Intel派がAMDの次世代CPUを語るスレ 1
AMDの次世代CPUについて語ろう
というスレッドが、厨房過ぎて激しく使えないので、
アム厨規制を排除したIntelユーザのための
より現実的になったAMDの次世代CPUを語るスレッド
が今ここに登場。
実性能はアレだが、
ロードマップの面白さだけなら最近はAMDが勝っている。
2ndマシンにAMDプロセッサはいかが??
AMDの次世代CPUについて語ろう 第48世代 [注:糞スレです]
http://hibari.2ch.net/test/read.cgi/jisaku/1288468228/
Intelの次世代CPUについて語ろう 44
http://hibari.2ch.net/test/read.cgi/jisaku/1285537224/
というスレッドが、厨房過ぎて激しく使えないので、
アム厨規制を排除したIntelユーザのための
より現実的になったAMDの次世代CPUを語るスレッド
が今ここに登場。
実性能はアレだが、
ロードマップの面白さだけなら最近はAMDが勝っている。
2ndマシンにAMDプロセッサはいかが??
AMDの次世代CPUについて語ろう 第48世代 [注:糞スレです]
http://hibari.2ch.net/test/read.cgi/jisaku/1288468228/
Intelの次世代CPUについて語ろう 44
http://hibari.2ch.net/test/read.cgi/jisaku/1285537224/
|
|
|
誤記訂正
アム厨規制を排除した
↓
アム厨を排除した
いきなり失敗したぞ。
アム厨規制を排除した
↓
アム厨を排除した
いきなり失敗したぞ。
削除依頼出しといてね
以降書き込み禁止
以降書き込み禁止
Intel-Achronix 22nm CPU-FPGA Deal: The Future of Atom?
http://www.brightsideofnews.com/news/2010/11/2/-intel-achronix-22nm-cpu-fpga-deal-the-future-of-atom.aspx
Stellarton to have a stellar future in low-power high-density servers,
the company needs to get as much experience in the field of 22nm FPGA as possible,
and here is where a smaller player such as Achronix comes along.
Atom+FPGAのやつはサーバ向けらしい。
Bulldozer~Bull 2
あたりと衝突の予感。
http://www.brightsideofnews.com/news/2010/11/2/-intel-achronix-22nm-cpu-fpga-deal-the-future-of-atom.aspx
Stellarton to have a stellar future in low-power high-density servers,
the company needs to get as much experience in the field of 22nm FPGA as possible,
and here is where a smaller player such as Achronix comes along.
Atom+FPGAのやつはサーバ向けらしい。
Bulldozer~Bull 2
あたりと衝突の予感。
http://citavia.blog.de/2010/10/21/signs-of-bulldozer-2-and-llano-9726240/
Bulldoezer NG(Bull 2)でサポートされる新しい命令
BMI (Bit Manipulation Instructions)
TBM (Trailing Bit Manipulation)
FMA3 (three operand FMA) instructions
FMA4は既にBull 1でサポートされているが、
FMA3はAVXとの互換性のためにあとから追加される。
Bulldoezer NG(Bull 2)でサポートされる新しい命令
BMI (Bit Manipulation Instructions)
TBM (Trailing Bit Manipulation)
FMA3 (three operand FMA) instructions
FMA4は既にBull 1でサポートされているが、
FMA3はAVXとの互換性のためにあとから追加される。
http://northwood.blog60.fc2.com/blog-entry-4336.html
>“Zambezi”の最初のEngineering Sampleは2010年12月にパートナーに渡されるという。
>生産立ち上げは2月となり、デスクトップ向けの“Bulldozer”アーキテクチャCPUの生産は4月開始となる。
>ローンチもその頃になると見られる
12月サンプルで4月投入なんて無理だろうなあ。
>“Zambezi”の最初のEngineering Sampleは2010年12月にパートナーに渡されるという。
>生産立ち上げは2月となり、デスクトップ向けの“Bulldozer”アーキテクチャCPUの生産は4月開始となる。
>ローンチもその頃になると見られる
12月サンプルで4月投入なんて無理だろうなあ。
基地外の典型的活動例だね
◆AMDサーバロードマップ
2011Q3-Q4に、G34/C3プラットフォームで第1世代のBulldozer登場。
2012-2013 G42/G44プラットフォームが登場。
第1世代のBulldozerコアをベースに、サーバ用のI/Oチップを統合。
サーバ向けのGPUも別途登場。
2013-2014 G42/G44プラットフォームにBulldozer-NG(Bulldozer 2)が登場。
コアが更新される。詳細不明だが、少なくとも下の3つの命令が追加される。
- BMI (Bit Manipulation Instructions)
- TBM (Trailing Bit Manipulation)
- FMA3 (three operand FMA) instructions
2014~ 新しいSocketにBull 2が移行。
移行、ストリームコアを統合し、
ヘテロジニアス&ファブリックなアーキテクチャへ進化していく。
2011Q3-Q4に、G34/C3プラットフォームで第1世代のBulldozer登場。
2012-2013 G42/G44プラットフォームが登場。
第1世代のBulldozerコアをベースに、サーバ用のI/Oチップを統合。
サーバ向けのGPUも別途登場。
2013-2014 G42/G44プラットフォームにBulldozer-NG(Bulldozer 2)が登場。
コアが更新される。詳細不明だが、少なくとも下の3つの命令が追加される。
- BMI (Bit Manipulation Instructions)
- TBM (Trailing Bit Manipulation)
- FMA3 (three operand FMA) instructions
2014~ 新しいSocketにBull 2が移行。
移行、ストリームコアを統合し、
ヘテロジニアス&ファブリックなアーキテクチャへ進化していく。
11 :Socket774:2010/11/07(日) 12:38:35 ID:S2BAQj28
今980X使ってるんで、これ以上の性能のを発売しろよ
話はそれから
話はそれから
>>4
いつからbullが組み込み向けになったんだw
いつからbullが組み込み向けになったんだw
14 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 15:28:51 ID:Jw/kKYNC
携帯電話の無線制御装置とかのネットワーク処理絡み向けのプラットフォームな気がするぜ
あれ高密度ブレード使うし。
このあたりは伝統的にIntelが強い。ネトバXeon時代にはんば強引に捻じ込んだからな。
AMDで基地局向けプラットフォームなんて聞いたことない。
あれ高密度ブレード使うし。
このあたりは伝統的にIntelが強い。ネトバXeon時代にはんば強引に捻じ込んだからな。
AMDで基地局向けプラットフォームなんて聞いたことない。
15 :Socket774:2010/11/07(日) 17:20:57 ID:jkFCjWm7
また、また淫厨が性懲りもなく糞スレ建てたのか
まあ、過疎ってるイソテル次世代スレをどうにも出来ないほどサンディ以降が駄目だから仕方無いのかな
まあ、過疎ってるイソテル次世代スレをどうにも出来ないほどサンディ以降が駄目だから仕方無いのかな
>>14
そもそもAMDにそのセグメントで使えるチップそのものが無いっしょ
そもそもAMDにそのセグメントで使えるチップそのものが無いっしょ
IntelのLarrabee内蔵CPUが出るのは早くて2015年のSky Lakeらしいから
CPUのヘテロジニアス化ではAMDに遅れる可能性が十分に高い
CPUのヘテロジニアス化ではAMDに遅れる可能性が十分に高い
そもそもAMDもGPUを統合した後にヘテロ化に向けてどう進むかが不透明でしょ
SandyとLlanoじゃL3を共有してる分Sandyの方が統合が進んでるぐらいだし
SandyとLlanoじゃL3を共有してる分Sandyの方が統合が進んでるぐらいだし
問題はAMDのゲーム向けGPUを統合してGPGPU的な何が出来るのよ、だろ
ちゃんとそっち向けに設計を振ったNVIDIAの方は
別にCPUに統合しないでも立派に(GPGPU的シェアとしては)使い物になってるし
ちゃんとそっち向けに設計を振ったNVIDIAの方は
別にCPUに統合しないでも立派に(GPGPU的シェアとしては)使い物になってるし
21 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 18:57:29 ID:Jw/kKYNC
http://www.intel.co.jp/jp/intel/pr/press2003/031014a.htm
このあたりからね
Prestonia 2GHz(+HT)と同等程度のCPU性能はAtom 1~2コア程度でも実現できるだろうし
どっちかというとパケット処理に特化した(かつロジックの再構成が可能な)アクセラレータが必要かも。
あとは画像処理とか輪転印刷機とか?
うちの師匠がFPGAのフリーランスエンジニアは結構食えるという話をしてたわ。
このあたりからね
Prestonia 2GHz(+HT)と同等程度のCPU性能はAtom 1~2コア程度でも実現できるだろうし
どっちかというとパケット処理に特化した(かつロジックの再構成が可能な)アクセラレータが必要かも。
あとは画像処理とか輪転印刷機とか?
うちの師匠がFPGAのフリーランスエンジニアは結構食えるという話をしてたわ。
22 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 19:01:38 ID:Jw/kKYNC
AMD to demo Bulldozer next week
http://www.semiaccurate.com/2010/11/06/amd-demo-bulldozer-next-week/
Bulldozerが来週ついにデモか!?
Orochiが4月か5月に登場する。
http://www.semiaccurate.com/2010/11/06/amd-demo-bulldozer-next-week/
Bulldozerが来週ついにデモか!?
Orochiが4月か5月に登場する。
>>17
Sky Lakeなんてコードネーム初めて聞いたぞ。
ソースどこ~?
AMDとIntelはいつも似たような方向性に進んでいるからな。
AMDのロードマップはIntelの動向の参考にもなる。
FPGAと普通のカスタムロジックの比は10:3だったかな。
今更感あるし、あまり期待してない。
Sky Lakeなんてコードネーム初めて聞いたぞ。
ソースどこ~?
AMDとIntelはいつも似たような方向性に進んでいるからな。
AMDのロードマップはIntelの動向の参考にもなる。
FPGAと普通のカスタムロジックの比は10:3だったかな。
今更感あるし、あまり期待してない。
同じ機能を実現するのに必要なトランジスタ数の比ね。
26 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 19:23:37 ID:Jw/kKYNC
AtomはFSB引きずってるから、多チップの高密度のサーバにするのに、
インターコネクト~ネットワークの強化するのだろうか。
もしくはオラクルに対抗してサーバのワークロードに特化したアクセラレータついたら
面白いがそれはないかな。
インターコネクト~ネットワークの強化するのだろうか。
もしくはオラクルに対抗してサーバのワークロードに特化したアクセラレータついたら
面白いがそれはないかな。
Intel announces Tunnel Creek - Atom E600 System on Chip
http://www.anandtech.com/show/3929/intel-announces-tunnel-creek-atom-e600-system-on-chip
なんか錆用に見えないな。
http://www.anandtech.com/show/3929/intel-announces-tunnel-creek-atom-e600-system-on-chip
なんか錆用に見えないな。
29 :,,・´∀`・,,)っ-○○○:2010/11/07(日) 19:53:09 ID:Jw/kKYNC
結局次世代Atomスレになりました。
FPGAって並列パターンマッチングとかに結構使えるんだよな
文字列処理を多用するサーバとかどう?
というか、ネットワーク関連だな。
FPGAって並列パターンマッチングとかに結構使えるんだよな
文字列処理を多用するサーバとかどう?
というか、ネットワーク関連だな。
暗号とかは?
結局Llanoっていつ発売すんの?
AMD信者があんまり持ち上げるからサンディスルーして買おうと思ったのに
AMD信者があんまり持ち上げるからサンディスルーして買おうと思ったのに
笠原記事だと2コア版がQ3、4コア版がQ4。
海外記事でデスクトップ版Llanoの量産開始が7月。
2011年第2四半期までに出る可能性はあまりなさそう。
海外記事でデスクトップ版Llanoの量産開始が7月。
2011年第2四半期までに出る可能性はあまりなさそう。
【法則発動】雑音犬畜生Part45【自己紹介】
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
ここで語るINTEL派の,,・´∀`・,,)っ-○○○の紹介スレッド置いてゆきますね
別名、雑音・テヘ権田・アムド虫連呼厨
最近はクソスレ乱立に明け暮れている。
雑豚こと,,・´∀`・,,)っ-○○○の立てたクソスレ一覧
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
AMD使いを怒らせる一言
http://hibari.2ch.net/test/read.cgi/jisaku/1288411267/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
彼氏がAMDのCPUを使ってた。別れたい…
http://hibari.2ch.net/test/read.cgi/jisaku/1283130761/
Core 2 Quad vs i7 vs i5 vs Phenom II Part2
http://hibari.2ch.net/test/read.cgi/jisaku/1252407087/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288836208/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288374617/
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
ここで語るINTEL派の,,・´∀`・,,)っ-○○○の紹介スレッド置いてゆきますね
別名、雑音・テヘ権田・アムド虫連呼厨
最近はクソスレ乱立に明け暮れている。
雑豚こと,,・´∀`・,,)っ-○○○の立てたクソスレ一覧
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
AMD使いを怒らせる一言
http://hibari.2ch.net/test/read.cgi/jisaku/1288411267/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
彼氏がAMDのCPUを使ってた。別れたい…
http://hibari.2ch.net/test/read.cgi/jisaku/1283130761/
Core 2 Quad vs i7 vs i5 vs Phenom II Part2
http://hibari.2ch.net/test/read.cgi/jisaku/1252407087/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288836208/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288374617/
35 :Socket774:2010/11/08(月) 10:04:38 ID:RaUysDWd
sandy出たら1090Tはいくらになる?
>>32
つまり一般市場向けAMD32nmCPUはあと半年以上出てこないということになる
同一プロセスの製品投入で1年半も遅れたのは2000年以降初めてじゃないか?
ttp://pc.watch.impress.co.jp/docs/2009/0323/kaigai02l.gif
分社化して更に泥沼って終わってる
つまり一般市場向けAMD32nmCPUはあと半年以上出てこないということになる
同一プロセスの製品投入で1年半も遅れたのは2000年以降初めてじゃないか?
ttp://pc.watch.impress.co.jp/docs/2009/0323/kaigai02l.gif
{kind=link}
分社化して更に泥沼って終わってる
情報入るのは明後日かもしれんが、明日がAnalyst Dayなんだからそろそろ噂話を元にした妄想はヤメたほうが良くないか?
39 :Socket774:2010/11/08(月) 11:51:16 ID:L1fhNqeU
ここはAM2に絶望して939からC2Dに乗り換えた元アム厨のスレなのか?w
32nmは資金繰りとかで色々遅れたけど22nm以降は際限なく投資してるから多分大丈夫だろ
41 :Socket774:2010/11/08(月) 13:13:38 ID:vy3MONS0
よくわからんけど、32nmで難航して22nmは順調なんてことがあり得るのか?
32nmは別にプロセスのせいじゃないんじゃないの?
そもそも、2009年にはGFは32nmプロセスは量産準備段階に入れたところ、
AMDの設計の遅れで、立ち上げ遅らせたんだし。
22nmもGFは順調だけど、AMD側の設計遅れで22nmの製品が遅れる可能性は出てくる。
そもそも、2009年にはGFは32nmプロセスは量産準備段階に入れたところ、
AMDの設計の遅れで、立ち上げ遅らせたんだし。
22nmもGFは順調だけど、AMD側の設計遅れで22nmの製品が遅れる可能性は出てくる。
http://www.anandtech.com/bench/CPU/2
アム厨のデマでむちゃくちゃになっているから、
一応わかっていると思うが確認のために貼っておく。
現状、AMDの最上位製品は、2年くらい前に発売された
Intel Core i7 920やCore 2 Quad 9650と同等以下の性能であり、
絶対性能面でのAMDの優位性はCore 2の発売移行4年以上にわたってない。
アム厨のデマでむちゃくちゃになっているから、
一応わかっていると思うが確認のために貼っておく。
現状、AMDの最上位製品は、2年くらい前に発売された
Intel Core i7 920やCore 2 Quad 9650と同等以下の性能であり、
絶対性能面でのAMDの優位性はCore 2の発売移行4年以上にわたってない。
LlanoはGPUを大きくとったのが災いしてるのか
激しく遅れてるな。
あと、後藤によるとLlanoからATI系のGPUでは初めてSOIになるらしく
そこが障害になっているのだろうか。
激しく遅れてるな。
あと、後藤によるとLlanoからATI系のGPUでは初めてSOIになるらしく
そこが障害になっているのだろうか。
K6-2とCeleronが張り合っていた時代に戻ってしまったな
OpenGL
ttp://benchmarkreviews.com/index.php?option=com_content&task=view&id=508&Itemid=63&limit=1&limitstart=4
DX11
ttp://benchmarkreviews.com/index.php?option=com_content&task=view&id=508&Itemid=63&limit=1&limitstart=6
最新ゲームやクリエイティブな作業でPhenomに負けるi7というのはIntel派を激怒させるに足るだろうか
ttp://benchmarkreviews.com/index.php?option=com_content&task=view&id=508&Itemid=63&limit=1&limitstart=4
DX11
ttp://benchmarkreviews.com/index.php?option=com_content&task=view&id=508&Itemid=63&limit=1&limitstart=6
最新ゲームやクリエイティブな作業でPhenomに負けるi7というのはIntel派を激怒させるに足るだろうか
Sandyには是非ともK10超えを果たして欲しいところ
>>44
どう考えても32nmSOIにGPUいきなり持ってきたせい
どう考えても32nmSOIにGPUいきなり持ってきたせい
>>29-30
文字列処理や暗号処理は
FPGAにオフロードして元が取れるほどの長いタスクが実際のところほとんど無い気がする。
メモリやキャッシュレベルでCPUコアとFPGAが通信出来るならいいけど、それはないしな。
文字列処理や暗号処理は
FPGAにオフロードして元が取れるほどの長いタスクが実際のところほとんど無い気がする。
メモリやキャッシュレベルでCPUコアとFPGAが通信出来るならいいけど、それはないしな。
FPGAを入れるのは、DSPの代わりというところだろう
>>46
オーバークロックしたPhenomが定格のi7に負けてるグラフにしか見えないが
オーバークロックしたPhenomが定格のi7に負けてるグラフにしか見えないが
INTELユーザーが激怒するのを必死に堪えるスレっすか?ここはw
53 :,,・´∀`・,,)っ-○○○:2010/11/08(月) 23:32:44 ID:3FffnnCD
>>49
想定してるのはコプロセッサ的な活用じゃないんだわ。
FPGAってのは初動のコンフィギュレーション以外CPUが関与するところはほとんどない。
むしろCPUに処理を流す前にFPGA側でデータを前処理してしまうような使い方。
想定してるのはコプロセッサ的な活用じゃないんだわ。
FPGAってのは初動のコンフィギュレーション以外CPUが関与するところはほとんどない。
むしろCPUに処理を流す前にFPGA側でデータを前処理してしまうような使い方。
インテル信者さんは何を怒ってるか知らないけどAMDが性能で劣るのは仕方ないことじゃないの?
つまりTorrenzaの二番煎じということだな
コレを機にAMDもTorrenzaを復活して対抗して欲しいところ
コレを機にAMDもTorrenzaを復活して対抗して欲しいところ
>>51
ああ、確かに負けてるね、コレは失敗した
ところで定格で1割強の差は4倍の値段差として妥当なんだろうか
まあ、それを言ったら965BEがコスパ最強になっちゃうな
1090Tダメじゃん
ところで、値段差で5870のCFやSATA3対応のSSD購入できるけどそこら辺はどう反論するの?
ああ、確かに負けてるね、コレは失敗した
ところで定格で1割強の差は4倍の値段差として妥当なんだろうか
まあ、それを言ったら965BEがコスパ最強になっちゃうな
1090Tダメじゃん
ところで、値段差で5870のCFやSATA3対応のSSD購入できるけどそこら辺はどう反論するの?
57 :,,・´∀`・,,)っ-○○○:2010/11/09(火) 00:18:53 ID:5t6+3pTh
取れんツァは復活も何も生まれてすらないだろ・・。
構想でっち上げるだけならMotorola(現Freescale)のほうが先進的
構想でっち上げるだけならMotorola(現Freescale)のほうが先進的
GeneseoやFSB-FPGAも爆死しなかったっけ?
と思ったけどFSB-FPGAはAlteraが製品化してたっぽい
と思ったけどFSB-FPGAはAlteraが製品化してたっぽい
>>56
ハイエンドはコストパフォーマンス悪いことは承知で、絶対性能求めるところじゃないの?
1割の性能差に価値を見いだせない人は、そもそも気にしなくていいような。
というか、AMDもIntelのハイエンドの頭抑えられるような製品だせるようになったら、
1割の性能差で大幅な価格差つけた製品だしてくるよ。
慈善事業やってるんじゃないんだから。
ハイエンドはコストパフォーマンス悪いことは承知で、絶対性能求めるところじゃないの?
1割の性能差に価値を見いだせない人は、そもそも気にしなくていいような。
というか、AMDもIntelのハイエンドの頭抑えられるような製品だせるようになったら、
1割の性能差で大幅な価格差つけた製品だしてくるよ。
慈善事業やってるんじゃないんだから。
60 :,,・´∀`・,,)っ-○○○:2010/11/09(火) 00:51:05 ID:5t6+3pTh
>>58
Geneseoはもともと2009-2010の予定じゃねーか
http://pc.watch.impress.co.jp/docs/2007/0417/kaigai351.htm
今回のはGeneseoがようやく具体的に動き出したって解釈も出来る
Geneseoはもともと2009-2010の予定じゃねーか
http://pc.watch.impress.co.jp/docs/2007/0417/kaigai351.htm
今回のはGeneseoがようやく具体的に動き出したって解釈も出来る
何も生み出していないGeneseoと比べれば、
Torrenzaは生み出した物がある。と言えますね。
DRC、Opteronソケットに実装するFPGAコプロセッサ
~Crayのスーパーコンピュータに採用
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
XtremeData XD1000 DEVELOPMENT SYSTEM
http://old.xtremedatainc.com/index.php?option=com_content&view=article&id=109&Itemid=170
HP Qualifies Celoxica RCHTX Acceleration Board
http://edageek.com/2007/09/17/celoxica-hp/
Torrenzaは生み出した物がある。と言えますね。
DRC、Opteronソケットに実装するFPGAコプロセッサ
~Crayのスーパーコンピュータに採用
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
XtremeData XD1000 DEVELOPMENT SYSTEM
http://old.xtremedatainc.com/index.php?option=com_content&view=article&id=109&Itemid=170
HP Qualifies Celoxica RCHTX Acceleration Board
http://edageek.com/2007/09/17/celoxica-hp/
Intelの次世代話すならこんなややこしいスレ使わないで元のインテル次世代スレ使えばいいのに
Bulldozerは明後日には何かおもしろい情報が入ってくるだろう。
動作デモもやるって話が出てきてるし。
動作デモもやるって話が出てきてるし。
Intelは来年のハイエンドをどうするのか早く決めないとやばくね?
Westmere 6コアのまま再来年のIvyまで行くのか
CFに不安があるB2にするのか、高コストのR(2011)にするのか、年末にIvyを前倒しにするのかをさ
まあ、BulldozerなんざH2で十分wとか思ってるならそれでもいいけどね
Westmere 6コアのまま再来年のIvyまで行くのか
CFに不安があるB2にするのか、高コストのR(2011)にするのか、年末にIvyを前倒しにするのかをさ
まあ、BulldozerなんざH2で十分wとか思ってるならそれでもいいけどね
14 名前: ,,・´∀`・,,)っ-○○○ Mail: 投稿日: 2010/11/07(日) 15:28:51 ID: Jw/kKYNC
携帯電話の無線制御装置とかのネットワーク処理絡み向けのプラットフォームな気がするぜ
あれ高密度ブレード使うし。
このあたりは伝統的にIntelが強い。ネトバXeon時代にはんば強引に捻じ込んだからな。
AMDで基地局向けプラットフォームなんて聞いたことない。
「はんば強引に」
中学生以下の語学力。
携帯電話の無線制御装置とかのネットワーク処理絡み向けのプラットフォームな気がするぜ
あれ高密度ブレード使うし。
このあたりは伝統的にIntelが強い。ネトバXeon時代にはんば強引に捻じ込んだからな。
AMDで基地局向けプラットフォームなんて聞いたことない。
「はんば強引に」
中学生以下の語学力。
半ば強引に
○なかばごういんに
×はんばごういんに
○なかばごういんに
×はんばごういんに
67 :,,・´∀`・,,)っ-○○○:2010/11/09(火) 21:05:23 ID:5t6+3pTh
カイジネタを知らん馬鹿はスッテンロ
○ほもはごういんに
69 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/09(火) 21:13:52 ID:5t6+3pTh
お約束だから一応・・・
______
| ,.へ、__,.ヘ/
| / \ ∠ヽ
|i^|「::::::ノ=l:::::ィ / ̄ ̄ ̄ ̄
,. -‐- 、 |ヽ| r_ \l | 静粛に……!
_/ \ ____/| ∧. (二二7! < 今>>65-66 は「なかば」ですよと
∠ ハヾミニ.r-、\∠L:r‐-‐-、:::::::::|/ ヽ_‐__.」`ー- | 文字レスのみをした
. /ィ ,L V∠ \l \\.)j j j j`二i\ /:|:::::::::::: | 言ったはずだ……
W、ゞi ,、~ __ 「 ̄∧ ヾ´´´ |. \ / |:::::::::::: | そういった行為は
,ゝし'/ ,ノ.| / i l. l \、.|:::::::::::: 一切認めていないと…!
l 、`ヾニンl\./\|l、_」 ヽ、 / ヾ::::::::::::
. | l | _l\ト、 | \r──‐┐ト/ / r‐┴-、:::
. |. | 7 l ヽ | /☆☆☆.| | ∨ {ニニヾヽ
______
| ,.へ、__,.ヘ/
| / \ ∠ヽ
|i^|「::::::ノ=l:::::ィ / ̄ ̄ ̄ ̄
,. -‐- 、 |ヽ| r_ \l | 静粛に……!
_/ \ ____/| ∧. (二二7! < 今>>65-66 は「なかば」ですよと
∠ ハヾミニ.r-、\∠L:r‐-‐-、:::::::::|/ ヽ_‐__.」`ー- | 文字レスのみをした
. /ィ ,L V∠ \l \\.)j j j j`二i\ /:|:::::::::::: | 言ったはずだ……
W、ゞi ,、~ __ 「 ̄∧ ヾ´´´ |. \ / |:::::::::::: | そういった行為は
,ゝし'/ ,ノ.| / i l. l \、.|:::::::::::: 一切認めていないと…!
l 、`ヾニンl\./\|l、_」 ヽ、 / ヾ::::::::::::
. | l | _l\ト、 | \r──‐┐ト/ / r‐┴-、:::
. |. | 7 l ヽ | /☆☆☆.| | ∨ {ニニヾヽ
Ontario/Zacate詳細
http://www.legitreviews.com/article/1464/3/
http://hothardware.com/Reviews/AMDs-Low-Power-Fusion-APU--Zacate-Unveiled/?page=4
http://www.pcper.com/article.php?aid=1036
Processor CPU cores CPU clock GPUALUs GPU clock TDP
AMD E-350 with Radeon HD 6310 graphics 2 1.6 GHz 80 500 MHz 18W
AMD E-240 with Radeon HD 6310 graphics 1 1.5 GHz 80 500 MHz 18W
AMD C-50 with Radeon HD 6250 graphics 2 1.0 GHz 80 280 MHz 9W
AMD C-30 with Radeon HD 6250 graphics 1 1.2 GHz 80 280 MHz 9W
http://www.legitreviews.com/article/1464/3/
http://hothardware.com/Reviews/AMDs-Low-Power-Fusion-APU--Zacate-Unveiled/?page=4
http://www.pcper.com/article.php?aid=1036
Processor CPU cores CPU clock GPUALUs GPU clock TDP
AMD E-350 with Radeon HD 6310 graphics 2 1.6 GHz 80 500 MHz 18W
AMD E-240 with Radeon HD 6310 graphics 1 1.5 GHz 80 500 MHz 18W
AMD C-50 with Radeon HD 6250 graphics 2 1.0 GHz 80 280 MHz 9W
AMD C-30 with Radeon HD 6250 graphics 1 1.2 GHz 80 280 MHz 9W
自作PC板で自分が知ってるネタを誰でも知ってると思い込んでる視野狭窄っっぷりが気色わるいですね
アニメキモヲタとかに多いよね、自分の常識=2chの常識とか思い込んでるデブ
アニメキモヲタとかに多いよね、自分の常識=2chの常識とか思い込んでるデブ
72 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/09(火) 22:09:25 ID:5t6+3pTh
連続投稿した恥ずかしい自分に対する最高に恥ずかしい言い訳だな
AMD公式Zacateのパフォーマンス比較図
ttp://img836.imageshack.us/img836/8941/58820003.jpg
おまけにnano dc
ttp://www.tomshardware.co.uk/chrome-520-nano-dc-vn1000,review-32034-11.html
クロック比較すりゃnanoにチョイ劣るCPUパフォーマンスか
メモリパフォーマンス最悪なnanoなのに
ttp://img836.imageshack.us/img836/8941/58820003.jpg
{kind=link}
おまけにnano dc
ttp://www.tomshardware.co.uk/chrome-520-nano-dc-vn1000,review-32034-11.html
クロック比較すりゃnanoにチョイ劣るCPUパフォーマンスか
メモリパフォーマンス最悪なnanoなのに
Intelがデモやるなって切れてるみたいだな
表現が作為的だと
表現が作為的だと
超GPU偏重だなw
バランス的にどうなのよと。
バランス的にどうなのよと。
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
> 673 名前:Socket774[もうねる] 投稿日:2010/11/09(火) 03:32:46 ID:j3ZORojC
> >>672
> レベル低いねお前も。 2chでミスタイプ見つけて大喜びかよ
> お前の厨房度も相当なもんだ
ミスタイプだと言って見たり2ch語だと言って見たり
分裂症もどんどん悪化してるようでなにより
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
> 673 名前:Socket774[もうねる] 投稿日:2010/11/09(火) 03:32:46 ID:j3ZORojC
> >>672
> レベル低いねお前も。 2chでミスタイプ見つけて大喜びかよ
> お前の厨房度も相当なもんだ
ミスタイプだと言って見たり2ch語だと言って見たり
分裂症もどんどん悪化してるようでなにより
78 :Socket774:2010/11/10(水) 16:58:35 ID:JGGXLLZy
※複数ID、複数回線でAMDへの嫌がらせに励む古株常連のZ豚>>1の情報※
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
どうでもいいがAnalyst Dayで使うスライドと
現場の技術担当とのすり合わせぐらい事前にやっとけ
ttp://pc.watch.impress.co.jp/img/pcw/docs/405/860/html/09.jpg.html
ttp://pc.watch.impress.co.jp/img/pcw/docs/405/860/html/11.jpg.html
上のAnalyst Dayでのスライドでは、TrinityのCPUコアについて、
次世代Bulldozerコアとなっている。しかし、技術を担当する
Chekib Akrout氏(Senior Vice President, Technology Group)は、
下のように、2012年に登場するのは拡張版Bulldozerで、
次世代Bulldozerは2013年と説明している。
現場の技術担当とのすり合わせぐらい事前にやっとけ
ttp://pc.watch.impress.co.jp/img/pcw/docs/405/860/html/09.jpg.html
{kind=link}
ttp://pc.watch.impress.co.jp/img/pcw/docs/405/860/html/11.jpg.html
{kind=link}
上のAnalyst Dayでのスライドでは、TrinityのCPUコアについて、
次世代Bulldozerコアとなっている。しかし、技術を担当する
Chekib Akrout氏(Senior Vice President, Technology Group)は、
下のように、2012年に登場するのは拡張版Bulldozerで、
次世代Bulldozerは2013年と説明している。
80 :Socket774:2010/11/11(木) 06:19:38 ID:izHXco1b
AMDはGPU重視の統合で勝負するしかないだろ
したがってゲーマー的にはますますIntel一択になってしまうが
したがってゲーマー的にはますますIntel一択になってしまうが
81 :Socket774:2010/11/11(木) 06:45:07 ID:uGazTn0c
Hybrid Crossfireみたいなこと内蔵GPUとラデで出来たらいいね
現状グラボはAMD優勢だし
現状グラボはAMD優勢だし
やったところで足をひっまるだけだが
83 :Socket774:2010/11/11(木) 07:59:37 ID:XnbBXlEJ
>>80
市場が膨大なMMOはラデ内蔵したAMD無双になるけどな
市場が膨大なMMOはラデ内蔵したAMD無双になるけどな
84 :Socket774:2010/11/11(木) 08:02:25 ID:XnbBXlEJ
ちなみにDX11ならイソテルよりAMDなのは実証されてる
イソテルはDX9専用
イソテルはDX9専用
ゲームゲームってガキのお遊びかよ
PCをゲームマシンにでもすんのか?さすが廃人
PCをゲームマシンにでもすんのか?さすが廃人
86 :Socket774:2010/11/11(木) 08:50:29 ID:izHXco1b
ベンチにしか使わない方がよほど俳人だろうが、カス
いんてるや
べんちまあくは
むしのこえ
べんちまあくは
むしのこえ
64bit環境ならAMD優勢なんていってた
馬鹿が昔いたな基地外アムド厨
買う価値もないAMDのごみCPU援護に必死すぎるチョンどもw
馬鹿が昔いたな基地外アムド厨
買う価値もないAMDのごみCPU援護に必死すぎるチョンどもw
大阪在住のコテ・テヘ権田こと団子(雑音)ってリアル身体障害者でピザ体型で生活保護受けてる在日朝鮮人だぜ、
そいつが大好きなのはインテルブランド、ぶっちゃけ同じ物使うのって恥ずかしくね?
そいつが大好きなのはインテルブランド、ぶっちゃけ同じ物使うのって恥ずかしくね?
その時代の淫厨はプを必死に擁護してたというw
91 :Socket774:2010/11/11(木) 12:23:18 ID:XnbBXlEJ
イソテルはπ焼き専用cpu
ゲームとレンダリングはAMD無双
ゲームとレンダリングはAMD無双
92 :Socket774:2010/11/11(木) 16:19:17 ID:s5N98g0p
ウンコみたいなオマケCPUしか作れねーAMDは終わりだな
今度からRADEON何とかって名前で売ればいいんじゃね?
RADEONのオマケにCPUが付いているというw
今度からRADEON何とかって名前で売ればいいんじゃね?
RADEONのオマケにCPUが付いているというw
in orderのatomは性能が低すぎて全くお話にならない。まともにofficeソフトが動かない
消費電力でもarmにボロ負けだからもはや存在価値がない
消費電力でもarmにボロ負けだからもはや存在価値がない
AMD 2010 Financial Analyst Dayの感想
http://blogs.itmedia.co.jp/kichi/2010/11/amd-2010-financ.html
http://blogs.itmedia.co.jp/kichi/2010/11/amd-2010-financ.html
※複数ID、複数回線でAMDへの嫌がらせに励む古株常連のZ豚>>1の情報※
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
Z豚の立てたスレ
【ATI】RADEONのドライバは糞過ぎる!
http://hibari.2ch.net/test/read.cgi/jisaku/1254766660/
【ノートン】ノートン社員の荒らしについて
http://hibari.2ch.net/test/read.cgi/sec/1274895438/
ゲームはゲフォ、ベンチはラデの原則
http://hibari.2ch.net/test/read.cgi/jisaku/1279674164/
AMDとセガは似てるよね
http://hibari.2ch.net/test/read.cgi/jisaku/1284032546/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
AMDのGPUはベンチ通りにゲームでは動かない
http://hibari.2ch.net/test/read.cgi/jisaku/1288205077/
AMD製CPUのプチフリは仕様
http://hibari.2ch.net/test/read.cgi/jisaku/1288221969/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
そもそもAMDがINTELに勝てるはずがないわけで・・・
http://hibari.2ch.net/test/read.cgi/jisaku/1288374504/
いまやアムドはデフォルトスタンダード
http://hibari.2ch.net/test/read.cgi/jisaku/1288391285/
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
アムド使いは「アムド」と呼んでやるだけで激怒する
http://hibari.2ch.net/test/read.cgi/jisaku/1288509251/
アムロ「ガンダム・・・う・・・イキます!!」
http://hibari.2ch.net/test/read.cgi/jisaku/1288510054/
Intel派がAMDの次世代CPUを語るスレ 1
http://hibari.2ch.net/test/read.cgi/jisaku/1289092258/
【ATI】RADEONのドライバは糞過ぎる!
http://hibari.2ch.net/test/read.cgi/jisaku/1254766660/
【ノートン】ノートン社員の荒らしについて
http://hibari.2ch.net/test/read.cgi/sec/1274895438/
ゲームはゲフォ、ベンチはラデの原則
http://hibari.2ch.net/test/read.cgi/jisaku/1279674164/
AMDとセガは似てるよね
http://hibari.2ch.net/test/read.cgi/jisaku/1284032546/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
AMDのGPUはベンチ通りにゲームでは動かない
http://hibari.2ch.net/test/read.cgi/jisaku/1288205077/
AMD製CPUのプチフリは仕様
http://hibari.2ch.net/test/read.cgi/jisaku/1288221969/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
そもそもAMDがINTELに勝てるはずがないわけで・・・
http://hibari.2ch.net/test/read.cgi/jisaku/1288374504/
いまやアムドはデフォルトスタンダード
http://hibari.2ch.net/test/read.cgi/jisaku/1288391285/
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
アムド使いは「アムド」と呼んでやるだけで激怒する
http://hibari.2ch.net/test/read.cgi/jisaku/1288509251/
アムロ「ガンダム・・・う・・・イキます!!」
http://hibari.2ch.net/test/read.cgi/jisaku/1288510054/
Intel派がAMDの次世代CPUを語るスレ 1
http://hibari.2ch.net/test/read.cgi/jisaku/1289092258/
97 :Socket774:2010/11/12(金) 15:20:35 ID:O3+HKIYg
最近は死体蹴りがひどいなw
98 :Socket774:2010/11/12(金) 17:07:09 ID:rI1XMR+P
サンディちゃんは一年の命でイビーちゃんはAPUに殺されるから必死なんだろう
99 :Socket774:2010/11/12(金) 21:59:59 ID:Lu57p7WZ
死体遺棄
※TFE 2010で披露されたZacateのデモにおいて,N-bodyの演算性能は21GFLOPS前後だったことを,記憶している読者も多いだろう。
それに対し,今回披露された「TFE 2010におけるLlanoのデモと同じ3タスクの同時実行デモ」では15~16GFLOPSまで3割ほど落ちているが,
これについてデモの担当者は,「3タスクのデモでは,円周率計算におけるCPU側のオーバーヘッドによって,
本来のパフォーマンスよりも20~25%ほど演算性能が落ちる」と説明していた。
ここで思い出してほしいのは,TFE 2010において3タスクの同時実行を行っていたLlanoが,
30GFLOPS程度を示していたことだ。LlanoがN-body演算を行ったときのGFLOPS値は,それより当然高くなる。
それに対し,今回披露された「TFE 2010におけるLlanoのデモと同じ3タスクの同時実行デモ」では15~16GFLOPSまで3割ほど落ちているが,
これについてデモの担当者は,「3タスクのデモでは,円周率計算におけるCPU側のオーバーヘッドによって,
本来のパフォーマンスよりも20~25%ほど演算性能が落ちる」と説明していた。
ここで思い出してほしいのは,TFE 2010において3タスクの同時実行を行っていたLlanoが,
30GFLOPS程度を示していたことだ。LlanoがN-body演算を行ったときのGFLOPS値は,それより当然高くなる。
↓淫厨は叩くときに相手を敬うのが常識(´;ω;`)
759 名前: Socket774 [sage] 投稿日: 2010/11/11(木) 10:02:10 ID:NRDWVwYU
単におたくらが目と耳を塞いでいるだけでしょ^^
764 名前: Socket774 [sage] 投稿日: 2010/11/11(木) 10:27:09 ID:NRDWVwYU
>>762
え?
まさか「おたく」をヲタという意味でしか認識してないの?
編厨は日本語も碌に使えないの?
お‐たく【▽御宅】 [名]
1 相手または第三者を敬って、その家・住居をいう語。「先生の―にうかがう」
2 相手または第三者の家庭を敬っていう語。「―は人数が多いからにぎやかでしょうね」
3 相手の夫を敬っていう語。「―はどちらへお勤めですの」
4 相手の属している会社・団体などの敬称。「―の景気はどうですか」
[代]同等の、あまり親しくない相手を、軽い敬意を込めていう語。「私より―のほうが適任でしょう」
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/758-
759 名前: Socket774 [sage] 投稿日: 2010/11/11(木) 10:02:10 ID:NRDWVwYU
単におたくらが目と耳を塞いでいるだけでしょ^^
764 名前: Socket774 [sage] 投稿日: 2010/11/11(木) 10:27:09 ID:NRDWVwYU
>>762
え?
まさか「おたく」をヲタという意味でしか認識してないの?
編厨は日本語も碌に使えないの?
お‐たく【▽御宅】 [名]
1 相手または第三者を敬って、その家・住居をいう語。「先生の―にうかがう」
2 相手または第三者の家庭を敬っていう語。「―は人数が多いからにぎやかでしょうね」
3 相手の夫を敬っていう語。「―はどちらへお勤めですの」
4 相手の属している会社・団体などの敬称。「―の景気はどうですか」
[代]同等の、あまり親しくない相手を、軽い敬意を込めていう語。「私より―のほうが適任でしょう」
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/758-
{kind=link}
Danubeってそんな横長のコアだったっけ?
104 :Socket774:2010/11/13(土) 02:07:46 ID:7Ubro9Wx
AMD遺体検視官
105 :Socket774 ♪:2010/11/14(日) 12:49:31 ID:IEnNhSLO
ポラックの法則からいくと、
CPUコアの面積が小さいBobcatも下手するとOOOのくせに
Atom未満の性能かもね。
CPUコアの面積が小さいBobcatも下手するとOOOのくせに
Atom未満の性能かもね。
でも自作的にサンディちゃん地雷ぽくね?OCtろか
もはや願望を呪文のようにブヒブヒと書き込むワキガ雑豚権田であった
108 :Socket774 ♪:2010/11/14(日) 12:58:52 ID:IEnNhSLO
OC興味ないから関係ないな。
自作erが皆OCやるわけじゃない。
というかBobcatとSandy Bridgeは競合しないだろ。
AtomとCULVだし。
自作erが皆OCやるわけじゃない。
というかBobcatとSandy Bridgeは競合しないだろ。
AtomとCULVだし。
ID:IEnNhSLOについて詳しく語り合われているスレ
【法則発動】雑音犬畜生Part45【自己紹介】
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
【法則発動】雑音犬畜生Part45【自己紹介】
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
昔、ATIが今でいうGPUのことをVPUと呼んでいたのだが、
結局普及しなかったのだが。
APUって言葉を無理に使う必要はないと思う。
まだコンセンサスもとれてないからなあ。
結局普及しなかったのだが。
APUって言葉を無理に使う必要はないと思う。
まだコンセンサスもとれてないからなあ。
そもそも、APUって定義あいまいすぎ。
http://picasaweb.google.com/lh/photo/CJ8OlhI7lw6R972ttK42uw?feat=embedwebsite
APU with CPUってなんだ?
APUってCPUがくっついた状態じゃなかったのか?
GPUはAPUだったのか?
わけわからん。AMDはこのへんの事情整理すべきだな。
http://picasaweb.google.com/lh/photo/CJ8OlhI7lw6R972ttK42uw?feat=embedwebsite
APU with CPUってなんだ?
APUってCPUがくっついた状態じゃなかったのか?
GPUはAPUだったのか?
わけわからん。AMDはこのへんの事情整理すべきだな。
>>111
ちゃんと読むだけで解決するだろ
ちゃんと読むだけで解決するだろ
それを無理な注文と言うのだよ。
114 :Socket774 ♪:2010/11/14(日) 14:29:11 ID:IEnNhSLO
Bobcatってもしかして、フェッチャも半速クロックだったりしてな。
128bitの等速クロックよりも、L2キャッシュとフェッチャの半速256bit
のほうがクロック下げられて同帯域で電力的にウマーだったり。
128bitの等速クロックよりも、L2キャッシュとフェッチャの半速256bit
のほうがクロック下げられて同帯域で電力的にウマーだったり。
AMD アナリストデイのスライド資料
http://phx.corporate-ir.net/External.File?item=UGFyZW50SUQ9Njk3NTJ8Q2hpbGRJRD0tMXxUeXBlPTM=&t=1
ブロック図ででてくるUVDってなんだっけ??
http://phx.corporate-ir.net/External.File?item=UGFyZW50SUQ9Njk3NTJ8Q2hpbGRJRD0tMXxUeXBlPTM=&t=1
ブロック図ででてくるUVDってなんだっけ??
Unified Video Decoderかな?
ハードウエアデコーダはIntelもAMDも同じトレンドか。
ハードウエアデコーダはIntelもAMDも同じトレンドか。
AMD's 2010 - 2011 Roadmaps: ~1B Transistor Llano APU, Bobcat and Bulldozer
http://www.anandtech.com/show/2871
AMD Roadmap 2010-2011
http://www.docstoc.com/docs/60961025/AMD-Roadmap-2010-2011
http://www.anandtech.com/show/2871
AMD Roadmap 2010-2011
http://www.docstoc.com/docs/60961025/AMD-Roadmap-2010-2011
つーか、BobcatコアってAtomとCULVのゾーン狙ってるんじゃなくて、
まんまAtomのゾーン狙ってる気がしてきた。
でかいGPU込みでTDP18&9Wでしょ。
GPU小さくした超モバイル版も考えてる気がする。
まんまAtomのゾーン狙ってる気がしてきた。
でかいGPU込みでTDP18&9Wでしょ。
GPU小さくした超モバイル版も考えてる気がする。
モロにAtom対抗で作られたんだよ。
でも思ったほど省電力にならなかったので、
TDP的にCULVのジャンルにも踏みこまざるをえなくなった。
超モバイル版は28(22?)nm世代から狙う予定らしい。
でも思ったほど省電力にならなかったので、
TDP的にCULVのジャンルにも踏みこまざるをえなくなった。
超モバイル版は28(22?)nm世代から狙う予定らしい。
>>117
> by Anand Lal Shimpi on 11/11/2009 12:50:00 PM
> by Anand Lal Shimpi on 11/11/2009 12:50:00 PM
121 :Socket774:2010/11/14(日) 17:01:10 ID:JR1IjaZL
TB自体がOCの代わりになっていくだろ。
一時的にTDPの枠を超えて動作するようになるからな。
一時的にTDPの枠を超えて動作するようになるからな。
TDPの枠は超えてないだろ。
少数のコアだけをOCしてほかをスリープして
TDP内におさめようっていうコンセプトじゃなかったっけ。
少数のコアだけをOCしてほかをスリープして
TDP内におさめようっていうコンセプトじゃなかったっけ。
>>122
それはPenrynで実装されたやつ。
Nehalemで実装されたTBは全コア動いていても、
余裕があれば全コアクロック上げるという仕様になっている。
SandyBridgeではアイドル状態でヒートシンク等冷えている場合は、
短時間だけTDP枠を超えてクロック上げて、冷却できなくなる前に、
クロックを通常に戻すという動作もありになっている。
それはPenrynで実装されたやつ。
Nehalemで実装されたTBは全コア動いていても、
余裕があれば全コアクロック上げるという仕様になっている。
SandyBridgeではアイドル状態でヒートシンク等冷えている場合は、
短時間だけTDP枠を超えてクロック上げて、冷却できなくなる前に、
クロックを通常に戻すという動作もありになっている。
それは意味があるのか……?
