Intel�̎�����CPU�ɂ��Č�낤 32
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 31
ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 3�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1160039483/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
Intel�̎�����CPU�ɂ��Č�낤 31
ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 3�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1160039483/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
|
|
|
���ߋ��X��
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
3 �FSocket774�F2007/10/29(��) 19:52:34 ID:g5EmB4+L
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
4 �FSocket774�F2007/10/29(��) 19:53:06 ID:g5EmB4+L
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
5 �FSocket774�F2007/10/29(��) 19:54:59 ID:g5EmB4+L
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@ �@��|
�@�@�@�@�@�_�Q�����������������m
Intel��CSI�{�����R����Nehalem���җ�ɗ~�����Ȃ��Ă�R��
(Intel>>>�z���Ă͂����Ȃ���>>>MS�����ǁj����ς菉���̓X���[�������������낤���H
(Intel>>>�z���Ă͂����Ȃ���>>>MS�����ǁj����ς菉���̓X���[�������������낤���H
Intel's 45nm Patch Machinery Exposed
http://hardware.slashdot.org/article.pl?sid=07/10/29/0227229
http://hardware.slashdot.org/article.pl?sid=07/10/29/0227229
CPU�͐l�����B
http://www.ne.jp/asahi/comp/tarusan/main174.htm
http://www.ne.jp/asahi/comp/tarusan/main174.htm
�����͒l�i���ȁE�E�E
������ɂ��܂Ȃ��̂Ȃ炢����Ȃ���
������ɂ��܂Ȃ��̂Ȃ炢����Ȃ���
11 �FSocket774�F2007/11/01(��) 04:10:58 ID:HT6Mn7TE
�������Ɏ����āu�}���`�R�A�����瑬���B�v��A�Ă���̂�CPU�x���_�[��PC�G���݂̂Ƃ����ƂȂ����B
�W�R�A��SPE�����ڂ��ꂽCELL������قǂ̍����\���ւ�Ȃ���Ȃ�PS3�����s�����̂����悭�l���Ă���������ΐ^�̏͂킩��Ǝv���B
�Ή��A�v���������Ă����̃}���`�R�A�Ȃ̂ł���B
�Ή��A�v���������Ă����̃}���`�R�A�Ȃ̂ł���B
>>13
���̓�����O�̂��Ƃ���A�Ԉ�����F����������A�Ӑ}�I�ɉR�������v�����������獢��B
���e�͑債�����ƂȂ����ǁA���������M����T�C�g�̑��݂͋M�d�B
���̓�����O�̂��Ƃ���A�Ԉ�����F����������A�Ӑ}�I�ɉR�������v�����������獢��B
���e�͑債�����ƂȂ����ǁA���������M����T�C�g�̑��݂͋M�d�B
15 �FMAC�I�^��14 �����F2007/11/01(��) 07:58:28 ID:CDRjF/Re
>>14
�@�@-----------------
�@�@���e�͑債�����ƂȂ����ǁA���������
�@�@-----------------
�u�������v�����B�B�B�Ȋw�Ɛ肢�̈Ⴂ���l���Ă݂邱�Ƃ������߂��邷�B
�@�@-----------------
�@�@���e�͑債�����ƂȂ����ǁA���������
�@�@-----------------
�u�������v�����B�B�B�Ȋw�Ɛ肢�̈Ⴂ���l���Ă݂邱�Ƃ������߂��邷�B
>>13
�ecpu�̃A�[�L�e�N�g�₻���̗��V�Ɍ��y�����́A
�����ł��قƂ�ǂ��Ȃ�����Ȃ����B�C�ɂ��Ă��Ȃ��؍��B
��O�͗�̕a�C�������炢���B
�ecpu�̃A�[�L�e�N�g�₻���̗��V�Ɍ��y�����́A
�����ł��قƂ�ǂ��Ȃ�����Ȃ����B�C�ɂ��Ă��Ȃ��؍��B
��O�͗�̕a�C�������炢���B
MAC�I�^�I�ɂ͂��̐�A���s���ɃR�A�������Ă����Ă�
PC�p�r�ŗL�����p���\�����Ďv���Ă����
PC�p�r�ŗL�����p���\�����Ďv���Ă����
���K�ɂȂ�Ή��ł��������I
19 �FMAC�I�^��15 �����F2007/11/01(��) 08:41:24 ID:CDRjF/Re
>>17
�@�@-----------------
�@�@MAC�I�^�I�ɂ͂��̐�A���s���ɃR�A�������Ă����Ă� PC�p�r�ŗL�����p���\��
�@�@-----------------
���Ȃ��ɂ�>>15�̈Ӗ������̂悤�ɓǂ߂邷���B�B�B
�@�@-----------------
�@�@MAC�I�^�I�ɂ͂��̐�A���s���ɃR�A�������Ă����Ă� PC�p�r�ŗL�����p���\��
�@�@-----------------
���Ȃ��ɂ�>>15�̈Ӗ������̂悤�ɓǂ߂邷���B�B�B
make -j��������薳�s���ȃR�A�̑����ɂ��Ӗ�������B
>>15
�������Ȃ��Ǝv���Ƃ��낪����Ȃ�A�{�l�ɒ��ڎw�E����Ⴂ���B
�������Ȃ��Ǝv���Ƃ��낪����Ȃ�A�{�l�ɒ��ڎw�E����Ⴂ���B
MAC�I�^�͐����������������Ȃ����Ȃ�Ă��邳��ɂ͂킩��Ȃ��Ƃ������Ƃ��w�E���Ă��邾���ł�����
����͗\�z�Ƃ�����莩���̊�]������
MAC�I�^�͖��O���ł��{���ł��A���J�[����
����ɕ��̈��p�ōs���g�������鏊�����Ƃ����ė~��������
MAC�I�^�͖��O���ł��{���ł��A���J�[����
����ɕ��̈��p�ōs���g�������鏊�����Ƃ����ė~��������
���邳��́A������������ă��f����P�����������邾��B
���ł��_�݂����ɂ����Ⴄ�l�ȂƂ��낪�U�������B�ϑz���������B
���ł��_�݂����ɂ����Ⴄ�l�ȂƂ��낪�U�������B�ϑz���������B
>>9
> �}���`�R�ACPU�łȂ���Vista�͎g���Ȃ��Ƃ������x���ł͌����ĂȂ��B
����ȏd��OS��N���]�ނI
Intel�̓A�C�h�����ɃL���b�V�����t���b�V�����Ă܂ŏȓd�͂ɐs�͂��Ă���Ƃ����̂ɁB
> �}���`�R�ACPU�łȂ���Vista�͎g���Ȃ��Ƃ������x���ł͌����ĂȂ��B
����ȏd��OS��N���]�ނI
Intel�̓A�C�h�����ɃL���b�V�����t���b�V�����Ă܂ŏȓd�͂ɐs�͂��Ă���Ƃ����̂ɁB
�t�H���_�ŃA�C�R�����N���b�N���Ă���
���̃t�H���_���J���܂ł������[�x��
Vista��
�Ȃ�Ă��������̕��������́ACPU��33MHz�������Ƃ��Ȃ�
���̃t�H���_���J���܂ł������[�x��
Vista��
�Ȃ�Ă��������̕��������́ACPU��33MHz�������Ƃ��Ȃ�
27 �FSocket774�F2007/11/02(��) 13:59:53 ID:mx571X5C
PS2�̃G�~��������CPU�̎g�p����GPU�̔M�̏オ����i�g�p���킩��߁j
���Ď����Ă����ǁACPU��80%�ʁAGPU�͂قƂ�ǃA�C�h�����Ƃ����Ȃ������B
�Ă��Ƃ͂��̏����̂قƂ�ǂ�CPU�ł܂��Ȃ��Ă���Ƃ����Ă悢�Ǝv���̂����A
������E6600�A3�f�gz��VF4��38�t���[�����炢�̕`��Ȃ̂Ńy���������J�Ō����Ă���悤��
����4�f�gz�z���Ă̏�p���\�Ȃ��50�t���[���ȏ�̂قڃt���t���[��
�ŗV�ׂ�悤�ɂȂ�Ƃ������ƂȂ̂ł��傤���H
������xbox360��vf5��҂����ɃG�~���̃l�b�g�ΐ�@�\��vf4��V�ѕ���Ƃ������ƂȂ�ł��傤���H
�ǂ����A�m���̂�����A�����ĉ������ȁB���肢���܂��B�������炷�����y�������~�����ł��B
�������Ⴂ�܂��B�܂��ŁB
���Ď����Ă����ǁACPU��80%�ʁAGPU�͂قƂ�ǃA�C�h�����Ƃ����Ȃ������B
�Ă��Ƃ͂��̏����̂قƂ�ǂ�CPU�ł܂��Ȃ��Ă���Ƃ����Ă悢�Ǝv���̂����A
������E6600�A3�f�gz��VF4��38�t���[�����炢�̕`��Ȃ̂Ńy���������J�Ō����Ă���悤��
����4�f�gz�z���Ă̏�p���\�Ȃ��50�t���[���ȏ�̂قڃt���t���[��
�ŗV�ׂ�悤�ɂȂ�Ƃ������ƂȂ̂ł��傤���H
������xbox360��vf5��҂����ɃG�~���̃l�b�g�ΐ�@�\��vf4��V�ѕ���Ƃ������ƂȂ�ł��傤���H
�ǂ����A�m���̂�����A�����ĉ������ȁB���肢���܂��B�������炷�����y�������~�����ł��B
�������Ⴂ�܂��B�܂��ŁB
�X���Ⴂ�ł�
�Q�n�ł�
30 �Fsage�F2007/11/02(��) 17:32:26 ID:sixQiGDt
�b�����������w
�g�p��80%�Ȃ�CPU���\�I�ɂ͖������Ă�̂ł͂Ȃ����ƁB
PS2�̃r�f�I���������`�b�v�����ŃC���^�[�t�F�C�X��2560bit(�ш�48GB/s)��4MB�Ƃ����ϑԍ\���Ȃ̂ŁAPC�̃��C���������͒ǂ����ĂȂ��B
PS2�G�~���̃t���[�����[�g��Penryn�̃L���b�V���e�ʑ��͈ӊO�ƌ����̂ł͂Ȃ����B
�g�p��80%�Ȃ�CPU���\�I�ɂ͖������Ă�̂ł͂Ȃ����ƁB
PS2�̃r�f�I���������`�b�v�����ŃC���^�[�t�F�C�X��2560bit(�ш�48GB/s)��4MB�Ƃ����ϑԍ\���Ȃ̂ŁAPC�̃��C���������͒ǂ����ĂȂ��B
PS2�G�~���̃t���[�����[�g��Penryn�̃L���b�V���e�ʑ��͈ӊO�ƌ����̂ł͂Ȃ����B
���@�ł�����ق�����ȁH���Ă����˂����݂͂��@�x��
�Ƃ������A�f����PS2�ł��ƁB
34 �FSocket774�F2007/11/02(��) 19:11:59 ID:7zR3HkIm
>31
���X�L��������܂��B
�܂胊�j�A�ɕ`�摬�x�͏オ��ɂ������L���b�V�����������ɍD�e����^����\���͂���Ƃ������Ƃł��ˁB
���ނ��A�y�����̍��N���b�N�ϐ��ɑ傫�����҂����̂ł��������c�O�ł��B
�������Ȃ�core MA�̓o�j�A�X�̍��̃R���Z�v�g����傫���͂����
����Ȃɂ����N���b�N�ւ̉��ёオ����A�܂����̕����֓˂��i�ނ̂ł��傤���H
����IPC�������A����ł��ׂĂ̕�������l�b�g�o�[�X�g�̐v�v�z�����S�ے肵�Ă��܂����ƂɂȂ�܂��B
�I���S���̃A�[�L�e�N�g�̐l����������Ƃ��킢�����B
���X�L��������܂��B
�܂胊�j�A�ɕ`�摬�x�͏オ��ɂ������L���b�V�����������ɍD�e����^����\���͂���Ƃ������Ƃł��ˁB
���ނ��A�y�����̍��N���b�N�ϐ��ɑ傫�����҂����̂ł��������c�O�ł��B
�������Ȃ�core MA�̓o�j�A�X�̍��̃R���Z�v�g����傫���͂����
����Ȃɂ����N���b�N�ւ̉��ёオ����A�܂����̕����֓˂��i�ނ̂ł��傤���H
����IPC�������A����ł��ׂĂ̕�������l�b�g�o�[�X�g�̐v�v�z�����S�ے肵�Ă��܂����ƂɂȂ�܂��B
�I���S���̃A�[�L�e�N�g�̐l����������Ƃ��킢�����B
��������PS2�̴Э�͖�����������
�܂Ƃ��ɃQ�[������̂͒��߂���������
�܂Ƃ��ɃQ�[������̂͒��߂���������
>>34
Netburst�̖{���̃��[�h�}�b�v���猩��Εʂɍ��N���b�N����Ȃ����B�B�B
Netburst�̖{���̃��[�h�}�b�v���猩��Εʂɍ��N���b�N����Ȃ����B�B�B
���ẴN���b�N�������A�R�A�������ɕς�낤�Ƃ��Ă���ȁB
�l���x���ł͂���Ȑ������Ă��L�����p�ł��Ȃ�����R�A�ЂƂ�����̐��\�����O�ꂵ�Ăق������̂����B
�l���x���ł͂���Ȑ������Ă��L�����p�ł��Ȃ�����R�A�ЂƂ�����̐��\�����O�ꂵ�Ăق������̂����B
�ۯ��Ɍ��E���������̂���
����HDD�̐��\���グ�ė~����
���̏�ŃR�A�����₵�Ă����������ƂȂ�
����HDD�̐��\���グ�ė~����
���̏�ŃR�A�����₵�Ă����������ƂȂ�
���j�[�R�A�Ȃ�Č��z�ł�
����
�s��������͕���PE�ɂ���������
�s��������͕���PE�ɂ���������
>>37
�Ԃ����Ⴐ���\�������������
����d�͂����Ɖ�����B
�܂�CPU���ȃG�l�撣���Ă�
���̓w�͂����������̂悤�Ƀr�f�I���d�C����Ă���܂����c
�Ԃ����Ⴐ���\�������������
����d�͂����Ɖ�����B
�܂�CPU���ȃG�l�撣���Ă�
���̓w�͂����������̂悤�Ƀr�f�I���d�C����Ă���܂����c
nehelam�ŕς���ˁB1�R�A������̃T�C�Y��Core2��1.5�{�ŁA
�V���O���X���b�h���\���������炵�����B
�V���O���X���b�h���\���������炵�����B
43 �FSocket774�F2007/11/06(��) 01:25:29 ID:u6rB/VpU
����
���è��5�܂��H
�R�A80�i���^���@���o�邩��
��������Penta����Ȃ�����A�A�[�L�e�N�`�������ɁE�E�E
Nonium�Ƃ�����Ȃ��́B
Nonium�Ƃ�����Ȃ��́B
�➙�܂��`�B
Nehalem���ڋ@���o��܂Ńy��M�ł����
PenM�͗D�G����`���A����(߄D�#)
CoreMA�̒��n�̌��c����(߄D�#)
�����߂�Ȃ����B
CoreMA�̒��n�̌��c����(߄D�#)
�����߂�Ȃ����B
TGDaily�̃e���X�P�[���v���Z�b�T�L��2�A�����B
Rattner�C���^�r���[ http://www.tgdaily.com/content/view/34668/113/
Terascale 2 http://www.tgdaily.com/content/view/34688/113/
�@�ETerascale�ɂ�A���R���t�B�K�u���R�A���܂ރw�e���\�����v��
�@�E��L�̍č\����ABIOS/�t�@�[���E�F�A���x���̃��m�Ŏ��s���̍č\����s��Ȃ��\��
�@�EIA�R�A��Terrascale 2���� (Polaris��p)��A���ݐv�i�s���B1MHz�����FPGA�V�~�����[�^
�@�@��B45nm�v���Z�X�Ŏ��삷��B
���X�B
Rattner�C���^�r���[ http://www.tgdaily.com/content/view/34668/113/
Terascale 2 http://www.tgdaily.com/content/view/34688/113/
�@�ETerascale�ɂ�A���R���t�B�K�u���R�A���܂ރw�e���\�����v��
�@�E��L�̍č\����ABIOS/�t�@�[���E�F�A���x���̃��m�Ŏ��s���̍č\����s��Ȃ��\��
�@�EIA�R�A��Terrascale 2���� (Polaris��p)��A���ݐv�i�s���B1MHz�����FPGA�V�~�����[�^
�@�@��B45nm�v���Z�X�Ŏ��삷��B
���X�B
������TGDaily�̃q���Y�{����ދL�����B�܂��ǂ�łȂ��̂ŁA���e���قǁB
http://www.tgdaily.com/content/view/34719/113/
http://www.tgdaily.com/content/view/34719/113/
Rambus�AIntel��XDR�̉\������
http://pc.watch.impress.co.jp/docs/2007/1108/rambus.htm
�㓡���̋L�������������悤���ˁB
http://pc.watch.impress.co.jp/docs/2007/1108/rambus.htm
�㓡���̋L�������������悤���ˁB
>>50
IA�R�A���ă��C�Z���X�̖��̓_�C�W���u�Ȃ����H
IA�R�A���ă��C�Z���X�̖��̓_�C�W���u�Ȃ����H
>>38
������SSD�ł���B
������SSD�ł���B
56 �FMAC�I�^��54 �����F2007/11/08(��) 20:30:35 ID:r2d0s3P9
>>54
x86�R�A���ď����������ǂ������݂������ˁB�B�B
���āA>>51�̋L�������ǐ��tweakers.net�ł����l�^��������Intel��Debug Lab�̘b���B
http://tweakers.net/reviews/740/chip-magicians-at-work-patching-at-45nm.html
�`�b�v��̔z���ڑ��삷�鑕�u�̘b��A�����[�����B
���Ȃ݂�Hillsboro��debug lab�ł�A����Gainestown (Nehalem�R�AXeon)�̃f�o�b�O�̐^���Œ�
�Ƃ̂��Ƃ��B
���Ȃ݂ɏ�L��tweakers.net�̋L����A���݂̃v���Z�b�T�J���̗��ꂪ�ǂ���������Ă��邷����A
�����̂���q�g�ɂ�K�ǂ̋L�����Ǝv�����B
x86�R�A���ď����������ǂ������݂������ˁB�B�B
���āA>>51�̋L�������ǐ��tweakers.net�ł����l�^��������Intel��Debug Lab�̘b���B
http://tweakers.net/reviews/740/chip-magicians-at-work-patching-at-45nm.html
�`�b�v��̔z���ڑ��삷�鑕�u�̘b��A�����[�����B
���Ȃ݂�Hillsboro��debug lab�ł�A����Gainestown (Nehalem�R�AXeon)�̃f�o�b�O�̐^���Œ�
�Ƃ̂��Ƃ��B
���Ȃ݂ɏ�L��tweakers.net�̋L����A���݂̃v���Z�b�T�J���̗��ꂪ�ǂ���������Ă��邷����A
�����̂���q�g�ɂ�K�ǂ̋L�����Ǝv�����B
>>50�ŏ����Y�ꂽ�����ǁA���R�̂��Ƃ�Intel��Terascale�v��̃\�t�g�E�F�A�I���ʂ��ŏd�v��
���Ă��Ă���Ƃ̂��Ƃ��B
�@�@---------------------
�@�@But I do think that, for Terascale, some very serious money is being spent. There are very
�@�@serious development teams at work, and I�fm speaking independent of the research--which
�@�@continues to progress and will ultimately feed that product pipeline over time.
�@�@---------------------
��̃��j�C�R�A�𒊏ۉ����ė��p����Ƃ����b�ɂ��A������������͗l���B
�@�@---------------------
�@�@You can actually run it on multi-cores today and it�fs pretty useful. But the idea is that you�fll
�@�@be able to take that same code and drop it on a Terascale class machine and it will just go.
�@�@---------------------
���Ă��Ă���Ƃ̂��Ƃ��B
�@�@---------------------
�@�@But I do think that, for Terascale, some very serious money is being spent. There are very
�@�@serious development teams at work, and I�fm speaking independent of the research--which
�@�@continues to progress and will ultimately feed that product pipeline over time.
�@�@---------------------
��̃��j�C�R�A�𒊏ۉ����ė��p����Ƃ����b�ɂ��A������������͗l���B
�@�@---------------------
�@�@You can actually run it on multi-cores today and it�fs pretty useful. But the idea is that you�fll
�@�@be able to take that same code and drop it on a Terascale class machine and it will just go.
�@�@---------------------
>>52
����
��XDR DRAM���g����ƌ�����̂́AIntel�̃n�C�X���[�v�b�g�v���Z�b�T�uLarrabee(�����r�[)�v���B
���ǂ���͉��������̂��낤
Intel Larabee samples in late 2008 Discrete graphics with GDDR5
http://www.theinquirer.net/default.aspx?article=38011
http://media.arstechnica.com/news.media/larrabee-pci.gif
����
��XDR DRAM���g����ƌ�����̂́AIntel�̃n�C�X���[�v�b�g�v���Z�b�T�uLarrabee(�����r�[)�v���B
���ǂ���͉��������̂��낤
Intel Larabee samples in late 2008 Discrete graphics with GDDR5
http://www.theinquirer.net/default.aspx?article=38011
http://media.arstechnica.com/news.media/larrabee-pci.gif
{kind=link}
Larrabee���̂��c��
����A�ő������߂Ă����̂͗ǂ����Ƃ��Ǝv����B
�g���b�v������1Gtorip/s���o�������Ɋ肤�B
�g���b�v������1Gtorip/s���o�������Ɋ肤�B
���\�̖��ʌ�����
http://www.ne.jp/asahi/comp/tarusan/main174.htm
���̕ӌ���N�A�b�h�R�A���債�Č����悭�Ȃ����Ƃ��킩��
���ۂɂ́uWindows�̃o�b�N�O���E���h�ŃE�B���X�\�t�g�풓�����Ă�̂ɏd���Ȃ�Ȃ��v�Ƃ����b�͂��邾�낤����
������f���A���R�A�܂ł�������������
Cell��PS4�ɍڂ�Ƃ�����ASPE�������u����LS��R�A���̂��̂̋����ɂƂǂ܂�̂��������낤
���������ASPE8���Ė{���ɃN�^�̔��w�����������炵���ȁE�E�E
���̕ӌ���N�A�b�h�R�A���債�Č����悭�Ȃ����Ƃ��킩��
���ۂɂ́uWindows�̃o�b�N�O���E���h�ŃE�B���X�\�t�g�풓�����Ă�̂ɏd���Ȃ�Ȃ��v�Ƃ����b�͂��邾�낤����
������f���A���R�A�܂ł�������������
Cell��PS4�ɍڂ�Ƃ�����ASPE�������u����LS��R�A���̂��̂̋����ɂƂǂ܂�̂��������낤
���������ASPE8���Ė{���ɃN�^�̔��w�����������炵���ȁE�E�E
�딚orz
>>63
�̫ʯ���
�̫ʯ���
>>50>>57
564 �FMAC�I�^ [sage] �F2007/10/06(�y) 23:19:12 ID:CLRn0sLW
���ς�炸CELL BE�@�����Ђǂ������ǁACELL BE�̗L�����p�ɍ��{�I�ȃv���O�����v�̌�����
���K�v�Ȃ��Ƃ�A�ŏ����画���Ă����b���B
1�N���炸�Ń\�t�g���o�Ă���̂��x������ƌ����Ē@���̂�A���܂�ɂ��C���������邷�B
569 �FSocket774 [sage] �F2007/10/06(�y) 23:54:10 ID:mpnp67Sl
��N���炸���낤�������낤���ACell/B.E.�̃\�t�g�E�F�A�ʂ͔ᔻ����Ă�����ׂ��B
�ʏ�ł���Γ��R�A�\�t�g�E�F�A�E�J�����Ƃ����v�f���݂�
�o�c���f�A�������f�A�J���v����s��Ȃ�������Ȃ��B
Intel��Larrabee���ɏo���ƁA�\�t�g�E�F�A�ʂ���Ɉӎ����Ă��邱�Ƃ��킩��B
�\���̕ω����炷��ƁA�����ă����[�X���}��������������T�d�ɂȂ��Ă��邱�Ƃ��킩��B
http://www.intel.co.jp/jp/intel/pr/press2007/070417.htm
��Larrabee�́A�����̑����̃\�t�g�E�F�A���g�����v���O���~���O���\
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
�����������ɂ��Ắu������CPU�wNehalem(�l�w�[����)�x���O�ɂȂ邩������Ȃ��v
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
http://www.xbitlabs.com/news/video/display/20070919151611.html
��In 2010 Intel will release its code-named Larrabee processor
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
564 �FMAC�I�^ [sage] �F2007/10/06(�y) 23:19:12 ID:CLRn0sLW
���ς�炸CELL BE�@�����Ђǂ������ǁACELL BE�̗L�����p�ɍ��{�I�ȃv���O�����v�̌�����
���K�v�Ȃ��Ƃ�A�ŏ����画���Ă����b���B
1�N���炸�Ń\�t�g���o�Ă���̂��x������ƌ����Ē@���̂�A���܂�ɂ��C���������邷�B
569 �FSocket774 [sage] �F2007/10/06(�y) 23:54:10 ID:mpnp67Sl
��N���炸���낤�������낤���ACell/B.E.�̃\�t�g�E�F�A�ʂ͔ᔻ����Ă�����ׂ��B
�ʏ�ł���Γ��R�A�\�t�g�E�F�A�E�J�����Ƃ����v�f���݂�
�o�c���f�A�������f�A�J���v����s��Ȃ�������Ȃ��B
Intel��Larrabee���ɏo���ƁA�\�t�g�E�F�A�ʂ���Ɉӎ����Ă��邱�Ƃ��킩��B
�\���̕ω����炷��ƁA�����ă����[�X���}��������������T�d�ɂȂ��Ă��邱�Ƃ��킩��B
http://www.intel.co.jp/jp/intel/pr/press2007/070417.htm
��Larrabee�́A�����̑����̃\�t�g�E�F�A���g�����v���O���~���O���\
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
�����������ɂ��Ắu������CPU�wNehalem(�l�w�[����)�x���O�ɂȂ邩������Ȃ��v
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
http://www.xbitlabs.com/news/video/display/20070919151611.html
��In 2010 Intel will release its code-named Larrabee processor
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
577 �FMAC�I�^��573 ���� [sage] �F2007/10/07(��) 00:12:10 ID:00wOqcSE
>>573
�����팾���Ă��A���j�C�R�A�ɑΉ����邽�߂ɂ�傫�ȃv���O���~���O�p���_�C���̕ύX���K�v�ɂȂ邷�B
Intel��������撣���Ă�10�N���Ct��C��C++��u�������Ă���Ƃ��v���Ȃ������ǁB�B�B
http://pc.watch.impress.co.jp/docs/2007/0925/idf10.htm
https://intel.wingateweb.com/us/published/TCRS003/TCRS003_100s.pdf
579 �FSocket774 [sage] �F2007/10/07(��) 00:27:50 ID:k1spTUWm
>>577
���������p���_�C�����ω�����Ƃ��v���Ȃ����A�ω�����Ȃ炻��܂ő҂����Ȃ��B
����Ct�₻�̑��̃\�t�g�E�F�A�J���̐V���ȃA�v���[�`����肭�����Ȃ��Ȃ�
�e���X�P�[���R���s���[�e�B���O�v��͎���i��ςݏd�˂Ă��邸�鉄��������܂ł��B
580 �FMAC�I�^��579 ���� [sage] �F2007/10/07(��) 00:36:15 ID:00wOqcSE
>>579
�@�@--------------
�@�@����܂ő҂����Ȃ��B
�@�@--------------
�����Ȗ\�_���ˁB32-bit�v���Z�b�T�̎������������ꂽ�����Ɛ��̃\�t�g�E�F�A���Ή�����悤��
�Ȃ��������Ƃ̍����v���o���ׂ����Ǝv�����B
�������A�h���X��Ԃ����̖��ŁA���ꂷ����B�B�B
>>573
�����팾���Ă��A���j�C�R�A�ɑΉ����邽�߂ɂ�傫�ȃv���O���~���O�p���_�C���̕ύX���K�v�ɂȂ邷�B
Intel��������撣���Ă�10�N���Ct��C��C++��u�������Ă���Ƃ��v���Ȃ������ǁB�B�B
http://pc.watch.impress.co.jp/docs/2007/0925/idf10.htm
https://intel.wingateweb.com/us/published/TCRS003/TCRS003_100s.pdf
579 �FSocket774 [sage] �F2007/10/07(��) 00:27:50 ID:k1spTUWm
>>577
���������p���_�C�����ω�����Ƃ��v���Ȃ����A�ω�����Ȃ炻��܂ő҂����Ȃ��B
����Ct�₻�̑��̃\�t�g�E�F�A�J���̐V���ȃA�v���[�`����肭�����Ȃ��Ȃ�
�e���X�P�[���R���s���[�e�B���O�v��͎���i��ςݏd�˂Ă��邸�鉄��������܂ł��B
580 �FMAC�I�^��579 ���� [sage] �F2007/10/07(��) 00:36:15 ID:00wOqcSE
>>579
�@�@--------------
�@�@����܂ő҂����Ȃ��B
�@�@--------------
�����Ȗ\�_���ˁB32-bit�v���Z�b�T�̎������������ꂽ�����Ɛ��̃\�t�g�E�F�A���Ή�����悤��
�Ȃ��������Ƃ̍����v���o���ׂ����Ǝv�����B
�������A�h���X��Ԃ����̖��ŁA���ꂷ����B�B�B
C��u����������Ăقǂ̂���Ȃ��A��������q���g��C�ɑ������Ē��x�̂���
�v���O�����I�ɂ�OpenMP��MPI���͊ȒP�Ȃ��Ǝv��
�v���O�����I�ɂ�OpenMP��MPI���͊ȒP�Ȃ��Ǝv��
�����ׂ������l����̂���ςȂ�
��������̊g���őΉ�������A����ɓ����������ꂪ���y���ė~��������
C����ł��I�u�W�F�N�g�w���Ńv���O�����ł��邯��
����ŃI�u�W�F�N�g�w��������邱�Ƃ͂Ȃ���
��������̊g���őΉ�������A����ɓ����������ꂪ���y���ė~��������
C����ł��I�u�W�F�N�g�w���Ńv���O�����ł��邯��
����ŃI�u�W�F�N�g�w��������邱�Ƃ͂Ȃ���
Intel�C45nm�Ńv���Z�T�uCore 2 Extreme QX9650�v�uXeon 5400�v��J�n�FITpro
http://itpro.nikkeibp.co.jp/article/NEWS/20071112/286945/
http://itpro.nikkeibp.co.jp/article/NEWS/20071112/286945/
45����Ȃ���65nm��intel����
http://processorfinder.intel.com/List.aspx?ProcFam=2559&sSpec=&OrdCode=
http://processorfinder.intel.com/List.aspx?ProcFam=2559&sSpec=&OrdCode=
SpecFinder�͌�A����������E�E�E�Ȃ�
65nm�ŃL���b�V��12MB�Ƃ��ǂ��c
>>63
�ȉ��A�f�X�N�g�b�v����PC����ł̂��b�B
(�T�[�o�[�p�r�ł̓}���`�R�A�͈⊶�Ȃ��͗ʂ��ł���Ǝv���̂�)
�܂��A���ɃR���p�C������Ă���A�v���P�[�V����������������̂ɂ́A�}���`�R�A�͌����Ȃ����낤�ˁB
���̕����Ŋ����A�v���P�[�V�����̍�������_���Ƃ���A�R�A���x���ł̓��@���s�Ƃ����낤���B
CPU�����̕ӂ̐���Ɏ��������A�ʔ��������B
���U�@�ł����Ȃ琫�\���o���ɂ̓\�t�g�ł̑Ή����K�{���낤�ˁB
�f�[�^�̋��L���@�Ƃ��A�v���Z�X�̍œK�ȘA�g���@�Ƃ��A
�����ɃR�A�Ԃ̏����҂����Ԃ����炷���Ƃ��A�f�b�h���b�N���Ȃ��悤�ɂƂ��A�J���R�X�g���オ��Ȃ��l�ɂƂ�
���ɔ����\�t�g�J���̍�����ǂ��܂ʼnB���ł��邩�������ȁ[�B
���[�U�[�Ɏ��p�����A�s�[���������Ȃ�A��͂�x86�}�[�P�b�g����Ɍ������Ă���
Microsoft�ɓ������ă}���`�R�A����������Windows��VisualStudio������Ă��炤�Ƃ��B
�ȉ��A�f�X�N�g�b�v����PC����ł̂��b�B
(�T�[�o�[�p�r�ł̓}���`�R�A�͈⊶�Ȃ��͗ʂ��ł���Ǝv���̂�)
�܂��A���ɃR���p�C������Ă���A�v���P�[�V����������������̂ɂ́A�}���`�R�A�͌����Ȃ����낤�ˁB
���̕����Ŋ����A�v���P�[�V�����̍�������_���Ƃ���A�R�A���x���ł̓��@���s�Ƃ����낤���B
CPU�����̕ӂ̐���Ɏ��������A�ʔ��������B
���U�@�ł����Ȃ琫�\���o���ɂ̓\�t�g�ł̑Ή����K�{���낤�ˁB
�f�[�^�̋��L���@�Ƃ��A�v���Z�X�̍œK�ȘA�g���@�Ƃ��A
�����ɃR�A�Ԃ̏����҂����Ԃ����炷���Ƃ��A�f�b�h���b�N���Ȃ��悤�ɂƂ��A�J���R�X�g���オ��Ȃ��l�ɂƂ�
���ɔ����\�t�g�J���̍�����ǂ��܂ʼnB���ł��邩�������ȁ[�B
���[�U�[�Ɏ��p�����A�s�[���������Ȃ�A��͂�x86�}�[�P�b�g����Ɍ������Ă���
Microsoft�ɓ������ă}���`�R�A����������Windows��VisualStudio������Ă��炤�Ƃ��B
�\�t�g�E�G�A�I�ȃp�C�v���C�j���O�̎�@�Ƃ��́A
�f�X�N�g�b�vPC�����̂ǂ̂��炢��������Ă���̂��낤���B
�Ⴆ�Γ���̈قȂ�v���Z�XA��B���A�^�C���V�F�A�����O����Ȃ��āA
���삷��n�[�h�E�G�A�ŁA���ꂼ�ꂪ�Ɨ����ē����Ă����ꍇ�ɁA
�v���Z�XA�ŏ��������f�[�^��B�ɗ����A���̗��������Ȃ��X���[�X�ɂ�������Ƃ��B
�p�C�v���C��1�i������ɂ����鏈�����Ԃ��A���̒i�ƈقȂ�ƌ����͗����邾�낤����A
�ł��邩����v���Z�XA��B�͂��Ȃ����炢�̏������ԂłȂ��Ƃ����Ȃ����낤���ǁA
���G�ȏ���������悤�ȏꍇ��A�����̈����R�[�h�ŁA
���������̂���������ɂ͂ǂ������炢���̂��낤���B
DSP�̃v���O���~���O�̗l�ȁA�D�L�����@�����ς����邩��A
���������Ȃ��ƂȂ�Ȃ����낤�Ȃ��B
���ƌ��O����鎖�ƌ����A�S�R�A������Ȃ�����ɓ��������Ƃ����Ƃ���
�������Ƃ�I/O�̑ш悪�����̂��Ƃ��A�Y�܂����B
�����̃������̓o�[�X�g�A�N�Z�X�͓��ӂ��������ǁA
�����_���A�N�Z�X�͋�肾�낤���A�e�R�A���������̑S�R�Ⴄ�Ԓn���A�N�Z�X���Ă�����A
���߂�f�[�^�̋������ߎS�����B
�܂��A���̕ς̓L���b�V�����ǂ��g�����ɂ���邯�ǁB
�f�X�N�g�b�vPC�����̂ǂ̂��炢��������Ă���̂��낤���B
�Ⴆ�Γ���̈قȂ�v���Z�XA��B���A�^�C���V�F�A�����O����Ȃ��āA
���삷��n�[�h�E�G�A�ŁA���ꂼ�ꂪ�Ɨ����ē����Ă����ꍇ�ɁA
�v���Z�XA�ŏ��������f�[�^��B�ɗ����A���̗��������Ȃ��X���[�X�ɂ�������Ƃ��B
�p�C�v���C��1�i������ɂ����鏈�����Ԃ��A���̒i�ƈقȂ�ƌ����͗����邾�낤����A
�ł��邩����v���Z�XA��B�͂��Ȃ����炢�̏������ԂłȂ��Ƃ����Ȃ����낤���ǁA
���G�ȏ���������悤�ȏꍇ��A�����̈����R�[�h�ŁA
���������̂���������ɂ͂ǂ������炢���̂��낤���B
DSP�̃v���O���~���O�̗l�ȁA�D�L�����@�����ς����邩��A
���������Ȃ��ƂȂ�Ȃ����낤�Ȃ��B
���ƌ��O����鎖�ƌ����A�S�R�A������Ȃ�����ɓ��������Ƃ����Ƃ���
�������Ƃ�I/O�̑ш悪�����̂��Ƃ��A�Y�܂����B
�����̃������̓o�[�X�g�A�N�Z�X�͓��ӂ��������ǁA
�����_���A�N�Z�X�͋�肾�낤���A�e�R�A���������̑S�R�Ⴄ�Ԓn���A�N�Z�X���Ă�����A
���߂�f�[�^�̋������ߎS�����B
�܂��A���̕ς̓L���b�V�����ǂ��g�����ɂ���邯�ǁB
�����_���猾���\�t�g�ł̑Ή��͊��҂��Ȃ��ق��������B
���������x�̑Ή��͂��邾�낤���ǂ��A�J����c��ȂȂ邱�ƁA�J�����Ԃ������Ȃ邱�Ƃ��l������Ɗ��҂ł��Ȃ��B
����ڏ����痧���Ȃ����d�ȊJ���͍s��Ȃ����A���_�ɊJ�����Ԃ����J���T�C�N�����L�т�悤���Ƃ���͂���Ŗ��ƂȂ�B
���������x�̑Ή��͂��邾�낤���ǂ��A�J����c��ȂȂ邱�ƁA�J�����Ԃ������Ȃ邱�Ƃ��l������Ɗ��҂ł��Ȃ��B
����ڏ����痧���Ȃ����d�ȊJ���͍s��Ȃ����A���_�ɊJ�����Ԃ����J���T�C�N�����L�т�悤���Ƃ���͂���Ŗ��ƂȂ�B
������
>>76
�A�v���P�[�V�����̃��W�b�N���l������A�f�o�b�O������Ƃ�����Ƃ̒��ɁA
���W�b�N������œK�������Ƃ�D�������̂́A
�������̗v�����������߂���P�[�X�Ŗ����ƁA�Δ�p���ʂ����ɍ���Ȃ�����A
���ʂ̃f�X�N�g�b�v�����A�v���P�[�V�����̊J���ɁA��������߂�͓̂���Ǝv���B
(����ł��A�f���Ƃ����y���������͖]�݂�����Ƃ͎v���B(�f�[�^���傫���̂Ō��ʂ��o�₷��))
������A�f�X�N�g�b�v��������ɂ��Ȃ�A����ȊO�̕���Ŋ撣��K�v������B
�����Ǝv�������̂��グ��ƁA
�EOS�̃}�C�N���J�[�l����(���̓��m���V�b�N�J�[�l���̃}���`�X���b�h��)
�EHDD��������̊e�R�A����̗v���ɑ��镉�ו��U�̍��x��
�EC#��Java���̎��s����(�C���^�v���^��JIT)�̃}���`�R�A���ւ̑Ή�
�EC��C++���̃��C�u�����̃}���`�R�A���ւ̑Ή�
�Ȃ��v�����B
�����́A�G���h���[�U�[�����̃A�v���P�[�V���������v���W�F�N�g�ւ͕��S�������Ȃ��B
�������OS��~�h���E�G�A����镔���ւ͕��S���|����̂ŁA�}���`�R�A�𐄏����郁�[�J�[���A
���炩�̌`�ŃR�X�g�S����K�v������Ǝv���B
�����o���������ƁA���N�Ȏ��ɂ͂Ȃ�Ȃ�����������A���ЂŃR���p�C����C�u�������J��������A
����OS��~�h���E�G�A���J�������Ƃ֎��Ђ̃G���W�j�A�𑗂荞��Ő��i�����ǂ�����Ƃ����ǂ��Ǝv���B
�A�v���P�[�V�����̃��W�b�N���l������A�f�o�b�O������Ƃ�����Ƃ̒��ɁA
���W�b�N������œK�������Ƃ�D�������̂́A
�������̗v�����������߂���P�[�X�Ŗ����ƁA�Δ�p���ʂ����ɍ���Ȃ�����A
���ʂ̃f�X�N�g�b�v�����A�v���P�[�V�����̊J���ɁA��������߂�͓̂���Ǝv���B
(����ł��A�f���Ƃ����y���������͖]�݂�����Ƃ͎v���B(�f�[�^���傫���̂Ō��ʂ��o�₷��))
������A�f�X�N�g�b�v��������ɂ��Ȃ�A����ȊO�̕���Ŋ撣��K�v������B
�����Ǝv�������̂��グ��ƁA
�EOS�̃}�C�N���J�[�l����(���̓��m���V�b�N�J�[�l���̃}���`�X���b�h��)
�EHDD��������̊e�R�A����̗v���ɑ��镉�ו��U�̍��x��
�EC#��Java���̎��s����(�C���^�v���^��JIT)�̃}���`�R�A���ւ̑Ή�
�EC��C++���̃��C�u�����̃}���`�R�A���ւ̑Ή�
�Ȃ��v�����B
�����́A�G���h���[�U�[�����̃A�v���P�[�V���������v���W�F�N�g�ւ͕��S�������Ȃ��B
�������OS��~�h���E�G�A����镔���ւ͕��S���|����̂ŁA�}���`�R�A�𐄏����郁�[�J�[���A
���炩�̌`�ŃR�X�g�S����K�v������Ǝv���B
�����o���������ƁA���N�Ȏ��ɂ͂Ȃ�Ȃ�����������A���ЂŃR���p�C����C�u�������J��������A
����OS��~�h���E�G�A���J�������Ƃ֎��Ђ̃G���W�j�A�𑗂荞��Ő��i�����ǂ�����Ƃ����ǂ��Ǝv���B
Intel�͕���v�Z�W�̃\�t�g�E�F�A�J���Ɋւ��đ����R�~�b�g���Ă��B
���X�uIntel�̓}���`�R�A����邾��������Ă����ă\�t�g�E�F�A�J���҂ɂ����蕉�S�������Ă�I�v�Ȃǂ�
�����z���o�Ă��邯�ǁA�܂������ԈႢ�ŁA�i���̓����ʂ��\�����͂��Ă����āj���Ȃ��Ƃ�����A�Ђ��͂����Ɠ������Ă���B
��ŏ����Ă�l�������������Ƃ͌���Ȃ����ǂˁB
���Ă�Intel�̓����^�C���x�[�X�E�v���O���~���O�̕��y�ŌÂ��\�t�g�E�F�A�Q�ł�
�V����CPU�̋@�\�𗘗p�������������\�ɂ���Ƃ����\�z��ł��o���Ă��āA
�������Ă����������������\�������͂��Ȃ̂����A
���R�̂��Ƃ�Microsoft���S�͂őj�~�����̂ŁA���܂��ɂ��̕ӂɊm�����c��Ƃ����s�s�`��������B
���X�uIntel�̓}���`�R�A����邾��������Ă����ă\�t�g�E�F�A�J���҂ɂ����蕉�S�������Ă�I�v�Ȃǂ�
�����z���o�Ă��邯�ǁA�܂������ԈႢ�ŁA�i���̓����ʂ��\�����͂��Ă����āj���Ȃ��Ƃ�����A�Ђ��͂����Ɠ������Ă���B
��ŏ����Ă�l�������������Ƃ͌���Ȃ����ǂˁB
���Ă�Intel�̓����^�C���x�[�X�E�v���O���~���O�̕��y�ŌÂ��\�t�g�E�F�A�Q�ł�
�V����CPU�̋@�\�𗘗p�������������\�ɂ���Ƃ����\�z��ł��o���Ă��āA
�������Ă����������������\�������͂��Ȃ̂����A
���R�̂��Ƃ�Microsoft���S�͂őj�~�����̂ŁA���܂��ɂ��̕ӂɊm�����c��Ƃ����s�s�`��������B
���͎��Ђ̐��i�����H���������������ɁA
Intel���ǂꂾ���͂����Ă��邩�Ƃ������B
�}���`�R�A�Ȑ���邾������āA
���Ƃ̓\�t�g������Ɋۓ����Ƃ��C�����̓���Ȃ����ł́A
Cell�݂����ȎU�X����ɂȂ��Ă��܂���B
Cell�Ƃ͈���ăT�[�o�[������HPC�����̎s��������Ă���̂ŁA
�����Ȃ��T���͂��Ȃ����낤���A�T�{��ƃf�X�N�g�b�v����ɉ��낹�Ȃ��댯���͗L��B
Intel�ɂ͊撣���ė~�����Ȃ��B
Intel���ǂꂾ���͂����Ă��邩�Ƃ������B
�}���`�R�A�Ȑ���邾������āA
���Ƃ̓\�t�g������Ɋۓ����Ƃ��C�����̓���Ȃ����ł́A
Cell�݂����ȎU�X����ɂȂ��Ă��܂���B
Cell�Ƃ͈���ăT�[�o�[������HPC�����̎s��������Ă���̂ŁA
�����Ȃ��T���͂��Ȃ����낤���A�T�{��ƃf�X�N�g�b�v����ɉ��낹�Ȃ��댯���͗L��B
Intel�ɂ͊撣���ė~�����Ȃ��B
�N�����t���[�����`�������̂ꂷ
82 �FSocket774�F2007/11/13(��) 22:12:03 ID:rmHKOYtw
���\�̎��ɁA���̃E�G�n����Ɏ����Č�����͉̂����Ӗ�����̂��H
���̐l�B�͋����I�ɁA������̃E�G�n���o���āu���ꂪ�V�^�����I�I�v�ƌ����Ă�����Ȃ������B
���̐l�B�͋����I�ɁA������̃E�G�n���o���āu���ꂪ�V�^�����I�I�v�ƌ����Ă�����Ȃ������B
���F�Œ��a30cm�̉~�Ղ͂��������i����������̓C���p�N�g������
>>76
���҂��邵�Ȃ�����Ȃ��A�������ʂ͏o���B
�Ή��ł��镪��͂��������Ή����I������B
�u�`�����N�ɂȂ�ΑΉ������v�u�����т��炤��]PG���v�Ƃ��������ė������ǁA������ꂽ�B
���҂��邵�Ȃ�����Ȃ��A�������ʂ͏o���B
�Ή��ł��镪��͂��������Ή����I������B
�u�`�����N�ɂȂ�ΑΉ������v�u�����т��炤��]PG���v�Ƃ��������ė������ǁA������ꂽ�B
>>82
�������ɉ����Ɖ�����������Ȃ��ˁB
�V���R���E�G�n�ɏĂ���������������B���Ď���m�炵�߂�Ӗ�������̂ł�?
������������ΐM�p����Ȃ����낤���B�Ή��Ƃ��Ă͂��ꂭ�炢���������镨���Ȃ������Ƃ����̂�����B
�������I�������ɁA�̐l���傫�Ȏʐ^���B��A
�ȑO�̃E�G�n�Ɣ�ׂĂǂꂭ�炢�����ڂ̌`���ǂꂭ�炢����Ă���Ƃ��́A�ߋ��̎ʐ^�Ɣ�r�ł���B
1�̃E�G�n����A�ő�ʼn����炢�`�b�v����ꂻ������������Ε����邩�B(�����������܂莟�悾���ǁB)
�f��ŃE�G�n���x�^�x�^������Ă���̂�����ƂȂܑ̂Ȃ��l�Ȋ��o�ɏP���Ă��܂��̂͗L��ȁ[�B
�ł��A�O�����̃v�����X�����[�X���s���͂ނ��߂ɂ͏d�v�Ȃ̂ŁA1�����炢�g���K�v�͗L��Ƃ͎v���B
�������ɉ����Ɖ�����������Ȃ��ˁB
�V���R���E�G�n�ɏĂ���������������B���Ď���m�炵�߂�Ӗ�������̂ł�?
������������ΐM�p����Ȃ����낤���B�Ή��Ƃ��Ă͂��ꂭ�炢���������镨���Ȃ������Ƃ����̂�����B
�������I�������ɁA�̐l���傫�Ȏʐ^���B��A
�ȑO�̃E�G�n�Ɣ�ׂĂǂꂭ�炢�����ڂ̌`���ǂꂭ�炢����Ă���Ƃ��́A�ߋ��̎ʐ^�Ɣ�r�ł���B
1�̃E�G�n����A�ő�ʼn����炢�`�b�v����ꂻ������������Ε����邩�B(�����������܂莟�悾���ǁB)
�f��ŃE�G�n���x�^�x�^������Ă���̂�����ƂȂܑ̂Ȃ��l�Ȋ��o�ɏP���Ă��܂��̂͗L��ȁ[�B
�ł��A�O�����̃v�����X�����[�X���s���͂ނ��߂ɂ͏d�v�Ȃ̂ŁA1�����炢�g���K�v�͗L��Ƃ͎v���B
>�f��ŃE�G�n���x�^�x�^
����������ʂɎ����Ă���E�G�n�͌���(�v������Ȃ��Đ������̌���)�i����B
���i�Ƃ��ďo�����Ȃ�A����1���������牽�S�������H
�ǂ����l�Ԃ̖ڂ��ጇ�ׂ��������Ă킩��Ȃ�����A����i�͎g���E�E�E
����������ʂɎ����Ă���E�G�n�͌���(�v������Ȃ��Đ������̌���)�i����B
���i�Ƃ��ďo�����Ȃ�A����1���������牽�S�������H
�ǂ����l�Ԃ̖ڂ��ጇ�ׂ��������Ă킩��Ȃ�����A����i�͎g���E�E�E
���i�Ƃ��ďo���悤���o���܂����E�F�n�ꖇ�Ă��̂ɂ�����R�X�g��
�������Ǝv����
�������Ǝv����
���׃`�b�v���������G��悤�ɏ�肢���Ǝ����Ă��
>>87
�R�X�g�͈ꏏ�ł��A��������o�闘�v�͑S�R�Ⴄ���낪�B
�R�X�g�͈ꏏ�ł��A��������o�闘�v�͑S�R�Ⴄ���낪�B
90 �FSocket774�F2007/11/14(��) 18:06:22 ID:eYg4XOqY
���C�o���̒ǐ��������Ȃ��Z�p�v�V�Ŗ�����\������Intel
http://news.livedoor.com/article/detail/3387929/
http://news.livedoor.com/article/detail/3387929/
�E�G�n���̂̐��������Ȃǒm�ꂽ���̂��낤�B
�������琻�i������R�X�g�̕�����قǂ�����B
�Ƃ������}�W���X����Ɛ��i�ɂ͂ł��Ȃ��t�@�[�X�g���b�g�̈ꖇ�ڂƂ������������낤���ǁB
�������琻�i������R�X�g�̕�����قǂ�����B
�Ƃ������}�W���X����Ɛ��i�ɂ͂ł��Ȃ��t�@�[�X�g���b�g�̈ꖇ�ڂƂ������������낤���ǁB
���́A"�������琻�i������R�X�g"���܂�ł���
Penryn�Ƃ�Nehalem�̃E�F�n��
�C���S�b�g�����o��������̐��̃E�F�n�Ƃ͈���ă}�X�N�R�X�g��f�U�C���R�X�g��O�H���t�@�u�̌������p����܂ޖ���
Penryn�Ƃ�Nehalem�̃E�F�n��
�C���S�b�g�����o��������̐��̃E�F�n�Ƃ͈���ă}�X�N�R�X�g��f�U�C���R�X�g��O�H���t�@�u�̌������p����܂ޖ���
�ꖇ������o�����������Ƃ����b�B�����͐������������ł���B
���������Ƃ������t�̎g��������������
�����ɂ͌��ޗ����
>�ꖇ������o�����������Ƃ����b
�Ⴄ
�M�d�ȑO�H���t�@�u�̃L���p�V�e�B�����ʂɂ���킯��
���̕����i�ɂ����E�F�n�̕��S���錸�����p���������
�܂��N�ԉ��\�����ƗʎY�����킯��������X������낤����
�����ɂ͌��ޗ����
>�ꖇ������o�����������Ƃ����b
�Ⴄ
�M�d�ȑO�H���t�@�u�̃L���p�V�e�B�����ʂɂ���킯��
���̕����i�ɂ����E�F�n�̕��S���錸�����p���������
�܂��N�ԉ��\�����ƗʎY�����킯��������X������낤����
�E�G�n1�����炢1000�~���炢����
5000�~��DVD�̌�����500�~�̂悤�ȕ�
5000�~��DVD�̌�����500�~�̂悤�ȕ�
�E�G�n�ꖇ�̐�������������ȂɈ���������A
�b�o�t�������̃_�C���傫���Ȃ��ĕ����܂肪�P�^�P�O���炢�ɂȂ��Ă�
�����R�X�g�ɂ͂قƂ�lje�����Ȃ����Ď��ɂȂ�B
�i�ꖇ�̃E�G�n����50�`200���炢�͂b�o�t�͍̂��̂�
�@�ꖇ��~�Ȃ�b�o�t����\�~�����炿����Ƃ₻���Ƃ̕����܂�͊W�Ȃ��͂��j
�����A���ۂ̓_�C��1.5�{�A�����܂肪�{�ω����邾���ł��Ȃ�
�R�X�g�͌������Ȃ�Ƃ�����Intel��AMD����������ԋC�ɂ��Ă邪�B
�b�o�t�������̃_�C���傫���Ȃ��ĕ����܂肪�P�^�P�O���炢�ɂȂ��Ă�
�����R�X�g�ɂ͂قƂ�lje�����Ȃ����Ď��ɂȂ�B
�i�ꖇ�̃E�G�n����50�`200���炢�͂b�o�t�͍̂��̂�
�@�ꖇ��~�Ȃ�b�o�t����\�~�����炿����Ƃ₻���Ƃ̕����܂�͊W�Ȃ��͂��j
�����A���ۂ̓_�C��1.5�{�A�����܂肪�{�ω����邾���ł��Ȃ�
�R�X�g�͌������Ȃ�Ƃ�����Intel��AMD����������ԋC�ɂ��Ă邪�B
�E�F�n1��1000�~���x��������
�ǂ��݂Ă��V���R���E�F�n���[�J�[������Ă����Ȃ����낗��
�ǂ��݂Ă��V���R���E�F�n���[�J�[������Ă����Ȃ����낗��
�@�@ �^�P�_
�@�@| �@�Oo�O�@|�@�� �E�F�n�[�X�@���������ł�
�@�@ �_�@�@�^
�@�@| �@�Oo�O�@|�@�� �E�F�n�[�X�@���������ł�
�@�@ �_�@�@�^
�o�O���݂̕]���p�E�F�n�[�Ȃ�ĉ����ɂł��]���Ă邾��B
�E�G�n���̏o�����i���x����1�����\���ł���B����~�Ŕ����邩�悗
������i�m�I�[�_�[�Ȃ̂ɕ����܂��8�`9���߂��Ƃ���ڎw���Ă�킯�ŁB
������i�m�I�[�_�[�Ȃ̂ɕ����܂��8�`9���߂��Ƃ���ڎw���Ă�킯�ŁB
�ʎY�H�ꂾ�ƌ����������������B
1�����炢���X������B
����ɂ���Ȃ������������ƌ����Ă���v���Z�X�J����CPU�J���Ȃ�ďo���B
1�����炢���X������B
����ɂ���Ȃ������������ƌ����Ă���v���Z�X�J����CPU�J���Ȃ�ďo���B
>>101
�P�`�L���Ƃ����������b����Ȃ�
�����ɃE�F�n�̒l�i�̘b��
>>86
>���i�Ƃ��ďo�����Ȃ�A����1���������牽�S�������H
�P�`�L���Ƃ����������b����Ȃ�
�����ɃE�F�n�̒l�i�̘b��
>>86
>���i�Ƃ��ďo�����Ȃ�A����1���������牽�S�������H
Intel�̎В��́A�u�f��v�Ŏ����Ă܂����B
�ܑ̖����A�j�Ėܑ̖���
�ܑ̖����A�j�Ėܑ̖���
���S���ł�Intel�В��⃀�[�A����������ĂԐl����̕�����������
�܂�����Ă��̂��B
�H�Ɛ��i�̗ʎY�i�Ȃ�ď������b�g�������Y�i�͌����p���p�������l�B
���R�}�[�W�������Ď���Ă邾�낤���B�����������ׂĂ����v�ސ��Y�i��
�Ȃ��Ȃ����炳�B
�H�Ɛ��i�̗ʎY�i�Ȃ�ď������b�g�������Y�i�͌����p���p�������l�B
���R�}�[�W�������Ď���Ă邾�낤���B�����������ׂĂ����v�ސ��Y�i��
�Ȃ��Ȃ����炳�B
>>105
�܂��������ȁB�����Ԃ̐��Y�Ȃ�Ēm�����炱���牽�Č�����B
�܂��������ȁB�����Ԃ̐��Y�Ȃ�Ēm�����炱���牽�Č�����B
�E�F�n1��20���~�Ȃ��E�E�E�B
�H��Ɛݔ��ɂ����͂����邪�A����Ă��܂��Ώ�Ƀt���ғ��Ȗ�ł��Ȃ�����
������x�̃R�X�g�ō����Bintel�N���X���ƃ}�X�N�ゾ���Ő��疜�����������B
�R�X�g�ӎ��͏d�v�����P�����炢�ŁA�������������悤�Ȑ��Y�ʂ����Ȃ��Ȃ�FPGA�ō��B
>>107
��inch�E�F�n�[�̘b�ȂB
������x�̃R�X�g�ō����Bintel�N���X���ƃ}�X�N�ゾ���Ő��疜�����������B
�R�X�g�ӎ��͏d�v�����P�����炢�ŁA�������������悤�Ȑ��Y�ʂ����Ȃ��Ȃ�FPGA�ō��B
>>107
��inch�E�F�n�[�̘b�ȂB
�Ƃ������ǂ�����̉\��������̂ɒf������z�������B
�����炽�������R�X�g����Ȃ��Ƃ��Ă��A���i�ɏo����E�F�n���
�j��������̂ŊO�ςɖ�肪�Ȃ����̂�����Ȃ炻�����g���Ǝv�����B
�����A���\�̏�Ńx�^�x�^������Ă����i�ɂ���̂ɖ�肪�Ȃ����
�܂����ʂɂ܂Ƃ��ȓz�����Ă��邩���ˁB
�����Ƃ������ȑO�ɂ����̘b����ˁH
�����ςɂȂm�������m������ɂ���ւ��邩�炨�������Ȃ�w
�����炽�������R�X�g����Ȃ��Ƃ��Ă��A���i�ɏo����E�F�n���
�j��������̂ŊO�ςɖ�肪�Ȃ����̂�����Ȃ炻�����g���Ǝv�����B
�����A���\�̏�Ńx�^�x�^������Ă����i�ɂ���̂ɖ�肪�Ȃ����
�܂����ʂɂ܂Ƃ��ȓz�����Ă��邩���ˁB
�����Ƃ������ȑO�ɂ����̘b����ˁH
�����ςɂȂm�������m������ɂ���ւ��邩�炨�������Ȃ�w
>>80
Cell�͔ėpPowerPC�������ʂō̗p����܂���̏�ł̗]��������A�R���s���[�^�ȊO�ł̗̍p���т̔���x86�͂������������
�Ⴆ�T�[�o�[����ł̓������Ƃ��Ă�
Cell�͔ėpPowerPC�������ʂō̗p����܂���̏�ł̗]��������A�R���s���[�^�ȊO�ł̗̍p���т̔���x86�͂������������
�Ⴆ�T�[�o�[����ł̓������Ƃ��Ă�
>>107
�����̉�Ѝ�10���Ŕ����Ă�̂�6���ɒl��������IBM�ɔ��낤�Ƃ��Ă邺
�����̉�Ѝ�10���Ŕ����Ă�̂�6���ɒl��������IBM�ɔ��낤�Ƃ��Ă邺
�{���������炻���������͌���Ȃ������ǂ����ƁB
���ʂɏ��R�k����ˁB
���ʂɏ��R�k����ˁB
�E�G�n�[�X�ƌĂ��ɃS�[�t���b�h�̕����ł��ėǂ�����
SSE4�Ɋւ��ẮA�O�]���Ƃ͋t�ɁA�����_�ł͖w�nj��ʂ͂Ȃ��������B
������t�����p�ł���G���R�[�_���o�ꂷ��܂ł́A���܂���҂��Ȃ������ǂ����낤�B
������t�����p�ł���G���R�[�_���o�ꂷ��܂ł́A���܂���҂��Ȃ������ǂ����낤�B
>>110
x86�T�[�o�[�͏o�א����������̖��������ł���B
��������̂�IBM����POWER�n(��PowerPC�ł͖���)�B
Sun�Ȃ�UltraSPARC T1������B
PowerPC�̎���̓G����MIPS�Ƃ�ARM����Ȃ���?
x86�T�[�o�[�͏o�א����������̖��������ł���B
��������̂�IBM����POWER�n(��PowerPC�ł͖���)�B
Sun�Ȃ�UltraSPARC T1������B
PowerPC�̎���̓G����MIPS�Ƃ�ARM����Ȃ���?
>>111
�`�b�v�T�C�Y��������Ό������킩��̂��ƊE�̏킾�낤���A
�����ƊE�Ȃ�ō����̐M�z�����́ASUMCO�ǂ��炩�̉��i���Ă��Ƃ�OK?
