Intel�̎�����CPU�ɂ��Č�낤 34
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 33
ttp://pc11.2ch.net/test/read.cgi/jisaku/1202775674/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
Intel�̎�����CPU�ɂ��Č�낤 33
ttp://pc11.2ch.net/test/read.cgi/jisaku/1202775674/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
|
|
|
���ߋ��X��
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
���ߋ��X�� ���̂Q
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
�܂������ĂȂ������݂����Ȃ̂ŗ��Ă��B
��Nehalem�̐��\�\���ǂ����B
��Nehalem�̐��\�\���ǂ����B
5 �FSocket774�F2008/05/01(��) 15:20:56 ID:bEyUS0cs
�@ �@ �@�@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,.��
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
�@�@___ �@�@�@�@�@�@�@ �@ �@ �@ �@ �@�@�@�@�@�@�@�@�@�@�@�@с@�@i
�@�u �_i�r�@�@�@ �@ �@�@�@�@�@�@ �@ �@�@�@�@�@�@�@�@�@�@�@�@ �T�@�q
�@ā@�m �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@i�j(()
�@i �@{ �@ �@�@�@�@�@�@�@ �@�@�@�Q�Q�Q_ �@ �@�@�@�@�@�@�@�@| �@�R
�@i�@�@i�@�@�@ �@�@�@�@�@�@�@�^__,�@ , �]-�_ �@ �@ �@ �@ �@�@i �@�@}
�@|�@�@ i�@�@�@�@�@�@ �@�@�^�i��) �@ ( �� )�_�@�@�@�@�@�@ {��@ ��
�@�g�|��.�@�@�@�@�@�@�^ �@ �@�i__�l__�j �@�@�@�_�@�@�@ ,�m�@�P ,!
�@i�@�@�@�T�_ �@�@�@�@|�@�@�@�@�@�L�P` �@ �@�@�@�@|�@,. '�Lʁ@�@�@,!
.�@�R�A �@�@�@�M`�@�,__�_ �@�@ �@ �@�@�@�@�@ �@ �^"�@�_ �@�R�^
�@�@�@�_�m�@Ɂ@�@�@ʁPr/:::r�\--�\/::�V�@�@ Ɂ@�@�@�@�^
�@ �@�@ �@ �R.�@�@�@�@�@�@�R::�q�G . '::. :' |::/�@�@ /�@�@�@,. "
�@�@�@�@�@�@�@ `� ��@�@�@�@�_�R::. ;::�F|/�@�@�@�@�@��'"
�@�@�@�@�@�^�P�����������������R
�@�@�@�@�@| �� |�@�@�@�@�@�@�@�@AMD��D���@�@�@�@�@�@�@��|
�@�@�@�@�@�_�Q�����������������m
6 �FSocket774�F2008/05/01(��) 15:31:46 ID:MH9UJ0Cd
�R�A2�g���I���o�邩��
7 �FSocket774�F2008/05/01(��) 15:35:20 ID:p1pe7wCC
���M����I��ڽ��̍ė�����I
8 �FSocket774�F2008/05/01(��) 15:47:49 ID:MH9UJ0Cd
�s���~�b�h�^5�R�A���邼�J���R�[�h:�J�C��
���x�͗��̂��I
���x�͗��̂��I
9 �FSocket774�F2008/05/01(��) 16:26:39 ID:+ai/6AO5
�����QX9775���ŋ�����߁H
�����̌Ӎ��Ǝ�ȁA�W���ɒr�c��쎁�Ɖ�k��
http://sankei.jp.msn.com/politics/situation/080501/stt0805011327004-n1.htm
http://sankei.jp.msn.com/politics/situation/080501/stt0805011327004-n1.htm
11 �FSocket774�F2008/05/01(��) 17:09:25 ID:MH9UJ0Cd
���̉��i����y�ѐV�K�����͂����B
>>12
����Q3��Q9400/Q9650�����B��N����7�����B
����Q3��Q9400/Q9650�����B��N����7�����B
>>11
10�N��̓W�����N��100�~���x������Ȃ��́H
10�N��̓W�����N��100�~���x������Ȃ��́H
10�N��̃W�����N�i�ɂ�Pentium�U�͂��肻���Ȉ���
Larrabee����x86��GPU���Ȃ猾���Ă���
����Intel���g��SIMD���Z��AVX�Ɉڍs�����悤�Ƃ��Ă�̂�
Larrabee���ĈӖ��Ȃ��ˁH
x86����ɂ��Ă��킯����
����Intel���g��SIMD���Z��AVX�Ɉڍs�����悤�Ƃ��Ă�̂�
Larrabee���ĈӖ��Ȃ��ˁH
x86����ɂ��Ă��킯����
�܂����A�܂��I�����B
��Intel��Cray�A�X�p�R���J���Œ�g
http://opentechpress.jp/enterprise/08/05/01/0349224.shtml
http://opentechpress.jp/enterprise/08/05/01/0349224.shtml
>>16
x86��SIMD�g���R�A������������ׂ��̂�Larrabee�Ȃ�Ȃ��́H
x86��SIMD�g���R�A������������ׂ��̂�Larrabee�Ȃ�Ȃ��́H
x86�i�̃f�R�[�h�j�͕��G�����āA���������Ă�������Ă��˂�
���Ă����̂�AVX���o�����Ƃ����̂ł���H
�������A�ߋ��̃����[�̋L����x86������A�v�����̊J����
�e�Ղ��Ƃ������̂�ɂ��Ă������킯����
�ŋ߂ł̓��C�g�������Ƃ������b���A���X�^���C�U������Ęb�ɂȂ�
�͂��߂�GPU�ł͂Ȃ��Ǝ咣���Ȃ��猋��GPU�ɂȂ�E�E
���Ă����̂�AVX���o�����Ƃ����̂ł���H
�������A�ߋ��̃����[�̋L����x86������A�v�����̊J����
�e�Ղ��Ƃ������̂�ɂ��Ă������킯����
�ŋ߂ł̓��C�g�������Ƃ������b���A���X�^���C�U������Ęb�ɂȂ�
�͂��߂�GPU�ł͂Ȃ��Ǝ咣���Ȃ��猋��GPU�ɂȂ�E�E
�ǂ������ߊg���A�lj����Ȃ����Ⴂ���Ȃ���
�����`���[�j���O�̂��ߏ��������Ȃ��Ⴂ���Ȃ�����
�V�K��ISA�ɂ����ق����}�V
��Intel�̒��̐l�ȊO�݂͂�Ȏv���Ă܂�
�����`���[�j���O�̂��ߏ��������Ȃ��Ⴂ���Ȃ�����
�V�K��ISA�ɂ����ق����}�V
��Intel�̒��̐l�ȊO�݂͂�Ȏv���Ă܂�
GPU�̃h���C�o�͂ł��ĂȂ���
Itanium���������������
���̂����Ј��͂��E���E���E��
Itanium���������������
���̂����Ј��͂��E���E���E��
�����AAVX��x86����Ȃ����Ă��Ƃ�
AVX���Ă�x86��x86���Ă��ƂȂ�Ȃ��́H
AVX���Ă�x86��x86���Ă��ƂȂ�Ȃ��́H
������intelCPU��AVX��̂�x86�R�A�͌݊����ێ��̂��߂ɓ��ڂ���邾���ɂȂ�
AltiVec�ς�ł�PowerPC��PowerPC�݂�����
AVX�ς�ł�x86��x86����H�Ⴄ�́H
AVX�ς�ł�x86��x86����H�Ⴄ�́H
>>24
�����Ăo�r�R�Ɠ��l�ɂȂ�A���Ă��B
�����Ăo�r�R�Ɠ��l�ɂȂ�A���Ă��B
AVX���ĐV���߂̂��ƂȂ̂��H
���͂Ă����薽�߃Z�b�g�����邽�߂ɗp�ӂ���t�H�[�����Ƃ������Ă����ǁB
���͂Ă����薽�߃Z�b�g�����邽�߂ɗp�ӂ���t�H�[�����Ƃ������Ă����ǁB
28 �FSocket774�F2008/05/02(��) 20:56:42 ID:skTMNfFf
ttp://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
Intel�̎���CPU�uNehalem(�l�n�[����)�v�́A
�ɂ߂ċ��͂ȃ}�C�N���A�[�L�e�N�`�������A
������x86 CPU�̕������_����������ɂ��Ă���B
���G��x86���߂̎��s�ɂƂ��Ȃ����̑����́A
��������Ȃ��܂c���ꂽ���炾
Intel�̎���CPU�uNehalem(�l�n�[����)�v�́A
�ɂ߂ċ��͂ȃ}�C�N���A�[�L�e�N�`�������A
������x86 CPU�̕������_����������ɂ��Ă���B
���G��x86���߂̎��s�ɂƂ��Ȃ����̑����́A
��������Ȃ��܂c���ꂽ���炾
�ނ���A�����Ȃ�ˁH
> �������AIntel�́A�����I�ɂ͖��߃t�H�[�}�b�g���̂�ς��邱�ƂŁA���̖����y�����悤�Ƃ��Ă���B
> Nehalem�̎��̐V�}�C�N���A�[�L�e�N�`���ł���uSandy Bridge(�T���f�B�u���b�W)�v�Ɏ�������
> �V���ߊg���uIntel Advanced Vector Extensions (Intel AVX)�v����́A�uVEX(Vector Extension)�v��
> �ĂԐV�v���t�B�b�N�X���g�����߃G���R�[�f�B���O�V�X�e���ŁA���ߒ��̈��k�ƃt�H�[�}�b�g�̐�����
> �}�邩�炾�BSSE���߂�AVX���߂ւƃR���o�[�g���Ă��܂��A���͌y�������B�n�[�h�E�F�A��
> �ł͂Ȃ��A���߃t�H�[�}�b�g���̂����ǂ��邱�Ƃ̕����Ǎ��Intel�͔��f�����悤���B
> �������AIntel�́A�����I�ɂ͖��߃t�H�[�}�b�g���̂�ς��邱�ƂŁA���̖����y�����悤�Ƃ��Ă���B
> Nehalem�̎��̐V�}�C�N���A�[�L�e�N�`���ł���uSandy Bridge(�T���f�B�u���b�W)�v�Ɏ�������
> �V���ߊg���uIntel Advanced Vector Extensions (Intel AVX)�v����́A�uVEX(Vector Extension)�v��
> �ĂԐV�v���t�B�b�N�X���g�����߃G���R�[�f�B���O�V�X�e���ŁA���ߒ��̈��k�ƃt�H�[�}�b�g�̐�����
> �}�邩�炾�BSSE���߂�AVX���߂ւƃR���o�[�g���Ă��܂��A���͌y�������B�n�[�h�E�F�A��
> �ł͂Ȃ��A���߃t�H�[�}�b�g���̂����ǂ��邱�Ƃ̕����Ǎ��Intel�͔��f�����悤���B
30 �FMAC�I�^��24 �����F2008/05/02(��) 21:30:20 ID:2LK+lQ82
>>24
�@�@-------------------
�@�@������intelCPU��AVX��̂�x86�R�A�͌݊����ێ��̂��߂ɓ��ڂ���邾���ɂȂ�
�@�@-------------------
10�N�O�Ɏ����悤�Șb�����悤�ȋC�����邷����(��)
http://pc.watch.impress.co.jp/docs/article/990601/kaigai01.htm
�@�@-------------------
�@�@������intelCPU��AVX��̂�x86�R�A�͌݊����ێ��̂��߂ɓ��ڂ���邾���ɂȂ�
�@�@-------------------
10�N�O�Ɏ����悤�Șb�����悤�ȋC�����邷����(��)
http://pc.watch.impress.co.jp/docs/article/990601/kaigai01.htm
Larrabee�̃R�A����IA++���Ă��邯�ǁA
�������AVX+x86���Ă��ƁH
�������AVX+x86���Ă��ƁH
������ɂ���x86���߃Z�b�g�͎c����Ă킯���ˁB
�����̃����r�[�v��͏�����
�������r�[�̓I���{GPU��EU��x86���߃f�R�[�h�ɑΉ��������㕨
�������r�[�̓I���{GPU��EU��x86���߃f�R�[�h�ɑΉ��������㕨
���ʂȑ㕨�ł���
�����ɂ܂��
>>34
����V�K���~�̏��Ȃ������r�[�ŁAAVX���s������Ėژ_�݂��L�肻�����B
����V�K���~�̏��Ȃ������r�[�ŁAAVX���s������Ėژ_�݂��L�肻�����B
39 �FSocket774�F2008/05/04(��) 07:40:22 ID:IIp8J6aw
�n
Itanium�ƈ����OS��h���C�o�͂��̂܂܂Ŏg���邩��AAVX��SSE�݂�����
�n���ɕ��y�����Ȃ��́H
�n���ɕ��y�����Ȃ��́H
�n�[�h�Ή����Ă��f�R�[�_��SSE��AVX�ŃG�~�����[�g���郍�W�b�N�lj����邾������H
IA32�R�A���ۂ��ƐςޕK�v��������Itanium�Ƃ͂����ԈႤ�悤��
IA32�R�A���ۂ��ƐςޕK�v��������Itanium�Ƃ͂����ԈႤ�悤��
����OS�̑Ή��͂���B�p�b�`���x���ōςނƎv����
�܂��x86���߂͂��̂܂܂ŕςȃv���t�B�N�X�������߂���AVX���H
�ėp���W�X�^���g�����ʂ�x86���߂ɂ�
VEX�v���t�B�b�N�X��t����3�I�y���ł���Ƃ����̂�
VEX�v���t�B�b�N�X��t����3�I�y���ł���Ƃ����̂�
Intel�̃}�j���A����MOVBE�Ƃ���Big-Endian�̃��[�h�E�X�g�A���߂��lj�����Ă���
ttp://download.intel.com/design/processor/manuals/253666.pdf
ttp://download.intel.com/design/processor/manuals/253667.pdf
Nehalem�Ŏ�������̂���?
ttp://download.intel.com/design/processor/manuals/253666.pdf
ttp://download.intel.com/design/processor/manuals/253667.pdf
Nehalem�Ŏ�������̂���?
���o�Ȃ�X�}�\
20 �Flogin:Penguin�F2008/05/05(��) 09:27:09 ID:Wya7TNDe
binutils-2.18.50.0.7 released
�Ȃ���AVX���T�|�[�g�����B
�����͗y����Ȃ̂ɋC������…
20 �Flogin:Penguin�F2008/05/05(��) 09:27:09 ID:Wya7TNDe
binutils-2.18.50.0.7 released
�Ȃ���AVX���T�|�[�g�����B
�����͗y����Ȃ̂ɋC������…
���o
�C���e���̖��ߒlj����ꂷ������Ȃ��H
���߂����G�ɂȂ肷���Ă��ǂ����ȁ[���Ďv����
���߂����G�ɂȂ肷���Ă��ǂ����ȁ[���Ďv����
�����AVX�Ő�������낤����
�������F��Intel��
�v���Z�b�T�̃A�[�L�e�N�g�ɂǂ���Z���X���������Ȃ�
�v���Z�b�T�̃A�[�L�e�N�g�ɂǂ���Z���X���������Ȃ�
�Z���X�i�j��
����ȁB
�Z���X�������ƉĂƂ��������
�Z���X�������ƉĂƂ��������
(�∀`) ����
���̃Z���X()�̖����A�[�L�e�N�g�A�����J������CPU�ɂ͉��������Ă������Ȃ���!��
�v���Z�X���x��͍��߂����ł���
�v���Z�X���x��͍��߂����ł���
��
AMD�Ƃ��W�˂�
�m�[�g�u�b�N�E�p�\�R���p266MHz�ł����166MHz��MMX(R)�e�N�m���WPentium�v���Z�b�T�́A
�ŐV��0.25�~�N�����̃v���Z�X�Z�p�ɂ�萻������Ă��܂��B��166MHz��MMX(R)�e�N�m���W
Pentium�v���Z�b�T�̓����R�A�d����1.8�{���g�œ��삵�A����d�͂�2.9���b�g�ł��B
�܂��A��266MHz��MMX(R)�e�N�m���WPentium�v���Z�b�T�̓����R�A�d����2.0�{���g�A
����d�͂�5.3���b�g�ł��B
�m�[�gPC�p266MHz/166MHz��MMX(R)�e�N�m���WPentium(R)�v���Z�b�T���\
http://www.intel.co.jp/jp/intel/pr/press98/266166.HTM
Atom������
�ŐV��0.25�~�N�����̃v���Z�X�Z�p�ɂ�萻������Ă��܂��B��166MHz��MMX(R)�e�N�m���W
Pentium�v���Z�b�T�̓����R�A�d����1.8�{���g�œ��삵�A����d�͂�2.9���b�g�ł��B
�܂��A��266MHz��MMX(R)�e�N�m���WPentium�v���Z�b�T�̓����R�A�d����2.0�{���g�A
����d�͂�5.3���b�g�ł��B
�m�[�gPC�p266MHz/166MHz��MMX(R)�e�N�m���WPentium(R)�v���Z�b�T���\
http://www.intel.co.jp/jp/intel/pr/press98/266166.HTM
Atom������
>>57
10�N�ȏ�O�̋L�������o���āA�ǂ������́H
10�N�ȏ�O�̋L�������o���āA�ǂ������́H
>>57
�Ƃ�����MMXpentium������ɍ��킹�č�蒼����Atom�̂������肳��ɂȂ�悤��
�Ƃ�����MMXpentium������ɍ��킹�č�蒼����Atom�̂������肳��ɂȂ�悤��
Intel�CSamsung�CTSMC��450mm�E�G�[�n�ւ̈ڍs�ŋ��́C2012�N�̃p�C���b�g���Y�ڎw��
ttp://techon.nikkeibp.co.jp/article/NEWS/20080506/151346/
Intel, Samsung Electronics, TSMC Reach Agreement for 450mm Wafer Manufacturing Transition
ttp://www.intel.com/pressroom/archive/releases/20080505corp.htm
ttp://techon.nikkeibp.co.jp/article/NEWS/20080506/151346/
Intel, Samsung Electronics, TSMC Reach Agreement for 450mm Wafer Manufacturing Transition
ttp://www.intel.com/pressroom/archive/releases/20080505corp.htm
>>60
���킽�c
���킽�c
>>60
�܂�ǂ��̐��Y�Z�p���قړ����ɂȂ�ƁH
�܂�ǂ��̐��Y�Z�p���قړ����ɂȂ�ƁH
450mm�E�F�n�Ɉڍs�����300mm�Ɉڍs�����݂����ɐ��Y�����オ����Ęb�ł�����
�v���Z�X�̋��͂���Ȃ����琶�Y�Z�p�������ɐ���킯����Ȃ���Ȃ��H
�v�����450mm�E�F�n�Ɉڍs������Intel��Sumsung�ATSMC��U���Ĉꏏ��450mm�E�F�n�Ɉڍs�����
����ň���450mm�Ή����u�̎��v��������瑕�u���[�J�[��450mm�E�F�n�Ή����u�J�����Ă˂��Č����Ă邾������Ȃ�
���܂Ŕ����̑��u���[�J�[��450mm�E�F�n�Ή����u�̊J���ɃR�X�g����ł��ˁ[������Ċ����ŏ��ɓI�������炵����
�v���Z�X�̋��͂���Ȃ����琶�Y�Z�p�������ɐ���킯����Ȃ���Ȃ��H
�v�����450mm�E�F�n�Ɉڍs������Intel��Sumsung�ATSMC��U���Ĉꏏ��450mm�E�F�n�Ɉڍs�����
����ň���450mm�Ή����u�̎��v��������瑕�u���[�J�[��450mm�E�F�n�Ή����u�J�����Ă˂��Č����Ă邾������Ȃ�
���܂Ŕ����̑��u���[�J�[��450mm�E�F�n�Ή����u�̊J���ɃR�X�g����ł��ˁ[������Ċ����ŏ��ɓI�������炵����
45cm�E�F�n�Ȃ�ăz���g�ɂ����́H
30cm�Ɣ�r����Ƃ��̂������R�X�g�����肻���Ȃ��ǁB
30cm�Ɣ�r����Ƃ��̂������R�X�g�����肻���Ȃ��ǁB
�E�G�n�[�傫������ƁA����ʂ������������Ȃ����
�N�̋L���œǂ����ȁH�㓡�̋L���������H
�N�̋L���œǂ����ȁH�㓡�̋L���������H
�ȂE�n�E�n����ȁB
�����
200mm�E�F�n�̐��Y�H��4�@��300mm�E�F�n�̍H��2�@��450�E�F�n�̍H��1�@
200mm�E�F�n�̐��Y�H��4�@��300mm�E�F�n�̍H��2�@��450�E�F�n�̍H��1�@
��o���ꏊ�ɂ�鍷���X�Ɍ����ɂȂ肻���Ȉ���
�l�I�ɂ͉����ɃV���R������������
�]�ʂ��Đ�o��������Ȃ����Ǝv���Ă������
�]�ʂ��Đ�o��������Ȃ����Ǝv���Ă������
�@���H
>>69
�P�����ɂȂ��ƈӖ���
�P�����ɂȂ��ƈӖ���
>>65
�E�F�n�[�͉~�`��LSI�̃R�A�͎l�p�B
���̂��ߎ��ӕ��͌`������Ȃ��Ė��ʂɂȂ�B
�E�F�n�[���傫���Ȃ�ƁA���̎��ӕ��̎g���Ȃ��ʐς̊������������Ȃ�B
���̎ʐ^�����čl���Ă݂悤�B
http://ja.wikipedia.org/wiki/%E7%94%BB%E5%83%8F:Wafer_2_Zoll_bis_8_Zoll_2.jpg
�E�F�n�[�͉~�`��LSI�̃R�A�͎l�p�B
���̂��ߎ��ӕ��͌`������Ȃ��Ė��ʂɂȂ�B
�E�F�n�[���傫���Ȃ�ƁA���̎��ӕ��̎g���Ȃ��ʐς̊������������Ȃ�B
���̎ʐ^�����čl���Ă݂悤�B
http://ja.wikipedia.org/wiki/%E7%94%BB%E5%83%8F:Wafer_2_Zoll_bis_8_Zoll_2.jpg
{kind=link}
2017�N�Ȃ�Ƃ�����2012�N�͂ǂ�����Ă�����
2017�N���Ĕ����͂ǂ��܂Ői��ł�̂��ȁH
10nm�ȉ��ɂȂ��Ă邩�ȁH
10nm�ȉ��ɂȂ��Ă邩�ȁH
SOI�͌����肻�����ȁB
>>79
���̂܂܂ł͖������ˁB�V�������N���Ă�����d�͂͌��I�ɂ͉�����Ȃ��B
���̍���ATOM�̌�pCPU������C2D���炢�̐��\��2W�Ƃ��ɂȂ��Ă�낤�B
���̂܂܂ł͖������ˁB�V�������N���Ă�����d�͂͌��I�ɂ͉�����Ȃ��B
���̍���ATOM�̌�pCPU������C2D���炢�̐��\��2W�Ƃ��ɂȂ��Ă�낤�B
>>80
11nm�������獡��C2D���炢2W�łȂ�Ƃ��Ȃ肻���B�����̍Đv�͕K�v���낤���ǁB
�c�c���Ă��Ƃ�2017�N�̃��o�C���[�����Ă���ȏ�ɑ������Ă��Ƃ��B
11nm�������獡��C2D���炢2W�łȂ�Ƃ��Ȃ肻���B�����̍Đv�͕K�v���낤���ǁB
�c�c���Ă��Ƃ�2017�N�̃��o�C���[�����Ă���ȏ�ɑ������Ă��Ƃ��B
2017�N����CPU+NB+SB�̃����`�b�v�ɁAPRAM�Ȃǂ̃t���b�V����DRAM��փ������̐ϑw
�Z�p���m�����Ă��܂����H
�Z�p���m�����Ă��܂����H
���������Q�O�P�V�N�ɉ��͐����Ă�̂��H
2012�N�ɋC�������Ⴄ��ł��ˁB�킩��܂��B
2014�N��LCL�ɂȂ����Ⴄ�l�����������B
�V���R���̎��オ�I���ɋ߂Â��Ă�����Ă����̂�
������S�T�Omm�E�F�n���E�E
������S�T�Omm�E�F�n���E�E
���ɐl�ނ͖ŖS���Ă���
16nm�����E�����āAintel�̌����������\���Ă��Ǝv�����B
�g�����W�X�^�����Ȃ�IBM��6nm�ANEC��5nm���������5�N���炢�O�ɔ��\���Ă邼�B
������ăQ�[�g������Ȃ��́H
2017�N��CPU��蕀���ް
����Sandybridge�܂ő҂��Ƃɂ����
32nm�͂������������ǁA22nm���O�ɂ��������D�悳��邩������Ȃ��\��
�������Ă��ȓd�͂ɂȂ�Ȃ��ƂȂ�ƁA�`�b�v�����������邩����d�͂��������Ȃ���
���͂�O�i�ł��Ȃ��Ƃ�������ɂȂ肻�������B
http://slashdot.jp/hardware/article.pl?sid=08/05/08/1014256
�������Ă��ȓd�͂ɂȂ�Ȃ��ƂȂ�ƁA�`�b�v�����������邩����d�͂��������Ȃ���
���͂�O�i�ł��Ȃ��Ƃ�������ɂȂ肻�������B
http://slashdot.jp/hardware/article.pl?sid=08/05/08/1014256
�������X�^���t���b�v�t���b�v�̑�ւ��ɂȂ邮�炢�����������炿����Ɩʔ������Ȃ�
��������Ɗ肤����B
��������Ɗ肤����B
460 Socket774 sage 2008/05/03(�y) 15:29:11 ID:PHaaFyfB
�_�f��E�̈ړ��x���d�q�̈ړ��x������Ƃ͎v���Ȃ�����
FF�̒u���������Ă̂͂Ȃ����낤��
�_�f��E�̈ړ��x���d�q�̈ړ��x������Ƃ͎v���Ȃ�����
FF�̒u���������Ă̂͂Ȃ����낤��
>>95
����͍�������������̂ɂ��Ă̘͂b�ƍl�������Ƃ���
����͍�������������̂ɂ��Ă̘͂b�ƍl�������Ƃ���
����X���Ԉ���Ă邾��AID�I�ɍl���āc
���Ƃ���ȊȒP�ɋZ�p�̒u���������i�ނƂ͎v���Ȃ��B
�����̎Y�Ƃ͐��Y�Ɋւ��Ă͐����ێ�I�B
�܂��������s���l�܂��Ă�킯�ł��Ȃ����ˁB
���Ƃ���ȊȒP�ɋZ�p�̒u���������i�ނƂ͎v���Ȃ��B
�����̎Y�Ƃ͐��Y�Ɋւ��Ă͐����ێ�I�B
�܂��������s���l�܂��Ă�킯�ł��Ȃ����ˁB
���ꂾ������22nm���D��Ȃ�āA�܂��܂����肦�Ȃ���
22nm ���悪�s���l��Ȃ��Ƃ͎v���Ȃ����A�ǂ��ȂȁE�E�E
>>99
�܂��̓_�u���Q�[�g�Ȃ�g���C�Q�[�g�Ȃ肪���邾�낤��
�܂��̓_�u���Q�[�g�Ȃ�g���C�Q�[�g�Ȃ肪���邾�낤��
�o�C�|�[������CMOS�ւ̈ڍs�����āA�Z�p�I�ɂ͂����Ƒ�����������\�������Ǝv�����A
���ۂɂ̓o�C�|�[�����s���l���Ă���ڍs��������ȁB
���ۂɂ̓o�C�|�[�����s���l���Ă���ڍs��������ȁB
���E��16nm�܂ł��Ƌ͂��A�͂Ă͂Ă��Ă���
65nm�����͎����玟�ւƎv��ʖ�肪�啬�o����\�������ĂȂ�Ȃ���
65nm�����͎����玟�ւƎv��ʖ�肪�啬�o����\�������ĂȂ�Ȃ���
�m���ɂˁB
���̐��E��̔����̃��[�J�[�ł���Intel�ł���A90nm�ł̃��[�N�d���̖����A
���ۂ̗ʎY�ɓ��閘�ɂ����ƔF���o�����Ɍ��蔭�Ԃ��A���NJ��S�ɂ͉���
�o�����ɏI������Ƃ������т����邩��Ȃ��B
45nm�ł���N�������Intel�́u�[�b�R�[�`���[�����I�v�݂����ɑ����@����
���̂ɊW���J������Atom�̒����ɂ��瓚������Ȃ����x�����A�ʎY�̐��𐮂�
���ĂȂ��݂��������B
���q�����x���ɂ܂ŗ��Ă��܂��������v���Z�X�ł́A�����H�ƓI�ȗ͋Z���i�J
�i�J�ʗp���Ȃ����낤���A����͂����ƈ�̓��ɂȂ炴��Ȃ����낤�B
���̐��E��̔����̃��[�J�[�ł���Intel�ł���A90nm�ł̃��[�N�d���̖����A
���ۂ̗ʎY�ɓ��閘�ɂ����ƔF���o�����Ɍ��蔭�Ԃ��A���NJ��S�ɂ͉���
�o�����ɏI������Ƃ������т����邩��Ȃ��B
45nm�ł���N�������Intel�́u�[�b�R�[�`���[�����I�v�݂����ɑ����@����
���̂ɊW���J������Atom�̒����ɂ��瓚������Ȃ����x�����A�ʎY�̐��𐮂�
���ĂȂ��݂��������B
���q�����x���ɂ܂ŗ��Ă��܂��������v���Z�X�ł́A�����H�ƓI�ȗ͋Z���i�J
�i�J�ʗp���Ȃ����낤���A����͂����ƈ�̓��ɂȂ炴��Ȃ����낤�B
ITRS�ɂ�HP��11nm�܂ł̃��[�h�}�b�v���ڂ��Ă邯�ǂȁB
Intel���g��8nm�܂ł̃X���C�h���o�������Ƃ����邵�B
Intel���g��8nm�܂ł̃X���C�h���o�������Ƃ����邵�B
���炠�ĂɂȂ���
10GHz�܂ł̃��[�h�}�b�v��������������
10GHz�܂ł̃��[�h�}�b�v��������������
�������M�͊ÎāA���O�@�Ɛڑ�����悤��CPU�N�[���[��W���ɂ��������Ȃ��́H
�G�A�R�������Ă����Ȃ��Ă���A�ʂɂ��������B
�R�A�����₵�Ă����A�v���[�`���́A�����Ƃ����Ǝv�����ȁB
�G�A�R�������Ă����Ȃ��Ă���A�ʂɂ��������B
�R�A�����₵�Ă����A�v���[�`���́A�����Ƃ����Ǝv�����ȁB
����ȓd�C�H���܂���̃q�[�^�[�A���ی�c�̂��ق��ĂȂ����낤w
cpu�����葬���Ă��˂��c
�_�C�o���G�[�V�����̃��C���i�b�v�A[]����MCM�ɂ��o���G�[�V�����lj��A
���L���̑������̂͂P�ŃJ�E���g�B
��Conroe�n 65nm
Conroe(x2,4MB)�A[Kentsfield(x2,4MB)x2]�AAllendale(x2,2MB)�AConroe-L(x1,1MB)
��Penryn�n 45nm
Wolfdale(x2,6MB)�A[Yorkfield(x2,6MB)x2]�AWolfdale-M(x2,3MB)�A[Yorkfield-M(x2,3MB)x2]
Dunnington(x6,16MB)
��Nehalem�n 45nm
Bloomfield(x4,8MB)�AHavendale(GPU,x2,4MB)
Beckton(x8,24MB)
��AMD 65nm
Brisbane(x2,1MB)�AAgena(x4,2MB)�ALima(x1,512KB)
��AMD 45nm
Deneb(x4,6MB)�APropus(x4,0MB)�ARegor(x2,0MB)�AIstanbul(x6,6MB)�ASao Paolo(x6,6MB)
[Magny-Cours(x6,6MB)x2]
Nehalem�n��L3�e�ʌ��炵���o���G�[�V�����͂��Ȃ��̂��ˁB�ቿ�i�т�Yorkfield/Wolfdale��
�J�o�[������肾�낤���B
���L���̑������̂͂P�ŃJ�E���g�B
��Conroe�n 65nm
Conroe(x2,4MB)�A[Kentsfield(x2,4MB)x2]�AAllendale(x2,2MB)�AConroe-L(x1,1MB)
��Penryn�n 45nm
Wolfdale(x2,6MB)�A[Yorkfield(x2,6MB)x2]�AWolfdale-M(x2,3MB)�A[Yorkfield-M(x2,3MB)x2]
Dunnington(x6,16MB)
��Nehalem�n 45nm
Bloomfield(x4,8MB)�AHavendale(GPU,x2,4MB)
Beckton(x8,24MB)
��AMD 65nm
Brisbane(x2,1MB)�AAgena(x4,2MB)�ALima(x1,512KB)
��AMD 45nm
Deneb(x4,6MB)�APropus(x4,0MB)�ARegor(x2,0MB)�AIstanbul(x6,6MB)�ASao Paolo(x6,6MB)
[Magny-Cours(x6,6MB)x2]
Nehalem�n��L3�e�ʌ��炵���o���G�[�V�����͂��Ȃ��̂��ˁB�ቿ�i�т�Yorkfield/Wolfdale��
�J�o�[������肾�낤���B
>>108
�d�M�X�g�[�u�ɕ���t������ی�c�̂Ȃ�ĕ��������Ƃˁ[��
�d�M�X�g�[�u�ɕ���t������ی�c�̂Ȃ�ĕ��������Ƃˁ[��
>>110
45nm����ł̓��C���X�g���[����艺��Wolfdale-M���S�����ۂ��B
�L���b�V��1.5MB��0.75MB�̃f���A���R�A�̉\������̂ŁB
45nm����ł̓��C���X�g���[����艺��Wolfdale-M���S�����ۂ��B
�L���b�V��1.5MB��0.75MB�̃f���A���R�A�̉\������̂ŁB
���Ȃ��Ƃ��T�[�o�[�pCPU�͑�ʂɈ�ӏ��Ŏg������A�f�[�^�Z���^�[���̂�
����d�͂�G�A�R���e�ʂ̌��E�������ɂȂ��Ă��܂�����ȁB
���������Ӗ��ł�����d�͑ΐ��\���ǂ�CPU�̃A�b�v�O���[�h�łȂ��ƁA�o�ϐ�
�����Ȃ��邩��A�N�������Ă���Ȃ��Ȃ��ȁB
����d�͂�G�A�R���e�ʂ̌��E�������ɂȂ��Ă��܂�����ȁB
���������Ӗ��ł�����d�͑ΐ��\���ǂ�CPU�̃A�b�v�O���[�h�łȂ��ƁA�o�ϐ�
�����Ȃ��邩��A�N�������Ă���Ȃ��Ȃ��ȁB
�㓡�O�X�����I
�ق�Ƃ��@�����Ă�
117 �FSocket774�F2008/05/11(��) 23:30:28 ID:Rttu3AQH
�����A�����r�[�ɂ��Č��� �b�o�t���m�ǂ�
���ށ|��CPU�ł͂Ȃ��E�E�Ƃ��������̂��H
nvidia�̃g�b�v�������ɂ̓����[��
power point�̃v���[���e�[�V�����̒��ɂ������݂��邻����
power point�̃v���[���e�[�V�����̒��ɂ������݂��邻����
���ʯʯ�
ttp://www.news.com/8301-10784_3-9939430-7.html?tag=nefd.top
"Larabee is a PowerPoint slide," Huang said.
"Larabee is a PowerPoint slide," Huang said.
IA32���𑽐��W�ς������̂����ް�ƌĂ�ł�����Ȃ��̂��H
QX9300�ŏȓd�̓N�A�b�h�}�V���Ƃ�����Ă݂���
�A�C�h���͏ȃG�l�A�g���Ƃ��̓N�A�b�h�̃p���[�łǂ��[����ċ��
�A�C�h���͏ȃG�l�A�g���Ƃ��̓N�A�b�h�̃p���[�łǂ��[����ċ��
http://pc.nikkeibp.co.jp/article/news/20080418/1001146/?SS=pco_imgview&FD=-649101646
�����Ȃ������m����
�����Ȃ������m����
http://www.tgdaily.com/content/view/37232/113/
Nvidia has recently voiced its concerns over Intel�fs advances
in a very public fashion and attacked Intel with cheap shots
such as calling Intel�fs Larrabee �gLaughabee�h.
Nvidia has recently voiced its concerns over Intel�fs advances
in a very public fashion and attacked Intel with cheap shots
such as calling Intel�fs Larrabee �gLaughabee�h.
���I�H
Atom16�R�A�̂��}���`�`�b�v�ł̂������32�R�A�ɂȂ肻���Ȃ̂ɁB
Atom16�R�A�̂��}���`�`�b�v�ł̂������32�R�A�ɂȂ肻���Ȃ̂ɁB
�~ �}���`�`�b�v
�� �f���A���_�C
�� �f���A���_�C
MCM�iMulti Chip Module�j
����������
�ЂƂ�FSB��32�R�A���Ԃ炳��������
FSB��400MHz���o���Ȃ����낗
���\���S�R�o�Ȃ������B
Atom16�R�A�������N���X�o�[�Ƃ������O�o�X�łȂ���悤��
�v�������Ă���C�ɂ��Ȃ����ǁB
FSB��400MHz���o���Ȃ����낗
���\���S�R�o�Ȃ������B
Atom16�R�A�������N���X�o�[�Ƃ������O�o�X�łȂ���悤��
�v�������Ă���C�ɂ��Ȃ����ǁB
���A���������B
16�R�A�ł���������o�Ȃ����ȁB
16�R�A�ł���������o�Ȃ����ȁB
>>123
�� EIST
�� EIST
���o�C���v���Z�b�T��EIST�ƒʏ��EIST���悤�Ɏ�炦�Ă�����Ă͍����
��҂��A�C�h������1GHz�㔼�܂ŗ����Ȃ��̂ɑ��āA���o�C���̂���͂Ȃ��1GHz�ɂ܂ŗ��Ƃ���̂���
��҂��A�C�h������1GHz�㔼�܂ŗ����Ȃ��̂ɑ��āA���o�C���̂���͂Ȃ��1GHz�ɂ܂ŗ��Ƃ���̂���
�l�n��SMT��������������
intel�Ƃ��Ă͒P��TLP�����߂�R�X�p�ȕ��@�Ƃ��čl���Ă�́H
����Ƃ��V���O���X���b�h�����̋�����ړI�Ƃ������@�I�X���b�f�B���O�̕z�ɂ������́H
intel�Ƃ��Ă͒P��TLP�����߂�R�X�p�ȕ��@�Ƃ��čl���Ă�́H
����Ƃ��V���O���X���b�h�����̋�����ړI�Ƃ������@�I�X���b�f�B���O�̕z�ɂ������́H
�P�ɐ��\�Γd�́A�R�X�g�ŗL��������������邾���ł́B
�Ď����Ƃ�����Pentium-4�ƑS���ʌn����Pentium-M�n���ɂ͕t���ĂȂ����������ŁB
�Ď����Ƃ�����Pentium-4�ƑS���ʌn����Pentium-M�n���ɂ͕t���ĂȂ����������ŁB
�g���݃V�X�e���J���Z�p�W���|�[�g
�`�e�Ђ���Ă�Atom���ڐ��i��W��/�f��
http://pc.watch.impress.co.jp/docs/2008/0515/esec.htm
�`�e�Ђ���Ă�Atom���ڐ��i��W��/�f��
http://pc.watch.impress.co.jp/docs/2008/0515/esec.htm
���o�`�[���̈Ӓn����ˁH
>>135
���ՂɊg���ł��邩�����Ă݂悤�Ƃ����b���Ǝv���
�Ȃɂ���A�����I�ȃ��W�X�^�[�{�ɑ��₵�āA���ߕϊ��łǂ���̗��ꂩ��̖��߂��Ŋ���U��ς���Ί���������ȁB
����3%���ʒ��x�łł���炵���B
���ʂ��ǂ��Ȃ邩�͕s�������A���l�I�A���Ă���I�ȃX�y�b�N���ȒP�ɂ�������B
���܂�D�܂����͂Ȃ��������Ƃ͎v���B
���ՂɊg���ł��邩�����Ă݂悤�Ƃ����b���Ǝv���
�Ȃɂ���A�����I�ȃ��W�X�^�[�{�ɑ��₵�āA���ߕϊ��łǂ���̗��ꂩ��̖��߂��Ŋ���U��ς���Ί���������ȁB
����3%���ʒ��x�łł���炵���B
���ʂ��ǂ��Ȃ邩�͕s�������A���l�I�A���Ă���I�ȃX�y�b�N���ȒP�ɂ�������B
���܂�D�܂����͂Ȃ��������Ƃ͎v���B
Nehalem�͎I�����̊g������������A���̈��SMT��������ˁH
�I����CPU�Ń}���`�X���b�f�B���O�Z�p�������ĂȂ��̂�AMD���������B
�I����CPU�Ń}���`�X���b�f�B���O�Z�p�������ĂȂ��̂�AMD���������B
SMT���{���Ɍ��ʂ���͎̂I�ނ��ł͂Ȃ��A�V���O���R�A��ATOM����B
����d�͂���p�t�H�[�}���X�Ɏ���܂ŁA���ׂĂ��Č��ʂ��グ�邾�낤�B
����d�͂���p�t�H�[�}���X�Ɏ���܂ŁA���ׂĂ��Č��ʂ��グ�邾�낤�B
performance/watt�Ƃ����l������s���i��K�͂�OoO�v���Z�b�T�ł͓��Ɂj�}���`�X���b�f�B���O�̗̍p�͕K�R������
HT�̌��ʂ��ł������Ď���
���X�̓X�J�X�J���Ď���
���X�̓X�J�X�J���Ď���
�܂�����Ȕn���������B
���₻��͊m������
�X�J�X�J�ȗ��R�ɂ���Ĕn���ɂ���邩�ǂ��������܂邪
�X�J�X�J�ȗ��R�ɂ���Ĕn���ɂ���邩�ǂ��������܂邪
���������C�e���V�B���̌��ʂ�?
�������҂��̂����ŃX�J�X�J
�t�����g�G���h��������X�J�X�J
�K�o�K�o�̏��ƃX�J�X�J�Ȃb�o�t�ǂ���������
ATOM��HT�͂����Ǝv����
���R���̂P
�L���b�V����������
���L���b�V���~�X�̃��C�e���V���B�����₷��
���R���̂Q
�����d�͂�PC����낤�Ǝv���Ȃ�A���Ӄ`�b�v�̃N���b�N���Ⴂ�ق��������B
���傫�ȃ��C�e���V���B�����₷��
���R���̂R
�V���O��CPU�ł���HT���̗p���Ă��ACPU�Ԃ̑Ώ̐�������Ȃ��}���`CPU�ł͂��ꂪ�������Ă��܂��B
��HT���L��CPU�̔�Ώ̐��Ɋւ�鈫�e���̔����]�n���Ȃ�
���R���̂S
HT�Z�p�́A�g�p�g�����W�X�^�̗ʂ��ƂĂ�������
�g�����W�X�^�͎g���Ă��Ȃ��Ă��A���݂��邾���ŏ���d�͔͂�������A�Z���ԂŌv�Z���I���ق����ǂ��B
���g�����W�X�^�̗L�����p�́A�����d�͂ɂ��v������
���R���̂T
����̃A�v���P�[�V����������l����ƁA�n�[�h�E�F�A�X���b�h�͓���炢�ł悢�B
����ȏ゠���Ă��A�V�x�����Ă��܂��B
�������ɍ����Ă���
���R���̂P
�L���b�V����������
���L���b�V���~�X�̃��C�e���V���B�����₷��
���R���̂Q
�����d�͂�PC����낤�Ǝv���Ȃ�A���Ӄ`�b�v�̃N���b�N���Ⴂ�ق��������B
���傫�ȃ��C�e���V���B�����₷��
���R���̂R
�V���O��CPU�ł���HT���̗p���Ă��ACPU�Ԃ̑Ώ̐�������Ȃ��}���`CPU�ł͂��ꂪ�������Ă��܂��B
��HT���L��CPU�̔�Ώ̐��Ɋւ�鈫�e���̔����]�n���Ȃ�
���R���̂S
HT�Z�p�́A�g�p�g�����W�X�^�̗ʂ��ƂĂ�������
�g�����W�X�^�͎g���Ă��Ȃ��Ă��A���݂��邾���ŏ���d�͔͂�������A�Z���ԂŌv�Z���I���ق����ǂ��B
���g�����W�X�^�̗L�����p�́A�����d�͂ɂ��v������
���R���̂T
����̃A�v���P�[�V����������l����ƁA�n�[�h�E�F�A�X���b�h�͓���炢�ł悢�B
����ȏ゠���Ă��A�V�x�����Ă��܂��B
�������ɍ����Ă���
Isaiah�ɂ��̗p���ăz�X�C�ȁB
������x�}���`�X���b�h�Z�p���������Ă��Ƃ��낶��Ȃ��Ƃ����ȒP�ɂ͎����ł��Ȃ���Ȃ��̂���
Atom�̃����b�g�������Ȃ�
ARM�ł������
ARM�ł������
ARM��WinCE�s�����Ax86�ȊO�̃A�[�L�͐h��
�܂��Windows��WinCE�����肵�Ă邩�̂悤�Ȍ�������
����҂ɑ��Č���������\���ł͂Ȃ����Ǝ��͎v���܂�
����҂ɑ��Č���������\���ł͂Ȃ����Ǝ��͎v���܂�
isaiah�̃t�����g�G���h�͋��낵���D�G�������̂�HT�s�v��
���s���j�b�g��Core��2/3����
���s���j�b�g��Core��2/3����
�l�I�ɂ́AATOM�ŃV�X�e�����l����Ǝ��X�Ɩ������̗��ꂪ�Ȃ����Ă����̂��ƂĂ��C���������Ǝv���Ă���B
�l�n���݂Ă���ƁA�X�̋@�\�͋����[������ǁA����ŃV�X�e����z���������łԂ�������ꂽ�݂����ɂȂ��ȁB
�l�n���݂Ă���ƁA�X�̋@�\�͋����[������ǁA����ŃV�X�e����z���������łԂ�������ꂽ�݂����ɂȂ��ȁB
�g�����X���^�łǂ������������H
�g���݂̐��E�ɂ�����ARM������������������������86�Ȃ̂�
WinCE�̃V�F�A���Ⴂ���Ƃ��S�Ă���Ă�
WinCE�̃V�F�A���Ⴂ���Ƃ��S�Ă���Ă�
���O�����m�Ȃ̂͂悭�킩�����B
936 �F�f�t�H���g�̖��������� [��] �F2008/05/16(��) 05:31:53
�G���b�^���X�g�ɊW���肻���ȋL�q���������B
http://download.intel.com/design/processor/specupdt/318733.pdf
> AW51.�@Short Nested Loops That Span Multiple 16-Byte Boundaries May
> �@�@�@�@�@Cause a Machine Check Exception or a System Hang
���������d���[�v�ŃV�X�e���n���O�������N�������̂�����ABIOS�őΏ��\�Ƃ̎��B
LSD�������悤�ȏ��������[�v�ő��d���[�v������Ƃ���P�[�X������̂ŁA
LSD���[�v���ł̓}�N���t���[�W�������ɂ��đΏ��������Ă��Ƃ��Ȃ��H
�G���b�^AW51�����̕����ɒlj����ꂽ����2008�N2��1���Ə�����Ă���A
�}�C�N���R�[�h�p�b�`ID:60B�̍쐬����2008�N1��19���Ȃ̂�
�����I�ɂ��߂��B
�G���b�^���X�g�ɊW���肻���ȋL�q���������B
http://download.intel.com/design/processor/specupdt/318733.pdf
> AW51.�@Short Nested Loops That Span Multiple 16-Byte Boundaries May
> �@�@�@�@�@Cause a Machine Check Exception or a System Hang
���������d���[�v�ŃV�X�e���n���O�������N�������̂�����ABIOS�őΏ��\�Ƃ̎��B
LSD�������悤�ȏ��������[�v�ő��d���[�v������Ƃ���P�[�X������̂ŁA
LSD���[�v���ł̓}�N���t���[�W�������ɂ��đΏ��������Ă��Ƃ��Ȃ��H
�G���b�^AW51�����̕����ɒlj����ꂽ����2008�N2��1���Ə�����Ă���A
�}�C�N���R�[�h�p�b�`ID:60B�̍쐬����2008�N1��19���Ȃ̂�
�����I�ɂ��߂��B
>>156
�������̒x�������͂ǂ����悤���Ȃ�����A����������ł��B���o����HT��
�K�v�ł��傤�B
Intel��AMD�̖w�ǂ�CPU���Q�R�A�ȏ�ɂȂ��Ă��܂��Ă錻��ł́A������
�N���C�A���g����CPU�Ƃ͂����A�V���O���X���b�h�����ł͕s�������AHT�Ȃ�
�Q�R�A�قǃg�����W�X�^�͗v��Ȃ����B
�������̒x�������͂ǂ����悤���Ȃ�����A����������ł��B���o����HT��
�K�v�ł��傤�B
Intel��AMD�̖w�ǂ�CPU���Q�R�A�ȏ�ɂȂ��Ă��܂��Ă錻��ł́A������
�N���C�A���g����CPU�Ƃ͂����A�V���O���X���b�h�����ł͕s�������AHT�Ȃ�
�Q�R�A�قǃg�����W�X�^�͗v��Ȃ����B
������Ƃ܂āA
���[�v�X�g���[���f�B�e�N�^���@�\���Ȃ����āA
���ꂶ��V���O���X���b�h�\�͂̌��オ�]�߂Ȃ����Ď��H
�l�n�łق��ɃV���O���X���b�h�\�͂ɍv������V�@�\���Ă����������H
���[�v�X�g���[���f�B�e�N�^���@�\���Ȃ����āA
���ꂶ��V���O���X���b�h�\�͂̌��オ�]�߂Ȃ����Ď��H
�l�n�łق��ɃV���O���X���b�h�\�͂ɍv������V�@�\���Ă����������H
Penryn�̘b���BNehalem�̃G���b�^���Ȃ��B
Penryn�̐��\������āANehalem�̃V���O���X���b�h���\��ǂ���������
�P�Ɍ��ׂ���
���ށA���������Ƃ�����
�����̒m�������X��
��������`�`������
��������`�`������
�m�������ł͂Ȃ��A�^�̎���>>172��
���̃X���Z�l�S���̊��҂̖ڂ��W�܂��Ă��邼�B
�y���݂��c�B�ǂ�ȐV�����������݂��҂��Ă���̂��B
���̃X���Z�l�S���̊��҂̖ڂ��W�܂��Ă��邼�B
�y���݂��c�B�ǂ�ȐV�����������݂��҂��Ă���̂��B
MSI��Atom���ڃ~�jPC�uWIND PC�v���r���[
http://pc.watch.impress.co.jp/docs/2008/0519/msi2.htm
http://pc.watch.impress.co.jp/docs/2008/0519/msi2.htm
�j�m
>>173
��C���ǂ߂Ȃ���ɐ��邱�Ƃ������b��̖��m�ɂ��ꂪ�\���Ǝv�����H
��C���ǂ߂Ȃ���ɐ��邱�Ƃ������b��̖��m�ɂ��ꂪ�\���Ǝv�����H
���Ă��A���̃X���ɃA�Z���u���o���o���̋Z�p�҂�����Ƃ��v����̂ł����E�E�E
�A�Z���u���Ȃ�Ă߂�ǂ��Ȃ��̂ō��������Ă�����킯�H�b�ł悭�ˁH
C�ł�����
>>178
Driver �J���ł̓A�Z���u���͌����ł��B
Driver �J���ł̓A�Z���u���͌����ł��B
C����SIMD�������Ȃ������
����10�NWEB����E�X�N���v�g�����
C��A�Z���u���̋L���͎��O���Ă�����
C��A�Z���u���̋L���͎��O���Ă�����
��Intel Core2�n�v���C�X���[�h�}�b�v
Core�@Clock�@�@L2�@�@�@FSB�@�@�@ TDP �@�@�@�@�@�@�@�@�@�@ ���݁@�@Q3
x4�@3.20GHz�@6MBx2....1600MHz..150W�@Ext QX9775�@.$1499
x4�@3.20GHz�@6MBx2....1600MHz..136W�@Ext QX9770�@.$1399
x4�@3.00GHz�@6MBx2....1333MHz..130W�@Ext QX9650�@�@$999�@ discon
x4�@3.00GHz�@6MBx2....1333MHz.�@95W . C2Q Q9650�@�@----�@�@$530
x4�@2.83GHz�@6MBx2....1333MHz.�@95W . C2Q Q9550�@�@$530�@�@$316
x4�@2.66GHz�@6MBx2....1333MHz.�@95W . C2Q Q9450�@�@$316�@ discon
x4�@2.66GHz�@3MBx2....1333MHz.�@95W . C2Q Q9400�@�@----�@�@$266
x4�@2.50GHz�@3MBx2....1333MHz.�@95W . C2Q Q9300�@�@$266�@ discon
x4�@2.66GHz�@4MBx2....1066MHz.�@95W . C2Q Q6700�@�@$266�@ discon
x4�@2.40GHz�@4MBx2....1066MHz.�@95W . C2Q Q6600�@�@$224�@�@$203
x2�@3.33GHz�@6MB �@�@1333MHz.�@65W �@C2D E8600�@�@----�@�@$266
x2�@3.16GHz�@6MB �@�@1333MHz.�@65W �@C2D E8500�@�@$266�@�@$183
x2�@3.00GHz�@6MB �@�@1333MHz.�@65W �@C2D E8400�@�@$183�@�@$163
x2�@2.83GHz�@6MB �@�@1333MHz.�@65W �@C2D E8300�@�@$163�@ discon
x2�@3.00GHz�@4MB �@�@1333MHz.�@65W �@C2D E6850�@�@$183
x2�@2.66GHz�@3MB �@�@1066MHz.�@65W �@C2D E7300�@�@----�@�@$133
x2�@2.53GHz�@3MB �@�@1066MHz.�@65W �@C2D E7200�@�@$133�@�@$113
x2�@2.60GHz�@2MB �@�@. 800MHz.�@65W �@C2D E4700�@�@$133
x2�@2.40GHz�@2MB �@�@. 800MHz.�@65W �@C2D E4600�@�@$113�@ discon
��discon�͖{���͐����I��/�̔��I���̈Ӗ������A�����ł͉��i�������������
�@��ʐ��i�Ɠ��z�ȏ�ɂȂ茻�s���C���i�b�v����ނ�����Ԃ��w���B
��QX9775��Skulltrail(Socket 771-2Way)�p�B
Core�@Clock�@�@L2�@�@�@FSB�@�@�@ TDP �@�@�@�@�@�@�@�@�@�@ ���݁@�@Q3
x4�@3.20GHz�@6MBx2....1600MHz..150W�@Ext QX9775�@.$1499
x4�@3.20GHz�@6MBx2....1600MHz..136W�@Ext QX9770�@.$1399
x4�@3.00GHz�@6MBx2....1333MHz..130W�@Ext QX9650�@�@$999�@ discon
x4�@3.00GHz�@6MBx2....1333MHz.�@95W . C2Q Q9650�@�@----�@�@$530
x4�@2.83GHz�@6MBx2....1333MHz.�@95W . C2Q Q9550�@�@$530�@�@$316
x4�@2.66GHz�@6MBx2....1333MHz.�@95W . C2Q Q9450�@�@$316�@ discon
x4�@2.66GHz�@3MBx2....1333MHz.�@95W . C2Q Q9400�@�@----�@�@$266
x4�@2.50GHz�@3MBx2....1333MHz.�@95W . C2Q Q9300�@�@$266�@ discon
x4�@2.66GHz�@4MBx2....1066MHz.�@95W . C2Q Q6700�@�@$266�@ discon
x4�@2.40GHz�@4MBx2....1066MHz.�@95W . C2Q Q6600�@�@$224�@�@$203
x2�@3.33GHz�@6MB �@�@1333MHz.�@65W �@C2D E8600�@�@----�@�@$266
x2�@3.16GHz�@6MB �@�@1333MHz.�@65W �@C2D E8500�@�@$266�@�@$183
x2�@3.00GHz�@6MB �@�@1333MHz.�@65W �@C2D E8400�@�@$183�@�@$163
x2�@2.83GHz�@6MB �@�@1333MHz.�@65W �@C2D E8300�@�@$163�@ discon
x2�@3.00GHz�@4MB �@�@1333MHz.�@65W �@C2D E6850�@�@$183
x2�@2.66GHz�@3MB �@�@1066MHz.�@65W �@C2D E7300�@�@----�@�@$133
x2�@2.53GHz�@3MB �@�@1066MHz.�@65W �@C2D E7200�@�@$133�@�@$113
x2�@2.60GHz�@2MB �@�@. 800MHz.�@65W �@C2D E4700�@�@$133
x2�@2.40GHz�@2MB �@�@. 800MHz.�@65W �@C2D E4600�@�@$113�@ discon
��discon�͖{���͐����I��/�̔��I���̈Ӗ������A�����ł͉��i�������������
�@��ʐ��i�Ɠ��z�ȏ�ɂȂ茻�s���C���i�b�v����ނ�����Ԃ��w���B
��QX9775��Skulltrail(Socket 771-2Way)�p�B
>>181
intrinsics���g���ق������͑����h����Ȃ���
intrinsics���g���ق������͑����h����Ȃ���
185 �FSocket774�F2008/05/21(��) 23:29:40 ID:POQHEy44
����C�����肽���Ȃ�
>>177
8bit������̋��o���o�������[��ł��������H
�ł��}���`�X���b�h�����Ĉȗ�C#���������Ă��
�K�x�R�����Ȃ��Ɗߋ�݂����ȃ��C�u���������ł��Ȃ��āA�܂Ƃ��Ƀv���O�����ł��Ȃ����B
�X���b�h�g��Ȃ��ŃV���O���X���b�h�ŃA�Z���u���o���o���`���[�����Ă����\�S�R�łȂ����B
8bit������̋��o���o�������[��ł��������H
�ł��}���`�X���b�h�����Ĉȗ�C#���������Ă��
�K�x�R�����Ȃ��Ɗߋ�݂����ȃ��C�u���������ł��Ȃ��āA�܂Ƃ��Ƀv���O�����ł��Ȃ����B
�X���b�h�g��Ȃ��ŃV���O���X���b�h�ŃA�Z���u���o���o���`���[�����Ă����\�S�R�łȂ����B
D����}���Z�[
�l�n�[��������Q4���Č������ǂ����ł��?
