AMD�̎�����CPU�ɂ��Č�낤 ��33����
1 �FSocket774�F
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��32����
http://pc11.2ch.net/test/read.cgi/jisaku/1263352294/l50
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��32����
http://pc11.2ch.net/test/read.cgi/jisaku/1263352294/l50
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
|
|
|
2 �FSocket774�F2010/02/11(��) 14:44:18 ID:/c0G9iQo
���ߋ��X���ꗗ
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
����
Llano�ɂ���
Llano�̃v���Z�X
�@ �E32nm SOI / High-K + Metal gate�v���Z�X�B
�� 2����̉t�Z�I���Z�p���p������B
Llano�̊T�v
�@ �E4��CPU�R�A
�@ �EDirectX 11�Ή�GPU
�@ �EDDR3�Ή��������R���g���[��
�@ �E�ŏ��̃T���v����2010�N�㔼���\��B
Llano��CPU�R�A
�@ �EL2�L���b�V�����������R�A�̃T�C�Y��9.69mm2
�@ �E1�R�A������̃g�����W�X�^����3500���ȏ�
�@ �E�i1�R�A������H�j2.5�`25W�̏���d��
�@ �E3GHz�ȏ�̎��g��
�@ �E�쓮�d����0.8�`1.3V
Bulldozer�ɂ���
Bulldozer�@�iZambezi�@4�`8�R�A�j
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�@�E3GHz����N���b�N�H
�@�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�@�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�@�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
�@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�@�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�@�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�@�E2ch DDR3-1866�܂őΉ�
�@�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
Llano�̃v���Z�X
�@ �E32nm SOI / High-K + Metal gate�v���Z�X�B
�� 2����̉t�Z�I���Z�p���p������B
Llano�̊T�v
�@ �E4��CPU�R�A
�@ �EDirectX 11�Ή�GPU
�@ �EDDR3�Ή��������R���g���[��
�@ �E�ŏ��̃T���v����2010�N�㔼���\��B
Llano��CPU�R�A
�@ �EL2�L���b�V�����������R�A�̃T�C�Y��9.69mm2
�@ �E1�R�A������̃g�����W�X�^����3500���ȏ�
�@ �E�i1�R�A������H�j2.5�`25W�̏���d��
�@ �E3GHz�ȏ�̎��g��
�@ �E�쓮�d����0.8�`1.3V
Bulldozer�ɂ���
Bulldozer�@�iZambezi�@4�`8�R�A�j
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�@�E3GHz����N���b�N�H
�@�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�@�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�@�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
�@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�@�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�@�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�@�E2ch DDR3-1866�܂őΉ�
�@�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
>>4
�� �@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
����ARadeon�̓A�[�L�e�N�`�����O���t�B�b�N�ɓ������邱�Ƃ�GPU���\�̃A�h�o���e�[�W�Ă���̂�
�������ĂƂ����̏�k���ƁB
�� �@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
����ARadeon�̓A�[�L�e�N�`�����O���t�B�b�N�ɓ������邱�Ƃ�GPU���\�̃A�h�o���e�[�W�Ă���̂�
�������ĂƂ����̏�k���ƁB
>>1�@��
��
>>5
Radeon�͎����ォ��ėp�������������V�v�ƂȂ�\��
6X��7X���͔����
�܂��ACPU�ɓ���������瑽�ړI�Ɏg����悤�ɂ��Ȃ��ƃV���R�������������Ȃ���
Radeon�͎����ォ��ėp�������������V�v�ƂȂ�\��
6X��7X���͔����
�܂��ACPU�ɓ���������瑽�ړI�Ɏg����悤�ɂ��Ȃ��ƃV���R�������������Ȃ���
�{�[�h��Radeon����
Ontario�ɂ���
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p (40nm�Ƃ����b�͂ǂ��Ȃ���?)
�@�EDual-Core CPU��GPU�𓋍ڂ��ADDR3, DDR3L�ɑΉ�
�@�E�p�b�P�[�W��BGA�A�gBrazos�h�v���b�g�t�H�[��
�@�EGPU��DX11�Ή� (Cedar�R�A?)
�@�ECPU�R�A��Bobcat�Ŕ�K10�ABulldozer�Ƃ��Ⴄ (Bulldozer�̃T�u�Z�b�g���ۂ�)
Bobcat�R�A
�@�EInt Pipe*2 + Lord pipe+Store pipe (2way?)
�@�Ex86-64�ASSE1-3�Ή�(SSSE3/4/4.1/4.2�͔�Ή�)
�@�E�R�A�̏���d�͂�1w�ȉ�
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p (40nm�Ƃ����b�͂ǂ��Ȃ���?)
�@�EDual-Core CPU��GPU�𓋍ڂ��ADDR3, DDR3L�ɑΉ�
�@�E�p�b�P�[�W��BGA�A�gBrazos�h�v���b�g�t�H�[��
�@�EGPU��DX11�Ή� (Cedar�R�A?)
�@�ECPU�R�A��Bobcat�Ŕ�K10�ABulldozer�Ƃ��Ⴄ (Bulldozer�̃T�u�Z�b�g���ۂ�)
Bobcat�R�A
�@�EInt Pipe*2 + Lord pipe+Store pipe (2way?)
�@�Ex86-64�ASSE1-3�Ή�(SSSE3/4/4.1/4.2�͔�Ή�)
�@�E�R�A�̏���d�͂�1w�ȉ�
>>5
> ����ARadeon�̓A�[�L�e�N�`�����O���t�B�b�N�ɓ������邱�Ƃ�GPU���\�̃A�h�o���e�[�W�Ă���̂�
> �������ĂƂ����̏�k���ƁB
����Ə�������������I�o�J����͋`���{������w�Z���炵�����Ă�������
> ����ARadeon�̓A�[�L�e�N�`�����O���t�B�b�N�ɓ������邱�Ƃ�GPU���\�̃A�h�o���e�[�W�Ă���̂�
> �������ĂƂ����̏�k���ƁB
����Ə�������������I�o�J����͋`���{������w�Z���炵�����Ă�������
�G���̌X���Ƃ��ĂȂ炱�̏ꍇ
PCIE��CPU�_�C�����̍����̂ق����\���Ƃ��Ēi�Ⴂ�ɍ���
PCIE��CPU�_�C�����̍����̂ق����\���Ƃ��Ēi�Ⴂ�ɍ���
>>11
�����Ă邱�Ƃ͓��ӂ������܂����������蒼�����ق��������B
�����Ă邱�Ƃ͓��ӂ������܂����������蒼�����ق��������B
Radeon�������A�[�L�e�N�`��������
���\�łȂ�����_��������
���\�łȂ�����_��������
�����Ă邱�Ƃɂ����ӂł����
����ł��̕���ŗ���Ă�̂�
�V�J���ł����Ȃ葼�Е��݂ɔėp������������Ȃ�ǂ�����J���Ȃ�
������J���𑱂��Ă�
���x�����f���`�F���W���o�ē����ɂȂ��Ό�̎�
����ł��̕���ŗ���Ă�̂�
�V�J���ł����Ȃ葼�Е��݂ɔėp������������Ȃ�ǂ�����J���Ȃ�
������J���𑱂��Ă�
���x�����f���`�F���W���o�ē����ɂȂ��Ό�̎�
�`�悪���������_���Z����Ȃ��Ǝv���Ă�\���͂���ɍ���
��������ATi Stream�Ƃ���
���C�u������{�C�ō���Ă��鎞�_��
��ЂƂ��đ̍ق��������Ă邵
���C�u������{�C�ō���Ă��鎞�_��
��ЂƂ��đ̍ق��������Ă邵
NVIDIA�ސ��̃x���`�ŕ����Ă邶���
>>15
���Ђƌ����Ă�NV��CPU�����ĂȂ�����O���{�Ƃ��Ă������Ȃ���
�܂����ꏊ�I��CPU�̎ז����Ă��̃S�~�Ɣ�ׂĂ��Ȃ����낤�ȁE�E�E
���Ђƌ����Ă�NV��CPU�����ĂȂ�����O���{�Ƃ��Ă������Ȃ���
�܂����ꏊ�I��CPU�̎ז����Ă��̃S�~�Ɣ�ׂĂ��Ȃ����낤�ȁE�E�E
�N���X�^�\����������ƈႤ���炢�Ŋ�{�I��GPU�̍\���Ȃ��
�ǂ�����������ς����B�P��GPU�ŐH���Ȃ��Ȃ�\�����l����
API������NV�ƁAAPI�̓I�[�v���K�i�ɔC���ĊJ��������D��
����ATI�Ƃ����Ⴂ�ɉ߂��Ȃ��B
�ǂ�����������ς����B�P��GPU�ŐH���Ȃ��Ȃ�\�����l����
API������NV�ƁAAPI�̓I�[�v���K�i�ɔC���ĊJ��������D��
����ATI�Ƃ����Ⴂ�ɉ߂��Ȃ��B
���C�u�����͖{�C�ō������_����������
�܂����ׂ�AMD�ސ��R���p�C���̂͂�����
���܂Ōo���Ă������C�u�����̃I���p���[�h
���܂Ōo���Ă������C�u�����̃I���p���[�h
Bulldozer�̍X�ɐ��������x�\�z�o��������
�R�A�����͂���ȏ�y�ʉ�����K�v�͂Ȃ�����������A10�N���炢�g�������B
�����AIntel�ɍ��킹��SIMD���j�b�g�͋������Ă������낤
AVX(128bit*2)��LNI(256bit*2)��LNI?(512bit*2)
�����A�݊����̂��߂ɑΉ��͂��邯�ǐ��\��������C�͂Ȃ��݂�����
������GPGPU�ɍœK������RADEON�ɕ��������_���Z��C���邩��ˁB
�L���b�V����L1/L2�͂��̂܂܂ŁAL3��4���W���[���P�ʂł̋��L�ŁAL3���m���N���X�o�[�������O�o�X�Ƃ��Őڑ����ȁB
����Ȋ�����(4�R�A�̕��т͓c����Ȃ������т��������)
�c-�c
�bX�b
�c-�c
�P����4�R�ACPU�̃}���`�v���Z�b�T�\���������`�b�v�������C���[�W
�R�A�����͂���ȏ�y�ʉ�����K�v�͂Ȃ�����������A10�N���炢�g�������B
�����AIntel�ɍ��킹��SIMD���j�b�g�͋������Ă������낤
AVX(128bit*2)��LNI(256bit*2)��LNI?(512bit*2)
�����A�݊����̂��߂ɑΉ��͂��邯�ǐ��\��������C�͂Ȃ��݂�����
������GPGPU�ɍœK������RADEON�ɕ��������_���Z��C���邩��ˁB
�L���b�V����L1/L2�͂��̂܂܂ŁAL3��4���W���[���P�ʂł̋��L�ŁAL3���m���N���X�o�[�������O�o�X�Ƃ��Őڑ����ȁB
����Ȋ�����(4�R�A�̕��т͓c����Ȃ������т��������)
�c-�c
�bX�b
�c-�c
�P����4�R�ACPU�̃}���`�v���Z�b�T�\���������`�b�v�������C���[�W
NV�ސ�CUDA�R���p�C����
���C�u�����Ŏ~�߂Ƃ����Ďv����
���C�u�����Ŏ~�߂Ƃ����Ďv����
�W���K�i�̃R���p�C����\�t�g�������Ƃ͕���قǂ��邩��AMD���C������č��K�v�������B
Intel��Nvidia�͍œK����A���ГƎ�API�y�����������玩�������ō��K�v�����邾���B
���F�����ǂ��撣���Ă�GCC��Visual Stadio�ɂ̓V�F�A�ł͐�Ώ��ĂȂ����ǂˁB
����Ȃ炢�������̊J�����Ƀn�[�h�Ǝd�l����ĊJ�����͂��邭�炢�Œ��x�����Ƃ����̂�AMD�̃X�^���X�B
Intel��Nvidia�͍œK����A���ГƎ�API�y�����������玩�������ō��K�v�����邾���B
���F�����ǂ��撣���Ă�GCC��Visual Stadio�ɂ̓V�F�A�ł͐�Ώ��ĂȂ����ǂˁB
����Ȃ炢�������̊J�����Ƀn�[�h�Ǝd�l����ĊJ�����͂��邭�炢�Œ��x�����Ƃ����̂�AMD�̃X�^���X�B
x86��GPU�̃x�N�^�Ό��̌������t���܂ł͗l�q������
�{����x86��SIMD�Ȃe�B�b�V���ɂ����ŃS�~���ɂł��˂����݂������낤
Bull��AVX�Ή��̂��߂�1�N�x�点���ƌ����Ă邪
GPGPU�̗l�q���̂��߂̒x��̈Ӗ�������Ǝv���iFUSION�̒x����܂߂āj
������l�q���ŕ`�������GPU�������Ȃ��Ă����I�Ȍ������Ă�
CPU�ɓ�������ƂȂ�Ƃ����Ƃ���ł͈Ӗ�������
�{����x86��SIMD�Ȃe�B�b�V���ɂ����ŃS�~���ɂł��˂����݂������낤
Bull��AVX�Ή��̂��߂�1�N�x�点���ƌ����Ă邪
GPGPU�̗l�q���̂��߂̒x��̈Ӗ�������Ǝv���iFUSION�̒x����܂߂āj
������l�q���ŕ`�������GPU�������Ȃ��Ă����I�Ȍ������Ă�
CPU�ɓ�������ƂȂ�Ƃ����Ƃ���ł͈Ӗ�������
bobcat��bobsap�Ɍ�����
���ɂ����E�E�E
���ɂ����E�E�E
>>18
ID��aTi
AMD�̊J���`�[�����č����������H
���܂ł͂܂��T�[�o�[CPU������āA�����PC�ɂ����Ƃ��Ă�����������������
�����ɂ��ēˑRBull���n�߂Ƃ��ăA�[�L�e�N�`���̎�ނ��������B
���ꂼ���1�`�[�����Ă��Ƃ͂Ȃ�����������ACPU+GPU����ł��`�[����
Bull�Ɓi���̃T�u�Z�b�g�����A�ƌ����Ă��邪�jBob��2�`�[�����炢���H
ID��aTi
AMD�̊J���`�[�����č����������H
���܂ł͂܂��T�[�o�[CPU������āA�����PC�ɂ����Ƃ��Ă�����������������
�����ɂ��ēˑRBull���n�߂Ƃ��ăA�[�L�e�N�`���̎�ނ��������B
���ꂼ���1�`�[�����Ă��Ƃ͂Ȃ�����������ACPU+GPU����ł��`�[����
Bull�Ɓi���̃T�u�Z�b�g�����A�ƌ����Ă��邪�jBob��2�`�[�����炢���H
�Ђ���Ƃ����Bob��Bull�͂����ȕ����g���Ă�̂����ȁB
�Z��݂����Ȃ��̂��ȁB
�Z��݂����Ȃ��̂��ȁB
>>29
���܂͒m��͎̂O�������ˁB
���܂͒m��͎̂O�������ˁB
4�T�Ƃ���Bobcat��Bulldozer�̋L�������Ėϑz���N�����H
Bobcat��Bulldozer
�ǂ���������͂łȂ���B���̂܂܂̌o�c���
�Ȃ�ALlano������Ɣ����ł��錩�ʂ������x������
�Ȃ�ALlano������Ɣ����ł��錩�ʂ������x������
�����\����
�N�ł����Ƃł�
�N�ł����Ƃł�
2009Q4�̎��_��AMD�͎��x�g���g���iIntel����̕ۏ؋������z�j�܂ʼn��Ă邼
>>36
����͉R�ł��˂��BIntel���炨�������グ�Ă܂�
�Ԏ��ł���B���N�x���ؓ����̕ԍϊ����̋߂�
�傫�ȍ������Ă��邩��A�܂Ƃ��Ɍo�c�ł����
�ƂĂ��v��Ȃ��ˁB
�����̂�グ����ɂ����s�������B�_���Ȃ�Ȃ����Ȃ�
����͉R�ł��˂��BIntel���炨�������グ�Ă܂�
�Ԏ��ł���B���N�x���ؓ����̕ԍϊ����̋߂�
�傫�ȍ������Ă��邩��A�܂Ƃ��Ɍo�c�ł����
�ƂĂ��v��Ȃ��ˁB
�����̂�グ����ɂ����s�������B�_���Ȃ�Ȃ����Ȃ�
�܂��A�������z�Ő��E10�`20�ʂ�Intel�Ɣ�ׂ���A2000�ʂɂ�����Ȃ�AMD�̊J���\�͂͂������m��Ă邾�낤���ǂ�
���Ȃ݂ɍ��␢�E�����N1,2,4�ʂ��������
���Ȃ݂ɍ��␢�E�����N1,2,4�ʂ��������
>>37
http://pc.watch.impress.co.jp/docs/news/20100122_344138.html
���������GF�̌��Z���ʂɂȂ邩��A�ǂ����ɂ��Ă��Ԏ��Ƃ��W�Ȃ��Ȃ邯�ǂ�
http://pc.watch.impress.co.jp/docs/news/20100122_344138.html
���������GF�̌��Z���ʂɂȂ邩��A�ǂ����ɂ��Ă��Ԏ��Ƃ��W�Ȃ��Ȃ邯�ǂ�
�Â��l�^�������Ŏ������閼�l�ł�����
�{���̎G�� ID:QYG5E9oE
>>39�̃\�[�X��
�d�x�̏�Q�����]���X�Ŕ��f����ΐԎ��Ɣ��f�o���邩������Ȃ�
�Ƃ��v�����̂���
������ł��@�́u�ł��v���Ă͉̂����낤���H
�\�[�X���͍̂����̋L�����Ɣ��f���Ă�̂��낤���H
�m�I��Q�̐��E�́i�����j����@�@�@�@�@�@�@�@�@�@�@by�Ђ�䂫
�d�x�̏�Q�����]���X�Ŕ��f����ΐԎ��Ɣ��f�o���邩������Ȃ�
�Ƃ��v�����̂���
������ł��@�́u�ł��v���Ă͉̂����낤���H
�\�[�X���͍̂����̋L�����Ɣ��f���Ă�̂��낤���H
�m�I��Q�̐��E�́i�����j����@�@�@�@�@�@�@�@�@�@�@by�Ђ�䂫
���{�̉Ɠd�E�d�C�n�̃��[�J�[���ǁ`���M��A�Ƃ����Ăق�����
�O��n�͕��u����{����H
Ontario�̃X�y�b�N��ϑz
�EL2 512KB�~2
�ESP 40
�EPCI-E�Ń`�b�v�Z�b�g�ɐڑ�
�EL2 512KB�~2
�ESP 40
�EPCI-E�Ń`�b�v�Z�b�g�ɐڑ�
Ontario�͌Â��X���C�h��"1MB�@Cache"�ɂȂ��Ă�����ˁB
���ƐV�����X���C�h�ł͐����v���Z�X���s���Ȉ�������������A
������40nm�Ȃ̂��낤���H
���ƌ����55nm�Ő��������"785G"�ł���SP40�͏���Ă���̂ŁA
SP40�͂��܂�ɏ��Ȃ�����C������B
���ƐV�����X���C�h�ł͐����v���Z�X���s���Ȉ�������������A
������40nm�Ȃ̂��낤���H
���ƌ����55nm�Ő��������"785G"�ł���SP40�͏���Ă���̂ŁA
SP40�͂��܂�ɏ��Ȃ�����C������B
>>41
�݂���
�݂���
�܂��Ȃ�Ƃł������Ă���������w
2011�N�ɂȂ��āA�������Ԃ̂͂��O�����̕�����
2011�N�ɂȂ��āA�������Ԃ̂͂��O�����̕�����
���͂�����̓[���Ȃ��玟�ɗ���̂�ID���ς���Ă���ɂ�����H
�����Ԏ��ɂȂ��Ă�
�悻�̂����ɏo���Ȃ���
�悻�̂����ɏo���Ȃ���
CPU�̉��z���x���@�\�����������b���ďo�Ă��Ă�?