�`�b�v�T�C�Y��������Ό������킩��̂��ƊE�̏킾�낤���A
�����ƊE�Ȃ�ō����̐M�z�����́ASUMCO�ǂ��炩�̉��i���Ă��Ƃ�OK?
�� intel�N���X���ƃ}�X�N�ゾ���Ő��疜����������
200mm�E�F�n�A180�`130nm����ɍ��ꂽ����
http://www.c.csce.kyushu-u.ac.jp/lab_db/papers/paper/pdf/2001/Yasuura01_1.pdf
�E�}�X�N��p��30�`50���̃}�X�N��1�Z�b�g�Ƃ��đ��z���疜�~
�E1�E�F�n������̐����R�X�g�͐��\���~
�E���i����10�����邠����܂ł͐v�E�}�X�N�R�X�g���R�X�g�̔����ȏ���߂�
�@1�疜���o�ׂł���悤�Ȑ��i�ł͐����R�X�g��e�X�g�E�p�b�P�[�W�R�X�g���S�̂̃R�X�g�����肷��
�u�}�X�N�� ���~�v�ŃO�O���Ă݂�
http://www.google.com/search?hl=ja&q=%E3%83%9E%E3%82%B9%E3%82%AF%E4%BB%A3+%E5%84%84%E5%86%86
200mm�E�F�n�A180�`130nm����ɍ��ꂽ����
http://www.c.csce.kyushu-u.ac.jp/lab_db/papers/paper/pdf/2001/Yasuura01_1.pdf
�E�}�X�N��p��30�`50���̃}�X�N��1�Z�b�g�Ƃ��đ��z���疜�~
�E1�E�F�n������̐����R�X�g�͐��\���~
�E���i����10�����邠����܂ł͐v�E�}�X�N�R�X�g���R�X�g�̔����ȏ���߂�
�@1�疜���o�ׂł���悤�Ȑ��i�ł͐����R�X�g��e�X�g�E�p�b�P�[�W�R�X�g���S�̂̃R�X�g�����肷��
�u�}�X�N�� ���~�v�ŃO�O���Ă݂�
http://www.google.com/search?hl=ja&q=%E3%83%9E%E3%82%B9%E3%82%AF%E4%BB%A3+%E5%84%84%E5%86%86
DDR3�̐��\�ƒl�i�����Ȃ��̂́A���Ȃ�H
Nehalem���łĂ��炩�ȁH
Nehalem���łĂ��炩�ȁH
Nehalem�̃����R���̓g���v���`�����l���݂��������ǁA�������[��DDR3�̎O��
��g�Ń������[�X���b�g�̐���4����6�ɂȂ�낤���H
�������[�ш��DDR3��1333MHz����x3��4000MHz�H
��g�Ń������[�X���b�g�̐���4����6�ɂȂ�낤���H
�������[�ш��DDR3��1333MHz����x3��4000MHz�H
�g���v���`�����l���H
�X���b�g�͉��ɂȂ�̂ł����H
�X���b�g�͉��ɂȂ�̂ł����H
���������ڐ��Ő��\�����E���鎞��ɓ˓��B
3�X���b�g�ɉ�A���邾������Ȃ��́H
3�X���b�g�ɉ�A���邾������Ȃ��́H
>>123
����I�p����B�f�X�N�g�b�v�łX�X���b�g�Ȃ�Ă��肦�Ȃ��B
�f�X�N�g�b�v�̓n�C�G���h�łU�A�����f���͂S���R������B
����I�p����B�f�X�N�g�b�v�łX�X���b�g�Ȃ�Ă��肦�Ȃ��B
�f�X�N�g�b�v�̓n�C�G���h�łU�A�����f���͂S���R������B
�܂�32bitOS�g���Ă镪�ɂ�1GB�~3�ŏ\������ȁB
�f�X�N�g�b�v�܂�3�`���l�������邩�͂܂����܂��ĂȂ��B
���������i�̖\�����l�����Nehalem�̍��ɂ�2GB�ǂ��납4GB���W���[����������O�ɂȂ��Ă����B
�K�R�I��64bit�ڍs���ȁB
�K�R�I��64bit�ڍs���ȁB
Nehalem���o�鍠�܂łɂ�WoW64�̃V���{�������Ƃ����ė~�����B
Windows3.1��Windows95�̊W���炢�܂łɂȂ��Ăق����ȁB
Windows3.1��Windows95�̊W���炢�܂łɂȂ��Ăق����ȁB
Silverthorn�̃}���`�X���b�h��SMT�Ȃ̂���
�ǂ��Ȃ낤�ȁB
ARM��Cortex-A9��SMP�\���ł���炵���B
���������ʂł́A
�����_�Ŕ��\����Ă���Silverthorne�̏���d�͂��ƁA�܂�������Ɛh�����͂���B
ARM��Cortex-A9��SMP�\���ł���炵���B
���������ʂł́A
�����_�Ŕ��\����Ă���Silverthorne�̏���d�͂��ƁA�܂�������Ɛh�����͂���B
>>126
�P�`���l���s�ǂȑI�ʗ����i�ׂ̈ɁA�f�X�N�g�b�v�͂Q�`���l���ɂȂ�Ɨ\�z�B
�P�`���l���s�ǂȑI�ʗ����i�ׂ̈ɁA�f�X�N�g�b�v�͂Q�`���l���ɂȂ�Ɨ\�z�B
>>128
WOW32�͌݊������������̂��H
WOW32�͌݊������������̂��H
133 �FSocket774�F2007/11/17(�y) 18:52:46 ID:I/JxbBBQ
http://www.nikkei.co.jp/kaigai/us/20071116D2M1603916.html
�`�l�c�͎�͕i�ł���l�o�t�i�����^���Z�������u�j�ŃC���e���Ƃ̃V�F�A�����������B
7�\9�����̍ŏI���v��4���h����̐Ԏ��ƂȂ�ȂNj�킵�Ă���B
�`�l�c�͎�͕i�ł���l�o�t�i�����^���Z�������u�j�ŃC���e���Ƃ̃V�F�A�����������B
7�\9�����̍ŏI���v��4���h����̐Ԏ��ƂȂ�ȂNj�킵�Ă���B
134 �FSocket774�F2007/11/18(��) 00:36:29 ID:h8I2+L57
>>134
Power6,UltraSPARC T2��C2D�Ȃ�
Power6,UltraSPARC T2��C2D�Ȃ�
Power6�͂Ƃ�����UltraSPARC T2�̓V���O���X���b�h�d���̐v����Ȃ�����
POWER�͏ォ�牺�܂ł̃T�|�[�g�ł���͈͂�x86�̔䂶��Ȃ�������͂�����
�ǂ̕������s���z���Ă邵��
������V�K�Q������ł��낤Silverthorne�����������ƁA
���POWER6��Ultra SPARC�̘b���o�Ă�̂ɖ��O���狓����Ȃ�It�Ȃ�Ƃ��݂����ɂȂ�
�Ȃ�nium�ƈ����x86�Ȃ̂��ő�̕��킾�낤��
�ǂ̕������s���z���Ă邵��
������V�K�Q������ł��낤Silverthorne�����������ƁA
���POWER6��Ultra SPARC�̘b���o�Ă�̂ɖ��O���狓����Ȃ�It�Ȃ�Ƃ��݂����ɂȂ�
�Ȃ�nium�ƈ����x86�Ȃ̂��ő�̕��킾�낤��
Power6����4.7GHz������̂�Core2������P4�݂����Ȑv�Ȃ̂��H
�l�n�[�����o����I��肶��Ȃ����H
�l�n�[�����o����I��肶��Ȃ����H
�l�n�[������core2�ȏ�Ƃ͌���Ȃ�����
POWER6�͉��i�I��Xeon�Ƃ͋������Ȃ�
�����ł�POWER6�͐��\�I��Xeon�Ƃ͋������Ȃ�
�����ł�POWER6�͐��\�I��Xeon�Ƃ͋������Ȃ�
>>132
Windows2000��Windows95�ƃf�o�h���݊����Ƃ�锤�������̂ɁA
Windows2000�̍��ɂȂ��āA���̕ӂ�WDM�Ƃ����`�Ńo�b�T���������ꂽ�B
���������IO�G�~�����[�V�����̃n�[�h���͉������Ă������Ȃ̂ɁA
WOW64��WDM�݊����̂ĂĂ��܂��Ă���_���C�ɂ���Ȃ��B
�ߋ��Ƃ̌݊��ׂ̈ɖ��������ȃV�X�e�����͓̂��ӂȂ���
Windows2000�ȍ~�̃f�o�h���͑Ή����ė~�����B>MS
#Windows3.1�̌��͊��Ⴂ�B
Windows2000��Windows95�ƃf�o�h���݊����Ƃ�锤�������̂ɁA
Windows2000�̍��ɂȂ��āA���̕ӂ�WDM�Ƃ����`�Ńo�b�T���������ꂽ�B
���������IO�G�~�����[�V�����̃n�[�h���͉������Ă������Ȃ̂ɁA
WOW64��WDM�݊����̂ĂĂ��܂��Ă���_���C�ɂ���Ȃ��B
�ߋ��Ƃ̌݊��ׂ̈ɖ��������ȃV�X�e�����͓̂��ӂȂ���
Windows2000�ȍ~�̃f�o�h���͑Ή����ė~�����B>MS
#Windows3.1�̌��͊��Ⴂ�B
142 �FSocket774�F2007/11/19(��) 02:34:31 ID:pc5BnA1J
�f�r�b�h�J�g���[���A�z�ŏI��
�ގЂ���
�ގЂ���
Penryn���܂�������オ���ȁB �N���b�N������ȏ�オ��Ȃ��������B
���N����Nehalem�܂ŁA�l�^�������H
���N����Nehalem�܂ŁA�l�^�������H
���̂Ƃ���R�����[�ł��������������Ă����������ȁB
�l�n�[���������M���ǂ����ŕς��ȁB
�l�n�[���������M���ǂ����ŕς��ȁB
�yAMD�z Phenom FX/9xx0/8xx0/Kuma Part6 �yK10�z
http://pc11.2ch.net/test/read.cgi/jisaku/1195471628/l50
Phenom�Ǔ����ւ悤����
http://pc11.2ch.net/test/read.cgi/jisaku/1195471628/l50
Phenom�Ǔ����ւ悤����
http://www16.big.or.jp/~bunnywk/cgi-bin/pimod/superpi.cgi
Penryn�AOC�ϐ������܂����݂������ˁB
���W�b�N�lj��������Ƃ������Ȃ̂��A����Ƃ�High-K�̉��x�����̉e���Ȃ̂��B
Penryn�AOC�ϐ������܂����݂������ˁB
���W�b�N�lj��������Ƃ������Ȃ̂��A����Ƃ�High-K�̉��x�����̉e���Ȃ̂��B
����Quad�ŁA5.8GHz�Ƃ��M���O���낗
>>146
Kentsfield�Ɣ�ׂĂ݂�悗
Kentsfield�Ɣ�ׂĂ݂�悗
Intel's Core 2 Extreme QX9770 Preview: Too Hot for TV
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3154&p=3
�Ȃ��Ȃ��M����
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3154&p=3
�Ȃ��Ȃ��M����
http://www.theinquirer.net/gb/inquirer/news/2007/11/21/amd-nv-green-double-shows
Yes, if you leave it on default settings, it is hotter than the QX9650 at the same 3.2 GHz FSB1600 settings.
The trick that seems to work on my Asus Maximus Extreme - beta BIOS 701:
lower the voltage for the QX9770 CPU and its PLL manually in BIOS, rather than leave it on Auto settings.
It works fine even at 1.22 volts, noticeably cooler - more on that tomorrow in our test!
Yes, if you leave it on default settings, it is hotter than the QX9650 at the same 3.2 GHz FSB1600 settings.
The trick that seems to work on my Asus Maximus Extreme - beta BIOS 701:
lower the voltage for the QX9770 CPU and its PLL manually in BIOS, rather than leave it on Auto settings.
It works fine even at 1.22 volts, noticeably cooler - more on that tomorrow in our test!
AthlonXP3000+����C2D�@E4500�ɕς������A
����ȂɈႤ�Ƃ͎v��Ȃ�������
�N���b�N�͂���Ȃɕς���ĂȂ��̂ɁA
�}���`�R�A�ɑΉ����ĂȂ��Q�[���ł�
�S�RFPS��������͉̂��ɂ͂��������o���܂���
����ȂɈႤ�Ƃ͎v��Ȃ�������
�N���b�N�͂���Ȃɕς���ĂȂ��̂ɁA
�}���`�R�A�ɑΉ����ĂȂ��Q�[���ł�
�S�RFPS��������͉̂��ɂ͂��������o���܂���
>>151
�����A�V���O���R�A����Dual�R�A�ւƌ������ׂ�̂��ԈႦ�Ă���B
���ƁAHDD�����V�K�ŕς����̂ł���A����ɊԈႦ�Ă���B
�V���O������Dual�ւ̕ύX�Ȃ�A�ʂ�CPU���ǂ������ύX�ł����Ă��A
�قƂ�ǂ̏ꍇ���̊��I�ɑ傫�ȈႢ���o��B
�����A�V���O���R�A����Dual�R�A�ւƌ������ׂ�̂��ԈႦ�Ă���B
���ƁAHDD�����V�K�ŕς����̂ł���A����ɊԈႦ�Ă���B
�V���O������Dual�ւ̕ύX�Ȃ�A�ʂ�CPU���ǂ������ύX�ł����Ă��A
�قƂ�ǂ̏ꍇ���̊��I�ɑ傫�ȈႢ���o��B
>>151
http://www.spec.org/cpu2000/results/res2003q1/cpu2000-20030224-01964.html
http://www.spec.org/cpu2000/results/res2006q3/cpu2000-20060821-07083.html
http://www.spec.org/cpu2000/results/res2003q1/cpu2000-20030224-01964.html
http://www.spec.org/cpu2000/results/res2006q3/cpu2000-20060821-07083.html
�Ȃ�ł��̘b�̗����spec���o�Ă���̂������
�V���O���X���b�h�ł�E4500��XP300+�̖�Q�{�����A���Č���������ł���B
SPEC�̓}���`�X���b�h��rate�����������ɏo����邱�Ƃ���������A�������Ă����Ȃ���
�킩��Ȃ��Ǝv����B
SPEC�̓}���`�X���b�h��rate�����������ɏo����邱�Ƃ���������A�������Ă����Ȃ���
�킩��Ȃ��Ǝv����B
XP300+�Ŏv���o�������A������XP����1GHz��1000+�ɂȂ���
>>151
E4500�̓V���O���X���b�h�ł�2004�N�̃n�C�G���h�N���X�̐��\������3000+��1�N�������Ȃ���
>>152�̎w�E�ʂ肾�Ǝv����
>>151
E4500�̓V���O���X���b�h�ł�2004�N�̃n�C�G���h�N���X�̐��\������3000+��1�N�������Ȃ���
>>152�̎w�E�ʂ肾�Ǝv����
���}���`�R�A�ɑΉ����ĂȂ��Q�[���ł��S�RFPS��������
���ď����Ă邶���B
���ď����Ă邶���B
XP3000+��L2=512KB�AE4500��L2=2MB�B�V���O���X���b�h����ł͂܂�܂�2MB�g����B
�Q�[���ł�L2�e�ʂ̉e���͑傫������A�Q�{�͂Ƃ�����E4500�ł��Ȃ�FPS������̂�
���̉e�����傫��������B
�Q�[���ł�L2�e�ʂ̉e���͑傫������A�Q�{�͂Ƃ�����E4500�ł��Ȃ�FPS������̂�
���̉e�����傫��������B
>>152,>>153,>>154,>>155,>>156,>>157,>>158
���X�T���N�X
BattleField2142���Ȃ���mAgicTV�Ńe���r�ԑg�B���Ă���A
�ȑO�iAthlonXP3000+�j�͘^�����ԑg���R�}�����݂����ɂȂ��Ă����A
C2D E4500�ł�30�R�}�ŕ��ʂɈ��肵�Ę^���Ă�
L2�e�ʂ�DDR��DDR2�ɕύX�������Ă�̂��ˁB�B
���X�T���N�X
BattleField2142���Ȃ���mAgicTV�Ńe���r�ԑg�B���Ă���A
�ȑO�iAthlonXP3000+�j�͘^�����ԑg���R�}�����݂����ɂȂ��Ă����A
C2D E4500�ł�30�R�}�ŕ��ʂɈ��肵�Ę^���Ă�
L2�e�ʂ�DDR��DDR2�ɕύX�������Ă�̂��ˁB�B
��BattleField2142���Ȃ���mAgicTV�Ńe���r�ԑg�B���Ă���
����͂���Ƀf���A���R�A�̉��b�����
����͂���Ƀf���A���R�A�̉��b�����
�m�b�x��߂���
>>150��INQ�L���ɂ���悤��ASUS��QX9770�Ή�Beta BIOS�̓f�t�H���g�d���̌��o�ɕs����L��Ƃ������Ƃ�>>149���X�V����Ă�
INQ
�Q�[�����̂��̂��}���`�R�A�ɑΉ����ĂȂ��Ă��AHDD��Video�ALAN�Ȃ�
�h���C�o�����Q�[���A�v���ƕʃX���b�h�ŕ��삷��A���������������
�ł́H
�ܘ_�A��ԗ����Ă�̂̓L���b�V���e�ʂ��Ƃ͎v�����ǁB
�h���C�o�����Q�[���A�v���ƕʃX���b�h�ŕ��삷��A���������������
�ł́H
�ܘ_�A��ԗ����Ă�̂̓L���b�V���e�ʂ��Ƃ͎v�����ǁB
�X���b�h�̗��p�ړI�͎��
1�D���o�͒x���A�ʐM�x���̉B��
2�D�Ώ̌^�}���`�v���Z�b�T�ł̕���
���R�Ȃ���1�̓V���O���R�A�ł����ʂ�����
1�D���o�͒x���A�ʐM�x���̉B��
2�D�Ώ̌^�}���`�v���Z�b�T�ł̕���
���R�Ȃ���1�̓V���O���R�A�ł����ʂ�����
Windows�ň�Ԃ悭�X���b�h���ĂĂ�鏈�����āA
���b�Z�[�W���[�v�̗�����Ƃ߂�Ƃ܂�������A
���Ԃ̂����鏈����ʃX���b�h�ɂ��Ď��s�Ƃ�������ւƎv����
����Ȏg�����Ȃ炻���炶�イ�̃A�v���ł���Ă��
���̏ꍇ�f���A���ɂ��Ă��N�A�b�h�ɂ��Ă��قƂ�lj����ς���
���b�Z�[�W���[�v�̗�����Ƃ߂�Ƃ܂�������A
���Ԃ̂����鏈����ʃX���b�h�ɂ��Ď��s�Ƃ�������ւƎv����
����Ȏg�����Ȃ炻���炶�イ�̃A�v���ł���Ă��
���̏ꍇ�f���A���ɂ��Ă��N�A�b�h�ɂ��Ă��قƂ�lj����ς���
�ŋ߂̓G���R��Q�[���Ń}���`�Ή��������Ă������ǃN�A�b�h��葝���Ă��Ή����đ����Ȃ�̂��ȁH
���N�̓~����ɂ�Core8���o��\�����������ė��N�̓~����ɂ�SUGEEEEE�����o��\�����������E�E�E
����1�N�ŃR�A�A�[�L�e�N�`����6����X�V����̂���
�܂�A�l�n�[������Core4�ɂȂ�ƁB
��������Nehalem��CMA�ł͂Ȃ��̂ł́H
Nehalem��Advanced Core MA�Ƃ����ł���Core 3�v���Z�b�T�Ƃ��̃u�����h�ŏo���ė����Ȃ��́H
Nehalem��Intel's K8MA�Ƃ��ɂȂ�������邯�ǂȂ�
Teratological Micro Architecture
�m���AIntel�����Core3���o�Ă���ƕ��������ǁE�E�E
Intel����Core3�o��Ƃ�����l�C�e�B�u�Ȃ̂��ȁH
>>168������
http://www.watch.impress.co.jp/akiba/hotline/20071123/etc_phenomev.html
> �����āu�l�����������̂�Core 2�͂������߂��Ǝv����ł��B�v�Ɣ����B
> ���C�o�����i�����o���Ƃ���ŏ���͔��ƂȂ����B�f���A���R�A�ƌ���
> �ׂ��Ƃ����Core 2�ƌ����ԈႦ���悤����
http://www.watch.impress.co.jp/akiba/hotline/20071123/etc_phenomev.html
> �����āu�l�����������̂�Core 2�͂������߂��Ǝv����ł��B�v�Ɣ����B
> ���C�o�����i�����o���Ƃ���ŏ���͔��ƂȂ����B�f���A���R�A�ƌ���
> �ׂ��Ƃ����Core 2�ƌ����ԈႦ���悤����
http://www.4gamer.net/games/030/G003078/20071124002/
�}�����̗\�z�炵�����A�l�n�[�����̃��C���X�g���[���̃o�X��QP�h�ł͂Ȃ��APCI-E��DMI���g���Ƃ̂��ƁB
�}�����̗\�z�炵�����A�l�n�[�����̃��C���X�g���[���̃o�X��QP�h�ł͂Ȃ��APCI-E��DMI���g���Ƃ̂��ƁB
180 �FSocket774�F2007/11/25(��) 15:29:07 ID:UH1NV8XZ
���̃\�P�b�g�͂����ł܂����H
LGA775�������ɂ����č����Ă��܂��B
LGA775�������ɂ����č����Ă��܂��B
�f�X�N�g�b�v�p�͍����LGA���Ǝv�����B PGA���������邱�Ƃ͂܂��Ȃ��B
478�ł�775�ł��S���ς��Ȃ��C������͉̂��������B
�}�����̗\�z���ƁA�܂��܂�intel�ȊO�̃`�b�v�Z�b�g�x���_�[���s�����ȁB
QPI��������Ȃ���DMI�̃��C�Z���X��������Ȃ��Ƃ����Ȃ�����Ȃ����B
Havendale�͂���GMCH��CPU�ɓ������������Ɍ����邵�B
�O���o�X��QPI�ADMI�{PCIe�ADMI���čň��\�P�b�g3�ɂȂ肻���Ȃ��A���̗\�z���ƁB
QPI��������Ȃ���DMI�̃��C�Z���X��������Ȃ��Ƃ����Ȃ�����Ȃ����B
Havendale�͂���GMCH��CPU�ɓ������������Ɍ����邵�B
�O���o�X��QPI�ADMI�{PCIe�ADMI���čň��\�P�b�g3�ɂȂ肻���Ȃ��A���̗\�z���ƁB
DMI����PCI-e�̃T�u�Z�b�g�Ȃ̂Ƀ��C�Z���X������̂��H
http://pc.watch.impress.co.jp/docs/2004/0423/ubiq58.htm
��PCI Express�Ɠ��������w�𗘗p���A�v���g�R��������Intel�Ǝ��̂��̂ɕύX��������
���̕����̂����ŁA���Ђ͏����DMI�g���Ȃ��͂��B
����QPI�ADMI�APCIe�������w�����ŁA�\�P�b�g�������ɏo�����Ƃ��Ă��ACPU�������Ă���
�O���o�X���Ⴄ����A
�h�����Ă������Ȃ����ꂪ�������B
�܂��A�ŏ�ʂ�Bloomfield�͕ʃv���b�g�t�H�[���Ȃ�A�܂��Ȃ�Ƃ��Ȃ肻�����B
Havendale��Lynnfield�pM/B�Ɏh����PCIe�X���b�g��1�{+�������Ȃ��Ƃ��ɂȂ邯�ǁB
��ʂƉ��ʂœ�����Ń\�P�b�g�Ⴂ�ɂ���̂͂���܂�intel�炵���Ȃ��Ǝv�����ǁB
��PCI Express�Ɠ��������w�𗘗p���A�v���g�R��������Intel�Ǝ��̂��̂ɕύX��������
���̕����̂����ŁA���Ђ͏����DMI�g���Ȃ��͂��B
����QPI�ADMI�APCIe�������w�����ŁA�\�P�b�g�������ɏo�����Ƃ��Ă��ACPU�������Ă���
�O���o�X���Ⴄ����A
�h�����Ă������Ȃ����ꂪ�������B
�܂��A�ŏ�ʂ�Bloomfield�͕ʃv���b�g�t�H�[���Ȃ�A�܂��Ȃ�Ƃ��Ȃ肻�����B
Havendale��Lynnfield�pM/B�Ɏh����PCIe�X���b�g��1�{+�������Ȃ��Ƃ��ɂȂ邯�ǁB
��ʂƉ��ʂœ�����Ń\�P�b�g�Ⴂ�ɂ���̂͂���܂�intel�炵���Ȃ��Ǝv�����ǁB
Gainestown/Bloomfield�{Tylersburg�͂����Ƃ���
�f�X�N�g�b�v�ȉ��͏���낱��ς���
�f�X�N�g�b�v�ȉ��͏���낱��ς���
�}���\�z�ł�PCI-E���������[
��C��SoC�����i�ނ�
��C��SoC�����i�ނ�
�G���v���g�ƃ��o�C��/�z�[���g�ōj�������ł�
�}���\�z���������Ƃ���ƁA
Bloomfiled��Dual CPU&�}���`GPU��p�v���b�g�t�H�[���p�B
�kynnfiled��Havendale�͋��ʃ\�P�b�g�Ɨ\�z�B��������Ƃl�a�����ލl������BHavendale��p��PCI-E16�X���b�g
���Ȃ���R�X�g�^�C�v��PCI-E16X�X���b�g������kynnfiled��Havendale�����g����i�A��Havendale��I����
���GPU���ݕs�j�^�C�v�B
�^��_�Ƃ��Ă�GPU����PCI-E������Dual Core������̂��H�Ȃ�����CPU��DC���g���������A�O�t����GPU�g���������[�U
�[���������ƂɂȂ�BDMI�ɐڑ������Ǝv����hCH10��PCI-E��4���[�����炢���g���ăX���b�g�`���16X�ɂ���Έꉞ���݉\
��MB�����邪�E�E�E�B
�^��_�͂��Ȃ����A�ڍׂ͎���IDF�܂Ŏ����z�����ȁB
Bloomfiled��Dual CPU&�}���`GPU��p�v���b�g�t�H�[���p�B
�kynnfiled��Havendale�͋��ʃ\�P�b�g�Ɨ\�z�B��������Ƃl�a�����ލl������BHavendale��p��PCI-E16�X���b�g
���Ȃ���R�X�g�^�C�v��PCI-E16X�X���b�g������kynnfiled��Havendale�����g����i�A��Havendale��I����
���GPU���ݕs�j�^�C�v�B
�^��_�Ƃ��Ă�GPU����PCI-E������Dual Core������̂��H�Ȃ�����CPU��DC���g���������A�O�t����GPU�g���������[�U
�[���������ƂɂȂ�BDMI�ɐڑ������Ǝv����hCH10��PCI-E��4���[�����炢���g���ăX���b�g�`���16X�ɂ���Έꉞ���݉\
��MB�����邪�E�E�E�B
�^��_�͂��Ȃ����A�ڍׂ͎���IDF�܂Ŏ����z�����ȁB
http://pc.watch.impress.co.jp/docs/2007/1126/ubiq204.htm
�}���\�z�̏ڍא����������B
QPI�̓n�C�G���h�݂̂ɂƂǂ܂�Ƃ��AGPU������MCM�ɕύX�Ƃ����ς�肷���B
�Ō�̕���DMI�̓��C�Z���X���Ȃ����낤���ď����Ă��邩��A3rd�p�[�e�B�̐S�z���̖��p�������͗l�B
�Ƃ������A�`�b�v�Z�b�g�悭�V���[�g���邭����3rd�ǂ��o���đ��v�Ȃ̂��H
�ꉞDMI��PCI-Express�̃T�u�Z�b�g������ADMI�Ƃ��Ă͖��������nj����������APCI-Express�Ƃ��ĂȂ�
�T�E�X���q��������ĉ\�����Ȃ��ɂ������炸�����ǁB
�}���\�z�̏ڍא����������B
QPI�̓n�C�G���h�݂̂ɂƂǂ܂�Ƃ��AGPU������MCM�ɕύX�Ƃ����ς�肷���B
�Ō�̕���DMI�̓��C�Z���X���Ȃ����낤���ď����Ă��邩��A3rd�p�[�e�B�̐S�z���̖��p�������͗l�B
�Ƃ������A�`�b�v�Z�b�g�悭�V���[�g���邭����3rd�ǂ��o���đ��v�Ȃ̂��H
�ꉞDMI��PCI-Express�̃T�u�Z�b�g������ADMI�Ƃ��Ă͖��������nj����������APCI-Express�Ƃ��ĂȂ�
�T�E�X���q��������ĉ\�����Ȃ��ɂ������炸�����ǁB
�}�����������Ȃ�����
�������\�O�ɂǂ��J�E�p��C���ςނ�
�������\�O�ɂǂ��J�E�p��C���ςނ�
���炭�̊��ԁA���N��IDF�܂ł͌㓡�匴�}���𗘗p�������˂��p������܂�
���y���݉�����
���y���݉�����
>>190
>GPU������MCM�ɕύX�Ƃ����ς�肷���B
�����Ă鎖�͂����Ƃ��Ȏ������ǂȁB
>�J���t�F�[�Y���قȂ�CPU��GPU�����ꂼ��ʁX�ɊJ�����A
>�o���f�[�V����(���쌟��)�̒i�K��1�ɂ܂Ƃ߂ăe�X�g���s�Ȃ����Ƃ��ł���B
>GPU�� CPU�ɓ��������ꍇ�A
>�Ⴆ��GPU���ɉ��炩�̕s��������ďC������Ƃ����ꍇ�A
>�W�̂Ȃ�CPU�������܂߂Ă�蒼���Ƃ������ƂɂȂ�̂�
>�������悭�Ȃ��B
����1�C2�N �㓡�O�Ƃ��������C�^�[������
GPU�u�R�A�����vNehalem�悩
ꡂ��Ɍ����ɑ��������b����B
>GPU������MCM�ɕύX�Ƃ����ς�肷���B
�����Ă鎖�͂����Ƃ��Ȏ������ǂȁB
>�J���t�F�[�Y���قȂ�CPU��GPU�����ꂼ��ʁX�ɊJ�����A
>�o���f�[�V����(���쌟��)�̒i�K��1�ɂ܂Ƃ߂ăe�X�g���s�Ȃ����Ƃ��ł���B
>GPU�� CPU�ɓ��������ꍇ�A
>�Ⴆ��GPU���ɉ��炩�̕s��������ďC������Ƃ����ꍇ�A
>�W�̂Ȃ�CPU�������܂߂Ă�蒼���Ƃ������ƂɂȂ�̂�
>�������悭�Ȃ��B
����1�C2�N �㓡�O�Ƃ��������C�^�[������
GPU�u�R�A�����vNehalem�悩
ꡂ��Ɍ����ɑ��������b����B
�挎�̒��̐l�̔����͂����������������̂�
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
�������A���݂̌v��ł́ANehalem��GPU�R�A���l�C�e�B�u�œ�������悤���B
�܂�ACPU��GPU��1�̃`�b�v�ɂ܂Ƃ߂悤�Ƃ��Ă���B
Smith���́AIDF�ł̃v���X�u���[�t�B���O��ɁAGPU������MCM�Ŏ�������̂�
�Ƃ�������ɑ��āA������ɐU���Ĕے肵���B�܂��A���̂悤�Ɍ�����B
�u��X��45nm�v���Z�X�ɂȂ��āA���߂ē����O���t�B�b�N�X�ƃ������R���g���[����
CPU���Ɉڂ����Ƃ��ł��邾���̃Q�[�g���̃o�W�F�b�g���B�������������1��
�̗��R���B45nm�v���Z�X�łȂ�A�������ɁA���σ_�C�T�C�Y�Ŗc��ȃy�i���e�B��
�������ƂȂ��A(CPU��GPU�R�A�ƃ������R���g���[����)�������邱�Ƃ��ł���v(Smith��)
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
�������A���݂̌v��ł́ANehalem��GPU�R�A���l�C�e�B�u�œ�������悤���B
�܂�ACPU��GPU��1�̃`�b�v�ɂ܂Ƃ߂悤�Ƃ��Ă���B
Smith���́AIDF�ł̃v���X�u���[�t�B���O��ɁAGPU������MCM�Ŏ�������̂�
�Ƃ�������ɑ��āA������ɐU���Ĕے肵���B�܂��A���̂悤�Ɍ�����B
�u��X��45nm�v���Z�X�ɂȂ��āA���߂ē����O���t�B�b�N�X�ƃ������R���g���[����
CPU���Ɉڂ����Ƃ��ł��邾���̃Q�[�g���̃o�W�F�b�g���B�������������1��
�̗��R���B45nm�v���Z�X�łȂ�A�������ɁA���σ_�C�T�C�Y�Ŗc��ȃy�i���e�B��
�������ƂȂ��A(CPU��GPU�R�A�ƃ������R���g���[����)�������邱�Ƃ��ł���v(Smith��)
>>193
194�������Ă��ꂽ���ǁA�}���̏�ς�肷�����ĈӖ�����Ȃ��āA���̐l��
�l�C�e�B�u�œ�������
�����Ă��̂��AMCM�ɂȂ����̂ŕς�肷�����ď������B
�㓡���̕������̐l�̃R�����g���ăl�C�e�B�u�������ď����Ă��낤���B
���̌�Г��ŐF�X������MCM�ɂȂ������ď�}�����̕��ɗ��ꂽ�낤�ȁB
�R�[�h�l�[���������̂��̑������B
194�������Ă��ꂽ���ǁA�}���̏�ς�肷�����ĈӖ�����Ȃ��āA���̐l��
�l�C�e�B�u�œ�������
�����Ă��̂��AMCM�ɂȂ����̂ŕς�肷�����ď������B
�㓡���̕������̐l�̃R�����g���ăl�C�e�B�u�������ď����Ă��낤���B
���̌�Г��ŐF�X������MCM�ɂȂ������ď�}�����̕��ɗ��ꂽ�낤�ȁB
�R�[�h�l�[���������̂��̑������B
>>193�͂����̔S���A�t�H����
�Г��ł�����������u����A���Ă̂͂悭�L��b������
�ʂɋL���̓��e���ŏI�I�ɂ����Ă����ǂ����͖�肶��Ȃ��́B
�㓡�O�������ŋߔM�S��GPU����CPU�Ƃ����̂�
�l�I�Ɉ�a���������āA���̈�a���̐��̂�
���̋L�����L���C�ɂ܂Ƃ߂Ă��ꂽ���>>193�����������������B
�J���X�p�����v���Z�b�T�Ƃ��Ă̕��������Ⴄ����
�R�A���x���œ�������̂�
�㓡���悭�����u���m�v���́u���āv�Ƃ͎v���Ȃ��A���ꂾ���B
�ʂɋL���̓��e���ŏI�I�ɂ����Ă����ǂ����͖�肶��Ȃ��́B
�㓡�O�������ŋߔM�S��GPU����CPU�Ƃ����̂�
�l�I�Ɉ�a���������āA���̈�a���̐��̂�
���̋L�����L���C�ɂ܂Ƃ߂Ă��ꂽ���>>193�����������������B
�J���X�p�����v���Z�b�T�Ƃ��Ă̕��������Ⴄ����
�R�A���x���œ�������̂�
�㓡���悭�����u���m�v���́u���āv�Ƃ͎v���Ȃ��A���ꂾ���B
>>193
�������������X�N����̂��߂����邵�A����Ƌ�����v���Z�X�H��^�p
���ꃌ�x���ł̓l�C�f�B�u�����������Ă��o�c�T�C�h�͕ʂ̔��f��������
Merom/Conroe�Ɠ��������o�C�������̃R�A���f�X�N�g�b�vPC�Ɋg������
�Ƃ�����@���Ƃ�̂��A���X�N����ƃR�X�g�ጸ���d�v���������炾�낤
�������������X�N����̂��߂����邵�A����Ƌ�����v���Z�X�H��^�p
���ꃌ�x���ł̓l�C�f�B�u�����������Ă��o�c�T�C�h�͕ʂ̔��f��������
Merom/Conroe�Ɠ��������o�C�������̃R�A���f�X�N�g�b�vPC�Ɋg������
�Ƃ�����@���Ƃ�̂��A���X�N����ƃR�X�g�ጸ���d�v���������炾�낤
�����̎�@�̃����b�g�́A�����_�C�Ƃ��Đ������邱�Ƃ��ł���̂ŁA
�������������D��Ă���g�[�^���Ō���Β�R�X�g�Ő����ł��邱�Ƃ��B
���̐������Ƃǂ�������ǂ����ł���������ȁH�v�����
65W�ō�������̂�35W�ɗ��Ƃ����ނ�肩��
35W�ō�������̂�65W�ɂ����Ă�������y�Ŋm������
�������������D��Ă���g�[�^���Ō���Β�R�X�g�Ő����ł��邱�Ƃ��B
���̐������Ƃǂ�������ǂ����ł���������ȁH�v�����
65W�ō�������̂�35W�ɗ��Ƃ����ނ�肩��
35W�ō�������̂�65W�ɂ����Ă�������y�Ŋm������
Havendale��MCM����I�\�P�b�g�݊��͂����Ă����ǁA�_�C�������Ǝv��������Havendale��PCI-E16X����͗\�z�s�B
���Ƃ�Ibexpeak��ICH10�ƕʕ����ۂ��_�C�A�O�����������Ȃ��E�E�E�Ǝv�������O���t�B�b�N�o�͊W���l����Γ��R���B
PCI�X���b�g��������g����̂���Ԃ̘N�B
���Ƃ�Ibexpeak��ICH10�ƕʕ����ۂ��_�C�A�O�����������Ȃ��E�E�E�Ǝv�������O���t�B�b�N�o�͊W���l����Γ��R���B
PCI�X���b�g��������g����̂���Ԃ̘N�B
��Bloomfiel
4�R�A�AL2(8MB)
�g���v���`�����l���������A�}���`�v���Z�b�T
�\�P�b�gLGA1366
�I�E���[�N�X�e�[�V����
��Lynnfield/Clarksfield
4�R�A�AL2(8MB)
GPU���t��PCIe
�\�P�b�gLGA1160
�Q�[�}�[�E���C���X�g���[��
��Havendale/Auburndale
2�R�A�AL2(4MB)
CPU����GPU�A�I�v�V������GPU���t��PCIe
�\�P�b�gLGA1160
�m�[�g�E�G���g���[
4�R�A�AL2(8MB)
�g���v���`�����l���������A�}���`�v���Z�b�T
�\�P�b�gLGA1366
�I�E���[�N�X�e�[�V����
��Lynnfield/Clarksfield
4�R�A�AL2(8MB)
GPU���t��PCIe
�\�P�b�gLGA1160
�Q�[�}�[�E���C���X�g���[��
��Havendale/Auburndale
2�R�A�AL2(4MB)
CPU����GPU�A�I�v�V������GPU���t��PCIe
�\�P�b�gLGA1160
�m�[�g�E�G���g���[
Intel��C2D�ȗ��̊v�V�I�ȓ��e�ł��ȁE�E�E
DMI����Display��p�o�X���́A���悢��`�b�v�Z�b�g�̃T�[�h�p�[�e�B��
�����c��Ȃ��Ȃ��Ă���Ȃ��B
�����Ȃ��nVidia���A���悢��VIA�݂�����x86CPU����荞�މ\��������
�Ȃ��Ă��������BCPU�ƃ`�b�v�Z�b�g�Ԃ�PCI-E�l�C�e�B�u�ŗǂ����B
�Ȃ�Ȃ�A�r�f�I�J�[�h��CPGPU��DIMM�������o�ڂŁAMB��CPU�\�P�b�g��
��̂܂܂œ��삷��PC�Ȃǂ������ˁB
�����c��Ȃ��Ȃ��Ă���Ȃ��B
�����Ȃ��nVidia���A���悢��VIA�݂�����x86CPU����荞�މ\��������
�Ȃ��Ă��������BCPU�ƃ`�b�v�Z�b�g�Ԃ�PCI-E�l�C�e�B�u�ŗǂ����B
�Ȃ�Ȃ�A�r�f�I�J�[�h��CPGPU��DIMM�������o�ڂŁAMB��CPU�\�P�b�g��
��̂܂܂œ��삷��PC�Ȃǂ������ˁB
������VIA�c
n��CPU����i�o?�A�Ȃ��Ȃ��A��Ζ����B
�܂��܂�3�]5�]���܂�
>>205
�����ł���낤�Ƃ��Ă邵�A����CPU�R�A��̐��\�Ȃ�ē��ł������A���Ƃ�
�g�����W�X�^���Ɛ��\�̃o�����X���Ƃ�Ώ[������B
AMD��Intel��CPU�����āA�����I�ɂ�x86���߃R�[�h��ϊ����Ă�����s���Ă邵�A
���s���j�b�g���͓̂���ȃ��m�͕s�v������A�f�X�N�g�b�v�������x�̐��\�Ȃ�A
��Ԕ\�͂��K�v�Ȃ̂�VIdeo�Ȃ̂����A�Ȃ�Ƃł��Ȃ�Ǝv���B
����CPU�R�A�̐��\�����A�L���b�V���e�ʂ̊m�ۂ̕������\����ɗL��������A
Intel�̐����\�͂ɁA������x�R�o����t�@�u�Ƒg�߂Ηǂ������ł��傤�B
�����ł���낤�Ƃ��Ă邵�A����CPU�R�A��̐��\�Ȃ�ē��ł������A���Ƃ�
�g�����W�X�^���Ɛ��\�̃o�����X���Ƃ�Ώ[������B
AMD��Intel��CPU�����āA�����I�ɂ�x86���߃R�[�h��ϊ����Ă�����s���Ă邵�A
���s���j�b�g���͓̂���ȃ��m�͕s�v������A�f�X�N�g�b�v�������x�̐��\�Ȃ�A
��Ԕ\�͂��K�v�Ȃ̂�VIdeo�Ȃ̂����A�Ȃ�Ƃł��Ȃ�Ǝv���B
����CPU�R�A�̐��\�����A�L���b�V���e�ʂ̊m�ۂ̕������\����ɗL��������A
Intel�̐����\�͂ɁA������x�R�o����t�@�u�Ƒg�߂Ηǂ������ł��傤�B
�ނ��날�ꂾ���ł��������ɉ��ō��܂Œ���(�̋��Y�}�x�z�n��)�v��CPU�����������̂��s�v�c
Intel��AMD�����������ǂꂾ���̎��ԁA���A�l��
�c��ȃ��\�[�X��x86�ɒ�������ł����Ǝv���Ă��
�c��ȃ��\�[�X��x86�ɒ�������ł����Ǝv���Ă��
IPC�����ł��ɂȂ������_�ŁA�ォ��o�Ă��������L���ɂȂ�͎̂d�����Ȃ��낤�B
�����}���`�R�A�ƃL���b�V������A���Ƃ̓q���[�W�������炢�����A���\�����
�]�n�������Ȃ��Ă�̂�����A���܂ł̒~�ςŏ��Ă�قNJÂ����E�ł͖������B
�����}���`�R�A�ƃL���b�V������A���Ƃ̓q���[�W�������炢�����A���\�����
�]�n�������Ȃ��Ă�̂�����A���܂ł̒~�ςŏ��Ă�قNJÂ����E�ł͖������B
���������[�o�J
�㔭���L���ɂȂ�悤�ȊÂ����E�����݂�����
�����t�@���h���炨��������Ԃ���Ԓ������܂�
�V�����͂����ӂꂩ���肻�̋ƊE�͊�����悷�E�E�E�͂�
http://pc.watch.impress.co.jp/docs/article/981014/kaigai01.htm
�����t�@���h���炨��������Ԃ���Ԓ������܂�
�V�����͂����ӂꂩ���肻�̋ƊE�͊�����悷�E�E�E�͂�
http://pc.watch.impress.co.jp/docs/article/981014/kaigai01.htm
x86�̊J�����n�߂�Ƃ��Ă��Œ�4�N�͂����邩��2009�N��Havendale��NVIDIA�͊Ԃɍ����܂���
����A�V�i�Ȃ��ƃ��x���Œm���Ƃ����W�Ƃ��ӏ��Ƃ��A�A�A
����Ȃ̃J���P�[�˂����ĂȂ���Ō㔭�L���Ƃ������������Ȃ����E�E�E
����Ȃ̃J���P�[�˂����ĂȂ���Ō㔭�L���Ƃ������������Ȃ����E�E�E
��H�}�܂�܂�p�N�b���Ƃ��Ă��Aintel��葬���N���b�N�B������͖̂�������
IBM��x�m�ʂ��{�C�o���Ă��AIntel�����x���̂������Ȃ�����
������V���[�J�[���������Ƃ���ŁA���݂���ȏ�̉����Ӗ��������͍��Ȃ�
IBM��x�m�ʂ��{�C�o���Ă��AIntel�����x���̂������Ȃ�����
������V���[�J�[���������Ƃ���ŁA���݂���ȏ�̉����Ӗ��������͍��Ȃ�
IBM�͂Ƃ������x�m�ʖ{�C���Ĕ�r�̈Ӗ�����̂���
�ɂق��傤�����Ă�ł���
>Intel�̐����\�͂ɁA������x�R�o����t�@�u�Ƒg�߂Ηǂ������ł��傤�B
�����炻�ꂪ�ˁ[��o�J��
�����炻�ꂪ�ˁ[��o�J��
�����Z�p�I�ɂ͑��Ђ̂Q�N���炢��s���Ă邵�iIBM�����͕ʁj�A���Y�\�͂ł�
Intel�ɕC�G����Ƃ���Ȃ�ĂȂ����B
Intel�ɕC�G����Ƃ���Ȃ�ĂȂ����B
�ނ���x�ߒ{�͑����ɊJ��������
���̂��ƋZ�p���悱���Ƃ���������
���̂��ƋZ�p���悱���Ƃ���������
IBM������ɂȂ�ˁ[��
�܁A���������������v���Z�X����Ȃ�����ˁB
IBM�̃G�A�M���b�v�Ƃ������p�����ꂽ��G��Ȃ�������B
�Ђ���Ƃ�����d�q�Ȃg��Ȃ��Ȃ邩���m��B
IBM�̃G�A�M���b�v�Ƃ������p�����ꂽ��G��Ȃ�������B
�Ђ���Ƃ�����d�q�Ȃg��Ȃ��Ȃ邩���m��B
3D�X�^�b�L���O�Ƃ�IBM�͖ʔ���
�ǂ��������p������ĂȂ���
�G�A�M���b�v�݂����ȐF���͓e���p
3D�X�^�b�L���O�݂����ɗL�]�����Ȃ̂�Intel������Ă邶���
�G�A�M���b�v�݂����ȐF���͓e���p
3D�X�^�b�L���O�݂����ɗL�]�����Ȃ̂�Intel������Ă邶���
�Ƃ���l�������Ă������A�����ɂ͐��N���X�̊�Ƃ����݂���Ƃ����B
�R�N���X��SQNY�̂悤�ȋU�R�s�[���ƁA
�Q�N���X�͐��I�ȃR�s�[����
�P�N���X�́A�V�F�A����
���E���ł�EVD�Ƃ����ADVD�ɕς�镨���o����Ƃ��L��Ƃ���
DVD�ł͂Ȃ�EVD�A���������ŃR�������S�ɐZ���������y������
�C�O��DVD�𒆍��Ŕ���ꍇDVD�ł͂Ȃ�EVD�����y���Ă���Ƃ�����A
�}�̂�DVD����EVD�ɕϊ�����K�v������A
EVD�𗘗p����ɂ������āA������Ƃɗ������x����Ȃ��Ă͂����Ȃ��Ȃ�B
EVD�����������Ő��Y�����A�X�ɑ���𗘗p���˂Ȃ�Ȃ��Ȃ�B
�����ŏ��������Ă����Ƃ��ɂ͑���𗘗p���˂Ȃ�Ȃ��Ȃ�����
�����̋K�i�𐢊E�ɔg�y�����悤�ƍl����̂��A�����̍l���������ȁB
�R�N���X��SQNY�̂悤�ȋU�R�s�[���ƁA
�Q�N���X�͐��I�ȃR�s�[����
�P�N���X�́A�V�F�A����
���E���ł�EVD�Ƃ����ADVD�ɕς�镨���o����Ƃ��L��Ƃ���
DVD�ł͂Ȃ�EVD�A���������ŃR�������S�ɐZ���������y������
�C�O��DVD�𒆍��Ŕ���ꍇDVD�ł͂Ȃ�EVD�����y���Ă���Ƃ�����A
�}�̂�DVD����EVD�ɕϊ�����K�v������A
EVD�𗘗p����ɂ������āA������Ƃɗ������x����Ȃ��Ă͂����Ȃ��Ȃ�B
EVD�����������Ő��Y�����A�X�ɑ���𗘗p���˂Ȃ�Ȃ��Ȃ�B
�����ŏ��������Ă����Ƃ��ɂ͑���𗘗p���˂Ȃ�Ȃ��Ȃ�����
�����̋K�i�𐢊E�ɔg�y�����悤�ƍl����̂��A�����̍l���������ȁB
�㓡�O��Weekly�C�O�j���[�X��
Intel����������GPU����CPU�uHavendale/Auburndale�v
http://pc.watch.impress.co.jp/docs/2007/1127/kaigai402.htm
�㓡�������ˁB�}���L���Ɩw�Ǔ������e�A�V���Ƃ��Ă͓���PCI-E��Gen2�Ƃ������Ƃ��炢���B
Intel����������GPU����CPU�uHavendale/Auburndale�v
http://pc.watch.impress.co.jp/docs/2007/1127/kaigai402.htm
�㓡�������ˁB�}���L���Ɩw�Ǔ������e�A�V���Ƃ��Ă͓���PCI-E��Gen2�Ƃ������Ƃ��炢���B
����
�摖���āi���ʓI�Ɂj�K�Z�l�^�͂܂���ċA���Ă����㓡
���D���l���Ă��Ƃō���̑����͏I�����B
�`���������Ƃ���ɂ��ƁE�E�Ȃ�ė]��A�e�ɂȂ��킯�ȁB�@
�摖���āi���ʓI�Ɂj�K�Z�l�^�͂܂���ċA���Ă����㓡
���D���l���Ă��Ƃō���̑����͏I�����B
�`���������Ƃ���ɂ��ƁE�E�Ȃ�ė]��A�e�ɂȂ��킯�ȁB�@
>>219
������A������x���ď����Ă邾��B
Intel�̓C�^�j�E�����璴�ȓd�͂܂ŁACPU���`�b�v�Z�b�g�S���Ńt�����C���i�b�v
�����A�S�Ẵt�@�u���Ő�[��45nm�̖�ł��Ȃ��B
nVidia��x86CPU�ɎQ�����ă����b�g������̂́A�~�h���m�[�g����~�h���f�X�N
�g�b�v���炢�̔��e����B����ȉ��ł͍���GPU�\�͂��v��Ȃ����A����ȏ�ł�
GPU�����ŏ������o����B
�Ő�[��C����t�@�u�ƁA���������̂�C����t�@�u�ƁA�����̃t�@�u�ɕ��U��
��Ώ[�������L���p�͊m�ۉ\����B
������A������x���ď����Ă邾��B
Intel�̓C�^�j�E�����璴�ȓd�͂܂ŁACPU���`�b�v�Z�b�g�S���Ńt�����C���i�b�v
�����A�S�Ẵt�@�u���Ő�[��45nm�̖�ł��Ȃ��B
nVidia��x86CPU�ɎQ�����ă����b�g������̂́A�~�h���m�[�g����~�h���f�X�N
�g�b�v���炢�̔��e����B����ȉ��ł͍���GPU�\�͂��v��Ȃ����A����ȏ�ł�
GPU�����ŏ������o����B
�Ő�[��C����t�@�u�ƁA���������̂�C����t�@�u�ƁA�����̃t�@�u�ɕ��U��
��Ώ[�������L���p�͊m�ۉ\����B
>>226
EVD�͗e�ʂ����s��DVD�Ɠ����Ȃ̂ŁA�S�R�����b�g�͖�����Ȃ��B
�l�I�ɂ�AVCHD�œ�wDVD�i8.4GB�j���g���AHQ���[�h(��9Mbps�j�Ŗ�Q����
�̘^�悪�\������A����ŏ[�����Ǝv���Ă�B
EVD�͗e�ʂ����s��DVD�Ɠ����Ȃ̂ŁA�S�R�����b�g�͖�����Ȃ��B
�l�I�ɂ�AVCHD�œ�wDVD�i8.4GB�j���g���AHQ���[�h(��9Mbps�j�Ŗ�Q����
�̘^�悪�\������A����ŏ[�����Ǝv���Ă�B
NVIDIA��x86 CPU������Ă��A����Fab�ł͂Ȃ�����A���ǁ��e�X�g�����ǂɎ��Ԃ�������A
��������p�������C�����ĂȂ킯�ł��Ȃ�����ACPU�N���b�N���オ��ɂ������낤�ȁB
���ʓI�Ɏ��͂̐i���ɂ��Ă������ɏI���B�[���B��������Intel������X������ˁH
��������p�������C�����ĂȂ킯�ł��Ȃ�����ACPU�N���b�N���オ��ɂ������낤�ȁB
���ʓI�Ɏ��͂̐i���ɂ��Ă������ɏI���B�[���B��������Intel������X������ˁH
>>228
�K�Z�l�^�������m���Ɋ�����������Ȃ�
�u���̎��_�ł�Intel������������Ƃ��������v�ł�����B
���Ƃ��A���[�������Ȃɂ��\���āA
������j���[�X������B
������ォ�犯�[�������ύX�����Ƃ��Ă��̐ӔC����Ȃ�����H
����͊��[���������\���������̂��u�����v������B
����ȏ�͓����ł����肵�ĂȂ��ȏ�A���̎��_�ł̎����ɂ͂������Ȃ��B
�����A���̏������ɏ���ɗ\�����āu���������̂��o���[��v��
�����Ƃ��ď������Ȃ炻��̓��C�^�[�̐摖�肾���A
�㓡�͂����܂ł���ĂȂ��B�u�����������m���o��\�������邾�낤�v�Ƃ�
�����̂͗\���̉���ɉ߂��Ȃ��B
�K�Z�l�^�������m���Ɋ�����������Ȃ�
�u���̎��_�ł�Intel������������Ƃ��������v�ł�����B
���Ƃ��A���[�������Ȃɂ��\���āA
������j���[�X������B
������ォ�犯�[�������ύX�����Ƃ��Ă��̐ӔC����Ȃ�����H
����͊��[���������\���������̂��u�����v������B
����ȏ�͓����ł����肵�ĂȂ��ȏ�A���̎��_�ł̎����ɂ͂������Ȃ��B
�����A���̏������ɏ���ɗ\�����āu���������̂��o���[��v��
�����Ƃ��ď������Ȃ炻��̓��C�^�[�̐摖�肾���A
�㓡�͂����܂ł���ĂȂ��B�u�����������m���o��\�������邾�낤�v�Ƃ�
�����̂͗\���̉���ɉ߂��Ȃ��B
���[�h�}�b�v���ύX���ꂽ��܂����H����BF�̃f���A���R�A�o�[�W�����̓L�����Z�����ꂽ�݂��������B
�����������[�N�������̂���肷����@�ɂ��g����
�ǂ���PCH�ɂȂ������Ȃ���AQPI�Ȃ�Ă��������ACPU����PCI-Express�o�X��
���ڂ͂₵�������V�X�e���S�̂̏���d�͂������Ă������Ă��ƂɂȂ����낤���H
DMI�{PCI-Expressx16�̕���QPI���ш拷���������ACPU�̃_�C�ʐς��������肻�������B
���ڂ͂₵�������V�X�e���S�̂̏���d�͂������Ă������Ă��ƂɂȂ����낤���H
DMI�{PCI-Expressx16�̕���QPI���ш拷���������ACPU�̃_�C�ʐς��������肻�������B
�`�b�v�����炷���߂���
�}�U�[�̏ȃG�l���y�уR�X�g�팸�A�Ӻݓ������ɂ��ȃG�l���y�ѓ`�����������ȂǓ��A�A�A����Ȃ��ł��傤��?
