hossyu
hossyu
初っ端から過疎ってるなw
プリフェッチ周りの思考実験が全然進まないので書き込んでなかったが、結果だけでも。
↓定量的な考察ができてないあたり、まるっきり理解してませんな。
メモリベンチをL2を切ったDothanでやって、L2ありの場合と比較する。
http://rerere.sytes.net/up/source/up11262.zip 普通のロードが遅い。これはL2に対するHWプリフェッチができない影響かな。
アクセス順変えは、L2ありだと2~3clkだけ効くが、L2なしだと全く効かない。
つまり、アクセス順序を変えることで帯域を引き出すテクニックはL2に対してしか
効かないということだ。メモリに対しては並べ替えられてしまう?
prefetcht0(L1のみにプリフェッチ)だとロードで変わらずストアでは速くなっている。
これは、L2があるとL2を経由してメモリに書き込まれて遅くなるからだろう。
prefetcht1(L2のみにプリフェッチ)だと全体的に遅くなる。切ってあるL2に転送できないしな。
prefetchnta(L1とL2両方にプリフェッチ)だとt0と同じクロック数になり、
L2ありと比較するとストアが微妙に遅い。
どちらでもストア性能を引き出せているが、HWプリフェッチの効かない分だけ
L2なしの方が遅くなったと思われる。
>>6 prefetcht2 が無いお。 (><)
prefetcht0 は、全てのキャッシュにプリフェッチ。
prefetcht1 は、L1を考慮してプリフェッチ。
prefetcht2 は、L2を考慮してプリフェッチ。
prefetchnta は、全てのキャッシュの中でプロセッサにより近く、
まだキャッシュ利用されてない箇所でキャッシュ汚染を最小にしてプリフェッチ。
現状 prefetcht2 と t1 の間には差が無い。
>>7 >>8 も指摘しているが、ちょっと違う。
だいたい nta はノンテンポラルなんだから、L1 L2 両方汚染するようなことはない。
Intelの最適化マニュアルによると、P3では、
t0はL1とL2両方、t1,t2はL2のみ、ntaはL1のみにプリフェッチするそうだ。
俺はt0とntaを逆に思っていたようだ(何回も読んだはずなんだがな・・・)。
つーかそんなことも気づかないくらい訳わからんわけで。
Pen4ではntaとt0って何か違うのだろうか。全部同じに見える。
以前の測定では、誤差にしては大きいが、有意差としては微妙な違いだった。
非テンポラルの意味もよくわからない。単にL1以外を汚染しないということかね。
L1から追い出されてもL2に行かないって複雑な処理のような。
ていうか普通のL1L2ミスするmovでL1と同時にL2にもデータが行ったりするわけ?
movによるプリフェッチに対するprefetch命令の利点として、
>・通常命令のリタイアメントをストールしない。
こんなことがマニュアルに書いてあったが、どういうことだろう。
全く依存性のないロードmovならprefetchと何が違うのかと思うが。
後の方の命令がプリフェッチ命令をいくらでも追い越して実行できるということなんだろうけど。
「アクセス順変え」とか言っても何のことかわからないので、ここでちゃんと説明しておく。
メモリ上の32bit整数を足し上げるコードの具体例で説明する。
ポインタのesiは64byteアラインされているものとする。
クロック数は、L1ミスL2ヒットのときのDothanでの数字。
decを使ってないのは、深い意味はないです。
「通常のコード」14.7clk/loop。
lp:
paddd xmm0,[esi]
paddd xmm0,[esi+16]
paddd xmm0,[esi+32]
paddd xmm0,[esi+48]
add esi,64
sub ecx,1
jnz lp
「通常のプリフェッチ」12.0clk/loop。
lp:
prefetcht0 [esi+64] ; L2ヒットしないときは64を512などにしないと効果が薄い
paddd xmm0,[esi]
paddd xmm0,[esi+16]
paddd xmm0,[esi+32]
paddd xmm0,[esi+48]
add esi,64
sub ecx,1
jnz lp
「movによるプリフェッチ」11.0clk/loop。
lp:
mov eax,[esi+64]
paddd xmm0,[esi]
paddd xmm0,[esi+16]
paddd xmm0,[esi+32]
paddd xmm0,[esi+48]
add esi,64
sub ecx,1
jnz lp
「アクセス順変えプリフェッチ」11.0clk/loop。//本来はmovによるプリフェッチより速い。
lp:
paddd xmm0,[esi+64] ; ループ前後に整合性を取るためのコードが数行必要
paddd xmm0,[esi+16]
paddd xmm0,[esi+32]
paddd xmm0,[esi+48]
add esi,64
sub ecx,1
jnz lp
>>10 ドキュメントより抜粋
NTA (non-temporal data with respect to all cache levels)―prefetch data into non-temporal
cache structure and into a location close to the processor, minimizing cache pollution.
キャッシュ汚染を最小にするとは書かれているけど、全く汚染しないとは書かれてないお。
それに
The implementation of prefetch locality hints is implementation-dependent,
と書かれているお。 実装依存だお。
>>14 俺が両方汚染すると書いたので、
>>10は「L2は汚染しない」と言ったんでそ。
まあ、そのCPUの実装に依存するわけなのだが、
どの程度の負荷のことをやってるのかなあ。
L2の範囲だと「movによるプリフェッチ」の方が1clk程度速くて、
メモリアクセスすると「通常のプリフェッチ」が圧倒的に速い。
その「1clk分の何か」が知りたい。
>>11 > movによるプリフェッチに対するprefetch命令の利点として、
> >・通常命令のリタイアメントをストールしない。
> こんなことがマニュアルに書いてあったが、どういうことだろう。
> 全く依存性のないロードmovならprefetchと何が違うのかと思うが。
リタイヤユニットはインオーダー実行なので、
movだとレジスタに格納するデータが来るまでリタイヤユニットが止まる。
prefetchならデータが来ていなくてもさっさとリタイヤして
次に進むって意味じゃないかな?
>>15 > L2の範囲だと「movによるプリフェッチ」の方が1clk程度速くて、
> メモリアクセスすると「通常のプリフェッチ」が圧倒的に速い。
> その「1clk分の何か」が知りたい。
http://www.intel.co.jp/jp/developer/technology/itj/2004/volume08issue01/art01_microarchitecture/p04_new.htm これはPrescottの新機能の説明なんだけど、こんな記述がある。
「また、トレース・キャッシュ上でエンコードするμop のタイプを、これまでより増やしました。(…続く)」
ここの説明を読むとソフトウェア・プリフェッチ命令はトレースキャッシュに格納できない程の複雑な命令で、
従来のNetburstプロセッサでは逐一マイクロコードROMからμopを供給していたと読めます。
Dothanではprefetch命令は何μopですか?
>>16 movだと、ロードが完了するまでリタイヤできず、そうなるとmovより後の命令は
一切リタイヤできなくなり、リオーダ・バッファに溜まってしまうということか。
(リタイヤがインオーダーって、知っていても忘れがちなのかもしれん)
prefetch命令は、「プログラムの動作に影響を与えない」という特異な命令なので、
何らかの命令をディスパッチしたら「何も確認せずに」リタイヤさせることができるのかも。
Dothanでのprefetch命令は、・・・1μopなんですねえ。
ただ、フュージョンしてる可能性は高いと思う。P6だとどうだろ。
prefetcht0は同じアドレスに対して繰り返すなら1clk/命令が出る。
更にprefetcht0 [esi] / add eax,eax / add ebx,ebx この3命令は1clkで実行できる。
よってprefetcht0は(同じアドレスに対してなら)ALUを使っていないとわかる。
prefetcht0 [esi] / mov eax,[esi] は2clkで当然かもしれないが、
prefetcht0 [esi] / mov [esi],eax も、2clkかかる。
prefetcht0 [esi] / mov eax,[esi] / mov [esi+16],ebx これでも2clk。
ロードとストア(データとアドレスのうち少なくとも片方)を1個ずつ使っているっぽい。
RDPMCを使ってみる。
イベント番号4Bh、すべてのキャッシュをミスしたprefetch命令の数。
イベント番号65h、バースト読み取りの数。
>>12「通常のプリフェッチ」をecx=10000(6MB程度)で試すと、
イベント4Bhが53300前後、イベント65hが97400前後。
何と、10万回中半分強しかプリフェッチが働いていない。
64byte程度の差では、プリフェッチの前にadddのロードが働くことも多いようだ。
prefetcht0 [esi+256] にすると、ほぼ10万回プリフェッチできている。
バースト転送も100100回くらいになった。
この方が当然速い。
気になるのは、[esi+64]のとき、バースト転送が10万回より2000回以上少ないこと。
そこで
>>12「通常のコード」を試す。
イベント65hが96600くらい。200KBくらいL2ヒットしていることになる。
(1回のバースト読み取りはキャッシュラインサイズの64byteと思われるので)
対象が6MBで、2MBのL2だが、LRU置換アルゴリズムなら全てミスヒットになるはず。
だいいち、prefetcht0のときも全てミスヒットだった。
ひょっとしてHWプリフェッチでアクセスされることで微妙にL2にデータが残るとか(わかりにく)?
そうだとすると、prefetch命令が働くことでHWプリフェッチが抑止される?
Dothan-1.1で測定。メモリ関係の命令なのに、クロックを600MHzに落としても同じ結果。
これはL1ヒットで15.2clk/loop、L1ミスL2ヒットで27.3clk/loop、メモリアクセスで28.7clk/loop。
lp:
prefetcht0 [esi] ; t0の代わりにt1,t2,ntaを使っても全く同じ結果。
prefetcht0 [esi+16]
prefetcht0 [esi+32]
prefetcht0 [esi+48]
add esi,64
sub ecx,1
jnz lp
これはL1ヒットで4.4clk/loop、L1ミスL2ヒットで7.3clk/loop、メモリアクセスで7.3clk/loop。
lp:
prefetcht0 [esi] ; t1のL1ヒットは5.5clk/loop。他のt0,t1,ntaも0.05clk単位の違い有り。
add esi,64
sub ecx,1
jnz lp
L2ヒットとL2ミスの数字が似ている、というかメモリアクセスの場合が速すぎる。
メモリにリクエスト出すだけ出して、メモリコントローラが「もうダメぽ」と言ってきても
耳を貸さずにリタイヤして逃げてしまう無責任な命令なのかしら。
倍率が変わっても同じクロック数ということは、プリフェッチが完了しようがしまいが
一定時間が過ぎるとあきらめてリタイヤ、後続の命令を止めないという設計に見える。
ていうかRDPMC使ったら、全くバースト転送してない・・・。イベント65hがゼロ。
×できる限りやる
○できない(不要な?)ことは初めからしない
上のコードが下のコードのほぼ4倍のクロック数だが、
これは「prefetcht0 [esi]を発行済みだからprefetcht0 [esi+16]は不要だね」とならずに、
ただ「[esi+16]はキャッシュにないのでプリフェッチしよう」とやっているだけだと思われる。
ところで、テストする前は WBINVD をちゃんとしてるのかお?
> Dothanでのprefetch命令は、・・・1μopなんですねえ。
> ただ、フュージョンしてる可能性は高いと思う。P6だとどうだろ。
インテルアーキテクチャ最適化リファレンス・マニュアル より
PREFETCH*
ポート2
ユニット AGU/memory cluster
レイテンシ 2
スループット 1
22 :
16:2006/01/12(木) 21:07:10
>>17 Dothanでは1μop、スループット1clk/命令ですか。
うちの32bit-P4で計測したところ(同一アドレスへのprefetcht0を並べる)、
prefetcht0は6μopで、うち4μopをトレースキャッシュから、
2μopをマイクロコードROMから取り出しているようです。
スループットは6clk/命令でした。
Netburstはやっぱり変なんですかね。
>>20 測定条件をちゃんと書いてなかったね。すまん。
同じコードを8回連続で測定して、基本的には一番速かったものを採用している。
だから、wbinvdするどころか、前回使ったメモリの最後の方は丸々キャッシュに残っている。
そういう前提で考察しているので問題ないはず。
>>21 prefetch命令のレイテンシって何を意味しているのだろう。。
>>22 プリフェッチするために、そのμop数が必要なのか。
一体何をやっているのか。
VBで、パイプラインの流れをシミュレートするプログラムを作ってみた。
知識が足りないのでいいものはできないが(ていうが諦めたが)、作ってるときに
「OoOコアで次に発行する命令はどうやって決めているか」がわからないのに気づいた。
40個もあるバッファの中で、同じ実行ポートに発行できる命令がいくつもあるとき、
たったの数クロックでCPUはどんな判断を下しているのか。
ebx=256
mm0=0
mm1=8040201008040201h
lp: ; 実際には4回アンロールしたもので測った
pmovmskb eax,mm0
shl eax,cl
movq mm7,[esi+eax*8]
paddb mm0,mm1
dec ebx
jnz lp
FFTアクセスの実験。
clの値を0~17の範囲で変えて測定。アクセス範囲は256*8*(2<<cl)byte。
連続して測定すると、256回しかループしないため、全てキャッシュに乗ってしまうようだ。
clの値によらず、523clkだった。ほぼ2clk/loop。
しかし、cl=17のときは256MBの範囲で1MBおきにアクセスしてるから、L1はおろかL2にも
乗らないはず。おかしい。
次に、測定前に毎回、2MBのメモリアクセスをして全てのデータをキャッシュから追い出しておく。
それでも8回連続で測定する初回を除き、1000clk前後(4clk/loop)で回る。何か速い。
初回はcl>=5のとき1万clk台になる。
ただ、毎回キャッシュから追い出しているのに極端に遅いのが初回だけというのは説明がつかない。
アクセス回数が256回と少ないのが効いていそうだが。
原因がHWプリフェッチにあるのではないかと思い、L2を切ってみる。
が、特に変化なし。全体的にやや遅くなっているだけだった。
キャッシュから追い出すのは、これを使った。
ediからの2MBを確保しておく。
こうすれば、この2MBがキャッシュを占有する「はず」である。
mov ecx,32768 ; =2MB/64byte
mov eax,0
lp0:
paddd mm7,[edi+eax] ; 別にaddしなくてもいいのだが何となく
add eax,64
dec ecx
jnz lp0
ところが、このように変更すると測定結果が変化した。
今まで測定結果がバラけていたのが、ある程度まとまった数字になった。
lp0:
paddd xmm7,[edi+eax]
paddd xmm7,[edi+eax+16]
paddd xmm7,[edi+eax+32]
paddd xmm7,[edi+eax+48]
add eax,64
dec ecx
jnz lp0
L2をオンに戻すと、どちらを使ってもバラけている。
わからん・・・。L2のダンプ吐かせるとかできませんか。
他力本願でアレだが、メジャーどころのプロセッサにおける
Store-Load Forwarding について講釈くれ。
>>26 前スレ906みたいなの?
lp:
movq [esi],mm0
movq [esi+8],mm1
movaps xmm0,[esi]
dec ecx
jnz lp
これは3clk/loopで速い。
lp:
movaps [esi],xmm0
movq mm0,[esi]
movq mm1,[esi+8]
dec ecx
jnz lp
これも3clk/loop。
P3最適化マニュアルより引用
↓
ストアからロードへのフォワード
直前にストアされたメモリ位置からのロードを行うときには注意する必要がある。
これは、特定のタイプのストア・フォワーディングは、他のタイプよりも長いレイテンシを持つからである。
特に、後のロードよりも小さいデータ・サイズの結果のストアは、64ビット・ロードが使用された場合には、
通常よりも長いレイテンシを持つことがある。これの例は、2つの 64 ビットMMXテクノロジのストア (movq)
の後の 128ビット・ストリーミング SIMD 拡張命令のロード (movaps)である。
↑
movapsは64bitアクセス2回に分解されるから遅くなる方がおかしいと思うが、
P3で間抜けだったのをPMで改良したということだろうか。
lp:
movd [esi],mm0
movd [esi+4],mm1
movq mm2,[esi]
dec ecx
jnz lp
こうすると、当然遅くなる。2つのストア命令のリタイヤを待たねばならない。11clk/loop。
lp:
movq [esi],mm2
movd mm0,[esi] ; ←ここはストア・フォワードできる
movd mm1,[esi+4]
dec ecx
jnz lp
これも遅い。10clk/loop。待つストア命令が1個少ないから1clk速いのかな?
lp:
movq [esi],mm2
movd mm0,[esi]
dec ecx
jnz lp
前スレで実験済みだが、これは2.3clk/loopと速い。
ストアアドレスとロードアドレスが一致し、ストアデータにロードデータが含まれれば、
ストア・フォワードができる。
今後、アドレス一致の条件は外せるように改良される可能性があると思う。
キャッシュラインをまたぐアクセスについて、
ストア・フォワードの観点から探ってみるとどうだろう。
lp: ; esi % 64==0 とする
movq [esi-7],mm2
dec ecx
jnz lp
まず、キャッシュラインをまたぐストア単体だと9clk/loop。
lp:
movq [esi-7],mm2
movd mm0,[esi-7]
dec ecx
jnz lp
ストア・フォワードが効くらしく、9.7clk/loop。
lp:
movq [esi-4],mm2
movd mm0,[esi]
dec ecx
jnz lp
movqが[esi]への4byteストアを生成すると思うのだが、13.3clk/loop。
あくまでも「esi-4」の部分の値が一致しないとストア・フォワードできないようだ。
lp:
movd [esi],mm2
movq mm0,[esi-4]
dec ecx
jnz lp
17clk/loop。上の13.3clkよりも遅いのはなんでだろう。
lp:
movq mm2,[esi-1]
dec ecx
jnz lp
これは10clk/loopだが、このループにALU命令をたくさん入れてみる。
60個入れたら31.9clk/loopになった。decとjnzもALUを使うので、62個。
ALUは2個なので、最低でも31clkはかかる。
そこにmovqを加えて31.9clkということは、movqが使うALUは高々1回ということになる。
同様にしてロード命令をたくさん入れてみると、ロードユニットの使用数は高々4回。
ストアは、ロードがストアアドレスに依存するため測れなかったが、たぶん0回だろう。
元のコードでRDPMCを使うと、リタイヤしたμopは3、メモリアクセス3。
μop数には数えられていないようだが、ロードは3回してるみたい。
まず1回ロードを試して、キャッシュラインをまたいでいたら2回に分けて読む、ということだろう。
これでロード3回だ。シフトしてるのかとも思ったが、ALU1回以下ではできないし。
元々movqはアライメントが合ってなくても平気なのでシフトも要らないのだろう。
実際のコードでどのくらいの負荷になるかは別途調べる必要があるね。
[RISC]CPUアーキテクチャについて語れ![VLIW]2
http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/ このスレから誘導されました。
CPUのキャッシュについて質問したいんですがスレ違いだったら誘導していただけますか?
http://up.mugitya.com/img/Lv.1_up20314.jpg このファイルをPDFにリネームして図1を見てください。
メモリーチェインというプログラムを用いてL1/2キャッシュアクセス時間と主記憶アクセス時間、ブロックサイズを推定するというものです。
CPUはAthlonXPのBartonコアを用いています。
配列の要素の大きさは4byteです。
一番低い線が64kBというサイズのチェインを実行したものでL1キャッシュ速度を推定できると考えました。
チェインの間隔を空けても空けなくても時間が掛からないのは一度に64kB分をL1キャッシュ上にロードしたために
どのチェインの要素をアクセスしようとしてもL1キャッシュに100%ヒットするからだと思います。
次に低い線は512kBです。
ここからL2キャッシュ速度を推定したいです。
チェインの間隔が4byte、すなわちチェインとチェインが連続になっている部分に着目するとL1キャッシュとほぼ同じ速度です。
これは一度のロードでL2キャッシュにほぼ総ての配列がロードされたからだと考えました。
それ以降、ほぼ比例的にチェイン間隔32バイトまでアクセス時間が上がっていくのは一度に512kB分をロードできないので
何度も小分けにロードするためと考えました。
4バイト間隔では1度のロード(64kB分ずつ)、8バイト間隔では2度のロード、16バイト間隔では4度のロード、32バイト間隔では8度のロード。
こう考えると64kBずつ8度のロードで512kBのL2キャッシュに総てのデータをロードすることができるのではないでしょうか。
しかしなぜ、チェイン間隔が32kBのところで32クロックという時間がかかったのかが分かりません。
間違えてキャッシュの一部を破棄してしまって再ロードしているのでしょうか。
詳しい方の解説をお聞きしたいです。
最も遅い線は2MBです。
これは主記憶に展開され,処理が必要なときにはそのたびに64kBずつL1キャッシュにロードされるのでしょうか?
http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/837 cpu-zのレイテンシ測定みたいなのをやっている。(mov eax,[eax]式)
リンク先のstrideとclk数のグラフが両対数なのだが、こうすると直線になるんだね(厳密には違う)。
グラフの折れ曲がっているところのstrideがキャッシュラインサイズなのに初めて気づいた。。
グラフを読むと、L2レイテンシは20clk(読むのにちょっと苦労)。
依存チェーンのない普通のリードでも20clkかかっているが、これはL2自体の反応速度というより
排他処理がネックなためだろう。
これは以前俺がBartonでやったメモリベンチの結果と一致している。
ただ、L1レイテンシが4だったり、チェーンなしのL1ロードが1clkに1個しかできなかったり、変。
L2の4byte-strideでは4.7clk程度で、L2の影響が(20clk-3clk)/(64byte/4byte)あるのを引けば
3clk台になるので、L1レイテンシは3clkで間違いないと思う。
アセンブラで書いてあるわけじゃないのかな、と思ったらCで書いても速そうなの吐いた。
L2のチェーンありリードの32KBで遅くなっているのは512KB/8Wayなせいかな?
32KBおきの8つのアドレスだけでループしてると思われるので、1つでもミスすると結果に響く。
ただ、8M回繰り返すって言ってるしなあ。プログラムの癖なのかCPUの癖なのか。
ちなみにPenMでこれやると、L1が8WayなのでL1ヒットしちまいます。
>>31 27~30を書き込んだ後、向こうのスレで31さんのレスを読んでコメント書いてましたぜ。
せっかくなので、このスレ向きのレスとしてそのまま載せました。
ここからは31へのレス
>キャッシュ速度を推定
このプログラムはキャッシュのレイテンシ(反応速度みたいなもん)を測定するもの。
メモリーチェーンというのはそれを測るためのうまい方法。
>一度に64kB分をL1キャッシュ上にロードしたために
違う。このプログラムは8M回繰り返すが、最初の16384回*4byteでL1キャッシュに乗る。
(access stepが4byteより大きければもっと早い)
測定が終わるまで別のメモリアクセスしないと思うので、一度乗ってしまえば乗りっぱなし。
最近のCPUは基本的にL1からしかロードしない。
メモリ上にあるデータを、Athlonなら64byte単位でL1に転送し、そこから読む。
L2上のデータも、L1に64byteずつ転送してから読む(たとえ4byteしか必要なくても)。
L1がいっぱいになると、データはL2に追い出される。
ちなみに、この64byteというのはグラフの折れている場所でわかる。
>チェインとチェインが連続になっている部分に着目すると
これは、L2に要求を出して64byte単位でL1に転送し最初の4byteを読み取るまでに20clk、
その後L1からの読み取りを15回、各3clk(L1レイテンシ)。これで4byte*16回の処理になる。
結局16回65clk、1回あたりだと4.06clkになるわけ。
(実際は何らかのオーバーヘッドで若干遅いようだが)
>なぜ、チェイン間隔が32kBのところで32クロックという時間がかかったのか
俺もよくわからないのだが、数字としてはメモリアクセスが1回入っているという感じ。
ソース(なければ実行ファイル)をアップしてくれれば解析してみたい。
で、別CPUでの測定結果とかあったら見たいです。
>33
>最初の16384回*4byteでL1キャッシュに乗る
キャッシュは普通,空間的局所性から必要な部分の周辺ごと一度にゴソっとキャッシュすると習いました。
そのブロックサイズも推定しなければならないのですが,
>ちなみに、この64byteというのはグラフの折れている場所でわかる。
これは図4のグラフですか?
図1や図2では32byteで折れているように読めるのですが。
>最近のCPUは基本的にL1からしかロードしない。
これが排他処理というものなのですね。
>>チェインとチェインが連続になっている部分に着目すると
その計算を各チェーン間隔について行うと以下です。()内は実測値
4byte-stride : 4.06(4.723)
8byte-stride : 5.125(5.393)
16byte-stride : 7.25 (9.251)
32byte-stride : 11.5(18.367)
64byte-stride : 20clk(約20.clk)
32byte-strideで実測値と離れているように思います。
これは大学の授業の課題で行ったものなの友達に結果を分けてもらえますがまだ書いてないと思うのでもう少しまって下さい。
#僕は計算機が専攻ではありませんが
35 :
31:2006/01/18(水) 18:58:39
実行ファイルはこれをDLして,拡張子を7zに変更して解凍してください。
http://up.mugitya.com/img/Lv.1_up20383.jpg ブロッピーブート(こちらのほうが正確だそうです)用のものと,Winからただ実行する用のものがあります。
僕はFDDを持っていなかったので後者を使いました。
理解した・まだ不明なことをまとめてみます。
1:L1キャッシュレイテンシが3clk (これはまだ理解していません)
2:L2キャッシュからブロック(64kB)でデータをL1にロードして読み取るまでのレイテンシが20clk
これは図1や図2のL2の線で,チェーン間隔が64kB以上だと20clk掛かっているので
実際のキャッシュで行われている上記のような処理に20clk掛かることが分かった。
しかし,1と2から計算できる各チェーン間隔での理論値が実測値と合っていない部分があるようです。
3:L2キャッシュで32byte-strideが32clkに跳ね上がっている(まだ分かっていません)
>>31 うちにもBartonがあるので似たようなテストをしてみたところ、
確かに32KB間隔でL1ミスL2ヒットロードを繰り返すと1ロードに30クロック以上かかる。
同一インデックスのキャッシュライン入れ替え(L1,L2間)が連続すると余分に時間がかかるもよう。
BartonはL1が32KB*2way set、L2が32KB*16way setなので、
32KB間隔で連続ロードすると同一インデックスに対して連続してキャッシュラインの入れ替えが起こる。
Exclusive Cache Architectureの弱点か。じゃあAthlon64でも
同じような事が起こっても不思議じゃないね。
38 :
デフォルトの名無しさん:2006/01/18(水) 21:55:34
Exclusive は関係ない
Pntium でも同様の現象は起こる。
間隔は違うけど。
>>38 Pentiumで起こる同様の現象って具体的に何?
>>34 >必要な部分の周辺ごと一度にゴソっとキャッシュする
そのサイズが64byte。ちょっと書き方が悪かった。
正確に言うと、最初の1回で64byteをL2からL1に転送し、最初の16回はそこから読む。
17回目で次の64byteをL2からL1に読み、32回目まではそこ(L1)から読む。
・・・これの繰り返しで、最後16369回目で最後の64byteを読んで64KBが読み終わる。
>図1や図2では32byteで折れているように読めるのですが。
本当だ。俺としては図1,2,4どれでもいい話のつもりだったが。
PentiumMでも同じ現象が起こる。折れているのは64byteだが、32byteがなぜか遅い。
原因は今のところ不明。
>これが排他処理というものなのですね
違う。排他処理とは、L1とL2の内容が被らないようにするAthlonの機能。IntelのCPUにはない。
ハードウエア的には、大きいL2にCPUから直接高速にアクセスするのは大変なので
L1からだけ読むようになっている。排他処理とは関係ない。
>>35 >1:L1キャッシュレイテンシが3clk
これは単に俺が知識として知っていただけではあるが。。
もし4clkとすると、
>>34の理論値がそれぞれ1clk弱ずつ大きくなるが、
そうすると実測値が理論値(これ以上速いのはありえない値)よりも速くなってしまい、
おかしいから4clkということはないと推測はできる。
chain-fでstrideが64byte以下の2MBアクセスの数字がchain-bより少し速いが、
これはハードウエアプリフェッチが効いたんじゃないかな。
実行ファイルの解析は時間かかるので後で。
専攻でもないのに授業でやるとはかなり大変そうですね。頑張ってください。
>>36 ということはプログラムの癖ではないみたいだね。
ただ、連続した入れ替えは、L1ミスさえすれはいつでも起こるので、32KBでだけ起こるのは
理由がわからない。
>>38 こういうのかな?
* 64K(データ) - 1次キャッシュ内で一度に1つだけが有効になる。
実行中の参照 (ロードまたはストア ) と次の参照 ( ロードまたはストア ) のリニア・アドレスの
ビット 0 ~ 15 が一致する場合は、最初の参照がキャッシュから排出されるまで 2 番目の参照
を開始できない。このエイリアシングを避けることによって、処理速度が 3 倍アップする。
これはPentium4最適化マニュアルの記述。具体的には次のページを参照。
http://homepage1.nifty.com/herumi/adv/adv43.html#016 なぜこんな制限があるのか考えてみた。
Pen4のL1は8KB、4Way、64byte line。まず、あるアドレスをL1に対して要求したときに、
まずアドレスの6~10bitでL1に格納されている128個の64byteデータの内、4つに絞る。
次に、11~15bitを見て4つの中に一致するものがあるか調べる。
このとき、一致するものがなければL1ミス決定だが、一致するものが存在した場合に
「下位16bit(0~15bit)が一致するデータをL1内に1個しか置かない」が守られていれば
一致した内の1つについてだけ15bit以上も一致するか調べればヒットかどうか判明する。
最初から11bit以上の全てを比較するのと比べてどれ程クロックを上げやすくなるか知らないが、
こんな感じの実装ならあんな制限が生まれるという仮説。
ハード屋さんいませんか?
>>41 > なぜこんな制限があるのか考えてみた。
Pen4の倍速ALU,AGUも関係あるのではないかと思う。
Pen4の32bit演算は下位16bitが先に出て、上位16bitは0.5サイクル遅れて来る。
実効アドレス計算の下位16bitの結果が出た時点でL1にアクセスしに行くので
レイテンシ2クロックの低レイテンシL1アクセスが実現しているのではないかと思う。
とりあえず仮想アドレスの下位16bitが一致するラインがあればキャッシュヒットとみなして、
処理を続行。あとから上位16bitが違っていたり、アドレス変換して物理アドレスが違っていたり
が判明したらリプレイ。と想像。
>>42 なるほど、下位16bitは先に使えるわけね。
Pen4のleaは遅いが、lea reg,[reg+reg] なら0.5clkと書いてあったので大丈夫だろう。
ちなみにPrescottでは下位22bit(英語のP4マニュアルより)らしい。
プレスコのALUは32bit*2なのでこれで問題ない。ただしALUレイテンシは0.5clk伸びた。
容量倍増、Way数倍増もあって、レイテンシも倍増(2clk→4clk)した(遅すぎだろ)。
>つまり、部分仮想アドレス・マッチングによって、ロードがキャッシュでヒットするか
>ミスするかをパイプラインの初期の段階で検出するようにしているのです。
調べたらIntelのページにはこのようにある。
>ロード実行が完了する前に、そのロードに依存した命令をディスパッチします。
データ・スペキュレーションでは、はなから全てをL1ヒットと決め付けていると思う。
リプレイはL1ミスすると常に起こるはずだから。
データ・スペキュレーションはレイテンシの削減が目的だが、
下位16bitだけで判断するのはパイプラインの細分化(クリティカルパス潰し)のために見える。
>>35 cn3.exeの中身を見ると、mov eax,[eax]を16回続けてloop命令を置くループがある。
これならオーバーヘッドなどないと思ったが、Athlon64の最適化ガイドによると
loop命令はVectorPath(デコードが大変)でレイテンシ9(Bartonでは違うかもしれない)。
だが、そんなの並列実行すればいいだけだし、命令あたり1clk(ループ全体で16clk)も遅れる
というのは考えにくい。一応、loop命令は遅いから使うなと書いてあるけど。
PentiumMでは、loop命令の空ループは6clkで、並列実行で完全に隠蔽できる。
誰かjnzで追試お願い。
32byte strideで遅くなる現象はPentiumMでも起こる。16byteだと起こらない。
32KB strideで遅くなる現象は128KB以上のときPentiumMでも起こる。
32byteのは、今は全くわからないが、考えてわかる問題のような気がする。
32KBの方はPen4の64KBと似た現象と思えなくもない。
PentiumMは、L1は32KB、4KB*8Way。L2は2MB、256KB*8Way。
依存チェーンを作ってメモリレイテンシを測定した。
64KBおき8回(stride=64KB,size=512KB)だと、レイテンシは3.0clk。
32MBおき4回(stride=32MB,size=128MB)でも3.0clk。
完全にL1に乗るので当然の結果。
128KBおき8回(stride=128KB,size=1MB)だと、レイテンシは8.0clk。
L1に乗っていて、普通にいけば3clkのはずが遅い。
RDPMCを使うと、メモリアクセスの回数がなぜか通常の倍になっているが、
メインメモリにもL2にも読みに行っていない。
>>44 > 128KBおき8回(stride=128KB,size=1MB)だと、レイテンシは8.0clk。
> L1に乗っていて、普通にいけば3clkのはずが遅い。
> RDPMCを使うと、メモリアクセスの回数がなぜか通常の倍になっているが、
> メインメモリにもL2にも読みに行っていない。
DTLBはヒットしてる?
PenMってDTLBミスはカウントできなかったっけ?
DothanのDTLBは4KBページで32set*4way=128entriesのようなので
4KB*32=128KBおきにアクセスした場合、
4つまでしか格納できないかと思ったので。
>>45 PenMのDTLBは、4KB*128entryの4Wayか。
つまり512KBで4Wayのキャッシュみたいな感じ。
それで当たりっぽいですな。
64KBおき16回(stride=64KB,size=1MB)だと、レイテンシは15.0clk。
L1ミスL2ヒットで、10clkのはずだが、TLBミスで5clk食われて15clkということだろう。
メモリアクセスの回数が倍なのも、毎回L1上のページテーブルにアクセスするからだ。
TLBの存在が測定にかかったのは初めてだ。
で、Bartonの場合だが、DTLBのL1が4KB*32entryのFull、L2が4KB*256の4Way。
32KBおき8回のアクセスをすると、32回以下なのでL1DTLBに完全ヒットするはず。
むしろ、4KBおき64回のときにL1DTLBミスしてるはずだが、L2キャッシュの遅さに
隠れてしまっているのかな。
排他処理をしている場合、純粋な反応速度と帯域による時間に加えて、
排他処理の時間もレイテンシに加算されるので、そこに並列実行の余地があるのかも。
そこがPenMでπが早い理由ですか
Dothanで測定。
依存チェーンありで、キャッシュラインをまたいだL2レイテンシは27.7clk。L1だと13.6clk。
>>28の続き。これは10clk/loop。
ストア・フォワードは関係ないが、ストアのリタイヤを待つ必要があるケース。
lp:
mov [esi+4096],ebx ; 4096byteとは、32KB/8Wayであるらしい(pentopt)
mov eax,[esi] ; と思ったら最適化マニュアルによるとPen4では16KBらしい
dec ecx
jnz lp
mov ecx, offset r1
push ecx
mov ax, 0xffff
mov edx, esp
_asm _emit 0x0f _asm _emit 0x34 //sysenter
r1:
・
・
↑キャシュヒットさせた状態で、無効なシステムコール(WindowsXP以降)を
したときのクロック数はどのくらいでしょう?
特にP4もっている方教えてください。ちなみにOp246 C0コアで240~270clkです。
ネトバだと激しく遅そうな希ガス
団子タン (;´Д`)ハァハァ
Merom楽しみやねえ。L2が4MBは測定にも一苦労なサイズだ。
期待は、μopフュージョンと4issueのパワー、それに付随するスケジュール能力。
ALUを4つ積むからにはSSEのスループットも期待してるぜ。
x86だけなんてケチなことを言わず、
SPARCとかPowerPCとかItaniumとかもやれよ。
御免被る。
>>54 そういう話ができる人はやっていいんじゃないかね。できれば実測も交えて。
YonahMacにPPCのコード食わせて測定してみたいよ。
普通に吐き出すと思います。
現在はゲームに使う分なら、浮動小数点命令の方が速いって本当なんすか?
>>60 ここで、本当、といわれたら単純に信用するのか?
62 :
デフォルトの名無しさん:2006/02/20(月) 23:30:05
うん
63 :
デフォルトの名無しさん:2006/02/21(火) 00:05:32
本日ここを発見して、非常に興味深く読んでいるのですが
リンク先が読めないところ多いですね。
今までの過去ログやアップされたソースどこか再アップできませんか?
てーか命令の速さってゲームとかの用途で変わったりするのかw
>>60 SSE で最適化できる範囲が問題領域ならってことだろ
>>60 参考までに各CPUでの、レイテンシ-スループット。ソースは俺の測定と
>>2。
PenM:add(1-0.5),mul(5-2),imul(4-1),div(39-37以下)
Pen4:add(1-0.4),mul(11-2),imul(10-1),div(80-30くらい)
K8 :add(1-0.3),mul(3-1),imul(3-1),div(39-39)
PenM:fadd(3-1),fmul(5-2),fdiv(31-31くらい) 注:FPU命令は倍精度での数字
Pen4:fadd(6-1),fmul(6-1),fdiv(40-40)
K8 :fadd(4-1),fmul(4-1),fdiv(20-20)
足し算なんかだと整数の方が扱いやすくて速いが、乗除だとそうでもない。
また、そんなことよりそもそも32bitの整数(固定小数点)でゲームの計算は難しい。
整数レジスタに対しては、ゲームで使われるであろう平方根命令もない。
整数を使って速くなる場合もあるだろうが、開発が煩雑になる上、大して速くならない。
FPUを使えば汎用レジスタがフリーになるという利点もある。
ということで最近(Pentium以降くらい)はFPUのが速いと言われるのだろう。
もちろん、整数の計算で済むならば整数命令の方が速いけど。
FPUを使うのは、3Dゲームの物理計算とかだよね。
>>60 仮に浮動小数点命令の方が遅かったとしても
固定少数点演算なんて今更やってられんだろ
俺は組み込み系だから仕方なくやってるけど、面倒だぜ?
>>63 過去ログは
>>7。つながらないときは、早朝とかに試すべし。
アップしたソースとかは、レス番指定してくれれば俺がアップし直すよ。
>>60 具体的な数字を出せないから躊躇してたら>67で数字が出たので四方山話でも。
ある画像フィルタリング処理の高速化を図ろうと思って、実数演算を整数演算に換えてみた。
結果、整数演算のためにレジスタとALUを使いまくるコードが得られた(あくまでCの範疇)。
しかし、整数演算と実数演算が並行動作していたものをわざわざシーケンシャルな実行に
してしまったようで却って遅くなってしまった。
結論、生兵法で無理に整数演算に置き換えても得るところは少ない。
pcmpeq{b,w,d} mm0, mm0
がレジスタリネーミングの対象になるかどうか調べてみてよ。
Intelの組み込み関数/クラスライブラリ見る限りでは、全ビット立てる際は
定数をロードするの推奨してるみたいだけど。
ロゼッタってAltiVecもサポートされてるという情報があるけど、
vpermをどうエミュレートしてるか気になるよね
>>72 ダメみたい。pcmpeq{b,w,d}はおろかpxorでもダメ。
movq mm0,[esi] なら依存性を断ち切れる。@PenM
やっぱり推奨の通りですね。改善の余地あり。
>>68 Windowsアプリケーションを作るのならC++が使えるから、その点はあまり問題ないと思う。
K8でもTurionなんかはまたL2の挙動が違ったりすんのかもしらんね
>>67 > FPUを使うのは、3Dゲームの物理計算とかだよね。
量的には 4x4 行列同士の乗算や、4x4 行列 と 1x4 行列(というか4要素ベクトル)の乗算がほとんど。
このスレを覗いていて言うのもアレだが、x86 には詳しくない。
なのに言うが、行列演算については SSE 使わなかったら、整数の方が速いと思う。
「現在はゲームに使う分なら、浮動小数点命令の方が速い」の理由は、
・SSE 使うから
・どうせライブラリ(DX, GL, etc..) に渡すときに変換する
が大きいと思う。
このスレを覗いていて言うのもアレだが、計測マンドクセ
整数にだってMMX/一部SSE/SSE2があるわけだが。
imulはアドレス計算に頻繁に使うからPen-M以外のレイテンシはいい加減にしる!と言いたい
そこまでFPUを使って整数乗算をする訳を聞きたいもんだ
シフトと足し算で頑張れということですよ。
>>77 おお! あなたの計測(or 憶測)では、整数行列演算の方がfloat行列演算より速い?
>>67間違い。
Pen4(プレスコ)のfmulは8-2。
>>76 ゲームは単精度でいいからSSEが効くね。
俺は、多くのゲームは使ってもコンパイラ任せのSISDだろうと思っていたけど、
行列計算が主なら、SIMDのライブラリができていて、みんな使っているということかな。
>行列演算については SSE 使わなかったら、整数の方が速いと思う。
考えに自信がありそうなので、もうちょっと理由をお願い。
俺は乗算が固定小数点でしかも小数点位置にシフトなどの工夫が要るから遅いと思った。
「現在の」ならその理由が大きい思うが、以前から「最近の」と言われていたと思うので、
P5時代からはFPUでやるのがセオリーだった(速度的に無難)んじゃないかな。
俺も詳しくないんで間違ってるかもしれんけど。
>>77 乗算が16bitしかないから。一応SSE2にはpmuludqがあるけど。
でも、何に使ったか知らないけどMMXの16bit*4で座標変換とか有名っぽいし、
MMXでFFTやってるところもあったな。
波紋シミュもMMXで簡単に作れたから、適材適所ですな。
>>78 PenM以外というかPen4だよね?
FPUで整数乗算するのは北森まででやめたよ。それでもレイテンシ10だけど。
Pentiumもimulのレイテンシが9だったらしいが、意外と遅かったんだな。
Pentium4は倍速ALUだから。
額面が3GHzなら、ALUは3GHzだけど、他は1.5GHz。
ALUが6GHzで、他が3GHzだという人がいるけど、
実際に試してみると、ALUは3GHzの速度しか出ない。
83 :
・∀・)っ-○●◎- ◆Pu/ODYSSEY :2006/02/23(木) 23:14:46
倍速ですよ。ただし16bitずつ、タイミングずらして実行してるから
Prescottで等速ALUが追加されていくつかの演算は等速にまわされてる。
add eax eaxを延々と繰り返してかかったクロック数を計測してみれば解るけど
美味く倍速ループに嵌ればクロックの2倍で処理されてるのがわかると思います。
命令帯域がネックになるのでスループットはそんなに出ないけどね。
SIMDは半速でFA。
x87/MMXのスループットが1なんだが
SSEと実行ユニットが違うのか?
85 :
・∀・)っ-○●◎- ◆Pu/ODYSSEY :2006/02/24(金) 00:06:54
Pen3の時から実行ユニットもポートも別でしたよ
AMDは共有してるらしいけど
ていうか、NetBurstはレイテンシやスループットがP6の倍になってるから、意味ないんだよね。
88 :
・∀・)っ-○●◎- ◆Pu/ODYSSEY :2006/02/24(金) 02:24:35
>>87 それを半速という。
もっと高クロックでブッチ切る予定だったんだろうけど、Athlonの1.4倍止まりだから
MMXとか0.7倍の性能しか出てないとwww
毎サイクル64bit計算できるそうだが
ttp://developer.intel.com/technology/itj/q12001/pdf/art_2.pdf Intel Technology Journal Q1, 2001
The Microarchitecture of the Pentiumニハ 4 Processor
p.10より引用
In the Pentium 4 processor,the FP adder can execute one
Extended-Precision (EP) addition, one Double-Precision(DP)
addition, or two Single-Precision (SP) additions
every clock cycle.
(中略)
The FP multiplier can execute either one EP multiply every two
clocks, or it can execute one DP multiply or two SP multiplies
every clock.
90 :
デフォルトの名無しさん:2006/02/24(金) 08:35:56
Pen4のMMXが2-1, SSE2で2-2
これって半速のALUが2基あるんじゃなくて?
もし等速が1基なら3-2になるだろ。
Intelの資料ってかなり嘘入ってるからあてにならないよ。
仮説だが、ポート構成が正しいとして、FP/SIMD演算ポートは、
それぞれ半速の演算器×2基に繋がってる。
SSE2は両方のMMX-ALUに同時に流し込める。
MMXは片方が空くからクロック毎に実行可能。
これでやっとpaddbのMMX版が2-1でSSE2版が2-2の辻褄があう。
浮動小数も大体同じかな。
>>82 それはPrescottで測定したからじゃないかな。
プレスコだとレイテンシが1clkになっている(倍速なのでスループットは0.5)。
依存関係がないように命令を配置すれば3GHzを超えているのはわかるはず。
俺が以前Noothwoodで測定したときは0.5clkレイテンシだった。
>>83 等速ALU(シフトとかやるとこ)はプレスコ以前もあったよ。
むしろ、プレスコでは1bitシフトが倍速ALUで実行されるようになった(1-0.5)。
>>84 >90,91の通りだと思うので、使ってるユニットは同じ。
>>85 ていうかP3の頃は128bit整数SIMDがなかった。
しかもP3のMMXとSSE(FP)は実行ポートを共有している(もちろんユニットは別だが)。
>>87 まあ、だからこその高クロックなわけで。実際SIMDの絶対性能ではP6をぶっちぎってる。
>>88 クロック表を見るとP4とK8のMMXはどちらも2-1で同じだ。P4の遅さはもっと別のところにある。
>>90 SSE2(FP)の場合、addssが4-2、addpsも4-2とIntelの資料にあるが、addpsは本当は6-2だ。
でも連続して実行すると上位と下位の並列性からレイテンシ4で回る。
代わりに、本当は2-2のandpsが4-2と書かれているので辻褄は合っている。
つまり、P4向けのIntel表記なら等速1基の場合でも3-2じゃなく2-2と書かれるだろうということ。
でもSIMDは半速だろうから、半速×2で合ってると思う。
ていうかこの辺のやりとりは前スレ639-で既出だ。
>>89を少し読んでみた。
This execution cluster has two 128-bit execution ports that can each begin a new
operation every clock cycle.
128bitというのは64bit*2ということかな。64bit*2としても使える128bitユニット?
この辺は表現の問題だろう。クロック数を計算するときは64bit*2で説明できる。
ポートが2つあると書いてあるが、この後に書いてあるようにその内の1つはFP_MOVEのみ。
addpsやmulps、シフト、パックなどは1つのポートにまとめられている。
元々はSSEのスループットを1にするつもりだったが、大変なのでやめたらしい。
性能が出ないから、という理由はかなり言い訳っぽいが。
FP命令を毎クロック実行できると書いてあるが、これは64bit半速ユニットが2つあるからだろう。
今気づいたが、faddのスループットが1なのはユニットが2つあるからか?
で、80bitだから1clk余計(ここは等速?)にレイテンシがあって5-1になると。
そうなるとaddsdが4-1でなく4-2なのが不思議だが、スケジュールを簡略化するために
xmmレジスタの上位と下位で、使うユニットを固定してあるからだと推測できる。
で、MMXやFPUは、さすがに片方だと性能が出ないので両方使えるようにしたと。
fmulは7-2でスループットがfaddの半分だが、これは半速ユニットで2clk(等速の4clk)なのか、
80bit演算は片方のユニットでしかできないのか、どっちだろう。
MMX乗算はFP_MULを使っているんだね。レイテンシは8。
そういやPen4ってキャッシュがライトスルーなんだよな
なんでそんな設計なんだろう
・L1が小さい
・L2の帯域が十分にある
・ライトバックより回路が単純で済む
・ストリーミングに特化
PPC G5のL1もwrite-through
ストアのときのキャッシュミスってどうなんの?
キャッシュライン分のメモリを読みに行く?
それともストアバッファに溜め込んでキャッシュラインがうまったら
読まずにすむ?
>>93 自作板の次世代のx86スレでも似たような議論が出ていたが、
交互の半速演算器2つと、2段パイプの等速演算器1つは、区別できないって結論だったような
投機的な実行には関係ないのかな?
AMDのK8LはFPユニットを2倍に増やすらしいですな。
しかし公称「1.5倍のスループット」ってずいぶん控えめだと思うのだけど、
やはり従来のパイプラインではこんなもんなんでしょうか。
64bit単位×2のままだとデコーダがネックになるうえμOPが膨れるので
命令帯域を圧迫して性能が伸びないのでは、と。
逆に言えばμOPを128bit単位にしてしまえばSSE/2演算のスループットも
飛躍的に向上すると思うのでつ。
でも、いまさらFPってどうよって思うのだが..。
>>99 なら、そうすればいいじゃん。
ユニットだけを2倍にして、スループットが1.5倍になるなら、十分だと思う。
演算器増やされても深刻なレジスタ不足に
拍車がかかるような
K8の128bitSSE命令は、デコーダが1.5命令/clk。
SSEのFPユニットは、1命令/clk(ADDとMULを混ぜたときのピーク)。
今まではFPユニットがネックだったのが、K8Lではデコーダネックに変わる。
1→1.5なので、ちょうど1.5倍だ。
(もっとも、FP_ADDだけのコードとかなら、2倍速くなるケースもあることになる)
K8Lの次は、デコーダ(もしくはフュージョン)を強化する番だね。
PenMなんかも、μopフュージョンで速くなったけど、たとえばL2がPenII並の遅さだったら
命令が使うデータを供給できずに、フュージョンは宝の持ちぐされになってしまうはず。
バランスが大事。
K8LでFP実効性能が大きく上がったとして、「FPユニット倍増の効果はすごい」と思うだろうが、
K7→K8でSSEのデコードを強化(1.5倍程度)してなかったらこの性能向上はありえない。
FP強化だけがすごいのではなく、かつてのデコード強化も縁の下の力持ち。
そういう意味では、Meromの4issueという基礎体力には非常に期待している。
色々な技術を投入していくとドンドン性能が上がっていきそう。
(すみません、Merom萌えな話ばっかりして)
IDFでいよいよ公開「Meromアーキテクチャ」
http://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm 気になる点を挙げてみると、
・Micro-OPs Fusionに加えて、Macro-OPs Fusionが導入される
・Yonahで浮動小数点演算性能が改善されたが、Meromではさらに2倍に強化される
・L2からCPUコア群へのデータ帯域も倍増された
・Santa-Rosaでは、通常のTDPは35Wのままだが、Turbo Mode時には最大42W
Macro-OPs Fusionは、デッドuOPsの除去という話が出ているが、
俺の感じでは単にスケジュール負荷(消費電力も含めて)の軽減のためな気がする。
意外とK8のPackに近いものかとも思ったが、あっちはALU/AGUが一緒になったものが
3つに分かれてるから必要になる処理だから違うか。
単精度SIMDの積和がスループット1というのは確かにYonahの倍だが、倍精度はどうだろう。
Dothanの倍精度SIMDは乗算のスループットが4と遅い(FPU*2と同じ)。
Meromで2にはなると思うが、1だったら嬉しい。
この辺が甘いと、元々乗算に強いK8を強化したK8LにFPベンチで負けてしまうぞ。
L2帯域はYonahで既に32byte/clkと激速。これが倍になるのか?なったら嬉しいけど。
ひょっとしてYonahではシングルスレッド時は16byte/clkというオチかね。
Dothan→YonahのSuperPIの性能向上は、たとえ帯域同じでレイテンシ増加であっても、
L1ミス時のL2アクセス同時リクエスト可能数が増えていれば説明が付く。
Turbo Modeって、要するにフル稼働するとクロックが下がるPenDと、逆の表現で同じ仕組み?
そう思うと何かイヤだなあ。
でもこれって、前スレ614で俺が欲しいと言っていた機能そのものじゃないか。
そう思うと何か嬉しい。
一連のレスを読み返すと、615に「シングルスレッド性能を維持」とある。
デュアルコアはTDPが増えるためクロックが下がるのが悩みだが、この機能の狙いは、
一時的な処理だけでなく、シングルスレッド時の性能向上にもあるのではないだろうか。
Turbo Modeを継続して使えるノートや10秒までのノートが出てくるのかな。
俺はよく分からないけど、CPUのアーキテクチャがすばらしかろうが、マザボの性能に左右されたりメモリの帯域などが理由で100%力が出せないのではないだろうか。
実際に100%(出なくても95%くらい)力を発揮しているのか?
>>105 チップセットはCPUのアーキにあわせて作られるのだから、
マザボに左右される性能がCPUの100パーセントだと思うがな。
メモリの速度は影響しまくりますな。
キャッシュ効いているうちは目立たんけど。
システムとして考えたら、最後はI/O性能じゃないかなあ。
PenMでπが早いのはL2アクセスがサイズ
大きくなっても遅くならないからじゃないのか。
反対に段々遅くなるのがK8で、
その分クロッコとメモリレイテンシで補ってるという感じがしたけど。
ベンチでL1L2に依存しまくる物と、
メモリIO回りに依存する物とか
別々にあると面白いんじゃないかと
次世代CPU「Conroe」の内部構成が明らかに
http://pc.watch.impress.co.jp/docs/2006/0307/idf01.htm FPUユニットが1ポートということはないだろう。
それで積和をスループット1でこなすには、1ポートに毎クロック2μop供給しないといけない。
(そのためのMacro-OPs Fusionか!?)
どっかのインタビューでALU*4と言っていたのはどうなるんだろ。
FPUって書いてあるポートにもALUを備えてあったらイイナ。
Loadが1個のままだとしたら少し残念だ。128bit/clkのロードはできるんだろうけど。
自作板でも失望の声が多くw
まあ、明日掲載されるであろう記事を待つしかないね。
あのダイアグラムから読み取れない部分もかなり多いと思われ。
>>108 L2サイズや帯域が同等の他CPUと比べてもPenMのPIは速い。
P6系はL2レイテンシが小さいから速いんでしょう。
レイテンシの増えたYonahでPIが更に速くなっているが、これは帯域もさることながら
共有処理の副作用で同時リクエスト数が増えたからじゃないかと思っている。
つーか未だにこんな古いベンチ(現在の実用アプリでの速度を反映しない)が
メジャーなんだよな。SuperPIのベンチスレでは明らかにCoreが過大評価されている。
まあ、CPUの特性を知る意味では貴重なベンチなんだけど。
CPUに詳しいおまいらが新しいベンチアプリ作ればいいじゃない
SSE多用よりFPU多用のほうがまだ現実的なきもしないでもない
そもそもFPU自体業務系じゃまったくつかわんけど
>>109 FP_MULはALUのどれかとポート共有してるという大胆仮説を立ててみる。
Load/Storeは128bitだと思うんだけど。
Storeの矢印が両方向に伸びてるのは何を意味するのかわからんのだけど、
双方向対応でLoad2本としても使えるとしたらSSEの利用には非常に便利なのですが。
SSE4について纏めてるんだけど
書きかけだけど、突っ込み入れてくだしあ><
http://www8.atwiki.jp/tripper/pages/23.html SIMDがどういうユニット構成になるかはわからんけど、XMMレジスタベースのほうが
パフォーマンス出そうな気がしている。
今更MMXの拡張もやってる時点で、未だにSIMDユニットはQWORD単位なんじゃないかとも思ったり。
個人的にはXMMレジスタベース整数演算のスループットが0.5になることを激しく望むのですが。
そーいやぁL2が共有型になったのは大きな違いだなぁ
>>109 もうベンチなんてその構成の特性を知る為の数値ぐらいにしか思えんのだが。
今、マンデルブロ集合を描くプログラムを作っているんだが、
PenMだとFPU→SSE2で1.5倍、FPU→SSEで3倍のスピードだ。
FPUとSSE2は、addとmulのクロック数が同じなのに1.5倍も高速化している。
比較のための便利な命令があるのと、レジスタ数が多いためだろう。
(FPUもXMMもレジスタは8本だが、XMMは2つ入り)
mulpdはmulpsより遅く、fmul*2と同じクロック数なので、SSE2は意外と健闘している。
>>111>>113 PIについては、他スレで「PIでの性能=CPUの性能」みたいなレスが少なくないので
ちょっと乱暴に書いてしまった。(煽りが大半なんだろうけどさ)
「性能の一面だ」というのを認識できるなら、尖ったベンチの方が役に立つんだけどねえ。
>>112 俺は64bit等速FP*4(ADD、MUL各2)だと信じていますがw
ていうかLoadの矢印の向きが逆じゃないのかと思った。そういうもんなのかな。
ただ、ストアポートでロードもできるという妄想は非常に萌えますなあ。
整数SIMDはPenMで既にスループット1だから0.5も期待できるかも。
後藤さんがFP積和がスループット1だと言っているし、ユニットが格段に強化されてるのは
間違いない。みんな、あのダイアグラム一つで沈みすぎだ!
