CPUÉAÅ[ÉLÉeÉNÉ`ÉÉDžǬǢǃåÍÇÍ 26
ÉwÉlÉVÅ[&ÉpÉ^Å[É\Éì
ÇÝÇÈÇ¢ÇÕâÕì∂ÇÃõõ
ÅyëOÉXÉåÅz
CPUÉAÅ[ÉLÉeÉNÉ`ÉÉDžǬǢǃåÍÇÍ 25
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
ÅyâþãéÉXÉåÅz
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
Part24 http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
Part25 http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
ÇÝÇÈÇ¢ÇÕâÕì∂ÇÃõõ
ÅyëOÉXÉåÅz
CPUÉAÅ[ÉLÉeÉNÉ`ÉÉDžǬǢǃåÍÇÍ 25
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
ÅyâþãéÉXÉåÅz
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
Part24 http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
Part25 http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
|
|
|
IntelÇÃéüê¢ë„CPUDžǬǢǃåÍÇÎǧ 73
http://anago.2ch.net/test/read.cgi/jisaku/1393440466/
AMDÇÃéüê¢ë„APU/CPUDžǬǢǃåÍÇÎǧ191ê¢ë„
http://anago.2ch.net/test/read.cgi/jisaku/1395407299/
ÅyCPUÅz ÉXÉ}Å[ÉgÉtÉHÉìÇÃSoC 7 ÅyGPUÅz
http://anago.2ch.net/test/read.cgi/smartphone/1390357886/
http://anago.2ch.net/test/read.cgi/jisaku/1393440466/
AMDÇÃéüê¢ë„APU/CPUDžǬǢǃåÍÇÎǧ191ê¢ë„
http://anago.2ch.net/test/read.cgi/jisaku/1395407299/
ÅyCPUÅz ÉXÉ}Å[ÉgÉtÉHÉìÇÃSoC 7 ÅyGPUÅz
http://anago.2ch.net/test/read.cgi/smartphone/1390357886/
ÅôARMÇÃéüê¢ë„core, SoCDžǬǢǃåÍÇÈÉXÉå #002Åô
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
NVLinkÇÕÅAÇÝÇ´ÇÁÇ©Ç…HPCï™ñÏÇë_ǡǃÇÈÇ≈
è´óàNVLink2Ç∆Ç©NVLink3Ç∆Ç©Ç™èoǃÅANVLinkÉXÉCÉbÉ`Ç∆Ç©ÇýèoÇΩDZÇÎÇ…ÇÕÅA
ÇÐÇ∂Ç≈ä˘ë∂ÇÃÉXÉpÉRÉìÉCÉâÉlÇðÇΩǢǻDZÇ∆DžǻǡÇΩÇËǵǃ
è´óàNVLink2Ç∆Ç©NVLink3Ç∆Ç©Ç™èoǃÅANVLinkÉXÉCÉbÉ`Ç∆Ç©ÇýèoÇΩDZÇÎÇ…ÇÕÅA
ÇÐÇ∂Ç≈ä˘ë∂ÇÃÉXÉpÉRÉìÉCÉâÉlÇðÇΩǢǻDZÇ∆DžǻǡÇΩÇËǵǃ
é©ëOÇÃÉvÉâÉbÉgÉtÉHÅ[ÉÄǙǻǢǩÇÁÇ∑ÇÆÇ…égÇÌÇÍÇ»Ç≠Ç»ÇÈÇÊ
6 ÅFSocket774ÅF2014/03/27(ñÿ) 14:59:24.22 ID:EOWZzhoK
Satoshi Matsuoka ?@ProfMatsuoka 4éûä‘
NVLinkÇÕGPUÇ∆ÇÕì∆óßǵÇΩÅAǩǬǃÇÃHypertransportÇÃçÇë¨î≈Ç∆ÇýåæǶÇÈÅB
ëÅë¨ã§ìØäJî≠ǵÇΩIBMÇ™PowerÇ≈çÃópÅAç°å„çÇê´î\ARMÉvÉçÉZÉbÉTÇýçÃópÇÃó\íËÇ∆ï∑Ç≠ÅB
â‰Ç™çëÇÃCPUÇ‚ÉlÉbÉgÉxÉìÉ_Å[Çýêœã…ìIÇ…çÃópÇ∑ÇÈéñÇ…ÇÊǡǃÅAÉGÉRÉVÉXÉeÉÄÇ…éQêÌÇ≈Ç´ã£ëàóÕÇ™ëùÇ∑ÇæÇÎǧÅB
NVLinkÇÕGPUÇ∆ÇÕì∆óßǵÇΩÅAǩǬǃÇÃHypertransportÇÃçÇë¨î≈Ç∆ÇýåæǶÇÈÅB
ëÅë¨ã§ìØäJî≠ǵÇΩIBMÇ™PowerÇ≈çÃópÅAç°å„çÇê´î\ARMÉvÉçÉZÉbÉTÇýçÃópÇÃó\íËÇ∆ï∑Ç≠ÅB
â‰Ç™çëÇÃCPUÇ‚ÉlÉbÉgÉxÉìÉ_Å[Çýêœã…ìIÇ…çÃópÇ∑ÇÈéñÇ…ÇÊǡǃÅAÉGÉRÉVÉXÉeÉÄÇ…éQêÌÇ≈Ç´ã£ëàóÕÇ™ëùÇ∑ÇæÇÎǧÅB
CPUåoóRǵǻǢÇ≈ÉAÉNÉZÉâÉåÅ[É^Å[íºÇ∆ǢǧòbÇ∆
NVLinkÅAPCI-EÅAìôâΩÇ≈ǬǻÇÆÇ©Ç∆ǢǧòbÇÕÇ≤ÇøÇ·ç¨Ç∫DžǵǻǢï˚ǙǢǢÅB
ëOé“ÇÕHPCÇå§ãÜǵǃǢÇÈÇ∆DZÇÎÇ≈ÇÕëOÇ©ÇÁàµÇ¡ÇƒÇÈòbÅB
å„é“ÇÕåéì˙ÇåoÇÈÇ…è]Ç¢ä˘ë∂ÇÊÇËÇýë¨Ç¢ÇýÇÃÇ™èoǃÇ≠ÇÈÇÃÇÕìñëR
NVLinkÅAPCI-EÅAìôâΩÇ≈ǬǻÇÆÇ©Ç∆ǢǧòbÇÕÇ≤ÇøÇ·ç¨Ç∫DžǵǻǢï˚ǙǢǢÅB
ëOé“ÇÕHPCÇå§ãÜǵǃǢÇÈÇ∆DZÇÎÇ≈ÇÕëOÇ©ÇÁàµÇ¡ÇƒÇÈòbÅB
å„é“ÇÕåéì˙ÇåoÇÈÇ…è]Ç¢ä˘ë∂ÇÊÇËÇýë¨Ç¢ÇýÇÃÇ™èoǃÇ≠ÇÈÇÃÇÕìñëR
ï Ç…çlǶï˚Ç∆ǵǃâÊä˙ìIÇ»ÇýÇÃÇ≈ÇýÇ»Ç≠ÅAçÇë¨Ç»ÉfÅ[É^ì]ëóǡǃÇæÇØÇæÇ©ÇÁÇ»ÇÝ
ǪÇÍà»ëOÇÃÇÅuè]óàå^ÅvÇ∆ǩǡǃǢǶÇÈÇÊǧǻì¡ï Ç»âΩÇ©Ç™ÇÝÇÈÇÌÇØÇ≈ÇýǻǢ
ÇýÇøÇÎÇÒë¨Ç¢ÇŸÇ§Ç™Ç¢Ç¢Ç…åàÇÐǡǃÇÈÇÌÇØÇæÇ™ÅAǫDZÇýçÇë¨ÉoÉXÇ≠ÇÁÇ¢äJî≠ǵǃÇÈÇ©ÇÁÇ»
ǪÇÍà»ëOÇÃÇÅuè]óàå^ÅvÇ∆ǩǡǃǢǶÇÈÇÊǧǻì¡ï Ç»âΩÇ©Ç™ÇÝÇÈÇÌÇØÇ≈ÇýǻǢ
ÇýÇøÇÎÇÒë¨Ç¢ÇŸÇ§Ç™Ç¢Ç¢Ç…åàÇÐǡǃÇÈÇÌÇØÇæÇ™ÅAǫDZÇýçÇë¨ÉoÉXÇ≠ÇÁÇ¢äJî≠ǵǃÇÈÇ©ÇÁÇ»
ǬÇÐÇËAMDÇ©ÇÁÉpÉNÉbÉ^Ç≠ÇπÇ…é©ï™ÇÃÉÇÉmÇðÇΩǢDžåæǡǃÇÈÇÃÇ©
ípímÇÁÇ∏Ç∑ǨÇæÇÎ
ípímÇÁÇ∏Ç∑ǨÇæÇÎ
DZǧÇ∑ÇÍnjǢǢÇ∆ǢǧǮëËñ⁄ÇÇ∆ǻǶÇÈÇÃÇÕä»íPÇ≈íNÇ≈ÇýÇ≈Ç´ÇÈÅB
ñ‚ëËÇÕìdãCìIÇ»ê´î\è⁄ç◊ÅAò_óùìIÇ»êðåvè⁄ç◊Ç™
ÇŸÇ⁄ìØÇ∂éñÇë_ǧëºÇÃÉvÉâÉìÇÊÇËÇýóDÇÍǃǢÇÈÇÃǩǫǧǩÅB
ñ‚ëËÇÕìdãCìIÇ»ê´î\è⁄ç◊ÅAò_óùìIÇ»êðåvè⁄ç◊Ç™
ÇŸÇ⁄ìØÇ∂éñÇë_ǧëºÇÃÉvÉâÉìÇÊÇËÇýóDÇÍǃǢÇÈÇÃǩǫǧǩÅB
GPUÇ∆GPUÇíºÇ≈ǬǻÇ∞ÇÈÇ∆ǢǧÇÃÇÕämÇ©Ç…HPCÇ∆Ç©Ç≈ÇÕóDà Ç…ì≠Ç≠ÇÃÇ©Ç»
í}îgëÂäwÇÃHP-PACSÇ≈éóÇΩÇÊǧǻéñǂǡǃÇΩÇÊǧǻ
í}îgëÂäwÇÃHP-PACSÇ≈éóÇΩÇÊǧǻéñǂǡǃÇΩÇÊǧǻ
ä‘à·Ç¶ÇΩHA-PACSÇæÇ¡ÇΩÇó
13 ÅFSocket774ÅF2014/03/27(ñÿ) 16:02:09.36 ID:EOWZzhoK
GPUDirectÇ∆Ç©ÇÃòbÇ∂ǷǻǢÇÃ
ÇÐÇüëSǃÇÕï®Ç™èoǃDZǻǢÇ∆ÇÀ
MaxwellÇ≈KeplerÇÃ2î{Çí¥Ç¶ÅAPascalÇÕǪÇÃ2î{í¥Ç¶Ç∆â\ÅB
5TFLOPSÇí¥Ç¶ÇÈÇ∆ǢǧÇÃÇ»ÇÁÅA
K40
Å@0.20Byte/FLOPÅ@Åi1430GFLOPS 288GB/sÅj
Å@0.011Byte/FLOP (1430GFLOPS 16GB/sÅj
PascalÅ@2016
Å@0.20Byte/FLOPÅ@Åi5TFLOPS 1TB/sÅj
Å@4x0.016Byte/FLOP Åi5TFLOPS 4x80GB/sÅj
ãûÅ@2012
Å@0.5Byte/FLOPÅ@Åi128GFLOPS 64GB/sÅj
Å@10x0.039Byte/FLOPÅ@Åi128GFLOPS 10x5GB/sÅj
SX-ACEÅ@2013
Å@1Byte/FLOPÅ@Åi256GFLOPS 256GB/sÅj
Å@2x0.031Byte/FLOPÅ@Åi256GFLOPS 2x8GB/sÅj
NVLinkÇÃÉoÉìÉhïùÇÕï DžǫǧÇ∆ǢǧDZÇ∆ÇÕǻǢÅB
2016îNÇ…FÅANÅAIÅACäeé–Ç™ãûÇ‚SX-ACEï¿ÇÃÇÐÇÐÇ∆ǢǧDZÇ∆ÇýǻǢÇæÇÎǧ
5TFLOPSÇí¥Ç¶ÇÈÇ∆ǢǧÇÃÇ»ÇÁÅA
K40
Å@0.20Byte/FLOPÅ@Åi1430GFLOPS 288GB/sÅj
Å@0.011Byte/FLOP (1430GFLOPS 16GB/sÅj
PascalÅ@2016
Å@0.20Byte/FLOPÅ@Åi5TFLOPS 1TB/sÅj
Å@4x0.016Byte/FLOP Åi5TFLOPS 4x80GB/sÅj
ãûÅ@2012
Å@0.5Byte/FLOPÅ@Åi128GFLOPS 64GB/sÅj
Å@10x0.039Byte/FLOPÅ@Åi128GFLOPS 10x5GB/sÅj
SX-ACEÅ@2013
Å@1Byte/FLOPÅ@Åi256GFLOPS 256GB/sÅj
Å@2x0.031Byte/FLOPÅ@Åi256GFLOPS 2x8GB/sÅj
NVLinkÇÃÉoÉìÉhïùÇÕï DžǫǧÇ∆ǢǧDZÇ∆ÇÕǻǢÅB
2016îNÇ…FÅANÅAIÅACäeé–Ç™ãûÇ‚SX-ACEï¿ÇÃÇÐÇÐÇ∆ǢǧDZÇ∆ÇýǻǢÇæÇÎǧ
16 ÅFSocket774ÅF2014/03/27(ñÿ) 18:34:29.16 ID:uJkNd+2H
IntelÇ∆AlteraÅA14nmÉvÉçÉZÉXÇÃÉ}ÉãÉ`É_ÉCSoCäJî≠Ç≈ã¶ã∆
http://pc.watch.impress.co.jp/docs/news/20140327_641569.html
FPGA/SoCÇ…ÅADRAMÅASRAMÅAASICÅAÉvÉçÉZÉbÉTÅAÉAÉiÉçÉOÉRÉìÉ|Å[ÉlÉìÉgÇ∆ǢǡÇΩ
àŸÇ»ÇÈÉ_ÉCÇ1ÉpÉbÉPÅ[ÉWÇ∆ǵǃïïì¸ÇµÅAAlteraÇÃàŸê´É}ÉãÉ`É_ÉCä‘ê⁄ë±ãZèpÇ≈ê⁄ë±Ç∑ÇÈÅB
http://pc.watch.impress.co.jp/docs/news/20140327_641569.html
FPGA/SoCÇ…ÅADRAMÅASRAMÅAASICÅAÉvÉçÉZÉbÉTÅAÉAÉiÉçÉOÉRÉìÉ|Å[ÉlÉìÉgÇ∆ǢǡÇΩ
àŸÇ»ÇÈÉ_ÉCÇ1ÉpÉbÉPÅ[ÉWÇ∆ǵǃïïì¸ÇµÅAAlteraÇÃàŸê´É}ÉãÉ`É_ÉCä‘ê⁄ë±ãZèpÇ≈ê⁄ë±Ç∑ÇÈÅB
NVLink Ç…IBMÇ™óçÇÒÇ≈Ç¢ÇÈÇÃÇ»ÇÁÅAÉmÅ[ÉhÇå◊Ç¢ÇæÉAÉhÉåÉXä«óùÅA
í¥MMUìIã@î\ÇÃéxâáÉnÅ[ÉhÉEÉFÉAìãç⁄ÇÃâ¬î\ê´Ç™ÇÝÇÈÅB
ÇΩǢǵÇΩDZÇ∆ǻǢÉoÉìÉhïùÇ»ÇÒÇ©ÇÊÇËÇýǪÇøÇÁÇÃï˚Ç™íçñ⁄Ç©ÇýǵÇÍǻǢ
éQçl
ttp://news.mynavi.jp/articles/2010/09/14/hot_chips22_scomputer/001.html
í¥MMUìIã@î\ÇÃéxâáÉnÅ[ÉhÉEÉFÉAìãç⁄ÇÃâ¬î\ê´Ç™ÇÝÇÈÅB
ÇΩǢǵÇΩDZÇ∆ǻǢÉoÉìÉhïùÇ»ÇÒÇ©ÇÊÇËÇýǪÇøÇÁÇÃï˚Ç™íçñ⁄Ç©ÇýǵÇÍǻǢ
éQçl
ttp://news.mynavi.jp/articles/2010/09/14/hot_chips22_scomputer/001.html
Ç∑Ç≈Ç…keplerà»ç~ÇÃgpudirect rdmaÇ≈ÉzÉXÉgÇÃíáâÓÇÕÇ¢ÇÁǻǢ
CUDAǡǃÉmÅ[Éhå◊ÇÆÇÊǧǻÉ|ÉCÉìÉ^Ç∆Ç©égǶÇÈÇÃÅH
ímÇÁÇÒÇØÇ«ÅAÇ»Ç≠ǃÇýÇÝÇ¡ÇΩǟǧǙÇÊÇ≥Ç∞Ç»ÇÁǪÇÃǧÇøé¿ëïÇ≥ÇÍÇÈÇæÇÎ
21 ÅFSocket774ÅF2014/03/28(ãý) 08:13:59.66 ID:Kbe/K39L
gpudirect rdmaǡǃǪǧǢǧã@î\Ç‚ÇÒÅH
http://www.jsces.org/research/sv/reference/6-naruse.pdf
http://www.jsces.org/research/sv/reference/6-naruse.pdf
HyperTransportDžǵÇÎQuickPathDžǵÇÎÉLÉÉÉbÉVÉÖÉRÉqÅ[ÉåÉìÉVÇÕégÇÌÇπǃÇýÇÁǶǻǢǩÇÁÅA
ì∆é©ÉoÉXÇÃäJî≠Çýédï˚ǻǢÇÊÇÀÅAÇ∆évÇ¡ÇΩÇÁëÊàÍíeÇ≈ÇÕÉLÉÉÉbÉVÉÖÉRÉqÅ[ÉåÉìÉVÇÕǻǵǩÅBǪÇÍÇÕǫǧǻÇÃÇ©ÅB
ì∆é©ÉoÉXÇÃäJî≠Çýédï˚ǻǢÇÊÇÀÅAÇ∆évÇ¡ÇΩÇÁëÊàÍíeÇ≈ÇÕÉLÉÉÉbÉVÉÖÉRÉqÅ[ÉåÉìÉVÇÕǻǵǩÅBǪÇÍÇÕǫǧǻÇÃÇ©ÅB
PCÇ‚ÉÇÉoÉCÉãí[ññÇÕñ≥éãǵǃÅiÇ∆ǢǧǩìdóÕìIÇ…é˘óvë§Ç©ÇÁëäéËÇ…Ç≥ÇÍǻǢÇæÇÎǧÉPÉhÅj
MPUÇ∆GPUÇÃÉRÅ[ÉhÇ™éûä‘Ç≈Ç´ÇÍǢDžï™Ç©ÇÍÇΩÇ®çsãVÇÃÇÊÇ¢ÉTÅ[ÉoÅ[ÉRÅ[Éhå¸ÇØÇÃã@î\Ç»ÇÒÇæÇÎǧÅB
MPUÇ∆GPUÇÃÉRÅ[ÉhÇ™éûä‘Ç≈Ç´ÇÍǢDžï™Ç©ÇÍÇΩÇ®çsãVÇÃÇÊÇ¢ÉTÅ[ÉoÅ[ÉRÅ[Éhå¸ÇØÇÃã@î\Ç»ÇÒÇæÇÎǧÅB
óùå§ÅAÉ|ÉXÉgÅuãûÅvÇ∆Ç»ÇÈÉGÉNÉTÉXÉPÅ[ÉãÉXÉpÉRÉìÇÃäJî≠Ç…íÖéË
Å`2020îNÇÃäÆê¨Çñ⁄éwÇ∑
http://pc.watch.impress.co.jp/docs/news/20140328_641867.html
ì˙ñ{ÇÃÉGÉNÉTÉXÉPÅ[ÉãÉVÉXÉeÉÄÇÃï˚å¸ê´Åiï‚ë´Åj
http://www.geocities.jp/andosprocinfo/wadai14/20140329.htm
Å`2020îNÇÃäÆê¨Çñ⁄éwÇ∑
http://pc.watch.impress.co.jp/docs/news/20140328_641867.html
ì˙ñ{ÇÃÉGÉNÉTÉXÉPÅ[ÉãÉVÉXÉeÉÄÇÃï˚å¸ê´Åiï‚ë´Åj
http://www.geocities.jp/andosprocinfo/wadai14/20140329.htm
Satoshi Matsuoka ?@ProfMatsuoka 12éûä‘
ǪÇÍDžǵǃÇýÅADZÇÃÇÊǧDžHPCÇÃÉvÉçÉZÉbÉTÉÅÅ[ÉJÅ[Ç™ÉnÅ[ÉhnjǩÇËÇ≈Ç»Ç≠ÅA
ëΩÇ≠ÇÃÉRÉ~ÉÖÉjÉeÉBǙǴÇøÇÒÇ∆égǶÇÈÇÊǧDžÉcÅ[ÉãÇ‚ÉmÉEÉnÉEÇäJî≠ǵÅAì`éˆÇ∑ÇÈÇÃÇÕñ{ìñÇ…ëfê∞ÇÁǵǢÅB
ç°ÇÃï°éGÇ»ï¿óÒÉvÉçÉZÉbÉTÇÕÉ\ÉtÉgñ Ç™ïÅãyÇ…ïsâ¬åáÇæÇ©ÇÁÇæÅB
çëÉvÉçÇ≈ÉnÅ[ÉhçÏǡǃè\êlǵǩégÇÌǻǢÇ∆Ç©ÇÝÇËìæǻǢÅB
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/020/shiryo/__icsFiles/afieldfile/2014/01/10/1343191_1.pdf
ǪÇÍDžǵǃÇýÅADZÇÃÇÊǧDžHPCÇÃÉvÉçÉZÉbÉTÉÅÅ[ÉJÅ[Ç™ÉnÅ[ÉhnjǩÇËÇ≈Ç»Ç≠ÅA
ëΩÇ≠ÇÃÉRÉ~ÉÖÉjÉeÉBǙǴÇøÇÒÇ∆égǶÇÈÇÊǧDžÉcÅ[ÉãÇ‚ÉmÉEÉnÉEÇäJî≠ǵÅAì`éˆÇ∑ÇÈÇÃÇÕñ{ìñÇ…ëfê∞ÇÁǵǢÅB
ç°ÇÃï°éGÇ»ï¿óÒÉvÉçÉZÉbÉTÇÕÉ\ÉtÉgñ Ç™ïÅãyÇ…ïsâ¬åáÇæÇ©ÇÁÇæÅB
çëÉvÉçÇ≈ÉnÅ[ÉhçÏǡǃè\êlǵǩégÇÌǻǢÇ∆Ç©ÇÝÇËìæǻǢÅB
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/020/shiryo/__icsFiles/afieldfile/2014/01/10/1343191_1.pdf
CPUÇ™âÊñ ï`âÊǡǃåæǧÇ∆20ê¢ãIèâì™ÇÃçÝÇ…ÇÐÇ≈òbÇ™ëkÇÈÇ©
20ê¢ãIèâì™ÇÃCPUǡǃǫÇÒÇ»ÇÃÅH
çLëÂÇ»ï~ínÇ≈
èóçHÇ≥ÇÒÇ™éËçÏã∆Ç≈åvéZǵǃÇΩ
èóçHÇ≥ÇÒÇ™éËçÏã∆Ç≈åvéZǵǃÇΩ
å√Ç´ó«Ç´éûë„Ç≈ÇÝÇÈÅB
ǪÇÎÇŒÇÒÇ‚åvéZé⁄
ÇÞǩǵÇÕÇÐÇ∂Ç≈ëÂäÈã∆ÇÃåoóùïîÇ…ÇÕÅAǪÇÎÇŒÇÒïîëýǙǢǃÅA
Ç–ÇΩÇ∑ÇÁǪÇÎÇŒÇÒÇ≈åvéZǵǃÇΩ
Ç–ÇΩÇ∑ÇÁǪÇÎÇŒÇÒÇ≈åvéZǵǃÇΩ
ësäœÇæÇ»ÇüÇó
èKÇ¢éñÇÃíËî‘ǙǪÇÎÇŒÇÒã≥é∫ÅAèKéöã≥é∫ÅB
ì™ÇÃíÜÇÃǪÇÎÇŒÇÒÇ≈à√éZǡǃêgDžǬÇØǃÇÈÇ∆ï÷óòÇÁǵǢÇØÇ«ÇÀ
ì™ÇÃíÜÇÃǪÇÎÇŒÇÒÇ≈à√éZǡǃêgDžǬÇØǃÇÈÇ∆ï÷óòÇÁǵǢÇØÇ«ÇÀ
Ç©Ç»ÇËÇÃåÖêîÇÃï°éGÇ»êîéöÇÃåvéZÇǪÇÁÇ≈èuéûÇ…Ç≈Ç´ÇÈóFêlǙǢÇΩÇ™ÅA
ìØÇ∂êlä‘Ç∆ÇÕévǶǻǩǡÇΩÇ»ÇüÇó
ìØÇ∂êlä‘Ç∆ÇÕévǶǻǩǡÇΩÇ»ÇüÇó
ÇøÇ»ÇðÇ…äÈã∆ǪÇÃëºÇÃåvéZïîëýópÇ…ÇÕéËâÒǵåvéZã@ÇýñYÇÍǃÇÕÇ¢ÇØǻǢ
ëÂäwÇ≈ÉzÉRÉäǩǑǡǃÇΩÇÃÇéùÇøèoǵǃóVÇÒÇæDZÇ∆Ç™ÇÝÇÈÇØÇ«
ëΩåÖÇÃåvéZÇ™ÉåÉoÅ[ÇÃâÒì]Ç≈ÉKÉVÉÉÉìÇ∆ǢǡǃäÆê¨Ç∑ÇÈÇÃÇÕÇ»ÇÒÇ©ãCéùÇøÇÊÇ©Ç¡ÇΩ
ëÂäwÇ≈ÉzÉRÉäǩǑǡǃÇΩÇÃÇéùÇøèoǵǃóVÇÒÇæDZÇ∆Ç™ÇÝÇÈÇØÇ«
ëΩåÖÇÃåvéZÇ™ÉåÉoÅ[ÇÃâÒì]Ç≈ÉKÉVÉÉÉìÇ∆ǢǡǃäÆê¨Ç∑ÇÈÇÃÇÕÇ»ÇÒÇ©ãCéùÇøÇÊÇ©Ç¡ÇΩ
>>15
ä‘à·Ç¶ÇΩÇÊǧÇæÅBàÍñ{Ç≈ÇÕÇ»Ç≠ÉgÅ[É^ÉãÇ™PCIe3.0 ÇÃ5Å`12î{ÇÁǵǢ
PascalÅ@2016
Å@0.20Byte/FLOPÅ@Åi5TFLOPS 1TB/sÅj
Å@4x0.004Å`4x0.0096Byte/FLOP Åi5TFLOPS 4x20Å`4x48GB/sÅj
ä‘à·Ç¶ÇΩÇÊǧÇæÅBàÍñ{Ç≈ÇÕÇ»Ç≠ÉgÅ[É^ÉãÇ™PCIe3.0 ÇÃ5Å`12î{ÇÁǵǢ
PascalÅ@2016
Å@0.20Byte/FLOPÅ@Åi5TFLOPS 1TB/sÅj
Å@4x0.004Å`4x0.0096Byte/FLOP Åi5TFLOPS 4x20Å`4x48GB/sÅj
nvlinkÇÕ20GbpsÇ≈8GbpsÇÃPCIe3.0ÇÃ5Å`12î{ǡǃåæǧÇÃÇÕǫǧǢǧåvéZÇ»ÇÒÇ∂Ç·ÇÎÇ©
nvidiaÇÕéZêîÇ™èoóàǻǢÇÒÇæÇÎ
>>37
ÅÑNVLink will provide between 80 and 200 GB/s of bandwidth
ttp://devblogs.nvidia.com/parallelforall/nvlink-pascal-stacked-memory-feeding-appetite-big-data/
PCIe Gen3 16x (16GB/s) ÇÃ5Å`12î{
ÅÑNVLink will provide between 80 and 200 GB/s of bandwidth
ttp://devblogs.nvidia.com/parallelforall/nvlink-pascal-stacked-memory-feeding-appetite-big-data/
PCIe Gen3 16x (16GB/s) ÇÃ5Å`12î{
20GB/s Ç™4ñ{ÇÝǡǃÇýëSǃìØéûÇ…ÉtÉãë—àÊÇégǶÇÈǩǫǧǩïsñæÇæ
amazonÇ∆nvidiaǙǂǡÇΩÉnÉCÉuÉäÉbÉhÉRÉìÉ\Å[ÉãÇÕñ¢óàÇä¥Ç∂ÇÈÇ»
ÉçÉ{ÉbÉgìôÇÃêlçHímî\Ç≈ÇýîΩéÀê_åoìIÇ»ë¶âûê´Ç™ïKóvÇ»ÇýÇÃÇÕí[ññÇ…íuÇ´
ǪÇÃëºÇÃÇýÇÃÇÕÉTÅ[ÉoÅ[Çë§Ç≈èàóùÇ∑ÇÈÇÊǧDžÇ∑ÇÍÇŒÇÊÇ¢ÇÃÇæÇ»Çü
ÉçÉ{ÉbÉgìôÇÃêlçHímî\Ç≈ÇýîΩéÀê_åoìIÇ»ë¶âûê´Ç™ïKóvÇ»ÇýÇÃÇÕí[ññÇ…íuÇ´
ǪÇÃëºÇÃÇýÇÃÇÕÉTÅ[ÉoÅ[Çë§Ç≈èàóùÇ∑ÇÈÇÊǧDžÇ∑ÇÍÇŒÇÊÇ¢ÇÃÇæÇ»Çü
>>41
2çsÇÝÇÈè„Ç™ÉÅÉCÉìÉÅÉÇÉäÉoÉìÉhïùÅAâ∫Ç™ÉmÅ[Éhä‘í êMÉoÉìÉhïùÅB
àÍïbÇÝÇΩÇËÇ≈ÇÕÇ»Ç≠64bitïÇìÆè¨êîì_ââéZàÍâÒÇÃèäóvéûä‘ÇÝÇΩÇËÅB
ââéZäÌÇ™ë¨Ç≠ǃÇýÉfÅ[É^ÇìÕÇØÇÈìπÇ™ç◊Ç©Ç¡ÇΩÇÁë´Ç™à¯Ç¡í£ÇÁÇÍÇÈ
Ç∆ǢǧDZÇ∆ÇÕ41ÇýímǡǃǢÇÈÇæÇÎǧÅHÅ@NVLinkÇÃHPCï™ñÏÇ≈ÇÃóLå¯ê´Ç
âþèËÇ…éùÇøè„Ç∞ÇÈÉåÉXÇ™ÇÝÇ¡ÇΩÇ©ÇÁåªé¿ÇêîéöÇ≈ì`ǶÇΩÇÃÇ™>15
2çsÇÝÇÈè„Ç™ÉÅÉCÉìÉÅÉÇÉäÉoÉìÉhïùÅAâ∫Ç™ÉmÅ[Éhä‘í êMÉoÉìÉhïùÅB
àÍïbÇÝÇΩÇËÇ≈ÇÕÇ»Ç≠64bitïÇìÆè¨êîì_ââéZàÍâÒÇÃèäóvéûä‘ÇÝÇΩÇËÅB
ââéZäÌÇ™ë¨Ç≠ǃÇýÉfÅ[É^ÇìÕÇØÇÈìπÇ™ç◊Ç©Ç¡ÇΩÇÁë´Ç™à¯Ç¡í£ÇÁÇÍÇÈ
Ç∆ǢǧDZÇ∆ÇÕ41ÇýímǡǃǢÇÈÇæÇÎǧÅHÅ@NVLinkÇÃHPCï™ñÏÇ≈ÇÃóLå¯ê´Ç
âþèËÇ…éùÇøè„Ç∞ÇÈÉåÉXÇ™ÇÝÇ¡ÇΩÇ©ÇÁåªé¿ÇêîéöÇ≈ì`ǶÇΩÇÃÇ™>15
SXÇ‚ãûÇ∆Ç©Ç∆î‰Ç◊ÇΩÇÁǵÇÂǧǙǻǢÇÒÇ≈ǻǢÇÃÅH
PascalÇ∆ÇËÇÝǶÇ∏5TFLOPSèoÇÈǡǃíPèÉÇ…Ç∑Ç≤Ç¢ÇÌ
NVlinké©ëÃÇÕÇÐÇÝDZÇÍÇ©ÇÁÇæǵ
ç°å„ÇÃâ¸ëPÇ≈ê´î\å¸è„Ç…Çýä˙ë“
PascalÇ∆ÇËÇÝǶÇ∏5TFLOPSèoÇÈǡǃíPèÉÇ…Ç∑Ç≤Ç¢ÇÌ
NVlinké©ëÃÇÕÇÐÇÝDZÇÍÇ©ÇÁÇæǵ
ç°å„ÇÃâ¸ëPÇ≈ê´î\å¸è„Ç…Çýä˙ë“
5TFLOPSǡǃǫÇÃÇ÷ÇÒÇÃâøäië—ÅH
TITANÇÃå„åpÅH
TITANÇÃå„åpÅH
>>43
Ç®ÇÍÇÕåªèÛÇÃnvidiaÇ™î≠ï\ǵÇΩNVlinkÇéùÇøè„Ç∞ǃÇÈÇÌÇØÇ∂Ç·Ç»Ç≠ǃÅA
è´óàNVlink2ÅENVlink3Ç∆Ç©Ç…Ç»ÇÍÇŒÅAÉXÉpÉRÉìÇÃâÂèÈÇã∫Ç©Ç∑â¬î\ê´Ç™ÇÝÇÈǡǃ
èëÇ´çûÇÒÇæÇæÇØÇæÇÊ
Ç®ÇÍÇÕåªèÛÇÃnvidiaÇ™î≠ï\ǵÇΩNVlinkÇéùÇøè„Ç∞ǃÇÈÇÌÇØÇ∂Ç·Ç»Ç≠ǃÅA
è´óàNVlink2ÅENVlink3Ç∆Ç©Ç…Ç»ÇÍÇŒÅAÉXÉpÉRÉìÇÃâÂèÈÇã∫Ç©Ç∑â¬î\ê´Ç™ÇÝÇÈǡǃ
èëÇ´çûÇÒÇæÇæÇØÇæÇÊ
NVlink ÇÕå¸è„Ç∑ÇÈÇæÇÎǧǙãûÇ‚SXÇÃå„åpÇýå¸è„Ç∑ÇÈÇæÇÎǧÅB
DZÇÍÇÐÇ≈èoǃǴÇΩNVlinkä÷òAÇÃòbÇæÇØÇ≈ÇÕ
ç∑Ç™èkÇÐÇÈÇ∆Ǣǧó\ëzÇÃç™ãíÇ…ÇÕë´ÇËǻǢ
DZÇÍÇÐÇ≈èoǃǴÇΩNVlinkä÷òAÇÃòbÇæÇØÇ≈ÇÕ
ç∑Ç™èkÇÐÇÈÇ∆Ǣǧó\ëzÇÃç™ãíÇ…ÇÕë´ÇËǻǢ
10êlǵǩégÇÌǻǢçëÉvÉçÇ©
ç≈êÊí[ǡǃÇÃÇÕÇ«ÇÃï™ñÏÇ≈ÇýǪÇÒÇ»ÇýÇÒÇæ
èàóùéûä‘Ç≥ǶãñóeÇ∑ÇÍÇŒímåbÇ∆ëΩè≠ÇÃÇ®è¨å≠Ç¢Ç≈ç≈êÊí[ÇÃê¨â ï®Ç…ãþÇ¢ÇýÇÃÇÅiêîîNëOÇÃç≈êÊí[Ç»ÇÁê¨â ǪÇÃÇýÇÃÇÅjÉoÉìÉsÅ[Ç≈ÇýÉvÉçëgêDñ≥ópÇÃîºï˙íuÇ≈éËÇ…ì¸ÇÍÇÁÇÍÇÈÇ©ÇÁ
ÉRÉìÉsÉÖÅ[É^ãZèpï™ñÏÇ…ä÷ǵǃÇÕåÎâǵÇøǷǧÇÒÇæÇÊÇ»ÅB
ÉRÉìÉsÉÖÅ[É^ãZèpï™ñÏÇ…ä÷ǵǃÇÕåÎâǵÇøǷǧÇÒÇæÇÊÇ»ÅB
0êlǵǩégÇÌǻǢÉ∞Ç…î‰Ç◊ÇΩÇÁÅáî{ÇÃóòópé“ÇæÇ»
DZÇÍÇŸÇ«ÇÃê¨â ÇèoǵÇΩçëâ∆ÉvÉçÉWÉFÉNÉgǙǩǬǃÇÝÇ¡ÇΩÇæÇÎǧǩ
DZÇÍÇŸÇ«ÇÃê¨â ÇèoǵÇΩçëâ∆ÉvÉçÉWÉFÉNÉgǙǩǬǃÇÝÇ¡ÇΩÇæÇÎǧǩ
ä÷åWé“ÇÝǢǩÇÌÇÁÇ∏ïKéÄÇæÇ»Å[ÅBÇ¢ÇÎÇÒÇ»êÍñÂâ∆Ç©ÇÁîìÔÇ≥ÇÍǃÇÈÇÃÇ…ÅB
èºâ™ÉZÉìÉZÇ™NVÇÃçLçêìÉÇðÇΩǢDžǻǡǃÇÈÇ»ÅB
Ç¢Ç≠ÇÁãýêœÇÐÇÍǃÇÈÇÒÇæÇÎ
55 ÅFSocket774ÅF2014/03/31(åé) 17:31:22.23 ID:/C8IeS1n
é¿ç€ñ‚ëË30êlñ¢ñûǵǩégÇÌǻǢÇÊǧǻÇýÇÃÇ≈É\ÉtÉgÇÃç≈ìKâªÇ∆Ç©ñ]ÇþÇÈÇýÇÒÇ»ÇÃÅH
ǵǩÇýäeÅXï Ç»ÉvÉçÉOÉâÉÄÇ»ÇÌÇØÇæÇÎ
ǵǩÇýäeÅXï Ç»ÉvÉçÉOÉâÉÄÇ»ÇÌÇØÇæÇÎ
ê≠ï{ÅEê≠é°ÅEçsê≠Çî·îªÇ∑ÇÈDZÇ∆é©ëÃÇ™ñ⁄ìIÇÃêlÇ™ÅAî·îªÇ∑ÇÈÉlÉ^Ç…ÉXÉpÉRÉìÇóòópǵǃÇÈÇæÇØǡǃä¥Ç∂Ç™Ç∑ÇÈ
>>55
É}ÉWÉåÉXÇ∑ÇÈÇ∆ÅAå§ãÜópÇ∆ÇÃÇŸÇ∆ÇÒÇ«ÇÃÉXÉpÉRÉìÇÃÉvÉçÉOÉâÉÄÇ»ÇÒǃCPUêîÇÇÎÇ≠Ç…äàÇ©ÇπǃǻǢÉNÉYÇðÇΩǢǻÇýÇÃÅB
ǪÇýǪÇýëÂëΩêîÇÃóòópé“Ç©ÇÁåæǶnjÅAå§ãÜê¨â DZǪǙëÂéñÇ≈ÅAÉvÉçÉOÉâÉÄÇ™ë¨Ç¢Ç»ÇÒǃéËíiíÜÇÃèdóvÇ≈ÇÕǻǢÇýÇÃÇÃ1ǬÇæÇ©ÇÁÇÀÅB
égÇ¡ÇΩDZÇ∆ǻǢǂǬÇÃÉCÉÅÅ[ÉWÇæÇØÇ™êÊçsǵǃÅAÉXÉpÉRÉìÇÃÉvÉçÉOÉâÉÄ=ÉXÅ[ÉpÅ[ÉnÉJÅ[Ç™ÉKÉ`Ç≈ç≈ìKâª
ÇðÇΩǢǻåÎÇ¡ÇΩå∂ëzÇ™çLǙǡǃǢÇÈÇæÇØÅBÇþÇ≠ÇÁÇÐǵÇÐǙǢÇÃãûÇæÇØÇ…íçñ⁄Ç∑ÇÈÇÒÇ≈Ç»Ç≠ǃÅAÇýÇ¡Ç∆Ç¢ÇÎÇÒÇ»óòópé“ÇÃä÷åWé“ÇÃà”å©Çí«Ç¡ÇΩǟǧǙó«Ç¢ÅB
É}ÉWÉåÉXÇ∑ÇÈÇ∆ÅAå§ãÜópÇ∆ÇÃÇŸÇ∆ÇÒÇ«ÇÃÉXÉpÉRÉìÇÃÉvÉçÉOÉâÉÄÇ»ÇÒǃCPUêîÇÇÎÇ≠Ç…äàÇ©ÇπǃǻǢÉNÉYÇðÇΩǢǻÇýÇÃÅB
ǪÇýǪÇýëÂëΩêîÇÃóòópé“Ç©ÇÁåæǶnjÅAå§ãÜê¨â DZǪǙëÂéñÇ≈ÅAÉvÉçÉOÉâÉÄÇ™ë¨Ç¢Ç»ÇÒǃéËíiíÜÇÃèdóvÇ≈ÇÕǻǢÇýÇÃÇÃ1ǬÇæÇ©ÇÁÇÀÅB
égÇ¡ÇΩDZÇ∆ǻǢǂǬÇÃÉCÉÅÅ[ÉWÇæÇØÇ™êÊçsǵǃÅAÉXÉpÉRÉìÇÃÉvÉçÉOÉâÉÄ=ÉXÅ[ÉpÅ[ÉnÉJÅ[Ç™ÉKÉ`Ç≈ç≈ìKâª
ÇðÇΩǢǻåÎÇ¡ÇΩå∂ëzÇ™çLǙǡǃǢÇÈÇæÇØÅBÇþÇ≠ÇÁÇÐǵÇÐǙǢÇÃãûÇæÇØÇ…íçñ⁄Ç∑ÇÈÇÒÇ≈Ç»Ç≠ǃÅAÇýÇ¡Ç∆Ç¢ÇÎÇÒÇ»óòópé“ÇÃä÷åWé“ÇÃà”å©Çí«Ç¡ÇΩǟǧǙó«Ç¢ÅB
59 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/03/31(åé) 20:31:31.41 ID:rVxPlXtx
èºâ™êÊê∂ÇÕnvÉxÉbÉ^ÉäÇ∑ǨÇÈÅB
ãåíÈëÂÇ‚NAISTÇÕäTÇÀPhiéxéùÇðÇΩǢǻï˚å¸ÇæÇÀ
ãåíÈëÂÇ‚NAISTÇÕäTÇÀPhiéxéùÇðÇΩǢǻï˚å¸ÇæÇÀ
CÅAFÅAIÅANäeé–ÇÃÉJÉXÉ^ÉÄÉCÉìÉ^Å[ÉRÉlÉNÉgÇ≈ÇÕÇ»Ç≠
InfinibandÇÕNVlinkÇ…êNêHÇ≥ÇÍÇÈÇ©ÇýǵÇÍǻǢÅB
NVlink Ç™Infinibandï¿Ç…à¿âøÇæÇ¡ÇΩÇÁÇæÇ™
InfinibandÇÕNVlinkÇ…êNêHÇ≥ÇÍÇÈÇ©ÇýǵÇÍǻǢÅB
NVlink Ç™Infinibandï¿Ç…à¿âøÇæÇ¡ÇΩÇÁÇæÇ™
ê¢ÇÃíÜÅAñäÑï™íSÇ≈Ç≈ǴǃǢÇÈÅB
å§ãÜé“Ç™îMêSÇ»ÇÃÇÕåvéZó ÇÃÉIÅ[É_Å[Çâ∫Ç∞ÇÈDZÇ∆Ç≈ÇÝǡǃ
ǪÇÃëOÇ…Ç©Ç©ÇÈåWêîÇ∂ǷǻǢÅBÉRÅ[ÉfÉBÉìÉOÇÃç≈ìKâªÇ≈
â∫Ç∞ÇÁÇÍÇÈÇÃÇÕåWêîÅBÉIÅ[É_Å[Ç»ÇÁã∆ê—Ç…Ç»ÇÈÇ™åWêîÇÕìÔǵǢÅB
åWêîâ∫Ç∞ÇÕÉRÉìÉsÉÖÅ[É^é©ëÃÇ™å§ãÜñ⁄ìIÇÃé“ÇÃíSìñï™ñÏÅB
å§ãÜé“Ç™îMêSÇ»ÇÃÇÕåvéZó ÇÃÉIÅ[É_Å[Çâ∫Ç∞ÇÈDZÇ∆Ç≈ÇÝǡǃ
ǪÇÃëOÇ…Ç©Ç©ÇÈåWêîÇ∂ǷǻǢÅBÉRÅ[ÉfÉBÉìÉOÇÃç≈ìKâªÇ≈
â∫Ç∞ÇÁÇÍÇÈÇÃÇÕåWêîÅBÉIÅ[É_Å[Ç»ÇÁã∆ê—Ç…Ç»ÇÈÇ™åWêîÇÕìÔǵǢÅB
åWêîâ∫Ç∞ÇÕÉRÉìÉsÉÖÅ[É^é©ëÃÇ™å§ãÜñ⁄ìIÇÃé“ÇÃíSìñï™ñÏÅB
ÉÅÉÇÉäÉoÉìÉhïùÅAÉmÅ[Éhä‘í êMÉoÉìÉhïùÅAïÇìÆè¨êîì_ââéZâÒêî
DZǧǢǡÇΩíPèÉâªÇµÇ∑ǨÇΩÉXÉyÉbÉNílÇæÇØÇ…é˙ÇÌÇÍǃçÏÇÈÇ∆ÅA
ÇπÇ¢Ç∫Ç¢LINPACKÇæÇØÇ™éÊÇËïøÇÃÉSÉ~ÇðÇΩǢǻÉRÉìÉsÉÖÅ[É^Å[Ç™Ç≈Ç´ÇÈÅB
DZÇÍì§Ç»ÅB
DZǧǢǡÇΩíPèÉâªÇµÇ∑ǨÇΩÉXÉyÉbÉNílÇæÇØÇ…é˙ÇÌÇÍǃçÏÇÈÇ∆ÅA
ÇπÇ¢Ç∫Ç¢LINPACKÇæÇØÇ™éÊÇËïøÇÃÉSÉ~ÇðÇΩǢǻÉRÉìÉsÉÖÅ[É^Å[Ç™Ç≈Ç´ÇÈÅB
DZÇÍì§Ç»ÅB
63 ÅFSocket774ÅF2014/04/01(âŒ) 07:42:26.93 ID:p4pYNAhC
ãûÇ≥ÇÒÅH
64 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/01(âŒ) 21:35:25.52 ID:jnhMi+WG
ñØä‘Ç≈çLÇ≠égÇÌÇÍǃÇÈÇýÇÃÇã…óÕóòópÇ∑ÇÈÇÃÇÕÅAê¨â ï®ÇÃ
É\ÉtÉgÉEÉFÉAãZèpÇñØä‘ì]ópǵǂÇ∑Ç≠Ç∑ÇÈà◊Ç≈ÇýÇÝÇÈÅB
É\ÉtÉgÉEÉFÉAãZèpÇñØä‘ì]ópǵǂÇ∑Ç≠Ç∑ÇÈà◊Ç≈ÇýÇÝÇÈÅB
è´óàÅ`Ç…ÉiÉåÉoÅ[
ñØä‘ì]ópÇ≥ÇÍÇΩÉ\ÉtÉgÉEÉFÉAãZèpÅH
Ç»ÇÒÇ∂ǷǪÇÁ
Ç»ÇÒÇ∂ǷǪÇÁ
Ç∆DZÇÎÇ≈ÅAãûå„åpã@äJî≠äJénÇ∆STAPç◊ñEùsë¢ã∂ëõÇ™
éûä˙ìIÇ…îÌǡǃǵÇÐÇ¡ÇΩÇÃÇÕâΩÇ©ä÷òAÇÝÇÈÇÒÇ∑Ç©ÇÀÅH ÅiâAñdò_ìIÇ»à”ñ°Ç≈
éûä˙ìIÇ…îÌǡǃǵÇÐÇ¡ÇΩÇÃÇÕâΩÇ©ä÷òAÇÝÇÈÇÒÇ∑Ç©ÇÀÅH ÅiâAñdò_ìIÇ»à”ñ°Ç≈
ãûÇ∆ÇÕä÷åWǻǢÇæÇÎ
ì¡éÍñ@êlîFâ¬ÇÃÉ^ÉCÉ~ÉìÉOÇ…çáÇÌÇπǃî≠ï\ǵǃãtÇ…óÝñ⁄Ç…Ç≈ÇΩÇÒÇæÇÎǧ
ì¡éÍñ@êlîFâ¬ÇÃÉ^ÉCÉ~ÉìÉOÇ…çáÇÌÇπǃî≠ï\ǵǃãtÇ…óÝñ⁄Ç…Ç≈ÇΩÇÒÇæÇÎǧ
Ç∆ÇËÇÝǶÇ∏ÅALinpackÇ≈ê¢äEàÍÇñ⁄éwÇ∑ÇÃÇ≈ÇÕÇ»Ç≠ǃÅA
ÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpÇÃò_ï∂çÃëêîÇ‚ÉVÉÖÉ~ÉåÅ[ÉVÉáÉìãZèpÇÃéYã∆óòópÇ≈ê¢äEàÍÇ…ñ⁄ïWêðíËÇïœÇ¶ÇƒÇŸÇµÇ¢ÅB
Ç∂ǷǻǢÇ∆ÅA10îNÇ…àÍìxÇÃó\éZó≠ÇþçûÇðÅ®ï®ó ìäì¸Ç≈ÉnÅ[Éhí≤íBÅAǡǃǢǧÇ≠ÇæÇÁÇÒÉTÉCÉNÉãÇ©ÇÁî≤ÇØèoÇπǻǢÅB
Ç«ÇÃÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpÇ…óÕÇì¸ÇÍÇÈÇÃÇ©ÇÇÐÇ∏ëIëÇ∑ÇÈÅB
F, N, Hé–ÇÃÇÊǧǻÉnÅ[ÉhÉÅÅ[ÉJÅ[Ç…ìäÇ∞ÇÈÇÒÇ≈ÇÕÇ»Ç≠ǃÅAóòópé“éÂì±Ç‚É\ÉtÉgÉEÉGÉAéÂì±Ç…ǵǃ
ã§ìØå§ãÜǵÇΩÇ¢É\ÉtÉgâÔé–ÇàÍî Ç©ÇÁïÂÇÈÇ◊Ç´ÇæÇ»ÅB
é¿ç€ÇÃÉnÅ[Éhî≠íçÇÕǪǢǬÇÁÇÃåüì¢Ç…àœÇÀÇÈÇ◊Ç´ÅB
Ç∆ǢǧÇÌÇØÇ≈MñÏéÅÅAóäÇðÇÐÇ∑ÇÌÅB
ÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpÇÃò_ï∂çÃëêîÇ‚ÉVÉÖÉ~ÉåÅ[ÉVÉáÉìãZèpÇÃéYã∆óòópÇ≈ê¢äEàÍÇ…ñ⁄ïWêðíËÇïœÇ¶ÇƒÇŸÇµÇ¢ÅB
Ç∂ǷǻǢÇ∆ÅA10îNÇ…àÍìxÇÃó\éZó≠ÇþçûÇðÅ®ï®ó ìäì¸Ç≈ÉnÅ[Éhí≤íBÅAǡǃǢǧÇ≠ÇæÇÁÇÒÉTÉCÉNÉãÇ©ÇÁî≤ÇØèoÇπǻǢÅB
Ç«ÇÃÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpÇ…óÕÇì¸ÇÍÇÈÇÃÇ©ÇÇÐÇ∏ëIëÇ∑ÇÈÅB
F, N, Hé–ÇÃÇÊǧǻÉnÅ[ÉhÉÅÅ[ÉJÅ[Ç…ìäÇ∞ÇÈÇÒÇ≈ÇÕÇ»Ç≠ǃÅAóòópé“éÂì±Ç‚É\ÉtÉgÉEÉGÉAéÂì±Ç…ǵǃ
ã§ìØå§ãÜǵÇΩÇ¢É\ÉtÉgâÔé–ÇàÍî Ç©ÇÁïÂÇÈÇ◊Ç´ÇæÇ»ÅB
é¿ç€ÇÃÉnÅ[Éhî≠íçÇÕǪǢǬÇÁÇÃåüì¢Ç…àœÇÀÇÈÇ◊Ç´ÅB
Ç∆ǢǧÇÌÇØÇ≈MñÏéÅÅAóäÇðÇÐÇ∑ÇÌÅB
>>69
ǪǧÇÕåæǡǃÇýÇæ
éYã∆óòópÇ…íºåãǵǻǢäÓëbå§ãÜÇæÇ©ÇÁDZǪçëÇÃÉoÉbÉNÉAÉbÉvÇ≈Ç‚ÇÁǻǴǷ!ǡǃÇÃÇýÇÝÇÈÇ©ÇÁÇ»Å`
éYã∆óòópÇ…íºåãÇ∑ÇÈÇ»ÇÁÅAäÈã∆ïRïtÇØå§ãÜÇ≈Ç‚ÇËÇ·ó«Ç¢ÇÒÇ∂ǷǻǢÇÃ?Ç∆évÇÌÇ»Ç≠Çýñ≥Ç¢
ǪǧÇÕåæǡǃÇýÇæ
éYã∆óòópÇ…íºåãǵǻǢäÓëbå§ãÜÇæÇ©ÇÁDZǪçëÇÃÉoÉbÉNÉAÉbÉvÇ≈Ç‚ÇÁǻǴǷ!ǡǃÇÃÇýÇÝÇÈÇ©ÇÁÇ»Å`
éYã∆óòópÇ…íºåãÇ∑ÇÈÇ»ÇÁÅAäÈã∆ïRïtÇØå§ãÜÇ≈Ç‚ÇËÇ·ó«Ç¢ÇÒÇ∂ǷǻǢÇÃ?Ç∆évÇÌÇ»Ç≠Çýñ≥Ç¢
>>70
à”ñ°ïsñæ~ÅBçëâ∆ÉvÉçÉWÉFÉNÉgÇ≈ãÔëÃìIÇ»êªïiäJî≠Ç∑ÇÈåªèÛÇÃǫDZǙäÓëbå§ãÜÇ»ÇÃ?
ç°ÇÃèÛë‘Ç™çëçÙÇ≈Ç‚ÇÈDZÇ∆Ç∂ǷǻǢÇ≈ǵÇÂÅB
â¥Ç™Ç¢Ç¢ÇΩÇ¢ÇÃÇÕÅAÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpëSî ÇÃíÜí∑ä˙ìIéãñÏÇ≈ÇÃǃDZì¸ÇÍÇ»ÇÒÇæÇÊÅB
ÉXÉpÉRÉìÇÕÉVÉ~ÉÖÉåÅ[ÉVÉáÉìÇ∑ÇÈÇΩÇþÇÃìπãÔÇ≈ǵǩǻǢÇÒÇæÇ©ÇÁÅAǪÇÍé©ëÃÇ™ñ⁄ìIÇÃêªïiäJî≠Ç»ÇÒÇ¥
íÜí∑ä˙ìIéãñÏÇ≈Ç‚ÇÈDZÇ∆Ç∂ǷǻǢÅB
à”ñ°ïsñæ~ÅBçëâ∆ÉvÉçÉWÉFÉNÉgÇ≈ãÔëÃìIÇ»êªïiäJî≠Ç∑ÇÈåªèÛÇÃǫDZǙäÓëbå§ãÜÇ»ÇÃ?
ç°ÇÃèÛë‘Ç™çëçÙÇ≈Ç‚ÇÈDZÇ∆Ç∂ǷǻǢÇ≈ǵÇÂÅB
â¥Ç™Ç¢Ç¢ÇΩÇ¢ÇÃÇÕÅAÉVÉ~ÉÖÉåÅ[ÉVÉáÉìãZèpëSî ÇÃíÜí∑ä˙ìIéãñÏÇ≈ÇÃǃDZì¸ÇÍÇ»ÇÒÇæÇÊÅB
ÉXÉpÉRÉìÇÕÉVÉ~ÉÖÉåÅ[ÉVÉáÉìÇ∑ÇÈÇΩÇþÇÃìπãÔÇ≈ǵǩǻǢÇÒÇæÇ©ÇÁÅAǪÇÍé©ëÃÇ™ñ⁄ìIÇÃêªïiäJî≠Ç»ÇÒÇ¥
íÜí∑ä˙ìIéãñÏÇ≈Ç‚ÇÈDZÇ∆Ç∂ǷǻǢÅB
É\ÉtÉgäJî≠ë§ÇýǪÇÃìdãCÉ[ÉlÉRÉìÇÃè®ÇðÇΩǢǻÇýÇÒÇ≈
ǮDZÇ⁄ÇÍÇ…óaǩǡǃÅA
ÇÐÇΩøÃàÍÇ©ÇÁçÏÇËÇÐÇ∑Ç∆Ç©êQåæåæǡǃǢÇÈǵǻ
ǮDZÇ⁄ÇÍÇ…óaǩǡǃÅA
ÇÐÇΩøÃàÍÇ©ÇÁçÏÇËÇÐÇ∑Ç∆Ç©êQåæåæǡǃǢÇÈǵǻ
>>72
â¥ÇýóùëzÇÕÉ[ÉlÉRÉìâªÇÕîÇØÇΩǢǙÅAåˆã§ìäéëÇ≈ÇÝÇÈà»è„ÅAäÆëSÇ…ÉNÉäÅ[ÉìÇ»ÇÃÇÕñ≥óùÇæÇ∆évǧÅB
F, N, Hé–Ç…ñ¢ÇæÇ…ãýìäì¸ÇµÇƒÇ¢ÇÈÇÃÇÕÅA80îNë„ÇÃì˙ñ{ÇÃîºì±ëÃÇ‚ÉXÉpÉRÉìê‚í∏ä˙ÇÃÉCÉÅÅ[ÉWÇ
ñ¢ÇæÇ…à¯Ç´Ç∏ǡǃǢÇÈÇ©ÇÁÇæÇ»ÅBñêlå¸ÇØÇÃÉAÉsÅ[ÉãÇ∆ǵǃÇýǫDZÇÃînÇÃçúÇ∆ÇýÇÌÇ©ÇÁǻǢÉ\ÉtÉgÉxÉìÉ_Å[ÇÊÇËÇý
ÇæÇÍÇ≈ÇýímǡǃÇÈF, N, Hé–Ç™äÊí£ÇÈǡǃǟǧǙìsçáǢǢǩÇÁÇ»ÅBé¿ç€ÇÕÅAéÄÇÒÇæéYã∆Ç…çëâ∆ó\éZÇÝǃǃÉ]ÉìÉrâªÇþÇ≠ÇÁÇÐǵÅB
ǫǧÇπÉ[ÉlÉRÉìâªÇ∑ÇÈÇ»ÇÁÅAÉ]ÉìÉrÇ…å¸ÇØÇÈÇÒÇ∂Ç·Ç≠ǃÅAé·Ç¢éYã∆å¸ÇØÇÃîÏǂǵDžǵÇΩï˚ǙǢǢÅB
â¥ÇýóùëzÇÕÉ[ÉlÉRÉìâªÇÕîÇØÇΩǢǙÅAåˆã§ìäéëÇ≈ÇÝÇÈà»è„ÅAäÆëSÇ…ÉNÉäÅ[ÉìÇ»ÇÃÇÕñ≥óùÇæÇ∆évǧÅB
F, N, Hé–Ç…ñ¢ÇæÇ…ãýìäì¸ÇµÇƒÇ¢ÇÈÇÃÇÕÅA80îNë„ÇÃì˙ñ{ÇÃîºì±ëÃÇ‚ÉXÉpÉRÉìê‚í∏ä˙ÇÃÉCÉÅÅ[ÉWÇ
ñ¢ÇæÇ…à¯Ç´Ç∏ǡǃǢÇÈÇ©ÇÁÇæÇ»ÅBñêlå¸ÇØÇÃÉAÉsÅ[ÉãÇ∆ǵǃÇýǫDZÇÃînÇÃçúÇ∆ÇýÇÌÇ©ÇÁǻǢÉ\ÉtÉgÉxÉìÉ_Å[ÇÊÇËÇý
ÇæÇÍÇ≈ÇýímǡǃÇÈF, N, Hé–Ç™äÊí£ÇÈǡǃǟǧǙìsçáǢǢǩÇÁÇ»ÅBé¿ç€ÇÕÅAéÄÇÒÇæéYã∆Ç…çëâ∆ó\éZÇÝǃǃÉ]ÉìÉrâªÇþÇ≠ÇÁÇÐǵÅB
ǫǧÇπÉ[ÉlÉRÉìâªÇ∑ÇÈÇ»ÇÁÅAÉ]ÉìÉrÇ…å¸ÇØÇÈÇÒÇ∂Ç·Ç≠ǃÅAé·Ç¢éYã∆å¸ÇØÇÃîÏǂǵDžǵÇΩï˚ǙǢǢÅB
ǫǧǵÇΩÇÁó«Ç≠Ç»ÇÈÇÒÇæÇÎǧÇÀDZǧǢǧÉvÉäÉWÉFÉNÉgÇÕÅB
ǪǧǢǶnjÅAé©ï™ÇΩÇøÇ≈ÇýåæǡǃÇΩÅBämêMî∆ÇæǡǃÅB
çëÇ©ÇÁê≈ãýÇ≈ãýèoǵǃñ·Ç¡ÇƒÅAì˙ñ{ÇÃãZèpÇÃäJî≠ÇÃÇΩÇþÇ∆Ç©ÇýÇ¡Ç∆ÇýÇÁǵǢóùóRÇïtÇØǃÅA
àÍÇ©ÇÁÉnÅ[ÉhçÏÇËéUÇÁǩǵǃÅAñ{óàÇ»ÇÁé¿ópä˙Çå}ǶÇÈçÝÇ…ÇÐÇΩéüÇÃäJî≠ÉvÉçÉWÉFÉNÉgÇ
óßÇøè„Ç∞ǃÅAà·Ç§ÇýÇÃàÍÇ©ÇÁçÏÇËǻǮǵǃãýÇâÒÇ∑ÉrÉWÉlÉXÉÇÉfÉãÇæÇ∆ÅB
îºì±ëÃãZèpÇýóùóRÇ∆ǵǃà¯Ç´çáǢDžèoÇ≥ÇÍǃǢÇΩDZÇ∆ÇýÇÝÇ¡ÇΩÇ™
åªèÛÇå©ÇÍÇŒÅAç°Ç∆ǻǡǃÇÕÇ®èŒÇ¢ÇÆÇ≥Ç©
ǪǧǢǶnjÅAé©ï™ÇΩÇøÇ≈ÇýåæǡǃÇΩÅBämêMî∆ÇæǡǃÅB
çëÇ©ÇÁê≈ãýÇ≈ãýèoǵǃñ·Ç¡ÇƒÅAì˙ñ{ÇÃãZèpÇÃäJî≠ÇÃÇΩÇþÇ∆Ç©ÇýÇ¡Ç∆ÇýÇÁǵǢóùóRÇïtÇØǃÅA
àÍÇ©ÇÁÉnÅ[ÉhçÏÇËéUÇÁǩǵǃÅAñ{óàÇ»ÇÁé¿ópä˙Çå}ǶÇÈçÝÇ…ÇÐÇΩéüÇÃäJî≠ÉvÉçÉWÉFÉNÉgÇ
óßÇøè„Ç∞ǃÅAà·Ç§ÇýÇÃàÍÇ©ÇÁçÏÇËǻǮǵǃãýÇâÒÇ∑ÉrÉWÉlÉXÉÇÉfÉãÇæÇ∆ÅB
îºì±ëÃãZèpÇýóùóRÇ∆ǵǃà¯Ç´çáǢDžèoÇ≥ÇÍǃǢÇΩDZÇ∆ÇýÇÝÇ¡ÇΩÇ™
åªèÛÇå©ÇÍÇŒÅAç°Ç∆ǻǡǃÇÕÇ®èŒÇ¢ÇÆÇ≥Ç©
F, N, Hé–ǡǃǫDZÅH
é–ñºÇíÜìrîºí[Ç…ÇÌÇ©ÇËÇ…Ç≠Ç≠Ç∑ÇÈà”ñ°ÇÝÇÈÇÃÅH
é–ñºÇíÜìrîºí[Ç…ÇÌÇ©ÇËÇ…Ç≠Ç≠Ç∑ÇÈà”ñ°ÇÝÇÈÇÃÅH
2ÇøÇ·ÇÒÉjÉÖÅ[ÉXî¬Ç‚ÉÑÉtÅ[ÉjÉÖÅ[ÉXå©ÇÈÇ∆ǩǬǃǻǢǟǫÇÃê®Ç¢Ç≈óùå§Ç™Ç‘Ç¡í@Ç©ÇÍÇ∆ÇÈÇ»Å[
>>75
åæÇ¡ÇøÇ·ÇÌÇÈǢǙǪÇÍÇ≈ï™Ç©ÇÁǻǢǻÇÁDZÇÃï™ñÏÇ…ÇÝÇÐÇËÇ…ÇýëaÇ∑ǨÅB
â¥Ç∂ǷǻǢÇØÇ«ëÂêlÇÃîzó∂Ç≈ó™ÇµÇΩDZÇ∆Çà´Ç≠ǢǧÇÃÇÕǫǧǩÇ∆évǧÇ∫ÅB
åæÇ¡ÇøÇ·ÇÌÇÈǢǙǪÇÍÇ≈ï™Ç©ÇÁǻǢǻÇÁDZÇÃï™ñÏÇ…ÇÝÇÐÇËÇ…ÇýëaÇ∑ǨÅB
â¥Ç∂ǷǻǢÇØÇ«ëÂêlÇÃîzó∂Ç≈ó™ÇµÇΩDZÇ∆Çà´Ç≠ǢǧÇÃÇÕǫǧǩÇ∆évǧÇ∫ÅB
>>75
çëìýÇ≈ÉÅÉCÉìÉtÉåÅ[ÉÄǂǡǃÇÈÅiǂǡǃÇΩÅjëÂéËäÈã∆ǡǃÉCÉjÉVÉÉÉãÇ…îÌÇËÇ™ñ≥ǢǩÇÁ
ïÅí ÇÕÉCÉjÉVÉÉÉãÇ≈îªÇÈÇÒÇæǙǻ
ttp://ja.wikipedia.org/wiki/%E4%B8%89%E5%A4%A7%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF%E3%83%BC%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97
çëìýÇ≈ÉÅÉCÉìÉtÉåÅ[ÉÄǂǡǃÇÈÅiǂǡǃÇΩÅjëÂéËäÈã∆ǡǃÉCÉjÉVÉÉÉãÇ…îÌÇËÇ™ñ≥ǢǩÇÁ
ïÅí ÇÕÉCÉjÉVÉÉÉãÇ≈îªÇÈÇÒÇæǙǻ
ttp://ja.wikipedia.org/wiki/%E4%B8%89%E5%A4%A7%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF%E3%83%BC%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97
ëÂêlÇÃîzó∂ǡǃâΩÅH
ïÅí ÇÕÉCÉjÉVÉÉÉãÇ≈ÇÌÇ©ÇÈÇÒÇæÇÎÅH
Ç∂Ç·ÇÝÉCÉjÉVÉÉÉãåæÇ¡ÇøÇ·ÇæÇþÇ∂Ç·ÇÀÅH
ïÅí ÇÕÉCÉjÉVÉÉÉãÇ≈ÇÌÇ©ÇÈÇÒÇæÇÎÅH
Ç∂Ç·ÇÝÉCÉjÉVÉÉÉãåæÇ¡ÇøÇ·ÇæÇþÇ∂Ç·ÇÀÅH
ÉCÉjÉVÉÉÉãâ]ÅXÇÕìýóeÇ∆ä÷åWǻǢǵÅAÇ®ÇÐǶÇÁï DžǫǧÇ≈ÇýǢǢÇæÇÎw
ëÂêlÇÃîzó∂ǡǃÇÃÇÕÉÇÉUÉCÉNÇðÇΩǢǻï®ÇæÇ»ÅB
òIçúÇ∂ǷǻǢÇ≠ÇÁÇ¢ÅAà”ñ°ÇµÇ©Ç»Ç¢ÅB
ǬǩìÀÇ¡çûÇðǫDZÇÎÇÕñ{ëËÇ∂Ç·Ç»Ç≠ǃǪDZǩÇÊÇó
ÇÕÇÕÇÒÅAä÷åWé“ÇÃçHçÏàıÇ™òbëËîΩÇÁǪǧÇ∆ǵǃÇÈÇ»∆‘∆‘Ç»ÇÒǬǡǃÅA
”œ¥ÇÕçHçÏàıñ¢ñûÇðÇΩÇ¢ÇæÇ©ÇÁǪÇÍÇÕǻǢǩÇó
òIçúÇ∂ǷǻǢÇ≠ÇÁÇ¢ÅAà”ñ°ÇµÇ©Ç»Ç¢ÅB
ǬǩìÀÇ¡çûÇðǫDZÇÎÇÕñ{ëËÇ∂Ç·Ç»Ç≠ǃǪDZǩÇÊÇó
ÇÕÇÕÇÒÅAä÷åWé“ÇÃçHçÏàıÇ™òbëËîΩÇÁǪǧÇ∆ǵǃÇÈÇ»∆‘∆‘Ç»ÇÒǬǡǃÅA
”œ¥ÇÕçHçÏàıñ¢ñûÇðÇΩÇ¢ÇæÇ©ÇÁǪÇÍÇÕǻǢǩÇó
ǪÇÍDžǵǃÇýÉ_ÉìÉSǡǃǻÇÒÇ≈ÇÝÇÒǻDžì™Ç™à´Ç¢ÇÒÇæÇÎǧ
ì‰Çæ
DZÇÃê¢ÇÃímìIê∂ñΩëÃÇ∆ÇÕÇ∆ǧǃǢévǶǻǢÅB
ì‰Çæ
DZÇÃê¢ÇÃímìIê∂ñΩëÃÇ∆ÇÕÇ∆ǧǃǢévǶǻǢÅB
ëÂêlÇÃîzó∂Ç≈ÇÕǻǢÇÌÇ»
ìTå^ìIÉLÉÇÉíÉ^ǡǃä¥Ç∂
ÉAÉCÉhÉãÉíÉ^Ç™AKBÇÃDZÇ∆AÉOÉãÅ[Év
SKEÇÃDZÇ∆SÉOÉãÅ[ÉvÇ∆Ç©åæǡǃÇΩÇÁÉLÉÇÇ¢Ç≈ǵÇÂ
í Ç∂ÇÈÇ∆Ç©í Ç∂ǻǢÇ∆ǩǡǃǢǧñ‚ëËÇ∂ǷǻǢ
ìTå^ìIÉLÉÇÉíÉ^ǡǃä¥Ç∂
ÉAÉCÉhÉãÉíÉ^Ç™AKBÇÃDZÇ∆AÉOÉãÅ[Év
SKEÇÃDZÇ∆SÉOÉãÅ[ÉvÇ∆Ç©åæǡǃÇΩÇÁÉLÉÇÇ¢Ç≈ǵÇÂ
í Ç∂ÇÈÇ∆Ç©í Ç∂ǻǢÇ∆ǩǡǃǢǧñ‚ëËÇ∂ǷǻǢ
äJî≠ÉTÉCÉNÉãÇ™10îNÇ»ÇÃÇÕÇÐÇ∏Ç¢ÇÊÇ»Çü
ÉRÉìÉsÉÖÅ[É^ÇÕí¬ïÖâªÇ™ëÅǢǩÇÁîÑÇÍÇÈÇÃÇÕî≠îÑÇ©ÇÁÇπÇ¢Ç∫Ç¢3îNÇÃä‘Ç≈ÅA
7îNä‘ÇÕîÑÇÈÇýÇÃÇ™âΩÇýǻǢèÛãµÇ…ǻǡǃǵÇÐǧ
ÉRÉìÉsÉÖÅ[É^ÇÕí¬ïÖâªÇ™ëÅǢǩÇÁîÑÇÍÇÈÇÃÇÕî≠îÑÇ©ÇÁÇπÇ¢Ç∫Ç¢3îNÇÃä‘Ç≈ÅA
7îNä‘ÇÕîÑÇÈÇýÇÃÇ™âΩÇýǻǢèÛãµÇ…ǻǡǃǵÇÐǧ
ǪǧǢǧòbëËÇÕǫDZǩó]èäÇ≈Ç‚ÇÍÇÊ
Aé–ÇæÇØÇÕãñÇπÇÈÇØÇ«Ç»
Intelé–ìýÇ≈Aé–ǙǫǧÇÃDZǧǡǃǢǧãLéñÇ™ÇÝÇ¡ÇΩÇ©ÇÁÇ≥
Intelé–ìýÇ≈Aé–ǙǫǧÇÃDZǧǡǃǢǧãLéñÇ™ÇÝÇ¡ÇΩÇ©ÇÁÇ≥
ÉLÉÇÉíÉ^Ç™ÉLÉÇÉíÉ^Çí@Ç≠ÇÃê}
ç°Ç∆êÃÇ≈ÇÕAÇÃà”ñ°Ç™à·Ç¡ÇƒÇÈǡǃǂǬǩÇó
Ç»ÇÒǩDZÇÃìWäJÇðÇÈÇ»ÇËÅAñ{ìñÇ…óòäQä÷åWé“Ç™
ÉXÉåó¨ÇªÇ§Ç∆ǵǃǢÇÈÇðÇΩÇ¢ÇæǺw ǢǴǻÇËèëÇ´çûÇðÇ™ëùǶÇΩÅBÉIÉåÉÇÉiÅ[ÅB
ÉXÉåó¨ÇªÇ§Ç∆ǵǃǢÇÈÇðÇΩÇ¢ÇæǺw ǢǴǻÇËèëÇ´çûÇðÇ™ëùǶÇΩÅBÉIÉåÉÇÉiÅ[ÅB
>>90
ê¿Ç¡ÇƒÇÊǵÅBÇ–Ç∆ÇËÇ≈ÅAǩǬèüéËÇ…ÅB
ê¿Ç¡ÇƒÇÊǵÅBÇ–Ç∆ÇËÇ≈ÅAǩǬèüéËÇ…ÅB
ÉWÉáÅ[ÉXÉ^Å[ãMólå©ÇƒÇ¢ÇÈÇ»
íNÇýégÇ¡ÇΩDZÇ∆ǙǻǢêÍópÉnÅ[ÉhÇãýÇégǡǃäJî≠Ç∑ÇÈ
íNÇýÇ™égÇ¡ÇΩDZÇ∆ÇÃÇÝÇÈÉnÅ[ÉhÇëgÇðçáÇÌÇπÇÈ
ÇÐÇüÅAàÍî êlÇ…ÇÕamazon,googleÇÃÉTÅ[ÉoÅ[ÉTÅ[ÉrÉXÇÃï˚Ç™èdóvÇ»ÇÒÇ≈
çëÉvÉçÇ∆ǩǫǧÇ≈ÇýǢǢǡÇøÇ·
ǢǢ
íNÇýÇ™égÇ¡ÇΩDZÇ∆ÇÃÇÝÇÈÉnÅ[ÉhÇëgÇðçáÇÌÇπÇÈ
ÇÐÇüÅAàÍî êlÇ…ÇÕamazon,googleÇÃÉTÅ[ÉoÅ[ÉTÅ[ÉrÉXÇÃï˚Ç™èdóvÇ»ÇÒÇ≈
çëÉvÉçÇ∆ǩǫǧÇ≈ÇýǢǢǡÇøÇ·
ǢǢ
ñTäœé“Ç∆ǵǃÇÕÅAâΩÇ©Ç‘Ç¡îÚÇÒÇæDZÇ∆ǵǃÇ≠ÇÍÇΩǟǧǙñ îíÇ¢
ê≈ãýÇæÇ∆Ç©åæǡǃÇýàÍêlìñÇΩÇËÇ∆çlǶÇÍÇŒè\ï™ãñóeîÕàÕ
ê≈ãýÇæÇ∆Ç©åæǡǃÇýàÍêlìñÇΩÇËÇ∆çlǶÇÍÇŒè\ï™ãñóeîÕàÕ
IntelÇ™1é–ÇæÇØÇ≈7nmÇÐÇ≈Ç¢ÇØÇÈÇ∆ǵǃÇý
14nmÅA10nmÅA7nmÇ∆ä˘Ç…ÇÝÇ∆3ê¢ë„ǵǩǻǢ
14nmÅA10nmÅA7nmÇ∆ä˘Ç…ÇÝÇ∆3ê¢ë„ǵǩǻǢ
DZÇÒÇ»ÇÃÇýÇÝÇÈÇÀ
ÉJÅ[É{ÉìÉiÉmÉ`ÉÖÅ[ÉuÇ©ÇÁê∂ÇÐÇÍÇΩÉvÉçÉZÉbÉTÅAìÆçÏÇ…ê¨å˜
http://eetimes.jp/ee/articles/1310/09/news053.html
âpçëê≠ï{ÇÁÇ™ÅAÉOÉâÉtÉFÉìÇÃå§ãÜ/äJî≠Ç…120â≠â~à»è„Çìäéë
http://eetimes.jp/ee/articles/1301/30/news046.html
ã¡àŸÇÃëfçÞÉOÉâÉtÉFÉìÅFê¨å˜Ç÷ÇÃìπÇÃÇËÇÕÅH
http://wired.jp/2013/09/05/graphene-2/
ÉJÅ[É{ÉìÉiÉmÉ`ÉÖÅ[ÉuÇ©ÇÁê∂ÇÐÇÍÇΩÉvÉçÉZÉbÉTÅAìÆçÏÇ…ê¨å˜
http://eetimes.jp/ee/articles/1310/09/news053.html
âpçëê≠ï{ÇÁÇ™ÅAÉOÉâÉtÉFÉìÇÃå§ãÜ/äJî≠Ç…120â≠â~à»è„Çìäéë
http://eetimes.jp/ee/articles/1301/30/news046.html
ã¡àŸÇÃëfçÞÉOÉâÉtÉFÉìÅFê¨å˜Ç÷ÇÃìπÇÃÇËÇÕÅH
http://wired.jp/2013/09/05/graphene-2/
Ǫǧévǧ/ǪǧévÇÌǻǢÇÃÉ|É`êîÇå©ÇÈÇ…ÉlÉbÉgñØäEåGÇÕ
à≥ì|ìIÇ…Åuóùå§Ç»ÇÒǃí◊ÇÍǃǵÇÐǶÅIÅvÇðÇΩǢǻãÛãCDžǻǡÇ∆ÇÈ
óùå§Ç≥ÇÒëÂè‰ïvÇ©Å`ÅH ǮǢ
ÇrÇsÇ`Çoò_ï∂Å@êMópé∏íƒÅAâ»äwéjÇ…écÇÈâòì_
http://headlines.yahoo.co.jp/hl?a=20140402-00000080-san-soci
ÇrÇsÇ`Çoò_ï∂ç≈èIïÒçêÅ@äjêSÅuùsë¢ÅvÇ∏Ç≥ÇÒå§ãÜ
http://headlines.yahoo.co.jp/hl?a=20140402-00000085-san-soci
ìDè¿Å@è¨ï€ï˚ÇuÇrÅDóùå§Å@íàÇ…ïÇÇ≠ÇrÇsÇ`ÇoÅ@Åuïsê≥ÇÕè¨ï€ï˚Ç≥ÇÒÇPêlÅvÅ@Å@
http://headlines.yahoo.co.jp/hl?a=20140402-00000089-san-soci
ÇrÇsÇ`Çoç≈èIïÒçêÅ@ì¡íËñ@êléwíËêÊëóÇË
http://headlines.yahoo.co.jp/hl?a=20140402-00000087-san-pol
Åuóùå§ëgêDÇÃê”îCñ‚ǶÅvÅ@ï∫å…ÇÃå§ãÜé“
http://headlines.yahoo.co.jp/hl?a=20140402-00000002-kobenext-sctch
à≥ì|ìIÇ…Åuóùå§Ç»ÇÒǃí◊ÇÍǃǵÇÐǶÅIÅvÇðÇΩǢǻãÛãCDžǻǡÇ∆ÇÈ
óùå§Ç≥ÇÒëÂè‰ïvÇ©Å`ÅH ǮǢ
ÇrÇsÇ`Çoò_ï∂Å@êMópé∏íƒÅAâ»äwéjÇ…écÇÈâòì_
http://headlines.yahoo.co.jp/hl?a=20140402-00000080-san-soci
ÇrÇsÇ`Çoò_ï∂ç≈èIïÒçêÅ@äjêSÅuùsë¢ÅvÇ∏Ç≥ÇÒå§ãÜ
http://headlines.yahoo.co.jp/hl?a=20140402-00000085-san-soci
ìDè¿Å@è¨ï€ï˚ÇuÇrÅDóùå§Å@íàÇ…ïÇÇ≠ÇrÇsÇ`ÇoÅ@Åuïsê≥ÇÕè¨ï€ï˚Ç≥ÇÒÇPêlÅvÅ@Å@
http://headlines.yahoo.co.jp/hl?a=20140402-00000089-san-soci
ÇrÇsÇ`Çoç≈èIïÒçêÅ@ì¡íËñ@êléwíËêÊëóÇË
http://headlines.yahoo.co.jp/hl?a=20140402-00000087-san-pol
Åuóùå§ëgêDÇÃê”îCñ‚ǶÅvÅ@ï∫å…ÇÃå§ãÜé“
http://headlines.yahoo.co.jp/hl?a=20140402-00000002-kobenext-sctch
óùå§ÉlÉ^ÇÕëºèäÇ≈ǂǡǃÇ≠ÇÍÅB
IntelÇÃÇÊǧǻã≠Ç¢äÈã∆ÇÕÅAâΩÇ©ëÂÇ´Ç»é∏îsÇǵÇΩÇÁê”îCÇéÊÇÁÇπÇÈDZÇ∆Çý
ÇýÇøÇÎÇÒǂǡǃÇÈÇ™ÅAìñéñé“ÇÃê”îCÇæÇØÇ≈ÇÕÇ»Ç≠ÅA
é∏îsÇ™î≠ê∂Ç∑ÇÈédëgÇðÇÃï™êÕÇ∆îrèúÇ™è„éËÇ¢ÇÒÇ∂ǷǻǢǩǻÅB
à„ó√âþåÎÇÃñ‚ëËÇ≈ÇýÅAåµî±âªÇÕî±âÒîñ⁄ìIÇ≈òcÇÒÇæïÒçêÇ™ëùǶÇÈÅAÇ∆ǵǃ
î±ã≠âªÇÕÇπÇ∏ÅAï™êÕÇ…éëÇ∑ÇÈòcÇÐǻǢéñé¿ÇÃé˚èWÇ…óÕÇì¸ÇÍǃëOêiǵÇΩÅB
ê”îCé“ǬÇÈǵÇÝÇ∞ǵǩǂÇÁǻǢï∂âªÇÃínàÊÇÕâ¸ëPÇ™íxÇ¢ÅB
ÇýÇøÇÎÇÒǂǡǃÇÈÇ™ÅAìñéñé“ÇÃê”îCÇæÇØÇ≈ÇÕÇ»Ç≠ÅA
é∏îsÇ™î≠ê∂Ç∑ÇÈédëgÇðÇÃï™êÕÇ∆îrèúÇ™è„éËÇ¢ÇÒÇ∂ǷǻǢǩǻÅB
à„ó√âþåÎÇÃñ‚ëËÇ≈ÇýÅAåµî±âªÇÕî±âÒîñ⁄ìIÇ≈òcÇÒÇæïÒçêÇ™ëùǶÇÈÅAÇ∆ǵǃ
î±ã≠âªÇÕÇπÇ∏ÅAï™êÕÇ…éëÇ∑ÇÈòcÇÐǻǢéñé¿ÇÃé˚èWÇ…óÕÇì¸ÇÍǃëOêiǵÇΩÅB
ê”îCé“ǬÇÈǵÇÝÇ∞ǵǩǂÇÁǻǢï∂âªÇÃínàÊÇÕâ¸ëPÇ™íxÇ¢ÅB
è¨ï€ï˚ÇÃÇðÇ»ÇÁÇ∏óùå§ÇýÇÎÇ∆ÇýìÞóéÇÃíÍÇ÷ìÀÇ´óéÇ∆ǪǧÇ∆Ç∑ÇÈïÒìπÇ™äàî≠DžǻǡǃǴÇΩÇ»Çó
ì¡Ç…STAPç◊ñEçƒåªê¨å˜ÉlÉ^(åãâ ìIÇ…ãïç\)ÇÉXÉbÉpî≤Ç´ÅAè¨ï€ï˚ÇéùÇøè„Ç∞ǃǴÇΩéYåoêVï∑Ç™çìÇ¢ÇóÇó
ÅgäyâÄÅhóùå§Ç…óíÅ@Åuå§ãÜã@ä÷ç≈çÇïÙÅvàÍì]ÅAÅuÇrÇsÇ`ÇoÅvà»äOÇ…Çýã^ñ‚ÇÃê∫
éYåoêVï∑ 4åé2ì˙ 15éû10ï™îzêM
ÅÑóùå§Ç…Ç∆ǡǃç°âÒÇÃñ‚ëËÇÕëÂÇ´Ç»É_ÉÅÅ[ÉWDžǻǡǃǢÇÈÅBä÷åWé“Ç…ÇÊÇÈÇ∆ÅAâeãøÇÕÇrÇsÇ`Çoç◊ñEà»äOÇÃå§ãÜÇ…ÇýãyÇÒÇ≈Ç¢ÇÈÇ∆ǢǧÅB
ÅÑÇÝÇÈóùå§ä÷åWé“ÇÕÅuç≈ãþDžǻǡǃÅAÇrÇsÇ`Çoç◊ñEà»äOÇÃå§ãÜÇ…ÇýÅwÇÝÇÃå§ãÜÇÕǮǩǵǢÇÃÇ≈ÇÕÅBÇ´ÇøÇÒÇ∆åüèÿǵÇΩï˚ǙǢǢÅx
ÅÑÇ∆ǢǡÇΩéwìEÇéÛÇØÇÈÇÊǧDžǻǡÇΩÅBDZÇÍÇÐÇ≈ÇÕóùå§ÇÃî≠ï\Ç∆ǢǧÇæÇØÇ≈êMóäÇ≥ÇÍǃǢÇΩÇÃÇ…ÅvÇ∆ë≈ÇøñæÇØÇÈÅB
ÅÑésñØÇ©ÇÁÇÃî·îªÇýëäéüǨÅAÇRåéà»ç~ÅAñÒÇTÇOÇOåèÇÃÉÅÅ[ÉãÇ™äÒÇπÇÁÇÍÅAìdòbÇýéEìûÅBëÂîºÇ™î·îªìIÇæÅB
ì¡Ç…STAPç◊ñEçƒåªê¨å˜ÉlÉ^(åãâ ìIÇ…ãïç\)ÇÉXÉbÉpî≤Ç´ÅAè¨ï€ï˚ÇéùÇøè„Ç∞ǃǴÇΩéYåoêVï∑Ç™çìÇ¢ÇóÇó
ÅgäyâÄÅhóùå§Ç…óíÅ@Åuå§ãÜã@ä÷ç≈çÇïÙÅvàÍì]ÅAÅuÇrÇsÇ`ÇoÅvà»äOÇ…Çýã^ñ‚ÇÃê∫
éYåoêVï∑ 4åé2ì˙ 15éû10ï™îzêM
ÅÑóùå§Ç…Ç∆ǡǃç°âÒÇÃñ‚ëËÇÕëÂÇ´Ç»É_ÉÅÅ[ÉWDžǻǡǃǢÇÈÅBä÷åWé“Ç…ÇÊÇÈÇ∆ÅAâeãøÇÕÇrÇsÇ`Çoç◊ñEà»äOÇÃå§ãÜÇ…ÇýãyÇÒÇ≈Ç¢ÇÈÇ∆ǢǧÅB
ÅÑÇÝÇÈóùå§ä÷åWé“ÇÕÅuç≈ãþDžǻǡǃÅAÇrÇsÇ`Çoç◊ñEà»äOÇÃå§ãÜÇ…ÇýÅwÇÝÇÃå§ãÜÇÕǮǩǵǢÇÃÇ≈ÇÕÅBÇ´ÇøÇÒÇ∆åüèÿǵÇΩï˚ǙǢǢÅx
ÅÑÇ∆ǢǡÇΩéwìEÇéÛÇØÇÈÇÊǧDžǻǡÇΩÅBDZÇÍÇÐÇ≈ÇÕóùå§ÇÃî≠ï\Ç∆ǢǧÇæÇØÇ≈êMóäÇ≥ÇÍǃǢÇΩÇÃÇ…ÅvÇ∆ë≈ÇøñæÇØÇÈÅB
ÅÑésñØÇ©ÇÁÇÃî·îªÇýëäéüǨÅAÇRåéà»ç~ÅAñÒÇTÇOÇOåèÇÃÉÅÅ[ÉãÇ™äÒÇπÇÁÇÍÅAìdòbÇýéEìûÅBëÂîºÇ™î·îªìIÇæÅB
ãûÇý≤◊»ÅB
ãûÇ≈åvéZǵÇΩåãâ ÇýëSïîåüèÿǵǻǮÇπÅI
ÇÌÇ©ÇþÇýêÖÇ≈ÇýÇ«ÇπÅI
106 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/02(êÖ) 21:48:58.46 ID:mdrpaETE
SimulationÇÉVÉÖÉ~ÉåÅ[ÉVÉáÉìǡǃèëÇ≠ÇÃÇÕâΩÇÃéÔñ°ÉåÅ[ÉVÉáÉìÅH
107 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/02(êÖ) 22:24:20.67 ID:mdrpaETE
è¨ï€âÕìýéÁéqÇ≥ÇÒÇÃà´å˚njǡǩÇËåæǧǻÇÊ
DZÇÃÉXÉåÇ≈ÇÕòbëËÇ…Ç»ÇÁǻǢÇQë„ñ⁄ínãÖÉVÉ~ÉÖÉåÅ[É^Ç™ÅAǻDžÇ∞Ç…ÇΩÇ≠Ç≥ÇÒóòópÇ≥ÇÍǃëÂÇ´Ç»ê¨â Çè„Ç∞ǃÇÈDZÇ∆Ç©ÇÁǵǃÅA
ãûÇýÇQë„ñ⁄Ç…ì¸Ç¡Çƒíçñ⁄Ç≥ÇÍÇ»Ç≠ǻǡÇΩDZÇÎÇ…ëÂÇ´Ç»ê¨â Çè„Ç∞ǃǪǧ
ãûÇýÇQë„ñ⁄Ç…ì¸Ç¡Çƒíçñ⁄Ç≥ÇÍÇ»Ç≠ǻǡÇΩDZÇÎÇ…ëÂÇ´Ç»ê¨â Çè„Ç∞ǃǪǧ
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇÕè≠Ç»Ç≠Ç∆ÇýãûÇÊÇËñ⁄ìIÇýÇÕÇ¡Ç´ÇËǵǃǢÇΩǵÅAå≥Ç©ÇÁí@Ç©ÇÍǃǻǢǩÇÁÇÀÅB
âΩÇ≈ÇýÇ©ÇÒÇ≈Çýà≈â_í@ǢǃǢÇÈÇÌÇØÇ∂Ç·ÇÝÇËÇÐÇπÇÒÅB
ãûÇÕåvâÊÇ™ã∂Ç¢ÇÐÇ≠ǡǃǃÅAéñã∆édï™ÇØà»ëOÇ©ÇÁÇ∏Ç¡Ç∆í@Ç©ÇÍÇÐÇ≠ÇËÅB
âΩÇ≈ÇýÇ©ÇÒÇ≈Çýà≈â_í@ǢǃǢÇÈÇÌÇØÇ∂Ç·ÇÝÇËÇÐÇπÇÒÅB
ãûÇÕåvâÊÇ™ã∂Ç¢ÇÐÇ≠ǡǃǃÅAéñã∆édï™ÇØà»ëOÇ©ÇÁÇ∏Ç¡Ç∆í@Ç©ÇÍÇÐÇ≠ÇËÅB
>>101
ÉGÉvÉäÉãÉtÅ[ÉãÇ…íÞÇÁÇÍÇΩéYåoç’ÇËäJç√íÜÅI
http://maguro.2ch.net/test/read.cgi/poverty/1396452809/
http://ai.2ch.net/test/read.cgi/newsplus/1396451556/
ÉGÉvÉäÉãÉtÅ[ÉãÇ…íÞÇÁÇÍÇΩéYåoç’ÇËäJç√íÜÅI
http://maguro.2ch.net/test/read.cgi/poverty/1396452809/
http://ai.2ch.net/test/read.cgi/newsplus/1396451556/
ínãÖÉVÉ~ÉÖÉåÅ[É^Å[ÇÕëäëŒìIÇ…ãKñÕÇ™è¨Ç≥Ç≠ǻǡǃǵÇÐÇ¡ÇΩÇ™éøÇÕ>15 >36ÇÝÇΩÇËÇ∆ÇÕ
äiÇ™à·Ç§ÅBç°Ç≈ÇýópìréüëÊÇ≈äàñÙÇ≈Ç´ÇÈÇÃÇÕìñëRÇ∆ǢǶnjìñëRÅB
DZDZÇÐÇ≈ÇÃéøÇÃÉVÉXÉeÉÄÅAÇ∆ǢǧèåèÇǬÇØÇÍÇŒç°Ç≈Çýê¢äEç≈ëÂ
ES2 2008
Å@2.5Byte/FLOPÅ@Åi102.4GFLOPS 256GB/sÅj
Å@0.078Byte/FLOPÅ@Åi819.2GFLOPS 64GB/sÅj
äiÇ™à·Ç§ÅBç°Ç≈ÇýópìréüëÊÇ≈äàñÙÇ≈Ç´ÇÈÇÃÇÕìñëRÇ∆ǢǶnjìñëRÅB
DZDZÇÐÇ≈ÇÃéøÇÃÉVÉXÉeÉÄÅAÇ∆ǢǧèåèÇǬÇØÇÍÇŒç°Ç≈Çýê¢äEç≈ëÂ
ES2 2008
Å@2.5Byte/FLOPÅ@Åi102.4GFLOPS 256GB/sÅj
Å@0.078Byte/FLOPÅ@Åi819.2GFLOPS 64GB/sÅj
http://ja.wikipedia.org/wiki/%E4%BA%AC_(%E3%82%B9%E3%83%BC%E3%83%91%E3%83%BC%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF)
>óùâªäwå§ãÜèäÇ™äJî≠ìríÜÇ≈ìPëÞǵÇΩNECÇ…ëŒÇµÇƒ70â≠â~ÇÃëπäQîÖèûÇãÅÇþǃãNDZǵǃǢÇΩçŸîªÇ…ëŒÇµÇƒÅANECÇ™óùâªäwå§ãÜèäÇ…2â≠â~ï•Ç§Ç±Ç∆Ç≈òaâǵÇΩ
Ç»ÇÒÇ©ÅADZÇÃÇ÷ÇÒÇÃëiè◊ÇÃëŒâûóÕÇÃÇ»Ç≥Ç∆Ç©ÅAç°êUÇËï‘ÇÍÇŒSTAPÇ…í Ç∂ÇÈÇýÇÃÇ™ÇÝÇÈÇ»ÇÝ
Ç‚Ç¡ÇœÇËóùå§ÇÕÉvÉçÉWÉFÉNÉgÇÃä«óùëÃêßÇ™ä√Ç¢ÇÒÇ∂ǷǻǢÇæÇÎǧǩÅcÅB
>óùâªäwå§ãÜèäÇ™äJî≠ìríÜÇ≈ìPëÞǵÇΩNECÇ…ëŒÇµÇƒ70â≠â~ÇÃëπäQîÖèûÇãÅÇþǃãNDZǵǃǢÇΩçŸîªÇ…ëŒÇµÇƒÅANECÇ™óùâªäwå§ãÜèäÇ…2â≠â~ï•Ç§Ç±Ç∆Ç≈òaâǵÇΩ
Ç»ÇÒÇ©ÅADZÇÃÇ÷ÇÒÇÃëiè◊ÇÃëŒâûóÕÇÃÇ»Ç≥Ç∆Ç©ÅAç°êUÇËï‘ÇÍÇŒSTAPÇ…í Ç∂ÇÈÇýÇÃÇ™ÇÝÇÈÇ»ÇÝ
Ç‚Ç¡ÇœÇËóùå§ÇÕÉvÉçÉWÉFÉNÉgÇÃä«óùëÃêßÇ™ä√Ç¢ÇÒÇ∂ǷǻǢÇæÇÎǧǩÅcÅB
ì˙ñ{Å@ÉvÉçÉWÉFÉNÉgÇ™é∏îsǵÇΩÇÁíSìñé“Çíðǵè„Ç∞
ÉAÉÅÉäÉJÅ@ÉvÉçÉWÉFÉNÉgÇ™é∏îsǵÇΩÇÁå¥àˆÇï™êÕÅAé∏îsǵǻǢÇÊǧDžÉ}ÉlÉWÉÅÉìÉgÇâ¸ó«
ÉAÉÅÉäÉJÅ@ÉvÉçÉWÉFÉNÉgÇ™é∏îsǵÇΩÇÁå¥àˆÇï™êÕÅAé∏îsǵǻǢÇÊǧDžÉ}ÉlÉWÉÅÉìÉgÇâ¸ó«
>>111
ÇÐÇÝç°Ç∆ÇÕÉÅÉÇÉäéñèÓÇýïœÇÌÇ¡ÇΩǵéûë„ê´à·Ç§Ç©ÇÁB/FÇç°çXî‰ärǵǃÇýÇÝÇÍÇ»ÇÒÇæÇ™ÅA
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇÕé¿ç€èoǃǵnjÇÁÇ≠ÇÕà≥ì|ìIÇæÇ¡ÇΩÇÀÅB
ÇÐÇÝç°Ç∆ÇÕÉÅÉÇÉäéñèÓÇýïœÇÌÇ¡ÇΩǵéûë„ê´à·Ç§Ç©ÇÁB/FÇç°çXî‰ärǵǃÇýÇÝÇÍÇ»ÇÒÇæÇ™ÅA
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇÕé¿ç€èoǃǵnjÇÁÇ≠ÇÕà≥ì|ìIÇæÇ¡ÇΩÇÀÅB
ç°âÒÇÃSTAPç◊ñEëõìÆÇ≈Åwïƒçëå§ãÜé“Ç™óùå§Çï÷óòÇ»çýïzÇ∆ǵǃóòópǵǃǢÇÈÅxÇ∆Ǣǧ
äjêSÇ÷êÿÇËçûÇýǧÇ∆Ç∑ÇÈÉÅÉfÉBÉAÇ™èoǃDZǻǢÇÝÇΩÇËÅAÉKÉbÉJÉää¥Ç≈ǢǡǜǢǂÇÌ
ì˙ñ{çëñØÇÃéëéYÇïƒçëÇ…å£è„Ç∑ÇÈÇ∆ǢǧàÍî‘åôÇ»ÉpÉ^Å[ÉìÇ»ÇÃÇ…
äjêSÇ÷êÿÇËçûÇýǧÇ∆Ç∑ÇÈÉÅÉfÉBÉAÇ™èoǃDZǻǢÇÝÇΩÇËÅAÉKÉbÉJÉää¥Ç≈ǢǡǜǢǂÇÌ
ì˙ñ{çëñØÇÃéëéYÇïƒçëÇ…å£è„Ç∑ÇÈÇ∆ǢǧàÍî‘åôÇ»ÉpÉ^Å[ÉìÇ»ÇÃÇ…
ïƒÇÃå§ãÜé“Ç™ãýåáÇ≈ÅAì˙ñ{ÇÃå§ãÜé“Çãýñ¨Ç∆ǵǃóòópǡǃâ]ÅXǡǃǂǬǩÅB
äjêSÇ∆Ǣǧǩïπçsǵǃ2ǬÇÃñ‚ëËÇ™ÇÝÇÈǧÇøÇÃÉoÉJÇ™ÇÁÇðÇÕÇýǧàÍï˚ÇæǻǡǃǩÇÒÇ∂ÇæÇ»ÅB
ÇÐÇÝÅAç°âÒÇÃéñåèÇÕñ{ìñÇÕëççáÇ∑ÇÈÇ∆ÉnÅ[ŸÅ[ÉhÇ‚WìcëÂÇÃï˚Ç™óùå§ÇÊÇËÇýçìǢǡǃÇÃÇÕéñé¿ÇæÇ»w
äjêSÇ∆Ǣǧǩïπçsǵǃ2ǬÇÃñ‚ëËÇ™ÇÝÇÈǧÇøÇÃÉoÉJÇ™ÇÁÇðÇÕÇýǧàÍï˚ÇæǻǡǃǩÇÒÇ∂ÇæÇ»ÅB
ÇÐÇÝÅAç°âÒÇÃéñåèÇÕñ{ìñÇÕëççáÇ∑ÇÈÇ∆ÉnÅ[ŸÅ[ÉhÇ‚WìcëÂÇÃï˚Ç™óùå§ÇÊÇËÇýçìǢǡǃÇÃÇÕéñé¿ÇæÇ»w
Åyë¨ïÒÅzMicrosoftÅAWindows 8.1 UpdateÇ4åé8ì˙Ç…åˆäJ
Å`ÉXÉ^Å[ÉgÉÅÉjÉÖÅ[Ç™ïúäàÅBMSDNÇ≈ÇÕñ{ì˙åˆäJ
http://pc.watch.impress.co.jp/docs/news/event/20140403_642651.html
Åyë¨ïÒÅzMicrosoftÅA9å^à»â∫ÇÃÉfÉoÉCÉXÇ…WindowsÇ…ñ≥èûâªÇî≠ï\
Å`Windows for IoTÇýî≠ï\
http://pc.watch.impress.co.jp/docs/news/event/20140403_642657.html
Å`ÉXÉ^Å[ÉgÉÅÉjÉÖÅ[Ç™ïúäàÅBMSDNÇ≈ÇÕñ{ì˙åˆäJ
http://pc.watch.impress.co.jp/docs/news/event/20140403_642651.html
Åyë¨ïÒÅzMicrosoftÅA9å^à»â∫ÇÃÉfÉoÉCÉXÇ…WindowsÇ…ñ≥èûâªÇî≠ï\
Å`Windows for IoTÇýî≠ï\
http://pc.watch.impress.co.jp/docs/news/event/20140403_642657.html
9å^à»â∫ñ≥èûǡǃǢǡǃÇýÅAëÂâÊñ èoóÕÇ∆Ç©Ç≈Ç´ÇÈã@î\ǬǢǃÇΩÇÁèúäOÇ»ÇÒÇæÇÎǧǻ
ÇÝÇ∆ÅA9å^à»â∫Ç≈Çýå¬êlÇ≈ÉCÉìÉXÉgÅ[ÉãÇ»èÍçáÇ…ÇÕñ≥èûDžǵǃÇ≠ÇÍǻǢÇÃÇýämîFǵǃǻǢÇØÇ«ÇŸÇ⁄ämé¿ÇæÇÎ
ÇÝÇ∆ÅA9å^à»â∫Ç≈Çýå¬êlÇ≈ÉCÉìÉXÉgÅ[ÉãÇ»èÍçáÇ…ÇÕñ≥èûDžǵǃÇ≠ÇÍǻǢÇÃÇýämîFǵǃǻǢÇØÇ«ÇŸÇ⁄ämé¿ÇæÇÎ
ǧÇøÇÃÉTÅ[ÉoÇýè¨Ç≥Ç¢ÉfÉBÉXÉvÉåÉCǬÇØÇÍÇŒñ≥èûÇ≈Ç∑Ç©ÇÀ
ÉåÉXÉäÅ[ÅEÉâÉìÉ|Å[ÉgÇ™É`ÉÖÅ[ÉäÉìÉOèÐ
ÉrÉUÉìÉ`Éìè´åRñ‚ëËǻǫï™éUÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÇÃêMóäê´Ç…ä÷Ç∑ÇÈ
çvå£Ç™éÛèÐóùóRÇÁǵǢÅBLaTeXÇ…ÇýåæãyÇ≥ÇÍǃǢÇÈÇ™
ǪÇÍÇÕóùóRÇ≈ÇÕǻǢÇÊǧÇæÅB
ttp://amturing.acm.org/award_winners/lamport_1205376.cfm
ÉrÉUÉìÉ`Éìè´åRñ‚ëËǻǫï™éUÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÇÃêMóäê´Ç…ä÷Ç∑ÇÈ
çvå£Ç™éÛèÐóùóRÇÁǵǢÅBLaTeXÇ…ÇýåæãyÇ≥ÇÍǃǢÇÈÇ™
ǪÇÍÇÕóùóRÇ≈ÇÕǻǢÇÊǧÇæÅB
ttp://amturing.acm.org/award_winners/lamport_1205376.cfm
121 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/03(ñÿ) 21:05:12.81 ID:y+bnAmCn
WindowsÇÃOEMî≈ÇÊÇËÉfÉBÉXÉvÉåÉCÇÃǟǧǙçÇÇ¢ÇÒÇ∂Ç·ÇÀÅ[ÇÃ
>>35
ÉEÉ`Ç…à¯Ç´éÊÇÁÇÍǃ1ë‰ÇÝÇÈÇ™ÅAÉzÉìÉgÇÊÇ≠Ç≈ǴǃÇÈÅB
ÉåÉWÉXÉ^Ç∆ÉAÉLÉÖÉÄÉåÅ[É^ÇÃä‘Ç≈ílÇëäåðÇ…à⁄ìÆÇ∑ÇÈã@ç\Çç≈ãþî≠å©ÇµÇƒã¡ú±ÇµÇΩÅB
ÉEÉ`Ç…à¯Ç´éÊÇÁÇÍǃ1ë‰ÇÝÇÈÇ™ÅAÉzÉìÉgÇÊÇ≠Ç≈ǴǃÇÈÅB
ÉåÉWÉXÉ^Ç∆ÉAÉLÉÖÉÄÉåÅ[É^ÇÃä‘Ç≈ílÇëäåðÇ…à⁄ìÆÇ∑ÇÈã@ç\Çç≈ãþî≠å©ÇµÇƒã¡ú±ÇµÇΩÅB
>>122
Ç∑Ç∞Å[ãªñ°ê[Ç¢Çó
Ç∑Ç∞Å[ãªñ°ê[Ç¢Çó
Ç∑ÇÆÇ…ãýÇ…Ç»ÇÈäÓëbå§ãÜǡǃÇÃÇ™ÇÝÇÈÇ∆Ç∑ÇÍÇŒëÂäÈã∆ǙǂǡǃÇÈÇÒÇæÇÊÇ»
125 ÅFSocket774ÅF2014/04/05(ìy) 21:04:14.69 ID:K8gbxpoe
ǢǩÇÒÇ≈ǵÇÂ
JAXAÅA3.4PFLOPSÇÃéüä˙ÉXÉpÉRÉìÇ…ïxémí êªïiÇçÃóp
http://pc.watch.impress.co.jp/docs/news/20140407_643087.html
http://pc.watch.impress.co.jp/docs/news/20140407_643087.html
>>126
DZÇÍÇ»ÇÒÇæÇÎǧǻ
ttp://news.mynavi.jp/column/sc13/007/
1TFLOPSÇÃÉmÅ[ÉhÇ™216Ç≈1ÉâÉbÉNÇ»ÇÁ16ÉâÉbÉNÇ≠ÇÁÇ¢ÇæÇ»
DZÇÍÇ»ÇÒÇæÇÎǧǻ
ttp://news.mynavi.jp/column/sc13/007/
1TFLOPSÇÃÉmÅ[ÉhÇ™216Ç≈1ÉâÉbÉNÇ»ÇÁ16ÉâÉbÉNÇ≠ÇÁÇ¢ÇæÇ»
128 ÅFSocket774ÅF2014/04/08(âŒ) 15:12:23.56 ID:joz1SuAQ
Ç‚Ç¡Çœì∆é©äJî≠ÇÕñ≥óùÇæÇ¡ÇΩ
http://pc.watch.impress.co.jp/docs/news/20140408_643256.html
Snapdragon 810ÇÕìØé–ÇÃç≈è„à ÉÇÉfÉãÅBCPUÇÕDZÇÍÇÐÇ≈ÇÃì∆é©ÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃKraitÇ≈ÇÕÇ»Ç≠ÅA
ÉNÉAÉbÉhÉRÉAÇÃCortex-A57Ç∆Cortex-A53ÇëgÇðçáÇÌÇπÇΩbig.LITTLEç\ê¨ÅBGPUÇ…Adreno 430ÇçÃópÅB
OpenGL ES 3.1ÇÉTÉ|Å[ÉgǵÅAÉeÉbÉZÉåÅ[ÉVÉáÉìÇ‚ÉWÉIÉÅÉgÉäÉVÉFÅ[É_ÅAÉvÉçÉOÉâÉ}ÉuÉãÉuÉåÉìÉfÉBÉìÉOÇ…ëŒâûÇ∑ÇÈÅB
è]óàÇÃAdreno 420Ç∆î‰ärÇ∑ÇÈÇ∆ÅAï`âÊê´î\ÇÕç≈ëÂ30%ÅAGPGPUÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOê´î\ÇÕ100%å¸è„ǵÅAè¡îÔìdóÕÇç≈ëÂ20%ó}ǶÇΩÅB
Snapdragon 808ÇÕ810ÇÃâ∫à ÉÇÉfÉãÇ≈ÅACPUÇÕCortex-A57ÇÃ2ÉRÉA+Cortex-A53ÇÃ4ÉRÉAÇÃ6ÉRÉAç\ê¨Ç∆Ç»ÇÈÅB
GPUÇÕAdreno 418ÇçÃópǵÅAOpenGL ES 3.1Ç‚ÉeÉbÉZÉåÅ[ÉVÉáÉìǻǫÇÃÉTÉ|Å[ÉgÇÕã§í ÇæÇ™ÅA
âëúìxÇÕ2,560Å~1,600ÉhÉbÉg(WQXGA)Ç™É^Å[ÉQÉbÉgÇ∆Ç»ÇÈÅBÉCÉÅÅ[ÉWÉVÉOÉiÉãÉvÉçÉZÉbÉTÇÕ12bitÇÃÉfÉÖÉAÉãç\ê¨ÅAÉÅÉÇÉäÇýLPDDR3ǻǫÇ∆Ç»ÇÈÅB
http://pc.watch.impress.co.jp/docs/news/20140408_643256.html
Snapdragon 810ÇÕìØé–ÇÃç≈è„à ÉÇÉfÉãÅBCPUÇÕDZÇÍÇÐÇ≈ÇÃì∆é©ÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃKraitÇ≈ÇÕÇ»Ç≠ÅA
ÉNÉAÉbÉhÉRÉAÇÃCortex-A57Ç∆Cortex-A53ÇëgÇðçáÇÌÇπÇΩbig.LITTLEç\ê¨ÅBGPUÇ…Adreno 430ÇçÃópÅB
OpenGL ES 3.1ÇÉTÉ|Å[ÉgǵÅAÉeÉbÉZÉåÅ[ÉVÉáÉìÇ‚ÉWÉIÉÅÉgÉäÉVÉFÅ[É_ÅAÉvÉçÉOÉâÉ}ÉuÉãÉuÉåÉìÉfÉBÉìÉOÇ…ëŒâûÇ∑ÇÈÅB
è]óàÇÃAdreno 420Ç∆î‰ärÇ∑ÇÈÇ∆ÅAï`âÊê´î\ÇÕç≈ëÂ30%ÅAGPGPUÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOê´î\ÇÕ100%å¸è„ǵÅAè¡îÔìdóÕÇç≈ëÂ20%ó}ǶÇΩÅB
Snapdragon 808ÇÕ810ÇÃâ∫à ÉÇÉfÉãÇ≈ÅACPUÇÕCortex-A57ÇÃ2ÉRÉA+Cortex-A53ÇÃ4ÉRÉAÇÃ6ÉRÉAç\ê¨Ç∆Ç»ÇÈÅB
GPUÇÕAdreno 418ÇçÃópǵÅAOpenGL ES 3.1Ç‚ÉeÉbÉZÉåÅ[ÉVÉáÉìǻǫÇÃÉTÉ|Å[ÉgÇÕã§í ÇæÇ™ÅA
âëúìxÇÕ2,560Å~1,600ÉhÉbÉg(WQXGA)Ç™É^Å[ÉQÉbÉgÇ∆Ç»ÇÈÅBÉCÉÅÅ[ÉWÉVÉOÉiÉãÉvÉçÉZÉbÉTÇÕ12bitÇÃÉfÉÖÉAÉãç\ê¨ÅAÉÅÉÇÉäÇýLPDDR3ǻǫÇ∆Ç»ÇÈÅB
ǪÇýǪÇýÉNÉAÉãÉRÉÄÇÃóDà ê´ÇÕCPUÉRÉAïîï™Ç…ÇÝÇÈÇÌÇØÇ∂ǷǻǢÇÃÇ≈ÅA
Ç◊ǬDžì∆é©äJî≠Ç≈ÇÝÇÈïKóvÇÕñ≥Ç¢
Ç◊ǬDžì∆é©äJî≠Ç≈ÇÝÇÈïKóvÇÕñ≥Ç¢
ïKóvÇ»ÇæÇØÇÃê´î\Ç™èoÇÈǡǃéñÇæÇÎǧǻÅAA57Ç∆Ç©Ç≈
É|Å[É^ÉuÉãÉfÉoÉCÉXópÇ∆ǵǃÇÕè\ï™Ç¡ÇƒÇ±Ç∆ÇæÇ»ÅB
ÇΩÇÒDžǬÇ≠ÇÍǻǩǡÇΩ
ǪÇÃÇÐÇÐç⁄ÇπÇÈÇæÇØÇ»ÇÁMediaTekÇ‚RockchipÅAAllwinnerÇ∆ÇÃã£ëàÇ™ë“ǡǃÇÈ
ÇÐÇÝAdrenoÇ™ÇÝÇÈÇ©ÇÁÇÐÇæëÂè‰ïvÇæÇØÇ«
ÇÐÇÝAdrenoÇ™ÇÝÇÈÇ©ÇÁÇÐÇæëÂè‰ïvÇæÇØÇ«
ÉJÉXÉ^ÉÄMPUÉÑÉãÇ∆ǵÇΩÇÁ
ã@î\ÉuÉçÉbÉNÇÃå¯ó¶ìIÇ»çƒîzíu
ÉåÉKÉVÅ[âÒòHÇÉKÉìÉKÉìçÌǡǃåyó âªÉ}ÉCÉNÉçÉRÅ[Éhâª
SIMDÇÃçÇë¨âª
ã@î\ÉuÉçÉbÉNÇÃå¯ó¶ìIÇ»çƒîzíu
ÉåÉKÉVÅ[âÒòHÇÉKÉìÉKÉìçÌǡǃåyó âªÉ}ÉCÉNÉçÉRÅ[Éhâª
SIMDÇÃçÇë¨âª
135 ÅFSocket774ÅF2014/04/09(êÖ) 14:31:15.92 ID:wEl2O+6m
èoóàÇ™ó«Ç≠ǃòMÇÈÇ∆DZñ≥Ç¢ÇÒÇæÇÎA57ÇÕ
ǪÇÍÇÊÇËÇÕAdrenoÇ∆ÉÇÉfÉÄÇ…ÉäÉ\Å[ÉXégÇ¡ÇΩï˚ǙǢǢ
ǪÇÍÇÊÇËÇÕAdrenoÇ∆ÉÇÉfÉÄÇ…ÉäÉ\Å[ÉXégÇ¡ÇΩï˚ǙǢǢ
136 ÅFSocket774ÅF2014/04/09(êÖ) 14:59:35.47 ID:gBy0vZBQ
qualcommÇÃÉÇÉfÉÄÇÕå≈íËã@î\ÇÃÇ©ÇΩÇÐÇËÇ≈
îÏëÂÇ∑ÇÈǢǡǀǧ
îÏëÂÇ∑ÇÈǢǡǀǧ
AdrenoÇ‚ÇþǃPowerVRÇ…Ç∑ÇÈÇ∆Ç©ï∑Ç¢ÇΩÇÒÇæÇ™ÉKÉZÅH
ì¡ãñÅAipǬǩǡǃÇý
ñºëOÇǩǶÇÈÇ∆ÇÕǩǨÇÁÇÒǵ
ñºëOÇǩǶÇÈÇ∆ÇÕǩǨÇÁÇÒǵ
FreescaleÇÃÉlÉbÉgÉèÅ[ÉNÉvÉçÉZÉbÉT ARM 64bit A57 x4ÅAx8
ttp://www.freescale.com/webapp/sps/site/prod_summary.jsp?code=LS2085A
ttp://www.freescale.com/webapp/sps/site/prod_summary.jsp?code=LS2085A
freescaleÇýíEPPCÇ≈Ç∑Ç©
PPCÇëÂÇ¡Ç“ÇÁÇ…égǧÇ∆DZÇÎÇÕîCìVì∞ÇæÇØÇ…Ç»ÇËǪǧÇæÇ»w
îCìVì∞Çýç≈ãþ
ÅuêòǶíuÇ´ã@Ç∆ågë—ã@ÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÇìùçáǵǃÉ\ÉtÉgÇÃäJî≠ä¬ã´ÇëµÇ¶ÇÈÅv
ǡǃåæǡǃÇÈÇ©ÇÁéüÇÕARMÇ©AMDÇ…Ç»ÇÈÇ©Ç∆
ÅuêòǶíuÇ´ã@Ç∆ågë—ã@ÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÇìùçáǵǃÉ\ÉtÉgÇÃäJî≠ä¬ã´ÇëµÇ¶ÇÈÅv
ǡǃåæǡǃÇÈÇ©ÇÁéüÇÕARMÇ©AMDÇ…Ç»ÇÈÇ©Ç∆
143 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/14(åé) 20:59:15.22 ID:WkuU2ztR
ågë—ã@Ç…AMDÇÕñ≥óùÇæÇÎ
AMDÇÃARMÇýÉTÅ[Éoå¸ÇØÇÁǵǢǵǻ
a57Ç≈ÇýqualcommÇÕågë—å¸ÇØ
ÅH
20nmÅ@4core+4coreÇæǵǻ
ÅH
20nmÅ@4core+4coreÇæǵǻ
PowerÇÃêVêðåvÇÕIBMÇÃÉÅÉCÉìÉtÉåÅ[ÉÄå¸ÇØÇæÇØÇ∆évǡǃÇΩÇ™
ê‚ëŒê´î\ÇýÉèÉbÉpÇýPPCÇÃè„Ç»ÇÃÇ…ÅcÅcÅEÅEÅE
ê‚ëŒê´î\ǧÇÒÇ ÇÒÇÊÇËÇý
Çýǧé©ï™Ç≈ÉRÉAçÏÇ¡ÇΩÇËÉRÉìÉpÉCÉâçÏÇ¡ÇΩÇËä¬ã´çÏÇ¡ÇΩÇËÇ∑ÇÈÇÃÇ™ÉÅÉìÉhÉEÇæÇ©ÇÁarmÇ»ÇÒÇæÇÎÅc
Çýǧé©ï™Ç≈ÉRÉAçÏÇ¡ÇΩÇËÉRÉìÉpÉCÉâçÏÇ¡ÇΩÇËä¬ã´çÏÇ¡ÇΩÇËÇ∑ÇÈÇÃÇ™ÉÅÉìÉhÉEÇæÇ©ÇÁarmÇ»ÇÒÇæÇÎÅc
ARMÇýÇΩǢǙǢÇæÇ™PPCÇÕǪÇÍà»è„Ç…ïœë‘Ç»Ç∆DZÇÎÇ™ÇÝÇÈ
MIPSÇ∂Ç·ÇæÇþÇ»ÇÒÇ≈Ç∑Ç©
MIPSÇ∂Ç·ÇæÇþÇ»ÇÒÇ≈Ç∑Ç©
mipsÇýè\ï™ïœë‘
ëfê´Ç™è„ïiÇ≈ÇýäJî≠ìäéëÇ™ïsè\ï™ÇæÇ∆ãtÇÃÇýÇÃÇ…åªï®Ç≈ïâÇØÇÈ
ïœë‘óvëfÇÕÉfÉBÉåÉCÉXÉçÉbÉgÇÆÇÁÇ¢ÇÃÇýÇÃÇ∂ǷǻǢǩ
ÇÝÇÝÅAâºëzãLâØÇýÇÝÇ¡ÇΩÇ©Ç»ÅcÅc
mipsÇÕÉtÉâÉOǙǻǢÇÃÇ≈ÉIÅ[ÉoÅ[ÉtÉçÅ[ÇÃàµÇ¢Ç…ç¢ÇÈí¥ïœë‘
armÇ»ÇÒǃǩÇÌǢǢÇýÇÒÇæ
armÇ»ÇÒǃǩÇÌǢǢÇýÇÒÇæ
MIPSÇÕÉRÉvÉçÉZÉbÉT0DžǬǻǙǡǃǢÇÈFPÉÜÉjÉbÉgÇ™ââéZíÜsubnormal numberÇ™èoǪǧDžǻÇÈÇ∆ÉAÉìÉ_Å[ÉtÉçÅ[ó·äOÇèoǵ
écÇËÇÃïÇìÆè¨êîââéZèàóùÇÕó·äOÉnÉìÉhÉâìýÇ≈É\ÉtÉgÉEÉFÉAââéZǵǃâ∫Ç≥Ç¢Ç∆Ǣǧsubnormal numberââéZÉnÅ[ÉhÉEÉFÉAè»ó™êðåvÇ™ÉGÉLÉTÉCÉeÉBÉìÉOÇæÇ¡ÇΩÅB
écÇËÇÃïÇìÆè¨êîââéZèàóùÇÕó·äOÉnÉìÉhÉâìýÇ≈É\ÉtÉgÉEÉFÉAââéZǵǃâ∫Ç≥Ç¢Ç∆Ǣǧsubnormal numberââéZÉnÅ[ÉhÉEÉFÉAè»ó™êðåvÇ™ÉGÉLÉTÉCÉeÉBÉìÉOÇæÇ¡ÇΩÅB
NECÇÃV80ÇÕî¸ÇµÇ¢ÇºÅB
>>155
alphaÇÃïÇìÆè¨êîì_ââéZÇÃó·äOÇ™íxÇÍÇÈÇÃÇ≈Ç≥Ç©ÇÃÇ⁄ǡǃÉÅÉìÉeÇ∑ÇÈÇÃÇÊÇËÉ}ÉV
alphaÇÃïÇìÆè¨êîì_ââéZÇÃó·äOÇ™íxÇÍÇÈÇÃÇ≈Ç≥Ç©ÇÃÇ⁄ǡǃÉÅÉìÉeÇ∑ÇÈÇÃÇÊÇËÉ}ÉV
ÇÐÇÝÅAÇ«ÇÃRISCånCPUÇýÅA64bitâªÇ…ÇÝÇΩǡǃÅA
ÉAÅ[ÉLÉeÉNÉ`ÉÉÇ‚ñΩóþÉZÉbÉgÇ™êÆóùÇ≥ÇÍǃÇÐÇ∆ÇýDžǻǡǃÇÈÇØÇ«ÇÀ
ÉAÅ[ÉLÉeÉNÉ`ÉÉÇ‚ñΩóþÉZÉbÉgÇ™êÆóùÇ≥ÇÍǃÇÐÇ∆ÇýDžǻǡǃÇÈÇØÇ«ÇÀ
PA-RISCÅEÅEÅE
SuperH!
