�@-------------------
IPF���Ȃ������A���������ǁASystem z�̍ŐVCPU "z6"��POWER6�R�A�Ɠ����p�C�v���C���\����
�Ő�[�l�C�e�B�u�E�N�A�h�R�A�v���Z�b�T�Ȃ��ǁB�B�B
http://journal.mycom.co.jp/articles/2007/09/11/hotchips1/index.html
�@�@-------------------
�@�@POWER6�Ƃ͌Z��̊W�ŁA���W�b�N�̍\���v�f�ƂȂ郉�b�`�A���W�X�^�t�@�C����SRAM�}�N���Ȃ�
�@�@�����p���Ă���A�����╂�������_���Z��A�������R���g���[���Ȃǂ��v�̑啔���������ł����
�@�@�����B�������A���߃Z�b�g��p�r���قȂ�̂ŁA�`�b�v�S�̂̃}�C�N���A�[�L�e�N�`���Ƃ��Ă͕ʕ���
�@�@�Ȃ��Ă���B
�@�@z6��POWER6�Ɠ���65nm SOI CMOS�v���Z�X�ō���Ă��邪�APOWER6���f���A���R�A�ł���
�@�@�̂ɑ��āAz6�̓N���b�h�R�A�ł���A���\�ʐ^�ł݂�ƁA�`�b�v�ʐ^�ł݂�� POWER6��1.5�{����
�@�@���̃T�C�Y�ŁA21.7mm�~20.0mm�Ƃ�������ȃ`�b�v�ł���B�e�R�A��64KB��1�����߃L���b�V���A
�@�@128KB��1 ���f�[�^�L���b�V����3MB��2���L���b�V���������Ă���B�`�b�v�S�̂̃g�����W�X�^����
�@�@991M�ŁA���z������6km�ɒB����Ƃ����B
�@�@-------------------
IBM���[���t���[������ES/9000�̂Ƃ��X�[�p�[�X�J���ɂ�������
CMOS���ŃV���O���C�V���[�ɖ߂������
�ŁASystem z�ŃX�[�p�[�X�J������
�܂����V���O���C�V���[�ł͂Ȃ���ˁH
CMOS���ŃV���O���C�V���[�ɖ߂������
�ŁASystem z�ŃX�[�p�[�X�J������
�܂����V���O���C�V���[�ł͂Ȃ���ˁH
z6�g����System z�͓o�ꎞ������A�܂����N�ȍ~�ł���
����ƃv���W�F�N�g�K�͂ɑ���n�[�h�E�F�A�R�X�g�̐�߂銄�����������s��Ƃ͌���
���C���t���[��System z�̃V�X�e�����i�͎���"���C���t���[���N���X"��IA-64�V�X�e����茅��1����
�i���߂���p���A�����\�͂̍Œ�C�����Ⴄ�j
����ƃv���W�F�N�g�K�͂ɑ���n�[�h�E�F�A�R�X�g�̐�߂銄�����������s��Ƃ͌���
���C���t���[��System z�̃V�X�e�����i�͎���"���C���t���[���N���X"��IA-64�V�X�e����茅��1����
�i���߂���p���A�����\�͂̍Œ�C�����Ⴄ�j
>>488
��k���Ǝv�������{�C�Ȃ̂�
�uIBM�ėp�@��Itanium�u���������W�J�v�A���y�c�̂̕ăC���e�����В�
http://itpro.nikkeibp.co.jp/article/NEWS/20071101/286216/
> �uSystem z��OS�ł���z/OS���A���̂܂�Itanium�T�[�o�[��ʼnғ�������
> ���Ƃ��ł����PSI�i�v���b�g�t�H�[���E�\�����[�V�����Y�Ёj�̋Z�p�v
Itanium��9�Ђ�1���~�ȏ�𓊎��A�x�m�ʁEEDS��09�N��IBM�����ɂ�
http://itpro.nikkeibp.co.jp/article/COLUMN/20060329/233762/
> �u�ăT�[�r�X�x���_�[�̊��G�͂����B���C���t���[���s����قړƐ肷��
> IBM���A���d�ȑԓx���Ƃ葱���Ă��邽�߁A�e�Ђ�zSystem�̑�ւƂȂ蓾��
> �������\�ƐM�����A���i���\���������T�[�o�[��~���Ă��邩�炾�v�B
> �u09�N��IBM�ɔߖ��グ������Ƃ����헪�ň�v���Ă���v�i�x�m�ʊ����j�B
��k���Ǝv�������{�C�Ȃ̂�
�uIBM�ėp�@��Itanium�u���������W�J�v�A���y�c�̂̕ăC���e�����В�
http://itpro.nikkeibp.co.jp/article/NEWS/20071101/286216/
> �uSystem z��OS�ł���z/OS���A���̂܂�Itanium�T�[�o�[��ʼnғ�������
> ���Ƃ��ł����PSI�i�v���b�g�t�H�[���E�\�����[�V�����Y�Ёj�̋Z�p�v
Itanium��9�Ђ�1���~�ȏ�𓊎��A�x�m�ʁEEDS��09�N��IBM�����ɂ�
http://itpro.nikkeibp.co.jp/article/COLUMN/20060329/233762/
> �u�ăT�[�r�X�x���_�[�̊��G�͂����B���C���t���[���s����قړƐ肷��
> IBM���A���d�ȑԓx���Ƃ葱���Ă��邽�߁A�e�Ђ�zSystem�̑�ւƂȂ蓾��
> �������\�ƐM�����A���i���\���������T�[�o�[��~���Ă��邩�炾�v�B
> �u09�N��IBM�ɔߖ��グ������Ƃ����헪�ň�v���Ă���v�i�x�m�ʊ����j�B
�uItanic ���Ƴ� �܂�����(��) ��� �x�� EPIC(��) 6���ߎ��s(��) �R���p�C���ɂ��œK��(��)�v
�ƃW���[�i�X�g�⎩��SIer��Q�����˂炪���X��7�N�Ԍ������������ʂ��R����
���ꂩ����ЂƂ�낵�����ނ�
�ƃW���[�i�X�g�⎩��SIer��Q�����˂炪���X��7�N�Ԍ������������ʂ��R����
���ꂩ����ЂƂ�낵�����ނ�
>>533
���Z�������W�J������]���ڋq�̎��Y�ی�{��ˁH
���܂܂ły�ł���ė����c�菭�Ȃ��ڋq�����̂Ă܂�������
�����[���A���z���ȂNj�g���ČÂ�OS���킴�킴���������Ă�
�A�v����binary compati�ł͖����̂ł������c�y�����Ȃ��z
���Z�������W�J������]���ڋq�̎��Y�ی�{��ˁH
���܂܂ły�ł���ė����c�菭�Ȃ��ڋq�����̂Ă܂�������
�����[���A���z���ȂNj�g���ČÂ�OS���킴�킴���������Ă�
�A�v����binary compati�ł͖����̂ł������c�y�����Ȃ��z
�������itanium�~�����Ȃ��Ă���
���x��Ă��Ă݂�
���x��Ă��Ă݂�
�����V����A740��̃N�A�b�h�R�AOpteron��
NEC�uSX-9�v�̃X�p�R����
http://pc.watch.impress.co.jp/docs/2007/1109/nao.htm
NEC�uSX-9�v�̃X�p�R����
http://pc.watch.impress.co.jp/docs/2007/1109/nao.htm
�����i����u�������e�Ձ@���l�T�X�@�V�b�o�t���O�X�N�x����
http://www.business-i.jp/news/ind-page/news/200711090007a.nwc
http://www.business-i.jp/news/ind-page/news/200711090007a.nwc
R�n�Ȃ̂��H
���S�Ǝ���CISC�i�̖͗l�B
�����A������16/32bit�̑��i���CISC CPU���A����Œu�������\�ɂ���
�ׂɁA������x�\�t�g�̈ڍs��e�Ղɂ���l����������ŁA�R�[�h������
����Ԃ̖ړI�Ƃ��āA�V�K�̖��ߑ̌n���N�������Ǝv���B
���l�T�X���A�VCPU�̃A�[�L�e�N�`���v���������A�t�@�~�������uRX�v�Ɍ���
�H ���E�ō����x���̐��\�A�R�[�h��������������CISC�A�[�L�e�N�`�� �H
http://japan.renesas.com/fmwk.jsp?cnt=press_release20071108.htm&fp=/company_info/news_and_events/press_releases
�b���Ђ́A����܂�16�r�b�g�����32�r�b�g��CISC �iComplex Instruction Set Computer�j�i��1�j�}�C�R���ł���uM16C�t�@�~���v
�b�uH8S�t�@�~���v�uR32C�t�@�~���v�uH8SX�t�@�~���v��ʎY���A�����A�����ԁA�Y�ƁAOA�A�ʐM���̕��L������ō̗p����Ă���A
�b�}�C�R�����Ƃł́A���E�g�b�v�V�F�A�i��2�j���l�����Ă��܂��B
�b�܂��A�}�C�R���s��́A���݁A8�r�b�g�A16�r�b�g�}�C�R���̎��v���傫���A���Ђ�16�r�b�g�}�C�R���ŁA���E�g�b�v�V�F�A�i��3�j��
�b�l�����Ă���܂��B����́A32�r�b�g�}�C�R�����s����������A16�r�b�g�y��32�r�b�g�}�C�R���̔䗦�����܂��Ă��邱�Ƃ���A
�b16�r�b�g�y��32�r�b�g��A�[�L�e�N�`���ɓ�������������CPU�R�A�ł���uRX�v���J�����܂����B
�����A������16/32bit�̑��i���CISC CPU���A����Œu�������\�ɂ���
�ׂɁA������x�\�t�g�̈ڍs��e�Ղɂ���l����������ŁA�R�[�h������
����Ԃ̖ړI�Ƃ��āA�V�K�̖��ߑ̌n���N�������Ǝv���B
���l�T�X���A�VCPU�̃A�[�L�e�N�`���v���������A�t�@�~�������uRX�v�Ɍ���
�H ���E�ō����x���̐��\�A�R�[�h��������������CISC�A�[�L�e�N�`�� �H
http://japan.renesas.com/fmwk.jsp?cnt=press_release20071108.htm&fp=/company_info/news_and_events/press_releases
�b���Ђ́A����܂�16�r�b�g�����32�r�b�g��CISC �iComplex Instruction Set Computer�j�i��1�j�}�C�R���ł���uM16C�t�@�~���v
�b�uH8S�t�@�~���v�uR32C�t�@�~���v�uH8SX�t�@�~���v��ʎY���A�����A�����ԁA�Y�ƁAOA�A�ʐM���̕��L������ō̗p����Ă���A
�b�}�C�R�����Ƃł́A���E�g�b�v�V�F�A�i��2�j���l�����Ă��܂��B
�b�܂��A�}�C�R���s��́A���݁A8�r�b�g�A16�r�b�g�}�C�R���̎��v���傫���A���Ђ�16�r�b�g�}�C�R���ŁA���E�g�b�v�V�F�A�i��3�j��
�b�l�����Ă���܂��B����́A32�r�b�g�}�C�R�����s����������A16�r�b�g�y��32�r�b�g�}�C�R���̔䗦�����܂��Ă��邱�Ƃ���A
�b16�r�b�g�y��32�r�b�g��A�[�L�e�N�`���ɓ�������������CPU�R�A�ł���uRX�v���J�����܂����B
541 �F�R�E�L�́M�E,,�j�����������������F2007/11/09(��) 19:46:37 ID:7doIdVdW
���l�T�X�ł��������̂̊J���̎d������Ă�̂��ĈɒO�̂ق��H
�Q���͐Q�ĉ�
�ȂN���b�N���炵�Ĕ����Ȑ��\���ۂ��ȁB
����A���̂��炢�̐��\�̂��̂����v�͂���낤���ǁc�c
����A���̂��炢�̐��\�̂��̂����v�͂���낤���ǁc�c
ARM9��������x�̐��\���ȓd��CISC�ŃJ�o�[�A���Ă̂�
��肭�����Ό����肪�傫�����Ă͔̂��邯�ǁB
�g�ѓd�b�p�r���\���ɑ_���邵�A�ꉞ�̓��l�T�X��16/32bitCISC�n��S���������Ēu����������\�͂Ȗ��B
�����A�������B
���l�T�X�A����Ń��C���i�b�v�̐���&�팸���o����̂��ǂ����c
��肭�����Ό����肪�傫�����Ă͔̂��邯�ǁB
�g�ѓd�b�p�r���\���ɑ_���邵�A�ꉞ�̓��l�T�X��16/32bitCISC�n��S���������Ēu����������\�͂Ȗ��B
�����A�������B
���l�T�X�A����Ń��C���i�b�v�̐���&�팸���o����̂��ǂ����c
�c�y�����z
�g������������@�N�̓f��
Renesas��4�r�b�g�}�C�R���ŋ�
��A���ɑg�ݍ��ތ���ł͂Ȃ�
LINPAC�̃x�N�g���ςŋƊE�ō������̐��\�ł����Ƃ�
�́X�̕���B
���[���A����ԑ�����Ă�����
LINPAC�̃x�N�g���ςŋƊE�ō������̐��\�ł����Ƃ�
�́X�̕���B
���[���A����ԑ�����Ă�����
���s�����狖�l�T�b�X
�[�����Sparc��Mips��Risc�`�b�v����UNIX���[�N�X�e�[�V�����̑��݂�
�G���Œm��A�����́uPC���n�C�G���h�ȍ����\UNIX-WS�����v��
�v���A�Ȃ������Ĕ��킸�Ɍ��݂Ɏ���B
����PC�ŏ\��������Ă邪���܂ɒ��Â�Unix-WS���~�����Ǝv�����Ƃ�����B
���ۂɎ����Sparc��SGI HP��UNIX�@���g���āA�����郂�m���Ă���́H
�G���Œm��A�����́uPC���n�C�G���h�ȍ����\UNIX-WS�����v��
�v���A�Ȃ������Ĕ��킸�Ɍ��݂Ɏ���B
����PC�ŏ\��������Ă邪���܂ɒ��Â�Unix-WS���~�����Ǝv�����Ƃ�����B
���ۂɎ����Sparc��SGI HP��UNIX�@���g���āA�����郂�m���Ă���́H
������
�ėp���W�X�^���P�U�{���Ă̂��Ӗ��[���ȁB
RISC�Ȃ��ƂR�Q�{�Ƃ��U�S�{�Ƃ��A�������A�N�Z�X�����炵����A���W�X�^
�̃Z�[�u���J�o�������炷�ׂɁA�X�ɂ��̔{�������W�X�^�Q�Ǘ����邭�炢��
�̂ɁB
x86��64bit���łW�{����P�U�{�ɑ��₵�������ŁA���̂R�Q�{���炢�܂ő��₳
�Ȃ��̂��Ȃ��A�Ǝv�������ACISC���Ƃ��܂葝�₷�Ӗ����������Ď����ȁH
RISC�Ȃ��ƂR�Q�{�Ƃ��U�S�{�Ƃ��A�������A�N�Z�X�����炵����A���W�X�^
�̃Z�[�u���J�o�������炷�ׂɁA�X�ɂ��̔{�������W�X�^�Q�Ǘ����邭�炢��
�̂ɁB
x86��64bit���łW�{����P�U�{�ɑ��₵�������ŁA���̂R�Q�{���炢�܂ő��₳
�Ȃ��̂��Ȃ��A�Ǝv�������ACISC���Ƃ��܂葝�₷�Ӗ����������Ď����ȁH
�g�ݍ��݂̃v���O��������32�{����Ȃ��A
16�{�Ő��\�o����ďꍇ������������
�ŁA���W�X�^������A���߂̃I�y�����h�����������Ȃ邱�Ƃ�
�v���O�����T�C�Y��}����ꂽ��
�X���b�h��ւ��̃��W�X�^�Ҕ������������āA���A���^�C�������悭�Ȃ���[�����b�g������
16�{�Ő��\�o����ďꍇ������������
�ŁA���W�X�^������A���߂̃I�y�����h�����������Ȃ邱�Ƃ�
�v���O�����T�C�Y��}����ꂽ��
�X���b�h��ւ��̃��W�X�^�Ҕ������������āA���A���^�C�������悭�Ȃ���[�����b�g������
x86�Ƃ��̃p�\�R���p�����肾�ƃ}���`�R�A�����Ă邩��A�X���b�h��ւ��̃��W�X�^�ޔ���
�ǂ��炩�Ƃ����ƌ��肻���Ɏv�����A����͂ǂ�Ȃ��Ȃ낤�H
�ǂ��炩�Ƃ����ƌ��肻���Ɏv�����A����͂ǂ�Ȃ��Ȃ낤�H
32�{�������Ă���̂̓A�����[������FP���C���̌v�Z���炢��
���������̃v���O�����Ȃ�A�ǂ��ł������悤�Ȉ�������������Ă��邱�Ƃ�����
���������̃v���O�����Ȃ�A�ǂ��ł������悤�Ȉ�������������Ă��邱�Ƃ�����
>>554-556
�m����RISC�̏ꍇ�͈�U���������烌�W�X�^�Ƀf�[�^�ړ����鎖�ŁA���Z��
�S�ă��W�X�^�Ԃɂ��ă������A�N�Z�X�����炷�ړI���������������A�L���b
�V���������̔��B�ŁA���̃����b�g�͔���Ă܂���ˁB
���ƃ��W�X�^�Q�Ɋւ��Ă��A�ǂ����Z�[�u���J�o�����K�v�ȏꍇ�A���W�X�^
�ȊO�̃f�[�^����ւ����K�v�ŁA���̏ꍇ�L���b�V������ʂɓ���ւ��
�������A���W�X�^�����������A�N�Z�X�������Ӗ��������Ȃ��Ă���Ċ���
�ł��傤���B
�m����RISC�̏ꍇ�͈�U���������烌�W�X�^�Ƀf�[�^�ړ����鎖�ŁA���Z��
�S�ă��W�X�^�Ԃɂ��ă������A�N�Z�X�����炷�ړI���������������A�L���b
�V���������̔��B�ŁA���̃����b�g�͔���Ă܂���ˁB
���ƃ��W�X�^�Q�Ɋւ��Ă��A�ǂ����Z�[�u���J�o�����K�v�ȏꍇ�A���W�X�^
�ȊO�̃f�[�^����ւ����K�v�ŁA���̏ꍇ�L���b�V������ʂɓ���ւ��
�������A���W�X�^�����������A�N�Z�X�������Ӗ��������Ȃ��Ă���Ċ���
�ł��傤���B
>>557
���W�X�^-�L���b�V���Ԃ̃��[�h/�X�g�A���߂��Ⴍ����Ԃ�����
����L2�L���b�V���̃��C�e���V�Ȃ��
32Bit������CPU���猩�����C���������Ȃ�
�f�X�N�g�b�v��T�[�o�[�ł̓R���e�L�X�g�X�C�b�`�̃��W�X�^�Ҕ��͖�肶��Ȃ��Ǝv��(�z��)
16Bit�g�ݍ��݂��ƁA�L���b�V�����X�Ƃ�������
�����������
���W�X�^-�L���b�V���Ԃ̃��[�h/�X�g�A���߂��Ⴍ����Ԃ�����
����L2�L���b�V���̃��C�e���V�Ȃ��
32Bit������CPU���猩�����C���������Ȃ�
�f�X�N�g�b�v��T�[�o�[�ł̓R���e�L�X�g�X�C�b�`�̃��W�X�^�Ҕ��͖�肶��Ȃ��Ǝv��(�z��)
16Bit�g�ݍ��݂��ƁA�L���b�V�����X�Ƃ�������
�����������
�A�Z���u���Ő�����̂̃v���O���������̂Ȃ�16�{�ł���������炵��
���[���A�Z���u���Ȃ�X�^�b�N��A�L���[�����[�^��A�[�L�e�B�N�`���ł�k�Ƃ�
���[���A�Z���u���Ȃ�X�^�b�N��A�L���[�����[�^��A�[�L�e�B�N�`���ł�k�Ƃ�
>>558
�}���`�^�X�N�ȏꍇ�A�^�X�N��ւ��ŕς�̂̓��W�X�^��������Ȃ��āA
�^�X�N���Ɋm�ۂ���Ă郁���������邩��A�����ɍ��X�P�U���[�h����
���W�X�^�̃Z�[�u���J�o����ߖ�Ӗ����A���邩�ǂ������Ęb�ł���ˁB
�m����16bit�g�ݍ��݂ŁA�}���`�^�X�N���������A�^�X�N���̃f�[�^������
���Ȃ��ꍇ�A���W�X�^���Q�Ǘ����ăZ�[�u���J�o�������Ȃ��ōςނ̂́A���\
�����\�͂ɍv������̂����H
�ǂ������s�D��x�̐��ōl����A��{�łS�Q���炢����ςނƎv�����B
�}���`�^�X�N�ȏꍇ�A�^�X�N��ւ��ŕς�̂̓��W�X�^��������Ȃ��āA
�^�X�N���Ɋm�ۂ���Ă郁���������邩��A�����ɍ��X�P�U���[�h����
���W�X�^�̃Z�[�u���J�o����ߖ�Ӗ����A���邩�ǂ������Ęb�ł���ˁB
�m����16bit�g�ݍ��݂ŁA�}���`�^�X�N���������A�^�X�N���̃f�[�^������
���Ȃ��ꍇ�A���W�X�^���Q�Ǘ����ăZ�[�u���J�o�������Ȃ��ōςނ̂́A���\
�����\�͂ɍv������̂����H
�ǂ������s�D��x�̐��ōl����A��{�łS�Q���炢����ςނƎv�����B
>>559
> ���[���A�Z���u���Ȃ�X�^�b�N��A�L���[�����[�^��A�[�L�e�B�N�`���ł�k�Ƃ�
�X�^�b�N�I�y���[�V�������Ĉˑ������������ăp�C�v���C���X�g�[���̂����܂�ɂȂ�Ȃ��ˁH
> ���[���A�Z���u���Ȃ�X�^�b�N��A�L���[�����[�^��A�[�L�e�B�N�`���ł�k�Ƃ�
�X�^�b�N�I�y���[�V�������Ĉˑ������������ăp�C�v���C���X�g�[���̂����܂�ɂȂ�Ȃ��ˁH
>>556
���\�������Ă�l���ˁAcompiler�₳�ȁH
��ԔߎS�Ȃ̂͑��dlist��stream������loop��pipeline/vector�������Ƃ��B
512�ł����~���炱�ڂ�܂���ő��[��܂���B�{�R�[�h������
���\�������Ă�l���ˁAcompiler�₳�ȁH
��ԔߎS�Ȃ̂͑��dlist��stream������loop��pipeline/vector�������Ƃ��B
512�ł����~���炱�ڂ�܂���ő��[��܂���B�{�R�[�h������
563 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 03:06:08 ID:Rho86Kao
�����������[�A�z
564 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 03:07:10 ID:Rho86Kao
�ėp���W�X�^������128�{�Ƃ������ŋ߂�CPU���āB
���W�X�^�t�@�C���̍��v�T�C�Y2KB���炢�z���Ă��Ȃ���
����Ȃ��C�e���V1�Ń��[�h�E���C�g�ł���Ώ\�����B
���W�X�^�t�@�C���̍��v�T�C�Y2KB���炢�z���Ă��Ȃ���
����Ȃ��C�e���V1�Ń��[�h�E���C�g�ł���Ώ\�����B
>>564
�����烌�C�e���V1����Ȃ�����
�����烌�C�e���V1����Ȃ�����
566 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 04:28:03 ID:cENxBA60
�����������[�A�z
568 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 11:03:24 ID:evWnKfih
>>553
�v���t�B�b�N�X�������ăR�[�h������������A�����ȁ[�B
16�{�Ɋg�����邾���ł��ϑԃG���R�[�h���Ă�̂ɂ���1�o�C�g���炢�v���t�B�b�N�X���Ȃ��Ƃ����Ȃ��Ȃ�ȁB
x64�A�Z���u���E�f�B�X�A�Z���u���������ŏ����Ă݁HAMD���Ƃ��Ƃ��ɂȂ�B
�v���t�B�b�N�X�������ăR�[�h������������A�����ȁ[�B
16�{�Ɋg�����邾���ł��ϑԃG���R�[�h���Ă�̂ɂ���1�o�C�g���炢�v���t�B�b�N�X���Ȃ��Ƃ����Ȃ��Ȃ�ȁB
x64�A�Z���u���E�f�B�X�A�Z���u���������ŏ����Ă݁HAMD���Ƃ��Ƃ��ɂȂ�B
569 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 11:13:50 ID:evWnKfih
Core 2�̃��W�X�^�t�@�C�����̂̃��[�h���C�e���V��1����Ȃ���
�A�L�������[�^�i3Way�j�ŌJ�肩�����ǂݏo�����l�������������ȁB
�[���A���ꂪx64�ł̐��\�ቺ�̗v���ł��ȁB
penryn��blendvps xmm1, xmm2 <xmm0>�̃X���[�v�b�g��2���Ă��ƍl�����
��̓����͂킩�����悤�Ȃ��́B
���������_��̓{�g���l�b�N�����̂ɂȂ�AMD��葬���H
�A�L�������[�^�i3Way�j�ŌJ�肩�����ǂݏo�����l�������������ȁB
�[���A���ꂪx64�ł̐��\�ቺ�̗v���ł��ȁB
penryn��blendvps xmm1, xmm2 <xmm0>�̃X���[�v�b�g��2���Ă��ƍl�����
��̓����͂킩�����悤�Ȃ��́B
���������_��̓{�g���l�b�N�����̂ɂȂ�AMD��葬���H
�R���p�C��������Ă�̂�intel
���@���[�h�A�������v���t�F�`�A��e�ʃL���b�V���Ȃǃ��������C�e���V�B����AMD���D��Ă���
���@���[�h�A�������v���t�F�`�A��e�ʃL���b�V���Ȃǃ��������C�e���V�B����AMD���D��Ă���
C2D��x64�ł�����Ɛ��\�ቺ����Ƃ��C�ɂ��Ă�l����܂��Ȃ���
����ȏ��x64�̖��߃t�H�[�}�b�g�C�ɂ���l�Ȃ�Ă��Ȃ�
����ȏ��x64�̖��߃t�H�[�}�b�g�C�ɂ���l�Ȃ�Ă��Ȃ�
>>569
���L���b�V���e��
���L���b�V���e��
�ǂ�ȗ��_����
574 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 14:39:31 ID:evWnKfih
>>573
FP/SIMD��INT�����^�p�C�v���C���͏��Ȃ��|�[�g�ɕ������Z�킪�Ԃ牺�����Ă�
Intel�p�C�v���C����蓯�����ߔ��s������������������������AMD���咣�������Ă闝�_�B
>>572
L2�L���b�V��1MB��Athlon64���Celeron 4xx�V���[�Y�̂ق����������H
FP/SIMD��INT�����^�p�C�v���C���͏��Ȃ��|�[�g�ɕ������Z�킪�Ԃ牺�����Ă�
Intel�p�C�v���C����蓯�����ߔ��s������������������������AMD���咣�������Ă闝�_�B
>>572
L2�L���b�V��1MB��Athlon64���Celeron 4xx�V���[�Y�̂ق����������H
>>574
�m���Â��Ȃ��H
�m���Â��Ȃ��H
576 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 15:11:56 ID:evWnKfih
>>544
�܂����l�T�X��RX�́A���������ڂ�������������o�Ă��Ȃ��ƁA�n�b�L��
�����]���͓���C���B
����ARM9����т��Ə���x�̐��\���ƁA�Q�N�ナ���[�X���ɂ͂ǂ��Ȃ��Ă�
���S�z�����B
�����i�̒u�������̗e�Ղ����AARM����RX�̈�Ԃ̃����b�g�Ȃ̂�����A
�����͔�����Ȃ��Ǝv�����B�i�Ƃ���������������瑶�݉��l���E�E�E�B�j
�܂����l�T�X��RX�́A���������ڂ�������������o�Ă��Ȃ��ƁA�n�b�L��
�����]���͓���C���B
����ARM9����т��Ə���x�̐��\���ƁA�Q�N�ナ���[�X���ɂ͂ǂ��Ȃ��Ă�
���S�z�����B
�����i�̒u�������̗e�Ղ����AARM����RX�̈�Ԃ̃����b�g�Ȃ̂�����A
�����͔�����Ȃ��Ǝv�����B�i�Ƃ���������������瑶�݉��l���E�E�E�B�j
�ŏ�ʂ���Ȃ����A���ʂ��܂��̓V���[�Y�̓���
�Ȃ̂����ȁA���Ƃ���Έ�̉��N�������Ă�̂��
�Ȃ̂����ȁA���Ƃ���Έ�̉��N�������Ă�̂��
RX�̃��C���^�[�Q�b�g��100MHz�ȉ��̎s�ꂶ��˂��́H
�����̃G���W�j�A���Ƃɂ����V����CISC����Ă݂���������
�v���t�B�b�N�X��x86��A�I�y�R�[�h�ƃA�h���b�V���O���[�h������2byte����VAX�Ƃ�
��\�ICISC���ď璷�ȕ���������
�����Ȃ�Ƃ������Ă�68000���A�v��Ȃ����߂Ɨv��̂Ɏ����ĂȂ�����(68020�ȍ~�͎����Ă�)����
�ϒ�ISA���Ė��ʂɉ����[��
�����̃G���W�j�A���Ƃɂ����V����CISC����Ă݂���������
�v���t�B�b�N�X��x86��A�I�y�R�[�h�ƃA�h���b�V���O���[�h������2byte����VAX�Ƃ�
��\�ICISC���ď璷�ȕ���������
�����Ȃ�Ƃ������Ă�68000���A�v��Ȃ����߂Ɨv��̂Ɏ����ĂȂ�����(68020�ȍ~�͎����Ă�)����
�ϒ�ISA���Ė��ʂɉ����[��
�R���p�C�������W�X�^�̗L�����p�ł���悤�ɂȂ����̂ƁA
�p�C�v���C�����삪������O�ɂȂ������ƂŁA�X�^�b�N�Ƃ��A�L���[�����[�^�A�[�L�e�B�L�`���͐�ł�����
X87�̓X�^�b�N�����ǁA�X�^�b�N����ւ����߂������A���̂���SSE�����������
�����X�^�b�N����Ȃ��Ȃ�����
JAVA�v���Z�b�T�Ƃ����X�^�b�N��v���Z�b�T�A�v�悳�ꂽ���ǁA����o�������H
�p�C�v���C�����삪������O�ɂȂ������ƂŁA�X�^�b�N�Ƃ��A�L���[�����[�^�A�[�L�e�B�L�`���͐�ł�����
X87�̓X�^�b�N�����ǁA�X�^�b�N����ւ����߂������A���̂���SSE�����������
�����X�^�b�N����Ȃ��Ȃ�����
JAVA�v���Z�b�T�Ƃ����X�^�b�N��v���Z�b�T�A�v�悳�ꂽ���ǁA����o�������H
�C���e����FP���Z�ɂ�X87���ߎg��Ȃ���SSE2���ߎg�����Č����Ă邭�炢�������
582 �F�R�E�L�́M�E,,�j�����������������F2007/11/11(��) 17:01:20 ID:evWnKfih
x86�͊��ɖ��߃Z�b�g�ƃ}�C�N���A�[�L�e�N�`������v���ĂȂ����B
ALU���肪�A�L�������[�^�Ń��W�X�^�t�@�C�����ď��������[�J���X�g���[�W�ł���B
�������W�X�^���g�����߂�A�����������Ƃ��ɐ��\���o��悤�Ƀ`���[������Ă�B
RISC�ɂ��肪���ȃ��W�X�^�����݂Ɏg���悤�ȃR�[�h��g�ނƎ����W�X�^�t�@�C����
�ǂݏ����ő҂�����邱�ƂɂȂ�̂ŋt�ɐ��\���o�Ȃ��B
�G���Ă݂�����Core 2�̓����͂���ȂƂ���B
>>581
K10 �����AMD������������B
������K10��insertq/extrq�̎g���������܂����킩���B
����̃r�b�g����ɂ͕֗��Ȃ낤���ǁB
ALU���肪�A�L�������[�^�Ń��W�X�^�t�@�C�����ď��������[�J���X�g���[�W�ł���B
�������W�X�^���g�����߂�A�����������Ƃ��ɐ��\���o��悤�Ƀ`���[������Ă�B
RISC�ɂ��肪���ȃ��W�X�^�����݂Ɏg���悤�ȃR�[�h��g�ނƎ����W�X�^�t�@�C����
�ǂݏ����ő҂�����邱�ƂɂȂ�̂ŋt�ɐ��\���o�Ȃ��B
�G���Ă݂�����Core 2�̓����͂���ȂƂ���B
>>581
K10 �����AMD������������B
������K10��insertq/extrq�̎g���������܂����킩���B
����̃r�b�g����ɂ͕֗��Ȃ낤���ǁB
>>582
���Ԃ�x�N�g�����̂��߂Ƀf�[�^�̃A���C�����g����閽�߂���ˁH
�悭�킩�Ȃ����ǂ�
Mac���^�Ȃ瓾�ӂ����Ȃ�Ŕނ̓o����}�c�x�V
���Ԃ�x�N�g�����̂��߂Ƀf�[�^�̃A���C�����g����閽�߂���ˁH
�悭�킩�Ȃ����ǂ�
Mac���^�Ȃ瓾�ӂ����Ȃ�Ŕނ̓o����}�c�x�V
��������K8�̎��_��x64���[�h�ł�x87����Ȃ���TFP���g���ƌ����Ă��C�����邪
>>582
> �������W�X�^���g�����߂�A�����������Ƃ��ɐ��\���o��悤�Ƀ`���[������Ă�B
> RISC�ɂ��肪���ȃ��W�X�^�����݂Ɏg���悤�ȃR�[�h��g�ނƎ����W�X�^�t�@�C����
> �ǂݏ����ő҂�����邱�ƂɂȂ�̂ŋt�ɐ��\���o�Ȃ��B
������āA���Z�X�e�[�W���I��������߂̃p�C�v���C������A����̈ˑ��W������
���߂̃p�C�v���C����fetch�ɃV���[�g�J�b�g���[�g���t���Ă��邾���Ƃ������Ƃł͂Ȃ��A
���ߎ��s�㏭�����ꂽ�ʒu�̖��ߓ��m�ł��A�����ȓ����A�L���[�����[�^���g����
����Ƃ������ƁH
> �������W�X�^���g�����߂�A�����������Ƃ��ɐ��\���o��悤�Ƀ`���[������Ă�B
> RISC�ɂ��肪���ȃ��W�X�^�����݂Ɏg���悤�ȃR�[�h��g�ނƎ����W�X�^�t�@�C����
> �ǂݏ����ő҂�����邱�ƂɂȂ�̂ŋt�ɐ��\���o�Ȃ��B
������āA���Z�X�e�[�W���I��������߂̃p�C�v���C������A����̈ˑ��W������
���߂̃p�C�v���C����fetch�ɃV���[�g�J�b�g���[�g���t���Ă��邾���Ƃ������Ƃł͂Ȃ��A
���ߎ��s�㏭�����ꂽ�ʒu�̖��ߓ��m�ł��A�����ȓ����A�L���[�����[�^���g����
����Ƃ������ƁH
586 �F�R�E�L�́M�E,,�j�����������������F2007/11/12(��) 00:58:18 ID:Dui4adkY
NetBurst�̔{�����[�v�Ȃ�Ă��̍����ȃA�L�������[�^�̓T�^����Ȃ���
587 �F�R�E�L�́M�E,,�j�����������������F2007/11/12(��) 01:16:30 ID:Dui4adkY
���ꃌ�W�X�^��SIMD�������߁�FP���߁A�܂��͂��̋t���ƃ��C�e���V1�N���b�N���x������̂́A
����������IEEE754�`������Ȃ��ē����`���ň����Ă邩��Ǝv���B
���������p�̃A�L�������[�^�����݂���ƍl���Ă������ƁB
�Ă�Agner�搶�̎����̎���
����������IEEE754�`������Ȃ��ē����`���ň����Ă邩��Ǝv���B
���������p�̃A�L�������[�^�����݂���ƍl���Ă������ƁB
�Ă�Agner�搶�̎����̎���
>>579
>RX�̃��C���^�[�Q�b�g��100MHz�ȉ��̎s�ꂶ��˂��́H
�ǂ����ɓ]��ł��ǂ��A�Ƃ����v�悾�낤�c�B
���\�����W�I�ɂ͒Ⴍ��ARM9�A�A�i�E���X�ł͕��������_���Z��܂ŏ�������ƌ����Ă邩��A
��낤�Ǝv����ARM11�����x�܂ł͈��������Ƃ������炵���c�B
�Ԃ����ႯATMEL��AVR32�݂�(ry
>>580
>JAVA�v���Z�b�T�Ƃ����X�^�b�N��v���Z�b�T�A�v�悳�ꂽ���ǁA����o�������H
�{�Ƃ͂Ƃ������AARM�Ƃ��ɂ͊g���d�l�Ƃ��Ď�荞�܂ꂽ�B
Jazelle�g��(ARM926EJ�Ƃ�)�́A�قƂ�ǂ̃o�C�g�R�[�h���l�C�e�B�u�Ƃ��Ď��s�ł���B
Thumb�݂����ȕ������ǁc�B
>RX�̃��C���^�[�Q�b�g��100MHz�ȉ��̎s�ꂶ��˂��́H
�ǂ����ɓ]��ł��ǂ��A�Ƃ����v�悾�낤�c�B
���\�����W�I�ɂ͒Ⴍ��ARM9�A�A�i�E���X�ł͕��������_���Z��܂ŏ�������ƌ����Ă邩��A
��낤�Ǝv����ARM11�����x�܂ł͈��������Ƃ������炵���c�B
�Ԃ����ႯATMEL��AVR32�݂�(ry
>>580
>JAVA�v���Z�b�T�Ƃ����X�^�b�N��v���Z�b�T�A�v�悳�ꂽ���ǁA����o�������H
�{�Ƃ͂Ƃ������AARM�Ƃ��ɂ͊g���d�l�Ƃ��Ď�荞�܂ꂽ�B
Jazelle�g��(ARM926EJ�Ƃ�)�́A�قƂ�ǂ̃o�C�g�R�[�h���l�C�e�B�u�Ƃ��Ď��s�ł���B
Thumb�݂����ȕ������ǁc�B
>���������p�̃A�L�������[�^
�킹�Ă����
591 �F�R�E�L�́M�E,,�j�����������������F2007/11/12(��) 04:11:58 ID:Dui4adkY
�A�L�������[�^�̖���CPU�͑��݂��Ȃ�
592 �F�R�E�L�́M�E,,�j�����������������F2007/11/12(��) 04:13:05 ID:Dui4adkY
�ǂ����ǂ����邩�w�E�ł��Ȃ����\���ɏ���
�ɂȂ�ĂقƂ�Ǔ��{�ł�������ĂȂ����R�X�g�p�t�H�[�}���X���������ˁH
���ǎ��s���댻��
���ǎ��s���댻��
594 �FSocket774�F2007/11/12(��) 06:26:31 ID:MBC5Pz5i
Intel�̌��Z���Ƃ��ڍׂȃ\�[�X����ˁ[���ǂ�
�ɂ��ĔN20��������Ă�
���ϒP����2000�h���ȏゾ�낤���琬������ˁH
�ɂ��ĔN20��������Ă�
���ϒP����2000�h���ȏゾ�낤���琬������ˁH
595 �F�R�E�L�́M�E,,�j�����������������F2007/11/12(��) 07:25:40 ID:Dui4adkY
���������G���v���p�r��CPU�̓R�X�g�p�t�H�[�}���X�������́B�@
�u�{���Ȃ獡����PC�͒ɂɂȂ��Ă��v�ƍl����Ȃ�厸�s����
�T���A�R���e�i�^�̃f�[�^�Z���^�[
�uProject Blackbox�v�����������J
http://pc.watch.impress.co.jp/docs/2007/1112/sun.htm
�uProject Blackbox�v�����������J
http://pc.watch.impress.co.jp/docs/2007/1112/sun.htm
�ŋ�SUN�̒��q�������܂��������ǁAUltraSPARC4+������Ă�Ƃ����̂��ӊO
�v�Z��WS����Ȃ��Ƃ�
Itanium 2�̍����肤
http://pc.watch.impress.co.jp/docs/2007/1113/hot515.htm
http://pc.watch.impress.co.jp/docs/2007/1113/hot515.htm
>�����z
('A`)
('A`)
�C�̓łȘb����IA-64�̎��Ƃ𐬌������邽�߂ɂ�
���{�I�Ɍ����Ă��镨������낤�ȁB
������Z�p�Ɛ��\�̈�_�����œ˔j���悤�Ƃ��Ă������ēD�����c
�������ɁA�Г��ł��u�b�@����܂���Ȃ낤
���{�I�Ɍ����Ă��镨������낤�ȁB
������Z�p�Ɛ��\�̈�_�����œ˔j���悤�Ƃ��Ă������ēD�����c
�������ɁA�Г��ł��u�b�@����܂���Ȃ낤
�����̖^�Ԕ����ȗL���d�C���[�J�[����ڂ��Əd�Ȃ��� orz
�Ƃ���ŁA���������p�̃A�L�������[�^���ĉ����H
�A�h���X�Ɏg������Ă�ŃV�b�^�J���ăA�L���Ȃ�Č����Ă낤�Ǝv��
606 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 02:19:56 ID:cDeiLe4a
>>604
���������_���Z��̏o�͂Ƀ��b�`�����邾�낤�A����̂��Ƃ���ˁH
���������_���Z��̏o�͂Ƀ��b�`�����邾�낤�A����̂��Ƃ���ˁH
608 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 02:46:14 ID:cDeiLe4a
addps xmm0, xmm1
��
�������ɂP�N���b�N�]���ɂ�����B
andps xmm0, xmm2
�n������Ȃ���A�킩�邾�뗝����
��
�������ɂP�N���b�N�]���ɂ�����B
andps xmm0, xmm2
�n������Ȃ���A�킩�邾�뗝����
>>608
�������������̂��킩��A���̗�̓o�C�p�X���W�b�N���P�`���Ă��邽�߂̂悤�Ɏv����
�������������̂��킩��A���̗�̓o�C�p�X���W�b�N���P�`���Ă��邽�߂̂悤�Ɏv����
610 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 02:57:05 ID:cDeiLe4a
IEEE754�`���������̓����`���ɕϊ�������܂����ɖ߂����肷����A
�����`���̂܂��X���Z�f�[�^�˂����ق������C�e���V���������Ȃ�ł��匴���I�ɁB
�r�b�g�_�����Z����ɂ�IEEE754�`���ɂ��Ă���s��Ȃ��Ƃ����Ȃ��̂�
�����������[�v�����������Ȃ��Ƃ����Ȃ��B
�����`���̂܂��X���Z�f�[�^�˂����ق������C�e���V���������Ȃ�ł��匴���I�ɁB
�r�b�g�_�����Z����ɂ�IEEE754�`���ɂ��Ă���s��Ȃ��Ƃ����Ȃ��̂�
�����������[�v�����������Ȃ��Ƃ����Ȃ��B
>�����������[�v
����܂��A�킹�Ă����
����܂��A�킹�Ă����
�A�����ĂȂA������
�����\���H���̂��Ƃ��H
614 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 22:33:02 ID:cDeiLe4a
2�A��1�s���X�̒�]�ƃ��X��H��
IEEE754�`���͉������̍ŏ�ʃr�b�g�͏��1�Ɖ��肵�ďȂ��Ă邪���߂ɐ��x�͂������ǓW�J�����͈�����
IEEE754�`���͉������̍ŏ�ʃr�b�g�͏��1�Ɖ��肵�ďȂ��Ă邪���߂ɐ��x�͂������ǓW�J�����͈�����
615 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 22:36:42 ID:cDeiLe4a
�Ƃ肠����
"����܂�.*�킹�Ă����"
�Ŕn�����u�t�B���^�ɓ���Ă�����
"����܂�.*�킹�Ă����"
�Ŕn�����u�t�B���^�ɓ���Ă�����
>>614
���������O��
�덷�̖�肪�����Ė���IEEE754�`���ɂ��Ȃ��Ǝ��̉��Z�ɂ����߂Ȃ���
FMAC�ł���A�덷�����Ȃ�����Ɩ��ɂȂ����Ƃ����̂�
���������O��
�덷�̖�肪�����Ė���IEEE754�`���ɂ��Ȃ��Ǝ��̉��Z�ɂ����߂Ȃ���
FMAC�ł���A�덷�����Ȃ�����Ɩ��ɂȂ����Ƃ����̂�
617 �F�R�E�L�́M�E,,�j�����������������F2007/11/13(��) 23:13:41 ID:cDeiLe4a
��������24bit or 53bit�ɐ藎�Ƃ������������낻���
���������o�C�i���t�H�[�}�b�g�܂Ŗ߂��Ă��K�v�͂ǂ��ɂ��Ȃ��B
��������SSE�̘b�����Ă�̂Ɍ덷�̌݊����̖��Ƃ�������������
���Ƃ���rcpps��rsqrtps�͌��ז��߂ł����H�L�����x12�r�b�g������
���������o�C�i���t�H�[�}�b�g�܂Ŗ߂��Ă��K�v�͂ǂ��ɂ��Ȃ��B
��������SSE�̘b�����Ă�̂Ɍ덷�̌݊����̖��Ƃ�������������
���Ƃ���rcpps��rsqrtps�͌��ז��߂ł����H�L�����x12�r�b�g������
�mWSJ�n �C���N�W�F�b�g�����Ŕ����̂����Z�p�A�V����Ƃ��J��
http://www.itmedia.co.jp/news/articles/0711/13/news098.html
http://www.itmedia.co.jp/news/articles/0711/13/news098.html
�ږ����킹�ĸ�ق�
>>617
�����_�̈ʒu�����킹�ĉ����������̃r�b�g���̂Ă邱�Ƃ�IEEE754�`���ɖ߂��ƌ�����A�o�[�Jwww
�܂����璷�\���̂܂��̉��Z�ɐH�킹��Ƃ��v���Ă��Ȃ����낤��
IEEE754������搂�����ɂ�SSE���낤���Ȃ낤���d�l�����Ƃ��K�v
�����_�̈ʒu�����킹�ĉ����������̃r�b�g���̂Ă邱�Ƃ�IEEE754�`���ɖ߂��ƌ�����A�o�[�Jwww
�܂����璷�\���̂܂��̉��Z�ɐH�킹��Ƃ��v���Ă��Ȃ����낤��
IEEE754������搂�����ɂ�SSE���낤���Ȃ낤���d�l�����Ƃ��K�v
�U�߂��Afmac�͂�����݂��[
622 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 00:32:46 ID:rfLFeImR
>>622
�Ƃ肠�������O�����������_���Z�𗝉����Ă��Ȃ����Ƃ͂킩����
�̂Ă�r�b�g�������߂邽�߂ɂ́A�����_���ŏ�ʃr�b�g�̏�Ɏ����Ă���悤�V�t�g���邵���Ȃ�����
���ꂪIEEE�`���ɖ߂���łȂ��ĂȂƌ����̂���
�Ƃ肠�������O�����������_���Z�𗝉����Ă��Ȃ����Ƃ͂킩����
�̂Ă�r�b�g�������߂邽�߂ɂ́A�����_���ŏ�ʃr�b�g�̏�Ɏ����Ă���悤�V�t�g���邵���Ȃ�����
���ꂪIEEE�`���ɖ߂���łȂ��ĂȂƌ����̂���
624 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 00:43:20 ID:rfLFeImR
SSE�͓��o�͂̃f�[�^�t�H�[�}�b�g�Ƃ���IEEE754�`�����̗p���Ă邪
���Z���ʂ̊ۂ߂̓I�v�V�������ȁB
Cell��SPE�Ȃ͐؎̂ăI�����[����Ȃ��������ȁB
���Z���ʂ̊ۂ߂̓I�v�V�������ȁB
Cell��SPE�Ȃ͐؎̂ăI�����[����Ȃ��������ȁB
625 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 00:46:20 ID:rfLFeImR
IEEE754�t�H�[�}�b�g���Ă̂͂����܂�1:8:23���邢��1:11:52�̃o�C�i���\���ł����čŏ�ʂ�����ێ����邾���Ȃ�
��A�̏����ɑg�ݍ��߂�㩁B
��A�̏����ɑg�ݍ��߂�㩁B
>��A�̏���
���ĂȂH����
���ĂȂH����
627 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 00:53:02 ID:rfLFeImR
������������IEEE754�t�H�[�}�b�g�ɖ߂��Ă���SSE4�̐V����round*�Ȃ͎g����ꏊ�Ȃ�đ��݂��܂���
�n��
�n��
�ȂɃt�@�r���b�ĂA���̃^�R��
�덷�̈�ѐ��Ȃ�Ăǂ��ł��ǂ��Ƃ������ł�������inst�g�������̘b���B
�덷�̈�ѐ��Ȃ�Ăǂ��ł��ǂ��Ƃ������ł�������inst�g�������̘b���B
>>625
�Ⴄ�Ⴄ
���RIEEE�ʼn��Z�덷���K�肳��Ă���̂ŁA���Z���I�邽�тɌ덷�ɉߕs���������Ă͂����Ȃ��킯
(���Ӗ��ȗႾ��)��H�I�ɂ͑��i���ł��A�i���O�ł����܂�Ȃ��̂����AIEEE�͉�H�ł̕\�����K�肵�Ă���킯����Ȃ��̂�
��A�̏����Ƃ����̂��Ӗ����킩���
��̓I�ɗ�������Ă���
�Ⴄ�Ⴄ
���RIEEE�ʼn��Z�덷���K�肳��Ă���̂ŁA���Z���I�邽�тɌ덷�ɉߕs���������Ă͂����Ȃ��킯
(���Ӗ��ȗႾ��)��H�I�ɂ͑��i���ł��A�i���O�ł����܂�Ȃ��̂����AIEEE�͉�H�ł̕\�����K�肵�Ă���킯����Ȃ��̂�
��A�̏����Ƃ����̂��Ӗ����킩���
��̓I�ɗ�������Ă���
630 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 01:06:16 ID:rfLFeImR
SSE4�̃v���O���~���O�}�j���A����x�ł��ڒʂ����H
����Ȗϑz������킯�Ȃ��B
round*�͉��Z��ɔ��s���܂��B��グ�邩��̂Ă邩�͂����Ō��܂�B
�t�Ɍ�����add*�Ƃ�mul*�̉��Z���I��������Ƃ̌��ʂ́y��IEEE754�t�H�[�}�b�g�ɕϊ������Ⴂ���Ȃ��z�ȁB
�������̏�ʂ���25bit�ڂ��邢��54bit�ڂ܂ł͉����A�L�������[�^���Č����Ă���̂̏�Ɏc���Ă�B
Penryn�ł����Ȃ�킯����Ȃ���B
SSE3�̒i�K�Ŋ���fisttp�݂����Ȗ��߂��邵�B
����Ȗϑz������킯�Ȃ��B
round*�͉��Z��ɔ��s���܂��B��グ�邩��̂Ă邩�͂����Ō��܂�B
�t�Ɍ�����add*�Ƃ�mul*�̉��Z���I��������Ƃ̌��ʂ́y��IEEE754�t�H�[�}�b�g�ɕϊ������Ⴂ���Ȃ��z�ȁB
�������̏�ʂ���25bit�ڂ��邢��54bit�ڂ܂ł͉����A�L�������[�^���Č����Ă���̂̏�Ɏc���Ă�B
Penryn�ł����Ȃ�킯����Ȃ���B
SSE3�̒i�K�Ŋ���fisttp�݂����Ȗ��߂��邵�B
���{��Ō��_�������āB
�����܂łŗǂ�����
�����܂łŗǂ�����
round??�͏����_�ȉ����ۂ߂閽�߂���Ȃ��̂��H
633 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 01:13:49 ID:rfLFeImR
>>632
�Ⴄ�BMXCSR���W�X�^�̏�����������炸�Ƀ_�C���N�g�ɍʼn��ʂ��ۂ߂�B
�����_�ȉ��̊ۂ߂�cvtps2pi/cvttps2pi�̎g�������ŏ\������
�Ⴄ�BMXCSR���W�X�^�̏�����������炸�Ƀ_�C���N�g�ɍʼn��ʂ��ۂ߂�B
�����_�ȉ��̊ۂ߂�cvtps2pi/cvttps2pi�̎g�������ŏ\������
�e���߂� Operation �� Intel C/C++ Compiler Intrinsic Equivalent �͖ڂ�ʂ����H
635 �F�R�E�L�́M�E,,�j�����������������F2007/11/14(��) 01:52:28 ID:rfLFeImR
�ǂ�ł����B
�������ł��镔�������c�����߂���
��P�Ƃ���B
�������ł��镔�������c�����߂���
��P�Ƃ���B
���E�����Ċ��Ⴂ�̂�����
��A�̈ꌾ����c
��������̂����X���ɏ������e����ɁA�܂�����
��A�̈ꌾ����c
��������̂����X���ɏ������e����ɁA�܂�����
�e���В��Ȃ�ŋ����Ă���Ă悗
NEC�G���A40nm�v���Z�X�̃Q�[���@�����V�X�e��LSI����
http://pc.watch.impress.co.jp/docs/2007/1116/necel.htm
http://pc.watch.impress.co.jp/docs/2007/1116/necel.htm
100���~���Ĉٗl�ɏ��Ȃ��Ȃ��H
http://blog.goo.ne.jp/ikedanobuo/e/fd6f41ee4f521ae5adf73b7980c8a26d
http://blog.goo.ne.jp/ikedanobuo/e/7a0b5fd9f33ff6d2be7f8e8255b7007f
�r�c�M�v vs ���炫�������� �푈�u��
http://blog.goo.ne.jp/ikedanobuo/e/fbfaca6dfadef82fccf2c9349c12ae91
http://d.hatena.ne.jp/arakik10/20071119/p1
http://blog.goo.ne.jp/ikedanobuo/e/7a0b5fd9f33ff6d2be7f8e8255b7007f
�r�c�M�v vs ���炫�������� �푈�u��
http://blog.goo.ne.jp/ikedanobuo/e/fbfaca6dfadef82fccf2c9349c12ae91
http://d.hatena.ne.jp/arakik10/20071119/p1
641 �FSocket774�F2007/11/24(�y) 16:09:42 ID:tPS9ugc8
���̍���CPU�͑��x�����낢�날��ǂ��Ȃ̂�������܂���B
Celeron�@M�́@1.2GHz ���o�C���p
��
Celeron�@NorthWood�@2.4GHz �̔����̑��x�����Ȃ�
�ƍl���Ă����̂ł��傤���H
Celeron�@M�́@1.2GHz ���o�C���p
��
Celeron�@NorthWood�@2.4GHz �̔����̑��x�����Ȃ�
�ƍl���Ă����̂ł��傤���H
���߂Ł[��
�ǂ��l���悤�ƍD���ɂ���
�����Ƃ͑S���Ⴄ����
�����Ƃ͑S���Ⴄ����
644 �F�R�E�L�́M�E,,�j�����������������F2007/11/24(�y) 17:05:11 ID:BJ7jZlpk
Pentium 4��Pentium M���ăN���b�N�����萫�\�{���炢�Ⴄ��ۂ��邵���ۂ���Ȃ��낤
�v���O�����̂ł��Ȃ�����l���A���X�Ȃ��烋�l�T�X��
H8��M16C�̖��߃Z�b�g�̃h�L�������g��ǂ�ł݂�
�E�����Ƃ�byte��(68k�̂悤��2byte�ςłȂ�)
�EH8�́Abit���얽�߂���ȊO����68k���V���v��
�EH8�̃��W�X�^�͔ėp8�{�Ƒf��
�EM16C��BCD�A���Ăяo���p���߂Ȃǂ�����A�����������b�`
�EM16C�́A�悭�킩��Ȃ���p���W�X�^�\��
�Ƃ���������
�����Ƃ��������v���O�������ƁA68k���R�[�h���������Ȃ肻��
���l�T�X�VCPU�ARX�ł�3�I�y�����h���܂ރA�h���b�V���O���[�h�g��
�ł���ɃR�[�h��������������Ă��Ƃ����ǁA����ł������Ȋ���
>>640
�����N��A��������B�B�B�B
H8��M16C�̖��߃Z�b�g�̃h�L�������g��ǂ�ł݂�
�E�����Ƃ�byte��(68k�̂悤��2byte�ςłȂ�)
�EH8�́Abit���얽�߂���ȊO����68k���V���v��
�EH8�̃��W�X�^�͔ėp8�{�Ƒf��
�EM16C��BCD�A���Ăяo���p���߂Ȃǂ�����A�����������b�`
�EM16C�́A�悭�킩��Ȃ���p���W�X�^�\��
�Ƃ���������
�����Ƃ��������v���O�������ƁA68k���R�[�h���������Ȃ肻��
���l�T�X�VCPU�ARX�ł�3�I�y�����h���܂ރA�h���b�V���O���[�h�g��
�ł���ɃR�[�h��������������Ă��Ƃ����ǁA����ł������Ȋ���
>>640
�����N��A��������B�B�B�B
646 �FSocket774�F2007/11/24(�y) 17:25:55 ID:tPS9ugc8
647 �F�R�E�L�́M�E,,�j�����������������F2007/11/24(�y) 17:34:40 ID:BJ7jZlpk
>>645
����R8C-Tiny��M16�x�[�X�ɓ����n�̃t�B�[�`������荞����
����R8C-Tiny��M16�x�[�X�ɓ����n�̃t�B�[�`������荞����
�v���O�����̂ł��Ȃ�����l���A���X�Ȃ���68000��
�I�y�R�[�h�t�H�[�}�b�g��(ry
�ȂႱ���[�[�[�[�[�[�[�[�[�[�[�[�[�[!!
x86�̃v���t�B�b�N�X���A��RISC�Ɋ�������قǕ��G�ȃt�H�[�}�b�g
680x0�����S���Ȃ�ɂȂ��āAx86�������c�����̂�
���Y�ʂ̈Ⴂ��������Ȃ������̂�
�I�y�R�[�h�t�H�[�}�b�g��(ry
�ȂႱ���[�[�[�[�[�[�[�[�[�[�[�[�[�[!!
x86�̃v���t�B�b�N�X���A��RISC�Ɋ�������قǕ��G�ȃt�H�[�}�b�g
680x0�����S���Ȃ�ɂȂ��āAx86�������c�����̂�
���Y�ʂ̈Ⴂ��������Ȃ������̂�
>>646
������O����Ȃ����B�A�[�L�e�N�`���̈ႤCPU�Ȃ�N���b�N������̐��\��
�܂������قȂ邵�A���������P�R�A��CPU�ƂS�R�A��CPU�œ����\��������
�Ȃ�̂��߂ɃR�A���킴�킴���₷��B
�[�����肶��Ȃ��Ȃ炻�̃��x���̒m�����x���̐l�͂��̃X���ɎQ��������ʖځB
�G�k�X���⏉�S�Ҏ���X���s���Ȃ����B
������O����Ȃ����B�A�[�L�e�N�`���̈ႤCPU�Ȃ�N���b�N������̐��\��
�܂������قȂ邵�A���������P�R�A��CPU�ƂS�R�A��CPU�œ����\��������
�Ȃ�̂��߂ɃR�A���킴�킴���₷��B
�[�����肶��Ȃ��Ȃ炻�̃��x���̒m�����x���̐l�͂��̃X���ɎQ��������ʖځB
�G�k�X���⏉�S�Ҏ���X���s���Ȃ����B
8086��286��386��486��Pentium��Pentium2��
�̂́A�N���b�N������̐��\���オ�葱���Ă������ǁA
PC����ʉƒ�ɂ����y����悤�ɂȂ���Pentium2�ȍ~�́A
�N���b�N������̐��\��������Ȃ��Ȃ�A
�N���b�N=���\�Ƃ����l�����Ƃ����l�����L�܂����̂ł͂Ȃ�����
�̂́A�N���b�N������̐��\���オ�葱���Ă������ǁA
PC����ʉƒ�ɂ����y����悤�ɂȂ���Pentium2�ȍ~�́A
�N���b�N������̐��\��������Ȃ��Ȃ�A
�N���b�N=���\�Ƃ����l�����Ƃ����l�����L�܂����̂ł͂Ȃ�����
>>650
�_�E�g�B286��386�̓N���b�N�����萫�\�͂킸����286����B������386�̕���
�N���b�N���̂͂��Ȃ�グ����B
���_�v���e�N�g���[�h�Ŏg���Ȃ�386�����I�������Ȃ����A�v���e�N�g���[�h�����ۂ�
�g���鍠�ɂ�286�Ȃǂ��͂�ߋ���CPU�������B
�_�E�g�B286��386�̓N���b�N�����萫�\�͂킸����286����B������386�̕���
�N���b�N���̂͂��Ȃ�グ����B
���_�v���e�N�g���[�h�Ŏg���Ȃ�386�����I�������Ȃ����A�v���e�N�g���[�h�����ۂ�
�g���鍠�ɂ�286�Ȃǂ��͂�ߋ���CPU�������B
>>651
16bit_bus���m����286�̂ق����������
�ł��A
386�@32bit_bus
286�@16bit_bus
���ƁA������Ȃ�ł�386�̂ق��������Ǝv��
16bit_bus���m����286�̂ق����������
�ł��A
386�@32bit_bus
286�@16bit_bus
���ƁA������Ȃ�ł�386�̂ق��������Ǝv��
����386�̂ق����N���b�N��������̂�
�O���L���b�V�����g�����Ƃ��A�������A�N�Z�X�ɃE�F�C�g�����ꂽ�Ƃ�
�̂������ŁA�f�R�[�_�`���s���j�b�g�ɂ�鍷�͂Ȃ��Ǝv��
286���ƁA2�o�X�T�C�N���Œ�Ȃ�ŁA20Mhz�ȏ�ɂł��Ȃ�������
�Ȃ���������?