�N��?�O����?
�N��?�O����?
�\�t�g�E�F�A���̂������n�[�h�����������̂悤�Ɍ��̂��A�������A
�����Ɍ܌��������̂�������ECL��H���Ă܂����݂��Ƃ�ȁH
�����Ɍ܌��������̂�������ECL��H���Ă܂����݂��Ƃ�ȁH
>>188
���ʐ��i�̔��\�\���Q4���Ă�������N���B
���ʐ��i�̔��\�\���Q4���Ă�������N���B
Intel��Wind River�A�ԍڗpLinux�C���t�H�e�C�������g�E�V�X�e���𐄐i
http://opentechpress.jp/opensource/08/05/22/0117223.shtml
>���Ђ́A���Ђ̊J���v���b�g�t�H�[�����g���v���W�F�N�g��Moblin Web�T�C�g�𗘗p����悤�v���O���}�[�ɑ������Ƃɂ��Ă���BMoblin��Intel���x������I�[�v���\�[�X�E�R�~���j�e�B�[�E�T�C�g�ŁA���݂̎���MID������Moblin Core Linux Stack���B
http://opentechpress.jp/opensource/08/05/22/0117223.shtml
>���Ђ́A���Ђ̊J���v���b�g�t�H�[�����g���v���W�F�N�g��Moblin Web�T�C�g�𗘗p����悤�v���O���}�[�ɑ������Ƃɂ��Ă���BMoblin��Intel���x������I�[�v���\�[�X�E�R�~���j�e�B�[�E�T�C�g�ŁA���݂̎���MID������Moblin Core Linux Stack���B
��ԗpLinux���ĉ��H �ƕ������Ƃ����䂪�y�̓o�J�ł���B
�[���R�p�̃��F�N�g���j�N�X���Ĕėp�̃\�t�g�E�F�A�������Ă�́H
�R�p�̓������̂��Ƃ������Ă�����
�R�p�̓������̂��Ƃ������Ă�����
�R�p�V�X�e����UNIX���悭�g���Ă邩��
Linux���ǂ����Ɏg���Ă��Ȃ�����
�A�����J���̋Z�p�͊�{�I�ɌR�p���疯�p�ɕ��������������̂�
�قƂ�ǂ�����
Linux���ǂ����Ɏg���Ă��Ȃ�����
�A�����J���̋Z�p�͊�{�I�ɌR�p���疯�p�ɕ��������������̂�
�قƂ�ǂ�����
F-22�̏ꍇ
>�A�r�I�j�N�X�͏]���̐퓬�@�Ɠ��l��Ada�ŊJ�����ꂽ�B
>�\�t�g�E�F�A�̊J���K�͂͋@�\�̃\�t�g�E�F�A�����i���Ƃɂ��AF-15A�̃\�t�g�E�G�A��200,000�s�ɉ߂��Ȃ������̂ɁA
>F-22�ł�2,200,000�s�ɂ��B���\�t�g�E�F�A�J�����퓬�@�J���ɐ�߂銄�������������B
>�\�t�g�E�F�A�̓���͍q�@28%�A���[�_�[12%�A�d�q��14%�A�ʐM14%�̎l����őS�̂�7���߂����߂Ă���B
>�܂����[�_�[�Ɠd�q�푕�u�����őS�̂̏���d�͂�90%���߂Ă���B
>�e�^�`�|�Q�Q���]�ɂ��Ă͌R�p�ɊJ�����ꂽ�������W�ω�H�|�u�g�r�h�b�𓋍ڂ����b�h�o�i���ʉ��������Z�������u�j�ƌĂ��R���s���[�^�[���Q�䂠��A
>���ꂼ��e�T�u�V�X�e���ƌ��t�@�C�o�[�̃f�[�^�o�X�Ōq�����Ă���B
>���̃R���s���[�^�[�͂e�|�P�T�d�̃R���s���[�^�[�ɑ��P�W�{�ȏ�̔\�͂�����ƌ����Ă���A
>���Z���x�͖��b�P�O�T�O����A�L���e�ʂ͂R�O�O�l�a�A�����]�n�͂܂��Q�O�O�����c���Ă���B
>�R���s���[�^�[�̃\�t�g�E�F�A�͕č����h�Ȃ̕W����������G�C�_�i�`�����j�ŏ�����Ă���A
>�@���ێ��ׂ̈Ƀ\�t�g�E�F�A�̓J�[�g���b�W�Ɏ��߂��Ă��āA�p�C���b�g�����掞�Ɏ�������Ń��[�h���s���B
>�A�r�I�j�N�X�͏]���̐퓬�@�Ɠ��l��Ada�ŊJ�����ꂽ�B
>�\�t�g�E�F�A�̊J���K�͂͋@�\�̃\�t�g�E�F�A�����i���Ƃɂ��AF-15A�̃\�t�g�E�G�A��200,000�s�ɉ߂��Ȃ������̂ɁA
>F-22�ł�2,200,000�s�ɂ��B���\�t�g�E�F�A�J�����퓬�@�J���ɐ�߂銄�������������B
>�\�t�g�E�F�A�̓���͍q�@28%�A���[�_�[12%�A�d�q��14%�A�ʐM14%�̎l����őS�̂�7���߂����߂Ă���B
>�܂����[�_�[�Ɠd�q�푕�u�����őS�̂̏���d�͂�90%���߂Ă���B
>�e�^�`�|�Q�Q���]�ɂ��Ă͌R�p�ɊJ�����ꂽ�������W�ω�H�|�u�g�r�h�b�𓋍ڂ����b�h�o�i���ʉ��������Z�������u�j�ƌĂ��R���s���[�^�[���Q�䂠��A
>���ꂼ��e�T�u�V�X�e���ƌ��t�@�C�o�[�̃f�[�^�o�X�Ōq�����Ă���B
>���̃R���s���[�^�[�͂e�|�P�T�d�̃R���s���[�^�[�ɑ��P�W�{�ȏ�̔\�͂�����ƌ����Ă���A
>���Z���x�͖��b�P�O�T�O����A�L���e�ʂ͂R�O�O�l�a�A�����]�n�͂܂��Q�O�O�����c���Ă���B
>�R���s���[�^�[�̃\�t�g�E�F�A�͕č����h�Ȃ̕W����������G�C�_�i�`�����j�ŏ�����Ă���A
>�@���ێ��ׂ̈Ƀ\�t�g�E�F�A�̓J�[�g���b�W�Ɏ��߂��Ă��āA�p�C���b�g�����掞�Ɏ�������Ń��[�h���s���B
�C�[�W�X�V�X�e���̃\�t�g�E�F�A��POSIX�����ŁA���̓��A���^�C��UNIX��œ����Ă�B
Linux�͂ǂ�����H
GPL�������N�����\��������邽�߂ɁA����v���b�g�t�H�[���Ƃ��Ă��J���v���b�g�t�H�[���Ƃ��Ă�
GPL�v���_�N�g�͉������A�Ă̂��K�v���낤���B
Linux�͂ǂ�����H
GPL�������N�����\��������邽�߂ɁA����v���b�g�t�H�[���Ƃ��Ă��J���v���b�g�t�H�[���Ƃ��Ă�
GPL�v���_�N�g�͉������A�Ă̂��K�v���낤���B
�����҈ȊO�Ƀo�C�i�����n�鎖���Ă��肦�Ȃ����������A���Ȃ���Ȃ��H
�A�o����͊�����u���b�N�{�b�N�X�ɂ��邱�Ƃ���������B
�\�[�X�R�[�h��n���ăR�s�[������ꂽ�獢�邶��Ȃ��B
�\�[�X�R�[�h��n���ăR�s�[������ꂽ�獢�邶��Ȃ��B
�O�O�����番����Ǝv����
�u���b�N�{�b�N�X���O��̌R�p�E�q�����OS�ɂ�Linux�����łɓ��荞��ł���
�W�҂͂��ꂩ���Unix���쒀���ă��C���ɂȂ�\��������Ǝ������Ă邼
GPL�̖����ǂ��������Ă�̂��m���
���R�����҈ȊO�ɂ̓\�[�X�R�[�h�͓n��Ȃ�
�������̌R�p�A�v���̏���͓��{�Ƃ͌����Ⴄ����Ȃ�
�u���b�N�{�b�N�X���O��̌R�p�E�q�����OS�ɂ�Linux�����łɓ��荞��ł���
�W�҂͂��ꂩ���Unix���쒀���ă��C���ɂȂ�\��������Ǝ������Ă邼
GPL�̖����ǂ��������Ă�̂��m���
���R�����҈ȊO�ɂ̓\�[�X�R�[�h�͓n��Ȃ�
�������̌R�p�A�v���̏���͓��{�Ƃ͌����Ⴄ����Ȃ�
����Ȃ��̂�GPL�R�[�h�������Ă邩�ǂ����Ȃ�ĒN�����ł���Ǝv���H
���낻��Ⴂ�ł́H
�ǂ�ȃv���b�g�t�H�[���������ĂĂ��A���C�Z���X�ᔽ���N�����z�͋N�����B
�R�[�h�̃��t�@�N�^�����O�őΏ����ׂ��B
�Ă��A���C�Z���X���i�����肩�łȂ����l�̃R�[�h��˂����ނȁA�Ă̂͂��̎�̂��̂̊�{���B
�\�[�X�R�[�h���[�������葼�Ђ�NDA���Ō��J���邱�Ƃ��������B
�R�[�h�̃��t�@�N�^�����O�őΏ����ׂ��B
�Ă��A���C�Z���X���i�����肩�łȂ����l�̃R�[�h��˂����ނȁA�Ă̂͂��̎�̂��̂̊�{���B
�\�[�X�R�[�h���[�������葼�Ђ�NDA���Ō��J���邱�Ƃ��������B
���āA�b��߂��Ƃ��Ȃ��d
�R���p��Intel�`�b�v�ā[�ƁA�p�g���I�b�g�~�T�C����i386�������悤�ȁB
�R���p��Intel�`�b�v�ā[�ƁA�p�g���I�b�g�~�T�C����i386�������悤�ȁB
>>198
�u���Z���x�͖��b�P�O�T�O����v���Ď��ۂɂ͉���\���������낤�H
�u���Z���x�͖��b�P�O�T�O����v���Ď��ۂɂ͉���\���������낤�H
MIPS����Ȃ��́H
Alpha�`�b�v
LGA1160���炨�܂���̑�D���ȃI�[�o�[�N���b�N���o���Ȃ��Ȃ�݂������ȁB
���͂��������ɍ\���b�b
Intel�}�U�[���D�Ƃ�����B
Intel�}�U�[���D�Ƃ�����B
�ǂ̂ւ��D�ł���H
214 �FSocket774�F2008/05/25(��) 00:42:21 ID:+1jldJtA
TDP������ɃV�X�e�������I�ɃI�[�o�[�N���b�N����@�\���lj�����邩��
���[�U�[�ɔC�ӂɃN���b�N�������Ă�Ƃ܂�����Ȃ���?
�ƁA�\�z���Ă����B
�}�j�A�ɂ̓A�������A���i�I�[�o�[�N���b�N�Ȃǂ��Ȃ���ʑ�O�ɂ͂���Ȃ�ɉ��b���肻���B
���[�U�[�ɔC�ӂɃN���b�N�������Ă�Ƃ܂�����Ȃ���?
�ƁA�\�z���Ă����B
�}�j�A�ɂ̓A�������A���i�I�[�o�[�N���b�N�Ȃǂ��Ȃ���ʑ�O�ɂ͂���Ȃ�ɉ��b���肻���B
>>213
�������f���A�F���V���v���A�n�C�G���h�ł��V���v���A���l�i���荠�A���[�J�[�ۏ�3�N�A
�����Ȃ̂Ń��t�@�����X�A���ĂƂ����ȁB������OC�@�\�͕n��B
�����ɂ��ẮA�~�h����艺�͂�����ƈ����������邩�������B
�������f���A�F���V���v���A�n�C�G���h�ł��V���v���A���l�i���荠�A���[�J�[�ۏ�3�N�A
�����Ȃ̂Ń��t�@�����X�A���ĂƂ����ȁB������OC�@�\�͕n��B
�����ɂ��ẮA�~�h����艺�͂�����ƈ����������邩�������B
>>211
�������Ă�LGA1366�����ΊW�Ȃ�����
�������Ă�LGA1366�����ΊW�Ȃ�����
�u������Photoshop��GPU����ѕ������Z�ɑΉ�����v
ttp://northwood.blog60.fc2.com/blog-entry-1990.html
�َ�R�A���g�����A�N�Z���[�V���������y����͓̂�����Ǝv���Ă������A
��������������NVIDIA����s�����ȁB
ttp://northwood.blog60.fc2.com/blog-entry-1990.html
�َ�R�A���g�����A�N�Z���[�V���������y����͓̂�����Ǝv���Ă������A
��������������NVIDIA����s�����ȁB
CUDA����Ȃ�AMD��k����Ȃ��Ɏ��S
>F-22�ł�2,200,000�s�ɂ��B���\�t�g�E�F�A�J�����퓬�@�J���ɐ�߂銄�������������B
���N�T�XLS�̃\�[�X�R�[�h��700���s
���N�T�XLS�̃\�[�X�R�[�h��700���s
�u���N�T�X�v������1000���s
ttp://it.nikkei.co.jp/business/column/aruga_gyokai.aspx?n=MMIT0z000023102006
ttp://it.nikkei.co.jp/business/column/aruga_gyokai.aspx?n=MMIT0z000023102006
�����Ȃ����P���T��X�e�b�v�̂r�p�k������
>>223
�R�[�_�[���H
�R�[�_�[���H
>>219
�]�v�ȋ@�\�����Ă���Ȃ��c�B�ǂ������������̂͂��Ȃ�悾����ǂ����ǁB
>>220
�������悭�킩��AGF�n�̃J�[�h��ς߂�����������Ȃ��́H
Intel���łȂ���Γ����Ȃ��̂��H
�]�v�ȋ@�\�����Ă���Ȃ��c�B�ǂ������������̂͂��Ȃ�悾����ǂ����ǁB
>>220
�������悭�킩��AGF�n�̃J�[�h��ς߂�����������Ȃ��́H
Intel���łȂ���Γ����Ȃ��̂��H
>>221
�X�e���X�l���ċ�͓I�ɖ����Ȑv������ŁA�\�t�g�ŃJ�o�[���Ȃ��Ⴂ���Ȃ��ʍ�B��F-22A
�ł��������퓬�@��Mig1.44�B
�X�e���X�l���ċ�͓I�ɖ����Ȑv������ŁA�\�t�g�ŃJ�o�[���Ȃ��Ⴂ���Ȃ��ʍ�B��F-22A
�ł��������퓬�@��Mig1.44�B
GPU�̃n�C�G���h�ł�300W�ł�����������
������TDP�グ������̂�
������TDP�グ������̂�
���E�̎嗬�̓m�[�g�Ɉڍs���Ă邩���
F-22�̊J���v�悪�n�܂����̂�1981�N�����B
IBM PC��8088 4.77MHz��PC/AT�݊��@�̗��j���X�^�[�g�����������āB
�[�i���ꂽ�̂�2005�N��������
�ŋ߂܂�PC�̗��j�ƈꏏ�ɊJ�����ꑱ���Ă�����s�@�ȂȁB
IBM PC��8088 4.77MHz��PC/AT�݊��@�̗��j���X�^�[�g�����������āB
�[�i���ꂽ�̂�2005�N��������
�ŋ߂܂�PC�̗��j�ƈꏏ�ɊJ�����ꑱ���Ă�����s�@�ȂȁB
Atom��Larrabee�ւ̕z����Ȃ��̂��B
Atom�����̃R�A��32���ƌ��݂�CPU�Ƃقڂ��Ȃ�64W�ɂȂ邵�B
Atom�����̃R�A��32���ƌ��݂�CPU�Ƃقڂ��Ȃ�64W�ɂȂ邵�B
�n���ۏo��
������F-22��F-35�̃A�r�I�j�N�X�ɍX�V����������������ɏo���邩���A���Ęb�͌��\�������Ă��
>>231
�ʔ����b����MCM���ƃ`�b�v�̑傫�������̂��������ƂɂȂ��B�����B
�ʔ����b����MCM���ƃ`�b�v�̑傫�������̂��������ƂɂȂ��B�����B
235 �FSocket774�F2008/05/26(��) 08:40:37 ID:JMQxHcPZ
���܂���Ђ�������������
http://pc.watch.impress.co.jp/docs/2008/0402/kaigai432.htm
Silverthorne�̃_�C�T�C�Y�͖�25����mm�B�R�A�P����15����mm���炢�B
Larrabee�I�ȗp�r�Ɏg���ɂ�SIMD-FP�̋������K�v�Ȃ̂ł���������Ƒ�����B
32�R�A�Ƃ���32nm�Ȃ�250�`300����mm�ĂƂ����BNehalem�Ɠ��N���X�A
�R�A��������łĂ����i�ɂȂ邩�畨���I�ɂ͏\���\���ȁB
Silverthorne�̃_�C�T�C�Y�͖�25����mm�B�R�A�P����15����mm���炢�B
Larrabee�I�ȗp�r�Ɏg���ɂ�SIMD-FP�̋������K�v�Ȃ̂ł���������Ƒ�����B
32�R�A�Ƃ���32nm�Ȃ�250�`300����mm�ĂƂ����BNehalem�Ɠ��N���X�A
�R�A��������łĂ����i�ɂȂ邩�畨���I�ɂ͏\���\���ȁB
32nm���B�Ƃ肠�����n�[�h�I�ɂ͂Ƃ�����AMD��nVIDIA���h���C�o��gdgd�Ȃ��Intel�ɂ͂��̕ӊ撣���Ă��炢�����B
Intel���Ȃ������č��܂ł�gdgd�������C�����Ȃ��ł��Ȃ����B
Intel���Ȃ������č��܂ł�gdgd�������C�����Ȃ��ł��Ȃ����B
�h���C�o��Intel���_���g�c��gdgd���낤�B
������Larrabee�͉��Z�R�v���Z�b�T�{�[�h�ł����ăQ�[���pVGA����Ȃ��̂�
�h���C�o�͊W�Ȃ��B
������Larrabee�͉��Z�R�v���Z�b�T�{�[�h�ł����ăQ�[���pVGA����Ȃ��̂�
�h���C�o�͊W�Ȃ��B
�o�J�ۏo���̐�`��
�ȑOLarrabee��65nm�ŁA2008�N�Ƀf����������悤�Ȃ��ƌ����Ă����ǁA
����͂����Ƃ����ɃL�����Z���H
����͂����Ƃ����ɃL�����Z���H
�Ă�����Larrabee���̂�Bulldozer�݂����Ȃ�����
���
���
���B������Larrabee�̂͂Ȃ��Ȃ��₪���Ă������Q�������낗Larrabee�͂��炭�n�C�G���h�R���s���[�^�[�����ʼn�X�ɂ͎�ɓ͂��Ȃ��㕨�B�f���͂X���̂h�c�e�͊ԈႢ�Ȃ��B�ڸ�X10�ɑΉ����Ƃ��B
�ˑR�����܂���B
�悭����ȏ������݂��������܂����{���ł��傤���H
�ɂ킩�ɂ͐M����̂ł����B
902 �FSocket774�F2008/05/26(��) 23:26:12 ID:P861PEAP
��Q9300�g���Ă��ł����A
e-SATA�̔F������l�b�g���[�N�ڑ���̃t�@�C�����쎞�ɁA
CPU�g�p���ɗ]�T������̂ɃV�X�e���S�̂��v�`�t���[�Y���₪��̂��s���ł��B
�������Ȃ���~�~�̗p�r�̂��߂�4�R�A�ɂ����̂ɁB
�l�C�e�B�u4�R�A��Phenom�͂�����������������͂Ȃ���ł��傤���H
905 �FSocket774�F2008/05/26(��) 23:48:48 ID:nS0opZbw
>>902
CORE2�͂���Ȃ��ADUO�͂����ƂЂǂ�
�L���v�{��TV�ςȂ���t�@�C���̈ړ��Ƃ����Ă�
��ʂ���������
���R�A�̂��������͈��ł͖��킦���B
�悭����ȏ������݂��������܂����{���ł��傤���H
�ɂ킩�ɂ͐M����̂ł����B
902 �FSocket774�F2008/05/26(��) 23:26:12 ID:P861PEAP
��Q9300�g���Ă��ł����A
e-SATA�̔F������l�b�g���[�N�ڑ���̃t�@�C�����쎞�ɁA
CPU�g�p���ɗ]�T������̂ɃV�X�e���S�̂��v�`�t���[�Y���₪��̂��s���ł��B
�������Ȃ���~�~�̗p�r�̂��߂�4�R�A�ɂ����̂ɁB
�l�C�e�B�u4�R�A��Phenom�͂�����������������͂Ȃ���ł��傤���H
905 �FSocket774�F2008/05/26(��) 23:48:48 ID:nS0opZbw
>>902
CORE2�͂���Ȃ��ADUO�͂����ƂЂǂ�
�L���v�{��TV�ςȂ���t�@�C���̈ړ��Ƃ����Ă�
��ʂ���������
���R�A�̂��������͈��ł͖��킦���B
�M�S
Windows�ɂ�Big Kernel Lock��������?
>>244
CPU�͊W�Ȃ��Ǝv����A�`�b�v�Z�b�g�h���C�o�̈Ⴂ�ł͍����o�邩������Ȃ��B
�܂��n�[�h�f�B�X�N�̍��ł��o��\��������AXBox360�̃n�[�h�f�B�X�N�����[�U�[�̎��R�Ƀ��[�J�[��I�����čw���ł��Ȃ��̂́A���ꂪ���R�̈���ƕ����Ă���B
OS�����蔲�����邽�߂ɁA�g�p�\�ȃn�[�h�f�B�X�N�̎d�l�����肵�Ă���炵���B
CPU�͊W�Ȃ��Ǝv����A�`�b�v�Z�b�g�h���C�o�̈Ⴂ�ł͍����o�邩������Ȃ��B
�܂��n�[�h�f�B�X�N�̍��ł��o��\��������AXBox360�̃n�[�h�f�B�X�N�����[�U�[�̎��R�Ƀ��[�J�[��I�����čw���ł��Ȃ��̂́A���ꂪ���R�̈���ƕ����Ă���B
OS�����蔲�����邽�߂ɁA�g�p�\�ȃn�[�h�f�B�X�N�̎d�l�����肵�Ă���炵���B
>>198
>�@���ێ��ׂ̈Ƀ\�t�g�E�F�A�̓J�[�g���b�W�Ɏ��߂��Ă��āA�p�C���b�g�����掞�Ɏ�������Ń��[�h���s���B
�h�N�^�[����������������(߁��)���������� !!
>�@���ێ��ׂ̈Ƀ\�t�g�E�F�A�̓J�[�g���b�W�Ɏ��߂��Ă��āA�p�C���b�g�����掞�Ɏ�������Ń��[�h���s���B
�h�N�^�[����������������(߁��)���������� !!
>>249
�t���b�s�[�J�������̂�IBM���悾��JK
�t���b�s�[�J�������̂�IBM���悾��JK
����A���{�̎�����퓬�@�u�S�_�v�̓I�[�v���\�[�X�ō�����B
252 �F,,�E�L�́M�E,,�j��-�������F2008/05/29(��) 21:27:36 ID:iBzJDYL/
>>177
���ꂨ��
���ꂨ��
�R�b�N�s�b�g����ăv���O�����ł���悤�ɂ���̂��R����W�J�ɕK�{���낤�A��l�i�������A�j���^�̏펯�j
�L���l�̂��Ƃ��[�[�[
�����͂��߂����炢��˂�
�����͂��߂����炢��˂�
�����XP�������Ăăt���[�Y����MAD�͏���
>>249
��A����Ă�����IBM���@�I�����N���A�ɂ��邽�߂ɘb��������̈�l�����������Ă��Ƃ炵�����B
�֘A���������Ă�z�ɕЂ��[���琺�����܂������Ƃ��B
��A����Ă�����IBM���@�I�����N���A�ɂ��邽�߂ɘb��������̈�l�����������Ă��Ƃ炵�����B
�֘A���������Ă�z�ɕЂ��[���琺�����܂������Ƃ��B
�������擾���Ă��������͎��̉~�ՂɋL�^������R�[�h�I�Z�p�ł���
�L��d�q�����W�Ŋ������āE�E�E���Ăȍ��b�����邭�炢�@�⌠���ɐT�d������
�܂��ꉞ�b�����Ƃ������炢�̂���Œ����͂܂�����FDD�ɍv�����ĂȂ���
�L��d�q�����W�Ŋ������āE�E�E���Ăȍ��b�����邭�炢�@�⌠���ɐT�d������
�܂��ꉞ�b�����Ƃ������炢�̂���Œ����͂܂�����FDD�ɍv�����ĂȂ���
�ނ͏ݖ�����邿��邭�炢�����܂Ƃ��Ȃ̍���ĂȂ���
>>258
FDD�ɂ͍v�����ĂȂ����낤���A�̑傾�ȁB
FDD�ɂ͍v�����ĂȂ����낤���A�̑傾�ȁB
260 �F,,�E�L�́M�E,,�j��-�������F2008/05/30(��) 12:36:40 ID:bAPgk5Zh
�Ƃ肠�����������t���b�s�[���X���Ⴂ����
���̊Ԃɂ�����Ȃɔ����܂����d��
http://ascii.jp/elem/000/000/123/123347/02-04_o_.jpg
����ɂ��Ă����̃X���C�h�̓��{��������܂����Ȃ���
Offset Engine���J�����Ă���Project Offset��ˬˬˬ
http://pc.watch.impress.co.jp/docs/2008/0530/intel_14.jpg
http://ascii.jp/elem/000/000/123/123347/02-04_o_.jpg
{kind=link}
����ɂ��Ă����̃X���C�h�̓��{��������܂����Ȃ���
Offset Engine���J�����Ă���Project Offset��ˬˬˬ
http://pc.watch.impress.co.jp/docs/2008/0530/intel_14.jpg
{kind=link}
263 �F,,�E�L�́M�E,,�j��-�������F2008/05/30(��) 22:28:48 ID:bAPgk5Zh
Intel���{�̎d���̈����ُ͈�
���߂�A�I���̂���
Diamondwille��Atom/1.6GHz�̃x���`���ʂ��B
���p�悪"FUD"zilla���Ă̂��A�������ǁA���ɝs������Ȃ������Ȃ̂ŁB�B�B
http://www.fudzilla.com/index.php?option=com_content&task=view&id=7595&Itemid=40
�@�@�ELame v3.97: 4.6757x (HT����), 6.7781x (HT)
�@�@�ESuperPI mod: 1'32"766 (1M), 75'38"172 (32M)
�@�@�ESandra Dhrystone ALU/Whetstone FPU
�@�@�@http://www.fudzilla.com/images/stories/2008/May/reviews/Atom/atom_sandra.gif
���p�悪"FUD"zilla���Ă̂��A�������ǁA���ɝs������Ȃ������Ȃ̂ŁB�B�B
http://www.fudzilla.com/index.php?option=com_content&task=view&id=7595&Itemid=40
�@�@�ELame v3.97: 4.6757x (HT����), 6.7781x (HT)
�@�@�ESuperPI mod: 1'32"766 (1M), 75'38"172 (32M)
�@�@�ESandra Dhrystone ALU/Whetstone FPU
�@�@�@http://www.fudzilla.com/images/stories/2008/May/reviews/Atom/atom_sandra.gif
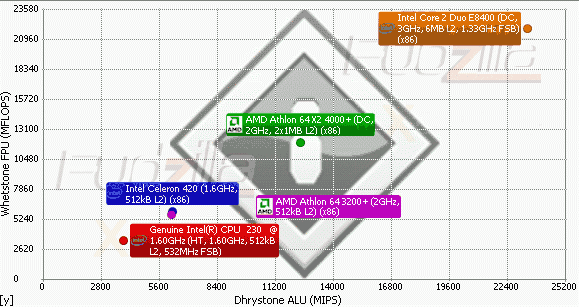{kind=link}
�����[�ɂ�AVX���H
6��2������n�܂�COMPUTEX TAIPEI 2008�ł��̃X���I�ɐV�����l�^�����邩�ȁH
�܂����������̌J��Ԃ�����ˁH
�V�l�^�͂X��
�V�l�^�͂X��
269 �FMAC�I�^��267 �����F2008/05/31(�y) 15:03:20 ID:Pt27hg8n
>>267
Nehalem�Ɋւ��Ă�A��X�I�Ƀf�������͗l���B
http://www.theinquirer.net/gb/inquirer/news/2008/05/28/computex-2008-amazing-hall-race
�@�@--------------------
�@�@Talking about Intel and AMD, we all know that, in four to five months, you should see the
�@�@first batch of Nehalems - Bloomfield high-end PC and Gainestown dual-socket workstation-
�@�@cum-server-cum-Skulltrail 2 - both running on variants of Tylersburg chipsets.
�@�@--------------------
Nehalem�Ɋւ��Ă�A��X�I�Ƀf�������͗l���B
http://www.theinquirer.net/gb/inquirer/news/2008/05/28/computex-2008-amazing-hall-race
�@�@--------------------
�@�@Talking about Intel and AMD, we all know that, in four to five months, you should see the
�@�@first batch of Nehalems - Bloomfield high-end PC and Gainestown dual-socket workstation-
�@�@cum-server-cum-Skulltrail 2 - both running on variants of Tylersburg chipsets.
�@�@--------------------
Core2�̎��̓x���`�̃��[�N�������������ǁA
����͐T�d���ˁB
�}�����R�������̂���ꗝ�R���낤���ǁB
����͐T�d���ˁB
�}�����R�������̂���ꗝ�R���낤���ǁB
Core2�ƈ���ă��C���^�[�Q�b�g���T�[�o�[���������烊�[�N�K�v�Ȃ���
���N��lynnfield�܂ő҂����ȁB
lynnfield�̃����R���AECC�Ή����Ă����Ε���͂Ȃ����B
lynnfield�̃����R���AECC�Ή����Ă����Ε���͂Ȃ����B
Bit-Tech.net��MSI��Bloomfileld�}�U�[�̏ڍʐ^���f�ڂ��Ă��邷�B
���i���x���̊J���̐i�����܂߂�Computex�ł�F�X�ȏ�o�Ă����Ȃ������ˁB
http://www.bit-tech.net/news/2008/05/30/nehalem-and-x58-show-up-in-taipei/1
���i���x���̊J���̐i�����܂߂�Computex�ł�F�X�ȏ�o�Ă����Ȃ������ˁB
http://www.bit-tech.net/news/2008/05/30/nehalem-and-x58-show-up-in-taipei/1
274 �FMAC�I�^��272 �����F2008/06/01(��) 10:23:02 ID:eQ8OIA4W
>>272
�@�@-----------------
�@�@lynnfield�̃����R���AECC�Ή����Ă����Ε���͂Ȃ����B
�@�@-----------------
���������ė~�������BPC�N���X�^�̏ꍇ�A������ECC�T�|�[�g�̃}�U�[���g����Ƃ������R������
�����AMD��I�����邷����B�B�B
�@�@-----------------
�@�@lynnfield�̃����R���AECC�Ή����Ă����Ε���͂Ȃ����B
�@�@-----------------
���������ė~�������BPC�N���X�^�̏ꍇ�A������ECC�T�|�[�g�̃}�U�[���g����Ƃ������R������
�����AMD��I�����邷����B�B�B
>>270
Core2�͏o�����ǂ������̂������čL�����ɂȂ���Ă̂��������낤��
Core2�͏o�����ǂ������̂������čL�����ɂȂ���Ă̂��������낤��
http://pc.watch.impress.co.jp/docs/2008/0602/kaigai442.htm
Nehalem-EP��4way�g�߂�ƂȂ�ƁAAMD��4way�ŗL���ȂƂ��낪
���Ȃ�Ȃ��Ȃ��Ȃ����낤���B
Nehalem-EP��4way�g�߂�ƂȂ�ƁAAMD��4way�ŗL���ȂƂ��낪
���Ȃ�Ȃ��Ȃ��Ȃ����낤���B
�������X
lynnfield��Q3�ȍ~���Ɓc?
���߂����Bloom���������ˁ[�����
���߂����Bloom���������ˁ[�����
279 �F,,�E�L�́M�E,,�j��-�������F2008/06/03(��) 11:21:40 ID:g39CiaOC
30���R�[�X�̗\��
�k���������������́A�ւ������32nm�v���Z�X�����グ���s���̕ی��ŁA
�Ȃɂ��Ȃ��������32nm�łɓ���ւ����Ă��܂����܂����Ȃ�˂��́H
Lynfield��32nm�����グ�����S�ɂ��Ԃ��Ă邱�Ƃɐ���
�Ȃɂ��Ȃ��������32nm�łɓ���ւ����Ă��܂����܂����Ȃ�˂��́H
Lynfield��32nm�����グ�����S�ɂ��Ԃ��Ă邱�Ƃɐ���
Lynnfield�AHavendale�o���Ƃ��Ɉ�C�Ƀv���b�g�t�H�[���u�����������Ƃ��B
����Ȃ��ƁA�n�C�G���h��LGA1366�A���C����LGA1160�A���[�G���h��LGA775��
3�\�P�b�g�����Ȃ�ĂЂǂ����ƂɂȂ邵�B
����Ȃ��ƁA�n�C�G���h��LGA1366�A���C����LGA1160�A���[�G���h��LGA775��
3�\�P�b�g�����Ȃ�ĂЂǂ����ƂɂȂ邵�B
>>281
G41�N���X��Havendale�ł����ɒu��������͖̂�������
G41�N���X��Havendale�ł����ɒu��������͖̂�������
ttp://www.fudzilla.com/index.php?option=com_content&task=view&id=7651&Itemid=1
Larrabee to launch at 300W TDP
Larrabee to launch at 300W TDP
�z�b�g�v���[�g�H
�n���o�[�O�Ă��邶���B����ł��邩�B
�p�\�R���Ɏ��O�@�t�������B
���R���Z���g�Ȃ�ʁA�R���Z���g�Ƃ���������֗����ȁ[�B
���p�̃G�A�R������Ȃ��́H
�܂��BFudzilla�ł�����B
290 �F,,�E�L�́M�E,,�j��-�������F2008/06/03(��) 18:28:28 ID:g39CiaOC
�N���b�N��2GHz�O��܂ʼn����Ă�i�����SIMD���j�b�g�������Ă邪�j�̂�1PE������10W����H������
90nm Cell���Ⴀ��܂���
90nm Cell���Ⴀ��܂���
GTX280���^�����Ȃ�
VR-zone��Computex Taipei�ɓW������Ă���Bloomfield�}�U�[���Љ�Ă��邷�B
http://www.vr-zone.com/articles/Intel_X58_Tylersburg_Mainboards_Pictured/5827.html
�����������ǁACPU-Z�摜��3DMark Vantage��CPU�X�R�A���B
http://www.vr-zone.com/articles/Intel_Bloomfield_On_X58_Board_Benchmarked/5825.html
�@Nehalem/2.67GHz, Vcore=0.856V
�@3DMark Vantage CPU: 16334
http://www.vr-zone.com/articles/Intel_X58_Tylersburg_Mainboards_Pictured/5827.html
�����������ǁACPU-Z�摜��3DMark Vantage��CPU�X�R�A���B
http://www.vr-zone.com/articles/Intel_Bloomfield_On_X58_Board_Benchmarked/5825.html
�@Nehalem/2.67GHz, Vcore=0.856V
�@3DMark Vantage CPU: 16334
CPU-Z�̕\�����f�^����������
>>292�Ɠ�����TheINQ��Nehalem�}�U�[�{�[�h�M�������[���B
�������2-socket�}�U�[���J�o�[���Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/06/03/computex-2008-great-wall
�������2-socket�}�U�[���J�o�[���Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/06/03/computex-2008-great-wall
Larrabee300W�͂ˁ[��c
�r�f�I�J�[�h�Ƃ��Ă͑�ꐢ�ォ��n�C�G���h�Ƃ��Ƃ��v����
�r�f�I�J�[�h�Ƃ��Ă͑�ꐢ�ォ��n�C�G���h�Ƃ��Ƃ��v����
����N�[���[�Ƀ_�N�g���t������12�p�t�@���Ԃ�Ă��s���ɂȂ郌�x��
intel������24pin+8pin���Ă̂��|���E�E�E4pin�̂����邱�������邪
����2�\�P��8pin�R�l�N�^2����
�d���ǂ�����E�E�Eorz
����2�\�P��8pin�R�l�N�^2����
�d���ǂ�����E�E�Eorz
Anandtech���Z�b�g�g�b�v�E�{�b�N�X��Eee Box�̃��r���[��Atom/1.6GHz�̃x���`���ʂ��f�ڂ���
���邷�B
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=6
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=7
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=8
�ȉ��AAtom/1.6GHz, Cel420/1.6GHz, Dothan/1.6GHz, Dothan/800MHz�̏��Ō��ʂ��܂Ƃ߂Ă������B
�@�ECPU-Z latency
�@�@�@�@�@�@�@�@�@Atom�@�@�@Cel420�@�@�@Dothan/1.6�@�@�@Dothan/0.8
�@�@L1:�@�@�@�@�@�@3�@�@�@�@�@�@3�@�@�@�@�@�@�@�@3�@�@�@�@�@�@�@�@�@-
�@�@L2:�@�@�@�@�@�@18�@�@�@�@�@14�@�@�@�@�@�@�@14�@�@�@�@�@�@�@�@�@-
�@�@Mem: �@�@�@�@129�@�@�@�@125�@�@�@�@�@�@172�@�@�@�@�@�@�@�@�@-
�@�ESYSMark2007
�@�@all:�@�@�@�@�@�@32�@�@�@�@�@55�@�@�@�@�@�@�@50�@�@�@�@�@�@�@�@�@29
�@�@Learning:�@�@33�@�@�@�@�@53�@�@�@�@�@�@�@52�@�@�@�@�@�@�@�@�@32
�@�@Video:�@�@�@�@36�@�@�@�@�@55�@�@�@�@�@�@�@45�@�@�@�@�@�@�@�@�@24
�@�@Productivity:31�@�@�@�@�@54�@�@�@�@�@�@�@44�@�@�@�@�@�@�@�@�@29
�@�@3D:�@�@�@�@�@�@30�@�@�@�@�@59�@�@�@�@�@�@�@58�@�@�@�@�@�@�@�@�@28
�@�EPCMark Vantage
�@�@TV&Movie:�@782�@�@�@�@1044�@�@�@�@�@882�@�@�@�@�@�@�@�@�@522
�@�@Music:�@�@�@�@1486�@�@�@2042�@�@�@�@�@1850�@�@�@�@�@�@�@�@1111
�@�@Comm.:�@�@�@1062�@�@�@1567�@�@�@�@�@1473�@�@�@�@�@�@�@�@802
�@�@Productivity:1110�@�@�@1759�@�@�@�@�@1633�@�@�@�@�@�@�@�@1095
�@�EDivX [�P��: sec.]
�@�@�@�@�@�@�@�@�@�@388�@�@�@�@207�@�@�@�@�@�@286�@�@�@�@�@�@�@�@�@597
���邷�B
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=6
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=7
http://www.anandtech.com/systems/showdoc.aspx?i=3321&p=8
�ȉ��AAtom/1.6GHz, Cel420/1.6GHz, Dothan/1.6GHz, Dothan/800MHz�̏��Ō��ʂ��܂Ƃ߂Ă������B
�@�ECPU-Z latency
�@�@�@�@�@�@�@�@�@Atom�@�@�@Cel420�@�@�@Dothan/1.6�@�@�@Dothan/0.8
�@�@L1:�@�@�@�@�@�@3�@�@�@�@�@�@3�@�@�@�@�@�@�@�@3�@�@�@�@�@�@�@�@�@-
�@�@L2:�@�@�@�@�@�@18�@�@�@�@�@14�@�@�@�@�@�@�@14�@�@�@�@�@�@�@�@�@-
�@�@Mem: �@�@�@�@129�@�@�@�@125�@�@�@�@�@�@172�@�@�@�@�@�@�@�@�@-
�@�ESYSMark2007
�@�@all:�@�@�@�@�@�@32�@�@�@�@�@55�@�@�@�@�@�@�@50�@�@�@�@�@�@�@�@�@29
�@�@Learning:�@�@33�@�@�@�@�@53�@�@�@�@�@�@�@52�@�@�@�@�@�@�@�@�@32
�@�@Video:�@�@�@�@36�@�@�@�@�@55�@�@�@�@�@�@�@45�@�@�@�@�@�@�@�@�@24
�@�@Productivity:31�@�@�@�@�@54�@�@�@�@�@�@�@44�@�@�@�@�@�@�@�@�@29
�@�@3D:�@�@�@�@�@�@30�@�@�@�@�@59�@�@�@�@�@�@�@58�@�@�@�@�@�@�@�@�@28
�@�EPCMark Vantage
�@�@TV&Movie:�@782�@�@�@�@1044�@�@�@�@�@882�@�@�@�@�@�@�@�@�@522
�@�@Music:�@�@�@�@1486�@�@�@2042�@�@�@�@�@1850�@�@�@�@�@�@�@�@1111
�@�@Comm.:�@�@�@1062�@�@�@1567�@�@�@�@�@1473�@�@�@�@�@�@�@�@802
�@�@Productivity:1110�@�@�@1759�@�@�@�@�@1633�@�@�@�@�@�@�@�@1095
�@�EDivX [�P��: sec.]
�@�@�@�@�@�@�@�@�@�@388�@�@�@�@207�@�@�@�@�@�@286�@�@�@�@�@�@�@�@�@597
299 �F,,�E�L�́M�E,,�j��-�������F2008/06/04(��) 08:23:07 ID:4r0/UDnW
�Ȃɂ���Wii�̃p�N��
300 �FMAC�I�^���c�q �����F2008/06/04(��) 08:25:38 ID:TAOTtXoA
>>299
AppleTV�̃p�N�肾�Ǝv�������ǁB�B�B
AppleTV�̃p�N�肾�Ǝv�������ǁB�B�B
301 �F,,�E�L�́M�E,,�j��-�������F2008/06/04(��) 08:27:18 ID:4r0/UDnW
�����R���̌`��
302 �F,,�E�L�́M�E,,�j��-�������F2008/06/04(��) 08:30:53 ID:4r0/UDnW
��������Eee Box��Nettop�ł�����STB����Ȃ�����
8����Siggraph�ł���Larrabee�̏ڍׂ����J����邷�B
http://www.siggraph.org/s2008/attendees/program/item/?type=&id=34
�@�@--------------------
�@�@Larrabee: A Many-Core x86 Architecture for Visual Computing
�@�@This paper introduces the Larrabee a many-core hardware
�@�@architecture, a new software rendering pipeline, a many-core
�@�@programming model, and performance analysis for several
�@�@applications. Larrabee uses multiple in-order x86 CPU cores that
�@�@are augmented by a wide vector processor unit, as well as
�@�@fixed-function co-processors. This provides dramatically higher
�@�@performance per watt and per unit of area than out-of-order CPUs
�@�@on highly parallel workloads and greatly increases the flexibility
�@�@and programmability of the architecture as compared to standard
�@�@GPUs.
�@�@--------------------
http://www.siggraph.org/s2008/attendees/program/item/?type=&id=34
�@�@--------------------
�@�@Larrabee: A Many-Core x86 Architecture for Visual Computing
�@�@This paper introduces the Larrabee a many-core hardware
�@�@architecture, a new software rendering pipeline, a many-core
�@�@programming model, and performance analysis for several
�@�@applications. Larrabee uses multiple in-order x86 CPU cores that
�@�@are augmented by a wide vector processor unit, as well as
�@�@fixed-function co-processors. This provides dramatically higher
�@�@performance per watt and per unit of area than out-of-order CPUs
�@�@on highly parallel workloads and greatly increases the flexibility
�@�@and programmability of the architecture as compared to standard
�@�@GPUs.
�@�@--------------------
304 �FMAC�I�^���⑫�F2008/06/04(��) 12:40:39 ID:1Mbdkmn7
Larrabee��PE�����ǁA��̃A�u�X�g���N�g�ɏ����Ă���悤��
�@�E�C���I�[�_�[x86�R�A
�@�E"wide" vector processor unit
�@�EFixed-function co-processor
�Ƃ������ƂŁA�ŏ���x86�R�A��������GPU�̍\�����̂��̂Ɍ����邷�B
GPU�ɂ���AHPC���p�ɂ���A�n�C�G���hGPU�Ƌ������邽�߂ɂ�AVPU������
���Z���\���W��Ă��锤������A���̕����ŏ���d�͂����ɑ傫��
�Ƃ����̂�I�����Ă���\�����������B
�����Ƃ��A"FUD"zilla�̃l�^��v�����ŏ����Ă邾�������ǂ�(��)
�@�E�C���I�[�_�[x86�R�A
�@�E"wide" vector processor unit
�@�EFixed-function co-processor
�Ƃ������ƂŁA�ŏ���x86�R�A��������GPU�̍\�����̂��̂Ɍ����邷�B
GPU�ɂ���AHPC���p�ɂ���A�n�C�G���hGPU�Ƌ������邽�߂ɂ�AVPU������
���Z���\���W��Ă��锤������A���̕����ŏ���d�͂����ɑ傫��
�Ƃ����̂�I�����Ă���\�����������B
�����Ƃ��A"FUD"zilla�̃l�^��v�����ŏ����Ă邾�������ǂ�(��)
����ӂɂȂ��ĖӐM�����肷��z�����邯�ǂ�
Computex��Nehalem�̓W���Ɋւ��Ă�A�����������������̃T�C�g�Ń��|�[�g���������
���邷�B�������TomsHardware�̋L���B
http://www.tomshardware.com/news/intel-nehalem-cpu,5560.html
�@�@---------------------
�@�@While we�fre unable to reveal the actual clock speed that the
�@�@sample was running at, Intel engineers pointed out that the system
�@�@was air cooled, running on "very healthy silicon." One Intel
�@�@engineered remarked "you won�ft believe it. It�fs insane." We did
�@�@get a sneak peak at a CPUID read out of the core frequency, and can
�@�@confirm that the system was running at a very impressive clock
�@�@rate. We�fll go out on a limb here and say that nothing else
�@�@currently available on the market matches it.
�@�@---------------------
�l�C�e�B�u�N�A�h�R�A�������œ���N���b�N���オ��Ȃ��Ȃ�ĊԔ����Ȃ��Ƃ햳������
�Ƃ������ƂŁB�B�B
���邷�B�������TomsHardware�̋L���B
http://www.tomshardware.com/news/intel-nehalem-cpu,5560.html
�@�@---------------------
�@�@While we�fre unable to reveal the actual clock speed that the
�@�@sample was running at, Intel engineers pointed out that the system
�@�@was air cooled, running on "very healthy silicon." One Intel
�@�@engineered remarked "you won�ft believe it. It�fs insane." We did
�@�@get a sneak peak at a CPUID read out of the core frequency, and can
�@�@confirm that the system was running at a very impressive clock
�@�@rate. We�fll go out on a limb here and say that nothing else
�@�@currently available on the market matches it.