ÉXÅ[ÉpÅ[Ç–ÇΩÇøÇ…64bitÇ∆Ç©ÇÝÇ¡ÇΩÇÃÇ©ÅB
ÇÞǩǵSH4Ç©âΩÇ©Çìãç⁄ǵÇΩNASÇ©âΩÇ©ÇÝÇ¡ÇΩÇÊÇ»ÅB
SHÇÃâhåıÇÇýǧàÍìx!
ÉEÉFÉAÉâÉuÉãí[ññÇ≈ä™Ç´ï‘ǵÅI
intel QuarkǻǫëäéËÇ≈ÇÕǻǩÇÎǧÅB
GPUÇÕPowerVRÇ©DMPÇÃÇÝÇÍÇ©...
SHÇÃâhåıÇÇýǧàÍìx!
ÉEÉFÉAÉâÉuÉãí[ññÇ≈ä™Ç´ï‘ǵÅI
intel QuarkǻǫëäéËÇ≈ÇÕǻǩÇÎǧÅB
GPUÇÕPowerVRÇ©DMPÇÃÇÝÇÍÇ©...
âøäiÅAê´î\ÅAè¡îÔìdóÕÅcÅAÇÝÇÁljÇÈäœì_Ç≈ã£çáêªïiÇ…äÆîsǵÇΩíNÇýîÉÇÌǻǢêªïiÇ™èoóàè„Ç™ÇÈÇ≈ǵÇÂǧÅB
165 ÅFSocket774ÅF2014/04/23(êÖ) 15:36:06.78 ID:u3V1c0Gb
MIPSÇÃ64bitǡǃç°Ç≈ÇýóòópÇ≥ÇÍǃÇÈÇÃÅH
>>164
Å`240MHzÅARXv2ÉRÉAÇÃRX700Ç∂Ç·ÅAåªçsÇÃSH4AÇ»ÇÒÇ©ÇÊÇ©à íuïtÇØÇýê´î\Çýâ∫ÇÃÉNÉâÉXÇ≈ǵÇÂÅB
Å`240MHzÅARXv2ÉRÉAÇÃRX700Ç∂Ç·ÅAåªçsÇÃSH4AÇ»ÇÒÇ©ÇÊÇ©à íuïtÇØÇýê´î\Çýâ∫ÇÃÉNÉâÉXÇ≈ǵÇÂÅB
167 ÅFSocket774ÅF2014/04/25(ãý) 12:21:00.68 ID:KNZnG6b0
http://news.mynavi.jp/news/2014/04/25/066/?gaibu=hon
IBMÅAÉRÉAÇÝÇΩÇËÇÃÉXÉåÉbÉhêîÇî{ëùÇ≥ÇπÇΩ22ÉiÉmÇÃÅuPOWER8Åv
IBMÅAÉRÉAÇÝÇΩÇËÇÃÉXÉåÉbÉhêîÇî{ëùÇ≥ÇπÇΩ22ÉiÉmÇÃÅuPOWER8Åv
168 ÅFSocket774ÅF2014/04/25(ãý) 12:25:19.08 ID:KNZnG6b0
http://cloud.watch.impress.co.jp/docs/news/20140425_646036.html
ì˙ñ{IBMÅAÅgí¥çÇë¨ÉvÉçÉZÉbÉTÅhPOWER8ìãç⁄ÉTÅ[ÉoÅ[ÅuPower System SÉNÉâÉXÅv
ì˙ñ{IBMÅAÅgí¥çÇë¨ÉvÉçÉZÉbÉTÅhPOWER8ìãç⁄ÉTÅ[ÉoÅ[ÅuPower System SÉNÉâÉXÅv
12ÉRÉAÇ©ÇÁÇ»Ç∫Ç©6ÉRÉA*2ÇÃMCMÇ…ÅH
íPèÉÇ…çlǶÇΩÇÁïýóØÇÐÇËÇ©Ç»ÅH
Core i7 ǻǫêVïiCPUÇ≈WindowsÇí Ç≥ǻǢÇ≈íºê⁄ÉnÅ[ÉhÇêßå‰Ç∑ÇÈÇÃÇÌÇ«Å[Ç∑ÇÍÇŒ
É\Å[ÉXÉRÅ[ÉhÇ™åˆäJÇ≥ÇÍǃÇÈOSÇÃkernelÇâ¸ïœÇ∑ÇÈÇÃÇ™ä»íP
ÉRÉAìñÇΩÇËL2 2MBÇ∆Ç©êœÇÒÇ≈Ç≠ÇÈÇ©Ç∆évǡǃÇΩÇÌ
IBM POWERÇ»ÇÁ
IBM POWERÇ»ÇÁ
22nmÉvÉçÉZÉXÇÃó éYÇÕIntelà»äOÇ≈ÇÕÇ∂ÇþǃÇ∂ǷǻǢǩÅH
SMTÇ≈8wayǡǃÇÃÇÕÇýÇÃÇ∑Ç≤ǢǙÅAÉTÅ[ÉoÉèÅ[ÉNÉçÅ[ÉhÇ≈ÇÕóLå¯Ç…ìÆÇ≠ǡǃéñÇ»ÇÒÇæÇÎǧǩÇÀ
IntelÇýè´óàìIÇ…í«è]Ç∑ÇÈÇÃÇæÇÎǧǩ
IntelÇýè´óàìIÇ…í«è]Ç∑ÇÈÇÃÇæÇÎǧǩ
176 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/04/25(ãý) 21:49:39.61 ID:+A7B6g4Z
POWERÇÕRISCÇæÇ©ÇÁÉVÉìÉOÉãÉXÉåÉbÉhê´î\ÇÇÝÇ∞ÇÈÇΩÇþÇ…
ÉpÉCÉvÉâÉCÉìï¿óÒìxÇÉAÉzÇðÇΩǢDžÇÝÇ∞ǃÇÈÇ™ÉsÅ[ÉNÇÕÇÊÇ≠ǃÇý
ïΩãœÇ≈ñ≥ë Ç™ëΩǢǩÇÁSMTÇ≈ÉVÉFÉAÇ»ÇÒÇ≈ǵÇÂÅB
IntelÇ≈ÇÕItaniumÇ™12IPCÇÃÉRÉAÇ≈4SMTǂǡǃÇÈÅB
CISCÉxÅ[ÉXÇÃx86ÇÕÇýÇ∆ÇýÇ∆ñΩóþÇÝÇΩÇËÇÃÉIÉyÉåÅ[ÉVÉáÉìñßìxÇ™çÇǢǩÇÁ
ǪDZÇÐÇ≈ÉpÉCÉvÉâÉCÉìï¿óÒìxÇè„Ç∞ÇÈïKóvÇ…ãÏÇÁÇÍǃǢǻǢǵ
ñ¢ÇæÉNÉâÉCÉAÉìÉgésèÍÇÃîÑè„Ç™ëΩÇ≠ÇêËÇþǃÇÈÇ©ÇÁ
ÉTÅ[ÉoÇ…ÇæÇØì¡âªÇ∑ÇÍnjǢǢÇ∆ǢǧòbÇ≈ÇýǻǢÅB
ÉpÉCÉvÉâÉCÉìï¿óÒìxÇÉAÉzÇðÇΩǢDžÇÝÇ∞ǃÇÈÇ™ÉsÅ[ÉNÇÕÇÊÇ≠ǃÇý
ïΩãœÇ≈ñ≥ë Ç™ëΩǢǩÇÁSMTÇ≈ÉVÉFÉAÇ»ÇÒÇ≈ǵÇÂÅB
IntelÇ≈ÇÕItaniumÇ™12IPCÇÃÉRÉAÇ≈4SMTǂǡǃÇÈÅB
CISCÉxÅ[ÉXÇÃx86ÇÕÇýÇ∆ÇýÇ∆ñΩóþÇÝÇΩÇËÇÃÉIÉyÉåÅ[ÉVÉáÉìñßìxÇ™çÇǢǩÇÁ
ǪDZÇÐÇ≈ÉpÉCÉvÉâÉCÉìï¿óÒìxÇè„Ç∞ÇÈïKóvÇ…ãÏÇÁÇÍǃǢǻǢǵ
ñ¢ÇæÉNÉâÉCÉAÉìÉgésèÍÇÃîÑè„Ç™ëΩÇ≠ÇêËÇþǃÇÈÇ©ÇÁ
ÉTÅ[ÉoÇ…ÇæÇØì¡âªÇ∑ÇÍnjǢǢÇ∆ǢǧòbÇ≈ÇýǻǢÅB
ÉÅÉÇÉäÉAÉNÉZÉXÇÇΩÇ≠Ç≥ÇÒéJÇØÇÈÇÊǧDžǻǡÇΩÇ©ÇÁíÞÇËçáǧÇÊǧDžÉXÉåÉbÉhÇëùǂǵÇΩÇæÇØÇ≈Ç∑
>>172
PICÇðÇΩǢDžOSÇ™êœÇþǻǢÉÅÉÇÉä16Kà»â∫ǵǩñ≥Ç¢É}ÉCÉRÉìégǶ
ÇøÇ»ÇðÇ…ÉäÉÇÉRÉìÇ»ÇÒÇ©ÇÕÅA4ÉrÉbÉgCPUÅ{êîÉLÉçÉoÉCÉgÇÃROMÅ{RAMÇ≈ìÆǢǃÇΩÇËÇ∑ÇÈÇÊ
PICÇðÇΩǢDžOSÇ™êœÇþǻǢÉÅÉÇÉä16Kà»â∫ǵǩñ≥Ç¢É}ÉCÉRÉìégǶ
ÇøÇ»ÇðÇ…ÉäÉÇÉRÉìÇ»ÇÒÇ©ÇÕÅA4ÉrÉbÉgCPUÅ{êîÉLÉçÉoÉCÉgÇÃROMÅ{RAMÇ≈ìÆǢǃÇΩÇËÇ∑ÇÈÇÊ
OpenPowerÇÃòb
Å@Å@Chinese firms join IBM's new chip-tech group alliance
Å@Å@ttp://usa.chinadaily.com.cn/epaper/2014-05/02/content_17479326.htm
> From 2002 to 2012, IBM's share of the market for the widely used
> Unix multiuser operating system jumped to more than 55 percent from 14 percent
> "IBM likely is targeting the large Chinese data centers such as Tencent, Alibaba,
> Baidu, and China Telecom," which have "deep collaborative relationships with Intel"
Å@ZTEÅ@íÜãªí êu
Å@Research Institute of Jiangsu Industrial TechnologyÅ@ç]ëhéYã∆ãZèpöÝç€å§ãÜâ@
Å@InspurÅ@òQí™
Å@TeamsunÅ@ñkãûâÿèüìVê¨â»ãZ
Å@Chuanghe Mobile CoÅ@ñkãû[ ]òaê¢[ ]í [ ]ãZ[ ]Å@ñkãûënòaê¢ãIí êuãZèp
Å@Suzhou PowerCore Technology Co ëhèBíÜùÓçGêcêMëßâ»ãZ
Å@VeriSiliconÅ@êcå¥
Å@Å@Chinese firms join IBM's new chip-tech group alliance
Å@Å@ttp://usa.chinadaily.com.cn/epaper/2014-05/02/content_17479326.htm
> From 2002 to 2012, IBM's share of the market for the widely used
> Unix multiuser operating system jumped to more than 55 percent from 14 percent
> "IBM likely is targeting the large Chinese data centers such as Tencent, Alibaba,
> Baidu, and China Telecom," which have "deep collaborative relationships with Intel"
Å@ZTEÅ@íÜãªí êu
Å@Research Institute of Jiangsu Industrial TechnologyÅ@ç]ëhéYã∆ãZèpöÝç€å§ãÜâ@
Å@InspurÅ@òQí™
Å@TeamsunÅ@ñkãûâÿèüìVê¨â»ãZ
Å@Chuanghe Mobile CoÅ@ñkãû[ ]òaê¢[ ]í [ ]ãZ[ ]Å@ñkãûënòaê¢ãIí êuãZèp
Å@Suzhou PowerCore Technology Co ëhèBíÜùÓçGêcêMëßâ»ãZ
Å@VeriSiliconÅ@êcå¥
ÉXÉpÉRÉìÇÃèåèÇ™1.5TFlopsÇ©ÇÁ50TFlopsÇ…à¯Ç´è„Ç∞ÇÁÇÍÇΩǺ
http://www.cas.go.jp/jp/seisaku/chotatsu/
http://www.cas.go.jp/jp/seisaku/chotatsu/
DZÇÍÇ≈MacProÇ™îÉǶÇÈÇ»('A`)
182 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/10(ìy) 10:48:08.77 ID:MGA8KM9P
å§ãÜã@ä÷å¸ÇØHPCÉTÅ[ÉoÇ™TeslaÇ‚Xeon PhiÇÇPñáÇæÇØǵǩìãç⁄ǵǃîÑÇÈDZÇ∆Ç™
Ç≈ǴǻǩǡÇΩÇÃÇ™ÅADZÇÃãKêßä…òaÇ≈ç≈ëÂ8ñáÇÐÇ≈ëùÇ‚Ç≥ÇÍÇΩ
Ç≈ǴǻǩǡÇΩÇÃÇ™ÅADZÇÃãKêßä…òaÇ≈ç≈ëÂ8ñáÇÐÇ≈ëùÇ‚Ç≥ÇÍÇΩ
ó\íËÇ≈ÇÕ2014îNÇÃâ∫îºä˙Ç…SKYLAKEÇ™ÉäÉäÅ[ÉXÇ≥ÇÍÇÈÇÃÇ≈ÇÕǻǩǡÇΩÅH
ǪÇýǪÇýH-RÇ»ÇÒǃó\íËÇ…ÇÕÇ»Ç≠éüÇÕBroadwellÇ»ÇÒÇ∂ǷǻǩǡÇΩÅH
14nmâªÇ™íxÇÍǃÇÈÇÃÇ©ÇÀ
ǪÇýǪÇýH-RÇ»ÇÒǃó\íËÇ…ÇÕÇ»Ç≠éüÇÕBroadwellÇ»ÇÒÇ∂ǷǻǩǡÇΩÅH
14nmâªÇ™íxÇÍǃÇÈÇÃÇ©ÇÀ
184 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/13(âŒ) 19:53:55.88 ID:wES8bJHD
>>183
SkylakeÇÕÇýÇ∆ÇýÇ∆2015îNó\íË
BroadwellÇÃÉfÉXÉNÉgÉbÉvî≈ÇÕèoǻǢó\íËÇæÇ¡ÇΩ
Haswell RefleshÇÕä˘ïÒÇ«Ç®ÇË
SkylakeÇÕÇýÇ∆ÇýÇ∆2015îNó\íË
BroadwellÇÃÉfÉXÉNÉgÉbÉvî≈ÇÕèoǻǢó\íËÇæÇ¡ÇΩ
Haswell RefleshÇÕä˘ïÒÇ«Ç®ÇË
BroadwellÇ≈LGAî≈IrisProóàÇÈÇÁǵǢÇ≈ÅB
186 ÅFSocket774ÅF2014/05/14(êÖ) 15:17:28.24 ID:u8kCr5hT
http://techon.nikkeibp.co.jp/article/NEWS/20140513/351641/
ïxémí Ç™éüä˙ÉXÉpÉRÉìÇÃÉÅÅ[ÉìÉ{Å[ÉhÇçëìýèâìWé¶ÅAëÂÇ´Ç≥ìñÇΩÇËÇÃèàóùî\óÕÇÕÅuãûÅvÇÃ22î{
ÉÅÅ[ÉìÉ{Å[ÉhÇ…ÇÕMPU1å¬ìñÇΩÇËÅA8å¬ÇÃDRAMÉÇÉWÉÖÅ[ÉãÇìãç⁄Ç∑ÇÈÅBDZÇÃDRAMÉÇÉWÉÖÅ[ÉãÇÕÅA
ïƒMicron Technologyé–ÇÃÅuHybrid Memory CubeÅiHMCÅjÅvÇ≈ÇÝÇÈ
http://jp.fujitsu.com/solutions/hpc/products/primehpc/?md=pd-cp-server-primehpc
çÇê´î\ÅAè»ìdóÕÇóºóßǵÇΩÉOÉäÅ[ÉìÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^
PRIMEHPC FX10ÇÃÉvÉçÉZÉbÉT SPARC64TM IXfxÇÕÅAìdóÕÇÝÇΩÇËÇÃê´î\Çã…å¿ÇÐÇ≈í«ãÅǵÇΩêðåvÇ∆êÖó‚ï˚éÆÇÃçÃópÇ…ÇÊÇËÅA
236.5GFLOPSÇ∆ǢǧçÇÇ¢ê´î\Ç∆2GFLOPS/WÇí¥Ç¶ÇÈóDÇÍÇΩìdóÕÇÝÇΩÇËÇÃê´î\ÇóºóßǵǃǢÇÐÇ∑ÅB
2GFLOPS/W
ïxémí Ç™éüä˙ÉXÉpÉRÉìÇÃÉÅÅ[ÉìÉ{Å[ÉhÇçëìýèâìWé¶ÅAëÂÇ´Ç≥ìñÇΩÇËÇÃèàóùî\óÕÇÕÅuãûÅvÇÃ22î{
ÉÅÅ[ÉìÉ{Å[ÉhÇ…ÇÕMPU1å¬ìñÇΩÇËÅA8å¬ÇÃDRAMÉÇÉWÉÖÅ[ÉãÇìãç⁄Ç∑ÇÈÅBDZÇÃDRAMÉÇÉWÉÖÅ[ÉãÇÕÅA
ïƒMicron Technologyé–ÇÃÅuHybrid Memory CubeÅiHMCÅjÅvÇ≈ÇÝÇÈ
http://jp.fujitsu.com/solutions/hpc/products/primehpc/?md=pd-cp-server-primehpc
çÇê´î\ÅAè»ìdóÕÇóºóßǵÇΩÉOÉäÅ[ÉìÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^
PRIMEHPC FX10ÇÃÉvÉçÉZÉbÉT SPARC64TM IXfxÇÕÅAìdóÕÇÝÇΩÇËÇÃê´î\Çã…å¿ÇÐÇ≈í«ãÅǵÇΩêðåvÇ∆êÖó‚ï˚éÆÇÃçÃópÇ…ÇÊÇËÅA
236.5GFLOPSÇ∆ǢǧçÇÇ¢ê´î\Ç∆2GFLOPS/WÇí¥Ç¶ÇÈóDÇÍÇΩìdóÕÇÝÇΩÇËÇÃê´î\ÇóºóßǵǃǢÇÐÇ∑ÅB
2GFLOPS/W
ëOé“Ç∆å„é“DžǫǧǢǧä÷åWÇ™
å„é“ÇÕIXfxǡǃǖÇ∆ê¢ë„ëOÇÃÉÇÉfÉãÇ∂Ç·ÇÀ
å„é“ÇÕIXfxǡǃǖÇ∆ê¢ë„ëOÇÃÉÇÉfÉãÇ∂Ç·ÇÀ
188 ÅFSocket774ÅF2014/05/14(êÖ) 16:50:24.25 ID:u8kCr5hT
ç°âÒÇÕÇ«ÇÃÇ≠ÇÁÇ¢ÇÃìdóÕå¯ó¶Ç…Ç»ÇÈÇÃÇ©Ç»Ç∆
HMCÇÃå¯â Çå©ÇÈÇ»ÇÁÉVÉXÉeÉÄëSëÃÇÃìdóÕå¯ó¶Çî‰ärÇ∑Ç◊Ç´Ç≈ÇÝǡǃ
ÉvÉçÉZÉbÉTíPëÃÇÃ2GFLOPS/WÇ∆Ǣǧóùò_ê´î\Çè¡îÔìdóÕÇ≈äÑÇ¡ÇΩílÇî‰ärǵǃÇýédï˚ǻǢÇÃÇ≈ÇÕ
ÉvÉçÉZÉbÉTíPëÃÇÃ2GFLOPS/WÇ∆Ǣǧóùò_ê´î\Çè¡îÔìdóÕÇ≈äÑÇ¡ÇΩílÇî‰ärǵǃÇýédï˚ǻǢÇÃÇ≈ÇÕ
190 ÅFSocket774ÅF2014/05/14(êÖ) 17:14:21.57 ID:u8kCr5hT
HMCǡǃìdóÕçÌå∏Ç…Ç»ÇÈÇÃÅH
ë—àÊÇÝÇΩÇËÇÃè¡îÔìdóÕó çÌå∏Ç™îOì™Ç≈ǵÇÂ>HMC
http://pc.watch.impress.co.jp/img/pcw/docs/638/791/16.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/638/791/16.jpg
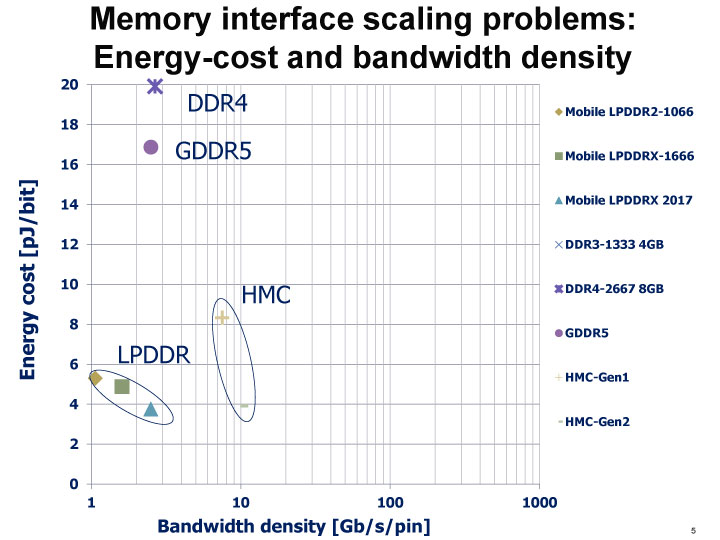{kind=link}
ǪÇËÇ·ÉfÅ[É^ì]ëóÇ™è¡îÔÉGÉlÉãÉMÅ[ÇÃÇ©Ç»ÇËÇÃïîï™êHǡǃÇÈÇ©ÇÁÇ»
ÉåÉWÉXÉ^Ç©ÇÁL2ìñÇΩÇËÇÐÇ≈ÇæÇ∆1åÖÉsÉRÉWÉÖÅ[Éãà»â∫Ç≈çœÇÞÇÃÇ™L3Ç≈åÖè„ǙǡǃÉÅÉCÉìÉÅÉÇÉäÇ≈2åÖè„Ǚǡǃǡǃè¡îÔÉGÉlÉãÉMÅ[Ç∆íxâÑǙǫÇÒÇ«ÇÒëùǶÇÈ
CPUÇ…Ç≈Ç´ÇÈÇæÇØãþÇ¢Ç∆DZDžÇ≈Ç©Ç≠ǃëÅÇ¢ÉÅÉÇÉäãlÇþçûÇþÇΩÇÁǪÇÍÇæÇØÇ≈ìdóÕè¡îÔÇÕå∏ÇÈ
ÉåÉWÉXÉ^Ç©ÇÁL2ìñÇΩÇËÇÐÇ≈ÇæÇ∆1åÖÉsÉRÉWÉÖÅ[Éãà»â∫Ç≈çœÇÞÇÃÇ™L3Ç≈åÖè„ǙǡǃÉÅÉCÉìÉÅÉÇÉäÇ≈2åÖè„Ǚǡǃǡǃè¡îÔÉGÉlÉãÉMÅ[Ç∆íxâÑǙǫÇÒÇ«ÇÒëùǶÇÈ
CPUÇ…Ç≈Ç´ÇÈÇæÇØãþÇ¢Ç∆DZDžÇ≈Ç©Ç≠ǃëÅÇ¢ÉÅÉÇÉäãlÇþçûÇþÇΩÇÁǪÇÍÇæÇØÇ≈ìdóÕè¡îÔÇÕå∏ÇÈ
GPUÇÃGDDRÇ™HBMÇ÷ÇÃà⁄çsÇ»ÇÒÇæÇ™
HMCÇÕó éYÇ≥ÇÍÇÈópìrÇÃÇÝǃÇÕÇÝÇÈÇÃÇ©ÇÀÅB
HMCÇÕó éYÇ≥ÇÍÇÈópìrÇÃÇÝǃÇÕÇÝÇÈÇÃÇ©ÇÀÅB
>>193
ã…í[Ç»ëÂó ê∂éYǵǻÇ≠ǃÇýç¢ÇÁǻǢÇÒÇ∂ǷǻǢÇÃÇ©?>HMC
êeãTÉÅÉÇÉäÉRÉìÉgÉçÅ[ÉâÇ…TSVÇÃWideI/OÉÅÉÇÉäç⁄ÇπÇΩÇæÇØÇ…å©Ç¶ÇÈñÛÇ≈
WideI/OÉÅÉÇÉäïîï™ÇÃó éYÇ™êiÇþÇŒó«Ç¢Ç¡ÇƒéñÇ»ÇÒÇ∂Ç·ÇÀ
ã…í[Ç»ëÂó ê∂éYǵǻÇ≠ǃÇýç¢ÇÁǻǢÇÒÇ∂ǷǻǢÇÃÇ©?>HMC
êeãTÉÅÉÇÉäÉRÉìÉgÉçÅ[ÉâÇ…TSVÇÃWideI/OÉÅÉÇÉäç⁄ÇπÇΩÇæÇØÇ…å©Ç¶ÇÈñÛÇ≈
WideI/OÉÅÉÇÉäïîï™ÇÃó éYÇ™êiÇþÇŒó«Ç¢Ç¡ÇƒéñÇ»ÇÒÇ∂Ç·ÇÀ
195 ÅFSocket774ÅF2014/05/15(ñÿ) 06:49:21.93 ID:lZTHJmA6
>>191
Energy CostÇÃpJǡǃâΩÇÃó™Ç≈Ç∑Ç©
Energy CostÇÃpJǡǃâΩÇÃó™Ç≈Ç∑Ç©
>>195
pJÇÕÉsÉRÉWÉÖÅ[ÉãÇ∆ì«ÇðÇÐÇ∑ÅB
ÉsÉRÇÕ1/1íõÇï\Ç∑íPà ÅA
ÉWÉÖÅ[ÉãÇÕ1WÅ~1ïbï™ÇÃÉGÉlÉãÉMÅ[Çï\Ç∑íPà Ç≈Ç∑ÅB
pJÇÕÉsÉRÉWÉÖÅ[ÉãÇ∆ì«ÇðÇÐÇ∑ÅB
ÉsÉRÇÕ1/1íõÇï\Ç∑íPà ÅA
ÉWÉÖÅ[ÉãÇÕ1WÅ~1ïbï™ÇÃÉGÉlÉãÉMÅ[Çï\Ç∑íPà Ç≈Ç∑ÅB
ÉsÉRÉWÉÖÅ[Éã
198 ÅFSocket774ÅF2014/05/15(ñÿ) 08:06:18.00 ID:lZTHJmA6
ÇÝÇËÇ™Ç∆ǧÇ≤ǥǢÇÐÇ∑
>>193
ëÂó ê∂éYǵǃílíiÇâ∫Ç∞Ç»Ç≠ǃÇýǢǢï™ñÏÇë_ǡǃÇÈÇ©ÇÁâΩÇ∆Ç©Ç»ÇÈÇÒÇ∂ǷǻǢÅH
ëÂó ê∂éYǵǃílíiÇâ∫Ç∞Ç»Ç≠ǃÇýǢǢï™ñÏÇë_ǡǃÇÈÇ©ÇÁâΩÇ∆Ç©Ç»ÇÈÇÒÇ∂ǷǻǢÅH
JEDECäOÇÃÉÅÉÇÉäÇÕǫǧǵǃÇýî˚ë¡Ç…å©Ç¶ÇƒÇµÇÐǧ
JEDECÇÃǮǩÇ∞Ç≈ÉÅÉÇÉäÇÕǢǬÇýîÉÇ¢éËésèÍ
ÉpÉ\ÉRÉìCPUÇ…ÇÕJEDECÇÃÇÊǧǻÇýÇÃǙǻÇ≠ǢǬÇýîÑÇËéËésèÍ
å„é“ÇÕç°å„ïˆÇÍÇÈÇ©ÇýǵÇÍǻǢǙ
ÉpÉ\ÉRÉìCPUÇ…ÇÕJEDECÇÃÇÊǧǻÇýÇÃǙǻÇ≠ǢǬÇýîÑÇËéËésèÍ
å„é“ÇÕç°å„ïˆÇÍÇÈÇ©ÇýǵÇÍǻǢǙ
îÉÇ¢éËésèÍÇæÇ¡ÇΩÇÃÇÕÇøÇÂÇ¡Ç∆ëOÇÐÇ≈
ÉhÉCÉcÅEì˙ñ{ÅEë‰òpÇÃDRAMÉÅÅ[ÉJÅ[Ç™éÄÇÒÇ≈ÅA
ÉTÉÄÉXÉìÅEÉnÉCÉjÉbÉNÉXÅEÉ}ÉCÉNÉçÉìÇÃ3é–ÇÃâ«êËésèÍDžǻǡÇΩÇÃÇ≈
ÇÞǵÇÎÇ¢ÇÐÇÕãtÇæÇÊ
ÉhÉCÉcÅEì˙ñ{ÅEë‰òpÇÃDRAMÉÅÅ[ÉJÅ[Ç™éÄÇÒÇ≈ÅA
ÉTÉÄÉXÉìÅEÉnÉCÉjÉbÉNÉXÅEÉ}ÉCÉNÉçÉìÇÃ3é–ÇÃâ«êËésèÍDžǻǡÇΩÇÃÇ≈
ÇÞǵÇÎÇ¢ÇÐÇÕãtÇæÇÊ
é©ï™íBÇ™ÉVÉFÉAÇéùǡǃǻǢã∆äEÇ…ëŒÇµÇƒÇÕê≠é°Ç‚ÇÁïWèÄãKäiÇ‚ÇÁ
ëΩï˚ñ Ç©ÇÁîÉÇ¢éËésèÍÇ…Ç»ÇÈÇÊǧDžÇÆÇ¢ÇÆÇ¢à≥óÕÇÇ©ÇØ
ÉVÉFÉAÇéùǡǃÇÈã∆äEÇÕÇÝÇÁljÇÈéËÇçuÇ∂ǃîÑÇËéËésèÍÇã≠âªÇ∑ÇÈ
ì˙ñ{ÇÃäÈã∆ÇÕãZèpÇ‚ÇÁïiéøÇ‚ÇÁÇ≈ê≥ñ Ç©ÇÁèüïâÇ…çsÇ≠Ç©
ìPëÞÇ∑ÇÈǩnjǡǩÇËÇ≈ÅADZǧǢǧDZÇ∆Ç…ëŒçRÇ≈Ç´Ç∏Ç…Ç‚ÇÁÇÍǡǜǻǵ
ëΩï˚ñ Ç©ÇÁîÉÇ¢éËésèÍÇ…Ç»ÇÈÇÊǧDžÇÆÇ¢ÇÆÇ¢à≥óÕÇÇ©ÇØ
ÉVÉFÉAÇéùǡǃÇÈã∆äEÇÕÇÝÇÁljÇÈéËÇçuÇ∂ǃîÑÇËéËésèÍÇã≠âªÇ∑ÇÈ
ì˙ñ{ÇÃäÈã∆ÇÕãZèpÇ‚ÇÁïiéøÇ‚ÇÁÇ≈ê≥ñ Ç©ÇÁèüïâÇ…çsÇ≠Ç©
ìPëÞÇ∑ÇÈǩnjǡǩÇËÇ≈ÅADZǧǢǧDZÇ∆Ç…ëŒçRÇ≈Ç´Ç∏Ç…Ç‚ÇÁÇÍǡǜǻǵ
éEÇÈãCÉ}ÉìÉ}ÉìÇæÇ©ÇÁÇ»ÅÑèîäOçë
ÉÅÉÇÉäÉÇÉWÉÖÅ[ÉãÅAÇ∆åæǧå`ë‘Ç™ÇýǧÇ∑ÇÆÇ®ÇÌÇËÇ©ÇØÇ»ÇÌÇØÇ≈
WideI/OÇðÇΩǢǻTSVÇ≈ê⁄ë±Ç∑ÇÈÉÅÉÇÉäÉ_ÉCÇæÇØÇã§í Ç…Ç∑ÇÈÅcǡǃï˚å¸ê´Ç»ÇÒÇæÇÎǧÇØÇ«
ÉXÉ^ÉbÉLÉìÉOÇ≈çÏÇÈǡǃÇÃÇÕÅAÇ‘Ç¡ÇøÇ·ÇØçÇâøÇ…Ç»ÇÈÇæÇØÇæÇ∆évǧǙǻÇü
ǪÇËÇ·ÅAICàÍǬÇêîñúà»è„Ç≈îÑÇÍÇÈópìrÇÕó«Ç¢ÇæÇÎǧÇØÇ«ÇÀÇ•Åc
ÉXÉ^ÉbÉLÉìÉOÇ≈çÏÇÈǡǃÇÃÇÕÅAÇ‘Ç¡ÇøÇ·ÇØçÇâøÇ…Ç»ÇÈÇæÇØÇæÇ∆évǧǙǻÇü
ǪÇËÇ·ÅAICàÍǬÇêîñúà»è„Ç≈îÑÇÍÇÈópìrÇÕó«Ç¢ÇæÇÎǧÇØÇ«ÇÀÇ•Åc
âºÇ…ç°ÇÃÉÅÉÇÉäÉÇÉWÉÖÅ[ÉãÇ™èIÇÌÇ¡ÇΩÇ∆ǵǃÅA
ç¢ÇÈÇÃÇÕDRAMÉÅÅ[ÉJÅ[Ç©ÇÁÉÅÉÇÉäÉ`ÉbÉvîÉǡǃDIMMìôÇÃÉÇÉWÉÖÅ[ÉãDžǵǃîÑǡǃÇÈÉÅÅ[ÉJÅ[Ç≈ÅA
DRAMÉÅÅ[ÉJÅ[ÇÕÇ◊ǬDžç¢ÇÁǻǢÇØÇ«ÇÀ
ç¢ÇÈÇÃÇÕDRAMÉÅÅ[ÉJÅ[Ç©ÇÁÉÅÉÇÉäÉ`ÉbÉvîÉǡǃDIMMìôÇÃÉÇÉWÉÖÅ[ÉãDžǵǃîÑǡǃÇÈÉÅÅ[ÉJÅ[Ç≈ÅA
DRAMÉÅÅ[ÉJÅ[ÇÕÇ◊ǬDžç¢ÇÁǻǢÇØÇ«ÇÀ
çÇë¨Ç»É}ÉUÅ[É{Å[ÉhíºïtÇÃÉÅÉÇÉäÇ∆
ÉÅÉÇÉäÉÇÉWÉÖÅ[ÉãÇ≈ëùêðÇ≈Ç´ÇÈí·ë¨Ç»ÉÅÉÇÉäÇ∆Ç≈
ÉÅÉCÉìÉÅÉÇÉäÇ2ǬDžï™ÇØǃ
OSÇ™égópïpìxÇ…âûÇ∂ǃÉ}ÉbÉsÉìÉOǵǃëŒâûÇ∑ÇÈÇ∆ǢǧÇÃÇÕǫǧǻÇÃÇ©Ç»ÅH
DZÇÍÇ≈ÇýÅAǫǧÇπÅAâºëzãLâØÇÉTÉ|Å[ÉgǵǃÇÈOSnjǩÇËÇ»ÇÃÇ≈
ò_óùÉAÉhÉåÉXãÛä‘ÇÕëSÇ≠ïœÇÌÇÁǻǢǩÇÁÉAÉvÉäë§Ç©ÇÁÇÕç°ÇÐÇ≈Ç∆ìØÇ∂Ç…å©Ç¶ÇÈ
ÉÅÉÇÉäÉÇÉWÉÖÅ[ÉãÇ≈ëùêðÇ≈Ç´ÇÈí·ë¨Ç»ÉÅÉÇÉäÇ∆Ç≈
ÉÅÉCÉìÉÅÉÇÉäÇ2ǬDžï™ÇØǃ
OSÇ™égópïpìxÇ…âûÇ∂ǃÉ}ÉbÉsÉìÉOǵǃëŒâûÇ∑ÇÈÇ∆ǢǧÇÃÇÕǫǧǻÇÃÇ©Ç»ÅH
DZÇÍÇ≈ÇýÅAǫǧÇπÅAâºëzãLâØÇÉTÉ|Å[ÉgǵǃÇÈOSnjǩÇËÇ»ÇÃÇ≈
ò_óùÉAÉhÉåÉXãÛä‘ÇÕëSÇ≠ïœÇÌÇÁǻǢǩÇÁÉAÉvÉäë§Ç©ÇÁÇÕç°ÇÐÇ≈Ç∆ìØÇ∂Ç…å©Ç¶ÇÈ
>>208
ë¨Ç¢ÉÅÉÇÉäÇ©ÇÁóDêÊìIÇ…égǡǃǢÇØnjǢǢÇæÇØÅBÉ}ÉãÉ`É`ÉÉÉlÉãÇ…óeó à·Ç¢ÇÃÉÅÉÇÉäç∑ǵÇΩéûÇ∆ǩǪǧǢǧìÆǴDžǻǡǃÇÈÅB
ë¨Ç¢ÉÅÉÇÉäÇ©ÇÁóDêÊìIÇ…égǡǃǢÇØnjǢǢÇæÇØÅBÉ}ÉãÉ`É`ÉÉÉlÉãÇ…óeó à·Ç¢ÇÃÉÅÉÇÉäç∑ǵÇΩéûÇ∆ǩǪǧǢǧìÆǴDžǻǡǃÇÈÅB
CPUÇ…ì\Ç¡ÇøǷǧǟǧǙë¨Ç≠ÇÀÅH
ǪÇËǷǪǧÇæÇ™ÅAîMÇ≈ÇÝÇ⁄ÇÒÅB
TSVÇÃåäÇäJÇØÇÊǧÇ∆Ç∑ÇÈÇ∆
ç≈êVÇÊÇËàÍê¢ë„ëOÇÃÉvÉçÉZÉXÇégǧDZÇ∆Ç…Ç»ÇÈÇ™
CPUÇ≈ǪÇÍÇÕãñÇ≥ÇÍǻǢ
ç≈êVÇÊÇËàÍê¢ë„ëOÇÃÉvÉçÉZÉXÇégǧDZÇ∆Ç…Ç»ÇÈÇ™
CPUÇ≈ǪÇÍÇÕãñÇ≥ÇÍǻǢ
SynopsysÇÃApplication Specific Processor(ASIP)êðåvÉcÅ[Éã
ttp://news.mynavi.jp/articles/2014/05/15/synopsys/
ttp://news.mynavi.jp/articles/2014/05/15/synopsys/
ǪǧǢǂAMDÇÃARMǡǃÅAÇò86Ç∆ÉsÉìåðä∑Ç…Ç∑ÇÈÇÁǵǢÇØÇ«
ìØÇ∂MBÇ≈ç∑ǵë÷ǶÇ≈Ç´ÇÈǡǃDZÇ∆Ç»ÇÃÇ©ÅAíPDžǮǻÇ∂ÉsÉìîzíuǡǃÇæÇØÇ»ÇÃÇ©ÅAÇ«Ç¡ÇøÇ…Ç»ÇÈÇÒÇæÇÎǧ
ìØÇ∂MBÇ≈ç∑ǵë÷ǶÇ≈Ç´ÇÈǡǃDZÇ∆Ç»ÇÃÇ©ÅAíPDžǮǻÇ∂ÉsÉìîzíuǡǃÇæÇØÇ»ÇÃÇ©ÅAÇ«Ç¡ÇøÇ…Ç»ÇÈÇÒÇæÇÎǧ
ÉuÅ[ÉgROMÇÕï ÇæÇ©ÇÁìØÇ∂É}ÉUÉ{Ç≈ç∑ǵë÷ǶǃÇÕÇ≈ǴǻǢǺÅB
óºópROMÇýçÏÇÍÇ»Ç≠ÇÕǻǢǙîÑÇÈë§Ç…âΩÇÃÉÅÉäÉbÉgÇýǻǢǩÇÁÇ»ÅB
óºópROMÇýçÏÇÍÇ»Ç≠ÇÕǻǢǙîÑÇÈë§Ç…âΩÇÃÉÅÉäÉbÉgÇýǻǢǩÇÁÇ»ÅB
Ç≥Ç∑ǙDžROMÇÕç∑ǵë÷ǶÇæÇÎǧÇ∆évǧÇØÇ«ÅAMBé©ëÃÇÕã§ópÇ≈ǴǻǢÇ∆ÇÝÇÒÇÐǵà”ñ°Ç™Ç»Ç¢ãCÇ™Ç∑ÇÈÇÒÇæÇÊÇ»('A`)
ÇÝÇ∆ãCÇ…Ç»ÇÈÇÃÇÕè¡îÔìdóÕÅBx86ï¿ÇðÇ…âΩè\WÇýégǧARMÇæÇ¡ÇΩÇÁÇøÇÂÇ¡Ç∆Ç∑Ç≤ǢǩÇýǡǃévÇÌÇ»Ç≠ÇýǻǢ
ÇÝÇ∆ãCÇ…Ç»ÇÈÇÃÇÕè¡îÔìdóÕÅBx86ï¿ÇðÇ…âΩè\WÇýégǧARMÇæÇ¡ÇΩÇÁÇøÇÂÇ¡Ç∆Ç∑Ç≤ǢǩÇýǡǃévÇÌÇ»Ç≠ÇýǻǢ
ARMÇ≈Çýx86Ç≈ÇýÇ«Ç¡ÇøÇýégǶÇÈMBÇèoǵǃÇ≠ÇÈMBÉÅÅ[ÉJÅ[ÇÕèoÇÈÇ©ÇýÇÀ
alphaÇ∆athlonÇÇÌÇ∑ÇÍÇΩÇÃÇ©
Slot BÇÃAthlonÇÕåãã«èoÇ≥ǻǩǡÇΩÇ©ÇÁåvâÊì|ÇÍÇ…
>>217
ǪǧǻÇÍÇŒâøäiÇýà¿Ç≠ǻǡǃNVIDIAÇÃÉ{Å[ÉhÇ∆ã£ëàÇ≈Ç´ÇÈÇ»
NVIDIAÅCTegra K1ìãç⁄ÇÃäJî≠ÉLÉbÉgÅuJetson TK1ÅvÇ192ÉhÉãÇ≈íÒãüäJénÅB
ì˙ñ{Ç≈ÇÃî≠îÑì˙ÇÕñ¢íË
http://www.4gamer.net/games/244/G024410/20140502089/
ǪǧǻÇÍÇŒâøäiÇýà¿Ç≠ǻǡǃNVIDIAÇÃÉ{Å[ÉhÇ∆ã£ëàÇ≈Ç´ÇÈÇ»
NVIDIAÅCTegra K1ìãç⁄ÇÃäJî≠ÉLÉbÉgÅuJetson TK1ÅvÇ192ÉhÉãÇ≈íÒãüäJénÅB
ì˙ñ{Ç≈ÇÃî≠îÑì˙ÇÕñ¢íË
http://www.4gamer.net/games/244/G024410/20140502089/
221 ÅFSocket774ÅF2014/05/21(êÖ) 06:59:58.35 ID:paVRNOwT
>>208
ç°å„ÇÕǪǧǢǧǔǧDžǻǡǃǢÇ≠ǡǃǻÇÒÇ©ÇÃãLéñÇ≈å©ÇΩãLâØÇ™ÇÝÇÈ
ç°å„ÇÕǪǧǢǧǔǧDžǻǡǃǢÇ≠ǡǃǻÇÒÇ©ÇÃãLéñÇ≈å©ÇΩãLâØÇ™ÇÝÇÈ
222 ÅFSocket774ÅF2014/05/21(êÖ) 07:01:49.31 ID:paVRNOwT
AMDÇ∆IntelÇ≈ÉsÉìåðä∑Ç∆Ç©ñ≥óùÇ»ÇÃÅH
TegraÇýëSïîìØÇ∂ãKäiÇ≈ǂǡǃǟǵǢÇÌ
TegraÇýëSïîìØÇ∂ãKäiÇ≈ǂǡǃǟǵǢÇÌ
CPUÇ…Ç¢ÇÎÇÒÇ»ï®ÇìùçáǵǃǢÇ≠ó¨ÇÍÇ»ÇÃÇ…ÉsÉìÇæÇØå≈íËǵǃÇýë´ûgDžǵǩǻÇÁÇÒÇæÇÎ
å≥ÇÕÉsÉìåðä∑ÇæÇ¡ÇΩÇÃÇ…ÉCÉìÉeÉãÇ™åôǙǡÇΩÇÒÇæÇÊÇ»ÅBÇ≈ÉtÉ@É~ÉRÉìÉJÉZÉbÉgÇðÇΩǢǻÇÃDžǻǡǃ
ǪÇÍÇ≈åðä∑CPUí◊ÇπÇÈÇ©Ç∆évÇ¡ÇΩÇÁÅAàƒäOAMDÇýì∆é©ÉsÉìîzíuÇ≈è§îÑÇ≈Ç´ÇøǷǡǃÅAÇ≈ç°Ç…éäÇÈ
ǪÇÍÇ≈åðä∑CPUí◊ÇπÇÈÇ©Ç∆évÇ¡ÇΩÇÁÅAàƒäOAMDÇýì∆é©ÉsÉìîzíuÇ≈è§îÑÇ≈Ç´ÇøǷǡǃÅAÇ≈ç°Ç…éäÇÈ
AMDÇÃARM-CPUÇÕÅAäJî≠ÅEÉfÉoÉbÉOópDžǬǩÇÌÇÍÇÈãCÇ™Ç∑ÇÈÇÊ
ÇýÇøÇÎÇÒÅAäJî≠ÅEÉfÉoÉbÉOÇ…égǧÇæÇØÇ≈é¿êªïiÇ…ÇÕǬǩÇÌÇÍǻǢǡǃǢǧÉpÉ^Å[Éì
ÇýÇøÇÎÇÒÅAäJî≠ÅEÉfÉoÉbÉOÇ…égǧÇæÇØÇ≈é¿êªïiÇ…ÇÕǬǩÇÌÇÍǻǢǡǃǢǧÉpÉ^Å[Éì
ǢǂǢǂäJî≠ÇÕÉGÉ~ÉÖÅ®ééçÏäÓî¬Ç≈ǵÇÂ
227 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/21(êÖ) 22:25:21.80 ID:/aJhoHl7
é¿ã@Ç∆ìØàÍÇ≈Ç∑ÇÁǻǢCPUÇ™ç⁄Ç¡ÇΩäÓî¬Ç»ÇÒǃǻÇÒÇÃåüèÿÇ…ÇýÇ»ÇÁǻǢǺ
ç≈èIäÓî¬Ç…ëgÇðçûÇÒÇ≈Ç‚ÇÈäJî≠ÅEÉfÉoÉbÉOÇ∂Ç·Ç»Ç≠ÅA
ǪÇÃëOÇÃíiäKÇÃäJî≠ÅEÉfÉoÉbÉOÇÀ
ǪÇÃëOÇÃíiäKÇÃäJî≠ÅEÉfÉoÉbÉOÇÀ
ÇæÇ©ÇÁǪDZÇ≈ïœÇ»äÓî¬Ç∆Ç©égǧÇÕÇ∏ǙǻǢÇæÇÎÅBîné≠ǩDZǢǬÇÕÅB
óBàÍÇÃó·äOÇÕPCåðä∑äÓî¬ÇÃäJî≠Ç…ÉnÅ[ÉhÉEÉFÉAåðä∑ê´ÇÃñ≥Ç¢PCÇégǧÉPÅ[ÉXÅB
ó·Ç¶ÇŒÉrÉfÉIÉ`ÉbÉvÇ™à·Ç§Ç∆Ç©CPUÇ™à·Ç§Ç∆Ç©ÇÝǡǃÇýêÊçsäJî≠ÇÕǪÇÃéûóLÇÈÇýÇÃÇégǧǵǩǻǢÅBǪÇÍDžDZÇÍÇÕå˙Ç¢OSÉ\ÉtÉgÉEÉFÉAëwÇ™à·Ç¢Çãzé˚ǵǃÇ≠ÇÍÇÈÇ©ÇÁÇ≈Ç´ÇÈÇ≈Ç´ÇÈDZÇ∆Ç≈ÇÝÇÈÅB
óBàÍÇÃó·äOÇÕPCåðä∑äÓî¬ÇÃäJî≠Ç…ÉnÅ[ÉhÉEÉFÉAåðä∑ê´ÇÃñ≥Ç¢PCÇégǧÉPÅ[ÉXÅB
ó·Ç¶ÇŒÉrÉfÉIÉ`ÉbÉvÇ™à·Ç§Ç∆Ç©CPUÇ™à·Ç§Ç∆Ç©ÇÝǡǃÇýêÊçsäJî≠ÇÕǪÇÃéûóLÇÈÇýÇÃÇégǧǵǩǻǢÅBǪÇÍDžDZÇÍÇÕå˙Ç¢OSÉ\ÉtÉgÉEÉFÉAëwÇ™à·Ç¢Çãzé˚ǵǃÇ≠ÇÍÇÈÇ©ÇÁÇ≈Ç´ÇÈÇ≈Ç´ÇÈDZÇ∆Ç≈ÇÝÇÈÅB
230 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/21(êÖ) 23:48:19.38 ID:/aJhoHl7
ǪÇÒǻDZÇ∆Ç™Ç≈Ç´ÇÈÇÃÇÕé¿ê—ÇÃÇÝÇÈëgÇðçûÇðÉ\ÉtÉgÉEÉFÉAÉXÉ^ÉbÉNÇéùǬ
WindriverÇóiÇ∑ÇÈIntelÇ™ÅAêVǵǢAtomÉ^Å[ÉQÉbÉgÇÃêÊçsäJî≠ópÇ…
Core i*ÇÃÉ{Å[ÉhÇíÒãüÇ∑ÇÈÇ∆ǢǧÉPÅ[ÉXÇ≠ÇÁÇ¢ÇæÇÊÅB
AMDÇ™ç≈èIêªïiÇíÒãüǵǻǢÇÃÇ≈ÇÝÇÍÇŒÅAíÜä‘Ç…ÇýAMDÇÃ
ÉvÉçÉZÉbÉTÇégǧïKóvǙǫDZDžÇýǻǢÇ∂ǷǻǢǩÅB
WindriverÇóiÇ∑ÇÈIntelÇ™ÅAêVǵǢAtomÉ^Å[ÉQÉbÉgÇÃêÊçsäJî≠ópÇ…
Core i*ÇÃÉ{Å[ÉhÇíÒãüÇ∑ÇÈÇ∆ǢǧÉPÅ[ÉXÇ≠ÇÁÇ¢ÇæÇÊÅB
AMDÇ™ç≈èIêªïiÇíÒãüǵǻǢÇÃÇ≈ÇÝÇÍÇŒÅAíÜä‘Ç…ÇýAMDÇÃ
ÉvÉçÉZÉbÉTÇégǧïKóvǙǫDZDžÇýǻǢÇ∂ǷǻǢǩÅB
à¿ÇØÇÍÇŒîÑÇÍÇÈÇæÇÎǧÇÀ
çÇÇ©Ç¡ÇΩÇÁîÑÇÍǻǢ
raspberry piǂǪÇÍÇ…óÞéóǵÇΩÉ{Å[ÉhÇÕÇΩÇ≠Ç≥ÇÒèoǃÇÈǵ
àÍïîÇÃêlÇΩÇøÇ…ÇÕîÒèÌÇ…êlãCÇ™ÇÝÇÈ
ÇÝÇ∆ÇÕìdéqçHäwÇ‚èÓïÒånÇÃäwê∂Ç≥ÇÒÇΩÇøÇÃé˘óv
DZÇÍÇýåãç\ÅAîné≠Ç…Ç»ÇÁǻǢ
Android SDKÇÃARMî≈ÇÃAndroidÉGÉ~ÉÖÇ™çÇë¨Ç…ìÆçÏÇ∑ÇÈÇ»ÇÁ
äwê∂Ç≥ÇÒÇΩÇøÇÃé˘óvÇÕǪÇÍÇ»ÇËÇ…ÇÝÇËǪǧ
çÇÇ©Ç¡ÇΩÇÁîÑÇÍǻǢ
raspberry piǂǪÇÍÇ…óÞéóǵÇΩÉ{Å[ÉhÇÕÇΩÇ≠Ç≥ÇÒèoǃÇÈǵ
àÍïîÇÃêlÇΩÇøÇ…ÇÕîÒèÌÇ…êlãCÇ™ÇÝÇÈ
ÇÝÇ∆ÇÕìdéqçHäwÇ‚èÓïÒånÇÃäwê∂Ç≥ÇÒÇΩÇøÇÃé˘óv
DZÇÍÇýåãç\ÅAîné≠Ç…Ç»ÇÁǻǢ
Android SDKÇÃARMî≈ÇÃAndroidÉGÉ~ÉÖÇ™çÇë¨Ç…ìÆçÏÇ∑ÇÈÇ»ÇÁ
äwê∂Ç≥ÇÒÇΩÇøÇÃé˘óvÇÕǪÇÍÇ»ÇËÇ…ÇÝÇËǪǧ
232 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 08:12:31.23 ID:xCsCg98m
x86î≈Ç»ÇÁPCÉGÉ~ÉÖÉåÅ[É^Ç≈è\ï™ÇæÇÎ
Ç»ÇÒÇ≈ARMî≈Ç≈ÇÝÇÈïKóvÇ™ÇÝÇÈÇÒÇæÇÊ
ì¡íËÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÉnÅ[ÉhÇ◊Ç¡ÇΩÇËÇ≈äJî≠Ç∑ÇÈÇ»ÇÒǃ
à´Ç¢ï»Ç™Ç¬Ç≠ÇæÇØÇæǺÅH
Ç»ÇÒÇ≈ARMî≈Ç≈ÇÝÇÈïKóvÇ™ÇÝÇÈÇÒÇæÇÊ
ì¡íËÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÉnÅ[ÉhÇ◊Ç¡ÇΩÇËÇ≈äJî≠Ç∑ÇÈÇ»ÇÒǃ
à´Ç¢ï»Ç™Ç¬Ç≠ÇæÇØÇæǺÅH
à´Ç¢ï»ÇæÇÎǧǙIntelà»äOÇ≈äJî≠ǵÇΩÇ≠ǻǢ!!!
234 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 08:27:57.81 ID:xCsCg98m
Åué¿ã@ÅvÇýà¿Ç¢ìzÇÕ1ñúǴǡǃÇÈǵǻÅ[
â∫éËÇ∑ÇÈÇ∆é¿ã@ÇÊÇËçÇÇ¢ÉnÅ[ÉhÉEÉFÉAÉGÉ~ÉÖÉåÅ[É^Ç»ÇÒǃíNÇýîÉÇÌǻǢÇÊ
â∫éËÇ∑ÇÈÇ∆é¿ã@ÇÊÇËçÇÇ¢ÉnÅ[ÉhÉEÉFÉAÉGÉ~ÉÖÉåÅ[É^Ç»ÇÒǃíNÇýîÉÇÌǻǢÇÊ
>>231
î≠ëzÇ™ítêŸÇ∑Ǩǃï–ïÝí…Ç¢ÇÌ
ìdéqÇ‚èÓïÒǂǡǃÇÈêlä‘ÇÕÇÌÇØÇÃÇÌÇ©ÇÁǻǢÉ{Å[ÉhÇîÉǧÇýÇÃÇæÇ∆Ǣǧ
évÇ¢çûÇðÇÝÇËÇ´Ç≈ÅAÇ»Ç∫AMDëIÇ‘ïKóvÇ™ÇÝÇÈÇÃÇ©
ëSÇ≠Çýǡǃà”ñ°ïsñæ
ã≥àÁÇ‚ìdéqçHçÏópä¬ã´Ç»ÇÁArduinoÇæÇÎ
Ç»Ç∫AndroidÇæÇÀÅH
ïsï◊ã≠Ç∑ǨǃòbÇ…Ç»ÇÁǻǢ
IntelÇÕGalileoÇÉ^É_Ç≈ëÂäwÇ…îzǡǃÇÈÅB
É^É_Ç≈ñ·Ç¶ÇÈÇýÇÃÇ™ÇÝÇÈÇÃÇ…ÅAÇ»Ç∫ãýÇèoǵǃîÉÇÌÇ»ÇØÇÍÇŒ
Ç»ÇÁÇÒÇÃÇæÇÀÅH
AMDÇÕã≥àÁópÇÃÉRÉìÉsÉÖÅ[É^Ç≈ǻDžǩé¿ê—ÇÕÇÝÇ¡ÇΩÇ©ÇÀÅH
ǻǢÅB
é©ï™ÇÃévÇ¢çûÇðÇå˚ëñÇÈëOÇ…ÇÐÇ∏åªé¿ê¢äEǙǫǧǻǡǃÇÈÇÃÇ©Ç
í≤Ç◊ÇÊǧǂÅB
î≠ëzÇ™ítêŸÇ∑Ǩǃï–ïÝí…Ç¢ÇÌ
ìdéqÇ‚èÓïÒǂǡǃÇÈêlä‘ÇÕÇÌÇØÇÃÇÌÇ©ÇÁǻǢÉ{Å[ÉhÇîÉǧÇýÇÃÇæÇ∆Ǣǧ
évÇ¢çûÇðÇÝÇËÇ´Ç≈ÅAÇ»Ç∫AMDëIÇ‘ïKóvÇ™ÇÝÇÈÇÃÇ©
ëSÇ≠Çýǡǃà”ñ°ïsñæ
ã≥àÁÇ‚ìdéqçHçÏópä¬ã´Ç»ÇÁArduinoÇæÇÎ
Ç»Ç∫AndroidÇæÇÀÅH
ïsï◊ã≠Ç∑ǨǃòbÇ…Ç»ÇÁǻǢ
IntelÇÕGalileoÇÉ^É_Ç≈ëÂäwÇ…îzǡǃÇÈÅB
É^É_Ç≈ñ·Ç¶ÇÈÇýÇÃÇ™ÇÝÇÈÇÃÇ…ÅAÇ»Ç∫ãýÇèoǵǃîÉÇÌÇ»ÇØÇÍÇŒ
Ç»ÇÁÇÒÇÃÇæÇÀÅH
AMDÇÕã≥àÁópÇÃÉRÉìÉsÉÖÅ[É^Ç≈ǻDžǩé¿ê—ÇÕÇÝÇ¡ÇΩÇ©ÇÀÅH
ǻǢÅB
é©ï™ÇÃévÇ¢çûÇðÇå˚ëñÇÈëOÇ…ÇÐÇ∏åªé¿ê¢äEǙǫǧǻǡǃÇÈÇÃÇ©Ç
í≤Ç◊ÇÊǧǂÅB
>>235
> IntelÇÕGalileoÇÉ^É_Ç≈ëÂäwÇ…îzǡǃÇÈÅB
http://news.mynavi.jp/news/2013/10/03/388/
> ǻǮÅAIntelÇ≈ÇÕÅAGalileoDžǬǢǃÅAç°å„18ÉJåéÇÃä‘Ç…ÅAëSê¢äE1000ÇÃëÂäwÇ…å¸ÇØ5ñúñáÇäÒïtÇ∑ÇÈ
> åvâÊÇ∆ǵǃǢÇÈÅB
ǃòbÇÕÇÝÇ¡ÇΩÇØÇ«é¿ç€îzÇ¡ÇΩÇËǵǃÇÒÇÃ? Galileo ǡǃÇÝÇÒÇÐåvâÊí ÇËÇ∂ǷǻǢÇðÇΩÇ¢ÇæÇØÇ«ÅB
http://pc.watch.impress.co.jp/docs/news/20140415_644447.html
> ïƒIntelÇÕ14ì˙(åªínéûä‘)ÅAArduinoåðä∑ÇÃQuark X1000ìãç⁄äJî≠É{Å[ÉhÅuGalileoÅvÇêªë¢èIóπÇ∑ÇÈÇ∆
> î≠ï\ǵÇΩÅBç≈èIéÛíçì˙ÇÕ6åé3ì˙Ç≈ÅAç≈èIèoâ◊ì˙ÇÕ12åé26ì˙ÅB
> IntelÇÕGalileoÇÉ^É_Ç≈ëÂäwÇ…îzǡǃÇÈÅB
http://news.mynavi.jp/news/2013/10/03/388/
> ǻǮÅAIntelÇ≈ÇÕÅAGalileoDžǬǢǃÅAç°å„18ÉJåéÇÃä‘Ç…ÅAëSê¢äE1000ÇÃëÂäwÇ…å¸ÇØ5ñúñáÇäÒïtÇ∑ÇÈ
> åvâÊÇ∆ǵǃǢÇÈÅB
ǃòbÇÕÇÝÇ¡ÇΩÇØÇ«é¿ç€îzÇ¡ÇΩÇËǵǃÇÒÇÃ? Galileo ǡǃÇÝÇÒÇÐåvâÊí ÇËÇ∂ǷǻǢÇðÇΩÇ¢ÇæÇØÇ«ÅB
http://pc.watch.impress.co.jp/docs/news/20140415_644447.html
> ïƒIntelÇÕ14ì˙(åªínéûä‘)ÅAArduinoåðä∑ÇÃQuark X1000ìãç⁄äJî≠É{Å[ÉhÅuGalileoÅvÇêªë¢èIóπÇ∑ÇÈÇ∆
> î≠ï\ǵÇΩÅBç≈èIéÛíçì˙ÇÕ6åé3ì˙Ç≈ÅAç≈èIèoâ◊ì˙ÇÕ12åé26ì˙ÅB
Galileo2ÇèoÇ∑Ç©ÇÁǡǃèëǢǃÇÝÇÈÇØÇ«âΩÇåæǡǃÇÈÇÒÇæ
îºîNǩǪDZÇÁÇ≈ÉÇÉfÉãÉ`ÉFÉìÉWÇ∑ÇÈêªïiǙǧÇÐÇ≠çsǡǃÇÈÇ∆Ç≈Çý?