����FM-TOWNS�́A�������ɃE�F�C�g����܂���(���������C�e���V������)
�Ȃ�ŁA386�ł������[�x������w
�O���L���b�V�����g�����Ƃ��A�������A�N�Z�X�ɃE�F�C�g�����ꂽ�Ƃ�
�̂������ŁA�f�R�[�_�`���s���j�b�g�ɂ�鍷�͂Ȃ��Ǝv��
286���ƁA2�o�X�T�C�N���Œ�Ȃ�ŁA20Mhz�ȏ�ɂł��Ȃ�������
�Ȃ���������?
����FM-TOWNS�́A�������ɃE�F�C�g����܂���(���������C�e���V������)
�Ȃ�ŁA386�ł������[�x������w
>>653
�������A386DX���286�̂ق���������!?
���A�����[�h���ƁA2byte�Ŗ��߂����܂�ꍇ��������������A
�Ђ���Ƃ�����E�E�E�Ə������ݒ���Ɏv�������ǁA
�����������̂�
�������A386DX���286�̂ق���������!?
���A�����[�h���ƁA2byte�Ŗ��߂����܂�ꍇ��������������A
�Ђ���Ƃ�����E�E�E�Ə������ݒ���Ɏv�������ǁA
�����������̂�
�܁[TOWNS��386�}�V���̒��ł̓N���b�N���Ⴉ�������Ȃ��B
���ォ��T�䔃����TOWNS�I�^�N�����������B
���ォ��T�䔃����TOWNS�I�^�N�����������B
�t�@�u���X����IP���肵�Ă郁�[�J�[�̐v�w�Ăǂꂾ���D�G�Ȃ�
�o�ׂ܂łɃ��r�W�����d�˂�x86���ɑ����G���̒��x��������ɂ��Ă�
�v���N���e�B�J���p�X��s���o�O�̓S���S���o�Ă��Ă锤�Ȃ̂�
�}�ʂ����Ő��i���d�グ��Ȃ��
�o�ׂ܂łɃ��r�W�����d�˂�x86���ɑ����G���̒��x��������ɂ��Ă�
�v���N���e�B�J���p�X��s���o�O�̓S���S���o�Ă��Ă锤�Ȃ̂�
�}�ʂ����Ő��i���d�グ��Ȃ��
658 �F�R�E�L�́M�E,,�j�����������������F2007/11/24(�y) 22:36:59 ID:BJ7jZlpk
ARM����IP������Ȃ��́H
���܂ǂ����������ł������傠���肾��
>>648
�l�o��encode�͏o�����B�ł�decode���o����
z80��09�̎��̗l�ɋ@�B��Ż���Ɠǂ�patch���Ă��Ȃ������B
�́X�̂��b�����A̯
�l�o��encode�͏o�����B�ł�decode���o����
z80��09�̎��̗l�ɋ@�B��Ż���Ɠǂ�patch���Ă��Ȃ������B
�́X�̂��b�����A̯
ARM��X86����APCI FAX�J�[�h�h���C�o��OS�S�̂��炢�v��Փx�Ⴄ��ˁH
�n�[�h�E�F�A�ŗႦ����AZ80��486���炢�̍��H
���ꂭ�炢�Ⴄ�悤��
�n�[�h�E�F�A�ŗႦ����AZ80��486���炢�̍��H
���ꂭ�炢�Ⴄ�悤��
1T�o�C�g�̃������[�ڑ��������ցA�����o�X�Ђ��V�Z�p���J��
http://www.eetimes.jp/contents/200711/28425_1_20071127165947.cfm
http://www.eetimes.jp/contents/200711/28425_1_20071127165947.cfm
663 �FSocket774�F2007/11/28(��) 01:07:29 ID:e3r5Yg4W
�y���e�B�A��4����1���������J���Ă���ǁA���̌��̎d�l�������Ă���Ȃ����H
�Ȃ����낤Silverthorne��MMXPentium�̌�p�i�Ɍ����Ă���
ttp://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
ttp://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
����VIA��C3/C7�̗��B
In-Order�{SMT����PPE��������������
�_�C�T�C�Y���̗^����ꂽ���\�[�X���ő�����p����ƂȂ�ƌ��ǂǂ�������Ă����Ă����Ⴄ�̂���
�_�C�T�C�Y���̗^����ꂽ���\�[�X���ő�����p����ƂȂ�ƌ��ǂǂ�������Ă����Ă����Ⴄ�̂���
�Ƃ���������d�͂�����̐��\�Njy�̌��ʂ���B
668 �FSocket774�F2007/11/28(��) 23:59:45 ID:01Uay1ix
>>666,667
P.A. Semi��PWRficient��AMCC��Titan��Out-of-order����B
PPE���Ă�����CELL���Č��ǁA�\�肵�Ă����\�̃R���p�C������ꂸ�A�A�Z���u��
�ŃV�R�V�R�����Ȃ��Ɨ\�肵�Ă������d�͂��o�Ȃ����׃A�[�L�e�N�`���ȃC���[�W
�����������A�ŋ߂͂����ł������̂��H
P.A. Semi��PWRficient��AMCC��Titan��Out-of-order����B
PPE���Ă�����CELL���Č��ǁA�\�肵�Ă����\�̃R���p�C������ꂸ�A�A�Z���u��
�ŃV�R�V�R�����Ȃ��Ɨ\�肵�Ă������d�͂��o�Ȃ����׃A�[�L�e�N�`���ȃC���[�W
�����������A�ŋ߂͂����ł������̂��H
CPU�v�Z�@�B
http://www.geocities.jp/onakasuita24/cpu/cpu_changer2.html
65 ���O�F�s���ȃf�o�C�X���� ���e���F04/06/11 12:34 ID:B++upyAe
>>61
�ʃX���ł��[��[�̂�������
*�ۯ�����̐��\
0.70 :Celeron(Northwood)
0.85 :Pentium4(Willamette)
0.90 :C3(Nehemiah)
0.95 :Pentium4A(Northwood, Prescott)
1.00 :Pentium4B(Northwood)
1.05 :Pentium4E(Prescott)
1.10 :Pentium4C(Northwood)
1.15 :Pentium4XE(Gallatin)
1.20 :Celeron(Tualatin256k)
1.25 :Duron(Morgan, Applebred)
1.25 :Athlon(Thunderbird)
1.25 :Pentium3(Tualatin256k)
1.30 :Pentium3-S(Tualatin512k)
1.40: AthlonXP(Thoroughbred, Thorton)
1.45: AthlonXP(Barton)
1.50 :Pentium-M(Banias)
1.50 :Athlon64(ClawHammer) 512KB HT800MHz SingleChannel
1.55 :Athlon64(ClawHammer) 1MB HT800MHz SingleChannel
1.55 :Athlon64(ClawHammer) 512KB HT1000MHz SingleChannel
1.60 :Athlon64(ClawHammer) 1MB HT1000MHz SingleChannel
1.60 :Athlon64FX(SledgeHammer) 1MB DualChannel
http://www.geocities.jp/onakasuita24/cpu/cpu_changer2.html
65 ���O�F�s���ȃf�o�C�X���� ���e���F04/06/11 12:34 ID:B++upyAe
>>61
�ʃX���ł��[��[�̂�������
*�ۯ�����̐��\
0.70 :Celeron(Northwood)
0.85 :Pentium4(Willamette)
0.90 :C3(Nehemiah)
0.95 :Pentium4A(Northwood, Prescott)
1.00 :Pentium4B(Northwood)
1.05 :Pentium4E(Prescott)
1.10 :Pentium4C(Northwood)
1.15 :Pentium4XE(Gallatin)
1.20 :Celeron(Tualatin256k)
1.25 :Duron(Morgan, Applebred)
1.25 :Athlon(Thunderbird)
1.25 :Pentium3(Tualatin256k)
1.30 :Pentium3-S(Tualatin512k)
1.40: AthlonXP(Thoroughbred, Thorton)
1.45: AthlonXP(Barton)
1.50 :Pentium-M(Banias)
1.50 :Athlon64(ClawHammer) 512KB HT800MHz SingleChannel
1.55 :Athlon64(ClawHammer) 1MB HT800MHz SingleChannel
1.55 :Athlon64(ClawHammer) 512KB HT1000MHz SingleChannel
1.60 :Athlon64(ClawHammer) 1MB HT1000MHz SingleChannel
1.60 :Athlon64FX(SledgeHammer) 1MB DualChannel
670 �FSocket774�F2007/11/29(��) 00:08:21 ID:att/DXVr
>666
In-order+VMT�ł́HSMT�͕��ʁAOut-of-order�̋@�\�𗬗p������́B
�f�R�[�_�̍�����86�n��In-order��VMT�Ȃ�A3�X���b�h/�R�A�̕����A
�o�����X�����Ǝv�����A���p���������Q��N������B
�L���b�V����24kB�Ƃ�3MB�Ƃ����\������B
In-order+VMT�ł́HSMT�͕��ʁAOut-of-order�̋@�\�𗬗p������́B
�f�R�[�_�̍�����86�n��In-order��VMT�Ȃ�A3�X���b�h/�R�A�̕����A
�o�����X�����Ǝv�����A���p���������Q��N������B
�L���b�V����24kB�Ƃ�3MB�Ƃ����\������B
ARM�͂Ƃ��Ƃ����N�o��Cortex-A9��OoO��
>>668
TDP�����W���Ⴄ
OoO�ɂ��Ă��A���\�͔{�ɂȂ�Ȃ��̂�
TDP�͊m���ɔ{�ȏ�ɂȂ�(�Ǝv��)
�C���I�[�_�[&���E���h���r�����}���`�X���b�h���Ȃ�đ��݂���Ӗ��Ȃ��C������
486�f���A���R�A�Ƃ�MMX Pentium�̕����}�V����ˁH
�Ƃɂ���ARM�Ƌ�������͖̂�������
TDP�����W���Ⴄ
OoO�ɂ��Ă��A���\�͔{�ɂȂ�Ȃ��̂�
TDP�͊m���ɔ{�ȏ�ɂȂ�(�Ǝv��)
�C���I�[�_�[&���E���h���r�����}���`�X���b�h���Ȃ�đ��݂���Ӗ��Ȃ��C������
486�f���A���R�A�Ƃ�MMX Pentium�̕����}�V����ˁH
�Ƃɂ���ARM�Ƌ�������͖̂�������
673 �FSocket774�F2007/11/29(��) 00:36:32 ID:att/DXVr
�ÓTRISC�Ȃ�u�����Ȋ���Ɏg�p�p�x���Ⴂ����v�Ŏ��������������悤��
16bit���Z�Ƃ��܂Ńn�[�h�����Ȃ��ƁA���\������d�͂��o�Ȃ��̂�����B
�}���`�X���b�h�̊Ǘ��@�\�����b�`�ɂ��Ă��ƁA�����I�ɃV���R��OS�ɂȂ�H
ttp://www.ny.ics.keio.ac.jp/b3/hardware.html
���̂Ƃ��A�̂�Transputer�݂������B
16bit���Z�Ƃ��܂Ńn�[�h�����Ȃ��ƁA���\������d�͂��o�Ȃ��̂�����B
�}���`�X���b�h�̊Ǘ��@�\�����b�`�ɂ��Ă��ƁA�����I�ɃV���R��OS�ɂȂ�H
ttp://www.ny.ics.keio.ac.jp/b3/hardware.html
���̂Ƃ��A�̂�Transputer�݂������B
���̃����N�A���A���^�C���w����SMT�Ƃ���������������悤��
�V���R���J�[�l���݂����ȍl�����Ėʔ�������
��������������܂Ȃ��̂��߂���
�V���R���J�[�l���݂����ȍl�����Ėʔ�������
��������������܂Ȃ��̂��߂���
>>673�̂��Ƃ���������Ă���������
SMT�����ŁA�D��x���n�[�h�E�F�A��X���b�h��ւ����Ǝv���Ɩʔ�����
SMT�����ŁA�D��x���n�[�h�E�F�A��X���b�h��ւ����Ǝv���Ɩʔ�����
>>672
���q�����
���q�����
677 �F�R�E�L�́M�E,,�j�����������������F2007/12/02(��) 20:56:49 ID:mth3ch+6
>>670
�����3IPC������A�Ƃ��H
�����3IPC������A�Ƃ��H
ISSCC�̃v���O�������o�Ă�̂ɐ���オ���ĂȂ��ȁB
�Ƃ͂����Ă��f�l�̉����݂����Ăǂ�������������ł����Ȃ�����
���̒��ŋC�ɂȂ����̂̓��l��8core&8 user RAM(SPE�݂����ɃR�A�����Ă��Ƃ��H)
�ɂ���Automatic Parallelizing Compiler�B
�ǂ�Ȋ����ɂȂ�낤�HCELL�ɉ��p�o�����肵�Ȃ����ȁH
����Silverthorne�炵���v���Z�b�T�ł�������2-issue��in-Order�Ə����Ă���ˁB
HT/SMT�炵�������͌�������Ȃ��B
�Ƃ͂����Ă��f�l�̉����݂����Ăǂ�������������ł����Ȃ�����
���̒��ŋC�ɂȂ����̂̓��l��8core&8 user RAM(SPE�݂����ɃR�A�����Ă��Ƃ��H)
�ɂ���Automatic Parallelizing Compiler�B
�ǂ�Ȋ����ɂȂ�낤�HCELL�ɉ��p�o�����肵�Ȃ����ȁH
����Silverthorne�炵���v���Z�b�T�ł�������2-issue��in-Order�Ə����Ă���ˁB
HT/SMT�炵�������͌�������Ȃ��B
679 �F�R�E�L�́M�E,,�j�����������������F2007/12/02(��) 22:39:45 ID:mth3ch+6
>>678
MMX Pentium�̌�p���H
MMX Pentium�̌�p���H
MMX P5���Ă݂�ȓ������ƁA�l�����W
681 �F�R�E�L�́M�E,,�j�����������������F2007/12/02(��) 23:12:32 ID:mth3ch+6
CPUID���Ă݂���Family 5�ȋC������B
���Pentium M�x�[�X��A100�Ȃ�Family 6��������
���Pentium M�x�[�X��A100�Ȃ�Family 6��������
682 �FSocket774�F2007/12/03(��) 01:59:47 ID:J7ydZ4ki
http://nueda.main.jp/blog/archives/003101.html
87 ���O�FSocket774 ���e���F2007/12/03(��) 00:35:20 ID:/hXBsUm0
>>71
�c�O�������ȁB
��(rabbit)�̓p���m�C�A���B
���������A�C���e���̋Z�p�͂����͔F�߂Ă���B
�����A�y���������o��ƌ����̂ɍ�����P���c��Q6600���o��������K�v�����A
Phenom���Ȃ߂�ȊO�ɖ�������A���̂悤�ɃR�����g�����B
�p���m�C�A�Ƃ����ׂ��́AAMD��Phenom�̃X���ɂ킴�킴Q6600�̘b��������ė��āA
�����̃I���^���̗ϗ��ς̂�������Ȃ������݂𑱂��Ă���z��̂��Ƃ��낤�B
������ɁA���͕ʂ�AMD�M�҂ł͖����B
���������̂Ȃ��C���e���̋��Ɨ͂ɂ��s��x�z�ƒ��r���[�Ȑv��CPU�A
���ߏ��AMD���[�U�[���Ȃ߂�C���e���M�҂��L���C�Ȃ������B
�����܂������������A�ʂ�AMD�D���D�����Ē�����Ȃ����
�����A����ȏ�ɲ��فA���ِM�҂��C�ɓ�����̘b
����C2D�o�Ă���ނ�݂ɏ����ւ��Ă���ً��͂��Ȃ賻
2ch�݂̂Ȃ炸رقł�����Ȃ̌������邩�獢�������̂��B
87 ���O�FSocket774 ���e���F2007/12/03(��) 00:35:20 ID:/hXBsUm0
>>71
�c�O�������ȁB
��(rabbit)�̓p���m�C�A���B
���������A�C���e���̋Z�p�͂����͔F�߂Ă���B
�����A�y���������o��ƌ����̂ɍ�����P���c��Q6600���o��������K�v�����A
Phenom���Ȃ߂�ȊO�ɖ�������A���̂悤�ɃR�����g�����B
�p���m�C�A�Ƃ����ׂ��́AAMD��Phenom�̃X���ɂ킴�킴Q6600�̘b��������ė��āA
�����̃I���^���̗ϗ��ς̂�������Ȃ������݂𑱂��Ă���z��̂��Ƃ��낤�B
������ɁA���͕ʂ�AMD�M�҂ł͖����B
���������̂Ȃ��C���e���̋��Ɨ͂ɂ��s��x�z�ƒ��r���[�Ȑv��CPU�A
���ߏ��AMD���[�U�[���Ȃ߂�C���e���M�҂��L���C�Ȃ������B
�����܂������������A�ʂ�AMD�D���D�����Ē�����Ȃ����
�����A����ȏ�ɲ��فA���ِM�҂��C�ɓ�����̘b
����C2D�o�Ă���ނ�݂ɏ����ւ��Ă���ً��͂��Ȃ賻
2ch�݂̂Ȃ炸رقł�����Ȃ̌������邩�獢�������̂��B
�y�������Ƃ��ǂ��ł��悭��
CRAY��X2�u���[�h��������Ɨ~����
CRAY��X2�u���[�h��������Ɨ~����
P5 with SSEx
SuperSEX
SuperSEX
�����r�[�̓V���O���X���b�h�̉������̗�����
�ˑR���������o����
�����Ȃ�DLP�̉�����
�����Ȃ�DLP�̉�����
687 �F�l�n���� LS �����r�[�F2007/12/05(��) 14:04:46 ID:cLxlFRXU
����Ȃ��̂͂����̗��K�䂾��
�����チ�����̉��v����������
�A���[�o�̂悤�ɓ��삷��CPU
�����チ�����̉��v����������
�A���[�o�̂悤�ɓ��삷��CPU
�C�X���G�����甭�M�����Intel�̎�����CPU�e�N�m���W�[
http://pc.watch.impress.co.jp/docs/2007/1211/kaigai406.htm
�b�����ŁAPenryn�ł�CPU�̒���CPU�R�A�̃X�e�C�g��Ҕ�������Ɨ��d����SRAM�̈�������BCPU�S�̂̓d���𗎂Ƃ��Ă��A
�bCPU�X�e�C�g��CPU���ɕێ��ł���悤�ɂ����B�킩��₷���Ⴆ��A��퓔�����邱�ƂŁA���C���̏Ɩ����ɒ[��
�b�Â����邱�Ƃ��ł���悤�ɂȂ����悤�Ȃ��̂��B
���ǂ���͕����I�ɁA���s�������v���Z�b�T�ɂ����l�Ȃ��̂��ȁH
�Ɨ��d����SRAM����Ȃ��āA�s��������������o�ڂ��������A���P���Ŋ���
�Ȑߓd�X�e�[�g�Ɉڍs�o����Ǝv�����A�A�N�Z�X���x�������Ȃ��ƃX�e�[�g��
�̈ڍs�╜�A���x���Ȃ��āA������X�|���X�������Ȃ邩�����낤
�ˁB
http://pc.watch.impress.co.jp/docs/2007/1211/kaigai406.htm
�b�����ŁAPenryn�ł�CPU�̒���CPU�R�A�̃X�e�C�g��Ҕ�������Ɨ��d����SRAM�̈�������BCPU�S�̂̓d���𗎂Ƃ��Ă��A
�bCPU�X�e�C�g��CPU���ɕێ��ł���悤�ɂ����B�킩��₷���Ⴆ��A��퓔�����邱�ƂŁA���C���̏Ɩ����ɒ[��
�b�Â����邱�Ƃ��ł���悤�ɂȂ����悤�Ȃ��̂��B
���ǂ���͕����I�ɁA���s�������v���Z�b�T�ɂ����l�Ȃ��̂��ȁH
�Ɨ��d����SRAM����Ȃ��āA�s��������������o�ڂ��������A���P���Ŋ���
�Ȑߓd�X�e�[�g�Ɉڍs�o����Ǝv�����A�A�N�Z�X���x�������Ȃ��ƃX�e�[�g��
�̈ڍs�╜�A���x���Ȃ��āA������X�|���X�������Ȃ邩�����낤
�ˁB
�Ƃ������CPU�_�C���ɕs���������������ꕔ�����u���͖̂�������
�i�s�\�ł͂Ȃ���������Ŏ��������傫�����Č����I����Ȃ��j
�i�s�\�ł͂Ȃ���������Ŏ��������傫�����Č����I����Ȃ��j
690 �F�ǂ��Ă������܂����F2007/12/11(��) 20:27:54 ID:FyOjrJWc
MRAM�̐����Z�p�����n�����CPU�ɕs�������������ڂ�������O�ɂȂ�Ǝv��
�܂�����ł����\�d����X86�ł̍��ڂ͖���������Ǝv������
�܂�����ł����\�d����X86�ł̍��ڂ͖���������Ǝv������
691 �F�R�E�L�́M�E,,�j�����������������F2007/12/11(��) 21:22:06 ID:xisgkavT
�s�������������͍��N���b�N�œ����Ȃ����������������������邩�烀���|
692 �FMAC�I�^��689-691 �����F2007/12/11(��) 21:41:11 ID:3ils/lK4
�w���[�����u�s����CPU�v���J�A�d���I�t�ł��f�[�^�������Ȃ��x
http://www.atmarkit.co.jp/news/200710/02/rohm.html
http://www.atmarkit.co.jp/news/200710/02/rohm.html
694 �FSocket774�F2007/12/11(��) 22:09:09 ID:4/4HzBbv
�c��̂��̌������ׂ����Ƃ��邯�ǃ}���`�X���b�h�Ȃ̂������ɂ����ĂȂ��� ���A���^�C�������͎��ԕۏ��K�v�Ȃ���}���`�R�A�ɂ��ׂ�����c
>>691
MRAM�͏��������̓N���A���Ă��B
MRAM�͏��������̓N���A���Ă��B
>>694
�N�͕����ĂȂ��悤�����A���\�[�X���\������V���O��CPU�ł��n�[�h���A���^�C���͏\���\
�X�P�W���[�����O��\�[�X���蓖�Ẵ|���V�[�Ȃǂ����낢��H�v���Č����悢�V�X�e���ɂ���̂���ڂȂ�
�N�͕����ĂȂ��悤�����A���\�[�X���\������V���O��CPU�ł��n�[�h���A���^�C���͏\���\
�X�P�W���[�����O��\�[�X���蓖�Ẵ|���V�[�Ȃǂ����낢��H�v���Č����悢�V�X�e���ɂ���̂���ڂȂ�
>>690
MRAM���ď��Ă��܂����炢���͂ƔM�Ɏア��Ȃ��������H
MRAM���ď��Ă��܂����炢���͂ƔM�Ɏア��Ȃ��������H
>>697
105�x�œ���MRAM�����Ă邩��M�͂����܂ŋC�ɂ��Ȃ��Ă������C������B
http://www.eetimes.jp/contents/200702/14499_1_20070206155716.cfm
105�x�œ���MRAM�����Ă邩��M�͂����܂ŋC�ɂ��Ȃ��Ă������C������B
http://www.eetimes.jp/contents/200702/14499_1_20070206155716.cfm
���݂����ȌÂ��l�Ԃ́ACDROM�u���Ƃ��ɂ����������ɂȂ����C�ɂ��Ă��܂���
MRAM����̐l�Ԃ�PC�̂��Ɏ����Ȃ����C������낤�ȁc�c
�ŁA�|���̂���������Ă�����PC�Ƀy�^��
MRAM����̐l�Ԃ�PC�̂��Ɏ����Ȃ����C������낤�ȁc�c
�ŁA�|���̂���������Ă�����PC�Ƀy�^��
>>688
ttp://journal.mycom.co.jp/articles/2007/12/12/iedm2/index.html
> �����̐�����F1�̂悤�ȋZ�p�̃`�����s�I�����������E�ł͂Ȃ��A�R�X�g�p�t�H�[�}���X���ɂ߂�
> �d�������B�Z�p�̓R�X�g���܂߂ĕ]������Ƃ���������O�̎��_���ɂ������B
ttp://journal.mycom.co.jp/articles/2007/12/12/iedm2/index.html
> �����̐�����F1�̂悤�ȋZ�p�̃`�����s�I�����������E�ł͂Ȃ��A�R�X�g�p�t�H�[�}���X���ɂ߂�
> �d�������B�Z�p�̓R�X�g���܂߂ĕ]������Ƃ���������O�̎��_���ɂ������B
F1�ƕ����ƁA�u�X�p�R���̓R���s���[�^��F1������]�X�v�Ƃ���
�w�{�R����葱���ĐԎ������ꗬ���Ă���J�X�A���̌�������v���o����
���_�����郏�C
�w�{�R����葱���ĐԎ������ꗬ���Ă���J�X�A���̌�������v���o����
���_�����郏�C
702 �F�R�E�L�́M�E,,�j�����������������F2007/12/13(��) 01:16:16 ID:yxdmL8tE
���������ʂ��̂͂��������ǃn�C�u���b�h�J�[�̓��[�V���O�J�[�Ƃ͑S�R�p���_�C���Ⴄ��
���[�V���O�J�[���́A���z���̎��ゾ
�͂��͂������̎���
���[�V���O�J�[���́A���z���̎��ゾ
�͂��͂������̎���
�ӂƎv���������ǂ�
MRAM�`�b�v��6�ʂ��狭���E��N�ɂŕ�ݍ���ǂ�ȋ����ɂȂ�낤
���E���ē���x�N�g���ʼn��Z���������H
MRAM�`�b�v��6�ʂ��狭���E��N�ɂŕ�ݍ���ǂ�ȋ����ɂȂ�낤
���E���ē���x�N�g���ʼn��Z���������H
�̂͐́B����F1�ɂ��Ă��X�p�R���ɂ��Ă��A
���Ȃ���ɂ�����ɑ��Ă��l�����Ă��܂���ˁB
�Ȃ̂Łu�X�p�R���K�͂̃v���W�F�N�g������v�ƁA
�Ԏ��𐂂ꗬ���l�͂��͂₽���̖��\!!
�����ЂƂ����ėܖڂȂ̂ł���B
�{���̗ܖڂ͌��������������ɂ��炢�Ȃ����ł���ww
���Ȃ���ɂ�����ɑ��Ă��l�����Ă��܂���ˁB
�Ȃ̂Łu�X�p�R���K�͂̃v���W�F�N�g������v�ƁA
�Ԏ��𐂂ꗬ���l�͂��͂₽���̖��\!!