>>233
ttp://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
>Intel��Nehalem��GPU�R�A�����邱�Ƃ͖��ĂɂȂ����B
�u�����������m���o��\�������邾�낤�v�Ƃ�����
�\���̉�����߂����\������ȁB
���[��������ʂ�̗Ⴆ�b�������Ă邪
���[�������ǂݏグ��v���X�����[�X�i���e�j��
���̎��_�ŃI�[�\���C�Y���ꂽ���{�̌�������������
���Ƃ���ύX���Ă��������Ȃ��낤�B
>GPU������MCM�Ŏ�������̂��Ƃ�������ɑ��āA
>������ɐU���Ĕے肵���B
������uMCM�͖����v�ƌ㓡�͏�������
���̎��_�ł�Intel�̌����������ᖳ������@�R���B
���̏������ɏ���ɗ\�����āu���������̂��o���[��v��
�����Ƃ��ď��������炻��̓��C�^�[�̐摖��B
ttp://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
>Intel��Nehalem��GPU�R�A�����邱�Ƃ͖��ĂɂȂ����B
�u�����������m���o��\�������邾�낤�v�Ƃ�����
�\���̉�����߂����\������ȁB
���[��������ʂ�̗Ⴆ�b�������Ă邪
���[�������ǂݏグ��v���X�����[�X�i���e�j��
���̎��_�ŃI�[�\���C�Y���ꂽ���{�̌�������������
���Ƃ���ύX���Ă��������Ȃ��낤�B
>GPU������MCM�Ŏ�������̂��Ƃ�������ɑ��āA
>������ɐU���Ĕے肵���B
������uMCM�͖����v�ƌ㓡�͏�������
���̎��_�ł�Intel�̌����������ᖳ������@�R���B
���̏������ɏ���ɗ\�����āu���������̂��o���[��v��
�����Ƃ��ď��������炻��̓��C�^�[�̐摖��B
�������ɂ���͌�����������B
�v���X�����[�X�ȊO�������Ƃ������Ȃ邼�B
����̘b�����Č�����������Ȃ����B
�v���X�����[�X�ȊO�������Ƃ������Ȃ邼�B
����̘b�����Č�����������Ȃ����B
�\�����ԈႦ��͓̂ǂ݈Ⴂ�ł����Đ摖��Ƃ͌����
�摖��͖��m������m���̂悤�ɕA�����ꂪ���ۂƈقȂ�ꍇ
�摖��͖��m������m���̂悤�ɕA�����ꂪ���ۂƈقȂ�ꍇ
����o�����ł́A2�R�A��GPU�����ł������ĂȂ����ǁA2�R�A��MCM��GMCH�����Ƃ������Ƃ�����A
�]���̃`�b�v�Z�b�g�̃p�^�[���ʂ�GPU�Ȃ���MCH�������āA���������̂��낤���H
���ꂪ����Ȃ�A��ƌ�����3D���\�ႢGPU�g����������GPU����2�R�A�Ƃ����o�Ă������B
�]���̃`�b�v�Z�b�g�̃p�^�[���ʂ�GPU�Ȃ���MCH�������āA���������̂��낤���H
���ꂪ����Ȃ�A��ƌ�����3D���\�ႢGPU�g����������GPU����2�R�A�Ƃ����o�Ă������B
LynnField��HavenField�̃\�P�b�g�Ɍ݊���������̂����C�ɂȂ�ˁB�s�����͓����悤������
>>205
Transmeta�̂��Ƃ����܂ɂ͎v���o���Ă����Ă�������
Transmeta�̂��Ƃ����܂ɂ͎v���o���Ă����Ă�������
>>226
����EVD���Ă̂̓v���C���[�Ƃ��Ă͂ǂ��Ȃ�̂��ȁB
DVD�v���C���[�ł��Đ��o����́H
�o���Ȃ���A��ݺۃI�����[�̋K�i�ŏI��肾�낤���ǁB
����EVD���Ă̂̓v���C���[�Ƃ��Ă͂ǂ��Ȃ�̂��ȁB
DVD�v���C���[�ł��Đ��o����́H
�o���Ȃ���A��ݺۃI�����[�̋K�i�ŏI��肾�낤���ǁB
>>239
�����Intel�̊����̓������j���[�X�\�[�X�Ƃ���
�u�C���^�r���[�̓��e���m�x�̍������v�ƌ����O��̋L���ɉ߂��Ȃ��B
������B���āu�����Ȃ邱�ƂɁh����h���܂����v���ď������炽���̔n�������ǁB
Intel�̊����ɗ�������āA����Ƀj���[�X�\�[�X�𖾂����āA���̊����̔���������
�\���𗧂āA�u�C���^�r���[�̓��e����A�����Ȃ邱�Ƃ͖��ĂƂȂ����v�ƌ����Ă�̂�
�����܂Łu���̎��_�ł́v�m�x�̍����\�z�ł����Ȃ��B
>���̎��_�ł�Intel�̌����������ᖳ������@�R���B
�������\�ł͂Ȃ����A������x�͌��������ƌ��Ă��������x������B
�����[�̎Ј����������Ă��ē����Ō�点�Ă��Ȃ����H
�����Ǝʐ^���o��������������C���^�r���[���B
�C���^�r���[���z��Intel�����Ƃ��ăW���[�i���X�g�ɃC���^�r���[�Č�������Ƃ�
�u���A����͈�ʐl�Ƃ��Ėϑz����������ł��{�N�v�Œʂ�킯�Ȃ����낤w
�Г��Œ����Ă����Ƃ���Ă���͈͂̂��Ƃ����������R�����Ă��Ȃ��͂��B
�܂�A���̎��_�ł�Intel���������Ƃ�������B
�����Intel�̊����̓������j���[�X�\�[�X�Ƃ���
�u�C���^�r���[�̓��e���m�x�̍������v�ƌ����O��̋L���ɉ߂��Ȃ��B
������B���āu�����Ȃ邱�ƂɁh����h���܂����v���ď������炽���̔n�������ǁB
Intel�̊����ɗ�������āA����Ƀj���[�X�\�[�X�𖾂����āA���̊����̔���������
�\���𗧂āA�u�C���^�r���[�̓��e����A�����Ȃ邱�Ƃ͖��ĂƂȂ����v�ƌ����Ă�̂�
�����܂Łu���̎��_�ł́v�m�x�̍����\�z�ł����Ȃ��B
>���̎��_�ł�Intel�̌����������ᖳ������@�R���B
�������\�ł͂Ȃ����A������x�͌��������ƌ��Ă��������x������B
�����[�̎Ј����������Ă��ē����Ō�点�Ă��Ȃ����H
�����Ǝʐ^���o��������������C���^�r���[���B
�C���^�r���[���z��Intel�����Ƃ��ăW���[�i���X�g�ɃC���^�r���[�Č�������Ƃ�
�u���A����͈�ʐl�Ƃ��Ėϑz����������ł��{�N�v�Œʂ�킯�Ȃ����낤w
�Г��Œ����Ă����Ƃ���Ă���͈͂̂��Ƃ����������R�����Ă��Ȃ��͂��B
�܂�A���̎��_�ł�Intel���������Ƃ�������B
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
InOrder�Ő��\�͂قǂقǂɗ}������Silverthorne�ł́AGPU��ϋɓI�Ɋ��p����͗l
AMD�������Č����Ă邱�Ƃ��ɂǂ�ǂ�Intel���������Ă����ȁB
InOrder�Ő��\�͂قǂقǂɗ}������Silverthorne�ł́AGPU��ϋɓI�Ɋ��p����͗l
AMD�������Č����Ă邱�Ƃ��ɂǂ�ǂ�Intel���������Ă����ȁB
�o�b�Ɍ��炸�A�J�����̑���L���Ƃ����̂͊�{�I�Ɍ���̎������p�݂����Ȃ�����ȁB
���ԕ�o�߂��ꍏ�������m�肽���ƌ������c���܂�����łȂ��Ɣ�������̎��ȐӔC�œǂނ��̂ł�����
���ۂɏo�Ęb���Ⴄ�A�Ɠ{���Ă��͂��܂��B
����܂�g���f���Ȑ������Ă�L���͂��̕��������X���[�����낵�B
��ԃN�\�Ȃ̂́A�\����������Ƃ��O�������A���C�^�[�̐����ƁA��������������ɂȂ��Ă��ĕ����s�\�ȋL���B
���ԕ�o�߂��ꍏ�������m�肽���ƌ������c���܂�����łȂ��Ɣ�������̎��ȐӔC�œǂނ��̂ł�����
���ۂɏo�Ęb���Ⴄ�A�Ɠ{���Ă��͂��܂��B
����܂�g���f���Ȑ������Ă�L���͂��̕��������X���[�����낵�B
��ԃN�\�Ȃ̂́A�\����������Ƃ��O�������A���C�^�[�̐����ƁA��������������ɂȂ��Ă��ĕ����s�\�ȋL���B
InOrder+HT��1.8G���Ă��Ȃ�̓T����
�����܂��E�E�P�[�^�C��Z�b�g�g�b�v�{�b�N�X�p�����ȁE�E
>>248
AMD�����A���Č����Ă���e�͂����������Łu�����ς݁v
GPU�����ɂ���A�R�A���̃N���b�N�����ɂ���A�m�[�X�u���b�W�����ɂ���AAMD�͌㔭
AMD�����A���Č����Ă���e�͂����������Łu�����ς݁v
GPU�����ɂ���A�R�A���̃N���b�N�����ɂ���A�m�[�X�u���b�W�����ɂ���AAMD�͌㔭
�^�̃N�A�b�h�R�A�i�j�����Đ��E������Ȃ�����
�Ƃ����intel��GPU�����͐�Ώo���Ȃ��ƌ������Ă��z��͂ǂ��������́H
�����܂ł��Ă��܂��F�߂ĂȂ��Ƃ�������
�����܂ł��Ă��܂��F�߂ĂȂ��Ƃ�������
���������`�b�v�Z�b�g�̋@�\��CPU�Ɉڂ����Ƃ͕������Ă����Ƃ���
���ꂪ�������x���������̖��Ȃ͂��Ȃ̂�
�Ȃ�Ő�Ώo���Ȃ��Ȃ�Č������낤�Ȃ��E�E�E
���ꂪ�������x���������̖��Ȃ͂��Ȃ̂�
�Ȃ�Ő�Ώo���Ȃ��Ȃ�Č������낤�Ȃ��E�E�E
������CPU�Ȃ�ĕK�v�Ȃ���
��Ώo���Ȃ�
����z���g��
����z���g��
��Ώo����
����܂���(��)
����܂���(��)
���㓡�O��Weekly�C�O�j���[�X��
Intel��GPU����CPU�uHavendale/Auburndale�v�Ƃ͉���
http://pc.watch.impress.co.jp/docs/2007/1128/kaigai403.htm
�lj��̋L��������
Intel��GPU����CPU�uHavendale/Auburndale�v�Ƃ͉���
http://pc.watch.impress.co.jp/docs/2007/1128/kaigai403.htm
�lj��̋L��������
http://www.itmedia.co.jp/news/articles/0711/28/news054.html
Lynnfield��Havendale���ł�2009�N���ƃm�[�gPC�̕����V�F�A����̉\�������ɍ�������A
�m�[�g�����̃f�U�C�����D�悳�ꂽ���Ă��Ƃ��낤���B
Lynnfield��Havendale���ł�2009�N���ƃm�[�gPC�̕����V�F�A����̉\�������ɍ�������A
�m�[�g�����̃f�U�C�����D�悳�ꂽ���Ă��Ƃ��낤���B
MCM���QPI�ł���Z�p����̂�
�Ȃ�ŃI�N�^�R�A�Ɏg��Ȃ��H
�Ȃ�ŃI�N�^�R�A�Ɏg��Ȃ��H
�����ς�炸�㓡���Ƃ���
Havendale/Auburndale��"GPU����CPU"�Ə����Ă邪
�u���_�C�I�ɁA�ǂ����Ă��m�[�X�u���b�W�����Ƃ���������Ǝv�����B
GPU�ƌ����Ă�GMA3X00����
(�Ƃ肠����3D�Q�[���͍Œ���œ���+�Đ��x���@�\�j��
�Q�t�H��f�̒P�̃J�[�h��
�K�`�Ō��܂������ł��Ȃ���������U���ȕ\�����B
�}�����̍l�@�ʂ�
Intel�ސ��`�b�v�Z�b�g�ȊO�̒��ߏo��(�Ԃ����ႰNVIDIA��j
���ړI�ŁA�ǂ����̂��Ԕ����C�^�[������
Intel���w�e���W�j�A�X�R�A�֑ǂ������A����
GPU�̔ėp���A�Ƃ͑S���W�����B
Havendale/Auburndale��"GPU����CPU"�Ə����Ă邪
�u���_�C�I�ɁA�ǂ����Ă��m�[�X�u���b�W�����Ƃ���������Ǝv�����B
GPU�ƌ����Ă�GMA3X00����
(�Ƃ肠����3D�Q�[���͍Œ���œ���+�Đ��x���@�\�j��
�Q�t�H��f�̒P�̃J�[�h��
�K�`�Ō��܂������ł��Ȃ���������U���ȕ\�����B
�}�����̍l�@�ʂ�
Intel�ސ��`�b�v�Z�b�g�ȊO�̒��ߏo��(�Ԃ����ႰNVIDIA��j
���ړI�ŁA�ǂ����̂��Ԕ����C�^�[������
Intel���w�e���W�j�A�X�R�A�֑ǂ������A����
GPU�̔ėp���A�Ƃ͑S���W�����B
http://northwood.blog60.fc2.com/blog-entry-767.html
Guiseppe Amato���ɂ���Fusion�͂܂�Multi-chip module�iMCM�j�œo�ꂷ��Ƃ����B
MCM�̓V���O���_�C�Ɣ�r���A���_����������邱�Ƃ��o�����Amato���͕t���������B
�Ⴆ�Ƃ��āAAMD��CPU��DirectX 10�Ή�GPU�������Ƃ���B�����A������DirectX 11��
�o�ꂵ�Ă��܂��ƁAAMD�̓`�b�v�̍Đv��1����s��Ȃ��Ă͂Ȃ�Ȃ��B�������AMCM�Ƃ���
���������CPU�����͂��̂܂܂ŁAGPU����������V�������̂ɂ�������B
Guiseppe Amato���ɂ���Fusion�͂܂�Multi-chip module�iMCM�j�œo�ꂷ��Ƃ����B
MCM�̓V���O���_�C�Ɣ�r���A���_����������邱�Ƃ��o�����Amato���͕t���������B
�Ⴆ�Ƃ��āAAMD��CPU��DirectX 10�Ή�GPU�������Ƃ���B�����A������DirectX 11��
�o�ꂵ�Ă��܂��ƁAAMD�̓`�b�v�̍Đv��1����s��Ȃ��Ă͂Ȃ�Ȃ��B�������AMCM�Ƃ���
���������CPU�����͂��̂܂܂ŁAGPU����������V�������̂ɂ�������B
�����ł��ˁH�킩��܂�������
(Intel|AMD)��CPU��DirectX n�Ή�GPU�������Ƃ���B
�����A������DirectX n+1���o�ꂵ�Ă��܂��ƁA
(Intel|AMD)�̓`�b�v�̍Đv��1����s��Ȃ��Ă͂Ȃ�Ȃ��B
�������AMCM�Ƃ��Ď��������CPU�����͂��̂܂܂ŁA
GPU����������V�������̂ɂ�������B
(Intel|AMD)��CPU��DirectX n�Ή�GPU�������Ƃ���B
�����A������DirectX n+1���o�ꂵ�Ă��܂��ƁA
(Intel|AMD)�̓`�b�v�̍Đv��1����s��Ȃ��Ă͂Ȃ�Ȃ��B
�������AMCM�Ƃ��Ď��������CPU�����͂��̂܂܂ŁA
GPU����������V�������̂ɂ�������B
>262
GPU����CPU��GPGPU����������ɂ��ĂȂ����H
�K�͂��������낤���傫���낤��GPU��GPU�����A��������ł�
�I���_�C�ɂ��Ă�����Č��������������
���ɕ\�����悤���Ȃ����낤�B
�u�K�͂̂������ႢGPU���ۂ��̂�CPU�Ɠ����p�b�P�[�W�ɂ���v��v
�ƕ\������Ƃł������̂�w
GPU����CPU��GPGPU����������ɂ��ĂȂ����H
�K�͂��������낤���傫���낤��GPU��GPU�����A��������ł�
�I���_�C�ɂ��Ă�����Č��������������
���ɕ\�����悤���Ȃ����낤�B
�u�K�͂̂������ႢGPU���ۂ��̂�CPU�Ɠ����p�b�P�[�W�ɂ���v��v
�ƕ\������Ƃł������̂�w
GPU��������ƃA�C�f���e�B�e�B������r����
GPU��������Ȃ��AMB��GPU����&�Ӻݓ���+GDDR�������Ƒ���
Nehalem�ł�MCM�ł�Westmere��Sandy Bridge�ł͊m���Ƀ_�C�ɓ������Ă���ł���B
Timna�v�����̕����ɂ����Ȃ��̂ɉ������܂��瑛���ł��
>>269
Timna�����āA�����ł���悤�₭x86�����A���ė��ꂾ���������
Timna�����āA�����ł���悤�₭x86�����A���ė��ꂾ���������
SoC��SiP�I�ȗ���Ō��邩�ǂ����ł܂����낢���
x86������Timna�̑O�ɂ��ł�MediaGX���������킯�łˁB
�܂��AIntel GPU�̓����Ȃ��
���ꂪ�ǂ������́H
�����ς�����́H
�����o����悤�ɂȂ�́H
���x��
���ꂪ�ǂ������́H
�����ς�����́H
�����o����悤�ɂȂ�́H
���x��
���Ǐ���҂Ɂu�����đ����ĔM���Ȃ��vPC�𑁂��o���邩�ǂ������̐S������ȁB
CPU�ƃO���t�B�b�N�����`�b�v�Z�b�g��
�����o�X�ڑ�������GPU����CPU�ɂȂ�Ƃ���
�㓡���w�����x��`�ɏ]���ƁA810�ȍ~��Intel��CPU��
�قƂ��GPU�����ɂȂ��Ă��܂�����Ȃ��B
�{���̈Ӗ��ł�GPU���������ꂽCPU��
�����T���v���R�A���瑶�݂��Ȃ�FUSION�Ƃ���
AMD�Ӑg�̃l�^CPU���o��܂ł��a�����ȁB
�����o�X�ڑ�������GPU����CPU�ɂȂ�Ƃ���
�㓡���w�����x��`�ɏ]���ƁA810�ȍ~��Intel��CPU��
�قƂ��GPU�����ɂȂ��Ă��܂�����Ȃ��B
�{���̈Ӗ��ł�GPU���������ꂽCPU��
�����T���v���R�A���瑶�݂��Ȃ�FUSION�Ƃ���
AMD�Ӑg�̃l�^CPU���o��܂ł��a�����ȁB
http://www.matbe.com/articles/lire/561/amd-phenom-9600-et-9500/
���͂�A�S�Ă̖ʂ�Intel�͗D��Ă܂���
���͂�A�S�Ă̖ʂ�Intel�͗D��Ă܂���
�I���_�C��GPU������̂ɂ͋^�⎋���Ă��z�͌��\�����������ǁA
�܂��������R���܂ŕʃ_�C�ŁA�܂�]����GMCH��MCM�œ����Ǝv���Ă��̂�
�����h���낤�ȁB
�㓡���Ƃ������A�C���e�������Ǝv�����ǁB���ł�AMD��FUSION��MCM����Ȃ�������
�b���o�Ă邵�B
TSMC��CPU�����Y����悤�ɂȂ�炵������A�m�[�g�����̓I���_�C�̉\�����\�����邯�ǁA
�f�X�N�g�b�v�����C���X�g���[��������FUSION�͂ǂ��Ȃ邱�Ƃ��B
�܂��������R���܂ŕʃ_�C�ŁA�܂�]����GMCH��MCM�œ����Ǝv���Ă��̂�
�����h���낤�ȁB
�㓡���Ƃ������A�C���e�������Ǝv�����ǁB���ł�AMD��FUSION��MCM����Ȃ�������
�b���o�Ă邵�B
TSMC��CPU�����Y����悤�ɂȂ�炵������A�m�[�g�����̓I���_�C�̉\�����\�����邯�ǁA
�f�X�N�g�b�v�����C���X�g���[��������FUSION�͂ǂ��Ȃ邱�Ƃ��B
>>275
����͌㓡����`����Ȃ��đ��O�̒�`����B�B
����͌㓡����`����Ȃ��đ��O�̒�`����B�B
����㓡��FUSION�W�̋L���Ō����Ă��̂�
�ƊE�S�̂̃g�����h���ǂ��Ƃ����\�̌���ׂ̈ɓ������K�{���Ƃ��̈�ۑ���ł���
������̓s�����Ƃ���߂���������Ȃ��z�̓����_�[���Ă�����
�ƊE�S�̂̃g�����h���ǂ��Ƃ����\�̌���ׂ̈ɓ������K�{���Ƃ��̈�ۑ���ł���
������̓s�����Ƃ���߂���������Ȃ��z�̓����_�[���Ă�����
�����̋C�ɓ����Ă��Ђ������o���ƁA�Ⴆ���ꂪ�ƊE�ł͕��y���ĂĂ��u�ƊE�̃g�����h�v�ƌ����Ă��܂��̂������̃g�����h
Intel�̏ꍇ�g�����h�ɋt�s���邩�g�����h����邩�ǂ��炩�����Ȃ��Ȃ�
�Ƃ�����GPU�����Ƃ������t�ɗx�炳��Ă��������݂��������猾���Ă������A
����̏ꍇGPU�����ł͂Ȃ���GMCH�̓����Ƃ����ׂ��B
Pxx�n��̂悤�ɍ���GPU���������������̂��o�Ă��Ă��S�R�����Ȃ��B
����̏ꍇGPU�����ł͂Ȃ���GMCH�̓����Ƃ����ׂ��B
Pxx�n��̂悤�ɍ���GPU���������������̂��o�Ă��Ă��S�R�����Ȃ��B
�⑫����ƁA�����GMCH�̓���(�Ƃ������ړ�)�̓{�[�h�g�[�^���̃R�X�g�����������A
�̂����̖ړI����B�ł���BGA2�悹�ė��ꂽ�Ƃ���ɓd���������Ȃ��Ă��ނ悤��
�Ȃ�킯�����ȁB���Ƃ��ƃm�[�g�p�ł͏ȃX�y�[�X���̓s����������Lynnfield�̂悤��
�W�J�������������ł���BMCM�̃����b�g�ǂ����������Ă��邪�����I�ɂ͒P��_�C��
�܂Ƃ܂�Ǝv���B
�̂����̖ړI����B�ł���BGA2�悹�ė��ꂽ�Ƃ���ɓd���������Ȃ��Ă��ނ悤��
�Ȃ�킯�����ȁB���Ƃ��ƃm�[�g�p�ł͏ȃX�y�[�X���̓s����������Lynnfield�̂悤��
�W�J�������������ł���BMCM�̃����b�g�ǂ����������Ă��邪�����I�ɂ͒P��_�C��
�܂Ƃ܂�Ǝv���B
PC Watch�������Ă����̂ŁA�㓡�L����S���ǂ܂��ɏ����Ă��܂������A
GMCH�̓����݂����ȋL���ł����Ə����Ă邶��Ȃ���
(������Lynnfield�͂�������GPU�Ȃ��̊G�ɂȂ��Ă邵)�B���܂�B
GMCH�̓����݂����ȋL���ł����Ə����Ă邶��Ȃ���
(������Lynnfield�͂�������GPU�Ȃ��̊G�ɂȂ��Ă邵)�B���܂�B
GMCH�̒��ɂ���GPU����
PS����8��10�ɑ��₵��GMA3100��p(DX10�t���Ή��j���ă��c����B
Nehalem����ɂȂ��Ă������r�f�I�͍����啝�Ɋg���o���Ȃ�����
����̃��C�A�E�g�̃����b�g�̓{�[�h�̃f�U�C�����y�ɂȂ邮�炢���ȁB
��m���Ȃ̂�Nehalem��
�w�e���W�j�A�X�}���`�R�A�Ȃ�Ĉӎ����ĂȂ��̂�
���ĂŖ��m�Ȃ͖̂��炩�ɂȂ����B�i�㓡�O�Ε��j
PS����8��10�ɑ��₵��GMA3100��p(DX10�t���Ή��j���ă��c����B
Nehalem����ɂȂ��Ă������r�f�I�͍����啝�Ɋg���o���Ȃ�����
����̃��C�A�E�g�̃����b�g�̓{�[�h�̃f�U�C�����y�ɂȂ邮�炢���ȁB
��m���Ȃ̂�Nehalem��
�w�e���W�j�A�X�}���`�R�A�Ȃ�Ĉӎ����ĂȂ��̂�
���ĂŖ��m�Ȃ͖̂��炩�ɂȂ����B�i�㓡�O�Ε��j
>>284
�Ƃ������A�����Ă��̏ꍇ�A�㓡�́u�l������
�S���̉\���v�ɂ��ď����Ă邾���Ȃ�
���̒��ň�ԁA
�u�ق�Ƃɏ�肭�s�����琦�����v�ȗ\�z�ɂ���
�~���ߏ蔽������
�����Ă�����͓�����́A�����܂ł̏�Q���̂�
���L���Ă�����ǑS���X���[������ȁB�B
�Ƃ������A�����Ă��̏ꍇ�A�㓡�́u�l������
�S���̉\���v�ɂ��ď����Ă邾���Ȃ�
���̒��ň�ԁA
�u�ق�Ƃɏ�肭�s�����琦�����v�ȗ\�z�ɂ���
�~���ߏ蔽������
�����Ă�����͓�����́A�����܂ł̏�Q���̂�
���L���Ă�����ǑS���X���[������ȁB�B
ttp://www.theinquirer.net/gb/inquirer/news/2007/11/29/x86-multicore-processing
X86 multicore processing parallelism is a dream
Firm adapts Cell, graphics compiler to X86
X86 multicore processing parallelism is a dream
Firm adapts Cell, graphics compiler to X86
CPU�ƃm�[�X�̐ڑ���FSB����QPI�ɕς����������
GPU����CPU�Ȃ�ď����ꂽ��
�u�����Ⴄ����v�ƃc�b�R�~���ꂽ���Ȃ�̂������邪�ȁB
�����̍Œ�Ӄr�f�I�J�[�h������SP��40��ς�ł邩��(TU�AROP�͓Ɨ��j
���F�͓����r�f�I�@�\�ł����ĒP��GPU�Ƃ͖��܂�Ȃ������L��킯�����B
�t���[�W������Radeon2600�����蓝������u�炵���v����
�A���͊ԈႢ�Ȃ�GPU����CPU�A�܂��{���ɏo�Ă��邩�͉��������c
GPU����CPU�Ȃ�ď����ꂽ��
�u�����Ⴄ����v�ƃc�b�R�~���ꂽ���Ȃ�̂������邪�ȁB
�����̍Œ�Ӄr�f�I�J�[�h������SP��40��ς�ł邩��(TU�AROP�͓Ɨ��j
���F�͓����r�f�I�@�\�ł����ĒP��GPU�Ƃ͖��܂�Ȃ������L��킯�����B
�t���[�W������Radeon2600�����蓝������u�炵���v����
�A���͊ԈႢ�Ȃ�GPU����CPU�A�܂��{���ɏo�Ă��邩�͉��������c
AMD��fusion��������MCM����
�}���`GPU�O����R700�����GPU�Ƃ����
GPU���̂�HT�����Ă�\��������
��Ԋy�Ȃ̂͂�������̂܂܃p�b�P�[�W���O���Ă��܂��Ηǂ�
(R700��1�_�C������100mm2�ȉ���500gflops(�P)�Ƃ̂��킳�j
�}���`GPU�O����R700�����GPU�Ƃ����
GPU���̂�HT�����Ă�\��������
��Ԋy�Ȃ̂͂�������̂܂܃p�b�P�[�W���O���Ă��܂��Ηǂ�
(R700��1�_�C������100mm2�ȉ���500gflops(�P)�Ƃ̂��킳�j
��Yorkfield (Quad Core�A45nm process�ALGA775) (���{�~�͌����_�ł̔̔��\�z���i)
�`�`�`
��QX9770�F3.20GHz (400x8.0/FSB1600)�AL2 6MBx2�ATDP 136W�A1399 US�h��(15��5000�~)
��QX9650�F3.00GHz (333x9.0/FSB1333)�AL2 6MBx2�ATDP 130W�A999 US�h��(10��9800�~)
�`�`�`
�� Q9550 �F2.83GHz (333x8.5/FSB1333)�AL2 6MBx2�ATDP 95W�A530 US�h��(5��7770�~)
�� Q9450 �F2.66GHz (333x8.0/FSB1333)�AL2 6MBx2�ATDP 95W�A316 US�h��(3��4440�~)
�� Q9300 �F2.50GHz (333x7.5/FSB1333)�AL2 3MBx2�ATDP 95W�A266 US�h��(2��9000�~)
�`�`�`
��Wolfdale (Dual Core�A45nm process�ALGA775)
�� E8500 �F3.16GHz (333x9.5/FSB1333)�AL2 6MB�ATDP 65W�A266 US�h��(2��9000�~)
�� E8400 �F3.00GHz (333x9.0/FSB1333)�AL2 6MB�ATDP 65W�A183 US�h��(1��9000�~)
�� E8300 �F2.83GHz (333x8.5/FSB1333)�AL2 6MB�ATDP 65W�A�|US�h��
�� E8200 �F2.66GHz (333x8.0/FSB1333)�AL2 6MB�ATDP 65W�A163 US�h��(1��8000�~)
�� E8190 �F2.66GHz (333x8.0/FSB1333)�AL2 6MB�ATDP 65W�A163 US�h��(1��8000�~)
�`�`�`
�`�`�`
��QX9770�F3.20GHz (400x8.0/FSB1600)�AL2 6MBx2�ATDP 136W�A1399 US�h��(15��5000�~)
��QX9650�F3.00GHz (333x9.0/FSB1333)�AL2 6MBx2�ATDP 130W�A999 US�h��(10��9800�~)
�`�`�`
�� Q9550 �F2.83GHz (333x8.5/FSB1333)�AL2 6MBx2�ATDP 95W�A530 US�h��(5��7770�~)
�� Q9450 �F2.66GHz (333x8.0/FSB1333)�AL2 6MBx2�ATDP 95W�A316 US�h��(3��4440�~)
�� Q9300 �F2.50GHz (333x7.5/FSB1333)�AL2 3MBx2�ATDP 95W�A266 US�h��(2��9000�~)
�`�`�`
��Wolfdale (Dual Core�A45nm process�ALGA775)
�� E8500 �F3.16GHz (333x9.5/FSB1333)�AL2 6MB�ATDP 65W�A266 US�h��(2��9000�~)
�� E8400 �F3.00GHz (333x9.0/FSB1333)�AL2 6MB�ATDP 65W�A183 US�h��(1��9000�~)
�� E8300 �F2.83GHz (333x8.5/FSB1333)�AL2 6MB�ATDP 65W�A�|US�h��
�� E8200 �F2.66GHz (333x8.0/FSB1333)�AL2 6MB�ATDP 65W�A163 US�h��(1��8000�~)
�� E8190 �F2.66GHz (333x8.0/FSB1333)�AL2 6MB�ATDP 65W�A163 US�h��(1��8000�~)
�`�`�`
E8400���������ȁB ������1���������H
183US�h����1��9,000�~���Ăǂ�Ȗ�����������I
2��2�`3,000�~���낤�ȁB
2��2�`3,000�~���낤�ȁB
�G������������
���܂�E6750�Ɠ����i�Ȃ�����{�ł̔��l���قړ���
�i������1500�~���x�̂��j�V�����j�Ɍ��܂��Ƃ�B
�i������1500�~���x�̂��j�V�����j�Ɍ��܂��Ƃ�B
Lynnfield�Ɋ��ҁB
http://northwood.blog60.fc2.com/blog-entry-1481.html#more
http://northwood.blog60.fc2.com/blog-entry-1481.html#more
Bloomfield��TDP130W��Lynnfield��95W�����āH
Bloomfield��Lynnfield�̈Ⴂ����
�����R���̃`���l�����ƁAQPI��PCIe2.0�ɕς�������x����B
���ꂾ����35W�������o��Ǝv����A
Bloomfield���Lynnfield�̃N���b�N�������Ĕ̔�������j���Ď������ȁH
Bloomfield��Lynnfield�̈Ⴂ����
�����R���̃`���l�����ƁAQPI��PCIe2.0�ɕς�������x����B
���ꂾ����35W�������o��Ǝv����A
Bloomfield���Lynnfield�̃N���b�N�������Ĕ̔�������j���Ď������ȁH
����QX��Q�̈Ⴂ�݂����Ȃ���Ȃ��́H
Bloomfield��TDP130W�Ɏ��܂�̂�1�C2��ނ����o���Ȃ���Ȃ����ȁB
�ǂ���Intel�̂��Ƃ�����ABloomfield��Nehalem-EP��QPI��1�����N���������]�p�ł��낤����A
�����Ȃ��Ă����v���낤���B
32nm�ɂȂ�����A���������PCI-Express��32���[�����ɂȂ��āABloomfield�����̂�
�Ȃ��Ȃ��Ă����肵�āB
Bloomfield��TDP130W�Ɏ��܂�̂�1�C2��ނ����o���Ȃ���Ȃ����ȁB
�ǂ���Intel�̂��Ƃ�����ABloomfield��Nehalem-EP��QPI��1�����N���������]�p�ł��낤����A
�����Ȃ��Ă����v���낤���B
32nm�ɂȂ�����A���������PCI-Express��32���[�����ɂȂ��āABloomfield�����̂�
�Ȃ��Ȃ��Ă����肵�āB
�����s���Ȃ̂���`�킩���B
�������܂ޏ��������㓡�Ȃ̂�
�㓡�̋L�����ĐV���ɋL���������C�O�T�C�g�Ȃ̂�
�C�O�T�C�g�̏����u���������v�Ƃ��Ď�舵���z�Ȃ̂��B
�������܂ޏ��������㓡�Ȃ̂�
�㓡�̋L�����ĐV���ɋL���������C�O�T�C�g�Ȃ̂�
�C�O�T�C�g�̏����u���������v�Ƃ��Ď�舵���z�Ȃ̂��B
�H
�����s���Ȃ�����
�ʔ������ۂ��Ȃ��A�Ǝv��������
�����s���Ȃ�����
�ʔ������ۂ��Ȃ��A�Ǝv��������
���̔S���Ńt�@�r�����Ă�̂͊�{�I�ɋL���ǂ܂Ȃ�����ȁB
�܂��ĉp��Ȃ�đS���ǂ߂₵�Ȃ�����X���[���邵���Ȃ���
�܂��ĉp��Ȃ�đS���ǂ߂₵�Ȃ�����X���[���邵���Ȃ���
303 �FSocket774�F2007/12/01(�y) 23:55:51 ID:EO1wBDlD
ID:ghPN/KKb
�ǂ��ł��������ǁA
GMCH�����ō����cpu�N���b�N�����̂܂܈ێ��Ȃ�Ă��Ƃ͂�߂Ă���B
5GHz�A���߂�4GHz�܂ł͂����Ă����B
GMCH�����ō����cpu�N���b�N�����̂܂܈ێ��Ȃ�Ă��Ƃ͂�߂Ă���B
5GHz�A���߂�4GHz�܂ł͂����Ă����B
�㓡�M�҂�
577 �FSocket774�F2007/12/01(�y) 22:07:53 ID:ghPN/KKb
>>565
���Ԏ�������f�ڂ��ꂽ�lj����ł��B
����A���X��TDP�AHavendale��CPU-�m�[�X�Ԑڑ���QPI�A
�ǂ�����4�`5���O�̌㓡�L���ɏ����Ă�����[��
�i��������x86watch�̋L���`���ɏ����Ă���A����͓��{��PC WATCH����̏���āj
�����Beckton��Gainestown�ɂ������Ă�
�k�X���g������ߋ��ɋL���ɂ��Ƃ�̂�
http://northwood.blog60.fc2.com/?q=Gainestown
�㓡�L���ł́u�`�Ɛ��������v�u�`�ƌ�����v
���������Ă�����ł��A�����̉\�T�C�g���o�R����Ɗ�����������ۼ���
>>565
���Ԏ�������f�ڂ��ꂽ�lj����ł��B
����A���X��TDP�AHavendale��CPU-�m�[�X�Ԑڑ���QPI�A
�ǂ�����4�`5���O�̌㓡�L���ɏ����Ă�����[��
�i��������x86watch�̋L���`���ɏ����Ă���A����͓��{��PC WATCH����̏���āj
�����Beckton��Gainestown�ɂ������Ă�
�k�X���g������ߋ��ɋL���ɂ��Ƃ�̂�
http://northwood.blog60.fc2.com/?q=Gainestown
�㓡�L���ł́u�`�Ɛ��������v�u�`�ƌ�����v
���������Ă�����ł��A�����̉\�T�C�g���o�R����Ɗ�����������ۼ���
PC Watch�����l�^�Ȃ�ł��ˁB�킩��܂����B
�k�X�͂��܂ɓ˂����݂ǂ��떞�ڂȂ��Ƃ�炩�����ǁA�T�˕֗��Ȃ���
���ق��Ă���
���ق��Ă���
>>306
���q�ł���3.8GHx���o���Ă�̂ɁACore2��4GHz�ȏ���o���Ȃ��̂͑Ӗ��������Ƃ��낾��ȁB
���ɖ��ʂȕ�����Tr��p���Ċg�����Ă���㩁B
���q�ł���3.8GHx���o���Ă�̂ɁACore2��4GHz�ȏ���o���Ȃ��̂͑Ӗ��������Ƃ��낾��ȁB
���ɖ��ʂȕ�����Tr��p���Ċg�����Ă���㩁B
�ނ�܂���?
>>315
Lynnfield�̓��C���X�g���[�����������牺�͂R�����x�B�}�U�[���Q���A
��������DDR3�ō����Ƃ͂������̍��Ȃ�4GB�łQ�����x���낤�B
�]�T����Ȃ��H
Lynnfield�̓��C���X�g���[�����������牺�͂R�����x�B�}�U�[���Q���A
��������DDR3�ō����Ƃ͂������̍��Ȃ�4GB�łQ�����x���낤�B
�]�T����Ȃ��H
���܂Œʂ肾�ƈ�ԉ���Quad��266�h�����炢�Ŕ������܂����H
�����A�V���O���_�C��280mm2������R�X�g�I�ɂ͂����������l�Ŕ��肽���Ƃ��낾�낤�B
��͂�AMD���悩�E�E�E�B
�����A�V���O���_�C��280mm2������R�X�g�I�ɂ͂����������l�Ŕ��肽���Ƃ��낾�낤�B
��͂�AMD���悩�E�E�E�B
Nehalem����͂ǂ��������i�̌n�ɂȂ�낤�B
Intel����MCH�AGMCH���s�v�ƂȂ�Lynnfield/Havendale�͂��̕�10�h����20�h�����炢
�������肻�������ǁB
Intel����MCH�AGMCH���s�v�ƂȂ�Lynnfield/Havendale�͂��̕�10�h����20�h�����炢
�������肻�������ǁB
>>317
�����x�̃_�C�T�C�Y�̃P���c��266�j�ɂȂ����͓̂o�ꂩ�甼�N�ゾ��
�����x�̃_�C�T�C�Y�̃P���c��266�j�ɂȂ����͓̂o�ꂩ�甼�N�ゾ��
�Q�l
$37�@945G
$33�@945P
$30�@P31/G31
$25�@945GC
$37�@945G
$33�@945P
$30�@P31/G31
$25�@945GC
>>320
������ăT�E�X���݂̒l�i����Ȃ��H
������ăT�E�X���݂̒l�i����Ȃ��H
Intel�̐V�^�`�b�v�Z�b�g�̉��i��AMD�̃f�X�N�g�b�vCPU��ASP��������
Lynnfield�̎��ɂ܂�Socket���ς�肻���ŋ�����(�L��֥`)
32nm��Westmere��2009Q4�����肩�B���������܂�DDR3���낤���AIntel���݊������ێ����悤��
����ΑΉ��\���ȁB�Z�p�I�ɂ͂ˁE�E�E�B
����ΑΉ��\���ȁB�Z�p�I�ɂ͂ˁE�E�E�B
DDR2�������ǁA�䖝����
327 �FSocket774�F2007/12/04(��) 12:58:50 ID:cqoyBxqD
�������ɂb�o�t�������Ǝv�����ǁA����ς肨�����߂��͒ʔ̂Ƃ��I�[�N�V�����Ƃ������Ȃ�ȁ`�H
�ǂ���Ǝv���H�H
�ǂ���Ǝv���H�H
�t�ɔN���N�n�͐l�����Ȃ��Ȃ邩��Ƃ�ł��Ȃ��j�i�ŗ������肷�邪��
�܂��A�����l�͏o�i���Ȃ����낤�ȁB
�܂��A�����l�͏o�i���Ȃ����낤�ȁB
>>327
1��20���ɍŏ�ʈȊO��Penryn�t�@�~���[�������Ƃ����\���E�E�E
�҂Ă�Ȃ�҂����������������B
http://northwood.blog60.fc2.com/blog-entry-1487.html
1��20���ɍŏ�ʈȊO��Penryn�t�@�~���[�������Ƃ����\���E�E�E
�҂Ă�Ȃ�҂����������������B
http://northwood.blog60.fc2.com/blog-entry-1487.html
>>9>>11
���ށA���C�ł���Ȃ��Ə��������
http://pc.watch.impress.co.jp/docs/2007/1205/shopping02.htm
��������Q�[�����\�����̂܂�CPU�̃R�A���Ɉˑ�����悤�Ȃ��̂��o�Ă��������B
���ށA���C�ł���Ȃ��Ə��������
http://pc.watch.impress.co.jp/docs/2007/1205/shopping02.htm
��������Q�[�����\�����̂܂�CPU�̃R�A���Ɉˑ�����悤�Ȃ��̂��o�Ă��������B
331 �FSocket774�F2007/12/06(��) 14:37:07 ID:DNGKRwQ4
Nehalem�͌����coreMA���z�����Ȃ��Ǝv����B
���͂�coreMA��X86�̊����`�B�����ȉ��ǂ�������Ǎ��i�ł�����z����86�݊���
���肦�Ȃ����A�����ɂ���͍����CPU���W�̂��߁A86�݊�CPU�̏I�����Ӗ����Ă���B
Nehalem��intel�����̌��f�𔗂��邽�߂̓k�ԁB�߂������ȁA�炭���Ƃ̖����Ō��86�݊��Ȃ̂��B
���͂�coreMA��X86�̊����`�B�����ȉ��ǂ�������Ǎ��i�ł�����z����86�݊���
���肦�Ȃ����A�����ɂ���͍����CPU���W�̂��߁A86�݊�CPU�̏I�����Ӗ����Ă���B
Nehalem��intel�����̌��f�𔗂��邽�߂̓k�ԁB�߂������ȁA�炭���Ƃ̖����Ō��86�݊��Ȃ̂��B
�ǂ���(ry
Windows��POWER�ɃV�t�g���Ă�����
Intel��PowerPC�Ƃ��݂Ă݂Ă�
Intel��PowerPC�Ƃ��݂Ă݂Ă�
>>331
386����������悤�Ȃ��ƌ����Ă������ǁA���ʂ�486���Ŕj�����܂����B
386����������悤�Ȃ��ƌ����Ă������ǁA���ʂ�486���Ŕj�����܂����B
>>334
���������̉r���֎~
���������̉r���֎~
�����������ď�������Ă��܂�����
386�̂Ƃ��́ARISC��1/3�̃g�����W�X�^��
���\��3�`10�{�Ƃ������������
CISC��RISC�ɏ��ĂȂ����Ă������`�͐�����������ł�
386�̂Ƃ��́ARISC��1/3�̃g�����W�X�^��
���\��3�`10�{�Ƃ������������
CISC��RISC�ɏ��ĂȂ����Ă������`�͐�����������ł�
���߂��A��������ʂ�����B
�����������������������B
386�̂Ƃ���ARISC��1/3�̃g�����W�X�^��
���\��3�`10�{�Ƃ����������B
CISC��RISC�ɏ��ĂȂ����Ă������`�͐���������B
386�̂Ƃ���ARISC��1/3�̃g�����W�X�^��
���\��3�`10�{�Ƃ����������B
CISC��RISC�ɏ��ĂȂ����Ă������`�͐���������B
����x86�ɐ��\�I�Ȍ���͖���
���ӋZ�p�̉��ǂ݂̂��s���Ă����Ηǂ��ȂǂƉߐM����
�ǂ����̃��[�J�[������ׂꂩ�����Ă��܂���
���ӋZ�p�̉��ǂ݂̂��s���Ă����Ηǂ��ȂǂƉߐM����
�ǂ����̃��[�J�[������ׂꂩ�����Ă��܂���
���̔�Ax86�����g���Ȃ��̃E���̃��[�U�[���W�܂��Ă邷�B
�������ɂ����\�����Ƃ��ď����邷�B
�������ɂ����\�����Ƃ��ď����邷�B
blackfin�}���Z�[
343 �FSocket774�F2007/12/07(��) 08:53:33 ID:yJnz30R8
>>335
���̎���͕����̔����ɁA�T�C�Y�̗]�T���������B
���������������鐻���v���Z�X���m������Ă��Ȃ����������B������A�����ɔ����A�L���b�V���̐i���A�N���b�N����A�ȂǂȂǂŌ݊�����ۂ��Ȃ���傫�Ȑi�����ʂ������B
�������͈Ⴄ�B���q�����̃��x���ɂ܂Ŕ������i�݁A����ȏ���H�ł��Ȃ�
�̈�܂ł��Ə����œ��B���Ă��܂��B���̗̈�܂ł��Ă͂��߂āA�ߋ��̈�Y������������
�܂܂̃A�[�L�e�N�`���A�ł͑傫�Ȕ��͖]�߂Ȃ��Ƃ����A�����ĂЂ�����Ԃ鎖�̖����^�̈Ӗ��ł̌����̕ǂɂԂ�������B
Nehalem�̍\���͑��~���Ă���悤�Ɏv����B�����R�����悹����AGPU��������A
������C�e���V�̉B���A���̑��@��̃{�g���l�b�N�����������i�������Ă���B
����͏����ȃR�A�Ƃ��Ă̏������x���オ����̂܂܂ł͍���Ƃ����\��ł�����B
intel��Nehalem�ŎU�X�����A�����ĉߋ��̈�Y�ƌ��ʂ���匈�f������Ɖ��͎v���B
���̎���͕����̔����ɁA�T�C�Y�̗]�T���������B
���������������鐻���v���Z�X���m������Ă��Ȃ����������B������A�����ɔ����A�L���b�V���̐i���A�N���b�N����A�ȂǂȂǂŌ݊�����ۂ��Ȃ���傫�Ȑi�����ʂ������B
�������͈Ⴄ�B���q�����̃��x���ɂ܂Ŕ������i�݁A����ȏ���H�ł��Ȃ�
�̈�܂ł��Ə����œ��B���Ă��܂��B���̗̈�܂ł��Ă͂��߂āA�ߋ��̈�Y������������
�܂܂̃A�[�L�e�N�`���A�ł͑傫�Ȕ��͖]�߂Ȃ��Ƃ����A�����ĂЂ�����Ԃ鎖�̖����^�̈Ӗ��ł̌����̕ǂɂԂ�������B
Nehalem�̍\���͑��~���Ă���悤�Ɏv����B�����R�����悹����AGPU��������A
������C�e���V�̉B���A���̑��@��̃{�g���l�b�N�����������i�������Ă���B
����͏����ȃR�A�Ƃ��Ă̏������x���オ����̂܂܂ł͍���Ƃ����\��ł�����B
intel��Nehalem�ŎU�X�����A�����ĉߋ��̈�Y�ƌ��ʂ���匈�f������Ɖ��͎v���B
�ν
�ױν
�M�K�X�u���[�J�[
>>343
���w�����L�̓`���V�̗��ɂł������Ă�B
���w�����L�̓`���V�̗��ɂł������Ă�B
>>331
64bit�A�v���̒x���v���Z�T�Ȃ�(߇��)���
64bit�A�v���̒x���v���Z�T�Ȃ�(߇��)���
�u�X�p�R�����m�[�gPC�T�C�Y�ցv�\�\IBM��CPU�R�A�ԒʐM������������V�Z�p���I
http://opentechpress.jp/enterprise/07/12/07/0954209.shtml
>�@�u�V���R���E�i�m�t�H�g�j�N�X�́ACPU�R�A�Ԃ̒ʐM�����������ȓd�͉�����������Z�p���v�iGreen���j
http://opentechpress.jp/enterprise/07/12/07/0954209.shtml
>�@�u�V���R���E�i�m�t�H�g�j�N�X�́ACPU�R�A�Ԃ̒ʐM�����������ȓd�͉�����������Z�p���v�iGreen���j
��CPU���ɷ�
�V�Z�p�͂ǂ��ł��������瑁�����p�����Ă���
�_�C���ǂ�ǂ�L���b�V���Ɋ���U���Ă錻�猾����
�R�A�Ɋv�V�I�Ȏ�@���������ĂȂ����Ƃ������Ă���B
�R�A�Ɋv�V�I�Ȏ�@���������ĂȂ����Ƃ������Ă���B
���Ɍ��������Ƃ��Ă��R�X�g�̖��Ŏ��������̂�
���p���̌����݂������Ă���5�N���炢�����邵�ȁE�E�E
���p���̌����݂������Ă���5�N���炢�����邵�ȁE�E�E
��R�X�g�Ȍ��z�������p������Ă�
PC���ƈӖ��Ȃ���A����
����A���������������M�����̐��������Ȃ�����
DRAM�Ɍ��z���̃g�����V�[�o�[���ڂ��
�b���͕ʂ����ǖ����ł���
PC���ƈӖ��Ȃ���A����
����A���������������M�����̐��������Ȃ�����
DRAM�Ɍ��z���̃g�����V�[�o�[���ڂ��
�b���͕ʂ����ǖ����ł���
355 �FSocket774�F2007/12/08(�y) 00:26:52 ID:lfrrOBba
>�y�Z�p/�����́zIBM�A���p���X���p�Łu����R�A�v�������`�b�v�ɓ��ڂ���V�Z�p���J��
>http://news24.2ch.net/test/read.cgi/scienceplus/1197034785/l50
>>354
�`�b�v��̋ɏ��̌��g�����V�[�o�[�����̂悤�ł��B
>http://news24.2ch.net/test/read.cgi/scienceplus/1197034785/l50
>>354
�`�b�v��̋ɏ��̌��g�����V�[�o�[�����̂悤�ł��B
>>354
���̋Z�p�̂������Ƃ���̓R�A�Ԃ��V���R���g���Č��ʐM������Ƃ���ɂ���̂����B
�z����R���P����R=��L/S�ŕ\�����Ƃ��Ă��AL������̂͌��ʑ�B
���̋Z�p�̂������Ƃ���̓R�A�Ԃ��V���R���g���Č��ʐM������Ƃ���ɂ���̂����B
�z����R���P����R=��L/S�ŕ\�����Ƃ��Ă��AL������̂͌��ʑ�B
357 �FSocket774�F2007/12/08(�y) 00:30:34 ID:lfrrOBba
355�̌��z���ł͏���d�͂��P�O���̂P�ɒጸ�ł��邻���ł��B
�R�A�Ԃ̒ʐM�̂�1/10�ɂ��Ă����ǃR�A�����̕����d�C�H�����炠�܂�Ӗ��Ȃ��ˁH
359 �FSocket774�F2007/12/08(�y) 00:41:45 ID:lfrrOBba
>>358
�Q�[�g�̔��M�����炷�Z�p��
�������邢�ł��B
>�y�Z�p/�����́z���[�N�d�����͂���ʼn������H�@��Clemson�傪�Vhigh-k�v���Z�X�J��
>http://news24.2ch.net/test/read.cgi/scienceplus/1197035548/l50
>�Q�[�g�d���Ŕ�������ߏ�ȃ��[�N�d���ɂ�锭�M���A45nm�ȍ~�̃v���Z�X�Z�p�ɂ����āA
>�ł��傫�ȉۑ�Ƃ���Ă����B���������̒��A��Clemson University�́A�u�Q�[�g�d�ɂ�
>���[�N�d����100������1�ɗ}�����鐻����@���J���������ƂŁA�Ő�[�̃v���Z�X�Z�p��
>�����Ɉڍs�ł���悤�ɂȂ�v�Ɣ��\�����B
�Q�[�g�̔��M�����炷�Z�p��
�������邢�ł��B
>�y�Z�p/�����́z���[�N�d�����͂���ʼn������H�@��Clemson�傪�Vhigh-k�v���Z�X�J��
>http://news24.2ch.net/test/read.cgi/scienceplus/1197035548/l50
>�Q�[�g�d���Ŕ�������ߏ�ȃ��[�N�d���ɂ�锭�M���A45nm�ȍ~�̃v���Z�X�Z�p�ɂ����āA
>�ł��傫�ȉۑ�Ƃ���Ă����B���������̒��A��Clemson University�́A�u�Q�[�g�d�ɂ�
>���[�N�d����100������1�ɗ}�����鐻����@���J���������ƂŁA�Ő�[�̃v���Z�X�Z�p��
>�����Ɉڍs�ł���悤�ɂȂ�v�Ɣ��\�����B
>>343
335�������܂�A����ȓ�����Ƃ���Ȃ���>>331��CoreMA��x86�̊����`���Č����Ă�����
���̐́ux86�ł͂���ȏ�̍�IPC���̓����v���Č����Ă������E��
486�͒��������Đ̘b�����������������B
335�������܂�A����ȓ�����Ƃ���Ȃ���>>331��CoreMA��x86�̊����`���Č����Ă�����
���̐́ux86�ł͂���ȏ�̍�IPC���̓����v���Č����Ă������E��
486�͒��������Đ̘b�����������������B
�m�[�g����Ȃ��l�̔]���ɓ��ڂł���悤�ɂ��Ă���B
�]��
ttp://www.techreport.com/discussions.x/13756
45nm Core 2 Quad launch delayed due to erratum?
45nm Core 2 Quad launch delayed due to erratum?
�G���b�^���B BIOS�őΏ��ł��Ȃ��قǂ̂��̂Ȃ̂��ȁB
�}�C�N���\�t�gXbox360
�|���́~�A�Ɠ��́�
�v���Ԃ�ɉ����ȃj���[�X
�؍��̃��f�B�A�����^
FNN-NEWS.COM �w�b�h���C��
http://s04.megalodon.jp/cacheclip/147050
�uXbox�v�Łu�|���v���o�^�ł��Ȃ��s��@�}�C�N���\�t�g�u�l�דI�~�X�v�ƎӍ߁@2007/12/07 17:41
http://www.fnn-news.com/headlines/CONN00123247.html
http://s03.megalodon.jp/cacheclip/147036
�j���[�X����@�\�[�X�F2007�N12��7���i���j�@�t�W�e���r �X�[�p�[�j���[�X
��Windows Media Player
300k http://www.fnn-news.com/windowsmedia/sn2007120702_300.asx
56k http://www.fnn-news.com/windowsmedia/sn2007120702_56.asx
��Real Player
300k http://www.fnn-news.com/realvideo/sn2007120702_300.ram
56k http://www.fnn-news.com/realvideo/sn2007120702_G2.ram
��YouTube
http://www.youtube.com/watch?v=s-qNZ652N_0
�|���́~�A�Ɠ��́�
�v���Ԃ�ɉ����ȃj���[�X
�؍��̃��f�B�A�����^
FNN-NEWS.COM �w�b�h���C��
http://s04.megalodon.jp/cacheclip/147050
�uXbox�v�Łu�|���v���o�^�ł��Ȃ��s��@�}�C�N���\�t�g�u�l�דI�~�X�v�ƎӍ߁@2007/12/07 17:41
http://www.fnn-news.com/headlines/CONN00123247.html
http://s03.megalodon.jp/cacheclip/147036
�j���[�X����@�\�[�X�F2007�N12��7���i���j�@�t�W�e���r �X�[�p�[�j���[�X
��Windows Media Player
300k http://www.fnn-news.com/windowsmedia/sn2007120702_300.asx
56k http://www.fnn-news.com/windowsmedia/sn2007120702_56.asx
��Real Player
300k http://www.fnn-news.com/realvideo/sn2007120702_300.ram
56k http://www.fnn-news.com/realvideo/sn2007120702_G2.ram
��YouTube
http://www.youtube.com/watch?v=s-qNZ652N_0
>>364
�R�����g�����ǂ����˂�
�R�����g�����ǂ����˂�
��������A���炢��������
368 �FSocket774�F2007/12/10(��) 17:27:45 ID:mhXN2+SC
�Ȃ��ے�I�Ȉӌ�����ł��ˁB
����B2�̃G���b�^���T���Ă��܂����AB3�X�e�b�v�ȍ~�͏����ɍ��N���b�N���E��d�͉����čs���ł��傤�B
����ɍ��N���b�N�̎��v����d�͂̎��v�̂ق��������ł��傤���A����͍����\���������d�͂ɏd�_��u���Ƃ������Ƃł��傤�ˁB
�������3GHz/130W�ȉ��ł͐��\�����ōŒ���K�v�Ȃ̂ŏo���Ă���ł��傤���B
rabbit
����B2�̃G���b�^���T���Ă��܂����AB3�X�e�b�v�ȍ~�͏����ɍ��N���b�N���E��d�͉����čs���ł��傤�B
����ɍ��N���b�N�̎��v����d�͂̎��v�̂ق��������ł��傤���A����͍����\���������d�͂ɏd�_��u���Ƃ������Ƃł��傤�ˁB
�������3GHz/130W�ȉ��ł͐��\�����ōŒ���K�v�Ȃ̂ŏo���Ă���ł��傤���B
rabbit
IEDM 2007 - Intel�A45nm�v���Z�X�̏ڍׂ\
http://journal.mycom.co.jp/articles/2007/12/12/iedm2/index.html
�����Ɍ����Đ����ȁB
Low-k�Ɋւ�����ێ�I�����ǃg�����W�X�^�̐��\�������B
LateNews��IBM�O���[�v��pMOS��1mA/um�̕ǂ�˔j�������Ă����̂�����������Intel�͂��łɓ˔j���Ă��ƁB
�����N���b�N���オ���B
http://journal.mycom.co.jp/articles/2007/12/12/iedm2/index.html
�����Ɍ����Đ����ȁB
Low-k�Ɋւ�����ێ�I�����ǃg�����W�X�^�̐��\�������B
LateNews��IBM�O���[�v��pMOS��1mA/um�̕ǂ�˔j�������Ă����̂�����������Intel�͂��łɓ˔j���Ă��ƁB
�����N���b�N���オ���B
Intel�A�ʎY�p45nm�v���Z�X�̏ڍׂ����\
http://pc.watch.impress.co.jp/docs/2007/1212/iedm03.htm
Impress�������B
MYCOM�Ƃ͈���Ĕw�i��������Ă�̂�������₷�����B
http://pc.watch.impress.co.jp/docs/2007/1212/iedm03.htm
Impress�������B
MYCOM�Ƃ͈���Ĕw�i��������Ă�̂�������₷�����B
>>372
���̋L���ɂ��ƁA���s������Intel������ԉ\��������悤�Ȃ��Ə����Ă���ȁB
����AMD������Ȃ���A���Ƃ����s���Ă��������������ƌ����낤���c
���̋L���ɂ��ƁA���s������Intel������ԉ\��������悤�Ȃ��Ə����Ă���ȁB
����AMD������Ȃ���A���Ƃ����s���Ă��������������ƌ����낤���c
����AMD�ɑR���ĂƂ�����Ȃ��Ă����ƑO����Z�p�J�����Ă�
���ꂪ���܂���45nm����̗p�������Ă����̎��ł���
���ꂪ���܂���45nm����̗p�������Ă����̎��ł���
���N�����ɂ�32nm��SRAM���씭�\����
���ł�SRAM�͍���Ă邼�B���̑O��IDF�Ŕ��\�ς݁B
������IBM��TSMC��32nm��SRAM�͍���Ă�݂����B
Intel����s���ĂĂ�SRAM�Ɍ���Δ��N���͖������������c�B
������IBM��TSMC��32nm��SRAM�͍���Ă�݂����B
Intel����s���ĂĂ�SRAM�Ɍ���Δ��N���͖������������c�B
>>373
Intel��CPU�̐����Ɣ̔��Ŏ�ɗ��v���グ�Ă��邪�A�{���I�ɂ͔����̂̊J���Ɛ��������ЁB
1980�N��㔼�ɕ��G��x86�̍��N���b�N���������͖������ƌ���������ꂽ���A
�E�n�[�h���C���[�h���W�b�N
�E�p�C�v���C��
�E�A�E�g�I�u�I�[�_�[���s
�E���ߕϊ��@�\
�E�n�U�[�h�����ׂ̈̎������x���ł̃��W�X�^������i���W�X�^�E�B���h�E�ɑ����j
�E����\��
�E��K�̓L���b�V��
�Ȃǂ̕��G�ȋ@�\�����Ђ̔����̋Z�p�őS�ăV���R����Ɏ������Ă݂��āA
���̌��E����ɑł��j���Ă����B
Intel�̐i���͏�Ɏ��Ђ̔����̋Z�p�Ƌ��ɂ���̂ŁA
�V�����v���Z�X�̊J���ɗ͂𒍂��͕̂ʂɕs�v�c�Ȏ��ł͖����B
Intel��CPU�̐����Ɣ̔��Ŏ�ɗ��v���グ�Ă��邪�A�{���I�ɂ͔����̂̊J���Ɛ��������ЁB
1980�N��㔼�ɕ��G��x86�̍��N���b�N���������͖������ƌ���������ꂽ���A
�E�n�[�h���C���[�h���W�b�N
�E�p�C�v���C��
�E�A�E�g�I�u�I�[�_�[���s
�E���ߕϊ��@�\
�E�n�U�[�h�����ׂ̈̎������x���ł̃��W�X�^������i���W�X�^�E�B���h�E�ɑ����j
�E����\��
�E��K�̓L���b�V��
�Ȃǂ̕��G�ȋ@�\�����Ђ̔����̋Z�p�őS�ăV���R����Ɏ������Ă݂��āA
���̌��E����ɑł��j���Ă����B
Intel�̐i���͏�Ɏ��Ђ̔����̋Z�p�Ƌ��ɂ���̂ŁA
�V�����v���Z�X�̊J���ɗ͂𒍂��͕̂ʂɕs�v�c�Ȏ��ł͖����B
�VCPU���S�������Ă���e���v���݂����̒����Ăق�������
�V�����g�ނ���Q�l�ɂ������B
�V�����g�ނ���Q�l�ɂ������B
>>378
�������̃X���ŁB
Intel Core 2 Duo/Quad Part84
http://pc11.2ch.net/test/read.cgi/jisaku/1197195273/6
�������̃X���ŁB
Intel Core 2 Duo/Quad Part84
http://pc11.2ch.net/test/read.cgi/jisaku/1197195273/6
�U������
>>376
�����܂�ƌ������p�l������V�F�A���}�i���Ȃ����荷�͏k�܂�Ȃ���
IBM��TSMC�̓}�X�N��f�U�C���R�X�g�̖�������
�ꔭ�t�]�̉\��������Ƃ�����3�����ϑw����
�����܂�ƌ������p�l������V�F�A���}�i���Ȃ����荷�͏k�܂�Ȃ���
IBM��TSMC�̓}�X�N��f�U�C���R�X�g�̖�������
�ꔭ�t�]�̉\��������Ƃ�����3�����ϑw����
3�����ϑw�̓R�X�g�̖�肪�傫��
�Z�p�̊J������̂Ƃ����Ђ�
�悻����Z�p�������Ă��邱�Ƃ���̂Ƃ����ЂƂ�
���͂̍������炩�ɂȂ��Ă�����
�悻����Z�p�������Ă��邱�Ƃ���̂Ƃ����ЂƂ�
���͂̍������炩�ɂȂ��Ă�����
>383
�����Ɖ����H
�����Ɖ����H
TSMC��32nmSRAM��2�d�I������Ă�����B�ʎY�ł���������H
intel��22nm����Q�d�I����炴��Ȃ����ȁBEUV�̐i���ɂ���ẮB
intel��22nm����Q�d�I����炴��Ȃ����ȁBEUV�̐i���ɂ���ẮB
22nm��EUV���Ԃɍ���Ȃ���_�u���p�^�[�j���O�����������낤�ȁB
���Ԃ�\������Ԃɍ���Ȃ����낤���B
�����ܗ��t�Z���Ԃɍ������������Ȃ��B
IBM��JSR�ƈꏏ�ɍ����ܗ��t�Z���J�����Ă�݂�������Intel�͂����܂Ŗ`�����Ȃ����낤�B
���Ԃ�\������Ԃɍ���Ȃ����낤���B
�����ܗ��t�Z���Ԃɍ������������Ȃ��B
IBM��JSR�ƈꏏ�ɍ����ܗ��t�Z���J�����Ă�݂�������Intel�͂����܂Ŗ`�����Ȃ����낤�B
TSMC�̏ڂ����L�������Ă��B
http://pc.watch.impress.co.jp/docs/2007/1213/iedm05.htm
���ƁAintel45nm����͓�������������Ă���Ƃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20071213/144157/
http://pc.watch.impress.co.jp/docs/2007/1213/iedm05.htm
���ƁAintel45nm����͓�������������Ă���Ƃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20071213/144157/
�ߐڏ���X�e�b�p�[�g��������x�@��̗��p���ł��邵�A32nm���s�����������B
�d�q�����\�O���t�B�̕����ǂ����ȋC�����邪�B
�d�q�����\�O���t�B�̕����ǂ����ȋC�����邪�B
>>383
�Ƃ肠��������������˂��c
�Ƃ肠��������������˂��c
EB�̓X���[�v�b�g�Ⴗ���ėʎY�͌������B EUV���{�����Ǝv���B
���N�̉Ă��炢�ɂ�Penryn�̉��ʃ��f��������Ȃ�ɒl���ꂷ�邩�ȁH
�l����[�����i����ł͏�ʃ��f���قǒl�����蕝���傫�����甃�����f���͑債�ĉ�����Ȃ��ł���
E6300�Ƃ��قƂ�lj������ĂȂ���
E6300�Ƃ��قƂ�lj������ĂȂ���
394 �FSocket774�F2007/12/22(�y) 11:51:12 ID:Qz+9ONxs
�グ�Ƃ���
45nm�v���Z�X�ɉ������\������Ă���Ƃ̂��Ƃ��B
http://www.theinquirer.net/gb/inquirer/news/2007/12/21/rumors-swirl-intel-45nm
�@�@--------------------
�@�@The first one was that Intel is having problems ramping the 45/High-K/Metal process to
�@�@volume so there is going to be a second 45nm non-High-K/non-Metal process to run the
�@�@lower end volume chips.
�@�@[����]
�@�@The next bit is sort of related, word is trickling out that Intel scrapped a whole run of
�@�@Harpertowns.