å©çûÇðÇÃǻǢè§ïiÇÉÇÉfÉãÉ`ÉFÉìÉWǵǃǫǧÇ∑ÇÒÇÃ
Galileo2Ç™QuarkÇ™ç⁄ǡǃǻǢëSÇ≠ï ï®Ç∆Ç©Ç»ÇÁÇ∆ÇýÇ©Ç≠ÇÀǶ
ëÂäwÇ÷ÇÃîzïzDžǬǢǃÇÕä˘Ç…400ÇÃëÂäwÇ…îzÇ¡ÇΩÇ∆ÇÝÇÈÇÀ
http://www.intel.com/content/www/us/en/education/university/galileo-for-universities.html
ëÂäwÇ÷ÇÃîzïzDžǬǢǃÇÕä˘Ç…400ÇÃëÂäwÇ…îzÇ¡ÇΩÇ∆ÇÝÇÈÇÀ
http://www.intel.com/content/www/us/en/education/university/galileo-for-universities.html
GPIOÇ™100kHzÇÃI2CǵǩëŒâûǵǃǻÇ≠ǃÉNÉ\íxÇ¢Ç∆Ç©VGAǙǻǢÇ∆Ç©
åáì_Ç™éwìEÇ≥ÇÍǃÇΩÇ©ÇÁǪÇÃÇÝÇΩÇËÇâ¸ëPǵÇΩêVǵǢÉ{Å[ÉhÇèoÇ∑ÇÃÇæÇ∆évǧÇÃÇæÇØÇ«ÇÀ
åáì_Ç™éwìEÇ≥ÇÍǃÇΩÇ©ÇÁǪÇÃÇÝÇΩÇËÇâ¸ëPǵÇΩêVǵǢÉ{Å[ÉhÇèoÇ∑ÇÃÇæÇ∆évǧÇÃÇæÇØÇ«ÇÀ
5ñúñáîzÇÈó\íËǬǡǃÇΩÇÃÇ™êÁñáÇ∂Ç·ÇÐÇæÇÐÇæǡǃä¥Ç∂ÇÀÅB
ÇÐÇÝIntel Ç®ìæà”ÇÃUSBå∞î˜ãæÇðÇΩǢǻÇýÇÒÇæÇ»
QuarkÇÕDAIKINÇ™é©é–ÉCÉìÉtÉâópÇ…100ñúíPà Ç≈çwì¸ÇµÇƒÇÈÇ©ÇÁÇ»
GalileoÇÕéYã∆ópÉ{Å[ÉhÇ∆ìØÇ∂édólÇæÇ©ÇÁ
îÁì˜î≤Ç´ÇÃÅuçDï]DžǬǴÅ`ÅvÇæÇÎÅB
Windows EmbeddedÇýQuarkëŒâûî≈Ç™èoÇÈDZÇ∆Džǻǡǃ
ÉÅÉÇÉäóeó Ç∆Ç©ÇÃí≤êÆÇ™ïKóvDžǻǡÇΩÇÒÇ∂Ç·ÇÀÅH
ÇæÇ¢ÇΩÇ¢DAIKINÇÝÇËÇ´ÇæÇ™IntelÇÃIoTïîñÂÇÕçïéöÇèoǵǃÇÈǵÅB
GalileoÇÕéYã∆ópÉ{Å[ÉhÇ∆ìØÇ∂édólÇæÇ©ÇÁ
îÁì˜î≤Ç´ÇÃÅuçDï]DžǬǴÅ`ÅvÇæÇÎÅB
Windows EmbeddedÇýQuarkëŒâûî≈Ç™èoÇÈDZÇ∆Džǻǡǃ
ÉÅÉÇÉäóeó Ç∆Ç©ÇÃí≤êÆÇ™ïKóvDžǻǡÇΩÇÒÇ∂Ç·ÇÀÅH
ÇæÇ¢ÇΩÇ¢DAIKINÇÝÇËÇ´ÇæÇ™IntelÇÃIoTïîñÂÇÕçïéöÇèoǵǃÇÈǵÅB
ARMÉVÉìÉOÉãÉRÉAÇ»ÇÁ50ÉhÉãÇ©ÇÁ100ÉhÉãÇ≠ÇÁÇ¢Ç≈
Linux PCÇ∆ǵǃégǶÇÈÇÃǙǢÇÎÇ¢ÇÎîÑǡǃÇÈ
Banana PiÇÕ1GhzÇÃCortex-A7ÇÃAllwinner A20Ç…ÉÅÉCÉìÉÅÉÇÉä1GBÇ≈ÇΩÇ¡ÇΩÇÃ50ÉhÉã
Raspberry PiÇñÕǵÇΩÅuBanana PiÅvÇ™î≠îÑ--íÜçëÇÃã≥àÁã@ä÷Ç™äJî≠
http://japan.zdnet.com/development/analysis/35047210/
ÉnÉCÉGÉìÉhÇÃARM SoCÇÃÉ{Å[ÉhÇ≈ÇÕ
NVIDIAÇ™Jetson TK1Ç192ÉhÉãÇ≈èoǵǃǴÇΩ
ëºÇ…ÇýExynos 5 OctaÇç⁄ÇπÇΩÉ{Å[ÉhÇ»ÇÒÇ©ÇýÇÝÇÈ
LinuxÇÃëºÇ…AndroidÇì¸ÇÍÇÁÇÍÇÈÉ{Å[ÉhÇ™ëΩÇ¢
ÉIÉNÉ^ÉRÉAÅi8ÉRÉAÅjÉvÉçÉZÉbÉT Exynos 5 ìãç⁄ÅA
Android 4.2 OS ëŒâûÇÃäJî≠é“å¸ÇØÉ{Å[ÉhÅuHardkernel ODROID-XUÅvî≠ï\
http://gpad.tv/develop/hardkernel-odroid-xu/
32bitARMópÇÃeclipseÇ‚JavaÇÕÇÝÇÈÇ™Android SDKÇÕǻǢǻ
Ç¢ÇÎÇ¢ÇÎÇ»ARMÇÃäià¿É{Å[ÉhÇ™èoǃǴǃ
ARMÇÃLinuxÇégǧêlÇ™ëùǶǃÇ≠ÇÍÇŒäJî≠ä¬ã´ÇÕêÆǡǃÇ≠ÇÈÇ©ÇýÇ»
64bitARMópÇýÇ»
Linux PCÇ∆ǵǃégǶÇÈÇÃǙǢÇÎÇ¢ÇÎîÑǡǃÇÈ
Banana PiÇÕ1GhzÇÃCortex-A7ÇÃAllwinner A20Ç…ÉÅÉCÉìÉÅÉÇÉä1GBÇ≈ÇΩÇ¡ÇΩÇÃ50ÉhÉã
Raspberry PiÇñÕǵÇΩÅuBanana PiÅvÇ™î≠îÑ--íÜçëÇÃã≥àÁã@ä÷Ç™äJî≠
http://japan.zdnet.com/development/analysis/35047210/
ÉnÉCÉGÉìÉhÇÃARM SoCÇÃÉ{Å[ÉhÇ≈ÇÕ
NVIDIAÇ™Jetson TK1Ç192ÉhÉãÇ≈èoǵǃǴÇΩ
ëºÇ…ÇýExynos 5 OctaÇç⁄ÇπÇΩÉ{Å[ÉhÇ»ÇÒÇ©ÇýÇÝÇÈ
LinuxÇÃëºÇ…AndroidÇì¸ÇÍÇÁÇÍÇÈÉ{Å[ÉhÇ™ëΩÇ¢
ÉIÉNÉ^ÉRÉAÅi8ÉRÉAÅjÉvÉçÉZÉbÉT Exynos 5 ìãç⁄ÅA
Android 4.2 OS ëŒâûÇÃäJî≠é“å¸ÇØÉ{Å[ÉhÅuHardkernel ODROID-XUÅvî≠ï\
http://gpad.tv/develop/hardkernel-odroid-xu/
32bitARMópÇÃeclipseÇ‚JavaÇÕÇÝÇÈÇ™Android SDKÇÕǻǢǻ
Ç¢ÇÎÇ¢ÇÎÇ»ARMÇÃäià¿É{Å[ÉhÇ™èoǃǴǃ
ARMÇÃLinuxÇégǧêlÇ™ëùǶǃÇ≠ÇÍÇŒäJî≠ä¬ã´ÇÕêÆǡǃÇ≠ÇÈÇ©ÇýÇ»
64bitARMópÇýÇ»
>>242
thousands of boardsÇêÁñáÇ∆ñÛÇ∑ÇÃÇÕÇ≥Ç∑ǙDžǻǢÇÌÇó
thousands of boardsÇêÁñáÇ∆ñÛÇ∑ÇÃÇÕÇ≥Ç∑ǙDžǻǢÇÌÇó
ÇÝÇÝÅAêîêÁñáÇ»
thousandsÇÃè„ÇÕmillionsÇ≈ÅAhundred thousandÇ…ÇýÇ»ÇËǧÇÈÇ©ÇÁ
thousands ofÇÕï∂ñ¨éüëÊÇ≈ÅuâΩñúÇýÇÃÅvÅuâΩè\ñúÇýÇÃÅvÇ∆ÇýñÛÇ≥ÇÍÇÈ
DZÇÃèÍçáçZêîÇ≈400/1000íBê¨ÇµÇΩÇÃÇæÇ©ÇÁë‰êîDžǬǢǃÇýǪÇÃíˆìxÇÃäÑçáÇíBê¨ÇµÇΩÇ∆ì«ÇÞÇÃÇ™ïÅí
thousands ofÇÕï∂ñ¨éüëÊÇ≈ÅuâΩñúÇýÇÃÅvÅuâΩè\ñúÇýÇÃÅvÇ∆ÇýñÛÇ≥ÇÍÇÈ
DZÇÃèÍçáçZêîÇ≈400/1000íBê¨ÇµÇΩÇÃÇæÇ©ÇÁë‰êîDžǬǢǃÇýǪÇÃíˆìxÇÃäÑçáÇíBê¨ÇµÇΩÇ∆ì«ÇÞÇÃÇ™ïÅí
249 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 19:26:55.13 ID:xCsCg98m
ID:OWGOvvPh
IntelÇâþè¨ï]âøǵÇΩÇ∆DZÇÎÇ≈éYã∆å¸ÇØÇ≈ÇÃï]âøÇ™0
ǫDZÇÎÇ©É}ÉCÉiÉXÇÃAMDÇ™çÃópÇ≥ÇÍÇÈÇÌÇØÇ∂ǷǻǢÇÒÇæÇ©ÇÁ
ǪǧïKéÄÇ…Ç»ÇÈÇ»ÇÊ
IntelÇâþè¨ï]âøǵÇΩÇ∆DZÇÎÇ≈éYã∆å¸ÇØÇ≈ÇÃï]âøÇ™0
ǫDZÇÎÇ©É}ÉCÉiÉXÇÃAMDÇ™çÃópÇ≥ÇÍÇÈÇÌÇØÇ∂ǷǻǢÇÒÇæÇ©ÇÁ
ǪǧïKéÄÇ…Ç»ÇÈÇ»ÇÊ
250 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 19:29:54.51 ID:xCsCg98m
ìdéqånÇÃäwâ»Ç™1äwîNÇÝÇΩÇË50êlíˆìxÇ∆Ç∑ÇÈÇ»ÇÁ400çZÇ≈20,000ë‰íˆìxÅB
è\ï™Ç∂ǷǻǢÇÃÅB
è\ï™Ç∂ǷǻǢÇÃÅB
251 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 19:58:09.32 ID:xCsCg98m
>>245
ìÆǢǃÇýàÍî ìIÇ»ARMÉfÉoÉCÉXÇ≈ÇÕégÇ¢ï®Ç…Ç»ÇÁǻǢÇ≈ǵÇÂ
ÅuÇÝÇÈÅvDZÇ∆Ç∆égÇ¢ï®Ç…Ç»ÇÈDZÇ∆ÇÕëSÇ≠ï ÅB
GoogleÇýAppleÇýARMÇÉvÉçÉ_ÉNÉVÉáÉìä¬ã´Ç∆ǵǃégǧDZÇ∆Ç
ëzíËǵǃǻǢÅBìñÇΩÇËëOÇæÇØÇ«ÅB
iOSå¸ÇØÇÃÉ\ÉtÉgäJî≠Ç…MacÇ™ïKóvÇæÇ©ÇÁMacÇ™îÑÇÍÇÈÅB
ǪǵǃGoogleÇýäJî≠ópí[ññÇ∆ǵǃêÑèßǵǃÇÈÇÃÇÕWindows, Mac, Linux
ÇÃx86(x64)î≈Ç≈ÇÝǡǃÅAAndroidÇ≈ÇÃÉZÉãÉtÉrÉãÉhÇÕǪÇýǪÇý
ëzíËǵǃǻǢÅB
Googleé©êgAndroidÇÕx86Ç‚MIPSå¸ÇØÇýçÏǡǃǃARMÇ◊Ç¡ÇΩÇË
åXì|Ç∑ÇÈà”ê}ÇýëSÇ≠ǻǢÅB
ìÆǢǃÇýàÍî ìIÇ»ARMÉfÉoÉCÉXÇ≈ÇÕégÇ¢ï®Ç…Ç»ÇÁǻǢÇ≈ǵÇÂ
ÅuÇÝÇÈÅvDZÇ∆Ç∆égÇ¢ï®Ç…Ç»ÇÈDZÇ∆ÇÕëSÇ≠ï ÅB
GoogleÇýAppleÇýARMÇÉvÉçÉ_ÉNÉVÉáÉìä¬ã´Ç∆ǵǃégǧDZÇ∆Ç
ëzíËǵǃǻǢÅBìñÇΩÇËëOÇæÇØÇ«ÅB
iOSå¸ÇØÇÃÉ\ÉtÉgäJî≠Ç…MacÇ™ïKóvÇæÇ©ÇÁMacÇ™îÑÇÍÇÈÅB
ǪǵǃGoogleÇýäJî≠ópí[ññÇ∆ǵǃêÑèßǵǃÇÈÇÃÇÕWindows, Mac, Linux
ÇÃx86(x64)î≈Ç≈ÇÝǡǃÅAAndroidÇ≈ÇÃÉZÉãÉtÉrÉãÉhÇÕǪÇýǪÇý
ëzíËǵǃǻǢÅB
Googleé©êgAndroidÇÕx86Ç‚MIPSå¸ÇØÇýçÏǡǃǃARMÇ◊Ç¡ÇΩÇË
åXì|Ç∑ÇÈà”ê}ÇýëSÇ≠ǻǢÅB
Cortex-A57Ç™ç⁄Ç¡ÇΩChromebookÇ∆Ç©èoÇΩÇÁÇøÇÂÇ¡Ç∆ó~ǵÇ≠Ç»ÇËǪǧ
253 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 20:25:42.20 ID:xCsCg98m
ChromeBookÇ»ÇÒǃǫǧÇπHTML+JavaScriptÇ≈ǵǩÉvÉçÉOÉâÉ~ÉìÉO
Ç≈ǴǻǢǩÇÁÇ«ÇÍégǡǃÇýìØÇ∂ÇÊÅB
Ç«ÇÍégǡǃÇýìØÇ∂ÇæÇ©ÇÁåãâ ìIÇ…ÉRÉXÉpÇ≈óDÇÍÇÈCeleronÇ™àÍî‘
çÃópÇ≥ÇÍǃÇÈÇÌÇØÅB
êVǵǢï®çDÇ´Ç™ÅuARMÇ≈ÇÝÇÈDZÇ∆ÅvÇ…âøílÇå©èoÇ∑ãCéùÇøÇýÇÌÇ©ÇÈÇ™
ǪÇÒÇ»ÇýÇÃÇÕëÂÇ´Ç»ÉrÉWÉlÉXÇ…Ç»ÇËǶǻǢÇÒÇæÇÊÅB
êVǵÇ≠Ç»Ç≠ǻǡÇΩéûì_Ç≈ãªñ°Çé∏ǧǩÇÁÇæÅB
ÇΩÇÐÇ…ìsâÔÇ©ÇÁó£ÇÍÇΩéRó—Ç≈ÉLÉÉÉìÉvÇǵÇΩÇ≠Ç»ÇÈãCéùÇøÇ∆àÍèèÅB
ÇΩÇÐÇ…Ç‚ÇÈÇ©ÇÁñ îíǢǩÇýǵÇÍǻǢǙñàì˙ñÏèhÇ»ÇÒǃǂÇÍÇÈÇ©ÅH
Ç≈ǴǻǢǩÇÁÇ«ÇÍégǡǃÇýìØÇ∂ÇÊÅB
Ç«ÇÍégǡǃÇýìØÇ∂ÇæÇ©ÇÁåãâ ìIÇ…ÉRÉXÉpÇ≈óDÇÍÇÈCeleronÇ™àÍî‘
çÃópÇ≥ÇÍǃÇÈÇÌÇØÅB
êVǵǢï®çDÇ´Ç™ÅuARMÇ≈ÇÝÇÈDZÇ∆ÅvÇ…âøílÇå©èoÇ∑ãCéùÇøÇýÇÌÇ©ÇÈÇ™
ǪÇÒÇ»ÇýÇÃÇÕëÂÇ´Ç»ÉrÉWÉlÉXÇ…Ç»ÇËǶǻǢÇÒÇæÇÊÅB
êVǵÇ≠Ç»Ç≠ǻǡÇΩéûì_Ç≈ãªñ°Çé∏ǧǩÇÁÇæÅB
ÇΩÇÐÇ…ìsâÔÇ©ÇÁó£ÇÍÇΩéRó—Ç≈ÉLÉÉÉìÉvÇǵÇΩÇ≠Ç»ÇÈãCéùÇøÇ∆àÍèèÅB
ÇΩÇÐÇ…Ç‚ÇÈÇ©ÇÁñ îíǢǩÇýǵÇÍǻǢǙñàì˙ñÏèhÇ»ÇÒǃǂÇÍÇÈÇ©ÅH
ñÏèhópDžǟǵǢǡǃòbÇæÇÎÇó
chrome bookǡǃǫÇÒÇ»É\ÉtÉgÇ™ÇÝÇÈÇÒÇ©ÇÃ
256 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/22(ñÿ) 20:54:13.60 ID:xCsCg98m
Google ChromeÇ≈ìÆÇ≠WebÉAÉvÉä(ÉvÉâÉOÉCÉì)ǙǪÇÃÇÐÇÐìÆÇ≠ÇæÇØÇÊ
flashÇÕÅH
DZÇÃÉ{Å[ÉhÇýÇ∑Ç≤Ǣǻ
Android Ç‚ Ubuntu OS ëŒâûÇÃ
í·è¡îÔìdóÕÇ»è¨å^ÉVÉìÉOÉãÉ{Å[ÉhÉRÉìÉsÉÖÅ[É^Å[ÅupcDuino3ÅvìoèÍÅA
âøäi77ÉhÉãÅiñÒ8,000â~Åj
http://gpad.tv/develop/pcduino3/
http://www.pcduino.com/pcduino-v3/
ÉXÉyÉbÉN
OS: Android 4.2 Jelly Bean, Ubuntu 12.04 ëŒâû
CPU: Allwinner A20 (Cortex-A7) Dual-core 1GHz
GPU: Mali-400
RAM: 1GB
ROM: 4GB
ÉTÉCÉY: 121Å~65mm
âÊñ èoóÕ: HDMI 1.4 (HDCP ÉTÉ|Å[Ég)
âëúìx: 1920Å~1080 Full-HD
í êM: Ethernet 10/100/1000Mbps (RJ45)
äOïîí[éq: microSD(Max 32GB), USB x1, HDMI, SATA, 3.5mmÉIÅ[ÉfÉBÉIÉWÉÉÉbÉN
ìdåπ: 5V (Li-Poly ÉoÉbÉeÉäÅ[ÉCÉìÉ^Å[ÉtÉFÉCÉXìãç⁄)
Android Ç‚ Ubuntu OS ëŒâûÇÃ
í·è¡îÔìdóÕÇ»è¨å^ÉVÉìÉOÉãÉ{Å[ÉhÉRÉìÉsÉÖÅ[É^Å[ÅupcDuino3ÅvìoèÍÅA
âøäi77ÉhÉãÅiñÒ8,000â~Åj
http://gpad.tv/develop/pcduino3/
http://www.pcduino.com/pcduino-v3/
ÉXÉyÉbÉN
OS: Android 4.2 Jelly Bean, Ubuntu 12.04 ëŒâû
CPU: Allwinner A20 (Cortex-A7) Dual-core 1GHz
GPU: Mali-400
RAM: 1GB
ROM: 4GB
ÉTÉCÉY: 121Å~65mm
âÊñ èoóÕ: HDMI 1.4 (HDCP ÉTÉ|Å[Ég)
âëúìx: 1920Å~1080 Full-HD
í êM: Ethernet 10/100/1000Mbps (RJ45)
äOïîí[éq: microSD(Max 32GB), USB x1, HDMI, SATA, 3.5mmÉIÅ[ÉfÉBÉIÉWÉÉÉbÉN
ìdåπ: 5V (Li-Poly ÉoÉbÉeÉäÅ[ÉCÉìÉ^Å[ÉtÉFÉCÉXìãç⁄)
>>251
ARMÇÃLinuxÉfÉBÉXÉgÉäÇ™èoǃǴÇΩÇÃǙDZDZÇQîNÇ≠ÇÁÇ¢ÇæÇ™
LinuxÇÃäJî≠ÉcÅ[ÉãÇÃëΩÇ≠Ç™égǶÇÈÇ©ÇÁÇ»
DevianÇ‚ubuntuǙǩǻÇËÇÃÇýÇÃÇópà”ǵǃÇ≠ÇÍǃÇÈ
ARMÇÃLinuxÉfÉBÉXÉgÉäÇ™èoǃǴÇΩÇÃǙDZDZÇQîNÇ≠ÇÁÇ¢ÇæÇ™
LinuxÇÃäJî≠ÉcÅ[ÉãÇÃëΩÇ≠Ç™égǶÇÈÇ©ÇÁÇ»
DevianÇ‚ubuntuǙǩǻÇËÇÃÇýÇÃÇópà”ǵǃÇ≠ÇÍǃÇÈ
DebianÇ»
>>259
x86ÉoÉCÉiÉäà»äOÇÃÉpÉbÉPÅ[ÉWÇýÇÝÇÒÇÃÇØ
x86ÉoÉCÉiÉäà»äOÇÃÉpÉbÉPÅ[ÉWÇýÇÝÇÒÇÃÇØ
ARMv8Ç≈miniITXÇ∆Ç©microATXÇ∆Ç©Ç≈ǃÇ≠ÇÈÇ∆ǧÇÍǵǢǙÅc
>>261
ÇýÇøÇÎÇÒÇÝÇÈ
DebianÇÕÇýÇ∆ÇýÇ∆Ç¢ÇÎÇ¢ÇÎÇ»CPUÇ…ëŒâûǵǃÇÈÉfÉBÉXÉgÉäÇæǵ
UbuntuÇÕ2îNà ëOÇ©ÇÁARMÇénÇþÇΩ
ÇýÇøÇÎÇÒÇÝÇÈ
DebianÇÕÇýÇ∆ÇýÇ∆Ç¢ÇÎÇ¢ÇÎÇ»CPUÇ…ëŒâûǵǃÇÈÉfÉBÉXÉgÉäÇæǵ
UbuntuÇÕ2îNà ëOÇ©ÇÁARMÇénÇþÇΩ
ÇýÇøÇÎÇÒÉ}ÉCÉiÅ[å¸ÇØÇÕïiéøÇ™çìÇ¢ÅB
ÇøÇ™Ç≠ǃ
android sdkÇÃ
android sdkÇÃ
Ç¢ÇÐÇÃÇ∆DZÇÎARMÇÃÉ{Å[ÉhÇAndroidÇÃäJî≠Ç…égǧDžÇÕ
ARMÇÃÉ{Å[ÉhÇ≈AndroidÇÃOSÇëñÇÁÇπǃ
é¿ã@Ç∆ǵǃǬǩǧǵǩǻǢǻ
AndroidÇ™ëñÇÈARMÉ{Å[ÉhÇÕëΩǢǵ
ARMÇÃÉ{Å[ÉhÇ≈AndroidÇÃOSÇëñÇÁÇπǃ
é¿ã@Ç∆ǵǃǬǩǧǵǩǻǢǻ
AndroidÇ™ëñÇÈARMÉ{Å[ÉhÇÕëΩǢǵ
268 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/23(ãý) 06:44:28.68 ID:vg4PIbwT
ÇæÇ©ÇÁé¿ã@Ç»ÇÒǃó]ÇËÇýÇÃÇÃï∂í¡ÅiégÇ¢å√ǵÇÃÉXÉ}ÉzÅjégǶnjǢǢÇ∂Ç·ÇÒ
Ç»ÇÒÇ≈äÓî¬îçÇ´èoǵÇÃñ≥çúÇ»É{Å[ÉhǬǩÇÌÇ…Ç·Ç»ÇÁÇÒÇÃÇæ
É^ÉbÉ`ÉpÉlÉãÅEÉfÉBÉXÉvÉåÉCǬǢǃÇÈÅH
Ç»ÇÒÇ≈äÓî¬îçÇ´èoǵÇÃñ≥çúÇ»É{Å[ÉhǬǩÇÌÇ…Ç·Ç»ÇÁÇÒÇÃÇæ
É^ÉbÉ`ÉpÉlÉãÅEÉfÉBÉXÉvÉåÉCǬǢǃÇÈÅH
Arduino(ìdéqçHçÏ)
Arm(ÉXÉ}Éz)
x86(PCÅAÉ^ÉuÉåÉbÉg)
DZÇÍà»äOÇÕé˘óvÇ»Ç≥Ç∑ǨǃçDÇ´èüéËÇ…Ç∑ÇÍnjǢǢÅB
ArduinoÇÃíuÇ´ä∑ǶDžIntelÇ∆Ç©AMDÇ∆Ç©ARMÇ∆Ç©Ç¢ÇÁǻǢǵÅAíNÇýñ]ÇÒÇ≈ǻǢǩÇÁÅB
Arm(ÉXÉ}Éz)
x86(PCÅAÉ^ÉuÉåÉbÉg)
DZÇÍà»äOÇÕé˘óvÇ»Ç≥Ç∑ǨǃçDÇ´èüéËÇ…Ç∑ÇÍnjǢǢÅB
ArduinoÇÃíuÇ´ä∑ǶDžIntelÇ∆Ç©AMDÇ∆Ç©ARMÇ∆Ç©Ç¢ÇÁǻǢǵÅAíNÇýñ]ÇÒÇ≈ǻǢǩÇÁÅB
Ç«ÇÃÉZÉOÉÅÉìÉgÇ…ÇýïKóvÇ∆Ç≥ÇÍǃǻǢÇÃÇ™ÇÝÇÞÇ«
>ArduinoÇÃíuÇ´ä∑ǶDžIntelÇ∆Ç©AMDÇ∆Ç©ARMÇ∆Ç©Ç¢ÇÁǻǢǵÅAíNÇýñ]ÇÒÇ≈ǻǢǩÇÁÅB
http://arduino.cc/en/Main/ArduinoBoardDue
http://arduino.cc/en/Main/ArduinoBoardZero
ÉpÉbÇ∆ǵǻǢDueÇÕÇ∆ÇýÇ©Ç≠ZeroÇÕÇÐÇæÇÌÇ©ÇÁÇÒÇÊÅB
http://arduino.cc/en/Main/ArduinoBoardDue
http://arduino.cc/en/Main/ArduinoBoardZero
ÉpÉbÇ∆ǵǻǢDueÇÕÇ∆ÇýÇ©Ç≠ZeroÇÕÇÐÇæÇÌÇ©ÇÁÇÒÇÊÅB
ìdéqçHçÏÇÃÇŸÇ∆ÇÒÇ«ÇÃópìrÇ≈ÉpÉèÅ[ǙǢÇÁǻǢÅB
ÉpÉèÅ[ǙǢÇÈÇÃÇ»ÇÁç°ìxÇÕLinuxÇÃÇÊǧǻOSÇýïKóvÇ…Ç»ÇÈÅBArmÇ…ArdunioÇÕñïsë´ÅB
ÉpÉèÅ[ǙǢÇÈÇÃÇ»ÇÁç°ìxÇÕLinuxÇÃÇÊǧǻOSÇýïKóvÇ…Ç»ÇÈÅBArmÇ…ArdunioÇÕñïsë´ÅB
273 ÅFSocket774ÅF2014/05/23(ãý) 10:11:52.48 ID:Dz295gix
>>269
É^ÉuÉåÉbÉgÇÕARMÇÃǟǧǙïÅãyǵǃǪǧÇæÇ™
É^ÉuÉåÉbÉgÇÕARMÇÃǟǧǙïÅãyǵǃǪǧÇæÇ™
ǧÇÞ
Ç`ÇéÇÑÇíÇèÇâÇÑÉ^ÉuÉåÉbÉgÇ…âŒÇǬÇØÇΩÇÃÇÕKindle FireÇ∆Nexus 7ÇÃí·âøäiïi
ChromebookÇ™ÉAÉÅÉäÉJÇ≈îÑÇÍÇΩÇÃÇÕÉTÉÄÉXÉìÇÃí·âøäiïi
ARMäJî≠É{Å[ÉhÇÕRaspberry Piǻǫí·âøäiÇÃÇýÇÃÇ™êlãCÇ™ÇÝÇÈ
ÉRÉìÉsÉÖÅ[É^Ç™à¿Ç≠éËÇ…ì¸ÇÈÇÊǧDžǻǡǃ
àÍêlÇ≈ï°êîë‰ÇýǃÇÈÇÊǧDžǻÇËì∆êËÇ™ïˆÇÍǃǴÇΩÇ»
ChromebookÇ™ÉAÉÅÉäÉJÇ≈îÑÇÍÇΩÇÃÇÕÉTÉÄÉXÉìÇÃí·âøäiïi
ARMäJî≠É{Å[ÉhÇÕRaspberry Piǻǫí·âøäiÇÃÇýÇÃÇ™êlãCÇ™ÇÝÇÈ
ÉRÉìÉsÉÖÅ[É^Ç™à¿Ç≠éËÇ…ì¸ÇÈÇÊǧDžǻǡǃ
àÍêlÇ≈ï°êîë‰ÇýǃÇÈÇÊǧDžǻÇËì∆êËÇ™ïˆÇÍǃǴÇΩÇ»
ì∆êËÇ™ïˆÇÍÇΩÇ∆ǢǧÇÊÇËêVÇΩÇ»ì∆êËÇÃénÇÐÇËÇ©Çý
2013îNÇÃê¢äEPCèoâ◊ë‰êîÇÕ11.2Åìå∏ÅAÉ^ÉuÉåÉbÉgÇÕ53.4ÅìëùÅAGartneró\ë™
http://itpro.nikkeibp.co.jp/article/NEWS/20131022/512666/
2013îNÇ…Ç®ÇØÇÈÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÉfÉoÉCÉXÇÃèoâ◊ë‰êîÇOSï Ç…å©ÇÈÇ∆ÅA
ÅuAndroidÅvÇ™8â≠7991ñúë‰Ç≈ç≈ÇýëΩÇ≠ÅA
ëSèoâ◊ë‰êîÇ…êËÇþÇÈäÑçáÇÕ38ÅìÇ…Ç»ÇÈå©í ǵÅB
DZÇÃå„ÅuWindowsÅvÇÃ3â≠3155ñúë‰ÅiÉVÉFÉAÇÕ14ÅìÅjÅA
ÅuiOS/Mac OSÅvÇÃ2â≠7194ñúë‰ÅiìØ12ÅìÅjÅA
ÅuBlackBerryÅiRIMÅjÅvÇÃ2310ñúë‰ÅiìØ1ÅìÅjÇ∆ë±Ç≠Ç∆ìØé–ÇÕó\ë™ÇµÇƒÇ¢ÇÈÅB
2013îNÇÃê¢äEPCèoâ◊ë‰êîÇÕ11.2Åìå∏ÅAÉ^ÉuÉåÉbÉgÇÕ53.4ÅìëùÅAGartneró\ë™
http://itpro.nikkeibp.co.jp/article/NEWS/20131022/512666/
2013îNÇ…Ç®ÇØÇÈÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÉfÉoÉCÉXÇÃèoâ◊ë‰êîÇOSï Ç…å©ÇÈÇ∆ÅA
ÅuAndroidÅvÇ™8â≠7991ñúë‰Ç≈ç≈ÇýëΩÇ≠ÅA
ëSèoâ◊ë‰êîÇ…êËÇþÇÈäÑçáÇÕ38ÅìÇ…Ç»ÇÈå©í ǵÅB
DZÇÃå„ÅuWindowsÅvÇÃ3â≠3155ñúë‰ÅiÉVÉFÉAÇÕ14ÅìÅjÅA
ÅuiOS/Mac OSÅvÇÃ2â≠7194ñúë‰ÅiìØ12ÅìÅjÅA
ÅuBlackBerryÅiRIMÅjÅvÇÃ2310ñúë‰ÅiìØ1ÅìÅjÇ∆ë±Ç≠Ç∆ìØé–ÇÕó\ë™ÇµÇƒÇ¢ÇÈÅB
ÇŸÇ⁄äÆëSÇ…Ç–Ç¡Ç≠ÇËǩǶǡÇøǷǡǃÇÈÇ©ÇÁÅAMSÇýÇ∆ÇøÇ≠ÇÈǡǃ8ÇÇÝÇÒǻǔǧDžǵÇΩÇÒÇæÇÎ
ÉRÉìÉsÉÖÅ[É^ÇÃóéjè„ÅAà¿Ç≠ǃëÂó Ç…èoǃÇÈǟǧǙǟÇ∆ÇÒÇ«èüǡǃÇÈÇ©ÇÁÅAÇýǧèüïâÇÕå©Ç¶ÇƒÇÈÇ∆ǢǡǃÇýǢǢ
ÉRÉìÉsÉÖÅ[É^ÇÃóéjè„ÅAà¿Ç≠ǃëÂó Ç…èoǃÇÈǟǧǙǟÇ∆ÇÒÇ«èüǡǃÇÈÇ©ÇÁÅAÇýǧèüïâÇÕå©Ç¶ÇƒÇÈÇ∆ǢǡǃÇýǢǢ
ÉRÉìÉeÉìÉcêßçÏå^ÉÜÅ[ÉUÅ[Ç∆ÉRÉìÉeÉìÉcè¡îÔå^ÇÃÉÜÅ[ÉUÅ[Ç™égǧÉRÉìÉsÉÖÅ[É^Ç™ï Ç…Ç»ÇÈǡǃǢǧ
ì]ä∑ä˙Ç»ÇÒÇæÇÊ
Ç¢ÇÐÇÐÇ≈ÇÕÅAÉRÉìÉeÉìÉcêßçÏå^ÇýÉRÉìÉeÉìÉcè¡îÔå^ÇýÇ«ÇøÇÁÇýìØÇ∂PCÇégǡǃÇΩÇ™ÅA
DZÇÍÇ©ÇÁÇÕÅAÉRÉìÉeÉìÉcêßçÏå^ÉÜÅ[ÉUÅ[Ç™PCÇégÇ¢ÅA
ÉRÉìÉeÉìÉcè¡îÔå^ÉÜÅ[ÉUÅ[Ç™ÉXÉ}ÉzÅEÉ^ÉuÉåÉbÉgÇégǧéûë„
ì]ä∑ä˙Ç»ÇÒÇæÇÊ
Ç¢ÇÐÇÐÇ≈ÇÕÅAÉRÉìÉeÉìÉcêßçÏå^ÇýÉRÉìÉeÉìÉcè¡îÔå^ÇýÇ«ÇøÇÁÇýìØÇ∂PCÇégǡǃÇΩÇ™ÅA
DZÇÍÇ©ÇÁÇÕÅAÉRÉìÉeÉìÉcêßçÏå^ÉÜÅ[ÉUÅ[Ç™PCÇégÇ¢ÅA
ÉRÉìÉeÉìÉcè¡îÔå^ÉÜÅ[ÉUÅ[Ç™ÉXÉ}ÉzÅEÉ^ÉuÉåÉbÉgÇégǧéûë„
è¡îÔë§Ç…îƒópî\óÕÇ™îÒèÌÇ…çÇÇ¢PCǙǪÇÃÇÐÇÐégÇÌÇÍǃǢÇΩÇ∆ǢǧÇÃÇ™
àÍéûìIÇ»åªè€ÇæÇ¡ÇΩÇÒÇ∂ǷǻǢǩÅB
å≥ÅXè¡îÔÇÕâ∆ìdìIÇ»å≈íËÉtÉ@Å[ÉÄÉEÉFÉAÇÃêÍópÉnÅ[ÉhÇÃíSìñÇæÇ¡ÇΩÅB
ǪDZDžPCÇ™êièoǵÇΩÇÌÇØÇæÇ™ÅAç°ìxÇÕê∂éYÇ…ÇÕÇÝÇÐÇËå¸Ç¢ÇƒÇ¢Ç»Ç¢
É^ÉuÉåÉbÉgÇ‚ÉXÉ}Å[ÉgÉtÉHÉìÇ…éÊÇËï‘Ç≥ÇÍǃǢÇÈ
àÍéûìIÇ»åªè€ÇæÇ¡ÇΩÇÒÇ∂ǷǻǢǩÅB
å≥ÅXè¡îÔÇÕâ∆ìdìIÇ»å≈íËÉtÉ@Å[ÉÄÉEÉFÉAÇÃêÍópÉnÅ[ÉhÇÃíSìñÇæÇ¡ÇΩÅB
ǪDZDžPCÇ™êièoǵÇΩÇÌÇØÇæÇ™ÅAç°ìxÇÕê∂éYÇ…ÇÕÇÝÇÐÇËå¸Ç¢ÇƒÇ¢Ç»Ç¢
É^ÉuÉåÉbÉgÇ‚ÉXÉ}Å[ÉgÉtÉHÉìÇ…éÊÇËï‘Ç≥ÇÍǃǢÇÈ
å¬êlìIÇ…ÇÕÉâÉbÉvÉgÉbÉvÇ≈ÇýARM-AndroidÇÃëIëéàÇ™ó~ǵǢ
>>280
aliexpressÇ∆Ç©Ç≈çDÇ´Ç»ÇæÇØîÉÇ¢ÇΩÇÐǶ
aliexpressÇ∆Ç©Ç≈çDÇ´Ç»ÇæÇØîÉÇ¢ÇΩÇÐǶ
ÇýÇ¡Ç∆ïÅãyǵǃåªé¿ìIÇ»ëIëéàDžǻǡǃǟǵǢ
,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÇ™ãCéùÇøà´Ç¢ÇÃÇÕx86Ç∆ǢǧÉAÅ[ÉLÉeÉNÉ`ÉÉÇ∆Ç©Ç∂Ç·Ç»Ç≠ÅAIntelÇÃÇ‚ÇÈDZÇ∆ÇÕëSǃê≥ǵǢÇ∆éÂí£ÇµÇƒÇÈÇ∆DZÇæÇÊÇ»ÅB
Ç¢Ç≠ÇÁÇýÇÁǶÇÒÇÃÅH
Ç¢Ç≠ÇÁÇýÇÁǶÇÒÇÃÅH
>>272
ìdéqçHçÏópÇÃÉ}ÉCÉRÉìÇÃÉpÉèÅ[Ç…ó]óTÇ™ÇÝÇ¡ÇΩÇ∆DZÇÎÇ≈ñ‚ëËÇ…Ç»ÇÈDZÇ∆ÇÕǻǢÅB
è¡îÔìdóÕÇó}ǶÇÈñ⁄ìIÇ≈ÉçÅ[ÉpÉèÅ[ÇÃMCUÇëIëÇ∑ÇÈDZÇ∆ÇÕÇÝÇÈÇ™ÅAArduinoÇ…ÇÕÉpÉèÅ[É}ÉlÉWÉÅÉìÉgä÷òAÇÃ
APIÇÕÇ»Ç≠è»ìdóÕÇ∆ǢǧçlǶÇÕîñÇ¢ÅBArduino UnoÇ…ìãç⁄Ç≥ÇÍǃÇÈ8bitÇÃATmegaÇ16MHzÇ≈ìÆçÏÇ≥ÇπÇÈÇÊÇË
Arduino ZeroÇ…ìãç⁄Ç≥ÇÍÇÈ32bitÇÃSAMD21Ç48MHzÇ≈ìÆçÏÇ≥ÇπÇÈï˚Ç™è¡îÔìdóÕÇýí·Ç¢ÅB
Arduino Uno/ATmegaÇÃóòì_Ç™âΩÇ©Ç∆çlǶÇÍÇŒ
ÅEéëóøÇ‚çÏó·Ç»Ç«Ç™ñLïxÇ…ëµÇ¡ÇƒÇ¢ÇÈ
ÅEGPIOÇÃó¨ÇπÇÈóeó Ç™ëÂÇ´Ç¢
DZÇÃìÒì_Ç≠ÇÁÇ¢ÇæÇÎǧÅBÇýǵArduino ZeroÇ™åªçsÇÃArduino UnoÇ∆ëÂǵǃïœÇÌÇÁǻǢâøäiÇ≈îÃîÑÇ≥ÇÍÇÍÇŒÅA
Arduino Uno ÇÃèàóùî\óÕÇ‚ÉÅÉÇÉäóeó Ç…ïsñûÇéùǡǃÇΩëwÇ‚êVǵï®çDÇ´ÇÕǪDZǪDZîÚǗǬǴǪǧǻãCÇÕÇ∑ÇÈÅB
>ÉpÉèÅ[ǙǢÇÈÇÃÇ»ÇÁç°ìxÇÕLinuxÇÃÇÊǧǻOSÇýïKóvÇ…Ç»ÇÈÅBArmÇ…ArdunioÇÕñïsë´
ǫǧǢǧä®à·Ç¢ÇµÇƒÇÈÇÃÇ©ímÇÁÇÒÇØÇ«ÅAARM ÇÃCortex-MÉVÉäÅ[ÉYÇÕLinuxìÆçÏÇ≥ÇπÇÈDZÇ∆Ç»ÇÒǃÉnÉiÇ¡Ç©ÇÁ
ëzíËǵǃǻǢǵÅALinuxÇ…å¿ÇÁÇ∏ǪÇÃëºRTOSÇäÐÇÞOSÇ™ä«óùÇ∑ÇÈÇÃÇÕÉäÉ\Å[ÉXëSî Ç≈ÇÝǡǃÅAÉpÉèÅ[ÇÃóLñ≥
Ç∆ÇÕíºê⁄ÇÕä÷åWǙǻǢÅB
ìdéqçHçÏópÇÃÉ}ÉCÉRÉìÇÃÉpÉèÅ[Ç…ó]óTÇ™ÇÝÇ¡ÇΩÇ∆DZÇÎÇ≈ñ‚ëËÇ…Ç»ÇÈDZÇ∆ÇÕǻǢÅB
è¡îÔìdóÕÇó}ǶÇÈñ⁄ìIÇ≈ÉçÅ[ÉpÉèÅ[ÇÃMCUÇëIëÇ∑ÇÈDZÇ∆ÇÕÇÝÇÈÇ™ÅAArduinoÇ…ÇÕÉpÉèÅ[É}ÉlÉWÉÅÉìÉgä÷òAÇÃ
APIÇÕÇ»Ç≠è»ìdóÕÇ∆ǢǧçlǶÇÕîñÇ¢ÅBArduino UnoÇ…ìãç⁄Ç≥ÇÍǃÇÈ8bitÇÃATmegaÇ16MHzÇ≈ìÆçÏÇ≥ÇπÇÈÇÊÇË
Arduino ZeroÇ…ìãç⁄Ç≥ÇÍÇÈ32bitÇÃSAMD21Ç48MHzÇ≈ìÆçÏÇ≥ÇπÇÈï˚Ç™è¡îÔìdóÕÇýí·Ç¢ÅB
Arduino Uno/ATmegaÇÃóòì_Ç™âΩÇ©Ç∆çlǶÇÍÇŒ
ÅEéëóøÇ‚çÏó·Ç»Ç«Ç™ñLïxÇ…ëµÇ¡ÇƒÇ¢ÇÈ
ÅEGPIOÇÃó¨ÇπÇÈóeó Ç™ëÂÇ´Ç¢
DZÇÃìÒì_Ç≠ÇÁÇ¢ÇæÇÎǧÅBÇýǵArduino ZeroÇ™åªçsÇÃArduino UnoÇ∆ëÂǵǃïœÇÌÇÁǻǢâøäiÇ≈îÃîÑÇ≥ÇÍÇÍÇŒÅA
Arduino Uno ÇÃèàóùî\óÕÇ‚ÉÅÉÇÉäóeó Ç…ïsñûÇéùǡǃÇΩëwÇ‚êVǵï®çDÇ´ÇÕǪDZǪDZîÚǗǬǴǪǧǻãCÇÕÇ∑ÇÈÅB
>ÉpÉèÅ[ǙǢÇÈÇÃÇ»ÇÁç°ìxÇÕLinuxÇÃÇÊǧǻOSÇýïKóvÇ…Ç»ÇÈÅBArmÇ…ArdunioÇÕñïsë´
ǫǧǢǧä®à·Ç¢ÇµÇƒÇÈÇÃÇ©ímÇÁÇÒÇØÇ«ÅAARM ÇÃCortex-MÉVÉäÅ[ÉYÇÕLinuxìÆçÏÇ≥ÇπÇÈDZÇ∆Ç»ÇÒǃÉnÉiÇ¡Ç©ÇÁ
ëzíËǵǃǻǢǵÅALinuxÇ…å¿ÇÁÇ∏ǪÇÃëºRTOSÇäÐÇÞOSÇ™ä«óùÇ∑ÇÈÇÃÇÕÉäÉ\Å[ÉXëSî Ç≈ÇÝǡǃÅAÉpÉèÅ[ÇÃóLñ≥
Ç∆ÇÕíºê⁄ÇÕä÷åWǙǻǢÅB
>278Å@>279
IBMÅ@ëÂå^èWíÜã@ÇæÇØÇ≈Ç»Ç≠ÉçÅ[ÉJÉãÉNÉâÉCÉAÉìÉgÇ≈ÇýàÍéûê¨å˜ÅA
Å@Å@Å@ÇæÇ™ÅAã∆äEÇÃêÖïΩï™ã∆âªÇ≈ãèèÍèäÇ™èkè¨ÅAëÂèOÇÕå©éÃǃÇÈòHê¸Ç÷
ÉAÉbÉvÉãÅ@MacOSÅAMachintoshÇ≈ê∂éYë§ÇÃéxéùÇÇÝÇÈíˆìxìæÇΩÇ™
Å@Å@Å@Å@Å@Å@è¡îÔë§Ç≈ÇÕÉVÉFÉAÇêLÇŒÇπÇ∏élãÍî™ãÍ
MSÅ@êEèÍÅAèëç÷ÇêßîeÅBë±Ç¢Çƒãèä‘ÇÃçUó™ÇîþäËÇ∆ǵǃ
Å@Å@Å@îSÇËÇ…îSǡǃǴÇΩÇ™évǧÇÊǧDžçsÇ©Ç∏ÅB
Å´
ÉAÉbÉvÉãÅ@PCÇ∆ÇÕï äpìxÇ©ÇÁiOSÇ∆ǪÇÃÉnÅ[ÉhÇ≈ÉAÉvÉçÅ[É`ǵ
Å@Å@Å@Å@Å@Å@ÉpÅ[É\ÉiÉãÇ©ÇÁÉäÉrÉìÉOÇÃîÕàÕÇÐÇ≈ê¨å˜ÇÃíõǵǙå©Ç¶énÇþÇÈÅAÇ™
ÉOÅ[ÉOÉãÅ@iOSÇ∆ìØólÇÃÉAÉvÉçÅ[É`Ç©ÇÁã}ê¨í∑ÅAÇ©Ç¡Ç≥ÇÁǧÅH
IBMÅ@ëÂå^èWíÜã@ÇæÇØÇ≈Ç»Ç≠ÉçÅ[ÉJÉãÉNÉâÉCÉAÉìÉgÇ≈ÇýàÍéûê¨å˜ÅA
Å@Å@Å@ÇæÇ™ÅAã∆äEÇÃêÖïΩï™ã∆âªÇ≈ãèèÍèäÇ™èkè¨ÅAëÂèOÇÕå©éÃǃÇÈòHê¸Ç÷
ÉAÉbÉvÉãÅ@MacOSÅAMachintoshÇ≈ê∂éYë§ÇÃéxéùÇÇÝÇÈíˆìxìæÇΩÇ™
Å@Å@Å@Å@Å@Å@è¡îÔë§Ç≈ÇÕÉVÉFÉAÇêLÇŒÇπÇ∏élãÍî™ãÍ
MSÅ@êEèÍÅAèëç÷ÇêßîeÅBë±Ç¢Çƒãèä‘ÇÃçUó™ÇîþäËÇ∆ǵǃ
Å@Å@Å@îSÇËÇ…îSǡǃǴÇΩÇ™évǧÇÊǧDžçsÇ©Ç∏ÅB
Å´
ÉAÉbÉvÉãÅ@PCÇ∆ÇÕï äpìxÇ©ÇÁiOSÇ∆ǪÇÃÉnÅ[ÉhÇ≈ÉAÉvÉçÅ[É`ǵ
Å@Å@Å@Å@Å@Å@ÉpÅ[É\ÉiÉãÇ©ÇÁÉäÉrÉìÉOÇÃîÕàÕÇÐÇ≈ê¨å˜ÇÃíõǵǙå©Ç¶énÇþÇÈÅAÇ™
ÉOÅ[ÉOÉãÅ@iOSÇ∆ìØólÇÃÉAÉvÉçÅ[É`Ç©ÇÁã}ê¨í∑ÅAÇ©Ç¡Ç≥ÇÁǧÅH
>>284
>Arduino ZeroÇ…ìãç⁄Ç≥ÇÍÇÈ32bitÇÃSAMD21Ç48MHzÇ≈ìÆçÏÇ≥ÇπÇÈï˚Ç™è¡îÔìdóÕÇýí·Ç¢ÅB
Ç≈Ç«ÇÍÇÆÇÁÇ¢ÇÃè¡îÔìdóÕÇ»ÇÃÅHÅ@20mWÇ∆Ç©Ç≈ìÆÇ≠ÇÃÅH
>Arduino ZeroÇ…ìãç⁄Ç≥ÇÍÇÈ32bitÇÃSAMD21Ç48MHzÇ≈ìÆçÏÇ≥ÇπÇÈï˚Ç™è¡îÔìdóÕÇýí·Ç¢ÅB
Ç≈Ç«ÇÍÇÆÇÁÇ¢ÇÃè¡îÔìdóÕÇ»ÇÃÅHÅ@20mWÇ∆Ç©Ç≈ìÆÇ≠ÇÃÅH
>>286
Ç»ÇÒÇ≈ÉfÅ[É^ÉVÅ[Égå©Ç»Ç¢ÇÃ?
Ç»ÇÒÇ≈ÉfÅ[É^ÉVÅ[Égå©Ç»Ç¢ÇÃ?
>>287
âRÇæÇ∆ímǡǃÇÈÇ©ÇÁÅB
âRÇæÇ∆ímǡǃÇÈÇ©ÇÁÅB
Ç»ÇÒÇæì™ÇÃà´Ç¢êlÇ©ÅB
ìdírìÆçÏÇÃã@äÌÇ…ArduinoÇÕégÇ¢ÇΩÇ≠ǻǢǻ
ARMÇÃëgÇðçûÇðÉ{Å[ÉhÇ»ÇÁmbedÇ™ÇÝÇÈÇ»
>>279
Ç∑Ç∞Å[î[ìæǵÇΩÅB
Ç∑Ç∞Å[î[ìæǵÇΩÅB
évǶnjÅASandyBridgeÇÃè’åÇÇÕÇ∑Ç≤Ç©Ç¡ÇΩ
2011îNÅ@32nmÅ@Sandy Bridge
2012îNÅ@22nmÅ@Ivy Bridge
2013îNÅ@22nmÅ@Haswell
2014îNÅ@14nmÅ@HaswellRefresh,Broadwell
2015îNÅ@Å@Å@Å@ǻǵ
2016îNÅ@14nmÅ@Skylake
2017îNÅ@10nmÅ@Cannonlake
2011îNÅ@32nmÅ@Sandy Bridge
2012îNÅ@22nmÅ@Ivy Bridge
2013îNÅ@22nmÅ@Haswell
2014îNÅ@14nmÅ@HaswellRefresh,Broadwell
2015îNÅ@Å@Å@Å@ǻǵ
2016îNÅ@14nmÅ@Skylake
2017îNÅ@10nmÅ@Cannonlake
294 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/24(ìy) 16:57:20.64 ID:kSRDc0s+
>>293
SkyBridgeÇýì¸ÇÍǃÇÝÇ∞ǃÇ≠ÇæÇ≥Ç¢
SkyBridgeÇýì¸ÇÍǃÇÝÇ∞ǃÇ≠ÇæÇ≥Ç¢
î@âΩÇ…çÇë¨ÉÅÉÇÉäÇ∆åæǶǫÅCç≈ëÂóeó 64GBÇ∆Ç©à´ñ≤Ç≈ǵǩǻǢÇÌ
ÉÅÉCÉìÉÅÉÇÉäÇÕç≈í·Ç≈Çý128BGÇÕó~ǵǢǺ
2018îNçÝÇ»ÇÁ
ÉÅÉCÉìÉÅÉÇÉäÇÕç≈í·Ç≈Çý128BGÇÕó~ǵǢǺ
2018îNçÝÇ»ÇÁ
L4$ 1GB
ÉÅÉCÉìÉÅÉÇÉä 1TB
2020îNÇ…ÇÕDZÇÍÇ≠ÇÁÇ¢ïKóv
ÉÅÉCÉìÉÅÉÇÉä 1TB
2020îNÇ…ÇÕDZÇÍÇ≠ÇÁÇ¢ïKóv
BGǡǃǢǧÇ∆ÉrÉWÉlÉXÉKÅ[ÉãÅiå„ÇÃOL)
>>296
WindowsÇÕïƒçëê≠ï{ã@ä÷ÇýégópÇ∑ÇÈåˆã§çýÇæÇ©ÇÁèüéËÇÕãñÇ≥ÇÍǻǢÇÊÅB
ç°ÇÐÇ≈è„Ç∞ǃǴÇΩóòâvÇ∆ëäâûÇÃê”îCÇ™ÇÝÇÈÅB
ëºÇ…îÑÇËìnǵÇΩÇ∆ǵǃÇýǪÇÃâÔé–Ç…ê”îCÇ™à⁄ÇÈÇæÇØÅB
ê”îCî\óÕÇ™ñ≥ÇØÇÍÇŒÉ\Å[ÉXåˆäJÇ≥ÇπÇÁÇÍÇÈÇ©ÇÁëºÇ…ÉTÉ|Å[ÉgÇ‚ÇÈâÔé–Ç‚ícëÃÇ™èoǃÇ≠ÇÈÇæÇÎǧÅB
WindowsÇÕïƒçëê≠ï{ã@ä÷ÇýégópÇ∑ÇÈåˆã§çýÇæÇ©ÇÁèüéËÇÕãñÇ≥ÇÍǻǢÇÊÅB
ç°ÇÐÇ≈è„Ç∞ǃǴÇΩóòâvÇ∆ëäâûÇÃê”îCÇ™ÇÝÇÈÅB
ëºÇ…îÑÇËìnǵÇΩÇ∆ǵǃÇýǪÇÃâÔé–Ç…ê”îCÇ™à⁄ÇÈÇæÇØÅB
ê”îCî\óÕÇ™ñ≥ÇØÇÍÇŒÉ\Å[ÉXåˆäJÇ≥ÇπÇÁÇÍÇÈÇ©ÇÁëºÇ…ÉTÉ|Å[ÉgÇ‚ÇÈâÔé–Ç‚ícëÃÇ™èoǃÇ≠ÇÈÇæÇÎǧÅB
ëΩçëê–äÈã∆ÇÃëÂÇ´Ç¢Ç∆DZÇÎÇÕè¨çëÇÊÇËåoçœãKñÕÇ™ëÂÇ´Ç¢ÇÃÇ∆ìØólÇ…
MSÇ»ÇÁÉRÉìÉVÉÖÅ[É}ÇÃWindowsÇÇ‚ÇþǃÇýÉrÉWÉlÉXï™ñÏÇæÇØÇ≈
ÇŸÇ∆ÇÒÇ«ÇÃÉ\ÉtÉgÉEÉFÉAäÈã∆ÇÊÇËëÂÇ´Ç¢ÇÒÇ∂ǷǻǢǩ
MSÇ»ÇÁÉRÉìÉVÉÖÅ[É}ÇÃWindowsÇÇ‚ÇþǃÇýÉrÉWÉlÉXï™ñÏÇæÇØÇ≈
ÇŸÇ∆ÇÒÇ«ÇÃÉ\ÉtÉgÉEÉFÉAäÈã∆ÇÊÇËëÂÇ´Ç¢ÇÒÇ∂ǷǻǢǩ
302 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/05/25(ì˙) 20:21:05.00 ID:D7JVguV0
ǪÇÃÉrÉWÉlÉXï™ñÏå¸ÇØÇÃWindowsÇÇ‚ÇþÇÈÇÌÇØǙǻǢǡǃòbÇ»ÇÒÇæÇ™
ÇÐÇüÇøÇÂÇ¡Ç∆êÃÇ…ÇÕÉZÉåÉçÉìêœÇÒÇæâ∆ìdÅAHDDÉåÉRÅ[É_ÇýÇÝÇËÇÐǵÇΩÅc(âìÇ¢ñ⁄)
ëΩólâªÇ≈DRAMÇ™ïœÇÌÇÈÅAÉÅÉÇÉääKëwÇ™ïœÇÌÇÈ
http://pc.watch.impress.co.jp/docs/column/kaigai/20140526_650009.html?ref=rss
http://pc.watch.impress.co.jp/docs/column/kaigai/20140526_650009.html?ref=rss
>>304
å„ì°ÇøÇ·ÇÒÇÕäÈã∆ÇÃÉçÉrÅ[äàìÆǵǩǂÇÁÇ»Ç≠ǻǡÇΩÇ»
å„ì°ÇøÇ·ÇÒÇÕäÈã∆ÇÃÉçÉrÅ[äàìÆǵǩǂÇÁÇ»Ç≠ǻǡÇΩÇ»
éëãýÇÃÇÝÇÈëÂäÈã∆Ç™ìÆÇ©Ç»ÇØÇÍÇŒâΩÇ©çÏÇÍǃÇýå§ãÜé∫ÇÃíÜÇ≈èIÇÌǡǃ
ǵÇÐǧǩÇÁÅAǪǧǢǧãLéñÇ…Ç»ÇÈÇÃÇÕÇÝÇÈíˆìxǵǩÇΩǙǻǢÇæÇÎǧÅB
ëÂäÈã∆ÇýÅAóùëzÇÃãZèpÉrÉWÉáÉìÇí«Ç§Ç±Ç∆ÇäîéÂÇ™ãñÇ∑Ç∆ÇÕå¿ÇÁǻǢÅB
ç°ÇÃé–âÔç\ë¢é©ëÃÇ™éùǬå¿äEÅB
ǵÇÐǧǩÇÁÅAǪǧǢǧãLéñÇ…Ç»ÇÈÇÃÇÕÇÝÇÈíˆìxǵǩÇΩǙǻǢÇæÇÎǧÅB
ëÂäÈã∆ÇýÅAóùëzÇÃãZèpÉrÉWÉáÉìÇí«Ç§Ç±Ç∆ÇäîéÂÇ™ãñÇ∑Ç∆ÇÕå¿ÇÁǻǢÅB
ç°ÇÃé–âÔç\ë¢é©ëÃÇ™éùǬå¿äEÅB
Ç≈ÇýÇÐÇÝé¿ç€ÅAǪÇÃãLéñÇ«Ç®ÇËÇ…Ç»ÇÈǩǫǧǩÇÕï Ç∆ǵǃâΩÇÁÇ©ÇÃïœâªÇÕÇÝÇÈÇæÇÎ
IntelÇ»ÇÁ•••IntelÇ»ÇÁǫǧDžǩǵǃÇ≠ÇÍÇÈ•••
309 ÅFSocket774ÅF2014/05/30(ãý) 13:45:26.75 ID:d0FxJbdx
http://jp.wsj.com/news/articles/SB10001424052702304817704579593084119885764
ÅÑ ÉpÉ\ÉRÉìå¸ÇØîºì±ëÃÇÃê®Ç¢Ç™é∏ÇÌÇÍÇÈåªèÛÇ…íºñ Ç∑ÇÈÉCÉìÉeÉãÇÕÅA
ÅÑ êVǵǢé˚âvåπÇñÕçıÇ∑ÇÈíÜÇ≈é©é–ÇÃãZèpÇÅué©ìÆâ^ì]é‘ÅvÇ…ì±ì¸Ç∑ÇÈéÊÇËëgÇðÇñ{äiâªÇµÇƒÇ¢ÇÈ
îÑÇÍǻǢǩÇÁǡǃëºï˚ñ Ç…ïÇãCÇ∑ÇÈÇÒÇ∂ǷǻǢÇÊ
ÅÑ ÉpÉ\ÉRÉìå¸ÇØîºì±ëÃÇÃê®Ç¢Ç™é∏ÇÌÇÍÇÈåªèÛÇ…íºñ Ç∑ÇÈÉCÉìÉeÉãÇÕÅA
ÅÑ êVǵǢé˚âvåπÇñÕçıÇ∑ÇÈíÜÇ≈é©é–ÇÃãZèpÇÅué©ìÆâ^ì]é‘ÅvÇ…ì±ì¸Ç∑ÇÈéÊÇËëgÇðÇñ{äiâªÇµÇƒÇ¢ÇÈ
îÑÇÍǻǢǩÇÁǡǃëºï˚ñ Ç…ïÇãCÇ∑ÇÈÇÒÇ∂ǷǻǢÇÊ
opencvÇÃäJî≠å≥Çæǵ
311 ÅFSocket774ÅF2014/05/30(ãý) 14:13:01.51 ID:ij6ImIt3
êVǵǢésèÍÇäJëÒÇ∑ÇÈÇÃÇÕó«Ç¢Ç±Ç∆Ç≈Ç∑ÇÊ
ÉXÉ}ÉtÉHÇÕǫǧǵÇΩ
Çýǧí˙ÇþÇΩÇÃÇ©
Çýǧí˙ÇþÇΩÇÃÇ©
313 ÅFSocket774ÅF2014/05/30(ãý) 17:09:50.24 ID:ij6ImIt3
ÇÞǵÇÎóÕì¸ÇÍÇ∑ǨǃÇÌÇØÇÌÇ©ÇÁÇÒ
Intel Atom SOC Roadmap For Tablets and Smartphones Leaked ? 14nm Airmont and Goldmont Based Chips Detailed
http://wccftech.com/intel-atom-soc-roadmap-tablets-smartphones-leaked-14nm-airmont-goldmont-based-chips-detailed/
http://www.forum-3dcenter.org/vbulletin/showthread.php?t=545126&page=3
http://cdn4.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Airmont-Goldmont.png
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-14nm-10nm-SOCs.png
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Android-Smartphone-Roadmap.png
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-AP-Roadmap.png
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Entry-Level-Roadmap.png
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-FES-Roadmap.png
http://cdn.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-FFRD-Roadmap.png
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Roadmap-Smartphone.png
http://cdn.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Tablet-Roadmap.png
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-LTE.png
Intel Atom SOC Roadmap For Tablets and Smartphones Leaked ? 14nm Airmont and Goldmont Based Chips Detailed
http://wccftech.com/intel-atom-soc-roadmap-tablets-smartphones-leaked-14nm-airmont-goldmont-based-chips-detailed/
http://www.forum-3dcenter.org/vbulletin/showthread.php?t=545126&page=3
http://cdn4.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Airmont-Goldmont.png
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-14nm-10nm-SOCs.png
{kind=link}
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Android-Smartphone-Roadmap.png
{kind=link}
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-AP-Roadmap.png
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Entry-Level-Roadmap.png
{kind=link}
http://cdn2.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-FES-Roadmap.png
{kind=link}
http://cdn.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-FFRD-Roadmap.png
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Roadmap-Smartphone.png
{kind=link}
http://cdn.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-Tablet-Roadmap.png
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/05/Intel-Atom-LTE.png
{kind=link}
é‘ç⁄ÇÕIoTÇÃñ{ä€Ç≈Ç∑ǵ
ì˙ñ{ÇÕîºì±ëÃã∆äEÇ™éÄÇ…Ç©ÇØÇæÇ©ÇÁé‘ç⁄ÉRÉìÉsÉÖÅ[É^ÇÃäJî≠ÇÃíxÇÍÇ…à¯Ç´Ç∏ÇÁÇÍǃ
é©ìÆé‘éYã∆é©ëÃÇ™äÎǧÇ≠Ç»ÇÈÇ©ÇýǵÇÍǻǢ
ì˙ñ{ÇÕîºì±ëÃã∆äEÇ™éÄÇ…Ç©ÇØÇæÇ©ÇÁé‘ç⁄ÉRÉìÉsÉÖÅ[É^ÇÃäJî≠ÇÃíxÇÍÇ…à¯Ç´Ç∏ÇÁÇÍǃ
é©ìÆé‘éYã∆é©ëÃÇ™äÎǧÇ≠Ç»ÇÈÇ©ÇýǵÇÍǻǢ
é‘ç⁄ǡǃåæǧǩé©ìÆâ^ì]é‘DžǻǡǃGoogleÇÃÉâÉCÉZÉìÉXǧÇØǃê∂éYǡǃDZÇ∆DžǻǡÇøÇ·ÇÌǻǢǩêSîz
è≈ì_ÇÕÅAǪDZÇæÇÊÇÀÅB
ÇæÇ©ÇÁDZǪÇÃÅATizenÇ»ÇÃÇ≈ÇÕ
ÇæÇ©ÇÁDZǪÇÃÅATizenÇ»ÇÃÇ≈ÇÕ
é©ìÆâ^ì]ÇÃï˚Ç™éËìÆâ^ì]ÇÊÇËà¿ëSÇ…Ç»ÇÈ
Å´
é©ìÆâ^ì]ÇÃèoóàǻǢé‘ÇÕîÃîÑã÷é~
Å´
é©ìÆâ^ì]ãZèpÇÃóÚÇÈì˙ñ{é‘ÇÕéÄñS or ÉAÉÅÉäÉJäÈã∆ÇÃé©ìÆâ^ì]ãZèpÇ…Ç◊Ç¡ÇΩÇËàÀë∂
Ç»ÇÒǃç≈à´ÇÃÉVÉiÉäÉIÇýÇÝÇËǧÇÈ
Å´
é©ìÆâ^ì]ÇÃèoóàǻǢé‘ÇÕîÃîÑã÷é~
Å´
é©ìÆâ^ì]ãZèpÇÃóÚÇÈì˙ñ{é‘ÇÕéÄñS or ÉAÉÅÉäÉJäÈã∆ÇÃé©ìÆâ^ì]ãZèpÇ…Ç◊Ç¡ÇΩÇËàÀë∂
Ç»ÇÒǃç≈à´ÇÃÉVÉiÉäÉIÇýÇÝÇËǧÇÈ
ìØÇ∂ÉVÉXÉeÉÄÇÃé‘ÇÕÉNÉâÉEÉhä«óùÇ≈çXÇ…à¿ëSê´Ç™ëùǵÇΩÇË
èaëÿâÒîÇÃÇΩÇþÉoÉâÉPÇ≥ÇπÇΩÇË
googleéxîzÇ»ÇÃǩǻǂǡǜÇË
èaëÿâÒîÇÃÇΩÇþÉoÉâÉPÇ≥ÇπÇΩÇË
googleéxîzÇ»ÇÃǩǻǂǡǜÇË
Ç∆ǢǧǩÅAñ@ó•ÇÃêÆîıÇÃíxÇÍÇ∆Ç©îΩëŒâ^ìÆÇ∆Ç©Ç≈ÅAì˙ñ{ÇÃé©ìÆâ^ì]ì±ì¸Ç™íxÇÍÇÈÅ®ãZèpÇ™íxÇÍÇÈÅ®ñ≈ñSǡǃǟǧǙ
ǪÇÃêÃé©ìÆé‘Ç…ÇÕê‘ä¯ñ@ǡǃÇÃÇ™ÇÝǡǃÇæÇ»ÅcÅcñ^ê≠ì}ã@ä÷éÜÇ∆ÇÕä÷åWÇ»Ç≠ÅAé©ìÆé‘Ç»ÇÒǃäÎåØÇæÇ©ÇÁ
é©ìÆé‘ÇÃëOÇêlä‘Ç™ê‘Ç¢ä¯ÇêUǡǃé©ìÆé‘Ç™óàÇÈÇÊǡǃímÇÁÇπÇÎǡǃñ@ó•ÇçÏÇ¡ÇΩçëÇ™ÇÝÇ¡ÇΩÇÒÇæ
àƒÇÃíËé©ìÆé‘ÇÃî≠íBÇ™íxÇÍǃÇ∆ÇËÇÃDZÇ≥ÇÍǃǖǫǢDZÇ∆Ç…
ǪÇÃêÃé©ìÆé‘Ç…ÇÕê‘ä¯ñ@ǡǃÇÃÇ™ÇÝǡǃÇæÇ»ÅcÅcñ^ê≠ì}ã@ä÷éÜÇ∆ÇÕä÷åWÇ»Ç≠ÅAé©ìÆé‘Ç»ÇÒǃäÎåØÇæÇ©ÇÁ
é©ìÆé‘ÇÃëOÇêlä‘Ç™ê‘Ç¢ä¯ÇêUǡǃé©ìÆé‘Ç™óàÇÈÇÊǡǃímÇÁÇπÇÎǡǃñ@ó•ÇçÏÇ¡ÇΩçëÇ™ÇÝÇ¡ÇΩÇÒÇæ
àƒÇÃíËé©ìÆé‘ÇÃî≠íBÇ™íxÇÍǃÇ∆ÇËÇÃDZÇ≥ÇÍǃǖǫǢDZÇ∆Ç…
íNÇýê”îCÇ∆ÇËÇΩÇ≠ǻǢǩÇÁÇÀ
íßêÌǵǻǢé“ÇÕâiâìÇ…ìæÇÁÇÍǻǢ
ǶÅAÇæǡǃäÿçëÇÃíæñvëDÇðÇΩǢDžǻǡÇΩÇÁǢǂÇ∂Ç·ÇÒ
ǪÇÍÇÕí©ëN
é©ìÆé‘ÇÃñ{ñΩÇÕñ≥êlé©ìÆÇ≈ÇÕÇ»Ç≠óLêlÉAÉVÉXÉgÇæÇ∆évǧǙǻÅB
ñ≥êlÇ»ÇÒǃǪǧä»íPÇ…ñ@êÆîıÇ≥ÇÍǻǢÇÃÇ≈ÇÕ
ñ≥êlÇ»ÇÒǃǪǧä»íPÇ…ñ@êÆîıÇ≥ÇÍǻǢÇÃÇ≈ÇÕ
DZǧǢǧãZèpÇÀÅ@éüê¢ë„EyeSight
ttp://car.watch.impress.co.jp/docs/news/20131003_617964.html
ttp://car.watch.impress.co.jp/docs/news/20131003_617964.html
Ç≈Çýé¿ç€ÅAâ^ì]ÇäyǵÇþÇÈÅiÇÕÇ∏ÇÃÅjÉ}ÉjÉÖÉAÉãÉgÉâÉìÉXÉ~ÉbÉVÉáÉìÇ™ÇÝÇ¡Ç≥ÇËãÏíÄÇ≥ÇÍ
àÍî‘å¯â ìIÇ»ìêìÔñhé~Ç»ÇÒǃåæÇÌÇÍÇÈÇÊǧDžǻǡÇøÇ·Ç¡ÇΩÇ≠ÇÁÇ¢Çæǵ
é¿ópâ¬î\Ç»ÉåÉxÉãÇÃÇýÇÃÇ™èoÇΩÇÁÅAÇÝÇ¡Ç≥ÇËóLêlâ^ì]ÇýãÏíÄÇ≥ÇÍÇøǷǧÇÃÇ≈ÇÕ
ÇΩÇ∆ǶnjéÄäpÇ»ÇÒÇ©ÇýǻǢǵÇ≥ÅBï°êîÉJÉÅÉâîzíuÇ∑ÇÍÇŒå„ÇÎå©Ç»Ç™ÇÁëOÇýå©ÇƒëñÇÍÇÈÇÒÇæÇ∫
é‘ëÃÇÃÉJÉQÇÃéqãüÇ‚ìÆï®Çýå©ì¶Ç≥ǻǢÅAÉAÉNÉZÉãÇ∆ÉuÉåÅ[ÉLÇýì•Çðä‘à·Ç¶Ç»Ç¢ÅAÇÊǪå©ÇýǵǻǢ
Ç´Ç¡ÇøÇËédè„ǙǡǃǢÇÈÇ∆âºíËÇ∑ÇÍÇŒÅAêlä‘ÇÃâ^ì]ÇÊÇËÇÊÇŸÇ«à¿ëSÇ»ÇÌÇØÇ≈Ç≥
ǵǩÇýé©ìÆâ^ì]â¬î\ÇæÇ¡ÇΩÇÁÅAêlä‘ÇÕñ∆ãñéÊÇÈÇΩÇþÇ…Ç‚ÇÈDZÇ∆ÇÕÇπÇ¢Ç∫Ç¢ï€åØÇ…ì¸ÇÈÇ≠ÇÁÇ¢Ç≈
é¿ãZÇýñ@ó•ÇýÇŸÇ∆ÇÒÇ«äwèKǵǻÇ≠ǃÇ∑ÇÞÇÒÇæÅiìñëRDZÇÍÇ…ÇÕñ@êÆîıǙǢÇÈÇØÇ«Åj
ÉÇÉmÇ™èoǃǴÇΩÇÁÅAÇÝÇ¡Ç≥ÇËì¸ÇÍë÷ÇÌÇÈÇ∆évǧÇÀ
àÍî‘å¯â ìIÇ»ìêìÔñhé~Ç»ÇÒǃåæÇÌÇÍÇÈÇÊǧDžǻǡÇøÇ·Ç¡ÇΩÇ≠ÇÁÇ¢Çæǵ
é¿ópâ¬î\Ç»ÉåÉxÉãÇÃÇýÇÃÇ™èoÇΩÇÁÅAÇÝÇ¡Ç≥ÇËóLêlâ^ì]ÇýãÏíÄÇ≥ÇÍÇøǷǧÇÃÇ≈ÇÕ
ÇΩÇ∆ǶnjéÄäpÇ»ÇÒÇ©ÇýǻǢǵÇ≥ÅBï°êîÉJÉÅÉâîzíuÇ∑ÇÍÇŒå„ÇÎå©Ç»Ç™ÇÁëOÇýå©ÇƒëñÇÍÇÈÇÒÇæÇ∫
é‘ëÃÇÃÉJÉQÇÃéqãüÇ‚ìÆï®Çýå©ì¶Ç≥ǻǢÅAÉAÉNÉZÉãÇ∆ÉuÉåÅ[ÉLÇýì•Çðä‘à·Ç¶Ç»Ç¢ÅAÇÊǪå©ÇýǵǻǢ
Ç´Ç¡ÇøÇËédè„ǙǡǃǢÇÈÇ∆âºíËÇ∑ÇÍÇŒÅAêlä‘ÇÃâ^ì]ÇÊÇËÇÊÇŸÇ«à¿ëSÇ»ÇÌÇØÇ≈Ç≥
ǵǩÇýé©ìÆâ^ì]â¬î\ÇæÇ¡ÇΩÇÁÅAêlä‘ÇÕñ∆ãñéÊÇÈÇΩÇþÇ…Ç‚ÇÈDZÇ∆ÇÕÇπÇ¢Ç∫Ç¢ï€åØÇ…ì¸ÇÈÇ≠ÇÁÇ¢Ç≈
é¿ãZÇýñ@ó•ÇýÇŸÇ∆ÇÒÇ«äwèKǵǻÇ≠ǃÇ∑ÇÞÇÒÇæÅiìñëRDZÇÍÇ…ÇÕñ@êÆîıǙǢÇÈÇØÇ«Åj
ÉÇÉmÇ™èoǃǴÇΩÇÁÅAÇÝÇ¡Ç≥ÇËì¸ÇÍë÷ÇÌÇÈÇ∆évǧÇÀ
ífåæǵÇÊǧÅA>326ÇÕ>325Çì«ÇÒÇ≈ǻǢ
>>327
ì«ÇÒÇ≈ÇÈÇÊÅAÇΩǵǩǪÇÃãLéñÇ™åfç⁄Ç≥ÇÍÇΩìñì˙Ç…Çýì«ÇÒÇæ
Ç∆ǢǧǩÅADZÇÃEyeSightǡǃÅAñ îíÇ¢ãZèpÇæÇØÇ«ÅAÇπÇ¢Ç∫Ç¢éüÇÃêVêªïiÇ≈ǵǩǻǢÇ∂Ç·ÇÒ
é©ï™Ç≈â^ì]ǵÇΩǢǡǃêlÇÕämÇ©Ç…Ç¢ÇÈÇæÇÎǧÇØÇ«ÅAÇ‘Ç¡ÇøÇ·ÇØê¢ä‘Ç≈ÇÕíPÇ…à⁄ìÆǵÇΩǢǡǃêlÇ™ëΩÇ¢ÇÌÇØÇ≈
ǪǧǢǧêlÇ…ÇÕÅAï‚èïÇ∂Ç·Ç»Ç≠äÆëSé©ìÆâ^ì]ǡǃǟǧǙÇÊÇŸÇ«ÇÝÇËÇ™ÇΩÇ¢ÇÌÇØÇæ
PCégǡǃÇÈêlÇÃÇŸÇ∆ÇÒÇ«Ç™ÅAç°Ç∂Ç·é©ï™Ç≈ÉvÉçÉOÉâÉÄëgÇÒÇæÇËǵǻǢÇÃÇ∆ìØÇ∂DZÇ∆ÇæÇÊ
ì«ÇÒÇ≈ÇÈÇÊÅAÇΩǵǩǪÇÃãLéñÇ™åfç⁄Ç≥ÇÍÇΩìñì˙Ç…Çýì«ÇÒÇæ
Ç∆ǢǧǩÅADZÇÃEyeSightǡǃÅAñ îíÇ¢ãZèpÇæÇØÇ«ÅAÇπÇ¢Ç∫Ç¢éüÇÃêVêªïiÇ≈ǵǩǻǢÇ∂Ç·ÇÒ
é©ï™Ç≈â^ì]ǵÇΩǢǡǃêlÇÕämÇ©Ç…Ç¢ÇÈÇæÇÎǧÇØÇ«ÅAÇ‘Ç¡ÇøÇ·ÇØê¢ä‘Ç≈ÇÕíPÇ…à⁄ìÆǵÇΩǢǡǃêlÇ™ëΩÇ¢ÇÌÇØÇ≈
ǪǧǢǧêlÇ…ÇÕÅAï‚èïÇ∂Ç·Ç»Ç≠äÆëSé©ìÆâ^ì]ǡǃǟǧǙÇÊÇŸÇ«ÇÝÇËÇ™ÇΩÇ¢ÇÌÇØÇæ
PCégǡǃÇÈêlÇÃÇŸÇ∆ÇÒÇ«Ç™ÅAç°Ç∂Ç·é©ï™Ç≈ÉvÉçÉOÉâÉÄëgÇÒÇæÇËǵǻǢÇÃÇ∆ìØÇ∂DZÇ∆ÇæÇÊ
óLêlâ^ì]Ç∆ñ≥êlâ^ì]Ç≈ïKóvñ∆ãñÇ™ïœÇÌÇÈ(óLêlñ∆ãñÇéùǡǃǢÇÍÇŒñ≥êlÇÕïsóv)ÇðÇΩǢǻä¥Ç∂Ç©Ç»ÅH
ãÏíÄÇ∆ǢǧǩÅAÉ}ÉjÉÖÉAÉãÇ©ÇÁÉIÅ[ÉgÉ}Ç…ëÂëΩêîÇ™à⁄çsǵÇΩÇðÇΩǢDž
óLêlé‘Ç©ÇÁñ≥êlé‘Ç÷à⁄çsÇ∑ÇÈÇ∆ǢǧÇÃÇÕÇÝÇËìæÇÈÇ©ÇýÇÀ
ǪÇÃèÍçáÅAóLêlé‘ÇÕè§ã∆é‘Ç‚é‘â^ì]çDÇ´ÇÃêlópÇðÇΩǢDžésèÍÇ™ïœâªÇ©Ç»ÅH
ãÏíÄÇ∆ǢǧǩÅAÉ}ÉjÉÖÉAÉãÇ©ÇÁÉIÅ[ÉgÉ}Ç…ëÂëΩêîÇ™à⁄çsǵÇΩÇðÇΩǢDž
óLêlé‘Ç©ÇÁñ≥êlé‘Ç÷à⁄çsÇ∑ÇÈÇ∆ǢǧÇÃÇÕÇÝÇËìæÇÈÇ©ÇýÇÀ
ǪÇÃèÍçáÅAóLêlé‘ÇÕè§ã∆é‘Ç‚é‘â^ì]çDÇ´ÇÃêlópÇðÇΩǢDžésèÍÇ™ïœâªÇ©Ç»ÅH
ÉNÉãÉ}ÇÃâ^ì]Ç…ëäìñÇ∑ÇÈÇÃÇÕÉèÅ[ÉhÇ‚ÉGÉNÉZÉãÇÃäÓñ{ëÄçÏÇ≈
É}ÉNÉççÏÇ¡ÇΩÇÁÇýǧé©ï™Ç≈ÉVÅ[ÉgÇ‚ÉnÉìÉhÉãÇë÷ǶÇÈêlÇæÇÎǧ
É}ÉNÉççÏÇ¡ÇΩÇÁÇýǧé©ï™Ç≈ÉVÅ[ÉgÇ‚ÉnÉìÉhÉãÇë÷ǶÇÈêlÇæÇÎǧ
>>326
Ç»ÇÒÇ≈ÉIÅ[ÉgÉ}Ç™ìêìÔñhé~Ç…ÅHÅiñ∆ãñéùǡǃǻǢÇÒÇ≈ÇÌÇ©ÇÁǻǢÅj
ÅÑÇÝÇ¡Ç≥ÇËóLêlâ^ì]ÇýãÏíÄÇ≥ÇÍÇøǷǧÇÃÇ≈ÇÕ
ñ∆ãñÇÕïKóvÇ»ÇÒÇæÇÎǧǻÅEÅEÅEçXêVÇ≈âΩïSâ~Ç©í•é˚Ç≈Ç´Ç»Ç≠Ç»ÇÈÇ©ÇÁ
Ç»ÇÒÇ≈ÉIÅ[ÉgÉ}Ç™ìêìÔñhé~Ç…ÅHÅiñ∆ãñéùǡǃǻǢÇÒÇ≈ÇÌÇ©ÇÁǻǢÅj
ÅÑÇÝÇ¡Ç≥ÇËóLêlâ^ì]ÇýãÏíÄÇ≥ÇÍÇøǷǧÇÃÇ≈ÇÕ
ñ∆ãñÇÕïKóvÇ»ÇÒÇæÇÎǧǻÅEÅEÅEçXêVÇ≈âΩïSâ~Ç©í•é˚Ç≈Ç´Ç»Ç≠Ç»ÇÈÇ©ÇÁ
>ñ∆ãñÇÕïKóvÇ»ÇÒÇæÇÎǧǻÅEÅEÅEçXêVÇ≈âΩïSâ~Ç©í•é˚Ç≈Ç´Ç»Ç≠Ç»ÇÈÇ©ÇÁ
âΩïSâ~??
http://www.keishicho.metro.tokyo.jp/menkyo/menkyo/kousin/kousin00.htm
>Ç»ÇÒÇ≈ÉIÅ[ÉgÉ}Ç™ìêìÔñhé~Ç…ÅHÅiñ∆ãñéùǡǃǻǢÇÒÇ≈ÇÌÇ©ÇÁǻǢÅj
ï™Ç©ÇÁǻǢǻÇÁñŸÇ¡ÇƒÇΩÇÁ?
âΩïSâ~??
http://www.keishicho.metro.tokyo.jp/menkyo/menkyo/kousin/kousin00.htm
>Ç»ÇÒÇ≈ÉIÅ[ÉgÉ}Ç™ìêìÔñhé~Ç…ÅHÅiñ∆ãñéùǡǃǻǢÇÒÇ≈ÇÌÇ©ÇÁǻǢÅj
ï™Ç©ÇÁǻǢǻÇÁñŸÇ¡ÇƒÇΩÇÁ?
>>331
ǢǂÅAÅuÉ}ÉjÉÖÉAÉãÇæÇ∆â^ì]Ç≈ǴǻǢÅiêlÇ™ëΩÇ¢ÅjÇ©ÇÁìêÇÐÇÍǻǢÅvǡǃòbÇó
ǢǂÅAÅuÉ}ÉjÉÖÉAÉãÇæÇ∆â^ì]Ç≈ǴǻǢÅiêlÇ™ëΩÇ¢ÅjÇ©ÇÁìêÇÐÇÍǻǢÅvǡǃòbÇó
ÉIÅ[ÉgÉ}Ç∂Ç·Ç»Ç≠ǃÉ}ÉjÉÖÉAÉãé‘Ç≈ǵÇÂ
atå¿íËÇÝÇÈÇ¢ÇÕç≈ãþÇÃatǵǩÇÃÇ¡ÇΩDZÇ∆ÇÃǻǢÉhÉâÉCÉoÅ[Ç≈ÇÕ
â^ì]Ç≈ǴǻǢÇýÇÃÇ…Ç»ÇËǬǬÇÝÇÈ
atå¿íËÇÝÇÈÇ¢ÇÕç≈ãþÇÃatǵǩÇÃÇ¡ÇΩDZÇ∆ÇÃǻǢÉhÉâÉCÉoÅ[Ç≈ÇÕ
â^ì]Ç≈ǴǻǢÇýÇÃÇ…Ç»ÇËǬǬÇÝÇÈ
intelÇÃé©ìÆâ^ì]ópÉRÉìÉsÉÖÅ[É^Ç…ÇÕéËénÇþÇ…AtomÇÃE3800ånóÒÇ™égópÇ≥ÇÍÇÈÇÃÇÀ
http://www.tv-tokyo.co.jp/mv/wbs/newsl/post_66013/
ÉãÉlÉTÉXÇ™ÉCÉìÉeÉãÇ∆ÉKÉ`ÉKÉ`ÇÃåñâÐÇ…Ç»ÇËǪǧǡǃWBSÇ≈åæǡǃÇΩÇ™ÅAnvidiaÇýtegraÇ≈éQêÌǵǃÇΩÇ©
PCÇðÇΩǢDžé‘ç⁄É`ÉbÉvÇåä∑Ç∑ÇÍÇŒçÇë¨Ç≈ÇÃë¨ìxêßå¿Ç™ä…Ç≠Ç»ÇÈólÇ»ï˚å¸Ç…ǻǡǃÇ≠ÇÍǻǢÇýÇÃÇ©
http://www.tv-tokyo.co.jp/mv/wbs/newsl/post_66013/
ÉãÉlÉTÉXÇ™ÉCÉìÉeÉãÇ∆ÉKÉ`ÉKÉ`ÇÃåñâÐÇ…Ç»ÇËǪǧǡǃWBSÇ≈åæǡǃÇΩÇ™ÅAnvidiaÇýtegraÇ≈éQêÌǵǃÇΩÇ©
PCÇðÇΩǢDžé‘ç⁄É`ÉbÉvÇåä∑Ç∑ÇÍÇŒçÇë¨Ç≈ÇÃë¨ìxêßå¿Ç™ä…Ç≠Ç»ÇÈólÇ»ï˚å¸Ç…ǻǡǃÇ≠ÇÍǻǢÇýÇÃÇ©
ÇQÇOÇQÇOîNë„Ç…ÇÕé©ìÆâ^ì]ÇÃǟǧǙéËìÆâ^ì]ÇÊÇËà¿ëSDžǻǡǃ
ëÂÇ´Ç≠ïÅãyÇ∑ÇÈÇÒÇ∂ǷǻǢǩÅH
ǪÇÃǧÇøÅAêVé‘Ç…ÇÕé©ìÆâ^ì]ïKê{Ç…Ç»ÇÈ
ëÂÇ´Ç≠ïÅãyÇ∑ÇÈÇÒÇ∂ǷǻǢǩÅH
ǪÇÃǧÇøÅAêVé‘Ç…ÇÕé©ìÆâ^ì]ïKê{Ç…Ç»ÇÈ
é©ìÆâ^ì]íÜÇÃéñåÃÇÃê”îCÇíNÇ™Ç∆ÇÈÇ©Ç™
10îNǂǪDZÇÁÇ∂Ç·âåàÇ≈Ç´ÇÒÇæÇÎÅB
10îNǂǪDZÇÁÇ∂Ç·âåàÇ≈Ç´ÇÒÇæÇÎÅB
é©ìÆâ^ì]ÇÃǟǧǙéËìÆâ^ì]ÇÊÇËà¿ëSÇ…Ç»ÇÈçÝÇ…Ç»ÇÍÇŒÅA
é©ìÆâ^ì]éûÇÃéñåÃDžǬǢǃÇÕÅAé©ìÆé‘ÉÅÅ[ÉJÅ[Ç‚ÇÁâ^ì]éËÇÃê”îCÇêßå¿Ç∑ÇÈñ@ó•Ç≈ÇýçÏÇÍnjǢǢÇÊ
é©ìÆâ^ì]éûÇÃéñåÃDžǬǢǃÇÕÅAé©ìÆé‘ÉÅÅ[ÉJÅ[Ç‚ÇÁâ^ì]éËÇÃê”îCÇêßå¿Ç∑ÇÈñ@ó•Ç≈ÇýçÏÇÍnjǢǢÇÊ
êlä‘ÇÃîªífÉ~ÉXÇ™éñåÃå¥àˆÇÃñwÇ«ÇÁǵǢǩÇÁÇ»Çü
éãîFǵǃǩÇÁëÄçÏǵǃÇýê‚ëŒÇ…ä‘Ç…çáÇÌǻǢêVä≤ê¸Ç…
â^ì]émǙǢÇÈDZÇ∆Ç…ÇÕóùóRÇ™ÇÝÇÈ
â^ì]émǙǢÇÈDZÇ∆Ç…ÇÕóùóRÇ™ÇÝÇÈ
é©ìÆé‘ÇÕç≈èIìIÇ…ÇÕäOå`Ç™ÉvÉåÉnÉuÇÃÇÊǧǻå`èÛÇÃóßï˚ëÃÇ∆Ç»ÇËÅAì¸ÇËå˚ÇÕâ∆ÇÃÉhÉAÇÃå`Ç…Ç»ÇÈÅB
â^ì]ê»Ç∆èïéËê»Ç™å„ÇÎå¸Ç´Ç…éÊÇËïtÇØÇÁÇÍÅAå„ïîç¿ê»ÇÕǔǩǔǩÇÃÉ\ÉtÉ@Å[Ç…Ç»ÇËÅAä‘Ç…ÉeÅ[ÉuÉãÇ™êòǶïtÇØÇÁÇÍÇÈÇæÇÎǧÅB
ëãÇ…ÇÕÉJÅ[ÉeÉìÇ™ïtǢǃǢÇÈÅB
í©ÇÃí ãŒëñçsíÜÇ…ÅAêlÇÕÉeÅ[ÉuÉãÇ…å¸Ç©Ç¡Çƒí©êHÇéÊÇËÅAÉRÅ[ÉqÅ[Çà˘ÇðǻǙÇÁêVï∑Çì«ÇÞÅB
â^ì]ê»Ç∆èïéËê»Ç™å„ÇÎå¸Ç´Ç…éÊÇËïtÇØÇÁÇÍÅAå„ïîç¿ê»ÇÕǔǩǔǩÇÃÉ\ÉtÉ@Å[Ç…Ç»ÇËÅAä‘Ç…ÉeÅ[ÉuÉãÇ™êòǶïtÇØÇÁÇÍÇÈÇæÇÎǧÅB
ëãÇ…ÇÕÉJÅ[ÉeÉìÇ™ïtǢǃǢÇÈÅB
í©ÇÃí ãŒëñçsíÜÇ…ÅAêlÇÕÉeÅ[ÉuÉãÇ…å¸Ç©Ç¡Çƒí©êHÇéÊÇËÅAÉRÅ[ÉqÅ[Çà˘ÇðǻǙÇÁêVï∑Çì«ÇÞÅB
>>341ÇÃDZÇ∆ÇêlÇÕóaåæé“Ç∆åƒÇ‘ÅB
ä˘Ç…GoogleÇÃç≈êVÇÃééçÏé‘ÇÃâ^ì]ê»Ç©ÇÁÇÕÉnÉìÉhÉãÇýÉuÉåÅ[ÉLÇýìPãéÇ≥ÇÍǃǢÇÈÅBñúàÍéñåÃÇ¡ÇΩéûÇ…ÇÕìãèÊàıÇ…ê”îCÇ™ñ≥Ç¢ÇÃÇÕñæÇÁÇ©ÅB
GoogleÇÕé©ìÆâ^ì]é‘éñã∆ÇénÇþÇÈÇ…ÇÝÇΩǡǃÅuåí éñåÃÇÇ»Ç≠Ç∑ÅvÇÃëºÇ…Åué‘Ç…èÊǡǃǢÇÈéûä‘ÇÃóLå¯äàópÅvÇ∆ÇÃñ⁄ïWÇåfÇ∞ǃǢÇÈÅB
ǪÇÃóùëzÇí«ãÅÇ∑ÇÈÇ∆ç≈å„Ç…ÇÕé©ìÆëñçsÇ∑ÇÈÉÇÅ[É^Å[ÉzÅ[ÉÄÇÃÇÊǧǻÇýÇÃÇ…Ç»ÇÈÇÃÇ≈ÇÕÅB
GoogleÇÕé©ìÆâ^ì]é‘éñã∆ÇénÇþÇÈÇ…ÇÝÇΩǡǃÅuåí éñåÃÇÇ»Ç≠Ç∑ÅvÇÃëºÇ…Åué‘Ç…èÊǡǃǢÇÈéûä‘ÇÃóLå¯äàópÅvÇ∆ÇÃñ⁄ïWÇåfÇ∞ǃǢÇÈÅB
ǪÇÃóùëzÇí«ãÅÇ∑ÇÈÇ∆ç≈å„Ç…ÇÕé©ìÆëñçsÇ∑ÇÈÉÇÅ[É^Å[ÉzÅ[ÉÄÇÃÇÊǧǻÇýÇÃÇ…Ç»ÇÈÇÃÇ≈ÇÕÅB
>>343
> ä˘Ç…GoogleÇÃç≈êVÇÃééçÏé‘ÇÃâ^ì]ê»Ç©ÇÁÇÕÉnÉìÉhÉãÇýÉuÉåÅ[ÉLÇýìPãéÇ≥ÇÍǃǢÇÈÅB
> ñúàÍéñåÃÇ¡ÇΩéûÇ…ÇÕìãèÊàıÇ…ê”îCÇ™ñ≥Ç¢ÇÃÇÕñæÇÁÇ©ÅB
ǫǧǢǧóùã¸??
> ä˘Ç…GoogleÇÃç≈êVÇÃééçÏé‘ÇÃâ^ì]ê»Ç©ÇÁÇÕÉnÉìÉhÉãÇýÉuÉåÅ[ÉLÇýìPãéÇ≥ÇÍǃǢÇÈÅB
> ñúàÍéñåÃÇ¡ÇΩéûÇ…ÇÕìãèÊàıÇ…ê”îCÇ™ñ≥Ç¢ÇÃÇÕñæÇÁÇ©ÅB
ǫǧǢǧóùã¸??
ëÄë« â¡ë¨ å∏ë¨Ç…êlä‘Ç™âÓì¸Ç≈Ç´ÇÈó]ínÇ™ñ≥Ǣǡǃóùã¸ÇæÇ∆évǧÇØÇ«
ÉnÉìÉhÉã ÉAÉNÉZÉã ÉuÉåÅ[ÉLÇ™ìPãéÇ≥ÇÍǃǢǃÇý
ãŸã}í‚é~É{É^ÉìÇðÇΩÇ¢ÇÃÇ™óLÇÈÇ©ñ≥ǢǩÇ≈ÇÐÇΩòbÇÕïœÇÌǡǃǴǪǧ
ÉnÉìÉhÉã ÉAÉNÉZÉã ÉuÉåÅ[ÉLÇ™ìPãéÇ≥ÇÍǃǢǃÇý
ãŸã}í‚é~É{É^ÉìÇðÇΩÇ¢ÇÃÇ™óLÇÈÇ©ñ≥ǢǩÇ≈ÇÐÇΩòbÇÕïœÇÌǡǃǴǪǧ
âÓì¸éËíiÇ™äFñ≥Ç»ÇÁÅAè≠êlêîå^ÇÃÉpÉjÉbÉNâfâÊÇ™çÏÇÍÇÈÇ»
èÊãqÇ∆ä«óùê”îCé“Ç™ìØàÍÇæÇ¡ÇΩÇËÇ≈ǻǩǡÇΩÇËÇ∑ÇÈÇæÇÎ
Ågâ^ì]éËÅhÇ™ëãÇÃäOÇäœé@ǵäÎåØÇâÒîÇ∑ÇÈçÏã∆ÇÕÅAé‘Ç…èÊǡǃǢÇÈéûä‘ÇÃóLå¯äàópÇ≈ÇÕÇÝÇËÇÐÇπÇÒÇÃÇ≈ÅA
ìãèÊǵÇΩêlÇÕíNÇýâ^ì]éËÇíSìñǵǻÇ≠ǃÇ∑ÇÞÇÊǧDžǻÇÈÇÃÇñ⁄ïWÇ…Ç∑ÇÈÇ≈ǵÇÂǧÅB
ìãèÊǵÇΩêlÇÕíNÇýâ^ì]éËÇíSìñǵǻÇ≠ǃÇ∑ÇÞÇÊǧDžǻÇÈÇÃÇñ⁄ïWÇ…Ç∑ÇÈÇ≈ǵÇÂǧÅB
åàÇÐÇ¡ÇΩÉãÅ[ÉgÇåàÇÐÇ¡ÇΩë¨ìxÇ≈åàÇÐÇ¡ÇΩéûä‘Ç≈ìÆǢǃǢÇÈä»íPëÄçÏÇ»ìdé‘Ç≈Ç∑ÇÁéñåÃÇÈÇ©ÇÁÇ»
ëSé©ìÆé©ìÆé‘Ç∆Ç©ç°ÇÃãZèpÇ≈çÏǡǃÇýéñåÃÇËÇÐÇ≠ÇËÇ…Ç»ÇÈÇæÇØ
ëSé©ìÆé©ìÆé‘Ç∆Ç©ç°ÇÃãZèpÇ≈çÏǡǃÇýéñåÃÇËÇÐÇ≠ÇËÇ…Ç»ÇÈÇæÇØ
é©ìÆâ^ì]DžǵÇΩÇÁÉqÉÖÅ[É}ÉìÉGÉâÅ[Çýñ≥Ç≠Ç»ÇÈÇÌÇØÇ≈ãtÇ…éñåÃÇ™å∏ÇÈÇ©ÇýÇÊ
ã}Ç…îÚÇ—èoǵǃÇ≠ÇÈéqÇ«ÇýǂǮnjÇøÇ·ÇÒÇ…ëŒâûÇ≈Ç´ÇÈÇ∆ÇýévǶÇÒǵÅA
à¿ëSÇÃÇΩÇþÇ…ñ@íËë¨ìxÇ≈ǵǩìÆǩǻǢǩÇÁÅAã}ǨÇΩÇ¢Ç∆ǴDžǫǧǵÇÊǧÇýÇ»Ç≠Ç»ÇÈ
ã}ÇÆÇΩÇþÇ…É}ÉjÉÖÉAÉãÉÇÅ[ÉhÇópà”ǵÇΩÇÁÅAëΩï™ÇªÇ¡ÇønjǩÇËégǧDZÇ∆Ç…Ç»ÇËǪǧ
åí ñ@ãKÇæÇØÇ∂Ç·Ç»Ç≠à√ñŸÇÃóπâìIǻDZÇ∆ÇýäÐÇþÇΩÉVÉXÉeÉÄÇ‚ÉvÉçÉOÉâÉÄÇ∆Ç©ï°éGÇ∑ǨǃïsãÔçáÇæÇÁÇØDžǵǩǻÇÁÇÒÇ∆évǧ
ǪÇÍÇ∆ÅAëSé©ìÆÇ≈ìÆDZǧÇ∆évÇ¡ÇΩÇÁÅAGPSÇ‚ÉlÉbÉgÉèÅ[ÉNÇ∆èÌéûê⁄ë±Ç∆Ç©Ç…Ç»ÇÈÇ∆évǧÇØÇ«ÅAÉEÉBÉãÉXÇ‚ÉnÉbÉLÉìÉOÇ∆Ç©ÇÃêSîzÇýìñëRèoǃÇ≠ÇÈÇæÇÎ
ÇÐÇÝÅAÇ»ÇÒÇæÅAïsà¿óvëfÇ™ëΩÇ∑Ǩǃñ≥óùÇæÇ»
ÇÐÇ∏ÇÕëSé©ìÆÇ≈ÇýéñåÃÇËÇ…Ç≠Ç¢ÇÊǧǻÉvÉçÉOÉâÉÄǵǂÇ∑Ç¢ñ@ó•Ç∆êÆîıÇ≥ÇÍÇΩìπÇçÏǡǃǩÇÁÇæÇÎǧ
à¿ëSÇÃÇΩÇþÇ…ñ@íËë¨ìxÇ≈ǵǩìÆǩǻǢǩÇÁÅAã}ǨÇΩÇ¢Ç∆ǴDžǫǧǵÇÊǧÇýÇ»Ç≠Ç»ÇÈ
ã}ÇÆÇΩÇþÇ…É}ÉjÉÖÉAÉãÉÇÅ[ÉhÇópà”ǵÇΩÇÁÅAëΩï™ÇªÇ¡ÇønjǩÇËégǧDZÇ∆Ç…Ç»ÇËǪǧ
åí ñ@ãKÇæÇØÇ∂Ç·Ç»Ç≠à√ñŸÇÃóπâìIǻDZÇ∆ÇýäÐÇþÇΩÉVÉXÉeÉÄÇ‚ÉvÉçÉOÉâÉÄÇ∆Ç©ï°éGÇ∑ǨǃïsãÔçáÇæÇÁÇØDžǵǩǻÇÁÇÒÇ∆évǧ
ǪÇÍÇ∆ÅAëSé©ìÆÇ≈ìÆDZǧÇ∆évÇ¡ÇΩÇÁÅAGPSÇ‚ÉlÉbÉgÉèÅ[ÉNÇ∆èÌéûê⁄ë±Ç∆Ç©Ç…Ç»ÇÈÇ∆évǧÇØÇ«ÅAÉEÉBÉãÉXÇ‚ÉnÉbÉLÉìÉOÇ∆Ç©ÇÃêSîzÇýìñëRèoǃÇ≠ÇÈÇæÇÎ
ÇÐÇÝÅAÇ»ÇÒÇæÅAïsà¿óvëfÇ™ëΩÇ∑Ǩǃñ≥óùÇæÇ»
ÇÐÇ∏ÇÕëSé©ìÆÇ≈ÇýéñåÃÇËÇ…Ç≠Ç¢ÇÊǧǻÉvÉçÉOÉâÉÄǵǂÇ∑Ç¢ñ@ó•Ç∆êÆîıÇ≥ÇÍÇΩìπÇçÏǡǃǩÇÁÇæÇÎǧ
ì˙éYÇ™çÏÇ¡ÇΩé©ìÆâ^ì]ÇÃééå±é‘ÇÕÅuPC10ë‰ï™ÇÃê´î\Ç…ïCìGÇ∑ÇÈÉèÅ[ÉNÉXÉeÅ[ÉVÉáÉìÇ1ë‰ìãç⁄ÅvÇ∆åæǡǃÇΩ
ÉAÉEÉfÉBÇÃêœÇÒÇ≈ÇÈtegraÉLÉbÉgÇÕ326GFLOPSÅAîÚÇ‘ÇÊǧDžÉnÉCÉGÉìÉhïiÇ™çÃópÇ≥ÇÍǃǢÇ≠Ç»
ÉAÉEÉfÉBÇÃêœÇÒÇ≈ÇÈtegraÉLÉbÉgÇÕ326GFLOPSÅAîÚÇ‘ÇÊǧDžÉnÉCÉGÉìÉhïiÇ™çÃópÇ≥ÇÍǃǢÇ≠Ç»
ç°å§ãÜǵǃÇÈÉåÉxÉãÇÃâ^ì]ï‚èïÇ≈ÅAîÚÇ—èoǵÇ∆Ç©Ç…ÇýëŒâûÇ≈Ç´ÇÈÇÒÇ∂ǷǻǢǩ
â¥Ç™ÉeÉåÉrÇ≈å©ÇΩÇÃÇÕÅAîÚÇ—èoǵÇ∂ǷǻǢÇØÇ«é‘ìπÇëñǡǃÇÈé©ì]é‘Ç™ìÀëRì|ÇÍDZÇÒÇ≈Ç´ÇΩÇ∆Ç´ÇÃâÒî
ÇØǡDZǧÇÊÇ≠Ç≈ǴǃÇΩÅB
â¥Ç™ÉeÉåÉrÇ≈å©ÇΩÇÃÇÕÅAîÚÇ—èoǵÇ∂ǷǻǢÇØÇ«é‘ìπÇëñǡǃÇÈé©ì]é‘Ç™ìÀëRì|ÇÍDZÇÒÇ≈Ç´ÇΩÇ∆Ç´ÇÃâÒî
ÇØǡDZǧÇÊÇ≠Ç≈ǴǃÇΩÅB
>>351
îÚÇ—èoǵǃÇ≠ÇÈêlëŒçÙÇÃÉvÉäÉNÉâÉbÉVÉÖÉuÉåÅ[ÉLÇÕä˘Ç…ésîÃé‘Ç…ìãç⁄Ç≥ÇÍǃǢÇÈÇÒÇæÇ™ÅB
âΩÇýímÇÁǻǢÇÃÇ…évÇ¢çûÇðÇ≈ìKìñÇ»éñnjǩÇËåæǧǻÇÊÅB
îÚÇ—èoǵǃÇ≠ÇÈêlëŒçÙÇÃÉvÉäÉNÉâÉbÉVÉÖÉuÉåÅ[ÉLÇÕä˘Ç…ésîÃé‘Ç…ìãç⁄Ç≥ÇÍǃǢÇÈÇÒÇæÇ™ÅB
âΩÇýímÇÁǻǢÇÃÇ…évÇ¢çûÇðÇ≈ìKìñÇ»éñnjǩÇËåæǧǻÇÊÅB
355 ÅF Åümiyuri//Z7LS ÅF2014/06/01(ì˙) 09:21:47.92 ID:lkc1l71f
îÚÇ—èoǵÇâÒîǵÇΩêÊÇ≈ÅAëºÇÃé©ìÆé‘Ç∆è’ìÀǡǃÉIÉ`Ç™óLÇËǪǧÇ≈ï|Ç¢ÅB
é©ì]é‘ÇùõÇÀÇÈÇ»ÇËÁÄÇ≠Ç»ÇËÇ∑ÇÈï˚Ç™à¿ëSǡǃéñÇ…ÅB
é©ì]é‘ÇùõÇÀÇÈÇ»ÇËÁÄÇ≠Ç»ÇËÇ∑ÇÈï˚Ç™à¿ëSǡǃéñÇ…ÅB
é©ìÆâ^ì]Ç™óàÇΩÇÁçëìπâàÇ¢ÇÃìXÇ™ëSñ≈ǵǪǧÇæÇ»
ǢǬÇýÇÃñ⁄ìIínÇ»ÇÁå´Ç¢înÇÃǮǩÇ∞Ç≈êQǃǃÇýíÖÇ≠îné‘ÅB
ëzëúÇ∑ÇÈÇ…ÅAînÇ…îCÇπÇÈDZÇ∆Ç…ÇÕÇÝÇÐÇËíÔçRÇä¥Ç∂ǻǢǙÅA
ǪÇÍÇÕîné©êgÇ™äÎåØÇåôÇ™ÇÈñ{î\ÇéùǡǃǢÇÈÇ©ÇÁÇæÇ»
ëzëúÇ∑ÇÈÇ…ÅAînÇ…îCÇπÇÈDZÇ∆Ç…ÇÕÇÝÇÐÇËíÔçRÇä¥Ç∂ǻǢǙÅA
ǪÇÍÇÕîné©êgÇ™äÎåØÇåôÇ™ÇÈñ{î\ÇéùǡǃǢÇÈÇ©ÇÁÇæÇ»
ǬÇÐÇËÉAÉEÉfÉBÇÕTegraìãç⁄Ç≈îMñ\ëñǵǃéñåÃÇÈÇ©ÇÁèÊÇÈǻǡǃDZÇ∆Ç©
ï≥èóÇÃï≥â^ì]Çå©ÇƒÇÈÇ∆é©ìÆâ^ì]Ç©ïÅãyǵÇΩï˚Ç™éñåÃÇ™å∏ÇÈÇÃÇÕâŒÇå©ÇÈÇÊÇËñæÇÁÇ©
ÉWÉTÉJÅ[Ç∆é‘ÉIÉ^ÇÃçýóÕÇ™ÉRÉâÉ{ǵÇΩÇÁÇ∆ÇÒÇ≈ÇýǻǢÉ`ÉÖÅ[ÉìǵǪǧ
ǃǩÅAì˙ñ{î≈GPSÅuÇðÇøÇ—Ç´ÅvÇ™â“ìÆÇ∑ÇÍÇŒCPUÉpÉèÅ[Ç…óäÇÁÇ∏Ç…ä»íPÇ…é¿ópâªÇ≈Ç´ÇÈÇÒÇ∂Ç·ÇÀÅH
çÇë¨ìπòHÇæÇØÇæÇÎǧÇØÇ«Ç≥
ǃǩÅAì˙ñ{î≈GPSÅuÇðÇøÇ—Ç´ÅvÇ™â“ìÆÇ∑ÇÍÇŒCPUÉpÉèÅ[Ç…óäÇÁÇ∏Ç…ä»íPÇ…é¿ópâªÇ≈Ç´ÇÈÇÒÇ∂Ç·ÇÀÅH
çÇë¨ìπòHÇæÇØÇæÇÎǧÇØÇ«Ç≥
é©ìÆâ^ì]Ç…ÇÕGPSÇÊÇËÇýãÛä‘Çà äÆý¯Ç» îFéØÇ™ÇÐÇ∏êÊÇæÇÎǧ
GPSÇ™ñ≥Ç≠ǃÇýìπòHëñÇÍÇÈÇ™ìπòH ïWéØ è·äQï®Ç™îFéØÇ≈ǴǻǢÇ∆ÇÐÇ∆ÇýÇ…ëñÇÍǻǢ
ínê}Ç™ñ≥Ç≠ǃÇýÉIÅ[ÉgÉ}ÉbÉsÉìÉOÇ∆ëçìñÇËÇ≈ñ⁄ìIínÇ…ãþÇ√Ç≠Ç»ÇÁâ¬î\Çæǵǻ
GPSÇ™ñ≥Ç≠ǃÇýìπòHëñÇÍÇÈÇ™ìπòH ïWéØ è·äQï®Ç™îFéØÇ≈ǴǻǢÇ∆ÇÐÇ∆ÇýÇ…ëñÇÍǻǢ
ínê}Ç™ñ≥Ç≠ǃÇýÉIÅ[ÉgÉ}ÉbÉsÉìÉOÇ∆ëçìñÇËÇ≈ñ⁄ìIínÇ…ãþÇ√Ç≠Ç»ÇÁâ¬î\Çæǵǻ
GPSÇ»ÇÒǃé~ÇÐǡǃÇÊǧǙïsê≥ämÇæÇÎǧǙéñåÃãNDZÇ≥ǻǢÇ≠ÇÁÇ¢ÇÃé©óßêßå‰î\óÕÇÕïKê{
ARMÇ™ë‰òpÇ…
IoTÇ∆ÉEÉFÉAÉâÉuÉãÇ…ÉtÉHÅ[ÉJÉXǵÇΩCPUêðåvÉZÉìÉ^Å[Çêðóß
http://pc.watch.impress.co.jp/docs/column/kaigai/20140603_651424.html
IoTÇ∆ÉEÉFÉAÉâÉuÉãÇ…ÉtÉHÅ[ÉJÉXǵÇΩCPUêðåvÉZÉìÉ^Å[Çêðóß
http://pc.watch.impress.co.jp/docs/column/kaigai/20140603_651424.html
>>363
Cortex-MånÇ≈óLñºÇ»ë‰òpäÈã∆ǡǃÇ≥Åc
Cortex-MånÇ≈óLñºÇ»ë‰òpäÈã∆ǡǃÇ≥Åc
>>355
â¥ÇÃÇ®Ç∂ÇÕÅAé‘Çâ^ì]íÜÇ…ÅAèóéqçÇê∂ÇÃèÊÇ¡ÇΩé©ì]é‘Ç©ÉgÉâÉbÉNÇ©ÅAÇ«ÇøÇÁÇ©Ç∆ê≥ñ è’ìÀÇ∆Ǣǧéñë‘Džǻǡǃ
ñ¿ÇÌÇ∏ÉgÉâÉbÉNÇ…ìÀÇ¡çûÇÒÇæñ“é“Ç≈ÇÝÇÈÅBâ¥ÇÕÇØǡDZǧë∏åhǵǃǢÇÈ
â¥ÇÃÇ®Ç∂ÇÕÅAé‘Çâ^ì]íÜÇ…ÅAèóéqçÇê∂ÇÃèÊÇ¡ÇΩé©ì]é‘Ç©ÉgÉâÉbÉNÇ©ÅAÇ«ÇøÇÁÇ©Ç∆ê≥ñ è’ìÀÇ∆Ǣǧéñë‘Džǻǡǃ
ñ¿ÇÌÇ∏ÉgÉâÉbÉNÇ…ìÀÇ¡çûÇÒÇæñ“é“Ç≈ÇÝÇÈÅBâ¥ÇÕÇØǡDZǧë∏åhǵǃǢÇÈ
ãtëñǵǃÇΩèóéqçÇê∂ÇÃé©ì]é‘ÇîÇØÇÈÇΩÇþÇ»ÇÁÉgÉâÉbÉNë§ÇÕÇ∆ÇÒÇæÇ∆njǡÇøÇËÇæÇ»
è⁄ç◊ÇÕï∑ǢǃǻǢǙéÄêlÇÕèoǃǻǢÇÃÇ≈ÅAÇÐÇÝïêóEì`ÇÃàÍéÌÇ∆ǢǧDZÇ∆Ç≈w
é©ì]é‘Ç…ìÀÇ¡çûÇÒÇ≈ÇΩÇÁâΩêlÇ©éÄÇÒÇ≈ÇΩÇæÇÎǧÇ∆ǢǧòbÇ≈ÇÕÇÝÇÈ
é©ì]é‘Ç…ìÀÇ¡çûÇÒÇ≈ÇΩÇÁâΩêlÇ©éÄÇÒÇ≈ÇΩÇæÇÎǧÇ∆ǢǧòbÇ≈ÇÕÇÝÇÈ
é‘Ç∆é©ì]é‘ÇÕìØÇ∂é‘ê¸ÇæÇÊ
ê≥ñ è’ìÀÇ∑ÇÈéñë‘Ç…ä◊ǡǃǢÇÈéûì_Ç≈ïŸâÇÃó]ínÇ™ñ≥Ç¢ÇØÇ«Ç»ÅB
>>270
ÉRÉìÉ\Å[ÉãêßîeǵÇΩǵDZÇÍÇ©ÇÁÇÕï™Ç©ÇÁÇÒǺ
ÉRÉìÉ\Å[ÉãêßîeǵÇΩǵDZÇÍÇ©ÇÁÇÕï™Ç©ÇÁÇÒǺ
372 ÅFSocket774ÅF2014/06/14(ìy) 04:59:43.96 ID:88O64tkJ
çÇê´î\ÉvÉçÉZÉbÉTå¸ÇØÉLÉÉÉbÉVÉÖÉÅÉÇÉäÇ≈ê¢äEç≈çÇÇÃìdóÕê´î\Çé¿åªÇ∑ÇÈ
êVï˚éÆé•ê´ëÃÉÅÉÇÉäSTT-MRAMâÒòHÇäJî≠
http://www.toshiba.co.jp/rdc/detail/1406_02.htm
êVï˚éÆé•ê´ëÃÉÅÉÇÉäSTT-MRAMâÒòHÇäJî≠
http://www.toshiba.co.jp/rdc/detail/1406_02.htm
373 ÅFSocket774ÅF2014/06/14(ìy) 05:00:22.59 ID:88O64tkJ
ÉnÉCÉGÉìÉhå¸ÇØÉ}ÉãÉ`ÉRÉAÉvÉçÉZÉbÉTÇÃçÇóeó ÉLÉÉÉbÉVÉÖÉÅÉÇÉäÇ…ìKópǵÇΩèÍçáÅA
è]óàÇÃÉvÉçÉZÉbÉTÇ…ëŒÇµÇƒê´î\óÚâªÇ™ñ≥Ç¢èÛë‘ÇÃÇÐÇÐÅAè¡îÔìdóÕÇ60ÅìçÌå∏Ç∑ÇÈDZÇ∆Ç™Ç≈Ç´ÇÐÇ∑ÅB
ǬÇÐÇËÅAìdóÕê´î\Ç™è]óàÇÃñÒ2.5î{Ç…å¸è„Ç∑ÇÈDZÇ∆Ç…Ç»ÇËÇÐÇ∑ÅB
è]óàÇÃÉvÉçÉZÉbÉTÇ…ëŒÇµÇƒê´î\óÚâªÇ™ñ≥Ç¢èÛë‘ÇÃÇÐÇÐÅAè¡îÔìdóÕÇ60ÅìçÌå∏Ç∑ÇÈDZÇ∆Ç™Ç≈Ç´ÇÐÇ∑ÅB
ǬÇÐÇËÅAìdóÕê´î\Ç™è]óàÇÃñÒ2.5î{Ç…å¸è„Ç∑ÇÈDZÇ∆Ç…Ç»ÇËÇÐÇ∑ÅB
è»ìdóÕÉLÉÉÉbÉVÉÖÇ∆åæǶnjMontecitoÇÃîÒìØä˙L3ÇæǙǪÇÃå„ÇÃçÃópéñó·Çï∑ǩǻǢÇÃÇÕǫǧǵǃÇæÇÎǧ
IntelÅAñ@êlå¸ÇØPCésèÍÇÃçDí≤Ç…ÇÊÇËëÊ2élîºä˙ã∆ê—Çè„ï˚èCê≥
http://pc.watch.impress.co.jp/docs/news/20140613_653249.html
http://pc.watch.impress.co.jp/docs/news/20140613_653249.html
XPì¸ÇÍë÷ǶÇ≈7Ç™îÑÇÍÇÐÇ≠Ç¡ÇΩÇ©ÇÁÇ»ÅB
ìñéûÇÃHWÉXÉyÉbÉNÇæÇ∆7Ç™ì¸ÇÁǻǢÉ}ÉVÉìǙǟÇ∆ÇÒÇ«ÇæǵÅB
Ǫǵǃ8ÇÃåôÇÌÇÍÇ¡Ç’ÇËÇ™ç€ÇæǬÇ∆ǢǧÅB
ìñéûÇÃHWÉXÉyÉbÉNÇæÇ∆7Ç™ì¸ÇÁǻǢÉ}ÉVÉìǙǟÇ∆ÇÒÇ«ÇæǵÅB
Ǫǵǃ8ÇÃåôÇÌÇÍÇ¡Ç’ÇËÇ™ç€ÇæǬÇ∆ǢǧÅB
ëÂå˚ñ@êlå¸ÇØÇæÇ∆OSì¸ë÷ǶǻÇÒǃñ ì|ǻDZÇ∆ǵǻǢǩÇÁÇ»
XP/VistaÇÕ8Ç…ÉäÉvÉåÅ[ÉXÅA7ÇÕåpë±Ç≈ÉäÅ[ÉXêÿÇÍéüëÊ8Ç…
ÉEÉ`Ç∆DZÇÕVistaÇ∆Office2010ÇÕÉXÉãÅ[ÅA7ì±ì¸ÇýíxÇ©Ç¡ÇΩÇÃÇ…
ǢǴǻÇË8(64bit)/0ffice2013Ç…ÉäÉvÉåÅ[ÉXǵÇΩÇØÇ«
XP/VistaÇÕ8Ç…ÉäÉvÉåÅ[ÉXÅA7ÇÕåpë±Ç≈ÉäÅ[ÉXêÿÇÍéüëÊ8Ç…
ÉEÉ`Ç∆DZÇÕVistaÇ∆Office2010ÇÕÉXÉãÅ[ÅA7ì±ì¸ÇýíxÇ©Ç¡ÇΩÇÃÇ…
ǢǴǻÇË8(64bit)/0ffice2013Ç…ÉäÉvÉåÅ[ÉXǵÇΩÇØÇ«
8ÇÃòIçúÇ»É}Ç≈Ç∑Ç©ÅH
7äÛñ]ǵǃÇýÅAäJî≠Ç≈ïKóvÇ∆Ç©ì¡ï Ç»óùóRǙǻǢå¿ÇËãpâ∫Ç≥ÇÍÇÈ
âÑí∑ÉTÉ|Å[Égä˙ä‘Ç≈åàÇþÇÁÇÍǃäµÇÍÇÈǵǩǻǢóLól
8ÇÕ8,1ÇæÇÃUpdate1ÇæÇÃÉTÉ|Å[Égä˙ä‘Ç™ñ≥à≈Ç…ï°éGÇ≈Ç«Å[Ç∑ÇÒÇÃÇÊÇ∆évǧǙ
âÑí∑ÉTÉ|Å[Égä˙ä‘Ç≈åàÇþÇÁÇÍǃäµÇÍÇÈǵǩǻǢóLól
8ÇÕ8,1ÇæÇÃUpdate1ÇæÇÃÉTÉ|Å[Égä˙ä‘Ç™ñ≥à≈Ç…ï°éGÇ≈Ç«Å[Ç∑ÇÒÇÃÇÊÇ∆évǧǙ
ÇhÇaÇlÅAÉtÉ@ÉEÉìÉhÉäÅ[âÔé–Ç÷ÇÃîºì±ëÃéñã∆îÑãpÇ≈çáà”Ç÷ÅÅí êMé–
http://jp.reuters.com/article/jpUSpolitics/idJPKBN0EM09U20140611
http://jp.reuters.com/article/jpUSpolitics/idJPKBN0EM09U20140611
>>380
ǟǧÅAIÇýîºì±ëÃêªë¢Ç©ÇÁÇÕÅAÅAÅAíEóéÇ©Åc
ÇÐÇøÇÂÇ¡Ç∆ǬǢǃǢÇ≠ÇÃǬÇÁǪǧÇæÇ¡ÇΩÇ©ÇÁÇ»ÅB
ÇÝÇ∆ÇÕêÊì™ÇëñǡǃǢÇÈÇÃÇÕIntellÇ∆TSMCÇæÇØÅH
îºì±ëÃÇ∆Ç©ÉRÉìÉsÉÖÅ[É^Å[ÇÃésèÍÇÕÅAêFÅXÇ»ñ Ç≈ÇÐÇΩïœâªÇ™ãNǴǪǧÇæÇ»ÅB
ì˙ñ{Ç™êÊì™ÇëñǡǃǢÇΩéûë„ÇýÇÝÇ¡ÇΩÇÒÇæÇØÇÍÇ«ÇýÅA
ìdéqóßçëì˙ñ{Ç»ÇÒǃÉoÉuÉãÇæÇ¡ÇΩÇÃÇ©ÅA
ÅyPCÅzÅuX68000ÇÃì˙ÅvÇ…ÅgÉåÉgÉçPCÅhÇ™ê®ÇºÇÎÇ¢Å@ÇÝÇÃâ©ãýéûë„ÇêUÇËï‘ÇÈÅ@2014/06/12
ttp://anago.2ch.net/test/read.cgi/bizplus/1402543432/
řDZÇÒÇ»ïΩòaÇ≈ì¡éÍÇ»éûë„ÇýÇÝÇ¡ÇΩÇÃÇ…ÇÀÅB
ǟǧÅAIÇýîºì±ëÃêªë¢Ç©ÇÁÇÕÅAÅAÅAíEóéÇ©Åc
ÇÐÇøÇÂÇ¡Ç∆ǬǢǃǢÇ≠ÇÃǬÇÁǪǧÇæÇ¡ÇΩÇ©ÇÁÇ»ÅB
ÇÝÇ∆ÇÕêÊì™ÇëñǡǃǢÇÈÇÃÇÕIntellÇ∆TSMCÇæÇØÅH
îºì±ëÃÇ∆Ç©ÉRÉìÉsÉÖÅ[É^Å[ÇÃésèÍÇÕÅAêFÅXÇ»ñ Ç≈ÇÐÇΩïœâªÇ™ãNǴǪǧÇæÇ»ÅB
ì˙ñ{Ç™êÊì™ÇëñǡǃǢÇΩéûë„ÇýÇÝÇ¡ÇΩÇÒÇæÇØÇÍÇ«ÇýÅA
ìdéqóßçëì˙ñ{Ç»ÇÒǃÉoÉuÉãÇæÇ¡ÇΩÇÃÇ©ÅA
ÅyPCÅzÅuX68000ÇÃì˙ÅvÇ…ÅgÉåÉgÉçPCÅhÇ™ê®ÇºÇÎÇ¢Å@ÇÝÇÃâ©ãýéûë„ÇêUÇËï‘ÇÈÅ@2014/06/12
ttp://anago.2ch.net/test/read.cgi/bizplus/1402543432/
řDZÇÒÇ»ïΩòaÇ≈ì¡éÍÇ»éûë„ÇýÇÝÇ¡ÇΩÇÃÇ…ÇÀÅB
>>381
AppleÇýSonyÇýMSÇýì¶Ç™ÇµÇΩÇ©ÇÁÇ»
AppleÇýSonyÇýMSÇýì¶Ç™ÇµÇΩÇ©ÇÁÇ»
ì˙ñ{ÇÃÉZÉ~ÉRÉìã∆äEÇÕé©ñØì}Ç™âÛñ≈Ç≥ÇπÇΩÇæÇØÇæÅB
>>381
ÉCÉìÉeÉãÅATSMCÅAÉOÉçÅ[ÉoÉãÉtÉ@ÉEÉìÉhÉäÅ[ÉYÅAǪǵǃÉTÉÄÉXÉì
ÉOÉçÅ[ÉoÉãÉtÉ@ÉEÉìÉhÉäÅ[ÉYÇý14nÉvÉçÉZÉXÇÕÉTÉÄÉXÉìÇÃÉâÉCÉZÉìÉXÇ…êÿë÷Çæǵ
å≥IBMòAçáÇ™åãâ Ç∆ǵǃÉTÉÄÉXÉìéÂì±Ç…óéÇøíÖǴǪǧÇ∆ÇÕÇ»ÇÝ
ÉCÉìÉeÉãÅATSMCÅAÉOÉçÅ[ÉoÉãÉtÉ@ÉEÉìÉhÉäÅ[ÉYÅAǪǵǃÉTÉÄÉXÉì
ÉOÉçÅ[ÉoÉãÉtÉ@ÉEÉìÉhÉäÅ[ÉYÇý14nÉvÉçÉZÉXÇÕÉTÉÄÉXÉìÇÃÉâÉCÉZÉìÉXÇ…êÿë÷Çæǵ
å≥IBMòAçáÇ™åãâ Ç∆ǵǃÉTÉÄÉXÉìéÂì±Ç…óéÇøíÖǴǪǧÇ∆ÇÕÇ»ÇÝ
ÇÐÇæìåé≈ÇÕäÊí£Ç¡ÇƒÇÈǵÅiêkǶê∫
386 ÅFSocket774ÅF2014/06/16(åé) 13:36:37.72 ID:J0DBmto8
ìåé≈ÇPé–ǵǩécǡǃǻǢ
ìåé≈Ç™äÊí£Ç¡ÇƒÇÈÇÃÇÕNAND flashÇÃÉvÉçÉZÉXÇæÇØÇ»
ÉÅÉÇÉäÇæÇØÇ»ÇÁÉ}ÉCÉNÉçÉìÅAHinixÇýí«è]ǵǃÇÈÇ©ÇÁÇ»
ÉçÉWÉbÉNÇÃòbÇ‚ÇÎ
ÉçÉWÉbÉNÇÃòbÇ‚ÇÎ
389 ÅFSocket774ÅF2014/06/16(åé) 18:25:26.60 ID:J0DBmto8
ì˙ñ{ê®Ç≈êÊí[ÉtÉ@ÉuéùǡǃÇÈÇÃÇÕìåé≈ÇPé–ÇÃÇðDžǻǡÇΩ
Ç≈ÇýÉçÉWÉbÉNÇÕǂǡǃǻǢÇÃÇ≈ÅAÉçÉWÉbÉNÇ≈êÊí[ÉtÉ@ÉuéùǡǃÇÈâÔé–ÇÕì˙ñ{Ç…ÇÕñ≥Ç¢
Ç≈ÇýÉçÉWÉbÉNÇÕǂǡǃǻǢÇÃÇ≈ÅAÉçÉWÉbÉNÇ≈êÊí[ÉtÉ@ÉuéùǡǃÇÈâÔé–ÇÕì˙ñ{Ç…ÇÕñ≥Ç¢
ì˙ñ{ÇÃÉçÉWÉbÉNånFabÇÕÉpÉiÉ\ÉjÉbÉNÇÃ32nmÇ™ç≈êÊí[Ç©
ïxémí ÉpÉiÇ≈ÉVÉXÉeÉÄLSIÉXÉsÉìÉAÉEÉgǡǃǫǧǻǡÇΩÇÒÇæÇ¡ÇØ
ÉãÉlÉTÉXÇÃEMMAÇýâþãéÇÃâhåıÇæǵÅAǢǬÇÐÇ≈ë±Ç≠Ç‚ÇÁ
ÉãÉlÉTÉXÇÃEMMAÇýâþãéÇÃâhåıÇæǵÅAǢǬÇÐÇ≈ë±Ç≠Ç‚ÇÁ
ìåé≈ÇÃÉnÉCÉuÉäÉåÉRÇÇÊǡǃÇΩǩǡǃí◊ǵÇΩÇÃÇ™èÑÇËèÑǡǃDZÇÃóLólÇæÇÊÅB
ãqÇÕégǢDžÇ≠Ç¢ÉpÉiÇÃï≥ã@Ç»ÇÒÇ©îÉÇÌÇ∏Ç…ÉåÉRÅAǖǢǃÇÕÉeÉåÉréãíÆÇ©ÇÁë´ÇêÙÇ¡ÇΩÇæÇØÅB
EMMAÇÕÉÅÉCÉìÇÃå⁄ãqÇé∏ǡǃèIóπÅB
ãqÇÕégǢDžÇ≠Ç¢ÉpÉiÇÃï≥ã@Ç»ÇÒÇ©îÉÇÌÇ∏Ç…ÉåÉRÅAǖǢǃÇÕÉeÉåÉréãíÆÇ©ÇÁë´ÇêÙÇ¡ÇΩÇæÇØÅB
EMMAÇÕÉÅÉCÉìÇÃå⁄ãqÇé∏ǡǃèIóπÅB
ÉpÉiÇÃêlÇ™ÉàÉCÉVÉáǵÇΩÇÃÇÕ
åoâcÇÃê_ólÇ≈ÇÝǡǃ
ãZèpé“Ç≈ǻǢÇ∆DZÇÎÇ™
åoâcÇÃê_ólÇ≈ÇÝǡǃ
ãZèpé“Ç≈ǻǢÇ∆DZÇÎÇ™
>>392
ÉAÉzÇ©
ìØÇ∂EMMA2RH/3égǡǃÇÒÇÃÇ…ï≥ã@ǵǩçÏÇÍǻǩǡÇΩìåé≈Ç™ï≥Ç»ÇæÇØ
ǮǻÇ∂SOCégǡǃÇÈÉVÉÉÅ[ÉvÅAÉ\ÉjÅ[ÇÕÉpÉiÇ…ëŒçRèoóàǃÇÈǵ
É\ÉtÉgâ¸ó«ÇæÇØÇ≈ÉTÉNÉTÉNÉ}ÉãÉ`É^ÉXÉNé¿åªÇµÇΩÇÃÇÕ
ǃÇþǶÇÁï≥RDÉ}ÉjÉAÇ™ÉoÉJDžǵǃÇΩÉVÉÉÅ[ÉvÇæÉhÉAÉz
ÉAÉzÇ©
ìØÇ∂EMMA2RH/3égǡǃÇÒÇÃÇ…ï≥ã@ǵǩçÏÇÍǻǩǡÇΩìåé≈Ç™ï≥Ç»ÇæÇØ
ǮǻÇ∂SOCégǡǃÇÈÉVÉÉÅ[ÉvÅAÉ\ÉjÅ[ÇÕÉpÉiÇ…ëŒçRèoóàǃÇÈǵ
É\ÉtÉgâ¸ó«ÇæÇØÇ≈ÉTÉNÉTÉNÉ}ÉãÉ`É^ÉXÉNé¿åªÇµÇΩÇÃÇÕ
ǃÇþǶÇÁï≥RDÉ}ÉjÉAÇ™ÉoÉJDžǵǃÇΩÉVÉÉÅ[ÉvÇæÉhÉAÉz
ÉeÉåÉrò^âÊï€ë∂ǵǻǢîhÇÕHDDò^âÊÇ≈è\ï™ñûë´Ç∑ÇÈÇÃÇ…
ï≥RDêMé“ÇÕê”îCì]â≈ǵǩǵÇÀǶ
ÉAÉiÉçÉORDêMé“Ç≈ÉfÉWÉ^Éãï˙ëóRDÇýA301ÅAX7ÅAX8ÅABZ710ÇÕîÉǡǃÇΩÇ™
ëÄçÏê´Ç∆ÉåÉXÉ|ÉìÉXÇ∆êMóäê´Çâ¸ëPǵǻǢìåé≈Ç∆
É\ÉåÇóiåÏǵǃâ¸ëPóvñ]ÉAÉìÉ`àµÇ¢Ç∑ÇÈï≥êMé“Ç…à§ëzǙǬǴÇΩ
ï≥RDêMé“ÇÕê”îCì]â≈ǵǩǵÇÀǶ
ÉAÉiÉçÉORDêMé“Ç≈ÉfÉWÉ^Éãï˙ëóRDÇýA301ÅAX7ÅAX8ÅABZ710ÇÕîÉǡǃÇΩÇ™
ëÄçÏê´Ç∆ÉåÉXÉ|ÉìÉXÇ∆êMóäê´Çâ¸ëPǵǻǢìåé≈Ç∆
É\ÉåÇóiåÏǵǃâ¸ëPóvñ]ÉAÉìÉ`àµÇ¢Ç∑ÇÈï≥êMé“Ç…à§ëzǙǬǴÇΩ
PS4OneÇÃCPUǡǃÅA360ÇÃCPU ÇÊÇËÇýí·ê´î\Ç»ÇÃÇégǡǃǢÇÈǡǃímǡǃÇΩÅH
http://dench.flatlib.jp/opengl/cpuflops
Xbox 360 Xenon 115.2 GFLOPS
Xbox One Jaguar 112.0 GFLOPS
http://dench.flatlib.jp/opengl/cpuflops
Xbox 360 Xenon 115.2 GFLOPS
Xbox One Jaguar 112.0 GFLOPS
>>396
óùò_ílÇ»ÅB
óùò_ílÇ»ÅB
> PS4OneÇÃCPUǡǃÅA
âΩ??