�����ЂƂ����ėܖڂȂ̂ł���B
�{���̗ܖڂ͌��������������ɂ��炢�Ȃ����ł���ww
���߂�
�X�J���[�͒P�̐��\�œO���ȃR���f�e�B�[��Core2,Opteron�̐��{�ȏ�A
�x�N�^�[�ɂ��Ă̓V�X�e����C/�o���R���f�e�B�[��Core2,Opteron�N���X�^�[�̐��{�ȏ�
�`�������W���O�Ȑ��ʂ�W�Ԃ���Ȃ��
���p�E�\�t�g�J�������disturb�����ނ����������M�����̍�����
�g���₷����v���Ɏ������Ȃ���Θb�ɂȂ�Ȃ��B
����͂��̋t�A���[�U�[���o�����Ȃ��̎����䌓QA�B�������˂̈ꌾ�B
������Ȃɐ������������낤���A�S���s���B
�X�J���[�͒P�̐��\�œO���ȃR���f�e�B�[��Core2,Opteron�̐��{�ȏ�A
�x�N�^�[�ɂ��Ă̓V�X�e����C/�o���R���f�e�B�[��Core2,Opteron�N���X�^�[�̐��{�ȏ�
�`�������W���O�Ȑ��ʂ�W�Ԃ���Ȃ��
���p�E�\�t�g�J�������disturb�����ނ����������M�����̍�����
�g���₷����v���Ɏ������Ȃ���Θb�ɂȂ�Ȃ��B
����͂��̋t�A���[�U�[���o�����Ȃ��̎����䌓QA�B�������˂̈ꌾ�B
������Ȃɐ������������낤���A�S���s���B
Core2��Opteron�̐��{�ȏ�̃X�J�����\�Ȃ�Ă�����������Ă��s�\�����A�ȂɃ^���S�g�����Ă��
�Ȃ�킴�킴����Ă����傤���Ȃ��Ȃ��H
>>688
���Ϗ���d�͂�傫���ጸ����Penryn���C6�X�e�C�g
http://pc.watch.impress.co.jp/docs/2007/1214/kaigai407.htm
�b���̂��߁AIntel��Penryn����́ACPU��ɁACPU�R�A1�ɂ�8KB���̐�pSRAM�uState Storage�v�����������B
�b����SRAM�́ACPU�̑��̗̈�Ƃ͈قȂ�p���[�v���[���ƂȂ��Ă���BCPU�d���d��(Vcc)����͓Ɨ�����I/O�d��
�b�uVccP�v(1.5V)����������ACPU���ǂ̏ȓd�̓X�e�C�g�ɂ��낤�ƁA�ႦVcc��0V�ł��낤�ƁA���e���ێ������B
�b�����Ă݂�A���p�Ҕ��G���A���B�X�e�C�g�X�g���[�WSRAM�ւ̓d���́AVccP�𗘗p���邽�߁A���ʂȓd������
�b�͕K�v�Ƃ��Ȃ����Ƃ��|�C���g���B
SRAM�ɂ�i/o�p��1.5V���g���Ă邩��A�ʓr�Ɨ��d���͕s�v�Ń��[�}���^�C�B
�b�������ACPU�X�e�C�g��ێ�����DC4�Ɣ�ׂ�ƁASRAM����A�N�e�B�u�X�e�C�g�ւ�
�b���A���C�e���V�͒����Ȃ�B150�`200��s�̃��C�e���V���K�v�ƂȂ�Ƃ����B
�b
�b���̂��߁AC6�X�e�C�g�ɕp�ɂɓ���ꍇ�ɂ́ACPU�X�e�C�g�̃Z�[�u&���[�h�ŕ���
�b����d�͂��t�ɏ㏸���Ă��܂��\��������BIntel�̎��Z�ł́AC6�X�e�C�g��3�`4ms
�b�ȉ��̕p�x�őJ�ڂ���ƁA���ϓd�͂��オ��Ƃ����B���̂��߁APenryn�ł́uAuto-Demote�v
�b�@�\����������B�p�ɂ�C6�X�e�C�g�ɓ���ꍇ�ɂ�C4�X�e�C�g�Ɏ~�߂�C6�ɓ���Ȃ��悤��
�b���䂷��B���V���R���ł̎����ł́A���̋@�\�ɂ���āA�ǍD�Ȍ��ʂ�����ꂽ�Ƃ����B
�ڍs�╜�A���r���������肻���ȏꍇ�́uAuto-Demote�v�Ńf�B�Z�[�u�����邵�B
���Ϗ���d�͂�傫���ጸ����Penryn���C6�X�e�C�g
http://pc.watch.impress.co.jp/docs/2007/1214/kaigai407.htm
�b���̂��߁AIntel��Penryn����́ACPU��ɁACPU�R�A1�ɂ�8KB���̐�pSRAM�uState Storage�v�����������B
�b����SRAM�́ACPU�̑��̗̈�Ƃ͈قȂ�p���[�v���[���ƂȂ��Ă���BCPU�d���d��(Vcc)����͓Ɨ�����I/O�d��
�b�uVccP�v(1.5V)����������ACPU���ǂ̏ȓd�̓X�e�C�g�ɂ��낤�ƁA�ႦVcc��0V�ł��낤�ƁA���e���ێ������B
�b�����Ă݂�A���p�Ҕ��G���A���B�X�e�C�g�X�g���[�WSRAM�ւ̓d���́AVccP�𗘗p���邽�߁A���ʂȓd������
�b�͕K�v�Ƃ��Ȃ����Ƃ��|�C���g���B
SRAM�ɂ�i/o�p��1.5V���g���Ă邩��A�ʓr�Ɨ��d���͕s�v�Ń��[�}���^�C�B
�b�������ACPU�X�e�C�g��ێ�����DC4�Ɣ�ׂ�ƁASRAM����A�N�e�B�u�X�e�C�g�ւ�
�b���A���C�e���V�͒����Ȃ�B150�`200��s�̃��C�e���V���K�v�ƂȂ�Ƃ����B
�b
�b���̂��߁AC6�X�e�C�g�ɕp�ɂɓ���ꍇ�ɂ́ACPU�X�e�C�g�̃Z�[�u&���[�h�ŕ���
�b����d�͂��t�ɏ㏸���Ă��܂��\��������BIntel�̎��Z�ł́AC6�X�e�C�g��3�`4ms
�b�ȉ��̕p�x�őJ�ڂ���ƁA���ϓd�͂��オ��Ƃ����B���̂��߁APenryn�ł́uAuto-Demote�v
�b�@�\����������B�p�ɂ�C6�X�e�C�g�ɓ���ꍇ�ɂ�C4�X�e�C�g�Ɏ~�߂�C6�ɓ���Ȃ��悤��
�b���䂷��B���V���R���ł̎����ł́A���̋@�\�ɂ���āA�ǍD�Ȍ��ʂ�����ꂽ�Ƃ����B
�ڍs�╜�A���r���������肻���ȏꍇ�́uAuto-Demote�v�Ńf�B�Z�[�u�����邵�B
>>707
���w���݂����Ȋ�������o���Ĕ��f���Ă���̂�705��707
���w���݂����Ȋ�������o���Ĕ��f���Ă���̂�705��707
�ł͂ǂ�Ȋ�ł���Ȃ��̍���Ă��
������Ȃ�ł�core�P�̂�PC�pcpu���x���Ȃ����낤�ȁA�����B
����ȑO�ɂ�����Ɠ����Ė��ɗ��낤�ȁB
�g���l�ɖ��f������������
������Ȃ�ł�core�P�̂�PC�pcpu���x���Ȃ����낤�ȁA�����B
����ȑO�ɂ�����Ɠ����Ė��ɗ��낤�ȁB
�g���l�ɖ��f������������
>>710
�ǂ����f������kwsk
�ǂ����f������kwsk
����ȏ��ɏ����邩�Aʹނ�
>>712
�g�������Ƃ��Ȃ��Ȃ�d���Ȃ����
�g�������Ƃ��Ȃ��Ȃ�d���Ȃ����
������ӂł����q�҂̃_���S��
�ڒ����ȏ������݂ŏ��a�܂��Ă����
�ǂ����ł��B
��
�ڒ����ȏ������݂ŏ��a�܂��Ă����
�ǂ����ł��B
��
�b
�b�@ �߁@ �ȁQ��
�b�� �@�@�i�E�́E�@�j�Ђ���I
�b�@ �߁@/�@ ��_��
�b�� �@�l�@ �@Y
�b�@ �߂�'��i�Q�j
��
�b�@ �߁@ �ȁQ��
�b�� �@�@�i�E�́E�@�j�Ђ���I
�b�@ �߁@/�@ ��_��
�b�� �@�l�@ �@Y
�b�@ �߂�'��i�Q�j
��
���������MMX���߂��ς�����
Loongson-2E and -2F support for binutils
ttp://sources.redhat.com/ml/binutils-cvs/2007-11/msg00131.html
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/opcodes/mips-opc.c.diff?cvsroot=src&r1=1.63&r2=1.64
Loongson-2E and -2F support for binutils
ttp://sources.redhat.com/ml/binutils-cvs/2007-11/msg00131.html
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/opcodes/mips-opc.c.diff?cvsroot=src&r1=1.63&r2=1.64
717 �F�R�E�L�́M�E,,�j�����������������F2007/12/15(�y) 01:45:48 ID:H7cx6eiY
LINPACK�̕��������_���Z���\�ł́A�R�A������ł݂Ă�
�R���f�e�B�[�ɑ��ČQ�����\������
���̏�A������v���Z�b�T�[�������Ⴂ�Ȃ̂�����
�V�X�e���S�̂̐��\�͈��|�I�ŁA�܂��ɒ��_��F1�ƌĂԂɂ��킵������
���ꂾ�������R���s���[�^�[�������Ă��Ă����ʂ��o���Ȃ��͎̂g�����̐ӔC
�R���f�e�B�[�ɑ��ČQ�����\������
���̏�A������v���Z�b�T�[�������Ⴂ�Ȃ̂�����
�V�X�e���S�̂̐��\�͈��|�I�ŁA�܂��ɒ��_��F1�ƌĂԂɂ��킵������
���ꂾ�������R���s���[�^�[�������Ă��Ă����ʂ��o���Ȃ��͎̂g�����̐ӔC
>>716
�_����commitlog�̌��{��
�_����commitlog�̌��{��
719 �F�R�E�L�́M�E,,�j�����������������F2007/12/15(�y) 17:34:26 ID:cTYD29hG
�j�[���j�b�N���̂܂܂���
�A�z����
�A�z����
720 �F�R�E�L�́M�E,,�j�����������������F2007/12/15(�y) 17:36:12 ID:cTYD29hG BE:250873463-2BP(1512)
>>717�́u�\�t�g�̂��߂Ƀn�[�h�͂���v���M���̉��ɂƂ��Ă͌����Ă���Ό���Ȃ����Ƃ���
721 �F�R�E�L�́M�E,,�j�����������������F2007/12/15(�y) 20:09:04 ID:wH3lXh5p
>>720
�������Ă���āB�����ƒނ�Ă���ćd
�������Ă���āB�����ƒނ�Ă���ćd
>>714
P35
P35
>>688
���@�s����SRAM
���@�s����SRAM
�Ƃ���ŁAx86�̓A�[�L�e�N�`���������ƌ���������͂ǂ�����
���ƂȂ�?���G=�������Ă��ƁH
�܂��A����ɂ��f�����b�g�͉��H
���ƂȂ�?���G=�������Ă��ƁH
�܂��A����ɂ��f�����b�g�͉��H
>>724
x86�������Ƃ͎v���Ă��Ȃ����ꂪ���X����̂��Ȃ�
�v���t�B�b�N�X�����낢����ĉϒ����߂������A�f�R�[�_�����G�A�Ƃ����̂��f�����b�g���낤
����~�̌������Ƃ͋C�ɂ����
x86�������Ƃ͎v���Ă��Ȃ����ꂪ���X����̂��Ȃ�
�v���t�B�b�N�X�����낢����ĉϒ����߂������A�f�R�[�_�����G�A�Ƃ����̂��f�����b�g���낤
����~�̌������Ƃ͋C�ɂ����
x86�̓I�y�R�[�h�͉�������EAX,EBX,ECX,EDX�̎g���������ƌ��܂��Ă邩��
���l�̏������A�Z���u���R�[�h�ł���r�I�ǂ݂₷�����B
�f�����b�g�̓f�R�[�_�����G����ɂȂ邩��ȓd�͂ɂ��ɂ������Ƃ��ȁB
���l�̏������A�Z���u���R�[�h�ł���r�I�ǂ݂₷�����B
�f�����b�g�̓f�R�[�_�����G����ɂȂ邩��ȓd�͂ɂ��ɂ������Ƃ��ȁB
�X�g�����O���߂Ƃ��A�P���߂Ƃ����ɂ͂ł������閽�߂����邩��ARISC��
���ꂽ�l�́u�����ꂗ�����v�ɂȂ��ˁH
���ꂽ�l�́u�����ꂗ�����v�ɂȂ��ˁH
728 �F�R�E�L�́M�E,,�j�����������������F2007/12/19(��) 21:00:41 ID:Huc6B9IM
�Ƃ肠����REX�v���t�B�b�N�X�l����AMD�͎��˂�
8080���炸���ƌ��đ������Ă��Ă邩��Ȃ�x86
730 �F�R�E�L�́M�E,,�j�����������������F2007/12/19(��) 21:25:21 ID:Huc6B9IM
�ւ�ݎ���xbyak��REX/DREX�܂����ǂ��������邩�͊y���݂��ȁB
64�r�b�g�Ɋւ��Ă͏������������Ȃ����Ǝv���Ă���B
64�r�b�g�Ɋւ��Ă͏������������Ȃ����Ǝv���Ă���B
4004���炶��Ȃ��̂���x86
732 �FSocket774�F2007/12/20(��) 15:55:32 ID:7Kg8PGBi
�ւ�݃T���Ƃ��F�B�̒c�q�A�Q
x86��1978�N����B���N�a��30���N����B
����30�N���B�������������O�ɂȂ�킯���B
��O�Ȃ́H
80486�ȍ��Ɏ�t�����ꂽ�e��������Љ�l������ȁB
737 �F�R�E�L�́M�E,,�j�����������������F2007/12/20(��) 19:15:57 ID:RVlL1I1T
�@
>>733
������I/O��ASCII�́u16�r�b�gCPU���W�v�݂����ȋL����ǂ��
�u16�r�b�g����̓��g���[���������ȁB68000�}���Z�[�v
���ė\�z���Ă���c�c�i�����ځj
������I/O��ASCII�́u16�r�b�gCPU���W�v�݂����ȋL����ǂ��
�u16�r�b�g����̓��g���[���������ȁB68000�}���Z�[�v
���ė\�z���Ă���c�c�i�����ځj
>>738
���͓�������Intel�h�������Ȃ��BPC-8801��Fm-8���������ꂽ�N����
�i�C�R���Ȃ̂ɖ���I/O��ASCII�����Ă��B
i386�o�����͊����������Ȃ��B
���͓�������Intel�h�������Ȃ��BPC-8801��Fm-8���������ꂽ�N����
�i�C�R���Ȃ̂ɖ���I/O��ASCII�����Ă��B
i386�o�����͊����������Ȃ��B
740 �F�R�@�@�@�E�L�@�@�́@�@�M�E�@�@,,,,�j�����������������F2007/12/20(��) 20:01:33 ID:RVlL1I1T
.
>>739
���
68000 > 8086
68020 > 80286
68030 > 80386
���Ǝv���Ă�����
MS-DOS�̎���Unix�̎��オ����ƐM���Ă����B
12,3�N�O�ɒm�荇����
�u�V�X�R���ĉ�Ђ̊�����ˁH�v
���Č����Ă���̒f��
98�N���Ƀ��t�[�̊������߂��Ă�����Ȃ������B
�����}���h�N�Z�Ɣޏ����̂Ă��炸���ƓŒj�B
���Â��\�����O���̂ɋC�Â����B
�����ďT����AM2�ȃ}�U�{�������c�c
���
68000 > 8086
68020 > 80286
68030 > 80386
���Ǝv���Ă�����
MS-DOS�̎���Unix�̎��オ����ƐM���Ă����B
12,3�N�O�ɒm�荇����
�u�V�X�R���ĉ�Ђ̊�����ˁH�v
���Č����Ă���̒f��
98�N���Ƀ��t�[�̊������߂��Ă�����Ȃ������B
�����}���h�N�Z�Ɣޏ����̂Ă��炸���ƓŒj�B
���Â��\�����O���̂ɋC�Â����B
�����ďT����AM2�ȃ}�U�{�������c�c
>>741
>68000 > 8086
>68020 > 80286
����Ⴛ�����낤�B
>68030 > 80386
����͈Ⴄ�B80386�͂���܂ł�86�n�Ƃ͂܂������ʕ�����B
Core2����ɂȂ��Ă�x86���߂�SSE���̊g�������������Ί�{�I��386�̂܂܁B
>68000 > 8086
>68020 > 80286
����Ⴛ�����낤�B
>68030 > 80386
����͈Ⴄ�B80386�͂���܂ł�86�n�Ƃ͂܂������ʕ�����B
Core2����ɂȂ��Ă�x86���߂�SSE���̊g�������������Ί�{�I��386�̂܂܁B
743 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2007/12/20(��) 21:35:05 ID:RVlL1I1T
SSE4����286��opcode�̈�H���Ԃ��Ă邵
x86�Ɠ��N�ɐ��܂ꂽ���͗��N���@�g���ɂȂ�܂�
68k���ڋ@���o�n�߂����ɂ�RISC�̋L������������悤�ɂȂ��Ă���
87�N�ɂ̓A���L���f�X���o����
������������CISC 16/32bitCPU�ɂ���ׂ�68k���ǂ��Ƃ��v�����A�ڂ����L�������������̂Ō��_������ڂɂ�����
87�N�ɂ̓A���L���f�X���o����
������������CISC 16/32bitCPU�ɂ���ׂ�68k���ǂ��Ƃ��v�����A�ڂ����L�������������̂Ō��_������ڂɂ�����
�L��ȃ�������Ԃɂ��Ă�16bitCPU�̒��ł͌Q���ʂ��Ă����68K
16bit�����ɁA���32bitCPU�Q�Ɣ�ׂ�Ƃ��낢���_�����邯��
����16bitCPU���肶��A��_�Ƃ�����8086�قǃ\�t�g���Ȃ����Ē��x�ł́H
16bit�����ɁA���32bitCPU�Q�Ɣ�ׂ�Ƃ��낢���_�����邯��
����16bitCPU���肶��A��_�Ƃ�����8086�قǃ\�t�g���Ȃ����Ē��x�ł́H
68k�͂��낢�남�����Ȑv����������(32bit�f�B�X�v���[�X�����g���g���Ȃ����Ƃ�A�������ȗ�O�X�^�b�N�t���[���A�x�����o�X�Ȃ�)�A
�t�@�~��IC���n��Ƃ����Ƃ��낪���͂��킢�ł���
������24�r�b�g���j�A�A�h���X��16032�͏ڂ��������������ĂȂ������̂ŁA�傫�Ȍ��_�͂��������C�Â��Ȃ������\���͂��邯�ǁA������̂ق��������Ɩ��͓I�Ɍ������B
�t�@�~��IC���n��Ƃ����Ƃ��낪���͂��킢�ł���
������24�r�b�g���j�A�A�h���X��16032�͏ڂ��������������ĂȂ������̂ŁA�傫�Ȍ��_�͂��������C�Â��Ȃ������\���͂��邯�ǁA������̂ق��������Ɩ��͓I�Ɍ������B
68k��SETcc���߂͂ǂ������킯���A0�܂���-1���Z�b�g���ꂽ�̂��ς�����
(���Ԃ��BASIC���O���ɂ������̂��Ǝv����)
�ȒP�Ȋ��荞�݃R���g���[������������Ă����̂͂����̂����A
�킴�킴68k���g���悤�ȃA�v���P�[�V�����Ŋ��荞�ݗv����7�ő����Ƃ͎v���Ȃ�����
�Ƃɂ��p�\�R���ł͑S�R����ĂȂ��������
32�r�b�g�f�[�^��16�r�b�g�A���C�����Ƃ������r���[�����C�ɂ���Ȃ�
16032�͔ėp���W�X�^����8�����A�e��|�C���^�������������ƁA
�v���O�������W���[���̃T�|�[�g(�_�C�i�~�b�N�����N�A�A�������N�݂����Ȃ��Ƃ��ȒP�ɂł���)
�ȂǁA��荂������������
(���Ԃ��BASIC���O���ɂ������̂��Ǝv����)
�ȒP�Ȋ��荞�݃R���g���[������������Ă����̂͂����̂����A
�킴�킴68k���g���悤�ȃA�v���P�[�V�����Ŋ��荞�ݗv����7�ő����Ƃ͎v���Ȃ�����
�Ƃɂ��p�\�R���ł͑S�R����ĂȂ��������
32�r�b�g�f�[�^��16�r�b�g�A���C�����Ƃ������r���[�����C�ɂ���Ȃ�
16032�͔ėp���W�X�^����8�����A�e��|�C���^�������������ƁA
�v���O�������W���[���̃T�|�[�g(�_�C�i�~�b�N�����N�A�A�������N�݂����Ȃ��Ƃ��ȒP�ɂł���)
�ȂǁA��荂������������
749 �FSocket774�F2007/12/21(��) 14:48:46 ID:aEXRFi9L
���܂��Ă����c�q�T�����ؗ�ɃX���[����Ă�A�Q
>>750
�㔭�ō����Ȃ��͍̂����\�ł�����܂������A���ׂĂ����ƈ�̉����r���Ă���̂��킩���悤�ɂȂ��Ă����
�㔭�ō����Ȃ��͍̂����\�ł�����܂������A���ׂĂ����ƈ�̉����r���Ă���̂��킩���悤�ɂȂ��Ă����
��������8bitCPU�̔�r��8088���o�Ă��肵�����w
68008������ɂ͎S�s�Ȃ낤����
68008������ɂ͎S�s�Ȃ낤����
753 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2007/12/22(�y) 09:06:15 ID:2ewGE2hu
386����32�r�b�g���Č����銄�ɂ�16bit CPU�Ƃ��Ďg���鎞�オ���������悤��
386�������̖{�i32bitOS����386BSD���H
386�������̖{�i32bitOS����386BSD���H
32bit�J�[�l��*2��64bit�g����ijϰ
���Ă킯�ɂ����Ȃ��H
���Ă킯�ɂ����Ȃ��H
>>754
33bit�ԂȁB
33bit�ԂȁB
DOS-EXTENDER�m���́H�@�m�Q�[����o���o���g���Ƃ�����B
LaTeX �Ŏg���Ă���BGO32 ����������
TOWNS��extender���������
demacs�ł��g���Ă� > go32
L3ENC.EXE(��)
SpecCPU2006��������Power6��Sparc64�Y��UltraSparc�W���P�Ƃ���
Core2�ɗ�邩�݊p�Ƃ������Ƃ����B
���Ă�Risc=x86��荂���\�̐}�������̘͐̂b�ɂȂ����ȁA�A�A
�ߋ��ɉ��x��UNIX���[�N�X�e�[�V�������`�����X���������̂Ɍ���
��intelCPU�̓���������PC�Ŗ�����������Ă�B
Core2�ɗ�邩�݊p�Ƃ������Ƃ����B
���Ă�Risc=x86��荂���\�̐}�������̘͐̂b�ɂȂ����ȁA�A�A
�ߋ��ɉ��x��UNIX���[�N�X�e�[�V�������`�����X���������̂Ɍ���
��intelCPU�̓���������PC�Ŗ�����������Ă�B
Alpha 20166���A����ς莩��@�������Ė����o�߂���
766 �FSocket774�F2007/12/26(��) 14:30:48 ID:4qs6UQWr
C2D T5500��T7250���Ƒ�̉��{�̍����ł�H
Core2�ł��Ȃ荷���ł�H �Z���������͂܂����낤����
Core2�ł��Ȃ荷���ł�H �Z���������͂܂����낤����
>>766
1.2�{
1.2�{
768 �FSocket774�F2007/12/26(��) 14:44:17 ID:4qs6UQWr
769 �FSocket774�F2007/12/26(��) 14:45:03 ID:4qs6UQWr
768=767��
771 �FSocket774�F2007/12/26(��) 14:55:36 ID:4qs6UQWr
>>770
�Z�������ł����Ȃ��̂��ȁB���ʂɃl�b�g�݂�Ԃ�ɂ́BVista���ƃL�c�C���ď������݂݂邯�ǁB
�Z�������ł����Ȃ��̂��ȁB���ʂɃl�b�g�݂�Ԃ�ɂ́BVista���ƃL�c�C���ď������݂݂邯�ǁB
���낻��X���Ⴂ�ł��鎖�𗝉����Ă���邩�ȁH
773 �FSocket774�F2007/12/26(��) 15:16:21 ID:4qs6UQWr
����ς�DualCore���B �Z���������Ⴋ�����BC2D�ɂ��܂�
774 �FSocket774�F2007/12/26(��) 15:31:25 ID:4qs6UQWr
Celeron DualCore ���C�ɂȂ�
775 �FSocket774�F2007/12/28(��) 17:00:43 ID:27a0YT1X
CPU�̐��\��胁�����𑝂₵�����������B
�V���O���X���b�h�ł��}���`�X���b�h�ł��œK������A���[�o�̂悤��CPU�͊m��
���̓A���[�o�̂悤�ȃt�@�C���V�X�e�����K�v�Ƃ���Ă�
���ɉ��̎��オ��
���̓A���[�o�̂悤�ȃt�@�C���V�X�e�����K�v�Ƃ���Ă�
���ɉ��̎��オ��
777 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2007/12/30(��) 01:06:34 ID:5QBRtpdy
>>776
�悤�^�l���o�E������
�悤�^�l���o�E������
�ŋ�OS��3�ł̖M��o�����Ǒ��ς�炸�����������Ȃ�
���ז����܂��B
Pen4�̃��A�����[�h�ł̓��쑬�x�ɂ��Ă��������������Ƃ�����܂��B
Pen4�����A�����[�h�œ��삳�������̕��������_���Z���x�ƃv���e�N�g���[�h�ł�
���������_���Z���x�͑傫���Ⴄ�̂ł��傤���B
���݂�Pen3(1GHz)�̏ꍇ�A���A���ł��v���e�N�g�ł��卷�Ȃ����Ƃ͊m�F���Ă���A
AthlonXP2400+�ł́@�@���A���ł̑��x(Pen2,100M���x)�@<<�@�v���e�N�g�ł̑��x�@�ł��B
���������_���Z�𑽗p����c�n�r�v���O�������Ȃ�ׂ��������s�����邽�߂�
Pen4�}�V���̍w�����������Ă��܂��B
�ǂȂ���������������������Ƃ��肪�����̂ł����B
��낵�����肢���܂��B
�i�ʂ̃X���ŁA����A���̎���������̂ł����A���A�����[�h�Ɋւ��ẮA�ˑR
�s���̂��߁A������Ŏ��₳���Ă��������܂��j
Pen4�̃��A�����[�h�ł̓��쑬�x�ɂ��Ă��������������Ƃ�����܂��B
Pen4�����A�����[�h�œ��삳�������̕��������_���Z���x�ƃv���e�N�g���[�h�ł�
���������_���Z���x�͑傫���Ⴄ�̂ł��傤���B
���݂�Pen3(1GHz)�̏ꍇ�A���A���ł��v���e�N�g�ł��卷�Ȃ����Ƃ͊m�F���Ă���A
AthlonXP2400+�ł́@�@���A���ł̑��x(Pen2,100M���x)�@<<�@�v���e�N�g�ł̑��x�@�ł��B
���������_���Z�𑽗p����c�n�r�v���O�������Ȃ�ׂ��������s�����邽�߂�
Pen4�}�V���̍w�����������Ă��܂��B
�ǂȂ���������������������Ƃ��肪�����̂ł����B
��낵�����肢���܂��B
�i�ʂ̃X���ŁA����A���̎���������̂ł����A���A�����[�h�Ɋւ��ẮA�ˑR
�s���̂��߁A������Ŏ��₳���Ă��������܂��j
x86���߂̏��v�N���b�N�v���X��Part3
http://pc11.2ch.net/test/read.cgi/tech/1168399966/
�������̃X����������B
Pentium 4�����A�����[�h�ł͂��炷��w
�d�͊Ǘ��������Ȃ��āA�M��duty������������旧�����肵�ĂȁB
http://pc11.2ch.net/test/read.cgi/tech/1168399966/
�������̃X����������B
Pentium 4�����A�����[�h�ł͂��炷��w
�d�͊Ǘ��������Ȃ��āA�M��duty������������旧�����肵�ĂȁB
>>780
�U���A���肪�Ƃ��������܂��B
�U���A���肪�Ƃ��������܂��B
age
783 �FSocket774�F2008/01/13(��) 01:02:52 ID:6cOJVFiD
����CPU�̐��\�������I��肩
�ŐV�v���Z�X�J���Ŏ��s���Ȃ����Ƃ���ꂾ�����
�f�U�C���I�ɂ̓R�A���₵�Ă������������܂��
�f�U�C���I�ɂ̓R�A���₵�Ă������������܂��
���� 4.5����܂ł̃R���s���[�^�[�̐��\������āA
��L���Ɖ��Z���I/O�̏������ʂ��ς������������
���̐���A����ȏ�̎��͖��������Ȃ�ȁB
�p�C�v���C����X�[�p�[�X�P�[���[�͓�����O�̎��ɂȂ�����
���Ƃ̓N���b�N���オ������A��(���Z��A�������e�ʁA�o���N��)���������肷�邾���B
��L���Ɖ��Z���I/O�̏������ʂ��ς������������
���̐���A����ȏ�̎��͖��������Ȃ�ȁB
�p�C�v���C����X�[�p�[�X�P�[���[�͓�����O�̎��ɂȂ�����
���Ƃ̓N���b�N���オ������A��(���Z��A�������e�ʁA�o���N��)���������肷�邾���B
�X�P�[�������b�g�̂���A�[�L�e�N�`���̏o����҂B
�}���`�R�A�E�n�C�p�[�X���b�f�B���O��������O�ɂ�����Ȃ�A
�X�[�p�[�X�P�[���K�v�Ȃ���łˁH���Ă̂�Menlow�̓����ł́H
�X�[�p�[�X�P�[���K�v�Ȃ���łˁH���Ă̂�Menlow�̓����ł́H
����Ӗ��A�}�C�N���v���Z�b�T�̐i���͑�^�Ƃ��X�[�p�[�R���s���[�^�����
�Z�p�ړ]�̗��j�݂����ȂƂ����������킯�����A���܂₻�������̂�
�}�C�N���v���Z�b�T�ō���Ă邩��Ȃ��c�c���l�^���Ȃ��Ȃ����������������
Windows�ƁA����Ӗ����Ă�
�Z�p�ړ]�̗��j�݂����ȂƂ����������킯�����A���܂₻�������̂�
�}�C�N���v���Z�b�T�ō���Ă邩��Ȃ��c�c���l�^���Ȃ��Ȃ����������������
Windows�ƁA����Ӗ����Ă�
>>787
TDP 30�`120W�̐��E�ł͏����ɂȂ�Ȃ��ł���
TDP 30�`120W�̐��E�ł͏����ɂȂ�Ȃ��ł���
�����܂���A�Ȃf�l�̎v�����Ȃ�ł�����
x86�R�[�h����\�t�g�I�ɃR���p�C�����ă}�C�N���R�[�h���Ă��
�͂�������exe��u�������邩�g�c�c�ɃL���b�V�����Ă����悤��
�h���C�o�Ƃ�����ăf�R�[�_�[�Ƃ��b�o�t�ɏ悹�Ȃ�������₷���Ȃ����肵�܂��H
�܂������Ȃ�����瓖�R���Ă��ł��傤���ǂ�
x86�R�[�h����\�t�g�I�ɃR���p�C�����ă}�C�N���R�[�h���Ă��
�͂�������exe��u�������邩�g�c�c�ɃL���b�V�����Ă����悤��
�h���C�o�Ƃ�����ăf�R�[�_�[�Ƃ��b�o�t�ɏ悹�Ȃ�������₷���Ȃ����肵�܂��H
�܂������Ȃ�����瓖�R���Ă��ł��傤���ǂ�
Transmeta��
>>790
�ŏ�����}�C�N���R�[�h�ɕϊ����Ă��܂��ƃR�[�h�����������Ȃ肷����B
�ŏ�����}�C�N���R�[�h�ɕϊ����Ă��܂��ƃR�[�h�����������Ȃ肷����B
>>792�Ȃ�ق�
>>790
RISC �̒a��������
RISC �̒a��������
>>790
FX32!�Ƃ��������Ȃ��c
FX32!�Ƃ��������Ȃ��c
�g�ѓd�b�̕W��CPU�uARM�R�A�v�̌���
�`ARM���{�@�l�̐����В��ɕ���
http://pc.watch.impress.co.jp/docs/2008/0115/arm.htm
�`ARM���{�@�l�̐����В��ɕ���
http://pc.watch.impress.co.jp/docs/2008/0115/arm.htm
�v���Ԃ��PowerPC�̘b��������悤�ȋC�����邷���ǁANEC���X�g���[�W�V�X�e���̃R���g���[��
�Ƃ��āAP.A. Semi��PWRficient�`�b�v���̗p����Ƃ̂��Ƃ��B
http://www.pasemi.com/news/pr_2008_01_10.html
�@�@------------------
�@�@"We are very pleased with the results of our evaluation of the P. A. Semi 1682M processor,"
�@�@said Mr. Tsuyoshi Kishino , Senior Manager , First Engineering Department, System Storage
�@�@Products Division, NEC. "In our application, we found that the 1682M delivers the highest
�@�@application performance at very low power dissipation. This combination of high performance
�@�@and low power enables us to develop very efficient, scalable storage controllers that meet
�@�@our high reliability and performance expectations."