SSE4のとこは見たよ。次世代Intelスレは見ているので。
興味深く見させてもらったが、ツッコミ入れるだけの経験値が俺にはない。
ところで、俺は以前からSIMDユニットを128bit化する意味は薄いと思っていた。
64bit臭い命令体系のx86SIMDなら、64bit*2の方が性能が出る。
実際はユニット増やすとスケジュール→発行あたりで大変なのかな。
#CPU設計の知識は、いくらアセンブラやっても身につかない罠
116 :
・∀・)っ-●○◎- ◆Pu/ODYSSEY :2006/03/08(水) 12:01:47
水平加算と積和算に関してはアレでほぼ間違いないと確信。
psign{b,w,d}については妄想だけで仕様・擬似コード書いちゃったけど
あの仕様だと0x8000(psignwの場合)の符号反転はどうなるのだろう?という疑問が。
ちなみにMSBを符号反転の条件とするという妄想はmaskmovq/maskmovdquから。
pabs{b,w,d}はまぁ、見たまんまの動きでしょうけど、0x80/0x8000/0x80000000は
そのまま返すでしょうな。多分。「unsignedとして解釈してくれ」の方向で。
これらの命令の細かな動きまでは憶測の域を出ないが、水平加算と積和演算の有効活用の為
(組み合わせで水平減算や積差演算が可能になる)という確信はアリ。
palignrは psrldq xmm0, N と pslldq xmm1, 16-N を重ねあわせるものだと思ってるのですが
アラインメントの揃ってないデータブロックを連続で読み書きする際に有用かと。
118 :
・∀・)っ-●○◎- ◆Pu/ODYSSEY :2006/03/08(水) 18:00:37
SSE3の水平加算ってどうやって実現してんだろうって思って、マニュアル読んでみたんだけど
shufps×2 と addpsの組み合わせでレイテンシ-スループットがピッタリ一致しますな。
するとYonahのは推定8-4で、デコードはComplex Decoderってところですか。
SSE4の水平加算も複合命令な気がしてきた。
vpermもどきのことが出来そうなpshufbが一番使えそうっすね
個々のユニットがリッチ化してんのかな。phadd*が1クロックならマジで凄いす。
>>117movupsはlddquの間違い。
movupsはキャッシュラインをまたぐと10clk以上損するが、
lddquにはそれがない。代わりにロード回数が倍になる。
>>118 なるほど。「それじゃ高速化しないじゃん」と思ったが、内部では3オペランドが使えるので
ちゃんとSSE3で速くなってるのね。よく思いついたね。
NetBurstだから、マイクロコードをちょいと弄るだけでSSE3に対応できたんだろうなあ。
shufps*2+addpsならプレスコで単純計算17-4になるんだが、
shufpsは6-2と表記されていても実質4-2で回せるということかな。
(マニュアルにも速くなる場合があるという表記あり)
でも、マニュアルを見るとhaddpsはFP_ADDとFP_MISCと書いてある。
shufpsはMMX_SHIFTだ。まあ、別の似た命令だとしても大した問題ではないか。
K8の最適化ガイドにはhaddpsは5-2と書いてある。これはaddpsと同じだ。
突貫工事のプレスコが遅いだけで、Yonahでもaddpsと同じ5-2だと予想する。
ネトバじゃあるまいし、SSE4も複合命令じゃ性能が出ないでしょ。
absは、Cでも0x80000000をそのまま返すので、それと同じだろうね。
いや、あくまでshufpsは6-2でしょう。
ただ2つのshufpsは依存関係無しで回り、addpsは両方が完了しないといけないので6+2+5の13クロック。
スループットはMMX_SHFTとFP_ADDが並列動作するので単純にMMX_SHFTのスループットが
ネックになるので4クロック。
こんな感じですな。
shufps xtmp0, xmm0, xmm1, ORDER(0,2,0,2) ; MMX_SHFT, 6-2
shufps xtmp1, xmm0, xmm1, ORDER(1,3,1,3) ; MMX_SHFT, 6-2
addps xmm0, xtmp0, xtmp1 ; FP_ADD, 5-2
Yonahは実機触らないとわからんすね。
IA32最適化マニュアルのPDFにはFinalなんて書いちゃってるし、やはり繋ぎでしかないのでしょうか。
なんかもうビット演算組み合わせて数値作る時代じゃないっぽいし
演算機とかパイプライン増やしてみたり分岐予測改良するよりも
もうメモリ帯域とかキャッシュメモリとかを糞のように増やしてテーブル参照速度上げた方が
最終的なパフォーマンス伸びるんじゃね?
なんとなく中間言語にも強そうな設計って事で
>>121 Macro-Fusionで、比較+分岐で融合させるというのは、
この命令の塊を優先的に実行して分岐ミス時のペナルティ軽減か!?
デコーダは最大4[内部命令]/clkだが、Macro-Fusionが働くと5[x86命令]/clkになる。
すげえな。
Fusionは、実行ポートが増えて大変になったスケジュール負荷の軽減の意味も大きい
とは思う。
FPUは2基だったんだな。64bit*4ではなく128bit*2だ。
64bit命令の性能が知りたい。
ALUはやっぱり3つだけか。まあいい。
SSE2整数はどうなんだ。paddは128bitで実装されていると思うが、
あの3個のALUポートの内、いくつにそれが入っているかだ!(3個をキボン・・)
ロード・ストアは普通に128bit*1っぽいねー。
非SIMDコードで32bitロード*2くらいはやってほしかったな。
古いコードはさほどブーストされなさそうだが、この分野は元々PenM系の得意とするところ。
Yonahと同等か少し上の性能を出してくれれば全く問題はない。
総括。
ピーク性能はほぼ想像通り。しかし、思った以上にFusionへのこだわりが感じられた。
FPUは、64bit*4ではなくμopを減らす128bit*2。ロードも帯域はともかく数は1個。
元のx86命令よりも内部命令数が減ることすらある。
とにかくまとめて強力に処理。
P6と比べて、実行ポート数はALUが1個増えただけ。
SIMD性能に注力というのは、「いい意味で」NetBurstの血を感じる。
まさに次世代をにらんだ、パワーのCPU。ありえねえ。こんな興奮したのは久しぶりだ。
>>119 http://pc.watch.impress.co.jp/docs/2006/0309/idf04.htm ここに簡単な解説が。
プリフェッチの強化って毎回言われてるけど、どう変化しているんだろう。
投機ロードの実装も気になる。
>>123 スマソ。思考回路が2オペランドなもんで依存関係があると勘違いしてた。
Yonahは、本来1年前に出ていたはずのCPUだからねえ。
64bit非対応でFP SIMDも遅い。CPUとしては、まさに「最強の小回り」だと思いますよ。
この完成度は、ファミコンの性能を極限まで引き出したマリオ3にも匹敵する。
>>124 メモリ帯域は技術的・熱的に難しいっぽいが、キャッシュ帯域・レイテンシはYonahの時点で
十分強い。中間言語はPenMで完成形(もう簡単には性能が伸びない)じゃないだろうか。
俺の場合はSIMDユニットを8個も16個も載せてくれと思っていた。
まあ、これは現実的じゃないんだろうけど。
現実問題としてランダムテーブル参照はコストがテラ高いのね。
・ロード・ストアがネックになる。
・キャッシュの省電力機構の動作を妨げる。
・L2の大容量化はレイテンシの増加を伴う諸刃の剣。
・上り128bit/clkの帯域っていっても1クロックに8bit×16回とか16bit値を8回とか参照できるわけではない。
8ビット値から8ビット値の写像をとるのに1byte * 8^2個 = 64byteのテーブルが必要
16ビット値から16ビット値の写像をとるのに2byte * 16^2個 = 512byteのテーブルが必要
(略)
まぁAltiVecのvpermみたいなのは1解になるかと。2つのベクトルレジスタ32バイトから
ランダムルックアップが可能す。これのスループットが1クロックサイクルだから凄い。
//vperm vD, vA, vB, vCの擬似コード
VecByte vperm(const VecByte vA, const VecByte vB, const VecByte vC) {
VecByte vDest;
for (int i = 0; i < 16; i++) {
vDest[i] = (vC[i] & 16)? vB[ vC[i] & 15 ] : vA[ vC[i] & 15 ];
}
return vDest;
}
pshufbで同等のことはできそうですがこちらはMMX版が8バイト・XMM版が16バイトと考えられますな
もっとも、XMM版はMMX版を上下くっつけただけ(上下のQWORDを跨いだシャッフルができないなど)
の糞仕様の可能性も拭いきれないので、あんま期待はしてませんが。
単純な整数論理演算ならクロックあたり演算ユニット数分処理できる。
テーブルを細かく砕けるなら砕いてL1にヒットさせつつ、ビット論理演算で組み立てたほうが
スループット上がる希ガス。
そもそも分岐をテーブル参照で置き換える程度のレベルならMMX/SSEで同時計算で済む気もス。
Meromはどうやらパックド整数ユニットは3基あるらしいし。
ごめん、いま大嘘書いたw
8ビット値から8ビット値の写像をとるのに1byte * 2^8個 = 256byteのテーブルが必要
16ビット値から16ビット値の写像をとるのに2byte * 2^16個 = 128Kbyteのテーブルが必要
pshufbでDESエンコード16並列実行うめぇwwwとか妄想してたんだ。
以下パイプライニングはハード任せ
__declspec align(16) const unsigned char SubstitutionBox1[4][16] = {
0xE,0x4,0xD,0x1,0x2,0xF,0xB,0x8,0x3,0xA,0x6,0xC,0x5,0x9,0x0,0x7,
0x0,0xF,0x7,0x4,0xE,0x2,0xD,0x1,0xA,0x6,0xC,0xB,0x9,0x5,0x3,0x8,
0x4,0x1,0xE,0x8,0xD,0x6,0x2,0xB,0xF,0xC,0x9,0x7,0x3,0xA,0x5,0x0,
0xF,0xC,0x8,0x2,0x4,0x9,0x1,0x7,0x5,0xB,0x3,0xE,0xA,0x0,0x6,0xD };
dest = SubstitutionBox1[A0*32 + A5*16 + A1 + A2*2 + A3*4 + A4*8]
; 入力 xmm0 : A0が1が立ってるかどうかのマスク×16
; xmm1 : A1~A4の4ビット×16
; xmm2 : A5が1が立ってるかどうかのマスク×16
movdqa xmm3, XMMWORD PTR[SubstitutionBox1+48]
pshufb xmm3, xmm1
pand xmm3, xmm0
pand xmm3, xmm2
movdqa xmm4, XMMWORD PTR[SubstitutionBox1+32]
pshufb xmm4, xmm1
pand xmm4 , xmm0
movdqa xmm7, xmm2
pandn, xmm7, xmm4
por xmm3, xmm7
movdqa xmm4, XMMWORD PTR[SubstitutionBox1+16]
pshufb xmm4, xmm1
pand xmm4, xmm2
movdqa xmm7, xmm0
pandn xmm7, xmm4
movdqa xmm4, XMMWORD PTR[SubstitutionBox1]
pshufb xmm4, xmm1
pandn xmm2, xmm0 ; 同じく破壊
pandn xmm0 , xmm2 ; 最後はマスク破壊
por xmm0, xmm7
por xmm0, xmm3
最後訂正
movdqa xmm4, XMMWORD PTR[SubstitutionBox1]
pshufb xmm4, xmm1
pandn xmm2, xmm4
pandn xmm0 , xmm2
por xmm0, xmm7
por xmm0, xmm3
MMX_ALUが128bitならかなり期待するんだが。
もし64bit×2だとポート2つも取るから経済的じゃないし。
3年もK8コア使ってたAMDウメェwww
ConroeはIntelの結晶とか言ってるが将来性あんのかなぁ…
>>130 パイプラインがきれいに流れなさそうなコードだね。
2倍の数のxmmレジスタが使えるLongモードにして、
16並列ではなく32並列または48並列にすると、
レジスタ間の依存のある命令の距離が離れて、
いい感じにパイプラインの隙間が埋まるよ。
32ビットなら、xmmレジスタだけでなく、
mmxレジスタや整数レジスタも使おう。
同じ演算ユニットを使うとしても、
依存関係でストールしてしまえば、
演算ユニットは空いているわけで、
空いているなら使ったほうがいい。
読点で改行しすぎ
>>133 Substitution-Boxは1から8まであるので並列化に関しては問題ないかと。
Intrinsicsをサポートしたらスケジューリングをコンパイラ任せにするのもアリかと思いますわ。
あと、ロード・ストアに余裕ができそうなので、スワップさせながらでも並列化させるのも
アリでしょうな。命令帯域には余裕があるみたいなんで。
マンデルブロ描いてたら、4倍精度が欲しくなって、作ってみようと思った。
しかし、拡張精度FPUでも厳密に扱える乗算は32bit*32bit=64bitが限界。
そこでSSE2整数のpmuludqを使うことにしたが、SIMDにはキャリーがない。
64bit加算のpaddqがあるので使ってみるか?何にせよ、乗算のコストは大きい。
ただ、この辺りはx64ならmul命令で64bit*64bit=128bitの整数乗算が可能になるので、
128bit固定小数点の乗算が、一気に現実的な時間でできるようななる。
そう思うと、めろんタンが出てから4倍精度作ればいいやという気になってしまった。
それでも最低3回の乗算とキャリー付き加算が必要なので面倒なことに変わりはないが。
本来はアセンブラを使うべきだが、四則演算をCの関数にでもしないとデバッグで死にそうだ。
そうなるとインラインでは関数の展開などの最適化が効かないので組み込み関数だな。
http://pc.watch.impress.co.jp/docs/2006/0310/idf07.htm 今回のIntelは、クロックを下げることににごだわりが見られるね。
周波数とIPCのバランスでは、現状IPCを上げる方が電力効率がよかったみたいだ。
コア数増加も、クロックを僅かに下げて電力を大きく削るというコンセプト。
>説明中に左右のコアをわかるように片側を逆向きにした図を見せたとき、
>講師は「こっちのコアはBig Endianだ」という冗談を言ったのだが、笑う人も少なかった。
禿ワロスww
新しい情報としては、Macro-Fusionが比較+分岐のみで、この命令を直接実行できること。
>MutiplyとAdd命令をくっつけてMultiply Accumulate命令にするMacro OP Fusion
安藤さんとこで見たこれは立ち消えかな。
それにしても、図中のcmpjne eax, [mem2], targ っていうuopは萌える。
プリフェッチ機構の図は、コアに2つあるデータ用はソフトウエアプリフェッチかな?
命令用まであるとは驚いた。
そしてL2にも共用なのに2つ付いている。2個だと各コアの要求に対応できるからだろうけど、
シングルスレッドでも2系列のアクセスをサポートしてくれそう。
(ここは後でPenMで実験したい。2系列のアクセスでHWプリフェッチが効くかどうか)
「1つおき」程度のパターンは読めるみたいだ。
HWプリフェッチが強化されると、ますますL2やメモリの素の力がわかりにくくなるな。
アセンブラで最適コードを見つけるのが大変になりそうだ(それでも性能は上がるだろうけど)。
最近ビデオカードの記事は流し読みだなあ。以前はけっこう楽しんで読んでたんだが。
なんとかシェーダが何個とか具体的に何がどう嬉しいのかよくわからんからなあ。
>>136 >The retirement buffer is used for handling of all the micro-op faults
>that occur when either memory commands can not be reordered.
これはどういう意味だ?In-Orderでないの?
>that can be executed in a single clock on a single ALU
Fusedなcmpjneは1clkで実行できる様子。すげー。
わざわざFusionを使うということは、実行ポートを増やすのは大変なんだろうね。
最近のx86は内部RISCと言われるが、CISCの発想も加えた理想のアーキに
近づいてる気がする。
>execute all of the SSE instructions up to 128-bits in a single cycle
強気だな。すべてってことは、あんな命令やこんな命令も?ワクワク。
(もちろん割り算と平方根は別だろうけどw)
レイテンシはaddpdで3を保てるかな。mulpdが4以下だったら神なんだが。
SSE命令4つがフル稼働してなお分岐ありALUが1個空いているというリッチさ。
>Intel’s architecture has the ability to determine (先行するストアに依存するかどうかを)
投機実行じゃなくて完全に読んじゃうの?
ところで、共有L2のおかげでメモリを介さずデータをもう片方のコアに送れるが、
データをすぐにL2に書き込む方法ってないよね?
コア0でL1修正済みのアドレスをコア1が読むとコア0からL2へ転送するという仕組みかな。
Intelligent Power Capabilityのとこの図で、命令フェッチまで休んでいるのはどういう訳だ。
ループ内側の命令が全部命令キューに入っていればフェッチすら省ける?
読むのに魔法のマウスを試用したが、自分で読んだ方が速いかも。やや作りこみが甘い。
FIFOを知っていたのにはちょっと感心したけど。
全然関係なくて申し訳ないがごだわりワロスw
>>139 AGUはリオーダステージの前にでもあるんでしょうか。
>>139 > >The retirement buffer is used for handling of all the micro-op faults
> >that occur when either memory commands can not be reordered.
> これはどういう意味だ?In-Orderでないの?
リオーダー出来ないメモリアクセスなのに、
誤って(予測ミスで)リオーダーして実行してしまった場合、
リタイヤユニットで順序違反を検出するって話では。
すまん。他記事見ると、ロードは投機ロードみたい。
英語が読めるのは、自分が既に理解している事柄だけだなあ(微妙に意味ない・・)。
>>142 ども。faultsってそういう意味か。
投機ロードが原因でP6よりも遅くなるコード例が知りたい。
SSEポート*2の他にFused分岐ALUがあるので、アンロールがばからしくなるな。
更に、Macro-Fusionは比較のみのサポートのようなので、dec ecx/jnzは相対的に遅くなる。
いかにも手書きアセンブラ的な基本作法が、一部用済みになる模様。
ちょっと横道にそれて、
現状PenMでもdec/jnzの空ループは1clk/loopを達成しているが、P6は2clkだった。
なぜ速くなったかが謎。ループ検出器は64回以下のループにしか働かないみたいだし、
むしろ検出器が働くと2clk/loopに落ちる。65回以上だとちゃんと分岐予測ミスをする。
投機ロードのせいか、データとアドレスに分かれていたストアユニットが一つになった。
だがコンプレックスデコーダが吐ける最大uOP数は4のまま減ってないのはなぜ、
と思ったらPenMの時点でフュージョンしてるからadd [esi],eax は3uOPsだった。
4つに分解していたものを3つにしか分解しないというMicroFusionもあるんだね。
mov tmp,[esi] / add tmp,eax / mov [esi],tmp
このように分解されていると思われるが、add tmp,eax,[esi] みたいに融合したりしないかな。
Meromのマイナーアップが今から楽しみだ。
MMX性能はともかく、SISD性能はそれなりに重要だと思うが、どうなんだろう。
mulsdのスループットが1だろうからYonahよりは速いはずだけど。
デコーダは4+1+1+1で吐けるみたいだが、7uOPsで送れるのかな。
図を見ると4が限界っぽいんだけど、P6は6uOPs/clkで送れたよね?
SSE5には是が非でもXMM版psadbwの128bitバージョンを入れてくれ。
今はCPUどころか命令仕様からして64bit*2で、せっかくの128bit演算器が泣く。
約6MBのサイズでHWプリフェッチの実験@Dothan-1.1GHz、PC2100。
lp:
movq mm0,[esi]
・・・
movq mm0,[esi+56]
add esi,64
dec ecx
jnz lp
これを、movqの1行目から順にコメントアウトしていくとこうなった。
43.8 44.7 42.3 42.8 37.9 38.0 38.0 38.0 1.5(clk/loop)
そもそもキャッシュラインは64byteまとめて更新するしかないと思うのだが。
1個だけコメントアウトしたときに少し遅くなるが、4個以降が速すぎる。
(というか4個で38clkが出せるなら通常で43clkもかかるのが遅すぎる)
2系統だと100clk/loopで、今のところ片方だけprefetchntaするのが一番速い。
よくわからんので詳しくはまた今度。
http://pcweb.mycom.co.jp/articles/2006/03/11/idf3/index.html (5)だが、リタイヤがOoOなCPUなんてあったっけ?
>ただ、実際にはRetirementの先がOOOとなっている関係で、
先って何やねん。ただ、言いたいことはわかる。
メモリアクセスの順序をIn-Orderで一度どこかで確かめる必要があるのだ。
(6)、SSEのスループットが2に最適化したコードでは逆に遅くなることがあるのでは?
遅くなるとしたらレイテンシが伸びた場合のみ。ところが、
>確かに可能性としてはあるが、
おい、なぜ馬鹿な質問だと一蹴しない。レイテンシ伸びてるのかよ。
>Photo41:3・4回目のアクセスはL1キャッシュから高速に行える
(7)、HWプリフェッチは今までと異なりL1にまでされるようだ。嫌だな。
BIOSで切れるようにしてほしい(性能より測定のしやすさを求める性癖)。
>>144(6)ちょっと間違ったかも。
秋山仁の本で、キャンプで作業の人数を増やすと不思議なことに遅くなる話ある。
タネは、開始できる作業があるときには直ちに開始しないといけないという条件。
もちろん、スケジュールが完璧なら絶対遅くはならないが、わざと休む大胆さが要る。
例。addps(3/2→3/1)、mulps(4/2→4/1)のようにスループットが倍に改善されたとする。
addps xmm0,xmm0 ; 0-2 / 0-2 //0-2とは、0clk目から2clk目まで実行中ということ
mulps xmm2,xmm2 ; 0-3 / 0-3 //addとmulは並列実行できる
addps xmm1,xmm1 ; 2-4 / 1-3
mulps xmm0,xmm1 ; 5-8 / 4-7
mulps xmm2,xmm2 ; 4-7 / 5-8
mulps xmm2,xmm2 ; 8-11 / 9-12 //Yonahは12clk、Meromは13clkかかっている
左がYonah、右がMeromを想定したクロック数。
この例だと休まなくてもスケジュールをうまくすればOKではある。
また、実際問題遅くなるケースってのはないと言っていいだろう。
YonahのSSEって、add/mulは別々のポートに割り当てられているの?
TextSS のWindowsXP(Professional)64bit化おながいします
もしくは64bitにネイティブ対応したテキスト置換ソフトありますか?
そういや64bitにネイティブ対応している2chブラウザてありましたっけ?
明らかにスレ違いだけど、
エディタとかテキスト置換ソフトで、
64ビット化のメリットって、すごく低くないか?
2chブラウザも同様。
というか、より以上にメリットがないはず。(デメリットもないが)
処理が重いマルチメディア処理とかには効くだろうが...
147は他のスレでも見かけたから単なるマルチポスト。
無視に限る。
>>148 16bit→32bit移行時期にも全く同じ話題が出たが、Windows3.1の
386エンハンスドモードを利用したいというユーザが急速に増えて32bit化
が進んだ。
ソフトウェアやOSで、64bitじゃなきゃダメという環境が増えれば多分急速
に進むのではないだろうか。そういう意味ではWindows Vistaはまだ通過点
に過ぎないだろうな。
386エンハンストモードは仮想86(DOS窓)と16bitプロテクトモードの混成で、
32bitじゃなくないっけ(32bitはWin32sの方)。
一般ユーザーの本格的な32bit化はWin95からだけど、32bit化の他にも
デスクトップ機能の強化とかプリエンプティブマルチタスク化とか
インターネット接続機能の標準化とか、これはって機能満載だったから
いいタイミングではあった。
石は386どころか486からPentiumに移行しはじめの時期で、
ハードは32bit readyだったのにOSの対応が微妙だったってのは
今とは微妙に逆かな?
そういう意味では、もすこし64bitハードが普及してないと本格移行は難しいかもね。
16→32の時も同じだったけど、
64bitならではのメリットが出てこないと厳しいでしょうな。
4Gの壁が邪魔になるとか。
WindowsNTを使わないのはマゾってくらい、16ビットは厳しかった。
64Kにはつまらん苦労を強いられたものですなあ…
ちまちまいじっていたら微妙に足りなくなって、
farに直したら妙なバグに悩まされたり…
9x系はノンプリエンプティブでそ。
95→98→98SE→Meとバージョンがあがる度に空きリソースが減っていった思い出
32bit空間がプリエンプトで、16bit空間はイベントドリブンだっけ?
互換性とるためなんだろうけど、ややこしいシステムですな。
>>157 イベントドリブンの意味まちがってるとおもわれ
キャッシュの古いデータの捨て方には、擬似LRU置換アルゴリズムが使われているらしい。
この辺り、ユーザーが制御できるようにしてほしいと思うことがある。
例えば2MBのキャッシュで、同じ3MBのデータを繰り返し扱う場合。
順次アクセスだと全てミスヒットになってしまう。そうでなくても、無駄にデータの入れ替えが起こる。
キャッシュに入れるのは、3MBのうち最も使用頻度の高い2MBで固定したいところだ。
movntqは場合によって大きく速度がアップするが、こういうキャッシュ関係の命令がもっとほしい。
まあ、これが近い将来に実現するとは思わないし、現実にやるべきだとも思わない。
「アセンブラを使ったときにC言語のよりも何倍も速くなるような設計になってたら
高速化のしがいがあって楽しいな」という個人的な話でしかない。
だが、一般的な処理に対して既に十分なCPUパワーがあるとすれば、Cでの性能を犠牲にしてでも、
アセンブラや組み込み命令を使ったときのピーク性能を上げるという選択はアリだろう。
NetBurstも似た設計思想だったが、時代が5年進んだこと、ネトバ失敗の原因は熱だったことを
考えれば、数年後は無理でも、その先で行き詰まったときに使える手ではあると思う。
>>146 Intelのマニュアルに書いてあるが、P6のときからポートは別々だった。
実際には、P6でSSE積和のスループットを2で回すのは難しかったけど。
Yonahならフュージョンがあるから回ると思うけど、実測してないのでわからない。
マンデルブロ集合のプログラムを作った。反復式はz←z^2+cだけでなく、z^3とz^4も。
更にそれぞれFPU版とSSE版、SSE2版を作成(z^3とz^4の最適化は適当だが最速に近いと思う)。
ベンチができるようにして、測定した。
左から、z^2、z^3、z^4のときの描写時間。
Noothwood-3.06GHz
FPU 3.478sec 5.433sec 7.820sec
SSE 0.609sec 1.183sec 1.532sec
SSE2 1.167sec 2.285sec 2.954sec
Coppermine-128K 400MHz
FPU 12.099sec 21.992sec 32.535sec
SSE 4.173sec 6.099sec 8.468sec
Dothan-1.1GHz
FPU 4.236sec 7.705sec 9.786sec
SSE 1.457sec 2.253sec 2.988sec
SSE2 2.809sec 4.842sec 6.215sec
P6向けにきつく最適化されたFPUコードでは、クロック当たりの性能で
Pen4はP6の半分以下に落ちる場合があることが確認できた。
SSE/2でも、さほどPen4のIPCが伸びない。P6の70~85%にとどまる。
Meromでも、SIMDのレイテンシがPen4の半分とかに減っているとは考えにくいので、
このベンチのSSEコードを使った場合、もちろん性能は大きく上がるだろうけど、
SSEパイプラインの充填率はPen4程度になると思われる。
PenMとP6の比較では、一部を除いてPenMが4%ほど速い。何だろう。
今度は1ループのクロック数も測れるようにした方がいいな。
そーゆーのは公開してくれくれしてみる
>>162 少なくともベンチのソースは公開すべきだったが、見せられない状態だったので。
最近、「きれいで速いコード」が好きになってきて、「汚い最速コード」への執着が減ってきた。
というわけで、Cのソースとバイナリ(win)を公開。(いつものアップローダどこいった?)
http://vista.x0.to/img/vi4414459572.zip それにしてもPen4のFPUは遅い。
faddのスループットはP6・P4共に1だが、レイテンシが2のびてまともに食らうと
1clkで回っていたものが1+2=3clkかかるようになってしまう。
よってP6向けにきつく最適化されたコードだと、最悪の場合P6比で3倍遅くなる。
Pen4向けに最適化をした人が少なかったのが痛い。
SIMDのクロック当たりの性能も決して高いとは言えないし。
ギヤ比3.5:1のレブチューンでカーブばっかりのコースを走るミニ四駆みたいでかわいそうだ。
ストレートコースを用意してやってもConroeには絶対性能で負けるだろうなあ。
いや、アセンブラで性能を引き出せるという意味で好きなんですよ?
Meromは楽しみだけど、LV版がB5ノートに載るのはけっこう先だろうなあ。
新アーキだけに、Merom+を待ちたいという気持ちもある。
でもMeromの場合、最初から完璧なアーキで登場しているように見えてしまう(欲目だ)。
PenProみたいなミスはないだろうけど、Banias→Dothan以上の変化はあると見るべきか?
まあ、SSE3/4とx64が載っているという時点で興奮が抑えきれないのだけど。
164 :
デフォルトの名無しさん:2006/04/10(月) 15:49:46
movntdq などの non-temporal 書き込み命令を使った場合、
実際にメモリに書き込まれるタイミングはどうなっているんでしょうか?
non-temporal なんだからライトバックのためにキャッシュにためられる
なんてことは無いですよね?
もしかして L1 だけは汚染されるってことでしょうか?
そういや prefetchnta は L1 にだけプリフェッチするんでしたよね。
Pentium III や Pentium M では。
Pentium 4 や Intel Xeon では prefetchnta では 1 way of L2 に
prefetchnt0 では L2 にプリフェッチされるとのことですが、
「1 way」の意味がわかりません。デュアルコアの場合に片方にだけってこと?
165 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/10(月) 23:12:07
>>164 > そういや prefetchnta は L1 にだけプリフェッチするんでしたよね。
> Pentium III や Pentium M では。
え?L2上にはマッピングされないの?
Athlon系じゃねそれ
166 :
デフォルトの名無しさん:2006/04/11(火) 11:55:12
Pentium 4 について
IA-32 Intel® Architecture Optimization
http://download.intel.com/design/Pentium4/manuals/24896613.pdf The Prefetch Instructions – Pentium 4 Processo Implementation
prefetchnta Fetch the data into the second-level cache, minimizing
cache pollution.
prefetcht0 Fetch the data into all cache levels, that is, to the
second-level cache for the Pentium 4 processor.
prefetcht1 Identical to prefetcht0
prefetcht2 Identical to prefetcht0
167 :
デフォルトの名無しさん:2006/04/11(火) 11:58:00
同文書から Pentium M についての記述
The Pentium M processor also provides a hardware prefetcher for data.
It can track 12 separate streams in the forward direction and
4 streams in the backward direction. This processor’s prefetchnta
instruction also fetches 64-bytes into the first-level data cache
without polluting the second-level cache.
168 :
デフォルトの名無しさん:2006/04/11(火) 12:00:36
>>166 の
「all cache levels, that is, to the second-level cache
for the Pentium 4 processor」 って記述見ると、
Pentium 4 における first-level chache って何なの?
って気になるな。
first-level cache って L1 cache のことと思っていいんだよね?
169 :
164:2006/04/11(火) 12:15:26
>>165 Athlon はそうなの?
データの参照(読み書き)のパターンは大きく分けて
1) temporal = 短時間で再利用される
2) non-temporal = 短時間で再利用されない
3) spatial = 短時間で近傍アドレスの他のデータが参照される
プリフェッチ命令は 1 か 2 かのヒントを与えるもので、
prefetchnta = non-temporal であることをプロセッサに指示
prefetcht0,1,2 = temporal であることをプロセッサに指示
するもの。spatial であるかどうかは明示的に指示するものではなくて、
キャッシュラインの幅として固定。という理解なんだけど、
なんでそれがプロセッサによって違うのかわかんね。
わかんね。わかんね。わかんね。わかんね。
170 :
164:2006/04/11(火) 13:13:57
171 :
164:2006/04/11(火) 13:17:48
http://www.codecomments.com/archive258-2004-6-222900.html prefetchnta only fetches data into the first way of the L1/L2 cache, which
means it won't evict data located in the other ways or in higher cache
levels. prefetcht1 fetches data into the least-recently used way of the L2
and L3 caches (as a normal load would do).
あんまり情報ないね・・・
>>164 >movntqのタイミング
PenMで試してみた。
L1にちょうど収まる処理の合間にmovntqを入れてもL1Dataが汚染される様子はなかった。
Dothanだと、多少順番が崩れたmovntqでも転送レートが落ちない(Baniasだと遅くなる)ので、
ある種のバッファみたいのはあるのだろうが、L1L2キャッシュとは別物と思われる。
PenMではmovntqがプリフェッチ付きロードと同等の帯域を出す。
Pen4だとどうだろうね。
以前PC1066のNoothwoodでメモリ帯域の実験したのによると、64byte転送にかかる時間が、
movntq,movntpsでは共に69clk、movapsロードが61clk、movqロードが77clkだった。
movapsがmovqより15clkも速いのは、L1ロードが128bit/clkというだけでは説明できないので、
内部命令数が半分で先読みがしやすいのも効いていると思われる。
で、movntpsにはその優位性がないので、「movqロードと比較して8clk速い」でいいだろう。
ただ、プリフェッチ付きmovqロード(61clk)と比較するとmovntpsが遅いんだよねえ。
まあ、バッファがそんなに速くないだけかな。
>>165 >>10で俺が指摘された間違いです。L2は汚染しない。
Athlonだとどうなんだろね。
>>169 単純にキャッシュラインのサイズがCPUによって違うからじゃないの?
173 :
164:2006/04/11(火) 15:00:14
>>172 >単純にキャッシュラインのサイズがCPUによって違うからじゃないの?
あ、ごめんごめん。言いたかったのは
prefetchnta でプリフェッチされる先が
Pentium M (L1) と Pentium 4 (L2) で異なるのは何でかな?
ってことです。
>>167 に書いたみたいに、Intelのマニュアルだと Pentium M について
This processor’s prefetchnta
instruction also fetches 64-bytes into the first-level data cache
without polluting the second-level cache.
ってなってるんですが、L1 は汚染されないんですかね?
>>167 >It can track 12 separate streams in the forward direction and
> 4 streams in the backward direction.
すげー。そんな多系統でできたのか(
>>144で気になっていた)。
>>168 all cache levelsが、Pen4ではsecond-level cacheを指すという単なる言葉遣いなのかな。
広帯域・ライトスルー・小容量という特殊なL1なので特別扱いを余儀なくされたとか?
>>170 メモリベンチでは、t0とntaでは数%の差だった。
で、171のように、t0はXeonではL3にもプリフェッチするという違いでいいんじゃない?
Northwoodを、XeonからL3を省いた廉価版と見れば、この動作に不思議はない。
2MBL3のXEでL3へプリフェッチできるかどうかは気になるね。
謎なのは、Pen4プリフェッチにおけるt0とntaのあるんだかないんだか不明な差。
そういえば、Pen4のメモリベンチで128byteおきにプリフェッチする実験はやってないな。
Pen4のL2は、64byteセクタ*2の128byteが1ラインになっている。
そもそも、セクタがあるのとないので何か動作が違うのだろうか。
>>173 Pen4は、なぜか知らんがL1にはプリフェッチできないアーキだというのを前提とすれば、
PenMもPen4も、最もレベルの低いキャッシュ階層1つのみにプリフェッチする、という点で
同じになる。
>L1 は汚染されないんですかね?
Pen4では、prefetchntaでは汚染されず、実際にデータを使うときに汚染される。
まあ、L2にあるデータをCPUが読むときは、必ずL1を通すので、「汚染」とは言わないだろう。
だからこそ、L2でなくL1にプリフェッチしないとntaの意味が薄れまくるんだけどね。
そもそもprefetchntaの利点は、「メモリへのライトバックにL2(L3)を経由する無駄」を省くこと。
で、長文書きながら問題の核心(なぜPen4はL1にプリフェッチしない?)がわかってない俺。
あと、Pen4のt0とntaの差。
175 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/12(水) 01:07:58
L1がライトスルーキャッシュなのと関係あり?
共有キャッシュだとL1はライトスルーのほうがCore0で書き込んだデータをCore1から参照したいって場合に
さほど複雑なアルゴリズムを必要とせずに実現できると思うのだが
YonahやMeromってどういう方式とってるんだろう?
176 :
164:2006/04/12(水) 01:36:00
プリフェッチ、というか、キャッシュをいじってて
いまだに理解できてないのも恥ずかしい限りなんだが、
なんで movntps なんかの non-temporal 系の命令で
レジスタ(含むXMM) → メモリの書き込みやると、
movaps でやるのに比べて早いんだろう。
単に non-temporal なデータでキャッシュが汚染されるのを
防ぐって言うだけなら、どうせメモリへの書き込みって
実際にメモリに書くところが律速段階なんだから
速度には影響ないような気もするんだけど。
メモリブロックのへの連続書き込みに movntps
を使った方がmovaps を使うより早くなるのはなんで?
キャッシュというとメモリからの読み出しにばかり気を
とられてて、メモリへの書き込みに関する効果あんまり気にしてなかった。
汚染覚悟でL2のライトバックキャッシュ使った方が
早くなりそうなもんなんだけどなぁ。
>>175 俺もライトスルーは怪しいと思っている。
YonahやMeromは、キャッシュのタグを見て更新されていたら相手コアから転送、
みたいな感じかねえ。予想だけど。
>>176 ・movaps [esi],xmm0の動作
L1に[esi]を含むキャッシュラインをメモリからロードする
そこにxmm0を書き込む
L1が一杯になるとL1からL2へ転送する
L2が一杯になるとL2からメモリへ転送する
・movntps [esi],xmm0の動作
xmm0からメモリへ転送する
というわけで、メモリからのロードが入る分、movapsが遅い。
この仕組みはライトアロケートとかいって、普段は速くなるんだけど
連続ストアやランダムストアに対しては遅くなってしまう。
178 :
164:2006/04/12(水) 02:15:50
>>177 >L1が一杯になるとL1からL2へ転送する
> :
>この仕組みはライトアロケートとかいって、普段は速くなるんだけど
なんか違くないか?
http://pcweb.mycom.co.jp/column/architecture/018/ 「…このバリエーションとして、書き込みに際して1次キャッシュをミスした場合に、
1次キャッシュにはラインを確保して書き込みを行なわず2次キャッシュへの書き込み
だけで済ませる方式と、まず、1次キャッシュにラインを確保して、それから1次キャッシュと
2次キャッシュに書き込みを行うWrite Allocate方式がある。書き込んだデータを再利用
する確率が高い場合は、Write Allocateが有利であるが、書きっ放しで、再度利用する確率が
低い場合は、Non Allocateの方が無駄が少ない。…」
>>182 引用してる部分とライトアロケートの説明が一致してない
>L1が一杯になるとL1からL2へ転送する
っていうか、
>>177の説明でなんで唐突にライトアロケートの説明が出るのか?
>>185 それはライトバックキャッシュなら普通の動作では?
>>186 movntpsはノーライトアロケートストア命令だからじゃない?
>>187 だったら、
「この仕組みは~」
って言ってるのは、どこを引用してるのか?
あっ!!177の言いたい事が今わかった。
177では、別にライトアロケートを説明してたわけでは無いのか!
ハヤトチリ ゴメソネ > 177
>>179 そのライトアロケートの説明は、ライトスルーの場合についてのものだと思う。
>>177は、ライトバック&ライトアロケートなCPUの説明だからちょっと違うけど、
「まずストアの前にL1へロードを行う」という点では同じで、それが>177で問題にした
ライトアロケートという仕組みだ。
ライトアロケートは、ストアが続くときは余計なロードが入るため不利になる。
このデメリットを回避するための命令がmovntpsなどのストア命令だから話題に出した。
ライトアロケートという仕組みがなければ、そもそもmovntpsという命令はいらない。
前スレ796も参照。ライトアロケートのオン、オフの違いで、
メモリへ8byteのストアをするのに、155clkと25clkの差が出る(K6-2)。
ただ、L1ミスのストアでL2へ書き込むCPUなんてあったのかな。
ライトアロケートなしのCPUでは、ストアでL1ミスのときどう動作するのが普通だったんだろう。
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html >HTが1つのプロセッサで2つの仮想的なプロセッサをエミュレートするものであるに対して、
>複数の物理プロセッサで1つの仮想的なプロセッサをエミュレートするという。
K8Lは強化FPUを2コアで共有、なんて噂もあるが、本題はそこではなくて。
これって、HTと何が違うのかな?
HTでは、命令フェッチが2系統、分岐予測とかも2個必要だ。あとは共有。
対してK10のやつは実行ユニットだけを共有して、あとは各コアが持っている。
以前俺は、「デュアルコア」よりも「実行ユニットを2倍に強化したHT」が完全優位だと考えた。
シングルスレッドでは実行ユニットが倍のHTが当然有利。
マルチスレッドでも同等か、ユニットを柔軟に使えるためそれ以上の性能になるはず。
共有部分が多いため、ダイサイズも小さくなる。
なのになぜIntelはこれをやらないか。
まず、実行ユニットだけでなく、フェッチ、リタイヤ、キャッシュのすべてを倍にする必要がある。
だが、コアを2つ載せるのに比べたら安いもんだし、シングルスレッド性能は捨てがたい。
で、決定的だと思ったのがスケジューラが倍どころではなく複雑になること。
K10(予定)は、スケジューラも各コアで持っているはずなのでOKなのだろう。
HTは5~10%のダイサイズ増大で実現できたが、結局、性能を追求すると
(2コアの場合)倍近くダイサイズが増えちゃうということかね。
L1データ・命令の出入口が各コアにあるというのがでかいよなあ。
> 4つの物理プロセッサを使えば、理論的には4倍の性能になるという。
個人的には、こういうシングルスレッド性能が上がる仕組みは大好きだ。
ただ、4倍のユニット相手にちゃんとスケジュールできるんだろうか。相当大変だと思う。
あ、でもそんな大量の命令をデコーダが吐けないか。
192 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/15(土) 13:57:26
>>191 配線の問題じゃね?
まぁMeromで性能が出なかったときはHT使ったかもわからんね。
パイプラインWay数3→4で既存のアプリの性能が1.2倍ならうまくやってると思う。
>>191 >実行ユニットを2倍
それをするんだったら、いっその事デュアルコア化した方が(コストパフォーマンス的に)良いって判断じゃないかな。
つーか、そもそも命令ユニットいくら増やしても相互に依存関係のない命令列がふえないと意味ないんじゃないか。
>>193 ようするに、ソフトウェアでやればいーじゃん、つーことか?
196 :
195:2006/04/16(日) 00:45:30
orz
195は194へのレス
>>192 配線か。確かに多くのユニットをぶら下げるのは大変かも。
Meromでも、とにかく内部命令数を減らして実行ユニットの増加も最小限に抑えているしなあ。
>>193 やっぱりコストがかかるんだよね。
素人考えだと、ユニット倍ならコストも倍って思っちゃうけど、そうはいかないんだろうな。
>>194 それは正論だが、仮にタダ同然でシングルスレッド時のユニットを増やせるならいいじゃん、
という話。それに、アセンブラ使いに有利になるから、バイアスかかってるw
実際は種々の問題で「タダ同然」とはいかないみたいだね。
これから、シングルスレッドの性能向上のための工夫は重要なポイントになると思う。
デュアルコアは、TDPとダイサイズが倍になるという大きなデメリットがある。
だから、クロックは下がるし、キャッシュや色々な機能もあまり増やせない。
結果、犠牲になっているのはシングルスレッド性能だ。
実行ユニットの共有は、ダイサイズでのデメリットを緩和する。共有L2も同じ思想だ。
(共有L2の場合、調停ユニットの追加とレイテンシ増加のデメリットがある)
TDPの面では「シングルスレッド動作時にはクロックを定格より上げる」という手があると思う。
198 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/18(火) 21:10:45
Ruby
会社で2038年問題の検証やった。いや、時計進めてみただけだけど
アホーセントラル即落ちた。駄目だこりゃ。
199 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/18(火) 21:11:31
gobaku
sine
CodeAnalystを使っているのですが
Dispatch, stalled due to Ls full
Dispatch, stalled due to FP scheduler full
のようなストールはどうやって解決すればいいのでしょうか。
ディスパッチとLode/Store, FPがどのように関係しているかがよく分からないです。
CodeAnalyst みたいなのって Intel は出してないの?
AMD のプロセッサ向けに最適化しちゃうよ。
俺 Intel のプロセッサしか使ってないのに。
つ VTune
>>203 それ、パイプラインの状況とかもシミュレートできる?
って、試用期間有ることを期待してみてみるわ。
フリーだとありがたいが・・・そりゃないだろうな。
>>201 CodeAnalystは使ったことないのであくまで推測だが、
(1)Athlonではデコードの後にALU/AGU(3つある)かFPUのスケジューラに命令を送り出す。
(2)そのスケジューラから実行ユニットへ命令を送る。
で、そのDispatchというのはおそらく(1)のことではないかと思う。
つまり、命令の供給に対して実行ユニットが対応しきれず、スケジューラが命令で一杯になって
しまい、それ以上命令をスケジューラに送れなくなってストールしたと。
命令同士に依存関係があると実行が遅れるので、意外とすぐに一杯になると思う。
解決方法については、コードを見ないことにはわからない。
ただ、良いコードとは、ストールしないコードではなく、実行が速いコードのこと。
ストールは、「ストールがなかったら(そのアルゴリズムでは)速度改善の余地はない」
というだけのこと。逆は必ずしも真ならず。ストールしていても改善の余地があるとは限らない。
アルゴリズムの改善が第一だし、完全に最速なコードも多分どこかではストールしている。
家に帰ったら詳しく書きますが、タイトなループで1クロックが効いてきます。
AthXPでは1クロックもストールしないのですが、
Ath64をシミュレートするとストールしてディスパッチが始まらない命令が出てくるのです。
せめてディスパッチだけでも先にしてくれれば後ろの命令がつっかえる事はないのですが…
パイプラインの深さに対してレジスタが8本しかない32bitモードはなかなか難しいですね。
Athlon64にとって、ロングモードを使ってあげる事こそが本望じゃないかなかな
資料作りに時間かかってしまいました。
ttp://rerere.sytes.net/up/source/up12338.zip for(i) a[i] += b[i] * c
を計算するだけのものです。
前方黄色がディスパッチ、後方黄緑がオペレーション、濃い灰色がリタイア、
赤い枠がストールでAthlon64のみデコードを青で示してくれます。
これを見ると、
SSE_8FP.pngは、AthlonXP(左)が10clk/8FP、Athlon64(右)が9clk/8FP。
3DNow_8FP.pngは、AthlonXP(左)が8clk/8FP、Athlon64(右)が13clk/8FP。
3DNow_16FP_Ath64.pngは、AthlonXPが22clk/16FP(画像割愛)、Athlon64が18clk/16FP。
となっていて、あちらを立てればこちらが立たずといった感じになっています。
>>206 つまりDispatchを行う為には実行ユニットをストールさせるなという事ですか。
>>207で「1クロックもストールしない」とか言っちゃってますが、
それはDispatchの話で、実行ユニットはストールしてますね。
最初は実行ユニットも含めて本当に1クロックもストールしてなかったのですが、
実行ユニットをストールさせてでもペアリングを優先した方が速かったので。
>>208 そう思います。その為に16本にしたのでしょう。
個人的な理由ですが、Athlon64持ってないのでデバッグ出来ないんですよね。
YonahがEM64T対応なら世の中も64bit化が加速したろうになあ。
>>209 い、意外と難しいな。
しかしうらやましい。CodeAnalystのためにAthlon機を買いたいくらいだ。
ていうかIntelもVTuneじゃなくてこういうの出してくれ。
この図は、横軸が時間(クロック)、縦は命令毎に分かれている(命令の順序)。
黄色のブロックは同じタテの列に3つまで、とも限らんか。リタイヤは3つまで。
K7の図はわかりやすい。普通の命令はDirectPathで3命令同時デコード。
SSE命令(プリフェッチを除く)はVectorPathで1clkに1命令のデコード。
SSEでAthlonXPが10clkだが、これは完全にデコードネックだ。
SSE命令のデコードが1.5倍速くなったAthlon64が、その分だけ勝っている。これは順当だ。
3DNow_16FPでAthlonXPが22clkとやたら遅いのはなぜ?
んで、3DNow_8FPのAthlon64。
>>201で言われていたストールってこういうことか。
確かにディスパッチされないのが謎だ。
ディスパッチの遅れる直接の原因は、実行ユニットではなくデコード(ていうかフェッチ?)が
遅れていることに見えるが、遅れる理由もないし、やっぱりROBが満杯なのかなぁ。
特に3DNow_8FPの19命令目が通常より2clkも遅れて始まっていて不思議。
でも、「Dispatch, stalled due to Ls full」とか言ってるくらいだからLs fullなのが原因なのだろう。
Athlon64では、基本的にディスパッチを3内部命令同時に行うように見えるが、
そこがデコードの3命令組と1命令ずれている(だからfullになる?)。
対症療法だが、nopをはさむとかしたら改善しないかしら。。
確かに、この図を見ると、タテに42命令が並んでいて、最後の命令をフェッチするときでも
まだ最初の命令が実行されていない。つまり、CPUの中にすごい数の命令があるわけで、
命令プールが一杯でストールが起きてもおかしくはない。
それに、ストアとロードが入り混じってるからOoOがやり難そう。
でもこんな酷くストールしてるのは3DNow_8FPのK8だけなんだよなあ。。
その他。
青いデコードのとこの長さが、まちまちなのは何だろう。
ていうかこんなにパイプライン長かったっけ。25段とかあるんだが。
OoO機構のせいだろうが、ほんとOoOにおけるパイプラインの長さって何なんだ。
あと、レジスタリネーミングが効いているのがわかるのが嬉しい。
movq [edi],mm1より先にmovq mm1,mm0を実行してるよ。
3DNow_8FPとSSE_8FPでは、prefetcht1が32byteおきに入っているので、
64byteのキャッシュラインを2回プリフェッチして効率が悪い。
PenMでSSE_8FPのコードを試してみたら、14clkだった。プリフェッチを外すと11clk。
ていうかAthlonはプリフェッチが邪魔にならないのかね(L1ヒット時)。すごいな。
3ALU/AGUの威力かな?
>>210 実行ユニットをストールさせるなということではなく、実行を速くしろということ。
207で実行ユニットがストールしている方が速かったというのは、そういうこと。
気にするべきはストールではなくて、実行ユニットの稼働率。
長々と書いたけど、結局、解決策の具体案としては
nopをはさんだらどうか、ということしか思いつかなかった。ゴメン。
nopはループの直前か中かだね。
ありがとうございます。
スレッドストッパーになってしまったかと思いました。
ttp://rerere.sytes.net/up/source/up12364.zip 3DNow_16FPにAthlonXPも含めておきました。
見ている場所が悪かったようで、常に22clkというわけでは無さそうです。
3DNow_8FP_nopはループ中に1箇所nopを挟んでみました。
この画像だけ気合いで2画面分収めてあります。(他は力尽きた)
3DNow_10FPは、3DNow_16FPの様に
1ループの演算数を決めてしまうとmm1が大変忙しくなってしまったので
1.mul, addが1clk内に2回現れない
2.mulとmul、addとaddの間は3命令(1clk)以上あける
3.依存した命令は6命令(2clk)以上あける
4.1clk内のメモリアクセスは2回まで
と明確に決めて書いてみました。
10FP/loopというのは僕の頭でそれを満たすものを考えたときにこうなったというだけです。
AthlonXPが11~12clk/10FP、Athlon64も11~12clk/10FPで
公約数的なものが得られた感じです。
それにしてもAthlonXPの3DNow_8FPが魅力的すぎ。
mulとaddで2の言ってる事に1も含まれてるや。
CPUを個別に判別してルーチンを沢山用意するのも馬鹿馬鹿しいですし、
将来の未知のCPUでどれを使うかという問題もあるので
3DNow!が使えるCPUは3DNow!を使って
それ以外ではSSEが使えたらSSEを使おうかと思ってます。
そうすればK6からIntel Coreまで対応出来て素敵。
そうしたときに
> 3DNow_8FPとSSE_8FPでは、prefetcht1が32byteおきに入っているので、
> 64byteのキャッシュラインを2回プリフェッチして効率が悪い。
をどうするかがよく分からないのですが、
キャッシュラインが32byteの古いCPUを考えると
2回prefetchするしか無いんじゃないでしょうか。
ループ前で数KBずつダミー転送するという面倒臭い方法もありますが。
とは言っても手持ちのAthlonXPではハードウェアプリフェチが効いているのか
3DNow_10FPのようにprefetchはずしても問題ない様子で、
prefetchの効能を確かめるのはなかなか難しいですね。
215 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/24(月) 23:02:28
Appleの開発ツールにSimG4とかSimG5とか付いてくるけど
アレでパイプライン見れるよ!(見れるよ!)
そのうちIntel版も出るんじゃね?
216 :
デフォルトの名無しさん:2006/04/25(火) 08:10:39
>>214 >とは言っても手持ちのAthlonXPではハードウェアプリフェチが効いているのか
>3DNow_10FPのようにprefetchはずしても問題ない様子で、
>prefetchの効能を確かめるのはなかなか難しいですね。
主として Pentium M でコード書いているんですが、
ハードウェアプリフェッチがうまく働いているせいか
prefetchnta/t0/t1/t2 命令の恩恵を感じません。
むしろプリフェッチ命令を入れない方が早かったり。
そうすると無駄じゃないプリフェッチ命令って
どういう時に使うべきなんだろうって悩みます。
プリフェッチのためというよりは、キャッシュ汚染を
防ぐために prefetchnta を使うってことなんでしょうかね?
>>213 このスレは人口が少ないので、たまにストッパーがかかります。
画像作成も時間がかかりそうだね。この絵が見られて嬉しい。
少しでも効率を上げようというコード作成の熱意も見習いたいくらいす。
(最近、このスレで自分の知識を垂れるだけで測定をあまりしてないからな)
さて、SSEが使えないCPUは、初期のK7を除いてキャッシュラインが32byteだから、
SSE版については64byteにしていいと思う。
複数種類のラインサイズに対応するには、基本的にルーチンを複数用意するしかないが、
3D Now!で32byteのとSSEで64byteのを作ればとりあえずOKかな。
プリフェッチを外しても問題ないのは、L1ヒットしているからではないかな。
ていうか10clk/8FPとかL1完全ヒットでないとあり得ない。
何回ループさせてる?
そもそも、この処理はどの程度のサイズのメモリに対して行う予定のものなの?
