AMD�̎�����CPU�ɂ��Č�낤 ��21����
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��20����
http://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
AMD�̎�����CPU�ɂ��Č�낤 ��20����
http://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
CPU�A�[�L�e�N�`���ɂ��Č�� 9
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
|
|
|
���ߋ��X���ꗗ
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���������悤�Ȃ̂ŗ��Ă܂����B
�ʎq�R���s���[�^�܂�����
�������ƍ��J�X
�������ƍ��J�X
���낻��Qch�𑲋Ƃ��悤�Ǝv��(�E�L��`�E)
6 �FSocket774�F2008/05/05(��) 00:56:43 ID:4LpOb2wh
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@AMD����D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@AMD����D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
�����������͂������͂������ǁA�}�U�[���Ȃ����ȁB
�����������̂������ɂ`�l�c�p�̃}�U�[�ɂ������������̃O���{���������ǁB
�����������̂������ɂ`�l�c�p�̃}�U�[�ɂ������������̃O���{���������ǁB
168 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:56:56 ID:9oqlrKcp
�O���X�ǂ�Ő�����������
���ꂗ�����A���~�����������̔n����I�悵���Ȃ�����
����IQ147������(�E�L��`�E)
169 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:57:38 ID:9oqlrKcp
�S�o
�O���X�ǂ�Ő�����������
���ꂗ�����A���~�����������̔n����I�悵���Ȃ�����
����IQ147������(�E�L��`�E)
169 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:57:38 ID:9oqlrKcp
�S�o
>8 �̔S�����`�l�c�̐ɂ���A�����������������A�A�A�A�A
>>7
AMD�}�U�[�ł����̂̓I���{������nvidia�̃O���{�g���ƈӖ��Ȃ��ˁH
AMD�}�U�[�ł����̂̓I���{������nvidia�̃O���{�g���ƈӖ��Ȃ��ˁH
>>4
����25�N���炢�Ō��q�R���s���[�^���o���邩�ǂ������ĂƂ��낾����Ȃ�
���V���R�����������Ȃ�A������ӂɂ�����ł��]�����Ă邵��
����25�N���炢�Ō��q�R���s���[�^���o���邩�ǂ������ĂƂ��낾����Ȃ�
���V���R�����������Ȃ�A������ӂɂ�����ł��]�����Ă邵��
13 �FMAC�I�^�F2008/05/05(��) 21:50:29 ID:S2tr9gEs
AMD�̎����������Ń}�C���X�g�[���Ƃ������ׂ�Cray-Intel�̒�g���A���傤�ǐV�����X���b�h������
�^�C�~���O�ŋN�����̂������̉��Ȃ̂�������Ȃ����B���̃j���[�X�̈Ӗ����X���b�h�J�n�ɓ�������
�����������B
�̔��ʂƂ��Ă튄�����������ɂ�������炸�ACray��AMD�ɂƂ��čŏd�v�̌ڋq���������B���ۂ�
AMD�̎����ネ�[�h�}�b�v��Cray�̍ŐV�X�[�p�[�R���s���[�^�̎d�l����ڍׂ����炩�ɂȂ邱�Ƃ�
�����ABulldozer�R�AOpteron�̎d�l�ɂ��Ă��������\�ȍł��M���̂��������Cray
"Cascade"�̎d�l���̂��̂��B
http://pvmmpi07.lri.fr/assets/documents/slides/invited-talk/Al%20Geist%20Invited%20Talk.pdf (p.3-4�Q��)
����Cray��"Cascade"�̃v���Z�b�T��Intel�ɕύX���邱�Ƃ�\�������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=207402549
�@�@--------------------
�@�@Cray is seeking approval from DARPA for its plans to shift the Cascade design to Intel
�@�@processors using QPI that provides links at up to 6.4 GTransfers/second.
�@�@--------------------
���R�A���̒�g�ɂ�������Intel��Cray�ɃA�[�L�e�N�`����ڍׂȐ��\�\�z���܂ގ�������Ă���
��������ACascade�p�v���Z�b�T��"�X�C�b�`"��o���̏ڍ׃��[�h�}�b�v��m�闧�ꂩ�画�f��������
�����m���B
���ꃋ�[�}�[�T�C�g��f�l�\�z��M����̂펩�R�����ǁA���Ƃ���̖��m�Ȕ��f��2008�N������
�i�K�ʼn����ꂽ�Ƃ���������A�o���Ă����ėǂ����Ǝv�����B�Ȃ��ACray "Cascade"��2011���ɓo��
�\�肷�BBulldozer vs. Sandy Bridge����̔����B
�^�C�~���O�ŋN�����̂������̉��Ȃ̂�������Ȃ����B���̃j���[�X�̈Ӗ����X���b�h�J�n�ɓ�������
�����������B
�̔��ʂƂ��Ă튄�����������ɂ�������炸�ACray��AMD�ɂƂ��čŏd�v�̌ڋq���������B���ۂ�
AMD�̎����ネ�[�h�}�b�v��Cray�̍ŐV�X�[�p�[�R���s���[�^�̎d�l����ڍׂ����炩�ɂȂ邱�Ƃ�
�����ABulldozer�R�AOpteron�̎d�l�ɂ��Ă��������\�ȍł��M���̂��������Cray
"Cascade"�̎d�l���̂��̂��B
http://pvmmpi07.lri.fr/assets/documents/slides/invited-talk/Al%20Geist%20Invited%20Talk.pdf (p.3-4�Q��)
����Cray��"Cascade"�̃v���Z�b�T��Intel�ɕύX���邱�Ƃ�\�������B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=207402549
�@�@--------------------
�@�@Cray is seeking approval from DARPA for its plans to shift the Cascade design to Intel
�@�@processors using QPI that provides links at up to 6.4 GTransfers/second.
�@�@--------------------
���R�A���̒�g�ɂ�������Intel��Cray�ɃA�[�L�e�N�`����ڍׂȐ��\�\�z���܂ގ�������Ă���
��������ACascade�p�v���Z�b�T��"�X�C�b�`"��o���̏ڍ׃��[�h�}�b�v��m�闧�ꂩ�画�f��������
�����m���B
���ꃋ�[�}�[�T�C�g��f�l�\�z��M����̂펩�R�����ǁA���Ƃ���̖��m�Ȕ��f��2008�N������
�i�K�ʼn����ꂽ�Ƃ���������A�o���Ă����ėǂ����Ǝv�����B�Ȃ��ACray "Cascade"��2011���ɓo��
�\�肷�BBulldozer vs. Sandy Bridge����̔����B
HKEPC�ɂ���TDP65W��2GHz��Phenom X4 9350e����3�l�����ɓo��\��Ƃ̂��Ƃ��B
http://www.hkepc.com/?id=1118&fs=c1h
�@�@---------------------
�@�@AMD �v�c�ݑ�O�G�������o�ꊼ����Վl�j�S�|����C�^�j�� Phenom X4 9350e �C TDP
�@�@����� 65W �C�A�j�S������ 2GHz �B
�@�@---------------------
����d�͂�������Δ����Ǝ咣���Ă���q�g������悤�����猋�\�Șb�Ȃ̂�������Ȃ������ǁA
AMD����L�̈ӌ����w�����������\�x����Ȃ����Ƃ��F���Ă��邩�Ǝv����(��)
http://www.hkepc.com/?id=1118&fs=c1h
�@�@---------------------
�@�@AMD �v�c�ݑ�O�G�������o�ꊼ����Վl�j�S�|����C�^�j�� Phenom X4 9350e �C TDP
�@�@����� 65W �C�A�j�S������ 2GHz �B
�@�@---------------------
����d�͂�������Δ����Ǝ咣���Ă���q�g������悤�����猋�\�Șb�Ȃ̂�������Ȃ������ǁA
AMD����L�̈ӌ����w�����������\�x����Ȃ����Ƃ��F���Ă��邩�Ǝv����(��)
������ƑO�܂ŢPower�ō��IIntel�Ȃ�ăJ�X�I�����쒀�����I����Č����Ă�
�z�����X�������Ă��M�����Ȃ���ȁB
�Ƃ�����MAC�I�^�̌�������9��5���O��邩��t��MAC�I�^���Ȃ�=AMD���ׂ���
�C������B
�z�����X�������Ă��M�����Ȃ���ȁB
�Ƃ�����MAC�I�^�̌�������9��5���O��邩��t��MAC�I�^���Ȃ�=AMD���ׂ���
�C������B
>>15
MAC�I�^��n���ɂ���ȁB
MAC�I�^��n���ɂ���ȁB
MAC�I�^�̕����ǂ݂ɂ���
18 �FMAC�I�^��15 �����F2008/05/05(��) 22:09:03 ID:S2tr9gEs
>>15
�@�@--------------------
�@�@������ƑO�܂ŢPower�ō��IIntel�Ȃ�ăJ�X�I�����쒀�����I�
�@�@--------------------
�VMac���܂ގ��̃J�L�R�~��A���݂ł��Q�Ɖ\���B
http://cpu.jisakuita.net/
http://www.megabbs.com/cgi-bin/readres.cgi?bo=mac&vi=0046
�撣���ă\�[�X��T���Ă��ė~������(��)
�@�@--------------------
�@�@������ƑO�܂ŢPower�ō��IIntel�Ȃ�ăJ�X�I�����쒀�����I�
�@�@--------------------
�VMac���܂ގ��̃J�L�R�~��A���݂ł��Q�Ɖ\���B
http://cpu.jisakuita.net/
http://www.megabbs.com/cgi-bin/readres.cgi?bo=mac&vi=0046
�撣���ă\�[�X��T���Ă��ė~������(��)
������Intel Fanboy
��ް
>>20
MAC�I�^��IntelFunboy����Ȃ���B�Ԉ�����m���Ől�����n���ɂ���̂��D���Ȃ����̍r�炵�B
MAC�I�^��IntelFunboy����Ȃ���B�Ԉ�����m���Ől�����n���ɂ���̂��D���Ȃ����̍r�炵�B
�����ȃI�^����Ɏ���
Isaiah�ɉ��L�̂悤�ȋL�q������̂ł���
The multiply unit also has a fused floating-point multiply-add function that is used by the
transcendental algorithms.
ttp://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
ttp://pc.watch.impress.co.jp/docs/2008/0410/kaigai_01.jpg
2010�N�ɂ܂��uIntel Advanced Vector Extensions (Intel AVX)�v��
>�uSandy Bridge(�T���f�B�u���b�W)�v�Ɏ�������A
>���̐��CPU�ł́uFused Multiply Add(FMA)�v�����������B
>�������A���̂��߂ɂ́A���߃Z�b�g��傫���g������K�v������B
>������Intel�́uIntel Advanced Vector Extensions (Intel AVX)�v�ƁuFused Multiply Add(FMA)�v�A
>AMD��SSE5�Ƃ��������ւƌ������Ă���BAVX/FMA���Ɏ��ƁA
>SSE����A�I�y�����h���f����ς���A�Ϙa�Z����������A�x�N�^(SIMD)����L���Ƃ������������B
>�ȒP�Ɍ����ARISC���̃��_���Ȗ��߂ɐ�ւ���B
�������Isaiah�����Ȃ��i�I���Ă��ƂȂ̂���
���߂Ƃ��ǂ�����̂������
Isaiah�ɉ��L�̂悤�ȋL�q������̂ł���
The multiply unit also has a fused floating-point multiply-add function that is used by the
transcendental algorithms.
ttp://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
ttp://pc.watch.impress.co.jp/docs/2008/0410/kaigai_01.jpg
{kind=link}
2010�N�ɂ܂��uIntel Advanced Vector Extensions (Intel AVX)�v��
>�uSandy Bridge(�T���f�B�u���b�W)�v�Ɏ�������A
>���̐��CPU�ł́uFused Multiply Add(FMA)�v�����������B
>�������A���̂��߂ɂ́A���߃Z�b�g��傫���g������K�v������B
>������Intel�́uIntel Advanced Vector Extensions (Intel AVX)�v�ƁuFused Multiply Add(FMA)�v�A
>AMD��SSE5�Ƃ��������ւƌ������Ă���BAVX/FMA���Ɏ��ƁA
>SSE����A�I�y�����h���f����ς���A�Ϙa�Z����������A�x�N�^(SIMD)����L���Ƃ������������B
>�ȒP�Ɍ����ARISC���̃��_���Ȗ��߂ɐ�ւ���B
�������Isaiah�����Ȃ��i�I���Ă��ƂȂ̂���
���߂Ƃ��ǂ�����̂������
24 �FMAC�I�^��23 �����F2008/05/06(��) 10:40:24 ID:VeL5EoZJ
>>23
�Ϙa���Z���j�b�g��x86�ȊO�Ȃ�ARM��g������PowerPC�ł����ڂ��Ă���̂ŁA�S�R�w��i�I�x
���ᖳ�����B
�EARM http://www.arm.com/products/CPUs/arch-simd.html
�@�@---------------------
�@�@ARMv6 SIMD Features:
�@�@�@[����]
�@�@�@- Dual 16x16 multiply-add/subtract
�@�@---------------------
�E�g������PowerPC http://www-306.ibm.com/chips/micronews/vol7_no4/mn_vol7_no4_fnl.pdf (p.27-29)
�@�@---------------------
�@�@Operation�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Cycle count latency/throughput
�@�@Floating (negative) multiply-add/subtract�@�@�@�@�@�@5/1
�@�@---------------------
�Ϙa���Z���j�b�g��x86�ȊO�Ȃ�ARM��g������PowerPC�ł����ڂ��Ă���̂ŁA�S�R�w��i�I�x
���ᖳ�����B
�EARM http://www.arm.com/products/CPUs/arch-simd.html
�@�@---------------------
�@�@ARMv6 SIMD Features:
�@�@�@[����]
�@�@�@- Dual 16x16 multiply-add/subtract
�@�@---------------------
�E�g������PowerPC http://www-306.ibm.com/chips/micronews/vol7_no4/mn_vol7_no4_fnl.pdf (p.27-29)
�@�@---------------------
�@�@Operation�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Cycle count latency/throughput
�@�@Floating (negative) multiply-add/subtract�@�@�@�@�@�@5/1
�@�@---------------------
�n��������
�܂�Intel�͂��Ȃ��i�Ƃ������
27 �FMAC�I�^��26 �����F2008/05/06(��) 12:54:45 ID:VeL5EoZJ
>>26
�@�@--------------------
�@�@�܂�Intel�͂��Ȃ��i�Ƃ������
�@�@--------------------
�c�O�Ȃ���@���̃l�^�ɂ�d���Ȃ���(��)
http://techon.nikkeibp.co.jp/article/NEWS/20070711/135799/
�@�@====================
�@�@��Intel Corp.�͑O����10��3���ɁuItanium�v�Ɩ�������IA-64�A�[�L�e�N�`���̃}�C�N���v���Z�T
�@�@�i�J���R�[�h���FMerced�j�̓����\�����C�uMicroprocessor Forum�v�Ŗ��炩�ɂ����B�ő�6��
�@�@�������߂��ɔ��s����B4��ALU�iMMX���߂ɑΉ��j��2�̕��������_�f�[�^��
�@�@�Ϙa���Z��i4��SSE���߂ɑΉ��j�C2�̃��[�h/�X�g�A�E���j�b�g���������B
�@�@====================
�@�@--------------------
�@�@�܂�Intel�͂��Ȃ��i�Ƃ������
�@�@--------------------
�c�O�Ȃ���@���̃l�^�ɂ�d���Ȃ���(��)
http://techon.nikkeibp.co.jp/article/NEWS/20070711/135799/
�@�@====================
�@�@��Intel Corp.�͑O����10��3���ɁuItanium�v�Ɩ�������IA-64�A�[�L�e�N�`���̃}�C�N���v���Z�T
�@�@�i�J���R�[�h���FMerced�j�̓����\�����C�uMicroprocessor Forum�v�Ŗ��炩�ɂ����B�ő�6��
�@�@�������߂��ɔ��s����B4��ALU�iMMX���߂ɑΉ��j��2�̕��������_�f�[�^��
�@�@�Ϙa���Z��i4��SSE���߂ɑΉ��j�C2�̃��[�h/�X�g�A�E���j�b�g���������B
�@�@====================
���̃X���̑��݈Ӌ`�͂�������X���݂����N�\�R�e���u�����邱�Ƃɂ���
�@���̃l�^�ɂ������͖����̂���
ttp://journal.mycom.co.jp/photo/articles/2004/10/07/fpf1/images/009l.jpg
4�N�O�̎��������ǁAFPU�W�̋������ڂ̈ꗗ��ala itanium�Ƃ���ԉ��ɂ���
2004�N�̒i�K��FMA���̋����\�肪�������Ǝv���邪
x86 CPU�ł̎������x���̂́Ax86������H
ttp://journal.mycom.co.jp/photo/articles/2004/10/07/fpf1/images/009l.jpg
{kind=link}
4�N�O�̎��������ǁAFPU�W�̋������ڂ̈ꗗ��ala itanium�Ƃ���ԉ��ɂ���
2004�N�̒i�K��FMA���̋����\�肪�������Ǝv���邪
x86 CPU�ł̎������x���̂́Ax86������H
PPC�͐Ϙa���߂����������ǃp�C�v���C�����ĂȂ���������
���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�ˑ��W�̂Ȃ��Ϙa�����������ƕ��Ԃ悤�ȏꍇ�͑������ǁB
���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�ˑ��W�̂Ȃ��Ϙa�����������ƕ��Ԃ悤�ȏꍇ�͑������ǁB
������x86�ɂ���̂�OS�ɂ���̂��A�A�v���ɂȂ�̂�
�͕s���B
���ׂĂɌ��������邾�낤���A�Ȃ��Ƃ����Ȃ����낤
�����ėp���\�����G���J������Ă��Ƃ��l�����
CPU�Ƃ��Ĕ�p�ɑ����ʂ��o�₷��������蒼��
����̂̓Z�I���[�A��CP
U�ɔ�ׂ�x86���x���̂͌�ɂ���Ă邾��
���ė��R�����
�͕s���B
���ׂĂɌ��������邾�낤���A�Ȃ��Ƃ����Ȃ����낤
�����ėp���\�����G���J������Ă��Ƃ��l�����
CPU�Ƃ��Ĕ�p�ɑ����ʂ��o�₷��������蒼��
����̂̓Z�I���[�A��CP
U�ɔ�ׂ�x86���x���̂͌�ɂ���Ă邾��
���ė��R�����
Intel�I�ɂ�AVX����ł��܂��̂���
33 �FMAC�I�^��30 �����F2008/05/06(��) 23:53:21 ID:VeL5EoZJ
>>30
�@�@------------------
�@�@PPC�͐Ϙa���߂����������ǃp�C�v���C�����ĂȂ���������
�@�@���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�@�@------------------
�p�C�v���C��������"fused" multiply-add���ᖳ���Ȃ邷���ǁB�B�B
�܂�PPC�햽�߃Z�b�g�ł����ē����A�[�L�e�N�`����K�肵�Ȃ�������A�ǂ�PowerPC�̂��Ƃ�
�����Ă���̂��m��Ȃ������ǁAG3�Ȃ�fadd�̃��C�e���V1�Afmadd�̃��C�e���V2���B
http://www.freescale.com/files/32bit/doc/ref_manual/MPC750UM.pdf (p.270�Q��)
�@�@------------------
�@�@PPC�͐Ϙa���߂����������ǃp�C�v���C�����ĂȂ���������
�@�@���ʂ̉����Z�܂Ń��C�e���V�����������ĂĖ{���]�|��������...
�@�@------------------
�p�C�v���C��������"fused" multiply-add���ᖳ���Ȃ邷���ǁB�B�B
�܂�PPC�햽�߃Z�b�g�ł����ē����A�[�L�e�N�`����K�肵�Ȃ�������A�ǂ�PowerPC�̂��Ƃ�
�����Ă���̂��m��Ȃ������ǁAG3�Ȃ�fadd�̃��C�e���V1�Afmadd�̃��C�e���V2���B
http://www.freescale.com/files/32bit/doc/ref_manual/MPC750UM.pdf (p.270�Q��)
34 �FMAC�I�^�������F2008/05/06(��) 23:57:18 ID:VeL5EoZJ
������ƕ\�̌����ԈႦ�����B
��������A�wG3�Ȃ�fadd�̃��C�e���V3�Afmadd�̃��C�e���V4���B �x�Ƃ������ƂŁB�B�B
��������A�wG3�Ȃ�fadd�̃��C�e���V3�Afmadd�̃��C�e���V4���B �x�Ƃ������ƂŁB�B�B
�ŋ߂�����Ə��ɑa����ŁA���o��������Ȃ�������puma�v���b�g�t�H�[���̘b���B
http://apcmag.com/amd_puma_pads_softly_into_100_notebooks.htm
�@- RS780M�����`�b�v�Z�b�g ����AMobility Radeon HD 3000 (DX10.1�T�|�[�g)
�@- �d�͏�GPU��ؑւ���PowerXPress�@�\
�@- Turion X2 Ultramobile with Hypertransport 3 (20.8GB/s)
�@- 6����Computex taipei�Ŕ��\
http://apcmag.com/amd_puma_pads_softly_into_100_notebooks.htm
�@- RS780M�����`�b�v�Z�b�g ����AMobility Radeon HD 3000 (DX10.1�T�|�[�g)
�@- �d�͏�GPU��ؑւ���PowerXPress�@�\
�@- Turion X2 Ultramobile with Hypertransport 3 (20.8GB/s)
�@- 6����Computex taipei�Ŕ��\
>>33
�Ȃ�ō��XG3...
�[������͔{���x�̏�Z�n���߂�+1cycle�����Ƃ���G3�̗L���Ȏd�l����
G4(7400/7410),G4(744x/745x),G5�͑S�������Z���Ϙa���������C�e���V�B
���ꂼ��3,5,6�B�܂��p�C�v���C�����[���Ȃ�G3�⏉��G4�ł͖��Ȃ��B
���͌��G4��G5�ŁA�P���x�Ȃ�AltiVec�Ńf�[�^����ɓ�����Ƃ���
�肪���邩�炢������(���Ɍ��G4�̓��C�e���V��������)�A�{���x��...
�v�͐������Z�ł���Ă�悤�ɉ��Z�n�Ə�Z�n�̃p�C�v���C�����ė~�����������Ď����B
����fp�p�C�v��2��G5�͕Е����C�e���V�ɂ�������
�R���V���[�}�����ł͑������\�͏オ�����Ǝv���B
�Ϙa���̉Ȋw�v�Z�n�x���`�}�[�N�ł͉����邾�낤��w
�܂����ƂȂ��Ă͂ǂ��ł������b�ł͂���B
�Ȃ�ō��XG3...
�[������͔{���x�̏�Z�n���߂�+1cycle�����Ƃ���G3�̗L���Ȏd�l����
G4(7400/7410),G4(744x/745x),G5�͑S�������Z���Ϙa���������C�e���V�B
���ꂼ��3,5,6�B�܂��p�C�v���C�����[���Ȃ�G3�⏉��G4�ł͖��Ȃ��B
���͌��G4��G5�ŁA�P���x�Ȃ�AltiVec�Ńf�[�^����ɓ�����Ƃ���
�肪���邩�炢������(���Ɍ��G4�̓��C�e���V��������)�A�{���x��...
�v�͐������Z�ł���Ă�悤�ɉ��Z�n�Ə�Z�n�̃p�C�v���C�����ė~�����������Ď����B
����fp�p�C�v��2��G5�͕Е����C�e���V�ɂ�������
�R���V���[�}�����ł͑������\�͏オ�����Ǝv���B
�Ϙa���̉Ȋw�v�Z�n�x���`�}�[�N�ł͉����邾�낤��w
�܂����ƂȂ��Ă͂ǂ��ł������b�ł͂���B
�ǂ����悤���Ȃ��n����MAC�I�^���ǂ��ɂ��������Ƃ����̂͂ǂ��ł������b�ł͂Ȃ���
38 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 12:22:51 ID:zZWj2lGD
Wii��Broadway��SIMD����C�e���V���T�C�N����
39 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 13:12:13 ID:zZWj2lGD
>>24
���Ȃ݂Ɍ�����x86�ɂ́APMADDWD���Ă���MMX Pentium���ォ�炠��Ϙa�Z���߂������Ă��ȁB
�[���A32bit�x�N�^����S�R�X���[�v�b�g�����Ȃ������B
���Ȃ݂Ɍ�����x86�ɂ́APMADDWD���Ă���MMX Pentium���ォ�炠��Ϙa�Z���߂������Ă��ȁB
�[���A32bit�x�N�^����S�R�X���[�v�b�g�����Ȃ������B
E7200�̖ҍU�̑O�ɂǂ��R���낤���c
45�ڍs�͏H�ȍ~�Ƃ��̂�т肷���₵�Ȃ���
45�ڍs�͏H�ȍ~�Ƃ��̂�т肷���₵�Ȃ���
41 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 20:57:41 ID:zZWj2lGD
���łɌ�����ARM��SIMD����Xscale��Wireless MMX�̂ق�������ۂǐ��\�ł܂���B
�܂����{�I�Ƀx�N�^�����Ⴄ���̔�ׂĂ��ǂ����悤���Ȃ����ǁB
�܂����{�I�Ƀx�N�^�����Ⴄ���̔�ׂĂ��ǂ����悤���Ȃ����ǁB
ttp://www.amd.com//us-en/assets/content_type/DownloadableAssets/MDL_No._1717_JJF_final.pdf
�������Ă킯�킩���
�������Ă킯�킩���
43 �F�R�E�L�́M�E,,�j�����������������F2008/05/07(��) 22:00:30 ID:zZWj2lGD
���h�肗��������
�Ȃɂ��̏؋��B�ŁH
�悭����ƍ��h��̂Ƃ����狫�E����������Ă邩��A�����h���Ă��玆���X�L�����������̂Ǝv����B
�Ȃɂ��̏؋��B�ŁH
�悭����ƍ��h��̂Ƃ����狫�E����������Ă邩��A�����h���Ă��玆���X�L�����������̂Ǝv����B
�y���Y�ł��B
>>40
�ҍU���Ȃɂ�Intel�Ƃ��Ă�E8xx0�̂�������̒�N���b�N�ł��̂�т�o���Ă邾������Ȃ����B
Intel��45nm�������̂͋��N11���Ȃ��甼�N���Ă��̂��炢�o����B
AMD�Ƃ��Ă�6����E3140�̕����_���[�W���낤�B
>45�ڍs�͏H�ȍ~�Ƃ��̂�т肷���₵�Ȃ���
Q4������~����
�ҍU���Ȃɂ�Intel�Ƃ��Ă�E8xx0�̂�������̒�N���b�N�ł��̂�т�o���Ă邾������Ȃ����B
Intel��45nm�������̂͋��N11���Ȃ��甼�N���Ă��̂��炢�o����B
AMD�Ƃ��Ă�6����E3140�̕����_���[�W���낤�B
>45�ڍs�͏H�ȍ~�Ƃ��̂�т肷���₵�Ȃ���
Q4������~����
AMD revamps server roadmap
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-revamps-server-roadmap
The new AMD roadmap restores a bit of confidence
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-roadmap-restores-bit
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-revamps-server-roadmap
The new AMD roadmap restores a bit of confidence
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-roadmap-restores-bit
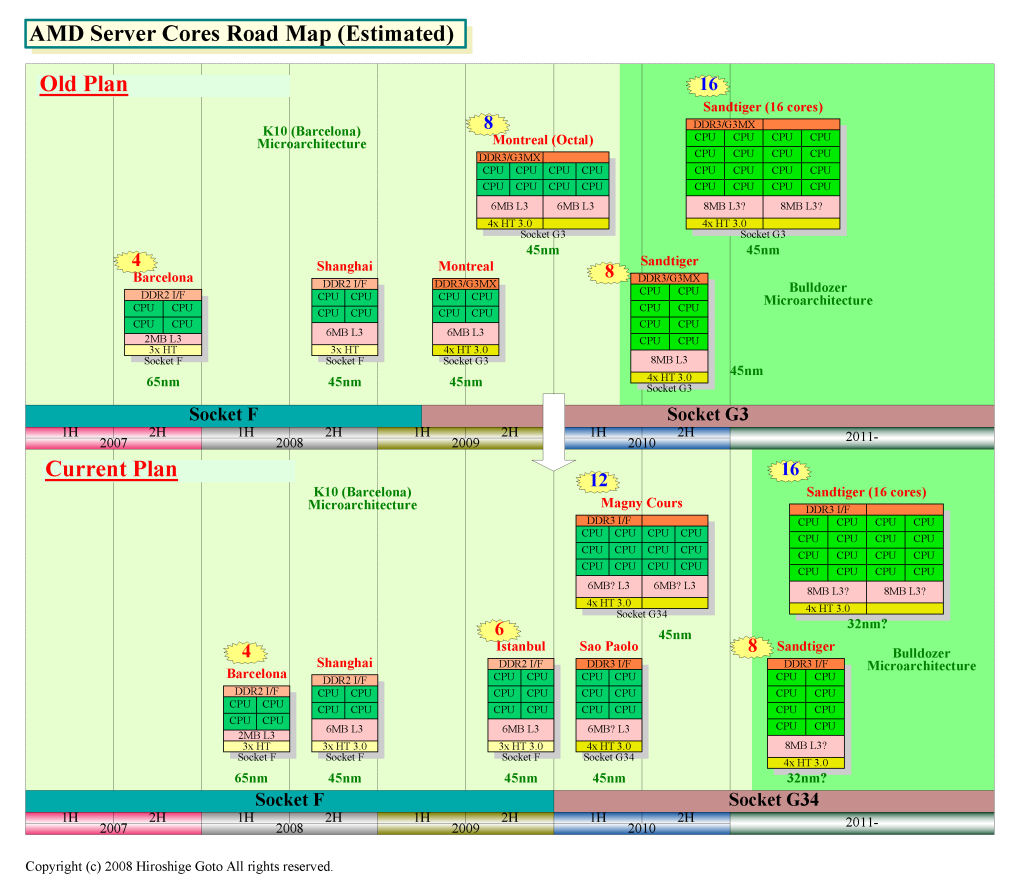
2008Q4�@Shanhai(4core, L2=512KBx4, L3=6MB)�@AMD�ɂ��Γ��N���b�N��Barcelona��20%����
Montreal�̓L�����Z��
2009Q4�@Istanbul(6core, L2=512KBx6, L3=6MB)�@Shanhai��6�R�A�ŁA�������O�̃��[�h�}�b�v�ɂ͂Ȃ��������̏ꂵ�̂�
2010�@Sao Paolo(6core, L2=512KBx6, L3=6MB)�@Istanbul�̃R�A���ǔŁASocket G34
2010?�@Magny-Cours(6core, L2=512KBx12, L3=12MB)�@Sao Paolo��MCM�j�R�C�`
�p����Ȃ�ŊԈ���Ă���������肢
Montreal�̓L�����Z��
2009Q4�@Istanbul(6core, L2=512KBx6, L3=6MB)�@Shanhai��6�R�A�ŁA�������O�̃��[�h�}�b�v�ɂ͂Ȃ��������̏ꂵ�̂�
2010�@Sao Paolo(6core, L2=512KBx6, L3=6MB)�@Istanbul�̃R�A���ǔŁASocket G34
2010?�@Magny-Cours(6core, L2=512KBx12, L3=12MB)�@Sao Paolo��MCM�j�R�C�`
�p����Ȃ�ŊԈ���Ă���������肢
>>47�@����
2010?�@Magny-Cours(12core, L2=512KBx12, L3=12MB)�@Sao Paolo��MCM�j�R�C�`
2010?�@Magny-Cours(12core, L2=512KBx12, L3=12MB)�@Sao Paolo��MCM�j�R�C�`
�o���Z���i�A��C�A�T���p�E���A�}�j�N�[��
�������F1���J�Â��Ă�s�s�ˁA�O�̂���
�������F1���J�Â��Ă�s�s�ˁA�O�̂���
50 �F�R�E�L�́M�E,,�j�����������������F2008/05/08(��) 08:07:11 ID:QQwu9ZkE
Bulldozer�͉���H
Sun���iIntel�̂��Ƃ����[�V���O�J�[�ɗႦ�āj���̃_���v�J�[�炵�����ǂˁB
Sun���iIntel�̂��Ƃ����[�V���O�J�[�ɗႦ�āj���̃_���v�J�[�炵�����ǂˁB
>>47
���W�X�g���G�f�B�^��L2�L���b�V���̒l��M�炸�u�t�q�q�cL2��6M������E8500�ŋ����v
�Ƃ��ق����Ă�n���������ς����鐢�̒��Ƃ͂���
���������L���b�V�����₵����ǂ��Ȃ낤���B
�@�l���������C���Ŏ��샆�[�U�[�����Ȃ��ˁH
�k�Q-2MB�~4�Ƃ��̏�C��������
���W�X�g���G�f�B�^��L2�L���b�V���̒l��M�炸�u�t�q�q�cL2��6M������E8500�ŋ����v
�Ƃ��ق����Ă�n���������ς����鐢�̒��Ƃ͂���
���������L���b�V�����₵����ǂ��Ȃ낤���B
�@�l���������C���Ŏ��샆�[�U�[�����Ȃ��ˁH
�k�Q-2MB�~4�Ƃ��̏�C��������
>>50
���ˑR�ႤMA�����ė��Ă�̂��̔n��
���ˑR�ႤMA�����ė��Ă�̂��̔n��
>>51
>���W�X�g���G�f�B�^��L2�L���b�V���̒l��M�炸�u�t�q�q�cL2��6M������E8500�ŋ����v
����SecondLevelDataCache�w��͂��܂�CPU�ł͈Ӗ��Ȃ����B
>���������L���b�V�����₵����ǂ��Ȃ낤���B
Nehalem��L2�Ȃ��256KB�����Ȃ����ǁB
>���W�X�g���G�f�B�^��L2�L���b�V���̒l��M�炸�u�t�q�q�cL2��6M������E8500�ŋ����v
����SecondLevelDataCache�w��͂��܂�CPU�ł͈Ӗ��Ȃ����B
>���������L���b�V�����₵����ǂ��Ȃ낤���B
Nehalem��L2�Ȃ��256KB�����Ȃ����ǁB
SecondLevelDataCache�Ƃ���
vista�͊W�Ȃ��Ă�XPSP2�͊W����ˁH
SP3�łǂ��Ȃ������͂܂��m��Ȃ�����
SP3�łǂ��Ȃ������͂܂��m��Ȃ�����
>>56
http://support.microsoft.com/default.aspx?scid=KB;en-us;q183063
it is only useful for computers with direct-mapped L2 caches.
Pentium II and later processors do not have direct- mapped L2 caches.
http://support.microsoft.com/default.aspx?scid=KB;en-us;q183063
it is only useful for computers with direct-mapped L2 caches.
Pentium II and later processors do not have direct- mapped L2 caches.
����XP�͎������ʂ̏��256KB�ƕ����Ă�����Â������̂��c
�Ă�GPU����CPU�����Ƃ������Ă�����6�R�A�ȍ~�͂ǂ��Ȃ�H
�R�A���₷��������I�����ł����킦�Ȃ�������
�Ă�GPU����CPU�����Ƃ������Ă�����6�R�A�ȍ~�͂ǂ��Ȃ�H
�R�A���₷��������I�����ł����킦�Ȃ�������
>>59
GPU������2009�N�㔼�B�m�[�g��p�B
GPU������2009�N�㔼�B�m�[�g��p�B
>>47
ttp://itpro.nikkeibp.co.jp/article/NEWS/20080508/300823/
����CPU�͂ǂ��ł��������AG3MX��Montreal�ɗ�������������̂�
�����meraSDRAM�g�����Ă̂��ɉ߂���B
ttp://itpro.nikkeibp.co.jp/article/NEWS/20080508/300823/
����CPU�͂ǂ��ł��������AG3MX��Montreal�ɗ�������������̂�
�����meraSDRAM�g�����Ă̂��ɉ߂���B
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/Roadmap_Update_Fact_Sheet_Final.pdf
���ꌩ���Sao Paolo�͒P�Ȃ�Istanbul��Socket G34�ł̂悤���B
2011�N�܂ŃR�A���ǂȂ������B
���ꌩ���Sao Paolo�͒P�Ȃ�Istanbul��Socket G34�ł̂悤���B
2011�N�܂ŃR�A���ǂȂ������B
Istanbul��2H09���Ă��Ƃ́Aintel��MP����8�R�A�Ƃ܂Ƃ��ɂԂ���̂��B
12�R�A��Magny Cours���x�ꂽ�炩�Ȃ肫���ȁB
12�R�A��Magny Cours���x�ꂽ�炩�Ȃ肫���ȁB
>>63
��2009Q4��Westmere�̓��C���X�g���[��/2P�T�[�o������6�R�A�������
��2009Q4��Westmere�̓��C���X�g���[��/2P�T�[�o������6�R�A�������
>>64
http://ludit.kuleuven.be/onderzoek/images/e/eb/16042008_Intel_HPC.pdf
�����11�y�[�W�ɂ��ƁAWestmere��4�R�A�̂܂܂炵���B
���̃X���C�h�̌��6�R�A�ɕύX���ĉ\�������邯�ǁB
http://ludit.kuleuven.be/onderzoek/images/e/eb/16042008_Intel_HPC.pdf
�����11�y�[�W�ɂ��ƁAWestmere��4�R�A�̂܂܂炵���B
���̃X���C�h�̌��6�R�A�ɕύX���ĉ\�������邯�ǁB
>>64
63�����������̂�Westmere����Ȃ���Beckton�̂��Ƃł���
63�����������̂�Westmere����Ȃ���Beckton�̂��Ƃł���
5�N�ȏ���M���Ă������Ƃ���u�Ŕے肳�ꂽ>>51���ܲ���B
http://pc.watch.impress.co.jp/docs/2008/0326/kaigai428.htm
�����܂Ō㓡���͂�����ƋL���ɂ����̂��K�Z�Ƃ͎v���ǂ˂�
�����܂Ō㓡���͂�����ƋL���ɂ����̂��K�Z�Ƃ͎v���ǂ˂�
ttp://www.internetnews.com/hardware/article.php/3745541/
| "Istanbul" will be a native six-core design,
L3���₳���ɃR�A����1.5�{�B�j�R�C�`�ł͂Ȃ�single die�B���̎��_�ł����`�������W�������B
�����܂�͂悭��barcelona���ɂȂ邾�낤����5�R�A�łƂ�4�R�A�ł��o�Ă��邾�낤�B
(����������������̂�IBM��Sun������Ă���̂ň����킯�ł͂Ȃ���)
�|���R�cShanghai�̃j�R�C�`����ʖڂȂ̂�?
native 6core��Istanbul��MCM 8core��Montreal��苣���͂�����̂�?
G3MX>>61�����A�����������metaSDRAM��G3MX���̂��̂������\��������B
DIMM�ɐςނ��}�U�[�ɐςނ��̈Ⴂ�BAMD�ɉ������邵�B
�܂�metaRAM��AMD���������āA
�R�X�g�I�ɂ͕s������Intel�����ɂ������DIMM���ڂ�I�Ƃ����킯�B
| "Istanbul" will be a native six-core design,
L3���₳���ɃR�A����1.5�{�B�j�R�C�`�ł͂Ȃ�single die�B���̎��_�ł����`�������W�������B
�����܂�͂悭��barcelona���ɂȂ邾�낤����5�R�A�łƂ�4�R�A�ł��o�Ă��邾�낤�B
(����������������̂�IBM��Sun������Ă���̂ň����킯�ł͂Ȃ���)
�|���R�cShanghai�̃j�R�C�`����ʖڂȂ̂�?
native 6core��Istanbul��MCM 8core��Montreal��苣���͂�����̂�?
G3MX>>61�����A�����������metaSDRAM��G3MX���̂��̂������\��������B
DIMM�ɐςނ��}�U�[�ɐςނ��̈Ⴂ�BAMD�ɉ������邵�B
�܂�metaRAM��AMD���������āA
�R�X�g�I�ɂ͕s������Intel�����ɂ������DIMM���ڂ�I�Ƃ����킯�B
MetaRAM��CEO�͌�AMD�A�[�L�e�N�g��FredWeber�����ȁB
���Ƃ͂��ĂȂ������ɂ���AFredWeber��AMD�̐헪��m���ĂĂ���ɉ�����
MetaRAM���J�������\���͏\���ɂ���ȁB
Intel�ł��̗p�����\���͏\���ɂ��邩��A��͂�ڂ̕t�������ǂ��낤�Ȃ��B
���Ƃ͂��ĂȂ������ɂ���AFredWeber��AMD�̐헪��m���ĂĂ���ɉ�����
MetaRAM���J�������\���͏\���ɂ���ȁB
Intel�ł��̗p�����\���͏\���ɂ��邩��A��͂�ڂ̕t�������ǂ��낤�Ȃ��B
ttp://www.fudzilla.com/index.php?option=com_content&task=view&id=7197&Itemid=1
Fudzilla������b�������Ď��ŁBK10.5�ARe��.D�ł�"High-K"���������͑��̋L���Ɣ�邪�B
�����A�l�C�e�B�u8�R�A��"Hydra"����������邻���ť���BMCM��16�R�A�łƂ��o���̂��낤���H
���ꂪ�{���Ȃ��AMD�͉�����肽���̂��悭�킩���
Fudzilla������b�������Ď��ŁBK10.5�ARe��.D�ł�"High-K"���������͑��̋L���Ɣ�邪�B
�����A�l�C�e�B�u8�R�A��"Hydra"����������邻���ť���BMCM��16�R�A�łƂ��o���̂��낤���H
���ꂪ�{���Ȃ��AMD�͉�����肽���̂��悭�킩���
���Ƌ����_��"L2����"��������ƉR���ۂ��B
�܂��B���Y�����Ȃ�Ă��āA�����܂肪�悭�Ȃ�A
L2�������l���邩���m��Ȃ����c���Ȃ낤���B
�܂��B���Y�����Ȃ�Ă��āA�����܂肪�悭�Ȃ�A
L2�������l���邩���m��Ȃ����c���Ȃ낤���B
�ł�Inquirer�̓n�b�L��512KB�̂܂܂Ƃ͌����ĂȂ���Ȃ��H
L2=1MB�̓A�����Ǝv���̂����B�����_�C�T�C�Y�͐S�z�B
High-k�Ɋւ��Ă�32nm�ƃg�����W�X�^�����ʉ�����Ȃ�45nm�̌㔼�ō̗p�͂��蓾��b���B
������Fudzilla�c�B
����I�t�B�V�����ň�x��L2=1MB�ƌ������킯�����c�B
�W��������Hydra�ƌ����Γ���9�B
�̗�1/4�B
CPU�Ƃ̊֘A���͎v��������ȁB
L2=1MB�̓A�����Ǝv���̂����B�����_�C�T�C�Y�͐S�z�B
High-k�Ɋւ��Ă�32nm�ƃg�����W�X�^�����ʉ�����Ȃ�45nm�̌㔼�ō̗p�͂��蓾��b���B
������Fudzilla�c�B
����I�t�B�V�����ň�x��L2=1MB�ƌ������킯�����c�B
�W��������Hydra�ƌ����Γ���9�B
�̗�1/4�B
CPU�Ƃ̊֘A���͎v��������ȁB
L2���₷���R�A�����₷�ق����ǂ����Ĕ��f�ɂȂ�����Ȃ����ȁH
�f�X�N�g�b�v���ǂ��키�̂��͂킩��Ȃ����ǁB
2009�N���ƃf�X�N�g�b�v�ƃm�[�g�̏o�ב䐔���t�]���Ă邾�낤����A
�f�X�N�g�b�v�ɗ͂�����̂͂�߂āA�m�[�g������Swift�ʼn҂������Ă��ƂȂ̂��낤���B
�f�X�N�g�b�v���ǂ��키�̂��͂킩��Ȃ����ǁB
2009�N���ƃf�X�N�g�b�v�ƃm�[�g�̏o�ב䐔���t�]���Ă邾�낤����A
�f�X�N�g�b�v�ɗ͂�����̂͂�߂āA�m�[�g������Swift�ʼn҂������Ă��ƂȂ̂��낤���B
>>75
>�ł�Inquirer�̓n�b�L��512KB�̂܂܂Ƃ͌����ĂȂ���Ȃ��H
>L2=1MB�̓A�����Ǝv���̂����B�����_�C�T�C�Y�͐S�z�B
The new stuff starts a year later with Istanbul, a six-core version of Shanghai.
There is nothing more to say about this one, same old same old +two cores.
6�R�A��Shanghai�B���Ɍ������Ƃ͉����Ȃ��B�Â��Â������R�A���Q�����������B
�܂�L2�������Ȃ��Ɩ��L�͂��ĂȂ��˂��B
>�ł�Inquirer�̓n�b�L��512KB�̂܂܂Ƃ͌����ĂȂ���Ȃ��H
>L2=1MB�̓A�����Ǝv���̂����B�����_�C�T�C�Y�͐S�z�B
The new stuff starts a year later with Istanbul, a six-core version of Shanghai.
There is nothing more to say about this one, same old same old +two cores.
6�R�A��Shanghai�B���Ɍ������Ƃ͉����Ȃ��B�Â��Â������R�A���Q�����������B
�܂�L2�������Ȃ��Ɩ��L�͂��ĂȂ��˂��B
���ꂪ�����ł���Ό��ꂵ�����[�h�}�b�v�ł���Ƃ��������悤������
����1�A�[�L�e�N�`���A���㕪�̒x�ꂾ��2010�N�ɂ�2�A�[�L�e�N�`���A���̒x��ƂȂ�
intel�Ƃ̍��͉v�X�J���Ă������낤���͊m��I�ɖ��炩
����1�A�[�L�e�N�`���A���㕪�̒x�ꂾ��2010�N�ɂ�2�A�[�L�e�N�`���A���̒x��ƂȂ�
intel�Ƃ̍��͉v�X�J���Ă������낤���͊m��I�ɖ��炩
>>78
Inq�̂͂Ƃ�����Montreal���L�����Z�������Istanbul�ɃX���C�h�����̂͌������\����B
AMD�A12�R�AOpteron�ȂǃT�[�o�[���[�h�}�b�v���X�V
http://pc.watch.impress.co.jp/docs/2008/0508/amd.htm
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/Roadmap_Update_Fact_Sheet_Final.pdf
Inq�̂͂Ƃ�����Montreal���L�����Z�������Istanbul�ɃX���C�h�����̂͌������\����B
AMD�A12�R�AOpteron�ȂǃT�[�o�[���[�h�}�b�v���X�V
http://pc.watch.impress.co.jp/docs/2008/0508/amd.htm
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/Roadmap_Update_Fact_Sheet_Final.pdf
AMD Announces 6 And 12-core Opterons
http://www.tomshardware.com/news/amd-opteron-phenom,5312.html
Tom's��������҂��ĂȂ��������ӊO�Ƒ��ł͏o�ĂȂ����
http://www.tomshardware.com/news/amd-opteron-phenom,5312.html
Tom's��������҂��ĂȂ��������ӊO�Ƒ��ł͏o�ĂȂ����
�}���`�\�P�b�gCPU�ȃV�X�e���̏ꍇ�ACPU�Ԃł̃f�[�^���L���厖������AL3
���ʂ̕������ʂ������ł���B
L2���ʂ͏��F�P�X���b�h�ł̐��\�E�v�ɂ����Ȃ�A�T�[�o�[�p�r�ł͌��X
�P�X���b�h�ł̐��\��������A�����X���b�h�ł̐��\���オ�L���Ȃ̂����B
����MetaRAM���ď���܂薳���݂��������A���̂܂�G3MX�̑���ɂȂ�
���Ęb�ɂȂ����́H
�܂������đ����čL�͈͂ɍ̗p�����̂Ȃ牽�ł��ǂ����B
���ʂ̕������ʂ������ł���B
L2���ʂ͏��F�P�X���b�h�ł̐��\�E�v�ɂ����Ȃ�A�T�[�o�[�p�r�ł͌��X
�P�X���b�h�ł̐��\��������A�����X���b�h�ł̐��\���オ�L���Ȃ̂����B
����MetaRAM���ď���܂薳���݂��������A���̂܂�G3MX�̑���ɂȂ�
���Ęb�ɂȂ����́H
�܂������đ����čL�͈͂ɍ̗p�����̂Ȃ牽�ł��ǂ����B
Shanghai will deliver about 20% more speed than Barcelona.
the idle power consumption of the new CPUs will be 20% below their 65 nm counterparts
����Ȃ�
the idle power consumption of the new CPUs will be 20% below their 65 nm counterparts
����Ȃ�
�T�[�o���ǂ����f�X�N�g�b�v�͂ǂ��Ȃ�낤�B
�n�C�G���h�͂Ƃ������Ƃ��ăn�C�p�t�H�[�}���X�܂�6�R�A���������Ȃ낤���B
����Ƃ�4�R�A�̂܂܂��B
����Ɍ������̉��̃��C���X�g���[����o�����[�́B
�m�[�g��������Fusion�����Ă���̂��Ȃ��B
Probe Filter�̎������@���C�ɂȂ�Ȃ��B
�n�C�G���h�͂Ƃ������Ƃ��ăn�C�p�t�H�[�}���X�܂�6�R�A���������Ȃ낤���B
����Ƃ�4�R�A�̂܂܂��B
����Ɍ������̉��̃��C���X�g���[����o�����[�́B
�m�[�g��������Fusion�����Ă���̂��Ȃ��B
Probe Filter�̎������@���C�ɂȂ�Ȃ��B
>>83
����Ȋ��������
$200�ȏ�@�@x4:Agena�@�@�@x4:Deneb�@�@x6:Istanbul
$200�`100�@x3:Agena�@�@�@x4:Propus�@�@x4:Deneb
$100�����@�@x2:Brisbane�@x2:Brisbane�@x4:Propus
����Ȋ��������
$200�ȏ�@�@x4:Agena�@�@�@x4:Deneb�@�@x6:Istanbul
$200�`100�@x3:Agena�@�@�@x4:Propus�@�@x4:Deneb
$100�����@�@x2:Brisbane�@x2:Brisbane�@x4:Propus
�I�@�R�A���₷
DT�@IPC���₷�i�A�[�L���ǁj
�m�[�g�@GPU�t����
���܂łR�Ƃ��قړ�������������
Fusion���@�ɕ����邩
����Ƃ�DT�͗D��x�Œ�ő��Q�̎g����
DT�@IPC���₷�i�A�[�L���ǁj
�m�[�g�@GPU�t����
���܂łR�Ƃ��قړ�������������
Fusion���@�ɕ����邩
����Ƃ�DT�͗D��x�Œ�ő��Q�̎g����
�f�X�N�g�b�v�̓T�[�o�̎g���܂킵���낤�ȁB�������łɂ��������B
���ς����Intel�̓n�C�G���h�̂ݎI�]�p�A�A�b�p�[�~�h���ȉ��̓m�[�g�]�p����
AMD�͂ǂ��R����낤
�P�R�A���\����Ȃ�����Ƃ����ĉ��ʂɂ܂ŃR�A�̑����I�Ή���܂��R�X�g���Ŏ��˂邼
AMD�͂ǂ��R����낤
�P�R�A���\����Ȃ�����Ƃ����ĉ��ʂɂ܂ŃR�A�̑����I�Ή���܂��R�X�g���Ŏ��˂邼
88 �FMAC�I�^���c�q �����F2008/05/08(��) 17:55:23 ID:UrOM/xel
>>50
Bulldozer��K9�̌��ǂ��������B
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-roadmap-restores-bit
�@�@------------------
�@�@The two biggest things are they aren't up to snuff core for core, and Bulldozer is looking
�@�@wounded if not dead.
�@�@------------------
Bulldozer��K9�̌��ǂ��������B
http://www.theinquirer.net/gb/inquirer/news/2008/05/07/amd-roadmap-restores-bit
�@�@------------------
�@�@The two biggest things are they aren't up to snuff core for core, and Bulldozer is looking
�@�@wounded if not dead.
�@�@------------------
�����̃j���[�X�Ō��y�����邷���ǁAAMD�̃T�[�o�[�����`�b�v�Z�b�g�̑��ł�����
nVidia�ɂ����̂Ă�ꂽ�͗l���B
http://www.tomshardware.com/news/amd-opteron-phenom,5312.html
�@�@------------------------
�@�@At least at this time AMD does not anticipate any Nvidia chipsets to support this platform
�@�@and says that it will couple the CPU with its own RD890S and RD870S northbridges as well
�@�@as the SB700S southbridge.
�@�@------------------------
�v���Z�b�T�J���݂̂Ȃ炸�A�`�b�v�Z�b�g�̒x��ŃT�[�o�[�s�����������܂ŏo�Ă������ˁB�B�B
nVidia�ɂ����̂Ă�ꂽ�͗l���B
http://www.tomshardware.com/news/amd-opteron-phenom,5312.html
�@�@------------------------
�@�@At least at this time AMD does not anticipate any Nvidia chipsets to support this platform
�@�@and says that it will couple the CPU with its own RD890S and RD870S northbridges as well
�@�@as the SB700S southbridge.
�@�@------------------------
�v���Z�b�T�J���݂̂Ȃ炸�A�`�b�v�Z�b�g�̒x��ŃT�[�o�[�s�����������܂ŏo�Ă������ˁB�B�B
N��AMD�s�ꂩ�狎��͎̂��Ԃ̖�肾�����̂��������X�E�E�E
�u���ڍ�
>>88
�����Ɠǂ߁BCharlie Demerjian�́uBulldozer��32nm�łȂ��Əo���Ȃ��̂�
������2010Q4�ɂȂ�v�ƌ����Ă�B
�s���̂����Ƃ��낾������ȁB
����Bulldozer�̓L�����Z���̉\���͏\������Ǝv�����ȁB�l�̋L����
���ӂ��˂��܂���͕̂ʂ̘b���B
�����Ɠǂ߁BCharlie Demerjian�́uBulldozer��32nm�łȂ��Əo���Ȃ��̂�
������2010Q4�ɂȂ�v�ƌ����Ă�B
�s���̂����Ƃ��낾������ȁB
����Bulldozer�̓L�����Z���̉\���͏\������Ǝv�����ȁB�l�̋L����
���ӂ��˂��܂���͕̂ʂ̘b���B
93 �FMAC�I�^��92 �����F2008/05/08(��) 18:50:24 ID:UrOM/xel
>>92
�������̂픻�邷���ǁAbulldozer�̏����v���45nm��16core������A����قǑ�K�͂ȃR�A��
�����햳���Ƃ����̂���ʂ̈ӌ����B�w32nm���K�v��bulldozer�x���đS�R���g���Ⴄ"����"��
�������ƂɂȂ邷�B
http://pc.watch.impress.co.jp/docs/2007/0801/kaigai377.htm
�@�@----------------------
�@�@Sandtiger�ɓ��ڂ���鎟����CPU�R�A�uBulldozer(�u���h�[�U)�v�R�A���A����قǑ傫��CPU�R�A
�@�@�łȂ����Ƃ������ł���B���Ȃ��Ƃ��A���s��K8/K10�n��CPU�R�A���A�傫����剻����������
�@�@�Ȃ��������B
�@�@----------------------
�������̂픻�邷���ǁAbulldozer�̏����v���45nm��16core������A����قǑ�K�͂ȃR�A��
�����햳���Ƃ����̂���ʂ̈ӌ����B�w32nm���K�v��bulldozer�x���đS�R���g���Ⴄ"����"��
�������ƂɂȂ邷�B
http://pc.watch.impress.co.jp/docs/2007/0801/kaigai377.htm
�@�@----------------------
�@�@Sandtiger�ɓ��ڂ���鎟����CPU�R�A�uBulldozer(�u���h�[�U)�v�R�A���A����قǑ傫��CPU�R�A
�@�@�łȂ����Ƃ������ł���B���Ȃ��Ƃ��A���s��K8/K10�n��CPU�R�A���A�傫����剻����������
�@�@�Ȃ��������B
�@�@----------------------
94 �FMAC�I�^���⑫�F2008/05/08(��) 18:51:28 ID:UrOM/xel
Gloo���w���x�Ə������Ӗ���A�����������O�̒m�����O��ɂȂ邷�B
��ʂ̈ӌ��Ƃ��W�Ȃ���ȁBCharlie Demerjian�͂��������Ă����B
�����ƕ��͍Ō�܂œǂ�łȂ��̂��B
HammerInfo�ɂ��ڂ��Ă邩��ǂ�ǂ���B
�����ƕ��͍Ō�܂œǂ�łȂ��̂��B
HammerInfo�ɂ��ڂ��Ă邩��ǂ�ǂ���B
96 �FMAC�I�^��95 �����F2008/05/08(��) 19:05:30 ID:UrOM/xel
>>95
������܂��̑f�{�������Ǝv���Ă���Ȃ�Groo��n���ɂ��������B
���Ȃ���Hammer-Info�̐M��҂��Ƃ������Ƃ헝�����������ǁA�������p���������ߋ����B�����߂�
�ߋ����O�����J���Ȃ��Ƃ����q�g������A�M���Ă������邾������(��)
������܂��̑f�{�������Ǝv���Ă���Ȃ�Groo��n���ɂ��������B
���Ȃ���Hammer-Info�̐M��҂��Ƃ������Ƃ헝�����������ǁA�������p���������ߋ����B�����߂�
�ߋ����O�����J���Ȃ��Ƃ����q�g������A�M���Ă������邾������(��)
>>96
The most distressing part is Bulldozer. Much was made of it not being on the roadmaps
last December, but that was a tempest in a tea kettle.
The real problems have come out since then, and the only way to say it is that
the architecture is a huge flop.
No, this isn't to say that it won't be fast or meet every spec that it was meant to,
simply that it can't be done on a 45nm process.
This means that it will be on the 32nm node pushing it out to late late 2010 best case.
It is probably a good time to mention that restoring confidence in the
AMD process roadmap might be a good thing right about now.
The most distressing part is Bulldozer. Much was made of it not being on the roadmaps
last December, but that was a tempest in a tea kettle.
The real problems have come out since then, and the only way to say it is that
the architecture is a huge flop.
No, this isn't to say that it won't be fast or meet every spec that it was meant to,
simply that it can't be done on a 45nm process.
This means that it will be on the 32nm node pushing it out to late late 2010 best case.
It is probably a good time to mention that restoring confidence in the
AMD process roadmap might be a good thing right about now.
��bulldozer�̏����v���45nm��16core������
45nm��16�R�A�Ƃ͖�������ĂȂ��͂������B
�O�T�ԑO��Bulldozer�͗��N�T���v�����Y����ƌ��������肾���琶���Ă͂��邾�낤�B
��������ł�Ȃ炠�̂Ƃ��m�[�R�����g�Œʂ����͂��B
����̃��[�h�}�b�v�����͊m���ɐ��i���o�����߂̂��̂��낤�ȁB
����Ōv��ʂ萻�i�������[�X�ł��Ȃ������B
���\�ʂ��S�z�ł͂��邪�܂��͕]���o���镨���o���Ė���Ƙb�ɂȂ��B
����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
Fab38���{�C�ŗ����グ�Đ키���肩�B
45nm��16�R�A�Ƃ͖�������ĂȂ��͂������B
�O�T�ԑO��Bulldozer�͗��N�T���v�����Y����ƌ��������肾���琶���Ă͂��邾�낤�B
��������ł�Ȃ炠�̂Ƃ��m�[�R�����g�Œʂ����͂��B
����̃��[�h�}�b�v�����͊m���ɐ��i���o�����߂̂��̂��낤�ȁB
����Ōv��ʂ萻�i�������[�X�ł��Ȃ������B
���\�ʂ��S�z�ł͂��邪�܂��͕]���o���镨���o���Ė���Ƙb�ɂȂ��B
����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
Fab38���{�C�ŗ����グ�Đ키���肩�B
99 �FMAC�I�^��98 �����F2008/05/08(��) 19:24:54 ID:UrOM/xel
>>98
�@�@-------------------
�@�@�O�T�ԑO��Bulldozer�͗��N�T���v�����Y����ƌ��������肾���琶���Ă͂��邾�낤�B
�@�@-------------------
Bulldozer�x�[�X�̐��i�̍ŏ��̌ڋq�ɂȂ��Ă���锤������Cray�ɓ�����ꂽ�̂�A�J�����j��
�ύX�̑傫�ȗ��R�ɂȂ肻�����B
�@�@-------------------
�@�@����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
�@�@Fab38���{�C�ŗ����グ�Đ키���肩�B
�@�@-------------------
����̓d�b��c�ł��L���p��]���Ă���ƌ����Ă������B
�@�@-------------------
�@�@�O�T�ԑO��Bulldozer�͗��N�T���v�����Y����ƌ��������肾���琶���Ă͂��邾�낤�B
�@�@-------------------
Bulldozer�x�[�X�̐��i�̍ŏ��̌ڋq�ɂȂ��Ă���锤������Cray�ɓ�����ꂽ�̂�A�J�����j��
�ύX�̑傫�ȗ��R�ɂȂ肻�����B
�@�@-------------------
�@�@����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
�@�@Fab38���{�C�ŗ����グ�Đ키���肩�B
�@�@-------------------
����̓d�b��c�ł��L���p��]���Ă���ƌ����Ă������B
>>98
>����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
Istanbul/Sao Paolo/Magny-Cours��1�_�C������6�R�A,L2=512KBx6,L3=6MB�B
Barcelona�Ɣ�ׂăR�A������L2�܂߂�1.5�{�AL3��2MB��6MB����
65nm��45nm�ւ̃V�������N�����l����ƃ_�C�T�C�Y��Barcelona�Ɠ����x���낤�B
>����ɂ��Ă�AMD�̓_�C�T�C�Y�Ɋւ��Ă͂��\���Ȃ����ȁB
Istanbul/Sao Paolo/Magny-Cours��1�_�C������6�R�A,L2=512KBx6,L3=6MB�B
Barcelona�Ɣ�ׂăR�A������L2�܂߂�1.5�{�AL3��2MB��6MB����
65nm��45nm�ւ̃V�������N�����l����ƃ_�C�T�C�Y��Barcelona�Ɠ����x���낤�B
101 �FMAC�I�^��100 �����F2008/05/08(��) 19:33:54 ID:UrOM/xel
>>100
�Ƃ팾���A���w���R�X�g�Ȑ��i���A�����������������x�Ƃ������Ԃ�����A45nm����ŏ����y��
������������Ȃ������ˁB�B�B
�Ƃ팾���A���w���R�X�g�Ȑ��i���A�����������������x�Ƃ������Ԃ�����A45nm����ŏ����y��
������������Ȃ������ˁB�B�B
���Ȃ݂Ɏ���A����̌����H����]�����Ă��邷�B
���[�G���h�s��Ō����ɐ����c�邱�Ƃ��ł���A�����핂���Ԑ������邷��B
���[�G���h�s��Ō����ɐ����c�邱�Ƃ��ł���A�����핂���Ԑ������邷��B
�p���������ߋ����Ȃ��������Ƃɂ��Ă�̂͂��݂��l���낤�B
105 �FMAC�I�^��103 �����F2008/05/08(��) 19:43:48 ID:UrOM/xel
>>103
���̏������݂�A�Q�����˂�̉ߋ����O�Ƃ��ĂقڑS�Ďc���Ă��邷��B
���̏������݂�A�Q�����˂�̉ߋ����O�Ƃ��ĂقڑS�Ďc���Ă��邷��B
�p���������ߋ����B�����߂Ƀg���b�v�����Ȃ��Ƃ����q�g������
>>100
Shanghai�ł��ł�250mm2�Ȃ��Ƃ��l����ƃR�A�������₵�Ă�300mm2�����͊m���ł���B
350mm2�܂ł͂����Ȃ��Ǝv�����ǁB
Shanghai�ł��ł�250mm2�Ȃ��Ƃ��l����ƃR�A�������₵�Ă�300mm2�����͊m���ł���B
350mm2�܂ł͂����Ȃ��Ǝv�����ǁB
I/O�����܂�V�������N���Ȃ����炩�ADRAM�C���^�[�t�F�C�X�̂���ӂ�8�����܂ł����V�������N���ĂȂ��B
���Ə璷�����̂������AL3�����ɂł����B
���Ə璷�����̂������AL3�����ɂł����B
�Ƃ肠����Catalunya�������I
Torrenza/Accelerated Computing�\�z�͑啝��ށH
http://www.4gamer.net/news/history/2006.12/20061220200838detail.html
> ���`���[�h���͈ꌾ�C�u������R�A�푈�͏I���v�ƁC�����ɒf���Ă݂���
http://journal.mycom.co.jp/articles/2006/12/16/amd1/002.html
> AMD�ɂ��A�P���ɃR�A�̐��\�␔���グ�邾���̎���͂��łɏI���
http://blog.livedoor.jp/amd646464/archives/50756163.html
> �u�M�K�w���c���[�X�����s�ɏI������悤�ɁA�}���`�R�A�v���Z�b�T�����s��
> �I��邱�Ƃ����肤��v�Əq�ׂĂ���A�u�z���W�j�A�X�^�̃}���`�R�A�͍���
> ���N�ł���ƕs�K���ƂȂ邾�낤�v�Əq�ׂĂ��܂�
http://www.4gamer.net/news/history/2006.12/20061220200838detail.html
> ���`���[�h���͈ꌾ�C�u������R�A�푈�͏I���v�ƁC�����ɒf���Ă݂���
http://journal.mycom.co.jp/articles/2006/12/16/amd1/002.html
> AMD�ɂ��A�P���ɃR�A�̐��\�␔���グ�邾���̎���͂��łɏI���
http://blog.livedoor.jp/amd646464/archives/50756163.html
> �u�M�K�w���c���[�X�����s�ɏI������悤�ɁA�}���`�R�A�v���Z�b�T�����s��
> �I��邱�Ƃ����肤��v�Əq�ׂĂ���A�u�z���W�j�A�X�^�̃}���`�R�A�͍���
> ���N�ł���ƕs�K���ƂȂ邾�낤�v�Əq�ׂĂ��܂�
>>111
�Ƃ肠�������ƂQ�N�ȓ��ɂ͂Ȃ���o�Ȃ�
�Ƃ肠�������ƂQ�N�ȓ��ɂ͂Ȃ���o�Ȃ�
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
http://pc.watch.impress.co.jp/docs/2006/0713/kaigai287.htm
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://www.itmedia.co.jp/news/articles/0804/14/news024.html
http://pc.watch.impress.co.jp/docs/2006/0713/kaigai287.htm
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://www.itmedia.co.jp/news/articles/0804/14/news024.html
�������߂�
�ő���y�ϓI�ȗ\���ǂ���Ƀ��[�h�}�b�v���i�Ƃ��Ă�Intel�ɏ��Ă�C�����Ȃ��B
����ƌܕ��ܕ��ɂȂ邭�炢���B
����ƌܕ��ܕ��ɂȂ邭�炢���B
���Ńg�`������L2��������Ȃ����������H
>>115
�ܕ��ܕ�����Harpertown�Ƃ��H
3.2G/4core/8SMT��Nehalem��2.8G/4core/4SMT��Shanghai�ő����ł��ł���Ƃ�
����v���Ȃ����B
�ܕ��ܕ�����Harpertown�Ƃ��H
3.2G/4core/8SMT��Nehalem��2.8G/4core/4SMT��Shanghai�ő����ł��ł���Ƃ�
����v���Ȃ����B
>>108
�������u���b�N�\���ɂ����̂��V�������N���������������̈�B
�ˑR6�R�A�Ƃ�������_��͂���݂��������c�B
>>115
�ܕ��ܕ��ɂȂ�ĂȂꂽ���̎�����B�R���邽�߂�6�R�A�ŁB
8�R�A�ŁBMCM12�R�A�B������������MCM16�R�A�Ȃ̂�������Ȃ����B
>>116
Nehalem�̐v�w����K8�n�Ɠ����B�����R���������邩��A
L2�AL3�Ƃ��ɂ��قǑ傫�ȗe�ʂ͕K�v���Ȃ��Ƃ̔��f�B
�����A�L���b�V���̐��\��Intel�̂��������ǂˁB
�������u���b�N�\���ɂ����̂��V�������N���������������̈�B
�ˑR6�R�A�Ƃ�������_��͂���݂��������c�B
>>115
�ܕ��ܕ��ɂȂ�ĂȂꂽ���̎�����B�R���邽�߂�6�R�A�ŁB
8�R�A�ŁBMCM12�R�A�B������������MCM16�R�A�Ȃ̂�������Ȃ����B
>>116
Nehalem�̐v�w����K8�n�Ɠ����B�����R���������邩��A
L2�AL3�Ƃ��ɂ��قǑ傫�ȗe�ʂ͕K�v���Ȃ��Ƃ̔��f�B
�����A�L���b�V���̐��\��Intel�̂��������ǂˁB
intel��̒������L���b�V������������
�I���������łȂ�R�A���\���R�A���Ƃ��i�H�j
�L���b�V����胁�����Ƃ����������ɂȂ�͉̂���
������
ttp://pc.watch.impress.co.jp/docs/2008/0318/intel.htm
��Nehalem�́A�m�[�g�u�b�N����n�C�p�t�H�[�}���X�T�[�o�[�܂ŕ��L���J�o�[�����R���V���[�}�������i�B
DT�Ȃǂł����������̃L���b�V�����\�̉��b���̂ċ���̂Ȃ�
����ς苶���������̃I���S�����Ȃ��Ǝv�킸�ɂ͂����Ȃ�
�܂��e�ʌ�����C�e���V��������Č�������
�z�u�I��L3�ł�L2�Ɠ����e�ʓ������C�e���V���Ă̂������ł���̂���
���ƃ����R�����S��d�o�X���̉��b��
�����₽�瑛����Ă����nj���AMDCPU�̃L�r�L�r���́h�ꕔ�h�Ȃ����ł���
�I�Ȃ�Ƃ������命���̃x���`�ɂ͖w�NJW�������낤��
�L���b�V����胁�����Ƃ����������ɂȂ�͉̂���
������
ttp://pc.watch.impress.co.jp/docs/2008/0318/intel.htm
��Nehalem�́A�m�[�g�u�b�N����n�C�p�t�H�[�}���X�T�[�o�[�܂ŕ��L���J�o�[�����R���V���[�}�������i�B
DT�Ȃǂł����������̃L���b�V�����\�̉��b���̂ċ���̂Ȃ�
����ς苶���������̃I���S�����Ȃ��Ǝv�킸�ɂ͂����Ȃ�
�܂��e�ʌ�����C�e���V��������Č�������
�z�u�I��L3�ł�L2�Ɠ����e�ʓ������C�e���V���Ă̂������ł���̂���
���ƃ����R�����S��d�o�X���̉��b��
�����₽�瑛����Ă����nj���AMDCPU�̃L�r�L�r���́h�ꕔ�h�Ȃ����ł���
�I�Ȃ�Ƃ������命���̃x���`�ɂ͖w�NJW�������낤��
Nehalem��L3�̃��C�e���V�͗ǂ���30�`40�Ƃ����b�Ȃ̂ŁA
Barcelona��L3��38�T�C�N���Ɣ�ׂĂ������������Ƃ����킯����Ȃ��͗l�B
L2�̗e�ʂ�L3�Ƃ̊W�����邾�낤���A�P���ɗe�ʌ��炵�����炾�߂��Ă킯����Ȃ����낤���ǁA
Nehalem��L2��L1.5�݂����Ɍ����͖̂���������悤�Ɏv���B
Barcelona��L3��38�T�C�N���Ɣ�ׂĂ������������Ƃ����킯����Ȃ��͗l�B
L2�̗e�ʂ�L3�Ƃ̊W�����邾�낤���A�P���ɗe�ʌ��炵�����炾�߂��Ă킯����Ȃ����낤���ǁA
Nehalem��L2��L1.5�݂����Ɍ����͖̂���������悤�Ɏv���B
122 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 13:16:21 ID:/IFgkn/u
Nehalem�̎����ゾ���ǃ��C�e���V��L2��9�A L3��33
ttp://microboy.seesaa.net/article/70255114.html
ttp://microboy.seesaa.net/article/70255114.html
123 �FSocket774�F2008/05/09(��) 13:18:04 ID:HCh+MZlP
>121
���ꂪ�ł���̂Ȃ�L2���炷�Ӗ����킩��ˁB���C�e���V���炷���߂�
L2���炵��L3�lj��Ȃ���B�����r���L���b�V���݂����ȕ��G�Ȃ��Ƃ�
���Ȃ����낤����K10��葁���̂͑��ς�炸�����Ǝv�����ǁB
���ꂪ�ł���̂Ȃ�L2���炷�Ӗ����킩��ˁB���C�e���V���炷���߂�
L2���炵��L3�lj��Ȃ���B�����r���L���b�V���݂����ȕ��G�Ȃ��Ƃ�
���Ȃ����낤����K10��葁���̂͑��ς�炸�����Ǝv�����ǁB
124 �FSocket774�F2008/05/09(��) 19:28:52 ID:f4dHj5Ik
>123
�C���e���̃L���b�V����L2��L3�Ƃ��ł������f�[�^�����̂ŁA
������x�̗e�ʂ̍����Ȃ��Ɣ�����ɂȂ��Ă��܂����炶��Ȃ����������B
L2�̍��v��4M����L3��8M�̂���������L2�Ɠ����f�[�^�������Ă��܂����ƂɂȂ�B
���ꂶ��L3�̌��ʂ�����邩��L2�����������Ȃ��Ƃ����Ȃ��B
�C���e���̃L���b�V����L2��L3�Ƃ��ł������f�[�^�����̂ŁA
������x�̗e�ʂ̍����Ȃ��Ɣ�����ɂȂ��Ă��܂����炶��Ȃ����������B
L2�̍��v��4M����L3��8M�̂���������L2�Ɠ����f�[�^�������Ă��܂����ƂɂȂ�B
���ꂶ��L3�̌��ʂ�����邩��L2�����������Ȃ��Ƃ����Ȃ��B
125 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 19:33:13 ID:/IFgkn/u
�t�ɍl�����ق������R�����ȁB�e�ʍ����������Ȃ��Ɣr���̈Ӗ��������ƁB
64KB+64KB���邩����2Way set associative��AMD�A�[�L��L1�͂ǂ��������Đ���Ă�B
64KB+64KB���邩����2Way set associative��AMD�A�[�L��L1�͂ǂ��������Đ���Ă�B
>>118
>�����R���������邩��A L2�AL3�Ƃ��ɂ��قǑ傫�ȗe�ʂ͕K�v���Ȃ��Ƃ̔��f�B
�Ⴄ���āB�l�C�e�B�u�N�A�b�h��Nehalem�ł͓���45nm�Ńj�R�C�`��Yorkfield��
����12MB���ς�_�C�T�C�Y���傫���Ȃ肷���邩�琫�\�ƃ_�C�T�C�Y��
�o�����X��8MB�ɂ��������B
Westmere�ł�6�R�A�ɑ��₵��L3��12MB�ɑ��ʂ����B
��������Istanbul��6�R�A�����邪L3��6MB�����u��������Westmere����ł�
�����L����B
>�����R���������邩��A L2�AL3�Ƃ��ɂ��قǑ傫�ȗe�ʂ͕K�v���Ȃ��Ƃ̔��f�B
�Ⴄ���āB�l�C�e�B�u�N�A�b�h��Nehalem�ł͓���45nm�Ńj�R�C�`��Yorkfield��
����12MB���ς�_�C�T�C�Y���傫���Ȃ肷���邩�琫�\�ƃ_�C�T�C�Y��
�o�����X��8MB�ɂ��������B
Westmere�ł�6�R�A�ɑ��₵��L3��12MB�ɑ��ʂ����B
��������Istanbul��6�R�A�����邪L3��6MB�����u��������Westmere����ł�
�����L����B
�C���N���[�V�u�ł͉��ʂ̗e�ʂ���ʂƓ����ɂ��邾���ňӖ��������Ȃ�
�G�N�X�N���[�V�u�ł͗e�ʍ����ǂꂾ������悤�Ƃ��Ӌ`�����S�ɖ����Ȃ�Ƃ������Ƃ͂Ȃ�
������킴�킴��������Ԃ��Ă���̂����̔n��>125
�G�N�X�N���[�V�u�ł͗e�ʍ����ǂꂾ������悤�Ƃ��Ӌ`�����S�ɖ����Ȃ�Ƃ������Ƃ͂Ȃ�
������킴�킴��������Ԃ��Ă���̂����̔n��>125
128 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 20:32:58 ID:/IFgkn/u
ha?