継続使用できないじゃん。
ベンチ対策?
継続使用できないじゃん。
ベンチ対策?
そのオーバークロック動作中に作業を終える可能性もあるので
意味があるのかないのかと問われればあるとしか言えない
意味があるのかないのかと問われればあるとしか言えない
Intelによるとアプリ起動時みたいな瞬間的に負荷がかかるような場合を想定している。
まあずっとTBかかるのは、Nehalemで実装されている稼働コア数関係なく、
TDP範囲内ならクロック上げる方だろうな。
まあずっとTBかかるのは、Nehalemで実装されている稼働コア数関係なく、
TDP範囲内ならクロック上げる方だろうな。
※複数ID、複数回線でAMDへの嫌がらせに励む古株常連のZ豚>>1の情報※
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
自作PC板の過去ログ(旧名 録音)
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
最悪板
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
現在はアスペル君(アスペルガー症候群の意)、
MACオタ、あっち糞、ダプオ(脱糞男)、GeForce9600GT厨、雑豚など
多数の名で知られている。淫厨なのに、自らアム厨などと名乗ることも多い。
<雑音ブタがテヘ権田に改名したころのもっさりスレの過去ログ>
http://toki.2ch.net/test/read.cgi/tubo/1279940532/11-12
Z豚の建てたスレ
【ATI】RADEONのドライバは糞過ぎる!
http://hibari.2ch.net/test/read.cgi/jisaku/1254766660/
【ノートン】ノートン社員の荒らしについて
http://hibari.2ch.net/test/read.cgi/sec/1274895438/
NOD32アンチウィルス Part64
http://hibari.2ch.net/test/read.cgi/sec/1272483870/
ゲームはゲフォ、ベンチはラデの原則
http://hibari.2ch.net/test/read.cgi/jisaku/1279674164/
AMDとセガは似てるよね
http://hibari.2ch.net/test/read.cgi/jisaku/1284032546/
【AMD】Phenom/PhenomII内蔵温度計問題【イカレてる】
http://hibari.2ch.net/test/read.cgi/jisaku/1281842104/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
AMDのGPUはベンチ通りにゲームでは動かない
http://hibari.2ch.net/test/read.cgi/jisaku/1288205077/
AMD製CPUのプチフリは仕様
http://hibari.2ch.net/test/read.cgi/jisaku/1288221969/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
そもそもAMDがINTELに勝てるはずがないわけで・・・
http://hibari.2ch.net/test/read.cgi/jisaku/1288374504/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288374617/
いまやアムドはデフォルトスタンダード
http://hibari.2ch.net/test/read.cgi/jisaku/1288391285/
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
アムド使いは「アムド」と呼んでやるだけで激怒する
http://hibari.2ch.net/test/read.cgi/jisaku/1288509251/
アムロ「ガンダム・・・う・・・イキます!!」
http://hibari.2ch.net/test/read.cgi/jisaku/1288510054/
Radeonは初心者を鴨にする為のVGA(二つ目)
http://hibari.2ch.net/test/read.cgi/jisaku/1288836208/
Intel派がAMDの次世代CPUを語るスレ 1
http://hibari.2ch.net/test/read.cgi/jisaku/1289092258/
【ATI】RADEONのドライバは糞過ぎる!
http://hibari.2ch.net/test/read.cgi/jisaku/1254766660/
【ノートン】ノートン社員の荒らしについて
http://hibari.2ch.net/test/read.cgi/sec/1274895438/
NOD32アンチウィルス Part64
http://hibari.2ch.net/test/read.cgi/sec/1272483870/
ゲームはゲフォ、ベンチはラデの原則
http://hibari.2ch.net/test/read.cgi/jisaku/1279674164/
AMDとセガは似てるよね
http://hibari.2ch.net/test/read.cgi/jisaku/1284032546/
【AMD】Phenom/PhenomII内蔵温度計問題【イカレてる】
http://hibari.2ch.net/test/read.cgi/jisaku/1281842104/
AMDのCPUはコスパが良いと思い込んでる奴の数→
http://hibari.2ch.net/test/read.cgi/jisaku/1287967094/
AMDのGPUはベンチ通りにゲームでは動かない
http://hibari.2ch.net/test/read.cgi/jisaku/1288205077/
AMD製CPUのプチフリは仕様
http://hibari.2ch.net/test/read.cgi/jisaku/1288221969/
インテル使いの奴を激怒させる一言part2
http://hibari.2ch.net/test/read.cgi/jisaku/1288369923/
そもそもAMDがINTELに勝てるはずがないわけで・・・
http://hibari.2ch.net/test/read.cgi/jisaku/1288374504/
Radeonは初心者を鴨にする為のVGA
http://hibari.2ch.net/test/read.cgi/jisaku/1288374617/
いまやアムドはデフォルトスタンダード
http://hibari.2ch.net/test/read.cgi/jisaku/1288391285/
AMD信者の特徴
http://hibari.2ch.net/test/read.cgi/jisaku/1288418780/
アムド使いは「アムド」と呼んでやるだけで激怒する
http://hibari.2ch.net/test/read.cgi/jisaku/1288509251/
アムロ「ガンダム・・・う・・・イキます!!」
http://hibari.2ch.net/test/read.cgi/jisaku/1288510054/
Radeonは初心者を鴨にする為のVGA(二つ目)
http://hibari.2ch.net/test/read.cgi/jisaku/1288836208/
Intel派がAMDの次世代CPUを語るスレ 1
http://hibari.2ch.net/test/read.cgi/jisaku/1289092258/
Athlon64の時、PCの用途は所詮シングルタスクが主流
マルチスレッドなんて特定用途以外ほとんど使われてない
1個のハイパフォーマンスコアで十分
従ってIPCの向上こそがCPUの道、と言ってた
AMDがその頃から開発してたアーキがBulldozerでしたってのが・・・
それから5年
未だにソフト側のマルチスレッド対応なんて
エンコードソフト以外ほとんど進んでない
サーバーならこのアーキは理にかなっているが
それを生かす機会がほとんどない一般のPCに向けに降ろそうとしてる点が
当時の発言からするとジョークに思える
マルチスレッドなんて特定用途以外ほとんど使われてない
1個のハイパフォーマンスコアで十分
従ってIPCの向上こそがCPUの道、と言ってた
AMDがその頃から開発してたアーキがBulldozerでしたってのが・・・
それから5年
未だにソフト側のマルチスレッド対応なんて
エンコードソフト以外ほとんど進んでない
サーバーならこのアーキは理にかなっているが
それを生かす機会がほとんどない一般のPCに向けに降ろそうとしてる点が
当時の発言からするとジョークに思える
エンコードソフト以外ほとんど進んでない
エンコードソフト以外ほとんど進んでない
エンコードソフト以外ほとんど進んでない
エンコードソフト以外ほとんど進んでない
そりゃお前の脳内(ry
エンコードソフト以外ほとんど進んでない
エンコードソフト以外ほとんど進んでない
エンコードソフト以外ほとんど進んでない
そりゃお前の脳内(ry
>ソフト側のマルチスレッド対応
OSとゲームはかなり進んだと思うんだが。
OSとゲームはかなり進んだと思うんだが。
マルチスレッドというかGPU対応が増えてきたね
動画デコードは言うに及ばず、ゲームの物理演算やブラウザまで対応してきている
エンコにしてもSandybridgeH2で専用回路積むし、レンダリングは元々OpenGL
動画デコードは言うに及ばず、ゲームの物理演算やブラウザまで対応してきている
エンコにしてもSandybridgeH2で専用回路積むし、レンダリングは元々OpenGL
ゲームのマルチスレッド対応なんて進んでないぞ。
一部のゲームが対応だけならしてるが、
GPUがやっていたような処理をCPUが行えばマルチコアは生きる。
プログラマも楽になる。
それをマルチコアで高速化したと情弱が勘違いしているだけ。
一部のゲームが対応だけならしてるが、
GPUがやっていたような処理をCPUが行えばマルチコアは生きる。
プログラマも楽になる。
それをマルチコアで高速化したと情弱が勘違いしているだけ。
何年先の人間だよ
いや何年先も何も今あるんだが。
現在 IntelプラットフォームではDirectXをCPUが行う→そういうプログラムをランタイム(?)に加えねばならずかえって面倒
未来 DirectXがどんどんGPGPUに対応しGPUでやれることが増える→それをCPUでやるのは昔取った杵柄で楽
未来 DirectXがどんどんGPGPUに対応しGPUでやれることが増える→それをCPUでやるのは昔取った杵柄で楽
DirectXはCPUだけでも実は動くように設計されているんだが。
だからGPUでサポートしている機能が欠落していてもゲームが動作する。
だからGPUでサポートしている機能が欠落していてもゲームが動作する。
動作はするだろうがまともな性能は出ないだろ
「現在 IntelプラットフォームではDirectXをCPUが行う」
何も他人に復唱されるほどのことじゃない
何も他人に復唱されるほどのことじゃない
HPCはGPUの時代になりつつあるんだな
違う、APU(CPU+GPU)の時代だ。
The Brazos Performance Preview: AMD E-350 Benchmarked
ttp://www.anandtech.com/show/4023/the-brazos-performance-preview-amd-e350-benchmarked
AMD's Brazos platform: The benchmarks
ttp://www.techreport.com/articles.x/19981
ttp://www.anandtech.com/show/4023/the-brazos-performance-preview-amd-e350-benchmarked
AMD's Brazos platform: The benchmarks
ttp://www.techreport.com/articles.x/19981
143 :Socket774 ♪:2010/11/16(火) 19:35:28 ID:iU5cfJXH
これはかなり優秀な結果だと思うが、
本スレではアム厨が馬鹿すぎて、評価いまいちのようだね。
簡単にK7/K8レベルの性能がでるわけないのに。
ちゃんとAtomに勝ってっているし、十分。
本スレではアム厨が馬鹿すぎて、評価いまいちのようだね。
簡単にK7/K8レベルの性能がでるわけないのに。
ちゃんとAtomに勝ってっているし、十分。
CULV級の18Wの消費電力でAtomに勝ってもしょうがないだろ。
問題は9WのOntarioでどこまでやれるかじゃないのか。
問題は9WのOntarioでどこまでやれるかじゃないのか。
145 :Socket774 ♪:2010/11/16(火) 20:20:36 ID:iU5cfJXH
いや、Intelのノート向けプロセッサの平均価格を下げている
原因の一つだから > CULV。だからIntelが数売るのには限界がある。
本来ULVはハイエンド扱いだったので。
というわけで通常電圧で戦えるBobcatの市場は
AMD的にはかなり戦いやすいと思う。
原因の一つだから > CULV。だからIntelが数売るのには限界がある。
本来ULVはハイエンド扱いだったので。
というわけで通常電圧で戦えるBobcatの市場は
AMD的にはかなり戦いやすいと思う。
146 :Socket774 ♪:2010/11/16(火) 20:21:47 ID:iU5cfJXH
どんなコアでもULV化すれば電力性能比は何倍にも向上する。
それで数がとれるかは別問題。
それで数がとれるかは別問題。
>本来ULVはハイエンド扱いだったので。
ああ、たしかにそんな設定もあったな。
CULVはAtomの安いお兄さん的な感覚でいたから忘れてた。
ああ、たしかにそんな設定もあったな。
CULVはAtomの安いお兄さん的な感覚でいたから忘れてた。
ontarioのFPUは半速なのか?
ttp://www.pcper.com/images/reviews/1039/sisoft-multimedia.jpg
ttp://www.pcper.com/images/reviews/1039/sisoft-multimedia.jpg
{kind=link}
149 :Socket774 ♪:2010/11/16(火) 22:03:08 ID:iU5cfJXH
FPUというかSIMDだろう。
SIMDは実装けちったっぽいな。
SIMDは実装けちったっぽいな。
AtomどころかCULVですらIONじゃないと太刀打ち出来ないだろ
SIMDは64bit一個、キャッシュは半速
そういうのはGPUで処理しないと性能出ない
そういうのはGPUで処理しないと性能出ない
GPUで何ができるんだい?
そもそもAPUでは何が高速化されるんだい?
そもそもAPUでは何が高速化されるんだい?
AMDわハーフスピード(笑)
SIMDで浮動小数点使うならGPU使ってーってことだろうか
のハーフスピードのi5 520M w
まあ、GPGPUソフトの普及は当分先だろうから、
当面はOpenGLやUVDの動画支援でCPU負荷を軽減するってところかね
当面はOpenGLやUVDの動画支援でCPU負荷を軽減するってところかね
つまり、AMDは遅い。という結論がでたな
BobcatはSSEは弱くても、GPUの支援のおかげで結果としてFireFoxとかでCULV用Cerelonより早い
CerelonじゃなくてCeleronか
LegitReviews
wPrime 32M
E-350・・・70.653
N330・・・61.742
P8700・・・34.589
x264 HD Video Encoding Benchmark
First Pass
E-350・・・13.54
N330・・・9.5
P8700・・・34.56
Second Pass
E-350・・・3.15
N330・・・2.83
P8700・・・8.02
PCMark Vantage
Overall
E-350・・・3298
P8700・・・4526
3DMark Vantage Entry Benchmark
Overall
E-350・・・3211
P8700・・・2520
GPU Score
E-350・・・4072
P8700・・・2211
CPU Score
E-350・・・1964
P8700・・・4335
Total System Power Consumption
Idle・・・11.3W
Prime 95・・・23W
Star Craft II・・・26.8W
Blu-ray Playback・・・29.4W
wPrime 32M
E-350・・・70.653
N330・・・61.742
P8700・・・34.589
x264 HD Video Encoding Benchmark
First Pass
E-350・・・13.54
N330・・・9.5
P8700・・・34.56
Second Pass
E-350・・・3.15
N330・・・2.83
P8700・・・8.02
PCMark Vantage
Overall
E-350・・・3298
P8700・・・4526
3DMark Vantage Entry Benchmark
Overall
E-350・・・3211
P8700・・・2520
GPU Score
E-350・・・4072
P8700・・・2211
CPU Score
E-350・・・1964
P8700・・・4335
Total System Power Consumption
Idle・・・11.3W
Prime 95・・・23W
Star Craft II・・・26.8W
Blu-ray Playback・・・29.4W
PC Perspective
CinBench 11 - OpenGL Test
AMD E-350 1.6GHz APU・・・7.52
Intel SU2300 CULV + ION・・・5.74
LAME 3.97a MT - MP3 Encoding
Single thread
AMD E-350 1.6GHz APU・・・369
Intel SU2300 CULV + ION・・・395
Multi thread
AMD E-350 1.6GHz APU・・・261
Intel SU2300 CULV + ION・・・277
3DMark Vantage - Entry
3DMark
AMD E-350 1.6GHz APU・・・3318
Intel SU2300 CULV + ION・・・3005
GPU Score
AMD E-350 1.6GHz APU・・・4247
Intel SU2300 CULV + ION・・・3330
CPU Score
AMD E-350 1.6GHz APU・・・2004
Intel SU2300 CULV + ION・・・2324
Left 4 Dead 2 - 1280*800 - Medium
AMD E-350 1.6GHz APU・・・Min FPS-15、Avg FPS-30.9
Intel SU2300 CULV + ION・・・Min FPS-12、Avg FPS-29.2
Valve Source Map Compilation
AMD E-350 1.6GHz APU・・・554
Intel SU2300 CULV + ION・・・598
HTML 5 Webvizbench Test - FireFox 4 Beta 6
1920*1200
AMD E-350 1.6GHz APU・・・5.56
Intel SU2300 CULV + ION・・・5.4
1280*800
AMD E-350 1.6GHz APU・・・8.11
Intel SU2300 CULV + ION・・・8.09
Poer Consumption
Idle
AMD E-350 1.6GHz APU・・・9.3W
Intel SU2300 CULV + ION・・・21.2W
Load - CineBench 11
AMD E-350 1.6GHz APU・・・19.1W
Intel SU2300 CULV + ION・・・29.2W
Load - Left 4 Dead 2
AMD E-350 1.6GHz APU・・・28.8W
Intel SU2300 CULV + ION・・・37.1W
CinBench 11 - OpenGL Test
AMD E-350 1.6GHz APU・・・7.52
Intel SU2300 CULV + ION・・・5.74
LAME 3.97a MT - MP3 Encoding
Single thread
AMD E-350 1.6GHz APU・・・369
Intel SU2300 CULV + ION・・・395
Multi thread
AMD E-350 1.6GHz APU・・・261
Intel SU2300 CULV + ION・・・277
3DMark Vantage - Entry
3DMark
AMD E-350 1.6GHz APU・・・3318
Intel SU2300 CULV + ION・・・3005
GPU Score
AMD E-350 1.6GHz APU・・・4247
Intel SU2300 CULV + ION・・・3330
CPU Score
AMD E-350 1.6GHz APU・・・2004
Intel SU2300 CULV + ION・・・2324
Left 4 Dead 2 - 1280*800 - Medium
AMD E-350 1.6GHz APU・・・Min FPS-15、Avg FPS-30.9
Intel SU2300 CULV + ION・・・Min FPS-12、Avg FPS-29.2
Valve Source Map Compilation
AMD E-350 1.6GHz APU・・・554
Intel SU2300 CULV + ION・・・598
HTML 5 Webvizbench Test - FireFox 4 Beta 6
1920*1200
AMD E-350 1.6GHz APU・・・5.56
Intel SU2300 CULV + ION・・・5.4
1280*800
AMD E-350 1.6GHz APU・・・8.11
Intel SU2300 CULV + ION・・・8.09
Poer Consumption
Idle
AMD E-350 1.6GHz APU・・・9.3W
Intel SU2300 CULV + ION・・・21.2W
Load - CineBench 11
AMD E-350 1.6GHz APU・・・19.1W
Intel SU2300 CULV + ION・・・29.2W
Load - Left 4 Dead 2
AMD E-350 1.6GHz APU・・・28.8W
Intel SU2300 CULV + ION・・・37.1W
Tech Report
7-Zip decompression
AMD Zacate 1.6GHz・・・2825
Zbox HD-ND22・・・2303
TrueCrypt - Overall average
AMD Zacate 1.6GHz・・・45
Zbox HD-ND22・・・42
Call of Duty 4 - 800*600 - Lowst detail
AMD Zacate 1.6GHz・・・61.1
Zbox HD-ND22・・・58.1
Call of Duty 4 - 1366*768 - Highest detail
AMD Zacate 1.6GHz・・・17.9
Zbox HD-ND22・・・17
Far Cry 2 - 1366*768 - Highest detail(DX10)
AMD Zacate 1.6GHz・・・6.9
Zbox HD-ND22・・・5.8
7-Zip decompression
AMD Zacate 1.6GHz・・・2825
Zbox HD-ND22・・・2303
TrueCrypt - Overall average
AMD Zacate 1.6GHz・・・45
Zbox HD-ND22・・・42
Call of Duty 4 - 800*600 - Lowst detail
AMD Zacate 1.6GHz・・・61.1
Zbox HD-ND22・・・58.1
Call of Duty 4 - 1366*768 - Highest detail
AMD Zacate 1.6GHz・・・17.9
Zbox HD-ND22・・・17
Far Cry 2 - 1366*768 - Highest detail(DX10)
AMD Zacate 1.6GHz・・・6.9
Zbox HD-ND22・・・5.8
HotHardware
x264 HD Benchmark - H.264 Video Encoding
First Pass
AMD Zacate E-350 1.6GHz・・・13.72
Intel Atom D525 and ION 2・・・12.47
LAME MT - MP3 Encoding
Single Threaded
AMD Zacate E-350 1.6GHz・・・2:04
Intel Atom D525 and ION 2・・・3:41
Multi Threaded
AMD Zacate E-350 1.6GHz・・・1:22
Intel Atom D525 and ION 2・・・2:34
Cinbench R11 - 3D Rendering
OpenGL Test
AMD Zacate E-350 1.6GHz・・・7.59
Intel Atom D525 and ION 2・・・5.93
CPU Test
AMD Zacate E-350 1.6GHz・・・0.62
Intel Atom D525 and ION 2・・・0.59
POV-Ray v3.7 Beta 39 - Ray Tracing Performance
Multi Threaded
AMD Zacate E-350 1.6GHz・・・568.2
Intel Atom D525 and ION 2・・・456.55
Single Threaded
AMD Zacate E-350 1.6GHz・・・286.85
Intel Atom D525 and ION 2・・・150.56
Futuremark 3DMark Vantage
3DMark,GPU Score,CPU Score
AMD Zacate E-350 1.6GHz・・・3307,4236,1995
Intel Atom D525 and ION 2・・・3183,4107,1901
ET:Quake Wars - Custom Time Demo
Normal Quality,No AA,8X Aniso
1024*768,1280*720,1366*768
AMD Zacate E-350 1.6GHz・・・20.4,19.5,18.6
Intel Atom D525 and ION 2・・・15.7,13.9
Left 4 Dead 2
High Quality,No AA w/8X Aniso
800*600,1024*768,1280*720
AMD Zacate E-350 1.6GHz・・・25.03,23.2,20.5
Intel Atom D525 and ION 2・・・19.92,15.09,13.61
Power Consumption - Total System Power Idle and Load
Load,Idle
AMD Zacate E-350 1.6GHz・・・31W,11W
Intel Atom D525 and ION 2・・・39.4W,18.2W
x264 HD Benchmark - H.264 Video Encoding
First Pass
AMD Zacate E-350 1.6GHz・・・13.72
Intel Atom D525 and ION 2・・・12.47
LAME MT - MP3 Encoding
Single Threaded
AMD Zacate E-350 1.6GHz・・・2:04
Intel Atom D525 and ION 2・・・3:41
Multi Threaded
AMD Zacate E-350 1.6GHz・・・1:22
Intel Atom D525 and ION 2・・・2:34
Cinbench R11 - 3D Rendering
OpenGL Test
AMD Zacate E-350 1.6GHz・・・7.59
Intel Atom D525 and ION 2・・・5.93
CPU Test
AMD Zacate E-350 1.6GHz・・・0.62
Intel Atom D525 and ION 2・・・0.59
POV-Ray v3.7 Beta 39 - Ray Tracing Performance
Multi Threaded
AMD Zacate E-350 1.6GHz・・・568.2
Intel Atom D525 and ION 2・・・456.55
Single Threaded
AMD Zacate E-350 1.6GHz・・・286.85
Intel Atom D525 and ION 2・・・150.56
Futuremark 3DMark Vantage
3DMark,GPU Score,CPU Score
AMD Zacate E-350 1.6GHz・・・3307,4236,1995
Intel Atom D525 and ION 2・・・3183,4107,1901
ET:Quake Wars - Custom Time Demo
Normal Quality,No AA,8X Aniso
1024*768,1280*720,1366*768
AMD Zacate E-350 1.6GHz・・・20.4,19.5,18.6
Intel Atom D525 and ION 2・・・15.7,13.9
Left 4 Dead 2
High Quality,No AA w/8X Aniso
800*600,1024*768,1280*720
AMD Zacate E-350 1.6GHz・・・25.03,23.2,20.5
Intel Atom D525 and ION 2・・・19.92,15.09,13.61
Power Consumption - Total System Power Idle and Load
Load,Idle
AMD Zacate E-350 1.6GHz・・・31W,11W
Intel Atom D525 and ION 2・・・39.4W,18.2W
AnandTech
Adobe Photoshop CS4 - Retouch Artists Benchmark
AMD E-350・・・88.5
Intel Atom D510・・・97.3
x264-HD Benchmark
1st Pass,2nd Pass
AMD E-350・・・14.2,3.5
Intel Atom D510・・・13.3,3.34
3dsmax 9 - SPECapc CPU Benchmark
AMD E-350・・・2.4
Intel Atom D510・・・1.9
Cinebench R10
Single Threaded,Multi Threaded
AMD E-350・・・1171,2250
Intel Atom D510・・・709,2024
Par2 - Multi-Threaded par2cmdline 0.4
AMD E-350・・・190.6
Intel Atom D510・・・199
WinRAR 3.8 Compression - 300MB Archive
AMD E-350・・・419.4
Intel Atom D510・・・448
Modern Warfare 2 - 1024*768 - Low Quality
AMD E-350・・・27.9
Intel Core i5 661・・・21.4
Intel Core i3 350M・・・16.7
BioShock 2 - 1024*768 - Low Quality
AMD E-350・・・23.1
Intel Core i5 661・・・23
Intel Core i3 350M・・・15.4
Modern Warfare 2 - 1366*768 - Fair Quality
AMD E-350・・・27.8
Intel Core i3 350M・・・17.7
Civilization V - DX10/DX11 - 1366*768 - Low Quality
AMD E-350・・・8.6
Intel Core i3 350M・・・5
Adobe Photoshop CS4 - Retouch Artists Benchmark
AMD E-350・・・88.5
Intel Atom D510・・・97.3
x264-HD Benchmark
1st Pass,2nd Pass
AMD E-350・・・14.2,3.5
Intel Atom D510・・・13.3,3.34
3dsmax 9 - SPECapc CPU Benchmark
AMD E-350・・・2.4
Intel Atom D510・・・1.9
Cinebench R10
Single Threaded,Multi Threaded
AMD E-350・・・1171,2250
Intel Atom D510・・・709,2024
Par2 - Multi-Threaded par2cmdline 0.4
AMD E-350・・・190.6
Intel Atom D510・・・199
WinRAR 3.8 Compression - 300MB Archive
AMD E-350・・・419.4
Intel Atom D510・・・448
Modern Warfare 2 - 1024*768 - Low Quality
AMD E-350・・・27.9
Intel Core i5 661・・・21.4
Intel Core i3 350M・・・16.7
BioShock 2 - 1024*768 - Low Quality
AMD E-350・・・23.1
Intel Core i5 661・・・23
Intel Core i3 350M・・・15.4
Modern Warfare 2 - 1366*768 - Fair Quality
AMD E-350・・・27.8
Intel Core i3 350M・・・17.7
Civilization V - DX10/DX11 - 1366*768 - Low Quality
AMD E-350・・・8.6
Intel Core i3 350M・・・5
参考データ
Zacate・・・40nm/75mm^2
Clarkdale・・・CPU:32nm/81mm^2 + GPU:45nm/114mm^2 = 195mm^2
Llano・・・32nm/220mm^2
SandyBridge・・・32nm/210~220mm^2
Intel Atom D510
動作周波数:1.66GHz
コア数/スレッド数:2/4
TDP:13W
AMD Zacate E-350
動作周波数:1.6GHz
コア数/スレッド数:2/2
TDP:18W
Intel Celeron SU2300
動作周波数は1.2GHz
コア数/スレッド数:2/2
TDP:10W
ION2(GT218)
TDP:12W
Zacate・・・40nm/75mm^2
Clarkdale・・・CPU:32nm/81mm^2 + GPU:45nm/114mm^2 = 195mm^2
Llano・・・32nm/220mm^2
SandyBridge・・・32nm/210~220mm^2
Intel Atom D510
動作周波数:1.66GHz
コア数/スレッド数:2/4
TDP:13W
AMD Zacate E-350
動作周波数:1.6GHz
コア数/スレッド数:2/2
TDP:18W
Intel Celeron SU2300
動作周波数は1.2GHz
コア数/スレッド数:2/2
TDP:10W
ION2(GT218)
TDP:12W
インテルは、最も大きなイスラエル支援企業のひとつです。
1999年、インテルはイスラエル政府によって略奪されたパレスチナ人の土地に工場を建設し、そこから大きな利益を得ています。
インテルの工場が立つ al-Manshiyya 村では、300軒あった家が全て破壊され 2000人のパレスチナ人が追放されました。
Intel は、主にコンピュータの主要なパーツである CPUを生産販売している企業です。
1999年、インテルはイスラエル政府によって略奪されたパレスチナ人の土地に工場を建設し、そこから大きな利益を得ています。
インテルの工場が立つ al-Manshiyya 村では、300軒あった家が全て破壊され 2000人のパレスチナ人が追放されました。
Intel は、主にコンピュータの主要なパーツである CPUを生産販売している企業です。
168 :Socket774:2010/11/17(水) 18:43:12 ID:vIFJZ12V
K8のIPCの8割以下という時点で、結果は大体わかってただろw
x86SIMDに必死にしがみ付くIntelと
SIMDはGPUに任せそれ以外の性能をより少ないリソースで過去と同等のものを作り出し
火病りIntelを横目で笑うAMD
SIMDはGPUに任せそれ以外の性能をより少ないリソースで過去と同等のものを作り出し
火病りIntelを横目で笑うAMD
こんな糞なamd印ノート、うれないわな( ̄◇ ̄;)
つかBobcatが投入されるのはCULVまでで、元から通常のノート向けの販売は無いよ
IONなけりゃゴミでしかないAtomやCULVがもうすぐ駆逐されるのか
>>173
Celeron SU2300 + ION2とか、壮大な
資源の無駄遣いだよな。単純な面積比で
3倍強って (しかもCPU部は32nm・・・)
製造コストは1桁違うんじゃねw
Zacate・・・40nm/75mm^2
Clarkdale・・・CPU:32nm/81mm^2 + GPU:45nm/114mm^2 = 195mm^2
ION (GT218)・・・GPU:40nm/57mm^2
Celeron SU2300 + ION2とか、壮大な
資源の無駄遣いだよな。単純な面積比で
3倍強って (しかもCPU部は32nm・・・)
製造コストは1桁違うんじゃねw
Zacate・・・40nm/75mm^2
Clarkdale・・・CPU:32nm/81mm^2 + GPU:45nm/114mm^2 = 195mm^2
ION (GT218)・・・GPU:40nm/57mm^2
175 :Socket774:2010/11/17(水) 23:15:07 ID:vIFJZ12V
ZacateのCPUは鼻糞並にしょぼいけどな。
>>172
性能の進歩でCULVでも十分になりつつある
性能の進歩でCULVでも十分になりつつある
Atomのシェアって既に14%有るんだよね
この半分でもBobcatにもってかれたらかなりシェアが落ちる
この半分でもBobcatにもってかれたらかなりシェアが落ちる
BobcatコアはAtomコアの約半分のサイズらしいな
コア設計はAMD、キャッシュはIntelということか
Intelはもう少し頑張ったほうがいい
コア設計はAMD、キャッシュはIntelということか
Intelはもう少し頑張ったほうがいい
Atomより2年以上後に出してプロセスの世代も新しいのに負けてたら話にならんだろ。
180 :Socket774:2010/11/18(木) 18:18:04 ID:k1OqLQn/
元々Intelはトランジスタ数の割にダイサイズが大きいけどな。
i7だって、トランジスタ数はK10より少ないのにコア面積は大きいだろ。
i7だって、トランジスタ数はK10より少ないのにコア面積は大きいだろ。
製造時の露光方法による制約じゃねーのか?>サイズの大きさ
32nmのCedarviewとOntarioだと性能差はどうなるんだろうな
Atomは組み込み用と設計同じだから、SoC用のスピードより低消費電力向けの
プロセスでCedarviewも作るはずなので、クロックは2GHz超えるかもしれないけど、
大幅に性能アップは期待できないと思われる
プロセスでCedarviewも作るはずなので、クロックは2GHz超えるかもしれないけど、
大幅に性能アップは期待できないと思われる
Zacateはなかなか良い。Atomがゴミに見える。
インテルはサンディのCULV前倒しくらいやれ。
インテルはサンディのCULV前倒しくらいやれ。
Zacateは普通にかなり期待している。
Bullは期待してないが。
Bullは期待してないが。
Zacateがバッティングするのはスペック的にCULVなんだから
Atomに勝って当たり前だと思うんだが、なんで下のCPUと比較されてるんだ?
まさかクロックだけで単純に比較してるのか?
基本、AtomはZacateとOntarioの間ぐらいで
Bobcatとは単純に比較できないと思うんだが
Atomに勝って当たり前だと思うんだが、なんで下のCPUと比較されてるんだ?
まさかクロックだけで単純に比較してるのか?
基本、AtomはZacateとOntarioの間ぐらいで
Bobcatとは単純に比較できないと思うんだが
ダイサイズがAtom並なのにCULVといい勝負してるのが問題なんだよ
Atom並っていうかAtomより余裕で小さい件について。
まあ、同価格帯なら普通Bobcatえらぶわな。
まあ、同価格帯なら普通Bobcatえらぶわな。
189 :Socket774:2010/11/20(土) 12:12:38 ID:vZsSBOwZ
-----ZacateE350---Intel Pentium U5400---Core i3-330UM
周波数 1.60GHz --------1.20GHz------------1.20GHz
Cinebench R10 Single-thread
-------1171-------------1691---------------1713
Cinebench R10Multi-thread
-------2250-------------3246---------------3899
ZacateE350 Core i3-330UM
http://images.anandtech.com/graphs/graph4023/34108.png
{kind=link}
http://images.anandtech.com/graphs/graph4023/34108.png
Intel Pentium U5400 1200 MHz 2 / 2
http://www.notebookcheck.net/Intel-Pentium-U5400-Notebook-Processor.31511.0.html
(/∇≦\)アチャ-!
190 :Socket774:2010/11/20(土) 17:59:08 ID:RN3z3hT1
でも、ここにきて、やたらZacateの小さいダイを褒めるのが笑えるよなw
今までデカいダイでIntelに対抗してたのによw
今までデカいダイでIntelに対抗してたのによw
191 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/20(土) 18:03:32 ID:jwSGJoVi
Magny-Cours=Westmereよりでかいダイ2個分
Magny-Coursのダウンクロック機能ってどこにソースあるんだっけ?
そろそろ調べようかと。
そろそろ調べようかと。
Zacateをダイサイズあたりの性能で持ち上げるってことは
PhenomⅡX6はその点で最低最悪だと認める訳だな
PhenomⅡX6はその点で最低最悪だと認める訳だな
AMDはBobcat以外で優位と言えるレベルのコアないから。
195 :Socket774:2010/11/20(土) 18:42:33 ID:C8MHvcNL
まあAMDはGPUメーカーとして生き残ってくれたらそれでいいやww
>簡単に言えば、Zacate/Ontarioは、AMDのローエンドGPUに、小さなBobcatコアを2個くっつけたシロモノだ。
Intelと正面対決しても勝てるわけが無いんだから、AMDがアドバンテージを得ようとしたら、
この方法しかないんだろ。
Intelと正面対決しても勝てるわけが無いんだから、AMDがアドバンテージを得ようとしたら、
この方法しかないんだろ。
197 :Socket774:2010/11/20(土) 20:05:37 ID:RyDr/mtK
■AMDの次世代Bulldozerコアは、なんと3割以上の低速化!!
>パフォーマンスは、Bulldozer世代でK10の2/3に落ちることになる。
>Bulldozer世代でK10の2/3に落ちる
>K10の2/3
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
現行K10ですらintelの足元にも及ばずもっさりなのに、AMDオワタ
Radeonと一緒に最適化してもらったらあっさり980Xを超えちゃったDirt2みたいなゲームも存在するしね
Radeonを自社に取り込んだAMDの快進撃が来年から始まるだろうな
Intelさんは爆熱でミドルやローエンドが弱いゲフォに最適化してもらえばいいよ
Radeonを自社に取り込んだAMDの快進撃が来年から始まるだろうな
Intelさんは爆熱でミドルやローエンドが弱いゲフォに最適化してもらえばいいよ
ついでに言うとDirt2はIntelにもしっかり最適化してある
>>148
アウトオブオーダーでFPUが弱いx86のCPUって言うと昔のK6系を思い出すな
アウトオブオーダーでFPUが弱いx86のCPUって言うと昔のK6系を思い出すな
しかし、Bulldozer Q2量産開始で、Q3リリースなのに国内のルーマー系ニュースサイト
誤訳なおさねぇな。
ぶっちゃけ、Llanoの方が遅いとかとても断定できないレベルで、
Llanoの方が早い可能性が高い。
誤訳なおさねぇな。
ぶっちゃけ、Llanoの方が遅いとかとても断定できないレベルで、
Llanoの方が早い可能性が高い。
202 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 00:35:53 ID:U79IzzU2
Pentium IIのFPUはP6当初からFADDとFMULに分かれてたがK6は1ユニットだった。
その代わりにMMXと別ユニットでfemmsでMMステートの高速切替が可能だったので
うまくやればMMX/3DNow!とx87を両方同時に使って性能を引き出すことも出来た。
これであってる?
その代わりにMMXと別ユニットでfemmsでMMステートの高速切替が可能だったので
うまくやればMMX/3DNow!とx87を両方同時に使って性能を引き出すことも出来た。
これであってる?
zacateとLlanoには期待してる
正確に言うとATiの内蔵GPUにだけ期待してる
正確に言うとATiの内蔵GPUにだけ期待してる
ネットブックにリッチなSIMDやFPUなんていらないからどうでもいいだろ
そもそも使い道が殆どない
そもそも使い道が殆どない
>>203
ATIは消えたのでゲフォで我慢してください
ATIは消えたのでゲフォで我慢してください
3D NowはFP/MMXレジスタと共用だからx87と混ぜたら無理なんじゃないのか?
MMX PentiumはFPとInt命令を同時発行できないので、K6にはアドバンテージあった。
MMX PentiumはFPとInt命令を同時発行できないので、K6にはアドバンテージあった。
SIMDなんか何に使うんだ?
まさかエンコとか言わないよな?それともレンダリングでもする気か?
動画再生はGPU支援があるから無くても困らない
つまりネットブックに於いてはGPU>SIMDということだ
まさかエンコとか言わないよな?それともレンダリングでもする気か?
動画再生はGPU支援があるから無くても困らない
つまりネットブックに於いてはGPU>SIMDということだ
わらた。
ネットブラウズするのにどれだけSIMD使われてると思ってるんだよ。
GPUなんてほんの一部の処理しか早くならん。
ネットブラウズするのにどれだけSIMD使われてると思ってるんだよ。
GPUなんてほんの一部の処理しか早くならん。
210 :Socket774:2010/11/21(日) 01:49:53 ID:gmLZWajW
AMDrの妄想が加速するなww
>>209
> ネットブラウズするのにどれだけSIMD使われてると思ってるんだよ。
知らないな、どの辺に使われてるの?
> GPUなんてほんの一部の処理しか早くならん。
ChromeとIE9とFF4ディスってんの?
> ネットブラウズするのにどれだけSIMD使われてると思ってるんだよ。
知らないな、どの辺に使われてるの?
> GPUなんてほんの一部の処理しか早くならん。
ChromeとIE9とFF4ディスってんの?
画像、音声、動画、パーサなどありとあらゆるところで使われてる。
というかBabcatのSIMD性能Sandra以外でそんな悪くないんだが。
必死にSIMD否定したい理由は何なんだろうな。
というかBabcatのSIMD性能Sandra以外でそんな悪くないんだが。
必死にSIMD否定したい理由は何なんだろうな。
ごめんなんでもない
>SIMDいるだろ
↓
>どれだけSIMD使われてると思ってるんだよ
↓
>必死にSIMD否定したい理由は何なんだろうな
いる、いらん、いる
花占いハジマタ!
↓
>どれだけSIMD使われてると思ってるんだよ
↓
>必死にSIMD否定したい理由は何なんだろうな
いる、いらん、いる
花占いハジマタ!
>どれだけSIMD使われてると思ってるんだよ
これが要らないって言ってるように読めたのか?
これが要らないって言ってるように読めたのか?
ああしまった
つい日本語として読んでた
つい日本語として読んでた
つまり、BobcatはSIMD性能も悪くない上、GPUでアクセラレートされる部分でもそれなりに効く
ダイサイズを小さくした割にはとても良いバランスAPUってことだな。
ダイサイズを小さくした割にはとても良いバランスAPUってことだな。
>BobcatはSIMD性能も悪くない上
Atom相手ならいいと思う
Atom相手ならいいと思う
まあ、TDP18Wクラスだと、Zacateはけちつけるほど悪くないよね。
本当にCPU性能が欲しいなら、ちょっと重いの我慢して、
25Wか35Wのノート選んだ方が良いだろうし。
本当にCPU性能が欲しいなら、ちょっと重いの我慢して、
25Wか35Wのノート選んだ方が良いだろうし。
ちょっと、言葉が足りないな。
TDP25Wか35WのCPUを載せたノートね。
TDP25Wか35WのCPUを載せたノートね。
BobのSIMD性能はGPUに頼っててSSEは手抜き
勿論GPGPUの今後を考えればそれでいいが
勿論GPGPUの今後を考えればそれでいいが
けど既存のハードを考えるとソフトが対応する度合いは知れてる
APUに対応しております、でもIntel GPUやNvでも動きます、って程度
普及しないとLlanoやBobcatを基準に出来ない
APUに対応しております、でもIntel GPUやNvでも動きます、って程度
普及しないとLlanoやBobcatを基準に出来ない
というかただ動くのと快適に動くのとは全然違うからねぇ
APUって言葉つかうのまだ早いから。
キモイからやめとけ。
キモイからやめとけ。
http://hothardware.com/Reviews/AMD-Zacate-E350-Processor-Performance-Preview/?page=1
こうしてみると、3D性能が特に高いというわけでもないんだよな。
こうしてみると、3D性能が特に高いというわけでもないんだよな。
APU対応ってなんだろ
中身はWindows向けだとAMD64+DX11、
LinuxやMacだとAMD64+OpenGLってだけで新しい特別な何かではないんだけど
もしかしてCUDAみたいな専用の環境が必要だとでも勘違いしてるのかな
>>224
快適かどうかは不明だけど、Zacateならネットブックのカテゴリーでは十分高性能だし、
LlanoはMMOやアマチュアレベルのグラフィック作成なら十分対応できる性能を持ってるよ
高価なQuadro必須なプロフェッショナル分野向けのCPUと勘違いしてはいけない
あくまで一般人が趣味で使うくらいの性能というだけ
中身はWindows向けだとAMD64+DX11、
LinuxやMacだとAMD64+OpenGLってだけで新しい特別な何かではないんだけど
もしかしてCUDAみたいな専用の環境が必要だとでも勘違いしてるのかな
>>224
快適かどうかは不明だけど、Zacateならネットブックのカテゴリーでは十分高性能だし、
LlanoはMMOやアマチュアレベルのグラフィック作成なら十分対応できる性能を持ってるよ
高価なQuadro必須なプロフェッショナル分野向けのCPUと勘違いしてはいけない
あくまで一般人が趣味で使うくらいの性能というだけ
APU対応=Fusion系のGPUでも動作保証あり。
APUのGPUはHD5000系のRADEONだから、
RADEONが対応していればFusionでも対応できる
いい加減APUには特別な対応が必要だと勘違いするのは止めた方がいい
RADEONが対応していればFusionでも対応できる
いい加減APUには特別な対応が必要だと勘違いするのは止めた方がいい
Acceleratedなのに、何も速くない件
実用じゃないけどゲームは速いよ
Zacateで重要なのはGPGPUでのアクセラレータじゃなくUVD3での動画支援
本格的にアクセラレートされるのはBull世代のTrinity以降
Llanoはソフト開発のための叩き台で、せいぜいゲームやアマチュアのOpenGLレンダ位が関の山
Zacateで重要なのはGPGPUでのアクセラレータじゃなくUVD3での動画支援
本格的にアクセラレートされるのはBull世代のTrinity以降
Llanoはソフト開発のための叩き台で、せいぜいゲームやアマチュアのOpenGLレンダ位が関の山
>Zacateで重要なのはGPGPUでのアクセラレータじゃなくUVD3での動画支援
(笑)
>Llanoはソフト開発のための叩き台で、
叩き台にもならんね
(笑)
>Llanoはソフト開発のための叩き台で、
叩き台にもならんね
キャッシュ共有すらせず、単にGPUをオンダイにしただけで叩き台もクソも無いわな。
メインメモリ帯域を食わない分外付けの方がマシ。
メインメモリ帯域を食わない分外付けの方がマシ。
キャッシュ共有すらせず、単にGPUをオンダイにしただけのLlanoですら遅滞してるんだよ。
それに専用ハードの動画支援はバッテリー等を考えたら重要。
それに専用ハードの動画支援はバッテリー等を考えたら重要。
だからそりゃCPUに統合しないと出来ない事じゃないだろ。
現時点でのGPGPUにキャッシュとか言ってるとNVみたいな目に遭う
239 :Socket774:2010/11/21(日) 16:54:46 ID:LZdEGuTU
APUを使うアプリってってAVXより普及するの?
外付けとかそんなコストがかかる余計なもんは不要
CPUで何でもできるならそれに越したことはない
キャッシュ共有は見た目かっこいいけどあまり意味が無いのは周知の事実
どんなデータをキャッシュするつもりなんだろ
どうせSandyはドライバが例のごとくグダグダでロクに機能しないと思うけどね
まあ、文句あるなら3DMARK11で相手してやるから、Llanoリリース日まで待ってな
CPUで何でもできるならそれに越したことはない
キャッシュ共有は見た目かっこいいけどあまり意味が無いのは周知の事実
どんなデータをキャッシュするつもりなんだろ
どうせSandyはドライバが例のごとくグダグダでロクに機能しないと思うけどね
まあ、文句あるなら3DMARK11で相手してやるから、Llanoリリース日まで待ってな
241 :Socket774:2010/11/21(日) 17:07:10 ID:LZdEGuTU
現時点ではCPU+GPUとFusionAPUの違いって
ノートにおけるコスト低減以外何もない
デスクトップというか自作じゃディスクリートの方が普通に高性能だし
ヘテロジニアスで御座い、というイメージだけが先行してるのが実態
Trinityだの未来語るのも結構だが、まずBull出してから言えよと
ノートにおけるコスト低減以外何もない
デスクトップというか自作じゃディスクリートの方が普通に高性能だし
ヘテロジニアスで御座い、というイメージだけが先行してるのが実態
Trinityだの未来語るのも結構だが、まずBull出してから言えよと
Trinityの三要素ってなに
>現時点ではCPU+GPUとFusionAPUの違いって
>ノートにおけるコスト低減以外何もない
そこが一番重要なんじゃないか。
PCヲタでないイッパンジンは、性能なんてわからない。
○○ベンチでこれだけ速い云々よりも、デュアルコア、
HD動画が見れる、カジュアル3Dゲームが動くって方が
売りになるでしょ。
CPUにコストをかけるよりも、ストレージに金を掛けた
ほうが快適になるのは、Intelも言ってるし。
>ノートにおけるコスト低減以外何もない
そこが一番重要なんじゃないか。
PCヲタでないイッパンジンは、性能なんてわからない。
○○ベンチでこれだけ速い云々よりも、デュアルコア、
HD動画が見れる、カジュアル3Dゲームが動くって方が
売りになるでしょ。
CPUにコストをかけるよりも、ストレージに金を掛けた
ほうが快適になるのは、Intelも言ってるし。
現状のチップセット統合と変わらんだろ
コスト低減を考えない企業は皆無
ディスクリートGPUを削れ、実装面積を削れるAPUの登場は待望されている
シングルスレッドや最高性能ばかり追い求めていたら時代に取り残されるよ
Nvidiaは早くノート向けのFermiを出すべき
IntelはGMAやHDグラフィックのDX11対応を急げ
どちらも無理そうだけど
>>245
> CPUにコストをかけるよりも、ストレージに金を掛けた
> ほうが快適になるのは、Intelも言ってるし。
SATA3に対応済みのAMD勝利フラグですね
もうすぐUSB3にも対応するけど
ディスクリートGPUを削れ、実装面積を削れるAPUの登場は待望されている
シングルスレッドや最高性能ばかり追い求めていたら時代に取り残されるよ
Nvidiaは早くノート向けのFermiを出すべき
IntelはGMAやHDグラフィックのDX11対応を急げ
どちらも無理そうだけど
>>245
> CPUにコストをかけるよりも、ストレージに金を掛けた
> ほうが快適になるのは、Intelも言ってるし。
SATA3に対応済みのAMD勝利フラグですね
もうすぐUSB3にも対応するけど
APUという言葉に囚われてはいけない。
CPUとGPUが載ったシステムはAPUと等価なので。
言葉が変わってみただけ。
CPUとGPUが載ったシステムはAPUと等価なので。
言葉が変わってみただけ。
>>245
そんならSandyどころかClarkdaleやArrandaleで
十分だ、ということになる
AMDの失敗はLlanoのコア統合に阿呆みたいに拘った点
特にノートではMCMでもいいから
ワンチップCPUを早期に投入すべきだった
それでもIntelよりGPU性能は上だったろう
>>245が主張する通りそこら辺を売りに出来た
それが来年半ばだのダイサイズ膨れ上がりました、だの
オイオイちょっと待てよ、って話
そんならSandyどころかClarkdaleやArrandaleで
十分だ、ということになる
AMDの失敗はLlanoのコア統合に阿呆みたいに拘った点
特にノートではMCMでもいいから
ワンチップCPUを早期に投入すべきだった
それでもIntelよりGPU性能は上だったろう
>>245が主張する通りそこら辺を売りに出来た
それが来年半ばだのダイサイズ膨れ上がりました、だの
オイオイちょっと待てよ、って話
APUのキモはオンダイによる高速低レイテンシ通信だからな
MCMじゃ意味がなくなる
Llanoは今後の高性能APU開発のための試作品だし、
ある程度の効率の悪さは問題にならんよ
2012年以降のおおまかなロードマップも発表されて、
Llano後継やHPC進出も想定されていたからね、
半年遅れを喜んでいたらいつの間にか逆転されてたみたいな、
兎と亀にならないようにIntelも頑張ったほうがいい
少なくとも3DMARK11で対決できるくらいにはね
MCMじゃ意味がなくなる
Llanoは今後の高性能APU開発のための試作品だし、
ある程度の効率の悪さは問題にならんよ
2012年以降のおおまかなロードマップも発表されて、
Llano後継やHPC進出も想定されていたからね、
半年遅れを喜んでいたらいつの間にか逆転されてたみたいな、
兎と亀にならないようにIntelも頑張ったほうがいい
少なくとも3DMARK11で対決できるくらいにはね
あのあぽーが28nm世代から採用するって話だしね。
デュアルチャネル化、4コア化、GPU強化だけで、
性能でCeleron/Pentium対抗にできそう。
それも圧倒的に低コストかつ省エネで。
デュアルチャネル化、4コア化、GPU強化だけで、
性能でCeleron/Pentium対抗にできそう。
それも圧倒的に低コストかつ省エネで。
高速低レイテンシ通信がしたいなら何でキャッシュすら共有しないんだ?