�@�@--------------------
G5/3GHz�̍���IBM���n�}�������ɁAIntel�������邷���ˁB�B�B
http://www.theinquirer.net/gb/inquirer/news/2007/12/21/rumors-swirl-intel-45nm
�@�@--------------------
�@�@The first one was that Intel is having problems ramping the 45/High-K/Metal process to
�@�@volume so there is going to be a second 45nm non-High-K/non-Metal process to run the
�@�@lower end volume chips.
�@�@[����]
�@�@The next bit is sort of related, word is trickling out that Intel scrapped a whole run of
�@�@Harpertowns.
�@�@--------------------
G5/3GHz�̍���IBM���n�}�������ɁAIntel�������邷���ˁB�B�B
���e�S�R���ĂȂ����ǁA9770/3.2GHz��970FX/2.5GHz���v���o�������
>>395
low end/volume�����̃v���Z�X����蒼���Ƃ������ƂȂ�u�ʎY�ł��Ȃ��v�u�R�X�g�������v��
�z���ł��邪�A������[������ɂȂ�Harpertown(��"run")�܂ł��~�߂Ă��܂��K�v��
����Ƃ������Ƃ́A����ȊO�̒v���I�Ȏ������̂ł͂Ȃ����Ɗ��J�炸�ɂ͂����Ȃ��B
low end/volume�����̃v���Z�X����蒼���Ƃ������ƂȂ�u�ʎY�ł��Ȃ��v�u�R�X�g�������v��
�z���ł��邪�A������[������ɂȂ�Harpertown(��"run")�܂ł��~�߂Ă��܂��K�v��
����Ƃ������Ƃ́A����ȊO�̒v���I�Ȏ������̂ł͂Ȃ����Ɗ��J�炸�ɂ͂����Ȃ��B
>>395�̂悤�Șb���������ŁARealWorldTech��David Kanter�����f����Intel��AMD�̌���ɂ���
�q�ׂĂ��邷�B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=85691&threadid=85424&roomid=2
Intel�ɂ��Ă�A
�@�@----------------------
�@�@In contrast, Intel has shown a lot of good milestones/indications on their way to production for Nehalem:
�@�@�@1. 45nm is fine for servers, see prior discussion
�@�@�@2. Nehalem already booted and was running apps
�@�@�@3. Inside information I can't share
�@�@----------------------
���̓��e�������Ƃ팾���A3�Ԗڂ�S�������Ǝv�����B
AMD�ɂ��Ă�A�N���ٌ�ł��Ȃ����ˁB�B�B
�@�@----------------------
�@�@1. They had a management change on manufacturing during implementation of 45nm. Not a good sign.
�@�@2. New guy (Doug Grose) is from IBM, which definitely knows how to get stuff out the door and is a good foundry, but AMD has a very different model than IBM, much more driven by yields and volume.
�@�@3. Barcelona fiasco @ 65nm
�@�@4. AMD's history of not actually closing the gap with Intel's process, but yet again claiming to do so.
�@�@5. AMD cutting their capex by 33%
�@�@6. No 45nm demos at analyst day --> no functional tape out
�@�@7. No frequency boost because they will have leakage issues
�@�@----------------------
�q�ׂĂ��邷�B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=85691&threadid=85424&roomid=2
Intel�ɂ��Ă�A
�@�@----------------------
�@�@In contrast, Intel has shown a lot of good milestones/indications on their way to production for Nehalem:
�@�@�@1. 45nm is fine for servers, see prior discussion
�@�@�@2. Nehalem already booted and was running apps
�@�@�@3. Inside information I can't share
�@�@----------------------
���̓��e�������Ƃ팾���A3�Ԗڂ�S�������Ǝv�����B
AMD�ɂ��Ă�A�N���ٌ�ł��Ȃ����ˁB�B�B
�@�@----------------------
�@�@1. They had a management change on manufacturing during implementation of 45nm. Not a good sign.
�@�@2. New guy (Doug Grose) is from IBM, which definitely knows how to get stuff out the door and is a good foundry, but AMD has a very different model than IBM, much more driven by yields and volume.
�@�@3. Barcelona fiasco @ 65nm
�@�@4. AMD's history of not actually closing the gap with Intel's process, but yet again claiming to do so.
�@�@5. AMD cutting their capex by 33%
�@�@6. No 45nm demos at analyst day --> no functional tape out
�@�@7. No frequency boost because they will have leakage issues
�@�@----------------------
399 �FMAC�I�^���⑫�F2007/12/23(��) 15:03:56 ID:C4BJwgUg
���Ȃ݂�David Kanter���ƌ����AAMD�ۛ��ƌ����Ă���l���Ȃ��ǂˁB�B�B
"Kanter: AMD Will Wipe the Floor with Intel for HPC"
http://www.dailytech.com/Kanter+AMD+Will+Wipe+the+Floor+with+Intel+for+HPC/article7338.htm
�@�@-------------------
�@�@Kanter closes, "Given the evidence I saw at ISSCC 2007, I'm pretty confident the chip can make it
�@�@to 2.8 GHz."
�@�@-------------------
"Kanter: AMD Will Wipe the Floor with Intel for HPC"
http://www.dailytech.com/Kanter+AMD+Will+Wipe+the+Floor+with+Intel+for+HPC/article7338.htm
�@�@-------------------
�@�@Kanter closes, "Given the evidence I saw at ISSCC 2007, I'm pretty confident the chip can make it
�@�@to 2.8 GHz."
�@�@-------------------
PenM�g���̉��ɂƂ���Penryn�͔��MCPU�ł�
30W�ȉ��̐VCPU�͂����o��̂ł��傤��
30W�ȉ��̐VCPU�͂����o��̂ł��傤��
PenM�����āA24W�Ɣ��M����n�܂��āu���M�����Ǒ���ɑ����d�����I��点�đS�̂̏���d�͂��팸�v
�ăR���Z�v�g����������
�ăR���Z�v�g����������
403 �F�R�E�L�́M�E,,�j�����������������F2007/12/26(��) 00:29:12 ID:mLaf+8eS
Banias�̃A�C�h��600MHz������Ă��Ȃ藝�z�I�������ȁB
����A�E�B���X�`�F�b�N���点���蓮��Đ������肷��ƑS�R����Ȃ��������ǂ�
����A�E�B���X�`�F�b�N���点���蓮��Đ������肷��ƑS�R����Ȃ��������ǂ�
TDP30W�ȉ��ƂȂ��2008�N�㔼�\��H��Montevina�v���b�g�t�H�[����
L2��3MB�ł�Penryn��TDP25W�g�łł��Ȃ����������H
�Ⴕ����2008Q2�ȍ~�ɓo��\���Silverthorne�̑g�ݍ���/�f�X�N�g�b�v������Diamondville�Ƃ�
���\�ɂ͊��҂ł���TDP�I�ɂ�Silverthorne1.86Ghz��2W�Ƃ�����Penryn�M�ƌ������Ⴄ401�ɂ͂҂����肾��
L2��3MB�ł�Penryn��TDP25W�g�łł��Ȃ����������H
�Ⴕ����2008Q2�ȍ~�ɓo��\���Silverthorne�̑g�ݍ���/�f�X�N�g�b�v������Diamondville�Ƃ�
���\�ɂ͊��҂ł���TDP�I�ɂ�Silverthorne1.86Ghz��2W�Ƃ�����Penryn�M�ƌ������Ⴄ401�ɂ͂҂����肾��
"Silverthorne"�͐��\�����܂荂���Ȃ����ۂ��b�Ȃ̂ŁA
TDP25W�g��Penryn���ł�Ȃ�A���ꂪ�ΏۂɂȂ�̂ł́H
"Merom"��"Yonah"�����ꂼ��TDP34W/31W�Ȃ̂ˁB
�m�[�g�Ŏg���悤�ȏꍇ�ł��Ȃ�����A�\����Ǝv���̂����c�B
TDP25W�g��Penryn���ł�Ȃ�A���ꂪ�ΏۂɂȂ�̂ł́H
"Merom"��"Yonah"�����ꂼ��TDP34W/31W�Ȃ̂ˁB
�m�[�g�Ŏg���悤�ȏꍇ�ł��Ȃ�����A�\����Ǝv���̂����c�B
�`�b�v�Z�b�g��45nm�v���Z�X�ő����o����B
�n���ɗD�����Ȃ��`�b�v����o���ĂȂ��ŁB
�n���ɗD�����Ȃ��`�b�v����o���ĂȂ��ŁB
INTEL�̃`�b�v�Z�b�g�͌������p�I����Ĉ�������1����O�̃v���Z�X�g�������
TSMC�̍ŐV�v���Z�X�g��ATi�ENVIDIA�ɔ�ׂ�Ə���d�͂�������
TSMC�̍ŐV�v���Z�X�g��ATi�ENVIDIA�ɔ�ׂ�Ə���d�͂�������
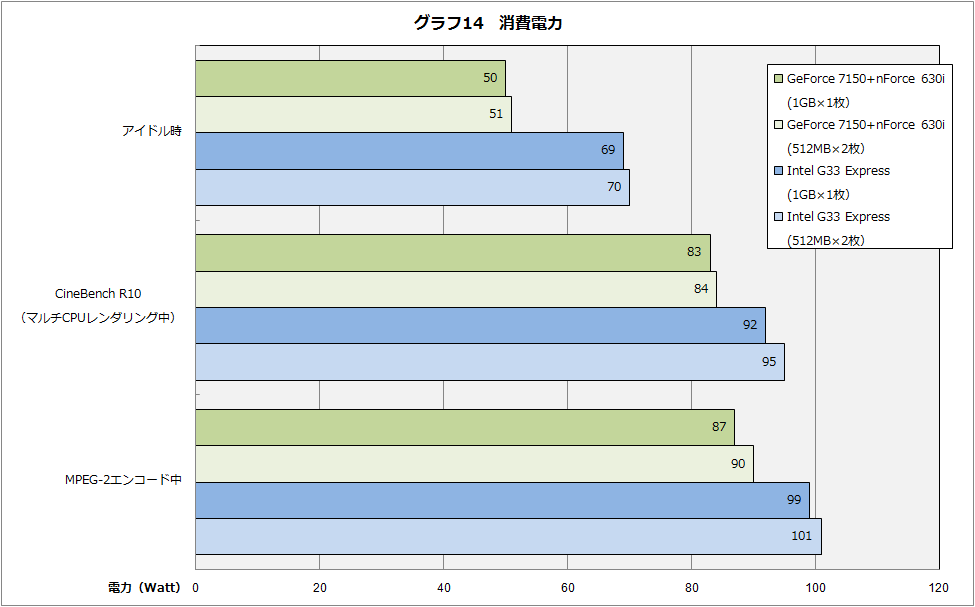{kind=link}
410 �F�R�E�L�́M�E,,�j�����������������F2007/12/28(��) 22:55:32 ID:uWLk8sm4
>>407
���o�C���`�b�v�Z�b�g�������Ȃ́H
���o�C���`�b�v�Z�b�g�������Ȃ́H
���o�C���������B
965�n��855�A915�A945�n�̐��ォ��ǂ�ǂ����d�͔n���H���ɂȂ��Ă�B
965�n��855�A915�A945�n�̐��ォ��ǂ�ǂ����d�͔n���H���ɂȂ��Ă�B
�Ȃ�Ă������I�I
�P�N�����Auburndale�ł̓����R����45nm�ɂȂ邩����Ȃ�
�O���t�B�b�N����
������̂��ѓd�C��H���A����Ȃ̂ɃQ�[�����\�ቺ
http://www.xbitlabs.com/articles/chipsets/display/ig965-gf6150_12.html
http://plusd.itmedia.co.jp/pcuser/articles/0711/30/news070_2.html
������̂��ѓd�C��H���A����Ȃ̂ɃQ�[�����\�ቺ
http://www.xbitlabs.com/articles/chipsets/display/ig965-gf6150_12.html
http://plusd.itmedia.co.jp/pcuser/articles/0711/30/news070_2.html
>>415
G35��G33������
G35��G33������
�f�X�N�g�b�v�����͎���Eaglelake����65nm�ɂȂ�݂���������
���o�C����Montevina����̃`�b�v�Z�b�g��Cantiga���Ăǂ��Ȃ�̂��ˁH
Cantiga�͑Ή��T�E�X��ICH9M������3�V���[�Y�Ɠ�������ۂ������Ȃ�
���o�C����������90nm����Ȃ���65nm�ō���Ă���Ȃ�
���o�C����Montevina����̃`�b�v�Z�b�g��Cantiga���Ăǂ��Ȃ�̂��ˁH
Cantiga�͑Ή��T�E�X��ICH9M������3�V���[�Y�Ɠ�������ۂ������Ȃ�
���o�C����������90nm����Ȃ���65nm�ō���Ă���Ȃ�
>>417
���C�o����AMD�����̑̂��炭���Ⴀ�A����Ȏ������Ȃ��Ă�����邩����Ȃ�����B
���C�o����AMD�����̑̂��炭���Ⴀ�A����Ȏ������Ȃ��Ă�����邩����Ȃ�����B
����ȑO��INTEL�̃`�b�v�Z�b�g���Ƃ͍H��̗L�����p���܂܂�邩��
65nm�Ɉڂ闝�R���Ȃ�
P35��G33�̐v(90nm)�𗬗p���Ă����v���Z�X�����ς���̂ɂ�
���Ȃ�̋���������
65nm�Ɉڂ闝�R���Ȃ�
P35��G33�̐v(90nm)�𗬗p���Ă����v���Z�X�����ς���̂ɂ�
���Ȃ�̋���������
�ł��T�[�h�p�[�e�B���V�������N�����v���Z�X�i�̃`�b�v�Z�b�g���o���܂�����
Intel�ɑR�ł���A����ȗI���Ȏ��͌����Ă��Ȃ�������ˁB
�R�X�g�������邩��A�Ȃ�Č����ʗp����̂́A���F���C�o���s�݂ȏꍇ�����B
Intel���o�X���C�Z���X�ŃT�[�h�p�[�e�B���`�b�v�Z�b�g���A���������E������
�o����̂͂`�l�c�����炵�Ȃ������Ȃ̂͊m�������B
Intel�ɑR�ł���A����ȗI���Ȏ��͌����Ă��Ȃ�������ˁB
�R�X�g�������邩��A�Ȃ�Č����ʗp����̂́A���F���C�o���s�݂ȏꍇ�����B
Intel���o�X���C�Z���X�ŃT�[�h�p�[�e�B���`�b�v�Z�b�g���A���������E������
�o����̂͂`�l�c�����炵�Ȃ������Ȃ̂͊m�������B
���ł������̂����ɂ�����
�ǂ����̍��̐l���H
�ǂ����̍��̐l���H
�m�[�g����Intel�̃O���t�B�b�N�����`�b�v�Z�b�g����ʂɂł����A
Montevina�̃^�C�~���O����65nm�̍H�ꂪ�ĂȂ���Ȃ����H
2008�N������CPU�ŗʂ��o��PenDC�ACeleron���܂�65nm�̂܂܂����A
Core2���ʂ�E4000���c���Ă邾�낤�B
Montevina�̃^�C�~���O����65nm�̍H�ꂪ�ĂȂ���Ȃ����H
2008�N������CPU�ŗʂ��o��PenDC�ACeleron���܂�65nm�̂܂܂����A
Core2���ʂ�E4000���c���Ă邾�낤�B
TSMC�̍ŐV�v���Z�X���Y�ʂȂ�Ă������m��Ă�
Intel�̃`�b�v�Z�b�g�ɂ���NVIDIA��GPU�ɂ��닌����v���Z�X���g���͕̂K�R
Intel�̃`�b�v�Z�b�g�ɂ���NVIDIA��GPU�ɂ��닌����v���Z�X���g���͕̂K�R
GeForce 7150�������V���O���`���l����
�Ă̒��s�]��������
�A�������C�Z���X����݂���Ȃ��́H
�Ă̒��s�]��������
�A�������C�Z���X����݂���Ȃ��́H
{kind=link}
����ɂ͑�s�]�ł�OEM�ɂƂ����Ⴡ����1��Vista Ready�����炠�肪�����B
>>426
> �A���͒P�ɊJ�����Ԃɍ���Ȃ�������������B
AMD�v���b�g�t�H�[���ŁA�قړ������ɔ�����AMD690G��Intel�łł���
X1250��07�N�t�ɓo�ꂵ�Ă���̂ɁA
7150�̊J���ɂ���قǎ��Ԃ�������Ƃ͎v���Ȃ��B
�ǂ��l���Ă�Intel�����̂ق����ׂ���͂��Ȃ̂ɁB
> ���ۂɂ�����Dual Ch�Ή��o�[�W�������o�Ă邵�B
MCP7A�͂܂���������Ă��Ȃ��B
�z���g�ɏo��̂��ˁH
��̂��Ƃ�G45�̐��\���O��`�قǔ����ł��Ȃ��̂ŁA
�s��������Ă�����Ȃ��悤�ɁA���C�Z���X�ō����~�߂Ă���悤�Ɍ�����B
Intel�̓����O���t�B�b�N�͒ᐫ�\�A�����M�A�����A��@�\�ŁA
�ǂ�����Intel�����Ă��Ƃ��炢���ƁB
> �A���͒P�ɊJ�����Ԃɍ���Ȃ�������������B
AMD�v���b�g�t�H�[���ŁA�قړ������ɔ�����AMD690G��Intel�łł���
X1250��07�N�t�ɓo�ꂵ�Ă���̂ɁA
7150�̊J���ɂ���قǎ��Ԃ�������Ƃ͎v���Ȃ��B
�ǂ��l���Ă�Intel�����̂ق����ׂ���͂��Ȃ̂ɁB
> ���ۂɂ�����Dual Ch�Ή��o�[�W�������o�Ă邵�B
MCP7A�͂܂���������Ă��Ȃ��B
�z���g�ɏo��̂��ˁH
��̂��Ƃ�G45�̐��\���O��`�قǔ����ł��Ȃ��̂ŁA
�s��������Ă�����Ȃ��悤�ɁA���C�Z���X�ō����~�߂Ă���悤�Ɍ�����B
Intel�̓����O���t�B�b�N�͒ᐫ�\�A�����M�A�����A��@�\�ŁA
�ǂ�����Intel�����Ă��Ƃ��炢���ƁB
>>428
�����R��������CPU���ɂ���AMD�Ń`�b�v�Z�b�g�ƁA
�����R���̒��������Ȃ���ΐ����Ȃ�Intel�`�b�v�Z�b�g�Ƃł́A
Intel�`�b�v�Z�b�g�̐����̕�������Ǝv�����ˁB
���ƁACPU�o�X���C�Z���X�������𗝉�����A
�����R�����V���O���`�����l���ɐ�������Ă���Ƃ�����Ȃ�����B
���邢�́A�V���O���`�����l���ɐ�������Ă�����A
NVIDIA�����琳���ɂ��̎|�ƕ���̒ʒB������C������B
�����R��������CPU���ɂ���AMD�Ń`�b�v�Z�b�g�ƁA
�����R���̒��������Ȃ���ΐ����Ȃ�Intel�`�b�v�Z�b�g�Ƃł́A
Intel�`�b�v�Z�b�g�̐����̕�������Ǝv�����ˁB
���ƁACPU�o�X���C�Z���X�������𗝉�����A
�����R�����V���O���`�����l���ɐ�������Ă���Ƃ�����Ȃ�����B
���邢�́A�V���O���`�����l���ɐ�������Ă�����A
NVIDIA�����琳���ɂ��̎|�ƕ���̒ʒB������C������B
>>412
�`�b�v�Z�b�g���ŐV�v���Z�X���g���ď���d�͂��팸���ė~�������A���v���Z�Xfab�̌������p�̖ʂ����ނ�����̂��˂��B
�`�b�v�Z�b�g���ŐV�v���Z�X���g���ď���d�͂��팸���ė~�������A���v���Z�Xfab�̌������p�̖ʂ����ނ�����̂��˂��B
440BX��0.35��m�ł��₦�₦������
i810��0.35��m�ł��₦�₦������
i820��0.35��m�ł��₦�₦������
i815��0.25��m�ł��₦�₦������
i850��0.25��m�ŗv�q�[�g�V���N
i845��0.18��m�ŗv�q�[�g�V���N
�i�ȉ����
i810��0.35��m�ł��₦�₦������
i820��0.35��m�ł��₦�₦������
i815��0.25��m�ł��₦�₦������
i850��0.25��m�ŗv�q�[�g�V���N
i845��0.18��m�ŗv�q�[�g�V���N
�i�ȉ����
432 �FSocket774�F2008/01/02(��) 08:11:04 ID:4pG5HCEn
i875��������ǁA�S�~�ɖ�����Ă���E�E�E�E
>>429
> Intel�`�b�v�Z�b�g�̐����̕�������Ǝv�����ˁB
�����R���������`�b�v�Z�b�g�̐����o��������or���Ȃ��̂Ȃ�
�Z�p�I���R�ł̒x���͗����ł��邪�B
> NVIDIA�����琳���ɂ��̎|�ƕ���̒ʒB������C������B
���ꂪ�\�ʉ�����Ƃ͌���Ȃ��킯�ŁB
Nehalem�ȍ~���`�b�v�Z�b�g�r�W�l�X�𑱂������̂Ȃ�A
�\������Intel�Ƃ̑Ό��͔����邾�낤���B
Intel�v���b�g�t�H�[���̃O���t�B�b�N�����`�b�v�Z�b�g�ɂ�
�\�ɏo�Ȃ��A���炩�̎Q����ǂ�����悤�Ɏv���ĂȂ�Ȃ��B
Intel�R�P�܂����Ă�̂ɁA����グ����Ȃ����ȁB
> Intel�`�b�v�Z�b�g�̐����̕�������Ǝv�����ˁB
�����R���������`�b�v�Z�b�g�̐����o��������or���Ȃ��̂Ȃ�
�Z�p�I���R�ł̒x���͗����ł��邪�B
> NVIDIA�����琳���ɂ��̎|�ƕ���̒ʒB������C������B
���ꂪ�\�ʉ�����Ƃ͌���Ȃ��킯�ŁB
Nehalem�ȍ~���`�b�v�Z�b�g�r�W�l�X�𑱂������̂Ȃ�A
�\������Intel�Ƃ̑Ό��͔����邾�낤���B
Intel�v���b�g�t�H�[���̃O���t�B�b�N�����`�b�v�Z�b�g�ɂ�
�\�ɏo�Ȃ��A���炩�̎Q����ǂ�����悤�Ɏv���ĂȂ�Ȃ��B
Intel�R�P�܂����Ă�̂ɁA����グ����Ȃ����ȁB
435 �FSocket774�F2008/01/02(��) 10:29:33 ID:FpicnCay
����ρA�n�b�����o�|�o��������Ȃ����ȁB
�����͂h���������I
�����͂h���������I
436 �FSocket774�F2008/01/02(��) 12:36:16 ID:t5rAH3Oo
�Ŕ������͂��H
�������������
�����͂Ȃ�
HKEPC���Nehelem�ڕB
http://www.hkepc.com/?id=568
�@�Ex1.2-2 MP���\
�@�Ex1.1-1.25 �V���O���X���b�h���\
�@�E���ꐫ�\��30%(Penryn��)�ȓd��
�@�EQuickPath x 4
��Bloomfield (highend)
�@�E2008Q4
�@�E8MB L2
�@�ELGA1366
�@�E�O�t�������R���g���[�� "Tylersburg"
�@�@- 3ch DDR3-1600, 2DIMMs/channel
�@�@- 8x PCIe2 x 4 + 1x PCIe2 x 4
�@�@- DMI�ڑ� ICH10
�@�E130W TDP
�@�EVRM 11.1
http://www.hkepc.com/?id=568
�@�Ex1.2-2 MP���\
�@�Ex1.1-1.25 �V���O���X���b�h���\
�@�E���ꐫ�\��30%(Penryn��)�ȓd��
�@�EQuickPath x 4
��Bloomfield (highend)
�@�E2008Q4
�@�E8MB L2
�@�ELGA1366
�@�E�O�t�������R���g���[�� "Tylersburg"
�@�@- 3ch DDR3-1600, 2DIMMs/channel
�@�@- 8x PCIe2 x 4 + 1x PCIe2 x 4
�@�@- DMI�ڑ� ICH10
�@�E130W TDP
�@�EVRM 11.1
>>439
BF�̓����R����CPU���ɂ͂Ȃ��H
BF�̓����R����CPU���ɂ͂Ȃ��H
441 �FMAC�I�^�������F2008/01/03(��) 21:36:49 ID:0OGEg5J1
��Lynnfield (midrange)
�@�E2009Q1
�@�E4-core
�@�E8MB L2
�@�ELGA1160
�@�E�����������R���g���[�� 2ch DDR3
�@�E���� 8x PCIe2 x 2
�@�EDMI�ڑ�ICH "lbexpeak"
�@�E95W TDP
�@�EVRM 11.1
�@�E2009Q1
�@�E4-core
�@�E8MB L2
�@�ELGA1160
�@�E�����������R���g���[�� 2ch DDR3
�@�E���� 8x PCIe2 x 2
�@�EDMI�ڑ�ICH "lbexpeak"
�@�E95W TDP
�@�EVRM 11.1
442 �FMAC�I�^�������F2008/01/03(��) 21:39:59 ID:0OGEg5J1
��Havendale (IGP)
�@�E2009Q2
�@�E2-core
�@�E4MB L2
�@�ELGA1160
�@�E����GPU (DirectX 10, Shader Model 4.0, OpenGL 2.1)
�@�E�����������R���g���[�� 2ch. DDR
�@�E����8x PCIe2 x 1?
�@�EDMI&DisplayLink�ڑ�ICH "lbexpeak"
�@�E75W TDP
�@�EVRM 11.1
�@�E2009Q2
�@�E2-core
�@�E4MB L2
�@�ELGA1160
�@�E����GPU (DirectX 10, Shader Model 4.0, OpenGL 2.1)
�@�E�����������R���g���[�� 2ch. DDR
�@�E����8x PCIe2 x 1?
�@�EDMI&DisplayLink�ڑ�ICH "lbexpeak"
�@�E75W TDP
�@�EVRM 11.1
Penryn��30�������Ă̂͂����[�Ȃ��E�E�E
444 �FMAC�I�^�������܂��F2008/01/03(��) 21:45:40 ID:0OGEg5J1
���̑��ATDP�̘g���ňꕔ�̃R�A��OC����"Turbo Mode"�̉���ƁA2009Q2��
"Clarksfield"��"Auburndale"�̃��o�C����Nehalem���\�肳��Ă���Ƃ����b���B
"Clarksfield"��"Auburndale"�̃��o�C����Nehalem���\�肳��Ă���Ƃ����b���B
�����܂����ƃ��X�N�팸�AOC�̃|�e���V��������̂��߂ɁA�����R����PCIe�͓�������ĂȂ�
���ď����Ă���ۂ��BGoogle�̒��p�|�܂��ƁB
�ł�1�y�[�W�߂�Nehalem�̃v���b�g�t�H�[���̐}���ƃ�������CPU�ɂȂ����Ă邩��A
Bloomfield�����O�t�������R���ŁAXeon�ł͓��������R�����Ă��ƂȂ̂��ȁH
���ď����Ă���ۂ��BGoogle�̒��p�|�܂��ƁB
�ł�1�y�[�W�߂�Nehalem�̃v���b�g�t�H�[���̐}���ƃ�������CPU�ɂȂ����Ă邩��A
Bloomfield�����O�t�������R���ŁAXeon�ł͓��������R�����Ă��ƂȂ̂��ȁH
446 �FMAC�I�^��445 �����F2008/01/03(��) 22:04:39 ID:0OGEg5J1
>>445
1�y�[�W�̐}��A���N��IDF�̃X���C�h�ł���ƒ��߂������Ă��邷�B
�����AXeon�틣���チ�����R���g���[����������A�x�߂̃������N���b�N��
��e�ʃ��������T�|�[�g����悤�ɂ��邱�ƂɂȂ锤���B
1�y�[�W�̐}��A���N��IDF�̃X���C�h�ł���ƒ��߂������Ă��邷�B
�����AXeon�틣���チ�����R���g���[����������A�x�߂̃������N���b�N��
��e�ʃ��������T�|�[�g����悤�ɂ��邱�ƂɂȂ锤���B
�i���̕���A�L�����̐}�ɂ���悤�Ƀ}�U�[�{�[�h�̃��t�@�����X�f�U�C���튮�����Ă���悤
�����ABloomfield�̃T���v�����}�U�{�x���_�ɔz�z����Ă���Ƃ̂��Ƃ��B
�ǂ��ɂ��������ɂ��A���Ɏ����x�[�X�̐F�X�ȃ��[�N������邱�ƂɂȂ肻�����B
�����ABloomfield�̃T���v�����}�U�{�x���_�ɔz�z����Ă���Ƃ̂��Ƃ��B
�ǂ��ɂ��������ɂ��A���Ɏ����x�[�X�̐F�X�ȃ��[�N������邱�ƂɂȂ肻�����B
���N��"WPC TOKYO 2008"���y���݂�
����
WPC���ĔN�X����ڂ��Ȃ��ĂˁH
���N�Ƃ����Ȃ�u�[�X���������E�E�E
���N�Ƃ����Ȃ�u�[�X���������E�E�E
�T�[�o�����������R���O�t���H
�ȂA�O�����Ă����̂Ƌt�̂悤�ȁB
�ȂA�O�����Ă����̂Ƌt�̂悤�ȁB
Bloomfield�͊O�t�������ǁA�I�p�܂ŊO�t���Ƃ͌��܂��ĂȂ���Ȃ����ȁB
���x�𗎂Ƃ�����DIMM�\�P�b�g���𑝂₷���߂̃\�����[�V��������Ȃ����H
E8500��XMB�̂悤��CPU�Ƃ͐�pIF�łȂ��郁�����R���g���[�����A���邢�̓o�b�t�@�`�b�v���A
�ǂ����Ȃ̂��͂܂��s���m�����ǁB
AMD�������������G3MX�Ƃ����o�b�t�@�`�b�v�\�����[�V�����𐄐i���Ă����肷��B
����̒��n�C�G���h�T�[�o�����ɂ́A��ʂ̕����������Ή����K�v���Ɨ��ЂƂ��l���Ă邾�낤���B
E8500��XMB�̂悤��CPU�Ƃ͐�pIF�łȂ��郁�����R���g���[�����A���邢�̓o�b�t�@�`�b�v���A
�ǂ����Ȃ̂��͂܂��s���m�����ǁB
AMD�������������G3MX�Ƃ����o�b�t�@�`�b�v�\�����[�V�����𐄐i���Ă����肷��B
����̒��n�C�G���h�T�[�o�����ɂ́A��ʂ̕����������Ή����K�v���Ɨ��ЂƂ��l���Ă邾�낤���B
���痠�I
�\��ł́A���N���с[�ł�ȁB
�➙���y���݂����A���с[���ǂ��������ɂȂ邩���y���݂��ȁB
�ĊO���с[��1�G�������g���➙�������Ƃ��������肵�āB�B�B
���[�y���݁B
�\��ł́A���N���с[�ł�ȁB
�➙���y���݂����A���с[���ǂ��������ɂȂ邩���y���݂��ȁB
�ĊO���с[��1�G�������g���➙�������Ƃ��������肵�āB�B�B
���[�y���݁B
PCI-E�Œ���������̂ł͂Ȃ����Ɨ\�z�B���ׂ̈ɃR���g���[���������������Ȃ����ȁB
�Ή��\�t�g��������g�������S���������������ǂˁB
�Ή��\�t�g��������g�������S���������������ǂˁB
��������CES���B����Ƃ͊W�Ȃ����ASilverthorne��Penryn���ڂ̃m�[�g������I�ڂ��ȁB
E8500/8400/8200�����\���邩����
>>459
�\�����T�ԋ߂��O�|���f�X���H�@�Ȃ��Ƃ������Ȃ��B�������ɁB
�\�����T�ԋ߂��O�|���f�X���H�@�Ȃ��Ƃ������Ȃ��B�������ɁB
>>460
��������Ȃ��攭�\
��������Ȃ��攭�\
�ߔN�̌X�����炷��Ɣ��\�Ɠ����ɔ�������Ȃ����ȁB
�����Ɍ����Ɣ�����ɔ��\
>>462
http://pc.watch.impress.co.jp/docs/2007/1221/ubiq207.htm
Core 2 Quad/Duo�ACeleron Dual-Core�Ɋւ��ẮA2008�N1��7���ɕč��̃��X�x�K�X��
�J�Â����International CES�ɂ��킹�Ĕ��\����A���i�̏o�J�n��1��20��(�č�����)
�Ƃ����\��ɂȂ��Ă����B���傤�ǁA1��7����CES�ɂ�����Intel��CEO�A�|�[���E�I�b�e���[�j�В�
�ɂ���u�����s�Ȃ���̂ŁA����ɂ��킹�Ă����̐��i�����\����邱�Ƃ�
�Ȃ��Ă����B
�����_�ł́A1��7���ɗ\�肳��Ă��鐻�i�̔��\���ǂ��Ȃ邩�͖���ŁA���\��
����߂ɂȂ���߂đ�1�l�����̌㔼�ɔ��\�����ĂƁA���i�o�ׂ͐悾��
�Ƃ肠�������\���������Ƃ���2�̈Ă�����Ƃ����B
http://pc.watch.impress.co.jp/docs/2007/1221/ubiq207.htm
Core 2 Quad/Duo�ACeleron Dual-Core�Ɋւ��ẮA2008�N1��7���ɕč��̃��X�x�K�X��
�J�Â����International CES�ɂ��킹�Ĕ��\����A���i�̏o�J�n��1��20��(�č�����)
�Ƃ����\��ɂȂ��Ă����B���傤�ǁA1��7����CES�ɂ�����Intel��CEO�A�|�[���E�I�b�e���[�j�В�
�ɂ���u�����s�Ȃ���̂ŁA����ɂ��킹�Ă����̐��i�����\����邱�Ƃ�
�Ȃ��Ă����B
�����_�ł́A1��7���ɗ\�肳��Ă��鐻�i�̔��\���ǂ��Ȃ邩�͖���ŁA���\��
����߂ɂȂ���߂đ�1�l�����̌㔼�ɔ��\�����ĂƁA���i�o�ׂ͐悾��
�Ƃ肠�������\���������Ƃ���2�̈Ă�����Ƃ����B
>>464
���B����͂���ȗ\�肾�����̂��B��������������ȁB
���႟�BWolfdale/Conroe�����\����āAYorkfiled�͂���Ȃ��Ƃ݂��B
���B����͂���ȗ\�肾�����̂��B��������������ȁB
���႟�BWolfdale/Conroe�����\����āAYorkfiled�͂���Ȃ��Ƃ݂��B
>>465
Conroe�̔����͂Ȃ���
Conroe�̔����͂Ȃ���
���ACelelon DC�̂��Ƃ�Conroe�ƌĂ��Ă��ƁH
�������������Allendale�B
�������������Allendale�B
468 �FSocket774�F2008/01/06(��) 23:26:32 ID:M6C8PwAt
>>468
�� QX9650
�� QX9650
470 �FSocket774�F2008/01/06(��) 23:29:24 ID:M6C8PwAt
�Ƃ���ʼn�����Xeon�n�̃v���Z�b�T��Core 2 Quad�n�̃v���Z�b�T�̔�r�Ƃ����Ă���T�C�g�N�������m�Ȃ��ł����H
Win32�x�[�X�͈͓̔��œ���\�ȍő��v�Z�T�[�o�[����肽���̂ł���
Win32�x�[�X�͈͓̔��œ���\�ȍő��v�Z�T�[�o�[����肽���̂ł���
http://slashdot.jp/hardware/article.pl?sid=08/01/06/223245
Intel��OLPC�����������炵��
Silverthorne�����̃v���W�F�N�g���Ǝv�������c
Intel��OLPC�����������炵��
Silverthorne�����̃v���W�F�N�g���Ǝv�������c
473 �FSocket774�F2008/01/07(��) 10:50:58 ID:RHrhs8Yj
��CPU�̓�����GPU����������m�[�X�u���b�W
���ꊮ����AMD�ׂ�����ˁH
CPU���������GPU���t���Ă�����Ď��́AGPU���l�����Ȃ��炸����킯��
�������`�b�v�Z�b�g�ɕt���Ă�I���{GPU�͐��オ�Â��Ȃ��Ă����������Â炢���ǁA
CPU�ɓ����Ȃ�CPU�������邾���ł����B��Ƀu���b�V���A�b�v����Ă�B
�@ATI��������AMD�I��
���ꊮ����AMD�ׂ�����ˁH
CPU���������GPU���t���Ă�����Ď��́AGPU���l�����Ȃ��炸����킯��
�������`�b�v�Z�b�g�ɕt���Ă�I���{GPU�͐��オ�Â��Ȃ��Ă����������Â炢���ǁA
CPU�ɓ����Ȃ�CPU�������邾���ł����B��Ƀu���b�V���A�b�v����Ă�B
�@ATI��������AMD�I��
>CPU�ɓ����Ȃ�CPU�������邾���ł����B��Ƀu���b�V���A�b�v����Ă�B
�����Ă݂��������
�`�b�v�Z�b�g���Ή����Ă����CPU������GPU�����ɂȂ���P�[�X��������Ă��Ƃ�
�����Ă݂��������
�`�b�v�Z�b�g���Ή����Ă����CPU������GPU�����ɂȂ���P�[�X��������Ă��Ƃ�
�f�l�ӌ��Ő\����Ȃ����ACPU��GPU�ꏏ�ɂȂ����甚�MCPU�ɂȂ�Ȃ����H
�������K�i���ς��Ȃ�����AMB�̌݊������ێ�����̂͋Z�p�I�ɂ͉\���낤����
�����Intel���悾����ȁB
QPI�����������܂����ADMI�����������܂����E�E�E�ƌ����Č݊������̂Ă�\�����E�E�E�B
�����Intel���悾����ȁB
QPI�����������܂����ADMI�����������܂����E�E�E�ƌ����Č݊������̂Ă�\�����E�E�E�B
���܂ł�Intel�@GPU���l����Ɗ��}�ł��Ȃ��B
>>476
������x�̑Ë��͕K�v���낤��
�m�[�X�u���b�W�T�E�X�u���b�WGPU���������ꂽCPU�͂�������̂ŁA���������̂��݂Ă݂�Ƃ���
������x�̑Ë��͕K�v���낤��
�m�[�X�u���b�W�T�E�X�u���b�WGPU���������ꂽCPU�͂�������̂ŁA���������̂��݂Ă݂�Ƃ���
�ǂ����݂̂�����OVERDRIVE�v���Z�b�T�Ƃ���������Ȃ���
��N���o�Ă\�P�b�g�ς�邵�Ȃ�
��N���o�Ă\�P�b�g�ς�邵�Ȃ�
�����tukigata�X��������������T��������
http://oshiete1.goo.ne.jp/qa1152486.html?ans_count_asc=1
http://oshiete1.goo.ne.jp/qa1152486.html?ans_count_asc=1
>>476
�����ȂƂ��낾�ȁB
Intel�̓`�b�v�Z�b�g�iGPU�����i���j����{�I�ɂP����O�̃v���Z�X�ō���āA
�H��̎g���܂킵�����Ă邵�AGPU����CPU��MCM�ō��݂���������ACPU�R�A
�����ŐV�v���Z�X�ɂ��āAGPU�R�A�����͋��v���Z�X�̉\�������邩��ȁB
�����ȂƂ��낾�ȁB
Intel�̓`�b�v�Z�b�g�iGPU�����i���j����{�I�ɂP����O�̃v���Z�X�ō���āA
�H��̎g���܂킵�����Ă邵�AGPU����CPU��MCM�ō��݂���������ACPU�R�A
�����ŐV�v���Z�X�ɂ��āAGPU�R�A�����͋��v���Z�X�̉\�������邩��ȁB
��p�n�̐��Fab�������܂Ŗ��i���Ă��Ȃ������炻��
�ꐢ��O�̃v���Z�X�ō��ꂽ�`�b�v�ɂ���
���Ђ͎�������o�Ă��Ȃ������Ǝv���B
�ꐢ��O�̃v���Z�X�ō��ꂽ�`�b�v�ɂ���
���Ђ͎�������o�Ă��Ȃ������Ǝv���B
���[�h�}�b�v����GPU��2009�N�ɂ�45nm�A2010�N�ɂ�32nm�̍ŐV�v���Z�X���g���B
���ꂪ�_�C������MCM���͕s�������ǁB
���ꂪ�_�C������MCM���͕s�������ǁB
��۾�:32��
�ۯ�:3.2GHz
FSB:1600MHz
L2�����:16MB
��:8��
�Ƃ肠�����A���̍\����CPU���o�鎖���F�O���܂��B
�ۯ�:3.2GHz
FSB:1600MHz
L2�����:16MB
��:8��
�Ƃ肠�����A���̍\����CPU���o�鎖���F�O���܂��B
>>486
45nm��Nehalem�łقڂ��̂܂�܂��o�邩��]�T�ŏo�邾��B
45nm��Nehalem�łقڂ��̂܂�܂��o�邩��]�T�ŏo�邾��B
�C���e���A45nm Hi-k�v���Z�X�̗p�̃m�[�g�����v���Z�b�T�Ȃ�16���i�\
http://enterprise.watch.impress.co.jp/cda/hardware/2008/01/08/11969.html
Intel�A45nm�v���Z�X�ɂ�鏉�̃��o�C���v���Z�b�T���\
http://www.itmedia.co.jp/news/articles/0801/08/news017.html
http://enterprise.watch.impress.co.jp/cda/hardware/2008/01/08/11969.html
Intel�A45nm�v���Z�X�ɂ�鏉�̃��o�C���v���Z�b�T���\
http://www.itmedia.co.jp/news/articles/0801/08/news017.html
�}�E�X�A�V�^Core 2 Duo�𓋍ڂ���15.4�^���C�h�m�[�g
http://pc.watch.impress.co.jp/docs/2008/0108/mcj.htm
http://pc.watch.impress.co.jp/docs/2008/0108/mcj.htm
>>486
�����I�ɔ�����
�����I�ɔ�����
>>486
FSB�p�~����Ă邩���ɖ����ƌ����Ă݂�e�X�g
FSB�p�~����Ă邩���ɖ����ƌ����Ă݂�e�X�g
>491
�Ȃ�قǂ�
�Ȃ�قǂ�
FSB�p�~���ĂȂ�Ƃǂ������d�g�݂ɂȂ�́H
FSB�����l�I�ɃK�^��������\���ɂȂ邩��\�L���Ȃ��Ȃ���Ď��H
FSB�����l�I�ɃK�^��������\���ɂȂ邩��\�L���Ȃ��Ȃ���Ď��H
>>493
AMD��Hammer�n�ƈꏏ�B
AMD��Hammer�n�ƈꏏ�B
���������̎��������Ă�����
ttp://pcparts.fc2web.com/cpu-intel-future.html
���ʃp����������V���A�������ɂȂ�ƃs���̐��Ƃ�
���肻���Ȃ��̂�����1366�{�Ƃ��ɂȂ�B���R�ȏ�Ɍ��R�B
����������AMD�̕��������R������������940�Ƃ��ȂȁB
ttp://pcparts.fc2web.com/cpu-intel-future.html
���ʃp����������V���A�������ɂȂ�ƃs���̐��Ƃ�
���肻���Ȃ��̂�����1366�{�Ƃ��ɂȂ�B���R�ȏ�Ɍ��R�B
����������AMD�̕��������R������������940�Ƃ��ȂȁB
>>495
�����R������������邩�瑝���Ă���̂͂��邩���ˁB
���Ȃ݂�AM2��940pin�ŁASocketF��1206��LGA�B
SocketF�͑���CPU�Ƃ�HT�ڑ������邩�瑝���Ă���B
������A������������Nehalem��8�R�A��4�R�A�ŁA
�n�C�G���h�Ƃ���ȉ��Ƃł̓s�������Ⴄ�\��������H
�����R������������邩�瑝���Ă���̂͂��邩���ˁB
���Ȃ݂�AM2��940pin�ŁASocketF��1206��LGA�B
SocketF�͑���CPU�Ƃ�HT�ڑ������邩�瑝���Ă���B
������A������������Nehalem��8�R�A��4�R�A�ŁA
�n�C�G���h�Ƃ���ȉ��Ƃł̓s�������Ⴄ�\��������H
>>497
���̃��X�ԂɂȂɂ����邩�����Ȃ����c�B
���̃��X�ԂɂȂɂ����邩�����Ȃ����c�B
>>487
Nehalem��8�R�A�̂�XeonMP��p�̒��������z����
Nehalem��8�R�A�̂�XeonMP��p�̒��������z����
>>493
�V�X�e���o�X��FSB������ȊO�ɂȂ邩�ǂ����̈Ⴂ
�V�X�e���o�X��FSB������ȊO�ɂȂ邩�ǂ����̈Ⴂ
>>499
�ʂ�Nehalem�ƌ��肵�Ă���킯����Ȃ����c
>>487��Nehalem��Xeon�ŏo�Ă�����玟����R�A�̃��C�g���[�U�[������
���̂��炢�̂͏o���Ȃ��H���Ă��Ƃ���Ȃ�?
�܂��A>>491�̒ʂ肾���ǂ�
�ʂ�Nehalem�ƌ��肵�Ă���킯����Ȃ����c
>>487��Nehalem��Xeon�ŏo�Ă�����玟����R�A�̃��C�g���[�U�[������
���̂��炢�̂͏o���Ȃ��H���Ă��Ƃ���Ȃ�?
�܂��A>>491�̒ʂ肾���ǂ�
���ʂ܂ł�L3�L���b�V��1GB�Ƃ����Ă݂����B
>>502
����3-40�N�������畁�ʂɂ݂�ꂻ������ˁB
����3-40�N�������畁�ʂɂ݂�ꂻ������ˁB
���̂���L3�L���b�V���Ƃ����T�O�͂���̂��낤���B
>>502
�L���b�V�����čl�������̂��̂��p�ꂻ�������ǂȁB
�L���b�V�����čl�������̂��̂��p�ꂻ�������ǂȁB
���ƂR�O�N�������烁�C���������Ƃ����T�O���̂��Ȃ��P�O�O�O�ȏ�̃R�A��
1GB���x�̏��ʂ̃��[�J�����������t������`�ԂɂȂ��
1GB���x�̏��ʂ̃��[�J�����������t������`�ԂɂȂ��
���̍��͂Ƃ�����PC�͂傣����̌`���Ă��
�V���R���̔����̌��E��2020�N��������A���̍X��18�N�ォ�B
�m�C�}���^�A�[�L�e�N�`���[�͌������̂��c�B
�債�Ĕ��W���Ȃ���Ό����ȋC�����邵�A
�R���s���[�^�[(?)�̓v���O������g�ނ̂ł͂Ȃ��ċ�����{���`�ԂɂȂ��Ă��邩������Ȃ��B
�w�K���ʂ̃R�s�[�͂ł��邾�낤����ʎY�͌��������Ƃ��A�z�����Ă݂�B
�m�C�}���^�A�[�L�e�N�`���[�͌������̂��c�B
�債�Ĕ��W���Ȃ���Ό����ȋC�����邵�A
�R���s���[�^�[(?)�̓v���O������g�ނ̂ł͂Ȃ��ċ�����{���`�ԂɂȂ��Ă��邩������Ȃ��B
�w�K���ʂ̃R�s�[�͂ł��邾�낤����ʎY�͌��������Ƃ��A�z�����Ă݂�B
Intel�A�wPenryn�x�̃��C���i�b�v��啝�Ɋg��
Intel �͐悲��A45�i�m���[�g�� (nm) �v���Z�b�T �t�@�~���wPenryn�x�������[�X�������A
���̑�1�e�́A����ނ̃T�[�o�p�wXeon�x�ƃf�X�N�g�b�v �t�@�~���̃n�C�G���h���f��
�wCore 2 Extreme�x�݂̂Ƃ����A���n���ȓ��e�������B�����A7������J�Â���Ă���
�C�x���g�w2008 International CES�x�ł́A�f�X�N�g�b�v�A���o�C���A���[�G���h�̃T�[�o�[
�������i�ȂǁA����ɑ����� Penryn �v���Z�b�T�����\����邱�ƂɂȂ����B
ttp://japan.internet.com/webtech/20080108/12.html?rss
AMD�ɂƂǂ߂��h���Ă���˂�
Intel �͐悲��A45�i�m���[�g�� (nm) �v���Z�b�T �t�@�~���wPenryn�x�������[�X�������A
���̑�1�e�́A����ނ̃T�[�o�p�wXeon�x�ƃf�X�N�g�b�v �t�@�~���̃n�C�G���h���f��
�wCore 2 Extreme�x�݂̂Ƃ����A���n���ȓ��e�������B�����A7������J�Â���Ă���
�C�x���g�w2008 International CES�x�ł́A�f�X�N�g�b�v�A���o�C���A���[�G���h�̃T�[�o�[
�������i�ȂǁA����ɑ����� Penryn �v���Z�b�T�����\����邱�ƂɂȂ����B
ttp://japan.internet.com/webtech/20080108/12.html?rss
AMD�ɂƂǂ߂��h���Ă���˂�
�I�[�o�[�L��
>>508
�V���m�����݂̓V�˂̍~�Ղ�҂��Ȃ��Ⴂ���Ȃ��킯���Ȃ�
�V���m�����݂̓V�˂̍~�Ղ�҂��Ȃ��Ⴂ���Ȃ��킯���Ȃ�
�Ԃ�V�̍��ɐA���t����ꂽ�]���̃`�b�v�������ɍ��킹�Ď��ʂ܂Ői������o�C�I�`�b�v�Ƃ����ȁB
�C���^�[�t�F�[�X�͎w��Ō݂��ɐG�ꍇ�������B
�C���^�[�t�F�[�X�͎w��Ō݂��ɐG�ꍇ�������B
�S�[�X�g�͚����܂����H
�d�]�����ǂ̓n�b�L���O��E�B���X���������܂����Ĕp����ˁE�E�E
���Ƃ���
���Ă݂���X���^�C�ʂ�̎�����̘b���
�������A���̐���������ɂԂ����ł����
�������A���̐���������ɂԂ����ł����
>>512
��A��N�ŋ��^�ɂȂ��Ă��܂������Ȃ���
��A��N�ŋ��^�ɂȂ��Ă��܂������Ȃ���
>>512
�Ԃ�V�̊Ԃɒm�\�������炭���W���Ă��܂��V���[���ȑz��������w
�Ԃ�V�̊Ԃɒm�\�������炭���W���Ă��܂��V���[���ȑz��������w
CPU�Ƃ͑S���|�����ꂽ���b�����A
"�T���@���nj�Q"�Ŕ�������悤�Ȕ\�͂͒N�ɂł������āA
�l�Ԃ��W�c�������������Ȃ����ňӐ}�I�Ɏ̂ĂĂ��������̂炵���B
������A�����N�ɂł��g����l�ɂ��邱�Ƃ͉\�ł͂Ȃ��̂��H
�I�Ȍ���������̂ȁB
"�T���@���nj�Q"�Ŕ�������悤�Ȕ\�͂͒N�ɂł������āA
�l�Ԃ��W�c�������������Ȃ����ňӐ}�I�Ɏ̂ĂĂ��������̂炵���B
������A�����N�ɂł��g����l�ɂ��邱�Ƃ͉\�ł͂Ȃ��̂��H
�I�Ȍ���������̂ȁB
�V���{���I�ȃA�v���[�`�A�_�o��H�I�ȃA�v���[�`�A���̃n�C�u���b�g�A���̑�
������ɂ��Ă��A����������Ɛl�̂Ɋw��ōH�w�I�ɂ��悢���f�������Ȃ��Ɣ��W�͂Ȃ������B
������ɂ��Ă��A����������Ɛl�̂Ɋw��ōH�w�I�ɂ��悢���f�������Ȃ��Ɣ��W�͂Ȃ������B
http://image.itmedia.co.jp/l/im/pcuser/articles/0801/09/l_kn_ces08um_07.jpg
�b�V�X�e����̒����Ɍ�����̂������`�b�v�\���́uPoulsbo�v�ŁA���̉E�Ɍ����鏬����
�b�`�b�v��CPU�́uSilverthorne�v�i�Ƃ��ɊJ���R�[�h���j��
CPU�̕����e���ɂȂ��Ă܂��ˁB�i�a�̕v�w�H�j
�����CPU�̑��݂͂���Ȋ����ɂȂ�̂��ȁH
{kind=link}
�b�V�X�e����̒����Ɍ�����̂������`�b�v�\���́uPoulsbo�v�ŁA���̉E�Ɍ����鏬����
�b�`�b�v��CPU�́uSilverthorne�v�i�Ƃ��ɊJ���R�[�h���j��
CPU�̕����e���ɂȂ��Ă܂��ˁB�i�a�̕v�w�H�j
�����CPU�̑��݂͂���Ȋ����ɂȂ�̂��ȁH
�_�C�T�C�Y�͂Ƃ������Ƃ���CPU���`�b�v�Z�b�g�̕����s������������̂͌����_�ł͕K�R������
>>523 ������L��
http://plusd.itmedia.co.jp/pcuser/articles/0801/09/news038.html
IT media�́A�摜�̒��������߂Ȃ��
http://plusd.itmedia.co.jp/pcuser/articles/0801/09/news038.html
IT media�́A�摜�̒��������߂Ȃ��
526 �F�R�E�L�́M�E,,�j�����������������F2008/01/10(��) 02:08:48 ID:l+bz7Jco
Nehalem��CPUID�̎����Ƃ��̎������ďo�Ă�H
AMD���ׂꂻ�������珕���M�����܂����B
http://www.itmedia.co.jp/news/articles/0801/11/news010.html
http://www.itmedia.co.jp/news/articles/0801/11/news010.html
�������A�Ƌ֖@�Ɏ���Ȃ�����Ă̂́A����Ӗ����J�I�Ȃ�Ȃ��낤���c
���J�Ȃ�Ăǂ��ł��������ǁA�Ƌ֖@�Ɏ���Ă���菟�ĂȂ�����ȁB
���J�Ȃ�Ċ������ЂȂ�SSE5�Ƃ��������Ȃ�����B
�܂�MS�ƃA�b�v���̎�����L�邵�AIntel������Ȑ����\�͂����āA���ۂ�
�Â��Ȃ���65nm�v���Z�X�Ő����������Ηǂ��̃W���}�C�J�B
�Â��Ȃ���65nm�v���Z�X�Ő����������Ηǂ��̃W���}�C�J�B
���J�Ƃ������B�Ƌ֖@�ɂ�����悤�Ȃ��Ƃ����Ȃ���A
��������Ȃ�����Intel�̕������ނׂ����Ƃ��������c�B
��������Ȃ�����Intel�̕������ނׂ����Ƃ��������c�B
��������悤�Ɣ���܂��Ƃ�邱�Ƃɕς��͂Ȃ�����
Intel��65nm�̓`�b�v�Z�b�g�⋐��ȃ_�C�T�C�Y��Tukwila�APenDC��CeleDC��
���Y���Ȃ��Ƃ����Ȃ��̂ŁA�����̂Ԃ����]�T�܂ł͂Ȃ�����B
���Y���Ȃ��Ƃ����Ȃ��̂ŁA�����̂Ԃ����]�T�܂ł͂Ȃ�����B
�Y�f�̒P���q�V�[�g�ɃV���R�����锼���̂̉\��
ttp://slashdot.jp/science/article.pl?sid=08/01/11/0111214
NewScientist Tech�L���o�R�A�}���`�F�X�^�[��w�̃v���X�����[�X���B
�Y�f�̒P���q�V�[�g�ł���O���t�F���igraphene�j�́A�ȑO����i�m�e�N�m���W�[�����̑ΏۂƂȂ��Ă��镨���ł������B
���̕����̓��������������}���`�F�X�^�[��w�A���V�AInstitute for Microelectronics Technology��
�I�����_���h�o�E�g�E�i�C���[�w����w�A�A�����J�~�V�K���H�ȑ�w�����w�ȂƂ̍��������`�[���́A
�d�q�ړ��x���V���R���̕S�{�ȏ���̒l�ł���200000cm^2/Vs�ɒB���邱�Ƃ������Ƃ����B
����܂Œm���Ă���J�[�{���i�m�`���[�u��A���`�������C���W�E���Ƃ������f�ވȏ�̓K���������Ă���A
���ɗL�]�ȑf�ނ��ƌ����ɎQ������Andre Geim�����͌���Ă���B
�O���t�F�����V���R����u��������悤�Ȃ��Ƃ�20�N�ȓ��ɂ���Ƃ͍l�����Ȃ��Ƌ������F�߂Ă��邪�A
����3�N����T�N�ȓ��ɃK�X�Z���T�[��e���w���c���U��^���o��Ƃ��������u�։��p�����悤�ɂȂ�̂ł͂�
���҂��Ă��邻�����B���̌������ʂ�Physical Review Letters��11 January 2008���ɂ��f�ڂ��ꂽ�B
�Ƃ肠�����C���e���Ƃ͖��W���������I��CPU�ɉ��p���ꂻ�����Ă��Ƃ�
ttp://slashdot.jp/science/article.pl?sid=08/01/11/0111214
NewScientist Tech�L���o�R�A�}���`�F�X�^�[��w�̃v���X�����[�X���B
�Y�f�̒P���q�V�[�g�ł���O���t�F���igraphene�j�́A�ȑO����i�m�e�N�m���W�[�����̑ΏۂƂȂ��Ă��镨���ł������B
���̕����̓��������������}���`�F�X�^�[��w�A���V�AInstitute for Microelectronics Technology��
�I�����_���h�o�E�g�E�i�C���[�w����w�A�A�����J�~�V�K���H�ȑ�w�����w�ȂƂ̍��������`�[���́A
�d�q�ړ��x���V���R���̕S�{�ȏ���̒l�ł���200000cm^2/Vs�ɒB���邱�Ƃ������Ƃ����B
����܂Œm���Ă���J�[�{���i�m�`���[�u��A���`�������C���W�E���Ƃ������f�ވȏ�̓K���������Ă���A
���ɗL�]�ȑf�ނ��ƌ����ɎQ������Andre Geim�����͌���Ă���B
�O���t�F�����V���R����u��������悤�Ȃ��Ƃ�20�N�ȓ��ɂ���Ƃ͍l�����Ȃ��Ƌ������F�߂Ă��邪�A
����3�N����T�N�ȓ��ɃK�X�Z���T�[��e���w���c���U��^���o��Ƃ��������u�։��p�����悤�ɂȂ�̂ł͂�
���҂��Ă��邻�����B���̌������ʂ�Physical Review Letters��11 January 2008���ɂ��f�ڂ��ꂽ�B
�Ƃ肠�����C���e���Ƃ͖��W���������I��CPU�ɉ��p���ꂻ�����Ă��Ƃ�
http://finance.yahoo.com/charts#chart3:symbol=amd;range=1m;indicator=dividend+split;charttype=line;crosshair=on;logscale=on;source=undefined
�Ƌ֖@�̂������ł����Ȃ芔�����������Ă�ȁB
�Ƌ֖@�̂������ł����Ȃ芔�����������Ă�ȁB
�A�����J�͊e�B���Ƃɔ��g���X�g�@�����肳��Ă邩�獑��Ƃ��W�Ȃ���ˁB
����������ŗL�߂ɂ������đ�l�̔F���Ƃ��Ăǂ���HIntel�̒��̐l���咣����Ȃ�܂�����
�啪�����ӌ����Ǝv�����ǂˁB
����������ŗL�߂ɂ������đ�l�̔F���Ƃ��Ăǂ���HIntel�̒��̐l���咣����Ȃ�܂�����
�啪�����ӌ����Ǝv�����ǂˁB
541 �F�R�E�L�́M�E,,�j�����������������F2008/01/12(�y) 05:30:07 ID:URArrAzO
AMD����100mm²���x�̃_�C���̎Z���C�����Đ̂��猾���Ă�����
�ߔN�͑傫�ȃ_�C�ł��̎Z�Ƃ��悤�ɂȂ����̂��H
270mm²����4�R�A�͑傫������Ǝv�����B
�ߔN�͑傫�ȃ_�C�ł��̎Z�Ƃ��悤�ɂȂ����̂��H
270mm²����4�R�A�͑傫������Ǝv�����B
�̂��Ă����H
�����\�͂������Ă邩��_�C�T�C�Y�����������������Ă̂͂��������ǁB
�����\�͂������Ă邩��_�C�T�C�Y�����������������Ă̂͂��������ǁB
543 �F�R�E�L�́M�E,,�j�����������������F2008/01/12(�y) 06:54:15 ID:URArrAzO
200mm�E�G�n�[����͕��ʂɌ����Ă���
�R�E�L�́M�E,,�j�����������������͊��o�Â�������B
WindsorFX�̃_�C�T�C�Y���ׂĂ݂�B
WindsorFX�̃_�C�T�C�Y���ׂĂ݂�B
K8������200mm�E�F�n����n�܂������Ǖ��ʂɖׂ��Ă��͂������B
�Ȃ̎Z���C�����_�C�T�C�Y�Ō��܂�ƌ�����ƈ�a�����o����ȁB
�Ȃ̎Z���C�����_�C�T�C�Y�Ō��܂�ƌ�����ƈ�a�����o����ȁB
546 �F�R�E�L�́M�E,,�j�����������������F2008/01/12(�y) 07:03:24 ID:URArrAzO
547 �F�R�E�L�́M�E,,�j�����������������F2008/01/12(�y) 07:09:12 ID:URArrAzO
���Ȃ݂�Windsor�̍��ɂ͊���300mm�Ɉڍs���Ă܂��ˁB
X2���D���̍��ɂ�ASP������Ȃ�ɏオ���Ă�����傫�ȃ_�C�ł��̎Z�Ƃꂽ��Ȃ��́B
���́A�ō����f����10���~���Ŕ����Ă�����Ƃ���ׂĐ����R�X�g���債�ė����Ȃ��܂�
���i������K6����ɂ��ǂ��Ă����Ă�B
���̏�AMD�Ƃ��Ă͑�����������Ȃ����ȂƁB
X2���D���̍��ɂ�ASP������Ȃ�ɏオ���Ă�����傫�ȃ_�C�ł��̎Z�Ƃꂽ��Ȃ��́B
���́A�ō����f����10���~���Ŕ����Ă�����Ƃ���ׂĐ����R�X�g���債�ė����Ȃ��܂�
���i������K6����ɂ��ǂ��Ă����Ă�B
���̏�AMD�Ƃ��Ă͑�����������Ȃ����ȂƁB
>>546
���܂��c���v���H�@C2D���o�Ă���Ɛт��������̂́A
���\�ʂ�C2D���D�ʂ��������炾��c�B
�����łȂ���Ɛт�������킯���˂��B
���܂��c���v���H�@C2D���o�Ă���Ɛт��������̂́A
���\�ʂ�C2D���D�ʂ��������炾��c�B
�����łȂ���Ɛт�������킯���˂��B
�̎Z���C�����Ȃ�ڂ�������Ȃ�����
Fab���݂��Đ����ʏグ���̂�Intel�̎s��V�F�A���܂�����������ĂȂ�
����͑啪��@�I�Ȃ�Ȃ����H
Fab���݂��Đ����ʏグ���̂�Intel�̎s��V�F�A���܂�����������ĂȂ�
����͑啪��@�I�Ȃ�Ȃ����H
MYCOM�ɂ�����Ə�����Ă����ǁAIBM�Ƒg�H��Ƃ̂���݂�������A
���̑i�ׂ͖����������낤�ˁB�܂萭���I�z���B
�N�I���A�܂�NY�B�m���̒n�ʂ�_���Ă��[�ˁB�ȑO�e��������Ă��B
�܂��A�ǂ��W�J���邩�킩���ȁB�n�܂���������ŋ��z�I�Ȃ��Ƃ��o�ĂȂ����B
���̑i�ׂ͖����������낤�ˁB�܂萭���I�z���B
�N�I���A�܂�NY�B�m���̒n�ʂ�_���Ă��[�ˁB�ȑO�e��������Ă��B
�܂��A�ǂ��W�J���邩�킩���ȁB�n�܂���������ŋ��z�I�Ȃ��Ƃ��o�ĂȂ����B
�����Ԃ̍H��ɂ��Ă������̂̍H��ɂ��Ă�
�K�������I�Ȃ��Ƃ肪����ł���A���傤���Ȃ�
�K�������I�Ȃ��Ƃ肪����ł���A���傤���Ȃ�
>>527
�K�L�����܂��͂���
�K�L�����܂��͂���
>>538
�m�������T���u�^�����ɂ��݂ɂ͎������\��錾�������肪��������Ƃ��������A
���������ה��M�ŃI�i�j�[�ł���l��͗������ȁB
�m�������T���u�^�����ɂ��݂ɂ͎������\��錾�������肪��������Ƃ��������A
���������ה��M�ŃI�i�j�[�ł���l��͗������ȁB
�R�s�y�r�炵���Ȃ��琸�_���������Ȃ�A���������鉻������ȁB
���낻��2�����̃K����������Ēǂ��o�����������B
���낻��2�����̃K����������Ēǂ��o�����������B
WindorFX�̃_�C�T�C�Y��220mm2����Ȃ����������H
65nm��512KB��126mm2���x�������Ǝv�����ǁD
�S�R�A��290mm2���������ȁD
65nm��512KB��126mm2���x�������Ǝv�����ǁD
�S�R�A��290mm2���������ȁD
558 �FSocket774�F2008/01/14(��) 20:38:16 ID:NfQjeX+7
a
559 �FSocket774�F2008/01/14(��) 23:29:24 ID:RzElBbbz
Intel��4�N��ɐ��i�������ł��낤�Ƃ���������i�������ɗ���Ă�����
����Ȃ�Ė��O�H
Penryn��Nehalem�Ƃ͌����ږ��炩�ɈႤ
����Ȃ�Ė��O�H
Penryn��Nehalem�Ƃ͌����ږ��炩�ɈႤ
�ʐ^������Δ��肵�Ă������B
>>560
�B�e�@�ގ������߂Ȃ�����B��͖̂�������
�B�e�@�ގ������߂Ȃ�����B��͖̂�������
�[���A�p�b�P�[�W���O�͉�?