�@�@---------------------
�l�C�e�B�u�N�A�h�R�A�������œ���N���b�N���オ��Ȃ��Ȃ�ĊԔ����Ȃ��Ƃ햳������
�Ƃ������ƂŁB�B�B
>306
�L���L����p������Ԃł̘b�������AES��6.4GHz�ŏ�p�������Ă����B
������A�N���b�N�͌��\������Ƃ݂Ă�����B>�l�n
�L���L����p������Ԃł̘b�������AES��6.4GHz�ŏ�p�������Ă����B
������A�N���b�N�͌��\������Ƃ݂Ă�����B>�l�n
�t�̒��f�łȂ�Pen4���ォ�炻�炢����Ă����낤���E�E�E
����ł�����p���E�͂��Ȃ艺
����ł�����p���E�͂��Ȃ艺
>>303
���Ƀ����[�����邩
�\�z���P��������������
���ق̴ݼ�Ʊ�B�������[�ɂ��Ȃ�͓���Ă�݂����ȋL���������������A�����[�̓o��ł��Â�NVIDIA�p�Ƃ��Ă��ƂɂȂ�ȁH
���Ƀ����[�����邩
�\�z���P��������������
���ق̴ݼ�Ʊ�B�������[�ɂ��Ȃ�͓���Ă�݂����ȋL���������������A�����[�̓o��ł��Â�NVIDIA�p�Ƃ��Ă��ƂɂȂ�ȁH
AVX�Ƃ��ς�łȂ�������
old type�̃����[�́A�����̔��M��
old type�̃����[�́A�����̔��M��
Siggraph��Larrabee�_�������ǁA�����҂̖��O����H��Ƃ���Ȍ����������邷�B
http://graphics.stanford.edu/papers/i3dkdtree/
���C�g���[�V���O�ւ̉��p�̘b�������̂�m���������B
http://graphics.stanford.edu/papers/i3dkdtree/
���C�g���[�V���O�ւ̉��p�̘b�������̂�m���������B
�װ����ӂ�
�^���p�N���̉�͂����Ȃ���
�����{��Super Hi-Vision�̉f�����������������Đ�
�^���p�N���̉�͂����Ȃ���
�����{��Super Hi-Vision�̉f�����������������Đ�
>>20
���̋L���H
Larrabee team member speaks on rasterization for the future
http://www.pcper.com/comments.php?nid=5548
���̋L���H
Larrabee team member speaks on rasterization for the future
http://www.pcper.com/comments.php?nid=5548
�͂��߂�GPU�ł͂Ȃ��Ƃ������Ă��̂͂����̈ꕔ�̃A�z������
Larrabee��ŏ��ɏo�Ă���������GPU�ƌ����Ă���
���B�W���A���R���s���[�e�B���O�O���[�v���o�����Ƃ�����GPU�Ɩ��L����Ă����B
�����ɂ�GPU�����Ȃ�Đ���Ȃ��A�f�B�X�N���[�gGPU�Q���Ȃ�Đ���Ȃ��Ƃ���
�A�z�S����������������M���Ă��Ƃ����炽���̃A�z�B
Larrabee��ŏ��ɏo�Ă���������GPU�ƌ����Ă���
���B�W���A���R���s���[�e�B���O�O���[�v���o�����Ƃ�����GPU�Ɩ��L����Ă����B
�����ɂ�GPU�����Ȃ�Đ���Ȃ��A�f�B�X�N���[�gGPU�Q���Ȃ�Đ���Ȃ��Ƃ���
�A�z�S����������������M���Ă��Ƃ����炽���̃A�z�B
�f�B�X�N���[�gGPU�Q���Ȃ�Đ���܂���i�����ς�
���Ƃ��ƌR�����Â���Z�����_���Ă��Ǐ�肭�H�����߂����ɂȂ�����
����Ń��C�g���╨�����Z��Q�[���W�̉�А��Ђ���C�ɔ���
������Ă��g�������Ȃ���ǂ����悤���Ȃ�����ł��������K���ł���
����Ń��C�g���╨�����Z��Q�[���W�̉�А��Ђ���C�ɔ���
������Ă��g�������Ȃ���ǂ����悤���Ȃ�����ł��������K���ł���
>>314
���ق͂��O�B�\�t�g�E�G�A�����_�����O�p�C�v���C���̈Ӗ��ł����ׂĂ�B
Intel�����i������Ƃ��ɂ�"GPU"�Ƃ��Ĕ���̂��Ƃ���ꂽ����No���B
���ق͂��O�B�\�t�g�E�G�A�����_�����O�p�C�v���C���̈Ӗ��ł����ׂĂ�B
Intel�����i������Ƃ��ɂ�"GPU"�Ƃ��Ĕ���̂��Ƃ���ꂽ����No���B
314�̕��I�^�̏X���p�����Ă݂������̂�
�O�̂��߂����Ƃ�����Larrabee�ƃn�C�G���hGPU�͑������܂苣�����Ȃ��B
��������̂�GPU�ł��Q�[���O���t�B�b�N�X�ȊO�̗p�r���Ǝv���B
��������̂�GPU�ł��Q�[���O���t�B�b�N�X�ȊO�̗p�r���Ǝv���B
>�����ɂ�GPU�����Ȃ�Đ���Ȃ�
�܂����Ƃ͎v����
�r�f�I�����m�[�X�u���b�W��MCM����������
GPU�u�����v�Ƃق����Ă�킯����ˁ[���낤�ȁH
�[�����܂��㓡����B
�܂����Ƃ͎v����
�r�f�I�����m�[�X�u���b�W��MCM����������
GPU�u�����v�Ƃق����Ă�킯����ˁ[���낤�ȁH
�[�����܂��㓡����B
ttp://picasaweb.google.co.uk/Fudzilla.com/ATI4800SeriesTechDemo/photo#5208079896638449394
�܂��AGPU���������������ɒB���Ă錻��
���X�����[�Ȃǖ��Ӗ�
������x86���āE�E�E
�܂��AGPU���������������ɒB���Ă錻��
���X�����[�Ȃǖ��Ӗ�
������x86���āE�E�E
http://pc.watch.impress.co.jp/docs/2008/0605/comp10.htm
��G45�ł́AHD�r�f�I���n�[�h�E�F�A�Ńf�R�[�h�����ăG���R�[�h���ł���悤�ɂȂ��Ă���B
G45�ŃG���R�[�h�H
��G45�ł́AHD�r�f�I���n�[�h�E�F�A�Ńf�R�[�h�����ăG���R�[�h���ł���悤�ɂȂ��Ă���B
G45�ŃG���R�[�h�H
>>325
�G���R�[�h���x������͗l�B�X���C�h�ɂ������Ă���B
http://pc.watch.impress.co.jp/docs/2008/0605/comp09.htm
�������ɂ�
���܂�h45+45�h�̑g�ݍ��킹��HD�R���e���c�̍쐬����v���C�o�b�N�܂ł��y���ɍs�Ȃ���Ƃ���B
�Ƃ��邩��AG45�P�̂ŃG���R�[�h���o����Ƃ����킯�ł͂Ȃ��͗l�B
G45���g���ACPU��������͂ł��G���R������Ȃ�ɂł���A�ƌ���������Ȃ����낤���B
���ۂǂ��������Ȃ��̂ł킩��ǁB
�G���R�[�h���x������͗l�B�X���C�h�ɂ������Ă���B
http://pc.watch.impress.co.jp/docs/2008/0605/comp09.htm
�������ɂ�
���܂�h45+45�h�̑g�ݍ��킹��HD�R���e���c�̍쐬����v���C�o�b�N�܂ł��y���ɍs�Ȃ���Ƃ���B
�Ƃ��邩��AG45�P�̂ŃG���R�[�h���o����Ƃ����킯�ł͂Ȃ��͗l�B
G45���g���ACPU��������͂ł��G���R������Ȃ�ɂł���A�ƌ���������Ȃ����낤���B
���ۂǂ��������Ȃ��̂ł킩��ǁB
SpursEngine���
328 �F,,�E�L�́M�E,,�j��-�������F2008/06/05(��) 19:50:17 ID:HtEOuHFr
���ł̐挩���̖����ُ͈�
by �X�}�[�g���f�B�A��Q�҂̉�
by �X�}�[�g���f�B�A��Q�҂̉�
>>314
��̃C���e�����f�X�N�g�b�v���T�[�o�[�pCPU�̃v���X���\��
IntegrationGPU�I�ȕ\�����g�������Ƃ͍��܂ň�x����������B
�㓡�^�̌l�I��]�����ϑz�����������L����
��������M���Ă�Ƃ����炨�O�͂����̃A�z�B
��̃C���e�����f�X�N�g�b�v���T�[�o�[�pCPU�̃v���X���\��
IntegrationGPU�I�ȕ\�����g�������Ƃ͍��܂ň�x����������B
�㓡�^�̌l�I��]�����ϑz�����������L����
��������M���Ă�Ƃ����炨�O�͂����̃A�z�B
8�X���b�h���\��������Ȃ��A1�Ƃ�2�X���b�h�̐��\�Ŕ�r���Ă݂Ă��炢�����ȁB
http://www.pcstats.com/articleview.cfm?articleid=2000&page=6
http://www.septor.net/archives/37358164.html
�l�g�o����HT�������L����CineBench +21%�ADiVX +16%�A3dsmax +10�`21%
http://www.septor.net/archives/37358164.html
�l�g�o����HT�������L����CineBench +21%�ADiVX +16%�A3dsmax +10�`21%
����
HT�̌��ʂ����Ȃ����Ă̂��H
�唼�̃x���`���������ݒ�ɖ�肪����(�V���O���`�����l���ƃg���v���`�����l���Ő��\���ς��Ȃ�)
�}�U�[�{�[�h�Ŏ�����B�B�B�Ƃ������y�ɒ��ӂ��ׂ����B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=2
�@�@----------------------
�@�@Not only was there no difference between single and triple channel memory configurations,
�@�@memory latency was high. We know this was a board specific issue since our second
�@�@Nehalem platform didn't exhibit any issues. Unfortunately we didn't have access to the
�@�@more mature platform for very long at all, meaning the majority of our tests had to be run
�@�@on the first setup
�@�@----------------------
�}�U�[�{�[�h�Ŏ�����B�B�B�Ƃ������y�ɒ��ӂ��ׂ����B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=2
�@�@----------------------
�@�@Not only was there no difference between single and triple channel memory configurations,
�@�@memory latency was high. We know this was a board specific issue since our second
�@�@Nehalem platform didn't exhibit any issues. Unfortunately we didn't have access to the
�@�@more mature platform for very long at all, meaning the majority of our tests had to be run
�@�@on the first setup
�@�@----------------------
������ă}�U�[�̖��Ȃ̂�
�ǂ���ɂ��Ă����������\�͂�����
Phenom 2.3GHz DDR2-800���Ɣ�ׂ�
���������[�h 2.1�{
���������C�g 2.8�{
���������C�e���V 0.6�{
Phenom��Everest�X�R�A�Q�l http://www.elitebastards.com/cms/index.php?option=com_content&task=view&id=550&Itemid=27&limitstart=3
Phenom 2.3GHz DDR2-800���Ɣ�ׂ�
���������[�h 2.1�{
���������C�g 2.8�{
���������C�e���V 0.6�{
Phenom��Everest�X�R�A�Q�l http://www.elitebastards.com/cms/index.php?option=com_content&task=view&id=550&Itemid=27&limitstart=3
�}�U�[�Ƃ������`�b�v�Z�b�g�̕s�����B
Nehalem���Ȃ��chipset�o�R�Ń������[�A�N�Z�X�H
341 �FMAC�I�^��337, 339 �����F2008/06/05(��) 22:25:17 ID:tPKJcPeV
>>337, >>339
>>336�Ɉ��p������߂����ł�"a board specific issue"���ƌ���Ă��邷�B
Anand�������Ă�������Q�̃V�X�e���̂����A�Е��ɂ��肪�Ȃ������B�B�B�Ƃ������Ă��邷�B
>>336�Ɉ��p������߂����ł�"a board specific issue"���ƌ���Ă��邷�B
Anand�������Ă�������Q�̃V�X�e���̂����A�Е��ɂ��肪�Ȃ������B�B�B�Ƃ������Ă��邷�B
Intel's 8-core Skulltrail Platform: Close to Perfecting the Niche
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3216&p=1
Penryn 4 core �� 8 core
3dsmax +40%
Cinebench +60%
POV-Ray +90%
DivX 6.8 +4%
x264/MKV +1%
Penryn 4 core �� Nehalem 4 core (8T)
3dsmax +40%
Cinebench +24%
POV-Ray +36%
DivX 6.8 +28%
x264/MKV +44%
������݂��3D�����_�����O�n��4��8Thread�̌��ʂ�����B
�����s���ɕ����Ƃ肾���郌�C�g���Ȃǂ�+90%�ȏア���Ă�B
�Ƃ��낪�G���R�[�h��8Thread�̉��b���w�ǂȂ��B
Nehalem�̃G���R�[�h���\�̍����͖{���B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3216&p=1
Penryn 4 core �� 8 core
3dsmax +40%
Cinebench +60%
POV-Ray +90%
DivX 6.8 +4%
x264/MKV +1%
Penryn 4 core �� Nehalem 4 core (8T)
3dsmax +40%
Cinebench +24%
POV-Ray +36%
DivX 6.8 +28%
x264/MKV +44%
������݂��3D�����_�����O�n��4��8Thread�̌��ʂ�����B
�����s���ɕ����Ƃ肾���郌�C�g���Ȃǂ�+90%�ȏア���Ă�B
�Ƃ��낪�G���R�[�h��8Thread�̉��b���w�ǂȂ��B
Nehalem�̃G���R�[�h���\�̍����͖{���B
>>341
Unganged/Ganged���[�h�Ƃ�����Ȃ��̂�
Unganged/Ganged���[�h�Ƃ�����Ȃ��̂�
344 �FMAC�I�^��u �����F2008/06/05(��) 22:30:46 ID:tPKJcPeV
>>342
�v���Z�b�T�Ԃ̓��������ɂȂ�2-socket�V�X�e���ƒP���ɔ�r����̂��l�����m���B
�v���Z�b�T�Ԃ̓��������ɂȂ�2-socket�V�X�e���ƒP���ɔ�r����̂��l�����m���B
�G���R�Ȃ盛���ތ����Ă��A���~���S���S�̗\��
346 �FMAC�I�^��343 �����F2008/06/05(��) 22:33:46 ID:tPKJcPeV
>>343
���������C�e���V�����ɑ傫���Ƃ������������� (Not only was there no difference between
single and triple channel memory configurations, memory latency was high. )�Ƃ��邷����A
���܂萳��ȏ�Ԃɂ팩���Ȃ����B
����������Anand���l���ς��Ə����Ă��邷����A�ς�������Ȃ������ˁB
���������C�e���V�����ɑ傫���Ƃ������������� (Not only was there no difference between
single and triple channel memory configurations, memory latency was high. )�Ƃ��邷����A
���܂萳��ȏ�Ԃɂ팩���Ȃ����B
����������Anand���l���ς��Ə����Ă��邷����A�ς�������Ȃ������ˁB
�ΏĂ���������A�F�߂Ă��B
>>344
�}���`�\�P�b�g�̃x���`���ʂ���̂ǂ������X�����͉ߋ��̃x���`����킩���Ă��ŁB
3D�����_�����O�W�ł�8 core > 4 core+SMT�Ȃ̂ɁA�G���R�n�ł́A
4 core+SMT > 8core �Ȃ̂����̏؋��̂P���ƁB
�}���`�\�P�b�g�̃x���`���ʂ���̂ǂ������X�����͉ߋ��̃x���`����킩���Ă��ŁB
3D�����_�����O�W�ł�8 core > 4 core+SMT�Ȃ̂ɁA�G���R�n�ł́A
4 core+SMT > 8core �Ȃ̂����̏؋��̂P���ƁB
349 �FMAC�I�^��u �����F2008/06/05(��) 22:44:41 ID:tPKJcPeV
>>348
�Ƃ����Skulltrail��x264/MKV���Ă��ꂷ��ˁB
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3216&p=12
�@�@Dual QX9775: 92sec.
�@�@Single QX9775: 173sec.
�Ƃ������ʂ�����A4core -> 8core��+88%����Ȃ������H
�Ƃ����Skulltrail��x264/MKV���Ă��ꂷ��ˁB
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3216&p=12
�@�@Dual QX9775: 92sec.
�@�@Single QX9775: 173sec.
�Ƃ������ʂ�����A4core -> 8core��+88%����Ȃ������H
>>349
���ւ��A�ԈႦ���c(;�L�D�M)
���ւ��A�ԈႦ���c(;�L�D�M)
���Ȃ݂�Bloomfield��肨�育���Lynnfield/Havedale��
�x��Ă₪�邨�����ŁA�܂��Server�d�l��Bloomfield(250mmsq�I�[�o�[)��
$316(?)���甃����AIntel���ĂȂ��قǂ̑�o�[�Q����Ԃ����(!)
�Ǝv���Ă��܂������g���R�ꂾ���݂����c(;�L�D�M)
�x��Ă₪�邨�����ŁA�܂��Server�d�l��Bloomfield(250mmsq�I�[�o�[)��
$316(?)���甃����AIntel���ĂȂ��قǂ̑�o�[�Q����Ԃ����(!)
�Ǝv���Ă��܂������g���R�ꂾ���݂����c(;�L�D�M)
Merom�t�@�~���[��E6600�Ƃ�������$316�H�̈ʒu�Â�����������A
Bloomfield���ʂɂ���ȍ����Ǝv��Ȃ��ł���
Bloomfield���ʂɂ���ȍ����Ǝv��Ȃ��ł���
Merom��143mmsq����������ȁB
�����A3�{���炢�R�X�g����ĂĂ����������Ȃ������B
�p�b�P�[�W���O���O�������������������B
Intel�I�ɂ͂��܂肨�������Ȃ����Ǝv���B
�����A3�{���炢�R�X�g����ĂĂ����������Ȃ������B
�p�b�P�[�W���O���O�������������������B
Intel�I�ɂ͂��܂肨�������Ȃ����Ǝv���B
$316�ŏo��Ȃ�ď��͈���Ȃ��
$316����o��Ȃ�ĂȂ�čK���]�݂�
>>354
�ȑO����$266����̉��i�т��Ă����Ă邯�ǁB
Intel��SKU��$266����͕���$316�ł���B
http://pc.watch.impress.co.jp/docs/2008/0602/kaigai01l.gif
�ȑO����$266����̉��i�т��Ă����Ă邯�ǁB
Intel��SKU��$266����͕���$316�ł���B
http://pc.watch.impress.co.jp/docs/2008/0602/kaigai01l.gif
{kind=link}
{kind=link}
����Bloomfield�̃N���b�N���ォ��3.00G/2.83G/2.66G�Ƃ��Ă�
York-2.83G��Bloom-2.66G�Ȃ�Ă��肦�Ȃ��Ǝv�����B
���N���b�N�ł͖��炩��Bloomfield�̕�����������B
York-2.83G��Bloom-2.66G�Ȃ�Ă��肦�Ȃ��Ǝv�����B
���N���b�N�ł͖��炩��Bloomfield�̕�����������B
York-2.83G��Bloom-2.66G�������i�Ȃ�Ă��肦�Ȃ��Ǝv�����B
��������
��������
York�͒ቿ�i�тցABloomfield�̍ʼn��ʂ�$316�ŏo�Ă�����Intel�_�B
��������(;�L�D�M)ʧ����A�܂�����
�R����ʗp���Ȃ��Ȃ��Ă����ȁB
�����܂�2ch���ނ���c(;�L�D�M)�͂��͂�
�����܂�2ch���ނ���c(;�L�D�M)�͂��͂�
������
�Ƃ肠�����ꔭ�����ĐQ��
�Ƃ肠�����ꔭ�����ĐQ��
���܂Ŕ�������ԍ���CPU��316�h�������A�N���ɂ͎��ȋL�^�X�V���邩����
530�h���ł�����o�������ŕ|��
316�h���Ń����[�X���Ă���Ȃ����Ȃ�( ߁��)
530�h���ł�����o�������ŕ|��
316�h���Ń����[�X���Ă���Ȃ����Ȃ�( ߁��)
QX9770��999�h���ȏ�̗̈悪�ł������������A�N���b�N3�i�K�ł��A
1399�h���A999�h���A530�h���̉\�������邩��ˁB
�ł��A316�h����Bloomfield��������A��o�[�Q���Ȃ̂͊m�����낤�B
1399�h���A999�h���A530�h���̉\�������邩��ˁB
�ł��A316�h����Bloomfield��������A��o�[�Q���Ȃ̂͊m�����낤�B
Nehalem�ŃG���R�������B
http://forums.vr-zone.com/showthread.php?t=285056
�ǂ����}�W�炵���B
�ǂ����}�W�炵���B
net burst�̈������Ă�^q^
�X�V��������B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=7
Cinebench��SingleThread�x���`�ł́AYork��Nehalem��2%��
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=7
Cinebench��SingleThread�x���`�ł́AYork��Nehalem��2%��
�V���O���X���b�h�̐��\�͕ς��Ȃ��̂��c
���܂肠�����ĂȂ����낤�Ȃ��Ă����̂͐���������ˁB
HTT���݂�20�`50%���Ă��Ƃ̓V���O���X���b�h���\��0�`20%���炢�̐L�т��낤�B
Tylersburg�݂����Ȃł����`�b�v�Z�b�g�ڂ��āA����d�͂����[�h��15W���ƍ��͏������B
CPU�̏���d�͂͂��܂葝���ĂȂ����낤����A3.4GHz���炢��45nm�ł��������������ȁB
HTT���݂�20�`50%���Ă��Ƃ̓V���O���X���b�h���\��0�`20%���炢�̐L�т��낤�B
Tylersburg�݂����Ȃł����`�b�v�Z�b�g�ڂ��āA����d�͂����[�h��15W���ƍ��͏������B
CPU�̏���d�͂͂��܂葝���ĂȂ����낤����A3.4GHz���炢��45nm�ł��������������ȁB
��������o�X���傫�����P����Ă邩��AMultiThread�E���X�|���X�͌��サ�Ă�ȁB
Merom + SingleThread 5�`10% �� Penryn
Merom + SingleThread 5�`20% + MultiThread 10�`50% ���@Nehalem
����Ȋ�������Ȃ����ˁB
Merom + SingleThread 5�`10% �� Penryn
Merom + SingleThread 5�`20% + MultiThread 10�`50% ���@Nehalem
����Ȋ�������Ȃ����ˁB
����ł��V���O���X���b�h���\���������ĂȂ������������ȁB
L1���C�e���V1.33�{�AL2�T�C�Y1/24���Ă��Ȃ苿������B
L1���C�e���V1.33�{�AL2�T�C�Y1/24���Ă��Ȃ苿������B
���܂ł��܂�ӎ����ĂȂ��Ƃ�������ǂ��܂����݂�����
���̐v��2�R�A�AL3�����AL2���ʂŐv������A�����Ƃ���CPU�ɂȂ�낤�ȁB
K8�AK10�����ӂ����ȃA�v���ō������������ȁB
Winrar�Ƃ��������x���`�̂悤��
Winrar�Ƃ��������x���`�̂悤��
���ǃ����R�����ڂ��Ă����܂���ʂ�������>>372���ĂȌ��ʂȂ̂���
>>380
�x���`�����V�X�e���̃���������ɕs��i1ch-3ch�ŕς��Ȃ��A���C�e���V���傫���j�����������ď����Ă���
�����R�����ڂ��Ӗ��Ȃ����Ă�肻�̂����ł���
�x���`�����V�X�e���̃���������ɕs��i1ch-3ch�ŕς��Ȃ��A���C�e���V���傫���j�����������ď����Ă���
�����R�����ڂ��Ӗ��Ȃ����Ă�肻�̂����ł���
2.93GHz�œ����Ă����ق��Ńx���`�Ƃ�悩�����̂�
383 �FMAC�I�^��373 �����F2008/06/06(��) 12:45:25 ID:+eoJsv58
>>373
�悭�l���Ă݂��4-thread���m�̔�r�ł�Penryn��藎���Ă���̂����邷�B
��Valve map compilation�x���`
�@�@�@�@�@�@�@�@�@�@�@�@�@�@Nehalem�@�@�@�@�@Penryn
�@8-thread�̏ꍇ�@�@�@�@�@197�@�@�@�@�@�@�@265�@�@�@�@[sec.]
�@4 -> 8�̍��@�@�@�@�@�@�@�@�@48�@�@�@�@�@�@�@127�@�@�@�@[sec]
�@4-thread�̏ꍇ�@�@�@�@�@149�@�@�@�@�@�@�@138�@�@�@�@[sec]
�悭�l���Ă݂��4-thread���m�̔�r�ł�Penryn��藎���Ă���̂����邷�B
��Valve map compilation�x���`
�@�@�@�@�@�@�@�@�@�@�@�@�@�@Nehalem�@�@�@�@�@Penryn
�@8-thread�̏ꍇ�@�@�@�@�@197�@�@�@�@�@�@�@265�@�@�@�@[sec.]
�@4 -> 8�̍��@�@�@�@�@�@�@�@�@48�@�@�@�@�@�@�@127�@�@�@�@[sec]
�@4-thread�̏ꍇ�@�@�@�@�@149�@�@�@�@�@�@�@138�@�@�@�@[sec]
����Lower is better
������49
����ȑO�ɁA���̕\�̈Ӗ����悭�������B
>>376
L2�T�C�Y1/24�������C�e���V1/3����H
�L���b�V�����\�͗e�ʂƃ��C�e���V�Ō��܂邩��
�e�ʂ��������Ă�������ΐ��\�͏o���H
���܂ł̋��L�L���b�V���v�̂܂܊g����������Ă���
8�X���b�h�ŋ��L�L���b�V���ɓ����A�N�Z�X����
7�X���b�h���̃A�N�Z�X�����҂������Đ��\������������B
����ȃP�[�X�̓��A������
L1=32KB����~�X��10%�͂��邻��������
8�X���b�h��������4�X���b�h�͓����ɃA�N�Z�X���Ă��邾�낤�ˁB
���C�e���V20�A�X���[�v�b�g10�ł����v50cycle�҂��ɂ͂Ȃ�͂��B
����悩����ۂǃ}�V�Ȃ낤��A���̌�L2�v�́B
L2�T�C�Y1/24�������C�e���V1/3����H
�L���b�V�����\�͗e�ʂƃ��C�e���V�Ō��܂邩��
�e�ʂ��������Ă�������ΐ��\�͏o���H
���܂ł̋��L�L���b�V���v�̂܂܊g����������Ă���
8�X���b�h�ŋ��L�L���b�V���ɓ����A�N�Z�X����
7�X���b�h���̃A�N�Z�X�����҂������Đ��\������������B
����ȃP�[�X�̓��A������
L1=32KB����~�X��10%�͂��邻��������
8�X���b�h��������4�X���b�h�͓����ɃA�N�Z�X���Ă��邾�낤�ˁB
���C�e���V20�A�X���[�v�b�g10�ł����v50cycle�҂��ɂ͂Ȃ�͂��B
����悩����ۂǃ}�V�Ȃ낤��A���̌�L2�v�́B
388 �FMAC�I�^��384 �����F2008/06/06(��) 17:10:06 ID:+eoJsv58
390 �F,,�E�L�́M�E,,�j��-�������F2008/06/06(��) 17:42:59 ID:JmWZ+wiD
>>378
L2�̑ш悪����Ȃ���B
���LL2�̌��_�͑ш����荇�����ƁB
�Ɨ��L���b�V���Ȃ�o�X���Ɨ��Őv�ł���B
2�X���b�h�ŃR�A�����L���邱�Ƃł����ł���L1�̃~�X�q�b�g�����������Ă�̂�
���XL2���L�ɂ͂ł���B
L2�̑ш悪����Ȃ���B
���LL2�̌��_�͑ш����荇�����ƁB
�Ɨ��L���b�V���Ȃ�o�X���Ɨ��Őv�ł���B
2�X���b�h�ŃR�A�����L���邱�Ƃł����ł���L1�̃~�X�q�b�g�����������Ă�̂�
���XL2���L�ɂ͂ł���B
{kind=link}
>>390
2�R�A���ď����Ă����ł����ǁH
2�R�A���ď����Ă����ł����ǁH
����ɂ�L3�ے�_�҂������B
�Ȃ����낤�B
�Ȃ����낤�B
>>393
Phenom�̉e������
Phenom�̉e������
395 �FMAC�I�^��393 �����F2008/06/06(��) 17:51:36 ID:+eoJsv58
>>393
���ۂɌ��������āABarcelona(�Ɨ����e��L2 + ���LL3)��Core�A�[�L�e�N�`��(���L��e��L2)��
�{���������Ă邩�炾�Ǝv�����B
���ۂɌ��������āABarcelona(�Ɨ����e��L2 + ���LL3)��Core�A�[�L�e�N�`��(���L��e��L2)��
�{���������Ă邩�炾�Ǝv�����B
396 �F,,�E�L�́M�E,,�j��-�������F2008/06/06(��) 17:52:05 ID:JmWZ+wiD
>>392
�������2�R�A�ł���������B
32KB��L1��2�X���b�h�œ����ɋ��L����悤�ɂȂ�����ǂ��~�X���������邩�l���Ă݂悤�ˁB
L1�𑝂₷�H
���C�e���V5�Ƃ��ɂȂ��B
�������2�R�A�ł���������B
32KB��L1��2�X���b�h�œ����ɋ��L����悤�ɂȂ�����ǂ��~�X���������邩�l���Ă݂悤�ˁB
L1�𑝂₷�H
���C�e���V5�Ƃ��ɂȂ��B
397 �F,,�E�L�́M�E,,�j��-�������F2008/06/06(��) 17:53:58 ID:JmWZ+wiD
>>395
,,�E�L�́M�E,,�j��-�������@���L���b�V���̂�������Ȃ����낻��B�@��������Nehalem�ɂȂ��Ă��L���b�V���e�ʂ̗D�ʂ͕ς���ĂȂ����B
,,�E�L�́M�E,,�j��-�������@���L���b�V���̂�������Ȃ����낻��B�@��������Nehalem�ɂȂ��Ă��L���b�V���e�ʂ̗D�ʂ͕ς���ĂȂ����B
398 �FMAC�I�^���c�q �����F2008/06/06(��) 17:56:52 ID:+eoJsv58
>>397
�ʂɋZ�p�I�D�������Ă������햳�����B�w��ۂ������x���R�̘b�B
�ʂɋZ�p�I�D�������Ă������햳�����B�w��ۂ������x���R�̘b�B
���̃x���`���āA������1ch�ł���Ă�́H
Intel�̃j���[�X���ᖳ�������ǁAPolaris�̔��\���Ɍ��ꂽ3D�_�C�X�^�b�L���O�̐i�W����B
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/755-756
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208402446
Larrabee�̂��̂܂����̐���ʂɂ허�邷���ˁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/755-756
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208402446
Larrabee�̂��̂܂����̐���ʂɂ허�邷���ˁB�B�B
TGDaily��Theo Valich��Nehalem�L�����B
http://www.tgdaily.com/content/view/37824/135/
�@�E"FUD"zilla�̃I�[�o�[�N���b�N�����@�\������Ƃ����L����R���ς�
�@�EBloomfield��DDR2-1600���T�|�[�g����B
�����l��"FUD"zilla�Ƃ��܂�ς��Ȃ����̋L�����c���Ă��邷���ǁB�B�B
http://www.tgdaily.com/content/view/37824/135/
�@�E"FUD"zilla�̃I�[�o�[�N���b�N�����@�\������Ƃ����L����R���ς�
�@�EBloomfield��DDR2-1600���T�|�[�g����B
�����l��"FUD"zilla�Ƃ��܂�ς��Ȃ����̋L�����c���Ă��邷���ǁB�B�B
L0.5��LSD�̌��ʂ͂ǂ�Ȃ���H
>>401
��̌��̈�ԉ��̃X�R�A���Ăǂ��̃T�C�g�H
��̌��̈�ԉ��̃X�R�A���Ăǂ��̃T�C�g�H
404 �FMAC�I�^��403 �����F2008/06/06(��) 21:07:20 ID:+eoJsv58
>>403
���R�̂��Ƃ��A1�i�ڂ���2�i�ڂ������Ηǂ����B
���R�̂��Ƃ��A1�i�ڂ���2�i�ڂ������Ηǂ����B
�������Turbo Mode�̏ڍ���ް?? ����
http://en.hardspell.com/doc/showcont.asp?news_id=3211
We get to know that Intel will change overclock policy when LGA1366 and LGA1160
to replace LGA775 and then Intel just allow high-end quad core Bloomfield to overclock.
Bloomfield�ł̂�Turbo Mode��support�����Ƃ����̂��ό`���ĕ��ꃋ�[�}�[��
�����\��������̂ŁA����������Turbo Mode��Bloomfield�݂̂̉\�����l���Ă�B
http://en.hardspell.com/doc/showcont.asp?news_id=3211
We get to know that Intel will change overclock policy when LGA1366 and LGA1160
to replace LGA775 and then Intel just allow high-end quad core Bloomfield to overclock.
Bloomfield�ł̂�Turbo Mode��support�����Ƃ����̂��ό`���ĕ��ꃋ�[�}�[��
�����\��������̂ŁA����������Turbo Mode��Bloomfield�݂̂̉\�����l���Ă�B
���ƁA�L���V���o�ꂵ�Ȃ��悤�ɔO�̂��߂����Ă������A
���s��$316 Yorkfield�̃V�X�e���̊��o�ł���ƁA
Bloomfield�̓}�U�[���������낤�����낵���B
���s��$316 Yorkfield�̃V�X�e���̊��o�ł���ƁA
Bloomfield�̓}�U�[���������낤�����낵���B
P6 1995/11
NetBurst 2000/11
Nehalem 2008 Q4
�\��ʂ�o��ƃI���S��Q4�t�B�[�o�[���ˁi�E�́E�j
NetBurst 2000/11
Nehalem 2008 Q4
�\��ʂ�o��ƃI���S��Q4�t�B�[�o�[���ˁi�E�́E�j
Bloomfield��Q3����Ȃ��������H
409 �F,,�E�L�́M�E,,�j��-�������F2008/06/06(��) 23:21:32 ID:JmWZ+wiD
Q3����7�`9�������B
���{�̏��K���Ƃ�������ɂȂ��ĂȂ���
���{�̏��K���Ƃ�������ɂȂ��ĂȂ���
����Ƃ͊��Ⴂ���ĂȂ����AQ4�������ȁB�������Ⴂ���B
���Ă��Ƃ͂܂��܂����ǂ̗]�n������ȁB
�{�i�I�ɂł�̂�2009�NQ3�����B
���Ă��Ƃ͂܂��܂����ǂ̗]�n������ȁB
�{�i�I�ɂł�̂�2009�NQ3�����B
Nehalem��IPC�オ���ĂȂ����ĔF���ł����Ȃ̂��ȁH
�p�b�P�[�W�������IPC�͑啝�ɏオ���Ă�B
�R�A�������IPC�����l�ɏオ���Ă�B
�X���b�h�������IPC�͔����B
IPC�Ƃ����T�O�̓}���`�R�A����ɂ͂�����Ȃ��̂ŁA�f���Ɂu���N���b�N�ł̐��\�v
�ƌ����������������B
�}���`�X���b�h���\�FYorkfield�̂P�D�R�`�P�D�S�{
�V���O���X���b�h���\�FWolfdale/Yorkfield�������
�R�A�������IPC�����l�ɏオ���Ă�B
�X���b�h�������IPC�͔����B
IPC�Ƃ����T�O�̓}���`�R�A����ɂ͂�����Ȃ��̂ŁA�f���Ɂu���N���b�N�ł̐��\�v
�ƌ����������������B
�}���`�X���b�h���\�FYorkfield�̂P�D�R�`�P�D�S�{
�V���O���X���b�h���\�FWolfdale/Yorkfield�������
����������ɕs��̂����Ԃł���Ȃ��������H
414 �FSocket774�F2008/06/07(�y) 11:21:09 ID:gjbHCDIx
�I���S���������������`�I �����D�c�T��
�܂������͔����邯�ǂ�
rdram��423�̎͌����ĖY��ʂ�
rdram��423�̎͌����ĖY��ʂ�
>383�ł���悤��Yorkfield�ɕ����Ă���̂́A�������̕s��������H
������������ɓ����Ă���i�炵���j2.93GHz����̃V�X�e����
���r���[���Ȃ������̂͂Ȃ����낤�B�������x���`�͂���Ă���̂�
������������ɓ����Ă���i�炵���j2.93GHz����̃V�X�e����
���r���[���Ȃ������̂͂Ȃ����낤�B�������x���`�͂���Ă���̂�
intel���炻�����̃x���`���ʂ͌��\�����炾�߂Ƃ����ł������ˁH
ES����ɓ���āA����Ƀx���`���ʃA�b�v���Ă�T�C�g����Ȃ����B
ES����ɓ���āA����Ƀx���`���ʃA�b�v���Ă�T�C�g����Ȃ����B
>>413
AM2���ŏ��x���`���o�Ă����Ƃ��́i����
AM2���ŏ��x���`���o�Ă����Ƃ��́i����
20�N�قǑO��i386���\�����Ƃ����炸���ƁAx86�A�[�L�e�N�`�������g�ɂȂ��Ă��邪�A
�݊��ێ��̂��߂ɂ͎d���Ȃ����Aintel�`�b�v�̏h��
8086��������A�܂���30�N������̖��߃Z�b�g�������c���Ă�Ƃ͎v�������Ȃ������B
�݊��ێ��̂��߂ɂ͎d���Ȃ����Aintel�`�b�v�̏h��
8086��������A�܂���30�N������̖��߃Z�b�g�������c���Ă�Ƃ͎v�������Ȃ������B
8086
�������炢�����Ă���̂��B
���Ȃ�̂�������ł��ˁB
�������炢�����Ă���̂��B
���Ȃ�̂�������ł��ˁB
>>420
��������
��������d��CPU�x�[�X���Č����Ē@����Ă���
�����Ƃ��̋c�_�͐s���Ȃ���
���g���[����68�n�ƃA�[�L�e�N�`���v�ŕ����Ă������AMSDOS��WNDOWS��Intel��
�����Ă��܂����B
����ȏ������A����Q6600�Ŗ������Ă��܂��Ă����
��������
��������d��CPU�x�[�X���Č����Ē@����Ă���
�����Ƃ��̋c�_�͐s���Ȃ���
���g���[����68�n�ƃA�[�L�e�N�`���v�ŕ����Ă������AMSDOS��WNDOWS��Intel��
�����Ă��܂����B
����ȏ������A����Q6600�Ŗ������Ă��܂��Ă����
422 �F,,�E�L�́M�E,,�j��-�������F2008/06/07(�y) 13:20:31 ID:eIHMW9R8
���g�Ƃ�����قǑ���ISA�̎������������h�ł��Ȃ���ȁB
Tom's Hardware��Atom���r���[���B
http://www.tomshardware.com/reviews/intel-atom-cpu,1947.html
��������x86�}�C�N���A�[�L�e�N�`����clock-for-clock�ł̔�r���s���Ă���̂������[�����B
��r�ΏƂ펟�̒ʂ�B
�@�EAtom230/1.6GHz
�@�EPentium-E 2160/1.8GHz (Core microarchitecture), 1.6GHz�Ƀ_�E��
�@�ESempron 3400+/1.8GHz (K8), 1.6GHz�Ƀ_�E��
�@�EC7-M/1.5GHz, Atom�̕���1.5GHz�Ƀ_�E��
�@�ECeleron-M/1.3GHz (Dothan), Atom�̕���1.3GHz�Ƀ_�E��
http://www.tomshardware.com/reviews/intel-atom-cpu,1947.html
��������x86�}�C�N���A�[�L�e�N�`����clock-for-clock�ł̔�r���s���Ă���̂������[�����B
��r�ΏƂ펟�̒ʂ�B
�@�EAtom230/1.6GHz
�@�EPentium-E 2160/1.8GHz (Core microarchitecture), 1.6GHz�Ƀ_�E��
�@�ESempron 3400+/1.8GHz (K8), 1.6GHz�Ƀ_�E��
�@�EC7-M/1.5GHz, Atom�̕���1.5GHz�Ƀ_�E��
�@�ECeleron-M/1.3GHz (Dothan), Atom�̕���1.3GHz�Ƀ_�E��
424 �FMAC�I�^���c�q �����F2008/06/07(�y) 13:22:41 ID:0SS3idWO
>>422
���g���G���f�B�A����2������ISA�튨�ق��ė~���������ǁB�B�B
���g���G���f�B�A����2������ISA�튨�ق��ė~���������ǁB�B�B
>>412
IPC���Ă̂̓V���O���X���b�h�̒l���Ǝv����
IPC���Ă̂̓V���O���X���b�h�̒l���Ǝv����
>>422
����Ax86�����o���ĕ����낤�B
8080�ǂ��납4004����̓`�����Ђ��Â��Ă�B
RISC���ȑO�A68000�Ƌ������Ă���Ƃ����疽�߃Z�b�g����
�Ƃ����Ă����ȁB
����Ax86�����o���ĕ����낤�B
8080�ǂ��납4004����̓`�����Ђ��Â��Ă�B
RISC���ȑO�A68000�Ƌ������Ă���Ƃ����疽�߃Z�b�g����
�Ƃ����Ă����ȁB
�Ȃ�Ƃ��Ȃ�����Ȃ́H
>>427
Intel���g�A���̕������牽�x���E�p�������Ǝv���Ă��āA
�Ō�ɂ�Itanium�Ƃ����l�ގj��ő�̓���������RISC�L���[�A�[�L�e�N�`��
�ŒE�p���悤�Ƃ��Ď��s�B�����āA�����S�Ă�x86�̂Ƃ����H���ύX�����Č����
������B
Intel���g�A���̕������牽�x���E�p�������Ǝv���Ă��āA
�Ō�ɂ�Itanium�Ƃ����l�ގj��ő�̓���������RISC�L���[�A�[�L�e�N�`��
�ŒE�p���悤�Ƃ��Ď��s�B�����āA�����S�Ă�x86�̂Ƃ����H���ύX�����Č����
������B
�������AVX��VEX�v���t�B�b�N�X�ŒE�p�Ȃ�ċL����
�������Ȃ�������S����B
�������Ȃ�������S����B
>>428
�Ȃ�قǁE�E�E
�Ȃ�قǁE�E�E
RISC�L���[�ɂȂ�\�肪���X�N������
�������₷�����A
Intel���g��x86�ɑ��邱�����͉ߋ��ɂ͂��܂�Ȃ������B
��������iAPX432, i860/960, StrongARM(Xscale), Itanium�Ȃǂ��ߋ��ɂ���������
�S�ēP�ނ��A��͉��̐헪����͘H���ύX���Ă��B
RISC�S���̂Ƃ��ɂ͖h�q�ɓO���邵���Ȃ���������x86�ɗ͂�����Ă����A
�ߋ��Ɍ��݂ق�x86�ɒ��͂������Ƃ͂Ȃ��B
Intel�ł�"x86 everywhere"�H���ύX�̌��ʂ��A
�T�[�o�����ɖ{�C�ɂȂ�n�߂�Nehalem�A
�g��/�g�ݍ��ݎs�������Atom
HPC/GPGPU�p�r��Larrabee
�Ȃ킯�B�����ق�Ƃ�x86���炯�B���f���o��B
Intel���g��x86�ɑ��邱�����͉ߋ��ɂ͂��܂�Ȃ������B
��������iAPX432, i860/960, StrongARM(Xscale), Itanium�Ȃǂ��ߋ��ɂ���������
�S�ēP�ނ��A��͉��̐헪����͘H���ύX���Ă��B
RISC�S���̂Ƃ��ɂ͖h�q�ɓO���邵���Ȃ���������x86�ɗ͂�����Ă����A
�ߋ��Ɍ��݂ق�x86�ɒ��͂������Ƃ͂Ȃ��B
Intel�ł�"x86 everywhere"�H���ύX�̌��ʂ��A
�T�[�o�����ɖ{�C�ɂȂ�n�߂�Nehalem�A
�g��/�g�ݍ��ݎs�������Atom
HPC/GPGPU�p�r��Larrabee
�Ȃ킯�B�����ق�Ƃ�x86���炯�B���f���o��B
�m����8086�͕����Ǝv������
386�l�C�e�B�u���[�h���Ă���Ȃɕ����Ȃ�
386�l�C�e�B�u���[�h���Ă���Ȃɕ����Ȃ�
x86���đ��̃A�[�L�e�N�`���Ɣ�ׂ�ƈڐA���ƌ݊����D���
�g�����Ă��Ă��邩��AOS��œ����\�t�g�̖ʂ���݂�Ƃ��܂�s�����Ȃ������ł���B
�n�[�h�AOS�A�R���p�C������鑤�̕��S���傫���B
����RISC���嗬����������C�̍œK���R���p�C����������邾�낤�ɁA
x86�͂Ȃ��B
�g�����Ă��Ă��邩��AOS��œ����\�t�g�̖ʂ���݂�Ƃ��܂�s�����Ȃ������ł���B
�n�[�h�AOS�A�R���p�C������鑤�̕��S���傫���B
����RISC���嗬����������C�̍œK���R���p�C����������邾�낤�ɁA
x86�͂Ȃ��B
>>426
�c�q�����ISA�́u�����v���Č����Ă��
�c�q�����ISA�́u�����v���Č����Ă��
�����A�������B
POWER�h�͔ے肷�邩������Ȃ����Ax86�̎������ŋ����낤�B
POWER�h�͔ے肷�邩������Ȃ����Ax86�̎������ŋ����낤�B
���ǁAISA�̍�������(�Ɋ|�������)�̍��̕����傫�����Ă��Ƃ�
438 �F�R�E�L�́M�E,,�j�����������������F2008/06/07(�y) 15:08:27 ID:RTZlTIi2
>>424
SuperH���o�J�ɂ����
�܂��Ԃ����Ⴏ�����������B�O�X����imm8���Ȃɂ������W�X�^�w��Ɏg����悤�ɂ���Ǝv���Ă��B
AVX�Ŗ{���ɂ��₪�����B
SuperH���o�J�ɂ����
�܂��Ԃ����Ⴏ�����������B�O�X����imm8���Ȃɂ������W�X�^�w��Ɏg����悤�ɂ���Ǝv���Ă��B
AVX�Ŗ{���ɂ��₪�����B
���܃f������n�߂�Bloomfiled+X58�`�b�v�Z�b�g�͂ǂ̂��炢�̉��i�ɂȂ��ł����ˁH
�}�U�[��CPU��7�`8���~���炢�Ȃ甃����������ǂȂ��B
�}�U�[��CPU��7�`8���~���炢�Ȃ甃����������ǂȂ��B
MB�ACPU���Ɉ����Ă�4���ギ�炢�͂������Ȋ������ȁB
�����������ƂȂ�ƍŒ�3GHz�͗~�����Ƃ��낾
�ł��Œ�N���b�N�ȊO�͍����낤�Ȃ��c
�ł��Œ�N���b�N�ȊO�͍����낤�Ȃ��c
�}�U�[�̓��[�J�[��킸�Ȃ�R���͐邾�낤
>>444
X38,X48,,P45�Ƃ��ƈꏏ�ň�胉�C���ȏ�����Ƃ�����3����������Č����Ă��ȁB
X38,X48,,P45�Ƃ��ƈꏏ�ň�胉�C���ȏ�����Ƃ�����3����������Č����Ă��ȁB
>>445
��胉�C�����ǂ��Ɉ����������AIntel��GIGA-DS5��X48�}�U�[�͂R�����Ă邩��B
��胉�C�����ǂ��Ɉ����������AIntel��GIGA-DS5��X48�}�U�[�͂R�����Ă邩��B
Lynnfield���x���Ȃ肻��������A���������Ă��䖝������Ȃ��l��
Bloomfiled���ɑ���낤�ȂƗ\�z�B
AMD���s�b��Ȃ�����AIntel���a�l���������Ȃ����Ƃ�����ƐS�z
���ȁB
���������Ӗ���AMD��45nmCPU�ɂ͂�����ė~�����B
Bloomfiled���ɑ���낤�ȂƗ\�z�B
AMD���s�b��Ȃ�����AIntel���a�l���������Ȃ����Ƃ�����ƐS�z
���ȁB
���������Ӗ���AMD��45nmCPU�ɂ͂�����ė~�����B
AMD�͓���K10.5��3GHz�z����CPU���o���Ȃ����낤����A
Intel���a�l����������̂͂قڌ��莖���B
��ԉ���2.66GHz���炢��AMD�Ɠ������x�Ɉ������Ă���邾�낤����
Intel���a�l����������̂͂قڌ��莖���B
��ԉ���2.66GHz���炢��AMD�Ɠ������x�Ɉ������Ă���邾�낤����
2.66G��$316�Ƃ����\���{���Ȃ�a�l�����ǂ��납�o�[�Q���Z�[����
�V���O���X���b�h���\���オ���ĂȂ��Ƃ����獡��Duo�g�͌������Ȃ�����
E8600�{P45�ŃV���O���X���b�h���\���z������̂�҂��Ă邺(�M��֥�L)
��������DDR3�ɂ��邯�ǂȁB
��������DDR3�ɂ��邯�ǂȁB
���z������̖��J�����߂Â��Ă��Ă��
2008/06/05 21:08�@���o�}�C�N���f�o�C�X
�����́C10G�r�b�g/�b�ȏ�̍����f�[�^�`��������������z�����C
�ėp�I�ȃv�����g�z�����Ɍ`���ł���ޗ����J�������B
���z���̎����v���Z�X�͈ȉ��̒ʂ�ł���B
�܂��C�v�����g���ɃN���b�h�w�p�̃V�[�g�ޗ����ĔM�d��������B
���ɁC�v�����g���ɔM�d�����������N���b�h�w�̏�ɁC
�R�A�w�p�̃V�[�g�ޗ���C�}�X�N����ĘI����C�A���J���������邱�ƂŁC
�����`������R�A�w���`������B
���̌�C�N���b�h�w�p�̃V�[�g�ޗ����ĔM�d������ƁC���z������������B
�N���b�h�w�p�̍ޗ��́C50��m�̒i�����܂ޕ��ʂR�ɖ��ߍ��ނ��Ƃ��ł���B
�v�����g�z�����Ɍ`���\�ɂ��邽�߂ɁC�J�������ޗ��̍d�����x��180���ȉ��Ƃ����B
���Ђł͌�-�d�C���ڃv�����g�z�����2010�N�����畁�y����Ɨ\�����Ă���B
���p����́C�Q�[���@�C�e���r�C�z�[���E�T�[�o�[�ȂǑ�e�ʂ̃f�[�^�������ɓ`������p�r�����ł���B
�`�����x��10G�r�b�g/�b�ȏ�̍����`�������z���ŁC�����̓d�C�z���őΉ��ł���`���͓d�C�z���Ŏg�������邱�Ƃ�z�肵�Ă���B
2008/06/05 21:08�@���o�}�C�N���f�o�C�X
�����́C10G�r�b�g/�b�ȏ�̍����f�[�^�`��������������z�����C
�ėp�I�ȃv�����g�z�����Ɍ`���ł���ޗ����J�������B
���z���̎����v���Z�X�͈ȉ��̒ʂ�ł���B
�܂��C�v�����g���ɃN���b�h�w�p�̃V�[�g�ޗ����ĔM�d��������B
���ɁC�v�����g���ɔM�d�����������N���b�h�w�̏�ɁC
�R�A�w�p�̃V�[�g�ޗ���C�}�X�N����ĘI����C�A���J���������邱�ƂŁC
�����`������R�A�w���`������B
���̌�C�N���b�h�w�p�̃V�[�g�ޗ����ĔM�d������ƁC���z������������B
�N���b�h�w�p�̍ޗ��́C50��m�̒i�����܂ޕ��ʂR�ɖ��ߍ��ނ��Ƃ��ł���B
�v�����g�z�����Ɍ`���\�ɂ��邽�߂ɁC�J�������ޗ��̍d�����x��180���ȉ��Ƃ����B
���Ђł͌�-�d�C���ڃv�����g�z�����2010�N�����畁�y����Ɨ\�����Ă���B
���p����́C�Q�[���@�C�e���r�C�z�[���E�T�[�o�[�ȂǑ�e�ʂ̃f�[�^�������ɓ`������p�r�����ł���B
�`�����x��10G�r�b�g/�b�ȏ�̍����`�������z���ŁC�����̓d�C�z���őΉ��ł���`���͓d�C�z���Ŏg�������邱�Ƃ�z�肵�Ă���B
�В����ς���Ă���̓����͒n�������ǂ��Ȃ�撣���Ă�ȁB
PCWatch��Nehalem�}�U�[�{�[�h�M�������[���B>>294��TheINQ���摜��ǂ����B
http://pc.watch.impress.co.jp/docs/2008/0609/comp19.htm
http://pc.watch.impress.co.jp/docs/2008/0609/comp19.htm
�ȑOHKEPC���������A�����n�̃T�C�g��Nehalem�ɂ�Turbomode��
���������悤�Ȃ��Ə����Ă��������ǁAAnandtech�̃x���`�ł�
����Turbomode�������ĂȂ���ˁB
��������Ȃ������̂��A�܂��`���[�j���O���ł��܂������Ȃ��̂��B
Turbomode�����܂������A�V���O���X���b�h���\�̌��オ�������Ă��A
�}���`�X���b�h�ɑΉ����Ă��Ȃ��A�v���ł�����Ȃ�Ɍ��ʂ��肻�������ǁB
���������悤�Ȃ��Ə����Ă��������ǁAAnandtech�̃x���`�ł�
����Turbomode�������ĂȂ���ˁB
��������Ȃ������̂��A�܂��`���[�j���O���ł��܂������Ȃ��̂��B
Turbomode�����܂������A�V���O���X���b�h���\�̌��オ�������Ă��A
�}���`�X���b�h�ɑΉ����Ă��Ȃ��A�v���ł�����Ȃ�Ɍ��ʂ��肻�������ǁB
bios�m�Ή����x��Ă�Ɨ\�z�B
�����͐�ɂ��Ă���Ǝv���B
�ނ���B���@�\���y���݂ȈʂɁB
�����͐�ɂ��Ă���Ǝv���B
�ނ���B���@�\���y���݂ȈʂɁB
DDR3�͂������傢�N���b�N�オ���Ă��Ȃ���DDR2�Ƃ̍��͂��Ȃ�����
����Ȕ��\���o������Ď��́A���������Ԏd�オ���Ă�낤��
������2.6Ghz399�h������A���Đ錾���Ă���Ď��͂�����x�̕����܂�̌����݂������Ă��
������2.6Ghz399�h������A���Đ錾���Ă���Ď��͂�����x�̕����܂�̌����݂������Ă��
Nehalem/2.4GHz��Super-PI�̃j���[�X������Ă��邷�B17.219s�Ƃ��B
http://www.expreview.com/news/hard/2008-06-11/1213151319d9157.html
�\�[�X��AJCornell���̌f�����e�̖͗l�Ȃ�ŁA�M�p�ł��邩�Ǝv���邷�B
http://www.xfastest.com/viewthread.php?tid=10903&extra=page%3D1 (PI�摜�������Ă��邷)
Conroe��Penryn�Ɣ�r����ƁA����Ȋ������B
�@Conroe: �`21sec
�@Penryn: �`20sec.
http://www.expreview.com/news/hard/2008-06-11/1213151319d9157.html
�\�[�X��AJCornell���̌f�����e�̖͗l�Ȃ�ŁA�M�p�ł��邩�Ǝv���邷�B
http://www.xfastest.com/viewthread.php?tid=10903&extra=page%3D1 (PI�摜�������Ă��邷)
Conroe��Penryn�Ɣ�r����ƁA����Ȋ������B
�@Conroe: �`21sec
�@Penryn: �`20sec.
�Ƃ��o����Ă��ȁE�E�E��
SSE4.2�̌��ʂ�������x���`�Ƃ��܂��Ȃ��̂�����
Super-PI�����Ō��_�͂ł���ł��傤����ǁA1.16�{�̐��\���オ����Ƃ������ł����A3Ghz�Ȃ�
3.0GHz��3.48GHz ���x�̍����\���ł���
���N���b�N�ł����������Ă���������Ȃ��͂Ȃ��Ǝv���܂��A���Ƃ͉��i���悩�ȁB
3.0��3.3���ƍ��������Ă�������͂���܂���3.0��3.6���x�܂ł����A����Ȃ�Ɏ������܂���ŁB
3.0GHz��3.48GHz ���x�̍����\���ł���
���N���b�N�ł����������Ă���������Ȃ��͂Ȃ��Ǝv���܂��A���Ƃ͉��i���悩�ȁB
3.0��3.3���ƍ��������Ă�������͂���܂���3.0��3.6���x�܂ł����A����Ȃ�Ɏ������܂���ŁB
Kentsfield 3.1GHz�ANehalem 2.4GHz ����łقړ������x���ȁB
2.4GHz / 3.1GHz * 100 = 77%
1.7�{���H
2.4GHz / 3.1GHz * 100 = 77%
1.7�{���H
http://ranobe.com/up/src/up277754.jpg
���ԂŌv�����Ă����\���͂킩��Ȃ�����A�������莞�Ԃ����炢�ɂ��đ����Ă݂��B
Kentsfield 3.1GHz =Nehalem 2.4GHz
�����1.7�{���B
{kind=link}
���ԂŌv�����Ă����\���͂킩��Ȃ�����A�������莞�Ԃ����炢�ɂ��đ����Ă݂��B
Kentsfield 3.1GHz =Nehalem 2.4GHz
�����1.7�{���B
>94 0'17" ��͂� Intel Core 2 Quad Q9450 2664 Unknown Unknown 2664MHz 333.0*8.0 ���e�[��FAN GIGABYTE GA-G31M-S2L Vista �v�X�̎���@
Kentsfield �Ȃ�
2.4GHz �Ȃ� 2.6GHz ��������
Kentsfield �Ȃ�
2.4GHz �Ȃ� 2.6GHz ��������
>>466
���Ԃ��ɂ��ăN���b�N��ς��Ă����Ȃ��ƌv�Z�Ȃo���Ȃ����B
���Ԃ��ɂ��ăN���b�N��ς��Ă����Ȃ��ƌv�Z�Ȃo���Ȃ����B
�H
>>468
���ԂŊ����Ă����\���͏o�Ă��Ȃ����Ă��ƁB
�N���b�N��ς��āA���Ԃ��قړ��^�C���ɍ��킹�āA�N���b�N���m�Ŋ���Ȃ���
���m�Ȑ��\���͂łĂ��Ȃ��B
���ԂŊ����Ă����\���͏o�Ă��Ȃ����Ă��ƁB
�N���b�N��ς��āA���Ԃ��قړ��^�C���ɍ��킹�āA�N���b�N���m�Ŋ���Ȃ���
���m�Ȑ��\���͂łĂ��Ȃ��B
��������Ȃ�W�Ȃ��Ǝv���
>>470
1M�̌v�Z�́A���\���傫���������Ă����Ƃ��Ă��A���Ɏ��Ԃ��Z������
���\�����o���͓̂���B
��̌v�Z�̓~�X
Conroe��Ȃ�Q6600 3.10GHz = Nehalem 2.4GHz �y1.29�{�z
Penryn��Ȃ�Q9550 2.83GHz = Nehalem 2.4GHz �y1.17�{�z
Conroe��Penryn �y1.09�{�z
1M�̌v�Z�́A���\���傫���������Ă����Ƃ��Ă��A���Ɏ��Ԃ��Z������
���\�����o���͓̂���B
��̌v�Z�̓~�X
Conroe��Ȃ�Q6600 3.10GHz = Nehalem 2.4GHz �y1.29�{�z
Penryn��Ȃ�Q9550 2.83GHz = Nehalem 2.4GHz �y1.17�{�z
Conroe��Penryn �y1.09�{�z
���X�g���x���̃L���b�V����2MB�����Ă�̂������Ă���̂��낤���ˁB
Intel Research Day�Ɋւ�����F�X�BLarrabee��Intel�̃}���`�v���Z�V���O
����"Ct"�A�ҋ@�d�͂̍팸�Z�p���ɂ��Č��ꂽ�Ƃ̂��Ƃ��B
�E���C�u���|�[�g �@Atom��WiMAX�̊J���N�\�������[�����B
�@http://www.ubergizmo.com/15/archives/2008/06/intel_research_day_keynote_live.html
�EEETimes http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=208403516
�@�@---------------------
�@�@Larrabee will sport about 100 new x86 instructions including
�@�@support for vector processing at a TFlop rate.
�@�@[��]
�@�@Intel said Larrabee will not ship until at least late 2009.
�@�@[��]
�@�@Unofficial reports have said Larabee will use 16 cores running up
�@�@to four threads each and sport a 1024-bit wide memory bus.
�@�@---------------------
����"Ct"�A�ҋ@�d�͂̍팸�Z�p���ɂ��Č��ꂽ�Ƃ̂��Ƃ��B
�E���C�u���|�[�g �@Atom��WiMAX�̊J���N�\�������[�����B
�@http://www.ubergizmo.com/15/archives/2008/06/intel_research_day_keynote_live.html
�EEETimes http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=208403516
�@�@---------------------
�@�@Larrabee will sport about 100 new x86 instructions including
�@�@support for vector processing at a TFlop rate.
�@�@[��]
�@�@Intel said Larrabee will not ship until at least late 2009.
�@�@[��]
�@�@Unofficial reports have said Larabee will use 16 cores running up
�@�@to four threads each and sport a 1024-bit wide memory bus.