そもそも通信先はCPUじゃないのか?w
メモリの共有->演算器の共有->CPUとGPUの命令セットの透過的な共有
という段階を踏んでAPUの完成度が高まるなら分かるが、
その第一段階すらやってないのに名前だけ先行しちゃってるからお笑い
そもそも通信先はCPUじゃないのか?w
メモリの共有->演算器の共有->CPUとGPUの命令セットの透過的な共有
という段階を踏んでAPUの完成度が高まるなら分かるが、
その第一段階すらやってないのに名前だけ先行しちゃってるからお笑い
255 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 18:50:46 ID:U79IzzU2
そもそもGPU-CPU間のデータ通信は今までどおりVRAM用領域にWrite-Combineで
いったんGPU側でメモリに書いたものをCPUで読み出す(あるいはその逆)だけ。
少なくともLlano世代ではCPU-GPU間のデータ転送レイテンシは、実はマザーボードGPUのときと殆ど変わらない。
Intelは知らん。SVMの研究やってるし何かしらキャッシュを介したデータ交換とか実現しそうだけど。
いったんGPU側でメモリに書いたものをCPUで読み出す(あるいはその逆)だけ。
少なくともLlano世代ではCPU-GPU間のデータ転送レイテンシは、実はマザーボードGPUのときと殆ど変わらない。
Intelは知らん。SVMの研究やってるし何かしらキャッシュを介したデータ交換とか実現しそうだけど。
>メインメモリ帯域を食わない分外付けの方がマシ。
↓
>メモリの共有(中略)その第一段階すらやってない
わざわざ同じIDでやってるとこがいかにも押入れ
↓
>メモリの共有(中略)その第一段階すらやってない
わざわざ同じIDでやってるとこがいかにも押入れ
>>256
何言ってんの?
単にGPU/GPGPUとしての性能が欲しいだけなら、外付けの方がマシ。
わざわざAPUと称してCPUとGPUの統合を掲げたいなら、キャッシュの共有すらやらないのはお笑い。
理解できないなら黙ってた方がいいよ
何言ってんの?
単にGPU/GPGPUとしての性能が欲しいだけなら、外付けの方がマシ。
わざわざAPUと称してCPUとGPUの統合を掲げたいなら、キャッシュの共有すらやらないのはお笑い。
理解できないなら黙ってた方がいいよ
?
やってないのか?
同一ダイなんでしょ?
やってないのか?
同一ダイなんでしょ?
「メモリを共有してない」というだけならとんでもない無知で済ませられるが
「メモリを共有してる(ので帯域取り合う)のにメモリを共有してない」となると完全に電波
簡単な理屈すら通らない、知能指数マイナス値の押入れ食糞族の本領発揮である
「メモリを共有してる(ので帯域取り合う)のにメモリを共有してない」となると完全に電波
簡単な理屈すら通らない、知能指数マイナス値の押入れ食糞族の本領発揮である
まあ要約するというまでもないんだけど、
AMDのFusionは構想の開陳ではIntelに先行していたが、
中身は遅れていたってわけだ。
Sandy Bridgeは既にFusion 第2世代であり、
キャッシュも共有されている。
キャッシュを介したデータのやりとりで変態協調プログラムを
書くことも可能だ。メモリでも可能だがレイテンシが何倍もことなる。
AMDのFusionは構想の開陳ではIntelに先行していたが、
中身は遅れていたってわけだ。
Sandy Bridgeは既にFusion 第2世代であり、
キャッシュも共有されている。
キャッシュを介したデータのやりとりで変態協調プログラムを
書くことも可能だ。メモリでも可能だがレイテンシが何倍もことなる。
それがAPUという言葉と
Fusionという魔法の言葉で、
さも新しいことが起こっているかのように宣伝されているわけで。
GPUコアがATIだってことが唯一の救い。
Fusionという魔法の言葉で、
さも新しいことが起こっているかのように宣伝されているわけで。
GPUコアがATIだってことが唯一の救い。
何でもかんでも共有して
「ベンチ(的処理)ではいいけど実用では切ったほうがいい(HTT)」なんてオチが付くのはIntelレベル
「メモリを共有してるのにメモリを共有してない」だと押入れレベル
「単体GPUでもキャッシュ載せてない(そういう構成&用途)のに統合でわざわざ共有化するとか・・・」
ってのはその中間レベルか
「ベンチ(的処理)ではいいけど実用では切ったほうがいい(HTT)」なんてオチが付くのはIntelレベル
「メモリを共有してるのにメモリを共有してない」だと押入れレベル
「単体GPUでもキャッシュ載せてない(そういう構成&用途)のに統合でわざわざ共有化するとか・・・」
ってのはその中間レベルか
元々780Gの時代から指摘されてた事で(信者はアーアーキコエナーイだったが)ATIの内臓GPUだと専用メモリが無いと完全にベンチ詐欺なんだよな。帯域の問題で
でも専用メモリありだと廉価GPUつけたほうがどう見てもコスパがよかったわけで。この時代から騙されてたやつはいまだにATIの内臓GPUはとんでもなくすぐれてるって思ってそうだよな
でも専用メモリありだと廉価GPUつけたほうがどう見てもコスパがよかったわけで。この時代から騙されてたやつはいまだにATIの内臓GPUはとんでもなくすぐれてるって思ってそうだよな
そういやsandyが出るとIntel,nvidia,viaはGPUにキャッシュ乗ってて
AMDだけ無なんだな
AMDだけ無なんだな
>メモリを共有してるのにメモリを共有してない
物理メモリとバスは共有するが
各々の領域にダイレクトアクセスできるわけじゃない
ってことだと思うが、普通は
そもそも領域わけしてる時点で・・
物理メモリとバスは共有するが
各々の領域にダイレクトアクセスできるわけじゃない
ってことだと思うが、普通は
そもそも領域わけしてる時点で・・
>>259
言葉遊びはどうでもいいから。
まさかDRAMの共有とオンダイのキャッシュの共有を混同してるとは想像以上のアホだったな。
CPUとデータをやり取りするのにオフチップのDRAMを介した経路しか無いAPUのキモが
「オンダイによる高速低レイテンシ通信」とは笑わせてくれる。
言葉遊びはどうでもいいから。
まさかDRAMの共有とオンダイのキャッシュの共有を混同してるとは想像以上のアホだったな。
CPUとデータをやり取りするのにオフチップのDRAMを介した経路しか無いAPUのキモが
「オンダイによる高速低レイテンシ通信」とは笑わせてくれる。
267 :Socket774:2010/11/21(日) 19:45:12 ID:LZdEGuTU
AMDはCPUがオマケレベル
押入れではどうか知らんが
メモリにデータをどう載せるかというのはプログラムの役割
多分、プログラムそのままなのに
DRAM用とVRAM用に別れているものをハードの仕様で統合とか無理
そのデータをキャッシュにどう載せるかとなるとハードの領分で
プログラムからは同じメモリになる
メモリを共有してるのにメモリを共有してない押入れではどうか知らんが
メモリにデータをどう載せるかというのはプログラムの役割
多分、プログラムそのままなのに
DRAM用とVRAM用に別れているものをハードの仕様で統合とか無理
そのデータをキャッシュにどう載せるかとなるとハードの領分で
プログラムからは同じメモリになる
メモリを共有してるのにメモリを共有してない押入れではどうか知らんが
269 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 19:54:54 ID:U79IzzU2
CPUとGPUでキャッシュを共有していればキャッシュ経由でデータ交換ができる可能性があるが
Llanoはそうなってない。
GPUとCPUのデータ交換にメモリを介さないとできない。
メモリ帯域を取り合うだけで協調などしない。
特にWrite-Combine領域の読み書きはSSE4.1のmovntdqaをサポートしてるかどうかで性能に雲泥の差ができるが
LlanoはK10ベースだからサポートしてなさそうだな。
movntdqaの効果はこのあたり
http://gpu.fixstars.com/index.php/WriteCombine%E3%83%A1%E3%83%A2%E3%83%AA%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E3%82%92%E9%AB%98%E9%80%9F%E5%8C%96%E3%81%99%E3%82%8B
Llanoはそうなってない。
GPUとCPUのデータ交換にメモリを介さないとできない。
メモリ帯域を取り合うだけで協調などしない。
特にWrite-Combine領域の読み書きはSSE4.1のmovntdqaをサポートしてるかどうかで性能に雲泥の差ができるが
LlanoはK10ベースだからサポートしてなさそうだな。
movntdqaの効果はこのあたり
http://gpu.fixstars.com/index.php/WriteCombine%E3%83%A1%E3%83%A2%E3%83%AA%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E3%82%92%E9%AB%98%E9%80%9F%E5%8C%96%E3%81%99%E3%82%8B
AMD GPUにキャッシュが載ってないわけ無いだろ
殆ど使い道がないから凄く少ないだけ
それにL3キャッシュ共有するより演算器満載したほうがカタログスペックで見栄えがいいから、
LlanoにはL3が存在しない
K10系だとL3は存在意味が殆ど無いからね
あれはマルチプロセッサ用みたいなもんだ
殆ど使い道がないから凄く少ないだけ
それにL3キャッシュ共有するより演算器満載したほうがカタログスペックで見栄えがいいから、
LlanoにはL3が存在しない
K10系だとL3は存在意味が殆ど無いからね
あれはマルチプロセッサ用みたいなもんだ
>AMD GPUにキャッシュが載ってないわけ無いだろ
>殆ど使い道がないから凄く少ないだけ
乗ってるのはただのリードバッファ
>殆ど使い道がないから凄く少ないだけ
乗ってるのはただのリードバッファ
272 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 20:03:05 ID:U79IzzU2
Write-Buffer的なものはないんだよな
なんならXbox360みたいにeDRAMでも繋げるか?
DDR3のバスとは別にHT経由で繋げばそれなりの帯域確保できるかもよ?
結局高コストになるからやらないだろうが。
なんならXbox360みたいにeDRAMでも繋げるか?
DDR3のバスとは別にHT経由で繋げばそれなりの帯域確保できるかもよ?
結局高コストになるからやらないだろうが。
273 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 20:31:21 ID:U79IzzU2
CPU開発しているAMDがリードバッファ止まりしか載せてないということは、
必要性を感じてないか載せる手間に見合わない程度だということだろ
アーキテクチャ的に載せ辛いというのはあるだろうけどね
eDRAMとMCMというのはちょっと欲しいな、是非出して欲しいところ
SlotAみたいな大仰なものじゃなくて、
ClarkdaleみたいなCPUソケットに挿せる程度のものなら作れそうなんだが
100Wのハイエンド限定なら多少のコストアップは多めに見てもらえるんじゃないかね
コストアップに繋がるLFBが結局ほとんどのマザーに搭載された前例もある
必要性を感じてないか載せる手間に見合わない程度だということだろ
アーキテクチャ的に載せ辛いというのはあるだろうけどね
eDRAMとMCMというのはちょっと欲しいな、是非出して欲しいところ
SlotAみたいな大仰なものじゃなくて、
ClarkdaleみたいなCPUソケットに挿せる程度のものなら作れそうなんだが
100Wのハイエンド限定なら多少のコストアップは多めに見てもらえるんじゃないかね
コストアップに繋がるLFBが結局ほとんどのマザーに搭載された前例もある
淫厨が必死だけど、どんなにAPUを貶そうと淫のGPUは遥かに糞でお話にならないw
そりゃあファビョるわなw
そりゃあファビョるわなw
276 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/21(日) 21:36:09 ID:U79IzzU2
別にGPUが必要ならCPUに内蔵されてる奴じゃなくて外付けのGPUを使えばいいじゃないの。
ハイエンドならピーク性能からして10倍以上違うわけですし
ハイエンドならピーク性能からして10倍以上違うわけですし
GPGPUでPCI-Expressを介す必要が無い
そういう意味では大きな進歩だよねSandyもLlanoも
そういう意味では大きな進歩だよねSandyもLlanoも
SandyはGPGPUに対応できません
スペック上は対応しているように見えても、ドライバがグダグダなので結局AVX頼み
ハイエンドGPUの需要は大して大きくないし、
HD5570程度のGPUを内蔵すればMMO RPG程度は難なくプレイ出来てしまい大抵の人は満足してしまう
スペック上は対応しているように見えても、ドライバがグダグダなので結局AVX頼み
ハイエンドGPUの需要は大して大きくないし、
HD5570程度のGPUを内蔵すればMMO RPG程度は難なくプレイ出来てしまい大抵の人は満足してしまう
GPGPUはどこに使ってあげればいいんですか?
havokはCPU(intel)だし
エンコは専用ユニットが付くし
暗号もAES-NIの方が速いし
havokはCPU(intel)だし
エンコは専用ユニットが付くし
暗号もAES-NIの方が速いし
気が向いたら誰か作ってくれるんじゃない?
とりあえずはサイバーリンクのPowerDirector9でも使ってみればいいんじゃないかな
とりあえずはサイバーリンクのPowerDirector9でも使ってみればいいんじゃないかな
そもそもMMOで言っちゃうとAMD爆死状態ジャン今。
今主流のDx9では完全にicore>>>>Phenom2系≧C2系な状況
今主流のDx9では完全にicore>>>>Phenom2系≧C2系な状況
CoreiのGPUは糞だからな
LlanoならHD5570クラスだからなんとかなる
なんとかなるなら問題はないだろ
LlanoならHD5570クラスだからなんとかなる
なんとかなるなら問題はないだろ
逆だと思う
3DMMOはむしろマイナーなGMAより
メジャーなGeForceやRADEONに最適化されている場合が多く
ドライバの完成度という点でもGMAは他二つに比べて劣っている
3DMMOはむしろマイナーなGMAより
メジャーなGeForceやRADEONに最適化されている場合が多く
ドライバの完成度という点でもGMAは他二つに比べて劣っている
MMOベンダーはGMAなんか全く相手にしてないだろう
ほとんどがゲフォ最適化の糞開発だろうけどラデでもそれなりに動く
ほとんどがゲフォ最適化の糞開発だろうけどラデでもそれなりに動く
285 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 01:06:30 ID:N21nPIFc
どのタイトルのこといってるんだ?
リネージュIIか?
リネージュIIか?
プリウスオンライン、ディビーナ、グランドファンタジア、ラテール、マスターオブエピック
タルタロスオンライン、タワーオブアイオン、ミスティックストーン、ベルアイル、グラナド・エスパダ
ルーセントハート、カバルオンライン、アークサイン、ファンタジーアース、ラペルズ、パンドラサーガ
マビノギ、アルカディアサーガ、アトランティカ、シルクロードオンライン、ブライトシャドウ
ROHAN、Soul of Ultimate Nation、ブレイドクロニクル、デカロン、パーフェクトワールド、リネージュⅡ
LEGEND of CHUSEN、フローレンシア、ファイナルファンタジー13、蒼天、エミル・クロニクル・オンライン
真・女神転生ONLINE IMAGINE、ファイナルファンタジー11、ラストカオス、リアノンライン、夢世界
アロッズオンライン、飛天オンライン、ルナティア、大航海時代オンライン、アイラオンライン
シールオンライン、RFオンライン、シャイヤ、ドラゴニカ、グランディアオンライン、天地大乱
もう許してくれよ団子・・・
タルタロスオンライン、タワーオブアイオン、ミスティックストーン、ベルアイル、グラナド・エスパダ
ルーセントハート、カバルオンライン、アークサイン、ファンタジーアース、ラペルズ、パンドラサーガ
マビノギ、アルカディアサーガ、アトランティカ、シルクロードオンライン、ブライトシャドウ
ROHAN、Soul of Ultimate Nation、ブレイドクロニクル、デカロン、パーフェクトワールド、リネージュⅡ
LEGEND of CHUSEN、フローレンシア、ファイナルファンタジー13、蒼天、エミル・クロニクル・オンライン
真・女神転生ONLINE IMAGINE、ファイナルファンタジー11、ラストカオス、リアノンライン、夢世界
アロッズオンライン、飛天オンライン、ルナティア、大航海時代オンライン、アイラオンライン
シールオンライン、RFオンライン、シャイヤ、ドラゴニカ、グランディアオンライン、天地大乱
もう許してくれよ団子・・・
287 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 01:37:11 ID:N21nPIFc
なんだGMA45kで十分動くタイトル多数だな
FF13?
やべえ笑いすぎて腹が痛い
FF13?
やべえ笑いすぎて腹が痛い
288 :Socket774:2010/11/22(月) 01:41:53 ID:xoydnu1v
それが、本当なら、だーれも単体グラボなんか買わないよ・・・・。
HD5550とか、5540、4350、GT210や220がこんだけ売れているのはどうしてかなぁ
HD5550とか、5540、4350、GT210や220がこんだけ売れているのはどうしてかなぁ
AMDはBobcatが唯一まともで、
それ以外はダメってことでいいだろ。
無理にAMD叩くスレでもあるまいし。
それ以外はダメってことでいいだろ。
無理にAMD叩くスレでもあるまいし。
>>287
無理です。十分動くと強がっているけどすべてカクカクします。
そしてカクカクどころか起動すらしないものもあります。
昔から最近のものまですべてGeForceやRADEONに最適化されてます。
団子さん残念です。私はむしろ失笑しましたよ。
無理です。十分動くと強がっているけどすべてカクカクします。
そしてカクカクどころか起動すらしないものもあります。
昔から最近のものまですべてGeForceやRADEONに最適化されてます。
団子さん残念です。私はむしろ失笑しましたよ。
291 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 02:00:36 ID:N21nPIFc
FF13が動くのってPS3と360(海外のみ)だった気がするんだけどRadeonで動くの?
292 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 02:19:13 ID:N21nPIFc
OpenGLドライバがバグバグで古いドライバやNVIDIAのそれをコピーしてもってこないと動かなかったりするのは
どこのAMD製GPUだったっけな
どこのAMD製GPUだったっけな
■後藤弘茂のWeekly海外ニュース■
偽のダイ写真で秘密を守るAMDのBulldozer
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20101122_408107.html
偽のダイ写真で秘密を守るAMDのBulldozer
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20101122_408107.html
INTELオンボのGLドライバは更にクソだがな
296 :Socket774:2010/11/22(月) 07:51:11 ID:Lr2N2Sbr
イソテルのGLとか罰ゲーム過ぎる
297 :Socket774:2010/11/22(月) 08:44:38 ID:/vFdbOpy
いまだにコア写真だせない程ヤヴァいのか
水子決定AMDオワタな( ̄◇ ̄;)
水子決定AMDオワタな( ̄◇ ̄;)
Bulldozerからシェンムー臭が漂ってきそうだ
フェイク写真ワロタ
ダイ写真すら出せないCPUが来年Q2に出るわけ無いだろ・・・
ダイ写真すら出せないCPUが来年Q2に出るわけ無いだろ・・・
なんという理解力の無さ!(ざわ・・・ざわ・・・
Q2って情報自体がフェイク。
ダイ写真と合わせ技でごまかしていると考えておいたほうが見のためだね。
本当に自身があるなら堂々と公開して、Sandy Bridgeに圧力かけてるはず。
ダイ写真と合わせ技でごまかしていると考えておいたほうが見のためだね。
本当に自身があるなら堂々と公開して、Sandy Bridgeに圧力かけてるはず。
302 :Socket774:2010/11/22(月) 18:23:14 ID:2lhGCYQi
これはひどいwwwwwwwwwwwww
どんなトンデモ理論で擁護するか楽しみだはwwwwwwwwwwww
どんなトンデモ理論で擁護するか楽しみだはwwwwwwwwwwww
2006年7月発売のMeromのダイ写真が公開されたのは同年3月のIDFがたぶん初めて
Bulldozarは順調に延期するんじゃないかな。
そしてLlanoのGPUは単体HD5550以下の性能になりそう。
俺の予想としては
HD5550>Llano>HD5450>890GX>Sandy>880G
そしてLlanoのGPUは単体HD5550以下の性能になりそう。
俺の予想としては
HD5550>Llano>HD5450>890GX>Sandy>880G
305 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 20:44:45 ID:N21nPIFc
>>303
しかし2005年にはXP x64 Editionが動くノートPCで実機デモしてるんだわ。
しかし2005年にはXP x64 Editionが動くノートPCで実機デモしてるんだわ。
一方、BullはAnalyst Dayでライブデモのみであった。
PCというモノ自体の存続がかかってるから、PCは使い易く、安価になる必要がある。
それには高機能なソフトが安いPCで快適に動かなくちゃいけない。
CPUの性能が短期間で二倍三倍に上がっていた時代は終わったから、後は総合力で性能を上げていかないと。
消費電力を下げて長時間動くようにして熱も持たないように。
CPUもマルチコアでプログラムの並列化を。
CPUだけにプログラムの実行をまかせるのではなく、GPUにも負担させる。
HDDが遅いならSSDにしてI/Oにかかる時間を短縮。などなど。
問題は総合力なので一番遅い、弱い部分が律速段階になるということ。
各部分を五段階評価していくとIntelは平均値としてはそこそこ高いのだけど2がある。
AMDは平均値はそこまで高くないけど最低値が3で済む。
Intelの高いシェアも合わせて考えるとPCというモノの生存発展を邪魔してるのはどちらか簡単に分かる。
Intelは弱点がない(=PCというモノが生き残れる)物が製造できるようになるまでシェアを下げて自重してほしい。
もちろんIntelもマルチコア用のプログラミングをしやすくしていたり、SSD普及に貢献したり良い仕事はしている。
単純にPC生き残りの邪魔をしなくなってから、また頑張ってほしいだけ。
それには高機能なソフトが安いPCで快適に動かなくちゃいけない。
CPUの性能が短期間で二倍三倍に上がっていた時代は終わったから、後は総合力で性能を上げていかないと。
消費電力を下げて長時間動くようにして熱も持たないように。
CPUもマルチコアでプログラムの並列化を。
CPUだけにプログラムの実行をまかせるのではなく、GPUにも負担させる。
HDDが遅いならSSDにしてI/Oにかかる時間を短縮。などなど。
問題は総合力なので一番遅い、弱い部分が律速段階になるということ。
各部分を五段階評価していくとIntelは平均値としてはそこそこ高いのだけど2がある。
AMDは平均値はそこまで高くないけど最低値が3で済む。
Intelの高いシェアも合わせて考えるとPCというモノの生存発展を邪魔してるのはどちらか簡単に分かる。
Intelは弱点がない(=PCというモノが生き残れる)物が製造できるようになるまでシェアを下げて自重してほしい。
もちろんIntelもマルチコア用のプログラミングをしやすくしていたり、SSD普及に貢献したり良い仕事はしている。
単純にPC生き残りの邪魔をしなくなってから、また頑張ってほしいだけ。
その小学生的評論家ごっこなんてどうでもよくて
常識的にユーザーは安価でいいものがほしいです。icoreはコア性能がいまのとこダントツ、ゲーミング等に弱いけどX6はエンコマニアには最適ですでいいじゃん
ゲハにしてもここにしてもマジで自称評論家多いよな
常識的にユーザーは安価でいいものがほしいです。icoreはコア性能がいまのとこダントツ、ゲーミング等に弱いけどX6はエンコマニアには最適ですでいいじゃん
ゲハにしてもここにしてもマジで自称評論家多いよな
>>308
>常識的にユーザーは安価でいいものがほしいです。
こう書きながらそれ以下の文につながる過程がよく分からないです。
GPU増設により「安価でいいもの」ではなく「それなりの価格でいいもの」と変わってしまいますから。
GPU増設なしのCorei単体で使われている方で、そのような考え方に至ったのなら…、なんと言えばいいのか…
私の書いた文をよく読んでください、というのが失礼にならない言い方でしょうか。
>常識的にユーザーは安価でいいものがほしいです。
こう書きながらそれ以下の文につながる過程がよく分からないです。
GPU増設により「安価でいいもの」ではなく「それなりの価格でいいもの」と変わってしまいますから。
GPU増設なしのCorei単体で使われている方で、そのような考え方に至ったのなら…、なんと言えばいいのか…
私の書いた文をよく読んでください、というのが失礼にならない言い方でしょうか。
一般人にはSORAでさえ十分なのに
最低限105じゃなきゃだめだとか言い張る
その上UltegraやDuraAceが欲しいとかw
所詮扱う人間のスペックしだいなのに
最低限105じゃなきゃだめだとか言い張る
その上UltegraやDuraAceが欲しいとかw
所詮扱う人間のスペックしだいなのに
一般人には~で十分、よりも全てにおいて最低一段階上のハードを大量に安価に提供して高機能なソフトの普及を狙う、ということです。
放っておいてもCPU性能が向上し、既存のプログラムも速くなっていた時期とは違いますから。
そして既存のプログラムが速くなる程度ではPCというモノが消えてしまう、と危惧しています。
もしかして、ここにいる皆さんはPCなどどうでも良いと思っている…のか。
だから、か。
理解できない理由が理解できた。
PCなどどうでも良いから、そういう言動で遊んでいるのか。
放っておいてもCPU性能が向上し、既存のプログラムも速くなっていた時期とは違いますから。
そして既存のプログラムが速くなる程度ではPCというモノが消えてしまう、と危惧しています。
もしかして、ここにいる皆さんはPCなどどうでも良いと思っている…のか。
だから、か。
理解できない理由が理解できた。
PCなどどうでも良いから、そういう言動で遊んでいるのか。
ゲームなんてしないからGPUなんて1レベルで構わない
そもそもこんなの不可能だから
>CPUだけにプログラムの実行をまかせるのではなく、GPUにも負担させる。
そもそもこんなの不可能だから
>CPUだけにプログラムの実行をまかせるのではなく、GPUにも負担させる。
直前までフェイク混じりの情報を流す
GPUでやってることをCPUでもやってるだけだな
ライバルに対抗策を取られないように情報統制するのは基本中の基本
ましてや相手が世界最強の悪徳パラノイアIntelとくればなおさらだろ
逆にAPU系統は対策取られようがないから情報バンバン流していくんじゃないかね
GPUでやってることをCPUでもやってるだけだな
ライバルに対抗策を取られないように情報統制するのは基本中の基本
ましてや相手が世界最強の悪徳パラノイアIntelとくればなおさらだろ
逆にAPU系統は対策取られようがないから情報バンバン流していくんじゃないかね
314 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 23:03:55 ID:N21nPIFc
対策か。たとえばIvy Bridgeで24EU搭載だったりすることか?
失礼。取り乱しました。
PCというモノ自体が好きな自分が同様の人しかいないと信じて安易に書き込むスレではありませんでした。
レスをくれた方々、ありがとうございました。以後ROMになります。
そういう考え方の人がこの自作PC板にいるという事実、勉強になりました。
PCというモノ自体が好きな自分が同様の人しかいないと信じて安易に書き込むスレではありませんでした。
レスをくれた方々、ありがとうございました。以後ROMになります。
そういう考え方の人がこの自作PC板にいるという事実、勉強になりました。
そもそもAMD自身がAPUとはGPUが凄くてムニャムニャ・・・程度で
具体的に何をどうするか考えてないんだから
対策なんてする必要もないがな
具体的に何をどうするか考えてないんだから
対策なんてする必要もないがな
317 :Socket774:2010/11/22(月) 23:22:13 ID:Ng+EvdlF
318 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/22(月) 23:33:40 ID:N21nPIFc
そりゃそうだな
SSE5のXOPが何に使えるか真剣に考えてみたんだが、要素毎のビットローテートが便利で
distributed.netのRC5-72カーネルを完全に4並列のSIMDで記述できるようになる。
AltiVecやCellのSPEでできてたことがようやくできるようになるわけなんだが。
しかしAMD的にはGPGPU使ったほうが速いってアピールしたほうがいいわけで
別に今更CPUで処理が早くなったからってどうってことはない。
そもそもRSAのコンテストは72ビット程度のRC5は暗号強度的に危険だから
使用をやめましょうって合衆国政府にアピールする趣旨なわけで、
実用的な意味も将来性もあるわけではないのを付け加えておく。
SSE5のXOPが何に使えるか真剣に考えてみたんだが、要素毎のビットローテートが便利で
distributed.netのRC5-72カーネルを完全に4並列のSIMDで記述できるようになる。
AltiVecやCellのSPEでできてたことがようやくできるようになるわけなんだが。
しかしAMD的にはGPGPU使ったほうが速いってアピールしたほうがいいわけで
別に今更CPUで処理が早くなったからってどうってことはない。
そもそもRSAのコンテストは72ビット程度のRC5は暗号強度的に危険だから
使用をやめましょうって合衆国政府にアピールする趣旨なわけで、
実用的な意味も将来性もあるわけではないのを付け加えておく。
結局HaswellではPowerVR頼みなの?
320 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/23(火) 00:09:34 ID:CY7gDViZ
PowerVRはDirectX10すら対応して無いだろ・・・
OpenGLのほうは歴史は長いが。
OpenGLのほうは歴史は長いが。
24EUだろうが48EUだろうがDX10止まりで糞ドライバをどうにかしない限り使い道がないけどな
え?結局HaswellにはLarrabee載らないの?
載りますん
載ったとしてもAVX後継のベクトル演算ユニットとしてだけどな
DX11対応の高性能GPUでは決して無い
DX11対応の高性能GPUでは決して無い
そもそもDX10以上の描写なんぞ今ほとんど使われてないというか使うとしたら現状のオンボじゃ話にならない件
その通りだからGPUの代わりにLarrabeeでタノムヨ
特にDirectX的なグラフィック用途には使わんでよろしいw
特にDirectX的なグラフィック用途には使わんでよろしいw
使ってもいいんじゃね。
オンボもいけますみたいな感じで。
オンボグラフィックの性能なんて,オンボ程度で十分な人にとっちゃ
GMAで十分だしね。それ以上必要ならもっと上の外付けVGA買うさ。
オンボもいけますみたいな感じで。
オンボグラフィックの性能なんて,オンボ程度で十分な人にとっちゃ
GMAで十分だしね。それ以上必要ならもっと上の外付けVGA買うさ。
>>293
>そのため2012年には、AMD CPUはBulldozerとBobcatで棲み分けるようになる。
>また、Bulldozerコア自体が、2009年に登場する計画だった。
さらっと書いてるが、これほどの遅れをやらかしてる会社が
「フェイク写真」とか聞くと、普通「見せられるレベルに達していない」
とか考えるもんなのよ。
Brazosにしても
http://www.anandtech.com/show/4023/the-brazos-performance-preview-amd-e350-benchmarked
未だにtest platformなのに、2011Q1って言っちゃう。無理ってわかるやん。
でも、ノートPCは出る、と言う。Mini-ITXボード出せないのに、ノートPCには収まるボードは作れる、と。
普通に考えたら、そんなの無理やん。
んで、Brazosはこの前みたら「上半期」になってた。
ここまで信用できないアナウンスが続くと、AMDはもう駄目なのかな?
と感じるんだが、信者さん達は相変わらず、ベンチマークの棒グラフで満足しちゃって
「いつ出るか」という質問がタブーになっている。
>そのため2012年には、AMD CPUはBulldozerとBobcatで棲み分けるようになる。
>また、Bulldozerコア自体が、2009年に登場する計画だった。
さらっと書いてるが、これほどの遅れをやらかしてる会社が
「フェイク写真」とか聞くと、普通「見せられるレベルに達していない」
とか考えるもんなのよ。
Brazosにしても
http://www.anandtech.com/show/4023/the-brazos-performance-preview-amd-e350-benchmarked
未だにtest platformなのに、2011Q1って言っちゃう。無理ってわかるやん。
でも、ノートPCは出る、と言う。Mini-ITXボード出せないのに、ノートPCには収まるボードは作れる、と。
普通に考えたら、そんなの無理やん。
んで、Brazosはこの前みたら「上半期」になってた。
ここまで信用できないアナウンスが続くと、AMDはもう駄目なのかな?
と感じるんだが、信者さん達は相変わらず、ベンチマークの棒グラフで満足しちゃって
「いつ出るか」という質問がタブーになっている。
ttp://www.inpai.com.cn/doc/hard/138458.htm
SandyBridge Core i7 2600K preview(中国語)
SandyBridge Core i7 2600K preview(中国語)
いまだにコア写真だせない程ヤヴァいのか
水子決定AMDオワタな( ̄◇ ̄;)
水子決定AMDオワタな( ̄◇ ̄;)
331 :Socket774:2010/11/23(火) 18:04:31 ID:uzOvaGeW
秘匿したいが順調であることをアピールするために、偽りのダイ写真を出したってことか?
もともとはGFの資料なんだけどね。
333 :Socket774:2010/11/24(水) 06:29:29 ID:vXAE1kGc
>>328
漠然と来年Q2に出ると信じてるようだが…
漠然と来年Q2に出ると信じてるようだが…
334 :Socket774:2010/11/24(水) 16:16:18 ID:7iS5s58R
結局bullって思ってたよりトランジスタ数多かったな
50%のリソース増加で80%のスループット向上て言ってなかったか?
てっきりK10から50%しかトランジスタ増加しないと思ってたよ
50%のリソース増加で80%のスループット向上て言ってなかったか?
てっきりK10から50%しかトランジスタ増加しないと思ってたよ
次世代CPU競争でも
相変わらずベンチスコアではIntelがリードするんだろうなあ
でも体感速度が良くなかったり
ゲームデモでFPSが瞬間的に落ちまくるのはINTELなんだよなあ
ゲームベンチにもIntel(資本)入ってます(Intel Inside)
相変わらずベンチスコアではIntelがリードするんだろうなあ
でも体感速度が良くなかったり
ゲームデモでFPSが瞬間的に落ちまくるのはINTELなんだよなあ
ゲームベンチにもIntel(資本)入ってます(Intel Inside)
これまでのまとめ
・PhenomⅡ
45nm SOI
HT速度・・・3.6GT/s
コア電圧・・・0.875~1.5V
L2キャッシュ・・・512KB/Core
L3キャッシュ・・・6MB
ダイサイズ・・・258平方mm
トランジスタ数・・・7億5800万個
・Bulldozer
32nm SOI High-K/Metal-gate
コア電圧・・・0.8~1.3V
L2キャッシュ・・・2MB/Module
L3キャッシュ・・・8MB
ダイサイズ・・・L2含んで30.9平方mm/Module
トランジスタ数・・・L2含んで2億1300万個/Module
・PhenomⅡ
45nm SOI
HT速度・・・3.6GT/s
コア電圧・・・0.875~1.5V
L2キャッシュ・・・512KB/Core
L3キャッシュ・・・6MB
ダイサイズ・・・258平方mm
トランジスタ数・・・7億5800万個
・Bulldozer
32nm SOI High-K/Metal-gate
コア電圧・・・0.8~1.3V
L2キャッシュ・・・2MB/Module
L3キャッシュ・・・8MB
ダイサイズ・・・L2含んで30.9平方mm/Module
トランジスタ数・・・L2含んで2億1300万個/Module
Bullはアレだろ
社内サンプル作ったはいいがエンコード以外の大半の処理で
同クロック同コア数のPhenomⅡとほとんど差がないか劣る場面が多く
どう言い繕おうか検討するのに時間掛かってるんだろ
それよりもっと問題なのがクライアントPCでは
2モジュールと4モジュールでエンコード以外ほとんど差が出ない状況とか
下手すりゃクロック高い2モジュール>>クロック低い4モジュールになって
どうやって誤魔化そうか絶賛検討中なんだろ
社内サンプル作ったはいいがエンコード以外の大半の処理で
同クロック同コア数のPhenomⅡとほとんど差がないか劣る場面が多く
どう言い繕おうか検討するのに時間掛かってるんだろ
それよりもっと問題なのがクライアントPCでは
2モジュールと4モジュールでエンコード以外ほとんど差が出ない状況とか
下手すりゃクロック高い2モジュール>>クロック低い4モジュールになって
どうやって誤魔化そうか絶賛検討中なんだろ
>>335
CPUも提灯もキャッシュを大量に入れてます byインテル
CPUも提灯もキャッシュを大量に入れてます byインテル
339 :Socket774:2010/11/24(水) 17:38:42 ID:vXAE1kGc
アプリのマルチスレッド対応が進んでないのに、シングルスレッド性能を捨てて
マルチスレッドに特化したら、多くの処理は遅くなるに決まってるだろ
AMDだって、それがわからないままCPU作っちゃうほどアホじゃない・・・はず
マルチスレッドに特化したら、多くの処理は遅くなるに決まってるだろ
AMDだって、それがわからないままCPU作っちゃうほどアホじゃない・・・はず
341 :Socket774:2010/11/24(水) 18:00:15 ID:7iS5s58R
Bullは3.5GHz以上らしいが、IPCが下がってることを考えれば、3.5GHzは製品ラインナップの最低ラインだろ。
342 :Socket774:2010/11/24(水) 18:02:40 ID:vXAE1kGc
てか、せっかく32nmにするんだからせめてクロックぐらいは上げないと…
そもそもAMDは目いっぱいの定格設定するからねえ
そもそもAMDは目いっぱいの定格設定するからねえ
343 :Socket774:2010/11/24(水) 18:28:57 ID:AOwJluQq
2/3スピード(笑)
マルチスレッドを捨ててx86SIMMMMに特化してるIntelを標準とすれば
Bullがおかしくも見えるだろうが・・・
Bullがおかしくも見えるだろうが・・・
345 :Socket774:2010/11/24(水) 18:36:53 ID:vXAE1kGc
おかしいとは思わない
要するにサーバー用に特化する方向で
デスクトップのハイエンドは戦略的に捨てている
Intelですらsandyのハイエンドデスクトップはラインナップを決めかねてるし…
要するにサーバー用に特化する方向で
デスクトップのハイエンドは戦略的に捨てている
Intelですらsandyのハイエンドデスクトップはラインナップを決めかねてるし…
>>マルチスレッドを捨てて
え?シングルスレッド性能の向上はマルチスレッド性能の向上にもつながるよ
その逆にはならないけど
え?シングルスレッド性能の向上はマルチスレッド性能の向上にもつながるよ
その逆にはならないけど
>>345
なら何故そのコアを来年以降ノートにまで拡げるんだと
なら何故そのコアを来年以降ノートにまで拡げるんだと
349 :Socket774:2010/11/24(水) 19:08:16 ID:vXAE1kGc
>>347
ノートのOEM用なら、その程度のコア性能の流用でOKということだろ
ノートのOEM用なら、その程度のコア性能の流用でOKということだろ
>>348
HTTで性能低下してもAMD以上だからなぁ。
HTTで性能低下してもAMD以上だからなぁ。
351 :Socket774:2010/11/24(水) 19:22:01 ID:vXAE1kGc
結局、ザンベジが来年上半期にとても間に合いそうにないことが致命的
353 :Socket774:2010/11/24(水) 19:57:24 ID:/pM88x1R
AMD印(笑)なだけでまったく売れなくなるのがノート業界なのが理解できないんだろか( ̄▽ ̄)
ノートPC CPU別 売れ行きシェア
http://bbsimg02.kakaku.k-img.com/images/bbs/000/783/783410_m.jpg
ノートPC CPU別 売れ行きシェア
http://bbsimg02.kakaku.k-img.com/images/bbs/000/783/783410_m.jpg
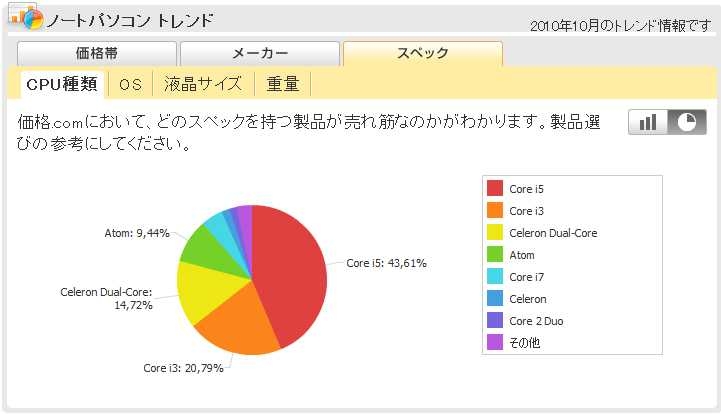{kind=link}
でもCore i5 520MってZacateに比べてハーフスピードなんでしょ?
暖房能力は倍だよ
>相変わらずベンチスコアではIntelがリードするんだろうなあ
AMDはGPU特化なベンチで提灯するのかなと思ってたが
GPU対応のsandraのエンコや暗号でもsandyが速くなりそうなんで、提灯にならないな
AVXも使えるし
AMDはGPU特化なベンチで提灯するのかなと思ってたが
GPU対応のsandraのエンコや暗号でもsandyが速くなりそうなんで、提灯にならないな
AVXも使えるし
実際は殆どのことがZacateは低性能だからなぁ。
APUが使える限られたアプリだけしか性能出せないAMD。
APUが使える限られたアプリだけしか性能出せないAMD。
むしろ2モジュールでもいいから初の4GHz超えをやってくれよ
例の3.5Ghz+ってどのモデルなんだろ?8コアなら凄いんだが
クロックは高いけどIPCは低く、コアは多いけどコアあたりの性能は低い
どう見てもBullは失敗作の予感しかしない
どう見てもBullは失敗作の予感しかしない
昔のIntelの悪い所だけを参考にして頑張って作ったBullゴミだね
365 :Socket774:2010/11/25(木) 03:27:23 ID:GycYDgy3
下がったIPCを動作クロックでカバーするのは電力効率が悪そうだが。
IPCは下がらない
昔のSEGAを見てる感覚なんだよなAMDって
けして視点は悪くないし、実績もある。でも今現在のように時代の一歩先いって実際のニーズとあってない時がある
現状本当にハイパワーを求められるのはエンコードとゲーミングが多いわけで、エンコとゲーミングどっちがっていえばゲーミングの方なんだけどX6をアプリが活かせるゲーミングは多くない
アプリが追いついてないのにマルチ性能だけ特化してもベンチ番長でしかなくなっちゃう。
まあベンチ信者多いからまったく無駄ってわけでもないんだろうが実使用だとなぁ
けして視点は悪くないし、実績もある。でも今現在のように時代の一歩先いって実際のニーズとあってない時がある
現状本当にハイパワーを求められるのはエンコードとゲーミングが多いわけで、エンコとゲーミングどっちがっていえばゲーミングの方なんだけどX6をアプリが活かせるゲーミングは多くない
アプリが追いついてないのにマルチ性能だけ特化してもベンチ番長でしかなくなっちゃう。
まあベンチ信者多いからまったく無駄ってわけでもないんだろうが実使用だとなぁ
368 :Socket774:2010/11/25(木) 04:19:47 ID:yC+wAgBI
>>363
失敗作というより、基本的にサーバー用
失敗作というより、基本的にサーバー用
>>368
あー、そっちには最高にいいのかな、マルチコア活かせる意味では
あー、そっちには最高にいいのかな、マルチコア活かせる意味では
370 :Socket774:2010/11/25(木) 05:20:10 ID:yC+wAgBI
マルチ処理の絶対性能はともかくとして
コア当たり単価削減は一応目標にしてるんじゃね
じゃないとコア性能落としてまで共用部分を作る意味がない
共用部分作ってコストがそんなに下がるものなのかは知らんけど
コア当たり単価削減は一応目標にしてるんじゃね
じゃないとコア性能落としてまで共用部分を作る意味がない
共用部分作ってコストがそんなに下がるものなのかは知らんけど
でも、基本的に自宅鯖以外はマルチCPUの鯖のほうが主流とちゃうの?俺鯖のことあまり詳しくないから鯖機としての今のIntelとAMDの関係を知りたいわ
APUとかいうわりに、GPU部分が演算に使えない構造のままだった
orz
orz
押入れってすげーな
374 :Socket774:2010/11/25(木) 07:48:41 ID:9QOmEXa+
使えるぞ
この手のスレの半分以上は押入れの中の話だよ
単独のシングルスレッドアプリしか起動しないってなら別だけど
Windows7ってマルチコア最適化が進んでるぢ
8コア、16コアになると多くの処理も速くなるんじゃない?
シングルスレッドアプリは現状性能で十分事足りてるが
エンコに代表されるようなソフトにはマルチスレッド処理の向上が時間短縮に効果絶大じゃないの
実際シングルスレッドならC2Dの2Gあれば十分だけど
マルチが必要な用途だと4コア推奨な状況ってあるわけで
シングルスレッドにこだわる必要性は薄くなってる
Windows7ってマルチコア最適化が進んでるぢ
8コア、16コアになると多くの処理も速くなるんじゃない?