メインメモリに対して行う場合、完全にメモリネックになる。
この処理は8byteの2FP単位で2ロード、1ストアだから、24byte/2FPの帯域を食う。
メモリ帯域は、例えば2GHzでPC3200の場合、1.6byte/clkが理論性能。
確実に75clk/10FPよりも遅くなる。
この場合、faddやfmulの配置を犠牲にしてでも、プリフェッチやmovntpsが効果的に
使えることを優先したコードを書くべきだ。
faddを最適化しても数clk速くなるだけだが、メモリ周りは一気に倍も速くなることがある。
(下の実験では、この処理はプリフェッチによって2割弱高速化した)
#ただし、俺は数clkを縮める最適化の方が好きだ。でも好きな方より速くなる方が一応重要だ。
L2キャッシュヒットでもキャッシュに律速されるが、場合によっては演算部も影響するかも。
下に示すように、俺がPenMで実験したところでは、L2の範囲で微妙に影響している。
また、L1に収まるようなサイズであっても、L1内で再利用されないデータなら結局ライトバックが
必要になってメモリに律速されてしまう。
lp:
movaps xmm0,[edi]
movaps xmm1,[esi]
mulps xmm1,xmm7
addps xmm0,xmm1
movaps [edi],xmm0
add edi,16
add esi,16
dec ecx
jnz lp
最適化してないけど、これで測定。PenM-1.1GHz(Dothan、PC2100)。
L1:7.0clk/4FP、L2:8.50clk/4FP、メモリ:51clk/4FP
これをアンロールして64byte毎の処理にしてみると、
L1:5.3clk/4FP、L2:8.45clk/4FP、メモリ:51clk/4FP
L2ヒットなら、
>>12-13のようなテクニックも存在するが、排他キャッシュのAthlonで
有効かどうかは知らない。
メモリに対してプリフェッチを使うなら、prefetchnta [edi+512] / prefetchnta [esi+512] がおすすめ。
この処理にL2は不要なので、L2を使わないntaは効果的。42clk/4FPまで高速化した。
ストアをmovntpsにしてもいいかと思ったが、ロードした場所へストアするので意味がないみたい。
そういえば、排他キャッシュのせいか、Athlonでプリフェッチのt0,t1,t2は同じ動作だね。
SSE_8FPではprefetcht1が使われているが、IntelのCPUで実行されることも考えると
prefetcht0がベター(L2ヒット時に速い;ベストはprefetchnta)。
SSEも使える場合は、3D Now!をメインにしていてもプリフェッチはprefetchntaを使うといい。
3D Now!だけのときは、ストアするんだからprefetchw [edi+200h] を使うのはどうだろう。
>常に22clkというわけではない
そういえば、測定しているときに11.7clkとか半端な結果になることがあるけど、
これも10clkの回と15clkの回が混ざってるとか、そういう感じなのかな。
にしてもnopあんま意味ないな。
3DNow_8FPのAthlonXPは、実行ユニットの能力をちゃんと引き出せてるよね。
他の場合はなぜこうならないのか知りたいなあ。
>ダミー転送
先にキャッシュに乗せてしまうの?それはむしろ遅くなる、と思って試してみたら、
別に遅くはならないみたい。速くなるかはわからなかった。
ここから別の話。
上の測定では、同じルーチンを8回連続で測定して最も速かったものを採用している。
で、メモリに対して測定するとき、2MBのL2に対し3MBのデータを使えばいいと思っていた。
ところが、どうも少しだけL2ヒットしているような速さに見えた(実際ヒットしていたと思う)。
esiとediの2系統のメモリを扱うので擬似LRUアルゴリズムの癖が出たか?
測定対象のルーチン直前に2MBのメモリアクセスをしてL2を関係ないデータで埋めて測定。
これで結果が安定し、望みの測定ができたはずだ。
ところが、ダミー転送の測定をするとまた結果が安定しない。41~47clk程度で振れる。
ここで仮説。「ダミー転送すると同じ場所に2回アクセスするからキャッシュに残りやすい」
そこで、関係ないデータでL2を埋める作業を4回やらせてみた。
すると45~48clkとなり、さっきより明らかに遅い。
擬似LRU法であれば、このようなことはないはずなんだが、ひょっとして違う方法なのか?
>>215 なるほど、そのうちSimCoreとかの出る期待が持てるわけだね!
Appleも、IntelCPU採用で、ちょっと身近になったな。
ttp://rerere.sytes.net/up/source/up12373.zip 今日は時間がなかったので昨日用意したものを。
でかいので、IEで開いてスクロールしてください。
3DNow_56FP_AthXPで分かったことは、パイプラインが乱れていなければ
movq r, r
pfmul r, m
を同クロックに行った場合、丁度pfmulの初期化分でmovqが完了するので
同クロックに書いてしまって問題ないということです。
そこでほんの少しだけ並び替えたのが3DNow_56FP_AthXP_2.gifなのですが、
このmm6が理不尽なストールをくらっています。
前方のピンクがDACC Cache and TLB hit、後方のピンクがSCHED FPU Schedulingで
ストールをくらっているのがSCHED FPU Schedulingなんですが、
どう考えてもこんなに待たされるほど忙しいとも思えず。
movqとpfmulが同クロックでも良い事を利用して、レジスタ8本使い切り
pfadd<->pfmul<->storeが5クロック空くようにしたコードも書いてみたのですが、
似たように理不尽なストールがあり、あまり速くありませんでした。
5clkも空ければ12clk/16FP達成かと思ったのにorz
221 :
220:2006/04/26(水) 00:20:19
>>215 今まで全然気付きませんでした。ずっと欲しかったのに。
今度試してみます。
>>216 アクセス順序がヘンテコな時と、ハードウェアプリフェッチが効かない古いCPUの為のヒントだと思っています。
あとは言われているように、prefetchnta、movntpsですね。
>>217-218 > 画像作成も時間がかかりそうだね
貼り付けと格子を引くのにひーひー言ってヘタレなだけです。
> SSE版については64byteにしていいと思う。
P6は全て64byteということですか?
> ていうか10clk/8FPとかL1完全ヒットでないとあり得ない。
> 何回ループさせてる?
> どの程度のサイズのメモリに対して行う予定のものなの?
?clk/?FPというのはCodeAnalystの表示を見ているだけで、実測したものではありません。
実際は仰る通りメモリネックで息絶えているかも。
このルーチンそのものはいろいろな場所で使うことを想定していますが
今現在は行列積でテストしているので、ediは反復、移動するのはesiのみです。
(ediのプリフェッチをしていないのはそのため)
> IntelのCPUで実行されることも考えると
> prefetcht0がベター(L2ヒット時に速い;ベストはprefetchnta)。
> 3D Now!だけのときは、ストアするんだからprefetchw [edi+200h] を使うのはどうだろう。
シーケンシャルだからL1に乗ってればいいや、としか考えていませんでした。
そうか、確かにL2に入れておく必要はないんですよね。
> どの程度のサイズのメモリに対して行う予定のものなの?
回答忘れてた。
ediがL1からはみ出ない程度のサイズを想定していますが、
テストは1ラインsizeof(float)*128で行っています。
> 3DNow_8FPのAthlonXPは、実行ユニットの能力をちゃんと引き出せてるよね。
> 他の場合はなぜこうならないのか知りたいなあ。
是非解明したいです。
3DNow_8FPは全編に渡ってディスパッチのストールが数えるほどしかありません。
> >ダミー転送
> 先にキャッシュに乗せてしまうの?それはむしろ遅くなる、と思って試してみたら、
> 別に遅くはならないみたい。速くなるかはわからなかった。
今ぐぐってみてもAMDのサイトがヒットしませんでしたが、(転載はある模様)
AMDが書いたmemcpy_amdというサンプルコードでprefetchの代わりに
ループの前で数KB空読みするコードが入っています。
メインのコピー処理はキャッシュに入っているであろう範囲だけ行い、
また数KB空読みするループまで戻って、と繰り返しています。
そういえばこれもDWORD読んで64byteインクリメント。32byteキャッシュラインは捨て置けってことか。
前回の3DNow_8FP_nop.pngの右で大きくストールしているところに注目した。
ディスパッチの始まるのが、38個前の命令がリタイヤしているのとピタリ同じタイミングだ。
つまり「理不尽なストール」の原因はFPスケジューラ(36エントリ)が満杯になったことか!?
(36エントリというのはAMDの最適化ガイドに出ている)
ただ、その38個の中にALU命令が8個、プリフェッチが1個ある。
プリフェッチがFP側かALU側か知らないが、多くても30個の命令しかFPスケジューラにないのに
命令がディスパッチされていない。
pfadd mm1,[edi] のようなLoad&Opは分解されているのかとも思ったが、それだと36個を超えて
しまう。36エントリのうち、細切れに空いていても利用できない場合があるのかな?
あ、でもリタイヤもイン・オーダーだから細切れにはならないのか。
36というのは12*3で、3個単位でしかディスパッチを受け入れられないというのはどうか。
ディスパッチは1clkに3命令ずつ行われるが、
ALU命令とFPU命令が混じっていて、FP側に1個しか行かないクロックがあったとする。
すると2個分のスペースが無駄になり、その命令がリタイヤするまで34エントリ分しか
働くことができない、という仮説。
OoOが働くと命令がCPUに滞在する時間が長くなる。
そして、CPUに居られる命令数には限界があるので長期滞在はスループットを下げる。
仮に全てFP命令で36エントリが限界とすると、IPCを3にするためには
ディスパッチからリタイヤまでの所要時間を最高でも12(=36/3)clkに抑える必要がある。
12clkというと、実行や実行以外にかかる時間も考えると大してOoOできない。
同様に、IPCを2以上にするためには黄色と濃い灰色の間隔を18clk以下にしなければならない。
それを防ぐには、やはり実行ユニットをストールさせてはいけない(=OoOを使わない)。
レジスタリネーミング発動も、極限性能を狙うときはあまりよろしくないということだ。
Athlon64で遅くなる場合というのは、ひょっとしてパイプラインが伸びているから?
図ではメモリ操作を伴う命令で2段ほど処理が増えているように見える。
命令のレイテンシは一緒であっても、実行以外の処理をしているときも
FPスケジューラを占有しているので、これは速度低下の直接的な原因となる。
対策としては、イン・オーダーCPUだと思って命令を配置すること。
上の仮説が正しければ、FP命令、ALU命令を3連続で配置することも有効かも。
ただ、1個ずれると目もあてられないので、試行錯誤でループ前にnopを置き、
1ループの命令数も3の倍数にする必要がある。
ただ、既に相当すごい最適化をしてあるんだよねえ。もう頭が限界だ。
とうことで、この図を利用して機械的に最適化できないかな。
各命令の黄緑の実行が始まる時刻に注目し、早く始まっている順に命令を並べ替える。
そうすればパイプラインがスムーズに流れる、気がする。
(もちろんレジスタリネーミングのところは仕方ないけど)
・ここまではイン・オーダーなので、ALU命令も、とばっちりを受けて待たされている。
・SSEは16個のMMXと同等のレジスタ量だから内部リソースも倍食う?
単純計算で3D Now!で「直列に」この処理を行うと、4命令で14clk/2FPになる。
これでは遅いので、並列実行する。8clk/8FPを実現するには7並列が必要となる。
ただし、実行ユニットが全く競合しなかった場合にのみギリギリで達成できる。
3DNow_8FPのAthlonXPは8並列で8clk/8FPなのでかなり優秀だ。
この処理はロード・ストア帯域が24byte/2FPを必要とし、16byte/clkが限界なので、
12clk/16FPが実行ユニットの理論限界になる。
ただし、上下合わせて16byte/clkの帯域を出すのは条件がきついと思われる。
また、10並列以上を要し、フリーなMMXレジスタ7個ではレジスタリネーミングが
必須となる。こうなると激しいOoOでスケジューラがFullになるのは当然である。。
>>220 更に上を狙うなら、アドレス指定に[edi+ecx]、[esi+ecx]を使い、sub ecx,64 / jnz でループ、
命令長は伸びるが、命令数を2減らせる。
(ALU命令を2個減らしても、AthlonはALU3個あるし、FP関係ないから影響は少ないか)
さらに、
movq mm1,mm0 / pfmul mm1,[esi] というような処理があるが、これは素直に
movq mm1,[esi] / pfmul mm1,mm0 と書いた方が処理が軽くなるんじゃないかな。
でも
>>220は本当に訳のわからんストール食らってるな。
>>221 プリフェッチの効き自体は最近のCPUの方がいいように思う。
キャッシュラインサイズが大きいし、内部もプリフェッチをうまく処理するようになっている気がする。
シーケンシャルリードで以前試したところによると、
P3がほとんど効かず、K8、K6-2が10%弱、K7が10%強、PenM、Pen4が20%程度効いていた。
K8はさすがメモリコントローラ内蔵といったところか。
確かに今後はシーケンシャルアクセスにプリフェッチは要らなくなってくるかもね。
>P6は全て64byteという
P3はSSEが使えるけど32byteライン。P6のことを完全に忘れていました。すんません。
まあ、P3はプリフェッチの効きが悪いので、結局64byte毎でいいとは思う。
CodeAnalystの仕組みをよく知らないけど、あれはL1ヒットのときのパイプラインだろう。
数KBの行列同士で演算を何百回も繰り返すのであればL1ヒットと見ていい。
もし[edi]が固定なら、[esi]がキャッシュを汚染しないことが重要になるね。
おそらくprefetchnta [esi]の出番。L1は汚染されるが、L1L2間の帯域を確保できる(はず)。
もし、L1ヒットで1clk単位の高速化を狙うならプリフェッチ命令は絶対に入れない。
L2に収まらない可能性があるなら、何も考えずプリフェッチを最優先にするべき。
L1ミスL2ヒットのときはprefetchntaを入れるとガクンと遅くなるので、可能性があるなら注意。
行列でa[i] += b[i] * c ということは内積だったのか。1個の行列がえらくでかいんだね。
>>222 >ダミー転送
そうだ、なぜダミー転送を思いついたのか尋ねようと思っていて忘れてた。
AMDがそういうコードを出していたのか。
以前測定したのによると、64byteおきのアクセス(8byteロード)は、
K7でL2:20clk、メモリ:54clk。K8でL2:9.7clk、メモリ:42clkだった。
通常の64byteロードにかかる時間は、
K7で、L1:5clk、L2:20clk、メモリ:87clk。K8で、L1:4clk、L2:13clk、メモリ:44clk。
通常の64byteストアにかかる時間は、
K7で、L1:8clk、L2:20clk、メモリ:137clk。K8で、L1:8clk、L2:16clk、メモリ:107clk。
ストアに関しては、ライトバックがあるのでこの数字ではわからないが、
K7のロードは確かにプリフェッチよりも速い感じがする。
ていうかなんで54clkと87clkの差が33clkもあるんだ。排他キャッシュのせいか?
>32byteキャッシュラインは捨て置け
Athlon向けのコードなんだろうな。もうK6シリーズもないだろうし。
でも、K6-2はラインサイズ32byteなのにプリフェッチがちゃんと効く優秀なヤツ。
> ディスパッチの始まるのが、38個前の命令がリタイヤしているのとピタリ同じタイミングだ。
> つまり「理不尽なストール」の原因はFPスケジューラ(36エントリ)が満杯になったことか!?
他のも数えてみたら、多分合ってそうですね。
> 各命令の黄緑の実行が始まる時刻に注目し、早く始まっている順に命令を並べ替える。
> そうすればパイプラインがスムーズに流れる、気がする。
ttp://rerere.sytes.net/up/source/up12377.zip 3DNow_16FPopt_1の時点では順調に始まるのですが、それ以降は
2~3画面下に行った3DNow_16FPopt_2みたいのがずっと続きます。
(位置が違うので収まってませんが、Athlon64で見られる4クロックのストールはAthlonXPでも見られます)
それで、実測していないのはどうかと思ったので、実測してみました。
プロセスのプライオリティはリアルタイム、
各ルーチンの実行前に8MBのメモリを10回読んでます。
MM8FP...3DNow_8FPのコード
MM8FP_2...MM8FPをmovq mm1,[esi] / pfmul mm1,mm0のように書き換えたもの
MM16FP..3DNow_16FPのコード
MM16FP_2...3DNow_16FPoptのコード
XMM8FP...該当無し。古いコード。
XMM8FP_2...SSE_8FPのコード。
厳密にはSSEでprefetcht1がprefetchntaに書き換わっています。
丁度友人がAthlon64とPentiumMを持っていたので実測を頼んだのですが、
AthlonXPとは違い、1024x1024でも全てキャッシュにヒットしていそうです。凄い。
Athlon64のタイムが倍くらいおかしいですが、何も書き換えてはいないそうです。
(タイムはQueryPerformanceCounter*1000/QueryPerformanceFrequencyで出してます)
AthlonXP上のMM8FPでしか試していませんが、prefetchをはずすと
10clk/FPになりましたので、一応効能を確認することが出来ました。
>>227 並べ替え計測ありがとう。
3DNow_16FPopt_1では割と平和に流れているように見える。
ところが3DNow_16FPopt_2ではストールの数が大幅に増えている。
これではディスパッチも止まるわけだ。
ただ、3DNow_16FPopt_2は命令の実行順序がほぼイン・オーダー。実にきれいだ。
すごくきれいなのに、何か、黄緑のブロックがちょっとずつ左にずれればいいじゃん、みたいな。
これでダメということは、本質的に36エントリのスケジューラではこれが限界ということかな。
最初はopt_1みたいにスマートに流れても、ループを重ねるごとに先送りにした命令が
溜まってきて、だんだんパイプラインが太ってくる。
いよいよ限界になると、opt_2のようにディスパッチがストールしてガス抜きする。
これで若干楽になるが、またジワジワと・・・以下繰り返し?
>test.exe
PenM-1.1で実行した。まあ普通の結果。
test.exe 32 とやったら見事に怒られましたよ。
533595 clk / 262144 FP = 2.0 clk / FP, 0.5 ms (PenM-1.1SpeedStepオフ)
520697 clk / 262144 FP = 2.0 clk / FP, 0.9 ms (PenM-1.7)
最初の項目だが、下の方が時間がかかっているのはSpeedStepオンで測ったな。
ここはL1の範囲だから同じ結果になっている。ただ、若干遅いのはプリフェッチが
入っているからかな。
L2の範囲では、倍率の高い1.7GHzの方がよりプリフェッチが邪魔になっている。
0.2clk/FPくらい1.1GHzのが勝っている(もちろん絶対性能ではボロ負け)。
細かい時間の解析まではちょっと無理。
Athlon64が1000*1000(4MB?)で1.9clk/FPというのは何なんだ。
L2は512KBだからなあ。プリフェッチが効いてるとかのレベルじゃないぞ。
そもそも、Athlonの排他L2で2clk/FPを切れるというのが、まるっきり予想外だ。
この処理はかなり局所性があるのかね。
そうなるとプリフェッチの仕方にも、もう一工夫する余地があるかも知れない。
> 下の方が時間がかかっているのはSpeedStepオンで測ったな。
そうか!
ということはAthlon64でクロックが速いのに時間が遅いのもCool'n Quietですね。
> Athlonの排他L2で2clk/FPを切れるというのが、まるっきり予想外だ。
排他L2というのはどういう仕組みなんですか?
> この処理はかなり局所性があるのかね。
a(1024x1024) = b(1024x1024) * c(1024x1024) //それぞれ4MB
とは言っても、上に書いた通り、a(edi)は1ラインを何度も読み書きしますからキャッシュに乗ります。
b(esi)は全体を何度も読むので、プリフェッチがあった方が良いかもしれません。
cは全体で1回しか読まないので今のところノータッチです。
っと書いていたら灯台下暗し、丁度CodeAnalystのチュートリアルで扱ってました。
http://developer.amd.com/articles.aspx?id=2&num=7 ところでAMD向けに書いたこのコードでもPentiumMでまあまあの記録を出していますが、
PrescottやSmithfieldで動かすとどれくらいのスピードが出るんでしょうね。
AthlonXP.txtでものすごいデタラメ書いてしまいました。
1.6GHzなのにL2が512KBとか。
Palomino 1.6GB/L1 64KB+64KB/L2 256KB/PC-3200 768MB
です。
>>229 なるほど、やっとその行列かけ算のやり方を理解した。こんな順番でやるとはねえ(感嘆)。
for (i=0; i<size; i++) a[i] += b[i] * c; をsize回やって1行分の答えが求まり、
それを更にsize回で全体が終わる。計算時間のオーダーはsizeの3乗か。
size回に1回、cの値を準備するが、1/sizeの寄与なので問題ないだろう。
ポインタaはsize^2回に1回、bはsize回に1回変える。
aは4*size byteだから余裕でL1に乗る。毎回アクセスされるから、L1から外されることもない。
cは4byteで、キャッシュラインに16個乗るから、L1外にアクセスするのは16回に1回だけ。
確かにaとcにプリフェッチは要らないね。
bは、やはりprefetchntaがいい。4MBはL2に収まらないから、どうせL2に書き戻すだけ無駄。
結局、aとcはメモリ帯域・レイテンシが問題にならず、bもL2を使わないので、
排他キャッシュのメリットもデメリットも表れないと思われる。
排他キャッシュというのは、L1とL2の内容が全く被らないキャッシュのこと。
この仕組みのため、Athlonは立て続けにL1ミスL2ヒットする処理が苦手(例えばトリップ検索)。
L1ミスL2ヒットすると、まずL1の古いキャッシュラインをVictimバッファに転送して確保、
L2ヒットしたデータをL2からL1へ転送してめでたしだが、その後でVictimバッファからL2へ
転送して、結果L1とL2の間でスワップをしている。
普通なら1回の転送で済むところを3回も転送するので、スループットは悪くなる。
だが、実際の処理でL1ミスL2ヒットばかりが続くことはあまりないので、
キャッシュの総容量が増えるメリットの方が大きいらしい。
さすがにL2が1MB以上になるとL1が128KBあっても排他は無駄な気がするけど。
メモリ帯域が4byte/FP(bのロード)必要なとき、
>>227のAthlon64では2.75clk/FPが理論値。
ところが実際はsize=1024でも1.8clk/FPを達成している。
キャッシュを使うことで4byte/FP未満のメモリアクセスで実現できるということになる。
例えば、size=1024の行列b,cを16個に分割して256KBずつ処理すれば、
L2内で完結する処理を16回すればOKになり、1.8clk/FPも出せる気がする。
>>227では何かそういう細工をしている?
>>230 Athlon向けのFPコードはPenMでもきれいに回るように思う。
このコードでPenMはAthlonに少し負けているが、これはパワーの差なので仕方ない。
PenM向けに最適化しても大して変わらないだろう。
234 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/04/29(土) 17:41:15
Athlon系ほどL/S強くないから緩めの明示的並列化でレジスタリネーミング任せした
ほうが速度伸びるかも。
整数SIMD演算がそんな感じだし。
PenMはレイテンシが短いからAthlon向け(レイテンシを隠蔽するためL/Sを頻発させてでも
x86コードレベルで並列化)のコードよりも、ややストレート目なコードのほうが伸びやすい印象。
なぜかPen4も同じような傾向(演算のレイテンシこそ長いが、20命令くらい平気で勝手に
並べ替えて実行できるからだと思う。ポートとかは考慮の必要アリ)
235 :
デフォルトの名無しさん:2006/04/29(土) 17:45:58
なんかすげぇ高度な話してるところで恐縮なんだけど、
prefetchnta/t0/t1/t2 命令って、実際にそのデータが必要になる
どの程度前にいれておくべきなんだろ?
あと、ちょっと前のレス読んでると、prefetch{nta|t0|t1|t2}
命令なんか入れずにハードウェアプリフェッチに任せなよ、
なんて話もあったけど、そもそもハードウェアプリフェッチって
どんなときに働いてくれるのかについての資料って
何見ればいいっすか?
> bは、やはりprefetchntaがいい。4MBはL2に収まらないから、どうせL2に書き戻すだけ無駄。
やはりそうですか。
> 排他キャッシュというのは、L1とL2の内容が全く被らないキャッシュのこと。
Athlon系ってVictimバッファあったんですか!
おどろきです。
> 普通なら1回の転送で済むところを3回も転送するので、スループットは悪くなる。
設計が複雑なだけで万能かと思っていたのですが、そうでもないんですね。
> 何かそういう細工をしている?
特別な事はしていません。AMDのチュートリアルと同じです。
3つあるループのうち、一番内側のループだけをインラインアセンブラで関数化しています。
> Athlon向けのFPコードはPenMでもきれいに回るように思う。
なら手持ちのAthlonを基準に最適化しちゃっても問題ないという事ですね。
続き。
FSB533のPentiumM1.7GHzで走らせてみたらAthlon64と同じく2.1clk/FP程度でした。
プリフェッチが有効に働いていてもまだメモリネックが強いようですね。
> Athlon系ほどL/S強くないから緩めの明示的並列化でレジスタリネーミング任せした
> ほうが速度伸びるかも。
そういえば以前PentiumMで測った時、レジスタリネーミングを多用した方が速かった記憶があります。
>>227のXMM8FPがそれです。
> PenMはレイテンシが短いからAthlon向け(レイテンシを隠蔽するためL/Sを頻発させてでも
> x86コードレベルで並列化)のコードよりも、ややストレート目なコードのほうが伸びやすい印象。
> なぜかPen4も同じような傾向
上のPenM含め、自分が持っていない色々なCPUの傾向が分かるのはありがたいです。
AMDなんかはop r, m系のメモリを参照した演算はがしがし使ってくれって言ってますが、
Intel系は多分分解した方が優しいんですよね。
> 高度な話してるところで恐縮なんだけど
にわか知識でCodeAnalyst使っていて実測していなかったり、駄目駄目です。
こんなに何日も相手にしてもらっていて恐縮してます。
> ハードウェアプリフェッチって
> どんなときに働いてくれるのかについての資料って
> 何見ればいいっすか?
IA-32 インテル アーキテクチャ最適化リファレンス・マニュアル
Software Optimization Guide for AMD Athlon 64 and AMD Opteron Processors
辺りでぐぐって下さい。
実は僕も全部は読んでいない。
> prefetchnta/t0/t1/t2 命令って、実際にそのデータが必要になる
> どの程度前にいれておくべきなんだろ?
IA-32 インテル アーキテクチャ最適化リファレンス・マニュアル
にハードウェアプリフェッチの動きが書いてあるので、それより遠くを読むと良いんじゃないでしょうか。
memcpy_amdでは[esi + (200*64/34+192)]という式になっています。
>>235 単純にメモリレイテンシ分前にプリフェッチしておくんじゃないかな。
普通、メモリから64byteロードするのに50clk前後、メモリレイテンシが200clk前後だから、
200/50*64=256byte前くらいかな?ストアする場合はまた違うのかも。
また、少しくらいならプリフェッチが早すぎても(前すぎても)問題ない。
経験的には、何も考えずprefetcht0 [esi+512] として問題ない気がする。
>HWプリフェッチ
>>138のリンク先を見ると、Meromは一定間隔なら読めるっぽい。
また、
>>31氏の結果によるとAthlonXPではアドレスが減る方向は少し苦手なようだ。
PenMで実験すると、逆向きのアクセスでも普通と同じにHWプリフェッチが効く。
おおむねシーケンシャルアクセスなら働くと思っていいだろう。
資料は俺も欲しい。
(いや、最適化ガイドは難しくてさ)
>>236 最初からAthlonのL2に収めるつもりなら、
233に書いたような分割をしてプリフェッチを使わずにやるのがいいかも。
>一番内側のループだけをインラインアセンブラで関数化
それだとコンパイラの最適化も効かないだろうからなあ。
Athlon64で1.8clk/FPは、かなり謎。
K8Lの話が色々出てる
ホッシュ
K8Lは'08年なのね。その頃やっとFPU倍加か。
ダイ上の配置が変わっているらしいので、デコーダが3*128bitSSEを1clkで吐くようになるかも。
この2年で、Intelに勝てるとしたら、古いアーキだからダイサイズと消費電力が抑えられる点か。
特に4コアにする場合は効くと思う。さすがのWoodcrestもコア数が倍の相手だと微妙だろう。
L2が256KBとかいう噂もあるが、それでも4コアやらなきゃ、普通に行ったら勝てないよ。
IntelもPenD式の4コア出すけど、工夫次第でいけると思う。
4コア版に載るL3はたった2MBらしいが、Victim Cacheであるという説が出ている。
Exclusive Cache(K8のL2がそう)との違いがまたややこしいんだな・・・。
Exclusive Cacheは(K8のL2の場合)、L1とL2の内容が絶対に被らないというキャッシュ。
L2にあるデータを使うときは、Victimバッファを介してL1とL2でデータの交換を行う。
キャッシュが埋まっていてメモリから読み込むときは、おそらくL2のデータを捨てたいだろうから、
L1のラインをVictimバッファに退避させ、そこにメモリから転送し、L2上の古いラインへ
Victimバッファから転送して上書きする、という感じかな?
データ交換などの動作で遅くはなるが、キャッシュの総容量をフルに使えるのでヒット率は高い。
L2が遅いと言ってもタカが知れているが、メモリは本当に遅いので、これは意味がある。
PenMなどのキャッシュは、あえて分類するならNon Inclusion Cacheか。
L2にあるデータを使うときは、単純にL1へ転送するだけだからExclusiveより速い。
メモリから読むときは、まずL1に読み込んで、L1から追い出されるとL2へ行く、と思っていたが、
これはVictim Cacheの動作だ。まあ、Victim Cacheは普通Non Inclusionだろうけど。
メモリからL2に入れて、それをまたL1に転送して読むという方法もある。
でもPenIIのときとか、FSBに対してBSBのL2だったから、メモリとL2は直結されてない?
どっちだかわからないが、作りやすさは別として、作ってしまった後の性能だけで考えると、
Victim CacheでL1とL2の容量差が小さい場合、Exclusive Cacheほどではないが、ヒット率が
上がる。Cyrixの最近のやつがそうだった。
Victim Cacheの続き。
基本的にL1から追い出されたデータがL2に入っているので、L1とL2の内容はあまり被らないが、
L2にあるデータをL1に読み込んで使うときにはデータが被ってしまうはず。
実はPenMもVictim Cacheなのかな。
ていうかVictim CacheでないNon Inclusion Cacheってメリットあるのか?
ちょっと思考実験してみると、L1+L2の容量以下のデータを繰り返し順番に扱うとき、
Victim CacheならばL2に収まる分は全てL2ヒットする(L1分の量はミスする)。
それを超えると、全てミスヒットとなってしまう。
最近のIntelのようにL2に比べてL1が小さいCPUだと大したメリットではない。
ただ、そのメリットを求めない理由もないように思う(が、考えに自信はない)。
PenMでは、L2キャッシュの容量より少し大きなメモリを繰り返しロードすると、
キャッシュヒット率が10%程度あるような感じになる(Tualatinもそうかな?)。
普通の、キャッシュデータを古い順に捨てる方式だと、ヒット率はゼロになるはずであり、
実際にPen4、K7、K8などで実測したらL2容量の倍の範囲でのヒット率はほぼゼロだった。
ただし、ストアで測定するとこの限りでない。どのCPUでもかなりのヒット率になる。
どういうことだ。。
Victim Cacheの方が処理が楽なんじゃないか?
Exclusive Cacheの場合、メモリから経由してきて格納されたデータも、
上位層から容量飽和して追い出されてきたデータも(排他)処理しなきゃあかんが、
Victim Cacheの場合、L2から追い出されてきたデータ「のみ」処理していけばいいだけなんだろ?
L1L2をExclusive Cacheと来て、さらにL3までExclusive Cacheにしたら、処理が煩雑で大変なんじゃね。
いや、詳しい事知らんから適当だけどさw
IntelCore手に入れたんだけど例のベンチやろうと思ったらさすがになくなってるね
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm 後藤記事来たね。
4FLOPS/clkと言っているから、2SSE命令/clkがいけるということであり、デコードもいけると
いうことだ(今のK8はデコードが1.5SSE命令/clk)。
おそらくMeromと同じように内部でも128bit命令として処理するのだろう。
ただ、ダイの図を見ると、FPユニットを単純に2コにしただけに見えるが、あれでいいのかね。
驚いたのは、128bitロード*2ができるということ。Merom負けたあ。
>>245 俺もそう思う。ていうかL2の排他はやめないのかね。
まあ、L2-L1間の帯域が増えてるし、マルチコア化でL2容量が減少傾向にあるからいいか。
ただ、2MBのL3はいい仕事をしそうな予感がする。
小さいからある程度速いだろうし、比較的弱いL2をうまくカバーすると思う。
とりあえず知りたいのは次の2点。
Victim CacheでないNon Inclusion Cacheのメリット(性能または作りやすさ)とその動作。
PenMはVictim Cacheか否か。
またキャッシュについては実測しないとダメだなあ。
もうCellのSPEみたいにプログラムが明示的にキャッシュするのでいいよ。
>>246 これお願いします。
http://rerere.sytes.net/up/source/up12488.zip
PentiumM725/1.6GHz
4KB 8KB 16KB 32KB 64KB 128KB 256KB 512KB 1MB 2MB 4MB 8MB 16MB 32MB
Lc 0.94 1.07 1.03 1.05 5.95 5.91 5.86 5.96 5.92 6.18 42.88 45.39 45.62 46.39
S 1.02 1.13 1.10 1.19 14.36 17.04 18.40 19.09 19.44 20.15 109.67 145.46 164.82 171.52
N 1.02 1.13 1.10 1.09 24.38 36.19 42.10 45.11 46.60 47.70 47.97 48.00 48.05 48.22
Ln 8.11 8.11 8.05 8.32 14.67 14.67 14.67 14.68 14.79 15.28 48.60 52.14 52.81 53.30
S 8.73 8.72 8.70 8.71 16.31 18.03 18.89 19.33 19.59 20.24 109.11 145.56 164.09 171.96
N 8.72 8.73 8.70 8.67 28.15 43.11 43.04 45.56 46.82 47.44 47.79 48.01 48.06 48.23
Lm 8.13 8.11 8.08 8.18 10.26 10.25 10.24 10.24 10.55 10.88 45.81 51.22 51.34 51.85
S 8.77 8.73 8.70 8.97 18.91 19.39 19.62 19.76 19.82 20.33 114.34 146.37 163.49 171.09
N 8.77 8.73 8.70 8.67 28.21 38.10 45.23 71.10 47.84 48.00 48.05 48.07 48.07 48.30
L0 9.14 9.14 9.10 9.59 12.06 12.03 12.02 12.01 12.05 12.30 42.72 43.41 44.09 44.55
S 8.58 8.21 9.69 9.51 13.83 15.07 15.53 15.83 15.88 16.10 111.41 145.73 162.65 170.64
N 8.39 8.18 8.09 9.03 16.00 15.97 16.00 15.98 15.98 16.11 143.13 175.14 179.16 178.11
L1 9.14 9.14 9.10 9.36 17.72 17.72 17.72 17.71 17.74 17.89 42.72 43.49 44.10 44.57
S 8.58 8.29 8.14 8.67 18.05 20.90 22.32 23.05 23.41 23.77 109.30 143.86 161.29 169.64
N 8.58 8.18 8.09 8.12 51.60 74.01 85.02 90.61 95.33 97.09 115.61 119.29 120.92 121.05
La 9.14 9.14 9.10 9.63 26.84 35.67 39.84 43.35 39.64 44.28 42.36 43.29 43.96 44.16
S 8.42 8.18 8.09 8.94 45.44 79.23 97.86 109.51 112.66 112.55 114.00 115.01 115.00 115.14
N 8.58 8.18 9.69 9.96 46.04 79.96 92.51 105.69 110.13 112.74 113.94 114.55 115.18 114.98
YonahT2300/1.66GHz
4KB 8KB 16KB 32KB 64KB 128KB 256KB 512KB 1MB 2MB 4MB 8MB 16MB 32MB
Lc 0.94 1.09 1.05 1.11 5.34 5.29 5.33 5.39 5.40 5.78 25.61 28.58 28.99 29.38
S 1.09 1.17 1.09 1.41 12.38 12.73 12.89 12.98 13.03 13.97 58.77 71.45 77.95 84.33
N 27.03 28.13 28.95 29.79 30.07 30.20 30.29 30.31 30.35 30.33 30.35 30.35 30.36 30.36
Ln 7.97 8.13 8.09 8.46 14.37 14.42 14.36 14.52 14.93 15.39 29.25 30.01 30.19 30.45
S 8.75 8.75 8.71 8.79 13.02 13.52 13.74 13.94 14.34 15.23 58.78 71.50 78.01 84.42
N 32.34 33.91 34.49 35.10 35.21 35.30 35.33 35.36 35.37 35.38 35.38 35.39 35.39 35.39
Lm 8.13 8.13 8.09 8.34 11.48 11.46 11.46 11.47 11.56 12.21 29.50 29.96 30.05 30.05
S 8.75 8.75 8.71 9.18 20.00 20.00 20.00 20.01 20.08 20.86 59.86 71.97 79.18 81.31
N 35.78 36.72 38.36 38.65 35.96 35.68 38.14 38.14 35.53 35.50 38.13 38.13 38.12 36.76
L0 9.06 9.14 9.10 9.63 12.07 12.04 12.02 12.02 12.06 12.37 25.64 28.65 28.89 28.90
S 8.59 9.14 9.69 9.82 11.03 10.95 10.97 10.98 11.05 11.45 50.92 68.16 76.46 80.48
N 62.81 67.19 69.30 70.04 70.47 70.68 70.73 70.81 70.81 71.12 73.56 73.80 73.41 73.54
L1 9.06 9.14 9.10 9.49 17.16 17.13 17.13 16.87 16.93 17.22 28.77 31.91 32.33 32.17
S 8.59 9.14 9.69 9.53 15.32 15.91 16.22 16.52 16.46 16.85 58.56 68.58 77.00 80.27
N 66.09 66.72 69.22 70.18 70.49 70.68 70.75 70.78 70.81 71.13 73.36 73.54 73.82 73.81
La 9.06 9.14 9.10 10.78 13.65 13.53 13.51 13.56 13.69 13.92 24.89 28.54 29.02 28.94
S 8.44 9.77 8.36 9.84 11.28 11.28 11.24 11.29 11.33 11.93 46.31 63.52 76.50 75.97
N 65.47 68.13 69.30 70.49 71.47 71.25 71.32 71.22 71.13 71.37 73.55 73.78 75.83 73.54
250 :
・∀・)っ-○●◎:2006/05/24(水) 02:07:42
こんな馬鹿が増殖したら日本は終わる
つーかお㍗
>>248-249ありがと。
まず予備知識。YonahのL2はレイテンシ14、帯域は32byte/clk。
PenMはレイテンシが9(Banias)または10(Dothan)、帯域は16byte/clk。
FSBと使用メモリ、チップセットの違いもあるが、まずはL2キャッシュに注目してみる。
まずLcのところ。64byteおきに8byteのロードをする。
PenMでは6clk程度だが、Yonahだと5.3clkと少し速い。
かなり意外だったのが、ノーマルロードがPenMと同等程度であること。
Baniasより遅く、Dothanより速い。
シングルスレッドでSSE3を使わないベンチでも、同クロックのPenMに対して高速なYonahだが、
これはL2の性能が上がったからだと思っていた。レイテンシは長くても、帯域は倍だし、
共有処理の副作用で多くのアクセスを並列にやってレイテンシ分をカバーしてると思ってた。
ところがロードは遅い。
Lcのとこでは速かったのになあ。若干だが、L1ミス連発に弱くなった感じがする。
んで更にビックリ仰天なのが、ストアがロードよりも速いこと。
(このベンチでのL2帯域の最大値はprefetcht0を使ったストアでの11clk/64byte)
ロードはL2→L1の転送のみ、ストアはL2-L1間を往復する必要がある。
ストアでこの速度が出せるなら、ロードでそれより遅くなるはずがないんだ。。
他、PenMの結果と比較すると、
アクセス順変えが(元々ストアで使うと遅くなってはいたが)著しく遅い。
prefetchntaでは、大幅に速くなっているが、prefetcht0より少し遅いと見るべきだろう。
今まではL2ヒットしたらL2を無効化してメモリから読んでいたのかな?
それがYonahではL2からL1へ転送してから、そのデータがL2を使わないようにする、
というようにうまい処理ができるようになったと。
大雑把に言ってロードはPenMと同等、ストアでかなり速くなっている。
このストアの速さがSuperPIでの強さかな。
L2以外の面。
1.66GHzと低クロックなこともあるが、メモリから64byte読むのに30clkというのは優秀だ。
メモリの帯域を最も引き出しているのはprefetch(t0/nta)だがこれは29clk。
アクセス順変えをしても影響がなくて、プリフェッチを使っても1clkしか速くならない。
更に、movntqも相対的に遅くなっているし、ストアに対するprefetchntaの効きも鈍い。
素のメモリアクセス性能が相当改善されている、もしくはプリフェッチが効かなくなった、どっちだ。
DDR2 667MHzだとしたら理論値は20clk/64byteなので、そこからすると29clkはやや遅い。
それとも、このチップセットでのDDR2っていうのはこんなもんなのかな。
まあ、HWプリフェッチは強化されてるんだろうな。
movntqによるストアは、L1ヒットであっても速くならない。
K7、P6、PenMではL1ヒットならL1に書き込み、K8、Pen4、Yonahではメモリに書く。
(顔ぶれを見ると、L1ヒットでもメモリに書くのが最近のCPUのやり方のようだ)
Yonah式のメリットとしては、L1に乗っているか調べる必要がないことかと思ったが、
どっちみちストアだから変更するのでL1、L2共に調べる必要がある。
movntaを使ったら再利用しないのだからキャッシュから強制的に追い出す方が重要だね。
キャッシュを汚染しないだけでなく、元々汚染していた分の掃除もできる命令なのだろう。
prefetcht0後のmovntqは、PenMでは少し遅かったが、それがなくなっているのは、
L1に書かなくなった恩恵と思われる。
プリフェッチをした後でmovntqを使うと遅くなるのが副作用だが、こんなコードは誰も書かないのでOK。
まとめ。
・prefetchntaがL2ヒット時でも遅くならなくなった。
・movntqが、L1ヒットでもL1に書かなくなる、よりノン・テンポラルな動作になった。
・シングルスレッドでの実効L2帯域はPenMと大差ない。
・L2へのストアが異様に速い。
・L2ストアでアクセス順変えすると遅くなる。
・遅いわけではないが、プリフェッチの効きは鈍い。
ちなみに「4」で計測しました
「2」で計測すると数値が半分くらいになるんだけれども、これはいいの?
あとPenMのほうは855GMEでDDR/333、
IntelCoreのほうは945GMでDDR2/533
855GMEのほうはUMAビデオなのも影響してるかも
945GMのほうはUMAモードと外付けビデオチップと切り替えできるから
UMAのモードにすると多少落ちるかも
>>250 起動してMeromと入れて実行したら413kTrips/sec程度だった@Dothan-1.1。
確か、Trip-MonaではYonahが同クロックのPenMに対して高性能ではなかったような?
同時に複数のキーを検索すれば(シングルスレッドでも)Yonahが速くなるのかな。
普通なら、完全にレイテンシを食らう処理だからL2レイテンシの大きい方が負ける。
で、なぜ推奨環境が1.3GHz以上ですかw
>>256 DDR2-533か。それだと理論値が25clk/64byteだから、29clkは特に悪くはなさそうだね。
>>257 「2」のところには32byte cache lineとあって、「4」の64byteの半分のサイズで計測している。
キャッシュの特性を知るためのベンチなので、キャッシュラインのサイズに合わせているのです。
プリフェッチを使う測定では半分より少しだけ遅くなるなどの違いがあるはずで、その違いが
結果を解析するときに邪魔になる。
L2帯域はどうなんだろうね。このベンチ結果を見ると、1コアあたり16byte/clkの帯域としか思えない。
これならMeromで倍になるというのもありえる。
また、Yonahで、コア0へロード、コア0からストア、コア1へロード、コア1からストア、
この4つのアクセスが同等に帯域を食うのか、組み合わせで得意不得意があるのかが気になる。
L2について、次のことがわかっている。
・64byteおきロードで、レイテンシが増えているのに少しだけ速くなった。
・普通のロードでは64byteおきロードほど速くなっていない。
・アクセス順変えストアが遅い。
・ストアがロード以上の帯域をマークする。
まず、レイテンシが増えたのに速くなっていることから、アクセスの並列性が増したことは確実だ。
ただし、多くのメモリ命令が同時に実行されないといけないので負荷は大きいはず。
アクセス順変えストアなどは、処理の限界に達しているような感じがする。
L2ストアが速いのは共有処理の副作用じゃないかと思うが、詳しい仕組みが知りたい。
Intelがいっていたyonahはただbaniasコアを2つつけただけじゃないってのは本当っぽいね
キャッシュ回りだけでこの結果
実際はパイプライン回りにも手が入ってるしね
適当にだれかバブルソートとかマンデルブロとかのベンチあげてほしいかも
261 :
201:2006/05/25(木) 19:45:54
PentiumM725 1.6GHz/1GB
size = 1024
3DNow! not supported, SSE supported
unroll = 1:
XMM8FP 3001482747 clk, 2.8 clk/FP, 1880.6 ms
XMM_CUBE_2 1783420321 clk, 1.7 clk/FP, 1117.4 ms
unroll = 4:
XMM8FP 1924132490 clk, 1.8 clk/FP, 1205.6 ms
XMM_CUBE_2 1626383347 clk, 1.5 clk/FP, 1019.0 ms
unroll = 8:
XMM8FP 2091947669 clk, 1.9 clk/FP, 1310.8 ms
XMM_CUBE_2 1552773485 clk, 1.4 clk/FP, 972.9 ms
IntelCoreT2300 1.66GHz/1.5GB
size = 1024
3DNow! not supported, SSE supported
unroll = 1:
XMM8FP 1750730280 clk, 1.6 clk/FP, 1050.4 ms
XMM_CUBE_2 1384365860 clk, 1.3 clk/FP, 830.6 ms
unroll = 4:
XMM8FP 1568730300 clk, 1.5 clk/FP, 941.2 ms
XMM_CUBE_2 1375265200 clk, 1.3 clk/FP, 825.1 ms
unroll = 8:
XMM8FP 1658217350 clk, 1.5 clk/FP, 994.9 ms
XMM_CUBE_2 1350285260 clk, 1.3 clk/FP, 810.1 ms
264 :
201:2006/05/26(金) 09:41:32
ありがとうございます。
IntelCoreのみならずPenMも底なし沼ですね。
XMM_CUBEは1ラインでテンポラルなメモリを8KB、
ノンテンポラルなメモリを4KBアクセスします。(XMM8FPは4KB+4KB)
未だに一番内側のループが関数化されていますし引数も多いので、
実際には+αがあるはずです。
外側のループが回っても毎回同じラインにアクセスする為、
速度を出すにはテンポラルな8KBが常にキャッシュに乗っている必要があります。
L1が16KB搭載とするとunroll=2でL1から足が出ると思うのですが、
裏切られました。どうなってるんだろう。unroll=2とunroll=16も入れておけばよかった。
もうこうなると、1clk/FPにどれだけ近づけるかですね。
265 :
201:2006/05/26(金) 09:54:36
間違えました。ノンテンポラルも8KBです。
258でレス番間違えた。逆だorz
失礼。
>>259 まあ、L2が共有だからキャッシュのベンチでは変わって当然だけどね。
確かにプリフェッチとノン・テンポラルストアは動作が改善されている。
他にはこういう拡張があるらしい。
□命令デコーダの改良
・uOPsフュージョンのSSE2命令への拡張
・128bit SSE2命令を3個のデコーダでデコード可能に
□SSE/SSE2命令最適化
・SSE2 ShuffleとUnpack命令を30%高速化
・整数除算(IDIV)の高速化
□SSE3命令サポート
・SSE3命令(10個)のサポート
□浮動小数点演算性能の向上
・FCW(FP precision/rounding control)レジスタのリネーミング
・データプリフェッチの拡張
・ライトアウトプットバッファの追加
ところで、Yonah=Banias×2 というのは、Yonahのトランジスタ数が少ないために出た推測。
結局、2コアで共有できるところは共有したから少なくなったらしいのだが、
L2キャッシュを除いたロジック部で共有できるトランジスタなんてあるんだろうか?
実際、YonahはL2以外にもかなり拡張されているので、仮にシングルコアバージョンがあったら
Dothanよりもトランジスタが多くなるはずだ。
>>264 PenM、YonahのL1Dataは32KB。
XMM8FPは、unroll = 8で少し遅くなっているが、これは(4KB+4KB)*8=64KBで
L1に収まらなくなったからだろう。
AthlonはL1Dataが64KBあるので大丈夫みたいだ。
ブロック化というのはXMM_CUBEだよね。
>>233のこと?別の工夫?
なぜ4KBでなく8KBなの?
アンロールというのは、
for (i=0; i<size; i++) a[i] += b[i] * c;
これを、
for (i=0; i<size; i++) a[i] += (b[i]+b[i+size]) * c;
こうしてる?
どんな処理でこの結果になったのか知りたいので、できればソースコード、
ダメなら簡単な擬似コードでもいいのでお願い(特にコアループの外)。
どうもL2ヒット率が思ったより高いのだ。
1FP=4byteだから、1.5clk/FPというのは8byteのロード*2+ストア*1を3clkでするということだ。
このうち、8byteロード*1がL1ミスをして足を引っ張るはず、という処理だよね。
>>261 ちなみに、Dothan-1.1 PC2100での結果。
メモリに対するクロック倍率が低いことを考慮すれば
>>262と同じ結果かな。
size = 1024
3DNow! not supported, SSE supported
unroll = 1:
XMM8FP 2658206833 clk, 2.5 clk/FP, 2422.6 ms
XMM_CUBE_2 1599790061 clk, 1.5 clk/FP, 1458.0 ms
unroll = 4:
XMM8FP 1832480730 clk, 1.7 clk/FP, 1670.1 ms
XMM_CUBE_2 1578431314 clk, 1.5 clk/FP, 1438.5 ms
unroll = 8:
XMM8FP 2040954652 clk, 1.9 clk/FP, 1860.1 ms
XMM_CUBE_2 1527810492 clk, 1.4 clk/FP, 1392.4 ms
>>263 見事だな、Yonah。色々なベンチで好成績を残しているのも頷ける。
http://pc7.2ch.net/test/read.cgi/notepc/1138100888/893 こんなレスがあったので、ちょっと確認のプログラムを組んだ。SpeedStepの反応速度を測る。
Yonahでの測定をお願いしたい(もし気が向けば同梱のマンデルブロ集合のベンチも頼みます)。
http://rerere.sytes.net/up/source/up12510.zip モバイルP3やCool'n Quiet付きAthlon、EIST付きPen4も、持ってる人がいたらお願いします。
PowerNowの方は試してみる?
GeodeNXに付け替えちゃって今動かないけど。
Athlon系はNorthBridge切断がデフォでONになってるマザボもあるから
そこら辺も調べておいた方がいいかもね。
>>261 諸事情によりFSB100で動かしてるK7皿だけど100x16で
size = 1024
3DNow! supported, SSE supported
unroll = 1:
MM8FP_2 7609838140 clk, 7.1 clk/FP, 4709.3 ms
MM_CUBE_3 3380273889 clk, 3.1 clk/FP, 2091.9 ms
XMM8FP 7858586588 clk, 7.3 clk/FP, 4863.3 ms
XMM_CUBE_2 3415346065 clk, 3.2 clk/FP, 2113.6 ms
unroll = 4:
MM8FP_2 2763660024 clk, 2.6 clk/FP, 1710.3 ms
MM_CUBE_3 1706754885 clk, 1.6 clk/FP, 1056.2 ms
XMM8FP 3197523404 clk, 3.0 clk/FP, 1978.8 ms
XMM_CUBE_2 1906031715 clk, 1.8 clk/FP, 1179.5 ms
unroll = 8:
MM8FP_2 2027563612 clk, 1.9 clk/FP, 1254.8 ms
MM_CUBE_3 1819111992 clk, 1.7 clk/FP, 1125.8 ms
XMM8FP 2467737807 clk, 2.3 clk/FP, 1527.2 ms
XMM_CUBE_2 2039055477 clk, 1.9 clk/FP, 1261.9 ms
size1024だと同封されてたパロミノより2,3割遅い。512だとほとんど誤差範囲で256以下は同等だった。
>>268 モバイル化+CrystalCPUIDでの可変。@Win2000
QueryPerformanceCounterの分解能:1/3579545sec
クロックを上げ始めるまでの時間:0.845sec
クロックを下げる動作が検出できませんでした。
>>268 マンデルブロ
100x16
FPU 3.315sec 5.532sec 7.579sec
SSE 0.962sec 1.587sec 2.163sec
100x10
FPU 5.322sec 8.854sec 12.155sec
SSE 1.535sec 2.539sec 3.468sec
PentiumM725/1.6GHz
FPU 2.924sec 5.322sec 6.756sec
SSE 1.008sec 1.555sec 2.066sec
SSE2 1.959sec 3.349sec 4.292sec
IntelCoreT2300/1.66GHz
FPU 2.797sec 5.081sec 6.451sec
SSE 0.952sec 1.486sec 1.971sec
SSE2 1.816sec 3.174sec 4.195sec
このベンチはあまり差がないね
やっぱりメモリアクセス等がはいってなんぼの改良がメインなのかな
2コアなのでベンチ動かしながら他の処理が余裕で動くのはやはりいいけどね
2つ同時に動かした場合
FPU 2.811sec 5.083sec 6.463sec
SSE 0.952sec 1.488sec 1.978sec
SSE2 1.815sec 3.175sec 4.205sec
274 :
201:2006/05/27(土) 07:38:44
>>267 ソースは夜時間があれば。取り急ぎ疑似コードだけ。
foreach (y) {
foreach (x) {
foreach (i) {
a[i] += b[i] += * c;
}}}
が
for (x;x<size;x+=2*unroll) {
for (y;y<size;y+=2) {
for (j;j<unroll;j++) {
c1=c[x,y];c2=c[x+1,y];c3=c[x,y+1];c4{x+1,y+1];
foreach (i) {
b1=b[i,y];b2=b[i,y];
a[i,x]+=b1*c1+b2*c3;
a[i,x+1]+=b1*c2+b2*c4;
}}}}
っていう感じになってます。
レジスタ数を半分に圧縮できメモリアクセスも減っています。
丁度レジスタ8本も奇麗に使えて気持ちいいです。
8本で2*2*2、15本で3*3*3、24本で4*4*4をレジスタに納める事が出来るので、
(その分メモリアクセスもどんどん減るので)
PowerPCなんかではかなり速くなるはず。
275 :
・∀・)っ-○●◎:2006/05/27(土) 09:41:28
つーかPPC-AltiVecで速くなる要因は積和算が1命令でできるってのが大きいかと
ちょっとG4しかないけど計測してみるね。
>>269 失礼。PowerNow!のことはすっかり忘れてた。
機会があったらお願いします。
>>270-271ありがとう。
クロックの切り替えは0.845秒か。これはK7だからPowerNow!だね。
クロックを下げるまでの時間は1秒しか確保してないのでそれ以上だったか。うかつだったな。
ある程度新しくてモバイル専用のPentiumMと比べるとやや遅いということか。
この時間は短いほどいいわけだが、技術的には何がネックなんだろうな。
単にソフトorOSを介しているから、そっちがネックというだけかな?