����GPU�̓G�~�����[�g�����ǁACPU�Ƃ̓����ő����͏͐i�W�����?
����GPU�̓G�~�����[�g�����ǁACPU�Ƃ̓����ő����͏͐i�W�����?
�ǂ������Ӗ��̉��z���ɂ�邩���ȁB
DirectX�̂悤�ȕ����Ńh���C�o�ɂ����CPU/GPU���ւ���̂�
�\�t�g�ˑ����ȁB�i�h���C�o�̏o������j
�f�o�t���G�~�����[�g�Ƃ����̂́A�ǂ̑g�ݍ��킹�ŁA�ǂ������@�\���g�����ꍇ��z�肵�Ă̔������
DirectX�̂悤�ȕ����Ńh���C�o�ɂ����CPU/GPU���ւ���̂�
�\�t�g�ˑ����ȁB�i�h���C�o�̏o������j
�f�o�t���G�~�����[�g�Ƃ����̂́A�ǂ̑g�ݍ��킹�ŁA�ǂ������@�\���g�����ꍇ��z�肵�Ă̔������
�Ȃ�
�{���Ȃ�DX11�����WDDM3.x�ɑΉ���
���z�}�V���ł��n�[�h�g����͂���������
DX10.1��WDDM2.x���炠�ځ[�Ă邵
�{���Ȃ�DX11�����WDDM3.x�ɑΉ���
���z�}�V���ł��n�[�h�g����͂���������
DX10.1��WDDM2.x���炠�ځ[�Ă邵
Llano��480SP�Ŗ�40mm2������ȁA
10mm2�ɍ���Ă�120SP�͐ς߂�v�Z�ɂȂ�
�܂�785G��3�{�̐��\w
Bobcat�R�A��K6-3�Ɏ��Ă��邩��A�g�����W�X�^����T�C�Y���������낤�Ɨ\�z (L2 256KB)
��3200���g�����W�X�^��3500���g�����W�X�^��K10�R�A�Ɠ��T�C�Y�ʂ���(10mm2)
(SSE��x64�Ή��ő��������Ă�4000���ʂŃT�C�Y�ɂ͑債���e���͂Ȃ���)
���ꂪ2�R�A��20mm2�ɂȂ�B
�����R���A�N���X�o�[�AHT�o�X�����v30mm2��
�f���A���R�A�A120SP GPU�A�A���R�A���̍��v�Ŗ�60mm2�Ƃ����Ƃ��납�ˁB
���Ȃ݂�pineview single��65mm2�ADual�R�A��87mm2�B
���ł�Ion2�炵��GT218(210)��55mm2���炢�B
�ȂA�y�������B
10mm2�ɍ���Ă�120SP�͐ς߂�v�Z�ɂȂ�
�܂�785G��3�{�̐��\w
Bobcat�R�A��K6-3�Ɏ��Ă��邩��A�g�����W�X�^����T�C�Y���������낤�Ɨ\�z (L2 256KB)
��3200���g�����W�X�^��3500���g�����W�X�^��K10�R�A�Ɠ��T�C�Y�ʂ���(10mm2)
(SSE��x64�Ή��ő��������Ă�4000���ʂŃT�C�Y�ɂ͑債���e���͂Ȃ���)
���ꂪ2�R�A��20mm2�ɂȂ�B
�����R���A�N���X�o�[�AHT�o�X�����v30mm2��
�f���A���R�A�A120SP GPU�A�A���R�A���̍��v�Ŗ�60mm2�Ƃ����Ƃ��납�ˁB
���Ȃ݂�pineview single��65mm2�ADual�R�A��87mm2�B
���ł�Ion2�炵��GT218(210)��55mm2���炢�B
�ȂA�y�������B
GPU�̉��z���Ƃ�����DirectX�̉��z�}�V���ł̎g�p��VirtualBOX�ł��ł��邩��ǂ��ł��悳��
785G�̂R�{���ƓK���Ɍ��ς�����HD5450��1.5�{���炢�H
���N���炢���ƃu���E�U��GPU�`�悾�����肷�邵
���̃N���X��CPU����GPU�x�������ꂵ���ˁB
���N���炢���ƃu���E�U��GPU�`�悾�����肷�邵
���̃N���X��CPU����GPU�x�������ꂵ���ˁB
AMD finally outs the 32nm Llano core
http://www.semiaccurate.com/2010/02/10/amd-finally-outs-32nm-llano-core/
��H�v���Ă��ׂ����Ƃ͂܂��܂����������
�}�C�N���A�[�L�e�N�`���ɒ��Ⴗ��̂��������ǁA�����������̉��̗͎����I�Ȃ��̂��������낢
http://www.semiaccurate.com/2010/02/10/amd-finally-outs-32nm-llano-core/
��H�v���Ă��ׂ����Ƃ͂܂��܂����������
�}�C�N���A�[�L�e�N�`���ɒ��Ⴗ��̂��������ǁA�����������̉��̗͎����I�Ȃ��̂��������낢
Llano����K10����˂�����
���N�̂��鎞�_�܂ł́AGPU������Bulldozer�R�A�ł���\�肾�������ǂˁB
�Ԃɍ���Ȃ��̂��A�f�X�N�g�b�v�����̐��\���o�Ȃ��̂��B
�Ԃɍ���Ȃ��̂��A�f�X�N�g�b�v�����̐��\���o�Ȃ��̂��B
�@�O���猻�s�R�A���ď�����Ă��C�����邯�ǁB�����������ɖ`��
����̂������Ƃ������R�ŁB
����̂������Ƃ������R�ŁB
�����[����GPU���������Ⴄ��Bulldozer�R�A�P�̂̑f�����������Ȃ邩��Ȃ��B
Globalfoundries: No AMD 45nm Microprocessors with HKMG Incoming.
http://www.xbitlabs.com/news/cpu/display/20100211053554_Globalfoundries_No_AMD_45nm_Microprocessors_with_HKMG_Incoming.html
����45nm�ł�HKMG�͖����A��
�c�O����
http://www.xbitlabs.com/news/cpu/display/20100211053554_Globalfoundries_No_AMD_45nm_Microprocessors_with_HKMG_Incoming.html
����45nm�ł�HKMG�͖����A��
�c�O����
2�R�A1�X���Ƃ���45nmHKMG�Ƃ���
�A���~�̖ϑz���ǂ�ǂ�ے肳��ă����X
�A���~�̖ϑz���ǂ�ǂ�ے肳��ă����X
�t�ɎG���̒m�\��Q�ƌ��o�ƔS���͂͂ǂ�ǂ�����Ă����Ԃ�L���C
>>63
�t�Ɍ�����45nm�ɗ��炸�����Ȃ�32nm�Ŗ��Ȃ����Ă��Ƃ��H
>>55
��������K6�Ƃ�K7��45nm�v���Z�X�ɂ����炷�������������Ȃ��
�t�Ɍ�����45nm�ɗ��炸�����Ȃ�32nm�Ŗ��Ȃ����Ă��Ƃ��H
>>55
��������K6�Ƃ�K7��45nm�v���Z�X�ɂ����炷�������������Ȃ��
67 �F,,�E�L�́M�E,,�j��-�������F2010/02/12(��) 09:15:29 ID:q7muIYR2
�u�C�������āv���K�v������
���ǕЎ�Ԃł����A���ꂾ���ł�
���ǕЎ�Ԃł����A���ꂾ���ł�
ttp://sourceforge.jp/projects/freshmeat_open64/
��Open64��Linux�삳���Ă���C���e����Itanium(TM)�ł̃V�X�e���œK���R���p�C���̊J���c�[���̃p�b�P�[�W�ł��B
���������H�܂��܂��m�I��Q�̉������肩�H
��Open64��Linux�삳���Ă���C���e����Itanium(TM)�ł̃V�X�e���œK���R���p�C���̊J���c�[���̃p�b�P�[�W�ł��B
���������H�܂��܂��m�I��Q�̉������肩�H
>>70
HKMG��32nm��GPU�ɂǂꂾ���v���ł��邩����
HKMG��32nm��GPU�ɂǂꂾ���v���ł��邩����
HKMG�̓R���Z�v�g�ʂ�̃p�t�H�[�}���X������A
����d�͌��邵�X�s�[�h���オ���ăE�n�E�n�B
���ۂ̏��́A���������v���Z�X���Ȃ����Ƃɂ͔��f�ł��Ȃ����ĂƂ����ȁB
�����͌��\�������Ă���l�q����
����d�͌��邵�X�s�[�h���オ���ăE�n�E�n�B
���ۂ̏��́A���������v���Z�X���Ȃ����Ƃɂ͔��f�ł��Ȃ����ĂƂ����ȁB
�����͌��\�������Ă���l�q����
HKMG����T-RAM��Z-RAM��eDRAM�𑁂��E�E
Open64��x64�ɑΉ����Ă�AMD����Ԍ����ꂵ�Ă�킯�����B
������������CPU�̃L���b�V���̍\���▽�߂̃X���[�v�b�g�̂悤�ȏd�v�����R�[�h�̃R�~�b�g��ʂ��Č��\�B
���ꂾ���̃��X�N������Ă܂ł���Ă�̂ɁA�Ў�Ԃ��Ƃ�����IPF�p���Ƃ��g�{�P�Ă����ʁB
������������CPU�̃L���b�V���̍\���▽�߂̃X���[�v�b�g�̂悤�ȏd�v�����R�[�h�̃R�~�b�g��ʂ��Č��\�B
���ꂾ���̃��X�N������Ă܂ł���Ă�̂ɁA�Ў�Ԃ��Ƃ�����IPF�p���Ƃ��g�{�P�Ă����ʁB
�v���
�u��������CPU�̃L���b�V���̍\���▽�߂̃X���[�v�b�g�̂悤�ȏd�v�����R�[�h�̃R�~�b�g��ʂ��Č��\�B
�Ȃ̂�
>25���J�����Ƀn�[�h�Ǝd�l����ĊJ�����͂��邭�炢
�͊ԈႢ��
Open64��AMD�������
������AMD64��Intel��������i���j�v
����ς肢���ǂ��肩�E�E�E
���^�������W�u����͎��̖ϑz���v
212 ���O�F Socket774 [sage] ���e���F 04/02/26 17:29 ID:05gJCEOC
�^����A���łɂ���ɂ������Ă���
�uAMD64�͎���Intel�哱 ���v�͂ǂ��Ȃ����H
39�ł���Ȃ��Ƃ͌����ĂȂ��ƌ����Ă������ԈႢ�Ȃ������Ă邼
�uAMD64�͎���Intel64�̖��O��ς������ɉ߂��Ȃ��v�Ƃ�
�R�������ŗ�����]�X�ĂȘb�ɍL�������̂���̃X���̗��ꂾ����
219 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/26 17:42 ID:hNdvEqFS
212
����͎��̖ϑz���B
������64bit�ɂȂ�o�C�i���[���ς��̂Ƀo�C�i���[�R�[�h�Ɏ��O�œK���������ߍ��܂�Ă��Ȃ��������炾�B
���ł��s�v�c���B
�u��������CPU�̃L���b�V���̍\���▽�߂̃X���[�v�b�g�̂悤�ȏd�v�����R�[�h�̃R�~�b�g��ʂ��Č��\�B
�Ȃ̂�
>25���J�����Ƀn�[�h�Ǝd�l����ĊJ�����͂��邭�炢
�͊ԈႢ��
Open64��AMD�������
������AMD64��Intel��������i���j�v
����ς肢���ǂ��肩�E�E�E
���^�������W�u����͎��̖ϑz���v
212 ���O�F Socket774 [sage] ���e���F 04/02/26 17:29 ID:05gJCEOC
�^����A���łɂ���ɂ������Ă���
�uAMD64�͎���Intel�哱 ���v�͂ǂ��Ȃ����H
39�ł���Ȃ��Ƃ͌����ĂȂ��ƌ����Ă������ԈႢ�Ȃ������Ă邼
�uAMD64�͎���Intel64�̖��O��ς������ɉ߂��Ȃ��v�Ƃ�
�R�������ŗ�����]�X�ĂȘb�ɍL�������̂���̃X���̗��ꂾ����
219 ���O�F ��Rb.XJ8VXow [sage] ���e���F 04/02/26 17:42 ID:hNdvEqFS
212
����͎��̖ϑz���B
������64bit�ɂȂ�o�C�i���[���ς��̂Ƀo�C�i���[�R�[�h�Ɏ��O�œK���������ߍ��܂�Ă��Ȃ��������炾�B
���ł��s�v�c���B
ID:3NLkAs1W
������������������
������������������
x64��AMD�̓Ǝ��K�i������AMD���撣��Ȃ��ʼn������撣��H
����ɁALinux�ɂ�Windows��MS�̂悤�ȁAAPI���x�z�����Ƃ����݂��Ȃ�����ȁA
�VAPI�����肵�����[�J�[���Ǝ��ɊJ�����邵���Ȃ��B
��������Linux�����͎������������������炵�����Ȃ��ˁB
�܂��A���̓w�͂̍b�゠����AMD64(x64)�͕W���K�i�̒n�ʂ��l��������ȁB
���Ȃ݂ɁA>>25�Ō����Ă�̂�OpenCL��DirectComute�Ƃ��̃R���p�C������ɂ��Ă���B
�W���K�i�́c���Č��肵�Ă邾��B����ɓƎ��K�i�͎����ō��Ƃ������Ă�B
AMD���Ǝ��K�i��x64�Ŋ撣���Ă�Ƃ��؈Ⴂ�̕��匾���Ă��m��ȁB
����ɁALinux�ɂ�Windows��MS�̂悤�ȁAAPI���x�z�����Ƃ����݂��Ȃ�����ȁA
�VAPI�����肵�����[�J�[���Ǝ��ɊJ�����邵���Ȃ��B
��������Linux�����͎������������������炵�����Ȃ��ˁB
�܂��A���̓w�͂̍b�゠����AMD64(x64)�͕W���K�i�̒n�ʂ��l��������ȁB
���Ȃ݂ɁA>>25�Ō����Ă�̂�OpenCL��DirectComute�Ƃ��̃R���p�C������ɂ��Ă���B
�W���K�i�́c���Č��肵�Ă邾��B����ɓƎ��K�i�͎����ō��Ƃ������Ă�B
AMD���Ǝ��K�i��x64�Ŋ撣���Ă�Ƃ��؈Ⴂ�̕��匾���Ă��m��ȁB
>>78
���Ȕے肷���ww
���Ȕے肷���ww
x64�͕ʂɓw�͂��Ȃ��ł�
�R��IA64���������_�ŕW������ꂽ�����R��������ˁ[�́H
�܂��ڂ����Ȃ��̂Ɍ���Ă�
���ꂪ�L�т������ł܂��G����
�uopen64��AMD�̂��̂Ɍ��܂��Ă�Ihttp://www.open64.net/�I�v
�Ƃ��\��o���Ă����邩�炱�̕ӂɂ��Ƃ�����
�R��IA64���������_�ŕW������ꂽ�����R��������ˁ[�́H
�܂��ڂ����Ȃ��̂Ɍ���Ă�
���ꂪ�L�т������ł܂��G����
�uopen64��AMD�̂��̂Ɍ��܂��Ă�Ihttp://www.open64.net/�I�v
�Ƃ��\��o���Ă����邩�炱�̕ӂɂ��Ƃ�����
�Z�M�u�m�[�gPC�����Ȃ�Inte�n�v
http://plusd.itmedia.co.jp/pcuser/articles/1002/12/news034.html
http://plusd.itmedia.co.jp/pcuser/articles/1002/12/news034.html
�m�[�g��������Tigris�ɂȂ��Ă���}�ɉe�����Ȃ����悤�ȥ��
Puma�̎��͂������傢���グ���Ă��̂�
Puma�̎��͂������傢���グ���Ă��̂�
>>83
�m�[�g�����O���t�B�b�N�h���C�o���X�V���邩�ǂ����́AAMD�ł͂Ȃ��m�[�g���[�J�[�Ɉς˂��Ă�̂���Ԃ̔s��
IGP�ł͂Ȃ�Mobility���ڂ��Ă��Ƃ��Ă��X�V�͂Ȃ�
AMD�̃G���g���[�N���X�̎������́A���͂ȃI���{�i����MobilityGPU�ɂ������ȃV�X�e�����
�O���t�B�b�N�h���C�o�̍X�V���Ȃ��A���̃I���{�̋@�\���t���ɐ������Ȃ��l�Ȍ���P�Ȃ�����ȃm�[�g
������A���̓h���C�o�̍X�V������ŐV�@�\���t���ɐ�������AnVIDIA_GPU���ڂ���Intel�m�[�g���w������Ƃ�����
AMD�̃m�[�g�͎����Ԃ̖��͂��̂ĂĂ�̂�����
�m�[�g�����O���t�B�b�N�h���C�o���X�V���邩�ǂ����́AAMD�ł͂Ȃ��m�[�g���[�J�[�Ɉς˂��Ă�̂���Ԃ̔s��
IGP�ł͂Ȃ�Mobility���ڂ��Ă��Ƃ��Ă��X�V�͂Ȃ�
AMD�̃G���g���[�N���X�̎������́A���͂ȃI���{�i����MobilityGPU�ɂ������ȃV�X�e�����
�O���t�B�b�N�h���C�o�̍X�V���Ȃ��A���̃I���{�̋@�\���t���ɐ������Ȃ��l�Ȍ���P�Ȃ�����ȃm�[�g
������A���̓h���C�o�̍X�V������ŐV�@�\���t���ɐ�������AnVIDIA_GPU���ڂ���Intel�m�[�g���w������Ƃ�����
AMD�̃m�[�g�͎����Ԃ̖��͂��̂ĂĂ�̂�����
nvidiaGPU���ڂ���intel�m�[�g(�j
�m�[�g�̃f�B�X�N���[�g�O���t�B�b�N�ł̃V�F�A�Ȃ�RADEON��NVIDIA�������Ă��
>>84
�Ƃ�������������TurionII�N���X���̗p����Ȃ��Ȃ��Ă�
�Ƃ�������������TurionII�N���X���̗p����Ȃ��Ȃ��Ă�
�ŁACapela�m�[�g�͂ǂꂭ�炢�o�ׂ���Ă��
�f�X�N�g�b�v�̏ꍇ��GPU�J�[�h���������Ȃ�����������
DirectX10.1�Ȃ���10�Ή���1�N���炢�߂����Ă��܂���������
�m�[�g�̏ꍇ�͖��N����������C�ɂȂ�Ȃ�����
DirectX11�Ή����Ă��Ȃ�������̂��C�ɂ͂Ȃ�Ȃ���
DirectX10.1�Ȃ���10�Ή���1�N���炢�߂����Ă��܂���������
�m�[�g�̏ꍇ�͖��N����������C�ɂȂ�Ȃ�����
DirectX11�Ή����Ă��Ȃ�������̂��C�ɂ͂Ȃ�Ȃ���
>>82���ĎG���炵���R���Ȃ�
92 �FSocket774�F2010/02/13(�y) 06:57:10 ID:Eicqgl24
�m�[�g��GPU�͌����ł��Ȃ��̂�?