2-way set assosiative�Ȃ�Ă��ꂱ���s�[�N���\�d����PPC970���炢�����Ȃ�����B
Mac��PPC����G4�܂ł�L1��32K+32K
G5�ɂȂ��Ă���64K+64K��2way set associative�ɂȂ�A����IPC���i�i�ɗ������B
AMD��IBM�̕a�C���������Ă�͎̂���
2-way set assosiative�Ȃ�Ă��ꂱ���s�[�N���\�d����PPC970���炢�����Ȃ�����B
Mac��PPC����G4�܂ł�L1��32K+32K
G5�ɂȂ��Ă���64K+64K��2way set associative�ɂȂ�A����IPC���i�i�ɗ������B
AMD��IBM�̕a�C���������Ă�͎̂���
Inside Nehalem: Intel's Future Processor and System
By: David Kanter
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719&p=7
L1D: 4 cycle
L2: 12 cycle����
L3: 30-40 cycle
By: David Kanter
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719&p=7
L1D: 4 cycle
L2: 12 cycle����
L3: 30-40 cycle
�܂�64+64 16 way��isaiah�ŋ�
�t�F�b�`���v���t�F�b�`������
ha?
ha?
�r���Ȃ̂�L2��16way�AL1��2way�̃o�����X���Ăǂ��Ȃ́H
�Ƃ������������Ƃ͘b��ɂ��ĂȂ�
�����ƈ�ʓI�ȁi���Ƃ̔��f����j
�u�����̒m�\���Ăǂ��Ȃ́H�v
�Ƃ������Ƃ������Ă���
�Ƃ������������Ƃ͘b��ɂ��ĂȂ�
�����ƈ�ʓI�ȁi���Ƃ̔��f����j
�u�����̒m�\���Ăǂ��Ȃ́H�v
�Ƃ������Ƃ������Ă���
�c�O�Ȃ���a�C�̎q��ɂ������_��>>132�̕����͊m�肵�Ă܂�
134 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 22:01:49 ID:/IFgkn/u
������AL1��Way����㏞�ɂ��đ傫����������炱���AL2�Ɣr���ɂ��郁���b�g���傫����������ł���B
250�`180nm�v���Z�X�ł�L2�T�C�Y��128K�`256K���炢����ʓI����������ˁB
250�`180nm�v���Z�X�ł�L2�T�C�Y��128K�`256K���炢����ʓI����������ˁB
>>129
L1 ���C�e���V3��4�B
L2 6MB��512KB�ɂȂ��āA���C�e���V15��11�ȉ��B
�ŁAL2 6MB����L3 8MB�ɂȂ��āA���C�e���V15��30�ȏ�B
�Ȃ]�v�ȂƂ���ύX���āA���������ʂȓw�͂����Ă銴��������B
Penryn�����ǂ���MCM��Core 3 Quad�o�����ق����R�X�g�����\���ǂ������ȋC��������B
L1 ���C�e���V3��4�B
L2 6MB��512KB�ɂȂ��āA���C�e���V15��11�ȉ��B
�ŁAL2 6MB����L3 8MB�ɂȂ��āA���C�e���V15��30�ȏ�B
�Ȃ]�v�ȂƂ���ύX���āA���������ʂȓw�͂����Ă銴��������B
Penryn�����ǂ���MCM��Core 3 Quad�o�����ق����R�X�g�����\���ǂ������ȋC��������B
�݂�Ȃ���ۂǃl�n������������(�E�L��`�E)
�I���S����Digital Enterprise Group������A�I�����Ŏア�Ƃ�����Ԃ��Ă�������Ȃ��́H
138 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 22:46:38 ID:/IFgkn/u
�ނ���Phenom�v�����̂��I���S���̃`�[�t�A�[�L�e�N�g����B
���ł��������瑁��GPU���ߓ������Ă���
>>134
way�����Ȃ���Ηe�ʃf�J�����Ȃ���Ȃ�Ȃ��킯�ł��Ȃ�����
way�Ɣr���͖��W
�ނ���1�f�[�^�T�C�Y�̖ڈ������߂Ă���Ȃ�
way�����点�Ηe�ʂ����炵
way�𑝂₹�Ηe�ʂ����₳�Ȃ���Ȃ�Ȃ�
�i�I��AMD�͒P�ʃT�C�Y���f�J���A�x���`�d���ŃL���b�V�������intel��way�𑝂₵������ł͂Ȃ��낤��
�@���ۂ̗L���T�C�Y���ǂ�Ȃ����Ƃ��͒m��ǁj
ttp://journal.mycom.co.jp/column/architecture/006/index.html
�Ƃ肠�����������Q�l�i�Ƃ������L�ۂ݁j�ɂ��Ă���
L1�ŃX���b�V���O�����������ꍇ
�C���N���[�V�u�i���ꊿ���ŏ����Ȃ����ˁj�Ȃ�L2�Ɏ��ɂ��������낤����
�G�N�X�N���[�V�u���ƃ������ɂ��������킯����ˁH
L2��L1�̓y��ł͂Ȃ��⍲�ł����Ȃ��r�������Ȃ̂�
way����2��12�Ő�������������Ă̂͂ǂ��Ȃ낤��
�ܘ_����͔n���ȊO�̐l�ɕ����Ă��
way�����Ȃ���Ηe�ʃf�J�����Ȃ���Ȃ�Ȃ��킯�ł��Ȃ�����
way�Ɣr���͖��W
�ނ���1�f�[�^�T�C�Y�̖ڈ������߂Ă���Ȃ�
way�����点�Ηe�ʂ����炵
way�𑝂₹�Ηe�ʂ����₳�Ȃ���Ȃ�Ȃ�
�i�I��AMD�͒P�ʃT�C�Y���f�J���A�x���`�d���ŃL���b�V�������intel��way�𑝂₵������ł͂Ȃ��낤��
�@���ۂ̗L���T�C�Y���ǂ�Ȃ����Ƃ��͒m��ǁj
ttp://journal.mycom.co.jp/column/architecture/006/index.html
�Ƃ肠�����������Q�l�i�Ƃ������L�ۂ݁j�ɂ��Ă���
L1�ŃX���b�V���O�����������ꍇ
�C���N���[�V�u�i���ꊿ���ŏ����Ȃ����ˁj�Ȃ�L2�Ɏ��ɂ��������낤����
�G�N�X�N���[�V�u���ƃ������ɂ��������킯����ˁH
L2��L1�̓y��ł͂Ȃ��⍲�ł����Ȃ��r�������Ȃ̂�
way����2��12�Ő�������������Ă̂͂ǂ��Ȃ낤��
�ܘ_����͔n���ȊO�̐l�ɕ����Ă��
>>138
������L3�ɂ������̂��E�E�E�B
������L3�ɂ������̂��E�E�E�B
142 �F�R�E�L�́M�E,,�j�����������������F2008/05/09(��) 23:01:00 ID:/IFgkn/u
����`�f�[�^�\������Way�������Ȃ��ƃL���b�V�������������Ȃ邪��
>>128
AMD��L1��64K+64K��2way set associative�Ȃ̂�Alpha21264����ł���
AMD��L1��64K+64K��2way set associative�Ȃ̂�Alpha21264����ł���
intel��L1��way���������̂́A1way�̑傫����4KB�܂łɗ}����������ł͂Ȃ��낤���B
�y�[�W�ϊ����Ă��A�h���X�̉���12bit�͕ω����Ȃ��̂ŁA
1way�̑傫����4KB�܂łȂ�y�[�W�ϊ�����O��set�ԍ������ł���B
�y�[�W�ϊ����Ă��A�h���X�̉���12bit�͕ω����Ȃ��̂ŁA
1way�̑傫����4KB�܂łȂ�y�[�W�ϊ�����O��set�ԍ������ł���B
16�R�A�̃}�V���͂���Ȃ����ǁA16�R�A�̃_�C�`���[���͂������ق����B
�_�C�`���[�����@�͂��ꂩ��������Ăق����B�ǂ����ޗ��͂����ς������B
�_�C�`���[�����@�͂��ꂩ��������Ăق����B�ǂ����ޗ��͂����ς������B
AMD Updates Server/Workstation Roadmap
http://www.vr-zone.com/articles/AMD_Updates_ServerWorkstation_Roadmap/5757.html
http://www.vr-zone.com/articles/AMD_Updates_ServerWorkstation_Roadmap/5757.html
>>118
>�������u���b�N�\���ɂ����̂��V�������N���������������̈�B
>�ˑR6�R�A�Ƃ�������_��͂���݂��������c�B
������P�N����AShanghai����P�N���6�R�A������������Istanbul�B
�������Ȃ�Ƃ��Ȃ���BBarcelona�ȍ~�AAMD�̃o���G�[�V�������f���̊J���y�[�X��
Intel�ɔ�ׂĒ���������Ă�B�܂��J��������Ȃ��낤���ǁB
�\��ɂȂ�6�R�A�����[�h�}�b�v�ɏ悹����\�肳��Ă�2�R�A��\��ʂ�o���ƁB
>�������u���b�N�\���ɂ����̂��V�������N���������������̈�B
>�ˑR6�R�A�Ƃ�������_��͂���݂��������c�B
������P�N����AShanghai����P�N���6�R�A������������Istanbul�B
�������Ȃ�Ƃ��Ȃ���BBarcelona�ȍ~�AAMD�̃o���G�[�V�������f���̊J���y�[�X��
Intel�ɔ�ׂĒ���������Ă�B�܂��J��������Ȃ��낤���ǁB
�\��ɂȂ�6�R�A�����[�h�}�b�v�ɏ悹����\�肳��Ă�2�R�A��\��ʂ�o���ƁB
Shanghai/Istanbul�͌��s�̃`�b�v�Z�b�g�ň�������悤�����A
HT 3.0��socket�Ԃ�����I/O��HT 2.0�ōs���Ƃ������Ƃ��낤���B
PCIe 2.0�f�o�C�X�̂قڊF����server�͂���œ��ɖ�肪����킯�ł͂Ȃ����A
HT 3.0��socket�Ԃ�����I/O��HT 2.0�ōs���Ƃ������Ƃ��낤���B
PCIe 2.0�f�o�C�X�̂قڊF����server�͂���œ��ɖ�肪����킯�ł͂Ȃ����A
>>147
"Shanghai"��2008�N�㔼�Ƃ�����08Q4����09Q1�\��B
������09H2�ɂ�"Istanbul"���o������\�������B
���Ԃ�"Rev.D"�R�A���낤���B
"Rev.D"���x�ꂽ��"Istanbul"���x��邾�낤���ǁB
"Shanghai"��2008�N�㔼�Ƃ�����08Q4����09Q1�\��B
������09H2�ɂ�"Istanbul"���o������\�������B
���Ԃ�"Rev.D"�R�A���낤���B
"Rev.D"���x�ꂽ��"Istanbul"���x��邾�낤���ǁB
Deneb��Propus���ׂ�ׂ�����Ȃ��̂��ˁB
���Ƃ�45nm��Kuma���ǂꂾ�������o�邩�Ƃ��B
���Ƃ�45nm��Kuma���ǂꂾ�������o�邩�Ƃ��B
���s��40%���ăl�g�o��萦����
���L���b�V�����������邾���̂��Ƃ͂���
���L���b�V�����������邾���̂��Ƃ͂���
>>149
09H2��09Q4�Ƃقړ��`����BIstanbul��Shanghai�̂��傤�ǂP�N��B
��������Shanghai������08H2�\�肾�����̂ɂ��ꂪ09Q1�ɒx���Ƃ�����
Istanbul���x��Ȃ��Ƃ悭�l������ˁB
09H2��09Q4�Ƃقړ��`����BIstanbul��Shanghai�̂��傤�ǂP�N��B
��������Shanghai������08H2�\�肾�����̂ɂ��ꂪ09Q1�ɒx���Ƃ�����
Istanbul���x��Ȃ��Ƃ悭�l������ˁB
�o���G�[�V�����_�C�̃��C���i�b�v�A[]����MCM�ɂ��o���G�[�V�����lj��A
���L���̑������̂͂P�ŃJ�E���g�B
��Conroe�n 65nm
Conroe(x2,4MB)�A[Kentsfield(x2,4MB)x2]�AAllendale(x2,2MB)�AConroe-L(x1,1MB)
��Penryn�n 45nm
Wolfdale(x2,6MB)�A[Yorkfield(x2,6MB)x2]�AWolfdale-M(x2,3MB)�A[Yorkfield-M(x2,3MB)x2]
Dunnington(x6,16MB)
��Nehalem�n 45nm
Bloomfield(x4,8MB)�AHavendale(GPU,x2,4MB)
Beckton(x6,24MB)
��AMD 65nm
Brisbane(x2,1MB)�AAgena(x4,2MB)�ALima(x1,512KB)
��AMD 45nm
Deneb(x4,6MB)�APropus(x4,0MB)�ARegor(x2,0MB)�AIstanbul(x6,6MB)�ASao Paolo(x6,6MB)
[Magny-Cours(x6,6MB)x2]
���L���̑������̂͂P�ŃJ�E���g�B
��Conroe�n 65nm
Conroe(x2,4MB)�A[Kentsfield(x2,4MB)x2]�AAllendale(x2,2MB)�AConroe-L(x1,1MB)
��Penryn�n 45nm
Wolfdale(x2,6MB)�A[Yorkfield(x2,6MB)x2]�AWolfdale-M(x2,3MB)�A[Yorkfield-M(x2,3MB)x2]
Dunnington(x6,16MB)
��Nehalem�n 45nm
Bloomfield(x4,8MB)�AHavendale(GPU,x2,4MB)
Beckton(x6,24MB)
��AMD 65nm
Brisbane(x2,1MB)�AAgena(x4,2MB)�ALima(x1,512KB)
��AMD 45nm
Deneb(x4,6MB)�APropus(x4,0MB)�ARegor(x2,0MB)�AIstanbul(x6,6MB)�ASao Paolo(x6,6MB)
[Magny-Cours(x6,6MB)x2]
�u"Istanbul"���x��邾�낤���ǁB�v�Ƃ���̂����ڂ�
�uIstanbul���x��Ȃ��Ƃ悭�l������ˁB�v�ȂǂƂ悭�������
�uIstanbul���x��Ȃ��Ƃ悭�l������ˁB�v�ȂǂƂ悭�������
>>153 ����
Beckton(x8,24MB)
Beckton(x8,24MB)
Regor��L3�L��Ɩ����Ɨ�������
���Č����ĂȂ����������H
���Č����ĂȂ����������H
>>157
L3�Ȃ�4�R�A��Propus������ȏ�ARegor��L3������I�����́v�Ȃ����낤�ˁB
Propus���_�C�T�C�Y�傫���Ȃ����Ⴄ��B
L3�Ȃ�4�R�A��Propus������ȏ�ARegor��L3������I�����́v�Ȃ����낤�ˁB
Propus���_�C�T�C�Y�傫���Ȃ����Ⴄ��B
Istanbul��6�R�A�Ƃ����̂́APhenomX3�Ɠ��l�ɁA8�R�A���Ő������āA
���ׂ̂���R�A���ɂ��āA6�R�A�Ƃ���̂�������Ȃ��B
�_�C�̖ʐς������Ă���ƁA�ǂ����Ă������܂肪�ቺ���邩��A
�ቿ�i��������Ȃ�A����������Ȃ��̂�������Ȃ��B
������wafer scale IC�ł͕K�{�̋Z�p���낤���AIntel���A���̂���
�������Ƃ��n�߂�̂ł�?
���ׂ̂���R�A���ɂ��āA6�R�A�Ƃ���̂�������Ȃ��B
�_�C�̖ʐς������Ă���ƁA�ǂ����Ă������܂肪�ቺ���邩��A
�ቿ�i��������Ȃ�A����������Ȃ��̂�������Ȃ��B
������wafer scale IC�ł͕K�{�̋Z�p���낤���AIntel���A���̂���
�������Ƃ��n�߂�̂ł�?
>>159
����͂Ȃ�
����͂Ȃ�
>>160
���ʂɂ��邾�� JK
���ʂɂ��邾�� JK
>>159
��������Phenom��X4���Ă�悤��8�R�A�ł����R�����B
�[��45nm��8�R�A�����ă_�C�T�C�Y�ǂ��[
Istanbul��5�R�A�ł͏o���\���͂���B
>>161
Agena�ɂ�L3�Ȃ��ł͂Ȃ�����Kuma�ƃ|�W�V�����������ɂȂ邱�Ƃ͂Ȃ��B
�܂����Ǐo�Ȃ������킯�����B
��������Phenom��X4���Ă�悤��8�R�A�ł����R�����B
�[��45nm��8�R�A�����ă_�C�T�C�Y�ǂ��[
Istanbul��5�R�A�ł͏o���\���͂���B
>>161
Agena�ɂ�L3�Ȃ��ł͂Ȃ�����Kuma�ƃ|�W�V�����������ɂȂ邱�Ƃ͂Ȃ��B
�܂����Ǐo�Ȃ������킯�����B
>>162
AMD�̐����Z�p�Ɛ����L���p���ǂ��������ς����Ă���悗
AMD�̐����Z�p�Ɛ����L���p���ǂ��������ς����Ă���悗
>>163
45n�͂U�R�A�܂ł�
32n�ɂȂ��Ă���W�R�A�����Ęb������
�G���R���ˁ[�Ȃ�w�LjӖ��Ȃ����������c
�Q�[�}�[�͂Q�R�A��4.5G�Ƃ�����Ă��ꂽ�ق����������̂ɂȂ�
45n�͂U�R�A�܂ł�
32n�ɂȂ��Ă���W�R�A�����Ęb������
�G���R���ˁ[�Ȃ�w�LjӖ��Ȃ����������c
�Q�[�}�[�͂Q�R�A��4.5G�Ƃ�����Ă��ꂽ�ق����������̂ɂȂ�
>>150
����Deneb��Propus�̐��\����������������L3��������L2�g��Ƃ�������肷��̂��ȁH
���̃R�A�Ƀf�[�^�n�����ɋ��LL3����ƕ֗��݂��������c
����Deneb��Propus�̐��\����������������L3��������L2�g��Ƃ�������肷��̂��ȁH
���̃R�A�Ƀf�[�^�n�����ɋ��LL3����ƕ֗��݂��������c
L2��1MB�ɑ��ʂ���͂�������Montreal���L�����Z���ɂȂ����̂ƁA
���܂Ńf�X�N�g�b�v�͎I�����𗬗p����������AL2���ʂ̉\���͒Ⴂ��Ȃ����ȁH
���܂Ńf�X�N�g�b�v�͎I�����𗬗p����������AL2���ʂ̉\���͒Ⴂ��Ȃ����ȁH
45nm��L2���ʔł̏o��\����Magny-Cours���L�����Z�������\���ȉ�����
>>163
PhenomX3��AMD���ł��o�������Ƃ́A���炩���ߏ璷�����������ă_�C��
����Ă����A���̌�A���ׂ̂��镔�����ɂ���Ƃ����������@��
�Ƃ�Ƃ������Ƃł͂Ȃ����낤���B
�R�A�����������_�C�ʐς��傫���Ȃ�ꍇ�A���ׂ����w�͂����ĕ���
�܂�����コ��������A���̂ق����ቿ�i���ɂȂ���ƍl���Ă����
��������Ȃ��B
PhenomX3��AMD���ł��o�������Ƃ́A���炩���ߏ璷�����������ă_�C��
����Ă����A���̌�A���ׂ̂��镔�����ɂ���Ƃ����������@��
�Ƃ�Ƃ������Ƃł͂Ȃ����낤���B
�R�A�����������_�C�ʐς��傫���Ȃ�ꍇ�A���ׂ����w�͂����ĕ���
�܂�����コ��������A���̂ق����ቿ�i���ɂȂ���ƍl���Ă����
��������Ȃ��B
�R�A1���S�Ȃ�Ċm���ǂꂾ������Ǝv���Ă�
�܂���8�R�A��2����ł�m���Ȃ�āE�E�E
����A���͂ǂꂾ�����邩�Ȃ�đS�������
�܂���8�R�A��2����ł�m���Ȃ�āE�E�E
����A���͂ǂꂾ�����邩�Ȃ�đS�������
>>169
�܂����Ȃ��Ƃ��U�R�A�̌��וi����A�S�R�A�i�͊ԈႢ�Ȃ��o���Ă��邾�낤�ˁB
���ɂT�R�A�i���o���Ă��邩�ǂ����͕�����B
�܂����Ȃ��Ƃ��U�R�A�̌��וi����A�S�R�A�i�͊ԈႢ�Ȃ��o���Ă��邾�낤�ˁB
���ɂT�R�A�i���o���Ă��邩�ǂ����͕�����B
>>170
UltraSPARC T2��on die 8 core�̃v���Z�b�T�B�T�[�o���C���i�b�v��4�A6�A8 core�Ƃ����������
4 -> 6 core��+$1,000�A6 -> 8 core��+$10,000�Ƃ����l�D�����Ă��܂��B
8�R�A���S�Ȃ�Ă��ꂭ�炢�E���g�����A�B���E����4�R�A�Ȃ�đ|���Ď̂Ă�قǍ���킯�ł��B
UltraSPARC T2��on die 8 core�̃v���Z�b�T�B�T�[�o���C���i�b�v��4�A6�A8 core�Ƃ����������
4 -> 6 core��+$1,000�A6 -> 8 core��+$10,000�Ƃ����l�D�����Ă��܂��B
8�R�A���S�Ȃ�Ă��ꂭ�炢�E���g�����A�B���E����4�R�A�Ȃ�đ|���Ď̂Ă�قǍ���킯�ł��B
�����P�Ȃ�t�����l���B
G80�Ȃ�ă_�C�T�C�Y�������Ƒ傫���̂Ɉ�������Ȃ����B
CPU�����ɃR�X�g���|�����Ă�킯�ł��Ȃ����낤���ȁB
G80�Ȃ�ă_�C�T�C�Y�������Ƒ傫���̂Ɉ�������Ȃ����B
CPU�����ɃR�X�g���|�����Ă�킯�ł��Ȃ����낤���ȁB
>>165
���ꂪ�܂�45nm��"8�R�A"�̉\�������B
���ꂪ�܂�45nm��"8�R�A"�̉\�������B
>>175
�\�Ƃ����̂͂����Ă��������Ȃ��AAMD�̏ꍇ�B
�\�Ƃ����̂͂����Ă��������Ȃ��AAMD�̏ꍇ�B
>>173
���������Ɩ��W�Ȓl�D��������4�R�A������Ă��܂�
���S��8�R�A��4�R�A�̉��i�Ŕ���H�ڂɂȂ�܂��B
- GPU�̃v���Z�b�T��CPU������r�ɂȂ�Ȃ��قǒP���ł������^�ł��B
- ���̏㓖�R�璷���������Ă��邩�炱���܂Ƃ��ȉ��i�ŏo�ׂł��Ă��܂��B
- �n�C�G���hGPU�̒l�D�͐Ԏ�����{�ŁA���C���X�g���[���̏����ȃR�A�ʼn҂��o�ύ\���ł��B
�ȏ�̂悤�ɂ�����CPU��GPU��P����r����͖̂��Ӗ��ł��B
3���̃v���Z�b�T��������GPU��"�p�[�t�F�N�g�R�A"�Ȃ�ă_�C�A�����h���ɋM�d�ł��傤�B
���������Ɩ��W�Ȓl�D��������4�R�A������Ă��܂�
���S��8�R�A��4�R�A�̉��i�Ŕ���H�ڂɂȂ�܂��B
- GPU�̃v���Z�b�T��CPU������r�ɂȂ�Ȃ��قǒP���ł������^�ł��B
- ���̏㓖�R�璷���������Ă��邩�炱���܂Ƃ��ȉ��i�ŏo�ׂł��Ă��܂��B
- �n�C�G���hGPU�̒l�D�͐Ԏ�����{�ŁA���C���X�g���[���̏����ȃR�A�ʼn҂��o�ύ\���ł��B
�ȏ�̂悤�ɂ�����CPU��GPU��P����r����͖̂��Ӗ��ł��B
3���̃v���Z�b�T��������GPU��"�p�[�t�F�N�g�R�A"�Ȃ�ă_�C�A�����h���ɋM�d�ł��傤�B
��- GPU�̃v���Z�b�T��CPU������r�ɂȂ�Ȃ��قǒP���ł������^�ł��B
GPU�����傾��c��̃��j�b�g���ɂ��Č����Ă�̂Ȃ�Ƃ�����
��3���̃v���Z�b�T��������GPU��"�p�[�t�F�N�g�R�A"�Ȃ�ă_�C�A�����h���ɋM�d�ł��傤�B
���ׂ̓R�A�̐�����Ȃ��ă_�C�̖ʐςɔ�Ⴗ�邾��
���̓_�ACPU��GPU�Ƀ��j�b�g���̍��������炠���Ă��ʐςɍ���������A
�����錇�ׂ̑����ɍ��͖����B�Ȃ��������������Ă�C��������ǂȁB
GPU�����傾��c��̃��j�b�g���ɂ��Č����Ă�̂Ȃ�Ƃ�����
��3���̃v���Z�b�T��������GPU��"�p�[�t�F�N�g�R�A"�Ȃ�ă_�C�A�����h���ɋM�d�ł��傤�B
���ׂ̓R�A�̐�����Ȃ��ă_�C�̖ʐςɔ�Ⴗ�邾��
���̓_�ACPU��GPU�Ƀ��j�b�g���̍��������炠���Ă��ʐςɍ���������A
�����錇�ׂ̑����ɍ��͖����B�Ȃ��������������Ă�C��������ǂȁB
>>177
8�R�A�ɂ��邾����+100���~�ɂȂ�قLj��������܂�Ȃ�đz���o����B
���ꂾ�ƃE�F�n�ꖇ������Ǖi��1���邩���Ȃ����̃��x���ɂȂ邼�B
GPU���P��������Ƃ����_�����藧���Ȃ��B
�A�[�L�e�N�`���ʂ���Ȃ�Ƃ����������ʂ��猩��ǂ�����������G�x�B
��G�c�Ȍv�Z�ł͂��邪Niagara2�̃_�C�T�C�Y�Ȃ�300mm�E�F�n����Ǖi��50���炢����B
���ꂾ�ƃE�F�n1����100���~�ƍl���Ă�1������2���~�B
Niagara2���x�̃_�C�T�C�Y�Œv���I�ȕ����܂�Ȃ甼���̎Y�Ƃ͂���Ă������B
����Ȃ��l�����_�C�T�C�Y���������Ă�͂��B
8�R�A�ɂ��邾����+100���~�ɂȂ�قLj��������܂�Ȃ�đz���o����B
���ꂾ�ƃE�F�n�ꖇ������Ǖi��1���邩���Ȃ����̃��x���ɂȂ邼�B
GPU���P��������Ƃ����_�����藧���Ȃ��B
�A�[�L�e�N�`���ʂ���Ȃ�Ƃ����������ʂ��猩��ǂ�����������G�x�B
��G�c�Ȍv�Z�ł͂��邪Niagara2�̃_�C�T�C�Y�Ȃ�300mm�E�F�n����Ǖi��50���炢����B
���ꂾ�ƃE�F�n1����100���~�ƍl���Ă�1������2���~�B
Niagara2���x�̃_�C�T�C�Y�Œv���I�ȕ����܂�Ȃ甼���̎Y�Ƃ͂���Ă������B
����Ȃ��l�����_�C�T�C�Y���������Ă�͂��B
180 �F�R�E�L�́M�E,,�j�����������������F2008/05/12(��) 00:35:47 ID:9L/NVF09
�܂�Intel���ő��IP���ƌ����邭�炢������ȁB
���ɓI�ɂ�Core 2 XE�ł��琻�������I�ɂ�Celeron�ȉ��ƁB
�g�ݍ��ݗpCPU��Intel���݂̃_�C�T�C�Y��CPU�ł����S�~�`�����Đ���~�B
�܂��g���Â��̃v���Z�X�g���Ă�̂����邪�B
���ǂ�Fab�̐ݔ���������`�����ł��邩�ǂ����ł��B
�ޗ��̃V���R�����̂͂قږ��s���ɂ���悤�Ȃ��̂���
AMD�͍Ő�[�v���Z�X������ǂ������AIntel�ɑ��鋣���͂̂��鉿�i�Œ��Ȃ��Ⴂ���Ȃ����炱��
1�v���Z�b�T������̐����R�X�g���V�r�A�ɋ����Ă���̂��B
�������Intel�͌������p�̏I�����Fab�Ń`�b�v�Z�b�g�Ȃǃ_�C�T�C�Y�����藘�v���̒Ⴂ���i�����B
�g�b�v��Ƃ̂Ȃ���Ƃ��B
���ɓI�ɂ�Core 2 XE�ł��琻�������I�ɂ�Celeron�ȉ��ƁB
�g�ݍ��ݗpCPU��Intel���݂̃_�C�T�C�Y��CPU�ł����S�~�`�����Đ���~�B
�܂��g���Â��̃v���Z�X�g���Ă�̂����邪�B
���ǂ�Fab�̐ݔ���������`�����ł��邩�ǂ����ł��B
�ޗ��̃V���R�����̂͂قږ��s���ɂ���悤�Ȃ��̂���
AMD�͍Ő�[�v���Z�X������ǂ������AIntel�ɑ��鋣���͂̂��鉿�i�Œ��Ȃ��Ⴂ���Ȃ����炱��
1�v���Z�b�T������̐����R�X�g���V�r�A�ɋ����Ă���̂��B
�������Intel�͌������p�̏I�����Fab�Ń`�b�v�Z�b�g�Ȃǃ_�C�T�C�Y�����藘�v���̒Ⴂ���i�����B
�g�b�v��Ƃ̂Ȃ���Ƃ��B
AMD��6�R�A���Ɣ��\���Ă�̂�8�R�A���ƌ�������d�g�ɂ������̂�
���̂ւ�ɂ��Ƃ�����
���̂ւ�ɂ��Ƃ�����
AMD��Rev.D��L2���ʂ���Ƃ����Ă���̂ɂ��Ȃ��ƌ�������d�g�ɂ������̂�
���̂ւ�ɂ��Ƃ�����BDeneb��Propus�̓_�C���̕ʂ��Ęb�Ȃ̂�L3�Ȃ���
L2���ʁARev.D��L3��������Ă̂͂���B
���̂ւ�ɂ��Ƃ�����BDeneb��Propus�̓_�C���̕ʂ��Ęb�Ȃ̂�L3�Ȃ���
L2���ʁARev.D��L3��������Ă̂͂���B
Fudzilla
http://northwood.blog60.fc2.com/blog-entry-1939.html
������AMD���������Montreal���폜�������[�h�}�b�v�����\���ꂽ�̂�
http://www.vr-zone.com/articles/AMD_Updates_ServerWorkstation_Roadmap/5757.html
�M�����Ⴄ�BHammer-Info�ł����S�X���[�����ǂˁB
http://northwood.blog60.fc2.com/blog-entry-1939.html
������AMD���������Montreal���폜�������[�h�}�b�v�����\���ꂽ�̂�
http://www.vr-zone.com/articles/AMD_Updates_ServerWorkstation_Roadmap/5757.html
�M�����Ⴄ�BHammer-Info�ł����S�X���[�����ǂˁB
>>182
Deneb�͍��������Ă���ł͏�C(Opteron)��phenom�ł�
propus��Deneb����L3�����������ŁA�܂���L3��������L2�ʂ������m�ɂȂ�B
��C�̓o���Z���i(�������Ă�K10)��45n�ł�
CPU�����̐ڑ���HT3���̗p���Ă��邪DDR3�ɂ͑Ή����Ȃ��B
DDR3�ւ͏�C�̎���K10.5���烁���R����ύX���đΉ�
��C�͗��N���`�t�ɔ������ADDR3�Ή����f����K10.5�͗��N�̉Ĉȍ~���Ď������B
Deneb�͍��������Ă���ł͏�C(Opteron)��phenom�ł�
propus��Deneb����L3�����������ŁA�܂���L3��������L2�ʂ������m�ɂȂ�B
��C�̓o���Z���i(�������Ă�K10)��45n�ł�
CPU�����̐ڑ���HT3���̗p���Ă��邪DDR3�ɂ͑Ή����Ȃ��B
DDR3�ւ͏�C�̎���K10.5���烁���R����ύX���đΉ�
��C�͗��N���`�t�ɔ������ADDR3�Ή����f����K10.5�͗��N�̉Ĉȍ~���Ď������B
���������C����K10.5�Ƃ������Ă邯��
���Ƃ��܂��܂�����ɂ�������
�P�Ȃ�o���̃V�������N�ł���˂��H
L2���ʂƂ�SSE�lj����x���ᕁ�ʃA�[�L�X�V�Ȃ��Ȃ���
10.5���ĉ��Ȃ�
���Ƃ��܂��܂�����ɂ�������
�P�Ȃ�o���̃V�������N�ł���˂��H
L2���ʂƂ�SSE�lj����x���ᕁ�ʃA�[�L�X�V�Ȃ��Ȃ���
10.5���ĉ��Ȃ�
187 �F�R�E�L�́M�E,,�j�����������������F2008/05/12(��) 08:43:42 ID:9L/NVF09
SSSE3��SSE4.1�����̗\��
����Ȃ炻��Ő�����IPC�̌���Ƃ����A�s�[���Ƃ͌��т��Ȃ��Ǝv�����B
�ȑOFudzilla�ł�IMC�̉��P�Ƃ������l�^�͂��������B
Development of AMD's first 45nm server processor, codenamed "Shanghai," is
on schedule to begin production in the second half of 2008 and will now feature
coherent HyperTransport 3.0 for processor-to-processor communication. In addition
to increasing the shared Level-3 cache from 2 MB to 6 MBm "Shanghai" will
include core and instruction-per-clock (IPC) enhancements.
�Ō�̕\��������ɃR�A�ɂ���͓����Ă����B
�R�A���ǂ����w���Ă�̂��͕�����ǃL���b�V��������̃��C�e���V���P
���Ă͖̂���Ȑ��ȋC������B
IPC����ɂ͌��ʂ͂������B
�Ƃ肠�����L���b�V�����ʂ�cHT3.0�����ł͏I���Ȃ������ȋC���B
�ȑOFudzilla�ł�IMC�̉��P�Ƃ������l�^�͂��������B
Development of AMD's first 45nm server processor, codenamed "Shanghai," is
on schedule to begin production in the second half of 2008 and will now feature
coherent HyperTransport 3.0 for processor-to-processor communication. In addition
to increasing the shared Level-3 cache from 2 MB to 6 MBm "Shanghai" will
include core and instruction-per-clock (IPC) enhancements.
�Ō�̕\��������ɃR�A�ɂ���͓����Ă����B
�R�A���ǂ����w���Ă�̂��͕�����ǃL���b�V��������̃��C�e���V���P
���Ă͖̂���Ȑ��ȋC������B
IPC����ɂ͌��ʂ͂������B
�Ƃ肠�����L���b�V�����ʂ�cHT3.0�����ł͏I���Ȃ������ȋC���B
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/001.html
��A: ����AIPC�̌���ɂ́AIPC per Watt�̌�����܂܂��B
��IPC���̂��̂͂��Â���`�Ȃ̂ł����āA�Ⴆ�Ή��z���ɂ�����
��User IPC�̌���ɂ�Virtualization�̐��\���P��IPC����ɂȂ��鎖�ɂȂ�B
�Ȃ�Ċ����������Ă��肷��̂ŁAAMD��IPC�����P���ɏ]���g���Ă����Ӗ���
�Ƃ炦��̂͂ǂ����ƁB
�ׂ��ȉ��ǂ�SSE�̑Ή��ŕ��ς�����A1���߂��ǂ��Ȃ��Ă���ăI�`����ˁH
��A: ����AIPC�̌���ɂ́AIPC per Watt�̌�����܂܂��B
��IPC���̂��̂͂��Â���`�Ȃ̂ł����āA�Ⴆ�Ή��z���ɂ�����
��User IPC�̌���ɂ�Virtualization�̐��\���P��IPC����ɂȂ��鎖�ɂȂ�B
�Ȃ�Ċ����������Ă��肷��̂ŁAAMD��IPC�����P���ɏ]���g���Ă����Ӗ���
�Ƃ炦��̂͂ǂ����ƁB
�ׂ��ȉ��ǂ�SSE�̑Ή��ŕ��ς�����A1���߂��ǂ��Ȃ��Ă���ăI�`����ˁH
Shanghai�͐������Z���j�b�g�������������Ęb���������n�Y�Ȃ��ǁA����͖����Ȃ����̂��ȁH
B3�Ő��\�������オ�����̂̓G���b�^�����̂��߂ɃL���b�V���R���g���[���Ɏ����ꂽ���ʂ��낤��
Winchester��Venice�Ɠ����悤�Ȋ�����
���ƁAK10�̐헪��(�R���V���[�}�ł�)�Ƃ��Ă��ق��̂̓w�N�^�[�E���C�Y��CEO������A�Ǝv���悤�ɂȂ�������
�ނ�IBM�̎���AMD���@�����邽�߂ɔh������Ă����A�Ȃ�Ėϑz�����Ă��܂����炢�ɐ헪������Ȃ�Ȃ����H
���ɂ܂��T���_�[�X��CEO��������Phenom�������ɃN�A�b�h����o�����ɁA�R�A��K10�����N�A�b�h�����ď���ǂ����n�Y����
B3�Ő��\�������オ�����̂̓G���b�^�����̂��߂ɃL���b�V���R���g���[���Ɏ����ꂽ���ʂ��낤��
Winchester��Venice�Ɠ����悤�Ȋ�����
���ƁAK10�̐헪��(�R���V���[�}�ł�)�Ƃ��Ă��ق��̂̓w�N�^�[�E���C�Y��CEO������A�Ǝv���悤�ɂȂ�������
�ނ�IBM�̎���AMD���@�����邽�߂ɔh������Ă����A�Ȃ�Ėϑz�����Ă��܂����炢�ɐ헪������Ȃ�Ȃ����H
���ɂ܂��T���_�[�X��CEO��������Phenom�������ɃN�A�b�h����o�����ɁA�R�A��K10�����N�A�b�h�����ď���ǂ����n�Y����
AMD cuts quad core power
Opteron drops to 55W
http://www.theinquirer.net/gb/inquirer/news/2008/05/12/amd-low-power-opteron
Opteron drops to 55W
http://www.theinquirer.net/gb/inquirer/news/2008/05/12/amd-low-power-opteron
Intel�ւ̑R�𔗂�ꂽAMD�̃T�[�o�[CPU���[�h�}�b�v
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai439.htm
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai439.htm
>>192
ID��AVX�E�E�E�B
ID��AVX�E�E�E�B
http://www.geocities.jp/andosprocinfo/wadai08/20080510.htm
�@�܂��C�f�X�N�g�b�v�̃��[�h�}�b�v�ɂ�GPU�Ƃ̓�����Fusion�̎p������܂���BFusion�̊��U��ł�����Phil Hester�������߂��e���ł��傤���H���邢�́C������ƁCHester���̎��C�́C���̘H���ύX�������ł������Ƃ��l�����܂��B
�@�����āC�i�s����10%�̐l���팸�C4��19���̘b��ŏЉ�����Z�̓��e����l����ƁCFusion��Bulldozer�����[�h�}�b�v����p���������̂́C�啝�ȃv���W�F�N�g�̌������̌��ʂƑz������܂��B
�@�܂��C�f�X�N�g�b�v�̃��[�h�}�b�v�ɂ�GPU�Ƃ̓�����Fusion�̎p������܂���BFusion�̊��U��ł�����Phil Hester�������߂��e���ł��傤���H���邢�́C������ƁCHester���̎��C�́C���̘H���ύX�������ł������Ƃ��l�����܂��B
�@�����āC�i�s����10%�̐l���팸�C4��19���̘b��ŏЉ�����Z�̓��e����l����ƁCFusion��Bulldozer�����[�h�}�b�v����p���������̂́C�啝�ȃv���W�F�N�g�̌������̌��ʂƑz������܂��B
>>192
�s�g�ȁE�E�E
�s�g�ȁE�E�E
�܂�����[�Ȃ�����B
���͎��s��Ƃ����X�N�͂Ȃ�ׂ����炳�Ȃ��ƁB
�܂�Barcelona�݂����Ȓx���N�������炻�ꂱ���|�Y�̊�@����ˁB
���͎��s��Ƃ����X�N�͂Ȃ�ׂ����炳�Ȃ��ƁB
�܂�Barcelona�݂����Ȓx���N�������炻�ꂱ���|�Y�̊�@����ˁB
�f�X�N�g�b�v�̃��[�h�}�b�v�͂ǂ��Ŕ��\���ꂽ�́H
AMD���ċ�����͈̂�̉��N��ȂH
����Ƃ����̂܂�VIA�݂����ɂȂ����Ⴄ�́H
����Ƃ����̂܂�VIA�݂����ɂȂ����Ⴄ�́H
�n����������P�����������蕨�������蓮����������A���O�ɓ��ꐫ���Ȃ��Ȃ��B
G3MX���摗�肩�`
8ch16Socket�Ƃ����ʔ����V�X�e����
���������ڐ�/CPU�ł��������o���h��/CPU�ł�
Intel���o�������͂��������̂ɁA������J���������ȁB
DDR2-800*2��6�R�A����A�R�A����̃������ш�͉ߋ��ŒႶ��Ȃ����B
8ch16Socket�Ƃ����ʔ����V�X�e����
���������ڐ�/CPU�ł��������o���h��/CPU�ł�
Intel���o�������͂��������̂ɁA������J���������ȁB
DDR2-800*2��6�R�A����A�R�A����̃������ш�͉ߋ��ŒႶ��Ȃ����B
�Ƃ肠����PCI-E2.0�Ή��̃`�b�v�Z�b�g�����o���Ƃ��A
���샆�[�U�[�͂��炭�����������ł͂���B
DDR3�Ƃ������܂�PCI-E2.0����
�ǂ���AM3�܂Ń����R���ς��Ȃ�����A
�o�X���炢���[�U�[�ɔz�����ė~��������
���샆�[�U�[�͂��炭�����������ł͂���B
DDR3�Ƃ������܂�PCI-E2.0����
�ǂ���AM3�܂Ń����R���ς��Ȃ�����A
�o�X���炢���[�U�[�ɔz�����ė~��������
>>201
�����o�Ă邶���c�B
�����o�Ă邶���c�B
204 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 12:54:18 ID:PeKKSLBV
>>203
����ł���ID�Ȃ̂��B
����ł���ID�Ȃ̂��B
>>196
���\�������[�h�}�b�v�͌����ƕ]����Ă�悤�����A�ʂ����Ăǂ����ˁB
Magny Cours��San Paolo�Ɠ���2010�N�O���Ȃ�āA�����܂����y�ϓI�Ȍ��ʂ����Ǝv�����B
AMD�ɂƂ��ď��߂Ă�MCM������ȊȒP�ɂł�����̂Ȃ�Shanghai�j�R�C�`��8�R�A��
2009�N���ɏo���������A���ꂪ�o����Ȃ�45nm�Ŗ������ăl�C�e�B�u6�R�A��
���K�v���Ȃ��B
���\�������[�h�}�b�v�͌����ƕ]����Ă�悤�����A�ʂ����Ăǂ����ˁB
Magny Cours��San Paolo�Ɠ���2010�N�O���Ȃ�āA�����܂����y�ϓI�Ȍ��ʂ����Ǝv�����B
AMD�ɂƂ��ď��߂Ă�MCM������ȊȒP�ɂł�����̂Ȃ�Shanghai�j�R�C�`��8�R�A��
2009�N���ɏo���������A���ꂪ�o����Ȃ�45nm�Ŗ������ăl�C�e�B�u6�R�A��
���K�v���Ȃ��B
>>205
"Shanghai"�ł̓A�C�h�����̏���d�͉��P�ƃN���b�N�BIPC�̉��P������炵�����A
���{�I�ȏ���d�͂̒ጸ�����قǐi�܂Ȃ��̂ł́H
���Ԃ�2009�N���ɃR�A�̉��ǂ�i�߂Ă悤�₭�t�����[�h����TDP�̒ጸ���\�ɂ��A
MCM��12�R�A���o���v��Ə���ɗ\�z����B
�悤�͏���45nm�ł͍��{�I��TDP�ጸ�͂���Ȃ��Ɨ\�z�B
"Shanghai"�ł̓A�C�h�����̏���d�͉��P�ƃN���b�N�BIPC�̉��P������炵�����A
���{�I�ȏ���d�͂̒ጸ�����قǐi�܂Ȃ��̂ł́H
���Ԃ�2009�N���ɃR�A�̉��ǂ�i�߂Ă悤�₭�t�����[�h����TDP�̒ጸ���\�ɂ��A
MCM��12�R�A���o���v��Ə���ɗ\�z����B
�悤�͏���45nm�ł͍��{�I��TDP�ጸ�͂���Ȃ��Ɨ\�z�B
Mario Rivas leaves AMD
http://www.theinquirer.net/gb/inquirer/news/2008/05/12/mario-rivas-leaves-amd
http://www.theinquirer.net/gb/inquirer/news/2008/05/12/mario-rivas-leaves-amd
>>205
MCM�ŏo���ɂ̓v���b�g�z�[�����̕ύX���K�v�Ȃ낤�B
���̃v���b�g�z�[���ɂ��̂܂悹��Ɖ����_�C����4socket��3hop�܂ő�������B
����ł͐��\���o�Ȃ�����~�߂���Ȃ����ȁB
MCM�ŏo���ɂ̓v���b�g�z�[�����̕ύX���K�v�Ȃ낤�B
���̃v���b�g�z�[���ɂ��̂܂悹��Ɖ����_�C����4socket��3hop�܂ő�������B
����ł͐��\���o�Ȃ�����~�߂���Ȃ����ȁB
MCM�̊J���͂����Ɨ��Ői�߂Ă��Ȃ��́H
���i�Ƃ��Ă͏o���Ȃ��Ă��A�J�����x���ł�MCM�̉ғ��i��
���邩������Ȃ����B
���i�Ƃ��Ă͏o���Ȃ��Ă��A�J�����x���ł�MCM�̉ғ��i��
���邩������Ȃ����B
�����Ȃ���intel��MCM���U�Ƃ����Ȃ��Ă��킯�ł��ˁc
>>210
�ʂɋ����ĂȂ�����BK8�R�A�͏�������Dual�R�A�O��őg��ł������A
HT�ɂ��R�A���X�P�[���u���ɑ��₷���Ƃ��O��ɂ��Ă������낤���B
�����A���ꂪ8�R�A�B12�R�A�Ȃǂǂ�ǂ�R�A�������Ă����ƁA
�_�C�T�C�Y�̊W�Ńl�C�e�B�u�Ƃ������Ă��Ȃ��Ȃ��Ă�����������B
Intel��Itanium�A"Tukwila"�̂悤�ȃo�J�݂�����
�ł����R�A�����L���p���Ȃ����낤���B
����Ă�����Opteron���ᐫ�\�I�����͂ƕt�����l���シ����B
����Fab�̃L���p�����\�I�����͂������������낤���ǁB
�ʂɋ����ĂȂ�����BK8�R�A�͏�������Dual�R�A�O��őg��ł������A
HT�ɂ��R�A���X�P�[���u���ɑ��₷���Ƃ��O��ɂ��Ă������낤���B
�����A���ꂪ8�R�A�B12�R�A�Ȃǂǂ�ǂ�R�A�������Ă����ƁA
�_�C�T�C�Y�̊W�Ńl�C�e�B�u�Ƃ������Ă��Ȃ��Ȃ��Ă�����������B
Intel��Itanium�A"Tukwila"�̂悤�ȃo�J�݂�����
�ł����R�A�����L���p���Ȃ����낤���B
����Ă�����Opteron���ᐫ�\�I�����͂ƕt�����l���シ����B
����Fab�̃L���p�����\�I�����͂������������낤���ǁB
Intel�ւ̑R�𔗂�ꂽAMD�̃T�[�o�[CPU���[�h�}�b�v
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai439.htm
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai_1.jpg
���Ƃ���MCM��Montreal8�R�A��2009�N�㔼�ɗ\�肵�Ă��̂�
MCM������2010�N�O���ɂ��ꂱ��ł�B
�܂������[�h�}�b�v�ł�MCM�ł̓x�[�X���P�i�K�x���\��ɂȂ��Ă�B���ꂪ�Ó��B
��͂�Magny Cours��2010�N�㔼�ɂ��ꂱ�ނ��A�V���[�g�����[�t�Ƃ���
Shaghai��MCM�j�R�C�`��8�R�A���}������邾�낤�ȁB
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai439.htm
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai_1.jpg
{kind=link}
���Ƃ���MCM��Montreal8�R�A��2009�N�㔼�ɗ\�肵�Ă��̂�
MCM������2010�N�O���ɂ��ꂱ��ł�B
�܂������[�h�}�b�v�ł�MCM�ł̓x�[�X���P�i�K�x���\��ɂȂ��Ă�B���ꂪ�Ó��B
��͂�Magny Cours��2010�N�㔼�ɂ��ꂱ�ނ��A�V���[�g�����[�t�Ƃ���
Shaghai��MCM�j�R�C�`��8�R�A���}������邾�낤�ȁB
>>210���������������̂�����Ȃ�
MCM���U�Ƃ������Ƃɕς��Ȃ����Ƃ�����Ȃ��n�����Ă����H
MCM���U�Ƃ������Ƃɕς��Ȃ����Ƃ�����Ȃ��n�����Ă����H
�t�Z�����͏����݂��������Ahigh-K���^���Q�[�g�̓����Ŏ�Ԏ���Ă邩��Ȃ�
���ꂳ�������Ȃ�32nm�܂ł͑R�o������c
IBM�𒆐S�Ƃ����C���e����͖Ԃ����݂̍j���ĂȂ�Ƃ������͖{��
���ꂳ�������Ȃ�32nm�܂ł͑R�o������c
IBM�𒆐S�Ƃ����C���e����͖Ԃ����݂̍j���ĂȂ�Ƃ������͖{��
>>214
����̃��[�h�}�b�v���\��32nm������������2010�NQ4�A�܂�Intel�̂��傤�ǂP�N�x��̂܂܁A
���Ă킩�������������ȁB
AMD�M�ғI�ɂ�45nm��Intel�̔��N�x��A32nm�Œǂ����Ƃ����y�ϗ\�z�������������B
����̃��[�h�}�b�v���\��32nm������������2010�NQ4�A�܂�Intel�̂��傤�ǂP�N�x��̂܂܁A
���Ă킩�������������ȁB
AMD�M�ғI�ɂ�45nm��Intel�̔��N�x��A32nm�Œǂ����Ƃ����y�ϗ\�z�������������B
�l�I�ɂ̓v���Z�X�ʂł̕s���͊����ĂȂ����ǂˁB
�s��������̂͐v�ʁB
���Y�������o���Ă����u�c���Ȃ���ǂ����悤���Ȃ��B
�uAMD����������̋Ɩ������ɂ��Č��y�A�����T�C�N���^�C����23�����P�����Ɩ������v
http://www.sijapan.com/content/l_news/2008/05/lo86kc0000001y4z.html
�����ʂ͊撣���Ă�݂����B
�s��������̂͐v�ʁB
���Y�������o���Ă����u�c���Ȃ���ǂ����悤���Ȃ��B
�uAMD����������̋Ɩ������ɂ��Č��y�A�����T�C�N���^�C����23�����P�����Ɩ������v
http://www.sijapan.com/content/l_news/2008/05/lo86kc0000001y4z.html
�����ʂ͊撣���Ă�݂����B
����ȉ�������Ƃɒǂ������炻��͂���ł��������B
�E�E�E���Ă�32nm�Œǂ����Ȃ�ė\�z���Ă��̂Ȃ�Ă��邩�ˁH
����ۂǂ̂��Ԕ��ȊO���Ȃ������Ǝv�����B
�E�E�E���Ă�32nm�Œǂ����Ȃ�ė\�z���Ă��̂Ȃ�Ă��邩�ˁH
����ۂǂ̂��Ԕ��ȊO���Ȃ������Ǝv�����B
218 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 17:56:59 ID:PeKKSLBV
>>213
�U���낤���l�C�e�B�u���낤�������������v�ɉ����čő���̃\�����[�V������p�ӂ���̂��d�����낤���B
�U���낤���l�C�e�B�u���낤�������������v�ɉ����čő���̃\�����[�V������p�ӂ���̂��d�����낤���B
AMD�̎�����CPU�ɂ��Č�낤 ��20����
http://pc11.2ch.net/test/read.cgi/jisaku/1203947286/779-
779 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 00:03:17 ID:wjwjBmkn
>>777
Shanghai�ɑ����V�A�[�L�e�N�`����2009��-2010�����ɓ���
�����32nm��2009�N���̂͂������炻��ɍ��킹����Ď�����
780 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 00:19:11 ID:J+tRmPOu
�h�i�ȐM�҂ł��u2009�N��32nm�v�͂������ɐM�����Ȃ����낤�c
785 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 01:48:35 ID:i+dclh8N
>>780
32nm��AMD�P�̊J������Ȃ�����B
�P�̊J�����������Ζ������낤�ˁB
786 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 01:58:56 ID:Wk+bYiX6
�EBulldozer��45nm�Ő����J�n�B2009�N�ɃT���v���J�n�\��
�Ə����Ă���̂�32nm�̂킯�ˁ[�ׁB
�����AMD�̗\�肾��32nm�͑�����2010�N�����炾���B
http://pc11.2ch.net/test/read.cgi/jisaku/1203947286/779-
779 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 00:03:17 ID:wjwjBmkn
>>777
Shanghai�ɑ����V�A�[�L�e�N�`����2009��-2010�����ɓ���
�����32nm��2009�N���̂͂������炻��ɍ��킹����Ď�����
780 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 00:19:11 ID:J+tRmPOu
�h�i�ȐM�҂ł��u2009�N��32nm�v�͂������ɐM�����Ȃ����낤�c
785 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 01:48:35 ID:i+dclh8N
>>780
32nm��AMD�P�̊J������Ȃ�����B
�P�̊J�����������Ζ������낤�ˁB
786 ���O�FSocket774[sage] ���e���F2008/04/19(�y) 01:58:56 ID:Wk+bYiX6
�EBulldozer��45nm�Ő����J�n�B2009�N�ɃT���v���J�n�\��
�Ə����Ă���̂�32nm�̂킯�ˁ[�ׁB
�����AMD�̗\�肾��32nm�͑�����2010�N�����炾���B
>>218
���ȁB
�l�K�L�����ɋ���ł����ŁA���܂Ōo���Ă����O��CPU��
�������Ȃ��A�Ȃ�ĕ�������ۂǃ��[�U�[��n���ɂ��Ă�B
���ȁB
�l�K�L�����ɋ���ł����ŁA���܂Ōo���Ă����O��CPU��
�������Ȃ��A�Ȃ�ĕ�������ۂǃ��[�U�[��n���ɂ��Ă�B
>>217
http://www.itmedia.co.jp/news/articles/0712/14/news048.html
AMD��2010�N�ɏ���32nm�v���Z�b�T���A2011�N�ɂ�22nm�v���Z�b�T�𓊓�����v�悾�B
�Ȃ��A�ǂ��v���H�@���Ȃ݂�Intel��2009�N����32nm�A2011�N����22nm�̗\�肾�B
http://www.itmedia.co.jp/news/articles/0712/14/news048.html
AMD��2010�N�ɏ���32nm�v���Z�b�T���A2011�N�ɂ�22nm�v���Z�b�T�𓊓�����v�悾�B
�Ȃ��A�ǂ��v���H�@���Ȃ݂�Intel��2009�N����32nm�A2011�N����22nm�̗\�肾�B
224 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 18:44:48 ID:PeKKSLBV
>>222
����Ȃ����������邶��Ȃ����B
MCM��������Đ��\�ʂŒv���I�ȃy�i���e�B������킯�ł��Ȃ���
�l�C�e�B�u�Ȃ̂Ƀj�R�C�`��萫�\�łȂ�������A�Ă̒�l�C���������肷��悤���Ɩ{���]�|�B
����Ȃ����������邶��Ȃ����B
MCM��������Đ��\�ʂŒv���I�ȃy�i���e�B������킯�ł��Ȃ���
�l�C�e�B�u�Ȃ̂Ƀj�R�C�`��萫�\�łȂ�������A�Ă̒�l�C���������肷��悤���Ɩ{���]�|�B
>>223
�����̃r�b�O�}�E�X����Ȃ����ˁE�E�E�B1�N���炸�Ď��v���Z�X�Ɉڍs������̂��납�B
�Ƃɂ���AMD�͖ق��āgIstanbul�h�Ȃ�gBulldozer�h�̊J��������ƁB
�����̃r�b�O�}�E�X����Ȃ����ˁE�E�E�B1�N���炸�Ď��v���Z�X�Ɉڍs������̂��납�B
�Ƃɂ���AMD�͖ق��āgIstanbul�h�Ȃ�gBulldozer�h�̊J��������ƁB
226 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 18:53:11 ID:PeKKSLBV
�O�Ⴉ�炢����AMD�̃r�b�O�}�E�X�̓v���Z�X�i���g��̃t���O�����̃T�C��
�N�Ƃ͂���Ȃ���
�u���v�ɉ����āv�ƌ����Ă邻����u����Ȃ������v���Ăǂ����悤���Ȃ��n������
�N�Ƃ͂���Ȃ���
�u���v�ɉ����āv�ƌ����Ă邻����u����Ȃ������v���Ăǂ����悤���Ȃ��n������
�N�Ƃ͂���Ȃ���
228 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 19:04:50 ID:PeKKSLBV
���ۂɃj�R�C�`�̕�������Ă邶��Ȃ����B�������̉��i���łȂ��ĉ��H
���\�łȂ��R�A�𖧌������Ă�����ς萫�\�łȂ���
���\�o��Ȃ�MCM�ł�����ς肻��Ȃ�ɐ��\�ł���Ă��ƁB
���\�łȂ��R�A�𖧌������Ă�����ς萫�\�łȂ���
���\�o��Ȃ�MCM�ł�����ς肻��Ȃ�ɐ��\�ł���Ă��ƁB
229 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 19:10:09 ID:PeKKSLBV
Intel�����͂����Ė^�l�C�e�B�u�N�A�b�h���i���̗p���Ȃ��悤�ɓ��������Ă�Ƃł����z�����Ă��邩�킢�����Ȏq�����܂�����
�������Ă�����ł��傤����
�������Ă�����ł��傤����
230 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 19:16:20 ID:PeKKSLBV
POWER 4
http://www-06.ibm.com/systems/jp/photo/p/picture/power4.jpg
POWER 5
http://www-06.ibm.com/systems/jp/photo/p/picture/power5_mcm.jpg
MCM�͕������]�X��MCM�̎����m�E�n�E�̂Ȃ���Ƃ��k�قȂ�B
�������悤�ȁB
http://www-06.ibm.com/systems/jp/photo/p/picture/power4.jpg
{kind=link}
POWER 5
http://www-06.ibm.com/systems/jp/photo/p/picture/power5_mcm.jpg
{kind=link}
MCM�͕������]�X��MCM�̎����m�E�n�E�̂Ȃ���Ƃ��k�قȂ�B
�������悤�ȁB
���Ȃ݂ɂ���o��������
AMD���j�R�C�`�͏o����
�������v���Z�X�̒x���烍�[�h���ȓd�͋@�\�̖����Ƃ���
�l�g�o���������Xintel��荂��TDP�ł���Ă����Ƃ��낪�d�Ȃ���
�������M�ɂȂ��Ă���
K8�Ƀ��[�h���ȓd�͋@�\�����t���ĐV���ɃR�A�J������Ȃ�Ĕn������
K10��2�R�A����肻����j�R�C�`�Ȃɂ���������Ɣn��
���ǂ̂Ƃ���v���Z�X�̈ڍs�n����҂��Ȃ���Ƃ������܂ł̗��ꂪ��Ԏ��R�Ȃ��Ƃ�
�ǂ����悤���Ȃ��n���ȊO�ɂ͔���̂ł͂Ȃ����낤���H
�����č���TDP�ɗ]�T���o���邾�낤�Ƃ����\��������
�j�R�C�`�ʂɏo���v��𗧂Ă��̂�������Ȃ�
AMD���j�R�C�`�͏o����
�������v���Z�X�̒x���烍�[�h���ȓd�͋@�\�̖����Ƃ���
�l�g�o���������Xintel��荂��TDP�ł���Ă����Ƃ��낪�d�Ȃ���
�������M�ɂȂ��Ă���
K8�Ƀ��[�h���ȓd�͋@�\�����t���ĐV���ɃR�A�J������Ȃ�Ĕn������
K10��2�R�A����肻����j�R�C�`�Ȃɂ���������Ɣn��
���ǂ̂Ƃ���v���Z�X�̈ڍs�n����҂��Ȃ���Ƃ������܂ł̗��ꂪ��Ԏ��R�Ȃ��Ƃ�
�ǂ����悤���Ȃ��n���ȊO�ɂ͔���̂ł͂Ȃ����낤���H
�����č���TDP�ɗ]�T���o���邾�낤�Ƃ����\��������
�j�R�C�`�ʂɏo���v��𗧂Ă��̂�������Ȃ�
232 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 19:35:30 ID:PeKKSLBV
AMD�̓l�C�e�B�u��MCM��萫�\�̗ǂ����̂��o�����Č�����B
�l�C�e�B�u�N�A�b�h��B���ł����C2Q���1�N�x��Ă��A���\�������Ă��A����d�͂������Ă�
�܂������\��Ȃ��Ȃ�Ă���������ĂȂ���B
��i�ƖړI������ւ���Ė{���̖ړI���B���ł����ɂ���B�����{���]�|�Ƃ����B
�l�C�e�B�u�N�A�b�h��B���ł����C2Q���1�N�x��Ă��A���\�������Ă��A����d�͂������Ă�
�܂������\��Ȃ��Ȃ�Ă���������ĂȂ���B
��i�ƖړI������ւ���Ė{���̖ړI���B���ł����ɂ���B�����{���]�|�Ƃ����B
�{���]�|�Ȃ͓̂��ӂ��邪�ǂ������������ł��c
�ׂ�Barcelona��Kentsfield�ɔ�ׂĐ��\�������킯����Ȃ������
���N���b�N�ł͐��\�͂قړ��������A�������x���̂��N���b�N���オ��Ȃ��̂�����d�͂�
�傫���̂����ׂăv���Z�X�̖�肾�B
AMD�̓v���Z�X������Intel�̂P�N�x��Ǝv���Ă邪�A�����\�ł͂Q�N�x��Ȃ�B
�����x�̐v�ł�Intel�Ƃ͏����ɂȂ�Ȃ��B
���N���b�N�ł͐��\�͂قړ��������A�������x���̂��N���b�N���オ��Ȃ��̂�����d�͂�
�傫���̂����ׂăv���Z�X�̖�肾�B
AMD�̓v���Z�X������Intel�̂P�N�x��Ǝv���Ă邪�A�����\�ł͂Q�N�x��Ȃ�B
�����x�̐v�ł�Intel�Ƃ͏����ɂȂ�Ȃ��B
����[�E�E�E�H
�L���ɂ����͑���Quad FX�̂��Ƃ��Ǝv������
����͂����̃f���A���v���Z�b�T�H
��������Ath�Ȃ�����Op2�Ɠ����悤�Ȃ���H
�������M�̓_����AMD�͋C�y�Ƀj�R�C�`�ł������Ȃ����낤���Ƃ͕ς��Ȃ�����
�L���ɂ����͑���Quad FX�̂��Ƃ��Ǝv������
����͂����̃f���A���v���Z�b�T�H
��������Ath�Ȃ�����Op2�Ɠ����悤�Ȃ���H
�������M�̓_����AMD�͋C�y�Ƀj�R�C�`�ł������Ȃ����낤���Ƃ͕ς��Ȃ�����
>>234
��AMD�̓v���Z�X������Intel�̂P�N�x��Ǝv���Ă邪�A�����\�ł͂Q�N�x��Ȃ�B
�������x�̐v�ł�Intel�Ƃ͏����ɂȂ�Ȃ��B
����͂��������A�킴�킴C2Q�Ɍ��ܔ������̂�AMD�̕������A��r����Ă��d���Ȃ��ł���B
�܂��A����̏ȓd�͉��⍂�N���b�N���Ɋ��҂������Ƃ���ł͂���B
��AMD�̓v���Z�X������Intel�̂P�N�x��Ǝv���Ă邪�A�����\�ł͂Q�N�x��Ȃ�B
�������x�̐v�ł�Intel�Ƃ͏����ɂȂ�Ȃ��B
����͂��������A�킴�킴C2Q�Ɍ��ܔ������̂�AMD�̕������A��r����Ă��d���Ȃ��ł���B
�܂��A����̏ȓd�͉��⍂�N���b�N���Ɋ��҂������Ƃ���ł͂���B
������HT�łȂ����Ă�͂���DualCPU Opteron�������ăe�X�g����Ă���
FSB��MCM��HT��MCM�̗D�����������ǂȁ[
http://journal.mycom.co.jp/special/2008/phenom01/013.html
����MCM�̃p�b�P�[�W�ł������ڑ������͈Ⴄ����˂��B
FSB��MCM��HT��MCM�̗D�����������ǂȁ[
http://journal.mycom.co.jp/special/2008/phenom01/013.html
����MCM�̃p�b�P�[�W�ł������ڑ������͈Ⴄ����˂��B
QuadFX�̓��������C�e���V�������āA�V���O���X���b�h���\���_�E�����A
2�X���b�h�܂ł̃A�v������Athlon64X2�ɕ�����Ƃ�����Ԃ������B
�o�������Ή��A�v�����Ȃ���������A��ʃ��[�U�[��������
����܂ς��Ƃ��Ȃ��x���`���ʂ�������B
2�X���b�h�܂ł̃A�v������Athlon64X2�ɕ�����Ƃ�����Ԃ������B
�o�������Ή��A�v�����Ȃ���������A��ʃ��[�U�[��������
����܂ς��Ƃ��Ȃ��x���`���ʂ�������B
�uAMD planning to outsource CPU production to TSMC in 2H08, say sources�v
http://www.digitimes.com/news/a20080513PD207.html
���[�ށA�}�W��CPU��TSMC�Ɉϑ����Y����̂��B
TSMC�Ɉϑ�����Ȃ�Bobcat���Ə���Ɏv���Ă����L���ɂ��ƍ��̂�Fusion�炵���B
������SOI�B
TSMC��SOI Industry Consortium�̎������ɖ���A�˂Ă��͈̂ɒB�␌������Ȃ������킯���B
http://www.digitimes.com/news/a20080513PD207.html
���[�ށA�}�W��CPU��TSMC�Ɉϑ����Y����̂��B
TSMC�Ɉϑ�����Ȃ�Bobcat���Ə���Ɏv���Ă����L���ɂ��ƍ��̂�Fusion�炵���B
������SOI�B
TSMC��SOI Industry Consortium�̎������ɖ���A�˂Ă��͈̂ɒB�␌������Ȃ������킯���B
������TSMC�̕��������Z�p�͏ゾ��
>>235
Quad FX�͒P�Ȃ�Dual CPU����c�B
>>242
VGA���݂���Ȃ����H�@�m��RADEON��TSMC�ł���B
CPU��GPU�ł͐����{�݂̍œK���̎d�����Ⴄ���낤���A
���Ђ̍H��ł�GPU�֘A�̐����m�E�n�E���Ȃ�����A
FUSION��TSMC�ɗ��ނ�Ȃ��H
Quad FX�͒P�Ȃ�Dual CPU����c�B
>>242
VGA���݂���Ȃ����H�@�m��RADEON��TSMC�ł���B
CPU��GPU�ł͐����{�݂̍œK���̎d�����Ⴄ���낤���A
���Ђ̍H��ł�GPU�֘A�̐����m�E�n�E���Ȃ�����A
FUSION��TSMC�ɗ��ނ�Ȃ��H
>>244
GPU�p�[�g����TSMC���Ęb�������̂�CPU�p�[�g��TSMC�ɂȂ肻���A���ċL��
GPU�p�[�g����TSMC���Ęb�������̂�CPU�p�[�g��TSMC�ɂȂ肻���A���ċL��
>>231
���[�h�����M��K8�̌��E����Ȃ����ȁD
�v���Z�X���ǂ�������_�����낤�ˁD
AMD����HT���q���ΊȒP�ɃN�A�b�h�R�A��ꂽ���낤��
�Ȃ�ō��Ȃ������낤���H
���[�h�����M��K8�̌��E����Ȃ����ȁD
�v���Z�X���ǂ�������_�����낤�ˁD
AMD����HT���q���ΊȒP�ɃN�A�b�h�R�A��ꂽ���낤��
�Ȃ�ō��Ȃ������낤���H
>>246
AMD���R�Ԃ��ق�MCM�͊ȒP����Ȃ�����
AMD���R�Ԃ��ق�MCM�͊ȒP����Ȃ�����
�p�b�P�[�W���HT�łȂ��Z�p��ʓr�J�����Ȃ��Ƃ����Ȃ����낤�B
MCM���ȒP�ɍ���悤�Ȃ��ƌ�����������̂�
���{AMD�̌Z�M�A�a�m����Ȃ��}�[�P�e�B���O�̐l�B
�C�O�̕��ł�MCM�ŊȒP�ɍ���悤�Ȃ��Ƃ܂ł͌����ĂȂ������͂��B
MCM���ȒP�ɍ���悤�Ȃ��ƌ�����������̂�
���{AMD�̌Z�M�A�a�m����Ȃ��}�[�P�e�B���O�̐l�B
�C�O�̕��ł�MCM�ŊȒP�ɍ���悤�Ȃ��Ƃ܂ł͌����ĂȂ������͂��B
�ȒP����
250 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 22:03:29 ID:PeKKSLBV
Opteron��32�v���Z�b�T�����̃V�X�e���������C���������A������ăx���_���x���őΉ������ȁB
���ʗ�������HT�Őڑ����ĉ]�X�B
�����������x���ł�MCM���Ă�����Multi-Socket Modules�Ȃ�HP��Itanium�ł���Ă邶��Ȃ����B
�O�t����L4�L���b�V���t������ȁB
Intel�������̂́A�����p�b�P�[�W�𑩂˂�̂ł͂Ȃ���̃p�b�P�[�W�̒���2�_�C�����܂��ē��삷��Z�p��
�ʎY���x���Ŏ����������ƁB
���ƁA���ʂ�MCM�Ȃ�2CPU���̃��C�Z���X�Ƃ��Ĉ�����̂�MS�ȂǂɁu1�v���Z�b�T�v�Ƃ��ĔF�߂��������ƁB
�����1�\�P�b�g���ł̓��삵���F�߂��Ȃ�XP home�ł�Core 2 Quad���g����悤�ɂȂ����B
�����Ƃ�Pentium D�̎��_�Ń��C�Z���X������Ă�̂����B
���ʗ�������HT�Őڑ����ĉ]�X�B
�����������x���ł�MCM���Ă�����Multi-Socket Modules�Ȃ�HP��Itanium�ł���Ă邶��Ȃ����B
�O�t����L4�L���b�V���t������ȁB
Intel�������̂́A�����p�b�P�[�W�𑩂˂�̂ł͂Ȃ���̃p�b�P�[�W�̒���2�_�C�����܂��ē��삷��Z�p��
�ʎY���x���Ŏ����������ƁB
���ƁA���ʂ�MCM�Ȃ�2CPU���̃��C�Z���X�Ƃ��Ĉ�����̂�MS�ȂǂɁu1�v���Z�b�T�v�Ƃ��ĔF�߂��������ƁB
�����1�\�P�b�g���ł̓��삵���F�߂��Ȃ�XP home�ł�Core 2 Quad���g����悤�ɂȂ����B
�����Ƃ�Pentium D�̎��_�Ń��C�Z���X������Ă�̂����B
>>245
�ʂɂ�����ˁH�@�̂���O���ϑ��̘b�͂��������A
���ꂪTSMC�ɗ��������������ł���B
�ǂ������̌��GPGPU�����������x�ϑ����邾�낤���A
�o���m�E�n�E�𗭂߂邽�߂ɂ͗ǂ��@��B
�����A�����ϑ�����ƌ��߂������Ɣ�ׂāA
�����AMD�̃A���ł�TSMC�ɗ��ވӖ����c�B
�ʂɂ�����ˁH�@�̂���O���ϑ��̘b�͂��������A
���ꂪTSMC�ɗ��������������ł���B
�ǂ������̌��GPGPU�����������x�ϑ����邾�낤���A
�o���m�E�n�E�𗭂߂邽�߂ɂ͗ǂ��@��B
�����A�����ϑ�����ƌ��߂������Ɣ�ׂāA
�����AMD�̃A���ł�TSMC�ɗ��ވӖ����c�B
����E�E�E�H
�_���S���Ă���Ȃɔn�������������H
�_���S���Ă���Ȃɔn�������������H
�Ȃ����s�̎d���Ƃ������A�������[�h���Z�K�������[�Ǝv�����B
�������߂Q�����˂�܂ŃQ�n�����B
�������߂Q�����˂�܂ŃQ�n�����B
254 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 22:38:14 ID:PeKKSLBV
���ꃌ�X�Ԕ��ł�
255 �F�R�E�L�́M�E,,�j�����������������F2008/05/13(��) 22:39:33 ID:PeKKSLBV
>>253
�������悗��������
�������悗��������
>>247
�`�l�c���R�Ԃ��Ă�킯����Ȃ��āA�Z�M���o�܂����Ō����Ă邾��(�E�L��`�E)
�`�l�c���R�Ԃ��Ă�킯����Ȃ��āA�Z�M���o�܂����Ō����Ă邾��(�E�L��`�E)
Bulldozer(���邢��Sandtiger)�̃L���b�V���e�ʂ��Č��J����Ă������H
�C�Â����ɃT�����Ɨ����Ă����A����ɂ�L2=512KB�AL3=8MB�Ə����Ă���ȁB
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai_2.jpg
�C�Â����ɃT�����Ɨ����Ă����A����ɂ�L2=512KB�AL3=8MB�Ə����Ă���ȁB
http://pc.watch.impress.co.jp/docs/2008/0513/kaigai_2.jpg
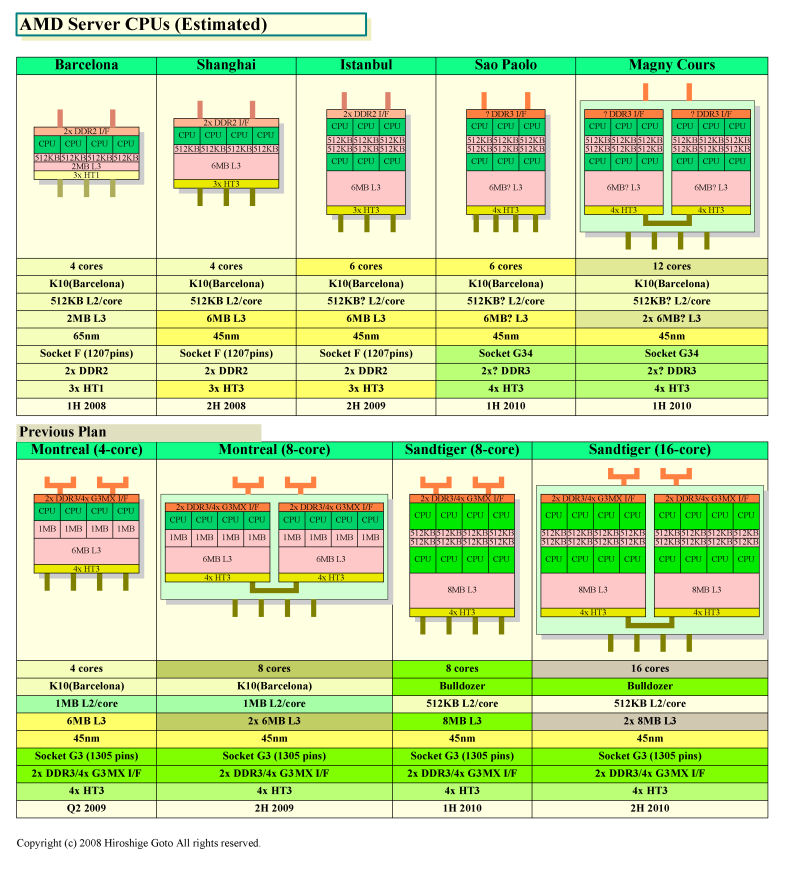{kind=link}
>>257
�ǂ����ɂ��덡�ƂȂ��Ă͂��̎d�l�̂܂o��킯�Ȃ�����ǂ��ł�������
�ǂ����ɂ��덡�ƂȂ��Ă͂��̎d�l�̂܂o��킯�Ȃ�����ǂ��ł�������
>>257
Bulldozer�͑S�����m�̑��݁B
Bulldozer�͑S�����m�̑��݁B
>>257
�����ڂ�����(�E�L��`�E)
http://ja.wikipedia.org/wiki/%E3%83%96%E3%83%AB%E3%83%89%E3%83%BC%E3%82%B6%E3%83%BC
�����ڂ�����(�E�L��`�E)
http://ja.wikipedia.org/wiki/%E3%83%96%E3%83%AB%E3%83%89%E3%83%BC%E3%82%B6%E3%83%BC
Deneb�͂����Ɠ~�ɂł�̂��낤��
264 �F�R�E�L�́M�E,,�j�����������������F2008/05/14(��) 12:00:26 ID:oBjLiF0C
���ځ[��Ō����Ȃ�
>>242�̊֘A�L�������ǁATGDaily��Theo Valich��TSMC�����猩��SOI�����ɏ��o��
���@�͂��Ă��邷�B�B
http://www.tgdaily.com/content/view/37423/118/
�@�@-------------------
�@�@The second manufacturer that might be lured into this technology may be Microsoft, who is
�@�@looking for a foundry partner to manufacture its �gValhalla�h chip. As previously reported,
�@�@Valhalla is a 45 nm SOI chip that combines IBM�fs triple-core Xenon CPU with ATI�fs Xenos GPU.