マンデルブロは、PenMとの比較でSSEではほぼ同等。
SSE命令のクロックタイミングが、加算のレイテンシでK7が1clk遅いだけなので、まあ妥当。
Athlonと言えばFPUの強力さが有名だが、FPUで少し遅いのが意外だった。
乗算がPenMより1clk早く終わるのだが、P6向け最適化コードだとこうなるのか。
ただ、z^3+cではさほど遅くない(PenMの0.96倍)。これだけ実は俺が書き起こしたコード。
z^2とz^4のコードは別のP6向け最強コードを元にして作った。これはPenMの0.88倍程度。
するとAthlonのFPUも万能というわけではないんだな。
また、100*16と100*10の比較ではクロック当たりの性能が全く同じになった。
これはそういうベンチなので予想通り。
しかし、世の中はIntel最適化コードで溢れてるんだよね、きっと。
本当は速くても、実際に色々なプログラムを走らせて遅かったらそれは遅いCPUだ。
Athlonに最適化したコードを書いて、速さを見せ付けてやりたいよ。
手元にないからできんけど。
>>273 ありがとう。PenMの結果とクロック当たりでピタリ同じだね。
SSE2でプラマイ2%程度の違いはあるけど、CPUごとのタイミングみたいなものだろう。
uOPsフュージョンの効果がないね・・・。実行ユニットネックか。
いかにメモリを使わないベンチとはいえ、2個同時で誤差程度の違いしかないのは驚いた。
マンデルブロ集合の描写にはデュアルコアで2倍の性能が期待できる、と。メモメモ。
あと、できればSpeedStepの方をお願いしたいのですが。。
>>274 ども。ブロック化してるね。これから考えてみます。
スピードステップの動きはメーカーごとに設定自由にかえれるから
同じマシンでも意味はないものだと思うけど
電源さしていれば常に最高クロックで動くとかすべて設定次第
発熱時にクロックを下げるかそれともクロックは出来るだけ維持して
ファンをまわすようにするかとか様々だしね
結果見てもめちゃくちゃな数字が出てるよ
実行するたびに変わるしね
>>278 少なくとも俺の環境では安定した結果が出ている。
そちらの環境を教えてください。
>スピードステップの動きはメーカーごとに設定自由にかえれる
反応速度には関係ないはず。
最近のやつはOSに無断でクロックを変えられるようになった。
昔のでも安定した結果が出ると思っていたが、どうだろう。
>電源さしていれば常に最高クロックで動くとかすべて設定次第
もちろんそこは手動でSpeedStepをオンにしてから測定してください。
>結果見てもめちゃくちゃな数字が出てるよ
もし、ダメだとすれば俺のプログラムがダメなせいだと思います。すみません。
で、USBマウスを抜いたら俺の環境でも変な数字が出せた!
CPU負荷がゼロになるとrdtscのクロックカウンタが止まるのでクロックを測れなくなるのだ。
このときは0.001secとか10MHzとかの数字が出力されてしまう。
そういうときはマウスを差すなり軽い処理をバックグラウンドで流すなりしてください。
プログラムの不備は申し訳ないね。。
そういえば、俺の結果を載せるの忘れてた。
Dothan-1.1のdynabookSSでの結果。
アイドル時のクロック:598.50MHz
ビジーな時のクロック:1097.21MHz
クロックを上げ始めるまでの時間:0.294sec
そのときのクロック:1097.21MHz
クロックを下げ始めるまでの時間:0.50sec
そのときのクロック:598.50MHz
ちなみに安定しない結果はPenMだけででる
最大クロックをいろいろと変更してみてもそれだけでいろんな数字がかなり変わるし
同じ設定でもクロック表示がおかしいとか安定しない
600MHzをきるような数字が出たりね
IntelCoreはどうやってもクロックは変動していませんみたいなメッセージがでてる
最大クロック変更してみたが、変化なし。0.294sec前後だ。
俺の予想では俺の測定プログラムのバグ。。
Coreの場合は、アイドル時のクロックとビジーな時のクロックで
ちゃんとしたSpeedStepしてるクロックが表示される?
そのプログラムはIntelCoreでは1.6GHzで固定表示されている模様
一番省電力な設定(おそらく最低クロックである1GHz固定かな)で
実際にビルドしてみると15秒だったのが29秒までさがるんで
クロックは下がってると思われ
マウスは常にさしっぱなしだしジョイパッドもさしてみたりしたがかわらんね
いや一番省電力ではクロックが最低クロックから上がらないでしょう。
SpeedStepがオンになっていることを確認する手段があればいいのだが・・・。
ノートのメーカーとか省電力プログラムがどんなだとかの話だなこりゃ。
すまんかった。今日はこの辺で落ちます。
数値の変動があるPentiumMのほうは
固定クロックにすると一応設定どおりのクロックは出ている模様
マイコンピュータのプロパティで現在のクロックが表示されるけど
ここをみるとたしかに省電力設定でIntelCoreは1GHzまでさがってる
いや1GHzの設定にしても1.6GHz固定という結果が出る
1GHz固定の結果なら正しい動作だろうさ
XPの電源設定でも同じだった
他のプログラムは1GHzとかでる
このプログラムはPenMのみ対応しているというところだろうか
他のクロック計測ツールも1.6GHz固定でかえってくる場合が多い
CrystalCPUIDはOSと同じく正常に現在のクロック取得してくるようだ
ようはクロック計測ルーチンの問題か
286 :
270:2006/05/28(日) 00:00:32
>>276 クロックを上げ始めるまでの時間:0.285sec
クロックを下げ始めるまでの時間:0.15sec
CrystalCPUIDの閾値を100msに設定してやったらこれ。
勿論クロックはきちんと変動してます。
287 :
201:2006/05/28(日) 12:06:40
昨夜中に出せなくて申し訳ありません。
ttp://rerere.sytes.net/up/source/up12523.zip 汚いんで、多機能なエディタで読み解いてください。
>>267 そうか、最初に足してもいいんですね!算数の基本だった…
>>268 やはり底なしですね。Palominoでのマンデルブロは
FPU 3.344sec 5.544sec 7.612sec
SSE 0.973sec 1.591sec 2.179sec
です。
>>270 ありがとうございます。あれ、確か皿の方が新しいんですよね?
キャッシュに乗ると誤差の範囲ということは、メモリが引っ張ってるんでしょうか。
>>274(自分) 擬似コードはxとy逆だし、2*2*2とか3乗してるけど、実際は2乗だし、めちゃくちゃでした。
>>275 ソースに最適化してないAltiVecコードを入れておいたので参考になれば。
素直なコードなんで命令間のレジスタが依存しまくりです。
>>276 > Intel最適化コードで溢れてる
確かに。でもデベロッパは好き者多そうですし、AMDも浸透してるんじゃないでしょうか。
>>287 intelは有望なアプリ開発してるところには実機貸し出しから技術者派遣まで最適化支援やってるからなぁ
>>287 噂には聞いたことがありますが、やはりそうなんですか。派遣羨ましい。
行列の積のメモリアクセスを数えたとき、
素直に書くとtotal+=b[]*c[]で、2回/1madd
>>229にするとa[]=a[]+b[]*cで、3回/1madd (しかしキャッシュに乗るので速くなる)
>>274のレジスタ8本だと
b1=b[]; b2=b[];
a[]=a[]+b1*c1+b2*c3;
a[]=a[]+b1*c2+b2*c4;
で、6回/4madd。(=3/2なので
>>229より少ない)
これはブロック一辺の長さをnとしたとき
メモリアクセスはn*3回/n^2madd、
必要レジスタ数はn*2+n^2になるので、
レジスタ15本(n=3)だと6回/9madd。<EM64Tとか
レジスタ24本(n=4)だと12回/16madd。<PPCとか
レジスタ120本(n=10)だと30回/100madd。<Cellとか
となります。
車輪の再発明なんでしょうけど、これに気付いた時、小躍りしながら実装してました。
もっとも、ブロックを大きくするとそれだけキャッシュも必要になるので現実は甘くないと思われます。
>>285 このプログラムは、QueryPerformanceCounterで時刻、rdtscでクロックを取得している。
0.00101秒間に2020000clk刻んだから2GHzとか。割り算で出している。
他のプログラムだと、実測ではなくOSにクロックが何MHzか尋ねている場合がある。
それだと微妙に違う数字になることもある。
今回の場合はわからないんだけど。
本当に1msで反応するから計測にかからない?まさかなあ。
PenMのみの対応というつもりは自分では全くない(可能な人は同梱のソースを見て下さい)。
最高クロックの1.66GHzではなく1600.00MHzになるの?
オーバークロックやダウンクロックはしてないよね?
(そういうことをするとQueryPerformanceCounterの数字が狂うことがある)
プログラムが終了するまでの時間は3.5秒程度だった?
(APIのSleep()が俺の意図通りに働いていない可能性があるかも)
http://www.geocities.co.jp/SiliconValley-Oakland/8259/ このプログラムで、右クリック→設定→CPUクロック、
更新間隔を0.5秒に、取得方法を実測にチェック、
これでリアルタイムにクロックが表示されるから、
俺のプログラムを実行したときのクロックの変動を確かめてほしい。
これのグラフを見れば、SpeedStepが働いているかもわかる。
ちょっとスレ違い気味の流れも、285氏に手間をかけてるのも、ほんと申し訳ないんだが、
何か悔しいので引き続きお願いします。
>>274 yは2ずつ動かしているけど、これはaへ足し込む(ストア&ロード)を半分にするためで、
x+=2*unrollの2も、bのロード回数を半分にするためか。
「n*n」のときにn*n(c)+n(b)+n(temp)=n*(n+2)本のレジスタでできるわけね。
このx方向のnとy方向のnが同じ数である必然性っていうのはあるの?
unrollの寄与は、x方向のnを増やしたのと似た感じかな。
size=1024の場合、bはL1を4*nKBしか汚染せず、しかも繰り返し使うので2回目以降がL1ヒット。
代わりにaは4*n*unrollKBが必ずキャッシュヒットすることを求められるが、bが速くなってるので
L1ミスL2ヒットでも、まあ許される。
>>229のコードだと、aがL1ヒット、bがL2ミスだったのが、
今度はbがL1ヒット(ただしn回中の初回はL2ミス)、aがL1またはL2ヒットとなる。
バランスとしては、aがL1ヒットする範囲でunroll回数を増やすのがいいと思われる。
Athlonでの結果はこの通りになっている。unroll=4でL1を40KB使うのが速い。
ところがPenMやYonahでの結果はunroll=8が最も高速になっている。
unroll=4でも既に40KBを消費するのでaはL1ミスになり、
同じL1ミスならbのL1ヒット率が高いunroll=8が速くなったのだろう。
aがL2ミスしない限りunroll回数は多い方がいいと思う(多くなると効果は極めて小さいが)。
これならunroll=32とかでもほんのわずか高速化しそうである。
unroll=2の結果が見てみたいね。これが最速になってる可能性もあると思う。
この理論に従って単純計算すると
>>268でunroll=2が1385msくらいになる。
でもunroll=32の方が速そう。
もう一つのバランスは、aがL2ヒットする範囲でunroll回数を増やすことだ。
Athlonと比べて、メモリとL2の速度差が大きいPenMではこちらがいいかな。
プリフェッチをするときは、データがどこにあるかを見極めてやる必要がある。
例えば、XMM_CUBEのunroll=32ならば、
bにプリフェッチは不要で、aに対してprefetcht0が効くようになると思われる。
従来のXMM8FPでは1ループのデータ量が半分だから、aがL1に乗ったまま倍のunrollができる。
つまり、size=1024でもunroll=4でaのL1ヒットが可能、という点でXMM_CUBEに比べ有利だ。
既にbのメモリアクセスは1/unroll=1/4にまで軽減されている(XMM_CUBEでは1/2)ので、
これでは更にunroll回数を増やしても、aがL1ミスするし、bも最大1/4しか速くならない。
素直にunroll=4を使うのがいい。
>>287 ありがとう。でももう頭が限界だ。
せっかくのソースだけど、読むのはまた後になりそうです。すまそ。
>>267のアンロール案は間違ってたな。cの値が共通してない。
正しくは、
>>274にあるように、a[i,x]+=b1*c1+b2*c3; だ。
>>233のアイデアは関係ないみたいね。
行列のかけ算は、size^2のデータ量に対してsize^3の計算量を要する。
つまり、size=1024ならメモリアクセスの遅さを1024倍にまで希釈できる可能性があるのだ。
考えがいがある。
>小躍りしながら実装してました。
いいなあこの感覚。俺も経験あると思うけど何だったかな。
とにかくすごい量のアイデアが詰まったアルゴリズムなので考えるのが大変だったよ。
>>286 >CrystalCPUIDの閾値を100msに設定
これはCrystalCPUIDを使ってPowerNow!の設定を変えたということ?
何かすごく速いですね。。
>>292 違う。
>モバイル化+CrystalCPUID
をよく見れ。
>>270はそもそもPowerNow!が働いていない。
CrystalCPUIDはPowerNow!とは別に周波数や電圧の変更命令を出してる。
>>286は設定を変更してCPU使用率が閾値を超えてからの待ち時間を変更したって話。
>>290 T2300は1.66GHzだ
なにもいじってはいない
結果は
>>270とおなじかな
上がるのが検出されたと出るときもあったりでないときもあったりで
下がるのはだいたい検出できないと表示される
表示クロックは1.66GHz近辺をうろついてる
CrystalCPUIDは毎回再読み込みするたびに微妙に違う値が出るからこれも計算してると思われ
MobileMeterもCPUZもクロックの表記は1.66GHzのまま
HDBenchとかやってもクロックが下がれば結果は綺麗に下がるからさがってるのは間違いないはず
そういやHDBenchで面白い結果が出た
1CPUしか使わないように設定するとメモリアクセスでリードがPenMより10%くらい少し低い結果となった
だが、ライトはかなり高く、1.5倍くらいをたたき出す
2CPUにするとリードは一気に2倍になるのだが、ライトは1.5倍程度でとまる
また、INT性能は1CPUで動かしてもPenMの20%UPくらいの結果がでるがFPUはなぜか1CPUも2CPUも同じ結果になる
>>289 のn=3は9回/9maddでした。
>>291 中途半端なコードで混乱させて申し訳ないです。
実際のコードからコピペすると、ループはこうなっています。(更にfの中でsizeだけループ)
for ( int j = 0; j < h; j += 2 * nUnroll )
{
for ( int i = 0; i < w; i += 2 )
{
for ( int k = 0; k < nUnroll; k++ )
{
f( &src1[i + (j+k*2)*rb1], size1, &src2[i*rb2], size2, &dest[(j+k*2)*rb3], size3 );
}
}
}
> unroll=2の結果が見てみたいね
ソースにunroll=2を入れてコンパイル済みの物が同梱されてますので興味がありましたら。
> もう頭が限界だ。
長い間お付き合いありがとうございました。
知識とアドバイスをいただけたおかげで、最初より見違えるほど速くなりました。
> size=1024ならメモリアクセスの遅さを1024倍にまで希釈できる可能性があるのだ。
> >小躍りしながら実装してました。
> いいなあこの感覚。俺も経験あると思うけど何だったかな。
このパズルがやめられないですよね。
> x方向のnとy方向のnが同じ数である必然性っていうのはあるの?
よく考えてみると確かに無さそうですね。計算してみましょう。
nx, nyとおくと、
メモリアクセス/演算量 = nx+ny*2 / (nx*ny)
レジスタ数 = nx+ny+nx*ny
メモリアクセス/演算量
ny\nx |1 |2 |3 |4 |5 |6 |7 |8 |9 |10
1 |3 |2 |1.66|1.5 |1.4 |1.33|1.28|1.25|1.22|1.2
2 |2.5 |1.5 |1.16|1 |0.9 |0.83|0.78|0.75|0.72|0.7
3 |2.33|1.33|1 |0.83|0.73|0.66|0.61
4 |2.25|1.25|0.91|0.75|0.65|0.58
5 |2.2 |1.2 |0.86|0.7 |0.6
レジスタ数
ny\nx |1 |2 |3 |4 |5 |6 |7 |8 |9 |10
1 |3 |5 |7 |9 |11|13|15|17|19|21
2 |5 |8 |11|14|17|20|23|26|29|32
3 |7 |11|15|19|23|27|31
4 |9 |14|19|24|29|34
5 |11|17|23|29|35
8本では2*2、16本では4*2と3*3、32本では7*3が最適となりそうです。
この単純計算ではnyが倍の比率を持っているので、この表で見たときに横2:縦1辺りが最適解でしょうか。
実際はaはキャッシュに入っていることがほぼ確定していますし、測定してみないと分からないですけれども。
>>293 なんと。てことは反応速度を上げること自体は簡単なのか!?
しかも、OSでもないいちソフトが。むむぅ。
>>294 MobileMatorで1.66GHzのままというのはクロック変動してないんじゃないのかね。
「クロックが下がれば結果は綺麗に下がる」とは本当にクロックが下がってる?
性能を下げて省電力にするだけで、クロックを下げない設定というのもありうる。
文句ばっかでゴメン・・・。正直わからないんだ。
2CPUにするとリードが倍になるというのは興味深い。
やはりL2の能力である32byte/clkより各コアへの帯域のが狭いんだろう。
ただ、ストアの結果を見ると、上り下り各16byte/clkの帯域が各コアにあるのかな?
ベンチのFPUコードはデュアルコア未対応なのだろう。
>>295 PenMでも、aがL1ヒットする範囲でunroll回数を増やすのがいいみたい。
まあ、大体予想通り。
基本的にunrollが多くなると速くなるが、ある点で急に遅くなる。
速くなるのはbのメモリアクセスが減るからで、遅くなるのはaがL1ミスするから。
unroll = 1:
XMM8FP 2633630154 clk, 2.45 clk/FP, 2400.22 ms
XMM_CUBE_2 1499507751 clk, 1.40 clk/FP, 1366.61 ms
unroll = 2:
XMM8FP 2036311760 clk, 1.90 clk/FP, 1855.84 ms
XMM_CUBE_2 1395124809 clk, 1.30 clk/FP, 1271.48 ms ←速い!
unroll = 4:
XMM8FP 1824191143 clk, 1.70 clk/FP, 1662.52 ms
XMM_CUBE_2 1533405244 clk, 1.43 clk/FP, 1397.51 ms
unroll = 8:
XMM8FP 2033472799 clk, 1.89 clk/FP, 1853.25 ms
XMM_CUBE_2 1494939641 clk, 1.39 clk/FP, 1362.45 ms
unroll = 16:
XMM8FP 1994069148 clk, 1.86 clk/FP, 1817.34 ms
XMM_CUBE_2 1482868175 clk, 1.38 clk/FP, 1351.45 ms
>>296 おお、これはわかりやすい。
キャッシュ関係も計算できそうだけど、自分で組んでみるかなあ。
>>297 1GHzとCrystalCPUIDで表示されてるときはあらゆるベンチがクロック比どおりさがってますよ
OSのクロック表示だってSpeedStep状態がそのまま反映されますし(負荷によって上がったり下がったりする)
ちなみに1GHzと表示されてるときはこれです
FPU 4.663sec 8.479sec 10.767sec
SSE 1.588sec 2.481sec 3.293sec
SSE2 3.033sec 5.298sec 6.999sec
>>273とくらべてみてください
分解能も3579545とPenMとおなじようです
そういやRDTSCはSMPとかマルチコアだと対処しないと大変なことになるんだっけ
>>298 速い。L1のサイズって言うのは簡単に分るんでしょうか。
そうでなければ最大公約数を取るしか無いですね。
友人にAthlon64で測ってもらいました。(size = 1024)
unroll = 1:
MM_CUBE_3 1383971698 clk, 1.29 clk/FP, 626.21 ms
XMM_CUBE_2 1241385232 clk, 1.16 clk/FP, 561.70 ms
unroll = 2:
MM_CUBE_3 1248898727 clk, 1.16 clk/FP, 565.10 ms
XMM_CUBE_2 1062773579 clk, 0.99 clk/FP, 480.88 ms
unroll = 4:
MM_CUBE_3 1177760924 clk, 1.10 clk/FP, 532.91 ms
XMM_CUBE_2 973013799 clk, 0.91 clk/FP, 440.27 ms
unroll = 8:
MM_CUBE_3 1414945366 clk, 1.32 clk/FP, 640.23 ms
XMM_CUBE_2 1175440276 clk, 1.09 clk/FP, 531.86 ms
unroll = 16:
MM_CUBE_3 1699342347 clk, 1.58 clk/FP, 768.91 ms
XMM_CUBE_2 1559021287 clk, 1.45 clk/FP, 705.42 ms
あと参考までにG4の結果も。(プロセッサ名はCHUDの表記、clkは恐らくバスクロック)
PowerPC 7447A v1.2/1.25GHz/L1 32KB+32KB/L2 512KB/Bus 166.5MHz
unroll = 1: VEC_CUBE 81537025 clk, 0.08 clk/FP, 1860.58 ms
unroll = 2: VEC_CUBE 69235676 clk, 0.06 clk/FP, 1534.64 ms
unroll = 4: VEC_CUBE 64906649 clk, 0.06 clk/FP, 1330.62 ms
unroll = 8: VEC_CUBE 59191861 clk, 0.06 clk/FP, 1249.24 ms
unroll = 16:VEC_CUBE 71553214 clk, 0.07 clk/FP, 1366.05 ms
>>299 つまり負荷によってクロックが変動するときでも、MobileMatorで変動が見られないのか。
>>301 それそれ!
でも、このベンチはシングルスレッドだから同じ側のコアからrdtscするんじゃないの?
いやきっとそれじゃダメなんだろうけど。
それについての詳細がわかるとこありませんか。
Intelの最適化マニュアルを見ていたら、rdtscについてこんなのがあった。
USBマウスが刺さってると、ディープ・スリープに入れないのだな。
>チップがディープ・スリープ・モードに入っていないときにインクリメントされる。
>>302 0.91clk/FP キター!!まさか本当に1clkを切ってくるとは。
キャッシュサイズはcpuid命令を使うとわかる。面倒だけど。
K7->K8で倍速になってるんだねぇ
>>303 シングルスレッドアプリは1コアだけ使うとまじめにおもってるの?
OSは空いているCPUにスレッドわたすよ
20msとかでタイムスライスしてまたふりわけたりしてる
CrystalCPUIDはソース公開されてるからみてごらん
RDTSC見る前にスレッドをCPU固定してるところしかソースの違いはみえないな
>>303 > キャッシュサイズはcpuid命令を使うとわかる。面倒だけど。
Intel系はEAX=0x2、AMD系はEAX=0x80000005と0x80000006ですね。Intel系面倒臭そう。
別のメーカだと他にもあるのかな。
> シングルスレッドだから同じ側のコアからrdtscするんじゃないの?
そういえばSMPの事を考慮していませんでした。
SetThreadAffinityMaskでいいんじゃないでしょうか。
マルチスレッドプログラミング相談室 その4
http://pc8.2ch.net/test/read.cgi/tech/1130984585/467-472 辺りで丁度出てきてますね。
> まさか本当に1clkを切ってくるとは。
手元に無いのが残念ですが、この結果を見るとAthlon64は最適化しやすそうですね。
IPCを上げやすいAthlon64と、ぶん回して力技で対処するPen4とどっちが速くなるのか興味が湧くところ。
G4も素直な奴で、4つあるvmaddfp郡を並列に並び替えただけで1.09clk/FPになりました。(クロックが測れないので時間から逆算)
これはレジスタ24本使って4*4ブロックで処理してるから依存命令を離しやすいんですね。
あーだめでした。
ただ、タスクマネージャを見るかぎりCPUは固定されているようでした。
あとたりないのはどこだろ。
>>308 ありがとう!使用コアは固定されているのにダメなんか。
申し訳ないやら情けないやら。
測定結果をそのままコピペしてもらえませんか。
ふらついていたら数回分全部でも。
新しいやつはやってないけど、古いやつはPentiumMですらも値がばらついてたよ。
ただ、放熱がファン優先かCPUのクロックを下げるの優先かそのバランスを取るかなど
設定次第でどうでも変わる上にクロック低下を優先にすると室内の温度に左右される。
だが、IntelCoreのノートは東芝製でないのでそのへんうまくコントロールができない。
モバイル用途はやっぱ東芝だな。レッツノートも持ってるけど電源管理がかなりへっぽこなせいで
バッテリもそれほど圧倒的でもないし熱暴走も多い。
おっとそれてしまった。
ただ、クロックはかるという基本的な部分だけにここはっきりさせたいな。
CrystalCPUIDのソースをまともにおったほうがいいかもしれん。
311 :
201:2006/06/01(木) 02:12:40
ttp://rerere.sytes.net/up/source/up12528.zip unrollをL1に合わせるようにしたのと、マルチプロセッサに対応しました(多分)。
L1: n KB
thread = n
の形で表示されるので、L1がCPUのL1のサイズと同じか、
マルチプロセッサで動くか、を確認していただけると助かります。
スレッドはSystemAffinityMaskを順に割り当ててるだけなので、
良いか悪いかは別にしてHyperThreadingみたいのでも振るはずです。
それとCodeAnalystでAthlon64にギシギシに最適化してみました。
CodeAnalystのシミュレーションではループ内のIPCが3DNow!で2.9ちょい(3にならないのは、ジャンプがペアリング出来ていない)、
SSEで1.5ちょい出てるようなので、多分限界です。
>>310 おかしいな。俺の(東芝)だとファンの設定は関係ない。
クロックを間引くときも、rdtscのクロックは動いているので影響がないはずだ。
ファン優先でもばらついてた?クロック低下優先で室温が高いときもばらついてた?
SpeedStepをオフにしたときは正しいクロックだった?
できれば結果を貼り付けてほしい。
CrystalCPUIDか。丸写ししたらいけるかなぁ。
そういや俺がアセンブラや各種APIを使えるようになったのもコピペからだったなあ。
様々な環境できちんと動くプログラムは、俺では力不足かもしれん。他の人に頼みたい。
(もちろん、俺でいいのならいくらでも頑張ります)
>>311 L2サイズを超える処理で実行ユニットの理論値を出すとはお見事。
クロックの数値がおかしいというやつは週末まで待ってくれ。時間が今ちとない。
>>311 PenM725/1.6GHz
1 CPU, SSE, L1Data: 32 KB, size: 64
unroll = 32, thread = 1:
XMM_CUBE_5 360956 clk, 1.38 clk/FP, 0.23 ms
1 CPU, SSE, L1Data: 32 KB, size: 128
unroll = 16, thread = 1:
XMM_CUBE_5 2489468 clk, 1.19 clk/FP, 1.56 ms
1 CPU, SSE, L1Data: 32 KB, size: 256
unroll = 8, thread = 1:
XMM_CUBE_5 19190173 clk, 1.14 clk/FP, 12.02 ms
1 CPU, SSE, L1Data: 32 KB, size: 512
unroll = 4, thread = 1:
XMM_CUBE_5 150378700 clk, 1.12 clk/FP, 94.22 ms
1 CPU, SSE, L1Data: 32 KB, size: 1024
unroll = 2, thread = 1:
XMM_CUBE_5 1433156187 clk, 1.33 clk/FP, 897.97 ms
IntelCoreT2300/1.66GHz
2 CPU, SSE, L1Data: 16 KB, size: 64
unroll = 16, thread = 1:
XMM_CUBE_5 323120 clk, 1.23 clk/FP, 0.20 ms
unroll = 16, thread = 2:
XMM_CUBE_5 634100 clk, 2.42 clk/FP, 0.38 ms
2 CPU, SSE, L1Data: 16 KB, size: 128
unroll = 8, thread = 1:
XMM_CUBE_5 2431550 clk, 1.16 clk/FP, 1.46 ms
unroll = 8, thread = 2:
XMM_CUBE_5 1642180 clk, 0.78 clk/FP, 0.99 ms
2 CPU, SSE, L1Data: 16 KB, size: 256
unroll = 4, thread = 1:
XMM_CUBE_5 18553330 clk, 1.11 clk/FP, 11.13 ms
unroll = 4, thread = 2:
XMM_CUBE_5 9761720 clk, 0.58 clk/FP, 5.86 ms
2 CPU, SSE, L1Data: 16 KB, size: 512
unroll = 2, thread = 1:
XMM_CUBE_5 143379190 clk, 1.07 clk/FP, 86.02 ms
unroll = 2, thread = 2:
XMM_CUBE_5 72157210 clk, 0.54 clk/FP, 43.29 ms
2 CPU, SSE, L1Data: 16 KB, size: 1024
unroll = 1, thread = 1:
XMM_CUBE_5 1285626130 clk, 1.20 clk/FP, 771.33 ms
unroll = 1, thread = 2:
XMM_CUBE_5 652794810 clk, 0.61 clk/FP, 391.65 ms
シングルスレッドでガリガリ最適化するのもいいけど、マルチスレッド化のほうが先だな
315 :
201:2006/06/02(金) 04:21:07
>>312 >>227-229の測定では、クロックが下がっても
時間だけ増えてrdtscのクロックは増えていないような気がしました。
>>313-314ありがとうございます。
やはりデュアルコアに対応すると、きっかり半分になるんですね。
それで、314はL1が正しく得られてないですかね?
コア当たり32KBあるのなら、unroll = 2になれば少し速くなりそうな気がします。
316 :
201:2006/06/02(金) 15:26:39
>>315 >時間だけ増えてrdtscのクロックは増えていない
クロックが下がれば時間は増えるし、L2ヒットならクロック当たりの性能は変わらない。
ということでそれは当然だと思うけど、何か別のこと?
何だか今までとアンロール回数によるクロック数の変動が違うと思ったら
処理が変わっているのね。
YonahのL1は各32KBのはず。
AMDの次期CPUの情報が色々出ている。
K8は優秀なコアだから性能伸びると思うけど、Intelに対抗できるかなあ。
ちょっと時間がない。次は月曜辺りに来ます。
318 :
201:2006/06/02(金) 22:08:02
> 何か別のこと?
その事です。
すみません。勘違いしていたようです。
では、QueryPerformanceCounterが動的なクロックに依存していて誤動作、何て事timeGetTime()でやってみるとかどうでしょう。
> 処理が変わっているのね。
速くなっている分にはいいですが、遅くなってますか?
> K8は優秀なコアだから性能伸びると思うけど、Intelに対抗できるかなあ。
AMDの肩を持っている訳でもありませんし(好きだけど電気食い過ぎ)、
ハイスペックなCPUとモバイルCPUを比較するのが間違っているかもしれませんが、
>>314を見ると、デュアルコアを使ってようやくAthlon64より速い、という感じですよね。(391.65ms vs 431.05ms)
Conroeでどうなるのかが楽しみです。
319 :
201:2006/06/02(金) 22:09:40
なんか化けました。
QueryPerformanceCounterが動的なクロックに依存していて誤動作、何て事は無いでしょうか。
timeGetTime()でやってみるとかどうでしょう。
の2つです。
>>318 それAthronに最適化してるとかはないの?
あと比較してるAthronはどれ?3500+だと2.2GHzもあるし
ここにでてるローエンドのIntelCoreはクロック1.66GHzだよ
322 :
201:2006/06/02(金) 23:12:22
>>320 > Athronに最適化
> 3500+だと2.2GHz
> IntelCoreはクロック1.66GHz
全てその通りです。
ですが双方のクロックの範囲からすればクロスしている部分は少ないですし、
別の角度から見れば価格だって大きく違うはずです。
(逆にPen4でAthlon64と同クロックに揃えたらPen4が不利のはず)
これもつまるところはIntelCoreがモバイル用である由縁です。
また、最適化がAthlon向きなのは僕がAthlonを使っているからというのと
CodeAnalystの使い方を覚えたかったからですが、
性能を伸ばしやすいというのも一つの要素です。
これら様々な違いは個性として楽しいと思っています。
>>318の言いたかった事は、
> Intelに対抗できるかなあ。
に対して、十分出来るのではないか、という事です。
Core2はアーキテクチャ改良がなくともTDP65WでYonah2.4GHzクラスが大量生産できれば
AMDはやばいかもね
しかしPen4PenDの捨て値スゴス
324 :
・∀・)っ-○●◎:2006/06/02(金) 23:42:57
淀橋の自作コーナー見てきたけどDothanとYonahってクロックあたりの価格あんま違わなくね?
あとSSE2の性能みたいな。
ICC9.1でSSE4使えるようになってるけど、まだVSインテグレーションではサポートされてないね
ただ、tmmintrin.hが追加されてるので公式な命令仕様は出たも同然
325 :
201:2006/06/03(土) 00:53:48
>>323 > TDP65WでYonah2.4GHzクラスが大量生産できればAMDはやばいかもね
やばいというのは、生産能力でしょうか。
性能的にはAthlon 64 X2でも問題ないと思います。
> しかしPen4PenDの捨て値スゴス
凄いですね。
この価格が性能にどれだけ影響が出るのかベンチ結果が欲しいです。
ベンチはあくまで自分で書いたコードのw
>>324 > DothanとYonahってクロックあたりの価格あんま違わなくね?
歩留まりが同程度という事かと。
> あとSSE2の性能みたいな。
MMX2ですか?それとも倍精度ですか?
>>316の倍精度化なら出来ますが、やりましょうか?
あとちょいとスレ違いですが、G4は僕が書いたのでやる気を削いでしまいましたでしょうか。
326 :
・∀・)っ-○●◎:2006/06/03(土) 01:04:57
倍精度もだけど、128bitパックド整数のMMXとの比較も。
Banias/Dothanだとデコーダネックで性能でなかったと思うんだけど。
>>316 もしかして早くなってる?
PenM/1.6GHz
1 CPU, SSE, L1Data: 32 KB, size: 64
unroll = 32, thread = 1:
XMM_CUBE_6 346604 clk, 1.32 clk/FP, 0.22 ms
1 CPU, SSE, L1Data: 32 KB, size: 128
unroll = 16, thread = 1:
XMM_CUBE_6 2351058 clk, 1.12 clk/FP, 1.47 ms
1 CPU, SSE, L1Data: 32 KB, size: 256
unroll = 8, thread = 1:
XMM_CUBE_6 18215407 clk, 1.09 clk/FP, 11.41 ms
1 CPU, SSE, L1Data: 32 KB, size: 512
unroll = 4, thread = 1:
XMM_CUBE_6 136693574 clk, 1.02 clk/FP, 85.65 ms
1 CPU, SSE, L1Data: 32 KB, size: 1024
unroll = 2, thread = 1:
XMM_CUBE_6 1347357263 clk, 1.25 clk/FP, 844.21 ms
IntelCore1.66GHz
2 CPU, SSE, L1Data: 32 KB, size: 64
unroll = 32, thread = 1:
XMM_CUBE_6 309700 clk, 1.18 clk/FP, 0.19 ms
unroll = 32, thread = 2:
XMM_CUBE_6 617600 clk, 2.36 clk/FP, 0.37 ms
2 CPU, SSE, L1Data: 32 KB, size: 128
unroll = 16, thread = 1:
XMM_CUBE_6 2257710 clk, 1.08 clk/FP, 1.36 ms
unroll = 16, thread = 2:
XMM_CUBE_6 1585420 clk, 0.76 clk/FP, 0.95 ms
2 CPU, SSE, L1Data: 32 KB, size: 256
unroll = 8, thread = 1:
XMM_CUBE_6 17701400 clk, 1.06 clk/FP, 10.62 ms
unroll = 8, thread = 2:
XMM_CUBE_6 9309460 clk, 0.55 clk/FP, 5.59 ms
2 CPU, SSE, L1Data: 32 KB, size: 512
unroll = 4, thread = 1:
XMM_CUBE_6 129176970 clk, 0.96 clk/FP, 77.50 ms
unroll = 4, thread = 2:
XMM_CUBE_6 65191470 clk, 0.49 clk/FP, 39.12 ms
2 CPU, SSE, L1Data: 32 KB, size: 1024
unroll = 2, thread = 1:
XMM_CUBE_6 1103833180 clk, 1.03 clk/FP, 662.26 ms
unroll = 2, thread = 2:
XMM_CUBE_6 559695620 clk, 0.52 clk/FP, 335.80 ms
SSEの拡張とかするみたいだねぇ…
もっとAMDの拡張命令も使われるといいのに…
そういやサンプルで入ってる結果片方はsize = 1024で固定だけど
これ付属したバイナリで同じように実行できないよね?
331 :
・∀・)っ-○●◎:2006/06/03(土) 01:38:09
332 :
201:2006/06/03(土) 07:45:28
>>326 整数だと何か別のサンプルを考えないといけないですね。
>>327 今までの[X]MM_CUBE_nは外側のループxやyでアンロールする事に気を取られていて、
一番内側のループが1要素(16byte)毎にprefetchを発行していたので、
[X]MM_nFPのように、一番内側のループもアンロールして32byteずつ処理するようにしました。
本当はPenMやIntelCoreの為には64byte毎の方が更に速いはずですが、
関数を複数用意して分岐するようなのはあまり好まないので、
[X]MMが使える最弱の環境に合わせてあります。
遂にIntelのCPUでもものによっては1clk切ったようですね。
size=1024でもほぼ1clk。感激です。
>>330 unrollやthreadは今のところ引数にしていませんが
sizeを変えるのはtest.exe 128みたいな感じで出来ますよ。
>>331 待ってました。やはり水平演算とアライメント整合が良さそうですね。
>>332 Athlonはunrollが4でsize1024が最もいい結果が出てるようなので
同じような測定が出来ないかなと
例のPentiumMでもEISTでばらつくというやつ、あげはじめのクロックというところだった
そこがばらばら
そしてもちろん時間もばらばら
ビジー時のクロックはきっちりあってる
336 :
201:2006/06/04(日) 19:05:51
Pen4に触れられる機会があったので速攻で計ってメモしておきました。
コアやクロックは不明です。
size=1024, unroll=1, thread=1
XMM_CUBE_6 1.63clk/FP
size=1024, unroll=1, thread=2(HyperThreading)
XMM_CUBE_6 1.44clk/FP
>>335同梱のAthlon64 3500+が2.2GHz, 0.95clk/FPなので、
2200MHz(Ath64) / 0.95clk(Ath64) * 1.44clk(Pen4) = 3334.7MHz
>>302の0.91clk/FPを使うと
2200MHz(Ath64) / 0.91clk(Ath64) * 1.44clk(Pen4) = 3481.3MHz
になり、このベンチマークでは
概ねAthlon64 3500+がPen4換算で3.3GHz~3.5GHzとなりました。
やっぱりハイパースレッディングはあんまりおいしくないですな
338 :
201:2006/06/04(日) 19:46:32
>>337 本来HyperThreadingの無いはずのCPUに
深すぎるパイプラインの隠滅と、
余っている演算器を有効活用する為の処置を施してある機構だと思うので、
少しでも速くなるだけ機構が生きているという事で儲け物だと思います。
HyperThreadingが無い世界を想像すると、
Athlon向けに最適化されているとはいえ、
Athlon64対Pen4クロック比が1.79倍(1.63clk/0.91clk)
にもなってしまうわけですから、恐ろしいです。
なんだ?ここは2chか?
意味不明OTL
>>335 PentiumM725
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 1
FPU_CUBE_C 363639800 clk, 2.71 clk/FP, 227.85 ms
SSE_CUBE_6 136688828 clk, 1.02 clk/FP, 85.65 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 1
SSE2_CUBE_6 336800246 clk, 2.51 clk/FP, 211.03 ms
IntelCoreT2300
2 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 2
FPU_CUBE_C 182757750 clk, 1.36 clk/FP, 109.65 ms
SSE_CUBE_6 64885650 clk, 0.48 clk/FP, 38.93 ms
2 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 2
SSE2_CUBE_6 149035750 clk, 1.11 clk/FP, 89.42 ms
さすがにPen4比はかわいそうな値だな
PenDは今手元にないので計ることが出来ん
341 :
201:2006/06/04(日) 22:00:12
>>339 CPU に興味があるなら、まずはIntelやらAMDのリファレンスと最適化ガイドを読むのがオススメです。
>>340 どうも倍精度が遅いと思ったら、
プリフェッチを1回多く発行してました。
1ループに2回プリフェッチしているコードで、
SSE2が使えるCPUならキャッシュラインが64byteはあるだろうと思い、
コピペでアンロールしたのですが(この時点で4回)、片方削除し忘れた(つまり3回)ようです。
影響としてはAthlon系が誤差の範囲、PenM系が1割程度と分っているのと、
CPUの特徴を見る上での指標としては十分な(というか測り直してもらうのが申し訳ない)ので
とりあえずそのままにしておきますが、
この値を参考にする人は注意して下さい。
>>340 あと2時間以内ならすぐにはかりなおせますよ
343 :
340:2006/06/04(日) 22:09:01
344 :
201:2006/06/04(日) 22:51:45
>>342 ありがとうございます。
お言葉に甘えまして、修正したものをアップします。
http://rerere.sytes.net/up/source/up12560.zip それにしてもAthlonXPはサイズが増える毎に、そしてunrollを増やす毎にどんどん遅くなるorz
そもそもL1をカツカツに使ってる時点でスタックなどの+αを考えていないので、
>>1さんの指摘していた排他キャッシュが効いているんでしょう。
本当はPenM系みたいにunrollを増やすほどL2が効いて速くなる方が
プログラマに優しいんですけど、AthlonXPのL2って意味あるんでしょうかね。
345 :
201:2006/06/04(日) 22:55:06
あとmovapsとmovapdで挙動が異なると怖いので、
movapdを使うようにしました。
346 :
340:2006/06/04(日) 23:08:03
>>344 結果はまったく変わりませんでした
PentiumM725
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 1
FPU_CUBE_C 363172486 clk, 2.71 clk/FP, 227.55 ms
SSE_CUBE_6 136679161 clk, 1.02 clk/FP, 85.64 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 1
SSE2_CUBE_6 337124171 clk, 2.51 clk/FP, 211.23 ms
IntelCoreT2300
2 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 2
FPU_CUBE_C 182875340 clk, 1.36 clk/FP, 109.72 ms
SSE_CUBE_6 64882460 clk, 0.48 clk/FP, 38.93 ms
2 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 2
SSE2_CUBE_6 148463950 clk, 1.11 clk/FP, 89.07 ms
347 :
201:2006/06/04(日) 23:33:58
>>346 あら。
PenM系でも1.5倍(2回のはずが3回)程度の過剰なプリフェッチでは影響が出ないんですね。
つまり無理にアンロールしなくても良いという事なので、嬉しいですね。
>>318 後でtimeGetTime()を使って作ろうと思います。
>速くなっている分にはいいですが、遅くなってますか?
いや、sizeの値によってunroll回数が変わるみたいなので、ちょっと混乱しただけです。
>> K8は優秀なコアだから性能伸びると思うけど、Intelに対抗できるかなあ。
これはCore2のことです。
現状のYonahの絶対性能ではIntelの負けだと思う。
正直言って、クロック当たりの性能でも、うまく行ってK8と同等が精一杯。
K8の2.6GHzの性能を出すには、消費電力も今の倍以上必要になるはず。
たとえデスクトップ用に電圧とTDPを上げたとしても、ブランド力込みで互角、
といったところだろう。
Core2の性能と、性能が上がるK8Lの登場がCore2に比べてずっと遅いことを考えると、
K8がCore2に対抗するのはきびしいと思う。
Core2に不安がないわけではない。
ネトバを掃くためか、Core2の生産が急には無理なのか、知らんけど、
今年のCoreアーキは、Intelが出荷するCPUの20%程度という話だし。
2.66GHzというクロックも微妙に低い。
IPCこそ異常に高いが、当然ながらクロックの上げやすさとはトレードオフだ。
まあ、大丈夫だとは思うけど。
ポイントは価格当たりの性能。電力効率は価格かクロックの高さに反映されている。
あれだけ高IPCで低TDP、価格も高くないということは、Core2の電力効率がいいのだ。
Yonahとのピーク性能比較で、SSEが倍、ALUが1.5倍強、L1ロードストア帯域が倍。
で、実性能ではここまで上がらないだろうから、アセンブラで引き出す性能が増えた。
いやだから何って言われてもそれが嬉しいんだ。
>>320 201さんのコードは確かにAthlon有利なのだと思う。
実機を持っていて実測を重ねながら改良しているのは強い。
でも、その人がAthlonの良さを感じているなら、本当に良いのだとも思う。
結局、ソースが開示されているとはいえ偏った1つのベンチであるわけで、
CPUの才能の一面しか見せてはくれない。
PenMのよさは散々俺が力説してきたし、Athlonのよさがわかるベンチもいいよね。
>>326 デコーダネックと言っても、ちょっと(5%とか)遅い程度でしょう。実行ユニットは一緒だし。
とはいえ、実性能に与えるインパクトは確かに知りたいなあ。
>>332 >[X]MMが使える最弱の環境に合わせてあります。
これはP3のことだよね。プリフェッチを2回に1回(64byte毎)に減らしてもいいと思う。
P3ではキャッシュラインが小さいためか、プリフェッチの効きがかなり悪い。
>>334 たとえばらばらでも結果を貼ってくれると嬉しいんですが・・。
timeGetTime()を使ったバージョンをアップしました。
http://rerere.sytes.net/up/source/up12567.zip >>338 ネトバはHyperThreading前提のアーキのはず。
最初のWillametteでもダイ上にHyperThreadingのロジックは(無効にされて)載っていたらしい。
儲け物だというのは同意。
>>344 >AthlonXPのL2って意味あるんでしょうかね。
さすがに無いよりは圧倒的に速いでしょう。
BIOSでL2を無効にできるなら試してみては?
>>344のやつ@Dothan-1.1GHz
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 1
FPU_CUBE_C 364625727 clk, 2.72 clk/FP, 332.31 ms
SSE_CUBE_6 136918017 clk, 1.02 clk/FP, 124.79 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 1
SSE2_CUBE_6 312605601 clk, 2.33 clk/FP, 284.90 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 1024, unroll-y 2, thread 1
FPU_CUBE_C 4895629013 clk, 4.56 clk/FP, 4461.73 ms
SSE_CUBE_6 1325860811 clk, 1.23 clk/FP, 1208.35 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 1024, unroll-y 1, thread 1
SSE2_CUBE_6 5722573442 clk, 5.33 clk/FP, 5215.38 ms ←
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 2048, unroll-y 1, thread 1
FPU_CUBE_C 39427115591 clk, 4.59 clk/FP, 35932.67 ms
SSE_CUBE_6 11140237945 clk, 1.30 clk/FP, 10152.88 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 2048, unroll-y 1, thread 1
SSE2_CUBE_6 24521949343 clk, 2.85 clk/FP, 22348.56 ms
「←」のところは遅いが、何回か計測すると3clk/FPくらいのときもある。
なぜかここだけ結果が不安定だった。
BIOSでL2をDisableにしたDothan-1.1GHz
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 4, thread 1
FPU_CUBE_C 483375425 clk, 3.60 clk/FP, 440.54 ms
SSE_CUBE_6 275817709 clk, 2.06 clk/FP, 251.37 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 512, unroll-y 2, thread 1
SSE2_CUBE_6 453402556 clk, 3.38 clk/FP, 413.22 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 1024, unroll-y 2, thread 1
FPU_CUBE_C 7031491226 clk, 6.55 clk/FP, 6408.29 ms
SSE_CUBE_6 2290994377 clk, 2.13 clk/FP, 2087.95 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 1024, unroll-y 1, thread 1
SSE2_CUBE_6 5032796345 clk, 4.69 clk/FP, 4586.74 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 2048, unroll-y 1, thread 1
FPU_CUBE_C 71622353461 clk, 8.34 clk/FP, 65274.43 ms
SSE_CUBE_6 18663718469 clk, 2.17 clk/FP, 17009.55 ms
1 CPU, MMX, SSE, SSE2, L1Data: 32 KB, size 2048, unroll-y 1, thread 1
SSE2_CUBE_6 112708047800 clk, 13.12 clk/FP, 102718.67 ms
352 :
・∀・)っ-○◎●:2006/06/05(月) 18:17:37
AMDの次世代CPUに実装されるSSE拡張4命令
EXTRQ / INSERTQ / MOVNTSD / MOVNTSS
ってあるじゃん。
後者2つは大体名前から想像可能だけど、前者は、何でしょうな?
PEXTRW/PINSRWのQWORD版じゃないかと思うんだけど。
XMMの上位か下位かをimm8で指定、みたいな。
汎用レジスタ-XMMレジスタのデータ交換を想定したものとすると、AMD64モード専用じゃないかなと。
(MM-XMM間やメモリ-XMM間も考えられなくもないが)
相互にデータの退避ができるようになってレジスタ不足の解消になりそうな上
GRベース演算とXMMベース整数演算の並列化とか柔軟にこなせそうな。
これは結構注目
また、そうだとするならば、これまでどおりXMMの物理レジスタは80bit幅のFP/MMレジスタ×2で実装するんでしょうな。
いつになったら物理的に128ビットのレジスタファイルが実装されるやら。
Intelが浮動小数点強化してくると考えて
写真で見るもう一個演算ユニット横にぽん付けみたいな
手軽な拡張出来るぐらいK8は考えられてたのかしら…
>>352 次の犬世代でメモリ空間拡張されるみたいだしその時では?
354 :
201:2006/06/05(月) 19:26:52
> いや、sizeの値によってunroll回数が変わるみたいなので、ちょっと混乱しただけです。
申し訳ないです。
> プリフェッチを2回に1回(64byte毎)に減らしてもいいと思う。
> P3ではキャッシュラインが小さいためか、プリフェッチの効きがかなり悪い。
効きが悪いとは言っても、プリフェッチを無くしてしまうと
64byte中32byteはメモリアクセスを宣告されている事になるので、
どれくらい差があるのか分かるといいのですが。
> timeGetTime()を使ったバージョンをアップしました。
あんま関係ないと思いますが、今まで何も検出されなかったAthlonXPで
クロックを上げる動作が検出されたので貼ります。
アイドル時のクロック:1601.97MHz
ビジーな時のクロック:1568.47MHz
クロックを上げ始めるまでの時間:1.01sec
そのときのクロック:1515.07MHz
クロックを下げる動作が検出できませんでした。
> ネトバはHyperThreading前提のアーキのはず。
HTは使えって事ですね。
355 :
201:2006/06/05(月) 19:38:12
> >AthlonXPのL2って意味あるんでしょうかね。
> さすがに無いよりは圧倒的に速いでしょう。
> BIOSでL2を無効にできるなら試してみては?
BIOSにL2と明示されている項目がないので
無効に出来るかは分かりませんが、
L1とスワップする対象がL2になるかメモリになるかで確かに速度は違うはずですね。
> ベンチ
わざわざL2無効まで試していただいてありがとうございます。
size=1024時の倍精度の不安定さは何でしょう。
L2無効時より圧倒的に遅いので、延々REALTIME_CLASSを走らされたOSが何か息切れしているのでしょうか。
>>352 FPUレジスタを流用していたのは知りませんでした。
MMX2とFPUを同時に使うとあまり美味しくないって事になるのでしょうか。
>>353 ぽん付け出来るなら初めからしちゃってくれると。
いやいや、それよりも、SSE~SSE4なんてちまちま増やさないで、
遅くても命令セットを初めから揃えてくれると
いつまで経っても古いCPUの為に新しい命令が使えないというジレンマが無くなるのに。
>>352 >いつになったら物理的に128ビットのレジスタファイルが実装されるやら。
確かにK8に関してはFP性能が倍になっても内部で64bit*2の可能性は高いね。
>>354 それぞれ、プリフェッチ無しと有りの場合のクロック数。
・Coppermine-128Kの場合
32byteのロードで、17.05clkと16.65clk。ストアで68.23clkと51.71clk。
・Dothanの場合
64byteのロードで、46.91clkと39.39clk。ストアで140.56clkと96.06clk。
まあ、俺だったらプリフェッチを減らすという意見を言っただけなので、気にしないで。
実際にどうするかはプログラム製作者の思想によりますね。
> timeGetTime()を使ったバージョン
測定どうもです。時計の精度が大きく落ちたので、クロックにばらつきが出るようです。
そのばらつきを検出してしまうみたいですな。作り慣れないプログラムなので申し訳ない。
>>355 >MMX2とFPUを同時に使うと
MMX2がMMXレジスタに対する命令のことなら、そもそも同時に使えない(切り替えが必要)。
SSE2の整数命令のことなら、確かに物理レジスタは競合するが、今のCPUは
論理レジスタが不足していて物理レジスタが多いので、問題にならないケースも多いと思う。
むしろ、実行ユニットや論理レジスタが競合しないので高速化につながる場合が多い。
「MMX2」について。
ttp://homepage1.nifty.com/herumi/adv/adv51.html そもそもMMX2という用語はここでしか使われていない気がする。
P3で追加されたMMXレジスタに対する命令のことみたいだ。
このスレでもこの意味で使いたいと思うが、実は一般的な単語じゃないっぽ。
#それに気づいたのは最近の話。
Integer SSEって奴のことか?
どうやら XScale に入ってるものの事を指すみたいな感じ。
俺はこういう風に呼んでいる。
paddd mm0,mm1 ; MMX2
paddd xmm0,xmm1 ; SSE2整数
addps xmm0,xmm1 ; SSE or SSE_FP
addpd xmm0,xmm1 ; SSE2 or SSE2_FP
addps,addpdを総称して ; SSE or SSE* or SSE/2
>>359 Wireless MMX2のことだね。
携帯機器向けCPUに載るマルチメディア命令セットのことらしい。
x86のMMXとは関係ないと思われる。
362 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/06/05(月) 22:45:44
ワード単位シャッフル命令のXMM版がかなりの萎え仕様なんで、pshufbが実装されたらあのへんの命令はまとめてお荷物になる気が。
363 :
201:2006/06/05(月) 22:54:36
> timeGetTime()を使ったバージョン
精度が向上するかは分りませんが、
timeBeginPeriod(1)はどうでしょうか。
> プリフェッチ無しと有りの場合のクロック数。
ありがとうございます。
>>344はロードのプリフェッチしか行わないのでそこだけ見ると、
Coppermineのロードが2%、Dothanのロードが19%。
2%の向上の為に32byteを維持する必要は無さそうですね。
SSEは64byteにしようと思います。
ただ逆に、あまりアンロールすると関数のピーク性能が
大きな配列に制限されるというのもあって、
>>346のように、アンロールしないでもいいのであれば
しないに超した事は無いのでバランスが難しいです。
> MMX2という用語はここでしか使われていない気がする。
ごめんなさい。
そのニモニック表をよく利用させてもらっているので、MMX2でも通るものだとばかり。
SSE2整数の事です。
>>362 vpermはやはり無謀なんですかね。
364 :
・∀・)っ-○●◎ ◆Pu/ODYSSEY :2006/06/05(月) 23:20:52
vpermは2つの128ビットレジスタの計32バイトのテーブルルックアップなんで、最低3つはレジスタを指定できないといかんでしょ。
x86のフォーマット的に無理だし仮に出来てもIBMの特許に抵触するという話をどっかで聞いた。
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai274.htm > 1カ月半前の計画では、今年第4四半期時点での上位ブランドデスクトップCPU中の
> Core 2の出荷比率は20%台前半だった。現在の計画ではそれが20%台中盤。
> AMDは製造キャパシティを増強しつつあり、供給能力の不足から
> AMDがシェアを一定以上伸ばすことができないという枷が外れつつある。
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm >「K8は130nmプロセスで作られ、それから、90nmにシュリンクした。
>次にデュアルコアを90nmで加え、デュアルコアK8は65nmへと向かう。これがRev. Gだ。
>そして、65nmでNew Coreが登場する。これがHoundで、次にはHoundを45nmに移行させる」
>しかし、結果から言えば、AMDはギャンブルに出た。
>Fab 30を大改装し、300mmウェハベースのFab 38として新生するという。
>>348で、ちょっとうろ覚えのことを書いてしまったので改めて。
Houndというのは、K8LとかRev. Hと言われていたもの。
FPパイプが倍になり、命令フェッチ幅も16byteから32byteへ強化される。
詳細は不明だが、分岐予測の強化、OoOのロード機構もある。
クアッドコアは、L2が512KB*4、共有のL3が2MBというもの。
Intelは、リーク電流が問題になるタイミングで電力効率の悪いNetBuestアーキテクチャを
投入し、そのためにつまづいた。
そのタイミングで生産能力の向上という勝負をかければ、成功した公算が高い。
だが、実際にAMDが増産できる頃には、予定通りならCore2が軌道に乗っている。
ちょっとタイミング的にAMDかわいそうかなあ、という感じだが、楽しみでもある。
>timeBeginPeriod(1)
ミリ秒の精度ではダメなアルゴリズムなので根本的に変えるしかなさ気。
366 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/06(火) 00:10:31
367 :
340:2006/06/06(火) 01:06:17
>>348 CPU単体ならいいけど実際のところチップセットと一緒にで使うわけで、それこみで考えるとやはり弱い
とはいえメモリコントローラ内蔵したことによってその影響を出来るだけ減らそうとした感じが非常に強い
nVidiaとかマザーから撤退したほうがいいんじゃね?とかまじでおもう
x86_64は?