�n���_�t������Ă���̂��ǂ�����Č��������B
�n���_�t�����Ȃ����Ƃ�
���傢�O����GPU�{�[�h�̃R�l�N�^���d�l�Ƃ��ďo����Ă��Ń{�[�h���Ɍ������\��������Ȃ�
ttp://journal.mycom.co.jp/news/2009/01/13/019/index.html
ttp://journal.mycom.co.jp/photo/news/2009/01/13/019/images/001l.jpg
�����m�[�g�̏ꍇ�A�ȃX�y�[�X�����߂��邩��
���c�t���œƎ�����w�ǂ��낤�ˁi�݊����Ȃ��j
ttp://journal.mycom.co.jp/news/2009/01/13/019/index.html
ttp://journal.mycom.co.jp/photo/news/2009/01/13/019/images/001l.jpg
{kind=link}
�����m�[�g�̏ꍇ�A�ȃX�y�[�X�����߂��邩��
���c�t���œƎ�����w�ǂ��낤�ˁi�݊����Ȃ��j
>>92
HP�̃��o�C�����[�N�X�e�[�V�������Ǝ�ւ��\�������肵��
HP�̃��o�C�����[�N�X�e�[�V�������Ǝ�ւ��\�������肵��
>>95
���ꂪ�o���l�ɂȂ�AAMD����̃h���C�o�����[�X�ɐ�ւ��̂���
�m�[�g���[�J���ł̃h���C�o�����[�X���ƑS���O���t�B�b�N�h���C�o�X�V���Ȃ�����ŐV�@�\���g���₵�Ȃ�
����AMD�̓m�[�g�����O���t�B�b�N�h���C�o�̃����[�X���AAMD���g�Ŕ��s����l�ɕύX���Ă����E�E�E
���ꂪ�o���l�ɂȂ�AAMD����̃h���C�o�����[�X�ɐ�ւ��̂���
�m�[�g���[�J���ł̃h���C�o�����[�X���ƑS���O���t�B�b�N�h���C�o�X�V���Ȃ�����ŐV�@�\���g���₵�Ȃ�
����AMD�̓m�[�g�����O���t�B�b�N�h���C�o�̃����[�X���AAMD���g�Ŕ��s����l�ɕύX���Ă����E�E�E
�������nvidia�Ɠ���MXM���W���[������Ȃ��̂�
>>98
�����������Ǝv��
�����������Ǝv��
2005�N���瑶�݂��ă��[�U�����p�Ƃ��Ă͕��y���ĂȂ�����ˁAMXM��AXIOM��
���܂��畁�y�������v�f����������Ȃ�
ttp://www.4gamer.net/specials/2005-2006_ati/2005-2006_ati.shtml
���܂��畁�y�������v�f����������Ȃ�
ttp://www.4gamer.net/specials/2005-2006_ati/2005-2006_ati.shtml
�����ƁA2004�N�ɂ��łɂ������݂�������
�K�i�哱���������āA���݂��݊������Ȃ���������ȁB
http://techon.nikkeibp.co.jp/article/NEWS/20100210/180114/
> SOI�v���Z�X�̗̍p�ɂ���āC�ʏ�̂������l�d����
> NMOS�g�����W�X�^��d���X�C�b�`�Ɏg�����B
SOI����NMOS���X�C�b�`�Ɏg����̂͂Ȃ�ŁH
NMOS���X�C�b�`���Ă��Ƃ͉��zVss��Vdd�d���܂�
�ނ邱�ƂɂȂ�낤���ǁA�ʏ��CMOS�ƈ����
�\�[�X�E�h���C������T�u�X�g���[�g�ւ̃��[�N�����Ȃ�
������Ă��ƂȂ̂��ȁH
> SOI�v���Z�X�̗̍p�ɂ���āC�ʏ�̂������l�d����
> NMOS�g�����W�X�^��d���X�C�b�`�Ɏg�����B
SOI����NMOS���X�C�b�`�Ɏg����̂͂Ȃ�ŁH
NMOS���X�C�b�`���Ă��Ƃ͉��zVss��Vdd�d���܂�
�ނ邱�ƂɂȂ�낤���ǁA�ʏ��CMOS�ƈ����
�\�[�X�E�h���C������T�u�X�g���[�g�ւ̃��[�N�����Ȃ�
������Ă��ƂȂ̂��ȁH
�m�[�g�̃f�B�X�N���[�g�O���t�B�b�N�ł̃V�F�A�Ȃ�RADEON��NVIDIA�������Ă��
>>104
CPU�ʔ������ꂽ�g�����W�X�^���ƕ��ʂ̃g�����W�X�^�̓����ƈႤ����
�ŐV�Z�p��CPU�v���Ă�z����Ȃ��Ɣ���Ȃ���ł́H
CPU�ʔ������ꂽ�g�����W�X�^���ƕ��ʂ̃g�����W�X�^�̓����ƈႤ����
�ŐV�Z�p��CPU�v���Ă�z����Ȃ��Ɣ���Ȃ���ł́H
�������AVX�ɂ��Ď���B
AVX��SSE�`SSE4.2+���̊g�����߂̏Ă��������Ǝv���Ă�����
�ꕔ��x86�̒u�������݂����Ȃ��Ə����Ă�l������
�S�R������Ȃ����ǁA�ǂ������ʒu�t���ȂH
AVX��SSE�`SSE4.2+���̊g�����߂̏Ă��������Ǝv���Ă�����
�ꕔ��x86�̒u�������݂����Ȃ��Ə����Ă�l������
�S�R������Ȃ����ǁA�ǂ������ʒu�t���ȂH
>>104
�f�l�l�������ǂ��Ԃ�����ˁH
�f�l�l�������ǂ��Ԃ�����ˁH
>>107
x86�̒u�������ł͂Ȃ���B�����܂�x86�̈ꕔ�B
���ߒ��������Ȃ肷����SSE�����������Ēu���������荡��̃x�N�^���̊g��ɑΉ����邽�߂̂��́B
�����R�[�h�ł����R���p�C���őΉ��ł��邩�牶�b����l�͑�����Ȃ����ȁB
x86�̒u�������ł͂Ȃ���B�����܂�x86�̈ꕔ�B
���ߒ��������Ȃ肷����SSE�����������Ēu���������荡��̃x�N�^���̊g��ɑΉ����邽�߂̂��́B
�����R�[�h�ł����R���p�C���őΉ��ł��邩�牶�b����l�͑�����Ȃ����ȁB
AVX�͍��̂Ƃ���SSE�̉�������
SSE�Ƃ̈Ⴂ�͖��߃R�[�h�̋K����
SSE�͂Ȃ������Ė��߃R�[�h�̋K������
x86�Ɠ������@�̂��̂��g���Ă����nj�������������
������AVX�ł͂����Ɏ���������Ă��A���ꂪ�ړI��AVX�������
���͐V�@�\�̂��߂�AVX�g������SSE�Ɠ����@�\���lj�����
�ŏI�I�ɂ�x86��ʖ��߂�AVX�ɒlj�����AVX�Ɉڍs������
SSE�Ƃ̈Ⴂ�͖��߃R�[�h�̋K����
SSE�͂Ȃ������Ė��߃R�[�h�̋K������
x86�Ɠ������@�̂��̂��g���Ă����nj�������������
������AVX�ł͂����Ɏ���������Ă��A���ꂪ�ړI��AVX�������
���͐V�@�\�̂��߂�AVX�g������SSE�Ɠ����@�\���lj�����
�ŏI�I�ɂ�x86��ʖ��߂�AVX�ɒlj�����AVX�Ɉڍs������
>�ŏI�I�ɂ�x86��ʖ��߂�AVX�ɒlj�����AVX�Ɉڍs������
���ɃR���͂Ȃ���ˁH
���ɃR���͂Ȃ���ˁH
�����r�[�̖��ߎ�������Ȃ����������H
>>113
IA-64�̎��Y��Ă��������BIA-64�Ȃ�čŏ����狏�Ȃ��������ɂ��Ă��������E�E�E
IA-64�̎��Y��Ă��������BIA-64�Ȃ�čŏ����狏�Ȃ��������ɂ��Ă��������E�E�E
�n�t�}�����k�����悤�ȉϒ��R�[�h�Ŗ��߃f�R�[�_�̕��ׂ��d������
��蒷�ɂ��Ă��B
���̌��ʂƂ��āA�������߂̃f�R�[�h�Ƃ��̌������オ����Đ��@���B
RISC�݂������ȁB��
��蒷�ɂ��Ă��B
���̌��ʂƂ��āA�������߂̃f�R�[�h�Ƃ��̌������オ����Đ��@���B
RISC�݂������ȁB��
�m��AMD�̃A�[�L�e�N�g�̘b���Ǝv�������ǁAx86�̓f�R�[�h��
�A�E�g�I�u�I�[�_�[�̔��s�����̂�������ςŁA�ǂ����������
���Ƃ�������f�R�[�h���낤���Č����Ă��ˁB�R���߂܂ł̓f�R�[�h
�\���낤���S�͓���Ƃ��B
>>116
�u�݂����v����Ȃ��ČŒ蒷���߃R�[�h�{���G���߂̔r���́A�܂��
RISC�̎v�z�B
�A�E�g�I�u�I�[�_�[�̔��s�����̂�������ςŁA�ǂ����������
���Ƃ�������f�R�[�h���낤���Č����Ă��ˁB�R���߂܂ł̓f�R�[�h
�\���낤���S�͓���Ƃ��B
>>116
�u�݂����v����Ȃ��ČŒ蒷���߃R�[�h�{���G���߂̔r���́A�܂��
RISC�̎v�z�B
>>117
RISC���߂����G�ɂȂ肷���āAPowerPC�Ƃ��͓����ŕ������Ă��Ȃ����������H
RISC���߂����G�ɂȂ肷���āAPowerPC�Ƃ��͓����ŕ������Ă��Ȃ����������H
���܂�RISC��CISC���ǂ������ǂ����炵���ˁB
>>107
AVX�̃}�j���A���ǂ߂�x86�̊g�������Ă킩��͂��Ȃ���
�ǂ܂Ȃ��z���㓡�̋L���ɒނ��Ă�낤��
x86����̒E�p��}��Intel�̐V���[�h�}�b�v
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
AVX�̃}�j���A���ǂ߂�x86�̊g�������Ă킩��͂��Ȃ���
�ǂ܂Ȃ��z���㓡�̋L���ɒނ��Ă�낤��
x86����̒E�p��}��Intel�̐V���[�h�}�b�v
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
�������̃T�C�g��ISSCC���|�[�g�ł����A���̏��͏o�Ă��Ȃ������悤�ȁc
http://www.geocities.jp/andosprocinfo/wadai10/20100213.htm
�@�@--------------------
�@�@���I�[���o�b�t�@��U�x�[�V�����X�e�[�V�����̃G���g�������������C
�@�@���������_���Z����̊���Z�̃��[�e���V�����P����Ă���悤�ł��B
�@�@--------------------
�{�����Ƃ���ƁA���\�Ȑ��\���オ���҂ł��邩���B
http://www.geocities.jp/andosprocinfo/wadai10/20100213.htm
�@�@--------------------
�@�@���I�[���o�b�t�@��U�x�[�V�����X�e�[�V�����̃G���g�������������C
�@�@���������_���Z����̊���Z�̃��[�e���V�����P����Ă���悤�ł��B
�@�@--------------------
�{�����Ƃ���ƁA���\�Ȑ��\���オ���҂ł��邩���B
�������������N���Ă邯�Ǐ��>>58�ł���
123 �FMAC�I�^��122 �����F2010/02/13(�y) 21:34:52 ID:QBVVRxhO
�@SF�I�ɋZ�p���x���╨���@�����Ⴄ�킯����Ȃ�����A����
�n���ȉ�͂ƍœK���Ō������グ�Ă��������Ȃ��낤�ˁB����
�������A���̕���K�v�ȏ��ɂ����ށB
�@�ł��A���̘H���Ŋ撣��Ƃǂ�ǂ�Intel�I�ȁu�n�}��Ƒ����vCPU��
�߂Â��Ă����낤�Ȃ��B
�n���ȉ�͂ƍœK���Ō������グ�Ă��������Ȃ��낤�ˁB����
�������A���̕���K�v�ȏ��ɂ����ށB
�@�ł��A���̘H���Ŋ撣��Ƃǂ�ǂ�Intel�I�ȁu�n�}��Ƒ����vCPU��
�߂Â��Ă����낤�Ȃ��B
Power6 5.0Ghz < Power7 3.0Ghz
�̕�������w
�̕�������w
�������āCIntel�͂���MPB�̊ԂŃf�[�^��]������MPI�Ɏ������C�u������p�ӂ����Ƃ̂��Ƃł��B
�������肾
�������肾
x86��x64�ƌ݊���������Ȃ���ł��D���Ȃ����g�����Ă�����
http://www.theinquirer.net/IMG/224/92224/amd-fusion-die-230x230.JPG?1265648264
����2�R�A�ł̔z�u�ǂ��ȂH
{kind=link}
����2�R�A�ł̔z�u�ǂ��ȂH
>>128
���Ԃ���������B
���Ԃ���������B
130 �F,,�E�L�́M�E,,�j��-�������F2010/02/13(�y) 22:02:11 ID:vRhn6ZdL
���Ԃ�����������A�������C���^�[�t�F�C�X��HT�̃C���^�[�t�F�C�X�܂Ő邱�ƂɂȂ邯�ǁB
>>131
�������������ŁA������HT�C���^�[�t�F�C�X�Ȃ̂��킩��̂��c�B
�������������ŁA������HT�C���^�[�t�F�C�X�Ȃ̂��킩��̂��c�B
ttp://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai1_1.jpg.html
����c�ق�ƁB�Ă��Ƃ͐�p�R�A���܂��ʂɂ���̂��H
{kind=link}
����c�ق�ƁB�Ă��Ƃ͐�p�R�A���܂��ʂɂ���̂��H
���ꂩ����Phenom�݂�����2�R�A������
2�R�A��GPU�������ŏc�ɐ���ۂ���
�R�A�ƍ��̃p�b�h�̒i����������
�R�A�ƍ��̃p�b�h�̒i����������
>>135
���ł����������\���B
���ł����������\���B
�ʂɐ�Ȃ��Ă����������
disable�ɂ����R�A�ɂ̓N���b�N�������Ȃ�������Ƃ��������̘b
disable�ɂ����R�A�ɂ̓N���b�N�������Ȃ�������Ƃ��������̘b
139 �FMAC�I�^��138 �����F2010/02/14(��) 00:09:45 ID:Wj71GeXX
�ŏ�����2�R�A�ō��ƁA1�R�A������ł�ƃA�E�g
�ŏ�����4�R�A�����ɂ��Ă�����1�`2�R�A���S�̂�2�`3�R�A�i�Ƃ��Ĕ���ق����A���ʂ��o�Ȃ������H
���ꂪGPU�����̃`�b�v�Ȃ�A2�R�A��p�i��v���������E�F�n������鐔��3�`4�����炢�������
GPU�����`�b�v�ł͂��͂�CPU�R�A����߂�ʐς̔䗦�͏������A2�R�A��p�`�b�v��v���Ă�����قǏ������Ȃ�Ȃ�
�܂�E�F�n������鐔�͂��܂葝���Ȃ�
�ŏ�����4�R�A�����ɂ��Ă�����1�`2�R�A���S�̂�2�`3�R�A�i�Ƃ��Ĕ���ق����A���ʂ��o�Ȃ������H
���ꂪGPU�����̃`�b�v�Ȃ�A2�R�A��p�i��v���������E�F�n������鐔��3�`4�����炢�������
GPU�����`�b�v�ł͂��͂�CPU�R�A����߂�ʐς̔䗦�͏������A2�R�A��p�`�b�v��v���Ă�����قǏ������Ȃ�Ȃ�
�܂�E�F�n������鐔�͂��܂葝���Ȃ�
>>140
�f�X�N�g�b�v�����͂���ł������ǁA
�m�[�g�����Ȃǂ̃M���M���őg�ޕ��́A
���ꂾ�ƕs�m��v�f���������āA
���[�J�[�������Ǝv�����B
�f�X�N�g�b�v�����͂���ł������ǁA
�m�[�g�����Ȃǂ̃M���M���őg�ޕ��́A
���ꂾ�ƕs�m��v�f���������āA
���[�J�[�������Ǝv�����B
�N���b�N��������Ȃ��R�A������ƃ��[�J�[����������
�Ӗ����������̂���
�Ӗ����������̂���
2�R�A�ł�AthlonIIx2 + 240sp�ɂȂ�̂��B
�A���R�A���͑��40mm2�ʂł��̂܂܂Ƃ��Ă�A
���������Ƃ������Ƃ́A100mm2���T�C�Y�ɂȂ��
�v���Z�X�V�������N���āAHKMG�ŁATB���ǂ���PowerGate�Ή��A���g���������ǂƂ��A
�ǂ��R�X�g�p�t�H�[�}���X�����낤�ȁB
�A���R�A���͑��40mm2�ʂł��̂܂܂Ƃ��Ă�A
���������Ƃ������Ƃ́A100mm2���T�C�Y�ɂȂ��
�v���Z�X�V�������N���āAHKMG�ŁATB���ǂ���PowerGate�Ή��A���g���������ǂƂ��A
�ǂ��R�X�g�p�t�H�[�}���X�����낤�ȁB
������ƌv�Z
2�R�A��4�R�A�`�b�v�̑傫���̍���4�F3�Ƃ���
�����܂��2�R�A��80���A4�R�A��95���Ƃ���
��4�R�A�`�b�v�ł�1�`2�R�A���S�i�����i�ɂȂ�̂ŁA�g���Ȃ��̂̓A���R�A������������炢
���̔䗦�Ōv�Z����ƁA1���̃E�F�n������鐔��
2�R�A�F4�R�A��4�~0.8�F3�~0.95��3.2�F2.85
���C����C���i�b�v�̑����ɂƂ��Ȃ��Ǘ��E���ʃR�X�g���l�����獷������
2�R�A�i���Ӗ�����������
2�R�A��4�R�A�`�b�v�̑傫���̍���4�F3�Ƃ���
�����܂��2�R�A��80���A4�R�A��95���Ƃ���
��4�R�A�`�b�v�ł�1�`2�R�A���S�i�����i�ɂȂ�̂ŁA�g���Ȃ��̂̓A���R�A������������炢
���̔䗦�Ōv�Z����ƁA1���̃E�F�n������鐔��
2�R�A�F4�R�A��4�~0.8�F3�~0.95��3.2�F2.85
���C����C���i�b�v�̑����ɂƂ��Ȃ��Ǘ��E���ʃR�X�g���l�����獷������
2�R�A�i���Ӗ�����������
150mm2(4�R�A)��100mm2(2�R�A)�Ő����R�X�g�����Z���Ă݂�B
300mm�E�F�n�̒[��10mm���͖��������Ƃ��Ė�������ƁA
���a280mm�ɂȂ�A�ʐς͖�60000mm2�ɂȂ�B
�����܂��90%��80%�ʂƗ\�z�B
4�R�A�̏ꍇ
60000/150*0.8=320��
2�R�A�̏ꍇ
60000/100*0.9=540��
540/320=1.7�{
����7���������o�Ă���ƕʂ̃_�C��p�ӂ����Ȃ����ȁB
4�R�A��2�R�A����2�R�A�̕����������������Ȃ葽�����낤���B
300mm�E�F�n�̒[��10mm���͖��������Ƃ��Ė�������ƁA
���a280mm�ɂȂ�A�ʐς͖�60000mm2�ɂȂ�B
�����܂��90%��80%�ʂƗ\�z�B
4�R�A�̏ꍇ
60000/150*0.8=320��
2�R�A�̏ꍇ
60000/100*0.9=540��
540/320=1.7�{
����7���������o�Ă���ƕʂ̃_�C��p�ӂ����Ȃ����ȁB
4�R�A��2�R�A����2�R�A�̕����������������Ȃ葽�����낤���B
Fusion��2�R�A�łȂ�Čv��Ȃ��Ǝv���Ă����B
AMD��GPU���������[�G���h���Ƒ����Ă��Ȃ�����B
AMD��GPU���������[�G���h���Ƒ����Ă��Ȃ�����B
�ŏI�I�ɂ͂��������A�����́c��������GPU��HD5000�n�����B
�����AMD�̃X���C�h��"Llano"�́u2�`4 Core�v�ƂȂ��Ă���B
������2�R�A���Ƃ��̉���"Ontario"�Ɣ�肻���ȗ\�����B
�����AMD�̃X���C�h��"Llano"�́u2�`4 Core�v�ƂȂ��Ă���B
������2�R�A���Ƃ��̉���"Ontario"�Ɣ�肻���ȗ\�����B
Ontario�̃X�y�b�N�͖����J������\�z���邵���Ȃ����ǁA
�����ʒu���l�b�g�u�b�N��ቿ�i�m�[�g�����̑�Atom������A�R�X�g��TDP�ɂ��Ȃ萧��������
�_�C�T�C�Y�̓f���A���R�A�ő���50mm2�O��ATDP��1�`10W�AGPU�̓I���{�[�h���x�̐��\�ɂȂ�Ǝv���B
CPU�R�A�ɂ��ẮA�������݂�SSE/x64�Ή�����K6-3�ʂ̔F���ŗǂ������B
L2�L���b�V����K6-3��Sempron�Ƃ��Ɠ���256KB���ȁB
GPU��HD5450�̃V�������N���Ǝv���B
�Ƃ�����HD5450��Ontario���ڂ�O��Ƃ�����s����i���Ǝv���B
�J���R�X�g����Ԃ�Z�k���邽��40nm�Ŏ��삵�āAOntario���ڂ͗]�v�ȕ������J�b�g���邾���ʼn\�Ƃ��ˁB
�قڊm��
Llano 4�R�A(150mm2) = K10(L2 1M)*4 + 480SP 65W/45W/35W (25W?)