�@�@------------------
�Ƃ��āAP.A. Semi��PWRficient�`�b�v���̗p����Ƃ̂��Ƃ��B
http://www.pasemi.com/news/pr_2008_01_10.html
�@�@------------------
�@�@"We are very pleased with the results of our evaluation of the P. A. Semi 1682M processor,"
�@�@said Mr. Tsuyoshi Kishino , Senior Manager , First Engineering Department, System Storage
�@�@Products Division, NEC. "In our application, we found that the 1682M delivers the highest
�@�@application performance at very low power dissipation. This combination of high performance
�@�@and low power enables us to develop very efficient, scalable storage controllers that meet
�@�@our high reliability and performance expectations."
�@�@------------------
���������Ȃ�����
799 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/17(��) 02:13:23 ID:cLYUDA9R
�R���s���[�^�A�[�L�e�N�`���̘b
��106�� �A�[�L�e�N�`�����ĉ���?
http://journal.mycom.co.jp/column/architecture/106/index.html
��106�� �A�[�L�e�N�`�����ĉ���?
http://journal.mycom.co.jp/column/architecture/106/index.html
��������ȑO�u���O���Ă��������
>�O��������
���ꂪ��������������������
���ꂪ��������������������
803 �FSocket774�F2008/01/24(��) 20:13:51 ID:xvx+/vSK
http://pc.watch.impress.co.jp/docs/2008/0124/ubiq208.htm
�Ƃ肠����VIA�̐V���i���ƁB�B�B�B
C7�ɂ͂��̂܂ܔ������Ă������
10�o��������܂����Ƃ�����ė~������
�Ƃ肠����VIA�̐V���i���ƁB�B�B�B
C7�ɂ͂��̂܂ܔ������Ă������
10�o��������܂����Ƃ�����ė~������
�x�m�ʐ������A������ƈӊO���ȁB
�܂�SPARC64�Ƃ�Efficeon�Ƃ�������킯������
���̋̐l���猩��ǂ����Ă��ƂȂ��낤���ǁB
�܂�SPARC64�Ƃ�Efficeon�Ƃ�������킯������
���̋̐l���猩��ǂ����Ă��ƂȂ��낤���ǁB
�x�m�ʂ��܂�200mm�E�F�n�������̂��т�����B
�Ă�����300mm�E�F�n���Ǝv���Ă��B
�Ă�����300mm�E�F�n���Ǝv���Ă��B
>>805
�O�d��90/65nm��300mm����i���E���)�B������ȂρB200mm���C����130nm�ȑO�B
�ʎY����́i���x�O�d�Ɉڂ邯�ǁj��������200mm�ł�邩�炨�������Ȃ��Ƃ������������Ȃ��C�����邯�ǁA
�ʐ^�ł�C7�̃E�G�n�ƃT�C�Y���ς��Ȃ�������悤�ȁB���Ƃ����300mm�̂͂��BIBM EastfishKill(B323)�͂��ł�300mm�����B
Burlington��90nm/200mm�����炻�����ō���Ă���������͂Ȃ����ǁB�Ƃ肠�����ǂ����ρB
�O�d��90/65nm��300mm����i���E���)�B������ȂρB200mm���C����130nm�ȑO�B
�ʎY����́i���x�O�d�Ɉڂ邯�ǁj��������200mm�ł�邩�炨�������Ȃ��Ƃ������������Ȃ��C�����邯�ǁA
�ʐ^�ł�C7�̃E�G�n�ƃT�C�Y���ς��Ȃ�������悤�ȁB���Ƃ����300mm�̂͂��BIBM EastfishKill(B323)�͂��ł�300mm�����B
Burlington��90nm/200mm�����炻�����ō���Ă���������͂Ȃ����ǁB�Ƃ肠�����ǂ����ρB
�O�d�̍H�ꂾ�ƁA��������߂��ȁB
�H�ꌩ�w�̎��ɁA���y�Y�Ŏ������Ă��ꂽ�肷��Ɩʔ����̂����B
���ł�Isaiah�\���Ƃ�Isaiah���݂Ƃ��p�ӂ��Ă����A�����ċA�邵�B
�H�ꌩ�w�̎��ɁA���y�Y�Ŏ������Ă��ꂽ�肷��Ɩʔ����̂����B
���ł�Isaiah�\���Ƃ�Isaiah���݂Ƃ��p�ӂ��Ă����A�����ċA�邵�B
>>803
�����Ă����Ȃ�B�����̂悤��16�R�A�Ƃ�
�����Ă����Ȃ�B�����̂悤��16�R�A�Ƃ�
�h���S���`�b�vIII���ȁB
NAS��DLNA�Ōl����ėp�I���{�i������^�C�~���O�ň�����d�͂�x86���ʋ����ł����
VIA�̑叟�����ĉ\���������͂Ȃ�����ˁ[
VIA�̑叟�����ĉ\���������͂Ȃ�����ˁ[
�lNAS�Ȃ��ARM�n��200�`300MHz�ŏ\���ł���
���F��VIA
>>810
Diamondville���w�Ǔ������ɔ�������邩��A�叟���͖������ۂ��C���B
Diamondville���w�Ǔ������ɔ�������邩��A�叟���͖������ۂ��C���B
�ǂ��l���Ă����\�Ⴄ��ˁB
Isaiah����Diamondville��C7
���ċC������B
�����͖������B
Isaiah����Diamondville��C7
���ċC������B
�����͖������B
���܂ł̏�炷��ƁAIsaiah���ƃg�����W�X�^�����炷���IPC��Banias���炢�͊��҂ł��邯�ǁA
Diamondville�̕���Banias�̔����ȉ����ۂ����ȁB
HT�g����Silverthorne��1.5�{���炢�炵���̂ŁA2�X���b�h�Ή��A�v�����Ɛ��\���͂��Ȃ菬�����Ȃ肻�������ǁB
��������Isaiah�̏���d�͂�����C7�Ɠ����Ȃ�2GHz��TDP20W���炢���낤����A
����TDP���m�̔�r�Ȃ�ADiamondville�̕���Isaiah��萫�\�ォ���ˁB
Diamondville�̕���Banias�̔����ȉ����ۂ����ȁB
HT�g����Silverthorne��1.5�{���炢�炵���̂ŁA2�X���b�h�Ή��A�v�����Ɛ��\���͂��Ȃ菬�����Ȃ肻�������ǁB
��������Isaiah�̏���d�͂�����C7�Ɠ����Ȃ�2GHz��TDP20W���炢���낤����A
����TDP���m�̔�r�Ȃ�ADiamondville�̕���Isaiah��萫�\�ォ���ˁB
�ėpHome�I����Ŕ�r�����Silverthorne�̏������ۂ����H
�g�ݍ��킹�o�ׂ����IO�`�b�v�̐��\�@�����������
�g�ݍ��킹�o�ׂ����IO�`�b�v�̐��\�@�����������
ttp://www.theinquirer.net/gb/inquirer/news/2008/01/24/via-releases-brand-core
| Another nifty feature is called adaptive P-State control. The chip has some smarts
| as far as power management goes, if it is running hot, it can lower the voltage, and
| conversely, if it is running cool, it can bump up the clocks.
Foxton���̂��̂ł��ˁB
Itanium2�����d�͂̕ϓ����͂邩�ɏ������̂Ŏ��p�����₷���Ƃ������Ƃł��傤���B
| Another nifty feature is called adaptive P-State control. The chip has some smarts
| as far as power management goes, if it is running hot, it can lower the voltage, and
| conversely, if it is running cool, it can bump up the clocks.
Foxton���̂��̂ł��ˁB
Itanium2�����d�͂̕ϓ����͂邩�ɏ������̂Ŏ��p�����₷���Ƃ������Ƃł��傤���B
������C7�̐��\����݂�Ɛ_�̂悤�Ȑ��\�̏オ����Ղ肾��ww
VIA�̂����ɂȂ܂�����
��������ăx���`�Ƃ��Ă݂�܂ł킩���B
�c�c�Ƃ͎v�������AVIA�̒ᐫ�\�͎��IO���\���Ǝv���̂ł��̕ӂŐi�����������̂����B
�c�c�Ƃ͎v�������AVIA�̒ᐫ�\�͎��IO���\���Ǝv���̂ł��̕ӂŐi�����������̂����B
IP���肵�Ă�CPU�̌݊�IP���[�J�Ƃ��o�����Ȃ��́H
����IP���g�����݊��`�b�v�Ȃ畁�ʂ����A�݊�IP�ƂȂ��
����͑���̒m�I���L���Ƀ����Ɉ���������Ǝv�����B
������N���X���C�Z���X�ł˂���������قǂ̉����������Ă���Ȃ�b�͕ʂ����B
����͑���̒m�I���L���Ƀ����Ɉ���������Ǝv�����B
������N���X���C�Z���X�ł˂���������قǂ̉����������Ă���Ȃ�b�͕ʂ����B
823 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/27(��) 15:34:13 ID:ujo+/xzc
�G�~�����[�^���ʖڂ������B
�C�V���̌g�ы@�͂�����ARM����Ȃ킯���B
�C�V���̌g�ы@�͂�����ARM����Ȃ킯���B
Lexra�̌����v���o���B
825 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/27(��) 16:49:16 ID:ujo+/xzc
�u������IP�݊��v���`���Ȃ��������
�Ȃ�ق�
�Ȃ�ق�
>������N���X���C�Z���X�ł˂���������قǂ̉����������Ă���Ȃ�b�͕ʂ����B
XScale�̎����[�[�I�I�I�I
XScale�̎����[�[�I�I�I�I
Extremetech.com��VIA Isaiah�̉���L���A�Ȃ�Ɠ��̃`�b�v�̃A�[�L�e�N�g Glenn Henry����e����
���邷�I
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�K���Ȏ���ɂȂ������m���ˁB�B�B
�L���̕������ǁAmicro-ops fusion���ꂽ���߂�ROB�łǂ̂悤�Ɉ����Ă��邩���A�ǂ�����Ȃ����B
ROB�̕��̉���ł�A
�@�@-------------------
�@�@The three incoming fused micro-ops are placed in the reorder buffer (ROB) and are then
�@�@expanded into up to six executable micro-ops, each of which is targeted for a single execution
�@�@unit.
�@�@-------------------
�ƁA���邷����ROB�̒��ł̊Ǘ��P�ʂ핪�����ꂽmicro-ops�Ɠǂ߂邷�B����A���߃��^�C�A�̉��
�����ł�A
�@�@-------------------
�@�@Up to three fused micro-ops can be retired each clock corresponding to up to three x86
�@�@instructions.
�@�@-------------------
�Ƃ���̂ŁAfusion���ꂽ�P�ʂŊǗ�����Ă���悤�Ɍ����邷�BPOWER4�̖��߃O���[�v�̊T�O��
�߂������ˁB�B�B�@�����OoO�̊Ǘ��P�ʂ�e�����ĕ��ׂ����������邽�߂̃��m������B
���邷�I
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�K���Ȏ���ɂȂ������m���ˁB�B�B
�L���̕������ǁAmicro-ops fusion���ꂽ���߂�ROB�łǂ̂悤�Ɉ����Ă��邩���A�ǂ�����Ȃ����B
ROB�̕��̉���ł�A
�@�@-------------------
�@�@The three incoming fused micro-ops are placed in the reorder buffer (ROB) and are then
�@�@expanded into up to six executable micro-ops, each of which is targeted for a single execution
�@�@unit.
�@�@-------------------
�ƁA���邷����ROB�̒��ł̊Ǘ��P�ʂ핪�����ꂽmicro-ops�Ɠǂ߂邷�B����A���߃��^�C�A�̉��
�����ł�A
�@�@-------------------
�@�@Up to three fused micro-ops can be retired each clock corresponding to up to three x86
�@�@instructions.
�@�@-------------------
�Ƃ���̂ŁAfusion���ꂽ�P�ʂŊǗ�����Ă���悤�Ɍ����邷�BPOWER4�̖��߃O���[�v�̊T�O��
�߂������ˁB�B�B�@�����OoO�̊Ǘ��P�ʂ�e�����ĕ��ׂ����������邽�߂̃��m������B
828 �FMAC�I�^�������F2008/01/29(��) 00:01:05 ID:U+YuE5q6
���s���j�b�g�̍\����AAMD��(���RISC�I��)Intel�Ɣ�r���Ă��A�X��RISC���Ɍ����邷�B
����ł��A�h���X�����ɐ�p�̎��s���j�b�g�����蓖�Ă��Ă���̂�Ax86���L�̎�����B�B�B
����ł��A�h���X�����ɐ�p�̎��s���j�b�g�����蓖�Ă��Ă���̂�Ax86���L�̎�����B�B�B
white paper�̃R�s�y?
Next-Generation VIA Isaiah x86 Processor Architecture
ttp://www.via.com.tw/en/products/processors/isaiah-arch/
white paper
ttp://www.via.com.tw/en/downloads/whitepapers/processors/WP080124Isaiah-architecture-brief.pdf
Next-Generation VIA Isaiah x86 Processor Architecture
ttp://www.via.com.tw/en/products/processors/isaiah-arch/
white paper
ttp://www.via.com.tw/en/downloads/whitepapers/processors/WP080124Isaiah-architecture-brief.pdf
830 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/29(��) 00:34:24 ID:UUB91VxK
�_�����W�X�^�������Ȃ����[�h�E�X�g�A�����p�x�B
���̑���A�h���b�V���O�����́B
x86�̌��_�ł���Ɠ����ɗ��_�ł�����B
���̑���A�h���b�V���O�����́B
x86�̌��_�ł���Ɠ����ɗ��_�ł�����B
���_���ăn�[�h�E�F�A���z�����e�ՁH
MAC�I�^�͑����p�ꂭ�炢�͓ǂ߂�悤�ɂȂ�Ȃ����B
ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
ROB������������̂��l����Ό������炢�����낤�ɁB
ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
ROB������������̂��l����Ό������炢�����낤�ɁB
�Ƃ����Isaiah��x64�́A����ς�Intel64�݊��Ȃ̂��ȁH
�݊��܂ł����Ȃ��Ă��AAMD64����Intel64�ɋ߂��Ƃ͎v�����A�ǂ��Ȃ낤�H
�܂�������ɂ��Ă�MS�̊֗^�͑傫�������Ă邾�낤����A�n�r��APL���Ή�����
�̂ɖʓ|�̏��Ȃ���Ԃɂ͂Ȃ��Ă�Ǝv�����ǁB
�݊��܂ł����Ȃ��Ă��AAMD64����Intel64�ɋ߂��Ƃ͎v�����A�ǂ��Ȃ낤�H
�܂�������ɂ��Ă�MS�̊֗^�͑傫�������Ă邾�낤����A�n�r��APL���Ή�����
�̂ɖʓ|�̏��Ȃ���Ԃɂ͂Ȃ��Ă�Ǝv�����ǁB
>>832
ROB�G���g���ɂ�x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops������B
�قځA�Ə������̂́Amacro fusion�őΉ�����x86���߂��Ȃ��Ȃ�ꍇ������Ǝv����̂ŁB
�}�C�N���R�[�h�Ŏ��s����閽�߂�x86���߂��̂��̂������Ă���ۂ��B
ROB�G���g���ɂ�x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops������B
�قځA�Ə������̂́Amacro fusion�őΉ�����x86���߂��Ȃ��Ȃ�ꍇ������Ǝv����̂ŁB
�}�C�N���R�[�h�Ŏ��s����閽�߂�x86���߂��̂��̂������Ă���ۂ��B
835 �FMAC�I�^��832, 834 �����F2008/01/29(��) 18:41:44 ID:XLWbSyiR
>>832,>>834
�@�@----------------------
�@�@ROB�G���g���ɂ�x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops������B
�@�@----------------------
AMD��C���ƕʂ�����micro-ops fusion�Ƃ����T�O�����݂��Ȃ�Pentium Pro��
���ォ��ROB�Ɋi�[�����̂�Cmicro-ops���̂��̂ƕ����Ă��邷(��)
�������炵���p��̎Q�l�������ǂ����B
http://www1.informatik.uni-jena.de/lehre/nlp/p-pro-1.pdf
�@�@======================
�@�@The ��ops are queued, and sent to the Register Alias Table (RAT) unit,
�@�@where the logical IA-based register references are converted into
�@�@Pentium Pro processor physical register references, and to the
�@�@Allocator stage, which adds status information to the ��ops and
�@�@enters them into the instruction pool. The instruction pool is
�@�@implemented as an array of Content Addressable Memory called the
�@�@ReOrder Buffer (ROB).
�@�@======================
�@�@----------------------
�@�@ROB�G���g���ɂ�x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops������B
�@�@----------------------
AMD��C���ƕʂ�����micro-ops fusion�Ƃ����T�O�����݂��Ȃ�Pentium Pro��
���ォ��ROB�Ɋi�[�����̂�Cmicro-ops���̂��̂ƕ����Ă��邷(��)
�������炵���p��̎Q�l�������ǂ����B
http://www1.informatik.uni-jena.de/lehre/nlp/p-pro-1.pdf
�@�@======================
�@�@The ��ops are queued, and sent to the Register Alias Table (RAT) unit,
�@�@where the logical IA-based register references are converted into
�@�@Pentium Pro processor physical register references, and to the
�@�@Allocator stage, which adds status information to the ��ops and
�@�@enters them into the instruction pool. The instruction pool is
�@�@implemented as an array of Content Addressable Memory called the
�@�@ReOrder Buffer (ROB).
�@�@======================
>>835
������F�߂��Ȃ�����Ƃ����āA���O���܂߂ĒN�����y���Ă��Ȃ�PentiumPro�Ȃ�Ď����o���Ȃ�www
������F�߂��Ȃ�����Ƃ����āA���O���܂߂ĒN�����y���Ă��Ȃ�PentiumPro�Ȃ�Ď����o���Ȃ�www
>>835
�W�Ȃ��b���ł����A
ROB��uops������ƁA��ł��낢���J���Ă���݂��������B
���O�ł��킩��悤�ɓ��{��̕������B
http://download.intel.com/jp/developer/jpdoc/impliment_j.pdf
�W�Ȃ��b���ł����A
ROB��uops������ƁA��ł��낢���J���Ă���݂��������B
���O�ł��킩��悤�ɓ��{��̕������B
http://download.intel.com/jp/developer/jpdoc/impliment_j.pdf
838 �FMAC�I�^��837 �����F2008/01/29(��) 19:09:45 ID:XLWbSyiR
���������A������F�߂�Ȃ炢����ł��ڂ����������Ă���H
���炭�Ȃ��O���̂ł��������Ă����B
�p��͂̂Ȃ�MAC�I�^�́Ax86���߂���������micro-ops�ɕ�������A
���ꂪmicro-fusion��fused micro-ops�ɂȂ�ƍl���Ă���悤�����A
����ł����������Ⴂ���o�Ă���B
>>827
> �ƁA���邷����ROB�̒��ł̊Ǘ��P�ʂ핪�����ꂽmicro-ops�Ɠǂ߂邷�B����A���߃��^�C�A�̉��
> �����ł�A
���ۂ̂Ƃ���́A�ex86���߂͒��Ԍ`�����o�āA����fused micro-ops�ɕϊ������B
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�� X86 INSTRUCTION TRANSLATION �̂Ƃ����
> Also, each micro-op generated by the translator can represent functions to be performed
> by more than one execution unit. This combining of execution unit micro-ops
> into more powerful micro-ops is called micro-op fusion.
�Ə����Ă���B
MAC�I�^�قǂ̂Ђǂ��p��͂łȂ���킩�邾�낤�B
�ŁA����fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����B
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
> and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
�p��͂̂Ȃ�MAC�I�^�́Ax86���߂���������micro-ops�ɕ�������A
���ꂪmicro-fusion��fused micro-ops�ɂȂ�ƍl���Ă���悤�����A
����ł����������Ⴂ���o�Ă���B
>>827
> �ƁA���邷����ROB�̒��ł̊Ǘ��P�ʂ핪�����ꂽmicro-ops�Ɠǂ߂邷�B����A���߃��^�C�A�̉��
> �����ł�A
���ۂ̂Ƃ���́A�ex86���߂͒��Ԍ`�����o�āA����fused micro-ops�ɕϊ������B
http://www.extremetech.com/article2/0,1697,2252201,00.asp
�� X86 INSTRUCTION TRANSLATION �̂Ƃ����
> Also, each micro-op generated by the translator can represent functions to be performed
> by more than one execution unit. This combining of execution unit micro-ops
> into more powerful micro-ops is called micro-op fusion.
�Ə����Ă���B
MAC�I�^�قǂ̂Ђǂ��p��͂łȂ���킩�邾�낤�B
�ŁA����fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����B
> The three incoming fused micro-ops are placed in the reorder buffer (ROB)
> and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
MAC�I�^�͉p����A�[�L�e�N�`�����S�R�������Ă��Ȃ����Ƃ��悭�킩��܂���w
843 �FMAC�I�^��841 �����F2008/01/29(��) 20:28:46 ID:U+YuE5q6
>>841
���Ȃ������p���Ă���A
�@�@---------------
�@�@Also, each micro-op generated by the translator can represent functions to be performed �B�B�B
�@�@---------------
�̂����O�̃p���O���t�ɂ�A
�@�@---------------
�@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
�@�@initial implementation) and an optional ROM address.
�@�@---------------
�Ə����Ă���ǁA>>832��>>834��2�x���J��Ԃ��ď����Ă���
�@�@===============
�@�@x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops
�@�@===============
���ꉽ����(��)
���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
�s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
���Ȃ������p���Ă���A
�@�@---------------
�@�@Also, each micro-op generated by the translator can represent functions to be performed �B�B�B
�@�@---------------
�̂����O�̃p���O���t�ɂ�A
�@�@---------------
�@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
�@�@initial implementation) and an optional ROM address.
�@�@---------------
�Ə����Ă���ǁA>>832��>>834��2�x���J��Ԃ��ď����Ă���
�@�@===============
�@�@x86���߂Ƃقڈ�Έ�ɑΉ�����fused micro-ops
�@�@===============
���ꉽ����(��)
���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
�s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
844 �FMAC�I�^���⑫�F2008/01/29(��) 20:32:43 ID:U+YuE5q6
����������>>841�ɏ����Ă���
�@�@----------------
�@�@�p��͂̂Ȃ�MAC�I�^�́Ax86���߂���������micro-ops�ɕ�������A
�@�@���ꂪmicro-fusion��fused micro-ops�ɂȂ�ƍl���Ă���悤�����A
�@�@----------------
���Ă̂�Ax86���߂ɑΉ�����0�`3��micro-ops�����"fused" ops�Ɍ����邲������
�]���Ȃ��ˁB�B�B
�@�@----------------
�@�@�p��͂̂Ȃ�MAC�I�^�́Ax86���߂���������micro-ops�ɕ�������A
�@�@���ꂪmicro-fusion��fused micro-ops�ɂȂ�ƍl���Ă���悤�����A
�@�@----------------
���Ă̂�Ax86���߂ɑΉ�����0�`3��micro-ops�����"fused" ops�Ɍ����邲������
�]���Ȃ��ˁB�B�B
>>843
> �@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
>�@�@initial implementation) and an optional ROM address.
���̒ʂ�Ax86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv���B
VLIW�݂����Ȋ����ŁB
> ���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B
�����������ł��ĂȂ�����Ƃ����Č����Ⴂ�Ȉ��������Ȃ��łˁB
> ���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
> �s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
�ǂ����Ă��������^��������̂��s�v�c�Ȃ��̂��B
�eRS��micro-ops�z����Ƃ��Ɍ��܂��Ă邾�낤�B
> �@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
>�@�@initial implementation) and an optional ROM address.
���̒ʂ�Ax86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv���B
VLIW�݂����Ȋ����ŁB
> ���Ȃ݂ɂ��Ȃ���Macro-ops fusion��Micro-ops fusion�̋�ʂ������ł��Ȃ��Ď��Ɋ��ݕt���Ă���
�悤�Ɍ����邷�B
�����������ł��ĂȂ�����Ƃ����Č����Ⴂ�Ȉ��������Ȃ��łˁB
> ���̋^���A �e���s���j�b�g�ɑΉ������ŏ��P�ʂ�micro-ops�ւ̕�����ROB��
> �s����̂��ARS�ōs����̂��H�B�B�B�Ƃ������m�Ȃ��ǁB
�ǂ����Ă��������^��������̂��s�v�c�Ȃ��̂��B
�eRS��micro-ops�z����Ƃ��Ɍ��܂��Ă邾�낤�B
���p����Ȃ�
�v���������͌������Ȃ����瓧�����ڂĂ�̂�
�v���������͌������Ȃ����瓧�����ڂĂ�̂�
���낻��ISSCC�̋G�߂��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=205920481
http://www.tgdaily.com/content/view/35817/135/
����̘b�����������ǁB�B�B
��45-nm CELL BE
�@- 65-nm������40%�ȓd��
�@- DFM (Design for Manufacturability)�ɒ��́@[���ł̎����v�ł����ˁB�B�B]
��Intel Silverthorne
�@- 45nm, 47M transistors, 25 mm^2
�@- 2GHz, 2W, 533MHz FSB
�@- dual-issue, in-order, 32KB ����L1, 24KB �f�[�^L1, 512KB L2
�@- 441-pin uFCBGA
�@- "The competition considers 2W laughable," said Will Strauss, principal of market watcher
�@�@Forward Concepts (Tempe, Ariz.). "600 mW is the power budget for an entire cellphone
�@�@processor and baseband," he said.