369 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/06(火) 20:59:42
トランスメタは携帯版 XBOX に搭載するという噂もあったね。
マルチコア時代はキャッシュ構成がさらに重要になってくるな。
373 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/09(金) 03:01:52
>同等の負荷の2スレッドを動かせばいい
まで読んだ
374 :
340:2006/06/09(金) 07:52:16
でも普通に性能下がってるよ、クロックどおりに。
CPUクロック測定ツールもものによってちゃんと動いてるし。
>>374 それはCPU外(ソフトとか)から見た話。Active と Idle の2モード管理。
P1~P6 ステートによる管理等は CPU 内部の話。
いや、だから両コア同じクロックで下がる
それがクロックのへんな表記とはまったく関係ないということ
つまり、クロックがおかしく表示されるのはソフトが悪いだけ
377 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/10(土) 00:26:59
とりあえずtimeGetTime使って計算すればいいと思うお
378 :
SOURCE ◆tAo.kQ2STk :2006/06/10(土) 16:40:37
>とりあえずtimeGetTime使って計算すればいいと思うお
動作時間からクロック数を求めることが容易に可能なら賛成ですね。
とりあえずディスアセンブル使ってニーモニックから想定クロック数を割り出せばいいと思う。
379 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/10(土) 16:53:17
それだとアウトオブオーダ並列実行の利きぐあいがわからん。
Pentium 4なんか20命令くらいなら平気で並べ替えて実行するからね。
まぁ、クロック数求めるだけならrdtscが最善かと。
あと、Intelアーキテクチャ最適化マニュアル
目的としてはクロック数求めるだけなのでtimeGetTimeの使い道がありません。
>>367-368 まあ、Yonah vs K8は仮の話なので色々とボロは出るね。
>>369 AMDと来たか。消えたと思ってたらこんなことやってたとは。
X-BOXの噂とかも含めて今後の動向が楽しみだ。
>>372 Pステイトが2つのコアでばらばらに制御されることが影響したかも。
バックに弱い負荷があっても測定対象のコアと違う方に数msでも割り当てられていたら
測定対象のコアがDeep Sleepに入ってrdtscのカウンタが止まってしまう。
>>377 とりあえず
>>349でtimeGetTimeを使ってる。
>>372で正解かな。
コア指定で軽い処理をバックの別スレッドで流して、そのコアで測定すればいい。
ええと、誰か作ってくれませんか。。Deep Sleepに入らない軽い処理の作り方がわからん。
>>371に関連して。
シングルコア・シングルスレッドでのメモリへのストアの遅さはなぜか。
Dothan-1.1GHzで、メモリに対して64byteのアクセスをするとき、
ロードだと47clk、ストアだと141clkかかる。
ストアには、ロードも伴うしL2を経由したライトバックの手間もあるから遅いのは当然だが、
それでも2倍ちょっとのはず。実測では3倍くらい遅い。
プリフェッチやノン・テンポラルのストアを使えば、どちらも39clk程度になる。
382 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/13(火) 22:40:51
383 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/13(火) 23:08:55
I337 SSE3 :HADDPS xmm, xmm L: 3.37ns= 9.0c TP: 1.12ns= 3.00c
I338 SSE3 :HADDPD xmm, xmm L: 1.87ns= 5.0c TP: 0.75ns= 2.00c
利用頻度はさほど高くないと見たのか、やっぱりこのへんだけは複合命令で実装してるっぽい。
SIMD転置ユニットのレイテンシ・スループットががそのまま反映されてるっぽい。
ここには書かれてないがSSE4の水平加減算のパフォーマンスも推して知るべし。
384 :
201:2006/06/13(火) 23:12:18
385 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/13(火) 23:16:17
>>384 PenM725での結果
何度やってもこんな感じ
最高クロックは1.6GHzだし
----
測定は約6.5秒間です。じっと待ってください。
測定が終わりました。
アイドル時のクロック:1426.07MHz
ビジーな時のクロック:591.97MHz
クロックを上げる動作が検出できませんでした。
クロックを下げる動作が検出できませんでした。
387 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/13(火) 23:21:50
388 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/13(火) 23:33:20
> UP TO 4DP FLOPS/cycle
addpdとmulpd同時実行で倍精度実数×4なのか、積和算で×4なのか、それが問題だ。
前者ならConroeの後追いに過ぎないし、後者ならCPU燃えるんじゃないのかと心配
Rev.Gでデコーダー増やしたり改良するみたいだけどどーなんのかねぇ…
焜炉へのキャッチアップぽくなっちゃうけど
またデッドヒート状態になるかな?
Rev.G は単なるシュリンクじゃない?
Rev.H 前倒しきう゛ぉん如
392 :
201:2006/06/14(水) 00:49:29
いや、グラフはクロック当たり3倍ちょっとだと思ってたら2倍ちょっとか。
忘れて下さい。
393 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/14(水) 00:50:30
浮動小数はクロックあたり2倍程度
4倍になるのは整数ですな。
394 :
・∀・)っ-○◎● ◆toBASh.... :2006/06/14(水) 00:54:42
>>382,387
ConroeのALUは普通に3つだね。ロードストアも128bit/clkで普通。
leaは1つのALUでしか実行できないみたいだが、どのユニットで実行するんだろう。
PenMだと乗算側のポートで実行される。また、PenMで加算とジャンプは同じポート。
なのでConroeでも乗算のポートでのみ実行されると予想。
シフトは2つのユニットで実行できるようになった。これはジャンプ以外の2つかな。
cmovやadcはPenMから変化なしで神速のK8には及ばず。
K8は、3つ同時にシフトできるし、キャリーを使う演算でも遅くならないのがすごい。
32bitのimulが3-1で、レイテンシが小さくなったのは評価できる。さすがに64bitでは5-2だが。
64bitのmulは7-7。K8は5-4と化け物だが、これも7-7という数字は悪くない。
divはYonahの時点でPenMから大幅に速くなってK8を抜いている。
Conroeになって微妙に遅くなっているが、あのK8を除算でぶっちぎってるのはすごい。
ただ、このdivって簡単な数値のdivじゃないよね。速すぎる気もする。
FPUだが、加算・乗算のクロック数はP6から変化していない。やはり80bit精度は大変なのか。
fdivやfsqrtも変わらず。ここはK8がぶっちぎりで強い。
ほんとにFPUだけをガリガリ使うコードだと、K8の優位は揺るがないことになる。
MMX系は基本的にSSE2整数と同じクロック数なので、SSE2を使った方が倍くらいお得。
1clkにつき、移動系は3つ、加算系は2つ、乗算系は1つ、64bit/128bitの整数SIMD命令を
実行できる。PenMでは、64bitのみで、移動系は2つまでだった。
SSE_FPでも、平方根や除算も含めて、64bitと同じクロックで128bitの演算ができる。
逆に言うと、64bitで使う限り性能面のメリットは少ない。
ただ、mulpdのスループットがYonahの4倍になってくれたのは嬉しかった。
レイテンシが伸びてないのも安心した。レジスタ間movapdのスループットもPenMの3倍。
128bit化するとレイテンシの隠蔽が倍難しくなるというのは不利な点だ。
Conroeに向けたSSEコードを書くときは、64bitモードで倍増したXMMレジスタを使い、
レイテンシを隠蔽するようにすると力を引き出せるだろう。
>>383 movhlpsやアンパックなどの命令でYonahより遅くなっているが、
これは演算ユニットを128bitにした弊害だろう。
64bitのレジスタと演算器ならただの移動で済むものも、128bitのレジスタと演算器だと
シフトが必要になってしまう(Pen4でmov bh,alが遅いのと少し似ている)。
せっかくのSSE3命令haddpsも、同じ理由で遅くなっているということか。
SSE4の水平加減算まで遅かったらちょっと嫌だなあ。
PrescottでSSE3が遅くても、「Meromでは速いだろうからいいや」と思えたけど、
結局、haddpsを実行する絶対時間はほとんど速くなってない。
(Core2アーキはNetBurstよりクロックが上げにくいので、多少IPCが高くても威張れない)
何のために、こんなに命令を追加してくるんだろう。
>>391 負荷がない状態ではDeepSleepに入ってしまい、俺のと同じ動作でダメです。
マルチスレッドはよくわからないけど、loooooopが呼ばれてない感じ?
俺はWindowsXPProだが、Sleep(1)でも10ms休み、これだとCPUがDeepSleepに入ってしまう。
ていうかそもそも10ms単位の計測ではクロックの下がり始めが正確に測れない。
そこで、μ秒単位でCPUを休ませる方法が知りたい。
あと、バックでCPU使用率1%の処理を各コアに流せれば、ちゃんと計測できるはず。
#正直、実機が手元にないのでやる気がダウン中。文字レスはします。
>そもそもノートに追い付かれる程停滞していたのが悪いんですよね。
NetBurstが予定通りなら今頃Conroe程度の性能を高クロックによって実現していたろうな・・。
398 :
・∀・)っ------:2006/06/14(水) 17:31:27
399 :
デフォルトの名無しさん:2006/06/14(水) 23:15:27
マターリ400取って見るか。
401 :
201:2006/06/16(金) 23:56:50
>>397 > loooooopが呼ばれてない感じ?
デュアルコアでは、裏でloooooopが回り続けます。
> バックでCPU使用率1%の処理を各コアに流せれば、ちゃんと計測できるはず。
メインスレッドから小刻みにSuspendThreadとResumeThreadを呼ぶとか、
loooooopはGetMessageでメッセージが来るまで永久待機にしておいて、
メインスレッドから小刻みにメッセージを飛ばすとかで
1ms以下のスリープを実現出来ないでしょうかね。
OSの精度が数十msだから無理なのかな。
>>401 デュアルコアでは正しく動作するのか。
シングルコアでダメなのはバグじゃなくてそういう仕様なのね。
>>391のでは、mp3の再生をしながらだとSpeedStepを正しく計測できたので、
Yonahでの結果が見てみたいところ。
>>398 misc系の命令に関しては128bit化することで今までと仕組みが大きく変わるね。
(加算や乗算と違って、演算器の数を倍にするだけでは済まない)
さしあたり、Conroeでは若干遅くなっている面が目立つ。
Yonahでは相変わらずだめです
>>403 残念。
>>387 lddquのスループットがYonahでも1.17と、ロード回数が常に倍になるわけではないみたい。
キャッシュラインをまたいだときだけ2回ロードするなどの工夫が内部でしてあるのかな。
movupdの数字と同じなので、このベンチはキャッシュラインをまたいでないっぽいけど。
405 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/19(月) 22:50:28
要するに連続的なデータであればアラインメントされてないデータ1つにつき必ずしも2回ロード
されるわけではないってことですな。
もうほとんどmovdquなんかのペナルティは隠蔽されてると思ってよさそうで砂。
ひょっとして、NetBurstのが異常に遅かったのって、結局シフトのスループットが悪すぎたから?
Meromのpalignrは推定1-1か2-1でシフト・ローテート演算器で処理されるとみた。
bswapが4-1だけど、操作がmm版pshufbのサブセットとみることができるから、
pshufb(MM版)も4-1程度かそれ以上、XMM版は最低でも8-4ってところかなと。
精度が欲しいのにカーネルモードで計測しないのは何故?
>>201 Yonahじゃアイドル時のクロック計測できんの?
408 :
201:2006/06/21(水) 00:14:46
>>406 アプリケーションモードで動けばそれに越した事は無いですし、
本音を言うと面倒臭そうだからです。
>>407 CoreDuoもですしPenMも持って無いので思いつきで作るのが難しいですね。
その思いつきですが、また1つ思いついたのでやってみました。
http://rerere.sytes.net/up/source/up12633.zip clktime.exe 10
の形で1CPU当たり引数に指定した数だけのスレッドを起動します。
省略時には10が採用され、この場合2CPUだと20スレッドです。
タスクマネージャのパフォーマンスタブにあるスレッド数で確認できるはず。
やってることは、1msをスレッド数で割った時間(例では1ms/10=100μ秒)ずつずらして起動し、
各スレッドは1msのスリープをひたすら繰り返します。
ただ、105-107行目のコメントを有効にしてCPU負荷を見てみたのですが、
AthlonXP上では100μ秒くらいではCPU占有率が0%のままなのが
うまくいっているのかどうかピンと来ません。
う、今見たら関数名が500usLoopとかなってますが
最初に500μ秒固定で作っていたときの名残なので気にしないで下さい。
あいかわらずYonahでは1Ghz固定クロックも
1GHzから1.66GHzの可変クロックもすべて1.66GHzとでてしまいます
crystalのコードを見直したほうがいいかもしれませんね
411 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/21(水) 00:43:10
CrystalのCPUの判別ルーチンのソースは結構参考になる
MeromのFamily=6ってのも意外だったな
ちなみに基本Model値はF。拡張Model値も使えば、いちおうあと10年分くらいは「P6アーキ」は出せるのね。
Pen4のファミリは実は15ではない
413 :
201:2006/06/21(水) 00:52:47
>>410 スレッド数を1とか500とかしても駄目ですか。
1GHz固定で1.66GHzと言う事はDeepSleepは関係無いのですかね。
crystalのコードはまだ読んだ事ありませんが、
アプリケーションのファイル構成を見るに
>>406でやってるんでしょうね。
カーネルモードはディープな設定の変更のみで
計測は普通にやってたりすると悔しいですね。
>>411 SSE~SSE4を初めから(ryというのと同じで
Intelの中の人は人の判別ルーチンを参考にしたくなるようなアーキじゃ不便だと思わないのですかね。
414 :
201:2006/06/21(水) 00:59:48
ばらばらに書いて繋げたら語尾が揃ってて何やら拙い文章に。
コードも文章も読み返さないから後から訂正だらけになるんだOTL
技術的に日本を支えてそうな人達が沢山いそうな気がするスレだが
おまえらなにものなんだぜ?
これが日本のトップレベルだったらたちどころにヤバい。
IT土方
至極名言ですな
頑張れよおまいら
>>406 できないから。。
>>409 100000でもDeepSleepに入ってダメだった。
ここまでくると実行時間が通常の10倍くらいかかる。
もっとも、YonahはDeepSleepしてないみたいだけど。
あと、readme.txtの変更とかしてくれるとありがたいです(俺も何も書いてないけど)。
もはや俺のプログラムじゃないので、たとえ内容は同じでも201氏の手で書いてほしい。
Yonahの1GHz固定で1.66GHzと出るのは、やはりタイマー?
それとも実はrdtscの仕様が違うとか。。
俺が実機を持っていたら、タイマーとrdtscの値をリアルタイムで表示するプログラムを作って、
PC外のストップウォッチと見比べる。誰かリモートデスクトップでYonah機操作させてくれ。
>>411 >MeromのFamily=6
意外だった。というかちょっとがっかり。
Meorm自体は間違いなくP6ではない新しいアーキだが(P6を参考にはしてるだろうけど)、
Family=6というナンバーは、P6の血が流れる最後のCPU、Yonahで締めてほしかった。
ネトバは6じゃないのにねえ。
お題。
・シングルコア・シングルスレッドでのメモリへのストアの遅さはなぜか。
・かなり前から自作板のAMD次世代スレで複数コアでのキャッシュのことで論争が続いている。
まともに理解している人が少ないか、いないために長く続いているのだと思うが、
実際どうなんでしょ。
MeromにもP6の血は色濃く流れてる気がするがな。
ブロック図を見るに参考にしてるどころか直系と言っていいと思うよ。
Pen3→Baniasに匹敵する拡張があって滅茶苦茶強力になってるけどさ。
それとは別にまだFamily=6を使う事には驚き
MACオタ・雑音・503・団子に続くヌーフェースジャマイカ?
423 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/21(水) 21:48:31
日下部先生も知らない冷やかしはお帰りください
424 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/21(水) 21:56:45
ちなみに、SSEx対応してるかどうかを調べるだけなら実際命令実行してみて例外を捕捉すればおk
でもVC2005ではC++のtry-catchブロックではデフォでは拾わなくなった(独自拡張の__try-__exceptでは拾える)
日下部が実在の人物である証拠は無い。
ちなみに、「オフ会で会った」と発言した
河野も架空の人物で佐藤文平の成りすましだと思う。
426 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/21(水) 22:12:48
早稲田在学のテニスプレイヤーがどうしてそこで出てくる
427 :
デフォルトの名無しさん:2006/06/21(水) 22:26:49
void先生の最盛期も知らない童貞はプレスコでオナニーしててください
428 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/22(木) 00:40:34
最盛期ってなんですか?
fjから2ch(NNTPでカキコできた時代)、今はmixiにご執心。
興味の対象が変わっただけで中の人の人格は何も変わっちゃおられません。
429 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/22(木) 00:54:34
>>426は俺なりのギャグだったんだけど、そっちの砂糖文平のことをマジで知らないと思われたなら心外
でも実際同姓同名のテニス選手のほうが有名になりすぎてるでしょ。皮肉なものですわ。
Rubyスレにshige氏が居たのもvoid先生と重なるんじゃね?
自慢じゃないがおいらのム板暦は実はROM・名無し時代から6年
アイタタタ
なんか日下部すれの誤爆くさい
団子よ
関係ないことはともかく
知らないことは黙っとけよ
な?
433 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/22(木) 01:26:24
そっちこそ糞レスする暇あるならスレタイ100回読んで手持ちのマシンのCPUのLatency Dumpでも投稿してくださいな。
>>419 知識は無くともキャッシュの議論をしたい一人なんだけど、論破しようとする人が多いせいか中々進まない。
議論を積み上げるのはあそこじゃ不可能なのかな。
435 :
デフォルトの名無しさん:2006/06/22(木) 01:47:49
>>421 確かに、ALUポートを1個追加してSIMDの幅を倍にしただけにも見えるけどね。
(他にもマイナーチェンジは数多くあるけど)
俺としてはパイプラインが4本になったことで、P6とは別物と見たい。
Intelもフルスクラッチだと言ってるし、たまたまP6と似たデザインになったんだろう。
(そりゃお前の希望的妄想だと言われればその通りですがw)
>>433 オマエモナー(いや、言ってみたかっただけ)
ところで、前スレの14氏や97氏は知ってる?
>>434 俺も似たような感じかな。
多分、知識(&ある程度の時間)のある人がいれば、あの騒ぎを鎮めることもできると思う。
俺もYonahとPenDくらい持ってたら実測重ねて論破してやりたいんだけどなあ。
Pentium 3→Pentium M(Banias)の時点で、かなりの変革
(NetBurstバス、μOPsフュージョン、クロックゲーティング・・・)
だったのに、Familyを刷新しなかった時点で、まぁCRISC・スーパーパイプライン
方式を取るうちはP6のままでいくんだなと思ってた。
うちがMeromでFamily変更だと思った根拠はModel値が足りなくなること。
あとトレースキャッシュ採用すると思ってたこと。
どっちも外れ(Model値については拡張Model値使う方針らしい)なんで
自然と納得してしまった。
多分次にFamilyが刷新されるのは多分
・ヘテロジニアスマルチコア(メニィコア)化
・PARROTアーキテクチャ
どっちが先か、あるいは両方なのかは知らないけど
ちなみにFamily=7は既にItaniumで使ってるのよね。
AMDは来年にモバイル用のコアを出す。
そこではCPUコアを拡張しないことで省電力を狙っている。
省電力が重要なモバイルだから、Core2のような高性能はいらないとうわけだ。
しかし、CPUの(クロック当たりの)性能が高ければ、クロックを下げるということができる。
Core2の設計思想はここで、IPCを大きく上げることでクロックは程々でよくなる。
クロックを下げると消費電力を非常に大きく削ることができる。
おそらく、AMDのモバイルコアの場合は、モバイルであまり使わないSIMD性能よりも
普段の体感速度と消費電力のバランスを考えたのだと思う。
他にも、リーク電流の少ないトランジスタを使うことで、(クロックは低くなるが)
消費電力は減らせる、というようなアプローチもしてるだろう(よく知らんけど)。
Core2はコアを拡張することで(クロックを下げて)電力効率を上げているのだから、
拡張しないことが省電力の直接の理由にはならない。
モバイルでのCore2の弱点はクロックの低さになると思う。
まあ、最近はモデルナンバーなのでそんなに問題にならないだろうけど。
SIMDの絶対性能ではAMDのモバイルコアを圧倒するだろう。
そうなると、A4ノートではCore2になるし、B5ノートに載るほどAMDが消費電力を
下げてこられるかというのも不安である。
Core2のクロック当たりの消費電力がやや不安。まあ、当然なんだけど。
現在のULVゾーンでは、CoreSoloの1.06GHzが出ているが、これならPenM-1.3GHzのがいい。
同じように、Core2-ULVの出始めではYonahにクロックで見劣りするだろう。
>>437 トレースキャッシュ来なかったなあ。次のアーキでやるのかな?
Meromは思ったよりパイプラインが短かった。
440 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/22(木) 23:44:29
ところでADCとVectorから8月開催のWWDCの案内が来てたんだけどさ
例のCore2ベースMacの発表とか、LeopardのEM64Tアプリケーション開発云々の話だろうけど
NECとかはT2300とかで抑えてくるのに、いきなり2GHzクラスのを使ってくるあたりがAppleクォリティ。
Appleの顧客はWinマシンよりいいものを使いたいって思うから必然的にハイエンドになる罠。
まぁ、SSE3までをサポートするCPUでIntelアーキ陣営に初参入したAppleにとってx87命令群は盲腸でしかない罠。
441 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/23(金) 00:33:05
442 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/23(金) 00:36:56
誤爆
ちょっと自作のSSE2整数アプリで実験してもらったんだけど、Core2のSIMD整数演算(SSE2)の実性能はCoreの2.3倍程度
単純にユニット幅が倍になっただけでなくアウトオブオーダ実行もかなり進化してると思っていいかと。
>>438 CPU単体ならそうなんだろうけど、実際はチップセットやメモリ、バス、ビデオがぜんぜん違うので
1GHzのsoloのほうが結局いいよ
バッテリもかなり違うし
マジレスする気も起きねえな。
445 :
201:2006/06/23(金) 02:08:31
>>419 readme.txtを署名と考えているのですね。変更しておきました。
http://rerere.sytes.net/up/source/up12649.zip いい加減crystal読んだ方がいいのですが、
100000スレッドでもDeepSleepしていたとの事なので
スレッドに割り当てたれた時間(10スレッドなら100μ秒)の半分は
CPUを回すようにしてみました。
>>410で指摘されている表記の問題は直らないかもしれませんが、
>>1さんのコードを触ろうと思った動機がDeepSleepに入ってしまうのをどうにかしたいという所なので
DeepSleepだけでもどうにかなれば。
そこで考えてみたのですが
100000スレッドでDeepSleepを引き起こすという事は
もしかするとスレッド数は関係なくて、
if (Max(EachThreadUtilization) < n%) DeepSleep()
っていう感じなんでしょうか。
10ms中5msをSleep()するスレッドは恐らくCPU使用率50%のスレッドなわけですが、
このスレッドを5msずらしてもう一つ起動してやると、
交互に5msずつCPUを回すので、全体で見ればCPU使用率は常に100%のはずです。
しかし、個々のスレッドを見ると忙しいスレッドは1つも無いので、DeepSleepしてしまうとか。
>>397 >そこで、μ秒単位でCPUを休ませる方法が知りたい。
HLT後、8253のようなタイマで起こす。
どうしてもやりたければ、DOS上ででも。
>>401 OSの精度とやらは、NT系Windowsであれば、KeQueryTimeIncrementで得られる。
私の環境(W2kSP4)では、1.5625[ms]らしく、1[ms]以下のsleepを行えない。
>>445 >if (Max(EachThreadUtilization) < n%) DeepSleep()
当然の事を、今更...。
>>442 2.3倍とはすごい。これは多分ALUが1個増えたせいだよ。
いくらスケジュールしたって、レイテンシ据え置きだから2倍以上は速くなりようがない。
>>443 そういえばチップセットはかなり違うね。Intel 915が電気食いだったから違いは大きい。
でも2割クロックが違うからなあ。俺の用途なら1.3GHzを選ぶ。微妙。
>>445 やったー!DeepSleepしなくなりました。
QueryPerformanceCounterを使うなら、精度が高いのでクロックを上げ始めるまでの時間の
表示するところを「%1.2f」から「%1.3f」などに換えた方がいいと思います。
あと、コメントアウトされてる俺のコードは消してもいいですよ。
#int main(int argc, char * argv[])の下にvoid main()があるとミジメだYO!
10000スレッドにしてタスクマネージャでCPU使用率を見ると、
Sleepを使ったときに(50%でなく)2%とかでそれ以外は100%。これは
>>408も同じ。
タスクマネージャのスレッド数表示は2020までしか増えない。
俺はもうデュアルコアの測定はMeromを手に入れてからやろうと思ってるけど、
いちおう協力はしますので、と。(そろそろついていけない予感)
>>446 >HLT後、8253のようなタイマで起こす。
特権ないと無理?
>当然の事を、今更...。
え、そうなの?
10ms中5msをSleep()するスレッドがあったら、
5msはCPU使用率100%で回して、残りの5msはDeepSleepすると思うが、
このスレッドが2つあると普通にCPU使用率100%でDeepSleepしないと思うけど。
>>447 >このスレッドが2つあると普通にCPU使用率100%でDeepSleepしないと思うけど。
相互の待ち合わせとかしないで単に50%の期間寝てるだけのスレッドだと、
同時に busy になる期間も同時に sleep している期間も発生しうる。
特にDual CoreやHTの場合は顕著に起きる。
>>448 5ms分の処理をやってその後(処理の時間も含めて)10ms経過するまで
Sleepして待つスレッドと間違えていた。
にしてもデュアルコアの測定って大変そうだなあ。
>>447 >>当然の事を、今更...。
sorry、斜め読みして勘違いしていた。
色々と動作を理解していない感じがしたから、突っ込みたかっただけ(ぉ
故に無かった事にしてもらいたい。
以下、どうでも良い事。
・CRystalCPUIDのsourcecodeを読んで解決するなら、読めば良い。
・OSがidle時のclock云々を調べる事は、飽くまでも、ソレ関連のsoftwareの解析をする事の範疇。
他に出せる情報は無いから、この辺で消えよう。
451 :
361:2006/06/23(金) 20:20:57
>>442 > ちょっと自作のSSE2整数アプリで実験してもらったんだけど、Core2のSIMD整数演算(SSE2)の実性能はCoreの2.3倍程度
> 単純にユニット幅が倍になっただけでなくアウトオブオーダ実行もかなり進化してると思っていいかと。
>>447 > 2.3倍とはすごい。これは多分ALUが1個増えたせいだよ。
> いくらスケジュールしたって、レイテンシ据え置きだから2倍以上は速くなりようがない。
PII/PIII/PM/Core では MMX-ALU と MMX-Shift が発行ポートを共有している
_____Port_0_________Port_1___
| MMX-ALU | MMX-ALU |
| | MMX-Shift |
~~~~~~~~~~~~~~~~~~~~~~~~~
Core 2 では別々の発行ポートになったのではないだろうか?
____Port_0________Port_1________Port_2___
| SSE-ALU | SSE-ALU | SSE-Shift |
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
デコード・発行も4/3に広がったのが大きいとオモ。
>>451 (1-0.5というのはレイテンシ1clk、スループット1命令/0.5clkの意味)
>>382によると、汎用レジスタのシフトは1-0.5で、2つのALUで実行できるようだ。
SSEのシフトは2-1だから、2-2のユニットが2つor2-1のユニットが1つになる。
おそらく、SSEは強力な128bitシフトやMISC系のポートが1個なんじゃないかな。
まあ、Yonahより遅いものが多いが、128bitでシフトの配線を引っ張る苦労を考えたら
強力と言いたくもなる。逆に2個は積めないだろうという予想。
ポートの配置は次のように予想する。シフトは汎用レジスタのみで、他は128bitが可。。
Port_0:移動、論理、ジャンプ(マクロフュージョン対応)
Port_1:移動、論理、整数加算、シフト、FP加算、MISC(含SIMDシフト)
Port_2:移動、論理、整数加算、シフト、整数乗算、lea、FP乗除√
Intelの最適化マニュアルによるとP6はこんなだった。基本的に64bit演算。
Port_0:移動、論理、整数加算、シフト、整数乗算、lea、fadd、FP乗除√
Port_1:移動、論理、整数加算、ジャンプ、FP加算(SIMD)、MISC(含SIMDシフト)
faddってなんで乗算側のユニットにあるんだろう。
今PenMでaddssとmulssを並べてみたが、1命令/clkの壁は破れそうにない。
addssは1uopなのでデコードがネックというわけでもないと思うんだけど。
そもそもaddssとmulssはポート別だから並列実行できると思ったのにな。
アンパックやシャッフルも、128bit化でレイテンシが伸びている。
64bit→128bitで、普通の演算なら倍にするだけだが、シャッフルなんかするわけだから
倍じゃ済まない。単純計算で要素間の移動パターンは2乗の4倍になる。
movhlpsは、Yonahで0.5-0.5、Conroeで1-1という結果だ。
スループットが0.5というのは変だが、後述するように依存関係がゆるいので誤測定されたと
思われる。演算器の幅を倍にしたConroeが遅くなっている。
movhlps xmm0,xmm1 で、xmm0=h0:l0、xmm1=h1:l1 とする。
Conroeだと、1clkで実行できるのでレジスタの上位と下位を結ぶ配線はあるのだろう。
だが、さすがにそんな線を2つも敷けないらしく、スループットは1にとどまる。
Yonahの場合、内部では64bitなので、movq l0,h1 という簡単な処理で済んでしまう。
更に、h0やl1との依存関係も発生しない。
これは、h0やl1を使う命令と並列実行できるということだ。
他。
FPの除算や平方根で、簡単な値のとき(√0とか)がYonahより1clkずつ遅くなっている。
パイプが1段長くなったのかな。別に痛くはないが。
rcppsは128bitでは3-2のまま。64bitでは3-1から3-2に遅くなった。
MMXのシフトpsrlq mm,mm が1-1だが、shr r64,cl は1-0.5だ。
同じような動作だが、MMXの方はpsrldなどもあるので合わせているのだろう。
455 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/23(金) 22:56:45
上位64bitと下位64bitの値の交換にクロック数を要してるとみた。
パイプラインになってて、MMXのときは1段目だけ実行、とかやってるのかなと思ったり。
456 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/23(金) 23:08:10
二つあるシフトユニットの一本だけがローテート命令を実行でき、また一本だけがSIMDのシフトユニットとして使える。
バイトローテート命令としても使えるpalignrのスループットが1と推定できることから、
ローテートが可能なユニットとSIMD兼用のシフトユニットは同一だと思う
>>456 なるほど。じゃあ
>>453のCore2のPort_1は、こうなるか。
Port_1:移動、論理、整数加算、シフト(含ローテート、SIMDシフト)、FP加算、MISC
MISCもシフトと共用してたりするかな。
>>452の言うデコードも含め、全パイプに渡ってALU1個分の命令帯域が
増えているというのは大きい。
2つのSIMDユニットがフル稼働している横で、アドレスのインクリメントや
比較・条件分岐などを悠々と並列実行できる。
そればかりか、レジスタ間のmovapsなども実行できてしまう。
ロードストア周りのOoOは詳しくはわからんけど、これも効きそう。
>>447 シングルCPUでもキャッシュ性能が段違いにいいので1.3GHz程度ならとんとんでは?
1次キャッシュに収まらない計算していたらPentiumM1.6GHzとIntelCore1GHzが同じくらいとか平気で結果が出るよ。
あのストア性能は異常。
459 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/24(土) 14:36:21
ヨタ話っぽ
>>458 そこまで言われると正直わからないな。実機持ってるわけじゃないし。
俺としては、絶対的な強さとなるクロックの高さを選んだのだ。
> PentiumM1.6GHzとIntelCore1GHzが同じくらいとか
それはベンチ結果などあったら知りたい。
>>459 ストアデータとストアアドレスが分かれているのが気になるが、まあそんな感じか。
>>460 >>191のやつだね。
きちんと依存関係を見て実行したり、順番通りにリタイヤさせたりするのを、
一体どうやって実現するのかが非常に疑問だ。
何しろ、別コアでデコードされた命令との依存関係を調べないといけないのだ。
更に別コアの計算結果を数clkで引っ張ってきたりする必要もある。
これじゃもう巨大な1コアCPUのハイパースレッディングだよねえ。
ただ、俺は投機的マルチスレッディングは嫌いだが、この技術は好きだ。
デュアルコアのリソースはシングルコアの倍あるんだし、
何とかすれば2割くらい速くすることもできなくはなさそうにも思う。
開発中止になったK9の経験が生かされてるといいな…。
でもやっぱ信用できね。
464 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/25(日) 00:19:13
JITコンパイラでマルチスレッド向けに再コンパイルして実行が現実的なところかなぁ
株価が下がり続けてるから何かの対策かと思ってしまった。
要するにあれ。風説の(ry
465 :
201:2006/06/25(日) 00:40:09
>>446 > タイマで起こす。
やはりカーネルモードですかね。
>>447 > このスレッドが2つあると普通にCPU使用率100%でDeepSleepしないと思うけど。
スレッド数をべらぼうに増やしたりしたらコンテクストスイッチだけでも忙しくで100%になっていいはずですが、
実際にはDeepSleepしたわけですから、
>>445のような今更な結論になったわけです。
>>448 しまった。同期を取らなければ動きがバラバラになっちゃいますね。
>>445のloooooopはnWakeUpTimeを持っているので、
tの値をgetTime()ではなくnWakeUpTimeからの相対時間で決めれば…
466 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/25(日) 00:45:55
MONITOR/MWAITって使い物にならない?
467 :
201:2006/06/25(日) 00:55:30
>>462-464 株価対策はあるかも。
ただ、マルチスレッドと違うのは素直に行った場合±数byteのほぼ同じアドレスをデコードする羽目になるので
同時にデコードして依存関係をお互いに確認するのは非効率なんじゃないでしょうか。
SMPと言えるかは分らないですが片方が中心になって、
「これとこれのレジスタに関するものは(依存関係が切れるまでは)お前に任せた」みたいに仕事を振れば
もう片方のコアが扱っているレジスタが必要になる事は減るんじゃないですかね。
比率で言えば大概の処理は最後の方まで少ないレジスタで完結していて、
最後のトータルとか結果を合わせる為に通信が必要になる感じ。
最近のCPUがOOOをどれくらいの範囲で行っているのか知りませんが、
現状既に広い範囲のOOOが出来ているのであれば
その範囲の依存関係は分っているわけですから、後先考えた振り方は出来るのではないかと。
なるほど、懐疑的ではあるけれども単なるデマって訳でもないって感じなのかな?
もしこれが有効に働くのであればかなり面白い技術ですね
469 :
201:2006/06/25(日) 03:19:51
>>466 どういうことです?
>>467の続き
実際どんな感じに動くのか妄想してみたかったので
>>268のsse1.cppのMLsseから一部を左右2つのプログラムに分けてみました。
無意識に選びましたが、たまたま都合が良いコードだったというだけであれば指摘お願いします。
lp0:movaps xmm2,xmm0 movaps xmm3,core0:xmm1
mulps xmm0,xmm0 movaps xmm2,core0:xmm0
mulps xmm1,xmm2 mulps xmm3,xmm3
addps xmm0,xmm6 addps xmm2,xmm3
addps xmm1,xmm1 cmpnleps xmm2,xmm5
subps xmm0,core1:xmm3 movmskps eax, xmm2
addps xmm1,xmm7 test eax, eax
jnz core1:eflags, mm jnz mm
re: dec ecx
jnz lp0 jnz core0:eflags, lp0
感想としては、思ったより簡単かつ奇麗に振り分けられた。
コア当たりの処理がタイトになるのでレジスタのストールが増えそう。
IPC6は眉唾。といった印象です。
conroeの64bit性能は?
471 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/26(月) 03:00:10
>>469 そういうレベルで再スケジューリングしても同期のオーバーヘッドでかえって性能が落ちるだけのような。。。
472 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/26(月) 03:10:08
実際にはこういうレベルでしかやれない気がする。
for ( i = 0; i < 10000; i++) a[i] = Foo( b[i] ) ;
↓
core0: for ( i = 0; i < 5000; i++) a[i] = Foo( b[i] ) ;
core1: for ( i = 5000; i < 10000; i++) a[i] = Foo( b[i] ) ;
こういうのがハードで提供されるのかソフトで提供されるのかが問題かと。
現状、L1同士がダイレクトコネクトされてるわけでもないし、もう片コアのデータにアクセスするにはクロスバーを経由するしかない。
たしかにループの分割がいいところだな。
>>469 都合のいい振り分けをCPUが考えるにも、デコードしないといけないし、
それでそれだけ他コアへの参照が発生するとなると普通なら無意味だよなあ。
まあ、IPC6を狙うというよりも、実効IPCが1.3のケースで1.5が出れば万々歳、
という技術だと思う。
>>472 それこそコンパイラが対応すべきでしょう。
ていうかそんな技術だったら(俺としては)期待外れもいいとこだ。
でもコア同士が密接に絡み合うって技術的にありえなそうだしなあ・・・。
>>470 完全に64bit化されてるだろうから心配いらないと思う。
「Core Microarchitecture」の速さの秘密は“CISCの美”
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm 結局、受け入れ元はx86命令として、実行しやすい命令に変換する、
そして内部のアーキテクチャを改善する、という方向性は変わっていない。
内部アーキテクチャを極限まで最適化しようという姿勢はNetBurstにも通ずる。
NetBurstの場合は、デコーダが切り離されていたので、より強いと言えるけど。
その内部命令の仕様が、消費電力のシバリがなければRISC系がよかったんだけど、
でも一定の電力で性能を追求するとCISC風な内部命令のがよかったということだ。
これからは、この内部命令がより改善され、
また内部命令への変換の手間を節約するためにトレースキャッシュも使われるだろう。
そう考えると、Crusoeも同じようなアプローチだったのかな。
uOPキャッシュがメインメモリまで侵食してるからネトバ以上の大胆さだが。
まあ結局はuOPsの粒度をどうするかって問題だわな。
forループの分割はOpenMPでも出来るしね。
477 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/26(月) 23:24:26
Crusoe/Efficeonと似たようなアプローチを取るってのは面白いと思う。
要するにコードモーフィングにより並列化するってことね。
Crusoeとは違う点は
・x86を元々ネイティブで実行できる
・デュアルコアなので、片コアで動かしつつ、もう片コアでバックグラウンドでプロファイリング&最適化
多分IA32ELみたいなソフトウェアとして提供されるのかな。
ハードだけでは多分無理だと思う。
若干ネックになりうるのがメモリ帯域。これはCrusoeはかなり酷かった。
>>472 ループにおいて依存関係がない場合は勝手にやってくれる、もしくは手間なくすぐにスレッド生成できるのがいい
.NETやJavaがそっち方面強いのでシングルスレッドでアセンブラでがんばるより
それなりのスピードで動く環境でマルチスレッドを駆使して使うのだ
問題はそれなりの依存関係がある場合だが・・・
アセンブラすら買えない時代のおっちゃんとしては寂しいものだがこれも時代の流れだな
Cなんてメモリ食うし遅くてやってられないというのを何度も聞いてきたのと同じ
479 :
201:2006/06/27(火) 00:30:42
>>472 それ何てOpenMP?
今OpenMPはVisualC++にも入ってるのでまともな規格なら普及するでしょう。
クラスタのようなものは複雑なのかもしれませんが、
単純ループをスレッドに分割するくらいなら簡単に出来るわけですから
基本的にはOpenMPを差し置いてわざわざ専用ソフトをこしらえるまでもないですし
IntelのCPU上でも同様に動くコードが出来上がるのでアドバンテージになりません。
逆に弱小AMDのCPUでしか動かないような代物(uOPsバイナリを吐くとか)であれば、
3DNow!の二の舞です。
OpenMPが使いにくい、まともじゃないというので
AMDが独自のツールを作るというのはアリですが、CPUの機能とは言えません。
>>477 その方法だと理論値を出し切ってもIPCは3に留まる気がします。
x87をコードモーフィングでSIMD化してIPC6を目指す、と無理矢理捉えられない事も無いですが。
>>474 今までIntelがロードと演算の命令を分けろと言っているのに対し、
AMDはレジスタ-メモリ演算命令を使用しろと言っていたのはこういうわけがあったんですね。
480 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/27(火) 00:55:11
Loadユニットは1本だから必然的にLoadは節約せざるを得なくなる。
整数SIMDのLatencyが1なのが救い
481 :
201:2006/06/27(火) 01:34:12
>>474 シングルコアにしたって必ずデコードしてるので、片コアの性能は落ちないはずです。
このデコード時に担当レジスタを決めてもう片方に伝えてしまえば、デコードに関する相互参照は無くなります。
もしくは、デコード時にCore1が「Core0はどのレジスタを担当しようとしているか」を
予測出来るスケジュール規則にしておけば、残りが自分の担当というわけで、担当レジスタを伝える必要も無くなります。
これなら片方が中心になる必要も無いので真にSMPで実現出来ますね。
「1.3のケースで1.5が出れば万々歳」には激しく同意です。
以下は
>>469を見ただけで理解出来た人には蛇足です。
>>469のコードで左側のコアに注目した場合、
右側のコアの最初の2行は、完全に同期してもほんの少しはIPCを上げられそうですが
実際には左のコアがレジスタの内容を非同期で送信してしまえば、
左のコアは止まる事無く勝手に続けてしまって構わないわけです。
バッファがいっぱいになれば、もしくはバッファを持たない場合で送信命令が連続している場合は
前の送信が完了するまで待つ必要がありますが、
実際には常時もう片方を参照しなければならないようなコードは稀なのでIPCは向上します。
片コアだけどんどん先に行ってしまうとバッファがいっぱいになり(バッファ無しでも同じ)
ただでさえボトルネックな通信が更にボトルネックになってしまうので、
通信を均等にさせるように振らないといけなそうですね。
あとは通信にかかる時間がどれくらいかですが…専用に繋がっていればもちろん速いですし、
L1の様な広大な空間&大きなラインサイズではなくレジスタの数とサイズはたかが知れているので速く出来ないですかね?
と、妄想なのに力説してしまいましたが、この方法が実現出来た場合に嬉しい事は、同じ事をマルチコアでやらせるのでは*無い*という事。
通信を無視すればデコーダと演算器の多いCPUとして機能するので、マルチスレッドかが困難なアプリケーションのIPCを上げられるという事です。
482 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/27(火) 02:17:05
>>479 いや、ある程度プロファイルができたら2スレッド分の実行コードを生成して各コアでそれを代わりに走らせる感じ。
Crusoe/Efficeonもギアが十分にかかったら最適化は辞める仕様になってるはず。
これ、なんとなく固有のCPUの機能とかじぁなくて、
MS(Windows)のインチキ新機能じゃないの?
>>474下補足
内部アーキの性能を上げるというコンセプトでも、内部命令への変換効率は問題になる。
そこで内部アーキをよりアグレッシブに変えるために、変換効率の寄与を下げる手段の一つが
トレースキャッシュの装備だ。
そういやあ、Efficeonをネイティブで動かすなんてことはしないのかなあ。
コードモーフィングに時間を食われ、命令のキャッシュまでメモリ上に必要となる、
そうまでしてもP3程度の性能になったんだから、素の性能はどんだけかと。
>>477 2コアを非対称に使うというのは面白い発想だ。
しかし元々がx86ネイティブだと最適化の余地は少ないと思う。
(ノーマル命令のSIMD化とか?)
もし
>>472やるんなら、
>>477>>482のような感じでできるかな。
>>479 > 今までIntelがロードと演算の命令を分けろと言っているのに対し、
それが周知徹底されたせいで、PenMで分けない方が速くなったら損したかな?
関係ないけど、この現状って、新アーキテクチャ(x86から離れる)を作るとしたら
命令セットはRISCよりCISCのがいいってことだよね。
>>480 Athlonって簡単なMMX命令でもレイテンシ2だったね。
何が阻害要因だったんだろう。
>>481 いや、デコードした「後で」振り分けないといけないということ(命令はデコーダを選べない)。
つまり、パイプラインの途中で命令を違うコアに送る必要が出てくる。
コア間通信の線を引っ張るコストはすごいと思うし、コアの設計をかなり変える必要がある。
また、振り分けを考えるのも大変な作業で、パイプラインが長くなると思う。
Core1がCore0の担当を予測することについては、Core1に入った命令を知る必要があるので
予測は不可能であり、高い通信コストをかけてCore0から教えてもらうしかない。
> 同じ事をマルチコアでやらせるのでは*無い*という事
うん、そこがこの技術のキモだと思う。これは本当に嬉しい。
しかし、だからこそ難しい。
以前(
>>191のとき)あったFPUを共有というのはどうだろう。
6IPCという看板は実行ユニットだけで、デコード・リタイヤは3IPCに止まるというもの。
だが、
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai_5.jpg この辺りのレイアウトを見ると、各コアのSIMDユニットは物理的に離れまくっている。
それどころか、数clkでコア間通信なども、とても無理そうだ。
3GHzなら、1clkで光が10cmしか進めない世界だからねえ。
何か自分で書いてて絶望的な気分になってきたよorz
依存関係のチェックをしてOoOのスケジュールとか、順番にリタイヤとか、
ただでさえ電力食いと言われる重い処理なのに、違うコアにある命令とできるわけがない。
本物の6IPCが可能なら、とっくにシングルコアでそうしてるはず(デュアルなんか出さずに)。
できないけど、何かを捨てることで、デュアルコアで6IPCの仮想CPUを作れた。
いやあ、相当捨てないとできそうにないです。。
でも何しろ、HTと違ってこちらは2コアのリソースを丸々使えるのだから、何とかなるかも・・・。
いや、AMDならきっと何とかしてくれる!
SSE2整数を使って最適化したコードをPentium 4上で、32bitと64bitで
比べてみたら殆ど違わなかった。
SIMD整数ユニットはTP:2に対し、Load/Storeも1だから、レジスタが増える
ことによる恩恵は無いのか、16本の論理XMMレジスタを有効活用するようにして
L/Sの頻度は確実に減らしてるのに、ほとんど同じ値が出てがっくし。
まぁ、Core 2になるとL/Sより実行ユニットのスループットのほうが勝るから、
伸びるでしょうな。
あと、どうやら pxor xmm0, xmm0 なんかがレジスタリネームのヒントとして認識
される ようになってるらしいけど、データの読み書きの頻度の高くないコードなら
ロードしたほうがかえっていいかもしれんね。
このへんの見極めは触ってみない限りはなんとも。
余談だけど、SSExでガリガリやってる部分はあっさりビルドできるのに、32ビット
では通ってたGUIとかライブラリ周りでコケる。
コンソールアプリはあっさり作れるんだけど。ネイティブで64bit対応は茨の道ですな。
(VC++はまだ対応してるだけマシだがDelphiは対応すらしてないし)
ホットな部分のみネイティブDLLにして全体をマネージドコードで書き直すのが一番幸せかも。
#Intelの中間言語アクセラレータ云々はどうなったかな?
487 :
201:2006/06/27(火) 18:45:32
いや、デコードは通常通り全命令行うんです。
なので今までと変わりありません。
最悪回路を拡張出来ないとしても、例えばxmm0-3はCore0、4-7はCore1と決め打ちしてしまえば、デコーダは関係のない命令を捨てるだけ、という感じです。
それに、同じ箇所を違うコアの同じデコード機構でデコードしてるわけですから、お互いの担当を予想するのは簡単なはず。
現実問題実装したら使えるのか使えないのか解らない機能を実装すれば
CPUのデコード~スケジューリングステージと同等以上のものをフロントエンドに
実装することになり、より多くのトランジスタを食うってことになるので、
やはりソフト実装になると思う。
デュアルコアだから、片コアで並列化作業を行ってる最中もアプリは
そのままもう片コアで実行できる。Clustered Multithreading
要するに
>>477,
>>482ってことだが。
489 :
201:2006/06/27(火) 21:21:04
>>484 > Efficeonをネイティブで動かすなんてことはしないのかなあ。
Itaniumみたいになるだけではないでしょうか。
> 命令セットはRISCよりCISCのがいいってことだよね。
最終的にはCISCの方がいいんじゃないかと思うのですが、
>>474の記事はCISCがどうのというより
メモリ-レジスタ演算を分解せずにそのままにしてるだけみたいですよね。
命令セットがCISCというのが可変長の事を指しているのであれば、
メモリ-レジスタ命令は命令長が32bit固定でも作れると思いますよ。
>>488 > 使えないのか解らない
どんな実装をしてくるにせよ、作ってる人達は分っているでしょう。
CISC、RISCといっても86みたいな変体CISCもあればSHのようにどこがRISCだよとかあるし
並列とメモリ効率を意識した命令セットがあればいい
単純にCISCがいいといってもさすがに86はえらばんだろ?
今はメモリのアクセススピードに比べて演算部分が無視できるからパック化ということだろうけど、
コンパイル時に解決できるものは解決したほうがいい
PPCのように複雑で結局分解してるようだとあんまりうまみもないけどな
まぁ一番バランス的に現実的に見えるのはLIWかな
DSPとかで一般的に使われてるがメモリ効率と安定してぶんまわすのに最も効率がいい
>>487 > いや、デコードは通常通り全命令行うんです。
つまり、デコーダの段階で3IPCに甘んじるという意味か。ピーク6IPCの話だと思ってた。
これなら確かに相手の担当を予想というか知ることができるね。
>>489 > Itaniumみたいになるだけではないでしょうか。
どういう意味で?x86のソフト資産は生かせないけど、Efficeon向けにコンパイルすれば
(↓のように)電力効率バツグンのCPUとして使えると思った。
>>489>>490 言われてみればMeromの内部命令ってどんなフォーマットなんだろう。
ある程度複雑な命令という意味ではCISCだが、確かに可変長だとは思えない。
あとは命令キャッシュの容量やフェッチ帯域を考えると可変長が有利になるが、
デコードの大変さとのトレードオフだから、やっぱり固定長がいいかな。
今後のトレースキャッシュ採用x86CPUの命令フォーマットが知りたいところだ。
Efficeonについては、内部アーキテクチャを極限まで効率化してから、
x86を無理矢理それに合わせている面があるので(Efficeonも多少は譲歩してるだろうが)、
内部アーキの性能・メモリにキャッシュされた命令フォーマットに関しては、
原理的にMerom内部のそれなどよりも高性能(実際どうかは知らんが)であるはずだ。
EfficeonはVLIWだった。
CISC風ってのはロード/ストアと演算命令が分離してないってだけで、
μOPレベルでわざわざ可変長命令にする必要はないだろ
VLIWはRISCを明示的並列させただけってのが多いけど
LIWは64bitに1つから3つを1命令に柔軟に入れるのが多い
FPGAとかでオリジナルCPUを作ろうと遊んでみればわかるけど
このクラスがちょうどいいんだよね
NOP大量に詰まったVLIWよりは
494 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/27(火) 23:53:55
HyperThreadingはわずかなトランジスタ追加で済む技術なのでつぶしが利くが、
各コアのL1やレジスタファイルをダイレクトコネクトとかのレベルまで吹っ飛んでるんで
はっきり言ってそれは新リビジョンとか通り越して新マイクロアーキテクチャっしょ
メモリ帯域は増えてるんで、コードモーフィングソフトを動かしても
さほどシングルスレッド性能は落ちないと踏んだと思う。
ちなみに、22nmプロセスくらいになると32MBくらいのSRAMをダイ上に乗っけるくらい余裕になるので
PARROTはこの頃かなと思ったり。
>>486 減らしたL/S以外のメモリレイテンシがネックだったか、
元から実行ユニットのスループットを使い切っていたか、だね。
Core2では、Yonahと比較してSIMDのスループットが倍でレイテンシ据え置きなので、
レイテンシを隠蔽することが相対的に難しくなっている→16本のレジスタ有効活用できる。
まさに論理レジスタの増えたタイミングピッタリという感じだ。
トリップ検索だと、L2レイテンシがもろに効くと思うのでCore2で性能が上がらない気もするが、
実際は速いらしいね。増えたレジスタを活用して2つのキーを同時に処理とかしてるの?
> どうやら pxor xmm0, xmm0 なんかがレジスタリネームのヒントとして認識
めでたいことだ。ALU増えてるから比較的ガンガン使えるんじゃない?
>>492 全くその通り。
>>493 そういう使用感は参考になる。
496 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/28(水) 00:18:37
>>495 DESのS-Boxのテーブル参照は入力値6bit・出力4ビットなんだけど、これをビット演算の組み合わせで
行うことで、レジスタ幅の分だけ並列化することができるす
http://www.darkside.com.au/bitslice/sboxes.c MMXやx64 ALUを使えば64並列、SSE2を使うと128並列に処理できるわけ
Conroeはビット論理は3ユニット全て使えるらしい。
並列実行による手法としては、前にAltiVecのVPERM命令を使って16並列実行する方法を思いついたけど
あんまり実用的でなかったので結局お蔵入り。
むりやりx86-SSEで書いたのが
>>130なんだけど、本家はS-Box1つにつき1回のVPERMオペレーションと
数回のビットシフト・論理演算だけで演算ができる。
CamelliaとかAESはテーブル参照をビット論理に展開するとかえって処理量が増える罠。
せいぜい攪拌処理をSSE4で高速化できるかな、とか思うくらい。
Conroeの命令フェッチは16Byte/サイクルか?
>>382を見るとNOPの命令長が一定以上になると同時に実行できる命令が
減っていく事がわかる
スループットが命令長と命令供給量に依存すると仮定すると
スループット ≒ 命令長 / (1サイクル辺りの命令供給量)
となる
>>382の測定値と理論値をまとめたもの
命令長 tp 理論値
1-5 0.33 5/16 = 0.3125(0.3333)
6 0.38 6/16 = 0.375
7 0.43 7/16 = 0.4375
8 0.50 8/16 = 0.5
9 0.56 9/16 = 0.5625
10 0.63 10/16 = 0.625
498 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/06/28(水) 00:40:57
AMDはロード・ストア多用推奨だからフェッチ帯域広めなんだよね。
>>496 正直そっち方面は詳しくないんだが、それだけ並列にできれば
L2レイテンシというより、ランダムなラインフィルの実効スループットが
ポイントになりそうだね。
>>497 ありゃ、見事に一致してるな。
他のCPUと比べれば速いが(トレースキャッシュは例外で命令長無関係だが)、
16byte/clkって内部命令帯域からすると意外と少ないね。
ただ、常に16byte/clkを出せるということは、16byte境界をまたげるわけで、
16byte alignの32byteを1clkでフェッチしてその中の16byteを取り出す感じかな?