シングルスレッドアプリは現状性能で十分事足りてるが
エンコに代表されるようなソフトにはマルチスレッド処理の向上が時間短縮に効果絶大じゃないの
実際シングルスレッドならC2Dの2Gあれば十分だけど
マルチが必要な用途だと4コア推奨な状況ってあるわけで
シングルスレッドにこだわる必要性は薄くなってる
377 :Socket774:2010/11/25(木) 09:16:37 ID:3bgibUKo
シングルスレッドが遅い時点で論外の産廃
負け犬の遠吠えは見苦しいわAMD(笑)
負け犬の遠吠えは見苦しいわAMD(笑)
車で行けば速いのに二足歩行にこだわってもな(笑)
目的に着くまでの時間効率を考えれば答えは一つ
使ってる単語を見ても相手になるだけ無駄か
目的に着くまでの時間効率を考えれば答えは一つ
使ってる単語を見ても相手になるだけ無駄か
379 :Socket774:2010/11/25(木) 09:26:26 ID:j0+CNCRu
>>376
一概には言えんよ
確かに4コアまではあった方がいいが、それ以上は使わないアプリも多い
個人的にはIntelで3GHzちょっとぐらいは、快適性のために欲しい
そのぐらいのクロックを確保した上で、
あとはコア数が多ければ多い方がいいといったところ
一概には言えんよ
確かに4コアまではあった方がいいが、それ以上は使わないアプリも多い
個人的にはIntelで3GHzちょっとぐらいは、快適性のために欲しい
そのぐらいのクロックを確保した上で、
あとはコア数が多ければ多い方がいいといったところ
もはやIntel派がAMDの次世代CPUを語るスレではなくネガキャンするスレと化したな
本当の目的はそれだったんだろうけどRADEON関連のような糞スレ連発もやめてほしい
本当の目的はそれだったんだろうけどRADEON関連のような糞スレ連発もやめてほしい
381 :Socket774:2010/11/25(木) 09:46:14 ID:j0+CNCRu
>>379
ほとんど同感ですよ
4コア以上を有効に使えるソフトやアプリの重要性は
個人の使用頻度などにかかってきますからね
マルチコアが有効な用途で必要な人には
相対的にシングルスレッドの差によるメリットが下がり
コア数の多さによるメリットが増えるということ
ほとんど同感ですよ
4コア以上を有効に使えるソフトやアプリの重要性は
個人の使用頻度などにかかってきますからね
マルチコアが有効な用途で必要な人には
相対的にシングルスレッドの差によるメリットが下がり
コア数の多さによるメリットが増えるということ
パソコンに詳しくない一般人からすると
同クロックの4コアが2コアの倍近く速くないどころか
ソフトによってはまるで効果なし
ソフトが対応しててもせいぜい2-3割程度しか効果がない
というのは大して違いがないのとほぼ一緒のレベル
本当にコア数>シングルスレッドというのなら
IntelはとっくにAtom8コアとか16コアを高値で出してるだろうし
2コアと4コアでわざわざクロック違うモデル出してないだろう
同クロックの4コアが2コアの倍近く速くないどころか
ソフトによってはまるで効果なし
ソフトが対応しててもせいぜい2-3割程度しか効果がない
というのは大して違いがないのとほぼ一緒のレベル
本当にコア数>シングルスレッドというのなら
IntelはとっくにAtom8コアとか16コアを高値で出してるだろうし
2コアと4コアでわざわざクロック違うモデル出してないだろう
とはいえそれは現状での話でね
何年か前まで2コアあれば十分で4コアは必要ないとか言われてました
来年か再来年には8コアあれば十分とか言われてるんじゃないのかと
何年か前まで2コアあれば十分で4コアは必要ないとか言われてました
来年か再来年には8コアあれば十分とか言われてるんじゃないのかと
IntelのIPCはx86SIMMMMMに頼ったものだから
そのうちLarrabeeの後を追って死ぬよ
そのうちLarrabeeの後を追って死ぬよ
386 :Socket774:2010/11/25(木) 10:26:57 ID:j0+CNCRu
ハードが発売、普及すれば対応するソフトも増える
ハードが開発、発売、普及してないのに対応するソフトが増えるはずがない
当たり前の話ですね
ハードが開発、発売、普及してないのに対応するソフトが増えるはずがない
当たり前の話ですね
5年で30%下落という価格曲線を維持しながら性能を上げるには、トランジスタ効率を上げるのが効果的
そしてトランジスタ効率を上げるにはコアは小さく、クロックは上げるのがベスト
ただし、そうすると高クロック帯での電力効率は落ちてゆく
これから先は、価格効率と電力効率という相反する2要素のどちらに振るかというだけの話
そしてトランジスタ効率を上げるにはコアは小さく、クロックは上げるのがベスト
ただし、そうすると高クロック帯での電力効率は落ちてゆく
これから先は、価格効率と電力効率という相反する2要素のどちらに振るかというだけの話
まじめに設計してもプレスコだとかララビが出来てしまうのでSIMDやらキャッシュやらとにかく1コアに詰め込めるだけ詰め込むか
それともSIMDはGPUに任せるなど効率を考えてバランス良く設計するか
というだけの話
それともSIMDはGPUに任せるなど効率を考えてバランス良く設計するか
というだけの話
>>ID:EXiKFmyE
煽りじゃないならこれだけ頭に入れてくれ
マルチスレッド性能=シングルスレッド性能×実行スレッド数
シングルスレッド性能をあげると、シングルからマルチまで全部のアプリが速くなる
実行スレッド数(≒コア数)を増やすと、マルチ”だけ”速くなる
だからこそシングルスレッド性能のほうが重要だって言われてるのよ
煽りじゃないならこれだけ頭に入れてくれ
マルチスレッド性能=シングルスレッド性能×実行スレッド数
シングルスレッド性能をあげると、シングルからマルチまで全部のアプリが速くなる
実行スレッド数(≒コア数)を増やすと、マルチ”だけ”速くなる
だからこそシングルスレッド性能のほうが重要だって言われてるのよ
やっぱ押入れはすげーや!
>>391
いやだからそれは俺が言ってることの範疇で同感ですよw
シングルスレッド性能の重要性と
シングルスレッド性能差における実効果の重要性の違いを話してるわけ
シングルスレッドよりマルチのほうが必ず重要なんて言ってませんしその逆も言いません
程度の問題をどう体感、評価するか
20-30%程度の差をほぼ一緒のレベルとして評価するなら
シングルスレッドの差も似たようなもの
そこで話は終了でしょ
いやだからそれは俺が言ってることの範疇で同感ですよw
シングルスレッド性能の重要性と
シングルスレッド性能差における実効果の重要性の違いを話してるわけ
シングルスレッドよりマルチのほうが必ず重要なんて言ってませんしその逆も言いません
程度の問題をどう体感、評価するか
20-30%程度の差をほぼ一緒のレベルとして評価するなら
シングルスレッドの差も似たようなもの
そこで話は終了でしょ
394 :Socket774:2010/11/25(木) 12:51:13 ID:9QOmEXa+
シングルもマルチも一般的には既に飽和しているけどな
サーバーやHPCはある程度シングルがあればあとはマルチのほうが重要
シングル重要とか間抜けな議論に意味はない
サーバーやHPCはある程度シングルがあればあとはマルチのほうが重要
シングル重要とか間抜けな議論に意味はない
395 :Socket774:2010/11/25(木) 13:02:28 ID:yC+wAgBI
>>393
まあ、それも使い方による
オレはゲーマーだからシングル性能で一割、二割ってのは正直大きい
またエンコソフトなどと違って、マルチ対応が進んでいるから
そのアプリを選ぶというわけにもいかない
面白ければマルチ非対応でも、面白くないのをやるよりずっといいわけで
まあ、それも使い方による
オレはゲーマーだからシングル性能で一割、二割ってのは正直大きい
またエンコソフトなどと違って、マルチ対応が進んでいるから
そのアプリを選ぶというわけにもいかない
面白ければマルチ非対応でも、面白くないのをやるよりずっといいわけで
マネージド言語ではAVXやSSE(32bitで)は使えない
だがDirectXは問題無く使える
MSがC#やDXを推し進めている状況で
x86SIMMMMMdに頼り切っているIntelは先生残れるのか
だがDirectXは問題無く使える
MSがC#やDXを推し進めている状況で
x86SIMMMMMdに頼り切っているIntelは先生残れるのか
397 :Socket774:2010/11/25(木) 17:37:59 ID:GycYDgy3
Bullってホント癖がありそうだよな。
俺の予想じゃ低速から中速コーナーで速くて
高速コーナーで遅い感じ。
前にAMDの上級副社長だかが『2スレッドから3スレッドが一番多い』って
言ってたけど、そこの効率はかなり高そう。
俺の予想じゃ低速から中速コーナーで速くて
高速コーナーで遅い感じ。
前にAMDの上級副社長だかが『2スレッドから3スレッドが一番多い』って
言ってたけど、そこの効率はかなり高そう。
399 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/25(木) 19:57:40 ID:tioA4bJu
Managed DirectXってUnmanagedで書かれたコードをCOM化してマネージドコードでラップしてるだけだけどなw
SSEやAVXを使ったコードをDLL化すればC#やVB.NETからでも呼び出せるよ。
JNIを使えばJavaからも呼べる。
毎度思うけどAMDスレって技術レベル低いな
SSEやAVXを使ったコードをDLL化すればC#やVB.NETからでも呼び出せるよ。
JNIを使えばJavaからも呼べる。
毎度思うけどAMDスレって技術レベル低いな
400 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/25(木) 20:24:36 ID:tioA4bJu
BSR(値0のビットをMSBから1が出現するまで数え上げる命令)の
各CPUにおけるレイテンシとスループット調べてみた。
Lat(clk) Thpt(clk/inst)
------------------------------------------
Pentium 4 (Prescott) 11 1
Core 2 (Merom) 2 1
Core i* (Nehalem) 3 1
Core i* (Sandy Bridge) 3 1 #シミュレータの計測値
Atom (Bonnel) 17 16
------------------------------------------
Phenom II (K10.5) 4 3
*参考:LZCNT 2 1
結論:K10は新命令のLZCNTを使うと速いんじゃなくて旧来命令のBSRが遅い
やっぱりAMDのほうが新命令依存度高いじゃん(しかもIntelがサポートしてない命令)
各CPUにおけるレイテンシとスループット調べてみた。
Lat(clk) Thpt(clk/inst)
------------------------------------------
Pentium 4 (Prescott) 11 1
Core 2 (Merom) 2 1
Core i* (Nehalem) 3 1
Core i* (Sandy Bridge) 3 1 #シミュレータの計測値
Atom (Bonnel) 17 16
------------------------------------------
Phenom II (K10.5) 4 3
*参考:LZCNT 2 1
結論:K10は新命令のLZCNTを使うと速いんじゃなくて旧来命令のBSRが遅い
やっぱりAMDのほうが新命令依存度高いじゃん(しかもIntelがサポートしてない命令)
なんかAMDってかわいそうだよな。
ネイティブにSATA3に対応してるのに
外部チップなSandyに負けるなんて・・・。
Intel-P67
http://img.inpai.com.cn/article/2010/11/25/a8ff851d-1923-4cf0-9c0a-6567ee0437f0.PNG
AMD-SB850
http://akiba-pc.watch.impress.co.jp/hotline/20100904/image/iam21.jpg
ネイティブにSATA3に対応してるのに
外部チップなSandyに負けるなんて・・・。
Intel-P67
http://img.inpai.com.cn/article/2010/11/25/a8ff851d-1923-4cf0-9c0a-6567ee0437f0.PNG
{kind=link}
AMD-SB850
http://akiba-pc.watch.impress.co.jp/hotline/20100904/image/iam21.jpg
{kind=link}
いやいやSandyはSATA3ネイティブ対応だから
SB850がSATA3対応で先行できたのが異例だったんだよ
基本的にディスク性能では、AMDもNvidiaもVIAもSiSもIntelには勝てない
SB850がSATA3対応で先行できたのが異例だったんだよ
基本的にディスク性能では、AMDもNvidiaもVIAもSiSもIntelには勝てない
403 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/25(木) 20:48:03 ID:tioA4bJu
内蔵GPUって少なからずディスプレイ出力にI/Oバスの帯域もってかれるから
安かろう悪かろうなソリューションだよ。
USB3.0やSATA3の性能を享受したいならGPUはディスクリートにしとけ。
(理屈上PCIeの帯域幅分しか食われない)
安かろう悪かろうなソリューションだよ。
USB3.0やSATA3の性能を享受したいならGPUはディスクリートにしとけ。
(理屈上PCIeの帯域幅分しか食われない)
「デッドスペースのあるSandyでは
C#に連携されたC++はC#に変わるからキャッシュは役立たず
だから隆盛(たかもり)くんに精子掛けろ」
やっぱり押入れはすげえや
C#に連携されたC++はC#に変わるからキャッシュは役立たず
だから隆盛(たかもり)くんに精子掛けろ」
やっぱり押入れはすげえや
>374
>使えるぞ
ただ動くだけのものを
”使える”とは言わない
>使えるぞ
ただ動くだけのものを
”使える”とは言わない
やっぱりすげえや
373 :Socket774 [↓] :2010/11/25(木) 07:45:21 ID:jm5UkZWs
375 :Socket774 [↓] :2010/11/25(木) 08:30:11 ID:jm5UkZWs
385 :Socket774 [↓] :2010/11/25(木) 10:16:56 ID:jm5UkZWs
390 :Socket774 [↓] :2010/11/25(木) 11:27:12 ID:jm5UkZWs
392 :Socket774 [↓] :2010/11/25(木) 11:58:59 ID:jm5UkZWs
396 :Socket774 [↓] :2010/11/25(木) 13:53:42 ID:jm5UkZWs
405 :Socket774 [↓] :2010/11/25(木) 20:51:42 ID:jm5UkZWs
373 :Socket774 [↓] :2010/11/25(木) 07:45:21 ID:jm5UkZWs
375 :Socket774 [↓] :2010/11/25(木) 08:30:11 ID:jm5UkZWs
385 :Socket774 [↓] :2010/11/25(木) 10:16:56 ID:jm5UkZWs
390 :Socket774 [↓] :2010/11/25(木) 11:27:12 ID:jm5UkZWs
392 :Socket774 [↓] :2010/11/25(木) 11:58:59 ID:jm5UkZWs
396 :Socket774 [↓] :2010/11/25(木) 13:53:42 ID:jm5UkZWs
405 :Socket774 [↓] :2010/11/25(木) 20:51:42 ID:jm5UkZWs
押入れではキャッシュやGPUなど
デッドスペース以外のものはただヌタヌタ動くだけの役立たずなんだよきっと
推測だけど
そして デッドスペース=押入れ で
Sandyは内部に押入れがあって
三連ウンコは「CPU内部で思う存分脱糞出来る」と大喜びなのではないかな
推測だけど
デッドスペース以外のものはただヌタヌタ動くだけの役立たずなんだよきっと
推測だけど
そして デッドスペース=押入れ で
Sandyは内部に押入れがあって
三連ウンコは「CPU内部で思う存分脱糞出来る」と大喜びなのではないかな
推測だけど
なんだニートか
断定だけど
373 :Socket774 [↓] :2010/11/25(木) 07:45:21 ID:jm5UkZWs
375 :Socket774 [↓] :2010/11/25(木) 08:30:11 ID:jm5UkZWs
385 :Socket774 [↓] :2010/11/25(木) 10:16:56 ID:jm5UkZWs
390 :Socket774 [↓] :2010/11/25(木) 11:27:12 ID:jm5UkZWs
392 :Socket774 [↓] :2010/11/25(木) 11:58:59 ID:jm5UkZWs
396 :Socket774 [↓] :2010/11/25(木) 13:53:42 ID:jm5UkZWs
405 :Socket774 [↓] :2010/11/25(木) 20:51:42 ID:jm5UkZWs
408 :Socket774 [↓] :2010/11/25(木) 22:02:49 ID:jm5UkZWs
断定だけど
373 :Socket774 [↓] :2010/11/25(木) 07:45:21 ID:jm5UkZWs
375 :Socket774 [↓] :2010/11/25(木) 08:30:11 ID:jm5UkZWs
385 :Socket774 [↓] :2010/11/25(木) 10:16:56 ID:jm5UkZWs
390 :Socket774 [↓] :2010/11/25(木) 11:27:12 ID:jm5UkZWs
392 :Socket774 [↓] :2010/11/25(木) 11:58:59 ID:jm5UkZWs
396 :Socket774 [↓] :2010/11/25(木) 13:53:42 ID:jm5UkZWs
405 :Socket774 [↓] :2010/11/25(木) 20:51:42 ID:jm5UkZWs
408 :Socket774 [↓] :2010/11/25(木) 22:02:49 ID:jm5UkZWs
「演算はしないが移動の出来るGPU」
まるで命を吹き込まれて2chで暴れる三連ウンコのようだ
まるで命を吹き込まれて2chで暴れる三連ウンコのようだ
すいませんAMD側の人
ID:jm5UkZWsの翻訳をお願いします
ID:jm5UkZWsの翻訳をお願いします
現実世界のGPUは
主に描画の演算はするが自力で動くのは有り得ない
主に描画の演算はするが自力で動くのは有り得ない
なに当たり前の事を言ってるんだ
Code name Die area[mm^2] Gross die Yield 1chip当り価格[$] 1chip当り価格[\]
Radeon
HD5870 Cypress/RV870 334 177 66.5% 42.47 3526
HD5770 Juniper 170 338 82.0% 18.04 1497
HD5670 Redwood 100 598 88.0% 9.50 789
HD6870 Barts 255 222 73.0% 30.85 2561
HD6970 Cayman 380 148 62.5% 54.05 4486
Geforce
GTX480 GF100 529 104 52.0% 92.45 7674
GTX580 GF110 520 104 52.4% 91.74 7615
GTX460 GF104 332 177 67.0% 42.16 3499
GTX450 GF106 238 236 74.5% 28.43 2360
GT430 GF108 116 509 87.0% 11.29 937
,,,
( ゚д゚)つ┃
Radeon
HD5870 Cypress/RV870 334 177 66.5% 42.47 3526
HD5770 Juniper 170 338 82.0% 18.04 1497
HD5670 Redwood 100 598 88.0% 9.50 789
HD6870 Barts 255 222 73.0% 30.85 2561
HD6970 Cayman 380 148 62.5% 54.05 4486
Geforce
GTX480 GF100 529 104 52.0% 92.45 7674
GTX580 GF110 520 104 52.4% 91.74 7615
GTX460 GF104 332 177 67.0% 42.16 3499
GTX450 GF106 238 236 74.5% 28.43 2360
GT430 GF108 116 509 87.0% 11.29 937
,,,
( ゚д゚)つ┃
競合で並べ替えてみた
HD6970 Cayman 380 148 62.5% 54.05 4486
GTX480 GF100 529 104 52.0% 92.45 7674
GTX580 GF110 520 104 52.4% 91.74 7615
HD5870 Cypress/RV870 334 177 66.5% 42.47 3526
HD6870 Barts 255 222 73.0% 30.85 2561
GTX460 GF104 364 177 67.0% 42.16 3499
HD5770 Juniper 170 338 82.0% 18.04 1497
GTX450 GF106 238 236 74.5% 28.43 2360
HD5670 Redwood 100 598 88.0% 9.50 789
GT430 GF108 116 509 87.0% 11.29 937
*GTX460のサイズが違っていたので訂正
ラデの効率の良さが半端ないな
HD6970 Cayman 380 148 62.5% 54.05 4486
GTX480 GF100 529 104 52.0% 92.45 7674
GTX580 GF110 520 104 52.4% 91.74 7615
HD5870 Cypress/RV870 334 177 66.5% 42.47 3526
HD6870 Barts 255 222 73.0% 30.85 2561
GTX460 GF104 364 177 67.0% 42.16 3499
HD5770 Juniper 170 338 82.0% 18.04 1497
GTX450 GF106 238 236 74.5% 28.43 2360
HD5670 Redwood 100 598 88.0% 9.50 789
GT430 GF108 116 509 87.0% 11.29 937
*GTX460のサイズが違っていたので訂正
ラデの効率の良さが半端ないな
ハイエンド構成に比べりゃ安かろう悪かろうなのは当然
Llanoはシングルダイで市場のほとんどの性能要求に応える為のチップだから、
多少の効率の悪さは全く問題にならないよ
ノースブリッジがSATA3+USB3対応だから、安価に対応マザーを開発できるのも大きなメリットになる
Sandy+ディスクリートGPU+USB3対応マザーと、
Llano+mATXorITXマザーのどちらが安価で省電力に構築できるかは馬鹿でもわかる
Sandyの方が高性能だろうけどLlanoの方でも十分満足できる性能だから、
コストと電力でかなり差をつけて人気が出る可能性はかなり高い
誰もかれも高性能に金をかけるわけじゃない
それなりの価格でそれなりの性能の方が需要は遥かに高いんだよ
Llanoはシングルダイで市場のほとんどの性能要求に応える為のチップだから、
多少の効率の悪さは全く問題にならないよ
ノースブリッジがSATA3+USB3対応だから、安価に対応マザーを開発できるのも大きなメリットになる
Sandy+ディスクリートGPU+USB3対応マザーと、
Llano+mATXorITXマザーのどちらが安価で省電力に構築できるかは馬鹿でもわかる
Sandyの方が高性能だろうけどLlanoの方でも十分満足できる性能だから、
コストと電力でかなり差をつけて人気が出る可能性はかなり高い
誰もかれも高性能に金をかけるわけじゃない
それなりの価格でそれなりの性能の方が需要は遥かに高いんだよ
LlanoはCPU性能が低いからなー・・・。
418 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/26(金) 00:23:45 ID:5anvXDB5
NVIDIAやAMDの無用なGPGPU戦略に乗せられる気は無いので基本CPU性能重視でいくけど
個人的には3画面出力くらいは欲しいからi7 2600 + H67 + 適当なグラボ(端子増設用)だな
個人的には3画面出力くらいは欲しいからi7 2600 + H67 + 適当なグラボ(端子増設用)だな
419 :Socket774:2010/11/26(金) 00:26:01 ID:7Xb13pPq
>それなりの価格でそれなりの性能の方が需要は遥かに高いんだよ
セレロン大勝利
セレロン大勝利
Pentiumブランド今本当に価値ねえな・・・
Coreが上手くいったとも言えるけど悲しい
Coreが上手くいったとも言えるけど悲しい
>>416
Llanoの低電圧版とか出た日にはMini-ITXでのZacateの存在価値が完全に消えるよな
Llanoの低電圧版とか出た日にはMini-ITXでのZacateの存在価値が完全に消えるよな
GPU,padlack,AES-NI暗号速度比較
ttp://mousou01.blog.ocn.ne.jp/photos/uncategorized/2010/11/11/ango.png
APU(笑)
ttp://mousou01.blog.ocn.ne.jp/photos/uncategorized/2010/11/11/ango.png
{kind=link}
APU(笑)
1万円以下でCPU買うとなるとAMDしか選択できねえ
GPU(Larrabee)は全てソフトウェア実装
CPUはピンポイントなハードウェア実装をいくつも搭載
汎用演算器と特化演算器を真逆のベクトルに向かわせるIntelの気持ち悪さ半端無い
CPUはピンポイントなハードウェア実装をいくつも搭載
汎用演算器と特化演算器を真逆のベクトルに向かわせるIntelの気持ち悪さ半端無い
プリウスオンライン、ディビーナ、グランドファンタジア、ラテール、マスターオブエピック
タルタロスオンライン、タワーオブアイオン、ミスティックストーン、ベルアイル、グラナド・エスパダ
ルーセントハート、カバルオンライン、アークサイン、ファンタジーアース、ラペルズ、パンドラサーガ
マビノギ、アルカディアサーガ、アトランティカ、シルクロードオンライン、ブライトシャドウ
ROHAN、Soul of Ultimate Nation、ブレイドクロニクル、デカロン、パーフェクトワールド、リネージュⅡ
LEGEND of CHUSEN、フローレンシア、ファイナルファンタジー14、蒼天、エミル・クロニクル・オンライン
真・女神転生ONLINE IMAGINE、ファイナルファンタジー11、ラストカオス、リアノンライン、夢世界
アロッズオンライン、飛天オンライン、ルナティア、大航海時代オンライン、アイラオンライン
シールオンライン、RFオンライン、シャイヤ、ドラゴニカ、グランディアオンライン、天地大乱
もう許してくれよ団子・・・
タルタロスオンライン、タワーオブアイオン、ミスティックストーン、ベルアイル、グラナド・エスパダ
ルーセントハート、カバルオンライン、アークサイン、ファンタジーアース、ラペルズ、パンドラサーガ
マビノギ、アルカディアサーガ、アトランティカ、シルクロードオンライン、ブライトシャドウ
ROHAN、Soul of Ultimate Nation、ブレイドクロニクル、デカロン、パーフェクトワールド、リネージュⅡ
LEGEND of CHUSEN、フローレンシア、ファイナルファンタジー14、蒼天、エミル・クロニクル・オンライン
真・女神転生ONLINE IMAGINE、ファイナルファンタジー11、ラストカオス、リアノンライン、夢世界
アロッズオンライン、飛天オンライン、ルナティア、大航海時代オンライン、アイラオンライン
シールオンライン、RFオンライン、シャイヤ、ドラゴニカ、グランディアオンライン、天地大乱
もう許してくれよ団子・・・
426 :Socket774:2010/11/26(金) 10:24:20 ID:nyJf7WJq
>>421
20Wを境に住み分けするから大丈夫
20Wを境に住み分けするから大丈夫
>>416
Sandyに省電力版(4コア45W、2コア35W)が出るのを意図的に無視か・・・
性能より省電力に振るならディスクリートGPUなんて使わないし
それでLlano4コア100W、2コア65Wの方が省電力です?
すばらしいトンデモ理論だな
Sandyに省電力版(4コア45W、2コア35W)が出るのを意図的に無視か・・・
性能より省電力に振るならディスクリートGPUなんて使わないし
それでLlano4コア100W、2コア65Wの方が省電力です?
すばらしいトンデモ理論だな
428 :Socket774:2010/11/26(金) 12:19:37 ID:nyJf7WJq
Llanoにも35Wや25Wがあるんだぜ
Intel基準だと二倍、三倍になる産廃AMD(笑)
>>428
それはノート用だろ
それはノート用だろ
433 :Socket774:2010/11/26(金) 17:16:14 ID:OK56Q9ZI
Llanoなんて穴埋めCPUだろw
穴埋めのくせにサンディと比べる自体おこがましい
穴埋めのくせにサンディと比べる自体おこがましい
434 :Socket774:2010/11/26(金) 17:19:41 ID:nyJf7WJq
直ぐに出るさ
435 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/26(金) 19:42:10 ID:5anvXDB5
>>425
FF13を14に訂正したので許してやるよ雑魚p
FF13を14に訂正したので許してやるよ雑魚p
基地外の団子が偉そうだなw
お前の妄想がことごとくブーメラン食らったのにまだコテつけて荒らすのかw
お前の妄想がことごとくブーメラン食らったのにまだコテつけて荒らすのかw
>>425
とりあえずGMAでは動作や起動があやしいゲームを挙げてみました
とりあえずGMAでは動作や起動があやしいゲームを挙げてみました
>>425みたいなのやる人は少なくともHD5650以上積んでるもんじゃない?
GMAどころか785Gも論外でしょ。当然HD5570相当とか言われてるLlanoも。
GMAどころか785Gも論外でしょ。当然HD5570相当とか言われてるLlanoも。
GMAはなにもかも無理ゲーだけど
HD5570がGF9600M GS以上ならほとんどの3DMMOは快適だろうね
なにせGF9600M GS持ってる本人が言うんだから
HD5570がGF9600M GS以上ならほとんどの3DMMOは快適だろうね
なにせGF9600M GS持ってる本人が言うんだから
GF9600MGS 21112
AMD790GX+PhenomII 10900
Core i3 530 9300
AMD780G+Phenom. 9200
AMD790GX+PhenomII 10900
Core i3 530 9300
AMD780G+Phenom. 9200
LlanoはHD5570(≒HD4670)相当と言ってるのもいるけど実際は
ハイエンドでHD5550相当かそれを下回るぐらいだと思う。
9600MGSはDDR2版の9600MGT(通常の9600MGTの80%程度)とほとんど
同等性能だから、HD5550相当が実現できればそれよりは圧倒的に
高性能。仮にHD5450程度に落ち着いたとしても同等性能が実現できる
ハイエンドでHD5550相当かそれを下回るぐらいだと思う。
9600MGSはDDR2版の9600MGT(通常の9600MGTの80%程度)とほとんど
同等性能だから、HD5550相当が実現できればそれよりは圧倒的に
高性能。仮にHD5450程度に落ち着いたとしても同等性能が実現できる
442 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/27(土) 18:14:19 ID:60rE//DR
クロック・構造が違うとはいえ480spも積んでて
HPCじゃなくてゲームですら32SPのMGTとドッコイなのか。
Sandy Bridgeは12EU版(48SP相当)なら案外勝てるかもしれんな。
GPU開発チームも今はイスラエルみたいだし。
HPCじゃなくてゲームですら32SPのMGTとドッコイなのか。
Sandy Bridgeは12EU版(48SP相当)なら案外勝てるかもしれんな。
GPU開発チームも今はイスラエルみたいだし。
いまさらAとNのSP数を単純に比較してるのか
444 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/27(土) 19:05:04 ID:60rE//DR
FLOPS数をCPUと単純比較するのも無意味だな
Sandy Bridgeの場合ほとんど再設計されてるしキャッシュの効果もあるから
既存品からの予測は不可能
と言ってもIntel自身がニッチなゲーム向けじゃなくて
メディアプロセッシング向けにしたといっている
既存品からの予測は不可能
と言ってもIntel自身がニッチなゲーム向けじゃなくて
メディアプロセッシング向けにしたといっている
446 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/27(土) 19:14:23 ID:60rE//DR
1EU=4MADじゃなくて8MADくらいになってたりするのかな?
Sandy bridgeでもEUの演算器が変わるのかはよくわからないけど
(積和算器だったのか疑問)
レジスタファイルを大きくすることで、パフォーマンスを上げているのと
それまでは、普通のGPUなら固定機能でやる内容も
EUで代替してた処理があったらしく、それを固定機能に移した
そしてその固定機能自体も強化されているらしい
でも目玉になるのはトランスコードの専用ユニットじゃないかな
(積和算器だったのか疑問)
レジスタファイルを大きくすることで、パフォーマンスを上げているのと
それまでは、普通のGPUなら固定機能でやる内容も
EUで代替してた処理があったらしく、それを固定機能に移した
そしてその固定機能自体も強化されているらしい
でも目玉になるのはトランスコードの専用ユニットじゃないかな
で、レジスタファイルの強化ってのは、S3 GraphicsもChrome 400から500にかけて行っており
(こちらは積和算器ではない)
強化の程度にもよるだろうけど、shader酷使する場合は結構な差になる
S3 Chrome 540 GTX VS S3 Chrome 440 GTX Shader Performance
ttp://www.youtube.com/watch?v=b32iKtPF15Q
動画頭のparticleはCPUがネックになって540が遅い
(こちらは積和算器ではない)
強化の程度にもよるだろうけど、shader酷使する場合は結構な差になる
S3 Chrome 540 GTX VS S3 Chrome 440 GTX Shader Performance
ttp://www.youtube.com/watch?v=b32iKtPF15Q
動画頭のparticleはCPUがネックになって540が遅い
4月にLlanoのサンプル配布、って観測あっただろ
同時期にSandyのサンプルも大量に配布されてて
OEMメーカーからSandyのGPU部分の予想外の強化を漏れ聞いて
青くなってLlanoを再設計した、ってのが実情じゃないの?
公開してたダイサイズのGPU部分が肥大化したことも説明がつく
同時期にSandyのサンプルも大量に配布されてて
OEMメーカーからSandyのGPU部分の予想外の強化を漏れ聞いて
青くなってLlanoを再設計した、ってのが実情じゃないの?
公開してたダイサイズのGPU部分が肥大化したことも説明がつく
ハードウェアが高性能になったからと言ってドライバ開発力も向上するわけじゃないからな
かえってドライバの覚醒が遅くなるだけな気がする
どうにもならなくて結局演算はAVXに丸投げするだけだろう
かえってドライバの覚醒が遅くなるだけな気がする
どうにもならなくて結局演算はAVXに丸投げするだけだろう
llanoはもともと半分隠したものを当初公開していたんだろうけど
規模に見合ったパフォーマンスが出せるのかは疑問
sandy bridgeは確か6EU物のテストが
どっかのサイトでやってた記憶がある
それでもclarkdaleよりは速かったようだけど
規模に見合ったパフォーマンスが出せるのかは疑問
sandy bridgeは確か6EU物のテストが
どっかのサイトでやってた記憶がある
それでもclarkdaleよりは速かったようだけど
青くなってBullやBobを非対称に再設計した、ってのが実情じゃないの?
公開してたダイのx86部分が歪なことも説明がつく
http://3.bp.blogspot.com/_cQNeXXm7CdI/TH7TKmEWSKI/AAAAAAAAJ_E/FIMW8udf6qw/s1600/AMD-Bulldozer-Orochi-8-cores.jpg
41 名前:Socket774 ♪[sage] 投稿日:2010/10/10(日) 14:46:56 ID:+MWdvyN8
Hansはウンコすぎる。なんでSRAMやGPUがCPUコアになるんだか。
まだ、こっちの方が信用できるな。
http://1.bp.blogspot.com/_4qvKWy79Suw/TIZ7nvumPOI/AAAAAAAACaA/rRyrCaQ7Md8/s1600/Bobcat_die2.jpg
公開してたダイのx86部分が歪なことも説明がつく
http://3.bp.blogspot.com/_cQNeXXm7CdI/TH7TKmEWSKI/AAAAAAAAJ_E/FIMW8udf6qw/s1600/AMD-Bulldozer-Orochi-8-cores.jpg
{kind=link}
41 名前:Socket774 ♪[sage] 投稿日:2010/10/10(日) 14:46:56 ID:+MWdvyN8
Hansはウンコすぎる。なんでSRAMやGPUがCPUコアになるんだか。
まだ、こっちの方が信用できるな。
http://1.bp.blogspot.com/_4qvKWy79Suw/TIZ7nvumPOI/AAAAAAAACaA/rRyrCaQ7Md8/s1600/Bobcat_die2.jpg
{kind=link}
455 :MACオタ>451 さん:2010/11/27(土) 21:13:03 ID:960720iP
>>451
-----------------
llanoはもともと半分隠したものを当初公開していたんだろうけど
-----------------
その通りで、下のリンクの投稿日付を見れば判るように、昨年の11月中に Llano の GPU 部分が隠されていたことは知られていました。
http://forum.beyond3d.com/showpost.php?s=7721d38bc8befaca6188d3ffef1e3f3d&p=1357640&postcount=18
今年の2月には Hans de Vries 氏が懇切丁寧なダイの予想画像を公開しています。
http://chip-architect.com/news/Llano_comp2.jpg
-----------------
llanoはもともと半分隠したものを当初公開していたんだろうけど
-----------------
その通りで、下のリンクの投稿日付を見れば判るように、昨年の11月中に Llano の GPU 部分が隠されていたことは知られていました。
http://forum.beyond3d.com/showpost.php?s=7721d38bc8befaca6188d3ffef1e3f3d&p=1357640&postcount=18
今年の2月には Hans de Vries 氏が懇切丁寧なダイの予想画像を公開しています。
http://chip-architect.com/news/Llano_comp2.jpg
{kind=link}
Cellっぽい感じの設計になるんだろうね
458 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/27(土) 23:37:00 ID:60rE//DR
459 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/27(土) 23:43:49 ID:60rE//DR
Intel発案のIntelの為の特化命令を互換のために無理やり積んでいる以上効率はどうしても劣る
他社特化命令が遅く自社特化命令が速いのはどこも一緒
別に騒ぐほどのことじゃない
他社特化命令が遅く自社特化命令が速いのはどこも一緒
別に騒ぐほどのことじゃない
【法則発動】雑音犬畜生Part45【自己紹介】
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
http://toki.2ch.net/test/read.cgi/tubo/1279940532/
「新:旧=汎用:特化」とは
流石に「C++=C#」「GPUは演算出来ないけど動き回れる」な押入れ族なだけはあるな
流石に「C++=C#」「GPUは演算出来ないけど動き回れる」な押入れ族なだけはあるな
>CPUには特殊命令積んでintel特化を求めるくせに、GPUは汎用志向とか
>矛盾してね?
とくに矛盾はしない
頻繁に使われる用途ならば、専用ユニットや命令で処理した方が効率が良いし、規模も小さく済む
>矛盾してね?
とくに矛盾はしない
頻繁に使われる用途ならば、専用ユニットや命令で処理した方が効率が良いし、規模も小さく済む
どっちも過渡期だからなぁ、あまり細かく突っ込んでもな
465 :Socket774:2010/11/28(日) 10:39:52 ID:MC7fvnDY
「CUDAを学ばないでも,GPUで高速演算」,MathWorksがMATLABの最新機能を紹介
http://techon.nikkeibp.co.jp/article/NEWS/20101126/187651/
> GPGPUの能力を引き出すには,NVIDIAの開発環境の「CUDA」を使って
>プログラミングする必要があろうが,「MATLABのParallel Computing Toolbox
>では,CUDAを学ばなくてもGPGPUを手軽に利用できるようにすることを狙った」
>(MathWorks)。説明会で見せた例題の「2次元フーリエ変換をGPGPU上で
>処理する」ためには,3行のコードを記述するだけでOKだった。
,,,
( ゚д゚)つ┃
http://techon.nikkeibp.co.jp/article/NEWS/20101126/187651/
> GPGPUの能力を引き出すには,NVIDIAの開発環境の「CUDA」を使って
>プログラミングする必要があろうが,「MATLABのParallel Computing Toolbox
>では,CUDAを学ばなくてもGPGPUを手軽に利用できるようにすることを狙った」
>(MathWorks)。説明会で見せた例題の「2次元フーリエ変換をGPGPU上で
>処理する」ためには,3行のコードを記述するだけでOKだった。
,,,
( ゚д゚)つ┃
>NVIDIA以外のGPU,例えば,米Advanced Micro Devices, Inc.の製品に関しては,
>
>「GPU自体の機能・能力,
>
>MATLABのユーザーのニーズの双方がそろえば,
>対応のGPUを増やしたい」(MathWorks)と述べた。
>
>「GPU自体の機能・能力,
>
>MATLABのユーザーのニーズの双方がそろえば,
>対応のGPUを増やしたい」(MathWorks)と述べた。
>>465
衰退確定なNvidia製のGPU依存とか怖すぎだしな>CUDA
http://www.xbitlabs.com/news/cpu/display/20101119124344_Intel_s_Sandy_Bridge_Will_Not_Skyrocket_Sales_of_Microprocessors_Analyst.html
Intel's Sandy Bridge Will Not Skyrocket Sales of Microprocessors - Analyst.
>thanks to much improved performance of built-in graphics core of Sandy Bridge,
>system makers will be able to drop low-end integrated graphics from ATI or Nvidia,
>which will reduce their costs and will boost profitability, or will allow them to make
>PCs more affordable.
PCメーカーはコストダウンに必死だから、もはや単体GPUを載せる余裕は無し。
統合GPUが進化して、ローエンドGPUのほうが性能で劣っているなら尚更。
NvidiaがTesla、Tegraに必死なのも、現状のGeforce依存に将来性が無いことが
分かりきっているからだろうし。
衰退確定なNvidia製のGPU依存とか怖すぎだしな>CUDA
http://www.xbitlabs.com/news/cpu/display/20101119124344_Intel_s_Sandy_Bridge_Will_Not_Skyrocket_Sales_of_Microprocessors_Analyst.html
Intel's Sandy Bridge Will Not Skyrocket Sales of Microprocessors - Analyst.
>thanks to much improved performance of built-in graphics core of Sandy Bridge,
>system makers will be able to drop low-end integrated graphics from ATI or Nvidia,
>which will reduce their costs and will boost profitability, or will allow them to make
>PCs more affordable.
PCメーカーはコストダウンに必死だから、もはや単体GPUを載せる余裕は無し。
統合GPUが進化して、ローエンドGPUのほうが性能で劣っているなら尚更。
NvidiaがTesla、Tegraに必死なのも、現状のGeforce依存に将来性が無いことが
分かりきっているからだろうし。
MATLABでやってるのも結局CUDAへの変換でしょ
469 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/28(日) 11:25:57 ID:XrB+mWbD
>>460
BSR/BSFって大昔からあるx86基本命令ですが。
BSR/BSFって大昔からあるx86基本命令ですが。
470 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/11/28(日) 12:17:43 ID:XrB+mWbD
ビットスキャン系の命令ってLZMA圧縮とかでも多用するから速いに越したことは無いんだけど
それにしてもVIA Nano/C7より遅いK10って一体・・・
http://www.freeweb.hu/instlatx64/CentaurHauls00006F8_CNB_Isaiah_InstLatX64.txt
313 X86 :BSF r16, r16 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
314 X86 :BSF r32, r32 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
315 AMD64 :BSF r64, r64 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
316 X86 :BSR r16, r16 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
317 X86 :BSR r32, r32 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
318 AMD64 :BSR r64, r64 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
それにしてもAtomの16サイクルはかかりすぎだろうと思うわけだが、C3と同等なんだな。
それにしてもVIA Nano/C7より遅いK10って一体・・・
http://www.freeweb.hu/instlatx64/CentaurHauls00006F8_CNB_Isaiah_InstLatX64.txt
313 X86 :BSF r16, r16 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
314 X86 :BSF r32, r32 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
315 AMD64 :BSF r64, r64 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
316 X86 :BSR r16, r16 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
317 X86 :BSR r32, r32 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
318 AMD64 :BSR r64, r64 L: 1.11ns= 2.0c T: 1.11ns= 2.00c
それにしてもAtomの16サイクルはかかりすぎだろうと思うわけだが、C3と同等なんだな。
てか、nehemiah(C5P(C3))とesther(C5J(C7))でもだいぶ違うんだね
>PCメーカーはコストダウンに必死だから、
それはメーカーによりけりじゃね?
むしろ、日本メーカーなんか、インテルGPU以外のを、
地デジ搭載モデルとかAVモデルで使ってるし、
i7とか一部i5の中から上限定で、高級モデルとスタンダートにしてるし、
今でもコストダウンに必死なのは、HPとかDELLとかエイサーなんかの激安直販メーカーくらいだろ。
それはメーカーによりけりじゃね?
むしろ、日本メーカーなんか、インテルGPU以外のを、
地デジ搭載モデルとかAVモデルで使ってるし、
i7とか一部i5の中から上限定で、高級モデルとスタンダートにしてるし、
今でもコストダウンに必死なのは、HPとかDELLとかエイサーなんかの激安直販メーカーくらいだろ。
日本はバカ高いクソパソコンをありがたがって買うマゾ民族だからいいが
海外ではそうはいかない。
海外ではそうはいかない。
474 :Socket774:2010/11/29(月) 22:12:17 ID:SB28/s91
http://www.semiaccurate.com/forums/showpost.php?p=84850&postcount=250
Caymanは”少し”遅れただけ
殆んどの延期の噂はNvidiaのFUD
Cayman siliconを見た
既にAIBに十分な量が渡ってる
歩留まりの問題もない、NvidiaのFUD
部品不足の証拠も無い
,,,
( ゚д゚)つ┃
Caymanは”少し”遅れただけ
殆んどの延期の噂はNvidiaのFUD
Cayman siliconを見た
既にAIBに十分な量が渡ってる
歩留まりの問題もない、NvidiaのFUD
部品不足の証拠も無い
,,,
( ゚д゚)つ┃
チャーリーデマ痔暗乙
Nvidia to paper launch GTX580 in a week
No chips, no hope, just spin
とか吹いてたSemiaccurateの言うことはやはり説得力があるな
No chips, no hope, just spin
とか吹いてたSemiaccurateの言うことはやはり説得力があるな
T-ZONEってGeForceに偏りすぎたから潰れたんでしょ?
>>476
普通ならペーパーになるレベルの製造量なのにHD6900に先行するために無理して販売しただけ
普通ならペーパーになるレベルの製造量なのにHD6900に先行するために無理して販売しただけ
ラデ厨はスレタイ読んだら巣に帰れ
480 :Socket774:2010/11/30(火) 23:41:09 ID:xZOySNPJ
もしかして賠償金の話がまだ上がらないのは
RambusさんがNvidaの株価下がるのを見計らって
買収するつもりだからじゃ・・・
それはないかRambusはGPUなんていらないだろうし。
GT6600のころからGDDR使ってたから足かけ6年?くらい勝手に使ってたわけだが・・・・
これ数億で済まされるレベルなのか?
,,,
( ゚д゚)つ┃
RambusさんがNvidaの株価下がるのを見計らって
買収するつもりだからじゃ・・・
それはないかRambusはGPUなんていらないだろうし。
GT6600のころからGDDR使ってたから足かけ6年?くらい勝手に使ってたわけだが・・・・
これ数億で済まされるレベルなのか?
,,,
( ゚д゚)つ┃
ラデ
482 :Socket774:2010/12/01(水) 03:41:21 ID:hrlZ5Xjf
関係ないけど、GIGAZINEギガジンの中の人ってこういう盗撮系の趣味の人なのか?
http://gigazine.net/index.php?/news/comments/20101130_pole_vault/
http://gigazine.net/index.php?/news/comments/20101130_pole_vault/
gigazineはあのキチガイ編集長の勘違い作文(新人募集)で見る気失せた
会社としての未熟さを個人の責任にでっちあげる日本人体質マジ異常
会社としての未熟さを個人の責任にでっちあげる日本人体質マジ異常
ゲームしなければってCPUの性能面へのブーメランじゃん
CPUパフォーマンスの向上は全てに効果があるが
GPUのパフォーマンスはゲームにしか効果がない
GPUのパフォーマンスはゲームにしか効果がない
シングルスレッド向上なんてもうCPUベンチマークとPS2エミュくらいにしか効果ない
GPU性能の向上はゲーム以外にもOpenGLを使うアドビ系やレンダリングに効果がある
GPU性能の向上はゲーム以外にもOpenGLを使うアドビ系やレンダリングに効果がある
487 :Socket774:2010/12/01(水) 21:56:27 ID:zMuFTpM5
(笑)
>>485
GPGPUとして使って、CPUの計算能力不足を、アシストさせるという使い方も。
3DCGのレンダリングでは、Corei7を使っても、1毎数分以上かかるぐらいであるのに、技術的にはより計算能力を必要とする物理シミュレーションに近づける方向。
GPGPUとして使って、CPUの計算能力不足を、アシストさせるという使い方も。
3DCGのレンダリングでは、Corei7を使っても、1毎数分以上かかるぐらいであるのに、技術的にはより計算能力を必要とする物理シミュレーションに近づける方向。
489 :Socket774:2010/12/01(水) 22:03:44 ID:zMuFTpM5
GPGPU(笑)
ブラウザも早くなるよ
>ブラウザも早くなるよ
DX9世代のオンボで十分(笑)
DX9世代のオンボで十分(笑)
>GPGPUとして使って、CPUの計算能力不足を、アシストさせるという使い方も。
何に使えるの?(笑)
>3DCGのレンダリングでは、Corei7を使っても、1毎数分以上かかるぐらいであるのに、技術的にはより計算能力を必要とする物理シミュレーションに近づける方向。
GPU向け手抜きリアルタイムレイトレですか?(笑)
何に使えるの?(笑)
>3DCGのレンダリングでは、Corei7を使っても、1毎数分以上かかるぐらいであるのに、技術的にはより計算能力を必要とする物理シミュレーションに近づける方向。
GPU向け手抜きリアルタイムレイトレですか?(笑)
CPUでレイトレとか何の罰ゲームだよ
ちなみにIntelもシングルスレッドの向上には見切りをつけてるよ、
ララビーみたいなベクトルユニットやメニーコアを研究してるし、
FPGA統合も計画中だからな
まあ、ネハレムコアを気合入れてパワーアップしたSandyですらIPCは1割も向上しないし、
クロックも4GHzには届かない体たらくだから仕方ないとは思う
ちなみにIntelもシングルスレッドの向上には見切りをつけてるよ、
ララビーみたいなベクトルユニットやメニーコアを研究してるし、
FPGA統合も計画中だからな
まあ、ネハレムコアを気合入れてパワーアップしたSandyですらIPCは1割も向上しないし、
クロックも4GHzには届かない体たらくだから仕方ないとは思う
494 :Socket774:2010/12/01(水) 23:23:47 ID:2PmrP15g
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
495 :Socket774:2010/12/01(水) 23:40:42 ID:PkJCJivE
三割高速化ってどこから出たの?