4�N�O�ɐ��i������\��̃V���R���Ȃ�ĂȂ��͂�����B
�����p�̎���i�ł�?
4�N�O�ɐ��i������\��̃V���R���Ȃ�ĂȂ��͂�����B
�����p�̎���i�ł�?
�S�N��ɏo��CPU�̎���i�Ȃ�Ă���킯�Ȃ�����
����Ƃ�����Polaris�݂����ȋZ�p���삾��
����Ȃ��ЊO�ɗ����Ƃ��v����
����Ƃ�����Polaris�݂����ȋZ�p���삾��
����Ȃ��ЊO�ɗ����Ƃ��v����
>>559
Pachimonos5����Ȃ��́H
Pachimonos5����Ȃ��́H
565 �FMAC�I�^��562 �����F2008/01/15(��) 00:05:32 ID:3dxtK4i7
>>562
3D�_�C�X�^�b�L���O�̃T���v����DRAM�x���_�ɑ����Ă���̂�������Ȃ�����B
3D�_�C�X�^�b�L���O�̃T���v����DRAM�x���_�ɑ����Ă���̂�������Ȃ�����B
566 �F�R�E�L�́M�E,,�j�����������������F2008/01/15(��) 00:07:31 ID:tZem3nYZ
��̃e���X�P�[���v���Z�b�T��
����A�ނ���p�b�P�[�W���O�Z�p�̃��J�j�J���T���v���ł���B
������p�b�P�[�W���O�`�Ԃ����ɂȂ��Ă�����B
������p�b�P�[�W���O�`�Ԃ����ɂȂ��Ă�����B
�݂�Ȓނ�ꂷ���B
�`�b�v�͂܂�����ĂȂ��p�b�P�[�W���O�݂̂̏�Ԃ���
Nehalem������ōŋ߂悭����Ă��邯��>>559�̂͌����ڂ����炩�ɈႤ
>>567
�p�b�P�[�W���O�`�Ԃ��ĉ���������̂��悭������Ȃ�
�������d���Ȃ�ŐQ��
�܂���ЂɎc���Ă���܂����Ă݂��
Nehalem������ōŋ߂悭����Ă��邯��>>559�̂͌����ڂ����炩�ɈႤ
>>567
�p�b�P�[�W���O�`�Ԃ��ĉ���������̂��悭������Ȃ�
�������d���Ȃ�ŐQ��
�܂���ЂɎc���Ă���܂����Ă݂��
NDA�Ƃ��Г��K��Ƃ��ǁ[�Ȃ�Ă�̂�
���i�K�ł������̏������݃o������N�N�r����
���i�K�ł������̏������݃o������N�N�r����
572 �FSocket774�F2008/01/15(��) 08:58:22 ID:L73ymEmj
�s���̈������Ƃ̓X���[����R�e�n���۽
�܂��A���ƍ���Ƃ���͊y�������Ȑl���߂Ă�g�R�ƁA
�����Ɏd���o���Ă�g�R���ȁB
�����Ɏd���o���Ă�g�R���ȁB
����ȂƂ���Œނ����Ėʔ����̂����
�����肵������
�ނ�łȂ���ΐM�Z������̉�Ђ��H
577 �FSocket774�F2008/01/19(�y) 14:23:49 ID:2brLz3Gw
4�N��ăl�n�����̎��̎��H
���̍��ɂ̓l�n�����Z�������o�Ă邩�ȁH
���̍��ɂ̓l�n�����Z�������o�Ă邩�ȁH
Intel�̎�����CPU�ɂ��Č�낤 32
nehalem���o���Ƃ��āApenryn��4G�߂��œ���������Ă邩��A
���̐��\�����邩���ā[�Ɣ�������Ȃ��̂��H
OC�ł̌��E���\���ăR�A�����̐i���łǂ̒��x�オ����́H
���̐��\�����邩���ā[�Ɣ�������Ȃ��̂��H
OC�ł̌��E���\���ăR�A�����̐i���łǂ̒��x�オ����́H
������YorkField��3.2GHz�őł��~�߂̗\��Ȃ킯�łˁB
Nehalem�̗����グ���������āA�Ȃ�����AMD���ǂ��グ�Ă����Ȃ�
�������N���b�N�i�𓊓����Ă���̂��낤���ANehalem�̗����グ�������ɂ����Ȃ�
�킴�킴���\�I�ɋ�������悤�ȕi�͏o���Ȃ��B
Nehalem�̗����グ���������āA�Ȃ�����AMD���ǂ��グ�Ă����Ȃ�
�������N���b�N�i�𓊓����Ă���̂��낤���ANehalem�̗����グ�������ɂ����Ȃ�
�킴�킴���\�I�ɋ�������悤�ȕi�͏o���Ȃ��B
>>579
�オ��Ƃ͌����B
QuickPathInterconnect�̃s���ӂ�6.4Gbps�Ƃ������\���炷��ƁADDR�����3.2GHz
�x�[�X�N���b�N200MHz*16���ĂƂ��낾��B
�����A���������{�g���l�b�N�ɂȂ邩�牺�����Ă��s�v�c����Ȃ��B
�オ��Ƃ͌����B
QuickPathInterconnect�̃s���ӂ�6.4Gbps�Ƃ������\���炷��ƁADDR�����3.2GHz
�x�[�X�N���b�N200MHz*16���ĂƂ��낾��B
�����A���������{�g���l�b�N�ɂȂ邩�牺�����Ă��s�v�c����Ȃ��B
���傤��AMD���オ��ɂ����̂Ɠ����ɂȂ�\����������Ă��Ƃ��ȁB
Lynnfield��Havendale��QPI�ڂŏ]����FSB
���ʂɍl�����GMCH��CPU�Ԃ�QPI������
>>583
CPU�p�b�P�[�W����CPU��GMCH�̐ڑ���QPI
��ŁACPU��PCH�i�`�b�v�Z�b�g�j�̐ڑ���DMI
�S�R�]����FSB����Ȃ����E�E�E
ttp://pc.watch.impress.co.jp/docs/2008/0122/kaigai411_03l.gif
CPU�p�b�P�[�W����CPU��GMCH�̐ڑ���QPI
��ŁACPU��PCH�i�`�b�v�Z�b�g�j�̐ڑ���DMI
�S�R�]����FSB����Ȃ����E�E�E
ttp://pc.watch.impress.co.jp/docs/2008/0122/kaigai411_03l.gif
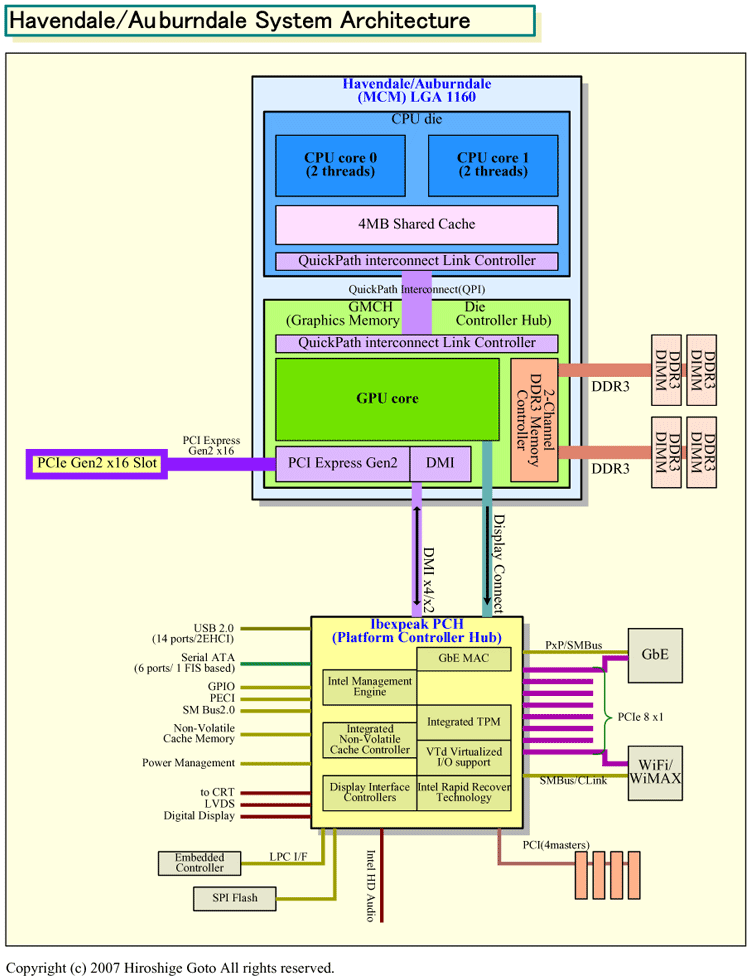{kind=link}
�㓡�̊G�͊Ԉ���Ă���!!
Lynnfield/Havendale��QPI�͎g�p���Ă��Ȃ����B
Lynnfield/Havendale��QPI�͎g�p���Ă��Ȃ����B
�[���AHKEPC�ɂ�QPI�g���ĂȂ����ď����Ă��邼�B
�ǂ������ق�ƂȂ��B
�ǂ������ق�ƂȂ��B
������Ă悤����ɁA�m�[�X�u���b�W��CPU�̉��Ɏ����Ă�����Ă��Ƃ���ˁB
�]���^���������b�g�͂���̂���
�]���^���������b�g�͂���̂���
�z�������ɂ߂ĒZ�����������āA���܂܂ł�FSB���i�i�ɍ����ɂ͏o�����Ȃ����ȁB
���܂܂ł�MCM�p�b�P�[�W�ƈ���āA�}���`�h���b�v�͗v������Ȃ����B
���܂܂ł�MCM�p�b�P�[�W�ƈ���āA�}���`�h���b�v�͗v������Ȃ����B
���܂���AGPU�����Ƃ�ׁBNorth���Ƃ�MCH�Ƃ������Ƃ͖Y���B
���Ȃ݂�>>585�͋C�����Ă��Ȃ��悤�����A
DMI�͏]�����炠����̂ł��BFSB�����x���̂ł��B
DMI�͏]�����炠����̂ł��BFSB�����x���̂ł��B
����GPU��PCI-E����CPU���Q�l�ɂ��Ă݂�Ƃ���
North��MCH�͖Y�ꂽ���ǁAGPU�����Ƃ͌ĂȂ�
>>591
PCH�͏]����ICH�Ƃقړ����ʒu�t�������炢����Ȃ��H
DMI��MCH-ICH�p�̃C���^�[�t�F�[�X����������I�Ȑ��\�ቺ�͂Ȃ����B
CPU����PCI-Express Gen2��PCH�ɓ��������PCI-Express Gen1�����S-ATA��USB��
���݂��l����V���A���C���^�[�t�F�[�X�̂܂ܓ`���ł���������������Ǝv�����ǁB
�킴�킴�A�V���A���|�p�������|�V���A���Ɠ�x���ϊ�������̂͌����������B
����CPU-MCH�Ԃ�FSB�ڑ��قǑш悪�K�v�ȕ�������Ȃ�����A��ւ̎������l������
����N���b�N�𗎂Ƃ����o�X�������炷���Ȃ肵�āA����DMI�Ƒ債�ĕς��Ȃ����̂�
�Ȃ��Ȃ��́H
PCH�͏]����ICH�Ƃقړ����ʒu�t�������炢����Ȃ��H
DMI��MCH-ICH�p�̃C���^�[�t�F�[�X����������I�Ȑ��\�ቺ�͂Ȃ����B
CPU����PCI-Express Gen2��PCH�ɓ��������PCI-Express Gen1�����S-ATA��USB��
���݂��l����V���A���C���^�[�t�F�[�X�̂܂ܓ`���ł���������������Ǝv�����ǁB
�킴�킴�A�V���A���|�p�������|�V���A���Ɠ�x���ϊ�������̂͌����������B
����CPU-MCH�Ԃ�FSB�ڑ��قǑш悪�K�v�ȕ�������Ȃ�����A��ւ̎������l������
����N���b�N�𗎂Ƃ����o�X�������炷���Ȃ肵�āA����DMI�Ƒ債�ĕς��Ȃ����̂�
�Ȃ��Ȃ��́H
1�p�b�P�[�W�Ɏ��������CPU��GMCH�Ԃ͏]����FSB��荂�����e�C���C�e���V�A�������ȃs������QPI�Ō�������邩��A
CPU�R�A�Ƀ_�C���x���œ���������ʃ��f���ɔ�ׂ�Ɨ����̂́ACPU�\�P�b�g��ʂ���GMCH�ƌ������Ă����]�����͐��\�̌��オ�����߂�B
�o�X���O���t�B�b�N�X�p�̍�����PCIe�Ǝ��Ӌ@��p��DMI���o�Ă��邵�A�S�����Ȃ��B
CPU�R�A�Ƀ_�C���x���œ���������ʃ��f���ɔ�ׂ�Ɨ����̂́ACPU�\�P�b�g��ʂ���GMCH�ƌ������Ă����]�����͐��\�̌��オ�����߂�B
�o�X���O���t�B�b�N�X�p�̍�����PCIe�Ǝ��Ӌ@��p��DMI���o�Ă��邵�A�S�����Ȃ��B
>>483
CPU�����^��GPU�v���Z�X����C�ɔ��������intel�͂���������Ă��܂�
CPU�����^��GPU�v���Z�X����C�ɔ��������intel�͂���������Ă��܂�
PC��V�������������悤�Ǝv���Ă���̂ł���
CPU�Ŗ����Ă��܂��B
Core 2 Duo E8500 3.16GHz
Core2�@Quad Q6600 2.40GHz
���̂Q�Ȃ̂ł����A�N���b�N���������ق������\���ǂ��̂ł��傤���H
���낢��Ȕ�r�T�C�g�������Quad�̂ق��������Ԑ��\���ǂ��悤�ɏ����Ă���
���������Ă��܂��B�N���b�N���͂��܂�W�Ȃ��̂ł��傤��
���S�҂Ő\����Ȃ��̂ł������ڝ��̒���낵�����肢�\���グ�܂�
CPU�Ŗ����Ă��܂��B
Core 2 Duo E8500 3.16GHz
Core2�@Quad Q6600 2.40GHz
���̂Q�Ȃ̂ł����A�N���b�N���������ق������\���ǂ��̂ł��傤���H
���낢��Ȕ�r�T�C�g�������Quad�̂ق��������Ԑ��\���ǂ��悤�ɏ����Ă���
���������Ă��܂��B�N���b�N���͂��܂�W�Ȃ��̂ł��傤��
���S�҂Ő\����Ȃ��̂ł������ڝ��̒���낵�����肢�\���グ�܂�
>>597
('A`)��Q6600����
('A`)��Q6600����
8500�����ƌ����Ă݂�e�X�g�B
�܁A�����O�ɃX���^�C��100��ǂق������ɂȂ邺��B
�܁A�����O�ɃX���^�C��100��ǂق������ɂȂ邺��B
>>597
�Ȃɂ����邩�ɂ��
�Ȃɂ����邩�ɂ��
>>597
����͋M���̗p�r���悾����Ȃ�Ƃ������Ȃ��B
�Ⴆ�Ε��ׂ̍����A�v���P�[�V�������g���ɂ��Ă��A���ꂪ�}���`�X���b�h�ɑΉ����ĂȂ�
�V���O���X���b�h�I�����[�̃A�v���P�[�V������1��2���炢�����g��Ȃ��Ƃ��A�f���A���R�A
�Ή��̃G���R�[�_���g�����ǃG���R���͑��̍�Ƃ͈���Ȃ��Ƃ������������Ƃł���A
�N���b�N�̍���E8500�̕������������ł���B
�t�ɁA�N�A�b�h�R�A�ɍœK������Ă��ăf���A���R�A�����i�i�ɐ��\�̌��シ��A�v���P�[�V����
�i���͏��Ȃ����ǁj���g�������Ƃ��A���ׂ̍����A�v���P�[�V������3��4�������ɋN������
���s���č�Ƃ��������Ƃ����������p�r�Ȃ�A�����N���b�N�͉����邯�ǃR�A���̑���Q6600�̕���
�L���ɂȂ�B
�������A�����̃A�v���P�[�V�������N�����ĂȂ����Ƃ�������ꍇ��E8500���L�������ǁA
����͂����܂�E8500�ɓ������Ƃ���点��Ɛ��\�̗������݂������ł��Ȃ��Ȃ邩��B
�Ⴆ�Ȃ����Ƃ�Q6600���L���������Ƃ��Ă��A���̂����ǂꂩ�P��̏�����E8500�Ő�O�������
Q6600���͑�����Ƃ��I���B
�v����ɁA�Ȃ����Ƃ����ꍇ��Q6600�̃����b�g�́u�����������Ȃ�v�̂ł͂Ȃ��u�x���Ȃ�ɂ����v���Ƃ�
����Ƃ����_�͗������Ƃ��ĂˁB
��͎����̗p�r�Ƃ�[�����k���Ăǂ�����I�Ԃ����߂�����B
����͋M���̗p�r���悾����Ȃ�Ƃ������Ȃ��B
�Ⴆ�Ε��ׂ̍����A�v���P�[�V�������g���ɂ��Ă��A���ꂪ�}���`�X���b�h�ɑΉ����ĂȂ�
�V���O���X���b�h�I�����[�̃A�v���P�[�V������1��2���炢�����g��Ȃ��Ƃ��A�f���A���R�A
�Ή��̃G���R�[�_���g�����ǃG���R���͑��̍�Ƃ͈���Ȃ��Ƃ������������Ƃł���A
�N���b�N�̍���E8500�̕������������ł���B
�t�ɁA�N�A�b�h�R�A�ɍœK������Ă��ăf���A���R�A�����i�i�ɐ��\�̌��シ��A�v���P�[�V����
�i���͏��Ȃ����ǁj���g�������Ƃ��A���ׂ̍����A�v���P�[�V������3��4�������ɋN������
���s���č�Ƃ��������Ƃ����������p�r�Ȃ�A�����N���b�N�͉����邯�ǃR�A���̑���Q6600�̕���
�L���ɂȂ�B
�������A�����̃A�v���P�[�V�������N�����ĂȂ����Ƃ�������ꍇ��E8500���L�������ǁA
����͂����܂�E8500�ɓ������Ƃ���点��Ɛ��\�̗������݂������ł��Ȃ��Ȃ邩��B
�Ⴆ�Ȃ����Ƃ�Q6600���L���������Ƃ��Ă��A���̂����ǂꂩ�P��̏�����E8500�Ő�O�������
Q6600���͑�����Ƃ��I���B
�v����ɁA�Ȃ����Ƃ����ꍇ��Q6600�̃����b�g�́u�����������Ȃ�v�̂ł͂Ȃ��u�x���Ȃ�ɂ����v���Ƃ�
����Ƃ����_�͗������Ƃ��ĂˁB
��͎����̗p�r�Ƃ�[�����k���Ăǂ�����I�Ԃ����߂�����B
EeePC�����Ƃɂ��܂��B���肪�Ƃ��������܂����B
�ߑa���Ă邩��F�q�}�ȂȁB����ȃX���`�ɐ^�ʖڂɉ���Ȃ�āB
���Ⴀ������ƃl�^�ɂȂ肻���Șb��ŁA����Ȃ̂͂ǂ��H
Diamondville(1.8GHz)�@�{�@Intel 945GC�@���́@SiS671�@�iDeskTop����ITX�j
�ƁA
Isaiah(1.8GHz)�@�{�@CN896
�́A���\�I�Ɍ��\�����������������ȋC�����邪�A�ʂ����Ď��ۂ͂ǂ��Ȃ̂�
�C�ɂȂ��Ă܂��B
�����Ă���Silverthorne�v���Z�b�T�̒������d�͂̔閧
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
VIA�A�V�v�A�[�L�e�N�`��CPU�uIsaiah�v��2008�N�O���ɐ��i����
http://pc.watch.impress.co.jp/docs/2008/0124/ubiq208.htm
���Ⴀ������ƃl�^�ɂȂ肻���Șb��ŁA����Ȃ̂͂ǂ��H
Diamondville(1.8GHz)�@�{�@Intel 945GC�@���́@SiS671�@�iDeskTop����ITX�j
�ƁA
Isaiah(1.8GHz)�@�{�@CN896
�́A���\�I�Ɍ��\�����������������ȋC�����邪�A�ʂ����Ď��ۂ͂ǂ��Ȃ̂�
�C�ɂȂ��Ă܂��B
�����Ă���Silverthorne�v���Z�b�T�̒������d�͂̔閧
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
VIA�A�V�v�A�[�L�e�N�`��CPU�uIsaiah�v��2008�N�O���ɐ��i����
http://pc.watch.impress.co.jp/docs/2008/0124/ubiq208.htm
Diamondville�̓p�t�H�[�}���X�I��Isaiah�ɓK��Ȃ���
�p�t�H�[�}���X�I�ɂ��Ԃ�̂�C7
�����A�}�[�P�b�g�I�ɂ�Isaiah�����Ԃ�
�p�t�H�[�}���X�I�ɂ��Ԃ�̂�C7
�����A�}�[�P�b�g�I�ɂ�Isaiah�����Ԃ�
Silverthorne�͂��傹��C���I�[�_�[�Ȃ̂ŁA�Ȃ���Ȃ�ɂ�OoO�ł���Issaih�ɂ͏��Ȃ��Ƃ��V���O���X���b�h�ɂ����Ă�
���Ȃ�Ȃ��̂ł͂Ȃ����Ǝv����B
���Ȃ�Ȃ��̂ł͂Ȃ����Ǝv����B
�_�C�T�C�Y��Isaiah�̔����ȉ�����
>>603 �i�⑫�j
Diamondville�F in-order��HT�@�^ L2:512KB�@�^�@�������Z�����������H
Isaiah�@�@�@�F out-of-order �^�@L2:1MB�@�@�^�@���������_���Z������
�܂�����d�͂ł́A�g�����W�X�^�����̂����|�I�ɏ��Ȃ�Diamondville��
�����ł��傤���ǁASilverthorne��SV�ł��������d�͂͑��ڂȔ��Ȃ̂ŁA
�卷���t���Ȃ��\�������邵�B
Diamondville�F in-order��HT�@�^ L2:512KB�@�^�@�������Z�����������H
Isaiah�@�@�@�F out-of-order �^�@L2:1MB�@�@�^�@���������_���Z������
�܂�����d�͂ł́A�g�����W�X�^�����̂����|�I�ɏ��Ȃ�Diamondville��
�����ł��傤���ǁASilverthorne��SV�ł��������d�͂͑��ڂȔ��Ȃ̂ŁA
�卷���t���Ȃ��\�������邵�B
����Diamondville��Isaiah�ɓ��N���b�N���ƓG��Ȃ��Ƃ��Ă��A�����x�̏���
�d�͂łƂ����b�Ȃ�A�Ⴆ�N���b�N����400MHz���炢�҂���C�����܂����A
�ǂ��Ȃ�ł��傤�H
���ƃ_�C�T�C�Y�������ȉ��Ȃ�A�l�i�����l������܂����A����������
�s��ɂłĂ���łȂ��Ɣ��f�o���܂��B
�d�͂łƂ����b�Ȃ�A�Ⴆ�N���b�N����400MHz���炢�҂���C�����܂����A
�ǂ��Ȃ�ł��傤�H
���ƃ_�C�T�C�Y�������ȉ��Ȃ�A�l�i�����l������܂����A����������
�s��ɂłĂ���łȂ��Ɣ��f�o���܂��B
Isaiah�����d��1W����?
Silverthorne�Ƃ̓Z�O�����g���Ⴄ�Ǝv���B
Silverthorne�Ƃ̓Z�O�����g���Ⴄ�Ǝv���B
isaiah�͐�������������Ă��
micro,macro-fusion������
micro,macro-fusion������
>>609
���܂�C7�Ɠ������x���炵���̂ŁA�������Ƃ������B
�����Isaiah��Silverthorne�Ƃ͐�Z�O�����g�Ⴄ��ˁB
Isaiah�͒���d�͔ł̃��o�C���R�A�Ƃ͏d�Ȃ肻�������ǂ��B
���܂�C7�Ɠ������x���炵���̂ŁA�������Ƃ������B
�����Isaiah��Silverthorne�Ƃ͐�Z�O�����g�Ⴄ��ˁB
Isaiah�͒���d�͔ł̃��o�C���R�A�Ƃ͏d�Ȃ肻�������ǂ��B
����C7��TDP3.5�`20W���炢�̂͂���Isaiah��C7�Ɠ������Ă��Ƃ�
0.6�`2W��Silverthorne����5.5W��ULV��C2S��11W��ULV��C2D�̂�
TDP�I�ɂ͋����������ȋC������
0.6�`2W��Silverthorne����5.5W��ULV��C2S��11W��ULV��C2D�̂�
TDP�I�ɂ͋����������ȋC������
�ʂ��D���^���H��
�u����d�̖͂��ł͂Ȃ��A�}�[�P�e�B���O�I�Ȑ��i�|�W�V�������ASilverThrone�ƂԂ����ł��B
�ܘ_���\�]�X�̖�������܂����ǂˁB�v
���������B
�u����d�̖͂��ł͂Ȃ��A�}�[�P�e�B���O�I�Ȑ��i�|�W�V�������ASilverThrone�ƂԂ����ł��B
�ܘ_���\�]�X�̖�������܂����ǂˁB�v
���������B
20W��UMPC��MID��?���ꂾ������w
CN�ɒ�N���b�N, Low Power�ł����邾������B
1.6-2.0GHz��CN�n�C�G���h��Silverthorne 1.86GHz�Ƃ͂��Ԃ�킯�Ȃ��̂�
�����C����B
1.6-2.0GHz��CN�n�C�G���h��Silverthorne 1.86GHz�Ƃ͂��Ԃ�킯�Ȃ��̂�
�����C����B
SilverThorne�̒ʏ�d���łł���Ƃ����Diamondville�͎v�������肩�Ԃ邯�ǁB
Diamondville���Ă����TDP�����Ȃ��������낤?
�������ASilverthorne�̒ʏ�d���ł�Silverthorne���B
Diamondville��TDP�̐������邭��������(3.5W)�B
Diamondville��TDP�̐������邭��������(3.5W)�B
����d�̖͂��ł͂Ȃ��A���������Z�O�����g�����Ԃ���Č����b����ȁB
Silverthorne�Ƃ�?w
Diamondville�Ƃ͈ꕔ���Ԃ肻�����Ǝv�������B
Diamondville�Ƃ͈ꕔ���Ԃ肻�����Ǝv�������B
������Diamondville�Ɣ����Č����Ă邶���B�܂������E�E�E
�[���͒Nj����Ȃ����ADiamondivlle�̓��[�R�X�g�m�[�g�ƃf�X�N�g�b�v�p�Ȃ�B
>>603�݂�����ITX�{�[�h�͂��܂�(�}���̊��Ⴂ)�B�S�����Ԃ�Ƃ������Ƃ͂Ȃ����B
>>603�݂�����ITX�{�[�h�͂��܂�(�}���̊��Ⴂ)�B�S�����Ԃ�Ƃ������Ƃ͂Ȃ����B
���[�R�X�g�m�[�g�ƃ��[�R�X�g�f�X�N�g�b�v
��R�X�g�ȃm�[�g��f�X�N�g�b�v�Ȃ�Ȃ������邯�ǁB
C7�̃}�[�P�b�g���
�����Diamonville�Ƃ͂��Ԃ�B���Ԃ�ɒ����B
>>618
3.5W���ᔚ�M��������̗p�����s�ꂪ����̂��H
����d��Core2�̉����J�o�[�͂ł��邪�A��ΐ��\�ō����傫���J����
�g�ݍ������ɂ͂ł������ĐV�K�̗p���ނ�
3.5W���ᔚ�M��������̗p�����s�ꂪ����̂��H
����d��Core2�̉����J�o�[�͂ł��邪�A��ΐ��\�ō����傫���J����
�g�ݍ������ɂ͂ł������ĐV�K�̗p���ނ�
�g�ݍ��݂��Ĉ���Ɍ����Ă��F�X���邩��ȁB
���e�ʂ̃o�b�e���[�œ������f�o�C�X�ɂ�3.5W�͑傫�����A
AC�A�_�v�^�[�œ������悤�ȕ��Ȃ�A����Ȃɖ��ł��Ȃ������B
��ΐ��\�ɂ��ẮA�����o�Ă��Ȃ��Ɖ��Ƃ������Ȃ��ȁB
���e�ʂ̃o�b�e���[�œ������f�o�C�X�ɂ�3.5W�͑傫�����A
AC�A�_�v�^�[�œ������悤�ȕ��Ȃ�A����Ȃɖ��ł��Ȃ������B
��ΐ��\�ɂ��ẮA�����o�Ă��Ȃ��Ɖ��Ƃ������Ȃ��ȁB
�H�Ɨp�u���[�h�Ƃ������đg�ݍ��݂����A���ъ�݂����ȃf�o�C�X�����肪�g�ݍ��݂���Ȃ������
���̒��x����10W���ł������킯�ŁA3.5W�ƂȂ�ƁA���̂Ƃ����o���Ă�1W�����Ɛ��\��@�\�I�ɔ��A�������͋@�\�I�ɗ��C������Ȃ��E�E�E
1W�����Ńm�[�X�u���b�W�����Ȃ�Ă��炾���A�킴�킴���߃Z�b�g��x86�ɐ�ւ��Ă܂ŁA���M�ŋ@�\�̏��Ȃ��̂��̗p���邾�낤��
Geode�̂Ƃ����������ƍl������
1W�����Ńm�[�X�u���b�W�����Ȃ�Ă��炾���A�킴�킴���߃Z�b�g��x86�ɐ�ւ��Ă܂ŁA���M�ŋ@�\�̏��Ȃ��̂��̗p���邾�낤��
Geode�̂Ƃ����������ƍl������
���ъ킗��
���ъ��x86�ς牽�ł���낤�Ȃ�
���ъ��x86�ς牽�ł���낤�Ȃ�
Diamondville�̓��[�R�X�g�̎s��p�Ȃ낤�ȁB
Silverthorne�Ƃ�����Menlow�̓`�b�v�Z�b�g��TDP���傫���̂ŁA�܂�Windows�ڂ���UMPC�A
MID�p���낤�B
intel������`�b�v�S�̂�1W��悤�ɂȂ�A�̗p���ꂤ��p�r����C�ɑ����邾�낤���ǁB
>>631
���ъ��64bitCPU���Ăǂꂾ���ѐ����̂Ƀ������g�����肾�悗
Silverthorne�Ƃ�����Menlow�̓`�b�v�Z�b�g��TDP���傫���̂ŁA�܂�Windows�ڂ���UMPC�A
MID�p���낤�B
intel������`�b�v�S�̂�1W��悤�ɂȂ�A�̗p���ꂤ��p�r����C�ɑ����邾�낤���ǁB
>>631
���ъ��64bitCPU���Ăǂꂾ���ѐ����̂Ƀ������g�����肾�悗
�Ȃg�ݍ��ݗp�ƕ����������Ŋ��Ⴂ���Ă���l�������ȁB�ʔ������炱�̂܂ܕ��u�ŗǂ����B
�g�����ĂЂƂ��ɂ����Ă��F�X���邾�낤��Intel�����X�����Ɠd�̐���̎s��ɖ��͂��������Ǝv���Ă���̂�w
�ŁADiamondville�͑g�ݍ��ݎs������ł͂Ȃ����Ƃ�>>622->>623�ɏ������Ƃ���Ȃ̂ł��B
3.5W����d�͂ƌ����Ă����͂ǂ������s��Ȃ̂��킩���ĂȂ�������B
�g�����ĂЂƂ��ɂ����Ă��F�X���邾�낤��Intel�����X�����Ɠd�̐���̎s��ɖ��͂��������Ǝv���Ă���̂�w
�ŁADiamondville�͑g�ݍ��ݎs������ł͂Ȃ����Ƃ�>>622->>623�ɏ������Ƃ���Ȃ̂ł��B
3.5W����d�͂ƌ����Ă����͂ǂ������s��Ȃ̂��킩���ĂȂ�������B
Intel�̈ʒu�t���͂��Ă����Ƃ��āA���ۂɂ�Diamondovile���̗p�����g�ݍ������̃u���[�h��
ITX�{�[�h���̑��͂����ς��o�邾�낤���ǂˁB
ITX�{�[�h���̑��͂����ς��o�邾�낤���ǂˁB
����������Torapai�̘b�͍ŋ߂��܂蕷���Ȃ��ȁB
�����Ƒg�ݍ��݂��ۂ��g�ݍ��ݗpIntel chip�Ƃ����ACanmore������B
�����Ƒg�ݍ��݂��ۂ��g�ݍ��ݗpIntel chip�Ƃ����ACanmore������B
Torapai����˂������Tolapai�B
�@�@�����c �@ �@ �@ _�@_�@ �@ �@ �@ �@ _�@_�@�@�@ �@ �@ _�@�@�@ �@ ���ς��I�I
�@�@ _�@_�@�@ �@ �@ ( ߁��)���@�@�@�@�m�ܤ )�@�@ �@ (��� )Ɂ@�@ �@ �@ _�@_
�@ ( ߁��)�@ �@ �@ /�@��/�@�@�@ ���@�@�l�j �@ �@ ���@ /�@�@ �@ �@ ( ߁��)��
�@���@ �Ɓj�@�@ ��....�@/�@�@�c�@�@ ��Ɂ@�@�@�~ �@ �i�����@ �@ �@ �T�@/
�@�@|��_Ɂ@ �c�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ ���@�@ �~�@�@ Ɂ@�@ |
�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �i�m ��J
�@�@ _�@_�@�@ �@ �@ ( ߁��)���@�@�@�@�m�ܤ )�@�@ �@ (��� )Ɂ@�@ �@ �@ _�@_
�@ ( ߁��)�@ �@ �@ /�@��/�@�@�@ ���@�@�l�j �@ �@ ���@ /�@�@ �@ �@ ( ߁��)��
�@���@ �Ɓj�@�@ ��....�@/�@�@�c�@�@ ��Ɂ@�@�@�~ �@ �i�����@ �@ �@ �T�@/
�@�@|��_Ɂ@ �c�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ ���@�@ �~�@�@ Ɂ@�@ |
�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �i�m ��J
�����ς��ł��ˁ[��
������������d�͂̍팸�ɐ������Ă���CPU�ɂ킴�킴
GPU�Ƃ��̔��M����@�\�𓋍ڂ��悤���Ă���
�I���S���`�[�����đ����̃A�z����B
�܂����Ă����M��������d�͂ւ̓���簐i����Ƃ͂ˁB
��͂�l�n�����̓X���[��������������ˁB
GPU�Ƃ��̔��M����@�\�𓋍ڂ��悤���Ă���
�I���S���`�[�����đ����̃A�z����B
�܂����Ă����M��������d�͂ւ̓���簐i����Ƃ͂ˁB
��͂�l�n�����̓X���[��������������ˁB
>>639
�M����CPU�ɂ��邩�`�b�v�Z�b�g�ɂ��邩�̈Ⴂ�Ȃ����B
����Ȏ�����������A����d�͂��팸���Ă���CPU��
�킴�킴�����R����m�[�Y�u���b�W���������ᔻ���Ȃ��ƁB
����ɂ�PCI-e�������������Ă�������ȁB
���ʓI�ɂ̓V�X�e���̃g�[�^������d�͂�������Ζ��Ȃ��킯�A
���[�J�[������p�ӏ�����J���ɏW��������������A
�z�����ȑf�ɂȂ邾�낤����A���Ԃ}����Ǝv�����B
�M����CPU�ɂ��邩�`�b�v�Z�b�g�ɂ��邩�̈Ⴂ�Ȃ����B
����Ȏ�����������A����d�͂��팸���Ă���CPU��
�킴�킴�����R����m�[�Y�u���b�W���������ᔻ���Ȃ��ƁB
����ɂ�PCI-e�������������Ă�������ȁB
���ʓI�ɂ̓V�X�e���̃g�[�^������d�͂�������Ζ��Ȃ��킯�A
���[�J�[������p�ӏ�����J���ɏW��������������A
�z�����ȑf�ɂȂ邾�낤����A���Ԃ}����Ǝv�����B
641 �FSocket774�F2008/01/27(��) 11:03:37 ID:n3+gPkkA
�����R����������AMD��OC�ϐ��ő傫����������ꂽ�����
��i�ŏ���d�͂�p�t�H�[�}���XUP���Ă�OC�ϐ����������玩��s�ꂶ��]���K�^�����Ȃ�Ȃ��́H
����s��͌����đ傫���͂Ȃ����Lj�ʏ���Ҍ����ւ̉e���͏��Ȃ��炸����
����s��œ����]������������Ȃ����̂������烄�o���\���͂����
DDR3�����N���܂łɉ����邩�͕����
����OS�ł���VISTA�̂悤�Ȉʒu�Â���CPU�ɂȂ��Ă��܂��\���͂���
��i�ŏ���d�͂�p�t�H�[�}���XUP���Ă�OC�ϐ����������玩��s�ꂶ��]���K�^�����Ȃ�Ȃ��́H
����s��͌����đ傫���͂Ȃ����Lj�ʏ���Ҍ����ւ̉e���͏��Ȃ��炸����
����s��œ����]������������Ȃ����̂������烄�o���\���͂����
DDR3�����N���܂łɉ����邩�͕����
����OS�ł���VISTA�̂悤�Ȉʒu�Â���CPU�ɂȂ��Ă��܂��\���͂���
����A�M����1�ӏ��ɏW�܂����ق�����₷�͓̂���B
644 �FSocket774�F2008/01/27(��) 15:34:47 ID:n3+gPkkA
OC�ϐ��������x�������炱���܂�C2D��AMDCPU�̐l�C���͂Ȃ������Ǝv������
��i���m�̔�r�Ȃ�AMD���R�X�g�I�Ɍ������Ă邵>>643���{���Ȃ炱���܂ō������ĂȂ���
����OC�ɂ���قǂ������Ȃ����ł�AMD���\������Ă邵
��i���m�̔�r�Ȃ�AMD���R�X�g�I�Ɍ������Ă邵>>643���{���Ȃ炱���܂ō������ĂȂ���
����OC�ɂ���قǂ������Ȃ����ł�AMD���\������Ă邵
>>644
�����͕̂��ʂɃx���`���ʂŐ��\���ǂ����炾��B
�����͕̂��ʂɃx���`���ʂŐ��\���ǂ����炾��B
�s���̏W�����قȂ�N���b�N��d���d�������荬����̂����
���l�����cell���ĉ��C�ɐ�������낤�Ƃ��Ă��̂ˁB
>>646
�s���̏W���͂���قǖ�肶��Ȃ��B
�ǂ���intel���f�U�C���K�C�h�Ƃ��o������A����ɏ]���Ă�Ⴂ���B
�z���I�ɂ́A�����z�����K�v�ȃp������FSB�������āA�z�����y��PCI-Express��DMI��
�Ȃ邱�Ƃ̕��������b�g�͑傫���B
FSB�̔z���X�y�[�X�����邩��ȃX�y�[�XPC���f�U�C�����₷���Ȃ�B
�d���d���́A�ǂ��������̍ۂɂ͉�H�v�͈�V�������A���ł�CPU�ɍ��킹��Ⴂ���B
���A�m�[�X�u���b�W�ɓ�������Ă�GPU�Ɠ����d���d�����ێ����Ȃ���Ȃ�R�͂Ȃ�����B
��������������Ȃ��APCI-Express��DMI���\�P�b�g�o�R�ɂȂ邱�ƂŁAOC�ϐ��̓V�X�e���S�̂�
�����邾�낤���AOC���Ȃ����[�J�[PC�ɂ͉��̊W���Ȃ����ȁB
�s���̏W���͂���قǖ�肶��Ȃ��B
�ǂ���intel���f�U�C���K�C�h�Ƃ��o������A����ɏ]���Ă�Ⴂ���B
�z���I�ɂ́A�����z�����K�v�ȃp������FSB�������āA�z�����y��PCI-Express��DMI��
�Ȃ邱�Ƃ̕��������b�g�͑傫���B
FSB�̔z���X�y�[�X�����邩��ȃX�y�[�XPC���f�U�C�����₷���Ȃ�B
�d���d���́A�ǂ��������̍ۂɂ͉�H�v�͈�V�������A���ł�CPU�ɍ��킹��Ⴂ���B
���A�m�[�X�u���b�W�ɓ�������Ă�GPU�Ɠ����d���d�����ێ����Ȃ���Ȃ�R�͂Ȃ�����B
��������������Ȃ��APCI-Express��DMI���\�P�b�g�o�R�ɂȂ邱�ƂŁAOC�ϐ��̓V�X�e���S�̂�
�����邾�낤���AOC���Ȃ����[�J�[PC�ɂ͉��̊W���Ȃ����ȁB
�ǂ��ɂ�����4�w�ō���悤�Ƀf�U�C���K�C�h���o���͂������ǁB
�d���h���C���͌��\�d�v�����B
CPU��GPU�͂��Ƃ������d���œ��삵�Ă�EIST���l����ƕ����������Ƃ���B
�Ƃ������Œ�ł�CPU��NB(GPU)�ɂ͕��������B
����Ɋe��IO���v���d���͈Ⴄ���낤���B
�o�����NB��GPU�R�A��������������CPU�R�A���̕������������Ƃ��낾�B
�������ɃR�X�g�������肷���邾�낤���B
�m�[�g�����Ȃ炠�蓾�邩�ȁB
CPU��GPU�͂��Ƃ������d���œ��삵�Ă�EIST���l����ƕ����������Ƃ���B
�Ƃ������Œ�ł�CPU��NB(GPU)�ɂ͕��������B
����Ɋe��IO���v���d���͈Ⴄ���낤���B
�o�����NB��GPU�R�A��������������CPU�R�A���̕������������Ƃ��낾�B
�������ɃR�X�g�������肷���邾�낤���B
�m�[�g�����Ȃ炠�蓾�邩�ȁB
CPU Voltage : 1.264V
CPU PLL Voltage : 1.5V
North Bridge Voltage : 1.47V
DRAM Voltage : 1.80V
FSB Termination Voltage : 1.42V
South Bridge Voltage : 1.075V
CPU PLL Voltage : 1.5V
North Bridge Voltage : 1.47V
DRAM Voltage : 1.80V
FSB Termination Voltage : 1.42V
South Bridge Voltage : 1.075V
653 �F�ǂ��Ă������܂����F2008/01/27(��) 17:46:14 ID:D/VvATid
�d����2�`3�n���ɂ��āACPU(Include NB)����
�����d���g�����Ă̂����肶��ˁH
FSB�M�������s�������邩��
�d���AGND�����₹�邾�낤��
�����d���g�����Ă̂����肶��ˁH
FSB�M�������s�������邩��
�d���AGND�����₹�邾�낤��
654 �FSocket774�F2008/01/27(��) 23:13:13 ID:n3+gPkkA
age
�I���_�CCMOS���M�����[�^���g����悤�ɂȂ�p���[���[���̖��͑����͉�������낤���ǂˁB
�f�X�N�g�b�v�ł͖������낤���������
�f�X�N�g�b�v�ł͖������낤���������
Nehalem���ł܂��㓡�����f�l���Ղ���N���Ă���͗l���B
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
�@�@-----------------------
�@�@���������_���Z(SPECfp_rate2006)��2.4�{�ȏ�Ƃ���Ă���B���ۂɃp�t�H�[�}���X�e�X�g��
�@�@�ł���T���v�����o��܂ł́A�{���̐��\�͂킩��Ȃ����A���������_���Z���\���ُ�ɍ�
�@�@�����Ƃ͊m�����낤�B2.4�{�Ƃ������l�́A���Ȃ�ُ�ŁA�啝�Ȋg�����\�z�����B
�@�@-----------------------
SPECfp��SPECfp�ł�"rate"�탁�����ш�̗v�f���傫�����B�R�A���_���_����K8�ł���A�\�P�b�g
���ɂ�ă������ш悪���₹��Ƃ��������̂�������Core2�ɏ��Ă邷����B�B�B
�@�@Intel X5365/3GHz x 8-core: 62.9(base)/66.5(peak)
�@�@�@http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070830-01903.html
�@�@AMD 8222SE/3GHz x 8-core: 92.6(base)/98.7(peak)
�@�@�@http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070430-00981.html
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
�@�@-----------------------
�@�@���������_���Z(SPECfp_rate2006)��2.4�{�ȏ�Ƃ���Ă���B���ۂɃp�t�H�[�}���X�e�X�g��
�@�@�ł���T���v�����o��܂ł́A�{���̐��\�͂킩��Ȃ����A���������_���Z���\���ُ�ɍ�
�@�@�����Ƃ͊m�����낤�B2.4�{�Ƃ������l�́A���Ȃ�ُ�ŁA�啝�Ȋg�����\�z�����B
�@�@-----------------------
SPECfp��SPECfp�ł�"rate"�탁�����ш�̗v�f���傫�����B�R�A���_���_����K8�ł���A�\�P�b�g
���ɂ�ă������ш悪���₹��Ƃ��������̂�������Core2�ɏ��Ă邷����B�B�B
�@�@Intel X5365/3GHz x 8-core: 62.9(base)/66.5(peak)
�@�@�@http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070830-01903.html
�@�@AMD 8222SE/3GHz x 8-core: 92.6(base)/98.7(peak)
�@�@�@http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070430-00981.html
�u�啝�Ȋg���v���������ш�̂��Ƃ��Ƃ��̂��Ɛ������Ă�����炢�������B
spec*_rate���y�����闝�R���Ȃ����B
spec*_rate���y�����闝�R���Ȃ����B
658 �FSocket774�F2008/01/29(��) 00:57:42 ID:braTC+b5
CPU�̃R�A������1.5�{�̃T�C�Y���Ɛ��\�͊��҂ł����������ǔ��M�͂��Ȃ肠�肻�����B
�܂��A������AMD��Intel�̊Ԃ��s�����肫���肵�Ă�Ј�������Ƃǂ����������悤�Ȃ��B
�܂��A������AMD��Intel�̊Ԃ��s�����肫���肵�Ă�Ј�������Ƃǂ����������悤�Ȃ��B
659 �FMAC�I�^��658 �����F2008/01/29(��) 01:05:38 ID:U+YuE5q6
>>658
�@�@------------------
�@�@CPU�̃R�A������1.5�{�̃T�C�Y���Ɛ��\�͊��҂ł����������ǔ��M�͂��Ȃ肠�肻�����B
�@�@------------------
����ł푽���̃g�����W�X�^���N���b�N�Q�[�e�B���O���A�}���`�Q�[�g���ŏȓd�͕��ʂɔ�₳��邷���ǁB�B�B
�@�@------------------
�@�@CPU�̃R�A������1.5�{�̃T�C�Y���Ɛ��\�͊��҂ł����������ǔ��M�͂��Ȃ肠�肻�����B
�@�@------------------
����ł푽���̃g�����W�X�^���N���b�N�Q�[�e�B���O���A�}���`�Q�[�g���ŏȓd�͕��ʂɔ�₳��邷���ǁB�B�B
�N���b�N�Q�[�e�B���O���āA����قǃg�����W�X�^�͐H��Ȃ��悤��
�}���`�Q�[�g���ƃg�����W�X�^��������Ă̂͂ǂ�������������
�}���`�Q�[�g���ƃg�����W�X�^��������Ă̂͂ǂ�������������
661 �F�R�E�L�́M�E,,�j�����������������F2008/01/29(��) 01:35:11 ID:UUB91VxK
�k����������̂Ƀ_�C�T�C�Y�����Ȃ��킯���Ȃ�����
�܂��I�^�̓�Ȃ��B
���͂�ǂޔ\�͂������̂��ˁB
���͂�ǂޔ\�͂������̂��ˁB
�I�^�ɓlj�͂��F���Ȃ��Ƃ����X�Ȃ���ǂ���������
>>661
���m�[�X�u���b�W�����͊W�Ȃ��Ȃ���
CPU�S�̂̃_�C�T�C�Y����Ȃ��āh�R�A�h�̃T�C�Y��1.5�{�ɂȂ���Ęb���Ă�悤�Ɏv������ǂ���H
���m�[�X�u���b�W�����͊W�Ȃ��Ȃ���
CPU�S�̂̃_�C�T�C�Y����Ȃ��āh�R�A�h�̃T�C�Y��1.5�{�ɂȂ���Ęb���Ă�悤�Ɏv������ǂ���H
665 �FSocket774�F2008/01/29(��) 12:50:40 ID:VVV5WqkK
�I�N�^�R�A���I�^�N�R�A�Ɍ����Č�
>>665
���̃l�^�͎g���Â��ꂷ����age���Ă������B���߁B
���̃l�^�͎g���Â��ꂷ����age���Ă������B���߁B
>����ł푽���̃g�����W�X�^���N���b�N�Q�[�e�B���O���A�}���`�Q�[�g���ŏȓd�͕��ʂɔ�₳��邷���ǁB�B�B
�����CMA�����Ĉꏏ�B
�������o�C�������R�A�Ȃ���B
CMA��ŐF�X�g���͂���邾�낤���A�ȓd�͌����̊g��������1.5�{�͂Ȃ�����E�E�E
���Ȃ��Ƃ��������̔����͐��\����ɐU���Ă�Ǝv�����B
����ɏȓd�͌����̊g���̓A�C�h�����ɂ͌��ʂ����邪�A�t���p���[�œ��삵�Ă鎞�͊W�Ȃ��B
�d�͐����H�����ăg�����W�X�^�ō\������Ă���A�t���p���[�œ����Ă�ᑽ���͓d�͂������B
�����CMA�����Ĉꏏ�B
�������o�C�������R�A�Ȃ���B
CMA��ŐF�X�g���͂���邾�낤���A�ȓd�͌����̊g��������1.5�{�͂Ȃ�����E�E�E
���Ȃ��Ƃ��������̔����͐��\����ɐU���Ă�Ǝv�����B
����ɏȓd�͌����̊g���̓A�C�h�����ɂ͌��ʂ����邪�A�t���p���[�œ��삵�Ă鎞�͊W�Ȃ��B
�d�͐����H�����ăg�����W�X�^�ō\������Ă���A�t���p���[�œ����Ă�ᑽ���͓d�͂������B
>>667
MAC�I�^�̃L�������̓R�s�y����ȁB���ˁB
MAC�I�^�̃L�������̓R�s�y����ȁB���ˁB
669 �F�R�E�L�́M�E,,�j�����������������F2008/01/30(��) 02:02:38 ID:LR0BibTm
>>664
�����A��������
1�N���b�N�Ŕ��s�ł��閽�߂œ����Q�Ƃł��郌�W�X�^�����ɒ[�ɏ��Ȃ����炻�̂ւ�����ǂ���Ƃ݂��B
Nehalem���ڎw���Ă�̂�SMT�Ή���N�R�A�Ƃ������A���I�ĕҐ��\��2�~N�R�A����Ȃ����Ǝv���B
Penryn�ł�MPSADBW���ӊO�Ɛ��\�Ⴂ�̂ƁA�e�L�X�g�T�[�`���߂̒lj������邵
����SIMD����̋������������ƂɂȂ�Ǝv���Ă���B
�����A��������
1�N���b�N�Ŕ��s�ł��閽�߂œ����Q�Ƃł��郌�W�X�^�����ɒ[�ɏ��Ȃ����炻�̂ւ�����ǂ���Ƃ݂��B
Nehalem���ڎw���Ă�̂�SMT�Ή���N�R�A�Ƃ������A���I�ĕҐ��\��2�~N�R�A����Ȃ����Ǝv���B
Penryn�ł�MPSADBW���ӊO�Ɛ��\�Ⴂ�̂ƁA�e�L�X�g�T�[�`���߂̒lj������邵
����SIMD����̋������������ƂɂȂ�Ǝv���Ă���B
���o�C��CPU�ɑ�3����SPARC�\�\Intel��Sun���VCPU�v����I��
http://www.itmedia.co.jp/news/articles/0801/30/news063.html
SPARC�����o�C��CPU���I�I�I�I�I�I�I�I�I
������Intel�Ƃ̋����J�������Ă��������������������I�I�I�I�I�I�I�I�I
�܂�܂ƃ^�C�g�����x���ꂽ���c�B
http://www.itmedia.co.jp/news/articles/0801/30/news063.html
SPARC�����o�C��CPU���I�I�I�I�I�I�I�I�I
������Intel�Ƃ̋����J�������Ă��������������������I�I�I�I�I�I�I�I�I
�܂�܂ƃ^�C�g�����x���ꂽ���c�B
>>670
�^�C�g����낷��
�^�C�g����낷��
�S�����܂���Ȃ��������́A�܂�Ȃ���l�ɂȂ��Ă��܂����̂��낤���H
�܂�Ȃ��q�����܂�Ȃ���l�ɂȂ�̂͐���i���ł͂Ȃ����B
�Ȃ�قǁA���������ʂ�
�ނ艳
>>651
���������^�[�Q�b�g�N���b�N���Ⴄ����
�R�A���������Ă����傤���Ȃ��B
CPU�łPGHz�̓A�C�h����Ԃ����AGPU���ᒴ�n�C�G���h�ȃN���b�N�B
CPU������GPU�����ŁA�S���ʂȃ����W�̉σN���b�N��������
�ŏ����番��������B
�������Ă��܂���CPU��GPU�Ń������ш�̎�荇���ɂȂ���
���N�Ȑ��\�͏o�Ȃ��B
�㓡�^�����̂������܂ŁuGPU�����v�ɌŎ�����̂������ς蕪�����B
���\�I�ɉ��������b�g���L��̂��H
���������^�[�Q�b�g�N���b�N���Ⴄ����
�R�A���������Ă����傤���Ȃ��B
CPU�łPGHz�̓A�C�h����Ԃ����AGPU���ᒴ�n�C�G���h�ȃN���b�N�B
CPU������GPU�����ŁA�S���ʂȃ����W�̉σN���b�N��������
�ŏ����番��������B
�������Ă��܂���CPU��GPU�Ń������ш�̎�荇���ɂȂ���
���N�Ȑ��\�͏o�Ȃ��B
�㓡�^�����̂������܂ŁuGPU�����v�ɌŎ�����̂������ς蕪�����B
���\�I�ɉ��������b�g���L��̂��H
>���������^�[�Q�b�g�N���b�N���Ⴄ����
>�R�A���������Ă����傤���Ȃ��B
�m�b�x��ł����c
>�R�A���������Ă����傤���Ȃ��B
�m�b�x��ł����c
>>676
�d���h���C���̘b�Ȃ̂ɂȂ��N���b�N���H
����d���h���C���ł�PLL��������N���b�N�͕ʁX�ɐ���\�B
����Phenom��CPU�R�A���͂��������B
GPU�̓����̓����b�g�����B
���Ȃ��Ƃ��O���C���^�[�t�F�[�X�̕��̏���d�͂�����B
����d�͌�����̕�CPU�̃N���b�N�グ�邱�Ƃ����ďo���邵�B
�������悤�����܂����������ш�͎�荇���Ǝv����B
�Ŏ���������Ȃ�������Intel��AMD��GPU�����Ɍ������Ă邩��ˁB
�d���h���C���̘b�Ȃ̂ɂȂ��N���b�N���H
����d���h���C���ł�PLL��������N���b�N�͕ʁX�ɐ���\�B
����Phenom��CPU�R�A���͂��������B
GPU�̓����̓����b�g�����B
���Ȃ��Ƃ��O���C���^�[�t�F�[�X�̕��̏���d�͂�����B
����d�͌�����̕�CPU�̃N���b�N�グ�邱�Ƃ����ďo���邵�B
�������悤�����܂����������ш�͎�荇���Ǝv����B
�Ŏ���������Ȃ�������Intel��AMD��GPU�����Ɍ������Ă邩��ˁB
��ԋ��ЂɎv���Ă�̂͑��̃x���^�[���ȁB
����҂Ƃ��āAIntel����������
����҂Ƃ��āAIntel����������
>>676
�㓡�͂����̃��C�^�[�ł����āAintel��GPU���������ƌ����Ă邩��L���������Ă邾���B
�㓡�͂����̃��C�^�[�ł����āAintel��GPU���������ƌ����Ă邩��L���������Ă邾���B
681 �F�R�E�L�́M�E,,�j�����������������F2008/01/31(��) 00:39:22 ID:WzxBT/HC
Bulldozer��16�r�b�g����������32�r�b�g���������𑊌ݕϊ����閽�߂�����邩��
�������瓝���ɂ��V�i�W�[���ʁi�j�_���ė�����[��
�������瓝���ɂ��V�i�W�[���ʁi�j�_���ė�����[��
Nehalem���^���ȃX�g���X�\�t�g�����肢���܂�
Bulldozer�͋��炭�w�e���ȃ}���`�R�A�ƂȂ邾�낤
AMD��cell
AMD��cell
GPU��������̂�FSB���l�b�N�ɂȂ肾���Ă邩�炶��Ȃ���
�����R����CPU���Ɉڂ邩�炾��
Intel�̏ꍇ
Intel�̏ꍇ
Nehalem�o����AMD���S�H
Nehalem�����S����\���������Ȃ���
Nehalem�Ƃ������I���S�������S��������Ȃ�����
Nehalem�Ƃ������I���S�������S��������Ȃ�����
���������A����CPU����FSB�̊T�O��������Ƃ�
��ANehalem��FSB�͔p�~����Ȃ����������H
FSB�Ƃ������̂͏����邪�AFSB�̑����QPI���ڂ邾��
�C���̒P�ʁ@�~���o�[�����@�w�N�g�p�X�J���ɂȂ������x�̈Ⴂ����ȁB���炭�E�E�E�B
�\�����̃K�ς��ƕ�������
�T�[�o/���[�N�X�e�[�V����/�G���X�[������Bloomfield�A�n�C�G���h������Lynnfield�ł̓������R���g���[�����A
CPU�Ƀ_�C���x���œ��������BBloomfield�ł̓}���`�\�P�b�g�p��QPI���p�ӂ���邪�A
Lynnfield�ł̓}���`�\�P�b�g�ւ̎g�p���S���l����K�v���Ȃ��̂ŁAQPI�͎g���Ȃ��B
CPU�p�b�P�[�W����MCM��CPU�R�A��GMCH����郁�C���X�g���[��Havendale�ł�GMCH-CPU�Ԃ�QPI���g����̂��낤���A
�ǂ݂̂��O���ɂ͏o�Ȃ��B
�Ƃ����̂�����ŏo�Ă�����ł͂��邪�A�ǂ����R�A�̃o���G�[�V��������������̂�Intel�炵���Ȃ��悤�ɂ��v���B