âΩ??
PSÇÃòbÇ»ÇÃÇ©îÝÇÃòbÇ»ÇÃÇ©
óùò_ílÇ≈ïâÇØǃǢÇÈÇÃÇ…ÅAé¿å¯ílÇ≈ÇÝÇÍnjǻǮÇ≥ÇÁïâÇØÇÈÇ≈ǵÇÂǧÅB
Xenos(PPU3ÉRÉA)Ç…Jaguar8ÉRÉAÇ™óùò_ílDžǮǢǃóÚǡǃǢÇÈÇ∆ǢǧÅB
Xenos(PPU3ÉRÉA)Ç…Jaguar8ÉRÉAÇ™óùò_ílDžǮǢǃóÚǡǃǢÇÈÇ∆ǢǧÅB
402 ÅFSocket774ÅF2014/06/17(âŒ) 19:53:31.60 ID:IuYxUjJC
XenonÇÕGPUÇÃê´î\Çýë´ÇµÇΩêîílDžǻǡǃÇÈÇØÇ«ÅA
JaguarÇÕCPUê´î\ÇæÇØÇæÇ©ÇÁÇ»
JaguarÇÕCPUê´î\ÇæÇØÇæÇ©ÇÁÇ»
óùò_ê´î\Ç∆é¿å¯ê´î\ÇÃî‰ÇÕÉ}ÉCÉNÉçÉAÅ[ÉLÉeÉNÉ`ÉÉà»äOÇÃóvëfÇýóçÇÒÇ≈ÅAî‰ärÇ…Ç»ÇÁǻǢǟǫï°éGÅB
ÉCÉìÉIÅ[É_Å[3ÉRÉAÇÃîÝ360Ç∆ÅAÉAÉEÉgÉIÉuÉIÅ[É_Å[8ÉRÉA+AVXÇÃPS4Ç‚îÝ1î‰Ç◊ǃîÝ360Ç™óDÇÍǃÇÈÇ∆Ç©w
îné≠Ç™ëΩÇ¢ÉAÉìÉ`AMDÇ∆ÇÕåæǶì™Ç™à´Ç¢Ç…ÇýÉzÉhÇ™ÇÝÇÈÇæÇÎ
îné≠Ç™ëΩÇ¢ÉAÉìÉ`AMDÇ∆ÇÕåæǶì™Ç™à´Ç¢Ç…ÇýÉzÉhÇ™ÇÝÇÈÇæÇÎ
405 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/17(âŒ) 22:56:23.00 ID:KDLX4szS
XenonÅ@3.2GHzÅ~3ÉRÉAÅ~6FMAÅÅ115.2GFLOPS
Jaguar 1.6GHzÅ~8ÉRÉAÅ~4(FMUL+FADD)ÅÅ102.4GFLOPS
åvéZÇÕä‘à·Ç¡ÇƒÇ»Ç¢
> XenonÇÕGPUÇÃê´î\Çýë´ÇµÇΩêîílDžǻǡǃÇÈÇØÇ«ÅA
ǻǡǃǻǢÅBCPUÇÃÇð
Jaguar 1.6GHzÅ~8ÉRÉAÅ~4(FMUL+FADD)ÅÅ102.4GFLOPS
åvéZÇÕä‘à·Ç¡ÇƒÇ»Ç¢
> XenonÇÕGPUÇÃê´î\Çýë´ÇµÇΩêîílDžǻǡǃÇÈÇØÇ«ÅA
ǻǡǃǻǢÅBCPUÇÃÇð
ÇæÇØÇ«ÉXÉJÉâFPUÇ™2ÉÜÉjÉbÉgÇÝÇÈÇÃÇÕñ{ìñÇ©ÇÀÅH
PPC970Ç∆ç¨ìØǵǃǻǢǩÇÀ
âºÇ…ÇÝÇ¡ÇΩÇ∆ǵǃÇý2ñΩóþî≠çsÇÃÉRÉAÇæÇ©ÇÁSIMD x1, ÉXÉJÉâ x1ÇÃëgÇðçáÇÌÇπÇ≈ǵǩÉsÅ[ÉNÇÕèoǻǢÇÕÇ∏
PPC970Ç∆ç¨ìØǵǃǻǢǩÇÀ
âºÇ…ÇÝÇ¡ÇΩÇ∆ǵǃÇý2ñΩóþî≠çsÇÃÉRÉAÇæÇ©ÇÁSIMD x1, ÉXÉJÉâ x1ÇÃëgÇðçáÇÌÇπÇ≈ǵǩÉsÅ[ÉNÇÕèoǻǢÇÕÇ∏
408 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/17(âŒ) 23:05:15.44 ID:KDLX4szS
ÉXÉJÉâFPUÇ≈íPê∏ìxÅ~2ÇÃSIMDââéZÇ≈Ç´ÇÈÇÊǧDžǵÇΩÉQÅ[ÉÄÉLÉÖÅ[ÉuÇÃägí£Ç∆
AltiVecóRóàÇÃ128ÉrÉbÉgFPÇóºï˚éùǡǃÇÈÇÃÇ™XenonÇÀ
ÇæÇ™2ñΩóþìØéûî≠çsÇ≈2ñΩóþÇ∆ÇýêœòaéZî≠çsǵÇΩÇÁÇŸÇ©Ç…âΩÇýÇ≈Ç´ÇÒÇ‚ÇÎ
ÇýÇøÇÎÇÒJaguarÇýFADD+FMULìØéûÇ…égÇ¡ÇΩÇÁÇŸÇ©Ç…âΩÇýÇ≈Ç´Ç»Ç≠Ç»ÇÈÇÌÇØÇæÇØÇ«ÇÀÅB
AltiVecóRóàÇÃ128ÉrÉbÉgFPÇóºï˚éùǡǃÇÈÇÃÇ™XenonÇÀ
ÇæÇ™2ñΩóþìØéûî≠çsÇ≈2ñΩóþÇ∆ÇýêœòaéZî≠çsǵÇΩÇÁÇŸÇ©Ç…âΩÇýÇ≈Ç´ÇÒÇ‚ÇÎ
ÇýÇøÇÎÇÒJaguarÇýFADD+FMULìØéûÇ…égÇ¡ÇΩÇÁÇŸÇ©Ç…âΩÇýÇ≈Ç´Ç»Ç≠Ç»ÇÈÇÌÇØÇæÇØÇ«ÇÀÅB
ÇÝÅ[ÅAÉXÉJÉâë§Ç≈Çý2ÉåÅ[ÉìÇÃSIMDÇ™égǶÇÈÇÃÇ©ÅBǪÇÍÇ»ÇÁî[ìæÅB
>>403
ǪǧǻÇÒÇæÇÊÇ»Åc
îÒê¸å`ç≈ìKâªñ‚ëËÇ≈ã…è¨ÇÃåäÇ⁄DZDžÇ∑Çƃ◊Ç¡Ç’Ç≥ÇÍǃõ∆ǡǃèoǃóàÇÍǻǢä¥Ç∂ÅB
ÇæÇ©ÇÁã¶ãcêßÇ≈è„ï”ÇæÇØò_óùìIÇ…êÑò_ǵǃÇΩÇ«ÇËíÖÇ¢ÇΩåãò_ÇÕabsolute nonsenceÇ»
Ç∆ÇÒÇ≈Çýåãò_njǡǩÇËÅB
ãìÇ∞ãÂÇÃâ ǃDžÅAÇ∂Ç·ÇÝÉLÉÉÉbÉVÉÖÇÕâΩÉÅÉKÇ≈ÅAÉåÉWÉXÉ^ÇÕâΩå¬ÇÝǡǃÅAÉoÉCÉg/flopÇÕäÙǬÇæÇ¡ÇΩÇÁ
îÑÇÍÇÈÉRÉìÉsÉÖÅ[É^Å[Ç…Ç»ÇÈÇÒÇæÇÊÇ∆Ç©êÍñÂÉoÉJÇ∆ǢǧǩÅAê^ê´ÉoÉJÇ…ì{ñ¬ÇÁÇÍǃÅB
ÇýǧÉAÉzÇ©Ç∆ÅA≤‘ð≈Ø¡¨Ç¡ÇΩÅAÇ∆Ç¡Ç≠Ç…ë´êÙÇ¡ÇΩÇØÇ«Çó
ǪǧǻÇÒÇæÇÊÇ»Åc
îÒê¸å`ç≈ìKâªñ‚ëËÇ≈ã…è¨ÇÃåäÇ⁄DZDžÇ∑Çƃ◊Ç¡Ç’Ç≥ÇÍǃõ∆ǡǃèoǃóàÇÍǻǢä¥Ç∂ÅB
ÇæÇ©ÇÁã¶ãcêßÇ≈è„ï”ÇæÇØò_óùìIÇ…êÑò_ǵǃÇΩÇ«ÇËíÖÇ¢ÇΩåãò_ÇÕabsolute nonsenceÇ»
Ç∆ÇÒÇ≈Çýåãò_njǡǩÇËÅB
ãìÇ∞ãÂÇÃâ ǃDžÅAÇ∂Ç·ÇÝÉLÉÉÉbÉVÉÖÇÕâΩÉÅÉKÇ≈ÅAÉåÉWÉXÉ^ÇÕâΩå¬ÇÝǡǃÅAÉoÉCÉg/flopÇÕäÙǬÇæÇ¡ÇΩÇÁ
îÑÇÍÇÈÉRÉìÉsÉÖÅ[É^Å[Ç…Ç»ÇÈÇÒÇæÇÊÇ∆Ç©êÍñÂÉoÉJÇ∆ǢǧǩÅAê^ê´ÉoÉJÇ…ì{ñ¬ÇÁÇÍǃÅB
ÇýǧÉAÉzÇ©Ç∆ÅA≤‘ð≈Ø¡¨Ç¡ÇΩÅAÇ∆Ç¡Ç≠Ç…ë´êÙÇ¡ÇΩÇØÇ«Çó
ÇÝÇÍÇ≈ÅAäwà éùǡǃéËìñÇΩÇËëOÇ»ÉåÉxÉãÇÃÉRÉìÉsÉÖÅ[É^Å[ÇÃêÍñÂâ∆èWícÇ∆ÇÕ
Ç∆ǧǃǢévǶǻǢÇÊǧǻí·ÉåÉxÉãÇ’ÇËÇÃãcò_ÇæÇ¡ÇΩÇ»Åc
ÇøÇÂÇ¡Ç∆Ç≈ÇýÉRÉìÉsÉÖÅ[É^Å[ÇégÇ¢çûÇÒÇæDZÇ∆Ç™ÇÝÇÍÇŒìñÇΩÇËëOÇÃî@Ç≠ï™Ç©ÇÈÇÊǧǻDZÇ∆Ç≈Ç∑ÇÁ
Ç∑ÇÆógÇ∞ë´éBÇÁÇÍǃõõóùã¸Ç≈îΩò_Ç≥ÇÍǃãäíeÅB
É\ÉtÉgÉEÉFÉAÇÇ≤ÇðÇÃî@Ç≠åyéãǵǃǢÇΩǵÅB
Ç»ÇÒÇæÇ¡ÇΩÇÒÇæÅAÇÝÇÃÉoÉJëõǨÇÕÅB
êlê∂ç≈à´ÇÃäJî≠ã∆ñ±ÇæÇ¡ÇΩÇ»ÅB
Ç∆ǧǃǢévǶǻǢÇÊǧǻí·ÉåÉxÉãÇ’ÇËÇÃãcò_ÇæÇ¡ÇΩÇ»Åc
ÇøÇÂÇ¡Ç∆Ç≈ÇýÉRÉìÉsÉÖÅ[É^Å[ÇégÇ¢çûÇÒÇæDZÇ∆Ç™ÇÝÇÍÇŒìñÇΩÇËëOÇÃî@Ç≠ï™Ç©ÇÈÇÊǧǻDZÇ∆Ç≈Ç∑ÇÁ
Ç∑ÇÆógÇ∞ë´éBÇÁÇÍǃõõóùã¸Ç≈îΩò_Ç≥ÇÍǃãäíeÅB
É\ÉtÉgÉEÉFÉAÇÇ≤ÇðÇÃî@Ç≠åyéãǵǃǢÇΩǵÅB
Ç»ÇÒÇæÇ¡ÇΩÇÒÇæÅAÇÝÇÃÉoÉJëõǨÇÕÅB
êlê∂ç≈à´ÇÃäJî≠ã∆ñ±ÇæÇ¡ÇΩÇ»ÅB
ǪÇÃì_ÅARegattaÇäJî≠ǵǃǢÇΩçÝÇÃIÇÕÉåÉxÉãçÇÇ©Ç¡ÇΩÇ»Å[ÅB
ëÂêlÇ∆éqãüÇÝÇÈÇ¢ÇÕÉvÉçèWícÇ∆ÉoÉuÉãê¢ë„ÇÃ≈ð¡¨Ø√é–âÔêlÅAéïÇ™óßÇΩǻǢǡǃä¥Ç∂ÅB
ç°ÇÕǫǧÇæÇ©ímÇÁǻǢǙÅB
ëÂêlÇ∆éqãüÇÝÇÈÇ¢ÇÕÉvÉçèWícÇ∆ÉoÉuÉãê¢ë„ÇÃ≈ð¡¨Ø√é–âÔêlÅAéïÇ™óßÇΩǻǢǡǃä¥Ç∂ÅB
ç°ÇÕǫǧÇæÇ©ímÇÁǻǢǙÅB
å§ãÜèäÇ™éñã∆ÇÃñÇ…ÇýóßǡǃǢǻǢåè
ljÇ≈ǙǶÇÈÇ∆ìØÇ∂ÇæÇ»
èôÅXDžDZǧǻǡÇΩÇ©ÇÁñ‚ëËÇæÇ∆ãCǙǬǩǻǢìýÇ…ä◊ÇÈ
ljÇ≈ǙǶÇÈÇ∆ìØÇ∂ÇæÇ»
èôÅXDžDZǧǻǡÇΩÇ©ÇÁñ‚ëËÇæÇ∆ãCǙǬǩǻǢìýÇ…ä◊ÇÈ
ÉLÉÉÉbÉVÉÖÇ‚eDRAMÇ≈åÎñÇâªÇµÇƒÇΩÉQÅ[ÉÄã@Ç≈
GDDR5Å@8GBÇÃëIëÇÕGJ>PS4
ÉQÅ[ÉÄãªñ°Ç»Ç¢Ç©ÇÁÇ»ÇÒÇýîÉÇÌǻǢÇØÇ«
GDDR5Å@8GBÇÃëIëÇÕGJ>PS4
ÉQÅ[ÉÄãªñ°Ç»Ç¢Ç©ÇÁÇ»ÇÒÇýîÉÇÌǻǢÇØÇ«
>>396
Atom J1900 (SilvermontǡǃǂǡǜÇËï≥íxǢǻ
Atom J1900 (SilvermontǡǃǂǡǜÇËï≥íxǢǻ
416 ÅFSocket774ÅF2014/06/18(êÖ) 03:52:01.62 ID:RlbwpztZ
ǪÇÒÇ»ÉJÉ^ÉçÉOÉXÉyÉbÉNÇÃFLOPSêîÇ≈ê´î\î‰ärÇ≥ÇÍǃÇýǪÇÒÇ»ÉpÉtÉHÅ[É}ÉìÉXèoÇÈåvéZé¿ç€Ç…ÇÕë∂çðǵǻǢ
ÇÐÇÝÇ≈ÇýLINPACKÇðÇΩǢDžóùò_ílÇÃ9äÑÇ≈ÇÈåvéZÇ…
é˘óvÇ™ëSÇ≠ǻǢÇÌÇØÇ≈ÇÕǻǢ
é˘óvÇ™ëSÇ≠ǻǢÇÌÇØÇ≈ÇÕǻǢ
é¿çsÉÜÉjÉbÉgÇÃî\óÕǵǩî‰ärǵǃǻǢÇ∂Ç·ÇÒÅBÉÅÉÇÉäÅ[ÇÕÇ®ÇÎÇ©ÅAÉtÉçÉìÉgÉGÉìÉhÇ‚ÉäÉ^ÉCÉÑÉÅÉìÉgÇÃÉåÉCÉeÉìÉVÅ[Ç∆Ç©ÇÃÉ}ÉCÉNÉçÉAÅ[ÉLÉeÉNÉ`ÉÉÇ…ä÷ÇÌÇÈê´î\Çýï]âøǵǃǻǢÅB
é¿çsÉÜÉjÉbÉgÇÃî\óÕǵǩî‰ärǵǻǢÇÃǡǃ
CPUÇ∆GPUÇÃFLOPSÇ‚ÉRÉAêîÇÉJÉ^ÉçÉOÉXÉyÉbÉNÇ≈çáéZǵÇøÇ·Ç¡ÇΩÇËÇ∑ÇÈAMDÇÃè\î™î‘Ç∂ǷǻǢÇ≈Ç∑Ç©
CPUÇ∆GPUÇÃFLOPSÇ‚ÉRÉAêîÇÉJÉ^ÉçÉOÉXÉyÉbÉNÇ≈çáéZǵÇøÇ·Ç¡ÇΩÇËÇ∑ÇÈAMDÇÃè\î™î‘Ç∂ǷǻǢÇ≈Ç∑Ç©
420 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/18(êÖ) 20:39:32.67 ID:Cwe5Wmc+
>>417
çsóÒêœââéZÇ≈óùò_ê´î\ÇÃ9äÑèoÇ∑ÇÃÇ∑ÇÁÅALoad+Broadcast+Multiply+AddÇ
1ÉTÉCÉNÉãÇ≈Ç≈ǴǻǢÇ∆Ç¢ÇØǻǢÇÒÇæÇ™ÅB
ëSïîÇÃFPUégÇ¢êÿÇ¡ÇΩéûì_Ç≈ÇŸÇ©Ç…ñΩóþÇÉfÉRÅ[ÉhÅEé¿çsÇ∑ÇÈó]ínǙǻÇ≠Ç»ÇÈéûì_Ç≈
óùò_ê´î\ÇÕà”ñ°ÇÇýÇΩǻǢÅBAMDÇÃCPU/GPUÇ…ÇÝÇËÇ™ÇøǻDZÇ∆ÇæÇ™ÅB
çsóÒêœââéZÇ≈óùò_ê´î\ÇÃ9äÑèoÇ∑ÇÃÇ∑ÇÁÅALoad+Broadcast+Multiply+AddÇ
1ÉTÉCÉNÉãÇ≈Ç≈ǴǻǢÇ∆Ç¢ÇØǻǢÇÒÇæÇ™ÅB
ëSïîÇÃFPUégÇ¢êÿÇ¡ÇΩéûì_Ç≈ÇŸÇ©Ç…ñΩóþÇÉfÉRÅ[ÉhÅEé¿çsÇ∑ÇÈó]ínǙǻÇ≠Ç»ÇÈéûì_Ç≈
óùò_ê´î\ÇÕà”ñ°ÇÇýÇΩǻǢÅBAMDÇÃCPU/GPUÇ…ÇÝÇËÇ™ÇøǻDZÇ∆ÇæÇ™ÅB
Broadcast?
('A`)
('A`)
422 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/19(ñÿ) 07:54:15.55 ID:ZTyIw3UP
http://stackoverflow.com/questions/21134279/difference-in-performance-between-msvc-and-gcc-for-highly-optimized-matrix-multp
ÇÝÇÝÅAåvéZÇÃèáî‘ïœÇ¶ÇÍÇŒñàÉTÉCÉNÉãÇÕïKóvǻǢÇÒÇæÇÀ
AVX512Ç»ÇÁâΩÇýçlǶÇ∏DZÇÍÇ≈Ç¢ÇØÇÈÇ∆ǢǧîFéØÇæÇØÇ«
vfmadd231ps zmm0, zmm2, [ptr]{1to16}
ÇÝÇÝÅAåvéZÇÃèáî‘ïœÇ¶ÇÍÇŒñàÉTÉCÉNÉãÇÕïKóvǻǢÇÒÇæÇÀ
AVX512Ç»ÇÁâΩÇýçlǶÇ∏DZÇÍÇ≈Ç¢ÇØÇÈÇ∆ǢǧîFéØÇæÇØÇ«
vfmadd231ps zmm0, zmm2, [ptr]{1to16}
423 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/19(ñÿ) 08:54:40.43 ID:ZTyIw3UP
Ç∆ǢǧǩǪÇÍà»ëOÇ…JaguarÇÕL2ÉLÉÉÉbÉVÉÖÇ™íxÇ∑ǨÇÈÇ©ÇÁHPCÇ…ÇÕå¸Ç©Ç»Ç¢Ç∆évǧ
HBMÇÕTSVÇÃèÁí∑âªÇýÇ‚ÇÈÇÒÇæÇ»
ttp://pc.watch.impress.co.jp/docs/news/event/20140619_654110.html
ttp://pc.watch.impress.co.jp/docs/news/event/20140619_654110.html
L2ÉLÉÉÉbÉVÉÖÇÃë¨Ç≥ǡǃCPUÇ≤Ç∆Ç…à·Ç§ÇÃÅH
SRAMÇÃíÜÇ≈Çýë¨Ç¢Ç∆Ç©íxÇ¢Ç∆Ç©ÇÝÇÈÇÒǩǶÅH
SRAMÇÃíÜÇ≈Çýë¨Ç¢Ç∆Ç©íxÇ¢Ç∆Ç©ÇÝÇÈÇÒǩǶÅH
ÉLÉÉÉbÉVÉÖÇâΩÇæÇ∆évǡǃÇÈÇÒÇæ
å≈íËíÔçRÇ≈Hìdà Ç∆Lìdà ÇÃÇ¢Ç∏ÇÍÇ©Çï\åªÇ∑ÇÈ1ÉrÉbÉgÇÃROMÇÃÇÊǧǻÇýÇÃÇ»ÇÁÅA
ò_óùìIÇ»ÉåÉCÉeÉìÉVÇÕñ≥éãǵǧÇÈÇÃÇ©ÇýǵÇÍǻǢÅB
ò_óùìIÇ»ÉåÉCÉeÉìÉVÇÕñ≥éãǵǧÇÈÇÃÇ©ÇýǵÇÍǻǢÅB
428 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/19(ñÿ) 20:48:15.40 ID:ZTyIw3UP
>>425
JaguarÇÕè»ìdóÕê´ÇçÇÇþÇÈÇΩÇþÇ…L2 CacheÇÃÉNÉçÉbÉNÇ™îºï™Ç…Ç≥ÇÍǃÇÈÅB
ǪǧǢǂPS4Ç∆Ç©Xbox oneÇÕǫǧǻǡǃÇÈÇÒÇæÇÎÅH
JaguarÇÕè»ìdóÕê´ÇçÇÇþÇÈÇΩÇþÇ…L2 CacheÇÃÉNÉçÉbÉNÇ™îºï™Ç…Ç≥ÇÍǃÇÈÅB
ǪǧǢǂPS4Ç∆Ç©Xbox oneÇÕǫǧǻǡǃÇÈÇÒÇæÇÎÅH
430 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/19(ñÿ) 22:04:36.69 ID:ZTyIw3UP
Cell PPEÇ‚XenonÇ∑ÇÁL2ÇÕíxÇ©Ç¡ÇΩÅiçÇÉåÉCÉeÉìÉVÅEí·ÉXÉãÅ[ÉvÉbÉgÅjéñé¿Çì•ÇÐǶÇÈÇ∆
ÉQÅ[ÉÄã@ÇæÇ©ÇÁë¨Ç≠Ç∑ÇÈÇ∆ǢǧóùåAÇÕïKÇ∏ǵÇýê¨ÇËóßÇΩǻǢÅB
ÉQÅ[ÉÄã@ÇæÇ©ÇÁë¨Ç≠Ç∑ÇÈÇ∆ǢǧóùåAÇÕïKÇ∏ǵÇýê¨ÇËóßÇΩǻǢÅB
íPÇ…ÅAÉRÉXÉgÉ_ÉEÉìÇ≠ÇÁÇ¡ÇΩÇæÇØÇ©ÇýímÇÍǻǢÇØÇ«Ç»Åc
SRAMǡǃÇÃÇÕà”äOÇ∆è¡îÔìdóÕÇ™çÇÇ¢ÅB
L1ÉLÉÉÉbÉVÉÖÇÃÉNÉçÉbÉNêîǡǃÉCÉRÅ[ÉãCPUÇÃÉNÉçÉbÉNêîÇ»ÇÒÇæÇ¡ÇØÅH
CPUëIÇ‘Ç∆Ç´Ç…ÇÕL2ÉLÉÉÉbÉVÉÖÇÃÉNÉçÉbÉNêîÇ…íçñ⁄ǵÇΩǟǧǙǢǢÇÃÇ©Ç»
DZÇÍÇÕñ”ì_ÇæÇ¡ÇΩ
CPUëIÇ‘Ç∆Ç´Ç…ÇÕL2ÉLÉÉÉbÉVÉÖÇÃÉNÉçÉbÉNêîÇ…íçñ⁄ǵÇΩǟǧǙǢǢÇÃÇ©Ç»
DZÇÍÇÕñ”ì_ÇæÇ¡ÇΩ
Ç»ÇÒÇæÇ©ÇÒÇæǢǡǃÉLÉÉÉbÉVÉÖÇ™ÉNÉçÉbÉNè„è∏ÇÃè·äQDžǻǡÇΩÇËǵǃǴÇΩÇ©ÇÁÇ»ÇÝ
ãtÇ…ÅAêÃÇÃDZÇ∆ÇæÇØÇ«ìÒéüÉLÉÉÉbÉVÉÖǻǩǡÇΩç≈èâÇÃÉZÉåÉçÉìÇ™ÉIÅ[ÉoÅ[ÉNÉçÉbÉNÇ∑Ç≤Ç©Ç¡ÇΩÇ»ÇÒǃòbÇýÇÝÇ¡ÇΩ
ãtÇ…ÅAêÃÇÃDZÇ∆ÇæÇØÇ«ìÒéüÉLÉÉÉbÉVÉÖǻǩǡÇΩç≈èâÇÃÉZÉåÉçÉìÇ™ÉIÅ[ÉoÅ[ÉNÉçÉbÉNÇ∑Ç≤Ç©Ç¡ÇΩÇ»ÇÒǃòbÇýÇÝÇ¡ÇΩ
>>433
ÇΩǵǩAMDÇÃL3 CacheÇ™NBÇ∆ìôë¨Ç≈íxÇ¢ÇØÇ«ÅAL2 Cacheîºë¨ÇÕJaguarÇæÇØÅB
IntelÇÕåªçsCPUÇ≈ÇÕëSïîCPUÉRÉAÇ∆ó•ë¨Ç»ÇÕÇ∏
ÇΩǵǩAMDÇÃL3 CacheÇ™NBÇ∆ìôë¨Ç≈íxÇ¢ÇØÇ«ÅAL2 Cacheîºë¨ÇÕJaguarÇæÇØÅB
IntelÇÕåªçsCPUÇ≈ÇÕëSïîCPUÉRÉAÇ∆ó•ë¨Ç»ÇÕÇ∏
ÉxÉìÉ`ÇÃåãâ å©ÇƒÇ»Ç∫íxǢǩÇçlé@Ç∑ÇÈÇÃÇ…ÉLÉÉÉbÉVÉÖÇÃë¨ìxÇ…å¥àˆÇãÅÇþÇΩÇËÇÕÇ∑ÇÈÇ™
ÉLÉÉÉbÉVÉÖÇÃë¨ìxÇðǃCPUê´î\ÇêÑë™Ç∑ÇÈÇÃÇÕÇ®Ç∑Ç∑ÇþǵǩÇÀÇÈÅB
ÉLÉÉÉbÉVÉÖÇÃë¨ìxÇðǃCPUê´î\ÇêÑë™Ç∑ÇÈÇÃÇÕÇ®Ç∑Ç∑ÇþǵǩÇÀÇÈÅB
FPGAÇ…ÉnÅ[ÉhÉEÉFÉAïÇìÆè¨êîì_DSPìýëÝÅAìdóÕå¯ó¶Ç≈GPGPUÇÃè„ÇçsÇ≠
http://eetimes.jp/ee/articles/1404/23/news063.html
http://eetimes.jp/ee/articles/1404/23/news063.html
FPGAégÇ¡ÇΩÇÁÉRÉXÉgÇýíµÇÀè„Ç™ÇËǪǧÇæÇ»
ǪÇýǪÇýàÍî ìIÇ»ÉOÉâÉtÉBÉbÉNèàóùÇ…égÇÌÇÍÇÈDirectXÇ‚OpenGLÇÃǬǢÇ≈Ç…ââéZèàóùÇýÇ∑ÇÈà¿âøÇ»GPUëäéËÇ…ââéZèàóùÇæÇØÇ≈èüǡǃÇýëSÇ≠à”ñ°ÇÕñ≥Ǣǻ
GPGPUÇÕç°Ç‚ÉpÉ\ÉRÉìÇæÇØÇ∂Ç·Ç»Ç≠ÉQÅ[ÉÄã@Ç‚ÉXÉ}ÉtÉHÇ≈Ç∑ÇÁëŒâûÇ≈Ç´ÇÈÇØÇ«ÅAFPGAÇÕÇ«ÇÒǻDžäÊí£Ç¡ÇƒÇýÉpÉ\ÉRÉìÇ…Ç∑ÇÁêœÇþǻǢ
ëΩè≠GPGPUÇ™îÒå¯ó¶Ç≈ÇýÅAêîÇ∆ÉRÉXÉgñ Ç≈à≥ì|ìIÇ…óDà ÇæÇ©ÇÁÅAFPGAÇ™GPGPUÇÃïÅãyÇ…ëŒÇµÇƒÇ«Ç§Ç…Ç©èoóàÇÈÇ∆ÇÕévǶǻǢǻ
ǪÇýǪÇýàÍî ìIÇ»ÉOÉâÉtÉBÉbÉNèàóùÇ…égÇÌÇÍÇÈDirectXÇ‚OpenGLÇÃǬǢÇ≈Ç…ââéZèàóùÇýÇ∑ÇÈà¿âøÇ»GPUëäéËÇ…ââéZèàóùÇæÇØÇ≈èüǡǃÇýëSÇ≠à”ñ°ÇÕñ≥Ǣǻ
GPGPUÇÕç°Ç‚ÉpÉ\ÉRÉìÇæÇØÇ∂Ç·Ç»Ç≠ÉQÅ[ÉÄã@Ç‚ÉXÉ}ÉtÉHÇ≈Ç∑ÇÁëŒâûÇ≈Ç´ÇÈÇØÇ«ÅAFPGAÇÕÇ«ÇÒǻDžäÊí£Ç¡ÇƒÇýÉpÉ\ÉRÉìÇ…Ç∑ÇÁêœÇþǻǢ
ëΩè≠GPGPUÇ™îÒå¯ó¶Ç≈ÇýÅAêîÇ∆ÉRÉXÉgñ Ç≈à≥ì|ìIÇ…óDà ÇæÇ©ÇÁÅAFPGAÇ™GPGPUÇÃïÅãyÇ…ëŒÇµÇƒÇ«Ç§Ç…Ç©èoóàÇÈÇ∆ÇÕévǶǻǢǻ
ǧÇÒÅAFPGAégǧà”ñ°Ç»ÇµÅB
ìdóÕå¯ó¶Ç…óDÇÍǃÇÈÇ»ÇÁÉXÉpÉRÉìópÇ∆Ç©ópìrÇÕÇÝÇÈǡǵÇÂ
ÉèÉbÉgÉpÉtÉHÅ[É}ÉìÉX2î{ÇÃFPGAÇ∆ÅAÉRÉXÉgÉpÉtÉHÅ[É}ÉìÉX2î{ÇÃGPGPUÇÃÇ«Ç¡ÇøÇëIÇ‘Ç©ÇæÇ»
442 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/21(ìy) 00:27:53.74 ID:LNZwKvi6
ÉvÉçÉOÉâÉ}Å[ÇÃçHêîÅEíPâøçlǶÇÍÇŒGPGPUÇÃÉRÉXÉgÉpÉtÉHÅ[É}ÉìÉXǙǢǢǻÇÒǃ
å˚Ç™óÙÇØǃÇýǢǶǻǢÅB1êlåé200ñúà»è„Ç™ëäèÍÇæÇÊÅB
è¨ãKñÕÇ»ÉVÉXÉeÉÄÇ»ÇÁXeonÇÉNÉâÉXÉ^ÉäÉìÉOǵÇΩǟǧǙÇÐǵÅB
ãtÇ…êîÇ™ëΩÇ≠Ç»ÇÈÇ∆ç°ìxÇÕìdóÕå¯ó¶Ç™ñ‚ÇÌÇÍÇÈÇ©ÇÁFPGAÇÃǟǧǙóLóòÅB
éYã∆å¸ÇØÇÃGPGPUÇÃé˘óvǡǃÉXÉpÉRÉìÇýäÐÇþǃç°ÇÕå∏è≠åXå¸ÇæÇØÇ«
FPGAÇÕXilinxÇýAlteraÇýÇ©Ç»ÇËêLǗǃǴǃÇÈåªé¿ÅB
GPGPUÇÃǟǧǙãèèÍèäè≠ǻǢ
å˚Ç™óÙÇØǃÇýǢǶǻǢÅB1êlåé200ñúà»è„Ç™ëäèÍÇæÇÊÅB
è¨ãKñÕÇ»ÉVÉXÉeÉÄÇ»ÇÁXeonÇÉNÉâÉXÉ^ÉäÉìÉOǵÇΩǟǧǙÇÐǵÅB
ãtÇ…êîÇ™ëΩÇ≠Ç»ÇÈÇ∆ç°ìxÇÕìdóÕå¯ó¶Ç™ñ‚ÇÌÇÍÇÈÇ©ÇÁFPGAÇÃǟǧǙóLóòÅB
éYã∆å¸ÇØÇÃGPGPUÇÃé˘óvǡǃÉXÉpÉRÉìÇýäÐÇþǃç°ÇÕå∏è≠åXå¸ÇæÇØÇ«
FPGAÇÕXilinxÇýAlteraÇýÇ©Ç»ÇËêLǗǃǴǃÇÈåªé¿ÅB
GPGPUÇÃǟǧǙãèèÍèäè≠ǻǢ
FPGAÇÕäJî≠å¯ó¶Ç™à´Ç¢ÅBÉçÉWÉbÉNÇýǪÇÒǻDžãlÇþçûÇþǻǢǵÅA
èàóùÇýäÓñ{ìIÇ…ÉpÉCÉvÉâÉCÉìâªÇ≈Ç´ÇÈÇýÇÃÇ≈Ç»ÇØÇÍÇŒéÊÇËàµÇ¶Ç»Ç¢
ǵǩǵópìrÇ…çáǡǃÇ≥ǶǢÇÍÇŒìdóÕå¯ó¶ÇÕ10î{Ç∆Ç©Ç…Ç»ÇÈÇÃÇ≈ÅAå≥Ç™éÊÇÍÇÈÇÕÇ∏Ç≈
èàóùÇýäÓñ{ìIÇ…ÉpÉCÉvÉâÉCÉìâªÇ≈Ç´ÇÈÇýÇÃÇ≈Ç»ÇØÇÍÇŒéÊÇËàµÇ¶Ç»Ç¢
ǵǩǵópìrÇ…çáǡǃÇ≥ǶǢÇÍÇŒìdóÕå¯ó¶ÇÕ10î{Ç∆Ç©Ç…Ç»ÇÈÇÃÇ≈ÅAå≥Ç™éÊÇÍÇÈÇÕÇ∏Ç≈
FPGAÇÕÉfÅ[É^ÉtÉçÅ[Ç™å≈íËÇ≈ÉÅÉÇÉäÉAÉNÉZÉXÇýè≠ǻǢâûópǵǩégǶǻǢ
ñ}ófÇ»îƒópÇ∆èâä˙îÔópÇ™çÇÇ¢êÍópASICÇÃíÜä‘Ç∆Ǣǧ
DZÇÍÇÐÇ≈ÇÃFPGAÇÃóßÇøà íuÇFloat ï™ñÏÇ…ÇýçLÇ∞ÇΩÇ∆ǢǧòbÇ©
DZÇÍÇÐÇ≈ÇÃFPGAÇÃóßÇøà íuÇFloat ï™ñÏÇ…ÇýçLÇ∞ÇΩÇ∆ǢǧòbÇ©
446 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/21(ìy) 08:28:44.77 ID:LNZwKvi6
ãþîNÇÕêªë¢ÉvÉçÉZÉXÉãÅ[ÉãÇ≈FPGAÇ™ASICÇëÂÇ´Ç≠ÉäÅ[ÉhÇ∑ÇÈÇÊǧDžǻǡÇΩDZÇ∆
ǪǵǃASICÇÕÉVÉÖÉäÉìÉNÇÃÇΩÇ—Ç…êªë¢ÉRÉXÉgÇ™çÇÇ≠Ç»ÇÈåXå¸ÅB
ç≈èIêªïiÇ∆ǵǃASICÇ≈ÇÕÇ»Ç≠ä∏ǶǃFPGAÇëIÇ‘ÉxÉìÉ_Å[Ç™ëùǶÇΩÅB
çëóßìVï∂ë‰ÇÃGRAPEÇæǡǃFPGAÇæÇÎÅH
ǪǵǃASICÇÕÉVÉÖÉäÉìÉNÇÃÇΩÇ—Ç…êªë¢ÉRÉXÉgÇ™çÇÇ≠Ç»ÇÈåXå¸ÅB
ç≈èIêªïiÇ∆ǵǃASICÇ≈ÇÕÇ»Ç≠ä∏ǶǃFPGAÇëIÇ‘ÉxÉìÉ_Å[Ç™ëùǶÇΩÅB
çëóßìVï∂ë‰ÇÃGRAPEÇæǡǃFPGAÇæÇÎÅH
åªé¿ÇÃìÆå¸ímÇÁǻǢPCÉíÉ^ëΩÇ∑Ǩ
448 ÅF Åümiyuri//Z7LS ÅF2014/06/21(ìy) 12:36:17.44 ID:jwCUJknR
ǔǫǧÇÃóßÇøà íu
Ç¢ÇÐÇæÇ…GPUÇÃÉRÉAÇ∆CPUÇÃÉRÉAÇ™ìØÇ∂ÇýÇÃÇæÇ∆évǡǃÇÈ
îné≠Ç™ëΩÇ≠ǃç¢ÇÈÅB
îné≠Ç™ëΩÇ≠ǃç¢ÇÈÅB
450 ÅFSocket774ÅF2014/06/21(ìy) 13:46:03.89 ID:tlujmSIa
FPGAÇÕÅAASICçÏÇÈÇŸÇ«êîÇ™èoǻǢã@äÌÇ‚ÅA
ÇÝÇ∆Ç≈ÉtÉ@Å[ÉÄÉEÉFÉAÉAÉbÉvÉfÅ[ÉgÇ≈ã@î\ÇèCê≥ÅEí«â¡ÅEïœçXǵǻǢÇ∆Ç¢ÇØǻǢÇÊǧǻ
ÉtÉ@ÉCÉAÉEÉHÅ[ÉãìôÇÃÉlÉbÉgÉèÅ[ÉNã@äÌÇ‚ÇÁåRéñópëgÇðçûÇðã@äÌÇ∆Ç©å¸ÇØÇæÇÎ
HPCópÇ»ÇÁǔǬǧDžASICǬÇ≠Ç¡ÇΩǟǧǙǢǢ
ÇÝÇ∆Ç≈ÉtÉ@Å[ÉÄÉEÉFÉAÉAÉbÉvÉfÅ[ÉgÇ≈ã@î\ÇèCê≥ÅEí«â¡ÅEïœçXǵǻǢÇ∆Ç¢ÇØǻǢÇÊǧǻ
ÉtÉ@ÉCÉAÉEÉHÅ[ÉãìôÇÃÉlÉbÉgÉèÅ[ÉNã@äÌÇ‚ÇÁåRéñópëgÇðçûÇðã@äÌÇ∆Ç©å¸ÇØÇæÇÎ
HPCópÇ»ÇÁǔǬǧDžASICǬÇ≠Ç¡ÇΩǟǧǙǢǢ
451 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/21(ìy) 14:18:34.92 ID:LNZwKvi6
HPCópASICÇ»ÇÒǃClearSpeedà»óàèoǃǻǢãCÇ™Ç∑ÇÈÇÃÇæÇ™
GRAPE?
453 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/21(ìy) 14:36:42.59 ID:LNZwKvi6
GRAPEÇýåªçsç≈êVÇÕFPGAÇæÇÊ
http://www.nikkan.co.jp/newrls/rls20131217o-02.html
http://www.nikkan.co.jp/newrls/rls20131217o-02.html
>>437
madVRópÇ…ó~ǵǢ
madVRópÇ…ó~ǵǢ
>>449
SPíPà Ç∂Ç·Ç»Ç≠ǃCUÇ‚SMX/SMMíPà Ç≈å©ÇΩǟǧǙǢǢÇÀ
é¿ç€APUÇ∆Ç©ÇÕ2M/4C+8CU(512SP)Ç≈çáåv12Ç∆åæÇ¡ÇøǷǡǃÇÈǵ
SPíPà Ç∂Ç·Ç»Ç≠ǃCUÇ‚SMX/SMMíPà Ç≈å©ÇΩǟǧǙǢǢÇÀ
é¿ç€APUÇ∆Ç©ÇÕ2M/4C+8CU(512SP)Ç≈çáåv12Ç∆åæÇ¡ÇøǷǡǃÇÈǵ
GPUÇ∆CPUÇ™ìØÇ∂ÉRÉAǡǃFM8Ç©YO
ÇÝÇÍGPUÇæÇ¡ÇΩÇÃÇ©ÅB
Ç∑ÇÈÇ∆PC-8001ÇÕAPUÇæÇ»ÅB
Ç∑ÇÈÇ∆PC-8001ÇÕAPUÇæÇ»ÅB
458 ÅFSocket774ÅF2014/06/21(ìy) 21:47:03.99 ID:PlgRiOha
å√Ç¢êßå‰ã@äBÇ∆Ç©Ç…ì¸Ç¡ÇƒÇÈPC-9801Ç∆Ç©ÅAFPGAâªÇ∑ÇÍnjǢǢÇÃDžǡǃǮÇýǧÇÌ
FPGAǡǃCPU+ROMÇASICǵÇΩÇÊǧǻÉCÉÅÅ[ÉWÇæÇ©ÇÁ
RAMÇ™ïKóvÇ»ópìrÇ…ÇÕÇÝÇÐÇËìKÇ≥ǻǢÇÒÇ∂Ç·ÅB
RAMÇ™ïKóvÇ»ópìrÇ…ÇÕÇÝÇÐÇËìKÇ≥ǻǢÇÒÇ∂Ç·ÅB
Ç◊ǬDžÇ∑Ç◊ǃÇÃã@î\ÇFPGAè„Ç…çÏÇÁÇ»Ç≠ǃÇýǢǢÇØÇ«ÇÀ
àÍïîÇÃã@î\ÇÕäOïîÇ…åqÇ¢ÇæDRAMÇ≈Çýñ‚ëËǻǢ
àÍïîÇÃã@î\ÇÕäOïîÇ…åqÇ¢ÇæDRAMÇ≈Çýñ‚ëËǻǢ
çÇë¨è¨óeó ÇÃÉÅÉÇÉäÇ∆ǵǃÉIÉìÉ_ÉCÇÃÉuÉçÉbÉNRAMÇ™
í·ë¨ëÂóeó ÇÃÉÅÉÇÉäÇ∆ǵǃäOïtÇØDRAMÇ™égǶÇÈ(DZǡÇøÇÕÉ\ÉtÉgorÉnÅ[ÉhÉ}ÉNÉçåoóRÇæÇØÇ«)
í·ë¨ëÂóeó ÇÃÉÅÉÇÉäÇ∆ǵǃäOïtÇØDRAMÇ™égǶÇÈ(DZǡÇøÇÕÉ\ÉtÉgorÉnÅ[ÉhÉ}ÉNÉçåoóRÇæÇØÇ«)
462 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/21(ìy) 23:56:12.85 ID:TIwZ/yg1
>>459
ãtÇæÇÊ
àÍî ÇÃÉvÉçÉZÉbÉTÇ™ÇÝÇÐÇËégÇÌǻǢÇÊǧǻçÇÉRÉXÉgÇ»çLë—àÊÉÅÉÇÉäÇÃóòópÇ…Çý
êÊï⁄ÇǬÇØǃǴÇΩÇÃÇ™AlteraÇ‚XilinxÇÃÉnÉCÉGÉìÉhFPGA
ÉAÉãÉeÉâÇ∆ Micron é–ÅAFPGA Ç∆ÉnÉCÉuÉäÉbÉhÅEÉÅÉÇÉäÅEÉLÉÖÅ[ÉuÇ∆Çà ëäåðê⁄ë±ê´ÇÃé¿åªÇ≈ã∆äEÇÉäÅ[Éh
http://www.altera.co.jp/corporate/news_room/releases/2013/products/nr-altera-micron-hmc.html
ãtÇæÇÊ
àÍî ÇÃÉvÉçÉZÉbÉTÇ™ÇÝÇÐÇËégÇÌǻǢÇÊǧǻçÇÉRÉXÉgÇ»çLë—àÊÉÅÉÇÉäÇÃóòópÇ…Çý
êÊï⁄ÇǬÇØǃǴÇΩÇÃÇ™AlteraÇ‚XilinxÇÃÉnÉCÉGÉìÉhFPGA
ÉAÉãÉeÉâÇ∆ Micron é–ÅAFPGA Ç∆ÉnÉCÉuÉäÉbÉhÅEÉÅÉÇÉäÅEÉLÉÖÅ[ÉuÇ∆Çà ëäåðê⁄ë±ê´ÇÃé¿åªÇ≈ã∆äEÇÉäÅ[Éh
http://www.altera.co.jp/corporate/news_room/releases/2013/products/nr-altera-micron-hmc.html
>>458
ãZèpìIÇ…ÇÕè\ï™â¬î\ÇæÇÎǧÇØÇ«ÅAè§îÑÇ…Ç»ÇÈÇ©ÇÕã^ñ‚ÅB
ÇÝÇÐÇËçÇâøÇæÇ∆ã@çÞàÍéÆÇçXêVǵÇΩï˚Ç™ó«Ç¢Ç∆ǢǧòbÇ…Ç»ÇÈǵÅA
ÇÐÇΩåªçsPC-98ÇÃï€éÁÇë±ÇØÇÈîÔópÇÊÇËà¿Ç≠ǻǢÇ∆ÉÅÉäÉbÉgÇ™îñÇ¢ÅB
ëºÇ…Çýè\îNíPà ÇÃÉTÉ|Å[ÉgÇ‚NECÇÃãñâ¬ÇÃópïsóvÇ∆Ç©ãZèpà»äOÇÃñ‚ëËÇ™éRêœÇ…évǧÅB
ãZèpìIÇ…ÇÕè\ï™â¬î\ÇæÇÎǧÇØÇ«ÅAè§îÑÇ…Ç»ÇÈÇ©ÇÕã^ñ‚ÅB
ÇÝÇÐÇËçÇâøÇæÇ∆ã@çÞàÍéÆÇçXêVǵÇΩï˚Ç™ó«Ç¢Ç∆ǢǧòbÇ…Ç»ÇÈǵÅA
ÇÐÇΩåªçsPC-98ÇÃï€éÁÇë±ÇØÇÈîÔópÇÊÇËà¿Ç≠ǻǢÇ∆ÉÅÉäÉbÉgÇ™îñÇ¢ÅB
ëºÇ…Çýè\îNíPà ÇÃÉTÉ|Å[ÉgÇ‚NECÇÃãñâ¬ÇÃópïsóvÇ∆Ç©ãZèpà»äOÇÃñ‚ëËÇ™éRêœÇ…évǧÅB
464 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 00:31:07.42 ID:8Y8UuoVt
É\ÉtÉgÉGÉ~ÉÖÉåÅ[É^Ç≈ǢǢÇ∂Ç·ÇÒ
T98ÇÕì¡åÝÉÇÅ[ÉhÇæÇØÇÉ\ÉtÉgÉGÉ~ÉÖÇ≈é¿çsÇ∑ÇÈï˚éÆÇçÃÇÎǧÇ∆ǵÇΩÇØÇ«
VMwareÇÃì¡ãñÇ…êGÇÍÇÈâ¬î\ê´Ç™ÇÝÇÈÇ∆Ç©Ç≈äJî≠í‚é~Ç…éäÇ¡ÇΩÇÁǵǢ
ÇŸÇÒÇ∆ǩǫǧǩÇÕǵÇÁÇÒ
T98ÇÕì¡åÝÉÇÅ[ÉhÇæÇØÇÉ\ÉtÉgÉGÉ~ÉÖÇ≈é¿çsÇ∑ÇÈï˚éÆÇçÃÇÎǧÇ∆ǵÇΩÇØÇ«
VMwareÇÃì¡ãñÇ…êGÇÍÇÈâ¬î\ê´Ç™ÇÝÇÈÇ∆Ç©Ç≈äJî≠í‚é~Ç…éäÇ¡ÇΩÇÁǵǢ
ÇŸÇÒÇ∆ǩǫǧǩÇÕǵÇÁÇÒ
>>464
êßå‰ópìrÇÃPC-98ÇÕCÉoÉXÇ…êÍópÉ{Å[ÉhÇ™éhÇ≥ǡǃǢÇÈàÛè€Ç™ÇÝÇÈÇÃÇæÇ™ÅA
É\ÉtÉgÉGÉ~ÉÖÇ≈ÇÕǪDZÇÐÇ≈òdǶǻǢÇÊÇÀ?
êßå‰ópìrÇÃPC-98ÇÕCÉoÉXÇ…êÍópÉ{Å[ÉhÇ™éhÇ≥ǡǃǢÇÈàÛè€Ç™ÇÝÇÈÇÃÇæÇ™ÅA
É\ÉtÉgÉGÉ~ÉÖÇ≈ÇÕǪDZÇÐÇ≈òdǶǻǢÇÊÇÀ?
ǪǧÅBCÉoÉXÇÕïKê{ÅBÉGÉ~ÉÖÇ≈ǢǢÇ∂Ç·ÇÒÇ∆Ç©åæǡǃÇÈìzÇÕÇ«ëfêlÅB
ì¡ãñÇ™êÿÇÍÇÈÇÐÇ≈98ÇëÂéñÇ…égǧǵǩǻǢǻÅB
êßå‰ópÇÕDOSÇÃÉäÉAÉãÉ^ÉCÉÄê´ëOíÒÇ≈égǡǃÇÈÇ∆DZÇÎÇ™ëΩÇ¢ÇæÇÎǧǩÇÁÉGÉ~ÉÖÇÕò_äOÇæÇÎǧ
http://www.elwsc.co.jp/page.jsp?id=3529
> iNHERITORÅi=åpè≥é“ÅjII-AÇÕÅANECêªPC-9800ÉVÉäÅ[ÉYÇÃÉpÉ\ÉRÉìè„Ç≈ìÆçÏǵǃǢÇÈÉVÉXÉeÉÄéëéYÇÅA
> ésîÃÇÃWindows PC ÅiPC/ATåðä∑ã@ÅjÇ≈åpë±ÇµÇƒóòópÇ∑ÇÈDZÇ∆Çâ¬î\DžǵÇΩÅAâÊä˙ìIÇ»êªïiÇ≈Ç∑ÅB
> ÉnÅ[ÉhÉEÉFÉAÇ∆É\ÉtÉgÉEÉFÉAÇÃÉGÉ~ÉÖÉåÅ[ÉVÉáÉìÇîƒópÇÃWindows PCè„Ç≈é¿åªÇ≥ÇπÇÈDZÇ∆Ç…ÇÊÇËÅA
> PC-9800ÉVÉäÅ[ÉYè„Ç≈ìÆçÏǵǃǢÇÈä˘ë∂ÇÃÉAÉvÉäÉPÅ[ÉVÉáÉìÇ‚ÉhÉâÉCÉoǻǫÇÃñLïxÇ»éëéYÇñ≥ë Ç…Ç∑ÇÈ
> DZÇ∆Ç»Ç≠à¯Ç´ë±Ç´Ç≤óòópÇ¢ÇΩÇæÇØÇÐÇ∑ÅB
> ì¡í∑
> CÉoÉXägí£É{Å[ÉhÇÅAïWèÄç\ê¨Ç≈ç≈ëÂ6ÉXÉçÉbÉgÇÐÇ≈ìãç⁄â¬î\
> iNHERITORÅi=åpè≥é“ÅjII-AÇÕÅANECêªPC-9800ÉVÉäÅ[ÉYÇÃÉpÉ\ÉRÉìè„Ç≈ìÆçÏǵǃǢÇÈÉVÉXÉeÉÄéëéYÇÅA
> ésîÃÇÃWindows PC ÅiPC/ATåðä∑ã@ÅjÇ≈åpë±ÇµÇƒóòópÇ∑ÇÈDZÇ∆Çâ¬î\DžǵÇΩÅAâÊä˙ìIÇ»êªïiÇ≈Ç∑ÅB
> ÉnÅ[ÉhÉEÉFÉAÇ∆É\ÉtÉgÉEÉFÉAÇÃÉGÉ~ÉÖÉåÅ[ÉVÉáÉìÇîƒópÇÃWindows PCè„Ç≈é¿åªÇ≥ÇπÇÈDZÇ∆Ç…ÇÊÇËÅA
> PC-9800ÉVÉäÅ[ÉYè„Ç≈ìÆçÏǵǃǢÇÈä˘ë∂ÇÃÉAÉvÉäÉPÅ[ÉVÉáÉìÇ‚ÉhÉâÉCÉoǻǫÇÃñLïxÇ»éëéYÇñ≥ë Ç…Ç∑ÇÈ
> DZÇ∆Ç»Ç≠à¯Ç´ë±Ç´Ç≤óòópÇ¢ÇΩÇæÇØÇÐÇ∑ÅB
> ì¡í∑
> CÉoÉXägí£É{Å[ÉhÇÅAïWèÄç\ê¨Ç≈ç≈ëÂ6ÉXÉçÉbÉgÇÐÇ≈ìãç⁄â¬î\
Cortex-M0ǡǃÇ∆ǡǃÇýè¨Ç≥Ç¢ÉRÉAÇ»ÇÒÇæÇ»
IntelǡǃDZÇÒÇ»ÉRÉAÇ…QuarkÇ≈ëŒçRǵÇÊǧÇ∆ǵǃÇÈÇÃÇ©ÅH
ǵǩÇýâøäiÇ™îÒèÌÇ…à¿Ç¢
http://ednjapan.com/edn/articles/1006/01/news103.html
Cortex-M0ÇÕÅAÇÌÇ∏Ç©1ñú2000ÉQÅ[ÉgÇ≈é¿ëïÇ≈Ç´ÇÈÉvÉçÉZÉbÉTÉRÉAÇ≈ÇÝÇÈÅB
ǵǩǵÅADZDZÇÐÇ≈ãKñÕÇè¨Ç≥Ç≠Ç∑ÇÈÇΩÇþÇ…ÅA
Cortex-M0Ç…ÇÕÅACortex-M3Ç™äÆëSÇ…ÉTÉ|Å[ÉgÇ∑ÇÈ
16ÉrÉbÉgÇÃñΩóþÉZÉbÉgÉAÅ[ÉLÉeÉNÉ`ÉÉÅuThumb2ÅvÇÃǧÇøÅA
ÇŸÇÒÇÃàÍïîÇÃÉTÉuÉZÉbÉgǵǩé¿ëïÇ≥ÇÍǃǢǻǢÅiê}1ÅjÅB
ARMé–ÇÕÅAThumb2ñΩóþÇÃíÜÇ≈ÅA
ìùåvìIÇ…ç≈ÇýÇÊÇ≠égópÇ≥ÇÍÇÈÇýÇÃÇëIÇÒÇ≈ÅA
DZÇÃÉTÉuÉZÉbÉgÇé¿ëïǵÇΩÅBǵǩǵÅADZÇÃÇÊǧǻé¿ëïÇ≈ÇÝÇÈDZÇ∆Ç©ÇÁÅA
Thumb2ÇäÆëSÇ…ÉTÉ|Å[ÉgǵǃǢÇÍÇŒ
íPàÍÇÃñΩóþÇ≈é¿çsÇ≈Ç´ÇÈÇÊǧǻèàóùÇ™ÅA
Cortex-M0Ç≈ÇÕï°êîÇÃñΩóþÇégópǵǻÇØÇÍÇŒé¿çsÇ≈ǴǻǢDZÇ∆Ç™ÇÝÇÈÅB
Å@2009îNññÇ…ÇÕÅANXPé–Ç™ÅA
ARMé–ÇÃÉvÉçÉZÉbÉTÉRÉAÅuCortex-M0ÅvÇçÃópǵÇΩêªïiÇ
65ïƒÉZÉìÉgÇ∆ǢǧâøäiÇ≈î≠ï\ǵÇΩÅB
DZÇÃâøäiÇÕÅAÇýÇÕÇ‚8ÉrÉbÉgÉvÉçÉZÉbÉTÇ∆ìØìôÇ≈ÇÝÇÈÅB
åˆï\Ç≥ÇÍǃǢÇÈâøäièÓïÒÇÃíÜÇ≈ÅA
ç≈Çýà¿âøÇ»8ÉrÉbÉgÉvÉçÉZÉbÉTÇÕ1å¬ìñÇΩÇË45ïƒÉZÉìÉgÅA
çÇÇ¢ÇýÇÃÇæÇ∆10ïƒÉhÉãÇ…íBÇ∑ÇÈÅñ3ÅjÅB
ëΩÇ≠ÇÃêlÅXÇ™ó\ë™ÇµÇƒÇ¢ÇΩÇ∆Ç®ÇËÅA
32ÉrÉbÉgÉvÉçÉZÉbÉTÇ∆8ÉrÉbÉgÉvÉçÉZÉbÉTÇÃâøäiÇÃç∑ÇÕ
å¿ÇËÇ»Ç≠É[ÉçÇ…ãþÇ√ǢǃǢÇÈÇÃÇæ
Cortex-M3ÇÕÉQÅ[ÉgêîÇÕ3ñú3000ÉQÅ[Ég
http://monoist.atmarkit.co.jp/mn/articles/0601/20/news107_2.html
ëÊ1íeÇÃCortex-M3ÇÕÉRÉAïîï™Ç™ÇÌÇ∏Ç©33kÉQÅ[Ég
Åié¸ï”âÒòHÇäÐÇþ60kÅjÅB
IntelǡǃDZÇÒÇ»ÉRÉAÇ…QuarkÇ≈ëŒçRǵÇÊǧÇ∆ǵǃÇÈÇÃÇ©ÅH
ǵǩÇýâøäiÇ™îÒèÌÇ…à¿Ç¢
http://ednjapan.com/edn/articles/1006/01/news103.html
Cortex-M0ÇÕÅAÇÌÇ∏Ç©1ñú2000ÉQÅ[ÉgÇ≈é¿ëïÇ≈Ç´ÇÈÉvÉçÉZÉbÉTÉRÉAÇ≈ÇÝÇÈÅB
ǵǩǵÅADZDZÇÐÇ≈ãKñÕÇè¨Ç≥Ç≠Ç∑ÇÈÇΩÇþÇ…ÅA
Cortex-M0Ç…ÇÕÅACortex-M3Ç™äÆëSÇ…ÉTÉ|Å[ÉgÇ∑ÇÈ
16ÉrÉbÉgÇÃñΩóþÉZÉbÉgÉAÅ[ÉLÉeÉNÉ`ÉÉÅuThumb2ÅvÇÃǧÇøÅA
ÇŸÇÒÇÃàÍïîÇÃÉTÉuÉZÉbÉgǵǩé¿ëïÇ≥ÇÍǃǢǻǢÅiê}1ÅjÅB
ARMé–ÇÕÅAThumb2ñΩóþÇÃíÜÇ≈ÅA
ìùåvìIÇ…ç≈ÇýÇÊÇ≠égópÇ≥ÇÍÇÈÇýÇÃÇëIÇÒÇ≈ÅA
DZÇÃÉTÉuÉZÉbÉgÇé¿ëïǵÇΩÅBǵǩǵÅADZÇÃÇÊǧǻé¿ëïÇ≈ÇÝÇÈDZÇ∆Ç©ÇÁÅA
Thumb2ÇäÆëSÇ…ÉTÉ|Å[ÉgǵǃǢÇÍÇŒ
íPàÍÇÃñΩóþÇ≈é¿çsÇ≈Ç´ÇÈÇÊǧǻèàóùÇ™ÅA
Cortex-M0Ç≈ÇÕï°êîÇÃñΩóþÇégópǵǻÇØÇÍÇŒé¿çsÇ≈ǴǻǢDZÇ∆Ç™ÇÝÇÈÅB
Å@2009îNññÇ…ÇÕÅANXPé–Ç™ÅA
ARMé–ÇÃÉvÉçÉZÉbÉTÉRÉAÅuCortex-M0ÅvÇçÃópǵÇΩêªïiÇ
65ïƒÉZÉìÉgÇ∆ǢǧâøäiÇ≈î≠ï\ǵÇΩÅB
DZÇÃâøäiÇÕÅAÇýÇÕÇ‚8ÉrÉbÉgÉvÉçÉZÉbÉTÇ∆ìØìôÇ≈ÇÝÇÈÅB
åˆï\Ç≥ÇÍǃǢÇÈâøäièÓïÒÇÃíÜÇ≈ÅA
ç≈Çýà¿âøÇ»8ÉrÉbÉgÉvÉçÉZÉbÉTÇÕ1å¬ìñÇΩÇË45ïƒÉZÉìÉgÅA
çÇÇ¢ÇýÇÃÇæÇ∆10ïƒÉhÉãÇ…íBÇ∑ÇÈÅñ3ÅjÅB
ëΩÇ≠ÇÃêlÅXÇ™ó\ë™ÇµÇƒÇ¢ÇΩÇ∆Ç®ÇËÅA
32ÉrÉbÉgÉvÉçÉZÉbÉTÇ∆8ÉrÉbÉgÉvÉçÉZÉbÉTÇÃâøäiÇÃç∑ÇÕ
å¿ÇËÇ»Ç≠É[ÉçÇ…ãþÇ√ǢǃǢÇÈÇÃÇæ
Cortex-M3ÇÕÉQÅ[ÉgêîÇÕ3ñú3000ÉQÅ[Ég
http://monoist.atmarkit.co.jp/mn/articles/0601/20/news107_2.html
ëÊ1íeÇÃCortex-M3ÇÕÉRÉAïîï™Ç™ÇÌÇ∏Ç©33kÉQÅ[Ég
Åié¸ï”âÒòHÇäÐÇþ60kÅjÅB
8bitÉvÉçÉZÉbÉTÇÕÅAâ∆ìdêªïiÅièÓïÒâ∆ìdÅEÉfÉWÉ^Éãâ∆ìdèúÇ≠ÅjÇ…ÇÊÇ≠égÇÌÇÍǃÇÈÇÊ
ǪǧǢǡÇΩÇÃÇ™32bitÇ…ë„ÇÌǡǃǢÇ≠ÇÃÇ©ÅH
ǪǧǢǡÇΩÇÃÇ™32bitÇ…ë„ÇÌǡǃǢÇ≠ÇÃÇ©ÅH
ïœÇÌÇÈïKóvÇÕǻǢÅiïKóvÇ™ÇÝÇÈï™ñÏÇÕÇ∆Ç¡Ç≠Ç…à⁄çsǵǃÇÈÅjÇ∆évǧÇØÇ«
äJî≠Ç…äµÇÍÇΩêlÇ™ëΩÇ¢Ç∆Ç©äJî≠ÉcÅ[ÉãÇ™ï÷óòÇðÇΩǢǻä¥Ç∂Ç≈32bitâªÇ¡ÇƒÇ±Ç∆ÇÕÇÝÇÈÇ©ÇýÇÀ
äJî≠Ç…äµÇÍÇΩêlÇ™ëΩÇ¢Ç∆Ç©äJî≠ÉcÅ[ÉãÇ™ï÷óòÇðÇΩǢǻä¥Ç∂Ç≈32bitâªÇ¡ÇƒÇ±Ç∆ÇÕÇÝÇÈÇ©ÇýÇÀ
>>470
> IntelǡǃDZÇÒÇ»ÉRÉAÇ…QuarkÇ≈ëŒçRǵÇÊǧÇ∆ǵǃÇÈÇÃÇ©ÅH
Quark Ç™ëzíËǵǃÇÈÇÃÇÕÉlÉbÉgÉèÅ[ÉNëŒâûÇÃâ∆ìdÇ∆Ç©Ç≈ÅACortex-M0 ÇÕÇýÇ¡Ç∆è¨ãKñÕÇ»ëgÇðçûÇðópìrÇ≈
É^Å[ÉQÉbÉgÇÕà·Ç§ÅB
> IntelǡǃDZÇÒÇ»ÉRÉAÇ…QuarkÇ≈ëŒçRǵÇÊǧÇ∆ǵǃÇÈÇÃÇ©ÅH
Quark Ç™ëzíËǵǃÇÈÇÃÇÕÉlÉbÉgÉèÅ[ÉNëŒâûÇÃâ∆ìdÇ∆Ç©Ç≈ÅACortex-M0 ÇÕÇýÇ¡Ç∆è¨ãKñÕÇ»ëgÇðçûÇðópìrÇ≈
É^Å[ÉQÉbÉgÇÕà·Ç§ÅB
ÉlÉbÉgÉèÅ[ÉNÇ…â∆ìdÇ≈ÅAQuarkǡǃǫǧǻÇÃǡǃãCÇ™Ç∑ÇÈÇØÇ«ÇÀ
QuarkÇ…ÇÕåªë„ìIÇ»CPUÇ™îıǶǃÇÈÉZÉLÉÖÉäÉeÉBã@ç\ǙǩÇØǃÇÈÇ©ÇÁÅA
ÉoÉOÇìÀÇ©ÇÍÉnÉbÉNÇ≥ÇÍǃëÂïœÇ»Ç±Ç∆DžǻǡÇΩÇËǵǪǧÇæÇØÇ«ÇÀ
ñ{ìñDžDZÇÒÇ»ÇÃÇÉlÉbÉgÉèÅ[ÉNâ∆ìdÇ…égǮǧÇ∆Ç∑ÇÈÇ∆Ç©ÅAì˙ñ{äÈã∆ÇÕITìIÇ…ëfêlÇ∆ǵǩåæÇ¢ÇÊǧǙǻǢ
Ç∑Ç≠Ç»Ç≠Ç∆ÇýAC100Vìôè§ópìdåπÇ…åqÇÆã@äÌÇ≈égǧÇ◊Ç´Ç≈ÇÕǻǢë„ï®
â∆ìdã@äÌÇÕÅAÇΩÇ∆ǶÉoÉbÉtÉ@ÉIÅ[ÉoÅ[ÉtÉçÅ[ǂǪÇÃëºÇ¢ÇÎÇÒÇ»éÌóÞÇÃÉoÉOÇ™ÇÝÇ¡ÇΩÇ∆ǵǃÇýÅA
åÎìÆçÏǵǃÇÕÇ¢ÇØǻǢÇýÇÃ
åªë„ìIÇ»ÉZÉLÉÖÉäÉeÉBÅ[ã@ç\Ç™èÊÇ¡ÇΩCPUÇ»ÇÁÅAèêñºçœÇðÉRÅ[ÉhǵǩìÆǩǻǢÇÊǧDžêðíËǵǃÅA
äOïîÇ©ÇÁïsê≥Ç»ÉRÅ[ÉhëóÇËçûÇÐÇÍÇΩÇËÇ∑ÇÈÇÃÇñhÇ∞ÇÈ
QuarkÇ…ÇÕåªë„ìIÇ»CPUÇ™îıǶǃÇÈÉZÉLÉÖÉäÉeÉBã@ç\ǙǩÇØǃÇÈÇ©ÇÁÅA
ÉoÉOÇìÀÇ©ÇÍÉnÉbÉNÇ≥ÇÍǃëÂïœÇ»Ç±Ç∆DžǻǡÇΩÇËǵǪǧÇæÇØÇ«ÇÀ
ñ{ìñDžDZÇÒÇ»ÇÃÇÉlÉbÉgÉèÅ[ÉNâ∆ìdÇ…égǮǧÇ∆Ç∑ÇÈÇ∆Ç©ÅAì˙ñ{äÈã∆ÇÕITìIÇ…ëfêlÇ∆ǵǩåæÇ¢ÇÊǧǙǻǢ
Ç∑Ç≠Ç»Ç≠Ç∆ÇýAC100Vìôè§ópìdåπÇ…åqÇÆã@äÌÇ≈égǧÇ◊Ç´Ç≈ÇÕǻǢë„ï®
â∆ìdã@äÌÇÕÅAÇΩÇ∆ǶÉoÉbÉtÉ@ÉIÅ[ÉoÅ[ÉtÉçÅ[ǂǪÇÃëºÇ¢ÇÎÇÒÇ»éÌóÞÇÃÉoÉOÇ™ÇÝÇ¡ÇΩÇ∆ǵǃÇýÅA
åÎìÆçÏǵǃÇÕÇ¢ÇØǻǢÇýÇÃ
åªë„ìIÇ»ÉZÉLÉÖÉäÉeÉBÅ[ã@ç\Ç™èÊÇ¡ÇΩCPUÇ»ÇÁÅAèêñºçœÇðÉRÅ[ÉhǵǩìÆǩǻǢÇÊǧDžêðíËǵǃÅA
äOïîÇ©ÇÁïsê≥Ç»ÉRÅ[ÉhëóÇËçûÇÐÇÍÇΩÇËÇ∑ÇÈÇÃÇñhÇ∞ÇÈ
475 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 12:19:56.24 ID:8Y8UuoVt
ìÔï»Ç∆ǵǩǢǢÇÊǧǙǻǢ
QuarkÇÃÉAÉvÉäÉPÅ[ÉVÉáÉìÇÕMcAfeeÇÃÉZÉLÉÖÉäÉeÉBÉ\ÉtÉgÉEÉFÉAÉXÉ^ÉbÉNÇÃè„Ç≈ìÆÇ≠ÇÊǧDž
ÉfÉUÉCÉìÇ≥ÇÍǃÇÈ
îjǡǃǩÇÁåæǡǃÇðÇÎÇ∆Ǣǧòb
QuarkÇÃÉAÉvÉäÉPÅ[ÉVÉáÉìÇÕMcAfeeÇÃÉZÉLÉÖÉäÉeÉBÉ\ÉtÉgÉEÉFÉAÉXÉ^ÉbÉNÇÃè„Ç≈ìÆÇ≠ÇÊǧDž
ÉfÉUÉCÉìÇ≥ÇÍǃÇÈ
îjǡǃǩÇÁåæǡǃÇðÇÎÇ∆Ǣǧòb
QuarkÇ≈Ç‚ÇÎǧÇ∆ǵǃÇÈÉZÉLÉÖÉäÉeÉBÇÅAÉnÅ[ÉhÉEÉFÉAÇ…ÇÊÇÈÉZÉLÉÖÉäÉeÉBéxâáã@ç\Ç™ÇÝÇÈCPUÇ≈Ç‚ÇÍÇŒÅA
ÇÊÇËã≠å≈Ç…é¿ëïÇ≈Ç´ÇÈÇÒÇ∂ǷǻǢǩǻÅH
ÇÊÇËã≠å≈Ç…é¿ëïÇ≈Ç´ÇÈÇÒÇ∂ǷǻǢǩǻÅH
477 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 13:12:08.65 ID:8Y8UuoVt
ä®à·Ç¢ÇµÇƒÇÈÇðÇΩÇ¢ÇæÇØÇ«x86ópÉZÉLÉÖÉäÉeÉBã@î\Ç∆ǵǃÉÇÉ_ÉìÇ»XD(Pentium 4Ç≈í«â¡ÅjÇ‚
SMEPÅiIvy Bridgeê¢ë„ÅjÇ∆ǢǡÇΩägí£ÇýÅALakemontÉRÉAÇÕÉTÉ|Å[ÉgǵǃÇÈÅB
DX4ǪÇÃÇÐÇÐÇæÇ∆évÇ¡ÇΩÇÃÅHnjǩǻÇÃÅH
SMEPÅiIvy Bridgeê¢ë„ÅjÇ∆ǢǡÇΩägí£ÇýÅALakemontÉRÉAÇÕÉTÉ|Å[ÉgǵǃÇÈÅB
DX4ǪÇÃÇÐÇÐÇæÇ∆évÇ¡ÇΩÇÃÅHnjǩǻÇÃÅH
ǶÅHǪǧǻÇÒÇæÅH
å√Ç¢ÉRÉAǪÇÃÇÐÇÐÇ∆Ç®ÇýǡǃÇΩ
å√Ç¢ÉRÉAǪÇÃÇÐÇÐÇ∆Ç®ÇýǡǃÇΩ
H8Ç∆SHÇ≈Ç®k
ÉãÉlÉTÉXÇÕCPUÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃìùîpçáÇêiÇþǃÇÈÇðÇΩÇ¢ÇæÇÀ
ÉãÉlÉTÉXÇ™8/16ÉrÉbÉgÉ}ÉCÉRÉìÇÅuRL78ÅvÇ…ìùçáÅA
2011îNìxññÇÐÇ≈Ç…700ïiéÌÇìäì¸
http://ednjapan.com/edn/articles/1011/17/news134.html
ÉãÉlÉTÉXÇ™32ÉrÉbÉgé‘ç⁄É}ÉCÉRÉìÇìùçáÇ÷ÅA
40nmÉvÉçÉZÉXçÃópÇÃÅuRH850ÅvÇî≠ï\
http://eetimes.jp/ee/articles/1202/29/news108.html
ÉãÉlÉTÉXÇ™8/16ÉrÉbÉgÉ}ÉCÉRÉìÇÅuRL78ÅvÇ…ìùçáÅA
2011îNìxññÇÐÇ≈Ç…700ïiéÌÇìäì¸
http://ednjapan.com/edn/articles/1011/17/news134.html
ÉãÉlÉTÉXÇ™32ÉrÉbÉgé‘ç⁄É}ÉCÉRÉìÇìùçáÇ÷ÅA
40nmÉvÉçÉZÉXçÃópÇÃÅuRH850ÅvÇî≠ï\
http://eetimes.jp/ee/articles/1202/29/news108.html
McAfeeÇÃÉZÉLÉÖÉäÉeÉBÉ\ÉtÉgÉEÉFÉAÉXÉ^ÉbÉNÇÃè„Ç≈ìÆÇ≠(∑ÿØ
ïsà¿ÇµÇ©Ç»Ç¢Ç≈Ç∑Ç‚ÇÒ
ïsà¿ÇµÇ©Ç»Ç¢Ç≈Ç∑Ç‚ÇÒ
482 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 16:40:09.05 ID:8Y8UuoVt
ÉrÉãä«óùÇÃàÍó¨äÈã∆Ç≈ÇÝÇÈDaikin McQuayÇ™ëæå€îªÇâüǵǃÇÈéñé¿Ç∆
éOó¨í·äwóÇ™ìΩñºåfé¶î¬Ç≈êÇÇÍó¨Ç∑FUDÇ∆
Ç«Ç¡ÇøÇ™êMópÇ≈Ç´ÇÈÇ©Ç∆ǢǧòbÇæÇ»
éOó¨í·äwóÇ™ìΩñºåfé¶î¬Ç≈êÇÇÍó¨Ç∑FUDÇ∆
Ç«Ç¡ÇøÇ™êMópÇ≈Ç´ÇÈÇ©Ç∆ǢǧòbÇæÇ»
É_ÉCÉLÉìÇΩÇæÇÃÉÜÅ[ÉUÅ[Ç≈Ç∑Ç‚ÇÒ
ÇýÇ¡Ç∆ÅIé¿ëïÇ…ë¶ÇµÇΩãZèpìIè⁄ç◊ÇÅI
ÇýÇ¡Ç∆ÅIé¿ëïÇ…ë¶ÇµÇΩãZèpìIè⁄ç◊ÇÅI
É_ÉCÉLÉìÇÃÉlÉbÉgÉèÅ[ÉNëŒâûÉGÉAÉRÉìÇ™ÉNÉâÉbÉNÇ≥ÇÍǃ
É{ÉbÉgÉlÉbÉgÇ…ëgÇðçûÇÐÇÍÇΩÇËǵǃ
É{ÉbÉgÉlÉbÉgÇ…ëgÇðçûÇÐÇÍÇΩÇËǵǃ
485 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 17:08:55.65 ID:8Y8UuoVt
http://www.geocities.jp/andosprocinfo/wadai13/20130914.htm
> EE TimesÇÕå@ÇËâ∫Ç∞ǃéÊçÞÇǵǃǮÇËÅCKrznichéÅÇ™é¶ÇµÇΩÉ`ÉbÉvÇÕ32nmÉvÉçÉZÉXÇ≈êªë¢ÇµÇΩ
> ÇýÇÃÇ≈ÅCx86åðä∑ÇæǪǧÇ≈Ç∑ÅBǪǵǃÅCãÛí≤ÉÅÅ[ÉJÅ[ÇÃÉ_ÉCÉLÉìÇ™äJî≠É{Å[ÉhÇégǡǃãÛí≤ã@ÇÃ
> ÉäÉÇÅ[ÉgÉÅÉìÉeÇÃÉVÉXÉeÉÄÇÃäJî≠ÇçsǡǃǢÇÈÇ∆ïÒÇ∂ǃǢÇÐÇ∑ÅBÉ_ÉCÉLÉìÇÕFreescleÇ‚ARMÇ∆
> î‰ärǵÇΩåãâ ÅCIntelÇÃQuarkÇëIÇÒÇæÇ∆ÇÃDZÇ∆Ç≈ÅCóùóRÇÕÉZÉLÉÖÉäÉeÉBÅ[ÇæǪǧÇ≈Ç∑ÅB
> CPUÇÃê´î\ÇÕñ‚ëËÇ…Ç»ÇÁǻǢǙÅCÉnÉbÉNÇ≥ÇÍǃãÛí≤ÇÃÉRÉìÉgÉçÅ[ÉãÇ™èÊÇ¡éÊÇÁÇÍÇÈäÎåØÇ™
> è¨Ç≥ǢDZÇ∆Ç™èdóvÇ∆ǢǧÇÃÇÕóùâÇ≈Ç´ÇÐÇ∑ÅBëgÇðçûÇðópOSÇÃWind RiverÅCÉZÉLÉÖÉäÉeÉBÅ[ÇÃ
> McAfeeÇéùǡǃÇÈIntelÇÃǟǧǙÅCFreeScaleÇ‚ARMÇÊÇËï]âøÇ™çÇÇ©Ç¡ÇΩÇ∆ǢǧÇÃÇýÅCÇÝÇËǪǧÇ≈Ç∑ÅB
> EE TimesÇÕå@ÇËâ∫Ç∞ǃéÊçÞÇǵǃǮÇËÅCKrznichéÅÇ™é¶ÇµÇΩÉ`ÉbÉvÇÕ32nmÉvÉçÉZÉXÇ≈êªë¢ÇµÇΩ
> ÇýÇÃÇ≈ÅCx86åðä∑ÇæǪǧÇ≈Ç∑ÅBǪǵǃÅCãÛí≤ÉÅÅ[ÉJÅ[ÇÃÉ_ÉCÉLÉìÇ™äJî≠É{Å[ÉhÇégǡǃãÛí≤ã@ÇÃ
> ÉäÉÇÅ[ÉgÉÅÉìÉeÇÃÉVÉXÉeÉÄÇÃäJî≠ÇçsǡǃǢÇÈÇ∆ïÒÇ∂ǃǢÇÐÇ∑ÅBÉ_ÉCÉLÉìÇÕFreescleÇ‚ARMÇ∆
> î‰ärǵÇΩåãâ ÅCIntelÇÃQuarkÇëIÇÒÇæÇ∆ÇÃDZÇ∆Ç≈ÅCóùóRÇÕÉZÉLÉÖÉäÉeÉBÅ[ÇæǪǧÇ≈Ç∑ÅB
> CPUÇÃê´î\ÇÕñ‚ëËÇ…Ç»ÇÁǻǢǙÅCÉnÉbÉNÇ≥ÇÍǃãÛí≤ÇÃÉRÉìÉgÉçÅ[ÉãÇ™èÊÇ¡éÊÇÁÇÍÇÈäÎåØÇ™
> è¨Ç≥ǢDZÇ∆Ç™èdóvÇ∆ǢǧÇÃÇÕóùâÇ≈Ç´ÇÐÇ∑ÅBëgÇðçûÇðópOSÇÃWind RiverÅCÉZÉLÉÖÉäÉeÉBÅ[ÇÃ
> McAfeeÇéùǡǃÇÈIntelÇÃǟǧǙÅCFreeScaleÇ‚ARMÇÊÇËï]âøÇ™çÇÇ©Ç¡ÇΩÇ∆ǢǧÇÃÇýÅCÇÝÇËǪǧÇ≈Ç∑ÅB
äÆïÜñ≥Ç´ÇÐÇ≈Ç…í@Ç´ÇÃÇþÇ≥ÇÍǃǃÇÌÇÎÇΩÇó
ç≈ãþÇÕÅAÉnÉCÉpÅ[ÉoÉCÉUÅEOSÅEÉAÉvÉäÇÃÇRíiäKDžǵǃ(ÉnÉCÉpÅ[ÉoÉCÉUÇÕÉlÉbÉgÉèÅ[ÉNã@î\ÇéùÇΩǻǢ)ÅA
OSÇ‚ÉAÉvÉäÇ…ÉZÉLÉÖÉäÉeÉBÉzÅ[ÉãÇ™ÇÝǡǃÇýèüéËÇ…ÉRÅ[ÉhìÆÇ©Ç≥ÇÍǻǢÇÊǧDžǵÇΩÇËǵǃÇÈÇ»
Ç≈ÅAÉnÉCÉpÅ[ÉoÉCÉUÇ…ÉZÉLÉÖÉäÉeÉBÅ[ÉzÅ[ÉãÇ™å©Ç¬Ç©Ç¡Çƒ
ǪDZǩÇÁÇ¢ÇÎÇ¢ÇÎòRÇÍǃÉNÉâÉbÉNÇ≥ÇÍÇΩÇÃÇ™PS3ǡǃä¥Ç∂Ç≈
OSÇ‚ÉAÉvÉäÇ…ÉZÉLÉÖÉäÉeÉBÉzÅ[ÉãÇ™ÇÝǡǃÇýèüéËÇ…ÉRÅ[ÉhìÆÇ©Ç≥ÇÍǻǢÇÊǧDžǵÇΩÇËǵǃÇÈÇ»
Ç≈ÅAÉnÉCÉpÅ[ÉoÉCÉUÇ…ÉZÉLÉÖÉäÉeÉBÅ[ÉzÅ[ÉãÇ™å©Ç¬Ç©Ç¡Çƒ
ǪDZǩÇÁÇ¢ÇÎÇ¢ÇÎòRÇÍǃÉNÉâÉbÉNÇ≥ÇÍÇΩÇÃÇ™PS3ǡǃä¥Ç∂Ç≈
>>485
ǪÇÍÇýì«ÇÒÇ≈ÇÈÇØÇ«ÅAé¿ëïDžǬǢǃâΩÇýåæǡǃǻǢDžìôǵǢÇ≈Ç∑ÇÊÇÀÅB
É_ÉCÉLÉìǙǪÇÃï˚ñ Ç≈é¿ê—Ç™ÇÝÇÈÇÌÇØÇ≈ÇýǻǢǵÅB
ǪÇÍÇýì«ÇÒÇ≈ÇÈÇØÇ«ÅAé¿ëïDžǬǢǃâΩÇýåæǡǃǻǢDžìôǵǢÇ≈Ç∑ÇÊÇÀÅB
É_ÉCÉLÉìǙǪÇÃï˚ñ Ç≈é¿ê—Ç™ÇÝÇÈÇÌÇØÇ≈ÇýǻǢǵÅB
ãÛîÑÇËÇýÇΩÇÐÇ…FUDêÇÇÍó¨Ç∑Ç©ÇÁÇ»ÇÝ
>>487
ÉnÉCÉpÅ[ÉoÉCÉUÅEOSÅEÉAÉvÉäÇÃÇRëwç\ë¢ÇÃÇΩÇþÇ…ÅA
ëgÇðçûÇðånÇÃCPUÇ≈Çýèàóùî\óÕÇ™ïKóvDžǻǡÇΩÇÃÇæÇÎǧÅB
ÇæÇ©ÇÁIntelÇ»ÇÃÇæÇÎǧÅB
ÉnÉCÉpÅ[ÉoÉCÉUÅEOSÅEÉAÉvÉäÇÃÇRëwç\ë¢ÇÃÇΩÇþÇ…ÅA
ëgÇðçûÇðånÇÃCPUÇ≈Çýèàóùî\óÕÇ™ïKóvDžǻǡÇΩÇÃÇæÇÎǧÅB
ÇæÇ©ÇÁIntelÇ»ÇÃÇæÇÎǧÅB
491 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 22:14:02.99 ID:5fymQ809
ÇÐÅAåªçsÇÃXeon E5Ç≈ÉTÉ|Å[ÉgǵǃÇÈÇÃÇ∆ìØìôÇÃÉJÅ[ÉlÉãï€åÏã@î\ÅiSMEPÅjÇ
ÉnÅ[ÉhÉEÉFÉAé¿ëïǵǃÇÈÇÃÇ…ïsè\ï™Ç»ÇÒǃåæÇ¢èoǵÇΩÇÁégǧÇýÇÒâΩÇýÇÀÅ[ÇÌÇ»ÇóÇóÇó
QuarkÇ…ÇÕâºëzâªã@î\ÇÕç⁄ǡǃǻǢÇÊÅB
ARMÇýÇæÇØÇ«ÇÀÅB
âºëzâªÇ™ïKóvÇ»ÇÁAtomÇ™ïKóvÇæÇÎǧÅB
DZÇÍÇýè¡îÔìdóÕìIÇ…IoTí[ññÇ…èÊÇπÇÈÇÃÇ™ì¡Ç…ìÔǵǢÇÌÇØÇ≈ÇÕǻǢ
ÉnÅ[ÉhÉEÉFÉAé¿ëïǵǃÇÈÇÃÇ…ïsè\ï™Ç»ÇÒǃåæÇ¢èoǵÇΩÇÁégǧÇýÇÒâΩÇýÇÀÅ[ÇÌÇ»ÇóÇóÇó
QuarkÇ…ÇÕâºëzâªã@î\ÇÕç⁄ǡǃǻǢÇÊÅB
ARMÇýÇæÇØÇ«ÇÀÅB
âºëzâªÇ™ïKóvÇ»ÇÁAtomÇ™ïKóvÇæÇÎǧÅB
DZÇÍÇýè¡îÔìdóÕìIÇ…IoTí[ññÇ…èÊÇπÇÈÇÃÇ™ì¡Ç…ìÔǵǢÇÌÇØÇ≈ÇÕǻǢ
492 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 22:26:47.71 ID:5fymQ809
êMópÇ≈ǴǻǢç™ãíÇ™é¶Ç≥ÇÍǃǻǢDZÇ∆Ç™ÅAǻDžÇÊÇËÇÃåòòSê´ÇÃèÿñæÇæÇÎǧÅB
îΩèÿÇÕÉZÉLÉÖÉäÉeÉBÇ™ìÀîjÇ≥ÇÍÇΩé¿ê—Çó·é¶Ç∑ÇÍÇŒçœÇÞòbÇ»ÇÒÇæÇ™
âΩÇýÇÝǙǡǃDZǻǢÇÀÅB
McAfeeÇÕêMópÇ≈ǴǻǢǻÇÒǃÇÃÇÕÅAÇΩÇæÇÃå¬êlìIÇ»àÛè€ÇåÍǡǃÇÈÇæÇØÇ…
Ç∑ǨǻǢÇ∆ǢǧDZÇ∆ÇæÅB
îΩèÿÇÕÉZÉLÉÖÉäÉeÉBÇ™ìÀîjÇ≥ÇÍÇΩé¿ê—Çó·é¶Ç∑ÇÍÇŒçœÇÞòbÇ»ÇÒÇæÇ™
âΩÇýÇÝǙǡǃDZǻǢÇÀÅB
McAfeeÇÕêMópÇ≈ǴǻǢǻÇÒǃÇÃÇÕÅAÇΩÇæÇÃå¬êlìIÇ»àÛè€ÇåÍǡǃÇÈÇæÇØÇ…
Ç∑ǨǻǢÇ∆ǢǧDZÇ∆ÇæÅB
>>490
à·Ç§ÇðÇΩÇ¢ÇÊÅB
http://eetimes.jp/ee/articles/1309/17/news063.html
> Å@Daikin McQuayÇÕÅAQuarkÇëIÇÒÇæóùóRÇ∆ǵǃÅAÅuëºé–ÇÃÉ`ÉbÉvÇ∆ÇÃê´î\ÇÃà·Ç¢Ç≈ÇÕǻǢÅBçÇÇ¢
> ÉZÉLÉÖÉäÉeÉBÇämï€ÇµÇ»Ç™ÇÁÅAÉäÉÇÅ[ÉgÉÅÉìÉeÉiÉìÉXÇçsÇ¢ÇΩÇ©Ç¡ÇΩÇ©ÇÁÇæÅvÇ∆èqÇ◊ǃǢÇÈÅB
à·Ç§ÇðÇΩÇ¢ÇÊÅB
http://eetimes.jp/ee/articles/1309/17/news063.html
> Å@Daikin McQuayÇÕÅAQuarkÇëIÇÒÇæóùóRÇ∆ǵǃÅAÅuëºé–ÇÃÉ`ÉbÉvÇ∆ÇÃê´î\ÇÃà·Ç¢Ç≈ÇÕǻǢÅBçÇÇ¢
> ÉZÉLÉÖÉäÉeÉBÇämï€ÇµÇ»Ç™ÇÁÅAÉäÉÇÅ[ÉgÉÅÉìÉeÉiÉìÉXÇçsÇ¢ÇΩÇ©Ç¡ÇΩÇ©ÇÁÇæÅvÇ∆èqÇ◊ǃǢÇÈÅB
é¿ëïÇímÇÁÇ∏Ç…êMópÇ∑ÇÈÉZÉLÉÖÉäÉeÉBÇ»ÇÒÇ©
ÇÝÇÈÇÌÇØǻǢÇ≈ǵÇÂǧÅAÉRÉìÉsÉÖÅ[É^ÇÃê¢äEÇ≈ÅB
ÇÝÇÈÇÌÇØǻǢÇ≈ǵÇÂǧÅAÉRÉìÉsÉÖÅ[É^ÇÃê¢äEÇ≈ÅB
495 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 23:15:03.20 ID:5fymQ809
Ç∂Ç·ÇÝé¿ëïDžǬǢǃí≤Ç◊ǃÇ≠ÇÍnjǢǢ
https://software.intel.com/en-us/articles/intel-xeon-processor-e5-2600-v2-product-family-technical-overview#osguard
https://software.intel.com/en-us/articles/intel-xeon-processor-e5-2600-v2-product-family-technical-overview#osguard
496 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 23:18:31.95 ID:5fymQ809
é¿ëïÇímÇÁÇ∏Ç…êMóäê´Çã^ǧÉoÉJÇÕã~Ç¢ÇÊǧǙñ≥Ç¢ÅAÉRÉìÉsÉÖÅ[É^ÇÃê¢äEÇ≈
497 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/22(ì˙) 23:35:01.19 ID:5fymQ809
ìñëRÇæÇ™QuarkÇ…ÉPÉ`ÇǬÇØÇΩà»è„ÇÕë„ë÷Ç∆Ç»ÇÈÉVÉXÉeÉÄÇÃêMóäê´Çý
é¶Ç≥Ç»Ç≠ǃÇÕÇ¢ÇØÇ»Ç≠Ç»ÇÈÇÀ
é¶Ç≥Ç»Ç≠ǃÇÕÇ¢ÇØÇ»Ç≠Ç»ÇÈÇÀ
ÉZÉLÉÖÉäÉeÉBÇ…ä÷ǵǃÇÕÅAOSÇ‚ÉAÉvÉäÇ…ê∆é„ê´Ç™ñ≥ǢǡǃǢǧÇÃÇçsǧÇÃǙǩǻÇËìÔǵǢÇΩÇþÅA
ê∆é„ê´Ç™ÇÝǡǃÇýÇπÇ¢Ç∫Ç¢ÉNÉâÉbÉVÉÖÇ∑ÇÈÇ≠ÇÁÇ¢Ç≈ÅAǪÇÍà»äOÇ…âeãøÇéÛÇØǻǢǡǃÇÃÇ™èdóv
ê∆é„ê´Ç™ÇÝǡǃÇýÇπÇ¢Ç∫Ç¢ÉNÉâÉbÉVÉÖÇ∑ÇÈÇ≠ÇÁÇ¢Ç≈ÅAǪÇÍà»äOÇ…âeãøÇéÛÇØǻǢǡǃÇÃÇ™èdóv
Ç»Ç∫Xeon?