��Intel Tukwila
�@- 65-nm, 2.05B transistors, 699 mm^2
�@- 170W
�@- 30MB L2
�@- 34GB/s memory bandwidth
�@- 96GB/s inter-processor bandwidth with QuickPath
��Sun Rock
�@- 65-nm, 396 mm^2
�@- 16-core, �`2.3GHz
�@- transactional memory
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=205920481
http://www.tgdaily.com/content/view/35817/135/
����̘b�����������ǁB�B�B
��45-nm CELL BE
�@- 65-nm������40%�ȓd��
�@- DFM (Design for Manufacturability)�ɒ��́@[���ł̎����v�ł����ˁB�B�B]
��Intel Silverthorne
�@- 45nm, 47M transistors, 25 mm^2
�@- 2GHz, 2W, 533MHz FSB
�@- dual-issue, in-order, 32KB ����L1, 24KB �f�[�^L1, 512KB L2
�@- 441-pin uFCBGA
�@- "The competition considers 2W laughable," said Will Strauss, principal of market watcher
�@�@Forward Concepts (Tempe, Ariz.). "600 mW is the power budget for an entire cellphone
�@�@processor and baseband," he said.
��Intel Tukwila
�@- 65-nm, 2.05B transistors, 699 mm^2
�@- 170W
�@- 30MB L2
�@- 34GB/s memory bandwidth
�@- 96GB/s inter-processor bandwidth with QuickPath
��Sun Rock
�@- 65-nm, 396 mm^2
�@- 16-core, �`2.3GHz
�@- transactional memory
���̃X���̈��p�I�^�ǂ���B
Micro Fusion��ROB�ǂ������Ȃ�č��ׂȘb���������Əd�v�ȁA
Cache�̒x����ш�A���s���j�b�g�̍\�����܂���ɘ_����ׂ����낤�B
�R��͂��C�������ǂȁB
Micro Fusion��ROB�ǂ������Ȃ�č��ׂȘb���������Əd�v�ȁA
Cache�̒x����ш�A���s���j�b�g�̍\�����܂���ɘ_����ׂ����낤�B
�R��͂��C�������ǂȁB
849 �FMAC�I�^��845 �����F2008/01/29(��) 23:07:53 ID:U+YuE5q6
>>845
�@�@-----------------
�@�@x86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
�@�@-----------------
�]���ϑz�ȊO�̍��������肢���邷�B
�@�@-----------------
�@�@�ǂ����Ă��������^��������̂��s�v�c�Ȃ��̂��B
�@�@-----------------
�ȒP�ɉ�����邷�B
AMD�̎��s���j�b�g�̎����̂悤�ɁA�S�Ă̎��s�p�C�v���C����AGU (�A�h���X�������j�b�g)��
�t�������Ă���ꍇ��AROB�܂ʼn��Z�ƃA�h���X�������t���[�W��������Macro-ops�ŕێ�����
���s���j�b�g�̒��O�ŕ�������̂�ȒP�����A�����I���B
�������AIntel��VIA�̎�����LSU��AGU��ALU�ƕ������ꂽ�Ɨ��̃o�C�v���C�����B���̏ꍇ��
���߂Ƀ��[�h�^�X�g�A�Ɖ��Z�����Ă������ƂɈӖ������邷�B
�������AROB��e���s���j�b�g�̃L���[�ŊǗ����閽�ߐ��폭�Ȃ��قǏ���d�͓I�ɂ�L���Ƃ���
�g���[�h�I�t�����݂��邷�B
�@�@-----------------
�@�@x86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
�@�@-----------------
�]���ϑz�ȊO�̍��������肢���邷�B
�@�@-----------------
�@�@�ǂ����Ă��������^��������̂��s�v�c�Ȃ��̂��B
�@�@-----------------
�ȒP�ɉ�����邷�B
AMD�̎��s���j�b�g�̎����̂悤�ɁA�S�Ă̎��s�p�C�v���C����AGU (�A�h���X�������j�b�g)��
�t�������Ă���ꍇ��AROB�܂ʼn��Z�ƃA�h���X�������t���[�W��������Macro-ops�ŕێ�����
���s���j�b�g�̒��O�ŕ�������̂�ȒP�����A�����I���B
�������AIntel��VIA�̎�����LSU��AGU��ALU�ƕ������ꂽ�Ɨ��̃o�C�v���C�����B���̏ꍇ��
���߂Ƀ��[�h�^�X�g�A�Ɖ��Z�����Ă������ƂɈӖ������邷�B
�������AROB��e���s���j�b�g�̃L���[�ŊǗ����閽�ߐ��폭�Ȃ��قǏ���d�͓I�ɂ�L���Ƃ���
�g���[�h�I�t�����݂��邷�B
850 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 01:10:20 ID:LR0BibTm
>>833
AMD64��Intel64�̖��߃Z�b�g�̈Ⴂ���ĉ����Ǝv���H
��������AMD��x86�݊���Intel�����̈Ⴂ�̉����ł����Ȃ���B
VIA�����܂Ō݊����Ă��ꂽ�Ȃ���Ȃ��ڍs�ł���ł���B
Intel�œ����Ȃ����Ƃ�����̂��ď�����AMD64�pLinux�f�B�X�g�����炢����B
����MacOS��Intel64��p���B
AMD64��Intel64�̖��߃Z�b�g�̈Ⴂ���ĉ����Ǝv���H
��������AMD��x86�݊���Intel�����̈Ⴂ�̉����ł����Ȃ���B
VIA�����܂Ō݊����Ă��ꂽ�Ȃ���Ȃ��ڍs�ł���ł���B
Intel�œ����Ȃ����Ƃ�����̂��ď�����AMD64�pLinux�f�B�X�g�����炢����B
����MacOS��Intel64��p���B
851 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 01:11:57 ID:LR0BibTm
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
>�@Valentine���ɂ��ƁA�e���s���j�b�g�ɂ��ꂼ�ꃊ�U�x�[�V�����X�e�[�V������
> �݂����Ă���Ƃ����BFused uOPs�̕����ƍăX�P�W���[�����O���s�Ȃ����
> �́A���̒��O�ƌ�����B�������ꂽuOPs�́A���U�x�[�V�����X�e�[�V�����őҋ@
> ���āA���s�ł���g�ݍ��킹�Ŕ��s�����B�l���悤�ɂ���ẮA
> �ux86���߁�Fused uOPs��uOPs�v�ƁA2�i�K�Ńf�R�[�h���ꂽ�ƌ��邱�Ƃ��ł���B
> �����Ƃ��A���ۂɂ͍ŏ��̃f�R�[�h�̒i�K�ŁA��i�ŕ������₷���悤��
> �t�H�[�}�b�g�ɂ���Ă���Ƃ����B
>�@Valentine���ɂ��ƁA�e���s���j�b�g�ɂ��ꂼ�ꃊ�U�x�[�V�����X�e�[�V������
> �݂����Ă���Ƃ����BFused uOPs�̕����ƍăX�P�W���[�����O���s�Ȃ����
> �́A���̒��O�ƌ�����B�������ꂽuOPs�́A���U�x�[�V�����X�e�[�V�����őҋ@
> ���āA���s�ł���g�ݍ��킹�Ŕ��s�����B�l���悤�ɂ���ẮA
> �ux86���߁�Fused uOPs��uOPs�v�ƁA2�i�K�Ńf�R�[�h���ꂽ�ƌ��邱�Ƃ��ł���B
> �����Ƃ��A���ۂɂ͍ŏ��̃f�R�[�h�̒i�K�ŁA��i�ŕ������₷���悤��
> �t�H�[�}�b�g�ɂ���Ă���Ƃ����B
853 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 01:54:35 ID:LR0BibTm
���U�x�[�V�����̎�O��4issue�Ŏ��s���j�b�g�̎�O��6issue����Ȃ����������B
3Way ALU��Load��Store��StoreAddress��6Way
AMD�̃u���b�N�}����ɁA�����p�C�v�̓f�R�[�h����Execute�܂ŃY�h�[���~3�{�Ɍ�����B
�����ׂ����ƂɃf�R�[�h�O�ɃX�P�W���[�����O�ł��邩��ˁB
����蕂�������ESIMD�p�p�C�v��Intel�̓����p�C�v���C���̂悤�ɕ��G�B
3Way ALU��Load��Store��StoreAddress��6Way
AMD�̃u���b�N�}����ɁA�����p�C�v�̓f�R�[�h����Execute�܂ŃY�h�[���~3�{�Ɍ�����B
�����ׂ����ƂɃf�R�[�h�O�ɃX�P�W���[�����O�ł��邩��ˁB
����蕂�������ESIMD�p�p�C�v��Intel�̓����p�C�v���C���̂悤�ɕ��G�B
854 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 02:34:13 ID:LR0BibTm
�Ƃ���Ń}�R�^����
AMD�̃p�C�v���C���ł͂��ꂪ�ǂ��������Ƀ�OPs�ɓW�J����邩���킩��H
addps xmm1 [eax + ecx*8 + 0x12345678]
AMD���Č����Ă�K8��K10�i�j�ł��Ⴄ���ǂ�
AMD�̃p�C�v���C���ł͂��ꂪ�ǂ��������Ƀ�OPs�ɓW�J����邩���킩��H
addps xmm1 [eax + ecx*8 + 0x12345678]
AMD���Č����Ă�K8��K10�i�j�ł��Ⴄ���ǂ�
>>849
>�@�@x86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
> �@�@-----------------
> �]���ϑz�ȊO�̍��������肢���邷�B
�ő�3��micro-ops�ɕϊ������Ƃ����͈̂ȉ��̒ʂ�B
can be directly�Ƃ����̂́A���s�R���e�L�X�g��K�v�Ƃ����A�Ƃ������炢�̈Ӗ����B
> �@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
>�@�@initial implementation) and an optional ROM address.
���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
> Also, each micro-op generated by the translator can represent functions to be performed
> by more than one execution unit.
�g�����X���[�^�ȑO�̃X�e�[�W��execution unit micro-ops�����Ă���L�q�͂Ȃ��B
MAC�I�^�͂��̂�����̎����̗����������Ă���H
�����łȂ��ƌ����悭�ԈႢ������ł����A�F�ɖ��f��������B
> �������AIntel��VIA�̎�����LSU��AGU��ALU�ƕ������ꂽ�Ɨ��̃o�C�v���C�����B���̏ꍇ��
> ���߂Ƀ��[�h�^�X�g�A�Ɖ��Z�����Ă������ƂɈӖ������邷�B
���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�ǂ������Ӗ�������H
Isaiah�ł̓��W�X�^���l�[����f�B�X�p�b�`�̑ш�͏\���̂悤�����H
>>851
�܂���NOP�̂��Ƃ��Ǝv����B
> NOP�ł��痥�V��ROB�܂ł͉^���B
Isaiah�͂��̂ւ�͂����菑���ĂȂ����A
x86��NOP����ϊ����ꂽfused micro-ops��0��micro-ops���܂�ł����܂����B
>>853
����͂ǂ̃v���Z�b�T�̘b�H
>�@�@x86���߂�0����3��micro-ops�ɕϊ�����邵�A����͈��fused micro-ops�ł�����B
> �@�@-----------------
> �]���ϑz�ȊO�̍��������肢���邷�B
�ő�3��micro-ops�ɕϊ������Ƃ����͈̂ȉ��̒ʂ�B
can be directly�Ƃ����̂́A���s�R���e�L�X�g��K�v�Ƃ����A�Ƃ������炢�̈Ӗ����B
> �@�@Each x86 instruction can be directly translated into zero, one, two or three micro-ops (in the
>�@�@initial implementation) and an optional ROM address.
���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
> Also, each micro-op generated by the translator can represent functions to be performed
> by more than one execution unit.
�g�����X���[�^�ȑO�̃X�e�[�W��execution unit micro-ops�����Ă���L�q�͂Ȃ��B
MAC�I�^�͂��̂�����̎����̗����������Ă���H
�����łȂ��ƌ����悭�ԈႢ������ł����A�F�ɖ��f��������B
> �������AIntel��VIA�̎�����LSU��AGU��ALU�ƕ������ꂽ�Ɨ��̃o�C�v���C�����B���̏ꍇ��
> ���߂Ƀ��[�h�^�X�g�A�Ɖ��Z�����Ă������ƂɈӖ������邷�B
���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�ǂ������Ӗ�������H
Isaiah�ł̓��W�X�^���l�[����f�B�X�p�b�`�̑ш�͏\���̂悤�����H
>>851
�܂���NOP�̂��Ƃ��Ǝv����B
> NOP�ł��痥�V��ROB�܂ł͉^���B
Isaiah�͂��̂ւ�͂����菑���ĂȂ����A
x86��NOP����ϊ����ꂽfused micro-ops��0��micro-ops���܂�ł����܂����B
>>853
����͂ǂ̃v���Z�b�T�̘b�H
856 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 05:40:43 ID:LR0BibTm
�s���ɂ����������肽���B
0�̃�OP�ɕϊ�����閽�߂��Ă���́H
NOP�ł����OP�������B
0�̃�OP�ɕϊ�����閽�߂��Ă���́H
NOP�ł����OP�������B
857 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/30(��) 05:43:56 ID:LR0BibTm
>>856�͒����B�������āB
>>853��Core MA�̘b�B
Store��StoreAddress�Ƃ�2���j�b�g�ɕ������̂́AMemory Disambiguation�̂��߂ł��傤�ȁB
����ɂ���āA���[�h�A�h���X�Əd�Ȃ�Ȃ������A��s���ă`�F�b�N����悤�X�P�W���[�����O���\�B
>>853��Core MA�̘b�B
Store��StoreAddress�Ƃ�2���j�b�g�ɕ������̂́AMemory Disambiguation�̂��߂ł��傤�ȁB
����ɂ���āA���[�h�A�h���X�Əd�Ȃ�Ȃ������A��s���ă`�F�b�N����悤�X�P�W���[�����O���\�B
>>854 �c�q ����
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
micro-ops�̐��̂Ɋւ���b���A�S�R���������Ƃ��������B
����K8��K10�Ŗ��ߏ����̃t�����g�G���h���J�����������͂�AMD�ɂ������Ƃ�A�v���Ȃ����B
>>855 ����
�@�@------------------
�@�@���ۂɂ̓g�����X���[�^�͈��fused micro-ops�ɕϊ����Ă���Ƃ����͈̂ȉ��̒ʂ�B
�@�@------------------
���̕��͂�fused micro-ops��x86���߂ɂ��ꂼ��Ή�����Ƃ����L�q��u��v���������ǁB�B�B
�t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
���̂悤�ɏ������R��A���L�̖₢�ɑ�������ɂ��Ȃ邩�Ǝv�����B
�@�@-------------------
�@�@���߁A�Ƃ����̂����������Ă���̂��킩��A�f�B�X�p�b�`�X�e�[�W���O�Ƃ������Ƃ��H
�@�@�ǂ������Ӗ�������H
�@�@-------------------
�[�I�ɂ�A��������RISC�̐v�����̂悤�ɍœK������Ă��邷�B
OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
�����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
�̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���߂ɖ��߂ނ��邱�Ƃ�A�����̌���Ɍq���邷��B
�X�Ɍ���̃v���Z�b�T�ł�A�ח��x�̓d�͊Ǘ��̂��߂Ɋe���߂��g�p���郊�\�[�X�𑁂߂Ɋm��
���ēd�͊Ǘ��̃X�P�W���[���𗧂Ă邱�Ƃ��d�v���B
>>858
> �t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
�H�HMAC�I�^�����ǂ��������������Ă���H
�����l���Ă���̂����������Ȃ����A���ꂱ���ǂ��ɂ��������L�q������H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���v���H
���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
��̓I�ɂ́A�L���b�V���~�X�������[�h���߂̌��ʂɈˑ����Ă��閽�ߌQ�Ƃ��B
�X���[�v�b�g���\������A���������_���߂��낤���������A�N�Z�X���߂��낤���A�ˑ����̂Ȃ�����͂ǂ�ǂ�o�Ă�����B
> �t���[�W�������Ĉ����������A�����ƌ��肳�ꂽ���m�Ȃ̂ł�H
�H�HMAC�I�^�����ǂ��������������Ă���H
�����l���Ă���̂����������Ȃ����A���ꂱ���ǂ��ɂ��������L�q������H
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B�Ƃ��낪���߂��ƂɎ��s���C�e���V��قȂ�̂ŁA���݂�����Ǝ���
> �̂����郍�[�h�^�X�g�A�╂�������_���߂��肪�L���[�ɋ����邱�Ƃ��Ȃ邷�B
���v���H
���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
��̓I�ɂ́A�L���b�V���~�X�������[�h���߂̌��ʂɈˑ����Ă��閽�ߌQ�Ƃ��B
�X���[�v�b�g���\������A���������_���߂��낤���������A�N�Z�X���߂��낤���A�ˑ����̂Ȃ�����͂ǂ�ǂ�o�Ă�����B
�y�����́zAMD������ȐԎ����v��@ATI���������ׂĂ̌����m08/01/21�n
http://news24.2ch.net/test/read.cgi/bizplus/1200903424/184
184 ���O�F���h�͐炵�Ă���܂���[sage] ���e���F2008/01/25(��) 04:14:59 ID:8xVRoTO5
�h�a�l��X86�s��ɎQ������̗p�����Ƃ�����������
�������ė~����
250 ���O�F���h�͐炵�Ă���܂���[] ���e���F2008/01/30(��) 22:02:01 ID:Kz3/CoeT
>>247
x86�A�[�L�e�N�`�����͕̂��G�ł����ł��Ȃ���ł�
����x��̕n��ȃA�[�L�e�N�`���̔���̒��Ő��\�����コ����d�g�݂����G�Ȃ����ŁB
����CPU�̂悤�ɁA�ŏ����烌�W�X�^���S�����Ă��
���W�X�^���l�[�~���O�Ƃ��A�E�g�I�u�I�[�_�[�Ƃ��v��Ȃ����B(��� x86 ��8��)
�ł� 20�N�ȏ�݊����ێ����AIntel8086 ����10���{�͐��\�オ���Ă�͂��BIntel��������B
http://news24.2ch.net/test/read.cgi/bizplus/1200903424/184
184 ���O�F���h�͐炵�Ă���܂���[sage] ���e���F2008/01/25(��) 04:14:59 ID:8xVRoTO5
�h�a�l��X86�s��ɎQ������̗p�����Ƃ�����������
�������ė~����
250 ���O�F���h�͐炵�Ă���܂���[] ���e���F2008/01/30(��) 22:02:01 ID:Kz3/CoeT
>>247
x86�A�[�L�e�N�`�����͕̂��G�ł����ł��Ȃ���ł�
����x��̕n��ȃA�[�L�e�N�`���̔���̒��Ő��\�����コ����d�g�݂����G�Ȃ����ŁB
����CPU�̂悤�ɁA�ŏ����烌�W�X�^���S�����Ă��
���W�X�^���l�[�~���O�Ƃ��A�E�g�I�u�I�[�_�[�Ƃ��v��Ȃ����B(��� x86 ��8��)
�ł� 20�N�ȏ�݊����ێ����AIntel8086 ����10���{�͐��\�オ���Ă�͂��BIntel��������B
>>860
���m�ۏo���̑f�l�������R�s�y���Ăǂ��������́H
���m�ۏo���̑f�l�������R�s�y���Ăǂ��������́H
��������A�u���[���C�g�j���O�Ƃ��������ȁc
���@�Ȃ�ĂȂ�
�ƌ����Ă��钆�Ő��������M�d�Ȗ��@�e�N�j�b�N���o�J�ɂ���Ƃ�
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt035.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt036.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt037.htm
�ƌ����Ă��钆�Ő��������M�d�Ȗ��@�e�N�j�b�N���o�J�ɂ���Ƃ�
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt035.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt036.htm
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt037.htm
864 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/01/31(��) 00:31:22 ID:WzxBT/HC
>>858
���Z���j�b�g��128bit����128bit SIMD���߂�1��OP�ň�����悤�ɂȂ�������
�f�R�[�_�̃X���[�v�b�g�����R���P�ł����B
�e���j�b�g������2�N���b�N������1���ߕ��f�R�[�h���Ă��̂�1�N���b�N�ōςނ悤�ɂȂ����B
���Z���j�b�g��128bit����128bit SIMD���߂�1��OP�ň�����悤�ɂȂ�������
�f�R�[�_�̃X���[�v�b�g�����R���P�ł����B
�e���j�b�g������2�N���b�N������1���ߕ��f�R�[�h���Ă��̂�1�N���b�N�ōςނ悤�ɂȂ����B
865 �FMAC�I�^��859 �����F2008/01/31(��) 20:56:08 ID:0C6GGRXK
>>859
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
IBM�����[�G���hPOWER6�T�[�o�[�\�������B
http://www-06.ibm.com/jp/press/2008/01/3002.html
�ŁA�ʔ����̂�R�R�B
�@�@-------------------
�@�@�����āA�uPowerVM Edition�v�V���[�Y�̖����I�v�V�����ł���uPowerVM Lx86�v��p���āA
�@�@x86�A�[�L�e�N�`���[�̃T�[�o�[�ʼnғ�����A�v���P�[�V������POWER^(TM)�v���Z�b�T�[���
�@�@Linux?�œ��������Ƃ��\�ɂȂ�܂��B�uPowerVM Lx86�v�ɂ������̃A�v���P�[�V������
�@�@���̂܂܊��p�ł��邽�߁A�ŏ����̎�ԂƃR�X�g��x86�T�[�o�[����System p�ւ̈ڍs��
�@�@�������܂��B*4
�@�@-------------------
�v���Ԃ��RISC����x86�ւ̒��킷���ǁA���\��ǂ�ȃ����Ȃ��ˁB�B�B
http://www-06.ibm.com/jp/press/2008/01/3002.html
�ŁA�ʔ����̂�R�R�B
�@�@-------------------
�@�@�����āA�uPowerVM Edition�v�V���[�Y�̖����I�v�V�����ł���uPowerVM Lx86�v��p���āA
�@�@x86�A�[�L�e�N�`���[�̃T�[�o�[�ʼnғ�����A�v���P�[�V������POWER^(TM)�v���Z�b�T�[���
�@�@Linux?�œ��������Ƃ��\�ɂȂ�܂��B�uPowerVM Lx86�v�ɂ������̃A�v���P�[�V������
�@�@���̂܂܊��p�ł��邽�߁A�ŏ����̎�ԂƃR�X�g��x86�T�[�o�[����System p�ւ̈ڍs��
�@�@�������܂��B*4
�@�@-------------------
�v���Ԃ��RISC����x86�ւ̒��킷���ǁA���\��ǂ�ȃ����Ȃ��ˁB�B�B
867 �FMAC�I�^���⑫�F2008/01/31(��) 22:56:50 ID:0C6GGRXK
���Ȃ݂ɏ��PowerVM Lx86�̒�AIntel Mac��"Rosetta"�ł�������݂̃G�~�����[�V����
�Z�p�̗Y�ATransitive�Ђ��B
http://www.transitive.com/news/news_20080129.htm
�@�@---------------------
�@�@Transitive? Corporation, the leading provider of cross-platform virtualization software that
�@�@enables the execution of applications across diverse computing platforms, today announced
�@�@that IBM will commence shipping PowerVM Lx86 with all copies of PowerVM Editions,
�@�@available across its entire line of System p servers. PowerVM Editions, a set of advanced
�@�@virtualization offerings developed by IBM for Power Systems platforms, now includes the Lx86
�@�@feature (developed for IBM by Transitive) which simplifies migration of x86 Linux applications
�@�@onto this popular platform for server consolidation and business application deployment.
�@�@---------------------
�Z�p�̗Y�ATransitive�Ђ��B
http://www.transitive.com/news/news_20080129.htm
�@�@---------------------
�@�@Transitive? Corporation, the leading provider of cross-platform virtualization software that
�@�@enables the execution of applications across diverse computing platforms, today announced
�@�@that IBM will commence shipping PowerVM Lx86 with all copies of PowerVM Editions,
�@�@available across its entire line of System p servers. PowerVM Editions, a set of advanced
�@�@virtualization offerings developed by IBM for Power Systems platforms, now includes the Lx86
�@�@feature (developed for IBM by Transitive) which simplifies migration of x86 Linux applications
�@�@onto this popular platform for server consolidation and business application deployment.
�@�@---------------------
>>865
������C���e���͊W�Ȃ�����c
�C�V���[����Ă��烊�^�C�A����܂ł̊Ԃ����߃L���[�Ɏc���Ăǂ��������B
���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
������C���e���͊W�Ȃ�����c
�C�V���[����Ă��烊�^�C�A����܂ł̊Ԃ����߃L���[�Ɏc���Ăǂ��������B
���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
869 �FMAC�I�^��868 �����F2008/01/31(��) 23:47:00 ID:0C6GGRXK
>>868
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
�@�@---------------
�@�@���I�[�_�o�b�t�@�͉��̂��߂ɂ���Ǝv���Ă��B
�@�@---------------
ROB��x86�p��Ȃ��ǁB�B�B
OoO����������RISC�̃u���b�N�}�ł����ėp����m�F���邱�Ƃ������߂��邷�B
870 �FMAC�I�^���⑫�F2008/01/31(��) 23:58:06 ID:0C6GGRXK
�Q�l�܂ł�OoO����������RISC�̃u���b�N�}���������B
http://www.azillionmonkeys.com/qed/21264.gif
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
http://www.design-reuse.com/news_img/20071008_arm4.gif
http://www.azillionmonkeys.com/qed/21264.gif
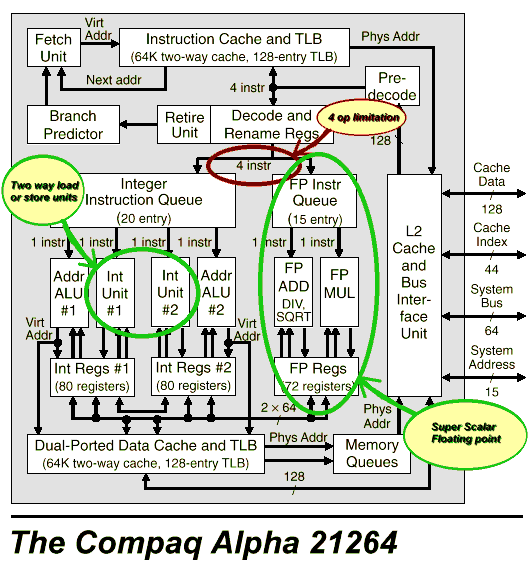{kind=link}
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
{kind=link}
http://www.design-reuse.com/news_img/20071008_arm4.gif
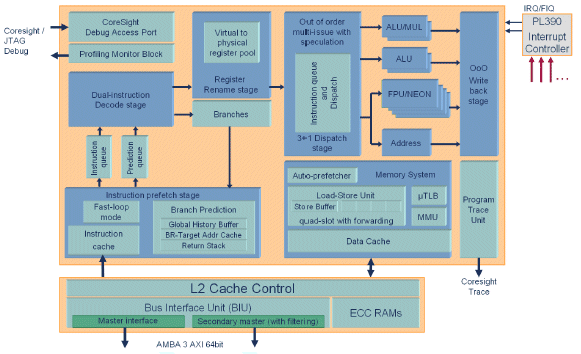{kind=link}
���炭�O�Ɏ��킱��Ȃ��Ƃ����������B
�@�@------------------
�@�@392 ���O�FMAC�I�^ ���e���F2007/05/25(��) 01:27:10 ID:6ojiKhut
�@�@�@�@�������PowerPC�l�^�����ǁA�J�Ò���Microprocessorr Forum��AMCC���VPowerPC 440
�@�@�@�@"Titan"�\�������B
�@�@�@�@[����]
�@�@�@�@���Ȃ݂�PPC440�R�A�̑�\�I���i�Ƃ�����Blue Gene/L�����ǁA�ʂ�����AMCC/Intrinsity -> IBM
�@�@�@�@�Ƃ����ɉ��ɂ܂�Ȃ��Z�p�̋t�]��L�邷���ˁB�B�B
�@�@------------------
�ŁA�Ă̒�IBM�픲���ږ�������o���Ă����Ƃ����b���B
http://investor.amcc.com/releasedetail.cfm?ReleaseID=289188
�@�@==================
�@�@IBM will incorporate the entire AMCC PowerPC(R) 4xx embedded processor product portfolio
�@�@into its Semiconductor Solutions offering, effective immediately
�@�@==================.
�@�@------------------
�@�@392 ���O�FMAC�I�^ ���e���F2007/05/25(��) 01:27:10 ID:6ojiKhut
�@�@�@�@�������PowerPC�l�^�����ǁA�J�Ò���Microprocessorr Forum��AMCC���VPowerPC 440
�@�@�@�@"Titan"�\�������B
�@�@�@�@[����]
�@�@�@�@���Ȃ݂�PPC440�R�A�̑�\�I���i�Ƃ�����Blue Gene/L�����ǁA�ʂ�����AMCC/Intrinsity -> IBM
�@�@�@�@�Ƃ����ɉ��ɂ܂�Ȃ��Z�p�̋t�]��L�邷���ˁB�B�B
�@�@------------------
�ŁA�Ă̒�IBM�픲���ږ�������o���Ă����Ƃ����b���B
http://investor.amcc.com/releasedetail.cfm?ReleaseID=289188
�@�@==================
�@�@IBM will incorporate the entire AMCC PowerPC(R) 4xx embedded processor product portfolio
�@�@into its Semiconductor Solutions offering, effective immediately
�@�@==================.