CPU�Ƀ_�C���x���œ��������BBloomfield�ł̓}���`�\�P�b�g�p��QPI���p�ӂ���邪�A
Lynnfield�ł̓}���`�\�P�b�g�ւ̎g�p���S���l����K�v���Ȃ��̂ŁAQPI�͎g���Ȃ��B
CPU�p�b�P�[�W����MCM��CPU�R�A��GMCH����郁�C���X�g���[��Havendale�ł�GMCH-CPU�Ԃ�QPI���g����̂��낤���A
�ǂ݂̂��O���ɂ͏o�Ȃ��B
�Ƃ����̂�����ŏo�Ă�����ł͂��邪�A�ǂ����R�A�̃o���G�[�V��������������̂�Intel�炵���Ȃ��悤�ɂ��v���B
>>693
Bloomfield��Lynnfield�͓���_�C�Ǝv����̂ŁA�_�C�̃o���G�[�V������2�͌����Core2�Ɠ�������B
Bloomfield��Lynnfield�͓���_�C�Ǝv����̂ŁA�_�C�̃o���G�[�V������2�͌����Core2�Ɠ�������B
Intel�����K���ɂȂ���DDR3�l�����ɓ����Ă邯��
Nehalem�{DDR3�̍\�����Penryn�{DDR3�̍\���̕����������肵��
Nehalem�X���[��SandyBridge�ɍs���l�����������肵��
Nehalem�{DDR3�̍\�����Penryn�{DDR3�̍\���̕����������肵��
Nehalem�X���[��SandyBridge�ɍs���l�����������肵��
DDR�R�l�����̓T���\���������Ă�݂��������B
697 �FMAC�I�^��693 �����F2008/01/31(��) 21:03:41 ID:0C6GGRXK
>>693
�㓡�M�҈ȊO��ABloomfiled�̃I���_�C�������R���g���[���햳��������Ă���Ƃ����F�������ǁB�B�B
http://www.hkepc.com/?id=568&page=2&fs=idn#view
�㓡�M�҈ȊO��ABloomfiled�̃I���_�C�������R���g���[���햳��������Ă���Ƃ����F�������ǁB�B�B
http://www.hkepc.com/?id=568&page=2&fs=idn#view
698 �FMAC�I�^���⑫�F2008/01/31(��) 21:11:16 ID:0C6GGRXK
���������y�[�W�̃��t�@�����X�}�U�[�̐}�ł�ADIMM�\�P�b�g�̈ʒu���v���Z�b�T���璼�ڐڑ�����Ă��Ȃ�
�Ɠ����z��������z�u�Ɍ����邷�B
����Ȗ�ŁA���ǒN���������̂����y���݂Ɍo�߂߂Ă��邷�B
�Ɠ����z��������z�u�Ɍ����邷�B
����Ȗ�ŁA���ǒN���������̂����y���݂Ɍo�߂߂Ă��邷�B
���{��ł���
700 �FMAC�I�^���⑫�F2008/01/31(��) 23:47:51 ID:Od4nUKxc
���������y�[�W�̃��t�@�����X�}�U�[�̐}�ł́ADIMM�\�P�b�g�̈ʒu���v���Z�b�T���璼�ڐڑ�����Ă��Ȃ�
�Ɠ����z��������z�u�Ɍ�����B
����Ȗ�ŁA���ǒN���������̂����y���݂Ɍo�߂߂Ă���B
�Ɠ����z��������z�u�Ɍ�����B
����Ȗ�ŁA���ǒN���������̂����y���݂Ɍo�߂߂Ă���B
701 �FSocket774�F2008/02/01(��) 01:44:06 ID:aYHzH/kq
>>673
�܂�A��莙�̃K�L�̕����������������߂�Ƃ��������H�H�H
�܂�A��莙�̃K�L�̕����������������߂�Ƃ��������H�H�H
>>701
��������
��������
703 �F�R�E�L�́M�E,,�j�����������������F2008/02/01(��) 01:51:25 ID:6do3ongq
�n�C�A�����Ŗ�莙�ƌ���ꂽ���l���ʂ�܂���
�N��P�O��Ȃ珫����������B
705 �F�R�E�L�́M�E,,�j�����������������F2008/02/01(��) 01:54:15 ID:6do3ongq
�����������l�ɂȂ�܂����B
intel������X38�}�U�[�ł��قړ����z�u������A�����z���͑債����肶��Ȃ��Ǝv�����ȁB
����QPI�̑ш悾�낤�B
QPI�̓s��������̓]�����[�g��6.4Gbps�ƁA���s��FSB1600MHz��4�{�ɂ��Ȃ邪�A
�o�X����32bit�Ō��sFSB�̔���������A�o�X�S�̂Ƃ��Ă̓]�����[�g�͐��X2�{�B
UP�T�[�o�[�����ł�QPI��1�{���Ęb������A�f�X�N�g�b�v��2�{�ڂ鎖�͂܂��Ȃ��B
�������A6.4Gbps�Ƃ����]�����[�g�̓T�[�o�[�����Ńf�X�N�g�b�v�����ł͏������������
�b�����邩��A���ۂɂ�FSB1333MHz�̔{���炢�����m���B
���ꂶ���C�Ƀ������ш悪�{�ȏ�ɂȂ�DDR3-3ch�͎x�����B
�{�g���l�b�N�����̂��߂�FSB�p�~����QPI�Ɉڍs����̂ɁA�����Ȃ�{�g���l�b�N�ɂȂ��Ă���Ӗ����Ȃ��B
����QPI�̑ш悾�낤�B
QPI�̓s��������̓]�����[�g��6.4Gbps�ƁA���s��FSB1600MHz��4�{�ɂ��Ȃ邪�A
�o�X����32bit�Ō��sFSB�̔���������A�o�X�S�̂Ƃ��Ă̓]�����[�g�͐��X2�{�B
UP�T�[�o�[�����ł�QPI��1�{���Ęb������A�f�X�N�g�b�v��2�{�ڂ鎖�͂܂��Ȃ��B
�������A6.4Gbps�Ƃ����]�����[�g�̓T�[�o�[�����Ńf�X�N�g�b�v�����ł͏������������
�b�����邩��A���ۂɂ�FSB1333MHz�̔{���炢�����m���B
���ꂶ���C�Ƀ������ш悪�{�ȏ�ɂȂ�DDR3-3ch�͎x�����B
�{�g���l�b�N�����̂��߂�FSB�p�~����QPI�Ɉڍs����̂ɁA�����Ȃ�{�g���l�b�N�ɂȂ��Ă���Ӗ����Ȃ��B
�I���S���`�[���̏�Ƃ��āA�ŏ��̐���̓_���|�ȋC�����邪�B
32�i�m������͔����H
32�i�m������͔����H
���t�@�����X�}�U�[�̐}�A�悭������IOH+ICH�ɂȂ��Ă�ȁE�E�E
�`�b�v�Z�b�g���Ƀ�������ڑ�����Ȃ�Aintel�̂���܂ł̊���ł�����
IOH����Ȃ���MCH��GMCH�ɂȂ�͂������B
����ρA�I���_�C�������R���g���[���g����Ȃ����H
�`�b�v�Z�b�g���Ƀ�������ڑ�����Ȃ�Aintel�̂���܂ł̊���ł�����
IOH����Ȃ���MCH��GMCH�ɂȂ�͂������B
����ρA�I���_�C�������R���g���[���g����Ȃ����H
���܂�I���S���`�[�����s�߂�Ȃ�c�B
Intel�����ŏ���Z�p�̂����͂��邾�낤�B
�C�X���G���`�[���̋Z�p���I���S���`�[���ɓ��������͂������A
����Ȃɍ������ɂ͂Ȃ�Ȃ��Ǝv�����B
�����A�F�X�����������ʂ̏���d�͏㏸�͊m���ɖ��m���B
�����ǁA���̕��V�X�e���S�̂̏���d�͂͌����Ȃ��H
Intel�����ŏ���Z�p�̂����͂��邾�낤�B
�C�X���G���`�[���̋Z�p���I���S���`�[���ɓ��������͂������A
����Ȃɍ������ɂ͂Ȃ�Ȃ��Ǝv�����B
�����A�F�X�����������ʂ̏���d�͏㏸�͊m���ɖ��m���B
�����ǁA���̕��V�X�e���S�̂̏���d�͂͌����Ȃ��H
710 �FSocket774�F2008/02/02(�y) 14:13:44 ID:77L0I4+r
Nehalem��TDP��Lynnfield��150W���炢����
�l�n�����͍���AMD��CPU�݂�����OC����Ȃ��Ȃ����H
�F��Ȃ��̉������߂�킯�����B
�F��Ȃ��̉������߂�킯�����B
�قڑS�Ă̐l�ɂƂ���DDR3���DDR2�̕������������
>>711
OC�ϐ��͈����Ȃ�ł��傤�ˁB�ł��AOC�Ȃ��
���F�C���M�����[�Ȋy���݂�����ǂ��ł��悭�ˁH
OC�ϐ�����ΐ��\���オ�������������B
�܂��BNehalem���łĂ��ǂ����n�C�G���h�����Ȃ�āA
�قƂ�ǂ̐l�ɂ͗��N�����炢�܂ł͊W�͂Ȃ����낤�ȁB
>>712
Intel���撣���ĉ��i�����悤�Ƃ��Ă��邩��A
����͂킩��B
OC�ϐ��͈����Ȃ�ł��傤�ˁB�ł��AOC�Ȃ��
���F�C���M�����[�Ȋy���݂�����ǂ��ł��悭�ˁH
OC�ϐ�����ΐ��\���オ�������������B
�܂��BNehalem���łĂ��ǂ����n�C�G���h�����Ȃ�āA
�قƂ�ǂ̐l�ɂ͗��N�����炢�܂ł͊W�͂Ȃ����낤�ȁB
>>712
Intel���撣���ĉ��i�����悤�Ƃ��Ă��邩��A
����͂킩��B
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
���㓡�O��Weekly�C�O�j���[�X��
2��CPU�J���`�[���ɋ��킹��Intel�̎Г��헪
�R�������A���̗���Ƀ}�b�`�������e���Ǝv���̂��B
���㓡�O��Weekly�C�O�j���[�X��
2��CPU�J���`�[���ɋ��킹��Intel�̎Г��헪
�R�������A���̗���Ƀ}�b�`�������e���Ǝv���̂��B
���܂��ɂ����ǂ��̂Ƃ��Ă�����ł���B
�����Ƃ����Ă��ǂ��炩�Е������̗p���Ȃ��킯����Ȃ����˂��B
����グ�ɒ������邶���
�o����CPU�̔���グ���r���邱�Ƃ�
�o����CPU�̔���グ���r���邱�Ƃ�
>>717
CPU�J���ɂ�������4�N���x�B
����������2�`�[�����J���X�^�[�g�B
4�N��ɗ����̃`�[�����J�����s�B
���v8�N�̃u�����N���K�v�ł����c�B
����Ȋy�������ʂł������̂��H
CPU�J���ɂ�������4�N���x�B
����������2�`�[�����J���X�^�[�g�B
4�N��ɗ����̃`�[�����J�����s�B
���v8�N�̃u�����N���K�v�ł����c�B
����Ȋy�������ʂł������̂��H
Diamondville��Dual core������Ȃ�ă��[�N���炵���X���C�h�����o���Ă邪�A�����ӂ�Silverthorne��MCM
�Ȃ̂��낤���H
http://xtreview.com/addcomment-id-4165-view-Diamondville-dual-core-processor.html
�Ȃ̂��낤���H
http://xtreview.com/addcomment-id-4165-view-Diamondville-dual-core-processor.html
MCM�����Ȃ�������B
FSB���낤���_�C�͂��łɌ��J���Ă邵�B
�Ƃ͌���DC�̓W�J�����ȁB
����Ȃ�Moorestown��MCM���Ǝv���Ă����ǃl�C�e�B�u���ȁB
FSB���낤���_�C�͂��łɌ��J���Ă邵�B
�Ƃ͌���DC�̓W�J�����ȁB
����Ȃ�Moorestown��MCM���Ǝv���Ă����ǃl�C�e�B�u���ȁB
ttp://www.ne.jp/asahi/comp/tarusan/main182.htm
�u�}���`�R�A�����瑬���B�v��A�Ă���PC�G�������A
C7�R�A�x�[�X�ł��}���`�R�A�������Vista�����K�ɓ������낤���H �Ƃ����_��
��x�^���ɍl���Ă݂ė~�����C������B (���T�C�g�̓��̒��ł́A���������K�Ƃ͎v���Ȃ��B)
�u�}���`�R�A�����瑬���B�v��A�Ă���PC�G�������A
C7�R�A�x�[�X�ł��}���`�R�A�������Vista�����K�ɓ������낤���H �Ƃ����_��
��x�^���ɍl���Ă݂ė~�����C������B (���T�C�g�̓��̒��ł́A���������K�Ƃ͎v���Ȃ��B)
VIA��CPU�R�A�̓V���O���R�A�Ő��\����̗]�n��
�܂��\�����݂��邩��A"C7"���}���`�R�A����������A
��{���\���g������"Isaiah"���������B
���Ċ������B�m���Ɍ��݂̃\�t�g�E�F�n�̑Ή������l����ƁA
�f���A�����V���O���ł̐��\�����ڎw�������������̂��B
�܂��B�L�����ɂ����邯��Intel��AMD��CPU�́A
���łɃR�A����剻���Ă��܂���̂ŁA
�}���`�R�A������̂͊m���ɕK�R���낤�Ȃ��B
�܂��\�����݂��邩��A"C7"���}���`�R�A����������A
��{���\���g������"Isaiah"���������B
���Ċ������B�m���Ɍ��݂̃\�t�g�E�F�n�̑Ή������l����ƁA
�f���A�����V���O���ł̐��\�����ڎw�������������̂��B
�܂��B�L�����ɂ����邯��Intel��AMD��CPU�́A
���łɃR�A����剻���Ă��܂���̂ŁA
�}���`�R�A������̂͊m���ɕK�R���낤�Ȃ��B
723 �FMAC�I�^��721 �����F2008/02/03(��) 11:48:07 ID:hp7kyZWe
>>721
�����d�g�n�T�C�g�ŋZ�p�I�ȓ��e��ԈႢ�Ȃ�ʼnL�ۂ݂ɂ��ׂ��ł햳�����B
���Ƃ�����̋L���ł��A
�@�@-----------------
�@�@��L2���e�ʉ����邽�߂ɂ�Out-of-Order���͕K�{�B �@�@
�@�@-----------------
�̂�����ɐF�X�g���f���Ȃ��Ƃ������Ă��邷�B�����Ƃ��Ă�A�L���b�V���~�X�ɂ��X�g�[��
�Ō�ɑ����S�Ă̖��ߎ��s����~���Ă��܂��C���I�[�_���s�̕�����e�ʃL���b�V����
�؎��ɕK�v�Ƃ��邷�B
Itanium��������̃v���Z�b�T�Ɣ�ׂĊi�i�ɑ傫�ȃI���_�C�L���b�V���𓋍ڂ��Ă���̂�
�����������R���B
�����d�g�n�T�C�g�ŋZ�p�I�ȓ��e��ԈႢ�Ȃ�ʼnL�ۂ݂ɂ��ׂ��ł햳�����B
���Ƃ�����̋L���ł��A
�@�@-----------------
�@�@��L2���e�ʉ����邽�߂ɂ�Out-of-Order���͕K�{�B �@�@
�@�@-----------------
�̂�����ɐF�X�g���f���Ȃ��Ƃ������Ă��邷�B�����Ƃ��Ă�A�L���b�V���~�X�ɂ��X�g�[��
�Ō�ɑ����S�Ă̖��ߎ��s����~���Ă��܂��C���I�[�_���s�̕�����e�ʃL���b�V����
�؎��ɕK�v�Ƃ��邷�B
Itanium��������̃v���Z�b�T�Ɣ�ׂĊi�i�ɑ傫�ȃI���_�C�L���b�V���𓋍ڂ��Ă���̂�
�����������R���B
�ŁASilverthorne��Dual��Vista�͉��K�Ȃ�ł����H
Nehalem�ɂ��ď��������B
���ĕ�ꂽ�������ŁA Nehalem�푽�K�w�̃L���b�V���\�������ƌ����
�Ă������B�Ⴆ�� http://www.ednjapan.com/content/l_news/2007/04/l_news070402_0501.html
�@�@----------------------
�@�@Gelsinger���̐����ɂ��ANehalem�ɂ́A�V����SSE4�����ATA�C���X�g���N�V����
�@�@�Z�b�g�A�[�L�e�N�`���̂ق��ɁA�����\�_�C�i�~�b�N�p���[�}�l�[�W�����g�@�\�A�X�}�[�g
�@�@�L���b�V���Z�p�A�}���`���x���L���b�V���Ȃǂ��܂܂��B
�@�@----------------------
���̂��߁A��N�H��IDF��Nehalem�̃_�C�ʐ^�����J���ꂽ�ۂɂ��������̃u���b�N��
�킴�킴L2��L3�ɕ�������Ȃ��o�Ă������B
http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
���ĕ�ꂽ�������ŁA Nehalem�푽�K�w�̃L���b�V���\�������ƌ����
�Ă������B�Ⴆ�� http://www.ednjapan.com/content/l_news/2007/04/l_news070402_0501.html
�@�@----------------------
�@�@Gelsinger���̐����ɂ��ANehalem�ɂ́A�V����SSE4�����ATA�C���X�g���N�V����
�@�@�Z�b�g�A�[�L�e�N�`���̂ق��ɁA�����\�_�C�i�~�b�N�p���[�}�l�[�W�����g�@�\�A�X�}�[�g
�@�@�L���b�V���Z�p�A�}���`���x���L���b�V���Ȃǂ��܂܂��B
�@�@----------------------
���̂��߁A��N�H��IDF��Nehalem�̃_�C�ʐ^�����J���ꂽ�ۂɂ��������̃u���b�N��
�킴�킴L2��L3�ɕ�������Ȃ��o�Ă������B
http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
{kind=link}
>>725
�L���ɂ����邩��A"Isaiah"��������ӂ肩��Ȃ��ˁH
45nm�Ƃ��ɂȂ�����ADual�R�A�����ꂽ"Isaiah"���o�������B
�c���N�Ƃ��ė��N�ӂ�H
�L���ɂ����邩��A"Isaiah"��������ӂ肩��Ȃ��ˁH
45nm�Ƃ��ɂȂ�����ADual�R�A�����ꂽ"Isaiah"���o�������B
�c���N�Ƃ��ė��N�ӂ�H
728 �FMAC�I�^�������F2008/02/03(��) 12:15:35 ID:hp7kyZWe
�Ƃ��낪�A���ݍł��ڍׂȏ������Ă���HKEPC.com�̋L���ł�A���Ɩ��m��L3��
���݂��ے肳��Ă��邷�B
http://www.hkepc.com/database/images/2008010316124060435399224.jpg
http://www.hkepc.com/?id=568&page=2
�@�@------------------
�@�@���������@�����ߝ\���������I Bloomfield �I�|�����{���C�����S�V�I�l�j
�@�@�S�|����̗p�����v�C 45 �ޕĐ�?�Z�p�C�s�đ� Yorkfield �ʍ̗p�_���Ԋj�S����I
�@�@�ˍ\�C�x���ގ� Hyper-Threading �Z�p���薼�� SMT (Simultaneous Multi-hreading) �C
�@�@�R�����l���j�S���p�����I 8MB Share Cache �C�e��嫔� Yorkfield �I 6MB x 2 ���C
�@�@�A�������L���B
�@�@[MAC�I�^��]
�@�@�ꕔ�̃}�U�[�{�[�h�x���_�͊���Bloomfield�̃G���W�j�A�����O�T���v������̂��Ă���B
�@�@Bloomfield�͌��s��Yorkfield�Ƃ͈قȂ�A45-nm�v���Z�X�̃V���O���_�C���4�R�A���W��
�@�@�����A�܂������V�����v�ƂȂ��Ă���B
�@�@Bloomfield��SMT�ƌĂ�Hyperthreading�Z�p�Ɠ��l�̋@�\���T�|�[�g����ƂƂ���4�R�A
�@�@�S�Ă�8MB�̃L���b�V�������L����B�ꌩ�����Yorkfield�ɂ�����6MB x 2��L2�L���b�V��
�@�@�Ɣ�r���đލs���Ă���悤�Ɏv���邪�A���ۂɂ͂������I�ɓ��삷��Ƃ����B
�@�@------------------
�@�@
���݂��ے肳��Ă��邷�B
http://www.hkepc.com/database/images/2008010316124060435399224.jpg
{kind=link}
http://www.hkepc.com/?id=568&page=2
�@�@------------------
�@�@���������@�����ߝ\���������I Bloomfield �I�|�����{���C�����S�V�I�l�j
�@�@�S�|����̗p�����v�C 45 �ޕĐ�?�Z�p�C�s�đ� Yorkfield �ʍ̗p�_���Ԋj�S����I
�@�@�ˍ\�C�x���ގ� Hyper-Threading �Z�p���薼�� SMT (Simultaneous Multi-hreading) �C
�@�@�R�����l���j�S���p�����I 8MB Share Cache �C�e��嫔� Yorkfield �I 6MB x 2 ���C
�@�@�A�������L���B
�@�@[MAC�I�^��]
�@�@�ꕔ�̃}�U�[�{�[�h�x���_�͊���Bloomfield�̃G���W�j�A�����O�T���v������̂��Ă���B
�@�@Bloomfield�͌��s��Yorkfield�Ƃ͈قȂ�A45-nm�v���Z�X�̃V���O���_�C���4�R�A���W��
�@�@�����A�܂������V�����v�ƂȂ��Ă���B
�@�@Bloomfield��SMT�ƌĂ�Hyperthreading�Z�p�Ɠ��l�̋@�\���T�|�[�g����ƂƂ���4�R�A
�@�@�S�Ă�8MB�̃L���b�V�������L����B�ꌩ�����Yorkfield�ɂ�����6MB x 2��L2�L���b�V��
�@�@�Ɣ�r���đލs���Ă���悤�Ɏv���邪�A���ۂɂ͂������I�ɓ��삷��Ƃ����B
�@�@------------------
�@�@
>>723
C7�̓L���b�V���~�X�ɂ��X�g�[���������s���Ԃ̕���ꡂ��Ɏ���
�������Ă邩��L���b�V���𑝂₷�͕̂s�o�ρB
OoO���ɂ���Ď��s���Ԃ��Z���Ȃ��Ă����̂ő��ΓI�ɃL���b�V���~�X
�̃y�i���e�B�������Ă�������L���b�V���𑝂₵���B
���������_�����Ǝv�����ǁB
����Itanium���L���b�V�������̂͂��������Z�O�����g������Ȃ�B
POWER5������OoO�ł��L���b�V���������B
C7�̓L���b�V���~�X�ɂ��X�g�[���������s���Ԃ̕���ꡂ��Ɏ���
�������Ă邩��L���b�V���𑝂₷�͕̂s�o�ρB
OoO���ɂ���Ď��s���Ԃ��Z���Ȃ��Ă����̂ő��ΓI�ɃL���b�V���~�X
�̃y�i���e�B�������Ă�������L���b�V���𑝂₵���B
���������_�����Ǝv�����ǁB
����Itanium���L���b�V�������̂͂��������Z�O�����g������Ȃ�B
POWER5������OoO�ł��L���b�V���������B
>>695
���������ADDR3���Ė{���Ɍ��ʂ���낤���ˁH
Core2�̌��ʂ����Ă���ƁA�L���b�V����4���K�o�C�g�������ӂ肩��A�������[�̃o�X�o���h���̌��ʂ������Ȃ��Ă��Ă���悤�Ɍ�����B
�Ȃ�A�������̂���3���L���b�V��32���K�o�C�g�Ƃ��悹�āA�������[�͂̂�܂ł��悢�l�ȋC������B
�܂��ꕔ�̉Ȋw�v�Z�̂悤�ȁA�X�g���[�����������邪�@���A�ǂݍ���ŐϘa���ď����o�������Ƃ��Ȃ�Ӗ��͂��肻�������ǁE�E�E�����GP-GPU�ł����������ق��������ȂƁB
���������ADDR3���Ė{���Ɍ��ʂ���낤���ˁH
Core2�̌��ʂ����Ă���ƁA�L���b�V����4���K�o�C�g�������ӂ肩��A�������[�̃o�X�o���h���̌��ʂ������Ȃ��Ă��Ă���悤�Ɍ�����B
�Ȃ�A�������̂���3���L���b�V��32���K�o�C�g�Ƃ��悹�āA�������[�͂̂�܂ł��悢�l�ȋC������B
�܂��ꕔ�̉Ȋw�v�Z�̂悤�ȁA�X�g���[�����������邪�@���A�ǂݍ���ŐϘa���ď����o�������Ƃ��Ȃ�Ӗ��͂��肻�������ǁE�E�E�����GP-GPU�ł����������ق��������ȂƁB
731 �FMAC�I�^�������F2008/02/03(��) 12:27:39 ID:hp7kyZWe
�������L2��L3�����L���Ă���Ƃ������������邩������Ȃ������ǁA������������������
�Ƃ��������Ă������B
�@�E�f�X�N�g�b�v��[�N�X�e�[�V�����Ȃ�2�\�P�b�g�ȉ��̃v���b�g�t�H�[���ł�
�@�@L2���L�̂�
�@�E�}���`�\�P�b�g�v���b�g�t�H�[���p��AL2�̈ꕔ��L3�p�̃^�O�܂���X�k�[�v�t�B���^
�@�@�Ƃ��č\���ł���_��������Ă���A�O�t��L3��ڑ�����B
�@�E�O�t��L3��O���������R���g���[��Tylersburg���l��QPI�Őڑ������B
�@�EL3��MCM�œ���p�b�P�[�W�ɓ��ꂽ�\�������݂��A�L���A���N���b�N�̐�pQPI��
�@�@�ڑ������
���̎O���ڂ�POWER�v���Z�b�T + wave pipelined interface�ł���Ă��邱�ƂƓ������B
���Ȃ݂ɁA�ꉞIntel�̓������������Ă݂������ǁA�Y������悤�Ȕ�����o�^����Ă��Ȃ��������B
�Ƃ��������Ă������B
�@�E�f�X�N�g�b�v��[�N�X�e�[�V�����Ȃ�2�\�P�b�g�ȉ��̃v���b�g�t�H�[���ł�
�@�@L2���L�̂�
�@�E�}���`�\�P�b�g�v���b�g�t�H�[���p��AL2�̈ꕔ��L3�p�̃^�O�܂���X�k�[�v�t�B���^
�@�@�Ƃ��č\���ł���_��������Ă���A�O�t��L3��ڑ�����B
�@�E�O�t��L3��O���������R���g���[��Tylersburg���l��QPI�Őڑ������B
�@�EL3��MCM�œ���p�b�P�[�W�ɓ��ꂽ�\�������݂��A�L���A���N���b�N�̐�pQPI��
�@�@�ڑ������
���̎O���ڂ�POWER�v���Z�b�T + wave pipelined interface�ł���Ă��邱�ƂƓ������B
���Ȃ݂ɁA�ꉞIntel�̓������������Ă݂������ǁA�Y������悤�Ȕ�����o�^����Ă��Ȃ��������B
>>727
Dual Core�������Ƃ��Ă�������̘b�ł��傤
45nm�ł͂��Ȃ��Ǝv��
������p�t�H�[�}���X���\���Ɍ��ʂ����鎞���ɂȂ��
���邢�̓l�C�e�B�u�ł���Ă��邩������Ȃ�����
����ɁA�}�U�[�̃��[�J�[���ŏ���Ƀ}���`CPU���o��������
���݂̃p�b�P�[�W�Ȃ�mini-ITX�ł�2 CPU�͍s����X�y�[�X�͂��邵
>>729
nehemiah->esther�ł͈ꉞL2�͔{�ɂȂ��Ă���
���̌��ʂ����҂��ꂽ�����ۂ̃p�t�H�[�}���X���͎��N���b�N�̍������x�ł����Ȃ�����
���炭esther�̒i�K�Ō��E�������Ă����Ǝv����A�O����
����esther�̂܂܂ŁA����ȏ�@�\���l�ߍ��ނƃp�C�v���C���������Ȃ邵
�p�t�H�[�}���X���グ��ɂ͌��ǃN���b�N���グ�邵���Ȃ��Ȃ邵
Dual Core�������Ƃ��Ă�������̘b�ł��傤
45nm�ł͂��Ȃ��Ǝv��
������p�t�H�[�}���X���\���Ɍ��ʂ����鎞���ɂȂ��
���邢�̓l�C�e�B�u�ł���Ă��邩������Ȃ�����
����ɁA�}�U�[�̃��[�J�[���ŏ���Ƀ}���`CPU���o��������
���݂̃p�b�P�[�W�Ȃ�mini-ITX�ł�2 CPU�͍s����X�y�[�X�͂��邵
>>729
nehemiah->esther�ł͈ꉞL2�͔{�ɂȂ��Ă���
���̌��ʂ����҂��ꂽ�����ۂ̃p�t�H�[�}���X���͎��N���b�N�̍������x�ł����Ȃ�����
���炭esther�̒i�K�Ō��E�������Ă����Ǝv����A�O����
����esther�̂܂܂ŁA����ȏ�@�\���l�ߍ��ނƃp�C�v���C���������Ȃ邵
�p�t�H�[�}���X���グ��ɂ͌��ǃN���b�N���グ�邵���Ȃ��Ȃ邵
733 �FMAC�I�^��729 �����F2008/02/03(��) 12:51:03 ID:hp7kyZWe
>>729
�@�@-------------------
�@�@����Itanium���L���b�V�������̂͂��������Z�O�����g������Ȃ�B
�@�@POWER5������OoO�ł��L���b�V���������B
�@�@-------------------
�e�K�w�̃L���b�V���̃��C�e���V�ɒ��ڂ��Ă��̋L����Table 2�����Ăق������B
http://www.realworldtech.com/page.cfm?ArticleID=RWT100404214638&p=3
�������Intel���g���펯�Ƃ��ĔF�����Ă���b���B
http://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
�@�@===================
�@�@Before the advent of thread-based prefetch techniques like SP, out-of-order (OOO)
�@�@execution [18][19][20] has been the primary microarchitecture technique to tolerate
�@�@cache miss latency. With the register renamer and reservation stations, an OOO
�@�@processor is able to dynamically schedule the in-flight instructions, and execute
�@�@those instructions independent of the missing loads, while the misses are being served.
�@�@===================
�@�@-------------------
�@�@����Itanium���L���b�V�������̂͂��������Z�O�����g������Ȃ�B
�@�@POWER5������OoO�ł��L���b�V���������B
�@�@-------------------
�e�K�w�̃L���b�V���̃��C�e���V�ɒ��ڂ��Ă��̋L����Table 2�����Ăق������B
http://www.realworldtech.com/page.cfm?ArticleID=RWT100404214638&p=3
�������Intel���g���펯�Ƃ��ĔF�����Ă���b���B
http://download.intel.com/technology/itj/2002/volume06issue01/art03_specprecomp/vol6iss1_art03.pdf
�@�@===================
�@�@Before the advent of thread-based prefetch techniques like SP, out-of-order (OOO)
�@�@execution [18][19][20] has been the primary microarchitecture technique to tolerate
�@�@cache miss latency. With the register renamer and reservation stations, an OOO
�@�@processor is able to dynamically schedule the in-flight instructions, and execute
�@�@those instructions independent of the missing loads, while the misses are being served.
�@�@===================
����A�ǂ��l���Ă�Itanium�͂��������s�ꂾ���炾��B
"�C���I�[�_���s�̕�����e�ʃL���b�V����؎��ɕK�v�Ƃ��邷"��
���邳�l�AMAC�I�^�̏���ȉ��߂̈���łĂȂ����낤�B>>733�̃\�[�X�Ȃ�ĂȂ�̏؋��ɂ��Ȃ��ĂȂ��B
�����ɂ�L2�̓�������OOO���y�Ɠ������A���y������ɐi��ł����킯������ȁB
�����POWER6��������latency��������܂������͎͂c����Ă����̂����AIBM��Intel�̋Z�p��������Ă��邾���̃\�[�X�ł����B
�������Intel��Silverthorne/Diamondville��in-order������cache����ɋ��������Ƃ����������Ȃ����B
"�C���I�[�_���s�̕�����e�ʃL���b�V����؎��ɕK�v�Ƃ��邷"��
���邳�l�AMAC�I�^�̏���ȉ��߂̈���łĂȂ����낤�B>>733�̃\�[�X�Ȃ�ĂȂ�̏؋��ɂ��Ȃ��ĂȂ��B
�����ɂ�L2�̓�������OOO���y�Ɠ������A���y������ɐi��ł����킯������ȁB
�����POWER6��������latency��������܂������͎͂c����Ă����̂����AIBM��Intel�̋Z�p��������Ă��邾���̃\�[�X�ł����B
�������Intel��Silverthorne/Diamondville��in-order������cache����ɋ��������Ƃ����������Ȃ����B
735 �FMAC�I�^��734 �����F2008/02/03(��) 14:31:25 ID:hp7kyZWe
>>734
�@�@---------------
�@�@���邳�l�AMAC�I�^�̏���ȉ��߂̈���łĂȂ����낤�B
�@�@---------------
���̂��邳��⎄�ł��畁�ʂɂ���Ă���u�Q�l���������Ď��������v�Ƃ����s�ׂ���
�ł��Ȃ����Ƃ�p���������Ȃ������H
����Ȃ��Ƃ�����]���ϑz�Ŋ������Ă�ƌ����邷��(��)
�@�@---------------
�@�@���邳�l�AMAC�I�^�̏���ȉ��߂̈���łĂȂ����낤�B
�@�@---------------
���̂��邳��⎄�ł��畁�ʂɂ���Ă���u�Q�l���������Ď��������v�Ƃ����s�ׂ���
�ł��Ȃ����Ƃ�p���������Ȃ������H
����Ȃ��Ƃ�����]���ϑz�Ŋ������Ă�ƌ����邷��(��)
MAC�I�^�͕������߂Ɍ�肪����Ƃ��ɁA
�Q�l�����������̂���
�Q�l�����������̂���
>>735
�ʂɎ�����W�J���ɂ��Ă���킯����Ȃ�����ȁB
>>733�ɂ́A
cache miss���������Ă��A�~�X����load�Ɉˑ����Ȃ��p�C�v���C�����̖��߂͎��s�ł��邩��A
OOO�̓L���b�V���~�X�x���Ɋ���ȋZ�p���Ə����Ă��邾���B
���ꂾ������in-order����OOO�̕����L���b�V���̒x�����B�����Ȃ�������ǂ��ǂݏo���邩��
��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
"�C���I�[�_���s�̕�����e�ʃL���b�V����؎��ɕK�v�Ƃ��邷"
�\�[�X��\��Ȃ�ł��������Ƃ����킯�ł͂Ȃ��Ƃ������Ƃ��B
�ʂɎ�����W�J���ɂ��Ă���킯����Ȃ�����ȁB
>>733�ɂ́A
cache miss���������Ă��A�~�X����load�Ɉˑ����Ȃ��p�C�v���C�����̖��߂͎��s�ł��邩��A
OOO�̓L���b�V���~�X�x���Ɋ���ȋZ�p���Ə����Ă��邾���B
���ꂾ������in-order����OOO�̕����L���b�V���̒x�����B�����Ȃ�������ǂ��ǂݏo���邩��
��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
"�C���I�[�_���s�̕�����e�ʃL���b�V����؎��ɕK�v�Ƃ��邷"
�\�[�X��\��Ȃ�ł��������Ƃ����킯�ł͂Ȃ��Ƃ������Ƃ��B
>���ꂾ������in-order����OOO�̕����L���b�V���̒x�����B�����Ȃ�������ǂ��ǂݏo���邩��
>��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
Isaiah���\�z�ɔ�����1MB���ς�ł����̂�
���̕ӂ̗��R������
>��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
Isaiah���\�z�ɔ�����1MB���ς�ł����̂�
���̕ӂ̗��R������
>>736
�����̂��Ƃ�w
�����̂��Ƃ�w
>>738
�Ƃ������A�V�������N�ł�����x�ȏ㏬�����Ȃ�ƁA�{���f�B���O��z�b�g�X�|�b�g
�̖�肪�o�邩��A�L���b�V���Ƀg�����W�X�^�𑽖ڂɊ���U�������Ċ����ł́H
�L���b�V�����ʂ��SMB���x�܂łȂ琫�\�A�b�v�ɏ[�����ʂ�����͔̂����Ă邵�A
OoO�̓x������X�[�p�[�p�C�v���C���̑��i�������A�L���b�V���𑝂₷����
�d�͑ΐ��\�ŗL���ɂȂ���Ĕ��f���������̂ł́H
���Ƙ_����H���������L���b�V���̗l�ȃ����������̕����A�������ׂɑ��ă��y�A
�����Ղ�����A�����܂�̃A�b�v�����ҏo���邵�A���y�A�s�\�Ȍ��וi�͎b���o����
����512KB�L���b�V���i�Ƃ��ďo���邵�B
�Ƃ������A�V�������N�ł�����x�ȏ㏬�����Ȃ�ƁA�{���f�B���O��z�b�g�X�|�b�g
�̖�肪�o�邩��A�L���b�V���Ƀg�����W�X�^�𑽖ڂɊ���U�������Ċ����ł́H
�L���b�V�����ʂ��SMB���x�܂łȂ琫�\�A�b�v�ɏ[�����ʂ�����͔̂����Ă邵�A
OoO�̓x������X�[�p�[�p�C�v���C���̑��i�������A�L���b�V���𑝂₷����
�d�͑ΐ��\�ŗL���ɂȂ���Ĕ��f���������̂ł́H
���Ƙ_����H���������L���b�V���̗l�ȃ����������̕����A�������ׂɑ��ă��y�A
�����Ղ�����A�����܂�̃A�b�v�����ҏo���邵�A���y�A�s�\�Ȍ��וi�͎b���o����
����512KB�L���b�V���i�Ƃ��ďo���邵�B
741 �FMAC�I�^��737 �����F2008/02/03(��) 17:21:01 ID:hp7kyZWe
>>737
�@�@-------------
�@�@�ʂɎ�����W�J���ɂ��Ă���킯����Ȃ�����ȁB
�@�@-------------
�������ړI�Ǝ������Ă�悤�ȋC��(��)
�@�@-------------
�@�@���ꂾ������in-order����OOO�̕����L���b�V���̒x�����B�����Ȃ�������ǂ��ǂݏo���邩��
�@�@��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
�@�@-------------
�Ȃ��Ȃ������ȉ��߂��ˁB�������킻�́u�L���b�V���x���v�Ƃ���艽�{���x���Ƃ������Ƃ�
�]�����甲�������Ă���悤���B�B�B
�@�@-------------
�@�@�ʂɎ�����W�J���ɂ��Ă���킯����Ȃ�����ȁB
�@�@-------------
�������ړI�Ǝ������Ă�悤�ȋC��(��)
�@�@-------------
�@�@���ꂾ������in-order����OOO�̕����L���b�V���̒x�����B�����Ȃ�������ǂ��ǂݏo���邩��
�@�@��e�ʉ��Ɍ����Ă���Ƃ��Ƃ�邾�낤�B
�@�@-------------
�Ȃ��Ȃ������ȉ��߂��ˁB�������킻�́u�L���b�V���x���v�Ƃ���艽�{���x���Ƃ������Ƃ�
�]�����甲�������Ă���悤���B�B�B
�A�E�g�I�[�_�[�^�̃v���Z�b�T���āA�C���I�[�_�[�ɔ�ׂă`�b�v�ʐω����������炢�ɂ��ł����ˁH
�A�E�g�I�[�_�[�^�̃v���Z�b�T�̓V���O���v���Z�b�T�Ȃ獂���ł��肪���ݑ�R������ǁA�}���`�v���Z�b�T�ɂ���Ɠ������������i�ɂ���K�v��������
�\�[�X�R�[�h���猴���Nj����ɂ������̕s���̃o�O���o�₷���ł��B
���i�ɂ���ƁA�R�[�h�����b�N�������炯�ɂȂ��Ă��̃I�[�o�[�w�b�h�̓A�E�g�I�[�_�[�̌��������̂�����Ɣ����ȋC������B
�ƁA����͕K������������ł͂Ȃ��̂ŁA�������C���I�[�_�[�ɂ��鎖�ɂ���Č������`�b�v�ʐςɃL���b�V����ςނƌ��ʂ͂����قǂɂȂ��ł��傤�ˁH
�A�E�g�I�[�_�[�^�̃v���Z�b�T�̓V���O���v���Z�b�T�Ȃ獂���ł��肪���ݑ�R������ǁA�}���`�v���Z�b�T�ɂ���Ɠ������������i�ɂ���K�v��������
�\�[�X�R�[�h���猴���Nj����ɂ������̕s���̃o�O���o�₷���ł��B
���i�ɂ���ƁA�R�[�h�����b�N�������炯�ɂȂ��Ă��̃I�[�o�[�w�b�h�̓A�E�g�I�[�_�[�̌��������̂�����Ɣ����ȋC������B
�ƁA����͕K������������ł͂Ȃ��̂ŁA�������C���I�[�_�[�ɂ��鎖�ɂ���Č������`�b�v�ʐςɃL���b�V����ςނƌ��ʂ͂����قǂɂȂ��ł��傤�ˁH
743 �FMAC�I�^��742 �����F2008/02/03(��) 17:37:13 ID:hp7kyZWe
>>742
�@�@-------------------
�@�@�\�[�X�R�[�h���猴���Nj����ɂ������̕s���̃o�O���o�₷���ł��B
�@�@-------------------
POWER ISA�̂悤�ɁA���X�������̃I�[�_�����O�������ɂ��A�[�L�e�N�`����ʂɂ���x86�ł�����Ȃ���
�N���邷���H
�@�@-------------------
�@�@�\�[�X�R�[�h���猴���Nj����ɂ������̕s���̃o�O���o�₷���ł��B
�@�@-------------------
POWER ISA�̂悤�ɁA���X�������̃I�[�_�����O�������ɂ��A�[�L�e�N�`����ʂɂ���x86�ł�����Ȃ���
�N���邷���H
>>732��
>nehemiah->esther�ł͈ꉞL2�͔{�ɂȂ��Ă���
>���̌��ʂ����҂��ꂽ�����ۂ̃p�t�H�[�}���X���͎��N���b�N�̍������x�ł����Ȃ�����
>���炭esther�̒i�K�Ō��E�������Ă����Ǝv����A�O����
������
�܂�
ttp://japan.cnet.com/blog/kichi/2008/01/28/entry_25004576/
�ɂ�Isaiah��L2�������ꍇ4500���g�����W�X�^���x�Ɨ\�z���Ă�
Esther�̖�{���ˁA�����Ƃ�Isaiah��64bit�≼�z�@�\�Ȃ�Ă̂�
�܂��߂ɂ���Ă��Ă邩��A�P���ɂ͔�r�ł��Ȃ����낤����
>nehemiah->esther�ł͈ꉞL2�͔{�ɂȂ��Ă���
>���̌��ʂ����҂��ꂽ�����ۂ̃p�t�H�[�}���X���͎��N���b�N�̍������x�ł����Ȃ�����
>���炭esther�̒i�K�Ō��E�������Ă����Ǝv����A�O����
������
�܂�
ttp://japan.cnet.com/blog/kichi/2008/01/28/entry_25004576/
�ɂ�Isaiah��L2�������ꍇ4500���g�����W�X�^���x�Ɨ\�z���Ă�
Esther�̖�{���ˁA�����Ƃ�Isaiah��64bit�≼�z�@�\�Ȃ�Ă̂�
�܂��߂ɂ���Ă��Ă邩��A�P���ɂ͔�r�ł��Ȃ����낤����
>>743
�����͎蔲��if������n�܂�̂ŁA�i�[��̓��W�X�^�[�ł��������[�ł��������܂���
�o��ƁA�܂�������^�������������A�ǂ����ďo��̂����W�b�N�𗝉�����̂�����A�������Y�܂��H�ڂɂȂ�܂��B
�����͎蔲��if������n�܂�̂ŁA�i�[��̓��W�X�^�[�ł��������[�ł��������܂���
�o��ƁA�܂�������^�������������A�ǂ����ďo��̂����W�b�N�𗝉�����̂�����A�������Y�܂��H�ڂɂȂ�܂��B
���ƃf�o�b�K�Œǂ��Ȃ����Ă̂��n���p�Ȃ��L�c�C
>>744�̕⑫�i���Ă��v�����j
�g�����W�X�^�����炷���
C7��Quad Core�i�������ˁj�ƍ����Isaiah��Single Core��
���K�͂ł���킯�ł��ȁE�E
���邳�ɂ����i���_��j4�{�̃p�t�H�[�}���X���������킯����
�����͂��Ȃ�����
�g�����W�X�^�����炷���
C7��Quad Core�i�������ˁj�ƍ����Isaiah��Single Core��
���K�͂ł���킯�ł��ȁE�E
���邳�ɂ����i���_��j4�{�̃p�t�H�[�}���X���������킯����
�����͂��Ȃ�����
�������C7�̃L���b�V���������₷���Ƃ��ł����͂���
���ʂ������
���ʂ������
����Ԃ������Đ\����Ȃ��B
�����ł̐��l�v�Z�Ƃ���邩��N�I�b�h�R�A��CPU�ς�PC�����������A
�ł����45nm�̓z�������B
�ƂȂ�ƌ����_�ł�Core2Extreme�����Ȃ����������ɍ����B
�����ŁA����Yorkfield�R�A�̂��̂��o��܂ő҂Ƃ����ȁ`�ƍl���Ă����A
�ǂ������N�̌㔼�ɂ̓A�[�L�e�N�`���̈ႤBloomfield�R�A���o�邱�ƍl������
�i���̌�̊g�����Ƃ��l������j����܂ōw���҂��������������ȁB
����Ƃ����̌�܂��F�X�ς�邾�낤���Ӗ��Ȃ����낤���E�E�E�B
�����ł̐��l�v�Z�Ƃ���邩��N�I�b�h�R�A��CPU�ς�PC�����������A
�ł����45nm�̓z�������B
�ƂȂ�ƌ����_�ł�Core2Extreme�����Ȃ����������ɍ����B
�����ŁA����Yorkfield�R�A�̂��̂��o��܂ő҂Ƃ����ȁ`�ƍl���Ă����A
�ǂ������N�̌㔼�ɂ̓A�[�L�e�N�`���̈ႤBloomfield�R�A���o�邱�ƍl������
�i���̌�̊g�����Ƃ��l������j����܂ōw���҂��������������ȁB
����Ƃ����̌�܂��F�X�ς�邾�낤���Ӗ��Ȃ����낤���E�E�E�B
�������ǂ����Ȃ�ӂ��̂ނ��������߂��ɂ�
TDP��_�C�T�C�Y���l����ƁAIsaiah���ď����ł���Ƃ��낪���Ȃ菭�Ȃ������ȁB
��ʂ�2GHz���ƃ��o�C������Celeron(TDP30W)�Ƃ��Ȃ肩�Ԃ邵�ADiamondville����������
TDP4W�����肾�ƁA�N���b�N�����Ȃ��Ƃ����܂�TDP������Ȃ�����A�V���O���X���b�h���\��
�����悤�Ȋ����ɂȂ��āA�_�C�T�C�Y�ł���Isaiah�̕����R�X�g�I�Ɍ������������B
10W�O�゠���肪���C���Ȃ낤���H
��ʂ�2GHz���ƃ��o�C������Celeron(TDP30W)�Ƃ��Ȃ肩�Ԃ邵�ADiamondville����������
TDP4W�����肾�ƁA�N���b�N�����Ȃ��Ƃ����܂�TDP������Ȃ�����A�V���O���X���b�h���\��
�����悤�Ȋ����ɂȂ��āA�_�C�T�C�Y�ł���Isaiah�̕����R�X�g�I�Ɍ������������B
10W�O�゠���肪���C���Ȃ낤���H
����A�����Ƃ�����Lynnfield�����痈�N�O���ɂȂ�܂��ȁB
>>750
Phenom���ĂȂ����\�����Ȃ��Čh�����Ă��ł����E�E�E
OC�͂��Ȃ��ɂ��Ă��A
�i�V���O��/�f���A���R�A�Ɣ�r�����Ƃ��Ɂj������x�̃p�t�H�[�}���X�͗~�����̂ł��B�B�B
Phenom���ĂȂ����\�����Ȃ��Čh�����Ă��ł����E�E�E
OC�͂��Ȃ��ɂ��Ă��A
�i�V���O��/�f���A���R�A�Ɣ�r�����Ƃ��Ɂj������x�̃p�t�H�[�}���X�͗~�����̂ł��B�B�B
�҂Ă�Ȃ�҂Ă������A�҂ĂȂ��Ȃ�65nm�B
65nm�ł����Ȃ�Core2 Quad�ł��A�^������Mac Pro�ł��A�����ς����邾��
65nm�ł����Ȃ�Core2 Quad�ł��A�^������Mac Pro�ł��A�����ς����邾��
1�N���҂Ă���Ď��͂܂�ʂɕK�v�Ƃ��ĂȂ����Ď����B
>>754
>>755
�m���ɁE�E�E�B
���Ƃ����̐�A�[�L�e�N�`���i���ɕ����I�Ȍ݊����Ƃ��j���傫���ς�邱�Ƃ��Ȃ��Ȃ�
1�N���炢�͑҂Ă��ł����A
�҂��Ă��ǂ����܂�1�N��Ɏ����悤�ȏɂȂ�Ȃ�
�������Ă��������ȁE�E�E�Ƃ͎v���܂��B
>>755
�m���ɁE�E�E�B
���Ƃ����̐�A�[�L�e�N�`���i���ɕ����I�Ȍ݊����Ƃ��j���傫���ς�邱�Ƃ��Ȃ��Ȃ�
1�N���炢�͑҂Ă��ł����A
�҂��Ă��ǂ����܂�1�N��Ɏ����悤�ȏɂȂ�Ȃ�
�������Ă��������ȁE�E�E�Ƃ͎v���܂��B
����45nm�����܂�
http://www1.jpn.hp.com/info/newsroom/pr/fy2008/fy08-041.html
http://www.jcsn.co.jp/products/spec/vin_rack_1uxef.html
http://www.fanatic.co.jp/product/server/xeon_4u.html
http://www.nec.co.jp/press/ja/0801/2801.html
http://www1.jpn.hp.com/info/newsroom/pr/fy2008/fy08-041.html
http://www.jcsn.co.jp/products/spec/vin_rack_1uxef.html
http://www.fanatic.co.jp/product/server/xeon_4u.html
http://www.nec.co.jp/press/ja/0801/2801.html
���� Core2 Quad��45nm �~�����ȁA����d�͂��������Ńp���[�L�肻������
�ŋߏ���d�͂��n���ɂȂ�Ȃ����A�܂��l���グ��Ƃ��A�������͂��������グ���
�ŋߏ���d�͂��n���ɂȂ�Ȃ����A�܂��l���グ��Ƃ��A�������͂��������グ���
����Ȑ[��ɉ��ʏグ���
�ߏ����f���I
�ߏ����f���I
���̃}�U�[��Lynnfield�Ƃ����čڂ�́H
761 �F�R�E�L�́M�E,,�j�����������������F2008/02/04(��) 01:32:20 ID:015DttvK
�\�P�b�g�ւ��̂Ŗ����ł��B
E8000�AQ9000�V���[�Y��LGA775�Ō�̃V���[�Y�ł��B
E8000�AQ9000�V���[�Y��LGA775�Ō�̃V���[�Y�ł��B
�ŋߏ��\�[�X�Ƃ��Ă悭��������xtreview.com��Bloomfield��O���������R���g���[���Ə����Ă��邷�ˁB
http://xtreview.com/addcomment-id-4164-view-Bloomfield-will-cost-less-then-400-dollars.html
�@�@---------------------------
�@�@Bloomfield will use motherboard with the traditional layout, which has a north and south bridge. Such
�@�@motherboard will be expensive.
�@�@---------------------------
�����̕��ꃋ�[�}�[�x���Ăǂ�ȃ����Ȃ��H
http://xtreview.com/addcomment-id-4164-view-Bloomfield-will-cost-less-then-400-dollars.html
�@�@---------------------------
�@�@Bloomfield will use motherboard with the traditional layout, which has a north and south bridge. Such
�@�@motherboard will be expensive.