�@�@-------------------
���@�͂��Ă��邷�B�B
http://www.tgdaily.com/content/view/37423/118/
�@�@-------------------
�@�@The second manufacturer that might be lured into this technology may be Microsoft, who is
�@�@looking for a foundry partner to manufacture its �gValhalla�h chip. As previously reported,
�@�@Valhalla is a 45 nm SOI chip that combines IBM�fs triple-core Xenon CPU with ATI�fs Xenos GPU.
�@�@-------------------
�Ă����̋L�����炷��ƁAXBOX360��45n�������ȃG�l���f�����o����SCE�̓}�W���b����
268 �F�R�E�L�́M�E,,�j�����������������F2008/05/15(��) 08:00:15 ID:JR6metm/
�\�j�[�Ɛє��\��ŁACell�͐�̕��܂Ő��Y�ς݂��Č����Ă�����ȁB
�n�����ˁB�Âɍɉߑ���45nm�v���Z�X�̗p�̌��ʂ��͓��������Ȃ����Ă��Ƃ����B
�n�����ˁB�Âɍɉߑ���45nm�v���Z�X�̗p�̌��ʂ��͓��������Ȃ����Ă��Ƃ����B
�H����Ďd����l�������Ȃ�O�ɍ�����܂��Ƃ��l�����̂��ˁH
RSX�̕��͑S�R��肾�߂��ĂȂ��݂�������
RSX�̕��͑S�R��肾�߂��ĂȂ��݂�������
270 �F�f�j���Ƃ���ꂻ���������F2008/05/15(��) 16:51:13 ID:7vVM66kr
>>268
���̓v���Z�X�ڍs���Ă����N���b�N�������d�͉�����Ȃ���
�d�͂ƈ��������ɃN���b�N�グ��]�n���ł���̂ƃR�X�g�팸���ʂ����Ȃ������
�Q�[���@����N���b�N�グ���Ȃ�����g�[�^���ŋ}���ňڍs���Ȃ��ق������オ����Ă��ƂɂȂ����낤
���̓v���Z�X�ڍs���Ă����N���b�N�������d�͉�����Ȃ���
�d�͂ƈ��������ɃN���b�N�グ��]�n���ł���̂ƃR�X�g�팸���ʂ����Ȃ������
�Q�[���@����N���b�N�グ���Ȃ�����g�[�^���ŋ}���ňڍs���Ȃ��ق������オ����Ă��ƂɂȂ����낤
�̂��݉������Ƃ��������ŏ���d�͕͂��ʂɌ���܂����B
45nm�Ȃ�Đ��i�ɏ��̂͂ǂ������N����B
Cell������45nm�ł͍���Ă����}���K�v�����B
Cell������45nm�ł͍���Ă����}���K�v�����B
cell���̂��̂Ɋւ��ẮAPS3�ȊO�Ɏg��ꂾ���Ă��炪�{�Ԃ������
274 �F�R�E�L�́M�E,,�j�����������������F2008/05/15(��) 19:49:59 ID:JR6metm/
SpursEngine�H�����˂��B�B�B
�X�}����HD DVD�̓��łł��B
�X�}����HD DVD�̓��łł��B
����������IBM���{���x������Cell�o������
276 �F�R�E�L�́M�E,,�j�����������������F2008/05/15(��) 20:23:52 ID:JR6metm/
4SP�E2DP�������Ȃ�x86����������
�v���Z�X�����ŏ���d�͂����邩�ǂ����́A���[�N�d���ɂǂꂾ���Ώ��ł��邩�ɂ��B
�����邱�Ƃ�����Ό��邱�Ƃ����邩��A���Ƃ������Ȃ���Ȃ����ȁB
�����邱�Ƃ�����Ό��邱�Ƃ����邩��A���Ƃ������Ȃ���Ȃ����ȁB
>>276
AVX�ڂ�ƃx�N�g���v���Z�b�T��
AVX�ڂ�ƃx�N�g���v���Z�b�T��
>>270
high-K���^���Q�[�g�݂����ɁA��H�Ɏ�������g�����W�X�^���̂��̂�ς���Ό��I�ɑ����Ȃ�����
����d�͂���������ǂ˂��B
IBM��AMD���撣���ĂP�P����Deneb�ɊԂɍ��킹�悤�Ƃ��Ă邩��
����Ɋ��҂��悤��
high-K���^���Q�[�g�݂����ɁA��H�Ɏ�������g�����W�X�^���̂��̂�ς���Ό��I�ɑ����Ȃ�����
����d�͂���������ǂ˂��B
IBM��AMD���撣���ĂP�P����Deneb�ɊԂɍ��킹�悤�Ƃ��Ă邩��
����Ɋ��҂��悤��
PS3��CELL��8�R�A��L2�L���b�V�����n��ȓ䕨��
���ł�CELL��2�R�A�Œ����d�͂ɓ����������\�͂��ێ����A
���R�[�_�⓮��ҏW�{�[�h���ւ̑g�ݍ��݂ŋ��͂ȃp�t�H�[�}���X������AV�p
IBM��CELL��CELL���{���ڎw���Ă����������Z�\�͂�B��������ׂɔ��W������CELL�̊��S��
PS3�i�j��CELL�ƈꏏ�ɂ�����l�ނ����[�h�����ЂɎ���
���ł�CELL��2�R�A�Œ����d�͂ɓ����������\�͂��ێ����A
���R�[�_�⓮��ҏW�{�[�h���ւ̑g�ݍ��݂ŋ��͂ȃp�t�H�[�}���X������AV�p
IBM��CELL��CELL���{���ڎw���Ă����������Z�\�͂�B��������ׂɔ��W������CELL�̊��S��
PS3�i�j��CELL�ƈꏏ�ɂ�����l�ނ����[�h�����ЂɎ���
281 �F�R�E�L�́M�E,,�j�����������������F2008/05/16(��) 13:32:03 ID:T4PiWiRY
SpursEngine��SPE 4�R�A�{MPEG/H.264�G���R�[�_�E�f�R�[�_
>>280
�m��������
�m��������
���{AMD�A�T�[�o�[�����v���Z�b�T���[�h�}�b�v�����
http://pc.watch.impress.co.jp/docs/2008/0516/amd.htm
http://pc.watch.impress.co.jp/docs/2008/0516/amd.htm
����������AMD�̐l���ٓ��Ɋւ���j���[�X�ŁA�v���Z�b�T�J���̃��[�h�A�[�L�e�N�g��
�ւ�������R��Ă��Ă����ŎQ�l�܂łɏ����Ă������B
http://www.edn.com/index.asp?layout=article&articleid=CA6560252
�@�@======================
�@�@The newly formed central engineering organization will be co-led by Chekib Akrout, who is
�@�@joining AMD from Freescale Semiconductor, and Jeff VerHeul, corporate VP of design
�@�@engineering at AMD, and is tasked with directing the development and execution of AMD�fs
�@�@technology and product roadmaps in partnership with AMD�fs business units.
�@�@======================
Akrout��CELL BE�̎�v�J���҂̈�l�����AVerHeul����IBM���B
������AMD�v���Z�b�T�J���w�̒��g��DEC����IBM�ɓ��ւ����悤�ŁB�B�B
�Q�l�܂łɐ̃Q�n��CELL�X���b�h�ɓ]�ڂ���Ă���CELL BE�J���X�g�[���[��Akrout���o�ꕔ��
�킱��Ȋ������B
�@�@======================
�@�@�u���ꂶ��A���������v
�@�@�d���������APLL�̓�����m�F�B����ڼ��𑀍삵�āA���ߏ�� SPE��������B
�@�@1GHz,1.2GHz,1.4GHz....�S���҂���ق��ƁA�ۯ�������� �����������Ă����B����
�@�@4GH���ɓ��B�B
�@�@�N����Ƃ��Ȃ����肪�B����ŏ\���������B���ӂ͏I���ɂ��悤�B �M�d�����߂��B������
�@�@��ɂ́B�N���������v�����B �Ƃ��낪�AIBM�̊J���ӔC�҂�����Vice President��Chekib
�@�@Akrout �͈�����B
�@�@�u�悵�A���g���������Əグ�悤�B�ǂ��܂œ��������킾�v
�@�@4.2GHz�A4.4GHz....�u���݁v�������オ��B�z��ȏ�̑�d���� �d��ڷޭڰ�����ꂽ�̂��B
�@�@�u�����Ƒ�e�ʂ̎����Ă����v�����Ȃ���Chekib�������B
�@�@����5.6GH���܂œ������B�\�z��啝�ɏ��鐬�ʂ��B
�@�@�������߂̌��͂��̌�������ɑ����ACPU�����܂����ߑS�̂� 4GH���ȏ�ł̓�����m�F�A
�@�@������ɂ�Linux���ްĂɐ����B
�@�@======================
����Akrout��Freescale����̃C���^�r���[�L�����\���Ă������B
http://techon.nikkeibp.co.jp/article/NEWS/20060426/116637/
�ւ�������R��Ă��Ă����ŎQ�l�܂łɏ����Ă������B
http://www.edn.com/index.asp?layout=article&articleid=CA6560252
�@�@======================
�@�@The newly formed central engineering organization will be co-led by Chekib Akrout, who is
�@�@joining AMD from Freescale Semiconductor, and Jeff VerHeul, corporate VP of design
�@�@engineering at AMD, and is tasked with directing the development and execution of AMD�fs
�@�@technology and product roadmaps in partnership with AMD�fs business units.
�@�@======================
Akrout��CELL BE�̎�v�J���҂̈�l�����AVerHeul����IBM���B
������AMD�v���Z�b�T�J���w�̒��g��DEC����IBM�ɓ��ւ����悤�ŁB�B�B
�Q�l�܂łɐ̃Q�n��CELL�X���b�h�ɓ]�ڂ���Ă���CELL BE�J���X�g�[���[��Akrout���o�ꕔ��
�킱��Ȋ������B
�@�@======================
�@�@�u���ꂶ��A���������v
�@�@�d���������APLL�̓�����m�F�B����ڼ��𑀍삵�āA���ߏ�� SPE��������B
�@�@1GHz,1.2GHz,1.4GHz....�S���҂���ق��ƁA�ۯ�������� �����������Ă����B����
�@�@4GH���ɓ��B�B
�@�@�N����Ƃ��Ȃ����肪�B����ŏ\���������B���ӂ͏I���ɂ��悤�B �M�d�����߂��B������
�@�@��ɂ́B�N���������v�����B �Ƃ��낪�AIBM�̊J���ӔC�҂�����Vice President��Chekib
�@�@Akrout �͈�����B
�@�@�u�悵�A���g���������Əグ�悤�B�ǂ��܂œ��������킾�v
�@�@4.2GHz�A4.4GHz....�u���݁v�������オ��B�z��ȏ�̑�d���� �d��ڷޭڰ�����ꂽ�̂��B
�@�@�u�����Ƒ�e�ʂ̎����Ă����v�����Ȃ���Chekib�������B
�@�@����5.6GH���܂œ������B�\�z��啝�ɏ��鐬�ʂ��B
�@�@�������߂̌��͂��̌�������ɑ����ACPU�����܂����ߑS�̂� 4GH���ȏ�ł̓�����m�F�A
�@�@������ɂ�Linux���ްĂɐ����B
�@�@======================
����Akrout��Freescale����̃C���^�r���[�L�����\���Ă������B
http://techon.nikkeibp.co.jp/article/NEWS/20060426/116637/
���GPU�J���̕������ǁATheINQ��Novakovic�L�҂���v�J���҂��ǂ�ǂ��o���Ă���
����͂��Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/05/14/daamit-intel-help
�@�@--------------------
�@�@One reason seems to be that steady stream [Shurely 'flood'? - Ed] of departures from the
�@�@GPU division of AMD. Are they saying "Daamit, I had enough of this"? Whatever the case,
�@�@it won't affect the R700 series and probably the 40nm shrink either. But, whatever the
�@�@roadmap in place, future GPU designs can't be done without the right people.
�@�@--------------------
������܂Łw������햳���x�Ƃ������ԂɂȂ�Ȃ����Ƃ��F����肷�B
����͂��Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/05/14/daamit-intel-help
�@�@--------------------
�@�@One reason seems to be that steady stream [Shurely 'flood'? - Ed] of departures from the
�@�@GPU division of AMD. Are they saying "Daamit, I had enough of this"? Whatever the case,
�@�@it won't affect the R700 series and probably the 40nm shrink either. But, whatever the
�@�@roadmap in place, future GPU designs can't be done without the right people.
�@�@--------------------
������܂Łw������햳���x�Ƃ������ԂɂȂ�Ȃ����Ƃ��F����肷�B
���܂��܃q�}�Ȃ̂��ATheINQ��Charlie "Groo" Demerjian��RealWorldTech�f���ɐF�X
�ʔ����b�������Ă��邷�B
�ŁAAMD�̎�����֘A������Phil Hestor�̑ގЂ�"Fusion"�v��ɉe�������肻�����Ƃ����b�B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=90410&threadid=90102&roomid=2
�@�@----------------------
�@�@FWIW, Hester was the visionary behind that [MAC�I�^��: Fusion�̂���] , and he is gone.
�@�@ -Charlie
�@�@----------------------
�ʔ����b�������Ă��邷�B
�ŁAAMD�̎�����֘A������Phil Hestor�̑ގЂ�"Fusion"�v��ɉe�������肻�����Ƃ����b�B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=90410&threadid=90102&roomid=2
�@�@----------------------
�@�@FWIW, Hester was the visionary behind that [MAC�I�^��: Fusion�̂���] , and he is gone.
�@�@ -Charlie
�@�@----------------------
����
������
�您
���{�̍������S�����E��d�������͊�������
��
���ƌ������̍ďA�E��ƂȂ�������@�l��Ɨ��s���@�l�Ȃǂɑ��A�����Q�O�O�U�N�x�A
���Ƃ̔�����⏕����t�ȂǂŌv�P�Q���U�O�S�V���~���x�o�������Ƃ����炩�ɂȂ����B
http://headlines.yahoo.co.jp/hl?a=20080326-00000000-yom-pol
��
���ƌ������̍ďA�E��ƂȂ�������@�l��Ɨ��s���@�l�Ȃǂɑ��A�����Q�O�O�U�N�x�A
���Ƃ̔�����⏕����t�ȂǂŌv�P�Q���U�O�S�V���~���x�o�������Ƃ����炩�ɂȂ����B
http://headlines.yahoo.co.jp/hl?a=20080326-00000000-yom-pol
�@���H��Ȃ���������������Ăɍ�������[���ɂ�����I
DDR3�Ή��ł��o��܂ŃX���[�������Ȃ��A5400+�ō���Ȃ���ȁH
E7200��4GH����D������
�������͖̂ڂ̑O�ɂ���̂ɂ킴�킴�����ɌŎ����ċꂵ�ނ��Ƃ͂Ȃ���Ȃ��H
Bobcat�́cBobcat�͎��̂��H
���ꂵ�ނ���
������ĂȂ��Ȃ�x64�ֈڍs�o�����A4GB������ɂȂ��Ă錻���PC�ŁA����
�Ƀ������������o���ăE�}�[���Ęb�ɂȂ�̂��ȁH
�����ɔ������������x�̖����A������x����o���锤�����B
�~32�r�b�g�\����512M�r�b�gDDR2 SDRAM�A
�ȃX�y�[�X�Əȓd�͂�����
http://www.ednjapan.com/content/l_news/2008/05/u0o686000000706i.html
�Ƀ������������o���ăE�}�[���Ęb�ɂȂ�̂��ȁH
�����ɔ������������x�̖����A������x����o���锤�����B
�~32�r�b�g�\����512M�r�b�gDDR2 SDRAM�A
�ȃX�y�[�X�Əȓd�͂�����
http://www.ednjapan.com/content/l_news/2008/05/u0o686000000706i.html
4chDDR3�����C���E�E�E�B
�܂��}�U�{������̂��Ə���(ry
ttp://pc.watch.impress.co.jp/docs/2008/0520/kaigai440.htm
�܂��}�U�{������̂��Ə���(ry
ttp://pc.watch.impress.co.jp/docs/2008/0520/kaigai440.htm
8�w�̃}�U�{�Ȃ��������Ȃ��ȁA��������
�܂��݂ɏ������G��Ԃł��̂ŁA���܂�^���ɍl���Ȃ��ʼn������B
Pico-ITX (10-layer)
Nano-ITX (8-layer)
Mini-ITX( 6-layer)
Nano-ITX (8-layer)
Mini-ITX( 6-layer)
>>300
PC�p��DRAM device��8bit��4bit bus�Ȃ̂�64bit��DIMM����邽�߂ɂ�
8�Ƃ�16�Ƃ��ڂ��邱�ƂɂȂ�B
�Ƃ��낪�g���@��͂���ȂɈ�tDRAM���ڂ���X�y�[�X���Ȃ����e�ʂ��������Ă���Ȃ��̂�
1��device�ōL��bus���~�����B���ꂪ���\���ꂽdevice�B
������g����PC�p��DIMM����낤����Ȃ�128MB�Ƃ�256MB�Ƃ��ł�����
����Ȃ�~������ł���?
PC�p��DRAM device��8bit��4bit bus�Ȃ̂�64bit��DIMM����邽�߂ɂ�
8�Ƃ�16�Ƃ��ڂ��邱�ƂɂȂ�B
�Ƃ��낪�g���@��͂���ȂɈ�tDRAM���ڂ���X�y�[�X���Ȃ����e�ʂ��������Ă���Ȃ��̂�
1��device�ōL��bus���~�����B���ꂪ���\���ꂽdevice�B
������g����PC�p��DIMM����낤����Ȃ�128MB�Ƃ�256MB�Ƃ��ł�����
����Ȃ�~������ł���?
4chDDR3���āA�ǂ���Opteron��������Ȃ��́H
�f�X�N�g�b�v�����͏]���ǂ���2ch���Ǝv�����B
�f�X�N�g�b�v�����͏]���ǂ���2ch���Ǝv�����B
http://pc.watch.impress.co.jp/docs/2008/0520/kaigai440.htm
�������A���{AMD�́A����̃��[�h�}�b�v�ύX�́ABulldozer�̊J�������ɂȂ����킯�ł͂Ȃ��A
DDR3�v���b�g�t�H�[�����ǂ̎��_�Ő��n���邩�A���̈ڍs���������ɂ߂����Ƃɂ��ύX���Ƃ����B
DDR3�̃T�|�[�g�́A�I���W�i���v�����ł�2009�N�O���ɓ�������\�肽����
�uMontreal(�����g���I�[��)�v���炾�������A���݂�2010�N�O����Sao Paulo��Magny-Cours����
�ƂȂ��Ă���BDDR3�v���b�g�t�H�[����1�N���炵�����ƂɂȂ�B�������ADRAM�x���_�[��
2009�N�ɏœ_�����킹��DDR3�������̏�����i�߂Ă���B
DDR2�������̒l�オ�葱���ADDR3�͋t�ɒl������(�������ň��l���)
http://www.watch.impress.co.jp/akiba/hotline/20080517/p_mem.html
�ǂ����Ă����ڂł��傤
�������A���{AMD�́A����̃��[�h�}�b�v�ύX�́ABulldozer�̊J�������ɂȂ����킯�ł͂Ȃ��A
DDR3�v���b�g�t�H�[�����ǂ̎��_�Ő��n���邩�A���̈ڍs���������ɂ߂����Ƃɂ��ύX���Ƃ����B
DDR3�̃T�|�[�g�́A�I���W�i���v�����ł�2009�N�O���ɓ�������\�肽����
�uMontreal(�����g���I�[��)�v���炾�������A���݂�2010�N�O����Sao Paulo��Magny-Cours����
�ƂȂ��Ă���BDDR3�v���b�g�t�H�[����1�N���炵�����ƂɂȂ�B�������ADRAM�x���_�[��
2009�N�ɏœ_�����킹��DDR3�������̏�����i�߂Ă���B
DDR2�������̒l�オ�葱���ADDR3�͋t�ɒl������(�������ň��l���)
http://www.watch.impress.co.jp/akiba/hotline/20080517/p_mem.html
�ǂ����Ă����ڂł��傤
DDR3 4ch���āC�C�ł��G�ꂽ���H
AMD���Ă�����Ƀf�J���ڕW�f���邯�ǁA�قƂ�ǂ̏ꍇ���Ƃŏk��������摗��ɂ��邩��
�ォ�瓯�l�̋Z�p�\����Intel����ɂȂ邱�Ƃ������Ȃ��Ă�����
�ォ�瓯�l�̋Z�p�\����Intel����ɂȂ邱�Ƃ������Ȃ��Ă�����
>>303
http://www.google.com/search?hl=ja&q=%E9%A4%85%E3%81%AB%E6%9B%B8%E3%81%84%E3%81%9F%E7%B5%B5&btnG=Google+%E6%A4%9C%E7%B4%A2&lr=
http://www.google.com/search?hl=ja&q=%E9%A4%85%E3%81%AB%E6%9B%B8%E3%81%84%E3%81%9F%E7%B5%B5&btnG=Google+%E6%A4%9C%E7%B4%A2&lr=
>>309
Magny Cours��Intel�����12�R�A���o���邩�ǂ��������ڂ���
Magny Cours��Intel�����12�R�A���o���邩�ǂ��������ڂ���
�R�A��intel�������i�Ɠ������Ɛ��\�����ŋ���������炾�낤���ǁA
����d�͂̉��P�ɖڏ����������炾�Ɗy�ώ�����������������c
����d�͂̉��P�ɖڏ����������炾�Ɗy�ώ�����������������c
Magny Cours�̓T�[�o��p���������d�͓͂x�O�����낤
��pDigitimes�ɂ���AMD�펟����GPU�p��������Quimonda (��Infineon)�Ƒg���
GDDR5�𐄐i����������B
http://www.digitimes.com/NewsShow/MailHome.asp?datePublish=2008/5/21&pages=PR&seq=203
�@�@--------------------
�@�@Qimonda today announced that the company has won AMD as launch partner for the new
�@�@graphics standard GDDR5. Qimonda already started mass production and the volume
�@�@shipping of GDDR5 512Mbit components with a speed of 4.0Gbps to AMD.
�@�@--------------------
GDDR5�𐄐i����������B
http://www.digitimes.com/NewsShow/MailHome.asp?datePublish=2008/5/21&pages=PR&seq=203
�@�@--------------------
�@�@Qimonda today announced that the company has won AMD as launch partner for the new
�@�@graphics standard GDDR5. Qimonda already started mass production and the volume
�@�@shipping of GDDR5 512Mbit components with a speed of 4.0Gbps to AMD.
�@�@--------------------
����CPU�X��
>>316
�����āA����Ȃ��Ɨ����ł��ĂȂ����c�����邩��d�����Ȃ��B
�����āA����Ȃ��Ɨ����ł��ĂȂ����c�����邩��d�����Ȃ��B
320 �F�R�E�L�́M�E,,�j�����������������F2008/05/22(��) 00:28:22 ID:PGzPUQz6
>>313
�I�̃��[�N���[�h�ł̓N���b�N���Ƃ��Ă��R�A����������g�[�^���ł͐��\���P����ꍇ�����邩��ˁB
�N���b�N�����Ƃ��Γd���𗎂Ƃ��邩�����d�͂����点��B
45nmSOI�̏o�����ǂ����������W�Ȃ��ɂ������������ɑǂ�炴��Ȃ���Ȃ��́B
�I����SMT�����������L�������ȁB
�I�̃��[�N���[�h�ł̓N���b�N���Ƃ��Ă��R�A����������g�[�^���ł͐��\���P����ꍇ�����邩��ˁB
�N���b�N�����Ƃ��Γd���𗎂Ƃ��邩�����d�͂����点��B
45nmSOI�̏o�����ǂ����������W�Ȃ��ɂ������������ɑǂ�炴��Ȃ���Ȃ��́B
�I����SMT�����������L�������ȁB
�T�[�o����������Ƃ����ăC���e����荂�R�X�g���Ƌ����͂Ȃ����h�H
>>317
MAC�I�^���ĕt�������Ă�l����H�悩�����獡�x�V�тɍs���Ȃ����H(�E�L��`�E)
MAC�I�^���ĕt�������Ă�l����H�悩�����獡�x�V�тɍs���Ȃ����H(�E�L��`�E)
�����͔��W�ꂶ��Ȃ�
���܂�AMD��CPU�l�^�͖]�߂Ȃ�
ttp://forums.vr-zone.com/showthread.php?t=278539
AMD official press release on employing GDDR5
>The days of monolithic mega-chips are gone.
ttp://forums.vr-zone.com/showthread.php?t=278539
AMD official press release on employing GDDR5
>The days of monolithic mega-chips are gone.
x86�̂܂܃C���e���ɑR���鎎�݂�Fusion�Ƃ��̌��GPGPU����
���炭�ŏI�I�ɂ̓R�A�̃A�[�L�����S�ɗZ��������GPGPU�̃N�A�b�h��ڎw�����Ƃ��Ă��锤
IBM�Ⓦ�ł�CELL�ł�낤�Ƃ��Ă���
���炭�ŏI�I�ɂ̓R�A�̃A�[�L�����S�ɗZ��������GPGPU�̃N�A�b�h��ڎw�����Ƃ��Ă��锤
IBM�Ⓦ�ł�CELL�ł�낤�Ƃ��Ă���
��Quimonda (��Infineon)�Ƒg���
�H�����H
�H�����H
>>321
�T�[�o�[�����Ȃ�Εʂ�Intel��荂�R�X�g�ł͂Ȃ�����B
���̑��̃`�b�v���o�b�t�@�̑��݂��K�v�Ȃ��܂܂ŁA
Intel�n������e�ʂ̃��������߂�킯�����B
����Ɋm����4ch�Őv����Ƃ����킯�ł��Ȃ����B
�T�[�o�[�����Ȃ�Εʂ�Intel��荂�R�X�g�ł͂Ȃ�����B
���̑��̃`�b�v���o�b�t�@�̑��݂��K�v�Ȃ��܂܂ŁA
Intel�n������e�ʂ̃��������߂�킯�����B
����Ɋm����4ch�Őv����Ƃ����킯�ł��Ȃ����B
329 �F�R�E�L�́M�E,,�j�����������������F2008/05/22(��) 19:43:38 ID:PGzPUQz6
�������� �T�C�N���� ����AV
XDR�����ԂɂȂ肽�����ɂ����������Ă���
>>303
�݂ɊG��`���Ăǂ�����w
�݂ɊG��`���Ăǂ�����w
>>331
��̌|�p���ƌ���������Ȃ����H
��̌|�p���ƌ���������Ȃ����H
333 �FSocket774�F2008/05/23(��) 13:52:06 ID:hQmnk8RG
>>331
�G�ɕ`�����݂ƈ���ĐH����ƌ����Ă��Ȃ����H
�G�ɕ`�����݂ƈ���ĐH����ƌ����Ă��Ȃ����H
334 �FSocket774�F2008/05/23(��) 14:13:59 ID:ZC+ZUssp
���̃��C�A�E�g�̂܂�3CPU�R�A�{GPU�R�A
��������3CPU�R�A�{��ʃL���V��
��������3CPU�R�A�{��ʃL���V��
336 �FSocket774�F2008/05/24(�y) 13:24:34 ID:DtJcl/rF
�ǂ��ŕ������炢�����킩��Ȃ������̂ł���
Athlon64X2��6400+��Core2Duo��E8500�ŔY��ł��܂��B
�ǂ���̕��������\�ł��傤���H
��͂�AMD�̕������|�I�ł����H
Athlon64X2��6400+��Core2Duo��E8500�ŔY��ł��܂��B
�ǂ���̕��������\�ł��傤���H
��͂�AMD�̕������|�I�ł����H
>>336
�I�p�r��2way�ȏ�Ȃ�AMD�̂ق��������\
�N�A�b�hXeon�~�S�ƃN�A�b�hOpteron�~�S����Xeon�}�W�ܖځB
�Q�[���pPC�̃V���O��CPU���ƃC���e���������
�I�p�r��2way�ȏ�Ȃ�AMD�̂ق��������\
�N�A�b�hXeon�~�S�ƃN�A�b�hOpteron�~�S����Xeon�}�W�ܖځB
�Q�[���pPC�̃V���O��CPU���ƃC���e���������
338 �FSocket774�F2008/05/24(�y) 13:47:26 ID:DtJcl/rF
>>338
6400+�ɂ��邭�炢�Ȃ�Core 2 Duo�ɂ��Ƃ��B
���݂���AMD�Ɏv�����ꂪ��������C���e����
�D������Ȃ������肷��Ȃ�A�������ǂȁB
6400+�͏���d�͂ł������B
6400+�ɂ��邭�炢�Ȃ�Core 2 Duo�ɂ��Ƃ��B
���݂���AMD�Ɏv�����ꂪ��������C���e����
�D������Ȃ������肷��Ȃ�A�������ǂȁB
6400+�͏���d�͂ł������B
�Ȃ� ��͂� �Ȃ̂��悭�킩��Ȃ���������B
6000+��6400+�̊Ԃɂ͉����������̂����Ă��炢����d�͂������Ă���
�ނ��납��TDP128W������6000+���܂�����89W�����ꂽ�킯�ŁB
���A125W���B
SSE�i�G���R���j�ƃL���b�V�����\�i�Q�[�����j�ł�
Ath64��ł�Core2�����|�I
���̂Q�ȊO�ł͂��������N���b�N�Ȃ�
Phenom�͍��{�I�ȏ����\�͂��オ���Ă���̂�
��̂Q�ȊO�ł�Core2�Ƃ�IPC��r�ł�Phenom����
���̂Q�����������������Ă���̂ő����͂ł������ł���悤�ɂȂ�����
�Ƃ���x���`�Q�̍��v�ł̓R�����ɂ����
�ƁA����Ȋ�����������
Ath64��ł�Core2�����|�I
���̂Q�ȊO�ł͂��������N���b�N�Ȃ�
Phenom�͍��{�I�ȏ����\�͂��オ���Ă���̂�
��̂Q�ȊO�ł�Core2�Ƃ�IPC��r�ł�Phenom����
���̂Q�����������������Ă���̂ő����͂ł������ł���悤�ɂȂ�����
�Ƃ���x���`�Q�̍��v�ł̓R�����ɂ����
�ƁA����Ȋ�����������
���MPhenom�Ƀo�J�ł����q�[�g�V���N�ƎR�m�̍����t�@������̂�������ȁB
�C���e���̃L���b�V���������͓̂䂾�Ȃ�
45nm��������}�ɑ����Ȃ����Ȃ�high-K���^���Q�[�g�̂��������Ɖ��邪�A
CoreMA�ɂȂ��Ă��炸���Ƒ�������Ȃ��B
45nm��������}�ɑ����Ȃ����Ȃ�high-K���^���Q�[�g�̂��������Ɖ��邪�A
CoreMA�ɂȂ��Ă��炸���Ƒ�������Ȃ��B
347 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 19:12:33 ID:/FK0JNgE
�ނ���AMD�̃L���b�V�����x���̂��䂾
����Ȃ��Ēx���܂܂ɂ��Ă�̂��䂾
����Ȃ��Ēx���܂܂ɂ��Ă�̂��䂾
�n���͉����l���Ȃ��Ă�����
349 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 19:28:40 ID:/FK0JNgE
�����l���Ȃ��n���̑ʕ��Ƃ�>>344�̂��Ƃ���
350 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 19:33:08 ID:/FK0JNgE
���͂�O����ƂȂ������[�G���h�N�A�b�h�R�A�iQ6600�j��
�l�C�e�B�u�N�A�b�h�R�A�i�j�̃n�C�G���h�ŁA���Ă�Ƃ����ĂȂ��Ƃ��_���Ă鎞�_��
�_�O���ƌ������ƁB
�l�C�e�B�u�N�A�b�h�R�A�i�j�̃n�C�G���h�ŁA���Ă�Ƃ����ĂȂ��Ƃ��_���Ă鎞�_��
�_�O���ƌ������ƁB
���Ȃ݂ɂ���o��������K87����K10�ŃL���b�V���̑ш�͔{�����Ă���
�n���̌���^�Ɏ�z�Ȃ�ĊF�����낤����킴�킴�����K�v���������m���
�n���̌���^�Ɏ�z�Ȃ�ĊF�����낤����킴�킴�����K�v���������m���
352 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 19:48:50 ID:/FK0JNgE
����o�����������茾�����Ⴄ�n���̌���^�Ɏ�z�͂��Ȃ����낤�ȁB
�L���b�V�����C���T�C�Y�{��������ш�{�ɂȂ��Ă����C�e���V�Z�k�ɂ͎���Ȃ��B
�r���L���b�V��������L1�p�[�W�̃��C�e���V�܂ōڂ�����̂͑O���瓯�������ˁB
�ނ���Core 2�Ȃ�L2�ɍڂ�����f�[�^����K10�ł͂���ɒx��L3���A�~�X�q�b�g���B
�L���b�V�����C���T�C�Y�{��������ш�{�ɂȂ��Ă����C�e���V�Z�k�ɂ͎���Ȃ��B
�r���L���b�V��������L1�p�[�W�̃��C�e���V�܂ōڂ�����̂͑O���瓯�������ˁB
�ނ���Core 2�Ȃ�L2�ɍڂ�����f�[�^����K10�ł͂���ɒx��L3���A�~�X�q�b�g���B
�u�ш�͑����ɊW�Ȃ�
�@����̂̓��C�e���V�̂�
�@�����AMD�͒x���܂܂ł���
�@������
�@ttp://www.xbitlabs.com/articles/cpu/display/core2duo-preview_9.html
�@3�F12��K8�ɔ�ׂ�3�F14��CoreMA�̓`���b������v
�ǂ����z�̔]���ł͂���Ȃ��ƂɂȂ��Ă���悤��
���̓t�F�b�`���v���t�F�b�`
�@����̂̓��C�e���V�̂�
�@�����AMD�͒x���܂܂ł���
�@������
�@ttp://www.xbitlabs.com/articles/cpu/display/core2duo-preview_9.html
�@3�F12��K8�ɔ�ׂ�3�F14��CoreMA�̓`���b������v
�ǂ����z�̔]���ł͂���Ȃ��ƂɂȂ��Ă���悤��
���̓t�F�b�`���v���t�F�b�`
�Ƃ����K10��L2���C�e���V���Ăǂ��Ȃ��Ă������H
355 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 20:09:59 ID:/FK0JNgE
�܂��Ŕn�����ȁB�T���ȉ����ȁB���Έȉ����ȁB
L2���C�e���V��12clk�Ȃ��Victim Buffer�ɋ�����ꍇ�̃x�X�g�G�t�H�[�g�ɂ����Ȃ��B
�r���L���b�V����Victim Buffer���l�܂��Ă���20clk���x�܂Œቺ���܂���B
L2���C�e���V��12clk�Ȃ��Victim Buffer�ɋ�����ꍇ�̃x�X�g�G�t�H�[�g�ɂ����Ȃ��B
�r���L���b�V����Victim Buffer���l�܂��Ă���20clk���x�܂Œቺ���܂���B
Ilya Gavrichenkov(�����N��̒��ҁH)��
���̃t�F�b�`���v���t�F�b�`���҂̂ǂ����M�p���邩�͂Ƃ肠�����u���Ƃ���
�u�����̓��C�e���V�̂݁v�ƌ����Ă���̂͊ԈႢ�Ȃ�������
���̃t�F�b�`���v���t�F�b�`���҂̂ǂ����M�p���邩�͂Ƃ肠�����u���Ƃ���
�u�����̓��C�e���V�̂݁v�ƌ����Ă���̂͊ԈႢ�Ȃ�������
357 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 20:14:57 ID:/FK0JNgE
�x�X�g�G�t�H�[�g�^CPU���đf�G�ł���
AMD�L��u���x��CPU��Load��128bit�~2��256bit�I�v
�ł�Store��64bit�ł�
AMD�L��u���x��CPU��Load��128bit�~2��256bit�I�v
�ł�Store��64bit�ł�
�x�X�g�G�t�H�[�g4���ߓ������s
360 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 20:38:04 ID:/FK0JNgE
Phenom���ē��N���b�N��C2Q�������Ă�̂�nBench�̃X�R�A�Ə���d�͂��炢�Ȃ�
de?
362 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 20:42:06 ID:/FK0JNgE
AMD�̍L��̐l��
�u�N���b�N������́v�Ȃ��
QX9775�Ɠ����Ƃ͌���Ȃ�����
���߂�QX9650�����̃N���b�N�̐��i�o���Ă��猾���Ă݂Ă�
�u�N���b�N������́v�Ȃ��
QX9775�Ɠ����Ƃ͌���Ȃ�����
���߂�QX9650�����̃N���b�N�̐��i�o���Ă��猾���Ă݂Ă�
he-
�����́AIntel�̊J���҂��Ȃ��H
�����ЂƂ��܂̐��i�łƂ�������
�����ЂƂ��܂̐��i�łƂ�������
365 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 20:57:52 ID:/FK0JNgE
K10�̊g���ɂ̓Z���X���������Ȃ�
�˔\�����@�����҂ɂ���ĖŒ��ꒃ�ɂ���Ă��܂���
����́A�Â��A��剻�����X���A�[�L�e�N�`����
�˔\�����@�����҂ɂ���ĖŒ��ꒃ�ɂ���Ă��܂���
����́A�Â��A��剻�����X���A�[�L�e�N�`����
>>364
�Ղ̈Ђ����
�Ղ̈Ђ����
369 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 21:17:48 ID:/FK0JNgE
>>368 �悤�A�d�Ԃ̒��̂���Ȑl
370 �F�P�P�P�P�P�P�u�P�P�P�P�P�P�P�P�P�P�P�P�P�F2008/05/24(�y) 21:38:00 ID:JalcyW2M
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@)))�
�@�@�@�@�@�@�@�@�@�@�@�@�Q�m�m))�j)
�@�@�@�@�@�@�@�@ �@�i�i�i�i�i�i�i�c�m)�@�@�@�@�@�@�@�@�@�@�@�@�@�Q
�@�@�@�@�@�@�@ �@�i�i�i�i�i(_( ���mɁ@�@�@�@�@�@�@�@�@ �@�^ �P�@�@�P �_
�@�@�@�@�@�@�@�@ (/jj7��_.�@,_ �t�@�@�@�@�@�@�@�@�@ /�A�@�@�@�@�@�@�@�@ �R�@
�@�@�@�@�@�@�@�@�cjj_T==i_��=tT|�@�@�@�@�@�@�@�@�@|�E |�\-�A�@�@�@�@�@�@ |
�@�@�@�@�@ �@ �@�c�~��P�E�E�P Ѓ��@�@�@�@�@�@�@�� -�L�@�� �R�@�@�@�@�@ |
�@�@�@�@�@�@�@�c' _lt�@�@'=t �@/__�@�@�@�@�@�@�@�@�m�Q�@�[�@ |�@�@�@�@�@|
�@�@�@�@ �@_,�@-t"lt__�@�@�@�@j l�@�O�''� ��@�@�@�@�@�_.�P�M�@ |�@ �@ �@�@/
�@�@�@�@�^ �@�@�@�@�R�P�@��7�@�@�@�@�@�_�@�@�@�@�@O���������� |
�@�@�@/�@�@�@�@�@�@�@`-�]''ށ@�@�@�@�@�@�@�@ �R�@�@�@/�@�@�@�@�@�@ �@�@ |
�@�@�@�@�@�@�@�@�@�@�@�@�Q�m�m))�j)
�@�@�@�@�@�@�@�@ �@�i�i�i�i�i�i�i�c�m)�@�@�@�@�@�@�@�@�@�@�@�@�@�Q
�@�@�@�@�@�@�@ �@�i�i�i�i�i(_( ���mɁ@�@�@�@�@�@�@�@�@ �@�^ �P�@�@�P �_
�@�@�@�@�@�@�@�@ (/jj7��_.�@,_ �t�@�@�@�@�@�@�@�@�@ /�A�@�@�@�@�@�@�@�@ �R�@
�@�@�@�@�@�@�@�@�cjj_T==i_��=tT|�@�@�@�@�@�@�@�@�@|�E |�\-�A�@�@�@�@�@�@ |
�@�@�@�@�@ �@ �@�c�~��P�E�E�P Ѓ��@�@�@�@�@�@�@�� -�L�@�� �R�@�@�@�@�@ |
�@�@�@�@�@�@�@�c' _lt�@�@'=t �@/__�@�@�@�@�@�@�@�@�m�Q�@�[�@ |�@�@�@�@�@|
�@�@�@�@ �@_,�@-t"lt__�@�@�@�@j l�@�O�''� ��@�@�@�@�@�_.�P�M�@ |�@ �@ �@�@/
�@�@�@�@�^ �@�@�@�@�R�P�@��7�@�@�@�@�@�_�@�@�@�@�@O���������� |
�@�@�@/�@�@�@�@�@�@�@`-�]''ށ@�@�@�@�@�@�@�@ �R�@�@�@/�@�@�@�@�@�@ �@�@ |
�K��AA�����
372 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 21:48:59 ID:/FK0JNgE
�c�q�g���b�v�̂Ă��́H
���Ŗق�́H������
376 �F�R�E�L�́M�E,,�j�����������������F2008/05/24(�y) 23:51:50 ID:/FK0JNgE
�@
�s�����܂���
���܂���B�݂��Ȃ������Ɛ키�͎̂��߂�B
��R�R�́A"AMD������CPU�X��"���B
�~�̔@�������Ŏ��ȓ������Ă�����̂�
�����U��Ӳ�l��͂ق��Ă����B
��R�R�́A"AMD������CPU�X��"���B
�~�̔@�������Ŏ��ȓ������Ă�����̂�
�����U��Ӳ�l��͂ق��Ă����B
ttp://northwood.blog60.fc2.com/blog-entry-1990.html
�������CPU�iSSE�j����iGP�jGPU�ւƎ��オ�ς���Ă����Ă��Ƃ��ȁH
���������琫�\�ǂ��Ȃ邩����Ĕ������M�͌�������
CPUor�}�U�{����+�t�@�����X�O�t�����炢���l�I�ɂ͗��z�ƍl���Ă邯��
�������CPU�iSSE�j����iGP�jGPU�ւƎ��オ�ς���Ă����Ă��Ƃ��ȁH
���������琫�\�ǂ��Ȃ邩����Ĕ������M�͌�������
CPUor�}�U�{����+�t�@�����X�O�t�����炢���l�I�ɂ͗��z�ƍl���Ă邯��
381 �FSocket774�F2008/05/26(��) 15:23:03 ID:mxADgabW
sse��fpu�̑��肶��Ȃ����ȁB
�܂��A�����╡���̃V���O���X���b�h���Z�͋��Ȃ͂��B
�܂��A�����╡���̃V���O���X���b�h���Z�͋��Ȃ͂��B
�c�q�̂������Ƃ͂�����x�����Ă������ق���������
���[���߂ɂȂ�
�{���̎��������߂���INTEL�X���ł���o����֎~�ɂȂ����`���̃R�e��
���[���߂ɂȂ�
�{���̎��������߂���INTEL�X���ł���o����֎~�ɂȂ����`���̃R�e��
�Z�p�҂Ƃ��Ă̒c�q�͔F�߂Ă邵�b�͎Q�l�ɂ��Ă�
�����A���i���c�t�Ȃ�
�����A���i���c�t�Ȃ�
�͂��͂���낷��낷
385 �FSocket774�F2008/05/26(��) 15:59:32 ID:j7Ky2EOx
�Ƃ肠�������f�I���͂��ƌ�������
386 �FSocket774�F2008/05/26(��) 16:02:10 ID:j7Ky2EOx
���f�͌��ǂȏ����܂ł����Ă��Q�t�H�ɏ����Ƃ͏o���Ȃ��B
�f�J���̂̓��f�~�̑ԓx�����B�{���ɒp���������z�炾�ȁB
�f�J���̂̓��f�~�̑ԓx�����B�{���ɒp���������z�炾�ȁB
�딚�����B�ǂ���牴�͖{���ɒp���������z�̂悤��
�c�q�͂����Ɨ����Ȏ����̂������o����ׂ�
HD4k�X���r�炻���Ƃ��Ă����ȁH
��������������K10�ƈ���ď����ɃA���`�Ɏ��܂�Ă�݂����őA�܂����B
��������������K10�ƈ���ď����ɃA���`�Ɏ��܂�Ă�݂����őA�܂����B
390 �F�R�E�L�́M�E,,�j�����������������F2008/05/26(��) 19:32:11 ID:SnuHi8tY
��R�����܂Ɍ�������b�����ɕ����Ƃ���
391 �FSocket774�F2008/05/26(��) 19:34:55 ID:j7Ky2EOx
AMD���Č㉽�N�킦��́H�������̑��݂����ł����ǁB
nv���͒���
393 �F�R�E�L�́M�E,,�j�����������������F2008/05/26(��) 22:11:18 ID:SnuHi8tY
���̂���http://amd.ati.com/�ɂȂ����H
�z�������̂�AMD�Ȃ̂ɂȂ��ati�̃T�u�h���C���Ȃ�
�t����
�t����
�����ǂ߂��]�B�B�B
http://ati.amd.ibm.com
�Ȃ�[����
�Ȃ�[����
���ꂪ�ǂ߂Ȃ������\�A�ǂ��炩�Ƃ����Ɩ��\
>>394
ATi�̃T�u�h���C�����ĉ��H
ATi�̃T�u�h���C�����ĉ��H
>>383
�Z�p�ҁi�j
�Z�p�ҁi�j
�������ł̂����������ȃ}���Z�[�̃p�^�[�����}�N�I�^�ɒʂ�����̂������w
401 �F�R�E�L�́M�E,,�j�����������������F2008/05/27(��) 13:02:00 ID:erChcAFh
ore ga itu gijutu sha ni nattanda
eigyo nanoni
eigyo nanoni
402 �FSocket774�F2008/05/28(��) 10:19:40 ID:yLxhB0XD
�C���e����DDR3�ɓ�������DDR3�\�������������ǁA
AMD�Ή���9�N������Ƃ����o���ˁH
�Ă�Deneb����939���Ɍ��̂Ă�ꂽ�q��ԂɂȂ肻���Ȃ�
����PC16000�������Ɩ\������̂��ˁH
PC14400�܂łƂ�����ꂽ�狃����
AMD�Ή���9�N������Ƃ����o���ˁH
�Ă�Deneb����939���Ɍ��̂Ă�ꂽ�q��ԂɂȂ肻���Ȃ�
����PC16000�������Ɩ\������̂��ˁH
PC14400�܂łƂ�����ꂽ�狃����
��PC16000
PC12800�܂łł�������c�����܂ō��������Ăǂ�����B�`�b�v����H���������
PC12800�܂łł�������c�����܂ō��������Ăǂ�����B�`�b�v����H���������
>>403
CPU�����߂��ă�������HDD�����Ă��Ȃ��̂����݂̒x���̑唼������A
��������PC16000(���݂̎���35000�~/GB)�ɂȂ���Ȃ胂�b�T���͉���������Ȃ����ȁH
CPU�����߂��ă�������HDD�����Ă��Ȃ��̂����݂̒x���̑唼������A
��������PC16000(���݂̎���35000�~/GB)�ɂȂ���Ȃ胂�b�T���͉���������Ȃ����ȁH
��u�ߋ��͊o���Ă��܂���v
PC3-16000��������B
���Ƒш悪�L���Ȃ��Ă����C�e���V���i����
���_�F
�u��������v�Ȃ�Č����z�͑���ɂ��Ȃ������g
���Ƒш悪�L���Ȃ��Ă����C�e���V���i����
���_�F
�u��������v�Ȃ�Č����z�͑���ɂ��Ȃ������g
DDR3-1600����Ȃ���PC3-16000�H
����ȑ����̏o��̂��H
DDR2-6400 PC2-800�ɑ�������̂�DDR3-12800 PC3-1600����B
����ȑ����̏o��̂��H
DDR2-6400 PC2-800�ɑ�������̂�DDR3-12800 PC3-1600����B
>>408
�����OC�i����BDDR2������jedec�����ĂȂ�DDR2-1200�Ƃ��������̂Ɠ����B
DDR3�͊�{DDR3-1600 PC3-12800�܂ł���B
http://pc.watch.impress.co.jp/docs/2007/0914/kaigai385.htm
�����OC�i����BDDR2������jedec�����ĂȂ�DDR2-1200�Ƃ��������̂Ɠ����B
DDR3�͊�{DDR3-1600 PC3-12800�܂ł���B
http://pc.watch.impress.co.jp/docs/2007/0914/kaigai385.htm
Intel���uCentrino 2�v�������B�����̓O���t�B�b�N�X�ƃ��C�����X
http://www.itmedia.co.jp/news/articles/0805/28/news030.html
�܂��ʂ���т�����㩂��E�E�E
http://www.itmedia.co.jp/news/articles/0805/28/news030.html
�܂��ʂ���т�����㩂��E�E�E
>���A����ȏ�ɑ傫�Ȗ��́AAMD�����̒x��ɂ�����ŁA
>Puma��Centrino�ɑ���L�͂ȑI�������Ǝ咣�ł���Ƃ������Ƃ��B
����͂ǂ��ȂˁH
ttp://plusd.itmedia.co.jp/pcuser/articles/0705/18/news032.html
Griffin�ARS780M�ASB700��3�`�b�v�\��
�`�b�v�Z�b�g�ɂ����ʂɍ��ȋ@�\������
�n�C�G���h�m�[�g�Ȃ����Ȃ낤����
���ʂ�������
ttp://www.viaopenbook.com/index.php
�ӊO�ɃR����isaiah���ڋ@���ł�Έ�C�ɍL�܂��Ă��܂�������
�܂��A�n�C�G���h�ł͂Ȃ����ǂ�
>Puma��Centrino�ɑ���L�͂ȑI�������Ǝ咣�ł���Ƃ������Ƃ��B
����͂ǂ��ȂˁH
ttp://plusd.itmedia.co.jp/pcuser/articles/0705/18/news032.html
Griffin�ARS780M�ASB700��3�`�b�v�\��
�`�b�v�Z�b�g�ɂ����ʂɍ��ȋ@�\������
�n�C�G���h�m�[�g�Ȃ����Ȃ낤����
���ʂ�������
ttp://www.viaopenbook.com/index.php
�ӊO�ɃR����isaiah���ڋ@���ł�Έ�C�ɍL�܂��Ă��܂�������
�܂��A�n�C�G���h�ł͂Ȃ����ǂ�
412 �FSocket774�F2008/05/28(��) 13:49:16 ID:yLxhB0XD
>>410
�ď���ɐV�^�m�[�g�̐�������Ȃ��̂͒v���I������
puma�ɂƂ��Ă͑�`�����X����ˁH
DELL�Ƃ�AMD�ƒ��������Ƃ��͍���̖����A
��荂����wifi��LAN�ƍ����O���t�B�b�N�X�@�\�������AMD�̃V�X�e���̑��Y��
���v�ɑΉ����悤�Ƃ��邩������Ȃ����B
�ď���ɐV�^�m�[�g�̐�������Ȃ��̂͒v���I������
puma�ɂƂ��Ă͑�`�����X����ˁH
DELL�Ƃ�AMD�ƒ��������Ƃ��͍���̖����A
��荂����wifi��LAN�ƍ����O���t�B�b�N�X�@�\�������AMD�̃V�X�e���̑��Y��
���v�ɑΉ����悤�Ƃ��邩������Ȃ����B
>>410
������ Intel ������ق�GPU��������������Ƃ͎v��Ȃ������낤�Ȃ��B
�ꎞ���̔��M�v���X�R90nm�Ǝ����l�ȏ����A�������̏�SOI�̗L����
����AMD������ATi��搉̂��Ă���ǁAIntel��65nm�Ŋ����Ԃ����݂����ɁA
�ǂ�����AMD���E�T�M�ƋT�݂����ɔ������낤�Ȃ��B
������ Intel ������ق�GPU��������������Ƃ͎v��Ȃ������낤�Ȃ��B
�ꎞ���̔��M�v���X�R90nm�Ǝ����l�ȏ����A�������̏�SOI�̗L����
����AMD������ATi��搉̂��Ă���ǁAIntel��65nm�Ŋ����Ԃ����݂����ɁA
�ǂ�����AMD���E�T�M�ƋT�݂����ɔ������낤�Ȃ��B
�́H
>>415
���̔��z�͖�������
�E>410�����N��́u�}�U�{�����O���`�̕s�(?)�v�𐫔\�̌��Ɠǂ݊ԈႤ
�Eintel��90nm�����M��65nm�̂��A�Ŋ����Ԃ����Ǝv���Ă���
�@�i90nm�̃h�^���̓o�j�A�X����̐L�ё�͏��Ȃ������悤�������Ɉ����͂Ȃ�
�@�@�t��65nm�V�_�~���͒�i�グ�撣�����Ƃ��Ă��債�����ƂȂ������Ɛ����j
�E�uATi��搉́v�Ƃ�������ǂ������Ԃ���
�ƑS�̓I�ɕς���������
���̔��z�͖�������
�E>410�����N��́u�}�U�{�����O���`�̕s�(?)�v�𐫔\�̌��Ɠǂ݊ԈႤ
�Eintel��90nm�����M��65nm�̂��A�Ŋ����Ԃ����Ǝv���Ă���
�@�i90nm�̃h�^���̓o�j�A�X����̐L�ё�͏��Ȃ������悤�������Ɉ����͂Ȃ�
�@�@�t��65nm�V�_�~���͒�i�グ�撣�����Ƃ��Ă��債�����ƂȂ������Ɛ����j
�E�uATi��搉́v�Ƃ�������ǂ������Ԃ���
�ƑS�̓I�ɕς���������
���[���⍡��AMD�̓`�v�Z�g��GPU��55nm�ŁACPU��65nm�Ė��ȏ�ԂȂ��
45nmCPU��ް�H
45nmCPU��ް�H
���ȏ�Ԃ����ǁA�����CPU�̕���GPU�A�`�b�v�Z�b�g�Ɠ������A�v���Z�X���[�����Â����Ă̂�
�P�퉻���邩���ˁB
�o���N��SOI���ĈႢ�����邯�ǁATSMC�����N����45nm�ʎY�\�肾���B
�P�퉻���邩���ˁB
�o���N��SOI���ĈႢ�����邯�ǁATSMC�����N����45nm�ʎY�\�肾���B
������IBM��TSMC��AMD�����������Y��ɓZ�܂�ˁH
421 �FSocket774�F2008/05/28(��) 18:33:42 ID:lIXYXIn/
�`�s�h�������͂f�o�t�������ꎩ�Ђ̂r�n�h�ō��悤��
����Ƃ����b���������悤�ȋC�����邪�A���ǂe�t�r�h�n�m
�܂Ŏ��А����͖����̂��˂��B
����Ƃ����b���������悤�ȋC�����邪�A���ǂe�t�r�h�n�m
�܂Ŏ��А����͖����̂��˂��B
Fusion��TSMC��SOI����
fusionasan
425 �FSocket774�F2008/05/28(��) 19:56:46 ID:lIXYXIn/
>>424
�Ƃ������Ƃ́A�s�r�l�b�ō�����f�o�t�p�[�g�����А�����
�b�o�t�p�[�g�Ƃl�b�l�łP�p�b�P�[�W�ɂ��邩�A�S������
�s�r�l�b�����ɂȂ�Ƃ��������B�m�������d�������v����
���Ƃ͎v�����ǁA�R�X�g�E���\��Nehalem�Ə����ɂȂ��
������H��҂̏ꍇ�A�`�l�c�̐����L���p�V�e�B���]��
�C���ɂȂ肻�������B
�Ƃ������Ƃ́A�s�r�l�b�ō�����f�o�t�p�[�g�����А�����
�b�o�t�p�[�g�Ƃl�b�l�łP�p�b�P�[�W�ɂ��邩�A�S������
�s�r�l�b�����ɂȂ�Ƃ��������B�m�������d�������v����
���Ƃ͎v�����ǁA�R�X�g�E���\��Nehalem�Ə����ɂȂ��
������H��҂̏ꍇ�A�`�l�c�̐����L���p�V�e�B���]��
�C���ɂȂ肻�������B
>>424�͉R����
429 �FSocket774�F2008/05/28(��) 20:46:45 ID:lIXYXIn/
>>427
���i�т�����Ă���Ȃ�Swift�ɂ�����Ȃ�Ƀ`�����X��
����낤�Ȃ��B�Ƃ͂����ACPU�EGPU�Ƃ��Ɍ���̃��t
�@�C���łł�����l�b�l�Ōq�������Ƃ����̂̓C���p�N�g��
�R�����C������B
Havendale/Auburndale��GPU�R�A������Intel�I���{�[�h
�Ƒ債�ĕς���悤�Ȑ��\�Ȃ�Swift���听�����邩��
����Ȃ����c�B
���i�т�����Ă���Ȃ�Swift�ɂ�����Ȃ�Ƀ`�����X��
����낤�Ȃ��B�Ƃ͂����ACPU�EGPU�Ƃ��Ɍ���̃��t
�@�C���łł�����l�b�l�Ōq�������Ƃ����̂̓C���p�N�g��
�R�����C������B
Havendale/Auburndale��GPU�R�A������Intel�I���{�[�h
�Ƒ債�ĕς���悤�Ȑ��\�Ȃ�Swift���听�����邩��
����Ȃ����c�B
>>428
���̑S�������ɓ\���Ă݂낗
���̑S�������ɓ\���Ă݂낗
�Ȃ�Ń����N������悤�Ƃ��Ȃ��H
>>429
Auburndale��GPU����G45�̔h���ŁB�܂��������炵�Ă�G45�����낤�B
GPU�͓��RSwift���D�邾�낤�ˁB
�o��̂����N���炢Swift�̕����ゾ���B
Auburndale��GPU����G45�̔h���ŁB�܂��������炵�Ă�G45�����낤�B
GPU�͓��RSwift���D�邾�낤�ˁB
�o��̂����N���炢Swift�̕����ゾ���B
�����B3 Opteron���ڃT�[�o�[���o�Ă���悤�ɂȂ������ʁASPEC2006�̓o�^�������Ă������B
�Ƃ����ɏo�Ă��Ă���w���x������2.66GHz�ɂ�y�Ȃ����̂́A2.5GHz�i��2360/8360�̌��ʂ�
Dell���o�^���Ă��邷�B�V���O���X���b�h���\�Ɏ��M�����ĂȂ����߂��A"rate"���������ǁB�B�B
�EOpteron 2360SE/2.5GHz int_rate: 92.4/106, fp_rate: 82.1/89.9
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04223.html
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04221.html
�EOpteron 8360SE/2.5GHz int_rate: 167/193, fp_rate: 152/166 (�������base/peak)
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04225.html
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04224.html
��r����ƁA����Ȋ������B
�� 2-socket
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@int_rate�@�@�@�@�@�@fp_rate
�@Xeon E5420/2.5GHz: 160/192�@�@�@�@�@64.7/72.3
�@Op 2360SE/2.5GHz: �@92.4/106�@�@�@�@�@82.1/89.9
�@Xeon X5460/3.16GHz: 113/138�@�@�@�@�@70.8/79.0
�@Power6/4.7GHz�@�@�@�@97.5/115�@�@�@�@�@105/118�@[��: 4-core]
�� 4-socket
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@int_rate�@�@�@�@�@�@fp_rate
�@Xeon E7340/2.4GHz: 98.3/120�@�@�@�@�@101/110
�@Op 8360SE/2.5GHz: �@167/193�@�@�@�@�@152/166
�@Xeon X7350/2.93GHz: 178/214�@�@�@�@�@108/114
�@Power6/4.7GHz�@�@�@�@204/234�@�@�@�@�@182/215�@[��: 8-core]
�Ƃ����ɏo�Ă��Ă���w���x������2.66GHz�ɂ�y�Ȃ����̂́A2.5GHz�i��2360/8360�̌��ʂ�
Dell���o�^���Ă��邷�B�V���O���X���b�h���\�Ɏ��M�����ĂȂ����߂��A"rate"���������ǁB�B�B
�EOpteron 2360SE/2.5GHz int_rate: 92.4/106, fp_rate: 82.1/89.9
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04223.html
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04221.html
�EOpteron 8360SE/2.5GHz int_rate: 167/193, fp_rate: 152/166 (�������base/peak)
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04225.html
�@http://www.spec.org/cpu2006/results/res2008q2/cpu2006-20080428-04224.html
��r����ƁA����Ȋ������B
�� 2-socket
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@int_rate�@�@�@�@�@�@fp_rate
�@Xeon E5420/2.5GHz: 160/192�@�@�@�@�@64.7/72.3
�@Op 2360SE/2.5GHz: �@92.4/106�@�@�@�@�@82.1/89.9
�@Xeon X5460/3.16GHz: 113/138�@�@�@�@�@70.8/79.0
�@Power6/4.7GHz�@�@�@�@97.5/115�@�@�@�@�@105/118�@[��: 4-core]
�� 4-socket
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@int_rate�@�@�@�@�@�@fp_rate
�@Xeon E7340/2.4GHz: 98.3/120�@�@�@�@�@101/110
�@Op 8360SE/2.5GHz: �@167/193�@�@�@�@�@152/166
�@Xeon X7350/2.93GHz: 178/214�@�@�@�@�@108/114
�@Power6/4.7GHz�@�@�@�@204/234�@�@�@�@�@182/215�@[��: 8-core]
���ς�炸�s���w���������͏�����MAC�I�^�����(��)
440 �FMAC�I�^��439 �����F2008/05/29(��) 07:52:47 ID:hZstmRxS
>>439
���w�E���ӂ��邷�B
���w�E���ӂ��邷�B
���̐l�������悤�ȃ~�X��������
�A���~��f�[�^��s�����炩��`�Ƃ������p���z���ł���B
�A���~��f�[�^��s�����炩��`�Ƃ������p���z���ł���B
Intel��SPEC�l����1��2��тʂ��Ă�̂����邾���ő��͂���Ȃɑ����Ȃ���ȁB
�R���p�C���܂Ŏ��Ђō���ĉ�Ђ̈АM�����ăJ���J���ɘM���Ă锤�Ȃ̂ɁB
���_�������y�j�X�͎��˂ƌ��������B
�R���p�C���܂Ŏ��Ђō���ĉ�Ђ̈АM�����ăJ���J���ɘM���Ă锤�Ȃ̂ɁB
���_�������y�j�X�͎��˂ƌ��������B
���₵���̂�
MAC�I�^����Power���������ǂ��Ȃ�낤�H
�n�Q�邾�낤���H����Ƃ��j�邾�낤���H
�n�Q�邾�낤���H����Ƃ��j�邾�낤���H
�k�ނ���
���݂�������Ԃɔ��U�����ˁH
Athlon X2 4850e����D���Ƃ̂��Ƃ��B
http://www.watch.impress.co.jp/akiba/hotline/20080531/etc_shopwatch.html
B3 Opteron���D�]�Ƃ̘b�����A���N�㔼�퍕�����ł���Ɨǂ����ˁB
�l�^�Ƃ��Ă�S�R�����ザ��Ȃ������ǁA�ߋ��̏������݂̌��ؗp�ɁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1197562571/433
�@�@=====================
�@�@433 ���O�FMAC�I�^ ���e���F2007/12/22(�y) 16:16:31 ID:0deFuoHF
�@�@�@�@�l�I�ɂ�A�����Ė]�܂����b����Ȃ������ǁA��Ђ̑������l����Ɓ@����AMD��V�K�̊J��
�@�@�@�@�������~�߂���ŁA���X�g����f�s���Ċ����̐��i��ቿ�i�Ŕ��邱�Ƃɒ��͂��ׂ����Ǝv�����B
�@�@�@�@ATI�̎��Y�Ɩ��ʂɍ����\�̍H���A�����MediaGX�̎����ɓ������Č�i�������ɔ��邷�B
�@�@�@�@�ǂ����ڋq����̐M���Ȃ�Ēn�̒�܂ŗ�����������A�������Ђ��R�X�g�������Đ��\���Ⴂ
�@�@�@�@���i�Ȃ�ăf�B�X�R���ɂ��Ă��܂��Ă��d����������Ȃ������ˁB�B�B
�@�@=====================
http://www.watch.impress.co.jp/akiba/hotline/20080531/etc_shopwatch.html
B3 Opteron���D�]�Ƃ̘b�����A���N�㔼�퍕�����ł���Ɨǂ����ˁB
�l�^�Ƃ��Ă�S�R�����ザ��Ȃ������ǁA�ߋ��̏������݂̌��ؗp�ɁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1197562571/433
�@�@=====================
�@�@433 ���O�FMAC�I�^ ���e���F2007/12/22(�y) 16:16:31 ID:0deFuoHF
�@�@�@�@�l�I�ɂ�A�����Ė]�܂����b����Ȃ������ǁA��Ђ̑������l����Ɓ@����AMD��V�K�̊J��
�@�@�@�@�������~�߂���ŁA���X�g����f�s���Ċ����̐��i��ቿ�i�Ŕ��邱�Ƃɒ��͂��ׂ����Ǝv�����B
�@�@�@�@ATI�̎��Y�Ɩ��ʂɍ����\�̍H���A�����MediaGX�̎����ɓ������Č�i�������ɔ��邷�B
�@�@�@�@�ǂ����ڋq����̐M���Ȃ�Ēn�̒�܂ŗ�����������A�������Ђ��R�X�g�������Đ��\���Ⴂ
�@�@�@�@���i�Ȃ�ăf�B�X�R���ɂ��Ă��܂��Ă��d����������Ȃ������ˁB�B�B
�@�@=====================
��
Isaiah���V�������N���ăf���A���R�A�������͎̂�����ƌ���
K8�R�A���g�����ăN�A�b�h�R�A������K10�͎�����ł͂Ȃ��ƌ����܂�����
K8�R�A���g�����ăN�A�b�h�R�A������K10�͎�����ł͂Ȃ��ƌ����܂�����
������l�^�Ƃ��Ă�S�R�����ザ��Ȃ������ǁA�ߋ��̏������݂̌��ؗp�ɁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/4,662,674
����Stars�R�A(Barcelona/Phenom/K10/K8L)�ɂ���
�����܂��猾���܂ł�����K8L��P�Ȃ�K8�̉������BK8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
��������Aerrata���C������悤���A�����v���Z�X�̉��P�����낤������傫������N���b�N�����シ��
�����Ƃ��������A�L���b�V���̑��ʈȊO��IPC����̗v�����������B
���L�`�K�C�̃q�g��A�����̂悤�ɍ݂鎖�������A���X�ɖϑz���O���Ă���悤��(��)
���@�@----------------
���@�@MAC��������������̃e���v���Ƃ������X���̓���
���@�@�u65nmK8�̃N���b�N�̌��E�����̃A�[�L�̌��E�v�Ƃ�
���@�@90nm�̂��Ɗ����s�����ē��ӋC�ɒ����Ă���
���@�@----------------
��>>4-12�ɊY������b�팩������Ȃ����ˁB�B�B
�i��F
�@1.����ł̓V���R���̔M���E����Ƀp�C�v���C�����_�l�̌��E�����Ă���
�@2.�p�C�v���C���̓A�[�L�e�N�`���̂����ɓ���Ȃ��j
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/4,662,674
����Stars�R�A(Barcelona/Phenom/K10/K8L)�ɂ���
�����܂��猾���܂ł�����K8L��P�Ȃ�K8�̉������BK8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
��������Aerrata���C������悤���A�����v���Z�X�̉��P�����낤������傫������N���b�N�����シ��
�����Ƃ��������A�L���b�V���̑��ʈȊO��IPC����̗v�����������B
���L�`�K�C�̃q�g��A�����̂悤�ɍ݂鎖�������A���X�ɖϑz���O���Ă���悤��(��)
���@�@----------------
���@�@MAC��������������̃e���v���Ƃ������X���̓���
���@�@�u65nmK8�̃N���b�N�̌��E�����̃A�[�L�̌��E�v�Ƃ�
���@�@90nm�̂��Ɗ����s�����ē��ӋC�ɒ����Ă���
���@�@----------------
��>>4-12�ɊY������b�팩������Ȃ����ˁB�B�B
�i��F
�@1.����ł̓V���R���̔M���E����Ƀp�C�v���C�����_�l�̌��E�����Ă���
�@2.�p�C�v���C���̓A�[�L�e�N�`���̂����ɓ���Ȃ��j
451 �FMAC�I�^��450 �����F2008/06/01(��) 12:13:06 ID:eQ8OIA4W
>>450
�����́w�V���R���̎��x����D���ȃL�`�K�C�̃q�g����(��)
����N���b�N�ƃp�C�v���C���v�̘b��APetium4����Ɍ�������Ă��邷�B�ǂ݂₷������
�����������Ă���������A��x�ǂ�œ�x�Ɠd�g�J�L�R�����Ȃ����Ƃ����肢���������B
http://pc.watch.impress.co.jp/docs/article/20000223/kaigai01.htm
http://www.atmarkit.co.jp/fpc/rensai/zunouhoudan007/pipline.html
http://www.4gamer.net/specials/softhard/cpu_2-01/cpu_2-01.shtml
�����́w�V���R���̎��x����D���ȃL�`�K�C�̃q�g����(��)
����N���b�N�ƃp�C�v���C���v�̘b��APetium4����Ɍ�������Ă��邷�B�ǂ݂₷������
�����������Ă���������A��x�ǂ�œ�x�Ɠd�g�J�L�R�����Ȃ����Ƃ����肢���������B
http://pc.watch.impress.co.jp/docs/article/20000223/kaigai01.htm
http://www.atmarkit.co.jp/fpc/rensai/zunouhoudan007/pipline.html
http://www.4gamer.net/specials/softhard/cpu_2-01/cpu_2-01.shtml
���ɈĂ̒肾��
���ꂾ���n���ɂ���Ă������ɂ��̐����f���Ă���Ƃ͂Ȃ�
�����������N1�Ԗڂł̓p�C�v���C�����ƃN���b�N���Ƃ̊W��������Ă��Ȃ��̂Ɏ����Ă���Ƃ�����]�Ԃ�
�i�N���b�N����̂��߁g���j�b�g�������u���h�Ƃ������͗L��j
2�Ԗڂł�http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/674
�̂P�s�ڂɓ\���Ă���̂ɂ܂������ė���Ƃ����s���Ԃ�
3�Ԗڂł͍Ō�̂ق���
��Pentium 4�́C�v���Z�X�Z�p�̐i���ɂ���āC3GHz���x�܂ł͏����ɓ���N���b�N���オ���Ă������C
��Prescott�R�A�ȍ~�ł͓���N���b�N���オIntel�̎v���悤�ɍs���Ă��Ȃ��B
����3����o���Ă���l�́CPentium 4�̓���N���b�N���オ��Ȃ��Ȃ������R���C����d�́����M�ɂ���Ɨ\�������Ǝv���B
�Ƃ���̂Ɋ����Ď����ė���Ƃ������s�Ԃ���⊶�Ȃ���������Ă����
���ꂾ���n���ɂ���Ă������ɂ��̐����f���Ă���Ƃ͂Ȃ�
�����������N1�Ԗڂł̓p�C�v���C�����ƃN���b�N���Ƃ̊W��������Ă��Ȃ��̂Ɏ����Ă���Ƃ�����]�Ԃ�
�i�N���b�N����̂��߁g���j�b�g�������u���h�Ƃ������͗L��j
2�Ԗڂł�http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/674
�̂P�s�ڂɓ\���Ă���̂ɂ܂������ė���Ƃ����s���Ԃ�
3�Ԗڂł͍Ō�̂ق���
��Pentium 4�́C�v���Z�X�Z�p�̐i���ɂ���āC3GHz���x�܂ł͏����ɓ���N���b�N���オ���Ă������C
��Prescott�R�A�ȍ~�ł͓���N���b�N���オIntel�̎v���悤�ɍs���Ă��Ȃ��B
����3����o���Ă���l�́CPentium 4�̓���N���b�N���オ��Ȃ��Ȃ������R���C����d�́����M�ɂ���Ɨ\�������Ǝv���B
�Ƃ���̂Ɋ����Ď����ė���Ƃ������s�Ԃ���⊶�Ȃ���������Ă����
�����z���x���̓N���b�N����̃{�g���l�b�N�Ƃ͂Ȃ蓾�Ȃ��Ɛ邤�����ł�����ˁB
��������V����Low-k�����p�����悤�Ƃ��Ă�ƊE�̓w�͉͂��ȂƁB
��������V����Low-k�����p�����悤�Ƃ��Ă�ƊE�̓w�͉͂��ȂƁB
�u����̍l���Ă����A�C�f�B�A�����p���ꂽ�I�v�Ɗ����Ă����n�O�����邾��B
���̊�n�O�͂���̋t�B
�u�ڂ�����Ɠ����咣�������ɂ�����I�v�Ə���ɖϑz�B
�[���G��ȁB
���̊�n�O�͂���̋t�B
�u�ڂ�����Ɠ����咣�������ɂ�����I�v�Ə���ɖϑz�B
�[���G��ȁB
455 �FMAC�I�^��453 �����F2008/06/01(��) 13:13:52 ID:eQ8OIA4W
>>453
�A�[�L�e�N�`���X���b�h�̔S�����L�`�K�C�̃q�g�Ɠ����x���Ƃ�������������ꂽ�̂�]�O�̊�т��B
�A�[�L�e�N�`���X���b�h�̔S�����L�`�K�C�̃q�g�Ɠ����x���Ƃ�������������ꂽ�̂�]�O�̊�т��B
�ŁA�A�[�L�e�N�`���X���ł̔��_�܂��[�H
�����Ă��肶�ጩ�Ă���Ƃ��Ă͂܂�Ȃ��ȁB
���ڂ����Ď��₵�Ă݂�����������lj������B
�z���x�����{�g���l�b�N�ł͂Ȃ��Ƃ������t����������C�͂Ȃ��悤���ˁB
IBM��AirGap���J�������̂͂Ȃ��Ȃ낤�ˁB
AMD���uAirGap�ɂ���ăN���b�N��10%���サ�ď���d�͂�10%�ጸ����v���Ĕ��\���Ă�̂ɁB
�܂�������R�e���p���ɂ����A�[�L�e�N�`���X���̐l�̖��_�̂��߂Ɍ����Ă������ǁA���͂��̐l�Ƃ͕ʐl�B
�ʂ���т������ˁB
�����Ă��肶�ጩ�Ă���Ƃ��Ă͂܂�Ȃ��ȁB
���ڂ����Ď��₵�Ă݂�����������lj������B
�z���x�����{�g���l�b�N�ł͂Ȃ��Ƃ������t����������C�͂Ȃ��悤���ˁB
IBM��AirGap���J�������̂͂Ȃ��Ȃ낤�ˁB
AMD���uAirGap�ɂ���ăN���b�N��10%���サ�ď���d�͂�10%�ጸ����v���Ĕ��\���Ă�̂ɁB
�܂�������R�e���p���ɂ����A�[�L�e�N�`���X���̐l�̖��_�̂��߂Ɍ����Ă������ǁA���͂��̐l�Ƃ͕ʐl�B
�ʂ���т������ˁB
457 �FMAC�I�^���L�`�K�C�̃q�g �����F2008/06/01(��) 13:34:33 ID:eQ8OIA4W
>>452
�ɒቷ�ł�OC���E�̌��ʂ����ĊԈႢ�𗝉����Ă���邱�Ƃ�ɖ]�ނ��B
http://www.ripping.org/database.php?act=records
�ɒቷ�ł�OC���E�̌��ʂ����ĊԈႢ�𗝉����Ă���邱�Ƃ�ɖ]�ނ��B
http://www.ripping.org/database.php?act=records
458 �FMAC�I�^��456 �����F2008/06/01(��) 13:36:35 ID:eQ8OIA4W
�G���F��~�̂悤�Ȃ̂Ɠ������x���܂ŗ����Ă��܂����܂�����B
���ꂾ��B
���ꂾ��B
�uAir cooling����ȂƂ����ċɒቷ������v
�����A�[�L�e�N�`���Ȃ̂ɍō��N���b�N�Ƀo����������̂�
�ɒቷAir cooling�i��t�̒��f���j�ł��O������̗�p�ł͐��Ȍ��ʂ͓����Ȃ�
�����ė��_�I�ȃp�C�v���C���ł̃N���b�N���E�͂܂��ゾ�Ƃ����ǂ��؋�����
�����A�[�L�e�N�`���Ȃ̂ɍō��N���b�N�Ƀo����������̂�
�ɒቷAir cooling�i��t�̒��f���j�ł��O������̗�p�ł͐��Ȍ��ʂ͓����Ȃ�
�����ė��_�I�ȃp�C�v���C���ł̃N���b�N���E�͂܂��ゾ�Ƃ����ǂ��؋�����
AMD��Isaiah�����C�Z���X���Y����Ηǂ���łˁH
Mazo
Aho
Casu
�I���
�^ܹ
Aho
Casu
�I���
�^ܹ
ID:o7h2sne0
MAC�I�^�̃L���C�������ݒ����Ă�˂��B���ˁB
MAC�I�^�̃L���C�������ݒ����Ă�˂��B���ˁB
�[���A���������܂��͂܂Ƃ߂Ď����̃X�����ĂĂ���B
CPU�֘A�̃X����p�j���Ă�����̂ɂƂ���
�������ǂ��������ɏ�������Ŗڏ��ł�!!