�@�@---------------------
474 �FSocket774�F2008/06/12(��) 13:00:57 ID:WNqruaNv
Nehalem����age
>>45�ŏ�����MOVBE(Big-Endian�̃��[�h�E�X�g�A����)��
Atom�Ɏ�������Ă���悤��
http://www.freeweb.hu/instlatx64/InstLatX64_GenuineIntel00106c2_Atom_Silverthorne_1600MHz.txt
Atom�Ɏ�������Ă���悤��
http://www.freeweb.hu/instlatx64/InstLatX64_GenuineIntel00106c2_Atom_Silverthorne_1600MHz.txt
477 �F,,�E�L�́M�E,,�j��-�������F2008/06/13(��) 20:42:55 ID:p7oDIxgh
Ct����Baker���ČĂ�Ă����̂��ȁH
����C���C�N�ŗ����������̂�
���₳���CUDA���D����
����C���C�N�ŗ����������̂�
���₳���CUDA���D����
�`�����������Ă�@�Ȃ��C�Ȃ��Ȃ鐻�i����
Kilocore1025�Ƃ��̂ق��������������ˁH
Kilocore1025�Ƃ��̂ق��������������ˁH
����y�[�p�[�����[�X�ŏI�����
>>479
�܂��I�H�G�ɕ`�����݂Ƃ́E�E
�܂��I�H�G�ɕ`�����݂Ƃ́E�E
Intel�ЁC�`�b�v�ԓ`���������m���V�b�N�^���ʐM�f�q��W��
http://techon.nikkeibp.co.jp/article/NEWS/20080613/153231/
http://techon.nikkeibp.co.jp/article/NEWS/20080613/153231/
>>452
���͒x���B
���͒x���B
8086�����̃v���Z�X�ō��Ɖ��̂�̂ł����H
>>484
Intel 8086��'78�N6��8���ɓo�ꂵ�A�g�����W�X�^����29,000�A
�����̓���N���b�N��5MHz�������B
YorkField��8��2000��
Intel 8086��'78�N6��8���ɓo�ꂵ�A�g�����W�X�^����29,000�A
�����̓���N���b�N��5MHz�������B
YorkField��8��2000��
>>485
�ȂA�v���[�`����ׂ��ł́A�R�A80�Ăǂ�Ȃ낤�H
�ȂA�v���[�`����ׂ��ł́A�R�A80�Ăǂ�Ȃ낤�H
28275�̂�ȁA������������8086�Ɣ�r����ƁA�ꖜ�{���x�͍��������Ă��邩��
�A�v���[�`��ς��Ă�����p�r�ł������\�͌����Ȃ�����
�A�v���[�`��ς��Ă�����p�r�ł������\�͌����Ȃ�����
�D���Ȃ̔����Ɩ�
http://monoist.atmarkit.co.jp/fembedded/07ipflex/ipflex01.html
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
http://ext.ricoh.co.jp/LSI/product_assp/ri/architecture/index.html
http://ascii24.com/news/i/topi/article/2005/06/27/656644-000.html
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
http://pc.watch.impress.co.jp/docs/2006/0601/spf08.htm
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
http://gigazine.net/index.php?/news/comments/20070213_intel_80/
http://www.atmarkit.co.jp/news/200708/21/tile.html
http://monoist.atmarkit.co.jp/fembedded/07ipflex/ipflex01.html
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
http://ext.ricoh.co.jp/LSI/product_assp/ri/architecture/index.html
http://ascii24.com/news/i/topi/article/2005/06/27/656644-000.html
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
http://pc.watch.impress.co.jp/docs/2006/0601/spf08.htm
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
http://gigazine.net/index.php?/news/comments/20070213_intel_80/
http://www.atmarkit.co.jp/news/200708/21/tile.html
����CPU�͑傫���ς����Ăق�ƁH
������Ȃ��Ă��߂������ς��́H
������Ȃ��Ă��߂������ς��́H
HKEPC�����NQ2�̃f�X�N�g�b�v����Nehalem�ɂ��ē`���Ă��邷�B
XE��3.2GHz�ƒʏ��2.93GHz & 2.66GHz�Ƃ��B
http://www.hkepc.com/?id=1316&fs=c1h
���i�ɂ��Ă̏���A�܂��o����ĂȂ��悤������2.66GHz���f���ɂ��Ă�ُ�ɍ����Ƃ���
���Ƃ햳���������B
���҂���鐫�\�����APenryn��15-30%�����Ƃ��B
XE��3.2GHz�ƒʏ��2.93GHz & 2.66GHz�Ƃ��B
http://www.hkepc.com/?id=1316&fs=c1h
���i�ɂ��Ă̏���A�܂��o����ĂȂ��悤������2.66GHz���f���ɂ��Ă�ُ�ɍ����Ƃ���
���Ƃ햳���������B
���҂���鐫�\�����APenryn��15-30%�����Ƃ��B
491 �FMAC�I�^�������F2008/06/15(��) 22:09:29 ID:fvrvWeGO
�ŏ��̍s����ԈႦ�Ă���̂ŁA�������B
�@�@�@���NQ2 -> ���NQ4
���Ă��ƂŁB
�@�@�@���NQ2 -> ���NQ4
���Ă��ƂŁB
�l�n�́A�Q�R�A���P�ɂ܂Ƃ߂�QPI�ɂ��ă����R���˂������ʃR�X�g�����Ȃ������A�����Ȃ���������Ԗ�肾��
���͑��������Ă������������ł���̂Ȃ�OK���ȂƎv����
�t�ɁA�����肠����ꂸ��Core2Quad�ɏ��ĂȂ�������A���S�ɈӖ��Ȃ��B
���\�͐����Z�p�̃`���[���ŃN���b�N�グ���ق��������悳���������ȁB
���͑��������Ă������������ł���̂Ȃ�OK���ȂƎv����
�t�ɁA�����肠����ꂸ��Core2Quad�ɏ��ĂȂ�������A���S�ɈӖ��Ȃ��B
���\�͐����Z�p�̃`���[���ŃN���b�N�グ���ق��������悳���������ȁB
SMT�ő啝�ɐ��\�����邩��
�_�C�`�p�b�P�[�W���O�̃R�X�g����
�������ł��邾��
���[���A�����\���̂��߂ɃR�X�g�A�b�v����̂͏펯
C2D�Ƃ�����O�͖Y��܂��傤
�_�C�`�p�b�P�[�W���O�̃R�X�g����
�������ł��邾��
���[���A�����\���̂��߂ɃR�X�g�A�b�v����̂͏펯
C2D�Ƃ�����O�͖Y��܂��傤
Penryn*2���_�C�T�C�Y���傫������P���ɐ����R�X�g��2�{�ȏ�B
�����܂�l����Ƃ����Ƃ������Ă邾�낤�B
�����A2CPU�ȏ�̍\�����ƍ���FSB���ƌ��E�����ɏo�Ă��邩��A
QPI�ƃ����R�����ڂ͕K�v���낤�B
1CPU�\���ł��}���`�X���b�h�Ή��x���`���Ƃ��Ȃ萫�\���サ�Ă������B
�����܂�l����Ƃ����Ƃ������Ă邾�낤�B
�����A2CPU�ȏ�̍\�����ƍ���FSB���ƌ��E�����ɏo�Ă��邩��A
QPI�ƃ����R�����ڂ͕K�v���낤�B
1CPU�\���ł��}���`�X���b�h�Ή��x���`���Ƃ��Ȃ萫�\���サ�Ă������B
SMT�Ő��\��������Ƃ͓���v���Ȃ����ASMT�ŃR�X�g��������Ƃ�����v���Ȃ��̂���w
>SMT�Ő��\��������Ƃ͓���v���Ȃ���
���O��SMT disable�ɂ�����������B
���O��SMT disable�ɂ�����������B
>>495
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=6
���ꂾ���}���`�X���b�h���\���オ���Ă���SMT�ȊO�̉����Ƃ����B
�V���O���X���b�h���\�͂قƂ�Ǖς���ĂȂ��̂ɁB
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=6
���ꂾ���}���`�X���b�h���\���オ���Ă���SMT�ȊO�̉����Ƃ����B
�V���O���X���b�h���\�͂قƂ�Ǖς���ĂȂ��̂ɁB
�V���O���X���b�h�́A2.4GHz�̎���17.0xx�b���炢������A1.2�{���炢�͐��\�オ���Ă�
SMT�Ő��\�オ��Ȃ��̂Ȃ�e�Ќ������Ă˂���
��������Ȃɔے肵�Ă�̂͂��O�B
�G���R�[�h�̐��\���オ�邱�Ƃ����O���������R�������B
�G���R�[�h�̐��\���オ�邱�Ƃ����O���������R�������B
�G���R��p�����@�ȂNjƎ҂ł��Ȃ�������p�͖������[��
PC�p�Ƀ}���`�X���b�h�Ή�CPU���o�͂��߂�
����5�N�ȏ�߂��o�Ƃ����̂ɁA
�����Ƀ}���`�X���b�h�����ʓI�ȃA�v�����G���R���x���Ă̂��ȁB
����5�N�ȏ�߂��o�Ƃ����̂ɁA
�����Ƀ}���`�X���b�h�����ʓI�ȃA�v�����G���R���x���Ă̂��ȁB
����ȃ��X����z�͂Ƃ��̐̂ɓ|��s��������
505 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 11:54:09 ID:529taapO
�����A�悭�P�����ꂽ���₳��
�悭�݂Ȃ��Ă�503�̓��e���������ɂ���
���������ۂ̂Ƃ���PC�����Ƃ��Ă̓G���R���炢�������ʂˁ[��ȁB
�����ɁB
���������������璴�𑜂Ƃ��o�Ă��邩������B
�V���O���X���b�h���\�͂����\���ƌ����l���������ǁA����ϑ����ɒ��������Ƃ͂Ȃ��B
�����ɁB
���������������璴�𑜂Ƃ��o�Ă��邩������B
�V���O���X���b�h���\�͂����\���ƌ����l���������ǁA����ϑ����ɒ��������Ƃ͂Ȃ��B
�G���R�Ȃ�āA�S�R�R�A���ŃX�P�[�����Ȃ�
��ԃR�A���ɔ�Ⴗ��̂́A3D�̃��C�g���[�V���O����
�R�A��*90%�ȏ�̓^�R�ȃA�[�L�e�N�`���ł�����
��ԃR�A���ɔ�Ⴗ��̂́A3D�̃��C�g���[�V���O����
�R�A��*90%�ȏ�̓^�R�ȃA�[�L�e�N�`���ł�����
�G���R���X�P�[�����Ȃ��̂ƃX�P�[������̂�����B
Penryn�̃x���`�̂ق����Ă�B
DivX��8 core�ł��S�R�͂₭�Ȃ��B
��������Ȃ̂ł��B
Penryn�̃x���`�̂ق����Ă�B
DivX��8 core�ł��S�R�͂₭�Ȃ��B
��������Ȃ̂ł��B
���G���R�����Ȃ�
�܂��I�^���炷��������낤����
PG�ASE�ɂƂ��ăR���p�C�����x���オ�遁�d���̌��������Ȃ킯��
�܂��I�^���炷��������낤����
PG�ASE�ɂƂ��ăR���p�C�����x���オ�遁�d���̌��������Ȃ킯��
�������ꂵ�������Ȃ��A����ȓz�Ȃ�ł���
512 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 23:01:34 ID:529taapO
�X�P�[���r���e�B�m�ۂȂA�܂��X���b�h���قړƗ����삳����Ɍ���B
�������ď���������K�v�Ȃ��B
Excel 2007����}�N�����}���`�X���b�h�Ή������您�܂���m���Ă���H
�������ď���������K�v�Ȃ��B
Excel 2007����}�N�����}���`�X���b�h�Ή������您�܂���m���Ă���H
���������AVB6�̉ƌn��VBA�Ői�����Â���̂�?
514 �F,,�E�L�́M�E,,�j��-�������F2008/06/16(��) 23:16:23 ID:529taapO
�A���ǂ����i�����Ă�́H
VBA��IDE��ʂ���Office 2007��UI�Ƃ��ꊴ�Ȃ����A�p���[���[�U�[�E�J���ґw�ɂ�Ribbon���]��UI�̂ق��������Ă�Ƃ������f���ȁH
VBA��IDE��ʂ���Office 2007��UI�Ƃ��ꊴ�Ȃ����A�p���[���[�U�[�E�J���ґw�ɂ�Ribbon���]��UI�̂ق��������Ă�Ƃ������f���ȁH
>>512
���ꂪ�����Ȃ��̃R�A�ɂ���Ӗ��͂܂������Ȃ����ǂ�w
���ꂪ�����Ȃ��̃R�A�ɂ���Ӗ��͂܂������Ȃ����ǂ�w
make -j�̂��Ƃ���B
�����ƍ��{�I�Șb�A�R���p�C�����x�����Ė��ɂȂ��Ă���C++��4�R�A�Ƃ�8�R�A�Ƃ�������Ă��ɐ���
���U�R���p�C�����c�[���g���ł���A30�`40�R�A���炢���ׂȂ��ƒx���Ă���Ă���B
VB��C#�͈�R�A�ŏ\���AOffice�̃}�N���ŁACore2��CPU�p���[������Ȃ��č��������ԂɊׂ������Ƃ�������w
���U�R���p�C�����c�[���g���ł���A30�`40�R�A���炢���ׂȂ��ƒx���Ă���Ă���B
VB��C#�͈�R�A�ŏ\���AOffice�̃}�N���ŁACore2��CPU�p���[������Ȃ��č��������ԂɊׂ������Ƃ�������w
�����č���̏ꍇ 4core �� 4 core+SMT
�����B���ɃV���O���X���b�h��IPC���������Ƃ��āA
Yorkfield��3.2/3.4GHz����ǂꂾ�������Ȃ������̂��ƁB
���̍�������2�N1�x�����Ȃ��̂ł���B
�����B���ɃV���O���X���b�h��IPC���������Ƃ��āA
Yorkfield��3.2/3.4GHz����ǂꂾ�������Ȃ������̂��ƁB
���̍�������2�N1�x�����Ȃ��̂ł���B
���ꂪ�}���`�X���b�h�̎����CPU�̐i���B
�����Ƃ��V���O���X���b�h���\��SIMD�Ȃǂ̖��ߒlj������邩��
���ۂɂ͂����Ƃ�����̂����A�}���`�X���b�h�͂��̒��̈�Ƃ����l����
���̂Ƃ��낾�Ƃ����Ȃ��ƁB
�����Ƃ��V���O���X���b�h���\��SIMD�Ȃǂ̖��ߒlj������邩��
���ۂɂ͂����Ƃ�����̂����A�}���`�X���b�h�͂��̒��̈�Ƃ����l����
���̂Ƃ��낾�Ƃ����Ȃ��ƁB
�����A�킩��ɂ����ȁB
�ėp������IPC��������A���ߒlj���SIMD�Ȃǂ̓��������������Ȃ�B
�����SMT��}���`�R�A�Ń}���`�X���b�h���\��������B
DLP, ILP, TLP�̎O�i�\��������̃g�����h�ł��B
�ėp������IPC��������A���ߒlj���SIMD�Ȃǂ̓��������������Ȃ�B
�����SMT��}���`�R�A�Ń}���`�X���b�h���\��������B
DLP, ILP, TLP�̎O�i�\��������̃g�����h�ł��B
ATOM���o�Ȃ����
523 �FMAC�I�^��522 �����F2008/06/16(��) 23:46:18 ID:fqpP/Io+
>>521
Intel�����ɒ��ڂ��Ă�>>522����̎w�E�����悤��Atom��ILP�����������Ă��邵�ATukwila��
ILP��d�_����O��Ă��邷�B
Intel�����ɒ��ڂ��Ă�>>522����̎w�E�����悤��Atom��ILP�����������Ă��邵�ATukwila��
ILP��d�_����O��Ă��邷�B
>>521
Intel��ILP��������߂Ă���킯����Ȃ��ł���B���������������o���Ă����B
������������Nehalem�őS��IPC�����サ�Ȃ��Ƃ͎v���ĂȂ�����B
���̂�����ʂ�̃x���`���ł��Nehalem�ő����Ȃ�A�v�������邾�낤�B
Core 2�́A�V���O���X���b�h��Pentium M��ł�20%�ȏ�IPC��������������ȁB
SMT�̌��ʂ̓}���`�X���b�h�ł�������30%���炢�B
���������ۂ�Bloomfield�Ō����͂��߂�̂�4�X���b�h����ꍇ��(����ȏقƂ�ǂˁ[)�B
5�X���b�h�ł�+5�`+10%���������������낤�B8�X���b�h��+30%�B
������AQPI���IMC�̕����ڂ������͎̂d���Ȃ��B
Intel��ILP��������߂Ă���킯����Ȃ��ł���B���������������o���Ă����B
������������Nehalem�őS��IPC�����サ�Ȃ��Ƃ͎v���ĂȂ�����B
���̂�����ʂ�̃x���`���ł��Nehalem�ő����Ȃ�A�v�������邾�낤�B
Core 2�́A�V���O���X���b�h��Pentium M��ł�20%�ȏ�IPC��������������ȁB
SMT�̌��ʂ̓}���`�X���b�h�ł�������30%���炢�B
���������ۂ�Bloomfield�Ō����͂��߂�̂�4�X���b�h����ꍇ��(����ȏقƂ�ǂˁ[)�B
5�X���b�h�ł�+5�`+10%���������������낤�B8�X���b�h��+30%�B
������AQPI���IMC�̕����ڂ������͎̂d���Ȃ��B
http://www.ne.jp/asahi/comp/tarusan/main182.htm
http://www.ne.jp/asahi/comp/tarusan/main183.htm
http://www.ne.jp/asahi/comp/tarusan/main186.htm
http://www.ne.jp/asahi/comp/tarusan/main187.htm
http://www.ne.jp/asahi/comp/tarusan/main183.htm
http://www.ne.jp/asahi/comp/tarusan/main186.htm
http://www.ne.jp/asahi/comp/tarusan/main187.htm
>>497��������x�݂Ă݂�Ƃ��Ƃ���
Cinebench�ł�Penryn���+3%�����Ȃ��Ă�(+2%���+3%�ɋ߂�)�B
�ŁASMT���������Ƃ���+24%������A����+20%���炢���������ĂȂ��B
���ꂪSMT�̎��́B
Cinebench�ł�Penryn���+3%�����Ȃ��Ă�(+2%���+3%�ɋ߂�)�B
�ŁASMT���������Ƃ���+24%������A����+20%���炢���������ĂȂ��B
���ꂪSMT�̎��́B
�������Atom�݂����ȃ��[�G���h�͏��O�B
Atom�݂����̂�������������A�n�C�G���h�̖����͂ǂ�ǂ�Â��Ȃ��Ă����������B
Atom�͌��s��1 core�����Ȃ�����SMT�Ɋւ��Ă���Bloomfield�Ƃ͂܂�ňႤ���ǂˁB
�ǂ������Ƃ�����(�o�b�O�O���E���h����, IO�A�N�Z�X�Ȃǂɑ����Ђ��ς���)
�x���Ȃ�Ȃ����Č��ʂ��傫���B����͎g�p���ɉe������̂ŏd�v�B
Atom�݂����̂�������������A�n�C�G���h�̖����͂ǂ�ǂ�Â��Ȃ��Ă����������B
Atom�͌��s��1 core�����Ȃ�����SMT�Ɋւ��Ă���Bloomfield�Ƃ͂܂�ňႤ���ǂˁB
�ǂ������Ƃ�����(�o�b�O�O���E���h����, IO�A�N�Z�X�Ȃǂɑ����Ђ��ς���)
�x���Ȃ�Ȃ����Č��ʂ��傫���B����͎g�p���ɉe������̂ŏd�v�B
>���ꂪSMT�̎��́B
�\������Ȃ���?
�����ł���X���b�h��2�{�ɂȂ������琫�\��2�{�ɂȂ�Ȃ�����������Ƃ����咣�̓A�z�̎q�̐ꔄ���������ǁB
����R�A�^���R�A�Ƃ������Ă�A���̂��ƂˁB
�\������Ȃ���?
�����ł���X���b�h��2�{�ɂȂ������琫�\��2�{�ɂȂ�Ȃ�����������Ƃ����咣�̓A�z�̎q�̐ꔄ���������ǁB
����R�A�^���R�A�Ƃ������Ă�A���̂��ƂˁB
SMT����������̂́A���\�ł͂Ȃ��Ĕ�Ώ̐�����
���\�����Ȃ�30%���オ��Ώ\���ɏオ�����ƌ����邾�낤���ǁA��Ώ̐���30%���\�������������˂Ȃ��v���������
�������킹��ƁA���\���サ�₷���A�v���P�[�V�����Əオ��Ȃ��A�v���P�[�V�����ɂ�����łĎ�舵���ɂ����Ȃ�Ƃ������B
���\�����Ȃ�30%���オ��Ώ\���ɏオ�����ƌ����邾�낤���ǁA��Ώ̐���30%���\�������������˂Ȃ��v���������
�������킹��ƁA���\���サ�₷���A�v���P�[�V�����Əオ��Ȃ��A�v���P�[�V�����ɂ�����łĎ�舵���ɂ����Ȃ�Ƃ������B
ATOM�̓o��͈�ʐl��PC�ɋ��߂鐫�\��������낻�댩���Ă������Ƃ������Ă��ł���
���\���L�тĂ��w���ӗ~���h���ł��Ȃ��Ȃ�����i�ޕ����͕ς��Ȃ��Ƃ����Ȃ�
���\���L�тĂ��w���ӗ~���h���ł��Ȃ��Ȃ�����i�ޕ����͕ς��Ȃ��Ƃ����Ȃ�
531 �FSocket774�F2008/06/17(��) 08:09:45 ID:ooNVZcyd
�܁ANehalem�̏ꍇ�A�g�������z�����ASMT�g���Ηǂ����낤���Ċ������ȁB
SMT�������ȓz�͎g���ł��\������B
�w�ǂ̃P�[�X��8�X���b�h�g����Ȃ��Ȃ�A���Ă��ω��������낤�i��
SMT�������ȓz�͎g���ł��\������B
�w�ǂ̃P�[�X��8�X���b�h�g����Ȃ��Ȃ�A���Ă��ω��������낤�i��
SMT���T�[�o�ł̌��ʂ͔F�߂邯�ǁB
���Ƃ���Nehalem�̓x�[�X���T�[�o�p������B
��ł����������U�R���p�C���Ȃ�Ă܂��ɃT�[�o�̎d���B
�Ƃł���ȍ����ȃr���h�������낦�ăR���p�C�����Ă����́A
�G���R�I�^�ȏ�̃I�^�N�Ȃ̂ň�ʂƂ͂����Ȃ��B
���Ƃ���Nehalem�̓x�[�X���T�[�o�p������B
��ł����������U�R���p�C���Ȃ�Ă܂��ɃT�[�o�̎d���B
�Ƃł���ȍ����ȃr���h�������낦�ăR���p�C�����Ă����́A
�G���R�I�^�ȏ�̃I�^�N�Ȃ̂ň�ʂƂ͂����Ȃ��B
��������̃v���O������SMT�����邩�ۂ��ŁA
�傫���R���p�C�����x�������悤�ȑ�K�̓v���W�F�N�g�Ȃ��
���ʂ̐l�͂���ĂȂ��B
�傫���R���p�C�����x�������悤�ȑ�K�̓v���W�F�N�g�Ȃ��
���ʂ̐l�͂���ĂȂ��B
���݊J�Ò���VLSI Symposium��Nehalem�֘A�̔��\���������Ƃ̂��Ƃ��B
http://crave.cnet.com/8301-1_105-9970055-1.html
http://www.bit-tech.net/news/2008/06/17/intel-sheds-more-light-on-nehalem/1
QPI, ���W�����[�v�A�ȓd�͋@�\�A���ɂ��Č��ꂽ�炵�����B
�ډ�����Ă�����e�ł߂ڂ������ڂ�A����Ȋ������B
�@�E�`�b�v�ԃC���^�R�l�N�g25GB/s, �������ш�32GB/s
�@�E���W�����v�ɂ��A�R�A�EI/O�E�������R���g���[����d���A�N���b�N�A�^�C�~���O�S�Ăɂ����ēƗ�
�@�@[MAC�I�^��: �������Ђ̂悤�ɓ����ɂ��R�A�̐��\�������邱�Ƃ햳���ƌ��������l��]
�@�EEIST��C1E�̃N���b�N�ς�56%�������B�d���̕ϓ��ɑ��ďu���ɃN���b�N���ł��邽��
�@�@�d�����s����ȏł����萫���啝����B
�@�E������N���b�N��펞�Ϗ�Ԃ̂��߁A�I�[�o�[�N���b�N�]�X�햳�Ӗ��B�ł����[�U�[��OEM�ɂ�
�@�@�s�]���ۂ�(��)�@[MAC�I�^���F���ꂪ��́wOC�ł��Ȃ����x�̐��̂炵����]
http://crave.cnet.com/8301-1_105-9970055-1.html
http://www.bit-tech.net/news/2008/06/17/intel-sheds-more-light-on-nehalem/1
QPI, ���W�����[�v�A�ȓd�͋@�\�A���ɂ��Č��ꂽ�炵�����B
�ډ�����Ă�����e�ł߂ڂ������ڂ�A����Ȋ������B
�@�E�`�b�v�ԃC���^�R�l�N�g25GB/s, �������ш�32GB/s
�@�E���W�����v�ɂ��A�R�A�EI/O�E�������R���g���[����d���A�N���b�N�A�^�C�~���O�S�Ăɂ����ēƗ�
�@�@[MAC�I�^��: �������Ђ̂悤�ɓ����ɂ��R�A�̐��\�������邱�Ƃ햳���ƌ��������l��]
�@�EEIST��C1E�̃N���b�N�ς�56%�������B�d���̕ϓ��ɑ��ďu���ɃN���b�N���ł��邽��
�@�@�d�����s����ȏł����萫���啝����B
�@�E������N���b�N��펞�Ϗ�Ԃ̂��߁A�I�[�o�[�N���b�N�]�X�햳�Ӗ��B�ł����[�U�[��OEM�ɂ�
�@�@�s�]���ۂ�(��)�@[MAC�I�^���F���ꂪ��́wOC�ł��Ȃ����x�̐��̂炵����]
>�E������N���b�N��펞�Ϗ�Ԃ̂��߁A�I�[�o�[�N���b�N�]�X�햳�Ӗ��B
���ꌋ�ǃN���b�N�ŕʂ��ĕ������i���C���i�b�v����̂�
�z���g�ɖ��Ӗ��Ȃ�ʼn��ʂł��ŏ�ʂƓ����Ƃ��܂Ŏ����ŏオ��Ƃ����肦��
�I�[�o�[�N���b�N�����Ӗ��ɂȂ�Ȃ�Ă��肦���ˁB
���ꌋ�ǃN���b�N�ŕʂ��ĕ������i���C���i�b�v����̂�
�z���g�ɖ��Ӗ��Ȃ�ʼn��ʂł��ŏ�ʂƓ����Ƃ��܂Ŏ����ŏオ��Ƃ����肦��
�I�[�o�[�N���b�N�����Ӗ��ɂȂ�Ȃ�Ă��肦���ˁB
536 �FSocket774�F2008/06/18(��) 07:17:26 ID:x9r4Z8Uv
>>532
�T�[�o�[�Ȃ�Ȃ��̎����萫���v�������̂ŁA�����I�ɂ͗ǂ��Ȃ��Ǝv���
�L���p�̔��蕶��ŁA�f�l���x���̂ɂ��傤�ǂ悢�Z�p���ƁAPS3�Ƃ���������w
�T�[�o�[�Ȃ�Ȃ��̎����萫���v�������̂ŁA�����I�ɂ͗ǂ��Ȃ��Ǝv���
�L���p�̔��蕶��ŁA�f�l���x���̂ɂ��傤�ǂ悢�Z�p���ƁAPS3�Ƃ���������w
�܂����܂����B
�L���p�̔��蕶���IBM��SUN�����̑��̃x���_�[���喇�͂����ċZ�p�������Ă�ȁB
>>536
�����ƁANiagara2�̈����͂����܂ł�
�����ƁANiagara2�̈����͂����܂ł�
���ł���ȂɃA���`SMT��������?
CGMT�ݾ�
>>536
���������A�T�[�o�p�̃n�C�G���h�͍��ł͖w��CGMT/SMT�̂ǂ��炩���̗p����Ă邼�B
���������A�T�[�o�p�̃n�C�G���h�͍��ł͖w��CGMT/SMT�̂ǂ��炩���̗p����Ă邼�B
543 �FSocket774�F2008/06/18(��) 21:30:59 ID:QiNoa8sf
Core2Quad������đ�ʃR�A�̌��ʂ̔������o�������炾��
���ʂ������ł���̂�2�܂ł���
���ʂ������ł���̂�2�܂ł���
544 �FSocket774�F2008/06/18(��) 21:32:26 ID:QiNoa8sf
>>542
������f�l�x�����������(�m
������f�l�x�����������(�m
�����̃A�z
FGMT�̂��Ƃ��v���o���Ă����ĉ�����
>>544
���O���ǂ��܂ŏ������݂̗����ǂ�ł���̂��m��Ȃ����A
�T�[�o�ł͈��萫�d��������ASMT�͂悭�Ȃ��݂����ȏ������݂���ɂ����āA
���͂���ɑ��Ĕ��_���������B
���O���ǂ��܂ŏ������݂̗����ǂ�ł���̂��m��Ȃ����A
�T�[�o�ł͈��萫�d��������ASMT�͂悭�Ȃ��݂����ȏ������݂���ɂ����āA
���͂���ɑ��Ĕ��_���������B
�X�����o�J�ɂ͂��̒��x�������ł������ɂ�������
���n������̂��߂Ɉꉞ�⑫���Ă��ƁA
Nehalem, POWER6, Barcelona, Rock, SPARC64 VII, Montecito/Montvale, Tukwila
���̂Ȃ��ŁAHardware MT���Ȃ��̂�1��������˂��B
>>536�͂��ꂵ������Ȃ������̂��낤���B
Nehalem, POWER6, Barcelona, Rock, SPARC64 VII, Montecito/Montvale, Tukwila
���̂Ȃ��ŁAHardware MT���Ȃ��̂�1��������˂��B
>>536�͂��ꂵ������Ȃ������̂��낤���B
550 �F,,�E�L�́M�E,,�j��-�������F2008/06/18(��) 21:59:30 ID:k35grsI0
���z���g����TLB�̃G���b�^�ŃN���b�V�����錇�ׂ���������M�����ʖڂ���
���N�O����Top500�����L���O�����ǁA���ς�炸Intel�̍D���Ԃ肪�ڗ����B
����v���Z�b�T�ʂ̓��v�����ǁA�������L���O����ƂȂ�Harpertown�����ŃV�F�A32.3%�B
���Ȃ݂ɓ������ɓ������ꂽ���ƂɂȂ��Ă���Barcelona��2.6%(��)
http://www.top500.org/stats/list/31/procgen
����v���Z�b�T�ʂ̓��v�����ǁA�������L���O����ƂȂ�Harpertown�����ŃV�F�A32.3%�B
���Ȃ݂ɓ������ɓ������ꂽ���ƂɂȂ��Ă���Barcelona��2.6%(��)
http://www.top500.org/stats/list/31/procgen
TOP500��NEC1��i�n��simlator�j�ACray1�䂩�E�E�B
�u�X�p�R���͎��v�Ƃ����Ă��ߌ��ł͂Ȃ��ȁB
Nehalem�ł��̗��ꂪ����ɉ�������낤�ȁB
�u�X�p�R���͎��v�Ƃ����Ă��ߌ��ł͂Ȃ��ȁB
Nehalem�ł��̗��ꂪ����ɉ�������낤�ȁB
553 �FMAC�I�^��552 �����F2008/06/19(��) 00:08:17 ID:qPRp6hfv
>>552
�@�@------------------
�@�@�u�X�p�R���͎��v�Ƃ����Ă��ߌ��ł͂Ȃ��ȁB
�@�@------------------
�v���Z�b�T���x���Ő�p�v��Blue Gene�V���[�Y��6.6%���߂Ă��邵�A�v���Z�b�T�ȊO��
��p�v��Cray XT4�Ȃ��ڗ����B
�w�x�N�g���͎��x�ƌ����������������H
�@�@------------------
�@�@�u�X�p�R���͎��v�Ƃ����Ă��ߌ��ł͂Ȃ��ȁB
�@�@------------------
�v���Z�b�T���x���Ő�p�v��Blue Gene�V���[�Y��6.6%���߂Ă��邵�A�v���Z�b�T�ȊO��
��p�v��Cray XT4�Ȃ��ڗ����B
�w�x�N�g���͎��x�ƌ����������������H
>���ł���ȂɃA���`SMT��������?
������?
�ꕔ�S�����撣���Ă�悤�ɂ���������A�����Ă鎖���A�z������̂�����
������?
�ꕔ�S�����撣���Ă�悤�ɂ���������A�����Ă鎖���A�z������̂�����
>>553
�m���ɁA�����������ق������m�������B
�m���ɁA�����������ق������m�������B
����ꕔ�i�G���R�[�h�E���C�g���[�V���O�E���U�R���p�C���Ȃ�)�ɂ������\�A�b�v�������߂Ȃ��A�Ƃ��A
�D�ӓI�Ɏ~�߂�A������"�����"�����炻�������_���ł���Ă���̂�������Ȃ�����
�������Ԃ̂�������̂ɑ��Č��ʂ�����̂ɁA�Ȃ��������̗p�r�ɍ���Ȃ����𗝗R��
SMT��ے肷��y�̂��Ƃ���B
�D�ӓI�Ɏ~�߂�A������"�����"�����炻�������_���ł���Ă���̂�������Ȃ�����
�������Ԃ̂�������̂ɑ��Č��ʂ�����̂ɁA�Ȃ��������̗p�r�ɍ���Ȃ����𗝗R��
SMT��ے肷��y�̂��Ƃ���B
PC�p�ɓo��ȗ�5�N�ȏ�o���Ă��A
�ˑR�Ƃ��āu����ꕔ�v�ɂ������\�A�b�v�������߂Ȃ��̂ɁA
�}���Z�[����y�����邩�炾��B
�ˑR�Ƃ��āu����ꕔ�v�ɂ������\�A�b�v�������߂Ȃ��̂ɁA
�}���Z�[����y�����邩�炾��B
SMT���ăV�X�e���S�̂̐��\�A�b�v���_������Ȃ��́H
�Ă鉉�Z���L���ɗ��p���邽�߂̂��̂�����
�A�v���P�̂̑��x�����サ�Ȃ��Ă������OK�Ȃ�H
�Ă鉉�Z���L���ɗ��p���邽�߂̂��̂�����
�A�v���P�̂̑��x�����サ�Ȃ��Ă������OK�Ȃ�H
>>560
SMT�́A������Ƃ����镡���̃V�X�e���̌�����������\���������
SMT�́A������Ƃ����镡���̃V�X�e���̌�����������\���������
SMT���{���ɗL���Ȃ̂́A�T�[�o�[�ł͂Ȃ���XBox360�̂悤�ȃV�X�e����
�n�[�h�E�F�A���A�v���P�[�V�����Œ肳��A�{�g���l�b�N�ɂȂ���s�\�������ǂ̃R�A�ő��点�邩�J���҂����S�ɔc���ł��鎖���̐S�B
�V�X�e���̔�Ώ̐������ɂȂ�̂́A�ėp���Ƒ�����Ȃ�����ł����Ďg�p�ړI�����m�Ȃ���͂Ȃ��̂ł��B
�\�t�g�����猩���SMT�͖��炩�ɔėp�R���s���[�^�����ł͂Ȃ��Ǝv�����A�n�[�h������݂�Ƃ킸���ȋ@�\�lj��Ő��\�����シ��(�悤�Ɍ�����)����d�v�ȋZ�p�Ȃ̂��낤�Ƃ͎v���B
���������Z�p�͓K�ޓK�����낤�Ƃ͎v���̂�����ǁA����CPU�̃g�����h�͂ǂ����K�ޓK���ɂȂ��Ă��Ȃ��悤�ȋC�͂���B
�n�[�h�E�F�A���A�v���P�[�V�����Œ肳��A�{�g���l�b�N�ɂȂ���s�\�������ǂ̃R�A�ő��点�邩�J���҂����S�ɔc���ł��鎖���̐S�B
�V�X�e���̔�Ώ̐������ɂȂ�̂́A�ėp���Ƒ�����Ȃ�����ł����Ďg�p�ړI�����m�Ȃ���͂Ȃ��̂ł��B
�\�t�g�����猩���SMT�͖��炩�ɔėp�R���s���[�^�����ł͂Ȃ��Ǝv�����A�n�[�h������݂�Ƃ킸���ȋ@�\�lj��Ő��\�����シ��(�悤�Ɍ�����)����d�v�ȋZ�p�Ȃ̂��낤�Ƃ͎v���B
���������Z�p�͓K�ޓK�����낤�Ƃ͎v���̂�����ǁA����CPU�̃g�����h�͂ǂ����K�ޓK���ɂȂ��Ă��Ȃ��悤�ȋC�͂���B
�}���`�R�A��SMT��g�ݍ��킹���V�X�e���́A�\�t�g������݂�Ɗm���ɖ���ȁB
>>562
��Ȃ����Ȃ��B�Ƃ������傰���B
���̋C�ɂȂ�ACPUID��SMT�Ƙ_���v���Z�b�T�̋�ʂ�lj�����
OS�ŃX�P�W���[�����O�ł���B
��Ȃ����Ȃ��B�Ƃ������傰���B
���̋C�ɂȂ�ACPUID��SMT�Ƙ_���v���Z�b�T�̋�ʂ�lj�����
OS�ŃX�P�W���[�����O�ł���B
SMT�Ƙ_���v���Z�b�T
����Ȃ���
SMT�ƃR�A
����Ȃ���
SMT�ƃR�A
>>558
>����ꕔ�i�G���R�[�h�E���C�g���[�V���O�E���U�R���p�C���Ȃ�)�ɂ������\�A�b�v�������߂Ȃ��A
�����N�̌����������݂����������̂����S�R�Ӑ}���ǂ߂ĂȂ��݂������ˁB
���ꂩ��̓}���`�X���b�h�����S�݂����Ȃ��Ƃ�������������̂ŁA
DPL, ILP, TLP�̎O�i�\�����Ə������BSMT���̂��̂�ے肵�ĂȂ�Ă��Ȃ����A
�������������G���R�[�h���炢���ʂɂ���Ă�B
>����ꕔ�i�G���R�[�h�E���C�g���[�V���O�E���U�R���p�C���Ȃ�)�ɂ������\�A�b�v�������߂Ȃ��A
�����N�̌����������݂����������̂����S�R�Ӑ}���ǂ߂ĂȂ��݂������ˁB
���ꂩ��̓}���`�X���b�h�����S�݂����Ȃ��Ƃ�������������̂ŁA
DPL, ILP, TLP�̎O�i�\�����Ə������BSMT���̂��̂�ے肵�ĂȂ�Ă��Ȃ����A
�������������G���R�[�h���炢���ʂɂ���Ă�B
>>564
�n�[�h���̗�������A�����ɂ͖ʓ|���������B
�n�[�h���̗�������A�����ɂ͖ʓ|���������B
>>567
�悭�n�[�h�����Č���������w
x86��OS�ł��������Ă�̂�?
��������XP��Vista�ł͊���OS�̃X�P�W���[�����x����
HT�ƃ}���`�R�A�̗D�揇�ʂ��ӂ�ł��Ă���̂Ɂc�B
�悭�n�[�h�����Č���������w
x86��OS�ł��������Ă�̂�?
��������XP��Vista�ł͊���OS�̃X�P�W���[�����x����
HT�ƃ}���`�R�A�̗D�揇�ʂ��ӂ�ł��Ă���̂Ɂc�B
http://codezine.jp/a/article/aid/247.aspx?p=2
����Ȃ̂��������B
����Ȃ̂��������B
�ŁA�b��߂���Sandy Bridge�ł�
Nehalem/Westmere��������Ƀ}���`�X���b�h�ɓ������邱�ƂɂȂ��Ă�̂��낤���B
������SMT�}���Z�[�h�A���ł́c�BBloomfield�̓T�[�o�p�v�����܂肢���炸�Ƀf�X�N�g�b�v��
���������́BNehalem�̓x�[�X���T�[�o�����B
Intel��AVX�̐����X���C�h�ł����܂Ȃ��������ė~�������̂��B
Nehalem/Westmere��������Ƀ}���`�X���b�h�ɓ������邱�ƂɂȂ��Ă�̂��낤���B
������SMT�}���Z�[�h�A���ł́c�BBloomfield�̓T�[�o�p�v�����܂肢���炸�Ƀf�X�N�g�b�v��
���������́BNehalem�̓x�[�X���T�[�o�����B
Intel��AVX�̐����X���C�h�ł����܂Ȃ��������ė~�������̂��B
SMT�}���Z�[�h���ĂȂ��c
���ʂ����遨���̂܂g��
���ʂ����������̂܂g��
�����������遨�I�t�ɂ���
SMT�I�t�ɂł��Ȃ���������@����闝�R�ɂȂ�̂��킩����B
���ʂ����遨���̂܂g��
���ʂ����������̂܂g��
�����������遨�I�t�ɂ���
SMT�I�t�ɂł��Ȃ���������@����闝�R�ɂȂ�̂��킩����B
572 �F,,�E�L�́M�E,,�j��-�������F2008/06/20(��) 08:30:02 ID:7yLgpzx8
SMT�̉������ʓI����
FP�̒������C�e���V�B���̂��߂̃A�����[���̂Ƀ��W�X�^���Ȃ������ˁB
AVX�ł̓x�N�^���̈��������ŃX���b�h������̃p�t�H�[�}���X�����_��
���W�X�^2�{�ɂȂ����̂ɋ߂����ʂ͓����邩��ˁB
���Z���j�b�g��256�r�b�g�ɂȂ邩��s�[�N���\2�{�H����Ȃ̐M���Ă�z���Ȃ��ł���B
FP�̒������C�e���V�B���̂��߂̃A�����[���̂Ƀ��W�X�^���Ȃ������ˁB
AVX�ł̓x�N�^���̈��������ŃX���b�h������̃p�t�H�[�}���X�����_��
���W�X�^2�{�ɂȂ����̂ɋ߂����ʂ͓����邩��ˁB
���Z���j�b�g��256�r�b�g�ɂȂ邩��s�[�N���\2�{�H����Ȃ̐M���Ă�z���Ȃ��ł���B
SMT�Ƃ������m��A
�@�E�X���[�v�b�g[�P�ʎ��Ԃ�����̍�Ɨ�]��オ��
�@�E�p�t�H�[�}���X[��Ƃ̊�������]�헎���邱�Ƃ�����
�Ƃ��������̘b������A��҂����������炤�̂툢�����B
�@���̏�A�V����SMT�̎�����X���b�h�̗D��x�ݒ肪�\������A�f�����b�g�����Ȃ��Ȃ�悤��
�Ȃ��Ă��邷�B
�@�E�X���[�v�b�g[�P�ʎ��Ԃ�����̍�Ɨ�]��オ��
�@�E�p�t�H�[�}���X[��Ƃ̊�������]�헎���邱�Ƃ�����
�Ƃ��������̘b������A��҂����������炤�̂툢�����B
�@���̏�A�V����SMT�̎�����X���b�h�̗D��x�ݒ肪�\������A�f�����b�g�����Ȃ��Ȃ�悤��
�Ȃ��Ă��邷�B
SMT�}���Z�[�h = �l�������݂̓��e��ǂ�łȂ�
���̂��S�ʔے肳��Ă���Ɣ�Q�ϑz
���̂��S�ʔے肳��Ă���Ɣ�Q�ϑz
�����H
���Ƃ��A
>>507
>PC�����Ƃ��Ă̓G���R���炢�������ʂˁ[���
>>510
>�܂��I�^���炷��������낤����
>PG�ASE�ɂƂ��ăR���p�C�����x���オ�遁�d���̌��������Ȃ킯��
>>532
>��ł����������U�R���p�C���Ȃ�Ă܂��ɃT�[�o�̎d���B
>�Ƃł���ȍ����ȃr���h�������낦�ăR���p�C�����Ă����́A
>�G���R�I�^�ȏ�̃I�^�N�Ȃ̂ň�ʂƂ͂����Ȃ��B
----------------------------------------------------------
>�Ȃ��������̗p�r�ɍ���Ȃ����𗝗R��
>SMT��ے肷��y�̂��Ƃ���B
>�p�t�H�[�}���X[��Ƃ̊�������]�헎���邱�Ƃ�����
>�Ƃ��������̘b������A��҂����������炤�̂툢�����B
>>507
>PC�����Ƃ��Ă̓G���R���炢�������ʂˁ[���
>>510
>�܂��I�^���炷��������낤����
>PG�ASE�ɂƂ��ăR���p�C�����x���オ�遁�d���̌��������Ȃ킯��
>>532
>��ł����������U�R���p�C���Ȃ�Ă܂��ɃT�[�o�̎d���B
>�Ƃł���ȍ����ȃr���h�������낦�ăR���p�C�����Ă����́A
>�G���R�I�^�ȏ�̃I�^�N�Ȃ̂ň�ʂƂ͂����Ȃ��B
----------------------------------------------------------
>�Ȃ��������̗p�r�ɍ���Ȃ����𗝗R��
>SMT��ے肷��y�̂��Ƃ���B
>�p�t�H�[�}���X[��Ƃ̊�������]�헎���邱�Ƃ�����
>�Ƃ��������̘b������A��҂����������炤�̂툢�����B
577 �FMAC�I�^��572 �����F2008/06/20(��) 18:50:29 ID:VL2Havpu
>>574
�@�@---------------
�@�@�l�������݂̓��e��ǂ�łȂ�
�@�@---------------
�Ȃ��Ȃ��X�S���������݂�����̂�ǂ�ł��邷(��)�@�ȉ��A����ƁB�B�B
>>562 �uSMT���{���ɗL���Ȃ̂́A�T�[�o�[�ł͂Ȃ���(�ȉ���)�v
>>536 �u�T�[�o�[�Ȃ�Ȃ��̎����萫���v�������̂ŁA�����I�ɂ͗ǂ��Ȃ�(�ȉ���)�v
�@�@---------------
�@�@�l�������݂̓��e��ǂ�łȂ�
�@�@---------------
�Ȃ��Ȃ��X�S���������݂�����̂�ǂ�ł��邷(��)�@�ȉ��A����ƁB�B�B
>>562 �uSMT���{���ɗL���Ȃ̂́A�T�[�o�[�ł͂Ȃ���(�ȉ���)�v
>>536 �u�T�[�o�[�Ȃ�Ȃ��̎����萫���v�������̂ŁA�����I�ɂ͗ǂ��Ȃ�(�ȉ���)�v
>>562, >>536
�͊m���ɓ��ӂ����˂�ȁB
���ANehalem���łďœ_�Ȃ̂́A
�ESMT�̌��ʂ͋�̓I�����炩??
�ESMT�ȊO�̕����̐��\����͂����炩??
�ENetBurst����Ɣ�ׂă}���`�X���b�h�����ǂꂾ���i�̂�??
SMT�₻�̑��̃}���`�X���b�f�B���O�Z�p���̂�
���Ȃ��Ƃ��T�[�o�p�ł݂��>>549�ɂ���Ƃ���A
���ɂ���������O�̋Z�p�ɂȂ����B
Intel��Core 2�nDunnington��AMD���ނ���x��Ă��邭�炢�B
�͊m���ɓ��ӂ����˂�ȁB
���ANehalem���łďœ_�Ȃ̂́A
�ESMT�̌��ʂ͋�̓I�����炩??
�ESMT�ȊO�̕����̐��\����͂����炩??
�ENetBurst����Ɣ�ׂă}���`�X���b�h�����ǂꂾ���i�̂�??
SMT�₻�̑��̃}���`�X���b�f�B���O�Z�p���̂�
���Ȃ��Ƃ��T�[�o�p�ł݂��>>549�ɂ���Ƃ���A
���ɂ���������O�̋Z�p�ɂȂ����B
Intel��Core 2�nDunnington��AMD���ނ���x��Ă��邭�炢�B
579 �FMAC�I�^�������F2008/06/20(��) 18:59:48 ID:VL2Havpu
���������̂����������ˁB
>>570 �uNehalem�̓x�[�X���T�[�o�����B �v
Intel��VLSI Symposia�̔��\�ł�A�������邷�B
http://www.bit-tech.net/news/2008/06/17/intel-sheds-more-light-on-nehalem/1
�@�@-----------------------
�@�@Since the Nehalem architecture will be used across an array of product segments�\servers,
�@�@ktops, notebooks�\Kumar said Intel engineers had to consider how they could change the
�@�@structure of the chips to fit within these different segments. They made the processing cores
�@�@modular so the cores could be easily switched out to meet the needs of different products.
�@�@-----------------------
>>570 �uNehalem�̓x�[�X���T�[�o�����B �v
Intel��VLSI Symposia�̔��\�ł�A�������邷�B
http://www.bit-tech.net/news/2008/06/17/intel-sheds-more-light-on-nehalem/1
�@�@-----------------------
�@�@Since the Nehalem architecture will be used across an array of product segments�\servers,
�@�@ktops, notebooks�\Kumar said Intel engineers had to consider how they could change the
�@�@structure of the chips to fit within these different segments. They made the processing cores
�@�@modular so the cores could be easily switched out to meet the needs of different products.
�@�@-----------------------
580 �FMAC�I�^�������F2008/06/20(��) 19:00:41 ID:VL2Havpu
�����N�ԈႦ�����B���������p���A�����炷�B
http://www.eweek.com/c/a/Infrastructure/Intel-Delves-Deeper-into-Nehalem/
http://www.eweek.com/c/a/Infrastructure/Intel-Delves-Deeper-into-Nehalem/
>>579->>580
�����ɂ͂����ȃZ�O�����g�ɑΉ��ł���悤�ɁA���W�����[�ȍ\���ɂ���
�Ə����Ă��邾���ŁA�x�[�X���T�[�o�����Ƃ����̂͂��̒ʂ�ł�������?
Sandy Bridge�̓��o�C������B
�����ɂ͂����ȃZ�O�����g�ɑΉ��ł���悤�ɁA���W�����[�ȍ\���ɂ���
�Ə����Ă��邾���ŁA�x�[�X���T�[�o�����Ƃ����̂͂��̒ʂ�ł�������?
Sandy Bridge�̓��o�C������B
582 �FMAC�I�^��581 �����F2008/06/20(��) 19:10:44 ID:VL2Havpu
>>581
�@�@-----------------
�@�@�x�[�X���T�[�o�����Ƃ����̂͂��̒ʂ�ł�������?
�@�@-----------------
�\�[�X��㓡�G����(��)
�@�@-----------------
�@�@�x�[�X���T�[�o�����Ƃ����̂͂��̒ʂ�ł�������?
�@�@-----------------
�\�[�X��㓡�G����(��)
>>582
�����A�܂��́ACPU��}�U�[�{�[�h�����ۂɔ���Ȃ��l������������Ȃ��������ƁB
�x�[�X���T�[�o�����Ƃ������T�[�o������D�悵���v�A�����[�X�ɂȂ��Ă���B
Merom(Core 2)�����o�C���������Ȃ肾�����̂ɁA
Nehalem�ł́ALynnfield��Havendale�����Ȃ�x��Ă���̂͂Ȃ��ł���??
�A�[�L�e�N�`������������ƕ����Ⴂ�܂��B
�����A�܂��́ACPU��}�U�[�{�[�h�����ۂɔ���Ȃ��l������������Ȃ��������ƁB
�x�[�X���T�[�o�����Ƃ������T�[�o������D�悵���v�A�����[�X�ɂȂ��Ă���B
Merom(Core 2)�����o�C���������Ȃ肾�����̂ɁA
Nehalem�ł́ALynnfield��Havendale�����Ȃ�x��Ă���̂͂Ȃ��ł���??
�A�[�L�e�N�`������������ƕ����Ⴂ�܂��B
(������o�C����Clarksfield��Auburndale���x��㩁B)
585 �FMAC�I�^���⑫�F2008/06/20(��) 19:16:23 ID:VL2Havpu
>>581
�@�@--------------
�@�@Sandy Bridge�̓��o�C������B
�@�@--------------
Core2���ăT�[�o�[����ŏ��ɔ��\�ɂȂ��������ǁA�T�[�o�[�p�v���Z�b�T�Ȃ�(��)
�w�C���e��? Core^(TM) �}�C�N���A�[�L�e�N�`���[�ɂ��ŏ��̐��i�𓊓��x
http://www.intel.co.jp/jp/intel/pr/press2006/060626a.htm
�@�@-----------------
�@�@�{���A�ʎY�^�̃T�[�o�[�A���[�N�X�e�[�V�����A�ʐM�A�X�g���[�W����ёg�ݍ��ݎs�ꕪ��Ɍ����A
�@�@������́u�f���A���R�A �C���e��? Xeon? �v���Z�b�T�[ 5100 �ԑ�v�i�J���R�[�h���FWoodcrest�j��
�@�@���\���܂����B
�@�@-----------------
�@�@--------------
�@�@Sandy Bridge�̓��o�C������B
�@�@--------------
Core2���ăT�[�o�[����ŏ��ɔ��\�ɂȂ��������ǁA�T�[�o�[�p�v���Z�b�T�Ȃ�(��)
�w�C���e��? Core^(TM) �}�C�N���A�[�L�e�N�`���[�ɂ��ŏ��̐��i�𓊓��x
http://www.intel.co.jp/jp/intel/pr/press2006/060626a.htm
�@�@-----------------
�@�@�{���A�ʎY�^�̃T�[�o�[�A���[�N�X�e�[�V�����A�ʐM�A�X�g���[�W����ёg�ݍ��ݎs�ꕪ��Ɍ����A
�@�@������́u�f���A���R�A �C���e��? Xeon? �v���Z�b�T�[ 5100 �ԑ�v�i�J���R�[�h���FWoodcrest�j��
�@�@���\���܂����B
�@�@-----------------
586 �FMAC�I�^��583 �����F2008/06/20(��) 19:19:10 ID:VL2Havpu
>>583
�@�@-------------------
�@�@Merom(Core 2)�����o�C���������Ȃ肾�����̂ɁA
�@�@-------------------
���Ɂw�V���R���̎��x�L�`�K�C�A�����ƈӌ��������q�g��A�������݂̒�̐��Ⴄ����(��)
�@�@-------------------
�@�@Merom(Core 2)�����o�C���������Ȃ肾�����̂ɁA
�@�@-------------------
���Ɂw�V���R���̎��x�L�`�K�C�A�����ƈӌ��������q�g��A�������݂̒�̐��Ⴄ����(��)
>>585
���\���ꂽ�̂͊m���ɃT�[�o�p��Woodcrest���炾������B
Merom��Penryn�͌��X���o�C���p�̃R�[�h�l�[���ŁA
NetBurst��������܂ł�Core 2�̓��o�C���p�Ƃ��ĊJ������Ă��̂�Y�ꂽ��??
���\���ꂽ�̂͊m���ɃT�[�o�p��Woodcrest���炾������B
Merom��Penryn�͌��X���o�C���p�̃R�[�h�l�[���ŁA
NetBurst��������܂ł�Core 2�̓��o�C���p�Ƃ��ĊJ������Ă��̂�Y�ꂽ��??
588 �FMAC�I�^��587 �����F2008/06/20(��) 19:21:10 ID:VL2Havpu
589 �F,,�E�L�́M�E,,�j��-�������F2008/06/20(��) 19:21:58 ID:7yLgpzx8
AVX��Atom�ɍ̗p���ė~������
��������Larrabee�Ƃ���ܕς��Ȃ��Ȃ邩
��������Larrabee�Ƃ���ܕς��Ȃ��Ȃ邩
>>586
>�w�V���R���̎��x�L�`�K�C�A����
�Ȃ����??�@����ɖϑz���Ă�Ȃ�B
�ECore 2�Ń��o�C�����o��܂łɂ�����������
�ENehalem�Ń��o�C�����o��܂łɂ�����������
�EBloomfield�̃}�U�[
���������Ă��ANehalem���f�������߂Ȃ��APC�Ɋւ��Ă͖��m�̂�����
�܂��B
>�w�V���R���̎��x�L�`�K�C�A����
�Ȃ����??�@����ɖϑz���Ă�Ȃ�B
�ECore 2�Ń��o�C�����o��܂łɂ�����������
�ENehalem�Ń��o�C�����o��܂łɂ�����������
�EBloomfield�̃}�U�[
���������Ă��ANehalem���f�������߂Ȃ��APC�Ɋւ��Ă͖��m�̂�����
�܂��B
591 �FMAC�I�^��590 �����F2008/06/20(��) 19:27:37 ID:VL2Havpu
>>590
�@�@------------------
�@�@�ENehalem�Ń��o�C�����o��܂łɂ�����������
�@�@------------------
������������悤�ŁA�Ȃɂ�肷�B�ł��\�[�X�ƌ����Ĕ[������q�g��F�����Ǝv�����B
�@�@------------------
�@�@����ɖϑz���Ă�Ȃ�B
�@�@------------------
��������L�`�K�C�������グ��������̂�C�^����������(��)
�R�s�y���K�v�Ȃ�A���ł����p���Ă����邷���ǁA�N�����Ă��������́B�B�B
�@�@------------------
�@�@�ENehalem�Ń��o�C�����o��܂łɂ�����������
�@�@------------------
������������悤�ŁA�Ȃɂ�肷�B�ł��\�[�X�ƌ����Ĕ[������q�g��F�����Ǝv�����B
�@�@------------------
�@�@����ɖϑz���Ă�Ȃ�B
�@�@------------------
��������L�`�K�C�������グ��������̂�C�^����������(��)
�R�s�y���K�v�Ȃ�A���ł����p���Ă����邷���ǁA�N�����Ă��������́B�B�B
>>591
�b������Ă�ȁB
�ENehalem�̓T�[�o�����p�r����ɗD�悵���킯����Ȃ�
�ESandy Bridge�̓��o�C���������x�[�X�ł͂Ȃ�
�ł�����ł���??