502 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/23(åé) 07:53:57.27 ID:W2RTogbB
éÑóßÇÕéÛå±ÇµÇΩDZÇ∆Ç∑ÇÁǻǢǻÅBóßñΩäŸÇ»ÇÁéÛÇØÇÊǧǩÇ∆ÇÕévÇ¡ÇΩÇ™ÅB
503 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/23(åé) 08:02:33.10 ID:W2RTogbB
>>499
SMEPǙǫǧǢǧã@î\Ç»ÇÃÇ©ÇêýñæÇ∑ÇÈÇÃÇ…ÇÌÇ©ÇËÇ‚Ç∑Ç¢ê}Ç™ÇÝÇ¡ÇΩÇýÇÃÇ≈ÇÀ
ç≈í·Ç≈ÇýDZÇÍÇÕñ⁄Çí ǵǃǻÇØÇÍÇŒâÔòbÇ…éQâ¡Ç∑ÇÈDZÇ∆Ç∑ÇÁãñÇ≥ÇÍÇÒÇæÇÎ
https://communities.intel.com/servlet/JiveServlet/downloadBody/21825-102-2-25117/Intel%20Quark%20Core%20HWRefMan_001.pdf
> 3.10 Paging Unit
> Intel? Quark Core supports the following: 4-Kbyte, 2-MB, and 4-MB paging, Supervisor
> Mode Execution Protection (SMEP), and Execute-Disable Page Protection (PAE.XD).
SMEPǙǫǧǢǧã@î\Ç»ÇÃÇ©ÇêýñæÇ∑ÇÈÇÃÇ…ÇÌÇ©ÇËÇ‚Ç∑Ç¢ê}Ç™ÇÝÇ¡ÇΩÇýÇÃÇ≈ÇÀ
ç≈í·Ç≈ÇýDZÇÍÇÕñ⁄Çí ǵǃǻÇØÇÍÇŒâÔòbÇ…éQâ¡Ç∑ÇÈDZÇ∆Ç∑ÇÁãñÇ≥ÇÍÇÒÇæÇÎ
https://communities.intel.com/servlet/JiveServlet/downloadBody/21825-102-2-25117/Intel%20Quark%20Core%20HWRefMan_001.pdf
> 3.10 Paging Unit
> Intel? Quark Core supports the following: 4-Kbyte, 2-MB, and 4-MB paging, Supervisor
> Mode Execution Protection (SMEP), and Execute-Disable Page Protection (PAE.XD).
ãÛí≤ÇÃÉäÉÇÅ[ÉgÉRÉìÉgÉçÅ[ÉãÇ»ÇÒǃ
èÌéûìdåπÇ™ãüããÇ≥ÇÍǃãÛí≤ÉVÉXÉeÉÄǪÇÃÇýÇÃÇ™ìdóÕè¡îÔÇ™åÉǵǢǩÇÁ
è¡îÔìdóÕÇÃêßñÒÇ™ÇÝÇÐÇËǻǢ
âøäiñ Ç≈Çýã∆ñ±ópÇÃãÛí≤ÉVÉXÉeÉÄÇ»ÇÁÇ®ãýÇÇ©ÇØÇÁÇÍÇÈópìr
QuarkÇ™É^Å[ÉQÉbÉgDžǵǃÇΩópìrÇ∆ÇÕÇøÇÂÇ¡Ç∆à·Ç§ÇÃÇ≈ÇÕÅH
ǵǩÇýÅAÇ¢ÇøÇ¢ÇøçÃópÇî≠ï\ǵǃÇÈDZÇ∆Ç©ÇÁ
IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
èÌéûìdåπÇ™ãüããÇ≥ÇÍǃãÛí≤ÉVÉXÉeÉÄǪÇÃÇýÇÃÇ™ìdóÕè¡îÔÇ™åÉǵǢǩÇÁ
è¡îÔìdóÕÇÃêßñÒÇ™ÇÝÇÐÇËǻǢ
âøäiñ Ç≈Çýã∆ñ±ópÇÃãÛí≤ÉVÉXÉeÉÄÇ»ÇÁÇ®ãýÇÇ©ÇØÇÁÇÍÇÈópìr
QuarkÇ™É^Å[ÉQÉbÉgDžǵǃÇΩópìrÇ∆ÇÕÇøÇÂÇ¡Ç∆à·Ç§ÇÃÇ≈ÇÕÅH
ǵǩÇýÅAÇ¢ÇøÇ¢ÇøçÃópÇî≠ï\ǵǃÇÈDZÇ∆Ç©ÇÁ
IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
>>504
> IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
ÇÐÇÝïÅí ÇÃå©óßǃÇæÇ∆ǪǧÇæÇÊÇÀÅBïsì¡íËÉÜÅ[ÉUÇÃîCà”ÇÃÉoÉCÉiÉäÇé¿çsÇ∑ÇÈÇÌÇØÇ≈ÇýǻǢëgÇðçûÇðä¬ã´Ç≈ÅAPXNÉrÉbÉgÇ™ÇýÇΩÇÁÇ∑â∂åbÇ»ÇÒǃǟÇ∆ÇÒǫǻǢǵÅB
> IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
ÇÐÇÝïÅí ÇÃå©óßǃÇæÇ∆ǪǧÇæÇÊÇÀÅBïsì¡íËÉÜÅ[ÉUÇÃîCà”ÇÃÉoÉCÉiÉäÇé¿çsÇ∑ÇÈÇÌÇØÇ≈ÇýǻǢëgÇðçûÇðä¬ã´Ç≈ÅAPXNÉrÉbÉgÇ™ÇýÇΩÇÁÇ∑â∂åbÇ»ÇÒǃǟÇ∆ÇÒǫǻǢǵÅB
ÉoÉJÇ©
ïKóvÇ…åàÇÐǡǃÇÈÇæÇÎ
ñ¢ímÇÃÉoÉbÉtÉ@ÉIÅ[ÉoÅ[ÉtÉçÅ[ǻǫÇÃê∆é„ê´ÇǬǢǃÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÇÃÉvÉçÉZÉXÇ™èÊÇ¡éÊÇÁÇÍǃÇý
IntelÇÃSMEPÇ‚ARMÇÃPXNǻǫÇÃã@ç\Ç™ÇÝÇÍÇŒÉJÅ[ÉlÉãåÝå¿ÇÃè∏äiÇñhÇÆDZÇ∆Ç™Ç≈Ç´ÇÈÇ©ÇÁ
âeãøÇç≈è¨å¿Ç…Ç≈Ç´ÇÈÅB
ïKóvÇ…åàÇÐǡǃÇÈÇæÇÎ
ñ¢ímÇÃÉoÉbÉtÉ@ÉIÅ[ÉoÅ[ÉtÉçÅ[ǻǫÇÃê∆é„ê´ÇǬǢǃÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÇÃÉvÉçÉZÉXÇ™èÊÇ¡éÊÇÁÇÍǃÇý
IntelÇÃSMEPÇ‚ARMÇÃPXNǻǫÇÃã@ç\Ç™ÇÝÇÍÇŒÉJÅ[ÉlÉãåÝå¿ÇÃè∏äiÇñhÇÆDZÇ∆Ç™Ç≈Ç´ÇÈÇ©ÇÁ
âeãøÇç≈è¨å¿Ç…Ç≈Ç´ÇÈÅB
ÉGÉAÉRÉìÇÃêßå‰Ç…Ç«ÇÍÇŸÇ«ÇÃOSÇégǡǃÇÈÇ©Çýï™Ç©ÇÁÇÒÇ∆DZÇÎÇ≈ÉJÅ[ÉlÉãåÝå¿â]ÅXÇ∆Ç©åæǡǃÇýà”ñ°Ç»Ç¢
508 ÅF Åümiyuri//Z7LS ÅF2014/06/23(åé) 12:52:21.08 ID:j09FHT0t
åüèÿÇè»Ç¢ÇƒÉRÉXÉgå∏ÇÁǵÇÐǵÇÂǧÇÀǡǃǢǧéñÉJÉiÅB
ÉÅÉJÉgÉçÇÃÉvÉçÉZÉbÉTÇ∆ÉIÉìÉâÉCÉìÉÅÉìÉeÇ≈WANÇæÇ©VPNÇæÇ©Ç…
ê⁄ë±Ç∑ÇÈOSÇ™ëñÇÈÉvÉçÉZÉbÉTÇÕï™Ç©ÇÍǃÇÈÇÒÇ∂ǷǻǢǩÅB
å„é“ÇÃàÍî ìIÇ»ÉlÉbÉgånÉZÉLÉÖÉäÉeÉBÇ…ÉvÉâÉXǵǃÅAëOé“Çýå„é“Ç©ÇÁÇÃ
éwé¶ìýóeÇ™ïsìñÇ»ÇÁè]ÇÌǻǢÅAÇ∆ǢǧíˆìxÇÃå´Ç≥ÇÕó~ǵǢÅB
ê⁄ë±Ç∑ÇÈOSÇ™ëñÇÈÉvÉçÉZÉbÉTÇÕï™Ç©ÇÍǃÇÈÇÒÇ∂ǷǻǢǩÅB
å„é“ÇÃàÍî ìIÇ»ÉlÉbÉgånÉZÉLÉÖÉäÉeÉBÇ…ÉvÉâÉXǵǃÅAëOé“Çýå„é“Ç©ÇÁÇÃ
éwé¶ìýóeÇ™ïsìñÇ»ÇÁè]ÇÌǻǢÅAÇ∆ǢǧíˆìxÇÃå´Ç≥ÇÕó~ǵǢÅB
Hot Chips: A Symposium on High Performance Chips
http://www.hotchips.org/
NVIDIAÅfs Denver Processor ÅFDarrell Boggs, Gary Brown, Bill Rozas, Nathan Tuck and K S Venkatraman
http://www.hotchips.org/
NVIDIAÅfs Denver Processor ÅFDarrell Boggs, Gary Brown, Bill Rozas, Nathan Tuck and K S Venkatraman
SMEPÇÕåªçsÇÃCeleronÇ‚AtomÇ…Çýç⁄ǡǃÇÈã@ç\Ç≈QuarkÇýëŒâû
Ç»ÇÃÇ…AMDÇÕÉTÉ|Å[ÉgǵǃǻǢǩÇÁïsóvÇ∆ǢǧDZÇ∆DžǵÇΩÇ¢ÇÒÇ≈Ç∑ÇÀ
ÇÌÇ©ÇËÇ‚Ç∑Ǣǻ
Ç»ÇÃÇ…AMDÇÕÉTÉ|Å[ÉgǵǃǻǢǩÇÁïsóvÇ∆ǢǧDZÇ∆DžǵÇΩÇ¢ÇÒÇ≈Ç∑ÇÀ
ÇÌÇ©ÇËÇ‚Ç∑Ǣǻ
CVE-2013-6885
>>502
ícéqÇ≥ÇÒǡǃãåíÈë≤ÅH
ícéqÇ≥ÇÒǡǃãåíÈë≤ÅH
514 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/23(åé) 21:11:13.31 ID:/enBRFq/
ÇÝÅ[ÅAìÏéRëÂÇÃó◊ÇÃñ^ãåíÈëÂÇ…ÇÕédéñÇ≈èoì¸ÇËÇÕǵǃÇΩÇØÇ«
DZDZÇÃäwê∂ÇæÇ¡ÇΩDZÇ∆ÇÕǻǢǻÅB
>>504
> èÌéûìdåπÇ™ãüããÇ≥ÇÍǃãÛí≤ÉVÉXÉeÉÄǪÇÃÇýÇÃÇ™ìdóÕè¡îÔÇ™åÉǵǢǩÇÁ
> è¡îÔìdóÕÇÃêßñÒÇ™ÇÝÇÐÇËǻǢ
> âøäiñ Ç≈Çýã∆ñ±ópÇÃãÛí≤ÉVÉXÉeÉÄÇ»ÇÁÇ®ãýÇÇ©ÇØÇÁÇÍÇÈópìr
> QuarkÇ™É^Å[ÉQÉbÉgDžǵǃÇΩópìrÇ∆ÇÕÇøÇÂÇ¡Ç∆à·Ç§ÇÃÇ≈ÇÕÅH
à”ñ°Ç™ÇÌÇ©ÇÒÇÀÅ[Ç»
> ǵǩÇýÅAÇ¢ÇøÇ¢ÇøçÃópÇî≠ï\ǵǃÇÈDZÇ∆Ç©ÇÁ
> IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
åæǡǃÇÈDZÇ∆Ç™ñµèÇǵǃÇÈDZÇ∆Ç…ãCÇ√ÇØÇÊÅB
Ç»ÇÒÇ≈QuarkÇÃÉ^Å[ÉQÉbÉgÇ∂ǷǻǢÇýÇÃÇ…IntelÇ™éxâáÇ∑ÇÈÇÒÇæÅH
ǃǩQuarkÇÃéYã∆å¸ÇØÇÃäÓî’ǡǃǫÇÒÇ»ÇÃÇ©ímǡǃÇÈÅH
GalileoÉ{Å[ÉhÇŸÇ⁄ǪÇÃÇÐÇÒÇÐÇæÇ∫
ÉÅÉÇÉäÇ©ÇÁâΩÇ©ÇÁç⁄ǡǃ1ñá5000â~êÿÇÈíˆìxÅB
ǪÇÍÇÊÇËçÇê´î\Ç™ïKóvÇ»ÇÁAtomÇ‚ÇÁCore i*ÇégǶnjǢǢÇÌÇØÇ≈
ǪÇÍÇ∑ÇÁïKóvǻǢǩÇÁQuarkÇ»ÇÌÇØÇæÅB
ïsïKóvÇ»ê´î\ÇéùÇΩÇπǻǢDZÇ∆ÇýëÂéñÇ»ÇÒÇæÇÊ
ǵÇÂǡǜǢê´î\ÇÃÉGÉAÉRÉìêßå‰É`ÉbÉvÇÉnÉCÉWÉÉÉbÉNǵÇΩÇ∆DZÇÎÇ≈
ÇΩǢǵÇΩÉÅÉäÉbÉgǻǢÇ∂Ç·ÇÒÅB
çUåÇÇÃà”ó~ÇçÌÇÆDZÇ∆ÇýÉZÉLÉÖÉäÉeÉBëŒçÙÇ»ÇÃÇæÇÊÅBÇ®ÇãÅH
>>509
ëOé“ÇÃÉãÅ[É`ÉìÇ…ïsãÔçáÇ™ÇÝÇ¡ÇΩÇÁǫǧÇ∑ÇÈÇÒÇæÇÊ
ÉäÉÇÅ[ÉgÇ≈èCê≥ǵÇÊǧDžÇýíeÇ©ÇÍÇøÇÐǧÇÊÅH
èÓïÒånÇ∆êßå‰ånÇ≈ï ÅXÇÃÉvÉçÉZÉbÉTÇégǧÇ∆ǢǧçlǶï˚ÇÕé‘Ç≈ÇÕìñÇΩÇËëOÇæÇ¡ÇΩÇØÇ«
é©ìÆâ^ì]Ç™ñ{äiìIÇ…Ç»ÇÈDžǬÇÍ1ǬDžǻÇËǬǬÇÝÇÈÇÀ
DZDZÇÃäwê∂ÇæÇ¡ÇΩDZÇ∆ÇÕǻǢǻÅB
>>504
> èÌéûìdåπÇ™ãüããÇ≥ÇÍǃãÛí≤ÉVÉXÉeÉÄǪÇÃÇýÇÃÇ™ìdóÕè¡îÔÇ™åÉǵǢǩÇÁ
> è¡îÔìdóÕÇÃêßñÒÇ™ÇÝÇÐÇËǻǢ
> âøäiñ Ç≈Çýã∆ñ±ópÇÃãÛí≤ÉVÉXÉeÉÄÇ»ÇÁÇ®ãýÇÇ©ÇØÇÁÇÍÇÈópìr
> QuarkÇ™É^Å[ÉQÉbÉgDžǵǃÇΩópìrÇ∆ÇÕÇøÇÂÇ¡Ç∆à·Ç§ÇÃÇ≈ÇÕÅH
à”ñ°Ç™ÇÌÇ©ÇÒÇÀÅ[Ç»
> ǵǩÇýÅAÇ¢ÇøÇ¢ÇøçÃópÇî≠ï\ǵǃÇÈDZÇ∆Ç©ÇÁ
> IntelÇ©ÇÁâΩÇÁÇ©ÇÃéxâáÇéÛÇØǃÇÈâ¬î\ê´çÇǪǧ
åæǡǃÇÈDZÇ∆Ç™ñµèÇǵǃÇÈDZÇ∆Ç…ãCÇ√ÇØÇÊÅB
Ç»ÇÒÇ≈QuarkÇÃÉ^Å[ÉQÉbÉgÇ∂ǷǻǢÇýÇÃÇ…IntelÇ™éxâáÇ∑ÇÈÇÒÇæÅH
ǃǩQuarkÇÃéYã∆å¸ÇØÇÃäÓî’ǡǃǫÇÒÇ»ÇÃÇ©ímǡǃÇÈÅH
GalileoÉ{Å[ÉhÇŸÇ⁄ǪÇÃÇÐÇÒÇÐÇæÇ∫
ÉÅÉÇÉäÇ©ÇÁâΩÇ©ÇÁç⁄ǡǃ1ñá5000â~êÿÇÈíˆìxÅB
ǪÇÍÇÊÇËçÇê´î\Ç™ïKóvÇ»ÇÁAtomÇ‚ÇÁCore i*ÇégǶnjǢǢÇÌÇØÇ≈
ǪÇÍÇ∑ÇÁïKóvǻǢǩÇÁQuarkÇ»ÇÌÇØÇæÅB
ïsïKóvÇ»ê´î\ÇéùÇΩÇπǻǢDZÇ∆ÇýëÂéñÇ»ÇÒÇæÇÊ
ǵÇÂǡǜǢê´î\ÇÃÉGÉAÉRÉìêßå‰É`ÉbÉvÇÉnÉCÉWÉÉÉbÉNǵÇΩÇ∆DZÇÎÇ≈
ÇΩǢǵÇΩÉÅÉäÉbÉgǻǢÇ∂Ç·ÇÒÅB
çUåÇÇÃà”ó~ÇçÌÇÆDZÇ∆ÇýÉZÉLÉÖÉäÉeÉBëŒçÙÇ»ÇÃÇæÇÊÅBÇ®ÇãÅH
>>509
ëOé“ÇÃÉãÅ[É`ÉìÇ…ïsãÔçáÇ™ÇÝÇ¡ÇΩÇÁǫǧÇ∑ÇÈÇÒÇæÇÊ
ÉäÉÇÅ[ÉgÇ≈èCê≥ǵÇÊǧDžÇýíeÇ©ÇÍÇøÇÐǧÇÊÅH
èÓïÒånÇ∆êßå‰ånÇ≈ï ÅXÇÃÉvÉçÉZÉbÉTÇégǧÇ∆ǢǧçlǶï˚ÇÕé‘Ç≈ÇÕìñÇΩÇËëOÇæÇ¡ÇΩÇØÇ«
é©ìÆâ^ì]Ç™ñ{äiìIÇ…Ç»ÇÈDžǬÇÍ1ǬDžǻÇËǬǬÇÝÇÈÇÀ
é‘ÇÃé©ìÆâ^ì]ǡǃǢǡǃÇýÅAÇ¢ÇÐÇÃÇ∆DZÇÎÉeÉXÉgíiäKÇæÇ©ÇÁÇ»Çü
è´óàìIÇ…é¿ópâªíiäKÇ…Ç»ÇÍnjǫǧǢǡÇΩå`Ç…Ç»ÇÈÇÃÇÕÇÊÇ≠ÇÌÇ©ÇÁǻǢǙÅA
ÉGÉAÉoÉbÉOÇÃêßå‰CPUÇ∆é©ìÆâ^ì]ÇÃCPUÇ™ìØàÍÇ…Ç»ÇÈDZÇ∆ÇÕǻǢÇ∆Ç®Çýǧǻ
ECUÇ∆é©ìÆâ^ì]ÇÕÇýǵǩǵÇΩÇÁàÍǬDžǻÇÈÇ©ÇýǵÇÍǻǢǵÅA
ECUÇÃCPUÇ∆é©ìÆâ^ì]CPUÇ≈Ç»ÇÒÇÁÇ©ÇÃÉvÉçÉgÉRÉãÇ≈Ç‚ÇËéÊÇËÇ∑ÇÈÇÊǧDžǻÇÈÇ©ÇýǵÇÍǻǢ
è´óàìIÇ…é¿ópâªíiäKÇ…Ç»ÇÍnjǫǧǢǡÇΩå`Ç…Ç»ÇÈÇÃÇÕÇÊÇ≠ÇÌÇ©ÇÁǻǢǙÅA
ÉGÉAÉoÉbÉOÇÃêßå‰CPUÇ∆é©ìÆâ^ì]ÇÃCPUÇ™ìØàÍÇ…Ç»ÇÈDZÇ∆ÇÕǻǢÇ∆Ç®Çýǧǻ
ECUÇ∆é©ìÆâ^ì]ÇÕÇýǵǩǵÇΩÇÁàÍǬDžǻÇÈÇ©ÇýǵÇÍǻǢǵÅA
ECUÇÃCPUÇ∆é©ìÆâ^ì]CPUÇ≈Ç»ÇÒÇÁÇ©ÇÃÉvÉçÉgÉRÉãÇ≈Ç‚ÇËéÊÇËÇ∑ÇÈÇÊǧDžǻÇÈÇ©ÇýǵÇÍǻǢ
êÊÇÕímÇÁǻǢǙç°ÇÕDZÇÒÇ»èÛë‘ÇÁǵǢ
>SpansionÇ™ç°âÒî≠ï\ǵÇΩÉ}ÉCÉRÉìÇÕÉfÉÖÉAÉãÉRÉAÇ≈ÅAé©ìÆé‘ìýÇÃ2ǬÇÃ
>ÉÇÅ[É^Ç1É`ÉbÉvÇ≈êßå‰ÇµÇÊǧÇ∆ǢǧÇýÇÃÅBçÏìÆÇ∑ÇÈÉÇÅ[É^1å¬Ç…ǬǴ1å¬ÇÃ
>ECU(Electronic Control Unit:ìdéqêßå‰ÉÜÉjÉbÉg)Ç™ïKóvÇæÇ™ÅA
>DZÇÃÉ}ÉCÉRÉìÇégǶnj2å¬ÇÃÉÇÅ[É^Ç1å¬ÇÃECUÇ≈ìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
ttp://news.mynavi.jp/series/car-electronics/061/
>SpansionÇ™ç°âÒî≠ï\ǵÇΩÉ}ÉCÉRÉìÇÕÉfÉÖÉAÉãÉRÉAÇ≈ÅAé©ìÆé‘ìýÇÃ2ǬÇÃ
>ÉÇÅ[É^Ç1É`ÉbÉvÇ≈êßå‰ÇµÇÊǧÇ∆ǢǧÇýÇÃÅBçÏìÆÇ∑ÇÈÉÇÅ[É^1å¬Ç…ǬǴ1å¬ÇÃ
>ECU(Electronic Control Unit:ìdéqêßå‰ÉÜÉjÉbÉg)Ç™ïKóvÇæÇ™ÅA
>DZÇÃÉ}ÉCÉRÉìÇégǶnj2å¬ÇÃÉÇÅ[É^Ç1å¬ÇÃECUÇ≈ìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
ttp://news.mynavi.jp/series/car-electronics/061/
>>514
> èÓïÒånÇ∆êßå‰ånÇ≈ï ÅXÇÃÉvÉçÉZÉbÉTÇégǧÇ∆ǢǧçlǶï˚ÇÕé‘Ç≈ÇÕìñÇΩÇËëOÇæÇ¡ÇΩÇØÇ«
> é©ìÆâ^ì]Ç™ñ{äiìIÇ…Ç»ÇÈDžǬÇÍ1ǬDžǻÇËǬǬÇÝÇÈÇÀ
ñ{ãCÇ≈åæǡǃÇÈ?
> èÓïÒånÇ∆êßå‰ånÇ≈ï ÅXÇÃÉvÉçÉZÉbÉTÇégǧÇ∆ǢǧçlǶï˚ÇÕé‘Ç≈ÇÕìñÇΩÇËëOÇæÇ¡ÇΩÇØÇ«
> é©ìÆâ^ì]Ç™ñ{äiìIÇ…Ç»ÇÈDžǬÇÍ1ǬDžǻÇËǬǬÇÝÇÈÇÀ
ñ{ãCÇ≈åæǡǃÇÈ?
518 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/23(åé) 21:46:16.63 ID:/enBRFq/
ç°ÇÃé‘ǡǃÉèÉìÉ`ÉbÉvÉ}ÉCÉRÉìÇÃâÚÇðÇΩǢǻÇýÇÒÇæÇ©ÇÁÇ»
ÇýÇøÇÎÇÒäÆëSÇ…1ǬÇÃÉ`ÉbÉvÇ≈ëSïîêßå‰Ç≈Ç´ÇÈÇ∆ÇÕévÇÌǻǢ
ÇýÇøÇÎÇÒäÆëSÇ…1ǬÇÃÉ`ÉbÉvÇ≈ëSïîêßå‰Ç≈Ç´ÇÈÇ∆ÇÕévÇÌǻǢ
çáó¨ÉåÅ[ÉìÇ…èÓïÒÉâÉWÉIÇÃé¸îgêîä≈î¬Ç™êðíuǵǃÇÝÇÈÇÊǧǻä¥Ç∂Ç©ÇÃǧ
ÉäÉÇÅ[ÉgèCê≥ÇÕÇÕÇ∂Ç©ÇÍÇΩǟǧǙǢǢÇÒÇ∂ǷǻǢÇÃ
ÅyÉTÅ[ÉoÅzÉåÉmÉ{ÅAIBMÇÃx86ÉTÅ[Éoéñã∆Çè≥åpÇ∑ÇÈéqâÔé–Çì˙ñ{Ç≈êðóßÅ@2014/06/24
ttp://anago.2ch.net/test/read.cgi/bizplus/1403535689/
ttp://anago.2ch.net/test/read.cgi/bizplus/1403535689/
ÉvÉçÉZÉTë§ÇÃóvãÅÇ…ÉÅÉÇÉäÇ™ÇÐÇ¡ÇΩÇ≠ìöǶÇÁÇÍǃǻǢèÛãµÇÕǢǬïœÇÌÇÈÇÒÇæÇÎǧǩ
ÉXÉ}ÉzÇ…Çý32GBÇ≠ÇÁÇ¢ÇÕç⁄ÇπǃÇ≠ÇÍ
ÉXÉ}ÉzÇ…Çý32GBÇ≠ÇÁÇ¢ÇÕç⁄ÇπǃÇ≠ÇÍ
HPCÇðÇΩǢDž16chDDR3Ç∆Ç©ç⁄ÇπÇÍÇŒ
ÇÆÇ¡Ç∆ëÅÇ≠Ç»ÇÈ
ÇÆÇ¡Ç∆ëÅÇ≠Ç»ÇÈ
Ç≥ÇÁÇ…ÉoÉbÉeÉäãÏìÆéûä‘íZÇ≠ǵǃÉXÉ}ÉzÇ≈âΩǙǵÇΩÇ¢ÇÒÇæÅH
IntelÇÃQuarkÇÕÇ∏Ç¡Ç∆ë±ÇØÇÈǬÇýÇËÇ»ÇÃÇ©Ç»ÅH
XScaleÇÕǪÇÍÇ»ÇËÇ…ê¨å˜ÇµÇΩÇÃÇ…îÑǡǃǵÇÐÇ¡ÇΩ
QuarkÇÕx86ÇæÇ©ÇÁëºé–Ç…îÑÇÈDZÇ∆Ç™Ç≈ǴǻǢǩÇýǵÇÍǻǢÇØÇ«
XScaleÇÕǪÇÍÇ»ÇËÇ…ê¨å˜ÇµÇΩÇÃÇ…îÑǡǃǵÇÐÇ¡ÇΩ
QuarkÇÕx86ÇæÇ©ÇÁëºé–Ç…îÑÇÈDZÇ∆Ç™Ç≈ǴǻǢǩÇýǵÇÍǻǢÇØÇ«
>>524
ãÏìÆéûä‘Ç™íZǢǻÇÁÇŒÅAÉoÉbÉeÉäÇëÂÇ´Ç≠Ç∑ÇÍÇŒó«Ç¢Ç∂Ç·Ç»Å`Ç¢!
âÊñ ÇýëÂÇ´Ç≠ǵǃÅAëSëÃÇàÍâÒÇËëÂÇ´Ç≠Ç∑ÇÍÇŒÅAÉoÉbÉeÉäÇ™ëÂÇ´Ç≠ǻǡÇΩéñÇåÎñÇâªÇπÇÈÇ∂Ç·Ç»Å`Ç¢!!
ãÏìÆéûä‘Ç™íZǢǻÇÁÇŒÅAÉoÉbÉeÉäÇëÂÇ´Ç≠Ç∑ÇÍÇŒó«Ç¢Ç∂Ç·Ç»Å`Ç¢!
âÊñ ÇýëÂÇ´Ç≠ǵǃÅAëSëÃÇàÍâÒÇËëÂÇ´Ç≠Ç∑ÇÍÇŒÅAÉoÉbÉeÉäÇ™ëÂÇ´Ç≠ǻǡÇΩéñÇåÎñÇâªÇπÇÈÇ∂Ç·Ç»Å`Ç¢!!
PentiumÇ…ARMÇÃPXNëäìñé¿ëïǵǃÉ_ÉCÉLÉìÇ…ãýèoǵÇΩÇ©ÇÁìVâ∫Ç∆ÇÍÇÈÇÊÅ[
528 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/25(êÖ) 09:17:04.88 ID:0O5bvD0J
> ARMÇÃPXNëäìñ
ÇæÇ©ÇÁǪÇÍÇ™SMEPÇæǡǃnj
è≠ǵëOÇÃÉåÉXÇ∑ÇÁì«ÇþǻǢÇÃÇ©
ÇæÇ©ÇÁǪÇÍÇ™SMEPÇæǡǃnj
è≠ǵëOÇÃÉåÉXÇ∑ÇÁì«ÇþǻǢÇÃÇ©
529 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/25(êÖ) 09:17:43.28 ID:0O5bvD0J
ÇÝÇ∆PentiumÇ∂Ç·Ç»Ç≠ǃ486Ç»
ÉrÉbÉOÉfÅ[É^èàóùê´î\ÇÃÉXÉpÉRÉìÉâÉìÉLÉìÉOÇ≈ì˙ñ{ê®Ç™ìÒä•
http://pc.watch.impress.co.jp/docs/news/20140625_654944.html?ref=rss
http://pc.watch.impress.co.jp/docs/news/20140625_654944.html?ref=rss
ARM64Ç∆GPUÇòAågÇ≥ÇπÇΩäJî≠ópHPCÉTÅ[ÉoÅ[Ç™7åéÇ…î≠îÑ
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566247/
64bitî≈ARMÉvÉçÉZÉbÉTÇ∆
ÅuTesla K20ÅvÇëgÇðçáÇÌÇπÇΩHPCå¸ÇØÉVÉXÉeÉÄÇÃèoâ◊Ç™énÇÐÇÈ
http://www.4gamer.net/games/121/G012181/20140621001/
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566247/
64bitî≈ARMÉvÉçÉZÉbÉTÇ∆
ÅuTesla K20ÅvÇëgÇðçáÇÌÇπÇΩHPCå¸ÇØÉVÉXÉeÉÄÇÃèoâ◊Ç™énÇÐÇÈ
http://www.4gamer.net/games/121/G012181/20140621001/
2UÇ´ÇÂǧëÃÇ≈ÅuãûÅv1ÉâÉbÉNï™ÅAïxémí Ç™ÉXÉpÉRÉìéüê¢ë„ã@ÇÃè⁄ç◊Çåˆï\
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566300/
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566300/
ãûÇÕSequoiaìôÇ…î‰Ç◊ÇΩÇÁå≥ÅXñßìxí·Ç¢Ç©ÇÁ
ãûÇ∆ëäëŒÇ≈çÇñßìxÇ≈ÇýÇÝÇÒÇÐÇËÇ∑Ç≤Ç≠ǻǢ
ãûÇ∆ëäëŒÇ≈çÇñßìxÇ≈ÇýÇÝÇÒÇÐÇËÇ∑Ç≤Ç≠ǻǢ
óÚìôê∂ÇÃéiîgÇ≥ÇÒÇýǢǡǃÇΩÇ∂Ç·ÇÒ
Åutop500(linpack)Ç≈ÇÕï]âøÇ≥ÇÍǻǢçÄñ⁄Ç≈Ç∑Ç©ÇÁÇÀÅv
Åutop500(linpack)Ç≈ÇÕï]âøÇ≥ÇÍǻǢçÄñ⁄Ç≈Ç∑Ç©ÇÁÇÀÅv
íNÇæÇÊ
SPARC64 XIfxÇ≈ǩǢǻ
730mm2ÇÕÇÝÇËǪǧ
730mm2ÇÕÇÝÇËǪǧ
ÉRÉAêîÇ∆SIMDã≠âªÇ≈8î{Ç…Ç»ÇÈÇ©ÇÁÉNÉçÉbÉNÇÕVIIIfxï¿ÇðÇÃ2GHzïtãþÇæÇ»ÅB
ÅhãûÇ∆ìØìôÇñ⁄éwÇ∑ÅhÇ≈1TFLOPSÇæÇ©ÇÁÉÅÉCÉìÉÅÉÇÉäÇÕ512GB/sÇ≠ÇÁÇ¢ÅA
HMCÇ™8ǬïtǢǃǢÇÈÇ©ÇÁàÍǬÇÝÇΩÇË64GB/sÇ©
ÅhãûÇ∆ìØìôÇñ⁄éwÇ∑ÅhÇ≈1TFLOPSÇæÇ©ÇÁÉÅÉCÉìÉÅÉÇÉäÇÕ512GB/sÇ≠ÇÁÇ¢ÅA
HMCÇ™8ǬïtǢǃǢÇÈÇ©ÇÁàÍǬÇÝÇΩÇË64GB/sÇ©
ïƒHewlett-PackardÇ‚ïƒDellǻǫÇÃÉÅÅ[ÉJÅ[ÇýÅA64ÉrÉbÉgARMÉTÅ[ÉoÅ[ÇÃèoâ◊ÇåvâÊǵǃǢÇÈÅBDZǧǵÇΩÉTÅ[ÉoÅ[ÇÕÉfÅ[É^ÉZÉìÉ^Å[ÇÃìdãCóøãýÇçÌå∏Ç≈Ç´ÇÈâ¬î\ê´Ç™ÇÝÇÈÅB
ARMÉvÉçÉZÉbÉTíPì∆ÇÃèàóùî\óÕÇ≈ÇÕÅAï°éGÇ»â»äwãZèpåvéZÇ‚êîäwìIââéZÇ÷ÇÃëŒâûÇÕìÔǵǢǙÅAGPUÇ∆ëgÇðçáÇÌÇπÇÍÇŒçÇë¨âªÇ™â¬î\ÇæÅB
Å@NVIDIAÇ≈ÉAÉNÉZÉâÉåÅ[ÉeÉbÉhÅEÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOíSìñÇÃÉoÉCÉXÉvÉåÉWÉfÉìÉgÇñ±ÇþÇÈIan BuckéÅÇ…ÇÊÇÈÇ∆ÅA
ARMÉvÉçÉZÉbÉTÇ∆GPUÇÃëgÇðçáÇÌÇπÇ…ä÷ǵǃÇÕÅAÉ^ÉìÉpÉNéøÇÃêÐÇËÇΩÇΩÇðç\ë¢ÅAêVñÚî≠å©ÅAå¥éqÉVÉ~ÉÖÉåÅ[ÉVÉáÉìǻǫÇÃå§ãÜï™ñÏÇ≈ä÷êSÇ™äÒÇπÇÁÇÍǃǢÇÈÇ∆ǢǧÅB
Å@ÅuDZǧǵÇΩï™ñÏÇ≈x86ÉTÅ[ÉoÅ[Ç…ë„ÇÌÇÈëIëéàÇ™Ç≈Ç´ÅAåüì¢ÇÃïùÇ™çLǙǡÇΩÅvÇ∆ìØéÅÇÕòbÇ∑ÅB
Å@åªçðÇÃÇ∆DZÇÎÅAÉXÉpÉRÉìÇÃëΩÇ≠ÇÕÅAïƒIntelÇ‚ïƒAMDÇÃx86ÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃÉvÉçÉZÉbÉTÇìãç⁄ǵǃǢÇÈÅBÉpÉ\ÉRÉìÇ∆ìØÇ∂ÉAÅ[ÉLÉeÉNÉ`ÉÉÇæÅB
ÇæÇ™ÅAâþãéÇÃåoàÐÇì•ÇÐǶǃçlǶÇÈÇ∆ÅAçÇâøÇ≈è¡îÔìdóÕÇÃëΩÇ¢x86ÉvÉçÉZÉbÉTÇ…ë„ÇÌÇËÅAÇ¢Ç∏ÇÍÇÕÉXÉpÉRÉìÇ≈ÇýÉXÉ}Å[ÉgÉtÉHÉìå¸ÇØÉ`ÉbÉvÇ™égÇÌÇÍÇÈÇÊǧDžǻÇÈâ¬î\ê´Ç™ÇÝÇÈÇ∆éÂí£Ç∑ÇÈå§ãÜé“ÇýÇ¢ÇÈÅB
http://itpro.nikkeibp.co.jp/article/IDG/20140625/566544/
ARMÉvÉçÉZÉbÉTíPì∆ÇÃèàóùî\óÕÇ≈ÇÕÅAï°éGÇ»â»äwãZèpåvéZÇ‚êîäwìIââéZÇ÷ÇÃëŒâûÇÕìÔǵǢǙÅAGPUÇ∆ëgÇðçáÇÌÇπÇÍÇŒçÇë¨âªÇ™â¬î\ÇæÅB
Å@NVIDIAÇ≈ÉAÉNÉZÉâÉåÅ[ÉeÉbÉhÅEÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOíSìñÇÃÉoÉCÉXÉvÉåÉWÉfÉìÉgÇñ±ÇþÇÈIan BuckéÅÇ…ÇÊÇÈÇ∆ÅA
ARMÉvÉçÉZÉbÉTÇ∆GPUÇÃëgÇðçáÇÌÇπÇ…ä÷ǵǃÇÕÅAÉ^ÉìÉpÉNéøÇÃêÐÇËÇΩÇΩÇðç\ë¢ÅAêVñÚî≠å©ÅAå¥éqÉVÉ~ÉÖÉåÅ[ÉVÉáÉìǻǫÇÃå§ãÜï™ñÏÇ≈ä÷êSÇ™äÒÇπÇÁÇÍǃǢÇÈÇ∆ǢǧÅB
Å@ÅuDZǧǵÇΩï™ñÏÇ≈x86ÉTÅ[ÉoÅ[Ç…ë„ÇÌÇÈëIëéàÇ™Ç≈Ç´ÅAåüì¢ÇÃïùÇ™çLǙǡÇΩÅvÇ∆ìØéÅÇÕòbÇ∑ÅB
Å@åªçðÇÃÇ∆DZÇÎÅAÉXÉpÉRÉìÇÃëΩÇ≠ÇÕÅAïƒIntelÇ‚ïƒAMDÇÃx86ÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃÉvÉçÉZÉbÉTÇìãç⁄ǵǃǢÇÈÅBÉpÉ\ÉRÉìÇ∆ìØÇ∂ÉAÅ[ÉLÉeÉNÉ`ÉÉÇæÅB
ÇæÇ™ÅAâþãéÇÃåoàÐÇì•ÇÐǶǃçlǶÇÈÇ∆ÅAçÇâøÇ≈è¡îÔìdóÕÇÃëΩÇ¢x86ÉvÉçÉZÉbÉTÇ…ë„ÇÌÇËÅAÇ¢Ç∏ÇÍÇÕÉXÉpÉRÉìÇ≈ÇýÉXÉ}Å[ÉgÉtÉHÉìå¸ÇØÉ`ÉbÉvÇ™égÇÌÇÍÇÈÇÊǧDžǻÇÈâ¬î\ê´Ç™ÇÝÇÈÇ∆éÂí£Ç∑ÇÈå§ãÜé“ÇýÇ¢ÇÈÅB
http://itpro.nikkeibp.co.jp/article/IDG/20140625/566544/
CPUÇÕÇ®ÇÐÇØǃǟÇ∆ÇÒÇ«GPUÉpÉèÅ[èüïâÇÃåvéZÇ»ÇÁÅA
CPUÇÕARMÇ≈ÇýǢǢÇ∆Ç®ÇýǧÇÊ
å¬êlÇ≈ÇýÅAÇ¢ÇÐó¨çsÇÃP2Pí âðçÃå@ÇÃèÍçáÅAGPGPUÇ‚ASICèüïâÇ≈ÅA
CPUÇÕceleronÇÃàÍî‘à¿Ç¢ìzÇ≈è\ï™Çæǵ
CPUÇÕARMÇ≈ÇýǢǢÇ∆Ç®ÇýǧÇÊ
å¬êlÇ≈ÇýÅAÇ¢ÇÐó¨çsÇÃP2Pí âðçÃå@ÇÃèÍçáÅAGPGPUÇ‚ASICèüïâÇ≈ÅA
CPUÇÕceleronÇÃàÍî‘à¿Ç¢ìzÇ≈è\ï™Çæǵ
>532Å@>537
êVǵǢ3TFLOPSÇÃXeon PhiÇÕÇÐÇæÉÅÉÇÉäÉoÉìÉhïùÇÕîÒåˆäJÇ©ÅB
ñ≥óùÇ∑ÇÍÇŒ0.5Byte/FLOPSÇýâ¬î\Ç©ÇýǵÇÍǻǢǙ
îÔópëŒå¯î\Ç≈î˜êoÇýä√Ç≥Çå©ÇπǻǢIntelÇÕǪDZÇÐÇ≈Ç‚ÇÁǻǢÇæÇÎǧǻ
êVǵǢ3TFLOPSÇÃXeon PhiÇÕÇÐÇæÉÅÉÇÉäÉoÉìÉhïùÇÕîÒåˆäJÇ©ÅB
ñ≥óùÇ∑ÇÍÇŒ0.5Byte/FLOPSÇýâ¬î\Ç©ÇýǵÇÍǻǢǙ
îÔópëŒå¯î\Ç≈î˜êoÇýä√Ç≥Çå©ÇπǻǢIntelÇÕǪDZÇÐÇ≈Ç‚ÇÁǻǢÇæÇÎǧǻ
ǵÇÐÇ¡ÇΩñÒ500GB/sÇ∆ä˘ímÇ©ÅBPOWERÇ‚SPARCǻǫÇ∆GPUÇ‚MICÇÃ
Ç«ÇøÇÁÇëIÇ‘Ç©ÇÕåvéZǵÇΩÇ¢êlÇ™ëIÇ‘Ç∆ǢǧèÛë‘ÇÕ
DZÇÃê¢ë„Ç≈ÇÕÇÐÇæë±Ç≠Ç∆ǢǧDZÇ∆Ç©Ç»
Ç«ÇøÇÁÇëIÇ‘Ç©ÇÕåvéZǵÇΩÇ¢êlÇ™ëIÇ‘Ç∆ǢǧèÛë‘ÇÕ
DZÇÃê¢ë„Ç≈ÇÕÇÐÇæë±Ç≠Ç∆ǢǧDZÇ∆Ç©Ç»
éüÇÃXeon PhiÇÕÅAÉÅÉÇÉäÇGDDR5Ç©ÇÁHMCDžǵǃçÇë¨âªÇ∑ÇÍnjǢǢÇÊ
CPUÇý
ÅEÉÅÉCÉìÉÅÉÇÉäÇÕDDR4ÇæÇØÇ«ëÂóeó L4%Ç∆ǵǃHMCçÃóp
ÅEÉÅÉCÉìÉÅÉÇÉäÇHMCâªÇ≈SIMDånââéZÇëÂïùã≠âª
DZÇÃÇ«Ç¡ÇøǩDžǢǴǪǧÇæÇ»
ÅEÉÅÉCÉìÉÅÉÇÉäÇÕDDR4ÇæÇØÇ«ëÂóeó L4%Ç∆ǵǃHMCçÃóp
ÅEÉÅÉCÉìÉÅÉÇÉäÇHMCâªÇ≈SIMDånââéZÇëÂïùã≠âª
DZÇÃÇ«Ç¡ÇøǩDžǢǴǪǧÇæÇ»
L4%Ç∂Ç·Ç»Ç≠L4$ÇÀ
>>543
ëÂóeó ÉLÉÉÉbÉVÉÖÇ…å∂ëzÇï¯Ç≠ÇÃÇÕé~ÇþÇÊǧ
ëÂóeó ÉLÉÉÉbÉVÉÖÇ…å∂ëzÇï¯Ç≠ÇÃÇÕé~ÇþÇÊǧ
ÉLÉÉÉbÉVÉÖÇÕèdóvÇæÇÀ
ÉLÉÉÉbÉVÉÖïsë´ÇæÇ∆âΩÇýîÉǶǻǢǩÇÁÇÀ('A`)
cashÇ∆cacheÇÃà·Ç¢Ç…ǬǢǃ
AlchipÅAê¢äEç≈çÇêÖèÄÇÃìdóÕå¯ó¶Çé¿åªÇµÇΩÉXÉpÉRÉìå¸ÇØÉvÉçÉZÉbÉT
http://pc.watch.impress.co.jp/docs/news/20140627_655452.html
Å@ë‰òpÇÃÉtÉ@ÉuÉåÉXASICÉxÉìÉ_Å[Alchip TechnologiesÇÕ27ì˙(ì˙ñ{éûä‘)ÅAìåãûçHã∆ëÂäwÅAàÍã¥ëÂäwÅAâÔí√ëÂäwÇ∆ã§ìØÇ≈ÅA
ê¢äEç≈çÇêÖèÄÇÃìdóÕê´î\î‰Çé¿åªÇµÇΩÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^å¸ÇØÉvÉçÉZÉbÉTÅuPACS-GÅvÇäJî≠ǵÇΩÇ∆î≠ï\ǵÇΩÅB
Å@1WÇÝÇΩÇËÇÃïÇìÆè¨êîì_ââéZê´î\Ç™ê¢äEç≈çÇêÖèÄÇ∆Ǣǧ30GFLOPSÇé¿åªÇµÇΩÉvÉçÉZÉbÉTÅBä˘ë∂ÇÃç≈êVGPUÇ∆î‰ärǵǃÇý
5î{à»è„çÇÇ¢Ç∆ǢǧÅBêªë¢ÇÕTSMCÇÃ28nm HPMÉvÉçÉZÉXÅAÉpÉbÉPÅ[ÉWÇÕÉtÉäÉbÉvÉ`ÉbÉvÇÃPBGAÇçÃópÇ∑ÇÈÅB
Å@PACS-GÉvÉçÉZÉbÉTÇÃäJî≠ÇéÂì±ÇµÇΩÅAå≥ìåãûçHã∆ëÂäwã≥éˆÇ≈ÅEåªóùâªäwå§ãÜèäåvéZå§ãÜã@ç\ÇÃñqñÏè~àÍòYéÅÇÕÉäÉäÅ[ÉXÇÃ
íÜÇ≈ÅuDZÇÃã§ìØÉvÉçÉWÉFÉNÉgÇ…ÇÊǡǃäJî≠ǵÇΩí·è¡îÔìdóÕãZèpÇ™ÅA100GFLOPS/WÇñ⁄éwÇ∑éüê¢ë„ÉvÉçÉWÉFÉNÉg(16nm/10nmê¢ë„)
Ç…égópÇ≥ÇÍÇÈDZÇ∆Çä˙ë“ǵǃǢÇÈÅvǻǫÇ∆ÉRÉÅÉìÉgǵǃǢÇÈÅB
http://pc.watch.impress.co.jp/docs/news/20140627_655452.html
Å@ë‰òpÇÃÉtÉ@ÉuÉåÉXASICÉxÉìÉ_Å[Alchip TechnologiesÇÕ27ì˙(ì˙ñ{éûä‘)ÅAìåãûçHã∆ëÂäwÅAàÍã¥ëÂäwÅAâÔí√ëÂäwÇ∆ã§ìØÇ≈ÅA
ê¢äEç≈çÇêÖèÄÇÃìdóÕê´î\î‰Çé¿åªÇµÇΩÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^å¸ÇØÉvÉçÉZÉbÉTÅuPACS-GÅvÇäJî≠ǵÇΩÇ∆î≠ï\ǵÇΩÅB
Å@1WÇÝÇΩÇËÇÃïÇìÆè¨êîì_ââéZê´î\Ç™ê¢äEç≈çÇêÖèÄÇ∆Ǣǧ30GFLOPSÇé¿åªÇµÇΩÉvÉçÉZÉbÉTÅBä˘ë∂ÇÃç≈êVGPUÇ∆î‰ärǵǃÇý
5î{à»è„çÇÇ¢Ç∆ǢǧÅBêªë¢ÇÕTSMCÇÃ28nm HPMÉvÉçÉZÉXÅAÉpÉbÉPÅ[ÉWÇÕÉtÉäÉbÉvÉ`ÉbÉvÇÃPBGAÇçÃópÇ∑ÇÈÅB
Å@PACS-GÉvÉçÉZÉbÉTÇÃäJî≠ÇéÂì±ÇµÇΩÅAå≥ìåãûçHã∆ëÂäwã≥éˆÇ≈ÅEåªóùâªäwå§ãÜèäåvéZå§ãÜã@ç\ÇÃñqñÏè~àÍòYéÅÇÕÉäÉäÅ[ÉXÇÃ
íÜÇ≈ÅuDZÇÃã§ìØÉvÉçÉWÉFÉNÉgÇ…ÇÊǡǃäJî≠ǵÇΩí·è¡îÔìdóÕãZèpÇ™ÅA100GFLOPS/WÇñ⁄éwÇ∑éüê¢ë„ÉvÉçÉWÉFÉNÉg(16nm/10nmê¢ë„)
Ç…égópÇ≥ÇÍÇÈDZÇ∆Çä˙ë“ǵǃǢÇÈÅvǻǫÇ∆ÉRÉÅÉìÉgǵǃǢÇÈÅB
>>549
î‰ärëŒè€Ç…î‰Ç◊ǃâΩÇýè»Ç©Ç∏Ç…ìdóÕÇæÇØ1/5Ç…Ç∑ÇÈDZÇ∆Ç»ÇÒǃ
Ç≈ǴǻǢÇÌÇØÇ≈ÅAâΩÇèúǢǃíBê¨ÇµÇΩÇÃÇ©Ç™èdóvÇæÇ∆évǧǙÅA
ãLéñÇÃí∑Ç≥ÇÃÇπǢǩè»ó™Ç≥ÇÍǃǵÇÐǡǃÇÈ
âΩÇ©ÇéÊÇËèúÇ¢ÇΩDZÇ∆Ç…ÇÊǡǃÇ≈Ç´Ç»Ç≠Ç»ÇÈDZÇ∆ÅAêVÇΩÇ…óvãÅÇ≥ÇÍÇÈDZÇ∆Ç™
åyî˜Ç»ÇÃÇ©ÅAǪÇÍÇ∆ÇýèdìƒÇ»ÇÃÇ©ÅBÇÐÇÝìñéñé“ÇÕìñëRǪÇÒǻDZÇ∆ÇÕ
ïŸÇ¶ÇƒÇ¢ÇƒÅAçLïÒÇ‚ãLé“Ç™Ç ÇÈÇ¢ÇæÇØÇæÇ∆évǧÇØÇ«ÅB
î‰ärëŒè€Ç…î‰Ç◊ǃâΩÇýè»Ç©Ç∏Ç…ìdóÕÇæÇØ1/5Ç…Ç∑ÇÈDZÇ∆Ç»ÇÒǃ
Ç≈ǴǻǢÇÌÇØÇ≈ÅAâΩÇèúǢǃíBê¨ÇµÇΩÇÃÇ©Ç™èdóvÇæÇ∆évǧǙÅA
ãLéñÇÃí∑Ç≥ÇÃÇπǢǩè»ó™Ç≥ÇÍǃǵÇÐǡǃÇÈ
âΩÇ©ÇéÊÇËèúÇ¢ÇΩDZÇ∆Ç…ÇÊǡǃÇ≈Ç´Ç»Ç≠Ç»ÇÈDZÇ∆ÅAêVÇΩÇ…óvãÅÇ≥ÇÍÇÈDZÇ∆Ç™
åyî˜Ç»ÇÃÇ©ÅAǪÇÍÇ∆ÇýèdìƒÇ»ÇÃÇ©ÅBÇÐÇÝìñéñé“ÇÕìñëRǪÇÒǻDZÇ∆ÇÕ
ïŸÇ¶ÇƒÇ¢ÇƒÅAçLïÒÇ‚ãLé“Ç™Ç ÇÈÇ¢ÇæÇØÇæÇ∆évǧÇØÇ«ÅB
ëÂäwÇ™óçÇÒÇ≈ÇÈÇÒÇæÇ©ÇÁÉvÉçÉOÉâÉÄÇ∆ÉRÉìÉpÉCÉâÇ™ëÂïœÇ…åàÇÐǡǃÇÈÅB
Xeon PhiÇÃëŒã…ÇçsÇ≠î≠ëzÇæÇÊÅB
Xeon PhiÇÃëŒã…ÇçsÇ≠î≠ëzÇæÇÊÅB
ì¡í•ìIÇ»ÇÃǡǃ
ÉçÅ[ÉJÉãÉÅÉÇÉäÅ[Ç≈ÇÃââéZÇ∆
ÉOÉçÅ[ÉoÉãÉÅÉÇÉäÇ÷ÇÃÉAÉNÉZÉXÇ≠ÇÁǢǩÇ∆
ÉIÉìÉ`ÉbÉvÉÅÉÇÉäÇ≈èàóùÇ∑ÇÈDZÇ∆Ç≈ìdóÕå¯ó¶ÇÇÝÇ∞
ǪÇ∆Ç…Çýñ≥ë Ç…ÉAÉNÉZÉXǵǻǢ
É}ÉXÉ^Å[ÉvÉçÉZÉbÉTÇ∆Ç©ÇÕmaxwellÇ≈denverÇ™ì¸ÇÈǵ
phiÇ≈ÇýcpuÉRÉAÇ™Ç∑Ç≈Ç…ÇÝÇÈ
Ç´Ç…Ç»ÇÈÇÃÇ™Ç∑Ç◊ǃÇÃpeÇ™ìØÇ∂ìÆçÏÇÇ∑ÇÈǡǃsimd extreme
DZÇÍÇæÇ∆ó±ìxÇ™Ç≈Ç©Ç∑ǨÇÕÇπÇÒÇæÇÎǧǩÅH
ÉçÅ[ÉJÉãÉÅÉÇÉäÅ[Ç≈ÇÃââéZÇ∆
ÉOÉçÅ[ÉoÉãÉÅÉÇÉäÇ÷ÇÃÉAÉNÉZÉXÇ≠ÇÁǢǩÇ∆
ÉIÉìÉ`ÉbÉvÉÅÉÇÉäÇ≈èàóùÇ∑ÇÈDZÇ∆Ç≈ìdóÕå¯ó¶ÇÇÝÇ∞
ǪÇ∆Ç…Çýñ≥ë Ç…ÉAÉNÉZÉXǵǻǢ
É}ÉXÉ^Å[ÉvÉçÉZÉbÉTÇ∆Ç©ÇÕmaxwellÇ≈denverÇ™ì¸ÇÈǵ
phiÇ≈ÇýcpuÉRÉAÇ™Ç∑Ç≈Ç…ÇÝÇÈ
Ç´Ç…Ç»ÇÈÇÃÇ™Ç∑Ç◊ǃÇÃpeÇ™ìØÇ∂ìÆçÏÇÇ∑ÇÈǡǃsimd extreme
DZÇÍÇæÇ∆ó±ìxÇ™Ç≈Ç©Ç∑ǨÇÕÇπÇÒÇæÇÎǧǩÅH
ñqñÏÇ≥ÇÒÉRÉlÉNÉVÉáÉìÉ}ÉVÉìÇÃÉÜÅ[ÉUÅ[ÇæÇ¡ÇΩÇÃÇ≈ÅADZǧǢǧÇÃçDÇ´Ç»ÇÒÇ≈Ç∑
çëéYÉGÉNÉTÉXÉPÅ[ÉãÇÕDZÇÍégǧÇÃÇ©Ç»Çü
kÇÃî·îªÇýÇ¢ÇÎÇ¢ÇÎÇÝÇ¡ÇΩÇØÇ«
kÇÃî·îªÇýÇ¢ÇÎÇ¢ÇÎÇÝÇ¡ÇΩÇØÇ«
556 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/27(ãý) 20:06:33.87 ID:Jhf2oEba
>>548
å≥ÇÃà”ñ°ÇÕcachÇàÍéûìIÇ…ï€ä«Ç∑ÇÈÇÃÇ™cache
å≥ÇÃà”ñ°ÇÕcachÇàÍéûìIÇ…ï€ä«Ç∑ÇÈÇÃÇ™cache
http://www.alchip.com/jp/news_01.php?id=178
http://www.nikkan.co.jp/newrls/pdf/20140627-09.pdf
pcwatchÇ∆Ç©ÇÌÇÁÇÒ
http://www.nikkan.co.jp/newrls/pdf/20140627-09.pdf
pcwatchÇ∆Ç©ÇÌÇÁÇÒ
>>553
ââéZÇÃó±ìxÇýÇæÇ™ÅAÉfÅ[É^à⁄ìÆÇýëΩêîÇÃPEDžǬǢǃìØÇ∂
à⁄ìÆÉxÉNÉgÉãÇðÇΩǢǻéwé¶ÇµÇ©èoÇπǻǢÇÒÇ∂ǷǻǢǩDZÇÍÅH
ââéZÇÃó±ìxÇýÇæÇ™ÅAÉfÅ[É^à⁄ìÆÇýëΩêîÇÃPEDžǬǢǃìØÇ∂
à⁄ìÆÉxÉNÉgÉãÇðÇΩǢǻéwé¶ÇµÇ©èoÇπǻǢÇÒÇ∂ǷǻǢǩDZÇÍÅH
ǪÇÎǪÇÎLinpackêÍópASICêœÇÒÇæCPUÇ™çÏÇÁÇÍǃÇýǢǢÇÕÇ∏
ÇΩÇ∆ǶnjÅAÉ_ÉCÇÃëΩÇ≠ÇLinpack-ASICÇ…äÑÇËìñǃÅAÇ®ÇÐÇØíˆìxÇÃARMÇ©MIPSÇÃCPUÇýǬÇÒÇæÉ`ÉbÉvÇçÏǡǃ
TOP500/Green500Ç≈è„à ÉâÉìÉNÉCÉìÇ∑ÇÈDZÇ∆ÇÃÇðÇ…ì¡âªÇµÇΩHPCçÏÇÈÇ◊Ç´
ÇΩÇ∆ǶnjÅAÉ_ÉCÇÃëΩÇ≠ÇLinpack-ASICÇ…äÑÇËìñǃÅAÇ®ÇÐÇØíˆìxÇÃARMÇ©MIPSÇÃCPUÇýǬÇÒÇæÉ`ÉbÉvÇçÏǡǃ
TOP500/Green500Ç≈è„à ÉâÉìÉNÉCÉìÇ∑ÇÈDZÇ∆ÇÃÇðÇ…ì¡âªÇµÇΩHPCçÏÇÈÇ◊Ç´
ÅÑ? PEÇÕÅAââéZÉÜÉjÉbÉgÇ∆ÉIÉìÉ`ÉbÉvÇÃÉçÅ[ÉJÉãÉÅÉÇÉä(LM)Ç©ÇÁÇ»ÇËÅAÉçÅ[ÉJÉãÉÅÉÇÉäè„ÇÃÉfÅ[É^ÇèàóùÅB
DZÇÍÇÕCell Broadband EngineÇðÇΩǢǻÇýÇÃÇ©ÅH
DZÇÍÇÕCell Broadband EngineÇðÇΩǢǻÇýÇÃÇ©ÅH
É}ÉXÉ^Å[ÉvÉçÉZÉbÉTÇ©ÇÁsimdñΩóþÇ≈àµÇÌÇÍÇÈǡǃÇÝÇÈÇ©ÇÁà·Ç§Ç∆évÇÌÇÍÇÈ
EPé©ëÃÇÕÇΩÇæÇÃââéZäÌÇ≈cellÇÃSPEÇÃÇÊǧǻå¬ï ÇÃCPUÇ≈ÇÕñ≥Ç¢Ç≈ǵÇÂǧ
ëSǃÇÃPEÇ™ìØÇ∂ìÆçÏÇÇ∑ÇÈǡǃÇÃÇýÇÀ
EPé©ëÃÇÕÇΩÇæÇÃââéZäÌÇ≈cellÇÃSPEÇÃÇÊǧǻå¬ï ÇÃCPUÇ≈ÇÕñ≥Ç¢Ç≈ǵÇÂǧ
ëSǃÇÃPEÇ™ìØÇ∂ìÆçÏÇÇ∑ÇÈǡǃÇÃÇýÇÀ
http://www.geocities.jp/andosprocinfo/wadai14/20140628.htm
Å@é¿ç€ÇÃââéZê´î\Ç‚è¡îÔìdóÕDžǬǢǃÇÕÅCî≠ï\Ç≥ÇÍǃǢÇÐÇπÇÒÅB
äwâÔǻǫÇ≈î≠ï\Ç≥ÇÍǃǢÇÈPACS-GÇÃStraw ManÇÕ4096PEÇìãç⁄ǵÅC
16TFlops/chipÇ∆ǢǧÇýÇÃÇ≈Ç∑Ç™ÅCDZÇÍÇÕ10nmíˆìxÇÃÉeÉNÉmÉçÉWÇëzíËǵÇΩÇýÇÃÇ≈Ç∑ÅB
íPèÉÇ…28nmÇ∆10nmÇÃî‰ó¶Ç≈çlǶÇÈÇ∆ÅC512PEÇ∆ǢǧåvéZÇ…Ç»ÇËÅC
1GHzÉNÉçÉbÉNÇ≈2TFlopsÅCè¡îÔìdóÕ66WÇ∆ǢǡÇΩÇ∆DZÇÎÇ≈ǵÇÂǧǩÅHÇ∆èëÇ¢ÇΩÇÃÇ≈Ç∑Ç™ÅC
ñ^èäÇ≈ÇÃî≠ï\Ç≈ÇÕ3mmÅ~2mmÇ∆Ǣǧè¨Ç≥Ç¢É`ÉbÉvÇ≈32ÉRÉAÇÃÉ`ÉbÉvÇçÏÇËÅC
ìýêœåvéZÇÃèÍçáÇÃèÛë‘Ç≈ÇÃë™íËÇ∆ÇÃDZÇ∆Ç≈Ç∑ÅB
PACSÇÕí}îgëÂÇÃÉXÉpÉRÉìÇÃñºëOÇ≈ÅCDZÇÍÇÐÇ≈ÇÃäwâÔî≠ï\ǻǫÇÕí}îgëÂÇÃç≤ì°êÊê∂ǙǂÇÁÇÍǃǢÇÈÇÃÇ™ëΩÇ¢ÇÃÇ≈Ç∑Ç™ÅC
É`ÉbÉvÇÃêðåvÅCäJî≠ÇÕ3åéññÇÐÇ≈ìåçHëÂÇ…çðê–ǵǃǮÇÁÇÍÇΩñqñÏêÊê∂ÇÃÉOÉãÅ[ÉvÇ™çsǡǃǢÇÈÇÊǧÇ≈ÅC
ìåçHëÂÅCàÍã¥ëÂÅCâÔí√ëÂÇ∆ǢǧÉÅÉìÉoÅ[DžǻǡǃǢÇÈÇÊǧÇ≈Ç∑ÅB
ǻǮÅCñqñÏêÊê∂ÇÕåªçðÇÃñ{ñ±ÇÕóùå§AICSÇ≈Ç∑ÅBǪÇÍÇ©ÇÁÅCPACS-GÇÃÉRÉìÉpÉCÉâÇ‚ÉAÉvÉäÇÃç≈ìKâªÇ»Ç«ÇÕí}îgëÂÇÃíSìñÇ≈Ç∑ÅB
Å@é¿ç€ÇÃââéZê´î\Ç‚è¡îÔìdóÕDžǬǢǃÇÕÅCî≠ï\Ç≥ÇÍǃǢÇÐÇπÇÒÅB
äwâÔǻǫÇ≈î≠ï\Ç≥ÇÍǃǢÇÈPACS-GÇÃStraw ManÇÕ4096PEÇìãç⁄ǵÅC
16TFlops/chipÇ∆ǢǧÇýÇÃÇ≈Ç∑Ç™ÅCDZÇÍÇÕ10nmíˆìxÇÃÉeÉNÉmÉçÉWÇëzíËǵÇΩÇýÇÃÇ≈Ç∑ÅB
íPèÉÇ…28nmÇ∆10nmÇÃî‰ó¶Ç≈çlǶÇÈÇ∆ÅC512PEÇ∆ǢǧåvéZÇ…Ç»ÇËÅC
1GHzÉNÉçÉbÉNÇ≈2TFlopsÅCè¡îÔìdóÕ66WÇ∆ǢǡÇΩÇ∆DZÇÎÇ≈ǵÇÂǧǩÅHÇ∆èëÇ¢ÇΩÇÃÇ≈Ç∑Ç™ÅC
ñ^èäÇ≈ÇÃî≠ï\Ç≈ÇÕ3mmÅ~2mmÇ∆Ǣǧè¨Ç≥Ç¢É`ÉbÉvÇ≈32ÉRÉAÇÃÉ`ÉbÉvÇçÏÇËÅC
ìýêœåvéZÇÃèÍçáÇÃèÛë‘Ç≈ÇÃë™íËÇ∆ÇÃDZÇ∆Ç≈Ç∑ÅB
PACSÇÕí}îgëÂÇÃÉXÉpÉRÉìÇÃñºëOÇ≈ÅCDZÇÍÇÐÇ≈ÇÃäwâÔî≠ï\ǻǫÇÕí}îgëÂÇÃç≤ì°êÊê∂ǙǂÇÁÇÍǃǢÇÈÇÃÇ™ëΩÇ¢ÇÃÇ≈Ç∑Ç™ÅC
É`ÉbÉvÇÃêðåvÅCäJî≠ÇÕ3åéññÇÐÇ≈ìåçHëÂÇ…çðê–ǵǃǮÇÁÇÍÇΩñqñÏêÊê∂ÇÃÉOÉãÅ[ÉvÇ™çsǡǃǢÇÈÇÊǧÇ≈ÅC
ìåçHëÂÅCàÍã¥ëÂÅCâÔí√ëÂÇ∆ǢǧÉÅÉìÉoÅ[DžǻǡǃǢÇÈÇÊǧÇ≈Ç∑ÅB
ǻǮÅCñqñÏêÊê∂ÇÕåªçðÇÃñ{ñ±ÇÕóùå§AICSÇ≈Ç∑ÅBǪÇÍÇ©ÇÁÅCPACS-GÇÃÉRÉìÉpÉCÉâÇ‚ÉAÉvÉäÇÃç≈ìKâªÇ»Ç«ÇÕí}îgëÂÇÃíSìñÇ≈Ç∑ÅB
>>552
äwê∂Ç…ç≈ìKâªÇ∆Ç©GPUëIï Ç∆Ç©Ç‚ÇÁÇπǃÇýÉRÉXÉgÉ[ÉçÅA
ÇÞǵÇÎäwê∂Ç™ëΩÇ¢ï˚Ç™ó\éZÇ™ëùǶÇÈèÍçáÇýÇÝÇÈÅAÇðÇΩǢǻÅH
äwê∂Ç…ç≈ìKâªÇ∆Ç©GPUëIï Ç∆Ç©Ç‚ÇÁÇπǃÇýÉRÉXÉgÉ[ÉçÅA
ÇÞǵÇÎäwê∂Ç™ëΩÇ¢ï˚Ç™ó\éZÇ™ëùǶÇÈèÍçáÇýÇÝÇÈÅAÇðÇΩǢǻÅH
564 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/28(ìy) 22:03:59.16 ID:85zSdIcm
>>559
ClearSpeedǙǟÇ⁄ǪÇÍÇæÇ¡ÇΩÇ∂Ç·ÇÒ
ÇŸÇ⁄çsóÒêœââéZÇÃÉpÉtÉHÅ[É}ÉìÉXÇ≈ê´î\Ç™ï]âøÇ≥ÇÍÇÈÇπÇ¢Ç≈
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇðÇΩǢǻë—àÊÉÇÉìÉXÉ^Å[Ç™ê≥ìñÇ»ï]âøÇÇ≥ÇÍǃǻǢÇ∆
íQǢǃÇÈêlÇýëΩÇ¢ÅB
ÇÝÇÍÇÕLINPACKÇ»ÇÒÇ©Ç≈ÇÕåvÇÍǻǢÉmÅ[Éhä‘í êMÇÃÉpÉtÉHÅ[É}ÉìÉXÇ™
èdóvÇ»ópìrå¸ÇØÇ…ëgÇÐÇÍǃÇÈÇ©ÇÁDZǪâøílÇ™ÇÝÇÈÅB
GPUÉXÉpÉRÉìÇÃó¨ëÃââéZÇÃé¿å¯ê´î\ÇÃí·Ç≥çlǶÇÈÇ∆
ÇÐÇ≥Ç…LINPACKêÍópASICÇ…ãþÇ¢ë∂çðÇæÇ∆évǡǃÇÈÇÃÇæÇ™
ClearSpeedǙǟÇ⁄ǪÇÍÇæÇ¡ÇΩÇ∂Ç·ÇÒ
ÇŸÇ⁄çsóÒêœââéZÇÃÉpÉtÉHÅ[É}ÉìÉXÇ≈ê´î\Ç™ï]âøÇ≥ÇÍÇÈÇπÇ¢Ç≈
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇðÇΩǢǻë—àÊÉÇÉìÉXÉ^Å[Ç™ê≥ìñÇ»ï]âøÇÇ≥ÇÍǃǻǢÇ∆
íQǢǃÇÈêlÇýëΩÇ¢ÅB
ÇÝÇÍÇÕLINPACKÇ»ÇÒÇ©Ç≈ÇÕåvÇÍǻǢÉmÅ[Éhä‘í êMÇÃÉpÉtÉHÅ[É}ÉìÉXÇ™
èdóvÇ»ópìrå¸ÇØÇ…ëgÇÐÇÍǃÇÈÇ©ÇÁDZǪâøílÇ™ÇÝÇÈÅB
GPUÉXÉpÉRÉìÇÃó¨ëÃââéZÇÃé¿å¯ê´î\ÇÃí·Ç≥çlǶÇÈÇ∆
ÇÐÇ≥Ç…LINPACKêÍópASICÇ…ãþÇ¢ë∂çðÇæÇ∆évǡǃÇÈÇÃÇæÇ™
NVIDIAÇÃTeslaÇ∆X-GeneÇégÇ¡ÇΩHPCå¸ÇØÉTÅ[ÉoÇ™èoǃǴÇΩ
ARM64Ç∆GPUÇòAågÇ≥ÇπÇΩäJî≠ópHPCÉTÅ[ÉoÅ[Ç™7åéÇ…î≠îÑ
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566247/
Ç¢Ç∏ÇÍÇýÅAïƒÉAÉvÉâÉCÉhÉ}ÉCÉNÉçÇ™äJî≠ǵÇΩ
2.4GHzìÆçÏÇÃ8ÉRÉAARM64ÉvÉçÉZÉbÉTÅuX-GeneÅvÇ∆ÅA
ÉGÉkÉrÉfÉBÉAÇÃGPUÉAÉNÉZÉâÉåÅ[É^Å[ÅuTesla K20ÅvÇëgÇðçáÇÌÇπÇΩÇýÇÃÅB
CPU1å¬ÅAGPU1å¬Ç≈1ÉeÉâFLOPSã≠ÇÃââéZê´î\ÇîıǶÇÈÅB
64ÉrÉbÉgARMÉTÅ[ÉoÅ[Ç™ìoèÍÅAGPUÇÃââéZî\óÕÇäàóp
http://itpro.nikkeibp.co.jp/article/IDG/20140625/566544/?k3
ARM64Ç∆GPUÇòAågÇ≥ÇπÇΩäJî≠ópHPCÉTÅ[ÉoÅ[Ç™7åéÇ…î≠îÑ
http://itpro.nikkeibp.co.jp/article/NEWS/20140624/566247/
Ç¢Ç∏ÇÍÇýÅAïƒÉAÉvÉâÉCÉhÉ}ÉCÉNÉçÇ™äJî≠ǵÇΩ
2.4GHzìÆçÏÇÃ8ÉRÉAARM64ÉvÉçÉZÉbÉTÅuX-GeneÅvÇ∆ÅA
ÉGÉkÉrÉfÉBÉAÇÃGPUÉAÉNÉZÉâÉåÅ[É^Å[ÅuTesla K20ÅvÇëgÇðçáÇÌÇπÇΩÇýÇÃÅB
CPU1å¬ÅAGPU1å¬Ç≈1ÉeÉâFLOPSã≠ÇÃââéZê´î\ÇîıǶÇÈÅB
64ÉrÉbÉgARMÉTÅ[ÉoÅ[Ç™ìoèÍÅAGPUÇÃââéZî\óÕÇäàóp
http://itpro.nikkeibp.co.jp/article/IDG/20140625/566544/?k3
íPÇ…FLOPSÇã£Ç§Ç»ÇÁÅAåæÇ¡ÇøÇ·ÇüÇ»ÇÒÇæǙDZǧǢǧπÞ√”…òHê¸Ç≈ƒÞðƒÞð
çsÇ≠Ç∆DZÇÎÇÐÇ≈çsǡǃÇýÇÁǡǃç\ÇÌǻǢÅB
ǪÇÍÇŒésèÍÇ∆Ç©øÃ≥¥±Ç∆Ç©ä÷åWǻǢê¢äEÅB
ǢǬÇÐÇ≈ǪǧǢǧDZÇ∆Ç…ê≈ãýÇǬǨçûÇÞëÃêßÇ™éùǬǩÇæÇØÇÃñ‚ëËÅB
µ⁄Ç…ÇýÅAëΩï™ëΩÇ≠ÇÃêlÇ…Çýä÷åWǻǢÅB
Ω þ∫ðÇÕÉeÉNÉjÉJÉãƒÞ◊≤ Þ∞ÇæÇ∆ǢǧÇÃÇÕâRÇæǵÅB
çsÇ≠Ç∆DZÇÎÇÐÇ≈çsǡǃÇýÇÁǡǃç\ÇÌǻǢÅB
ǪÇÍÇŒésèÍÇ∆Ç©øÃ≥¥±Ç∆Ç©ä÷åWǻǢê¢äEÅB
ǢǬÇÐÇ≈ǪǧǢǧDZÇ∆Ç…ê≈ãýÇǬǨçûÇÞëÃêßÇ™éùǬǩÇæÇØÇÃñ‚ëËÅB
µ⁄Ç…ÇýÅAëΩï™ëΩÇ≠ÇÃêlÇ…Çýä÷åWǻǢÅB
Ω þ∫ðÇÕÉeÉNÉjÉJÉãƒÞ◊≤ Þ∞ÇæÇ∆ǢǧÇÃÇÕâRÇæǵÅB
ëÂîºÇÃå¬êlÇ…ä÷åWÇ™ÇÝÇÈǩǻǢǩÇ∆
êlä‘é–âÔÇ…èdóvǩǫǧǩÇÃä‘ÇÃëää÷Ç™ã≠Ç¢Ç∆évÇ¡ÇΩDZÇ∆ÇÕÇÝÇÐÇËǻǢ
êlä‘é–âÔÇ…èdóvǩǫǧǩÇÃä‘ÇÃëää÷Ç™ã≠Ç¢Ç∆évÇ¡ÇΩDZÇ∆ÇÕÇÝÇÐÇËǻǢ
>>567
Ç»ÇÁÇŒÅAêlÇ™äæêÖǻǙǵǃâ“Ç¢ÇæãýégǡǃǻÇ∫ǪÇÒÇ»ÉSÉ~ÇðÇΩǢǻÇýÇÃçÏÇÈÇÃÇ≥ÅB
ò_ï∂Ç©Ç´Ç·Å[ǢǡǃǩÅH
ǪÇÃÇ‚ÇËï˚Çå¯ó¶ÇÊÇ≠Ç‚ÇÈâÑí∑è„Ç…STAPÇÃÇÊǧǻñ‚ëËÇ™ãNÇ´ÇÈÇÒÇæÇÎÅB
ÇæÇ©ÇÁì˙ñ{ÇÃâ»äwãZèpÇÕìÒó¨Ç≈ÅAãZèpóßçëÇ»ÇÒǃǧǪÇæÇ∆Ç©åæÇÌÇÍÇÈÇÒÇæÇÊÅB
ǪÇýǪÇýǪÇÒÇ»ë„ï®égÇÌÇπÇÁÇÍÇÈêlÇÃñ¿òfÇýè≠ǵÇÕçlǶÇÎÅB
îΩè»ÇµÇÎÉJÉXÇ™ÅB
Ç»ÇÁÇŒÅAêlÇ™äæêÖǻǙǵǃâ“Ç¢ÇæãýégǡǃǻÇ∫ǪÇÒÇ»ÉSÉ~ÇðÇΩǢǻÇýÇÃçÏÇÈÇÃÇ≥ÅB
ò_ï∂Ç©Ç´Ç·Å[ǢǡǃǩÅH
ǪÇÃÇ‚ÇËï˚Çå¯ó¶ÇÊÇ≠Ç‚ÇÈâÑí∑è„Ç…STAPÇÃÇÊǧǻñ‚ëËÇ™ãNÇ´ÇÈÇÒÇæÇÎÅB
ÇæÇ©ÇÁì˙ñ{ÇÃâ»äwãZèpÇÕìÒó¨Ç≈ÅAãZèpóßçëÇ»ÇÒǃǧǪÇæÇ∆Ç©åæÇÌÇÍÇÈÇÒÇæÇÊÅB
ǪÇýǪÇýǪÇÒÇ»ë„ï®égÇÌÇπÇÁÇÍÇÈêlÇÃñ¿òfÇýè≠ǵÇÕçlǶÇÎÅB
îΩè»ÇµÇÎÉJÉXÇ™ÅB
ï Ç…LINPACKî‘í∑Ç…é^ê¨ÇµÇƒÇÈÇÌÇØÇ≈ÇÕǻǢÇÊÅB>567Å@ÇÕàÍî ò_ÅB
567ÇÃìÒǬÇÃé⁄ìxÇÃëää÷Ç™ã≠Ç¢ÇÃÇ»ÇÁÇŒå[ñ÷Ç»ÇÒǃǢǧåæótÇÕê∂ÇÐÇÍǻǢÅB
ÇΩÇ∆ǶLINPACKî‘í∑Ç≈ÇýǻǢÇÊÇËÇÕÇÝÇ¡ÇΩï˚Ç™ÇÐǵǻDZÇ∆ÇÕãcò_ÇÃó]ínǙǻǢÅB
ñ‚ëËÇÕǪÇÒÇ»ÇýÇÃÇÊÇËÇýêÊÇ…Ç‚ÇÈÇ∆DZǙÇÝÇÈÇÃǩǫǧǩÇ≈ǵǩǻǢÅB
Lî‘í∑Ç™óvÇÁǻǢÇ∆Ǣǧò_ÇÕíPì∆Ç≈ÇÕê¨ÇËóßÇΩÇ∏
ï ÇÃÇýÇÃÇãìÇ∞ÇÈDZÇ∆Ç≈èâÇþǃà”ñ°Ç™ÇÝÇÈÅB
567ÇÃìÒǬÇÃé⁄ìxÇÃëää÷Ç™ã≠Ç¢ÇÃÇ»ÇÁÇŒå[ñ÷Ç»ÇÒǃǢǧåæótÇÕê∂ÇÐÇÍǻǢÅB
ÇΩÇ∆ǶLINPACKî‘í∑Ç≈ÇýǻǢÇÊÇËÇÕÇÝÇ¡ÇΩï˚Ç™ÇÐǵǻDZÇ∆ÇÕãcò_ÇÃó]ínǙǻǢÅB
ñ‚ëËÇÕǪÇÒÇ»ÇýÇÃÇÊÇËÇýêÊÇ…Ç‚ÇÈÇ∆DZǙÇÝÇÈÇÃǩǫǧǩÇ≈ǵǩǻǢÅB
Lî‘í∑Ç™óvÇÁǻǢÇ∆Ǣǧò_ÇÕíPì∆Ç≈ÇÕê¨ÇËóßÇΩÇ∏
ï ÇÃÇýÇÃÇãìÇ∞ÇÈDZÇ∆Ç≈èâÇþǃà”ñ°Ç™ÇÝÇÈÅB
LINPACKÇÃÇðÇ™ëÂÅXìIÇ…éÊÇËè„Ç∞ÇÁÇÍÇÈÇÃÇ™ñ‚ëËÇ»ÇÃÇ≈ÇÝǡǃÅA
LINPACKÉxÉìÉ`ÇÕç°Ç≈Çýê´î\ÇÃÇÝÇÈë§ñ Çï]âøÇ∑ÇÈÇÃÇ…ÇÕóLóp
LINPACKÉxÉìÉ`ÇÕç°Ç≈Çýê´î\ÇÃÇÝÇÈë§ñ Çï]âøÇ∑ÇÈÇÃÇ…ÇÕóLóp
>>569
LINPACÇjǵǩî\ÇÃǻǢ ∞ƒÞÇÃäJî≠Ç…îúëÂÇ»åˆîÔÇÕñ‚ëËÇæÇÎÅB
ãcò_ÇÃó]ínǙǻǢÇ∆ǩǟǥǢǃÇÈíiäKÇ≈î]ñ°ëXïÖǡǃÇÈÇ∆é©äoÇπÇÊÅB
LINPACÇjǵǩî\ÇÃǻǢ ∞ƒÞÇÃäJî≠Ç…îúëÂÇ»åˆîÔÇÕñ‚ëËÇæÇÎÅB
ãcò_ÇÃó]ínǙǻǢÇ∆ǩǟǥǢǃÇÈíiäKÇ≈î]ñ°ëXïÖǡǃÇÈÇ∆é©äoÇπÇÊÅB
LINPACKǵǩî\ÇÃǻǢÉnÅ[ÉhǡǃâΩÅH
êœòaÇ∆ÉXÉãÅ[ÉvÉbÉgÇ÷ÇÃê´î\ì¡âªÅA
DGEMMÇ…ìKçáǵÇΩÉnÅ[Éhêðåv
ÅcǬǩé©ï™Ç≈çlǶÇÈì™Ç»Ç¢ÇÃÇ©ÇÊ
êuǩǻǴǷï™Ç©ÇÁǻǻǢǩ
DGEMMÇ…ìKçáǵÇΩÉnÅ[Éhêðåv
ÅcǬǩé©ï™Ç≈çlǶÇÈì™Ç»Ç¢ÇÃÇ©ÇÊ
êuǩǻǴǷï™Ç©ÇÁǻǻǢǩ
dgemmÇ™ë¨ÇØÇËÇ·linpackà»äOÇ…ÇýÇ¢ÇÎÇ¢ÇÎë¨Ç¢Ç≈Ç∑Ç™
êœòaÇ™ñwÇ«ÇÃèàóùéûä‘ÇêËÇþÇÈâûópÇÕï¬Ç∂ÇΩï™ñÏÇ…ÇΩÇ©Ç™ímÇÍǃÇÈ
ésèÍÇ≈ïtâ¡âøílÇê∂ÇÞâûópÇÕÇÝÇ¡ÇΩÇ¡ÇØ
ésèÍÇ≈ïtâ¡âøílÇê∂ÇÞâûópÇÕÇÝÇ¡ÇΩÇ¡ÇØ
>>574
Ç®ÇÁÅADZÇÃê¢Ç…ílë≈ÇøÇÃÇÝÇÈê¨â ÇÕñ¢ÇæǩǬǃÇÝÇ¡ÇΩÇ¡ÇØǡǃ
ǴǢǃÇÒÇæÇÎÇó
DZÇΩǶÇÎÇÊ
ÉxÉìÉ`ǵǩǵǃǻǢÇæÇÎ
Ç®ÇÁÅADZÇÃê¢Ç…ílë≈ÇøÇÃÇÝÇÈê¨â ÇÕñ¢ÇæǩǬǃÇÝÇ¡ÇΩÇ¡ÇØǡǃ
ǴǢǃÇÒÇæÇÎÇó
DZÇΩǶÇÎÇÊ
ÉxÉìÉ`ǵǩǵǃǻǢÇæÇÎ
ÉåÉxÉãí·Ç∑ǨÅB
òbÇ…Ç»ÇÁǻǢÅB
òbÇ…Ç»ÇÁǻǢÅB
ìÿÇ…ê^éÏÇ∆ǢǧåæótÇ™ÇÝÇËÇÐǵǃ
>>577
ÇýǧàÍìxèëÇ´ÇΩÇ≠ǻǡÇΩÅB
Ç®ëOÅAÉåÉxÉãí·Ç∑ǨÅB
òbÇ…Ç»ÇÁǻǢÅB
HPCÇÃÉ\ÉtÉgçÏǡǃǻǢDZÇ∆ÇÕó«Ç≠ÇÌÇ©Ç¡ÇΩÅB
ÇýǧàÍìxèëÇ´ÇΩÇ≠ǻǡÇΩÅB
Ç®ëOÅAÉåÉxÉãí·Ç∑ǨÅB
òbÇ…Ç»ÇÁǻǢÅB
HPCÇÃÉ\ÉtÉgçÏǡǃǻǢDZÇ∆ÇÕó«Ç≠ÇÌÇ©Ç¡ÇΩÅB
ÇýǵǩǵǃÅAêåǡǃÇÈÅH
>>580
ǧÇÒÅBÇÃÇÒÇ≈ÇΩÇó
ǧÇÒÅBÇÃÇÒÇ≈ÇΩÇó
Ç≈ÇýÇÐÇüêåǡǃǢǻÇ≠ǃÇýÅADZÇÃDZÇÃï™ñÏÇ≈LINPACKÇ∆Ç©PFLOPSÇ∆Ç©äJå˚àÍî‘åæǡǃÇÈǂǬÇÕ
ñ{ìñÇÃÇ∆DZÇÎÉRÉìÉsÉÖÅ[É^Å[Ç‚É\ÉtÉgÉEÉFÉAÇó«Ç≠ÇÌǩǡǃãèǻǢÇ∆évǧÅB
ÇÐǵǃǂésèÍÇÕÅcDZǢǬÇÁÇ…ÇÕéïÇ™óßÇΩǻǢǻñ≥óùÇæÇ»Ç∆évǧ
ñ{ìñÇÃÇ∆DZÇÎÉRÉìÉsÉÖÅ[É^Å[Ç‚É\ÉtÉgÉEÉFÉAÇó«Ç≠ÇÌǩǡǃãèǻǢÇ∆évǧÅB
ÇÐǵǃǂésèÍÇÕÅcDZǢǬÇÁÇ…ÇÕéïÇ™óßÇΩǻǢǻñ≥óùÇæÇ»Ç∆évǧ
ÉCÉmÉxÅ[ÉVÉáÉìÇ©ÇÁç≈ÇýâìÇ¢Ç∆DZÇÎDžǢǃÅA
ÇØǡǵǃǪDZǩÇÁà íuÇïœÇ¶ÇÊǧÇ∆ǵǻǢêlÇΩÇø
ǪÇÍÇ™ÅAÇÝÇ»ÇΩíBÇ…ëŒÇ∑ÇÈéÑÇÃàÛè€Ç≈Ç∑
ÇØǡǵǃǪDZǩÇÁà íuÇïœÇ¶ÇÊǧÇ∆ǵǻǢêlÇΩÇø
ǪÇÍÇ™ÅAÇÝÇ»ÇΩíBÇ…ëŒÇ∑ÇÈéÑÇÃàÛè€Ç≈Ç∑
DZÇÃï”Ç≈ìyëfêlÇÃÉ_ÉìÉSǙǢǬÇýÇÃ
Ç∑Ç¡Ç∆Ç⁄ÇØǃìIÇäOǵÇΩàÍåæÇ≈ÅAèÍÇòaÇÐÇπǃÇ≠ÇÍÇÈ
î§
Å´
Ç∑Ç¡Ç∆Ç⁄ÇØǃìIÇäOǵÇΩàÍåæÇ≈ÅAèÍÇòaÇÐÇπǃÇ≠ÇÍÇÈ
î§
Å´
585 ÅFSocket774ÅF2014/06/29(ì˙) 08:03:54.13 ID:CYS3mUGp
ãûÇ©ÇÁîhê∂ǵÇΩFÇÃÉ}ÉVÉìÇÕÇÝÇÐÇËîÑÇÍǃǢǻǢÇ∆ǢǧòbÇæÇØÇÍÇ«ÅA
Ç∂Ç·ÇÝǫDZǙàÍî‘îÑÇÍǃǢÇÈÇÃÅH
ëÂäwÇ‚çëÇÃå§ãÜã@ä÷Ç÷ÇÃî[ì¸ÇÕï DžǵǃÅAèÉêàÇ…ñØä‘ÉåÉxÉãÇ≈ÇÃòbÅB
Ç∂Ç·ÇÝǫDZǙàÍî‘îÑÇÍǃǢÇÈÇÃÅH
ëÂäwÇ‚çëÇÃå§ãÜã@ä÷Ç÷ÇÃî[ì¸ÇÕï DžǵǃÅAèÉêàÇ…ñØä‘ÉåÉxÉãÇ≈ÇÃòbÅB
586 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 08:39:12.64 ID:0Ix5MPvv
GRAPEÇ∆ìØÇ∂DZÇ∆ÇÅuçsóÒêœÉpÉCÉvÉâÉCÉìÅvÇ∆ǵǃǂÇÍÇŒégǶǻǢìxÉAÉbÉvÇ∑ÇÈÇ©ÇýÇóÇóÇó
587 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 09:20:05.94 ID:0Ix5MPvv
ê≈ãýï•Ç¡ÇƒÇÈÇÒÇæÇ©ÇÁÅAÅuãûÅvÇÃóòópÇÃâþíˆÇ≈Ç«ÇÒÇ»é¿ópìIÇ»É\ÉtÉgÉEÉFÉAÇ™
ê∂ÇðèoÇ≥ÇÍÇΩÇ©Ç≠ÇÁÇ¢ÇÕímǡǃǮǢǃó«Ç¢ÇÃÇ≈ÇÕǻǢǩÇ∆
https://www.islim.org/islim-dl_j.html
ê∂ÇðèoÇ≥ÇÍÇΩÇ©Ç≠ÇÁÇ¢ÇÕímǡǃǮǢǃó«Ç¢ÇÃÇ≈ÇÕǻǢǩÇ∆
https://www.islim.org/islim-dl_j.html
ínãÖÉVÉ~ÉÖÉåÅ[É^ÇÕÅAê¢äEàÍÇæÇ∆Ç©É}ÉXÉRÉ~Ç™ëõÇ¢Ç≈ÇÈǧÇøÇÕóLå¯óòópÇ≥ÇÍǃǻǩǡÇΩÇ™ÅA
É}ÉXÉRÉ~Ç™íçñ⁄ǵǻÇ≠ǻǡǃǩÇÁÇ∑Ç¡Ç≤Ç≠óLå¯óòópÇ≥ÇÍǃÇÈä¥Ç∂
ãûÇýÉ}ÉXÉRÉ~Ç™íçñ⁄ǵǻÇ≠ǻǡÇΩç°Ç…ǻǡǃǩÇÁÇ©Ç»ÇËóLå¯óòópÇ≥ÇÍǃÇÈ
É}ÉXÉRÉ~Ç™íçñ⁄ǵǻÇ≠ǻǡǃǩÇÁÇ∑Ç¡Ç≤Ç≠óLå¯óòópÇ≥ÇÍǃÇÈä¥Ç∂
ãûÇýÉ}ÉXÉRÉ~Ç™íçñ⁄ǵǻÇ≠ǻǡÇΩç°Ç…ǻǡǃǩÇÁÇ©Ç»ÇËóLå¯óòópÇ≥ÇÍǃÇÈ
589 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 09:44:50.28 ID:0Ix5MPvv
ÇæǡǃÅuê¢äEàÍÅvÇ™î€íËÇ≥ÇÍÇΩÇÁê¨â Ç≈èüïâÇ∑ÇÈǵǩǻǢÇ∂Ç·ÇÒ
ÇýǧÇøÇÂÇ¡Ç∆îƒópê´ÇÃçÇÇ¢ÉnÉCÉGÉìÉhCPUÇ™ó~ǵǢǻ
åvéZÇ∆Ç©ÉTÅ[ÉoÅ[ópìrDžǵǩégǶǻǢCPUÇ™ëΩÇ∑ǨÇÈ
åvéZÇ∆Ç©ÉTÅ[ÉoÅ[ópìrDžǵǩégǶǻǢCPUÇ™ëΩÇ∑ǨÇÈ
>>588
ǪÇÒÇ»éñé¿ÇÕǫDZDžÇýǻǢÅBÉlÉgÉEÉàÇÕÇŸÇÒÇ∆ùsë¢ÇŒÇ©ÇËÇæÇ»ÅB
ǪÇÒÇ»éñé¿ÇÕǫDZDžÇýǻǢÅBÉlÉgÉEÉàÇÕÇŸÇÒÇ∆ùsë¢ÇŒÇ©ÇËÇæÇ»ÅB
592 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 14:27:20.74 ID:0Ix5MPvv
àÍâûãûÇégÇ¡ÇΩò_ï∂Ç™ÉSÅ[ÉhÉìÅEÉxÉãèÐÇ∆ǡǃÇÈÇ©ÇÁê¨â ÇÁǵǢê¨â ÇÕÇÝÇÈÇ∆ǢǶnjÇÝÇÈ
ÅiÇ‚Ç¡ÇΩDZÇ∆ÇÕé©ñùÇÃÉCÉìÉ^Å[ÉRÉlÉNÉgê´î\ǙǪÇÍÇŸÇ«ñ‚ÇÌÇÍǻǢëΩëÃââéZÇæÇ¡ÇΩÇØÇ«ÇÀÅj
ÅiÇ‚Ç¡ÇΩDZÇ∆ÇÕé©ñùÇÃÉCÉìÉ^Å[ÉRÉlÉNÉgê´î\ǙǪÇÍÇŸÇ«ñ‚ÇÌÇÍǻǢëΩëÃââéZÇæÇ¡ÇΩÇØÇ«ÇÀÅj
ç≈êÊí[ÇÃÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^ǡǃÅAêVÉAÅ[ÉLÉeÉNÉ`ÉÉÅiCPUÇæÇØÇ»ÇÁä˘ë∂ÇÃǡǃÇÃÇýÇÝÇÈÇØÇ«ëSëÃÇ∆ǵǃÅjÇ»ÇÌÇØÇæÇ©ÇÁ
Ç¢ÇÎÇ¢ÇÎòbëËDžǻǡǃÇÈç≈êVâsÇÃDZÇÎÇÊÇËÅAÇÝÇÈíˆìxÇΩǡǃégǢDZǻÇπÇÈÇÊǧDžǻǡǃǩÇÁÇÃǟǧǙ
äeéÌÇÃê¨â Ç™è„Ç™ÇÈǡǃÇÃÇÕÅAǪÇÒÇ»ïsévãcÇ≈ÇýǻǢãCÇÕÇ∑ÇÈ
Ç¢ÇÎÇ¢ÇÎòbëËDžǻǡǃÇÈç≈êVâsÇÃDZÇÎÇÊÇËÅAÇÝÇÈíˆìxÇΩǡǃégǢDZǻÇπÇÈÇÊǧDžǻǡǃǩÇÁÇÃǟǧǙ
äeéÌÇÃê¨â Ç™è„Ç™ÇÈǡǃÇÃÇÕÅAǪÇÒÇ»ïsévãcÇ≈ÇýǻǢãCÇÕÇ∑ÇÈ
DZÇÃÉäÉXÉgÇ…ãûÇÃÉVÉXÉeÉÄëSëÃÇÃê´î\ÇégǡǃDZǪìæÇÁÇÍÇΩê¨â ÇÕÇÝÇÈÇÃÇ©ÅH
ÉpÅ[ÉeÉBÉVÉáÉìÇ≈ç◊êÿÇÍÇ…êÿÇ¡ÇΩè¨ãKñÕÉVÉXÉeÉÄÇ≈ï¿óÒìxÉTÉ`ÇËÅA
é¿ÇÕè¨ãKñÕÇ»ÉVÉXÉeÉÄÇ≈è]óàÇ≈Çýè\ï™äJî≠Ç≈Ç´ÇΩï®ÇÇÌÇ¥ÇÌÇ¥àÍÇ©ÇÁ
ÉAÅ[ÉLÉeÉNÉ`ÉÉÇ◊Ç¡ÇΩÇËÇ…ÇÐÇΩäJî≠ǵǃÇÒÇæÇÎÅB
ǵǩÇýå§ãÜÇÃÇΩÇþÇÃå§ãÜÇðÇΩǢǻò_ï∂Ç™ê¨â ñ⁄ìInjǩÇËÅB
Ç»ÇÒÇæÇ©Ç»Å[
ÉpÅ[ÉeÉBÉVÉáÉìÇ≈ç◊êÿÇÍÇ…êÿÇ¡ÇΩè¨ãKñÕÉVÉXÉeÉÄÇ≈ï¿óÒìxÉTÉ`ÇËÅA
é¿ÇÕè¨ãKñÕÇ»ÉVÉXÉeÉÄÇ≈è]óàÇ≈Çýè\ï™äJî≠Ç≈Ç´ÇΩï®ÇÇÌÇ¥ÇÌÇ¥àÍÇ©ÇÁ
ÉAÅ[ÉLÉeÉNÉ`ÉÉÇ◊Ç¡ÇΩÇËÇ…ÇÐÇΩäJî≠ǵǃÇÒÇæÇÎÅB
ǵǩÇýå§ãÜÇÃÇΩÇþÇÃå§ãÜÇðÇΩǢǻò_ï∂Ç™ê¨â ñ⁄ìInjǩÇËÅB
Ç»ÇÒÇæÇ©Ç»Å[
596 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 16:31:20.61 ID:0Ix5MPvv
ÇýÇøÇÎÇÒîÁì˜ÇÃǬÇýÇËÇ≈ó·é¶ÇµÇΩÇÒÇæÇØÇ«Ç»
óùå§ÇÃÉ|Å[ÉgÉAÉCÉâÉìÉhãíì_ÇÕïsèÀéñÇýëΩǢǵǻÅ[
ÉIÉ{É{É{
óùå§ÇÃÉ|Å[ÉgÉAÉCÉâÉìÉhãíì_ÇÕïsèÀéñÇýëΩǢǵǻÅ[
ÉIÉ{É{É{
ínãÖÉVÉ~ÉÖÉåÅ[É^Å[ÇýãûÇýÅAÇTîNÇ…àÍìxÇ≠ÇÁÇ¢ÉnÅ[ÉhÉEÉFÉAì¸ÇÍë÷ǶǃçÇë¨âªÇ∑ÇÍÇŒÅA
ǪÇÍÇ»ÇËÇ…óLå¯óòópÇ≈Ç´ÇÈÇ≈ǵÇÂÅH
ǪÇÍÇ»ÇËÇ…óLå¯óòópÇ≈Ç´ÇÈÇ≈ǵÇÂÅH
598 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 17:48:47.76 ID:0Ix5MPvv
5îNÇ∆åæÇÌÇ∏îÒëŒèÃÉmÅ[Éhå^Džǵǃ1Å`2îNÇ≤Ç∆Ç…ç≈êVÇÃÉnÅ[ÉhÇ…ïîï™ìIÇ…ì¸ÇÍë÷ǶÇËÇ·
ǢǢÇ∆évǧÇØÇ«ÇÀÅAìåçHëÂÇðÇΩǢDž
ÇýÇ∆ÇýÇ∆NECÉxÉNÉgÉãÉRÉìÉsÉÖÅ[É^Ç∆ÇÃîÒëŒèÃÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÇ≈Ç‚ÇÈó\íËÇæÇ¡ÇΩÇÒÇæÇÎ
ǢǢÇ∆évǧÇØÇ«ÇÀÅAìåçHëÂÇðÇΩǢDž
ÇýÇ∆ÇýÇ∆NECÉxÉNÉgÉãÉRÉìÉsÉÖÅ[É^Ç∆ÇÃîÒëŒèÃÉRÉìÉsÉÖÅ[ÉeÉBÉìÉOÇ≈Ç‚ÇÈó\íËÇæÇ¡ÇΩÇÒÇæÇÎ
599 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 17:57:06.35 ID:0Ix5MPvv
îºì±ëÃãZèpÇÕ1Å`2îNÇ≈ç¸êVÇ≥ÇÍÇÈÅB
çëÉvÉçéÂì±Ç≈5îNÇ…1âÒëÂå^ó\éZǬÇ≠ÇÃÇÇÝǃDžǵÇΩCPUÇ»ÇÒǃ
ñØä‘Ç≈ÇÃã£ëàóÕìæÇÁÇÍÇÈÇÌÇØǙǻǢÇæÇÎǧ
çëÉvÉçéÂì±Ç≈5îNÇ…1âÒëÂå^ó\éZǬÇ≠ÇÃÇÇÝǃDžǵÇΩCPUÇ»ÇÒǃ
ñØä‘Ç≈ÇÃã£ëàóÕìæÇÁÇÍÇÈÇÌÇØǙǻǢÇæÇÎǧ
íÜÇÃêlÇýëÂïœÇ»ÇÒÇæÇ»Çü
ǃǩÇÊÇ≠ǬÇ≠ÇÍÇΩÇ»Ç∆
http://jun.artcompsci.org/talks/fukui20120614.pdf
ÅuãûÅvÇÃêiÇðï˚ÇÃñ‚ëËì_Ç∆évÇÌÇÍÇÈÇýÇÃ
1.âΩÇÇ∑ÇÈÇΩÇþÇ…çÏÇÈÇÃÇ©ÇÅuÉèÅ[ÉLÉìÉOÉOÉãÅ[ÉvÇ≈ãcò_Åv
2.åãã«ÅAÅuâΩÇÃÇΩÇþÅvÇ©ÇÕÇÕÇ¡Ç´ÇËǵǻǢÇÐÇÐÉXÉ^Å[Ég
3.åvâÊÉXÉ^Å[ÉgÇÐÇ≈Ç…ñ⁄ïWê´î\Ç™ìÒì]éOì]ǵÇΩÅB
4.ÉAÅ[ÉLÉeÉNÉ`ÉÉÇýìÒì]éOì]ǵÇΩÅB
5.äJénǵǃǩÇÁÉÅÅ[ÉJÅ[Ç™ç~ÇËÇÈÇ∆ǢǧëOë„ñ¢ï∑ÇÃéñë‘Ç…Ç¢ÇΩÇ¡ÇΩÅB
?¸FÇ™äJî≠ÇéÛÇØÇÈÇ…ÇÝÇΩǡǃÇÕé©é–ÇÃ45nmÉvÉçÉZÉXÇ≈ÅAÇ∆ǢǧèåèÇ™ÇÝÇ¡ÇΩÇÁǵǢÇ∆Ǣǧâ\
??â\Ç™éñé¿Ç©Ç«Ç§Ç©ÇÕÇ∆ÇýÇ©Ç≠ÅAFÇÕÅuãûÅvÇÃÉvÉçÉZÉbÉTÇÕé©é–ÇÃÉâÉCÉì(íAǵÉpÉCÉçÉbÉgÉâÉCÉìÇ≈ó éYópÇ≈ÇÕǻǢ)Ç≈êªë¢ÅA
è§ïiî≈ÇÃFX10ÇÕTSMCÇÃ40nm
??ǫǧǢǧÇÌÇØÇ©45nmÇ©ÇÁ40nmDžǻǡÇΩÇæÇØÇ≈8ÉRÉAÇ©ÇÁ16ÉRÉAÇ…ÅB
??åãâ ìIÇ…ÇÕÅAFÇÃ45nmÇÕÅuÇ∑ÇÈÇ◊Ç´Ç≈ÇÕǻǩǡÇΩìäéëÅv
ÉÅÅ[ÉJÅ[å©êœÇËÇ™çÇÇ¢óùóR:ÉAÅ[ÉLÉeÉNÉ`ÉÉÅEäJî≠ÉÇÉfÉãÇ™éûë„íxÇÍDžǻǡǃǢÇΩÇ©ÇÁ
ǬÇÐÇË:äJî≠Ç∑ÇÈDZÇ∆DžǵÇΩÇýÇÃÇýÅAäJî≠ÇÃǵǩÇΩÇýä‘à·Ç¡ÇƒÇ¢ÇΩåãã«ÅAäJî≠é©ëÃÇ™ñ≥óùÅAÇ∆ǢǧDZÇ∆Ç≈ÉÅÅ[ÉJÅ[ìPëÞÅB
ç™ñ{Ç…ÇÕÅuà√ñŸÇÃëÂëOíÒÅvÇ™ÇÝÇÈÅB
ÉXÉpÉRÉìÇäJî≠Ç∑ÇÈDZÇ∆Ç™ñ⁄ìIÇ≈ÅAâΩÇÃÇΩÇþÇ…âΩÇ™Ç≈Ç´ÇÈÉXÉpÉRÉìÇçÏÇÈÇ©ÅAÇ™åáóéǵǃǢÇÈ
Ç≈ÇÕâΩåÃÉAÉNÉZÉâÉåÅ[É^ÇÕïsçÃópÅH
åˆéÆÇÃêýñæ2é“ÇÃÉVÉXÉeÉÄç\ê¨Ç…ÇÊÇËÅAñ⁄ïWê´î\íBê¨ÇÃå©çûÇðÇ™ämîFÇ≈Ç´ÇΩÇΩÇþÅAÉAÉNÉZÉâÉåÅ[É^ÇÃçÃópÇÕçló∂ǵǻǢ
åæÇ¢ä∑ǶÇÈÇ∆:ÉAÉNÉZÉâÉåÅ[É^ÇÃǟǧǙà¿Ç≠Ç≈Ç´ÇÈÇ∆Ç©ê´î\çÇÇ¢Ç∆Ç©ÇÝÇÈÇ©ÇýǵÇÍǻǢÇØÇ«
îƒópÇ≈ñ⁄ïWÇÕíBê¨Ç≈Ç´ÇÈÇÃÇ≈ǪǡÇøÇÕçlǶǻǢ
Ç»ÇÒÇæǪÇÍÅH
http://jun.artcompsci.org/talks/shiodome20120820.pdf
ǃǩÇÊÇ≠ǬÇ≠ÇÍÇΩÇ»Ç∆
http://jun.artcompsci.org/talks/fukui20120614.pdf
ÅuãûÅvÇÃêiÇðï˚ÇÃñ‚ëËì_Ç∆évÇÌÇÍÇÈÇýÇÃ
1.âΩÇÇ∑ÇÈÇΩÇþÇ…çÏÇÈÇÃÇ©ÇÅuÉèÅ[ÉLÉìÉOÉOÉãÅ[ÉvÇ≈ãcò_Åv
2.åãã«ÅAÅuâΩÇÃÇΩÇþÅvÇ©ÇÕÇÕÇ¡Ç´ÇËǵǻǢÇÐÇÐÉXÉ^Å[Ég
3.åvâÊÉXÉ^Å[ÉgÇÐÇ≈Ç…ñ⁄ïWê´î\Ç™ìÒì]éOì]ǵÇΩÅB
4.ÉAÅ[ÉLÉeÉNÉ`ÉÉÇýìÒì]éOì]ǵÇΩÅB
5.äJénǵǃǩÇÁÉÅÅ[ÉJÅ[Ç™ç~ÇËÇÈÇ∆ǢǧëOë„ñ¢ï∑ÇÃéñë‘Ç…Ç¢ÇΩÇ¡ÇΩÅB
?¸FÇ™äJî≠ÇéÛÇØÇÈÇ…ÇÝÇΩǡǃÇÕé©é–ÇÃ45nmÉvÉçÉZÉXÇ≈ÅAÇ∆ǢǧèåèÇ™ÇÝÇ¡ÇΩÇÁǵǢÇ∆Ǣǧâ\
??â\Ç™éñé¿Ç©Ç«Ç§Ç©ÇÕÇ∆ÇýÇ©Ç≠ÅAFÇÕÅuãûÅvÇÃÉvÉçÉZÉbÉTÇÕé©é–ÇÃÉâÉCÉì(íAǵÉpÉCÉçÉbÉgÉâÉCÉìÇ≈ó éYópÇ≈ÇÕǻǢ)Ç≈êªë¢ÅA
è§ïiî≈ÇÃFX10ÇÕTSMCÇÃ40nm
??ǫǧǢǧÇÌÇØÇ©45nmÇ©ÇÁ40nmDžǻǡÇΩÇæÇØÇ≈8ÉRÉAÇ©ÇÁ16ÉRÉAÇ…ÅB
??åãâ ìIÇ…ÇÕÅAFÇÃ45nmÇÕÅuÇ∑ÇÈÇ◊Ç´Ç≈ÇÕǻǩǡÇΩìäéëÅv
ÉÅÅ[ÉJÅ[å©êœÇËÇ™çÇÇ¢óùóR:ÉAÅ[ÉLÉeÉNÉ`ÉÉÅEäJî≠ÉÇÉfÉãÇ™éûë„íxÇÍDžǻǡǃǢÇΩÇ©ÇÁ
ǬÇÐÇË:äJî≠Ç∑ÇÈDZÇ∆DžǵÇΩÇýÇÃÇýÅAäJî≠ÇÃǵǩÇΩÇýä‘à·Ç¡ÇƒÇ¢ÇΩåãã«ÅAäJî≠é©ëÃÇ™ñ≥óùÅAÇ∆ǢǧDZÇ∆Ç≈ÉÅÅ[ÉJÅ[ìPëÞÅB
ç™ñ{Ç…ÇÕÅuà√ñŸÇÃëÂëOíÒÅvÇ™ÇÝÇÈÅB
ÉXÉpÉRÉìÇäJî≠Ç∑ÇÈDZÇ∆Ç™ñ⁄ìIÇ≈ÅAâΩÇÃÇΩÇþÇ…âΩÇ™Ç≈Ç´ÇÈÉXÉpÉRÉìÇçÏÇÈÇ©ÅAÇ™åáóéǵǃǢÇÈ
Ç≈ÇÕâΩåÃÉAÉNÉZÉâÉåÅ[É^ÇÕïsçÃópÅH
åˆéÆÇÃêýñæ2é“ÇÃÉVÉXÉeÉÄç\ê¨Ç…ÇÊÇËÅAñ⁄ïWê´î\íBê¨ÇÃå©çûÇðÇ™ämîFÇ≈Ç´ÇΩÇΩÇþÅAÉAÉNÉZÉâÉåÅ[É^ÇÃçÃópÇÕçló∂ǵǻǢ
åæÇ¢ä∑ǶÇÈÇ∆:ÉAÉNÉZÉâÉåÅ[É^ÇÃǟǧǙà¿Ç≠Ç≈Ç´ÇÈÇ∆Ç©ê´î\çÇÇ¢Ç∆Ç©ÇÝÇÈÇ©ÇýǵÇÍǻǢÇØÇ«
îƒópÇ≈ñ⁄ïWÇÕíBê¨Ç≈Ç´ÇÈÇÃÇ≈ǪǡÇøÇÕçlǶǻǢ
Ç»ÇÒÇæǪÇÍÅH
http://jun.artcompsci.org/talks/shiodome20120820.pdf
ÉAÉvÉäÉPÅ[ÉVÉáÉìÇ©ÇÁ??