(2�`3gHz?)
�\��
Llano 2�R�A(100mm2) = K10(L2 1M)*2 + 240SP 45W/35W/25W (20W?)
�v��Llano 4�R�A�̂��傤�ǔ���
(1.5�`2.5GHz?)
Ontario 2�R�A(50mm2) = Bobcat(L2 256k)*2 + 80SP 15W�`1W
(1�`1.5GHz?)
����Ȋ����̃��C���i�b�v�������Ȃ�����
�����ʒu���l�b�g�u�b�N��ቿ�i�m�[�g�����̑�Atom������A�R�X�g��TDP�ɂ��Ȃ萧��������
�_�C�T�C�Y�̓f���A���R�A�ő���50mm2�O��ATDP��1�`10W�AGPU�̓I���{�[�h���x�̐��\�ɂȂ�Ǝv���B
CPU�R�A�ɂ��ẮA�������݂�SSE/x64�Ή�����K6-3�ʂ̔F���ŗǂ������B
L2�L���b�V����K6-3��Sempron�Ƃ��Ɠ���256KB���ȁB
GPU��HD5450�̃V�������N���Ǝv���B
�Ƃ�����HD5450��Ontario���ڂ�O��Ƃ�����s����i���Ǝv���B
�J���R�X�g����Ԃ�Z�k���邽��40nm�Ŏ��삵�āAOntario���ڂ͗]�v�ȕ������J�b�g���邾���ʼn\�Ƃ��ˁB
�قڊm��
Llano 4�R�A(150mm2) = K10(L2 1M)*4 + 480SP 65W/45W/35W (25W?)
(2�`3gHz?)
�\��
Llano 2�R�A(100mm2) = K10(L2 1M)*2 + 240SP 45W/35W/25W (20W?)
�v��Llano 4�R�A�̂��傤�ǔ���
(1.5�`2.5GHz?)
Ontario 2�R�A(50mm2) = Bobcat(L2 256k)*2 + 80SP 15W�`1W
(1�`1.5GHz?)
����Ȋ����̃��C���i�b�v�������Ȃ�����
��86��2�R�A�͏������̂ŕ����܂�I�ɃZ�[�t
��86��2�R�A+GPU�͏璷�o���镔���������čX�ɃZ�[�t
��86��2�R�A+GPU�͏璷�o���镔���������čX�ɃZ�[�t
Llano 2P�͑������Ȃ��ƌl�I�ɂ͎v���BOntario�����邵�A�K�v�Ȃ�R�A���E���ă��C���i�b�v
�𑝂₹�������ƁB���̑���2012�N�ɂ̓u���h�[�U�[+6000�V���[�Y�Ɉڍs�łP���W���[��
��2���W���[����2�_�C�̃o���G�[�V�����ɂȂ�Ƃ݂��B�O�ꂽ��Ⴆ�Ȃ��W���[�N�Ƃ���(ry
�𑝂₹�������ƁB���̑���2012�N�ɂ̓u���h�[�U�[+6000�V���[�Y�Ɉڍs�łP���W���[��
��2���W���[����2�_�C�̃o���G�[�V�����ɂȂ�Ƃ݂��B�O�ꂽ��Ⴆ�Ȃ��W���[�N�Ƃ���(ry
���͒m��Ȃ����A�m���Ă��Ă�ry
AMD��GPU����CPU�uLlano�v��CPU�R�A�̋Z�p�\
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
GPU�����̑O�ɃL���b�V�����Ȃ�Ƃ�����
�o���������K10��������ɂ������Ƃ���Ƃ���A�݂����ȉ��ǂ��Ղ肾�ȁB
�������蔲���H������悤�ŁB
��������O��I�ɂ��Ɓc
>�i�p���[�Q�[�e�B���O�Ɋւ��āj�AAMD�̎����ł́ACPU�R�A�̃X�e�C�g�́ACPU�O����DRAM�ɑҔ������B
>���̂��߁A�����I�ɁiCPU�R�A�̃X�e�C�g��ێ�������ʂ�SRAM��CPU�Ɏ��������j
>Intel�̃p���[�Q�[�e�B���O���A�I���I�t�̃��C�e���V�������B
��������O��I�ɂ��Ɓc
>�i�p���[�Q�[�e�B���O�Ɋւ��āj�AAMD�̎����ł́ACPU�R�A�̃X�e�C�g�́ACPU�O����DRAM�ɑҔ������B
>���̂��߁A�����I�ɁiCPU�R�A�̃X�e�C�g��ێ�������ʂ�SRAM��CPU�Ɏ��������j
>Intel�̃p���[�Q�[�e�B���O���A�I���I�t�̃��C�e���V�������B
����͎蔲���Ƃ����̂͂��킢�����ȋC�����邯��
intel���K�������ĉ��ǂ��Ă���̂��X�s�[�h�ŃL���b�`�A�b�v�ł���͂����Ȃ�
TB���l���̃v���Z�X�ō̗p�ɂȂ�̂ł�
intel���K�������ĉ��ǂ��Ă���̂��X�s�[�h�ŃL���b�`�A�b�v�ł���͂����Ȃ�
TB���l���̃v���Z�X�ō̗p�ɂȂ�̂ł�
�v���Z�X�X�V�ƂƂ��ɐV�Z�p����������̂����X�N���傫��
Bulldozer�ł͂Ȃ�K10�n���̗p�����ƌ������Ƃŕێ�I�Ȑ��i�ł�����킯����
Bulldozer�ł͂Ȃ�K10�n���̗p�����ƌ������Ƃŕێ�I�Ȑ��i�ł�����킯����
Intel�̐^������Intel�Ɠ��ʂ̃G���b�^�ɂȂ����猙����
Intel�Ɠ��ʂ̃G���b�^�͓��ꌩ�����Ȃ��̂ŐS�z���p
32nmK10��Atom�Ɠ��l�A�V�����S���Ȃ̂ŃR�X�g�D��Ȃ�ł���
���Z��n�ɂ͖w�ǎ�����ꂸ�A�ȓd�͊W�̉��ǂ����C��������V�����G���b�^�Ƃ��͖���������
�����T�[�o�[�p�r���C���̃R�A�ŊJ����������AMD�ȊO������Ă������ăG���b�^�T�����s���Ă��邩��A
���X�G���b�^�͂�������݂��Ȃ���B
Intel�݂����ȑ����̃G���b�^�Ȃǂ��ł������K���Ȑv�ƈꏏ�ɂ��Ă͉������B
�����T�[�o�[�p�r���C���̃R�A�ŊJ����������AMD�ȊO������Ă������ăG���b�^�T�����s���Ă��邩��A
���X�G���b�^�͂�������݂��Ȃ���B
Intel�݂����ȑ����̃G���b�^�Ȃǂ��ł������K���Ȑv�ƈꏏ�ɂ��Ă͉������B
163 �FSocket774�F2010/02/15(��) 12:05:09 ID:YzadsrBA
APU������32nm��K10 ������AM3�ŏo���Ă���E�E�E
Intel�̂��͗y���Ƀ}�V�Ƃ͂���
�n�C�G���hGPU��~����w�ɂƂ��Ă�Llano�����ʂȂ��̂��낤��
GPU�L��͑������̂����Ń\�P�b�g�ς�邵
�hG�hPU������32nm��K10AM3�̓��C���i�b�v�ɑ����Ă��炢�����Ƃ���
�n�C�G���hGPU��~����w�ɂƂ��Ă�Llano�����ʂȂ��̂��낤��
GPU�L��͑������̂����Ń\�P�b�g�ς�邵
�hG�hPU������32nm��K10AM3�̓��C���i�b�v�ɑ����Ă��炢�����Ƃ���
�����v���Z�X���x��ĂȂ�����������̂��o�Ă����낤��
K10
�ȓd�͋@�\����
4�R�A
GPU����
L2�@512KB(�R�A��
L3�@10MB
K10
�ȓd�͋@�\����
4�R�A
GPU����
L2�@512KB(�R�A��
L3�@10MB
>>165
��������"Bulldozer"�ւ̈ȍ~������̂ɁA
�Ȃ�ł��Ȃ�K10�����X���ƘJ�͂Ǝ��Ԃ������āA
�V�������N���Ȃ���Ȃ�Ȃ��̂��Ɓc�B
����Ȏ����͂ƊJ���͂�����A
��Intel��������Ɗy�ɐi�߂Ă���Ǝv�����H
��������"Bulldozer"�ւ̈ȍ~������̂ɁA
�Ȃ�ł��Ȃ�K10�����X���ƘJ�͂Ǝ��Ԃ������āA
�V�������N���Ȃ���Ȃ�Ȃ��̂��Ɓc�B
����Ȏ����͂ƊJ���͂�����A
��Intel��������Ɗy�ɐi�߂Ă���Ǝv�����H
>>156
����HK10��L3�ɑޔ�������̎������Ă����Ȃ̂ɂȂ�ŁH
����HK10��L3�ɑޔ�������̎������Ă����Ȃ̂ɂȂ�ŁH
��ƋK�͂��Ⴂ�����邵�A�����x�������߂�ق����������ȁB
�g�����W�X�^�K�͂�����̐��\�ł�C2Q�ƌ݊p���炢������A
�R�X�g���d������{���\���グ���Ă����悤�ȕ���������
�Ȃ����ˁB
�g�����W�X�^�K�͂�����̐��\�ł�C2Q�ƌ݊p���炢������A
�R�X�g���d������{���\���グ���Ă����悤�ȕ���������
�Ȃ����ˁB
�����̌͂ꂽ�R�A�Ɏ�����ēO��I�ɂ���Ԃ�s�������Ă̂�
�V�K�R�A�iBulldozer�CBabcat�j���������ꍇ�̕ی��Ƃ��ėL���ł���B
�R�X�g����ҁi�V�K�j�قǂ͂�����Ȃ����낤���B
�V�K�R�A�iBulldozer�CBabcat�j���������ꍇ�̕ی��Ƃ��ėL���ł���B
�R�X�g����ҁi�V�K�j�قǂ͂�����Ȃ����낤���B
>>168
L3�ɑޔ�������̂̓L���b�V�����C��
Intel��C6SRAM�ɑޔ�������̂�CPU�R�A�����̏�ԏ��
�����Llano�ɂ�L3��������
L3�ɑޔ�������̂̓L���b�V�����C��
Intel��C6SRAM�ɑޔ�������̂�CPU�R�A�����̏�ԏ��
�����Llano�ɂ�L3��������
CPU�R�A�����̏�ԏ����āH
���߂ĕ������t�Ȃ����W�X�^�Ƃ����H
���߂ĕ������t�Ȃ����W�X�^�Ƃ����H
TLB�Ƃ�BTB�Ƃ����W�X�^�Ƃ��Z�O�����g�Ƃ����ˁB
��ƋK�͂�10�{�ȏ�Ⴄ���ǁACPU�̊J���K�͎��͖̂w�Ǖς��Ȃ���B
Intel�̎�͂̓C�X���G���ŁA�I���S���͂��̉��ǒS���A���Atom�`�[�����炢���B
AMD��Bulldozer�`�[���ALlano�`�[���ABobcat�`�[���Ɠ����̑̐���~���Ă�B
Intel�̎�͂̓C�X���G���ŁA�I���S���͂��̉��ǒS���A���Atom�`�[�����炢���B
AMD��Bulldozer�`�[���ALlano�`�[���ABobcat�`�[���Ɠ����̑̐���~���Ă�B
>>167
Fab��10�ʂ���intel�ɔ�ׂ��GF�iAMD�j�̐��Y�K�͂͌����Ă邵
Fab1��Fab2�̗��݂������Ȃ���?
Fab2�̖{�ғ��i2012�j�܂łɂ�32nm�̐��Y�̐��͐g�������Ȃ����낤��
���s�ł��Ȃ������������łȂ������H
Fab��10�ʂ���intel�ɔ�ׂ��GF�iAMD�j�̐��Y�K�͂͌����Ă邵
Fab1��Fab2�̗��݂������Ȃ���?