500 :
201:2006/06/28(水) 07:52:24
>>491 > つまり、デコーダの段階で3IPCに甘んじるという意味か。ピーク6IPCの話だと思ってた。
あら、もしかして同時に3命令デコードだと6IPCは目指せないですか?
シングルコアの場合でもOoOの為に先を読んでるかと思ったのですが。
デコードの段階なのかOoOの段階なのか分りませんが、
捨てる命令が出来るだけなので6IPCには近づくと思ったのです。
>> Itaniumみたいになるだけではないでしょうか。
>どういう意味で?x86のソフト資産は生かせないけど
Itaniumのx86互換機構を使わない状態とEfficeonのx86互換機構を使わない状態が
VLIWという意味で似たようなものではないかという事です。
> 電力効率バツグンのCPUとして使えると思った。
確かに。
501 :
201:2006/06/28(水) 07:59:11
> OoOの為に先を読んでるかと思ったのですが。
先を読んでないとしても、3命令読んで1~2命令捨てて残りの1~2命令実行を繰り返していれば
実際に各ユニットの使用率は半分に減るので、
パイプラインに突っ込めるコード範囲が倍になります。
するとリタイア時点で1コア当たり3IPC、計6IPCにならないでしょうか。
>>500 > シングルコアの場合でもOoOの為に先を読んでるかと思ったのですが。
それは根本的に違うと思う。
デコードが3命令/clkで、実行が1命令/clkのとき、1clkに2命令が内部に溜まっていき、
その溜まった命令の中でOoOをやるのだ。
デコードは完全にインオーダーだから、ストールしない限り単純に3命令/clkを続けるだけ。
> 実際に各ユニットの使用率は半分に減るので、
1~2命令捨てるという作業をするまでのユニット使用は半分にならない。
今までの倍の命令をフェッチして、1コアで6命令同時デコードをする必要がある。
もしくは、本当に3命令読んで1~2命令捨てるならピークIPCは2コアで3になる。
503 :
201:2006/06/28(水) 21:01:14
>>502 >1~2命令捨てるという作業をするまでのユニット使用は半分にならない。
そうですが、演算器とパイプラインは使用しません。
すると、
>>223のような「理不尽なストール」が起こるのが
通常の倍のコード範囲先にならないでしょうか。
>今までの倍の命令をフェッチして、1コアで6命令同時デコードをする必要がある。
>もしくは、本当に3命令読んで1~2命令捨てるならピークIPCは2コアで3になる。
デコーダ性能は2コアで3になりますが、
>>501で言いたかったのは処理全体の性能です。
ディスパッチ可能な命令数が平均1.5命令/clkだったとしても、
リタイアは3命令/clk行えるわけですから、
パイプラインを有効に使える(処理時間の異なる)命令を交互に入れていけば
ピーク性能は6IPCになるんじゃないかと。
例えば、Intelの最適化マニュアルによると一部のNOPは特別な命令として最適化されるとあります。
実際、Athlon系でもmov eax, eaxなんかを1~2命令(平均1.5命令)ごとに挟んでも速度の低下はわずかであり、
倍の時間かかるという事は無いです。
これの応用で出来ないですかね。
YonahのU2500が出た模様。TDPが9Wの超低電圧版で、1.2GHzのデュアルコア。
以前のULVはTDPが5.5Wだったからなあ。どんな機種に載るんだろ。
>>503 > パイプラインを有効に使える(処理時間の異なる)命令を交互に入れていけば
> ピーク性能は6IPCになるんじゃないかと。
実際にx86命令を1clkに3つしか処理できない状況を「ピーク性能は6IPC」と言われても、
「スケジューラの能力が」とか「実行ユニットが」とか説明がないとわからないす。
デコーダは3IPC/コアが限界なので、どうやってもピークIPCは3が限界だけど、
「理不尽なストール」や実行ユニットの性能は倍になるから速くなるということか。
これが、片肺デコードの単純な実行ユニット共有に勝っている点は、
スケジュール関係のリソースが倍使えるところだな。
どちらにしろ、コアのレイアウトを見るに通信できそうな距離じゃないんだが・・・。
リタイヤも障壁になると思う。
>アーキテクチャ上の状態を元の順序で更新し、例外の順序を管理する
隣のコアの管理までしてたら、コアに命令が溜まりすぎてしまう。
こんだけ期待させといてウソ技術だったら許さねえぞ!
元々ただの噂レベルな件
こんだけ期待させといて
こんだけ期待させといて
こんだけ期待させといて
判りやすいねえ。
507 :
201:2006/06/29(木) 21:39:42
>>504 >「スケジューラの能力が」とか「実行ユニットが」とか説明がないとわからないす。
ごめんなさい。CPUの仕組みを鮮明に理解しているわけではないので漠然としがちですが、
デコードより後から速くなり、リタイヤ6IPCでリタイア出来る事を想定しています。
>>アーキテクチャ上の状態を元の順序で更新し、例外の順序を管理する
>隣のコアの管理までしてたら、コアに命令が溜まりすぎてしまう。
通信の時点で同期しなければならないというか、順番通りに行わなければならないので、
通信が正しく出来ているならリタイアは同期しなくてもいいと考えました。
その通信に関しても、
>>481のように(OoO機構で?)正しく依存関係を把握出来ていれば
非同期に通信してしまって構わないと考えています。
元々1本のコードなので、送信側は何も考えずに送信してしまい、
受信側はFIFOで取り出すだけで「この時点でのレジスタの内容はxxだった」
という時系列は考慮しなくても考慮出来ているはず。
というかFIFOという考え方が一種の時系列管理機構。
例えば
>>468の1行目
movaps�xmm3,core0:xmm1
をcore0は通常通りデコードするわけですが、xmm3は自分の担当レジスタではないので
実行しない事を決定します。
しかし、xmm1は自分の担当レジスタなので、core1にxmm1の内容を勝手に送りつけます。
core1はこのコードにさしかかった時に初めてバッファからいつ送信したかも分らない
xmm1の内容を取り出しますが、FIFOで時系列順にバッファに納める事だけは決まっているので
この内容が自分が欲しい時点でのxmm1の内容に撒き戻っている事が保証されているという寸法。
> リタイヤも障壁になると思う。
> どちらにしろ、コアのレイアウトを見るに通信できそうな距離じゃないんだが・・・。
やはり無謀ですかね。
>>505 すみません。スレ違いな上に妄想バラ撒き過ぎました。
508 :
201:2006/06/30(金) 03:27:20
>通信の時点で同期しなければならないというか
曖昧でした。通信とは、お互いのレジスタを参照する為の通信です。
>例えば
>>468の1行目
s/
>>468/
>>469/
コア間でリタイアの同期が要らないというのは、core0に注目すれば下のコードを通常通り実行するだけで良いという事です。
lp0: movaps xmm2, xmm0
mulps xmm0, xmm0
send core1:xmm1, xmm1 ; movaps xmm3, xmm1
mulps xmm1, xmm2
send core1:xmm2, xmm2 ; movaps xmm2, xmm2
nop ; mulps xmm3, xmm3
addps xmm0, xmm6
nop ; addps xmm2, xmm3
addps xmm1, xmm1
nop ; cmpnleps
subps xmm0, core1:xmm3
nop ; movmskps eax, xmm2
addps xmm1, xmm7
nop ; test eax, eax
jnz core1:eflags, mm
re: dec ecx
jnz lp0
メモリが対象の命令は、拡張出来なければ全てcore0に振ってしまえば良いでしょう。
それで遅くなるようであればメモリネックの可能性が高いので、そもそもマルチコアの恩恵は受けにくいです。
拡張する余裕があれば外部、例えばメモリコントローラ辺りにバッファを設けます。メモリリタイアユニットと言ってもいいかもしれません。
あとコードモーフィングだとOpenMPと違ってヒントが無いので解析が大変ではないかと。dec reg/jnz形式
かつ配列のインデックスが超単純であれば分割しやすいですけれど、memmoveのように配列がクロスしても動くようにするのは中々骨が折れます。
問題は片方のコアを止めるなりクロック下げるなりして、もう片方のクロックを上げた方が
素直に性能が出そうなことなんだよなあ。
難しい方法より安易な方法のほうが即効性があるというのは世の常か。むしろ当然か。
510 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/07/01(土) 02:28:31
ソフトウェアでスレッド分割して実行する説を信じて疑わない。
ハードの性能的にはEfficeonよりだいぶ条件はいいしね。
データ依存関係の無い2スレッドがきれいに並列に動いてはじめて6IPCが実現されるわけで
何の手も入れてない素のシングルスレッドコードをハードだけで振り分けるのは
ところで、私は昔、数万クロックサイクルで一周のビジーループを最適化してるとき、
Hyper Threadingを使えば並列実行でスループット稼げるかもと思い、2スレッドで同期を取りながら動く
コードを書いてみたことがあります。
結果は・・・まぁお察しのとおり。
実はIntelも同様の技術に対応してるらしいけど、そのコードモーフィングソフト出す会社がAMDでもIntelでもなく
Microsoftあたりだったりする可能性も疑ってみる。
511 :
201:2006/07/01(土) 02:48:23
>>509は一理あるのですが
>>510の疑わない点をお聞かせいただければ。
いや、端から見ていれば難癖付けて突っかかっているように見えるのでしょうけれど、
純粋に自分の理解が弱いというか、なんでそう思えるのか理解出来ないので。
今まで妄想してきた点については、多分(本当に多分としか)他の方法に比べて実装コストが少なく、
そして現実的に高速化を実現出来ますし、
ループ分割だとインデックスレジスタが2つ登場するだけでmemmoveと同じような
アドレス空間がクロスした状態になるので解決が難しくなると思うのですが。
最終的には団子さんの株価対策という意見に賛成で、効果がなくても良いものだと思っています。
が、Intelも実装しているならばそれなりの根拠がありそうな気も。
> Hyper Threadingを使えば並列実行でスループット稼げるかもと思い、2スレッドで同期を取りながら動く
「結果は・・・まぁお察しのとおり。」とある通り、同期を取っている時点で(ry
専用の実装を行う限り、上に述べてきた通り同期は最小限で済むはず。
>>507 まあ、俺も詳しくないし。
リタイヤに関しては、それでいいならリタイヤがインオーダーである意味が・・・とか
思ってしまう。というか正直、反論も同意もできないです。
CPUのOoOやレジスタリネーミング、分岐の投機実行、リタイヤ、
それぞれの具体的動作が全然わからん。
>>509 そうなんだよなあ。。
俺の「感情」で言えば、
>>507のような実装はコストが大きすぎて無理。
団子さん説は不可能ではない。が、
>>507のが好き。
理想は、真の6命令同時デコードのCPUに見えてほしいが、
それは201氏説や団子さん説以上に難しい。
株価対策にはシブシブ同意しながらも、最初の期待を裏切ってほしくない。
というところ。
単なる俺の思いなので信憑性はないです。
メモリのクロック数に関して書いてたんだけどまとまらん。
また次の書き込みのときに。
515 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/07/01(土) 17:16:34
コードモーフィングソフトによるクラスタードスレッディングの実装の利点はトランジスタを増やさずに済むという点かと。
デュアルコアの片コアのリソースが十分に使い切れてないことが逆に、初動時にコードモーフィング用
スレッドを並列実行することによるオーバーヘッドを隠蔽できる。
メインメモリ上にプロファイルを読み書きできるので、80:20ルールにのっとって本当に必要な部分だけ
を最適化(スレッドレベル並列化)することが可能。
基本的にTransmetaやIA32ELなんかのコードモーフィングはコードの8割は無視しても
速度上重要な2割を重点的に最適化するって思想だからね。
「AM2から対応」ってのは、コードモーフィングソフトのハードウェアサポートの特権命令じゃないかなって思ったり。
OpenMPでやれるレベルのことしかやらないとしても、マルチスレッドに最適化しきれてない
昔のアプリを並列化させられるならそれで十分かなと。
今は家庭用ゲーム専用機ですらマルチコア前提の時代なんで、新しいソフトのマルチコア化は
進んでくるだろうし、どっちかというと古いのソフトのアクセラレーションを狙ったものじゃないかなと。
516 :
201:2006/07/01(土) 19:01:20
マルチスレッド化しやすい処理として
void ADD(int *A,int *B,int C,int SIZE){
while(--SIZE) *A++=*B++ + C;
}
みたいなコードはよくあると思います。
ですが、これが別配列同士の演算ではなく、
A、B共に同じ配列でポインタがずれたものが入ってくるかもしれず
どういう使い方がされるかは直前まで分からないわけです。
そうなると、おいそれと分割は出来ないと思うのですが、どうでしょうか。
517 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/07/01(土) 20:33:21
並列化しにくい部分はしなくても良いのでは。って考えてますが。
複数スレッドに分割できる部分を抽出すればいいかと。
たとえば、引数値をチェックして、依存が生じる場合と生じない場合でディスパッチしても、
お釣りがくるかなと。
ハードオンリーで実装した場合の問題は、マルチスレッドに最適化されてないプログラムを動かしてるからといっても
複数のプロセス・スレッドが走ってるわけですから、そういったものとの並列動作も考慮に入れないといけないし、
切り替えのアルゴリズムも複雑になる気がするす。
特に、コンテクスト切り替えのオーバーヘッドの劇的な増大は避けられないかと。
必然的にロジック部に使うトランジスタも増大するはずですが、コアのトランジスタ数が劇的に増えた事実もないですし
やっぱりソフトでやるための何らかの特権命令なのかなと(DEPを一時的に無効にしたり調停したり)
ソフトでやった場合はほぼ一般的なスレッドとして実装できるので、既存のマルチプロセッシングの
延長で扱える気がします。モード切替的なものも必要ないかと。
●◎○-ヽ(,,゚∀゚)ノ-○◎● ダニーダー
キャッシュライン
検索するつもりが…すまそん。
>>509 と言っても片方のコア止めたぐらいで、どれほどクロックを上げられるかな。
耐性が十分にあったとしても熱密度に縛られるのでせいぜい1.3倍が限度じゃないだろうか。
522 :
・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/07/02(日) 22:52:07
クロック上昇が行き詰ったからこそのデュアルコアなんだよな
予想通りのオチだったな
>>461 GJ!!!!
>>462- お疲れ
>>513 何の知識もない人に、知ったかでそういう話をすることはできると思う。
でも、もっとミクロに、どんな回路でOoOを実装してるかとか、イメージができない。
全加算器の仕組みもよく知らない俺だって、整数加算のコストがどのくらいか、
というのはイメージがつく。乗算も、適当なイメージなら浮かぶ。
でも、OoOとかリタイヤとか、そんな適当なイメージすらできない。
>>517 >>525でorzした後のレスになってしまったが、、
for (i=0; i<100; i++) func(i);
例えばこれを、
Core0:for (i=0; i<50; i++) func(i);
Core1:for (i=50; i<100; i++) func(i);
こう分解したとして、
Core0の途中で例外が発生したら、Core1の処理をなかったことにしないとダメじゃない?
func()の処理内容にもよるんだろうけど。
やっぱり、やるとしたらソフト実装しかない感じかなあ。
もうちょっとコマ切れにしてもいいかも。
>>521 いや、1.3倍は無理でしょ。電圧必要だろうし。俺は1.2倍くらいを期待している。
現実的な線で、1.1倍でも十分に有用だと思う。(例:2.66GHz→2.93GHzの値段差)
>>524 Core2のmulpdのレイテンシは5だったか。(
>>382にもあった)
mulpdのレイテンシは、Yonahが5で、K8が4。まあこんなもんか。
L2レイテンシの14(Yonahから据え置き)が本当だったらちょっと嬉しい。しかも16Wayだ。
Dothan-1.1GHzとPC2100にてメモリアクセスの考察。
数字は、基本的に以前上げたメモリベンチの32MBでの数値を四捨五入したもの。
ただ、これって繰り返し実行すると147clkが156clkになったりするんだよねぇ。
clflushを使って予め測定対象をキャッシュから追い出しても同じ傾向。
ただし、少し速くなる。ライトバックの手間が少し減るためだと思われる。
普通にシーケンシャルリードすると、64byte(キャッシュラインサイズ)につき47clk。
L2へのHWプリフェッチが効いているはず。
BIOSでL2を切ると75clkに遅くなるが、これがHWプリフェッチだけのためかは不明。
64byte毎に1回のロードをすると、1回あたり40clk。L2オフでは60clk。
64byteを転送しているはずだが、リタイヤできないロード命令が少ないために並列性が上がる。
prefetcht0またはprefetchntaを使うと、L2がオンでもオフでも39clk。
プリフェッチ命令はデータ転送が完了しなくてもリタイヤできるので、更に速くなる。
また、ソフトプリフェッチが順調に効けばHWプリフェッチの追加効果は無い様子。
次にストア。
普通のシーケンシャルライトは64byteで141clk。
これは(なぜかロードの場合と違って)64byte毎に1回のアクセスでも変わらない。
L2をオフにすると若干遅くなるようにも見える(1~2clk程度)。
動作としては、64byteがメモリ-キャッシュ間を往復している。
movntqの動作は、L1ヒットならL1に書き込んでライトバックはしない。
L1にヒットしないときは、直接メモリに書き込む。
どちらにしろ、L2にキャッシュされたアドレスだったらL2の該当ラインの無効化が必要。
movntqを使うと40clk。ノーマルロードの47clkより速いのは、内部に工夫が?
更に、64byte毎に1回のmovntqなら33clkまで高速化する。
これは、他のアクセス方法と違って64byteでなく8byteの転送で済むからだろう。
えーと、今回は基礎知識だけで終わり。
ロードした直後にmovntqでストアするのを思いついて測定しようと思うが、どうでしょ。
IntelCoreやAthlon64の考察もよろ
conroeも結局64bitはダメpみたいですねぇ・・・
>>529 是非やりたいが、実機持ってないから無理です。
>>530 これだね。
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-002.html? 64bit化することで普通なら高速化するのに、4割も遅くなるケースがある。
他のでは少し遅くなる程度。ベンチの選択に恣意的なものを感じないでもないが。
4割も遅くなったケースで、遅くなる原因が特別多く使われていると考えられる。
> レジスタを「64bitレジスタとして使う」場合、あるいは「64bitで拡張されたR8~R15、
> XMM8~XMM15などのレジスタを使う」場合に、命令の途中に“REX”という
> 拡張符号(プリフィクス)が追加される。
Core2は、命令フェッチで16byte/clkが限界である。
が、これはK8も同じことで、
>>382>>387を見ると、むしろCore2のフェッチのが上手そうだ。
さて、32bitコードと比べて4割も遅くなるというのは異常だ。
元々Core2がすごく速くて、その「ハマり」が外されて遅くなるというのならありかもしれないが、
命令フェッチが多少制限されたとしても、絶対性能でK8を大きく下回る理由にはならない。
何か他に「弱点を突かれた」ような要素があるのではないか。
Intelの最適化マニュアルより
> Pentium II およびPentium III プロセッサは、7 バイトより長い命令の場合は、
> 一度に1 つの命令しかデコードできない。
仮にCore2にこの仕様が継承されていたら?うーん、置換処理で使うかな。
コンパイルがAthlon64に最適化されて行われた可能性は高い。
配布ページに行って落としてみたが、動作確認環境がAthlon64 3200+となっている。
でも、K8が有利にはなっても、Core2がここまで遅くなる言い訳にはならない。
x64のコンパイラ自体の完成度が低いのはあるかも。
Core2がK8に劣っている点で明らかなのは、クロック当たりのロード回数が倍違うこと。
L1キャッシュのサイズも、倍の差がある。これは最適化の仕方によっては相当な差になる。
32bit版ではデータの処理単位が16KBだったのが、64bit版では64KBだったとしたら、
K8では少し速くなるだけだが、Core2ではガクンと遅くなるはず。
でも、x64版の製作者が、そこまでコードを改変してるとは思えない。
実行ユニットで64bitコードが遅いというのはまず考えられないし、
プリフィックスがあると言っても高々1byte増えるだけ。
64byte即値なんか使ったらK8でも性能出ないだろう。
するとREXプリフィックスに対するデコードの負荷が高い?
そんなあからさまなダメ仕様のCPUを今更Intelが出すかなあ。
このCore2が4割遅くなったベンチでのPen4での結果や、
他の64bitベンチでのCore2の結果が知りたい。
てか、こんなこと書いてないで早くメモリの測定しろよ俺orz
メモリって読んだ後にすぐ書き込むとペナルティがある?
同じところに書き込むのならすでにキャッシュがヒットしているからそれを前提に最適化・・・している可能性もありそうだが
普通はプリチャージおわればどうとでもじゃね?
DDR2になって改善されてる部分がそこだが
>>532 Server 2003 SP1 PSDKのx64コンパイラはVS2005の上位エディションについてる
x64コンパイラのサブセットですわ。
現状Windows向けのx64コンパイラでまともに使えるのはIntelとMSしかないってこと
になるわけなんですが、このx64コンパイラ、AMD64とEM64Tで別々の最適化オプションが
用意されてます。
この最適化を施すと、一方では速くなるけどもう一方では遅くなるみたいですわ。
問題のサクラエディタはコンパイル済みのバイナリっしょ
普通にコンパイルしたらAthlon64でも遅くなるから
AMD64専用の最適化を施したのかもしれんね
休み明けに会社で個人持ちのプレス子マシンで試してみますわ
ついでだからEM64T最適化のオプションでリビルドした結果もね。
linuxのバイナリだったら俺もxeonとかでためせるんだがなー
536 :
201:2006/07/15(土) 20:40:50
> コンパイルがAthlon64に最適化されて行われた可能性は高い。
コンパイラメーカがAMD64を主力においている可能性もありますね。
以前どっかの記事(Impressとかそれ系)で64bitの性能を確かめる為に
VC++やらICCやら使ってベンチしてましたが、
意外にもICCが64bitネイティブで有為に遅くなってました。
記事の出た頃がまだ成熟していなかったからかもしれませんが
(未だに成熟していませんが)
出だしでAMDに主導権を取られてしまったので、
IntelはCPUだけでなくコンパイラも含めて余り64bitに興味が無いのかも。
Core2とかその先のCPUで勢力(発言権)を取り戻したら、64bit改革に乗り出すつもりとか?
あと64bitで遅くなっているのは、レジスタ数が増えているからじゃないかと思ってみたり。
レジスタファイルや演算器、リタイアユニットの数がそのままだと、
きちんと最適化しない限りストールが増えるだけで良い事無いんじゃないかと思います。
申し訳程度のレジスタ数でコンパイラに負担を強いて、
自分は楽をしていたツケが回ってきたということじゃないかと。
サクラのソース一式斜めに目を通して思ったこと。
6.0だとCランタイムライブラリはANSI版APIに最適化されてるから
現行のx64コンパイラはPSDKも含めてVC8(VS2005)相当のMS-C/C++ Compiler 14.0では
ライブラリがUNICODEに最適化されてます。
MBCSは変換のオーバーヘッドのためか露骨に遅くなります。
Makefileを見る限りでは文字列表現にMBCSを使うようになってるし、コードを見ても
UNICODEバイナリを組むための考慮はされてませんわ。
ANSI(MBCS)バイナリ用のソースと見るべきです。
実際、32bit版はVC6.0でビルドされてるでしょうな。これはこれでライブラリがANSI/MBCS向けに
チューニングされてるから、速度は問題ないのでしょう。
しかし、現行のコンパイラでビルドすれば速度は格段に落ちると考えられます。
64bitにかかわらず、もちろん32bitでも。
そのx64版を作った人が、Athlon64でビルド・動作確認をやってるらしいので
自ずと、AMD64特化の最適化が行われた可能性は十分高いですわ。
いずれにせよ、サクラのx64移植にあたってはどこそこ書き直してUNICODE化したほうがいいと思います。
UNICODEならBOOST Regex++なんかが使え、これで正規表現が使えない問題は解決するし、
NT系OSはもともとUNICODEのほうがネイティブに近いので、それだけでもだいぶパフォーマンスは
改善できるかと思います。
クロック数計測の話題からは脱線しましたが、サクラのx64での異常な速度低下は
Conroeのアーキテクチャに起因する部分は少ないと思われるということで、結論を。
>>537 INSERTQ/EXTRQは汎用レジスタ-XMMレジスタ間の交換だと思ってたけど、
どうやらXMMレジスタ同士のQWORDの交換っぽいですな
ダイフォトを見るに、汎用レジスタとFP/MM/XMMレジスタは結構離れた配置になってるので
あんまりレジスタファイル同士のデータ交換の高速化には期待しないほうがいいかも
逆にレジスタファイルもスケジューラも実行ユニットもそれぞれで別個に動くので
並列度を高めやすいとも言えるかも。
64bit最適化出来てないけどK8特有のごり押しですか?
FireFoxもVS2005でビルドすると6.0や2003よりも遅くなる問題が確認されてますな。
これが、例のPGOを使っても改善されない極悪っぷりだそうで。
Windows 9xが切り捨て時なんでUNICODEにチューニングしたんでしょうが
アプリのほうも切り替えていく必要があるかと思われ。
逆にUNICODEバイナリのパフォーマンスはかなり上がってる模様。
テテさんのと綾川さんのは十分拮抗してると思うが。
>>533 事の発端はノーマルストアがロードの倍よりも更に遅いことなんだけど、
ノーマルストアでは、ロード(ライトアロケート)とストアが同時に行われるので、
同時にやると遅くなるのかな、と。
この場合、キャッシュが介在するので、ロードとストアのアドレスはある程度離れている。
> DDR2になって改善されてる部分がそこだが
くわしくお願いします。
>>536 なるほど、論理レジスタが増えたら確かにスケジュールとか大変になりそうだな。
普通だと、32bitコードを64bitコードのサブセットとして捉えて、64bitコードに最適化すれば、
どちらのコードも高速に実行できるスケジューラになると思う(素人考えですが)。
仮に32bit用スケジューラに少し手を加えただけのようなものだったとすると、
64bitでかなり悲惨なことになりそうだから、さすがにそれはないと思いたいが・・・。
>>534 おう、それは測定結果が楽しみなり。
>>538 ANSIとUNICODEの変換オーバーヘッドですかい。VBみたいだな。
しかしConroeをあそこまで遅くさせるコードで、Athlon64では何事もないとは、
いかにAthlon64向けの最適化をコネコネしても考えづらいんでないかな。
>>539 Athlonの最適化ガイドを見ると、movd mm,reg32 のレイテンシは9だね(P6では1)。
movd reg32,mm は4、なぜ倍以上違う。どちらもデコードはDoublePath。
K8のブロック図を見ても、汎用ALUとSIMDユニットは離れてるしなあ。
汎用レジスタとSIMDレジスタを分けているAthlon系アーキテクチャの功罪だね。
FPUのスケジュールの強さなどは、ここに起因しているのかな?
>>543 VS2005の上位エディションに追加されたPGOっていう機能は、実際にマシンで動作プロファイリングを
行ってそれを最適化に反映させるというものなんだけどプロファイリング用のビルドを動かした環境に
大きく依存したチューニングが最終的に行われることになるんですわ。
ライブラリ自体がAMD64にチューニングされてる可能性も否定できないし、このへんは
わからないですな。
で、ためしにいちおうPSDKでビルド試してみたんですけど、日本語を含む文字列のところで
コンパイルエラーが出るみたいなんで、なんで、コードの修正が必要そうですわ。
英語版コンパイラ特有の、Shift-JISの2バイト目の問題ですな。
ICCも英語版なんで、このへん直さないとビルドしなおすってのはちと苦しいと思いました。
どのみちConroeでのプロファイリングができないとあんまり突っ込んだ最適化はできなさそう。
>>514を見ると、Coreアーキでは
オペランド・サイズ・プリフィックス66Hやアドレス・サイズ・プリフィックス67Hを使って
即値やディスプレースメントのサイズを変えると5サイクルもストールする
って書いてあるんだけど、今までのプロセッサではこんな制限なかったよね?
>>544 オプションによっては環境依存のコードを吐くのか。
>>545 and ax,0f0f0h(66H付き)をPenMで測定しても別に遅くなかった。
デコーダの問題、なのかな。
66HはSSEにも付くが、さすがにそれはOKなんだろうけど。
にしても、CoreDuoがCoreアーキでないって、改めてややこしいな。
>>528の続き。毎度ながら、PenMでの測定です。
lp:
paddd mm0,[esi] ; ←
movq [esi],mm0 ; 一応前のロードに依存したストア
add esi,64
dec ecx
jnz lp
これで32MBのアクセスをする。
ただのストアだと150.5clk/loopだが、これに矢印の行を追加すると147.9clkになる。
かえって速くなってるが、若干プリフェッチのようなものとして効くのだろう。
ここから、単なるストアも、ロードしてそれをストアするのと同程度の負荷があるとわかる。
ちなみに、L1ヒットになるのでmovqをmovntqに変えても(PenMでは)変化なし。
mov eax,n
lp:
paddd mm0,[esi+eax]
movntq [esi],mm0
add esi,64
dec ecx
jnz lp
次に、上のコードを少し変えてみる。nが0なら上と同じような内部動作になる。
このnを-65536から65536まで64刻みで変えたときのクロック数をプロットした。
http://rerere.sytes.net/up/source/up12821.zip nが32K(32768)以上になると、movntqは全くL1ヒットしなくなる。
L1へのロードと、メモリへ直接のストアがあるだけで、キャッシュのライトバックなどはない。
このときの1loop当たりのクロック数は、およそ77clk。
これは、ノーマルロードとmovntqストアのクロック数を足した76clk(42+34)に近い。
(違うアドレスの)メモリに対して同時にロード・ストアのアクセスを続けても、
それ自体のペナルティは特にないみたいだ。
(
>>533の言うように、プリチャージおわればどうとでも、という感じか)
さて、nが0から32Kまでは遅くなっているが、これは32KBのL1データキャッシュのせいだろう。
movntqがL1ヒットすると、まずL1に書き込んで、実際にメモリにストアされるのは
データがキャッシュから追い出されるときだ。
nが0のとき、またはnが32Kの半分よりある程度小さいときは、movntqは全てL1ヒットする。
padddがL1にロードしたものが捨てられる前に、そこへのストアができる。
nが大きくなってくると、だんだんmovntqはL1ミスするようになってくる。
L1ミスすれば、当然ながらキャッシュを通さず直接ストアする。
上のプロットした図を見ると、nが32Kの半分に近づいたところから、
だんだん速くなっていくのがわかる。
なぜか4KB刻みで速くなっていくが、L1キャッシュの1Way分の容量(32KB/8Way)だからか?
さて、キャッシュを通したmovntqが、なぜ遅くなるのか、
つまり「L1へのロードと、メモリへ直接のストア」と「L1へのロードと、キャッシュのライトバック」で
なぜ70clk近くも差が出るのか、というのが疑問だ。
だが、この問題は置いといて、上のプロット図にはあと二つ、あからさまに気になる点がある。
一つは、-1024<n<0で34clk程度しかかかっていないこと。
これは、ストア・フォワード機能とかいうやつだろう。ここでは、15個分の溜めが機能している。
ロードはメモリからではなく、CPU内のバッファから行われ、ストアの時間だけがかかっている。
また、nが-1024付近で遅いのは、上の機能があふれて使えず、ストアの完了を待ってロードを
しなければならないからだろう。
もう一つは、クロック数が、(nの)4Kの周期で極端に遅くなることだ。
このケースでは、独立にロードとストアをしているだけで、キャッシュの使われ方はクリアーだ。
一方では[esi+eax]からロード(キャッシュのデータを捨てる動作もあるが影響はないはず)、
一方では[esi]へストア。
このアドレスの差のmod 4Kがポイントということになる。
( (esi+eax) - esi ) % 4096 が4096に近づくと急激に遅くなる。
DRAMのバンクがどの程度の粒度なのか知らないが、仮に4KB周期の単位があったとすると、
eax%4096=4032のときなどは、ストアが終わった同じバンクからすぐにロードすることになり、
何らかのペナルティがある可能性が考えられる。
ただ、プリチャージが必要なのはロードの方なので、これは逆なように思うが・・・。
4KBは、L1キャッシュの1Way分の容量であり、またメモリ管理のページサイズでもあるが、
これらは関係ないのかな?
#メモリは同じバンクに連続した物理アドレスを割り当てないようにしてるらしい。
#(並列にアクセスするため)
#上の4KB周期とはそのことで、バンクのサイズが4KBという意味ではない。
積み残しが多いが、続きはまた後で。。
アセンブラスレの質問がここ向けのような希ガスる強固の頃。
550 :
201:2006/07/17(月) 20:46:11
>>546 > 若干プリフェッチのようなものとして効くのだろう。
ストアの場合は、何が書き込まれるのかがその瞬間まで分りませんし、
movqだったりmovntqだったりしてプリフェチが必要かどうかも分らないですが、
読み込みに関しては先読みして損する事はあまり無いので
ハードウェアプリフェチが働くんでしょうね。
>>547-548 > キャッシュを通したmovntqが、なぜ遅くなるのか、
単純にはノンテンポラル・ライトがL1にヒットした場合、
L1のフラッシュとメモリへのライトを行わなければならないと思うのですが、
PenMはL1の更新だけで済むのでしょうか?
> クロック数が、(nの)4Kの周期で極端に遅くなる
最適化マニュアルに出てくる
・4K ページ境界をまたぐプリフェッチは実行されない。
・メモリバンクの競合問題を解決する。
辺りですね。
>>549 昼に見たけど、メモリ測定があるからすっかり忘れてたよ。
そういえば、インラインアセンブラって、アセンブラな人から見るとぬるいし、
C言語な人から見ると組み込み関数使え、って感じで微妙な立場だ。
>>550 上。
ライトアロケートが働くので、movqでのストアには(キャッシュヒットしなければ)
必ずロードが伴う。そのロードの話なのでストアは関係ない。
HWプリフェッチはノーマルストアのみでも元から効いてると思われる。
中。
>>248-249の測定によると、PenMではL1の更新だけで済むっぽい。
それに対し、YonahではL1のフラッシュとメモリへのライトを行うっぽい。
L2の扱いは今後調べたいところ。
ていうか疑問なのは普通のストアの遅さのことです。
たまたまPenMではL1ヒット時にmovqとmovntqの振る舞いが同じっぽいというだけで。
下。
2系統の独立したシーケンシャルアクセスなので、4Kページ境界をまたぐ云々は関係ないかと。
メモリバンクは「ストア→ロード」と「ロード→ストア」の違いとかあるのかなあ。
上の測定結果だと、「ストア→ロード」のみ遅くなってるように思うのだが、正しいのかどうか。
VS2005は互換性のために32bitではインラインアセンブラ残してるけど
どうみても撲滅したいように見える
553 :
545:2006/07/17(月) 22:07:48
>>546 わざわざ検証どうもです。やはりPenMではストールしないんですね。
Coreアーキの場合、16bit即値を多用している32or64bitアプリは影響が出そうですね。
554 :
d(ry:2006/07/18(火) 12:43:39
sakura.exeのAMD64版の命令コードの逆アセンブルしてみますた。
VC2005 Expressにも付属するdumpbinツールを用いました。
http://download.kousaku.in/misc/sakura.asm.gz かなり巨大なので注意。
x64アプリ全般における問題として、REXプリフィックスが付いたことで
16byte/clockのフェッチ帯域で律速され、4issueのパイプラインが生かすのは
困難であることが理解いただけるかと。
目視で、1命令平均5バイト程度で収まってます。
Athlon64のほうが速くなる云々は抜きにして、Core2で32bit版以上の
パフォーマンスを得るのは正直難しい気がします。
555 :
デフォルトの名無しさん:2006/07/18(火) 13:05:22
おまえらっていっつも
今日も何クロック節約したぜ、ハアハア
みたいな事やってんの?
64bitは苦手なCore Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm キター!しかしタイミングいいな後藤。
Intel独自の64bit拡張Yamhillはレジスタ拡張がなかったと言われ、
AMD64に合わせることになったのは2003年後半、その頃には既に
レジスタ8個のCPUとして設計が進んじゃってたというわけか。
内部動作としては、まず命令をフェッチ(16byte/clk)し、
それに対してプリデコード(最大6命令/clk)を行い、命令キュー(18段)に溜める。
そこから最大で5命令がデコーダに渡され、4内部命令としてデコードされる。
まず、64bitモードでは、Core2の看板機能であるMacro-Fusionが使えない。
拡張レジスタを使ってないときだけでもFusionすればいいのに、とも思うが、
まあ、そうもいかないんだろう。
次に、
>>514にも出ているプリフィックス66H、67Hの問題。
1~6clkのペナルティがあり、更に16byte境界をまたぐと最大11clkも損する。
これはプリデコードの段階のことで、かなり例外的な処理として扱っているようだ。
この辺りはコンパイラが対応すれば済む話だろうが、はまるとインパクトが大きい。
そして、拡張レジスタを使うときのREXプリフィックスだが、
これは特にペナルティがあるわけではなく、単に命令長が1byte伸びるというだけらしい。
しかし、これが6命令/clkのプリデコードに、それなりの影響を与えるようだ。
プリデコーダは、フェッチした16byteしか処理できないため、命令長が長くなると
プリデコードできる命令数が減ってしまう。
更に、16byteの中に7命令が含まれていた場合、まず6命令を1clkでプリデコードして、
次のクロックでは残りの1命令だけをプリデコードするはめになる。
このように、プリデコードが4命令/clkを割るケースはけっこう多そうなので、
少しでも命令スループットを上げるため、REXプリフィックスを使わないことが望ましい。
しかし、64bit化のメリットのかなり大きい部分を占めるレジスタ増加を生かせないのは痛い。
ALUもSSEもそうだが、Core2では実行リソースが極めて豊富になっている。
しかし命令のレイテンシは従来のCPUと同程度ということで、
増えた論理レジスタを使って並列実行してやることによって、真の性能を発揮できるのだ。
32bitモードの8レジスタでも十分速いんだが、そんなことはこの際どうでもよくて、
スループットの改善とレジスタの増加は表裏一体だと思っていたので、
そのちぐはぐさが残念なのだ。
ただ、命令長が1byte長くなっても、短い命令の中に置けば、
7命令/16byteだったのが6命令/16byteになって高速化、というケースも考えられ、
アセンブラ使いにとっては腕の見せ所となる。
Macro-Fusionが使えないのもアンロールでおおまかカバーできるし、
66H67Hプリフィックスは使わなきゃいい。
ところで、命令長が短くて16byteに7命令が入っている場合でも、3.5命令/clkが出るはずだが、
命令キューが空に近くなるとペナルティでもあるんだろうか。
そういえばAthlonにはこんな機能があった。
http://pc.watch.impress.co.jp/docs/article/20011102/kaigai01.htm > HammerのL1命令キャッシュはAMD伝統のプレデコード(pre-decode)キャッシュだ。
> つまり、可変長のx86命令の区切りや、どの命令が分岐命令かといった情報を示す
> プレデコードビットを、キャッシュに取り込む際に加える。
キャッシュに取り込むときに処理しちゃうのは、若干トレースキャッシュっぽい。
>>554 ざっとスクロールさせてみても、48hや44hが目立つな。
検索すると、66hも少しあるね。さすがにあそこまで遅くなるのは66hのせいだろう。
典型的なメモリアクセスが5byteになっちゃうんだなあ。
しかし、命令長伸びて、Athlon64では遅くならないんかね。
>>555 そりゃあ節約できたらハアハアしますよ。
なかなかうまくいかんけど。
L2を切って、
>>547の続きをやってみた。
ちなみに普通のL2オフのクロック数は、これまで通り64byte毎に8byteアクセスするとして、
ノーマルロードは63.0clk。movntqストアは33.9clk。ノーマルストアは142~151clkくらいを動く。
何ですかこの32KBおきのきれいな山は(;´Д`)
http://rerere.sytes.net/up/source/up12836.png 横軸はnで64刻み、縦軸は1loop当たりの所要クロック数。
すべて、キャッシュクリアとかせずに、普通に繰り返し測ったもの。
ピンクの点はL2オン、青い点はL2オフで
>>547のコード、
黄色い点はL2オフで下のコード。
lp:
paddd mm0,[esi+eax]
movq [esi],mm0 ; 単にここをmovqにしただけ
add esi,64
dec ecx
jnz lp
しかしCore2でこれから2年。
MSのやる気次第だろうけど、2年も経つと全体的な64bit化も避けられないような?
なんていうか今までのAMD側のSSE関係がIntelのには及ばずなのが、
AMD64では逆になったっていう感じかなぁ。
>>551 >
>>248-249の測定によると、PenMではL1の更新だけで済むっぽい。
>それに対し、YonahではL1のフラッシュとメモリへのライトを行うっぽい。
IA-32のメモリモデルは「Processor-ordered Memory Model」、すなわち
・一つのプロセッサ内では,そのプロセッサに与えられたプログラムと同じ順番で,メモリの読み書きは反映される.
・ローカルプロセッサに書き込みが反映されたのと同じ順番で,遠隔プロセッサに対して書き込みは反映される.
とキャッシュのフラッシュ順の制約がキツイので、マルチコアのYonahでは頻繁にL1キャッシュの
フラッシュが起きているんじゃないだろうか。
Itanium のメモリモデルならフラッシュの順序はどうでもいいのだけれども。
>>560 なるほど、Yonahはマルチコアだったな。これで仕様変更の理由は納得できた。
Itaniumだとmov [edi],eax / mov [edi],ebx (ニーモニック違うけど)ってやったときに
[edi]にebxが入ってるとは限らんってこと?
あと、メモリに自コアのストアの順番を正しく反映させるだけなら(性能は置いといて)、
別にL1フラッシュは頻繁にやらなくてもいいと思ってしまうが、見当違い?
>>562 ㌧クス。
> ダーティになった順序を覚えておいてその順にフラッシュする
すべての時刻でストアの順番を正しく反映させてないといかんわけか。
とりあえず、変数a、bがあってコア0がa、bの順に書き込んだとき、
コア1がb、aの順にロードしてbだけ更新されている、ということが
あってはならないことに、今まで思いが回ってなかったと自覚。
コア0で、[edi]はL1ヒット、[esi]はL1ミスのときに
movntq [edi],mm0 / movntq [esi],mm1 とすると、
PenMの仕様じゃ[esi]へ先に書き込まれてしまう。
思った以上に難しいんですね。まいりました。
>>559 「AMD64」を採用させたのは大きいね。
逆に言えば、こういう苦労をAMDは常にしてきたんだなあ。
AMD64を採用させたっていうか、MSのDavid Cutlerが癒着してできた
ISAですから、IntelのYamhillが蹴られるのは必然だったと。
ようやく出たItaniumデュアルコアの性能がすさまじい件について
http://www.spec.org/cpu/results/res2006q3/cpu2000-20060626-06270.html ところでNetBurstの12kμOPsのトレースキャッシュって
結局何バイトの固定長命令なのかわからんかね?
仮説だけど
Willamette 1μOP = 2byte
Prescott 1μOP = 4byte
とすると、24k(trace)+8k(data) = 32k, 48k(trace)+16k(data) = 64k
でちょうど2のべき乗になる。
いや、あくまで想像。
>>564 命令キャッシュとデータキャッシュのサイズが違うプロセッサは過去に数多くあった。
だいいち、命令キャッシュとデータキャッシュは構造に違いがあって、
同じ容量でも実装面積やトランジスタ数などが多少ながら(?)違う。
アクセス時のウェイトだって違う場合は多い。
電顕とかでダイの解析して決定するしかないんじゃないか?
Montecitoとかねー
>>567 インテル・チューニング・コンテストか面白そうだな
AMDはATIとヘテロを作るのか・・・ダイ統合のメリットとデメリットが微妙な気もするが・・・
キャッシュ大盛りのほうが現実的なアプローチだな。
ホモジニアスでも投機スレッディングとかで性能伸ばす道もあるだろうに。
ソフト屋が居ないからベクトルプロセッサとのヘテロジニアスマルチコアに
逃げようとしてるなら大間違いだ。ソフト屋こそ重要だっつーに。
そんな事はAMDのアーキテクトも考えてるでしょ。
色々考えた結果が今回の決定。
IntelはIntelでx64が課題だし、どっちもどっちだなぁ。
Microsoftが痺れを切らす前にフュージョンを対応させられるだろうか。
それは大丈夫だと思うよ。
痺れを切らされるのは、自身の提案であるはずのAMD64なのに、
64bit状態でベンチ計測しても、フュージョンが効いてないCore2Duoに負ける事の方が多いAMDの方だと思われ。
これは、Micorsoft云々以前に、
AMDの設計者はかなり屈辱的だと思う、(´・ω・`)テラカワイソス。
K8での64bitはレジスタ共用とかじゃなかったのか
575 :
デフォルトの名無しさん:2006/08/01(火) 22:51:39
上げてみる
576 :
デフォルトの名無しさん:2006/08/03(木) 01:11:30
>>576 こうして比較してみると、やはり良くできているな・・・K8は。
結局殺人国家イスラエルの人達の仕事のうちの最も重要だったのはL1の高速化か。
うむ。K8があるお陰で、Core2Duoがいまいちパッとしない。
K8がなかったら、今頃大勢の人が飛びついていただろうに。
ベンチを見る限りCore2Duoの性能はSIMDユニット増強の効果に依存する部分が大きいような。
SSEユニットが強化されるK8Lでも十分戦える気がする
いつ出るのかは知らんが。
580 :
デフォルトの名無しさん:2006/08/03(木) 16:54:41
HoundはL1帯域が
L1-D 8byte→16byte
L1-I 16byte→32byte
に増えて、浮動小数点ユニットも倍増。
SSE4にも対応とくればCoreMAと並ぶのは確実じゃね?
あとはキャッシュがどうなるかだけ。
581 :
デフォルトの名無しさん:2006/08/03(木) 17:56:58
64bitやSSEは命令サイズが肥大化しやすいから
バランスよく伸びるにはフェッチ帯域の増強は欠かせない
CoreMAはまさに命令フェッチ帯域ネックなんだよな。
SIMDユニットを馬鹿みたいに積んでる割には、頭打ちが結構早い。
NetBurstはx86レベルで命令サイズを気にする必要があんまりなかった
だけに、最大限に引き出すにはかなりの根気は必要かもね。
なんとなくK7 vs Coppermineを思い出すような結果だな。
ロジック部分のアーキテクチャで勝るAMDと、キャッシュで勝るINTEL。
キャッシュでだけ勝ってるわけじゃないでしょ
キャッシュ周りのアルゴリズムはYonahからあんま進化してない希ガス
MYCOMで見るとロードストア以外はK8優勢だから
ボトルネックの解析で勝ったのかもしれない。
持ちうる全てを注ぎ込んだ結果生まれる性能が全てじゃ?
何と言うか、車で例えるとエンジンは良いけど…的な。
AMD的には逆に馬鹿にされてるような気さえする。
K8が出荷されたの2003年だろ?
CoreMAには圧倒的な差を期待していたのだがな。
微細化と省電力、キャッシュ以外の部分は殆どK8とかわらんようなもんだしな。
手法の違いはあっても、有効実行ユニット考えるとほんと大差ないし。
MYCOMの記事見ると、CoreのK8に対するアドバンテージの元は
L1キャッシュの帯域だけみたいに読める。
3年も差があって性能差がこの程度とは、いよいよCPUの進化も
頭打ちになったって事か。
591 :
デフォルトの名無しさん:2006/08/08(火) 22:59:32
Core2組んでみたので、ちょっと計測。
前スレのこのコードを実行してみたら、2clk/loopで回ります。
Memory Disambiguationが機能していることを確認。
mov [esi],0
align 16
lp:
mov eax,[esi]
imul eax,eax
imul eax,eax
mov [esi+eax+16],eax ; ストアアドレスもストアデータもeaxを含むので依存関係がある
dec ecx
jnz lp
次に、ピークIPCがきちんと出るかどうか計測。
align 16
lp:
add eax,[esi]
mov [esi+16],ecx
inc ecx
cmp ecx,ebx
jb lp
このループだと、1clk/loopで回ります。
ピークIPC=5が出ることを確認。
593 :
592:2006/08/09(水) 10:33:39
先ほどの、1clk/loopで回るループだけど、
次のように書き換えると2clk/loopに落ち込んでしまう。
align 16
lp:
add eax,[esi]
mov [esi+16],edx ; この行
inc ecx
cmp ecx,ebx
jb lp
またこのループも2clk/loop。
lea edi,[esi+16]
align 16
lp:
add eax,[esi]
mov [edi],ecx ; この行
inc ecx
cmp ecx,ebx
jb lp
このループは1clk/loop。
align 16
lp:
add eax,[esi]
mov [esi+16],ebx ; この行
inc ecx
cmp ecx,ebx
jb lp
どうも、同時に使用できるレジスタの数に制限があるっぽい?
EAXとEBXしか使うなという御達しですか?
595 :
592:2006/08/09(水) 16:48:00
連投ですいません。
add bx,0x2345
のような66Hプリフィックスを伴った16bit即値を含む命令だけど、
必ずストールするという訳じゃないみたい。
同じ命令でも配置によってストールしたりしなかったりする。
どういった配置でストールするのかは、よくわからない。
たとえばこのループだと、2clk/loopで回る。全くストールしていない感じ。
align 16
lp:
add ax,0x1234
add bx,0x2345
add dx,0x3456
add si,0x4567
dec ecx
jnz lp
プリフィックス有りがある程度連続してればストール要因にならないんじゃないかな?
SSE*の128bit整数命令には当然ながら66Hがつくわけだけど
こいつでストールしてたら致命的じゃないか
66H付きプリフィックス命令ある程度連続してるものと仮定してプリデコード(命令長の推定?)を行うのかも。
実機未だ持ってないからわからないけど、SSE命令と汎用命令を
交互に流すようなコードは致命的になるかもしれない。
パイプラインをきれいに回そうと思ったら、処理の間に他の命令を挟むのは常套手段のような。
毎度ながら古いコードはシラネってスタンスなのかな。
598 :
592:2006/08/09(水) 17:14:47
> Do Not Mix SSE FP and SSE Integer on the Same Register
> SSE FP has an additional cycle of latency. For example, use PXOR with SSE integer only.
> Use XORPS or XORPD with FP when dealing with single and double precision, respectively.
ただの同じオペレーションの別名だと思ってたが、きちんと区別する必要があるようだな。
SSEの組み込み関数おなじXMMレジスタなのに整数と単精度・倍精度で型が別々でやたら不便だと
思ってたが、やっぱり合理的な理由はあるんだろうな。
たるさんが天狗になっとる・・・
たるるが立った!
なんあ凄い必死さが伝わるな>たるたる
×なんあ
○なんか
Netburst関係の記事の方が面白かったな。
トレースキャッシュ搭載&HyperTreadingは有用、という件も、
Conroeには載らなかったけどNehalemで復活という、
面白い事になったしな。
Netburst一生懸命叩いてた方々には不評だったのかも知れんけど。
>>592 漏れはアセンブラやったことないけど、ループ内の命令数を18命令以上にすれば、命令キューから命令が溢れてLSDが働かずに
LCPストールの影響をもろに受けるはずでしょ。やってみて。
606 :
592:2006/08/15(火) 00:28:28
>>605 なるほど、LCPストールはデコード段で発生するのではなく、
プリデコード段で発生するので、プリデコード済みの命令キューの中の命令を
繰り返しループ実行する場合は、LCPストールは発生しないという訳ですね。
謎が解けました。早速試してみたところ、
1ループ中の命令数が18を越えると確実にLCPストールが発生するようです。
PMCで調べたところ、1ループ中に add reg16,imm16 を20個並べてループさせると、
1ループあたり6~7回LCPストールが発生し、
1回のLCPストールで5clk以上ロスしているようです。
SSE4のスループット悪くないね。
予想通り水平加減算は複合オペレーションだけど。
609 :
592:2006/08/15(火) 10:21:05
>>607 こんなにいい資料があったんですね。
レジスタファイルから同時に読めるレジスタ数に制限があるとは知らなかった。
PenPro~PenIIIが2つまで、PenM~Core2が3つまで同時読み可能で、
それ以外に、結果が出て間もないレジスタはレジスタファイルへの書き込み前に
バイパスして読めるということかな。
>>593の2例もギリギリでこの条件を満たしてはいるけど、
レジスタファイルを3つ同時に読めない場合もあるとも書いてあるので
そういったケースなんでしょうね。
>レジスタファイルから同時に読めるレジスタ数に制限
haddpsのレイテンシが単純計算より若干大きくなってる理由はやっぱりこれだと思った
743 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/08/16(水) 03:25:17 ID:thAe/y1Q
Core2の命令フェッチ帯域の節約法見つけた。。。
SSEでも整数に関してはCore2優勢は続くと思う。
744 :Socket774:2006/08/16(水) 03:26:34 ID:t+vKI5rd
>>743 サンプルコード公開して
746 :・∀・)っ-○◎●新世紀ダンゴリオン ◆DanGorION6 :2006/08/16(水) 03:36:18 ID:thAe/y1Q
movdqa/pand/pandn/por/pxor
これらは全部4バイト長(+アドレッシング)
movaps/andps/andnps/orps/xorps
は3バイト(+アドレッシング)だから、1バイトずつ節約できる。
もっとも、整数演算と混ぜて使うとレイテンシが増加する問題があるらしいので、
論理演算とロード・ストアだけで済む箇所にだけに限定して置き換えればいい。
612 :
デフォルトの名無しさん:2006/08/28(月) 16:03:28
あげ
613 :
デフォルトの名無しさん:2006/08/29(火) 20:10:50
さて、Tulsaが発表されたわけだが。
誰も買わないよなあ。
>>579 SIMDユニットを増強して、増強した分だけ性能がアップするのは、
それだけの基礎体力があるからだ。
決してSIMDユニット強化だけの手柄ではない。
>>581 Core2は本当に32bitをターゲットに最適化されてる感じだね。
64bit用のコードを走らせると、命令長が1byte伸びるだけでガタガタとバランスが崩れる。
>>586 想定外の64bitを除けば、圧倒的だと思う。
AMDのCPUも優秀だから、これ以上の差は同じ時代同士ではなかなか生まれないだろう。
>>592 ちゃんと投機ロードが働くのね。
更に、x86命令数でIPC5もOKか。
>>593 1clkに扱える論理レジスタ数が4までということかな。
Core2の場合は「4」がポイントか。
RISKだと1クロックだね。
とか言うと「帰れ」とか言われるんだろうね。
あ、間違えた。
そんなリスクがあるのか・・・
www.ne.jp/asahi/comp/tarusan/main147.htm
実際のアプリではLOAD、STORE系の命令が混じるわけで、特にx86系命令セットではRISC系のCPU命令
セットよりその傾向が強い。従って、4命令デコードはそのような状況を想定して設計されているわけである。
単純に同一の命令がひたすら続くという状況は実アプリからはかけ離れており、 LOAD、STOREユニットが
ガラ空きであること、およびCore 2 Duoの売りであるFusion系の機能が全く働かないベンチであることの2点が、
4命令デコードがこのベンチマークで生かされない原因ではないだろうか? 当サイトの解釈で言うと、
Core 2 Duoの内部では3命令/CycleのALU処理能力に対しデコード能力が4命令/Cycleであるため、
RightMark Memory Analyzerのテストでは命令キューが溢れかえっていると想像(妄想?)している。
少なくともデコード能力が4命令/Cycleであったとしても、 NOP、SUB、XOR、TEST、XOR & ADDという
命令だけが連続して実行されればALUのリソース数から言って4命令/Cycleは達成できない事は明白で、
このベンチマーク結果をもってデコード能力の限界と断定するには今一歩証拠不十分であろう。
load/store の execute は平均 1cycle で終わるのか?