Åuó~ǵǩǡÇΩÇÃÇÕDZÇÍÇ∂Ç·Ç»Å[Ç¢!!ÅvÇ∆ã©ÇŒÇ»Ç¢ÇΩÇþÇ…
ó~ǵǩǡÇΩÇÃÇÕ
http://www.gundam.jp/tv/world/mecha/images/ef/ef001.jpg
ìÕÇ¢ÇΩÇÃÇÕ
http://www.zariganiworks.co.jp/taroshooten/catalog/img/robo/robo_01.jpg
Åuó~ǵǩǡÇΩÇÃÇÕDZÇÍÇ∂Ç·Ç»Å[Ç¢!!ÅvÇ∆ã©ÇŒÇ»Ç¢ÇΩÇþÇ…
ó~ǵǩǡÇΩÇÃÇÕ
http://www.gundam.jp/tv/world/mecha/images/ef/ef001.jpg
{kind=link}
ìÕÇ¢ÇΩÇÃÇÕ
http://www.zariganiworks.co.jp/taroshooten/catalog/img/robo/robo_01.jpg
{kind=link}
602 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 20:20:55.47 ID:0Ix5MPvv
ÇÐÇÝÇÌÇËÇ∆ÉeÉLÉgÅ[ÇæÇÊÇÀ
> Åyâ¡ì°éÂç∏ÅzÅ@Å@èëÇ≠Ç∆Ç∑ÇÈÇ∆ÅCÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃóÞéóê´ÇíSï€Ç∑ÇÈDZÇ∆Ç™èdóvÇæÇØÇÍÇ«ÇýÅC
> ǪÇÍÇ™íSï€Ç≥ÇÍǻǢÇ∆Ç´ÇÃÇΩÇþÇ…ÉGÉ~ÉÖÉåÅ[É^ìIÇ»ä¬ã´Çýópà”ǵǃǟǵǢÇ∆ǢǧèëÇ´
> Ç‘ÇËÇ…Ç»ÇÈÇ∆évÇ¢ÇÐÇ∑ÅBÇýÇ¡Ç∆íºê⁄ìIÇ…åæǧÇ∆ÅCç°ÅuãûÅvÇ≈É`ÉÖÅ[ÉjÉìÉOǵǃǢÇÈ
> ÉAÉvÉäÉPÅ[ÉVÉáÉìǙǪÇÃÇÐÇÐIntelÇÃXeon PhiÇ≈ÇýìÆÇ≠ÇÊǧDžÇ≈Ç´ÇÈÇýÇÃÇýópà”Ç∑ÇÈÇ◊Ç´
> ÇæÇ∆ǢǧÉäÉNÉGÉXÉgÇèoÇ∑Ç∆ǢǧDZÇ∆Ç…Ç»ÇËÇÐÇ∑ÅB
> Åyà…ì°àœàıÅzÅ@Å@åªèÛÇ≈ÇÕëΩï™Xeon PhiǻǫÇ≈ìÆÇ≠ÇÊǧǻÇýÇÃDžǵǃǢÇΩÇæÇ¢ÇΩï˚Ç™
> éYã∆äEÇ…Ç∆ǡǃÇÕÇÊÇ¢Ç∆évÇ¢ÇÐÇ∑ÅBDZÇÍÇ™7îNêÊÇ…èÛãµÇ™ëÂÇ´Ç≠ïœÇÌÇÈǩǫǧǩÇÕ
> ÇÊÇ≠ÇÌÇ©ÇÁǻǢÇÃÇ≈ÅCÉ\ÉtÉgÉEÉFÉAÇ…ÇÊÇÈíSï€Ç™ïKóvÇ≈ÇÕǻǢǩÇ∆évÇ¢ÇÐÇ∑ÅB
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/028/028-2/gijiroku/1341491.htm
> Åyâ¡ì°éÂç∏ÅzÅ@Å@èëÇ≠Ç∆Ç∑ÇÈÇ∆ÅCÉAÅ[ÉLÉeÉNÉ`ÉÉÇÃóÞéóê´ÇíSï€Ç∑ÇÈDZÇ∆Ç™èdóvÇæÇØÇÍÇ«ÇýÅC
> ǪÇÍÇ™íSï€Ç≥ÇÍǻǢÇ∆Ç´ÇÃÇΩÇþÇ…ÉGÉ~ÉÖÉåÅ[É^ìIÇ»ä¬ã´Çýópà”ǵǃǟǵǢÇ∆ǢǧèëÇ´
> Ç‘ÇËÇ…Ç»ÇÈÇ∆évÇ¢ÇÐÇ∑ÅBÇýÇ¡Ç∆íºê⁄ìIÇ…åæǧÇ∆ÅCç°ÅuãûÅvÇ≈É`ÉÖÅ[ÉjÉìÉOǵǃǢÇÈ
> ÉAÉvÉäÉPÅ[ÉVÉáÉìǙǪÇÃÇÐÇÐIntelÇÃXeon PhiÇ≈ÇýìÆÇ≠ÇÊǧDžÇ≈Ç´ÇÈÇýÇÃÇýópà”Ç∑ÇÈÇ◊Ç´
> ÇæÇ∆ǢǧÉäÉNÉGÉXÉgÇèoÇ∑Ç∆ǢǧDZÇ∆Ç…Ç»ÇËÇÐÇ∑ÅB
> Åyà…ì°àœàıÅzÅ@Å@åªèÛÇ≈ÇÕëΩï™Xeon PhiǻǫÇ≈ìÆÇ≠ÇÊǧǻÇýÇÃDžǵǃǢÇΩÇæÇ¢ÇΩï˚Ç™
> éYã∆äEÇ…Ç∆ǡǃÇÕÇÊÇ¢Ç∆évÇ¢ÇÐÇ∑ÅBDZÇÍÇ™7îNêÊÇ…èÛãµÇ™ëÂÇ´Ç≠ïœÇÌÇÈǩǫǧǩÇÕ
> ÇÊÇ≠ÇÌÇ©ÇÁǻǢÇÃÇ≈ÅCÉ\ÉtÉgÉEÉFÉAÇ…ÇÊÇÈíSï€Ç™ïKóvÇ≈ÇÕǻǢǩÇ∆évÇ¢ÇÐÇ∑ÅB
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/028/028-2/gijiroku/1341491.htm
ÉAÉvÉäÉPÅ[ÉVÉáÉìÇÃë§Ç©ÇÁÇÕ
ó~ǵǢÇýÇÃ:â¥ÇÃÉRÅ[ÉhÇ™ë¨Ç≠ëñÇÈåvéZã@ÇÇÊDZÇπ!
íAǵ:Åuâ¥ÇÃÉRÅ[ÉhÅvÇ…ÇÕâ∑ìxç∑ÇÝÇË
??ïKóvÇ»ÇÁÉAÉZÉìÉuÉâÇ≈Ç≈Çý
??ÉRÉìÉpÉCÉâÇÃèoóÕå©ÇÈÇÃÇÕäÓñ{ÇæÇÊÇÀÅH
??ÉvÉçÉtÉ@ÉCÉâégÇ¡ÇΩDZÇ∆ÇÝÇÈ
??OpenMPÇ∆Ǣǧåæótï∑Ç¢ÇΩDZÇ∆Ç™ÇÝÇÈ
??ï¿óÒâªÇ¡ÇƒÉRÉìÉpÉCÉâǙǵǃÇ≠ÇÍÇÈÇÒÇ≈ǵÇÂÅH
1ÉXÉeÉbÉvÇýǫǡǃçlǶÇÈ
âΩåÃï™éUÉÅÉÇÉä+ê[Ç¢ÉÅÉÇÉääKëwÇ»ÇÃÇ©ÅH
É`ÉbÉvìýÇÃèàóùî\óÕÇÃëùâ¡Ç…î‰Ç◊ǃÉ`ÉbÉvä‘ÉfÅ[É^ì]ëóî\óÕÇ™è„Ç™ÇÁǻǢǩÇÁ
DZÇÍÇÕÅAåæÇ¢ä∑ǶÇÈÇ∆ÅAåªçðÇÃìTå^ìIÉ}ÉCÉNÉçÉvÉçÉZÉbÉTÇÃêðåvÇ≈ÇÕ
??ââéZî\óÕÇÕÉfÅ[É^ì]ëóî\óÕÇ…î‰Ç◊ǃëäëŒìIÇ…à¿Ç¢
??DZÇÍÇÕêªë¢ÉRÉXÉgÇæÇØÇ≈Ç»Ç≠ìdóÕÉRÉXÉgÇýÇ∆ǢǧDZÇ∆
Ç≥ÇÁÇ…åæÇ¢ä∑ǶÇÈÇ∆
??ÅuãûÅvÇÊÇËââéZê´î\ÇëÂïùÇ…è„Ç∞ÇÈÇÃÇÕÅAÉÅÉÇÉäÉoÉìÉhïùÇ‚ÉlÉbÉgÉèÅ[ÉNÉoÉìÉhïùÇÇÝÇ∞Ç»Ç≠ǃÇýǢǢǻÇÁ
ìdóÕÅEÉRÉXÉgÇëÂÇ´Ç≠ÇÕëùÇ‚Ç≥Ç»Ç≠ǃÇýÇ≈Ç´ÇΩÇÕÇ∏
??ãtÇ…ÅAHPL10PFÇæÇØÇ»ÇÁÇýÇ¡Ç∆à¿âøÇ…ÇýÇ≈Ç´ÇΩÇ©ÇýǵÇÍǻǢ
??ÉÅÉÇÉäÉoÉìÉhïùÇëùÇ‚Ç∑Ç»ÇÁëSÇ≠ï ÇÃçÏÇËÇ©ÇΩÇýÇÝÇ¡ÇΩÇ©Çý
íçà”
??ÅuîƒópÅvÇÕîƒópÇ≈ÇÕǻǢ(ÅuãûÅvÇ≈ǧÇÐÇ≠å¯ó¶Ç™Ç≈ǻǢÉAÉvÉäÉPÅ[ÉVÉáÉìÇÕÇ¢Ç≠ÇÁÇ≈ÇýÇÝÇÈ)
??Åuóeó ÅEë—àÊÅvÇ™ñ{ìñDžǪÇÃÇ«Ç¡ÇøÇ©Ç≈Çýé¿åªÇ≈Ç´ÇÈêðåvâÇ™ÇÝÇÈǩǫǧǩÇÕé©ñæÇ≈ÇÕǻǢ
??ââéZèdéãÇÕóvÇ∑ÇÈÇ…B/FóvãÅÇ™í·Ç¢ÇýÇÃÇëŒè€Ç…Ç∑ÇÈ
??ÅuÉÅÉÇÉäçÌå∏ÅvÇÕÉIÉìÉ`ÉbÉvÉÅÉÇÉäǻǢǵ3éüå≥é¿ëïÇ≈ÉoÉìÉhïùÇëùÇ‚Ç∑ÇÃÇ™ñ{éøÅB
è¨óeó Ç…Ç»ÇÈÇÃÇÕåãâ
ÉAÉNÉZÉâÉåÅ[É^ÇçÃópǵǻǩǡÇΩóùóR
åˆéÆÇÃêýñæ
2é“ÇÃÉVÉXÉeÉÄç\ê¨Ç…ÇÊÇËÅAñ⁄ïWê´î\íBê¨ÇÃå©çûÇðÇ™ämîFÇ≈Ç´ÇΩÇΩÇþÅAÉAÉNÉZÉâÉåÅ[É^ÇÃçÃópÇÕçló∂ǵǻǢ
??ñ⁄ïW=LINPACK10PF+HPCC4éÌ1à
??ÉAÉvÉäÉPÅ[ÉVÉáÉìÇÃDZÇ∆ÇÕÇ∑Ç¡Ç©ÇËñYÇÍÇÁÇÍÇΩÅAÅAÅA
ã≥åPìIÇ»ÇýÇÃ
??ÉvÉçÉWÉFÉNÉgÇÕ(é¿åªâ¬î\Ç»ÇÁ)êðíËǵÇΩñ⁄ïWí ÇËÇÃÇýÇÃÇ™é¿åªÇ≥ÇÍÇÈ
??ÅuÉvÉçÉOÉâÉÄÇÕévÇ¡ÇΩí ÇËÇ≈ÇÕÇ»Ç≠ÅAèëÇ¢ÇΩí ÇËÇ…ìÆÇ≠ÅvÇ∆ìØÇ∂
??Ç»ÇÃÇ≈ÅATop5001à Ç∆Ç©HPCC1à Ç∆Ç©Çñ⁄ïWDžǵǃÉAÉvÉäÉPÅ[ÉVÉáÉìÇÃDZÇ∆ÇñYÇÍÇÁÇÍǃÇÕç¢ÇÈ
??ñ⁄ïWÇÇøÇ·ÇÒÇ∆åàÇþÇÊǧ
ó~ǵǢÇýÇÃ:â¥ÇÃÉRÅ[ÉhÇ™ë¨Ç≠ëñÇÈåvéZã@ÇÇÊDZÇπ!
íAǵ:Åuâ¥ÇÃÉRÅ[ÉhÅvÇ…ÇÕâ∑ìxç∑ÇÝÇË
??ïKóvÇ»ÇÁÉAÉZÉìÉuÉâÇ≈Ç≈Çý
??ÉRÉìÉpÉCÉâÇÃèoóÕå©ÇÈÇÃÇÕäÓñ{ÇæÇÊÇÀÅH
??ÉvÉçÉtÉ@ÉCÉâégÇ¡ÇΩDZÇ∆ÇÝÇÈ
??OpenMPÇ∆Ǣǧåæótï∑Ç¢ÇΩDZÇ∆Ç™ÇÝÇÈ
??ï¿óÒâªÇ¡ÇƒÉRÉìÉpÉCÉâǙǵǃÇ≠ÇÍÇÈÇÒÇ≈ǵÇÂÅH
1ÉXÉeÉbÉvÇýǫǡǃçlǶÇÈ
âΩåÃï™éUÉÅÉÇÉä+ê[Ç¢ÉÅÉÇÉääKëwÇ»ÇÃÇ©ÅH
É`ÉbÉvìýÇÃèàóùî\óÕÇÃëùâ¡Ç…î‰Ç◊ǃÉ`ÉbÉvä‘ÉfÅ[É^ì]ëóî\óÕÇ™è„Ç™ÇÁǻǢǩÇÁ
DZÇÍÇÕÅAåæÇ¢ä∑ǶÇÈÇ∆ÅAåªçðÇÃìTå^ìIÉ}ÉCÉNÉçÉvÉçÉZÉbÉTÇÃêðåvÇ≈ÇÕ
??ââéZî\óÕÇÕÉfÅ[É^ì]ëóî\óÕÇ…î‰Ç◊ǃëäëŒìIÇ…à¿Ç¢
??DZÇÍÇÕêªë¢ÉRÉXÉgÇæÇØÇ≈Ç»Ç≠ìdóÕÉRÉXÉgÇýÇ∆ǢǧDZÇ∆
Ç≥ÇÁÇ…åæÇ¢ä∑ǶÇÈÇ∆
??ÅuãûÅvÇÊÇËââéZê´î\ÇëÂïùÇ…è„Ç∞ÇÈÇÃÇÕÅAÉÅÉÇÉäÉoÉìÉhïùÇ‚ÉlÉbÉgÉèÅ[ÉNÉoÉìÉhïùÇÇÝÇ∞Ç»Ç≠ǃÇýǢǢǻÇÁ
ìdóÕÅEÉRÉXÉgÇëÂÇ´Ç≠ÇÕëùÇ‚Ç≥Ç»Ç≠ǃÇýÇ≈Ç´ÇΩÇÕÇ∏
??ãtÇ…ÅAHPL10PFÇæÇØÇ»ÇÁÇýÇ¡Ç∆à¿âøÇ…ÇýÇ≈Ç´ÇΩÇ©ÇýǵÇÍǻǢ
??ÉÅÉÇÉäÉoÉìÉhïùÇëùÇ‚Ç∑Ç»ÇÁëSÇ≠ï ÇÃçÏÇËÇ©ÇΩÇýÇÝÇ¡ÇΩÇ©Çý
íçà”
??ÅuîƒópÅvÇÕîƒópÇ≈ÇÕǻǢ(ÅuãûÅvÇ≈ǧÇÐÇ≠å¯ó¶Ç™Ç≈ǻǢÉAÉvÉäÉPÅ[ÉVÉáÉìÇÕÇ¢Ç≠ÇÁÇ≈ÇýÇÝÇÈ)
??Åuóeó ÅEë—àÊÅvÇ™ñ{ìñDžǪÇÃÇ«Ç¡ÇøÇ©Ç≈Çýé¿åªÇ≈Ç´ÇÈêðåvâÇ™ÇÝÇÈǩǫǧǩÇÕé©ñæÇ≈ÇÕǻǢ
??ââéZèdéãÇÕóvÇ∑ÇÈÇ…B/FóvãÅÇ™í·Ç¢ÇýÇÃÇëŒè€Ç…Ç∑ÇÈ
??ÅuÉÅÉÇÉäçÌå∏ÅvÇÕÉIÉìÉ`ÉbÉvÉÅÉÇÉäǻǢǵ3éüå≥é¿ëïÇ≈ÉoÉìÉhïùÇëùÇ‚Ç∑ÇÃÇ™ñ{éøÅB
è¨óeó Ç…Ç»ÇÈÇÃÇÕåãâ
ÉAÉNÉZÉâÉåÅ[É^ÇçÃópǵǻǩǡÇΩóùóR
åˆéÆÇÃêýñæ
2é“ÇÃÉVÉXÉeÉÄç\ê¨Ç…ÇÊÇËÅAñ⁄ïWê´î\íBê¨ÇÃå©çûÇðÇ™ämîFÇ≈Ç´ÇΩÇΩÇþÅAÉAÉNÉZÉâÉåÅ[É^ÇÃçÃópÇÕçló∂ǵǻǢ
??ñ⁄ïW=LINPACK10PF+HPCC4éÌ1à
??ÉAÉvÉäÉPÅ[ÉVÉáÉìÇÃDZÇ∆ÇÕÇ∑Ç¡Ç©ÇËñYÇÍÇÁÇÍÇΩÅAÅAÅA
ã≥åPìIÇ»ÇýÇÃ
??ÉvÉçÉWÉFÉNÉgÇÕ(é¿åªâ¬î\Ç»ÇÁ)êðíËǵÇΩñ⁄ïWí ÇËÇÃÇýÇÃÇ™é¿åªÇ≥ÇÍÇÈ
??ÅuÉvÉçÉOÉâÉÄÇÕévÇ¡ÇΩí ÇËÇ≈ÇÕÇ»Ç≠ÅAèëÇ¢ÇΩí ÇËÇ…ìÆÇ≠ÅvÇ∆ìØÇ∂
??Ç»ÇÃÇ≈ÅATop5001à Ç∆Ç©HPCC1à Ç∆Ç©Çñ⁄ïWDžǵǃÉAÉvÉäÉPÅ[ÉVÉáÉìÇÃDZÇ∆ÇñYÇÍÇÁÇÍǃÇÕç¢ÇÈ
??ñ⁄ïWÇÇøÇ·ÇÒÇ∆åàÇþÇÊǧ
ÇÐÅAÇÞÇøÇ·Ç≠ÇøÇ·Çæ„©ÅB
åãç\ì™Ç¢Ç¢ìzÇ™ëµÇ¡ÇƒÇ¢ÇÈî§Ç»ÇÃÇ…èWícÇ≈ã¶ãcÇ∑ÇÈÇ∆ëçîíË≥âªÇðÇΩǢǻÅB
ÇØÇ¡Ç´ÇÂÇ≠ÅAílë≈ÇøÇ™ÇÝÇÈÇ©ÇÕÇ¡Ç´ÇËï™Ç©ÇÁǻǢÇÃÇ…ä‘à·Ç¡ÇƒãêäzÇÃó\éZÇ™ïtÇ≠Ç©ÇÁ
ãýÇ™ó~ǵǢǪÇÃéËíiÇ…å§ãÜÇǵǃǢÇÈ≤ð¡∑Ç™ïûíÖÇΩÇÊǧǻîyÇ™ÊÎÁªÅB
àÍï˚ÇÃíÜÇÕëÂïœÅAé¿í é“Ç…ÇÕéÄêlÇ™èoÇÈÇÊǧǻâþçìÇ≥ÅB
Çe1ÇæÉeÉNÉmÉçÉWÉhÉâÉCÉoÅ[ÇæÇ»ÇÒǃÇÐÇ¡ê‘Ç»âRÇ≈ÅAãZèpÇ∆É\ÉtÉgÉEÉFÉAÇÃïÊèÍÇðÇΩǢǻê¢äEÅB
åãç\ì™Ç¢Ç¢ìzÇ™ëµÇ¡ÇƒÇ¢ÇÈî§Ç»ÇÃÇ…èWícÇ≈ã¶ãcÇ∑ÇÈÇ∆ëçîíË≥âªÇðÇΩǢǻÅB
ÇØÇ¡Ç´ÇÂÇ≠ÅAílë≈ÇøÇ™ÇÝÇÈÇ©ÇÕÇ¡Ç´ÇËï™Ç©ÇÁǻǢÇÃÇ…ä‘à·Ç¡ÇƒãêäzÇÃó\éZÇ™ïtÇ≠Ç©ÇÁ
ãýÇ™ó~ǵǢǪÇÃéËíiÇ…å§ãÜÇǵǃǢÇÈ≤ð¡∑Ç™ïûíÖÇΩÇÊǧǻîyÇ™ÊÎÁªÅB
àÍï˚ÇÃíÜÇÕëÂïœÅAé¿í é“Ç…ÇÕéÄêlÇ™èoÇÈÇÊǧǻâþçìÇ≥ÅB
Çe1ÇæÉeÉNÉmÉçÉWÉhÉâÉCÉoÅ[ÇæÇ»ÇÒǃÇÐÇ¡ê‘Ç»âRÇ≈ÅAãZèpÇ∆É\ÉtÉgÉEÉFÉAÇÃïÊèÍÇðÇΩǢǻê¢äEÅB
>>604
é¿í é“Å®é¿òJé“
â¥ìIÇ…ÇÕäÆëSÇ…ÉIÉèÉRÉìÇÃï™ñÏÅB
ç°å„Çýï¿óÒìxÇè„Ç∞ǃêœòaÇÃflopsÇæÇØÇ≈ê¨â Ç∆Ç©éÂí£ÇµÇƒÇ¢Ç≠ÇÃÇ©ÇÀÅB
é¿í é“Å®é¿òJé“
â¥ìIÇ…ÇÕäÆëSÇ…ÉIÉèÉRÉìÇÃï™ñÏÅB
ç°å„Çýï¿óÒìxÇè„Ç∞ǃêœòaÇÃflopsÇæÇØÇ≈ê¨â Ç∆Ç©éÂí£ÇµÇƒÇ¢Ç≠ÇÃÇ©ÇÀÅB
ÊÎÁªÇµÇΩÇÃǡǃíNÇÃDZÇ∆ÅHÅ@àÍêlÇ≈ǢǢǩÇÁè–âÓǵǃÇ≠ÇÍ
607 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 21:15:21.85 ID:0Ix5MPvv
ì™ÇÕǢǢìzÇÁÇæÇ∆évǧÇÊÅB
äØóªÇ‚ǪÇÃOBÇ»ÇÒǃÇýÇÃÇÕîné≠Ç»ÉtÉäÇǵǃéÑïûÇîÏÇ‚Ç∑ìVçÀÇ≥ÅB
äØóªÇ‚ǪÇÃOBÇ»ÇÒǃÇýÇÃÇÕîné≠Ç»ÉtÉäÇǵǃéÑïûÇîÏÇ‚Ç∑ìVçÀÇ≥ÅB
éOé–ÉnÉCÉuÉäÉbÉhÇ»ÇÒǃê´î\â]ÅXà»ëOÇ…ÇÐÇ∆ÇýÇ…ìÆÇ≠ï™ÇØǻǢǡǃÇÃÇ…Åc
ÉOÉäÉbÉhÇæǡǃÇÐÇ∆ÇýÇ»ê¨â èoǃǻÇ≠ǃÅA
ÉtÉåÅ[ÉÄÉèÅ[ÉNÇÕàÍâûçÏÇ¡ÇΩÇØÇ«ÅAÉSÉ~ÇðÇΩǢǻë„ï®Ç≈ëSëRégÇ¢ï®Ç…Ç»ÇÁǻǢǵÅB
Ç‚Ç¡ÇœçëîÔÇìäÇ∂ÇÈÉRÉìÉsÉÖÅ[É^Å[ä÷åWÇÃãêëÂÉvÉçÉWÉFÉNÉgÅA
ãqäœìIÇ»ï]âøÇéÛÇØÇÈDZÇ∆Ç»Ç≠ÉCÉìÉ`ÉLǵǂÇ∑Ç¢ï™ÅA
ÇýÇÃÇ…ÇÕÅcÇ»ÇÁǻǢÇÒÇæÇ»ÅB
ÉOÉäÉbÉhÇæǡǃÇÐÇ∆ÇýÇ»ê¨â èoǃǻÇ≠ǃÅA
ÉtÉåÅ[ÉÄÉèÅ[ÉNÇÕàÍâûçÏÇ¡ÇΩÇØÇ«ÅAÉSÉ~ÇðÇΩǢǻë„ï®Ç≈ëSëRégÇ¢ï®Ç…Ç»ÇÁǻǢǵÅB
Ç‚Ç¡ÇœçëîÔÇìäÇ∂ÇÈÉRÉìÉsÉÖÅ[É^Å[ä÷åWÇÃãêëÂÉvÉçÉWÉFÉNÉgÅA
ãqäœìIÇ»ï]âøÇéÛÇØÇÈDZÇ∆Ç»Ç≠ÉCÉìÉ`ÉLǵǂÇ∑Ç¢ï™ÅA
ÇýÇÃÇ…ÇÕÅcÇ»ÇÁǻǢÇÒÇæÇ»ÅB
>>606
ãæÇ≈ÇýÇðÇ∆ÇØÅB
ãæÇ≈ÇýÇðÇ∆ÇØÅB
àÍêlÇýîcà¨ÇµÇƒÇ¢Ç»Ç¢ÇÃÇ…ÅAǪǧǢǧêlä‘ǙǢÇΩÇ…åàÇÐǡǃǢÇÈÇ∆
åàÇþïtÇØǃÇÈÇÌÇØÇÀÅBìTå^ìIÇæÇ»
åàÇþïtÇØǃÇÈÇÌÇØÇÀÅBìTå^ìIÇæÇ»
åãã«ëÂëOíÒÇÃê´î\éwïWÇæÇØÇ™ÇÝǡǃ
ǻDžDžégǧÇÃǩǡǃñ⁄ìIǙǻǩǡÇΩ
10PFǡǃââéZéËíiÇñ⁄ìIDžǵǃǵÇÐÇ¡ÇΩÇÃÇ≈
Ç»ÇÒÇ©Ç⁄ÇÒÇ‚ÇËǵǃǵÇÐǡǃÇÈ
ìríÜÇ≈Ç‚ÇþÇΩnǡǃnecÅH
ǻDžDžégǧÇÃǩǡǃñ⁄ìIǙǻǩǡÇΩ
10PFǡǃââéZéËíiÇñ⁄ìIDžǵǃǵÇÐÇ¡ÇΩÇÃÇ≈
Ç»ÇÒÇ©Ç⁄ÇÒÇ‚ÇËǵǃǵÇÐǡǃÇÈ
ìríÜÇ≈Ç‚ÇþÇΩnǡǃnecÅH
L3ÉLÉÉÉbÉVÉÖǙǫÇÍÇæÇØà”ñ°ÇÝÇÈÇÃÇ©ímÇËÇΩÇ¢
http://anago.2ch.net/test/read.cgi/jisaku/1404045030/
http://anago.2ch.net/test/read.cgi/jisaku/1404045030/
>>610
ǪǢǂÅAÉIÉ{ÇðÇΩǢǻëÂÉXÉ^Å[DžǻǡÇΩÇÃÇÕÇ∑ÇÆévÇ¢ìñÇΩÇÁǻǢǻÅB
ëÂï®ÇýǢǻǢÇÌÇØÇ≈ÇÕǻǢÇØÇ«ÅB
ÅuflopsÇ™ëÂǴǢŮë¨Ç¢ÉRÉìÉsÉÖÅ[É^ÅvÇ∆ǢǧÇÊǧǻåÎÇ¡ÇΩàÍî âªÇÃã\·‘Ç‚
è„ÇÃÉåÉXÇ≈ÉXÉeÉ}ǵǃÇÈêÍópÇÃÉAÉNÉZÉâÉåÅ[É^Ç™îƒópê´ÇÕǻǢÇ∆Ç´ÇøÇÒÇ∆ñæåæǵǻǩǡÇΩÇËÅA
ǪÇÍÇŸÇ«ÇÃDZÇ∆Ç≈ÇýǻǢÇÃÇ…ê¨â ÇðÇΩǢDžÉfÉRÉåÅ[ÉgǵǃâåÇ…ä™Ç¢ÇΩÇË
Ç´ÇËǙǻǢÅBêgãþÇ…ÇýÅBDZÇÃÉXÉåÇ…ÇýÅB
ǪDZDžÇýÅBÇæÇ©ÇÁÇÐÇ∏ÇÕãæÇÇðÇ∆ǴǻǡǃÅB
ǪǢǂÅAÉIÉ{ÇðÇΩǢǻëÂÉXÉ^Å[DžǻǡÇΩÇÃÇÕÇ∑ÇÆévÇ¢ìñÇΩÇÁǻǢǻÅB
ëÂï®ÇýǢǻǢÇÌÇØÇ≈ÇÕǻǢÇØÇ«ÅB
ÅuflopsÇ™ëÂǴǢŮë¨Ç¢ÉRÉìÉsÉÖÅ[É^ÅvÇ∆ǢǧÇÊǧǻåÎÇ¡ÇΩàÍî âªÇÃã\·‘Ç‚
è„ÇÃÉåÉXÇ≈ÉXÉeÉ}ǵǃÇÈêÍópÇÃÉAÉNÉZÉâÉåÅ[É^Ç™îƒópê´ÇÕǻǢÇ∆Ç´ÇøÇÒÇ∆ñæåæǵǻǩǡÇΩÇËÅA
ǪÇÍÇŸÇ«ÇÃDZÇ∆Ç≈ÇýǻǢÇÃÇ…ê¨â ÇðÇΩǢDžÉfÉRÉåÅ[ÉgǵǃâåÇ…ä™Ç¢ÇΩÇË
Ç´ÇËǙǻǢÅBêgãþÇ…ÇýÅBDZÇÃÉXÉåÇ…ÇýÅB
ǪDZDžÇýÅBÇæÇ©ÇÁÇÐÇ∏ÇÕãæÇÇðÇ∆ǴǻǡǃÅB
ì˙èÌìIDžǪǧǢǧîyÇ∆ïtÇ´çáǡǃǢÇÈÇ∆ÅAínìπÇ…ï®éñÇ…éÊÇËëgÇÞÇÃǙnjǩnjǩǵÇ≠ä¥Ç∂ÇÁÇÍñ{ìñÇ…åôãCÇ™ç∑Ç∑ÅB
615 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/29(ì˙) 22:01:09.39 ID:0Ix5MPvv
ÉSÅ[ÉhÉìÉxÉãèÐÇÕÉXÉpÉRÉìóòópÇ…Ç®ÇØÇÈç≈çÇåÝà–ÇÃèÐÇ∆ǢǧîFéØÇæÇØÇ«ÅH
> ç°îNìxÇÃÉSÅ[ÉhÉìÉxÉãèÐÇÕêŒéRåNÅAéóíπåNÇ∆ÅAàÍâûñqñÏÇýã§íòé“Ç…ÇÕǢǡǃǢ ÇÈÅA
> ÅuãûÅvëSëÃÇégÇ¡ÇΩâFíàò_ìI N ëÃåvéZÇ≈ 5.67PF (10åéÇÃç≈èIÉAÉbÉvÉfÅ[ Égå„)Ç
> íBê¨ÇµÇΩÇ∆Ǣǧò_ï∂Ç…ó^ǶÇÁÇÍÇÐǵÇΩÅB
>
> éÑÇÕå˚ÇÇæÇ∑Ç∆Ç©ò_ï∂Ç…ê‘ÇÇ¢ÇÍÇÈÇ∆Ç©ÉtÉãÉmÅ[Éhé¿çsÇÃéûä‘çÏǡǃÇ∆
> òAågêÑêiâÔãcÇ≈Ç®äËÇ¢Ç∑ÇÈÇ∆Ç©Ç≠ÇÁǢǵǩǵǃǻǢÇÃÇ≈ÅADZÇÍÇÕäÓñ{ìIÇ…
> ëSǃêŒéRåNÇ∆éóíπåNÇÃê¨â Ç≈Ç∑ÅB
jun-makino.Ç≥Ç≠ÇÁ.ne.jp/articles/future_sc/note115.html
Å@Å@Å@Å@Å@Å@Å@~~~~~
řDZDZíuä∑ÇÀÅBJIMäÓínäOÇ∑ÇÆÇÈÇóÇóÇó
ì˙ñ{êlå§ãÜé“ǡǃå™ãïÇæÇÊÇÀÅB
äCäOÇ…çsÇ≠Ç∆Ç∑ÇÆé©ï™ÇÃéËïøDžǵÇΩÇ™ÇÈäwé“Ç≥ÇÒÇÃëΩǢDZÇ∆ÅB
> ç°îNìxÇÃÉSÅ[ÉhÉìÉxÉãèÐÇÕêŒéRåNÅAéóíπåNÇ∆ÅAàÍâûñqñÏÇýã§íòé“Ç…ÇÕǢǡǃǢ ÇÈÅA
> ÅuãûÅvëSëÃÇégÇ¡ÇΩâFíàò_ìI N ëÃåvéZÇ≈ 5.67PF (10åéÇÃç≈èIÉAÉbÉvÉfÅ[ Égå„)Ç
> íBê¨ÇµÇΩÇ∆Ǣǧò_ï∂Ç…ó^ǶÇÁÇÍÇÐǵÇΩÅB
>
> éÑÇÕå˚ÇÇæÇ∑Ç∆Ç©ò_ï∂Ç…ê‘ÇÇ¢ÇÍÇÈÇ∆Ç©ÉtÉãÉmÅ[Éhé¿çsÇÃéûä‘çÏǡǃÇ∆
> òAågêÑêiâÔãcÇ≈Ç®äËÇ¢Ç∑ÇÈÇ∆Ç©Ç≠ÇÁǢǵǩǵǃǻǢÇÃÇ≈ÅADZÇÍÇÕäÓñ{ìIÇ…
> ëSǃêŒéRåNÇ∆éóíπåNÇÃê¨â Ç≈Ç∑ÅB
jun-makino.Ç≥Ç≠ÇÁ.ne.jp/articles/future_sc/note115.html
Å@Å@Å@Å@Å@Å@Å@~~~~~
řDZDZíuä∑ÇÀÅBJIMäÓínäOÇ∑ÇÆÇÈÇóÇóÇó
ì˙ñ{êlå§ãÜé“ǡǃå™ãïÇæÇÊÇÀÅB
äCäOÇ…çsÇ≠Ç∆Ç∑ÇÆé©ï™ÇÃéËïøDžǵÇΩÇ™ÇÈäwé“Ç≥ÇÒÇÃëΩǢDZÇ∆ÅB
>>613
>604Å@ÇÃÊÎÁªÇ…ÇÕ2chÇ≈ÉåÉXÇ∑ÇÈÇ≠ÇÁǢǵǩãûÇ∆ÇÃä÷ÇÌÇËǙǻǢÇÊǧǻ
êlä‘Çýì¸Ç¡ÇƒÇ¢ÇƒÅAǪǧǢǧÉoÉJÉoÉJǵǢǟǫçLÇ¢îÕàÕÇÐÇ≈îFÇþǃÇý
â¥Ç∆ǢǧÇΩÇ¡ÇΩàÍêlǵǩè–âÓÇ≈ǴǻǢÇ∆ǢǧDZÇ∆ÇÀ
>604Å@ÇÃÊÎÁªÇ…ÇÕ2chÇ≈ÉåÉXÇ∑ÇÈÇ≠ÇÁǢǵǩãûÇ∆ÇÃä÷ÇÌÇËǙǻǢÇÊǧǻ
êlä‘Çýì¸Ç¡ÇƒÇ¢ÇƒÅAǪǧǢǧÉoÉJÉoÉJǵǢǟǫçLÇ¢îÕàÕÇÐÇ≈îFÇþǃÇý
â¥Ç∆ǢǧÇΩÇ¡ÇΩàÍêlǵǩè–âÓÇ≈ǴǻǢÇ∆ǢǧDZÇ∆ÇÀ
Ç◊ǬDž2ÇøÇ·ÇÒÇÃèëǴDZÇðå©ÇƒÉXÅ[ÉpÅ[ÉRÉìÉsÉÖÅ[É^ê≠çÙåàÇþÇÈÉoÉJÇ»ÇÒǃǢǂǵǻǢÇÒÇæǵ
à´å˚èëǢǃÇýîlì|ǵï‘ǵǃÇýÅAÇ«Ç¡ÇøÇýà”ñ°Ç»Ç¢Ç∆évǧǺ
à´å˚èëǢǃÇýîlì|ǵï‘ǵǃÇýÅAÇ«Ç¡ÇøÇýà”ñ°Ç»Ç¢Ç∆évǧǺ
GPUÉXÉpÉRÉìǡǃì¡íËÇÃèåèâ∫Ç∂ǷǻǢÇ∆ê´î\Çî≠äˆÇµÇ»Ç¢Ç©ÇÁÇÀÅB
íºê¸î‘í∑ÇÃÉhÉâÉbÉOÉåÅ[ÉTÅ[ÇðÇΩǢǻÇýÇÒÅBF-1É}ÉVÉìÇ∆ë¨Ç≥ÇÃéøÇ™
à·Ç§ÇÃÇ…éóǃÇÈÅB
íºê¸î‘í∑ÇÃÉhÉâÉbÉOÉåÅ[ÉTÅ[ÇðÇΩǢǻÇýÇÒÅBF-1É}ÉVÉìÇ∆ë¨Ç≥ÇÃéøÇ™
à·Ç§ÇÃÇ…éóǃÇÈÅB
ï Ç…ñúî\Ç≈ÇÝÇÈïKóvÇÕǻǢÇÒÇ‚Ç≈
ñ⁄ìIÇ∆Ç∑ÇÈópìrÇ≈égǶÇÍÇŒÇÊÇ¢
ǪÇÃï”Ç⁄ÇÒÇ‚ÇËǵǃÇÈÇ∆KÇÃÇÊǧDžǻÇÈ
ñ⁄ìIÇ∆Ç∑ÇÈópìrÇ≈égǶÇÍÇŒÇÊÇ¢
ǪÇÃï”Ç⁄ÇÒÇ‚ÇËǵǃÇÈÇ∆KÇÃÇÊǧDžǻÇÈ
620 ÅFSocket774ÅF2014/06/30(åé) 21:47:17.91 ID:7ZGoI1GT
{kind=link}
Ǭ68000
Ç¢ÇÐÇæDžDZÇÒǻDZÇ∆åæǡǃÇÈǂǬǙǢÇÈÇ∆ÇÕ
>>619
âΩǵǩÇ≈ǴǻǢÇ∆ç≈å„ÇÐÇ≈ê”îCéùǡǃåæǢǴǡǃÇ≠ÇÍÇÍnjǻÅB
ǪÇÃï”ÇûBñÜDžǵǃé¸ÇËÇ…åÎÇ¡ÇΩä˙ë“éùÇΩÇπÇÈÇ∆ÅA
êFÅXòbÇ™àÍêlïýǴǵénÇþǃÅAçƒåÍúbégǧêlÇ…ñ¿òfÇ©ÇØÇÈǺÅB
âΩǵǩÇ≈ǴǻǢÇ∆ç≈å„ÇÐÇ≈ê”îCéùǡǃåæǢǴǡǃÇ≠ÇÍÇÍnjǻÅB
ǪÇÃï”ÇûBñÜDžǵǃé¸ÇËÇ…åÎÇ¡ÇΩä˙ë“éùÇΩÇπÇÈÇ∆ÅA
êFÅXòbÇ™àÍêlïýǴǵénÇþǃÅAçƒåÍúbégǧêlÇ…ñ¿òfÇ©ÇØÇÈǺÅB
åüì¢íiäKÇ≈äeéÌÉpÉtÉHÅ[É}ÉìÉXå©ÇƒÇÈÇÕÇ∏ÇæÇØÇ«
>>623
ǪÇÍåæÇ¡ÇøÇ·Ç¡ÇΩÇÁäJî≠ÉSÅ[Ç≈ǻǩǡÇΩÇËǵǃǻÅB
ǪÇÍåæÇ¡ÇøÇ·Ç¡ÇΩÇÁäJî≠ÉSÅ[Ç≈ǻǩǡÇΩÇËǵǃǻÅB
628 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/30(åé) 22:50:41.72 ID:I3tZ4nuO
>>620
16ÉrÉbÉgÉRÅ[ÉhÇ»ÇÒǃç°çXíNÇ™èëÇ≠ÇÒÇæÇÊ
òVäQǙǢǢîNDZǢǃñGǶìÿǂǡǃÇÈDZÇ∆ÇÃǟǧǙãCéùÇøà´Ç¢ÇÌ
16ÉrÉbÉgÉRÅ[ÉhÇ»ÇÒǃç°çXíNÇ™èëÇ≠ÇÒÇæÇÊ
òVäQǙǢǢîNDZǢǃñGǶìÿǂǡǃÇÈDZÇ∆ÇÃǟǧǙãCéùÇøà´Ç¢ÇÌ
>>628
Ç®ëOÇÕíNÇ©ÇÁÇýïKóvÇ∆Ç≥ÇÍǃǻǢìÿà»â∫ÇæÇØÇ«ÇÀ
Ç®ëOÇÕíNÇ©ÇÁÇýïKóvÇ∆Ç≥ÇÍǃǻǢìÿà»â∫ÇæÇØÇ«ÇÀ
ÇÝÇÍÅAímÇÁǻǢìýÇ…32bit x86ÇÐÇ≈archÇ™ê¨í∑ǵǃÇΩ
ÇÐǶÇÕ8086ÇæÇ¡ÇΩÇÊǧǻãCǙǵÇΩÇ™ÅB
ÇÐǶÇÕ8086ÇæÇ¡ÇΩÇÊǧǻãCǙǵÇΩÇ™ÅB
EmacsÇýgccÇýÉuÉâÉEÉUìýÇÃí[ññÇ≈ìÆÇ≠ÇÒÇæÇÊÇ»ÅB
ǵǩÇýfirefoxÇæÇ∆ǪDZǪDZÇÃë¨ìxÇ≈Ç≥ÅB
ÇýǧÅAí¥èŒÇ¡ÇøǷǧÇó
ÉNÉâÉEÉhx86 linux EmuǡǃǩÅH
èoêÊÇ©ÇÁÇøÇÂÇ¡Ç∆LinuxégÇ¢ÇΩÇ¢Ç∆Ç´Ç…ÇΩÇÐÇ…égÇ¡ÇΩÇËǵǃw
ǵǩÇýfirefoxÇæÇ∆ǪDZǪDZÇÃë¨ìxÇ≈Ç≥ÅB
ÇýǧÅAí¥èŒÇ¡ÇøǷǧÇó
ÉNÉâÉEÉhx86 linux EmuǡǃǩÅH
èoêÊÇ©ÇÁÇøÇÂÇ¡Ç∆LinuxégÇ¢ÇΩÇ¢Ç∆Ç´Ç…ÇΩÇÐÇ…égÇ¡ÇΩÇËǵǃw
633 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/06/30(åé) 23:53:31.05 ID:I3tZ4nuO
ãŸã}ëŒâûÇÃÇΩÇþÇ…ÉXÉ}ÉzÇ©ÇÁäJî≠ópÉTÅ[ÉoÇÃÉäÉÇÅ[ÉgÉVÉFÉãÇΩÇΩÇØÇÈÇÊǧDžǵǃÇÈÇØÇ«
í@Ç´ÇΩÇ≠ÇÕǻǢǻ
í@Ç´ÇΩÇ≠ÇÕǻǢǻ
1985îNÇ…386Ç≈ÇÕÇ»Ç≠386SXÇ™èoǃÇΩÇÁ
32bitOSÇ™ÇýÇ¡Ç∆ëÅÇ≠ïÅãyǵÇΩÇ©ÇýÇÀ
DOSÇ™32bitâªÇµÇƒÇΩÇ©ÇýǵÇÍǻǢ
32bitOSÇ™ÇýÇ¡Ç∆ëÅÇ≠ïÅãyǵÇΩÇ©ÇýÇÀ
DOSÇ™32bitâªÇµÇƒÇΩÇ©ÇýǵÇÍǻǢ
ìñéûÇÃDZÇ∆ÇâΩÇýímÇÁǻǢÇÒÇæÇ»ÅB
PC-98Ç™286ÇçÃópǵÇΩÇÃÇÕ1987îNÇÃVXÇ©ÇÁ
ìñéû32bitÉpÉ\ÉRÉìÇÕÇÐÇæçÇäzÇæÇ¡ÇΩÇΩÇþïÅãyÇπÇ∏
286ÇÃë„ÇÌÇËÇ…386SXÇ™ïÅãyǵǃÇΩÇÁéûë„ÇÕämé¿Ç…ïœÇÌǡǃǢÇΩ
386ÅA386SXÇÕÉvÉçÉeÉNÉgÉÇÅ[ÉhÇ©ÇÁÉäÉAÉãÉÇÅ[ÉhÇ…ñþÇÍÇΩǵ
âºëz86ÉÇÅ[ÉhÇ™ÇÝÇ¡ÇΩÇ©ÇÁ
DOSÇóòópǵǬǬÉvÉçÉeÉNÉgÉÇÅ[ÉhÇóLå¯äàópÇ≈Ç´ÇΩÇÕÇ∏
ìñéû32bitÉpÉ\ÉRÉìÇÕÇÐÇæçÇäzÇæÇ¡ÇΩÇΩÇþïÅãyÇπÇ∏
286ÇÃë„ÇÌÇËÇ…386SXÇ™ïÅãyǵǃÇΩÇÁéûë„ÇÕämé¿Ç…ïœÇÌǡǃǢÇΩ
386ÅA386SXÇÕÉvÉçÉeÉNÉgÉÇÅ[ÉhÇ©ÇÁÉäÉAÉãÉÇÅ[ÉhÇ…ñþÇÍÇΩǵ
âºëz86ÉÇÅ[ÉhÇ™ÇÝÇ¡ÇΩÇ©ÇÁ
DOSÇóòópǵǬǬÉvÉçÉeÉNÉgÉÇÅ[ÉhÇóLå¯äàópÇ≈Ç´ÇΩÇÕÇ∏
FM-TOWNSÇ™386Ç≈DOSÉGÉNÉXÉeÉìÉ_Å[Çégǡǃ32bitä¬ã´ÇíÒãüǵǃÇΩÇ»
ÇÝÇÍÇ™èoÇΩÇÃÇÕ1989îNÇæÇ¡ÇΩÇØÇ«Ç»
386SXÇ™ïÅãyǵǃÇΩÇÁÇÝÇÃÇÊǧǻä¬ã´Ç™
ÇýÇ¡Ç∆àÍî ìIÇ…é¿åªÇ≥ÇÍǃǢÇΩÇÕÇ∏
ÇÝÇÍÇ™èoÇΩÇÃÇÕ1989îNÇæÇ¡ÇΩÇØÇ«Ç»
386SXÇ™ïÅãyǵǃÇΩÇÁÇÝÇÃÇÊǧǻä¬ã´Ç™
ÇýÇ¡Ç∆àÍî ìIÇ…é¿åªÇ≥ÇÍǃǢÇΩÇÕÇ∏
386ÅA486Ç™ïÅãyǵǃÇýâþãéÇÃÉoÉCÉiÉäéëéYéÃǃǃÇÐÇ≈32bitî≈DOSÇÃé˘óvǻǫǻǩǡÇΩÇ™ÅB
MSÇ™DOSéëéYÇà¯Ç´åpÇ¢Çæ32ÉrÉbÉgOSÇǬÇ≠Ç¡ÇΩÇÁ
ÇÐÇ∆ÇýÇ…ìÆÇ≠ÇÐÇ≈Ç…95îNÇÐÇ≈Ç©Ç©Ç¡ÇΩÅBǪÇÍÇæÇØÅB
CPUÇÃïÅãyà»ëOÇ…ÅAÉÅÉÇÉäÇ‚HDDÇ™çÇâøÇæÇ¡ÇΩÇÃÇ™80îNë„ÅB
80386ÇÕÉrÉãÉQÉCÉcÇ™Åu640KBÇýÇÝÇÍÇŒñ¢óàâiçÖè\ï™ÇæÅvÇ∆åæÇ¡ÇΩ
ÇÌÇ∏Ç©4îNå„ÇÃêªïiÇæÅB
ÇýÇøÇÎÇÒìñéû32ÉrÉbÉgî≈DOSÇÃà íuÇ√ÇØÇÃOSÇçÏÇÎǧÇ∆Ǣǧ
ã@â^ǙǻǩǡÇΩÇÌÇØÇ≈ÇÕǻǢÅiOS/2Åj
CPUÇæÇØÇ™ãZèpävêVÇë±ÇØǃǴÇΩÇ∆ä®à·Ç¢Ç∑ÇÈÇÃÇÕÇ¢ÇΩÇæÇØǻǢÇÀÅB
ÇÐÇ∆ÇýÇ…ìÆÇ≠ÇÐÇ≈Ç…95îNÇÐÇ≈Ç©Ç©Ç¡ÇΩÅBǪÇÍÇæÇØÅB
CPUÇÃïÅãyà»ëOÇ…ÅAÉÅÉÇÉäÇ‚HDDÇ™çÇâøÇæÇ¡ÇΩÇÃÇ™80îNë„ÅB
80386ÇÕÉrÉãÉQÉCÉcÇ™Åu640KBÇýÇÝÇÍÇŒñ¢óàâiçÖè\ï™ÇæÅvÇ∆åæÇ¡ÇΩ
ÇÌÇ∏Ç©4îNå„ÇÃêªïiÇæÅB
ÇýÇøÇÎÇÒìñéû32ÉrÉbÉgî≈DOSÇÃà íuÇ√ÇØÇÃOSÇçÏÇÎǧÇ∆Ǣǧ
ã@â^ǙǻǩǡÇΩÇÌÇØÇ≈ÇÕǻǢÅiOS/2Åj
CPUÇæÇØÇ™ãZèpävêVÇë±ÇØǃǴÇΩÇ∆ä®à·Ç¢Ç∑ÇÈÇÃÇÕÇ¢ÇΩÇæÇØǻǢÇÀÅB
386ÇÕçÇÇ∑ǨÇΩ
32bitÉèÅ[ÉNÉXÉeÅ[ÉVÉáÉìÇ™âΩïSñúâ~Ç≈îÑÇÁÇÍǃÇΩéûë„Ç…
32bitÉpÉ\ÉRÉìÇ™çÇâøÇ…Ç»ÇÈÇÃÇÕìñÇΩÇËëOÇ≈
ÇæÇ©ÇÁ386SX
286ÇÃë„ÇÌÇËÇ…386SXÇ™égÇÌÇÍǃǢÇÍÇŒ
DOSÇÃê¢äEǪÇÃÇýÇÃÇ™ïœÇÌǡǃǢÇΩÇÕÇ∏
1980îNë„îºÇŒÇ©ÇÁå„îºÇÕ
32bitÉåÉWÉXÉ^ÇéùÇøêîMÉoÉCÉgÇÃÉAÉhÉåÉXÇ
ÉäÉjÉAÇ…àµÇ¶ÇÈ16bitCPUÇ…é˘óvÇ™ÇÝÇ¡ÇΩ
ÇæÇ©ÇÁ68000ÇégÇ¡ÇΩAmigaÅAAtari STÅAX68000ǻǫÇÃ
ÉpÉ\ÉRÉìÇ™èoǃǪÇÍÇ»ÇËÇ…ê¨å˜Çé˚ÇþÇΩ
32bitÉèÅ[ÉNÉXÉeÅ[ÉVÉáÉìÇ™âΩïSñúâ~Ç≈îÑÇÁÇÍǃÇΩéûë„Ç…
32bitÉpÉ\ÉRÉìÇ™çÇâøÇ…Ç»ÇÈÇÃÇÕìñÇΩÇËëOÇ≈
ÇæÇ©ÇÁ386SX
286ÇÃë„ÇÌÇËÇ…386SXÇ™égÇÌÇÍǃǢÇÍÇŒ
DOSÇÃê¢äEǪÇÃÇýÇÃÇ™ïœÇÌǡǃǢÇΩÇÕÇ∏
1980îNë„îºÇŒÇ©ÇÁå„îºÇÕ
32bitÉåÉWÉXÉ^ÇéùÇøêîMÉoÉCÉgÇÃÉAÉhÉåÉXÇ
ÉäÉjÉAÇ…àµÇ¶ÇÈ16bitCPUÇ…é˘óvÇ™ÇÝÇ¡ÇΩ
ÇæÇ©ÇÁ68000ÇégÇ¡ÇΩAmigaÅAAtari STÅAX68000ǻǫÇÃ
ÉpÉ\ÉRÉìÇ™èoǃǪÇÍÇ»ÇËÇ…ê¨å˜Çé˚ÇþÇΩ
PC-98ÇÕ1991îNÇÐÇ≈286É}ÉVÉìÇîÑǡǃÇΩÇ©ÇÁ
286ÇêÿÇËéÃǃÇÈDZÇ∆ÇÕÇ≈ǴǻǩǡÇΩ
Windows3.1ÇégǧDZÇ∆ÇëOíÒÇ…çÏÇÁÇÍǃ98MateÇ™èoÇΩÇÃÇÕ1993îNÇ≈
ǪÇÃ2îNå„Ç…ÇÕWindows 95Ç™èoÇΩ
286ÇêÿÇËéÃǃÇÈDZÇ∆ÇÕÇ≈ǴǻǩǡÇΩ
Windows3.1ÇégǧDZÇ∆ÇëOíÒÇ…çÏÇÁÇÍǃ98MateÇ™èoÇΩÇÃÇÕ1993îNÇ≈
ǪÇÃ2îNå„Ç…ÇÕWindows 95Ç™èoÇΩ
PentiumProÇ™16ÉrÉbÉgÉRÅ[ÉhÇ™íxǢǡǃÇ≥ÇÒÇ¥ÇÒí@Ç©ÇÍÇÐÇ≠ǡǃÇΩÇÊÇ»Çó
Ç≈ÅAPentiumIIÇÕ16ÉrÉbÉgÉRÅ[ÉhÇýë¨Ç¢ÇÊǡǃDZÇ∆Ç≈éÛÇØì¸ÇÍÇÁÇÍÇΩÇ∆
Ç≈ÅAPentiumIIÇÕ16ÉrÉbÉgÉRÅ[ÉhÇýë¨Ç¢ÇÊǡǃDZÇ∆Ç≈éÛÇØì¸ÇÍÇÁÇÍÇΩÇ∆
>>639
DOSÉGÉNÉXÉeÉìÉ_ÇÕä˘Ç…ë∂çðǵǃÇΩÇ™
286Çã∆äEÇ™êÿÇËéÃǃÇÁÇÍǻǩǡÇΩÇæÇØ
é¿ç€ÅATOWNSÇÕDOSÉxÅ[ÉXÇÃOSÇégÇ¢ÅADOSÉGÉNÉXÉeÉìÉ_Å[Çégǡǃ
32bitä¬ã´ÇíÒãüǵǃǢÇΩ
DOSÉGÉNÉXÉeÉìÉ_ÇÕä˘Ç…ë∂çðǵǃÇΩÇ™
286Çã∆äEÇ™êÿÇËéÃǃÇÁÇÍǻǩǡÇΩÇæÇØ
é¿ç€ÅATOWNSÇÕDOSÉxÅ[ÉXÇÃOSÇégÇ¢ÅADOSÉGÉNÉXÉeÉìÉ_Å[Çégǡǃ
32bitä¬ã´ÇíÒãüǵǃǢÇΩ
ǪÇýǪÇýÉfÅ[É^ÉoÉX16ÉrÉbÉgÇ∂Ç·32ÉrÉbÉgÉRÅ[ÉhÇ≈ÇÐÇ∆ÇýÇ…
ê´î\èoÇÈÇÌÇØǻǢÇæÇÎÅB386SXÇâþëÂï]âøǵÇ∑ǨÅB
ìñéûÇÕ32ÉrÉbÉgÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇÃéûë„Ç∆åæÇÌÇÍǃÇΩÇÒÇæÇÊÅB
Ç≈ÇýÇÐÇ∆ÇýÇ…ìÆÇ©Ç∑ÇÃÇ…èàóùê´î\Ç™í·Ç∑ǨÇΩÅB
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇ©É}ÉCÉNÉçÉJÅ[ÉlÉãÇ©ÇÃãcò_ÇÕ20ê¢ãIññÇÐÇ≈
ë±Ç¢ÇƒÇΩÇ™åãã«NTÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇéÃǃÇΩǵ
AmoebaÇÕñ¢äÆê¨ÅAGNU HurdÇÕäÆê¨ÇπÇ∏LinuxÇ™ïÅãyǵÇΩÅB
ê´î\èoÇÈÇÌÇØǻǢÇæÇÎÅB386SXÇâþëÂï]âøǵÇ∑ǨÅB
ìñéûÇÕ32ÉrÉbÉgÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇÃéûë„Ç∆åæÇÌÇÍǃÇΩÇÒÇæÇÊÅB
Ç≈ÇýÇÐÇ∆ÇýÇ…ìÆÇ©Ç∑ÇÃÇ…èàóùê´î\Ç™í·Ç∑ǨÇΩÅB
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇ©É}ÉCÉNÉçÉJÅ[ÉlÉãÇ©ÇÃãcò_ÇÕ20ê¢ãIññÇÐÇ≈
ë±Ç¢ÇƒÇΩÇ™åãã«NTÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇéÃǃÇΩǵ
AmoebaÇÕñ¢äÆê¨ÅAGNU HurdÇÕäÆê¨ÇπÇ∏LinuxÇ™ïÅãyǵÇΩÅB
68000ÇÕ286ÇÊÇËê´î\Ç™í·Ç¢ÇÃÇ…68000ÇçÃópǵÇΩÉpÉ\ÉRÉìÇÕèoÇΩ
Ç«ÇÍÇý1980îNë„îºÇŒçÝÇ…èoÇΩÇýÇÃnjǩÇË
AmigaÅAAtari STÅAMacintoshÅAX68000
DZÇÍÇÁÇÃÉpÉ\ÉRÉìÇÕǪÇÍÇ»ÇËÇ…ê¨å˜Çé˚ÇþÇΩ
ê´î\ÇÕ32bitâªÇ∆ÇÕíºê⁄ä÷åWǻǢ
Ç«ÇÍÇý1980îNë„îºÇŒçÝÇ…èoÇΩÇýÇÃnjǩÇË
AmigaÅAAtari STÅAMacintoshÅAX68000
DZÇÍÇÁÇÃÉpÉ\ÉRÉìÇÕǪÇÍÇ»ÇËÇ…ê¨å˜Çé˚ÇþÇΩ
ê´î\ÇÕ32bitâªÇ∆ÇÕíºê⁄ä÷åWǻǢ
68000ÇÕ32bitÉåÉWÉXÉ^Ç16ñ{îıǶǃǢǃ
16MBÇÃÉAÉhÉåÉXãÛä‘ÇÉäÉjÉAÇ…àµÇ¶ÇΩ
32bitÇÃèÊéZÅAèúéZÇ™Ç≈ǴǻǩǡÇΩÇØÇ«
68000ÇÃÇÊǧDž32bitÉåÉWÉXÉ^ÇîıǶÇΩ
16MBÇÃÉAÉhÉåÉXãÛä‘ÇÉäÉjÉAÇ…àµÇ¶ÇÈ16bit CPUÇ…é˘óvÇ™ÇÝÇ¡ÇΩÇÌÇØÇæ
16MBÇÃÉAÉhÉåÉXãÛä‘ÇÉäÉjÉAÇ…àµÇ¶ÇΩ
32bitÇÃèÊéZÅAèúéZÇ™Ç≈ǴǻǩǡÇΩÇØÇ«
68000ÇÃÇÊǧDž32bitÉåÉWÉXÉ^ÇîıǶÇΩ
16MBÇÃÉAÉhÉåÉXãÛä‘ÇÉäÉjÉAÇ…àµÇ¶ÇÈ16bit CPUÇ…é˘óvÇ™ÇÝÇ¡ÇΩÇÌÇØÇæ
>>646
ÉZÉOÉÅÉìÉgÇÃñ‚ëËǙǻÇ≠ǻǡÇΩÇÌÇØ
ó¨ÇÍìIDžǪǧǢǧòbDžǻǡǃÇÈǵ
AmigaÅAAtari STÅAMacintoshÅAX68000Ç«ÇÍÇý
ǪÇÃå„ÅA32bitâªÇ≥ÇÍǃÇÈǵǻ
ÉZÉOÉÅÉìÉgÇÃñ‚ëËǙǻÇ≠ǻǡÇΩÇÌÇØ
ó¨ÇÍìIDžǪǧǢǧòbDžǻǡǃÇÈǵ
AmigaÅAAtari STÅAMacintoshÅAX68000Ç«ÇÍÇý
ǪÇÃå„ÅA32bitâªÇ≥ÇÍǃÇÈǵǻ
http://pc.watch.impress.co.jp/docs/column/kaigai/20140701_655839.html
20îNå„ÇÃç°ÇýéäÇÈèäÇ≈ê∂Ç´écǡǃǢÇÈPentiumÉAÅ[ÉLÉeÉNÉ`ÉÉ
20îNå„ÇÃç°ÇýéäÇÈèäÇ≈ê∂Ç´écǡǃǢÇÈPentiumÉAÅ[ÉLÉeÉNÉ`ÉÉ
8086Ç∆286Ç∆386Ç∂Ç·àµÇ¢Ç™ïœÇÌÇ¡ÇΩǡǃÇÃÇ™ÇþÇÒÇ«Ç≠Ç≥Ç≠Ç»ÇÈàÍàˆÇ∂ǷǻǢǩ
DZÇÃéOǬÇã§í ÇÃÉRÅ[ÉhÇ≈ìÆǩǪǧÇ∆ǵÇΩÇÁ8086Ç∆ǵǃégǧǵǩǻǢ
DZÇÃéOǬÇã§í ÇÃÉRÅ[ÉhÇ≈ìÆǩǪǧÇ∆ǵÇΩÇÁ8086Ç∆ǵǃégǧǵǩǻǢ
86ÇÃÉZÉOÉÅÉìÉgÇ–Ç∆ǬÇ≈ãSÇÃéÒÇÇ∆Ç¡ÇΩÇðÇΩǢDžåæǧǙÅA
68kÉVÉäÅ[ÉYÇæǡǃè\ï™ñ ì|èLÇ¢ÅBMacÇÃÉAÉvÉäçÏÇÈÇ»ÇÒǃÇ≥ÇÁÇ…ínçñÅB
68kÉVÉäÅ[ÉYÇæǡǃè\ï™ñ ì|èLÇ¢ÅBMacÇÃÉAÉvÉäçÏÇÈÇ»ÇÒǃÇ≥ÇÁÇ…ínçñÅB
286ÇÕÇ»Ç≠ǃÇýÇÊÇ©Ç¡ÇΩ
ÇÝÇÍÇ™Ç∆ǃÇýïÅãyǵǃǵÇÐÇ¡ÇΩÇπÇ¢Ç≈
ÇðÇÒÇ»ÉZÉOÉÅÉìÉgÇÃñ‚ëËÇ≈ãÍǵÇÞDZÇ∆DžǻǡÇΩ
286Ç™32bitÉåÉWÉXÉ^ÇîıǶÇÈÇÊǧǻägí£ÇæÇ¡ÇΩÇÁÇÊÇ©Ç¡ÇΩÇÃÇ…Ç»
ÇÝÇÍÇ™Ç∆ǃÇýïÅãyǵǃǵÇÐÇ¡ÇΩÇπÇ¢Ç≈
ÇðÇÒÇ»ÉZÉOÉÅÉìÉgÇÃñ‚ëËÇ≈ãÍǵÇÞDZÇ∆DžǻǡÇΩ
286Ç™32bitÉåÉWÉXÉ^ÇîıǶÇÈÇÊǧǻägí£ÇæÇ¡ÇΩÇÁÇÊÇ©Ç¡ÇΩÇÃÇ…Ç»
653 ÅFSocket774ÅF2014/07/01(âŒ) 12:10:33.39 ID:et5NIseM
èÉêàÇ»8bitÅAèÉêàÇ»16bitÇÃCPUǡǃÇÝÇÐÇËégÇÌÇÍǃǻǢÇÒÇæÇÊÇ»
ÇÐÇ∏èÉêàÇ»8bitÇæÇ∆ÉÅÉÇÉäÇ™ÇΩÇ¡ÇΩ256ÉoÉCÉgǡǃDZÇ∆DžǻǡǃégÇ¢à´Ç∑ǨÇΩǵÅA
åvéZÇ∑ÇÈÇ…Çý0Å`255ÇæÇ∆è≠Ç»Ç∑ǨÇΩ
ÇæÇ©ÇÁÅAäÓñ{8bitÇæÇØÇ«16bitÉåÉWÉXÉ^ÇýîıǶǃ
16bitñΩóþÇýÇÝÇÈÇÃÇ™ïÅí ÇæÇ¡ÇΩ
16bitââéZÇìýïî8bitÇ≈âΩìxÇ©Ç‚ÇÈÇ©ÅAǪÇÍÇ∆ÇýìýïîÇý16bitÇ≈ââéZÇ∑ÇÈÇ©ÇÕCPUÇ…ÇÊǡǃàŸÇ»Ç¡ÇΩ
ÇÐÇΩÅA16bitCPUÇýÅAÉÅÉÇÉäè„å¿64kÇ≈è≠Ç»Ç∑ǨÇΩÇÃÇ≈ÅAäeé–Ç∆Çý20bitÇ∆Ç©24bitÇ∆Ç©Ç…ägí£ÇµÇƒégǡǃÇΩ
ÉZÉOÉÅÉìÉgï˚éÆǡǃǢǧï»ÇÃÇÝÇÈédëgÇðÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÇýÇÝÇ¡ÇΩÇØÇ«ÇÀ
ÇÐÇ∏èÉêàÇ»8bitÇæÇ∆ÉÅÉÇÉäÇ™ÇΩÇ¡ÇΩ256ÉoÉCÉgǡǃDZÇ∆DžǻǡǃégÇ¢à´Ç∑ǨÇΩǵÅA
åvéZÇ∑ÇÈÇ…Çý0Å`255ÇæÇ∆è≠Ç»Ç∑ǨÇΩ
ÇæÇ©ÇÁÅAäÓñ{8bitÇæÇØÇ«16bitÉåÉWÉXÉ^ÇýîıǶǃ
16bitñΩóþÇýÇÝÇÈÇÃÇ™ïÅí ÇæÇ¡ÇΩ
16bitââéZÇìýïî8bitÇ≈âΩìxÇ©Ç‚ÇÈÇ©ÅAǪÇÍÇ∆ÇýìýïîÇý16bitÇ≈ââéZÇ∑ÇÈÇ©ÇÕCPUÇ…ÇÊǡǃàŸÇ»Ç¡ÇΩ
ÇÐÇΩÅA16bitCPUÇýÅAÉÅÉÇÉäè„å¿64kÇ≈è≠Ç»Ç∑ǨÇΩÇÃÇ≈ÅAäeé–Ç∆Çý20bitÇ∆Ç©24bitÇ∆Ç©Ç…ägí£ÇµÇƒégǡǃÇΩ
ÉZÉOÉÅÉìÉgï˚éÆǡǃǢǧï»ÇÃÇÝÇÈédëgÇðÇÃÉAÅ[ÉLÉeÉNÉ`ÉÉÇýÇÝÇ¡ÇΩÇØÇ«ÇÀ
16bitCPUÅA32bitCPUäeé–èüéËÇ»íËã`Ç»ÇÃÇ…
èÉêàÇ»Å`Ç∆ǩǻDžà”ñ°ïsñæÇ»éùò_ìWäJǵǃÇÈÇÒÇæÅB
èÉêàÇ»Å`Ç∆ǩǻDžà”ñ°ïsñæÇ»éùò_ìWäJǵǃÇÈÇÒÇæÅB
ÇæÇ©ÇÁx86å¸ÇØÇÃ32ÉrÉbÉgOSÇ»ÇÁ80îNë„Ç…äÆê¨ÇµÇƒÇÈÇÊÅB
É}ÉCÉNÉçÉJÅ[ÉlÉãÇæÇ¡ÇΩÇØÇ«ÅB
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇæÇ¡ÇΩÇÁǪDZǪDZé¿ópìIÇ»ë¨ìxÇ≈
ìÆÇ©ÇπÇΩÇ©ÇýǵÇÍǻǢǙÅAñ¢óàÇ…â–ç™ÇécÇ∑DZÇ∆Ç…Ç»ÇÈÇ∆
çlǶÇÁÇÍÇΩÇ©ÇÁǪǧÇÕǵǻǩǡÇΩÅB
NTÇÕäÆëSÇ»É}ÉCÉNÉçÉJÅ[ÉlÉãDZǪí˙ÇþÇΩÇ™
ÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÉhÉâÉCÉoÇ‚ÉTÅ[ÉrÉXǻǫ
ç™ñ{évëzÇÕà¯Ç´åpÇ¢Ç≈Ç¢ÇÈÅB
Çýǵ386ÇÃê´î\Ç…çáÇÌÇπǃíÜìrîºí[Ç»ÇýÇÃÇçÏǡǃÇΩÇÁ
ç°ìxÇÕ64ÉrÉbÉgéûë„Ç…â–ç™ÇécǵǃÇΩÇ©ÇýǵÇÍǻǢÇÀÅB
MacÇÕ68kÇéÃǃǃPPCÇ…à⁄çsǵÇΩÇ™ÅA
ATåðä∑ã@ÇÕå„ï˚åðä∑ÇéÃǃǻǩǡÇΩÅB
òVäQÇÃíLÉåÉoíËêHÇÕàðÇýÇΩÇÍÇ™Ç∑ÇÈÇÀÅB
É}ÉCÉNÉçÉJÅ[ÉlÉãÇæÇ¡ÇΩÇØÇ«ÅB
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇæÇ¡ÇΩÇÁǪDZǪDZé¿ópìIÇ»ë¨ìxÇ≈
ìÆÇ©ÇπÇΩÇ©ÇýǵÇÍǻǢǙÅAñ¢óàÇ…â–ç™ÇécÇ∑DZÇ∆Ç…Ç»ÇÈÇ∆
çlǶÇÁÇÍÇΩÇ©ÇÁǪǧÇÕǵǻǩǡÇΩÅB
NTÇÕäÆëSÇ»É}ÉCÉNÉçÉJÅ[ÉlÉãDZǪí˙ÇþÇΩÇ™
ÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÉhÉâÉCÉoÇ‚ÉTÅ[ÉrÉXǻǫ
ç™ñ{évëzÇÕà¯Ç´åpÇ¢Ç≈Ç¢ÇÈÅB
Çýǵ386ÇÃê´î\Ç…çáÇÌÇπǃíÜìrîºí[Ç»ÇýÇÃÇçÏǡǃÇΩÇÁ
ç°ìxÇÕ64ÉrÉbÉgéûë„Ç…â–ç™ÇécǵǃÇΩÇ©ÇýǵÇÍǻǢÇÀÅB
MacÇÕ68kÇéÃǃǃPPCÇ…à⁄çsǵÇΩÇ™ÅA
ATåðä∑ã@ÇÕå„ï˚åðä∑ÇéÃǃǻǩǡÇΩÅB
òVäQÇÃíLÉåÉoíËêHÇÕàðÇýÇΩÇÍÇ™Ç∑ÇÈÇÀÅB
ãtÇ…çlǶÇÍÇŒ16bitÇÃêßå¿Ç™1995îNÇ…èoÇΩWindows95ÇÐÇ≈ÇÝÇ¡ÇΩÇ©ÇÁ
ëºÇÃãKäiÇÃÉpÉ\ÉRÉìÇÃë∂çðâøílÇ™ÇÝÇ¡ÇΩÇÃÇ©ÇýÇ»
Windows95Ç™èoǃëºÇÃãKäiÇÃÉpÉ\ÉRÉìÇ™âÛñ≈èÛë‘DžǻǡǃǵÇÐÇ¡ÇΩ
ëºÇÃãKäiÇÃÉpÉ\ÉRÉìÇÃë∂çðâøílÇ™ÇÝÇ¡ÇΩÇÃÇ©ÇýÇ»
Windows95Ç™èoǃëºÇÃãKäiÇÃÉpÉ\ÉRÉìÇ™âÛñ≈èÛë‘DžǻǡǃǵÇÐÇ¡ÇΩ
>>655
íÜìrîºí[Ç»ÇýÇÃDžǻǡǃÇΩÇ©ÇÁ
Windows 95Ç©ÇÁNTånÇÃXPÇ÷ÇÃà⁄çsÇ™ÇÝÇ¡ÇΩÇÌÇØÇ≈
Windows 95Ç™èoÇΩìñéûÅA
16MBÇÃÉÅÉÇÉäÇ≈Ç‚Ç¡Ç∆OSÇæÇØÇ™ìÆçÏÇ∑ÇÈNTånÇÕïKóvÇ∆Ç≥ÇÍǻǩǡÇΩÇ©ÇÁ
íÜìrîºí[Ç»ÇýÇÃDžǻǡǃÇΩÇ©ÇÁ
Windows 95Ç©ÇÁNTånÇÃXPÇ÷ÇÃà⁄çsÇ™ÇÝÇ¡ÇΩÇÌÇØÇ≈
Windows 95Ç™èoÇΩìñéûÅA
16MBÇÃÉÅÉÇÉäÇ≈Ç‚Ç¡Ç∆OSÇæÇØÇ™ìÆçÏÇ∑ÇÈNTånÇÕïKóvÇ∆Ç≥ÇÍǻǩǡÇΩÇ©ÇÁ
î˜ñ≠ÅAǡǃÉåÉxÉãÇ≈ÇÕǻǢÇ∆évǧǙw
ǪÇÍÇÕÇ≥ǃǮǴOSÇÃòbÇÕÉXÉåà·Ç¢Ç«Ç±ÇÎÇ©î¬à·Ç¢Ç»ÇÃÇ≈íEê¸ÇýíˆÅXÇ…ÅB
ǪÇÍÇÕÇ≥ǃǮǴOSÇÃòbÇÕÉXÉåà·Ç¢Ç«Ç±ÇÎÇ©î¬à·Ç¢Ç»ÇÃÇ≈íEê¸ÇýíˆÅXÇ…ÅB
éûë„çlèÿÇ™ÇþÇøÇ·Ç≠ÇøÇ·Ç∑ǨǃDZǡÇøÇÐÇ≈ì™í…Ç¢ÇÌ
Win95ÇÕìñèâÇ©ÇÁNTÉJÅ[ÉlÉãÇ…ìùçáÇ∑ÇÈÇÐÇ≈ÇÃåqǨÇÃOSÇ∆ǵǃçÏÇÁÇÍÇΩÅB
Win32 APIÇýç≈èâÇ©ÇÁNTÇ÷ÇÃìùçáÇëOíÒÇ…êðåvÇ≥ÇÍǃÇÈÅB
DOSéëéYǙDZDZÇÐÇ≈ë´à¯Ç¡í£ÇÁǻǴǷXPÇÐÇ≈ë“ÇΩÇ≥ÇÍÇÈDZÇ∆ÇÕ
ñ≥Ç©Ç¡ÇΩÇæÇÎǧÇØÇ«Ç»ÅB
MacOSÇÕâþãéÇ…âΩìxÇýéëéYÇÉoÉbÉTÉäêÿǡǃÇÈÇ™ÅAåðä∑ê´Ç™êÿÇÁÇÍǃÇý
ǬǢǃǢÇ≠ÇÊǧǻíâêΩêSÇÃçÇÇ¢ÉÜÅ[ÉUÅ[Ç…àÕÇÐÇÍǃÇÈÇ©ÇÁDZǪÇ≈Ç´ÇΩÇýÇÃÅB
Win95ÇÕìñèâÇ©ÇÁNTÉJÅ[ÉlÉãÇ…ìùçáÇ∑ÇÈÇÐÇ≈ÇÃåqǨÇÃOSÇ∆ǵǃçÏÇÁÇÍÇΩÅB
Win32 APIÇýç≈èâÇ©ÇÁNTÇ÷ÇÃìùçáÇëOíÒÇ…êðåvÇ≥ÇÍǃÇÈÅB
DOSéëéYǙDZDZÇÐÇ≈ë´à¯Ç¡í£ÇÁǻǴǷXPÇÐÇ≈ë“ÇΩÇ≥ÇÍÇÈDZÇ∆ÇÕ
ñ≥Ç©Ç¡ÇΩÇæÇÎǧÇØÇ«Ç»ÅB
MacOSÇÕâþãéÇ…âΩìxÇýéëéYÇÉoÉbÉTÉäêÿǡǃÇÈÇ™ÅAåðä∑ê´Ç™êÿÇÁÇÍǃÇý
ǬǢǃǢÇ≠ÇÊǧǻíâêΩêSÇÃçÇÇ¢ÉÜÅ[ÉUÅ[Ç…àÕÇÐÇÍǃÇÈÇ©ÇÁDZǪÇ≈Ç´ÇΩÇýÇÃÅB
>>658
UNIXånOSÇÕX Window SystemÇëñÇÁÇπÇÈÇ∆16MBÇÕç≈í·êHÇ¡ÇΩ
WindowsNTÇýOSÇëñÇÁÇπÇÈÇæÇØÇ≈16MBÇêHÇ¡ÇΩ
Windows 95Ç™èoÇΩìñéûÇÃÉpÉ\ÉRÉìÇÃëΩÇ≠ÇÕÉÅÉÇÉäÇ16MBǵǩêœÇÒÇ≈ǻǢ
Windows 95ÇÕ16MBÇÃÉÅÉÇÉäÇ≈
OSÇæÇØÇ≈Ç»Ç≠ÉAÉvÉäÇýé¿ópìIÇ…é¿çsÇ≈ǴǃǢÇΩ
UNIXånOSÇÕX Window SystemÇëñÇÁÇπÇÈÇ∆16MBÇÕç≈í·êHÇ¡ÇΩ
WindowsNTÇýOSÇëñÇÁÇπÇÈÇæÇØÇ≈16MBÇêHÇ¡ÇΩ
Windows 95Ç™èoÇΩìñéûÇÃÉpÉ\ÉRÉìÇÃëΩÇ≠ÇÕÉÅÉÇÉäÇ16MBǵǩêœÇÒÇ≈ǻǢ
Windows 95ÇÕ16MBÇÃÉÅÉÇÉäÇ≈
OSÇæÇØÇ≈Ç»Ç≠ÉAÉvÉäÇýé¿ópìIÇ…é¿çsÇ≈ǴǃǢÇΩ
Windows95Ç™ïsà¿íËÇæÇ¡ÇΩÇ©ÇÁÅAÇ®ÇÍÇÕWindowsNT4.0WorkstationégǡǃÇΩÇÌ
95Ç∆NT4ÇÃÉfÉÖÉAÉãÉuÅ[ÉgÇæÇ¡ÇΩÇØÇ«ÅAÇŸÇ∆ÇÒÇ«NT4égǡǃÇΩ
Windows2000DžǻǡǃǩÇÁÇÕÅA9xånOSÇÕégÇÌÇ∏Ç…
äÆëSÇ…NTånOSÇ…à⁄çsǵÇΩ
95Ç∆NT4ÇÃÉfÉÖÉAÉãÉuÅ[ÉgÇæÇ¡ÇΩÇØÇ«ÅAÇŸÇ∆ÇÒÇ«NT4égǡǃÇΩ
Windows2000DžǻǡǃǩÇÁÇÕÅA9xånOSÇÕégÇÌÇ∏Ç…
äÆëSÇ…NTånOSÇ…à⁄çsǵÇΩ
ÇæÇ©ÇÁÇ»ÇÒÇæÅH
ítêŸÇ»íLÉåÉoò_ǵǩåæǶǻǢîné≠ÇÕñŸÇÍÇÊ
ítêŸÇ»íLÉåÉoò_ǵǩåæǶǻǢîné≠ÇÕñŸÇÍÇÊ
http://pc.watch.impress.co.jp/docs/article/960731/iodata2.htm
1996îNà»ëOÇÃÉÅÉÇÉäÇÕîÒèÌÇ…çÇâøÇæÇ¡ÇΩ
16MBÇ≈5ñúâ~ãþÇ≠ǵÇΩÇ©ÇÁÇ»
Windows NTÇÕ3.5Ç©ÇÁégǡǃÇΩÇ™20MBÇÃÉÅÉÇÉäÇ≈ÇýêhÇ©Ç¡ÇΩ
1996îNà»ëOÇÃÉÅÉÇÉäÇÕîÒèÌÇ…çÇâøÇæÇ¡ÇΩ
16MBÇ≈5ñúâ~ãþÇ≠ǵÇΩÇ©ÇÁÇ»
Windows NTÇÕ3.5Ç©ÇÁégǡǃÇΩÇ™20MBÇÃÉÅÉÇÉäÇ≈ÇýêhÇ©Ç¡ÇΩ
èÆçXÅu386SXÉKÅ[ÅvÇÃÉAÉzÇ»âºíËÇ™ê¨óßǵÇÀÅ[Ç∂Ç·ÇÒ
96îNÇ≈Ç∑ÇÁ16MBÇ≈5ñúÇæÇÎÅH
ǪÇÃ10îNëOÇÕÅHï∑Ç≠ÇÐÇ≈ÇýǻǢÇÊÇ»
CPUÇæÇØóıâøÇ≈ÇýäÃêSÇÃ32ÉrÉbÉgOSÇìÆÇ©ÇπÇÈä¬ã´Ç™ÉnÅ[ÉhÉãÇ™çÇÇ¢
Ç®ëOÇÃò_óùìWäJÇÕç≈èâÇ©ÇÁñ≥óùÇ™ÇÝÇÈÅBà»è„ÅB
96îNÇ≈Ç∑ÇÁ16MBÇ≈5ñúÇæÇÎÅH
ǪÇÃ10îNëOÇÕÅHï∑Ç≠ÇÐÇ≈ÇýǻǢÇÊÇ»
CPUÇæÇØóıâøÇ≈ÇýäÃêSÇÃ32ÉrÉbÉgOSÇìÆÇ©ÇπÇÈä¬ã´Ç™ÉnÅ[ÉhÉãÇ™çÇÇ¢
Ç®ëOÇÃò_óùìWäJÇÕç≈èâÇ©ÇÁñ≥óùÇ™ÇÝÇÈÅBà»è„ÅB
>>660
MacOSÇÃÉoÉbÉTÉäÇÕÅAé¿ÇÕÇØǡDZǧÉTÉ|Å[ÉgÇ≥ÇÍǃÇΩÇ©ÇÁÇ»
68ånÅ®PPCÇÃèÍçáÅAÇŸÇ⁄äÆý¯Ç»ÉGÉ~ÉÖÉåÅ[É^ǙǬǢǃǃÅAÇŸÇ∆ÇÒÇ«ÇÃÉ\ÉtÉgÇ™ëSÇ≠ìØÇ∂ÇÊǧDžìÆçÏǵÇΩÅiFPUä÷òAÇ™É_ÉÅÇæÇ¡ÇΩãCÇ™Åj
MacOS9Å®OSXÇÃèÍçáÇÕÅAãåOSÇ™ìÆÇ≠ä¬ã´Ç™êîÉoÅ[ÉWÉáÉìà€éùÇ≥ÇÍÇΩÅïMacOS9ÇÃDZÇÎÇ…ÇÕXÇ≈ÇýìÆÇ≠ÇÊǧDžÉ\ÉtÉgÇçÏê¨Ç≈Ç´ÇΩ
PPCÅ®IntelÇÃèÍçáÅAî‰ärìIêVǵǢÉ\ÉtÉgÇÕìÆçÏÇ∑ÇÈÉGÉ~ÉÖǙǬǢǃǢÇΩ
ÅcÅcǡǃǻä¥Ç∂Ç≈ÅAíºãþÇÃÉ\ÉtÉgÇ»ÇÁÇŸÇ⁄ñ‚ëËÇ»Ç≠égǶÇΩÇÌÇØÇ≈ÅAêMé“Ç≈Ç»Ç≠ǃÇýà⁄çsÇ≈Ç´ÇÈèÛãµÇæÇ¡ÇΩÇÊ
WindowsÇ≈ÇΩÇ∆ǶÇÈÇ»ÇÁÅA95ånÇ©ÇÁNTånÇ…à⁄çsǵÇΩÇÃÇ∆ÇΩǢǵǃïœÇÌÇÁǻǢä¥Ç∂
MacOSÇÃÉoÉbÉTÉäÇÕÅAé¿ÇÕÇØǡDZǧÉTÉ|Å[ÉgÇ≥ÇÍǃÇΩÇ©ÇÁÇ»
68ånÅ®PPCÇÃèÍçáÅAÇŸÇ⁄äÆý¯Ç»ÉGÉ~ÉÖÉåÅ[É^ǙǬǢǃǃÅAÇŸÇ∆ÇÒÇ«ÇÃÉ\ÉtÉgÇ™ëSÇ≠ìØÇ∂ÇÊǧDžìÆçÏǵÇΩÅiFPUä÷òAÇ™É_ÉÅÇæÇ¡ÇΩãCÇ™Åj
MacOS9Å®OSXÇÃèÍçáÇÕÅAãåOSÇ™ìÆÇ≠ä¬ã´Ç™êîÉoÅ[ÉWÉáÉìà€éùÇ≥ÇÍÇΩÅïMacOS9ÇÃDZÇÎÇ…ÇÕXÇ≈ÇýìÆÇ≠ÇÊǧDžÉ\ÉtÉgÇçÏê¨Ç≈Ç´ÇΩ
PPCÅ®IntelÇÃèÍçáÅAî‰ärìIêVǵǢÉ\ÉtÉgÇÕìÆçÏÇ∑ÇÈÉGÉ~ÉÖǙǬǢǃǢÇΩ
ÅcÅcǡǃǻä¥Ç∂Ç≈ÅAíºãþÇÃÉ\ÉtÉgÇ»ÇÁÇŸÇ⁄ñ‚ëËÇ»Ç≠égǶÇΩÇÌÇØÇ≈ÅAêMé“Ç≈Ç»Ç≠ǃÇýà⁄çsÇ≈Ç´ÇÈèÛãµÇæÇ¡ÇΩÇÊ
WindowsÇ≈ÇΩÇ∆ǶÇÈÇ»ÇÁÅA95ånÇ©ÇÁNTånÇ…à⁄çsǵÇΩÇÃÇ∆ÇΩǢǵǃïœÇÌÇÁǻǢä¥Ç∂
ÇæÇ©ÇÁ386SXÇ™1985îNÇ…èoǃÇÍÇŒ
Windows 3.0Ç©ÇÁ95Ç™èoÇÈÇÐÇ≈ÇÃ5îNÇ≠ÇÁÇ¢ÇÃä‘ÅA
DOSÅAWindowsÇ≈32bitä¬ã´Ç™égǶÅA
ÉZÉOÉÅÉìÉgÇÃñ‚ëËÇ…ì™ÇîYÇÐÇπÇÈDZÇ∆ÇÕǻǩǡÇΩÇ∆ǢǧDZÇ∆
Windows 3.0Ç©ÇÁ95Ç™èoÇÈÇÐÇ≈ÇÃ5îNÇ≠ÇÁÇ¢ÇÃä‘ÅA
DOSÅAWindowsÇ≈32bitä¬ã´Ç™égǶÅA
ÉZÉOÉÅÉìÉgÇÃñ‚ëËÇ…ì™ÇîYÇÐÇπÇÈDZÇ∆ÇÕǻǩǡÇΩÇ∆ǢǧDZÇ∆
ID:WKDrQEyyÇÕñ{äiìIÇ»32bitOSÇ…é∑íÖǵǃÇÈǙǪÇÒǻDZÇ∆ǫǧÇ≈ÇýǢǢ
ÉZÉOÉÅÉìÉgÇÃêßå¿Ç≈ì™ÇîYÇÐÇπÇÈïKóvÇ™ÇÝÇ¡ÇΩǩǻǩǡÇΩÇ©ÇÃï˚Ç™èdóv
ÉZÉOÉÅÉìÉgÇÃêßå¿Ç≈ì™ÇîYÇÐÇπÇÈïKóvÇ™ÇÝÇ¡ÇΩǩǻǩǡÇΩÇ©ÇÃï˚Ç™èdóv
ǪÇÒÇ»ÇÃÇÕÇ»ÇÒÇÃç™ãíÇýǻǢ
ñ≥óùÇ™ÇÝÇÈÇÒÇæÇ©ÇÁñŸÇÍÇÊ
ñ≥óùÇ™ÇÝÇÈÇÒÇæÇ©ÇÁñŸÇÍÇÊ
>>668
ÇÝÇÈÇ…åàÇÐǡǃÇÈÇæÇÎ
NTÇÃå≥DžǻǡÇΩOS2 1.0ÇÕÇ∆ǃÇý386SXÇÃïné„Ç»É}ÉVÉìÇ≈
ÇÐÇ∆ÇýÇ…ìÆÇ©ÇπÇÈë„ï®Ç≈ÇÕñ≥Ç©Ç¡ÇΩî§Çæ
ǪÇÍÇ∆ÇýÅAÇ®ëOǙǪÇÃéûä˙Ç…386SXÇ≈âıìKÇ…ìÆÇ©ÇπÇÈ32ÉrÉbÉgOSÇçÏÇÍÇΩ
Ç∆Ç≈ÇýǢǧÇÃÅH
ǪÇÍÇÕëfêlÇÃévÇ¢è„Ç™ÇËÇæÅB
ÇÝÇÈÇ…åàÇÐǡǃÇÈÇæÇÎ
NTÇÃå≥DžǻǡÇΩOS2 1.0ÇÕÇ∆ǃÇý386SXÇÃïné„Ç»É}ÉVÉìÇ≈
ÇÐÇ∆ÇýÇ…ìÆÇ©ÇπÇÈë„ï®Ç≈ÇÕñ≥Ç©Ç¡ÇΩî§Çæ
ǪÇÍÇ∆ÇýÅAÇ®ëOǙǪÇÃéûä˙Ç…386SXÇ≈âıìKÇ…ìÆÇ©ÇπÇÈ32ÉrÉbÉgOSÇçÏÇÍÇΩ
Ç∆Ç≈ÇýǢǧÇÃÅH
ǪÇÍÇÕëfêlÇÃévÇ¢è„Ç™ÇËÇæÅB
286ÇÃÉvÉçÉeÉNÉgÉÇÅ[ÉhÇÕåãã«ÇŸÇ∆ÇÒÇ«óòópÇ≥ÇÍÇÈDZÇ∆Ç»Ç≠èIóπǵǃǵÇÐÇ¡ÇΩDZÇ∆Ç©ÇÁï™Ç©ÇÈí ÇËïsóvÇ»ÇýÇÃÇ≈ÇÝÇ¡ÇΩÅB
ÉäÉAÉãÉÇÅ[ÉhÇ∆386ÇÃ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÅAǪǵǃâºëz86ÉÇÅ[ÉhÇæÇØÇÝÇÍÇŒó«Ç©Ç¡ÇΩÅB
Ǫǵǃ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇÃÉZÉåÉNÉ^Å[(ÉZÉOÉÅÉìÉg)Ç…ÇÊÇÈâºëzãLâØÇýïsóvÇ≈ÇÝÇËÅAÉyÅ[ÉWÉìÉOÇæÇØÇ≈ó«Ç©Ç¡ÇΩÅB
ÇΩÇæ286Ç∆ǢǧCPUÇÕçÇë¨Ç»8086Ç∆ǵǃÇæÇØÇ≈Çýë∂çðâøílÇ™ÇÝÇÈÅB
386SXÇÃílíiÇÕäià¿Ç≈ÇÝÇ¡ÇΩÇ™ÅADZÇÍÇÕAMDÇÃ286åðä∑CPUÇ÷ÇÃâøäiëŒçRÇÃÇΩÇþÇ≈ÇÝÇÈÅB
ÉoÉXÉTÉCÉYÇÃèkè¨Ç∆ÉvÉâÉXÉ`ÉbÉNQFPÉpÉbÉPÅ[ÉWÇégópÇ∑ÇÈDZÇ∆Ç…ÇÊÇÈÉRÉXÉgÉ_ÉEÉìÇÕÇÝÇ¡ÇΩÇýÇÃÇÃÉ_ÉCǪÇÃÇýÇÃÇÕ386DXÇ∆ìØìôÇÃÇýÇÃÇ≈ÇÝÇËÅAÉgÉâÉìÉWÉXÉ^êîÇÕ286ÇÃ2î{Ç…ãyÇ‘ÅB
286Ç∆ìØéûä˙Ç…386SXÇ286ìØólÇÃÉpÉbÉPÅ[ÉWÇ≈îÑÇËèoÇπÇŒílíiÇÕìrï˚ÇýÇ»Ç≠çÇÇ¢ÇýÇÃÇ∆ǻǡÇΩÇæÇÎǧÅB
ÇøÇ»ÇðÇ…16bitÉRÅ[ÉhÇé¿çsǵǃÇýìØÉNÉçÉbÉNÇÃ386DXÇ∆386SXÇÃä‘Ç…ÇÕ1Å`2äÑÇÃê´î\ç∑Ç™ÇÝÇ¡ÇΩÅBÉfÅ[É^ÉAÉNÉZÉXÇÕ16bitíPà Ç≈ÇÝǡǃÇýÉRÅ[ÉhÉtÉFÉbÉ`ÇÕ32bitÉoÉXÇ™óLå¯Ç…ì≠Ç¢ÇΩÇÃÇ≈ÇÝÇÈÅB
DZÇÒÇ»ÇýÇ¡ÇΩǢǻǢ386SXÇÕAMDí◊ǵÇæÇØÇñ⁄ìIÇ∆ǵÇΩÉfÉ`ÉÖÅ[ÉìïiÇ≈ÇÝÇËAMDÇÃ286ǙǻÇØÇÍÇŒë∂çðǵǶǻǩǡÇΩÅB
ÉäÉAÉãÉÇÅ[ÉhÇ∆386ÇÃ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÅAǪǵǃâºëz86ÉÇÅ[ÉhÇæÇØÇÝÇÍÇŒó«Ç©Ç¡ÇΩÅB
Ǫǵǃ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇÃÉZÉåÉNÉ^Å[(ÉZÉOÉÅÉìÉg)Ç…ÇÊÇÈâºëzãLâØÇýïsóvÇ≈ÇÝÇËÅAÉyÅ[ÉWÉìÉOÇæÇØÇ≈ó«Ç©Ç¡ÇΩÅB
ÇΩÇæ286Ç∆ǢǧCPUÇÕçÇë¨Ç»8086Ç∆ǵǃÇæÇØÇ≈Çýë∂çðâøílÇ™ÇÝÇÈÅB
386SXÇÃílíiÇÕäià¿Ç≈ÇÝÇ¡ÇΩÇ™ÅADZÇÍÇÕAMDÇÃ286åðä∑CPUÇ÷ÇÃâøäiëŒçRÇÃÇΩÇþÇ≈ÇÝÇÈÅB
ÉoÉXÉTÉCÉYÇÃèkè¨Ç∆ÉvÉâÉXÉ`ÉbÉNQFPÉpÉbÉPÅ[ÉWÇégópÇ∑ÇÈDZÇ∆Ç…ÇÊÇÈÉRÉXÉgÉ_ÉEÉìÇÕÇÝÇ¡ÇΩÇýÇÃÇÃÉ_ÉCǪÇÃÇýÇÃÇÕ386DXÇ∆ìØìôÇÃÇýÇÃÇ≈ÇÝÇËÅAÉgÉâÉìÉWÉXÉ^êîÇÕ286ÇÃ2î{Ç…ãyÇ‘ÅB
286Ç∆ìØéûä˙Ç…386SXÇ286ìØólÇÃÉpÉbÉPÅ[ÉWÇ≈îÑÇËèoÇπÇŒílíiÇÕìrï˚ÇýÇ»Ç≠çÇÇ¢ÇýÇÃÇ∆ǻǡÇΩÇæÇÎǧÅB
ÇøÇ»ÇðÇ…16bitÉRÅ[ÉhÇé¿çsǵǃÇýìØÉNÉçÉbÉNÇÃ386DXÇ∆386SXÇÃä‘Ç…ÇÕ1Å`2äÑÇÃê´î\ç∑Ç™ÇÝÇ¡ÇΩÅBÉfÅ[É^ÉAÉNÉZÉXÇÕ16bitíPà Ç≈ÇÝǡǃÇýÉRÅ[ÉhÉtÉFÉbÉ`ÇÕ32bitÉoÉXÇ™óLå¯Ç…ì≠Ç¢ÇΩÇÃÇ≈ÇÝÇÈÅB
DZÇÒÇ»ÇýÇ¡ÇΩǢǻǢ386SXÇÕAMDí◊ǵÇæÇØÇñ⁄ìIÇ∆ǵÇΩÉfÉ`ÉÖÅ[ÉìïiÇ≈ÇÝÇËAMDÇÃ286ǙǻÇØÇÍÇŒë∂çðǵǶǻǩǡÇΩÅB
Ç∆ÅAÉpÉ\ÉRÉìǵǩå©Ç¶ÇƒÇ»Ç¢ê~ñ[Ç™ê\ǵǃǮÇËÇÐÇ∑
386ÇÃ16ÉrÉbÉgê´î\ÇÕ286ÇÊÇËà´Ç©Ç¡ÇΩÅB
ÇæÇ©ÇÁ286ÇÕä∏ǶǃçÇÉNÉçÉbÉNïiÇópà”ǵǻǩǡÇΩÇÊǧÇæÇ™
16ÉrÉbÉgÉoÉXÇ»ÇÁà¿Ç¢Ç©ÇÁëÂÉqÉbÉgÅHÇÝÇËǶǻǢwww
ÇΩÇæÇ≈Ç≥Ƕ286ÇÊÇËçÇê´î\Ç≈Ç»ÇØÇÍnjǢÇØǻǢÇÃÇ…
ãéê®ÇµÇƒÇÈó]óTÇÕǻǢÅB
ǪÇýǪÇý386SXÇÕDXÇÃóıâøî≈Ç≈ÇÝǡǃï®óùìIÇ»êªë¢ÉRÉXÉgǙǩÇÌÇÈÇÌÇØÇ≈ÇÕǻǢÅB
ç°Ç≈åæǧCeleronÇ∆ìØÇ∂ÅBÇ»Ç∫DXÇ∆ǵǃîÑÇÍÇŒçÇÇ≠îÑÇÍÇÈç≈êVCPUÇ
IntelíPì∆ÇÃê∂éYó Ç™èÅëÚÇ≈ÇÕÇ»Ç≠ésèÍÇÃëΩÇ≠Ç™åðä∑CPUÇ…óäǡǃÇΩéûë„Ç…
è„à êªïiÇÃê∂éYó ÇçÌǡǃÇÐÇ≈à¿Ç¢â∫à êªïiÇçÏÇÈÇÃÇ…ÇÕì¡ï Ç»óùóRÇ™ïKóvÇæÇÎǧÅB
ÇÞÇÎÇÒǪÇÒÇ»ÇÃÇÕë∂çðǵǶǻǢÅB
ÇæÇ©ÇÁ286ÇÕä∏ǶǃçÇÉNÉçÉbÉNïiÇópà”ǵǻǩǡÇΩÇÊǧÇæÇ™
16ÉrÉbÉgÉoÉXÇ»ÇÁà¿Ç¢Ç©ÇÁëÂÉqÉbÉgÅHÇÝÇËǶǻǢwww
ÇΩÇæÇ≈Ç≥Ƕ286ÇÊÇËçÇê´î\Ç≈Ç»ÇØÇÍnjǢÇØǻǢÇÃÇ…
ãéê®ÇµÇƒÇÈó]óTÇÕǻǢÅB
ǪÇýǪÇý386SXÇÕDXÇÃóıâøî≈Ç≈ÇÝǡǃï®óùìIÇ»êªë¢ÉRÉXÉgǙǩÇÌÇÈÇÌÇØÇ≈ÇÕǻǢÅB
ç°Ç≈åæǧCeleronÇ∆ìØÇ∂ÅBÇ»Ç∫DXÇ∆ǵǃîÑÇÍÇŒçÇÇ≠îÑÇÍÇÈç≈êVCPUÇ
IntelíPì∆ÇÃê∂éYó Ç™èÅëÚÇ≈ÇÕÇ»Ç≠ésèÍÇÃëΩÇ≠Ç™åðä∑CPUÇ…óäǡǃÇΩéûë„Ç…
è„à êªïiÇÃê∂éYó ÇçÌǡǃÇÐÇ≈à¿Ç¢â∫à êªïiÇçÏÇÈÇÃÇ…ÇÕì¡ï Ç»óùóRÇ™ïKóvÇæÇÎǧÅB
ÇÞÇÎÇÒǪÇÒÇ»ÇÃÇÕë∂çðǵǶǻǢÅB
ì˙ñ{Ç≈ÇÕV30Ç™ëÂÉqÉbÉgǵÇΩÇÒÇæÇ©ÇÁÇýǧǢǢÇæÇÎǧÅB
ÉpÉ\ÉRÉìÇÕCPUÇæÇØÇ≈Ç≈ǴǃÇÈÇÌÇØÇ∂ǷǻǢ
ÉoÉXÇ™32bitÇ…Ç»ÇÈÇæÇØÇ≈çÇâøÇ…Ç»ÇÈ
ägí£ÉoÉXÇÃégópÇæǡǃEISAÇæÇÃNESAÇæÇÃ
âøäiÇ™çÇì´Ç∑ÇÈédólǙǃÇÒDZê∑ÇËÇæÇ¡ÇΩ
ìñéûÅAIBMǻǫÇÃíÜå^ÉRÉìÉsÉÖÅ[É^Ç‚
É~ÉjÉRÉìÅAÉèÅ[ÉNÉXÉeÅ[ÉVÉáÉìÇîÃîÑǵǃÇΩÉÅÅ[ÉJÅ[ÇÕ
32bitÇÃ386ÉpÉ\ÉRÉìÇÕà¿Ç≠îÑÇËÇΩÇ≠ǻǢ
ǪǧǢǧê≠é°ìIÇ»évòfÇýì≠ǢǃÇΩÇÌÇØÇ≈
ÉoÉXÇ™32bitÇ…Ç»ÇÈÇæÇØÇ≈çÇâøÇ…Ç»ÇÈ
ägí£ÉoÉXÇÃégópÇæǡǃEISAÇæÇÃNESAÇæÇÃ
âøäiÇ™çÇì´Ç∑ÇÈédólǙǃÇÒDZê∑ÇËÇæÇ¡ÇΩ
ìñéûÅAIBMǻǫÇÃíÜå^ÉRÉìÉsÉÖÅ[É^Ç‚
É~ÉjÉRÉìÅAÉèÅ[ÉNÉXÉeÅ[ÉVÉáÉìÇîÃîÑǵǃÇΩÉÅÅ[ÉJÅ[ÇÕ
32bitÇÃ386ÉpÉ\ÉRÉìÇÕà¿Ç≠îÑÇËÇΩÇ≠ǻǢ
ǪǧǢǧê≠é°ìIÇ»évòfÇýì≠ǢǃÇΩÇÌÇØÇ≈
>ÉpÉ\ÉRÉìÇÕCPUÇæÇØÇ≈Ç≈ǴǃÇÈÇÌÇØÇ∂ǷǻǢ
DZÇÃàÍåæÇ≈CPUÇæÇØǵǩå©Ç¶ÇƒÇ»Ç¢Ç®ëOÇÃÅu386SXÉKÅ[ÅvêýÇÃ
ëSî€íËÇ…Ç»ÇÈÇØǫǢǢÇÃÅH
DZÇÃàÍåæÇ≈CPUÇæÇØǵǩå©Ç¶ÇƒÇ»Ç¢Ç®ëOÇÃÅu386SXÉKÅ[ÅvêýÇÃ
ëSî€íËÇ…Ç»ÇÈÇØǫǢǢÇÃÅH
>>676
Ç»Ç∫ÅH
16bitÉoÉXÇÃ386SXÇ»ÇÁà¿Ç≠çÏÇÍÇΩÇÕÇ∏
32bitñΩóþÇ∆ǢǡǃÇý386ÇÃ32bitñΩóþÇÕ16bitñΩóþÇ∆ñΩóþí∑ÇÕïœÇÌÇÁǻǢ
16bitÉAÉvÉäÇæǡǃÉAÉhÉåÉXÇÃéwíËÇÕÉZÉOÉÅÉìÉgÇ∆ÉIÉtÉZÉbÉgÇÇÝÇÌÇπÇΩ
32bitÇÃÉ|ÉCÉìÉ^ïœêîÇégǡǃÇΩǵǻ
Ç»Ç∫ÅH
16bitÉoÉXÇÃ386SXÇ»ÇÁà¿Ç≠çÏÇÍÇΩÇÕÇ∏
32bitñΩóþÇ∆ǢǡǃÇý386ÇÃ32bitñΩóþÇÕ16bitñΩóþÇ∆ñΩóþí∑ÇÕïœÇÌÇÁǻǢ
16bitÉAÉvÉäÇæǡǃÉAÉhÉåÉXÇÃéwíËÇÕÉZÉOÉÅÉìÉgÇ∆ÉIÉtÉZÉbÉgÇÇÝÇÌÇπÇΩ
32bitÇÃÉ|ÉCÉìÉ^ïœêîÇégǡǃÇΩǵǻ
678 ÅFSocket774ÅF2014/07/01(âŒ) 14:19:29.57 ID:WKDrQEyy
386SXÇÕï®óùìIÇ…ìØDXÇ∆ìØÇ∂ÇýÇÃÅB
x87ÇÃóLñ≥ìØólÅAìØÇ∂É_ÉCÇã@î\Ç≈ç∑ï âªÇµÇƒâøäiÇ
ï™ÇØǃÇÈÇæÇØÅB
ÉfÉ`ÉÖÅ[ÉìÇ≈êªë¢ÉRÉXÉgÇ™â∫Ç™ÇÈÇÌÇØÇ∂ǷǻǢÅB
ÇÌÇ©ÇÒÇÀÅ[Ç»ÇÁñŸÇÍÇÊ