シングルスレッドスカラ性能は重要だが
SIMMMMは力を入れれば入れるほどLarrabeeに近付きそして死亡
現時点でもマルチスレッドSIMD(GPU)にボロ負けなのを見ないふりして耐えてるだけだし
SIMMMMは力を入れれば入れるほどLarrabeeに近付きそして死亡
現時点でもマルチスレッドSIMD(GPU)にボロ負けなのを見ないふりして耐えてるだけだし
ontarioとatom比較ではマルチスレッドはベンチでしか意味がないといい
bulldozerとsandybridgeではシングルはベンチでしか意味がないといい
ころころ大変だねAMDは
bulldozerとsandybridgeではシングルはベンチでしか意味がないといい
ころころ大変だねAMDは
494 名前:Socket774[] 投稿日:2010/12/01(水) 23:23:47 ID:2PmrP15g
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
笑わせんなw
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
笑わせんなw
その辺は押入れ内のLianoやBuLidozerの話だから
501 :Socket774:2010/12/02(木) 09:18:21 ID:+DICe/Ox
Dual channeでしかもL3付きのSandyBridgeが
たかだかSingle channelでL2がコア毎に512KBしかなく
さらにキャッシュがコアの半分の速度のZacateに
3D性能を測るベンチでどうして僅かにしか勝てないのか
たかだかSingle channelでL2がコア毎に512KBしかなく
さらにキャッシュがコアの半分の速度のZacateに
3D性能を測るベンチでどうして僅かにしか勝てないのか
502 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/02(木) 09:33:13 ID:+MB8u3pa
うわ臭っ!
そもそも80SPが6EUの24SP相当品に負けてるのって
どうなの
どうなの
そもそも32nmが40nmに辛勝してるのってどうなの
そもそも24SP相当ってRADEON換算なの
そもそも220mm^2が75mm^2相手に辛勝ってどうなの
そもそも24SP相当ってRADEON換算なの
そもそも220mm^2が75mm^2相手に辛勝ってどうなの
>>502
勝てないのは省エネ性だけだね
勝てないのは省エネ性だけだね
大変だなAMDは
だいたいインテルとAMDのSP単位は同等なのか?
509 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 01:27:04 ID:xvqM71OY
1SPを単精度MAC1基とするなら1EU=4SP相当。
分岐粒度的にはIntelが一番小回りがきくはずだが、実性能はどうだかねえ
分岐粒度的にはIntelが一番小回りがきくはずだが、実性能はどうだかねえ
510 :Socket774:2010/12/03(金) 01:33:08 ID:BDYL9YTT
ダイ換算で言ったらPhenom2 x6 + 890GXなんて悲惨だなw
AMD信者はCPU性能とGPU性能の区別すら付いてないのか
512 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 02:06:14 ID:yQ1WQHOl
GPUコアを1GHz動作と仮定しても12[EU] * 8[FMAC] * 1[GHz] = 96GFLOPS
CPUのほうが倍速い。
Ivy Bridgeでは24EUになるがCPU側も強化されるので追いつかなさそうだな。
IntelにはGPGPU(笑)なんてやる機運は当然無い。
CPUのほうが倍速い。
Ivy Bridgeでは24EUになるがCPU側も強化されるので追いつかなさそうだな。
IntelにはGPGPU(笑)なんてやる機運は当然無い。
GPGPUは開発力不足で失敗したからキャンセル
タダのベクトルプロセッサとして再出発して細々と研究中
タダのベクトルプロセッサとして再出発して細々と研究中
514 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 02:48:45 ID:xvqM71OY
GPGPU(笑)ちげーよ
コプロセッサ化したCPUでGPUやるんだよ。立場がまったく違う。
LNI関連の特許文書にはOoO実行エンジンが書かれてたり最初から
従来型CPUコアに載せることをにおわせていた
結局ハードウェアなんて何でも良いんだ。
命令セットと演算ユニットがLarrabeeの真骨頂。
エンドユーザーに関係ありそうなGPGPUアプリってAVIVO(笑)くらいしかないんだし
Intelとしては動画のハードウェアエンコーダ・デコーダ搭載で十分じゃねーの?w
コプロセッサ化したCPUでGPUやるんだよ。立場がまったく違う。
LNI関連の特許文書にはOoO実行エンジンが書かれてたり最初から
従来型CPUコアに載せることをにおわせていた
結局ハードウェアなんて何でも良いんだ。
命令セットと演算ユニットがLarrabeeの真骨頂。
エンドユーザーに関係ありそうなGPGPUアプリってAVIVO(笑)くらいしかないんだし
Intelとしては動画のハードウェアエンコーダ・デコーダ搭載で十分じゃねーの?w
そうなんだよ
H2は本当に一般ユーザー向けだよね
H2は本当に一般ユーザー向けだよね
>1SPを単精度MAC1基とするなら1EU=4SP相当。
amdのGPUの命令数計測
ttp://img9.imageshack.us/img9/4316/83530192.png
積和算器じゃないchromeと同程度なので
少なくてもclarkdaleのEUは積和算器じゃないと思うんだ
AMD換算なら1/2にして数えないとね
ま、演算器が単純にパフォーマンスに影響するわけじゃないみたいだけど
ttp://www.youtube.com/watch?v=ZNHoi8iEHrk
amdのGPUの命令数計測
ttp://img9.imageshack.us/img9/4316/83530192.png
{kind=link}
積和算器じゃないchromeと同程度なので
少なくてもclarkdaleのEUは積和算器じゃないと思うんだ
AMD換算なら1/2にして数えないとね
ま、演算器が単純にパフォーマンスに影響するわけじゃないみたいだけど
ttp://www.youtube.com/watch?v=ZNHoi8iEHrk
517 :Socket774:2010/12/03(金) 07:55:28 ID:0bZ+eeSF
518 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 09:33:55 ID:xvqM71OY
サーバサイドのメディアプロセッサ市場はそこそこ拡大市場だからまるっきしニッチでもない
Sandyに12EUモデルあるけどそれって最上位にしかないんだよね
24EUもSandyに習って最上位モデルにしかないだろうし
ていうかこれってCore i5 661みたいな買えないけどとりあえず存在してます
みたいなモデルじゃない?
24EUもSandyに習って最上位モデルにしかないだろうし
ていうかこれってCore i5 661みたいな買えないけどとりあえず存在してます
みたいなモデルじゃない?
デスクトップ版はK付きのみ12EU。基本6EU。
モバイル版は今わかっている上位モデルは全部12EU。
モバイル版は今わかっている上位モデルは全部12EU。
521 :Socket774:2010/12/03(金) 12:36:36 ID:mx2jTMBs
内臓GPU(笑)な時点で全て五十歩百歩
帯に短し襷に長しなガラクタぢゃん
帯に短し襷に長しなガラクタぢゃん
Bulldozer→完全に鯖向け。低性能多スレッドはPC用途じゃ活躍できない
Llano→CPUもGPUも中途半端すぎる。しかも専用ソケットで誰得
Bobcat→IONの後継にはなれそう。メーカーへの働きかけがカギ
Llano→CPUもGPUも中途半端すぎる。しかも専用ソケットで誰得
Bobcat→IONの後継にはなれそう。メーカーへの働きかけがカギ
524 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 19:52:29 ID:xvqM71OY
Z68なんて噂もあるけど
Sandyの上位は外部GPUとの組合せが殆どだろ
下位のi3辺りにこそ12EUとかが必要なのに6EUしかない
インテルの製品プランは意味不明すぎる
下位のi3辺りにこそ12EUとかが必要なのに6EUしかない
インテルの製品プランは意味不明すぎる
2600Kそのままで使う予定だが
1EUでいい
529 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/03(金) 23:50:18 ID:xvqM71OY
倍率変更いらないならKなしでいいじゃん
もうこのまま永久にベンチマーク棒グラフしか出そうにないAMD・・・
>倍率変更いらないならKなしでいいじゃん
うん、でもoffになってるものがあるのって嫌じゃないですか
$23の差なら完全なものがほしい
sandybridgeの詳しい情報はまだ良く分からないけど
clarkdaleのときみたいに661でVT-dがoffだったり、i3でAES-NIがoffだったりとかも嫌なんで
それにメディアプロセッサとしてのGPUにも期待してる
うん、でもoffになってるものがあるのって嫌じゃないですか
$23の差なら完全なものがほしい
sandybridgeの詳しい情報はまだ良く分からないけど
clarkdaleのときみたいに661でVT-dがoffだったり、i3でAES-NIがoffだったりとかも嫌なんで
それにメディアプロセッサとしてのGPUにも期待してる
>clarkdaleのときみたいに661でVT-dがoffだったり、i3でAES-NIがoffだったり
へぇ、細かく差別化してるんだなぁ
へぇ、細かく差別化してるんだなぁ
533 :Socket774:2010/12/04(土) 13:24:45 ID:nIuBr9Uw
価格.com CPUトレンド 12月4日現在
Intel=49.55%
AMD =50.45%
史上初。なんぼなんでも、これはやばい。
Intel=49.55%
AMD =50.45%
史上初。なんぼなんでも、これはやばい。
534 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/04(土) 13:28:52 ID:Yn7ubbQA
新ソケットのCPUが出る前って大概そんなもんだよ。
535 :Socket774:2010/12/04(土) 14:06:06 ID:fHXjFnAQ
K付がVT-dオフの可能性もあるけどな
GPU内蔵4コアだけは欲しいな。
8コアもいらね。2コアならi5の方がいい。
8コアもいらね。2コアならi5の方がいい。
537 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/04(土) 14:09:31 ID:Yn7ubbQA
Intelは本音i7 2600Kを買わせたいんだよ。
L3を削ったりHTを無効にしたりGPUを半分に削ったのはそのため。
3.1GHzと3.4GHzじゃ大した差がないからね
L3を削ったりHTを無効にしたりGPUを半分に削ったのはそのため。
3.1GHzと3.4GHzじゃ大した差がないからね
538 :Socket774:2010/12/06(月) 20:10:03 ID:1XRb9drx
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
>>538
お前の脳内ではなw
お前の脳内ではなw
540 :Socket774 ♪:2010/12/09(木) 19:59:54 ID:oU6vO3MQ
New AMD code name: Steamroller, possibly a successor to Bulldozer.
Enhanced BD and BD NG are for 2012/13,SR might be the APU for ~2014+.
Enhanced BD and BD NG are for 2012/13,SR might be the APU for ~2014+.
コードネームばっか乱発してないで実際にモノ出せよw
ttp://www.fudzilla.com/home/item/21250-amd-tsmc-execs-face-insider-trading-probe
AMD, TSMC execs face insider trading probe
US Attorney's Office files subpoenas
AMD, TSMC execs face insider trading probe
US Attorney's Office files subpoenas
543 :Socket774:2010/12/19(日) 11:07:50 ID:zIyZzN9o
Intelが次世代CPU「Sandy Bridge」の詳細を発表
http://pc.watch.impress.co.jp/docs/column/kaigai/20100916_394037.html
なぜSandy Bridgeはそんなにパフォーマンスが高いのか
http://pc.watch.impress.co.jp/docs/column/kaigai/20100917_394622.html
トリックを重ねたSandy Bridgeマイクロアーキテクチャ
http://pc.watch.impress.co.jp/docs/column/kaigai/20100922_395394.html
12コア以上のIvy Bridgeへ結ぶSandy Bridgeのリングバス
http://pc.watch.impress.co.jp/docs/column/kaigai/20100924_395972.html
今どきのGPUコアへと生まれ変わるSandy Bridge
http://pc.watch.impress.co.jp/docs/column/kaigai/20101207_412173.html
汎用コンピューティングを強化したSandy Bridgeのグラフィックス
http://pc.watch.impress.co.jp/docs/column/kaigai/20101214_413951.html
http://en.inpai.com.cn/doc/enshowcont.asp?id=7948
i5 2500のigpは890gxと抜きつ抜かれつつ互角ってところか
intel側は時々できないゲームがあるみたいで安定性は相変わらずw
i5 2500のigpは890gxと抜きつ抜かれつつ互角ってところか
intel側は時々できないゲームがあるみたいで安定性は相変わらずw
545 :Socket774:2010/12/23(木) 00:25:19 ID:wxB2MDXP
ザンベジ、4月に出るらしいじゃん
4月に量産開始するのに4月に出せると思っちゃうのが凄い
極めて順調に行けば4月量産開始->6月出荷開始->7月発売開始だろう
極めて順調に行けば4月量産開始->6月出荷開始->7月発売開始だろう
まぁ、AMDがもっと頑張ってくれないと、Intelが、新製品を出し渋るからこまる。
CPUの設計においてベンチマークに向けたチューニングを実施することは、特段に難しいわけではない。
ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い。
またピークパフォーマンスは高くなるが、アベレージパフォーマンスが若干落ちる。
賢い人はフェイクを好まない。馬鹿はフェイクを全く見抜けない。
使用していて違和感を感じた人は、馬鹿ではない。むしろ賢い。
ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い。
またピークパフォーマンスは高くなるが、アベレージパフォーマンスが若干落ちる。
賢い人はフェイクを好まない。馬鹿はフェイクを全く見抜けない。
使用していて違和感を感じた人は、馬鹿ではない。むしろ賢い。
>ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い
妄想乙
妄想乙
550 :Socket774:2010/12/24(金) 17:22:24 ID:wx8wd81n
>ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い。
詳しく
詳しく
AthlonXPはクールだったのに
>ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い
GPU側が使えるcacheの無いllano,ontarioは頻繁にカクカクするね
GPU側が使えるcacheの無いllano,ontarioは頻繁にカクカクするね
ベンチに最適化って言ったら普通は、そのベンチに有意な回路の追加だろ
CPUの高速化は、最初の汎用回路を組んだ後は、何種類の専用回路を積むかって話だ
CPUの高速化は、最初の汎用回路を組んだ後は、何種類の専用回路を積むかって話だ
こんな状況が来たらこっちの専用回路に投げる
あんな状況が来たらあっちの専用回路に投げる
数百数千のパターンのうち、使用頻度や回路の増大量、消費電力の増加量のバランスを見ながら
利点の多いものは専用回路にやらせるようにし、少ないものは削って汎用回路にやらせるようにする
あんな状況が来たらあっちの専用回路に投げる
数百数千のパターンのうち、使用頻度や回路の増大量、消費電力の増加量のバランスを見ながら
利点の多いものは専用回路にやらせるようにし、少ないものは削って汎用回路にやらせるようにする
555 :,,・´∀`・,,)<一番良い -○○○ を頼む:2010/12/24(金) 20:46:15 ID:vSHX2Exd
>ただそういった設計を採れば、多少動作のもたつきが発生する可能性が高い。
AMDのCPUのことか。
ピーキーだもんなぁL1の2-Way Set Associative構造とか最大9issueの演算ユニットとか。
ハマれば速いが平均点をとるとIntelに負ける。
SPECのような、いろんなアプリケーションの重たい部分を集めたような総合ベンチマークは
一部機能に特化するようなごまかしが利かない。真の意味での総合力が試される。
AMDのCPUのことか。
ピーキーだもんなぁL1の2-Way Set Associative構造とか最大9issueの演算ユニットとか。
ハマれば速いが平均点をとるとIntelに負ける。
SPECのような、いろんなアプリケーションの重たい部分を集めたような総合ベンチマークは
一部機能に特化するようなごまかしが利かない。真の意味での総合力が試される。
GeodeLXが128bit AES(CBC/EBC)をサポートしていたのはここだけの秘密だ
ECBだった
メリクリ♪
INTEL && nVidia
. Λn п
/|田|||★ 几
{:~:~:~:~:~:~:~:~:} |::::|
{゜。゜。゜。゜。゜} .|::::| ▲ N V
^^^^^^^^^^^^  ̄ ⊥ ⊥ ⊥
INTEL && nVidia
. Λn п
/|田|||★ 几
{:~:~:~:~:~:~:~:~:} |::::|
{゜。゜。゜。゜。゜} .|::::| ▲ N V
^^^^^^^^^^^^  ̄ ⊥ ⊥ ⊥
最近はNAS組むのにも64bit multi core 8GBとか欲しくなっているな・・
ZFSとかChecksumにCPUの暗号処理も使われるようになってるし
ZFSとかChecksumにCPUの暗号処理も使われるようになってるし
ルイスってゾンビだよ?何いってんの
Sandyがでたらいまつかってる670をFreeBSD使って
RAID Z1なNASにするよてい
FreeNASだとPadlockが使えたけど
AES-NIはまだだった
或はソフトでサポートしているのか?
geli?
RAID Z1なNASにするよてい
FreeNASだとPadlockが使えたけど
AES-NIはまだだった
或はソフトでサポートしているのか?
geli?
SSD(SLC)をキャッシュとして使えたりするからな
FreeNASはお手軽でいい
FreeNASはお手軽でいい
563 :Socket774 ♪:2010/12/27(月) 00:15:39 ID:EWchLKuO
Llano Spectulations
http://www.semiaccurate.com/forums/showthread.php?p=90424#poststop
Llano X4 @29W (4 x 2.5W + 19W) tops @2.0GHZ, turbo: 2.2GHZ all cores, 3.3GHZ one core
Llano X4 @39W (4 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.9GHZ one core
Llano X4 @49W (4 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 4.2GHZ one core
Llano X3 @34W (3 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.7GHZ one core
Llano X3 @42W (3 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 3.9GHZ one core
Llano X2 @20W (2 x 2.5W + 15W) tops @2.0GHZ, turbo: 2.2GHZ all cores, 2.6GHZ one core
Llano X2 @25W (2 x 5W + 15W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.3GHZ one core
Llano X2 @29W (2 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.3GHZ one core
Llano X2 @34W (2 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 3.7GHZ one core
Llano X2 @39W (2 x 10W + 19W) tops @3.1GHZ, turbo: 3.3GHZ all cores, 3.9GHZ one core
http://www.semiaccurate.com/forums/showthread.php?p=90424#poststop
Llano X4 @29W (4 x 2.5W + 19W) tops @2.0GHZ, turbo: 2.2GHZ all cores, 3.3GHZ one core
Llano X4 @39W (4 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.9GHZ one core
Llano X4 @49W (4 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 4.2GHZ one core
Llano X3 @34W (3 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.7GHZ one core
Llano X3 @42W (3 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 3.9GHZ one core
Llano X2 @20W (2 x 2.5W + 15W) tops @2.0GHZ, turbo: 2.2GHZ all cores, 2.6GHZ one core
Llano X2 @25W (2 x 5W + 15W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.3GHZ one core
Llano X2 @29W (2 x 5W + 19W) tops @2.4GHZ, turbo: 2.6GHZ all cores, 3.3GHZ one core
Llano X2 @34W (2 x 7.5W + 19W) tops @2.8GHZ, turbo: 3.0GHZ all cores, 3.7GHZ one core
Llano X2 @39W (2 x 10W + 19W) tops @3.1GHZ, turbo: 3.3GHZ all cores, 3.9GHZ one core
564 :Socket774:2010/12/27(月) 09:12:23 ID:1mPIR5DC
また産廃x3を垂れ流すのか
無駄な発熱体入りノートなんか欲しがるアホは居ないぞ
無駄な発熱体入りノートなんか欲しがるアホは居ないぞ
565 :Socket774:2010/12/27(月) 09:20:48 ID:iznhfj/p
3台目PC初めてインテルにしたがAMDとの違いが何も感じない。
ゲームもエンコしないせいか?
安ければどちらでもOK!!
ゲームもエンコしないせいか?
安ければどちらでもOK!!
566 :Socket774:2010/12/31(金) 02:27:35 ID:UGkRWch0
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
567 :Socket774:2011/01/01(土) 16:13:28 ID:8vtNQi6c
■AMDの次世代Bulldozerコアは、なんと3割以上の低速化!!
>パフォーマンスは、Bulldozer世代でK10の2/3に落ちることになる。
>Bulldozer世代でK10の2/3に落ちる
>K10の2/3
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
現行K10ですらintelの足元にも及ばずもっさりなのに、AMDオワタ
568 :Socket774:2011/01/01(土) 18:00:43 ID:q4gqSxmA
後藤の言うトランジスタ効率って、単純にALUを2つに減らしても、スケジューラやレジスターファイルの増大で相殺されてんじゃないか?つうか逆にトランジスタ増えてんじゃって気がするんだが。
それでIPC下がってたら何のための効率化なんだか。
確かにパイプライン効率は高まるだろうけどな。
レジスタ数 K10 40本→ブル96本
RSエントリー K10 24エントリー→ブル40エントリー
K10のダイ写真見てもALUよりレジスターファイルやスケジューラのほうが大きいもんな。
それでIPC下がってたら何のための効率化なんだか。
確かにパイプライン効率は高まるだろうけどな。
レジスタ数 K10 40本→ブル96本
RSエントリー K10 24エントリー→ブル40エントリー
K10のダイ写真見てもALUよりレジスターファイルやスケジューラのほうが大きいもんな。
569 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/01/01(土) 22:44:22 ID:IWntw59S
K10は30じゃね?ただし3-way×10エントリの分散型。
Bulldozerからはメモリオペレーションと整数オペレーションを分離する構造になってる。
つまりK10をBulldozerに換算すれば(最大)60エントリに相当するので、むしろユニット数相応に減っている。
つか、そもそも性能下がるといってる奴はK7~K10パイプラインの構成を過大評価してるんじゃね?
分散型RSはひとつのALUレーンが空いても他のALUに振り分けられたμOPsを再配置できないので
100%の効率を得るのは難しい。
実効IPCはYonah≒K8くらいだったと思ってるが。
2ALU + 2 LSUで集中型RSてのはPentium Pro~Core Duo(Yonah)までのIntelアーキテクチャの
3issueパイプラインの構成でもある。
1モジュール1スレッド動かす場合にPhenom IIとそれほど遜色ない程度のIPCは達成できる
可能性は十分あると思うが。
むしろL1Dの構成が劣化Intel化してるのが気になる。
Bulldozerからはメモリオペレーションと整数オペレーションを分離する構造になってる。
つまりK10をBulldozerに換算すれば(最大)60エントリに相当するので、むしろユニット数相応に減っている。
つか、そもそも性能下がるといってる奴はK7~K10パイプラインの構成を過大評価してるんじゃね?
分散型RSはひとつのALUレーンが空いても他のALUに振り分けられたμOPsを再配置できないので
100%の効率を得るのは難しい。
実効IPCはYonah≒K8くらいだったと思ってるが。
2ALU + 2 LSUで集中型RSてのはPentium Pro~Core Duo(Yonah)までのIntelアーキテクチャの
3issueパイプラインの構成でもある。
1モジュール1スレッド動かす場合にPhenom IIとそれほど遜色ない程度のIPCは達成できる
可能性は十分あると思うが。
むしろL1Dの構成が劣化Intel化してるのが気になる。
こっちはもう馬鹿専用てことでいいな
571 :Socket774:2011/01/02(日) 13:06:39 ID:IXwWsFj9
あと1週間で買えるSandyBridge
対して、写真一枚出せない水子ブルドーザーw
Intelが次世代CPU「Sandy Bridge」の詳細を発表
http://pc.watch.impress.co.jp/docs/column/kaigai/20100916_394037.html
なぜSandy Bridgeはそんなにパフォーマンスが高いのか
http://pc.watch.impress.co.jp/docs/column/kaigai/20100917_394622.html
トリックを重ねたSandy Bridgeマイクロアーキテクチャ
http://pc.watch.impress.co.jp/docs/column/kaigai/20100922_395394.html
12コア以上のIvy Bridgeへ結ぶSandy Bridgeのリングバス
http://pc.watch.impress.co.jp/docs/column/kaigai/20100924_395972.html
今どきのGPUコアへと生まれ変わるSandy Bridge
http://pc.watch.impress.co.jp/docs/column/kaigai/20101207_412173.html
汎用コンピューティングを強化したSandy Bridgeのグラフィックス
http://pc.watch.impress.co.jp/docs/column/kaigai/20101214_413951.html
SandyBridgeが眩し過ぎてAMD信者失禁発狂
夢は現実をみないから夢であるという
573 :Socket774:2011/01/03(月) 12:10:58 ID:xa/NYLuk
amd派は誇大妄想ばかりいう
寝言は寝てから頼むわ
寝言は寝てから頼むわ
574 :Socket774:2011/01/04(火) 12:47:37 ID:U92woONo
【多和田新也のニューアイテム診断室】 AMDの普及価格帯CPUを一掃するSandy Bridgeこと「Core i7-2600K/i5-2500K」
http://pc.watch.impress.co.jp/docs/column/tawada/20110103_417994.html
>AMDの普及価格帯CPUを一掃するSandy Bridge
>AMDの普及価格帯CPUを一掃する
>AMDの
一掃されたのは「INTELの旧世代CPU全部」だよね
10万円の980Xすら上回るとか、オレゴンチーム涙目過ぎる
10万円の980Xすら上回るとか、オレゴンチーム涙目過ぎる
576 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/01/04(火) 13:20:32 ID:IcgoFNOk
あるべき姿だろ。
Pentium D/XEがCore 2 Duoに食われ・・・
中間レンジの製品でもAMDのハイエンドを食えるだけのパフォーマンス設定もあの頃と同じ。
Pentium D/XEがCore 2 Duoに食われ・・・
中間レンジの製品でもAMDのハイエンドを食えるだけのパフォーマンス設定もあの頃と同じ。
>>574
わざわざ主題を工作する意味がわからん
わざわざ主題を工作する意味がわからん
いや、昨日は
AMDの普及価格帯CPUを一掃するSandy Bridgeこと「Core i7-2600K/i5-2500K」
だったんだよ
さすがに苦情でもいったか
AMDの普及価格帯CPUを一掃するSandy Bridgeこと「Core i7-2600K/i5-2500K」
だったんだよ
さすがに苦情でもいったか
昨日から捏造しっ放しだったな
「Sandy Bridge」レビュー。従来製品をまとめて葬り去る新製品は「買い」だ
ttp://www.4gamer.net/games/098/G009883/20110103001/
Intelの次世代CPU「Sandy Bridge」がいよいよ登場の気配である。
4Gamerでは倍率ロックフリーモデル2製品と,通常モデル1製品を入手できたので,
常用を想定したオーバークロック動作も含め,ゲーム用途での性能を検証してみたい。
「空冷5GHz到達」「2万円のCPUがExtreme Editionを粉砕」というキーワードから導き出される
答えは,「買い」だ。
統合されたグラフィックス機能に関しては稿をあらためたいと思うが,単体グラフィックスカードと組み合わせたいと考えている大多数のPCゲーマーにとって,状況は「Sandy Bridge一択」である。
●デスクトップPC向けSandy Bridgeの主なスペック(※省スペースPC向けを除く)
i7-2600K:95W,4C8T,3.40-3.80GHz,8MB L3,2ch DDR3-1333,317ドル
i7-2600:95W,4C8T,3.40-3.80GHz,8MB L3,2ch DDR3-1333,294ドル
i5-2500K:95W,4C4T,3.30-3.70GHz,6MB L3,2ch DDR3-1333,216ドル
i5-2500:95W,4C4T,3.30-3.70GHz,6MB L3,2ch DDR3-1333,205ドル
i5-2400:95W,4C4T,3.10-3.40GHz,6MB L3,2ch DDR3-1333,184ドル
i5-2300:95W,4C4T,2.80-3.10GHz,6MB L3,2ch DDR3-1333,177ドル
i3-2120:65W,2C4T,3.30GHz,3MB L3,2ch DDR3-1333,138ドル
i3-2100:65W,2C4T,3.10GHz,3MB L3,2ch DDR3-1333,117ドル
ttp://www.4gamer.net/games/098/G009883/20110103001/
Intelの次世代CPU「Sandy Bridge」がいよいよ登場の気配である。
4Gamerでは倍率ロックフリーモデル2製品と,通常モデル1製品を入手できたので,
常用を想定したオーバークロック動作も含め,ゲーム用途での性能を検証してみたい。
「空冷5GHz到達」「2万円のCPUがExtreme Editionを粉砕」というキーワードから導き出される
答えは,「買い」だ。
統合されたグラフィックス機能に関しては稿をあらためたいと思うが,単体グラフィックスカードと組み合わせたいと考えている大多数のPCゲーマーにとって,状況は「Sandy Bridge一択」である。
●デスクトップPC向けSandy Bridgeの主なスペック(※省スペースPC向けを除く)
i7-2600K:95W,4C8T,3.40-3.80GHz,8MB L3,2ch DDR3-1333,317ドル
i7-2600:95W,4C8T,3.40-3.80GHz,8MB L3,2ch DDR3-1333,294ドル
i5-2500K:95W,4C4T,3.30-3.70GHz,6MB L3,2ch DDR3-1333,216ドル
i5-2500:95W,4C4T,3.30-3.70GHz,6MB L3,2ch DDR3-1333,205ドル
i5-2400:95W,4C4T,3.10-3.40GHz,6MB L3,2ch DDR3-1333,184ドル
i5-2300:95W,4C4T,2.80-3.10GHz,6MB L3,2ch DDR3-1333,177ドル
i3-2120:65W,2C4T,3.30GHz,3MB L3,2ch DDR3-1333,138ドル
i3-2100:65W,2C4T,3.10GHz,3MB L3,2ch DDR3-1333,117ドル
まあintelの提灯記事だな。
あはははは
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
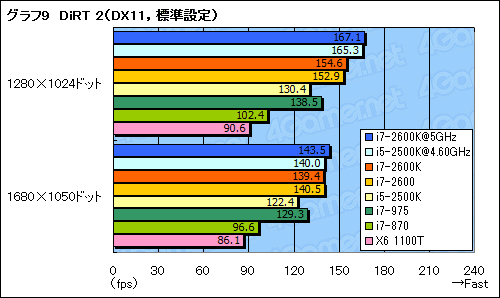{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
{kind=link}
583 :Socket774:2011/01/04(火) 19:57:59 ID:Gw80ewAm
あむど期待のしんせいひんが腐ったお節料理だった件について(-_-;
M/Bごと(同一ベンダーでも違いがあるのか?)で、TurboBoostのデフォルトの挙動が違うのか。
設定クロックの上限にも違いがでそうだし、M/B選択がさらにややこしくなりそう。
設定クロックの上限にも違いがでそうだし、M/B選択がさらにややこしくなりそう。
しかし、3万レベルの製品が現行EEを凌いだんじゃあ、AMDは
相当がんばらないとなあ。
>>580 じゃないけど、既存のCore i製品もPhenomも葬り去られそうだわ。
救いはマザーから新調だという点くらいしかないし。
相当がんばらないとなあ。
>>580 じゃないけど、既存のCore i製品もPhenomも葬り去られそうだわ。
救いはマザーから新調だという点くらいしかないし。
あむどはなんでこんなにていせいのうなんですか?
あむどはなんでこんなにていせいのうなんですか?
あむどはなんでこんなにていせいのうなんですか?
>>586
デフォルトスタンダード乙
デフォルトスタンダード乙
>>586
デフォルトスタンダード乙
デフォルトスタンダード乙
589 :Socket774:2011/01/05(水) 12:32:25 ID:hBTmOMoM
Intel次世代、三割高速化
AMD次世代、三割低速化
なぜ差がついたのか
851 名前:最低人類0号[sage] 投稿日:2011/01/05(水) 09:23:47 ID:q9+VsgjN0
自作PC板全体で7~8レスしか付かない時間帯に
ひとつのスレにAMDアンチな書き込みを5レス近くしたらいくらID変えても意味ナイだろwwwwwww
あほって言うか、ココまで来ると本格的に脳に障害持ってるんじゃないかな、
例えばあいつの年齢的を考えたらロボトミー手術を受けてる可能性がリアルで高い。
自作PC板全体で7~8レスしか付かない時間帯に
ひとつのスレにAMDアンチな書き込みを5レス近くしたらいくらID変えても意味ナイだろwwwwwww
あほって言うか、ココまで来ると本格的に脳に障害持ってるんじゃないかな、
例えばあいつの年齢的を考えたらロボトミー手術を受けてる可能性がリアルで高い。
>>586
デフォルトスタンダード乙
デフォルトスタンダード乙
あはははは
http://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/049.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/047.gif
これもな
{kind=link}
http://www.4gamer.net/games/098/G009883/20110103001/TN/047.gif
{kind=link}
これもな
10日になればベンチも出そろうしそれから検討しても遅くない。
買い逃したらそれもまたよし。
買い逃したらそれもまたよし。
>>586
デフォルトスタンダード乙
デフォルトスタンダード乙
596 :Socket774:2011/01/08(土) 12:49:20 ID:kCKbnPDY
前夜祭だぞおまいら!
え?
通夜ですか?
通夜ですか?
AMDのな
Sandy Bridgeまとめ
http://images.hardwarecanucks.com/image/mac/reviews/intel/sandybridge/chart24.jpg
i3より遅いi7 980X
http://www.pcper.com/images/reviews/776/farcry2-1920.jpg
http://images.anandtech.com/graphs/amdphenomiix4955_042209194837/18911.png
FarCry2
1920*1200 very high
X4 965・・・Ave74.1 Min42
1680*1050 medium
X4 955・・・51.2
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/014.gif 122.1/110.1
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/048.gif 93.3/86.4
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/015.gif 82.2/75.4
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif 50.4/46.0
ttp://www.4gamer.net/games/077/G007794/20100920020/TN/016.gif 103.1/100.7
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif 85.9/81.0
上:X6 1090T+HD5870-1GB+6V250F0 250GB+32bit版Win7+Catalyst10.9
下:X6 1100T+GTX580-1536MB+HDT722516DLA380 160GB+64bit版Win7+Catalyst10.12+ForceWare 263.09
http://images.hardwarecanucks.com/image/mac/reviews/intel/sandybridge/chart24.jpg
{kind=link}
i3より遅いi7 980X
http://www.pcper.com/images/reviews/776/farcry2-1920.jpg
{kind=link}
http://images.anandtech.com/graphs/amdphenomiix4955_042209194837/18911.png
{kind=link}
FarCry2
1920*1200 very high
X4 965・・・Ave74.1 Min42
1680*1050 medium
X4 955・・・51.2
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/014.gif 122.1/110.1
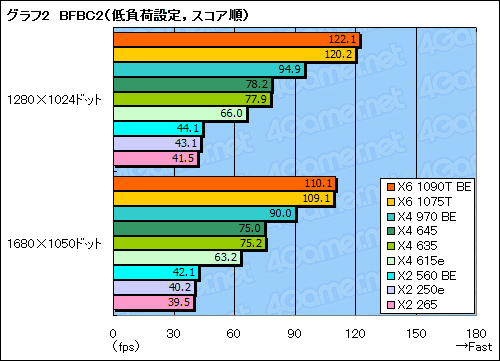{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/048.gif 93.3/86.4
{kind=link}
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/015.gif 82.2/75.4
{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif 50.4/46.0
ttp://www.4gamer.net/games/077/G007794/20100920020/TN/016.gif 103.1/100.7
{kind=link}
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif 85.9/81.0
上:X6 1090T+HD5870-1GB+6V250F0 250GB+32bit版Win7+Catalyst10.9
下:X6 1100T+GTX580-1536MB+HDT722516DLA380 160GB+64bit版Win7+Catalyst10.12+ForceWare 263.09
あはははは
http://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/052.gif
http://www.4gamer.net/games/098/G009883/20110103001/TN/054.gif
>>586
デフォルトスタンダード乙
デフォルトスタンダード乙
602 :Socket774:2011/01/10(月) 16:56:58 ID:IhGW+Xdg
サンディの内蔵GPU半端ねええええ
MHFベンチ2700だとぉおお!?890GXの3倍以上の超性能!
安かろう悪かろうのAMDもここまで差が着くとさすがに完全死亡か!?
MHFベンチ2700だとぉおお!?890GXの3倍以上の超性能!
安かろう悪かろうのAMDもここまで差が着くとさすがに完全死亡か!?
603 :Socket774:2011/01/11(火) 12:48:43 ID:i0OjMNqX
6コア最上位の1100Tが4コアHTなしの2500Kにぼろ負けすなあ
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/15
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/17
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/18
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/19
エンコでも負けるとかw
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/16
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/15
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/17
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/18
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/19
エンコでも負けるとかw
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/16
現実から逃げるな
【LGA1155】SandyBridge H2 Part30【←実質】
http://hibari.2ch.net/test/read.cgi/jisaku/1294610757/
誰一人歓喜の声をあげてない現実
【LGA1155】SandyBridge H2 Part30【←実質】
http://hibari.2ch.net/test/read.cgi/jisaku/1294610757/
誰一人歓喜の声をあげてない現実
605 :Socket774:2011/01/11(火) 15:03:34 ID:H26lIilr
で、発売前にエンコ4分を2秒でとか言ってたのはどこ行ったの?
恥ずかしさの余り逃げだしました
Intel 少女時代に救援を求める
ついにいかれたようですね?
ついにいかれたようですね?
現実
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110111_419567.html
予想外のCEO辞任で揺れるAMD
AMDは財政面で厳しい状況が続いている。そうした会社のCEOが辞任すること自体は意外ではない。
しかし、急な発表と、わざわざ“合意(mutual agreement)”の上と断るあたりに、
AMDの混乱が透けて見える。役員会が無理矢理Meyer氏の首を切ったのではないと言いたいわけだ。
ちなみに、ニュースリリースの中に、通常なら見られるようなMeyer氏自身の辞任のメッセージはない。
少し、緊迫したものを感じさせるリリースとなっている。
そのため、Meyer氏の辞任に関する社内政治の話題が、しばらくは業界を賑わすだろう。
●ビジョナリなCEOを失うAMD
最大のポイントは、AMDがビジョナリなCEOを失うことだ。
AMDの優れたCPUアーキテクチャ戦略を引っ張ってきた、最上位のビジョナリ(新しいビジョンを提示できる人)がいなくなる。
Meyer氏以降は、CPUアーキテクチャのいくつかの重要なポイントで、AMDはライバルIntelに先んじるか、同列に並ぶことができた。
AMDが技術上のリーダーシップを取っているイメージは、Meyer氏によって作られたと言っていい。
AMDが次期CPUアーキテクチャ「Bulldozer(ブルドーザ)」で、依然としてラディカルな路線を走っていることは、
Meyer氏のビジョンが維持されていることを示していた。
●AMDの技術&製品戦略も変化は免れない?
Meyer氏の辞任は、AMDの、技術優先の文化の終焉を意味するのかも知れない。
例えば、リスクの大きなBulldozerへのアーキテクチャ転換は後回しにして、マーケティングにフォーカスするといった。
そこまで大きな変化はなくとも、AMDに戦略面での変化が起こる可能性が高い。
なぜなら、今回の辞任劇は、Meyer氏の技術ビジョン路線自体の否定であると推測されるからだ。
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110111_419567.html
予想外のCEO辞任で揺れるAMD
AMDは財政面で厳しい状況が続いている。そうした会社のCEOが辞任すること自体は意外ではない。
しかし、急な発表と、わざわざ“合意(mutual agreement)”の上と断るあたりに、
AMDの混乱が透けて見える。役員会が無理矢理Meyer氏の首を切ったのではないと言いたいわけだ。
ちなみに、ニュースリリースの中に、通常なら見られるようなMeyer氏自身の辞任のメッセージはない。
少し、緊迫したものを感じさせるリリースとなっている。
そのため、Meyer氏の辞任に関する社内政治の話題が、しばらくは業界を賑わすだろう。
●ビジョナリなCEOを失うAMD
最大のポイントは、AMDがビジョナリなCEOを失うことだ。
AMDの優れたCPUアーキテクチャ戦略を引っ張ってきた、最上位のビジョナリ(新しいビジョンを提示できる人)がいなくなる。
Meyer氏以降は、CPUアーキテクチャのいくつかの重要なポイントで、AMDはライバルIntelに先んじるか、同列に並ぶことができた。
AMDが技術上のリーダーシップを取っているイメージは、Meyer氏によって作られたと言っていい。
AMDが次期CPUアーキテクチャ「Bulldozer(ブルドーザ)」で、依然としてラディカルな路線を走っていることは、
Meyer氏のビジョンが維持されていることを示していた。
●AMDの技術&製品戦略も変化は免れない?
Meyer氏の辞任は、AMDの、技術優先の文化の終焉を意味するのかも知れない。
例えば、リスクの大きなBulldozerへのアーキテクチャ転換は後回しにして、マーケティングにフォーカスするといった。
そこまで大きな変化はなくとも、AMDに戦略面での変化が起こる可能性が高い。
なぜなら、今回の辞任劇は、Meyer氏の技術ビジョン路線自体の否定であると推測されるからだ。
早く現実に帰ってこいよ
無理だろ、コイツ夢の中で花を食べながら生きてるんだぜ
韓国人気ガールズグループ「少女時代」が
米インテルのアジア圏モデルを務める。所属事務所のSMエンターテインメントが10日に明らかにした。
インテルの次世代パソコン用プロセッサラインアップ
第2世代Coreプロセッサ・ファミリーの発売に合わせてのモデル起用で
同日からアジア地域のユーザーを対象に、音楽、2D(平面)と3D(立体)映像で制作されたミュージックビデオ、インターネットウェブサイト、写真やパソコン販売店の展示などを通じ
さまざまなキャンペーンを展開する。
また「少女時代」は、インテルとともに制作したミュージックビデオを17日に公開するほか
18日のインテルの新製品発表会で新曲のライブステージを披露する。
米インテルのアジア圏モデルを務める。所属事務所のSMエンターテインメントが10日に明らかにした。
インテルの次世代パソコン用プロセッサラインアップ
第2世代Coreプロセッサ・ファミリーの発売に合わせてのモデル起用で
同日からアジア地域のユーザーを対象に、音楽、2D(平面)と3D(立体)映像で制作されたミュージックビデオ、インターネットウェブサイト、写真やパソコン販売店の展示などを通じ
さまざまなキャンペーンを展開する。
また「少女時代」は、インテルとともに制作したミュージックビデオを17日に公開するほか
18日のインテルの新製品発表会で新曲のライブステージを披露する。
613 :Socket774:2011/01/14(金) 06:24:33 ID:/O5GKS/w
で、ザンベジいつ出るの?
四月
【Sandy厨死亡】Intel次世代CPU“IvyBridge”はDirectX11対応、年内発売
http://hato.2ch.net/test/read.cgi/news/1294814912/
http://hato.2ch.net/test/read.cgi/news/1294814912/
616 :Socket774:2011/01/18(火) 08:04:33 ID:tHNZyRws
http://vr-zone.com/forums/1009228/amd-quad-core-fusion-l1ano-faster-than-core-i3-540.html
AMD Quad Core Fusion L1ano faster than Core i3 540 (笑)
あははははははははははははははははは
GeForce製品を購入される方はまず↓のスレを覗いてみてください
テンプレだけを読んでもかまいません
リネーム品を掴まされた!劣化品を買ってしまった><
とならないようにみんなが幸せになるように情報収集を怠らないでください
【ミドルレンジ】GeForce合同葬儀場⑪③【GTX560】
http://hibari.2ch.net/test/read.cgi/jisaku/1295118923/
テンプレだけを読んでもかまいません
リネーム品を掴まされた!劣化品を買ってしまった><
とならないようにみんなが幸せになるように情報収集を怠らないでください
【ミドルレンジ】GeForce合同葬儀場⑪③【GTX560】
http://hibari.2ch.net/test/read.cgi/jisaku/1295118923/
今のAMDのCPUにある機能
・都合の悪いことを見えなくする機能
・自分のところだけ有利に解釈する機能
・人を信じられなくする機能
・自分は選ばれた人間だと思える機能
・コピペ機能
・たくさんの敵を一人にする機能
・性能よりコア数を重んじる機能
・他社製品が先行すると無駄といい、AMDが先行すると絶対必要という機能
次世代は何が搭載されるんだろうか。
・都合の悪いことを見えなくする機能
・自分のところだけ有利に解釈する機能
・人を信じられなくする機能
・自分は選ばれた人間だと思える機能
・コピペ機能
・たくさんの敵を一人にする機能
・性能よりコア数を重んじる機能
・他社製品が先行すると無駄といい、AMDが先行すると絶対必要という機能
次世代は何が搭載されるんだろうか。
淫厨のカキコってエラッタ満載だけの事はあるね
Sandy Bridgeまとめ
http://images.hardwarecanucks.com/image/mac/reviews/intel/sandybridge/chart24.jpg
i3より遅いi7 980X
http://www.pcper.com/images/reviews/776/farcry2-1920.jpg
http://images.anandtech.com/graphs/amdphenomiix4955_042209194837/18911.png
FarCry2
1920*1200 very high
X4 965・・・Ave74.1 Min42
1680*1050 medium
X4 955・・・51.2
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/014.gif 122.1/110.1
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/048.gif 93.3/86.4
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/015.gif 82.2/75.4
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif 50.4/46.0
ttp://www.4gamer.net/games/077/G007794/20100920020/TN/016.gif 103.1/100.7
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif 85.9/81.0
上:X6 1090T+HD5870-1GB+6V250F0 250GB+32bit版Win7+Catalyst10.9
下:X6 1100T+GTX580-1536MB+HDT722516DLA380 160GB+64bit版Win7+Catalyst10.12+ForceWare 263.09
http://images.hardwarecanucks.com/image/mac/reviews/intel/sandybridge/chart24.jpg
i3より遅いi7 980X
http://www.pcper.com/images/reviews/776/farcry2-1920.jpg
http://images.anandtech.com/graphs/amdphenomiix4955_042209194837/18911.png
FarCry2
1920*1200 very high
X4 965・・・Ave74.1 Min42
1680*1050 medium
X4 955・・・51.2
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/014.gif 122.1/110.1
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/048.gif 93.3/86.4
ttp://www.4gamer.net/games/077/G007794/20100920020/SS/015.gif 82.2/75.4
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/050.gif 50.4/46.0
ttp://www.4gamer.net/games/077/G007794/20100920020/TN/016.gif 103.1/100.7
ttp://www.4gamer.net/games/098/G009883/20110103001/TN/051.gif 85.9/81.0
上:X6 1090T+HD5870-1GB+6V250F0 250GB+32bit版Win7+Catalyst10.9
下:X6 1100T+GTX580-1536MB+HDT722516DLA380 160GB+64bit版Win7+Catalyst10.12+ForceWare 263.09
【デフォスタ】雑音犬畜生Part46【脳欠損】
http://toki.2ch.net/test/read.cgi/tubo/1295314503/
http://toki.2ch.net/test/read.cgi/tubo/1295314503/
一方intelはチャクチャクと・・
AVXCloth
serial
ttp://img291.imageshack.us/img291/8211/avxcloth1.png
128bit
ttp://img413.imageshack.us/img413/2762/avxcloth4.png
256bit
ttp://img821.imageshack.us/img821/550/avxcloth8.png
ついでにiGPUの単純な命令発行数
ttp://img197.imageshack.us/img197/6569/shdaertest.png
PSのfloat5見る限り、今世代では積和算器になったみたいだな
一応超越関数のsqrt(serial)がfloat5と変わらないってのはすごいな、おい
一方でcacheの効果が期待されたGS関係はそれほど高くはない
概ねChrome 540GTXの半分程度だ
ttp://img529.imageshack.us/img529/3522/advancedparticles201101.png
ttp://img153.imageshack.us/img153/5188/cubemapgs20110119221854.png
ttp://img413.imageshack.us/img413/7885/pipesgs2011011922191929.png
ttp://img829.imageshack.us/img829/1303/main102011011922232783.png
shader performance pt2 Geforce 9400GT(32SP) VS RadeonHD4670 VS Chrome540GTX
ttp://www.youtube.com/watch?v=pmBd9HQgTCQ
S3 Chrome 540 GTX VS nVIDIA GeForce9600GT VS ATi RadeonHD4670 Shader Performance
ttp://www.youtube.com/watch?v=pGnrBu3N2QE
やはりGPUブロック外のcacheは遅いようだ
というかchromeの実装が神すぎるのか
AVXCloth
serial
ttp://img291.imageshack.us/img291/8211/avxcloth1.png
{kind=link}
128bit
ttp://img413.imageshack.us/img413/2762/avxcloth4.png
{kind=link}
256bit
ttp://img821.imageshack.us/img821/550/avxcloth8.png
{kind=link}
ついでにiGPUの単純な命令発行数
ttp://img197.imageshack.us/img197/6569/shdaertest.png
{kind=link}
PSのfloat5見る限り、今世代では積和算器になったみたいだな
一応超越関数のsqrt(serial)がfloat5と変わらないってのはすごいな、おい
一方でcacheの効果が期待されたGS関係はそれほど高くはない
概ねChrome 540GTXの半分程度だ
ttp://img529.imageshack.us/img529/3522/advancedparticles201101.png
{kind=link}
ttp://img153.imageshack.us/img153/5188/cubemapgs20110119221854.png
{kind=link}
ttp://img413.imageshack.us/img413/7885/pipesgs2011011922191929.png
{kind=link}
ttp://img829.imageshack.us/img829/1303/main102011011922232783.png
{kind=link}
shader performance pt2 Geforce 9400GT(32SP) VS RadeonHD4670 VS Chrome540GTX
ttp://www.youtube.com/watch?v=pmBd9HQgTCQ
S3 Chrome 540 GTX VS nVIDIA GeForce9600GT VS ATi RadeonHD4670 Shader Performance
ttp://www.youtube.com/watch?v=pGnrBu3N2QE
やはりGPUブロック外のcacheは遅いようだ
というかchromeの実装が神すぎるのか
【デフォスタ】雑音犬畜生Part46【脳欠損】
http://toki.2ch.net/test/read.cgi/tubo/1295314503/
http://toki.2ch.net/test/read.cgi/tubo/1295314503/
624 :Socket774:2011/01/22(土) 22:00:50 ID:+5VXo7kN
Bulldozer延期wwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
AMD逝ったああああああああああああああああああああああああ
新CEOがBulldozer?