TulsaのL3のレイテンシ知らない?
遅レスになるが、ここ2ヶ月のレスの内容を把握するためにも書いときます。
>>564 Noothwoodで調べたが、32bit即値を使うと命令スループットが落ちる。
つまり、トレースキャッシュに格納されている命令上では、即値が16bitであるっぽい。
これは
>>576の002.htmlでの結果にも合致する。
前スレ895からの引用。
> Pen4のμOPは、入力レジスタ2,出力レジスタ1,即値 の
> オペランド形式になっているんじゃないかと思う。
> mov [esi+edx*4+16],eax は入力レジスタが3つあるので、
> 1μOPで処理できないって事じゃないかな。
これを正しいと仮定して考えてみる。
レジスタ3つの指定には9bitが必要となる。即値は16bit。全体で32bitとすると、残りは7bit。
7bit=128通りの内部命令しかないのかなあ?
更に、前スレ890によると、Willametteでmov eax,[esi+edx*4+16]が1uopであるらしい。
40bitくらいで半端な長さの命令でも不思議はないな。
また、Prescottでは64bitモードで拡張レジスタも使えるから3レジスタの指定に12bit必要だ。
命令長を少しだけ伸ばした可能性もある。ネトバなら柔軟に対応できるんじゃないかしら。
>>567 こういうコンテストでアセンブラ禁止というのは寂しいな。
>>570 ホモジニアスだと、1~2コアしか使わないケースでは、たとえ投機実行などの技術があっても
ヘテロの大コアのようには性能が伸びないと思う。
また、マルチコア時代にボトルネックとなるのは、まさにそういう処理で、
スレッドに分解しきれない純粋なシングルスレッド処理をこなす性能が必要だと思う。
でも、4~8コアの近未来にはさすがにホモだろうから、どうするんだろ?
ていうかサーバー用途ならホモでいいのか。
>>576 nopを処理できるのがALUだけだとすれば、ALUが3つのCore2でnopが3命令/clkなのは当然。
デコード幅が3という状況証拠にすらなっていない。
早いとこ
>>592のコードでピークIPCが5だと確認してほしいなあ。
まあ、ああいう記事を書くにあたって自前のベンチは使いにくいから、苦労してるんだろうけど。
あと、あのベンチでK8のL1帯域が8byte/clkしかないのはなぜだろう。
俺が以前測定したときにはK7でも16byte/clk近く出せたぞ。
キャッシュに関しては、Core2のL1でなくL2が最強なのだと思われる。
それにしても、ずいぶんな内容の記事だなあ。。
>>580 対Core MAの切り札となるAMDの「Hound」コア~AMDの新戦略(3)
http://pc.watch.impress.co.jp/docs/2006/0703/kaigai286.htm L1Dataも16byte→32byteらしい(Core2の更に倍!)。128bitLoad*2ができるのは強い。
命令フェッチも32byteに強化される(これもCore2の倍)が、3issueは変わらず。
完全にデコードとリタイヤがネックになるだろうと思っていたが、
SSEデコードが現状のDoubleでなくDirectPathになっていれば、これは強い。
考えてみればSIMDユニットが128bitになるなら2命令に分割デコードする必要がない。
しかも32byteフェッチなら、多少条件が悪くても確実に毎クロック3命令を取り込めるだろう。
実効IPCで今のCore2に迫るのは間違いない。
x86命令ベースでピークIPCが3のままなのは痛いが、実効性能で追い越す可能性も高い。
もっとも、その頃にはCore2が弱点を補強してくるのではないかと俺は期待しているのだが。
AMDのCPUはL2キャッシュが貧相に見えてしまうが、メモリコントローラを内蔵していることと
トレードオフなんだね。確かに弱点ではあるが、あまり大きなデメリットにならない。
>>592 GJ!
>>595は、
>>605で当たりか。
18命令以下でループに収めれば、命令長とかアライメントとか考えなくていいのかな?
>>599 整数とFPが混ざっていないと仮定することでスケジュールが楽になるからとか?
>>607>>609 最近使ったレジスタなら読めるから計測にもかかりにくいし、難しいな。
add eax,[esi+edx]
add ebx,edi
PenMでこれを80個並べると、ループ処理込みで94.7clk。
1clkに4個以上のレジスタを使えている。まあ、意味のないコードだけど。
mov [esi+edx+16],eax ; ←
sub ecx,eax
jnz lp
これはPenMで1clk/loop。ただし、←のeaxをedxに変えると2clk/loopになってしまう。
instruction_tables.pdfを見ると、整数乗算がfaddのポートだぞ。変なの。
>>611 この手法は使えそうだな。
FPと整数の混在がどのような組み合わせで遅くなるかを調べることにも意味が出てきた。
>>613 俺も欲しくはないが、ここにきてネトバは洗練されてきたよ。
電力効率がかなり上がってるっぽいのは、意図的にクロックを抑えているせいもあるかな?
YonahとCore2での、cpu-z付属のレイテンシ測定を知りたいな。
俺も測定してもらいたいと思ったが、Core2はrdtscの仕様が変わったとか聞いたような・・・。
投機的マルチスレッディングによる完全なメモリレイテンシの隠蔽の効果が、
ヘテロの大コアで実行した結果よりも良好ならば何の問題もないはずだけど、
ヘテロの大コアで投機的マルチスレッディングを実装できない理由はないので、
コアそのものの性能はむやみに捨てられないと予想。
いや、それは完全に捨てて、コアそのものの性能が余り表面化しないようなベンチマーク全盛になるのかな、たぶん。
こっちの方が現実的だw
>マルチコア時代にボトルネックとなるのは、まさにそういう処理で、
>スレッドに分解しきれない純粋なシングルスレッド処理をこなす性能が必要だと思う。
激しく同意。
投機的マルチスレッディングを魔法のスレッド分解技術と勘違いしてる連中が多いのが気にかかる。
某anti-HyperThreadingを鵜呑みにしてしまうような層とかぶってるのかな…
>>628 >K8だとmovdqaはFMISCポートでしか発行できず、2ロードorストア同時発行できないからだと思う。
ストアはFSTORE実行なのでその通りだけど
ロードは3パイプいずれでも実行できるので理論スループットは1
CodeAnalystでもそのように報告される。
(発行はロードストアともにDouble)
例のベンチにおけるパフォーマンス阻害要因はなんだろうね?
なお、FSTOREを介さないALUのストアは64ビットを2発行可能。
630 :
628:2006/09/25(月) 18:29:10
631 :
628:2006/09/25(月) 18:54:39
AMDの最適化マニュアルにもMOVDQA xmmreg,mem128はFADD/FMUL/FSTOREで実行可と書いてありますね。
K8のmovdqa xmm,memでスループット1が出せるのかどうか非常に興味があるので、
持っている人は誰か計測して下さい。
あと、movaps xmm,memのスループットもできれば知りたいです。
632 :
628:2006/09/25(月) 23:00:02
>>631 てけとーに測ってみた@Athlon64X2
ロード・ストアとも2cyc/DQを超えることはなかった。
MOVAPS も同様。
ただし。
PAND xmm,xmm はスループット1だった。
>>628が正解。AMDの資料は間違い?
634 :
628:2006/09/26(火) 06:10:50
>>633 計測ありがとうです。
MOVDQA,MOVAPSのロード・ストアはやはりスループット2なのですね。
K8のロードは、movqだと64bit*2で同時実行できるけど、
128bitのロードを64bit*2に分割したものはFMISCでしか実行できないのか。
マニュアルでは、movapsは空欄で、movapd,movdqaは3ポート。
ただ、マニュアルが間違っているのはいいとして、
>>629の
> CodeAnalystでもそのように報告される。
というのは気になるな。
ああいうソフトって、人間のミスが入り込めるような作り方をしてるのか?
まあ、一般公開するくらいだから、CPUの論理構造をそのまま入れたりはできないだろうが。
K8Lについて、俺がちょっと希望的観測をしているのが、SSEの128bit演算の方法。
後藤サンによると、ダイの写真でSSEの実行ユニットが単純に今までのものが2個付いている。
(ただ、あそこって後にライターの推測間違いが判明しても過去の記事を直さないんだよなあ)
つまり、演算器自体は64bit*2で、もちろんuopはフュージョンして内部では128bit扱いにする。
YonahもSSEでMicroフュージョンするが、演算器は64bit*1なので遅い。
これの64bit*2バージョンのようなものがK8Lではないかというのが俺の推測or希望。
ピーク性能は、もちろんK8の倍、Core2と同等。
しかも、Yonah→Core2で遅くなった一部の命令(
>>454)で遅くならない(64bit単位だから)。
Core2に比べて悪い点は、スケジュール。XMMレジスタが、Core2では16個なのに対し、
このK8Lだと半XMMレジスタが32個ということになる。
この差は倍では済まない。
ただ、K8は元々SSEが内部64bitなので、既存のスケジューラが一応(遅いけど)使える。
スケジュール・発行が追いつかなくて増えた実行ユニットを遊ばせてしまう、というのが
具体的な弱点として考えられる。
新規のCore2に対し、K8Lは既存のアーキの改良だから、アプローチも違うはず。
まあ、普通なら完全に128bit化した方が簡単だけどね。
>>625 > YonahとCore2での、cpu-z付属のレイテンシ測定を知りたいな。
E6600で実行してみました。
Cache latency computation, ver 1.0
www.cpuid.com
Computing ...
stride 4 8 16 32 64 128 256 512
size (Kb)
1 3 3 3 3 3 3 3 3
2 3 3 3 3 3 3 3 3
4 3 3 3 3 3 3 3 3
8 3 3 3 3 3 3 3 3
16 3 3 3 3 3 3 3 3
32 3 3 3 3 3 3 3 3
64 3 4 5 9 14 14 14 14
128 3 4 5 9 14 14 14 14
256 3 4 5 9 14 14 14 14
512 3 4 5 9 14 14 14 14
1024 3 4 5 9 14 14 14 14
2048 3 4 5 9 14 15 15 15
4096 3 4 5 9 16 17 16 17
8192 3 4 5 9 34 134 152 156
16384 3 4 6 9 33 172 169 176
32768 3 4 5 9 33 172 177 180
2 cache levels detected
Level 1 size = 32Kb latency = 3 cycles
Level 2 size = 4096Kb latency = 14 cycles
>>636 あ、プリデコードだから、まだマーキングしただけで命令長にバラつきがあるんだ。
だからbyte数が関係するのか。
しかし、byte数と命令数の両方で制限がかかるというのは、内部形式が想像しづらい。
byte数に余裕があっても、常に18命令入るわけでもなさそうだな。
> 16byte×4blockを越えると速度が落ちてしまいます。
これはLCPストール関係なしに遅くなるってこと?
まあ、平均命令長が長くなれば当然遅くはなるだろうけど、
キューに収まらないループだから遅いなんてことはないよね、という確認。
>>637 ありがとうです。
L1ミスL2ヒットの部分、例えば64KBに渡って32byte毎にアクセスすると、9clkかかっている。
Dothan(L2レイテンシ10clk)でも9clkで、なぜか理論値((10+3)/2=6.5clk)より大きかった。
Core2ではちょうどL2レイテンシの14clkとL1レイテンシの3clkの中間の9clkになっていて、
謎の遅さが解消されている(謎は解明する必要あり)。
最近のCPUに特徴的なのは、strideが64のときと128のときの差。
128byteおきのアクセスになると、HWプリフェッチが効かないのだろう。
昔のCPUは、sizeが大きくなるとstrideが短くてもそれなりに遅かった。
謎なのが、strideが32byteのときに9clkしかかかっていないところ。
プリフェッチが更に強く効いたとも考えられるが、64byteで33clkだから4倍近い差だ。
Dothanでも16byte以下で急に速くなる。
32byteでも速い分、Core2の方が速いと言える。
というかこのベンチから見て取れるDothanとの違いはこの2つだけだ。
HWプリフェッチが強化された、ということですかね。
まずDothanのHWプリフェッチについて調べないと、Core2について知ることも無理みたい。
>635
> 演算器自体は64bit*2で、もちろんuopはフュージョンして内部では128bit扱いにする。
> YonahもSSEでMicroフュージョンするが、演算器は64bit*1なので遅い。
> これの64bit*2バージョンのようなものがK8Lではないかというのが俺の推測or希望。
> (中略)
> ただ、K8は元々SSEが内部64bitなので、既存のスケジューラが一応(遅いけど)使える。
> スケジュール・発行が追いつかなくて増えた実行ユニットを遊ばせてしまう、というのが
> 具体的な弱点として考えられる。
Micro OPs Fusionの正体はuopsを分解しないこと(正確には、実行の直前に分解する)
だったはず。
スケジュールの段階では分解されないと思うんだが。
>>638 > > 16byte×4blockを越えると速度が落ちてしまいます。
> これはLCPストール関係なしに遅くなるってこと?
> まあ、平均命令長が長くなれば当然遅くはなるだろうけど、
LCPストールではなく、命令長が長くて命令フェッチ帯域の制限等を受けて遅くなるという意味です。
LSDが効くループの場合は、命令フェッチ帯域(16byte/clk)の制限は受けないようです。
>>639 それはその通り。
だが、
>>454のmovq l0,h1 のような処理を行い、更にh0やl1をフリーにするには、
128bit単位よりも細かい64bit単位のスケジュールが必要になる。
でも、確かに指摘されてみるとK8のSSEがDirectPathでないことを忘れていた。
>>635で書いたよりもスケジュールは楽になるのかな。
そして、フュージョンした上で64bitの小回りを効かせるYonahも意外とすごいかも。
フュージョンしてても実行の直前の分解はけっこう手間だったりするんだろうか。
MISC系の64bit処理の方が有利な命令を考慮するコストはどのくらいなのだろうか。
ひょっとしてMerom+辺りで高速化できる可能性のあるタイプの処理なのかな。
ちょっとわからない。
というわけで、確かに
>>635はちょっと勘違いしてた上に考えが浅かったです。
>>640 > LCPストールではなく、命令長が長くて命令フェッチ帯域の制限等を受けて遅くなるという意味です。
わかりました(変なペナルティがなくてよかった)。
> LSDが効くループの場合は、命令フェッチ帯域(16byte/clk)の制限は受けないようです。
それなら将来フェッチ帯域を上げれば性能の伸びが期待できるかも。
64bitモード等の平均命令長が長いケースでは、18命令以下ならアンロールしない方がいい、
ということも言えそうですね。
えーっと、pshufdやpshufbの128ビット版が速いのって、
64bit×64bitの転置ユニットが2基セットになってて、128ビットになってるわけじゃないと思う
1.上下QWORD入れ替えたベクトルを作成
↓
2.転置1
↓
3.転置2
↓
4.2と3の合成
の4オペレーションになってるような。
PowerPC(AltiVec)のvperm命令は32バイトのテーブル参照だからこのへんの命令は
いまだにPPCには追いついてませんな。
まあ、実際にはさほど利用頻度の高い命令じゃないはずだけど。
水平加減算も含め、このへんは将来的に速度を解決するから今は遅くても仕様を
躊躇うな、的なことが書いてありますたね。
> pshufdやpshufbの128ビット版が速いのって、
遅いのっての間違い
>644
>Supplemental SSE3すらろくなドキュメントみたことないってのに
一週間前に公開されているが
ttp://www.intel.com/design/pentium4/manuals/index_new.htm IntelR 64 and IA-32 Architectures Software Developer's Manual, Volume 2A:
Instruction Set Reference, A-M
IntelR 64 and IA-32 Architectures Software Developer's Manual, Volume 2B:
Instruction Set Reference, N-Z
なんで今まで無かったのってつっこみたくなるような命令が大半
っていうか、半分くらいは、別にあってもなくても微妙だったり。
ゼロ符号拡張命令にしたって、unpack命令で十分じゃなかろうかと。
CRC32とPINSR{B,D,Q}、pextr{b,d,q
何のために新しく3バイトオペコードを定義したんだか
少なくとも
0F 48 {00-FF}
0F 49 {00-FF}
は全部使える
PMOVZXBWとかって本当に必要なのかしら?
pxor xmm1. xmm1
punpcklbw xmm0, xmm1
と等価なら、要らんぞ。
レジスタ節約の為とか
movq r64, mm
と等価な
pextrq r64, mm, imm8
とかもあるんだろうな
*おおっと ダイの中*
じゃあ、逆にどんな命令が欲しい?
Core2に関して言えば、俺はシャッフルの高速化をまず望む。
欲しい命令は、うーんXMMレジスタを使った条件ジャンプとか。
jzpsa xmm0 ; xmm0が全て0ならジャンプ
jzpse xmm0 ; xmm0が1つでも0ならジャンプ
まあ、他の命令で代用が効くっちゃ効くけど、
CPUに気持ちを伝える言語の表現力が上がるってのはいいことだ。
従来の命令で済みそうな細かい命令を追加してきたというのは、
将来のトレースキャッシュをにらんでのことかもしれない。
CPUに細かく指示を出せれば、それに応じてトレースキャッシュへ
格納する命令もより適切なものにできる。
逆にこれを、
pxor xmm1, xmm1
punpcklbw xmm0, xmm1
PMOVZXBW xmm0 に変換とかもトレースキャッシュならできそうだが、
xmm1という「16個しかない論理レジスタ」を節約したいというのは大きい。
まあ、キャッシュ構成によって命令追加のコストがどう違うとか、わからんけど。
>653
> 欲しい命令は、うーんXMMレジスタを使った条件ジャンプとか。
> jzpsa xmm0 ; xmm0が全て0ならジャンプ
> jzpse xmm0 ; xmm0が1つでも0ならジャンプ
たぶん、PTESTはTESTのXMMレジスタ版かな。これとJccを組み合わせれば実現できるだろう。
ついでに、マクロフュージョンができるといいな。
(現行のCore2ではCOMISS等とJccのフュージョンは出来ない。)
palingr xmm, xmm, r8
が欲しい。なんで即値しかないのよ。自己書き換えコードでも書けってか。
ジャンプテーブル
Data Cache : 8K byte cache size 4-way set associative 64 byte line size dual-sectored line
WCPUIDでこういう結果が出たのですが、
dual-sectored lineというのは何ですか?
psraqキボンヌ
CELLカードのほうがナンボか有用な希ガス
http://folding.stanford.edu/FAQ-highperformance.html Which GPUs will be supported? We have not made any final decisions on this issue. However, our software will likely require the very latest GPUs from ATI (especially now that the newest ATI GPUs support 32 bit floating point operations).
ATIイラネ
後藤さん、リンクミスするくらいならちゃんと前の記事に修正入れてくれ
>>655 必要な分(16通り)のコードを用意しろってことじゃないですかね。
また、palingrを使わない方法として、読み込み元のデータを、
アライメントを1byteずつ変えて16個用意するという手もあるw
>>656 tjmp reg, immA, immB, immC ; reg=0ならAに、reg<0ならBに、reg>0ならCにジャンプ。
こんなのあったら欲しいなあ。
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm 命令セット拡張の図がわかりやすくてよかった。
Core2に入ってるのはSupplemental SSE3(略称SSSE3?)で、
SSE4は45nm世代のCPUに搭載されるというわけね。
しかし未来のアセンブラ使いは大変だろうなあ。拡張命令がすごく多いもんな。
リアルタイム世代なら命令が追加され次第少しずつ覚えていけばいい。
俺はSSE2のときには命令数が多くて怯んだ。
それにしてもMMXは偉大だったなあ。ほんと手軽に何倍も速くなるもんな。
自動ベクタ化は、そんなにうまく働くとも思えないが、もう他に高速化の余地がないんだろう。
コプロ統合も、「なんでもできるCPU」の中に「特定処理用のコプロ」を入れるという
ちょっと変則的な方向なわけで、シングルコア性能の限界を感じさせる。
まあ、こんなことができるのも2年で倍になるトランジスタ資源のお陰で、ありがたいけど。
シングルコアの性能が伸びなくなったからコアを増やす新アプローチになったが、
コア数を倍にしても性能は倍にならないわけで、結局のところ
CPUの性能がダイサイズの平方根に比例するというポラックの法則が成立してるんだよね。
インテル様は専用ロジック&拡張命令増やすが今後の方向性になりそうな・・・
SSE4はCRC32とビットカウント?なんだそりゃ
だっせー
668 :
デフォルトの名無しさん:2006/10/04(水) 10:14:04
ソース嫁カス
SSE4の約50命令とpopcnt, crc32命令は別物。
SSEと呼ばれるのは伝統的にFP/MMレジスタおよびXMMレジスタを使ったオペレーションのみ。
PNIはCRC32とビットカウント?なんだそりゃ
だっせー
ビットカウントは重要だよ~
通信関連の制御とかで。
Hacker's Delightのネタになってたが
実用性はあまり思い浮かばなかった
CRC32やストリング命令は便利そうだけど。
AlphaとSparcにもPOPCNTがあるんだけど
どんなことに使われてるの?
主にパリティの生成じゃないかな。
回路も小規模だし、ハードでやれば速いわりにソフトでは遅いから。
論理回路なら加算機をカスケード接続するだけだからな。
プログラムでやる時はビットの分離のコストが高いってことだ。
何倍早くなるか楽しみだな
Complex命令だったら指差して笑ってやろっと
>>672 SPARCのアレは利用頻度低いから無効命令になってて、
OSで例外をトラップしてソフトウェアで実行するようになってるらしい。
多分、最初からソフトでやったほうが速い。
おまえら、所要クロック 書 か な い か ?
こうして、IDF直後なのに過疎スレに逆戻りしたのであった(完)
>>680 ブログの方で話が進んでないと思ったら、こんなとこに書いてたのか。
「実質的にはx86命令で3命令/Cycleを狙ったアーキテクチャである」
って大原さんは前から言ってるけど、そもそも意味がわからん。
「ピークIPC」と「エンコするときのIPC」と「ゲームしてるときのIPC」はどれも異なるが、
エンコやゲームでのIPCを上げるために、IntelはピークIPC「4+」の道を選んだのだ。
> 筆者が一番重要視したいのは、Sustained Performance、
> つまりピークのIPCではなく平均的なIPCである。
これには同意。というかライターやってるくらいだから俺より知識があって当たり前だった。
ただ、ちょっと書き方が嫌だな、というところに文句つけている(↑のも)。
まず、一瞬で終わる処理やネットワークやHDDネックな処理ではIPCを考える必要がない。
IPCが倍になっても全くメリットがないから。
で、例えば前スレ899のマンデルブロ集合のコードだと、DothanのIPCは0.947だ。
まず、これは手で最適化してありメモリも使わないのでSSEコードとしては圧倒的にIPCが高い。
しかしSSEはSIMDで、1命令で多くの処理をするのでIPCの数字としては低くなる。
DothanのピークIPCは3なので、1/3も出ていない。
mov eax,[eax]
dec ecx
jnz lp
このコードだと、L1ミスL2ヒットでDothanのIPCは0.3になる(10clk/loop)。
トリップ検索を単純化したような処理だが、L2キャッシュというのはこの程度に遅い。
当然、メインメモリにアクセスすれば更に遅くなる。
このように、命令が違えばとIPCはクロック当たりの性能に一致「しない」し、
処理内容によってもIPCは10倍単位のスケールで大きく変化する。
これの総合(当然遅い部分が足を引っ張る)が「平均的なIPC」なわけだ。
性能をIPCで語りだすとややこしいんですよ。
俺はクロック当たりの性能の意味でIPCって使っちゃうし(同じコードでなら正しいので)。
まだ使える石ねーだろwwww
K8Lあたりはそろそろ一部の向けにESが出回ってるかも
ヒント:等価コードの計測
x86_64の所要クロック計測まだー
オペランドはどうなるんだろ
POPCNTはAMDと同様に POPCNT r, r/m だと思うけど、CRC32が予想できない
VIAのPadLockは参考になるかな
rep lods
てけとーにでっち上げてみた
DWORD PopCountDW_SSSE3(DWORD src) {
DWORD dest;
static const __m128i table = { 0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4 };
__asm {
movd xmm1, dword ptr [src]
movd xmm0, xmm1
psrlq xmm1, 4
punpckldq xmm0, xmm1
pshufb xmm0, xmmword ptr [table]
pxor xmm1, xmm1
psadbw xmm0, xmm1
movd dword ptr [dest], xmm0
}
return dest;
}
それ早いのか?
それ旨いのか?
安そうだけどね?
movd xmm0, xmm1
→movdqa xmm0, xmm1
それ動くのか?
動くんじゃね?たぶんwwwww
3回読み直しても意味不明だったが
pshufbのオペランドが逆だったら意味は通るかも試練と思った
つまりテーブルはレジスタに移さないとだめだしソースにはマスクが必要じゃないのか
あとクロック計測よろ
多分そんんくらいか
いや単にpsadbw使えるんじゃね?って思ったから。そんだけ。
ラップアラウンドしないんだっけ?
そこじゃない
pshufb のソースオペランドに最上位ビットが立ったバイトがあるとまずいんじゃないのか
Description
PSHUFB performs in-place shuffles of bytes in the destination operand (the first
operand) according to the shuffle control mask in the source operand (the second
operand). The instruction permutes the data in the destination operand, leaving the
shuffle mask unaffected. If the most significant bit (bit[7]) of each byte of the shuffle
control mask is set, then constant zero is written in the result byte. Each byte in the
shuffle control mask forms an index to permute the corresponding byte in the destination
operand. The value of each index is the least significant 4 bits (128-bit operation)
or 3 bits (64-bit operation) of the shuffle control byte. Both operands can be
MMX register or XMM registers. When the source operand is a 128-bit memory
operand, the operand must be aligned on a 16-byte boundary or a general-protection
exception (#GP) will be generated.
In 64-bit mode, use the REX prefix to access additional registers.
PSHUFB with 64 bit operands:
for i = 0 to 7 {
if (SRC[(i * 8)+7] == 1 ) then
DEST[(i*8)+7...(i*8)+0] <- 0;
else
index[2..0] <- SRC[(i*8)+2 .. (i*8)+0];
DEST[(i*8)+7...(i*8)+0] <- DEST[(index*8+7)..(index*8+0)];
endif;
}
PSHUFB with 128 bit operands:
for i = 0 to 15 {
if (SRC[(i * 8)+7] == 1 ) then
DEST[(i*8)+7..(i*8)+0] <- 0;
else
index[3..0] <- SRC[(i*8)+3 .. (i*8)+0];
DEST[(i*8)+7..(i*8)+0] <- DEST[(index*8+7)..(index*8+0)];
endif
}
ほほう、MSBが立ってると0になるらしい・・・
その人やたらと話がくどいよな
一つの記事の中で段落変えて同じ内容を3回以上は書いてる
洗脳効果を狙ってるのか?
昔はそうでもなかった
有名になってからクレーマーが沢山憑いて意見や妄想や予想が気軽に書けなくなったんだと思う
707 :
デフォルトの名無しさん:2006/10/13(金) 00:26:40
708 :
デフォルトの名無しさん:2006/10/13(金) 20:54:11
>>707の記事で解説してない項目がある
誰か解説して
・ Data-dependent divide latency
・ More Fastpath
- CALL and RET-Imm instrutions
- Data movement between FP & INT
> ・ Data-dependent divide latency
レイテンシあたりのデータ依存性?
SIMD演算でpandとかpadddとかで2クロックかかってたのが気になってたんだけど、
あのへんが改良されてると見ていいのかな。
> - CALL and RET-Imm instrutions
プログラムスタックを高速に処理するための回路って感じでせうか
> - Data movement between FP & INT
ブロック図を見る限り、FMISCから整数ALUに直接データを渡すための回路みたいなのが
追加されてますね。
movdとかpextrwとかの演算が速くなるんでしょ。
>>709 ・ Data-dependent divide latency
K8では入力データによらずレイテンシ固定だった除算命令が
PenMのように入力データによってレンテンシが変動する。
・ More Fastpath
- CALL and RET-Imm instrutions
- Data movement between FP & INT
今までVectorPathデコーダでデコードしていたCALL, RET imm, CVTSI2SS等?の命令を
DirectPath(FastPath)デコーダでデコードする。
712 :
711:2006/10/14(土) 17:11:04
除算命令は整数除算DIV, IDIV命令の事だと思う。
ああそっちのことか
納得
インテルCoreクヮッドてどうなるんだろう
>>715 Dothanで実験してみた。命令を連続で配置し、1000回ループで測定。
cmp eax,1000h ; 5byte
実行ユニットが2命令/clkなので10byte/clk。
cmp ax,1000h ; 4byte
1ループ当たり10命令ずつでやったときは2命令/clk近く出ていたのだが、
並べる命令数を増やすと遅くなった。
12命令/loopでは7.2clk/loopと普通だが、13命令/loopになると30clk/loopと大きく落ち込む。
これはaxとbxを混合させた場合だが、axのみにすると13命令では遅くならず14命令で遅くなる。
ax、bxの他にcxも混合させると、12命令で遅くなってしまう。dxまで混合させても変わらず。
命令数を増やしていくと、とりあえず8命令で10clkのペースで遅くなっていく。
128命令だと232clkで、2byte/clk強というところ。
>>715のグラフと大体一致する。
Core2と似た挙動と言えなくもない。Core2はもっと激しく遅いだろうけど。
Dothanにも命令を蓄えるキューみたいのがあるんだろうか。
でも、そうじゃなくて、単にLCP命令を処理する部位が追っつかなくなってるように見える。
命令数が少ないときでも微妙に(0.1clkくらい)LCP付きのが遅かったんだよな。
しかしなぜあのテストがDecode Bandwidthという名前になってるんだろ。
ネックになるのがデコードかスゲジューラか実行ユニットかリタイヤかわからないのに。
>>711 それで
>>382>>387ではdivでK8が負けてたのね。
スタックエンジンも載るらしいし、K8Lも全方位に抜かりがないなあ。
SSEは手抜きじゃん
718 :
デフォルトの名無しさん:2006/10/16(月) 00:05:19
719 :
デフォルトの名無しさん:2006/10/16(月) 00:06:56
なんかL3の制御がインテリジェンスな気がする
早期投入のためか排他キャッシュのままあれこれ弄繰り回した手抜き設計ですから
随分前から変えた方が良いと言われていたのに
L2は512KBに減ってるしまだマシじゃね
L3共有予定でL2まで共有にしたらクロスバーがパンクするのは目に見えてるだろ
小容量L3ってあたりで現行をいかにいじらないで・・・という感じがするな
拡張可能だけどね。
65nm世代中にZ-RAMとか妄想してしまう。
283mm^2より更に肥大化させるとか、もうねアフォかt(ry
>>701 ここ の京速についての予想、技術的には真っ当と思うけど技術的に真っ当な予想が 当たるほど世の中は甘くないというか甘過ぎるというか、、、
Home Page of Jun Makinoより引用
えっ、、、と... や っ ぱ り 京速計算機は迷走中ってことですか?
そうじゃなくてNとHとFの駆け引き中
>>716 LCPストールはConroeで新たにできた制限ではなく、以前からあったのですね。
P6で試してみましたが、やはりLCPストールは発生します。
P6のパフォーマンスモニタリングイベントにもILD_STALLという
LCPストールの回数をカウントするイベントがあるので試してみましたが、
LCPストールは命令16byteブロック毎にストールするようで、
16byte中に複数のLCPが含まれていても、ストールは1回だけのようです。
LCPストール1回につき5clkぐらいストールします。
このあたりはConroeと同じです。
P6の場合は、1ループ中の命令数が少なくてもストールします。
Loop bufferが導入されたのはPenMからのようですね。
>>728 と、いうことはP6ではcmp ax,1000hが短いループでも遅いということ?
で、16byteと言われ気づいたが、x86の基本事項を見落としていた。
cmp ax,1000h は4byteだが、cmp bx,1000h は5byteだ。やっぱりCISCだなあ(苦笑)。
多くのレジスタを使うと何かあるのかと思ってたが、単に命令のbyte数が増えたから
bx、cxの混在コードで遅くなったというわけか。
cmp ax,1000hが13個(4byte*13)とループ処理(3byte)で合計55byte。
14個だとダメだったから、59byteはアウト。bx混在の12個は54+3byteで57byteでもOK。
ていうかnopをはさめばよかったw
結論、ループ当たり58byteならOKで、59byte以上になると遅くなってしまう。
cmp ebx,1000hは6byte、これとcmp ax,1000hを混在させてみたが、特に変わらず。
ループ当たり59byteになると普通通り遅くなる。
cmp ax,1000hを1つだけ入れたループにnopを入まくって59byte/loopにしてみたが、
これは遅くならない。しかし、なぜ境目が58なんだ?
で、nopの数とcmpの数を色々変えて測定してみた。
58byte以下なら高速に処理されるのでそれでいいとして、59byteの場合を調べた。
まずcmp命令を並べ、次にnop、最後にdec ecx / jnz という1000回ループ。
9*cmp bx,1000h,11*nop 30clk
8*cmp bx,1000h,16*nop 24clk
6*cmp bx,1000h,26*nop 24clk
5*cmp bx,1000h,31*nop 19clk
4*cmp bx,1000h,36*nop 21.3clk //ALUネック、42命令なので21clk以上はかかる
このクロック数の変わり方は命令数じゃなくて命令バイト数・位置が関係しているはずだ。
そんで詳しく調べようとalign 16をループ前に置いたら、cmp8個のコードが13clkに高速化!orz
16byte境界が見えるアセンブラのエディタがマジ欲しい。ちょうと1レス分なので終わり。
LCP以外に調べることってねーのかな
731 :
728:2006/10/19(木) 19:40:43
>>729 > と、いうことはP6ではcmp ax,1000hが短いループでも遅いということ?
そうです。このことから、P6にはLoop bufferが無いことがわかります。
>>731 実際に遅いわけか。ていうか何で元P6使いの俺が知らなかったんだ。
P6だとCore2と比べて元々が遅いしストールで損する絶対clk数もCore2よりはマシだろうから
そんなに問題にはならなかったのだろうな。
PenMにはLoop bufferがあるというのは、どこにあるんだろうね。
Core2のような構造とも思えないし、俺はLCPをどこかに記憶しておくような仕組みを想像する。
別の種類の命令で64byteを超えると遅くなるようなものがあればLoop bufferが確認できるな。
ここから前回の続き。
align 16をループ前に置いたら速くなったと書いたが、
この場合は64byte/loopまでは高速に処理できて、65byteから遅くなるということになった。
はあ、つまりアラインされた64byteの中に収まっているかどうかということね。
前回のは実に間抜けな測定だった。
今回の測定ではcmp bx,1000hとcmp eax,1000hが共に5byteなことを使い、並べ替えてみた。
やっぱり16byteの中にLCPがあるかどうかが問題になるようだ。
64byteを超えて16byteのブロック(align 16)5つに収まっているループで測定すると、
LCP付き命令が入っている16byteブロックの数とclk数の関係は、
ブロック数が5,4,3,2,1個のとき、36,30,24,18,12clk(ALUネックのときはそちらのclk数)。
単純な関係だが、1個のとき12clkなら0個でも6clk、ブロック毎の処理以外に6clk消費する?
次に、16byte境界をまたいでLCP付き命令がある場合。
cmp bx,1000hでは、前後共、1byteはみ出していても関係なし(はみ出ていないのと同じ)、
2~3byteはみ出すとダブルカウントされる。つまり最悪2つのLCPで30clk/loopになる。
cmp ax,1000h(4byte)では、頭が1byteはみ出ても、お尻が1~2byteはみ出ても変わらない。
こちらはダブルカウントの場合なしだ。法則性が見えん。
おそらくこの挙動は
>>728に書かれているP6のものと同じなのだろう。
これは1ブロックでストールしただけなら12clk/64byteloopで済むわけで、大きな被害じゃない。
>>606も、16byteブロック毎のストールならアライメントのない20命令で20*4/16+1=6回、か?
PenMとの挙動の違いが気になる。
>>732 > 別の種類の命令で64byteを超えると遅くなるようなものがあればLoop bufferが確認できるな。
命令長が長い命令を並べた場合はどうなりますか?
49~63byteのループで3clk/loopで回るものがあれば、
16byte/clkの命令フェッチ帯域を越えられる事が分かるのですが。
>>733 add ebx,[esi+eax*8-800]
mov [esi+eax*8-800+8],edx
add edx,1000h
これで20byteだが、これを実行ユニットは1clkでギリギリ処理できるかもしれないけど、
実測してみるととても無理という感じ。スループットは2clkに20byte(⊂16byte*2)かな?
ていうかCore2であっても18命令のキューにはバイト数制限もある。
おそらくはCore2の命令フェッチ帯域も16byte/clkの壁は破れないと思う。
ここはプリデコードなので命令に印を付けた程度の生に近いデータを流しているはず。
>>636にあるように、Core2のキューも16byteブロック4つ分。う、PenMと同じだ。
ただ、
>>729のときに31命令でストールしないコードがあったので、Core2とは違う。
PenMでは時間のかかるループならLCPストールを完全に隠蔽してしまうが、
Core2ではどうなのかを調べたいところ。
ところで、Core2は18命令までというきつい制限まであって、LSDっていうのは
PenMのループ検出器とは別物なのか?
PenMで64byteを超えるループを書いてみたが、特に遅くはならない。
>>734 Core2だと、この59byteのループが3clk/loopで回るので
LSDが効く場合は16byte/clkを越える事ができますが、Dothanではどうですか?
align 16
lp:
mov dword ptr [esi+1040],1000
mov ebx,dword ptr [esi+1024]
sub ecx,1
mov dword ptr [esi+1040],1000
mov ebx,dword ptr [esi+1024]
lea edx,[esi+1024]
mov dword ptr [esi+1040],1000
mov ebx,dword ptr [esi+1024]
jnz lp
>>735 ええっ、できるんだ!これは嬉しい誤算だ。
64byteのキューの中からなら、ある程度自由に命令を取り出せるんだね。
そのコードはDothanで6clk/loopでした。
4clkでできてもいい気がするが、LoadやStoreの同時実行もきついのかな。
いや、長い命令やまたいだ命令のフェッチ能力が低いのが原因か。
やはり、同じ16byteでもCore2と比べたらDothanの命令フェッチは弱いんだろうね。
>>736 そうでしたか…。やはりDothanのLoop bufferとCore2のLSDは別物なのですね。
>>607の資料にもCore2で小さいループは32byte/clkの命令フェッチ帯域と書いてあるので
LSDで16byte/clkを越えられるのは間違いはないと思います。
739 :
737:2006/10/20(金) 00:59:52
32byte/clkの命令フェッチ帯域じゃなくて32byte/clkのデコード帯域ですね…。
>O原様
Melomなんてコードネームは存在しません><
大原は10月下旬まで仕事したくなかったからLCPの(無意味な)話で連載3回引っ張ったわけだが
別におまえらは真似しなくていいんだぞ
>大原は10月下旬まで仕事したくなかったからLCPの(無意味な)話で連載3回引っ張った
IDFのレポートはまじめにやってるのでそれは無い
>>737 >>640にレスを返す
>>641。
なのに
>>734では「16byte/clkの壁は破れないと思う」。俺はもうダメだ。
すまんかった。
再び書いておくと、Core2で命令フェッチやLCPがネックになっている場合、
18命令16byte*4以内のループに収めることで高速化できる、と。
>>741 無意味とは言わんが、大原記事は、このスレとしてはつまらない話が続いてるね。
前スレの最後に貼ったようなスレのまとめリンクを作成中。
やっぱり前スレの方がバラエティに富んだ話題があっていいな。
このスレの目玉はやはりYonahとMeromの話題。新しいために実測結果が少なめ。
行列のかけ算は、このスレにしてはちょっと複雑で応用的な話題だったが、
有効なキャッシュ利用の例として意義があった。
マルチコアでのクロック測定のノウハウを確立することは今後の課題だ。
あと次スレタイ案ある?俺は今のがいいと思ってるが。
/onecpuで強制的に1コアだけ認識させるとか
Core 2 DuoはRDTSCはFSBから取得してるからどのコアでも常に同期がとれてるんじゃなかったっけ?
>>744 さんくす。まあ、俺が測定するのは実機を手に入れてからになると思うけど。
もちろん測定したい人がいたらコアループの提供くらいはしますよ。
rdtscがFSBクロックなのってそういう理由が考えられるか!
「時刻」が離れたコア同士でもわかるというのは実用性があるかもしれん。
将来コア毎に動作周波数が変わるようになっても安心だな。
Tulsaは確かコアごとにクロック制御できるよね。
バスの話は歴史を一通りおさらいできて役に立ったけど
今回は何もせずにああでもないこうでもないと言ってるだけだからなー
μopsの詳細がわからない限り、社外の人間が正確な評価は出来ないから
焦らせると言うより、何とか引き伸ばしてるだけの予感。
NetBurstの利点がその柔軟性だとintel以外が理解したのは
その最終期だったわけで。
>>747 引き伸ばしは、上からそうするように言われてるってのもあるんでないか?
Core2機で実験のできる立場にあって未だにIPCが4を超えるケースを知らないことはあるまい。
ていうかブログにこのスレが書いてあったけど、(個人的に)読んで、実験してくれたんだろうか。
まあ、以前のPenMのFusionテストでもイマイチピントが合ってなかったから、
CPUのあまりにも局所的な話は専門外なのかもしれないけど。
でもやっぱり、この処理をこのCPUにやらせたらこれだけのクロック数だ!と
実行する前にわかってしまう気持ちよさが欲しい。
確かにP6以降のCPUは複雑怪奇になってきたけど、わからないなりに原因を切り分けて、
VC++6.0を立ち上げっぱなしで思いつくコードを測定・記録(記録をしないと混乱する(汗))、
結果から考察推測、また検証コードを書くという繰り返し、
これで不確かで狭いながらもCPUの景色は見えてくるし、今のCPUのことだけでなく、
次世代CPUに関することも理解しやすくなる(何が欲しいかの判断基準ができてるから)。
脱線してしまったが、要するに、アセンブラで測定してくれるPCニュースサイトはないですか。
>>750 企画まとめて出版社に殴り込めば?採用してくれるかもよ。
752 :
デフォルトの名無しさん:2006/11/03(金) 21:12:57
うーん、今回は簡単だとぼくは思っていた。だって、Intel MultiCoreProcessorは高発熱のプロセッサだもんね。
これからも当分抜かれることのない消費電力のはずなのだ。この質問のこたえなんて考えるまでもない。
けれど、Intel MultiCoreProcessorを、みんながどんなふうに感じているのか、それが探りたくてこのテーマにしたのだ。
するとあらら、不思議。寄せられたのは親Intel MultiCoreProcessorのメールばかりだった。
なぜなのかしらん? というわけで、今回は多数を占める「Intel MultiCoreProcessorは優れた製品」派からいってみよう。
「プロセッサの消費電力の低さは、普及価格帯ですら、『望ましい』ことであって、ましてやエンスージアスト向けならば、『なすべき』ことではない」(住所不明・匿名さん)
「競合する他社製品と同等の発熱で二倍の能力があるから。」(住所不明・匿名さん)
「消費電力は低いほうがいいに決まっているが、パフォーマンスを大きくさげてまで低くする必要はない」(海外在住・匿名さん)。
「低発熱低性能なXE向け製品ならいらない。必要があれば省電力化し、なければパフォーマンスに振り分けるくらいでちょうどいい」(北海道旭川市・優子さん)。
ふー、びっくりした。でも、擁護派の意見はほぼ一点に集中している。
相対的な観点から見ると優れた製品だから、特に発熱だけを問題視する必要はないというもの。
それほんとなのかなあ。今回の答えは数字の上では「しなくていい」派が圧倒的だったけれど、
応募しなかった多数のサイレントマジョリティを考慮にいれて決定させてもらいます。
発熱は低いほうがいい、だからIntel MultiCoreProcessorは失敗作。あたりまえの話だよね。
753 :
デフォルトの名無しさん:2006/11/03(金) 21:32:22
命令よりレジスタがほしいです。
少なすぎ。
命令フォーマット的に無理です。
その意味PowerPC Macって良かったんだけどねー。
755 :
デフォルトの名無しさん:2006/11/03(金) 21:36:00
フォーマットってModR/Mのこと?
756 :
デフォルトの名無しさん:2006/11/03(金) 21:37:22
プレフィックス増やせばいいんじゃないの?
1個のレジスタ指定に使えるビットが3bitしかないからね
INC命令を潰して無理やりレジスタ拡張プレフィックス付けたりとかそういう方法に頼らんと駄目なわけで。
ああ、imm8で拡張レジスタ指定でもするのか。
やめてー
レジスタが多いと退避が大変。ItaniumなんかではCGMTまで使ってペナルティ回避してる。
759 :
デフォルトの名無しさん:2006/11/03(金) 21:45:02
退避したくないからレジスタほしいんだけど。
ハードウエアのことはインテルが何とかすればいいし、
OSのことはマイクロソフトが何とかすればいいでしょ。
ね?レジスタはたくさんあったほうがいい。
コンテクストの切り替えや関数コール時に不利って話。
やってるじゃん、CPU内部で8本のレジスタを128本のレジスタファイルに再割り当てとか。
>>759 かつて、MIPSやAlpha、PPC版のWindows NTがありました。
でも、結局x86しか残りませんでした。
762 :
デフォルトの名無しさん:2006/11/03(金) 21:56:06
レジスタが32本あったらいいのにな。
763 :
デフォルトの名無しさん:2006/11/03(金) 21:57:49
8本っていっても実質4本だもんな。
じゃあMMXとXMMをダイレクトに交換する命令があるからまだマシ。AltiVecとか使ってると
その辺周りでストレスたまる。
>>752 こんなところまでサイレント魔女リティかよ。
PowerPCなんか、レジスタが使えるのはいいんだけど、アドレッシングモードとかの不便はあるし
32bitの即値が使えないとか、平均的には相殺されてる。
MPC7450ですらAltiVec命令のレイテンシが大きいから、アンロールしてやらないと駄目だし
そうなると32本のSIMDレジスタもあっという間に使い果たす。
結果的にはCoreアーキのほうが扱いやすい(俺の感想)
アドレシングモードって、書く方にしたら便利だけど、
ストールしまくって速度を落とす場合が多いんじゃないの?
769 :
デフォルトの名無しさん:2006/11/03(金) 23:49:49
>>768 アドレッシングモードってアセンブラの仕事じゃないの?
>>760 関数コール時に影響はないね。
contextSwitchについては、benchmarkでも走らせるべきだけど、
秒間1000回程度なら、気にする程の事でも無いような。
>>768 それは初期P6アーキテクチャでComplex Decorderパスでしかデコードできないから
ストールするとかの問題じゃなくて?
AthlonやPentium M以降はそういう制約無いよ。
>>770 実際のとこ、初期Itaniumがタスク切り替えが遅いって言われたのは
コードサイズに比べて命令キャッシュが小さいのもあるからレジスタ数の問題とも言い切れない鴨
レジスタが少ないことによるパフォーマンスの影響は、現行アーキテクチャで他のRISC等のアーキテクチャと
比較しても差し引きで1割程度って言われてる。
複雑な命令フォーマットをとることでデコーダが複雑になり消費電力が増すくらいなら現行でも十分かと。
773 :
デフォルトの名無しさん:2006/11/04(土) 04:12:52
複雑なコードがいやならバイトコードにして名前もジャバチップに変えてしまえばいい。
結局ソフト実装しか流行らんかったな
AMD が余ったトランジスタの使い道として VM のサポートを挙げてなかったっけ?
意外と、まだ始まってないだけかもよ
VMっていったらIntel VT(Vanderpool/LaGrande)とかAMD-V(Pacifica)が思い浮かぶ
中間言語アクセラレータの噂はIntelにもあるね。
LaGrande = TXT
いやそうなんだけど、一部技術は既にVTの特権命令群に含まれてるお
それはしらなんだ
*Tsは一日にして成らずってことか
>>766 関係あるが、秒単位でなくクロック単位の計測だとなおいいか。
まず、Athlon64が2.0GHzなので8byte/clkが14.90GB/sec。
Core2は2.93GHzだから8byte/clkが21.86GB/sec、16byte/clkが43.71GB/sec。
ここの測定でのMAXがCore2の38.42GB/secというL2帯域だから、あんまり大したことない。
1コアだと23.09GB/secで、L1帯域の半分強。これはPenMからちょうど倍になった感じ。
Yonahで見られたストアの変な速さはない(測定方法依存かもしれないが)。
1コアで見ればYonahの倍。Yonahで2コア使ったL2帯域はどうだったんだろう。
AthlonX2は各コア独立してL2を持っているが、
それでも同時アクセスのペナルティがほとんどないというのは優秀だ。
Core2の共有L2は、まあこんなもんだろう。共有処理はそれなりによくできてるのかな。
メインメモリの領域では、2コアからのリードアクセスで1.5倍に伸びるAthlonX2と1.1倍のCore2。
AthlonX2はメモコン内蔵だから処理が増えても伸びる?
Core2は最初からHWプリフェッチが限界近くまで効いてるということかな。
Core2のライトが遅いのは何でだ?L2の範囲では見られない傾向だ。
共有L2からのライトバックの順番を維持するため、じゃないよな1コアでも遅いし。
その後の測定とかも興味あるが、英語読んでる時間とやる気がないな。
自分で測定したいなあ。まったくもどかしいことこの上ない。
俺が次にPCを買い換えるときは、時期的にVistaになっちゃうんだろうなあ。
その頃なら64bitでいいだろう。64bitで使うMerom。VC6.0ではさすがにきついか。
GRAPE-DRキタ━━━━(゚∀゚)━━━━!!
785 :
デフォルトの名無しさん:2006/11/07(火) 10:46:36
雑音(503です・団子・MACオタなど)の行動についての解説 統合第4版
●IDが数個 そのうち再出現ID1or2個のような時
・自演をしている可能性が高いです。
・固定IPの使用者は1回線契約でもプロバイダーによっては3~4つのグローバルIPアドレスを持つことができます。
・複数回線で自演をする者はこれを巧みに利用しており、レス投稿間隔も概ね似通っています。
・IDがリセットされれば複数のグローバルIPアドレスもリセットされることになるのでIDは全て変わります。
そこで固定IP用アドレスともうひとつの動的IPアドレスの2回線を巧みに使って、
ひとつまたは複数以上のIDを残しつつ、すべてが自演という活動をします。
●大勢のネラーが居るように見えるからといっても無闇にレスを返さない 。
・自演をする人は、文体などを巧みに変えつつあらかじめ用意してある文章を貼り付けてレスをつけたりします。
それに惑わされることなく、なるべくレスを付けずそのような相手の行動を助長しないようにしましょう。
●見破るにはどうすればいいの
・一般の人とは違う生活を営むタイプの人ですから見破るのは簡単ですが、レスだけでは判断しづら い場合があります。
レスの内容自体はスレごとに統一するだけで、大きくこだわることはありません。
自演を行っている人のいい加減な性格を明確に物語っています。
あるスレではintelを称え別のスレではAMDを持ち上げるような事を平気でします。
それと思しきコテハンが自作板のレスの多いスレに常駐しています。
・主に未確定の情報についての妄想を述べるのが得意で、
既定の事実について述べると、ボロを出して叩かれまくります。
発言に窮すると、鸚鵡返しや意味不明な書き込み・AA連投・アンカーだけレスのなどの行為を行ないます。
・文体の特徴としては撥音促音拗音や係り受けやカナタイプによる誤入力に見られます。
!や?や・。、などを多用連用する特徴はVIPPERの証しです。
その他に特徴的な助詞の欠落や「な」「ろ」「ぁ」「ぇ」や「ない」が「ん」になる癖があり、
「ん?」や「ん、」・「んで」・「ってか」「てか」「つか」「つーか」「のが」の多用がみられます。
特に「ん」の使い方には注意してください。例 それで→そんで すぎるぞ→すぎんぞ 分からなかった→分からんかった
>>784 512コア60Wか。USB(笑)外付けで5万円なら買う(100万とか無理)。
コア当たりだと、1clkで乗算と加算か。倍精度でも384G FLOPSは嬉しい。
でも、アセンブラはともかく、制御が難しそうだ。
>>786 前置きだけで終わりそうな予感・・・。
× 512コア
○ 512PE
COLLADAとかCgどーなるんだ
無駄なトランジスタ使ったなあといった感じ
>>346 それ、ここ以外では「計算量」って呼ばない方がいいですよ。
>このプログラム(というかmyfunc)を実行するために使われたCPUのクロック数です。
単にNUMを大きめにして time で計測し、NUM * クロックで割ればそれなりの精度で
でてくると思うが、正確に計測するのはなかなか難しい。
誤爆しました
>>792 キター!!
でも英語かあ。実機ないと読む気起こらんな。。
とりあえずストアユニットはアドレスとデータに分かれてるのね。
>>795 > "32 discontiguous microops considered for dispatch per cycle"
> スケジューラ/ROBの組み合わせでは1cycleあたり最大32のMicroOpsを比較して、
> 同時に出せる命令を探すという構造になっている事が判る。
これは嬉しい情報だ。どう使ったらいい情報かはわからんが。
> Core MicroarchitectureのスケジューラやROBが「こんなに単純で大丈夫なのか?」と思えてしまう。
これは俺も思うな。ほんとに単純かどうかはさておき、双方の仕組みに功罪があるはずだ。
Intelがフュージョンを頑張ってる理由もここだろう。
> これは単なるPeak Performanceであって、Sustained Performanceとは解釈しにくい。
デコーダと実行ユニットを考えて書けば多くの場合IPC5を維持できると思うけどなあ。
まあ、実測してない俺の言えたことではないが。
で、K8はデコード3、スケジュール3。Core2はデコード4、スケジュール3。
そう主張したいようだが、Core2がスケジュール4と考えない強力な理由があるんだろうなあ。。
> (*2)こちらのコメント先にこの話は出ておりまして、当然目を通しております。
な、なんだってー
>>795 なぜ(*2)の「このスレ見てるよwww」に突っ込まない
ってかFusion系の効果は無視かよ
そもそもIPC3狙った設計のK8よりクロック当りの性能が20%強上回るのだから
CoreはIPC4を狙った設計ってことでいいじゃん
いい加減他のCPUとの比較話はやめてCoreと真剣に向き合って頂きたい
主にアセンブラを使ってw
798 :
797:2006/11/10(金) 00:35:03
めっちゃかぶってるし…リロードすればよかったorz
絶対IPC4じゃないお、intelの言ってることは違うおヽ(τωヽ)ノ、と
延々主張してるようにしか見えん。
実際IPCがいくつだろうと、メモリコントローラ内蔵した対抗CPUより速いと言う事実が大事なんだと思うのだが。
そして発熱も消費電力も低い。
そもそもK8の平均IPCが3以下なんじゃないか?
ワラタ
>コアの素性そのものは悪くなかったからだ。
こういう書き方は、将来TDPに縛られてコア本来の性能が出せない時とか
すごく便利そうですね。
消費電力を考慮しなければコアの性能は互角以上といえる、とか。
>平均IPC3未満のK8はIPC3を狙った設計であると言える。
ん?K8って「ピークが」3じゃなかったっけ?