x87ÇÃóLñ≥ìØólÅAìØÇ∂É_ÉCÇã@î\Ç≈ç∑ï âªÇµÇƒâøäiÇ
ï™ÇØǃÇÈÇæÇØÅB
ÉfÉ`ÉÖÅ[ÉìÇ≈êªë¢ÉRÉXÉgÇ™â∫Ç™ÇÈÇÌÇØÇ∂ǷǻǢÅB
ÇÌÇ©ÇÒÇÀÅ[Ç»ÇÁñŸÇÍÇÊ
>>673
386ÇÃéûë„Ç…ÇÕIntelÇÃê∂éYóÕÇ™å¸è„ǵǃåðä∑CPUí◊ǵDžñÙãNDžǻǡÇΩÇÒÇæÇÊÅB
ÇÐÇ∏ÇÕÉZÉJÉìÉhÉ\Å[ÉXÇîpé~ǵǃåðä∑CPUÇÃêªë¢Çç¢ìÔDžǵÅAì¡ãñëiè◊Ç≈ì∆é©äJî≠ÇÃåðä∑CPU V30Çí◊Ç∑ÅBǪǵǃç≈å„Ç…AMDÇÃ286Ç386SXÇÃà¿îÑÇËÇ≈í◊ǵÇΩÅB
386ÇÃéûë„Ç…ÇÕIntelÇÃê∂éYóÕÇ™å¸è„ǵǃåðä∑CPUí◊ǵDžñÙãNDžǻǡÇΩÇÒÇæÇÊÅB
ÇÐÇ∏ÇÕÉZÉJÉìÉhÉ\Å[ÉXÇîpé~ǵǃåðä∑CPUÇÃêªë¢Çç¢ìÔDžǵÅAì¡ãñëiè◊Ç≈ì∆é©äJî≠ÇÃåðä∑CPU V30Çí◊Ç∑ÅBǪǵǃç≈å„Ç…AMDÇÃ286Ç386SXÇÃà¿îÑÇËÇ≈í◊ǵÇΩÅB
>>675
16bitÉoÉXÇ≈32bit CPUÇÃPCÇ™ì˙ñ{Ç≈ÇýñkïƒÇ≈ÇýÉoÉJîÑÇÍǵÇΩñÛÇæÇ™ÅB
286å„ä˙ÇÃíiäKÇ≈Ç∑Ç≈Ç…I/OÉoÉXÇ∆CPUÉoÉXÇÃÉNÉçÉbÉNÇ…ëÂç∑Ç™ïtǢǃǢÇΩÇÃÇ≈Ç«ÇÃÇðÇøCPUíºåãÇÃDRAMÇ∆ÉoÉXÉäÉsÅ[É^Å[ÇâÓǵÇΩI/OÉfÉoÉCÉXÇ∆Ǣǧç\ê¨Ç…ǵǻǢå¿ÇËCPUÇÃê´î\ÇëSÇ≠î≠äˆÇ≈Ç´Ç»Ç≠ǻǡǃǮÇËÅA386DXÇÕǪÇÃâÑí∑è„Ç≈î‰ärìIóeà’Ç…é¿ëïÇ≈Ç´ÇΩÅB
16bitÉoÉXÇ≈32bit CPUÇÃPCÇ™ì˙ñ{Ç≈ÇýñkïƒÇ≈ÇýÉoÉJîÑÇÍǵÇΩñÛÇæÇ™ÅB
286å„ä˙ÇÃíiäKÇ≈Ç∑Ç≈Ç…I/OÉoÉXÇ∆CPUÉoÉXÇÃÉNÉçÉbÉNÇ…ëÂç∑Ç™ïtǢǃǢÇΩÇÃÇ≈Ç«ÇÃÇðÇøCPUíºåãÇÃDRAMÇ∆ÉoÉXÉäÉsÅ[É^Å[ÇâÓǵÇΩI/OÉfÉoÉCÉXÇ∆Ǣǧç\ê¨Ç…ǵǻǢå¿ÇËCPUÇÃê´î\ÇëSÇ≠î≠äˆÇ≈Ç´Ç»Ç≠ǻǡǃǮÇËÅA386DXÇÕǪÇÃâÑí∑è„Ç≈î‰ärìIóeà’Ç…é¿ëïÇ≈Ç´ÇΩÅB
>>680
ǪÇÍÇÕ286ÇÃå„ä˙Ç≈386SXÇ™ésèÍÇ…èoâÒǡǃÇΩéûë„
386Ç™èoÇΩìñéûÇÕ32bitägí£ÉoÉXÇÃ100ñúâ~Ç≠ÇÁÇ¢ÇÃâøäiÇ≈îÑÇÁÇÍǃÇΩ
16bitÉfÅ[É^ÉoÉXÇÃ386SXÇ»ÇÁà¿Ç≠èoÇπÇΩÇÕÇ∏
PC-98Ç»ÇÒǃ286ÇèâÇþǃìãç⁄ǵÇΩVXÇÕ286Ç∆V30ÇÃóºï˚Çìãç⁄ǵǃÇΩ
ǪÇÍÇÕ286ÇÃå„ä˙Ç≈386SXÇ™ésèÍÇ…èoâÒǡǃÇΩéûë„
386Ç™èoÇΩìñéûÇÕ32bitägí£ÉoÉXÇÃ100ñúâ~Ç≠ÇÁÇ¢ÇÃâøäiÇ≈îÑÇÁÇÍǃÇΩ
16bitÉfÅ[É^ÉoÉXÇÃ386SXÇ»ÇÁà¿Ç≠èoÇπÇΩÇÕÇ∏
PC-98Ç»ÇÒǃ286ÇèâÇþǃìãç⁄ǵÇΩVXÇÕ286Ç∆V30ÇÃóºï˚Çìãç⁄ǵǃÇΩ
Ç»ÇÒÇ≈IntelÇ™ç≈êVâsÇÃÉvÉçÉZÉbÉTÇãåê¢ë„êªïiÇ…ëŒÇ∑ÇÈ
ê´î\óDà ÇäÎǧÇ≠ǵǃÇÐÇ≈16ÉrÉbÉgÉoÉXÇï–ï˚ñ≥å¯Ç…ǵǃ
à¿Ç≠îÑÇÈÇ»ÇÒǃévǧÇÃÅH
ÉoÉJÇ»ÇÃÅH
ê´î\óDà ÇäÎǧÇ≠ǵǃÇÐÇ≈16ÉrÉbÉgÉoÉXÇï–ï˚ñ≥å¯Ç…ǵǃ
à¿Ç≠îÑÇÈÇ»ÇÒǃévǧÇÃÅH
ÉoÉJÇ»ÇÃÅH
Ç‚Ç¡ÇœÇËòbÇ…Ç»ÇÁǻǢÉoÉJÇæÇ»
Ç¢ÇÐÇæÇ…óùâÇ≈ǴǻǢÇ∆ǢǧÇÊÇËísïÇÃè«èÛÇ©Ç»
è„à êªïiÇÃâøílÇóéÇ∆Ç≥ǻǢÇΩÇþÇ…à¿îÑÇËópÇÃê´î\Ç
åÃà”Ç…óÚâªÇ≥ÇπǃÇÈÇæÇØÇæÅB
Ç¢ÇÐÇæÇ…óùâÇ≈ǴǻǢÇ∆ǢǧÇÊÇËísïÇÃè«èÛÇ©Ç»
è„à êªïiÇÃâøílÇóéÇ∆Ç≥ǻǢÇΩÇþÇ…à¿îÑÇËópÇÃê´î\Ç
åÃà”Ç…óÚâªÇ≥ÇπǃÇÈÇæÇØÇæÅB
>>666
MacÇÃèÍçáÇÕïÅãyó¶Ç™í·Ç≠ǃÉJÉXÉ^ÉÄÉAÉvÉäésèÍÇ‚ÉRÉìÉVÉÖÅ[É}Å[ÉAÉvÉäésèÍÇ™âÛñ≈ǵǃǢÇΩÇÃÇ™çKÇ¢ÇæÇ¡ÇΩÇÊÇÀÅB
IBMÇ™PS/55ÉVÉäÅ[ÉYÇDOS/VÇ…êÿÇËë÷ǶÇÈéûÇ…í≤Ç◊ÇΩÇÁàÍëæòYǻǫÇÌÇ∏Ç©êîéÌóÞÇÃã∆ñ±ÉAÉvÉäǵǩégópÇ≥ÇÍǃǢǻǩǡÇΩÇÃÇ≈ǪÇÍÇÁÇDOS/VÇ…ëŒâûÇ≥ÇπÇÈÇæÇØÇ≈çœÇÒÇæÇ∆ǢǧàÌòbÇ™ÇÝÇÈÅBïÅãyǵǃǢǻǢÇ∆ǢǧDZÇ∆ÇÕéüê¢ë„Ç÷ÇÃà⁄çsDžǮǢǃëÂïœÇ»ã≠ÇðÇ≈ÇÝÇÈñÛÇæÅB
PCÇÃèÍçáÇÕêÃçÏÇ¡ÇΩÉJÉXÉ^ÉÄÉAÉvÉäÇ‚ÉQÅ[ÉÄÉAÉvÉäÇ™ÉoÅ[ÉWÉáÉìÉAÉbÉvÇýÇ≈ǴǻǢÇ∆ǢǧèÛë‘Ç™OSÇÃãåÉoÅ[ÉWÉáÉìêÿÇËéÃǃÇãñÇ≥ǻǢèÛãµÇë±ÇØǃǵÇÐÇ¡ÇΩÅB
êVãKÉAÉvÉäÇæÇØÇ»ÇÁWindows2000ÇÃíiäKÇ≈32bitâªÇ™â¬î\Ç≈ÇÝÇ¡ÇΩÇÃÇæÇ™ÅAåãã«PCÇîÉÇ¢ë÷ǶÇÈéûÇÐÇ≈à¯Ç´Ç∏ǡǃǵÇÐÇ¢16bitÇÃÉTÉ|Å[ÉgÇǪÇÃå„Çýë±ÇØÇÈDZÇ∆DžǻǡǃǵÇÐÇ¡ÇΩÅB
MacÇÃèÍçáÇÕïÅãyó¶Ç™í·Ç≠ǃÉJÉXÉ^ÉÄÉAÉvÉäésèÍÇ‚ÉRÉìÉVÉÖÅ[É}Å[ÉAÉvÉäésèÍÇ™âÛñ≈ǵǃǢÇΩÇÃÇ™çKÇ¢ÇæÇ¡ÇΩÇÊÇÀÅB
IBMÇ™PS/55ÉVÉäÅ[ÉYÇDOS/VÇ…êÿÇËë÷ǶÇÈéûÇ…í≤Ç◊ÇΩÇÁàÍëæòYǻǫÇÌÇ∏Ç©êîéÌóÞÇÃã∆ñ±ÉAÉvÉäǵǩégópÇ≥ÇÍǃǢǻǩǡÇΩÇÃÇ≈ǪÇÍÇÁÇDOS/VÇ…ëŒâûÇ≥ÇπÇÈÇæÇØÇ≈çœÇÒÇæÇ∆ǢǧàÌòbÇ™ÇÝÇÈÅBïÅãyǵǃǢǻǢÇ∆ǢǧDZÇ∆ÇÕéüê¢ë„Ç÷ÇÃà⁄çsDžǮǢǃëÂïœÇ»ã≠ÇðÇ≈ÇÝÇÈñÛÇæÅB
PCÇÃèÍçáÇÕêÃçÏÇ¡ÇΩÉJÉXÉ^ÉÄÉAÉvÉäÇ‚ÉQÅ[ÉÄÉAÉvÉäÇ™ÉoÅ[ÉWÉáÉìÉAÉbÉvÇýÇ≈ǴǻǢÇ∆ǢǧèÛë‘Ç™OSÇÃãåÉoÅ[ÉWÉáÉìêÿÇËéÃǃÇãñÇ≥ǻǢèÛãµÇë±ÇØǃǵÇÐÇ¡ÇΩÅB
êVãKÉAÉvÉäÇæÇØÇ»ÇÁWindows2000ÇÃíiäKÇ≈32bitâªÇ™â¬î\Ç≈ÇÝÇ¡ÇΩÇÃÇæÇ™ÅAåãã«PCÇîÉÇ¢ë÷ǶÇÈéûÇÐÇ≈à¯Ç´Ç∏ǡǃǵÇÐÇ¢16bitÇÃÉTÉ|Å[ÉgÇǪÇÃå„Çýë±ÇØÇÈDZÇ∆DžǻǡǃǵÇÐÇ¡ÇΩÅB
Ç‚Ç¡ÇœÇËòbÇ…Ç»ÇÁǻǢÉoÉJÇæÇ»
Ç¢ÇÐÇæÇ…óùâÇ≈ǴǻǢÇ∆ǢǧÇÊÇËísïÇÃè«èÛÇ©Ç»
âΩìxÇýåæǧǙÅAǪǧǢǧâ∫à êªïiÇÕêªë¢ÉRÉXÉgÇâ∫Ç∞ǃà¿Ç≠ǵǃÇÈÇÌÇØÇ≈ÇÕÇ»Ç≠
è„à êªïiÇÃâøílÇóéÇ∆Ç≥ǻǢÇΩÇþÇ…à¿îÑÇËópÇÃê´î\ÇåÃà”Ç…óÚâªÇ≥ÇπǃÇÈÇæÇØÇæÅB
ç°ÇÃCeleronÇ∆ìØÇ∂ÅBǢǢǩÇ∞ÇÒÇÌÇ©ÇÍÇÊÉ{ÉPòVäQ
Ç¢ÇÐÇæÇ…óùâÇ≈ǴǻǢÇ∆ǢǧÇÊÇËísïÇÃè«èÛÇ©Ç»
âΩìxÇýåæǧǙÅAǪǧǢǧâ∫à êªïiÇÕêªë¢ÉRÉXÉgÇâ∫Ç∞ǃà¿Ç≠ǵǃÇÈÇÌÇØÇ≈ÇÕÇ»Ç≠
è„à êªïiÇÃâøílÇóéÇ∆Ç≥ǻǢÇΩÇþÇ…à¿îÑÇËópÇÃê´î\ÇåÃà”Ç…óÚâªÇ≥ÇπǃÇÈÇæÇØÇæÅB
ç°ÇÃCeleronÇ∆ìØÇ∂ÅBǢǢǩÇ∞ÇÒÇÌÇ©ÇÍÇÊÉ{ÉPòVäQ
CeleronÇ∆ìØÇ∂Ç≈ÇýǢǢ
1985îNÇ…386SXÇ™èoǃÇÍÇŒWindows 3.0ÇÕ32bitédólÇæÇ¡ÇΩÇÕÇ∏
DOSÇýDOSÉGÉNÉXÉeÉìÉ_Å[Ç≈ägí£Ç≥ÇÍ
ÉZÉOÉÅÉìÉgÇÃêßå¿Ç…îYÇÐÇ≥ÇÍÇÈDZÇ∆ÇÕǻǩǡÇΩÇÕÇ∏
1985îNÇ…386SXÇ™èoǃÇÍÇŒWindows 3.0ÇÕ32bitédólÇæÇ¡ÇΩÇÕÇ∏
DOSÇýDOSÉGÉNÉXÉeÉìÉ_Å[Ç≈ägí£Ç≥ÇÍ
ÉZÉOÉÅÉìÉgÇÃêßå¿Ç…îYÇÐÇ≥ÇÍÇÈDZÇ∆ÇÕǻǩǡÇΩÇÕÇ∏
ÇæÇ©ÇÁâºíËÇ…ñ≥óùÇ™ÇÝÇÒÇæÇÎ
é©ï™êFÇÃévÇ¢èoòbÇÕÉ`ÉâÉVÇÃóÝÇ…Ç≈ÇýèëǢǃÇÎ
é©ï™êFÇÃévÇ¢èoòbÇÕÉ`ÉâÉVÇÃóÝÇ…Ç≈ÇýèëǢǃÇÎ
x86Ç™ïÅãyǵÇΩÇ´Ç¡Ç©ÇØÇÃèâë„IBM-PCÇ™çÃópǵÇΩ8088Çý
åÃà”Ç…8bitÉoÉXÇ…êßå¿ÇµÇƒâøäiÇâ∫Ç∞ÇΩêªïi
ÉgÉâÉìÉWÉXÉ^êîÇÕ8086Ç∆ìØÇ∂ÇæÇ¡ÇΩ
åÃà”Ç…8bitÉoÉXÇ…êßå¿ÇµÇƒâøäiÇâ∫Ç∞ÇΩêªïi
ÉgÉâÉìÉWÉXÉ^êîÇÕ8086Ç∆ìØÇ∂ÇæÇ¡ÇΩ
>>683
386SXÇÕAMDÇÃ286ëŒçR
486SXÇÕAMDÇÃ386ëŒçR
Pentium75MHzÇÕAMDÇÃ486ëŒçR
AMDÇÃK5ÇÕé©îö
èâë„CeleronÇÕAMDÇÃK6ëŒçR
IntelÇÃäià¿CPUÇÕÇ∑Ç◊ǃAMDÇÃã£çáïií◊ǵÇÃÇΩÇþÇ…äJî≠Ç≥ÇÍǃǢÇÈÇ∆Ǣǧéñé¿ÇäwÇÒÇæï˚ǙǢǢÅB
386SXÇÕAMDÇÃ286ëŒçR
486SXÇÕAMDÇÃ386ëŒçR
Pentium75MHzÇÕAMDÇÃ486ëŒçR
AMDÇÃK5ÇÕé©îö
èâë„CeleronÇÕAMDÇÃK6ëŒçR
IntelÇÃäià¿CPUÇÕÇ∑Ç◊ǃAMDÇÃã£çáïií◊ǵÇÃÇΩÇþÇ…äJî≠Ç≥ÇÍǃǢÇÈÇ∆Ǣǧéñé¿ÇäwÇÒÇæï˚ǙǢǢÅB
32bitÇÃ386Ç∆ǡǃÇý
ÇΩÇ¡ÇΩ286ÇÃ2î{ÇÃÉgÉâÉìÉWÉXÉ^êî
32bitÇ∆ǢǧÇæÇØÇ≈386ÇÕîÒèÌÇ…çÇâøÇæÇ¡ÇΩ
ǪÇÍÇÕêîÇ™èoǻǢǩÇÁ
ÉgÉâÉìÉWÉXÉ^ìIÇ…ÇÕCPUÇÃâøäiÇ™çÇÇ¢Ç∆ǢǡǃÇý1ÅA2ñúâ~Ç≠ÇÁÇ¢ÇæÇÎÅH
ìñéûÇÃÉpÉ\ÉRÉìÇÕ30ñúâ~ÅA40ñúâ~ǵǃÇΩÇÌÇØÇ≈
ÇΩÇ¡ÇΩ286ÇÃ2î{ÇÃÉgÉâÉìÉWÉXÉ^êî
32bitÇ∆ǢǧÇæÇØÇ≈386ÇÕîÒèÌÇ…çÇâøÇæÇ¡ÇΩ
ǪÇÍÇÕêîÇ™èoǻǢǩÇÁ
ÉgÉâÉìÉWÉXÉ^ìIÇ…ÇÕCPUÇÃâøäiÇ™çÇÇ¢Ç∆ǢǡǃÇý1ÅA2ñúâ~Ç≠ÇÁÇ¢ÇæÇÎÅH
ìñéûÇÃÉpÉ\ÉRÉìÇÕ30ñúâ~ÅA40ñúâ~ǵǃÇΩÇÌÇØÇ≈
>>689
IBMÇ™8088ÇçÃópǵÇΩóùóRÇÕé¸ï”âÒòHÇ…8bitCPUópÇÃêŒÇó¨ópǵǃéËëÅÇ≠äJî≠Ç∑ÇÈÇΩÇþÇæǺÅB
NECÇÕ8086Ç≈PC-9801ÇäJî≠ǵÇΩÇ™ï íiçÇÇ≠ÇÕǻǡǃǢǻǢÅB
IBMÇ™8088ÇçÃópǵÇΩóùóRÇÕé¸ï”âÒòHÇ…8bitCPUópÇÃêŒÇó¨ópǵǃéËëÅÇ≠äJî≠Ç∑ÇÈÇΩÇþÇæǺÅB
NECÇÕ8086Ç≈PC-9801ÇäJî≠ǵÇΩÇ™ï íiçÇÇ≠ÇÕǻǡǃǢǻǢÅB
>682
386ÉpÉ\ÉRÉìÇÕ100ñúâ~Ç≠ÇÁǢǵÇΩǺ
DZÇÒÇ»âøäiÇ≈ïÅãyÇ∑ÇÈÇÌÇØǙǻǢ
386ÉpÉ\ÉRÉìÇÕ100ñúâ~Ç≠ÇÁǢǵÇΩǺ
DZÇÒÇ»âøäiÇ≈ïÅãyÇ∑ÇÈÇÌÇØǙǻǢ
>>691
ǬǢç≈ãþÇÐÇ≈ÇÃìdãCêªïiÇÃèÌéØÇ∆ǵǃêªïiâøäiÇÕêªë¢å¥âøÇÃ3î{Ç∆ǢǧÇÃÇ™ÇÝÇÈDZÇ∆ÇímǡǃǮǢÇΩï˚ǙǢǢÅB
ǬǢç≈ãþÇÐÇ≈ÇÃìdãCêªïiÇÃèÌéØÇ∆ǵǃêªïiâøäiÇÕêªë¢å¥âøÇÃ3î{Ç∆ǢǧÇÃÇ™ÇÝÇÈDZÇ∆ÇímǡǃǮǢÇΩï˚ǙǢǢÅB
>>693
ÇæÇ©ÇÁ386SXÇ™ÇÝǡǃégǡǃÇý100ñúâ~DžǻǡÇΩǡǃDZÇ∆ÇæÇÊÇÀÅB
ÇæÇ©ÇÁ386SXÇ™ÇÝǡǃégǡǃÇý100ñúâ~DžǻǡÇΩǡǃDZÇ∆ÇæÇÊÇÀÅB
>>695
ǪÇÍÇÕǻǢ
ǪÇÍÇÕǻǢ
>>696
8088Ç∆8086ÇégÇ¡ÇΩêªïiÇ…âøäiç∑Ç™ñ≥Ç¢óùóRÇÕâΩÅH
8088Ç∆8086ÇégÇ¡ÇΩêªïiÇ…âøäiç∑Ç™ñ≥Ç¢óùóRÇÕâΩÅH
486DXÇ∆486SXÇÃÉpÉ\ÉRÉìÇÃâøäiç∑ÇÕâΩÅH
à◊ë÷ÇÃâeãøÇýÇÝÇ¡ÇΩÇ©ÇýÇ»
1ÉhÉã240â~ÇÃéûë„ÇæÇ¡ÇΩǵ
http://ja.wikipedia.org/wiki/IBM
1981îN8åé11ì˙Ç…IBM PCÇäÆê¨Ç≥ÇπÇΩÅB
ïWèÄâøäiÇÕ1,565ÉhÉãÇ≈åàǵǃà¿Ç≠ÇÕñ≥ǢǙ
ÉrÉWÉlÉXÇ…égópâ¬î\Ç≈ÇÝÇËÅAPCÇçwì¸ÇµÇΩÇÃÇýäÈã∆ÇæÇ¡ÇΩÅB
1ÉhÉã240â~ÇÃéûë„ÇæÇ¡ÇΩǵ
http://ja.wikipedia.org/wiki/IBM
1981îN8åé11ì˙Ç…IBM PCÇäÆê¨Ç≥ÇπÇΩÅB
ïWèÄâøäiÇÕ1,565ÉhÉãÇ≈åàǵǃà¿Ç≠ÇÕñ≥ǢǙ
ÉrÉWÉlÉXÇ…égópâ¬î\Ç≈ÇÝÇËÅAPCÇçwì¸ÇµÇΩÇÃÇýäÈã∆ÇæÇ¡ÇΩÅB
Ç≥Ç¡Ç´Ç©ÇÁéÂí£ÇÃé≤ǙǑÇÍǃÇÒǺ
âΩÇéÂí£ÇµÇΩÇ¢ÇÃÇ©é©ï™ÇÃì™Ç≈êÆóùǵǃǩÇÁèëÇØÇÊÅB
ǪÇýǪÇýMSÇÕIBMÇ∆åñâÐï ÇÍÇ∑ÇÈÇÐÇ≈OS/2ÇóBàÍÇÃ32ÉrÉbÉgOSÇ∆Ç∑ÇÈ
ó\íËÇæÇ¡ÇΩÇÌÇØÇæÇ©ÇÁOS/2Ç∆ǪÇÃîhê∂ÇÃNTà»äOÇ…ï Ç…32ÉrÉbÉgOSÇ
ǪÇÃìñéûÇ…ïKóvÇ∆Ç∑ÇÈóùóRǙǻǢÅB
Win95ÇÕÉRÉìÉVÉÖÅ[É}PCÇ≈16MBà»è„ÇÃÉÅÉÇÉäÇégǧïKóvÇ™ê∂Ç∂ǃ
NTÇÃAPIÇà⁄êAǵǃçÏÇ¡ÇΩÉnÉäÉ{ÉeOSÇ≈ÇÝǡǃ
ÉRÉìÉVÉÖÅ[É}DOS/VésèÍǙDZDZÇÐÇ≈î≠ìWÇ∑ÇÈDZÇ∆ÇÕìñÇÃMSÇ∑ÇÁ
ëzíËǵǃǻǩǡÇΩî§ÇæÅB
MSÇÕè≠Ç»Ç≠Ç∆ÇýÉGÉìÉvÉâésèÍÇ≈x86ÇéÃǃÇÈãCÇæÇ¡ÇΩÅB
NTÇÃRISCÉvÉçÉZÉbÉTî≈ÇÕǪÇÃÇΩÇþÇ…ópà”ǵÇΩÇýÇÃÇæǵ
IA64Çýå≥ÅXMSÇÃà”å¸Ç…âàÇ¡ÇΩÇýÇÃÅB
âΩÇéÂí£ÇµÇΩÇ¢ÇÃÇ©é©ï™ÇÃì™Ç≈êÆóùǵǃǩÇÁèëÇØÇÊÅB
ǪÇýǪÇýMSÇÕIBMÇ∆åñâÐï ÇÍÇ∑ÇÈÇÐÇ≈OS/2ÇóBàÍÇÃ32ÉrÉbÉgOSÇ∆Ç∑ÇÈ
ó\íËÇæÇ¡ÇΩÇÌÇØÇæÇ©ÇÁOS/2Ç∆ǪÇÃîhê∂ÇÃNTà»äOÇ…ï Ç…32ÉrÉbÉgOSÇ
ǪÇÃìñéûÇ…ïKóvÇ∆Ç∑ÇÈóùóRǙǻǢÅB
Win95ÇÕÉRÉìÉVÉÖÅ[É}PCÇ≈16MBà»è„ÇÃÉÅÉÇÉäÇégǧïKóvÇ™ê∂Ç∂ǃ
NTÇÃAPIÇà⁄êAǵǃçÏÇ¡ÇΩÉnÉäÉ{ÉeOSÇ≈ÇÝǡǃ
ÉRÉìÉVÉÖÅ[É}DOS/VésèÍǙDZDZÇÐÇ≈î≠ìWÇ∑ÇÈDZÇ∆ÇÕìñÇÃMSÇ∑ÇÁ
ëzíËǵǃǻǩǡÇΩî§ÇæÅB
MSÇÕè≠Ç»Ç≠Ç∆ÇýÉGÉìÉvÉâésèÍÇ≈x86ÇéÃǃÇÈãCÇæÇ¡ÇΩÅB
NTÇÃRISCÉvÉçÉZÉbÉTî≈ÇÕǪÇÃÇΩÇþÇ…ópà”ǵÇΩÇýÇÃÇæǵ
IA64Çýå≥ÅXMSÇÃà”å¸Ç…âàÇ¡ÇΩÇýÇÃÅB
Windows NTÇÕUNIXëŒçR
ÇæÇ©ÇÁCåæåÍÇ≈ëºÇÃCPUÇ…à⁄êAÇ≈Ç´ÇÈÇÊǧDžèëÇ©ÇÍÇΩ
ÇæÇ™ÅAǪÇÃï™ÅAÉÅÉÇÉäÇUNIXï¿ÇðÇ…è¡îÔÇ∑ÇÈOSDžǻǡÇΩ
É}ÉCÉNÉçÉ\ÉtÉgÇÕWindowsÉpÉ\ÉRÉìå¸ÇØÇ…Windows 3.0ÇèoǵÇΩÇÌÇØ
Windows NTÇ∆ÇÕÉ^Å[ÉQÉbÉgÇ™à·Ç§
ÇæÇ©ÇÁCåæåÍÇ≈ëºÇÃCPUÇ…à⁄êAÇ≈Ç´ÇÈÇÊǧDžèëÇ©ÇÍÇΩ
ÇæÇ™ÅAǪÇÃï™ÅAÉÅÉÇÉäÇUNIXï¿ÇðÇ…è¡îÔÇ∑ÇÈOSDžǻǡÇΩ
É}ÉCÉNÉçÉ\ÉtÉgÇÕWindowsÉpÉ\ÉRÉìå¸ÇØÇ…Windows 3.0ÇèoǵÇΩÇÌÇØ
Windows NTÇ∆ÇÕÉ^Å[ÉQÉbÉgÇ™à·Ç§
Windows 3.0ÇÕStandard ModeÇ≈286ÇÉTÉ|Å[ÉgǵǃǢÇΩ
ÇæÇ©ÇÁWindows 3.0ÅA3.1ÇÕ16bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇégǧDZÇ∆DžǻǡÇΩ
ÇæÇ©ÇÁWindows 3.0ÅA3.1ÇÕ16bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇégǧDZÇ∆DžǻǡÇΩ
286ÇÃë„ÇÌÇËÇ…386SXÇ™ïÅãyǵǃǢÇΩÇÁ
Windows 3.0ÇÕ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇÉTÉ|Å[ÉgǵǃǢÇΩÇÕÇ∏
Windows 3.0ÇÕ32bitÉvÉçÉeÉNÉgÉÇÅ[ÉhÇÉTÉ|Å[ÉgǵǃǢÇΩÇÕÇ∏
OS/2ǡǃÉRÉ}ÉìÉhÉâÉCÉìÇ≈égǡǃÇÈï™Ç…ÇÕåãç\åyÇ©Ç¡ÇΩÇÊ
>>698
ã£çáëºé–Ç™é©é–ÇÃç≈çÇãâïiÇÊÇËÇ‚Ç‚óÚÇÈê´î\ÇÃè§ïiǵǩîÃîÑÇ≈ǴǻǢèÛãµâ∫Ç≈êÌó™ìIÇ…â∫à è§ïiÇÃóıâøîÃîÑÇçsǧÇΩÇþÇ…ÅAìñéûê´î\èdóvÇ»éwêjÇ≈ÇÝÇ¡ÇΩÉNÉçÉbÉNé¸îgêîÇóéÇ∆Ç∑DZÇ∆Ç»Ç≠ê´î\ÇóéÇ∆ǵÇΩêªïiÇäJî≠ǵîÃîÑÇ∑ÇÈÅB
DZÇÃäÓñ{Ç™ï™Ç©ÇÁǻǢÇÒÇæÇÀÅBÇÐÇÝédï˚ǻǢÇÊÇÀÅB
ã£çáëºé–Ç™é©é–ÇÃç≈çÇãâïiÇÊÇËÇ‚Ç‚óÚÇÈê´î\ÇÃè§ïiǵǩîÃîÑÇ≈ǴǻǢèÛãµâ∫Ç≈êÌó™ìIÇ…â∫à è§ïiÇÃóıâøîÃîÑÇçsǧÇΩÇþÇ…ÅAìñéûê´î\èdóvÇ»éwêjÇ≈ÇÝÇ¡ÇΩÉNÉçÉbÉNé¸îgêîÇóéÇ∆Ç∑DZÇ∆Ç»Ç≠ê´î\ÇóéÇ∆ǵÇΩêªïiÇäJî≠ǵîÃîÑÇ∑ÇÈÅB
DZÇÃäÓñ{Ç™ï™Ç©ÇÁǻǢÇÒÇæÇÀÅBÇÐÇÝédï˚ǻǢÇÊÇÀÅB
OS/2ÇÃóRóàÇÕDOSÇëÊ1ÇÃOSÇ∆ǵǃǪÇÃéüÇ…ÇÝÇΩÇÈÇýÇÃÅB
ǪÇýǪÇýx86ǙDZDZÇÐÇ≈îSÇ¡ÇΩÇÃÇ™äeÉÅÅ[ÉJÅ[Ç…Ç∆ǡǃëzíËäOÇ≈
IBMÇýMSÇýç≈èâÇ©ÇÁx86ÇÕì•Çðë‰Ç∆çlǶǃǢÇΩÅB
ìñÇÃIntelÇ∑ÇÁëÊ7ê¢ë„Ç≈x86Çé´ÇþÇÈãCÇæÇ¡ÇΩǵÅB
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÕÉfÉoÉCÉXàÀë∂Çîrèúǵà⁄êAê´ÇçÇÇþÇÁÇÍÇÈ
é¿ç€ä»íPÇ…à⁄êAÇ≈Ç´ÇΩǵÅAÉJÅ[ÉlÉãÇÃì∆óßê´Ç™çÇÇ¢ï™
Win3.xÇ‚95ÇÊÇËóyÇ©Ç…åòòSÇæÇ¡ÇΩÅB
ǪÇýǪÇýx86ǙDZDZÇÐÇ≈îSÇ¡ÇΩÇÃÇ™äeÉÅÅ[ÉJÅ[Ç…Ç∆ǡǃëzíËäOÇ≈
IBMÇýMSÇýç≈èâÇ©ÇÁx86ÇÕì•Çðë‰Ç∆çlǶǃǢÇΩÅB
ìñÇÃIntelÇ∑ÇÁëÊ7ê¢ë„Ç≈x86Çé´ÇþÇÈãCÇæÇ¡ÇΩǵÅB
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÕÉfÉoÉCÉXàÀë∂Çîrèúǵà⁄êAê´ÇçÇÇþÇÁÇÍÇÈ
é¿ç€ä»íPÇ…à⁄êAÇ≈Ç´ÇΩǵÅAÉJÅ[ÉlÉãÇÃì∆óßê´Ç™çÇÇ¢ï™
Win3.xÇ‚95ÇÊÇËóyÇ©Ç…åòòSÇæÇ¡ÇΩÅB
Ç∆DZÇÎÇ≈åªèÍÇÃPGÇ©ÇÁÇÕ8086ÇÃÉZÉOÉÅÉìÉgÉÇÉfÉãÇÕǪÇÍÇŸÇ«åôÇÌÇÍǃǻǢÇÒÇæÇ»ÅB
ǫǧÇπÉvÉçÉOÉâÉÄÇÃãKñÕÇ»ÇÒǃǪÇÒǻDžëÂÇ´Ç≠ǻǩǡÇΩéûë„ÇæǵÉRÅ[Éh(CS)ÅAÉXÉ^ÉbÉN(SS)ÅAÉfÅ[É^(DS)ÅAäOïîÉfÅ[É^(ES)ǙǪÇÍǺÇÍ64KBÇ≈ÇýÇ≥ǵǃñ‚ëËǻǢÅB
ǪǵǃÉZÉOÉÅÉìÉgÉÇÉfÉãÇ™ÉIÅ[ÉoÅ[ÉåÉCÇ∆ǢǧâºëzãLâØÇÃé¿åªÇ…ÇýǬǻǙǡǃǢÇÈÅBé¿ÉÅÉÇÉäÇ™1MBÇ…ñûÇΩǻǢéûë„Ç…ÇÕîÒèÌÇ…óLå¯Ç»éËíiÇ≈ÇÝÇ¡ÇΩÅB
68KÇ™çDÇÐÇÍÇΩóùóRÇÕñLïxÇ»îƒópÉåÉWÉXÉ^ÅAíºåê´Ç™çÇÇ≠çÇã@î\Ç»ÉAÉhÉåÉbÉVÉìÉOÉÇÅ[ÉhÅAçÇã@î\Ç»ÉrÉbÉgââéZñΩóþÅA16êiêîÇ≈óeà’Ç…óùââ¬î\Ç»ñΩóþÉoÉCÉiÉäÅ[ǻǫDžÇýÇÝǡǃ32bitÉäÉjÉAÇ»ÉAÉhÉåÉXãÛä‘ÇÕï Ç…ëÂÇ´Ç»ÉEÉFÅ[ÉgÇêËÇþǃǢǻǢÅB
386DXÇ™ëgÇðçûÇðÇ…égÇÌÇÍÇæǵÇΩìñèâÇýÉäÉAÉãÉÇÅ[ÉhÇ≈ìÆǩǵǃ32bitââéZÇÕÉvÉäÉtÉBÉbÉNÉXÇ≈çsǧDZÇ∆Ç™ÇÊÇ≠ÇÝÇ¡ÇΩÅB
ǫǧÇπÉvÉçÉOÉâÉÄÇÃãKñÕÇ»ÇÒǃǪÇÒǻDžëÂÇ´Ç≠ǻǩǡÇΩéûë„ÇæǵÉRÅ[Éh(CS)ÅAÉXÉ^ÉbÉN(SS)ÅAÉfÅ[É^(DS)ÅAäOïîÉfÅ[É^(ES)ǙǪÇÍǺÇÍ64KBÇ≈ÇýÇ≥ǵǃñ‚ëËǻǢÅB
ǪǵǃÉZÉOÉÅÉìÉgÉÇÉfÉãÇ™ÉIÅ[ÉoÅ[ÉåÉCÇ∆ǢǧâºëzãLâØÇÃé¿åªÇ…ÇýǬǻǙǡǃǢÇÈÅBé¿ÉÅÉÇÉäÇ™1MBÇ…ñûÇΩǻǢéûë„Ç…ÇÕîÒèÌÇ…óLå¯Ç»éËíiÇ≈ÇÝÇ¡ÇΩÅB
68KÇ™çDÇÐÇÍÇΩóùóRÇÕñLïxÇ»îƒópÉåÉWÉXÉ^ÅAíºåê´Ç™çÇÇ≠çÇã@î\Ç»ÉAÉhÉåÉbÉVÉìÉOÉÇÅ[ÉhÅAçÇã@î\Ç»ÉrÉbÉgââéZñΩóþÅA16êiêîÇ≈óeà’Ç…óùââ¬î\Ç»ñΩóþÉoÉCÉiÉäÅ[ǻǫDžÇýÇÝǡǃ32bitÉäÉjÉAÇ»ÉAÉhÉåÉXãÛä‘ÇÕï Ç…ëÂÇ´Ç»ÉEÉFÅ[ÉgÇêËÇþǃǢǻǢÅB
386DXÇ™ëgÇðçûÇðÇ…égÇÌÇÍÇæǵÇΩìñèâÇýÉäÉAÉãÉÇÅ[ÉhÇ≈ìÆǩǵǃ32bitââéZÇÕÉvÉäÉtÉBÉbÉNÉXÇ≈çsǧDZÇ∆Ç™ÇÊÇ≠ÇÝÇ¡ÇΩÅB
ÅyÇÐÇ∆ÇþÅz
32ÉrÉbÉgOSÇÃOS/2Ç‚NTÇ™ä˘Ç…ÇÝÇ¡ÇΩÇ©ÇÁDZǪDOSÇÕ16ÉrÉbÉgÇÃÇÐÇÐï˙íu
Ç≥ÇÍÇΩÇÒÇæÇÊÇ»é¿ç€ÇÕÅB
Win95Ç™ìÀä—ÇÃ32ÉrÉbÉgÉJÅ[ÉlÉãÇêœÇÒÇæÇÃÇÕïÅãyâøäië—ÇÃPCÇÃÉÅÉÇÉäÇÃ
ëÂóeó âªÇ≈24ÉrÉbÉgÇÃägí£ÉAÉhÉåÉXãÛä‘Ç≈ÇÕç™ñ{ìIÇ…ë´ÇËÇ»Ç≠ǻǡÇΩÇ©ÇÁÇ…
ëºÇ»ÇÁǻǢÅB
ÉÅÉÇÉäÇ™çÇâøÇ≈ǻǮǩǬ32ÉrÉbÉgOSÇ∆ǵǃNTÇ™ÇÝÇ¡ÇΩà»è„
Win3.xÅié¿ëÃÇÕMS-DOS6.2Ç∆ǪÇÃGUIÉVÉFÉãÅjÇ™
32ÉrÉbÉgâªÇ≥ÇÍÇÈDZÇ∆ÇÕê‚ëŒÇÝÇËǶǻǩǡÇΩî§ÅB
386SXǙǫǧÇ∆Ç©Ç»ÇÒǃëSÇ≠ä÷åWǻǢÅB
32ÉrÉbÉgOSÇÃOS/2Ç‚NTÇ™ä˘Ç…ÇÝÇ¡ÇΩÇ©ÇÁDZǪDOSÇÕ16ÉrÉbÉgÇÃÇÐÇÐï˙íu
Ç≥ÇÍÇΩÇÒÇæÇÊÇ»é¿ç€ÇÕÅB
Win95Ç™ìÀä—ÇÃ32ÉrÉbÉgÉJÅ[ÉlÉãÇêœÇÒÇæÇÃÇÕïÅãyâøäië—ÇÃPCÇÃÉÅÉÇÉäÇÃ
ëÂóeó âªÇ≈24ÉrÉbÉgÇÃägí£ÉAÉhÉåÉXãÛä‘Ç≈ÇÕç™ñ{ìIÇ…ë´ÇËÇ»Ç≠ǻǡÇΩÇ©ÇÁÇ…
ëºÇ»ÇÁǻǢÅB
ÉÅÉÇÉäÇ™çÇâøÇ≈ǻǮǩǬ32ÉrÉbÉgOSÇ∆ǵǃNTÇ™ÇÝÇ¡ÇΩà»è„
Win3.xÅié¿ëÃÇÕMS-DOS6.2Ç∆ǪÇÃGUIÉVÉFÉãÅjÇ™
32ÉrÉbÉgâªÇ≥ÇÍÇÈDZÇ∆ÇÕê‚ëŒÇÝÇËǶǻǩǡÇΩî§ÅB
386SXǙǫǧÇ∆Ç©Ç»ÇÒǃëSÇ≠ä÷åWǻǢÅB
OS/2 1.xÇÕ16bitÇ≈286ÉpÉ\ÉRÉìÇ≈ÇýìÆçÏǵÇΩ
OS/2Ç™32bitDžǻǡÇΩÇÃÇÕ2.0Ç©ÇÁ
OS/2 2.0ÇÕIBMÇÃPCÇ≈ǵǩìÆçÏǵǻǩǡÇΩ
ïÅí ÇÃATåðä∑ã@Ç≈ìÆçÏÇ∑ÇÈÇÊǧDžǻǡÇΩÇÃÇÕ1993îNÇÃOS/2 2.1Ç©ÇÁ
OS/2ÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ≈ÇýǻǢ
UNIXÇÃSolarisÅAHP-UXÅAAIXÅABSDÇýÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ∂ǷǻǢǵ
LinuxÇýÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ∂ǷǻǢ
OS/2Ç™32bitDžǻǡÇΩÇÃÇÕ2.0Ç©ÇÁ
OS/2 2.0ÇÕIBMÇÃPCÇ≈ǵǩìÆçÏǵǻǩǡÇΩ
ïÅí ÇÃATåðä∑ã@Ç≈ìÆçÏÇ∑ÇÈÇÊǧDžǻǡÇΩÇÃÇÕ1993îNÇÃOS/2 2.1Ç©ÇÁ
OS/2ÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ≈ÇýǻǢ
UNIXÇÃSolarisÅAHP-UXÅAAIXÅABSDÇýÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ∂ǷǻǢǵ
LinuxÇýÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ∂ǷǻǢ
POWER8ÇÃSPEC CPU2006
http://www.spec.org/cpu2006/results/res2014q2/cpu2006-20140424-29429.html
http://www.spec.org/cpu2006/results/res2014q2/cpu2006-20140424-29430.html
ämÇ©Ç…ÉRÉAÇÝÇΩÇËÇ≈å©ÇÈÇ∆ë¨Ç¢ÇÒÇæÇØÇ«baseÇ∆peakÇ≈ç∑Ç™ÇÝÇËÇ∑ǨÇ∂Ç·ÇÀ
http://www.spec.org/cpu2006/results/res2014q2/cpu2006-20140424-29429.html
http://www.spec.org/cpu2006/results/res2014q2/cpu2006-20140424-29430.html
ämÇ©Ç…ÉRÉAÇÝÇΩÇËÇ≈å©ÇÈÇ∆ë¨Ç¢ÇÒÇæÇØÇ«baseÇ∆peakÇ≈ç∑Ç™ÇÝÇËÇ∑ǨÇ∂Ç·ÇÀ
MicrosoftÇ™äJî≠ǵǃÇΩOS/2 3.xÇ™ñºëOÇïœÇ¶ÇƒWindowsÇÃÉVÉFÉãÇ
ǬÇØÇΩÇÃÇ™NTÇ≈ÅAMachÉxÅ[ÉXÇÃ32ÉrÉbÉgÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇæÅB
IBMî≈3.xÇýåãã«NTÇ∆ìØÇ∂Ç≠x86îÒàÀë∂ÇÃÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ…à⁄çsǵǃÇÈÅB
LinuxÇÕëΩîNñÿã≥éˆÇÃâäè„éñåèÇ™óLñº
ǬÇØÇΩÇÃÇ™NTÇ≈ÅAMachÉxÅ[ÉXÇÃ32ÉrÉbÉgÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇæÅB
IBMî≈3.xÇýåãã«NTÇ∆ìØÇ∂Ç≠x86îÒàÀë∂ÇÃÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ…à⁄çsǵǃÇÈÅB
LinuxÇÕëΩîNñÿã≥éˆÇÃâäè„éñåèÇ™óLñº
>>685
PCÇŸÇ«Ç≈ÇÕǻǢǙÅAëäìñÇ»êîèoǃÇΩǺàÍî å¸ÇØÉ\ÉtÉgÇ‚ÉQÅ[ÉÄÇýÅB
ì¡Ç…68KÅ®PPCÇÃDZÇÎÇÕWindowsÇý3.1Ç∆Ç©ÇæÇ¡ÇΩÇÃÇ≈ÅAã√Ç¡ÇΩÉQÅ[ÉÄÇ™êÊÇ…MacÇ≈Ç∆Ç©Çý
ǪÇÒǻDžíøǵÇ≠ǻǩǡÇΩÅBÉQÅ[ÉÄÇ∂ǷǻǢǙÉGÉNÉZÉãÇýMacÇ™êÊÇæǵǻ
Ç≈ÅAǪǧǢǡÇΩÉQÅ[ÉÄóÞÇýà⁄çsÇÃíºëOÇ…èoÇΩÉ\ÉtÉgÇ≈ìÆǩǻǩǡÇΩǡǃÇÃÇÕÇŸÇ∆ÇÒǫǻǢÅBâ¥ÇÃéËéùÇøÇ≈ìÆǩǻǩǡÇΩÇÃÇÕ
CDÇÃê⁄ë±Ç™SCSIÇ©ÇÁIDEÇ…ïœÇÌÇ¡ÇΩÇ∆Ç´ÅiéÂóÕã@Ç≈ÇÕG3Ç≈à⁄çsÅAóıâøî≈ÇæÇ∆ÇýǧÇøÇÂÇ¢ëOÅjÇÃåıâhÇÃÉQÅ[ÉÄÇ≠ÇÁÇ¢Çæ
ÅiCDÇ™ÉLÅ[DžǻǡǃǃSCSIÇ…íTǵDžçsÇ≠ÇÃÇ≈ÅAIDEÇÃÉhÉâÉCÉuÇ‚ÉfÉBÉXÉNÉCÉÅÅ[ÉWÇÉ}ÉEÉìÉgǵǃǃÇýåüímǵǻǩǡÇΩÇóÅj
PCÇŸÇ«Ç≈ÇÕǻǢǙÅAëäìñÇ»êîèoǃÇΩǺàÍî å¸ÇØÉ\ÉtÉgÇ‚ÉQÅ[ÉÄÇýÅB
ì¡Ç…68KÅ®PPCÇÃDZÇÎÇÕWindowsÇý3.1Ç∆Ç©ÇæÇ¡ÇΩÇÃÇ≈ÅAã√Ç¡ÇΩÉQÅ[ÉÄÇ™êÊÇ…MacÇ≈Ç∆Ç©Çý
ǪÇÒǻDžíøǵÇ≠ǻǩǡÇΩÅBÉQÅ[ÉÄÇ∂ǷǻǢǙÉGÉNÉZÉãÇýMacÇ™êÊÇæǵǻ
Ç≈ÅAǪǧǢǡÇΩÉQÅ[ÉÄóÞÇýà⁄çsÇÃíºëOÇ…èoÇΩÉ\ÉtÉgÇ≈ìÆǩǻǩǡÇΩǡǃÇÃÇÕÇŸÇ∆ÇÒǫǻǢÅBâ¥ÇÃéËéùÇøÇ≈ìÆǩǻǩǡÇΩÇÃÇÕ
CDÇÃê⁄ë±Ç™SCSIÇ©ÇÁIDEÇ…ïœÇÌÇ¡ÇΩÇ∆Ç´ÅiéÂóÕã@Ç≈ÇÕG3Ç≈à⁄çsÅAóıâøî≈ÇæÇ∆ÇýǧÇøÇÂÇ¢ëOÅjÇÃåıâhÇÃÉQÅ[ÉÄÇ≠ÇÁÇ¢Çæ
ÅiCDÇ™ÉLÅ[DžǻǡǃǃSCSIÇ…íTǵDžçsÇ≠ÇÃÇ≈ÅAIDEÇÃÉhÉâÉCÉuÇ‚ÉfÉBÉXÉNÉCÉÅÅ[ÉWÇÉ}ÉEÉìÉgǵǃǃÇýåüímǵǻǩǡÇΩÇóÅj
>>712
à⁄çsÇÃíºëOÇ…î≠îÑÇ≥ÇÍǃìÆÇ≠ÇÃÇÕìñÇΩÇËëOÅB
ñ‚ëËÇÕêîîNëOÇÃÇýÇÃÇÐÇ≈Ç´ÇøÇÒÇ∆ìÆÇ≠Ç©ÇæÇÊÅB
MacÇÕǪDZǙëSñ≈ÇæÇ©ÇÁÅB
à⁄çsÇÃíºëOÇ…î≠îÑÇ≥ÇÍǃìÆÇ≠ÇÃÇÕìñÇΩÇËëOÅB
ñ‚ëËÇÕêîîNëOÇÃÇýÇÃÇÐÇ≈Ç´ÇøÇÒÇ∆ìÆÇ≠Ç©ÇæÇÊÅB
MacÇÕǪDZǙëSñ≈ÇæÇ©ÇÁÅB
>>713
âΩîNëOÇÃÇ™ìÆÇØÇŒñûë´Ç»ÇÃÇ©ÇÕímÇÁÇÒÇØÇ«ÅAì¡Ç…ÉÜÅ[ÉUÅ[Ç∆ǵǃïsï÷ÇÕä¥Ç∂ǻǩǡÇΩÇÊ
iBookG4ÅiOSXÇ≈ǵǩãNìÆǵǻǢPowerPCã@ÅjÇ≈MacPlusÅi68000égópÇÃç≈èâä˙ÇÃMac)Ç…îÉǡǃÇÝÇ¡ÇΩÉQÅ[ÉÄÇýìÆÇ¢ÇΩÇËǵÇΩǵǻ
Ç≥Ç∑ǙDžǪÇÃÇ≠ÇÁÇ¢à·Ç§Ç∆ìÆǩǻǢÉ\ÉtÉgÇýÇÝÇÈÇØÇ«ÅAǪÇËÇ·PCÇ≈ÇýéóÇΩÇÊǧǻÇýÇÒÇæ
ÇÞǵÇÎ9801Å®PCÇÃà⁄çsÇçlǶÇÍÇŒÅAMacÇÃǟǧǙí∑Ç≠égǶÇΩÇýÇÃÇ™ëΩǢǩǻâ¥ÇÃèÍçá
âΩîNëOÇÃÇ™ìÆÇØÇŒñûë´Ç»ÇÃÇ©ÇÕímÇÁÇÒÇØÇ«ÅAì¡Ç…ÉÜÅ[ÉUÅ[Ç∆ǵǃïsï÷ÇÕä¥Ç∂ǻǩǡÇΩÇÊ
iBookG4ÅiOSXÇ≈ǵǩãNìÆǵǻǢPowerPCã@ÅjÇ≈MacPlusÅi68000égópÇÃç≈èâä˙ÇÃMac)Ç…îÉǡǃÇÝÇ¡ÇΩÉQÅ[ÉÄÇýìÆÇ¢ÇΩÇËǵÇΩǵǻ
Ç≥Ç∑ǙDžǪÇÃÇ≠ÇÁÇ¢à·Ç§Ç∆ìÆǩǻǢÉ\ÉtÉgÇýÇÝÇÈÇØÇ«ÅAǪÇËÇ·PCÇ≈ÇýéóÇΩÇÊǧǻÇýÇÒÇæ
ÇÞǵÇÎ9801Å®PCÇÃà⁄çsÇçlǶÇÍÇŒÅAMacÇÃǟǧǙí∑Ç≠égǶÇΩÇýÇÃÇ™ëΩǢǩǻâ¥ÇÃèÍçá
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÕÉoÉCÉiÉäÉåÉxÉãÇ≈ÉÇÉWÉÖÅ[ÉãâªÇ≥ÇÍǃÇÈÇ™ÅA
Ç◊ǬDžÉoÉCÉiÉäÉåÉxÉãÇ≈ÉÇÉWÉÖÅ[ÉãâªÇµÇ»Ç≠ǃÇýÅAÉ\Å[ÉXÉRÅ[ÉhÉåÉxÉãÇ≈ÉÇÉWÉÖÅ[ÉãâªÅEÉfÉoÉCÉXîÒàÀë∂âªÇ∑ÇÍÇŒÅA
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇ≈ÇýàÀë∂à⁄êAê´ÇÕçÇÇ¢ÇÒÇæÇÊÇ»
èâä˙ÇÃà⁄êAê´Ç™í·Ç¢LinuxÇÕÇ∆ÇýÇ©Ç≠ÅA
Ç¢ÇÐÇÃLinux/FreeBSD/NetBSDÇ∆Ç©ÅAÉ\Å[ÉXÉRÅ[ÉhÉåÉxÉãÇ≈ÇÕç◊Ç©Ç≠ÉÇÉWÉÖÅ[ÉãâªÇ≥ÇÍǃ
à⁄êAê´Ç™Ç∑Ç≤Ç≠ó«Ç≠ǻǡǃÇÈ
Ç◊ǬDžÉoÉCÉiÉäÉåÉxÉãÇ≈ÉÇÉWÉÖÅ[ÉãâªÇµÇ»Ç≠ǃÇýÅAÉ\Å[ÉXÉRÅ[ÉhÉåÉxÉãÇ≈ÉÇÉWÉÖÅ[ÉãâªÅEÉfÉoÉCÉXîÒàÀë∂âªÇ∑ÇÍÇŒÅA
ÉÇÉmÉäÉVÉbÉNÉJÅ[ÉlÉãÇ≈ÇýàÀë∂à⁄êAê´ÇÕçÇÇ¢ÇÒÇæÇÊÇ»
èâä˙ÇÃà⁄êAê´Ç™í·Ç¢LinuxÇÕÇ∆ÇýÇ©Ç≠ÅA
Ç¢ÇÐÇÃLinux/FreeBSD/NetBSDÇ∆Ç©ÅAÉ\Å[ÉXÉRÅ[ÉhÉåÉxÉãÇ≈ÇÕç◊Ç©Ç≠ÉÇÉWÉÖÅ[ÉãâªÇ≥ÇÍǃ
à⁄êAê´Ç™Ç∑Ç≤Ç≠ó«Ç≠ǻǡǃÇÈ
DZÇÃÉXÉåÇÃïΩãœîNóÓÇ¢Ç≠ǬÅHÇó
50ë„Ç∆Ç©Ç¢ÇÈÇÒÇ≈ÇÀÅ[ÇÃÅHÇó
50ë„Ç∆Ç©Ç¢ÇÈÇÒÇ≈ÇÀÅ[ÇÃÅHÇó
718 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 20:08:54.75 ID:ns+15eQG
îNäÒÇËÇÃÇΩÇÁÇÍÇŒò_ÇÕäTǵǃâºíËÇ∆åãò_ÇÃä÷åWÇ™íZóçǵǃÇÈÇÃÇ»
ícéqÇ≥ÇÒǡǃǢÇ≠ǬÅH
720 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 20:21:06.65 ID:ns+15eQG
ÉlÉIîûÇ∆ìØÇ¢îNÇæÇ∆åæÇ¡ÇΩî§ÇæÇ™
722 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 20:47:51.58 ID:qK/BC4o3
50ë„ǫDZÇÎÇ©ícâÚÇ™ãèÇÈ
ÀÆ¥∞Ç∂Ç∂Ç¢ÇæÇ¡ÇΩÇÒÇæÅB
ÇýÇ¡Ç∆êKÇÃëìÇ¢ãÏÇØèoǵǩÇ∆évǡǃÇΩÅB
ÇýÇ¡Ç∆êKÇÃëìÇ¢ãÏÇØèoǵǩÇ∆évǡǃÇΩÅB
ç≤âÍåßç≤âÍésÇPÇVçŒ
ícéqÇ≥ÇÒÅAñlÇ∆ìØÇ∂Ç≈ÇÐÇæ30ë„ëOîºÇ»ÇÃÇ…ÅAâÔé–ÇÃèdóvÇ»édéñǵǃǃǩǡDZǢǢÅB
ícéqÇ≥ÇÒÇðÇΩǢǻÉXÅ[ÉpÅ[ÉGÉìÉWÉjÉAÇ…Ç»ÇËÇΩǢǻÅB
ícéqÇ≥ÇÒÇðÇΩǢǻÉXÅ[ÉpÅ[ÉGÉìÉWÉjÉAÇ…Ç»ÇËÇΩǢǻÅB
ǻDžDZÇÍé©ââÅH
DZǧǢǧÇÃǙǟǵǢÇ≈Ç∑
https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=81346&item_no=1&page_id=13&block_id=8
??ÉoÉCÉiÉäÉgÉâÉìÉXÉåÅ[ÉVÉáÉìÇ…ÇÊÇÈÉãÅ[ÉvîΩïúä‘ÇÃÉfÅ[É^àÀë∂âêÕ
https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=81346&item_no=1&page_id=13&block_id=8
??ÉoÉCÉiÉäÉgÉâÉìÉXÉåÅ[ÉVÉáÉìÇ…ÇÊÇÈÉãÅ[ÉvîΩïúä‘ÇÃÉfÅ[É^àÀë∂âêÕ
728 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 21:17:40.04 ID:qK/BC4o3
éãSÂKÂNêπìl
ÉlÉIîûíÉ
èHótå¥í ÇËñÇ
ï–éRljǧÇøÇ·ÇÒ
Ç®Ç⁄ÇøÇ·ÇÒ
ÉlÉIîûíÉ
èHótå¥í ÇËñÇ
ï–éRljǧÇøÇ·ÇÒ
Ç®Ç⁄ÇøÇ·ÇÒ
729 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 21:20:04.22 ID:qK/BC4o3
ǮǡÇ∆ÅAÇ®Ç⁄ÇøÇ·ÇÒÇÕ83îNÇæÇ¡ÇΩ
730 ÅF Åümiyuri//Z7LS ÅF2014/07/01(âŒ) 21:59:09.86 ID:mM2I9Bjp
80386à»ç~ÇÕÅAàÍíU32[bit]Ç≈ÉäÉjÉAÇ»ÉZÉOÉÅÉìÉgDžǵǃǩÇÁ16[bit]Ç…ñþÇ∑Ç∆à»â∫ó™Ç¡ÇƒÇ¢Ç§óÝÉèÉUÇ™óLÇ¡ÇΩÇÊǧǻÅB
>>727
ÅuDZǧǢǧÇÃÅvǡǃâΩÇÊÇó
ò_ï∂Ç…ÇÊÇÈÇ∆ÅA
Åuñ{çeÇ≈ÇÕÉãÅ[ÉvîΩïúä‘ÇÃÉfÅ[É^àÀë∂ÇÃóLñ≥Çé¿çséûÇ…ÉvÉçÉtÉ@ÉCÉäÉìÉOÇ∑ÇÈDZÇ∆Ç…ÇÊÇËÉãÅ[Évï¿óÒê´ÇÃíäèoÇ‚ÉnÅ[ÉhÉEÉFÉAÇ÷ÇÃÉ}ÉbÉsÉìÉOÇéxâáÇ∑ÇÈã@ç\ÇÉoÉCÉiÉäÉgÉâÉìÉXÉåÅ[É^ÇópǢǃé¿ëïÇ∑ÇÈÅBÅv
ÇæÇ¡ÇΩÇÁàÍâÒé¿çsǵǃÅAindexÉ_ÉìÉvǵǃé©ï™Ç≈àÀë∂ÇÃǻǢîzóÒÇ…ï™ÇØÇÍÇŒÅH
Ç»ÇÒÇøÇ¡ÇøÇó
Ǭǩå√ìTìIëOèàóùǙǪÇÍÇ…ãþÇ¢ÇýÇÃÇÝÇÈÇÃÇ≈ÇÕÅH
ò_ï∂ÇÕñ{ÉãÅ[ÉvàÀë∂ÉvÉçÉtÉ@ÉCÉâÇøDŽǧÇýÇÃÇçÏÇ¡ÇΩèäÇì∆é©ê´éÂí£ÇµÇƒÇÈÇØÇ«
”œ¥Ç≥ÇÒÇÕé‘ó÷ÇÃçƒî≠ñæǵǻǢÇÊǧDžÇÀÅ`Çó
ÅuDZǧǢǧÇÃÅvǡǃâΩÇÊÇó
ò_ï∂Ç…ÇÊÇÈÇ∆ÅA
Åuñ{çeÇ≈ÇÕÉãÅ[ÉvîΩïúä‘ÇÃÉfÅ[É^àÀë∂ÇÃóLñ≥Çé¿çséûÇ…ÉvÉçÉtÉ@ÉCÉäÉìÉOÇ∑ÇÈDZÇ∆Ç…ÇÊÇËÉãÅ[Évï¿óÒê´ÇÃíäèoÇ‚ÉnÅ[ÉhÉEÉFÉAÇ÷ÇÃÉ}ÉbÉsÉìÉOÇéxâáÇ∑ÇÈã@ç\ÇÉoÉCÉiÉäÉgÉâÉìÉXÉåÅ[É^ÇópǢǃé¿ëïÇ∑ÇÈÅBÅv
ÇæÇ¡ÇΩÇÁàÍâÒé¿çsǵǃÅAindexÉ_ÉìÉvǵǃé©ï™Ç≈àÀë∂ÇÃǻǢîzóÒÇ…ï™ÇØÇÍÇŒÅH
Ç»ÇÒÇøÇ¡ÇøÇó
Ǭǩå√ìTìIëOèàóùǙǪÇÍÇ…ãþÇ¢ÇýÇÃÇÝÇÈÇÃÇ≈ÇÕÅH
ò_ï∂ÇÕñ{ÉãÅ[ÉvàÀë∂ÉvÉçÉtÉ@ÉCÉâÇøDŽǧÇýÇÃÇçÏÇ¡ÇΩèäÇì∆é©ê´éÂí£ÇµÇƒÇÈÇØÇ«
”œ¥Ç≥ÇÒÇÕé‘ó÷ÇÃçƒî≠ñæǵǻǢÇÊǧDžÇÀÅ`Çó
>>711
Windows NTÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇæÇ™MachÉxÅ[ÉXÇ∂ǷǻǢ
DECÇ©ÇÁÉ}ÉCÉNÉçÉ\ÉtÉgÇ…à⁄Ç¡ÇΩÉJÉgÉâÅ[ÇÃÉ`Å[ÉÄÇ™íÜêSDžǻǡǃ
É}ÉCÉNÉçÉ\ÉtÉgÇ™1Ç©ÇÁçÏÇËè„Ç∞ÇΩOS
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÕJobsÇ™çÏÇ¡ÇΩNeXTÇ™
MachÇçÃópǵǃóLñºÇ…ǻǡÇΩÇæ
NeXTÇÕÇÝÇÐÇËîÑÇÍǻǩǡÇΩÇ™òbëËÇ…ÇÕǻǡÇΩ
MarchÉxÅ[ÉXÇ»ÇÃÇÕNeXTÇÃó¨ÇÍÇãÇÇÞMacOS X
Windows NTÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇæÇ™MachÉxÅ[ÉXÇ∂ǷǻǢ
DECÇ©ÇÁÉ}ÉCÉNÉçÉ\ÉtÉgÇ…à⁄Ç¡ÇΩÉJÉgÉâÅ[ÇÃÉ`Å[ÉÄÇ™íÜêSDžǻǡǃ
É}ÉCÉNÉçÉ\ÉtÉgÇ™1Ç©ÇÁçÏÇËè„Ç∞ÇΩOS
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÕJobsÇ™çÏÇ¡ÇΩNeXTÇ™
MachÇçÃópǵǃóLñºÇ…ǻǡÇΩÇæ
NeXTÇÕÇÝÇÐÇËîÑÇÍǻǩǡÇΩÇ™òbëËÇ…ÇÕǻǡÇΩ
MarchÉxÅ[ÉXÇ»ÇÃÇÕNeXTÇÃó¨ÇÍÇãÇÇÞMacOS X
733 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 22:36:31.02 ID:qK/BC4o3
âŒìÍèeÇÃêªñ@Ç≠ÇÁǢǫǧÇ≈ÇýǢǢǻ
MachÇ™àÍéûä˙éÊÇËì¸ÇÍÇΩï®ÇÃÅAÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇÕå¯ó¶Ç™à´Ç∑ǨǃÅAÇÝÇ¡Ç∆åæǧä‘Ç…MachÇÕÉ}ÉCÉNÉçÉJÅ[ÉlÉãé~ÇþÇøÇ·Ç¡ÇΩÅc
735 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 22:40:23.55 ID:qK/BC4o3
NT4.0Å`XPÇ≈GDIÇÉJÅ[ÉlÉãÇ…ìùçáǵÇΩÇÃÇÕåòòSê´ÇÃäœì_Ç©ÇÁǢǶnj
DZǢǬÇÁì™Ç®Ç©ÇµÇ¢Ç∆ǵǩ
DZǢǬÇÁì™Ç®Ç©ÇµÇ¢Ç∆ǵǩ
>>735
ìñéûÇÃCPUÉpÉèÅ[Ç≈ÇÕÅAåãã«ÅAÉ}ÉCÉNÉçÉJÅ[ÉlÉãå©ÇΩǢǻòbÇÕä˜è„ÇÃãÛò_ÇæÇ¡ÇΩÅB
ÇΩÇæÅAǪÇÍÇæÇØÇÃéñÅc
ìñéûÇÃCPUÉpÉèÅ[Ç≈ÇÕÅAåãã«ÅAÉ}ÉCÉNÉçÉJÅ[ÉlÉãå©ÇΩǢǻòbÇÕä˜è„ÇÃãÛò_ÇæÇ¡ÇΩÅB
ÇΩÇæÅAǪÇÍÇæÇØÇÃéñÅc
è„Ç≈8086 ÇÃSegmentÇÃñüâÊÇ™í£ÇÁÇÍǃ68000Ç∆Ç©⁄ΩïtÇ¢ÇΩÇÝÇΩÇËÇ©ÇÁ
å≥ þø∫ðè≠îNÇÃÇ»ÇÍÇÃâ ǃÇðÇΩǢǻûΩéqÇ™ã}Ç…óNǢǃǴǃÉXÉåÇ™
â˘å√ǡǀǢÇ∆Ǣǧǩ25îNëOÇÃÉGÉìÉhÉÜÅ[ÉUÇÃò_ëàÇðÇΩǢDžǻǡÇΩÇ»Åc
å≥ þø∫ðè≠îNÇÃÇ»ÇÍÇÃâ ǃÇðÇΩǢǻûΩéqÇ™ã}Ç…óNǢǃǴǃÉXÉåÇ™
â˘å√ǡǀǢÇ∆Ǣǧǩ25îNëOÇÃÉGÉìÉhÉÜÅ[ÉUÇÃò_ëàÇðÇΩǢDžǻǡÇΩÇ»Åc
>>736
é¿ç€ÅAê´î\à´Ç¢ÇÒÇæÇÊÅB
ì¡Ç…ï¿óÒÉXÉPÅ[ÉâÉrÉäÉeÉBÅ[Ç™ÅB
Ç≈åãã«àÍñáä‚ÇðÇΩǢǻÉJÅ[ÉlÉãÇÃíÜÇÉJÅ[ÉlÉãÉXÉåÉbÉhÉrÉÖÉìÉrÉÖÉìéæÇÁÇπǃ
Ç´Çþç◊Ç©Ç¢ÉçÉbÉNÇπêßå‰Çê¨ènÇ≥ÇπǃǢǴÅAÇÐÇüå©ÇΩñ⁄ÇÄYóÌÇ≥ÇÕÇ∆ÇýÇ©Ç≠è\ï™é¿ópìI
DžǻǡÇøÇÐǡǃèüïâÇÝÇËÅB
é¿ç€ÅAê´î\à´Ç¢ÇÒÇæÇÊÅB
ì¡Ç…ï¿óÒÉXÉPÅ[ÉâÉrÉäÉeÉBÅ[Ç™ÅB
Ç≈åãã«àÍñáä‚ÇðÇΩǢǻÉJÅ[ÉlÉãÇÃíÜÇÉJÅ[ÉlÉãÉXÉåÉbÉhÉrÉÖÉìÉrÉÖÉìéæÇÁÇπǃ
Ç´Çþç◊Ç©Ç¢ÉçÉbÉNÇπêßå‰Çê¨ènÇ≥ÇπǃǢǴÅAÇÐÇüå©ÇΩñ⁄ÇÄYóÌÇ≥ÇÕÇ∆ÇýÇ©Ç≠è\ï™é¿ópìI
DžǻǡÇøÇÐǡǃèüïâÇÝÇËÅB
739 ÅF Åümiyuri//Z7LS ÅF2014/07/01(âŒ) 22:52:49.63 ID:mM2I9Bjp
>>735
http.sys DžǬǢǃÇÕÅAǫǧévǧÅH
http.sys DžǬǢǃÇÕÅAǫǧévǧÅH
740 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 22:58:27.77 ID:qK/BC4o3
ÉÜÅ[ÉUÅ[ÉAÉJÉEÉìÉgçÏê¨Ç≈conÇ∆Ç©prnÇ∆Ç©ÇÃñºëOïtÇØÇÈÇ∆
ǮǩǵǻãììÆÇ…Ç»ÇÈÇÃÇÕǫǧDžǩǵǃǟǵǢÇ∆DZÇÎÇæÇÀ
ǮǩǵǻãììÆÇ…Ç»ÇÈÇÃÇÕǫǧDžǩǵǃǟǵǢÇ∆DZÇÎÇæÇÀ
ÉRÉìÇ∆Ç©É|ÉãÉmÅc
742 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 23:09:06.12 ID:qK/BC4o3
LinuxÇÃèÍçáÇÕÉIÅ[ÉvÉìÉ\Å[ÉXÇÕïsãÔçáÇå©Ç¬ÇØÇÍÇŒíNÇ©Ç™íºÇ∑Ç∆ǢǧëOíÒÇÃÇýÇ∆Ç…
êMóäê´Ç™ê¨ÇËóßǡǃÇÈÇ™ÉNÉçÅ[ÉYÉhÇæÇ∆ǪǧÇÕǢǩÇÒÇæÇÎ
OpenGLÇÃÉhÉâÉCÉoÇÃïsãÔçáÇ≈OSÇ≤Ç∆óéÇøÇÈÇ∆Ç©âΩéñÇÊ
êMóäê´Ç™ê¨ÇËóßǡǃÇÈÇ™ÉNÉçÅ[ÉYÉhÇæÇ∆ǪǧÇÕǢǩÇÒÇæÇÎ
OpenGLÇÃÉhÉâÉCÉoÇÃïsãÔçáÇ≈OSÇ≤Ç∆óéÇøÇÈÇ∆Ç©âΩéñÇÊ
743 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/01(âŒ) 23:44:24.67 ID:qK/BC4o3
>>739
LinuxÇÃIPÉXÉ^ÉbÉNÇýÉJÅ[ÉlÉãÇ…ëgÇðçûÇÐÇÍǃÇÈǵï Ç…ñ‚ëËǻǢÇÒÇ∂Ç·ÅH
ÇÞǵÇÎìKê≥Ç»åÝå¿ä«óùÇ…ÇÊÇËÅAÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÇ≈é¿ëïÇ∑ÇÈÇÊÇËÇýÉZÉLÉÖÉäÉeÉBÇ
ämï€ÇµÇ‚Ç∑Ç¢ÇÕÇ∏ÅB
ǪÇýǪÇýÉJÅ[ÉlÉãÉÇÅ[ÉhÉhÉâÉCÉoÇ™ñ≥èåèÇ…äÎåØÇ»ÇÌÇØÇ≈ÇÕǻǢ
OSÇÃÉNÉâÉbÉVÉÖÇÃå¥àˆÇ∆ǵǃÉgÉbÉvÇÃé¿ê—Ç™ÇÝÇÈÇ∂Ç·ÇÒÉrÉfÉIÉJÅ[ÉhÇÃÉhÉâÉCÉoÇÕ
LinuxÇÃIPÉXÉ^ÉbÉNÇýÉJÅ[ÉlÉãÇ…ëgÇðçûÇÐÇÍǃÇÈǵï Ç…ñ‚ëËǻǢÇÒÇ∂Ç·ÅH
ÇÞǵÇÎìKê≥Ç»åÝå¿ä«óùÇ…ÇÊÇËÅAÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÇ≈é¿ëïÇ∑ÇÈÇÊÇËÇýÉZÉLÉÖÉäÉeÉBÇ
ämï€ÇµÇ‚Ç∑Ç¢ÇÕÇ∏ÅB
ǪÇýǪÇýÉJÅ[ÉlÉãÉÇÅ[ÉhÉhÉâÉCÉoÇ™ñ≥èåèÇ…äÎåØÇ»ÇÌÇØÇ≈ÇÕǻǢ
OSÇÃÉNÉâÉbÉVÉÖÇÃå¥àˆÇ∆ǵǃÉgÉbÉvÇÃé¿ê—Ç™ÇÝÇÈÇ∂Ç·ÇÒÉrÉfÉIÉJÅ[ÉhÇÃÉhÉâÉCÉoÇÕ
ÇÞǩǵÇÃUNIXÇ≈ÅAXÉTÅ[ÉoÇ™ÉãÅ[ÉgåÝå¿ÇÃÉÜÅ[ÉUÅ[ÉÇÅ[ÉhÇ≈ìÆǢǃÇΩéûë„Ç≈ÇýÅA
XÉTÅ[ÉoÇÕÇΩÇÐÇ…OSä™Ç´çûÇÒÇ≈óéÇøǃÇΩǺ
ãtÇ…Windows7Ç∆Ç©ÅAÉOÉâÉtÉBÉbÉNÉhÉâÉCÉoÇ™ÉNÉâÉbÉVÉÖǵÇΩÇÁÅAÉhÉâÉCÉoÇæÇØçƒãNìÆǵǃ
ïúãåÇ∑ÇÈDZÇ∆Ç™ëΩÇ¢
XÉTÅ[ÉoÇÕÇΩÇÐÇ…OSä™Ç´çûÇÒÇ≈óéÇøǃÇΩǺ
ãtÇ…Windows7Ç∆Ç©ÅAÉOÉâÉtÉBÉbÉNÉhÉâÉCÉoÇ™ÉNÉâÉbÉVÉÖǵÇΩÇÁÅAÉhÉâÉCÉoÇæÇØçƒãNìÆǵǃ
ïúãåÇ∑ÇÈDZÇ∆Ç™ëΩÇ¢
ÉfÉtÉHÉãÉgÇ≈ÇýKP41Ç≈ÇΩÇÐÇ…óéÇøÇÈÇÊDžǧǻǡÇΩÇÃÇÕ
CPUÇÃêðåvÇ…ñ‚ëËÇ™ÇÝÇÈÇÃÇ≈ÇÕǻǢǩÅBBSoDÇ…ÇýÇ»ÇÁÇ∏ÉXÉgÅ[ÉìǡǃóéÇøÇ‚Ç™ÇÈÅB
CPUÇÃêðåvÇ…ñ‚ëËÇ™ÇÝÇÈÇÃÇ≈ÇÕǻǢǩÅBBSoDÇ…ÇýÇ»ÇÁÇ∏ÉXÉgÅ[ÉìǡǃóéÇøÇ‚Ç™ÇÈÅB
748 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/02(êÖ) 07:34:30.70 ID:4HOmMuI3
>>744
Vistaà»ç~ÅAÉOÉâÉtÉBÉbÉNÉhÉâÉCÉoÇÕàÍéÌÇÃÉTÉìÉhÉ{ÉbÉNÉXÇ≈ìÆÇ≠ÇÊǧDžǻǡÇΩ
ÇæÇ©ÇÁÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ÷ÇÃâÒãAÇ∆Ç¢ÇÌÇÍǃÇÈ
Vistaà»ç~ÅAÉOÉâÉtÉBÉbÉNÉhÉâÉCÉoÇÕàÍéÌÇÃÉTÉìÉhÉ{ÉbÉNÉXÇ≈ìÆÇ≠ÇÊǧDžǻǡÇΩ
ÇæÇ©ÇÁÉ}ÉCÉNÉçÉJÅ[ÉlÉãÇ÷ÇÃâÒãAÇ∆Ç¢ÇÌÇÍǃÇÈ
749 ÅFSocket774ÅF2014/07/02(êÖ) 13:14:37.38 ID:sVrSS1j+
É}ÉCÉNÉçÉJÅ[ÉlÉãÇæÇ©ÇÁå¯ó¶Ç™à´Ç¢Ç∆Ç©å¿ÇÁǻǢÇÃÇ≈ÇÕ
http://ja.wikipedia.org/wiki/QNXÅ@Ç»ÇÒÇ©ÇÕè\ï™Ç»å¯ó¶ÅEê´î\Çæǵ
Ç»Ç∫MachÇÕQNXÇðÇΩǢDžå¯ó¶ìIÇ»ÉJÅ[ÉlÉãÇ∆Ç»ÇÁǻǩǡÇΩÇÃÇæÇÎǧǩÅc
http://ja.wikipedia.org/wiki/QNXÅ@Ç»ÇÒÇ©ÇÕè\ï™Ç»å¯ó¶ÅEê´î\Çæǵ
Ç»Ç∫MachÇÕQNXÇðÇΩǢDžå¯ó¶ìIÇ»ÉJÅ[ÉlÉãÇ∆Ç»ÇÁǻǩǡÇΩÇÃÇæÇÎǧǩÅc
Name of your amazing
http://www.centtech.com/
ç≈ãþÇÃì¡ãñ
Microprocessor that performs x86 isa and arm isa machine language program instructions
by hardware translation into microinstructions executed by common execution pipeline
https://www.google.com/patents/US20120260067
Microprocessor with fast execution of call and return instructions
http://www.google.com.tr/patents/US8423751
Microprocessor that performs x86 ISA and ARM ISA machine language program instructions by hardware translation
http://www.google.com/patents/EP2508978A1?cl=en
https://patentimages.storage.googleapis.com/US20120260067A1/US20120260067A1-20121011-D00009.png
x86Ç∆armóºï˚ìÆÇ≠CPUçÏǡǃÇÈÅH
Microprocessor that translates conditional load/store instructions into variable number of microinstructions
http://www.google.com/patents/US20140122847
http://www.centtech.com/
ç≈ãþÇÃì¡ãñ
Microprocessor that performs x86 isa and arm isa machine language program instructions
by hardware translation into microinstructions executed by common execution pipeline
https://www.google.com/patents/US20120260067
Microprocessor with fast execution of call and return instructions
http://www.google.com.tr/patents/US8423751
Microprocessor that performs x86 ISA and ARM ISA machine language program instructions by hardware translation
http://www.google.com/patents/EP2508978A1?cl=en
https://patentimages.storage.googleapis.com/US20120260067A1/US20120260067A1-20121011-D00009.png
{kind=link}
x86Ç∆armóºï˚ìÆÇ≠CPUçÏǡǃÇÈÅH
Microprocessor that translates conditional load/store instructions into variable number of microinstructions
http://www.google.com/patents/US20140122847
VIAÅH
VIAÇÕAtomÇ™èoǃǩÇÁâeÇ™îñÇ≠ǻǡÇΩÇÊÇÀÅB
VIAÇÕAtomÇ™èoǃǩÇÁâeÇ™îñÇ≠ǻǡÇΩÇÊÇÀÅB
753 ÅF Åümiyuri//Z7LS ÅF2014/07/02(êÖ) 19:34:11.38 ID:336RB4gN
GPGPUÇ»égÇ¢ï˚ÇÇ∑ÇÈèÍçáÅAÉÜÅ[ÉUÉÇÅ[ÉhÇ…íuÇ≠ï˚Ç™äǵǢÅB
ǪÇÃï”ÇËÇýçlǶǃÅAWindows VistaÇ≈ïœÇ¶ÇΩÇÃÇ©ÇýÅB
ǪÇÃï”ÇËÇýçlǶǃÅAWindows VistaÇ≈ïœÇ¶ÇΩÇÃÇ©ÇýÅB
754 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/02(êÖ) 19:41:30.40 ID:4HOmMuI3
É}ÉCÉNÉçÉJÅ[ÉlÉãÇÃǟǧǙÉ}ÉãÉ`ÉRÉAå¸ÇØÇ»ÇÒÇæÇÊÇÀ
Ç≈ÇýWindowsÇÃèÍçáÇÕWDDMÇ™Ç∏Ç¡Ç∆ÉVÉìÉOÉãÉRÉAå¸ÇØÇ≈
É}ÉãÉ`ÉRÉAÇê∂Ç©ÇπǻǢÇØÇ«ÇÀ
É}ÉãÉ`ÉRÉAÇê∂Ç©ÇπǻǢÇØÇ«ÇÀ
œ∑∞…ÇÃåæãyÇÕì˙èÌ
Ç»ÇÒÇ©ç≈ãþJWasmǡǃǢǧMASMÉRÉìÉpÉ`ÇÃ2ÉXÉeÅ[ÉWÇÃÉAÉZÉìÉuÉâÇ™ÇÝÇÈÇÒÇæÇÀÅB
ç≈ãþÇ≈ÇýǻǢǩÅB
ç≈ãþÇ≈ÇýǻǢǩÅB
Windowså¸ÇØCPUÇÃÉVÉìÉOÉãÉRÉAê‚ñ≈ÇÕǬǢç≈ãþÇæǵ
É}ÉãÉ`ÉRÉAëOíÒDžǻǡǃǴÇΩÇÃWDDM1.2à»å„Ç∂Ç·ÇÀ
É}ÉãÉ`ÉRÉAëOíÒDžǻǡǃǴÇΩÇÃWDDM1.2à»å„Ç∂Ç·ÇÀ
760 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/03(ñÿ) 20:30:46.36 ID:CCUnjCTQ
èüéËÇ…éEÇ∑Ç»Å[
http://ark.intel.com/ja/products/78476/Intel-Atom-Processor-E3815-512K-Cache-1_46-GHz
DZǧǢǧÇÃÉVÉìÉNÉâÇ∆Ç©ëgÇðçûÇðópìrÇ≈ÇÕé˘óvÇÝÇÈÇÃÇ≈ÇÕÅH
ï Ç…É}ÉãÉ`ÉXÉåÉbÉhÇégÇ¡ÇΩÉ\ÉtÉgÇÕÉ}ÉãÉ`ÉRÉAÇ≈ǻǢÇ∆ìÆǩǻǢÇÌÇØÇ∂ǷǻǢÇ∫
http://ark.intel.com/ja/products/78476/Intel-Atom-Processor-E3815-512K-Cache-1_46-GHz
DZǧǢǧÇÃÉVÉìÉNÉâÇ∆Ç©ëgÇðçûÇðópìrÇ≈ÇÕé˘óvÇÝÇÈÇÃÇ≈ÇÕÅH
ï Ç…É}ÉãÉ`ÉXÉåÉbÉhÇégÇ¡ÇΩÉ\ÉtÉgÇÕÉ}ÉãÉ`ÉRÉAÇ≈ǻǢÇ∆ìÆǩǻǢÇÌÇØÇ∂ǷǻǢÇ∫
êÃÇÃÉ}ÉãÉ`ÉXÉåÉbÉhégÇ¡ÇΩÉAÉvÉäÇÕÉ}ÉãÉ`ÉRÉADžǻǡǃ
ÇÐÇ∆ÇýÇ…ìØä˙èàóùé¿ëïǵǃǻÇ≠ǃÉtÉäÅ[ÉYǵÇÐÇ≠Ç¡ÇΩÇØÇ«ÅB
ÇÐÇ∆ÇýÇ…ìØä˙èàóùé¿ëïǵǃǻÇ≠ǃÉtÉäÅ[ÉYǵÇÐÇ≠Ç¡ÇΩÇØÇ«ÅB
àÍî å¸ÇØWindowså¸ÇØÇ»Å@ÇþÇÒÇ«Ç≠ÇπǶ
Windows ÇìÆÇ©Ç∑Ç∆Ç»ÇÈÇ∆ÉVÉìÉNÉâÇ∆ÇÕǢǶåãã«ÇÕǪÇÍÇ»ÇËÇÃê´î\Ç™ïKóvÇ∆Ç»ÇÈÇÌÇØÇæǵÅB
WinAPIégǡǃÉKÉäÉKÉäÉvÉçÉOÉâÉ~ÉìÉOǵǃÇÈÇÒÇæÇØÇ«ÅA
Ç–ÇÂÇ¡Ç∆ǵǃéûë„íxÇÍÇ©Ç»Çü•••ÅH
Ç–ÇÂÇ¡Ç∆ǵǃéûë„íxÇÍÇ©Ç»Çü•••ÅH
é˘óvå∏è≠ÇÃéûë„ÇèÊÇËêÿÇÍÇŒÅAécë∂é“óòâvÇÉAÉåèoóàÇÈDZÇ∆Ç™Ç≈Ç´ÇÈÇ©ÇýÇÀ
>>765
écë∂é“óòâvÇ©ÅAÇ»ÇÈÇŸÇ«ÅB
ê¢ÇÃíÜÅAÉÄÉ_ǻDZÇ∆ÇÕàÍǬÇýǻǢÇÀÅB
ǪǧǢǂÅAnVidiaÇÃDenverǡǃè⁄ç◊ï™Ç©Ç¡ÇΩÇÒÇæÇ¡ÇØÅH
écë∂é“óòâvÇ©ÅAÇ»ÇÈÇŸÇ«ÅB
ê¢ÇÃíÜÅAÉÄÉ_ǻDZÇ∆ÇÕàÍǬÇýǻǢÇÀÅB
ǪǧǢǂÅAnVidiaÇÃDenverǡǃè⁄ç◊ï™Ç©Ç¡ÇΩÇÒÇæÇ¡ÇØÅH
767 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/03(ñÿ) 21:57:39.56 ID:CCUnjCTQ
ǪÇÒÇ»ÉRÉ{ÉâÅ[ÇðÇΩǢǻî≠ëzÇÕåôÇæ
ï Ç…åNÇÕǪǧǢǧî≠ëzǵǻÇ≠ǃÇýǢǢÇÌÇØ
â¥ÇýëΩï™ÇµÇ»Ç¢Çµ
â¥ÇýëΩï™ÇµÇ»Ç¢Çµ
Windows RuntimeÇ÷à⁄çsÇ™êiÇðÅAè´óàÇÃWindowsÇ≈Win32APIÇ™îpé~Ç≥ÇÍÇÈÇ∆åæÇÌÇÍǃǢÇΩÇ™ÅAÇ«ÇÃÇ≠ÇÁÇ¢Ç≈îpé~Ç≥ÇÍÇÈÉçÅ[ÉhÉ}ÉbÉvÇ»ÇÒÇæÇÎǧÇÀÅB
64ÉrÉbÉgî≈WindowsÇ≈Win16Ç™îpé~Ç≥ÇÍÇΩÇ™ÅAÇÝÇÝǢǡÇΩljǡÇΩÇËǵÇΩä¥Ç∂ÇÃà⁄çsÇ»ÇÃÇ©Ç»ÅB
Ç∑Ç≈Ç…Windows8Ç…WinAPIÇ©ÇÁÇÕåƒÇ—èoÇπÇ∏ÅAWindows RuntimeÇ©ÇÁåƒÇ‘ïKóvÇ™ÇÝÇÈWindowsÇÃã@î\ǙǢÇ≠ǬǩÇÝÇÈÇÃÇ™ãCDžǻǡǃǢÇÈÅB
64ÉrÉbÉgî≈WindowsÇ≈Win16Ç™îpé~Ç≥ÇÍÇΩÇ™ÅAÇÝÇÝǢǡÇΩljǡÇΩÇËǵÇΩä¥Ç∂ÇÃà⁄çsÇ»ÇÃÇ©Ç»ÅB
Ç∑Ç≈Ç…Windows8Ç…WinAPIÇ©ÇÁÇÕåƒÇ—èoÇπÇ∏ÅAWindows RuntimeÇ©ÇÁåƒÇ‘ïKóvÇ™ÇÝÇÈWindowsÇÃã@î\ǙǢÇ≠ǬǩÇÝÇÈÇÃÇ™ãCDžǻǡǃǢÇÈÅB
WinAPIÇÕOSñ{ëÃÇ©ÇÁêÿÇËó£ÇµÇƒÉTÉìÉhÉ{ÉbÉNÉXÇ≈ÉGÉ~ÉÖÇíÒãüÇ∑ÇÍnjǢǢÅB
ÉåÉKÉVÅ[ÉAÉvÉäÇ™ìÆÇ≠ÇÃÇÕMSÇÃóòì_ÇæǵÅAǪÇÒǻDžä»íPÇ…êÿÇÁÇÍǻǢÇ≈ǵÇÂÅH
Win32ìGéãǵǃÇÈÇÃÇÕÉRÅ[ÉhèëǩǻǢÉAÉzÇæÇ©ÇÁÉXÉãÅ[Ç≈ok
Win32îpé~DžǻǡÇΩÇÁXPëõìÆÇí¥Ç¶ÇÈñ‚ëËÇ…Ç»ÇËǪǧ
îpé~Ç…Ç»ÇÈDZÇÎÇ…ÇÕÅAÇðÇÒÇ»AndroidÇ©iOSÇ…à⁄çsçœÇðÇæÇ©ÇÁíNÇýñ‚ëËDžǵǻǢÇæÇÎ
2020îNÇ…î≠îÑÇ≥ÇÍÇÈwindowsDžǻǡǃÇýwin32ÇÕìÆÇ≠ÇæÇÎ
Win32îpé~ÇÕìñï™êÊÇÃòbÇæÇÎǧÇØÇ«ÅA9Ç©ÇÁÇÕ64bitî≈ÉIÉìÉäÅ[Ç…Ç»ÇÈÇ∆évǧÇÊ
777 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/04(ãý) 22:16:54.04 ID:FAe13dnt
ǪÇýǪÇýÅuWin64 APIÅvÇ∆ǢǧÇýÇÃÇ™íËã`Ç≥ÇÍǃÇÈÇÌÇØÇ≈ÇÕǻǢÅB
QtÇ∆Ç©ÉLÉÇÇ¢ÅB
WinAPIÇ™àÍî‘ÅB
WinAPIÇ™àÍî‘ÅB
É\ÉtÉgã∆äEÇÃì‰Å`è¡Ç¶ÇΩCåæåÍÉvÉçÉOÉâÉ}Å[Å`
http://www.benedict.co.jp/Smalltalk/talk-258.htm
ÉzÉbÉgÇ»òbëËÅB
é©ï™ÇÕÇÐÇ≥Ç…ÉVÉ~ÉÖÉåÅ[É^Å[âΩÇ©ÇǂǡǃÇÈÇ©ÇÁÉoÉäÉoÉäC++ÇæÇ©ÇÁãCDžǵǃǻǩǡÇΩÇÒÇæÇØÇ«ÅA
ê¢ÇÃíÜìIÇ…ÇÕ Java >> C/C++ Ç»ÇÒÇæÇÀ•••ÅB
http://www.benedict.co.jp/Smalltalk/talk-258.htm
ÉzÉbÉgÇ»òbëËÅB
é©ï™ÇÕÇÐÇ≥Ç…ÉVÉ~ÉÖÉåÅ[É^Å[âΩÇ©ÇǂǡǃÇÈÇ©ÇÁÉoÉäÉoÉäC++ÇæÇ©ÇÁãCDžǵǃǻǩǡÇΩÇÒÇæÇØÇ«ÅA
ê¢ÇÃíÜìIÇ…ÇÕ Java >> C/C++ Ç»ÇÒÇæÇÀ•••ÅB
780 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 01:06:22.94 ID:BwtcxBPu
DZDZÇÕé©çÏPCî¬ÇæÇ©ÇÁÉXÉ^ÉìÉhÉAÉçÉìå^ÇÃÉ\ÉtÉgǙǢÇÐÇæÇ…éÂó¨ÇæÇ∆
évÇ¢çûÇÒÇ≈ÇÈÉoÉJÇ™ëΩÇ¢ÇØÇ«ã∆äEÇ≈ÇÕ10îNà»è„ëOÇ©ÇÁÉTÅ[ÉoÉTÉCÉhÇ…
ÉEÉFÉCÉgǙǮǩÇÍÇÈÇÊǧDžǻǡǃÇÈÇÒÇæÇÊÇÀ
évÇ¢çûÇÒÇ≈ÇÈÉoÉJÇ™ëΩÇ¢ÇØÇ«ã∆äEÇ≈ÇÕ10îNà»è„ëOÇ©ÇÁÉTÅ[ÉoÉTÉCÉhÇ…
ÉEÉFÉCÉgǙǮǩÇÍÇÈÇÊǧDžǻǡǃÇÈÇÒÇæÇÊÇÀ
386SXÇÕíxÇ≠ǃêßå¿ÇÃëΩÇ¢í¥óÚâªCPUÇ∆ǢǧàµÇ¢ÇæÇ¡ÇΩÇ™ÅB
ǪÇýǪÇýC++ÇÕê∂éYê´Ç™à´Ç∑ǨÇÈÇÌÇ»ÅB
>>780
Ç®ÇÐÅAímÇÁǻǢDZÇ∆ÇýÇ¡Ç∆ÇýÇÁǵÇ≠Ǣǧï»é~ÇþÇΩï˚Ç™ÅB
Ç®ÇÐÅAímÇÁǻǢDZÇ∆ÇýÇ¡Ç∆ÇýÇÁǵÇ≠Ǣǧï»é~ÇþÇΩï˚Ç™ÅB
80376ÇÃóßèÍÇÕ
êîÇæÇØÇ≈åæÇ¡ÇΩÇÁÅAÉXÉ}ÉzÇ∆Ç©å¸ÇØÇ…çÏÇÁÇÍǃÇÈÉ\ÉtÉgÇ™àÍî‘ëΩÇ¢ÇæÇÎǧǩÇÁ
ÉXÉ^ÉìÉhÉAÉçÉìÇæÇÎǧǙÉTÅ[ÉoÅ[ÉTÉCÉhÇæÇÎǧǙÉNÉâÉCÉAÉìÉgÉTÉCÉhÇæÇÎǧǙ
JavaÇ™ê¢äEÇ¢ÇøÇ°Ç°Ç°!!Ç…Ç»ÇÈÇÃÇÕìñëRÇ≈ÇÕñ≥Ǣǩ?