Fab2�̖{�ғ��i2012�j�܂łɂ�32nm�̐��Y�̐��͐g�������Ȃ����낤��
���s�ł��Ȃ������������łȂ������H
>>172
���܂�A��ԏ����Ă̂͏���Ɍ��������t
�㓡��CPU�X�e�[�g�ƌ����Ă�
http://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212014.html
��CPU�X�e�[�g�ɂ́A�S�Ă�IA�A�[�L�e�N�`����̃X�e�[�g�ƁA
��CPU�̃}�C�N���A�[�L�e�N�`����̃X�e�[�g�A�܂�}�C�N��
���R�[�h�̃X�e�[�g�̂قƂ�ǂ��܂܂��
Intel�̃X���C�h�ɂ��Εۑ������̂�Architectural State
http://www.4gamer.net/games/043/G004345/20081102001/screenshot.html?num=014
http://ja.wikipedia.org/wiki/Architectural_state
���܂�A��ԏ����Ă̂͏���Ɍ��������t
�㓡��CPU�X�e�[�g�ƌ����Ă�
http://pc.watch.impress.co.jp/docs/column/kaigai/20090602_212014.html
��CPU�X�e�[�g�ɂ́A�S�Ă�IA�A�[�L�e�N�`����̃X�e�[�g�ƁA
��CPU�̃}�C�N���A�[�L�e�N�`����̃X�e�[�g�A�܂�}�C�N��
���R�[�h�̃X�e�[�g�̂قƂ�ǂ��܂܂��
Intel�̃X���C�h�ɂ��Εۑ������̂�Architectural State
http://www.4gamer.net/games/043/G004345/20081102001/screenshot.html?num=014
http://ja.wikipedia.org/wiki/Architectural_state
177 �FSocket774�F2010/02/15(��) 13:42:18 ID:952ML9Ua
�V�W�T�f�̂`�l�R�}�U�[�Ŏg����V�����b�o�t�ł�́H
�ڂ������Ƌ�����
�ڂ������Ƌ�����
>>175
���Y�]�X�ł͂Ȃ��ALlano"��32nm�ŃR�A������A���W���[���v�Ƃ͂����A
�o���オ������̐��i�`�F�b�N����Ԏ��Ԃ������邩��̗\���B
���܂�AMD��"Bulldozer"���ǂ����݂ŁA"Llano"���`�F�b�N���āA
"Bobcat"���`�F�b�N���āA����ɉ�����GPU������K10���H�@L3�������āH
��������H�@���Y�̐���v�Z�p�̘b���A�l���I�ɖ����Șb���Ǝv���B
������32nm�ł�"K10"�Ȃ�Ăǂ��̉��i���C���ɓ˂����ނ́H�@���Ęb������B
���Y�]�X�ł͂Ȃ��ALlano"��32nm�ŃR�A������A���W���[���v�Ƃ͂����A
�o���オ������̐��i�`�F�b�N����Ԏ��Ԃ������邩��̗\���B
���܂�AMD��"Bulldozer"���ǂ����݂ŁA"Llano"���`�F�b�N���āA
"Bobcat"���`�F�b�N���āA����ɉ�����GPU������K10���H�@L3�������āH
��������H�@���Y�̐���v�Z�p�̘b���A�l���I�ɖ����Șb���Ǝv���B
������32nm�ł�"K10"�Ȃ�Ăǂ��̉��i���C���ɓ˂����ނ́H�@���Ęb������B
Bulldozer���o�Ă����Ƃ��Ƀ\�P�b�g���ĕς��́H
��������܂�PhenomX6�o�ĂȂ������E�E�E
>177
���N���\�����m����Thuban
���N���\�Ⴂ�m����Zambezi�i�ꉞ�\�P�b�g�͐V�����Ȃ�j
>177
���N���\�����m����Thuban
���N���\�Ⴂ�m����Zambezi�i�ꉞ�\�P�b�g�͐V�����Ȃ�j
>>180
���Ԃ�ς��Ȃ��B�ς��̂ł����AM3r2�Ȃ�ĕt���Ȃ����낤���B
�����A���x�o��RD800�ȏ�łȂ���t���@�\�T�|�[�g�͂���Ȃ��Ǝv���B
����ȑO��AM3�̓T�|�[�g���Ȃ����A���邢�̓t���T�|�[�g�ł͂Ȃ��H
���Ԃ�ς��Ȃ��B�ς��̂ł����AM3r2�Ȃ�ĕt���Ȃ����낤���B
�����A���x�o��RD800�ȏ�łȂ���t���@�\�T�|�[�g�͂���Ȃ��Ǝv���B
����ȑO��AM3�̓T�|�[�g���Ȃ����A���邢�̓t���T�|�[�g�ł͂Ȃ��H
AM�R�Ď����Z���̂�
�܂��}�U�[�Ƃb�o�t���Ɣ����ĐV�����̂ɂ���Ηǂ�����
�܂��}�U�[�Ƃb�o�t���Ɣ����ĐV�����̂ɂ���Ηǂ�����
AM3(��AM3r2)�̏���
1.�G���X�[�꒼��
2.Regor�̌�p��32nm�ł����
3.����ς�C���ς����45nm��HKMG�������ăo���o�������i����߂����j
1.�G���X�[�꒼��
2.Regor�̌�p��32nm�ł����
3.����ς�C���ς����45nm��HKMG�������ăo���o�������i����߂����j
>>183
AM3�͋��N�o�āA���NQ1�ɏo��"Bulldozer"�̎��_��2�N�B
������"Bulldozer"����ł�AM3����������\��Ȃ̂ɁA
�ǂ����u�������Z���v�̂��낤���c�B��ł���B
>>184
1.4�`8�R�A�H�i2���W���[������4���W���[���j�œW�J�B�ォ��^�܂œ����\��B
2."Regor"�̌�p��"Llano"�ł����c�B
3.45nm��HKMG�͂��łɔے�ς݁BHKMG�𓊓�����Ȃ�A
�@���̂��߂ɃR�A�̍Đv������̂ŁA�����͍ė��N���炢�H
�@���X45nm��HKMG�p�ɍĐv����Ȃ��32nm��"K10"�̕��������I�B
�@����"Llano"��32nm��HKMG�Őv���ꂽ"K10"�R�A�����邩��B
AM3�͋��N�o�āA���NQ1�ɏo��"Bulldozer"�̎��_��2�N�B
������"Bulldozer"����ł�AM3����������\��Ȃ̂ɁA
�ǂ����u�������Z���v�̂��낤���c�B��ł���B
>>184
1.4�`8�R�A�H�i2���W���[������4���W���[���j�œW�J�B�ォ��^�܂œ����\��B
2."Regor"�̌�p��"Llano"�ł����c�B
3.45nm��HKMG�͂��łɔے�ς݁BHKMG�𓊓�����Ȃ�A
�@���̂��߂ɃR�A�̍Đv������̂ŁA�����͍ė��N���炢�H
�@���X45nm��HKMG�p�ɍĐv����Ȃ��32nm��"K10"�̕��������I�B
�@����"Llano"��32nm��HKMG�Őv���ꂽ"K10"�R�A�����邩��B
186 �FSocket774�F2010/02/15(��) 15:08:29 ID:952ML9Ua
>>185
����͂��܂̂`�l�R�ł�����̂��˂a�h�n�r�@�t�o�Ƃ���
����͂��܂̂`�l�R�ł�����̂��˂a�h�n�r�@�t�o�Ƃ���
>>186
AM2/AM2+�̒f�w���������̂Ɠ����ƍl���������ˁH
�����A���̎�����������BIOS�Ή��Ō��\�������̂ŁA
����Ȃ��BIOS�őΉ������Ⴄ�͑������ȗ\���B
�����A������Ƃ��Ă��ȓd�͌n�̋@�\�̈ꕔ��"C3 Performance Boost"�ȂǁA
�����������ڋʋ@�\��RD700�̔Ȃǂł͎g���Ȃ����낤�ˁB
�����DDR3�͕K�{�ɂȂ����Ⴄ��Ȃ����ȁH
�܂��B���x�o��RD800�̔�"Thuban"�ɑΉ��ł��邵�c�Ƃ������B
�l�I��M/B�Ή�/��Ή��̕ǂ�"Bulldozer"�̈ʒu�ɂ���̂ł͂Ȃ��āA
���x�o��"Phenom X6"�B"Thuban"�̈ʒu�Ɂu�ǁv������Ǝv���B�����ő���B
AM2/AM2+�̒f�w���������̂Ɠ����ƍl���������ˁH
�����A���̎�����������BIOS�Ή��Ō��\�������̂ŁA
����Ȃ��BIOS�őΉ������Ⴄ�͑������ȗ\���B
�����A������Ƃ��Ă��ȓd�͌n�̋@�\�̈ꕔ��"C3 Performance Boost"�ȂǁA
�����������ڋʋ@�\��RD700�̔Ȃǂł͎g���Ȃ����낤�ˁB
�����DDR3�͕K�{�ɂȂ����Ⴄ��Ȃ����ȁH
�܂��B���x�o��RD800�̔�"Thuban"�ɑΉ��ł��邵�c�Ƃ������B
�l�I��M/B�Ή�/��Ή��̕ǂ�"Bulldozer"�̈ʒu�ɂ���̂ł͂Ȃ��āA
���x�o��"Phenom X6"�B"Thuban"�̈ʒu�Ɂu�ǁv������Ǝv���B�����ő���B
Regor���o�����[AM3�̘b���Ă�̂ɓd�g�Ŋ��荞�܂Ȃ��ł����H
Zambezi���p�r���悶��K10�ɗ��
>>187
������Llano��L3�͖����Ƃ���
������Llano��L3�͖����Ƃ���
�����I�ɓd�����Ƃ��̂��~�\������A�\�P�b�g�݊����łƂ������Ƃ͖�����
AM3�̌�p�\�P�b�g��934pin(FM1)���Ɨ\�z����B
2011�N�\��B
2011�N�\��B
http://pc.watch.impress.co.jp/img/pcw/docs/348/705/html/1.jpg.html
�Ȃ㓡��FM1���炢�m���Ă���悤���ȁB
{kind=link}
�Ȃ㓡��FM1���炢�m���Ă���悤���ȁB
�܂�GPU�������ă\�P�b�g�ς��Ȃ��Ƃ����蓾�Ȃ�����Ȃ��B
Bulldozer��+50%�̖ʐς�1���W���[���������Ă��铖����A
1�R�A�����̃_�C�T�C�Y�͂��Ȃ菬�����͂�����B���ΓI��K10�����������B
���̕���葽���R�A���W�Ϗo�����̂������B
�R�A�͏������������i�U�������₷�����炢�����ǂȁB
1�R�A�����̃_�C�T�C�Y�͂��Ȃ菬�����͂�����B���ΓI��K10�����������B
���̕���葽���R�A���W�Ϗo�����̂������B
�R�A�͏������������i�U�������₷�����炢�����ǂȁB
+50%�̖ʐς��Ă̂͋�����䂶��Ȃ���
�܂�Bulldozer�̂���܂łɖ��炩�ɂȂ��������݂āA
K10�����R�A���ł����Ƃ��v���Ă��͈�̉��l�Ȃ낤�ˁB
Bulldoze��K10���ł����R�A�������牿�i���\��ň��̕��v���Z�b�T�K���Ȃ̂�
���̎咣�ɕK���Ƃ�Bull�~�̎v�l�������ɋ����Ă���B
K10�����R�A���ł����Ƃ��v���Ă��͈�̉��l�Ȃ낤�ˁB
Bulldoze��K10���ł����R�A�������牿�i���\��ň��̕��v���Z�b�T�K���Ȃ̂�
���̎咣�ɕK���Ƃ�Bull�~�̎v�l�������ɋ����Ă���B
K10�R�A���傫���Ƃ��N����������
�L�T�}������ɂ����v���Ĉ�l�ʼn�b���Ă邾�����Ⴄ��
�L�T�}������ɂ����v���Ĉ�l�ʼn�b���Ă邾�����Ⴄ��
203 �FSocket774�F2010/02/15(��) 19:43:20 ID:952ML9Ua
���̖����_�w�S�݂����Ȃ��������b�o�t�͂��o����������C�ɂȂ�
>>202
�����E�E�E����Ȃ̂ɒn���̌��t���ʂ���Ǝv���Ȃ�
�ꉞ�������悤�Ɗώ@�L�^�t�����肷�邱�Ƃ����邯�ǂ��܂�ɋC�����������̓X���[����
���͂܂�����ȂƂ���
�����E�E�E����Ȃ̂ɒn���̌��t���ʂ���Ǝv���Ȃ�
�ꉞ�������悤�Ɗώ@�L�^�t�����肷�邱�Ƃ����邯�ǂ��܂�ɋC�����������̓X���[����
���͂܂�����ȂƂ���
�������łȂ��Ƃǂ��Ȃ邩�킩��Ȃ��킯�ŁE�E�E
�����ɂ����˂�̂悤�ȏ������݂̕~���̂��ɗ͒Ⴍ����
�y���m���̌f���ŁA�ώ@�L�^�܂ŔM�S�ɂ��Ă���Ƃ͋������܂����B
�y���m���̌f���ŁA�ώ@�L�^�܂ŔM�S�ɂ��Ă���Ƃ͋������܂����B
>>192
�\�P�b�g�݊��d�����Đ��\��̎��ɂ��Ă��琢�b������w
�J�����A�P�ɂ����܂œ�������ĂȂ��������A�������Ă��Ă��o���Ȃ�������Ȃ����Ȃ��Ɩϑz�B
Intel���̗p�������������Ă����X�������Q|�P|�����ĂȂ��Ă��Ȃ����ȁB
�\�P�b�g�݊��d�����Đ��\��̎��ɂ��Ă��琢�b������w
�J�����A�P�ɂ����܂œ�������ĂȂ��������A�������Ă��Ă��o���Ȃ�������Ȃ����Ȃ��Ɩϑz�B
Intel���̗p�������������Ă����X�������Q|�P|�����ĂȂ��Ă��Ȃ����ȁB
�����ɍl������AM3�\�P�b�g��K10��p��Bulldozer����
700�ԑ�͂Ƃ�����800�ԑ�̃`�b�v�Z�b�g�ł�
Bulldozer���i���Ȃ�̊m���Łj�ڂ���Ă�����
700�ԑ�͂Ƃ�����800�ԑ�̃`�b�v�Z�b�g�ł�
Bulldozer���i���Ȃ�̊m���Łj�ڂ���Ă�����
�A�C�h�����p���[�I�t�̂��߂̃f�[�^�ޔ��̕p�x��
SRAM(L1�`L3)��DRAM�̃��C�e���V�����|�����킹��
�����܂ł���قǂ̍����o����ǂ��������܂��m�肽��
SRAM(L1�`L3)��DRAM�̃��C�e���V�����|�����킹��
�����܂ł���قǂ̍����o����ǂ��������܂��m�肽��
SRAM�ɓd�������ăX�e�[�^�X���ێ����Ă��������ADRAM�ɂ܂Œǂ��o��������CPU�̑ҋ@�d�͂͌����łȂ��́H
>>210
���̑���ɕ��A�܂ł̒x����������̂ƁA
DeepState�̏ꍇ��CPU��SRAM�����̕����A
DRAM�ɓd���������Ă����������ҋ@�d�͂͌���̂ł́H
���̑���ɕ��A�܂ł̒x����������̂ƁA
DeepState�̏ꍇ��CPU��SRAM�����̕����A
DRAM�ɓd���������Ă����������ҋ@�d�͂͌���̂ł́H
CPU���[�h�}�b�v�@Bulldozer�́A�R���V���[�}�ƃT�[�o�̖����ւ̉�
http://cybergarden.cocolog-nifty.com/blog/2010/02/cpubulldozer-1f.html
������
http://cybergarden.cocolog-nifty.com/blog/2010/02/cpubulldozer-1f.html
������
AMD�����{�C�o����������
Intel���q����Ă܂�
Intel���q����Ă܂�
>>210
�ǂ��l���Ă����t���b�V�����v��Ȃ�SRAM�̕����ȓd�͂����
�ǂ��l���Ă����t���b�V�����v��Ȃ�SRAM�̕����ȓd�͂����
�ȓd�̓��[�h�̎����ă��C���������̏�Ԃ��Ăǂ��Ȃ��Ă��
�`�b�v�̒l�i�Ƃ̐܂荇��������˂��B
D-RAM�̓d�����Ƃ��Ă�����Ȃ�A�R�[���h�X���[�v��
��v�ȃf�[�^�S���g�c�c�ɂł��ޔ����Ȃ����Ȃ�B
�M�́c���܂���Ȃ�����A�ʐς�����̔��M�U������ɂ�
�s����������������Ȃ����ǁB
D-RAM�̓d�����Ƃ��Ă�����Ȃ�A�R�[���h�X���[�v��
��v�ȃf�[�^�S���g�c�c�ɂł��ޔ����Ȃ����Ȃ�B
�M�́c���܂���Ȃ�����A�ʐς�����̔��M�U������ɂ�
�s����������������Ȃ����ǁB
�ޔ�p�������lj��ƃf�o�b�O�̎�Ԃ��Ȃ�����������
DRAM�ޔ��Ȃ�ʓ|�Ȃ��Ƃ͈�Ȃ�����
�ޔ��ɂ�����d�͂́A�ǂ���mW���x�����낤���A�ȓd�͂Ƃ��͌��Ђ��W�Ȃ����낤���A
State�̗e�ʂ�����������KB�ŁA���C�e���V��x���Ƃ��������o���郌�x�����낤��
DRAM�ޔ��Ȃ�ʓ|�Ȃ��Ƃ͈�Ȃ�����
�ޔ��ɂ�����d�͂́A�ǂ���mW���x�����낤���A�ȓd�͂Ƃ��͌��Ђ��W�Ȃ����낤���A
State�̗e�ʂ�����������KB�ŁA���C�e���V��x���Ƃ��������o���郌�x�����낤��
>>197
>K10���{32nm�{HK+GPU����
�u�����Ƃ����A���������̂𑁂��o�����Ęb����
>>217
�����b���C�A�E�g������悤�Ȏ�Ԃ͔�������
>>218
CPU�_�C���SRAM�ɃX�e�[�g�ێ��������
���Ń��C���������̃f�[�^�������Ȃ��Ⴂ���Ȃ��H
>K10���{32nm�{HK+GPU����
�u�����Ƃ����A���������̂𑁂��o�����Ęb����
>>217
�����b���C�A�E�g������悤�Ȏ�Ԃ͔�������
>>218
CPU�_�C���SRAM�ɃX�e�[�g�ێ��������
���Ń��C���������̃f�[�^�������Ȃ��Ⴂ���Ȃ��H
>>219
218�́ACPU�̃X�e�[�g��SRAM�Ɏc����CPU�ɓd�C���葱����Ȃ�ADRAM�̕��̓f�[�^��HDD�ɂł��債�ēd�C���Ƃ��Ȃ���Ӗ��������������Č����Ă��ł���
�t�Ɍ����ADRAM�̓d�C�𗎂Ƃ��Ȃ��Ȃ�CPU�̃X�e�[�g��DRAM�֑ޔ��ŗǂ��������Ď�����
218�́ACPU�̃X�e�[�g��SRAM�Ɏc����CPU�ɓd�C���葱����Ȃ�ADRAM�̕��̓f�[�^��HDD�ɂł��債�ēd�C���Ƃ��Ȃ���Ӗ��������������Č����Ă��ł���
�t�Ɍ����ADRAM�̓d�C�𗎂Ƃ��Ȃ��Ȃ�CPU�̃X�e�[�g��DRAM�֑ޔ��ŗǂ��������Ď�����
>>219
��p���o��̂ɁA�Â��R�A�����̂܂܃V�������N�Ƃ����肦�Ȃ�����I
�ڍs���ɕK�����������z���킭���Ȃ�Ȃ낤�ȁH
�����"Llano"�͂��Ȃ背�C�A�E�g��M���Ă��܂����c�B
��p���o��̂ɁA�Â��R�A�����̂܂܃V�������N�Ƃ����肦�Ȃ�����I
�ڍs���ɕK�����������z���킭���Ȃ�Ȃ낤�ȁH
�����"Llano"�͂��Ȃ背�C�A�E�g��M���Ă��܂����c�B
>DRAM�̓d�C�𗎂Ƃ��Ȃ��Ȃ�CPU�̃X�e�[�g��DRAM�֑ޔ��ŗǂ�
�����Ō����Ƃ����Ȃ邪�A�������Ђ�SRAM�����Ă�̂̓X�e�[�g�ڍs�̃��C�e���V�팸�̂��߂����Ȃ�
���Ђ��Ȃ����ɏ�ɂ������茾���Ă邠���瑤�̐l�ɂ͉䖝�Ȃ�Ȃ��d�l���Ǝv����
�����͐M�S�ŏ����ė~�����A���P�����܂�
�����Ō����Ƃ����Ȃ邪�A�������Ђ�SRAM�����Ă�̂̓X�e�[�g�ڍs�̃��C�e���V�팸�̂��߂����Ȃ�
���Ђ��Ȃ����ɏ�ɂ������茾���Ă邠���瑤�̐l�ɂ͉䖝�Ȃ�Ȃ��d�l���Ǝv����
�����͐M�S�ŏ����ė~�����A���P�����܂�
AM3��Llano(32nm HKMG)�Ή��ł�����Ă��ƂȂ�A
�����AM3�̃}�U�[��CPU�̃Z�b�g�͂��Ȃ�R�X�g�p�t�H�[�}���X���������ƂɂȂ��
���X���҂ł�����
�����AM3�̃}�U�[��CPU�̃Z�b�g�͂��Ȃ�R�X�g�p�t�H�[�}���X���������ƂɂȂ��
���X���҂ł�����
CPU�R�A�̃X�e�C�g��ǂꂾ���������T�C�Y���낤�ƁA
DRAM�Ƃ̂��Ƃ�i�Ҕ�/���A�j�ɗv���郌�C�e���V�����ȉ��ɏ������Ȃ�킯����Ȃ����Ȃ��B
�R�A�����̐�pSRAM�i���L���b�V���ɏ����郌�C�e���V�H�j�Ƃ͔�ׂ�ׂ����Ȃ��B
���[�X�g�P�[�X�Ƃ��ẮA�ׂ����I��/�I�t���悤�Ƃ���Ƃ��̃��C�e���V�����\��̞g�ƂȂ��Ă��܂��ׁA
���^�p�ł͎v���悤�ɃR�A���I�t�ɏo���Ȃ��i���p���[�Q�[�e�B���O�̌��ʂ��ڌ���j���ĕӂ肩�B
Intel�Ɠ����ɂ���Ƃ͌���Ȃ����A
���\�[�X�������Ȃ��͕̂����邪�������傢��肢��͂Ȃ������̂��ƁB
DRAM�Ƃ̂��Ƃ�i�Ҕ�/���A�j�ɗv���郌�C�e���V�����ȉ��ɏ������Ȃ�킯����Ȃ����Ȃ��B
�R�A�����̐�pSRAM�i���L���b�V���ɏ����郌�C�e���V�H�j�Ƃ͔�ׂ�ׂ����Ȃ��B
���[�X�g�P�[�X�Ƃ��ẮA�ׂ����I��/�I�t���悤�Ƃ���Ƃ��̃��C�e���V�����\��̞g�ƂȂ��Ă��܂��ׁA
���^�p�ł͎v���悤�ɃR�A���I�t�ɏo���Ȃ��i���p���[�Q�[�e�B���O�̌��ʂ��ڌ���j���ĕӂ肩�B
Intel�Ɠ����ɂ���Ƃ͌���Ȃ����A
���\�[�X�������Ȃ��͕̂����邪�������傢��肢��͂Ȃ������̂��ƁB
>>223
�����B���邢�͓������ꂽGPU���g���Ȃ��B
�����B���邢�͓������ꂽGPU���g���Ȃ��B
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100216_349232.html
Intel��48�R�A�̃��j�C�R�A���T�[�`�`�b�v�̋Z�p�����J
Intel��48�R�A�̃��j�C�R�A���T�[�`�`�b�v�̋Z�p�����J
48�R�A�Ƃ������킯�킩���
�܂���Intel�͐�pSRAM�ڂ����b��悤�Ƃ���
�O��I��onoff�p�x�����߂����ʂ����̃o�O���炯CPU�Ȃ̂��H
L1D���[�h�̕p�x���H
�O��I��onoff�p�x�����߂����ʂ����̃o�O���炯CPU�Ȃ̂��H
L1D���[�h�̕p�x���H
���O�͉��Ɛ����(ry
�f�l�l��������Bulldozer�̎��ł͂P���W���[��������4core�ɂȂ����肷��́H
>>227
�����悭�g����\�t�g�E�F�A�������I
�����悭�g����\�t�g�E�F�A�������I
����1:2�ł��A1��2�R�A�ŋ��L������A2��4�R�A�ŋ��L����ق��������͂悭�Ȃ�ȁB
���̕����G�E����ɂȂ��ĕs���Ȃ̂ƁA���x��4�ɑ�����̂ƂŁA
���ۂɂ�邩�ǂ����͂킩��ǁB
���̕����G�E����ɂȂ��ĕs���Ȃ̂ƁA���x��4�ɑ�����̂ƂŁA
���ۂɂ�邩�ǂ����͂킩��ǁB
FM1���Ă܂���LGA����Ȃ����낤�ȁc
ID:u87Ky3GY�͎G���N���낗
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
���̒��x�̃��x���̉��z�Ȏq������
���ɘA�������Ƃ��͂₳���������Ă��悗
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
���̒��x�̃��x���̉��z�Ȏq������
���ɘA�������Ƃ��͂₳���������Ă��悗
DRAM�͋��d���~�߂Ȃ�����A������CPU�X�e�[�g���i�[���悤�����܂�������d�͎͂����I�ɕς���
SRAM�͋��d���K�v�Ȃ���A������CPU�X�e�[�g���i�[�����Ȃ�ASRAM�̎��܂��Ă�CPU�ւ̋��d���~�߂��Ȃ�
SRAM�͋��d���K�v�Ȃ���A������CPU�X�e�[�g���i�[�����Ȃ�ASRAM�̎��܂��Ă�CPU�ւ̋��d���~�߂��Ȃ�
SRAM��CPU�͕ʁX�ɋ��d�����邱�Ƃ��o���邾��B
�ł��A�ŋ߂�SRAM�̓��[�N�d�����傫���̂ʼn����DRAM����
�d�͂��\��������B
�p�ɂ�on/off��������ŁA�p�t�H�[�}���X�㐔msec�̒x���������Ȃ����
SRAM���K�v����Ǝv�����A���܂�l���ɂ����B
sleep�ɂȂ��Ă���R�A������ƁA�����オ�肪�������肵�Ă���Ƃ��˂����ݓ����
����͂���Ŏd�����������B
�ł��A�ŋ߂�SRAM�̓��[�N�d�����傫���̂ʼn����DRAM����
�d�͂��\��������B
�p�ɂ�on/off��������ŁA�p�t�H�[�}���X�㐔msec�̒x���������Ȃ����
SRAM���K�v����Ǝv�����A���܂�l���ɂ����B
sleep�ɂȂ��Ă���R�A������ƁA�����オ�肪�������肵�Ă���Ƃ��˂����ݓ����
����͂���Ŏd�����������B
���A������A�ςȌ��O���v�������B
�}�C�N���R�[�h�̂悤�ȃZ�L���A�ȃR�[�h���c�q�`�l�ɗ��Ƃ��ƁA
���ς��ꂽ�ꍇ�̃Z�L�����e�B�z�[�����o����\�����̂Ă���Ȃ��ȁB
�}�C�N���R�[�h�̂悤�ȃZ�L���A�ȃR�[�h���c�q�`�l�ɗ��Ƃ��ƁA
���ς��ꂽ�ꍇ�̃Z�L�����e�B�z�[�����o����\�����̂Ă���Ȃ��ȁB
�܂��j���p�̃z�[���ɂǂꂾ���̉��l������̂����Ċ��������B
>>219
>�u�����Ƃ����A���������̂𑁂��o�����Ęb����
�m����Bulldozer���Llano�̕������i�Ƃ��ċ͗ǂ��B
�l�i�Ɣ��������ŁA�~�h����艺���K�b�`�����������B
Bulldozer��Intel�����NQ3��22nm�Ɉڍs���邩��
�������N�㔼����n�C�G���h�ł͂܂�ŏ����ɂȂ��B
>�u�����Ƃ����A���������̂𑁂��o�����Ęb����
�m����Bulldozer���Llano�̕������i�Ƃ��ċ͗ǂ��B
�l�i�Ɣ��������ŁA�~�h����艺���K�b�`�����������B
Bulldozer��Intel�����NQ3��22nm�Ɉڍs���邩��
�������N�㔼����n�C�G���h�ł͂܂�ŏ����ɂȂ��B
242 �FSocket774�F2010/02/16(��) 18:52:07 ID:E98lLRlK
�C���e���̓n�C�G���h����22nm�g���́H
���m�ȉ��ɋ����ė~������
Liano���āA���s��Regor���_�C�T�C�Y�͏������Ȃ�̂��H
Liano���āA���s��Regor���_�C�T�C�Y�͏������Ȃ�̂��H
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091112_328392.html
�u�قړ��k�ڂƐ��肳���傫���ɑ����Ă݂��v�}������
�u�قړ��k�ڂƐ��肳���傫���ɑ����Ă݂��v�}������
�����APropus�Ɠ������炢���B
�����Ƃ�Regor���f�J���Ȃ邩��A���傱���ƍ����Ȃ肻�����B
�����Ƃ�Regor���f�J���Ȃ邩��A���傱���ƍ����Ȃ肻�����B
2�R�A��4�R�A��GPU�ς�ō���Athlon�U�Ɠ����ʂ���
�`�b�v�Z�b�g��100�����А��ɂȂ邩��R�X�g�I�ɂ͉����鎖�ɂȂ邾�낤
�`�b�v�Z�b�g��100�����А��ɂȂ邩��R�X�g�I�ɂ͉����鎖�ɂȂ邾�낤
>>241
�o�Ă����Ȃ����i�ƁA�o�Ă����Ȃ����i���ׂāA
�u�܂�ŏ����ɂȂ�Ȃ��v���Đ����ϑz���ȁB
���ǂ́u�ǂ��炪����ɛƂ邩�v���Ǝv�����ȁB
�o�Ă����Ȃ����i�ƁA�o�Ă����Ȃ����i���ׂāA
�u�܂�ŏ����ɂȂ�Ȃ��v���Đ����ϑz���ȁB
���ǂ́u�ǂ��炪����ɛƂ邩�v���Ǝv�����ȁB
K10���琮�����Z�p�C�v��1�{������Ƃ���ŃR�A�̃T�C�Y��3�����炢�����������Ȃ�Ȃ�
CPU�S�̂��猩����2���Ƃ�
���ʂɍl������ABulldozer���R�A�y�ʉ��H�����Ă͕̂�
�����Ӗ����L��͂��E�E�E
CPU�S�̂��猩����2���Ƃ�
���ʂɍl������ABulldozer���R�A�y�ʉ��H�����Ă͕̂�
�����Ӗ����L��͂��E�E�E
�y�ʉ����Ă̂̓R�A�T�C�Y����Ȃ��ĔR�����̕�����B
250 �FSocket774�F2010/02/16(��) 21:57:33 ID:E98lLRlK
�x�N�^�R�A���ւ�ł��傤��
>>250
�����������E�E�E��������Y�����
�m���ɁA���̐���̃x�N�^�R�A�Ƃ��Ȃ��CPU�R�A�̔������x�N�^���j�b�g�ɂȂ�
�R�A���Ƃ�1�����Ă��狰�낵�����ɂȂ邩
�����������E�E�E��������Y�����
�m���ɁA���̐���̃x�N�^�R�A�Ƃ��Ȃ��CPU�R�A�̔������x�N�^���j�b�g�ɂȂ�
�R�A���Ƃ�1�����Ă��狰�낵�����ɂȂ邩
�x�N�^�R�A���Ă̂������ς肾
AMD���o����"Bulldozer"�̃A�[�L�e�B�N�`���̃X���C�h�̈��
�܂Ƃ��ɊςĂ��Ȃ��낤���Ă̂͂킩�邪�B
�܂Ƃ��ɊςĂ��Ȃ��낤���Ă̂͂킩�邪�B
�I�ɓ�������Ƃ������Ƃ��ȁB
�s�[�N���\�ǂ킸�V���R���ʐς�����̌����d���Ƃ������Ƃ���
�C���e���͐����v���Z�X���i��ł邩�烊�b�`�Ȑv�ł�
�R�X�g�����M���}�����Ă��܂��ď����ڂ��Ȃ��B
�s�[�N���\�ǂ킸�V���R���ʐς�����̌����d���Ƃ������Ƃ���
�C���e���͐����v���Z�X���i��ł邩�烊�b�`�Ȑv�ł�
�R�X�g�����M���}�����Ă��܂��ď����ڂ��Ȃ��B
>241
�Ƃ肠��������GPU�̑f���̗ǂ���
DELL�ӂ肪��D���ȗ������f�����ł߂�̂�
AMD�I�Ɍ����H���ȋC�����Ȃ����Ȃ�
Bulldozer��Sandy��Ivy����ɏ��Z���邩�ƂȂ��
�����̃T�v���C�Y����������]�ݔ����ۂ����Ȃ��E�E
�Ƃ肠��������GPU�̑f���̗ǂ���
DELL�ӂ肪��D���ȗ������f�����ł߂�̂�
AMD�I�Ɍ����H���ȋC�����Ȃ����Ȃ�
Bulldozer��Sandy��Ivy����ɏ��Z���邩�ƂȂ��
�����̃T�v���C�Y����������]�ݔ����ۂ����Ȃ��E�E
Bulldozer���ăo���Z���i�̃��t�@�r�b�V���i����H
Power�̐l����������Ă�Ȃ�A����ȑ�l����������Ȃ��Ƃ���
eDRAM���ڂ��Ȃ���
Power���̐��\�͓����Ȃ���
Power���̐��\�͓����Ȃ���
�R�QMB�̃L���b�V����ς�POWER�V�����̐��\��������AINTEL�����ł�����
AMD�̓T�[�o����ł́AeDRAM�ȊO�̊��H�͂Ȃ���
�f�X�N�g�b�v��ATOM���̐��\�����o���Ȃ�����c�_�̗]�n�͂����Ȃ�����
�f�X�N�g�b�v��ATOM���̐��\�����o���Ȃ�����c�_�̗]�n�͂����Ȃ�����
�ȂႻ���w
�s�b�N���͐��m���̂���z���ق���
�s�b�N���͐��m���̂���z���ق���
���Ȃɂ���B
eDRAM�����߂��ɂm�f���[�h�ɂ��Ă݂�
����̃A����ID�ς������������B
�v���Z�X�Z�p��Intel�Ɏ���x��ɂ���Ă�ȏ�A
���̍����Ђ�����Ԃ��ɂ͗͋Ƃł͂Ȃ����M���邵���Ȃ��킯�ŁB
�s�[�N���\���̂ĂČ����ɑ�����Ă̂́A�T�[�o�[�p�r�Ŏ��������Ȃ�A�������ǁA
�R���V���[�}�p�r��}�[�P�e�B���O�ʂł͕s���Ȑ킢�ɂȂ邾�낤���Ƃ͑z���ɓ�Ȃ��B
���f�B�A���������Ď��グ��x���`�}�[�N�̗ނł́A
��������ł́i��������Intel���i���j���邱�Ƃ�����A���Ē��x���ւ̎R�ł͖����낤���B
�B��̋~����Intel��GPU�����b�ɂȂ�Ȃ����x�������Ă��Ƃ��B
�v���Z�X�Z�p��Intel�Ɏ���x��ɂ���Ă�ȏ�A
���̍����Ђ�����Ԃ��ɂ͗͋Ƃł͂Ȃ����M���邵���Ȃ��킯�ŁB
�s�[�N���\���̂ĂČ����ɑ�����Ă̂́A�T�[�o�[�p�r�Ŏ��������Ȃ�A�������ǁA
�R���V���[�}�p�r��}�[�P�e�B���O�ʂł͕s���Ȑ킢�ɂȂ邾�낤���Ƃ͑z���ɓ�Ȃ��B
���f�B�A���������Ď��グ��x���`�}�[�N�̗ނł́A
��������ł́i��������Intel���i���j���邱�Ƃ�����A���Ē��x���ւ̎R�ł͖����낤���B
�B��̋~����Intel��GPU�����b�ɂȂ�Ȃ����x�������Ă��Ƃ��B
���Ȃɂꂷ�B
Bulldozer�̔��z�́u���̃A�[�L�e�N�`�����琫�\�ቺ�������ǂ��܂ō��邩�v�Ȃ̂ɁA
����ς߂��̂���ς߂��̌����Ă��̓A�z��
���AMD����ꐢ��u���ł����Ȃ�Intel�R���Ƃ����Ȃ�čl���ĂȂ�����
�{���̏�����Fusion���u���ɂ܂ŋy����
����ς߂��̂���ς߂��̌����Ă��̓A�z��
���AMD����ꐢ��u���ł����Ȃ�Intel�R���Ƃ����Ȃ�čl���ĂȂ�����
�{���̏�����Fusion���u���ɂ܂ŋy����
�s�[�N�s�[�N���邳���z�������邽�߂�
Intel�͐���10����CPU�ł�����Ă��
�C���I�[�_�ŃL���b�V�������Ă��\���
Intel�͐���10����CPU�ł�����Ă��
�C���I�[�_�ŃL���b�V�������Ă��\���
48 core(Pentium)�Ȃ�T���v���o���������
270 �FSocket774�F2010/02/17(��) 09:27:03 ID:k+sDZIpq
Liano����TA790GEX 128M�Ŏg����́H
�����̃}�U�[���ᑽ����������
BIOSTAR�ɉ������҂��Ă��
�������@���Ⴀi5-750�ɂ���
���肪�Ƃ�
���肪�Ƃ�
> �{���̏�����Fusion���u���ɂ܂ŋy����
�Ȃɂ��̗\�h��
�Ȃɂ��̗\�h��
>���ʂɍl������ABulldozer���R�A�y�ʉ��H�����Ă͕̂�
>�����Ӗ����L��͂��E�E�E
PhenomII���V���O���X���b�h������3����2�ɂȂ�Ӗ�������B
�ȓd�͌���+���M�}������+�N���b�N�グ��ˁH
�����p�t�H�[�}���X���]���ɂ���? AMD�́uBulldozer�v
AMD��2011�N�ɓ������鎟����CPU�A�[�L�e�N�`���uBulldozer(�u���h�[�U)�v�B