>これを4 x86命令/cycleと取るか3 x86命令/Cycleと取るかは人に依るのだろうが、
>AMDはK7の時代からこれを3命令/Cycleをターゲットにしたアーキテクチャだと公言し、
>我々を含む業界全体でこの数字をリーズナブルなものだというコンセンサスが取れていた事を考えれば、
>Coreもx86命令で3命令/Cycle見なすのが無難なだろうと筆者は考える。
3issueのパイプラインにALU2本で2命令+αを狙ったPentium Mに実質IPC
並ばれてたんだから実際K8パイプラインって効率そんなによくないんでしょう
大原は実験上がりなので理論的なことは不向きというか電波に近い。
後藤は理論はキッチリ抑えるがマーケティングとかトレンドに絡めると空振り気味。
元麻布とかは最近何してんだろうな…。
Intel・AMD両社のx86系CPUで、スーパースカラの限界である3命令/Cycleに初めて到達したのがC2D
これ以上はVLIWへどうぞ
>>796 K7はROB=72entry、RS int=18entry,fp=36entry
K8はROB=72entry、RS int=24entry,fp=36entry
Core2はROB=96entry、RS=36entry
AMDのRSがintとfpで分かれているってだけで、
OOOの仕組みはAMDもIntelもほとんど同じだと思いますよ。
809 :
808:2006/11/11(土) 20:48:02
数字まちがえた。
Core2はROB=96entry、RS=32entry
>>808 K8はint、fpのスケジューラの前で、依存関係の解消をある程度やってるらしい。
>>792 pxorとxorpsとxorpdで全部スループット違うのか・・・
813 :
792:2006/11/12(日) 02:43:06
気になったこと
・ Integer SIMD ALU は2器だがpadd/psub/pcmpの
スループットが0.33になっている
・ imul r32/imm32のスループットが0.5になっている
FP MUL と Integer SIMD MULが別々のポートなので
それぞれのポートに発行できるのだろうか?
QWSHUFFLEが2基なのにMMXのシャッフル命令のスループット1って変じゃね?
ひょっとして上位QWORD用と下位QWORD用に分かれてる?
予想が正しければ、pshufhw xmm, xmmとpshuflw xmm, xmmは同時実行可能ってことに。。。
シャッフル演算は64bitごとに処理やってるんだろうなってのは見当ついてたけど
やっぱりなー。
>>813 手持ちのConroeで32bitOSで試してみましたが、
paddb xmm,xmm は3つ同時実行は無理ですね。2つ同時実行なら可能でした。
imulも2つ同時発行は無理のようです。
mulpdとpmullwの同時発行は可能でした。
>>815 シャッフル命令の発行ポートをちょっと調べてみました。
pshufd xmm,xmm,i : port0=1uop, port5=1uop 計2uop T=1
pshufhw xmm,xmm,i : port5=1uop 計1uop T=1
pshuflw xmm,xmm,i : port5=1uop 計1uop T=1
pshufb xmm,xmm : port0=1uop port1=1uop port5=2uop 計4uop T=2
shufpd xmm,xmm,i : port0=1uop 計1uop T=1
shufps xmm,xmm,i : port0=1uop, port1=1uop, port5=1uop 計3uop T=1
なんだかよく分からないですね…。
pshufhwとpshuflwは発行ポートが同じなので同時実行は無理でした。
> pshufb xmm,xmm : port0=1uop port1=1uop port5=2uop 計4uop T=2
port0はシフト、port1は論理和
とすると
port5で上位QWORDと下位QWORD別個にシャッフル演算できるって形だよなぁ
シフトユニットが見あたらないし。
Intelマニュアルって例によって間違いだらけの悪寒
話題の大原記事についての続き。
まず、「それを言ったらK8の平均IPCは3より低いじゃん」という反論は適当でないと思う。
そもそも、IPCというのはコードによって大きく変動するものだから、
「IPC3がターゲット」の意味は「ある程度うまくいったときIPC3になる設計」と解釈するべきだ。
(「ある程度」の解釈は以下の文脈から読み取ってください)
当然IPC4(内部命令で)のケースがあることを知って、その上で大原サンは、
3命令デコードのK8と、全域4命令のCore2を同列に並べる理由があると言うんだから
叩きどころはその「理由」のダメさだ。
まあ、その理由がいつまで経っても出てこないんだけど。
たとえば、
増やした実行ユニットを生かすため、命令供給の効率を上げたいとする。
そのためには例えば、デコーダの能力を少し過剰にし、命令の不足を起きにくくする手がある。
P6も基本的にIPCは3(内部命令換算)で設計されているが、
3[x86命令]同時デコードでクロックあたり最大6uOP(いわゆる4-1-1)を吐くことができる。
スケジューラに6uOP/clkで送れるとは思えないが、デコードのつまづきを隠蔽するくらいなら
多分できるだろう。これも意味があると言える(スケジュールは関係ないが)。
そして、スケジューラ以外を全てIPC4設計にしてしまえば、更に高速化する。
命令はガンガン送られてくるし、速攻で実行してリタイヤしてくれるから、ROBも詰まらない。
もっと進めて、スケジューラはIPC3をキープしつつも簡単なケースは4命令処理もできる、
という設計にすれば、いよいよIPC4を狙ったCPUの名を冠することも視野に入ってくる。
そのCPUに合わせてチューニングすれば、まあIPC4も出るかな、という感じ。
これがCore2だとすれば、大原予想は当たったと言っていいと思う。
ただ、おいらはそうは思わない。スケジューラ以外を強化しといて、それじゃ効率が悪い。
P6やK8をIPC3と呼んでいいのなら、Core2もIPC4と呼べるくらいの性能はあるはずだ。
(いや、ほんと俺は実測してないので申し訳ないですが)
IPC2.8と3.3でいいよ
>>801 ちゃんと引用しないから勘違いしたじゃんか。
> 来年前半くらいまではAMDのこのビハインドは続くと思うが、その後にはちょっと良い勝負ができそうな気がする。
> というのは、RMMAの結果を見る限りコアの素性そのものは悪くなかったからだ。
この記事については前にも少し書いたが、Core2高性能の理由の観点からもう一度。
L1性能については、どちらも一長一短あり、俺はCore2が僅かに上と思うがわからない。
L2は、広帯域でレイテンシもYonah程度、容量も非共有・排他K8の総容量に勝っている。
>>766を見ると、2コアアクセス時のストア帯域ではCore2が遅い。弱点もある。
まあ、Core2のL2は速い。PenM系もそうだったが、ここは大きなアドバンテージだ。
更に、デコーダ・スケジューラ・リタイヤユニットなどが4命令/clk対応。
これにより他の増強点がよりストレートに性能アップにつながりやすくなる。
内部命令の粒度が違う点も見逃せない。
Macroフュージョンもそうだが、SSE命令はCore2では実行時さえ分解しない。
内部命令換算のIPCの数字以上に性能が出るということだ。
あと、当たり前だがSSEのピーク性能がK8の倍になってるのは大きい。
ここで、K8が根本的に負けているのはL2キャッシュと3issue、と言いたいなあ。
継ぎ足しで改善できなさそうだもん。
確かにK8コアの素性はいい。
K8L、3issueでの性能がどうなるか、非常に楽しみなところだ。
>そして、スケジューラ以外を全てIPC4設計にしてしまえば、更に高速化する。
設計複雑化がペイしないくらい微量な高速化しかしない
昔はIPC3設計でさえ費用対効果が悪いから2で十分と言われてきた
だから行き詰まったx86を捨ててVLIWにしようとか、スレッドレベル並列性を上げる方向に向かったのが
ここ十数年の業界の流れで、AMD64やCoreMAは異端
>>804 これがどうしても論理の飛躍にしか見えないのだが、
x86で4issueは意味がないという結論にでも落とすつもりなんだろうか。
まさか、ALUが4個ないと真のIPC4を狙えないとでも思ってるんじゃないだろうな。
>>805 K8とPenM・Yonahで、両者の得意不得意を決めたのはL2が大きいでしょう。
確かにK8のユニット稼働率は低いけど、それは別に悪いことじゃない。
強力な演算器で、パワーではPenMを圧倒していたはずです。
>>806 書く対象に対して適切な実験をしない、実験結果を適切に読み取れない、
というのがいけないと思う。
このテーマでやるなら、x86命令1個のレベルでの検証、また大きなコードで理論値が出るか、
出ないならそれは単純な原因で実行ユニットかデコーダかフェッチか、いずれでもないなら
スケジューラやメモリ、その他CPUの癖などを考慮に入れ、原因を切り分けていく。
俺ならこういう流れで実験をする。
命令数個のアセンブラ実験は、P5以前ならば有効な手段だったと思う。
P6(K5?)以降はOoO機構のために難しいと言われるが、ぶっちゃけ普通にできる。
もちろん、ユニット構成を理解した上で、原因の切り分けができる測定をする方が望ましいが。
この方法はCore2であってもまだ通用するはずだ。
どうあがいても実行ユニットの理論性能以上は出ないし、理論性能が出たらそれが限界だ。
(将来、トレースキャッシュで変な機能付いたらその判定も難しくなるが)
だが、それが圧倒的な市場性を持っているのもまた事実である。
>>821 >設計複雑化がペイしないくらい微量な高速化しかしない
>昔はIPC3設計でさえ費用対効果が悪いから2で十分と言われてきた
この常識を覆すのがOPsFusionである
>>808 俺がK8有利だと思う点は、小分けにスケジュールできるところ。
intとfpの依存性が少ないとはいえ、全部(ROB=96entry)を相手にするのは大変だ。
1clkに32命令も相手にできるというが、それでも96エントリの1/3にすぎない。
対してK8は、スケジューラが2個あるし、ミスしても2つ合計でIPC3が出ればそれでいい。
int=24entry,fp=36entryということで、1clkに32命令を調べるとかしなくて済みそう。
そのK7K8のRSというのはスケジューラで、Core2のRSとは全く違うと思うのだが、自信はない。
ていうか
>>796の「最大32のMicroOps」ってRSのサイズなのか。
>>821 ちゃんと効率悪いからそうは思わないって書いたよ。
スケジューラも4にすればCore2方式なら(Intelも採用したし)見合うと思う。
> 昔はIPC3設計でさえ費用対効果が悪いから2で十分と言われてきた
今は(x86に求められる用途なら)IPC3設計がいいという感じかね。
Core2のIPC4も、もう命令の並列性の抽出限界だから大して性能が伸びないんだよね。
それでもシングルスレッド性能の向上は嬉しい。
それにしてもx86なんてアーキをここまで高速にした執念はすごいねえ。
>>824 そのIPCはx86命令でのIPCだな。実行ユニットが速いことは大前提だ。
フュージョン自体は、IPC(内部命令)を上げずにIPC(x86命令)を上げる
という特徴を持っているからな。
>>810 ちゃんとSSE2使うと反応してくれて面白いなあ。rdpmcで読んでるわけか。
使い方は考えちゃうけど、お手軽なところがいいと思う。
>>812 pxorとxorpsは同じだよね?
xorpdのスループット1命令/clkは、1つのユニットでしか実行できないということなのか?
doubleは内部形式が違うとかあるかな(
>>599が気になる、スケジュール関係だろうけど)。
もっとも、
>>813>>816単なる誤表記の可能性が大きいが。
>>815 MMXは完全に切り捨てに来てるね。
まずSSEの性能を考えてユニットを作り、それを邪魔しないようにMMXへ流用させる、
という感じか。
>>816 シャッフルって複雑だなあ。。
>>812 xorpdのスループットを実測してみたら0.33(3つ同時実行可能)でした。
やはり誤記みたいですね。
泥沼の気配。
どうまとめるのやら。
内容以前にそちらのほうが興味が沸く。
ところで最後の比較はAMDは完全に3命令/Cycle出ていると言う大前提がないと、
否定する材料としてはちょっと弱い希ガス。
問題は命令を単体で使ったときじゃなくて、命令の組み合わせの問題のほうが大きいような。
同じレジスタで整数演算と浮動小数演算を混ぜて使ったときに数クロックの遅延が生じるとある。
スケジューリングの問題な希ガス。
> 筆者はこのSchedulerの性能について、「命令ユニットに3命令/Cycleで
> Sustainedで供給するためには、Schedulerまでは4命令/Cycleで持って
> こないと間に合わないだろうなぁ」と見ている。もっともこう書くと「K8の
> デコーダは3命令/Cycleでしかない筈だ」という反論は当然ありそうである。
> 実際これはその通りなのだが、この3命令/Cycleという数字はデコーダ部
> が読み込むx86命令の数であって、CPU内部で使われるμOpに関しては
> 一度も数字を出していない。今問題になっているのはμOpに変換した後の、
> デコーダ/スケジューラのスループットである。
> 従ってスケジューラに投入されるμOpのスループットは、
> 3より多い可能性が非常に高い事を指摘しておきたい。
おひおひ、非常に高いのかよ
>>829 大原の主張
CoreはIPC3.75(3*1.25)を狙った設計
>>829 今回はノーコメント。
内容がなさすぎて、いちいち反論するのも馬鹿らしくなってきた。
FB-DIMMやPCI-Expressネタの方がまだ面白い
paddb、スループット0.33出るよ?
大原は原稿料で1か団子にQX6700買ってやれwww
4ページ目と5ページ目が面白い。
QX6700のベンチ集はスレと全然関係無いし見飽きた代物だけど。
ここ、すっかり大原雄介のヲチスレになってるなw
K8が大好きだということしか伝わってこないような記事書いてるからなぁ('A`)
○るさんの素人記事のほうが余程はっきりわからんものはわからんと書いてあって好印象だw
プロじゃないからそういった切り口で書けるんだろうけどさ。
842 :
デフォルトの名無しさん:2006/11/30(木) 01:17:52
>>842 欲しかった機能、キタ━━━━(゚∀゚)━━━━!!Santa Rosa!
やっぱりただのTurbo Modeじゃ無意味だもんね。
マルチコアの弱点をおおまかカバー!
チップセットのTDPがちょっと心配だが、改善されることを祈ろう。
最近のIntel神懸かってるな
しかし上がっても200MHz程度じゃなあ。
ノートだとCPUよりHDDって気もするし。
1.5倍とかになれば面白いんだが。
(alphaの絡みで)マルチスレッド系の技術と、この技術の特許をIntelが抑えてるからAMDはGPGPUに逝くのか?
などと思った。
>>845 IDAのさらに隠れた機能としてマルチコア動作時もクロックアップし続ける(ユーザー責任で)
というのも絶対ありなのだ。
しかし、そもそも1~10ms毎に入ってくるスケジューラのタイマー割り込みとか、いい加減ハードでやってくれないかな・・
そもそもWindowsXPコアをCPUに取り込んだモバイル機欲しい。Core2Duo-Kernelとか絶対に劇速。
それもCPUに書き込む部分をカスタマイズできれば尚最高。またはL2-16GBでL2を1GB単位でロック可能とか。
そんだけありゃOS丸ごと入ってるよな。
>>847 そんなことしてもXPなんか使う用途じゃ1~2%くらいしか速度上がらないと思うけど・・・
>>849 TLBの切り替えコストのことを言っているなら、それはすでにCPUに入ってる。
HTのようにして根本的にマルチスレッド性能を上げろというのならわかるけど、
キャッシュ汚染がひどくなるという問題もあって、コンテキスト切り替えだけ
速くしてもさほど性能でない。
キャッシュメモリの利用効率はまだまだ高められるだろ
#つーか根本的な解決策があっても実現できないんだからその方向で議論するだけ無駄
>>851 ごめん、何言ってるのかよくわからない。
キャッシュ汚染を深刻化させれば、キャッシュの利用効率が上がるという主張?
>>845 200MHz程度下げることで大きく消費電力を下げているのがデュアルコアだから、
その分の200MHz程度しか上がらないのは当然だ。
>>847 それじゃただのオーバークロックと何も変わらないじゃないか。
IDAはそんなつまらん技術じゃないっっ!
もうね、Baniasのフュージョン以来の嬉しい技術ですよ。
好きな漫画がアニメ化されたような気分。
>好きな漫画がアニメ化されたような気分。
それはそれは残念な気分ですね。
>>844 netburstは商品なんかじゃない
intel本来の力を押さえ込むための拘束具(ry
その呪縛が今、自らの力で解かれてい(ry
1.6GHzが1.8GHzになるなら十分魅力的じゃん。あとは自己責任でFSBクボックですよ。
200MHzしか上がらないっていうソースは?
Coreのリークはダイナミックの何割程度なのか公開されてた?
859 :
デフォルトの名無しさん:2006/12/01(金) 15:43:15
SantaRosaはベースクロックが200MHzだから、CPUはそれの整数倍で動作。
ソース無しってことね
YonahのDuoとSoloでそれぞれTDP 31Wと27Wだから、片コア落としただけで節約できる電力
ってせいぜい4W程度だと思われ。
Merom-800は35Wならクロック据え置きで片コア落とすと31W程度か。
IDAモードをはTDP 42Wを要するらしいけど、200MHz程度上げるだけでそんなに食うかって
思うと確かに疑問。せめて400MHzだろ。
だからTDP=消費電力ではないと何度言えば分かるのか
っていうかいろいろと理解してない
熱設計消費電力(廃熱のための設計目安)ね。んなこたわかってる。
団子じゃないけど。
YonahのDuoとSoloでそれぞれ推定消費電力 25Wと17.4Wだから、片コア落としただけで節約できる電力
ってせいぜい7.6W程度だと思われ。
Merom-800は30Wならクロック据え置きで片コア落とすと22.4W程度か。
IDAは30Wを以内を要するらしいけど、200MHz程度上げるだけでそんなに食うかって
思うと確かに疑問。
1.6Gが1.8Gになるのと2.6Gが2.8Gになるのは大分違う気がする件
なんとなく2.4G→2.8GHzな希ガス
差別化の方法としてはありそう。。。
まあ単にDothanと合わせただけかもな
消費電力/発熱量ってのは結構ばらつきがあるから基準が緩めのほうが当然歩留まりが上がる。
なんで、その辺もあってSoloのほうが多目に余裕見てる可能性はありそうだが。
Dothanからクロック400MHz下がってプロセス微細化したのにTDPは同じとか余裕を見るにもほどがあると思うよ。
45nmまでは保守的な手法で製造するらしいのでかなり余裕を見る予感
製造手法は保守的だが性能が保守的とは限らない
ばらつき
個体差
45nmの歩留まりが70nm程度出ると思ったら大間違い。
#最早、可視光では見えない世界だ。
可視光で見えないなんて10年以上前からだろ。
>>863 消費電力の多いコアをSoloにするなど、コア数に起因しないTDPの違いがあったら
その計算は意味がないだろう。
単純に、クロックの3乗に比例した消費電力と考えると1.8GHz→2.0GHzで37%の上昇。
(最高クロックは電圧に比例し、消費電力がクロック×電圧^2に比例すると仮定)
実際はスタティック電力がそれなりに大きいからそこまでは行かないだろうけど、
3割くらい増えても全然おかしくないんじゃない?
って何で42Wまで増えとるのだ。
>>864 ええと、TDPはこれだけ廃熱できるようにしとけという目安だから、
実際は発熱量がTDPより低ければ何でもよく、コアごとにバラつきがあり、
平均的なコアの発熱がTDPからは正確にわからないということだよね。
Dothan-ULVを使っているが、600MHzと1100MHzではアイドル時の消費電力がけっこう違う。
キャッシュは切らないわけだし、確かに片コアを止めて半分近くも電力を削るのは難しいだろう。
熱密度による廃熱の問題もあるし、その範囲で上げるクロックとなると、1割程度だと思う。
コア毎にクロックと電圧を変えられるようになったらもうちょっと行けそうかな。
あくまで、デュアルコアCPUの持つ能力を十分に引き出すという技術であって、
それ以上にわざわざシングルスレッド性能を上げようというものではないと思う。
高クロック動作を確認する必要がある分面倒だが、最近クロックを向上させてないから
電力の問題を除けばクロックに関してはそれなりのマージンがあると予想する。
メモ
IDA:Intel Dynamic Acceleration
なるほど。
42Wって言われてた時期は2コアのブーストを想定してたとすれば合点がいく
885 :
デフォルトの名無しさん:2006/12/11(月) 09:51:49
886 :
デフォルトの名無しさん:2006/12/11(月) 10:12:24
大原は今週あと二本連載書け
正直大原が何が言いたいのかさっぱりわからなくなってきたが
ここまで読んで思ったのはCoreは極力ピーキーさを排した設計だということぐらいか
intelの主張は違うといいたいだけなんだろう。
例えばAMDの主張が間違っている時にはここまで粘着質に固執するだろうか?
固執しなけりゃ研究や調査にならん。
腑に落ちない部分があるから調べてるのだろう。
AMDだのなんだのは関係なかろう。いきなり引っ張り出すなよ。
確かにAMDはどうでもいいな
ふー、びっくりした、と同じ香りがするんだよね。
腑に落ちないのは自分だけで、結論ありきというか。
まぁ生暖かくヲチは続けさせてもらうけど。
>ふー、びっくりした、と同じ香りがするんだよね。
久々にワロタw
お米券1枚進呈です
895 :
デフォルトの名無しさん:2006/12/18(月) 20:10:21
812 :Socket774:2006/12/18(月) 11:13:25 ID:k8iKtMC4
【775】PCの中にマルチスレッド非対応のアプリがいます
Q:私の愛用しているお絵かきソフトのことです。
もう7~8年アップデートがありません。
以前から、最高性能のプロセッサであるQX6700に対して、ひとつのコアだけ虐めるという幼稚な嫌がらせをしたりしていましたが、
最近はそれがエスカレートしております。
Intel: まさかとは思いますが、この「マルチスレッド非対応のアプリ」とは、あなたの想像上の存在にすぎないのでは
ないでしょうか。もしそうだとすれば、あなた自身が統合失調症であることに
ほぼ間違いないと思います。
あるいは、「マルチスレッド非対応のアプリ」は実在して、しかしここに書かれているような異常な事態には
全く陥っておらず、すべてはあなたの妄想という可能性も読み取れます。
この場合も、あなた自身が統合失調症であることにほぼ間違いないということになります。
正直まだた○さんのほうが面白い
> というわけで、一部の方にはお待たせしてしまったが、次回からこの5命令/Cycleをもう少し検証してみたい
どうみてもこのスレです。本当にありがとうございました。
原稿おせーんだよおおおおお!
185から186の間は丸二週開いてるし、これだって先週分のだし。
というわけで今年中にあと三本は書け。
わかったか!
>>896 相変わらずですなあ。。
今回はまともに反論してみることにする。
> 案外にAthlon 64 X2とCore 2のスコアに大きな違いが無いことがお分かりいただけよう。
例えばFile Compressionではクロック当たりの性能で15%の差がある。
これがどんなに大きな差なのかわからないのだろうか。
PenDではなく、K8に対して15%も高速に実行するという性能はマジですごい。
これを3issueのアーキで達成したら逆にすごいよ。
> 逆に言えば、演算パイプラインや実行ユニットのアーキテクチャの違いだけを見たときに、
> K8とCore 2は殆ど同じ性能に見える、
確かにキャッシュはCore2の強みだ。
だが、ここまで強いキャッシュを生かすコア性能はK8にはないだろう。
仮に、K8がCore2に匹敵するコア性能を持っていたとしたら、
K8の設計者がコア性能を殺すようなキャッシュしか載せない阿呆ということになる。
> コアの性能が同じ程度なら、Core 2もやはり『x86で3命令/Cycle』と表すべきだろう
そもそも今回のベンチでIPCがどれだけ出ていただろうか。
今、
>>810でzip圧縮時のIPCを見てみたが、1.2程度だった。
K8やCore2でも2未満なのは確実。
大原さんの基準だと、性能がK8に大きく劣るPenProは何命令/Cycleを狙ってるのだろうね。
仮にコア性能が同じだったとしたら、
Core2は4命令/Cycleを狙っているが効率が悪い、と評されるべきだ。
『x86で3命令/Cycle』の「3」が何を意味するかわかっていたら、Core2は「4」に決まってる。
まあ、コア性能はCore2のが上だけど。
そういえば、K5はIPC4を狙ったと言えるのか。
実クロックこそ低かったが、クロック当たりの性能だけならそれなりにあったよね?
K5向けに最適化してIPCいくつまで出せるか気になるな。
スケジューラの性能が2命令/clkとかいうオチかな。
ALUが3本だから3IPCだと言いたいんじゃねーのかな
それだとPentium Mは2IPCになるが
>ALUが3本だから3IPC
ふー、びっくりしたwww
うーん、今回は簡単だとぼくは思っていた。だって、Intel CoreMicroarchitectureはALUが3基のプロセッサだもんね。
IPC3を狙った設計のはずなのだ。この質問のこたえなんて考えるまでもない。
けれど、Intel CoreMicroarchitectureを、みんながどんなふうに感じているのか、それが探りたくてこのテーマにしたのだ。
するとあらら、不思議。寄せられたのは親Intel CoreMicroarchitectureのメールばかりだった。
なぜなのかしらん? というわけで、今回は多数を占める「Intel CoreMicroarchitectureはIPC4を狙った設計」派からいってみよう。
「実行ユニットの対称性は、『望ましい』ことであって、『なすべき』ことではない」(住所不明・匿名さん)
「IPC4以上を達成できる設計だから。」(住所不明・匿名さん)
ふー、びっくりした。でも、IPC4派の意見はほぼ一点に集中している。
K8と比較すると優れたコア性能だから、IPC4は妥当であるというもの。
それほんとなのかなあ。今回の答えは数字の上では「Intel CoreMicroarchitectureはIPC4を狙った設計」派が圧倒的だったけれど、
応募しなかった多数のサイレントマジョリティを考慮にいれて決定させてもらいます。
IPC3のK8と比較すると大差がないように見える、だからIntel CoreMicroarchitectureはIPC3を狙った設計。あたりまえの話だよね。
メールをくれた「多数派」はあまりIntelに踊らされないほうがいいのではないかな。
富士通「SPARC64 VI」マイクロプロセサの動作 - Fall MPF 2006より
ttp://journal.mycom.co.jp/articles/2006/12/11/sparc64/ > ということで、4命令の同時デコードを行うアウトオブオーダのスーパスカラアーキテクチャという
> 点では、富士通のSPARC64 V/VIは、IntelのCoreアーキテクチャのプロセサと、概略、同程度の
> 複雑さのプロセサである。
> IntelがBaniasアーキテクチャからコアアーキテクチャに拡張するに当たって、3命令実行から4命
> 令実行に強化したことは、多分、10%程度の性能向上効果で、本当の性能改善は、1命令も実行
> できなかったサイクルを減らすという点での、色々な改善によって達成されているのではないか
> と思われる。
>3命令実行から4命令実行に強化した
まあ、
>>903みたいな考え方が普通だよねぇ。
まさか3命令実行から4命令になったからって、性能が33%アップとか、
そんなことは考えてないよな。
x86命令と内部命令の関係についても、AMDとIntelのサイトから
資料を落とせばある程度わかるのだが。
ときに、反論ばかりしてると、Core2のコア性能が高いという話が続いてしまうが、
たまには逆のことも言わないと気持ち悪い。
俺は、Core2の4issueは将来の性能アップのためのヘッドルームという意味があると思う。
最初の4issueだから、将来の4issueCPUと比べると命令帯域を生かせてないはず。
3.5issueなどというのは作れないから、仕方ない。
また、以前からL2キャッシュ性能がIntelCPUの強みだった。
一方、K7/K8はALUを3つ積んでいて資料上ではadcなんかが速い。
2ロード/clkと合わせてL1キャッシュの範囲ではまればCore2でも勝てないと思う。
Nehalemは4GHz~らしい…
GHz競争終わってねえなw
>>905 そう考えてんじゃないの?
K8に対するCoreMAの性能向上はパイプライン構造の差よりもキャッシュとか他の要因が大きい。
もしパイプラインが4IPCを狙ったものならもっと性能差があってもいいんじゃないか、と。
多少なりともキャッシュが高速化されるらしいK8LがCoreMAに追いつければ、大原の言ってることは正しくなるんじゃね。
K8は3デコーダでALU+AGUのペアを3組持っている。
よってこれは3IPCを狙ったものだ。
CoreMAは4デコーダだが、実行ユニットは3ALU+1AGU。
なぜ3つしかALUが無いのか?4IPCを狙いたければ増やせばいいのに。
→ それは4IPCではなく3IPCを狙った設計だからだ。
なぜ4IPCを狙わない?
→ 4IPCにしようとするとスケジューラが複雑になりすぎるからだ。
スケジューラが3IPCなので、ALUも3つしか必要としない。
なぜ3IPCを狙った設計なのに4デコーダなのか?
→ スケジューラで3IPCを達成しようとすると、命令の供給が3IPCでは足りないからだ。
コラムを読み返してみたけど、大原の考えてる理屈としてはこんな感じかな?
>K8に対するCoreMAの性能向上はパイプライン構造の差よりもキャッシュとか他の要因が大きい。
脳内(ry
909 :
デフォルトの名無しさん:2006/12/20(水) 14:04:57
>>907 わかりやすいまとめGJ。
CPUのことをよく知らない人が見たら信じちゃいそうだな。
まず、同時命令実行数を1→2→3→4と増やしていったとき、それに付随した性能の伸びが
どんどん鈍化していくというのは、常識だろう。
「4命令/clkは意味がない、だから嘘だろう」と思うのならまだしも、
「15%しか伸びてないから4命令/clkではないだろう」と思うのは神経がおかしい。
「3命令/clkでもキャッシュ等の強化で15%のアップは可能」というのなら俺も少し思う。
3命令/clkのK8Lが、非SSEコードでどの程度の伸びを見せてくれるか楽しみだ。
俺は、
>>899でも少し書いたが、3issueのままでCore2に追いつくのは難しいと予想している。
追いつくかもしれないが、追いついたとしても、別にCore2が3命令/clkになるわけではない。
大原さんの記事の中で、「Core2のコア性能はK8と同程度」「だからCore2も3命令/Cycle」
という主張があるが、タチが悪いのは後者である。
性能が同程度だからといって3命令/Cycleという数字まで同じである理由にはならない。
まあ、状況証拠として使ってるんだろうが、それにしてもお粗末だ。
SSEに関しては、また強化の仕方が違ってくる(上の「コア性能」の話と異なる)ので、
こちらではK8LがCore2を超える可能性も大きいと見ている。
総合性能でどの程度の勝負になるのか楽しみだ。
> 結果として議論が深まったと思う。
いや屁理屈議論で引き伸ばしてたのはどこの(ry
まさかさ、連載の最後に「
>>1乙」とか書かれて釣りでした、なんてことないよな?((;゚Д゚))
>>908 俺も実測してないから脳内。これは常に自戒せねばならん。
そもそもの間違い
×AGUは1本
○leaは1命令/clk
>>907 そもそもCore 2では
Loadアドレスを生成するユニット(Load)と
Storeアドレスを生成するユニット(Store Address)と
LEA命令を実行するユニット(ALU0)
が、全く別みたいですね
別にアドレス生成してもロード・ストアは合わせて2つしか発行できないわけなので
この点でCore2が劣ってる部分はないかと思います。
マイクロアーキテクチャがそもそも違うのにユニット数だけをみて単純比較しようと
してるのが、O腹のそもそもの過ちかなと。
誤爆したけど、ともかくCore2悪化の例は無茶じゃないか?
ついにレス番指定か!
中継ぎであることは真実だと思うけど、新しいアーキティクチャであることも割と真実だと思うんだぜ?
ピークだろうと平均だろうと、結果叩き出される性能がすべてだと思うんだぜ?
それとCPUは演算機だけで対決するわけじゃないから
intelがキャッシュで勝てると見込んで実際勝ったことはなんら問題ないと思うんだぜ?
(IPC4を狙うという)その態度を気に入る気に入らないレベルの話だったのなら俺が悪かった。
O原氏の壮大なつりでした。
ネタにしてもひでーなww
nopで実行ユニット使うと思ってるところがひどい。
NetBurstのトレースキャッシュにnop大量に詰め込んで遊んだことがあるけど
ぴったり3IPCなのねアレ。
ループの内側が12kを越すと途端に命令処理速度1/3に落ちるのが面白かった。
なによりnopでもキャッシュされるんだなというのが衝撃だった。
実行されないとなると、ROBでそのままリタイヤかな?
xchg eax, eax
大原は酉付きでここに書き込んでよ。
暇な時でいいから。
公私混同して無いか気になるこのごろ
本気って言うか、このスレで出た話題をパクって記事書いただけにしかみえんのだが。
逆に言うと、このスレで何かしらネタ出せば御大が記事にしてくれるってことじゃねーのかな。
Core 2悪化の例・・・ただ単にLoadユニットの本数差がそのまま出てるだけだろ。
Intelは伝統的にLoadとStoreは別ユニットだがK8でLoad専用+Load/Store両用なので
ストア命令が無い場合はLoadを2命令/clk実行できる。
まさにK8に都合良くハマるコードなわけだ。
現実のコードではメモリのロードだけがひたすら続くことはあり得ない。
というか、わかっててミスリード?
「Coreの妙な癖」をICCが上手く回避できるならIPC4でいいじゃん
そんなわけで、Verうpまだぁ?
>>916 キャッシュは、あれだよな。
あくまで(帯域上げるにしても共有にするにしても容量増やすにしても)レイテンシ維持が前提だよな。
Core系で性能が(キャッシュで)あげられたのもレイテンシを最小に留められたからだと思うわけよ。
レイテンシは諦めていいからヒット率とバンド幅にフォーカスしたL3をつけて欲しいなあ
L3よりCELLカードみたくXDR(GDDR)を上に置くとかのがいいのかな
キャッシュはキャッシュ、メモリはメモリ
どちらも補完し合うモノで競合するもんでもないと思うけど。
eDRAMは高い
まあオンチップなら数百GB/sとか達成できるだろうけど
でもどちらか選べといわれたらGDDRかな
最近の流行はCoCでCPUとDRAMはりつけじゃないか?
久しぶりにたるさん見たけど散々ベクトルマンセーしまくってたのにCoreには冷めた反応だな。
でもT7200を買ったみたいだし、Aゴニョゴニョ fanboyに叩かれない様に自制してるのかな?
HTTやPrescottの時は手酷くやられたみたいだし。
Prescott関連もHTTに関しての考察等も良かったと思うけど…。
変な奴らのメールにウンザリしてるかもしれないのは同情する。
not プロ(貶す意味は含まれない)であることを生かした、
プロには書けないすっきりとした記事を書いていただきたい。
、と大原の記事を読んで思った。
code組んでclock.数を計るスキル無い奴の
発言大杉。擦れ違い。
スキルと呼べるほどのものじゃないだろ。
そんな役に立つのか微妙なやつ使うぐらいならはじめからVTune使えよ
>>932 彼はMeromをNetburstと期待してた人だからね。
>MeromをNetburstと期待してた人
というか、周りがNetBurstを叩く中、ちゃんと中身を評価できてた人だと思う。
トレースキャッシュを低消費電力のアーキティクチャには持って来い、という持論が
そんな誤解を生じさせただけでそ。
MeromにはHTTとトレースキャッシュはなかったけど、Nehalemには付くということだから
見方自体は間違ってない良い証拠だと思われ。
IPC4かどうかの話なんて相手にならないほど興味深かったよ。
tarusan年度末決算キタ
今年は面白ネタ少なかったな
x86の速度向上が頭打ちになっている現実が辛いっす。
何か新しいブレイクスルーはもうないんですかね?
日本語でおk
>>932 fanboy達は叩いた事も忘れてるんじゃないかw まぁでもあのサイトがblogでなくて本当に良かったと思う。
いっそメアド取っ払って書きたいだけ書いてしまえばってのは安易かなぁ・・
>>945 どのぐらいの反響があるかは知りたいんじゃない?
お前ら仕事早すぎw
http://ja.wikipedia.org/wiki/Core2 >同時使用レジスタ数に対するパフォーマンスの低下
> Core2は同時に使用するレジスタ数が少ないと非常に高いパフォーマンスを発揮する。
>しかしレジスタ数が増えるとパフォーマンスは劇的に低下する。
>整数レジスタが3個+メモリ参照が1個+条件分岐命令が1個の場合、5命令同時に1クロックで実行を完了する。
>しかし整数レジスタへのアクセスが1つ増えると処理にかかるクロックが1クロック増加する(すなわち性能が半分になる)。
>さらにレジスタ数を増やせば増やすほどIPCは低下しP6マイクロアーキテクチャと大差のない(すなわちK8よりも遅い)結果に至る。[1]
> 以上のように大原雄介氏が考察しているわけだが、このテストコードにおいてはCoreではLoad命令の処理が律速条件になっているのは明らかであり、
>同時使用レジスタ数の増加によって劇的にパフォーマンスが低下していると結論付けるのは早計である。
いくら相手がそれで食ってるライターだからってWikipediaにそんな当て付けみたいにして書かんでも…
セカンドオピニオンが終わって、一段落するまでコメントアウトしとけばいいじゃん
編集合戦になりそうだし
優良スレだったのに、
最近は余所に絡むばかりになって品性が感じられないと思う。
新ネタが枯渇してるのかな。
>>950 2006年最後の日なんだから「品格」を使おうぜw
噛みつかれるだけの電波だったということなんじゃね?
だんごりおんと1が出てこないようだが、件の総括についてご意見伺いたく候。
おかしい人なのは疑いようがないとして。。。。
追試のしがいが有るところはむしろ、PenM/Yonahの2.5クロックんとこかな。
> align 16
> lp:
> add eax,[esi]
> add edx,[esi+4]
> inc ecx
> cmp ecx,ebx
> jb lp
Core 2はこれでちょうど2クロックだよね。
1. add eax, [esi] / inc eax
2. add edx, [esi+4] / cmp ecx,ebx + jb lp
Banias/Dothan/Yonahは、Macro-OPs Fusionもなく&整数ALUが2基しかない2クロックでは
実行できないんだけど、おそらくこういう風に並べ替えて2.5クロック/周に納めてる。
1. add eax, [esi](1) / inc ecx(1)
2. add edx, [esi+4](1) / cmp ecx,ebx(1)
3. jb lp(1) / inc ecx(2)
4. add eax, [esi](2) / cmp ecx,ebx(2)
5. add edx, [esi+4](2) / jb lp (2)
その点、K8は3つめのパターンで3clk/周に一気に落ちてる点から、あんまり柔軟性がないんじゃないのかな。
Pentium MがK8とほぼ互角、Core 2がそれ以上の、性能を出しうる要因は、この辺の機構にこそあると思うんだよね。
繰り返しておくと、ここまでロードの発行頻度が高い(しかもストア発行無し)コードは極めて稀。
例のサクラエディタですら、こんなんにはなってない。
ただただロードを繰り返す特殊なコードにおいてはK8のほうが多少分があるとは思っている。
俺なら焦れったいからこうやるけどなwwww
paddd mm0, MMWORD PTR [esi]
>>954 それはおそらく、ボトルネックが異なるからだと思います。
ここで示されているDothanで2.5clk/週のループは、1ループ5命令または6命令です。
1ループを2clkでデコードできます。
しかし実行ユニットが不足しており、実行に1ループあたり平均2.5clkかかっています。
ボトルネックは実行ユニットです。
K8で3clk/週のループは、1ループ7命令です。
1ループのデコードに3clkかかります。分岐命令と分岐先の命令は同時にデコードできないからです。
ボトルネックはデコーダです。
ああそうかなるほど。。。
デコーダネックにならずユニット数の少なさがネックになるケースで計測の必要有りだね。
>>913 実験については、
>>925に同意で、IPC3とは関係ない実験だと思う。
2chへリンク張ったのが驚きだった。
> 途中でYamhillをEM64Tに置き換えただけ、という印象を受ける。
これはそうだと思うが、これはつまりIPCは4だけど設計の弱みがあるという結論になる。
すると、IPCが3だという主張をむしろ否定する要素だ。
一般アプリでのK8のIPCが3近いと思っているかのような議論の進め方だよなあ。
>>920 ネトバのデコード帯域の1命令/clkがきれいに見えるんだな。
>>939 ネトバの話は周りに流されずしっかり中身を見ていて確かによかったな。
当時ああいう話をしている人は少なかったはず。
>>955 lp:
mov eax,[esi]
mov [esi+8],ebx
nop
nop
nop
dec ecx
jnz lp
PenMでこれ測ったら3clk。nopを1つ減らすと2clk。
やはり、3issueのCPUが7命令ループで3clkを切ることは無理なのかな。
スレまとめを作成したのでこれから張る。
このスレも残り10KB。
スレのまとめ。専用ブラウザを使ってジャンプしよう。
今年前半にMeromの詳細が明らかになり、意外とYonahの話題は少なかったり。
>12-13 アクセス順変えの説明
>18 prefetch命令とHWプリフェッチの相性?
>27-30 Store-Load Forwardingについて
>41-43 Pen4のキャッシュでエイリアシングを避けたい理由
>44-47 DTLBが測定にかかった
>72-73 DothanのMMXは依存関係を断ち切ることに改善の余地あり
>82-98 NetBurstの特殊性は混乱をもたらす
>104 IDFでいよいよ公開「Meromアーキテクチャ」
>118>123 水平加算の内部処理
>121>125>138-143 改めてMeromアーキテクチャ
>144 HWプリフェッチの積み残し
>148-159 たまに出る懐古ネタ16bit
>161 マンデルブロ集合のベンチ
>164-190 プリフェッチ関係
>191-197 Anti-HTは結局なかったのだが、いかに無理っぽいかの議論ができた
>201-239 キャッシュを最大限に生かす行列演算>229が計算方法
>241-247 K8LのL3はVictim Cacheか、またその功罪
>249-259>266 Yonahのメモリベンチ
行列演算は工夫のしがいがある。K8Lの中身もだんだん見えてきた。
>261-270>287-289>291-292>295-296>298 行列演算ブロック化>274が計算方法
この後も、>363辺りまでプリフェッチやアンロールなどを色々試す
>268-270>276-286>290>293-294>297>299-301 泥沼のSpeedStep反応速度測定
>372-381>391>401-403>409-413>445-450>465 201氏が引き継いで進行
>268>271-273>276-277 マンデルブロ集合のベンチ
>352-353 次世代AMDのSSE拡張
>356-360 MMX2って?
>365>366>624>635>639>641>707-712>718-725 AMDの次世代CPUについて
>382>383>385 Core2の命令毎のクロック数、その他のCPUは>387、>398辺りまで
>411>419>421>436>437 MeromはどのくらいP6の血を引いているか
>438-443>451-459 CPUについて色々、MeormのSSEなど
>460-527 Anti-HTに対する議論の続き
>474 「CISCの美」について>492くらいまで
>486 64bitで書いてみた
>497 Conroeの命令帯域は16byte/clkが限界みたいです(>735も参照)
>519 この謎の書き込みの正体は如何に、答えは>520
>528>546-551>558 DothanとPC2100にてメモリアクセスの考察
>530-558 Conroeが64bitコードで遅くなる!
>560-563 メモリモデルって難しい
>564>622>627 NetBurstのトレースキャッシュの命令長
>569-589 Core2とK8の今後
Core2での実測!後半は大原さんへの反論に終始する
>592-598>605-611 Core2実測キター!投機ロード、ピークIPC、同時使用レジスタ、66Hストール
>628-635 K8のL1帯域は16byte/clkだが、movaps等のSSE命令だと8byte/clk
>636-641 LSDが機能するには/Core2のcpu-zレイテンシ
>642-643>815-817 Core2の128bitシャッフル
>644-677>682-700 SSE3を補完するSSSE3の次の、SSE4の話
>576>591>680>715>738>795>829>885>896>913 Core MicroArchitectureをもうすこし(1~12)
>716>728-739 Core2のLCPストールをPenMの測定なども交えて
>753-782 レジスタ数の話から脱線してJavaへ
>766>783 Core2とK8のキャッシュ帯域(デュアルコア!)
>784>787-791 GRAPE-DR
>810>936 rdpmcツール
>842-882 これを待っていた!Intel Dynamic Acceleration
>954-957 デコーダネックか実行ユニットネックか
>958-960 スレのまとめ
K8L以降のHT3.0世代でVGAのRAM共有が出てくるんじゃないかなぁと思うコノゴロ。
平均IPCを語るのに、キャッシュミスや分岐予測ミスにともなうパイプラインストールを
考慮しないのはおかしい。
ところでK8 Rev.GのL2の性能劣化激しいけど、レイテンシだけでなく帯域えらく落ちてるのは
L1→Victim Buffer→L2の転送レイテンシが増加してるからなんだよね多分。
L2ヒットのデータロードが連続さえしなければさほどパフォーマンスには影響ないのだろう
もちろんレイテンシ分は性能悪くなってるだろうが。
(NetBurstはNorthwood→PrescottでL2レイテンシが格段に増えたが
帯域は落ちてなかった)
まあ、そんなにL2からのロードが連続することも現実のコードでは稀ではあろうけどね。
ベンチに弱いアーキテクチャとはよく言ったものだが、レイテンシの増加そのものは凄く痛い。
テーブルルックアップってなんだかんだでよく使うんだよね。
特に、ここ近年のMS謹製の開発環境は文字まわりをUNICODE化してきてるし
BM法とか使うだけでもL2の容量や性能がネックになりそう。
1乙
>>964 そういう意味での平均IPCだったら、3とか4とかの世界で話す方がおかしい。
よく知らないけどK8で1とか1.3とかそういう世界だよね。
>>965 そもそも、K8のL2レイテンシの変化が単純なL2帯域ベンチの結果に対して
リニアに効くものなのかどうかわからない。
また、レイテンシの数字に関しては純粋な反応速度という意味ではcpu-zの方が正しいと思う。
mov eax,[eax]のように依存関係を作って測っているから。
(ただし、実性能という面から言えば他のベンチの数字の方が近いはず)
以前cpu-zで試したことがあるが、
K7のL2レイテンシは20clk。しかし、これは例外的に、反応速度ではないと思われる。
おそらく、帯域が64bit/clkしかないために排他処理がネックとなっている。
K8では14clkと出たが、64byte stride付近で17clkだったり、他では13clkだったりと
安定しなかった。
cpu-zで20clkという数字が出たのは、その不安定なところを偶然拾ってしまった可能性がある。
もしくは、本当にレイテンシが20clkで、並列処理数を増やすことでカバーしているとか。
「14 cyclesが正しく」という情報もあるが、何が14なのだろう。
>>966までで497.78KB。いよいよ終わりが近い。
次スレ建てに挑戦してきます。
それRev.Gじゃないから。
MYCOMの中の人はさぼりすぎ。
大原の原稿早くあげろよ。
/⌒ヽ,,
<⌒ の )∧∧
 ̄ノ /(゚Д゚,,)
ノ く,, ⊂ )
(,,, ⌒し,,/<
\, =<
\ ,,,<
//⌒\\ (´⌒(´⌒;;
∑/ / 〉 ≡≡≡(´⌒;;;≡≡≡
次スレ
x86命令の所要クロック計測スレPart3
http://pc10.2ch.net/test/read.cgi/tech/1168399966/ {kind=link}
{kind=link}
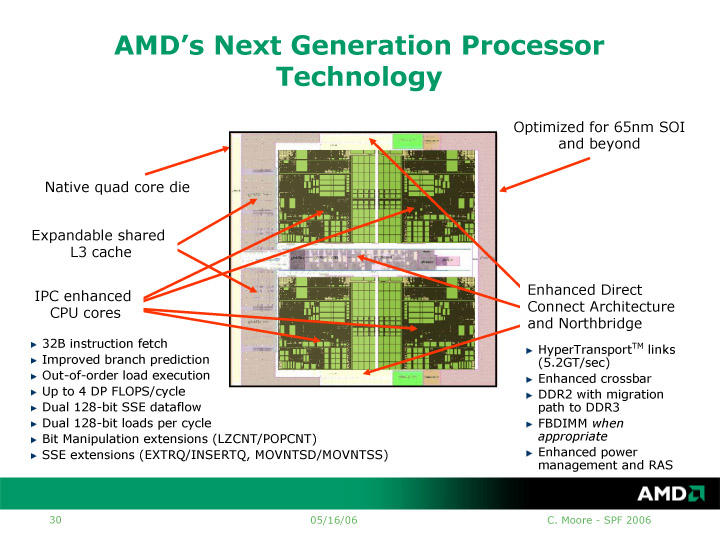{kind=link}
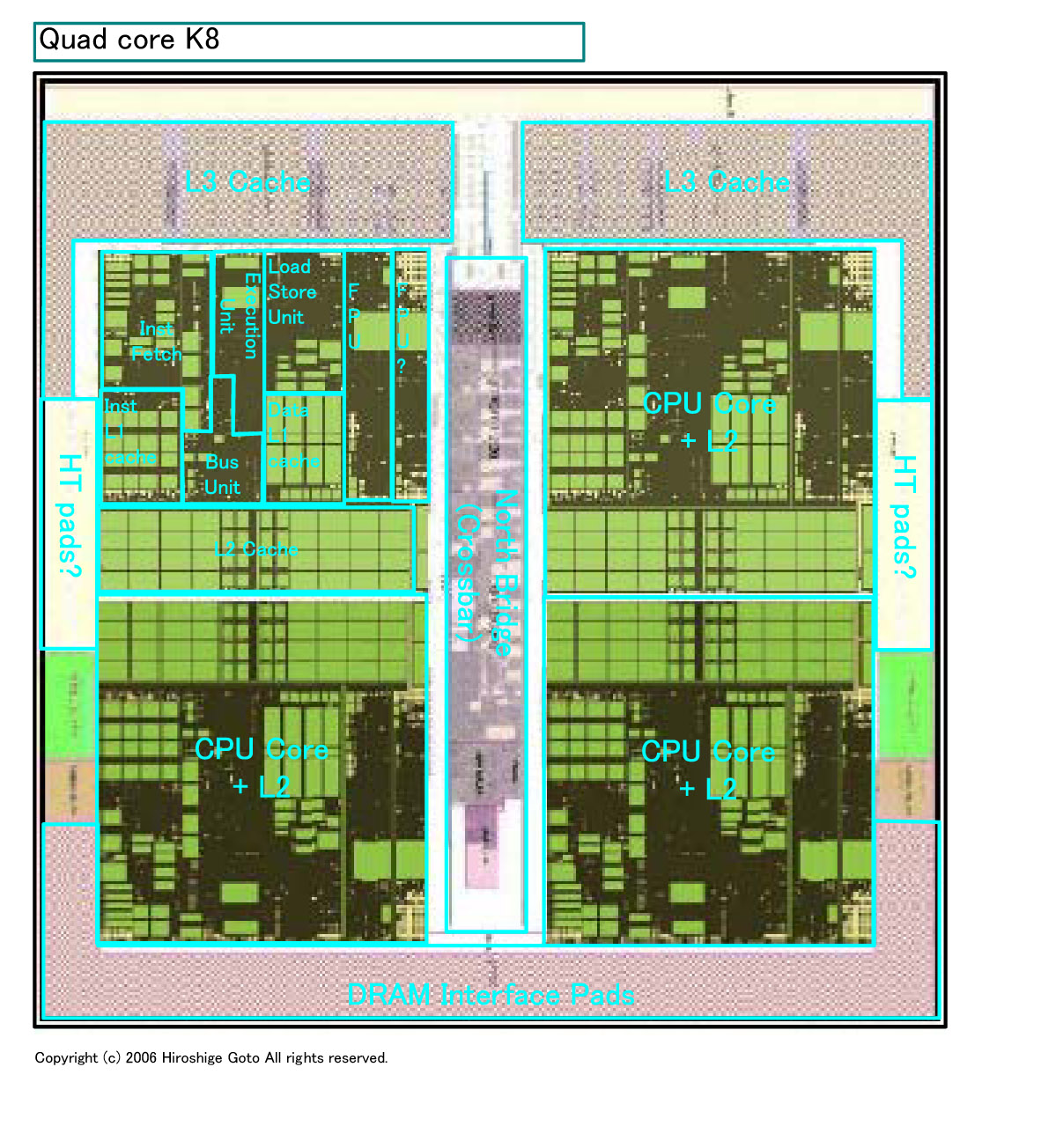{kind=link}
{kind=link}
{kind=link}
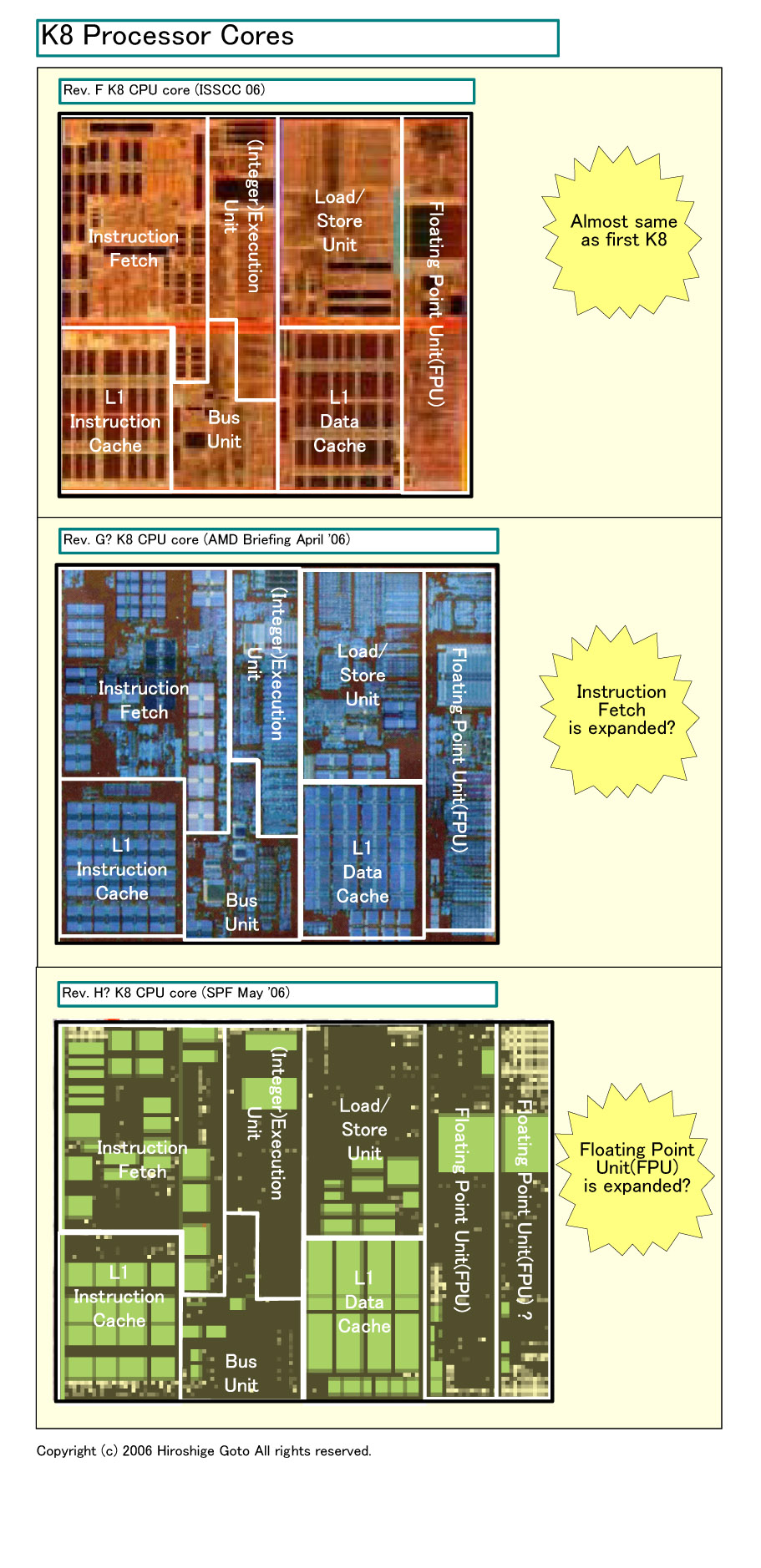{kind=link}