何でしたっけ
それ?
とか言わなきゃいいが
何でしたっけ
それ?
とか言わなきゃいいが
626 :Socket774:2011/01/23(日) 04:49:31 ID:Of67oxWO
とりあえず選択肢がsandyH2しかないって状況をどうにかしてくれ
年内にIvyが発売されるのでゴミSandyは買わないほういい。
要するに自作する時期ではないって事か?
629 :Socket774:2011/01/23(日) 20:46:44 ID:/uzVLTiN
同じ65Wのi3 2100(110$)にフルボッコされるPhenomII X4 910(13,960円)
http://www.anandtech.com/bench/Product/85?vs=289
1分29敗、アムドマジ産廃
64bitOSのインテルPCと32bitOSのAMDマシンの比較になんの意味があるんだろう
631 :Socket774:2011/01/23(日) 23:49:31 ID:msMvKan4
64bitをAMDで動かすともっと悲惨な結果になりますよ
intelの方が遥かに速い
intelの方が遥かに速い
>>630
そりゃ、自己満足だろ。
そりゃ、自己満足だろ。
CPU単体なら確かにAMDはアレだけど、ママンの値段考えたらそうでもないよ?
”アレ”が価格を表してるのか性能を表すか・・・。
636 :Socket774:2011/01/24(月) 07:46:38 ID:NriGIOF9
■またひとつZacateの欠陥が判明
http://www.4gamer.net/games/101/G010100/20110123001/
>ただ,Brazosプラットフォームには,“フレームレートに現れないもっさり感”があったことも,付記しておきたいと思う。
屁~
AMDの方が遥かに速いのに売れない不思議
わかって買ってる俺は情強(キリッ
ですね。わかります(キリッ
わかって買ってる俺は情強(キリッ
ですね。わかります(キリッ
淫厨はへんな奴が多いのなw
いったい何と戦ってるんだろう
自分のプライドとでもたたかってるのか?
いったい何と戦ってるんだろう
自分のプライドとでもたたかってるのか?
1項目でも負けるのが嫌なんだろw
事実を受け止められないんだよ
事実を受け止められないんだよ
実際ブルーレイドライブ買ってきて付属ソフトで再生したムービーがカクカクブツブツだったら
AMDのせいじゃないのかと疑ってしまうよな
やっぱ検証用にIntelマシンも置いておかないと
AMDのせいじゃないのかと疑ってしまうよな
やっぱ検証用にIntelマシンも置いておかないと
ドライブの不具合
付属ソフトの不具合
グラボの不具合
著作権認証がらみの不具合
CPUを疑うのはさらにずっと後だなw
付属ソフトの不具合
グラボの不具合
著作権認証がらみの不具合
CPUを疑うのはさらにずっと後だなw
ttp://journal.mycom.co.jp/articles/2011/01/24/cayman/index.html
AMDのPhenom IIを使う限り性能が改善できそうにない、
というAMDプラットフォームそのものの問題である。
AMDのPhenom IIを使う限り性能が改善できそうにない、
というAMDプラットフォームそのものの問題である。
改善するほどの問題点ある?
どうせ改善したらしたでブーブー言うんだろ?豚だし
どうせ改善したらしたでブーブー言うんだろ?豚だし
>AMDのPhenom IIを使う限り性能が改善できそうにない
このオッサンは二年前のCPUをつかまえて今さら何を言ってるんだ……
このオッサンは二年前のCPUをつかまえて今さら何を言ってるんだ……
645 :某スレ38 ◆.E2TEo4Lhs :2011/01/25(火) 00:50:43 ID:dIJKFy03
http://hiroyukt1985.web.fc2.com/pchard/20110124-Intel_vs_AMD/20110124.htm
面白そうだから,まとめてみました.まだSandra2011だけですけど
面白そうだから,まとめてみました.まだSandra2011だけですけど
646 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/01/25(火) 01:00:37 ID:La+8ZGZB
CPUの性能差って出てるか?
計測誤差の範疇と思ってたが
計測誤差の範疇と思ってたが
1100Tは2010年12月に出たばかりのAMDの最新鋭ハイエンド製品じゃないのか。
ゲーム用途なら2011年1月にリリースされたX4 975のほうがマシじゃないかという議論はあるにせよ
ゲーム用途なら2011年1月にリリースされたX4 975のほうがマシじゃないかという議論はあるにせよ
648 :Socket774:2011/01/25(火) 01:15:37 ID:rb89Md3R
6コア最上位の1100Tが4コアHTなしの2500Kにぼろ負けすなあ
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/15
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/17
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/18
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/19
エンコでも負けるとかw
http://www.anandtech.com/show/4083/the-sandy-bridge-review-intel-core-i7-2600k-i5-2500k-core-i3-2100-tested/16
>>645が貼ってある部分は誤差レベルだけど、
誤差で済まないほど差があいてるベンチが後の方にいくつもある。
誤差で済まないほど差があいてるベンチが後の方にいくつもある。
で、誤差で済まないベンチの差がどれだけ実際に使ってて便利になるの?それとも不自由になるの?
>>653
3Dゲームやらないから、知らないよ。
大体そんなこといったら、エンコやレンダリングのような一部の重い処理しないなら、
たいていの人にとって、Fusionで十分だから、次世代CPUなんて気にしなくていいだろ?
3Dゲームやらないから、知らないよ。
大体そんなこといったら、エンコやレンダリングのような一部の重い処理しないなら、
たいていの人にとって、Fusionで十分だから、次世代CPUなんて気にしなくていいだろ?
じゃあ大抵の人にとってはやっぱ誤差の範囲で済むレベルじゃん
アドバンスドモッサリデバイス
658 :,,・´∀`・,,)<一番良い -○○○ を頼む:2011/01/27(木) 20:22:07 ID:UaT9qFW4
SandraのGPU項目でCPUの性能を比較するのは不可能だよ
ベンチでしかわから無い誤差程度のゴミ次世代なんていらないからもっと豪快に速い次世代が欲しいよね。
661 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/01/28(金) 07:40:21 ID:BEDl1xa0
冷凍睡眠って実用化されてるの?
http://ja.uncyclopedia.info/wiki/%E3%83%81%E3%83%AB%E3%83%8E
http://ja.uncyclopedia.info/wiki/%E3%83%81%E3%83%AB%E3%83%8E
アメリカで問題になってるよな冷凍睡眠
663 :Socket774:2011/01/28(金) 16:07:03 ID:EtiKHxko
Bulは出せなくてもLianoぐらいは出せよ
>>647
システム的には2年前のdenebの発展形だぜい。言うなればC2Qのシステムのまま
あれこれ手入れして維持してきたようなもので3世代も刷新したsandyのそれと普通に
比べたらインテルとてつらいだろ~。
あとゲームでフレームレート60ぐらい行けるんならまずまずじゃね?
余力があればいいのは確かだけれどもゲームができない環境、というわけでもない。
達成できないテストにおいては現状2600kさえも力不足の面もあるし、多少の余力に妥協すれば
2万↓のリーズナブルなシステムで組めるX6でもX4もアリだろ。
システム的には2年前のdenebの発展形だぜい。言うなればC2Qのシステムのまま
あれこれ手入れして維持してきたようなもので3世代も刷新したsandyのそれと普通に
比べたらインテルとてつらいだろ~。
あとゲームでフレームレート60ぐらい行けるんならまずまずじゃね?
余力があればいいのは確かだけれどもゲームができない環境、というわけでもない。
達成できないテストにおいては現状2600kさえも力不足の面もあるし、多少の余力に妥協すれば
2万↓のリーズナブルなシステムで組めるX6でもX4もアリだろ。
お前はいいんじゃね
667 :Socket774:2011/01/29(土) 14:06:13 ID:lOF1Yw0V
AMDはサーバー用で安い石をたくさん並べておけばなんとかなるようなところで
勝負するべきだったな
勝負するべきだったな
それがx86である理由があればいいけど・・・・
x86でなくていいなら
AMD無くなっちゃうね
AMD無くなっちゃうね
AMD次世代スレで暴れてるARM厨を引き取ってくれ。
671 :Socket774:2011/01/30(日) 01:15:58 ID:Psl3bV7A
ザンベジを出すまではダメだ
672 :Socket774:2011/01/30(日) 16:50:48 ID:N1MxOLNz
↓アムラーマジ文盲w
584 :Socket774:2011/01/23(日) 22:30:53 ID:jrp1HnFV
同じ65Wのi3 2100(110$)にフルボッコされるPhenomII X4 910(13,960円)
http://www.anandtech.com/bench/Product/85?vs=289
1分29敗、アムドマジ産廃
591 :Socket774:2011/01/23(日) 23:00:13 ID:bSyuh3Ml
1分29敗って言ってる人のページ見ると俺のところだと13勝1分14敗なんだけど・・・
どうなってんの?
593 :Socket774:2011/01/23(日) 23:08:34 ID:msMvKan4
>1分29敗って言ってる人のページ見ると俺のところだと13勝1分14敗なんだけど・・・
>1分29敗って言ってる人のページ見ると俺のところだと13勝1分14敗なんだけど・・・
>1分29敗って言ってる人のページ見ると俺のところだと13勝1分14敗なんだけど・・・
Higher is Better.と Lower is Better. も読めないのかwwwwwwwwww
さすが無職ハライテー
↑アムラーマジ文盲w
ARM厨残して別スレ立てたほうがいいような
AMDの次世代CPUブルドーザについて語ろう
AMDの次世代CPUブルドーザについて語ろう
【自作PC】SandyBridgeヤバイ チップセットにエラッタで速度低下 早くも新リビジョンでリコールか
http://hato.2ch.net/test/read.cgi/news/1296494191/
http://hato.2ch.net/test/read.cgi/news/1296494191/
675 :Socket774:2011/02/02(水) 23:15:44 ID:RSCxQzDD
あげとくかw
676 :Socket774:2011/02/03(木) 00:18:33 ID:pBGf4np8
途端に沈黙ですな。見事な位。
627 :Socket774:2011/01/23(日) 05:06:09 ID:aWV/k36m
年内にIvyが発売されるのでゴミSandyは買わないほういい。
年内にIvyが発売されるのでゴミSandyは買わないほういい。
みごとにゴミになってしまったな
P67チップセット内のSATAポートにクロックを付加しているトランジスタが
過度に電力を供給していてそのリークが機器にダメージを与えている
ビットエラーが蓄積されていき、それが溜まり過ぎると最悪機器が使えなくなる
欠陥はSATAポートにクロックを供給しているPLLの経路のトランジスタに
与える電圧が高過ぎたためリーク電流が想定以上になり、トランジスタのばらつきによっては
リークが増大して行き最終的にはSATAポートの破壊に至る
過度に電力を供給していてそのリークが機器にダメージを与えている
ビットエラーが蓄積されていき、それが溜まり過ぎると最悪機器が使えなくなる
欠陥はSATAポートにクロックを供給しているPLLの経路のトランジスタに
与える電圧が高過ぎたためリーク電流が想定以上になり、トランジスタのばらつきによっては
リークが増大して行き最終的にはSATAポートの破壊に至る
しゃれにならんねコレ。マジ脂肪だわ
つまり、経年劣化という表現は誤りでSATA機器を使えば確実に被害をこうむるが
そのSATAポートに機器をに接続しようがしまいがクロックジェネレータが動いてる限り
放っておいても勝手に壊れる
そしてその崩壊を回避する手段は無い
通電させなければ問題ない
まぁよーするに使うなということだ
まぁよーするに使うなということだ
たしかに神棚へ飾っておけば問題ないな。
バグったチップセットのSandy Bridge機と、
バグってないチップセットのPhenom機と、
比較しても、Sandyを普通選んぶのは何故か?
バグってないチップセットのPhenom機と、
比較しても、Sandyを普通選んぶのは何故か?
七輪を置く台にでも使って練炭焚いて部屋を暖めればいいと思うよ
>>684
狂信者はインテルが入ってればコンセント刺さなくても満足できる人種だからです
狂信者はインテルが入ってればコンセント刺さなくても満足できる人種だからです
,,・´∀`・,,)<一番良い -○○○ を頼む
の人はリコール以降、一切書き込みがないんだね。
なんつーか、どういう人なんかわかったような気がする。
の人はリコール以降、一切書き込みがないんだね。
なんつーか、どういう人なんかわかったような気がする。
中味は他人を装った雑音だからな
初物には飛びつくなっていう10年前まで良く聞かれたアドバイスを思い出した
「安定が欲しければ、新製品が出てから枯れた旧製品を買え」
とかね。
とかね。
Prescottが出てからNorthwoodを買った。
遅さに耐えられなくなってPentiumM(Dothan)を下駄使って載せた。
Nehalemが出てからYorkfieldを買った
Sandy Bridgeが出たらNehalemの32nm版を買おうと思ってたらXeonでしか出なかった。
Haswellが出てからIvy Bridgeを買おうと思っていたが耐えられそうもない。
Intelの商品展開や商習慣が好きではなくなってしまったのでbulldozerを買うと思う。
PC-9821でK6-2に換装して以来だから正直楽しみだ。
遅さに耐えられなくなってPentiumM(Dothan)を下駄使って載せた。
Nehalemが出てからYorkfieldを買った
Sandy Bridgeが出たらNehalemの32nm版を買おうと思ってたらXeonでしか出なかった。
Haswellが出てからIvy Bridgeを買おうと思っていたが耐えられそうもない。
Intelの商品展開や商習慣が好きではなくなってしまったのでbulldozerを買うと思う。
PC-9821でK6-2に換装して以来だから正直楽しみだ。
>>691
bulldozerが出たらLianoを買う、まで読んだ
bulldozerが出たらLianoを買う、まで読んだ
クルマだってモデル末期が買い時って何十年も前から言われてるが。
初期に不具合のあったパーツは対策品に換えられてるし、ライン工の熟練度が
こなれてきて製造公差も減ってるし、更に在庫一掃のために値段も安い。
初期に不具合のあったパーツは対策品に換えられてるし、ライン工の熟練度が
こなれてきて製造公差も減ってるし、更に在庫一掃のために値段も安い。
695 :Socket774:2011/02/07(月) 22:42:06 ID:TGVUFJtY
淫厨が・・・
とスレタイ直せっハゲッがwww
とスレタイ直せっハゲッがwww
696 :Socket774:2011/02/07(月) 23:34:55 ID:k+SiEXaa
>>695
巣靴へ帰れ、キチガイ
巣靴へ帰れ、キチガイ
AMDのOC耐性とシングルタスク性能がcore2並になったらLGA775を捨てるんだけどな・・・
ソケ775使いは情報弱者か浦島太郎なのか?1090Tは定格電圧で4GHz回る石も珍しくないってのに
OC耐性はわかった。シングルスレッド性能は?
700 :Socket774:2011/02/08(火) 15:18:28 ID:I0NYWCET
>>698
IPCが低い
IPCが低い
>>698 情弱ですまん。大変参考になった。
ただ私の中ではOC耐性に関して倍率の比重が大きいのさ。
E2160を[email protected] E5200を[email protected]で常用してるのでねえ
ともあれ965BE辺りで見積もってみべえ
ただ私の中ではOC耐性に関して倍率の比重が大きいのさ。
E2160を[email protected] E5200を[email protected]で常用してるのでねえ
ともあれ965BE辺りで見積もってみべえ
702 :Socket774:2011/02/09(水) 01:53:02 ID:fXZnMvm6
Core2となら、IPCの稼ぎ方違うだけで、ほぼ一緒。
あれからAMDのCPUはSSSE3が使えるようになりましたか?
SSE4とか4.1とか4.2はとりあえずもういいので(贅沢は言いません)
SSE4とか4.1とか4.2はとりあえずもういいので(贅沢は言いません)
この間出たZacate/OntarioではSSSE3対応のようだが
うわ、それは予想外。
今更過ぎるにもほどがあるw
AVXまで寝たろう路線だとばかり思ってた。
つ SSE4A
今更過ぎるにもほどがあるw
AVXまで寝たろう路線だとばかり思ってた。
つ SSE4A
706 :Socket774:2011/02/11(金) 19:51:31 ID:u9qA663e
2月になれど、Bulの情報はなし
707 :Socket774:2011/02/15(火) 21:18:19 ID:nC62Zjf3
ザンベジってsandyH2より面白そうではあるな
アーキテクチャ刷新ってのは、興味と期待が盛り上がるよな
嘘かほんとか分からんけどAMD曰く相当性能高いらしいしね。
ES品のベンチスコアリークの情報で雑豚がヨダレ巻き散らしながら発狂してる所をみるとかなり期待できる。
ベンチだと8コアフルに使ってくれるけど、実アプリだとどうなるかって所だな
712 :Socket774:2011/02/16(水) 04:40:29 ID:fDIln+0P
むしろ4コアしか使用しない時のシングル性能がポイントじゃないか
当初は共用化部分を作る分k10より遅くなるという話だったが
浮動演算ユニットが倍になるから速くなるかもしれんという話もあって
当初は共用化部分を作る分k10より遅くなるという話だったが
浮動演算ユニットが倍になるから速くなるかもしれんという話もあって
つまり今のAM3までのAMDのCPUはゴミだと。そーですか。
一般人にとってはゴミでも、信者には有り難いお布施なんだから
黙って白い目で見てれば良い
黙って白い目で見てれば良い
>>浮動演算ユニットが倍になるから速くなる
ならないよ、1コア(1スレッド)が使えるのは1ユニットだけ
4コア使用時に全ユニットを使えたらそれは4コアCPUだし
ならないよ、1コア(1スレッド)が使えるのは1ユニットだけ
4コア使用時に全ユニットを使えたらそれは4コアCPUだし
1モジュール内にあるFPU2ユニットを占有できるって意味じゃないの?
倍になるってのは。
倍になるってのは。
>>716
K10も1コア内にFPUは2ユニットあるんだけど
K10も1コア内にFPUは2ユニットあるんだけど
今、AMDのCPUを選択する理由って何だろうなぁ。
ちょっと前だと1Uの鯖で24コア(= 24プロセスあるいは24スレッド)走らせる
ことができたんだけど、SandyのXeonが20スレッド実現するみたいだし、デスク
トップでAMDのCPUを選択するっていうのも(現状では)ちょっと考え難い。
だいぶ前、Core2XeonとOpteronだと、10GbEの平均帯域がかなり違うことが
わかって(InfiniBandもおなじようなもんだろな)、それ以降はOpteron機
ばっか使ってきたけど今となってはそんなに差は無いだろうし。
ブルがどんなものになるのか、かなーり気にはなるな。
ちょっと前だと1Uの鯖で24コア(= 24プロセスあるいは24スレッド)走らせる
ことができたんだけど、SandyのXeonが20スレッド実現するみたいだし、デスク
トップでAMDのCPUを選択するっていうのも(現状では)ちょっと考え難い。
だいぶ前、Core2XeonとOpteronだと、10GbEの平均帯域がかなり違うことが
わかって(InfiniBandもおなじようなもんだろな)、それ以降はOpteron機
ばっか使ってきたけど今となってはそんなに差は無いだろうし。
ブルがどんなものになるのか、かなーり気にはなるな。
721 :Socket774:2011/02/20(日) 12:42:02.58 ID:DZQRd2+3
>>709
あくまでもK10と比較してじゃないか
あくまでもK10と比較してじゃないか
48コアで32コアより速いぜってのが今のAMDの売り方だから苦しいんだよな。
馬鹿でかいコアを低価格で叩き売らないといけないから。
しかも数も出せないし。
商売としては末期的だ。
馬鹿でかいコアを低価格で叩き売らないといけないから。
しかも数も出せないし。
商売としては末期的だ。
コアがでかいっつーよりは、ダイ(シリコンのチップ)がでかいっていう方が正しいね。
でも、まぁ、でかいってことは、一枚のウエファから取れる数が少ないってことだし、
一個あたりのプロセスコストはバッチ投入コストを収穫で割った値だから、面積のでかい
ダイは高くつくし、おまけにAMDはSOI(いまだにSOSかね)だから余計のことだよな。
間接費や開発費を差し引いてもインテルの方が一個あたりの利益は大きいだろう。
でも、まぁ、でかいってことは、一枚のウエファから取れる数が少ないってことだし、
一個あたりのプロセスコストはバッチ投入コストを収穫で割った値だから、面積のでかい
ダイは高くつくし、おまけにAMDはSOI(いまだにSOSかね)だから余計のことだよな。
間接費や開発費を差し引いてもインテルの方が一個あたりの利益は大きいだろう。
AMDのいいとこはソケット寿命がながくAM2,AM2+.AM3みたいに互換性あるマザーがあることだね
インテルのサイクル早過ぎるんだよなぁそこと互換対応マザー出せばサンディのCorei3で低発熱静音PC史上は独占できるのに
インテルのサイクル早過ぎるんだよなぁそこと互換対応マザー出せばサンディのCorei3で低発熱静音PC史上は独占できるのに
>>717
そのK10の1コアにあるFPUユニットの2倍がブルの1モジュールに搭載されてる。
そして、1スレッドでそのFPUユニットを全て使える。
なので、2モジュールなら浮動小数点演算2スレッドまで、4モジュールなら4スレッドまでは
単純計算でK10時代の2倍の演算性能。
浮動小数点演算スレッドが1モジュールあたり2スレッドとなると、
FPUユニットを半分づつ各スレッドに割り当てるが、それでもK10並の演算性能があり、
コア数が増えているので同時に処理できるスレッドが増えてるぶん、速く処理できる。
2モジュールなら4スレッド、4モジュールなら8スレッド同時処理が可能だ
そのK10の1コアにあるFPUユニットの2倍がブルの1モジュールに搭載されてる。
そして、1スレッドでそのFPUユニットを全て使える。
なので、2モジュールなら浮動小数点演算2スレッドまで、4モジュールなら4スレッドまでは
単純計算でK10時代の2倍の演算性能。
浮動小数点演算スレッドが1モジュールあたり2スレッドとなると、
FPUユニットを半分づつ各スレッドに割り当てるが、それでもK10並の演算性能があり、
コア数が増えているので同時に処理できるスレッドが増えてるぶん、速く処理できる。
2モジュールなら4スレッド、4モジュールなら8スレッド同時処理が可能だ
FPUって、ブルのは単精度ならコアの数だけあるでしょ? 倍精度だと2コア分
(つまりは1モジュール分)使うようなアーキみたいだけど。
でも、倍精度演算をがしがし使うようなアプリって、HPC以外には思いつかないなー。
(つまりは1モジュール分)使うようなアーキみたいだけど。
でも、倍精度演算をがしがし使うようなアプリって、HPC以外には思いつかないなー。
BulldozerのFPUはFMACが処理できる演算器を二つ、1モジュールで共用している。
だから、単精度だろうが、倍精度だろうが、2ユニットを2スレッドで共用。
ただ、AVXの256bit命令のときは、2ユニットで処理する必要があるってだけで、
単精度だからコア数分、倍精度だと1モジュール分じゃない。
単精度で8命令処理だと、2ユニット両方合わせて処理する必要あるんだから。
だから、単精度だろうが、倍精度だろうが、2ユニットを2スレッドで共用。
ただ、AVXの256bit命令のときは、2ユニットで処理する必要があるってだけで、
単精度だからコア数分、倍精度だと1モジュール分じゃない。
単精度で8命令処理だと、2ユニット両方合わせて処理する必要あるんだから。
そうなのか、俺はそれぞれのコアに単精度のモジュールがあって、
倍精度だと両方使うのかって思ってたよ。
でも、実アプリでFP性能が効くのって、座標計算くらいしか思い
つかないなぁ、ゲームではがしがし使われるんだろうけど。
倍精度だと両方使うのかって思ってたよ。
でも、実アプリでFP性能が効くのって、座標計算くらいしか思い
つかないなぁ、ゲームではがしがし使われるんだろうけど。
731 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/02/20(日) 21:27:25.39 ID:cKO27Sxz
未だに勘違いしてるのがいるが
128ビット×2ユニットで256ビットSIMDユニットとして使うんじゃなくて
128ビット単位の2オペレーションに分割して実行するだけだろ
128ビット×2ユニットで256ビットSIMDユニットとして使うんじゃなくて
128ビット単位の2オペレーションに分割して実行するだけだろ
>>731
妄想乙
妄想乙
別に外れてもないだろ
128ビット単位の2オペレーションに分割して2ユニットで並列に実行して、最後に足す
128ビット単位の2オペレーションに分割して2ユニットで並列に実行して、最後に足す
735 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/02/22(火) 18:42:48.66 ID:qkltTr6H
>>732-733
情弱乙
>>734
「並列」である必要も無いけどね。
基本的に256ビット水平演算には上下に依存関係がないから1本のFMACだけで2サイクルかけても2本を同時に使っても
見た目のレイテンシは同じだ。
むしろデコーダはK8のSSE2のそれと同様にDouble Pathで2サイクルかけて128ビットオペレーションを2つ吐き出すような
動きになるかもね。
おそらく256ビットで1μOPになるような機構は持たないだろう。
Bulldozerはもともと128ビットSSE5用に設計され、AVXのためにデコードスキームを置き換えただけの突貫再設計なんだから
256ビット処理に最適化されたユニットなんて作れるわけが無いだろ。
情弱乙
>>734
「並列」である必要も無いけどね。
基本的に256ビット水平演算には上下に依存関係がないから1本のFMACだけで2サイクルかけても2本を同時に使っても
見た目のレイテンシは同じだ。
むしろデコーダはK8のSSE2のそれと同様にDouble Pathで2サイクルかけて128ビットオペレーションを2つ吐き出すような
動きになるかもね。
おそらく256ビットで1μOPになるような機構は持たないだろう。
Bulldozerはもともと128ビットSSE5用に設計され、AVXのためにデコードスキームを置き換えただけの突貫再設計なんだから
256ビット処理に最適化されたユニットなんて作れるわけが無いだろ。
Netburstのように演算器を2サイクル回して倍幅の演算を1μopで
実行できないのか
実行できないのか
737 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/02/22(火) 19:41:51.99 ID:qkltTr6H
どのみち4μOPs幅のスケジューラで実行ユニットもFP2本+Int.SIMD 2本なんだからμOPsを統合しなくとも
理屈上スループットは変わらんよ。
物理レジスタファイルを圧迫してそうな気はするね。
常に2スレッドで128ビットSIMDレジスタ64本最低必要なわけだし。
理屈上スループットは変わらんよ。
物理レジスタファイルを圧迫してそうな気はするね。
常に2スレッドで128ビットSIMDレジスタ64本最低必要なわけだし。
うーん、SIMDユニットとかいうのがどういう動作をするのかじぇんじぇんわからんのだが、
通常のFP演算を考えると、仮数部だけはそのまんま演算して指数部は加減算だけだよね?
IEEE754で言う倍精度って64bitだし、128bitの演算ユニットがあれば2サイクルいらない
ようにも思うんだけど違う?
むしろ256bit演算だと積和計算で4回の演算が必要なようにも思うけど...(ちっと頭が
古いのかな、俺は)。
通常のFP演算を考えると、仮数部だけはそのまんま演算して指数部は加減算だけだよね?
IEEE754で言う倍精度って64bitだし、128bitの演算ユニットがあれば2サイクルいらない
ようにも思うんだけど違う?
むしろ256bit演算だと積和計算で4回の演算が必要なようにも思うけど...(ちっと頭が
古いのかな、俺は)。
取り敢えずここまで読んで半分くらいしかわからなかった俺はどうすれば良いと思う?
笑えばいいと思うよ
741 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/02/24(木) 20:12:51.24 ID:MJtZ8GLw
むしろμOPs Fusionみたいな技術って辞める方針だと思うけどね
Bulldozerは整数のμOPがALUとAGUで別々になったじゃん。
ちなみにSandy BridgeはRSが54エントリあるらしいが、これもどうも6μOPs×9サイクル分な気がする。
Bulldozerは整数のμOPがALUとAGUで別々になったじゃん。
ちなみにSandy BridgeはRSが54エントリあるらしいが、これもどうも6μOPs×9サイクル分な気がする。
FPUとAGUは別々だけどDirect Pathで処理できていた
743 :Socket774:2011/02/27(日) 12:23:01.73 ID:wcLMONrT
BulはマルチCPU可能にならないかな
もはやコア数で圧倒するしかないような気がするんだが
もはやコア数で圧倒するしかないような気がするんだが
CPU多少非力でもいいからHD5870を統合して欲しい。
2万円以下で。
2万円以下で。
746 :Socket774:2011/02/27(日) 12:53:28.06 ID:wcLMONrT
オプテロンはクロック低すぎ、XEONは値段高過ぎ
747 :Socket774:2011/02/27(日) 14:31:46.79 ID:8cCkIE2z
以上をまとめると、AMDは性能低すぎ。という結論が出たな
748 :Socket774:2011/02/27(日) 14:34:36.13 ID:g2YY5gBm
つまり互角程度のイソテルも低性能ということだな
互角じゃないだろ、ぶち抜かれてるじゃねえか。
でも日常じゃπ焼きなんてしないからなあ
コア数多くてブレードに向くのは、やっぱOpteron12コアだと思うけどね。
インターネット接続用だと、マルチコアで多階層アーキを取ったサーバならCPUあたりの性能は
それほど高い必要は無い。
IntelのCPU(Nehalem以降)は演算サーバ向きっていう感じかねぇ、実際に演算性能高いし。
まぁK10とNehalemでは世代が違うから、Bullでどこまで迫れるか、ってとこかね。
そういやここのところI/O性能は測ってなかったな。
インターネット接続用だと、マルチコアで多階層アーキを取ったサーバならCPUあたりの性能は
それほど高い必要は無い。
IntelのCPU(Nehalem以降)は演算サーバ向きっていう感じかねぇ、実際に演算性能高いし。
まぁK10とNehalemでは世代が違うから、Bullでどこまで迫れるか、ってとこかね。
そういやここのところI/O性能は測ってなかったな。
752 :Socket774:2011/02/27(日) 20:47:03.01 ID:xemjC7i1
>コア数多くてブレードに向くのは、やっぱOpteron12コアだと思うけどね
>コア数多くてブレードに向くのは、やっぱOpteron12コアだと思うけどね
>コア数多くてブレードに向くのは、やっぱOpteron12コアだと思うけどね
寝言は寝てから頼むw
製品版SSDをSB850でテストした結果(MS製AHCIドライバ)
http://akiba-pc.watch.impress.co.jp/hotline/20110305/image/vmi17.html
製品版SSDをSB850でテストした結果(AMD製AHCIドライバ)
http://akiba-pc.watch.impress.co.jp/hotline/20110305/image/vmi18.html
MSの方が普通に優秀なんだなw
http://akiba-pc.watch.impress.co.jp/hotline/20110305/image/vmi17.html
製品版SSDをSB850でテストした結果(AMD製AHCIドライバ)
http://akiba-pc.watch.impress.co.jp/hotline/20110305/image/vmi18.html
MSの方が普通に優秀なんだなw
>>746
Xeonは8コアで2.26GHzまでしか出てないんじゃなかったっけ?
Xeonは8コアで2.26GHzまでしか出てないんじゃなかったっけ?
>>753
演算サーバでもOpteronじゃないかな?
Opteron 6180 SE Cint rate=430 base=371 (12Core,2.5GHz 2CPU)
Intel Xeon X5680 Cint rate=378 base=353 (6Core,12thread 3.33GHz 2CPU)
http://www.spec.org/cpu2006/results/res2011q1/cpu2006-20110131-14305.html
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100413-10533.html
Opteron 6180 SE Cfp rate=335 base=308 (12Core,2.5GHz 2CPU)
Intel Xeon X5680 Cint rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100413-10533.html
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100330-10309.html
姫野なんかだともっと差が付くみたいだし
演算サーバでもOpteronじゃないかな?
Opteron 6180 SE Cint rate=430 base=371 (12Core,2.5GHz 2CPU)
Intel Xeon X5680 Cint rate=378 base=353 (6Core,12thread 3.33GHz 2CPU)
http://www.spec.org/cpu2006/results/res2011q1/cpu2006-20110131-14305.html
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100413-10533.html
Opteron 6180 SE Cfp rate=335 base=308 (12Core,2.5GHz 2CPU)
Intel Xeon X5680 Cint rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100413-10533.html
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100330-10309.html
姫野なんかだともっと差が付くみたいだし
あー!1つリンクミスった
Opteronのfpはこっちだ
http://www.spec.org/cpu2006/results/res2011q1/cpu2006-20110131-14304.html
Opteronのfpはこっちだ
http://www.spec.org/cpu2006/results/res2011q1/cpu2006-20110131-14304.html
連投ですまん
Intel Xeon X5680 Cint rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
は
Intel Xeon X5680 Cfp rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
です・・・('A`)
Intel Xeon X5680 Cint rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
は
Intel Xeon X5680 Cfp rate=228 base=222 (6Core,12thread 3.33GHz 2CPU)
です・・・('A`)
そりゃ346mm2x2の巨大チップを250mm2のチップと同程度の価格で叩き売ってるからな。
AMDの方がコストパフォーマンスが高いのは道理。
だが経営面ではでかなり苦しいだろうな。
AMDの方がコストパフォーマンスが高いのは道理。
だが経営面ではでかなり苦しいだろうな。
どうせバックに石油会社があるんだからいくら赤字が出てもへっちゃらwww
後藤弘茂のWeekly海外ニュース■
ついに明らかになったAMDのBulldozer
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110301_430044.html
ブルのリーク電流
http://pc.watch.impress.co.jp/img/pcw/docs/430/044/html/3.jpg.html
Westmereが23%だから同程度か
ブログでMagnyCours(12コア*2ソケット)からInterlagos(16コア*2ソケット)に交換する動画上がってるね。
Opteron 4100/6100から簡単にBulldozerに変えれるって動画みたい
ttp://blogs.amd.com/work/2011/02/25/filling-the-sockets/
Cebit 2011: MSI bringt AMD-Bulldozer-taugliche AM3-Mainboards sowie BIOS-Update
ttp://www.pcgameshardware.de/aid,813945/Cebit-2011-MSI-bringt-AMD-Bulldozer-taugliche-AM3-Mainboards-sowie-BIOS-Update
http://blog.livedoor.jp/amd646464/archives/52148437.html
BIOSのアップでBullがAM3でも動作可能らしい
Hardware-Infosによると、Bulldozerコア搭載のZambeziはBIOSアップデートすればSocket AM3マザーでも動作するとのこと
実際に2つのSocket AM3マザーでBIOSアップデートによりZambeziのサンプルが動作したとのことです
ただしAM3+マザーを使った場合にはノース・サウス間の帯域が倍になり、
HTリンクやメモリクロックも向上するとのことで、このあたり差は出てきそうです
とりあえずAM3マザーでも動作するなら嬉しいですよね
http://www.xbitlabs.com/news/cpu/display/20110227225120_AMD_to_Showcase_Bulldozer_Microprocessors_at_CeBIT_Trade_Show.html
demonstrate and announce
ついに明らかになったAMDのBulldozer
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20110301_430044.html
ブルのリーク電流
http://pc.watch.impress.co.jp/img/pcw/docs/430/044/html/3.jpg.html
{kind=link}
Westmereが23%だから同程度か
ブログでMagnyCours(12コア*2ソケット)からInterlagos(16コア*2ソケット)に交換する動画上がってるね。
Opteron 4100/6100から簡単にBulldozerに変えれるって動画みたい
ttp://blogs.amd.com/work/2011/02/25/filling-the-sockets/
Cebit 2011: MSI bringt AMD-Bulldozer-taugliche AM3-Mainboards sowie BIOS-Update
ttp://www.pcgameshardware.de/aid,813945/Cebit-2011-MSI-bringt-AMD-Bulldozer-taugliche-AM3-Mainboards-sowie-BIOS-Update
http://blog.livedoor.jp/amd646464/archives/52148437.html
BIOSのアップでBullがAM3でも動作可能らしい
Hardware-Infosによると、Bulldozerコア搭載のZambeziはBIOSアップデートすればSocket AM3マザーでも動作するとのこと
実際に2つのSocket AM3マザーでBIOSアップデートによりZambeziのサンプルが動作したとのことです
ただしAM3+マザーを使った場合にはノース・サウス間の帯域が倍になり、
HTリンクやメモリクロックも向上するとのことで、このあたり差は出てきそうです
とりあえずAM3マザーでも動作するなら嬉しいですよね
http://www.xbitlabs.com/news/cpu/display/20110227225120_AMD_to_Showcase_Bulldozer_Microprocessors_at_CeBIT_Trade_Show.html
demonstrate and announce
A8-3510MX APU (Llano)とi7-2630QM(Sandy Bridge)の比較
http://www.youtube.com/watch?v=mdPi4GPEI74
インテルガクガクってる
http://www.youtube.com/watch?v=mdPi4GPEI74
インテルガクガクってる
http://www.youtube.com/watch?v=mdPi4GPEI74#t=70s
PC出荷の7割を占める法人向けはやっぱIntel天下だな
PC出荷の7割を占める法人向けはやっぱIntel天下だな
764 :Socket774:2011/03/02(水) 14:48:20.73 ID:Sjq6XdXI
Bul今年後半じゃ、いらんだろ
AMDは互換性のお陰で少しずつパーツを交換出来て良いよな
インテルで775DUAL-SATA2から卒業したら後が続かない
インテルで775DUAL-SATA2から卒業したら後が続かない
>>765
0. (既存ビデオがAGPなら)PCIeビデオ購入
1. DDR2/3両対応の775M/B購入
2. DDR3メモリ購入(既存メモリがDDRなら1. と同時)
3. CPUと対応M/B購入……の頃にはPCIe3.0になってたりDDR4になってたりw
0. (既存ビデオがAGPなら)PCIeビデオ購入
1. DDR2/3両対応の775M/B購入
2. DDR3メモリ購入(既存メモリがDDRなら1. と同時)
3. CPUと対応M/B購入……の頃にはPCIe3.0になってたりDDR4になってたりw
>>766
今のメモリ価格(買取/販売)調べてみろ、1の意味がねぇぞw
今のメモリ価格(買取/販売)調べてみろ、1の意味がねぇぞw
768 :Socket774:2011/03/06(日) 15:19:07.21 ID:GKLqREio
専用マザーが産廃になったintelよりはマシだな。
770 :Socket774:2011/03/06(日) 15:38:15.42 ID:nZvficG2
◆“SandyBridge”と“IvyBridge”―2つのLGA1155は相互互換性を有する事が判明!
http://vr-zone.com/articles/intel-s-lga-1155-cross-platform-compatibility-confirmed/11232.html
http://en.expreview.com/2011/02/18/intel-confirms-lga-1155-cross-platform-compatibility/14742.html
アムド脂肪確認
こっちでもコピペ荒らししてるのか、ひでえなw
772 :Socket774:2011/03/06(日) 15:44:46.41 ID:u9pN/1Iy
脊髄反射カッコワルイ
773 :Socket774:2011/03/06(日) 21:36:54.60 ID:+pr2OmOh
競合他社の件はどうでもいいが、
『BulldozerはAM3マザーに載る可能性が高い。だからAMDは今買ってOK』
『BulldozerはBIOS更新で載るからIntelとは違う』
とかお花畑してほざいてた連中は目と耳から血を流して絶命するべき
>>769
遊んで燃やしたのに新品に交換してくれるんだぜ、神すぐるwww
遊んで燃やしたのに新品に交換してくれるんだぜ、神すぐるwww
ここまで思い込むなんてなにがそうさせるのかしら
http://hissi.org/read.php/jisaku/20110306/eXBpSFF0eUg.html
865 :Socket774[sage]:2011/03/06(日) 05:38:16.53 ID:ypiHQtyH
リコールなのにまるで叩かずに
とぼけて済ますとはさすが買収済みのメディアだな
545 :Socket774[sage]:2011/03/06(日) 20:48:52.18 ID:ypiHQtyH
一見あたりさわりのない単発のネガティブな書込みが、
実は淫厨の工作であるという分かりやすい実例にはなったな
http://hissi.org/read.php/jisaku/20110306/eXBpSFF0eUg.html
865 :Socket774[sage]:2011/03/06(日) 05:38:16.53 ID:ypiHQtyH
リコールなのにまるで叩かずに
とぼけて済ますとはさすが買収済みのメディアだな
545 :Socket774[sage]:2011/03/06(日) 20:48:52.18 ID:ypiHQtyH
一見あたりさわりのない単発のネガティブな書込みが、
実は淫厨の工作であるという分かりやすい実例にはなったな
776 :Socket774:2011/03/09(水) 04:19:10.96 ID:NrRi617q
6月からはBul参戦とZ68投入で少しは盛り上がりそうじゃん
777
とりあえず予告通り、BullはQ2リリースになりそうやね
こっから伸びるんだよ。
まだまだ初心者だなw
まだまだ初心者だなw
どこの高卒投手だよw
781 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/03/12(土) 17:19:37.23 ID:FanYd+vT
>>759
カメレスだけど
基本的にサーバってCPU以外の部分の消費電力&価格が大きいから
CPUの性能をあげたほうが電力効率/コストパフォーマンスよくなるんだよね。
で、シングルダイのShanghaiがサーバ市場では全く競争力なくて売れない。
CPU安くしても筐体価格はそれほど落ちないからね。
逆に言えばコストかけてでも性能の高いチップを作ったほうがAMD的にはましということ。
そうでもしないとFabの生産ラインが止まってしまうから。
サーバ市場シェアが10%を割ったからこそできる苦肉の策だね。
逆に言えば市場の90%はMagny-Coursのようなものは求めてないということ。
いわばニッチソリューション。
カメレスだけど
基本的にサーバってCPU以外の部分の消費電力&価格が大きいから
CPUの性能をあげたほうが電力効率/コストパフォーマンスよくなるんだよね。
で、シングルダイのShanghaiがサーバ市場では全く競争力なくて売れない。
CPU安くしても筐体価格はそれほど落ちないからね。
逆に言えばコストかけてでも性能の高いチップを作ったほうがAMD的にはましということ。
そうでもしないとFabの生産ラインが止まってしまうから。
サーバ市場シェアが10%を割ったからこそできる苦肉の策だね。
逆に言えば市場の90%はMagny-Coursのようなものは求めてないということ。
いわばニッチソリューション。
782 :Socket774:2011/03/17(木) 22:15:23.08 ID:d2HDwYiK
おいAM3でぶるおkらしいwwwwwwwwwww大逆転wwwwwwwwwwwすげえええええ
現物を見るまで信じねぇ
785 :Socket774:2011/03/19(土) 22:42:35.33 ID:X+4xrIRA
■AM3にはBulldozerが挿さらない!現行屁マザボすべて産廃オワタ
http://pc.nikkeibp.co.jp/article/news/20110302/1030536/
◆“SandyBridge”と“IvyBridge”―2つのLGA1155は相互互換性を有する事が判明!
http://vr-zone.com/articles/intel-s-lga-1155-cross-platform-compatibility-confirmed/11232.html
http://en.expreview.com/2011/02/18/intel-confirms-lga-1155-cross-platform-compatibility/14742.html
アムド脂肪確認
786 :Socket774:2011/03/19(土) 23:31:32.99 ID:zefDV0Tr
BullのチップセットGPUにはLlanoの内蔵GPUよりも高性能なものが搭載される可能性があるのだろうか。
ブルには来年の22nでも性能で勝てないんだってよ
どうするんだインテル
どうするんだインテル
788 :Socket774:2011/03/20(日) 00:46:25.48 ID:mD1EZIaP
いまだにセレロン以下の低性能CPUしか売るものがないAMDがいってもw
いまだにセレロン烏賊の性能としか認識できない
インテル脳症が何言った所で…合掌
インテル脳症が何言った所で…合掌
内蔵GPUなんてものはそこそこでいいんだよ。
ごついGPUをCPUと一緒にしたところでメモリ帯域を圧迫して共倒れだって。
GPGPU的にはどうかしらんがな。
ごついGPUをCPUと一緒にしたところでメモリ帯域を圧迫して共倒れだって。
GPGPU的にはどうかしらんがな。
未だにIntel派だのAMD派だの言ってる奴らって居るのか……
スポーツチームじゃあるまいし肩入れする意味が分からんw
都合のいい方を都合のいいように使えばいいのに
スポーツチームじゃあるまいし肩入れする意味が分からんw
都合のいい方を都合のいいように使えばいいのに
そんなの言ってるのは極一部の異常に固執したやつが目立つだけだから。
スポーツチームも肩入れする意味分からん。
スポーツチームも肩入れする意味分からん。
せやな
>>786
100%ない
100%ない
問題は事実に反する発言をする人が非常に多いことなんだよ。
特に伝統的にAMD厨がね。
Intel派とかAMD派とかやっている分にはいいんだが。
特に伝統的にAMD厨がね。
Intel派とかAMD派とかやっている分にはいいんだが。
セレロン以下とか本気で言ってるのか?頭おかしいんじゃない?