�@�@---------------------------
�����̕��ꃋ�[�}�[�x���Ăǂ�ȃ����Ȃ��H
�\�P�b�g���A��������DDR2����DDR3�Ɋ����̂��傫��
Nehalem���o�ꂵ�Ă��b����DDR3�̍��l�����y�̑����������邾�낤��
Nehalem���o�ꂵ�Ă��b����DDR3�̍��l�����y�̑����������邾�낤��
Nehalem�ɍ��킹�đ傫�����Y���Ă�����v�B
766 �FSocket774�F2008/02/04(��) 06:51:32 ID:ZjwPjB30
767 �F�R�E�L�́M�E,,�j�����������������F2008/02/04(��) 07:02:56 ID:015DttvK
Nehalem��DDR3�T�|�[�g�ƍŒ�ł�2�R�A4�X���b�h�Ȃ̂Ń~�b�h�����W�ȏ�����B
Wolfdale���o�����[�Z�O�����g�Ɏc�������ł���B
2010�N�Ȃ�32nm�͂܂��o�n�߂����B
32nm��Penryn�V�������N�́A�܂������ł���B
Wolfdale���o�����[�Z�O�����g�Ɏc�������ł���B
2010�N�Ȃ�32nm�͂܂��o�n�߂����B
32nm��Penryn�V�������N�́A�܂������ł���B
768 �FSocket774�F2008/02/04(��) 07:08:05 ID:ZjwPjB30
2010�N���܂ł��Ⴍ�Č㔼�܂Ŏc���
E8x50�V���[�Y�͊m���ɏo�邵�A�Ō��E9000�V���[�Y���o��Ǝv��
32nm���o�邩�ǂ�����Nehalem���R�P�邩�ǂ�������
E8x50�V���[�Y�͊m���ɏo�邵�A�Ō��E9000�V���[�Y���o��Ǝv��
32nm���o�邩�ǂ�����Nehalem���R�P�邩�ǂ�������
�����R���̓����Ɏ��s�����H
770 �FSocket774�F2008/02/04(��) 07:12:28 ID:ZjwPjB30
Nehalem�Ŋ�{���\�オ���ĂĂ�OC�ϐ���Phenom����DDR3��
���܂��l�����ł��Ȃ�������R�P��\������Ǝv�����ǂ�
2010�N�܂�Penryn������������Ȃ�Penryn��SandyBridge�ɂȂ�l��������
���܂��l�����ł��Ȃ�������R�P��\������Ǝv�����ǂ�
2010�N�܂�Penryn������������Ȃ�Penryn��SandyBridge�ɂȂ�l��������
���샆�[�U�[�Ȃ�Penryn��OC�̕����������Ă����w���o�Ă���\�����邾�낤���A
Nehalem�����3GHz�O�����i�ŏo����A�I��2CPU�̃��[�N�X�e�[�V������Nehalem�Ɉڍs���낤�ȁB
��i�N���b�N��Nehalem�ł��܂藎���Ȃ��Ȃ�A���[�J�[��PC���~�h�������W����n�C�G���h��
Havendale��Lynnfield��2009�N�~���f�����炢����ڍs���n�߂邾�낤���B
�ނ��딭�M��Nehalem��32nm�ł���킷��Ȃ�A�m�[�g������Penryn�������������Ȃ����낤���B
Nehalem�����3GHz�O�����i�ŏo����A�I��2CPU�̃��[�N�X�e�[�V������Nehalem�Ɉڍs���낤�ȁB
��i�N���b�N��Nehalem�ł��܂藎���Ȃ��Ȃ�A���[�J�[��PC���~�h�������W����n�C�G���h��
Havendale��Lynnfield��2009�N�~���f�����炢����ڍs���n�߂邾�낤���B
�ނ��딭�M��Nehalem��32nm�ł���킷��Ȃ�A�m�[�g������Penryn�������������Ȃ����낤���B
�����R���̓������s�̓z�b�g�X�|�b�g����������
G71��낵���ˑR���ł��������H
�܂������R����p�R�A��HT���̐ڑ�����Ηǂ��������낤����
�������A���s�������E�E
G71��낵���ˑR���ł��������H
�܂������R����p�R�A��HT���̐ڑ�����Ηǂ��������낤����
�������A���s�������E�E
Bloomfield�͗����̏�ł̓p�t�H�[�}���X�������Ă������p�t�H�[�}���X�͂��܂�o�Ȃ���ł͂Ȃ����Ƃ����\�t�g���Ƃ��Č��ȗ\����������
���̖��̓}���`�R�A�ł�HT�́A�X���b�h�X�P�W���[���[���ǍD�ɓ��삵�Ă���Ȃ����ƁA�ނ��눫�e���B
Core2�̏������L���b�V���Ȃ�DDR3�Ɍ��ʂ͂Ȃ������ȗ\��������B
���̖��̓}���`�R�A�ł�HT�́A�X���b�h�X�P�W���[���[���ǍD�ɓ��삵�Ă���Ȃ����ƁA�ނ��눫�e���B
Core2�̏������L���b�V���Ȃ�DDR3�Ɍ��ʂ͂Ȃ������ȗ\��������B
OC�ϐ������y�ɉe����^����Ȃ��100%�Ȃ�����B
2.0GHz��4.0GHz�ɉ�����悤�Ȑ�������e�����邾�낤�ȁB
>>776
����Ⴛ�����BBIOS���̂��E�E�E���ꂾ����ȁB
����Ⴛ�����BBIOS���̂��E�E�E���ꂾ����ȁB
778 �F�R�E�L�́M�E,,�j�����F2008/02/04(��) 12:16:44 ID:mLPJzq7Y
>>773
�l�g�o�̂Ƃ������������ǁAHT�~2�R�A�̂Ƃ���2�X���b�h������
1�R�A�����ɗ����̃X���b�h�����蓖�Ă��邱�Ƃ�������Ƃ��H
��₱�������ǃ\�t�g�ŋ�ʂ�����@���������͂��BCodeZine���Q�ƁB
�X���b�h���ɃA�t�B�j�e�B��ݒ肷��v���Z�b�T���Œ�ł���B
�p�C�v���C�����̂̃X�P�W���[�����O�̖��̂��ƂȂ�A�\�t�g�ł͑Ώ����悤���Ȃ��ˁB
�l�g�o�̂Ƃ������������ǁAHT�~2�R�A�̂Ƃ���2�X���b�h������
1�R�A�����ɗ����̃X���b�h�����蓖�Ă��邱�Ƃ�������Ƃ��H
��₱�������ǃ\�t�g�ŋ�ʂ�����@���������͂��BCodeZine���Q�ƁB
�X���b�h���ɃA�t�B�j�e�B��ݒ肷��v���Z�b�T���Œ�ł���B
�p�C�v���C�����̂̃X�P�W���[�����O�̖��̂��ƂȂ�A�\�t�g�ł͑Ώ����悤���Ȃ��ˁB
>>778
HT�̖�肾����ǁA�\�t�g�����Ȃ�Ă̂͋C�������x����A���\����͒������ł��B
���\�������Ǝv�����炻�ꂱ���Q�[���̃`���[���̔@����邵���Ȃ������
Windows���̔ėpOS�ł�OS���X�̃A�v���̓����܂ŕ߂炦��悤�Ȏ��͂ł��܂���̂ŁB
HT�̖�肾����ǁA�\�t�g�����Ȃ�Ă̂͋C�������x����A���\����͒������ł��B
���\�������Ǝv�����炻�ꂱ���Q�[���̃`���[���̔@����邵���Ȃ������
Windows���̔ėpOS�ł�OS���X�̃A�v���̓����܂ŕ߂炦��悤�Ȏ��͂ł��܂���̂ŁB
������Ɛ�������������������̂ŁA������������ƒlj�
�}���`�v���Z�b�T�ɑΉ�����Ȃ�A�X���b�h�����R�ɋN�������藎�Ƃ����肷�鎖���̐S�ɂȂ�܂��B
�n�[�h����Ă���Ȃ�C�����͂킩��Ǝv���܂����A�v����ɂǂ�ȉ�H�ł����邯��ǂ��A
���ۂɎg���̂� nor nand �݂̂Ƃ������悤�ȃC���[�W�������Ă��炦��Ή���Ǝv���B
�R�[�f�B���O�e�N�j�b�N�I�Ƀv���Z�b�T�Œ�͂܂�����ł��ˁB
���������Ă��܂��ƁA�ꓖ�����H�Ȃ�ʏꓖ����`���[���ɂȂ��Ă��܂��܂��A�ێ瓖���l���Ă�����͔����������B
�}���`�v���Z�b�T�ɑΉ�����Ȃ�A�X���b�h�����R�ɋN�������藎�Ƃ����肷�鎖���̐S�ɂȂ�܂��B
�n�[�h����Ă���Ȃ�C�����͂킩��Ǝv���܂����A�v����ɂǂ�ȉ�H�ł����邯��ǂ��A
���ۂɎg���̂� nor nand �݂̂Ƃ������悤�ȃC���[�W�������Ă��炦��Ή���Ǝv���B
�R�[�f�B���O�e�N�j�b�N�I�Ƀv���Z�b�T�Œ�͂܂�����ł��ˁB
���������Ă��܂��ƁA�ꓖ�����H�Ȃ�ʏꓖ����`���[���ɂȂ��Ă��܂��܂��A�ێ瓖���l���Ă�����͔����������B
HT��OS�̍œK�������҂ł��Ȃ��ƁA�\�t�g�̋N���̏�������Ő��\���ω������肵�Ĉ�ʂɂ͎g���ɂ����Ȃ肻������
Yorkfield����32nm�̃^�C�~���O�Ŕ����ւ����������������
Yorkfield����32nm�̃^�C�~���O�Ŕ����ւ����������������
HT�ɂ��闝�R�Ƃ����̂́A�Ƃǂ̂܂背�C�e���V�̂��郊�\�[�X�ʂȂ��g�������Ƃ��������Ǝv��
�ł���A�������R�ŋ@�\����OoO�����܂��@�\���邩���m��Ȃ��Ƃ�����Ǝv�����B
���̐���͈ꎟ�L���b�V��������OoO���@�\���₷������
�ł���A�������R�ŋ@�\����OoO�����܂��@�\���邩���m��Ȃ��Ƃ�����Ǝv�����B
���̐���͈ꎟ�L���b�V��������OoO���@�\���₷������
�����I�ɂ�helper thread�Ƃ��ē�����Ȃ���?
ttp://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
���㓡�O��Weekly�C�O�j���[�X��
Intel�����悢��Silverthorne��Tukwila�̊T�v�\��
�L���b�V����������C7�Ɠ����x�̋K�͂�������
���㓡�O��Weekly�C�O�j���[�X��
Intel�����悢��Silverthorne��Tukwila�̊T�v�\��
�L���b�V����������C7�Ɠ����x�̋K�͂�������
���̐�VIA���i�_�C���傫���j�R�X�g�������邽�߃L�����Z������C5X��HT�ł���
Silverthorne
Silverthorne
>>783
Sun��Rock��Helper Thread�g���炵�����Ǐ���d�͂�250W�����Ă��B
Helper Thread�͏���d�͑��傳����Ȃ��B
Rock��16�R�A������P�ɂ��̂�����������ǂ����B
>>784
�����ƕ��������ŕ�������Ă�̂��B
Sun��Rock��Helper Thread�g���炵�����Ǐ���d�͂�250W�����Ă��B
Helper Thread�͏���d�͑��傳����Ȃ��B
Rock��16�R�A������P�ɂ��̂�����������ǂ����B
>>784
�����ƕ��������ŕ�������Ă�̂��B
Nehalem��CPU-Z�X�N���[���V���b�g
http://xtreview.com/addcomment-id-4172-view-Intel-Nehalem-cpuz.html
L1D:�@4 x 16KB
L1I.: �@4 x 32KB
L2:�@�@4 x 256KB
L3:�@�@8MB
�ȂႱ���
http://xtreview.com/addcomment-id-4172-view-Intel-Nehalem-cpuz.html
L1D:�@4 x 16KB
L1I.: �@4 x 32KB
L2:�@�@4 x 256KB
L3:�@�@8MB
�ȂႱ���
���̎��_�ŁA0.975V��2GHz�o�Ă�̂������ȁB
>0.975V�łQGhz
����͂��Ȃ�ȓd�͂ɂ����҂ł�����
����͂��Ȃ�ȓd�͂ɂ����҂ł�����
http://cgipocket.com/member/a115/celeron-D/2.html
90nm��Netburst��2GHz��0.95V
90nm��Netburst��2GHz��0.95V
90nm�����2GHz���x���ƁA1V������ʓI�����
NetBurst�ł����0.95V�܂ʼn���������x�cx86�͓d���������̂�
NetBurst�ł����0.95V�܂ʼn���������x�cx86�͓d���������̂�
793 �F�R�E�L�́M�E,,�j�����F2008/02/04(��) 20:58:14 ID:mLPJzq7Y
>>787
��k����������
��k����������
L2 7cycles �L�^�H
�g���[�X�L���b�V���̕������H
Netburst���Ƃ��ꂾ���ǁACore�A�[�L�ŃR�A1.5�{�Ɋg������Ă�0.975V�i�����_�j�Ȃ猒�����Ă����B
�S��CPU-Z�����o�������z
L2��512KB���Ǝv��������256KB��
>>787
16�n�[�h�E�F�A�X���b�h�����ԃ^�X�N�}�l�[�W���[�͍����ł���
>>792
������L2�����߂Ȃ̂��C�ɂȂ�ANehalem�͕]�����ł܂�܂ł�����ƕ|����
��͂�o�����X�������ȗ\��������
16�n�[�h�E�F�A�X���b�h�����ԃ^�X�N�}�l�[�W���[�͍����ł���
>>792
������L2�����߂Ȃ̂��C�ɂȂ�ANehalem�͕]�����ł܂�܂ł�����ƕ|����
��͂�o�����X�������ȗ\��������
L2��256KB�Ȃ�ĉ���Wilammet�ƕς��˂���
���ƈ�N���邵�A6MB���炢�ɂȂ�Ȃ����낤���B
���ƈ�N���邵�A6MB���炢�ɂȂ�Ȃ����낤���B
����Ɉ�N��ɂ�144MB�ɁI
>>801
���₵�Ⴂ�����Ă���Ȃ��ł��傤��w
���₵�Ⴂ�����Ă���Ȃ��ł��傤��w
Bloomfield��L2��8MB�ƑO������łĂ����
L3@8MB�ƂȂ��Ă�̂�L2���낤�A
L1��L2�̕�����L1�ɊY�������Ȃ���
CPU-Z�����܂��F���ł��ĂȂ�����
L3@8MB�ƂȂ��Ă�̂�L2���낤�A
L1��L2�̕�����L1�ɊY�������Ȃ���
CPU-Z�����܂��F���ł��ĂȂ�����
804 �F�R�E�L�́M�E,,�j�����F2008/02/04(��) 22:01:14 ID:mLPJzq7Y
L2���������Ԃ�~�X�q�b�g���C�e���V��������
�ƌ����Ă݂�B
L2�Ɛ��肳�ꂽ�u���b�N��256k�ɂ��Ă̓f�J���̂ʼn�������M�~�b�N�͂���Ǝv����
�ĊO�AL2��L3�ɓ����ɒT������������d�l���������ˁB
����łȂ��Ƃ��ASMT�͑��ΓI�Ƀ��C�e���V���B���ł��邵�ĊO���\�ł邩����B
�ƌ����Ă݂�B
L2�Ɛ��肳�ꂽ�u���b�N��256k�ɂ��Ă̓f�J���̂ʼn�������M�~�b�N�͂���Ǝv����
�ĊO�AL2��L3�ɓ����ɒT������������d�l���������ˁB
����łȂ��Ƃ��ASMT�͑��ΓI�Ƀ��C�e���V���B���ł��邵�ĊO���\�ł邩����B
>>804
���C�e���V�̖����C�ɂ�������AL2��Core2���x�ɂ��āAL1�̋����̌��ʂ����肻���ȗ\�������܂��B
Core2�����܂��s���Ă���͎̂�ނ̃A�v���P�[�V�����ɂ��āA�e�v���O�����������K�v�Ƃ���f�[�^��L2�ɂ����ނˑS����荞�߂�����ł͂Ȃ����Ǝv���̂�
���ɒNj����ׂ��_��L1�ł͖������ƁE�E�E
�ŋߎv�����ƂȂ�ł����A�������[�̓f�B�X�N����ŁAL2�����������[�A�����Ƀy�[�W���O���s����L1��������L���b�V���Ƃ����F�����炢�ɂ��Ă������̂ł͂Ǝv�����肵�܂��B
DRAM����L2�Ɏ�荞�ނƂ��ADRAM�̓��e�Ȃ�łԂ����Ă������Ǝv����ł���A�y�[�W�A�E�g�ŏ������ނƂ���DRAM�Ƀ��C�g�o�b�N�Ƃ�����Ζ��Ȃ��ł���
�y�[�W�C������Ă���DRAM�ɂ��Ă͂������t���b�V�����炵�Ȃ��œd�͏���ʉ҂��Ƃ��ˁB
DRAM�̍\���̒P���ɂȂ��ă��C�e���V�҂���̂ł͂Ǝv�����肷��̂ł����A���������̂��Ă͖̂����ł����ˁH
���C�e���V�̖����C�ɂ�������AL2��Core2���x�ɂ��āAL1�̋����̌��ʂ����肻���ȗ\�������܂��B
Core2�����܂��s���Ă���͎̂�ނ̃A�v���P�[�V�����ɂ��āA�e�v���O�����������K�v�Ƃ���f�[�^��L2�ɂ����ނˑS����荞�߂�����ł͂Ȃ����Ǝv���̂�
���ɒNj����ׂ��_��L1�ł͖������ƁE�E�E
�ŋߎv�����ƂȂ�ł����A�������[�̓f�B�X�N����ŁAL2�����������[�A�����Ƀy�[�W���O���s����L1��������L���b�V���Ƃ����F�����炢�ɂ��Ă������̂ł͂Ǝv�����肵�܂��B
DRAM����L2�Ɏ�荞�ނƂ��ADRAM�̓��e�Ȃ�łԂ����Ă������Ǝv����ł���A�y�[�W�A�E�g�ŏ������ނƂ���DRAM�Ƀ��C�g�o�b�N�Ƃ�����Ζ��Ȃ��ł���
�y�[�W�C������Ă���DRAM�ɂ��Ă͂������t���b�V�����炵�Ȃ��œd�͏���ʉ҂��Ƃ��ˁB
DRAM�̍\���̒P���ɂȂ��ă��C�e���V�҂���̂ł͂Ǝv�����肷��̂ł����A���������̂��Ă͖̂����ł����ˁH
Intel��LLC�ȊO�͓`���I�ɏ��e��&�����h����B
256kB�����������ĂȂ��CPU����ɂ����Ă�B
256kB�����������ĂȂ��CPU����ɂ����Ă�B
>>806
��ς悢���ʂ�������Core2�ɑ��Ăł��������H
��ς悢���ʂ�������Core2�ɑ��Ăł��������H
>>807
L3�܂Ńl�C�e�B�u�Ŏ����Ă�CPU��L2�͕��ʏ���������B�O�����t�g���͕ʂƂ��Ă��B
Itanium������Madison 9M�܂ł�����256kB�����������B
L3�����邩��L2�̓��C�e���V���҂������ɍs���͖̂������Ȃ��B
�������ANehalelm��CPU-Z�������ł�Ȃ�ĂȁB
ISSCC�̋L�����ꡂ��ɏՌ��I����B
L3�܂Ńl�C�e�B�u�Ŏ����Ă�CPU��L2�͕��ʏ���������B�O�����t�g���͕ʂƂ��Ă��B
Itanium������Madison 9M�܂ł�����256kB�����������B
L3�����邩��L2�̓��C�e���V���҂������ɍs���͖̂������Ȃ��B
�������ANehalelm��CPU-Z�������ł�Ȃ�ĂȁB
ISSCC�̋L�����ꡂ��ɏՌ��I����B
>>806
Phenom�Ɣ�ׂĂ��������ł��������H
Phenom�Ɣ�ׂĂ��������ł��������H
���_�AYorkfield��L2 12MB����L1+L2 256kB�AL3 8MB�̕������͂��B
���ꂾ����IPC��1���������Ă����������͂Ȃ���B�ϑz�����ǁB
>>809
�r���͊e�K�w�̗e�ʍ������Ȃ��̂����ʂ��B
���ꂾ����IPC��1���������Ă����������͂Ȃ���B�ϑz�����ǁB
>>809
�r���͊e�K�w�̗e�ʍ������Ȃ��̂����ʂ��B
http://pc.watch.impress.co.jp/docs/2008/0204/kaigai415.htm
>Tukwila��IA-64�A�[�L�e�N�`���̃N�A�b�h�R�ACPU�ŁA
>FB-DIMM�C���^�[�t�F�C�X��QuickPath�C���^�[�R�l�N�g���������A30MB�̃L���b�V�������������ڂ���B65nm�v���Z�X�ŁA
>�g�����W�X�^���͖�2B(20��)�ɒB���A�_�C�T�C�Y����700����mm�Ƃ��������X�^�[���B
>�^�[�Q�b�g������g����2GHz��TDP(Thermal Design Power:�M�v����d��)��170W(�ێ�110�x)�B
>QuickPath�̓t�����̃C���^�[�R�l�N�g��4�ƃn�[�t����2�ō��v�̑ш��96GB/s�AFB-DIMM�̑ш��34GB/sec�ƂȂ�B
>Tukwila��IA-64�A�[�L�e�N�`���̃N�A�b�h�R�ACPU�ŁA
>FB-DIMM�C���^�[�t�F�C�X��QuickPath�C���^�[�R�l�N�g���������A30MB�̃L���b�V�������������ڂ���B65nm�v���Z�X�ŁA
>�g�����W�X�^���͖�2B(20��)�ɒB���A�_�C�T�C�Y����700����mm�Ƃ��������X�^�[���B
>�^�[�Q�b�g������g����2GHz��TDP(Thermal Design Power:�M�v����d��)��170W(�ێ�110�x)�B
>QuickPath�̓t�����̃C���^�[�R�l�N�g��4�ƃn�[�t����2�ō��v�̑ш��96GB/s�AFB-DIMM�̑ш��34GB/sec�ƂȂ�B
>>811
�ڍׂłĂȂ�����Tukwila�͂��߃I�[�����łĂ�ˁB
2GHz���ᓖ���̗\�薢�������A�O�ɂłĂ��X���C�h�Ƃ��܂���e�����Ȃ����B
4S���m�̔�r��Montvale��2�{�ȏ�Ȃ�Ă���܂��ɏo�����Ȃ��̂��킴�킴�����Ă��鎞�_
�ł܂����B
�ڍׂłĂȂ�����Tukwila�͂��߃I�[�����łĂ�ˁB
2GHz���ᓖ���̗\�薢�������A�O�ɂłĂ��X���C�h�Ƃ��܂���e�����Ȃ����B
4S���m�̔�r��Montvale��2�{�ȏ�Ȃ�Ă���܂��ɏo�����Ȃ��̂��킴�킴�����Ă��鎞�_
�ł܂����B
Silverthorne�̃_�C�T�C�Y��25mm2�Ƃ̂��Ƃ����A���i�I�ɂ͂ǂꂮ�炢���낤���B
�`�b�v�Z�b�g�ƃZ�b�g��50�h���͐�Ǝv�����E�E�E�B
�`�b�v�Z�b�g�ƃZ�b�g��50�h���͐�Ǝv�����E�E�E�B
814 �FSocket774�F2008/02/04(��) 23:00:51 ID:ZjwPjB30
����������������Ă��Ƃ͂Ȃ��Ǝv������
TabletPC����\25k���������������H
Silverthorne�́A�ǂ������s��헪���l���Ă���̂�������ƕs�v�c�Ȉ�ۂ���
�������������������̂Ȃ�AGPU��烀�[�r�[�̃f�R�[�_�[���F�X�悹�ăV�X�e��LSI�ɂ����ق����֗������ȗ\���������ł����ǂˁB
DS���ۂ��Ɠ˂�����ŁADS�t��TabletPC�Ƃ��Ȃ炿����Ǝ���o�������C�����A���肦�Ȃ����낤����w
�������������������̂Ȃ�AGPU��烀�[�r�[�̃f�R�[�_�[���F�X�悹�ăV�X�e��LSI�ɂ����ق����֗������ȗ\���������ł����ǂˁB
DS���ۂ��Ɠ˂�����ŁADS�t��TabletPC�Ƃ��Ȃ炿����Ǝ���o�������C�����A���肦�Ȃ����낤����w
>>787
Family��6�̂܂܂Ȃ̂�
Family��6�̂܂܂Ȃ̂�
������Nehalem��Penryn���x�[�X����
http://www.hkepc.com/?id=568&page=1#view
http://www.hkepc.com/database/images/2008010213523656679420453.jpg
http://www.hkepc.com/?id=568&page=1#view
http://www.hkepc.com/database/images/2008010213523656679420453.jpg
{kind=link}
>>816
������ƁA���̃V�X�e��LSI�̐��{�̏���d�͂ɂȂ邩��c
������ƁA���̃V�X�e��LSI�̐��{�̏���d�͂ɂȂ邩��c
>>819
�ʃ`�b�v�ɂ��邭�炢�Ȃ瓯��`�b�v��ɍڂ����ق�����ՃT�C�Y������d�͂��������čςނƎv�����ǂ�
�����PC�ɂ���ȏ�CPU�ƃ����������Ŋ����ł��Ƃ�����ɂ͍s���Ȃ�����
�ʃ`�b�v�ɂ��邭�炢�Ȃ瓯��`�b�v��ɍڂ����ق�����ՃT�C�Y������d�͂��������čςނƎv�����ǂ�
�����PC�ɂ���ȏ�CPU�ƃ����������Ŋ����ł��Ƃ�����ɂ͍s���Ȃ�����
Silverthorne�A�f���A���R�A�ł����ʂɂ�����Ă��Ƃ�
���o�C���f�o�C�X�ȊO�ɂ��AEeePC��Let'sNote R7�N���X�̃~�j�m�[�g�A
B5���o�C���̗����łƂ��ɂ��g���銴���͂���Ȃ�
���ۂ���CPU�����ALet'sNote�݂����ȃm�[�g�����������Z�p�͖����Ă����邾�낤��
���o�C���f�o�C�X�ȊO�ɂ��AEeePC��Let'sNote R7�N���X�̃~�j�m�[�g�A
B5���o�C���̗����łƂ��ɂ��g���銴���͂���Ȃ�
���ۂ���CPU�����ALet'sNote�݂����ȃm�[�g�����������Z�p�͖����Ă����邾�낤��
822 �F�R�E�L�́M�E,,�j�����������������F2008/02/05(��) 06:17:39 ID:hwruG8gV
���Ă������ALet's Note��➑̐v���_�B
>>812
Tukwila�̃^�[�Q�b�g�N���b�N���ǂ̂��炢���Ęb�͂����������H
�O��Tukwila�Ȃ�А��̂����b�͂��������ǁB
Madison�ȍ~�A���[���ƃN���b�N�قƂ�Ǐオ���ĂȂ���ˁB
quad�ɂȂ���2GHz�܂ŏオ���Ȃ�A������Ȃ����H�Ƃ��v���Ă��܂��B
�����A�撣���Ă����̃R�A�ł͌��I�ɃN���b�N���オ�邱�Ƃ͖����ł��傤�B
�܂��APoulson�Ɋ��҂���Ƃ������ƂŁE�E�E�B
MAC�I�^�������Ă����ǁA�L���b�V���e�ʂ̘b�́A�o�ϓI�ɂǂ̂��炢
�̃_�C�T�C�Y���\���A����A�L���b�V���͂ǂꂭ�炢�ɂȂ邩����
�b�ł���BTukwila�ł͂P�������L3�͂��Ȃ�팸����Ă�B
Tukwila�̃^�[�Q�b�g�N���b�N���ǂ̂��炢���Ęb�͂����������H
�O��Tukwila�Ȃ�А��̂����b�͂��������ǁB
Madison�ȍ~�A���[���ƃN���b�N�قƂ�Ǐオ���ĂȂ���ˁB
quad�ɂȂ���2GHz�܂ŏオ���Ȃ�A������Ȃ����H�Ƃ��v���Ă��܂��B
�����A�撣���Ă����̃R�A�ł͌��I�ɃN���b�N���オ�邱�Ƃ͖����ł��傤�B
�܂��APoulson�Ɋ��҂���Ƃ������ƂŁE�E�E�B
MAC�I�^�������Ă����ǁA�L���b�V���e�ʂ̘b�́A�o�ϓI�ɂǂ̂��炢
�̃_�C�T�C�Y���\���A����A�L���b�V���͂ǂꂭ�炢�ɂȂ邩����
�b�ł���BTukwila�ł͂P�������L3�͂��Ȃ�팸����Ă�B
>>821
�ꉞ�i�����u���́j�g�ݍ��݂ƂȂ��Ă���炵���̂Ń��o�C�������̓V���O���R�A�B
�܂��A���m�[�gPC���[�J�[���o���Ȃ��Ă��ǂ������f���A���R�A�m�[�g���o���Ǝv�����B
�ꉞ�i�����u���́j�g�ݍ��݂ƂȂ��Ă���炵���̂Ń��o�C�������̓V���O���R�A�B
�܂��A���m�[�gPC���[�J�[���o���Ȃ��Ă��ǂ������f���A���R�A�m�[�g���o���Ǝv�����B
�ȂL���b�V���K�w��amd���ۂ��Ȃ�����
�u0.975V��2GHz�o��قǏo���������v�̂��A
�u0.975V��2GHz�܂ŗ}���Ȃ��Ɠd�͓I�Ɍ������v�̂��E�E�E
��������肾�ȁB
�u0.975V��2GHz�܂ŗ}���Ȃ��Ɠd�͓I�Ɍ������v�̂��E�E�E
��������肾�ȁB
���l���������Ƃ���
�u0.975V��Windows���N������v
��������ˁB
���ׂ������痎����ƁB
�����Ƃ����ׂ����Ă����v�Ȃقǂ̃T���v���Ȃ̂��͒m��B
�u0.975V��Windows���N������v
��������ˁB
���ׂ������痎����ƁB
�����Ƃ����ׂ����Ă����v�Ȃقǂ̃T���v���Ȃ̂��͒m��B
���Nehalem��CPU-Z
����オ���Ă���̂�XtremeSystems
http://www.xtremesystems.org/forums/showthread.php?t=175737
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
�@�@--------------------
�@�@Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
�@�@could get out of him.
�@�@He says:
�@�@�@1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
�@�@�@2) Nehalem boots and runs stable under load on all major OSes
�@�@�@3) Intel could have it "rushed" to market in 2 months if need be, but they don't
�@�@�@�@feel the competitive pressure to do so (thanks AMD).
�@�@�@4) most of what is being worked on now are the chipsets for the various platforms �@�@�@�@�@�@(desktop, server, etc.)
�@�@--------------------
����オ���Ă���̂�XtremeSystems
http://www.xtremesystems.org/forums/showthread.php?t=175737
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
�@�@--------------------
�@�@Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
�@�@could get out of him.
�@�@He says:
�@�@�@1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
�@�@�@2) Nehalem boots and runs stable under load on all major OSes
�@�@�@3) Intel could have it "rushed" to market in 2 months if need be, but they don't
�@�@�@�@feel the competitive pressure to do so (thanks AMD).
�@�@�@4) most of what is being worked on now are the chipsets for the various platforms �@�@�@�@�@�@(desktop, server, etc.)
�@�@--------------------
830 �FMAC�I�^���ē��e�F2008/02/05(��) 18:01:02 ID:BcBkcfja
���Nehalem��CPU-Z�摜�ɂ��ď������ׂĂ݂������ǁA���̘b��ň�Ԑ���オ���Ă���̂�
XtremeSystems�f�����������B
http://www.xtremesystems.org/forums/showthread.php?t=175737
�ŁA���̏o�����̂�A���̌f���炵�����B�U�摜�Ƌ^���q�g�������l���B
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems�f���ɏ������܂ꂽ���Ŗʔ������Ȃ̂�A���ꂷ���ˁB�B�B
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
�@�@--------------------
�@�@Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
�@�@could get out of him.
�@�@He says:
�@�@�@1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
�@�@�@2) Nehalem boots and runs stable under load on all major OSes
�@�@�@3) Intel could have it "rushed" to market in 2 months if need be, but they don't
�@�@�@�@feel the competitive pressure to do so (thanks AMD).
�@�@�@4) most of what is being worked on now are the chipsets for the various platforms
�@�@�@�@(desktop, server, etc.)
�@�@--------------------
�摜���̂̐^�U��ʂɂ��Ă��A�����ʂ���悤�ȃ��m���ᖳ���������B
XtremeSystems�f�����������B
http://www.xtremesystems.org/forums/showthread.php?t=175737
�ŁA���̏o�����̂�A���̌f���炵�����B�U�摜�Ƌ^���q�g�������l���B
http://www.chiphell.com/?action-viewnews-itemid-178
XtremeSystems�f���ɏ������܂ꂽ���Ŗʔ������Ȃ̂�A���ꂷ���ˁB�B�B
http://www.xtremesystems.org/forums/showpost.php?p=2747254&postcount=118
�@�@--------------------
�@�@Contacted a buddy in D1D at Oregon about this SS and for what Nehalem info I
�@�@could get out of him.
�@�@He says:
�@�@�@1) not a fake, but CPU-Z is off on several things (he won't tell exactly what)
�@�@�@2) Nehalem boots and runs stable under load on all major OSes
�@�@�@3) Intel could have it "rushed" to market in 2 months if need be, but they don't
�@�@�@�@feel the competitive pressure to do so (thanks AMD).
�@�@�@4) most of what is being worked on now are the chipsets for the various platforms
�@�@�@�@(desktop, server, etc.)
�@�@--------------------
�摜���̂̐^�U��ʂɂ��Ă��A�����ʂ���悤�ȃ��m���ᖳ���������B
CPU-Z�X�N���[���V���b�g�̃L���b�V���K�w�̕��������ǁA���x����>>726-731�Ńl�^�ɂ����Ƃ��낷����A
�����ɓ���M���ł�����ɂ��Ă����A�����Ă������B
�܂��A���N�̏t��IDF�ōŏ���Nehalem�̃_�C�ʐ^�����J���ꂽ����Anand��Stephen L Smith�� (Intel VP
and Director of the Digital Enterprise Group) �� Gelsinger���Ƃ̃C���^�r���[�����ɏ�����������B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2955&p=3
�@�@----------------------------
�@�@Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that only the highest level of
�@�@cache would be shared, meaning that Nehalem could very well have a similar cache hierarchy to AMD's
�@�@Barcelona (independent L1/L2 caches per core, but a shared L3 cache).
�@�@----------------------------
���K�w�̃L���b�V���������A�ŏI���x���̃L���b�V���݂̂����L�����Ƃ��������Ă��邷�BAnand��
AMD���l��L1, L2���Ɨ���L3�����L�Ɖ��߂��Ă���A����̃X�N���[���V���b�g�ƈ�v���邷�B
����H��IDF�̍��Ɍ㓡����Intel�����̘b�����ɏ������L����A������ƈ���Ă��邷�A�B
http://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
�@�@----------------------------
�@�@Gelsinger���́ANehalem����pL1�Ƌ��LL2�������ƔF�߂��B�܂��AGlenn J. Hinton(�O�����EJ�E�q���g��)��
�@�@(Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)�́AIDF��Fellow
�@�@Shop Talk�ŁA���̂悤�Ɍ�����B
�@�@[����]
�@�@���݁A��X�͐����x���̃L���b�V���K�w�������Ă���BNehalem��3���x���̃L���b�V���K�w�����v
�@�@----------------------------
�������u���LL2�v�Ɩ�������Ă��邷�B
�����ɓ���M���ł�����ɂ��Ă����A�����Ă������B
�܂��A���N�̏t��IDF�ōŏ���Nehalem�̃_�C�ʐ^�����J���ꂽ����Anand��Stephen L Smith�� (Intel VP
and Director of the Digital Enterprise Group) �� Gelsinger���Ƃ̃C���^�r���[�����ɏ�����������B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2955&p=3
�@�@----------------------------
�@�@Nehalem will also use multi-level shared cache. Pat Gelsinger indicated that only the highest level of
�@�@cache would be shared, meaning that Nehalem could very well have a similar cache hierarchy to AMD's
�@�@Barcelona (independent L1/L2 caches per core, but a shared L3 cache).
�@�@----------------------------
���K�w�̃L���b�V���������A�ŏI���x���̃L���b�V���݂̂����L�����Ƃ��������Ă��邷�BAnand��
AMD���l��L1, L2���Ɨ���L3�����L�Ɖ��߂��Ă���A����̃X�N���[���V���b�g�ƈ�v���邷�B
����H��IDF�̍��Ɍ㓡����Intel�����̘b�����ɏ������L����A������ƈ���Ă��邷�A�B
http://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
�@�@----------------------------
�@�@Gelsinger���́ANehalem����pL1�Ƌ��LL2�������ƔF�߂��B�܂��AGlenn J. Hinton(�O�����EJ�E�q���g��)��
�@�@(Intel Fellow, Digital Enterprise Group, Director, IA-32 Microarchitecture Development)�́AIDF��Fellow
�@�@Shop Talk�ŁA���̂悤�Ɍ�����B
�@�@[����]
�@�@���݁A��X�͐����x���̃L���b�V���K�w�������Ă���BNehalem��3���x���̃L���b�V���K�w�����v
�@�@----------------------------
�������u���LL2�v�Ɩ�������Ă��邷�B
�U���^�f���肩�A���̎��_�łłĂ���̂��ς�����
���͌g�тȂ�ŁA�����N��͓ǂ�łȂ����Ǎ���̃X�N���[���V���b�g�˂��^�f�A�������M���ł�����ɑ��Ă͖����Ȃ��Ƃ������ł����H
���͌g�тȂ�ŁA�����N��͓ǂ�łȂ����Ǎ���̃X�N���[���V���b�g�˂��^�f�A�������M���ł�����ɑ��Ă͖����Ȃ��Ƃ������ł����H
�������MSkulltrail�v���b�g�t�H�[���̘b�肻�炵�Ɍ��܂��Ă�
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/index.html
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
�܂��A�����������Ă��܂��ƁANehalem��CPU-Z�摜�͊m���ɋU�������ǂȁB
>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
���ꉽ�������낤�ȁA�X���b�h�X�P�W���[��������ł�̂��AI/O���l���Ă���̂��A�P�ɃG���R�A�v�����^�R�Ȃ̂��H
���łɕ\���I�v�V�����ŃJ�[�l�����Ԃ��\�����ė~����������
1KW���Ƃ��A���Ă��镪�ɂ͖ʔ������ǐ�Δ���Ȃ���w
http://pc.watch.impress.co.jp/docs/2007/0921/idf07_03.jpg
http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
{kind=link}
���ꉽ�������낤�ȁA�X���b�h�X�P�W���[��������ł�̂��AI/O���l���Ă���̂��A�P�ɃG���R�A�v�����^�R�Ȃ̂��H
���łɕ\���I�v�V�����ŃJ�[�l�����Ԃ��\�����ė~����������
1KW���Ƃ��A���Ă��镪�ɂ͖ʔ������ǐ�Δ���Ȃ���w
http://pc.watch.impress.co.jp/docs/2007/0921/idf07_03.jpg
{kind=link}
>>823
2.4�`2.5GHz��������B���ꂩ�痎�����B
4S�ł�Montvale�Ƃ̔�r�Ȃ̂ŁA�L���b�V���������Ă�2�{���ŏ����Ȃ���ǂ����悤���Ȃ��B
��������QuickPath�ڍs������B�t�ɂ����ƁAQuickPath�̂������ŃL���b�V�����点���Ƃ����Ȃ����Ȃ��B
2.4�`2.5GHz��������B���ꂩ�痎�����B
4S�ł�Montvale�Ƃ̔�r�Ȃ̂ŁA�L���b�V���������Ă�2�{���ŏ����Ȃ���ǂ����悤���Ȃ��B
��������QuickPath�ڍs������B�t�ɂ����ƁAQuickPath�̂������ŃL���b�V�����点���Ƃ����Ȃ����Ȃ��B
���R�A�̌��z�͎U������
QuickPath�̂������ŃL���b�V�����点���͌����߂����B700�����邵
��������Intel������ȏ�ł����_�C�͍l���ĂȂ�������������ȁB
�ł��L���b�V�����X�P�[���r���e�B�ɗ^����e���͌��������낤�B
��������Intel������ȏ�ł����_�C�͍l���ĂȂ�������������ȁB
�ł��L���b�V�����X�P�[���r���e�B�ɗ^����e���͌��������낤�B
>>838
�܂��܂��A����͂���Ńv���O���������n�߂�ƌ��\�ʔ�������A��
�����̐l�����]��L���b�V���ɂ͋����Ȃ������Ȑl�������ǁA
�̂̓L���b�V���e�ʐv�ɂ���Ǝv���A�������o�X�o���h�����C�e���V�������܂ňȏ�ɍ����L�l��
���Z�ʃA�b�v�Ƃ��R�A�v�Ȃ�Ăǂ��ł��������Ă��炢���ʂȂ��A�ł��L���b�V���̂��Ă���z�C�z�C��ʌv�Z�ł���
�v�킸���������Ƃ��Ȃ�B
���[�U�[�ɂ͊W������������w
�܂��܂��A����͂���Ńv���O���������n�߂�ƌ��\�ʔ�������A��
�����̐l�����]��L���b�V���ɂ͋����Ȃ������Ȑl�������ǁA
�̂̓L���b�V���e�ʐv�ɂ���Ǝv���A�������o�X�o���h�����C�e���V�������܂ňȏ�ɍ����L�l��
���Z�ʃA�b�v�Ƃ��R�A�v�Ȃ�Ăǂ��ł��������Ă��炢���ʂȂ��A�ł��L���b�V���̂��Ă���z�C�z�C��ʌv�Z�ł���
�v�킸���������Ƃ��Ȃ�B
���[�U�[�ɂ͊W������������w
http://journal.mycom.co.jp/articles/2008/02/04/skulltrail1/images/Photo06l.jpg
��Photo06:CPU�ւ̓d��������H�����A���̍���ɕ���EPS 12V��8P�R�l�N�^��2����ł��鎖�ɋ��|����B
�匴�����|�̃Y���h�R�ɗ��Ƃ������Ƃ͂��������B
{kind=link}
��Photo06:CPU�ւ̓d��������H�����A���̍���ɕ���EPS 12V��8P�R�l�N�^��2����ł��鎖�ɋ��|����B
�匴�����|�̃Y���h�R�ɗ��Ƃ������Ƃ͂��������B
>>841
���a�c�̋L�����
>�O�q�̎����ɂ��g�m�[�}���I�y���[�V�����̏ꍇ��1��2�~4�R�l�N�^�ɐڑ��A
>�I�[�o�[�N���b�N����2��2�~4�R�l�N�^�ɐڑ��h�Ƃ���A
>�ʏ험�p�ł���A�Ƃ肠����1�ŗǂ��Ə�����Ă���B
�匴��Intel�l�̎����������Ƀe�X�g���Ă���ۂ��Ȃ�
���a�c�̋L�����
>�O�q�̎����ɂ��g�m�[�}���I�y���[�V�����̏ꍇ��1��2�~4�R�l�N�^�ɐڑ��A
>�I�[�o�[�N���b�N����2��2�~4�R�l�N�^�ɐڑ��h�Ƃ���A
>�ʏ험�p�ł���A�Ƃ肠����1�ŗǂ��Ə�����Ă���B
�匴��Intel�l�̎����������Ƀe�X�g���Ă���ۂ��Ȃ�
843 �F�ǂ��Ă������܂����F2008/02/06(��) 00:54:20 ID:TmXkzHs4
itanium���āA�L���b�V������e�ʂ����ǃ��C�e���V������������
�L���b�V���e�ʂ̊��ɑ����Ȃ����Ă̂��邾��
3��9MB��L3�L���b�V����������ߒ���
�Z�b�g�A�\�V�G�e�B�u��WAY��������ܑ��₳�Ȃ��Ƃ�
1�R�A12MB L3�ɂ����Ƃ��A�������ĕ��σ��C�e���V��������Ƃ�������킯��
�Ȃ��Tukwilla�̃L���b�V���������́A���C�e���V�ቺ�������
����܉e���Ȃ���ˁH
�킩��ˁ[���ǂ�
����itaniam�̃L���b�V���̈�ԃ_���ȂƂ���
L1���߃L���b�V���̕s������
���G�ȃT�[�o�[�A�v������������
L1���߃~�X���́A10%�ȏ�Ƃ��̂����������ɂȂ��Ă�ˁH
montecito�ŁAL2���߃L���b�V��1MB�Ȃ�Ă̂����������
���߂̃L���b�V���~�X�͍�����
�T�[�o�[���[�X������f�[�����~�X������
����̓}���`�X���b�f�B���O�Ń��C�e���V���B�����邭�炢�����Ώ��@���Ȃ�
�L���b�V���e�ʂ̊��ɑ����Ȃ����Ă̂��邾��
3��9MB��L3�L���b�V����������ߒ���
�Z�b�g�A�\�V�G�e�B�u��WAY��������ܑ��₳�Ȃ��Ƃ�
1�R�A12MB L3�ɂ����Ƃ��A�������ĕ��σ��C�e���V��������Ƃ�������킯��
�Ȃ��Tukwilla�̃L���b�V���������́A���C�e���V�ቺ�������
����܉e���Ȃ���ˁH
�킩��ˁ[���ǂ�
����itaniam�̃L���b�V���̈�ԃ_���ȂƂ���
L1���߃L���b�V���̕s������
���G�ȃT�[�o�[�A�v������������
L1���߃~�X���́A10%�ȏ�Ƃ��̂����������ɂȂ��Ă�ˁH
montecito�ŁAL2���߃L���b�V��1MB�Ȃ�Ă̂����������
���߂̃L���b�V���~�X�͍�����
�T�[�o�[���[�X������f�[�����~�X������
����̓}���`�X���b�f�B���O�Ń��C�e���V���B�����邭�炢�����Ώ��@���Ȃ�
itanium���_���Ȃ̂͂��C�Ȃ���C�ł����ς������炶��˂���
�Ȃ�[���J���w�̂�錩�邩��ɋC�܂�ĂȂ��H
�Ȃ�[���J���w�̂�錩�邩��ɋC�܂�ĂȂ��H
844 �ւ�Ȃ܂�������ł��܂���
�Ȃ�[���J���w�̂��C�����邩��ɐ܂�ĂȂ��H
�Ȃ�[���J���w�̂��C�����邩��ɐ܂�ĂȂ��H
>>788 >>827
�X�e�b�s���O���d�˂ăN���e�B�J���p�X��ׂ��Ă����Ă�
��d���쓮�ł̌��E�N���b�N�͂������ĕς��Ȃ�����A
�����Ƃ������Ȃ��Ƃ������Ȃ���Ǝv���B
�X�e�b�s���O���d�˂ăN���e�B�J���p�X��ׂ��Ă����Ă�
��d���쓮�ł̌��E�N���b�N�͂������ĕς��Ȃ�����A
�����Ƃ������Ȃ��Ƃ������Ȃ���Ǝv���B
>>846
�Ă��A2GHz/0.95V���āA65nm����̐��������
�Ă��A2GHz/0.95V���āA65nm����̐��������
�ŏ�ʂ̃p�t�H�[�}���X�B���ł��������H�ق�l���ꂽ��
�I�Ȋ����͂���ȁA�܂������l���ĂȂ����[���A�ǂ�����C��ll�Ƃ������̂�f�i�������
�I�Ȋ����͂���ȁA�܂������l���ĂȂ����[���A�ǂ�����C��ll�Ƃ������̂�f�i�������
>>842
�E�E�E���O�A�匴�̋L�������Ɠǂ�łȂ�����H
�������A���̃}�U�[���ĂċC���������A���������Ĉ�ԉ��ɂ���4�s���R�l�N�^��
�}���ĂȂ�������Ȃ����H
ASUS�Ƃ���SLI�Ή��}�U�[�ł悭�g���p�^�[�������B
�E�E�E���O�A�匴�̋L�������Ɠǂ�łȂ�����H
�������A���̃}�U�[���ĂċC���������A���������Ĉ�ԉ��ɂ���4�s���R�l�N�^��
�}���ĂȂ�������Ȃ����H
ASUS�Ƃ���SLI�Ή��}�U�[�ł悭�g���p�^�[�������B
>>847
���オ���Ă�E8000�V���[�Y�̕��������
65nm�Ɣ�ׂ�ƒ�d���ϐ��͊��҂����قǂł͂Ȃ����ۂ��B
����ł�����d�͉͂������Ă邩�炢�����ǁB
���̐l��E8400��2GHz��0.85V
http://www2.ocn.ne.jp/~ayut/E8400_Idle.htm
���オ���Ă�E8000�V���[�Y�̕��������
65nm�Ɣ�ׂ�ƒ�d���ϐ��͊��҂����قǂł͂Ȃ����ۂ��B
����ł�����d�͉͂������Ă邩�炢�����ǁB
���̐l��E8400��2GHz��0.85V
http://www2.ocn.ne.jp/~ayut/E8400_Idle.htm
>>851
�X�}���A2GHz���x�̃v���Z�b�T�S�ʂ̘b��
�X�}���A2GHz���x�̃v���Z�b�T�S�ʂ̘b��
����d�͂�������ɂ����͔̂������̂��̗̂��R�Ȃ�ł����ˁA����ʌ������Ǔ��l�B
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416_01l.gif
http://pc.watch.impress.co.jp/docs/2008/0206/kaigai416_01l.gif
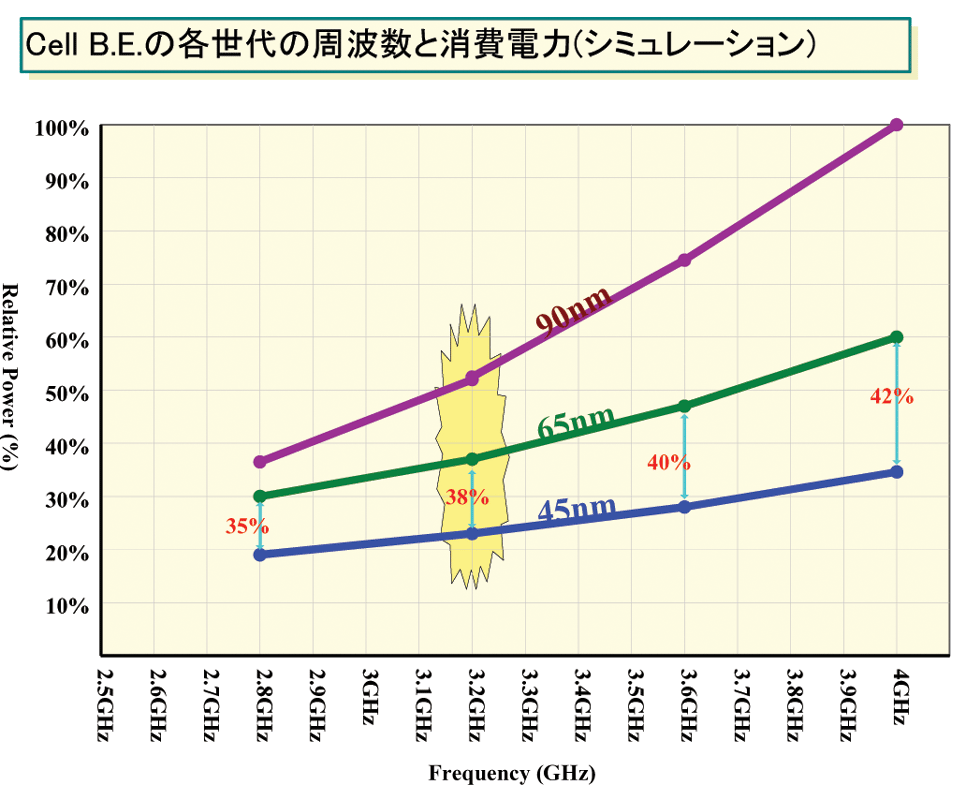{kind=link}
�����ƁA�d���̘b���������E�E�E
��d������Vt���Ⴍ���Ȃ���Ȃ�Ȃ������[�N�d������
���Ă킯�Œ�d�����͒��X�������B
���ɍ�������g�����W�X�^�͌�����Vt���Ⴂ�̂łȂ�����B
ITRS�ł����[�N�d�������ɂȂ��Ă��������œd���d���̒ቺ�������ɂ��Ȃ������炢�����B
���Ă킯�Œ�d�����͒��X�������B
���ɍ�������g�����W�X�^�͌�����Vt���Ⴂ�̂łȂ�����B
ITRS�ł����[�N�d�������ɂȂ��Ă��������œd���d���̒ቺ�������ɂ��Ȃ������炢�����B
ISSCC 2008 - Intel�A�������d��IA�v���Z�b�T�uSliverthorne�v�\
http://journal.mycom.co.jp/articles/2008/02/06/isscc3/index.html
SSE3�ȍ~�͑Ή����ĂȂ����H
�ł�C2D���S�݊��Ƃ����Ȃ�Ή����ĂĂ��悳���������B
SSE4�͖����ɂ��Ă��B
�܂����\���o�邩�͕�����ǁB
���ƃL���b�V����
L1I�@ 32KB
L1D�@24KB
L2�@�@512KB(8-way)
�������ŁB
http://journal.mycom.co.jp/articles/2008/02/06/isscc3/index.html
SSE3�ȍ~�͑Ή����ĂȂ����H
�ł�C2D���S�݊��Ƃ����Ȃ�Ή����ĂĂ��悳���������B
SSE4�͖����ɂ��Ă��B
�܂����\���o�邩�͕�����ǁB
���ƃL���b�V����
L1I�@ 32KB
L1D�@24KB
L2�@�@512KB(8-way)
�������ŁB
���A����Penryn�Ɣ�ׂ�ƃv���Z�X�Ⴄ�炵���B
���̃N���X���ƃ��[�N�͑�G�������R���B
���̃N���X���ƃ��[�N�͑�G�������R���B
>16 stage��dual-decode dual-issue in-order���s�ŁA
�`���C������
�`���C������
ttp://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
>����HT�e�N�m���W�����p�����ꍇ�A�܂�}���`�X���b�h���Ńx���`�}�[�N���Ƃ�ƁA
>Silverthorne�̍ŏ��SKU��SV��(1.86GHz/2W)�́A���s��A110(800MHz)�ɔ�ׂ�
>1.5�`1.6�{���x�̐��\���������Ă���ق��AMV��(1.1GHz/1W)��A110�ɕC�G����悤��
>���\���������Ă����Intel���������Ă���Ɠ`����B�������A�V���O���X���b�h�ł́A
>SV��(1.8GHz)��A110�Ɠ������炢�AMV��(1.1GHz)��A100(600MHz)�Ɠ������x�̐��\�ƌ��ς����Ă���悤���B
Hyper-Threading���������邱�Ƃɂ��A15%���x�̏���d�͂̏㏸�ŁA
30%�̃p�t�H�[�}���X�Q�C����������Ƃ��Ă���A�\���Ɍ��ʓI�Ɣ��f���Ă���B
�ȂT���߂ɂȂ�����
>����HT�e�N�m���W�����p�����ꍇ�A�܂�}���`�X���b�h���Ńx���`�}�[�N���Ƃ�ƁA
>Silverthorne�̍ŏ��SKU��SV��(1.86GHz/2W)�́A���s��A110(800MHz)�ɔ�ׂ�
>1.5�`1.6�{���x�̐��\���������Ă���ق��AMV��(1.1GHz/1W)��A110�ɕC�G����悤��
>���\���������Ă����Intel���������Ă���Ɠ`����B�������A�V���O���X���b�h�ł́A
>SV��(1.8GHz)��A110�Ɠ������炢�AMV��(1.1GHz)��A100(600MHz)�Ɠ������x�̐��\�ƌ��ς����Ă���悤���B
Hyper-Threading���������邱�Ƃɂ��A15%���x�̏���d�͂̏㏸�ŁA
30%�̃p�t�H�[�}���X�Q�C����������Ƃ��Ă���A�\���Ɍ��ʓI�Ɣ��f���Ă���B
�ȂT���߂ɂȂ�����
>>850
�t���T�C�Y��E-ATX�}�U�[�ł��A8�s����2�t���Ă�̂͂قƂ�ǂȂ�����ȁB
4-Way�p�}�U�[���ƕW���I�ɕt���Ă邪�B
�Ɩ��o���̂���匴�Ȃ炻�̕ӂ͂悭�m���Ă邾�낤����A�܂��т����肷�邾��B
�M�җp�Ƃ͂����ꉞ�f�X�N�g�b�v�����̃}�U�[�����ȁB
�t���T�C�Y��E-ATX�}�U�[�ł��A8�s����2�t���Ă�̂͂قƂ�ǂȂ�����ȁB
4-Way�p�}�U�[���ƕW���I�ɕt���Ă邪�B
�Ɩ��o���̂���匴�Ȃ炻�̕ӂ͂悭�m���Ă邾�낤����A�܂��т����肷�邾��B
�M�җp�Ƃ͂����ꉞ�f�X�N�g�b�v�����̃}�U�[�����ȁB
�uSkullTrail�v��AMD���L�����Z�������A���Ɠ�������H
�M�җp�Ƃ������n�C�G���h�Q�[�}�[�d�l��PC�ł���B
�M�җp�Ƃ������n�C�G���h�Q�[�}�[�d�l��PC�ł���B
�����܂ł���ƃn�C�G���h�Q�[�}�[�ł���Ȃo���Ȃ���w
�X���f�����x���`�}�[�J�[�p����
�X���f�����x���`�}�[�J�[�p����
nvidia������v���b�g�t�H�[���͎��s����
����XBOX
PS3
4X4
����XBOX
PS3
4X4
>>861
Nehalem�Ƃ̔�r�p����
UP������Penryn�Ƃ��قǐ��\���ς��Ȃ�����
(OC���l������ƃf�X�N�g�b�v���ł͉����邩������Ȃ�)
Nehalem��DP���s���ē�������A����Ȃ��q��Skulltrail�Ɣ�r����
�u����Ȃɐ��\���オ��܂����v�ƁA������ł��邩��B
Nehalem�Ƃ̔�r�p����
UP������Penryn�Ƃ��قǐ��\���ς��Ȃ�����
(OC���l������ƃf�X�N�g�b�v���ł͉����邩������Ȃ�)
Nehalem��DP���s���ē�������A����Ȃ��q��Skulltrail�Ɣ�r����
�u����Ȃɐ��\���オ��܂����v�ƁA������ł��邩��B
Nehalem�͑厸�s�łȂ��Ă͂Ȃ�Ȃ�
�I���S���͔��M�łȂ��Ă͂Ȃ�Ȃ�
����E8400��Nehalem�ɕ�����Ȃǂ����Ă͂Ȃ�Ȃ�
�I���S���͔��M�łȂ��Ă͂Ȃ�Ȃ�
����E8400��Nehalem�ɕ�����Ȃǂ����Ă͂Ȃ�Ȃ�
�S����Core 2 Duo�̉��i���肠��݂��������ǂǂꂭ�炢�₷���Ȃ�́H
867 �FSocket774�F2008/02/06(��) 18:39:05 ID:LiKlk/JZ
���Ȃ�Ėk�XP4 2.6CGHz���I�I
�����S�`�T�N�o�̂����烀�[�A�̖@���ɂ��
Nehalem�͂P�O�{�߂����\�łȂ���Ȃ�Ȃ��I�I
�����S�`�T�N�o�̂����烀�[�A�̖@���ɂ��
Nehalem�͂P�O�{�߂����\�łȂ���Ȃ�Ȃ��I�I
>>866
�����������
�����������
869 �FSocket774�F2008/02/06(��) 19:04:19 ID:Wcddg2ae
�I�N�^�}�b�N�̂��łɍ�����B
���Ȃ͂��Ȃ��B
���Ȃ͂��Ȃ��B
870 �F�R�E�L�́M�E,,�j�����F2008/02/06(��) 19:11:19 ID:sSfBEA4n
>>869
��������̏ڍ����
��������̏ڍ����
>>867
2�N�O��Core2 Extreme 2.93GHz���A���悻10.0000%�قǑ���E8500���킸��3���~��Ŕ����Ă��܂��I
2�N�O��Core2 Extreme 2.93GHz���A���悻10.0000%�قǑ���E8500���킸��3���~��Ŕ����Ă��܂��I
>>867
���[�A�̖@���́A���\����Ȃ��āA�g�����W�X�^�̏W�ϖ��x�Ȃ��c
���[�A�̖@���́A���\����Ȃ��āA�g�����W�X�^�̏W�ϖ��x�Ȃ��c
�P�O�{�͒��߂�A���߂�3.5�`4�{�̐��\�t�o�����ҁB
����͒��߂Ȃ��I
�y��M1.2GHz����Nehalem�ɕς�����ڋʂ���яo�邭�炢�����Ȃ�낤��
�M������d�͂����ˏオ�邾�낤����
�M������d�͂����ˏオ�邾�낤����
>>871
�_�̈ʒu���C�ɂ��Ă������ł����H
�_�̈ʒu���C�ɂ��Ă������ł����H
�ȁA�Ȃ��ā[
�n�C�p�[�X���b�e�B���O�Ȃ�ŕ����������H
HT�Ƃ����A���@�I�}���`�X���b�f�B���O�͎��������̂��ˁH
���ꂪ�����������������Ȃ��́B
ttp://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
���ꂩ��5�N�������o���Ă�B
���ꂪ�����������������Ȃ��́B
ttp://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
���ꂩ��5�N�������o���Ă�B
�����̓X�Q�[�Ǝv�����B
1CPU��2CPU�ɂ݂������ċĂ�Ƃ�����t�����p���Ȃ��
�n�[�h�E�F�A�I�ɂ��\�t�g�E�F�A�I�ɂ����N�����Ȃ����Ƃ��v�������̂���
���ł͖k�XHT��4�N�ȏ�g���|���Ă邵�A���������������Ǝv���Ă�B
�l�n������4�R�A��8�X���b�h�ɂ��Ă͔̂����ȋC�����邯�ǁB
1CPU��2CPU�ɂ݂������ċĂ�Ƃ�����t�����p���Ȃ��
�n�[�h�E�F�A�I�ɂ��\�t�g�E�F�A�I�ɂ����N�����Ȃ����Ƃ��v�������̂���
���ł͖k�XHT��4�N�ȏ�g���|���Ă邵�A���������������Ǝv���Ă�B
�l�n������4�R�A��8�X���b�h�ɂ��Ă͔̂����ȋC�����邯�ǁB
���ꂪ�������d�́uSilverthorne�v�̐��̂�
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
http://pc.watch.impress.co.jp/docs/2008/0207/kaigai417.htm
���o�C���p���n�C�G���h�̏��~�����悧
core2�̂Ƃ��ƈ���ĂȂ��Ȃ����Ȃ���Ă��Ȃ���
core2�͎��O�Ƀx���`�Ƃ��̏���\����Ă��C������
core2�͎��O�Ƀx���`�Ƃ��̏���\����Ă��C������
core2�o��O�܂ł�AMD�ɐ��\�I�ɗ���Ă܂�����Łc
���͏���ς���āA���߂ɏ��o���Đ���K�v������
���͏���ς���āA���߂ɏ��o���Đ���K�v������
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=2
���߂�conroe�̃x���`���o���̂�3��
������7��
���߂�conroe�̃x���`���o���̂�3��
������7��
�܂��u�����o�Ă��C������v�Ɗ�����Ȃ�
coreduo(yonah)�͂Ƃ����ɔ��������2ch�ł��b��ɂȂ��Ă��̂�
����ƋL������������ɂȂ��Ă�낤
coreduo(yonah)�͂Ƃ����ɔ��������2ch�ł��b��ɂȂ��Ă��̂�
����ƋL������������ɂȂ��Ă�낤
���x��IDF��Nehalem�̏���܂�o�Ă��Ȃ����������ł����Ƃ����B
�����R���������s�̎��_�Ń��o�C���W���i�C�m
890 �FMAC�I�^��879-881 �����F2008/02/07(��) 08:13:42 ID:bP9IwOOH
>>879-881
SMT (=HyperThreading)�Ɋւ��Ă�A�T�|�[�g�̂��߂ɂǂ̒��x�R�A���g�����邩�őS�R���\���Ⴄ���B
Pentium4��"������5%(�_�C�T�C�Y����я���d��)�̊g���ŁA�ő�30%�̐��\����"�Ƃ����v���B
http://softwarecommunity.intel.com/articles/eng/2503.htm
�t�ɑ傫���g��������Ƃ��Ă�APOWER5��"10%(�R�A�g�����W�X�^��)�̊g���ōő�41%�̐��\����(ST
���[�h��SMT���[�h�̔�r����)"�Ƃ����v���B
http://www.research.ibm.com/journal/rd/494/sinharoy.html
http://www.research.ibm.com/journal/rd/494/mathis.html