CPU�֘A�̃X����p�j���Ă�����̂ɂƂ���
�������ǂ��������ɏ�������Ŗڏ��ł�!!
�C���e���̃Z�J���h�\�[�X����ɖ߂�ƁH
467 �F�R�E�L�́M�E,,�j�����������������F2008/06/01(��) 23:53:40 ID:VrQgTyj0
amd.samsung.co.kr�̐����o�Ă�����
>>467
���ł�IBM�Ȃ��^������
�T���X���Ȃ獡��ꐶ����Ȃ���A�}�W�ł�߂ė~�����B
IBM�ƃC���e���̒���Ό��Ƃ��������b��푈�݂����Ȃ̂͌�������
�T���X���Ƃ��`���������Ⴕ���o�ė�����}�W�ڏ��B
���T���X������C�Z�p�҂̑唼�����{�l�ƃA�����J�l�Ȗ��
�{�����N�l�͐l�ނɂƂ��ĊQ�����̂��̂���
���ł�IBM�Ȃ��^������
�T���X���Ȃ獡��ꐶ����Ȃ���A�}�W�ł�߂ė~�����B
IBM�ƃC���e���̒���Ό��Ƃ��������b��푈�݂����Ȃ̂͌�������
�T���X���Ƃ��`���������Ⴕ���o�ė�����}�W�ڏ��B
���T���X������C�Z�p�҂̑唼�����{�l�ƃA�����J�l�Ȗ��
�{�����N�l�͐l�ނɂƂ��ĊQ�����̂��̂���
>>453
45nm�ȏ�Ō�������z���x����[�N�d���̑�Ƃ���
�}�U�[�{�[�h�̊K�w�\���̗l�Ɋђʔz����p�������̍\���I�Ȕz�����o����A
���j�b�g�Ԃ̔z���x���͌��I�ɉ��P��������IBM���҃v�b�V�����Ă邭�炢�Ȃ̂ɂ˂�
45nm�ȏ�Ō�������z���x����[�N�d���̑�Ƃ���
�}�U�[�{�[�h�̊K�w�\���̗l�Ɋђʔz����p�������̍\���I�Ȕz�����o����A
���j�b�g�Ԃ̔z���x���͌��I�ɉ��P��������IBM���҃v�b�V�����Ă邭�炢�Ȃ̂ɂ˂�
>>458
IEEE�̃v���X����o�p�\�R���ǂ�ł���
�z���x�������ݍő�̃{�g���l�b�N���Ă͓̂�����O�̘b�Ȃ��c
�ђʔz����p�������̃��������e��SSD�ɑg�ݍ��ތ������n�܂��Ă邵��
IEEE�̃v���X����o�p�\�R���ǂ�ł���
�z���x�������ݍő�̃{�g���l�b�N���Ă͓̂�����O�̘b�Ȃ��c
�ђʔz����p�������̃��������e��SSD�ɑg�ݍ��ތ������n�܂��Ă邵��
472 �FMAC�I�^��470-471 �����F2008/06/02(��) 21:44:02 ID:41DXMChA
>>470-471
�wIEEE�̃v���X�x����(��)�@ITRS�̃��|�[�g���炢��m���Ă���Ǝv�������ǁA�Y���ӏ���Z���p��
�Ȃ�Ŗ|�Ă݂�Ɨǂ��Ǝv�����B
http://www.itrs.net/Links/2007ITRS/2007_Chapters/2007_Interconnect.pdf
�@�@-----------------------
�@�@The increasing RC delay is one of the most crucial parameters especially for high
�@�@performance products. While scaled wires in the local and intermediate wiring levels
�@�@are less critical and show only a moderate increase in RC, the fixed length interconnects
�@�@in the semiglobal and global wiring levels are much more sensitive and need the
�@�@introduction of repeating inverters to keep the RC delay within viable limits. However,
�@�@the introduction of these repeaters requires additional chip area and increases the
�@�@power consumption. In some designs this increased RC delay can be handled by
�@�@modifications such as modular architectures to reduce the need for fixed length lines.
�@�@One recent approach in this direction is the dual- or multi-core architecture in
�@�@state-of-the-art microprocessors. Parallel data processing in the multi-cores allows
�@�@comparable or even higher processor performance at lower core frequencies and reduced
�@�@power consumption as compared to a single core high performance processor.
�@�@However, such significant modifications to circuit architecture suffer from the disadvantages
�@�@of needing new design tools and new software and are not generally applicable to all designs.
�@�@-----------------------
���Ȃ݂Ɋђʓd�ɂɂ��Ă�o�X�������I�ɍL���邱�Ƃ��ł����@�Ƃ��āA���ړx���������B
�wIEEE�̃v���X�x����(��)�@ITRS�̃��|�[�g���炢��m���Ă���Ǝv�������ǁA�Y���ӏ���Z���p��
�Ȃ�Ŗ|�Ă݂�Ɨǂ��Ǝv�����B
http://www.itrs.net/Links/2007ITRS/2007_Chapters/2007_Interconnect.pdf
�@�@-----------------------
�@�@The increasing RC delay is one of the most crucial parameters especially for high
�@�@performance products. While scaled wires in the local and intermediate wiring levels
�@�@are less critical and show only a moderate increase in RC, the fixed length interconnects
�@�@in the semiglobal and global wiring levels are much more sensitive and need the
�@�@introduction of repeating inverters to keep the RC delay within viable limits. However,
�@�@the introduction of these repeaters requires additional chip area and increases the
�@�@power consumption. In some designs this increased RC delay can be handled by
�@�@modifications such as modular architectures to reduce the need for fixed length lines.
�@�@One recent approach in this direction is the dual- or multi-core architecture in
�@�@state-of-the-art microprocessors. Parallel data processing in the multi-cores allows
�@�@comparable or even higher processor performance at lower core frequencies and reduced
�@�@power consumption as compared to a single core high performance processor.
�@�@However, such significant modifications to circuit architecture suffer from the disadvantages
�@�@of needing new design tools and new software and are not generally applicable to all designs.
�@�@-----------------------
���Ȃ݂Ɋђʓd�ɂɂ��Ă�o�X�������I�ɍL���邱�Ƃ��ł����@�Ƃ��āA���ړx���������B
�{�C�ŃG�R����肽���Ȃ�9150e�𑁂��o��
puma�����\�ɂȂ������BAMD�̃v���X�����[�X����������Ă����ŁA�v���X�L�b�g�̃����N���B
http://www.amd.com/us-en/0,,3715_15692,00.html?redir=pumapresskit
�̐S��Turion X2 Ultra�̎d�l�������[�X���甲�������Ă��邷���ǁAeWeek�L����
�������������B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Puma-Ready-to-Pounce/
�@�@-------------------------
�@�@AMD is offering three new Turion Ultra processors with the new
�@�@platform. These include the ZM-86 chip with 2MB of L2 cache and a
�@�@clock speed of 2.4GHz. The other two chips – the ZM-82 (2.2GHz) and
�@�@the ZM-80 (2.1GHz) – have 1MB of L2 cache each. These processors
�@�@are built on the company�fs 65-nanometer manufacturing process.
�@�@-------------------------
65-nm��2MB L2���f�������A������HT3�T�|�[�g�Ƃ������ƂŃf�X�N�g�b�v������
���i�����҂���q�g��������Ȃ������ˁB�B�B
���̑��ATurion X2 Ultra���̂̓�����A���̕ӂ��B
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_12651_15667%5E15669,00.html
http://www.amd.com/us-en/0,,3715_15692,00.html?redir=pumapresskit
�̐S��Turion X2 Ultra�̎d�l�������[�X���甲�������Ă��邷���ǁAeWeek�L����
�������������B
http://www.eweek.com/c/a/Desktops-and-Notebooks/AMD-Puma-Ready-to-Pounce/
�@�@-------------------------
�@�@AMD is offering three new Turion Ultra processors with the new
�@�@platform. These include the ZM-86 chip with 2MB of L2 cache and a
�@�@clock speed of 2.4GHz. The other two chips – the ZM-82 (2.2GHz) and
�@�@the ZM-80 (2.1GHz) – have 1MB of L2 cache each. These processors
�@�@are built on the company�fs 65-nanometer manufacturing process.
�@�@-------------------------
65-nm��2MB L2���f�������A������HT3�T�|�[�g�Ƃ������ƂŃf�X�N�g�b�v������
���i�����҂���q�g��������Ȃ������ˁB�B�B
���̑��ATurion X2 Ultra���̂̓�����A���̕ӂ��B
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_12651_15667%5E15669,00.html
�������X���ď�Ԃ����ǁA�V���O���\�P�b�gK8L��Budapest�����\���ꂽ���B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543_15434~126159,00.html
�@�@----------------------
�@�@The new Quad-Core AMD Opteron Models 1352 (2.1GHz), 1354 (2.2GHz),
�@�@and 1356 (2.3GHz) processors are designed to empower small to
�@�@mid-market customers to meet growing IT and budgetary demands and
�@�@increase business productivity.
�@�@----------------------
�v���X�����[�X�ɂ����邷���ǁA����ł����Cray��XT4���܂Ƃ��ɔ[���ł���悤��
�Ȃ������ƂɂȂ邷�B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543_15434~126159,00.html
�@�@----------------------
�@�@The new Quad-Core AMD Opteron Models 1352 (2.1GHz), 1354 (2.2GHz),
�@�@and 1356 (2.3GHz) processors are designed to empower small to
�@�@mid-market customers to meet growing IT and budgetary demands and
�@�@increase business productivity.
�@�@----------------------
�v���X�����[�X�ɂ����邷���ǁA����ł����Cray��XT4���܂Ƃ��ɔ[���ł���悤��
�Ȃ������ƂɂȂ邷�B
�n��������
turion ultra���ĂЂ���Ƃ��āA���F����Ȃ����H
Kuma��K10�AGriffin�̓��o�C�������ɏȓd�͋@�\����R���AHT���������Ă��邯�ǁA
CPU�R�A���̂�K8�̂܂܁B��������L2��2MB���Ď��_��Kuma����Ȃ����B
CPU�R�A���̂�K8�̂܂܁B��������L2��2MB���Ď��_��Kuma����Ȃ����B
Kuma���o���Ȃ�Rana���o���Ȃ�Griffin�͏o��������AM2�ł͏o������
2�R�A�͂�����Brisbane�̂܂܂Ƃ������̂͂������ɉ��肷����Ƃ����v���Ȃ�
2�R�A�͂�����Brisbane�̂܂܂Ƃ������̂͂������ɉ��肷����Ƃ����v���Ȃ�
�o���Ȃ�����Ȃ��A�o���Ȃ��ɕϊ�����Ƃ��ׂĔ[���������B
���������ΈȑO�̏��ł�����L2�팸�łƂ��V���O���R�A�łƂ���
Griffin�̉��ɂ��郂�f���͂ǂ��Ȃ����̂��ˁH
Griffin�̉��ɂ��郂�f���͂ǂ��Ȃ����̂��ˁH
Turion X2 Ultra�̔��\�ł��A���ς�炸AMD�L���O�_�O�_���B
�R�R�̕\1�ɏ����Ă���L2�̎d�l�ƁA
http://pc.watch.impress.co.jp/docs/2008/0605/comp12.htm
AMD�T�C�g��L2�d�l��A�ǂ��炪�{���Ȃ��H
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_12651_15667%5E15674,00.html
���Ȃ݂ɊC�O�ł�����2���f����L2�퍇�v1MB�Ɣ��\����Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/06/04/amd-puts-puma
�@�@-----------------------
�@�@There are three new CPUs so far, the ZM-86 (2.4GHz/2M), ZM-82 (2.2GHz/1M), and
�@�@ZM-80 (2.1GHz/1M), all are dual core and will be put under the Turion X2 Ultra brand.
�@�@-----------------------
�R�R�̕\1�ɏ����Ă���L2�̎d�l�ƁA
http://pc.watch.impress.co.jp/docs/2008/0605/comp12.htm
AMD�T�C�g��L2�d�l��A�ǂ��炪�{���Ȃ��H
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_12651_15667%5E15674,00.html
���Ȃ݂ɊC�O�ł�����2���f����L2�퍇�v1MB�Ɣ��\����Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/06/04/amd-puts-puma
�@�@-----------------------
�@�@There are three new CPUs so far, the ZM-86 (2.4GHz/2M), ZM-82 (2.2GHz/1M), and
�@�@ZM-80 (2.1GHz/1M), all are dual core and will be put under the Turion X2 Ultra brand.
�@�@-----------------------
>>485
���ӁI�A���[�g�I�[�v�����I (1)
���ӁI���[�v�^�O���I (1)
���ӁI�]���r �E�B���h�E���I (1)
�u���N���`�F�b�N���I�����܂����B
���ӁISet-Cookie���g���Ă��܂��B
���ӁI���̓t�H�[�������܂����B
���ӁIYahoo!�U���̉\������B
���ӁISSL�ł͂���܂���B
�t�B�b�V���O�`�F�b�N���I�����܂����B
[���̃A�h���X�̈��S�x 45%]
[�t�B�b�V���O���\�Ȃǂ̉\�� : 75%]
���ӁI�A���[�g�I�[�v�����I (1)
���ӁI���[�v�^�O���I (1)
���ӁI�]���r �E�B���h�E���I (1)
�u���N���`�F�b�N���I�����܂����B
���ӁISet-Cookie���g���Ă��܂��B
���ӁI���̓t�H�[�������܂����B
���ӁIYahoo!�U���̉\������B
���ӁISSL�ł͂���܂���B
�t�B�b�V���O�`�F�b�N���I�����܂����B
[���̃A�h���X�̈��S�x 45%]
[�t�B�b�V���O���\�Ȃǂ̉\�� : 75%]
���N�̑��l�����ŁA�܂�AMD��V�F�A�𗎂Ƃ����Ƃ̂��Ƃ��B
http://www.idc.com/getdoc.jsp?containerId=prUS21263208
�@��2008Q1 AMD�s��V�F�A
�@�@Total: 20.9%�@(-2.2%)
�@�@�@Mobile: 14.5% (-3.3%)
�@�@�@Server: 13.0% (-1.6%)
�@�@�@Desktop: 26.7% (-1.0%)
http://www.idc.com/getdoc.jsp?containerId=prUS21263208
�@��2008Q1 AMD�s��V�F�A
�@�@Total: 20.9%�@(-2.2%)
�@�@�@Mobile: 14.5% (-3.3%)
�@�@�@Server: 13.0% (-1.6%)
�@�@�@Desktop: 26.7% (-1.0%)
TGDaily��Theo Valich�ɂ���Computex��AMD���w�����`�b�v�Z�b�g���ڂ����}�U�[�{�[�h
�ɓ��ڂ����Phenom������ɍ��N���b�N�œ��삷��x���ĉB���@�\�\�����炵�����B
�����̏�k�Ȃ��ˁB�B�B
http://www.tgdaily.com/content/view/37816/135/
�@�@--------------------
�@�@The name of the game is called �gunlocking the multiplier�h, which will be played with the
�@�@SB700 and SB750 southbridge chips. If you are running an upcoming 2.8 GHz Black Edition
�@�@CPU, a motherboard with the old SB600 model (RD690) will keep the processor cores
�@�@operating at 2.8 GHz. However, if you have a motherboard with the SB700 chipset, you
�@�@will receive a free upgrade to 3.0 GHz. And if you get a motherboard with a SB750 chip,
�@�@your processor will run at 3.2 GHz, which matches the clock speed of the Athlon X2 6400+
�@�@- the highest clocked processor AMD ever offerred.
�@�@--------------------
�ɓ��ڂ����Phenom������ɍ��N���b�N�œ��삷��x���ĉB���@�\�\�����炵�����B
�����̏�k�Ȃ��ˁB�B�B
http://www.tgdaily.com/content/view/37816/135/
�@�@--------------------
�@�@The name of the game is called �gunlocking the multiplier�h, which will be played with the
�@�@SB700 and SB750 southbridge chips. If you are running an upcoming 2.8 GHz Black Edition
�@�@CPU, a motherboard with the old SB600 model (RD690) will keep the processor cores
�@�@operating at 2.8 GHz. However, if you have a motherboard with the SB700 chipset, you
�@�@will receive a free upgrade to 3.0 GHz. And if you get a motherboard with a SB750 chip,
�@�@your processor will run at 3.2 GHz, which matches the clock speed of the Athlon X2 6400+
�@�@- the highest clocked processor AMD ever offerred.
�@�@--------------------
The actual overclocking is done either through the BIOS,
a utility, or simply by pressing a physical button on certain motherboards.
�܂��s���̈����Ƃ���͔����o���Ȃ��A��
�ǂ���"�����"�Ȃ�o�J��
a utility, or simply by pressing a physical button on certain motherboards.
�܂��s���̈����Ƃ���͔����o���Ȃ��A��
�ǂ���"�����"�Ȃ�o�J��
490 �FMAC�I�^��489 �����F2008/06/06(��) 18:56:39 ID:+eoJsv58
>>489
����lj����������ʔ������������ˁH�m���ɃR�����g����
�@�w�^�[�{�[�{�^������ (www�x
�@�w�̂̉�������p����PC�ɕt���Ă�����(�m�x
�I�Ȃ̂��肷(��)
����lj����������ʔ������������ˁH�m���ɃR�����g����
�@�w�^�[�{�[�{�^������ (www�x
�@�w�̂̉�������p����PC�ɕt���Ă�����(�m�x
�I�Ȃ̂��肷(��)
�o�J�Ƃ�����蕨�����n���Ȃ���
�u�s���̈����Ƃ���͔����o���Ȃ��v
�ȂǂƂ����H���o����قǂ̒m�\�͖����ł���
�P�ɗ������ĂȂ�����
�u�s���̈����Ƃ���͔����o���Ȃ��v
�ȂǂƂ����H���o����قǂ̒m�\�͖����ł���
�P�ɗ������ĂȂ�����
>>488
Theo�L����PV�グ��s�ׂ����
Theo�L����PV�グ��s�ׂ����
493 �FMAC�I�^��492 �����F2008/06/06(��) 20:47:46 ID:+eoJsv58
>>492
Theo Valich��AMD�ɕ@���k�����ꂽ�L���ȊO��A�ʔ�������B
Theo Valich��AMD�ɕ@���k�����ꂽ�L���ȊO��A�ʔ�������B
���o�C���ɍœK�����ꂽ�uTurion X2 Ultra(Griffin)�v�̎���
http://pc.watch.impress.co.jp/docs/2008/0609/kaigai444.htm
http://pc.watch.impress.co.jp/docs/2008/0609/kaigai444.htm
������Intel�̛Z��k������Ă�̂͒I�ɏグ�Ă�����
�Z��
�����@��i�͂Ȃ�����j���i�т₭�j�Ɠǂ���Ă�̂�
�p���������z
�p���������z
�㓡����Griffin�L�����B�L�c�����Ƃ������Ă��邷���ǁA�����ǂ��c������Ă���Ǝv�����B
http://pc.watch.impress.co.jp/docs/2008/0609/kaigai444.htm
�@�@----------------------
�@�@�������AAMD�̋Z�p�̗���Ō���ƁA�����Puma�ł́ACPU���̂����Ȃ�d�v���B�Ȃ��Ȃ�A
�@�@Griffin�́AAMD�ɂƂ��ă��o�C���ɓ��������ŏ���CPU�ł���AFUSION�ƌĂ�ł���
�@�@�uAccelerated Processing Unit(APU)�v�ւ̃}�C���X�g�[���ł��邩�炾�B
�@�@----------------------
http://pc.watch.impress.co.jp/docs/2008/0609/kaigai444.htm
�@�@----------------------
�@�@�������AAMD�̋Z�p�̗���Ō���ƁA�����Puma�ł́ACPU���̂����Ȃ�d�v���B�Ȃ��Ȃ�A
�@�@Griffin�́AAMD�ɂƂ��ă��o�C���ɓ��������ŏ���CPU�ł���AFUSION�ƌĂ�ł���
�@�@�uAccelerated Processing Unit(APU)�v�ւ̃}�C���X�g�[���ł��邩�炾�B
�@�@----------------------
���Əo�x�ꂽ�݂������ˁB�B�B���炵�����B
�G���n�͕@��ǂ��납����������
���߂Ĕ�����PC�̓^�[�{�{�^�������ƒ�i�̔����̃N���b�N�ɂȂ�d�l�������Ȃ��B
486SX/20MHz��10MHz
�Q�[���Ƃ��̑��x�����p�ȊO�̗p�r�͕s��
486SX/20MHz��10MHz
�Q�[���Ƃ��̑��x�����p�ȊO�̗p�r�͕s��
>>494
�S���Ɨ��̃��M�����[�^���K�v�i���Q�͓d���ϗv�j�Ȍ��ɑ��āA�v���b�g�t�H�[��
�̃R�X�g�A�b�v�̑���ǂ����邩�A�����������ݍ����g�݂�AMD�ɗ~�����Ȃ��B
�S���Ɨ��̃��M�����[�^���K�v�i���Q�͓d���ϗv�j�Ȍ��ɑ��āA�v���b�g�t�H�[��
�̃R�X�g�A�b�v�̑���ǂ����邩�A�����������ݍ����g�݂�AMD�ɗ~�����Ȃ��B
>>504
������B�S�����ƂV�n�����B
�bGriffin�ɂ́AVDD0/VDD1/VDDNB�̑��ɁA�A�i���O�n��I/O�����̓d���v���[����4�n������BHyperTransport�����N�ɋ��������
�bVLDT 1.2V�ADDR2 I/O�ɋ��������VDDIO��VTT�A�I���_�CPLL�ɋ��������VDDA 2.5V�ŁA��������d���͌Œ肳��Ă���B
������B�S�����ƂV�n�����B
�bGriffin�ɂ́AVDD0/VDD1/VDDNB�̑��ɁA�A�i���O�n��I/O�����̓d���v���[����4�n������BHyperTransport�����N�ɋ��������
�bVLDT 1.2V�ADDR2 I/O�ɋ��������VDDIO��VTT�A�I���_�CPLL�ɋ��������VDDA 2.5V�ŁA��������d���͌Œ肳��Ă���B
HyperTransport������͑��葤�ɂ������d�����K�v������O��������������Ă���Ηǂ��B
�R�A�ւ̋����ɂ��Ă��m�[�g���������e�ʂ͕K�v�����������܂ŃR�X�g�I�Ɍ��������Ȃ�낤�B
Intel�̃f�X�N�g�b�v�����}�U�[�̕�������ۂ�VRM�ɗ͂����Ă�Ǝv���B
�R�A�ւ̋����ɂ��Ă��m�[�g���������e�ʂ͕K�v�����������܂ŃR�X�g�I�Ɍ��������Ȃ�낤�B
Intel�̃f�X�N�g�b�v�����}�U�[�̕�������ۂ�VRM�ɗ͂����Ă�Ǝv���B
�`�l�c�ƒ�g����h�a�l�̃����b�g���Ă���́H
�����܂�̌���
��AMD�̓A�s�[�����Ă�B
AMD������l�͔h�����Ă�킯���������b�g���F���Ȃ킯�͂Ȃ����낤�B
��AMD�̓A�s�[�����Ă�B
AMD������l�͔h�����Ă�킯���������b�g���F���Ȃ킯�͂Ȃ����낤�B
�X�p�R����Opteron��ʂɎg���Ă邵��
������I�@��������H���������C�������H
(ttp://sankei.jp.msn.com/affairs/crime/080610/crm0806102056041-n1.htm)
�N�}����������āH���z����ˁ`
ttp://northwood.blog60.fc2.com/blog-entry-2041.html
�ł����ꌩ�Ă�
ttp://pc.watch.impress.co.jp/docs/2007/0920/kaigai388_15l.gif
intel�̃��C���i�b�v�͎������ɂȂ邭�炢��AMD�̃X�s�[�h�ƒނ荇�����Ċ����H
���������\�͂���ˁ`
AMD�����i�̖��O���R���R���ς��Ă�̂͂���ƒ��荇�����߂��ȁH
�������O��������Ȃ����g�܂Ŏ�ޑ��₵���������
����L���߂��ōׂ������ǒ����Ȃ��ǂ����Ȃ��Ȃ��Ĕj�]�����Ⴄ�����ˁI
�X�����������������
Brisbane�Ɣ�ׂē��ɔ���̖���Kuma��������̂������Ƃ�����
�j�R�C�`�������I�ɍl����l�C�e�B�u�ɏ���킯�ł��Ȃ�
���M����ɃM���M���ȏł͍̗p���Ȃ������̂���������
�ł����x���\����j�R�C�`�͔��M�̂ق����v���Ȃ��H
����ȃX�������y���߂�CPU���ď��߂Ă���I
���Ⴀ�@�I���X�~�`
(ttp://sankei.jp.msn.com/affairs/crime/080610/crm0806102056041-n1.htm)
�N�}����������āH���z����ˁ`
ttp://northwood.blog60.fc2.com/blog-entry-2041.html
�ł����ꌩ�Ă�
ttp://pc.watch.impress.co.jp/docs/2007/0920/kaigai388_15l.gif
{kind=link}
intel�̃��C���i�b�v�͎������ɂȂ邭�炢��AMD�̃X�s�[�h�ƒނ荇�����Ċ����H
���������\�͂���ˁ`
AMD�����i�̖��O���R���R���ς��Ă�̂͂���ƒ��荇�����߂��ȁH
�������O��������Ȃ����g�܂Ŏ�ޑ��₵���������
����L���߂��ōׂ������ǒ����Ȃ��ǂ����Ȃ��Ȃ��Ĕj�]�����Ⴄ�����ˁI
�X�����������������
Brisbane�Ɣ�ׂē��ɔ���̖���Kuma��������̂������Ƃ�����
�j�R�C�`�������I�ɍl����l�C�e�B�u�ɏ���킯�ł��Ȃ�
���M����ɃM���M���ȏł͍̗p���Ȃ������̂���������
�ł����x���\����j�R�C�`�͔��M�̂ق����v���Ȃ��H
����ȃX�������y���߂�CPU���ď��߂Ă���I
���Ⴀ�@�I���X�~�`
�ŏ���Fusion��m�[�g�����v���b�g�t�H�[��"Shrike"�Ƃ��ēo�ꂷ��Ƃ̂��Ƃ��B
http://www.trustedreviews.com/notebooks/news/2008/06/09/Shrike-Is-AMDs-First-Fusion-Platform/p1
�ESwift APU (K8 core x2 + Next Gen GPU Core + PCIe interface)
�@�EDDR3 SO-DIMM
http://www.trustedreviews.com/notebooks/news/2008/06/09/Shrike-Is-AMDs-First-Fusion-Platform/p1
�ESwift APU (K8 core x2 + Next Gen GPU Core + PCIe interface)
�@�EDDR3 SO-DIMM
���N�O�ɏo�Ă�b�B
���Ă�CPU��K8�R�A�Ƃ��R�����Ȃ�B
���Ă�CPU��K8�R�A�Ƃ��R�����Ȃ�B
CPU�R�A�́A�L�����ɂ͌��sPhenom�Ɠ����R�A���ď����Ă��邯�ǁH
�R�[�h�l�[����STARS�V���[�Y�ɂȂ����̂�K10�R�A���炾���A
�]�����ǂ���Swift��K10�n�̃R�A�̗p���ƁB
�R�[�h�l�[����STARS�V���[�Y�ɂȂ����̂�K10�R�A���炾���A
�]�����ǂ���Swift��K10�n�̃R�A�̗p���ƁB
���ƌÂ��j���[�X�����ǁAIDG�n�̃j���[�X�T�C�g��Fusion�`�b�v�펩�ЍH���
��������Ƃ����b����Ă���B
http://www.infoworld.com/article/08/06/03/AMD_will_manufacture_first_Fusion_chips_1.html
�@�@----------------------
�@�@The first Fusion processors will be made at AMD's chip plant in
�@�@Dresden, Germany, said Rick Bergman, senior vice president and
�@�@general manager of AMD's Graphics Products Group, during an
�@�@interview.
�@�@"There are some lower-end models that we're considering that we
�@�@might use the fabless model for," Bergman said, indicating the
�@�@production of these chips would be outsourced.
�@�@----------------------
��������Ƃ����b����Ă���B
http://www.infoworld.com/article/08/06/03/AMD_will_manufacture_first_Fusion_chips_1.html
�@�@----------------------
�@�@The first Fusion processors will be made at AMD's chip plant in
�@�@Dresden, Germany, said Rick Bergman, senior vice president and
�@�@general manager of AMD's Graphics Products Group, during an
�@�@interview.
�@�@"There are some lower-end models that we're considering that we
�@�@might use the fabless model for," Bergman said, indicating the
�@�@production of these chips would be outsourced.
�@�@----------------------
515 �FMAC�I�^��512-123 �����F2008/06/11(��) 12:55:55 ID:2AW4op/U
>>512-513
�������ӂ��邷�BK8L���ď������肾��������B
�������ӂ��邷�BK8L���ď������肾��������B
Shrike����SouthBridge��PCIe�łȂ��悤������ANVIDIA��South����邱�Ƃ�
���ۂ��Ȃ����Ă��Ƃ��ȁH
���ۂ��Ȃ����Ă��Ƃ��ȁH
>>516
����̓T�E�X�����鎖�������Ȃ邾�낤����A
NVIDIA���̂��T�E�X��P�Ƃőn�闘�_�͂��܂�傫���Ȃ���ˁB
�W�Ȃ���SLI��CF�ŋK�i�ꂷ��Ηǂ������̂��낤���ǁA
NVIDIA�ɂ��Ă݂�A����͎�����肾�����낤�Ȃ��B
����̓T�E�X�����鎖�������Ȃ邾�낤����A
NVIDIA���̂��T�E�X��P�Ƃőn�闘�_�͂��܂�傫���Ȃ���ˁB
�W�Ȃ���SLI��CF�ŋK�i�ꂷ��Ηǂ������̂��낤���ǁA
NVIDIA�ɂ��Ă݂�A����͎�����肾�����낤�Ȃ��B
SLI��CF�ŋK�i����Ƃ�����
PCIe�����GPU�̘A���Z�p�Ƃ��������Ńn�[�h�E�F�A�̕����͂قƂ�Ljꏏ����
�����h���C�o���\�t�g�E�F�A�w���܂������Ⴄ����
����Ȃ�Ăǂ��������Ă�����
PCIe�����GPU�̘A���Z�p�Ƃ��������Ńn�[�h�E�F�A�̕����͂قƂ�Ljꏏ����
�����h���C�o���\�t�g�E�F�A�w���܂������Ⴄ����
����Ȃ�Ăǂ��������Ă�����
���Ⴀ�ǂ����ł������h���C�o�������炦�����B����B
HKEPC�������d�͔�Phenom X3�A8250e��8450e�ɂ��ĕĂ��邷�B
http://www.hkepc.com/?id=1295&fs=c1n
8���������ʎY�J�n�Ƃ������Ƃ�����A�s��ɏo���̂�H���BLast Order��2008Q4-2009H1
�Ƃ̂��Ƃ�����A�Z���������B
http://www.hkepc.com/?id=1295&fs=c1n
8���������ʎY�J�n�Ƃ������Ƃ�����A�s��ɏo���̂�H���BLast Order��2008Q4-2009H1
�Ƃ̂��Ƃ�����A�Z���������B
>>510��Kuma & Phenom FX�̃L�����Z���̕ADigitimes������������B
http://www.digitimes.com/news/a20080611PD204html
���邢�b���A���̂�����B�S�Ă�45nm�̐��ۂɂ������Ă���͗l���B
�@�@--------------------
�@�@However, AMD is still on track with the launch schedule for its 45nm Deneb FX processors.
�@�@--------------------
http://www.digitimes.com/news/a20080611PD204html
���邢�b���A���̂�����B�S�Ă�45nm�̐��ۂɂ������Ă���͗l���B
�@�@--------------------
�@�@However, AMD is still on track with the launch schedule for its 45nm Deneb FX processors.
�@�@--------------------
�����n�����₽��ƌ��C
Kuma�L�����Z���Ɋւ���ے�R�����g���o�����B
http://news.cnet.com/8301-13924_3-9966067-64.html
�@�@-----------------------
�@�@"We're still on track to launch a dual-core--code-named Kuma--part
�@�@in the second half of '08. It will be 65 nanometers, still be based
�@�@on the Star's core. So, that's coming."
�@�@-----------------------
�Ƃ����킯�ŁA���N�㔼�����y���݂ɁB�B�B�Ƃ������Ƃ��B
http://news.cnet.com/8301-13924_3-9966067-64.html
�@�@-----------------------
�@�@"We're still on track to launch a dual-core--code-named Kuma--part
�@�@in the second half of '08. It will be 65 nanometers, still be based
�@�@on the Star's core. So, that's coming."
�@�@-----------------------
�Ƃ����킯�ŁA���N�㔼�����y���݂ɁB�B�B�Ƃ������Ƃ��B
AMD�A�uKuma�v�`�b�v�J�����~����ے�
http://japan.cnet.com/news/ent/story/0,2000056022,20375145,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20375145,00.htm
�y�o�ρz�ukuma�v�`�b�v�̊J���͏����c�J�����~����ے� - AMD
http://mamono.2ch.net/test/read.cgi/newsplus/1213241389/
http://mamono.2ch.net/test/read.cgi/newsplus/1213241389/
>>519
�����NVIDIA���R������B
�����NVIDIA���R������B
�x�m�ʁA�u���b�N�ɓ��ꂵ�����r���OPC�uFMV-TEO�v
�`AMD�gPuma�h�v���b�g�t�H�[�����̗p
http://pc.watch.impress.co.jp/docs/2008/0612/fujitsu.htm
�`AMD�gPuma�h�v���b�g�t�H�[�����̗p
http://pc.watch.impress.co.jp/docs/2008/0612/fujitsu.htm
AMD�C�V����m�[�gPC�����v���b�g�t�H�[���uPuma�v���������\�B
���{�ł�Hybrid CrossFireX�Ή��m�[�gPC���o���
ttp://www.4gamer.net/games/039/G003995/20080612042/
���肰�Ȃ�Turion X2 Ultra�̉��ʃ��f����
���{�ł�Hybrid CrossFireX�Ή��m�[�gPC���o���
ttp://www.4gamer.net/games/039/G003995/20080612042/
���肰�Ȃ�Turion X2 Ultra�̉��ʃ��f����
AMD�K������(�E�L��`�E)
Puma�͖ʔ���������
����ɔ�ׂăf�X�N�g�b�v������m9(^�D^)�߷ެ���ԂȂ̂�
�ǂ��ɂ����Ăق�����
����ɔ�ׂăf�X�N�g�b�v������m9(^�D^)�߷ެ���ԂȂ̂�
�ǂ��ɂ����Ăق�����
531 �FMAC�I�^��530 �����F2008/06/14(�y) 15:33:02 ID:FTZODmG6
>>530
Puma��ʔ����Ǝv�������ǁA�����܂ŁwGriffin�̐��\�������̂ɖڂ��Ԃ�x�Ƃ����O��
�t���̂���肷�B���Ԃ̕]����A���̕ӂ��ƁB
http://www.tgdaily.com/content/view/37780/135/
�@�@-------------------
�@�@AMD may not have the edge in CPU performance, but it does outrun Intel in graphics performance.
�@�@-------------------
�����������������]�����Ƃ����Ȃ邷�B�f�X�N�g�b�v�ł̎S���A������ɂ������Ă��邷�B
�@�@-------------------
�@�@The down-side is where CPU or battery life is concerned, they will lose just as badly.
�@�@Pick your poison.
�@�@-------------------
Puma��ʔ����Ǝv�������ǁA�����܂ŁwGriffin�̐��\�������̂ɖڂ��Ԃ�x�Ƃ����O��
�t���̂���肷�B���Ԃ̕]����A���̕ӂ��ƁB
http://www.tgdaily.com/content/view/37780/135/
�@�@-------------------
�@�@AMD may not have the edge in CPU performance, but it does outrun Intel in graphics performance.
�@�@-------------------
�����������������]�����Ƃ����Ȃ邷�B�f�X�N�g�b�v�ł̎S���A������ɂ������Ă��邷�B
�@�@-------------------
�@�@The down-side is where CPU or battery life is concerned, they will lose just as badly.
�@�@Pick your poison.
�@�@-------------------
532 �FMAC�I�^��507 �����F2008/06/14(�y) 15:41:34 ID:FTZODmG6
>>507
�@�@-----------------
�@�@�`�l�c�ƒ�g����h�a�l�̃����b�g���Ă���́H
�@�@-----------------
�R�����g�x���Ȃ��Đ\����Ȃ������ǁA�P����AMD��������x�����Ă��邩�炷�B
IBM�킨���ł��������Ȃ���Ђ�����B�B�B
http://news.cnet.com/8301-13924_3-9880862-64.html
�@�@=================
�@�@This kind of know-how is not cheap. AMD's 2007 10K form says the following about the
�@�@agreement that extends to December 31, 2011: "We anticipate that, under this agreement,
�@�@we will pay fees to IBM of approximately $400 million in connection with joint development
�@�@projects between 2008 and 2011."
�@�@=================
�@�@-----------------
�@�@�`�l�c�ƒ�g����h�a�l�̃����b�g���Ă���́H
�@�@-----------------
�R�����g�x���Ȃ��Đ\����Ȃ������ǁA�P����AMD��������x�����Ă��邩�炷�B
IBM�킨���ł��������Ȃ���Ђ�����B�B�B
http://news.cnet.com/8301-13924_3-9880862-64.html
�@�@=================
�@�@This kind of know-how is not cheap. AMD's 2007 10K form says the following about the
�@�@agreement that extends to December 31, 2011: "We anticipate that, under this agreement,
�@�@we will pay fees to IBM of approximately $400 million in connection with joint development
�@�@projects between 2008 and 2011."
�@�@=================
���o�C�������v���Z�b�T���Đ��\������d�͂ɏœ_���W�܂��Ă邩��
35W�ł��ꂾ���̐��\�Ȃ�y��_�Ȃ�Ȃ��́H
C2D�̓��o�C���Ɍ����Ȃ����炱��Atom�Ƃ��J�����Ă����킯����
35W�ł��ꂾ���̐��\�Ȃ�y��_�Ȃ�Ȃ��́H
C2D�̓��o�C���Ɍ����Ȃ����炱��Atom�Ƃ��J�����Ă����킯����
�N���b�N�_�E��������ԂŎg�����猋�ǐ��\���K�v�ɂȂ��
535 �FMAC�I�^��533 �����F2008/06/14(�y) 16:44:58 ID:FTZODmG6
>>533
�@�@------------------
�@�@C2D�̓��o�C���Ɍ����Ȃ�
�@�@------------------
Core2��Banias, Dothan, Yonah�̗�������ރ��o�C�������̃R�A�����ǁB�B�B
���o�C���ł�TDP�ɂ��Ă�A�����炷�B
http://processorfinder.intel.com/List.aspx?ProcFam=2643&sSpec=&OrdCode=
�@�@------------------
�@�@C2D�̓��o�C���Ɍ����Ȃ�
�@�@------------------
Core2��Banias, Dothan, Yonah�̗�������ރ��o�C�������̃R�A�����ǁB�B�B
���o�C���ł�TDP�ɂ��Ă�A�����炷�B
http://processorfinder.intel.com/List.aspx?ProcFam=2643&sSpec=&OrdCode=
>>533
�m�[�g�p��Core2�͂܂�TDP�Ⴄ��B�ő�ō��̂Ƃ���35W�B
�Ȃm�[�g�pExtreme��4�R�ATDP45W�Ȃo�����Ęb�����邯�ǁB
��������TDP65W����ԒႢ�Ȃ�AB5�p�m�[�g��Core2�ڂ�Ȃ������
�m�[�g�p��Core2�͂܂�TDP�Ⴄ��B�ő�ō��̂Ƃ���35W�B
�Ȃm�[�g�pExtreme��4�R�ATDP45W�Ȃo�����Ęb�����邯�ǁB
��������TDP65W����ԒႢ�Ȃ�AB5�p�m�[�g��Core2�ڂ�Ȃ������
�܂Ă܂�
���������m�[�g�p���f�X�N�g�b�v�p��Core2�̓_�C���ꏏ��
�v�̓m�[�g�p��TDP���x�[�X�ɂ��Ă��
���������l�������ƍ���AMD��Turion�͂��Ƃ��ƃf�X�N�g�b�v�E�I�p��K8��
�����Ă��Ă����A�͂邩�Ƀm�[�g�Ɍ����ĂȂ��v�ɂȂ��Ă邶��Ȃ���
Turion X2 Ultra�����đ������ǎ{��������
����TDP�g�ŃN���b�N�オ��Ȃ��̂�����Ε����邱�Ƃ���
���������m�[�g�p���f�X�N�g�b�v�p��Core2�̓_�C���ꏏ��
�v�̓m�[�g�p��TDP���x�[�X�ɂ��Ă��
���������l�������ƍ���AMD��Turion�͂��Ƃ��ƃf�X�N�g�b�v�E�I�p��K8��
�����Ă��Ă����A�͂邩�Ƀm�[�g�Ɍ����ĂȂ��v�ɂȂ��Ă邶��Ȃ���
Turion X2 Ultra�����đ������ǎ{��������
����TDP�g�ŃN���b�N�オ��Ȃ��̂�����Ε����邱�Ƃ���
538 �FMAC�I�^��537 �����F2008/06/14(�y) 17:38:47 ID:FTZODmG6
>>537
�����ȑO����T�[�o�[�탂�o�C�����̏ȓd�͂��v������Ă��邷�B
http://www.atmarkit.co.jp/fsys/zunouhoudan/041zunou/efficeon.html
���Ȃ݂ɂ��̌�̓W�J��A
http://www.nikkeibp.co.jp/archives/280/280267.html
������
http://www.itmedia.co.jp/enterprise/articles/0511/08/news014.html
���̌�Core2�̎���Ɏ��邷�B
�����ȑO����T�[�o�[�탂�o�C�����̏ȓd�͂��v������Ă��邷�B
http://www.atmarkit.co.jp/fsys/zunouhoudan/041zunou/efficeon.html
���Ȃ݂ɂ��̌�̓W�J��A
http://www.nikkeibp.co.jp/archives/280/280267.html
������
http://www.itmedia.co.jp/enterprise/articles/0511/08/news014.html
���̌�Core2�̎���Ɏ��邷�B
turion�E���g�����Ă����i�������ȁB
�t���T�C�Y�m�[�g�����łȂ����ƂȂ���ˁH
�t���T�C�Y�m�[�g�����łȂ����ƂȂ���ˁH
���܋C�t���������ǁA>>531��TheINQ�Ɠ����R�����g��>>528��4gamer�L���ł����邱�Ƃ��ł��邷�B
�@�@-------------------------
�@�@��̕\�ŁCTurion X2 Ultra��TDP��32�`35W�ƂȂ��Ă������C�ʓr�uBlu-ray Disc�̍��𑜓x
�@�@�r�f�I���Đ������Ƃ��ɁC�]���̃m�[�gPC�Ɣ�ׂď���d�͂��Ⴂ�v�Ƃ��Ď����ꂽ�X���C�h�ɂ́C
�@�@���𑜃r�f�I�Đ����ɂ�����m�[�g PC�̏���d�͂�35�`46W�Ƃ���Ă���BCPU�g�p����33��
�@�@�ł��̒l�Ȃ̂�����CAMD M780G��TDP�́C�m�[�gPC�p�Ƃ������Ƃ��l����ƁC���Ȃ荂�����ł���B
�@�@[����]
�@�@�o�b�e���[�쓮���Ԃ͂��܂���҂ł��Ȃ����낤�B
�@�@-------------------------
�@�@-------------------------
�@�@��̕\�ŁCTurion X2 Ultra��TDP��32�`35W�ƂȂ��Ă������C�ʓr�uBlu-ray Disc�̍��𑜓x
�@�@�r�f�I���Đ������Ƃ��ɁC�]���̃m�[�gPC�Ɣ�ׂď���d�͂��Ⴂ�v�Ƃ��Ď����ꂽ�X���C�h�ɂ́C
�@�@���𑜃r�f�I�Đ����ɂ�����m�[�g PC�̏���d�͂�35�`46W�Ƃ���Ă���BCPU�g�p����33��
�@�@�ł��̒l�Ȃ̂�����CAMD M780G��TDP�́C�m�[�gPC�p�Ƃ������Ƃ��l����ƁC���Ȃ荂�����ł���B
�@�@[����]
�@�@�o�b�e���[�쓮���Ԃ͂��܂���҂ł��Ȃ����낤�B
�@�@-------------------------
541 �FMAC�I�^���⑫�F2008/06/14(�y) 23:58:19 ID:FTZODmG6
�����Y��Ă��邱�ƂɋC�t����������>>531�̉��̃R�����g��A���L��TheINQ�L������̈��p���B
http://www.theinquirer.net/gb/inquirer/news/2008/06/04/amd-puts-puma
http://www.theinquirer.net/gb/inquirer/news/2008/06/04/amd-puts-puma
�����o���̃T�[�o�[�͔���ĂȂ��ł���(�E�L��`�E)
543 �F�R�E�L�́M�E,,�j�����������������F2008/06/15(��) 19:28:51 ID:5bcntWF7
�o�[���̂悤�Ȃ��̂₳��p�T�[�o��Mac mini�ł���
http://www.ednjapan.com/content/l_news/2006/01/23_01.html
>����ɁA���b�g���\�Ƃ����V������̒�ĂƂ��̏d�v����i�����Ă����A�������ЂƂ̗D�ʐ��������Ă������j���v�Əq�ׂ�
�������ĂĂȂ�Ńo���Ȃ�č����������낤��(�E�L��`�E)
>����ɁA���b�g���\�Ƃ����V������̒�ĂƂ��̏d�v����i�����Ă����A�������ЂƂ̗D�ʐ��������Ă������j���v�Əq�ׂ�
�������ĂĂȂ�Ńo���Ȃ�č����������낤��(�E�L��`�E)
545 �F�R�E�L�́M�E,,�j�����������������F2008/06/15(��) 20:10:40 ID:5bcntWF7
��������TDP�̍��������܂������߂�ACP
�����o�����������Z�[���X�|�C���g�T�������(�E�L��`�E)
������
�n����������
�n����������
>>539
�t���T�C�Y�m�[�g�ł����łȂ���Ȃ��H
���ꂩ�f�X�N�g�b�vPC���ǂ��炩�B
>>528��4�T�L���ɂ���ʂ�ɁA�`�b�v�Z�b�g���l�b�N���ۂ��B
�g�[�^���ōl�����Puma��TDP�����������Ȃ��H
���{�ł̓f�X�N�g�b�v�m�[�g�͂���Ȃ�ɃV�F�A������̂ŁA
���قǔߊς������ł��Ȃ��c�̂�������Ȃ��B
���^�m�[�g�ɑg�ݍ��ނɂ͖����ł��傤���ǁB
�t���T�C�Y�m�[�g�ł����łȂ���Ȃ��H
���ꂩ�f�X�N�g�b�vPC���ǂ��炩�B
>>528��4�T�L���ɂ���ʂ�ɁA�`�b�v�Z�b�g���l�b�N���ۂ��B
�g�[�^���ōl�����Puma��TDP�����������Ȃ��H
���{�ł̓f�X�N�g�b�v�m�[�g�͂���Ȃ�ɃV�F�A������̂ŁA
���قǔߊς������ł��Ȃ��c�̂�������Ȃ��B
���^�m�[�g�ɑg�ݍ��ނɂ͖����ł��傤���ǁB
��������(�E�L��`�E)
�E�l�g�o������d�͒Ⴂ�@���@���ꂩ��̓��b�g���\���A�s�[��
���̌�(�E�L��`�E)
�E����d�͂ŃR�A�ɕ����@���@���ꂩ���ACP���A�s�[��
�E�l�C�e�B�u��ACP�������@���@ACP�͖����������Ƃ�
�E�����܂�������@���@�_�C�`���[���쐬
�E�����܂肳��Ɉ����@���@�g���v���Ŕ������Ⴆ
�E�G���b�^�ꂽ�@���@�y�m���Ŕ������Ⴆ
�E�l�g�o������d�͒Ⴂ�@���@���ꂩ��̓��b�g���\���A�s�[��
���̌�(�E�L��`�E)
�E����d�͂ŃR�A�ɕ����@���@���ꂩ���ACP���A�s�[��
�E�l�C�e�B�u��ACP�������@���@ACP�͖����������Ƃ�
�E�����܂�������@���@�_�C�`���[���쐬
�E�����܂肳��Ɉ����@���@�g���v���Ŕ������Ⴆ
�E�G���b�^�ꂽ�@���@�y�m���Ŕ������Ⴆ
���̌�Q(�E�L��`�E)
�E�l�b�g�ɃG���[�����@���@�H������S�ăG���b�^�۔F
�EVISTA SP1�ŋ����p�b�`�@���@�W�T�b�J�[�u�[�C���O
�E�����p�b�`���O���ăG���b�^�L���ɂ���c�[���@���@�W�T�b�J�[����
�E�l�b�g�ɃG���[�����@���@�H������S�ăG���b�^�۔F
�EVISTA SP1�ŋ����p�b�`�@���@�W�T�b�J�[�u�[�C���O
�E�����p�b�`���O���ăG���b�^�L���ɂ���c�[���@���@�W�T�b�J�[����
551 �F�A���~�����F2008/06/15(��) 23:00:44 ID:DQdhiPbU
131 ���O�F FROM��������an [sage] ���e���F 2008/05/10(�y) 11:58:25
4����K���o���Ă�o�C�g��Ő�T�X���ɏI�������Ă�܂���
���̂܂܂���V�l����������Ă��邵������(�N�r)��
���͂���Ă�̂ɂ������������Ă��鏀�Ђ̏�������������������������ɍׂ������ӂ��Ă���
�������X��������Ƃ��Ɍ�����
�����������A���̐l�������邱�Ƃ����Ă����肾����������ĂȂ�
�܂��j�[�g�ɖ߂邩���c
136 ���O�F FROM��������an [sage] ���e���F 2008/05/10(�y) 12:01:25
�V�t�g�����ĉ�������]�ʂ肶��Ȃ����Ƃ����Ȃ葽���c
�ق��̐l�͖w�ǃV�t�g�ʂ�Ȃ̂ɂ�
�t���[�^�[�͎g���̂Ă��Ďv���Ă���
146 ���O�F FROM��������an [sage] ���e���F 2008/05/10(�y) 12:14:35
�d���ł��Ȃ����Ă������ׂ��߂����
���ЂȂ�ėႦ�Ή������������ւ�������̓_���Ƃ������Ă��̕��������Ƃ������̈ӌ������t���邵�~�X���Ă����������Ȃ�L�c��������
���Ђ̏��Ɍ����Ă��
�C���J���ʂ��Č�������X���̎��ɂ������ĉ����o���Ȃ��Ǝv����
�m���Ƀo�C�g�����玫�߂Ă��������܂��������T���̂��Ȃ�
�T��1�A2�����Ȃ����l�̏��͂�k�ŏT5�Ŋ撣���Ă鉴�̂����Ȃ̂���
���Ԃ͉��ȊO���������ʂ�����
�O�`���������܂���
(��L��`�)
������ƃX�b�L������
(��L��`�)
4����K���o���Ă�o�C�g��Ő�T�X���ɏI�������Ă�܂���
���̂܂܂���V�l����������Ă��邵������(�N�r)��
���͂���Ă�̂ɂ������������Ă��鏀�Ђ̏�������������������������ɍׂ������ӂ��Ă���
�������X��������Ƃ��Ɍ�����
�����������A���̐l�������邱�Ƃ����Ă����肾����������ĂȂ�
�܂��j�[�g�ɖ߂邩���c
136 ���O�F FROM��������an [sage] ���e���F 2008/05/10(�y) 12:01:25
�V�t�g�����ĉ�������]�ʂ肶��Ȃ����Ƃ����Ȃ葽���c
�ق��̐l�͖w�ǃV�t�g�ʂ�Ȃ̂ɂ�
�t���[�^�[�͎g���̂Ă��Ďv���Ă���
146 ���O�F FROM��������an [sage] ���e���F 2008/05/10(�y) 12:14:35
�d���ł��Ȃ����Ă������ׂ��߂����
���ЂȂ�ėႦ�Ή������������ւ�������̓_���Ƃ������Ă��̕��������Ƃ������̈ӌ������t���邵�~�X���Ă����������Ȃ�L�c��������
���Ђ̏��Ɍ����Ă��
�C���J���ʂ��Č�������X���̎��ɂ������ĉ����o���Ȃ��Ǝv����
�m���Ƀo�C�g�����玫�߂Ă��������܂��������T���̂��Ȃ�
�T��1�A2�����Ȃ����l�̏��͂�k�ŏT5�Ŋ撣���Ă鉴�̂����Ȃ̂���
���Ԃ͉��ȊO���������ʂ�����
�O�`���������܂���
(��L��`�)
������ƃX�b�L������
(��L��`�)
�ꉞAMD�Ƃ������Ƃ�
ttp://pc.watch.impress.co.jp/docs/2008/0616/amd.htm
AMD�A1TFLOPS�̉��Z���\������GPGPU
�uFireStream 9250�v
�g�p�X���b�g��1�X���b�g�݂̂ŁA����d�͂�150W�ȉ�
ttp://pc.watch.impress.co.jp/docs/2008/0616/amd.htm
AMD�A1TFLOPS�̉��Z���\������GPGPU
�uFireStream 9250�v
�g�p�X���b�g��1�X���b�g�݂̂ŁA����d�͂�150W�ȉ�
553 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 23:03:25 ID:529taapO
�����������������Ă��ꂽ�甃���\��
��������
>>552
GPGPU�Ƃ͂����A�g�p���镪�삪�S���Ⴄ�Ǝv���c�B
GPGPU�Ƃ͂����A�g�p���镪�삪�S���Ⴄ�Ǝv���c�B
556 �FMAC�I�^��552 �����F2008/06/16(��) 23:22:47 ID:fqpP/Io+
>>552
NVIDIA�̎���Tesra�����\���ꂽ�����ǁAGPGPU�I�ɍ����ATI�̏������ۂ����ˁB
http://www.tgdaily.com/content/view/37955/135/
�@�@----------------------
�@�@Nvidia told us that double-precision calculations will result in a 90% speed penalty
�@�@and deliver only 100 GFlops per T10P processor.
�@�@----------------------
NVIDIA�̎���Tesra�����\���ꂽ�����ǁAGPGPU�I�ɍ����ATI�̏������ۂ����ˁB
http://www.tgdaily.com/content/view/37955/135/
�@�@----------------------
�@�@Nvidia told us that double-precision calculations will result in a 90% speed penalty
�@�@and deliver only 100 GFlops per T10P processor.