>>796
頭おかしいからカネを払ってセレロンなんてゴミを掴む
頭おかしいからカネを払ってセレロンなんてゴミを掴む
ノートパソコンでも安くしたいからとceleronなんて買う負け組
4525s/CT買っとけっちゅーの
4525s/CT買っとけっちゅーの
http://ninja.2ch.net/test/read.cgi/newsplus/1300657403/
【東日本大震災】 紀子さまの実弟・川嶋氏が被災地支援陣頭指揮 「報道以上に現地混乱」 [03/21 6:00]
【東日本大震災】 紀子さまの実弟・川嶋氏が被災地支援陣頭指揮 「報道以上に現地混乱」 [03/21 6:00]
世界のシリコンウエハーの4分の1の生産が停止、IHS iSuppliが報告
http://itpro.nikkeibp.co.jp/article/NEWS/20110322/358529/
http://itpro.nikkeibp.co.jp/article/NEWS/20110322/358529/
AMDは完全に低コストで普通に使えるPC向け
今なら235e、低コスト+低電力+マシなオンボだけのために存在する
今なら235e、低コスト+低電力+マシなオンボだけのために存在する
現実的には、
遅いCPU+鉄板>>>>速いCPU+地雷板
K10はそろそろアレかと思うけど、遅くて困ってるわけでもないという。
BULL買う理由を作りたいが・・
遅いCPU+鉄板>>>>速いCPU+地雷板
K10はそろそろアレかと思うけど、遅くて困ってるわけでもないという。
BULL買う理由を作りたいが・・
_|/|__
/____ \
// \.\ .__ ―――― __
|/| |/| .// ̄Y ̄\ \ <人生やりなおし機~!!
|/| |/| ./ | ´ | ` | . \
|/| |/| | .人____人____人_ ヽ
\.\___ // | /ミ ● 彡 \ |
\____________/ .|| 匚______|____________ .| |
(_____) | \ / / .| ./
.\. \__. \ \_____/U ./ /
. \  ̄ ̄ ̄\_______________∠/
/____ \
// \.\ .__ ―――― __
|/| |/| .// ̄Y ̄\ \ <人生やりなおし機~!!
|/| |/| ./ | ´ | ` | . \
|/| |/| | .人____人____人_ ヽ
\.\___ // | /ミ ● 彡 \ |
\____________/ .|| 匚______|____________ .| |
(_____) | \ / / .| ./
.\. \__. \ \_____/U ./ /
. \  ̄ ̄ ̄\_______________∠/
タマシイムマシンでおk
805 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/07(木) 21:52:04.25 ID:b2TBjklW
806 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 00:15:13.44 ID:MxZ4lNh4
とりあえず簡単に感想まとめ
<浮動小数点の場合>
2つのFMACとのうち1つとXBAR(Permute Unit)がポート共用
たとえばIntelの場合は256ビットVFADD*とVFMUL*, VPERM*を並列実行できるが
同じ考えでソフトを組むと性能を半分も引き出せない。
AVXをサポートしたから最適化コードを共有できるとかそういうものではなく
Bulldozer専用の最適化が必要。
<SIMD整数の場合>
整数の場合だとMMX-ALU1つとFSTOREが共有。K10の場合はMMX2つとFSTOREは並列に実行できた。
従来SSEだと論理レジスタの少ない32ビットのコードでK10より性能が低下する可能性がある。
2コア分の性能どころかおおよそK10 1コア分の性能すら出ない。
AVX/XOPを使わなければ厳しい。
<浮動小数点の場合>
2つのFMACとのうち1つとXBAR(Permute Unit)がポート共用
たとえばIntelの場合は256ビットVFADD*とVFMUL*, VPERM*を並列実行できるが
同じ考えでソフトを組むと性能を半分も引き出せない。
AVXをサポートしたから最適化コードを共有できるとかそういうものではなく
Bulldozer専用の最適化が必要。
<SIMD整数の場合>
整数の場合だとMMX-ALU1つとFSTOREが共有。K10の場合はMMX2つとFSTOREは並列に実行できた。
従来SSEだと論理レジスタの少ない32ビットのコードでK10より性能が低下する可能性がある。
2コア分の性能どころかおおよそK10 1コア分の性能すら出ない。
AVX/XOPを使わなければ厳しい。
SSE5のダメージ引きずってるのかね
>>806の感想通りなら、
Bulldozer出たときのベンチは、クライアント向けでSSE多用するものだと
がっかりスコアになる可能性大ってこと?
鯖やHPC向けの、自分でコンパイルできるベンチで性能アピールするのだろうか、発表時は。
Bulldozer出たときのベンチは、クライアント向けでSSE多用するものだと
がっかりスコアになる可能性大ってこと?
鯖やHPC向けの、自分でコンパイルできるベンチで性能アピールするのだろうか、発表時は。
809 :Socket774:2011/04/08(金) 10:56:24.83 ID:k1nSsdCa
状況は3DNowの時と同じだ
最適化されれば早いが、前回と事情が異なるのは今はソフトの開発はARMが中心で
PCソフトの最適化は昔の様には行かないって事だ
Sandyに対する優位点は
・256bit-FMACが使える
・128bit-FMACなら潤沢にある
・256bitのSIMD整数がある
点かな?
最適化されれば早いが、前回と事情が異なるのは今はソフトの開発はARMが中心で
PCソフトの最適化は昔の様には行かないって事だ
Sandyに対する優位点は
・256bit-FMACが使える
・128bit-FMACなら潤沢にある
・256bitのSIMD整数がある
点かな?
810 :Socket774:2011/04/08(金) 11:32:33.53 ID:k1nSsdCa
逆にIntelにとってありがたいのは、将来サポート予定ものを殆どBullが積んでくれたので
自社の移行の時にはソフトが潤沢に出回っているだろうって点だな
自社の移行の時にはソフトが潤沢に出回っているだろうって点だな
AMDのFMAはFMA4で、Intelが実装するのはFMA3の予定。
整数はAMD独自のXOPなので、Intelとは無関係。
SandyBridgeのAVXにない命令は、Bulldozer独自なので、Intelがその恩恵被ることなんてない。
整数はAMD独自のXOPなので、Intelとは無関係。
SandyBridgeのAVXにない命令は、Bulldozer独自なので、Intelがその恩恵被ることなんてない。
812 :Socket774:2011/04/08(金) 13:35:41.09 ID:k1nSsdCa
後藤の記事を見る限りじゃ今後もAVXの拡張は進められ、FMA4なども実装されるらしいよ
命令セットは当然違うが、似たような機能ならソフトメーカーの対応も容易だろうという意味
命令セットは当然違うが、似たような機能ならソフトメーカーの対応も容易だろうという意味
813 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 15:40:09.55 ID:MxZ4lNh4
Sandy BridgeはSandy Bridge固有の最適化が必要になる(Bulldozerでは性能が出ない)
BulldozerはXOPなどの独自命令も駆使しなければならない(ベッタリに組んだ場合Intel CPUでの動作は未来永劫期待できない)
3DNow!とSSEが並立してたときと実質的には変わらん。
>>806のSIMD整数に補足しておくと、Port0,1にも複雑な整数演算向けのロジックを積んでるので
常にPort2, Port3が使われるわけではない。
うまく並列動作すればK10の1コアのSIMDユニットよりも性能が上がるケースもある。
一般的にはSIMD整数で使う頻度の高い命令ってPort2,3側なんだよね。
整数Port0は乗算・SAD用、Port1はデータの攪拌・転置と、XOPのビット選択命令などの特殊命令主体。
一番使う論理加減算がPort2, 3だ。
そして論理・加減算を伴わない128ビットLoadにすらPort2,3を使うのが痛い。目に見えてここが忙しくなる。
この構成で性能向上を得ようと思えばかなりアプリを選ぶ。
もちろん1コア当たりの性能の話はしてない。1モジュール(2コア)と従来の1コアを比べての話な。
フォローしておくなら、常にSIMDユニットを動かしてるわけではないので、2スレッドトータルでは
スループットは上がる可能性はある。
(もちろんこれもSandy BridgeのHyperThreadingに対して優位性があるという話ではない)
BulldozerはXOPなどの独自命令も駆使しなければならない(ベッタリに組んだ場合Intel CPUでの動作は未来永劫期待できない)
3DNow!とSSEが並立してたときと実質的には変わらん。
>>806のSIMD整数に補足しておくと、Port0,1にも複雑な整数演算向けのロジックを積んでるので
常にPort2, Port3が使われるわけではない。
うまく並列動作すればK10の1コアのSIMDユニットよりも性能が上がるケースもある。
一般的にはSIMD整数で使う頻度の高い命令ってPort2,3側なんだよね。
整数Port0は乗算・SAD用、Port1はデータの攪拌・転置と、XOPのビット選択命令などの特殊命令主体。
一番使う論理加減算がPort2, 3だ。
そして論理・加減算を伴わない128ビットLoadにすらPort2,3を使うのが痛い。目に見えてここが忙しくなる。
この構成で性能向上を得ようと思えばかなりアプリを選ぶ。
もちろん1コア当たりの性能の話はしてない。1モジュール(2コア)と従来の1コアを比べての話な。
フォローしておくなら、常にSIMDユニットを動かしてるわけではないので、2スレッドトータルでは
スループットは上がる可能性はある。
(もちろんこれもSandy BridgeのHyperThreadingに対して優位性があるという話ではない)
814 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 16:20:32.86 ID:MxZ4lNh4
> ・256bit-FMACが使える
128ビットオペレーション×2ですけどね。
まあ2個あるから256ビット1基分相当の性能にはなるけど。
1基分のFMACの性能は独立したFMULとFADDの組み合わせに対して、理論上50~100%の性能ということになる。
加算と乗算を常に融合できるわけではないからね。
FMACの優位性は乗算を正規化で丸められる下位ビットを持ち越した上で加算を行えるので
わずかに演算精度が向上すること(MXCSR依存?)
それはそれで、従来のCPU同等に精度落ちさせないとデータ整合性がとれないなんて問題も起きるので
ネットゲーム開発者なんかは注意して使わないといけない。
> ・128bit-FMACなら潤沢にある
128ビットまでならピークFLOPS数で優位ってのはAMDも主張してたことだけど、FMAを使う時点で
AVXを使うことは前提となる。
従来コードを256ビット版乗算・加算に置き換える手間と、FMAに置き換える使う手間は大して変わりません。
その他の利点・欠点は256ビットの場合と同じ。
FMAを使わなくとも従来SSEでもFADDないしFMULを2つ同時に使える分有利という考え方もできるが
レイテンシが大きいし、先にも言ってるが1基はXBARとポート共有なのでパフォーマンスには制限が付く。
> ・256bitのSIMD整数がある
VPCMOVなんかのことだろうけど、それ128bit演算ユニットで2回実行するだけですけどね。
これ以外の整数演算命令はほとんど128ビット。YMM上位は使わない。
128ビットオペレーションを2回通すだけの256ビット命令を使うためにわざわざvinsertf128, vextractf128を
都度発行するような本末転倒なことは普通やらないでしょ。
128ビットオペレーション×2ですけどね。
まあ2個あるから256ビット1基分相当の性能にはなるけど。
1基分のFMACの性能は独立したFMULとFADDの組み合わせに対して、理論上50~100%の性能ということになる。
加算と乗算を常に融合できるわけではないからね。
FMACの優位性は乗算を正規化で丸められる下位ビットを持ち越した上で加算を行えるので
わずかに演算精度が向上すること(MXCSR依存?)
それはそれで、従来のCPU同等に精度落ちさせないとデータ整合性がとれないなんて問題も起きるので
ネットゲーム開発者なんかは注意して使わないといけない。
> ・128bit-FMACなら潤沢にある
128ビットまでならピークFLOPS数で優位ってのはAMDも主張してたことだけど、FMAを使う時点で
AVXを使うことは前提となる。
従来コードを256ビット版乗算・加算に置き換える手間と、FMAに置き換える使う手間は大して変わりません。
その他の利点・欠点は256ビットの場合と同じ。
FMAを使わなくとも従来SSEでもFADDないしFMULを2つ同時に使える分有利という考え方もできるが
レイテンシが大きいし、先にも言ってるが1基はXBARとポート共有なのでパフォーマンスには制限が付く。
> ・256bitのSIMD整数がある
VPCMOVなんかのことだろうけど、それ128bit演算ユニットで2回実行するだけですけどね。
これ以外の整数演算命令はほとんど128ビット。YMM上位は使わない。
128ビットオペレーションを2回通すだけの256ビット命令を使うためにわざわざvinsertf128, vextractf128を
都度発行するような本末転倒なことは普通やらないでしょ。
団子がこんだけ力説するってことは、Bullは高性能なんだろうなぁ
団子の分析が当たったことねーしw
団子の分析が当たったことねーしw
816 :Socket774:2011/04/08(金) 16:59:26.49 ID:k1nSsdCa
>>814
依存関係の有る乗算と加算を繰り返す場合、FMULとFADDが独立していたらFMACの半分の性能しか出ないんじゃないの
あと、AMDが言ってるのは128bit以下の長さのデータの処理だろう
Bullは128bit以下のデータの処理を行う場合は8スレッド走らせられるって意味じゃないの
依存関係の有る乗算と加算を繰り返す場合、FMULとFADDが独立していたらFMACの半分の性能しか出ないんじゃないの
あと、AMDが言ってるのは128bit以下の長さのデータの処理だろう
Bullは128bit以下のデータの処理を行う場合は8スレッド走らせられるって意味じゃないの
817 :Socket774:2011/04/08(金) 17:05:19.71 ID:k1nSsdCa
そもそもSIMDの長さを拡大すればするほどの充填率が下がり無駄が増えるのに
IntelがSIMDを拡張したいのはララビーとの整合性を取るためだよね
IntelがSIMDを拡張したいのはララビーとの整合性を取るためだよね
プレス子スレにてSIMMとSIMDの勘違いをした決定的瞬間のログ(雑音が"録音"と呼ばれていた時代のログ)
http://web.archive.org/web/20080518103351/http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
http://web.archive.org/web/20080518103351/http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
819 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 17:25:58.65 ID:MxZ4lNh4
>>816
> 依存関係の有る乗算と加算を繰り返す場合、FMULとFADDが独立していたらFMACの半分の性能しか出ないんじゃないの
どうやら通じてないな。
FMACユニットでaddpsとmulpsで別々に実行したらvfmaddpsの半分の性能だねってこと。
常に乗算と加算が融合できるとは限らないので
理論FLOPS数が同じなら加算ユニットと乗算ユニットが独立してたほうが実効性能では有利だねってこと。
>>817
GPUを統合したいのはAMDも同じだろう?最新のVLIW4ですら1クラスタで8192ビット相当の並列度じゃないか。
いつぞ言ってた「SSEをGPUで実行」なんてまさにそれこそ充填率が下がり無駄が増えるのは明らかだな。夢は寝て見ろ。
> 依存関係の有る乗算と加算を繰り返す場合、FMULとFADDが独立していたらFMACの半分の性能しか出ないんじゃないの
どうやら通じてないな。
FMACユニットでaddpsとmulpsで別々に実行したらvfmaddpsの半分の性能だねってこと。
常に乗算と加算が融合できるとは限らないので
理論FLOPS数が同じなら加算ユニットと乗算ユニットが独立してたほうが実効性能では有利だねってこと。
>>817
GPUを統合したいのはAMDも同じだろう?最新のVLIW4ですら1クラスタで8192ビット相当の並列度じゃないか。
いつぞ言ってた「SSEをGPUで実行」なんてまさにそれこそ充填率が下がり無駄が増えるのは明らかだな。夢は寝て見ろ。
820 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 17:36:13.52 ID:MxZ4lNh4
ちなみに>>814あたりは趣味でBulldozerでの動作を想定したにソフト書いてる身として
パフォーマンス上の問題点のメモとして書いたものだ。
不当にAMDを蔑むためのものではない。
で、SIMD整数コードの性能問題の打開策としてできること(マニュアルには書いてない)
VPCMOVはオペランドの1つを0にすればVPAND/VPANDNの代替として使える。
乗算に加算が続く場合はできるだけIMAC命令を使うようにする。
この辺のテクニックを使えばPort2, Port3の負担を軽減することができる。
もちろんSandy Bridgeでは動かなくなるけどね。
パフォーマンス上の問題点のメモとして書いたものだ。
不当にAMDを蔑むためのものではない。
で、SIMD整数コードの性能問題の打開策としてできること(マニュアルには書いてない)
VPCMOVはオペランドの1つを0にすればVPAND/VPANDNの代替として使える。
乗算に加算が続く場合はできるだけIMAC命令を使うようにする。
この辺のテクニックを使えばPort2, Port3の負担を軽減することができる。
もちろんSandy Bridgeでは動かなくなるけどね。
821 :Socket774:2011/04/08(金) 17:40:44.11 ID:k1nSsdCa
>>819
ここはIntel派のスレだろ
AMDがGPUでSIMDとかはどうでもいいよ
そもそもAMDがCPUに融合しようとしてるGPUって現行のVLIW5/4を使ったGPUとは別シリーズだろ
Bulldozer同様に、というかBulldozerより更に延期されて2012年以降になってるが
ここはIntel派のスレだろ
AMDがGPUでSIMDとかはどうでもいいよ
そもそもAMDがCPUに融合しようとしてるGPUって現行のVLIW5/4を使ったGPUとは別シリーズだろ
Bulldozer同様に、というかBulldozerより更に延期されて2012年以降になってるが
822 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 17:41:25.39 ID:MxZ4lNh4
>>815
http://www.realworldtech.com/page.cfm?ArticleID=RWT033011040021
http://www.realworldtech.com/includes/images/articles/bulldozer-benchmarks-1.png
プロファイリングしてみたらこの結果になるのは納得できたよ
http://www.realworldtech.com/page.cfm?ArticleID=RWT033011040021
http://www.realworldtech.com/includes/images/articles/bulldozer-benchmarks-1.png
{kind=link}
プロファイリングしてみたらこの結果になるのは納得できたよ
823 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 17:42:08.53 ID:MxZ4lNh4
>>821
AMDのCPUを語るスレだが?w
AMDのCPUを語るスレだが?w
824 :Socket774:2011/04/08(金) 17:46:50.19 ID:k1nSsdCa
多分延期の理由はララビーと同じで電力効率が悪かったからだと思うがね
で、FMACが別個の乗算と加算を同時に行えないのは判ってるよ
知りたいのは、乗加算1→乗加算2→乗加算3→乗加算4・・・と続き、それぞれが前の乗加算の結果に依存するとき
FADD+FMULとFMACの所要サイクル数どうなるかだ
で、FMACが別個の乗算と加算を同時に行えないのは判ってるよ
知りたいのは、乗加算1→乗加算2→乗加算3→乗加算4・・・と続き、それぞれが前の乗加算の結果に依存するとき
FADD+FMULとFMACの所要サイクル数どうなるかだ
825 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 17:48:10.54 ID:MxZ4lNh4
ちなみにこの表でいう「Core」はモジュールのことだな。
Zambeziは最大4コア、Interlagosは8コアという扱いになる。
もちろんマーケティング上はスレッド数=コア数だが。
Zambeziは最大4コア、Interlagosは8コアという扱いになる。
もちろんマーケティング上はスレッド数=コア数だが。
826 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 18:05:03.65 ID:MxZ4lNh4
>>824
行列積問題でオペレーションの依存関係ができるのは本質的には加算を反復する部分だけだろう?
値のロードと乗算はレジスタリネーミングで別々の物理レジスタに割り当てて並列に行えるのでレイテンシは隠蔽できる。
Sandy BridgeのFADDのレイテンシは3だ。FMULは5+ロードレイテンシ分かかるが前後に依存関係がないので
レジスタリネーミングで並列実行可能だ。したがってコードシーケンスを3並列以上インターリーブすれば
ほぼ100%の効率を出せる(データがL1キャッシュあるいはレジスタに載ってる場合)
これがBulldozerのFMACになると、加算も乗算も乗加算も全てレイテンシ6だから256ビットSIMDでも6回、
128ビットだと12回分のインターリーブが必要になる。
デスティネーションオペランドに対して依存関係のショートカットをする機構(反復して加算する場合は
denormalizeせずに次のFMADDで使うなど)が無いかと、マニュアルをあたってみたが
どうやらそういう機構はなさそうだ。
行列積問題でオペレーションの依存関係ができるのは本質的には加算を反復する部分だけだろう?
値のロードと乗算はレジスタリネーミングで別々の物理レジスタに割り当てて並列に行えるのでレイテンシは隠蔽できる。
Sandy BridgeのFADDのレイテンシは3だ。FMULは5+ロードレイテンシ分かかるが前後に依存関係がないので
レジスタリネーミングで並列実行可能だ。したがってコードシーケンスを3並列以上インターリーブすれば
ほぼ100%の効率を出せる(データがL1キャッシュあるいはレジスタに載ってる場合)
これがBulldozerのFMACになると、加算も乗算も乗加算も全てレイテンシ6だから256ビットSIMDでも6回、
128ビットだと12回分のインターリーブが必要になる。
デスティネーションオペランドに対して依存関係のショートカットをする機構(反復して加算する場合は
denormalizeせずに次のFMADDで使うなど)が無いかと、マニュアルをあたってみたが
どうやらそういう機構はなさそうだ。
827 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 18:18:13.15 ID:MxZ4lNh4
Sandy Bridgeの場合。
乗算5+加算3で合計レイテンシ8だが実際にチェインが発生するのは加算の3サイクルのみ。
***□□□□□■■■
***□□□□□■■■
***□□□□□■■■
Bulldozerは積和算で6サイクル分。Sandy Bridgeの倍のインターリーブ数が必要。
***■■■■■■
***■■■■■■
***■■■■■■
これは>>822のパフォーマンス低下の原因のひとつだね。K10まではFADDはレイテンシ4だったが6に悪化した。
もちろん原因がわかってれば改善も出来る。
1スレッドあたり論理レジスタ16本の縛りが結構きついけど、ロードユニットが1モジュール全体で4本
(整数コア毎に2本)あるので、なんとか酷使してやればスループットを改善できる。
乗算5+加算3で合計レイテンシ8だが実際にチェインが発生するのは加算の3サイクルのみ。
***□□□□□■■■
***□□□□□■■■
***□□□□□■■■
Bulldozerは積和算で6サイクル分。Sandy Bridgeの倍のインターリーブ数が必要。
***■■■■■■
***■■■■■■
***■■■■■■
これは>>822のパフォーマンス低下の原因のひとつだね。K10まではFADDはレイテンシ4だったが6に悪化した。
もちろん原因がわかってれば改善も出来る。
1スレッドあたり論理レジスタ16本の縛りが結構きついけど、ロードユニットが1モジュール全体で4本
(整数コア毎に2本)あるので、なんとか酷使してやればスループットを改善できる。
828 : 忍法帖【Lv=14,xxxPT】 :2011/04/08(金) 18:22:56.46 ID:4aEYnbAj
AMD次世代本スレよりこちらのほうが面白くなっているな
様々な角度・視点から可能性を論じるのは良いことだ
無駄な罵りあいや荒らしはご勘弁
様々な角度・視点から可能性を論じるのは良いことだ
無駄な罵りあいや荒らしはご勘弁
829 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 18:30:50.63 ID:MxZ4lNh4
というか性能が悪いベンチも包み隠さずAMD公式に出したほうが良いんだけどね。
そのほうがソフト側でボトルネックの対処をしやすい。
都合のいい数字だけ出してファンの一時の安心を誘ったところで最終的にはAMDが損をする。
そのほうがソフト側でボトルネックの対処をしやすい。
都合のいい数字だけ出してファンの一時の安心を誘ったところで最終的にはAMDが損をする。
団子が一人で戯言言ってるだけだな
スレ自体が放置されてるのをいいことに好き勝手やってる
スレ自体が放置されてるのをいいことに好き勝手やってる
831 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 22:20:06.83 ID:MxZ4lNh4
RWTの記者は科学技術計算だから一般のアプリではそんなに関係ないかもしれない
みたいなことを言ってるが、行列積とかFFTなんてもろにPCアプリで使う分野だぜ。
単精度4x4行列はゲームで頻繁に使う。それも大量に。
行列の規模が小さいほどレイテンシの問題はシビアになる。
FFTは動画や音声のエンコーディングなどでも使われてるし
さらに言えばbzip2圧縮で速度落ちてるならZIPやCABが落ちてない可能性も否定できない。
というかこの程度は想定内の数字なんで驚きはしない。
あとこれは禁句だったかもしれないが全体的にSandy Bridgeより命令のレイテンシ・スループットが悪い。
みたいなことを言ってるが、行列積とかFFTなんてもろにPCアプリで使う分野だぜ。
単精度4x4行列はゲームで頻繁に使う。それも大量に。
行列の規模が小さいほどレイテンシの問題はシビアになる。
FFTは動画や音声のエンコーディングなどでも使われてるし
さらに言えばbzip2圧縮で速度落ちてるならZIPやCABが落ちてない可能性も否定できない。
というかこの程度は想定内の数字なんで驚きはしない。
あとこれは禁句だったかもしれないが全体的にSandy Bridgeより命令のレイテンシ・スループットが悪い。
832 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 22:24:15.22 ID:MxZ4lNh4
○ZIPやCABも落ちてる可能性も否定できない。
これbzip2は同クロックで5%ほど性能上がってるんじゃないの?
最後のカラムは
>A value over 1 indicates that Bulldozer is faster per cycle,
>while anything below 1 shows the reverse.
なんだから
最後のカラムは
>A value over 1 indicates that Bulldozer is faster per cycle,
>while anything below 1 shows the reverse.
なんだから
834 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 23:01:21.28 ID:MxZ4lNh4
ここで言うコアは1モジュールのことらしいけどな。
モジュール数はK10より減ってるので結果性能ダウンと。
モジュール数はK10より減ってるので結果性能ダウンと。
835 :,,・´∀`・,,)<一番良い ⑨ を頼む:2011/04/08(金) 23:08:30.48 ID:MxZ4lNh4
ちなみに俺も比較の際はSandy Bridge 1コアとBulldozer 1モジュールの比較しかしてない。
1モジュールには明らかに2コア分の性能はないから。
1モジュールには明らかに2コア分の性能はないから。
857 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:26:18.90 ID:ERbCKnad
地震の影響でニコンの工場が閉鎖されIntelの22nmプロセスFabの量産計画に支障がでるかもしれないことについて
海外のAMDファンボーイは大喜びしてるし、似たようなもんだろ
858 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:47:11.88 ID:ERbCKnad
なんだ急に静かになりやがってよ
日本が震災にあったおかけでAMDはプロセスルールの遅れを取り戻せる可能性が出てきた。
飯がうまいだろ?
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
863 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 22:04:04.19 ID:ERbCKnad
大地震による津波が日本を襲い、ニコンの工場が閉鎖され、Intelの生産に支障がでたところでAMDが躍進する。
津波をイメージしたVisionのパッケージ絵にはそういう熱い思いが込められている
ただの生ぽニートかと思ったら史上最低の屑野郎だった
地震の影響でニコンの工場が閉鎖されIntelの22nmプロセスFabの量産計画に支障がでるかもしれないことについて
海外のAMDファンボーイは大喜びしてるし、似たようなもんだろ
858 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:47:11.88 ID:ERbCKnad
なんだ急に静かになりやがってよ
日本が震災にあったおかけでAMDはプロセスルールの遅れを取り戻せる可能性が出てきた。
飯がうまいだろ?
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
863 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 22:04:04.19 ID:ERbCKnad
大地震による津波が日本を襲い、ニコンの工場が閉鎖され、Intelの生産に支障がでたところでAMDが躍進する。
津波をイメージしたVisionのパッケージ絵にはそういう熱い思いが込められている
ただの生ぽニートかと思ったら史上最低の屑野郎だった
>そもそもAMDがCPUに融合しようとしてるGPUって現行のVLIW5/4を使ったGPUとは別シリーズだろ
十年先の話か?
十年先の話か?
といってもIntelも同じ道辿るし規定路線でしょ
規定路線でも標準になるのはintel規格でしょうがね
DirectCompute、OpenCL、CUDAを超えるものをインテルがもってるらしい。
しかもそれら全てを押し退けて業界の標準になる公算が高いニダ、ときた。
しかもそれら全てを押し退けて業界の標準になる公算が高いニダ、ときた。
オープンで緩いライセンスならどうでもいい
そんなAPIレベルのくそ遅いものなんて流行るわけが無い
cpuから透過的に使える命令でなければ、無意味
nvidiaですらソフト開発側からtegraでのgpgpuにnoをだされ
128bit neonを搭載することになったんだし
cpuから透過的に使える命令でなければ、無意味
nvidiaですらソフト開発側からtegraでのgpgpuにnoをだされ
128bit neonを搭載することになったんだし
初めは遅くても世代がカバーするんじゃないの?
開発の容易さ以上の甘い蜜はないと思う
開発の容易さ以上の甘い蜜はないと思う
用意じゃないから使われない
今までも
今までも
>>843
エンコ位しか、用途が無いよな。
データを、ディスクリートGPUのメモリに転送して、
演算が終わるを待ってからデータを引き上げないといけないし。
Quick Sync Videoがまともに使えるようになったら、無用の長物か。
AMDはGPUコア統合して、SIMD命令をGPU側で処理させようとしてるよね。
とても良いアプローチだと思うんだけど。
(ディスクリートGPU前提のCPUだと、SIMD性能大幅ダウンなんて事にならなければ。)
エンコ位しか、用途が無いよな。
データを、ディスクリートGPUのメモリに転送して、
演算が終わるを待ってからデータを引き上げないといけないし。
Quick Sync Videoがまともに使えるようになったら、無用の長物か。
AMDはGPUコア統合して、SIMD命令をGPU側で処理させようとしてるよね。
とても良いアプローチだと思うんだけど。
(ディスクリートGPU前提のCPUだと、SIMD性能大幅ダウンなんて事にならなければ。)
846 :Socket774:2011/04/11(月) 13:06:33.95 ID:IhdM9T7E
CPUのSIMD演算基で1命令1サイクルないし2サイクルで完結できるレベルの並列度の演算命令を
低クロックで並列度が無駄に高いGPUにそのまんまもっていったところでそれこそ性能ダウンだろw
結局GPUでできるのはAPIレベルだろ。
低クロックで並列度が無駄に高いGPUにそのまんまもっていったところでそれこそ性能ダウンだろw
結局GPUでできるのはAPIレベルだろ。
CPUではやい処理はCPUで
GPUではやい処理はGPUで
それだけ追求したAPUを作ればいいだけ
GPUではやい処理はGPUで
それだけ追求したAPUを作ればいいだけ
そんなの無いは
849 :,,・´∀`・,,)っ-○○○:2011/04/12(火) 00:49:58.53 ID:UMrWC45V
GPUでCPUのSIMD命令を置き換え可能でなおかつCPUのそれより効率的に実行できるとするなら
CPUのSIMDユニットは最初からGPUと同じ構造になってるはずだろ?
構造が根本から違うってことは不適ってことなんだよ。
CPUのSIMDユニットは最初からGPUと同じ構造になってるはずだろ?
構造が根本から違うってことは不適ってことなんだよ。
砂橋
CPUではやい処理はCPU
GPUではやい処理もCPU
Llano
CPUではやい処理はCPU
GPUではやい処理はGPU
ただそれだけ
CPUではやい処理はCPU
GPUではやい処理もCPU
Llano
CPUではやい処理はCPU
GPUではやい処理はGPU
ただそれだけ
いや、Llanoはそこまで進化してないから…
>>849
256-bit長のAVXなんて、CPUで処理させないといけない様な物なの?
普段は殆ど遊んでるFP Schedulerを、その為に拡張するの?
そんな無駄なリソース割く位なら、Int Schedulerを実装した方が良いんじゃないの?
っていう解が、Bulldozerなんだろう?
256-bit長のAVXなんて、CPUで処理させないといけない様な物なの?
普段は殆ど遊んでるFP Schedulerを、その為に拡張するの?
そんな無駄なリソース割く位なら、Int Schedulerを実装した方が良いんじゃないの?
っていう解が、Bulldozerなんだろう?
それで旧世代より劣化したの?
intelの場合int,fpでスケジューラ分かれてたっけ?
そもそもalu,fp,avxでport共有だったと思うので
遊びなんて出ないと思うのだが
そもそもalu,fp,avxでport共有だったと思うので
遊びなんて出ないと思うのだが
そもそもイッパンジンが256bitをフルレングスで使える場面ってあるのだろうか
AMDいがいのSOA型なら普通に使うだろ
AMDの10240bit 8192bitはどうかしらんが
AMDの10240bit 8192bitはどうかしらんが
で、恩恵はありそうなの?
ええ有りますよ
とくに物理演算はリニアに上がります
AMDのVLIWと違って
とくに物理演算はリニアに上がります
AMDのVLIWと違って
それだけ?
256bitとか、そんな無理するくらいなら、
もうさっさとGPUに統合しろよと言いたくなる。
もうさっさとGPUに統合しろよと言いたくなる。
またぞろIntelさまが妨害して、
結局ユーザが不便で高い市場に閉じ込められるわな。
まぁ見てろ。
結局ユーザが不便で高い市場に閉じ込められるわな。
まぁ見てろ。
862 :,,・´∀`・,,)っ-○○○:2011/04/14(木) 04:42:23.25 ID:R/6iYv8v
つーか乗算と後続の加算に依存関係がある場面でしか使えないFMACを使いこなすことより
256ビットのほうが簡単だけどな
>>860
NehalemまででFPとInt.で別々に分かれてたSIMD実行ユニットの2レーンを並列に動かして
256ビットとして使ってるので、SIMDユニットの実装面積なんてほとんど増えてないというのが
Intelの主張。
実装面積を食いがちな除算ユニットもBulldozerモジュールは2つの整数クラスタとFPクラスタで
計3基あるが、Intelはスケジューラ・ユニットが統合されてるので1基だけで済んでいる。
128ビットのままユニットを増やして性能を伸ばそうとするほうがスケジューラが複雑になるよ。
ユニットごと256ビット化ならスケジューラは128ビットのそれと同じコストで済む。
CPUは命令の実行によるデータ処理よりもデコードやスケジューリングなどの前段処理のほうが
電力を食いがちなので、1命令で今までの2倍のデータを処理できるなら2倍近い電力効率を
得ることができる。
256ビットのほうが簡単だけどな
>>860
NehalemまででFPとInt.で別々に分かれてたSIMD実行ユニットの2レーンを並列に動かして
256ビットとして使ってるので、SIMDユニットの実装面積なんてほとんど増えてないというのが
Intelの主張。
実装面積を食いがちな除算ユニットもBulldozerモジュールは2つの整数クラスタとFPクラスタで
計3基あるが、Intelはスケジューラ・ユニットが統合されてるので1基だけで済んでいる。
128ビットのままユニットを増やして性能を伸ばそうとするほうがスケジューラが複雑になるよ。
ユニットごと256ビット化ならスケジューラは128ビットのそれと同じコストで済む。
CPUは命令の実行によるデータ処理よりもデコードやスケジューリングなどの前段処理のほうが
電力を食いがちなので、1命令で今までの2倍のデータを処理できるなら2倍近い電力効率を
得ることができる。
863 :,,・´∀`・,,)っ-○○○:2011/04/14(木) 05:38:54.51 ID:R/6iYv8v
つーかAoSのままでも256ビットで性能は出るだろう。
128ビットのデータを2並列に動かせばいい。
ただしBulldozerとは違ってPermuteユニットは乗算・加算ユニットと独立で動作するので
都度データを組み替えても十分な性能は維持できる。
更にはvblendvpsでプレディケートもできる。
おまいらゲーム好きだろ?
たとえばDirectXのベクトルセットアップもCPU側の仕事だ。
GPUを活用しようとすればするほどCPUの性能はむしろ重要になる。
D3DMatrixなどのクラスはSSEを透過的に扱えるが今後は256ビットAVXやFMAにも対応していく。
128ビットのデータを2並列に動かせばいい。
ただしBulldozerとは違ってPermuteユニットは乗算・加算ユニットと独立で動作するので
都度データを組み替えても十分な性能は維持できる。
更にはvblendvpsでプレディケートもできる。
おまいらゲーム好きだろ?
たとえばDirectXのベクトルセットアップもCPU側の仕事だ。
GPUを活用しようとすればするほどCPUの性能はむしろ重要になる。
D3DMatrixなどのクラスはSSEを透過的に扱えるが今後は256ビットAVXやFMAにも対応していく。
>256bitとか、そんな無理するくらいなら、
>もうさっさとGPUに統合しろよと言いたくなる。
うんそうだね、amdもぶるどーざで
avxに対応しないで、そうすりゃよかったのにね
ほんとうに速くなるんならね
>もうさっさとGPUに統合しろよと言いたくなる。
うんそうだね、amdもぶるどーざで
avxに対応しないで、そうすりゃよかったのにね
ほんとうに速くなるんならね
Intelはこの後FMA導入とSIMDの512bit化が控えてるわけだが
AMDも512bitに追随するならどんな形になるんだろうね
128bit×4とか?
それとも無難に256bit×2かな?
AMDも512bitに追随するならどんな形になるんだろうね
128bit×4とか?
それとも無難に256bit×2かな?
で、256bit化の一般人に対してのアピールは物理演算だけなの?
まぁPhysX(笑)にはそれで死滅してもらっても全然かまわないが
まぁPhysX(笑)にはそれで死滅してもらっても全然かまわないが
もういい加減後出しの付加機能追加での高性能化は廃れていくんじゃないか?
インテルが新たな規格をつくる度に市場がいちいち対応させられるわけで無駄な徒労が求められている。
いっとき将来にわたって変動の無いインターフェースを策定し、HWの刷新部分はミドルウェアとかに任せれば
苦労減るだろ。
SIMDの高機能化が当面の課題のようだけど、実際のところ演算力だけ見ればCPUに付加されるものよりも
GPUの方が高いんだよな。
ただソフトウェアの対応はさておき向かう先は同様なんだから、CPUだけがこの機構を追求しなくともいいと思う。
インテルが新たな規格をつくる度に市場がいちいち対応させられるわけで無駄な徒労が求められている。
いっとき将来にわたって変動の無いインターフェースを策定し、HWの刷新部分はミドルウェアとかに任せれば
苦労減るだろ。
SIMDの高機能化が当面の課題のようだけど、実際のところ演算力だけ見ればCPUに付加されるものよりも
GPUの方が高いんだよな。
ただソフトウェアの対応はさておき向かう先は同様なんだから、CPUだけがこの機構を追求しなくともいいと思う。
870 :,,・´∀`・,,)っ-○○○:2011/04/14(木) 23:10:36.44 ID:R/6iYv8v
別にAVXをダイレクトに叩きたくなければ既成のライブラリ使えば良いじゃん。
Intelだって提供してるし。ICMLとか。
Intelだって提供してるし。ICMLとか。
871 :,,・´∀`・,,)っ-○○○:2011/04/14(木) 23:19:41.06 ID:R/6iYv8v
正しい略称はIntel MKLか
>>869
流行の命令をドンドン追加して行けるのがCISCの強みだし、いまさら転換する事は無いよ。
現にSandy BridgeではVEXなんて持ち出したし、今後もドンドン追加するよ。
Intel様がAVX持ち出したんだから、Bullも完全に対応してパフォーマンス上げないといけなかった。ビジネス戦略として。
こんなんじゃ、TMPG辺りがAVX対応した途端、ベンチで叩かれまくるのが目に見えてる。
CELLのアプローチが美しいよなぁ。SIMDユニットを大量に載っけて、GPUは固定機能のチップで済ますっていう。
PPEにもっと高性能な物を載せとけば、もう少し流行ったのかなぁ?
流行の命令をドンドン追加して行けるのがCISCの強みだし、いまさら転換する事は無いよ。
現にSandy BridgeではVEXなんて持ち出したし、今後もドンドン追加するよ。
Intel様がAVX持ち出したんだから、Bullも完全に対応してパフォーマンス上げないといけなかった。ビジネス戦略として。
こんなんじゃ、TMPG辺りがAVX対応した途端、ベンチで叩かれまくるのが目に見えてる。
CELLのアプローチが美しいよなぁ。SIMDユニットを大量に載っけて、GPUは固定機能のチップで済ますっていう。
PPEにもっと高性能な物を載せとけば、もう少し流行ったのかなぁ?
高性能がリニアに高数値を出すアーキテクチャなんぞ
Intel様が許すものかよ。
ベンチを曲げて好きに性能を落とせる「自社だけ数値」
仕様こそが流行。
このIntel仕様は既定であり絶対。
例外などあり得ない。利益と性能はIntelの為だけにある。
ユーザなど不要。
連中はただ踊ればいい。
メディアの笛太鼓で。
Intel様が許すものかよ。
ベンチを曲げて好きに性能を落とせる「自社だけ数値」
仕様こそが流行。
このIntel仕様は既定であり絶対。
例外などあり得ない。利益と性能はIntelの為だけにある。
ユーザなど不要。
連中はただ踊ればいい。
メディアの笛太鼓で。
こういうKitty Guyは勢いのある本スレで頑張ってよ
GPUの方が速いのなら今までなんで使われなかったんだろうね
876 :Socket774:2011/04/15(金) 09:34:57.93 ID:Iu82azJv
最上位ですらCPUが速攻ボトルネックになるんだからGPUで誤魔化すしかなくなるよねー
512ビット化よりAVXのスループット上げる方が先だろう。
Core2でSSEが速くなったみたいにね。
Core2でSSEが速くなったみたいにね。
878 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 00:33:48.58 ID:IjG782mV
>>877
Sandy BridgeのAVXは最初から256ビットのSIMDユニットを搭載している。
あとはユニットそのものを増やすとかFMA化くらいしかないと思うが。
実装が命令に追いついてないのってLSUと除算ユニットくらいじゃね?
Intelは今回は最初からソフト開発者に飴を与えることにしたんだよ。
理由は簡単。スループット改善が伴わない256ビット命令を用意したところで
移行が進まないのが目に見えてるから。
IntelはSSEのときは64ビットのFP SIMD命令を用意しなかったので移行がスムーズにいった。
逆にPentium 4におけるSSE2のSIMD整数命令の実装はMMXの64ビットを2回分実行するだけで
旨みが無かったため、ソフトの移行があまり進まなかった。
(Pentium MにいたってはMMXのほうが速い始末)
Sandy BridgeのAVXは最初から256ビットのSIMDユニットを搭載している。
あとはユニットそのものを増やすとかFMA化くらいしかないと思うが。
実装が命令に追いついてないのってLSUと除算ユニットくらいじゃね?
Intelは今回は最初からソフト開発者に飴を与えることにしたんだよ。
理由は簡単。スループット改善が伴わない256ビット命令を用意したところで
移行が進まないのが目に見えてるから。
IntelはSSEのときは64ビットのFP SIMD命令を用意しなかったので移行がスムーズにいった。
逆にPentium 4におけるSSE2のSIMD整数命令の実装はMMXの64ビットを2回分実行するだけで
旨みが無かったため、ソフトの移行があまり進まなかった。
(Pentium MにいたってはMMXのほうが速い始末)
879 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 00:51:23.38 ID:IjG782mV
って言ってしまうと256ビット化されてない整数ではAVXの意味がないように思えてしまうだろうが
3オペランド化によるMOVオペレーションの削減って十分な旨みだぜ
3オペランド化によるMOVオペレーションの削減って十分な旨みだぜ
http://www.geocities.jp/andosprocinfo/wadai11/20110416.htm
> Itaniumベースのサーバの売り上げは,AMDのOpteronベースのサーバの売り上げより多いとの
> ことで,Itaniumの開発はペイしているのかもしれませんが,この発言を聞くと,正常な経営感覚を
> 持ったソフト会社ならItanium向けのソフトの開発に資源を割こうとはしないと思います。
> Itaniumベースのサーバの売り上げは,AMDのOpteronベースのサーバの売り上げより多いとの
> ことで,Itaniumの開発はペイしているのかもしれませんが,この発言を聞くと,正常な経営感覚を
> 持ったソフト会社ならItanium向けのソフトの開発に資源を割こうとはしないと思います。
881 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 17:06:50.06 ID:IjG782mV
逆にいまのOpteronの売上げってItaniumより少なかったのかwwwwww
つーか、安藤さんはCPU作ってた人だからそういう視点になっても仕方ないが
別に中身がItaniumってことを意識して最適化コードを書いてるプログラマは多くないと思うよ。
それこそHP-UXだったりACOS向けに高級言語で書いてるのであって。
つーか、安藤さんはCPU作ってた人だからそういう視点になっても仕方ないが
別に中身がItaniumってことを意識して最適化コードを書いてるプログラマは多くないと思うよ。
それこそHP-UXだったりACOS向けに高級言語で書いてるのであって。
誰も最適化なんて言ってないだろ。
最適化脳の人はこれだから困る。
最適化脳の人はこれだから困る。
高級言語レベルの話なら
CPUの違いを意識して作ってるやつのほうがまれだろ
だったら、opteronだろうがitaniumだろうが関係ないじゃん
CPUの違いを意識して作ってるやつのほうがまれだろ
だったら、opteronだろうがitaniumだろうが関係ないじゃん
Xeon(Westmere-EXのことね)が、Itanium並のRAS機能搭載したから、
ItaniumでもXeonでも、どっちでも好きな方つかえって話であって、
OpteronはRAS機能ではまだまだだから、Itaniumの代替にはなれないよ。
ItaniumでもXeonでも、どっちでも好きな方つかえって話であって、
OpteronはRAS機能ではまだまだだから、Itaniumの代替にはなれないよ。
885 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 17:26:56.83 ID:IjG782mV
そそ、せいぜいバイトオーダの違いくらいだな。Itaniumはバイエンディアンだからどっちでもいけるが
大きい会社だとそういうのも社内ミドルウェアで違いを吸収するようにしてるのが普通。
大きい会社だとそういうのも社内ミドルウェアで違いを吸収するようにしてるのが普通。
なんか動作確認もしないでIA64版リリースできるし、サポートしてもカネかかんねーよ。
みたいなバカがおおいのな。そんな互換性楽勝ならx86がここまで市場支配してないぞ。現実味ない。
みたいなバカがおおいのな。そんな互換性楽勝ならx86がここまで市場支配してないぞ。現実味ない。
888 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 17:57:09.64 ID:IjG782mV
まあそうだけどさ。
コンソーシアムから企業が続々撤退してるからIntelとて事業継続するのは厳しい。
今後はパイは広がらないどころか小さくなるから新規にやろうという企業は皆無だろうが
今までやってきた大手ベンダー系ソフトハウス屋が急に撤退するなんてことも現実にはない。
(WindowsやRHELがなくなるからオープン屋はまず手を出さなくなるだろうが)
コンソーシアムから企業が続々撤退してるからIntelとて事業継続するのは厳しい。
今後はパイは広がらないどころか小さくなるから新規にやろうという企業は皆無だろうが
今までやってきた大手ベンダー系ソフトハウス屋が急に撤退するなんてことも現実にはない。
(WindowsやRHELがなくなるからオープン屋はまず手を出さなくなるだろうが)
889 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 18:02:43.52 ID:IjG782mV
> んな互換性楽勝ならx86がここまで市場支配してないぞ。
これはむしろ逆だな。コードの互換性が問題になるならそもそもx86はRISCサーバ&WS市場を奪えてないわけで。
x86がサーバ市場を支配できたのはPCベースのオープンハード仕様による価格の安さだよ。
そしてItaniumも高度なRAS機能を持ちながらハイエンドRISCベースのシステムより一桁は安い。
これはむしろ逆だな。コードの互換性が問題になるならそもそもx86はRISCサーバ&WS市場を奪えてないわけで。
x86がサーバ市場を支配できたのはPCベースのオープンハード仕様による価格の安さだよ。
そしてItaniumも高度なRAS機能を持ちながらハイエンドRISCベースのシステムより一桁は安い。
まあそれはそうだな。
x86の普及の原因は圧倒的なコストパフォーマンスだから。
コード資産の既得権益説は実は最近あまり信用してない。
x86の普及の原因は圧倒的なコストパフォーマンスだから。
コード資産の既得権益説は実は最近あまり信用してない。
ちょっと前まで
「Atomの優位性は普及しまくってるx86であること
ARMなんて問題にならない(キリッ」
みたいなこと言ってた人が居た気がするけど誰だっけ
「Atomの優位性は普及しまくってるx86であること
ARMなんて問題にならない(キリッ」
みたいなこと言ってた人が居た気がするけど誰だっけ
Itaniumの開発リソースを
極秘プロジェクトでIntel版○R○に回す可能性すらあると思うよ。
Atomうまくいってないしね。
極秘プロジェクトでIntel版○R○に回す可能性すらあると思うよ。
Atomうまくいってないしね。
893 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 18:19:22.62 ID:IjG782mV
>>891
え?ARMには64ビットプロセッサあったっけ?