1�`2�N��ɂ͏�����ɗ��Ă�邩��A�܂��̋C���ς���ĂȂ����Ƃ��F���B
�b������Ă�ȁB
�ENehalem�̓T�[�o�����p�r����ɗD�悵���킯����Ȃ�
�ESandy Bridge�̓��o�C���������x�[�X�ł͂Ȃ�
�ł�����ł���??
1�`2�N��ɂ͏�����ɗ��Ă�邩��A�܂��̋C���ς���ĂȂ����Ƃ��F���B
593 �FMAC�I�^��592 �����F2008/06/20(��) 19:36:09 ID:VL2Havpu
>>592
�h�T�N�T�ɂ܂���ď���Ƀg���f�����������Ă邷���ǁA1-2�N�o�Ă��Ȃ��ł����Ȃ猋�\�Șb���B
�h�T�N�T�ɂ܂���ď���Ƀg���f�����������Ă邷���ǁA1-2�N�o�Ă��Ȃ��ł����Ȃ猋�\�Șb���B
�N����������Nehalem�̓T�[�o�������낤�B
MAC�I�^�̖ό��ɕt�������Ă��K�v�Ȃ����āB
MAC�I�^�̖ό��ɕt�������Ă��K�v�Ȃ����āB
Nehalem�͂������ɃT�[�o�[�������낤�ȁB�ܘ_������ƌ����āA�����Ƀ��o�C���Ɍ����Ȃ��Ƃ���
���_�ɂȂ�킯�ł͂Ȃ����E�E�E�B
���_�ɂȂ�킯�ł͂Ȃ����E�E�E�B
596 �FMAC�I�^��594-595 �����F2008/06/20(��) 23:29:31 ID:VL2Havpu
>>594-595
�F����w�T�[�o�[�x�Ƃ������t��]���̌Œ�ϔO�ƘA�����������Ǝv�����B
�T�[�o�[�p�ƃ��o�C���p�Ƃ����̂�A�Η��T�O����Ȃ����B������Nehalem�œ������ꂽ�V�Z�p��
core��un-core�ɕ����čl���Ă݂ė~�������B���o�C����Nehalem��Bloomfield��un-core�����̂܂�
���P�����ł햳�����B
���Ȃ݂ɐ܂肵������Șb����B�B�B
"ARM to duel with Intel in the server space"
http://www.networkworld.com/news/2008/061908-arm-to-duel-with-intel.html
�F����w�T�[�o�[�x�Ƃ������t��]���̌Œ�ϔO�ƘA�����������Ǝv�����B
�T�[�o�[�p�ƃ��o�C���p�Ƃ����̂�A�Η��T�O����Ȃ����B������Nehalem�œ������ꂽ�V�Z�p��
core��un-core�ɕ����čl���Ă݂ė~�������B���o�C����Nehalem��Bloomfield��un-core�����̂܂�
���P�����ł햳�����B
���Ȃ݂ɐ܂肵������Șb����B�B�B
"ARM to duel with Intel in the server space"
http://www.networkworld.com/news/2008/061908-arm-to-duel-with-intel.html
>>571
��������Ȃ炻��ł��������ǁA���������ȃT�[�o�[�����̏ꍇ�͉ς̋@�\�͍ŏ����ɂ��ׂ�����
�g���u���̌����ɂȂ���]�v�ȋ@�\�͍ő���폜���Ă����Ȃ��Ƒʖڂ��B
��������Ȃ炻��ł��������ǁA���������ȃT�[�o�[�����̏ꍇ�͉ς̋@�\�͍ŏ����ɂ��ׂ�����
�g���u���̌����ɂȂ���]�v�ȋ@�\�͍ő���폜���Ă����Ȃ��Ƒʖڂ��B
���E�X�p�R��TOP500�C75%����Intel���v���Z�T���̗p
http://itpro.nikkeibp.co.jp/article/NEWS/20080619/308614/
��N11���̃V�F�A�@70.8������ �@���@75��
Opteron�̗̍p���@11��
http://itpro.nikkeibp.co.jp/article/NEWS/20080619/308614/
��N11���̃V�F�A�@70.8������ �@���@75��
Opteron�̗̍p���@11��
����Ђ낢�I�l�^�����ǁAIntel��Z-RAM�̘b�肷�B
http://www.semiconductor.net/article/CA6571575.html
�@�@--------------------
�@�@While it is �gnot quite as fast�h as conventional SRAMs, Mayberry said that the FBC memory
�@�@would enjoy a much smaller cell size than the six-transistor (6T) SRAM now used, adding
�@�@that 6T SRAM technology �gcan continue to scale, but has some optimization problems.�h
�@�@--------------------
�u16-nm����ō̗p�̉\���v�ĂȘb���B
http://www.semiconductor.net/article/CA6571575.html
�@�@--------------------
�@�@While it is �gnot quite as fast�h as conventional SRAMs, Mayberry said that the FBC memory
�@�@would enjoy a much smaller cell size than the six-transistor (6T) SRAM now used, adding
�@�@that 6T SRAM technology �gcan continue to scale, but has some optimization problems.�h
�@�@--------------------
�u16-nm����ō̗p�̉\���v�ĂȘb���B
600 �FMAC�I�^��597 �����F2008/06/21(�y) 00:00:05 ID:QtBsYZWJ
>>597
�@�@---------------------
�@�@�ς̋@�\�͍ŏ����ɂ��ׂ�����
�@�@---------------------
>>534�̂悤��Intel��u�ϋ@�\�ň��萫�����シ��v�ƌ����Ă��邷�B
�@�@---------------------
�@�@�ς̋@�\�͍ŏ����ɂ��ׂ�����
�@�@---------------------
>>534�̂悤��Intel��u�ϋ@�\�ň��萫�����シ��v�ƌ����Ă��邷�B
>>600
����d�͑�͕K�v�ȋ@�\�����琷�荞�܂Ȃ��Ƃ����̂͂��蓾�Ȃ����A�]�v�Ȃ��̂͊O�����ق���������
�M�����A�b�v�̒�ł��傤�A����́B
����d�͑�͕K�v�ȋ@�\�����琷�荞�܂Ȃ��Ƃ����̂͂��蓾�Ȃ����A�]�v�Ȃ��̂͊O�����ق���������
�M�����A�b�v�̒�ł��傤�A����́B
�Ƃ���ň��萫�����ƂȂ�T�[�o�[���ăv���Z�b�T��烁�����̃z�b�g�X���b�v���T�|�[�g����悤��
�Ȃ��Ă��āu�n�[�h�E�F�A�̏ɂ�����薳�����삷��v���Ă̂�����Ȃ�B�B�B
�w��������=����x���Ă̂퉽���̎���̘b�Ȃ��ˁH
�Ȃ��Ă��āu�n�[�h�E�F�A�̏ɂ�����薳�����삷��v���Ă̂�����Ȃ�B�B�B
�w��������=����x���Ă̂퉽���̎���̘b�Ȃ��ˁH
�n�[�h�g���u���������z�b�g�X���b�v����̉������@���낤���A�\�t�g���g���u����B
�n�[�h�������݂Ė��S���Ƃ��v��Ȃ��悤�ɁB
�n�[�h�������݂Ė��S���Ƃ��v��Ȃ��悤�ɁB
605 �FMAC�I�^��604 �����F2008/06/21(�y) 00:09:54 ID:QtBsYZWJ
Rmax�ł��������H
����܂�^�ʖڂɌv�Z���ĂȂ����ǁA����Ȋ����H
�@Intel�@50%
�@IBM�@33%
�@AMD�@16%
����܂�^�ʖڂɌv�Z���ĂȂ����ǁA����Ȋ����H
�@Intel�@50%
�@IBM�@33%
�@AMD�@16%
Intel��51%��
�܂��A�덷���Ă��Ƃ�
�܂��A�덷���Ă��Ƃ�
�[��
http://www.top500.org/stats/list/31/procfam
�̕����킩��₷�������
���������AAlpha��SPARC����������
http://www.top500.org/stats/list/31/procfam
�̕����킩��₷�������
���������AAlpha��SPARC����������
609 �FMAC�I�^��608 �����F2008/06/21(�y) 00:58:43 ID:QtBsYZWJ
CPU��64bit������Ă���ˁH
OS��64bit������邩�ǂ����͕ʂ̘b
OS��64bit������邩�ǂ����͕ʂ̘b
PC�o�ב䐔���E��̃��[�J�[�͊���ƐϋɓI����
>�ς̋@�\�͍ŏ����ɂ��ׂ�����
����������l�͍ŏ�����off�ōs�����낤�B
on�Ńg���u�������邩��(���邾�낤����)�A�ƌ��������ϔO����͊��S�ɓ�������B
�Ƃ���ő��Ђ�SMT�Ɋւ��Ă��������Ƃ������̂��ˁB
����������l�͍ŏ�����off�ōs�����낤�B
on�Ńg���u�������邩��(���邾�낤����)�A�ƌ��������ϔO����͊��S�ɓ�������B
�Ƃ���ő��Ђ�SMT�Ɋւ��Ă��������Ƃ������̂��ˁB
613 �FMAC�I�^��612 �����F2008/06/21(�y) 09:05:18 ID:QtBsYZWJ
>>612
�@�@------------------
�@�@����������l�͍ŏ�����off�ōs�����낤�B
�@�@------------------
����ȑO�Ɉ��萫(�Ƃ������ۏ�)�d���̃q�g��A����Ȃ��Ȃ����ABIOS��x���_��
�ݒ肵���f�t�H���g�̂܂܂ɂ��邷�B
SMT��ON/OFF�Ȃ�ăx���_�������Č��߂郂�m���ƁB
�@�@------------------
�@�@����������l�͍ŏ�����off�ōs�����낤�B
�@�@------------------
����ȑO�Ɉ��萫(�Ƃ������ۏ�)�d���̃q�g��A����Ȃ��Ȃ����ABIOS��x���_��
�ݒ肵���f�t�H���g�̂܂܂ɂ��邷�B
SMT��ON/OFF�Ȃ�ăx���_�������Č��߂郂�m���ƁB
ID:TBUcSauZ
> �ς̋@�\�͍ŏ����ɂ��ׂ�����
> �\�t�g���g���u����B
����������Ƙ_���I�Ɏv�l���Ă�E�E�E�B
> �ς̋@�\�͍ŏ����ɂ��ׂ�����
> �\�t�g���g���u����B
����������Ƙ_���I�Ɏv�l���Ă�E�E�E�B
>>597
>��������Ȃ炻��ł��������ǁA
SMT���T�|�[�g���Ă�CPU�̃T�[�o�ł��A
���ۂɂ�off�ɂ��Ă���x���_�[���������ă\�[�X���炢��
�Œ���o���ė~������ȁB�ϑz�łȂ��Ă��B
>��������Ȃ炻��ł��������ǁA
SMT���T�|�[�g���Ă�CPU�̃T�[�o�ł��A
���ۂɂ�off�ɂ��Ă���x���_�[���������ă\�[�X���炢��
�Œ���o���ė~������ȁB�ϑz�łȂ��Ă��B
>>613
���̃x���_�̋�J���킩���Ă���A�ŋ߂͂�������V�X�e�������G�����Ă����ɂȂ���
���ڂ͈�����邲�ƂɌ����ׂ����́A���̃p�����[�^�̌��{�ɂȂ�B
���O�A�ŋ߂̃x���_���Ȃ����͂ȃn�[�h��ɂ����ɁA�����ČÂ��O���{���g�����肵�Ă���w�i���킩��Ȃ��낤�H
>>614
���O����Ԙ_���I�łȂ��B
���̃x���_�̋�J���킩���Ă���A�ŋ߂͂�������V�X�e�������G�����Ă����ɂȂ���
���ڂ͈�����邲�ƂɌ����ׂ����́A���̃p�����[�^�̌��{�ɂȂ�B
���O�A�ŋ߂̃x���_���Ȃ����͂ȃn�[�h��ɂ����ɁA�����ČÂ��O���{���g�����肵�Ă���w�i���킩��Ȃ��낤�H
>>614
���O����Ԙ_���I�łȂ��B
>>615
�V���v���C�Y�x�X�g�͋Z�p�҂̏펯�A���n�͖ق��Ă�Ď����B
�V���v���C�Y�x�X�g�͋Z�p�҂̏펯�A���n�͖ق��Ă�Ď����B
>>618
�ϑz��Y�͂��O����
�ϑz��Y�͂��O����
ID:c3B4J8e8
����A���n�ŊJ������Ă邯�lj���?
�����L�~����������������c�B
����A���n�ŊJ������Ă邯�lj���?
�����L�~����������������c�B
>>620
�Ȃ炫���ƃL�~�̓N�^�^���݂����ȁA�S�̂����ʂ��Ȃ��l�Ȃ�ł���w
�Ȃ炫���ƃL�~�̓N�^�^���݂����ȁA�S�̂����ʂ��Ȃ��l�Ȃ�ł���w
ID:c3B4J8e8
���n
�N�^�^���݂���
�����v��?
�����\�[�X������A�ϑz�����̔\�Ȃ�����B
���n
�N�^�^���݂���
�����v��?
�����\�[�X������A�ϑz�����̔\�Ȃ�����B
>>616
�T�[�o�ɌÂ��i���邢�́A�ᑬ�ȁj�O���t�B�b�N�X�`�b�v���g���Ă�̂͒P�ɍ����O���t�B�b�N�X���\���K�v�Ȃ����炶��Ȃ��̂��ˁB
CPU��R���p�j�I���f�o�C�X�ɐV�����@�\���t���Ă��邹���Ōv�Z�@�������\��]������̂ɍ�Ɨʂ������đ�ς��A
���Ă����͕̂ʂɍ��Ɏn�܂������Ƃ���Ȃ����AHardware MT�����ʂ��Ƃ������Ƃ͑S�R�Ȃ��B
CPU���ɁA�u���\��]������̂���ς�����V�@�\��lj������Ȃ��ď]���̋@�\�����ō����������������v
�ȂǂƗv������v�Z�@���������炻��͓�������Ă�����ׂ������ȁB
�T�[�o�ɌÂ��i���邢�́A�ᑬ�ȁj�O���t�B�b�N�X�`�b�v���g���Ă�̂͒P�ɍ����O���t�B�b�N�X���\���K�v�Ȃ����炶��Ȃ��̂��ˁB
CPU��R���p�j�I���f�o�C�X�ɐV�����@�\���t���Ă��邹���Ōv�Z�@�������\��]������̂ɍ�Ɨʂ������đ�ς��A
���Ă����͕̂ʂɍ��Ɏn�܂������Ƃ���Ȃ����AHardware MT�����ʂ��Ƃ������Ƃ͑S�R�Ȃ��B
CPU���ɁA�u���\��]������̂���ς�����V�@�\��lj������Ȃ��ď]���̋@�\�����ō����������������v
�ȂǂƗv������v�Z�@���������炻��͓�������Ă�����ׂ������ȁB
�V�@�\��lj����鎖�ƃI�v�V�������S�`���S�`������͈̂Ⴄ�Ǝv��
�V�w���C�Ybest
�����炳���ASMT�ŕs����ɂȂ���Ď咣���Ă���
���Ԃ��܂����m�ɔc�����Ă���ĂȂ��Ƃ����B
���ۂɂ���Ŗ�肪�N����A������T�[�o�x���_�[��[�U�݂͂��off�ɂ��Ă����
�Ƃ������Ԃ��܂��Ȃ��Ƌc�_�ɂȂ�Ȃ��B
���O�炪���Ƃ������Ă���̂ł��Ƃ����ɉ��P��Ή����i��ł���̂��������̂���B
�܂��A�؋��������B
���Ԃ��܂����m�ɔc�����Ă���ĂȂ��Ƃ����B
���ۂɂ���Ŗ�肪�N����A������T�[�o�x���_�[��[�U�݂͂��off�ɂ��Ă����
�Ƃ������Ԃ��܂��Ȃ��Ƌc�_�ɂȂ�Ȃ��B
���O�炪���Ƃ������Ă���̂ł��Ƃ����ɉ��P��Ή����i��ł���̂��������̂���B
�܂��A�؋��������B
��������Ȃ��A�ŏ\���ȓ��@�ɂȂ��ł���B
�ǂ���Ȃ��A�l���ꂼ��ŁB
����SMT�g�����ǂˁB
�ǂ���Ȃ��A�l���ꂼ��ŁB
����SMT�g�����ǂˁB
>>596
>���o�C����Nehalem��Bloomfield��un-core�����̂܂�
>���P�����ł햳�����B
�f�����Ă邯�ǁA��̓I�ɂǂ��ς���낤�ˁB
Nehalem�̓T�[�o�D��ł��邱�Ƃ͊ԋ߂��Ȃ��̂ɁB
���W�����[�ɉߏ�Ȋ��҂��ĂȂ�?
>���o�C����Nehalem��Bloomfield��un-core�����̂܂�
>���P�����ł햳�����B
�f�����Ă邯�ǁA��̓I�ɂǂ��ς���낤�ˁB
Nehalem�̓T�[�o�D��ł��邱�Ƃ͊ԋ߂��Ȃ��̂ɁB
���W�����[�ɉߏ�Ȋ��҂��ĂȂ�?
>>626
�L�~�͑S�R�������Ă��Ȃ��ˁAoff�ɂ���Έ���Ƃ�����Ȃ��āA�I�v�V���������邱�Ǝ��̂��ǂ��Ȃ���B
���Ƃ��AASUS�̃}�U�[�{�[�hStriker�V���[�Y�A������I�[�o�[�N���b�N�̃��j���[�𓋍ڂ��鍂�@�\MB����
������T�[�o�[�Ɏg�����Ȃ�ĊԔ����͋��Ȃ�����A����Ȏ���������\������܂Ƃ��ɓ����Ȃ��B
�L�~�͑S�R�������Ă��Ȃ��ˁAoff�ɂ���Έ���Ƃ�����Ȃ��āA�I�v�V���������邱�Ǝ��̂��ǂ��Ȃ���B
���Ƃ��AASUS�̃}�U�[�{�[�hStriker�V���[�Y�A������I�[�o�[�N���b�N�̃��j���[�𓋍ڂ��鍂�@�\MB����
������T�[�o�[�Ɏg�����Ȃ�ĊԔ����͋��Ȃ�����A����Ȏ���������\������܂Ƃ��ɓ����Ȃ��B
630 �FMAC�I�^��628 �����F2008/06/22(��) 01:30:42 ID:7EkjfsSX
>>628
�@�@------------------
�@�@�f�����Ă邯�ǁA��̓I�ɂǂ��ς���낤�ˁB
�@�@------------------
���o�̃l�^��R�̗l�ɁB�B�B
http://www.hkepc.com/?id=568&page=3&fs=idn#view
http://pc.watch.impress.co.jp/docs/2007/1126/ubiq204.htm
http://pc.watch.impress.co.jp/docs/2007/1127/kaigai402.htm
�@�@------------------
�@�@�f�����Ă邯�ǁA��̓I�ɂǂ��ς���낤�ˁB
�@�@------------------
���o�̃l�^��R�̗l�ɁB�B�B
http://www.hkepc.com/?id=568&page=3&fs=idn#view
http://pc.watch.impress.co.jp/docs/2007/1126/ubiq204.htm
http://pc.watch.impress.co.jp/docs/2007/1127/kaigai402.htm
>>629
����Ȃ閳�m���Ȃ�����w
�T�[�o�Ǝ���PC���ɍl����Ȃ�B
BIOS�v���O�����Ȃ�Ă̂̓x���_�[���J�X�^�}�C�Y�ł��邵�A
SMT�@�\���ŏ�������I���ł��Ȃ����邱�Ƃ��炢�ȒP����B
����Ȃ閳�m���Ȃ�����w
�T�[�o�Ǝ���PC���ɍl����Ȃ�B
BIOS�v���O�����Ȃ�Ă̂̓x���_�[���J�X�^�}�C�Y�ł��邵�A
SMT�@�\���ŏ�������I���ł��Ȃ����邱�Ƃ��炢�ȒP����B
���j���[�ɂȂ��Ⴂ�����Ă���Ȃ����A�����̂��낤�ȁE�E�E
>>630
���̒���MAC�I�^��un-core�̕����̃��o�C���Ǝ��̎������Ǝv���Ă���̂͂ǂ�?
������������ŗL��/�����̘b����Ȃ��āB
>���o�C����Nehalem��Bloomfield��un-core�����̂܂�
>���P�����ł햳�����B
���������Ă��B�������A�㓡�L�����p���Ă邶��˂����B
���̒���MAC�I�^��un-core�̕����̃��o�C���Ǝ��̎������Ǝv���Ă���̂͂ǂ�?
������������ŗL��/�����̘b����Ȃ��āB
>���o�C����Nehalem��Bloomfield��un-core�����̂܂�
>���P�����ł햳�����B
���������Ă��B�������A�㓡�L�����p���Ă邶��˂����B
>>632
>�ŋ߂̃x���_���Ȃ����͂ȃn�[�h��ɂ����ɁA�����ČÂ��O���{���g�����肵�Ă���w�i���킩��Ȃ��낤�H
�T�[�o�ŃO���{(��)���ǂ����������Ă鎞�_�ŃA�z���Ǝv�������ǁA
SMT�������Ȃ���ԂŁASMT���ǂ���������̂���?
���O���m�Ȃ̂��Ȃ�B
>�ŋ߂̃x���_���Ȃ����͂ȃn�[�h��ɂ����ɁA�����ČÂ��O���{���g�����肵�Ă���w�i���킩��Ȃ��낤�H
�T�[�o�ŃO���{(��)���ǂ����������Ă鎞�_�ŃA�z���Ǝv�������ǁA
SMT�������Ȃ���ԂŁASMT���ǂ���������̂���?
���O���m�Ȃ̂��Ȃ�B
���̂����A�T�[�o���Ăǂ������g��������̂��킩���Ă�̂�?
�킴�킴�����ȃr�f�I�J�[�h�Ȃ�Ă���Ȃ���B
�܂��Ă�O���{�Ȃ�č������쏉�S�҂����g��Ȃ��I�^�p�����������w
�킴�킴�����ȃr�f�I�J�[�h�Ȃ�Ă���Ȃ���B
�܂��Ă�O���{�Ȃ�č������쏉�S�҂����g��Ȃ��I�^�p�����������w
637 �FMAC�I�^��633 �����F2008/06/22(��) 01:41:22 ID:7EkjfsSX
>>633
�@�@------------------
�@�@un-core�̕����̃��o�C���Ǝ��̎���
�@�@------------------
�v�l�̏��Ԃ��ԈႦ�Ă���悤�����ǁA�����l���Ă݂Ă�@�������H
�@�E���j�I��SoC�탂�o�C���̋Z�p�ł����ăT�[�o�[�̃��m�ł햳��
�@�@(�@�\���_�C�T�C�Y�Ő���邽��)
�@�EBloomfield��un-core�v�f(QPI��3ch�������C���^�[�t�F�[�X)��T�[�o�[����
�@�@------------------
�@�@un-core�̕����̃��o�C���Ǝ��̎���
�@�@------------------
�v�l�̏��Ԃ��ԈႦ�Ă���悤�����ǁA�����l���Ă݂Ă�@�������H
�@�E���j�I��SoC�탂�o�C���̋Z�p�ł����ăT�[�o�[�̃��m�ł햳��
�@�@(�@�\���_�C�T�C�Y�Ő���邽��)
�@�EBloomfield��un-core�v�f(QPI��3ch�������C���^�[�t�F�[�X)��T�[�o�[����
����������Nehalem��core���l�����T�[�o��������B
SMT�Ȃ��o�C�����Ⴂ���B
TLB���F�X�M���Ă邵�B
SMT�Ȃ��o�C�����Ⴂ���B
TLB���F�X�M���Ă邵�B
>>637
>�E���j�I��SoC�탂�o�C���̋Z�p�ł����ăT�[�o�[�̃��m�ł햳��
SoC�����j�I�ɃT�[�o�̋Z�p�ł͂Ȃ����Ƃ�
Nehalem���T�[�o�D��̐v�łȂ����ƂƂǂ��W�����?
�������������̂��悭�킩���B
Nehalem��IMC�Ȃ̂�QuickPath�ɂ��P2P�ڑ��ɑΉ����邽�߂�
���C�A�E�g��̖�肪��ԑ傫���Ǝv�����B
>�EBloomfield��un-core�v�f(QPI��3ch�������C���^�[�t�F�[�X)��T�[�o�[����
����͊m���ɃT�[�o���������A���o�C���ł�p�ӂ���̂�Intel�͂Ȃ����Ԃ��������Ă�̂ł��傤��?
Core 2�̂Ƃ��Ɣ�r���Ă����炩�ɒx��Ă邾�낤�B
�����āA1366pin�Ń_�C�T�C�Y������ȃT�[�o�����̃R�A����ɓ�������āA
�f�X�N�g�b�v�ł��g��Ȃ��Ⴂ���R��?
���W�����[���Ă��������Ē����ɂ����Ȕh���`�b�v��p�ӂł���킯����Ȃ��B
���Ԕ��߂��B
>�E���j�I��SoC�탂�o�C���̋Z�p�ł����ăT�[�o�[�̃��m�ł햳��
SoC�����j�I�ɃT�[�o�̋Z�p�ł͂Ȃ����Ƃ�
Nehalem���T�[�o�D��̐v�łȂ����ƂƂǂ��W�����?
�������������̂��悭�킩���B
Nehalem��IMC�Ȃ̂�QuickPath�ɂ��P2P�ڑ��ɑΉ����邽�߂�
���C�A�E�g��̖�肪��ԑ傫���Ǝv�����B
>�EBloomfield��un-core�v�f(QPI��3ch�������C���^�[�t�F�[�X)��T�[�o�[����
����͊m���ɃT�[�o���������A���o�C���ł�p�ӂ���̂�Intel�͂Ȃ����Ԃ��������Ă�̂ł��傤��?
Core 2�̂Ƃ��Ɣ�r���Ă����炩�ɒx��Ă邾�낤�B
�����āA1366pin�Ń_�C�T�C�Y������ȃT�[�o�����̃R�A����ɓ�������āA
�f�X�N�g�b�v�ł��g��Ȃ��Ⴂ���R��?
���W�����[���Ă��������Ē����ɂ����Ȕh���`�b�v��p�ӂł���킯����Ȃ��B
���Ԕ��߂��B
�܂���SMT���r�f�I�J�[�h���I�[�o�[�N���b�N�̘b�Ɠ���Ɉ����قǂ̔n�����Ƃ͎v��Ȃ�����
�P��Netburst��A�z������ޗ��ɂȂ��ăC�����Ȃ������Ǝv����ROM���Ă���
������₱�����b�ɂȂ��Ă�Ȃ�
������₱�����b�ɂȂ��Ă�Ȃ�
>SMT�Ȃ��o�C�����Ⴂ���B
��atom
intel�̍l���͈Ⴄ�悤�ł��B
��atom
intel�̍l���͈Ⴄ�悤�ł��B
643 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 07:45:25 ID:YpuPayhY
>>641
NetBurst�i����Northwood�j�́AHT�g����1�X���b�h������L1������A
�L���b�V���~�X�ŋp���đS�̂̌����������˂Ȃ����炢��L1�������������B
�悭�œK�����ꂽ�R�[�h�i���ɐ�����́j���ƕ�����s�Ō����オ��قǃp�C�v���C���̋��Ȃ������̂�����
Core MA��4Way�p�C�v���C���������I�Ɏg���_��SMT�̓����b�g�傫���Ǝv���Ă邪�B
�����̃v���O������2IPC���x�o��Ό�̎�������
NetBurst�i����Northwood�j�́AHT�g����1�X���b�h������L1������A
�L���b�V���~�X�ŋp���đS�̂̌����������˂Ȃ����炢��L1�������������B
�悭�œK�����ꂽ�R�[�h�i���ɐ�����́j���ƕ�����s�Ō����オ��قǃp�C�v���C���̋��Ȃ������̂�����
Core MA��4Way�p�C�v���C���������I�Ɏg���_��SMT�̓����b�g�傫���Ǝv���Ă邪�B
�����̃v���O������2IPC���x�o��Ό�̎�������
645 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 08:01:19 ID:YpuPayhY
�N���b�N�����W���グ�ăp�t�H�[�}���X�グ����͏��Ȃ����
646 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 09:54:36 ID:YpuPayhY
���ƁA�R�A�����₷���g�����W�X�^���I�ɂ��d�͓I�ɂ��G�R�m�~�[
647 �FMAC�I�^��639 �����F2008/06/22(��) 10:36:00 ID:7EkjfsSX
>>639
�@�@-------------------
�@�@Core 2�̂Ƃ��Ɣ�r���Ă����炩�ɒx��Ă邾�낤�B
�@�@-------------------
>>630�ɓ\����HKEPC�̃��t�@�����X�f�U�C���̎����������āA���������ό����������z�������ł��Ȃ����B
Core2�o�ꎞ��Woodcrest����s�����̂Ɠ��l�ɁAIntel�ɂƂ��ċ������ׂ��s�ꂩ�珇�ԂɃ����[�X��
�n�߂邾�����ƁB
���Ȃ݂�HKEPC�̃X�N�[�v��ABloomfield�ł�����������R���g���[���햳��������Ă���Ɠ`���Ă���A
���̕����̊J���ōs���l�����ꍇ�����[�X���Ԃɍ��킹�邽�߂Ƀo�b�N�A�b�v�v����(Tylersburg�o�R��
�������A�N�Z�X�j���p�ӂ���Ă������Ƃ�I�悵�����B
�@�@-------------------
�@�@Core 2�̂Ƃ��Ɣ�r���Ă����炩�ɒx��Ă邾�낤�B
�@�@-------------------
>>630�ɓ\����HKEPC�̃��t�@�����X�f�U�C���̎����������āA���������ό����������z�������ł��Ȃ����B
Core2�o�ꎞ��Woodcrest����s�����̂Ɠ��l�ɁAIntel�ɂƂ��ċ������ׂ��s�ꂩ�珇�ԂɃ����[�X��
�n�߂邾�����ƁB
���Ȃ݂�HKEPC�̃X�N�[�v��ABloomfield�ł�����������R���g���[���햳��������Ă���Ɠ`���Ă���A
���̕����̊J���ōs���l�����ꍇ�����[�X���Ԃɍ��킹�邽�߂Ƀo�b�N�A�b�v�v����(Tylersburg�o�R��
�������A�N�Z�X�j���p�ӂ���Ă������Ƃ�I�悵�����B
>>647
Core 2�̎���Woodcrest����Merom���ł�܂łɉ������������Ǝv���Ă��B
Nehalem�̏ꍇ�́ABloomfield����Lynnfield���ł�܂ł�3�l�����B
�������A>>630�̃��t�@�����X�f�U�C����Lynnfield�̂��̂���B
���o�C����LGA1160�ł͂Ȃ�rPGA989������A�ʃf�U�C���B
�K���Ȗϑz���炾�珑���Ă�Ȃ�BMAC�I�^�̏ꍇ���ʂ����������ɁA���f�B
���m��MAC�I�^�����ɑ匴�L�����Ă���B�匴�L���͂���͌��������ǁB
Nehalem��core�����Ō��Ă��T�[�o�����̊g���������̂͂�������܂ł̏��Ŗ��炩�B
���W�����[�Ƃ����Ă�����قǒZ���ԂŔh���`�b�v��p�ӂł���킯�ł͂Ȃ����Ƃ�
Nehalem���g�������Ď����Ă���Ă���킯�ŁB�I�^�̔F���͎���x��B
IDF Shanghai 2008 - Nehalem���𑍂܂Ƃ߁A�R�A�̓����\������v���b�g�t�H�[���܂�
http://journal.mycom.co.jp/articles/2008/04/10/idf09/index.html
Core 2�̎���Woodcrest����Merom���ł�܂łɉ������������Ǝv���Ă��B
Nehalem�̏ꍇ�́ABloomfield����Lynnfield���ł�܂ł�3�l�����B
�������A>>630�̃��t�@�����X�f�U�C����Lynnfield�̂��̂���B
���o�C����LGA1160�ł͂Ȃ�rPGA989������A�ʃf�U�C���B
�K���Ȗϑz���炾�珑���Ă�Ȃ�BMAC�I�^�̏ꍇ���ʂ����������ɁA���f�B
���m��MAC�I�^�����ɑ匴�L�����Ă���B�匴�L���͂���͌��������ǁB
Nehalem��core�����Ō��Ă��T�[�o�����̊g���������̂͂�������܂ł̏��Ŗ��炩�B
���W�����[�Ƃ����Ă�����قǒZ���ԂŔh���`�b�v��p�ӂł���킯�ł͂Ȃ����Ƃ�
Nehalem���g�������Ď����Ă���Ă���킯�ŁB�I�^�̔F���͎���x��B
IDF Shanghai 2008 - Nehalem���𑍂܂Ƃ߁A�R�A�̓����\������v���b�g�t�H�[���܂�
http://journal.mycom.co.jp/articles/2008/04/10/idf09/index.html
>>648
>�����Č����ƁANehalem�́uCore Microarchitecture���T�[�o�[�����ɍč\�z���Ȃ������v�Ƃ����������B
>�����Č����ƁANehalem�́uCore Microarchitecture���T�[�o�[�����ɍč\�z���Ȃ������v�Ƃ����������B
�f�X�N�g�b�v�����ɍ���Ă���Ȃ��ƍ��邶���B
�T�[�o�[�����ɍ���Ă��ʂɂ��ꂵ���Ȃ������B
Nehalem�͉��I�ɂ͊��҂͂��ꂾ�����Ƃ������Ƃ��B
����CPU�Ɋ��҂��ȁB
�T�[�o�[�����ɍ���Ă��ʂɂ��ꂵ���Ȃ������B
Nehalem�͉��I�ɂ͊��҂͂��ꂾ�����Ƃ������Ƃ��B
����CPU�Ɋ��҂��ȁB
ttp://nueda.main.jp/blog/archives/003620.html
�܂��V�����x���`�B���x��2.93GHz��Bloomfield�ŁB
�܂��V�����x���`�B���x��2.93GHz��Bloomfield�ŁB
652 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 15:11:28 ID:YpuPayhY
>>650
AMD�t�@���{�[�C�ȕ��͎I�����v���X�e�[�^�X�Ȃ�ł����ǂ�
AMD�t�@���{�[�C�ȕ��͎I�����v���X�e�[�^�X�Ȃ�ł����ǂ�
�܂���������������Ƃ�����
Intel�I���DELL�p�\�Ǝ����悤�Ȃ��̂��ւ��ւ��g��ł��ȂƂ�����
Intel�I���DELL�p�\�Ǝ����悤�Ȃ��̂��ւ��ւ��g��ł��ȂƂ�����
>>652
���������݂Œc�q����Ƀ��X���Ă��炦�Ă��������ꂵ���ł��B
AMD�M�҂̖ϐM�Ԃ�͂������Ǝv���܂��B�������Ȃ��B����A�z���g�ɂ������B
���������݂Œc�q����Ƀ��X���Ă��炦�Ă��������ꂵ���ł��B
AMD�M�҂̖ϐM�Ԃ�͂������Ǝv���܂��B�������Ȃ��B����A�z���g�ɂ������B
>>638
�V���O���R�A���o�C���ɂ�SMT�͌����Ă���Ǝv����
SMT���p�t�H�[�}���X����Ɠ����Ƀp�t�H�[�}���X�ቺ�݂����̂̓}���`�R�A�̏ꍇ�Ɍ���B
�V���O���R�A���o�C���ɂ�SMT�͌����Ă���Ǝv����
SMT���p�t�H�[�}���X����Ɠ����Ƀp�t�H�[�}���X�ቺ�݂����̂̓}���`�R�A�̏ꍇ�Ɍ���B
�b��ɂ��Ă�̂�Nehalem�Ȃ̂Łc
657 �F,,�E�L�́M�E,,�j��-�������F2008/06/22(��) 18:22:51 ID:YpuPayhY
SMT�l�K�L�����h��NetBurst�̗Ⴞ�����Č����Ă��ˁH
NetBurst�̍ő�̖���SMT�ł͂Ȃ��悤�ȁc�c
�����Əd��Ȏ��̂悤�ȁc�c
�����Əd��Ȏ��̂悤�ȁc�c
Fanboy�͂Ƃ������Ƃ��āA
PC�̐i���̗��j�i�n�[�h�E�F�A���\�t�g�E�F�A���j����RISC�ėp�@���̑�^�ō����ȋ@�B�̋@�\��
�^�����Ă����悤�Ȃ��̂�����A�T�[�o�����v�Ƃ����̂Ɉ،h�̔O������̂͂��傤���Ȃ��̂������ꂸ�B
PC�̐i���̗��j�i�n�[�h�E�F�A���\�t�g�E�F�A���j����RISC�ėp�@���̑�^�ō����ȋ@�B�̋@�\��
�^�����Ă����悤�Ȃ��̂�����A�T�[�o�����v�Ƃ����̂Ɉ،h�̔O������̂͂��傤���Ȃ��̂������ꂸ�B
�T�[�o�p�r�́A���͈��肵�Ă��Ē����d�͂Ȃ��̂��D�܂��悤�����ǂ�
���\�Ɋւ��Ă͍��̃~�h�������W�v���Z�b�T�Ȃ���͖��Ȃ��Ȃ��Ă��邵�B
�����\��v������̂�HPC�T�[�o�[�A�������̓��[�N�X�e�[�V�����Ɍ�����ł��傤�B
�q���[���b�g�p�b�J�[�h�̃��C���i�b�v���݂Ă݂�Ƃ���Ȋ������ˁB
����ɂ��Ă�Dell�͂�������_���_���ɂȂ����ȁc�c
���\�Ɋւ��Ă͍��̃~�h�������W�v���Z�b�T�Ȃ���͖��Ȃ��Ȃ��Ă��邵�B
�����\��v������̂�HPC�T�[�o�[�A�������̓��[�N�X�e�[�V�����Ɍ�����ł��傤�B
�q���[���b�g�p�b�J�[�h�̃��C���i�b�v���݂Ă݂�Ƃ���Ȋ������ˁB
����ɂ��Ă�Dell�͂�������_���_���ɂȂ����ȁc�c
http://ascii.jp/elem/000/000/119/119223/index-2.html
IBM�̃��C���t���[���̏����\�͂�2��MIPS����܂��B
���ꂾ���̐��\��������̂����Ɏg����ł����H�@�Ƃ����b������܂��B
2��MIPS�Ƃ������l�́A���E������g�����U�N�V�������W�����Ă��ς����鐔�l�ł��B
IBM�̃��C���t���[���̏����\�͂�2��MIPS����܂��B
���ꂾ���̐��\��������̂����Ɏg����ł����H�@�Ƃ����b������܂��B
2��MIPS�Ƃ������l�́A���E������g�����U�N�V�������W�����Ă��ς����鐔�l�ł��B
���C���t���[����I/O�̐��\��PC�Ƃ͌��Ⴂ������A�Q�l�ɂ͂Ȃ�Ȃ��Ǝv����
�ڑ��\�ȃl�b�g���[�N�|�[�g�̐��Ƃ���PC�n�T�[�o�[�Ƃ͂܂�ňႤ���c�c
QPI�����͂����Ȃ̂ŁANehalem���C���t���[�����Ă̂͗L�肩���m��Ȃ���
�ł������������̂̓T�[�o�[�Ƃ͂܂��Ⴄ�悤�ȕ��ɂȂ邩���B
�����Ȃ̂́A�����ň��̃A�N�Z�X�����ւ�܂��ɂ���2ch�̕��j����
http://pc11.2ch.net/test/read.cgi/jisaku/924080501/l50
�ڑ��\�ȃl�b�g���[�N�|�[�g�̐��Ƃ���PC�n�T�[�o�[�Ƃ͂܂�ňႤ���c�c
QPI�����͂����Ȃ̂ŁANehalem���C���t���[�����Ă̂͗L�肩���m��Ȃ���
�ł������������̂̓T�[�o�[�Ƃ͂܂��Ⴄ�悤�ȕ��ɂȂ邩���B
�����Ȃ̂́A�����ň��̃A�N�Z�X�����ւ�܂��ɂ���2ch�̕��j����
http://pc11.2ch.net/test/read.cgi/jisaku/924080501/l50
663 �FMAC�I�^��655 �����F2008/06/22(��) 21:01:20 ID:qnOJouEZ
>>655
�@�@----------------------
�@�@SMT���p�t�H�[�}���X����Ɠ����Ƀp�t�H�[�}���X�ቺ�݂����̂̓}���`�R�A�̏ꍇ�Ɍ���B
�@�@----------------------
������atom�ɂ�f���A���R�A�ł��o��Ƃ����\��(��)
http://www.electronista.com/articles/08/03/10/intel.atom.roadmap.leaked/
�@�@======================
�@�@However, a new 300 series would also see the first dual-core Atoms with a 1.87GHz,
�@�@Atom 300 processor.
�@�@======================
�@�@----------------------
�@�@SMT���p�t�H�[�}���X����Ɠ����Ƀp�t�H�[�}���X�ቺ�݂����̂̓}���`�R�A�̏ꍇ�Ɍ���B
�@�@----------------------
������atom�ɂ�f���A���R�A�ł��o��Ƃ����\��(��)
http://www.electronista.com/articles/08/03/10/intel.atom.roadmap.leaked/
�@�@======================
�@�@However, a new 300 series would also see the first dual-core Atoms with a 1.87GHz,
�@�@Atom 300 processor.
�@�@======================
664 �FMAC�I�^���⑫�F2008/06/22(��) 21:07:37 ID:qnOJouEZ
�j���[�X�Ƃ��Ă�A������̕����V�����̂Œlj����B
http://www.xbitlabs.com/news/cpu/display/20080528231831_Intel_Plans_to_Start_Manufacturing_of_Dual_Core_Atom_Processors_Shortly_Media_Report.html
�@�@-------------------------
�@�@The lineup of desktop Intel Atom central processing units (CPUs) will consist of Atom
�@�@Z200-series with one processing engines and Z300-series with two processing engines.
�@�@Both families will feature multi-threading technology which allows to execute two threads
�@�@of code on one core, which means that dual-core Intel Atom processor will be able to
�@�@execute four threads at once.
�@�@[����]
�@�@Intel plans to begin production of Atom Z230 and Atom Z330 in Q3 2008, a news-story at
�@�@DigiTimes web-site claims.
�@�@-------------------------
http://www.xbitlabs.com/news/cpu/display/20080528231831_Intel_Plans_to_Start_Manufacturing_of_Dual_Core_Atom_Processors_Shortly_Media_Report.html
�@�@-------------------------
�@�@The lineup of desktop Intel Atom central processing units (CPUs) will consist of Atom
�@�@Z200-series with one processing engines and Z300-series with two processing engines.
�@�@Both families will feature multi-threading technology which allows to execute two threads
�@�@of code on one core, which means that dual-core Intel Atom processor will be able to
�@�@execute four threads at once.
�@�@[����]
�@�@Intel plans to begin production of Atom Z230 and Atom Z330 in Q3 2008, a news-story at
�@�@DigiTimes web-site claims.
�@�@-------------------------
OLTP�����X���G�ɂȂ��Ă邩��
20000MIPS�ł��g����̗]�T����
20000MIPS�ł��g����̗]�T����
2��MIPS����C2Q������炢�����?
intel�̔����y�[�X�����Ȃ�
��������nehalem���悤
��������nehalem���悤
Aceshardware�f���Ō��������ǁA�h�C�c�̌v�Z�@�Z���^�[�̘A����HLRN��������
�\�肵�Ă���SGI���V�X�e����Gainestown(DP��4-core)��Bechton(MP��8-core)���̗p
�����Ƃ̂��Ƃ��B
http://aceshardware.freeforums.org/nehalem-in-sgi-supercomputers-t546.html
�����킱����B
http://www.hlrn.de/newsletter/aktuell.pdf
http://www.rrzn.uni-hannover.de/fileadmin/organisation/pdf/pocketguide_2008_web.pdf
�@��Beckton�V�X�e��
�@�@- 5 SGI Ultra Violet System
�@�@- 136 �m�[�h
�@�@- 272 x Beckton Octo-Core
�@�@- �`21.7 TFlops peak
�@�@- NumaLink5 �C���^�R�l�N�g
�@�@- 2009Q3�\��
�@��Gainestown�V�X�e��
�@�@- SGI ICE8200
�@�@- 916 �m�[�h
�@�@- 1832 x Gainestown Quad-Core
�@�@- 99.7 TFlops peak
�@�@- Infiniband 4x �C���^�R�l�N�g
�@�@- 2009Q1�\��
MP�ł������قǑ����o�ꂷ��Ƃ������ƂɂȂ邷�B
�\�肵�Ă���SGI���V�X�e����Gainestown(DP��4-core)��Bechton(MP��8-core)���̗p
�����Ƃ̂��Ƃ��B
http://aceshardware.freeforums.org/nehalem-in-sgi-supercomputers-t546.html
�����킱����B
http://www.hlrn.de/newsletter/aktuell.pdf
http://www.rrzn.uni-hannover.de/fileadmin/organisation/pdf/pocketguide_2008_web.pdf
�@��Beckton�V�X�e��
�@�@- 5 SGI Ultra Violet System
�@�@- 136 �m�[�h
�@�@- 272 x Beckton Octo-Core
�@�@- �`21.7 TFlops peak
�@�@- NumaLink5 �C���^�R�l�N�g
�@�@- 2009Q3�\��
�@��Gainestown�V�X�e��
�@�@- SGI ICE8200
�@�@- 916 �m�[�h
�@�@- 1832 x Gainestown Quad-Core
�@�@- 99.7 TFlops peak
�@�@- Infiniband 4x �C���^�R�l�N�g
�@�@- 2009Q1�\��
MP�ł������قǑ����o�ꂷ��Ƃ������ƂɂȂ邷�B
>>666
���̋L�������ł͂Ȃ�Ƃ������Ȃ����AIBM���C���t���[���̖��߃Z�b�g��68000�܂łƂ͍s���Ȃ����̂�
���\���s����������|����Ȗ��߃Z�b�g�ŁA���ꂪ��Ȃ猋�\�����Ǝv���B�Ƃ�킯10�i����I�ɂȂ�Ǝv���܂��B
�t��PowerPC���Ȃɂ��ŃG�~�����[�V�������Ă��āA���̌���CPU��MIPS���Ȃ�C2D���x���낤�ˁB
���̋L�������ł͂Ȃ�Ƃ������Ȃ����AIBM���C���t���[���̖��߃Z�b�g��68000�܂łƂ͍s���Ȃ����̂�
���\���s����������|����Ȗ��߃Z�b�g�ŁA���ꂪ��Ȃ猋�\�����Ǝv���B�Ƃ�킯10�i����I�ɂȂ�Ǝv���܂��B
�t��PowerPC���Ȃɂ��ŃG�~�����[�V�������Ă��āA���̌���CPU��MIPS���Ȃ�C2D���x���낤�ˁB
������ɂ��Ă�I/O�����͂Ȃ獡����CPU���ƁA������҂�n�C�G���h�Ő��E������̃��N�G�X�g���J���͓̂���Ȃ����낤�ˁB
google�Ƃ��͗�O�ɂȂ肻���ł����c�c
�������܂ł����ƁA�n�C�G���h�ł���Ӗ��͂Ȃ��đ䐔�������ˁB
google�Ƃ��͗�O�ɂȂ肻���ł����c�c
�������܂ł����ƁA�n�C�G���h�ł���Ӗ��͂Ȃ��đ䐔�������ˁB
����MIPS���Ă̂�VAX MIPS����Ȃ���
���C���t���[��MIPS�Ȃ�Ŋ�s��
���ɐ�SUN��US3 750MHz��100���C���t���[��MIPS���Ă����Ă̂�
��ɂ���ƁAC2Q��3000�`4000MIPS�������ȁH
�����ƃ��C���t���[��MIPS���đO���ヂ�f�����
�����Ȃ�܂������炢�̈Ӗ������Ȃ��ł�
���C���t���[��MIPS�Ȃ�Ŋ�s��
���ɐ�SUN��US3 750MHz��100���C���t���[��MIPS���Ă����Ă̂�
��ɂ���ƁAC2Q��3000�`4000MIPS�������ȁH
�����ƃ��C���t���[��MIPS���đO���ヂ�f�����
�����Ȃ�܂������炢�̈Ӗ������Ȃ��ł�
MIPS�{���̈Ӗ�=100������/s
���݈�ʓI�ȈӖ�=�h���C�X�g�[���̃X�R�A��VAX 780/11�̃X�R�A�Ŋ���������
���C���t���[����MIPS=IBM360/65�������̑��Βl�����_
���������݂͊���s��
���݈�ʓI�ȈӖ�=�h���C�X�g�[���̃X�R�A��VAX 780/11�̃X�R�A�Ŋ���������
���C���t���[����MIPS=IBM360/65�������̑��Βl�����_
���������݂͊���s��
1CPU�ōŐV��linux�̃J�[�l����make��3���ȓ��ɏI����
���V�X�e���S�̂̏���d�͂��A�C�h����40W�ȓ�
�t�����[�h��80W�����Ɏ��܂�v���b�g�t�H�[����v�����܂�
���V�X�e���S�̂̏���d�͂��A�C�h����40W�ȓ�
�t�����[�h��80W�����Ɏ��܂�v���b�g�t�H�[����v�����܂�
675 �FSocket774�F2008/06/28(�y) 07:21:55 ID:l36jxqID
Atom
�@�@�@�@�@�@�� �݁@�@�@�@�@���������`
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���������`
�@�@ �@ �@ ���@�݁@�@�V�@ �ȁQ�ȁ@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P
�@ �@ �@ �@�@�R�@�Q�Q_�_�i�_�E�́E�j�@���@�ʎq�܂��`�H
�@ �@ �@ �@ �@ �@ �_�Q�^���@���Q )�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �@ �@ �@ �@ �^�P�P�P�P�P�P �^|
�@�@�@�@�@�@�@|�P�P�P�P�P�P�P|�@ |
�@�@�@�@�@�@�@|�@�@���Q�݂���@|�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���������`
�@�@ �@ �@ ���@�݁@�@�V�@ �ȁQ�ȁ@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P
�@ �@ �@ �@�@�R�@�Q�Q_�_�i�_�E�́E�j�@���@�ʎq�܂��`�H
�@ �@ �@ �@ �@ �@ �_�Q�^���@���Q )�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �@ �@ �@ �@ �^�P�P�P�P�P�P �^|
�@�@�@�@�@�@�@|�P�P�P�P�P�P�P|�@ |
�@�@�@�@�@�@�@|�@�@���Q�݂���@|�^
����H
>>676
�ŋߐ�]�I�ɐi��ł��Ȃ��ˁA��肪�����̂��H����Ƃ��A���݂̕����@�����Ԉ���Ă���̂��H
�ŋߐ�]�I�ɐi��ł��Ȃ��ˁA��肪�����̂��H����Ƃ��A���݂̕����@�����Ԉ���Ă���̂��H
�����Z�p�ň�ԗL�]���ȂƎv���̂̓_�C�������h�����̂���
��������L�����A�ړ����x���������A�Y�f���q�̓P�C�f���q��菬�����Ă������̉\�������邵
�M�̈ړ����x���������A���d���ɂ��ς����邵�A�����ɂ��ς����邵�B
���쌴�������݂̃P�C�f���̂Ɠ����Ńm�E�n�E��������������(�n�[�h�I�ɂ��\�t�g�I�ɂ�)�B
��������L�����A�ړ����x���������A�Y�f���q�̓P�C�f���q��菬�����Ă������̉\�������邵
�M�̈ړ����x���������A���d���ɂ��ς����邵�A�����ɂ��ς����邵�B
���쌴�������݂̃P�C�f���̂Ɠ����Ńm�E�n�E��������������(�n�[�h�I�ɂ��\�t�g�I�ɂ�)�B
���ׂĂ̓R�X�g����
>>679
����͐l�H�_�C�A�������ƈ�������悤�ɂȂ�Ȃ��Ɩ����ł���
�����ϋv���̖ʂŔ��ɗL�]������Ă邩��
PC���ɂ͎g���Ȃ��Ă����ۉF���X�e�[�V�����Ƃ�
�ُ�ȑϋv�������߂���Ƃ���ɂ͎g����悤�ɂȂ邩����
����͐l�H�_�C�A�������ƈ�������悤�ɂȂ�Ȃ��Ɩ����ł���
�����ϋv���̖ʂŔ��ɗL�]������Ă邩��
PC���ɂ͎g���Ȃ��Ă����ۉF���X�e�[�V�����Ƃ�
�ُ�ȑϋv�������߂���Ƃ���ɂ͎g����悤�ɂȂ邩����
���ǂǂ�ȍޗ��ł�MOS Tr�Ƃ��ē��삳����ɂ�
�≏��������ɍ��鎖�ƊE�ʃg���b�v�����Ȃ��ł��鎖����Ώ���
�≏��������ɍ��鎖�ƊE�ʃg���b�v�����Ȃ��ł��鎖����Ώ���
�ǂ�ȍޗ��Ƃ����Ă��A����ޗ��Ƃ₳�����ޗ���������SiC���̉������n�͐�������Ǝv��
�������n�͑傫���Ȃ��Ă���ƒP�������������낵������ɂȂ肻���ȗ\��������B
�������n�͑傫���Ȃ��Ă���ƒP�������������낵������ɂȂ肻���ȗ\��������B
�q���̍��ɖ����̃R���s���[�^�̓W���Z�t�\���f�q�ō����Ƃ��l�H�m�\���ڂ��Ă�����Ă��������ǎ������Ȃ��ȁB
�����J���͎~�߂��̂��H
�����J���͎~�߂��̂��H
�W���Z�t�\���f�q��10GHz���炢�ł������A�����Ȑ��\������������Ȃ��̂���
�V���R���ł��撣�����璴�`�����x���܂ŗ�₳�Ȃ��Ă�7-8GHz���x�s����������w
�V���R���ł��撣�����璴�`�����x���܂ŗ�₳�Ȃ��Ă�7-8GHz���x�s����������w
�����ŃV���R�����ǂ�ǂ��ɂ���������������
����ς���ɋ���Ȏs��ł��Ă鍁��t�̓��\�[�X��ʓ����ł��邩��i�K�I�ȉ��Ǘ͍ŋ��Ƃ������Ƃ�
����ς���ɋ���Ȏs��ł��Ă鍁��t�̓��\�[�X��ʓ����ł��邩��i�K�I�ȉ��Ǘ͍ŋ��Ƃ������Ƃ�
���ł����܂��`�������Ă��Ȃ��
���ɕ����Ԃ�`���[�u�^�̓��H�͉����ցE�E�E
���ɕ����Ԃ�`���[�u�^�̓��H�͉����ցE�E�E
�q���̍��̖{�ɂ��ƃ��j�A�������Ă�͂��������B
�����ĐΖ��͖����Ȃ��Ă�B
�����ĐΖ��͖����Ȃ��Ă�B
�����ĕX�͊��B
�C���J���U�߂Ă���B
�C���J���U�߂Ă���B
{kind=link}
�Ȃ��ꂗ
�Ȃ����Ă邵��
�Ȃ����Ă邵��
693 �FSocket774�F2008/06/30(��) 12:22:53 ID:W0hEf14F
���ɂȂ�����r�k�Ŕ����ƃA���h�����_�s��������H
694 �F�R�E�L�́M�E,,�j�����������������F2008/06/30(��) 14:04:07 ID:8LW5xfFH
��O�V�����s�ǂ��H
�C���^�[�l�b�g�͌��\�����Z�p���Ǝv����
�v���O���������C�u�������h���C�o��
�����܂�CPU������
�n�[�h�E�F�A���o��
�����܂�GPU������
����GPU��CPU�Ɠ����@�\���������Ă��āA
���C�u�������C���ł���̂Ȃ�
�v���O���������C�u�����̈ꕔ
�����܂�CPU������
���C�u�����̎��́��h���C�o?���n�[�h�E�F�A���o��
�����܂�GPU������
�Ƃ��A�ł��Ȃ��̂��܂���H
�����܂�CPU������
�n�[�h�E�F�A���o��
�����܂�GPU������
����GPU��CPU�Ɠ����@�\���������Ă��āA
���C�u�������C���ł���̂Ȃ�
�v���O���������C�u�����̈ꕔ
�����܂�CPU������
���C�u�����̎��́��h���C�o?���n�[�h�E�F�A���o��
�����܂�GPU������
�Ƃ��A�ł��Ȃ��̂��܂���H
���̐������ƈႢ��������Ȃ�
psp��gpgpu���Ęb?