�@�@----------------------
557 �F�R�E�L�́M�E,,�j�����������������F2008/06/16(��) 23:28:21 ID:529taapO
�������Z�~�̉��I�ɂ͍�����͂ǂ���N�Y
�c�q�̑����FPGA�ł��Ă��ĂĂ��������B
�V���O���X���b�h�̃^�X�N���}���`�X���b�h�Ő��\�グ����(���@�X���b�h�H)��
PC�p�r�Ŏg����GPGPU����
�ǂ������n�[�h���Ⴍ�āA��Ɏg����悤�ɂȂ肻���Ȃ́H
PC�p�r�Ŏg����GPGPU����
�ǂ������n�[�h���Ⴍ�āA��Ɏg����悤�ɂȂ肻���Ȃ́H
560 �FMAC�I�^��559 �����F2008/06/16(��) 23:51:21 ID:fqpP/Io+
562 �FMAC�I�^��561 �����F2008/06/17(��) 00:35:11 ID:nI52Pwa8
>>561
�S�ē������BRock�������������d�͂��B
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
�@�@----------------------
�@�@������g��2.3GHz/�d���d��1.2V�̂Ƃ��̏���d�͂�250W�ł���B
�@�@----------------------
�_�C�ʐς포�����̂ɁB�B�B�Ƃ������܂����t�����B
http://journal.mycom.co.jp/articles/2008/03/02/isscc3/001.html
�S�ē������BRock�������������d�͂��B
http://pc.watch.impress.co.jp/docs/2008/0205/isscc02.htm
�@�@----------------------
�@�@������g��2.3GHz/�d���d��1.2V�̂Ƃ��̏���d�͂�250W�ł���B
�@�@----------------------
�_�C�ʐς포�����̂ɁB�B�B�Ƃ������܂����t�����B
http://journal.mycom.co.jp/articles/2008/03/02/isscc3/001.html
�������܂���������
>>561
�܂Ƃ��ɉ�b��������Ȃ�n���͂�������X���[���邱��
�u�^�����@�X���b�h�v�ŃO�O����2�Ԗ�1�i�����Ńq�b�g���邱��̂��Ƃ���
ttp://pc.watch.impress.co.jp/docs/article/20010830/kaigai01.htm
GPGPU�iGPU�����܂łƂ͕ʂ̗p�r�ɂ��j�Ȃ�Ă����g�����ԂȂ̂�
�������͋L���̋�ł͂܂������̈���o�ĂȂ��͂�
�܂Ƃ��ɉ�b��������Ȃ�n���͂�������X���[���邱��
�u�^�����@�X���b�h�v�ŃO�O����2�Ԗ�1�i�����Ńq�b�g���邱��̂��Ƃ���
ttp://pc.watch.impress.co.jp/docs/article/20010830/kaigai01.htm
GPGPU�iGPU�����܂łƂ͕ʂ̗p�r�ɂ��j�Ȃ�Ă����g�����ԂȂ̂�
�������͋L���̋�ł͂܂������̈���o�ĂȂ��͂�
�c�c�u�c�Ƃ��������A���������Ή��\�t�g���o���̂��H
���@�}���`�X���b�f�B���O�͍��̂Ƃ���R���p�C���̎x�����O��ł��邱�Ƃ�����
�X�[�p�[�X�J��/�A�E�g�I�u�I�[�_�݂�����HW�����ł͌�����
�X�[�p�[�X�J��/�A�E�g�I�u�I�[�_�݂�����HW�����ł͌�����
�����㍂���x��������HDTV�p�v���Z�b�T�Ȃǂɒ���
2008 Symposium on VLSI Technology
http://pc.watch.impress.co.jp/docs/2008/0617/vlsi00.htm
> IBM��AMD�A���ł�22nm�Z�p��FinFET�̋����������ʂ����\�肾(�u���ԍ�2.1)�B
22nm��FinFET�Ō��܂肩�B
Intel��22nm�܂ő҂̂�����Ƃ�32nm�Ńg���C�Q�[�g�Ƀ`�������W�����Ⴄ�̂��B
> 2GHz�ƍ����ɓ��삷�閄�ߍ���DRAM�Z�p��IBM��AMD�������ŕ���(�u���ԍ�21.1)�B45nm��SOI CMOS�Z�p����g�����B
�ǂ����Z-RAM��IBM�Ɏ���đ���ꂽ�݂����˂��B
����ɈȑOeDRAM�\�����Ƃ���IBM�P�Ƃ��������Ǎ����AMD�̖��O������B
�Ƃ������Ƃ́c�c���i���͂��ł����H
2008 Symposium on VLSI Technology
http://pc.watch.impress.co.jp/docs/2008/0617/vlsi00.htm
> IBM��AMD�A���ł�22nm�Z�p��FinFET�̋����������ʂ����\�肾(�u���ԍ�2.1)�B
22nm��FinFET�Ō��܂肩�B
Intel��22nm�܂ő҂̂�����Ƃ�32nm�Ńg���C�Q�[�g�Ƀ`�������W�����Ⴄ�̂��B
> 2GHz�ƍ����ɓ��삷�閄�ߍ���DRAM�Z�p��IBM��AMD�������ŕ���(�u���ԍ�21.1)�B45nm��SOI CMOS�Z�p����g�����B
�ǂ����Z-RAM��IBM�Ɏ���đ���ꂽ�݂����˂��B
����ɈȑOeDRAM�\�����Ƃ���IBM�P�Ƃ��������Ǎ����AMD�̖��O������B
�Ƃ������Ƃ́c�c���i���͂��ł����H
�k�X���� - AMD��Atom�RCPU
ttp://northwood.blog60.fc2.com/blog-entry-2056.html
AMD��Atom�ɑR��������d��CPU���J�����Ă���悤���B
���̂܂����O�̂Ȃ�CPU��64-bit�Ή��� Single-core CPU�Ŏ��g����1GHz�ƂȂ�B
�R�A��K8����̂��̂��g�p���ADDR2�������R���g���[��������A800MHz��HyperTransport�����N���̗p���A256kB��L2�L���b�V���𓋍ڂ���B
�p�b�P�[�W��812 pin��BGA�p�b�P�[�W�ƂȂ�B����1GHz CPU�̓m�[�X�u���b�W�Ƃ��킹��TDP��8W�ƂȂ��Ă���B
�����v���Z�X�ɂ��Ă͌��y���Ȃ����A�����炭65nm�v���Z�X�Ǝv����B
ttp://northwood.blog60.fc2.com/blog-entry-2056.html
AMD��Atom�ɑR��������d��CPU���J�����Ă���悤���B
���̂܂����O�̂Ȃ�CPU��64-bit�Ή��� Single-core CPU�Ŏ��g����1GHz�ƂȂ�B
�R�A��K8����̂��̂��g�p���ADDR2�������R���g���[��������A800MHz��HyperTransport�����N���̗p���A256kB��L2�L���b�V���𓋍ڂ���B
�p�b�P�[�W��812 pin��BGA�p�b�P�[�W�ƂȂ�B����1GHz CPU�̓m�[�X�u���b�W�Ƃ��킹��TDP��8W�ƂȂ��Ă���B
�����v���Z�X�ɂ��Ă͌��y���Ȃ����A�����炭65nm�v���Z�X�Ǝv����B
SempronULV�i�j
�����Atom�R�Ƃ�������Nano�R���Ċ������ȁB
�܂�Turion�̃f�O���[�h�iL2�k���A��d�̓v���Z�X�Aetc�j���Ċ��������B
�܂�Turion�̃f�O���[�h�iL2�k���A��d�̓v���Z�X�Aetc�j���Ċ��������B
572 �F�R�E�L�́M�E,,�j�����������������F2008/06/17(��) 20:58:16 ID:WRDwzsBB
�����������
�ǂ������Ƃ����ƍ���GeodeNX�̌�p�ƍl��������������Ղ��ȁB
DDR1�ȃ������������������������i�ɂȂ��Ă邵�A������������K8�A�[�L
�Ȃ�ASocketA��GeodeNX�݂����Ƀm�[�X�`�b�v��ʓr�p�ӂ���K�v���������A
�D�s�����B
DDR1�ȃ������������������������i�ɂȂ��Ă邵�A������������K8�A�[�L
�Ȃ�ASocketA��GeodeNX�݂����Ƀm�[�X�`�b�v��ʓr�p�ӂ���K�v���������A
�D�s�����B
574 �F�R�E�L�́M�E,,�j�����������������F2008/06/17(��) 21:10:35 ID:WRDwzsBB
���̂͂��̂܂�܁uGeode 64�v�ȗ\��
Intel��VIA�͂��̎s��̂��߂ɐV�K�ɐv�������i�𓊓����Ă�Ƃ����̂ɁA
AMD�Ɨ�����㔭�Ȃ̂�K8�������V���O���R�A���قڂ��̂܂�
ATOM�l�C�����čQ�Ăč��n�߂��Ƃ����c
�����̑R�ƍl�����ɂ��̐��i����������Δ��ɖ��͓I�Ȑ��i�̂悤�ȋC�����邯��
AMD�Ɨ�����㔭�Ȃ̂�K8�������V���O���R�A���قڂ��̂܂�
ATOM�l�C�����čQ�Ăč��n�߂��Ƃ����c
�����̑R�ƍl�����ɂ��̐��i����������Δ��ɖ��͓I�Ȑ��i�̂悤�ȋC�����邯��
576 �F�R�E�L�́M�E,,�j�����������������F2008/06/17(��) 21:23:02 ID:WRDwzsBB
�����̓A������u�T�[�o����UMPC�܂ʼn��p�ł���K8�R�A�͑f���炵���v�̐M�ҕ��
VIA�̂́A�悻���甃�����v�Ȃ��
�E���g�����o�C����g�ݍ������Ƃ͌���Ȃ�
���[���A���W�b�N4000���g�����W�X�^�ȏ��
�g�ݍ��ݗp�Ȃ킯���Ȃ�
�Ђ���Ƃ�����Phenom�⟸�ψȏ�̃g�����W�X�^��
����GeodeNX���Â��Ȃ��Ă��ŁAK8�ł𓊓�����̑Ó�����
�E���g�����o�C�������Ƃ��Č��Ă�
Atom���o���a���Ă��ŁA���i����ŏ[�������ł���
�E���g�����o�C����g�ݍ������Ƃ͌���Ȃ�
���[���A���W�b�N4000���g�����W�X�^�ȏ��
�g�ݍ��ݗp�Ȃ킯���Ȃ�
�Ђ���Ƃ�����Phenom�⟸�ψȏ�̃g�����W�X�^��
����GeodeNX���Â��Ȃ��Ă��ŁAK8�ł𓊓�����̑Ó�����
�E���g�����o�C�������Ƃ��Č��Ă�
Atom���o���a���Ă��ŁA���i����ŏ[�������ł���
�v���Z�X���i���������
�V���O���R�A�̌��E�ɋ߂�4issue OoO�`�b�v�ł�
�N���b�N�}�����10W�����œ��������Ⴂ�܂�����
�����̘b������
�V���O���R�A�̌��E�ɋ߂�4issue OoO�`�b�v�ł�
�N���b�N�}�����10W�����œ��������Ⴂ�܂�����
�����̘b������
579 �F�R�E�L�́M�E,,�j�����������������F2008/06/17(��) 21:53:03 ID:WRDwzsBB
K8��3issue��
��OPs���x���ł�9issue�������B������薳�������ǁB
��OPs���x���ł�9issue�������B������薳�������ǁB
���^�p�b�P�[�W�̃m�E�n�E��ςނ̂͗ǂ����Ƃ��Ǝv���܂��B
RISC�v���Z�b�T���炢�܂ł̖��ߗ��x�Ȃ�
9issue�Ƃ��]�T����
���_�͑����Ȃ�Ȃ����Ď�������
9issue�Ƃ��]�T����
���_�͑����Ȃ�Ȃ����Ď�������
K8��Complex Decoder*3 , Lode/Store Unit*3������
����4issue�I�[�o�[����
L/SU��3�ȏ���đ��ɂ�ITANIC�����Ȃ��͂�
�������AK8��uops�̔��s���Ƃ��ׂ������͒m��Ȃ��ł�
����4issue�I�[�o�[����
L/SU��3�ȏ���đ��ɂ�ITANIC�����Ȃ��͂�
�������AK8��uops�̔��s���Ƃ��ׂ������͒m��Ȃ��ł�
�� LOAD
�~ LODE
�~ LODE
584 �F�R�E�L�́M�E,,�j�����������������F2008/06/17(��) 22:20:26 ID:WRDwzsBB
Int.�p�C�v����ALU+AGU�̃y�A��3�ƁAFP�p�C�v���ɂ�SIMD���j�b�g�����˂�FPadd, FPmul, FPstore�Ōv9�B
���Ȃ݂�AGU�͌v2�@��Load/Store���j�b�g�Ɍq�����Ă���A3�����ɃA�h���X���������Ƃ����L/S���Ԃɍ���Ȃ��B
���ʂɍl�����AGU����������̂ˁB
IPC���グ�邽�߂ƌ������́A�ǂ������Ƃ����Ə璷�\���ɂ���Int.�p�C�v�̃X�P�W���[�����O��
�ȑf�ɂ���ړI������Ǝv���Ă邪�B
���Ȃ݂�Intel CPU�ł�AGU��Load/Store�ɓ�������ĂāALEA�͐�����Z���j�b�g�Ŕ��s���������ȁB
���Ȃ݂�AGU�͌v2�@��Load/Store���j�b�g�Ɍq�����Ă���A3�����ɃA�h���X���������Ƃ����L/S���Ԃɍ���Ȃ��B
���ʂɍl�����AGU����������̂ˁB
IPC���グ�邽�߂ƌ������́A�ǂ������Ƃ����Ə璷�\���ɂ���Int.�p�C�v�̃X�P�W���[�����O��
�ȑf�ɂ���ړI������Ǝv���Ă邪�B
���Ȃ݂�Intel CPU�ł�AGU��Load/Store�ɓ�������ĂāALEA�͐�����Z���j�b�g�Ŕ��s���������ȁB
586 �FMAC�I�^��585 �����F2008/06/18(��) 00:43:42 ID:g8Utdww1
>>585
�@�@-------------------
�@�@XBOX360�Ŏ����I�Ɏg�����Z�p������PC�ɂ��I
�@�@-------------------
�Ȃ�ł�AMD�Ɋ֘A�t�����̂�������Ȃ������ǁAxbox360��eDRAM��NEC��->TSMC�����B
http://techon.nikkeibp.co.jp/article/NEWS/20051005/109392/
http://www.itmedia.co.jp/news/articles/0708/17/news012.html
����ɂ��Ă��Ɠd�p�̃`�b�v���u�����I�v����(��)
�@�@-------------------
�@�@XBOX360�Ŏ����I�Ɏg�����Z�p������PC�ɂ��I
�@�@-------------------
�Ȃ�ł�AMD�Ɋ֘A�t�����̂�������Ȃ������ǁAxbox360��eDRAM��NEC��->TSMC�����B
http://techon.nikkeibp.co.jp/article/NEWS/20051005/109392/
http://www.itmedia.co.jp/news/articles/0708/17/news012.html
����ɂ��Ă��Ɠd�p�̃`�b�v���u�����I�v����(��)
AcesHardware�f���̓��e�����ǁAAgner���H���wSSE5�͎���ł���x�������B
http://aceshardware.freeforums.org/intel-avx-kills-amd-sse5-t538.html
http://aceshardware.freeforums.org/intel-avx-kills-amd-sse5-t538.html
Digitimes�����N�̃��[�h�}�b�v��Ă��邷�B
http://www.digitimes.com/news/a20080617PD207.html
�����ǂ߂Ȃ��Ȃ�T�C�g������]�ڂ��Ă������B
�@�@-----------------------
�@�@AMD to update its low-power CPU lineup
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Tuesday 17 June 2008]
�@�@�@AMD is planning to launch several low-power triple-core and quad-core CPUs during the
�@�@second half of 2008 all featuring a TDP of 65W, according to sources at motherboard makers.
�@�@�@Two low-power triple-core Phenom CPUs -- X3 8250e and 8450e -- will feature core
�@�@frequencies of 1.9GHz and 2.1GHz, respectively, and both include an L2 cache of 1.5MB and
�@�@L3 cache of 2MB. The two CPUs will enter DVT in July and start mass production at the
�@�@beginning of August. If the process goes smoothly, the two CPUs should appear in the
�@�@channel by mid to late August, the sources said.
�@�@-----------------------
http://www.digitimes.com/news/a20080617PD207.html
�����ǂ߂Ȃ��Ȃ�T�C�g������]�ڂ��Ă������B
�@�@-----------------------
�@�@AMD to update its low-power CPU lineup
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Tuesday 17 June 2008]
�@�@�@AMD is planning to launch several low-power triple-core and quad-core CPUs during the
�@�@second half of 2008 all featuring a TDP of 65W, according to sources at motherboard makers.
�@�@�@Two low-power triple-core Phenom CPUs -- X3 8250e and 8450e -- will feature core
�@�@frequencies of 1.9GHz and 2.1GHz, respectively, and both include an L2 cache of 1.5MB and
�@�@L3 cache of 2MB. The two CPUs will enter DVT in July and start mass production at the
�@�@beginning of August. If the process goes smoothly, the two CPUs should appear in the
�@�@channel by mid to late August, the sources said.
�@�@-----------------------
589 �FMAC�I�^�������F2008/06/18(��) 01:36:20 ID:g8Utdww1
�@�@--------------------------
�@�@�@Meanwhile the company will launch the low-power quad-core Phenom X4 9350e in the third
�@�@quarter and another model in the fourth quarter, the sources added, and in the first quarter
�@�@of 2009, AMD will begin to roll out its 45nm quad-core CPUs (Propus) targeting core frequencies
�@�@between 2.3-2.6GHz.
�@�@�@AMD also plans for the Phenom X4 9850 (2.5GHz) and 9950 (2.6GHz) to enter DVT in the t
�@�@hird quarter, and ship in the fourth quarter, and is scheduling to launch two 45nm Phenom X4
�@�@CPUs by the end of the fourth quarter with core frequencies between 2.4-2.8GHz, the sources
�@�@revealed.
�@�@�@In other news, AMD has given notice that final orders for the Phenom X4 9100e will be taken
�@�@at the end of the second quarter, while the Phenom X3 8250e and X4 9150e will both enter final
�@�@ordering around the end of the fourth quarter, the sources detailed. Orders for the dual-core
�@�@Athlon X2 4050e are also scheduled to stop at the end of the third quarter.
�@�@--------------------------
�@�@�@Meanwhile the company will launch the low-power quad-core Phenom X4 9350e in the third
�@�@quarter and another model in the fourth quarter, the sources added, and in the first quarter
�@�@of 2009, AMD will begin to roll out its 45nm quad-core CPUs (Propus) targeting core frequencies
�@�@between 2.3-2.6GHz.
�@�@�@AMD also plans for the Phenom X4 9850 (2.5GHz) and 9950 (2.6GHz) to enter DVT in the t
�@�@hird quarter, and ship in the fourth quarter, and is scheduling to launch two 45nm Phenom X4
�@�@CPUs by the end of the fourth quarter with core frequencies between 2.4-2.8GHz, the sources
�@�@revealed.
�@�@�@In other news, AMD has given notice that final orders for the Phenom X4 9100e will be taken
�@�@at the end of the second quarter, while the Phenom X3 8250e and X4 9150e will both enter final
�@�@ordering around the end of the fourth quarter, the sources detailed. Orders for the dual-core
�@�@Athlon X2 4050e are also scheduled to stop at the end of the third quarter.
�@�@--------------------------
��͂�N���b�N����ܐL�тȂ�������
45nm��intel���i��65nm�Œ��ނƂ͗]�����M�������
593 �FMAC�I�^�������܂��F2008/06/18(��) 01:48:10 ID:g8Utdww1
�܂Ƃ߂�ƁA�������B
�@�������d�͔�65nm 3-core
�@�@- X3 8250e/1.9GHz��X3 8450e/2.1GHz�B512KB L2 + 2MB L3
�@�@- 7����DVT�T���v���A8�����ʎY�J�n�\��
�@�@- �����Ȃ��8����-���{�Ɏs���
�@�������d�͔�4-core
�@�@- 2008Q3: X4 9350e
�@�@- 2008Q4: ������i��
�@�@- 2009Q1: 45nm Propus/2.3-2.6GHz
�@�������\��65nm 4-core
�@�@- X4 9850/2.5GHz, X4 9950/2.6GHz
�@�@- ����2008Q3��DVT�T���v����
�@�@- 2008Q4�o�ח\��
�@�������\��45nm 4-core
�@�@- 2.4-2.8GHz��2008Q4��2�i�픭�\
�@���p�~�i��
�@�@- 9100e: 2008Q2��
�@�@- Athlon X2 4050e: 2008Q3��
�@�@- X3 8250e��X4 9150e: 2008Q4��
�@�������d�͔�65nm 3-core
�@�@- X3 8250e/1.9GHz��X3 8450e/2.1GHz�B512KB L2 + 2MB L3
�@�@- 7����DVT�T���v���A8�����ʎY�J�n�\��
�@�@- �����Ȃ��8����-���{�Ɏs���
�@�������d�͔�4-core
�@�@- 2008Q3: X4 9350e
�@�@- 2008Q4: ������i��
�@�@- 2009Q1: 45nm Propus/2.3-2.6GHz
�@�������\��65nm 4-core
�@�@- X4 9850/2.5GHz, X4 9950/2.6GHz
�@�@- ����2008Q3��DVT�T���v����
�@�@- 2008Q4�o�ח\��
�@�������\��45nm 4-core
�@�@- 2.4-2.8GHz��2008Q4��2�i�픭�\
�@���p�~�i��
�@�@- 9100e: 2008Q2��
�@�@- Athlon X2 4050e: 2008Q3��
�@�@- X3 8250e��X4 9150e: 2008Q4��
>>591
���Ԃ�Puma�ŊJ�������ȓd�͋Z�p���Ԃ����ނ��肾�낤�B
AMD�̊J�����\�[�X���l����A���ꂪ��ԑÓ��ȍl���B
�����i�s��2�̒����d�͂�CPU���J���ł���Ƃ͎v���Ȃ��B
����Ȃ��Ƃ��o������A�܂�KUMA���o�ꂵ�Ȃ��������Ęb�͂Ȃ��B
������A���̒����d��CPU�̓o��������Ĉ�N�ギ�炢����Ȃ����H
>>592
�v���Z�X�M�͈Ӗ����Ȃ����Ăǂ����̋L���œǂB
�v���Z�X��萻���Z�p�ɂ�肻�̍������܂���Ęb�B
���ۂ�Intel��AMD��90nm��65nm�ŏؖ������B
���Ԃ�Puma�ŊJ�������ȓd�͋Z�p���Ԃ����ނ��肾�낤�B
AMD�̊J�����\�[�X���l����A���ꂪ��ԑÓ��ȍl���B
�����i�s��2�̒����d�͂�CPU���J���ł���Ƃ͎v���Ȃ��B
����Ȃ��Ƃ��o������A�܂�KUMA���o�ꂵ�Ȃ��������Ęb�͂Ȃ��B
������A���̒����d��CPU�̓o��������Ĉ�N�ギ�炢����Ȃ����H
>>592
�v���Z�X�M�͈Ӗ����Ȃ����Ăǂ����̋L���œǂB
�v���Z�X��萻���Z�p�ɂ�肻�̍������܂���Ęb�B
���ۂ�Intel��AMD��90nm��65nm�ŏؖ������B
�����Ԃ�Puma�ŊJ�������ȓd�͋Z�p���Ԃ����ނ��肾�낤�B
�l���Ă݂��Intel�̓f�X�N�g�b�v�p�ɂ͏ȓd�͋Z�p���o���ɂ��݂��邫�炢���������ȁB
����Intel�͂ǂ������킩��B
�l���Ă݂��Intel�̓f�X�N�g�b�v�p�ɂ͏ȓd�͋Z�p���o���ɂ��݂��邫�炢���������ȁB
����Intel�͂ǂ������킩��B
>>594
intel��90nm�͂�����ƐL�ёオ���Ȃ��������ȁ`���x�ŁiPenM�j
AMD65nm�̗����̔�ł͂Ȃ�
�ה�����͐��\�������R�X�g�����ɋ������
atom�Ȃ����ɃR�X�g�����_��
intel��90nm�͂�����ƐL�ёオ���Ȃ��������ȁ`���x�ŁiPenM�j
AMD65nm�̗����̔�ł͂Ȃ�
�ה�����͐��\�������R�X�g�����ɋ������
atom�Ȃ����ɃR�X�g�����_��
597 �FSocket774�F2008/06/18(��) 11:07:02 ID:A+0cZgjb
RV770��250mm2�Ă��Ƃ́A���Ȃ�RV670��120mm�ʂō���Ƃ������Ƃ��ȁB
��������A���Ȃ�X2��MCM�ŁA����t���[�W������250mm�ʂō����Ȃ����H
itx��dtx�ŏo���Ȃ����ȁB
��������A���Ȃ�X2��MCM�ŁA����t���[�W������250mm�ʂō����Ȃ����H
itx��dtx�ŏo���Ȃ����ȁB
598 �FSocket774�F2008/06/18(��) 11:15:46 ID:bMNs6Onv
RV670�̃v���Z�X��RV770�Ƃ��Ȃ�����
>>596
�l�g�o�n������M������D����
�l�g�o�n������M������D����
�l�g�o���Ⴀ130�̃R�A���V�������N����90���Ă̂���������
180��130�A90��65�̔�r�����o����
������65�̒�i�͂킴�Ɨ}�����Ă���
�p�C�v���C�����A�[�L�₻�����̂��l���Ĕ�ׂ��
�ǂ�����s�Ƃ�����v���Z�X�͖�������
����������l�g�o�̒�i�݂̂Ō���90��65���厸�s�ƂȂ�
180��130�A90��65�̔�r�����o����
������65�̒�i�͂킴�Ɨ}�����Ă���
�p�C�v���C�����A�[�L�₻�����̂��l���Ĕ�ׂ��
�ǂ�����s�Ƃ�����v���Z�X�͖�������
����������l�g�o�̒�i�݂̂Ō���90��65���厸�s�ƂȂ�
����
�l�g�o�����������f�ޗ�������������
�v���X�R�̕��v���ז�����90nm�v���Z�X�̗ǔۂ܂Ŕ��f���y�Ȃ�
�l�g�o�����������f�ޗ�������������
�v���X�R�̕��v���ז�����90nm�v���Z�X�̗ǔۂ܂Ŕ��f���y�Ȃ�
>>600
����l�g�o�n�B�m�R�A������M������D����
����l�g�o�n�B�m�R�A������M������D����
�����������́u�v���X�R�̕��v�v���ԈႦ�B
�ʂɁuPrescott�v�͕��v�ł����ł��Ȃ��B
����AMD���̗p����SOI�⌻��Core2�Ȃǂ��̗p����
�uHigh-k�v�Ȃǂ́u�����Z�p�v�������܂��A
���̂܂܂�����Ɣ��f�����̂����s�B
�����Ƃ����ꂪ�u�v���X�R�̕��v�v�Ƃ����̂Ȃ�m���B
�����A���̌�ɏ��X�̋@�\��g�ݍ��uCedarMill�v�����
�uPrescott�v����Ɠ����v���Z�X�����ǂ���Ȃ�ɗD�G�������̂��Y�ꂸ�ɁB
�ʂɁuPrescott�v�͕��v�ł����ł��Ȃ��B
����AMD���̗p����SOI�⌻��Core2�Ȃǂ��̗p����
�uHigh-k�v�Ȃǂ́u�����Z�p�v�������܂��A
���̂܂܂�����Ɣ��f�����̂����s�B
�����Ƃ����ꂪ�u�v���X�R�̕��v�v�Ƃ����̂Ȃ�m���B
�����A���̌�ɏ��X�̋@�\��g�ݍ��uCedarMill�v�����
�uPrescott�v����Ɠ����v���Z�X�����ǂ���Ȃ�ɗD�G�������̂��Y�ꂸ�ɁB
�����p�C�v���C���Ƃ��V�������N�Ƃ�180(nm)�̈Ӗ���������ĂȂ��悤�Ɍ�����
>>603
> �����A���̌�ɏ��X�̋@�\��g�ݍ��uCedarMill�v�����
> �uPrescott�v����Ɠ����v���Z�X�����ǂ���Ȃ�ɗD�G�������̂��Y�ꂸ�ɁB
Prescott�@90nm
CedarMill�@65nm
> �����A���̌�ɏ��X�̋@�\��g�ݍ��uCedarMill�v�����
> �uPrescott�v����Ɠ����v���Z�X�����ǂ���Ȃ�ɗD�G�������̂��Y�ꂸ�ɁB
Prescott�@90nm
CedarMill�@65nm
���B�������B�������Ⴂ���I
�m��180nm�B�k�X��130nm�B�v���X�q����90nm�B�����݂邳��65nm�������B
�Ȃ������ԈႦ���I
�m��180nm�B�k�X��130nm�B�v���X�q����90nm�B�����݂邳��65nm�������B
�Ȃ������ԈႦ���I
�E�E�E�ꉞ�⑫���Ƃ���
�A�[�L�́i�}�C�N���j�A�[�L�e�N�`���̗�
�v���Z�X�̓v���Z�X���[���̗�
�v�̓A�[�L�e�N�`���v�̂���
�����Ă����̐l�ɂ͒ʂ���͂��Ȃ̂ł��̂܂�����
�A�[�L�́i�}�C�N���j�A�[�L�e�N�`���̗�
�v���Z�X�̓v���Z�X���[���̗�
�v�̓A�[�L�e�N�`���v�̂���
�����Ă����̐l�ɂ͒ʂ���͂��Ȃ̂ł��̂܂�����
>>597
�M����1�����ɏW��������킯������A�����������Ƃ��̔��M�������`���Ȃ��Ȃ��ƁA
��p����ςɂȂ��Č��ǃR�X�g�Ƃ�➑̃T�C�Y�Ƃ��̃����b�g�����ꂻ�������ǂȁB
�M����1�����ɏW��������킯������A�����������Ƃ��̔��M�������`���Ȃ��Ȃ��ƁA
��p����ςɂȂ��Č��ǃR�X�g�Ƃ�➑̃T�C�Y�Ƃ��̃����b�g�����ꂻ�������ǂȁB
609 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 14:50:16 ID:k35grsI0
>>603
High-K��45nm����̗̍p�Ȃ̂�Core 2��65nm��K8DC���ȓd�͂ȗ��R�Ƃ��Ă͕s�K��
���̂ˁA����ς�}�C�N���A�[�L�e�N�`�����N�\�Ȃ�B
�{��ALU�Ƃ��n�C�p�[�p�C�v���C���݂����ȓd�͌����������ăN���b�N�����グ��v�z���̂��̂�
IPC�d���^�ɕ������B
High-K��45nm����̗̍p�Ȃ̂�Core 2��65nm��K8DC���ȓd�͂ȗ��R�Ƃ��Ă͕s�K��
���̂ˁA����ς�}�C�N���A�[�L�e�N�`�����N�\�Ȃ�B
�{��ALU�Ƃ��n�C�p�[�p�C�v���C���݂����ȓd�͌����������ăN���b�N�����グ��v�z���̂��̂�
IPC�d���^�ɕ������B
�������Ȃ��A���̎v�z�ōs���Ă����̓��[�N�̖�肪�؎�����Ȃ���������B
AMD�������d���ɐ�ւ����̂͐挩�̖��ƌ������A
�N���b�N�グ��h���ɕ������Ƃ������B
AMD�������d���ɐ�ւ����̂͐挩�̖��ƌ������A
�N���b�N�グ��h���ɕ������Ƃ������B
AMD��K8�̌�p�œ������H�낤�Ƃ������Ǔr���łۂ��������Ȃ�����������
>>609
�n���͓ˑR���ʂɍs���Ăǂ������H
�p�C�v���C�����P�̗��h�Ȏ�@
���ۂɖk�X�͓�����K8�ɏ����Ă�i�Ƃ����b�j
���q�����Ȃ͖̂k�X�Ŋ���TDP90�AL3�t����3���s�����̂�
�ה����őS�Ă��܂��s���Ǝv�����̂��܂��p�C�v���C����11�i�����₵������
�p�C�v���C���𑝂₷�Ƌt�ɏȓd�͂ɂȂ�Ƃ����������邭�炢��
���ꂪ���ڔ��M�̌����Ƃ͂Ȃ�Ȃ����낤��
�R�A�d���͏�������������Ȃ��̂Ƀg�����W�X�^�͕��ʂɔ{�������Ē����M
�܊p�̃p�C�v���C���������S���֑̎���
�m�ʼn����w�Ȃ������̂��ƁE�E�E
��������>603�́�Core2�Ȃǂ��̗p����uHigh-k�v�Ȃǂ́u�����Z�p�v
�Ə����Ă���̂ɂ����ʂ�S���lj��o���ĂȂ��l�q
>611
�ۂ��������Ȃ���
���߂̃L�����Z������
����ƃ}���`�X���b�h�Ώd�ł��ꂪ����ɍ���Ȃ����낤�Ƃ����\������
�n���͓ˑR���ʂɍs���Ăǂ������H
�p�C�v���C�����P�̗��h�Ȏ�@
���ۂɖk�X�͓�����K8�ɏ����Ă�i�Ƃ����b�j
���q�����Ȃ͖̂k�X�Ŋ���TDP90�AL3�t����3���s�����̂�
�ה����őS�Ă��܂��s���Ǝv�����̂��܂��p�C�v���C����11�i�����₵������
�p�C�v���C���𑝂₷�Ƌt�ɏȓd�͂ɂȂ�Ƃ����������邭�炢��
���ꂪ���ڔ��M�̌����Ƃ͂Ȃ�Ȃ����낤��
�R�A�d���͏�������������Ȃ��̂Ƀg�����W�X�^�͕��ʂɔ{�������Ē����M
�܊p�̃p�C�v���C���������S���֑̎���
�m�ʼn����w�Ȃ������̂��ƁE�E�E
��������>603�́�Core2�Ȃǂ��̗p����uHigh-k�v�Ȃǂ́u�����Z�p�v
�Ə����Ă���̂ɂ����ʂ�S���lj��o���ĂȂ��l�q
>611
�ۂ��������Ȃ���
���߂̃L�����Z������
����ƃ}���`�X���b�h�Ώd�ł��ꂪ����ɍ���Ȃ����낤�Ƃ����\������
���Ԕ����Ȃ�
ttp://journal.mycom.co.jp/special/2006/trendspring/002.html
���A�[�L�e�N�`���I�ɂ͍X�ɍ�IPC��_�������̂ƕ����Ă��邪(����͏��ɂ�茾�������Ⴄ�̂ŁA�����ȂƂ���͔���Ȃ�)
���`��E�E�E
K9�}���`�X���b�h�̋L���͌��nj����炸
���A�[�L�e�N�`���I�ɂ͍X�ɍ�IPC��_�������̂ƕ����Ă��邪(����͏��ɂ�茾�������Ⴄ�̂ŁA�����ȂƂ���͔���Ȃ�)
���`��E�E�E
K9�}���`�X���b�h�̋L���͌��nj����炸
K9�͌�������L�����Z���Ȃ낤�H
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
���̉���ɂ��ƁAK9��K10���킩��Ȃ����ǁA�}���`�X���b�h�Z�p��
�̗p����v��͂������͗l�B
���̉���ɂ��ƁAK9��K10���킩��Ȃ����ǁA�}���`�X���b�h�Z�p��
�̗p����v��͂������͗l�B
>>616
����l�g�o�����ȃA�[�L�̗\�肾�����ۂ���
����l�g�o�����ȃA�[�L�̗\�肾�����ۂ���
>>612
> �ۂ��������Ȃ���
> ���߂̃L�����Z������
�����B���͌����l���ȁB
�l�g�o��ǂ���10GH��(w��K9��K10���s��ɂۂ��������ȁB
�{���ɑ��߂̃L�����Z�����ł��Ă�����A
K8�̉��ǂōŒႠ��3�N�키�Ȃ�Ă�����]�I�ȏɂ͂Ȃ�Ȃ����������ȁB
> �ۂ��������Ȃ���
> ���߂̃L�����Z������
�����B���͌����l���ȁB
�l�g�o��ǂ���10GH��(w��K9��K10���s��ɂۂ��������ȁB
�{���ɑ��߂̃L�����Z�����ł��Ă�����A
K8�̉��ǂōŒႠ��3�N�키�Ȃ�Ă�����]�I�ȏɂ͂Ȃ�Ȃ����������ȁB
621 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 19:05:52 ID:k35grsI0
>>612
�Ƃ��낪�ACedarMill/Presler��Core 2�̓V���R����̐����Z�p���͓̂����ł��B
�O�̐����Prescott��Dothan�������B
�N���b�N�Q�[�e�B���O�ɂ��O�ꂵ���d�͊Ǘ��̎��ł���
�Ղ��Ձ[
�Ƃ��낪�ACedarMill/Presler��Core 2�̓V���R����̐����Z�p���͓̂����ł��B
�O�̐����Prescott��Dothan�������B
�N���b�N�Q�[�e�B���O�ɂ��O�ꂵ���d�͊Ǘ��̎��ł���
�Ղ��Ձ[
>>621
���ς�炸��߂���m�\��ɂ��C�������N���Ă���Ȃ�
���߉������Ă�̂�������������炭
Core2���i�ᔭ�M���v���Z�X�����j
Pen4���i���M���v���Z�X���s�j
�@�i�j���͔n���̑S�����ϑz����
��CPU�������������u�Ԃɔ]���Ŗ�Ă��܂��낤
�u�v���X�R�̕��v�v�i���A�[�L�̎��s�j
�Ƃ������͂ȂNJ��ɋL���̔ޕ��ւƔ�ы����Ă��܂��Ă���Ƃ���
����ɉ����ā�Core2�Ȃǂ��̗p����uHigh-k�v�Ȃǂ́u�����Z�p�v
���ꂪ�����ɓlj��o���Ă��Ȃ��ƌ���
�܂�ID:/Bjii+Dw���ǂ������Ӗ��ŏ������̂��܂ł͒m���
���{��Ƃ��ēǂ߂�
�ESOI�Ƃ������ʂȁu�����Z�p�v
�E�uHigh-k�v�Ƃ������ʂȁu�����Z�p�v�i�u���ʂȁv�́u�����܂��v����ސ��j
�Ɠ��ʂȁu�����Z�p�v�Ƃ������̂�b���Ă���
�܂�u90nm�ɗ͂���ꂸ���s�������̂��v���X�R���s�̌����v�Ƃ����咣��
�������Core2�Ȃǂ��̗p����uHigh-k�v�@�̕������������ڂɓ��炸
�uCore2�͑S��High-k���v�ƂƂ�ł��Ȃ��ϊ������Ă��܂��̂����̖ϑz�n��
���ς�炸��߂���m�\��ɂ��C�������N���Ă���Ȃ�
���߉������Ă�̂�������������炭
Core2���i�ᔭ�M���v���Z�X�����j
Pen4���i���M���v���Z�X���s�j
�@�i�j���͔n���̑S�����ϑz����
��CPU�������������u�Ԃɔ]���Ŗ�Ă��܂��낤
�u�v���X�R�̕��v�v�i���A�[�L�̎��s�j
�Ƃ������͂ȂNJ��ɋL���̔ޕ��ւƔ�ы����Ă��܂��Ă���Ƃ���
����ɉ����ā�Core2�Ȃǂ��̗p����uHigh-k�v�Ȃǂ́u�����Z�p�v
���ꂪ�����ɓlj��o���Ă��Ȃ��ƌ���
�܂�ID:/Bjii+Dw���ǂ������Ӗ��ŏ������̂��܂ł͒m���
���{��Ƃ��ēǂ߂�
�ESOI�Ƃ������ʂȁu�����Z�p�v
�E�uHigh-k�v�Ƃ������ʂȁu�����Z�p�v�i�u���ʂȁv�́u�����܂��v����ސ��j
�Ɠ��ʂȁu�����Z�p�v�Ƃ������̂�b���Ă���
�܂�u90nm�ɗ͂���ꂸ���s�������̂��v���X�R���s�̌����v�Ƃ����咣��
�������Core2�Ȃǂ��̗p����uHigh-k�v�@�̕������������ڂɓ��炸
�uCore2�͑S��High-k���v�ƂƂ�ł��Ȃ��ϊ������Ă��܂��̂����̖ϑz�n��
623 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 19:53:05 ID:k35grsI0
�n���ۏo���Ȃ�ł�3�s�ł��ځ[��
624 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 19:59:36 ID:k35grsI0
�n���̎q�ɂ͂킩��Ȃ����낤���Ǎ��N���b�N�̃p�C�v���C�������x���Ƃ����C�h�ȃp�C�v���C���̕����A
�g���ĂȂ��u���b�N���x�܂���d�͂̍œK���͂��₷����ˁB
�N���b�N�Q�[�e�B���O���}�C�N���A�[�L�e�N�`���́u�����v�̈ꕔ�ł��̂ŁB
�ޗ��ǂ��̂����̂���Ȃ��̂�B
�[���NetBurst�̍��N���b�N��_�����A�v���[�`������ɂ�����Ȃ������͖̂��炩���낤��
�����ɐM��҂����
�g���ĂȂ��u���b�N���x�܂���d�͂̍œK���͂��₷����ˁB
�N���b�N�Q�[�e�B���O���}�C�N���A�[�L�e�N�`���́u�����v�̈ꕔ�ł��̂ŁB
�ޗ��ǂ��̂����̂���Ȃ��̂�B
�[���NetBurst�̍��N���b�N��_�����A�v���[�`������ɂ�����Ȃ������͖̂��炩���낤��
�����ɐM��҂����
�A�z�ɉ��������Ă����ʂł��B
����̃��X��S���ǂ܂��ɔ��_�������I�ȋZ�p��
��ݺނ͂����Ʊ��݂ƌ����S���ǂ�ł����
�ł��]�Ɏ��܂肫�炸�ɕЂ��ς����珟��ɱ��݂���Ă��܂���
�ł��]�Ɏ��܂肫�炸�ɕЂ��ς����珟��ɱ��݂���Ă��܂���
628 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 20:49:00 ID:k35grsI0
���߂�A�ߓǂ݂͂��Ă�B
���X�Ԃ����ł���Ǝv������c�q�����Ă����̂��B
MAC���ƃ_���S��NG�w�肵�Ă邩�炱�̃X�������炯��w
�Ă��A�S����MAC���ƃ_���S���ځ[�Ċ��S�����Řb���悤��w
�Ă��A�S����MAC���ƃ_���S���ځ[�Ċ��S�����Řb���悤��w
�ނ��낻�̓�l�̂���ꂠ��������̂����̃X���Ȃ�ł�Ȃ��B
�M�҂��Ďv�l�����W�A�����Ă�ȊO�͐��������������Ă邵�B
�e�w�Ƃ͑�Ⴂ
�M�҂��Ďv�l�����W�A�����Ă�ȊO�͐��������������Ă邵�B
�e�w�Ƃ͑�Ⴂ
Mxc�I�^�̎������X���B
633 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 21:25:26 ID:k35grsI0
������PPC�Ɍ��z���Ă�悤�ȓ��҂͗v���Ƃł�
�R���V���[�}PC�����Ƃ��Ă͏I������A�[�L
�R���V���[�}PC�����Ƃ��Ă͏I������A�[�L
�c�O�Ȃ���A�c�q�̎咣�͐������ȁB
ID:CZ3qJm3q�����̃��x���ȏ�̏������݁B
����Ĉ����������炢�B
�܂��A���ǂ�����Ă����B
ID:CZ3qJm3q�����̃��x���ȏ�̏������݁B
����Ĉ����������炢�B
�܂��A���ǂ�����Ă����B
�����A>>630�̃��X�g�P�s�ɉF���܂Ńn�Q�h�E�B
�����A�ǂ����S������������Ė�������ƁA�c�q��}�N�I�^��
�S�������_���ł���Ȃ���ʐl�Ƃ����ݒ�ŐV�����R�e������Ă��āA
���_�����ƁA�u�������̌����Ă邱�Ƃ͐������v�@�u�������_���Ă���̃��x�����Ⴂ�v�Ƃ���
�����̖������i�삪�������܂��̂ł���
�����A�ǂ����S������������Ė�������ƁA�c�q��}�N�I�^��
�S�������_���ł���Ȃ���ʐl�Ƃ����ݒ�ŐV�����R�e������Ă��āA
���_�����ƁA�u�������̌����Ă邱�Ƃ͐������v�@�u�������_���Ă���̃��x�����Ⴂ�v�Ƃ���
�����̖������i�삪�������܂��̂ł���
636 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 22:00:48 ID:k35grsI0
�������i��Ȃ���k�َ҂���郂���ł�
>�S�������_���ł���Ȃ���ʐl�Ƃ����ݒ�ŐV�����R�e������Ă��āA
���������~�[�ɂ��肪���Ȗϑz�͂�߂Ƃ�������������B
���͌��ɂ��̎�̏������݂������肷�钣�{�l�����ǂˁB
�������MAC�I�^�ł��c�q�ł��Ȃ��B
�����f���͉��������Ă��邩�����B
���������~�[�ɂ��肪���Ȗϑz�͂�߂Ƃ�������������B
���͌��ɂ��̎�̏������݂������肷�钣�{�l�����ǂˁB
�������MAC�I�^�ł��c�q�ł��Ȃ��B
�����f���͉��������Ă��邩�����B
�������ރX���ԈႦ���BAMD������X��������B
�A�[�L�e�N�`���X�����Ǝv�����BNetBurst�l�^���������炾�܂��ꂽ���B
�A�[�L�e�N�`���X�����Ǝv�����BNetBurst�l�^���������炾�܂��ꂽ���B
���ۂ͢���_���Ă�z���̃����F�����Ⴂ����Č����Ă�z�̃��x�����Ⴂ���Ė�ł����B
�c�O�Ȃ��獡��̃_���E�S���I�͎咣���̂͑債�����Ƃ��Ă��Ȃ�
���炩�ɊԈ���Ă闝���Ƃ������̂�����
�����Ђ�����ɓlj�͂��A���Ȃ���
����ā��c�O�Ȃ���A�c�q�̎咣�͐������ȁB
�Ƃ������X���o��̂��ʂɂ��������͂Ȃ�
���炩�ɊԈ���Ă闝���Ƃ������̂�����
�����Ђ�����ɓlj�͂��A���Ȃ���
����ā��c�O�Ȃ���A�c�q�̎咣�͐������ȁB
�Ƃ������X���o��̂��ʂɂ��������͂Ȃ�
�Ȃ�ł��킢�����Ȏq�̑��������̂�?
642 �F�R�E�L�́M�E,,�j�����������������F2008/06/18(��) 22:16:54 ID:k35grsI0
Core2���i�ᔭ�M���v���Z�X�����j
Pen4���i���M���v���Z�X���s�j
���@���Ă������ǂ���ǂ������Ӗ��������B
Prescott��Dothan�ACedarMill��Conroe�͓����v���Z�X����H
�킩���ĂȂ�����������
Pen4���i���M���v���Z�X���s�j
���@���Ă������ǂ���ǂ������Ӗ��������B
Prescott��Dothan�ACedarMill��Conroe�͓����v���Z�X����H
�킩���ĂȂ�����������
�A�[�L�͈Ⴄ���ǃv���Z�X�͓�������
�܂��ǂ��ł��������ǁB
�܂��ǂ��ł��������ǁB
>>644
�����ŋc�_����ɂ͂܂�����
�e�w�ƋY��Ă��傤�ǂ������x�����Ǝv���E�E�E�B
�����O��t�����Ȃ��Ƌc�_���o���Ȃ�����
�O������ł߂Ȃ��ŋc�_�ł���̂̓e�w���炢
�����ŋc�_����ɂ͂܂�����
�e�w�ƋY��Ă��傤�ǂ������x�����Ǝv���E�E�E�B
�����O��t�����Ȃ��Ƌc�_���o���Ȃ�����
�O������ł߂Ȃ��ŋc�_�ł���̂̓e�w���炢
�����痼�҂���Ȃ������Ȃ��Ƃ͂����ĂȂ����Ă��ƂŁB
�܂��A������w
�܂��A������w
>637
> >�S�������_���ł���Ȃ���ʐl�Ƃ����ݒ�ŐV�����R�e������Ă��āA
> ���������~�[�ɂ��肪���Ȗϑz�͂�߂Ƃ�������������B
���������~�[�ɂ��肪���Ȗϑz���Ǝv�����ޖϑz�͂�߂��ق���������w
�V�����R�e������Ă��ĂƂ͌����Ă��邪
����l���̕ʃR�e�ȂǂƂ͑S�������Ă��Ȃ��B�����������l�̂��ƂȂ̂Ƀ}���ł��˂�
> >�S�������_���ł���Ȃ���ʐl�Ƃ����ݒ�ŐV�����R�e������Ă��āA
> ���������~�[�ɂ��肪���Ȗϑz�͂�߂Ƃ�������������B
���������~�[�ɂ��肪���Ȗϑz���Ǝv�����ޖϑz�͂�߂��ق���������w
�V�����R�e������Ă��ĂƂ͌����Ă��邪
����l���̕ʃR�e�ȂǂƂ͑S�������Ă��Ȃ��B�����������l�̂��ƂȂ̂Ƀ}���ł��˂�
>>586
CPU��AMD������Ȃ����������H
CPU��AMD������Ȃ����������H
���N�O����Top500�����L���O�����\���ꂽ�����ǁA�܂���AMD��B�B�B
http://www.top500.org/stats/list/31/procfam
�@�@�@�@�@�@�@�@�@�@�@�@�䐔�@(2007����) (2007���)
�@�@Intel EM64T�@�@�@356 <- 322 <- 232
�@�@Power�@�@�@�@�@�@�@68 <- 31 <- 85
�@�@AMD x86_64�@�@�@55 <- 79 <- 108
http://www.top500.org/stats/list/31/procfam
�@�@�@�@�@�@�@�@�@�@�@�@�䐔�@(2007����) (2007���)
�@�@Intel EM64T�@�@�@356 <- 322 <- 232
�@�@Power�@�@�@�@�@�@�@68 <- 31 <- 85
�@�@AMD x86_64�@�@�@55 <- 79 <- 108
Power��������
651 �FMAC�I�^��648 �����F2008/06/18(��) 22:50:19 ID:g8Utdww1
>>648
�@�@------------------
�@�@CPU��AMD������Ȃ����������H
�@�@------------------
http://pc.watch.impress.co.jp/docs/2005/0514/kaigai178.htm
�@�@------------------
�@�@CPU��AMD������Ȃ����������H
�@�@------------------
http://pc.watch.impress.co.jp/docs/2005/0514/kaigai178.htm
>>647
�A�[�L�e�N�`���X���̓W�J�ɂ�����݂�Ȃ��肩�肵�Ă�Ȃ�
�Ǝv���Ċ�@�����������̂ŏ�������AAMD������CPU�X���������Ƃ���㩁c�B
���ɂ��Ȃ���OK�B
���Ȃ݂ɑ����M���Ȃ�����w�ǂ��낤���A�������̃X����part.1�����Ă�w
���͖w�Ǐ������݂����Ȃ����ߋ��̘b������ǂ��ł��悢���Ƃ����ǂȁB
�����f���͂��̏�̊���I�Ȃ��Ƃ�Ƃ��͂��܂�d�v�ł͂Ȃ���B
�����Ƒ�ǓI�ȗ��ꂪ�厖�B
�����̍r�炵���~�[���R�e�����쎩�����H������܂߂Ē����ڂł݂���悤�ɂȂ�������������B
�����̉Q�̗\��
�A�[�L�e�N�`���X���̓W�J�ɂ�����݂�Ȃ��肩�肵�Ă�Ȃ�
�Ǝv���Ċ�@�����������̂ŏ�������AAMD������CPU�X���������Ƃ���㩁c�B
���ɂ��Ȃ���OK�B
���Ȃ݂ɑ����M���Ȃ�����w�ǂ��낤���A�������̃X����part.1�����Ă�w
���͖w�Ǐ������݂����Ȃ����ߋ��̘b������ǂ��ł��悢���Ƃ����ǂȁB
�����f���͂��̏�̊���I�Ȃ��Ƃ�Ƃ��͂��܂�d�v�ł͂Ȃ���B
�����Ƒ�ǓI�ȗ��ꂪ�厖�B
�����̍r�炵���~�[���R�e�����쎩�����H������܂߂Ē����ڂł݂���悤�ɂȂ�������������B
�����̉Q�̗\��
���y����
�@�@�@ �@�Q�Q__
�@�@�@�^�Q_.�j)ɁR
�@�@ .|�~.l�@_�@ ._ i.�j
�@ �i�O'�/.�L�E .�q�E � �@�@���̃X���̓��V����Ă�
�@�@.��i �@�@r�_�j |
�@�@�@ |�@ `��' /
�@�@�@Ɂ@`��\i�L
�@�@�@�^�Q_.�j)ɁR
�@�@ .|�~.l�@_�@ ._ i.�j
�@ �i�O'�/.�L�E .�q�E � �@�@���̃X���̓��V����Ă�
�@�@.��i �@�@r�_�j |
�@�@�@ |�@ `��' /
�@�@�@Ɂ@`��\i�L
�Ƃ������̂�AMD�̎�����X����Intel�̎�����X���������ăA�[�L�e�N�`���X��
1�ɓZ�܂��Ă����B������MAC����G������荞��ł��ăX�����r��܂�����
�A�[�L�e�N�`���X����AMD�X����Intel�X���ɕ����ꂽ�B�����Ă����Ō���Ă�
���e�͂ǂ̃X�����قړ��������������܂�A���̑��̓_���S��MAC���ɂ��r�炵�B
�܂�ID:DgzWSZt3�Ɍ�����������
�@�@ _,,....,,_�@ �Q�l�l�l�l�l�l�l�l�l�l�l�l�l�l�l�Q
-''":::::::::::::�M''���@������肵�����ʂ����ꂾ��I�I�I��
�R:::::::::::::::::::::�P^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�P
�@|::::::;�m�L�P�_:::::::::::�__,. -�]��@�@�@�@�@�Q_�@�@ _____�@�@ �Q_____
�@|::::Ɂ@�@�@�R��Rr-r'"�L�@�@�i.__�@�@�@�@,�L�@_,, '-�L�P�P�M-�T �A_ �C�A
_,.!�C_�@�@_,.Ͱ�'��ʓ�R���,_7�@�@�@'r �L�@�@�@�@�@�@�@�@�@�@�R�A݁A
::::::r�''7�-�]'"�L�@ �@ ;�@ ',�@�M�R/�M7�@,'��=��-�@�@�@ �@ -��=��',�@i
r-'�'"�L/�@ /!�@� �@�n�@ !�@�@i�S_Ɂ@i�@��@i�T�A��l���^_���R� i�@|
!�C�L ,' |�@/__,.!/�@V�@�!__ʁ@ ,'�@,�T�@�زi (�_] �@�@ �@�_� ).| .|�Ai .||
`! �@!/�i'�@(�_] �@�@ �@�_� �'i�@Ɂ@�@�@!Y!""�@ ,�Q__, �@ "" �u !� i�@|
,'�@ � �@ !'"�@ �@ ,�Q__,�@ "' i .�'�@�@�@�@L.',.�@ �@�R _݁@�@�@�@L�v �| .|
�@�i�@�@,ʁ@�@�@�@�R _݁@ �@�l! �@�@�@�@ | ||�R�A�@�@�@�@�@�@ ,�| ||�| /
,.�,�j��@�@�j��,� _____,�@,.�C�@ �n�@�@�@�@�� ���M �[--�� �L��ځ@ځL
1�ɓZ�܂��Ă����B������MAC����G������荞��ł��ăX�����r��܂�����
�A�[�L�e�N�`���X����AMD�X����Intel�X���ɕ����ꂽ�B�����Ă����Ō���Ă�
���e�͂ǂ̃X�����قړ��������������܂�A���̑��̓_���S��MAC���ɂ��r�炵�B
�܂�ID:DgzWSZt3�Ɍ�����������
�@�@ _,,....,,_�@ �Q�l�l�l�l�l�l�l�l�l�l�l�l�l�l�l�Q
-''":::::::::::::�M''���@������肵�����ʂ����ꂾ��I�I�I��
�R:::::::::::::::::::::�P^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�x^�P
�@|::::::;�m�L�P�_:::::::::::�__,. -�]��@�@�@�@�@�Q_�@�@ _____�@�@ �Q_____
�@|::::Ɂ@�@�@�R��Rr-r'"�L�@�@�i.__�@�@�@�@,�L�@_,, '-�L�P�P�M-�T �A_ �C�A
_,.!�C_�@�@_,.Ͱ�'��ʓ�R���,_7�@�@�@'r �L�@�@�@�@�@�@�@�@�@�@�R�A݁A
::::::r�''7�-�]'"�L�@ �@ ;�@ ',�@�M�R/�M7�@,'��=��-�@�@�@ �@ -��=��',�@i
r-'�'"�L/�@ /!�@� �@�n�@ !�@�@i�S_Ɂ@i�@��@i�T�A��l���^_���R� i�@|
!�C�L ,' |�@/__,.!/�@V�@�!__ʁ@ ,'�@,�T�@�زi (�_] �@�@ �@�_� ).| .|�Ai .||
`! �@!/�i'�@(�_] �@�@ �@�_� �'i�@Ɂ@�@�@!Y!""�@ ,�Q__, �@ "" �u !� i�@|
,'�@ � �@ !'"�@ �@ ,�Q__,�@ "' i .�'�@�@�@�@L.',.�@ �@�R _݁@�@�@�@L�v �| .|
�@�i�@�@,ʁ@�@�@�@�R _݁@ �@�l! �@�@�@�@ | ||�R�A�@�@�@�@�@�@ ,�| ||�| /
,.�,�j��@�@�j��,� _____,�@,.�C�@ �n�@�@�@�@�� ���M �[--�� �L��ځ@ځL
656 �FMAC�I�^��655 �����F2008/06/18(��) 23:59:02 ID:g8Utdww1
>>655
�@�@-------------------
�@�@�Ƃ������̂�AMD�̎�����X����Intel�̎�����X���������ăA�[�L�e�N�`���X��
�@�@1�ɓZ�܂��Ă����B
�@�@-------------------
�A�����푧������悤�ɉR������(��)
����Intel������X���b�h�w������CPU�APentium5�ɂ��Č�낤�x
http://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
�@�@=====================
�@�@1 ���O�F�₮�₮ ���e���F03/07/16 22:20 ID:FCj0OvEc
�@�@=====================
����A�[�L�e�N�`���X���b�h�w[x86]CPU�A�[�L�e�N�`���ɂ��Č��I[RISC]�x
http://pc4.2ch.net/test/read.cgi/jisaku/1082357989/
�@�@=====================
�@�@1 ���O�FSocket774 ���e���F04/04/19 15:59 ID:xbBch3+r
�@�@=====================
�p�N����AMD�ɑ��������A������X�����Č㔭���B�wAMD�̎�����CPU�ɂ��Č�낤�x
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���ǂݒ�����1�팚�ē��������A���ɕ��X�����ۂ��n�܂��Ă��邷(��)
�@�@=====================
�@�@1 ���O�FSocket774 ���e���F2005/08/20(�y) 22:00:12 ID:I3YVU0JX
�@�@�@�@AMD�̃v���Z�b�T�E���[�h�}�b�v
�@�@�@�@http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_608,00.html
�@�@�@�@http://www.amd.com/us-en/assets/content_type/styleone/33275A-0_roadmap.gif
�@�@2 ���O�F�������G�� ��yGAhoNiShI ���e���F2005/08/20(�y) 22:01:27 ID:TTT3DgDh
�@�@�@�@������낤���I�I
�@�@�@�@�����m���
�@�@=====================
�@�@-------------------
�@�@�Ƃ������̂�AMD�̎�����X����Intel�̎�����X���������ăA�[�L�e�N�`���X��
�@�@1�ɓZ�܂��Ă����B
�@�@-------------------
�A�����푧������悤�ɉR������(��)
����Intel������X���b�h�w������CPU�APentium5�ɂ��Č�낤�x
http://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
�@�@=====================
�@�@1 ���O�F�₮�₮ ���e���F03/07/16 22:20 ID:FCj0OvEc
�@�@=====================
����A�[�L�e�N�`���X���b�h�w[x86]CPU�A�[�L�e�N�`���ɂ��Č��I[RISC]�x
http://pc4.2ch.net/test/read.cgi/jisaku/1082357989/
�@�@=====================
�@�@1 ���O�FSocket774 ���e���F04/04/19 15:59 ID:xbBch3+r
�@�@=====================
�p�N����AMD�ɑ��������A������X�����Č㔭���B�wAMD�̎�����CPU�ɂ��Č�낤�x
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���ǂݒ�����1�팚�ē��������A���ɕ��X�����ۂ��n�܂��Ă��邷(��)
�@�@=====================
�@�@1 ���O�FSocket774 ���e���F2005/08/20(�y) 22:00:12 ID:I3YVU0JX
�@�@�@�@AMD�̃v���Z�b�T�E���[�h�}�b�v
�@�@�@�@http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_608,00.html
�@�@�@�@http://www.amd.com/us-en/assets/content_type/styleone/33275A-0_roadmap.gif
{kind=link}
�@�@2 ���O�F�������G�� ��yGAhoNiShI ���e���F2005/08/20(�y) 22:01:27 ID:TTT3DgDh
�@�@�@�@������낤���I�I
�@�@�@�@�����m���
�@�@=====================
�v���Ԃ�ɔ`���Č����AMD�X���Ȃ̂Ƀl�g�o�k�`�Ő���オ���Ă�̂���
�Ȃ�ł���܂Ƃ߂ɍm��ے肷�邩���₱�����Ȃ���
�l�g�o�̃A�[�L�e�N�`��(�v�v�z)���̂͂Ȃ�����s�����ĂȂ���
�Ԉ���Ă����Ȃ��������AIPC��2�������Ă��N���b�N��5���オ���
���ʓI�ɐ��\�͏オ������Ă̂��l�g�o�̍��{�����́B
���ɃV���v�����A�̂�P6���炠�ꂾ���傫�ȕύX���o����
���Ȃ݂ɃN���b�N�����`���Ă͉̂c�ƃT�C�h�̎��悩�����̂�ˁB
������H�����ł͑傫���Ԉ���Ă��A���ۂɂ�
IPC�̒ቺ��2�����Ⴗ�܂Ȃ�������
(�����̎��_�ŃA���Ӗ��v�v�z�̒ʂ�ł͖����Ȃ��Ă�)
�d�͌����������v������ɂ͍����ĂȂ�����
�����intel�̃��[�N�d���ɑ��錩�ʂ����Â������B
���̌��ʃl�g�o�͎��s�������Ă��Ƃł�����Ȃ�����
�Ȃ�ł���܂Ƃ߂ɍm��ے肷�邩���₱�����Ȃ���
�l�g�o�̃A�[�L�e�N�`��(�v�v�z)���̂͂Ȃ�����s�����ĂȂ���
�Ԉ���Ă����Ȃ��������AIPC��2�������Ă��N���b�N��5���オ���
���ʓI�ɐ��\�͏オ������Ă̂��l�g�o�̍��{�����́B
���ɃV���v�����A�̂�P6���炠�ꂾ���傫�ȕύX���o����
���Ȃ݂ɃN���b�N�����`���Ă͉̂c�ƃT�C�h�̎��悩�����̂�ˁB
������H�����ł͑傫���Ԉ���Ă��A���ۂɂ�
IPC�̒ቺ��2�����Ⴗ�܂Ȃ�������
(�����̎��_�ŃA���Ӗ��v�v�z�̒ʂ�ł͖����Ȃ��Ă�)
�d�͌����������v������ɂ͍����ĂȂ�����
�����intel�̃��[�N�d���ɑ��錩�ʂ����Â������B
���̌��ʃl�g�o�͎��s�������Ă��Ƃł�����Ȃ�����
658 �FMAC�I�^���⑫�F2008/06/19(��) 00:02:27 ID:qPRp6hfv
�����Đ^�̃A�[�L�e�N�`���X���b�h�̌�����A�Vmac�̂���Ǝv���邷�B
�w���ɁI�@G5�I�I�I�x
http://pc.2ch.net/mac/kako/1000/10007/1000793921.html
�@�@----------------------
�@�@1 ���O�F���̖��ݒ� ���e���F01/09/18 15:18 ID:9oGWxrQ6
�@�@----------------------
�w���ɁI�@G5�I�I�I�x
http://pc.2ch.net/mac/kako/1000/10007/1000793921.html
�@�@----------------------
�@�@1 ���O�F���̖��ݒ� ���e���F01/09/18 15:18 ID:9oGWxrQ6
�@�@----------------------
>>655 ���ꓖ��������?
�������܂菑�������Ȃ����ǁA
����͂�����ƈႤ��B
��̂́A����ɃA�[�L�e�N�`���̘b��͂قƂ�ǂȂ��B
mac�ɏ������������炢�B���ꂩ�炿����Ƃ���AMD�n�̃X���ŃA�[�L�b���������B
Intel�n�̃X���͖w�ǂȂ��ď�ɂ���Ă����B
����ŃA�[�L�b���ł�悤�ɂȂ����̂́t�@�����X��=�^�� ��
�łĂ��������肩��B
���̌�AHammer�X���Ō���I�ɂ��̎�̘b�肪�����Ȃ����B
���ꂩ��Itanium�X�����o�R���āA������CPU�X���ɍ��͗���Ă�B
�A�[�L�e�N�`���X���̕���Intel������CPU�X�������㔭�B
���̃X����Intel������CPU�X���̌��X�u���h���X���B
���͂��Ă����Ă����ł���Ȃɏ����ĂȂ�����ĂĂȂ�w
�ߋ���x86�����n�̃X���͊F���s���Ă��āA�����X���̘b�����̃X�������Ă�
���������炢�Ɋm�������āAx86������X���݂����ȃX���^�C�ł��������Lj�u�ŏ������ˁB
�A�[�L�e�N�`�������X���͐̂���Ǝ��H���ōŐV��CPU�l�^�͂���Ȃɑ����Ȃ�������B
�Z���w�����̎���̃X���ƈႤ�������������Ǔ��e�͔Z�������B
������CPU�X���Ɠ������͋C�ɂȂ����͍̂ŋ߂ŁA����͒c�q��MAC�I�^�̉e����
���邾�낤���ǁB
�������܂菑�������Ȃ����ǁA
����͂�����ƈႤ��B
��̂́A����ɃA�[�L�e�N�`���̘b��͂قƂ�ǂȂ��B
mac�ɏ������������炢�B���ꂩ�炿����Ƃ���AMD�n�̃X���ŃA�[�L�b���������B
Intel�n�̃X���͖w�ǂȂ��ď�ɂ���Ă����B
����ŃA�[�L�b���ł�悤�ɂȂ����̂́t�@�����X��=�^�� ��
�łĂ��������肩��B
���̌�AHammer�X���Ō���I�ɂ��̎�̘b�肪�����Ȃ����B
���ꂩ��Itanium�X�����o�R���āA������CPU�X���ɍ��͗���Ă�B
�A�[�L�e�N�`���X���̕���Intel������CPU�X�������㔭�B
���̃X����Intel������CPU�X���̌��X�u���h���X���B
���͂��Ă����Ă����ł���Ȃɏ����ĂȂ�����ĂĂȂ�w
�ߋ���x86�����n�̃X���͊F���s���Ă��āA�����X���̘b�����̃X�������Ă�
���������炢�Ɋm�������āAx86������X���݂����ȃX���^�C�ł��������Lj�u�ŏ������ˁB
�A�[�L�e�N�`�������X���͐̂���Ǝ��H���ōŐV��CPU�l�^�͂���Ȃɑ����Ȃ�������B
�Z���w�����̎���̃X���ƈႤ�������������Ǔ��e�͔Z�������B
������CPU�X���Ɠ������͋C�ɂȂ����͍̂ŋ߂ŁA����͒c�q��MAC�I�^�̉e����
���邾�낤���ǁB
�������G�ցc
661 �FMAC�I�^��659 �����F2008/06/19(��) 00:16:08 ID:qPRp6hfv
>>659
�@�@------------------
�@�@����͒c�q��MAC�I�^�̉e�������邾�낤���ǁB
�@�@------------------
���Ȃ��Ƃ����평��Hammer�X���b�h���炢�邷���ǁB�B�B
http://pc.2ch.net/test/read.cgi/jisaku/1002101624/366
�@�@--------------------
�@�@366 ���O�FMAC�I�^��364 ���� ���e���F02/01/27 17:56 ID:qE6HC4i3
�@�@�@�@���߃Z�b�g�̈ڍs��OS��A�v���̑Ή��ɐ������Ԃ�������
�@�@�@�@������A�z���g�ɂ��C�Ȃ�V���R���Ɏ�������O�ɃR���Z�v�g
�@�@�@�@�\����Ǝv�����B
�@�@--------------------
�@�@------------------
�@�@����͒c�q��MAC�I�^�̉e�������邾�낤���ǁB
�@�@------------------
���Ȃ��Ƃ����평��Hammer�X���b�h���炢�邷���ǁB�B�B
http://pc.2ch.net/test/read.cgi/jisaku/1002101624/366
�@�@--------------------
�@�@366 ���O�FMAC�I�^��364 ���� ���e���F02/01/27 17:56 ID:qE6HC4i3
�@�@�@�@���߃Z�b�g�̈ڍs��OS��A�v���̑Ή��ɐ������Ԃ�������
�@�@�@�@������A�z���g�ɂ��C�Ȃ�V���R���Ɏ�������O�ɃR���Z�v�g
�@�@�@�@�\����Ǝv�����B
�@�@--------------------
�L�����N�^�[���L�������邱�Ƃɂ���ĒN��������ɂȂ肷�܂���B
�������炻�̓��@�ɂȂ�̂�����B
�������炻�̓��@�ɂȂ�̂�����B
>>657
�����������Ƃ�ˁB�����A���[�N�d���ւ̑Ή��������Ƃ��Ă���A
�ႦTDP��100W�O��𐄈ڂ��Ă����Ƃ��Ă��A
�N���b�N�͏����ɏオ���Ă�����������ˁB
��ŁAHTT�̉��ǂ�����c�ƁA�Ȃ��Ȃ��y�����킢���ς�ꂽ�����B
>>659
�������B�����̗��j�Ȃ�Č���Ă��E�U�C�����ł��B
�`���V�̗��ɏ����Ă��������B
�����������Ƃ�ˁB�����A���[�N�d���ւ̑Ή��������Ƃ��Ă���A
�ႦTDP��100W�O��𐄈ڂ��Ă����Ƃ��Ă��A
�N���b�N�͏����ɏオ���Ă�����������ˁB
��ŁAHTT�̉��ǂ�����c�ƁA�Ȃ��Ȃ��y�����킢���ς�ꂽ�����B
>>659
�������B�����̗��j�Ȃ�Č���Ă��E�U�C�����ł��B
�`���V�̗��ɏ����Ă��������B
�����Z�p�ɍ���Ȃ����_�ł��̃A�[�L�e�N�`���͎��s���Ǝv�����ǂȂ��B
�������ɁA�ǂ����u�v���炵�č��{�I�ɊԈ���Ă�v���ă��x���̂͏o���Ă��Ȃ��ł���
�����Z�p��A�o�Ă��������A���������̂����݂ł̔��f�ɂǂ����Ă��Ȃ�B
�����Z�p��A�o�Ă��������A���������̂����݂ł̔��f�ɂǂ����Ă��Ȃ�B
>>665
�����������Z�p�s���͕s���̎��Ԃ������Ƃ�����Ȃ�
�v��������\���ł���͈͓�
�u�g���r���^�J���Y�ނ悤�Ȋ����ȃv���Z�X�Z�p����Ȃ��������玸�s�����v
�Ƃ���Ȋ����ɂȂ��Ă�
�����������Z�p�s���͕s���̎��Ԃ������Ƃ�����Ȃ�
�v��������\���ł���͈͓�
�u�g���r���^�J���Y�ނ悤�Ȋ����ȃv���Z�X�Z�p����Ȃ��������玸�s�����v
�Ƃ���Ȋ����ɂȂ��Ă�
�����A�s���̎��Ԃ���B�o�O�������ăX�e�b�s���O�ύX�̎��Ԃ�������
����������B
����������B
669 �F�R�E�L�́M�E,,�j�����������������F2008/06/19(��) 13:19:58 ID:3pElVF0X
>>663
�R�[�h�M�A�X�ł����H
�R�[�h�M�A�X�ł����H
>>665
��̕���2���f�����炢�̓N���b�N���������Đ����Z�p�ɍ����ĂȂ��C�����邯��
�A�[�L�e�N�`�����͎̂��s����Ȃ��ł���
��̕���2���f�����炢�̓N���b�N���������Đ����Z�p�ɍ����ĂȂ��C�����邯��
�A�[�L�e�N�`�����͎̂��s����Ȃ��ł���
671 �F�R�E�L�́M�E,,�j�����������������F2008/06/19(��) 19:44:01 ID:3pElVF0X
PenM��Banias�̍�����v���Ă���B
�������f�X�N�g�b�v�����ɃN���b�N�����W�����グ��ŋ�����ˁ[�̂��āB
Tejas�̌v�悪�|�V����܂ł�������Ȃ�����Intel�̓A�z�ł��B
�������f�X�N�g�b�v�����ɃN���b�N�����W�����グ��ŋ�����ˁ[�̂��āB
Tejas�̌v�悪�|�V����܂ł�������Ȃ�����Intel�̓A�z�ł��B
�m�[�g�����Ƀ_�C�T�C�Y�팸�̂��߂�Micro-Fusion�̗p
�����ꂪ�x���`�ɗL�����Ɣ��胈�i�ł���ɉ�������į�߂������
�����݃x���`CPU�l�C����
�i���F�����j
�����ꂪ�x���`�ɗL�����Ɣ��胈�i�ł���ɉ�������į�߂������
�����݃x���`CPU�l�C����
�i���F�����j
674 �F�R�E�L�́M�E,,�j�����������������F2008/06/19(��) 20:01:04 ID:3pElVF0X
�[���A�}���`�X���b�f�B���O�Ńg�[�^���X���[�v�b�g�������グ��悤�ƊE��
�����t�������_��NetBurst�͏I����Ă��B
���Ƃ͓d�͌����d���ŃR���p�N�g�ȃR�A����ׂ�CPU���䓪����B
PenM����{�Ƃ����A�[�L�e�N�`���̎��オ���邱�Ƃ��\���ł����킯�ŁB
���Ȃ��Ƃ�NetBurst�͂��蓾��Ǝv�����B
�����m�[�g�ł�Pen4-M�Ȃb�ɂȂ�Ȃ��������B
>>673
PenM�̃�OPs-Fusion���̂�AMD��K7�̎��_�œ����̋@�\������Ă����B
�܂�AMD�͂����ƃx���`��pCPU����Ă����́H
�����t�������_��NetBurst�͏I����Ă��B
���Ƃ͓d�͌����d���ŃR���p�N�g�ȃR�A����ׂ�CPU���䓪����B
PenM����{�Ƃ����A�[�L�e�N�`���̎��オ���邱�Ƃ��\���ł����킯�ŁB
���Ȃ��Ƃ�NetBurst�͂��蓾��Ǝv�����B
�����m�[�g�ł�Pen4-M�Ȃb�ɂȂ�Ȃ��������B
>>673
PenM�̃�OPs-Fusion���̂�AMD��K7�̎��_�œ����̋@�\������Ă����B
�܂�AMD�͂����ƃx���`��pCPU����Ă����́H
K7�̓x���`��P6�ɂ��Ȃ�ǂ��������Ă��炵������܂��ɂ�������
�����ʂ�
CISC�͕��G�Ȗ��߂������̂Ń��\�[�X�H���Ăł�RISC�P��������
�Ƃ����������Ƃ炵����
�Ȃ�Ό��X�P���Ȗ��߂Ȃ番�����邾�����Ȃ̂ł́H�ƂȂ�
�t�Ɍ����ƕ��G�Ȗ��߂͂�͂����RISC�������i�����j
Fusion�͂��������ɑ��ʃf�[�^�p�Ƀ����R���ς̂�K8�iK10��L3�́E�E�E�j
RISC�p����i�߂ăL���b�V�����₵�Ă������̂�Core
Core1�2�ő���superpi�͕������P�������Ȃ̂��ǂ���
������Micro-Fusion�̎g���Ȃ�64bit��K8�ɑ�s�����T�N���G�f�B�^�̒P���u��������
32bit�ł͋t�ɑ叟�����̂��ǂ����̎����m�F�͂ł��Ȃ���
�����ʂ�
CISC�͕��G�Ȗ��߂������̂Ń��\�[�X�H���Ăł�RISC�P��������
�Ƃ����������Ƃ炵����
�Ȃ�Ό��X�P���Ȗ��߂Ȃ番�����邾�����Ȃ̂ł́H�ƂȂ�
�t�Ɍ����ƕ��G�Ȗ��߂͂�͂����RISC�������i�����j
Fusion�͂��������ɑ��ʃf�[�^�p�Ƀ����R���ς̂�K8�iK10��L3�́E�E�E�j
RISC�p����i�߂ăL���b�V�����₵�Ă������̂�Core
Core1�2�ő���superpi�͕������P�������Ȃ̂��ǂ���
������Micro-Fusion�̎g���Ȃ�64bit��K8�ɑ�s�����T�N���G�f�B�^�̒P���u��������
32bit�ł͋t�ɑ叟�����̂��ǂ����̎����m�F�͂ł��Ȃ���
676 �F�R�E�L�́M�E,,�j�����������������F2008/06/19(��) 21:08:21 ID:3pElVF0X
�T�N����64�r�b�g�ł̓|�C���^�T�C�Y�̑������A�e�L�X�g�o�b�t�@�̃f�[�^�T�C�Y����������݂����B
64bit�̃p�t�H�[�}���X�A�b�v�ƃ_�E���̕���_�����x70���O�ゾ�����Ɖ����𗧂ĂĂ݂�B
�o�b�t�@���傫���Ȃ��L2�L���b�V���̌����������Ȃ邵�A�����R�����ڂ��Ă镪X2�̂ق���
�L���ɂȂ�Ƃ������P���ȗ��R����
�܂��A�T�N���Ȃ̂��߂�CPU�I�ԓz��������
�G�ۃG�f�B�^�ɋ������ƌ����܂����ǂ�
�����u��������1���ǂ��납10�b���������B
64bit�̃p�t�H�[�}���X�A�b�v�ƃ_�E���̕���_�����x70���O�ゾ�����Ɖ����𗧂ĂĂ݂�B
�o�b�t�@���傫���Ȃ��L2�L���b�V���̌����������Ȃ邵�A�����R�����ڂ��Ă镪X2�̂ق���
�L���ɂȂ�Ƃ������P���ȗ��R����
�܂��A�T�N���Ȃ̂��߂�CPU�I�ԓz��������
�G�ۃG�f�B�^�ɋ������ƌ����܂����ǂ�
�����u��������1���ǂ��납10�b���������B
�G�ۂ̒u�������͕��x���Ďg����Ǝv���Ă���A
������T�{���x���G�f�B�^������̂��B
������T�{���x���G�f�B�^������̂��B
�l�g�o�ƌ�����atom��P4�Ɏ��Ă镔��������
atom�̐v�v�z���Ă̂��d�͌�����Nj����邱�Ƃ�
�g�����W�X�^����}���鎖���d������Ă�킯��
���̂ւ�̓l�g�o�Ƃ͂܂������Ⴄ�A�v���[�`�Ȃ͂�������
�o���オ����atom���Ă�ƃV���v���ȉ�H������]������悤��
����Ă�A�o���_�͂܂�ňႤ�̂ɏo���オ���(�����I��)
���Ă���̂ɂȂ��Ă�AIPC���̂�Core�n���i�i�ɗ����Ă�
��IPC��`�ł��������ˁA�v�����d�͓��ɗ}���邽�߂�
�N���b�N����������Ă邩��N���b�N�����`�ł��Ȃ���
��������d�͓I�ɍ������ȉ�H�v������s����
�o���オ��i�̓l�g�o�Ɏ������̂������Ƃ����I�`
���������������Ă��l�b�g�o�[�X�g�A�[�L�e�N�`���͎��s��������
�l�b�g�o�[�X�g�A�[�L�e�N�`���̃A�[�L�e�N�`�������͎��s�ł�
����������Ȃ����Ǝv���A�v�͉�H�����ɂ����ĂȂɂ�D�悵��
�Ȃɂ��]���ɂ��邩�̃g���[�h�I�t�̃T�W�����Ȃ�ˁB
atom�̐v�v�z���Ă̂��d�͌�����Nj����邱�Ƃ�
�g�����W�X�^����}���鎖���d������Ă�킯��
���̂ւ�̓l�g�o�Ƃ͂܂������Ⴄ�A�v���[�`�Ȃ͂�������
�o���オ����atom���Ă�ƃV���v���ȉ�H������]������悤��
����Ă�A�o���_�͂܂�ňႤ�̂ɏo���オ���(�����I��)
���Ă���̂ɂȂ��Ă�AIPC���̂�Core�n���i�i�ɗ����Ă�
��IPC��`�ł��������ˁA�v�����d�͓��ɗ}���邽�߂�
�N���b�N����������Ă邩��N���b�N�����`�ł��Ȃ���
��������d�͓I�ɍ������ȉ�H�v������s����
�o���オ��i�̓l�g�o�Ɏ������̂������Ƃ����I�`
���������������Ă��l�b�g�o�[�X�g�A�[�L�e�N�`���͎��s��������
�l�b�g�o�[�X�g�A�[�L�e�N�`���̃A�[�L�e�N�`�������͎��s�ł�
����������Ȃ����Ǝv���A�v�͉�H�����ɂ����ĂȂɂ�D�悵��
�Ȃɂ��]���ɂ��邩�̃g���[�h�I�t�̃T�W�����Ȃ�ˁB
���s�Ƃ������������x���̘b����Ȃ����Ƃ����������킩���ė~����
�A�[�L�I�ɂ͎��s�ł��Ȃ�ł��Ȃ�����
���͂u�f�`��ATI��NV�œ�������_�ɂ��邾��
�P�R�A�ō����\�Ȃ̂������̂�
���U�����łQ�R�A�������̂��B
���̂܂܂m�u���˂��i�߂��intel���l�g�o���o���̂�5�N�������������̂���
���͂u�f�`��ATI��NV�œ�������_�ɂ��邾��
�P�R�A�ō����\�Ȃ̂������̂�
���U�����łQ�R�A�������̂��B
���̂܂܂m�u���˂��i�߂��intel���l�g�o���o���̂�5�N�������������̂���
GPU�̏ꍇ�́A���Ƃ���R�A�͑����ŁA�`�b�v����i�ȏ�H�j�ɂȂ��Ă邾�������ǂ�
�����I�ɂ͂ǂ�����u�R�قǂ̃R�A�ŕ����v�Ȃ킯�Łc�c�����O�o�X��������N���X�o�������肷�邯��
�����I�ɂ͂ǂ�����u�R�قǂ̃R�A�ŕ����v�Ȃ킯�Łc�c�����O�o�X��������N���X�o�������肷�邯��
682 �F�R�E�L�́M�E,,�j�����������������F2008/06/20(��) 07:39:48 ID:7yLgpzx8
>>678
�S�R�Ⴄ����B
PenM/Core�}�C�N���A�[�L������d�̓����W�ɗ��p����ɂ̓N���b�N��啝�ɗ��Ƃ������Ȃ������B
Atom��OoO�����������N���b�N������قlj����Ȃ��Ă��d�͏���i�i�ɉ��������B
�[���A45nm�v���Z�X��CPU�̒��ł͂ނ����N���b�N�ȕ����B
Pen4��128�G���g���̃��I�[�_�o�b�t�@������A����ł�IPC�������グ��w�͂��Ă����B
���������������������������ǂ�
L1�f�[�^�L���b�V���������������ˁB������8KB�BHT�L�����ɂ͂���ɂ���������B
�g�[�^���Ō��ăp�t�H�[�}���X�v�͎��s�������ƌ��킴��Ȃ��B
�S�R�Ⴄ����B
PenM/Core�}�C�N���A�[�L������d�̓����W�ɗ��p����ɂ̓N���b�N��啝�ɗ��Ƃ������Ȃ������B
Atom��OoO�����������N���b�N������قlj����Ȃ��Ă��d�͏���i�i�ɉ��������B
�[���A45nm�v���Z�X��CPU�̒��ł͂ނ����N���b�N�ȕ����B
Pen4��128�G���g���̃��I�[�_�o�b�t�@������A����ł�IPC�������グ��w�͂��Ă����B
���������������������������ǂ�
L1�f�[�^�L���b�V���������������ˁB������8KB�BHT�L�����ɂ͂���ɂ���������B
�g�[�^���Ō��ăp�t�H�[�}���X�v�͎��s�������ƌ��킴��Ȃ��B
>>680
NV�̃_�C�T�C�Y�͊����Ƃ������B���̔��M�͂���ǁB
NV�̃_�C�T�C�Y�͊����Ƃ������B���̔��M�͂���ǁB
>>680
�A�[�L�ɂ̓}�N����}�C�N���������
�A�[�L�ɂ̓}�N����}�C�N���������
>>684
�v���Z�X���[�����M�ʂ͉������邩��
������������p�f�Ȃ�Ȃ��̂���
�`�s�h�͐V�R�A���J�����R�A�����₵�đΉ���������Ƃ����������B
>>685
�܂�������������ˁ[��ƌ��������킯���ȁH
�ł�����
�ł��Ă����i�`�`��
�v���Z�X���[�����M�ʂ͉������邩��
������������p�f�Ȃ�Ȃ��̂���
�`�s�h�͐V�R�A���J�����R�A�����₵�đΉ���������Ƃ����������B
>>685
�܂�������������ˁ[��ƌ��������킯���ȁH
�ł�����
�ł��Ă����i�`�`��
2900��������������p�f�������킯����
��̑I�����ԈႦ�āu10�N������I�v�ƌ����邱�Ƃ����������Ȃ킯�ł���
>>684
����Ń{�[�h��8���~�Ƃ��ɂ����Ȃ�Ȃ�����A������ˁB
���v���̍����T�[�o�[����CPU����
Op�Ƃ���8xx�V���[�Y��10���I�[�o�[�Ŕ����̂Ɣ�ׂĂ��܂���
�悭���̃T�C�Y�ō������ƁB
����Ń{�[�h��8���~�Ƃ��ɂ����Ȃ�Ȃ�����A������ˁB
���v���̍����T�[�o�[����CPU����
Op�Ƃ���8xx�V���[�Y��10���I�[�o�[�Ŕ����̂Ɣ�ׂĂ��܂���
�悭���̃T�C�Y�ō������ƁB
Quadro��Tesla�ʼn�������Ȃ��́H
���Ԃ�n�C�G���hGPU�ł��Ԏ��ł͔����ĂȂ��Ǝv���B
Xeon��Opteron���E�n�E�n�Ȃ����B
Xeon��Opteron���E�n�E�n�Ȃ����B
Nvidia�̓J�[�h�������i��75%��������Ă�̂�GT200�ł����]�T�ł��B
�J�[�h�x���_�͐Ԏ��ɂȂ����肵�Ă邯�ǁB
�J�[�h�x���_�͐Ԏ��ɂȂ����肵�Ă邯�ǁB
>>569�̃l�^�ADigitimes�ɂ��ƔN���܂łɃ����[�X����Ƃ̂��Ƃ��B
http://www.digitimes.com/mobos/a20080619PD218.html
�@�@---------------------
�@�@AMD to launch low-cost PC processor by year-end
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Friday 20 June 2008]
�@�@�@AMD has recently notified its partners it is developing a processor to enter the low-cost
�@�@PC market alongside Intel's Atom and Via Technologies' Nano CPUs. The new CPUs will be
�@�@officially launched by the end of this year, while related netbook products will begin shipping
�@�@in the first half of 2009, according to sources at PC makers.