ARMの省電力の拠り所はメモリやI/Oの帯域をケチってることにある。
PCに匹敵する性能を出そうと思えばその時点でご自慢の電力効率は破綻する。
だからARMはキャッシュ内に収まるベンチマークでは強いがメモリアクセスが多いベンチマークでは
パフォーマンスが劇的に落ちる。
ついでに言うとARMにはオープンな共通ハード規格なんてないよ。
だからベンダー独自の機能をつけてぼったくりやすい。
そしてiPadみたいな原価の数倍の価格付けて売るハードが蔓延する。
今のところサーバ向けのARMは売り込みに失敗している。根本的に性能不足だからな。
ARMは64ビット化の計画すらまだ具体化してないし他を揺るがすだけの影響力も無いだろう。
x86の命令フォーマットは64ビットにおいてはRISCよりコード密度および性能で他のRISCと比べても圧倒的に有利だ。
なぜなら32ビットや64ビットの即値をコード上にそのままとれるから。
16ビットないし32ビット固定の語長じゃこうはできない。
ARMもコード効率を上げるには可変長方式をとる必要があるだろうが、デコーダがシンプルにできる
だのの世迷言は捨て去る必要が出来る(Thumb2とか採用した時点で既に可変長なんだが)
え?ARMには64ビットプロセッサあったっけ?
ARMの省電力の拠り所はメモリやI/Oの帯域をケチってることにある。
PCに匹敵する性能を出そうと思えばその時点でご自慢の電力効率は破綻する。
だからARMはキャッシュ内に収まるベンチマークでは強いがメモリアクセスが多いベンチマークでは
パフォーマンスが劇的に落ちる。
ついでに言うとARMにはオープンな共通ハード規格なんてないよ。
だからベンダー独自の機能をつけてぼったくりやすい。
そしてiPadみたいな原価の数倍の価格付けて売るハードが蔓延する。
今のところサーバ向けのARMは売り込みに失敗している。根本的に性能不足だからな。
ARMは64ビット化の計画すらまだ具体化してないし他を揺るがすだけの影響力も無いだろう。
x86の命令フォーマットは64ビットにおいてはRISCよりコード密度および性能で他のRISCと比べても圧倒的に有利だ。
なぜなら32ビットや64ビットの即値をコード上にそのままとれるから。
16ビットないし32ビット固定の語長じゃこうはできない。
ARMもコード効率を上げるには可変長方式をとる必要があるだろうが、デコーダがシンプルにできる
だのの世迷言は捨て去る必要が出来る(Thumb2とか採用した時点で既に可変長なんだが)
なんでこんなに必死…
Atomのメインターゲットってサーバなのか
携帯みたいな分野でARMと勝負するつもりだと思ってたんだが
Atomのメインターゲットってサーバなのか
携帯みたいな分野でARMと勝負するつもりだと思ってたんだが
895 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 18:38:12.41 ID:IjG782mV
> Atomのメインターゲットってサーバなのか
ARMがx86市場を食おうとしてるのはまず省電力サーバからなんだが。
ウェハ単価が高騰を続けてるので薄利多売で維持するのは厳しいから
高単価で売れる市場を探してるんだよ。
で、それを迎え撃つ弾はAtomが適任と。MSも待望している。
Atomは当初は高密度サーバ向けのメニーコアプロセッサとして開発されてるから、
サーバ向けがターゲットになるのは当然の流れだと思うけどね。
Intelは今更ARMを自力開発するくらいならMarvellからXScale買い戻す、というより
会社ごと買うと思うけどな。
そもそもIntelの市場拡大路線は高騰するプロセス開発費の捻出を独力で維持するためってのが
根底にあるのでそれさえ達成できれば別にx86にこだわる必要はない。
独占的な契約を結んでFab屋をはじめるのも手だ。
ARMがx86市場を食おうとしてるのはまず省電力サーバからなんだが。
ウェハ単価が高騰を続けてるので薄利多売で維持するのは厳しいから
高単価で売れる市場を探してるんだよ。
で、それを迎え撃つ弾はAtomが適任と。MSも待望している。
Atomは当初は高密度サーバ向けのメニーコアプロセッサとして開発されてるから、
サーバ向けがターゲットになるのは当然の流れだと思うけどね。
Intelは今更ARMを自力開発するくらいならMarvellからXScale買い戻す、というより
会社ごと買うと思うけどな。
そもそもIntelの市場拡大路線は高騰するプロセス開発費の捻出を独力で維持するためってのが
根底にあるのでそれさえ達成できれば別にx86にこだわる必要はない。
独占的な契約を結んでFab屋をはじめるのも手だ。
ネットブック、ネットワーク家電、組込機器のARMシェアを奪うのが目的だろ?
64bitなんて、必要あんの?
64bitなんて、必要あんの?
>>884
XeonってCPUのホットスワップできるようになったの?
XeonってCPUのホットスワップできるようになったの?
ARM社自体は何の発表もして無いが、他のメーカーの64bit-ARMの搭載予定とかを見ると製品の登場時期は2015年辺りだろう
ARMがサーバーに適するかどうかは知らないが、今企業のサーバーは軽量CPUマシンを束ねた物理サーバーへの移行が始まっている
※その方が記憶装置の接続数を稼げるから
その点ではARMも選択肢になりうるかもしれない
尚、製品において半導体部品が占める比率の上限は30%と言われ、近年はこのラインにかなり近づいていた
ARMが売れるのはやはり低価格という点が大きいだろう
ARMがサーバーに適するかどうかは知らないが、今企業のサーバーは軽量CPUマシンを束ねた物理サーバーへの移行が始まっている
※その方が記憶装置の接続数を稼げるから
その点ではARMも選択肢になりうるかもしれない
尚、製品において半導体部品が占める比率の上限は30%と言われ、近年はこのラインにかなり近づいていた
ARMが売れるのはやはり低価格という点が大きいだろう
899 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 20:42:48.64 ID:IjG782mV
>>896
ARM搭載機器のハイエンドはメインメモリ1GBくらいに到達しているし
32ビットじゃ足りなくなるのも時間の問題。
いずれにせよ長期的な計画だから短期の利益だけを期待する人にはAtomは面白くないかもな。
ARM搭載機器のハイエンドはメインメモリ1GBくらいに到達しているし
32ビットじゃ足りなくなるのも時間の問題。
いずれにせよ長期的な計画だから短期の利益だけを期待する人にはAtomは面白くないかもな。
ちなみに米国の最新鋭戦闘機でもPowerPC300Mhzとか
高性能の代名詞のイージス艦とかでも今じゃ中身は普通のPC+Linuxに置き換わってる
なのでARMで性能が不足する分野は極めて限られる
高性能の代名詞のイージス艦とかでも今じゃ中身は普通のPC+Linuxに置き換わってる
なのでARMで性能が不足する分野は極めて限られる
901 :,,・´∀`・,,)っ-○○○:2011/04/16(土) 21:25:58.79 ID:IjG782mV
軍事向けなんて昔から枯れたCPUを使ってる典型例出して何がいいたいの?
少し前までMS-DOS使ってたよ。
少し前までMS-DOS使ってたよ。
ようやくゼッパチも引退か・・・・
>>902
つ パチンコ主基板
つ パチンコ主基板
627 名前:,,・´∀`・,,)っ-○○○[sage] 投稿日:2011/04/19(火) 08:07:16.41 ID:84xmPIAP (9回)
> 1つの演算器で複数同時に演算出来るのがアウトオブオーダ
こんなことを真顔で言っちゃうバカに人間としての常識を求めるほうが間違いでしょう
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
自分の事を棚に上げて常識を語るクソコテ
> 1つの演算器で複数同時に演算出来るのがアウトオブオーダ
こんなことを真顔で言っちゃうバカに人間としての常識を求めるほうが間違いでしょう
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
自分の事を棚に上げて常識を語るクソコテ
amd信者は馬鹿ばかりな
>アム厨は馬鹿
そんな分かりきった事を今さら言われてもねぇ
そんな分かりきった事を今さら言われてもねぇ
CPUはインテルしか買わないくてVGAはラデしか買わない俺は普通
いつ頃Atom様はスマートフォンに載るんだい?
タブレットやネットブックじゃZacateに勝てないのにいつまでチンタラ足踏みしてるんだ
Itaniumはもうオワコン寸前だし、Larrabeeはリネームしたけど実用化の目処が全く立ってない
MICはそもそも方向性や目的が良く解らん
GPUはウンコだし、チップセットは大したことない
Intel様はもう、Nehalem系のCoreをシュリンクして小改良していくだけの簡単なお仕事しかまともに出来ないんだな
タブレットやネットブックじゃZacateに勝てないのにいつまでチンタラ足踏みしてるんだ
Itaniumはもうオワコン寸前だし、Larrabeeはリネームしたけど実用化の目処が全く立ってない
MICはそもそも方向性や目的が良く解らん
GPUはウンコだし、チップセットは大したことない
Intel様はもう、Nehalem系のCoreをシュリンクして小改良していくだけの簡単なお仕事しかまともに出来ないんだな
オートンの居なくなったATIチームはR600を増量してく簡単なお仕事しかまともに出来ないんだな
SP削っても爆熱大喰いが改善されないGTX550Tiをディスってんの?
>>908
今のインテルを的確に言い表しててワロタ
今のインテルを的確に言い表しててワロタ
Radeonは保守的なアーキテクチャだからこそいいんだよ
今のGPUはやっぱりグラフィックの描画性能高いのが一番なわけで、GPGPUとか特定の用途に特化したらFermiとかLarrabeeみたいになっちまう
今のGPUはやっぱりグラフィックの描画性能高いのが一番なわけで、GPGPUとか特定の用途に特化したらFermiとかLarrabeeみたいになっちまう
AMDだけ取り残されていまだにVLIW
VLIWなGPUが使えるのはamdだけ
nv,intel,viaはvliwではない
amdだけGSがくそ遅い
VLIWなGPUが使えるのはamdだけ
nv,intel,viaはvliwではない
amdだけGSがくそ遅い
914 :,,・´∀`・,,)っ-○○○:2011/04/21(木) 23:24:43.93 ID:qKWRRYN2
K10をシュリンクするだけの簡単なお仕事
すらIntelの1年半遅れでやってるAMD(笑)
すらIntelの1年半遅れでやってるAMD(笑)
>MICはそもそも方向性や目的が良く解らん
ブルドーザは何をしたいのかよくわからない
ブルドーザは何をしたいのかよくわからない
消防が好きそうな乗り物の名前からパクった例のアレはマダー?(・∀・)
販売まで2ヶ月切ったのにどしたの(笑)
販売まで2ヶ月切ったのにどしたの(笑)
917 :,,・´∀`・,,)っ-○○○:2011/04/21(木) 23:59:36.05 ID:qKWRRYN2
Vision Black FXだったっけ
視界の見えない外貨先物取引
視界の見えない外貨先物取引
>>909
HD6xxxからはなぜか減量に向かっているが
HD6xxxからはなぜか減量に向かっているが
言い方が悪かったかな?
Intelはバックアッププランが全部死んでメインプランのNehalemだけを小改良することしかできないってことなんだが
Larrabeeが遅れまくりで512bit SIMD対応も白紙になりそう
AMDはK10はLlanoで終わってパフォーマンス系はBulldozerにシフトするし、省電力系はBobcatに切り替わる
RADEONもDX!!世代ではゲフォを圧倒してるし、4way VLIWになって扱いやすくなった
要は巨大コアCPU1個だけのIntelと、大小2個のCPU+GPUコアの組み合わせのAMDでの競争になる
Intelはバックアッププランが全部死んでメインプランのNehalemだけを小改良することしかできないってことなんだが
Larrabeeが遅れまくりで512bit SIMD対応も白紙になりそう
AMDはK10はLlanoで終わってパフォーマンス系はBulldozerにシフトするし、省電力系はBobcatに切り替わる
RADEONもDX!!世代ではゲフォを圧倒してるし、4way VLIWになって扱いやすくなった
要は巨大コアCPU1個だけのIntelと、大小2個のCPU+GPUコアの組み合わせのAMDでの競争になる
>RADEONもDX!!世代ではゲフォを圧倒してるし、4way VLIWになって扱いやすくなった
そう思ってるのはAMD信者だけ
Caymanは明らかに失敗作
cypressに対して20%のスレッドと固定機能増量したはずなのに
あのありさま
>Intelはバックアッププランが全部死んでメインプランのNehalemだけを小改良することしかできないってことなんだが
AMDのことじゃん
そう思ってるのはAMD信者だけ
Caymanは明らかに失敗作
cypressに対して20%のスレッドと固定機能増量したはずなのに
あのありさま
>Intelはバックアッププランが全部死んでメインプランのNehalemだけを小改良することしかできないってことなんだが
AMDのことじゃん
Caymanのどこが失敗作なんだ?
クロック上げすぎでリーク電流の影響受けたHD6970でさえ、GeForceと比較すりゃワットパフォーマンス悪くない
HD6950はワットパフォーマンスで全GPU中でもトップだ
Caymanは明らかに失敗作だと思ってるのはnvidia信者だけだな
クロック上げすぎでリーク電流の影響受けたHD6970でさえ、GeForceと比較すりゃワットパフォーマンス悪くない
HD6950はワットパフォーマンスで全GPU中でもトップだ
Caymanは明らかに失敗作だと思ってるのはnvidia信者だけだな
922 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 06:16:44.91 ID:o5GMnakW
AMDはメインプランのK9が死んでバックアッププランのK8のマルチコア化・小改良しかできなかった。
更にBulldozerのSSE5というメインプランも死んでAVX対応のために2年も投入を遅らせている。
事実上「Intel 64」がx86命令セットの主導権を握っておりAMDは後追いしか出来ない状況。
更にBulldozerのSSE5というメインプランも死んでAVX対応のために2年も投入を遅らせている。
事実上「Intel 64」がx86命令セットの主導権を握っておりAMDは後追いしか出来ない状況。
923 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 06:30:56.99 ID:o5GMnakW
ちなみにLarrabeeのABI(L1OM)は64bit専用だ。
AVXは32ビットでも64ビットでも使えるようになってるし当分先まで32ビットコードは延命される。
したがってLRBniをCPUコアに統合、あるいはMICコプロセッサをGPUシェーダとしてダイに混載
なんて話になるのは、32ビットが十分レガシーになった後の話だろうな。
2015年とか2016年に統合なんてゴシップ記者の飛ばしでIntelは最初から何のコメントもしていない。
AVXは32ビットでも64ビットでも使えるようになってるし当分先まで32ビットコードは延命される。
したがってLRBniをCPUコアに統合、あるいはMICコプロセッサをGPUシェーダとしてダイに混載
なんて話になるのは、32ビットが十分レガシーになった後の話だろうな。
2015年とか2016年に統合なんてゴシップ記者の飛ばしでIntelは最初から何のコメントもしていない。
P/wってのは絶対的な消費電力のことではないんだよ
かりにcaymanのp/wが優秀であるならば
なぜその派生版がまったく出ないのか?
それは失敗作だから
かりにcaymanのp/wが優秀であるならば
なぜその派生版がまったく出ないのか?
それは失敗作だから
627 名前:,,・´∀`・,,)っ-○○○[sage] 投稿日:2011/04/19(火) 08:07:16.41 ID:84xmPIAP (9回)
> 1つの演算器で複数同時に演算出来るのがアウトオブオーダ
こんなことを真顔で言っちゃうバカに人間としての常識を求めるほうが間違いでしょう
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
自分の事を棚に上げて常識を語るクソコテ
> 1つの演算器で複数同時に演算出来るのがアウトオブオーダ
こんなことを真顔で言っちゃうバカに人間としての常識を求めるほうが間違いでしょう
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
861 名前:,,・´∀`・,,)<一番良い -○○○ を頼む[sage] 投稿日:2011/04/05(火) 21:58:41.63 ID:ERbCKnad
多数の日本人の死体の上に築かれるAMDのシェア
自分の事を棚に上げて常識を語るクソコテ
>>924
言っている意味が分からないが
まぁ今のGeForceが失敗作なのは確かだから、それと同レベルのワットパフォーマンスになってるというのはあまりよろしくないかもね
ミドル以下はGeForceにボロ勝ちできてるから、わざわざ時間をかけてCaymanの下位モデルを作る必要もないんだろうな
言っている意味が分からないが
まぁ今のGeForceが失敗作なのは確かだから、それと同レベルのワットパフォーマンスになってるというのはあまりよろしくないかもね
ミドル以下はGeForceにボロ勝ちできてるから、わざわざ時間をかけてCaymanの下位モデルを作る必要もないんだろうな
Intelのバックアッププランって何?
Larrabeeはメニーコアでの小型コア担当で、NehalemやSandyBridgeを置き換えるものじゃないし、
Larrabeeはぽしゃったけど、この小型コアの計画自体はまだ生きているんだけど。
それに、Larrabeeこける前のCore2のときから、IntelはCore2への最適化は6年無駄にならないって
言ってるんだから、IvyBridgeまでCoreMA改良なのは既定路線じゃあ?
Larrabeeはメニーコアでの小型コア担当で、NehalemやSandyBridgeを置き換えるものじゃないし、
Larrabeeはぽしゃったけど、この小型コアの計画自体はまだ生きているんだけど。
それに、Larrabeeこける前のCore2のときから、IntelはCore2への最適化は6年無駄にならないって
言ってるんだから、IvyBridgeまでCoreMA改良なのは既定路線じゃあ?
>>924
>なぜその派生版がまったく出ないのか?
>それは失敗作だから(キリッ
ただたんに「つなぎ」だからだよ負け犬君
TSMCのプロセス更新1個飛ばしのせいで、シュリンクしないまま出さざるを
えなかっただけのこと。
今年後半にシュリンクした本命が出るから、今頃Caymanの派生とか時間の無駄w
下位はBobcat、Llanoの内蔵GPUでIntelどころかnVidiaも追従できてない
>なぜその派生版がまったく出ないのか?
>それは失敗作だから(キリッ
ただたんに「つなぎ」だからだよ負け犬君
TSMCのプロセス更新1個飛ばしのせいで、シュリンクしないまま出さざるを
えなかっただけのこと。
今年後半にシュリンクした本命が出るから、今頃Caymanの派生とか時間の無駄w
下位はBobcat、Llanoの内蔵GPUでIntelどころかnVidiaも追従できてない
HD7000は全部Cayman系なんだがw
Caymanが失敗とかどこの情弱さんですか?
次にゲフォ厨はこう云うだろう
「だったら28nmのHD7000も失敗作だなw」と
Caymanが失敗とかどこの情弱さんですか?
次にゲフォ厨はこう云うだろう
「だったら28nmのHD7000も失敗作だなw」と
>>927
IvyどころかHaswellやRockwellも派生系の小改良に過ぎないんだが
本当はその世代でLarrabee統合して512bit SIMDスゲーってなるはずだった
今じゃ当のInntelですら諦めかけてるけど
要はLarrabeeこそが次世代の要でAVXのバックアッププランなんだよ
IvyどころかHaswellやRockwellも派生系の小改良に過ぎないんだが
本当はその世代でLarrabee統合して512bit SIMDスゲーってなるはずだった
今じゃ当のInntelですら諦めかけてるけど
要はLarrabeeこそが次世代の要でAVXのバックアッププランなんだよ
931 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 09:37:51.24 ID:o5GMnakW
>>930
まさにお前の脳内ではな、だな
512~1024ビット版のAVXは別にありますよ。
そもそもLarrabeeのSIMD命令はVEXフォーマットじゃないしSIMDレジスタも16本じゃなくて32本だ。
まさにお前の脳内ではな、だな
512~1024ビット版のAVXは別にありますよ。
そもそもLarrabeeのSIMD命令はVEXフォーマットじゃないしSIMDレジスタも16本じゃなくて32本だ。
バックアッププランって普通、メインの予定が崩れたから出てくるんじゃないの?
>>930の言ってることだとLarrabee統合がメインプランで、それが崩れたから、
HaswellがSandy改良+普通のGPU統合のバックアッププランになったの方が
意味が通じるんだけど。
>>930の言ってることだとLarrabee統合がメインプランで、それが崩れたから、
HaswellがSandy改良+普通のGPU統合のバックアッププランになったの方が
意味が通じるんだけど。
933 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 09:42:12.92 ID:o5GMnakW
コプロとしてダイ上に併設するってのとCPUコア組み込みのSIMD機能として追加するってのは
全く意味が違うんだが。支離滅裂にも程がある。
全く意味が違うんだが。支離滅裂にも程がある。
淫虫はコプロを否定してたよねw
ビデオカード(笑)の話はスレチですよ
>淫虫はコプロを否定してたよねw
AMDのVLIWじゃコプロに成りえないじゃん遅すぎて
同規模でスレッド数20%あがるはずのcaymanがcypressにf@hで負けるのはどういうことなんだろうね
shaderは単に簡略化してTMUの数を増やしただけで終わったのがcayman
AMDのVLIWじゃコプロに成りえないじゃん遅すぎて
同規模でスレッド数20%あがるはずのcaymanがcypressにf@hで負けるのはどういうことなんだろうね
shaderは単に簡略化してTMUの数を増やしただけで終わったのがcayman
AMDのAPUも今のところCPUとGPUを1チップにしましたってだけだからな。
GPGPUの活用はユーザーが各自努力してくださいだし。
その先は、青写真もあるか怪しい状態だけど。
GPGPUの活用はユーザーが各自努力してくださいだし。
その先は、青写真もあるか怪しい状態だけど。
caymanは32nmがキャンセルされた影響で、5xxxをベースに、32nmで予定していた機能の一部
を載せたものだから、イマイチなのは仕方が無いだろう
28nmが出る前にソフトメーカーにVLIEW4に馴染んでもらうための布石といったところか
ちなみにGPGPUをコプロとして使って速度が出ないのは当然だ
PCにおけるGPGPUはGPUが使われて無いときに遊んでいるリソースを回収するためのもの
HPCにおけるGPGPUはまた別だが
を載せたものだから、イマイチなのは仕方が無いだろう
28nmが出る前にソフトメーカーにVLIEW4に馴染んでもらうための布石といったところか
ちなみにGPGPUをコプロとして使って速度が出ないのは当然だ
PCにおけるGPGPUはGPUが使われて無いときに遊んでいるリソースを回収するためのもの
HPCにおけるGPGPUはまた別だが
単にドライバの成熟度の違いだな
SP構成を弄って既存のアプリが影響受けないわけがない
今の段階でもGPGPUアプリじゃCypress比で下がってるのもあれば上がってるのもある
SP構成を弄って既存のアプリが影響受けないわけがない
今の段階でもGPGPUアプリじゃCypress比で下がってるのもあれば上がってるのもある
SSEやAVXの経験あるからRadeonのSIMD化は可能だろ
単に回路の簡略化のためVLIW>SIMDって判断してるだけ
そういえば団子って以前Larrabeeの512bit SIMDがAVXの次世代って息巻いて絶賛してたよな
いつの間にAVXの512bitや1024bitなんてものに宗旨替えしたんだ?
そもそもそれがホントならLarrabee統合に意味は全く無いだろ
単に回路の簡略化のためVLIW>SIMDって判断してるだけ
そういえば団子って以前Larrabeeの512bit SIMDがAVXの次世代って息巻いて絶賛してたよな
いつの間にAVXの512bitや1024bitなんてものに宗旨替えしたんだ?
そもそもそれがホントならLarrabee統合に意味は全く無いだろ
RadeonをSIMD化するってどういう意味?
たとえばVLIW4を128bitSIMDにするとか?
たとえばVLIW4を128bitSIMDにするとか?
サーバー向けはともかく
一般向けにsimdコプロは不要
アクセラレータがあればよい
一般向けにsimdコプロは不要
アクセラレータがあればよい
>単に回路の簡略化のためVLIW>SIMDって判断してるだけ
その分リアルタイムでコンパイルしVLIWを発行する負荷がCPUに増える
その分リアルタイムでコンパイルしVLIWを発行する負荷がCPUに増える
>>942
そんな感じ
ただし制御回路とかくっつける必要があるから回路規模というかダイサイズが倍位になる
ゲフォは倍速化使ってサイズを半分にしてるから小さい(大きいけどな)
VLIWだからデコードやスケジューリングをCPUが受け持ってるけど、
CPUとGPU、メインメモリとGPUメモリが物理的に離れていてレイテンシが大きいし、
転送速度も遅くて効率が非常に悪い
そんな感じ
ただし制御回路とかくっつける必要があるから回路規模というかダイサイズが倍位になる
ゲフォは倍速化使ってサイズを半分にしてるから小さい(大きいけどな)
VLIWだからデコードやスケジューリングをCPUが受け持ってるけど、
CPUとGPU、メインメモリとGPUメモリが物理的に離れていてレイテンシが大きいし、
転送速度も遅くて効率が非常に悪い
946 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 19:14:27.47 ID:o5GMnakW
> そういえば団子って以前Larrabeeの512bit SIMDがAVXの次世代って息巻いて絶賛してたよな
それ言ったのは後藤だっつーのw
> いつの間にAVXの512bitや1024bitなんてものに宗旨替えしたんだ?
もちろんIntelがAVXと別物と言った時点で
> そもそもそれがホントならLarrabee統合に意味は全く無いだろ
逆に言えば統合しなくともCPUコアのSIMD拡張計画には全く支障は無いということね。
CPUコアにSIMD機能を統合するのか単にダイ上にコアを載せるのか
お前の想定してるのはどっちだよ。話が進んでるとすれば後者のほうだ。
それ言ったのは後藤だっつーのw
> いつの間にAVXの512bitや1024bitなんてものに宗旨替えしたんだ?
もちろんIntelがAVXと別物と言った時点で
> そもそもそれがホントならLarrabee統合に意味は全く無いだろ
逆に言えば統合しなくともCPUコアのSIMD拡張計画には全く支障は無いということね。
CPUコアにSIMD機能を統合するのか単にダイ上にコアを載せるのか
お前の想定してるのはどっちだよ。話が進んでるとすれば後者のほうだ。
947 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 19:23:52.27 ID:o5GMnakW
IntelがSIMD拡張を率先してやるとAMDのファンボーイがそれを貶す
でもAMDはIntelについていく。
そのパターンの繰り返しいい加減飽きたよ
でもAMDはIntelについていく。
そのパターンの繰り返しいい加減飽きたよ
>>946
> > そういえば団子って以前Larrabeeの512bit SIMDがAVXの次世代って息巻いて絶賛してたよな
> それ言ったのは後藤だっつーのw
ほうほう
271 名前:,,・´∀`・,,)っ[sage] 投稿日:2008/08/22(金) 03:46:06 ID:6R6YXCRn
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
Ctについては>>182あたりに書いたことがドンピシャ。
Larrabee新命令はどうやら既存命令とはOpcode食い合わないらしい
(=512ビット版AVXそのものの先行実装の可能性大)
Larrabeeの位置づけといい、俺どれだけエスパーだよ
あまりに予想が当たりすぎててもう笑うしかねー
639 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/10/29(水) 08:00:59 ID:PL3EJ2gj [2/2]
(略)
ごめんね、実はAVXまでは既に対応出来てるんだ
Larrabeeはこれを512ビットに引き延ばすだけでいけると思うんだ
868 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/11/21(金) 01:36:03 ID:IoVgtMoH [1/2]
AVXに関しては、整数512-bit/浮動小数1024-bitまでの拡張計画打ち出してるから
まさに512-bit/1024-bitがLarrabeeのそれなんじゃないの?
(略)
> > そういえば団子って以前Larrabeeの512bit SIMDがAVXの次世代って息巻いて絶賛してたよな
> それ言ったのは後藤だっつーのw
ほうほう
271 名前:,,・´∀`・,,)っ[sage] 投稿日:2008/08/22(金) 03:46:06 ID:6R6YXCRn
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
Ctについては>>182あたりに書いたことがドンピシャ。
Larrabee新命令はどうやら既存命令とはOpcode食い合わないらしい
(=512ビット版AVXそのものの先行実装の可能性大)
Larrabeeの位置づけといい、俺どれだけエスパーだよ
あまりに予想が当たりすぎててもう笑うしかねー
639 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/10/29(水) 08:00:59 ID:PL3EJ2gj [2/2]
(略)
ごめんね、実はAVXまでは既に対応出来てるんだ
Larrabeeはこれを512ビットに引き延ばすだけでいけると思うんだ
868 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/11/21(金) 01:36:03 ID:IoVgtMoH [1/2]
AVXに関しては、整数512-bit/浮動小数1024-bitまでの拡張計画打ち出してるから
まさに512-bit/1024-bitがLarrabeeのそれなんじゃないの?
(略)
こんなんもあったわ
どう見ても息巻いて……なんでもないよ
170 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/10/15(水) 00:08:21 ID:ucUcLpmM [1/15]
>>169
継承するコード資産は高級言語でいいじゃん。最適化なんてIntelコンパイラに任せておけよ。
Cellが何が駄目って、2005年の電撃的な発表以来、未だにIBM謹製のXL C/C++が「開発版」なんだぜ。
その意味じゃIntelは使い古したアーキテクチャの拡張故に地に足がついてる。
ちなみにLarrabeeはIntelの将来のCPUで搭載される命令を先行実装してるって言う意味では
過去の資産よりは「未来への資産」を重視してる。
AVXの更に先の世代ではLarrabeeのSIMD拡張は普通のCPUに搭載されることになる。
(略)
どう見ても息巻いて……なんでもないよ
170 名前:,,・´∀`・,,)っ-○◎●[sage] 投稿日:2008/10/15(水) 00:08:21 ID:ucUcLpmM [1/15]
>>169
継承するコード資産は高級言語でいいじゃん。最適化なんてIntelコンパイラに任せておけよ。
Cellが何が駄目って、2005年の電撃的な発表以来、未だにIBM謹製のXL C/C++が「開発版」なんだぜ。
その意味じゃIntelは使い古したアーキテクチャの拡張故に地に足がついてる。
ちなみにLarrabeeはIntelの将来のCPUで搭載される命令を先行実装してるって言う意味では
過去の資産よりは「未来への資産」を重視してる。
AVXの更に先の世代ではLarrabeeのSIMD拡張は普通のCPUに搭載されることになる。
(略)
LNIの仕様が出る前、出た後で変わったんじゃないの?
一時期、サイトの方でLNIをVEXフォーマットで表現できないか考察してたと思うけど。
一時期、サイトの方でLNIをVEXフォーマットで表現できないか考察してたと思うけど。
951 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 21:23:35.03 ID:o5GMnakW
>>950
まあそういうことだな
64ビット専用だからVEXに押し込む必要ないからねぇ。
たとえば回収されたBCD命令のOpcodeをリードバイトに使っても収まる。
VEXじゃ32本(5ビット)のSIMDレジスタ×3オペランド+マスク(3ビット)を表現するのは
難しい。できなくはないけど、mmmmmの予約空間が半分近く使われる。
VEXの寿命縮めてまでLarrabee独自命令を押し込む必要は無い。
AVXの命令のほとんどはRISCに倣ってに1命令1サイクルで実行できる
(今はできないものもあるが将来的にはできる)ようにデザインされてるが、
LRBniはCISC的に何サイクルもかけるものが多いし、単純な積和算にせよ1サイクルのスループットで
完結させようと思えば従来CPUのような高クロック化は難しい。
命令フォーマットの設計思想が全く違う。
まあそういうことだな
64ビット専用だからVEXに押し込む必要ないからねぇ。
たとえば回収されたBCD命令のOpcodeをリードバイトに使っても収まる。
VEXじゃ32本(5ビット)のSIMDレジスタ×3オペランド+マスク(3ビット)を表現するのは
難しい。できなくはないけど、mmmmmの予約空間が半分近く使われる。
VEXの寿命縮めてまでLarrabee独自命令を押し込む必要は無い。
AVXの命令のほとんどはRISCに倣ってに1命令1サイクルで実行できる
(今はできないものもあるが将来的にはできる)ようにデザインされてるが、
LRBniはCISC的に何サイクルもかけるものが多いし、単純な積和算にせよ1サイクルのスループットで
完結させようと思えば従来CPUのような高クロック化は難しい。
命令フォーマットの設計思想が全く違う。
952 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 21:42:46.48 ID:o5GMnakW
参考までに、LRBniからは8/16ビット整数オペレーションが省かれてるので
これをそのまんまSSE/AVXのポストに据え置くのは難しいわな。
もしCPUコアにLRBniを組み込むとして512ビットAVXとLRBniの2系統の命令を同時に
サポートするということになるんじゃね?
それは単純にLRB側のコードをそのままCPUで動くようにするためだな。
フォーマットが複雑すぎるのでmicrocodeデコードになるだろうが、Sandy Bridgeで追加された
μOPs cacheがあるのでループする処理に関しては性能の問題は軽減されるかも。
これをそのまんまSSE/AVXのポストに据え置くのは難しいわな。
もしCPUコアにLRBniを組み込むとして512ビットAVXとLRBniの2系統の命令を同時に
サポートするということになるんじゃね?
それは単純にLRB側のコードをそのままCPUで動くようにするためだな。
フォーマットが複雑すぎるのでmicrocodeデコードになるだろうが、Sandy Bridgeで追加された
μOPs cacheがあるのでループする処理に関しては性能の問題は軽減されるかも。
>microcodeデコード
これ何?
これ何?
954 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 22:46:28.56 ID:o5GMnakW
x86の1命令と内部μOP(s)が1~2つで対応してる場合は、ハードワイヤードロジックで実装された
Simple Decoderでの対応になる。モダンなx86が1クロック3~4命令同時デコードできるってのは
Simple Decoderで処理できるものだけ。
複雑な命令は、Complex Decoderのmicrocode ROMテーブルから対応する複数のオペレーションを
引っ張ってきて複数サイクルかけて吐き出すような動作になる。
んでもってμOPs cacheにヒットしてればこの遅いDecoderでの処理を飛ばすことができるので
パイプラインを乱さずに処理することができる。Sandy Bridgeの速さの理由のひとつだね。
じゃあトレースキャッシュNetBurstだってもっと速くてもよかったじゃないかというと、
それもそうなんだが、処理可能なオペレーションが単純すぎて、それほど複雑でも無い普通の
命令までもμOPs数そのものが増えて結果的に遅かった。
Simple Decoderでの対応になる。モダンなx86が1クロック3~4命令同時デコードできるってのは
Simple Decoderで処理できるものだけ。
複雑な命令は、Complex Decoderのmicrocode ROMテーブルから対応する複数のオペレーションを
引っ張ってきて複数サイクルかけて吐き出すような動作になる。
んでもってμOPs cacheにヒットしてればこの遅いDecoderでの処理を飛ばすことができるので
パイプラインを乱さずに処理することができる。Sandy Bridgeの速さの理由のひとつだね。
じゃあトレースキャッシュNetBurstだってもっと速くてもよかったじゃないかというと、
それもそうなんだが、処理可能なオペレーションが単純すぎて、それほど複雑でも無い普通の
命令までもμOPs数そのものが増えて結果的に遅かった。
それは
複数のμOPに分解される命令の話で
複雑なフォーマットの命令の話ではないよな
複数のμOPに分解される命令=複雑なフォーマットの命令
なのか?
複数のμOPに分解される命令の話で
複雑なフォーマットの命令の話ではないよな
複数のμOPに分解される命令=複雑なフォーマットの命令
なのか?
via cpuのx87命令の大半みたいなものかな
957 :,,・´∀`・,,)っ-○○○:2011/04/22(金) 23:44:41.23 ID:o5GMnakW
ロードしてBroadcastして型変換してプレディケートつき積和算みたいなのを従来CPUで
1~2μOPsでできるかっつーの。
でもComplexにだけ実装すればsimpleデコーダのコストは省けるよね。
Sandy BridgeでもAVXのうちvpblendvbのような4オペランド命令はComplex Decoderでしか
デコードできない。
1~2μOPsでできるかっつーの。
でもComplexにだけ実装すればsimpleデコーダのコストは省けるよね。
Sandy BridgeでもAVXのうちvpblendvbのような4オペランド命令はComplex Decoderでしか
デコードできない。
これについて聞きたいんだけど
>フォーマットが複雑すぎるのでmicrocodeデコードになるだろうが
μOPの話ばかりして、命令フォーマットの話はスルーか?
>フォーマットが複雑すぎるのでmicrocodeデコードになるだろうが
μOPの話ばかりして、命令フォーマットの話はスルーか?
959 :,,・´∀`・,,)っ-○○○:2011/04/23(土) 00:04:59.83 ID:vH/Ah5Lq
フォーマットが複雑ってのはハードワイヤードロジックで実装するとコストがかかるってことも意味する。
ハードワイヤードで処理できたとしても全部のデコーダで対応したらコストがかかるだろう?
Complex Decoderで処理される命令全てがmicrocode ROMで処理されるわけではないが
フォーマットが複雑な命令はほぼすべてComplex Decoderで処理されるのが通例。
P54CのU/VパイプってのはまさにComplex DecoderとSimple Decoderの組み合わせだ。
ハードワイヤードで処理できたとしても全部のデコーダで対応したらコストがかかるだろう?
Complex Decoderで処理される命令全てがmicrocode ROMで処理されるわけではないが
フォーマットが複雑な命令はほぼすべてComplex Decoderで処理されるのが通例。
P54CのU/VパイプってのはまさにComplex DecoderとSimple Decoderの組み合わせだ。
960 :,,・´∀`・,,)っ-○○○:2011/04/23(土) 01:04:36.18 ID:vH/Ah5Lq
ちなみにLarrabeeネイティブでもSIMD命令のほとんどはComplex Decoderのパスだし
Simple Decoder処理できるのはシンプルなスカラ演算とマスク演算、vstore命令くらいしかない
ってIntelが言ってるだろう。
そもそも根本的な話として、LRBniフォーマットが複雑なのは、複数のオペレーションを
1命令に詰め込めるようにしたからなわけで、Wide-issueでμOPsに分解して処理するモダンな
CPUでは大半がmicrocodeデコードになって然るべきだろう。
Simple Decoder処理できるのはシンプルなスカラ演算とマスク演算、vstore命令くらいしかない
ってIntelが言ってるだろう。
そもそも根本的な話として、LRBniフォーマットが複雑なのは、複数のオペレーションを
1命令に詰め込めるようにしたからなわけで、Wide-issueでμOPsに分解して処理するモダンな
CPUでは大半がmicrocodeデコードになって然るべきだろう。
プレス子スレにてSIMMとSIMDの勘違いをした決定的瞬間のログ(団子こと雑音が"録音"と呼ばれていた時代のログ)
http://web.archive.org/web/20080518103351/http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
http://web.archive.org/web/20080518103351/http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
>>961
(録音が)あまりに無様すぎて乾いた笑いが出てくるレベルだな・・・
(録音が)あまりに無様すぎて乾いた笑いが出てくるレベルだな・・・
最近だとデフォルトスタンダード、ビター文か?
せざるおえん っていうのもある
965 :,,・´∀`・,,)っ-○○○:2011/04/25(月) 22:37:58.60 ID:OyPMlNid
パッチもん っていうのもある
正しい日本語:雑音語
ビタ一文→ビター文
せざるを得ない→せざるおえん
laugh→lahgh
デファクトスタンダード→デフォルトスタンダード
SIMD→SIMM
脊髄反射→脊髄反応
骨折り損のくたびれ儲け→骨折り損のくたびれ損
馬脚を現す→馬鹿ってすぐ脚をだす
提灯記事→行灯記事
ビタ一文→ビター文
せざるを得ない→せざるおえん
laugh→lahgh
デファクトスタンダード→デフォルトスタンダード
SIMD→SIMM
脊髄反射→脊髄反応
骨折り損のくたびれ儲け→骨折り損のくたびれ損
馬脚を現す→馬鹿ってすぐ脚をだす
提灯記事→行灯記事
translation:
Author never thought that this thread could be so noticeable...so do doubts.
Please be neutral, this processor ain't the best from AMD or it might consists some bugs(causing low in score).
Take this test with a pinch of salt. Both CPU taken for comparison support turbo feature (Intel is slightly better than AMD in this case).
Benchmarks conducted had left turbo enabled.
For the sake of equality, all parameters are unified, CPU from AMD has turned off Turbo Core/CIE/CnQ and for Intel side, it has TB/C3,C6/EIST/CIE turned off. (edited: left out of the keyword "turned off")
Benchmark software is now updated to Cinebench R11.5
(笑)なんていってそのサイトのURLコピペするとか中国語も英語も読めないんだろうな
Author never thought that this thread could be so noticeable...so do doubts.
Please be neutral, this processor ain't the best from AMD or it might consists some bugs(causing low in score).
Take this test with a pinch of salt. Both CPU taken for comparison support turbo feature (Intel is slightly better than AMD in this case).
Benchmarks conducted had left turbo enabled.
For the sake of equality, all parameters are unified, CPU from AMD has turned off Turbo Core/CIE/CnQ and for Intel side, it has TB/C3,C6/EIST/CIE turned off. (edited: left out of the keyword "turned off")
Benchmark software is now updated to Cinebench R11.5
(笑)なんていってそのサイトのURLコピペするとか中国語も英語も読めないんだろうな
969 :,,・´∀`・,,)っ-○○○:2011/04/29(金) 09:37:55.57 ID:c15ZwRFu
Turboがきいてもスコア改善率はせいぜい1~2割だろ。
いい訳にならない差だな
いい訳にならない差だな
971 :,,・´∀`・,,)っ-○○○:2011/04/29(金) 10:06:46.52 ID:c15ZwRFu
必死だなw
対sandyで概ね半分のパフォーマンスだよね
同クロックだと
同クロックだと
いっぽうSandyはLlanoに比べて80%低速(19.21/3.99)
974 :,,・´∀`・,,)っ-○○○:2011/04/29(金) 10:23:33.50 ID:c15ZwRFu
http://www.4gamer.net/games/128/G012877/20110215083/
以前よくIntelびびってるってことで、取り上げられていたのが
>Intelは,Sandy Bridge-Eの4コアモデルやIvy Bridgeで,動作クロックを引き上げることにより,
>同価格帯の「Bulldozer」(ブルドーザ,開発コードネーム)比で10~30%高い性能を発揮できる
http://www.anandtech.com/show/4291/additional-details-on-sandy-bridgee-processors-x79-and-lga2011
SandyBridge-E 4コア版のクロックが、定格3.6GHz、TB最大3.9GHz
とクロックわかったから、4gamerの記事にあるIntelの言に合わせると、
Bulldozerの3~5万ゾーンは、
SandyBridge-Eの定格2.8~3.3GHz
TB時も考慮すると3~3.6GHz
くらいの性能と、Intelは推測してるっぽいな。
以前よくIntelびびってるってことで、取り上げられていたのが
>Intelは,Sandy Bridge-Eの4コアモデルやIvy Bridgeで,動作クロックを引き上げることにより,
>同価格帯の「Bulldozer」(ブルドーザ,開発コードネーム)比で10~30%高い性能を発揮できる
http://www.anandtech.com/show/4291/additional-details-on-sandy-bridgee-processors-x79-and-lga2011
SandyBridge-E 4コア版のクロックが、定格3.6GHz、TB最大3.9GHz
とクロックわかったから、4gamerの記事にあるIntelの言に合わせると、
Bulldozerの3~5万ゾーンは、
SandyBridge-Eの定格2.8~3.3GHz
TB時も考慮すると3~3.6GHz
くらいの性能と、Intelは推測してるっぽいな。
hammerの頃もこんな感じで馬鹿が勝利宣言してましたよ
Intelが言ったということからすると、Intelは>>975で書いたくらいの性能だと
推測してるんじゃないの?
別に実際のBulldozerの性能がこれくらいだと言ってるわけじゃないのに。
あと、SandyBridge-EとLGA1155のSandyBridgeの性能差もわからないんだけど。
推測してるんじゃないの?
別に実際のBulldozerの性能がこれくらいだと言ってるわけじゃないのに。
あと、SandyBridge-EとLGA1155のSandyBridgeの性能差もわからないんだけど。
978 :,,・´∀`・,,)っ-○○○:2011/04/29(金) 12:29:03.00 ID:2Yx8Ejco
直接影響しそうなのはL3キャッシュ容量とメモリチャネル数くらい
Bulldozerが6月、Sandy Bridge-EがQ4なんだから、Sandy Bridge-Eを出すときに価格決めるってだけじゃないか?
>>979
Intelはランク付けで大体価格決まっている。
P1が300ドル前後で、P2が600ドル前後と900ドル前後、Extremeが999ドル以上って感じに。
4コアSandyBridge-EはP1なので、基本300ドル前後。
高くてもP2の600ドル前後まではいかない。
Intelはランク付けで大体価格決まっている。
P1が300ドル前後で、P2が600ドル前後と900ドル前後、Extremeが999ドル以上って感じに。
4コアSandyBridge-EはP1なので、基本300ドル前後。
高くてもP2の600ドル前後まではいかない。
Sandybridgeと比較して小さいとはいえないBulldozerのFPU
http://repositories.lib.utexas.edu/bitstream/handle/2152/3082/quinnelle60861.pdf
P.141
Table 6.3.2 Bridge fused multiplier-adder results
より
65nm AMD SOI
FPADD_DP 72,075um^2
FPMUL_DP 131,130um^2
FMA_DP 186,930 um^2
であるから
FMA_DP/(FPADD_DP + FPMUL_DP) = 0.919908
となる
Bulldozerは50%が拡張倍精度(EP)対応
Sandybridgeは25%がEP対応だから
実際の差はより小さいと推測される
http://repositories.lib.utexas.edu/bitstream/handle/2152/3082/quinnelle60861.pdf
P.141
Table 6.3.2 Bridge fused multiplier-adder results
より
65nm AMD SOI
FPADD_DP 72,075um^2
FPMUL_DP 131,130um^2
FMA_DP 186,930 um^2
であるから
FMA_DP/(FPADD_DP + FPMUL_DP) = 0.919908
となる
Bulldozerは50%が拡張倍精度(EP)対応
Sandybridgeは25%がEP対応だから
実際の差はより小さいと推測される