�������X������X�}�\
>>696 �ł����ˁH�Ȃ�̈Ӗ�������̂������ς蕪�����
Intel�~���[�W�A��/���{���w�L
�`4004�d�삩��ŐV�Z�p�܂�
http://pc.watch.impress.co.jp/docs/2008/0701/hot556.htm
�`4004�d�삩��ŐV�Z�p�܂�
http://pc.watch.impress.co.jp/docs/2008/0701/hot556.htm
>>687
x86�ł��S����������
x86�ł��S����������
http://journal.mycom.co.jp/articles/2007/10/05/idf/index.html
Larrabee�͂���ƃ����N����킯��
����Ȃ痧���ʒu���͂����肷��
Larrabee�͂���ƃ����N����킯��
����Ȃ痧���ʒu���͂����肷��
����łĂ������H
�uNehalem�̃\�P�b�g��3��ނ���v
ttp://www.fudzilla.com/index.php?option=com_content&task=view&id=8137&Itemid=1
LGA1160�ł�Display Connect�Ή�����/�Ȃ����o�Ă���͓̂��R�����ǁA�����I�������͓d�C�I��
���S�ɕʕ����ǂ����́A�u�H�v���ȁB�܂�Fudzilla�����B
�uNehalem�̃\�P�b�g��3��ނ���v
ttp://www.fudzilla.com/index.php?option=com_content&task=view&id=8137&Itemid=1
LGA1160�ł�Display Connect�Ή�����/�Ȃ����o�Ă���͓̂��R�����ǁA�����I�������͓d�C�I��
���S�ɕʕ����ǂ����́A�u�H�v���ȁB�܂�Fudzilla�����B
�Ȃ玝���Ă���܂ł��Ȃ�
���̎�̃T�C�g�ɃG�T�^���Ȃ���������
���̎�̃T�C�g�ɃG�T�^���Ȃ���������
>>704
�ǂ����A�X���b�N�����Ή��ł���
�ǂ����A�X���b�N�����Ή��ł���
DDR2��2�{�ADDR3��2�{�A����Ώ\���Ǝv���Ă���B
DDR2�͏\����������ŏ��͂����2GB*2�ɂ��Ă�����
DDR3�������Ȃ�����DDR3��2GB*2�ɂ�������B
�h���C�o����Ӌ@��̊W��32bitOS���g������A����ł������ȂƁB
DDR2�͏\����������ŏ��͂����2GB*2�ɂ��Ă�����
DDR3�������Ȃ�����DDR3��2GB*2�ɂ�������B
�h���C�o����Ӌ@��̊W��32bitOS���g������A����ł������ȂƁB
���Ƀj���[�X�ł����������ǁA�����Reseach@Intel Day�̃T�C�g���B
http://www.intel.com/pressroom/archive/releases/20080611corp_sm.htm?iid=pr1_marqmain_research08
http://www.intel.com/pressroom/archive/releases/20080611corp_sm.htm?iid=pr1_marqmain_research08
���o965�g���ĂāA�b�o�t�͂d6600�ł��B
���HD 4870���w��������ł����A�ǂ����Ȃ�}�U�[���b�o�t���ς��悤�Ǝv���Ă܂��B
����ŐV�b�o�t��7�����ɏo�āA�\�P�b�g���ς��Ƃ����̂ł����҂��ĕς��悤�ƍl���Ă��܂���
�{����7������ɓo�ꂷ���ł��傤���H
���HD 4870���w��������ł����A�ǂ����Ȃ�}�U�[���b�o�t���ς��悤�Ǝv���Ă܂��B
����ŐV�b�o�t��7�����ɏo�āA�\�P�b�g���ς��Ƃ����̂ł����҂��ĕς��悤�ƍl���Ă��܂���
�{����7������ɓo�ꂷ���ł��傤���H
Larrabee�����s����O�̗��R
1.GPU�Ƃ��ăp�t�H�[�}���X���[�_�[�ɂȂ��͂��Ȃ����A���v���łȂ�
2.HPC�p�̃A�i�E���X���Ȃ��Ȃ������ƂŁAHPC�p�Ƃ��Ă͎��s�m��
3.HPC����GPU���̗h��Â��鐻�i�Ƃ��Ă̈ʒu�Â��A������肠��́H
�O�̖ϑz�������ɂȂ����Ƃ��āA����ł�Larrabee������Ȃ��q�ł͂Ȃ����R
Intel��Larrabee�Ŏ������悤�Ƃ��Ă���̂�
�wMS��DirectX��x86GPU�ɂ̂ݑΉ�����悤�Ȋ������x����
���ꂪ��������AnVidia��GPGPU�ɂ����邾���ɂȂ邵
AMD��CPU+GPU�̃v�������ׂ���
AMD��Larrabee-clone����邩������Ȃ������
��ǂ������悤�ȏ�Intel�Ƃ��Ă�'�]�ނƂ���'�̂͂�
�܂��A����ȏ�k��M����o�J�͂��Ȃ��Ǝv�������
�wx86���j�Ƃ����A����R���s���[�e�B���O�̕W���x�̃^�_�̈ˑ�Ƃ���
���s��Larrabee���AIntel�͍����J�����Â��Ă���͂�����
�wx86���j�iry�x�̎����́ALarrabee��GPU��HPC�p�Ƃ��Đ��������鎖��������낤����
1.GPU�Ƃ��ăp�t�H�[�}���X���[�_�[�ɂȂ��͂��Ȃ����A���v���łȂ�
2.HPC�p�̃A�i�E���X���Ȃ��Ȃ������ƂŁAHPC�p�Ƃ��Ă͎��s�m��
3.HPC����GPU���̗h��Â��鐻�i�Ƃ��Ă̈ʒu�Â��A������肠��́H
�O�̖ϑz�������ɂȂ����Ƃ��āA����ł�Larrabee������Ȃ��q�ł͂Ȃ����R
Intel��Larrabee�Ŏ������悤�Ƃ��Ă���̂�
�wMS��DirectX��x86GPU�ɂ̂ݑΉ�����悤�Ȋ������x����
���ꂪ��������AnVidia��GPGPU�ɂ����邾���ɂȂ邵
AMD��CPU+GPU�̃v�������ׂ���
AMD��Larrabee-clone����邩������Ȃ������
��ǂ������悤�ȏ�Intel�Ƃ��Ă�'�]�ނƂ���'�̂͂�
�܂��A����ȏ�k��M����o�J�͂��Ȃ��Ǝv�������
�wx86���j�Ƃ����A����R���s���[�e�B���O�̕W���x�̃^�_�̈ˑ�Ƃ���
���s��Larrabee���AIntel�͍����J�����Â��Ă���͂�����
�wx86���j�iry�x�̎����́ALarrabee��GPU��HPC�p�Ƃ��Đ��������鎖��������낤����
�L���c
713 �FMAC�I�^��711 �����F2008/07/04(��) 00:05:14 ID:Z3ysYc2m
>>711
�@�@-------------------
�@�@Larrabee�����s����O�̗��R
�@�@-------------------
x86��CELL B.E.���ŐV�̐����v���Z�X�ő���Ƃ���A�Z�p�I�ɂ���Ɏ��s���闝�R��
�������Ǝv�����BGPU�̃}�[�P�b�g���Q�[���R���\�[���قǑ傫�����ǂ�����^�₷���ǁB�B�B
�@�@-------------------
�@�@Larrabee�����s����O�̗��R
�@�@-------------------
x86��CELL B.E.���ŐV�̐����v���Z�X�ő���Ƃ���A�Z�p�I�ɂ���Ɏ��s���闝�R��
�������Ǝv�����BGPU�̃}�[�P�b�g���Q�[���R���\�[���قǑ傫�����ǂ�����^�₷���ǁB�B�B
>MS��DirectX��x86GPU�ɂ̂ݑΉ�����悤�Ȋ������
�|�C���g�ł����Ǝv�����A���ꂪ��������Ȃ�F�X�ȕ����Ȍ��ɂȂ�B
������Ɨ~�����A����GPU�����b�`�ɂȂ�X���͑������낤��������ǂ����Ō����_�͂��邩�ƁB
�|�C���g�ł����Ǝv�����A���ꂪ��������Ȃ�F�X�ȕ����Ȍ��ɂȂ�B
������Ɨ~�����A����GPU�����b�`�ɂȂ�X���͑������낤��������ǂ����Ō����_�͂��邩�ƁB
�ǁ[�Ȃ�AGPU��CIL����@���悤�ɂ����邩��Ȃ�
GPU��DirectX8�ň�ʂ芮���̈���݂Ă���̂ŁA���ꂩ��͔ėp���ƍ��₷�����S�ɂȂ��
�K�v�Œ���̐��\������Cell�ł�GPU�Ƃ����̂̓A�E�g�����A�傫�ȗ���͔ėp���ł��邱�Ƃ͊ԈႢ�Ȃ��B
CPU�Ɠ����A�[�L�e�N�`��������V�X�e���Ώ̐��͑啝�Ɍ��サ�ĊJ�������₷���Ȃ邩��A���p���x���ɂȂ�ΕK���v���͔�������B
�K�v�Œ���̐��\������Cell�ł�GPU�Ƃ����̂̓A�E�g�����A�傫�ȗ���͔ėp���ł��邱�Ƃ͊ԈႢ�Ȃ��B
CPU�Ɠ����A�[�L�e�N�`��������V�X�e���Ώ̐��͑啝�Ɍ��サ�ĊJ�������₷���Ȃ邩��A���p���x���ɂȂ�ΕK���v���͔�������B
>>715
Tera-scale Computing
http://www.intel.com/technology/itj/2007/v11i3/2-exoskeleton/2-intro.htm
http://www.intel.com/technology/itj/2007/v11i3/2-exoskeleton/figures/figure_1_lg.gif
CHI runtime library -> DirectX
���肦��i�j
���Ƃ��̂͂Ȃ��ALarrabee��GPU�ɂȂ�̂Ȃ�
Havendale��GMCH��GPUcore��Larrabee�̂��̂��g���Ă����Ȃ��Ȃ�
����GMCH�́Ax86core�ƃ������R���g���[��,QPI,PCIe,DMI������邱�ƂɂȂ邪
����̓R�A�̈Ⴂ�ȊO�ɑ���Nehalem�Ƃǂ����Ⴄ�̂��H
���Ȃ��Ȃ�A����Ȃ̗p�ӂ��ĂȂ���Nehalem�����̂܂g������
�ϑz�͖ϑz�A��������
Tera-scale Computing
http://www.intel.com/technology/itj/2007/v11i3/2-exoskeleton/2-intro.htm
http://www.intel.com/technology/itj/2007/v11i3/2-exoskeleton/figures/figure_1_lg.gif
{kind=link}
CHI runtime library -> DirectX
���肦��i�j
���Ƃ��̂͂Ȃ��ALarrabee��GPU�ɂȂ�̂Ȃ�
Havendale��GMCH��GPUcore��Larrabee�̂��̂��g���Ă����Ȃ��Ȃ�
����GMCH�́Ax86core�ƃ������R���g���[��,QPI,PCIe,DMI������邱�ƂɂȂ邪
����̓R�A�̈Ⴂ�ȊO�ɑ���Nehalem�Ƃǂ����Ⴄ�̂��H
���Ȃ��Ȃ�A����Ȃ̗p�ӂ��ĂȂ���Nehalem�����̂܂g������
�ϑz�͖ϑz�A��������
>>718
�n�[�h�E�F�A���猩�Ă������ǂ������v�]������̂������Ă��Ȃ����낤�ȁA����Ȃ�PS3���ł����܂���www
�ł��Ȃ��Ƃ��ϑz�Ƃ�����Ȃ���A����Ε֗����Ƃ������B
�n�[�h�E�F�A���猩�Ă������ǂ������v�]������̂������Ă��Ȃ����낤�ȁA����Ȃ�PS3���ł����܂���www
�ł��Ȃ��Ƃ��ϑz�Ƃ�����Ȃ���A����Ε֗����Ƃ������B
�\�t�g���̗v�]�ɂ��������Ă�Ɛi���̃X�s�[�h���x���Ȃ����܂������
�o�����X�����
�o�����X�����
Havendale��GMA�ł�EU��12�ڂ���炵�����ǁANehalem�Ɠ����R�A�ł�
��������2�R�A���炢�����ڂ�Ȃ��Ǝv�����B
Nehalem��2�R�A��EU12���j�b�g���̐��\�o��́H
��������2�R�A���炢�����ڂ�Ȃ��Ǝv�����B
Nehalem��2�R�A��EU12���j�b�g���̐��\�o��́H
������������O��
>>720
�ǂ��ȂˁH
�ŋ߂̋Z�p�I�i�W�͂����\�t�g���ɂ��������悤�Ɍ����邯�ǂ�
Cell�Ƃ����Ă���Ǝ��ɂ���ȋC�������A�ςȃA�[�L���l���Ă��A�ǂ��Ȃ鏊������Έ����Ȃ�Ƃ��낪�K�������č��������O
���ʂ͔������ꂪ�������ďI���Ƃ����̂����ƁB
���n�[�h�I�ɂ����Ƃ��Z�p�̐i�����x�������̂̓v���Z�X���[���̐i���Ƃ������������S�ɂȂ��Ă���Ƃ����C�������B
������HDL�Ƃ������Ƀ\�t�g�I�ɂȂ��Ă��܂��āA�\�t�g�J���̃m�E�n�E���Ȃ��ނ炪����Ă��ǂ����ʂ��o���Ȃ�����ɂȂ��Ă����B
�ǂ��ȂˁH
�ŋ߂̋Z�p�I�i�W�͂����\�t�g���ɂ��������悤�Ɍ����邯�ǂ�
Cell�Ƃ����Ă���Ǝ��ɂ���ȋC�������A�ςȃA�[�L���l���Ă��A�ǂ��Ȃ鏊������Έ����Ȃ�Ƃ��낪�K�������č��������O
���ʂ͔������ꂪ�������ďI���Ƃ����̂����ƁB
���n�[�h�I�ɂ����Ƃ��Z�p�̐i�����x�������̂̓v���Z�X���[���̐i���Ƃ������������S�ɂȂ��Ă���Ƃ����C�������B
������HDL�Ƃ������Ƀ\�t�g�I�ɂȂ��Ă��܂��āA�\�t�g�J���̃m�E�n�E���Ȃ��ނ炪����Ă��ǂ����ʂ��o���Ȃ�����ɂȂ��Ă����B
���ł�Intel���\�t�g��
>>724
�܂Ƃ��ȃh���C�o���n�[�h�̔������ɏo���Ă�������
�܂Ƃ��ȃh���C�o���n�[�h�̔������ɏo���Ă�������
HDL���\�t�g�I�ɂȂ��Ă���Ăǂ��������ƁH
>>726
�f�W�^����H�̐v���Ă̂́A�\�t�g�J���ƕς��Ȃ���
http://ja.wikipedia.org/wiki/Verilog
����Ȍ�����g���đg�ނA�f�ނ��ǂ��Ȃ��Ă���Ƃ��A����ȃ��x���͈ӎ����Ȃ��B
�t��C#��LINQ�Ɍ�����悤�Ȏ��Ƃ����T�O�́A�Ή��������_���ɒu���������炻�̂܂�� nor nand �Q�[�g���̕��B
�ׂ����_�͂Ƃ������Ƃ��ċ�ʂ����܂�Ȃ���A�A�i���O��H�ɂȂ�Ƃ����Ԃ�l�����Ⴄ���ǂˁB
�f�W�^����H�̐v���Ă̂́A�\�t�g�J���ƕς��Ȃ���
http://ja.wikipedia.org/wiki/Verilog
����Ȍ�����g���đg�ނA�f�ނ��ǂ��Ȃ��Ă���Ƃ��A����ȃ��x���͈ӎ����Ȃ��B
�t��C#��LINQ�Ɍ�����悤�Ȏ��Ƃ����T�O�́A�Ή��������_���ɒu���������炻�̂܂�� nor nand �Q�[�g���̕��B
�ׂ����_�͂Ƃ������Ƃ��ċ�ʂ����܂�Ȃ���A�A�i���O��H�ɂȂ�Ƃ����Ԃ�l�����Ⴄ���ǂˁB
>>725
�r�f�I���傪�����ȁB���͂܂��܂��Ȃ��d
�r�f�I���傪�����ȁB���͂܂��܂��Ȃ��d
>>727
����Ȃ��Ƃ͂Ȃ��B
�����ڂ̓\�t�g�J���ƂɂĂ��邪�A�l���邱�Ƃ͂���Ⴄ�B
����Intel�݂����Ȑ�[�̃}�C�N���v���Z�b�T������Ă���悤��
��Ђł͘_���v���̂̊J���̔�d�����������A�f�W�^���Ƃ����Ă��A�i���O��H
�݂����ȗ̈�ɂȂ��Ă�B
����Ȃ��Ƃ͂Ȃ��B
�����ڂ̓\�t�g�J���ƂɂĂ��邪�A�l���邱�Ƃ͂���Ⴄ�B
����Intel�݂����Ȑ�[�̃}�C�N���v���Z�b�T������Ă���悤��
��Ђł͘_���v���̂̊J���̔�d�����������A�f�W�^���Ƃ����Ă��A�i���O��H
�݂����ȗ̈�ɂȂ��Ă�B
�����˂����b
�m�C�}�����m�C�}���^�R���s���[�^�����O�A�܂��R���s���[�^���^��ǂœ����Ă�������̓v���O�����̓n�[�h�E�F�A�őg�܂�Ă����B
�m�C�}�����Q�[�f��(�s���S���藝�ŗL��)�̍l�����Q�[�f����(�s���S���藝�̍\�z�Ɏg��ꂽ)�̃A�C�f�B�A�ɃC���X�p�C�������
�@�u���v�Ɓu�l�v�������ł����u�n�[�h�E�F�A�v�Ɓu�f�[�^�v�������ł���
���̎����Ɋ�Â��āA�u�v���O������H�v���u�����̗�v�ɑΉ����鎖���l�����A���ꂪ���݂̃}�V����œ��삷�邢����m�C�}���^�R���s���[�^�̌��^�B
�����ł���Ȃ�A�u�v���O�����v���u�n�[�h�E�F�A�v�ւ̑Ή��͑��݂��āA�\�[�X����n�[�h�E�F�A�ւ̃R���p�C��������Ƃ������B
>HDL���\�t�g�I�ɂȂ��Ă���Ăǂ��������ƁH
���͍ŏ�����A�����I�ɂ����������Ȃ�B
�m�C�}�����m�C�}���^�R���s���[�^�����O�A�܂��R���s���[�^���^��ǂœ����Ă�������̓v���O�����̓n�[�h�E�F�A�őg�܂�Ă����B
�m�C�}�����Q�[�f��(�s���S���藝�ŗL��)�̍l�����Q�[�f����(�s���S���藝�̍\�z�Ɏg��ꂽ)�̃A�C�f�B�A�ɃC���X�p�C�������
�@�u���v�Ɓu�l�v�������ł����u�n�[�h�E�F�A�v�Ɓu�f�[�^�v�������ł���
���̎����Ɋ�Â��āA�u�v���O������H�v���u�����̗�v�ɑΉ����鎖���l�����A���ꂪ���݂̃}�V����œ��삷�邢����m�C�}���^�R���s���[�^�̌��^�B
�����ł���Ȃ�A�u�v���O�����v���u�n�[�h�E�F�A�v�ւ̑Ή��͑��݂��āA�\�[�X����n�[�h�E�F�A�ւ̃R���p�C��������Ƃ������B
>HDL���\�t�g�I�ɂȂ��Ă���Ăǂ��������ƁH
���͍ŏ�����A�����I�ɂ����������Ȃ�B
ESL�Ƃ����������b����Ȃ��킯��
�ʂ�Verilog�g���Ă邩��\�t�g�I���Ă��Ƃ͂Ȃ����
#�Ƃ�@�Ȃ�ă\�t�g�ɂ͂��܂�Ȃ��T�O����Ȃ��H
�ʂ�Verilog�g���Ă邩��\�t�g�I���Ă��Ƃ͂Ȃ����
#�Ƃ�@�Ȃ�ă\�t�g�ɂ͂��܂�Ȃ��T�O����Ȃ��H
�͂邩�́A�n�[�h�E�F�A�͍����ō��̂�����ŁA�ʓ|���������ɂ߂镨�������̂ŁB
�m�C�}���́A�v���O�������f�[�^�����邱�ƂŕύX�̕K�v�ȑS�Ă��f�[�^�ɂ��čŏ����̃n�[�h�E�F�A�������\�z����Ηǂ��悤�ɂ����B
����Ńn�[�h�E�F�A�̕ύX�͎����s�v�A�n�[�h���P�������ɂȂ�����B
�������ŋ߂ɂȂ��ĂȂ�ڂĂ��g�����W�X�^���g����悤�ɂȂ�ƁA����ς���Ă���B
���G�ȃn�[�h�E�F�A�́A�g�����W�X�^���`���^����Âg�ݍ��킹��Ȃ�Ă͔̂��I�A�ꉭ���������b�ň�g�ݗ��ĂĂ��s���s�x�ŎO�N�ȏ�|���Ă��܂��B
�����ŁA�����I�ɂƂ������ƂɂȂ�ƁA��ɋ������t�ϊ��A�܂�\�t�g�I�ɂȂ�킯�B
�m�C�}���́A�v���O�������f�[�^�����邱�ƂŕύX�̕K�v�ȑS�Ă��f�[�^�ɂ��čŏ����̃n�[�h�E�F�A�������\�z����Ηǂ��悤�ɂ����B
����Ńn�[�h�E�F�A�̕ύX�͎����s�v�A�n�[�h���P�������ɂȂ�����B
�������ŋ߂ɂȂ��ĂȂ�ڂĂ��g�����W�X�^���g����悤�ɂȂ�ƁA����ς���Ă���B
���G�ȃn�[�h�E�F�A�́A�g�����W�X�^���`���^����Âg�ݍ��킹��Ȃ�Ă͔̂��I�A�ꉭ���������b�ň�g�ݗ��ĂĂ��s���s�x�ŎO�N�ȏ�|���Ă��܂��B
�����ŁA�����I�ɂƂ������ƂɂȂ�ƁA��ɋ������t�ϊ��A�܂�\�t�g�I�ɂȂ�킯�B
�Ӂ[��A�悭�킩��Ȃ���
�X����������
�X����������
>>730
�܂��A�d�C�E�d�q��HDL�n�̃X���ł����Ă݂��?
���ۏ����Ă��鑤���炷��ƁAHDL�������̂ƃ\�t�g�������̂ł�
���̒��ōl���Ă��邱�Ƃ͂܂�ňႤ�B���������b��͂悭���邩��B
���Ă�̂͌����ڂ����B
�\�t�g�̂悤�Ȓ����L�q����n�[�h����������Z�p��
�����ɂ��܂������ĂȂ��B
�܂��A�d�C�E�d�q��HDL�n�̃X���ł����Ă݂��?
���ۏ����Ă��鑤���炷��ƁAHDL�������̂ƃ\�t�g�������̂ł�
���̒��ōl���Ă��邱�Ƃ͂܂�ňႤ�B���������b��͂悭���邩��B
���Ă�̂͌����ڂ����B
�\�t�g�̂悤�Ȓ����L�q����n�[�h����������Z�p��
�����ɂ��܂������ĂȂ��B
����Intel�͏�肭�E�n�t�j�E���o����̂��H
���v�̍������A���^���͍����I�O���Ɍ͊�����?
http://slashdot.jp/science/article.pl?sid=08/07/04/103204
�ƃA�E�O�X�u���N��w�̍ޗ����w�҂ł���Armin Reller���ɂ��ƁA�K���E���͂��Ɛ��N�Ŏg���ʂ����Ă��܂�
���ꂪ����A�C���W�E���̖����ʂ�10�N���x���������Ȃ��\��������Ƃ̂��ƁB�����悤�Ƀn�t�j�E����2017�N
�ɂ͌͊����A������20�N�ȓ��Ɍ͊�����Ɨ\�����Ă��܂��B���̖����ʂ͂܂��������ł����A���E�I���v������
�\�ʂ��邽�߁A�����I���ɂ͌͊�����Ƃ̂��ƁB
���v�̍������A���^���͍����I�O���Ɍ͊�����?
http://slashdot.jp/science/article.pl?sid=08/07/04/103204
�ƃA�E�O�X�u���N��w�̍ޗ����w�҂ł���Armin Reller���ɂ��ƁA�K���E���͂��Ɛ��N�Ŏg���ʂ����Ă��܂�
���ꂪ����A�C���W�E���̖����ʂ�10�N���x���������Ȃ��\��������Ƃ̂��ƁB�����悤�Ƀn�t�j�E����2017�N
�ɂ͌͊����A������20�N�ȓ��Ɍ͊�����Ɨ\�����Ă��܂��B���̖����ʂ͂܂��������ł����A���E�I���v������
�\�ʂ��邽�߁A�����I���ɂ͌͊�����Ƃ̂��ƁB
>>729
�J�X�^�����W�b�N�Ȃ�A�Q�[�g���x��(���肷���g�����W�X�^���x��)�܂�
�~��Đv���Ă邾�낤���A�d�͋C�ɂ���悤�ɂȂ���
�����g���ĂȂ���������Ȃ����ǁA�A�N�e�B�u��H�g���Ă����ɂ�SPICE�K�{
���낤���˂�
�}�C�N���A�[�L�e�N�`���I�Ȑi��������Ă�̂���
����ς�p���[�E�H�[������Ԃ̌������Ǝv���Ȃ�
�J�X�^�����W�b�N�Ȃ�A�Q�[�g���x��(���肷���g�����W�X�^���x��)�܂�
�~��Đv���Ă邾�낤���A�d�͋C�ɂ���悤�ɂȂ���
�����g���ĂȂ���������Ȃ����ǁA�A�N�e�B�u��H�g���Ă����ɂ�SPICE�K�{
���낤���˂�
�}�C�N���A�[�L�e�N�`���I�Ȑi��������Ă�̂���
����ς�p���[�E�H�[������Ԃ̌������Ǝv���Ȃ�
���s���ρc orz
>>736
�g���C�Q�[�g��HighK�K�{�������H
�g���C�Q�[�g��HighK�K�{�������H
>>735
���A���^���ނ͂܂��S�z���Ȃ��Ă����v���Ǝv����A�Ƃ����̂͂��̎�̎����͕��Y���ł����݂��Ă���P�[�X��������
�l�i���オ���Ă���Ǝ�v���Y�������ŁA����ȊO�͎̂ĂĂ����z�R�������Ȃ萶�Y�J�n�����Ăǂ��Ƃ��Ȃ��N���Ă��邩��B
��Ηʂ����Ȃ��̂ł͂Ȃ��Č����̂悢���Y�n�����Ȃ��Ƃ��������|�C���g���Ǝv���B
�����d�ɗp�̃C���W���[���Ƃ������Ȃ�o�Ă��ĉ��i�}�������ˁB
�ʂ������i�̃u���̑傫�����R���C�C������A�g�p�ς݃`�b�v�����܂�����ł���悤�ɂ��āA���ł����o�ł���悤�ɏ������Ă��������������ɑ��邯�ɂȂ邩��
����̓G�R�����˂Ă����������Ƃ��������������낤�ˁB
���A���^���ނ͂܂��S�z���Ȃ��Ă����v���Ǝv����A�Ƃ����̂͂��̎�̎����͕��Y���ł����݂��Ă���P�[�X��������
�l�i���オ���Ă���Ǝ�v���Y�������ŁA����ȊO�͎̂ĂĂ����z�R�������Ȃ萶�Y�J�n�����Ăǂ��Ƃ��Ȃ��N���Ă��邩��B
��Ηʂ����Ȃ��̂ł͂Ȃ��Č����̂悢���Y�n�����Ȃ��Ƃ��������|�C���g���Ǝv���B
�����d�ɗp�̃C���W���[���Ƃ������Ȃ�o�Ă��ĉ��i�}�������ˁB
�ʂ������i�̃u���̑傫�����R���C�C������A�g�p�ς݃`�b�v�����܂�����ł���悤�ɂ��āA���ł����o�ł���悤�ɏ������Ă��������������ɑ��邯�ɂȂ邩��
����̓G�R�����˂Ă����������Ƃ��������������낤�ˁB
742 �F�R�E�L�́M�E,,�j�������������������F2008/07/05(�y) 17:28:32 ID:SeM2cjfK
Larrabee�͖łтʁI
���x�ł��h�邳
�Ƃ���ł��̐AMMX Pentium�̃p�C�v���C���\���𗬗p�����Ƃ����b�����邵�A
�R�P�Ēɂ��قǂ��܂��͂������Ȃ���ˁH
CPU���̂��̂��V����SIMD���߂y�����邱�Ƃ����ʂ̖ړI�ɂȂ肻����
�ɂ�ATi�~�͘_�������{�I�ɋ����Ă�̂ŕ��u��
���x�ł��h�邳
�Ƃ���ł��̐AMMX Pentium�̃p�C�v���C���\���𗬗p�����Ƃ����b�����邵�A
�R�P�Ēɂ��قǂ��܂��͂������Ȃ���ˁH
CPU���̂��̂��V����SIMD���߂y�����邱�Ƃ����ʂ̖ړI�ɂȂ肻����
�ɂ�ATi�~�͘_�������{�I�ɋ����Ă�̂ŕ��u��
744 �F�R�E�L�́M�E,,�j�������������������F2008/07/05(�y) 18:03:24 ID:SeM2cjfK
GPU�ł����A�S�̂ł�SIMD������4way SIMD���߂����A�x�N�g���X�p�R���̐��ނ������R�̂ЂƂ�
�x�N�g����(=SIMD��)������āA�J�X�^���A�v���̏ꍇ�A����50-70%���x�̃x�N�g��������
�S�R���\���o�Ȃ����Ă����
����l�����AVX���Đ��\�o��́H���Ďv��
���̕ӂ��猾���Ă܂�GPU�Ɏg���͖̂��������W
�x�N�g����(=SIMD��)������āA�J�X�^���A�v���̏ꍇ�A����50-70%���x�̃x�N�g��������
�S�R���\���o�Ȃ����Ă����
����l�����AVX���Đ��\�o��́H���Ďv��
���̕ӂ��猾���Ă܂�GPU�Ɏg���͖̂��������W
>745
�x�N�g�����̂Ƃ���́ACt���������Ă�����A�����ƁB
�x�N�g�����̂Ƃ���́ACt���������Ă�����A�����ƁB
747 �F�R�E�L�́M�E,,�j�������������������F2008/07/05(�y) 21:30:00 ID:SeM2cjfK
3�`4�I�y�����h���Ƃ��������p�ӂ��Ă���̂�AVX�̌����B
�K�v�Ȃ����YMM�̏�ʂ͎g��Ȃ��������B
�\�[�X���W�X�^�̑Ҕ����K�v�Ȃ��Ȃ镪���ꂾ���ł�������`1.5�{���x�̐��\���オ�����߂�B
�f�����b�g�͂Ȃ��ȁB
�K�v�Ȃ����YMM�̏�ʂ͎g��Ȃ��������B
�\�[�X���W�X�^�̑Ҕ����K�v�Ȃ��Ȃ镪���ꂾ���ł�������`1.5�{���x�̐��\���オ�����߂�B
�f�����b�g�͂Ȃ��ȁB
4�I�y�����h����50%������Ƃ����肦�ˁ[����www
749 �F�R�E�L�́M�E,,�j�������������������F2008/07/06(��) 07:18:24 ID:oqfcK7TC
>>748
�オ��Ƃ���͏オ��旝����́B
�Œ�ł����W�X�^�Ԃ̑Ҕ����K�v�Ȃ��Ȃ镪�́B
dest��src��ˑ��̃��W�X�^���w�肷�邱�ƂŎ��s�����Ɏ��R�������悤�ɂȂ邵�A
���W�X�^���l�[���̃q���g���܂߂邱�Ƃɂ��Ȃ�̂Ŗ��߃��x���������i�ł���B
���ƕ��������Ɋւ��Ă̓��C�e���V���傫������A�����[���ɂ������������K�v�����A
8�{�̘_�����W�X�^�͏��Ȃ�����B
���Ƃ����j�b�g��128�r�b�g�̂܂܂ł����W�X�^����2�{�ɂ��邱�ƂŃ��C�e���V�߂���B
���������߃T�C�Y�̐ߖ���ł���B
�オ��Ƃ���͏オ��旝����́B
�Œ�ł����W�X�^�Ԃ̑Ҕ����K�v�Ȃ��Ȃ镪�́B
dest��src��ˑ��̃��W�X�^���w�肷�邱�ƂŎ��s�����Ɏ��R�������悤�ɂȂ邵�A
���W�X�^���l�[���̃q���g���܂߂邱�Ƃɂ��Ȃ�̂Ŗ��߃��x���������i�ł���B
���ƕ��������Ɋւ��Ă̓��C�e���V���傫������A�����[���ɂ������������K�v�����A
8�{�̘_�����W�X�^�͏��Ȃ�����B
���Ƃ����j�b�g��128�r�b�g�̂܂܂ł����W�X�^����2�{�ɂ��邱�ƂŃ��C�e���V�߂���B
���������߃T�C�Y�̐ߖ���ł���B
>>745
>�x�N�g����(=SIMD��)�������
��鎖�����G�����R�[�h�̋K�͂��ł����Ȃ遨�x�N�g���������
���̉ߒ����Ԃɓ����Ă���Ǝv�ӁA�̂͂����ƊȒP�Ƀx�N�g�����ł����悤�ȋC������̂ŁB
>�x�N�g����(=SIMD��)�������
��鎖�����G�����R�[�h�̋K�͂��ł����Ȃ遨�x�N�g���������
���̉ߒ����Ԃɓ����Ă���Ǝv�ӁA�̂͂����ƊȒP�Ƀx�N�g�����ł����悤�ȋC������̂ŁB
>>736
�����Ő^��ǁi����
�����Ő^��ǁi����
�}�C�N���^��ǂ�
���̂ɂȂ�̂��ˁH
���̂ɂȂ�̂��ˁH
ttp://en.expreview.com/2008/07/07/larrabee-unleashes-2-tflops-capacity/
Larrabee unleashes 2 TFLOPS capacity
Last month, Intel reported the Larrabee featuring IA(Intel Architecture) core,
which means it can adapt present x86 architecture. And now we get to know that
the IA core is actually P54C, which is well known for over 13 years since the Pentium 75, according
to Pat Gelsinger, the Intel�fs Chief Technology Officer.
And what�fs more, this monster requires a 300W TDP, which also frustrates NVIDIA�fs biggest monster.
Larrabee unleashes 2 TFLOPS capacity
Last month, Intel reported the Larrabee featuring IA(Intel Architecture) core,
which means it can adapt present x86 architecture. And now we get to know that
the IA core is actually P54C, which is well known for over 13 years since the Pentium 75, according
to Pat Gelsinger, the Intel�fs Chief Technology Officer.
And what�fs more, this monster requires a 300W TDP, which also frustrates NVIDIA�fs biggest monster.
Intel��CPU��OS���������Ă�A�����łȂ��Ă�MS�Ƃ̒������قǗ₦����łȂ���A
����Apple�̂悤��CPU�A�[�L�e�N�`���ύX�{�G�~�����[�^�[�ňڍs���Ă���������Ȃ���
����MS����AMD�ۛ�������̂��c64Bit�Ȃ��Athlon64���^�[�Q�b�g�ɂ��Ă�n���c
����Apple�̂悤��CPU�A�[�L�e�N�`���ύX�{�G�~�����[�^�[�ňڍs���Ă���������Ȃ���
����MS����AMD�ۛ�������̂��c64Bit�Ȃ��Athlon64���^�[�Q�b�g�ɂ��Ă�n���c
NT�Œ��߂���A�A�[�L�e�N�`���ύX�͂��Ȃ���Ȃ��Ăł��Ȃ��B
Alpha�p NT �Ƃ����肵�Ȃ��Ďg���Ȃ��������ȁB
��������.Net Framework�̓W�J����ł͍ĂуA�[�L�e�N�`���ύX�\�ɂȂ邩���m���
Alpha�p NT �Ƃ����肵�Ȃ��Ďg���Ȃ��������ȁB
��������.Net Framework�̓W�J����ł͍ĂуA�[�L�e�N�`���ύX�\�ɂȂ邩���m���
�ł�PPC�pNT�͂��邶����
�Ƃ͌����A����Ԑ�������̂�x86������ύX���鎖�͖������낤��
�Ƃ͌����A����Ԑ�������̂�x86������ύX���鎖�͖������낤��
Larrabee�܂���"x86�̓\�t�g�����₷��>����������g���Ă��镪�ɂ͑卷�Ȃ�"
���āA�悭�����Ă��邯��ǁA������ăR���p�C����C�u�����̊J���ł����l�Ȃ́H
MS��HPC��Windows�荞�݂����݂��������A
����̈�Ƃ��Ă͖��͂������Ȃ����ȁH x86����Ă邾�낤��
���ۂ̂Ƃ���ALarrabee����ԗ~�������Ă�̂���Microsoft����Ȃ��́H
http://www.4gamer.net/news/history/2007.04/20070420195746detail.html
���āA�悭�����Ă��邯��ǁA������ăR���p�C����C�u�����̊J���ł����l�Ȃ́H
MS��HPC��Windows�荞�݂����݂��������A
����̈�Ƃ��Ă͖��͂������Ȃ����ȁH x86����Ă邾�낤��
���ۂ̂Ƃ���ALarrabee����ԗ~�������Ă�̂���Microsoft����Ȃ��́H
http://www.4gamer.net/news/history/2007.04/20070420195746detail.html
����͂܂��������x�����ĂȂ��悤�ȋC������̂ŁA���p�Ƃ��ė~������l�͂��Ȃ��悤�ȋC������
Cell���}�V���x����ėp�ɂ��鎖�͂ł���GPU�ɂ��ł��Ȃ��B
Cell���}�V���x����ėp�ɂ��鎖�͂ł���GPU�ɂ��ł��Ȃ��B
����ƁA�}�C�N���\�t�g�͂��ׂẴA�[�L�e�N�`���œ��삷��������ł��ڎw�����Ă�̂͊ԈႢ�Ȃ��Ǝv����B
��낤�Ƃ��ẮA���ǂ��܂������Ȃ��̌J��Ԃ��̗l�����ǂˁB
��낤�Ƃ��ẮA���ǂ��܂������Ȃ��̌J��Ԃ��̗l�����ǂˁB
TheINQ��Novakovic�L�҂ɂ��Penryn->Nehalem�ڍs���̃��C���i�b�v�̘b�肷�B
http://www.theinquirer.net/gb/inquirer/news/2008/07/07/launch-nehalem-penryns
�@�E���s��1600MHz FSB��V���O���\�P�b�g���f���ł�\�������Ȃ��߁A�����������R���g���[��
�@�@+ QPI������قǔ���I�Ȑ��\�����������ł햳��
�@�E�~�b�h�����WNehalem�̓o��܂ł̌����߂Ƃ��āAE0 stepping��Penryn���o��\��
�@�@�d���ETDP�����u���Ł`3.6GHz?
�@�ENehalem��3.6GHz��Extreme Edition����Ȃ������[�X�ł������Ȉ��
http://www.theinquirer.net/gb/inquirer/news/2008/07/07/launch-nehalem-penryns
�@�E���s��1600MHz FSB��V���O���\�P�b�g���f���ł�\�������Ȃ��߁A�����������R���g���[��
�@�@+ QPI������قǔ���I�Ȑ��\�����������ł햳��
�@�E�~�b�h�����WNehalem�̓o��܂ł̌����߂Ƃ��āAE0 stepping��Penryn���o��\��
�@�@�d���ETDP�����u���Ł`3.6GHz?
�@�ENehalem��3.6GHz��Extreme Edition����Ȃ������[�X�ł������Ȉ��
Xtreme Systems�f����J.Cornell������I���Ă���̂Ǝ����悤��Nehalem�̃T���v����
��p��Tom's Hardware�����J���Ă��邷�B���RNDA�Ńx���`���ʓ��햳�������ǁA�ڂ���������
�`�b�v�ʐ^�t���B
http://www.tomshardware.com/news/intel-x58-nehalem,5829.html
��p��Tom's Hardware�����J���Ă��邷�B���RNDA�Ńx���`���ʓ��햳�������ǁA�ڂ���������
�`�b�v�ʐ^�t���B
http://www.tomshardware.com/news/intel-x58-nehalem,5829.html
762 �FMAC�I�^��753 �����F2008/07/08(��) 01:48:26 ID:dhOdnMRV
>>753
����\�[�X��h�C�c�̗L��PC�G���AC't�̋L�����B
http://www.heise.de/ct/08/15/022/
���p�����ȊO�ɂ��A�F�X�������Ȃ��Ƃ������Ă��邷�B�B�B
�@�E512-bit SIMD
�@�E32-core
�@�E2GHz
�@�E2TFlops
�@�E300W
����\�[�X��h�C�c�̗L��PC�G���AC't�̋L�����B
http://www.heise.de/ct/08/15/022/
���p�����ȊO�ɂ��A�F�X�������Ȃ��Ƃ������Ă��邷�B�B�B
�@�E512-bit SIMD
�@�E32-core
�@�E2GHz
�@�E2TFlops
�@�E300W
300W���ė�p�o����́H�܂�������K�{�̃V�X�e���ł����H
764 �FSocket774�F2008/07/08(��) 06:21:08 ID:kkLERpkt
���������ްقͳ���ްق̌�p�I�Ȉʒu�t�����Ǝv�����ǁA��ٰ�̨���ނ���̨���ނ̈ʒu�t�������܂����������
Intel�Ƃ��Ă������ްقƿ��Ă����ʂ���̨���ނ�ְ�̨���ނ̌�p�Ƃ������́H
���Ƃ�������ٰ�̨���ނ�LGA771�݂����Ɉʒu�t���ɂȂ�̂��H
Intel�Ƃ��Ă������ްقƿ��Ă����ʂ���̨���ނ�ְ�̨���ނ̌�p�Ƃ������́H
���Ƃ�������ٰ�̨���ނ�LGA771�݂����Ɉʒu�t���ɂȂ�̂��H
>>760
>�N���b�N�������x�AQPI��FBS1600MH���ő��F�Ȃ��B
�v�X���H���ɂȂ�Ǝv�����ANehalem�t�@�~���[��Penryn�t�@�~���[�B
�ǂ�ł�Ƒ����̏���Ȉ�ۂ�����݂���������Ȃ�Ƃ������Ȃ����A
E�O�X�e�b�s���O��3.6�܂ŐU���Ă���Ȃ�A
Extreme�͂SG�܂ŐU���Ƃ��Ȃ��ƃA�s�[���Ȃ��Ȃ�Ȃ����H
SMT�H
>�N���b�N�������x�AQPI��FBS1600MH���ő��F�Ȃ��B
�v�X���H���ɂȂ�Ǝv�����ANehalem�t�@�~���[��Penryn�t�@�~���[�B
�ǂ�ł�Ƒ����̏���Ȉ�ۂ�����݂���������Ȃ�Ƃ������Ȃ����A
E�O�X�e�b�s���O��3.6�܂ŐU���Ă���Ȃ�A
Extreme�͂SG�܂ŐU���Ƃ��Ȃ��ƃA�s�[���Ȃ��Ȃ�Ȃ����H
SMT�H
>�E���s��1600MHz FSB��V���O���\�P�b�g���f���ł�\�������Ȃ��߁A�����������R���g���[��
>�@�@+ QPI������قǔ���I�Ȑ��\�����������ł햳��
Core2�ł���FSB�ł��܂萫�\�ɉe���Ȃ��͕̂������Ă�������A����X������B
�ނ���C���e�������̓_���������邱�ƂɈ�a�����犴���Ă����̂ŁB
>�@�@+ QPI������قǔ���I�Ȑ��\�����������ł햳��
Core2�ł���FSB�ł��܂萫�\�ɉe���Ȃ��͕̂������Ă�������A����X������B
�ނ���C���e�������̓_���������邱�ƂɈ�a�����犴���Ă����̂ŁB
FSB800MHz��1600MHz���Ƒ̊����\�ς���Ă��邼�B
>>767
�������ĕς��Ȃ���AQX9650�����Ă�̂Ŏ����ς�
�������ĕς��Ȃ���AQX9650�����Ă�̂Ŏ����ς�
>>768
E4500��333x9��266x11�Ŏg���Ă����̊����\������B
E4500��333x9��266x11�Ŏg���Ă����̊����\������B
�܂��L���b�V���̊W������̂����m��Ȃ�
�����̓L���b�V���ł�����Ȃ�L���b�V���������Ǝv���Ă���B
�����̓L���b�V���ł�����Ȃ�L���b�V���������Ǝv���Ă���B
�Ƃ͌������C�e���V�̒ጸ�ɂ͑������ʂ��邾�낤�B
�c�Ǝv�����Ai965�̎��_��FSB���������Ȃ�AMD��CPU��背�C�e���V�Ⴉ�������A
����ȏ�͂���܂���P�Ȃ������ˁB
Nehalem�̃R�A���ǂ̓R���V���[�}�����͂Ƃ������A�G���^�[�v���C�Y�����ł͌��ʂ�����A
�A�s�[���Ȃ����Ď��͖����Ǝv����B
SSE4.2�̌��ʂ������Ă����x���`���ʂ������������ǁADB�Ȃł͂��̐������ʂ�����B�͂�
�c�Ǝv�����Ai965�̎��_��FSB���������Ȃ�AMD��CPU��背�C�e���V�Ⴉ�������A
����ȏ�͂���܂���P�Ȃ������ˁB
Nehalem�̃R�A���ǂ̓R���V���[�}�����͂Ƃ������A�G���^�[�v���C�Y�����ł͌��ʂ�����A
�A�s�[���Ȃ����Ď��͖����Ǝv����B
SSE4.2�̌��ʂ������Ă����x���`���ʂ������������ǁADB�Ȃł͂��̐������ʂ�����B�͂�
http://nueda.main.jp/blog/archives/003620.html
���łɂ��ꂪ�{���Ȃ�A�}���`�X���b�h�Ō����1.5�{�`2.0�{
�V���O���X���b�h��1.2�{�ƗD�G�Ȍ��ʂ��o�Ă�B
�}���`�X���b�h�F 2.93GHz(Bloomfield) �� 4.4 or 4.5GHz(Yorkfield)
�V���O���X���b�h�F 2.93GHz(Bloomfield) �� 3.5GHz(Yorkfield)
��̂���Ȋ�����
���łɂ��ꂪ�{���Ȃ�A�}���`�X���b�h�Ō����1.5�{�`2.0�{
�V���O���X���b�h��1.2�{�ƗD�G�Ȍ��ʂ��o�Ă�B
�}���`�X���b�h�F 2.93GHz(Bloomfield) �� 4.4 or 4.5GHz(Yorkfield)
�V���O���X���b�h�F 2.93GHz(Bloomfield) �� 3.5GHz(Yorkfield)
��̂���Ȋ�����
> E4500��333x9��266x11�Ŏg���Ă����̊����\������B
���ꃁ�����ݒ肪����Ă邩�炶��Ȃ�����?
�������ݒ肪�����Ȃ�̊��o����悤�ȍ��͔������Ȃ����B
���ꃁ�����ݒ肪����Ă邩�炶��Ȃ�����?
�������ݒ肪�����Ȃ�̊��o����悤�ȍ��͔������Ȃ����B
���\�Ɋւ��Ă͎��̂Ƃ��날�܂���҂͂��Ă��Ȃ��A�����R�������Ƃ��Œ����I�ɂ̓R�X�g�������Ȃ��Ȃ�����
������̕��������͒��ړx�������ǂ�
������̕��������͒��ړx�������ǂ�
>>776
OCer��FSB�ɌŎ����闝�R���ȂƂ������Ă��
OCer��FSB�ɌŎ����闝�R���ȂƂ������Ă��
>>778
����͈Ⴄ�B
�x���`�ł�FSB��������X�R�A�͐L�т�B
FSB���Ⴂ�ƂЂ�������iAMD�ł�����������j�����܂��B
����266x11��333x9��janestyle�̋N�����ׂ�ƌ�҂̕����X���[�Y�������B
����͈Ⴄ�B
�x���`�ł�FSB��������X�R�A�͐L�т�B
FSB���Ⴂ�ƂЂ�������iAMD�ł�����������j�����܂��B
����266x11��333x9��janestyle�̋N�����ׂ�ƌ�҂̕����X���[�Y�������B
����Vista�̃X�R�A�ł�333x9����5.6�����A400x8����5.9�ɂȂ�B
�L���b�V���������c�_�͖��Ӗ�����A����CPU�̐��\�ł̓������ɃA�N�Z�X����Ƃ����s�ׂ��̂��̂��v���I��
�����炱�ꂪ����ɒx���Ȃ��Ă��ʖډ����Ƃ������Ԃ�m���Ă����ׂ����B
�����炱�ꂪ����ɒx���Ȃ��Ă��ʖډ����Ƃ������Ԃ�m���Ă����ׂ����B
>>781
����͂��̘b�ɑS���W�Ȃ��ȁB�L���b�V���ɂ�鍷�ł�������Ƃ����̂͂��邾�낤���ȁB
FSB�ɂ�鍷�Ƃ����̂́A�X�R�A�ł͋ɒ[�ɂ͂łȂ����̊��ł͑傫���B
�L���b�V�����Ɏ��܂�Ȃ��\�t�g�E�F�A�����A���R�������ɃA�N�Z�X���s���킯������
���̂Ƃ��AFSB���Ⴏ��������芴�����܂��B
����FSB�̓��C�e���V���傫������AAMD��HT�Ɣ�ׂ�Ƃ�������ɂȂ�B
����͂��̘b�ɑS���W�Ȃ��ȁB�L���b�V���ɂ�鍷�ł�������Ƃ����̂͂��邾�낤���ȁB
FSB�ɂ�鍷�Ƃ����̂́A�X�R�A�ł͋ɒ[�ɂ͂łȂ����̊��ł͑傫���B
�L���b�V�����Ɏ��܂�Ȃ��\�t�g�E�F�A�����A���R�������ɃA�N�Z�X���s���킯������
���̂Ƃ��AFSB���Ⴏ��������芴�����܂��B
����FSB�̓��C�e���V���傫������AAMD��HT�Ɣ�ׂ�Ƃ�������ɂȂ�B
>>782
�ނ���唼�̃R�[�h���L���b�V���Ɏ��߂Ă��܂��悤�ɐv����̂��������Ǝv��
���Ƀ}���`CPU�Ȃ�o�X�̋��������邱�ƂȂ���ʐM�g���t�B�b�N�͍ŏ����ɂ���悤�ɂ������������B
�ނ���唼�̃R�[�h���L���b�V���Ɏ��߂Ă��܂��悤�ɐv����̂��������Ǝv��
���Ƀ}���`CPU�Ȃ�o�X�̋��������邱�ƂȂ���ʐM�g���t�B�b�N�͍ŏ����ɂ���悤�ɂ������������B
>>783
>�ނ���唼�̃R�[�h���L���b�V���Ɏ��߂Ă��܂��悤�ɐv����̂��������Ǝv��
����͂������Ƃ�
>���Ƀ}���`CPU�Ȃ�o�X�̋��������邱�ƂȂ���ʐM�g���t�B�b�N�͍ŏ����ɂ���悤�ɂ�����������
���̂��߂�FSB����QPI�ɕύX������Ȃ��̂��H
�T�[�o�����ɂ����������}���`�X���b�h���\��傫�����コ�����B
>�ނ���唼�̃R�[�h���L���b�V���Ɏ��߂Ă��܂��悤�ɐv����̂��������Ǝv��
����͂������Ƃ�
>���Ƀ}���`CPU�Ȃ�o�X�̋��������邱�ƂȂ���ʐM�g���t�B�b�N�͍ŏ����ɂ���悤�ɂ�����������
���̂��߂�FSB����QPI�ɕύX������Ȃ��̂��H
�T�[�o�����ɂ����������}���`�X���b�h���\��傫�����コ�����B
>>785
���܂��B
L2�L���b�V�����Ɏ��܂�Ȃ���������ɃA�N�Z�X����������B
���C�e���V���傫��FSB�Ȃ�A���̍��͌����B
���܂��B
L2�L���b�V�����Ɏ��܂�Ȃ���������ɃA�N�Z�X����������B
���C�e���V���傫��FSB�Ȃ�A���̍��͌����B
������"��������"�Č��t�����܂��킯�ŁAL2�����Ȃ��Ă���C�e���V�A�L�ш�ł����
����Ȃ��Ƃ������Ȃ���ȁB
����Ȃ��Ƃ������Ȃ���ȁB
>>768-787
�A���~����?
�A���~���ĕs�v�c�Ȑ���
AthlonXP�̎��ォ��L�r�L�r�Ƃ������Ă��B
�������߂������Ƃɍ�����v���L�ш悶��Ȃ��B
�A���~����?
�A���~���ĕs�v�c�Ȑ���
AthlonXP�̎��ォ��L�r�L�r�Ƃ������Ă��B
�������߂������Ƃɍ�����v���L�ш悶��Ȃ��B
>>789
�܂�
C2D��AthlonXP���y���ɃL�r�L�r���Ă��Ƃ�FA?
6ifHhkvs����̌��������Ƌɒ[�ɂ������肵�Ă���ƌ����Ă�悤�ɂ����������Ȃ��̂����ǂ��E�E�E
�܂�
C2D��AthlonXP���y���ɃL�r�L�r���Ă��Ƃ�FA?