�@�@�@AMD's low-cost PC processor will be based on the company's previous-generation K8
�@�@architecture and will support 64-bit instructions. The CPUs will be a single-core model with a
�@�@frequency of 1.2GHz and will be manufactured on the company's 65nm process.
�@�@�@AMD expects its low-cost PC processor to be priced slightly lower than Intel's Atom and
�@�@has started negotiating with Micro-Star International (MSI), Hewlett-Packard (HP), Acer and
�@�@vendors in China to win orders.
�@�@�@AMD declined the opportunity to respond to this report saying it cannot comment on
�@�@unannounced products.
�@�@---------------------
http://www.digitimes.com/mobos/a20080619PD218.html
�@�@---------------------
�@�@AMD to launch low-cost PC processor by year-end
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Friday 20 June 2008]
�@�@�@AMD has recently notified its partners it is developing a processor to enter the low-cost
�@�@PC market alongside Intel's Atom and Via Technologies' Nano CPUs. The new CPUs will be
�@�@officially launched by the end of this year, while related netbook products will begin shipping
�@�@in the first half of 2009, according to sources at PC makers.
�@�@�@AMD's low-cost PC processor will be based on the company's previous-generation K8
�@�@architecture and will support 64-bit instructions. The CPUs will be a single-core model with a
�@�@frequency of 1.2GHz and will be manufactured on the company's 65nm process.
�@�@�@AMD expects its low-cost PC processor to be priced slightly lower than Intel's Atom and
�@�@has started negotiating with Micro-Star International (MSI), Hewlett-Packard (HP), Acer and
�@�@vendors in China to win orders.
�@�@�@AMD declined the opportunity to respond to this report saying it cannot comment on
�@�@unannounced products.
�@�@---------------------
�uBobcat�܂ł̂Ȃ��v���Ďv���Ă����ǁA���߂ė\�z����������!!
���q�ɏ���đ����\�z
GPU��690G����̗��p�{����Đ��x��
Griffin�̏ȏ���d�͋@�\�͎g���Ȃ�
Bobcat��2009�N
���q�ɏ���đ����\�z
GPU��690G����̗��p�{����Đ��x��
Griffin�̏ȏ���d�͋@�\�͎g���Ȃ�
Bobcat��2009�N
��
�~2009�N
��2010�N45nm
�~2009�N
��2010�N45nm
�������Digitimes�L��(>>588-593)�A�ǂ��܂Ƃ܂��Ă���Ƃ��v���Ă�����A������O�ꂪ����
�����\�����o�������B
http://www.gdm.or.jp/voices.html (6/20��)
�@�@--------------------
�@�@TDP 140W��Phenom 9950(2.6GHz)��7��2������̔������Ƃ̂��ƁB���i�͖�\30,000�B�ǂ�
�@�@���x��M/B�œ��삷��̂��s��������X���������B
�@�@--------------------
���Ȃ݂�Digitimes���̋L�q�킱����B(>>589)
�@�@====================
�@�@�@AMD also plans for the Phenom X4 9850 (2.5GHz) and 9950 (2.6GHz) to enter DVT in the t
�@�@hird quarter, and ship in the fourth quarter,
�@�@====================
Digitimes���Ĕ���L��(Apple��OEM�l�^�Ƃ�)�����������ǁA���ꂾ�����߂̃l�^�łƂ�B�B�B
�D�ӓI�ɍl�����140W��q�h������̂ŁA����ǂ����X�e�b�s���O����������Ă���̂����B
�����\�����o�������B
http://www.gdm.or.jp/voices.html (6/20��)
�@�@--------------------
�@�@TDP 140W��Phenom 9950(2.6GHz)��7��2������̔������Ƃ̂��ƁB���i�͖�\30,000�B�ǂ�
�@�@���x��M/B�œ��삷��̂��s��������X���������B
�@�@--------------------
���Ȃ݂�Digitimes���̋L�q�킱����B(>>589)
�@�@====================
�@�@�@AMD also plans for the Phenom X4 9850 (2.5GHz) and 9950 (2.6GHz) to enter DVT in the t
�@�@hird quarter, and ship in the fourth quarter,
�@�@====================
Digitimes���Ĕ���L��(Apple��OEM�l�^�Ƃ�)�����������ǁA���ꂾ�����߂̃l�^�łƂ�B�B�B
�D�ӓI�ɍl�����140W��q�h������̂ŁA����ǂ����X�e�b�s���O����������Ă���̂����B
RV770��AMD�ɂƂ���Nvidia�͓G�ł͂Ȃ��Ȃ����ȁB
����Nvidia�̃^�[����2�x�Ƃ��Ȃ��B
���Ƃ�GPU������Fusion��Intel�������ɂԂ��̂߂��������B
55nm��250mm2�ATDP110W�A1TFlops(�{���x200G)�ɂł����Ȃ�A
45nm�ȍ~��Fusion�Ȃ�RV770�̔������x�̃R�A��CPU�ɑg�ݍ��߂�ȁB
�����Ȃ�����ANehalem����r�[��RV770�̔�������CPU�Ő��l���Z�Ό����ĕ�����C���S�����Ȃ��B
���Ȃ݂�AMD�̖{����Fusion������A��C��C�X�^���u�[����Nehalem�Ƀt���{�b�R���Ƃ��Ă��A
�S���C�ɂ���K�v���Ȃ��Ǝv���B
����Nvidia�̃^�[����2�x�Ƃ��Ȃ��B
���Ƃ�GPU������Fusion��Intel�������ɂԂ��̂߂��������B
55nm��250mm2�ATDP110W�A1TFlops(�{���x200G)�ɂł����Ȃ�A
45nm�ȍ~��Fusion�Ȃ�RV770�̔������x�̃R�A��CPU�ɑg�ݍ��߂�ȁB
�����Ȃ�����ANehalem����r�[��RV770�̔�������CPU�Ő��l���Z�Ό����ĕ�����C���S�����Ȃ��B
���Ȃ݂�AMD�̖{����Fusion������A��C��C�X�^���u�[����Nehalem�Ƀt���{�b�R���Ƃ��Ă��A
�S���C�ɂ���K�v���Ȃ��Ǝv���B
�Ƃ����ϑz�ł����B
GPGPU���{�i�n������܂ł�
intel����Ƀx���`�����͂����ƌ������܂܂���
intel����Ƀx���`�����͂����ƌ������܂܂���
700 �F�A���~�F2008/06/21(�y) 12:51:01 ID:lZeQ5mRB
CUDA�݂����ɕ��y������w�͂��Ȃ���g���Ă��炦���(�E�L��`�E)
�������������ŏI���
��Fusion
�����������`�b�vPC���Ńn�C�G���hGeode�Ƃ���炩���ė~����
�����̑O�Ƀm�[�X�ւ�LFB�������������Ǝ������Ă���
�����b�����ɋt�]�K�E�u���[�͖�����
�����������`�b�vPC���Ńn�C�G���hGeode�Ƃ���炩���ė~����
�����̑O�Ƀm�[�X�ւ�LFB�������������Ǝ������Ă���
�����b�����ɋt�]�K�E�u���[�͖�����
���܂ł�Nvidia���ז��ŕ��y���Ȃ��������A
HD4850�̑�q�b�g�Ԃ肩��Ή��A�v����Q�[�����J������Ƃ���������Ă��邾��B
1Tflops(�{���x��200G)�Ƃ����n�[�h�������āA���ꂪ�n����������A���㐔�N�ŏ͈�ς���B
HD4850�̑�q�b�g�Ԃ肩��Ή��A�v����Q�[�����J������Ƃ���������Ă��邾��B
1Tflops(�{���x��200G)�Ƃ����n�[�h�������āA���ꂪ�n����������A���㐔�N�ŏ͈�ς���B
704 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 13:31:17 ID:JRtNSvsA
Brook+�͂���ϖ�����
>>703
�{���x200Gflops���BGrape-DR�I���̂��m�点�����B
�{���x200Gflops���BGrape-DR�I���̂��m�点�����B
706 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 13:40:38 ID:JRtNSvsA
���ƁADX10.x��Vista�ł����g���Ȃ��̂�Vista�ɑΉ����ĂȂ��Ƃ��{���]�|���Ǝv�����ȁB
CUDA��2.0����32�r�b�g�E64�r�b�g�Ƃ���Vista�Ή��ς݁B
�܂��A���ʂ�GPGPU�]�X���Q�[�����\���낤��
nVIDIA���l�����������͂����ATi�O�b�W���u�Ȃ��B�B
CUDA��2.0����32�r�b�g�E64�r�b�g�Ƃ���Vista�Ή��ς݁B
�܂��A���ʂ�GPGPU�]�X���Q�[�����\���낤��
nVIDIA���l�����������͂����ATi�O�b�W���u�Ȃ��B�B
HD4850�������I��9800GTX+�ɏ����Ă��鎞�_�ŁA
Nvidia��GPU���w������Ӗ����S���Ȃ��B
�M���I�M�҈ȊO�w�����Ȃ�����K�R�I��CUDA���I���B
CAL��Brook+������Vista�Ή��Ȃlj��P���邾�낤���A
���XRadeon��Geforce��艉�Z���\�͈��|�I�ɍ�����������A
���X�ɊJ����Cuda����Cal�ɐ�ւ��čs����Ȃ����ȁB
200Gflops��2���~���A���ʂ�PC�Ɏ�������B
�R�����\�t�g�J���҂ɂƂ��Ăǂ�ȈӖ��������m��Ȃ����A
�f�l�ڂɌ��Ă�,���Ȃ薣�͓I�ɂ݂���B
��̓\�t�g�������ǁA����}���ɐ����Ă�������B
Nvidia��GPU���w������Ӗ����S���Ȃ��B
�M���I�M�҈ȊO�w�����Ȃ�����K�R�I��CUDA���I���B
CAL��Brook+������Vista�Ή��Ȃlj��P���邾�낤���A
���XRadeon��Geforce��艉�Z���\�͈��|�I�ɍ�����������A
���X�ɊJ����Cuda����Cal�ɐ�ւ��čs����Ȃ����ȁB
200Gflops��2���~���A���ʂ�PC�Ɏ�������B
�R�����\�t�g�J���҂ɂƂ��Ăǂ�ȈӖ��������m��Ȃ����A
�f�l�ڂɌ��Ă�,���Ȃ薣�͓I�ɂ݂���B
��̓\�t�g�������ǁA����}���ɐ����Ă�������B
�������ɐM�҂�����
709 �FMAC�I�^��707 �����F2008/06/21(�y) 14:25:31 ID:QtBsYZWJ
>>707
����Ȃ����ƂȂ�A������C�Ɍ��Ȃ���Ηǂ��Ǝv�������ǁB�B�B
�@�@--------------------
�@�@�R�����\�t�g�J���҂ɂƂ��Ăǂ�ȈӖ��������m��Ȃ����A
�@�@�f�l�ڂɌ��Ă�,���Ȃ薣�͓I�ɂ݂���B
�@�@--------------------
http://www.geocities.jp/andosprocinfo/wadai08/20080621.htm
�@�@=====================
�@�@�{���x���������_���Z���\�́CnVIDIA��Tesla 10P�Ɠ����x�CAMD��FireStream 9250�̔������x
�@�@�ł����C������GPU��150W���x�̏���d�͂ł���̂ɑ��āCCSX600��12W�Ɛ��\/�d�͂�
�@�@���|�I�ɗL���ł��B�܂��C������v�Z�������Ƃ����Ă��C�G���[�`�F�b�N������GPU�ŋ��Z�V�~��
�@�@���[�V����������Ĕ���Ȃ����������������CClearspeed�̐��i�́CDRAM�Ȃǂ�ECC���t��
�@�@�Ă���̂�����ł��B����C���܂Ƀr�b�g�������Ă����ł��Ȃ�GPU���́C���̕ӂ��������ĂȂ��āC
�@�@�{���x���������_���Z�����t�����HPC�ɂ������Ǝv���Ă���悤�ł����C�����Â��͂Ȃ���
�@�@�v���܂��B
�@�@=====================
����Ȃ����ƂȂ�A������C�Ɍ��Ȃ���Ηǂ��Ǝv�������ǁB�B�B
�@�@--------------------
�@�@�R�����\�t�g�J���҂ɂƂ��Ăǂ�ȈӖ��������m��Ȃ����A
�@�@�f�l�ڂɌ��Ă�,���Ȃ薣�͓I�ɂ݂���B
�@�@--------------------
http://www.geocities.jp/andosprocinfo/wadai08/20080621.htm
�@�@=====================
�@�@�{���x���������_���Z���\�́CnVIDIA��Tesla 10P�Ɠ����x�CAMD��FireStream 9250�̔������x
�@�@�ł����C������GPU��150W���x�̏���d�͂ł���̂ɑ��āCCSX600��12W�Ɛ��\/�d�͂�
�@�@���|�I�ɗL���ł��B�܂��C������v�Z�������Ƃ����Ă��C�G���[�`�F�b�N������GPU�ŋ��Z�V�~��
�@�@���[�V����������Ĕ���Ȃ����������������CClearspeed�̐��i�́CDRAM�Ȃǂ�ECC���t��
�@�@�Ă���̂�����ł��B����C���܂Ƀr�b�g�������Ă����ł��Ȃ�GPU���́C���̕ӂ��������ĂȂ��āC
�@�@�{���x���������_���Z�����t�����HPC�ɂ������Ǝv���Ă���悤�ł����C�����Â��͂Ȃ���
�@�@�v���܂��B
�@�@=====================
MAC�I�^�����߂Ċi�D�ǂ����������Ă̓��ł�����
�X���^�C�ʂ��AMD�̎�����CPU�ɂ��Č���Ă��邾�������������������Ƃ��낪���邩�H
���Ȃ茻���I�Ȃ��肾���B
HD4850�Ƃ͌���Ȃ����A45nm��kuma��HD4650�N���X�̃R�A�̑g�ݍ��킹���Ȃ�
200mm2�ȉ���TDP��100W�肻�������B
����CPU��CAL�ō�����v���O�����𑖂点����
CUDA�ł�����9800GTX�œ������̂Ɠ����ȏ�ɑ�������B
���܂���HD4850�ƘA�g�����ē��������ꍇ���l�����intel���ܖڂɂȂ�B
�����������Ȃ�A45nm kuma��45nm RV770��MCM��TDP120W�ʂŊJ�����āA
CAl�ō������p�G���R�[�h�\�t�g�������ł�����A
�l�n�����w���\��̈��~�����������D����Ǝv���B
���������\����Fusion�͎����Ă��āA�����HD4850�̑�q�b�g���l��������A
���̒��x�̖ϑz�͂قƂ�nj������x������B
���Ȃ茻���I�Ȃ��肾���B
HD4850�Ƃ͌���Ȃ����A45nm��kuma��HD4650�N���X�̃R�A�̑g�ݍ��킹���Ȃ�
200mm2�ȉ���TDP��100W�肻�������B
����CPU��CAL�ō�����v���O�����𑖂点����
CUDA�ł�����9800GTX�œ������̂Ɠ����ȏ�ɑ�������B
���܂���HD4850�ƘA�g�����ē��������ꍇ���l�����intel���ܖڂɂȂ�B
�����������Ȃ�A45nm kuma��45nm RV770��MCM��TDP120W�ʂŊJ�����āA
CAl�ō������p�G���R�[�h�\�t�g�������ł�����A
�l�n�����w���\��̈��~�����������D����Ǝv���B
���������\����Fusion�͎����Ă��āA�����HD4850�̑�q�b�g���l��������A
���̒��x�̖ϑz�͂قƂ�nj������x������B
�ǂ��ł��������Ƃ����ǁA������u��v����ˁH
>>707
���А�CPU�R���p�C�������܂��ɒł��Ȃ���Ƃ̃\�t�g�����ɂ悭�����܂Ŋ��҂ł����
GPGPU���ʂɊւ��Ă�Larrabee�̂ق����܂������I������
���А�CPU�R���p�C�������܂��ɒł��Ȃ���Ƃ̃\�t�g�����ɂ悭�����܂Ŋ��҂ł����
GPGPU���ʂɊւ��Ă�Larrabee�̂ق����܂������I������
CPU��MCM�œ�������Ȃ�A�������ш悪1/3���x�ɂȂ����A
HD4850�ǂ��납4650�ł��I�[�o�[�X�y�b�N�ɂȂ肻�������B
����ɁA�G���h���[�U�����̃A�v���̃f�����o�Ă��Ȃ��ƁA�������͑S�R�Ȃ����ǁB
CUDA�Ђ������āAAMD���J�������܂���NVIDIA�ł����N�悤�₭�A�v����
�o�n�߂Ă����Ȃ��Ċ����Ȃ̂ɁB
HD4850�ǂ��납4650�ł��I�[�o�[�X�y�b�N�ɂȂ肻�������B
����ɁA�G���h���[�U�����̃A�v���̃f�����o�Ă��Ȃ��ƁA�������͑S�R�Ȃ����ǁB
CUDA�Ђ������āAAMD���J�������܂���NVIDIA�ł����N�悤�₭�A�v����
�o�n�߂Ă����Ȃ��Ċ����Ȃ̂ɁB
���Ȃ݂ɕ��iMAC�I�^��NG NAME / NG WORD�o�^���Ă��邪�A
HD4850�Ղ�ɋ������������ŁA�������ځ[����������ď������B
AMD �{ ATI�̖{�C���\�z�ȏ�ɂ������AHD4850��Fusion�̋P���関���������C�������B
�Ԃ����Ⴏ��C��C�X�^���u�[���Ƃ��͂ǂ��ł������B
4870X2�ɂ�AMD��CPU�����J���̃n�u�R�l�N�g�Z�p���g���Ă���
�}���`GPU�Ō��������Ȃ�㏸���Ă���炵�����A
R800�̓V���O���R�A��2000SP��2Tflops�Ƃ������킳������B
CAL�̕��y��RV770�̂������Ŏ��Ԃ̖�肾�낤���A�悤�₭��Intel�ւ̔����̖ڏ��������Ǝv���B
���Ȃ݂Ƀl�n����(�Ƃ��̎�����)����r�[�͂��܂苺�ЂɊ����Ă͂��Ȃ��B
��������C��C�X�^���u�[���ł͂��Ȃ�ꂵ���Ƃ͎v�����ǁA�Ȃ�Ƃ��ς���ł���B
�Ƌ֖@�Ƃ����邵�AIntel���{�C�ł͐ӂ߂�Ȃ����B
����ɁA�����炭����ł��낤Intel�̉B�������A�ǂ�Ȃ��̂ɂȂ�̂���z������̂����͊y���݂ł͂���B
���Ȃ݂ɂ��̍�Nvidia�ׂ͒�Ă��邩Matrox�݂����ɂǂ����ōׁX�Ƃ���Ă���Ǝv���B
HD4850�Ղ�ɋ������������ŁA�������ځ[����������ď������B
AMD �{ ATI�̖{�C���\�z�ȏ�ɂ������AHD4850��Fusion�̋P���関���������C�������B
�Ԃ����Ⴏ��C��C�X�^���u�[���Ƃ��͂ǂ��ł������B
4870X2�ɂ�AMD��CPU�����J���̃n�u�R�l�N�g�Z�p���g���Ă���
�}���`GPU�Ō��������Ȃ�㏸���Ă���炵�����A
R800�̓V���O���R�A��2000SP��2Tflops�Ƃ������킳������B
CAL�̕��y��RV770�̂������Ŏ��Ԃ̖�肾�낤���A�悤�₭��Intel�ւ̔����̖ڏ��������Ǝv���B
���Ȃ݂Ƀl�n����(�Ƃ��̎�����)����r�[�͂��܂苺�ЂɊ����Ă͂��Ȃ��B
��������C��C�X�^���u�[���ł͂��Ȃ�ꂵ���Ƃ͎v�����ǁA�Ȃ�Ƃ��ς���ł���B
�Ƌ֖@�Ƃ����邵�AIntel���{�C�ł͐ӂ߂�Ȃ����B
����ɁA�����炭����ł��낤Intel�̉B�������A�ǂ�Ȃ��̂ɂȂ�̂���z������̂����͊y���݂ł͂���B
���Ȃ݂ɂ��̍�Nvidia�ׂ͒�Ă��邩Matrox�݂����ɂǂ����ōׁX�Ƃ���Ă���Ǝv���B
716 �FMAC�I�^��711 �����F2008/06/21(�y) 14:56:29 ID:QtBsYZWJ
>>711
���̎�́w�ނ胏�[�h�x���Ȃ���A�ӌ����Ă��炦��Ǝv�����B
�@�@------------------
�@�@intel���ܖڂɂȂ�B
�@�@�B�B�B
�@�@���~�����������D����Ǝv���B
�@�@�B�B�B
�@�@�ϑz�͂قƂ�nj������x��
�@�@------------------
�Ō�̂햼�����x������(��)
���̎�́w�ނ胏�[�h�x���Ȃ���A�ӌ����Ă��炦��Ǝv�����B
�@�@------------------
�@�@intel���ܖڂɂȂ�B
�@�@�B�B�B
�@�@���~�����������D����Ǝv���B
�@�@�B�B�B
�@�@�ϑz�͂قƂ�nj������x��
�@�@------------------
�Ō�̂햼�����x������(��)
717 �FMAC�I�^��712 �����F2008/06/21(�y) 14:57:12 ID:QtBsYZWJ
>>712
http://dictionary.goo.ne.jp/search.php?MT=%A4%B7%A4%BF%A4%EA%A4%B2&kind=jn&mode=0&base=1&row=0
http://dictionary.goo.ne.jp/search.php?MT=%A4%B7%A4%BF%A4%EA%A4%B2&kind=jn&mode=0&base=1&row=0
���A�����肰���Č��t������̂�
����͈�����Ȃ�����
���肪�Ƃ�
�ł��u�C�v�͊ԈႢ����ˁH
����͈�����Ȃ�����
���肪�Ƃ�
�ł��u�C�v�͊ԈႢ����ˁH
�ʂɁA�����œ��{��̕��킴�킴���Ȃ��Ă��������B
�Ӗ����Ȃ�ƂȂ�������X���[�����
�Ӗ����Ȃ�ƂȂ�������X���[�����
������A��������
���܂���
���܂���
721 �FMAC�I�^��718 �����F2008/06/21(�y) 15:07:00 ID:QtBsYZWJ
>>718
�@�@----------------
�@�@�ł��u�C�v�͊ԈႢ����ˁH
�@�@----------------
�����݂������BIM�ŏo�Ȃ������̂����R�����������B�B�B
�@�@----------------
�@�@�ł��u�C�v�͊ԈႢ����ˁH
�@�@----------------
�����݂������BIM�ŏo�Ȃ������̂����R�����������B�B�B
1Tflops���ăs�[�N�l�̘b�������A���ےN�����R�[�h�g��Ō�����܂ł́A
GPU�Ƃ��Ă�ATI�̃^�[���ɓ������Ƃ��Ă��AGPGPU�Ƃ��Ă̏o���͂ǂ��Ȃ̂���
�܂��^�╄�����܂܂���Ȃ����H
GPU�Ƃ��Ă�ATI�̃^�[���ɓ������Ƃ��Ă��AGPGPU�Ƃ��Ă̏o���͂ǂ��Ȃ̂���
�܂��^�╄�����܂܂���Ȃ����H
>>709
���������ꂽ�L�����u���ɂ��Č����������̌����\�́E�E�E
��̂ǂ�قǂ̃y�[�W�ɔS�����Ă���̂�
������
�������v���Z�X��55nm�Ń��C�o��nVIDIA��65nm�̐V���i�Ɣ�r����Ɣ�����i�����̃v���Z�X���g�p��
�Ԋu���M���M���ɋl�߂������Ő���͑S���i��łȂ���Ȃ����H
���������ꂽ�L�����u���ɂ��Č����������̌����\�́E�E�E
��̂ǂ�قǂ̃y�[�W�ɔS�����Ă���̂�
������
�������v���Z�X��55nm�Ń��C�o��nVIDIA��65nm�̐V���i�Ɣ�r����Ɣ�����i�����̃v���Z�X���g�p��
�Ԋu���M���M���ɋl�߂������Ő���͑S���i��łȂ���Ȃ����H
724 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 15:22:26 ID:JRtNSvsA
��CAl�ō������p�G���R�[�h�\�t�g�������ł�����A
���l�n�����w���\��̈��~�����������D����Ǝv���B
�܂��̓\�t�g����Ă�
����͎��ʒK�̔�Z�p
���l�n�����w���\��̈��~�����������D����Ǝv���B
�܂��̓\�t�g����Ă�
����͎��ʒK�̔�Z�p
725 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 15:26:36 ID:JRtNSvsA
���Ă�����Larrabee��Bulldozer/Fusion���Ăǂ�������ɏo�܂����H
�ǂ�����Nehalem����̋C���������
����G���R�[�_�E�f�R�[�_��GPU�x���Ȃ�nVIDIA�̂ق�����s���ĂˁH
�N������Ă���������Ԃ���N�����܂���
�ǂ�����Nehalem����̋C���������
����G���R�[�_�E�f�R�[�_��GPU�x���Ȃ�nVIDIA�̂ق�����s���ĂˁH
�N������Ă���������Ԃ���N�����܂���
>>706
Vista�ł�������BSDKv1.1beta�ŃR���p�C������F@H��DLL�œ������B
Vista�ł�������BSDKv1.1beta�ŃR���p�C������F@H��DLL�œ������B
727 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 15:32:02 ID:JRtNSvsA
����Vista x64�Ȃ���
XP x64�p�������H
XP x64�p�������H
>>723
> ��̂ǂ�قǂ̃y�[�W�ɔS�����Ă���̂�
��������̃y�[�W�͕��ʓǂ�łȂ����H
> �Ԋu���M���M���ɋl�߂������Ő���͑S���i��łȂ���Ȃ����H
�z���s�b�`�Ƃ��͕ς��Ȃ������m��Ȃ����ǁA�v���Z�X���P�Ŋm���ɐ��\�͗ǂ��Ȃ��Ă�Ǝv��
��������Ȃ��ƃn�[�t�m�[�h�̈Ӗ��Ȃ���
> ��̂ǂ�قǂ̃y�[�W�ɔS�����Ă���̂�
��������̃y�[�W�͕��ʓǂ�łȂ����H
> �Ԋu���M���M���ɋl�߂������Ő���͑S���i��łȂ���Ȃ����H
�z���s�b�`�Ƃ��͕ς��Ȃ������m��Ȃ����ǁA�v���Z�X���P�Ŋm���ɐ��\�͗ǂ��Ȃ��Ă�Ǝv��
��������Ȃ��ƃn�[�t�m�[�h�̈Ӗ��Ȃ���
�E�F�n����̂��ʂ̕����d�v�Ȃ�?�@>�n�[�t�m�[�h
���\���オ��Ȃ��Ƃ������Ȃ����d�_�͂�������Ȃ��ƌ������B
���\���オ��Ȃ��Ƃ������Ȃ����d�_�͂�������Ȃ��ƌ������B
>>727
������B�T���v��������A�v����������B
������B�T���v��������A�v����������B
731 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 15:39:24 ID:JRtNSvsA
�d���Ȃ��B
�|�`�邩�B
����Ȃ�nVIDIA
�|�`�邩�B
����Ȃ�nVIDIA
>>725 �c�q����
�@�@-----------------
�@�@���Ă�����Larrabee��Bulldozer/Fusion���Ăǂ�������ɏo�܂����H
�@�@-----------------
AMD�̕���A�����N�����������Ă��M�p�ł��Ȃ���Ԃ����ǁALarrabee��2009�N���Ƃ����B
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/473
>>728 ����
�@�@-----------------
�@�@�z���s�b�`�Ƃ��͕ς��Ȃ������m��Ȃ����ǁA�v���Z�X���P�Ŋm���ɐ��\�͗ǂ��Ȃ��Ă�Ǝv��
�@�@-----------------
�n�[�t�m�[�h��A�z���s�b�`�̂ݏk�����ăg�����W�X�^�̐��\����햳�����B
�@�@-----------------
�@�@���Ă�����Larrabee��Bulldozer/Fusion���Ăǂ�������ɏo�܂����H
�@�@-----------------
AMD�̕���A�����N�����������Ă��M�p�ł��Ȃ���Ԃ����ǁALarrabee��2009�N���Ƃ����B
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/473
>>728 ����
�@�@-----------------
�@�@�z���s�b�`�Ƃ��͕ς��Ȃ������m��Ȃ����ǁA�v���Z�X���P�Ŋm���ɐ��\�͗ǂ��Ȃ��Ă�Ǝv��
�@�@-----------------
�n�[�t�m�[�h��A�z���s�b�`�̂ݏk�����ăg�����W�X�^�̐��\����햳�����B
>>716
���ꂭ�炢�̒ނ�͂��킢������
�����ŏ�������ł邾�������C�ɂ����
>�ϑz�͂قƂ�nj������x��
>�@�@------------------
>�Ō�̂햼�����x������(��)
���ꂾ�Ɖ����Ċ�Ȃ��l�݂�������
����͂����܂�kuma + RV770�N���X��CPU�̎������ɂ��Ă�����
�������ǂ��Ȃ邩�͕�����Ȃ�����S���I�O�ꂩ�������
GPGPU�����Ė��\���Ƃ͎v���Ă��Ȃ�
�ł�wktk���~�܂�Ȃ���
�����AMD�D��������Ƃ������Ƃ�
���ꂭ�炢�̒ނ�͂��킢������
�����ŏ�������ł邾�������C�ɂ����
>�ϑz�͂قƂ�nj������x��
>�@�@------------------
>�Ō�̂햼�����x������(��)
���ꂾ�Ɖ����Ċ�Ȃ��l�݂�������
����͂����܂�kuma + RV770�N���X��CPU�̎������ɂ��Ă�����
�������ǂ��Ȃ邩�͕�����Ȃ�����S���I�O�ꂩ�������
GPGPU�����Ė��\���Ƃ͎v���Ă��Ȃ�
�ł�wktk���~�܂�Ȃ���
�����AMD�D��������Ƃ������Ƃ�
�����DX11��Fusion�݂͌������Ȃ�ӎ����ĊJ������Ă���Ƃ����ϑz�����Ă���
�܂�DX11��SSE5(����AVX�݂����ɃJ�b�R�C�C���̂ɂȂ�)�ɍœK�������
������������Windows7���̂��̂��Ή����邩��
RV770�ȍ~��SSE5���ӎ��������m�ɂȂ邾�낤���A
AMD��MS�ɋ��͂Ƀv�b�V�����邾�낤�����
��������MS��Vista�ȍ~��GPU��ϋɓI�Ɋ��p����Ɩ������Ă��邵
�����ϑz���~�܂�Ȃ�
�͂₭Fusion�Ŏ��삵������
�܂�DX11��SSE5(����AVX�݂����ɃJ�b�R�C�C���̂ɂȂ�)�ɍœK�������
������������Windows7���̂��̂��Ή����邩��
RV770�ȍ~��SSE5���ӎ��������m�ɂȂ邾�낤���A
AMD��MS�ɋ��͂Ƀv�b�V�����邾�낤�����
��������MS��Vista�ȍ~��GPU��ϋɓI�Ɋ��p����Ɩ������Ă��邵
�����ϑz���~�܂�Ȃ�
�͂₭Fusion�Ŏ��삵������
>>735
4850�̋��������̂܂������݂��Ċ����������邯��
�l�`�b���^���݂����Ƀ\�[�X�����Ă���Ȃ��ƁB
�Ȃɂ���{�c�����������Ƃł�����j�ς��̂�
����ĂȂ������Ȃ�Ėϑz�͈͓̔�����
�ʂ̖^�X���͖ϑz��������Ȃ��z�����邶���H
4850�̋��������̂܂������݂��Ċ����������邯��
�l�`�b���^���݂����Ƀ\�[�X�����Ă���Ȃ��ƁB
�Ȃɂ���{�c�����������Ƃł�����j�ς��̂�
����ĂȂ������Ȃ�Ėϑz�͈͓̔�����
�ʂ̖^�X���͖ϑz��������Ȃ��z�����邶���H
>>709
���Ȃ݂�RV770��R800�Ƃ��͂����܂�GPU�ł���
GPGPU�Ƃ��Ă͂���قNJ��҂��Ă͂��Ȃ�
������̓����ɍœK������Ηǂ������ɂȂ�Ƃ͎v������
FP64������������F�X�ƕs����ȕ��������邾�낤��
Fusion������ɂ�����A�{���xFP�̑��݂�ACPU��R�}���h�v���Z�b�T�[�̉��ǂŕ���čs����Ȃ��̂���
��{�I�ɃV���O���X���b�h������Z�n��CPU�R�A�ŁA
�}���`�X���b�h��SSE���������̂�GPGPU�Ƃ����ӂ��ɕ��ʂɐU�蕪���ď������邾��
�v�͂��ꂾ�A�ŋ߃X�p�R��1�ʂɂȂ��� Opteron + cell��PC�����ɂ����悤�Ȃ��B
������1PetaFlops���������H�����1/5000�X�P�[���ʂ�
���Ȃ݂�RV770��R800�Ƃ��͂����܂�GPU�ł���
GPGPU�Ƃ��Ă͂���قNJ��҂��Ă͂��Ȃ�
������̓����ɍœK������Ηǂ������ɂȂ�Ƃ͎v������
FP64������������F�X�ƕs����ȕ��������邾�낤��
Fusion������ɂ�����A�{���xFP�̑��݂�ACPU��R�}���h�v���Z�b�T�[�̉��ǂŕ���čs����Ȃ��̂���
��{�I�ɃV���O���X���b�h������Z�n��CPU�R�A�ŁA
�}���`�X���b�h��SSE���������̂�GPGPU�Ƃ����ӂ��ɕ��ʂɐU�蕪���ď������邾��
�v�͂��ꂾ�A�ŋ߃X�p�R��1�ʂɂȂ��� Opteron + cell��PC�����ɂ����悤�Ȃ��B
������1PetaFlops���������H�����1/5000�X�P�[���ʂ�
�R( �E�́E)Ɂ� �ݺ�
741 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 16:23:06 ID:JRtNSvsA
��������
SSE5��GPU�̃f�[�^16�r�b�g���xFP�ƒP���xFP�̑��ݕϊ����߂����邪
�Â�GPU��CPU�́u�Z���v�͍s���Ȃ����Ƃ��Ӗ�����B
���������N���b�N�������̃v���Z�X���Ⴄ���̂��p�C�v���C�����x���Ō����ł���킯���Ȃ�����
HT�ɂ��I���_�C�a�����������Ƃ���
SSE5��GPU�̃f�[�^16�r�b�g���xFP�ƒP���xFP�̑��ݕϊ����߂����邪
�Â�GPU��CPU�́u�Z���v�͍s���Ȃ����Ƃ��Ӗ�����B
���������N���b�N�������̃v���Z�X���Ⴄ���̂��p�C�v���C�����x���Ō����ł���킯���Ȃ�����
HT�ɂ��I���_�C�a�����������Ƃ���
742 �FMAC�I�^��739 �����F2008/06/21(�y) 16:25:36 ID:QtBsYZWJ
>>739
�@�@------------------
�@�@�ŋ߃X�p�R��1�ʂɂȂ��� Opteron + cell��PC�����ɂ����悤�Ȃ��B
�@�@------------------
����AOpteron�̂����Ő��\�������Ă���Ƃ����b�����邷�B
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/923-924
�@�@------------------
�@�@�ŋ߃X�p�R��1�ʂɂȂ��� Opteron + cell��PC�����ɂ����悤�Ȃ��B
�@�@------------------
����AOpteron�̂����Ő��\�������Ă���Ƃ����b�����邷�B
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/923-924
>>737
���܂�Fusion�l�^�ɑ���\�[�X�͓��ɂȂ�
kuma + HD4850����\�z���Ă��邾��
55nm�v���Z�X�ŁA800SP�A1Tflops�A�{���x200Gflops�ATMU40�ATDP110W �Ƃ�����Ղ���������
AMD + ATI�@�̊J���w�Ȃ�A������CPU�R�A�ł���Ղ��N�����Ă�����Ȃ����Ɗ��҂��Ă��邾��
���ہAATI�̊J����AMD�̊J���w�����݂�����RV770�Ȃ�ďo��������A
�������Ƃ�CPU�ł��o�����Ȃ����ȂƎv���킯�ł���
���܂�Fusion�l�^�ɑ���\�[�X�͓��ɂȂ�
kuma + HD4850����\�z���Ă��邾��
55nm�v���Z�X�ŁA800SP�A1Tflops�A�{���x200Gflops�ATMU40�ATDP110W �Ƃ�����Ղ���������
AMD + ATI�@�̊J���w�Ȃ�A������CPU�R�A�ł���Ղ��N�����Ă�����Ȃ����Ɗ��҂��Ă��邾��
���ہAATI�̊J����AMD�̊J���w�����݂�����RV770�Ȃ�ďo��������A
�������Ƃ�CPU�ł��o�����Ȃ����ȂƎv���킯�ł���
744 �FMAC�I�^���c�q �����F2008/06/21(�y) 16:30:04 ID:QtBsYZWJ
>>741
�@�@---------------
�@�@���������N���b�N�������̃v���Z�X���Ⴄ���̂�
�@�@---------------
�v���Z�X�퓯���ɂȂ�Ƃ����\�����邷�B(>>514�Q��)
�@�@---------------
�@�@���������N���b�N�������̃v���Z�X���Ⴄ���̂�
�@�@---------------
�v���Z�X�퓯���ɂȂ�Ƃ����\�����邷�B(>>514�Q��)
745 �FMAC�I�^��743 �����F2008/06/21(�y) 16:32:36 ID:QtBsYZWJ
>>743
�@�@---------------------
�@�@ATI�̊J����AMD�̊J���w�����݂�����RV770�Ȃ�ďo��������A
�@�@---------------------
��{�c�����������Ă���̂��m��Ȃ������ǁA���ꂾ�����X�g������Ă�̂�AMD���ɂ���Ȑl�I�]�T
�햳�����B
�@�@---------------------
�@�@ATI�̊J����AMD�̊J���w�����݂�����RV770�Ȃ�ďo��������A
�@�@---------------------
��{�c�����������Ă���̂��m��Ȃ������ǁA���ꂾ�����X�g������Ă�̂�AMD���ɂ���Ȑl�I�]�T
�햳�����B
���m�N���Ă邾���ł��A���Ȃ�ŁA������ƒ��ׂĂ݂�
TSMC�̃n�[�t�m�[�h�͌��w�I�V�������N���ۂ�
�yDAC 2008�zTSMC�C40nm��������̃��t�@�����X�v�t���[9.0�����J
http://techon.nikkeibp.co.jp/article/NEWS/20080611/153139/
�}2������
TSMC�̃n�[�t�m�[�h�͌��w�I�V�������N���ۂ�
�yDAC 2008�zTSMC�C40nm��������̃��t�@�����X�v�t���[9.0�����J
http://techon.nikkeibp.co.jp/article/NEWS/20080611/153139/
�}2������
>>741
64bitFP�g���Ȃ�GPGPU�ɑ��݉��l�͂Ȃ�
����Ȃ���AMD���m��Ȃ��Ǝv�����H
�N���b�N�Ȃǂ��ł���������
���ł����j�b�g�P�ʂŃN���b�N�����ł��邵
�I���_�C�a������Swift���낤���A�J���v���Z�X���ǂ��ɂ������Ȃ����A
�Ƃ����������������Ȃ����Intel�ɑR�ł��Ȃ�
����܂�AMD�̋Z�p�҂Ȃ߂�ȁA���O�̌����Ă邱�ƂȂ������ė\�z�ł���
����ɋC�Â��ĂȂ��͂��Ȃ�����
CPU�J���̃G���[�g + GPU�J���̃G���[�g + GPGPU�\�t�g�J���̃G���[�g���͂��킹�Ă���A
�㐔�N����ΐF�X�Ɖ������邾��
���Ȃ݂Ƀo�b�N�ɂ�IBM��MS�����邱�Ƃ�Y����
64bitFP�g���Ȃ�GPGPU�ɑ��݉��l�͂Ȃ�
����Ȃ���AMD���m��Ȃ��Ǝv�����H
�N���b�N�Ȃǂ��ł���������
���ł����j�b�g�P�ʂŃN���b�N�����ł��邵
�I���_�C�a������Swift���낤���A�J���v���Z�X���ǂ��ɂ������Ȃ����A
�Ƃ����������������Ȃ����Intel�ɑR�ł��Ȃ�
����܂�AMD�̋Z�p�҂Ȃ߂�ȁA���O�̌����Ă邱�ƂȂ������ė\�z�ł���
����ɋC�Â��ĂȂ��͂��Ȃ�����
CPU�J���̃G���[�g + GPU�J���̃G���[�g + GPGPU�\�t�g�J���̃G���[�g���͂��킹�Ă���A
�㐔�N����ΐF�X�Ɖ������邾��
���Ȃ݂Ƀo�b�N�ɂ�IBM��MS�����邱�Ƃ�Y����
�������������Ȃ�Aintel��Larrabee�������������Ȃ���
���̊Ԃ�intel���ł��ˁc
�܂�������A�ϑz���Ď����Ō����Ă邭�炢�����A
���̈ʓd�g����z�����Ȃ��Ɩʔ����Ȃ����ˁA�X���I�ɂ�
�܂�������A�ϑz���Ď����Ō����Ă邭�炢�����A
���̈ʓd�g����z�����Ȃ��Ɩʔ����Ȃ����ˁA�X���I�ɂ�
>>748
�v���X�R�Ƃ��i�ׂƂ�
�v���X�R�Ƃ��i�ׂƂ�
>>742
Opteron��Cell�ɉ��Z���\�ŗ�邩�痎���ē��R����
�Ȃ�őS��Cell�����ɂ��Ȃ���Opteron��ς�ł���̂��l����Ε����邾��
���Ȃ݂�Cell���Ă����GPGPU�Ƃ��Ďg���Ă���悤�Ȃ�����
����Cell��Opteron�ō�����X�p�R�������E1�ʂƂ�������A
AMD��Fusion�\�z�͐������Ǝv��
PS3���HD3870�̂ق���F@h�̐��\�͂�������A�������ǂ��Ȃ邱�Ƃ͖��炩
���Ȃ݂�geforce���ƍX��3�{���\����炵�����ǁA������������Ȃ�
�N���m���Ă����狳���Ă�������
Opteron��Cell�ɉ��Z���\�ŗ�邩�痎���ē��R����
�Ȃ�őS��Cell�����ɂ��Ȃ���Opteron��ς�ł���̂��l����Ε����邾��
���Ȃ݂�Cell���Ă����GPGPU�Ƃ��Ďg���Ă���悤�Ȃ�����
����Cell��Opteron�ō�����X�p�R�������E1�ʂƂ�������A
AMD��Fusion�\�z�͐������Ǝv��
PS3���HD3870�̂ق���F@h�̐��\�͂�������A�������ǂ��Ȃ邱�Ƃ͖��炩
���Ȃ݂�geforce���ƍX��3�{���\����炵�����ǁA������������Ȃ�
�N���m���Ă����狳���Ă�������
NV vs ATI�X���ɓ��Ă��Ă�̂��m����fanatic������l�����Ă���悤�ł���
������Ȃ�ł��@�N���b�N�Ȃǂ��ł���������@�͌�������
>>748
����������r�[�����s����Ƃ͂����ĂȂ��ł�
�������atom�݂����ȏ��^CPU��50��100�ς���ł���H
�}���`�X���b�h�ɓ��������A�v���Ȃ�L�����낤����
�V���O���X���b�h�A�v���͑債�����ƂȂ��Ǝv���Ă���
�ƂĂ�word��G�N�Z���A�u���E�U�Ȃ�K10�R�A�ȏ�̐��\�����Ă�Ƃ͎v���Ȃ��B
GPU�Ƃ��ĂȂ�Intel�̃h���C�o�J���\�͂�����̂܂܂Ȃ�G�ɂȂ�Ȃ�
������ˑRIntel�ɓV�˂�����āA�_����ȃh���C�o�����Ȃ番����Ȃ���
���ꂱ���ϑz����H
����������r�[�����s����Ƃ͂����ĂȂ��ł�
�������atom�݂����ȏ��^CPU��50��100�ς���ł���H
�}���`�X���b�h�ɓ��������A�v���Ȃ�L�����낤����
�V���O���X���b�h�A�v���͑債�����ƂȂ��Ǝv���Ă���
�ƂĂ�word��G�N�Z���A�u���E�U�Ȃ�K10�R�A�ȏ�̐��\�����Ă�Ƃ͎v���Ȃ��B
GPU�Ƃ��ĂȂ�Intel�̃h���C�o�J���\�͂�����̂܂܂Ȃ�G�ɂȂ�Ȃ�
������ˑRIntel�ɓV�˂�����āA�_����ȃh���C�o�����Ȃ番����Ȃ���
���ꂱ���ϑz����H
756 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:05:24 ID:JRtNSvsA
>>747
16�r�b�gFP�̐Ϙa�Z���̂��܂܂�Ă��炸�A�ϊ����߂��������邱�Ƃɂ��Ă̌�����
�ϑz�Ȃ��ł��肢���܂��B
CPU��GPU�ŕʁX�Ƀv���O���~���O���Ȃ��Ƃ����Ȃ���Ȃ��āH��
16�r�b�gFP�̐Ϙa�Z���̂��܂܂�Ă��炸�A�ϊ����߂��������邱�Ƃɂ��Ă̌�����
�ϑz�Ȃ��ł��肢���܂��B
CPU��GPU�ŕʁX�Ƀv���O���~���O���Ȃ��Ƃ����Ȃ���Ȃ��āH��
757 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:06:00 ID:JRtNSvsA
>>755
���^�R�A�����S���ς̂�GPU�ł����ǁH��
���^�R�A�����S���ς̂�GPU�ł����ǁH��
758 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:06:52 ID:JRtNSvsA
��������ˑRIntel�ɓV�˂�����āA�_����ȃh���C�o�����Ȃ番����Ȃ���
�����ꂱ���ϑz����H
AMD�ɒu�������Ă���������ȁB
��������SSE5��GPU���̂��̂��쓮���閽�߂ł͂Ȃ��B
�����ꂱ���ϑz����H
AMD�ɒu�������Ă���������ȁB
��������SSE5��GPU���̂��̂��쓮���閽�߂ł͂Ȃ��B
Larrabee��HPC�����̃v���Z�b�T�Ȃ̂ɁA�Ȃ�ł����Ȃ�word��G�N�Z���A�u���E�U�Ȃ�
�o����H
HD4850��word��G�N�Z���A�u���E�U�������Ȃ�Ȃ�����Core2�ȏ�̐��\�͎��Ă�Ƃ�
�v���Ȃ��A�Ȃ�Č����������疾�炩�ɂ����������낤��
�o����H
HD4850��word��G�N�Z���A�u���E�U�������Ȃ�Ȃ�����Core2�ȏ�̐��\�͎��Ă�Ƃ�
�v���Ȃ��A�Ȃ�Č����������疾�炩�ɂ����������낤��
761 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:14:09 ID:JRtNSvsA
MCM����GPU�̃��W�X�^��CPU�̃��W�X�^�Ԃ̃f�[�^�ړ����牽�\�N���b�N�A
�Ϙa�Z�����ł�CPU������݂��牽�N���b�N��������킯�ł����B
SSE�̑�։]�X�Ȃ�Ă͖̂����ł��B
1�C���X�g���N�V�����ɉ��\�`���S�N���b�N������̑O��̃I�y���[�V�����̑�ւɂ͂Ȃ邾�낤���ǁB
GPU���̂��̂�x86���߂Œ@���̂�Larrabee�̃A�v���[�`�̂ق������ɂ��Ȃ��Ă��
�Ϙa�Z�����ł�CPU������݂��牽�N���b�N��������킯�ł����B
SSE�̑�։]�X�Ȃ�Ă͖̂����ł��B
1�C���X�g���N�V�����ɉ��\�`���S�N���b�N������̑O��̃I�y���[�V�����̑�ւɂ͂Ȃ邾�낤���ǁB
GPU���̂��̂�x86���߂Œ@���̂�Larrabee�̃A�v���[�`�̂ق������ɂ��Ȃ��Ă��
Fusion��PC�p�r��CPU�R�A���₷���Ă����Ă����E���邵
�L���b�V�����ʂ��Ă����̂����T�`�邵
�]�����g�����W�X�^�����Ɏg���́H���Ď���
GPU�����^�`�b�v�Z�b�g�Ƃ��������Ⴆ����Ă��
GPGPU�Ƃ͂�����ƕ��������Ⴄ�悤�ȋC������Ȃ�
�L���b�V�����ʂ��Ă����̂����T�`�邵
�]�����g�����W�X�^�����Ɏg���́H���Ď���
GPU�����^�`�b�v�Z�b�g�Ƃ��������Ⴆ����Ă��
GPGPU�Ƃ͂�����ƕ��������Ⴄ�悤�ȋC������Ȃ�
>>756
SSE5�̎d�l�͂悭������A���̎d�l���ǂ����낤�ƍ���
CPU�Ƃ��Ďg������ǂ��ɂ������Ȃ����H
���͑f�l������ڂ������Ƃ̓V���l
>>757
����A����͎�������
�����r�[�̓}���`�R�A����Ȃ��̂��H
>>758
GPU�Ƃ��Č����ꍇ�ɂ��Č�������������AIntel�̃h���C�o�̓N�\�͏펯����
�����錋�ʂ��S��
�V�˂͂��Ȃ�
���݂��疢���͐��`�I�ɐi������Ƃ��Đ������邾��
�Ԃ����ႯFusion��CPU�R�A��X2�ł������Ǝv���Ă���
GPGPU�R�A���d�v�����ARV770����R800��R900�𐄑�������
wktk�߂��ă����r�[�Ƃ��ǂ��ł�����
SSE5�̎d�l�͂悭������A���̎d�l���ǂ����낤�ƍ���
CPU�Ƃ��Ďg������ǂ��ɂ������Ȃ����H
���͑f�l������ڂ������Ƃ̓V���l
>>757
����A����͎�������
�����r�[�̓}���`�R�A����Ȃ��̂��H
>>758
GPU�Ƃ��Č����ꍇ�ɂ��Č�������������AIntel�̃h���C�o�̓N�\�͏펯����
�����錋�ʂ��S��
�V�˂͂��Ȃ�
���݂��疢���͐��`�I�ɐi������Ƃ��Đ������邾��
�Ԃ����ႯFusion��CPU�R�A��X2�ł������Ǝv���Ă���
GPGPU�R�A���d�v�����ARV770����R800��R900�𐄑�������
wktk�߂��ă����r�[�Ƃ��ǂ��ł�����
Intel���ǂ�ȉB���ʂ����Ă��邩�킩��Ȃ�����˂��AGPU�����悭�Ă��o�����X������B
45nm High-K�v���Z�X���AAMD�ł�2009�N�㔼�炵������Intel�����2�N�߂���
�x���悤�����E�E�E
http://northwood.blog60.fc2.com/blog-entry-2057.html
���̍��ɂ�Intel��32nm�Ɉڍs���͂��߂Ă��A���N�̐��������32nm�̋Z�p�̏ڍ�
���킩���Ȃ��H�����IBM���悾�������ǁA45nm�ł�High-K�̂��Ƃ�����������
�����Intel�������肻���ȋC�����邪�B
45nm High-K�v���Z�X���AAMD�ł�2009�N�㔼�炵������Intel�����2�N�߂���
�x���悤�����E�E�E
http://northwood.blog60.fc2.com/blog-entry-2057.html
���̍��ɂ�Intel��32nm�Ɉڍs���͂��߂Ă��A���N�̐��������32nm�̋Z�p�̏ڍ�
���킩���Ȃ��H�����IBM���悾�������ǁA45nm�ł�High-K�̂��Ƃ�����������
�����Intel�������肻���ȋC�����邪�B
765 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:27:30 ID:JRtNSvsA
Nintendo 64�����GPU��MIPS���}�C�N���R�[�h�ʼn]�X�Ƃ�����Ă�����
�A�������Ǎ��Â炩���������ŁB
�����_�̏��AFusion��Cell��PPE��SPE�݂����ɈႤ���߃Z�b�g���s�������邾���ƒf���ł���B
�Ȃ�̂��Ƃ͂Ȃ��AGPU��CPU�����̃R�[�h�������H�ڂɂȂ邾���ł���B
GPGPU�����s�邩�́A���ɓI�ɂ́A1�Z�b�g��C�\�[�X�R�[�h����œK������CPU��GPU�����̃R�[�h��
��������悤�Ȍ����R���p�C���ł��ł��邩���Ă��Ƃɂɂ������Ă�B
������A���܂����Џ����R���p�C�������������Ƃ̂Ȃ����[�J�[�ɏo����H
Larrabee�͖��߃Z�b�g���x���ł�CPU�Ƃ̓��ꐫ����邩��A�������̂ق������������ˁB
�A�������Ǎ��Â炩���������ŁB
�����_�̏��AFusion��Cell��PPE��SPE�݂����ɈႤ���߃Z�b�g���s�������邾���ƒf���ł���B
�Ȃ�̂��Ƃ͂Ȃ��AGPU��CPU�����̃R�[�h�������H�ڂɂȂ邾���ł���B
GPGPU�����s�邩�́A���ɓI�ɂ́A1�Z�b�g��C�\�[�X�R�[�h����œK������CPU��GPU�����̃R�[�h��
��������悤�Ȍ����R���p�C���ł��ł��邩���Ă��Ƃɂɂ������Ă�B
������A���܂����Џ����R���p�C�������������Ƃ̂Ȃ����[�J�[�ɏo����H
Larrabee�͖��߃Z�b�g���x���ł�CPU�Ƃ̓��ꐫ����邩��A�������̂ق������������ˁB
SIMD�g�������V���v���R�A�̃}���`/���j�[���ĕ���
�v���O�����͏����₷���悤�ȋC�������
���������̂���GPGPU���Ă̂Ƃ͈Ⴄ�悤�ȋC�����邯��
�v���O�����͏����₷���悤�ȋC�������
���������̂���GPGPU���Ă̂Ƃ͈Ⴄ�悤�ȋC�����邯��
>>760
PC�p��CPU�Ƃ��čl�����ꍇ�ł�
HPC�����Ȃ�FireStream�Ƃ̘A�g���\������܂��܂������r�[�͂���Ȃ�
>>761
�ׂ������Ƃ͒m���
Fusion��CPU��FPU/SSE���j�b�g��GPGPU�ɒu�����������̂��ƃC���[�W���Ă���B
AVX��SSE5�͂ǂ��炪�������₷���ł��傤����
����܂�ς��Ȃ��悤�ȋC������
��̓V�F�A�Ȃ낤���ǁARadeon��SSE5�ɑΉ����邩�瑍���I�ɂ�SSE5����Ȃ����ȁB
>>762
Fusion�͒P�Ȃ�GPGPU�ł͂Ȃ��ACPU+GPGPU������V���O�����낤�ƃ}���`���낤�Ǝ��p�͑S���Ȃ��Ǝv��
PC�p��CPU�Ƃ��čl�����ꍇ�ł�
HPC�����Ȃ�FireStream�Ƃ̘A�g���\������܂��܂������r�[�͂���Ȃ�
>>761
�ׂ������Ƃ͒m���
Fusion��CPU��FPU/SSE���j�b�g��GPGPU�ɒu�����������̂��ƃC���[�W���Ă���B
AVX��SSE5�͂ǂ��炪�������₷���ł��傤����
����܂�ς��Ȃ��悤�ȋC������
��̓V�F�A�Ȃ낤���ǁARadeon��SSE5�ɑΉ����邩�瑍���I�ɂ�SSE5����Ȃ����ȁB
>>762
Fusion�͒P�Ȃ�GPGPU�ł͂Ȃ��ACPU+GPGPU������V���O�����낤�ƃ}���`���낤�Ǝ��p�͑S���Ȃ��Ǝv��
>>765
>Cell��PPE��SPE�݂����ɈႤ���߃Z�b�g���s�������邾��
�����̖��ߑ̌n�ɂ���̂�SSE5�ł́H
�����SSE5��x86��u����������̂Ƃ���AMD���l���Ă���V�������߃Z�b�g
�������Fusion��x86����������B�Œ�K10�R�A�ʂɂ�
�����͂ǂ����邩�m��Ȃ����ǂ��ɂ����邾�낤
>Cell��PPE��SPE�݂����ɈႤ���߃Z�b�g���s�������邾��
�����̖��ߑ̌n�ɂ���̂�SSE5�ł́H
�����SSE5��x86��u����������̂Ƃ���AMD���l���Ă���V�������߃Z�b�g
�������Fusion��x86����������B�Œ�K10�R�A�ʂɂ�
�����͂ǂ����邩�m��Ȃ����ǂ��ɂ����邾�낤
wktk���~�܂�Ȃ��l�̘b�̓A�����ȁA
���w�����A�D���Ȗ���̃L�����A�ǂ������������Ŕ��M����̂Ǝ��Ă�ȁB
���w�����A�D���Ȗ���̃L�����A�ǂ������������Ŕ��M����̂Ǝ��Ă�ȁB
770 �FMAC�I�^���c�q �����F2008/06/21(�y) 17:45:18 ID:QtBsYZWJ
>>765
�@�@-------------------
�@�@Larrabee�͖��߃Z�b�g���x���ł�CPU�Ƃ̓��ꐫ�����
�@�@-------------------
Siggraph��Larrabee�_���̃A�u�X�g���N�g��ǂƎv�������ǁA���ꕁ�ʂ�GPU�Ɠ����\������
�Ȃ������H����ɂȂ��Ă����p"wide"�x�N�g�����j�b�g��ISA�푼��IA�Ƃ�ʂ̃��m�̗l���B
SPE ISA��POWER ISA���x�̑��ւ����������������ǁB�B�B
�@�@-------------------
�@�@Larrabee�͖��߃Z�b�g���x���ł�CPU�Ƃ̓��ꐫ�����
�@�@-------------------
Siggraph��Larrabee�_���̃A�u�X�g���N�g��ǂƎv�������ǁA���ꕁ�ʂ�GPU�Ɠ����\������
�Ȃ������H����ɂȂ��Ă����p"wide"�x�N�g�����j�b�g��ISA�푼��IA�Ƃ�ʂ̃��m�̗l���B
SPE ISA��POWER ISA���x�̑��ւ����������������ǁB�B�B
771 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:45:55 ID:JRtNSvsA
����\�P�b�g���CPU��GPU���ׂāAGPGPU���Ƃ���CPU-GPU�ԃf�[�^������
���C�e���V�팸���܂��傤�A���Ă̂�Fusion�̖{���B
����ȏ�ł�����ȉ��ł��Ȃ��B
GPU��CPU��SSE�̌�����]�X�́ACPU�������I��GPU�ɖ��ߔ��s�����Ȃ���
�v���O���}�[����J���Ă���Ă�����Ęb�Ȃ�ŁA�܂����ꎩ�̂͐�i���͂Ȃ��킯�ł��B
���C�e���V�팸���܂��傤�A���Ă̂�Fusion�̖{���B
����ȏ�ł�����ȉ��ł��Ȃ��B
GPU��CPU��SSE�̌�����]�X�́ACPU�������I��GPU�ɖ��ߔ��s�����Ȃ���
�v���O���}�[����J���Ă���Ă�����Ęb�Ȃ�ŁA�܂����ꎩ�̂͐�i���͂Ȃ��킯�ł��B
772 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:46:59 ID:JRtNSvsA
773 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:51:53 ID:JRtNSvsA
>>770
���̂��[�AAVX��YMM���W�X�^�̕����Ă����炾���������H
���̃x�N�g�����̐Ϙa�Z���eSP�ł���Ă�����B��FLOPS�ɂȂ�H
���̒l�Ƃ҂����肾��B
���̂��[�AAVX��YMM���W�X�^�̕����Ă����炾���������H
���̃x�N�g�����̐Ϙa�Z���eSP�ł���Ă�����B��FLOPS�ɂȂ�H
���̒l�Ƃ҂����肾��B
>>767
���[��AGPGPU���āA�n�C�G���h��GPU���Ɛ��\������̃R�X�g���Ⴂ����
�\�t�g�����̂ɋ�J���Ă��A����ȏ�̌��Ԃ肪�������Ă��Ƃł���H
Fusion��GPU���ƁA�ǂ����Ă��n�C�G���h��GPU���Ă킯�ɂ͂����Ȃ�����
���\������̃R�X�g�����[�ŁA�\�t�g�̏����ɂ����Ƃ����f�����b�g�ɑł����ĂȂ��悤��
���������������悤�ɁA�]�����g�����W�X�^�̎g�����Ƃ��ẮA����قNj������Ƃ�
�v��Ȃ��̂ŁAFusion���̂�S�ʓI�ɔے肷��킯�ł͂Ȃ����ǂ�
���[��AGPGPU���āA�n�C�G���h��GPU���Ɛ��\������̃R�X�g���Ⴂ����
�\�t�g�����̂ɋ�J���Ă��A����ȏ�̌��Ԃ肪�������Ă��Ƃł���H
Fusion��GPU���ƁA�ǂ����Ă��n�C�G���h��GPU���Ă킯�ɂ͂����Ȃ�����
���\������̃R�X�g�����[�ŁA�\�t�g�̏����ɂ����Ƃ����f�����b�g�ɑł����ĂȂ��悤��
���������������悤�ɁA�]�����g�����W�X�^�̎g�����Ƃ��ẮA����قNj������Ƃ�
�v��Ȃ��̂ŁAFusion���̂�S�ʓI�ɔے肷��킯�ł͂Ȃ����ǂ�
775 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 17:57:28 ID:JRtNSvsA
�ǂ������Ƃ����ƃ��[�G���h�v���Z�b�T�ɔ������I��GPU�𓋍ڂ��邱�Ƃ�
GPGPU�����[�G���h����n�C�G���h�܂Ŏg�����Ԃɂ��邱�Ƃ��ړI�̂悤�Ɏv���邯�ǂˁB
GPGPU�����[�G���h����n�C�G���h�܂Ŏg�����Ԃɂ��邱�Ƃ��ړI�̂悤�Ɏv���邯�ǂˁB
�c�q����̃y�[�X�ɂ��Ă����Ȃ���
>>771
> GPU��CPU��SSE�̌�����]�X�́ACPU�������I��GPU�ɖ��ߔ��s�����Ȃ���
> �v���O���}�[����J���Ă���Ă�����Ęb�Ȃ�ŁA�܂����ꎩ�̂͐�i���͂Ȃ��킯�ł��B
����ς�A�����Ȃ��ˁH
>>771
> GPU��CPU��SSE�̌�����]�X�́ACPU�������I��GPU�ɖ��ߔ��s�����Ȃ���
> �v���O���}�[����J���Ă���Ă�����Ęb�Ȃ�ŁA�܂����ꎩ�̂͐�i���͂Ȃ��킯�ł��B
����ς�A�����Ȃ��ˁH
>>747
32bit���������_���S�Ɏg����Ȃ�h264�������G���R�[�h�o����Ǝv����B
32bit���������_���S�Ɏg����Ȃ�h264�������G���R�[�h�o����Ǝv����B
�Ƃ肠�������N��Fusion�͂܂����i�K���Ă��Ƃ��B
���������ɐi�߂邩�ǂ����͂킩���B
���������ɐi�߂邩�ǂ����͂킩���B
781 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:05:38 ID:JRtNSvsA
Intrinsics��_mm_mul_ps��_mm_add_ps���y�A�ɂ���FMADDPS�ɓZ�߂�悤�Ȍ����R���p�C���ł�����ė~��������
�����GCC�͂��̃��x�����������
�����GCC�͂��̃��x�����������
782 �FMAC�I�^���c�q �����F2008/06/21(�y) 18:10:46 ID:QtBsYZWJ
>>773
AVX��FMA�g���̎�����ALarrabee���シ�B
http://softwarecommunity.intel.com/articles/eng/3775.htm
�@�@-------------------
�@�@Intel AVX supported by a wide range of Intel platforms starting in the 2010 timeframe.