872 �FMAC�I�^���⑫�F2008/02/01(��) 00:09:56 ID:JA4OoS/6
����A������̓W�J�����邩�ǂ������y���݂��ˁB�B�B
�@�@---------------------
�@�@671 ���O�FMAC�I�^���⑫ ���e���F2007/06/26(��) 22:35:03 ID:E+b+TZBO
�@�@�@�@�Ƃ肠����884,736-processor�̍ő�\����2-PetaFlops�풴���邷�B����PPC44x�x�[�X��
�@�@�@�@�R�A��90nm�o���NCMOS��2GHz���邱�Ƃ��\�Ȃ��Ƃ��ؖ�����Ă��邷����(>>392�Q��)�A
�@�@�@�@Blue Gene��A���̂܂܂̐v�ł����N�ȓ���5-PetaFlops���郍�[�h�}�b�v�팻���I���B
�@�@---------------------
�@�@---------------------
�@�@671 ���O�FMAC�I�^���⑫ ���e���F2007/06/26(��) 22:35:03 ID:E+b+TZBO
�@�@�@�@�Ƃ肠����884,736-processor�̍ő�\����2-PetaFlops�풴���邷�B����PPC44x�x�[�X��
�@�@�@�@�R�A��90nm�o���NCMOS��2GHz���邱�Ƃ��\�Ȃ��Ƃ��ؖ�����Ă��邷����(>>392�Q��)�A
�@�@�@�@Blue Gene��A���̂܂܂̐v�ł����N�ȓ���5-PetaFlops���郍�[�h�}�b�v�팻���I���B
�@�@---------------------
����͂Ƃ������AMAC�I�^�̗�������Ƃ���ɂ��ROB�̐��������Ă�����
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
���́A������������������ɂ͂���B
�ǂ����āu���^�C�A����܂Łv���߃L���[�Ɏ�菜����邱�Ƃ��Ȃ��̂��������Ă����B
���肪�����}���o���Ă��ꂽ�̂ʼn�����Ƃ��ƁA
��ԏ��Alpha 21264�̓��I�[�_�o�b�t�@����Ȃ��ă`�F�b�N�|�C���g�ŃC���I�[�_��Ԃ������e���Ă�B
�`�F�b�N�|�C���g�Ƃ����̂́A���̎��_�ł̃��W�X�^�}�b�v(�̃R�s�[)�Ȃ��ǁA�������^�C�v���ˁB
��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
IBM�̍D���ȓƎ��p�ꂾ�ˁB
�O�Ԗڂ�ARM�ɂ��Ă͒m��Ȃ��̂ŁA
OoO Write back stage�Ƃ����̂�ROB�ɑ������邩�A�{����OoO commit����̂��͂킩��Ȃ����A
�ǂ���ɂ��施�߃L���[����issue���ɖ��߂���菜���Ȃ����R�͂Ȃ��Ȃ�B
���́A������������������ɂ͂���B
�ǂ����āu���^�C�A����܂Łv���߃L���[�Ɏ�菜����邱�Ƃ��Ȃ��̂��������Ă����B
���肪�����}���o���Ă��ꂽ�̂ʼn�����Ƃ��ƁA
��ԏ��Alpha 21264�̓��I�[�_�o�b�t�@����Ȃ��ă`�F�b�N�|�C���g�ŃC���I�[�_��Ԃ������e���Ă�B
�`�F�b�N�|�C���g�Ƃ����̂́A���̎��_�ł̃��W�X�^�}�b�v(�̃R�s�[)�Ȃ��ǁA�������^�C�v���ˁB
��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
IBM�̍D���ȓƎ��p�ꂾ�ˁB
�O�Ԗڂ�ARM�ɂ��Ă͒m��Ȃ��̂ŁA
OoO Write back stage�Ƃ����̂�ROB�ɑ������邩�A�{����OoO commit����̂��͂킩��Ȃ����A
�ǂ���ɂ��施�߃L���[����issue���ɖ��߂���菜���Ȃ����R�͂Ȃ��Ȃ�B
877 �FMAC�I�^��875 �����F2008/02/01(��) 01:07:39 ID:JA4OoS/6
>>875
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
���ɗ�����ƌ��������ƌ����ׂ����B�B�B
�@�@-------------------
�@�@��Ԗڂ�POWER5�́AGlobal completion table�Ƃ����̂�ROB���̂��̂���B
�@�@IBM�̍D���ȓƎ��p�ꂾ�ˁB
�@�@-------------------
http://www.research.ibm.com/journal/rd/494/sinharoy.html
�@�@===================
�@�@An entry is de-allocated from the GCT when the group is committed.
�@�@===================
"commit"���ǂ̒i�K�������ł��Ȃ��̂��S�z�ɂȂ��Ă����̂ŁA���̐}�����Ă�����(��)
http://www.research.ibm.com/journal/rd/494/sinha3.jpg
>>877
���߃O���[�v���R�~�b�g==���^�C�A�����Ƃ���GCT����deallocate�������ď����Ă邶���c
Shared issue queues���Ă̂��ʂɂ��邾��A��������issue���ꂽ���߂͂����Ɏ�菜������B
����͂Ƃ������AMAC�I�^�̗�������ROB�̓����ƁA���^�C�A�܂Ŗ��߂����߃L���[�Ɏc���Ă��闝�R��������Ă���患
���߃O���[�v���R�~�b�g==���^�C�A�����Ƃ���GCT����deallocate�������ď����Ă邶���c
Shared issue queues���Ă̂��ʂɂ��邾��A��������issue���ꂽ���߂͂����Ɏ�菜������B
����͂Ƃ������AMAC�I�^�̗�������ROB�̓����ƁA���^�C�A�܂Ŗ��߂����߃L���[�Ɏc���Ă��闝�R��������Ă���患
�����͂���邾����MAC�I�^��
>>879
�Ȃ�ɂ��������Ă��Ȃ��̂ŁA�����͂���邵���\���Ȃ���
> MAC�I�^�̗�������ROB�̓����ƁA���^�C�A�܂Ŗ��߂����߃L���[�Ɏc���Ă��闝�R��������Ă���患
�̐������ł��Ȃ��Ǝv�����ǁB
�������ȒP�Ȃ��ƂȂ̂ɂˁB
�Ȃ�ɂ��������Ă��Ȃ��̂ŁA�����͂���邵���\���Ȃ���
> MAC�I�^�̗�������ROB�̓����ƁA���^�C�A�܂Ŗ��߂����߃L���[�Ɏc���Ă��闝�R��������Ă���患
�̐������ł��Ȃ��Ǝv�����ǁB
�������ȒP�Ȃ��ƂȂ̂ɂˁB
�Ȃ�877�̃����N��ɂ͂���ȕ������邶��Ȃ���
>Control information for each group of dispatched instructions is placed in
> a global completion table (GCT) at the time of dispatch [1].
�ǂ��݂Ă�ROB�ł��B�{����ry
>Control information for each group of dispatched instructions is placed in
> a global completion table (GCT) at the time of dispatch [1].
�ǂ��݂Ă�ROB�ł��B�{����ry
882 �FMAC�I�^��878 �����F2008/02/01(��) 01:33:57 ID:JA4OoS/6
>>878
�@�@-----------------
�@�@Shared issue queues���Ă̂��ʂɂ��邾��A��������issue���ꂽ���߂͂�����
�@�@��菜������B
�@�@-----------------
�������x86�Ō����Ƃ����RS (Reservation Station)�Ȃ��ǁB�B�B
>>870�̃u���b�N�}��x86������ׂė~�������B
http://www.azillionmonkeys.com/qed/p3-architecture.gif
�@�@-----------------
�@�@Shared issue queues���Ă̂��ʂɂ��邾��A��������issue���ꂽ���߂͂�����
�@�@��菜������B
�@�@-----------------
�������x86�Ō����Ƃ����RS (Reservation Station)�Ȃ��ǁB�B�B
>>870�̃u���b�N�}��x86������ׂė~�������B
http://www.azillionmonkeys.com/qed/p3-architecture.gif
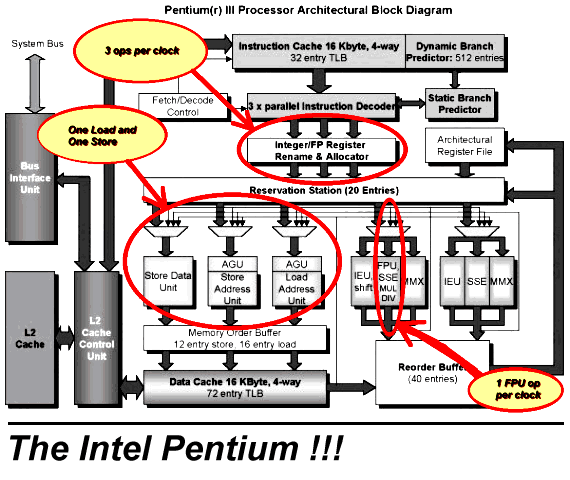{kind=link}
>>882
���������������Ǝv���c
���߃L���[�Ƃ����߃E�B���h�E�Ƃ�RS�Ƃ��Ă����͓̂������̂���B
���������@�\���j�b�g���Ƃɕ�������Ă���̂�RS�ƌĂ�邭�炢�ŁB
�������v���T�b�T���ɂ͖��߂𗭂߂��ރL���[�͂ق��ɂ����邯�ǁAMAC�I�^�̌����Ƃ����
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
���̏ꍇ�̖��߃L���[�͂��Ȃ킿RS�����i���B
���������������Ǝv���c
���߃L���[�Ƃ����߃E�B���h�E�Ƃ�RS�Ƃ��Ă����͓̂������̂���B
���������@�\���j�b�g���Ƃɕ�������Ă���̂�RS�ƌĂ�邭�炢�ŁB
�������v���T�b�T���ɂ͖��߂𗭂߂��ރL���[�͂ق��ɂ����邯�ǁAMAC�I�^�̌����Ƃ����
> OoO�p�̖��߃L���[�Ƃ������m��A�Ȃ�ׂ���R�̖��߂���荞��œ������s�\�ȑg�ݍ��킹��
> �����ł��邱�ƂɈӖ������邷�B
���̏ꍇ�̖��߃L���[�͂��Ȃ킿RS�����i���B
> MAC�I�^�̗�������ROB�̓����ƁA���^�C�A�܂Ŗ��߂����߃L���[�Ɏc���Ă��闝�R��������Ă���患
�܂��[�H(����
�܂��[�H(����
885 �FMAC�I�^��883 �����F2008/02/01(��) 02:14:00 ID:JA4OoS/6
>>883
�������q�g����(��)
�܂��A�����ɂ��Ƃ팾���Aissue queue��ʏ���s���j�b�g���ƂɓƗ����Ă��邷�B�Ⴆ����Ȋ����B
http://arstechnica.com/cpu/03q1/ppc970/images/fpiq.png
http://arstechnica.com/cpu/03q1/ppc970/images/iuiq.png
�܂�issue queue(=RS)�̒i�K�ł���s���j�b�g�Ԃ̕���m�肵�Ă��邷�B
�X�ɖ��߂̗���̏�ŁuROB -> RS�v�ƂȂ��Ă��邷����AROB�������C�e���V�̖��߂ŋl�܂�A
RS�ɖ��ߋ������邱�Ƃ���ł��Ȃ����B
���̕ӂ̎���Ƒ��A���POWER5�_����"Dynamic Resource Balancing"�̐߂ł��q�ׂ��Ă��邷�B
�@�@----------------------
�@�@Similarly, resource-balancing logic monitors the GCT to determine the number of entries
�@�@each thread is using. If the balancing logic detects that one thread is beginning to use too
�@�@many GCT entries, potentially blocking the other thread, it throttles back the thread that is
�@�@using excessive GCT entries.
�@�@----------------------
�������q�g����(��)
�܂��A�����ɂ��Ƃ팾���Aissue queue��ʏ���s���j�b�g���ƂɓƗ����Ă��邷�B�Ⴆ����Ȋ����B
http://arstechnica.com/cpu/03q1/ppc970/images/fpiq.png
{kind=link}
http://arstechnica.com/cpu/03q1/ppc970/images/iuiq.png
{kind=link}
�܂�issue queue(=RS)�̒i�K�ł���s���j�b�g�Ԃ̕���m�肵�Ă��邷�B
�X�ɖ��߂̗���̏�ŁuROB -> RS�v�ƂȂ��Ă��邷����AROB�������C�e���V�̖��߂ŋl�܂�A
RS�ɖ��ߋ������邱�Ƃ���ł��Ȃ����B
���̕ӂ̎���Ƒ��A���POWER5�_����"Dynamic Resource Balancing"�̐߂ł��q�ׂ��Ă��邷�B
�@�@----------------------
�@�@Similarly, resource-balancing logic monitors the GCT to determine the number of entries
�@�@each thread is using. If the balancing logic detects that one thread is beginning to use too
�@�@many GCT entries, potentially blocking the other thread, it throttles back the thread that is
�@�@using excessive GCT entries.
�@�@----------------------
> �܂�issue queue(=RS)�̒i�K�ł���s���j�b�g�Ԃ̕���m�肵�Ă��邷�B
���肰�Ȃ������Ă����̂Ō����������A��������߂��Ȃ���www
���肰�Ȃ������Ă����̂Ō����������A��������߂��Ȃ���www
�O�gCISC�Œ��gRISC���ۂ����ǎ���CISC���ۂ�������intelcpu�͕ϑԂ�����
�ł��M�A���\�̃R�X�g�p�t�H�[�}���X���X�Q�[
AMD��intel�݂��������ϑԂ��ۂ����Ƃ���Ă�́H
�ȂR�A�������ɂ��Ȃ��ăR�A�A�[�L�e�N�`���̊g�����s���ĂȂ��݂���������
�ł��M�A���\�̃R�X�g�p�t�H�[�}���X���X�Q�[
AMD��intel�݂��������ϑԂ��ۂ����Ƃ���Ă�́H
�ȂR�A�������ɂ��Ȃ��ăR�A�A�[�L�e�N�`���̊g�����s���ĂȂ��݂���������
���������ĕϑԂ��ۂ��Ƃ������͂킩��Ǐ[���ϑԓI���낤�B
�m���ɖ��߃R�[�h���ϑԂ��Ă��ȁA�܂�ō����݂����ɁB
�����c����匁������@�Ɠ����ŁA�ꌩ���ʂȎ������Ă�l�ɂ��������Ȃ����A
����Ȃ�ɈӖ�������̂����Ă�B
�����c����匁������@�Ɠ����ŁA�ꌩ���ʂȎ������Ă�l�ɂ��������Ȃ����A
����Ȃ�ɈӖ�������̂����Ă�B
���l�T�X�A�J�[�i�r������1920MIPS�̃f���A���R�A�v���Z�b�T���J��
http://www.ednjapan.com/content/l_news/2008/01/u3eqp3000001nk0z.html
http://www.ednjapan.com/content/l_news/2008/01/u3eqp3000001nk0z.html
893 �F�ǂ��Ă������܂����F2008/02/01(��) 23:13:55 ID:Ig0O8+EJ
SH-5�łȂ��ASH-4A�f���A���Ȃ̂�W
���т�SH-4�̕�������Ƃ͂����J���I����Ă����SH-5��헪���Ƃ��Ă������̂ɂȁB
���R�̓\�t�g�E�F�A���Y���ȁH
���R�̓\�t�g�E�F�A���Y���ȁH
895 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/02/02(�y) 01:42:35 ID:+XGKOnGR
���l�T�X�}�C�R���ɂ�����i�r�̎�͂�SH4�A�g�т�SH���o�C���ł��B
>>894
NEC�G���N�g���j�N�X���pARM�Ђ������J�������A�������\��1920MIPS�Ƃ����uNaviEngine�v
��SH-5���Ꮯ�ĂȂ����炾��B
NEC�G���N�g���j�N�X���pARM�Ђ������J�������A�������\��1920MIPS�Ƃ����uNaviEngine�v
��SH-5���Ꮯ�ĂȂ����炾��B
>>640�̑���
�R�`��w����������ł̔M���o�g�����W�J��
http://d.hatena.ne.jp/arakik10/
http://www.cm.kj.yamagata-u.ac.jp/blog/index.php?logid=7608
http://blog.goo.ne.jp/ikedanobuo/e/976e4283567f163f7f92c02cc1e6cddc
�R�`��w����������ł̔M���o�g�����W�J��
http://d.hatena.ne.jp/arakik10/
http://www.cm.kj.yamagata-u.ac.jp/blog/index.php?logid=7608
http://blog.goo.ne.jp/ikedanobuo/e/976e4283567f163f7f92c02cc1e6cddc
���������Ό��ǃI�^�͓����o�����̂��H
899 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/02/03(��) 00:39:52 ID:StNrwm7X
�f���A���R�ASH-4��1�R�A������960MIPS����Dhrystone���Ȃ̎����l���ˁH
MAC�I�^�͂�͂蓦�����悤�����A
���Ԏ����ł��҂��Ă���
���Ԏ����ł��҂��Ă���
901 �FMAC�I�^��900 �����F2008/02/04(��) 23:53:49 ID:DAIDb1BY
>>900
���������������H
���������������H
�Ώ����A�����ĂȂ�����A�R���j���N�ⓚ
>>901
ROB�̉���ƁA���߂����^�C�A����܂�RS�Ɏc���Ă��闝�R�̐��������肢���܂��B
ROB�̉���ƁA���߂����^�C�A����܂�RS�Ɏc���Ă��闝�R�̐��������肢���܂��B
904 �FMAC�I�^��903 �����F2008/02/05(��) 00:28:49 ID:3Wu0Bm5o
>>903
��̔]���ϑz�̃q�g����������(��)
�������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
���Ȃ��̈Ӑ}�����ꂳ��̂悤�ɋ��ݎ���Ă�����̂�A������Ɩ������B
��̔]���ϑz�̃q�g����������(��)
�������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
���Ȃ��̈Ӑ}�����ꂳ��̂悤�ɋ��ݎ���Ă�����̂�A������Ɩ������B
��
�u������ĉ��������Ă�̂�������Ȃ����B���ɂ�������悤�ɘb���ė~�������B
���ꂳ��ɋ����t�������̂͂������̕����B�v
�u������ĉ��������Ă�̂�������Ȃ����B���ɂ�������悤�ɘb���ė~�������B
���ꂳ��ɋ����t�������̂͂������̕����B�v
���݂܂���B�킽���̎咣�͑S���]���ϑz�ł����B
�g�[�V���̕��ۂŃo�J�����咣�����Đ\����܂���ł����B
�Ȃ̂ŁAROB�̉���ƁA���߂����^�C�A����܂�RS�Ɏc���Ă��闝�R��������ċ����Ă��������B
�g�[�V���̕��ۂŃo�J�����咣�����Đ\����܂���ł����B
�Ȃ̂ŁAROB�̉���ƁA���߂����^�C�A����܂�RS�Ɏc���Ă��闝�R��������ċ����Ă��������B
������������Y��Ă��܂���������܂���̂ŁA���ꂩ�疈�����肢���Ă����܂��B
908 �F�R�E�L�́M�E,,�j�����������������F2008/02/05(��) 01:46:18 ID:pLMfAL1G
�������
909 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/02/05(��) 02:29:04 ID:hwruG8gV
�O���^��
���[�Ɓc
�\�[�X�͂邾���Ő����ł��Ȃ�MAC�I�^�́A���܂��ă\�[�X�����͂��Ă�!
�����͔]���ϑz���撣��!���Ă��Ƃł���
�\�[�X�͂邾���Ő����ł��Ȃ�MAC�I�^�́A���܂��ă\�[�X�����͂��Ă�!
�����͔]���ϑz���撣��!���Ă��Ƃł���
>>904
>�������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
�������̂��� 2ch ����o�Ă����Ă��炦��Ƃ��肪�������B
blog �ł���Ă�B���ɂ�������B
>�������̎咣���\�[�X�����Ĕ���₷�������ł���悤�ɂȂ�����A�����肳���Ă����������B
�������̂��� 2ch ����o�Ă����Ă��炦��Ƃ��肪�������B
blog �ł���Ă�B���ɂ�������B
Sun���T�[�o�[�����n�C�G���h�v���Z�b�T�uRock�v�̊T�v�����\
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
��̃J�L�R�~�Ɠ������AISSCC��Rock�ɂ��Ă�ArsTechnica�̉�����B
���e��OoO���^�C�A�ɏd�_��u���Ă��邷�B
http://arstechnica.com/news.ars/post/20080204-sun-can-you-smell-what-the-rock-is-cookin.html
�l�I�Ȋ��z�����ǁA�ŏ���"Scout Thread"�Ƃ����b���o���ہA�P�Ȃ�v���t�F�b�`�̂��߂̃X���b�h
���Ǝv���Ă������B�g�����U�N�V���i����������OoO���^�C�A�Ƒg�ݍ��킹�ăX�g�[����ɓ��@�I���s��
���Ƃ�������B
POWER6��"load/branch lookahead"�������悤�ȃX�g�[�����ǁA�������v���Z�b�T�̃X�e�[�g
���ύX����Ȃ��͈͂Ŏ��s���邾�����B
���e��OoO���^�C�A�ɏd�_��u���Ă��邷�B
http://arstechnica.com/news.ars/post/20080204-sun-can-you-smell-what-the-rock-is-cookin.html
�l�I�Ȋ��z�����ǁA�ŏ���"Scout Thread"�Ƃ����b���o���ہA�P�Ȃ�v���t�F�b�`�̂��߂̃X���b�h
���Ǝv���Ă������B�g�����U�N�V���i����������OoO���^�C�A�Ƒg�ݍ��킹�ăX�g�[����ɓ��@�I���s��
���Ƃ�������B
POWER6��"load/branch lookahead"�������悤�ȃX�g�[�����ǁA�������v���Z�b�T�̃X�e�[�g
���ύX����Ȃ��͈͂Ŏ��s���邾�����B
MAC�I�^�搶�AROB�̉���Ɩ��߂����^�C�A����܂�RS�Ɏc���Ă��闝�R�̐��������肢���܂��B
�܂��������ł��ĂȂ���������ł��Ȃ��Ȃ�Ă��Ƃ͂Ȃ��ł���ˁH
�܂��������ł��ĂȂ���������ł��Ȃ��Ȃ�Ă��Ƃ͂Ȃ��ł���ˁH
MAC�I�^�搶�AOoO retirement�̂ǂ����������̂�������Ă�������><
ISSCC�Ɏ�����Cell B.E. 45nm�ł��o��
�`6GHz����A�d�͂�30%�ȏ�팸
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416.htm
�`6GHz����A�d�͂�30%�ȏ�팸
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416.htm
>>916
I/O�̔z�u�������Ƃ��o���Ȃ��̂��ȁH
I/O�̔z�u�������Ƃ��o���Ȃ��̂��ȁH
>>640>>897����
�R���s���[�^�[�A�[�L�e�N�`���Ƃ͊W�Ȃ��A��������P�Ȃ�P���J�ɂȂ��Ă��܂��܂�����
J-CAST�ɂ܂łƂ肠������n��
��100��PV�̐l�C�l�u���O�@�������m�̖��_�����_�����u��
http://headlines.yahoo.co.jp/hl?a=20080205-00000003-jct-sci
�R���s���[�^�[�A�[�L�e�N�`���Ƃ͊W�Ȃ��A��������P�Ȃ�P���J�ɂȂ��Ă��܂��܂�����
J-CAST�ɂ܂łƂ肠������n��
��100��PV�̐l�C�l�u���O�@�������m�̖��_�����_�����u��
http://headlines.yahoo.co.jp/hl?a=20080205-00000003-jct-sci
���l�T�X���g�ѓd�b�@�p�ŐV�v���Z�b�T�uSH-Mobile G3�v���I
http://pc.watch.impress.co.jp/docs/2008/0206/isscc03.htm
http://pc.watch.impress.co.jp/docs/2008/0206/isscc03.htm
�A�[�L�e�N�`���͂����ǂ����ł�����
���ǂ���Ŏd����Ɩ��������i�ނȂ�
���[�U�[�Ƀ����b�g������Ȃ肷������������ȁE�E�E
���ǂ���Ŏd����Ɩ��������i�ނȂ�
���[�U�[�Ƀ����b�g������Ȃ肷������������ȁE�E�E
ISSCC 2008 - Tilera�A�^�C���v���Z�b�T�uTILE64�v�̏ڍׂ\
http://journal.mycom.co.jp/articles/2008/02/06/isscc6/index.html
http://journal.mycom.co.jp/articles/2008/02/06/isscc6/index.html
>>921
�b�x�[�X�Ƃ��Ă�MIPS�A�[�L�e�N�`���ɋ߂��Ƃ̂��ƁB��̃R�A�����ŁASMP Linux��
�b���삷�邱�Ƃ��m�F����Ă���B
���ۂɂU�S�R�A�œ��삷��Linux�̃V�X�e�����o�Ă���ƁA���낢��ʔ������B
�b�x�[�X�Ƃ��Ă�MIPS�A�[�L�e�N�`���ɋ߂��Ƃ̂��ƁB��̃R�A�����ŁASMP Linux��
�b���삷�邱�Ƃ��m�F����Ă���B
���ۂɂU�S�R�A�œ��삷��Linux�̃V�X�e�����o�Ă���ƁA���낢��ʔ������B
>>922
�O���炠���B�����ʔ����H
�O���炠���B�����ʔ����H
TILE64�ŁA����B���\��r���o���邩��ˁB
����d�͂R���̂P�̉����E�f���p�v���Z�b�T�[�c���ł��J��
http://www.business-i.jp/news/ind-page/news/200802060028a.nwc
�������CELL�����p�����A����CPU�̐V�ł��H
�������f�B�A�����G���W�����W���Ă̂�CELL���̂��̂��ۂ����A�g�щ��y�v���[���[��
�g�ѓd�b�[���ɂ��g������Ęb���炷��ƁA�S�R�Ⴄ���ۂ����B
http://www.business-i.jp/news/ind-page/news/200802060028a.nwc
�������CELL�����p�����A����CPU�̐V�ł��H
�������f�B�A�����G���W�����W���Ă̂�CELL���̂��̂��ۂ����A�g�щ��y�v���[���[��
�g�ѓd�b�[���ɂ��g������Ęb���炷��ƁA�S�R�Ⴄ���ۂ����B
Sun�ARock�̃����[�X��2009�N�ɉ���
http://www.itmedia.co.jp/news/articles/0802/07/news052.html
Helper Thread�Ƃ�Transactional Memory�Ƃ��ӗ~�I�߂����˂��B
���N���͖������Ǝv���Ă�����N�x��Ƃ́B
�Ƃ��������C�Â�������Rock����45nm����Ȃ������ȁB
�Ȃ���45nm���Ɗ��Ⴂ���Ă���B
2009�N����45nm�ŏo���Ă����肷�邩�ȁB
250W�͂����牽�ł��M���B
http://www.itmedia.co.jp/news/articles/0802/07/news052.html
Helper Thread�Ƃ�Transactional Memory�Ƃ��ӗ~�I�߂����˂��B
���N���͖������Ǝv���Ă�����N�x��Ƃ́B
�Ƃ��������C�Â�������Rock����45nm����Ȃ������ȁB
�Ȃ���45nm���Ɗ��Ⴂ���Ă���B
2009�N����45nm�ŏo���Ă����肷�邩�ȁB
250W�͂����牽�ł��M���B
927 �FMAC�I�^��926 �����F2008/02/07(��) 19:34:11 ID:bOOaD76T
>>926
�܂�������ISSCC��TI��45-nm�v���Z�X�̃`�b�v�\���Ă��邷�B
Rock���ʎY�i��C45-nm�ŏo�Ă���̂�������Ȃ����ˁB�B�B
http://techon.nikkeibp.co.jp/article/NEWS/20080206/147061/
�܂�������ISSCC��TI��45-nm�v���Z�X�̃`�b�v�\���Ă��邷�B
Rock���ʎY�i��C45-nm�ŏo�Ă���̂�������Ȃ����ˁB�B�B
http://techon.nikkeibp.co.jp/article/NEWS/20080206/147061/
�A�i���X�g��MIPS�Ђ̍�������w�E�AARM�ЂɃ`�����X������
http://www.eetimes.jp/contents/200802/30885_1_20080207114342.cfm
http://www.eetimes.jp/contents/200802/30885_1_20080207114342.cfm
�g�ݍ��݂�ARM�D��������
����MIPS�C���l
����MIPS�C���l
�l�h�o�r���Ȃ�ǂ��H
�P�D�`�q�l
�Q�D�h�m�s�d�k
�R�D�`�l�c
�S�D���̑�
�P�D�`�q�l
�Q�D�h�m�s�d�k
�R�D�`�l�c
�S�D���̑�
>>930
5.NEC�֘A���
��VR�q����ŏ����Ă݂����������c���������낤���Ӗ����������B
ARM�͑����A������Ȃ���?
�ʃR�A�����������Ӗ��͖������낤���A���������l�����Ȃ�IP��Ƃ�����
������ł��ׂ����Ă��ŁA�及�щ�����̂͏����Ƃ��Ă͕s�����낤�B
5.NEC�֘A���
��VR�q����ŏ����Ă݂����������c���������낤���Ӗ����������B
ARM�͑����A������Ȃ���?