6ifHhkvs����̌��������Ƌɒ[�ɂ������肵�Ă���ƌ����Ă�悤�ɂ����������Ȃ��̂����ǂ��E�E�E
������MAC�I�^�������Ă����O���t���ƁADDR2����ł�FSB�͌��\�A�N�Z�X���C�e���V�ɋ����Ă��B
�Ƃ������AFSB�̐L�тɏ]���đf���ɃA�N�Z�X���C�e���V���������Ă�
�ł��A�������̃��C�e���V��HT�ĊW�Ȃ��ˁH>>782
NUMA���Ȃ�Ƃ�����
�Ƃ������AFSB�̐L�тɏ]���đf���ɃA�N�Z�X���C�e���V���������Ă�
�ł��A�������̃��C�e���V��HT�ĊW�Ȃ��ˁH>>782
NUMA���Ȃ�Ƃ�����
�m���ɁA333��400���炢�L�ш�Ȃ�A���̍��͕�����Ȃ��ȁB
200��266��333�A�܂�Allendale��Conroe�̍��͌��\�킩��B
�܂��A�����L2�̗e�ʂ��Ⴄ�����T�ɔ�r����͓̂�����ǁB
200��266��333�A�܂�Allendale��Conroe�̍��͌��\�킩��B
�܂��A�����L2�̗e�ʂ��Ⴄ�����T�ɔ�r����͓̂�����ǁB
>>790
Athlon�l�o*2�Ƃb2�c�͖w�Ǖς��Ȃ����Ă��Ƃ�
�x�[�X�N���b�N���c�c�q2�Ƃ͂���667����166������
���nj��������x����Ă邪AthlonXP�̂e�r�a166�ƂȂ��ς��Ȃ�
����������Ƒ҂��ė~����
����Ȃ��Ƃ�萫�\�����Ă���
���炩�ɂ��̎���̂b�o�t�Ɣ�ו��ɂȂ�Ȃ�����
�����炱��ȏ�e�r�a�Ƃ��ł��߂��
�l�n�[�����łǂ��������R���ςނ��B
Athlon�l�o*2�Ƃb2�c�͖w�Ǖς��Ȃ����Ă��Ƃ�
�x�[�X�N���b�N���c�c�q2�Ƃ͂���667����166������
���nj��������x����Ă邪AthlonXP�̂e�r�a166�ƂȂ��ς��Ȃ�
����������Ƒ҂��ė~����
����Ȃ��Ƃ�萫�\�����Ă���
���炩�ɂ��̎���̂b�o�t�Ɣ�ו��ɂȂ�Ȃ�����
�����炱��ȏ�e�r�a�Ƃ��ł��߂��
�l�n�[�����łǂ��������R���ςނ��B
�I�J���g�I�[�f�B�I�݂����ȃX���ɂȂ��Ă�����
795 �F�R�E�L�́M�E,,�j�������������������F2008/07/08(��) 09:18:38 ID:vYuKTZ/4
>>764
Broomfield��QX9775(Harpertown�̓]�p)�̌�p�̈ʒu�t����2�\�P�b�g�EDDR3�g���v���`���l���Ή�
Lynnfield���~�b�h�����W�ȏ���J�o�[������̂��ƁB
Penryn����̈ڍs�Ȃ�L���b�V�����ʂ����Westmare�҂��������悳���B
�ł�Westmare�܂ő҂�����SandyBridge���E�E�E
Broomfield��QX9775(Harpertown�̓]�p)�̌�p�̈ʒu�t����2�\�P�b�g�EDDR3�g���v���`���l���Ή�
Lynnfield���~�b�h�����W�ȏ���J�o�[������̂��ƁB
Penryn����̈ڍs�Ȃ�L���b�V�����ʂ����Westmare�҂��������悳���B
�ł�Westmare�܂ő҂�����SandyBridge���E�E�E
���ł�Westmare�܂ő҂�����SandyBridge���E�E�E
����Ȏ������Ă���tick-tock�ł͂��܂ł����Ă�CPU�������܂���
����Ȏ������Ă���tick-tock�ł͂��܂ł����Ă�CPU�������܂���
>>796
��Âɍl����Ƃ��܂ǂ��p�\�R���Ȃ�ĉ���܂Ŕ���������K�v�Ȃ���
��Âɍl����Ƃ��܂ǂ��p�\�R���Ȃ�ĉ���܂Ŕ���������K�v�Ȃ���
798 �F�R�E�L�́M�E,,�j�������������������F2008/07/08(��) 09:43:46 ID:vYuKTZ/4
�}�U�[�������������������Ȃ̂��ɂ�
���̉��̃}�V����DDR2 800��2G��4����8G�����ǁADDR3�ł����ς�ǂꂾ����������
���̉��̃}�V����DDR2 800��2G��4����8G�����ǁADDR3�ł����ς�ǂꂾ����������
���Ԃ��������Ă�����
�܂��A������X���������
>>801
22nm�v���Z�X���āA���N1������A32nm��Westmare�̃_�C�ʐ^�����J����āA22nm�͉č�
����SRAM����N�ǂ��蔭�\�����̂��ȁH������2�N�����Ȃ炻��Ȋ����������H
22nm�v���Z�X���āA���N1������A32nm��Westmare�̃_�C�ʐ^�����J����āA22nm�͉č�
����SRAM����N�ǂ��蔭�\�����̂��ȁH������2�N�����Ȃ炻��Ȋ����������H
Intel��32nm�v���Z�X�����Ƀj�R���̉t�Z�I�����u������Ƃ̂��Ƃ��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208803035
�@�@----------------------
�@�@At 32-nm, Intel will exclusively use Nikon's 193-nm immersion tools for the ''critical layers''
�@�@at 32-nm; the chip giant will also use Nikon's tools for the non-critical layers, according to
�@�@sources.
�@�@----------------------
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=208803035
�@�@----------------------
�@�@At 32-nm, Intel will exclusively use Nikon's 193-nm immersion tools for the ''critical layers''
�@�@at 32-nm; the chip giant will also use Nikon's tools for the non-critical layers, according to
�@�@sources.
�@�@----------------------
���[�U�[���i�����ĂĎ��O���I�����o�������Ȋ��������A
22nm�͂�����悤�ȋC������B
16nm�͊m���ɐ悪�������
22nm�͂�����悤�ȋC������B
16nm�͊m���ɐ悪�������
CG�A�j���[�V���������Dreamworks��Intel�ɃX�C�b�`�����Ƃ̂��Ƃ��B
�ȉ��AIntel�̃v���X�����[�X���B
http://www.intel.com/pressroom/archive/releases/20080708corp.htm?iid=pr1_releasepri_20080708r
�@�@--------------------------
�@�@To meet the increased demands of creating 3-D animated feature films, Intel will provide
�@�@DreamWorks Animation with the latest high-performance processing technologies, including
�@�@future chips with multiple processing cores.
�@�@--------------------------
�Ȃ��A����"future chips with multiple processing cores"�����ǁATGDaily�ɂ��Ɠ�����Nehalem�A
����Larrabee�Ƃ̂��Ƃ��B
http://www.tgdaily.com/html_tmp/content-view-38293-135.html
�@�@==========================
�@�@Intel spokesman Nick Knupffer told TG Daily that the �gfuture chips�h note refers to Nehalem
�@�@CPUs as well Larrabee cGPUs, an upcoming multi-core graphics and floating point accelerator
�@�@architecture.
�@�@==========================
Larrabee�������Ɣ��荞�ݐ��m�ۂ�����Ƃ������ƂŁB�B�B
�ȉ��AIntel�̃v���X�����[�X���B
http://www.intel.com/pressroom/archive/releases/20080708corp.htm?iid=pr1_releasepri_20080708r
�@�@--------------------------
�@�@To meet the increased demands of creating 3-D animated feature films, Intel will provide
�@�@DreamWorks Animation with the latest high-performance processing technologies, including
�@�@future chips with multiple processing cores.
�@�@--------------------------
�Ȃ��A����"future chips with multiple processing cores"�����ǁATGDaily�ɂ��Ɠ�����Nehalem�A
����Larrabee�Ƃ̂��Ƃ��B
http://www.tgdaily.com/html_tmp/content-view-38293-135.html
�@�@==========================
�@�@Intel spokesman Nick Knupffer told TG Daily that the �gfuture chips�h note refers to Nehalem
�@�@CPUs as well Larrabee cGPUs, an upcoming multi-core graphics and floating point accelerator
�@�@architecture.
�@�@==========================
Larrabee�������Ɣ��荞�ݐ��m�ۂ�����Ƃ������ƂŁB�B�B
http://japan.cnet.com/news/ent/story/0,2000056022,20376943,00.htm
�y���e�B�A�������M�A�킩��܂��B
�y���e�B�A�������M�A�킩��܂��B
�Ƃ肠����GPU�Ƃ��čU�߂�Ƃ������ł����A�܂��Ó��Ȋ����͂��܂��ˁB
Tom's Hardware��>>761�̑��B�����x���`�}�[�N��
http://www.tomshardware.com/news/intel-nehalem-core,5854.html
�@���\��
�@�@Nehalem/2.93GHz
�@�@prototype x58 motherboard
�@�@DDR3-1600 1GBx2
�@�@Radeon 4850 HD, 1280x1024
�@������
�@�@3DMark 06 (1280x1024 noAA)
�@�@�@- total: 12786
�@�@�@- SM2.0: 4605
�@�@�@- HDR/SM3.0: 5600
�@�@�@- CPU: 5183
�@�@PCMark05
�@�@�@- total: 9852
�@�@�@- CPU: 9583
�@�@�@- Memory: 9010
�@�@3DMark Vantage
�@�@�@- CPU total: 17966
�@�@�@- CPU Test1: 2515.1 [plans/s]
�@�@�@- CPU Test2: 23.08 [steps/s]
http://www.tomshardware.com/news/intel-nehalem-core,5854.html
�@���\��
�@�@Nehalem/2.93GHz
�@�@prototype x58 motherboard
�@�@DDR3-1600 1GBx2
�@�@Radeon 4850 HD, 1280x1024
�@������
�@�@3DMark 06 (1280x1024 noAA)
�@�@�@- total: 12786
�@�@�@- SM2.0: 4605
�@�@�@- HDR/SM3.0: 5600
�@�@�@- CPU: 5183
�@�@PCMark05
�@�@�@- total: 9852
�@�@�@- CPU: 9583
�@�@�@- Memory: 9010
�@�@3DMark Vantage
�@�@�@- CPU total: 17966
�@�@�@- CPU Test1: 2515.1 [plans/s]
�@�@�@- CPU Test2: 23.08 [steps/s]
809 �FMAC�I�^��807 �����F2008/07/10(��) 22:39:19 ID:eIbyEQ62
>>807
�@�@----------------------
�@�@�Ƃ肠����GPU�Ƃ��čU�߂�Ƃ������ł����A
�@�@----------------------
�����_�[�t�@�[����AGPU�Ƃ��Ă̗p�r���ᖳ�����B
�@�@----------------------
�@�@�Ƃ肠����GPU�Ƃ��čU�߂�Ƃ������ł����A
�@�@----------------------
�����_�[�t�@�[����AGPU�Ƃ��Ă̗p�r���ᖳ�����B
810 �FMAC�I�^��806 �����F2008/07/10(��) 22:40:46 ID:eIbyEQ62
�o�J�̃I�i�j�[�������͂��ȁ@���̎�̂��������藘�p���Ă���A��
812 �F�R�E�L�́M�E,,�j�������������������F2008/07/11(��) 20:35:14 ID:zSpAZ5Y4
P5�Ƃ̋��ʓ_����U/V�p�C�v�ȏ�ł��ȉ��ł��������낽�Ԃ�B
256bit��SIMD�T�|�[�g�ł����ł����_�C�ʐϐH������
P6����OoO�����������(Atom�̂���)�����X�Ȃ�
�p�C�v���C���̒P�������K�v�������ɈႢ�Ȃ��B
256bit��SIMD�T�|�[�g�ł����ł����_�C�ʐϐH������
P6����OoO�����������(Atom�̂���)�����X�Ȃ�
�p�C�v���C���̒P�������K�v�������ɈႢ�Ȃ��B
HKEPC�ɂ���SLI��QPI�̃��C�Z���X�Ɋւ���NVIDIA�Ƃ̌����܂Ƃ܂����͗l���B
http://www.hkepc.com/?id=1440&fs=c1h
�@�@�ENVIDIA��QPI�̃o�X���C�Z���X���擾�BSocket1160����(Havendale/Linfield)������
�@�@�@�`�b�v�Z�b�g���J������
�@�@�EBloomfield�����SLI�T�|�[�g��ASkulltrail�Ɠ��l��NVIDIA��PCIe�u���b�WnForce200��
�@�@�@�}�U�[�{�[�h�ɓ��ڂ��邱�ƂŎ�������
http://www.hkepc.com/?id=1440&fs=c1h
�@�@�ENVIDIA��QPI�̃o�X���C�Z���X���擾�BSocket1160����(Havendale/Linfield)������
�@�@�@�`�b�v�Z�b�g���J������
�@�@�EBloomfield�����SLI�T�|�[�g��ASkulltrail�Ɠ��l��NVIDIA��PCIe�u���b�WnForce200��
�@�@�@�}�U�[�{�[�h�ɓ��ڂ��邱�ƂŎ�������
814 �FMAC�I�^���c�q �����F2008/07/11(��) 22:23:38 ID:ZjfUBvyG
>>812
�@�@------------------
�@�@256bit��SIMD�T�|�[�g��
�@�@------------------
����512-bit���Ƃ����\������Ă��邷���ǁB�B�B
�@�@------------------
�@�@256bit��SIMD�T�|�[�g��
�@�@------------------
����512-bit���Ƃ����\������Ă��邷���ǁB�B�B
����NVIDIA�̓��[�G���h���t�HATOM���������Ă����́H
816 �F�R�E�L�́M�E,,�j�������������������F2008/07/12(�y) 09:07:55 ID:cL+fyQY2
x87�x�[�X��2DP�ƌ��\����Ă邩��2���j�b�g�͊m�肾�낤�B
�[��512bit�͂܂��悾�낤�B
�[��512bit�͂܂��悾�낤�B
817 �FMAC�I�^���c�q �����F2008/07/12(�y) 09:14:58 ID:KULmXOzq
>>816
x87�H�܂���X��掃R�s�y�̃l�^�ɂȂ�悤�ȏ������݂��B�B�B
x87�H�܂���X��掃R�s�y�̃l�^�ɂȂ�悤�ȏ������݂��B�B�B
818 �FMAC�I�^���⑫�F2008/07/12(�y) 09:21:47 ID:KULmXOzq
�^�U��ʂɂ��āA�ŋ߂̉\���\�[�X�t�ł܂Ƃ߂Ă���Ƃ����_�ł�Wikipedia���ǂ��������B
�ϑz�𐂂ꗬ���O�Ɉ�ǂ��鉿�l��L���Ȃ������ˁB�B�B
http://en.wikipedia.org/wiki/Larrabee_(GPU)#More_recent_information
�ϑz�𐂂ꗬ���O�Ɉ�ǂ��鉿�l��L���Ȃ������ˁB�B�B
http://en.wikipedia.org/wiki/Larrabee_(GPU)#More_recent_information
��������
>>678
�������͐^��ɂ͉������݂��Ă��Ȃ��Ǝv���Ă������A����Ȃ̂͊ԈႢ�������I
�^��Ƃ̓N�I�[�N�Ɣ��N�I�[�N�����߂������ꂾ������I
���������Ȃ��ā[�I
�Ƃ������l�ȋc�_���Ă���薳������ˁH
�������͐^��ɂ͉������݂��Ă��Ȃ��Ǝv���Ă������A����Ȃ̂͊ԈႢ�������I
�^��Ƃ̓N�I�[�N�Ɣ��N�I�[�N�����߂������ꂾ������I
���������Ȃ��ā[�I
�Ƃ������l�ȋc�_���Ă���薳������ˁH
821 �F,,�E�L�́M�E,,�j���F2008/07/12(�y) 10:18:01 ID:cL+fyQY2
x87��݊��Ƃł��H
����k��
����k��
822 �F,,�E�L�́M�E,,�j���F2008/07/12(�y) 10:23:47 ID:cL+fyQY2
Wikipedia�ɂ��ySSE�Ȃ��Łz2DP/clk���ď����Ă���ȁB
�[��x87���߂��܂߂Č݊����Ƃ邱�Ƃ�Intel�����̃X���C�h�ł����炩�Ȃ�
�[��x87���߂��܂߂Č݊����Ƃ邱�Ƃ�Intel�����̃X���C�h�ł����炩�Ȃ�
>>820
������܂߂Ă̌����e�[�}���Ǝv����Aqubit�v�Z���C����������
�r�b�g���₷���Ƃɔ{�������ԁA�������I�y���[�V���������j�^���ϊ��ʼnt�ɂȂ��Ă���B
���ɖ߂���Ă��Ƃ́A���������Ă��Ȃ����Ď��ŁA1000qubit����������� 2^1000 ���̏�����邱�ƂȂ��ǂ����ɑ��݂�����āE�E�E�ǂ�Ȃ���Ă����B
���̉F���̑f���q�S���̉�����������s�F��������̂��A�f���q�̒��ɂ͉F�����鉽��������̂��E�E�E
������܂߂Ă̌����e�[�}���Ǝv����Aqubit�v�Z���C����������
�r�b�g���₷���Ƃɔ{�������ԁA�������I�y���[�V���������j�^���ϊ��ʼnt�ɂȂ��Ă���B
���ɖ߂���Ă��Ƃ́A���������Ă��Ȃ����Ď��ŁA1000qubit����������� 2^1000 ���̏�����邱�ƂȂ��ǂ����ɑ��݂�����āE�E�E�ǂ�Ȃ���Ă����B
���̉F���̑f���q�S���̉�����������s�F��������̂��A�f���q�̒��ɂ͉F�����鉽��������̂��E�E�E
824 �FMAC�I�^���c�q �����F2008/07/12(�y) 10:41:48 ID:KULmXOzq
>>822
"Tera Tera Tera"�̏��ƁA"Recent Informations"�̏�������邱�ƂɋC�t���Ȃ��q�g�ɂ�A����ŏ\���Ȃ��ˁB�B�B
�����ɂ�ڍׂ����������Ƃ������_�Ŕ]���ϑz��f��������Ă̂�A�������������K�v�Ȃ̂�������Ȃ�������(��)
"Tera Tera Tera"�̏��ƁA"Recent Informations"�̏�������邱�ƂɋC�t���Ȃ��q�g�ɂ�A����ŏ\���Ȃ��ˁB�B�B
�����ɂ�ڍׂ����������Ƃ������_�Ŕ]���ϑz��f��������Ă̂�A�������������K�v�Ȃ̂�������Ȃ�������(��)
�I�^�ƒc�q�̑����͓��Q�o�Ɏ��Ă���
Recent Informations���\�[�X�ɂ��ď����Ă�|��̕��͂����Ȃ��܂��Ă邩��A
���Ăɂ��Ȃ��ق��������Ǝv�����c
Larrabee�Ƃ��ɂ��ē�������������Ă�̂́A��������Gelsinger����Ȃ��āA
Justin Rattner������
���Ăɂ��Ȃ��ق��������Ǝv�����c
Larrabee�Ƃ��ɂ��ē�������������Ă�̂́A��������Gelsinger����Ȃ��āA
Justin Rattner������
�����ƓK���Ƀh�C�c��ǂ��ǁAP54C�Ƃ����̂�Heise�̋L�҂̐����B
P54C�ŁA�L���b�V�����Ō���I�ɂȂ��Ă�Ƃ����������������B
Rattner���������Ƃ����̂Ŋm���Ȃ̂́A32bit��64bit���̎���ɁA
�Sintel�A�[�L�e�N�g���x�����Ă�����ĕ��������B
512bit�ɂ��ẮA�Ђ���Ƃ���Ƃ������������A����܂��L�҂̐����B
����Ȃ킯�ŁAWikipedia�̋L����Heise�̐�����������������Gelsinger�����̂悤��
���������̂悤�ɏ����Ă�̂ŁA�������̂��ƁB
P54C�ŁA�L���b�V�����Ō���I�ɂȂ��Ă�Ƃ����������������B
Rattner���������Ƃ����̂Ŋm���Ȃ̂́A32bit��64bit���̎���ɁA
�Sintel�A�[�L�e�N�g���x�����Ă�����ĕ��������B
512bit�ɂ��ẮA�Ђ���Ƃ���Ƃ������������A����܂��L�҂̐����B
����Ȃ킯�ŁAWikipedia�̋L����Heise�̐�����������������Gelsinger�����̂悤��
���������̂悤�ɏ����Ă�̂ŁA�������̂��ƁB
���������ו������̂���ȂɋC�ɂȂ�̂����s�v�c�łȂ�Ȃ�
x86�A�[�L��intel�ɂƂ��ďd�v�Ǝv���鎑�Y�ŁA������g�����Ƃ͌���
�������R�A�Ȃ�A�̍����P54C�Ȃ肪�Q�l�ɂȂ�A�����痬�p���悤�Ƃ����b����B
�ו��𐳊m�ɋl�߂Ă����ʕ��͑傫���͕ς��܂��Ǝv������B
x86�A�[�L��intel�ɂƂ��ďd�v�Ǝv���鎑�Y�ŁA������g�����Ƃ͌���
�������R�A�Ȃ�A�̍����P54C�Ȃ肪�Q�l�ɂȂ�A�����痬�p���悤�Ƃ����b����B
�ו��𐳊m�ɋl�߂Ă����ʕ��͑傫���͕ς��܂��Ǝv������B
�\�[�X���ϑz�̓`��
>>827 ����
�ׂ����Ƃ��낷���ǁAHeise��o�ŎЂ̖��O��C't���G�������B
web�ȑO���瑶�݂���ƕ�PC�G���̘V�܂Ȃ�ŁA������M���x�̍����\�[�X�Ƃ��Ĉ����Ă��邷�B
http://en.wikipedia.org/wiki/C%27t
>>828 ����
�@�@------------------
�@�@���������ו������̂���ȂɋC�ɂȂ�̂����s�v�c�łȂ�Ȃ�
�@�@------------------
�C���I�[�_�[��2-way�X�[�p�[�X�P�[���̃X���[���R�A���d�͌����̓_�ő�K�̓}���`�R�A��
�̗p����₷���B�B�B�Ƃ����g�R������A�݂�Ȃ��[�����Ă������B�Ƃ��낪����ɂ҂����蓖�Ă͂܂�
Silverthorne�R�A���o�ꂵ������ɁA�ǂ������ʂ̃R�A��Larrabee�ɍ̗p����Ƃ����b�肪�o�Ă���
�̂ŁA�����ɂȂ��Ă���B�B�B�Ƃ������Ƃ��ƁB
�ׂ����Ƃ��낷���ǁAHeise��o�ŎЂ̖��O��C't���G�������B
web�ȑO���瑶�݂���ƕ�PC�G���̘V�܂Ȃ�ŁA������M���x�̍����\�[�X�Ƃ��Ĉ����Ă��邷�B
http://en.wikipedia.org/wiki/C%27t
>>828 ����
�@�@------------------
�@�@���������ו������̂���ȂɋC�ɂȂ�̂����s�v�c�łȂ�Ȃ�
�@�@------------------
�C���I�[�_�[��2-way�X�[�p�[�X�P�[���̃X���[���R�A���d�͌����̓_�ő�K�̓}���`�R�A��
�̗p����₷���B�B�B�Ƃ����g�R������A�݂�Ȃ��[�����Ă������B�Ƃ��낪����ɂ҂����蓖�Ă͂܂�
Silverthorne�R�A���o�ꂵ������ɁA�ǂ������ʂ̃R�A��Larrabee�ɍ̗p����Ƃ����b�肪�o�Ă���
�̂ŁA�����ɂȂ��Ă���B�B�B�Ƃ������Ƃ��ƁB
>>830
�����A�������A�������ˁB�w�E�����B
�����A���\�[�X���M���ł��Ă��AWikipedia�̕����ǂ����͂܂��ʂ����B
C�f���̕��͎�ނ��ăQ�b�g������낤����A��������Ȃ��ē`���̕����悩�������ȁB
512bit�͂Ђ���Ƃ���Ƃ��ĕ������Ă�̂ŁA������Ɣ��������ǁB
�����A�������A�������ˁB�w�E�����B
�����A���\�[�X���M���ł��Ă��AWikipedia�̕����ǂ����͂܂��ʂ����B
C�f���̕��͎�ނ��ăQ�b�g������낤����A��������Ȃ��ē`���̕����悩�������ȁB
512bit�͂Ђ���Ƃ���Ƃ��ĕ������Ă�̂ŁA������Ɣ��������ǁB
832 �F�R�E�L�́M�E,,�j�������������������F2008/07/12(�y) 14:38:55 ID:cL+fyQY2
512bit����AVX��2byte VEX�͎g���Ȃ��������_�ł̔��\�ςݖ��߂Ƃ��݊����͂Ȃ����ƂɂȂ邼
AVX��Larrabee�̒��j�Z�p�Ƃ����Q������̔����Ƃ���������B
AVX��Larrabee�̒��j�Z�p�Ƃ����Q������̔����Ƃ���������B
833 �FMAC�I�^���c�q �����F2008/07/12(�y) 14:47:41 ID:KULmXOzq
>>832
�V���߃Z�b�g��A����ɂł��L�͂ȊJ���҂̋������������Ƃ�K�v�Ƃ��邷�B
�ɂ�������炸�AAVX�̔��\����Larrabee�ł̃T�|�[�g���������Ȃ������̂�A�w���m���Ⴄ����A
��肽���Ă��ł��Ȃ������x�Ƃ������߂����藧���B
���Ȃ����v���Ă���قǎ����Șb���ᖳ�����B�������Larrabee��AVX���T�|�[�g����u�\���v��
�ے�킵�Ȃ����B
�V���߃Z�b�g��A����ɂł��L�͂ȊJ���҂̋������������Ƃ�K�v�Ƃ��邷�B
�ɂ�������炸�AAVX�̔��\����Larrabee�ł̃T�|�[�g���������Ȃ������̂�A�w���m���Ⴄ����A
��肽���Ă��ł��Ȃ������x�Ƃ������߂����藧���B
���Ȃ����v���Ă���قǎ����Șb���ᖳ�����B�������Larrabee��AVX���T�|�[�g����u�\���v��
�ے�킵�Ȃ����B
834 �F,,�E�L�́M�E,,�j���F2008/07/12(�y) 14:55:55 ID:cL+fyQY2
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
>��Larrabee�����̑傫�Ȗ��߃Z�b�g�g��
>�@�u��X�́A���߃Z�b�g���f���́A�A�[�L�e�N�`���A�v���[�`�̖{���I�ȕ����ł���
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
> ����炪���߃Z�b�g�̊g���ɑ����т����l�����������Ă��Ȃ����߂��ƍl���Ă���B
>�@��X�́A�����ɂ킽���āA���߃Z�b�g������Ɋg���������邱�Ƃ��ł���ƌ��Ă���B
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B(�ȉ���
�Q���������B
���N���\���ꂽAVX��SandyBridge��Larrabee���ʂ̐V���߂ł��邱�Ƃ͎����B
8�16DP/core�Ƃ����������A��1���オ256bit FMUL+FADD��
���̐��オ256bit FMA*2�ƍl����Β��K���������B
>��Larrabee�����̑傫�Ȗ��߃Z�b�g�g��
>�@�u��X�́A���߃Z�b�g���f���́A�A�[�L�e�N�`���A�v���[�`�̖{���I�ȕ����ł���
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
> ����炪���߃Z�b�g�̊g���ɑ����т����l�����������Ă��Ȃ����߂��ƍl���Ă���B
>�@��X�́A�����ɂ킽���āA���߃Z�b�g������Ɋg���������邱�Ƃ��ł���ƌ��Ă���B
> SSE4�\�������A����ȍ~��SSE�̒�`���i�߂Ă���B����ɁA���傫�Ȗ��߃Z�b�g��
> �g�����ALarrabee�̈ꕔ�Ƃ��Đi�߂Ă���B(�ȉ���
�Q���������B
���N���\���ꂽAVX��SandyBridge��Larrabee���ʂ̐V���߂ł��邱�Ƃ͎����B
8�16DP/core�Ƃ����������A��1���オ256bit FMUL+FADD��
���̐��オ256bit FMA*2�ƍl����Β��K���������B
835 �F,,�E�L�́M�E,,�j���F2008/07/12(�y) 15:14:35 ID:cL+fyQY2
�[��512�r�b�g����Cell�݂�����Even/Odd�p�C�v��O��Ƃ����������Ǝv���Ă邪�B
Atom�Ɠ����������Ƃ�A2issue�̗������ɕ����������Z�Ɏg�����Ƃ��\�B
�]����256�r�b�g�~2�Ŏ������B
Atom�Ɠ����������Ƃ�A2issue�̗������ɕ����������Z�Ɏg�����Ƃ��\�B
�]����256�r�b�g�~2�Ŏ������B
7/20�̎��̃v���C�X�J�b�g�͂��H
ttp://blog.livedoor.jp/amd646464/archives/51229432.html
> Duo��7��20���AQuad��8��10���������ł�
> Duo��7��20���AQuad��8��10���������ł�
�N�[���[�̓v�b�V���s���ȊO�ɂ��Ȃ�̂��낤�c
�v�b�V���s���̓��e�[���݂����Ȃ��������������Ƃ��͕֗��Ȃ�
��^�̗₦��N�[���[������Ƃ��͂܂�Â炭�ăC���C������
������l������͂��������Ⴄ�I�����͂Ȃ������̂��Ɩ₢����
��^�̗₦��N�[���[������Ƃ��͂܂�Â炭�ăC���C������
������l������͂��������Ⴄ�I�����͂Ȃ������̂��Ɩ₢����
�P�[�X�̉��J���������ɂ��ĕ��ʂɐ�@���ĂƂ�������ˁH
����ȃN�[���[���Ƃ��ɃJ�l�|���邱�ƂȂ�����
����ȃN�[���[���Ƃ��ɃJ�l�|���邱�ƂȂ�����
841 �F,,�E�L�́M�E,,�j���F2008/07/13(��) 06:46:51 ID:fQY2QJ6V
�������Opcode�\���߂Ă݂��B
LFS/LGS/LSS���������A�h���b�V���O�݂̂��B
2byte�VEX�̃��[�h�o�C�g�Ƃ��ė��p�ł��������ȁB
66 0F 38 XX ModRM (SIB) (DISP)
66 0F 3A XX ModRM (SIB) (DISP) imm8
��������k���ł�����Ă��ƂȁB
LFS/LGS/LSS���������A�h���b�V���O�݂̂��B
2byte�VEX�̃��[�h�o�C�g�Ƃ��ė��p�ł��������ȁB
66 0F 38 XX ModRM (SIB) (DISP)
66 0F 3A XX ModRM (SIB) (DISP) imm8
��������k���ł�����Ă��ƂȁB
842 �F,,�E�L�́M�E,,�j���F2008/07/13(��) 06:54:02 ID:fQY2QJ6V
�������Opcode�\���߂Ă݂��B
LFS/LGS/LSS���������A�h���b�V���O�̂݁Bx64�Œׂ���Ă�ƁB
�܂�V����VEX�̃��[�h�o�C�g�Ƃ��ė��p�ł��������ȁB�܂�SSSE3/SSE4��
66 0F 38 XX ModRM (SIB) (DISP)
66 0F 3A XX ModRM (SIB) (DISP) imm8
��������k���ł��邩�����Ă��ƂȁB
LFS/LGS/LSS���������A�h���b�V���O�̂݁Bx64�Œׂ���Ă�ƁB
�܂�V����VEX�̃��[�h�o�C�g�Ƃ��ė��p�ł��������ȁB�܂�SSSE3/SSE4��
66 0F 38 XX ModRM (SIB) (DISP)
66 0F 3A XX ModRM (SIB) (DISP) imm8
��������k���ł��邩�����Ă��ƂȁB
843 �F,,�E�L�́M�E,,�j���F2008/07/13(��) 06:55:02 ID:fQY2QJ6V
�A���딚
>�@�u��X�́A���߃Z�b�g���f���́A�A�[�L�e�N�`���A�v���[�`�̖{���I�ȕ����ł���
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
���݉^�p���ɁA�݊��̂Ȃ������̖��߃Z�b�g�̃R�[�h�����݂����
�Ăяo�����v���Z�b�TA,�v���Z�b�TB�Ƃ���Ƃ�
A->B->A->B
�Ƃ����������ŃT�u���[�`���R�[�������悤�ȏꍇ(�T�u���[�`���ȊO�ɂ��n�[�h��O�A�����O������C�x���g�ʒm�����낢�날��)��₱�������������N�����B
���S�ɂ͖����ł� A �� B �̏�ʌ݊��ł��铙�ł��͂����ԉ��P������ȁB
����ȊO�ɂ��p�t�H�[�}���X�̔�Ώ̂̓p�t�H�[�}���X100%�o������Ȃ������ɂ��Ȃ���A����͗p�r������Ƃ������Ƃł܂����肩�ȂƁB
����͉�Ђł����A�d���l�Ԃ̂Ƃ���Ɏd�����W�����ċt�Ɍ����ቺ�Ƃ����B
> ��т���K�v������ƍl���Ă���BCell B.E.���n�߂Ƃ����A�v���[�`���������Ă��Ȃ��̂́A
���݉^�p���ɁA�݊��̂Ȃ������̖��߃Z�b�g�̃R�[�h�����݂����
�Ăяo�����v���Z�b�TA,�v���Z�b�TB�Ƃ���Ƃ�
A->B->A->B
�Ƃ����������ŃT�u���[�`���R�[�������悤�ȏꍇ(�T�u���[�`���ȊO�ɂ��n�[�h��O�A�����O������C�x���g�ʒm�����낢�날��)��₱�������������N�����B
���S�ɂ͖����ł� A �� B �̏�ʌ݊��ł��铙�ł��͂����ԉ��P������ȁB
����ȊO�ɂ��p�t�H�[�}���X�̔�Ώ̂̓p�t�H�[�}���X100%�o������Ȃ������ɂ��Ȃ���A����͗p�r������Ƃ������Ƃł܂����肩�ȂƁB
����͉�Ђł����A�d���l�Ԃ̂Ƃ���Ɏd�����W�����ċt�Ɍ����ቺ�Ƃ����B
�\�Ȃ疽�߃Z�b�g�ɂ��Ă͊��S�݊��������ȁA�p�t�H�[�}���X�̓����̈Ⴂ�����ɂ��Ă��܂���
�����R�[�h���ǂ���ł�����悤�ɂȂ��Ă���̂����z�I�B
�v���O���}���猩��A�ǂ�CPU�ɂǂ̃X���b�h������U�邩���ւ��邾���ōςނ悤�ɂȂ��
�����̒����̓X���b�h�X�P�W���[�����������ɂȂ�A�{�̕����͕ύX�ɑ��ĕ��G�����ăp�t�H�[�}���X��������悤�Ȃ烁�C��CPU��
�P�������ăp�t�H�[�}���X��������悤�Ȃ�Larrabee�ւƐ�ւ��邾����OK�ƂȂ�Ό��ʓI�B
�����R�[�h���ǂ���ł�����悤�ɂȂ��Ă���̂����z�I�B
�v���O���}���猩��A�ǂ�CPU�ɂǂ̃X���b�h������U�邩���ւ��邾���ōςނ悤�ɂȂ��
�����̒����̓X���b�h�X�P�W���[�����������ɂȂ�A�{�̕����͕ύX�ɑ��ĕ��G�����ăp�t�H�[�}���X��������悤�Ȃ烁�C��CPU��
�P�������ăp�t�H�[�}���X��������悤�Ȃ�Larrabee�ւƐ�ւ��邾����OK�ƂȂ�Ό��ʓI�B
846 �F,,�E�L�́M�E,,�j���F2008/07/13(��) 17:03:45 ID:fQY2QJ6V
�ǂ݂̂�MS�ɋ����Ă��炤���ƂɂȂ���ǂȁB
32���邢��64�X���b�h�܂ł����T�|�[�g���Ȃ�OS��128�X���b�h�ȏ��
�L���Ɏg���锤���Ȃ��B
PS3Linux�ł����Ƃ����SPE�̊Ǘ��@�\�݂����Ȃ̂���������
�A�v�����璼�ڎg����悤�ɂ�����Ď�����邯�ǁB
������ɂ���VAPI���K�v��
32���邢��64�X���b�h�܂ł����T�|�[�g���Ȃ�OS��128�X���b�h�ȏ��
�L���Ɏg���锤���Ȃ��B
PS3Linux�ł����Ƃ����SPE�̊Ǘ��@�\�݂����Ȃ̂���������
�A�v�����璼�ڎg����悤�ɂ�����Ď�����邯�ǁB
������ɂ���VAPI���K�v��
>PS3Linux�ł����Ƃ����SPE�̊Ǘ��@�\�݂����Ȃ̂���������
>�A�v�����璼�ڎg����悤�ɂ�����Ď�����邯�ǁB
�����A�����������A���ꂾ���̓}�W����
>�A�v�����璼�ڎg����悤�ɂ�����Ď�����邯�ǁB
�����A�����������A���ꂾ���̓}�W����
��Windows�ɂ���Z�p�Ŏ�������Ȃ�WCF(Windows Communication Foundation)�x�[�X��Larrabee�v���Z�X��ԂƂ̒ʐM����Ԃ��₷�����ȁB
����Ȃ�GPU�炵����������Ԃ��Ɨ����Ă��Ă��A����Ȃ�Ɏg����Ǝv����B
�������̃�������Ԃ����L�Ƃ����킯�ɂ��s���Ȃ��Ȃ邾�낤����A�������v���Z�b�T���܂Ƃ߂Ă̓c���[��ɂ܂Ƃ߂�K�v���łĂ��邾�낤���B
����Ȃ�GPU�炵����������Ԃ��Ɨ����Ă��Ă��A����Ȃ�Ɏg����Ǝv����B
�������̃�������Ԃ����L�Ƃ����킯�ɂ��s���Ȃ��Ȃ邾�낤����A�������v���Z�b�T���܂Ƃ߂Ă̓c���[��ɂ܂Ƃ߂�K�v���łĂ��邾�낤���B
>32���邢��64�X���b�h�܂ł����T�|�[�g���Ȃ�OS
�T�[�o�[�p�������Ȃ�?�A2008�Ƃ��B
�T�[�o�[�p�������Ȃ�?�A2008�Ƃ��B
>>849
������Ή�����Ƃ͎v�����ǁA�X���b�h�ڑ��삷��悤��API�͔�݊��ɂȂ炴��Ȃ��Ǝv��
CPU�̑��݂��r�b�g�ŕ\������� UINT �ł���肵�Ă��邩��A����̂܂܂ł�32�ȏ�ɂł��Ȃ��B
������Ή�����Ƃ͎v�����ǁA�X���b�h�ڑ��삷��悤��API�͔�݊��ɂȂ炴��Ȃ��Ǝv��
CPU�̑��݂��r�b�g�ŕ\������� UINT �ł���肵�Ă��邩��A����̂܂܂ł�32�ȏ�ɂł��Ȃ��B
MS��Itanium�ŋ���������x86�x�[�X�̉����ȊO���Ȃ��悤��Intel�ɓB�h������Ȃ��H��
852 �F,,�E�L�́M�E,,�j���F2008/07/14(��) 16:38:26 ID:dyZabc0Z
�Ƃ͂����A��������蔠���ŃJ�X�^��PPC�g���Ă��肷�邵
���̃��C�Z���X�����J����A�[�L�Ȃ���͂Ȃ�ł��悩������B
���̃��C�Z���X�����J����A�[�L�Ȃ���͂Ȃ�ł��悩������B
HKEPC�ɂ���Bloomfield�̃��[�G���h�i2.66GHz���f����A$284�ȂƂ��B
http://www.hkepc.com/?id=1447&fs=c1h
�@�E2.66GHz: $284
�@�E2.93GHz: $562
�@�E3.2GHz: $999
�X��Havendale��$80-$90�ɂȂ�Ƃ������Ă��邷�B
http://www.hkepc.com/?id=1447&fs=c1h
�@�E2.66GHz: $284
�@�E2.93GHz: $562
�@�E3.2GHz: $999
�X��Havendale��$80-$90�ɂȂ�Ƃ������Ă��邷�B
$316����X��sage���̂�
���͂���Ȋ������ȁB
Bloomfield 2.93GHz $562
DDR3-1600 2GBx3 $300(�\�z)
ASUS P6B Deluxe $266
�܂��A15������Η]�T�Ŕ����������ȁB
Bloomfield 2.93GHz $562
DDR3-1600 2GBx3 $300(�\�z)
ASUS P6B Deluxe $266
�܂��A15������Η]�T�Ŕ����������ȁB
�Q�[���x���`�Ō�����E8600�ɕ����ăQ�[�}�[�w�ɃX���[���ꂻ��
Quad��IGP�tDual�����I�����Ȃ��̂��������
Quad��IGP�tDual�����I�����Ȃ��̂��������
>>813�ŏo�Ă���nForce 200���ڂ�x58�}�U�[��SLI�T�|�[�g�̌��ANVIDIA���琳����
�v���X�����[�X���o�����B
http://www.nvidia.com/object/io_1216019719164.html
�v���X�����[�X���o�����B
http://www.nvidia.com/object/io_1216019719164.html
TDP95w�g�ɂ͗}�����Ȃ�������(�L��֥�M)
�܂�Core2��2.93GHz����3.2GHz����X�^�[�g����̂̓C�C(�E�́E)�ˁB
�܂�Core2��2.93GHz����3.2GHz����X�^�[�g����̂̓C�C(�E�́E)�ˁB
860 �F,,�E�L�́M�E,,�j���F2008/07/15(��) 20:41:40 ID:D8MRlUJo
Broomfield����
�����Lynnfield�̈ʒu�t��������ȁB
�����Lynnfield�̈ʒu�t��������ȁB
���Ă��āA�������牽���܂ň����Ȃ邩�ȁH
���\�s����Ȃ����Ƒz����
���\�s����Ȃ����Ƒz����
�ߐڏ�������[��
��C����22nm�̉�H�ł��������ȁB
��C����22nm�̉�H�ł��������ȁB
22nm�̎����ǂ��Ȃ�̂���������
�yAMD�叟���zIntelCPU�ɏd��Ȍ��ׁI�ǂ�OS�Ɋւ�炸CPU�̌��ׂ�˂���AHDD�����̉\��
http://namidame.2ch.net/test/read.cgi/news/1216189040/
http://namidame.2ch.net/test/read.cgi/news/1216189040/
865 �F,,�E�L�́M�E,,�j���F2008/07/17(��) 10:16:46 ID:i+kryn6g
���ɂ����Ă��A�s���V���b�g�_�E�������̎�̍U�������ł��Ȃ����_��
�U���̎�i�Ƃ��Ă͗L�����Ȃ������B
�U���̎�i�Ƃ��Ă͗L�����Ȃ������B
�o�J�̑�������邾������w
����CPU�̕⏞�͂ǂ������
�����I�ɏC���s�\�ł��v�Z���ԈႦ��Ȃ烊�R�[�������łȂ��H
CPU�̓}�C�N���R�[�h���Ă����v���O���������̈悪���邩��A����Ńi���g�J�Ȃ�Ȃ烊�R�[�����Ȃ��B
�ƁA�v���B
CPU�̓}�C�N���R�[�h���Ă����v���O���������̈悪���邩��A����Ńi���g�J�Ȃ�Ȃ烊�R�[�����Ȃ��B
�ƁA�v���B
Expreview�f�ڂ�Intel�̃f�X�N�g�b�v���[�h�}�b�v��Lynnfield, Havendale���`�b�v�̓�����
�q�ׂ��X���C�h���B
http://en.expreview.com/2008/07/16/intel-roadmap-indicates-multiple-havendale-incoming-q309/
Havendale�̕���A���[�G���h���o������������ E5200�N���X�Ƃ̂��Ƃ�����A>>853��$100���Ƃ���
���M�ߐ����������B
Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
�q�ׂ��X���C�h���B
http://en.expreview.com/2008/07/16/intel-roadmap-indicates-multiple-havendale-incoming-q309/
Havendale�̕���A���[�G���h���o������������ E5200�N���X�Ƃ̂��Ƃ�����A>>853��$100���Ƃ���
���M�ߐ����������B
Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
�C���e���̌��Z���\�d�b��ŁuAtom�v�ւ̌��O�����o
http://japan.cnet.com/news/biz/story/0,2000056020,20377394,00.htm
http://japan.cnet.com/news/biz/story/0,2000056020,20377394,00.htm
871 �F,,�E�L�́M�E,,�j���F2008/07/18(��) 08:39:40 ID:T6A7gPNZ
>>868
Java��JIT�Ƃ������Ă鎞�_�Ŏ��ȏ��������̌��ׂ�t����������
�܂����ʂ͋C�ɂ��Ȃ��Ă����B
����ȍU���o�J�炵���ĒN�����Ȃ��B
Java��JIT�Ƃ������Ă鎞�_�Ŏ��ȏ��������̌��ׂ�t����������
�܂����ʂ͋C�ɂ��Ȃ��Ă����B
����ȍU���o�J�炵���ĒN�����Ȃ��B
�c�q����͂��̎|�������̃u���O�ɂ܂Ƃ߂Ă����Ƃ��肪����
2�����ŕ��͐��ꗬ������ʐl�ւ̐M�ߐ�����������
2�����ŕ��͐��ꗬ������ʐl�ւ̐M�ߐ�����������
N���̔n���͈���ŏ���ɐM�ߐ����܂����Ă��C�����Ȃ���
>>871
�c�[������Ă�܂��o�J�����邩��A���x�ɂ�����B
�c�[������Ă�܂��o�J�����邩��A���x�ɂ�����B
���X����
�@ttp://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
��Intel�̐�`�헪�ɏ悹���Ă���
�����x���ꂽ���z�Ȃ�ċ����̂��ȁH
�@ttp://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
��Intel�̐�`�헪�ɏ悹���Ă���
�����x���ꂽ���z�Ȃ�ċ����̂��ȁH
���̃X���̑啔������
�J�b�ƂȂ������n���Q�ォ
��`�ł��헪�ł��Ȃ���
879 �FSocket774�F2008/07/18(��) 19:53:13 ID:TYq9Ibha
���o�C�����Ă��ɂȂ�����N�\�p�t�H�[�}���X����E�p�ł����
880 �FMAC�I�^��879 �����F2008/07/18(��) 20:09:51 ID:zBSaUuz1
>>879
�����ŕ����悤�ɂȂ鍠�ɂ�A�����Ȃ��Ȃ������ˁH
�����ŕ����悤�ɂȂ鍠�ɂ�A�����Ȃ��Ȃ������ˁH
�܂�ˁ@�������^�c�����E�����^������z��
�i�@�L�́M�j���I�}�G�K�i�[
883 �FSocket774�F2008/07/18(��) 23:27:19 ID:2M9NzyN9
G45�}�U�[�����o��A���拭���̐VGPU�R�A����
http://www.watch.impress.co.jp/akiba/hotline/20080719/etc_smicro.html
���o�C��Core 2�V���f�����o��ATDP25W/2.53GHz��P9500�Ȃ�
http://www.watch.impress.co.jp/akiba/hotline/20080719/etc_intel.html
http://www.watch.impress.co.jp/akiba/hotline/20080719/etc_smicro.html
���o�C��Core 2�V���f�����o��ATDP25W/2.53GHz��P9500�Ȃ�
http://www.watch.impress.co.jp/akiba/hotline/20080719/etc_intel.html
>>869
�T�[�o�������Ă̂͊�b�v�����Ă��ƁB
�������Lynnfield, Havendale������p�t�H�[�}���X�`���[�G���h�܂Ŕh������������
�Ƃ������Ǝ��͉̂����V���ł͂Ȃ��B
�܂�A�z�͂��O�B
�T�[�o�������Ă̂͊�b�v�����Ă��ƁB
�������Lynnfield, Havendale������p�t�H�[�}���X�`���[�G���h�܂Ŕh������������
�Ƃ������Ǝ��͉̂����V���ł͂Ȃ��B
�܂�A�z�͂��O�B
885 �FMAC�I�^��884 �����F2008/07/19(�y) 00:14:53 ID:2eUAebpx
>>884
�@�@------------------
�@�@�T�[�o�������Ă̂͊�b�v�����Ă��ƁB
�@�@------------------
��b�v(��)
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719
�@�@==================
�@�@Nehalem differs from the previous generation in that it was explicitly designed not only to
�@�@scale across all the different product lines, but to be optimized for all the different product
�@�@segments, from mobile to MP server.
�@�@==================
�@�@------------------
�@�@�T�[�o�������Ă̂͊�b�v�����Ă��ƁB
�@�@------------------
��b�v(��)
http://www.realworldtech.com/page.cfm?ArticleID=RWT040208182719
�@�@==================
�@�@Nehalem differs from the previous generation in that it was explicitly designed not only to
�@�@scale across all the different product lines, but to be optimized for all the different product
�@�@segments, from mobile to MP server.
�@�@==================
�ǂ��ł������ł����
Larrabee���Ă����o��́H
>>869
����Nehalem�Ƃ��ďЉ��Ă����̂̓������C���^�[�t�F�C�X���I���_�C�ɂ���Bloomfield����������ˁB
Opteron�Ɠ��l��MP�I���ӎ������v�Ǝv���Ă����B
�������C���X�g���[������Nehalem�̓������C���^�[�t�F�C�X���I�t�_�C��
MCH/GMCH��MCM�œ�������v�悾�Ƃ͒N���v���Ă��Ȃ��������ˁB
Lynnfield/Havendale��SocketA�Ɏh����Athlon64�݂����Ȃ���ł���B
�܂�FSB�̕ς���QPI�ɐi�����Ă��邯�ǁB
����Nehalem�Ƃ��ďЉ��Ă����̂̓������C���^�[�t�F�C�X���I���_�C�ɂ���Bloomfield����������ˁB
Opteron�Ɠ��l��MP�I���ӎ������v�Ǝv���Ă����B
�������C���X�g���[������Nehalem�̓������C���^�[�t�F�C�X���I�t�_�C��
MCH/GMCH��MCM�œ�������v�悾�Ƃ͒N���v���Ă��Ȃ��������ˁB
Lynnfield/Havendale��SocketA�Ɏh����Athlon64�݂����Ȃ���ł���B
�܂�FSB�̕ς���QPI�ɐi�����Ă��邯�ǁB
>>885
���̃��o�C������MP�T�[�o�܂ŃX�P�[������Ȃ�Ă̂��Ƃ����̐̂ɂłĂ�́B
���݂̂悤�ȃA�z��IDF�ȍ~�Ŗ�����ɂ��ꂽ����ǂ��ĂȂ�����A
���̂悤�Ȃ������̏��ɂ��܂����킯�B
���̃��o�C������MP�T�[�o�܂ŃX�P�[������Ȃ�Ă̂��Ƃ����̐̂ɂłĂ�́B
���݂̂悤�ȃA�z��IDF�ȍ~�Ŗ�����ɂ��ꂽ����ǂ��ĂȂ�����A
���̂悤�Ȃ������̏��ɂ��܂����킯�B
���������匴�L�����炢��߂�悤�ɂȂ��Ă���p���ł����p�����B
�����̓A�[�L�e�N�`���̒��g���ǂݕԂ��ė~�����B
�����̓A�[�L�e�N�`���̒��g���ǂݕԂ��ė~�����B
MAC�I�^�͑S�̔c�����ė������ĂȂ������ɁA
�ڂɂ��������̓s���̂��������������������Ă��邩�獢��B
���ƁA�C�O�̌f���ŒN�������������Ƃӂ���2�����ɏ����Ă�̂ɁB
���x���������A�J�X���B
�ڂɂ��������̓s���̂��������������������Ă��邩�獢��B
���ƁA�C�O�̌f���ŒN�������������Ƃӂ���2�����ɏ����Ă�̂ɁB
���x���������A�J�X���B
���ƁA�C�O�̌f���ŒN�������������Ƃӂ���2�����ɏ����Ď����̈ӌ��̂悤�ɂ��Ă���B
�������A���̓��e���Ԉ���Ă����肵�Ĕ��_�����ƌ����Ԃ���������B
�������A���̓��e���Ԉ���Ă����肵�Ĕ��_�����ƌ����Ԃ���������B
google�����㗝�l��RSS���[�h�㗝�l�ɑ��ĉ��Ǝ���ȕ�������
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���p���ł����p�����B
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
������
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���p���ł����p�����B
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
�����������匴�L�����炢��߂�悤�ɂȂ��Ă���
������
�[���A�A�zMAC�I�^�́ANehalem�ʼn��ǂ��ꂽ�|�C���g�܂Ƃ��ɂ�������̂�?
RealWorldTech�̉���݂����đS����߂T�[�o�p�r�ɒ��͂����Ă킩�邾�낤�ɁB
Lynnfield��Havendale��Nehalem�̌㔭�h���`�b�v�B
�X�P�[�����₷���Ȃ����B�h���`�b�v�����₷���Ȃ����Ƃ����Ă�
�T�[�o���������ɂȂ��Ă���Ă����Ă��? �킩��?
Lynnfield��Havendale���Ȃ�Œx��Ă�̂������Ă���̂���B
RealWorldTech�̉���݂����đS����߂T�[�o�p�r�ɒ��͂����Ă킩�邾�낤�ɁB
Lynnfield��Havendale��Nehalem�̌㔭�h���`�b�v�B
�X�P�[�����₷���Ȃ����B�h���`�b�v�����₷���Ȃ����Ƃ����Ă�
�T�[�o���������ɂȂ��Ă���Ă����Ă��? �킩��?
Lynnfield��Havendale���Ȃ�Œx��Ă�̂������Ă���̂���B
>Havendale�̕���A���[�G���h���o������������ E5200�N���X�Ƃ̂��Ƃ�����A>>853��$100���Ƃ���
>���M�ߐ����������B
>Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
�_���I�ɕ������l�����Ȃ��n���̓T�^�B
�x�[�X���T�[�o�����̃R�A�Ŕh���`�b�v��Havendale�����[�G���h�Ƃ�������
�Ń����[�X�����B����Ȃ͍̂��X�V�����L�������p���Ȃ��Ă��Ƃ����ɂ킩���Ă�B
���ꂪ��\MAC�I�^�N�̔]���ł͂�͂�T�[�o�x�[�X�ł͂Ȃ�����!!�Ƃ������߂ɂȂ�炵���B
Bloomfield��UP�T�[�o�Ƌ��p�v���b�g�t�H�[���Ȃ̂ɋC�����Ȃ�
(������PC�p�[�c�����Ȃ����犴�o���킩��Ȃ�)�B
�����AMAC�I�^�Ƃ��̒�\��芪���A���͂Ȃ�Lynnfield��Havendale���x��Ă�̂�
�������Ă����B���W�����[�����Ă�ᖜ�\�Ƃ��������Ă邨�Ԕ��Ȃ̂�?
>���M�ߐ����������B
>Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
�_���I�ɕ������l�����Ȃ��n���̓T�^�B
�x�[�X���T�[�o�����̃R�A�Ŕh���`�b�v��Havendale�����[�G���h�Ƃ�������
�Ń����[�X�����B����Ȃ͍̂��X�V�����L�������p���Ȃ��Ă��Ƃ����ɂ킩���Ă�B
���ꂪ��\MAC�I�^�N�̔]���ł͂�͂�T�[�o�x�[�X�ł͂Ȃ�����!!�Ƃ������߂ɂȂ�炵���B
Bloomfield��UP�T�[�o�Ƌ��p�v���b�g�t�H�[���Ȃ̂ɋC�����Ȃ�
(������PC�p�[�c�����Ȃ����犴�o���킩��Ȃ�)�B
�����AMAC�I�^�Ƃ��̒�\��芪���A���͂Ȃ�Lynnfield��Havendale���x��Ă�̂�
�������Ă����B���W�����[�����Ă�ᖜ�\�Ƃ��������Ă邨�Ԕ��Ȃ̂�?
�匴�L���Ƃ�����Ȃ����悩�����̂Ɂc
�ȂΕa���Ă����
�N�\�R�e�ɐ���Ȃ��ƉΕa��
�������o�J�̊
�������o�J�̊
4�A���̂���2�A�����Ă��u�K�����ȁv���Ďv���Ă����傤���Ȃ�����
�܂��Ăł�����B
903 �FMAC�I�^��896-897 �����F2008/07/19(�y) 08:08:55 ID:2eUAebpx
>>896-897
�@�@------------------
�@�@Lynnfield��Havendale���Ȃ�Œx��Ă�̂������Ă���̂���B
�@�@------------------
�P���ɋ�����}���K�v���������炷�B�ނ���Bloomfield���I�t�_�C�������R���g���[���̃o�b�N�A�b�v
�v������p�ӂ��Ă܂ŋ}�������Ƃɒ��ڂ��ׂ����Ǝv���邷�B
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
�@�@------------------
�@�@Nehalem�ʼn��ǂ��ꂽ�|�C���g
�@�@------------------
SMT��Atom�ł̗̍p�ŁA�w�T�[�o�[�����x�Z�p���ᖳ�����Ƃ햾�炩�ɂȂ����Ǝv�������ǁB�B�B
�������R���g���[��������SoC�I�v�f��A�ނ���g���`�b�v�Ő�s���Ď�������Ă���Z�p���B
�@�@------------------
�@�@Lynnfield��Havendale���Ȃ�Œx��Ă�̂������Ă���̂���B
�@�@------------------
�P���ɋ�����}���K�v���������炷�B�ނ���Bloomfield���I�t�_�C�������R���g���[���̃o�b�N�A�b�v
�v������p�ӂ��Ă܂ŋ}�������Ƃɒ��ڂ��ׂ����Ǝv���邷�B
http://www.hkepc.com/database/images/2008010314080787929002081.jpg
{kind=link}
�@�@------------------
�@�@Nehalem�ʼn��ǂ��ꂽ�|�C���g
�@�@------------------
SMT��Atom�ł̗̍p�ŁA�w�T�[�o�[�����x�Z�p���ᖳ�����Ƃ햾�炩�ɂȂ����Ǝv�������ǁB�B�B
�������R���g���[��������SoC�I�v�f��A�ނ���g���`�b�v�Ő�s���Ď�������Ă���Z�p���B
904 �FMAC�I�^���⑫�F2008/07/19(�y) 08:12:55 ID:2eUAebpx
�X��Intel�̌���H�v�ɂ�����"Nehalem highlight"��A�����d�͂�W�����v�ɂ�������
����Ƃ������Ƃɂ����ڂ��B
http://www.intel.com/pressroom/archive/reference/IntelatVLSI_summary.pdf
�@�@==================
�@�@Nehalem Highlights:
�@�@Configurable clocking, fastlock low-skew PLLs, high reference clock frequencies, analog
�@�@supply tracking system, adaptive frequency clocking, low jitter Intel QuickPath interconnect
�@�@and integrated memory controller clock generation, and jitter-attenuating DLLs.