�@�@-------------------
�Ƃ������Ƃ�AVX���̂�2010�ȍ~�̎����B�܂�FMA��AAVX Programming Reference�̒��ł���
��`����Ă��邷�B
http://softwarecommunity.intel.com/isn/downloads/intelavx/Intel-AVX-Programming-Reference-31943302.pdf
�@�@-------------------
�@�@FMA is a future extension of Intel AVX, FMA provides floating-point, fused
�@�@multiply-add instructions supporting 256-bit and 128-bit SIMD vectors.
�@�@-------------------
�ŏ��̎����ɂ�܂܂�Ă��Ȃ��l���ˁB
���łɃx�N�g�����ɂ��āA�����ӎ����Ă�AVX��g���̗]�n��^���Ă��邷�B
�@�@--------------------
�@�@- Future Vector Integer support to 256 and 512 bits.
�@�@--------------------
�����v���W�F�N�g�o�g��Larrabee��256-bit�~�܂�Ȃ̂��ǂ�����A����ł��Ƃ��������悤���������B
AVX��FMA�g���̎�����ALarrabee���シ�B
http://softwarecommunity.intel.com/articles/eng/3775.htm
�@�@-------------------
�@�@Intel AVX supported by a wide range of Intel platforms starting in the 2010 timeframe.
�@�@-------------------
�Ƃ������Ƃ�AVX���̂�2010�ȍ~�̎����B�܂�FMA��AAVX Programming Reference�̒��ł���
��`����Ă��邷�B
http://softwarecommunity.intel.com/isn/downloads/intelavx/Intel-AVX-Programming-Reference-31943302.pdf
�@�@-------------------
�@�@FMA is a future extension of Intel AVX, FMA provides floating-point, fused
�@�@multiply-add instructions supporting 256-bit and 128-bit SIMD vectors.
�@�@-------------------
�ŏ��̎����ɂ�܂܂�Ă��Ȃ��l���ˁB
���łɃx�N�g�����ɂ��āA�����ӎ����Ă�AVX��g���̗]�n��^���Ă��邷�B
�@�@--------------------
�@�@- Future Vector Integer support to 256 and 512 bits.
�@�@--------------------
�����v���W�F�N�g�o�g��Larrabee��256-bit�~�܂�Ȃ̂��ǂ�����A����ł��Ƃ��������悤���������B
>>771
�ʂɂ��̃��x���ł��������ǁA
�̗p��������SSE�Ή��ʂɂ͍L�܂��ł͂Ȃ�����
��͗\�z�ʂ�̔������\��������A����ɍL�܂�ł���
�Ȃc�q��MAC�I�^�������Ă����
���͉�����2�l����l�����Ǝv���Ă�����
����Ƃ������H
>>774
����Ȃ����\�́A�����炭SSE5�ɑΉ����Ă���RADEON�ɋ��͂��Ă��炤
SSE5�Ƃ�����Fusion�Ƃ̘A�g�����R�l������Ă��邾�낤����ASSE5�Ή��\�t�g��
�K�R�I��Radeon���R�v���Ƃ��Ă��g�����Ȃ�����
���̂ւf�����b�g���郁���b�g�ɂȂ�Ǝv��
�ʂɂ��̃��x���ł��������ǁA
�̗p��������SSE�Ή��ʂɂ͍L�܂��ł͂Ȃ�����
��͗\�z�ʂ�̔������\��������A����ɍL�܂�ł���
�Ȃc�q��MAC�I�^�������Ă����
���͉�����2�l����l�����Ǝv���Ă�����
����Ƃ������H
>>774
����Ȃ����\�́A�����炭SSE5�ɑΉ����Ă���RADEON�ɋ��͂��Ă��炤
SSE5�Ƃ�����Fusion�Ƃ̘A�g�����R�l������Ă��邾�낤����ASSE5�Ή��\�t�g��
�K�R�I��Radeon���R�v���Ƃ��Ă��g�����Ȃ�����
���̂ւf�����b�g���郁���b�g�ɂȂ�Ǝv��
784 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:20:44 ID:JRtNSvsA
>>782
��Ȃ��Ƃ͂킩���Ă�B
���͐Ϙa��SandyBridge�̂��Ƃƌ������̂�Gesher�}�C�N���A�[�L�e�N�`���ł̎����Ɍ������b�Ɖ��߂��Ă邪�B
���������Ϙa�łȂ��Ƃ�VMULPS/D��VADDPS/D��2issue���s�ł��������Ȃ��ǂˁB
�܂��ALarrabee��x87��SSE*�܂ߊ��m�̖��߂̓T�|�[�g������j�̂悤������
�������߂�ׂ��悤�Ȑ^���͂��Ȃ��ł���B
�܁A�ǂ݂̂�8���ɂ͔�������Ǝv����̂ʼn����͂��̂ւ�ŁB
��Ȃ��Ƃ͂킩���Ă�B
���͐Ϙa��SandyBridge�̂��Ƃƌ������̂�Gesher�}�C�N���A�[�L�e�N�`���ł̎����Ɍ������b�Ɖ��߂��Ă邪�B
���������Ϙa�łȂ��Ƃ�VMULPS/D��VADDPS/D��2issue���s�ł��������Ȃ��ǂˁB
�܂��ALarrabee��x87��SSE*�܂ߊ��m�̖��߂̓T�|�[�g������j�̂悤������
�������߂�ׂ��悤�Ȑ^���͂��Ȃ��ł���B
�܁A�ǂ݂̂�8���ɂ͔�������Ǝv����̂ʼn����͂��̂ւ�ŁB
>>775 �c�q ����
�@�@----------------
�@�@GPGPU�����[�G���h����n�C�G���h�܂Ŏg�����Ԃɂ���
�@�@----------------
���܂苭�����@�ɂ팩���Ȃ����ˁB
���ł��O���t�B�b�N���C�u������A�n�[�h�E�F�A�������Ȃ疳���Ȃ�Ƀ\�t�g�E�F�A�Ŏ��s����邷�B
�܂��A�ق�̐��N�O�܂ł핂�������_���߂���\�t�g�ŃG�~�����[�g����Ă������B
�������������炪��ړI�Ȃ�AISA��ABI���ŏ��ɒ��锤�����B�B�B
>>787 ����
���N������̃A�[�L�e�N�`���X���b�h��CELL/B.E�@���ɋ��ޒc�q����̋��Ԃ�ǂ߂A�l���w�i
���ǂ�����Ǝv�����B
�@�@----------------
�@�@GPGPU�����[�G���h����n�C�G���h�܂Ŏg�����Ԃɂ���
�@�@----------------
���܂苭�����@�ɂ팩���Ȃ����ˁB
���ł��O���t�B�b�N���C�u������A�n�[�h�E�F�A�������Ȃ疳���Ȃ�Ƀ\�t�g�E�F�A�Ŏ��s����邷�B
�܂��A�ق�̐��N�O�܂ł핂�������_���߂���\�t�g�ŃG�~�����[�g����Ă������B
�������������炪��ړI�Ȃ�AISA��ABI���ŏ��ɒ��锤�����B�B�B
>>787 ����
���N������̃A�[�L�e�N�`���X���b�h��CELL/B.E�@���ɋ��ޒc�q����̋��Ԃ�ǂ߂A�l���w�i
���ǂ�����Ǝv�����B
786 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:26:14 ID:JRtNSvsA
�������X��
>>783
��������ˁ[���H
MAC�̈��������܂����MAC�I�^�����������邩��
���ɂn�r�̘b��������Ȃ����H
�l�`�b�ɂ����intel��������Œc�q�܂ŗU����������
�Ă�MAC���^���Ēc�q���o�Ă�����O���瑶�݂��Ă邺
��������ˁ[���H
MAC�̈��������܂����MAC�I�^�����������邩��
���ɂn�r�̘b��������Ȃ����H
�l�`�b�ɂ����intel��������Œc�q�܂ŗU����������
�Ă�MAC���^���Ēc�q���o�Ă�����O���瑶�݂��Ă邺
788 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:26:43 ID:JRtNSvsA
�����Ď����ŃQ�b�g
���Ƃ��Ă�AVIVO�G���R�[�_�[�̊�����҂���тĂ�B���݂���SD�ɖт�������
���x�̂���Ȃ��t��HD�Œ��n�C�r�b�g���[�g�̓��������10�{�ʂ̑����ŃG���R
�o������A���͂��Ȃ�~�����B
���x�̂���Ȃ��t��HD�Œ��n�C�r�b�g���[�g�̓��������10�{�ʂ̑����ŃG���R
�o������A���͂��Ȃ�~�����B
��̑O�ɂł�AVIVO�G���R�[�_�[�͑�������
���W�X�g�����`�s�h�ő�������Ă��
�ʂɑΏۂu�f�`�łȂ��Ă��g���鍼�\�A�v�����������ǂ�
���W�X�g�����`�s�h�ő�������Ă��
�ʂɑΏۂu�f�`�łȂ��Ă��g���鍼�\�A�v�����������ǂ�
SpursEngine�Œ��𑜁A�݂����Ȃ̂�GPU�ŏo������Ȃ�~����
792 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:33:00 ID:JRtNSvsA
>>787�Ɏ��]����
793 �FMAC�I�^��791 �����F2008/06/21(�y) 18:33:20 ID:QtBsYZWJ
>>791
�@�@---------------
�@�@SpursEngine�Œ��𑜁A�݂����Ȃ̂�GPU�ŏo������Ȃ�~����
�@�@---------------
���̑O��Spurs Engine PCIe�J�[�h���o�������B
http://journal.mycom.co.jp/articles/2008/06/07/computex13/
�@�@---------------
�@�@SpursEngine�Œ��𑜁A�݂����Ȃ̂�GPU�ŏo������Ȃ�~����
�@�@---------------
���̑O��Spurs Engine PCIe�J�[�h���o�������B
http://journal.mycom.co.jp/articles/2008/06/07/computex13/
�����͉�����2�l����l�����Ǝv���Ă�����
������Ƃ肦�̔n���������Ɍ����s�v�c�Ƃ�����ł���
������Ƃ肦�̔n���������Ɍ����s�v�c�Ƃ�����ł���
795 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:38:30 ID:JRtNSvsA
����SpursEngine����1.5GHz��4SPE��48GFLOPS(�P���x�A�{���x���Ƃ��Ԃ�4GFLOPS���x)
����
�s�[�NFLOPS�~�ɂ͎₵����
�܂��ȓd�͂��낤����
����
�s�[�NFLOPS�~�ɂ͎₵����
�܂��ȓd�͂��낤����
796 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 18:39:54 ID:JRtNSvsA
�悭����Ƃ�������MAC�I�^�ƒc�q�̃X����������
���Ǎ�����HD4850�����ɍs�����тꂽ
�����������s���Δ����邩�ȁH����Ƃ������Ŕ���ꂩ�H
�����������Ə������炷�����肵����
�X�������X�}�\
���Ǎ�����HD4850�����ɍs�����тꂽ
�����������s���Δ����邩�ȁH����Ƃ������Ŕ���ꂩ�H
�����������Ə������炷�����肵����
�X�������X�}�\
>>790
����AVIVO�G���R�[�_�[�͂Ȃ�ő��������낤��
�N���m���Ă���l�͂��܂����H
>>794
���Ȃ݂ɖ^�X���̃e�ւ�����l�����Ǝv���Ă�
����AVIVO�G���R�[�_�[�͂Ȃ�ő��������낤��
�N���m���Ă���l�͂��܂����H
>>794
���Ȃ݂ɖ^�X���̃e�ւ�����l�����Ǝv���Ă�
vista��FAH�������Ă�ȏ�
CLA��VISTA�ł����Ȃ��͂�����
CLA��VISTA�ł����Ȃ��͂�����
CAL��
AVIVO�͌��ǃ\�t�g�E�F�A�Ńg�����X�R�[�h���Ă邾������Ȃ���������
>>730
���߂�⑫�B64bit��F@H���Ȃ�����64bit�o�C�i����COM�݂����Ȃ��Ƃ��Ȃ��Ɩ����ˁB
32bit�o�C�i���Ȃ畁�ʂɓ���
ttp://www7.axfc.net/uploader/Img/so/14483.png
���߂�⑫�B64bit��F@H���Ȃ�����64bit�o�C�i����COM�݂����Ȃ��Ƃ��Ȃ��Ɩ����ˁB
32bit�o�C�i���Ȃ畁�ʂɓ���
ttp://www7.axfc.net/uploader/Img/so/14483.png
{kind=link}
���X�Ԃ���Ď��ȃ��X��orz
>>731�ˁB
>>731�ˁB
804 �F�R�E�L�́M�E,,�j�����������������F2008/06/21(�y) 22:25:30 ID:JRtNSvsA
����COM���E�E�E
64�r�b�g-32�r�b�g�̉��ʂ��ėp�ӂ���Ă������ȁH
�ƂӂƎv�����B
64�r�b�g-32�r�b�g�̉��ʂ��ėp�ӂ���Ă������ȁH
�ƂӂƎv�����B
MAC�I�^
��
���̐l�Ȃ�ł����܂ŃA���`AMD/ATI�ɂȂ���H
����AMD���ő呹�������o���ł�����낤��
��
���̐l�Ȃ�ł����܂ŃA���`AMD/ATI�ɂȂ���H
����AMD���ő呹�������o���ł�����낤��
806 �FMAC�I�^��805 �����F2008/06/22(��) 12:24:41 ID:7EkjfsSX
>>805
�@�@--------------------
�@�@�A���`AMD/ATI
�@�@--------------------
����Mac���[�U�[������A�p���I��Macintosh�v���b�g�t�H�[���̖ʓ|�����Ă����ATI�ɂ�
�[�����ӂ��Ă��邷�B��������A����ȃj���[�X���B
http://www.4gamer.net/games/044/G004473/20080617040/
�@�@--------------------
�@�@�A���`AMD/ATI
�@�@--------------------
����Mac���[�U�[������A�p���I��Macintosh�v���b�g�t�H�[���̖ʓ|�����Ă����ATI�ɂ�
�[�����ӂ��Ă��邷�B��������A����ȃj���[�X���B
http://www.4gamer.net/games/044/G004473/20080617040/
>>805
�̂́BMac��D���BPower�n��D���������B
���܂�Mac��Intel CPU���̗p���Ă��邩��Intel��D���B
�����AMac��AMD�n���̗p���������AMD��D���ɂȂ�B
�̂́BMac��D���BPower�n��D���������B
���܂�Mac��Intel CPU���̗p���Ă��邩��Intel��D���B
�����AMac��AMD�n���̗p���������AMD��D���ɂȂ�B
MAC���^�͕ʂɃA���`���Ăقǂł��Ȃ��ˁH
��Âɕ��͂������CELL����������ۛ����Ă邮�炢�Ȃ���
��Âɕ��͂������CELL����������ۛ����Ă邮�炢�Ȃ���
��Âȕ��́cMAC���^�̏������݂���Âȕ��͂ƂƂ��Ȃ�A
�o�[������m�O�ѐ~����Âȕ��͂��ȁB
�o�[������m�O�ѐ~����Âȕ��͂��ȁB
811 �FMAC�I�^��808 �����F2008/06/22(��) 13:28:15 ID:7EkjfsSX
>>808
�@�@-----------------
�@�@���܂�Mac��Intel CPU���̗p���Ă��邩��Intel��D���B
�@�@-----------------
�P��A�����̒����������݂���J�l���B�����ʂ�ɉR���\����邾��������(��)
�yAMD�z������CPU�����X���b�h�yIntel�z
http://pc7.2ch.net/test/read.cgi/jisaku/1095271508/108
�@�@==================
�@�@108 ���O�FMAC�I�^��T.A. ���� ���e���F2005/03/27(��) 19:54:25 ID:rIrqKEE5
�@�@�@�@[��]
�@�@�@�@��Ђ̍D�������Ō����A�m�[�x���܋��̉Ȋw�҂��W�܂��đn������Ђł���Intel��A
�@�@�@�@���ꂻ�̂��̂��B
�@�@==================
Apple��Intel�ڍs�̔��\������A�����炷�B
http://www.apple.com/jp/news/2005/jun/07intel.html
�@�@-----------------
�@�@���܂�Mac��Intel CPU���̗p���Ă��邩��Intel��D���B
�@�@-----------------
�P��A�����̒����������݂���J�l���B�����ʂ�ɉR���\����邾��������(��)
�yAMD�z������CPU�����X���b�h�yIntel�z
http://pc7.2ch.net/test/read.cgi/jisaku/1095271508/108
�@�@==================
�@�@108 ���O�FMAC�I�^��T.A. ���� ���e���F2005/03/27(��) 19:54:25 ID:rIrqKEE5
�@�@�@�@[��]
�@�@�@�@��Ђ̍D�������Ō����A�m�[�x���܋��̉Ȋw�҂��W�܂��đn������Ђł���Intel��A
�@�@�@�@���ꂻ�̂��̂��B
�@�@==================
Apple��Intel�ڍs�̔��\������A�����炷�B
http://www.apple.com/jp/news/2005/jun/07intel.html
>>810
�o�[���͓I�m�����Aintel�h�b�v���ł��������ߕt���v�f��������
�����Ă鎖���̂͐��m�����
��n�O�u�A���~�v�i�ŗL�����j�͘_�O����B�L�����ȊO�̌`�e���ł��Ȃ�
�o�[���͓I�m�����Aintel�h�b�v���ł��������ߕt���v�f��������
�����Ă鎖���̂͐��m�����
��n�O�u�A���~�v�i�ŗL�����j�͘_�O����B�L�����ȊO�̌`�e���ł��Ȃ�
813 �FMAC�I�^��810 �����F2008/06/22(��) 13:33:52 ID:7EkjfsSX
>>810
�@�@---------------------
�@�@MAC���^�̏������݂���Âȕ��͂ƂƂ��Ȃ��
�@�@---------------------
�����Ɏ������N�O����AMD�Ɋւ��Ă����ŏ����Ă������Ƃ�A�قƂ�ǓI�����Ă��邷���ǁB�B�B
�@�@---------------------
�@�@MAC���^�̏������݂���Âȕ��͂ƂƂ��Ȃ��
�@�@---------------------
�����Ɏ������N�O����AMD�Ɋւ��Ă����ŏ����Ă������Ƃ�A�قƂ�ǓI�����Ă��邷���ǁB�B�B
>>813
�_�O�ȎG���搶�Ɗm�M�Ƃ̃A���~�Ƃ������v�����݂̂���o�[��������ۂ�
�l�`�b�I�^���̂ق����܂Ƃ������
���܂�VIA�~�̂s�`���ƎG��������ł邪�G�������������ŏ����Ƃ܂�˂����B
���s�`���������v������
�ǂ����Ԉ���Ă邩������Ȃ����ȁB
������Intel�l�`�b�����̂Ƃ��̍Q�ĂԂ�͂��̂����������B�}�W�ŁB
�_�O�ȎG���搶�Ɗm�M�Ƃ̃A���~�Ƃ������v�����݂̂���o�[��������ۂ�
�l�`�b�I�^���̂ق����܂Ƃ������
���܂�VIA�~�̂s�`���ƎG��������ł邪�G�������������ŏ����Ƃ܂�˂����B
���s�`���������v������
�ǂ����Ԉ���Ă邩������Ȃ����ȁB
������Intel�l�`�b�����̂Ƃ��̍Q�ĂԂ�͂��̂����������B�}�W�ŁB
815 �FMAC�I�^��814 �����F2008/06/22(��) 13:44:08 ID:7EkjfsSX
>>814
�@�@-----------------
�@�@VIA�~�̂s�`��
�@�@-----------------
VIA�}���ĖЏ@�����ƁB
T.A.����A�������~�[�����ᖳ��������(���ꂾ���ł��Q�����˂�ł�H�L������)�A�P�Ȃ�
�m���������B�₢�l�߂���ƃ��A���̌o���������������悤�ȃq�g������B�B�B
�@�@-----------------
�@�@VIA�~�̂s�`��
�@�@-----------------
VIA�}���ĖЏ@�����ƁB
T.A.����A�������~�[�����ᖳ��������(���ꂾ���ł��Q�����˂�ł�H�L������)�A�P�Ȃ�
�m���������B�₢�l�߂���ƃ��A���̌o���������������悤�ȃq�g������B�B�B
���Ȃ݂ɒc�q�����A�V�����I���W�ƃL�`�K�C���肪�W�܂�A�[�L�e�N�`���n�c�_�̒��ł�
�M�d�ȐV��������A�F�X�ȈӖ��ő厖�ɂ��ׂ����B
����Ȃ��Ə����ƁA�܂��@�����낤�Ǝv��������(��)
�M�d�ȐV��������A�F�X�ȈӖ��ő厖�ɂ��ׂ����B
����Ȃ��Ə����ƁA�܂��@�����낤�Ǝv��������(��)
ID:XMGrZShl��MAC�I�^�̎��쎩���B
MAC�I�^�L������B���ˁB
MAC�I�^�L������B���ˁB
818 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 14:01:16 ID:YpuPayhY
��Transmeta�}�ł�
MAC�I�^�����Ȏ咣���Ȃ��Ƃ��܂��Ă��炦�Ȃ��Ȃ��Ă�����
���Ⴂ���Ȃ��悤�ɕ⑫�����
�قƂ�ǓI�����Ă̂͏�̃\�[�X���D�G�Ȃ���
�������A�قڌ��ʕŏI�i�K�܂Ŏϋl�܂��Ă���̂�
�\�z�������̂悤�ȓ��e�ł����Ă��B
���Ⴂ���Ȃ��悤�ɕ⑫�����
�قƂ�ǓI�����Ă̂͏�̃\�[�X���D�G�Ȃ���
�������A�قڌ��ʕŏI�i�K�܂Ŏϋl�܂��Ă���̂�
�\�z�������̂悤�ȓ��e�ł����Ă��B
820 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 15:08:12 ID:YpuPayhY
���Ⴀ�\�z���Ă�����
Larrabee��SIMD��AVX�t�H�[�}�b�g�̐���B�l�C�e�B�u256�r�b�gSIMD���Z��𓋍ڂ��AFMA����s��������B
����SandyBridge��SIMD���j�b�g��128bit�̂܂܁B
�܂��A�ȉ��Ȃ��Ɏ����ǂ߂��������\�z�ɂ��ǂ蒅������
Larrabee��SIMD��AVX�t�H�[�}�b�g�̐���B�l�C�e�B�u256�r�b�gSIMD���Z��𓋍ڂ��AFMA����s��������B
����SandyBridge��SIMD���j�b�g��128bit�̂܂܁B
�܂��A�ȉ��Ȃ��Ɏ����ǂ߂��������\�z�ɂ��ǂ蒅������
��Cyrix�}�ł�(�E�L��`�E)
Larrabee����j�R�Aatom����
ttp://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
MIMD��x86��intel��SIMDGPU��AMNV��
���̏��������̏������ǂ���������32�R�A����
�p�C�v���C�����Ȃ̂ɂ����������ō����M���L���b�V�����C�e���V�ȃv���X�R��f�i�Ƃ������
����SSE���݂ȂƂ���
ttp://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
MIMD��x86��intel��SIMDGPU��AMNV��
���̏��������̏������ǂ���������32�R�A����
�p�C�v���C�����Ȃ̂ɂ����������ō����M���L���b�V�����C�e���V�ȃv���X�R��f�i�Ƃ������
����SSE���݂ȂƂ���
823 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 16:42:46 ID:YpuPayhY
nVIDIA����GeForce 8�ȍ~��MIMD����ˁH
���������A������240SP��1TFlops�\(�E�L��`�E)
825 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 16:49:08 ID:YpuPayhY
> �@��X�́A�����ɂ킽���āA���߃Z�b�g������Ɋg���������邱�Ƃ��ł���ƌ��Ă���B
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B�܂�AILP(Instruction-Level Parallelism)��
> ���߂邾���łȂ��A�V���߃Z�b�g���f���ɂ��A�x�N�^���x���̕������߂Ă䂭�B
> ���N(2008�N)�ɂ́A���߃Z�b�g�ɂ��Ă����Əڍׂ𖾂炩�ɂł��邾�낤�v
����2008�N�Ɍ��J�����̂�AVX�ł����Ƃ��B
�܂�����͑��ɂ���ȊO�̌݊����̂Ȃ�SIMD�g����p�ӂ��Ă�ƍl���Ă邻��������
���肦�Ȃ���ˁH
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B�܂�AILP(Instruction-Level Parallelism)��
> ���߂邾���łȂ��A�V���߃Z�b�g���f���ɂ��A�x�N�^���x���̕������߂Ă䂭�B
> ���N(2008�N)�ɂ́A���߃Z�b�g�ɂ��Ă����Əڍׂ𖾂炩�ɂł��邾�낤�v
����2008�N�Ɍ��J�����̂�AVX�ł����Ƃ��B
�܂�����͑��ɂ���ȊO�̌݊����̂Ȃ�SIMD�g����p�ӂ��Ă�ƍl���Ă邻��������
���肦�Ȃ���ˁH
ttp://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
> ��������16way��SIMD�g���܂ʼn\�ɂ��閽�߃t�H�[�}�b�g
> �u5�o�C�g�o�[�W������2�ڂ̃y�C���[�h�̓t���ł͂Ȃ��B�����̊g���̂��߂�3�r�b�g��
> �c����Ă���B3bits����A1,000�ȏ�̐V���߂������邱�Ƃ��ł���B�V�����t�B�[�`���A
> �V�������W�X�^�A�V�����x�N�^���B�قƂ�ǂȂ�ł������邱�Ƃ��ł���v(Valentine��)�B
>
> VEX�̃t�H�[�}�b�g�̖��ߒ��̂܂܂ŁA512�r�b�g�܂���1,024bits��SIMD�������ł���Ƃ����B
> ��������16way��SIMD�g���܂ʼn\�ɂ��閽�߃t�H�[�}�b�g
> �u5�o�C�g�o�[�W������2�ڂ̃y�C���[�h�̓t���ł͂Ȃ��B�����̊g���̂��߂�3�r�b�g��
> �c����Ă���B3bits����A1,000�ȏ�̐V���߂������邱�Ƃ��ł���B�V�����t�B�[�`���A
> �V�������W�X�^�A�V�����x�N�^���B�قƂ�ǂȂ�ł������邱�Ƃ��ł���v(Valentine��)�B
>
> VEX�̃t�H�[�}�b�g�̖��ߒ��̂܂܂ŁA512�r�b�g�܂���1,024bits��SIMD�������ł���Ƃ����B
�D�������ł�������TA����ԋ�肾�ȁB
���A���ł̐��i����Ԃ�������B
���A���ł̐��i����Ԃ�������B
AMD�n�X���ɔS�����Ă���
MAC�I�^
�R�E�L�́M�E,,�j����������������
�A���~
�e��
������P�Ȃ�A���`AMD�ň��~����
NGName���Ă��Ă��A���肪�ނ��邩��Ӗ����Ȃ�
���s���Ă������Ȃ�����ǂ����悤���Ȃ���
�ז������瑁������ł���
MAC�I�^
�R�E�L�́M�E,,�j����������������
�A���~
�e��
������P�Ȃ�A���`AMD�ň��~����
NGName���Ă��Ă��A���肪�ނ��邩��Ӗ����Ȃ�
���s���Ă������Ȃ�����ǂ����悤���Ȃ���
�ז������瑁������ł���
829 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 19:19:49 ID:YpuPayhY
���������˂ΑS�Ă���������܂���
831 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 19:26:37 ID:YpuPayhY
���������ĂȂ��̂Ɠ����������
����Ȃ�A�ɂق̂ӂ��䂤�ȂЂ�
����Ȃ�A�ɂق̂ӂ��䂤�ȂЂ�
>>831
>���������ĂȂ��̂Ɠ����������
>����Ȃ�A�ɂق̂ӂ��䂤�ȂЂ�
���̓��{��͂ǂ��ł�����
���ȂȂ�����S���������A���O�����ʂ����Ȃ�����Ƃ����Ӗ���
>���������ĂȂ��̂Ɠ����������
>����Ȃ�A�ɂق̂ӂ��䂤�ȂЂ�
���̓��{��͂ǂ��ł�����
���ȂȂ�����S���������A���O�����ʂ����Ȃ�����Ƃ����Ӗ���
�Ƃ肠�������̃X���ŁA
�����r�[�Ƃ�����AtomX32�̃}���`�R�ACPU��AIA64���ǂ���AVX�Ȃǂ��ł�����
Intel������X���ł���
�V���O���X���b�h���\�E���R��PC����g���Ȃ����A
GPU�Ƃ��Ă̓h���C�o���E���R������R�����_���A���\�����炭�_��
Stream�v���Z�b�T�[�Ƃ��Ă�FireStream�Ƀ{������
Nehalem���ŏ��͖҈Ђ�U�邤���낤����
��C�ƃC�X�^���u���łȂ�Ƃ��ς���
Sandy Bridge�ɂ�Swift�Ō݊p�ȏ�
Fusion�����ŃN���e�B�J���q�b�g
������Intel��AMD��|�Y�����邱�Ƃ��ł��Ȃ�����AFusion�����܂œ|�Y�͂��蓾�Ȃ�
����܂ł�GPU���傪AMD���x����
Fusion���� = Intel���S or �K�͏k���͌��莖��
���̌��
AMD��Fusion + FireStream VS IBM��Power
�����r�[�Ƃ�����AtomX32�̃}���`�R�ACPU��AIA64���ǂ���AVX�Ȃǂ��ł�����
Intel������X���ł���
�V���O���X���b�h���\�E���R��PC����g���Ȃ����A
GPU�Ƃ��Ă̓h���C�o���E���R������R�����_���A���\�����炭�_��
Stream�v���Z�b�T�[�Ƃ��Ă�FireStream�Ƀ{������
Nehalem���ŏ��͖҈Ђ�U�邤���낤����
��C�ƃC�X�^���u���łȂ�Ƃ��ς���
Sandy Bridge�ɂ�Swift�Ō݊p�ȏ�
Fusion�����ŃN���e�B�J���q�b�g
������Intel��AMD��|�Y�����邱�Ƃ��ł��Ȃ�����AFusion�����܂œ|�Y�͂��蓾�Ȃ�
����܂ł�GPU���傪AMD���x����
Fusion���� = Intel���S or �K�͏k���͌��莖��
���̌��
AMD��Fusion + FireStream VS IBM��Power
�܂��N����
Nehalem���ŏ��͖҈Ђ�U�邤���낤����
��C�ƃC�X�^���u���łȂ�Ƃ��ς���
Sandy Bridge�ɂ�Swift�Ō݊p�ȏ�
Fusion�����ŃN���e�B�J���q�b�g
������Intel��AMD��|�Y�����邱�Ƃ��ł��Ȃ�����AFusion�����܂œ|�Y�͂��蓾�Ȃ�
����܂ł�GPU���傪AMD���x����
Fusion���� = Intel���S or �K�͏k���͌��莖��
---------
��������!!
��C�ƃC�X�^���u���łȂ�Ƃ��ς���
Sandy Bridge�ɂ�Swift�Ō݊p�ȏ�
Fusion�����ŃN���e�B�J���q�b�g
������Intel��AMD��|�Y�����邱�Ƃ��ł��Ȃ�����AFusion�����܂œ|�Y�͂��蓾�Ȃ�
����܂ł�GPU���傪AMD���x����
Fusion���� = Intel���S or �K�͏k���͌��莖��
---------
��������!!
>>832
�S�`���b�J�[�͂��܂�����B���f����(�E�L��`�E)
�S�`���b�J�[�͂��܂�����B���f����(�E�L��`�E)
837 �FSocket774�F2008/06/22(��) 20:13:17 ID:/Uvbr1de
AMD�֘A�̘b�ɂȂ�Ɩϑz�����o�Ă��Ȃ�����ȁB
������AIntel�̘b�ɂȂ�킯���ȁB
������AIntel�̘b�ɂȂ�킯���ȁB
>>833
Intel���S�̌�������AMD��ł���\����99.8%���肦��B
�����������Ƃ��N�������Ƃ��Ă��A�Œ�ł�����10�N�A20�N�ȓ��͂��肦�Ȃ��B
�܂��AIntel AVX�͂͂����茾����AMD�ɂƂ��Ă͎������B
�\�t�g�J���\�͂��アAMD�͗ǂ���������Intel����Ă����Y��
���p���ăR�R�܂Ő��������Ă��ꂽ�B
�����AIntel��AVX�����C�Z���X���Ȃ��ꍇ�ɂ́A
AMD�͓Ǝ��Ŗ��߃Z�b�g���g��������A������T�|�[�g���A
���A�\�t�g��Ђɔ��荞��ł����Ȃ���Ȃ�Ȃ��B
���ꂪ�o���Ȃ�����A�\�t�g�E�F�A�J���\�͂ł�����Intel�ɏ��Ă�킯���Ȃ��B
����āAFUSION���������ꂽ���x�ł́A������������D�ʂɗ��Ă�\���͂��邪�A
Intel AVX�̃T�|�[�g�����ӂ��i�߂��ꍇ�ɂ́AAMD�ɂ͂��̑R��i���Ȃ��̂ŁA
���̗D�ʂ͂킸�����N�ŏI���B
�����AMD�����Ȃ���s���Ȃ��̂͐����Z�p�ƃR�A�̉��ǂƂƂ��ɁA
�\�t�g�E�F�A�J���\�͂̏㏸���}���ł���B
�l�g�o�n�̗���݂Ă킩��ʂ�ɁA�����͂�����Hammer�n�̃R�A���ǎ��ł������Ƃ��Ă��A
�\�t�g�E�F�A�T�|�[�g�ɂ���Ă͂��̍��͋����قǏk�܂����͎̂��m�̎����B
FUSION�͗D�G�ŃL���[�I�ȃR�A�ɂȂ�\���͂��邪�A
FUSION�ƂƂ��ɂ����L���Ɏg����\�t�g�E�F�A�����ӂɔz�z�ł��A
��������͂��T�|�[�g���Ȃ�����AFUSION���x�ł�Intel�ɂ͑債���Ō��͗^�����Ȃ��B
�t��Intel AVX�ɂ����AMD���v���I�ȃ_���[�W����m���̕��������B
Intel���S�̌�������AMD��ł���\����99.8%���肦��B
�����������Ƃ��N�������Ƃ��Ă��A�Œ�ł�����10�N�A20�N�ȓ��͂��肦�Ȃ��B
�܂��AIntel AVX�͂͂����茾����AMD�ɂƂ��Ă͎������B
�\�t�g�J���\�͂��アAMD�͗ǂ���������Intel����Ă����Y��
���p���ăR�R�܂Ő��������Ă��ꂽ�B
�����AIntel��AVX�����C�Z���X���Ȃ��ꍇ�ɂ́A
AMD�͓Ǝ��Ŗ��߃Z�b�g���g��������A������T�|�[�g���A
���A�\�t�g��Ђɔ��荞��ł����Ȃ���Ȃ�Ȃ��B
���ꂪ�o���Ȃ�����A�\�t�g�E�F�A�J���\�͂ł�����Intel�ɏ��Ă�킯���Ȃ��B
����āAFUSION���������ꂽ���x�ł́A������������D�ʂɗ��Ă�\���͂��邪�A
Intel AVX�̃T�|�[�g�����ӂ��i�߂��ꍇ�ɂ́AAMD�ɂ͂��̑R��i���Ȃ��̂ŁA
���̗D�ʂ͂킸�����N�ŏI���B
�����AMD�����Ȃ���s���Ȃ��̂͐����Z�p�ƃR�A�̉��ǂƂƂ��ɁA
�\�t�g�E�F�A�J���\�͂̏㏸���}���ł���B
�l�g�o�n�̗���݂Ă킩��ʂ�ɁA�����͂�����Hammer�n�̃R�A���ǎ��ł������Ƃ��Ă��A
�\�t�g�E�F�A�T�|�[�g�ɂ���Ă͂��̍��͋����قǏk�܂����͎̂��m�̎����B
FUSION�͗D�G�ŃL���[�I�ȃR�A�ɂȂ�\���͂��邪�A
FUSION�ƂƂ��ɂ����L���Ɏg����\�t�g�E�F�A�����ӂɔz�z�ł��A
��������͂��T�|�[�g���Ȃ�����AFUSION���x�ł�Intel�ɂ͑債���Ō��͗^�����Ȃ��B
�t��Intel AVX�ɂ����AMD���v���I�ȃ_���[�W����m���̕��������B
�m������˂��B�m������B
>>833
����̓z���E�E�E
�Ɓu�ϑz�v�ŃX����������
>758����������SSE5��GPU���̂��̂��쓮���閽�߂ł͂Ȃ��B
�Ȃ�ďo�ė������
>822�̃����N���
��SSE5���߂̈ꕔ�́ACPU�R�A�ł͂Ȃ��AGPU�R�A�ɔ��s����Ď��s�����悤�ɂȂ�B
������>820������SandyBridge��SIMD���j�b�g��128bit�̂܂܁B
>826�����N�恄Sandy Bridge��SIMD���Z���j�b�g�̉��Z����256bits�Ɋg��
���₨��E�E�E������Ƃق������������ł������p�x�ł���
�킴�Ƃ������綺��
����̓z���E�E�E
�Ɓu�ϑz�v�ŃX����������
>758����������SSE5��GPU���̂��̂��쓮���閽�߂ł͂Ȃ��B
�Ȃ�ďo�ė������
>822�̃����N���
��SSE5���߂̈ꕔ�́ACPU�R�A�ł͂Ȃ��AGPU�R�A�ɔ��s����Ď��s�����悤�ɂȂ�B
������>820������SandyBridge��SIMD���j�b�g��128bit�̂܂܁B
>826�����N�恄Sandy Bridge��SIMD���Z���j�b�g�̉��Z����256bits�Ɋg��
���₨��E�E�E������Ƃق������������ł������p�x�ł���
�킴�Ƃ������綺��
DENEB���o�Ă�C2Q�͒l�i�����Ă��Ȃ����낤����Ȃ�
45nm�̃t�F�m���͔������Ǝv�����B�S�R�A��95W�Ȃ�܂��܂��Ȃ�Ȃ����ƁB
45nm�̃t�F�m���͔������Ǝv�����B�S�R�A��95W�Ȃ�܂��܂��Ȃ�Ȃ����ƁB
http://www.techreport.com/articles.x/14968
AMD refines its approach to Stream Computing
And wages the GPU compute war on many fronts
AMD refines its approach to Stream Computing
And wages the GPU compute war on many fronts
>>833
���b���ǂ��Ȃ��Ă邩�m��Ȃ���Power��SPARC��Opteron�ƌ݊��\�P�b�g�ɂȂ����
�b���������B����������������Intel����̉����Ă�������AMDCPUvs������Power
���ĂȂ���AMDCPU��Power�̋����̕����\���͍����Ǝv���B
���b���ǂ��Ȃ��Ă邩�m��Ȃ���Power��SPARC��Opteron�ƌ݊��\�P�b�g�ɂȂ����
�b���������B����������������Intel����̉����Ă�������AMDCPUvs������Power
���ĂȂ���AMDCPU��Power�̋����̕����\���͍����Ǝv���B
>>843
���������b���Ȃ��B�A���͂ǂ��Ȃ��Ă�̂��˂��B
������ƃO�O���Ă݂���A�uPower7�v���݊��ɂ�����Ęb�������炵�����B
���������b���Ȃ��B�A���͂ǂ��Ȃ��Ă�̂��˂��B
������ƃO�O���Ă݂���A�uPower7�v���݊��ɂ�����Ęb�������炵�����B
>>838
>Intel���S�̌�������AMD��ł���\����99.8%���肦��B
�����\�����ߌ��߂��܂����APC��x86�T�[�o�[�s��Ƃ������Ƃł�
>�����AIntel��AVX�����C�Z���X���Ȃ��ꍇ�ɂ́A
���C�Z���X����Ă��Ή�����̂ɐ��N������܂�
�Ƃ������A�V�KCPU�̊J���ɂȂ�ł��傤����Ή�����̂�5�N�͂�����ł��傤�B
�Ή�����̂ɈӖ��͂Ȃ��ł��ˁA�S�ʐ푈�ł�
���Ȃ݂ɂ��݂�x86���̂Ă�킯�͂Ȃ��̂ŁA�����\�t�g�̓���ɂ͑S�����Ȃ��ł�
>AMD�͓Ǝ��Ŗ��߃Z�b�g���g��������A������T�|�[�g���A
>���A�\�t�g��Ђɔ��荞��ł����Ȃ���Ȃ�Ȃ��B
���ꂪSSE5�ł���
3DNow�̌o��������̂ʼn��Ƃ��Ȃ�ł��傤(�����͂Ȃ��ł�)
���̎��ł���DirectX6�Ή�������A�Ή��Q�[��������܂����B
mp3�G���R�\�t�g��GOGO�Ƃ������t���[�\�t�g������܂��B
���p�\�t�g�͎g���Ă��Ȃ��̂ŕ�����܂��A
�t���[�̃G���R�\�t�g�ɂ�3DNow�Ή����Ă���̂����\����܂�
�Ƃ������ƂŎs�ꂩ�犮�S�����Ƃ������Ƃ͂Ȃ��ł��傤�B
������SSE5�ł�Radeon��1Tflops���̉��Z���\���g����킯�ł�����
���̎������͗ǂ��Ǝv���܂�
DirectX11�ɂ��Ă�GPGPU�ɑΉ�����Ɩ������Ă���ȏ�A
GPGPU���ő�����p����SSE5�Ƃ̘A�g�͓��R���Ǝv���܂�
�Ԃɍ���Ȃ����DX12�ł����܂��܂���
�J�����͂����܂�Intel��Nvidia�ɗ���Ă��邾���ŁA����Cal��Brook+��SDK�͂���܂�
PC�����ŊȒP�ɗ��p�ł���悤�ɂȂ�ɂ͂܂����Ԃ��K�v�ł��傤���A
����͎��ԂƂƂ��ɉ�������܂�����A���Ȃ��ł��傤�B
�Ή��\�t�g�E�F�A�́A�T���v���Ƃ��ăG���R�[�h�\�t�g�Ƃ��������Z�𑽗p�����Q�[���̂P�ł����A���
�\���Ȑ��\������Ɣ��f�����Ώ���ɑ��������ł��B
�Ԃ����Ⴏ�G���R�[�h�\�t�g���L���[�\�t�g�ɂȂ��ŁA
AVIVO�G���R�[�_�[��Ή����Ă����Α��͂���Ȃ��ł���
>Intel���S�̌�������AMD��ł���\����99.8%���肦��B
�����\�����ߌ��߂��܂����APC��x86�T�[�o�[�s��Ƃ������Ƃł�
>�����AIntel��AVX�����C�Z���X���Ȃ��ꍇ�ɂ́A
���C�Z���X����Ă��Ή�����̂ɐ��N������܂�
�Ƃ������A�V�KCPU�̊J���ɂȂ�ł��傤����Ή�����̂�5�N�͂�����ł��傤�B
�Ή�����̂ɈӖ��͂Ȃ��ł��ˁA�S�ʐ푈�ł�
���Ȃ݂ɂ��݂�x86���̂Ă�킯�͂Ȃ��̂ŁA�����\�t�g�̓���ɂ͑S�����Ȃ��ł�
>AMD�͓Ǝ��Ŗ��߃Z�b�g���g��������A������T�|�[�g���A
>���A�\�t�g��Ђɔ��荞��ł����Ȃ���Ȃ�Ȃ��B
���ꂪSSE5�ł���
3DNow�̌o��������̂ʼn��Ƃ��Ȃ�ł��傤(�����͂Ȃ��ł�)
���̎��ł���DirectX6�Ή�������A�Ή��Q�[��������܂����B
mp3�G���R�\�t�g��GOGO�Ƃ������t���[�\�t�g������܂��B
���p�\�t�g�͎g���Ă��Ȃ��̂ŕ�����܂��A
�t���[�̃G���R�\�t�g�ɂ�3DNow�Ή����Ă���̂����\����܂�
�Ƃ������ƂŎs�ꂩ�犮�S�����Ƃ������Ƃ͂Ȃ��ł��傤�B
������SSE5�ł�Radeon��1Tflops���̉��Z���\���g����킯�ł�����
���̎������͗ǂ��Ǝv���܂�
DirectX11�ɂ��Ă�GPGPU�ɑΉ�����Ɩ������Ă���ȏ�A
GPGPU���ő�����p����SSE5�Ƃ̘A�g�͓��R���Ǝv���܂�
�Ԃɍ���Ȃ����DX12�ł����܂��܂���
�J�����͂����܂�Intel��Nvidia�ɗ���Ă��邾���ŁA����Cal��Brook+��SDK�͂���܂�
PC�����ŊȒP�ɗ��p�ł���悤�ɂȂ�ɂ͂܂����Ԃ��K�v�ł��傤���A
����͎��ԂƂƂ��ɉ�������܂�����A���Ȃ��ł��傤�B
�Ή��\�t�g�E�F�A�́A�T���v���Ƃ��ăG���R�[�h�\�t�g�Ƃ��������Z�𑽗p�����Q�[���̂P�ł����A���
�\���Ȑ��\������Ɣ��f�����Ώ���ɑ��������ł��B
�Ԃ����Ⴏ�G���R�[�h�\�t�g���L���[�\�t�g�ɂȂ��ŁA
AVIVO�G���R�[�_�[��Ή����Ă����Α��͂���Ȃ��ł���
�T�^�I�Ȑ~�[�W�T�J�[���z
���ł���`�l�c�œK���̊�����������A
CUDA�݊����[�h�Ƃ��t���ĂЂ�������̂��I�`����(�E�L��`�E)
CUDA�݊����[�h�Ƃ��t���ĂЂ�������̂��I�`����(�E�L��`�E)
���\���Ȑ��\������Ɣ��f������
����ɂ�F@H�Ńn�[�h�X�y�b�N�Ɍ����������\�������ł��Ă��Ȃ����Ƃ��I�悵���܂������
����ɂ�F@H�Ńn�[�h�X�y�b�N�Ɍ����������\�������ł��Ă��Ȃ����Ƃ��I�悵���܂������
>>844
�Ή�������Intel�̊��S�s�k�ł���
����������ǂ��Ő����c���ł��傤���ˁ@(PC�ȊO�͂悭�킩��Ȃ�)
�Ή����Ă��Ȃ��Ă��A���݂͊W���ǍD�Ȃ̂ł��܂�ǂ��ł������ł���
�����G�ΊW�ɂȂ����Ƃ��̂��Ƃ��l����ƁA�ƂĂ����낵���ł����A
Nvidia��Intel�ƃV�F�A�푈���Ă����o���ƁAFusion��FireStream�̐��\�ƁAx86�\�t�g���Y
������ΐ킦��ƐM���Ă��܂�
( �킦�܂����? )
�Ή�������Intel�̊��S�s�k�ł���
����������ǂ��Ő����c���ł��傤���ˁ@(PC�ȊO�͂悭�킩��Ȃ�)
�Ή����Ă��Ȃ��Ă��A���݂͊W���ǍD�Ȃ̂ł��܂�ǂ��ł������ł���
�����G�ΊW�ɂȂ����Ƃ��̂��Ƃ��l����ƁA�ƂĂ����낵���ł����A
Nvidia��Intel�ƃV�F�A�푈���Ă����o���ƁAFusion��FireStream�̐��\�ƁAx86�\�t�g���Y
������ΐ킦��ƐM���Ă��܂�
( �킦�܂����? )
>>848
>F@H�Ńn�[�h�X�y�b�N�Ɍ����������\�������ł��Ă��Ȃ�
�����ł��Ă��Ȃ��Ȃ�A����̍œK���Ŋ�]������܂�
�A�����{���̐��\�Ȃ獢�������̂ł�
F@h�X���ł́A�V�F�[�_�[�\���̗��x�̑傫����Nvidia�ɗ�邻���ł�
RV770��80X10���ƍœK������̂�������ł����A���̂ւ��R800�ȍ~�ʼn��P���ė~�����ł���
>F@H�Ńn�[�h�X�y�b�N�Ɍ����������\�������ł��Ă��Ȃ�
�����ł��Ă��Ȃ��Ȃ�A����̍œK���Ŋ�]������܂�
�A�����{���̐��\�Ȃ獢�������̂ł�
F@h�X���ł́A�V�F�[�_�[�\���̗��x�̑傫����Nvidia�ɗ�邻���ł�
RV770��80X10���ƍœK������̂�������ł����A���̂ւ��R800�ȍ~�ʼn��P���ė~�����ł���
�����T�������ˁ[����
>>815
�Џ@�͍�S3��Chrome400��shader�p�t�H�[�}���X�iGS�Astream out���j���ُ�ɍ����̂��C�ɂȂ��Ă�
440GTX�@2���������炵������
ttp://xs228.xs.to/xs228/08256/cubemapgs440gtx774.jpg
ttp://xs128.xs.to/xs128/08256/cubemapgs3870793.jpg
ttp://xs228.xs.to/xs228/08256/metaballs440gtx858.jpg
ttp://xs228.xs.to/xs228/08256/metaballs3870933.jpg
ttp://xs128.xs.to/xs128/08256/particlesgs440gtx263.jpg
ttp://xs228.xs.to/xs228/08256/particlesgs3870619.jpg
ttp://xs128.xs.to/xs128/08256/pipesgs440gtx960.jpg
ttp://xs128.xs.to/xs128/08256/pipesgs3870985.jpg
�Џ@�͍�S3��Chrome400��shader�p�t�H�[�}���X�iGS�Astream out���j���ُ�ɍ����̂��C�ɂȂ��Ă�
440GTX�@2���������炵������
ttp://xs228.xs.to/xs228/08256/cubemapgs440gtx774.jpg
{kind=link}
ttp://xs128.xs.to/xs128/08256/cubemapgs3870793.jpg
{kind=link}
ttp://xs228.xs.to/xs228/08256/metaballs440gtx858.jpg
{kind=link}
ttp://xs228.xs.to/xs228/08256/metaballs3870933.jpg
{kind=link}
ttp://xs128.xs.to/xs128/08256/particlesgs440gtx263.jpg
{kind=link}
ttp://xs228.xs.to/xs228/08256/particlesgs3870619.jpg
{kind=link}
ttp://xs128.xs.to/xs128/08256/pipesgs440gtx960.jpg
{kind=link}
ttp://xs128.xs.to/xs128/08256/pipesgs3870985.jpg
{kind=link}
853 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 22:13:52 ID:YpuPayhY
>>833
�����Ԃ�Ԕ�����
�����Ԃ�Ԕ�����
854 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 22:16:43 ID:YpuPayhY
>>850
>���x���グ��
��SIMD�����߂ăX�J���ɂ���
���ꂾ�ƃs�[�N���\�^����d�͂͑啝�ɗ������Ⴂ�܂��˂�������
�ł�nVIDIA�̓s�[�N���\����GPGPU�Ƃ��Ă̔ėp����I�킯�ŁB
>���x���グ��
��SIMD�����߂ăX�J���ɂ���
���ꂾ�ƃs�[�N���\�^����d�͂͑啝�ɗ������Ⴂ�܂��˂�������
�ł�nVIDIA�̓s�[�N���\����GPGPU�Ƃ��Ă̔ėp����I�킯�ŁB
855 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 22:37:05 ID:YpuPayhY
��������SSE5��GPGPU�A�g����
16bit���x�x�N�^��32bit���x�x�N�^�̍\���̂�
�ϊ��@�u�����v�@�����}�W��
����ϑz���Ă�̂��͒m��Ȃ����A��̈����w��̕s���R�ȐϘa�Z����GPU����Ȃ���
CPU������SSE���j�b�g�ł����B
�i���AVX�ł�FMA�͐^��4�I�y�����h���Z�������j
�܂������炭�p��̃h�L�������g���ǂ߂Ȃ��A�z�̎q������d���Ȃ����ǂ��B
16bit���x�x�N�^��32bit���x�x�N�^�̍\���̂�
�ϊ��@�u�����v�@�����}�W��
����ϑz���Ă�̂��͒m��Ȃ����A��̈����w��̕s���R�ȐϘa�Z����GPU����Ȃ���
CPU������SSE���j�b�g�ł����B
�i���AVX�ł�FMA�͐^��4�I�y�����h���Z�������j
�܂������炭�p��̃h�L�������g���ǂ߂Ȃ��A�z�̎q������d���Ȃ����ǂ��B
���~�������PC��g�����ƌv�撆������AMD�ɂ��Ă͂܂������킩��Ȃ���(�L�E�ցE�M)
���A�g���Ă��鎩��PC��Intel��E6600+G965�̑g�ݍ��킹�����ǂˁB
����̃e�[�}�́u�ȃG�l�ł���Ȃ��獂���\+�ᔭ�M+�É��v�őg��ł��B
������e�[�}�͕ς��Ȃ��ŏ������\������_���Ă������AMD�͂ǂ�Ȃ̂��ǂ��H
(�ł���̂Ȃ�E6600+G965�Ƃ̔�r���~������(�L�E�ցE)�x���`�}�[�N�Ȃ��H)
���A�g���Ă��鎩��PC��Intel��E6600+G965�̑g�ݍ��킹�����ǂˁB
����̃e�[�}�́u�ȃG�l�ł���Ȃ��獂���\+�ᔭ�M+�É��v�őg��ł��B
������e�[�}�͕ς��Ȃ��ŏ������\������_���Ă������AMD�͂ǂ�Ȃ̂��ǂ��H
(�ł���̂Ȃ�E6600+G965�Ƃ̔�r���~������(�L�E�ցE)�x���`�}�[�N�Ȃ��H)
ID:J4rXJ/yN�@�̒ɂ��͑f���炵���ȁB
>>856
�X���Ⴂ�B�X���̋�C��ǂ߂Ȃ��f�l�͎���Ȃ�Ă��Ȃ��ŁA
�������ƃ��[�J�[��PC�ł����������Ǝv����B
�N���������������ł����ς��肷��X��73
http://pc11.2ch.net/test/read.cgi/jisaku/1214110852/
�X���Ⴂ�B�X���̋�C��ǂ߂Ȃ��f�l�͎���Ȃ�Ă��Ȃ��ŁA
�������ƃ��[�J�[��PC�ł����������Ǝv����B
�N���������������ł����ς��肷��X��73
http://pc11.2ch.net/test/read.cgi/jisaku/1214110852/
860 �F�R�E�L�́M�E,,�j�����������������F2008/06/22(��) 23:01:21 ID:YpuPayhY
>>856
Intel�Ȃ�E7200�{G45�ŗǂ��Ǝv�����B
�i���\�I�ɂ�E6600�Ƃǂ����������ȓd�͉��͌��ʂ��邩���ˁB�j
AMD�ŏȓd�͑_���Ȃ炻������X�y�b�N�_�E���͖Ƃ�Ȃ��Ǝv���
AMD�ɍS��Ȃ�45nm�v���Z�X�҂��������ǂ��B
Intel�Ȃ�E7200�{G45�ŗǂ��Ǝv�����B
�i���\�I�ɂ�E6600�Ƃǂ����������ȓd�͉��͌��ʂ��邩���ˁB�j
AMD�ŏȓd�͑_���Ȃ炻������X�y�b�N�_�E���͖Ƃ�Ȃ��Ǝv���
AMD�ɍS��Ȃ�45nm�v���Z�X�҂��������ǂ��B
>>860
�d�d�@�c������
���~������őg�����Ǝv���Ă����̂�Intel�̉��i�����G45�̔����҂��Ȃ킯����
AMD�v�������҂����E�E�E���̊Ԃɋߍ���PC�p�[�c�ɂ��ĕ����邩(�L�́M)
�Ƃ����>>858�������ɂ͎����̃��X�̓X���Ⴂ�Ȃ킯�����{�X���͂ǂ��ł����H
�d�d�@�c������
���~������őg�����Ǝv���Ă����̂�Intel�̉��i�����G45�̔����҂��Ȃ킯����
AMD�v�������҂����E�E�E���̊Ԃɋߍ���PC�p�[�c�ɂ��ĕ����邩(�L�́M)
�Ƃ����>>858�������ɂ͎����̃��X�̓X���Ⴂ�Ȃ킯�����{�X���͂ǂ��ł����H
>>857
�܂��ϑz���ꗬ���Ă��邾��������ȁA�C�ɂ����
�f�l�u�ȍ~�ɂ�����Ȃ�Ɋ��҂͂��Ă��邪�APhenom���炻��قǕς���Ă��Ȃ�����
���Ɍ�邱�Ƃ��Ȃ���
L3�L���b�V����6M�ɑ�������ADDR3�ɑΉ����邱�Ƃ����C���ŁA
�����R�A�ɂ͎�����邩������A45nm�v���Z�X�ɍœK�����邭�炢����
��́A���\�I�ɂ́A6�R�A�̃C�X�^���u�����l�n�����ɐH��������邩
L3�L���b�V���Ȃ���Propus�́ATDP��R�X�g�Ɋ��҂��炢����
��C����ɑ債�Ċ��҂��Ă��Ȃ����̋�����Fusion�ɂ����Ȃ��킯�ŁA
�A�[�L�e�N�`���[���猈�܂��Ă��Ȃ�����ϑz���邵���o���Ȃ��̂����y�����ǂ�
�܂��ϑz���ꗬ���Ă��邾��������ȁA�C�ɂ����
�f�l�u�ȍ~�ɂ�����Ȃ�Ɋ��҂͂��Ă��邪�APhenom���炻��قǕς���Ă��Ȃ�����
���Ɍ�邱�Ƃ��Ȃ���
L3�L���b�V����6M�ɑ�������ADDR3�ɑΉ����邱�Ƃ����C���ŁA
�����R�A�ɂ͎�����邩������A45nm�v���Z�X�ɍœK�����邭�炢����
��́A���\�I�ɂ́A6�R�A�̃C�X�^���u�����l�n�����ɐH��������邩
L3�L���b�V���Ȃ���Propus�́ATDP��R�X�g�Ɋ��҂��炢����
��C����ɑ債�Ċ��҂��Ă��Ȃ����̋�����Fusion�ɂ����Ȃ��킯�ŁA
�A�[�L�e�N�`���[���猈�܂��Ă��Ȃ�����ϑz���邵���o���Ȃ��̂����y�����ǂ�
���t�����̊Ԃɂ��ς���Ă����
�����x�݂��I��肾�����͑ގU�����
�Ƃ肠�������O������ƌ���Ă���A�ʔ����b�������Ă���
MAC�I�^�ƒc�q�ƃA���~�͎���
�����x�݂��I��肾�����͑ގU�����
�Ƃ肠�������O������ƌ���Ă���A�ʔ����b�������Ă���
MAC�I�^�ƒc�q�ƃA���~�͎���
>>862
�ŏ���FUSION�āA�m�[�g�p�̃g�����X���^�݂����ȓz�Ȃ�Ȃ����H
�ŏ���FUSION�āA�m�[�g�p�̃g�����X���^�݂����ȓz�Ȃ�Ȃ����H
>>864
�g�����X���^�݂����Ƃ����ƁA�R�[�h���[�t�B���O�݂����ȃ\�t�g����ē������Ƃ������Ƃł�����
�g�����X���^�̃N���[�\�[��G�t�B�V�I���͖ڂ���ł������A�������D�����������
���l�̍\���ł������ł���
�R�}���h�v���Z�b�T�[�̉���CPU�R�A��GPU�R�A�������ĥ��
�����������A�R�}���h�v���Z�b�T���R�[�h���[�t�B���O�̑���Ȃ̂��A���C�Â���
��������ƁAGPU���͊���Fusion�ɑΉ����鏀���͐����Ă���̂�
��́A�R�}���h�v���Z�b�T��CPU�R�A�̗Z���ň�ԓ�q���Ă���̂�
�g�����X���^��CPU�ɋ߂��\���̉\���͍����ł��ˁA�Ƃ���������ȊO�Ȃ��悤�ȋC������
�v�����̂́A�R�}���h�v���Z�b�T�̉��ɐ������Z�����R�A��GPU�R�A������œ����ł���
���������GPU�R�A���唼���߂�̂ł��傤����
�G�t�B�V�I���J���w������AMD�ɂ��āAFusion�̊J���Ɋւ��Ă����肷��Ƃ��Ȃ��ł�����
�g�����^+AMD+ATI�Ƃ��A�h���[���`�[���߂��Ăǂ����悤
�g�����X���^�݂����Ƃ����ƁA�R�[�h���[�t�B���O�݂����ȃ\�t�g����ē������Ƃ������Ƃł�����
�g�����X���^�̃N���[�\�[��G�t�B�V�I���͖ڂ���ł������A�������D�����������
���l�̍\���ł������ł���
�R�}���h�v���Z�b�T�[�̉���CPU�R�A��GPU�R�A�������ĥ��
�����������A�R�}���h�v���Z�b�T���R�[�h���[�t�B���O�̑���Ȃ̂��A���C�Â���
��������ƁAGPU���͊���Fusion�ɑΉ����鏀���͐����Ă���̂�
��́A�R�}���h�v���Z�b�T��CPU�R�A�̗Z���ň�ԓ�q���Ă���̂�
�g�����X���^��CPU�ɋ߂��\���̉\���͍����ł��ˁA�Ƃ���������ȊO�Ȃ��悤�ȋC������
�v�����̂́A�R�}���h�v���Z�b�T�̉��ɐ������Z�����R�A��GPU�R�A������œ����ł���
���������GPU�R�A���唼���߂�̂ł��傤����
�G�t�B�V�I���J���w������AMD�ɂ��āAFusion�̊J���Ɋւ��Ă����肷��Ƃ��Ȃ��ł�����
�g�����^+AMD+ATI�Ƃ��A�h���[���`�[���߂��Ăǂ����悤
http://www.geocities.jp/andosprocinfo/wadai08/20080315.htm
�ŋ߂̘b�� 2008�N3��15��
Transmeta�n�Ǝ҂�Dave Ditzel����Intel�ɓ���
�ŋ߂̘b�� 2008�N3��15��
Transmeta�n�Ǝ҂�Dave Ditzel����Intel�ɓ���
867 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 02:44:56 ID:EIWcDaUX
>>865
���A�t�H�Ȃ��ƌ����Ă��
Transmeta��CPU�͒P�Ƀ`�b�v�Z�b�g����������������
���Ȃ݂ɃR�[�h���[�t�B���O�]�X�̋Z�p�҂�����Intel�̎Ј��ł��B
���A�t�H�Ȃ��ƌ����Ă��
Transmeta��CPU�͒P�Ƀ`�b�v�Z�b�g����������������
���Ȃ݂ɃR�[�h���[�t�B���O�]�X�̋Z�p�҂�����Intel�̎Ј��ł��B
>>866
����A�n�Ǝ҂Ƃ��ǂ��ł���������
�d�v�Ȃ̂̓R�[�h���[�t�B���O�̊J���w
Intel�ɍs�����Ƃ����ǂ��ł������AAMD�ɂ����炢���ȂƂ����b
���Ȃ��Ȃ炢�Ȃ��ŁA�d���Ȃ��Ȃƒ��߂邾��
����A�n�Ǝ҂Ƃ��ǂ��ł���������
�d�v�Ȃ̂̓R�[�h���[�t�B���O�̊J���w
Intel�ɍs�����Ƃ����ǂ��ł������AAMD�ɂ����炢���ȂƂ����b
���Ȃ��Ȃ炢�Ȃ��ŁA�d���Ȃ��Ȃƒ��߂邾��
870 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 02:58:46 ID:EIWcDaUX
��i�I��VLIW�A�[�L��IA64�����ꂸ�Ɉ��Ղ�x86��64�r�b�g�g����擱����AMD��
�Ǝ���VLIW�ȂJ���ł���킯���Ȃ��B
�Ǝ���VLIW�ȂJ���ł���킯���Ȃ��B
�܂�����Ȃ��Đ������������ȁB
872 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 03:16:43 ID:EIWcDaUX
�[��GPU��VLIW�Ƃ͍��{�I�ɕʕ�
Crusoe��Efficeon�̃R�[�h���[�t�B���O��
�����A��Sun�̃v���Z�b�T�A�[�L�e�N�g�ł���Ditzel�������グ���ƌ����Ă���
�����A��Sun�̃v���Z�b�T�A�[�L�e�N�g�ł���Ditzel�������グ���ƌ����Ă���
>>870
IA64�ȂV���l
IA32���x���A�[�L�Ȃǂ��ł�����
PC�����ő厖�Ȃ̂�x86�Ƃ̌݊������A�J�����₷��x86��64�r�b�g�g���ɐi�ނ͓̂��R
Intel�������q���������H���l�̊g����i�߂Ă�����
VLIW������GPU�Ŋ��ɓ����ς݂��ARadeon�̍\���ƃR�}���h�v���Z�b�T�m���Ă邩�H
����2�N�ȏ�̃m�E�n�E������
�܂��ACPU�Ƃ��ē]�p����̂ɂǂ�قǂ̍�������邩�m��Ȃ�����
���O�n���Ȃ���Â��ɂ��Ă���
�����������肵�Ă��鉴���n�������ǂ�
IA64�ȂV���l
IA32���x���A�[�L�Ȃǂ��ł�����
PC�����ő厖�Ȃ̂�x86�Ƃ̌݊������A�J�����₷��x86��64�r�b�g�g���ɐi�ނ͓̂��R
Intel�������q���������H���l�̊g����i�߂Ă�����
VLIW������GPU�Ŋ��ɓ����ς݂��ARadeon�̍\���ƃR�}���h�v���Z�b�T�m���Ă邩�H
����2�N�ȏ�̃m�E�n�E������
�܂��ACPU�Ƃ��ē]�p����̂ɂǂ�قǂ̍�������邩�m��Ȃ�����
���O�n���Ȃ���Â��ɂ��Ă���
�����������肵�Ă��鉴���n�������ǂ�
875 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 03:33:40 ID:EIWcDaUX
����ATi�͂����������ˁBnVIDIA�͐��������ǁB
���̌��ʂ����O����D����F@H��nVIDIA�ɎS�s���ᐢ�b������B
GPU��CPU�ɋ߂Â���ɂ̓X�J�����̂ق��������������킯���B
���̌��ʂ����O����D����F@H��nVIDIA�ɎS�s���ᐢ�b������B
GPU��CPU�ɋ߂Â���ɂ̓X�J�����̂ق��������������킯���B
�����VLIW�Ȃ�
�܂���AMD�����œƎ��Ɍ����J�����Ȃ�����
Intel�ȊO��VLIW�ɏڂ�����Ђ⌤���҂ɋ��͂��Ă��炤���낤����
Intel�ɂ��錳�g�����^�̋Z�p�҂��w�b�h�n���e�B���O���Ă�������
�Ȃ�VLIW�O��Řb���Ă��܂������A�ʂ�VLIW���ᖳ���Ă�������
�����Ɨ\�z�̎ߏ�̖ڂ���ŃR�����u�X�̗��I�Ȃ��̂𗊂ނ�AMD����
�܂���AMD�����œƎ��Ɍ����J�����Ȃ�����
Intel�ȊO��VLIW�ɏڂ�����Ђ⌤���҂ɋ��͂��Ă��炤���낤����
Intel�ɂ��錳�g�����^�̋Z�p�҂��w�b�h�n���e�B���O���Ă�������
�Ȃ�VLIW�O��Řb���Ă��܂������A�ʂ�VLIW���ᖳ���Ă�������
�����Ɨ\�z�̎ߏ�̖ڂ���ŃR�����u�X�̗��I�Ȃ��̂𗊂ނ�AMD����
877 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 03:44:03 ID:EIWcDaUX
Intel����w�b�h�n���g�H�ǂ��ɂ�����ȋ�
��������AMD�u�����h��Efficeon���o�����炢�ڋ߂��Ă���B
�f�B�b�c�F���l���~�����Ȃ�Intel�ɐ����O�Ɋm�ۂ��Ă�������B
�v����ɂ����������Ƃ��B
�܂��܂��͎��{�͋������ȁB
�����������Ă̓T���X���ɐg���肷��̂��m�����Ǝv���̂����B
��������AMD�u�����h��Efficeon���o�����炢�ڋ߂��Ă���B
�f�B�b�c�F���l���~�����Ȃ�Intel�ɐ����O�Ɋm�ۂ��Ă�������B
�v����ɂ����������Ƃ��B
�܂��܂��͎��{�͋������ȁB
�����������Ă̓T���X���ɐg���肷��̂��m�����Ǝv���̂����B
�����ɂ���
�����d���Ȃ̂ɑ����Q��扴
>>875
F@H�͔[���ł��Ȃ����A�����������݂���������d���Ȃ�
RV770�ł̌��ʑ҂������AR800��R900�ł����P���邾��
�X�J�����Ƃ�VLIW�Ƃ��ʂɂǂ��ł��������A�������������Ȃ�����]������ł���
�Ӓn�͂��Ă��Ȃ��\�������邯�ǂ�
�d�v�Ȃ̂�AMD��Fusion������������intel�炵�߂邱�Ƃ�����A
�r�������]�Ȑ܂͎��̍�Ƃ��Ċy���ނ������A���O�̃��X���܂߂Ă�
���i�͓������ځ[�Ă��邯�ǂ�
�����d���Ȃ̂ɑ����Q��扴
>>875
F@H�͔[���ł��Ȃ����A�����������݂���������d���Ȃ�
RV770�ł̌��ʑ҂������AR800��R900�ł����P���邾��
�X�J�����Ƃ�VLIW�Ƃ��ʂɂǂ��ł��������A�������������Ȃ�����]������ł���
�Ӓn�͂��Ă��Ȃ��\�������邯�ǂ�
�d�v�Ȃ̂�AMD��Fusion������������intel�炵�߂邱�Ƃ�����A
�r�������]�Ȑ܂͎��̍�Ƃ��Ċy���ނ������A���O�̃��X���܂߂Ă�
���i�͓������ځ[�Ă��邯�ǂ�
����Ȑ~�[�ϑz����Љ�l��
��Г�or�����ɂ��Ȃ����Ƃ��F��܂�
��Г�or�����ɂ��Ȃ����Ƃ��F��܂�
>>877
���Ȃǂ��ɂł��Ȃ�
�h�C�c��A���u�̂��������Ƃ����o�b�N�ɂ��邵
����RV770��Nvidia�ɑ叟��������A����̓V�F�A���サ�Ď��v���オ��ł���
�o���Z���iOpteron���D���炵����
���o����������A�����Ă����Ƃ��������Ȃ����H
�Ƃɂ���AMD�͍��m���m��������ǂ��̔����ɂ������Ȃ�����
(�Ԏ������ǂ�)
���Ȃǂ��ɂł��Ȃ�
�h�C�c��A���u�̂��������Ƃ����o�b�N�ɂ��邵
����RV770��Nvidia�ɑ叟��������A����̓V�F�A���サ�Ď��v���オ��ł���
�o���Z���iOpteron���D���炵����
���o����������A�����Ă����Ƃ��������Ȃ����H
�Ƃɂ���AMD�͍��m���m��������ǂ��̔����ɂ������Ȃ�����
(�Ԏ������ǂ�)
>�o���Z���iOpteron���D��
�݂݂͂ł�
�݂݂͂ł�
>>882
���Ƀ\�[�X�͂Ȃ��ł�
�P�Ƀo���Z���i���ڃT�[�o�[�̋L�������������������ł�
B2�ł�����B3�܂Ŕ��N���������̂ɐ��i�o�ĂĂ悩�����Ƃ�������
�Ƃ��Ƃƌ�������Xeon��F�ɂȂ�Ǝv���Ă����̂�
���ۂ̂Ƃ���͑�2�l�������Z�҂��ł���
�����͐Ԏ��������Ă�Ƃ����ȥ��
���Ƀ\�[�X�͂Ȃ��ł�
�P�Ƀo���Z���i���ڃT�[�o�[�̋L�������������������ł�
B2�ł�����B3�܂Ŕ��N���������̂ɐ��i�o�ĂĂ悩�����Ƃ�������
�Ƃ��Ƃƌ�������Xeon��F�ɂȂ�Ǝv���Ă����̂�
���ۂ̂Ƃ���͑�2�l�������Z�҂��ł���
�����͐Ԏ��������Ă�Ƃ����ȥ��
8600�Ȃ�āA����GPU������������z���K���ł���
����nv�͐��ނ̈�r
�����[�͎U��
����肾��
����nv�͐��ނ̈�r
�����[�͎U��
����肾��
>>870
IA64�͑��Ђ��݊�CPU���Ȃ��悤�Ɏ��ӂ�������̏��W���̂ŃK�`�K�`�Ɍł߂Ă���낤�Ǝv������
�i���Ȃ݂�ISA���̂ɂ͒��쌠�͔������Ȃ��j
IA64�͑��Ђ��݊�CPU���Ȃ��悤�Ɏ��ӂ�������̏��W���̂ŃK�`�K�`�Ɍł߂Ă���낤�Ǝv������
�i���Ȃ݂�ISA���̂ɂ͒��쌠�͔������Ȃ��j
IA64�̓p�t�H�[�}���X���o�����߂ɂ̓R���p�C���ɂ�������d��������Ă��炤�K�v������킯�ŁA
���ЂŎ��А��i�ɍœK�����ꂽ�R���p�C�����o���Ă�Intel�Ȃ���邯�ǁA
�ق��̂Ƃ���̃R���p�C�����g�킴��Ȃ�AMD��IA64�����͖̂����ł���B�Z�J���h�\�[�X�Ȃ�Ƃ������B
���ЂŎ��А��i�ɍœK�����ꂽ�R���p�C�����o���Ă�Intel�Ȃ���邯�ǁA
�ق��̂Ƃ���̃R���p�C�����g�킴��Ȃ�AMD��IA64�����͖̂����ł���B�Z�J���h�\�[�X�Ȃ�Ƃ������B
887 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 12:21:25 ID:EIWcDaUX
>>885
���Ȃ��͂Ȃ��ł���B���C�Z���X������B
>>886
IA64�łȂ��Ƃ�����VLIW�S�ʂɌ����邱�Ƃ�����
�[��GPU�̃g�b�v�V�F�A�̓_���g�c��Intel GMA�Ȃ��Ƃ�Y��Ă�������邪
Larrabee��GPU�ƌ����ʒu�Â��Ȃ�A�g�����͂Ƃ�����
���y�͖��ꂽ�悤�Ȃ��́B
�܂�Nehalem�ȍ~�̕��y���i�т�CPU�R�A�ׂ̗ɂ�
GMA���ڂ���Ă��Ƃ̈Ӗ����l���������ǂ��B
�܂�GMA��Larrabee�x�[�X�ɒu�������̂͂��炭��ɂȂ邾�낤���ǂ�
���Ȃ��͂Ȃ��ł���B���C�Z���X������B
>>886
IA64�łȂ��Ƃ�����VLIW�S�ʂɌ����邱�Ƃ�����
�[��GPU�̃g�b�v�V�F�A�̓_���g�c��Intel GMA�Ȃ��Ƃ�Y��Ă�������邪
Larrabee��GPU�ƌ����ʒu�Â��Ȃ�A�g�����͂Ƃ�����
���y�͖��ꂽ�悤�Ȃ��́B
�܂�Nehalem�ȍ~�̕��y���i�т�CPU�R�A�ׂ̗ɂ�
GMA���ڂ���Ă��Ƃ̈Ӗ����l���������ǂ��B
�܂�GMA��Larrabee�x�[�X�ɒu�������̂͂��炭��ɂȂ邾�낤���ǂ�
>>886
��������Ԃ̃l�b�N����ȁBx86-64�����Č��ǂ�MS���肾���A
�����l�����SSE5��MS�ɗ��ނ��A�Ǝ��ł���Ă��炤���ɂȂ�낤�ȁB
�h���C�o���x���łǂ������ł�����Ȃ�A���Ƃ��Ȃ肻�������A
�ł�����ς茋�ǂ͕��y���Ȃ��ŏ�����m�������������ȁBSSE5�B
��������Ԃ̃l�b�N����ȁBx86-64�����Č��ǂ�MS���肾���A
�����l�����SSE5��MS�ɗ��ނ��A�Ǝ��ł���Ă��炤���ɂȂ�낤�ȁB
�h���C�o���x���łǂ������ł�����Ȃ�A���Ƃ��Ȃ肻�������A
�ł�����ς茋�ǂ͕��y���Ȃ��ŏ�����m�������������ȁBSSE5�B
Intel GMA�Ȃ��GPU�Ƃ��ĔF�߂Ȃ�
IA64�͎��オ��������
�Ƃ������R���r�t�m����̐��i�Q����
�Ƃ������R���r�t�m����̐��i�Q����
GMA�ɐ��\���Ƃ߂�z�͂��Ȃ��B
���A�O�t���O���{�h������h�����ŁAx86���߃Z�b�g�̃X�g���[���v���Z�b�T���B
Larrabee��GPGPU��H���Ƃ����̂͂܂������������Ƃ��ȁB
�ւ��ɕ��y�����AMD��GPU�܂ł���Intel��Ǐ]������Ȃ��Ȃ�B
�����������ςȐ헪��Intel�����̃p���m�C�A���鏊�Ȃ�
���A�O�t���O���{�h������h�����ŁAx86���߃Z�b�g�̃X�g���[���v���Z�b�T���B
Larrabee��GPGPU��H���Ƃ����̂͂܂������������Ƃ��ȁB
�ւ��ɕ��y�����AMD��GPU�܂ł���Intel��Ǐ]������Ȃ��Ȃ�B
�����������ςȐ헪��Intel�����̃p���m�C�A���鏊�Ȃ�
>GMA�ɐ��\���Ƃ߂�z�͂��Ȃ��B
���\��10�{�ɂ���炵����B���Ԃ̂��炢�܂ŋ�������A
����XBOX360/PS3/PC�̃}���`�^�C�g�����~�f�B�A���ݒ�œ��������炢�͂ł���悤�ɂȂ�Ǝv���B
���\��10�{�ɂ���炵����B���Ԃ̂��炢�܂ŋ�������A
����XBOX360/PS3/PC�̃}���`�^�C�g�����~�f�B�A���ݒ�œ��������炢�͂ł���悤�ɂȂ�Ǝv���B
>>875
GPU�Ƃ��č����\�ȕ�����遨�Ƃ肠����CPU�ɂ��������
�����Z�̓V�F�[�_�ɂ�����l�ɃR�A������
�����߃Z�b�g������
��AMD�͒i�K�I�ɂ������
�܂����i�K�Ȗ�
GPU�Ƃ��č����\�ȕ�����遨�Ƃ肠����CPU�ɂ��������
�����Z�̓V�F�[�_�ɂ�����l�ɃR�A������
�����߃Z�b�g������
��AMD�͒i�K�I�ɂ������
�܂����i�K�Ȗ�
894 �FSocket774�F2008/06/23(��) 15:33:15 ID:nTqWTbHf
�C���e���̃h���C�o���E���R�Ȃ̂��F�Y�ꂽ�̂��H
�z�ʂ͌���A�����\�͒ቺ�Ƃ�����炵������
GPGPU���6�R�AMCM��12�R�A�̕���
����ۂnj����������p���l�����肻���ȋC������͉̂��������H
�P���x���Z�ł͋y�Ȃ����A�{���x���Z�Ȃ牽�Ƃ������x��������
12�X���b�h���s�ł���܂Ƃ��ł́B
�܂��M�Ɠd�͂�2GHz�������Ƃ��낾�낤���ǂȁ[
����ۂnj����������p���l�����肻���ȋC������͉̂��������H
�P���x���Z�ł͋y�Ȃ����A�{���x���Z�Ȃ牽�Ƃ������x��������
12�X���b�h���s�ł���܂Ƃ��ł́B
�܂��M�Ɠd�͂�2GHz�������Ƃ��낾�낤���ǂȁ[
12�R�A�܂ōs���ƕ����̂��Ȃ荂���v���O��������Ȃ��Ɛ��\�o�Ȃ��Ȃ�B
��
�����̍����v���O�������
��
����HGPGPU�ł�����������\�オ�邵����d�͓I�ɂ�������ŁH
��
GPGPU����
��
�����̍����v���O�������
��
����HGPGPU�ł�����������\�オ�邵����d�͓I�ɂ�������ŁH
��
GPGPU����
>>897
���ǃ\�t�g�E�F�A�̑g�ݕ����悩��B
���ǃ\�t�g�E�F�A�̑g�ݕ����悩��B
�Ƃ������A���v���悶��ˁH
���ł������PC�̐��\�́A��ʐl�ɂ͑���Ă����
�ނ��덡��͐��\���ȓd�͂��Ă��ƂɂȂ邩������Ȃ�
�G���R�ɂ��Ă��A���l�͂��������Ȃ����A�Q�[���Ȃ���{����Q�[���@����
�ǂ��������v���@��N������邩�ŁA�ǂꂪ�����c�邩�ς���Ă���݂�����
���ł������PC�̐��\�́A��ʐl�ɂ͑���Ă����
�ނ��덡��͐��\���ȓd�͂��Ă��ƂɂȂ邩������Ȃ�
�G���R�ɂ��Ă��A���l�͂��������Ȃ����A�Q�[���Ȃ���{����Q�[���@����
�ǂ��������v���@��N������邩�ŁA�ǂꂪ�����c�邩�ς���Ă���݂�����
AMD��GPGPU�W�̊J������nVidia��CUDA�ɂ�����������t�����Ă邩��˂��B
����ł͑��Ђ̃\�t�g�E�F�A���g���镪x86�R�A����ׂ�����������Ȃ��̂��B���Ȃ��Ƃ�����ł́B
����ł͑��Ђ̃\�t�g�E�F�A���g���镪x86�R�A����ׂ�����������Ȃ��̂��B���Ȃ��Ƃ�����ł́B
901 �FSocket774�F2008/06/23(��) 17:43:19 ID:nTqWTbHf
12�R�A�̓C�X�^���u�[��*2�����邩��ǂ��ł������ȁB
�v��3���~�ʂ�1T�ȏ�̐��\�̐��o���邩������B
�C���e���͏o���C�͖����Ǝv���ȁB
�v��3���~�ʂ�1T�ȏ�̐��\�̐��o���邩������B
�C���e���͏o���C�͖����Ǝv���ȁB
Larrabee�����邶���
�C���e����10�{�͌`�ɂȂ�������3�{���炢������c
�Ōォ�琫�\10�{���i50�{�̂��o����
�Ōォ�琫�\10�{���i50�{�̂��o����
>>896
GPU�ɔ{���x���K�v�ɂȂ����烆�j�b�g���₷�ł���
ttp://pc.watch.impress.co.jp/docs/2008/0620/kaigai449.htm?ref=rss
GPU�ɔ{���x���K�v�ɂȂ����烆�j�b�g���₷�ł���
ttp://pc.watch.impress.co.jp/docs/2008/0620/kaigai449.htm?ref=rss
905 �FSocket774�F2008/06/23(��) 18:17:28 ID:H1a99ANN
�h���C�o�[�����ƌ����AATI�������̂��������ȁB
GPU�Ƃ��Ă̋@�\�{���̕t�����l�����邩��H����"����"����Ȃ��킯��
GPGPU�̋��݂��Ă����ł���
���ꂪ������������Larrabee�ɂ�GPU�Ƃ��Ă̋@�\�������邱�Ƃɂ�����Ȃ�
GPGPU�̋��݂��Ă����ł���
���ꂪ������������Larrabee�ɂ�GPU�Ƃ��Ă̋@�\�������邱�Ƃɂ�����Ȃ�
907 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 20:31:05 ID:EIWcDaUX
>>906
�����v���B������x86�x�[�X�̃X�g���[�~���O�v���Z�b�T���ᕁ�y������͓̂������ˁB
���Ƃ���Larrabee�̓��C���X�g���[���ɕ��y������\�肾�����Ǝv����B
�㓡�{�l�͖Y��Ă��������A���v�������Larrabee���̂��́B
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai02l.gif
����Nehalem����ь㑱�A�[�L�A�^��Larrabee�A�E���ŏI�`�ԂƎv����B
Larrabee��AVX/FMA���s��������Ƃ������_���l����ΑÓ�
�i�ŏI�`�ԂɂȂ����Ƃ��ɖ��߃Z�b�g���x���ł͋ψ�ł���K�v������j
�������Ă݂��Intel�͗p�ӎ������ȂƎv����B
AMD�̍����Ώۂ�nVIDIA��ATi���A���邢�͍����ł��邩����
���܂�܂ł͂����肵�ĂȂ����������l�����
Fusion���̂��̂��ˊт̍\�z�Ɍ����Ďd�����Ȃ��B
����SSE5���́AIntel���̗p���Ȃ����ƑO��ō���Ă�悤�Ɍ����邵�ȁB
�����v���B������x86�x�[�X�̃X�g���[�~���O�v���Z�b�T���ᕁ�y������͓̂������ˁB
���Ƃ���Larrabee�̓��C���X�g���[���ɕ��y������\�肾�����Ǝv����B
�㓡�{�l�͖Y��Ă��������A���v�������Larrabee���̂��́B
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai02l.gif
{kind=link}
����Nehalem����ь㑱�A�[�L�A�^��Larrabee�A�E���ŏI�`�ԂƎv����B
Larrabee��AVX/FMA���s��������Ƃ������_���l����ΑÓ�
�i�ŏI�`�ԂɂȂ����Ƃ��ɖ��߃Z�b�g���x���ł͋ψ�ł���K�v������j
�������Ă݂��Intel�͗p�ӎ������ȂƎv����B
AMD�̍����Ώۂ�nVIDIA��ATi���A���邢�͍����ł��邩����
���܂�܂ł͂����肵�ĂȂ����������l�����
Fusion���̂��̂��ˊт̍\�z�Ɍ����Ďd�����Ȃ��B
����SSE5���́AIntel���̗p���Ȃ����ƑO��ō���Ă�悤�Ɍ����邵�ȁB
>>899
����PC�������錾���ꂵ���Ȃ��Ă��ȁE�E
PEN/166�@���@K6/400�@�@�@�@�@���[�h��G�N�Z�����y���Ȃ�܂��I�@�@�@����
��6�@�@�@�@�@���@PEN3/800�@�@�@IE�������ɗ����オ��܂��I�@�@�@�@�@�@�@����
PEN3�@�@�@���@K8/2.2G�@�@�@�@IE�����\�����グ�Ă��h����ł��I�@�@����
K8�@�@�@�@�@���@�@C2Q or K10�@�@�G���R���Ă̂������炵���ł��I�@�@�@�@�p��
�Ȃǂ��\�t�g�Ȃ��̂��@orz
����PC�������錾���ꂵ���Ȃ��Ă��ȁE�E
PEN/166�@���@K6/400�@�@�@�@�@���[�h��G�N�Z�����y���Ȃ�܂��I�@�@�@����
��6�@�@�@�@�@���@PEN3/800�@�@�@IE�������ɗ����オ��܂��I�@�@�@�@�@�@�@����
PEN3�@�@�@���@K8/2.2G�@�@�@�@IE�����\�����グ�Ă��h����ł��I�@�@����
K8�@�@�@�@�@���@�@C2Q or K10�@�@�G���R���Ă̂������炵���ł��I�@�@�@�@�p��
�Ȃǂ��\�t�g�Ȃ��̂��@orz
larrabee��GPU���\���AATI/NV�̐����ɒB����Ƃ͎v���Ȃ�
GPU�Ƃ��Ďg���ɂ̓s�N�Z���ǂݏ����ɑ�ʂ̃g�����W�X�^�������Ȃ��ƃ_��������
������lbrrabee��Intel����o�Ă�HPC�̃j�b�`�ȗ̈�ł�������Ȃ��͂���
���ۂɐ��i�ɂȂ�̂͂��Ȃ薢���ɂȂ�Ǝv��
GPU�Ƃ��Ďg���ɂ̓s�N�Z���ǂݏ����ɑ�ʂ̃g�����W�X�^�������Ȃ��ƃ_��������
������lbrrabee��Intel����o�Ă�HPC�̃j�b�`�ȗ̈�ł�������Ȃ��͂���
���ۂɐ��i�ɂȂ�̂͂��Ȃ薢���ɂȂ�Ǝv��
910 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 20:56:48 ID:EIWcDaUX
��larrabee��GPU���\���AATI/NV�̐����ɒB����Ƃ͎v���Ȃ�
������B����K�v�Ȃ���B
GPU�Ƃ��Ă̐��\�]�X�����A�ėp�v���O���~���O�̕��y���ړI�B
�p�t�H�[�}���X���C�ɓ���Ȃ��Ȃ�O�t���J�[�h�t���Ă��������A��
GPU�Ƃ��Ă�Larrabee�͍��܂ł�GMA�̎p���Ɠ����B
�ŁA�O�t��GPU�t����ƁA�ŐV��x86�̖��߃Z�b�g�𓋍ڂ����X�g���[�~���O�R�A���c��B
�����ŏ��߂ăv���O���~���O���Ă݂悤�Ƃ������z�Ɏ���킯���B
x86�����������₷���B
CUDA��CAL�̂悤�Ȓׂ��̗����Ȃ�GPGPU�v���O���~���O����
�c�O�Ȃ��瑽���̐l�̋������䂩�Ȃ�����ˁB
������B����K�v�Ȃ���B
GPU�Ƃ��Ă̐��\�]�X�����A�ėp�v���O���~���O�̕��y���ړI�B
�p�t�H�[�}���X���C�ɓ���Ȃ��Ȃ�O�t���J�[�h�t���Ă��������A��
GPU�Ƃ��Ă�Larrabee�͍��܂ł�GMA�̎p���Ɠ����B
�ŁA�O�t��GPU�t����ƁA�ŐV��x86�̖��߃Z�b�g�𓋍ڂ����X�g���[�~���O�R�A���c��B
�����ŏ��߂ăv���O���~���O���Ă݂悤�Ƃ������z�Ɏ���킯���B
x86�����������₷���B
CUDA��CAL�̂悤�Ȓׂ��̗����Ȃ�GPGPU�v���O���~���O����
�c�O�Ȃ��瑽���̐l�̋������䂩�Ȃ�����ˁB
���\�������y
�܂������v���X�R
�܂������v���X�R
��������Ȃ�����A�g���邩�g���Ȃ����킩��Ȃ��`�b�v��
������͂���܂��Ȃ�
���f�B�A�v���Z�b�T�Ǝg������O�ɁA�ėpCPU��GPU�Ƃ��Ďg���Ȃ���
�N������Ȃ��Ǝv��
����x86�����������₷���B
���������Ƀ`���[�j���O���Ȃ��Ⴂ���Ȃ�����
���߃Z�b�g�Ȃ�ĊW�Ȃ���
�A�Z���u���ŏ������Ă̂Ȃ�ʂ����ǂ�
������͂���܂��Ȃ�
���f�B�A�v���Z�b�T�Ǝg������O�ɁA�ėpCPU��GPU�Ƃ��Ďg���Ȃ���
�N������Ȃ��Ǝv��
����x86�����������₷���B
���������Ƀ`���[�j���O���Ȃ��Ⴂ���Ȃ�����
���߃Z�b�g�Ȃ�ĊW�Ȃ���
�A�Z���u���ŏ������Ă̂Ȃ�ʂ����ǂ�
913 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:06:50 ID:EIWcDaUX
��x86��VLIW�@�@x86�̊g���A�[�L�e�N�`��
����H�����Ɏ��Ă��
����H�����Ɏ��Ă��
���߃Z�b�g�Ƃ��݊����ȑO�ɁAitanium�͒P���ɃR�X�g�p�t�H�[�}���X��
��������
�T�[�o�[��HPC����ł́ARISC�}�V���̂ق����ߋ��̎��Y���ē_��
�[�����Ă��̂ɁA�R�X�g�p�t�H�[�}���X�Ō��ǂ�x86�����������Ă̂�
���������Ⴞ��
��������
�T�[�o�[��HPC����ł́ARISC�}�V���̂ق����ߋ��̎��Y���ē_��
�[�����Ă��̂ɁA�R�X�g�p�t�H�[�}���X�Ō��ǂ�x86�����������Ă̂�
���������Ⴞ��
915 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:12:35 ID:EIWcDaUX
>>912
�ʓr���킹��K�v�Ȃ���
GMA��Nehalem�ȍ~�̓f���A���R�A�ȉ���CPU�I���_�C������ˁB
���ꂪ�ǂ����̃^�C�~���O��Larrabee�̏��K�͔łɒu�������Ǝv���B
�ʓr���킹��K�v�Ȃ���
GMA��Nehalem�ȍ~�̓f���A���R�A�ȉ���CPU�I���_�C������ˁB
���ꂪ�ǂ����̃^�C�~���O��Larrabee�̏��K�͔łɒu�������Ǝv���B
�R�X�g�p�t�H�[�}���X�I�ɑf����GMA�Ƃ������A�]���̃V�F�[�_�[��
�����ōs���Ǝv�����ǁE�E�E
�`�b�v�Z�b�g���������O���t�B�b�N�X��
�����ōs���Ǝv�����ǁE�E�E
�`�b�v�Z�b�g���������O���t�B�b�N�X��
>>914
���Ə���d�͂��n���p�����������B
�܂��v�����������d�͂������\�}���Z�[�Ŏn�܂��Ă�����d�����������A
���A�ŃT�[�o�[�����ɂ�x86-64�ɑR�o�����A�ėp�@�̒u�������ʼn��Ƃ�����
���тĂ邾�������B
���Ə���d�͂��n���p�����������B
�܂��v�����������d�͂������\�}���Z�[�Ŏn�܂��Ă�����d�����������A
���A�ŃT�[�o�[�����ɂ�x86-64�ɑR�o�����A�ėp�@�̒u�������ʼn��Ƃ�����
���тĂ邾�������B
918 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:16:52 ID:EIWcDaUX
�Ƃ��낪Larrabee��GMA�́u�v���I�Ȍ�p�v�Ƃ����ʒu�Â��ł�
�����Ƃ��낪Larrabee��GMA�́u�v���I�Ȍ�p�v�Ƃ����ʒu�Â��ł�
���Q���ق����ĂA�Ǝv���āALarrabee�AGMA�A�v�V�I�A��p��
�O�O������HIT����HIT���邗
���۽������
���Q���ق����ĂA�Ǝv���āALarrabee�AGMA�A�v�V�I�A��p��
�O�O������HIT����HIT���邗
���۽������
adobe���ǂ�ǂ�GPU�ɑΉ����Ă���Ă̂�
intel�͎���@����ėV��łĂ����̂���
����ł��Ԏ��ɂȂ肻���ɂȂ����ǂ�
intel�͎���@����ėV��łĂ����̂���
����ł��Ԏ��ɂȂ肻���ɂȂ����ǂ�
921 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:23:19 ID:EIWcDaUX
���̂��o�Ă݂Ȃ��Ƃ�
RADEON�͊���3���ȉ����炢�̒l�i�ŁA1TFlops�B�����Ă��܂��Ă�
��ŁALarrabee������ɑR����ɂ́A1TFlops��啝�ɏ���Ȃ���
�����Ȃ��킯�ŁA�ǂ��l���Ă�����Ǝv��
RADEON�͊���3���ȉ����炢�̒l�i�ŁA1TFlops�B�����Ă��܂��Ă�
��ŁALarrabee������ɑR����ɂ́A1TFlops��啝�ɏ���Ȃ���
�����Ȃ��킯�ŁA�ǂ��l���Ă�����Ǝv��
923 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:28:58 ID:EIWcDaUX
>>922
����P���x�ł���
Larrabee��1�R�A��8�`16DP�i�{���x�j����B
8 * 2.5(GHz) * 32(Core)
���������H
�P���x�Ȃ炻�̔{���낤����
����P���x�ł���
Larrabee��1�R�A��8�`16DP�i�{���x�j����B
8 * 2.5(GHz) * 32(Core)
���������H
�P���x�Ȃ炻�̔{���낤����
924 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:32:39 ID:EIWcDaUX
�����AIntel�͓����̊�GMA��GPGPU���C�������Ƃ�\�����Ă邩��
Larrabee GPU��GMA�Ƃ��ē��ڂ����̂������܂œ�����̘b�Ɣc�����Ă���܂��B
�����͏o�Ă�Tesla��FireStream�̋������i����
HPC�ɂ͔{���x���厖����
Larrabee GPU��GMA�Ƃ��ē��ڂ����̂������܂œ�����̘b�Ɣc�����Ă���܂��B
�����͏o�Ă�Tesla��FireStream�̋������i����
HPC�ɂ͔{���x���厖����
8DP��FMAC��32�R�A�Ƃ��A�ǂ��l���Ă���������Ƃ͎v���Ȃ�
�����Ȃ��Ƒ������\���ǂ��Ă����y���Ȃ�
�����Ȃ��Ƒ������\���ǂ��Ă����y���Ȃ�
Larrabee�������O�ɔ{���x���j�b�g���₵��GPU���f���o����ėܖ�
���݂̍j��x86�ƃ}�[�P�e�B���O�̂�
���݂̍j��x86�ƃ}�[�P�e�B���O�̂�
927 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:38:41 ID:EIWcDaUX
���{���x���j�b�g���₵��GPU���f��
�ւ�����
����GPU���{���x�u���j�b�g�v�����Ă�Ǝv���Ă�́H
�Q�[���ł̐��\�ɖ��ʂȃ��j�b�g�Ȃ�ē��ڂ��������d�͔n���H���ƒ@�����̂������B
�ւ�����
����GPU���{���x�u���j�b�g�v�����Ă�Ǝv���Ă�́H
�Q�[���ł̐��\�ɖ��ʂȃ��j�b�g�Ȃ�ē��ڂ��������d�͔n���H���ƒ@�����̂������B
928 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:46:42 ID:EIWcDaUX
���s��GPU�ł͔{���x���Z�͒P���x���j�b�g�ŕ������ă\�t�g���s�ł��B
�ł��AHPC�p�ɔ{���x���������o�[�W�����Ȃ�����炻���p�Ƀ_�C�v���K�v�ɂȂ���
����HPC�p�̃X�g���[���v���Z�b�T�ɑ��鉿�i�I�����b�g���Ȃ��Ȃ邺
���Ƃ܂�����������Ă����ǁAECC��������Ή��Ƃ��AHPC�ł͘_�O�ł��傤�ˁB
�W�Ȃ�����ATi��nVIDIA��GPU�͓���T�~�b�g�Ŋ��Ɉ������i�Ɩ��w���Œ@�����
�ƌ����b���܂������{���ł��傤����
�ł��AHPC�p�ɔ{���x���������o�[�W�����Ȃ�����炻���p�Ƀ_�C�v���K�v�ɂȂ���
����HPC�p�̃X�g���[���v���Z�b�T�ɑ��鉿�i�I�����b�g���Ȃ��Ȃ邺
���Ƃ܂�����������Ă����ǁAECC��������Ή��Ƃ��AHPC�ł͘_�O�ł��傤�ˁB
�W�Ȃ�����ATi��nVIDIA��GPU�͓���T�~�b�g�Ŋ��Ɉ������i�Ɩ��w���Œ@�����
�ƌ����b���܂������{���ł��傤����
>>927
�s��������>904�̃����N��̕��͂�������x�ǂ݂Ȃ���
�s��������>904�̃����N��̕��͂�������x�ǂ݂Ȃ���
�o�[���͎v�����݂��������̂���_
GPU���{���x���Z���j�b�g�����Ă��炻���}�W�łт����肾��ȁB
30���炢�[��Ƃ��B������������IEEE754������������B
���c�q����������̂��܂菑�����݂�߂邩���B
30���炢�[��Ƃ��B������������IEEE754������������B
���c�q����������̂��܂菑�����݂�߂邩���B
>>929-930
���[�Ԃɍ���Ȃ������B���O�瑬�����B
���[�Ԃɍ���Ȃ������B���O�瑬�����B
HPC�Ő�������ɂ́AHPC�ȊO�̕����
�����o���ĉ��i�������Ƃ��Ȃ��Ƃ����Ȃ�
�ėpCPU��GPU�ł̐�������O��
BlueGene/L�݂����ȗ�O�����邯��
�v�̃R�X�g�͓��X�����Ȃ��Ă�
HPC��p�̐v�ōs���͓̂���Ȃ���
�����o���ĉ��i�������Ƃ��Ȃ��Ƃ����Ȃ�
�ėpCPU��GPU�ł̐�������O��
BlueGene/L�݂����ȗ�O�����邯��
�v�̃R�X�g�͓��X�����Ȃ��Ă�
HPC��p�̐v�ōs���͓̂���Ȃ���
935 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:53:47 ID:EIWcDaUX
>>929
��������SP��g�ݍ��킹�Ĕ{���x���Z�����s��������@
���ăL�[���[�h���o�Ă�ˁB
ATi�͂��̕��@�Ŏ��s���Ă�
nVIDIA�͍������d���Ȃ��ɒP���x8�ɑ��{���x1�𓋍ڂ��Ă�悤������
���ꑝ�₵��������ƔM���������Ȃ��B
���Ȃ݂Ɍ��s��IA�͔{���x���j�b�g�ŒP���x�~2�ł��B
��������SP��g�ݍ��킹�Ĕ{���x���Z�����s��������@
���ăL�[���[�h���o�Ă�ˁB
ATi�͂��̕��@�Ŏ��s���Ă�
nVIDIA�͍������d���Ȃ��ɒP���x8�ɑ��{���x1�𓋍ڂ��Ă�悤������
���ꑝ�₵��������ƔM���������Ȃ��B
���Ȃ݂Ɍ��s��IA�͔{���x���j�b�g�ŒP���x�~2�ł��B
936 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:55:25 ID:EIWcDaUX
GT200��24SP��SPs�̒���2��
RV700��5SP�̓�����{���x���j�b�g���ڂ��Ă�B
�����Ƃ��P���x���j�b�g�ŕ������ă\�t�g���s�ł͂Ȃ��B
RV700��5SP�̓�����{���x���j�b�g���ڂ��Ă�B
�����Ƃ��P���x���j�b�g�ŕ������ă\�t�g���s�ł͂Ȃ��B
938 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 21:56:54 ID:EIWcDaUX
256bit FMA���B�Ȃ�قǃX�[�p�[�X�J�����B��������Y��Ă������B
�����non-SSE�ł�2 DP������킯���BCELL�Ƃ͂���ϑS�R�Ⴄ�ȁB
�����non-SSE�ł�2 DP������킯���BCELL�Ƃ͂���ϑS�R�Ⴄ�ȁB
FMA�Ȃ��ŁA8DP (2 way�X�[�p�[�X�J��+AVX�T�u�Z�b�g)
���Ă̂��L�͂ȋC������B8DP��16DP���͂܂��킩��Ȃ����ȁB
���Ă̂��L�͂ȋC������B8DP��16DP���͂܂��킩��Ȃ����ȁB
942 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:00:54 ID:EIWcDaUX
>>937
937�ւ����炢
�����疳�ʂɓd�͐H���Ă�̂�
���������ׂ�Ă���Ȃ����Ȃ���2��GPU���[�J�[
���s�c�菑�����ɂ��قǂ�����B
937�ւ����炢
�����疳�ʂɓd�͐H���Ă�̂�
���������ׂ�Ă���Ȃ����Ȃ���2��GPU���[�J�[
���s�c�菑�����ɂ��قǂ�����B
>>934
�ނ���AGPU���V�F�[�_�̐����₷��������
���E�������Ă邩��{���x������肵�āA
�O���t�B�b�N�ȊO�̓���͍����Ă���킯�ŁB
�C�����Ă�A�{���x�ƒP���x���ʉ����Ă邩����B
�g������Larrabee�ɋ߂��Ȃ�����B
�ނ���AGPU���V�F�[�_�̐����₷��������
���E�������Ă邩��{���x������肵�āA
�O���t�B�b�N�ȊO�̓���͍����Ă���킯�ŁB
�C�����Ă�A�{���x�ƒP���x���ʉ����Ă邩����B
�g������Larrabee�ɋ߂��Ȃ�����B
������ɂ���ALarrabee���ᓯ�����̃~�h����GPU�ɂ�
���ĂȂ����낤�ȁB�Q�[���O���t�B�b�N�X�ł́B
����ȊO�̕���łǂꂭ�炢Intel���\�t�g�C���t���L�߂��邩�������ȁB
���ĂȂ����낤�ȁB�Q�[���O���t�B�b�N�X�ł́B
����ȊO�̕���łǂꂭ�炢Intel���\�t�g�C���t���L�߂��邩�������ȁB
945 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:05:49 ID:EIWcDaUX
�����炱��Havok�����Ő���ł�����
Intel�I�ɃO���t�B�b�N�X������GPU��������
�ߋ��̂��̂ƈ�ۂÂ����邩���˂��B
���ۂ�GMA�̌�p�܂ł������Ƃ�
�Ȃ��Ǝv���Ă邯�ǁB
�ߋ��̂��̂ƈ�ۂÂ����邩���˂��B
���ۂ�GMA�̌�p�܂ł������Ƃ�
�Ȃ��Ǝv���Ă邯�ǁB
�c�O����GT200��30�ARV770��160�̔{���x���j�b�g�������Ă���
VLIW��64bit���Ă̂͌㓡���̒P�Ȃ�ϑz
VLIW��64bit���Ă̂͌㓡���̒P�Ȃ�ϑz
>>923
8 * 2.5(GHz) * 32(Core)=0.64TFlops���H
4850*4������ĂƂ��낾���E�E�E4850�͂���1���Ŕ����Ă��ˁB
���N����o���ŁA���Ⴂ���炢�ŏ��Ă�p�t�H�[�}���X���o����̂�����B
8 * 2.5(GHz) * 32(Core)=0.64TFlops���H
4850*4������ĂƂ��낾���E�E�E4850�͂���1���Ŕ����Ă��ˁB
���N����o���ŁA���Ⴂ���炢�ŏ��Ă�p�t�H�[�}���X���o����̂�����B
�Ă������㓡�̋L���ɂ���Ȏ������ĂȂ�����
���������I���������������ď����Ă��邾���B
���������I���������������ď����Ă��邾���B
950 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:20:57 ID:EIWcDaUX
>>948
�܂����ۂɏo�Ă鐻�i�ƊG�ɕ`�����݂��ׂ�C�͂Ȃ�����
4WayCF��Larrabee�̃^�[�Q�b�g��TDP150W�Ɏ��܂�Ƃ͎v�����A����
Intel�̗D�ʂ͋ƊE�Ő�[�v���Z�X���낤�A���Ԃ�
�܂����ۂɏo�Ă鐻�i�ƊG�ɕ`�����݂��ׂ�C�͂Ȃ�����
4WayCF��Larrabee�̃^�[�Q�b�g��TDP150W�Ɏ��܂�Ƃ͎v�����A����
Intel�̗D�ʂ͋ƊE�Ő�[�v���Z�X���낤�A���Ԃ�
Larrabee����300W�Ƃ������ĂȂ���������
�Ă��A������̖ڂɌ����Ă�W����
�Ă��A������̖ڂɌ����Ă�W����
952 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:23:16 ID:EIWcDaUX
�������\�[�X��http://www.fudzilla.com/
����A�d�͈ȊO�ł���
>�Ƃ�������������O�ɂ�86���オ�I���ق����悾�Ǝv��
�����[��
�ނ���ŋ�x86�̐������܂��܂������ĂȂ���?
x86�̎����莩��p�\�R�����ł̕����͂₩�����肵�ĂȁB
�����[��
�ނ���ŋ�x86�̐������܂��܂������ĂȂ���?
x86�̎����莩��p�\�R�����ł̕����͂₩�����肵�ĂȁB
10�N�O�̐l�������ɂ�86�������ƒm�����炳���������낤�Ȃ�
>>955
IYHer���������A����͉i���ɕs�łł�><;
IYHer���������A����͉i���ɕs�łł�><;
958 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:47:46 ID:EIWcDaUX
�ŏ���Larrabee���i��45nm��16�R�A��150W�炵�����Ď����͂��邪
300W�̐��i�Ȃ�Ăǂ��ɂ������ĂȂ���
fudzilla�̃A�z��150W��16�R�A��P��2�{����32�R�A�Ȃ�300W���ƌ����Ă��Ȃ�����
�����A�\�[�X�����_�����O���đf�E�G��
32nm�v���Z�X�ŏ���d�͂������R�A���{���ł╡���`�b�v���ڐ��i���o����Ƃ̏��Ȃ猩������
300W�̐��i�Ȃ�Ăǂ��ɂ������ĂȂ���
fudzilla�̃A�z��150W��16�R�A��P��2�{����32�R�A�Ȃ�300W���ƌ����Ă��Ȃ�����
�����A�\�[�X�����_�����O���đf�E�G��
32nm�v���Z�X�ŏ���d�͂������R�A���{���ł╡���`�b�v���ڐ��i���o����Ƃ̏��Ȃ猩������
����������Larrabee x 2�̃n�C�G���h�J�[�h or SLI�܂���
�̌v�悪����Ƃ�?
�̌v�悪����Ƃ�?
Larrabee���āA90W����150W����300W�������܂܂łɂłĂ�ˁ`�B
�ł��AIntel�̂��Ƃ�����Ō�̍Ō�܂�TDP�͂킩���̂ł���B
Bloomfield�����đS��130W�ɂȂ����܂������B
�ł��AIntel�̂��Ƃ�����Ō�̍Ō�܂�TDP�͂킩���̂ł���B
Bloomfield�����đS��130W�ɂȂ����܂������B
961 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 22:55:15 ID:EIWcDaUX
PS3��380W���ď�ŋ߂܂Ź�ʂł܂���ʂ��Ă��B
����d���ł��B
����d���ł��B
>>958
���\���ǂ��܂ŏo�邩�͂����܂Őʐ^���Ƃ��Ă�
�g�����W�X�^���ő�̗\�z���o����
http://www.pcper.com/article.php?aid=456
65nm�@1428�s���̃\�P�b�g���g�p�@�g�����W�X�^��1��
�s�[�N���\��2TFlops�ł��̎��̃N���b�N��6.26GHz�A����d�͂�150W
0.95V���ɂ�62W��1.01TFlops�A0.75V���ɂ�19.4GFlops�i����������j
���M��4850�ƃh�b�R�C����ˁ[�́H����d�͂��B
���\�͂Q�{�i�ɂȂ�����ȁj
�Ƃ������炢�ɂ����ǂ߂Ȃ�
���\���ǂ��܂ŏo�邩�͂����܂Őʐ^���Ƃ��Ă�
�g�����W�X�^���ő�̗\�z���o����
http://www.pcper.com/article.php?aid=456
65nm�@1428�s���̃\�P�b�g���g�p�@�g�����W�X�^��1��
�s�[�N���\��2TFlops�ł��̎��̃N���b�N��6.26GHz�A����d�͂�150W
0.95V���ɂ�62W��1.01TFlops�A0.75V���ɂ�19.4GFlops�i����������j
���M��4850�ƃh�b�R�C����ˁ[�́H����d�͂��B
���\�͂Q�{�i�ɂȂ�����ȁj
�Ƃ������炢�ɂ����ǂ߂Ȃ�
963 �F�R�E�L�́M�E,,�j�����������������F2008/06/23(��) 23:16:10 ID:EIWcDaUX
>>962��Polaris��Larrabee�Ƃ͑S�R�W�Ȃ���Ȃ����������H
>>960
�S������B���Ԃ�B
�S������B���Ԃ�B
�u�z���g�ɏo���Ȃ�c�v (6/20)
-----�^�V���b�v�X���k
�@TDP 140W��Phenom 9950(2.6GHz)��7��2������̔������Ƃ̂��ƁB
���i�͖�\30,000�B�ǂ̒��x��M/B�œ��삷��̂��s��������X���������B
-----�^�V���b�v�X���k
�@TDP 140W��Phenom 9950(2.6GHz)��7��2������̔������Ƃ̂��ƁB
���i�͖�\30,000�B�ǂ̒��x��M/B�œ��삷��̂��s��������X���������B
�o�[���̃��X�A�c�b�R�~�ǂ��둽��������
����Larrabee��Radeon���J�^���O�X�y�b�N�œ������Ƃ����ꍇ�A
���������߂�̂̓h���C�o�̍œK���ɂȂ�
���܂��ɂ܂Ƃ���DX10�h���C�o�����Ȃ��C���e��
Nvidia�Ɛ����������Ă���ATI (AMD)
�����͉������薾�炩
�������Z�ɂ��Ă��AnVidia��physX��AMD�ɂ��Ή����ė~�����݂��������A
Intel�͊���havok�Ή���AMD�ɂ��肢���Ă���
�ǂ������嗬�ɂȂ��Ă�AMD�E�}�[
GPGPU�Ƃ��čl���Ă݂�
SSE5�P�̂Ŋ���Radeon�̗L�����p���o����A���Z���\�Ō���I�ȍ����o����
���p�ł��Ȃ��Ă��ASSE5��CALorSDKorBrook+�Ƃ��̕ϑԃv���O���~���O��
�ނ���A�g������Ƃ����������
�����r�[������ɂ��Ȃ��Ƃ����Ȃ��̂́A
FusionCPU�P�̂ł�Radeon�P�̂ł������A
FusionCPU + ����GPU + Radeon�Ƃ���
PC�ۂ��ƑS�ĉ��Z�@�ɂȂ���AMD�v���b�g�t�H�[���ɂȂ�
�����A�ǂ�ȂɃ����r�[�����͂������Ƃ��Ă�
�ŐVGPU��CrossFireX����Radeon�������p�ł���\��������Fusion��
�����ł��͏o���Ȃ�����
�������S�D����AMD����́A�C���e���ɂ�CrossFireX����Radeon���g�킹�Ă���邩��
�g�[�^���̐��\�͌݊p�ɂȂ邩������Ȃ����ǂ�
����Larrabee��Radeon���J�^���O�X�y�b�N�œ������Ƃ����ꍇ�A
���������߂�̂̓h���C�o�̍œK���ɂȂ�
���܂��ɂ܂Ƃ���DX10�h���C�o�����Ȃ��C���e��
Nvidia�Ɛ����������Ă���ATI (AMD)
�����͉������薾�炩
�������Z�ɂ��Ă��AnVidia��physX��AMD�ɂ��Ή����ė~�����݂��������A
Intel�͊���havok�Ή���AMD�ɂ��肢���Ă���
�ǂ������嗬�ɂȂ��Ă�AMD�E�}�[
GPGPU�Ƃ��čl���Ă݂�
SSE5�P�̂Ŋ���Radeon�̗L�����p���o����A���Z���\�Ō���I�ȍ����o����
���p�ł��Ȃ��Ă��ASSE5��CALorSDKorBrook+�Ƃ��̕ϑԃv���O���~���O��
�ނ���A�g������Ƃ����������
�����r�[������ɂ��Ȃ��Ƃ����Ȃ��̂́A
FusionCPU�P�̂ł�Radeon�P�̂ł������A
FusionCPU + ����GPU + Radeon�Ƃ���
PC�ۂ��ƑS�ĉ��Z�@�ɂȂ���AMD�v���b�g�t�H�[���ɂȂ�
�����A�ǂ�ȂɃ����r�[�����͂������Ƃ��Ă�
�ŐVGPU��CrossFireX����Radeon�������p�ł���\��������Fusion��
�����ł��͏o���Ȃ�����
�������S�D����AMD����́A�C���e���ɂ�CrossFireX����Radeon���g�킹�Ă���邩��
�g�[�^���̐��\�͌݊p�ɂȂ邩������Ȃ����ǂ�
>>967
�Ȃ�ł��̎q�͉��x���ے肳��Ă邱�Ƃ������ɂ��Ėϑz�����Ă�́H
�Ȃ�ł��̎q�͉��x���ے肳��Ă邱�Ƃ������ɂ��Ėϑz�����Ă�́H
GPU�Ƃ��Ďg�����Ƃ���Ζ{����GPU�ɗ��ł��낤Larrabee��
�킴�킴�{���x���Z�p�ɓ�������̂��H
GPU�Ƃ��Ďg���邱�Ƃ����Ŕ{���x���Z�͑�낤�B
�{���x���Z��Larrabee�Ɣ�ׂĂ������Ƃ͎v���ǁB
�킴�킴�{���x���Z�p�ɓ�������̂��H
GPU�Ƃ��Ďg���邱�Ƃ����Ŕ{���x���Z�͑�낤�B
�{���x���Z��Larrabee�Ɣ�ׂĂ������Ƃ͎v���ǁB
�[�����̎�̉��Z��͎g���Ă��炤�����̂ɈӖ�������킯��
IA���̗p���Ă�Larrabee�̃����b�g�͌v��m��Ȃ��Ǝv�����B
IA���̗p���Ă�Larrabee�̃����b�g�͌v��m��Ȃ��Ǝv�����B
>>968
�����ǂ��N�ɔے肳��Ă���̂������Ă���
�܂���Fusion�\�z�ŁARadeon�̉��Z�͂����邱�Ƃ͂Ȃ��ł���
>>970
IA�̗p���Ă��Ă�����AVX�ŐV�K�ɊJ�����Ȃ��Ƃ����Ȃ��킯�ŁA
SSE5�Ɠ�Փx�͂����卷�Ȃ��Ǝv���̂ł���
���Ȃ݂�SSE5��AVX�̈Ⴂ�́A3DNow��SSE�݂����Ȃ��̂��Ǝv���Ă���
�ׂ������Ƃ͔����ɂ��āA���\���͑債�����ƂȂ��A
�P�ɑΉ����i�̐��̍��ł����Ȃ��Ǝv��
AMDCPU�̃V�F�A�����Ȃ猵�������A
Radeon��SSE5�Ή��ɂ�����A�݊p�ɂ͐킦��Ǝv��
SSE5�Ή��Ƃ������AFusion�ƘA�g���₷���\���ɂ���Ƃ������ق���������
�������C���e���v���b�g�t�H�[���ł����삷�邯�ǁAAVX���l�������\���Ƃ�����킯�Ȃ�����A
DX11�ʂ��Ă̌�������GPGPU�Ƃ��Ă̓���~�܂�
�����ǂ��N�ɔے肳��Ă���̂������Ă���
�܂���Fusion�\�z�ŁARadeon�̉��Z�͂����邱�Ƃ͂Ȃ��ł���
>>970
IA�̗p���Ă��Ă�����AVX�ŐV�K�ɊJ�����Ȃ��Ƃ����Ȃ��킯�ŁA
SSE5�Ɠ�Փx�͂����卷�Ȃ��Ǝv���̂ł���
���Ȃ݂�SSE5��AVX�̈Ⴂ�́A3DNow��SSE�݂����Ȃ��̂��Ǝv���Ă���
�ׂ������Ƃ͔����ɂ��āA���\���͑債�����ƂȂ��A
�P�ɑΉ����i�̐��̍��ł����Ȃ��Ǝv��
AMDCPU�̃V�F�A�����Ȃ猵�������A
Radeon��SSE5�Ή��ɂ�����A�݊p�ɂ͐킦��Ǝv��
SSE5�Ή��Ƃ������AFusion�ƘA�g���₷���\���ɂ���Ƃ������ق���������
�������C���e���v���b�g�t�H�[���ł����삷�邯�ǁAAVX���l�������\���Ƃ�����킯�Ȃ�����A
DX11�ʂ��Ă̌�������GPGPU�Ƃ��Ă̓���~�܂�
���Ȃ݂ɂ��������L����������
�u�f�X�N�g�b�v���X�p�R���ɂ���v�VGPU�͎����ς��邩
ttp://wiredvision.jp/news/200806/2008062322.html
��Apple�Ђ���Ă���wOpenCL�x���
�n�[�h�E�F�A�ɂƂ��ꂸ�A�Ȃ��݂̌�����g�p���āA�}���`�R�A��GPU��CPU�̐��\���ő���ɐ������W���B
����́A�����̈Ӗ��ɂ����āA�J���҂������҂��]��ł�����̂��B
penCL�́A�����GPU�Ɉˑ����Ȃ��I�[�v���ȋK�i
OpenCL��]������CWG�ɂ́AAMD�ЁANvidia�ЁA�pARM�ЁA��Freescale Semiconductor�ЁA��IBM�ЁA
�pImagination Technologies�ЁA�t�B�������hNokia�ЁA��Motorola�ЁA��Qualcomm�ЁA
�؍�Samsung Electronics�ЁA��Texas Instruments�ЂȂǂ̊��
Intel��"�Ȃǂ̊��"���������͂��Ȃ�����A���S�ɒ��Ԃ͂���ł�
���Ȃ݂�DirectX11��MS�AAMD�ANvidia�A������������S3�Ŏd�l���蒆�ł��BIntel�͒m���
�ǂ����Ă�Intel VS Intel�ȊO�̊�Ƃ�GPGPU�푈���ł���
�������������ɁAIntel�ɏ����ڂ�����Ƃ͂Ƃ��Ă��v���܂���A�{���ɂ��肪�Ƃ��������܂���
�u�f�X�N�g�b�v���X�p�R���ɂ���v�VGPU�͎����ς��邩
ttp://wiredvision.jp/news/200806/2008062322.html
��Apple�Ђ���Ă���wOpenCL�x���
�n�[�h�E�F�A�ɂƂ��ꂸ�A�Ȃ��݂̌�����g�p���āA�}���`�R�A��GPU��CPU�̐��\���ő���ɐ������W���B
����́A�����̈Ӗ��ɂ����āA�J���҂������҂��]��ł�����̂��B
penCL�́A�����GPU�Ɉˑ����Ȃ��I�[�v���ȋK�i
OpenCL��]������CWG�ɂ́AAMD�ЁANvidia�ЁA�pARM�ЁA��Freescale Semiconductor�ЁA��IBM�ЁA
�pImagination Technologies�ЁA�t�B�������hNokia�ЁA��Motorola�ЁA��Qualcomm�ЁA
�؍�Samsung Electronics�ЁA��Texas Instruments�ЂȂǂ̊��
Intel��"�Ȃǂ̊��"���������͂��Ȃ�����A���S�ɒ��Ԃ͂���ł�
���Ȃ݂�DirectX11��MS�AAMD�ANvidia�A������������S3�Ŏd�l���蒆�ł��BIntel�͒m���
�ǂ����Ă�Intel VS Intel�ȊO�̊�Ƃ�GPGPU�푈���ł���
�������������ɁAIntel�ɏ����ڂ�����Ƃ͂Ƃ��Ă��v���܂���A�{���ɂ��肪�Ƃ��������܂���
>>973
���ꂾ������łĂ�MS�̋C������ȋC�����ĂȂ�Ȃ�
���ꂾ������łĂ�MS�̋C������ȋC�����ĂȂ�Ȃ�
>>972
�ꉞ�J�^���O�X�y�b�N�ł̔{���x���Z�\�͂�
���s4850��200GFlops
Larrabee��8DP*2.5GHz*32core��640GFlops
�ꉞLarrabee���̏����B
�������ǂ�����s�[�N���\�ł�����
�������ш悪����Ȃ���Ύ��s���\�͗����邵
���Ȃ�����悤�Ƀh���C�o�ɂ��ˑ�����B
�{���x���Z�킵���������Ȃ�4850�̏���d�͂��@���قǂ܂ŗ����邩�͖��m������
�J�^���O�X�y�b�N�͒P�@��150W
Larrabee�͏������邪�ꉞ150W
�J�^���O�X�y�b�N��ł�3�{�ق�Larrabee�̏����ˁB
�������\�����ł͕�����ǁB
�ꉞ�J�^���O�X�y�b�N�ł̔{���x���Z�\�͂�
���s4850��200GFlops
Larrabee��8DP*2.5GHz*32core��640GFlops
�ꉞLarrabee���̏����B
�������ǂ�����s�[�N���\�ł�����
�������ш悪����Ȃ���Ύ��s���\�͗����邵
���Ȃ�����悤�Ƀh���C�o�ɂ��ˑ�����B
�{���x���Z�킵���������Ȃ�4850�̏���d�͂��@���قǂ܂ŗ����邩�͖��m������
�J�^���O�X�y�b�N�͒P�@��150W
Larrabee�͏������邪�ꉞ150W
�J�^���O�X�y�b�N��ł�3�{�ق�Larrabee�̏����ˁB
�������\�����ł͕�����ǁB
�܂��N���B
���邽�тɍ����Ȃ��Ă�ȁB
�N������������������
���邽�тɍ����Ȃ��Ă�ȁB
�N������������������
>>975
����GPGPU�Ή��͂��܂��@�\�݂����Ȃ�����1/5�����ǁA
������S���Ή����Ă��邩������Ȃ�����A
�����݊p���x�ɂ͂Ȃ邾��
���̏ꍇ�A�V�F�[�_�[�̌��͔������炢�ɂȂ邩������Ȃ�����
����GPGPU�Ή��͂��܂��@�\�݂����Ȃ�����1/5�����ǁA
������S���Ή����Ă��邩������Ȃ�����A
�����݊p���x�ɂ͂Ȃ邾��
���̏ꍇ�A�V�F�[�_�[�̌��͔������炢�ɂȂ邩������Ȃ�����
978 �FSocket774�F2008/06/24(��) 09:09:06 ID:M141enuS
���\�݊p�Ńh���C�o����Ȃ�AMD�̏�������Ȃ����H
Intel��AMD�ȏ�̂܂Ƃ��ȃh���C�o����Ƃ͎v���Ȃ����A���������ƁB
Intel��AMD�ȏ�̂܂Ƃ��ȃh���C�o����Ƃ͎v���Ȃ����A���������ƁB
Larrabee��x86�R�A������h���C�o�Ȃ�Ă���Ȃ����ǁH
GPU�Ƃ��ē������Ȃ牽flops���낤�����������Q�l�ɂȂ�Ȃ����B
GPU�Ƃ��ē������Ȃ牽flops���낤�����������Q�l�ɂȂ�Ȃ����B
���x�������Ă邱�Ƃ���SSE5�͊�����SSE�̏Ă������ł�����GPU���̂��̂��g�����߂���Ȃ��B
Larrabee�̓f�[�^�̕��̍��������ɂ�����Xeon�̐��{�̃X���[�v�b�g���������o����x86
�Ƃ��������ŃL���[�Ȃ�
�X�p�R���g�b�v500����Xeon�̃V�F�A������A�f�[�^���̍��������ɂ����Ă���x86�̎��v���������Ƃ��킩��B
�܂肻�̕�������Larrabee�ɍ������v������B
x86�̑��ݗ��R���̂��̂������c�闝�R�B
Intel�ɂƂ��Ă�GPU����邱�Ƃ���x86�}���`�R�A�y���������̃��j�[�R�A�Ɍq���邱�Ƃ��厖������
ATi��NV�̃Q�[�}�[�pGPU�s��Ȃŏ����狻���͂Ȃ��B
Larrabee�̓f�[�^�̕��̍��������ɂ�����Xeon�̐��{�̃X���[�v�b�g���������o����x86
�Ƃ��������ŃL���[�Ȃ�
�X�p�R���g�b�v500����Xeon�̃V�F�A������A�f�[�^���̍��������ɂ����Ă���x86�̎��v���������Ƃ��킩��B
�܂肻�̕�������Larrabee�ɍ������v������B
x86�̑��ݗ��R���̂��̂������c�闝�R�B
Intel�ɂƂ��Ă�GPU����邱�Ƃ���x86�}���`�R�A�y���������̃��j�[�R�A�Ɍq���邱�Ƃ��厖������
ATi��NV�̃Q�[�}�[�pGPU�s��Ȃŏ����狻���͂Ȃ��B
>973
�Ƃ͂����AMacBook��iMac�̗����łƂ���GPU�ς�łȂ����
���l�����Apple
�Ƃ͂����AMacBook��iMac�̗����łƂ���GPU�ς�łȂ����
���l�����Apple
>>972
SSE5�̋�̓I�ɂǂ���ATI��GPU�ɓK���Ă��ł����H
���Ȃ݂�AVX�Ή��R���p�C����SSE1�`4��Intrinsics�����̂܂�AVX�Ɉڍs�ł���B
�܂荂�����ꃌ�x���̃\�[�X�Ȃ�ăR���p�C�������ŃR�[�h�̒lj���C���͕K�v�Ȃ��B
SSE5�̋�̓I�ɂǂ���ATI��GPU�ɓK���Ă��ł����H
���Ȃ݂�AVX�Ή��R���p�C����SSE1�`4��Intrinsics�����̂܂�AVX�Ɉڍs�ł���B
�܂荂�����ꃌ�x���̃\�[�X�Ȃ�ăR���p�C�������ŃR�[�h�̒lj���C���͕K�v�Ȃ��B
>>982
SSE5���g����ATI��GPU���ڂ��Ă�PC����X87�R�v���b�T�݂����ɁA
SSE���߂�GPU���Ɋۓ����ł�����Ďv������ł邩��������߂Ă��ϑz�����Ԃ��Ă��Ȃ���B
SSE5���g����ATI��GPU���ڂ��Ă�PC����X87�R�v���b�T�݂����ɁA
SSE���߂�GPU���Ɋۓ����ł�����Ďv������ł邩��������߂Ă��ϑz�����Ԃ��Ă��Ȃ���B
SSE5�͐�intel������Ă����r�r�d���ڂ̐^����
��86�ŃR�A�P�̂̔\�͂��オ��Ȃ��Ă��ȒP�ɐ��\���オ��
�f�����b�g�̓R�A�T�C�Y�������鎖
��64����ɂȂ�Ȃ���AMD�͂ǂ��������Ă��^�̎��͂͏o���Ȃ�
�������intel�����̍��ɂ͂��킹�ĉ��ǂ��Ă��邾�낤
intel�͐��E�̂�86���炘64�ڍs���鎞���܂�
���R�ɃR���g���[���ł���͂�����̂����
��86�ŃR�A�P�̂̔\�͂��オ��Ȃ��Ă��ȒP�ɐ��\���オ��
�f�����b�g�̓R�A�T�C�Y�������鎖
��64����ɂȂ�Ȃ���AMD�͂ǂ��������Ă��^�̎��͂͏o���Ȃ�
�������intel�����̍��ɂ͂��킹�ĉ��ǂ��Ă��邾�낤
intel�͐��E�̂�86���炘64�ڍs���鎞���܂�
���R�ɃR���g���[���ł���͂�����̂����
>>983
�����
�x�N�^����1024�Ƃ�2048�Ƃ��ɂ��ĕ���x�����܂���Ζ��߃��x����GPU�ɓ�����Ӗ��͂��邪
128�r�b�g�̂܂�܂���낭�ɕ���x�������C�e���V�Ń{���{��
�t��AVX�݂����Ȃ̂ق������������̂Ɍ����Ă�͔̂�����ȁB
�����
�x�N�^����1024�Ƃ�2048�Ƃ��ɂ��ĕ���x�����܂���Ζ��߃��x����GPU�ɓ�����Ӗ��͂��邪
128�r�b�g�̂܂�܂���낭�ɕ���x�������C�e���V�Ń{���{��
�t��AVX�݂����Ȃ̂ق������������̂Ɍ����Ă�͔̂�����ȁB
>>986
��H
SSE5�����s�ł���悤��GPU�����ւ��Ă����Ƃ����Ӗ��ɂ��������Ȃ���
��������s��VLIW�^GPU�ł͂Ȃ��V���[�g�x�N�g���^��
SSE5���̂��x�N�^����L���悤�Ȃ��Ƃ��ق̂߂����Ă��
�t�ɍs���ƍ���GPU�ł͕s�����Ƃ����킯��
�Ȃ{���]�|�Șb�ɂȂ��Ă�����
��H
SSE5�����s�ł���悤��GPU�����ւ��Ă����Ƃ����Ӗ��ɂ��������Ȃ���
��������s��VLIW�^GPU�ł͂Ȃ��V���[�g�x�N�g���^��
SSE5���̂��x�N�^����L���悤�Ȃ��Ƃ��ق̂߂����Ă��
�t�ɍs���ƍ���GPU�ł͕s�����Ƃ����킯��
�Ȃ{���]�|�Șb�ɂȂ��Ă�����
SSE5�͈�T�Ɉ����Ƃ͌����Ȃ��Ƃ������B
�v���Z�b�T��GPU�̓������x�����ǂ��Ȃ邩�ɂ�邾�낤�ȁB
�����A����ς��i����g�����ɂ�����Intel AVX�̂��D�G�B
�܂��AIntel�̃\�t�g�E�F�A�J���\�͂�AMD�̂���ɏ���A
AVX�𐄐i���Ă����낤���ASSE5�͂��قǒ��ڂ�����Ȃ����낤�ˁB
���ڂ�����Ȃ��Ă��m���Ɏg���ΐ��\���オ��������A
���́u�g������v��AMD�����͂ɒł��邩�Ƃ�������c�B
�܂��A"SSE5"����������"Larrabee"��"�h���C�o�[���c"�Ƃ������Ă��邪�A
"Larrabee"���������Ƃ��ł���\�t�g�E�F�A��Intel������Θb�͏I���B
�����āAIntel�ɂ͂�����ł���\�͂�����B��̕���"OpenCL"�Ƃ��邪�A
Intel�Ƃ��Ă͕ʂ�"OpenCL"�̃R���\�[�V�A���ɓ��闝�R�͂Ȃ��A
"OpenCL"���m�肵����"OpenCL"��"Larrabee"��ʼn�������
"OpenCL"�p�̊J���\�t�g�E�F�A���������B
AMD�������悤��"SSE5"��lj�����\�t�g�E�F�A��Q�[���������ł���
�J�����������������̘b�����c���܂ł̗��ꂩ�炷��ƁA
�ǂ��l���Ă�AMD�ɂ͂���Ȕ\�͂��Ȃ��B��������҂���Ȃ������B
�v���Z�b�T��GPU�̓������x�����ǂ��Ȃ邩�ɂ�邾�낤�ȁB
�����A����ς��i����g�����ɂ�����Intel AVX�̂��D�G�B
�܂��AIntel�̃\�t�g�E�F�A�J���\�͂�AMD�̂���ɏ���A
AVX�𐄐i���Ă����낤���ASSE5�͂��قǒ��ڂ�����Ȃ����낤�ˁB
���ڂ�����Ȃ��Ă��m���Ɏg���ΐ��\���オ��������A
���́u�g������v��AMD�����͂ɒł��邩�Ƃ�������c�B
�܂��A"SSE5"����������"Larrabee"��"�h���C�o�[���c"�Ƃ������Ă��邪�A
"Larrabee"���������Ƃ��ł���\�t�g�E�F�A��Intel������Θb�͏I���B
�����āAIntel�ɂ͂�����ł���\�͂�����B��̕���"OpenCL"�Ƃ��邪�A
Intel�Ƃ��Ă͕ʂ�"OpenCL"�̃R���\�[�V�A���ɓ��闝�R�͂Ȃ��A
"OpenCL"���m�肵����"OpenCL"��"Larrabee"��ʼn�������
"OpenCL"�p�̊J���\�t�g�E�F�A���������B
AMD�������悤��"SSE5"��lj�����\�t�g�E�F�A��Q�[���������ł���
�J�����������������̘b�����c���܂ł̗��ꂩ�炷��ƁA
�ǂ��l���Ă�AMD�ɂ͂���Ȕ\�͂��Ȃ��B��������҂���Ȃ������B
>>987
�Ⴄ�Ⴄ�B
�v�_���������o�[���̂悤�Ȃ��̂�
��intel�ɂƂ��Ă�GPU����邱�Ƃ���x86�}���`�R�A�y���������̃��j�[�R�A�Ɍq���邱�Ƃ��厖������
��ATi��NV�̃Q�[�}�[�pGPU�s��Ȃŏ����狻���͂Ȃ��B
�Ƃ����l�@
�b�o�t�O�ɂr�r�d���Z�⏕���j�b�g��u����
�b�o�t���\�����̎���intel�R���p�C���ŃR�[�e�B���O���ꂽ���i���g������
�b�o�t�O������u�[�X�g���悤�Ƃ��Ă邾���̘b
����AMD�������Ă�R�v�����j�b�g�O�����̂ς���
�Ⴄ�Ⴄ�B
�v�_���������o�[���̂悤�Ȃ��̂�
��intel�ɂƂ��Ă�GPU����邱�Ƃ���x86�}���`�R�A�y���������̃��j�[�R�A�Ɍq���邱�Ƃ��厖������
��ATi��NV�̃Q�[�}�[�pGPU�s��Ȃŏ����狻���͂Ȃ��B
�Ƃ����l�@
�b�o�t�O�ɂr�r�d���Z�⏕���j�b�g��u����
�b�o�t���\�����̎���intel�R���p�C���ŃR�[�e�B���O���ꂽ���i���g������
�b�o�t�O������u�[�X�g���悤�Ƃ��Ă邾���̘b
����AMD�������Ă�R�v�����j�b�g�O�����̂ς���
>>989
���߂�����፪�{�I�ɂ킩���ĂȂ���
���Ⴂ������
��������1�N���b�N��3���ߒ��x�������s�ł��Ȃ�x86�̃o�b�N�G���h�ɉ��\����̃X�g���[���v���Z�b�T�������Ă������������\�オ��Ȃ���
�Ӗ��킩��Ȃ��H
�x�N�g������啝�Ɉ����グ��Ƃ����Ȃ�����ȁB
�����Ă���͊��ɍ����\����Ă�128�r�b�g�x�N�^��SSE5�Ƃ͕ʕ�
���߂�����፪�{�I�ɂ킩���ĂȂ���
���Ⴂ������
��������1�N���b�N��3���ߒ��x�������s�ł��Ȃ�x86�̃o�b�N�G���h�ɉ��\����̃X�g���[���v���Z�b�T�������Ă������������\�オ��Ȃ���
�Ӗ��킩��Ȃ��H
�x�N�g������啝�Ɉ����グ��Ƃ����Ȃ�����ȁB
�����Ă���͊��ɍ����\����Ă�128�r�b�g�x�N�^��SSE5�Ƃ͕ʕ�
�c�q���c�q�Ō�����Ă��ˁB
SSE5��GPU�Ƃ̊֘A���x<->�P���x���������_�ϊ��������Ǝv���������Ă�悤�����ǁA
���ꂻ������GPGPU�ɂ͊W�Ȃ��̂�ˁBR600�̎��_�Ŕ����x���߂������ĂȂ��킯�ŁB
SSE5��GPU�Ƃ̊֘A���x<->�P���x���������_�ϊ��������Ǝv���������Ă�悤�����ǁA
���ꂻ������GPGPU�ɂ͊W�Ȃ��̂�ˁBR600�̎��_�Ŕ����x���߂������ĂȂ��킯�ŁB
>>991
Fusion�ɍڂ�����GPU�ɂ͓��ڂ����ˁH
Fusion�ɍڂ�����GPU�ɂ͓��ڂ����ˁH
OpenCL��intel���Q�����ĂȂ����āAintel��intel��C�����\���Ă邵�A
Larrabee�͖��߃��x���ł̓z��������w�e���W�j�A�X�p��OpenCL�ɎQ������Ӌ`��
���܂�Ȃ���Ȃ��́H
Larrabee��HPC�p�̃v���Z�b�T�Ƃ��Č������AGPU�ƈ����intel�̃h���C�o�̏o��������ڂ��Ȃ��
�b�͂��܂�W�Ȃ��Ǝv�����B
Larrabee�͖��߃��x���ł̓z��������w�e���W�j�A�X�p��OpenCL�ɎQ������Ӌ`��
���܂�Ȃ���Ȃ��́H
Larrabee��HPC�p�̃v���Z�b�T�Ƃ��Č������AGPU�ƈ����intel�̃h���C�o�̏o��������ڂ��Ȃ��
�b�͂��܂�W�Ȃ��Ǝv�����B
>>989
���ƁA�����������
Intel�����j�[�R�A�\�z��ł��o�����̂�2004�N�ŁA���ɂ��̍��ɂ�Larrabee�̌����J���͎n�܂��Ă�
�܂�p�N�����Ƃ�����Ȃ�ATI�ƍ������Ă����̓I�\�z�̌��܂���AMD�̕�����
�܁A��x86���ڂ�Intel�ƈႤ��������I�̂�AMD�Ȃ���R���p�C�������ꂩ���AMD�Ǝ��ɐ����̔����Ȃ��Ƃ�
���ƁA�����������
Intel�����j�[�R�A�\�z��ł��o�����̂�2004�N�ŁA���ɂ��̍��ɂ�Larrabee�̌����J���͎n�܂��Ă�
�܂�p�N�����Ƃ�����Ȃ�ATI�ƍ������Ă����̓I�\�z�̌��܂���AMD�̕�����
�܁A��x86���ڂ�Intel�ƈႤ��������I�̂�AMD�Ȃ���R���p�C�������ꂩ���AMD�Ǝ��ɐ����̔����Ȃ��Ƃ�
���܂łǂ���gcc�M���čς܂��ł���B
�����x�������Ă邱�Ƃ���SSE5�͊�����SSE�̏Ă������ł�����GPU���̂��̂��g�����߂���Ȃ��B
��
��SSE5���߂̈ꕔ�́ACPU�R�A�ł͂Ȃ��AGPU�R�A�ɔ��s����Ď��s�����悤�ɂȂ�B
��
��SSE5�����s�ł���悤��GPU�����ւ��Ă����Ƃ����Ӗ��ɂ��������Ȃ���
�\�P�b�g��K�i���ς���Đ̂̐��ڂ�Ȃ��Ȃ����Ƃ��Ă�CPU��CPU
���l�ɍ\�����ς���Ă�GPU��GPU
����GPU��SSE5�Ή����ǂ������Ă�ł����H
��
��SSE5���߂̈ꕔ�́ACPU�R�A�ł͂Ȃ��AGPU�R�A�ɔ��s����Ď��s�����悤�ɂȂ�B
��
��SSE5�����s�ł���悤��GPU�����ւ��Ă����Ƃ����Ӗ��ɂ��������Ȃ���
�\�P�b�g��K�i���ς���Đ̂̐��ڂ�Ȃ��Ȃ����Ƃ��Ă�CPU��CPU
���l�ɍ\�����ς���Ă�GPU��GPU
����GPU��SSE5�Ή����ǂ������Ă�ł����H
168 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:56:56 ID:9oqlrKcp
�O���X�ǂ�Ő�����������
���ꂗ�����A���~�����������̔n����I�悵���Ȃ�����
����IQ147������(�E�L��`�E)
169 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:57:38 ID:9oqlrKcp
�S�o
�O���X�ǂ�Ő�����������
���ꂗ�����A���~�����������̔n����I�悵���Ȃ�����
����IQ147������(�E�L��`�E)
169 ���O�F�R(�M�D�L)Ɂ@�ܧ���[sage] ���e���F2008/05/05(��) 03:57:38 ID:9oqlrKcp
�S�o
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/