�ʃR�A�����������Ӗ��͖������낤���A���������l�����Ȃ�IP��Ƃ�����
������ł��ׂ����Ă��ŁA�及�щ�����̂͏����Ƃ��Ă͕s�����낤�B
>>931
�������Ǝv�������ɏ������l�������Ȃ��c�c
NEC�͉������C�Ȃ̂�����܂�킩��Ȃ������������B
�N���C�Ƃ�SGI�̉\�������邪�A�����Ƃ��Ă�IBM�����ˁB
�������Ǝv�������ɏ������l�������Ȃ��c�c
NEC�͉������C�Ȃ̂�����܂�킩��Ȃ������������B
�N���C�Ƃ�SGI�̉\�������邪�A�����Ƃ��Ă�IBM�����ˁB
�����S������������
MAC�I�^�搶�AROB�̉���ƁA���߂����^�C�A����܂�RS�Ɏc���Ă��闝�R��������Ă��������B
�����Ȃ��ł��������ˁB
�����Ȃ��ł��������ˁB
MAC�I�^�A����͉i���̓��S�ҁB
����N���������ő��肵�āA�ߌ��@���Ă��������Ǝv����B
���̐l�̃g���E�}�͏����ɒ~�ς��Ă����Ă邵�B
����N���������ő��肵�āA�ߌ��@���Ă��������Ǝv����B
���̐l�̃g���E�}�͏����ɒ~�ς��Ă����Ă邵�B
���������\�t�g�E�F�A�̕����ǂ��t���ĂȂ������
�\�t�g�E�F�A���ǂ��������ƂȂ�āA���܂����ĂȂ�����
>>928
�g�юs���w��ARM�ɋ��ꂽ�̂�����ł�������Ȃ��B
���[�^�[�Ƃ��A��⍂���\���v�������s���MIPS�̕����D���������݂��������ǁA
�g�тɔ�ׂ�Ǝs��K�͂����Ⴂ���������B
���ƍ����\�H�i�Ƃ���������d�͂ɂ��قnj������Ȃ��j�ȗ̈�ɂ́Ax86���N�U����
���Ă邩��A�܂��܂������������Ȃ����B
�g�юs���w��ARM�ɋ��ꂽ�̂�����ł�������Ȃ��B
���[�^�[�Ƃ��A��⍂���\���v�������s���MIPS�̕����D���������݂��������ǁA
�g�тɔ�ׂ�Ǝs��K�͂����Ⴂ���������B
���ƍ����\�H�i�Ƃ���������d�͂ɂ��قnj������Ȃ��j�ȗ̈�ɂ́Ax86���N�U����
���Ă邩��A�܂��܂������������Ȃ����B
IO�����IP���������č����R���p�j�I���`�b�v�ɐ�O����B
�h�n���������č����z�e�g���R���p�j�I���̃`�b�v�ɐ�O����B
��������ROB��RS�̐�����낵��>�I�^
��������ROB��RS�̐�����낵��>�I�^
IO���G���ƓǂނȂ�āA�ǂ��Â��l�^����
�g�т�ARM, �Q�[����PowerPC, PC��x64(x86)
944 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/02/09(�y) 02:52:46 ID:rIBi1EFd
�Q�[������ARM���ڋ@�ŋ������ǂ�
DS��
EETimes��ISSCC�̃p�l���f�B�X�J�b�V����"Can Multicore Integration Justify the Increased Cost of
Process Scaling?"�ɂ��ĕĂ��邷�B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206105179
�Q���p�l���X�g�����̊e�Ђ̎�����̕�����������������e�ɂȂ��Ă��邩�Ǝv�����B
�@��AMD (Chuck Moore ��)
�@�@���s�̌g�ѓd�b����p�@�\�̕����̃`�b�v�ō\������Ă���悤�ɁA�v���Z�b�T���w�e���R�A�\����
�@�@�������B���̌��ʁA�\�t�g�E�F�A�������̖��߃Z�b�g���J�o�[�ł���悤��API�P�ʂł̋��ʉ��������B
�@�@DirectX���D��ƂȂ�B[MAC�I�^��: ��"x86 everywhere"���������̂�A�ǂ̉�Ђ����������ˁB�B�B]
�@�����l�T�X (���J��@�� ��)
�@�@AMD�ɓ��ӂ���Ƃ̂���
�@��Tilea (Anant Agarwal ��)
�@�@�ėp�R�A���}���`�R�A�����Ă����̂��\�t�g�E�F�A���猩��ƍł��P���B�R�A�̐��̓��[�A�̖@���ʂ��
�@�@18�������Ƃ�2�{�ɑ����čs���A2017�N�ɂ͑g��������4,096�R�A�A�T�[�o�[��512�R�A�A�f�X�N�g�b�v��
�@�@128�R�A�ƂȂ�ł��낤�B
�@�@����ɂ�ăX���b�h�ƃL���b�V���������K�v�Ȍ��s��OS�̓R�A���ɃX�P�[�����Ȃ��̂ŖłԂ������B
�@�@�@�@--------------------
�@�@�@�@"SMP Linux will go the way of the dinosaur," said Agarwal.
�@�@�@�@--------------------
�@�@
Process Scaling?"�ɂ��ĕĂ��邷�B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206105179
�Q���p�l���X�g�����̊e�Ђ̎�����̕�����������������e�ɂȂ��Ă��邩�Ǝv�����B
�@��AMD (Chuck Moore ��)
�@�@���s�̌g�ѓd�b����p�@�\�̕����̃`�b�v�ō\������Ă���悤�ɁA�v���Z�b�T���w�e���R�A�\����
�@�@�������B���̌��ʁA�\�t�g�E�F�A�������̖��߃Z�b�g���J�o�[�ł���悤��API�P�ʂł̋��ʉ��������B
�@�@DirectX���D��ƂȂ�B[MAC�I�^��: ��"x86 everywhere"���������̂�A�ǂ̉�Ђ����������ˁB�B�B]
�@�����l�T�X (���J��@�� ��)
�@�@AMD�ɓ��ӂ���Ƃ̂���
�@��Tilea (Anant Agarwal ��)
�@�@�ėp�R�A���}���`�R�A�����Ă����̂��\�t�g�E�F�A���猩��ƍł��P���B�R�A�̐��̓��[�A�̖@���ʂ��
�@�@18�������Ƃ�2�{�ɑ����čs���A2017�N�ɂ͑g��������4,096�R�A�A�T�[�o�[��512�R�A�A�f�X�N�g�b�v��
�@�@128�R�A�ƂȂ�ł��낤�B
�@�@����ɂ�ăX���b�h�ƃL���b�V���������K�v�Ȍ��s��OS�̓R�A���ɃX�P�[�����Ȃ��̂ŖłԂ������B
�@�@�@�@--------------------
�@�@�@�@"SMP Linux will go the way of the dinosaur," said Agarwal.
�@�@�@�@--------------------
�@�@
948 �FMAC�I�^�������F2008/02/09(�y) 11:56:32 ID:37ie/uQZ
�@��SUN (Rick Hetherington ��)
�@�@�T�[�o�[�v���Z�b�T��2018�N�܂ł�32-128�R�A�ƂȂ�B�\�t�g�E�F�A�I�ɂ͌��s�̃X���b�h���f����
�@�@�����c��A�R�A������500-1000�X���b�h����������B
�@�@SUN�ł̓}���`�R�A�v���Z�b�T�̗p�r�Ƃ���Google�̂悤��web�A�v���P�[�V������z�肵�Ă���Ƃ̂��ƁB
�@��Intel (Shekhar Borkar ��)
�@�@�}���`�R�A�ɂނ��āA�P��R�A�͋ɒ[�ɃV���v���ɂȂ�B
�@�@�@�@----------------
�@�@�@�@"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
�@�@�@�@----------------
�@�@�\�t�g�E�F�A���͊v���I�ȕϑJ���N����Ƃ̎��B
�@��IBM (Brad McCredie ��)
�@�@��{�I�ɂ̓w�e���R�A�Ɍ������BCELL�̂悤�Ȕėp�R�A+�A�N�Z�����[�^����A�����͔ėp�R�A�{
�@�@����̐�p�R�A�Ƃ����\���ցB
�@�@�}���`�R�A�T�[�o�[�̎s��͕K�������X���b�h�����e�Ղ�web�A�v������ł͂Ȃ��B�V���O���X���b�h
�@�@���\���d�v�B
�@�@�T�[�o�[�v���Z�b�T��2018�N�܂ł�32-128�R�A�ƂȂ�B�\�t�g�E�F�A�I�ɂ͌��s�̃X���b�h���f����
�@�@�����c��A�R�A������500-1000�X���b�h����������B
�@�@SUN�ł̓}���`�R�A�v���Z�b�T�̗p�r�Ƃ���Google�̂悤��web�A�v���P�[�V������z�肵�Ă���Ƃ̂��ƁB
�@��Intel (Shekhar Borkar ��)
�@�@�}���`�R�A�ɂނ��āA�P��R�A�͋ɒ[�ɃV���v���ɂȂ�B
�@�@�@�@----------------
�@�@�@�@"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
�@�@�@�@----------------
�@�@�\�t�g�E�F�A���͊v���I�ȕϑJ���N����Ƃ̎��B
�@��IBM (Brad McCredie ��)
�@�@��{�I�ɂ̓w�e���R�A�Ɍ������BCELL�̂悤�Ȕėp�R�A+�A�N�Z�����[�^����A�����͔ėp�R�A�{
�@�@����̐�p�R�A�Ƃ����\���ցB
�@�@�}���`�R�A�T�[�o�[�̎s��͕K�������X���b�h�����e�Ղ�web�A�v������ł͂Ȃ��B�V���O���X���b�h
�@�@���\���d�v�B
MAC�I�^����A�����������Ă���悤�Ȃ�A�ʂ�ROB��RS�̐��������Ă�������
RS���Ă��ꂶ��˂��H�����x�@�ɏo�Ă���RS......
MAC���^�͂b�o�t�l�^�I�����[��blog�����H
���v�������CPU���[�J�[�Ɍق��Ă��炦�邩���悗
���v�������CPU���[�J�[�Ɍق��Ă��炦�邩���悗
�������B
�ŋ߂�MAC�I�^����CPU�W�̃X���ɂ��Ⴕ���o�Ă��ẮA���l�̔ᔻ�������Ă܂���Ă��ȁB
���������̂�2ch�ȊO�ł��������������Ȃ���?
���������̂�2ch�ȊO�ł��������������Ȃ���?
�\���ė~������B
MAC�I�^�X���ɂȂ��Ă邗����
���X���ɂ�ROB��RS�̐������o����悤�ɂȂ��Ă��痈�Ă��������ˁB
����A�}�WCPU�l�^blog�������猩�ɍs����
amd�X���Ƃ��ł݂��Ƃ��Ȃ��@���Ƃ����Ă�̂�
�E�U����������
amd�X���Ƃ��ł݂��Ƃ��Ȃ��@���Ƃ����Ă�̂�
�E�U����������
�R�s�y�ȊO��MAC�I�^�̕��͂��������Ƃ͌���Ȃ����i
960 �FMAC�I�^��959 �����F2008/02/12(��) 17:42:21 ID:LsO/GKj6
>>959
�킽�����Q�����˂�ɂ��̎�̘b��������悤�ɂȂ��āA�����v���Z�b�T2���㕪�ɂȂ邷�B
�ߋ����O�@��A�ǂ̒��x�̓I���������������邩�Ǝv�����B
�g������肪�������̌f���ŁA�ߋ��̃J�L�R�~�����X�Ɠ\��t�����ĔS������邱�Ƃ�����
�Ƃ��������ł��A�傫�ȊԈႢ�햳�������Ƃ����ؖ��ƌ����邩������Ȃ���(��)
�킽�����Q�����˂�ɂ��̎�̘b��������悤�ɂȂ��āA�����v���Z�b�T2���㕪�ɂȂ邷�B
�ߋ����O�@��A�ǂ̒��x�̓I���������������邩�Ǝv�����B
�g������肪�������̌f���ŁA�ߋ��̃J�L�R�~�����X�Ɠ\��t�����ĔS������邱�Ƃ�����
�Ƃ��������ł��A�傫�ȊԈႢ�햳�������Ƃ����ؖ��ƌ����邩������Ȃ���(��)
�ł�������@���O��ROB��RS�̐��������Ă��������B
�o���Ȃ���Hwww
�o���Ȃ���Hwww
�ߋ��̏������݂���X�m�F�Ȃ��ˁ[���[�́B
�ǂꂾ���ɐl�Ȃ��Ęb�B
�ǂꂾ���ɐl�Ȃ��Ęb�B
MAC�I�^�͎����ɓs���̈����������݂͖������邩���
�e�[�v�A�E�g�̎��̂悤�ɂ����ԓ����Ă݂��www
�e�[�v�A�E�g�̎��̂悤�ɂ����ԓ����Ă݂��www
964 �FMAC�I�^��961, 963 �����F2008/02/12(��) 18:15:52 ID:LsO/GKj6
>>961, >>963
>>904�ɏ������ʂ肷�B���̃J�L�R�~���e�ɋ^�`������Ȃ烊���N�ƈ��p�����Ď�������肢���邷�B
�����e���ᖳ��������A���Ȃ��̔]���ŏ���ɐ������ꂽ�uMAC�I�^�̃g���f�������v�Ȃ郂�m
�𗝉����Ă����邱�Ƃ��ł��Ȃ�����B�B�B
���Ȃ݂Ɏ���>>832��
�@�@---------------
�@�@ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
�@�@---------------
�g���f�������ɂ��؋����������̂ʼn����s�v��(��)
>>904�ɏ������ʂ肷�B���̃J�L�R�~���e�ɋ^�`������Ȃ烊���N�ƈ��p�����Ď�������肢���邷�B
�����e���ᖳ��������A���Ȃ��̔]���ŏ���ɐ������ꂽ�uMAC�I�^�̃g���f�������v�Ȃ郂�m
�𗝉����Ă����邱�Ƃ��ł��Ȃ�����B�B�B
���Ȃ݂Ɏ���>>832��
�@�@---------------
�@�@ROB�̃G���g���ɂ�x86���߂��i�قځj���̂܂ܓ���B
�@�@---------------
�g���f�������ɂ��؋����������̂ʼn����s�v��(��)
ROB��RS�̈�ʓI�ȉ�������Ă�������
�o���Ȃ���H
�o���Ȃ���H
966 �FMAC�I�^��962 �����F2008/02/12(��) 18:28:39 ID:LsO/GKj6
>>962
�@�@----------------
�@�@�ߋ��̏������݂���X�m�F�Ȃ��ˁ[���[�́B
�@�@----------------
����Ȃ��Ƃ����畅�ꃋ�[�}�[����Ƃ̃v���o�K���_���Ɉ���������Ǝv�����B
���탋�[�}�[�T�C�g�⍑���O�̌f�����̐^�U����������ۂɁA���҂̉ߋ��̗�����
���ׂ邷�B
�@�@----------------
�@�@�ߋ��̏������݂���X�m�F�Ȃ��ˁ[���[�́B
�@�@----------------
����Ȃ��Ƃ����畅�ꃋ�[�}�[����Ƃ̃v���o�K���_���Ɉ���������Ǝv�����B
���탋�[�}�[�T�C�g�⍑���O�̌f�����̐^�U����������ۂɁA���҂̉ߋ��̗�����
���ׂ邷�B
ROB��RS�ɂ��āAMAC�I�^�̗�����������Ă�������
�Ԉ���ė������Ă���̂��w�E�����̂��|���낤��
�Ԉ���ė������Ă���̂��w�E�����̂��|���낤��
���������Ԉ���Ă��痝�����ĂȂ��̂��ȁH
�Ƃɂ����A���ꂾ�������܂���Ă���̂́A��قǎ��M���Ȃ��悤��
>>966
���O�̘b����B���O�́B
����DAT��������̂Ɉ�X�ߋ����O�Ȃ����Ă�����ɂ���Ȃ�����B���ʂ́B
�����܂ŏ������݂�M�ߐ����m���߂ė~�����Ȃ�A�����̏������݃��O�����J�ł�����ȁB
�S���B
���O�̘b����B���O�́B
����DAT��������̂Ɉ�X�ߋ����O�Ȃ����Ă�����ɂ���Ȃ�����B���ʂ́B
�����܂ŏ������݂�M�ߐ����m���߂ė~�����Ȃ�A�����̏������݃��O�����J�ł�����ȁB
�S���B
971 �FMAC�I�^��970 �����F2008/02/12(��) 18:42:14 ID:LsO/GKj6
>>970
��l�̓w�͂ʂɂ��Ă�A�����Ȃ����B
>>1
�@�@-----------------
�@�@�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
�@�@http://cpu.jisakuita.net/
�@�@-----------------
��l�̓w�͂ʂɂ��Ă�A�����Ȃ����B
>>1
�@�@-----------------
�@�@�����CPU�n�X���b�h ���s�X���ē����ߋ����O�ۑ��T�C�g
�@�@http://cpu.jisakuita.net/
�@�@-----------------
970�ɂ͂�����������MAC�I�^���A���܂ł����Ă�ROB��RS�ɂ��Ă̎����̗�����������Ȃ��̂͂ǂ����Ăł���><
10��������Ώ�����悤�Ȃ��̂Ȃ��ǂ˂��AROB��RS�̉�����炢
NVIDIA�A�X�}�[�g�t�H��������720p�Đ��Ή��v���Z�b�T
http://www.watch.impress.co.jp/av/docs/20080212/nvidia.htm
http://www.watch.impress.co.jp/av/docs/20080212/nvidia.htm
975 �FMAC�I�^��974 �����F2008/02/12(��) 20:29:21 ID:LsO/GKj6
>>974
ARM�R�A�����W��A�ȑO��PoralPlayer�����Ŏ�ɓ��ꂽ�Ƃ����b���B
http://jp.nvidia.com/object/IO_37106.html
ARM�R�A�����W��A�ȑO��PoralPlayer�����Ŏ�ɓ��ꂽ�Ƃ����b���B
http://jp.nvidia.com/object/IO_37106.html
����������ROB��RS�̐����ł����Ă݂���ǂ����H
���߂����^�C�A����܂�RS�Ɏc��Ȃ�Č����悤�ł͗���������������
���߂����^�C�A����܂�RS�Ɏc��Ȃ�Č����悤�ł͗���������������
�O�O���Ē��ׂ��Ƃ���A�����̊ԈႢ���킩�����̂œ������Ȃ��Ȃ�����ww
>>947�ɏ�����AMD��ISSCC�̃p�l���f�B�X�J�b�V�����Ō�����b�A������̓I�Șb���o�Ă������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206501805
���̊��z��AAMD������X���b�h�ɏ��������B
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/672
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=206501805
���̊��z��AAMD������X���b�h�ɏ��������B
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/672
�����AROB��RS�̂��Ƃ��������ƒ��ׂď�����ww
�����璲�ׂĂ��A�u���߂����^�C�A����܂�RS�ɗ��܂�v�Ȃ�ċL�q���o�Ă��Ȃ��āA���������Ă������Ȃ��낤��www
�����璲�ׂĂ��A�u���߂����^�C�A����܂�RS�ɗ��܂�v�Ȃ�ċL�q���o�Ă��Ȃ��āA���������Ă������Ȃ��낤��www
981 �FSocket774�F2008/02/13(��) 22:23:27 ID:KxU3v4tp
865 ���O�F MAC�I�^��859 ���� [sage] ���e���F 2008/01/31(��) 20:56:08 ID:0C6GGRXK
>>859
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B ���R�R�ɒ���
>>859
�̂đ䎌��ʂƂ��āA���������p�ł��Ȃ��Ȃ����Ƃ������Ƃ�]���ϑz�ɉ��̍������������Ƃ�
�F�߂��Ǝv���ėǂ������H
�@�@-------------------
�@�@�H�HMAC�I�^�����ǂ��������������Ă���H
�@�@-------------------
Isaiah�̎��s���j�b�g�̎�����AMD���Intel�ɋ߂�RISC�x���������m�����ǁA����Intel�ɂ����Ă�
Micro-ops fusion�����̖��߂݂̂ʼn\�ɂȂ��Ă��邷�B
http://www.agner.org/optimize/instruction_tables.pdf [fusion�@�\�̂���v���Z�b�T��P.17 ���]
�@�@-------------------
�@�@���߃L���[�ɋ�����̂́A�����C�e���V���߂ɒ��ځE�ԐړI�Ɉˑ��������߂���B
�@�@-------------------
�f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
�e���|�[�g���Ă��邷��(��)
�������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B ���R�R�ɒ���
> �f�B�X�p�b�`����Ă��烊�^�C�A����܂ŃL���[�ȊO�̉����ɂ��邷���ˁB�B�B���Ȃ��̔]���ɂł�
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
MAC�I�^�搶�A�͂₭�ߖ����Ȃ��ƒp�����炵������͂߂ɂȂ邷��(��)
> �e���|�[�g���Ă��邷��(��)
> �������Ă��������ǁu���^�C�A����܂ŁvOoO�̖��߃L���[�����菜����邱�Ƃ�Ȃ����B
MAC�I�^�搶�A�͂₭�ߖ����Ȃ��ƒp�����炵������͂߂ɂȂ邷��(��)
���ɂȂ��Ă��ߖ����Ȃ��̂�A�����̃~�X�⊨�Ⴂ�ł�Ȃ��A���{�I�ɊԈ���ė������Ă����Ƃ������Ƃł��������H(��)
�E�U�S�������������ƃR�e�t�����B
985 �FMAC�I�^�I�^�F2008/02/13(��) 22:57:24 ID:KxU3v4tp
���ꂪ�l�ɕ��𗊂ނƂ��̑ԓx�ł���(��)
MAC�I�^��
�EROB��Intel�p��
�͊m���ɃC�^�C���A�S�������
�E ROB�ɂ�x86���߂�����
�E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
���̕ӂ̂܂����������邩��ȁB�ǂ�����ԈႢ�����������A�����ł�MAC�I�^�̕���x86���ӂ̎�����
�������Ă����̂ŏ����ƌ������Ƃɂ��悤�B
�EROB��Intel�p��
�͊m���ɃC�^�C���A�S�������
�E ROB�ɂ�x86���߂�����
�E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
�E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
���̕ӂ̂܂����������邩��ȁB�ǂ�����ԈႢ�����������A�����ł�MAC�I�^�̕���x86���ӂ̎�����
�������Ă����̂ŏ����ƌ������Ƃɂ��悤�B
>>986
�����Ԍ�����Ă��邼
> �E ROB�ɂ�x86���߂�����
x86���߂��̂��̂���Ȃ��āA(�����i��)fused micro-op������
http://www.extremetech.com/article2/0,1697,2252205,00.asp
MICRO-OP RETIREMENT��
Each clock, the retirement logic looks at the next oldest micro-ops in the ROB and retires those that have completed execution.
Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
> �E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
������̂��ƂȂ�ł����܂őz�������A����Ȃ�ɍ����͂���
PCwatch�̋L���Ƃ����Ă���
> �E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
MICRO-OP RENAME��
The three incoming fused micro-ops are placed in the reorder buffer (ROB)
and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
�����Ԍ�����Ă��邼
> �E ROB�ɂ�x86���߂�����
x86���߂��̂��̂���Ȃ��āA(�����i��)fused micro-op������
http://www.extremetech.com/article2/0,1697,2252205,00.asp
MICRO-OP RETIREMENT��
Each clock, the retirement logic looks at the next oldest micro-ops in the ROB and retires those that have completed execution.
Up to three fused micro-ops can be retired each clock corresponding to up to three x86 instructions.
> �E fused micro-ops�Ƃ����̂́A������͂����炭�P��3��micro-ops���p�b�N���������̂��̂��Ǝv��
������̂��ƂȂ�ł����܂őz�������A����Ȃ�ɍ����͂���
PCwatch�̋L���Ƃ����Ă���
> �E fused micro-ops��ROB�ɓ�����āA���̌�ł͂��߂ĕ�������Ċe���s���j�b�g��RS�ɑ�����
MICRO-OP RENAME��
The three incoming fused micro-ops are placed in the reorder buffer (ROB)
and are then expanded into up to six executable micro-ops, each of which is targeted for a single execution unit.
988 �F�R�@�@�@�@�E�L�@�@�@�́@�@�@�M�E�@�@�@,,,,�j�����������������F2008/02/13(��) 23:23:42 ID:Dxn6WIfc
VIA��Core 2�������Intel��C7����鎞�ォ
AMD�͉������c
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
���܂�^�C�g���ԈႦ���B
�X����Ȃ��ĂP�O�ȁB
�X����Ȃ��ĂP�O�ȁB
>>987
��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
�܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
���������̘_�_�͂��̏��̊Ǘ��P�ʂ�fused micro-op�����s��micro-op���������B
VIA�̉���Ŗ��߂��̂��̂����邩�̂悤�ɂ�����Ă���͎̂蔲����������炾�냁�f�B�A�̉�����悭�Ԉ���Ă�B
���ꂩ��fused micro-op��x86���߂�K�v�ȏ�ɕ������Ȃ����߂̂��̂ł���B�ʂɗZ�����Ă���킯����Ȃ��B
�����x86���L�̂��́BRISC�ł���Ă�ϊ��Ƃ��Ⴄ�B3issue�Ƃ��͊W�Ȃ����낤�B
��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
�܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
���������̘_�_�͂��̏��̊Ǘ��P�ʂ�fused micro-op�����s��micro-op���������B
VIA�̉���Ŗ��߂��̂��̂����邩�̂悤�ɂ�����Ă���͎̂蔲����������炾�냁�f�B�A�̉�����悭�Ԉ���Ă�B
���ꂩ��fused micro-op��x86���߂�K�v�ȏ�ɕ������Ȃ����߂̂��̂ł���B�ʂɗZ�����Ă���킯����Ȃ��B
�����x86���L�̂��́BRISC�ł���Ă�ϊ��Ƃ��Ⴄ�B3issue�Ƃ��͊W�Ȃ����낤�B
������(�Ǝ��s����)
>>992
�؈Ⴂ�̃C�`����������̂͂�߂Ă��������B
> ��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
> ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
> �܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
����Ȃ�MAC�I�^�ȊO�͑S���������Ă��B
�킩���ĂȂ��̂�MAC�I�^�����ŁA���������X�˂�����ł���킯�B
> ���ꂩ��fused micro-op��x86���߂�K�v�ȏ�ɕ������Ȃ����߂̂��̂ł���B�ʂɗZ�����Ă���킯����Ȃ��B
�Z�����̂Ȃ�̂Ƃ����b�����Ă���̂�MAC�I�^�����Ȃ�B
> �����x86���L�̂��́BRISC�ł���Ă�ϊ��Ƃ��Ⴄ�B3issue�Ƃ��͊W�Ȃ����낤�B
�����������̘b��x86��ʂ���Ȃ��āAIsaiah�ŗL�̂��ƂȂ��ǁB
3issue�Ȃ��烊�^�C�A��3���߂܂łƂ����͓̂��R����B
�؈Ⴂ�̃C�`����������̂͂�߂Ă��������B
> ��������ROB�ɂ�x86���߂�micro-op�����̂��͓̂���Ȃ�����B���̕ӂ�MAC�I�^�����Ⴂ���Ă���悤�����B
> ROB�̓C���f�b�N�X�����ꂽ���߂̃A�h���X�Ƃ��̎��s����etc��ێ����Ă���̂����ʂ����B
> �܂萧�����ێ����Ă���̂ł����āA���߂��̂��̂�ێ����Ă���RS�ƈႤ�̂ō������Ȃ��łق����B
����Ȃ�MAC�I�^�ȊO�͑S���������Ă��B
�킩���ĂȂ��̂�MAC�I�^�����ŁA���������X�˂�����ł���킯�B
> ���ꂩ��fused micro-op��x86���߂�K�v�ȏ�ɕ������Ȃ����߂̂��̂ł���B�ʂɗZ�����Ă���킯����Ȃ��B
�Z�����̂Ȃ�̂Ƃ����b�����Ă���̂�MAC�I�^�����Ȃ�B
> �����x86���L�̂��́BRISC�ł���Ă�ϊ��Ƃ��Ⴄ�B3issue�Ƃ��͊W�Ȃ����낤�B
�����������̘b��x86��ʂ���Ȃ��āAIsaiah�ŗL�̂��ƂȂ��ǁB
3issue�Ȃ��烊�^�C�A��3���߂܂łƂ����͓̂��R����B
��
��ƁB���ȂB
������
��
�Ȃ�B
��
�Ȃ�B
>>994
�܂���{��\�̖͂����Ă��Ƃ�?
>>986-987�̕��ʂ�ǂ��>>992�ɑ��� >>994�̕ԓ����������Ă���̂��R��ɂ͑S�������ł��Ȃ����B
�܂���{��\�̖͂����Ă��Ƃ�?
>>986-987�̕��ʂ�ǂ��>>992�ɑ��� >>994�̕ԓ����������Ă���̂��R��ɂ͑S�������ł��Ȃ����B
>>998
����MAC�I�^�ȊO�ɓ��{��\�͂Ɍ������������Ƃ͎v��Ȃ������B
���܂�ȁB
1) ROB�ɖ��߂�����
2) ROB�ɖ��߂ɑΉ����鐧������
��������ROB���̂��̂̐���������Ƃ��Ȃ�傫�ȈႢ�����ǂ��A
�݂�ȗ������Ă��鎖�������A��������Isaiah��ROB�̘b�����Ă������A
��������2)�݂����ɏ����̂͏璷�����邾��H
����MAC�I�^�ȊO�ɓ��{��\�͂Ɍ������������Ƃ͎v��Ȃ������B
���܂�ȁB
1) ROB�ɖ��߂�����
2) ROB�ɖ��߂ɑΉ����鐧������
��������ROB���̂��̂̐���������Ƃ��Ȃ�傫�ȈႢ�����ǂ��A
�݂�ȗ������Ă��鎖�������A��������Isaiah��ROB�̘b�����Ă������A
��������2)�݂����ɏ����̂͏璷�����邾��H
ID:KxU3v4tp ID:htfQwYQt �̑��݂��璷
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/