�@�@==================
����Ƃ������Ƃɂ����ڂ��B
http://www.intel.com/pressroom/archive/reference/IntelatVLSI_summary.pdf
�@�@==================
�@�@Nehalem Highlights:
�@�@Configurable clocking, fastlock low-skew PLLs, high reference clock frequencies, analog
�@�@supply tracking system, adaptive frequency clocking, low jitter Intel QuickPath interconnect
�@�@and integrated memory controller clock generation, and jitter-attenuating DLLs.
�@�@==================
����AAtom��SMT����Ȃ���FGMT�Ȃ�ł���H
MAC�I�^�I�ɁB
511 ���O�FMAC�I�^��505 ����[sage] ���e���F2008/05/08(��) 22:37:06 ID:UrOM/xel
>>505
�V�����ڂ̋Z�p������A������g���f�����Ƃ܂Ō�����E�C�햳�������ǁACELL PPE��Atom��
FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
CELL PPE: http://www.research.ibm.com/journal/rd/515/chen2.gif
Atom: http://images.anandtech.com/reviews/cpu/intel/silverthorne/blockdiag.jpg
�ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
MAC�I�^�I�ɁB
511 ���O�FMAC�I�^��505 ����[sage] ���e���F2008/05/08(��) 22:37:06 ID:UrOM/xel
>>505
�V�����ڂ̋Z�p������A������g���f�����Ƃ܂Ō�����E�C�햳�������ǁACELL PPE��Atom��
FGMT�ɕ��ނ���̂����ʂ��Ǝv�����B
CELL PPE: http://www.research.ibm.com/journal/rd/515/chen2.gif
{kind=link}
Atom: http://images.anandtech.com/reviews/cpu/intel/silverthorne/blockdiag.jpg
{kind=link}
�ǂ�����f�B�X�p�b�`�̎�O�܂ŃX���b�h���Ƃɕ������Ă��邷�B
>�P���ɋ�����}���K�v���������炷�B�ނ���Bloomfield���I�t�_�C�������R���g���[���̃o�b�N�A�b�v
>�v������p�ӂ��Ă܂ŋ}�������Ƃɒ��ڂ��ׂ����Ǝv���邷�B
>�P���ɋ�����}���K�v���������炷�B
Bloomfield�̉��i�݂Ă悭����������ȁB
���ۂɔ���Ȃ�����ӎ����܂��Ȃ��낤���ǁA
Bloomfield�̃_�C�T�C�Y��$300�����Ȃ�Ė{���͂�肽���Ȃ��̂�
��������������B
EPT�Ƃ�TLB�̊g���Ƃ��͂ǂ��v���Ă��??
L3���R�q�[�����V����ɍœK������Ă��܂���?
����炪Lynnfield��Havendale�ōč\������Ă���킯�͂Ȃ��B
���Ƃ���1�R�A�����Ȃ�Atom��SMT��Nehalem��SMT���������ꂽ�Ӗ��͈Ⴄ�B
>�v������p�ӂ��Ă܂ŋ}�������Ƃɒ��ڂ��ׂ����Ǝv���邷�B
>�P���ɋ�����}���K�v���������炷�B
Bloomfield�̉��i�݂Ă悭����������ȁB
���ۂɔ���Ȃ�����ӎ����܂��Ȃ��낤���ǁA
Bloomfield�̃_�C�T�C�Y��$300�����Ȃ�Ė{���͂�肽���Ȃ��̂�
��������������B
EPT�Ƃ�TLB�̊g���Ƃ��͂ǂ��v���Ă��??
L3���R�q�[�����V����ɍœK������Ă��܂���?
����炪Lynnfield��Havendale�ōč\������Ă���킯�͂Ȃ��B
���Ƃ���1�R�A�����Ȃ�Atom��SMT��Nehalem��SMT���������ꂽ�Ӗ��͈Ⴄ�B
�����A�L���b�V�����炢�͍č\������Ă�\�����肩�B
MAC�I�^��RealWorldTech�̃R�A�����̉���܂Ƃ��ɂ��łȂ�����B
QuickPath��IMC�܂ł͍ŋ߂̗��ꂾ���A���ꂾ���ŃT�[�o�����R�A�Ƃ͂����ĂȂ��B
�������IDF�Ŗ��炩�ɂȂ����R�A�̍ו����T�[�o�����ɂȂ��Ă���B
���ǂ̂Ƃ���Nehalem��Merom��QuickPath�����āA����Intel�̓T�[�o��AMD�ɂ�����Ă���
�̂����Ԃ����߂ɃT�[�o�����̊g����F�X�R�A�ɑg�ݍ����́B
QuickPath��IMC�܂ł͍ŋ߂̗��ꂾ���A���ꂾ���ŃT�[�o�����R�A�Ƃ͂����ĂȂ��B
�������IDF�Ŗ��炩�ɂȂ����R�A�̍ו����T�[�o�����ɂȂ��Ă���B
���ǂ̂Ƃ���Nehalem��Merom��QuickPath�����āA����Intel�̓T�[�o��AMD�ɂ�����Ă���
�̂����Ԃ����߂ɃT�[�o�����̊g����F�X�R�A�ɑg�ݍ����́B
Mac��QPI�ɂȂ�́H
910 �FMAC�I�^��908 �����F2008/07/19(�y) 15:29:30 ID:2eUAebpx
>>906-908
>>885�Ɉ��p������߂̒ʂ�w���o�C������}���`�\�P�b�g�T�[�o�[�Ɏ���S���i���C�������x��
�œK�����s���Ă���Ƃ��������̘b���B�����̐v�ɂ����āA�g�����W�X�^���̂�]��ق�
���邷����A����d�͂ɉe�����Ȃ�����@�\���������Ƃ�A���o�C�������ɂȂ�爫���e����
�^���Ȃ����B
���Ȃ��̘_�@��ASilverthorn��Intel 64���T�|�[�g���邱�Ƃ𗝗R�ɁA64-bit OS�֍œK������Ă����
�咣����悤�ȃ��m���ƁB�B�B
>>885�Ɉ��p������߂̒ʂ�w���o�C������}���`�\�P�b�g�T�[�o�[�Ɏ���S���i���C�������x��
�œK�����s���Ă���Ƃ��������̘b���B�����̐v�ɂ����āA�g�����W�X�^���̂�]��ق�
���邷����A����d�͂ɉe�����Ȃ�����@�\���������Ƃ�A���o�C�������ɂȂ�爫���e����
�^���Ȃ����B
���Ȃ��̘_�@��ASilverthorn��Intel 64���T�|�[�g���邱�Ƃ𗝗R�ɁA64-bit OS�֍œK������Ă����
�咣����悤�ȃ��m���ƁB�B�B
�킩�肢��������܂Ƃ߁B
IDF��Intel�����J����Nehalem�̏ڍׂ�RealWorldTech�̉���L����ǂތ���A
�ENehalem��"�R�A"�̕�����Core 2�ɑ���g�������̓T�[�o�����Ǝv������̂���
�ENehalem��"�A���R�A"�̕������T�[�o�����̂��̂��肾���A
�@�����Gainestown/Bloomfield�̘b�ŁALynnfield��Havendale�ł͈قȂ�B
Nehalem�̓T�[�o�̎��ƕ��ŊJ������Ă��āA
Gainestown/Bloomfield�𒆐S�ɃA�[�L�e�N�`���������ɏЉ��A
Lynnfield��Havendale�����Ȃ�x��ēo�ꂷ�邱�Ƃ����
�T�[�o�������ŃR�A��V�X�e����v���A
���C���X�g���[���f�X�N�g�b�v��o�C����"�A���R�A"�̕�����
�t��������`�Ŕh���Ή�����Ƃ����V���������ɒ��킵���B
���̂��߂ɂ���̂�"���W�����v"�Ȃ킯�B
"���W�����v"�͂�����ƒm��������l�����܂��̂ɂ͗L���Ȏ�i�̂悤�����A
���ۂ̂Ƃ���Lynnfield��Westmere����Ɛ蕪���ł��Ȃ��Ƃ���܂Œx��Ă���B
(Lynnfield���_�C�͂��Ȃ�ł����v�Z�Ȃ̂�Bloomfield�̒��`���ʂ̒u��������$200�������C���ɂȂ�Ǝv����B
Havendale����Âɂ݂�A2 Nehalem core+GMCH�Ȃ̂�$80�`90��Havendale�̒��ł͍ʼn��ʃ]�[������̘b��
����Ƃ݂���)�B
����Intel�ł����̗l�Ȃ̂ŁA�����A�n�C�G���h�����W�����v�Ŕh���J������������̗͂̂��郁�[�J�[��
Intel�ȊO1�Ђ�����������낤�B�R��̓��W�����v�̏����ɂ���Ȋ��҂͂��ĂȂ��B
MAC�I�^��"���W�����v"�ɉߏ�Ȋ��҂��悹�Ă���炵���A
"���o�C��"��"�T�[�o"�Ƃ������W�������킯�̔��z�����������Â��B
Sandy Bridge�ł��T�[�o��������s����B
�ȂǂƂ̂��Ԕ��ϑz���Ƃ��Ă邪�A�I�^�̘b�͐M���Ȃ����������Ǝv����B
IDF��Intel�����J����Nehalem�̏ڍׂ�RealWorldTech�̉���L����ǂތ���A
�ENehalem��"�R�A"�̕�����Core 2�ɑ���g�������̓T�[�o�����Ǝv������̂���
�ENehalem��"�A���R�A"�̕������T�[�o�����̂��̂��肾���A
�@�����Gainestown/Bloomfield�̘b�ŁALynnfield��Havendale�ł͈قȂ�B
Nehalem�̓T�[�o�̎��ƕ��ŊJ������Ă��āA
Gainestown/Bloomfield�𒆐S�ɃA�[�L�e�N�`���������ɏЉ��A
Lynnfield��Havendale�����Ȃ�x��ēo�ꂷ�邱�Ƃ����
�T�[�o�������ŃR�A��V�X�e����v���A
���C���X�g���[���f�X�N�g�b�v��o�C����"�A���R�A"�̕�����
�t��������`�Ŕh���Ή�����Ƃ����V���������ɒ��킵���B
���̂��߂ɂ���̂�"���W�����v"�Ȃ킯�B
"���W�����v"�͂�����ƒm��������l�����܂��̂ɂ͗L���Ȏ�i�̂悤�����A
���ۂ̂Ƃ���Lynnfield��Westmere����Ɛ蕪���ł��Ȃ��Ƃ���܂Œx��Ă���B
(Lynnfield���_�C�͂��Ȃ�ł����v�Z�Ȃ̂�Bloomfield�̒��`���ʂ̒u��������$200�������C���ɂȂ�Ǝv����B
Havendale����Âɂ݂�A2 Nehalem core+GMCH�Ȃ̂�$80�`90��Havendale�̒��ł͍ʼn��ʃ]�[������̘b��
����Ƃ݂���)�B
����Intel�ł����̗l�Ȃ̂ŁA�����A�n�C�G���h�����W�����v�Ŕh���J������������̗͂̂��郁�[�J�[��
Intel�ȊO1�Ђ�����������낤�B�R��̓��W�����v�̏����ɂ���Ȋ��҂͂��ĂȂ��B
MAC�I�^��"���W�����v"�ɉߏ�Ȋ��҂��悹�Ă���炵���A
"���o�C��"��"�T�[�o"�Ƃ������W�������킯�̔��z�����������Â��B
Sandy Bridge�ł��T�[�o��������s����B
�ȂǂƂ̂��Ԕ��ϑz���Ƃ��Ă邪�A�I�^�̘b�͐M���Ȃ����������Ǝv����B
�I�^�Ɍ��炸
�M������b�́A�ǂ��ɂ��A�Ȃ�
�M������b�́A�ǂ��ɂ��A�Ȃ�
�ߋ��ɔے肳�ꂽ�_��Y�ꂽ���ɂڂ肩������
"���̂Ƃ��̂�����͔n��������"�݂����Ȃ̂͂�߂Ăق����ˁB
�����܂Ŏ����̍l���Ɏ��M�������āA���L�̌f���ł����܂�
�Ȃ��Ȃ��咣�������ʂ����Ƃ����̂Ȃ�A�l�u���O�ł����ĂĂ���ė~�����B
>>911���P�Ȃ�R��̍l���ɂ����Ȃ����A�M����M���Ȃ��͎��R�B
�v�͎����ōl����ƁB
"���̂Ƃ��̂�����͔n��������"�݂����Ȃ̂͂�߂Ăق����ˁB
�����܂Ŏ����̍l���Ɏ��M�������āA���L�̌f���ł����܂�
�Ȃ��Ȃ��咣�������ʂ����Ƃ����̂Ȃ�A�l�u���O�ł����ĂĂ���ė~�����B
>>911���P�Ȃ�R��̍l���ɂ����Ȃ����A�M����M���Ȃ��͎��R�B
�v�͎����ōl����ƁB
�������̐v�ɂ����āA�g�����W�X�^���̂�]��قǂ��邷����A����d�͂�
���e�����Ȃ�����@�\���������Ƃ�A���o�C�������ɂȂ�爫���e����
���^���Ȃ����B
�g�����W�X�^�𑝂₷���Ƃ�����d�͂ɉe������Ƃ������Ƃ𗝉����ĂȂ��悤���B
���e�����Ȃ�����@�\���������Ƃ�A���o�C�������ɂȂ�爫���e����
���^���Ȃ����B
�g�����W�X�^�𑝂₷���Ƃ�����d�͂ɉe������Ƃ������Ƃ𗝉����ĂȂ��悤���B
�C���e��0.13��m�v���Z�X
80����mm�@�@�@ 4400����ݼ��@�@Tualatin�@�@TDP 31.6W��1.4GHz
82.8����mm�@�@ 7700����ݼ��@�@Banias�@ �@ TDP 24.5W��1.7GHz
Larrabee�ɒǂ���NVIDIA��GT200�Ɏ{����GPGPU�����g��
http://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
���̘b���炷��ƁALarrabee��GPGPU�H���Ō�ǂ��ɂȂ���AnVIDIA�Ɠ���
���i�ɛƂ�댯���������ȋC������̂����B
x86�݊��̏璷���͑��Ђ��P�����N�i�ŐV�v���Z�X�ŃJ�o�[����Ƃ��Ă��A
GPU�P�̂Ƃ��Ă̏璷����Video�J�[�h�p�r�ɂ́AAMD��ATi���R�X�g�I�ɕs����
�͔̂ۂ߂Ȃ����B
�܂��ACUDA�Ş��q�����Ă�nVidia�Ɠ��l�ɁADirectX10�pGPU�̃h���C�o�J����
���q�����Ă�Intel���ACUDA�𗽉킷��V�X�e����o����Ƃ͎v���ɂ������B
�܂��Ǝ��̃R���p�C�����o���Ă�Intel������A���̓_�͏����͉��Ƃ��Ȃ�̂�
������B
http://pc.watch.impress.co.jp/docs/2008/0716/kaigai453.htm
���̘b���炷��ƁALarrabee��GPGPU�H���Ō�ǂ��ɂȂ���AnVIDIA�Ɠ���
���i�ɛƂ�댯���������ȋC������̂����B
x86�݊��̏璷���͑��Ђ��P�����N�i�ŐV�v���Z�X�ŃJ�o�[����Ƃ��Ă��A
GPU�P�̂Ƃ��Ă̏璷����Video�J�[�h�p�r�ɂ́AAMD��ATi���R�X�g�I�ɕs����
�͔̂ۂ߂Ȃ����B
�܂��ACUDA�Ş��q�����Ă�nVidia�Ɠ��l�ɁADirectX10�pGPU�̃h���C�o�J����
���q�����Ă�Intel���ACUDA�𗽉킷��V�X�e����o����Ƃ͎v���ɂ������B
�܂��Ǝ��̃R���p�C�����o���Ă�Intel������A���̓_�͏����͉��Ƃ��Ȃ�̂�
������B
918 �FMAC�I�^��911 �����F2008/07/19(�y) 16:45:55 ID:2eUAebpx
>>911
�@�@-----------------
�@�@�ENehalem��"�R�A"�̕�����Core 2�ɑ���g�������̓T�[�o�����Ǝv������̂���
�@�@-----------------
�����ɍő�̕Ό�������Ǝv�������ǁB�B�B
http://journal.mycom.co.jp/photo/articles/2008/04/10/idf09/images/Photo04l.jpg
�@�ESSE 4.2
�@�EImploved Lock Support
�@�EAdditional Caching Hielarchy
�@�EDeeper Buffers
�@�ESMT
�@�ELoop-Stream Detector
�@�EVirtualization (TLB��)
�@�EBetter Branch Prediction (�X�^�b�N������)
�R�����āu�T�[�o�����Ǝv������̂���v�Ȃ��H���̑�������Ȋ��������ǁA�T�[�o�[
�����@�\���ᖳ�����ˁB
�@�EMacro Fusion�g��
�@�E�A���C�����g�����̊ɘa
�@�@-----------------
�@�@�ENehalem��"�R�A"�̕�����Core 2�ɑ���g�������̓T�[�o�����Ǝv������̂���
�@�@-----------------
�����ɍő�̕Ό�������Ǝv�������ǁB�B�B
http://journal.mycom.co.jp/photo/articles/2008/04/10/idf09/images/Photo04l.jpg
{kind=link}
�@�ESSE 4.2
�@�EImploved Lock Support
�@�EAdditional Caching Hielarchy
�@�EDeeper Buffers
�@�ESMT
�@�ELoop-Stream Detector
�@�EVirtualization (TLB��)
�@�EBetter Branch Prediction (�X�^�b�N������)
�R�����āu�T�[�o�����Ǝv������̂���v�Ȃ��H���̑�������Ȋ��������ǁA�T�[�o�[
�����@�\���ᖳ�����ˁB
�@�EMacro Fusion�g��
�@�E�A���C�����g�����̊ɘa
�ESSE 4.2
�ESMT
�͂������T�[�o�������Ǝv��
�ESMT
�͂������T�[�o�������Ǝv��
Larrabee ���������Ȃ��Ă����A�����������ق�����
�������N�ł�Intel�̖{���Ƀ`�b�v�ɂȂ肻���ȗ\���B
�������N�ł�Intel�̖{���Ƀ`�b�v�ɂȂ肻���ȗ\���B
>>918
�Ƃ肠����MAC�I�^���g���ŏ��Ɉ��p����RealWorldTech�̋L���̕����ǂ���B
����\������Ƃ��Ă݂Ă��T�[�o�����̃`���[�j���O�B
queue/buffer�ނ�SMT�����ɑ��₵�����Ă̂������Ă���B
���_�����ɂ������Ă���
�@�ESSE 4.2
�@�EImploved Lock Support
�@�EAdditional Caching Hielarchy
�@�EDeeper Buffers
�@�ESMT
�@�EVirtualization
�@�EBetter Branch Prediction
�̓T�[�o�����̂��̂���ł���B
PenM��Core 2�̎��̊g���Ɣ�r���Ă݂Ȃ�B
�Ƃ肠����MAC�I�^���g���ŏ��Ɉ��p����RealWorldTech�̋L���̕����ǂ���B
����\������Ƃ��Ă݂Ă��T�[�o�����̃`���[�j���O�B
queue/buffer�ނ�SMT�����ɑ��₵�����Ă̂������Ă���B
���_�����ɂ������Ă���
�@�ESSE 4.2
�@�EImploved Lock Support
�@�EAdditional Caching Hielarchy
�@�EDeeper Buffers
�@�ESMT
�@�EVirtualization
�@�EBetter Branch Prediction
�̓T�[�o�����̂��̂���ł���B
PenM��Core 2�̎��̊g���Ɣ�r���Ă݂Ȃ�B
�I�����͐��\�I�ɂ� Core2Duo �ŊԂɍ����Ă��܂������ȗ\��������͉̂��������B
�ቿ�i���ƍ����x���ƐM��������ƒᔭ�M�̗v�����������c���ĂȂ��悤�ȁE�E�E
�ቿ�i���ƍ����x���ƐM��������ƒᔭ�M�̗v�����������c���ĂȂ��悤�ȁE�E�E
>>918�ɋ��������X�g�A�ӊO�ȃ��m���T�[�o�[�p�ƔF�����Ă���q�g�����邷�ˁB�B
�@�ESSE4.2: ��Ƃ��ĕ��������߂̋����Ȃ�Ŕėp�̋@�\����
�@�@(��: http://smallcode.weblogs.us/2007/11/23/strcmp-and-strlen-using-sse-42-instructions/)
�@�EAdditional Caching Hielarchy: ���ꂱ�����W�����[���̂��߂̎d�l���B
�@�EDeeper Buffers: SMT�x��
�@�ESMT: �d�͌������� (Silverthorne�Q��)
�Ԉ���Ă��邷���H
�@�ESSE4.2: ��Ƃ��ĕ��������߂̋����Ȃ�Ŕėp�̋@�\����
�@�@(��: http://smallcode.weblogs.us/2007/11/23/strcmp-and-strlen-using-sse-42-instructions/)
�@�EAdditional Caching Hielarchy: ���ꂱ�����W�����[���̂��߂̎d�l���B
�@�EDeeper Buffers: SMT�x��
�@�ESMT: �d�͌������� (Silverthorne�Q��)
�Ԉ���Ă��邷���H
925 �FMAC�I�^���⑫�F2008/07/19(�y) 18:31:56 ID:2eUAebpx
�悭�ǂ�A����܂Łw�T�[�o�[�d�l�x���Ă��ƂɂȂ��Ă�q�g�����邷���B�B�B
�@�EBetter Branch Prediction
�v���Z�b�T�̃{�g���l�b�N�������𗝉����Ă���̂��͂Ȃ͂��^��ɂȂ��Ă������B
�@�@------------------
�@�@PenM��Core 2�̎��̊g���Ɣ�r���Ă݂Ȃ�B
�@�@------------------
http://www.intel.com/technology/architecture-silicon/core/
�@�@===================
�@�@Further efficiencies include more accurate branch prediction, deeper instruction buffers for
�@�@greater execution flexibility, and additional features to reduce execution time.^(1)
�@�@===================
�@�EBetter Branch Prediction
�v���Z�b�T�̃{�g���l�b�N�������𗝉����Ă���̂��͂Ȃ͂��^��ɂȂ��Ă������B
�@�@------------------
�@�@PenM��Core 2�̎��̊g���Ɣ�r���Ă݂Ȃ�B
�@�@------------------
http://www.intel.com/technology/architecture-silicon/core/
�@�@===================
�@�@Further efficiencies include more accurate branch prediction, deeper instruction buffers for
�@�@greater execution flexibility, and additional features to reduce execution time.^(1)
�@�@===================
�@�ESSE4.2: �������̍������̖ړI��XML�p�[�T��K�\���̍������B��͂�T�[�o�u���BItantium�����l�̊g������B
�@�EAdditional Caching Hielarchy: L3���T�[�o�����Ƀ`���[�j���O����Ă�BL2�܂łł����W�����[���ł��Ȃ������Ȃ��B
�@�EDeeper Buffers: SMT�x���@��
�@�ESMT: �X���[�v�b�g���\�̌���(�d�͌����̈������鍂�����Ȃ�Ă��������S�����Ȃ����j)�B
�@�EAdditional Caching Hielarchy: L3���T�[�o�����Ƀ`���[�j���O����Ă�BL2�܂łł����W�����[���ł��Ȃ������Ȃ��B
�@�EDeeper Buffers: SMT�x���@��
�@�ESMT: �X���[�v�b�g���\�̌���(�d�͌����̈������鍂�����Ȃ�Ă��������S�����Ȃ����j)�B
RealWorldTech���A
>Intel simply states that they use �gbest in class�h branch predictors and that their predictors are tuned to work with SMT.
�\���킪SMT�Ƀ`���[������Ă�B
https://intel.wingateweb.com/SHchina/published/NGMS001/SP08_NGMS001_100r_eng.pdf
���ƁA������16���ڂ݂Ă�BL2 BTB�̓f�[�^�x�[�X�����B
�P�ɕ���\���Ƃ����Ă�Nehalem�̏ꍇ�͓��ɃT�[�o�����ɂȂ��Ă�̂�B
>Intel simply states that they use �gbest in class�h branch predictors and that their predictors are tuned to work with SMT.
�\���킪SMT�Ƀ`���[������Ă�B
https://intel.wingateweb.com/SHchina/published/NGMS001/SP08_NGMS001_100r_eng.pdf
���ƁA������16���ڂ݂Ă�BL2 BTB�̓f�[�^�x�[�X�����B
�P�ɕ���\���Ƃ����Ă�Nehalem�̏ꍇ�͓��ɃT�[�o�����ɂȂ��Ă�̂�B
�Ƃ����悤�ɂ����Ɠ��e�܂Ŋm�F���A��������A
Nehalem�̊e�X�̊g�����T�[�o�u���ł��邱�Ƃ��킩��͂��ł��B
MAC�I�^�͂���𗝉����Ă��Ȃ��B������������C���Ȃ����j�̂悤���B
�Ƃ肠���������ň��p�����\�[�X�͂����Ɠǂ������B
�P�Ȃ�ʂ肩���薼�����̖ό��Ȃ�悢�̂����A
MAC�I�^�͏������݂̕p�x�����������A���������獢��B
Nehalem�̊e�X�̊g�����T�[�o�u���ł��邱�Ƃ��킩��͂��ł��B
MAC�I�^�͂���𗝉����Ă��Ȃ��B������������C���Ȃ����j�̂悤���B
�Ƃ肠���������ň��p�����\�[�X�͂����Ɠǂ������B
�P�Ȃ�ʂ肩���薼�����̖ό��Ȃ�悢�̂����A
MAC�I�^�͏������݂̕p�x�����������A���������獢��B
�I�����˂��A�ǂ�������������ʂ����҂ł������ɂȂ��\���������
�@�\�g�����]�v�ȕ��o�b�T���藎�Ƃ����������I�����v���ɍ��������ȗ\���B
�@�\�g�����]�v�ȕ��o�b�T���藎�Ƃ����������I�����v���ɍ��������ȗ\���B
����T�[�o�[�����̎��������
���ꌩ��ΎI���������������悤�Ɋ�����̂͂��傤���Ȃ�
���ꌩ��ΎI���������������悤�Ɋ�����̂͂��傤���Ȃ�
Nehalem�̏ꍇ�AMerom+CSI����{�ɂȂ��Ă��Ă��Ƃ͑傫�ȃR�A�̊g���͂Ȃ��B
���̏������g�����T�[�o�����Ȃ́B
Nehalem�̊J�������́AIntel��Opteron�ɃT�[�o���ʂŒǂ��Ă��������������̂ŁA
���̎�_�S�ʂ߂�A�������͏���悤�ɉ��ǂ��Ă�����Ă����B
���̏������g�����T�[�o�����Ȃ́B
Nehalem�̊J�������́AIntel��Opteron�ɃT�[�o���ʂŒǂ��Ă��������������̂ŁA
���̎�_�S�ʂ߂�A�������͏���悤�ɉ��ǂ��Ă�����Ă����B
>>930
����Ȃ����Ȃ��B
Nehalem���T�[�o�W�̎��ƕ������������̂����炻��������̂͂��傤���Ȃ����B
�Ȃ�f�X�N�g�b�v�����ƃ��o�C�������̎����Ƃ��������ė~�������̂��B
����Ȃ����Ȃ��B
Nehalem���T�[�o�W�̎��ƕ������������̂����炻��������̂͂��傤���Ȃ����B
�Ȃ�f�X�N�g�b�v�����ƃ��o�C�������̎����Ƃ��������ė~�������̂��B
��{�I�ɎЊO�鎑�������猩�����Ȃ�����
����Ƃ͕ʂ̎��������݂��邱�Ƃ͊m������
����Ƃ͕ʂ̎��������݂��邱�Ƃ͊m������
���Ȃ݂ɃI�����I�����Ƃ��č����̗v���ɍ��킹��CPU��v����Ȃ�
Core2�̕����͂��̂܂܁A���̐��゠����܂ł����Ό͂�ĐM���x���\�����낤�A
���@�\���ŏ�Q�������������̍����������ɂȂ�Ǝv���B
�L���b�V���͂���ɑ��ʁA�ǂ�Ȍ����̈����R�[�h�ɂ��ς�����d�l�ɂ���
�`���[�j���O�����܂肵�Ȃ��Ă������\�ɂȂ鎖��ɂ���B
�����R�����̎��ӂ͉\�Ȍ���S�������A���i�_�����ŏ����ɂȂ�悤�Ɏd�����č����x����ɂ���B
���Z���\�͌��݂̃~�h�������W�N���X���x�ŗ}���Ă����B
Core2�̕����͂��̂܂܁A���̐��゠����܂ł����Ό͂�ĐM���x���\�����낤�A
���@�\���ŏ�Q�������������̍����������ɂȂ�Ǝv���B
�L���b�V���͂���ɑ��ʁA�ǂ�Ȍ����̈����R�[�h�ɂ��ς�����d�l�ɂ���
�`���[�j���O�����܂肵�Ȃ��Ă������\�ɂȂ鎖��ɂ���B
�����R�����̎��ӂ͉\�Ȍ���S�������A���i�_�����ŏ����ɂȂ�悤�Ɏd�����č����x����ɂ���B
���Z���\�͌��݂̃~�h�������W�N���X���x�ŗ}���Ă����B
935 �FMAC�I�^��931 �����F2008/07/19(�y) 19:19:46 ID:2eUAebpx
>>931
�@�@------------------
�@�@Intel��Opteron�ɃT�[�o���ʂŒǂ��Ă�������
�@�@------------------
���Ȃ��Ƃ����̗��R��w�R�A�x�̐v�ɖ����Ƃ������Ƃ�F�����Ă�������A���Ȃ���1�s�ڂɏ�����
����Ƃ����Ȃ��������ǁB�B�B
�@�@------------------
�@�@Intel��Opteron�ɃT�[�o���ʂŒǂ��Ă�������
�@�@------------------
���Ȃ��Ƃ����̗��R��w�R�A�x�̐v�ɖ����Ƃ������Ƃ�F�����Ă�������A���Ȃ���1�s�ڂɏ�����
����Ƃ����Ȃ��������ǁB�B�B
�Ƃ肠�����A
�h���ō���u�ς����镔���v�Ɓu�Œ�̕����v�̌����������Ȃ��l������
�悭�킩�����B
Merom��CSI���������āAP2P�ɂȂ��đ���肪Opteron�����ȏ�Ȃ������ŁA
�R�A���T�[�o�����ɋ����������̂�Nehalem�B
�h���͂��̃R�A�𗬗p���ăA���R�A������ς������́B
������T�[�o�d�l��Nehalem����s������B
�������ꂾ���̂��ƁBTickTock������??������t�ł��B
�h���ō���u�ς����镔���v�Ɓu�Œ�̕����v�̌����������Ȃ��l������
�悭�킩�����B
Merom��CSI���������āAP2P�ɂȂ��đ���肪Opteron�����ȏ�Ȃ������ŁA
�R�A���T�[�o�����ɋ����������̂�Nehalem�B
�h���͂��̃R�A�𗬗p���ăA���R�A������ς������́B
������T�[�o�d�l��Nehalem����s������B
�������ꂾ���̂��ƁBTickTock������??������t�ł��B
937 �FMAC�I�^��936 �����F2008/07/19(�y) 19:36:02 ID:2eUAebpx
>>936
�Ƃ肠�����B�B�B�����B
����������Ȃ�AK8, Core2�Ƒ����ăT�[�o�[�E�f�X�N�g�b�v�E���o�C���̑S�Ă̕���ŒP��R�A�v��
���p����Ƃ������j���傫�Ȑ��������߂Ă����Ƃ����傫�ȗ�����������āA������邱�Ƃ��ł��Ȃ�
���Ǝv�����B
������A�w�d�͌����x������������̐��t���B
�Ƃ肠�����B�B�B�����B
����������Ȃ�AK8, Core2�Ƒ����ăT�[�o�[�E�f�X�N�g�b�v�E���o�C���̑S�Ă̕���ŒP��R�A�v��
���p����Ƃ������j���傫�Ȑ��������߂Ă����Ƃ����傫�ȗ�����������āA������邱�Ƃ��ł��Ȃ�
���Ǝv�����B
������A�w�d�͌����x������������̐��t���B
�Ȃ��ӂ̒E�����[�h�ɓ��낤�Ƃ��Ă�ȁB
>Havendale�̕���A���[�G���h���o������������ E5200�N���X�Ƃ̂��Ƃ�����A>>853��$100���Ƃ���
>���M�ߐ����������B
>Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
"Havendale��$100��̂�Nehalem�̓T�[�o�����̐v�ł͂Ȃ������B"
�� �T�[�o�����ɐv���ꂽ�v���Z�b�T�̔h����$100�����炻��Ȃɂ��������̂�? ��炢�B
������MAC�I�^�ɂƂ��ĕ��ɂȂ����ȁB
>K8, Core2�Ƒ����ăT�[�o�[�E�f�X�N�g�b�v�E���o�C���̑S�Ă̕���ŒP��R�A�v��
>���p����Ƃ������j���傫�Ȑ��������߂Ă���
Nehalem�̊J�������ɂ�Core 2�͎s��ɂ܂��o�Ă܂�����?
2005�N���_��Merom+CSI�̘b�łĂ���B�����Ə����ł�̂�?
>Havendale�̕���A���[�G���h���o������������ E5200�N���X�Ƃ̂��Ƃ�����A>>853��$100���Ƃ���
>���M�ߐ����������B
>Nehalem��T�[�o�[�����Ƃ�����ł����q�g�������悤�ȋC�����邷���ǁB�B�B
"Havendale��$100��̂�Nehalem�̓T�[�o�����̐v�ł͂Ȃ������B"
�� �T�[�o�����ɐv���ꂽ�v���Z�b�T�̔h����$100�����炻��Ȃɂ��������̂�? ��炢�B
������MAC�I�^�ɂƂ��ĕ��ɂȂ����ȁB
>K8, Core2�Ƒ����ăT�[�o�[�E�f�X�N�g�b�v�E���o�C���̑S�Ă̕���ŒP��R�A�v��
>���p����Ƃ������j���傫�Ȑ��������߂Ă���
Nehalem�̊J�������ɂ�Core 2�͎s��ɂ܂��o�Ă܂�����?
2005�N���_��Merom+CSI�̘b�łĂ���B�����Ə����ł�̂�?
���K�\���̓n�[�h�ʼn��Ƃ�����O�Ƀ\�t�g�̃A���S���Y���ς����ق����ǂ���Ȃ����Ȃ��Ɖ��͎v���̂ł���
����ɂ���đS�R�������x�Ⴄ��
����ɂ���đS�R�������x�Ⴄ��
940 �FSocket774�F2008/07/19(�y) 20:04:34 ID:pfU8QaNa
�M���c�_����݂ł�(�L�E�ցE`)�B
nehalem�͌����CPU�Ƃ͑S���݊�����������ł����A
���������������ƁAsocket478��LGA775�̎��̂悤��
��C�ɃA�[�L�e�N�`���̍��V���i�ނƎv���܂����H
������l������A���̉Ă͔����T������ׂ����Y�ށB�B�B
nehalem�͌����CPU�Ƃ͑S���݊�����������ł����A
���������������ƁAsocket478��LGA775�̎��̂悤��
��C�ɃA�[�L�e�N�`���̍��V���i�ނƎv���܂����H
������l������A���̉Ă͔����T������ׂ����Y�ށB�B�B
LGA775������������Ǝv���܂�
942 �FMAC�I�^��938 �����F2008/07/19(�y) 20:08:18 ID:2eUAebpx
>>938
�@�@----------------
�@�@�T�[�o�����ɐv���ꂽ�v���Z�b�T�̔h����$100�����炻��Ȃɂ��������̂�?
�@�@----------------
�T�[�o�[�����ɐv�����v���Z�b�T��ቿ�i�Ŕ��炴��Ȃ�������Ђ̖��H�����ꂷ(��)
http://journal.mycom.co.jp/news/2008/07/18/009/index.html
�@�@----------------
�@�@�T�[�o�����ɐv���ꂽ�v���Z�b�T�̔h����$100�����炻��Ȃɂ��������̂�?
�@�@----------------
�T�[�o�[�����ɐv�����v���Z�b�T��ቿ�i�Ŕ��炴��Ȃ�������Ђ̖��H�����ꂷ(��)
http://journal.mycom.co.jp/news/2008/07/18/009/index.html
�\�P�b�g���A�[�L�e�N�`���Ȃ̂�
944 �FSocket774�F2008/07/19(�y) 20:12:59 ID:pfU8QaNa
>>941
���������܂����ˁH
775���o�����ɁA�\�Z�̓s���Ŋ�����478�̃\�P�b�g�Ŏ��삵����ł����A
��������������Ă�̂ŁB�B�B
nehalem��Core2���������Ă����悤�ȓW�J�ɂȂ�����̂ł����B
>>943
�f�l�Ȃ��̂ŁA���t�̎g�������w���ł��݂܂���(�L�E�ցE`)�B
���������܂����ˁH
775���o�����ɁA�\�Z�̓s���Ŋ�����478�̃\�P�b�g�Ŏ��삵����ł����A
��������������Ă�̂ŁB�B�B
nehalem��Core2���������Ă����悤�ȓW�J�ɂȂ�����̂ł����B
>>943
�f�l�Ȃ��̂ŁA���t�̎g�������w���ł��݂܂���(�L�E�ցE`)�B
���i�тɂ��B
>>940���n�C�G���h�����݂Ă��Ȃ��̂Ȃ�}���Ɉڍs���i�ނ��A
�~�h���`���[�G���h���݂Ă���̂Ȃ�i�܂Ȃ��B
Nehalem�̏ꍇ�A1366pin�̂�1160pin�̂Ƃ�
�f�X�N�g�b�v�ł��\�P�b�g��2��ނ��邩��ꌾ�������������Ȃ��Ȃ��B
�܂��A�T�[�o�p��1366pin����s���Ė{���f�X�N�g�b�v�p��1160pin���x��Ă���
�����ŁA�ŏ���1366pin�Ńf�X�N�g�b�v���ł����ƂɁA1160pin�̔䗦��������
���ƂɂȂ邩�炳�BIntel�Ƃ��Ă��ꂵ���헪���ƁB
���Ȃ݂ɐl�ɂ���Ă�
Intel�͋������i�����܂�Ȃ�����Ƃ������R�ł킴��1160pin���i�������点�Ă���
�Ƃ������Ƃ炵���B����ɂ��̃|�W�e�B�u�ȉ��߂͗����ł��Ȃ����B
>>940���n�C�G���h�����݂Ă��Ȃ��̂Ȃ�}���Ɉڍs���i�ނ��A
�~�h���`���[�G���h���݂Ă���̂Ȃ�i�܂Ȃ��B
Nehalem�̏ꍇ�A1366pin�̂�1160pin�̂Ƃ�
�f�X�N�g�b�v�ł��\�P�b�g��2��ނ��邩��ꌾ�������������Ȃ��Ȃ��B
�܂��A�T�[�o�p��1366pin����s���Ė{���f�X�N�g�b�v�p��1160pin���x��Ă���
�����ŁA�ŏ���1366pin�Ńf�X�N�g�b�v���ł����ƂɁA1160pin�̔䗦��������
���ƂɂȂ邩�炳�BIntel�Ƃ��Ă��ꂵ���헪���ƁB
���Ȃ݂ɐl�ɂ���Ă�
Intel�͋������i�����܂�Ȃ�����Ƃ������R�ł킴��1160pin���i�������点�Ă���
�Ƃ������Ƃ炵���B����ɂ��̃|�W�e�B�u�ȉ��߂͗����ł��Ȃ����B
�܂��\�P�b�g�̒������Ȃ�ė\�z�����ɓ��
DP-Xeon�ł��g���킯������LGA1366���\�����������Ȃ��H
�Ǝv���B���܂ő҂����Ȃ�Bloomfield�܂ő҂��Ă����H
�܂�����ɔ��_���悤�Ǝv���Ί��ł��o�������
���F�͐����\�z�Ȃ�ŁB
DP-Xeon�ł��g���킯������LGA1366���\�����������Ȃ��H
�Ǝv���B���܂ő҂����Ȃ�Bloomfield�܂ő҂��Ă����H
�܂�����ɔ��_���悤�Ǝv���Ί��ł��o�������
���F�͐����\�z�Ȃ�ŁB
SMT���T�[�o�����ł��邱�Ƃ�^��������ے肷��n���ɂ��܂��̂�߂��
���Ȃ��Ƃ�LGA775�͐V�K�ō���邱�Ƃ͂����Ȃ��i�~�h���A���[�G���h�N���X�͕ʁj
LGA775����CPU�ڂ������������Ă�����CPU�ȊO�������Ă��Ƃ����͊m���B
LGA775����CPU�ڂ������������Ă�����CPU�ȊO�������Ă��Ƃ����͊m���B
LGA1366�͍���LGA771�݂����Ȉ����ɂȂ�̂���
���C����LGA1066�܂ő҂��������ǂ���1�N�ʐ�E�E�E
���C����LGA1066�܂ő҂��������ǂ���1�N�ʐ�E�E�E
�}�U�[�̒l�i�ɂ��Ǝv�����ǁA�N�A�b�h��Bloomfield�̍ʼn��ʂ�2.66GHz��
�嗬�ɂȂ��Ȃ��H$284���Ɣ��������Q9450���������ALynnfield��
�҂��Bloomfield�����ق��������悤�ȋC������B
�嗬�ɂȂ��Ȃ��H$284���Ɣ��������Q9450���������ALynnfield��
�҂��Bloomfield�����ق��������悤�ȋC������B
>>950
�܂�CPU�̒l�i������������Ȃ�ȁB
�}�U�[����胁�[�J�[���f�X�N�g�b�v�����Ƃ��āA�ǂ�ǂ�o���Ă�����
�ӊO�Ɉ����Ȃ邩�������ˁB
DDR3�͍��N�̖��ɂ�1GB������5��~�ȉ��i2GB���W���[����1���~�ȉ��j
�S��������
CPU 3.5���~
MB 3���~
DDR3 2GBx3 3���~
10���~�ȉ���3�_�Z�b�g������A���\Bloomfield���s���邩�ȁB
�܂�CPU�̒l�i������������Ȃ�ȁB
�}�U�[����胁�[�J�[���f�X�N�g�b�v�����Ƃ��āA�ǂ�ǂ�o���Ă�����
�ӊO�Ɉ����Ȃ邩�������ˁB
DDR3�͍��N�̖��ɂ�1GB������5��~�ȉ��i2GB���W���[����1���~�ȉ��j
�S��������
CPU 3.5���~
MB 3���~
DDR3 2GBx3 3���~
10���~�ȉ���3�_�Z�b�g������A���\Bloomfield���s���邩�ȁB
�T�o�d�l�Ȃ獂���C�e���V�ł���FSB��QPI�ɕς��邾���ŏ\�����ȁB
��̓��j�[�R�A��CPU + GPU���v���₷���悤�A�[�L�e�N�`���[����������x�Ȃ��B
�������{�����d�͂Ȃ炻�ꂾ���ŏ\���B
��̓��j�[�R�A��CPU + GPU���v���₷���悤�A�[�L�e�N�`���[����������x�Ȃ��B
�������{�����d�͂Ȃ炻�ꂾ���ŏ\���B
DDR3��2GB�͂��łɍň���12800�~�Ȃ���N����1����Ȃ�ė]�T����
>>951
Lynnfield�͂ł�܂Ŏ��Ԃ������邵�AWestmere�����������ʼn���������
�����Z���Ȃ肻���ȗ\���BC2Q��Q9650�����������N��Q1�Ƀf�B�X�R���ɂȂ邵
Intel�Ƃ��ẮALynnfield���x���̂�Bloomfield���f�X�N�g�b�v�����ɔ����悤��
������Ȃ����Ǝv����悤��CPU�̉��i�ݒ肾����ˁB
�ȓd�͌����́A����E8xxx�n�ȉ���Q8xxx�n�ɂȂ肻���A�O���t�B�b�N������Havendale���x��邵�B
Lynnfield�͂ł�܂Ŏ��Ԃ������邵�AWestmere�����������ʼn���������
�����Z���Ȃ肻���ȗ\���BC2Q��Q9650�����������N��Q1�Ƀf�B�X�R���ɂȂ邵
Intel�Ƃ��ẮALynnfield���x���̂�Bloomfield���f�X�N�g�b�v�����ɔ����悤��
������Ȃ����Ǝv����悤��CPU�̉��i�ݒ肾����ˁB
�ȓd�͌����́A����E8xxx�n�ȉ���Q8xxx�n�ɂȂ肻���A�O���t�B�b�N������Havendale���x��邵�B
�[��Lynnfield���������B�}�U�[��������2ch����ō�����Ȃɍ����Ȃ���B
cpu�Ŕ������x��邱�Ƃ͑��X���邯�ǁA�O�|������邱�Ƃ͉ߋ��������̂��ȁH
Lynnfield���������܂�ɒx������
Lynnfield���������܂�ɒx������
��AMD��1GHz�����ƃf���A���R�A�����̂Ƃ��ɂ���ĂȂ���������
�ǂ̃\�P�b�g�������ɂȂ邩�̓}�U�[�{�[�h���[�J�[����Ԓm�肽�����Ƃ��낤
>>168
�\�P�b�g���[�J�[�̒��̐l����ς��낤�B
�\�P�b�g���[�J�[�̒��̐l����ς��낤�B
LGA�s���̎������s�����܂�ቺ�Ń}�U�{�x���_�ܖ�
Larrabee �M����������A��������
959�̃o�J���ُ͈�
963 �FSocket774�F2008/07/22(��) 21:30:13 ID:I0h/UGld
���k�傪�O���t�F�����V���R�����ɐ�������̂ɐ��������炵���ˁA�\�[�X�͓��o�Y�ƐV���B
���̍ޗ������Ȃ�̐��\���肻���Ȃ�ŁA�O����C�ɂȂ��Ă����ǁB
���̍ޗ������Ȃ�̐��\���肻���Ȃ�ŁA�O����C�ɂȂ��Ă����ǁB
�V�[�g��̂��̂ɃV���R�����������āA
���̂܂Ă��H���ɂ܂킷���Ă����̂͂ǂ����Ȃ�
�O����v���Ă������ǁA�܂�������E�E�E
>>963
�V���R�����̃O���t�F�������쐻�ɏ��߂Đ���
�i�����̒�������K�͏W�σf�o�C�X�ɓ��j
ttp://www.jst.go.jp/pr/announce/20080624/index.html
���̂ւ����H
���̂܂Ă��H���ɂ܂킷���Ă����̂͂ǂ����Ȃ�
�O����v���Ă������ǁA�܂�������E�E�E
>>963
�V���R�����̃O���t�F�������쐻�ɏ��߂Đ���
�i�����̒�������K�͏W�σf�o�C�X�ɓ��j
ttp://www.jst.go.jp/pr/announce/20080624/index.html
���̂ւ����H
�{���ɏ��߂ĂȂ̂��Ȃ��E�E�E
SiC�M�������ăO���t�F�����Č��\�ǂ������b�̂悤�ȋC������
���N�O���炢��Science��STM�ŃO���t�F�����Ă��_���ڂ��Ă����ǁASiC���������Ă��悤��
SiC�M�������ăO���t�F�����Č��\�ǂ������b�̂悤�ȋC������
���N�O���炢��Science��STM�ŃO���t�F�����Ă��_���ڂ��Ă����ǁASiC���������Ă��悤��
�悭�ǂ�łȂ��������番����Ȃ���������
�c�����Ȃ��O���t�F����M�����ō�ꂽ���Ă̂��V�K���Ȃ�
�Ȃ�قǂˁ[�悤����
�c�����Ȃ��O���t�F����M�����ō�ꂽ���Ă̂��V�K���Ȃ�
�Ȃ�قǂˁ[�悤����
�R�R���|�C���g��
�{�����O���[�v�́ASi���Ɉ�x�A�W�Onm�Ƃ����ɂ߂Ĕ���SiC�������`�����A
�����M�������邱�Ƃ�Si���ւ̃O���t�F���쐻�ɐ������܂����B
���̍ہASi������SiC�����̊Ԃɑ��݂����Q�O���̊i�q�s�������X�j
���������邽�߁A����܂łƂ͈قȂ�����ɐ�o����Si�������p�������Ƃ��u���[�N�X���[�ƂȂ�܂����B
���̍H�v�ɂ��ASi��̏�ɁA����܂ł��c���S���̂P�ɗ}����ꂽSiC�����𐬒������邱�Ƃ��\�ɂȂ�A
���̌��ʁA�O���t�F���`���ɐ������܂����B
�{�����O���[�v�́ASi���Ɉ�x�A�W�Onm�Ƃ����ɂ߂Ĕ���SiC�������`�����A
�����M�������邱�Ƃ�Si���ւ̃O���t�F���쐻�ɐ������܂����B
���̍ہASi������SiC�����̊Ԃɑ��݂����Q�O���̊i�q�s�������X�j
���������邽�߁A����܂łƂ͈قȂ�����ɐ�o����Si�������p�������Ƃ��u���[�N�X���[�ƂȂ�܂����B
���̍H�v�ɂ��ASi��̏�ɁA����܂ł��c���S���̂P�ɗ}����ꂽSiC�����𐬒������邱�Ƃ��\�ɂȂ�A
���̌��ʁA�O���t�F���`���ɐ������܂����B
969 �FSocket774�F2008/07/22(��) 23:06:27 ID:MfEe9pin
�����߂Ēm������ł���
�Ƃ���ŃC���W�E���K���E����f�͂ǂ��Ȃ����H
http://en.hardspell.com/doc/showcont.asp?news_id=3782
������`tom�͏��߂Ă�32nm�̗p���i�ŁA�h�c�e�Ńf������炵���Ƃ̂��ƁB
������`tom�͏��߂Ă�32nm�̗p���i�ŁA�h�c�e�Ńf������炵���Ƃ̂��ƁB
�R�s�y����
TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ�
�J���Ҍ����ɔz�z�����Ɠ`���Ă��邷�B
����N���b�N��R�A����A�ŏI���i�ƈقȂ�Ƃ̂��ƁB
http://www.theinquirer.net/gb/inquirer/news/2008/07/22/larrabee-boards-coming-november
�@�@----------------------------------
�@�@The initial boards are meant to code against, and they will do
�@�@that nicely. They will not be at the final clock, final core
�@�@counts, or final anything however. If you want to get your feet
�@�@wet, Intel should have a board for you in a few months.
�@�@----------------------------------
�J���Ҍ����ɔz�z�����Ɠ`���Ă��邷�B
����N���b�N��R�A����A�ŏI���i�ƈقȂ�Ƃ̂��ƁB
http://www.theinquirer.net/gb/inquirer/news/2008/07/22/larrabee-boards-coming-november
�@�@----------------------------------
�@�@The initial boards are meant to code against, and they will do
�@�@that nicely. They will not be at the final clock, final core
�@�@counts, or final anything however. If you want to get your feet
�@�@wet, Intel should have a board for you in a few months.
�@�@----------------------------------
����ς����N�o��͓̂r���o�߂̈�i���B
��N�O�}�N�I�^�������Ă����ʂ肾�ȁB
��N�O�}�N�I�^�������Ă����ʂ肾�ȁB
Lincroft��32nm�Ȃ̂�?
Moorestown�v���b�g�t�H�[����45nm���Č����Ă��悤�ȋC�������...
���̃N���J�T�C�Y�̃}�U�[�{�[�h��45nm�������̂�32nm�O�����̂����C�ɂȂ�B
����d�͎��悾���\���ɏ��^���ł����iPhone�ɓ��邩��
Moorestown�v���b�g�t�H�[����45nm���Č����Ă��悤�ȋC�������...
���̃N���J�T�C�Y�̃}�U�[�{�[�h��45nm�������̂�32nm�O�����̂����C�ɂȂ�B
����d�͎��悾���\���ɏ��^���ł����iPhone�ɓ��邩��
>>971
32nm�ւ��̂܂܃V�������N����ƁA�_�C���������Ȃ肷���Ĕz���p�b�h�������m�ۏo���Ȃ�
�C�����邩��ADualCore���f�t�H�ɂ��Ȃ��Ƒʖڂ������ȁB
32nm�ւ��̂܂܃V�������N����ƁA�_�C���������Ȃ肷���Ĕz���p�b�h�������m�ۏo���Ȃ�
�C�����邩��ADualCore���f�t�H�ɂ��Ȃ��Ƒʖڂ������ȁB
32nm��Atom���ĂȂ�ł��B
Moorestown/Lincroft��45nm�������n�Y�B
http://pc.watch.impress.co.jp/docs/2007/0921/idf06_18.jpg
http://ascii.jp/elem/000/000/137/137958/moore1_o_.jpg
http://pc.watch.impress.co.jp/docs/2008/0307/cebit11.htm
�P�f�B�A���ɂ���LINCROFT��45nm�v���Z�X���[���Ő�������Ă���A
Silverthorne�̃R�A�Ƀ������R���g���[���AGPU�A�r�f�I�f�R�[�_/
�G���R�[�_�Ȃǂ����������`�ɂȂ�Ƃ����B
Moorestown/Lincroft��45nm�������n�Y�B
http://pc.watch.impress.co.jp/docs/2007/0921/idf06_18.jpg
{kind=link}
http://ascii.jp/elem/000/000/137/137958/moore1_o_.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2008/0307/cebit11.htm
�P�f�B�A���ɂ���LINCROFT��45nm�v���Z�X���[���Ő�������Ă���A
Silverthorne�̃R�A�Ƀ������R���g���[���AGPU�A�r�f�I�f�R�[�_/
�G���R�[�_�Ȃǂ����������`�ɂȂ�Ƃ����B
�^�C�~���O�I�ɂ�32nm�v���Z�X�̎���CPU�����x��IDF�Ŕ�I�����̂͑Ó������ǂˁB
�g�����W�X�^���Ȃ��Ċ������邩��A�����ɂ͂����Ă������Ă킯���B
�������ȁB
�������ȁB
32nm�łǂꂾ������d�͗�����̂����҂��Ă�����
GPU�������Ȃ��r�ł��Ȃ��ȁB
GPU�������Ȃ��r�ł��Ȃ��ȁB
�V�X�e���S�̂Ŕ�r�����炴������Ⴄ�����ˁB
984 �FSocket774�F2008/07/23(��) 23:26:51 ID:NYcuyEih
���X���܂����H
���ɑ傫�����i�Ⴂ�ɂȂ�
�{����UMPC
�{����UMPC
986 �FSocket774�F2008/07/23(��) 23:54:52 ID:iVwCiWMT
�~�j�p�\��32nm�������Ăق���W
pico�ɓ˓�����̂͂��Ɖ��\�N�����邱�Ƃ��E�E�E
988 �FSocket774�F2008/07/24(��) 00:01:15 ID:HfyASPfF
�~�j�p�\��
�~�j�p�\ �Ɉ�v������{��̃y�[�W �� 3,100 ���� 1 - 10 ���� (0.20 �b)
990
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/l50
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
http://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
Intel�̎�����CPU�ɂ��Č�낤 34
http://pc11.2ch.net/test/read.cgi/jisaku/1209622524/l50
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
http://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
�����X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
����>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
���̃X���ɂ͕s�v�B
���X����980�ŏ\���B
����>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
���̃X���ɂ͕s�v�B
���X����980�ŏ\���B
950��
���߂�
���߂�
995 �FSocket774�F2008/07/24(��) 00:51:44 ID:ZdUQ0uPx
>>993
�ƑP�I�ȃX�����Ă�����ɂ͉������Ă�����
�ƑP�I�ȃX�����Ă�����ɂ͉������Ă�����
>>993
��肠����搂�����݂����Ȋ�����
>>994
�������H
�Ȃ玟���炻�����Ă���
��肠�����U��
Intel�̎�����CPU�ɂ��Č�낤 35
http://pc11.2ch.net/test/read.cgi/jisaku/1216827994/
��肠����搂�����݂����Ȋ�����
>>994
�������H
�Ȃ玟���炻�����Ă���
��肠�����U��
Intel�̎�����CPU�ɂ��Č�낤 35
http://pc11.2ch.net/test/read.cgi/jisaku/1216827994/
�Ղ�i�s�Ȃ�Ė�����A���̃X���ɂ�
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/