���̐V�A�[�L�e�N�`���ŁAAMD�͑傫�Ȍ��f�������B����͐����p�C�v���ׂ����邱�Ƃ��B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091216_335956.html
Bulldozer�ł́A�����炭�A���s��AMD CPU���V���O���X���b�h�̐������S�̃A�v���P�[�V�����̐��\�͉�����B
CPU�\���̊ȑf���ŁACPU�̓�����g�����グ�邱�Ƃ��ł���A�ቺ���ߍ��킹�邱�Ƃ��ł��邩���m��Ȃ����A�N���b�N������̐��\�͉����邾�낤�B
>�����Ӗ����L��͂��E�E�E
PhenomII���V���O���X���b�h������3����2�ɂȂ�Ӗ�������B
�ȓd�͌���+���M�}������+�N���b�N�グ��ˁH
�����p�t�H�[�}���X���]���ɂ���? AMD�́uBulldozer�v
AMD��2011�N�ɓ������鎟����CPU�A�[�L�e�N�`���uBulldozer(�u���h�[�U)�v�B
���̐V�A�[�L�e�N�`���ŁAAMD�͑傫�Ȍ��f�������B����͐����p�C�v���ׂ����邱�Ƃ��B
http://pc.watch.impress.co.jp/docs/column/kaigai/20091216_335956.html
Bulldozer�ł́A�����炭�A���s��AMD CPU���V���O���X���b�h�̐������S�̃A�v���P�[�V�����̐��\�͉�����B
CPU�\���̊ȑf���ŁACPU�̓�����g�����グ�邱�Ƃ��ł���A�ቺ���ߍ��킹�邱�Ƃ��ł��邩���m��Ȃ����A�N���b�N������̐��\�͉����邾�낤�B
��������A�[�L�e�N�`������߂肳����悤�Ɍ�����AMD�̑I���̈Ӑ}�͖������B
CPU�R�A�̌��������߂邱�Ƃ��B�������߂̎��s�ш�����߂�ACPU�̃p�t�H�[�}���X�����͂�荂���Ȃ�B
�_�C�ʐϓ�����A���邢�͏���d�͓�����̃p�t�H�[�}���X�������Ȃ�B
CPU�\���̊ȑf���ŁACPU�̓�����g�����グ�邱�Ƃ��ł���A�ቺ���ߍ��킹�邱�Ƃ��ł��邩���m��Ȃ��B
�@�������A���Ă͍L�����������������p�C�v�̕������߂�Ƃ����̂́A���Ȃ胊�X�N�̂���I�����B
���̓_�ŁAAMD�͎v���������f���������ƂɂȂ�B
AMD��Bulldozer�ŁA�������Z�p�t�H�[�}���X���]���ɂ��Ă��A�������グ��Ƃ�����]����}�邱�ƂɂȂ�B
CPU�R�A�̌��������߂邱�Ƃ��B�������߂̎��s�ш�����߂�ACPU�̃p�t�H�[�}���X�����͂�荂���Ȃ�B
�_�C�ʐϓ�����A���邢�͏���d�͓�����̃p�t�H�[�}���X�������Ȃ�B
CPU�\���̊ȑf���ŁACPU�̓�����g�����グ�邱�Ƃ��ł���A�ቺ���ߍ��킹�邱�Ƃ��ł��邩���m��Ȃ��B
�@�������A���Ă͍L�����������������p�C�v�̕������߂�Ƃ����̂́A���Ȃ胊�X�N�̂���I�����B
���̓_�ŁAAMD�͎v���������f���������ƂɂȂ�B
AMD��Bulldozer�ŁA�������Z�p�t�H�[�}���X���]���ɂ��Ă��A�������グ��Ƃ�����]����}�邱�ƂɂȂ�B
PC�̎s��K�͂�3�`4����/�N
�T�[�o�̎s��K�͂�2�`3�S����/�N
�`�b�v���[�J�[�Ƃ�������ł̓T�[�o�[��p�`�b�v�͊J���R�X�g������ł��Ȃ��͖̂��炩��
���ʂɍl�����炻��ȕ��͊�悵�Ȃ�
Bulldozer�ɂ�PC�ƎI�ő�������v���𗼗������鉽�������邱�Ƃ����҂��Ă�
�T�[�o�̎s��K�͂�2�`3�S����/�N
�`�b�v���[�J�[�Ƃ�������ł̓T�[�o�[��p�`�b�v�͊J���R�X�g������ł��Ȃ��͖̂��炩��
���ʂɍl�����炻��ȕ��͊�悵�Ȃ�
Bulldozer�ɂ�PC�ƎI�ő�������v���𗼗������鉽�������邱�Ƃ����҂��Ă�
���������ΑO�X����Bulldozer�̖��߃��C�e���V�Ƃ���
�o�Ă����ǁA�������1���W���[��/1(�����_)�X���b�h�̎���
1���W���[��/2(�����_)�X���b�h�̎��ŕς��Ȃ��̂��ȁH
�o�Ă����ǁA�������1���W���[��/1(�����_)�X���b�h�̎���
1���W���[��/2(�����_)�X���b�h�̎��ŕς��Ȃ��̂��ȁH
CPU�̐���ꎮ�̉��i�ōl�����
PC�̎s��Ɠ������炢�厖���낤
Atom������Ă�intel�ɂƂ��Ă͂���ȂɊ������Ȃ�����
MS�Ɗ|�������Ăł����CULV�킹�悤�Ƃ��Ă���킯��
K7���g�����Ă�����K10.5�܂ł���Ă���AMD�̂���
���N�O����J���𑱂��Ă���Bulldozer�͂܂��ʔ���CPU�ɂȂ邾�낤
PC�̎s��Ɠ������炢�厖���낤
Atom������Ă�intel�ɂƂ��Ă͂���ȂɊ������Ȃ�����
MS�Ɗ|�������Ăł����CULV�킹�悤�Ƃ��Ă���킯��
K7���g�����Ă�����K10.5�܂ł���Ă���AMD�̂���
���N�O����J���𑱂��Ă���Bulldozer�͂܂��ʔ���CPU�ɂȂ邾�낤
280 �FSocket774�F2010/02/17(��) 12:03:18 ID:X/PXIEdI
bobcat�͂ǂ��Ȃ��ł���
>>265
���܂܂ł͒x��Ă������A22nm�̓����͂������č����Ȃ��\�肾���ǂȁB
AMD�̕���1Q��1H�قǒx�����B
>>277
ASP���痘�v�����c�Ƃ����̂�m���Ă����炻��Ȃ��Ə����Ȃ����B
�m���ɃT�[�o�[�u�����v�ł͔��������ǂˁB
�ł����̏��Ȃ��o�א��ŗ��v��50%�ȏゾ���͂ł��Ⴄ�ƌ����c�B
���܂܂ł͒x��Ă������A22nm�̓����͂������č����Ȃ��\�肾���ǂȁB
AMD�̕���1Q��1H�قǒx�����B
>>277
ASP���痘�v�����c�Ƃ����̂�m���Ă����炻��Ȃ��Ə����Ȃ����B
�m���ɃT�[�o�[�u�����v�ł͔��������ǂˁB
�ł����̏��Ȃ��o�א��ŗ��v��50%�ȏゾ���͂ł��Ⴄ�ƌ����c�B
22nm�̓����������x��Ă��A28nm�����邩�猻���I�ɂ͋C�ɂ���قǂ̍��͂Ȃ��Ǝv���B
Ontario��28nm�g����������Ȃ��Ƃ����b������B
Intel��AVX��������r�[�̊J��������Ε�����悤�ɁASIMD(MIMD?)����Z�ō��㐫�\���グ�čs�����Ƃ��Ă���͖̂��炩�B
AVX�Ή����i�߂A�����悤��GPGPU���Ή������ȏ�ɐi�ނƎv���B
AVX�̗��_���\�͏ڂ����m��A4�R�ASandy��100GFlops�ʂ��ȁH
Llano����500GFlops�������5�{�̐��\���ɂȂ�B
�܂��A���F���_��������ۂɂ�2�{���x���낤�B
����v���Z�X�Ŕ{���x�̐��\���������ł��邩��A22nm�ő�����s����Ă��x�N�g�����\���̂͌݊p�ɕۂ��Ƃ͂ł���B
���������ACPU������SSE��AVX��GPU�ƘA�g���ĕ��Z�o����̂��ȁB
���ꂪ�o����ABulldozer�����APU��AVX+GPGPU�ł��Ȃ�ʔ������Ƃ��ł������B
Ontario��28nm�g����������Ȃ��Ƃ����b������B
Intel��AVX��������r�[�̊J��������Ε�����悤�ɁASIMD(MIMD?)����Z�ō��㐫�\���グ�čs�����Ƃ��Ă���͖̂��炩�B
AVX�Ή����i�߂A�����悤��GPGPU���Ή������ȏ�ɐi�ނƎv���B
AVX�̗��_���\�͏ڂ����m��A4�R�ASandy��100GFlops�ʂ��ȁH
Llano����500GFlops�������5�{�̐��\���ɂȂ�B
�܂��A���F���_��������ۂɂ�2�{���x���낤�B
����v���Z�X�Ŕ{���x�̐��\���������ł��邩��A22nm�ő�����s����Ă��x�N�g�����\���̂͌݊p�ɕۂ��Ƃ͂ł���B
���������ACPU������SSE��AVX��GPU�ƘA�g���ĕ��Z�o����̂��ȁB
���ꂪ�o����ABulldozer�����APU��AVX+GPGPU�ł��Ȃ�ʔ������Ƃ��ł������B
AVX�͐Ϙa���Z�����邩��A4�R�A3GHz���炢�Ȃ�A200GFlops���炢�B
�{�����͂��Ȃ����ƁB
�{�����͂��Ȃ����ƁB
>>281
AMD��Intel��CPU���T�[�o�[�s��ŗ��v���傫���̂́A����PC�pCPU�𓊓��ł��邩�炾��
AMD��Intel��CPU���T�[�o�[�s��ŗ��v���傫���̂́A����PC�pCPU�𓊓��ł��邩�炾��
285 �FSocket774�F2010/02/17(��) 20:20:31 ID:Y3Z/rkeX
Bulldozer(4GHz)��҂��܂��傤�B
�����Ȃ́H
�T�[�o�[�s��ł̗��v���傫������PC�p��CPU�����������ł���̂��Ǝv���Ă���B
�T�[�o�[�s��ł̗��v���傫������PC�p��CPU�����������ł���̂��Ǝv���Ă���B
>>97
��3�����J�\���ATI Catalyst 10.3����́AATI Mobility Radeon HD 2000�ȍ~�̃��o�C���nGPU�̐��\����ы@�\�A���萫�̌�����A�p���I��ATI Catalyst�Ŏ��{����v��B
���Ή��m�[�gPC��Windows Vista/7���ڂ̐��i�ŁA�قƂ�ǂ̃m�[�gPC���[�J�[�ŃT�|�[�g�����Ƃ����B
�悤�₭Intel�m�[�g�Ɠ����y�U�ɗ�����
��3�����J�\���ATI Catalyst 10.3����́AATI Mobility Radeon HD 2000�ȍ~�̃��o�C���nGPU�̐��\����ы@�\�A���萫�̌�����A�p���I��ATI Catalyst�Ŏ��{����v��B
���Ή��m�[�gPC��Windows Vista/7���ڂ̐��i�ŁA�قƂ�ǂ̃m�[�gPC���[�J�[�ŃT�|�[�g�����Ƃ����B
�悤�₭Intel�m�[�g�Ɠ����y�U�ɗ�����
>>284
���������z������Ɗy�����ȁB�]�����[���S�J�ŁB
���������z������Ɗy�����ȁB�]�����[���S�J�ŁB
GMA��MobilityRADEON����GMA�̂ق������i���킯�ŁB
>>286
�ߋ��̗��j��k���Č���Ɨǂ���
PC�ƃT�[�o�[�̗��j�́APC�Ƃ�������s��Ĉ�����鎖���o����悤�ɂȂ���X86��
X86�ȊO��CPU����̂��Ă����T�[�o�[�s��ɉ��肱�ݐN�H���Ă���������
�ߋ��̗��j��k���Č���Ɨǂ���
PC�ƃT�[�o�[�̗��j�́APC�Ƃ�������s��Ĉ�����鎖���o����悤�ɂȂ���X86��
X86�ȊO��CPU����̂��Ă����T�[�o�[�s��ɉ��肱�ݐN�H���Ă���������
>>288
�{���ɉ����m��Ȃ��ȁB
x86�����i���Workstation��Server���ǂ�ǂ�N�H�A�ėp�@����PC�T�[�o�ւ��Ă���
���������Ă��������B�܂�x86���嗬�̈�ł����Ȃ���������NT4.0��CD������Δ���B
����Workstation�ł�����
http://blogs.yahoo.co.jp/tom_my_way/38898095.html
x86�̑���MIPS�AAlpha�APowerPC������B�����͖����ł��Ȃ������B
�ł�����PC�s����o�b�N�ɑ�ʐ��Y�ň����A���\���オ������x86�����|�I�ɂȂ����B
GPU�������B�n�C�G���h�݂̂ɒ��͂������[�J3DLabs�Ƃ��͎���ŁA�R���V���[�}������GPU�]�p��
NVIDIA��ATI�����������c����B
�{���ɉ����m��Ȃ��ȁB
x86�����i���Workstation��Server���ǂ�ǂ�N�H�A�ėp�@����PC�T�[�o�ւ��Ă���
���������Ă��������B�܂�x86���嗬�̈�ł����Ȃ���������NT4.0��CD������Δ���B
����Workstation�ł�����
http://blogs.yahoo.co.jp/tom_my_way/38898095.html
x86�̑���MIPS�AAlpha�APowerPC������B�����͖����ł��Ȃ������B
�ł�����PC�s����o�b�N�ɑ�ʐ��Y�ň����A���\���オ������x86�����|�I�ɂȂ����B
GPU�������B�n�C�G���h�݂̂ɒ��͂������[�J3DLabs�Ƃ��͎���ŁA�R���V���[�}������GPU�]�p��
NVIDIA��ATI�����������c����B
ATI�͂Ȃ�����
���������������肵�������Ȃ��Ȃ�������
>>291
����x86�n�ł�PC-9800�V���[�Y�p�����������ȁB
Windows2000���Ō�ɏ��������B
TOWNS�Ȃ��Windows95�E�E�E�B
����x86�n�ł�PC-9800�V���[�Y�p�����������ȁB
Windows2000���Ō�ɏ��������B
TOWNS�Ȃ��Windows95�E�E�E�B
GF�͍��NARM�悤�̏o�ׂɐ�O����
�����Œ������Ă����
�����Œ������Ă����
296 �FSocket774�F2010/02/18(��) 00:05:15 ID:HCyq/yMn
Bulldozer���āA�����R�X�g�i�_�C�̑傫���������j�ł���A
Intel�����i�Ɣ�ׂ�ƁA�y���Ƀ}���`�X���b�h���̃s�[�N���\��
�d�͌������ǂ����Ď��ł���H
SandyBridg�@6�R�A�{HTT�AWestmere�@6�R�A�{HTT�@���@Bulldozer�@8�R�A�i4���W���[���j
�V���O���X���b�h�͂ǂ�����̂��m��Ȃ����ǁB
Intel�����i�Ɣ�ׂ�ƁA�y���Ƀ}���`�X���b�h���̃s�[�N���\��
�d�͌������ǂ����Ď��ł���H
SandyBridg�@6�R�A�{HTT�AWestmere�@6�R�A�{HTT�@���@Bulldozer�@8�R�A�i4���W���[���j
�V���O���X���b�h�͂ǂ�����̂��m��Ȃ����ǁB
�V���O���X���b�h���\���������ė����Ȃ��Ƃ������������炢����
�v����B�R���߃f�R�[�h�A�E�g�I�u�I�[�_�[�ł�IPC���Q����
�P�[�X�͏��Ȃ�����A�S���߃f�R�[�h�̑���ɂQ�R�A���y�A��
���邱�ƂŁA�g�����W�X�^�����܂葝�₳���Ƀp�t�H�[�}���X����
��_���݂���������B
Bulldozer�̓g�����W�X�^�������グ�ă}���`�X���b�h���\������
���邱�Ƃ�ړI�ɂ��Ă���悤�Ɍ�����B�V���O���X���b�h�A�v��
�ł��S���߃f�R�[�h�Ő��\�͎�オ�邵�ˁB
�v����B�R���߃f�R�[�h�A�E�g�I�u�I�[�_�[�ł�IPC���Q����
�P�[�X�͏��Ȃ�����A�S���߃f�R�[�h�̑���ɂQ�R�A���y�A��
���邱�ƂŁA�g�����W�X�^�����܂葝�₳���Ƀp�t�H�[�}���X����
��_���݂���������B
Bulldozer�̓g�����W�X�^�������グ�ă}���`�X���b�h���\������
���邱�Ƃ�ړI�ɂ��Ă���悤�Ɍ�����B�V���O���X���b�h�A�v��
�ł��S���߃f�R�[�h�Ő��\�͎�オ�邵�ˁB
���N���b�N��K10�Ɣ�r���Đ����̃V���O���X���b�h���\�����ɑ��������낤���܂��������Ȃ���B
Bulldozer��4���ߔ��s�̃f�R�[�_�[����
���W���[������2���ߔ��s�̃f�R�[�_�[��2������Ď����ȁH
���W���[������2���ߔ��s�̃f�R�[�_�[��2������Ď����ȁH
�����̃V���O���X���b�h���\�ቺ������
�����v���I�ł���B
��Spark�ł���A�������\1.4�{�߂��㏸�����Ă���̂�
AMD�͉����H���\�ቺ�Ƃ����肦�ˁ[����
�����v���I�ł���B
��Spark�ł���A�������\1.4�{�߂��㏸�����Ă���̂�
AMD�͉����H���\�ቺ�Ƃ����肦�ˁ[����
>>300
4���߂��t���āA��Ɏ��s�ł��閽�߂�T���Ă���
�Q�Âf�B�X�p�b�`����Ȃ���
>>301
IBM�͂����Ⴒ�����H���₷�̌����݂�������B
http://japan.zdnet.com/sp/interview/story/0,2000056426,20097277,00.htm
�m���ɖ��ߕ��ёւ���̂Ɏ��Ԃ���������A��H���c��ɂȂ����肵����Ӗ��Ȃ�㩁B
BULLDOZER�|FX�͏����Ⴄ�悤�Ȏ��g���ŏo���Ă����Ɗ��҂��Ă���B