ÉXÉ^ÉìÉhÉAÉçÉìÇæÇÎǧǙÉTÅ[ÉoÅ[ÉTÉCÉhÇæÇÎǧǙÉNÉâÉCÉAÉìÉgÉTÉCÉhÇæÇÎǧǙ
JavaÇ™ê¢äEÇ¢ÇøÇ°Ç°Ç°!!Ç…Ç»ÇÈÇÃÇÕìñëRÇ≈ÇÕñ≥Ǣǩ?
>>783
C++ÇÕñ{äiìIÇ…Ç‚ÇÎǧÇ∆Ç∑ÇÈÇ∆ìÔǵǢ
ÇæÇ©ÇÁÇýÇ¡Ç∆àµÇ¢Ç‚Ç∑Ç¢ÉIÉuÉWÉFÉNÉgéwå¸åæåÍÇ™ÇΩÇ≠Ç≥ÇÒçÏÇÁÇÍÇÈÇÒÇæÇÎǧÇÀ
C++ÇÕñ{äiìIÇ…Ç‚ÇÎǧÇ∆Ç∑ÇÈÇ∆ìÔǵǢ
ÇæÇ©ÇÁÇýÇ¡Ç∆àµÇ¢Ç‚Ç∑Ç¢ÉIÉuÉWÉFÉNÉgéwå¸åæåÍÇ™ÇΩÇ≠Ç≥ÇÒçÏÇÁÇÍÇÈÇÒÇæÇÎǧÇÀ
CåæåÍÇÕëºÇÃéËë±Ç´å^åæåÍÇëíÇËãéÇ¡ÇΩÇÃÇ∆ÇÕëŒè∆ìI
ÇÐÇæégÇÌÇÍǃÇÈëºÇÃéËë±Ç´å^åæåÍÇýÇÝÇÈÇ©ÇÁ
ëíÇËãéÇ¡ÇΩÇ∆ǢǧÇÃÇÕåæÇ¢Ç∑Ǩǩ
ÇæÇ™ÅAÇ©Ç»ÇËÇÃéËë±Ç´å^åæåÍÇëíÇ¡ÇΩÇÃÇÕéñé¿
ëíÇËãéÇ¡ÇΩÇ∆ǢǧÇÃÇÕåæÇ¢Ç∑Ǩǩ
ÇæÇ™ÅAÇ©Ç»ÇËÇÃéËë±Ç´å^åæåÍÇëíÇ¡ÇΩÇÃÇÕéñé¿
CåæåÍÇÃê¶Ç¢Ç∆DZÇÎÇÕÉAÉZÉìÉuÉâÇëíÇËãéÇ¡ÇΩÇ∆DZÇÎÇ≈ǵÇÂǧ
ÇÐÇÝÅAÉAÉZÉìÉuÉâÇ™äÆëSÇ…Ç»Ç≠ǻǡÇΩÇÌÇØÇ∂ǷǻǢǙÅA
ÉAÉZÉìÉuÉâÇ™ïKóvÇ»ÉvÉçÉOÉâÉÄÇÃèÍçáÅA
ÇŸÇ∆ÇÒÇ«ÇÃïîï™ÇCåæåÍÇ≈ǬÇ≠ǡǃÅAǫǧǵǃÇýÉAÉZÉìÉuÉâÇ™ïKóvÇ»ïîï™ÇÕÅA
CåæåÍÇÃÉ\Å[ÉXÉcÉäÅ[ÇÃíÜÇ…ÉAÉZÉìÉuÉâÇç¨Ç∫ÇÈÇ∆Ç©ÅAÉCÉìÉâÉCÉìÉAÉZÉìÉuÉâÇégǧÇ∆Ç©ÅA
ǪǧǢǡÇΩégÇ¢ï˚DžǻǡǃÇÈ
ǩǬǃÇÕÉAÉZÉìÉuÉâÇ™ïKê{ÇæÇ¡ÇΩOSÇ‚ÉfÉoÉCÉXÉhÉâÉCÉoÇÕÅAÇŸÇ∆ÇÒÇ«CåæåÍÇ≈çÏÇÁÇÍÇÈÇÊǧDžǻǡÇΩ
ÇÐÇÝÅAÉAÉZÉìÉuÉâÇ™äÆëSÇ…Ç»Ç≠ǻǡÇΩÇÌÇØÇ∂ǷǻǢǙÅA
ÉAÉZÉìÉuÉâÇ™ïKóvÇ»ÉvÉçÉOÉâÉÄÇÃèÍçáÅA
ÇŸÇ∆ÇÒÇ«ÇÃïîï™ÇCåæåÍÇ≈ǬÇ≠ǡǃÅAǫǧǵǃÇýÉAÉZÉìÉuÉâÇ™ïKóvÇ»ïîï™ÇÕÅA
CåæåÍÇÃÉ\Å[ÉXÉcÉäÅ[ÇÃíÜÇ…ÉAÉZÉìÉuÉâÇç¨Ç∫ÇÈÇ∆Ç©ÅAÉCÉìÉâÉCÉìÉAÉZÉìÉuÉâÇégǧÇ∆Ç©ÅA
ǪǧǢǡÇΩégÇ¢ï˚DžǻǡǃÇÈ
ǩǬǃÇÕÉAÉZÉìÉuÉâÇ™ïKê{ÇæÇ¡ÇΩOSÇ‚ÉfÉoÉCÉXÉhÉâÉCÉoÇÕÅAÇŸÇ∆ÇÒÇ«CåæåÍÇ≈çÏÇÁÇÍÇÈÇÊǧDžǻǡÇΩ
792 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 08:24:55.25 ID:BwtcxBPu
é©çÏPCî¬ÇÕê¢ä‘ÇÊÇËÉpÉ\ÉRÉìÇ≈égÇÌÇÍǃǻǢJavaÇÃï]âøÇ™í·Ç≠GPGPUÇÃï]âøÇ™àŸèÌÇ…çÇÇ¢
JavaÅAC#ÇÕã§Ç…íPàÍåpè≥Ç∆ÉCÉìÉ^Å[ÉtÉFÅ[ÉXÇÃëgÇðçáÇÌÇπ
ëΩèdåpè≥ÇÕÉgÉâÉuÉãÇÃå≥Ç∆ǢǧDZÇ∆Ç©
ëΩèdåpè≥ÇÕÉgÉâÉuÉãÇÃå≥Ç∆ǢǧDZÇ∆Ç©
å„î≠Ç≈ïÅãyǵǃǢÇÈåæåÍÇ…ÇÕǪÇÍÇ»ÇËÇÃóòì_Ç∆ǢǧÇýÇÃÇ™ÇÝÇÈÇÃÇæÇÊÅB
Ç∑Ç◊ǃÇÃåæåÍÇìëëøÇ∑ÇÈÇ∆ìoèÍǵÇΩJavaÇÕÅAåãã«ÇÕÉTÅ[ÉoÉTÉCÉhÇ≈ǵǩñÇ…óßÇΩǻǢï≥åæåÍÅB
åæåÍÇ∆ǵǃÇÕívñΩìIÇ»åáä◊ïiÅBÇπÇ¢Ç∫Ç¢COBOLÇÃë„ë÷ïiÇ≈ǵǩǻǢÅB
åæåÍÇ∆ǵǃÇÕívñΩìIÇ»åáä◊ïiÅBÇπÇ¢Ç∫Ç¢COBOLÇÃë„ë÷ïiÇ≈ǵǩǻǢÅB
ê¢Ç™ê¢Ç»ÇÁågë—í[ññè„ÇÃÉAÉvÉäÉPÅ[ÉVÉáÉìÇÕCOBOLÇ≈èëÇ©ÇÍǃǢÇΩ
Ç∆ǢǧéÂí£Ç≈ÇÝÇËÅAñ≤Ç™ÇÝÇÈÇ»Ç∆évÇ¢ÇÐǵÇΩÅB
Ç∆ǢǧéÂí£Ç≈ÇÝÇËÅAñ≤Ç™ÇÝÇÈÇ»Ç∆évÇ¢ÇÐǵÇΩÅB
Blu-rayÇ≈ÇýJavaÇ™égǶÇÈÇÒÇæÇÊÇÀÅH
ÉpÉ\ÉRÉìà»äOÇ≈ÇÕJavaÇÕåãç\égÇÌÇÍǃÇÈÇÒÇ∂ǷǻǢÇÃÅH
ÉKÉâÉPÅ[ÇæǡǃJavaégǡǃÇΩ
ÉpÉ\ÉRÉìà»äOÇ≈ÇÕJavaÇÕåãç\égÇÌÇÍǃÇÈÇÒÇ∂ǷǻǢÇÃÅH
ÉKÉâÉPÅ[ÇæǡǃJavaégǡǃÇΩ
Blu-rayÇ‚ÉKÉâÉPÅ[ÇÃJavaÇÕJavaÇýÇ«Ç´Ç≈ñ{äiJavaÇ∂ǷǻǢÇ≈ǵÇÂÅH
swingÇ∆Ç©ìÆǩǻǢǵ
swingÇ∆Ç©ìÆǩǻǢǵ
JavaÇýÇ«Ç´Ç≈ÇýJavaÇ…ÇÕïœÇÌÇËǻǢ
AndroidÇýJavaÇýÇ«Ç´ÇæÇÀ
AndroidÇýJavaÇýÇ«Ç´ÇæÇÀ
Blu-rayÇÃÇÕÇøÇ·ÇÒÇ∆îFíËéÊǡǃÇÈÇ©ÇÁÅAçŸîªçπëøDžǻǡÇΩAndroidÇ»ÇÒÇ©Ç∆î‰Ç◊ÇΩÇÁÅAÇýÇ«Ç´Ç≈ÇýÇ»ÇÒÇ≈ÇýǻǢǻ
ǬǩÅAëgÇðçûÇðÇ…égÇÌÇÍǃÇÈÇ©ÇÁǡǃÅAÇýÇ«Ç´Ç∆Ç©åæǧà”ñ°Ç»Ç¢ÇæÇÎ
ǬǩÅAëgÇðçûÇðÇ…égÇÌÇÍǃÇÈÇ©ÇÁǡǃÅAÇýÇ«Ç´Ç∆Ç©åæǧà”ñ°Ç»Ç¢ÇæÇÎ
êÃÅAJavaÇýÇ«Ç´ÇÕJavaÇ≈ÇÕǻǢÇ∆ëiǶÇΩâÔé–Ç™ÇÝǡǃǻÅB
802 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 10:58:31.85 ID:BwtcxBPu
BD-JavaÇÕåˆéÆÇÃJ2MEÇégǡǃÇÈÇ©ÇÁåàǵǃÇýÇ«Ç´Ç≈ÇÕǻǢ
åˆéÆè§ñ@Ç©ÅBåæåÍÇÃèüéËÇ»é¿ëïÇÕîFÇþǻǢÇ∆ǢǧDZÇ∆ÅB
Ç‚Ç¡ÇœÇËï≥Ç∑ǨÇÈÅBÉAÉbÉvÉãè§ñ@Ç∆ìØÇ∂Ç≠â∫óÚÅB
Ç‚Ç¡ÇœÇËï≥Ç∑ǨÇÈÅBÉAÉbÉvÉãè§ñ@Ç∆ìØÇ∂Ç≠â∫óÚÅB
BDÇÃèÍçáÇÕÅAåˆéÆÇ…JavaîFíËÇÇ∆Ç¡ÇΩJavaÇýǫǴǡǃä¥Ç∂ÇæÇÀ
OracleǙDZÇÒÇ»ÇÃçÏǡǃÇÈÇó
http://www.oracle.com/technetwork/jp/ondemand/java/20110519-java-a-5-visionare-400526-ja.pdf
http://www.oracle.com/technetwork/jp/ondemand/java/20110519-java-a-5-visionare-400526-ja.pdf
806 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 11:36:02.27 ID:BwtcxBPu
>>804
ÇæÇ©ÇÁJ2MEÇÕåˆéÆÇÃëgÇðçûÇðå¸ÇØÉGÉfÉBÉVÉáÉìÇæǡǃåæǡǃÇÈÇæÇÎÅB
ÇýÇ∆ÇýÇ∆SwingÇÕJ2MEÇ≈ìÆÇ≠ÇÊǧDžÇÕçÏÇÁÇÍǃǻǢÅB
åNÇÃî≠åæÇÕx86-Win32ÇÃPEÇ™ìÆǩǻǢǩÇÁWindowsCEÇÕWindowsÇ∂ǷǻǢǡǃ
ê¿Ç¡ÇƒÇÈÇÃÇ∆ìØÇ∂Ç≠ÇÁÇ¢DQN
ÇæÇ©ÇÁJ2MEÇÕåˆéÆÇÃëgÇðçûÇðå¸ÇØÉGÉfÉBÉVÉáÉìÇæǡǃåæǡǃÇÈÇæÇÎÅB
ÇýÇ∆ÇýÇ∆SwingÇÕJ2MEÇ≈ìÆÇ≠ÇÊǧDžÇÕçÏÇÁÇÍǃǻǢÅB
åNÇÃî≠åæÇÕx86-Win32ÇÃPEÇ™ìÆǩǻǢǩÇÁWindowsCEÇÕWindowsÇ∂ǷǻǢǡǃ
ê¿Ç¡ÇƒÇÈÇÃÇ∆ìØÇ∂Ç≠ÇÁÇ¢DQN
WindowsCEÇÕÇ‚Ç¡ÇœÇËÇ¢ÇÐÇ¢ÇøÇ»êªïiÇ≈ÇÝÇËÉlÅ[É~ÉìÉOÇæÇ¡ÇΩç°Ç»Ç®évǧǻÅ[
>>806
ÉvÉçÉ_ÉNÉVÉáÉìñºÇ≈ÇÝÇÈWindowsÇ
ÇÝÇΩÇ©ÇýÉvÉâÉbÉgÉtÉHÅ[ÉÄñºÇ∆ǵǃåæǡǃÇÈÇ®ÇÐǶǙàÍî‘ÇÃDQNÅB
çºã\étÅBÇÐÇÈÇ≈É}ÉJÅ[ÅB
ÉvÉçÉ_ÉNÉVÉáÉìñºÇ≈ÇÝÇÈWindowsÇ
ÇÝÇΩÇ©ÇýÉvÉâÉbÉgÉtÉHÅ[ÉÄñºÇ∆ǵǃåæǡǃÇÈÇ®ÇÐǶǙàÍî‘ÇÃDQNÅB
çºã\étÅBÇÐÇÈÇ≈É}ÉJÅ[ÅB
809 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 12:16:04.17 ID:BwtcxBPu
ǧÇÌÅ[ÉåÉxÉãí·Ç∑
ÉKÉâÉPÅ[Ç‚BDå¸ÇØÇÃJ2MEÇÕÉoÉCÉgÉRÅ[ÉhÇÃÉtÉHÅ[É}ÉbÉgÇ…åðä∑ÇÕÇÝÇÈ
ëgÇðçûÇðå¸ÇØÇÃóvåèÇ…ÇÝÇÌÇπÇÈÇΩÇþÇ…ÉâÉCÉuÉâÉäÇÕçÌǡǃÇÈÇ™
ǪÇýǪÇýÉâÉCÉuÉâÉäÇÃåðä∑ê´ÇÕJavaÇÃåðä∑ê´ÇÃîÕ·eäOÅB
ÉfÉoÉCÉXàÀë∂ÇÃÉlÉCÉeÉBÉuÉRÅ[ÉhåƒÇ—èoǵǻǫÇ≥ǶǻÇØÇÍÇŒ
äÓñ{ìIÇ…ëSÇ≠ìØÇ∂ÉRÅ[ÉhÇìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
AndroidÇÃDarvikÇÕǪÇýǪÇýÉoÉCÉiÉäåðä∑ǙǻǢÅB
DZÇÍÇ™åˆéÆÇ∆îÒåˆéÆÇÃç∑ÅB
ÉKÉâÉPÅ[Ç‚BDå¸ÇØÇÃJ2MEÇÕÉoÉCÉgÉRÅ[ÉhÇÃÉtÉHÅ[É}ÉbÉgÇ…åðä∑ÇÕÇÝÇÈ
ëgÇðçûÇðå¸ÇØÇÃóvåèÇ…ÇÝÇÌÇπÇÈÇΩÇþÇ…ÉâÉCÉuÉâÉäÇÕçÌǡǃÇÈÇ™
ǪÇýǪÇýÉâÉCÉuÉâÉäÇÃåðä∑ê´ÇÕJavaÇÃåðä∑ê´ÇÃîÕ·eäOÅB
ÉfÉoÉCÉXàÀë∂ÇÃÉlÉCÉeÉBÉuÉRÅ[ÉhåƒÇ—èoǵǻǫÇ≥ǶǻÇØÇÍÇŒ
äÓñ{ìIÇ…ëSÇ≠ìØÇ∂ÉRÅ[ÉhÇìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
AndroidÇÃDarvikÇÕǪÇýǪÇýÉoÉCÉiÉäåðä∑ǙǻǢÅB
DZÇÍÇ™åˆéÆÇ∆îÒåˆéÆÇÃç∑ÅB
ÇÕÇ¢ÇÕÇ¢ÅAWrite once, run anywhere.(èŒ) Ç≈Ç∑ÇÀw
éUÅXVMÇÃä¬ã´àÀë∂ÉoÉOèoǵÇ∆Ǣǃç°çXÉoÉCÉgÉRÅ[Éhåðä∑Çã≠í≤Ç≥ÇÍǃÇýÇÀÅB
éUÅXVMÇÃä¬ã´àÀë∂ÉoÉOèoǵÇ∆Ǣǃç°çXÉoÉCÉgÉRÅ[Éhåðä∑Çã≠í≤Ç≥ÇÍǃÇýÇÀÅB
811 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/05(ìy) 12:34:31.13 ID:BwtcxBPu
> ä¬ã´àÀë∂ÉoÉO
ä¬ã´àÀë∂ïîÇÕJNIåoóRÇ≈C++ÉRÅ[ÉhÇåƒÇ—èoÇ∑ÇæÇØÇæÇ©ÇÁëÂíÔC++ÉRÅ[ÉhèëÇ¢ÇΩǂǬÇÃê”îCÇæÇÊ
ä¬ã´àÀë∂ïîÇÕJNIåoóRÇ≈C++ÉRÅ[ÉhÇåƒÇ—èoÇ∑ÇæÇØÇæÇ©ÇÁëÂíÔC++ÉRÅ[ÉhèëÇ¢ÇΩǂǬÇÃê”îCÇæÇÊ
>ÉfÉoÉCÉXàÀë∂ÇÃÉlÉCÉeÉBÉuÉRÅ[ÉhåƒÇ—èoǵǻǫÇ≥ǶǻÇØÇÍÇŒ
>äÓñ{ìIÇ…ëSÇ≠ìØÇ∂ÉRÅ[ÉhÇìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
DZÇÍǡǃx86ÇýǪǧÇæÇÊÇ»ÅB
ã@éÌàÀë∂ǵǻǢÉRÅ[ÉhÇÕPCÇ≈ÇýëgÇðçûÇðÇ≈Çýåðä∑ê´Ç™ÇÝÇÈÅB
DZÇÒǻDZÇ∆Ç≈à–í£Ç¡ÇƒÇÈÇ©ÇÁâÔé–í◊ÇÍÇÈÇÒÇæÇÊÅB
>äÓñ{ìIÇ…ëSÇ≠ìØÇ∂ÉRÅ[ÉhÇìÆÇ©Ç∑DZÇ∆Ç™Ç≈Ç´ÇÈÅB
DZÇÍǡǃx86ÇýǪǧÇæÇÊÇ»ÅB
ã@éÌàÀë∂ǵǻǢÉRÅ[ÉhÇÕPCÇ≈ÇýëgÇðçûÇðÇ≈Çýåðä∑ê´Ç™ÇÝÇÈÅB
DZÇÒǻDZÇ∆Ç≈à–í£Ç¡ÇƒÇÈÇ©ÇÁâÔé–í◊ÇÍÇÈÇÒÇæÇÊÅB
ǫǧǵǃǪǧǢǧòbÇ…ÅH
ñ⁄ìIñ≥Ç≠çÏÇ¡ÇΩ
http://www.geocities.jp/andosprocinfo/wadai14/20140705.htm
ÇSÅDìVâÕ2çÜÇýëÂïœÇªÇ§
Å@Å@7åéèâÇþÇ©ÇÁñ{äiâ^ópÇ…ì¸Ç¡ÇΩíÜçëÇ™å÷ÇÈTop500 1à ÇÃìVâÕ2çÜÇ≈Ç∑Ç™ÅC
2014îN6åé30ì˙ÇÃSouth China Morning PostÇ™êˆçðÉÜÅ[ÉUÇÕÇÝÇÐÇËä¥êSǵǃǢǻǢÇ∆ïÒÇ∂ǃǢÇÐÇ∑ÅB
Å@Å@ǪÇÃëÊ1ÇÃóùóRÇÕ1ì˙ÇÃìdãCë„Ç™40ñúå≥Å`60ñúå≥Åi66ñúâ~Å`99ñúâ~Åjä|Ç©ÇËÅCç≈èIìIÇ…ÇÕÉÜÅ[ÉUÇÃïâíSÇ…Ç»ÇÈÇÃÇ≈ÅCégópóøÇ™ëÂïœÇ∆ǢǧÇýÇÃÇ≈Ç∑Ç™ÅC
DZÇÍÇÕç≈èâÇ©ÇÁï™Ç©Ç¡ÇƒÇ¢ÇΩòbÇ≈ÅCç°çXÅCéùÇøèoÇ≥ÇÍǃÇýÇ∆Ǣǧä¥Ç∂ÇýǵÇÐÇ∑ÅB
ÇÐÇΩÅCââéZÇÝÇΩÇËÇÃìdãCë„ÇÕÅCDZÇÍÇÐÇ≈ÇÃÉXÉpÉRÉìÇÊÇËå∏ǡǃǢÇÈî§Ç≈Ç∑ÅB
Å@Å@ÇÊÇËñ{éøìIÇ»ÇÃÇÕÅCDZÇÍÇÐÇ≈ÇÃìäéëÇ™ÉnÅ[ÉhÇ…ïŒÇ¡ÇƒÇ¢ÇΩÇΩÇþÇ…ÅCÉ\ÉtÉgÇ™ñ≥Ç≠ÅCÉÜÅ[ÉUÇ™é©ï™Ç≈èëÇ©Ç»ÇØÇÍÇŒégǶǻǢÇ∆Ǣǧì_Ç≈Ç∑ÅB
DZÇÍÇÐÇ≈ÅCìSìπÇÃêðåvÅCínêkÉVÉ~ÉÖÉåÅ[ÉVÉáÉìÅCìVëÃï®óùÅCà‚ì`éqå§ãÜÇ…égÇÌÇÍǃǢÇÐÇ∑Ç™ÅCDZÇÍÇÐÇ≈ÇÃÉNÉâÉCÉAÉìÉgÇÕ120É`Å[ÉÄÇ≈ÅCî\óÕÇÃ34%ǵǩégÇÌÇÍǃǢǻǢÇ∆ÇÃDZÇ∆Ç≈Ç∑ÅB
Ç∆ǢǧDZÇ∆Ç≈ÅCTop500Ç≈ÇÕ1à Ç»ÇÃÇ≈Ç∑Ç™ÅCǪÇÃóLå¯ê´ÇÕÅCïƒçëÇ‚ì˙ñ{ÇÃÉXÉpÉRÉìÇ…ëÂÇ´Ç≠óÚÇÈÇ∆ï]âøǵǃǢÇÐÇ∑ÅB
Å@Å@ǻǮÅCìVâÕ2çÜÇÕIntelÇÃXeonÇ∆Xeon PhiÇégǡǃǮÇËÅCDZÇÁÇÍÇÃÉ`ÉbÉvÇÃóAì¸ÇÃèåèÇ∆ǵǃåRéñóòópÇÕã÷Ç∂ÇÁÇÍǃǢÇÐÇ∑ÅB
http://www.geocities.jp/andosprocinfo/wadai14/20140705.htm
ÇSÅDìVâÕ2çÜÇýëÂïœÇªÇ§
Å@Å@7åéèâÇþÇ©ÇÁñ{äiâ^ópÇ…ì¸Ç¡ÇΩíÜçëÇ™å÷ÇÈTop500 1à ÇÃìVâÕ2çÜÇ≈Ç∑Ç™ÅC
2014îN6åé30ì˙ÇÃSouth China Morning PostÇ™êˆçðÉÜÅ[ÉUÇÕÇÝÇÐÇËä¥êSǵǃǢǻǢÇ∆ïÒÇ∂ǃǢÇÐÇ∑ÅB
Å@Å@ǪÇÃëÊ1ÇÃóùóRÇÕ1ì˙ÇÃìdãCë„Ç™40ñúå≥Å`60ñúå≥Åi66ñúâ~Å`99ñúâ~Åjä|Ç©ÇËÅCç≈èIìIÇ…ÇÕÉÜÅ[ÉUÇÃïâíSÇ…Ç»ÇÈÇÃÇ≈ÅCégópóøÇ™ëÂïœÇ∆ǢǧÇýÇÃÇ≈Ç∑Ç™ÅC
DZÇÍÇÕç≈èâÇ©ÇÁï™Ç©Ç¡ÇƒÇ¢ÇΩòbÇ≈ÅCç°çXÅCéùÇøèoÇ≥ÇÍǃÇýÇ∆Ǣǧä¥Ç∂ÇýǵÇÐÇ∑ÅB
ÇÐÇΩÅCââéZÇÝÇΩÇËÇÃìdãCë„ÇÕÅCDZÇÍÇÐÇ≈ÇÃÉXÉpÉRÉìÇÊÇËå∏ǡǃǢÇÈî§Ç≈Ç∑ÅB
Å@Å@ÇÊÇËñ{éøìIÇ»ÇÃÇÕÅCDZÇÍÇÐÇ≈ÇÃìäéëÇ™ÉnÅ[ÉhÇ…ïŒÇ¡ÇƒÇ¢ÇΩÇΩÇþÇ…ÅCÉ\ÉtÉgÇ™ñ≥Ç≠ÅCÉÜÅ[ÉUÇ™é©ï™Ç≈èëÇ©Ç»ÇØÇÍÇŒégǶǻǢÇ∆Ǣǧì_Ç≈Ç∑ÅB
DZÇÍÇÐÇ≈ÅCìSìπÇÃêðåvÅCínêkÉVÉ~ÉÖÉåÅ[ÉVÉáÉìÅCìVëÃï®óùÅCà‚ì`éqå§ãÜÇ…égÇÌÇÍǃǢÇÐÇ∑Ç™ÅCDZÇÍÇÐÇ≈ÇÃÉNÉâÉCÉAÉìÉgÇÕ120É`Å[ÉÄÇ≈ÅCî\óÕÇÃ34%ǵǩégÇÌÇÍǃǢǻǢÇ∆ÇÃDZÇ∆Ç≈Ç∑ÅB
Ç∆ǢǧDZÇ∆Ç≈ÅCTop500Ç≈ÇÕ1à Ç»ÇÃÇ≈Ç∑Ç™ÅCǪÇÃóLå¯ê´ÇÕÅCïƒçëÇ‚ì˙ñ{ÇÃÉXÉpÉRÉìÇ…ëÂÇ´Ç≠óÚÇÈÇ∆ï]âøǵǃǢÇÐÇ∑ÅB
Å@Å@ǻǮÅCìVâÕ2çÜÇÕIntelÇÃXeonÇ∆Xeon PhiÇégǡǃǮÇËÅCDZÇÁÇÍÇÃÉ`ÉbÉvÇÃóAì¸ÇÃèåèÇ∆ǵǃåRéñóòópÇÕã÷Ç∂ÇÁÇÍǃǢÇÐÇ∑ÅB
åRéñóòópã÷é~Ç»ÇÒǃéÁǡǃÇÈÇÌÇØǻǢÇ∂Ç·ÇÒÇó
816 ÅFSocket774ÅF2014/07/05(ìy) 22:13:38.55 ID:6pbNtMWH
>>814
ì˙ñ{Ç∆ìØÇ∂åãâ ÅBÉlÉgÉEÉàÇýç∂óÉÇýîné≠Ç∆ǢǧDZÇ∆ÅB
ì˙ñ{Ç∆ìØÇ∂åãâ ÅBÉlÉgÉEÉàÇýç∂óÉÇýîné≠Ç∆ǢǧDZÇ∆ÅB
>>816
ïƒçëÇ‚ì˙ñ{ÇÃÉXÉpÉRÉìÇ…ëÂÇ´Ç≠óÚÇÈÇ∆ï]âøǵǃǢÇÐÇ∑ǡǃèëǢǃÇÝÇÈÇÃÇ™ì«ÇþǻǢÇÃÇ©
ïƒçëÇ‚ì˙ñ{ÇÃÉXÉpÉRÉìÇ…ëÂÇ´Ç≠óÚÇÈÇ∆ï]âøǵǃǢÇÐÇ∑ǡǃèëǢǃÇÝÇÈÇÃÇ™ì«ÇþǻǢÇÃÇ©
>>817
íˆìxÇÃDZǪÇÝÇÍÉoÉJÇ…à·Ç¢ÇÕǻǢÇæÇÎǧÅB
íˆìxÇÃDZǪÇÝÇÍÉoÉJÇ…à·Ç¢ÇÕǻǢÇæÇÎǧÅB
ëΩèdåpè≥Ç∆ââéZéqÉIÅ[ÉoÅ[ÉçÅ[ÉhÇÕäQǵǩǻǢÅB
Ç≈ÇýÅAçsóÒÇÃèÊéZÇ*Ç≈Ç≈Ç´ÇÈÇÃÇÕëfê∞ÇÁǵǢÇ∆évǧÇÊÅB
>>820
Å~ëfê∞ÇÁǵǢ
ÅõÇΩÇÐÇ…ï÷óòÇ»Ç∆Ç´Ç™ÇÝÇÈ
Åùè¨Ç≥Ç¢ÉvÉçÉOÉâÉÄÇ»ÇÁÇÐÇæó«Ç¢Ç™ÅAëÂãKñÕÇ»É\ÉtÉgÉEÉFÉAÇ≈
Å@ǪÇÍǂǡǃÇÈÇ∆ç¨óêÇÃå≥Ç≈äQÇ™ÇÝÇÈ
Å~ëfê∞ÇÁǵǢ
ÅõÇΩÇÐÇ…ï÷óòÇ»Ç∆Ç´Ç™ÇÝÇÈ
Åùè¨Ç≥Ç¢ÉvÉçÉOÉâÉÄÇ»ÇÁÇÐÇæó«Ç¢Ç™ÅAëÂãKñÕÇ»É\ÉtÉgÉEÉFÉAÇ≈
Å@ǪÇÍǂǡǃÇÈÇ∆ç¨óêÇÃå≥Ç≈äQÇ™ÇÝÇÈ
822 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 00:52:28.51 ID:ND+h/L4E
Mix-inÇýëΩèdåpè≥ÇÃï˚ñ@ÇÃÇ–Ç∆ǬÇæÇÊÅB
ëΩèdåpè≥Ç…ñ‚ëËÇ™ÇÝÇÈÇ∆Ç¢ÇÌÇÍÇÈÇÃÇÕ
ÅuÇ∑Ç◊ǃÇÃÉNÉâÉXÇÕObjectÉNÉâÉXÇ©ÇÁîhê∂Ç∑ÇÈÅv
Ç∆ǢǧÉNÉâÉXäKëwêðåvÇ™ëOíÒÇÃÇ∆Ç´ÇÃòb
íPèÉÇ»òbÇ≈ÅAinterfaceÇÕäÓíÍÉNÉâÉXÇéùÇΩǻǢǩÇÁïõçÏópǙǻǢ
C++ÇÕiostreamÇÃêðåvÇ™î¸ÇµÇ≠ǻǢÇÊÇ»
É_ÉCÉÑÉÇÉìÉhåpè≥ÇÉ_ÉCÉÑÉÇÉìÉhåpè≥ÇÃÇÐÇÐǂǡǃÇÈ
ëΩèdåpè≥Ç…ñ‚ëËÇ™ÇÝÇÈÇ∆Ç¢ÇÌÇÍÇÈÇÃÇÕ
ÅuÇ∑Ç◊ǃÇÃÉNÉâÉXÇÕObjectÉNÉâÉXÇ©ÇÁîhê∂Ç∑ÇÈÅv
Ç∆ǢǧÉNÉâÉXäKëwêðåvÇ™ëOíÒÇÃÇ∆Ç´ÇÃòb
íPèÉÇ»òbÇ≈ÅAinterfaceÇÕäÓíÍÉNÉâÉXÇéùÇΩǻǢǩÇÁïõçÏópǙǻǢ
C++ÇÕiostreamÇÃêðåvÇ™î¸ÇµÇ≠ǻǢÇÊÇ»
É_ÉCÉÑÉÇÉìÉhåpè≥ÇÉ_ÉCÉÑÉÇÉìÉhåpè≥ÇÃÇÐÇÐǂǡǃÇÈ
>>822
njǩÇþÅAóîópÇ™äQÇÇýÇΩÇÁÇ∑Ç∆åæǧòbÇ…
ÉåÉAÉPÅ[ÉXèoǵǃîΩò_ãCéÊÇËÇ©ÇÊ
Ç‚ÇÕÇËÇ®ëOÇ…ÇÕÇÐÇæâ¥ÇÃëäéËÇÕñ≥óùǪǧÇæÇ»
njǩÇþÅAóîópÇ™äQÇÇýÇΩÇÁÇ∑Ç∆åæǧòbÇ…
ÉåÉAÉPÅ[ÉXèoǵǃîΩò_ãCéÊÇËÇ©ÇÊ
Ç‚ÇÕÇËÇ®ëOÇ…ÇÕÇÐÇæâ¥ÇÃëäéËÇÕñ≥óùǪǧÇæÇ»
ãcò_ÇíPèÉâªÇµÇ∑ǨǃǢǃÅAǫǧì]ÇÒÇ≈Çýì™à´Ç¢ä¥Ç∂DžǵǩǻÇÁǻǢ
TOP500ÉâÉìÉLÉìÉOé©ëÃîpé~Ç≥ÇπÇÈDZÇ∆ÇÕâ¬î\Ç»ÇÃÇ©
TOP500ÇLinpackÇæÇØÇ∂Ç·Ç»Ç≠ÅAêîéÌóÞÇÃåvéZégǧÇÃÇ™ìKêÿÇ»ÇÊǧǻ
ǪÇÍÇÕÇ¢ÇÐÇ©ÇÁÇ‚ÇÈÇ∆DZÇÎÇ≈Ç∑Ç©ÇÁ
828 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 09:42:02.70 ID:BHt0mlSb
>>823
Ç®ëOÇðÇΩǢǻÉoÉJÇíNÇýëäéËÇ…ÇýǵÇΩÇ≠ǻǢǩÇÁè¡Ç¶ÇƒÇ¢Ç¢ÇÊèüéËÇ…
C++Ç≈ÇÕinterfaceÇÕäÓíÍÉIÉuÉWÉFÉNÉgÉNÉâÉXÇéùÇΩǻǢëÄçÏÉNÉâÉXÇæ
JavaÇÃinterfaceÇýRubyÇÃModuleÇýäÓíÍÉNÉâÉXÇéùÇΩǻǢ
ATLÇ∆Ç©WTLÇÕmix-inÅiëΩèdåpè≥ÅjÇëOíÒÇ…ÉNÉâÉXÇ™êðåvÇ≥ÇÍǃÇÈÇ©ÇÁ
égÇÌÇ∏èëÇ≠ï˚Ç™ñ≥óùÇæÇ»
Ç®ëOÇðÇΩǢǻÉoÉJÇíNÇýëäéËÇ…ÇýǵÇΩÇ≠ǻǢǩÇÁè¡Ç¶ÇƒÇ¢Ç¢ÇÊèüéËÇ…
C++Ç≈ÇÕinterfaceÇÕäÓíÍÉIÉuÉWÉFÉNÉgÉNÉâÉXÇéùÇΩǻǢëÄçÏÉNÉâÉXÇæ
JavaÇÃinterfaceÇýRubyÇÃModuleÇýäÓíÍÉNÉâÉXÇéùÇΩǻǢ
ATLÇ∆Ç©WTLÇÕmix-inÅiëΩèdåpè≥ÅjÇëOíÒÇ…ÉNÉâÉXÇ™êðåvÇ≥ÇÍǃÇÈÇ©ÇÁ
égÇÌÇ∏èëÇ≠ï˚Ç™ñ≥óùÇæÇ»
829 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 09:53:56.59 ID:BHt0mlSb
öMì˚óÞÉNÉâÉXÇ©ÇÁîhê∂Ç∑ÇÈÅuå~ÅvÉNÉâÉXÇ…ÅAãõÉNÉâÉXÇ∆ìØÇ∂ÅuêÖíÜÇâjÇÆÅvÇ∆ǢǧÉÅÉ\ÉbÉhÇ
éùÇΩÇπÇΩÇ¢èÍçáÅAëΩèdåpè≥à»äOÇÃÉXÉ}Å[ÉgÇ»ï˚ñ@ÇÝÇÈÇ©Ç»ÅH
ÇýÇøÇÎÇÒã§í ÇÃÅuìÆï®ÅvÉNÉâÉXÇ…ÅuâjÇÆÅvÇí«â¡Ç∑ÇÈÇ∆ǢǧÇÃÇýÉ_ÉTÇ¢
ÇýÇøÇÎÇÒå~ÇÕãõÇ≈ÇÕǻǢÇÃÇ≈ãõÉNÉâÉXÇåpè≥Ç∑ÇÈÇ∆ǢǧÇÃÇýä‘à·Ç¢
ÅuâjÇÆÅvÇÉCÉìÉ^Å[ÉtÉFÅ[ÉXÇ∆ǵǃíÒãüÇ∑ÇÍnjǢǢÇ∂Ç·ÇÒ
éùÇΩÇπÇΩÇ¢èÍçáÅAëΩèdåpè≥à»äOÇÃÉXÉ}Å[ÉgÇ»ï˚ñ@ÇÝÇÈÇ©Ç»ÅH
ÇýÇøÇÎÇÒã§í ÇÃÅuìÆï®ÅvÉNÉâÉXÇ…ÅuâjÇÆÅvÇí«â¡Ç∑ÇÈÇ∆ǢǧÇÃÇýÉ_ÉTÇ¢
ÇýÇøÇÎÇÒå~ÇÕãõÇ≈ÇÕǻǢÇÃÇ≈ãõÉNÉâÉXÇåpè≥Ç∑ÇÈÇ∆ǢǧÇÃÇýä‘à·Ç¢
ÅuâjÇÆÅvÇÉCÉìÉ^Å[ÉtÉFÅ[ÉXÇ∆ǵǃíÒãüÇ∑ÇÍnjǢǢÇ∂Ç·ÇÒ
>>829
StrategyÉpÉ^Å[ÉìÅH
StrategyÉpÉ^Å[ÉìÅH
>>829
ÉÄî¬ÇÃJavaÇÃèâêSé“ÉXÉåï”ÇËÇ≈Ç‚ÇÍÇŒÅH
ÉÄî¬ÇÃJavaÇÃèâêSé“ÉXÉåï”ÇËÇ≈Ç‚ÇÍÇŒÅH
832 ÅFSocket774ÅF2014/07/06(ì˙) 11:45:15.44 ID:lFSzb+1p
>>819
ÇΩÇ∆Ƕnj256bitêÆêîÉNÉâÉXÇíËã`ǵÇΩÇ∆ǵÇÊǧÅB
â¡éZÇ…AddÉÅÉ\ÉbÉhǵǩégǶǻǢJavaǡǃÉAÉzÇ∆ÇÕévÇÌǻǢÇÃÇ©ÅB
ÇΩÇ∆Ƕnj256bitêÆêîÉNÉâÉXÇíËã`ǵÇΩÇ∆ǵÇÊǧÅB
â¡éZÇ…AddÉÅÉ\ÉbÉhǵǩégǶǻǢJavaǡǃÉAÉzÇ∆ÇÕévÇÌǻǢÇÃÇ©ÅB
ñæämÇ…åpè≥Ç™ìKǵǃǢÇÈèÍçáà»äOÅA
äÓñ{Ç…óßÇøï‘ǡǃàœè˜égǶÇÊ πÞÇ«Çý
ÇøÇ¡ÇøÇ·Ç¢ÅuÉvÉçÉOÉâÉÄÅvǵǩêGÇ¡ÇΩDZÇ∆ñ≥ÇØÇÍÇŒé¿ä¥Ç»Ç¢ÇæÇÎǧǙ
åpè≥Ç≈àÀë∂ä÷åWçÏÇËÇÐÇ≠ÇËÇÃø∞ΩÇÕâ¬ì«ê´Çâ∫Ç∞ÉÅÉìÉeÉiÉìÉXÉRÉXÉgíµÇÀè„Ç™ÇÈǺ
ǬǩÅADZǧǢǧòbÇÕÉÄî¬ÇÃèâêSé“ÉXÉåÇ≈Ç‚ÇÍÇÊ
ÇÝÇ∆mix-inÇ∆ǢǶnjflavorÇ‚CLOSÇëÊàÍÇ…évÇ¢ïÇÇ©Ç◊ÇÈÇ™
ÇÝÇÍÇŒëçèÃä÷êîmethodÇ™ÇÐÇ∏ÇÝÇËÇ´Ç≈ÅAÉNÉâÉXä‘ÇÃåpè≥ä÷åWÇ∆ç¨ìØÇÕïsé©ëRÇæǺ
>>824
DZǧÇ≠Ç«Ç≠Ç«èëǢǃñ·ÇÌǻǢÇ∆É\ÉtÉgÇÃäÓñ{ÇýÉèÉJÉâÉìÇ©ÅH
äÓñ{Ç…óßÇøï‘ǡǃàœè˜égǶÇÊ πÞÇ«Çý
ÇøÇ¡ÇøÇ·Ç¢ÅuÉvÉçÉOÉâÉÄÅvǵǩêGÇ¡ÇΩDZÇ∆ñ≥ÇØÇÍÇŒé¿ä¥Ç»Ç¢ÇæÇÎǧǙ
åpè≥Ç≈àÀë∂ä÷åWçÏÇËÇÐÇ≠ÇËÇÃø∞ΩÇÕâ¬ì«ê´Çâ∫Ç∞ÉÅÉìÉeÉiÉìÉXÉRÉXÉgíµÇÀè„Ç™ÇÈǺ
ǬǩÅADZǧǢǧòbÇÕÉÄî¬ÇÃèâêSé“ÉXÉåÇ≈Ç‚ÇÍÇÊ
ÇÝÇ∆mix-inÇ∆ǢǶnjflavorÇ‚CLOSÇëÊàÍÇ…évÇ¢ïÇÇ©Ç◊ÇÈÇ™
ÇÝÇÍÇŒëçèÃä÷êîmethodÇ™ÇÐÇ∏ÇÝÇËÇ´Ç≈ÅAÉNÉâÉXä‘ÇÃåpè≥ä÷åWÇ∆ç¨ìØÇÕïsé©ëRÇæǺ
>>824
DZǧÇ≠Ç«Ç≠Ç«èëǢǃñ·ÇÌǻǢÇ∆É\ÉtÉgÇÃäÓñ{ÇýÉèÉJÉâÉìÇ©ÅH
åpè≥ǡǃëΩë‘ÇÃÇΩÇþÇ…ç≈è¨å¿óòópÇ∑ÇÈÇæÇØÇ≈ÅA
èoóàÇÈå¿ÇËèWñÒÅiàœè˜ÅjÇ…Ç∑Ç◊Ç´ÇæÇÊÇÀÅB
ñ{Ç…èëǢǃÇÈDZÇ∆ÇæÇØÇ«ÅAé©ï™Ç≈ǂǡǃÇðǃÇýǪÇÃí ÇËÇæÇ∆µ”¿ÅB
èoóàÇÈå¿ÇËèWñÒÅiàœè˜ÅjÇ…Ç∑Ç◊Ç´ÇæÇÊÇÀÅB
ñ{Ç…èëǢǃÇÈDZÇ∆ÇæÇØÇ«ÅAé©ï™Ç≈ǂǡǃÇðǃÇýǪÇÃí ÇËÇæÇ∆µ”¿ÅB
ÉCÉìÉ^Å[ÉtÉFÅ[ÉX=édól
É~ÉbÉNÉXÉCÉì=é¿ëï
É~ÉbÉNÉXÉCÉì=é¿ëï
ǪǧÅAinterfaceÇ∆classÇìØàÍê¸è„Ç≈òbǵÇΩÇËÇ∑Ç≤Ç¢à·òaä¥ÇÝÇÈÅB
C++ÇÕǵÇÂǧǙǻǢǩÇÁäÆëSâºëzÇ≈ë„ópǵǃǢÇÈÇÃÇ…ÅB
Ç»ÇÒÇ»ÇÃÅHÇÝÇÃÉRÉeÅAì™óNǢǃǢÇÈÇÃÅH
C++ÇÕǵÇÂǧǙǻǢǩÇÁäÆëSâºëzÇ≈ë„ópǵǃǢÇÈÇÃÇ…ÅB
Ç»ÇÒÇ»ÇÃÅHÇÝÇÃÉRÉeÅAì™óNǢǃǢÇÈÇÃÅH
é©ï™Ç≈ÉXÉåÉ`Ç∆åæÇ¡Ç∆ǢǃÉXÉãÅ[Ç≈ǴǻǢÇÃÇÕ
î]ÇðǪDžé¿ëïǙǻǢÇÒÇæÇÎǧǻÅB
î]ÇðǪDžé¿ëïǙǻǢÇÒÇæÇÎǧǻÅB
Ç∂Ç·ÇÝÅAAhSKI!ÇÃÉAÉzÇÃÉâÉCÉ^Å[Ç™16032Ç™68000ÇÊÇËë¨Ç¢Ç∆évÇ¢çûÇÒÇ≈Ç¢ÇΩåèDžǬǢǃ
C++ÇÃÉIÉxÉâÉìÉhÉIÅ[ÉoÅ[ÉâÉCÉhÇÕîÒèÌÇ…âˆÇµÇ¢ç\ï∂Ç…Ç»ÇÈÇÃǙǢÇØǻǢÅB
ï°ëfêîÇ‚çsóÒÇÃÇÊǧǻägí£ÇµÇΩÉfÅ[É^ÉNÉâÉXÇÃââéZÇ…égǧï™Ç…ÇÕó«Ç¢Ç™
cout <<Ç∆ǩǶǶǡǃä¥Ç∂Ç™Ç∑ÇÈÅB
ï°ëfêîÇ‚çsóÒÇÃÇÊǧǻägí£ÇµÇΩÉfÅ[É^ÉNÉâÉXÇÃââéZÇ…égǧï™Ç…ÇÕó«Ç¢Ç™
cout <<Ç∆ǩǶǶǡǃä¥Ç∂Ç™Ç∑ÇÈÅB
840 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 13:50:46.71 ID:BHt0mlSb
C++Ç…Ç®ÇØÇÈinterfaceÇÕÉLÅ[ÉèÅ[ÉhÇ∆ǵǃÇÕclassÇÃÉGÉCÉäÉAÉXÇ≈ÇÝÇËÅA
égÇ¢ï˚Ç∆ǵǃÇÕëÄçÏÇÃÇðÇíËã`Ç∑ÇÈclassÇÃêðåvï˚êjÇ≈ÇÝǡǃ
ÇÐÇ¡ÇΩÇ≠ï ÇÃäTîOÇ≈ÇÕǻǢÅB
JavaǵǩégÇ¡ÇΩDZÇ∆ǻǢÇÒÇæÇÎǧǩDZÇÃÉoÉJÇÕÇó
> ǪǧÅAinterfaceÇ∆classÇìØàÍê¸è„Ç≈òbǵÇΩÇËÇ∑Ç≤Ç¢à·òaä¥ÇÝÇÈÅB
ÇêÇêÇê
égÇ¢ï˚Ç∆ǵǃÇÕëÄçÏÇÃÇðÇíËã`Ç∑ÇÈclassÇÃêðåvï˚êjÇ≈ÇÝǡǃ
ÇÐÇ¡ÇΩÇ≠ï ÇÃäTîOÇ≈ÇÕǻǢÅB
JavaǵǩégÇ¡ÇΩDZÇ∆ǻǢÇÒÇæÇÎǧǩDZÇÃÉoÉJÇÕÇó
> ǪǧÅAinterfaceÇ∆classÇìØàÍê¸è„Ç≈òbǵÇΩÇËÇ∑Ç≤Ç¢à·òaä¥ÇÝÇÈÅB
ÇêÇêÇê
841 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 13:52:20.31 ID:BHt0mlSb
>>839
ï Ç…ÅH
ÇΩǢǃǢÇÃÉXÉNÉäÉvÉgåæåÍÇ≈ << égǧÇ∂Ç·ÇÒ
PerlÇ≈ÇýRubyÇ≈ÇýÇ»ÇÒÇ≈ÇýǢǢǙÉqÉAÉhÉLÉÖÉÅÉìÉgÇ∆Ç©égÇÌǻǢÇÃÅH
ï Ç…ÅH
ÇΩǢǃǢÇÃÉXÉNÉäÉvÉgåæåÍÇ≈ << égǧÇ∂Ç·ÇÒ
PerlÇ≈ÇýRubyÇ≈ÇýÇ»ÇÒÇ≈ÇýǢǢǙÉqÉAÉhÉLÉÖÉÅÉìÉgÇ∆Ç©égÇÌǻǢÇÃÅH
842 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 15:02:13.45 ID:BHt0mlSb
>>834
åNÇÕRuby on RailsÇímǡǃÇÈÇ©ÇÀÅH
ActiveRecordêGÇ¡ÇΩDZÇ∆ÇÝÇÈÇ©ÇÀÅH
äeModelÉNÉâÉXÇ…ìØìôã@î\ÇÃÉÅÉ\ÉbÉhÇí«â¡Ç∑ÇÈÇÃÇ…
ï ÇÃÉNÉâÉXÇ…àœè˜Ç»ÇÒǃãCéùÇøà´Ç¢Ç±Ç∆ÇÕïÅí Ç‚ÇÁǻǢÇÊÅB
Rails4Ç…app/model/concernsǡǃÇÝÇÈÇ∂Ç·ÇÒ
ã§í âªÇ∑ÇÈã@î\Çmix-inÉÇÉWÉÖÅ[ÉãèëǢǃ
àÀë∂ïîÇÕÉNÉçÅ[ÉWÉÉâªÇµÇƒäeModelÉNÉâÉXìýÇ…âBï¡Ç∑ÇÈÅB
TableÇ∆ModelÉNÉâÉXÇ™1:1Ç≈ïRÇ√ǢǃÇÈÇ©ÇÁDZǪå©í ǵǙÇÊÇ≠Ç»ÇÈÇÃÇ…
ÇÐÇΩï ÇÃÉNÉâÉXÇ…ìäÇ∞ÇÈÇ∆Ç©ÅAà´Ç≠Ç»ÇÈÇæÇØÇ∂Ç·ÇÒÅB
>>835
ǬÇÐÇÁÇÒåæótóVÇ—ÇæÇÀÅ[
C++Ç≈îƒópìIÇ»mix-inÉNÉâÉXÇèëÇ≠Ç»ÇÁtemplateÇ≈èëǢǃïKóvÇ…âûÇ∂ǃtraitsÇ≈
é¿ëïÇì¡éÍâªÇ∑ÇÈÇ©Ç»ÅB
templateÇÕäÓñ{ìIÇ…íËã`Ç∆é¿ëïÇÃãÊï ÇÕë∂çðǵǻǢǩÇÁÇÀÅB
ǪÇÃè„Ç≈ïKóvÇ»ã@î\Çåpè≥Ç∑ÇÈÅB
class Hoge :
Å@Å@public FooImpl<Hoge>,
Å@Å@public BarImpl<Hoge>,
Å@Å@public BazImpl<Hoge>
{
Å@Å@Å@ÇŸÇ∞ÇŸÇ∞
};
Modern C++ Designì«ÇÒÇ≈ÇÀÅB
é¿ëHìIÇ»ÇýÇÃÇå©ÇÈÇ»ÇÁC++ïWèÄÉâÉCÉuÉâÉäÇÃstring/wstringÇ∆Ç©boost::regexÇ∆Ç©
ëSïîÉwÉbÉ_Ç…ãLèqÇ≥ÇÍǃÇÈÇ©ÇÁâ…Ç»ÇÁì«ÇþÇÈÇ≈ǵÇÂÅB
ǪÇÍDžǵǃÇýJavaǵǩégǶǻǢêlǡǃévÇ¢è„Ç™ÇËåÉǵǢÇÊÇÀÅB
åNÇÕRuby on RailsÇímǡǃÇÈÇ©ÇÀÅH
ActiveRecordêGÇ¡ÇΩDZÇ∆ÇÝÇÈÇ©ÇÀÅH
äeModelÉNÉâÉXÇ…ìØìôã@î\ÇÃÉÅÉ\ÉbÉhÇí«â¡Ç∑ÇÈÇÃÇ…
ï ÇÃÉNÉâÉXÇ…àœè˜Ç»ÇÒǃãCéùÇøà´Ç¢Ç±Ç∆ÇÕïÅí Ç‚ÇÁǻǢÇÊÅB
Rails4Ç…app/model/concernsǡǃÇÝÇÈÇ∂Ç·ÇÒ
ã§í âªÇ∑ÇÈã@î\Çmix-inÉÇÉWÉÖÅ[ÉãèëǢǃ
àÀë∂ïîÇÕÉNÉçÅ[ÉWÉÉâªÇµÇƒäeModelÉNÉâÉXìýÇ…âBï¡Ç∑ÇÈÅB
TableÇ∆ModelÉNÉâÉXÇ™1:1Ç≈ïRÇ√ǢǃÇÈÇ©ÇÁDZǪå©í ǵǙÇÊÇ≠Ç»ÇÈÇÃÇ…
ÇÐÇΩï ÇÃÉNÉâÉXÇ…ìäÇ∞ÇÈÇ∆Ç©ÅAà´Ç≠Ç»ÇÈÇæÇØÇ∂Ç·ÇÒÅB
>>835
ǬÇÐÇÁÇÒåæótóVÇ—ÇæÇÀÅ[
C++Ç≈îƒópìIÇ»mix-inÉNÉâÉXÇèëÇ≠Ç»ÇÁtemplateÇ≈èëǢǃïKóvÇ…âûÇ∂ǃtraitsÇ≈
é¿ëïÇì¡éÍâªÇ∑ÇÈÇ©Ç»ÅB
templateÇÕäÓñ{ìIÇ…íËã`Ç∆é¿ëïÇÃãÊï ÇÕë∂çðǵǻǢǩÇÁÇÀÅB
ǪÇÃè„Ç≈ïKóvÇ»ã@î\Çåpè≥Ç∑ÇÈÅB
class Hoge :
Å@Å@public FooImpl<Hoge>,
Å@Å@public BarImpl<Hoge>,
Å@Å@public BazImpl<Hoge>
{
Å@Å@Å@ÇŸÇ∞ÇŸÇ∞
};
Modern C++ Designì«ÇÒÇ≈ÇÀÅB
é¿ëHìIÇ»ÇýÇÃÇå©ÇÈÇ»ÇÁC++ïWèÄÉâÉCÉuÉâÉäÇÃstring/wstringÇ∆Ç©boost::regexÇ∆Ç©
ëSïîÉwÉbÉ_Ç…ãLèqÇ≥ÇÍǃÇÈÇ©ÇÁâ…Ç»ÇÁì«ÇþÇÈÇ≈ǵÇÂÅB
ǪÇÍDžǵǃÇýJavaǵǩégǶǻǢêlǡǃévÇ¢è„Ç™ÇËåÉǵǢÇÊÇÀÅB
RoRÇ»ÇðÇÃÉvÉçÉOÉâÉ~ÉìÉOÇÃÇ‚ÇËÇ‚Ç∑Ç≥Ç≈ÅA
C/C++Ç≈Ç≤ÇËÇ≤ÇËèëÇ¢ÇΩÇÊǧǻÉpÉtÉHÅ[É}ÉìÉXÇ™
èoÇÍnjǢǢÇÃÇ…
C/C++Ç≈Ç≤ÇËÇ≤ÇËèëÇ¢ÇΩÇÊǧǻÉpÉtÉHÅ[É}ÉìÉXÇ™
èoÇÍnjǢǢÇÃÇ…
ícéqÇ≥ÇÒìIÇ…ÇýÇ¡Ç∆Çýê∂éYê´ÇÃçÇÇ¢åæåÍǡǃâΩÅH
ÉpÉtÉHÅ[É}ÉìÉXÇÕñ≥éãǵǃÅB
ÉpÉtÉHÅ[É}ÉìÉXÇÕñ≥éãǵǃÅB
Ç©Ç»ÇËä÷åWǻǢÇØÇ«ÅAågë—Ç∆Ç©Ç≈JavaégǧǡǃǢǧÇÃÇÕÇøÇÂÇ¡Ç∆ÉAÉzÇðÇΩÇ¢Ç∆ç≈èâÇÕévÇ¡ÇΩ
êÐäpìdóÕå¯ó¶ÇÃó«Ç¢SHÇ»ÇËARMÇ»ÇËÇégǡǃÇÈÇÒÇæÇ©ÇÁê∂Ç©Ç≥ǻǢÇ∆ÅB
JavaÇ»ÇÒÇ©égǧÇÆÇÁÇ¢ÇæÇ¡ÇΩÇÁÇýÇ¡Ç∆íxÇ≠ǃí·è¡îÔìdóÕÇ»SoCDžǵÇΩǟǧǙÉnÅ[ÉhÉEÉFÉAÇ…Ç©ÇØÇÈÉRÉXÉgìIÇ…ÇýìdírÇÃéùÇøÇýâ¸ëPÇ∑ÇÈÇÃÇ…ÅB
É\ÉtÉgÇ÷ÇÃìäéëǙǪÇÒǻDžåôÇ»ÇÃÇ©ÅB
ìIǻDZÇ∆ÇêÃçlǶǃÇΩÅB
êÐäpìdóÕå¯ó¶ÇÃó«Ç¢SHÇ»ÇËARMÇ»ÇËÇégǡǃÇÈÇÒÇæÇ©ÇÁê∂Ç©Ç≥ǻǢÇ∆ÅB
JavaÇ»ÇÒÇ©égǧÇÆÇÁÇ¢ÇæÇ¡ÇΩÇÁÇýÇ¡Ç∆íxÇ≠ǃí·è¡îÔìdóÕÇ»SoCDžǵÇΩǟǧǙÉnÅ[ÉhÉEÉFÉAÇ…Ç©ÇØÇÈÉRÉXÉgìIÇ…ÇýìdírÇÃéùÇøÇýâ¸ëPÇ∑ÇÈÇÃÇ…ÅB
É\ÉtÉgÇ÷ÇÃìäéëǙǪÇÒǻDžåôÇ»ÇÃÇ©ÅB
ìIǻDZÇ∆ÇêÃçlǶǃÇΩÅB
846 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 18:38:07.69 ID:BHt0mlSb
BREWÇ»ÇÒǃå¬êlÉAÉvÉääJî≠é“Ç™í˜ÇþèoÇ≥ÇÈÇÌ
QualcommÇ…ÉsÉìÉnÉlÇ≥ÇÍÇÈÇÌÇ≈ÉvÉçÉOÉâÉ}Ç…âΩÇÃÉÅÉäÉbÉgÇýÇýÇΩÇÁÇ≥ǻǩǡÇΩÇØÇ«Ç»
QualcommÇ…ÉsÉìÉnÉlÇ≥ÇÍÇÈÇÌÇ≈ÉvÉçÉOÉâÉ}Ç…âΩÇÃÉÅÉäÉbÉgÇýÇýÇΩÇÁÇ≥ǻǩǡÇΩÇØÇ«Ç»
WebånÇÕÅAÉXÉ^Å[ÉgÉAÉbÉvÇÕRoRÇ∆Ç©Ç≈çÏÇÈ
ñúÇ™àÍëÂÉqÉbÉgǵǃÉTÅ[Éoë‰êîÇ«ÇÒÇ«ÇÒëùǶǃÇ≠ÇÍÇŒÅA
ÉTÅ[Éoë„çÌå∏Ç∑ÇÈÉRÉXÉgå¯â Ç™ëÂÇ´Ç≠Ç»ÇÈÇΩÇþÇ…ÅA
RoRÇ©ÇÁÇ◊ǬÇÃçÇë¨Ç≈ǩǬñ ì|Ç»åæåÍÇ…Ç∑ÇÈ
ñúÇ™àÍëÂÉqÉbÉgǵǃÉTÅ[Éoë‰êîÇ«ÇÒÇ«ÇÒëùǶǃÇ≠ÇÍÇŒÅA
ÉTÅ[Éoë„çÌå∏Ç∑ÇÈÉRÉXÉgå¯â Ç™ëÂÇ´Ç≠Ç»ÇÈÇΩÇþÇ…ÅA
RoRÇ©ÇÁÇ◊ǬÇÃçÇë¨Ç≈ǩǬñ ì|Ç»åæåÍÇ…Ç∑ÇÈ
849 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 20:16:02.25 ID:BHt0mlSb
ÇÒÇÐÇÝC++ÇÃâºëzä÷êîÉeÅ[ÉuÉãÇÕÇÕÇ¡Ç´ÇËåæǡǃÉSÉ~ÇæÇ»
é¿çséûÉ|ÉäÉÇÅ[ÉtÉBÉYÉÄÅièŒÅjÇ∆Ç©ÉeÉìÉvÉåÅ[ÉgÇ™è„éËÇ≠égǶǻǢêlÇÃÇΩÇþÇÃÇýÇÃÅB
GoogleÇýÉRÅ[ÉfÉBÉìÉOãKñÒÇ≈vtableã÷é~ÅERTTIã÷é~ÅEó·äOã÷é~Ç∆ǩǻǩǡÇΩÇ¡ÇØÇ»
é¿çséûÉ|ÉäÉÇÅ[ÉtÉBÉYÉÄÅièŒÅjÇ∆Ç©ÉeÉìÉvÉåÅ[ÉgÇ™è„éËÇ≠égǶǻǢêlÇÃÇΩÇþÇÃÇýÇÃÅB
GoogleÇýÉRÅ[ÉfÉBÉìÉOãKñÒÇ≈vtableã÷é~ÅERTTIã÷é~ÅEó·äOã÷é~Ç∆ǩǻǩǡÇΩÇ¡ÇØÇ»
>>849
RTTIã÷é~ÅEó·äOã÷é~ÇÕï™Ç©ÇÈÇØÇ«ÅA
vtableã÷é~ǡǃÅAÉIÉuÉWÉFÉNÉgéwå¸Ç≈Ç´ÇÈÇÃÅHÅHÇó
ÉfÉUÉCÉìÉpÉ^Å[ÉìÇŸÇ∆ÇÒÇ«égǶǻǢÇ∂Ç·ÇÒÇó
RTTIã÷é~ÅEó·äOã÷é~ÇÕï™Ç©ÇÈÇØÇ«ÅA
vtableã÷é~ǡǃÅAÉIÉuÉWÉFÉNÉgéwå¸Ç≈Ç´ÇÈÇÃÅHÅHÇó
ÉfÉUÉCÉìÉpÉ^Å[ÉìÇŸÇ∆ÇÒÇ«égǶǻǢÇ∂Ç·ÇÒÇó
851 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 20:36:58.50 ID:BHt0mlSb
ÉeÉìÉvÉåÅ[ÉgÇégÇ¡ÇΩê√ìIÉ|ÉäÉÇÅ[ÉtÉBÉYÉÄÇÕvtableÇégÇÌǻǢÇÊ
ǪÇýǪÇýC++ÇÕÉIÉuÉWÉFÉNÉgéwå¸åæåÍÇ≈ÇÕÇ»Ç≠É}ÉãÉ`ÉpÉâÉ_ÉCÉÄåæåÍ
MSì∆é©ägí£ÇæÇØÇ«vtableÇê∂ê¨ÇµÇ»Ç¢éwé¶ÇýÇ≈Ç´ÇÈ
http://ascii.asciimw.jp/pb/msdn/article/a01_0029.html
C++ÇÕê´î\Çã]êµÇ…ǵǃÇÐÇ≈ìÆìIåæåÍÇÃï®ê^éóÇÇ‚ÇÈïKóvÇÕǻǢÇ∆évǡǃÇÈÅB
Ç÷ÇÒÇ…MFCÇðÇΩǢǻï≥ÉâÉCÉuÉâÉäégǡǃé¿çséûä‘ÇÃ3Å`4äÑÇ
ï∂éöóÒÇ‚VariantÉNÉâÉXÇÃÉRÉìÉXÉgÉâÉNÉ^Ç…ÇýǡǃǩÇÍÇÈÇ∆ǩǧÇÒÇ¥ÇËÇ≈Ç∑ǵ
ÉtÉâÉbÉgÇ»ÉNÉâÉXÅiÉeÉìÉvÉåÅ[ÉgÅjÇ≈ëΩèdåpè≥ÇÃǟǧǙê√ìIåæåÍÇÃÉÅÉäÉbÉgÇ
ç≈ëÂå¿ãùéÛÇ≈Ç´ÇÈÇ∆évǧÇØÇ«ÇÀÅB
ǪÇýǪÇýC++ÇÕÉIÉuÉWÉFÉNÉgéwå¸åæåÍÇ≈ÇÕÇ»Ç≠É}ÉãÉ`ÉpÉâÉ_ÉCÉÄåæåÍ
MSì∆é©ägí£ÇæÇØÇ«vtableÇê∂ê¨ÇµÇ»Ç¢éwé¶ÇýÇ≈Ç´ÇÈ
http://ascii.asciimw.jp/pb/msdn/article/a01_0029.html
C++ÇÕê´î\Çã]êµÇ…ǵǃÇÐÇ≈ìÆìIåæåÍÇÃï®ê^éóÇÇ‚ÇÈïKóvÇÕǻǢÇ∆évǡǃÇÈÅB
Ç÷ÇÒÇ…MFCÇðÇΩǢǻï≥ÉâÉCÉuÉâÉäégǡǃé¿çséûä‘ÇÃ3Å`4äÑÇ
ï∂éöóÒÇ‚VariantÉNÉâÉXÇÃÉRÉìÉXÉgÉâÉNÉ^Ç…ÇýǡǃǩÇÍÇÈÇ∆ǩǧÇÒÇ¥ÇËÇ≈Ç∑ǵ
ÉtÉâÉbÉgÇ»ÉNÉâÉXÅiÉeÉìÉvÉåÅ[ÉgÅjÇ≈ëΩèdåpè≥ÇÃǟǧǙê√ìIåæåÍÇÃÉÅÉäÉbÉgÇ
ç≈ëÂå¿ãùéÛÇ≈Ç´ÇÈÇ∆évǧÇØÇ«ÇÀÅB
Ç¢Å[â¡å∏ÉXÉåà·Ç¢ÇÕè¡Ç¶ÇÎÉEÉ[Ƕ
853 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/06(ì˙) 21:40:41.05 ID:BHt0mlSb
DZÇÃòbëËÇ™ÉXÉåà·Ç¢ÇæÇ∆évǧñ≥î\ÇÕDZÇÃÉXÉåÇ…óvÇÁǻǢǩÇÁåNǙǢǻÇ≠Ç»ÇÍnjǢǢÇÊ
ÉÇÉ_ÉìÇ»CPUÇÃï™äÚó\ë™Ç‚ÉLÉÉÉbÉVÉÖÇÃäKëwç\ë¢ÇÕÉ\ÉtÉgÉEÉFÉAÇÃé¿ëïÇ∆
åãǗǬǢǃÇÈÇÌÇØÇæÇ©ÇÁÇÀ
ÉnÅ[ÉhÇÝÇËÇ´Ç≈É\ÉtÉgÇåyéãÇ∑ÇÈÇ∆ÉSÉ~Ç™èoóàè„Ç™ÇÈÇ∆ǢǧÇÃÇ™ÉRÉìÉsÉÖÅ[É^ÇÃóéjÅB
ÉÇÉ_ÉìÇ»CPUÇÃï™äÚó\ë™Ç‚ÉLÉÉÉbÉVÉÖÇÃäKëwç\ë¢ÇÕÉ\ÉtÉgÉEÉFÉAÇÃé¿ëïÇ∆
åãǗǬǢǃÇÈÇÌÇØÇæÇ©ÇÁÇÀ
ÉnÅ[ÉhÇÝÇËÇ´Ç≈É\ÉtÉgÇåyéãÇ∑ÇÈÇ∆ÉSÉ~Ç™èoóàè„Ç™ÇÈÇ∆ǢǧÇÃÇ™ÉRÉìÉsÉÖÅ[É^ÇÃóéjÅB
>>853
C++Ç‚JavaÇÃèâïýìIÇ»µÃÞºÞ™∏ƒéwå¸ÇÃÂ]í~ÇΩÇÍǃÇÈÇæÇØÇ≈ÅA
ÉAÅ[ÉLÉeÉNÉ`ÉÉÅ[Ç…ä÷òAÇ∑ÇÈòbÇ…åãǗǬǢǃǢǻǢÅB
èâïýìIÇ»µÃÞºÞ™∏ƒéwå¸ÇÃÂ]í~ÇýÇÐÇüåãç\ÇæÇ™
ìKçÞìKèäÇ≈Ç‚Ç¡ÇΩï˚Ç™ÇÊÇ¢ÇæÇÎǧÅB
C++Ç‚JavaÇÃèâïýìIÇ»µÃÞºÞ™∏ƒéwå¸ÇÃÂ]í~ÇΩÇÍǃÇÈÇæÇØÇ≈ÅA
ÉAÅ[ÉLÉeÉNÉ`ÉÉÅ[Ç…ä÷òAÇ∑ÇÈòbÇ…åãǗǬǢǃǢǻǢÅB
èâïýìIÇ»µÃÞºÞ™∏ƒéwå¸ÇÃÂ]í~ÇýÇÐÇüåãç\ÇæÇ™
ìKçÞìKèäÇ≈Ç‚Ç¡ÇΩï˚Ç™ÇÊÇ¢ÇæÇÎǧÅB
ó]íkÇæÇ™C++ÇÕÇ≥ÇÁÇ…ìÆìIÇñ⁄éwÇ∑ÇÒÇæÇÊÇÀÅB0xà»ç~çXÇ…çXÇ…ÅB
ǪÇ∂ǷǻǢÇ∆ëºÇÃåæåÍÇ…ïâÇØÇøǷǧÅB
ǪÇÍÇ≈ƒÞðƒÞðǮǩǵǻåæåÍDžǻǡǃǢÇ≠ÅB
ǪÇ∂ǷǻǢÇ∆ëºÇÃåæåÍÇ…ïâÇØÇøǷǧÅB
ǪÇÍÇ≈ƒÞðƒÞðǮǩǵǻåæåÍDžǻǡǃǢÇ≠ÅB
>>854
ÅyåvéZã@â»äwÅzÉXÉpÉRÉì14îNè„ä˙TOP500ÅAíÜçëÅuìVâÕ2çÜÅvÇ™à¯Ç´ë±Ç´éÒà ì˙ñ{ÇÃÅuãûÅvÇÕ4à
ttp://anago.2ch.net/test/read.cgi/scienceplus/1403562703/541
DZÇÍèëÇ¢ÇΩûΩéqÅADZDZDžÇÕèoì¸ÇËǵǃǻǢǩÅB
àÍâû(Ç∆Ç©åæÇ¡ÇøÇ·Å[à´Ç¢Ç™)ǪÇÃìπÇ≈êHÇ◊ǃÇÈÇ»Ç∆Ç®ÇýÇΩÅB
ÅyåvéZã@â»äwÅzÉXÉpÉRÉì14îNè„ä˙TOP500ÅAíÜçëÅuìVâÕ2çÜÅvÇ™à¯Ç´ë±Ç´éÒà ì˙ñ{ÇÃÅuãûÅvÇÕ4à
ttp://anago.2ch.net/test/read.cgi/scienceplus/1403562703/541
DZÇÍèëÇ¢ÇΩûΩéqÅADZDZDžÇÕèoì¸ÇËǵǃǻǢǩÅB
àÍâû(Ç∆Ç©åæÇ¡ÇøÇ·Å[à´Ç¢Ç™)ǪÇÃìπÇ≈êHÇ◊ǃÇÈÇ»Ç∆Ç®ÇýÇΩÅB
858 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/07(åé) 01:09:19.18 ID:cFDKDzZF
àÍëÃâΩÇ™ìÆìIÇæÇ∆ǢǧÇÃÇ©
859 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/07(åé) 01:13:51.07 ID:cFDKDzZF
>>857
> 71+1 ÅFñºñ≥ǵÇÃÇ–ÇðǬÅóì]ç⁄ÇÕã÷é~ [] ÅF2014/06/24(âŒ) 10:00:07.93 ID:YM7OBK+R (2/6)
> ÉzÉìÉgÇ…ÉXÉpÉRÉìÉXÉåÇÕímÇ¡ÇΩÇ©Ç‘ÇËÇÃÉÑÉcnjǩÇËÅEÅEÅEÅE
>
> ǢǢǩÅAãûÇÃäJî≠îÔÇÃîºï™à»è„ÇÕÉ\ÉtÉgäJî≠îÔÇæÅBÉnÅ[ÉhÇ∂ǷǻǢÇÒÇæÇÊ
> DZÇÍÇ™âΩÇà”ñ°ÇµÇƒÇÈÇ©ÇÌÇ©ÇÈÇ©ÅHÅBólÅXÇ»åvéZñ@Ç…å¯ó¶ÇÊÇ≠ÉtÉBÉbÉgÇ∑ÇÈÇÊǧDžçÏÇ¡ÇΩÇÃÇ™ãûÇ»ÇÒÇæÇÊ
> LIMPACKÇæÇØë¨Ç≠åvéZÇ≥ÇπÇÈÇÒÇ»ÇÁǪÇËÇ·à¿Ç≠Ç≈Ç´ÇÈÇæÇÎǧÇÊ
ǪÇÃÉ\ÉtÉgǡǃ>>587ÇÃǂǬÇÃDZÇ∆Ç©ÇÀÅHǫǧÇðǃÇýãûÇ™â“ìÆǵÇΩå„Ç…äJî≠Ç≥ÇÍǃÇÈÇÒÇæÇ™ÅB
Ç–ÇÂÇ¡Ç∆ǵǃÉ\ÉtÉgǡǃê⁄ë“îÔÇ©Ç»ÇÒÇ©ÇÃDZÇ∆ÇåæǡǃÇÈÇÃÇ©Ç»ÅH
> 71+1 ÅFñºñ≥ǵÇÃÇ–ÇðǬÅóì]ç⁄ÇÕã÷é~ [] ÅF2014/06/24(âŒ) 10:00:07.93 ID:YM7OBK+R (2/6)
> ÉzÉìÉgÇ…ÉXÉpÉRÉìÉXÉåÇÕímÇ¡ÇΩÇ©Ç‘ÇËÇÃÉÑÉcnjǩÇËÅEÅEÅEÅE
>
> ǢǢǩÅAãûÇÃäJî≠îÔÇÃîºï™à»è„ÇÕÉ\ÉtÉgäJî≠îÔÇæÅBÉnÅ[ÉhÇ∂ǷǻǢÇÒÇæÇÊ
> DZÇÍÇ™âΩÇà”ñ°ÇµÇƒÇÈÇ©ÇÌÇ©ÇÈÇ©ÅHÅBólÅXÇ»åvéZñ@Ç…å¯ó¶ÇÊÇ≠ÉtÉBÉbÉgÇ∑ÇÈÇÊǧDžçÏÇ¡ÇΩÇÃÇ™ãûÇ»ÇÒÇæÇÊ
> LIMPACKÇæÇØë¨Ç≠åvéZÇ≥ÇπÇÈÇÒÇ»ÇÁǪÇËÇ·à¿Ç≠Ç≈Ç´ÇÈÇæÇÎǧÇÊ
ǪÇÃÉ\ÉtÉgǡǃ>>587ÇÃǂǬÇÃDZÇ∆Ç©ÇÀÅHǫǧÇðǃÇýãûÇ™â“ìÆǵÇΩå„Ç…äJî≠Ç≥ÇÍǃÇÈÇÒÇæÇ™ÅB
Ç–ÇÂÇ¡Ç∆ǵǃÉ\ÉtÉgǡǃê⁄ë“îÔÇ©Ç»ÇÒÇ©ÇÃDZÇ∆ÇåæǡǃÇÈÇÃÇ©Ç»ÅH
ÇøÇÒÇøÇÒÇ’ÇÁÇ’ÇÁÇ’ÇÁÇÁ
äJî≠ÇÕâΩé–Çýâ∫êøÇ…ä€ìäÇ∞ǵǃǢÇ≠Ç©ÇÁÅA
äJî≠îÔÇÃÇŸÇ∆ÇÒÇ«ÇÕìVâ∫ÇËäØóªÇÃâ˘Ç…ì¸ÇÈÅBé¿éøäØóªÇÃê⁄ë“îÔÅB
äJî≠îÔÇÃÇŸÇ∆ÇÒÇ«ÇÕìVâ∫ÇËäØóªÇÃâ˘Ç…ì¸ÇÈÅBé¿éøäØóªÇÃê⁄ë“îÔÅB
862 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡ nfmv001100047.uqw.ppp.infoweb.ne.jpÅF2014/07/07(åé) 01:28:22.93 ID:cFDKDzZF
ÇÌÇ¢ÇÌÇ¢ýŒÂˆWiMAX
ÉXÉ}ÉtÉHÇ∆ë´ÇµÇƒ3Å`4IDégǶÇÐÇ∑
VPNégǶnjÇýÇ¡Ç∆ëùÇ‚ÇπÇÐÇ∑
ÇÐÇ≈ÇÕì«ÇÒÇæ
VPNégǶnjÇýÇ¡Ç∆ëùÇ‚ÇπÇÐÇ∑
ÇÐÇ≈ÇÕì«ÇÒÇæ
864 ÅFSocket774ÅF2014/07/07(åé) 01:42:37.75 ID:LmSdrHu9
ÉXÉåÇ∆ïKéÄÉ`ÉFÉbÉJÅ[ìYïtǵǃÉvÉçÉoÉCÉ_Ç…çrÇÁǵí ïÒÇ∑ÇÍÇŒó«Ç¢ÇÒÇ∂Ç·ÇÀÅH
VIAÇÃêVx86 CPUÅ\ÅgIsaiah IIÅhÇÃÉxÉìÉ`É}Å[ÉNÅEÅEÅEÇ»ÇÃ
http://northwood.blog60.fc2.com/blog-entry-7622.html
http://northwood.blog60.fc2.com/blog-entry-7622.html
IntelÇ™ATOMêœã…ìIÇ…îÑÇËèoǵǃǩÇÁÇÕVIAÇÕÇýǧíéÇÃëßǡǃä¥Ç∂ÇæÇ»ÇüÅEÅEÅE
CentOSÇì¸ÇÍǃãNìÆÇ∑ÇÈÇ∆ÅAãNìÆìríÜÇ…CentaurHauls-ÉTÉ|Å[ÉgǵǻǢCPUÇ∆ï\é¶Ç≥ÇÍÇÈÅB
àÍìxÇýñ‚ëËÇ™ãNÇ´ÇΩDZÇ∆ǙǻǢǙãCÇ…Ç»ÇÈï\é¶ÇæÅBVIAé–Ç©ÇÁRedHaté–Ç÷ÇÃè„î[ãýÇ™ë´ÇËǻǢíˆìxÇÃê≠é°ìIÉÅÉbÉZÅ[ÉWÇæÇÎǧÇ∆ëzëúǵǃǢÇÈ
àÍìxÇýñ‚ëËÇ™ãNÇ´ÇΩDZÇ∆ǙǻǢǙãCÇ…Ç»ÇÈï\é¶ÇæÅBVIAé–Ç©ÇÁRedHaté–Ç÷ÇÃè„î[ãýÇ™ë´ÇËǻǢíˆìxÇÃê≠é°ìIÉÅÉbÉZÅ[ÉWÇæÇÎǧÇ∆ëzëúǵǃǢÇÈ
win7ÇæÇ©vistaÇæÇ©ñYÇÍÇΩÇ™
64bitëŒâûÇæÇ¡ÇΩÇÃÇ…CPUIDÇ≈íeÇ©ÇÍǃÉCÉìÉXÉgÅ[ÉãÇ≈ǴǻǩǡÇΩ
ǮǪÇÁÇ≠ǪÇÃÇΩÇÆÇ¢ÇæÇÎǧ
64bitëŒâûÇæÇ¡ÇΩÇÃÇ…CPUIDÇ≈íeÇ©ÇÍǃÉCÉìÉXÉgÅ[ÉãÇ≈ǴǻǩǡÇΩ
ǮǪÇÁÇ≠ǪÇÃÇΩÇÆÇ¢ÇæÇÎǧ
869 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/07(åé) 08:39:38.26 ID:G3/AzS8o
CMPXCHG16B, LAHF/SAHFîÒëŒâûCPUÇæÇ∆ǪǧǻÇÈÅB
870 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/07(åé) 08:45:50.00 ID:G3/AzS8o
ÇÝÅAVIAÇæÇ©ÇÁÇ©ÅB
É`ÉFÉbÉNÉãÅ[É`ÉìÇ™IntelÇ∆AMDǵǩëŒâûǵǃǻǢÇÃÇ©Ç»
CPUIDÇÃï‘ÇËílÇBIOSêðíËÇ≈èëÇ´ä∑ǶÇÁÇÍǻǩǡÇΩÇ¡ÇØÅH
ÉoÉOïÒçêǵÇΩǟǧǙǢǢÇ∆évǧ
É`ÉFÉbÉNÉãÅ[É`ÉìÇ™IntelÇ∆AMDǵǩëŒâûǵǃǻǢÇÃÇ©Ç»
CPUIDÇÃï‘ÇËílÇBIOSêðíËÇ≈èëÇ´ä∑ǶÇÁÇÍǻǩǡÇΩÇ¡ÇØÅH
ÉoÉOïÒçêǵÇΩǟǧǙǢǢÇ∆évǧ
VIAǡǃLKMLÇ∆Ç©Ç…é©é–CPUëŒâûÇÃÉpÉbÉ`ìäÇ∞ÇΩÇËÅA
ÉÅÉìÉeÉiÅ[åŸÇ¡ÇƒÅAé©é–CPUÇ…ëŒâûÇ≥ÇπÇΩÇËǵǃǻǢÇÃÅH
ÉÅÉìÉeÉiÅ[åŸÇ¡ÇƒÅAé©é–CPUÇ…ëŒâûÇ≥ÇπÇΩÇËǵǃǻǢÇÃÅH
åpè≥Çêiâªò_Ç≈åÍÇÈÇÃÇÕìTå^ìIÇ»í·î\
873 ÅF,,ÅEÅLÅÕÅMÅE,,ÅjÇ¡-ÅõÅõÅõÅF2014/07/08(âŒ) 07:21:05.65 ID:6dokpfRb
êiâªò_Ç»ÇÒǃåæótíNÇýòbǵǃǻǢÇÃÇ…ìÀëRå˚ëñÇÈîíísǙDZDZDžǢÇÈÇÊǧÇæ
874 ÅFSocket774ÅF2014/07/08(âŒ) 08:47:18.43 ID:KRcUnsh0
ï≥ícéq(ìcë∫)Ç¥ÇÐÇüÇó
http://anago.2ch.net/test/read.cgi/jisaku/1368457357/
http://peace.2ch.net/test/read.cgi/mmo/1404127146/
http://anago.2ch.net/test/read.cgi/jisaku/1368457357/
http://peace.2ch.net/test/read.cgi/mmo/1404127146/
875 ÅF(ÅÐ(Ñv)ÅÐ)Ç¡-ÅõÅõÅõ ÅüM2TLe2H2No ÅF2014/07/08(âŒ) 08:56:02.99 ID:6dokpfRb
876 ÅF(ÅÐ(Ñv)ÅÐ)Ç¡ nfmv001150166.uqw.ppp.infoweb.ne.jpÅF2014/07/08(âŒ) 08:57:12.57 ID:6dokpfRb
#ì¸ÇÍÇΩÇÁÉ_ÉÅÇ©
877 ÅFSocket774ÅF2014/07/08(âŒ) 09:06:32.62 ID:vOJTzzn5
ÇæÇ©ÇÁÅH
878 ÅFSocket774ÅF2014/07/08(âŒ) 09:13:07.06 ID:vOJTzzn5
ÅyîÒíEçñÅziPhoneÇÃà íuèÓïÒÇãUëïÇ∑ÇÈï˚ñ@
http://www.youtube.com/watch?v=AFdl272YIeA
http://www.youtube.com/watch?v=AFdl272YIeA
879 ÅF(ÅÐ(Ñv)ÅÐ)Ç¡ nfmv001013073.uqw.ppp.infoweb.ne.jpÅF2014/07/08(âŒ) 09:14:37.68 ID:uplKcItj
ínâ∫ìSǻǧ
IntelÅAÉpÉiÉ\ÉjÉbÉNÇÃ14nm SoCÇêªë¢
http://pc.watch.impress.co.jp/docs/news/20140708_656855.html
http://pc.watch.impress.co.jp/docs/news/20140708_656855.html
éóÇΩÇÊǧǻDZÇ∆ÇÕDZDZÇ≈ÇýÇ≥ÇÒÇ¥ÇÒèëÇ©ÇÍǃÇÈÇ©ÇÁÇ»
ÅyÉKÉUëÂãséEÅzÉCÉXÉâÉGÉãÅAïlï”Ç≈óVÇÒÇ≈Ç¢ÇΩéqãü4êlÇñCåÇǵéEäQ çëç€ìIî·îªÇ™çÇÇÐÇÈíÜÅA5éûä‘ãxêÌ éÄé“225êlÇ…(ìÆâÊÇ∆âÊëúÇÝÇË)
http://peace.2ch.net/test/read.cgi/newsplus/1405593961/
http://peace.2ch.net/test/read.cgi/newsplus/1405593961/
ïxémí ÅAîºì±ëÃÇÃê∂éYÇ©ÇÁìPëÞÇ÷ éOèdçHèÍÇÕë‰òpUMCÇ…îÑãp
http://sankei.jp.msn.com/economy/news/140718/biz14071810050005-n1.htm
ÇsÇrÇlÇbÇ∆ÇýîÑãpåè¬ÇêiÇþǃǢÇΩÇ™ÅAèåèÇ™êÐÇËçáÇÌÇ∏ÅAç°âÒÅAÇtÇlÇbÇ÷ÇÃè˜ìnÇåàÇþÇΩÅB
àÍï˚ÅAé‘ç⁄ópîºì±ëÃÇê∂éYÇ∑ÇÈâÔí√é·èºçHèÍÇýïƒÉIÉìÅEÉZÉ~ÉRÉìÉ_ÉNÉ^Å[Ç…îÑãpÇ∑ÇÈï˚å¸Ç≈í≤êÆǵǃǢÇÈÅB
http://sankei.jp.msn.com/economy/news/140718/biz14071810050005-n1.htm
ÇsÇrÇlÇbÇ∆ÇýîÑãpåè¬ÇêiÇþǃǢÇΩÇ™ÅAèåèÇ™êÐÇËçáÇÌÇ∏ÅAç°âÒÅAÇtÇlÇbÇ÷ÇÃè˜ìnÇåàÇþÇΩÅB
àÍï˚ÅAé‘ç⁄ópîºì±ëÃÇê∂éYÇ∑ÇÈâÔí√é·èºçHèÍÇýïƒÉIÉìÅEÉZÉ~ÉRÉìÉ_ÉNÉ^Å[Ç…îÑãpÇ∑ÇÈï˚å¸Ç≈í≤êÆǵǃǢÇÈÅB