Pentium4 HTT�̌o�����玟�����HyperThreading��A���\�Ə���d�͂��ɂ�ŗǂ��o�����X��I���
����Ǝv���邷�B
SMT (=HyperThreading)�Ɋւ��Ă�A�T�|�[�g�̂��߂ɂǂ̒��x�R�A���g�����邩�őS�R���\���Ⴄ���B
Pentium4��"������5%(�_�C�T�C�Y����я���d��)�̊g���ŁA�ő�30%�̐��\����"�Ƃ����v���B
http://softwarecommunity.intel.com/articles/eng/2503.htm
�t�ɑ傫���g��������Ƃ��Ă�APOWER5��"10%(�R�A�g�����W�X�^��)�̊g���ōő�41%�̐��\����(ST
���[�h��SMT���[�h�̔�r����)"�Ƃ����v���B
http://www.research.ibm.com/journal/rd/494/sinharoy.html
http://www.research.ibm.com/journal/rd/494/mathis.html
Pentium4 HTT�̌o�����玟�����HyperThreading��A���\�Ə���d�͂��ɂ�ŗǂ��o�����X��I���
����Ǝv���邷�B
>>889
�����R���������s���ĉ����H
�����R���������s���ĉ����H
892 �FMAC�I�^��891 �����F2008/02/07(��) 08:17:27 ID:bP9IwOOH
>>891
��ꐢ��ƂȂ�Bloomfield���O�t�������R���g���[���炵���Ƃ����b���炶��Ȃ����Ǝv���邷�B
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
����ǂ��o�b�N�A�b�v�v����������Ƃ������x���Ǝv�������ǁB�B�B
��ꐢ��ƂȂ�Bloomfield���O�t�������R���g���[���炵���Ƃ����b���炶��Ȃ����Ǝv���邷�B
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
{kind=link}
����ǂ��o�b�N�A�b�v�v����������Ƃ������x���Ǝv�������ǁB�B�B
>>879
�l�g�o�n�ł��܂肢����ۂ���Ȃ����ǁAHTT�͂悢�Z�p�B
�Ȃ��Ȃ�X���b�h�������I�Ɏg���邩��B
>>888
�����A�\���ȂقǏo�Ă��邶��Ȃ�����
>>885���������Ƃ����C2D�̎���Intel���K������������A
���\�ʂŐ���ɐ��������A���\�������Ă����̎�̏����o���Ă��܂��ƁA
C2D�̔���グ�ɋ����\��������̂ŁA�i���ȏ�̏��͏o�Ȃ��Ǝv���B
>>891
�\�[�X���Ȃ��]���ϑz�͂���Ȃ��B
�l�g�o�n�ł��܂肢����ۂ���Ȃ����ǁAHTT�͂悢�Z�p�B
�Ȃ��Ȃ�X���b�h�������I�Ɏg���邩��B
>>888
�����A�\���ȂقǏo�Ă��邶��Ȃ�����
>>885���������Ƃ����C2D�̎���Intel���K������������A
���\�ʂŐ���ɐ��������A���\�������Ă����̎�̏����o���Ă��܂��ƁA
C2D�̔���グ�ɋ����\��������̂ŁA�i���ȏ�̏��͏o�Ȃ��Ǝv���B
>>891
�\�[�X���Ȃ��]���ϑz�͂���Ȃ��B
>>893
>HTT�͂悢�Z�p
����͂���ǂ��Ȃ��Ǝv����A30%���x���\�A�b�v�Ɋ�^����Ƃ���A���ۂɂ��̒��x�͂���Ǝv����
�}���`�R�A�ł́A�X���b�h�̃X�P�W�[�������\�������Ȃ�30%�ȏ�̐��\�_�E���͔������Ȃ��B
�V���O���R�A�Ȃ炱�̋Z�p�͑����Ɏ^��
>HTT�͂悢�Z�p
����͂���ǂ��Ȃ��Ǝv����A30%���x���\�A�b�v�Ɋ�^����Ƃ���A���ۂɂ��̒��x�͂���Ǝv����
�}���`�R�A�ł́A�X���b�h�̃X�P�W�[�������\�������Ȃ�30%�ȏ�̐��\�_�E���͔������Ȃ��B
�V���O���R�A�Ȃ炱�̋Z�p�͑����Ɏ^��
���ӂƎv�����A����̌������Ă����������Ȃ�˂��̂��ȁH
�G���R�قǃ}���`�R�A�ɒ��q�̗ǂ����̂������͂��Ȃ̂ɁA�܂������L�����p�ł��Ă��Ȃ����Ă̂�
>836 �FSocket774�F2008/02/05(��) 23:17:13 ID:hO/diETv
>>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
>
>http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
>���ꉽ�������낤�ȁA�X���b�h�X�P�W���[��������ł�̂��AI/O���l���Ă���̂��A�P�ɃG���R�A�v�����^�R�Ȃ̂��H
>���łɕ\���I�v�V�����ŃJ�[�l�����Ԃ��\�����ė~����������
�G���R�قǃ}���`�R�A�ɒ��q�̗ǂ����̂������͂��Ȃ̂ɁA�܂������L�����p�ł��Ă��Ȃ����Ă̂�
>836 �FSocket774�F2008/02/05(��) 23:17:13 ID:hO/diETv
>>http://journal.mycom.co.jp/articles/2008/02/04/skulltrail2/index.html
>
>http://journal.mycom.co.jp/photo/articles/2008/02/04/skulltrail1/images/Photo42l.jpg
>���ꉽ�������낤�ȁA�X���b�h�X�P�W���[��������ł�̂��AI/O���l���Ă���̂��A�P�ɃG���R�A�v�����^�R�Ȃ̂��H
>���łɕ\���I�v�V�����ŃJ�[�l�����Ԃ��\�����ė~����������
>>896
�����S�����ԈႢSkullTrail�͒P��Quad�Q���ŁAHT�͖��������E�E�E
�����S�����ԈႢSkullTrail�͒P��Quad�Q���ŁAHT�͖��������E�E�E
Silverthorne���Č��s��C7�����_�C�ʐς����������ۂ����ǁA�{���f�B���O��
���͏o�Ȃ��̂��ȁH
�ᔭ�M������z�b�g�X�|�b�g�̐S�z�͖����̂��낤���ǁB
45nm��CELL�Ȃ�IO�z���X�y�[�X�̂����ŁA�V�������N���ז�����Ă�b��
���������B
���͏o�Ȃ��̂��ȁH
�ᔭ�M������z�b�g�X�|�b�g�̐S�z�͖����̂��낤���ǁB
45nm��CELL�Ȃ�IO�z���X�y�[�X�̂����ŁA�V�������N���ז�����Ă�b��
���������B
>>895
�X���b�h�̃X�P�W�[�������\�������Ȃ�A���Ă̂́A�\�t�g���̖�肾��B
�n�[�h�������̗ǂ��d�g�݂���Ă��A�\�t�g��������g�����Ȃ���l��
�Ȃ閘�ɂ́A����������͕̂��ʂ̘b�����B�iCELL��x64�A���z�@�\�Aetc�j
�X���b�h�̃X�P�W�[�������\�������Ȃ�A���Ă̂́A�\�t�g���̖�肾��B
�n�[�h�������̗ǂ��d�g�݂���Ă��A�\�t�g��������g�����Ȃ���l��
�Ȃ閘�ɂ́A����������͕̂��ʂ̘b�����B�iCELL��x64�A���z�@�\�Aetc�j
>>899
>�n�[�h�������̗ǂ��d�g�݂���Ă��A�\�t�g��������g�����Ȃ���l��
�܂��A���肦�Ȃ��Ǝv���܂����ǂ�
���ꂪ�\�Ȃ̂͂��������Q�[���̂悤�ȁA���s���Ă���A�v���P�[�V���������ׂĔc������Ă���ꍇ�Ɍ���Ǝv���܂���B���������肳���Ǝv���܂��B
���ׂłǂ�ȃA�v�������삵�Ă��邩�킩��Ȃ��ōœK���ȂǑz���s�\����
���ꂩ��͂ǂ�ǂ�K�͂��傫���Ȃ�Ȃ�A�}���`�X���b�h�Ή��̃��C�u���������R�ǂ�ǂ�łĂ���ł��傤��
���C�u�����̓u���b�N�{�b�N�X�����ĂȂ�ڂ̂��̂ł��B
�g���Ă��鑤�ƁA�g���Ă��鑤�̈ӎv�a�ʂ͂ǂ�ǂ��Ȃ��Ă䂭�ł��傤�A�܂��Ɨ����̓\�t�g�̐��E�ł͐��`�ł��B�����炻�����������͐i�܂Ȃ��Ǝv���܂��B
���������`���[������̂ƁA�n�[�h�̐��\����҂��Ȃ�ԈႢ�Ȃ���҂�҂Ǝv����ł���A�Ȃ��Ȃ獂�X30%���x�ł�����B
��������Ɖ����N����̂��Ƃ����ƁA�Ή��Ȃǂ��Ȃ��A����Ă��K���Ƃ������_�ɂȂ�Ǝv���܂��B
�����Ȃ�܂��ƁA�����������ꂽ�@�\���L�����p����邱�Ƃ��Ȃ��A�P�ɐ��\��s���肵�āA���W�b�N�K�͂��Ӗ��������₵�ďI��肾�Ǝv���܂��B
�Ȃ�A���̕������Ȃ����āA��������������ʂȏ���d�͂�����ăN���b�N�ł����サ���ق����y���Ɍ��ʓI���Ǝv���̂ł����E�E�E
>�n�[�h�������̗ǂ��d�g�݂���Ă��A�\�t�g��������g�����Ȃ���l��
�܂��A���肦�Ȃ��Ǝv���܂����ǂ�
���ꂪ�\�Ȃ̂͂��������Q�[���̂悤�ȁA���s���Ă���A�v���P�[�V���������ׂĔc������Ă���ꍇ�Ɍ���Ǝv���܂���B���������肳���Ǝv���܂��B
���ׂłǂ�ȃA�v�������삵�Ă��邩�킩��Ȃ��ōœK���ȂǑz���s�\����
���ꂩ��͂ǂ�ǂ�K�͂��傫���Ȃ�Ȃ�A�}���`�X���b�h�Ή��̃��C�u���������R�ǂ�ǂ�łĂ���ł��傤��
���C�u�����̓u���b�N�{�b�N�X�����ĂȂ�ڂ̂��̂ł��B
�g���Ă��鑤�ƁA�g���Ă��鑤�̈ӎv�a�ʂ͂ǂ�ǂ��Ȃ��Ă䂭�ł��傤�A�܂��Ɨ����̓\�t�g�̐��E�ł͐��`�ł��B�����炻�����������͐i�܂Ȃ��Ǝv���܂��B
���������`���[������̂ƁA�n�[�h�̐��\����҂��Ȃ�ԈႢ�Ȃ���҂�҂Ǝv����ł���A�Ȃ��Ȃ獂�X30%���x�ł�����B
��������Ɖ����N����̂��Ƃ����ƁA�Ή��Ȃǂ��Ȃ��A����Ă��K���Ƃ������_�ɂȂ�Ǝv���܂��B
�����Ȃ�܂��ƁA�����������ꂽ�@�\���L�����p����邱�Ƃ��Ȃ��A�P�ɐ��\��s���肵�āA���W�b�N�K�͂��Ӗ��������₵�ďI��肾�Ǝv���܂��B
�Ȃ�A���̕������Ȃ����āA��������������ʂȏ���d�͂�����ăN���b�N�ł����サ���ق����y���Ɍ��ʓI���Ǝv���̂ł����E�E�E
901 �F�R�E�L�́M�E,,�j�����F2008/02/07(��) 22:12:50 ID:V2BzcBFP
SSE��ے肷��l�����邯�ǁA�قƂ�ǂ̃}�V���Ŏg����ėp���Z�A�N�Z�����[�^�Ƃ��Ă̈Ӗ��͑傫���B
���w���C�u�����⓮��Đ��Ȃł������I�ɂ͎g���Ă��B
���w���C�u�����⓮��Đ��Ȃł������I�ɂ͎g���Ă��B
x64����SSE2�ȏ�K�{�ɂȂ��Ă����
903 �F�R�E�L�́M�E,,�j�����F2008/02/07(��) 22:51:08 ID:V2BzcBFP
���̒���(��)�ɂ���Pen4�ł�HT���L���ȏꍇ�A
���[�J�[�X���b�h�̃A�t�B�j�e�B���Œ肵������
�p�t�H�[�}���X�オ��炵���B
���M�Ȃ��Ȃ烆�[�U�[�Ŏw��ł���悤�ɂ���悭�ˁH
���[�J�[�X���b�h�̃A�t�B�j�e�B���Œ肵������
�p�t�H�[�}���X�オ��炵���B
���M�Ȃ��Ȃ烆�[�U�[�Ŏw��ł���悤�ɂ���悭�ˁH
>>903
�Œ肷������ق����オ���A�Œ肵�Ă�����Ƃ���Off�ɂ��Ė��Ȃ�����
�Œ肷������ق����オ���A�Œ肵�Ă�����Ƃ���Off�ɂ��Ė��Ȃ�����
���[�J�[�X���b�h�����I�ɐ�������Ȃ��\�t�g���ǂꂾ�����邩���Ă��̖�肾�ȁA���������唼�͓��I��������
����Ȃ̂ǂ�����ČŒ肷���w
���������[�U�[��www
����Ȃ̂ǂ�����ČŒ肷���w
���������[�U�[��www
906 �F�R�E�L�́M�E,,�j�����������������F2008/02/08(��) 00:23:50 ID:Mrud8d6W
�͂��H
http://msdn.microsoft.com/library/ja/default.asp?url=/library/ja/jpdllpro/html/_win32_setthreadaffinitymask.asp
http://www.linux.or.jp/JM/html/LDP_man-pages/man2/sched_setaffinity.2.html
���̓��I�ɐ�������X���b�h�ɂ��āA�v���O�������ŃR�A���Ȃ�ׂ��Œ�œ����悤�ɃA�t�B�j�e�B��ݒ肷��B
���M�������Ȃ�A�A�v������X���b�h�̊��蓖�Ă��蓮�Ŏw�肷��I�v�V���������[�U�[�ɊJ�����Ă�
���Č����Ă��ł���A�P�ɁB
�^�X�N�}�l�[�W������v���Z�X�A�t�B�j�e�B���炢�͎w��ł���ȁB
�X���b�h��q�v���Z�X�̃A�t�B�j�e�B�͐e�X���b�h/�v���Z�X�̃A�t�B�j�e�B�ɏ]��������
�匳��1�v���Z�b�T�ɌŒ肵�Ă��܂��Ύq�v���Z�X/�X���b�h�͂���ɏ]�����ƂɂȂ�B
Win32��*NIX����̘b�����Ǖϑ�OS�͒m���B
http://msdn.microsoft.com/library/ja/default.asp?url=/library/ja/jpdllpro/html/_win32_setthreadaffinitymask.asp
http://www.linux.or.jp/JM/html/LDP_man-pages/man2/sched_setaffinity.2.html
���̓��I�ɐ�������X���b�h�ɂ��āA�v���O�������ŃR�A���Ȃ�ׂ��Œ�œ����悤�ɃA�t�B�j�e�B��ݒ肷��B
���M�������Ȃ�A�A�v������X���b�h�̊��蓖�Ă��蓮�Ŏw�肷��I�v�V���������[�U�[�ɊJ�����Ă�
���Č����Ă��ł���A�P�ɁB
�^�X�N�}�l�[�W������v���Z�X�A�t�B�j�e�B���炢�͎w��ł���ȁB
�X���b�h��q�v���Z�X�̃A�t�B�j�e�B�͐e�X���b�h/�v���Z�X�̃A�t�B�j�e�B�ɏ]��������
�匳��1�v���Z�b�T�ɌŒ肵�Ă��܂��Ύq�v���Z�X/�X���b�h�͂���ɏ]�����ƂɂȂ�B
Win32��*NIX����̘b�����Ǖϑ�OS�͒m���B
��������_���Ăقǂ̂��̂���Ȃ����Nj����Ă����܂�
�����ł́A�����Ȃ��������ǂ����Ă��c���Ă��̕�����������������̂ł���
���ɂ����A���_�[���̖@���Ƃ������̂ł�
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
�n�C�p�[�X���b�f�B���O���X���b�h�ɂ͈Ⴂ�Ȃ��̂ŁA������鑤�̃R�[�h�ƂȂ�܂��B
����͉����Ӗ����Ă��邩�Ƃ����ƁA���������̌����A�b�v�����܂��Ă��܂���ł���B
30%�̌����A�b�v�������Ă��A���_�[�����ł���Ԃ����ƈ�̉��p�[�Z���g���L���ɂȂ�̂��H
�܂�������������鍂�x�ȃX���b�h�X�P�W���[�����ł����Ɖ��ɂ��܂��A�������܂����̃R�[�h���g���܂��I�[�o�[�w�b�h�ƂȂ��Ĉ����|���鎖�ɂ��Ȃ�܂��B
���āA�����Ńn�C�p�[�X���b�h��������߂āA�R�A�����X���b�h�̐��\�����}�����Ƃ��܂��B
���ł��A�ǂ̕����Ɍ��ʂ��܂��ł��傤���H
����������܂��B
�����ł́A�����Ȃ��������ǂ����Ă��c���Ă��̕�����������������̂ł���
���ɂ����A���_�[���̖@���Ƃ������̂ł�
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
�n�C�p�[�X���b�f�B���O���X���b�h�ɂ͈Ⴂ�Ȃ��̂ŁA������鑤�̃R�[�h�ƂȂ�܂��B
����͉����Ӗ����Ă��邩�Ƃ����ƁA���������̌����A�b�v�����܂��Ă��܂���ł���B
30%�̌����A�b�v�������Ă��A���_�[�����ł���Ԃ����ƈ�̉��p�[�Z���g���L���ɂȂ�̂��H
�܂�������������鍂�x�ȃX���b�h�X�P�W���[�����ł����Ɖ��ɂ��܂��A�������܂����̃R�[�h���g���܂��I�[�o�[�w�b�h�ƂȂ��Ĉ����|���鎖�ɂ��Ȃ�܂��B
���āA�����Ńn�C�p�[�X���b�h��������߂āA�R�A�����X���b�h�̐��\�����}�����Ƃ��܂��B
���ł��A�ǂ̕����Ɍ��ʂ��܂��ł��傤���H
����������܂��B
�Ƃ܂��ȏ�ŁA���ɂ���������A�b�v�͌���I�Ȍ��ʂ������炳�Ȃ�����Ӗ����Ȃ��Ǝv���܂��B
�Q�ߓI�O�i�́A�X�J���[�I�ȍ������̕����L�����Ǝv���܂��B
�Q�ߓI�O�i�́A�X�J���[�I�ȍ������̕����L�����Ǝv���܂��B
909 �F�R�E�L�́M�E,,�j�����������������F2008/02/08(��) 00:41:31 ID:Mrud8d6W
�I�m�ɃA�t�B�j�e�B���Œ肷�邱�ƂŃp�t�H�[�}���X�����シ��͉̂�����CPU/OS�ł��������Ƃł��B
http://docs.sun.com/app/docs/doc/820-1930/6ndimh1kn?l=ja&a=view
>>779�Ɍ������тꂽ���ǁA�܂��v���Z�b�T�̌Œ�ɉ��a�ɂȂ��Ă�`�L��PG�̓}���`�X���b�h�g��Ȃ����Ƃ��������Ǝv���܂��B
�A�t�B�j�e�B�i���ĂȂ��X���b�h�[�ɑ�ʂɍ���Ă����̃v���Z�X�̖��f�ɂȂ肩�˂܂���B
���ۂ�����HT Xeon�ŃA�t�B�j�e�B�Œ肵�Ă�邱�ƂŃp�t�H�[�}���X���P�������Ⴊ����B
�܂��A�X���b�h�A�t�B�j�e�B�͏ɉ����ĉ��x�ł��Đݒ�ł��܂��̂ł��̂ւ�͍H�v�ł��傤�B
�q���g�F���Ƃ���Win32�͑S�Ẵv���Z�X�E�X���b�h�Ƀ��b�Z�[�W�L���[������܂��B
http://docs.sun.com/app/docs/doc/820-1930/6ndimh1kn?l=ja&a=view
>>779�Ɍ������тꂽ���ǁA�܂��v���Z�b�T�̌Œ�ɉ��a�ɂȂ��Ă�`�L��PG�̓}���`�X���b�h�g��Ȃ����Ƃ��������Ǝv���܂��B
�A�t�B�j�e�B�i���ĂȂ��X���b�h�[�ɑ�ʂɍ���Ă����̃v���Z�X�̖��f�ɂȂ肩�˂܂���B
���ۂ�����HT Xeon�ŃA�t�B�j�e�B�Œ肵�Ă�邱�ƂŃp�t�H�[�}���X���P�������Ⴊ����B
�܂��A�X���b�h�A�t�B�j�e�B�͏ɉ����ĉ��x�ł��Đݒ�ł��܂��̂ł��̂ւ�͍H�v�ł��傤�B
�q���g�F���Ƃ���Win32�͑S�Ẵv���Z�X�E�X���b�h�Ƀ��b�Z�[�W�L���[������܂��B
>>909
>�A�t�B�j�e�B�i���ĂȂ��X���b�h�[�ɑ�ʂɍ���Ă����̃v���Z�X�̖��f�ɂȂ肩�˂܂���B
���[�A�قƂ�ǃX���[�v�Ƃ͂����Ă��A����OS�ł͓�����O�̂悤��100�X���b�h�ȏ㑖���Ă܂���`
>�A�t�B�j�e�B�i���ĂȂ��X���b�h�[�ɑ�ʂɍ���Ă����̃v���Z�X�̖��f�ɂȂ肩�˂܂���B
���[�A�قƂ�ǃX���[�v�Ƃ͂����Ă��A����OS�ł͓�����O�̂悤��100�X���b�h�ȏ㑖���Ă܂���`
911 �F�R�E�L�́M�E,,�j�����������������F2008/02/08(��) 00:47:13 ID:Mrud8d6W
�Q�[���Ȃr�W�[���[�v�̓U�������ǁB
HT���Ă͓̂����p�C�v���C���ɏ������Γ�̃X���b�h���ɂȂ����Z�p�Ȃ�ˁH
����ɂ�闘�_���Ă����̂�����������f�[�^��疽�߂�load���鎞�Ԃ̉B�����\�ł��邱�ƁB
�Ŗ��ɂȂ��Ă�̂́AHT��2�X���b�h�����������ł��Ȃ����p�ɂɂ������āA
1�X���b�h��total�̏������Ԃ��������邱�Ƃł��̌�̈ˑ������������X���b�h�̏������x���Ƃ������ƁB
�ėp�v�Z�@���ƈˑ����̂���X���b�h�̏��������S������A
�f�����b�g�̂ق������傫����Ȃ������Ă��Ƃ��X���ł͌����Ă��ˁB
���C�e���V�̉B�����ł��Ȃ��Ă����̃R�A���g�p���ď������Ԃ�Z������ق����A
�ˑ����̂���X���b�h�����ł͂����̂ł͂Ȃ����H���Ă̂�HT�ے�h�̈ӌ����Ɛ����������ǂ����Ă�H
��������intel����̓I��HT�̐��\�㏸�������C�e���V�B���ɂ����̂�
�����������ɂ����̂���������������Ȃ��̂��������ǂȁB
intel���炵�Ă݂������̃}�[�P�e�B���O��瓊�@�X���b�h�̕z�ΈȊO�A
���l���Ȃ����Ă����Ă���ۂ����ǁB
���ƁA���@�X���b�W���O�ɂ��Ă�����ۂ��̂��B
ttp://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
����ɂ�闘�_���Ă����̂�����������f�[�^��疽�߂�load���鎞�Ԃ̉B�����\�ł��邱�ƁB
�Ŗ��ɂȂ��Ă�̂́AHT��2�X���b�h�����������ł��Ȃ����p�ɂɂ������āA
1�X���b�h��total�̏������Ԃ��������邱�Ƃł��̌�̈ˑ������������X���b�h�̏������x���Ƃ������ƁB
�ėp�v�Z�@���ƈˑ����̂���X���b�h�̏��������S������A
�f�����b�g�̂ق������傫����Ȃ������Ă��Ƃ��X���ł͌����Ă��ˁB
���C�e���V�̉B�����ł��Ȃ��Ă����̃R�A���g�p���ď������Ԃ�Z������ق����A
�ˑ����̂���X���b�h�����ł͂����̂ł͂Ȃ����H���Ă̂�HT�ے�h�̈ӌ����Ɛ����������ǂ����Ă�H
��������intel����̓I��HT�̐��\�㏸�������C�e���V�B���ɂ����̂�
�����������ɂ����̂���������������Ȃ��̂��������ǂȁB
intel���炵�Ă݂������̃}�[�P�e�B���O��瓊�@�X���b�h�̕z�ΈȊO�A
���l���Ȃ����Ă����Ă���ۂ����ǁB
���ƁA���@�X���b�W���O�ɂ��Ă�����ۂ��̂��B
ttp://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
�X���b�h����2�{�ɂ��������A�R�A��2�{�ɂ��������������
http://japan.cnet.com/news/ent/story/0,2000056022,20267807-2,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20267807-2,00.htm
914 �F�R�E�L�́M�E,,�j�����������������F2008/02/08(��) 02:08:47 ID:Mrud8d6W
�X���b�h�̈ˑ����͂ł��邾�������ق����������ǂˁB
�ł����A�j�R�C�`�N�A�b�h�Ƃ�NUMA�Ƃ��A�R�A�ɑ���X���b�h�̊���U����Ő��\���傫���ς��ł���B
SMT���ƃ}���`�R�A���L���b�V���̒��₪�y�B�Ƃ����������ɂ���Ă͂܂������s�v�B
���Ȃ݂�Pentium 4��HT��SMT�̎����Ƃ��Ă͂���܂�X�}�[�g����Ȃ��炵���B
�ڂ������Ƃ͒m���
�ł����A�j�R�C�`�N�A�b�h�Ƃ�NUMA�Ƃ��A�R�A�ɑ���X���b�h�̊���U����Ő��\���傫���ς��ł���B
SMT���ƃ}���`�R�A���L���b�V���̒��₪�y�B�Ƃ����������ɂ���Ă͂܂������s�v�B
���Ȃ݂�Pentium 4��HT��SMT�̎����Ƃ��Ă͂���܂�X�}�[�g����Ȃ��炵���B
�ڂ������Ƃ͒m���
915 �FMAC�I�^��912 �����F2008/02/08(��) 02:42:43 ID:ZhH23SBF
>>912
�@�@-------------------
�@�@�ˑ������������X���b�h�̏������x���Ƃ������ƁB
�@�@-------------------
>>914�Œc�q�������Ă���ʂ肷�B
http://pc.watch.impress.co.jp/docs/2004/0812/kaigai110.htm
�@�@===================
�@�@�����ATLP�ɂ���ĕ����X���b�h�����ɑ��点��ꍇ�ɂ͘b������Ă���BTLP�ł͈ˑ����̔���
�@�@�����̃C���X�g���N�V�����t���[������ł��閽�߂����ꂼ�ꒊ�o���邽�߁ACPU�S�̂ł�
�@�@IPC���]���A�[�L�e�N�`�����啝�ɍ��߂邱�Ƃ��ł���B����������ƁACPU�̏����̕����A
�@�@���߃��x������X���b�h���x���ւƈ����グ�邱�ƂŁA��荂������x����������̂�TLP�Ƃ���
�@�@�킯���B
�@�@===================
�u�ˑ����̔��������̃C���X�g���N�V�����t���[�v�ɒ��ڂ��B
�@�@-------------------
�@�@�ˑ������������X���b�h�̏������x���Ƃ������ƁB
�@�@-------------------
>>914�Œc�q�������Ă���ʂ肷�B
http://pc.watch.impress.co.jp/docs/2004/0812/kaigai110.htm
�@�@===================
�@�@�����ATLP�ɂ���ĕ����X���b�h�����ɑ��点��ꍇ�ɂ͘b������Ă���BTLP�ł͈ˑ����̔���
�@�@�����̃C���X�g���N�V�����t���[������ł��閽�߂����ꂼ�ꒊ�o���邽�߁ACPU�S�̂ł�
�@�@IPC���]���A�[�L�e�N�`�����啝�ɍ��߂邱�Ƃ��ł���B����������ƁACPU�̏����̕����A
�@�@���߃��x������X���b�h���x���ւƈ����グ�邱�ƂŁA��荂������x����������̂�TLP�Ƃ���
�@�@�킯���B
�@�@===================
�u�ˑ����̔��������̃C���X�g���N�V�����t���[�v�ɒ��ڂ��B
916 �FMAC�I�^���c�q �����F2008/02/08(��) 02:47:29 ID:ZhH23SBF
>>914
�@�@-----------------
�@�@���Ȃ݂�Pentium 4��HT��SMT�̎����Ƃ��Ă͂���܂�X�}�[�g����Ȃ��炵���B
�@�@-----------------
���̕ӂ�P4 HTT�ȍ~��SMT�̎����Ƃ̈Ⴂ���B
http://www.google.com/search?q=POWER5+dynamic-resource-balancing
����>>890�ŏ������悤�ɁA�ǂ̒��x�@�\�����̂��߂̃g�����W�X�^�𑝂₷���Ƃ����I���̖�肩�Ǝv�����B
�@�@-----------------
�@�@���Ȃ݂�Pentium 4��HT��SMT�̎����Ƃ��Ă͂���܂�X�}�[�g����Ȃ��炵���B
�@�@-----------------
���̕ӂ�P4 HTT�ȍ~��SMT�̎����Ƃ̈Ⴂ���B
http://www.google.com/search?q=POWER5+dynamic-resource-balancing
����>>890�ŏ������悤�ɁA�ǂ̒��x�@�\�����̂��߂̃g�����W�X�^�𑝂₷���Ƃ����I���̖�肩�Ǝv�����B
�܂�SMT�g�p���͔�g�p���Ɣ�ׂāAOS�Ȃǂ̃\�t�g��������ɍœK������ĂȂ��Ɛ��\��������\����������Ď��ł���H
�����Ȃ�ƃ\�t�g���̍œK���̘b�ɂȂ��Ă��邩��B
SMT���̂̓L���b�V�������L���Ă���R�A�Ƃ����������ł��邵�m���Ɍ����͂����Ǝv�����ǁB
intel��SMT�̕����Ƃ��ăg�����W�X�^�ƕ���x�̃R�X�g�p�t�H�[�}���X�̂Ƃ�̂��A
����Ƃ��f�[�^�▽�߂̃v���t�F�b�`�@�\���Ƃ�̂��A
���̂������intel�̐��������������A�[�L�e�N�g�̎�ɂȂ��Ă����Ȃ��́H
�����Ȃ��Ƃ��������������Ƃ���قǃI���S���͉��\����Ȃ��Ǝv���B
�����Ȃ�ƃ\�t�g���̍œK���̘b�ɂȂ��Ă��邩��B
SMT���̂̓L���b�V�������L���Ă���R�A�Ƃ����������ł��邵�m���Ɍ����͂����Ǝv�����ǁB
intel��SMT�̕����Ƃ��ăg�����W�X�^�ƕ���x�̃R�X�g�p�t�H�[�}���X�̂Ƃ�̂��A
����Ƃ��f�[�^�▽�߂̃v���t�F�b�`�@�\���Ƃ�̂��A
���̂������intel�̐��������������A�[�L�e�N�g�̎�ɂȂ��Ă����Ȃ��́H
�����Ȃ��Ƃ��������������Ƃ���قǃI���S���͉��\����Ȃ��Ǝv���B
�`���[���͕K���啨��Ώ����Ă��ꂩ�珬����Ώ�����菇�ł���ΕK�����s�����
����Ԃ̑啨��
1.�L���b�V���q�b�g�~�X
2.�X���b�h�ȉ������Ă��Ȃ�����
1�́A�L���b�V���̗e�ʂ����܂��v���邱�ƂŐ�������Ǝv�� Core2 ���悭���Ă����ׂ�
2�́A�R�A�̑Ώ̐���������������܂��������@������
����ȊO�͎��������Ă����Ȃ��Ă����ʂ͂Ȃ���
�ʂ̂������@�����邩��Ƃ����ď�̓���Ԃ����͑����厸�s�ɏI���Ǝv����
���Ƃ��A���߂��p�C�v���C���𗐂��Č��������̂ŁA�L���b�V�����O�����ǐ�p�C�v���C��������Ȃ��ǂ����@���������̂ō̗p�Ƃ����蓾�Ȃ��B
����Ԃ̑啨��
1.�L���b�V���q�b�g�~�X
2.�X���b�h�ȉ������Ă��Ȃ�����
1�́A�L���b�V���̗e�ʂ����܂��v���邱�ƂŐ�������Ǝv�� Core2 ���悭���Ă����ׂ�
2�́A�R�A�̑Ώ̐���������������܂��������@������
����ȊO�͎��������Ă����Ȃ��Ă����ʂ͂Ȃ���
�ʂ̂������@�����邩��Ƃ����ď�̓���Ԃ����͑����厸�s�ɏI���Ǝv����
���Ƃ��A���߂��p�C�v���C���𗐂��Č��������̂ŁA�L���b�V�����O�����ǐ�p�C�v���C��������Ȃ��ǂ����@���������̂ō̗p�Ƃ����蓾�Ȃ��B
�uCore 2 Duo�v�͓����N�Q--�đ�w�A�C���e�����i
http://japan.cnet.com/news/ent/story/0,2000056022,20366876,00.htm
�Ȃ���B
����\���Ɋւ��邱�Ƃ��ˁB
2001�N�ɂ��ł�Intel�ɓ��������Ă����Ă��Ƃ�NetBurst����̗p���ꂽ�Z�p���B
http://japan.cnet.com/news/ent/story/0,2000056022,20366876,00.htm
�Ȃ���B
����\���Ɋւ��邱�Ƃ��ˁB
2001�N�ɂ��ł�Intel�ɓ��������Ă����Ă��Ƃ�NetBurst����̗p���ꂽ�Z�p���B
intel�����
http://hell.2ch.ru/fg/src/1201558697217.jpg
http://hell.2ch.ru/fg/src/1201558697217.jpg
{kind=link}
(#߄D�)��٧!!
���Ă��[������Ȃ����I
���Ă��[������Ȃ����I
>>919
Memory Disambiguation�̎�����Ȃ��H
Memory Disambiguation�̎�����Ȃ��H
�������A�L���I
���ꂪ�E�B�X�R���V����w���C���e����i�����i��
ttp://www.warf.org/uploads/media/Complaint_with_patent_as_filed.pdf
����̃y�[�W5�ɁACore microarchitecture��Smart Memory Access�A
memory disambiguation technique��������N�Q���Ă���Ə�����Ă��܂��B
ttp://www.warf.org/uploads/media/Complaint_with_patent_as_filed.pdf
����̃y�[�W5�ɁACore microarchitecture��Smart Memory Access�A
memory disambiguation technique��������N�Q���Ă���Ə�����Ă��܂��B
����P4�g���ĂĈ�N���PS�����ς���g�Ƃ��Ă�
Core2Duo�Ȃ��u�b�`�M���ő���CPU�ɂ��ė~����
�܂��A������b�o�t�������Ȃ��Ă�HDD���x�����Ⴀ�܂�Ӗ��Ȃ��낤���ǁE�E�E
�������N��ɂ�SDD���U�SGB��12000�~�ɂȂ��Ă���Ă�Ƃ�����
�����windows7���o�Ă���Ƃ��ꂵ��
�����Geforce11000Ultra��ς�
�Ƃɂ����ŋ�PC��������͕����g��m9(^�D^)
Core2Duo�Ȃ��u�b�`�M���ő���CPU�ɂ��ė~����
�܂��A������b�o�t�������Ȃ��Ă�HDD���x�����Ⴀ�܂�Ӗ��Ȃ��낤���ǁE�E�E
�������N��ɂ�SDD���U�SGB��12000�~�ɂȂ��Ă���Ă�Ƃ�����
�����windows7���o�Ă���Ƃ��ꂵ��
�����Geforce11000Ultra��ς�
�Ƃɂ����ŋ�PC��������͕����g��m9(^�D^)
�n�R���Ă��킢��������
PS3����������ς͂܂��ł���
{kind=link}
�uTukwila�v�̓_�C�T�C�Y�ł�������
NVidia�̎�����n�C�G���hG100��10���g�����W�X�^���Ƃ����Ă�̂ɁA�{��20�������������w
������Z�p�ŁA���ɕ����킹�Ă����ő�̃_�C�T�C�Y�͂ǂ̒��x�Ȃ��ˁH
SRAM���\GByte + ���\�R�A�̃����`�b�vPC�Ƃ���k�ō��Ȃ��̂���
SRAM���\GByte + ���\�R�A�̃����`�b�vPC�Ƃ���k�ō��Ȃ��̂���
�E�F�n�̍ő傪30cm������l��t�ꌩ��H
�����̃X���ɂ��Ă�̂�SRAM�̃_�C�T�C�Y�Ƃ����l�����Ȃ��̂Ȃ�
�Ƃ��ƂƉ�������Ďs��
�Ƃ��ƂƉ�������Ďs��
Nehalem�X���ɂ����������ǁA�ߑa���Ă�̂ł������ɂ��B
ttp://nueda.main.jp/blog/archives/003280.html
�ΏĂ����[�N�����܂����B8�b�ƂȁB
ttp://nueda.main.jp/blog/archives/003280.html
�ΏĂ����[�N�����܂����B8�b�ƂȁB
935 �F�R�E�L�́M�E,,�j�����������������F2008/02/09(�y) 09:39:29 ID:rIBi1EFd
�ޫ���ްق̔{�A������_�u��
936 �FMAC�I�^��934 �����F2008/02/09(�y) 10:02:32 ID:37ie/uQZ
>>934
�s�����B�m�F����������A�������"Super Pi Checksum Validation" ���ǂ����B
http://www.xtremesystems.com/superpi/
�s�����B�m�F����������A�������"Super Pi Checksum Validation" ���ǂ����B
http://www.xtremesystems.com/superpi/
�Ƃ����in-order�����ƂȂ�Silverthorne��R���p�C���̍œK���ɐ��\�����E����邱�Ƃ��e�Ղɗ\�z�����
�����ǁA���̕ӂǂ��Ȃ邷���ˁB�B�B
�����ǁA���̕ӂǂ��Ȃ邷���ˁB�B�B
>>932
�E�G�n�S���g����́H
�X�J���n�̒��������Z���v���͂���Ǝv����ŁA�\�Ȃ�ǂ����̃X�[�p�[�R���s���[�^�ɍ̗p����Ă��Ă��s�v�c����Ȃ������ȋC������̂���
�S�R����Șb�͕����Ȃ�����
�E�G�n�S���g����́H
�X�J���n�̒��������Z���v���͂���Ǝv����ŁA�\�Ȃ�ǂ����̃X�[�p�[�R���s���[�^�ɍ̗p����Ă��Ă��s�v�c����Ȃ������ȋC������̂���
�S�R����Șb�͕����Ȃ�����
>>938
�V���R�����傫���قǕ����܂艺���邩��A�E�F�n�S���g������ُ��
�����܂肪�������ˁH
�����Ȃ�Ƃ������ɃX�p�R���Ƃ����ǁA����ȃ`�b�v�g���Ȃ��Ǝv���ȁB
�V���R�����傫���قǕ����܂艺���邩��A�E�F�n�S���g������ُ��
�����܂肪�������ˁH
�����Ȃ�Ƃ������ɃX�p�R���Ƃ����ǁA����ȃ`�b�v�g���Ȃ��Ǝv���ȁB
�X�p�R���ɕ����܂�W�L��́H
�`�b�v�ʐς�������Ƌ}���Ɉ����Ȃ邩��A�Ȃ��Ƃ͌����Ȃ��Ǝv���B
�������A����������肶��Ȃ��Č���I�ɂł��Ȃ����R������̂ł͂Ȃ����Ǝv���̂����B
�������A����������肶��Ȃ��Č���I�ɂł��Ȃ����R������̂ł͂Ȃ����Ǝv���̂����B
������������ȑ傫���̃e�X�^���Ή��ł���̂����
���̃f�X�N�g�b�v�p�`�b�v�Ȃ�A�N�@�b�h�R�A�{�`�b�v�Z�b�g�����S1�`�b�v�ɓ������Ă�
�\���R�X�g�I�Ɍ��������x���ɂȂ��Ă�
�P�ɂ�������Ȃ��̂̓o���f�[�V�������������
�\���R�X�g�I�Ɍ��������x���ɂȂ��Ă�
�P�ɂ�������Ȃ��̂̓o���f�[�V�������������
�X�[�p�[�R���s���[�^�p�̃`�b�v�Ȃ�A
�`�b�v�ɃR�X�g����������Ǝv���Ă���z���ԈႢ�B
�X�[�p�[�R���s���[�^�͋��Ɏ��ڂ����Ȃ��A
���i���\��ō\�����l���Ȃ��Ǝv���Ă���̂�?
�`�b�v�ɃR�X�g����������Ǝv���Ă���z���ԈႢ�B
�X�[�p�[�R���s���[�^�͋��Ɏ��ڂ����Ȃ��A
���i���\��ō\�����l���Ȃ��Ǝv���Ă���̂�?
I/O�������������Ă��܂��ƁA�������č��R�X�g�ɂȂ��Ă��܂��̂ł́H
�㓡�L������Ȃ����A�T�E�X�u���b�W�����͍�����ʃ`�b�v���Ǝv���B
�㓡�L������Ȃ����A�T�E�X�u���b�W�����͍�����ʃ`�b�v���Ǝv���B
�m�[�X�u���b�W�@�\��VGA�����͉�����
MCM�Ȃ�o�邾�낤����
�J���T�C�N��������Ȃ����͎�荞�܂�
MCM�Ȃ�o�邾�낤����
�J���T�C�N��������Ȃ����͎�荞�܂�
���Ƃ��ΉF���D�ɐς܂Ȃ���s���Ȃ��Ƃ�����ȏȂ��邩���ˁB
�A�|�����Đ^��ǂ��߂Ȃ��ăg�����W�X�^�̃R���s���[�^���������Ȃ��������B
�A�|�����Đ^��ǂ��߂Ȃ��ăg�����W�X�^�̃R���s���[�^���������Ȃ��������B
>>947
VRAM����onboard�܂���onchip�œ����ł���A�g���J�[�h���GPU�͂قƂ�Ǖs�v�ɂȂ�B
�����łȂ��Ă��AGPU�͊O�t���\������_�C��ɓ������Ă��܂��Ă��j�b�`�ɑΏ��ł���B
VRAM����onboard�܂���onchip�œ����ł���A�g���J�[�h���GPU�͂قƂ�Ǖs�v�ɂȂ�B
�����łȂ��Ă��AGPU�͊O�t���\������_�C��ɓ������Ă��܂��Ă��j�b�`�ɑΏ��ł���B
>>937
���XOoO���L���ɓ����l�ȃR�[�h��f���R���p�C���́A����Ӗ����\�Ȗ�ŁA
����ȃR���p�C���ŃR�[�h�����ꂽ�\�t�g�́A���Ȃ苌���̂��������̂ł́H
���̃R���p�C�����A�킴�킴OoO������l�ȃR�[�h��f���Ƃ͎v���ɂ���
���A���I�ȏ����ω��ɂ��OoO���L���ɂȂ�ꍇ���Ă̂́A����Ȃɑ����Ȃ�
�C�����邵�B
���XOoO���L���ɓ����l�ȃR�[�h��f���R���p�C���́A����Ӗ����\�Ȗ�ŁA
����ȃR���p�C���ŃR�[�h�����ꂽ�\�t�g�́A���Ȃ苌���̂��������̂ł́H
���̃R���p�C�����A�킴�킴OoO������l�ȃR�[�h��f���Ƃ͎v���ɂ���
���A���I�ȏ����ω��ɂ��OoO���L���ɂȂ�ꍇ���Ă̂́A����Ȃɑ����Ȃ�
�C�����邵�B
>>950
GPU�����`�b�v�Z�b�g���A�O�t��GPU�Ƌ����œ���������l�ɂȂ��Ă��Ă邩��A
GPU���I���_�C�œ������Ă��S�����[�}���^�C����ˁB
�T�E�X�����͗��ɓ���i�Z�p�I�ɂł͂Ȃ��ď��i�I�Ɂj�Ǝv�����B
GPU�����`�b�v�Z�b�g���A�O�t��GPU�Ƌ����œ���������l�ɂȂ��Ă��Ă邩��A
GPU���I���_�C�œ������Ă��S�����[�}���^�C����ˁB
�T�E�X�����͗��ɓ���i�Z�p�I�ɂł͂Ȃ��ď��i�I�Ɂj�Ǝv�����B
953 �FMAC�I�^��951 �����F2008/02/09(�y) 20:03:44 ID:37ie/uQZ
>>951
���s���j�b�g�������߃��C�e���V���A�������N�ԂŔ�������Ă���v���Z�b�T�ƑS���قȂ邷���ǁB�B�B
���s���j�b�g�������߃��C�e���V���A�������N�ԂŔ�������Ă���v���Z�b�T�ƑS���قȂ邷���ǁB�B�B
Dual Core�{GPU��Quad Core��2�_�C�œ��ʂ�OK����܂����H
Dual Core�ŊO�t��GPU�g�������l��Quad Core�ŊO�t��GPU�s�v�Ȑl��
������Ƃ����]�v�ȃR�X�g�S���邱�ƂɂȂ�̂͂��D���l�Ƃ������ƂŁB
Dual Core�ŊO�t��GPU�g�������l��Quad Core�ŊO�t��GPU�s�v�Ȑl��
������Ƃ����]�v�ȃR�X�g�S���邱�ƂɂȂ�̂͂��D���l�Ƃ������ƂŁB
Silverthorne�Ɍ��z�����Ă�l������
��xC7�g���Ă݂�Ɨǂ���
��xC7�g���Ă݂�Ɨǂ���
C7���x���̂͒m���Ă��B
�����A�����C7���x���̂ł����āA
Silverthorne���x���Ƃ����ؖ��ɂȂ��ł͖����B
inorder���Ă����ŁA�����܂Ŗϑz�ł���̂͂��߂ł����B
�����A�����C7���x���̂ł����āA
Silverthorne���x���Ƃ����ؖ��ɂȂ��ł͖����B
inorder���Ă����ŁA�����܂Ŗϑz�ł���̂͂��߂ł����B
Intel���Ă����ŁA�����܂Ŗϑz�ł���̂͂��߂ł����B
�����A�x���`�͑���������
�Ƃ���sandra
�����A�x���`�͑���������
�Ƃ���sandra
>>953
�������>>937�� in-order�ւ̃R���p�C���̍œK���̘b�Ƃ͕ʂ���H
���s���j�b�g���̏��Ȃ��▽�߃��C�e���V�[�̑����ɑ��āA�R���p�C����
�œK�����v���o����b�͖����Ǝv�����B
>>956
C7�̒x���ň�Ԃ̖��́A�������A�N�Z�X���\�̒Ⴓ�������Ǝv���̂ŁA����
�l�b�N��Silverthorne������A���Ȃ�Ⴄ�Ǝv���B
�������>>937�� in-order�ւ̃R���p�C���̍œK���̘b�Ƃ͕ʂ���H
���s���j�b�g���̏��Ȃ��▽�߃��C�e���V�[�̑����ɑ��āA�R���p�C����
�œK�����v���o����b�͖����Ǝv�����B
>>956
C7�̒x���ň�Ԃ̖��́A�������A�N�Z�X���\�̒Ⴓ�������Ǝv���̂ŁA����
�l�b�N��Silverthorne������A���Ȃ�Ⴄ�Ǝv���B
�܂�����
960 �F�R�E�L�́M�E,,�j�����������������F2008/02/09(�y) 21:18:03 ID:rIBi1EFd
���ȁBmov��xor�Ń��W�X�^���l�[�~���O�Ƃ��̃m�E�n�E�͂܂��g���Ȃ���
�ň��t���ʂ��ȁB
NetBurst���肵��ɍ��V�t�g��A�����Z�ɒu��������^�R���p�C�����ł̋����͑S�����ɗ����Ȃ��Ȃ����B
�ň��t���ʂ��ȁB
NetBurst���肵��ɍ��V�t�g��A�����Z�ɒu��������^�R���p�C�����ł̋����͑S�����ɗ����Ȃ��Ȃ����B
961 �FMAC�I�^��958 �����F2008/02/09(�y) 21:23:44 ID:37ie/uQZ
>>958
�@�@--------------
�@�@���s���j�b�g���̏��Ȃ��▽�߃��C�e���V�[�̑����ɑ��āA�R���p�C����
�@�@�œK�����v���o����b�͖����Ǝv�����B
�@�@--------------
�ꉞ���s�p�C�v���C����2�{���邷���ǁB�B�B
���߂̃y�A�����O�Ƃ����ɕ����Ȃ��q�g���o�Ă����Ƃ������Ƃ�APentium����������Ȃ�ɂ���
�Ƃ������ƂȂ��ˁB
�@�@--------------
�@�@���s���j�b�g���̏��Ȃ��▽�߃��C�e���V�[�̑����ɑ��āA�R���p�C����
�@�@�œK�����v���o����b�͖����Ǝv�����B
�@�@--------------
�ꉞ���s�p�C�v���C����2�{���邷���ǁB�B�B
���߂̃y�A�����O�Ƃ����ɕ����Ȃ��q�g���o�Ă����Ƃ������Ƃ�APentium����������Ȃ�ɂ���
�Ƃ������ƂȂ��ˁB
962 �F�R�E�L�́M�E,,�j�����������������F2008/02/09(�y) 21:30:29 ID:rIBi1EFd
OoO�������Ă��A�ǂ̖��߂Ƃǂ̖��߂�������s�ł��邩�Ƃ��A��G�c�ɂł��c�����Ă����Ȃ���
���\�͈����o���܂���B
�܂��A�ǂ݂̂����\�̑債�ĕK�v�̖����Ƃ���̓R���p�C���C���ł������ǂˁB
���\�͈����o���܂���B
�܂��A�ǂ݂̂����\�̑債�ĕK�v�̖����Ƃ���̓R���p�C���C���ł������ǂˁB
�Ƃ�����C7��x���Ǝv���w��
Silverthorne�͍���Ȃ�����
�ǂ��l���Ă�
Silverthorne�͍���Ȃ�����
�ǂ��l���Ă�
964 �F�R�E�L�́M�E,,�j�����������������F2008/02/10(��) 10:21:48 ID:YVen/PEY
A100/A110�i����ULV-Dothan 512k�j��葬���������
965 �FMAC�I�^��MAC�I�^�F2008/02/10(��) 11:04:39 ID:L+RPXY/9
>>964
�@�@------------------
�@�@A100/A110�i����ULV-Dothan 512k�j��葬���������
�@�@------------------
�V���O���X���b�h�ł퓯���x�Ɠ`�����Ă��邷�B
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
�@�@==================
�@�@�������A�V���O���X���b�h�ł́ASV��(1.8GHz)��A110�Ɠ������炢�AMV��(1.1GHz)��A100(600MHz)�Ɠ���
�@�@���x�̐��\�ƌ��ς����Ă���悤���B
�@�@==================
�@�@------------------
�@�@A100/A110�i����ULV-Dothan 512k�j��葬���������
�@�@------------------
�V���O���X���b�h�ł퓯���x�Ɠ`�����Ă��邷�B
http://pc.watch.impress.co.jp/docs/2007/1128/ubiq205.htm
�@�@==================
�@�@�������A�V���O���X���b�h�ł́ASV��(1.8GHz)��A110�Ɠ������炢�AMV��(1.1GHz)��A100(600MHz)�Ɠ���
�@�@���x�̐��\�ƌ��ς����Ă���悤���B
�@�@==================
�����ă}���`�Ȃ�60%�����Ƃ����Ă����͂�����
����30%�ɂȂ���
����30%�ɂȂ���
>>961
�����炻��͎��in-order�ɑ���b�ŁA����ɑ����>>951�ŏ����Ă���肾���B
�ŏ���in-order�̘b����n�߂����Ȃ̂ɁA�������Ⴂ������̂��H
�����炻��͎��in-order�ɑ���b�ŁA����ɑ����>>951�ŏ����Ă���肾���B
�ŏ���in-order�̘b����n�߂����Ȃ̂ɁA�������Ⴂ������̂��H
in-order�̏ꍇ�A���߂̕��ёւ����o���Ȃ�����A���ߓ������s�����A�������Q�ōς܂�
�Ă邩��A�R���p�C�����������s�\�Ȗ��߂�A�������`�œf���o���Ă���Ȃ��Ƒʖڂ���
���ŁA����͍�����R���p�C���Ȃ畁�ʂɍs���Ă锤������ASilverthorne��p�ōœK����
��K�v�͖������Ęb���������肾���B
OoO�Ȃ疽�߂̕��ёւ����o���邩��A�Ⴆ�T�`�U���x�̖��߂̕��т���A�������Ă���s���j�b�g
�����̓������s�A�Ⴆ�R�������\�����Q�����̕p�x�������Ȃ邩��Ain-order��萫�\�������A
��������B
���ߎ��s���j�b�g���i�f�R�[�h���j�b�g�����W���邪�j�����Ȃ����ƁAin-order�̂����œ������s����
�@����Ȃ������A��������ɂ��Ȃ��ŗ~�����̂����B
�Ă邩��A�R���p�C�����������s�\�Ȗ��߂�A�������`�œf���o���Ă���Ȃ��Ƒʖڂ���
���ŁA����͍�����R���p�C���Ȃ畁�ʂɍs���Ă锤������ASilverthorne��p�ōœK����
��K�v�͖������Ęb���������肾���B
OoO�Ȃ疽�߂̕��ёւ����o���邩��A�Ⴆ�T�`�U���x�̖��߂̕��т���A�������Ă���s���j�b�g
�����̓������s�A�Ⴆ�R�������\�����Q�����̕p�x�������Ȃ邩��Ain-order��萫�\�������A
��������B
���ߎ��s���j�b�g���i�f�R�[�h���j�b�g�����W���邪�j�����Ȃ����ƁAin-order�̂����œ������s����
�@����Ȃ������A��������ɂ��Ȃ��ŗ~�����̂����B
�A���X�}�\
�������̃R���p�C�����AOoO��CPU��O��ɂ��āA�������s�\�Ȗ��߃R�[�h���A
�킴�킴�A���ɕ��ׂȂ��l�Ȏ蔲�������Ă�ꍇ�����ʂ��A���Ęb�Ȃ�A>>937
�̋^��ɂ��[�����������A���̂�����͂ǂ��Ȃ́H
�������̃R���p�C�����AOoO��CPU��O��ɂ��āA�������s�\�Ȗ��߃R�[�h���A
�킴�킴�A���ɕ��ׂȂ��l�Ȏ蔲�������Ă�ꍇ�����ʂ��A���Ęb�Ȃ�A>>937
�̋^��ɂ��[�����������A���̂�����͂ǂ��Ȃ́H
gcc��march�̐ݒ肵��
���ꂼ�ꌩ�Ă݂��
���ꂼ�ꌩ�Ă݂��
MS�̃R���p�C���̓f�[�^�̈ˑ������Ȃ����ē������s���₷���R�[�h�����邾������B
972 �FMAC�I�^��968 �����F2008/02/10(��) 15:38:53 ID:L+RPXY/9
>>968
�@�@-----------------
�@�@����͍�����R���p�C���Ȃ畁�ʂɍs���Ă锤������
�@�@-----------------
OoOE�ɂ����āA�R���p�C��(=�v���O���})�����߂����s����^�C�~���O�𐧌䂷�邱�Ƃ��s�\���B
�A�h���X��A���������߂������ɃC�V���[�����ۏ�S���������B
�܂��C���I�[�_�[�̏ꍇ�A���߂̕��т���s���C�e���V���l�����Đ�s���߂����ʂ�����
�^�C�~���O�ɍ��킹�Ĉˑ����߂�z�u���Ȃ��ƁA�o�u�����������邷�B
�A�[�L�e�N�`���␢�ゲ�Ƃɖ��߂̎��s���C�e���V��قȂ邷����A�œK���̂�肩�������x
�X�V����K�v���o�Ă��邷�B
����2�_�������Ă��u������vOoOE��x86�v���Z�b�T�p�̃R���p�C����Silverthrone�����łȂ�����
�픻�邩�Ǝv�����B
�@�@-----------------
�@�@����͍�����R���p�C���Ȃ畁�ʂɍs���Ă锤������
�@�@-----------------
OoOE�ɂ����āA�R���p�C��(=�v���O���})�����߂����s����^�C�~���O�𐧌䂷�邱�Ƃ��s�\���B
�A�h���X��A���������߂������ɃC�V���[�����ۏ�S���������B
�܂��C���I�[�_�[�̏ꍇ�A���߂̕��т���s���C�e���V���l�����Đ�s���߂����ʂ�����
�^�C�~���O�ɍ��킹�Ĉˑ����߂�z�u���Ȃ��ƁA�o�u�����������邷�B
�A�[�L�e�N�`���␢�ゲ�Ƃɖ��߂̎��s���C�e���V��قȂ邷����A�œK���̂�肩�������x
�X�V����K�v���o�Ă��邷�B
����2�_�������Ă��u������vOoOE��x86�v���Z�b�T�p�̃R���p�C����Silverthrone�����łȂ�����
�픻�邩�Ǝv�����B
����Ȗ��Intel�̃R���p�C���̒��̐l�͂������Ď��ł�
����������
>>972
������2�_�������Ă��u������vOoOE��x86�v���Z�b�T�p�̃R���p�C����Silverthrone�����łȂ�����
���픻�邩�Ǝv�����B
���ꂭ�炢�͒N�ł��������Ă���̂ł͂Ȃ��낤���H
>>972
������2�_�������Ă��u������vOoOE��x86�v���Z�b�T�p�̃R���p�C����Silverthrone�����łȂ�����
���픻�邩�Ǝv�����B
���ꂭ�炢�͒N�ł��������Ă���̂ł͂Ȃ��낤���H
Nehalem��Super Pi�摜�̑����ǁA�s���Ŋm��Ƃ̂��Ƃ��B
http://www.xtremesystems.org/forums/showpost.php?p=1547196&postcount=21
���e���ɒ��ځA�܂������Â��l�^���������ˁB�B�B
http://www.xtremesystems.org/forums/showpost.php?p=1547196&postcount=21
���e���ɒ��ځA�܂������Â��l�^���������ˁB�B�B
976 �FMAC�I�^���⑫�F2008/02/10(��) 15:56:58 ID:L+RPXY/9
����҂̃R�����g���B
http://www.xtremesystems.org/forums/showpost.php?p=2761352&postcount=194
�@�@------------------
�@�@5min photochop in 2006 posted in a joke thread turn in to this
�@�@------------------
�Ƃ���ō����̕��ꃋ�[�}�[�T�C�g���������o�邷���ˁB�B�B
http://www.xtremesystems.org/forums/showpost.php?p=2761352&postcount=194
�@�@------------------
�@�@5min photochop in 2006 posted in a joke thread turn in to this
�@�@------------------
�Ƃ���ō����̕��ꃋ�[�}�[�T�C�g���������o�邷���ˁB�B�B
���ꃋ�[�}�[�T�C�g����Ȃ��ă��[�}�[�Љ�T�C�g����B
����Ȃ̂̓\�[�X�̕��B�ǂ��܂ł����_���䂪��ł���z���B
�W�̂Ȃ��l�T�C�g�܂ōU���������Ƃ͂ȁB
�ǂ��������Ńy�[�W���J�����͂��Ȃ������ɁB
����Ȃ̂̓\�[�X�̕��B�ǂ��܂ł����_���䂪��ł���z���B
�W�̂Ȃ��l�T�C�g�܂ōU���������Ƃ͂ȁB
�ǂ��������Ńy�[�W���J�����͂��Ȃ������ɁB
MAC���^���u���O���������A��u�ʼn��サ������
979 �FMAC�I�^��977-978 �����F2008/02/10(��) 17:42:45 ID:L+RPXY/9
���t�͈��������������ӂȂ�
>>979
>�x����Ċ�сA�^����m�炳��Ē@���B
�N�����܂���ĂȂȂ��ł�������?
�M�ߐ��̔����y�[�W�͕ʂɂ݂Ȃ��Ⴂ�����A�݂Ă��M���Ȃ�������B
�P�ɓ����f���Ōl�T�C�g�@���Ȃ�Ă���Ă�MAC�I�^�̐��_���䂪��ł��邾���̂��Ƃ��B
>�x����Ċ�сA�^����m�炳��Ē@���B
�N�����܂���ĂȂȂ��ł�������?
�M�ߐ��̔����y�[�W�͕ʂɂ݂Ȃ��Ⴂ�����A�݂Ă��M���Ȃ�������B
�P�ɓ����f���Ōl�T�C�g�@���Ȃ�Ă���Ă�MAC�I�^�̐��_���䂪��ł��邾���̂��Ƃ��B
�Ƃ������E�����邯�ǁA�j���[�X�Љ�n�̃T�C�g����
�\�[�X�����������ǂ����̓t�B���^�����ɂƂ肠�������e�𐂂ꗬ���̂����ʂ̉^�c���j����B
���ƐM���邩�M���Ȃ����͓ǂݎ�̎��悾��B�ǂݎ�����[�}�[�͏��F���[�}�[���Ƃ�肫����
���O�������W���Ă������ȁB
�����܂Ő^�����L�߂邱�Ƃɂ������Ȃ�2ch�ɂ�����炸�ɁA����T�C�g���J���Ȃǂ�����
���͓I�Ȋ��������Ă��炢�������̂��B��������Ȃ�MAC�I�^�͂��������f���Ƃ������S�ȏꏊ��
�Ђ�����@���ėD�z���ɐZ�肽�������Ȃ̂��낤�B
�\�[�X�����������ǂ����̓t�B���^�����ɂƂ肠�������e�𐂂ꗬ���̂����ʂ̉^�c���j����B
���ƐM���邩�M���Ȃ����͓ǂݎ�̎��悾��B�ǂݎ�����[�}�[�͏��F���[�}�[���Ƃ�肫����
���O�������W���Ă������ȁB
�����܂Ő^�����L�߂邱�Ƃɂ������Ȃ�2ch�ɂ�����炸�ɁA����T�C�g���J���Ȃǂ�����
���͓I�Ȋ��������Ă��炢�������̂��B��������Ȃ�MAC�I�^�͂��������f���Ƃ������S�ȏꏊ��
�Ђ�����@���ėD�z���ɐZ�肽�������Ȃ̂��낤�B
�ԍ������ł�Ǝv������܂���n�OMAC�I�^���N���Ă₪��̂��B
MAC�I�^�͎��ˁB���łɂ��̎�芪����������B
MAC�I�^�͎��ˁB���łɂ��̎�芪����������B
MAC�I�^���ɂȂ��L���������
�\����30���ł����݂���ꂽ>>936��GJ!
�\����30���ł����݂���ꂽ>>936��GJ!
�܂��N�Y���N���Ă��www
���������˂�
���������˂�
�@�@�R�\�[�X�ł��������琂�ꗬ�����Ă�����
�@�@�ߑa���萷��オ���ċc�_���[�܂邱�Ƃ����邾��H
�����Nehalem�Ɋւ��Ă͏Љ�T�C�g���M�ߐ��͉������Ə����Ă��C�����邪�B
CELL�����̂܂܃\�P�b�g�S�V�W�ɂ��Ĕ������Ă�������
�ȂɂȂɁH����8�R�A�Ƃ��ł鎞��Ȃ́H
BlueGene(PPC440����)�݂����ɋ➙�����ň����Ă����ƃl�^�ɂȂ肻��
64���̃^�X�}�l��������������E�E
>>972
����MAC�I�^�������Ă邩�A�ǂ�����������B
����MAC�I�^�������Ă邩�A�ǂ�����������B
994 �FMAC�I�^��991 �����F2008/02/11(��) 18:08:26 ID:m5coYQS8
>>991
���i���o�Ă��邩�ǂ�����ʂƂ��āAIntel���������������������������Ă��邱�Ƃ�����ԈႢ�������B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/947-948
�@�@========================
�@�@��Intel (Shekhar Borkar ��)
�@�@�@�@�}���`�R�A�ɂނ��āA�P��R�A�͋ɒ[�ɃV���v���ɂȂ�B
�@�@�@�@�@�@----------------
�@�@�@�@�@�@"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
�@�@�@�@�@�@----------------
�@�@�@�@�\�t�g�E�F�A���͊v���I�ȕϑJ���N����Ƃ̎��B
�@�@========================
���i���o�Ă��邩�ǂ�����ʂƂ��āAIntel���������������������������Ă��邱�Ƃ�����ԈႢ�������B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/947-948
�@�@========================
�@�@��Intel (Shekhar Borkar ��)
�@�@�@�@�}���`�R�A�ɂނ��āA�P��R�A�͋ɒ[�ɃV���v���ɂȂ�B
�@�@�@�@�@�@----------------
�@�@�@�@�@�@"A core will look like a NAND gate in the future. You won't want to mess with it," said Borkar.
�@�@�@�@�@�@----------------
�@�@�@�@�\�t�g�E�F�A���͊v���I�ȕϑJ���N����Ƃ̎��B
�@�@========================
������Silverthorne�ɍœK�����ꂽPC�����\�t�g�Ȃ�ďo��킯����
��ɃX�p�R������Ń\�t�g�E�F�A�̊v�������ꑱ����30�N
100�N����������ƌ����Ă�����
100�N����������ƌ����Ă�����
�V���v�����R�A���ăT�[�o�[�����ł���H
HPC�̒��̓��蕪�����
>>995 ����
Silverthorne��PC�p�v���Z�b�T�Ŗ������Ƃ퓯�ӂ��邷�B
�����������̃��o�C���f�o�C�X���A����PC�ōs���Ă���悤�ȋ@�\�������Ƃ��e�Ղɑz���ł��邷�B
>>996 ����
�P�ɕ������Ƃ��������̘b�����ǁA�_���Q�[�g�̂��Ƃ��v���Z�b�T�R�A���g�p����悤�ɂȂ�Ƃ�����g��A
�����v���������Ƃ��l���Ă���ƌ����邷�B
Silverthorne��PC�p�v���Z�b�T�Ŗ������Ƃ퓯�ӂ��邷�B
�����������̃��o�C���f�o�C�X���A����PC�ōs���Ă���悤�ȋ@�\�������Ƃ��e�Ղɑz���ł��邷�B
>>996 ����
�P�ɕ������Ƃ��������̘b�����ǁA�_���Q�[�g�̂��Ƃ��v���Z�b�T�R�A���g�p����悤�ɂȂ�Ƃ�����g��A
�����v���������Ƃ��l���Ă���ƌ����邷�B
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/