4���߂��t���āA��Ɏ��s�ł��閽�߂�T���Ă���
�Q�Âf�B�X�p�b�`����Ȃ���
>>301
IBM�͂����Ⴒ�����H���₷�̌����݂�������B
http://japan.zdnet.com/sp/interview/story/0,2000056426,20097277,00.htm
�m���ɖ��ߕ��ёւ���̂Ɏ��Ԃ���������A��H���c��ɂȂ����肵����Ӗ��Ȃ�㩁B
BULLDOZER�|FX�͏����Ⴄ�悤�Ȏ��g���ŏo���Ă����Ɗ��҂��Ă���B
>>301
���������z�́u���N���b�N�ł́v�Ƃ��������߂�ǂ܂Ȃ���ȁB
�Ȃ��"TB"�݂����ȋ@�\��ςނ����������Ă��Ȃ��Ȃ��낤�ȁB
���������z�́u���N���b�N�ł́v�Ƃ��������߂�ǂ܂Ȃ���ȁB
�Ȃ��"TB"�݂����ȋ@�\��ςނ����������Ă��Ȃ��Ȃ��낤�ȁB
�G���ɍ\����
�f�R�[�_��3��4Way���������̂悤��
ALU��3��2�{�ɂȂ������ƂŐ��\��������ƌ���Ă���悤�Ɍ��������
���A�v���ł�ALU�n���߂Ɣ�ALU�n���߁i�������n+FPU/SIMD�n�j�̔䗦��
�ǂ̒��x�ƍl���Ă�H
ALU��3��2�{�ɂȂ������ƂŐ��\��������ƌ���Ă���悤�Ɍ��������
���A�v���ł�ALU�n���߂Ɣ�ALU�n���߁i�������n+FPU/SIMD�n�j�̔䗦��
�ǂ̒��x�ƍl���Ă�H
AMD�̎�����R�A�Ȃ�����҂������̂́i�A���`�ȊO�j�F�����B
���Ƃ����āA������ł͊��}�o���Ȃ��i�R�P����ɂ����ȁj�C�z���Y���Ă���A�ƁB
���́A�V���O���X���b�h���\�����}���`�X���b�h���̌������d�������v��
�s��Ŏx����̂��ǂ����B
AMD64��������O�ɂȂ�ix64��Windows����ʌ������[�J�[PC�ł��I�����Ƃ��ďo�Ă���j
�܂łƓ������炢�C�̒����b�ɂȂ�Ƃ�����A
�ŏ���Bulldozer�R�A�̗pCPU�͓���p�r�ȊO�ł͂��̖{����]������Ȃ��̂ł͂Ȃ����Ɗ뜜���Ă�B
���Ƃ����āA������ł͊��}�o���Ȃ��i�R�P����ɂ����ȁj�C�z���Y���Ă���A�ƁB
���́A�V���O���X���b�h���\�����}���`�X���b�h���̌������d�������v��
�s��Ŏx����̂��ǂ����B
AMD64��������O�ɂȂ�ix64��Windows����ʌ������[�J�[PC�ł��I�����Ƃ��ďo�Ă���j
�܂łƓ������炢�C�̒����b�ɂȂ�Ƃ�����A
�ŏ���Bulldozer�R�A�̗pCPU�͓���p�r�ȊO�ł͂��̖{����]������Ȃ��̂ł͂Ȃ����Ɗ뜜���Ă�B
PC�T�[�o�[���i��AMD64�K�i�̂��������낤�B
AMD���̂��A��RISC�w�c����荞�݂Â���X�^�C�������B
Alpha���Ȃ����CoreMA�̓o����Ȃ��������낤�ȁB
INTEL�ɂ͎��̊G���Ȃ���B�����r�[�Ƃ��r�߂Ă�̂���
AMD���̂��A��RISC�w�c����荞�݂Â���X�^�C�������B
Alpha���Ȃ����CoreMA�̓o����Ȃ��������낤�ȁB
INTEL�ɂ͎��̊G���Ȃ���B�����r�[�Ƃ��r�߂Ă�̂���
>>300
�u���b�N�}����[������Ƃ����B
�u���b�N�}����[������Ƃ����B
>>307
�܂��BK8�̏o�����Ɠ�����ˁB�������܂ł�OS���}���`�X���b�h�Ȃ̂ŁA
��ʓI�ȑ���ł͑��슴�͌��シ�邾�낤�B
���Ƃ̓Q�[���⋌����A�v���E�}���`�X���b�h��Ή��A�v���₾�낤���ǁA
������A�v���͌���ł����\�ߏ肾������͂Ȃ��B
�}���`�X���b�h��Ή��A�v����TB�Ɠ����悤�ȋ@�\�łȂ�Ƃ��Ȃ邾�낤�Ǝv���B
���Ƃ͍œK���̖�肾�����Ƃ������Ȃ��B
�܂��BK8�̏o�����Ɠ�����ˁB�������܂ł�OS���}���`�X���b�h�Ȃ̂ŁA
��ʓI�ȑ���ł͑��슴�͌��シ�邾�낤�B
���Ƃ̓Q�[���⋌����A�v���E�}���`�X���b�h��Ή��A�v���₾�낤���ǁA
������A�v���͌���ł����\�ߏ肾������͂Ȃ��B
�}���`�X���b�h��Ή��A�v����TB�Ɠ����悤�ȋ@�\�łȂ�Ƃ��Ȃ邾�낤�Ǝv���B
���Ƃ͍œK���̖�肾�����Ƃ������Ȃ��B
�����p�C�v�̓���͂܂����\����ĂȂ���ŁA�����p�C�v��
����Ƃ������_���肫�Ȃ̂͒P�Ƀl�K�L���������������ɂ���
�����Ȃ��B
����Ƃ������_���肫�Ȃ̂͒P�Ƀl�K�L���������������ɂ���
�����Ȃ��B
�ŐV�Q�[����BATTLEFIELD BAD COMPANY2�̓N�A�b�h�R�A�œK��
������Q�[����PHENOM�ł�100FPS�Ƃ��o���ŁA�t���̌��E�z����B
SUPER�ł��APEN4�̂RGHz�iIPC=�P�j��ATHLON�QGHz�iIPC���R�j���r����ƁA
�������������̐��\�B�܂�ATHLON�ł�ILP��2�ȉ�
INTEL��HTT�͘_���R�A�����Ă�L1�͈�����Ȃ��̂ŁA���\�ɂ͌��E����
K9��IPC���₻���Ƃ��������
����ł����s���j�b�g���₵�������Ƃ���
������Q�[����PHENOM�ł�100FPS�Ƃ��o���ŁA�t���̌��E�z����B
SUPER�ł��APEN4�̂RGHz�iIPC=�P�j��ATHLON�QGHz�iIPC���R�j���r����ƁA
�������������̐��\�B�܂�ATHLON�ł�ILP��2�ȉ�
INTEL��HTT�͘_���R�A�����Ă�L1�͈�����Ȃ��̂ŁA���\�ɂ͌��E����
K9��IPC���₻���Ƃ��������
����ł����s���j�b�g���₵�������Ƃ���
>>311
���� ALU x2 + Load/Store x2 �͊m��I�ȏ�Ǝv����
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091217_336298.html
> Bulldozer�A�[�L�e�N�`���ł́A1�X���b�h�����s����1�̐����R�A��4�{�̐����p�C�v������Ă���B
> AMD�ɂ��ƁA���̂���2�{�͐������Z�p�C�v�A2�{�����[�h/�X�g�A�n�p�C�v���ƌ����B
ttp://ascii.jp/elem/000/000/489/489200/
> �Ƃ��낪�A����Ɋւ��Ă͓��{AMD�o�R�ŕ�AMD���A
> ���m�Ɂu�X���b�h������ALU��2�AAGU��2�̍��v4�ł���v�Ƃ������A���Ă����B
�ǂ���̋L�����uAMD�������Ă���v�Ə����Ă���
���� ALU x2 + Load/Store x2 �͊m��I�ȏ�Ǝv����
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091217_336298.html
> Bulldozer�A�[�L�e�N�`���ł́A1�X���b�h�����s����1�̐����R�A��4�{�̐����p�C�v������Ă���B
> AMD�ɂ��ƁA���̂���2�{�͐������Z�p�C�v�A2�{�����[�h/�X�g�A�n�p�C�v���ƌ����B
ttp://ascii.jp/elem/000/000/489/489200/
> �Ƃ��낪�A����Ɋւ��Ă͓��{AMD�o�R�ŕ�AMD���A
> ���m�Ɂu�X���b�h������ALU��2�AAGU��2�̍��v4�ł���v�Ƃ������A���Ă����B
�ǂ���̋L�����uAMD�������Ă���v�Ə����Ă���
>>311
�����A>>306�ł����������ǁAALU��2�{�Ɍ��邱�Ƃ�����������
IPC��������Ƃ����̂̓l�K�L�����Ƃ͂���Ȃ�����
�����͂Ɍ�����悤�ȋC������
���Ƃ��AALU�n���߂̔䗦��2/3�i��66.7%�j���Ƃ����
K7�n�iK10���܂ށj�̏ꍇ�A�ғ�����ALU��2����/�N���b�N
Bull�̏ꍇ���A�ғ�����ALU��2����/�N���b�N�Ɠ����ɂȂ�͂�
�܂��AALU�n���߂̔䗦��1/2�i=50%�j���Ƃ����
K7�n�̏ꍇ�A�ғ�����ALU��1.5����/�N���b�N
Bull�̏ꍇ�́A�ғ�����ALU��2����/�N���b�N��Bull������͂�
�t��ALU�n���߂̔䗦��3/4�i=75%�j���Ƃ����
K7�n�̏ꍇ�A�ғ�����ALU��2.25����/�N���b�N
Bull�̏ꍇ�́A�ғ�����ALU��2����/�N���b�N��K7�n������͂�
�Ƃ����킯�ŁA���߂̃~�b�N�X�ɂ���Đ��\���ς���Ă���͂��Ȃ̂�
������ƒf�����Ă���l�͂ǂ̒��x�̃~�b�N�X�ł���Ɖ��肵�Ă��邩��
>>306�ŕ����Ă݂����ǒN�������Ă���Ȃ� orz
�����A>>306�ł����������ǁAALU��2�{�Ɍ��邱�Ƃ�����������
IPC��������Ƃ����̂̓l�K�L�����Ƃ͂���Ȃ�����
�����͂Ɍ�����悤�ȋC������
���Ƃ��AALU�n���߂̔䗦��2/3�i��66.7%�j���Ƃ����
K7�n�iK10���܂ށj�̏ꍇ�A�ғ�����ALU��2����/�N���b�N
Bull�̏ꍇ���A�ғ�����ALU��2����/�N���b�N�Ɠ����ɂȂ�͂�
�܂��AALU�n���߂̔䗦��1/2�i=50%�j���Ƃ����
K7�n�̏ꍇ�A�ғ�����ALU��1.5����/�N���b�N
Bull�̏ꍇ�́A�ғ�����ALU��2����/�N���b�N��Bull������͂�
�t��ALU�n���߂̔䗦��3/4�i=75%�j���Ƃ����
K7�n�̏ꍇ�A�ғ�����ALU��2.25����/�N���b�N
Bull�̏ꍇ�́A�ғ�����ALU��2����/�N���b�N��K7�n������͂�
�Ƃ����킯�ŁA���߂̃~�b�N�X�ɂ���Đ��\���ς���Ă���͂��Ȃ̂�
������ƒf�����Ă���l�͂ǂ̒��x�̃~�b�N�X�ł���Ɖ��肵�Ă��邩��
>>306�ŕ����Ă݂����ǒN�������Ă���Ȃ� orz
��ʓI�ɂ́Aload/store��6���Aalu3�A���̑���1�Ƃ����Ă�ȁB
������core�n��LSU�Ώd�v�ő��x�������ł�킯�ŁB
������core�n��LSU�Ώd�v�ő��x�������ł�킯�ŁB
>>315
������āARISC�̋��ȏ��ɍڂ��Ă���i�T�^�I��RISC�́j�~�b�N�X����Ȃ��H
x86�̓��W�X�^���Ȃ�����RISC����Load/Store�̔䗦��������͂��Ȃ���
�c���ď������Ǝv������uload/store��6���v����
�uload/store��3���Aalu6�A���̑���1�v����ˁH
������āARISC�̋��ȏ��ɍڂ��Ă���i�T�^�I��RISC�́j�~�b�N�X����Ȃ��H
x86�̓��W�X�^���Ȃ�����RISC����Load/Store�̔䗦��������͂��Ȃ���
�c���ď������Ǝv������uload/store��6���v����
�uload/store��3���Aalu6�A���̑���1�v����ˁH
�[��Bulldozer��6�R�A�A8�R�A������A�Z�[���X�|�C���g�ŁA
�V���O���X���b�h���\�����Ă������I�ɖ��Ȃ��āA
���ɏo��Bulldozer2�ŁA���ɖ߂���Bulldozer���V���O���X���b�h���\33���A�b�v���L���b�`�t���[�Y�ɂ���\��Ȃ�B
��x�ɁA���z�o���Ȃ�������@�����B
�b�o�t�P������̔����i�����v���������Ă邩��A�Z���T�C�N���Ŕ����������v�@��N�����͓̂��R���B
�V���O���X���b�h���\�����Ă������I�ɖ��Ȃ��āA
���ɏo��Bulldozer2�ŁA���ɖ߂���Bulldozer���V���O���X���b�h���\33���A�b�v���L���b�`�t���[�Y�ɂ���\��Ȃ�B
��x�ɁA���z�o���Ȃ�������@�����B
�b�o�t�P������̔����i�����v���������Ă邩��A�Z���T�C�N���Ŕ����������v�@��N�����͓̂��R���B
�f�R�[�_��4-way�Ƃ����̂̓��W���[��������̘b���낤�H
2�{�̃p�C�v*2�R�A�ɑΉ����邽�߂ɑ��₵���̂ł����āA
�f�R�[�_�d���̐v�ɂ������Ď�����Ȃ��B
1�R�A������ōl����ƁA���߃f�R�[�h&���s�̑ш�Ǝ��s�ш�̊W��K10�̎��ƕς���ĂȂ��B
>>314�ւ̉ɂȂ邩�͔��������A
���̗��ш�̊W�A�����Ă����������ς��Ă��Ȃ����Ď���AMD�̑z�肷��
�w���߂̃~�b�N�X�x�Ƃ����ԐړI�Ɏ����Ă���Ǝv���B
1���W���[�������S��1�X���b�h�Ő�L�o����i�V���O���R�A�Ƃ��Ďg����j��ԂȂ�
�����p�C�v�����������ƃf�R�[�_�������͑��E�����̂����m��Ȃ��B
���҂̃o�����X���ς��킯������A����s���肪�ς����������\�ɂ͂Ȃ蓾�Ȃ��A���B
�V���O���X���b�h���\���ቺ�]�X�Ƃ����̂́A���W���[���𗼎҂��Γ���2�R�A�Ƃ��Č����ꍇ��
1�R�A�Ɋ��蓖�Ă��郊�\�[�X���������Ă���Ď��ɐs����킯�ŁB
2�{�̃p�C�v*2�R�A�ɑΉ����邽�߂ɑ��₵���̂ł����āA
�f�R�[�_�d���̐v�ɂ������Ď�����Ȃ��B
1�R�A������ōl����ƁA���߃f�R�[�h&���s�̑ш�Ǝ��s�ш�̊W��K10�̎��ƕς���ĂȂ��B
>>314�ւ̉ɂȂ邩�͔��������A
���̗��ш�̊W�A�����Ă����������ς��Ă��Ȃ����Ď���AMD�̑z�肷��
�w���߂̃~�b�N�X�x�Ƃ����ԐړI�Ɏ����Ă���Ǝv���B
1���W���[�������S��1�X���b�h�Ő�L�o����i�V���O���R�A�Ƃ��Ďg����j��ԂȂ�
�����p�C�v�����������ƃf�R�[�_�������͑��E�����̂����m��Ȃ��B
���҂̃o�����X���ς��킯������A����s���肪�ς����������\�ɂ͂Ȃ蓾�Ȃ��A���B
�V���O���X���b�h���\���ቺ�]�X�Ƃ����̂́A���W���[���𗼎҂��Γ���2�R�A�Ƃ��Č����ꍇ��
1�R�A�Ɋ��蓖�Ă��郊�\�[�X���������Ă���Ď��ɐs����킯�ŁB
�s�[�N���\�Ǝ������\�̋�ʂ����ċc�_���ė~����
�������\�Ƃ��Ă�
����2way������K6��3way��K7�̐������\����������������A
K10��Bull���������Ǝv����B
���肷��ᑝ�z���܂����Č�������K10�����V�v�ȕ����\�������\�����炠��
����2way������K6��3way��K7�̐������\����������������A
K10��Bull���������Ǝv����B
���肷��ᑝ�z���܂����Č�������K10�����V�v�ȕ����\�������\�����炠��
K6��K7���������������獡��������Ȃ��A�͋ɘ_������ł���
L2���������O�t�����݂����ȈႢ���������\�ɉe�����Ă���
K10��Bulldozer�ŃL���b�V���e�ʂɂ��������邵
Llano�ł̓C���t���C�g�Ő���ł��閽�ߐ�������������AALU������
�ōl�����Bulldozer�ł������邩���m���
���������̂������ł��l������ł̌��_�Ȃ炢�����ǂ�
L2���������O�t�����݂����ȈႢ���������\�ɉe�����Ă���
K10��Bulldozer�ŃL���b�V���e�ʂɂ��������邵
Llano�ł̓C���t���C�g�Ő���ł��閽�ߐ�������������AALU������
�ōl�����Bulldozer�ł������邩���m���
���������̂������ł��l������ł̌��_�Ȃ炢�����ǂ�
�s�[�N���\�Ǝ������\�͂�������ł�������
����x�Ɛ��\�̋�ʂ���
����x�Ɛ��\�̋�ʂ���
Thunderird��K6-3�̃N���b�N������̐������\�͑�̈ꏏ��������
����Ɍ��_�Ȃ�ĒN�������ĂȂ���A�\���������ƌ���������
���g�̏ڂ������ƂȂ�����ǁA������K6-3�Ɏ��Ă邩��A����̉��ǔł݂����Ȃ��̂��낤�Ɨ\�z���Ă��邾��
�����琮�����\�Ɋւ�����ς��Ȃ��\���̕������������ȂƎv������
�N���b�N������̐��\���A���Ȃ��Ƃ�K6-3�ȉ��ɂȂ邱�Ƃ͂Ȃ����낤���ˁB
����Ɍ��_�Ȃ�ĒN�������ĂȂ���A�\���������ƌ���������
���g�̏ڂ������ƂȂ�����ǁA������K6-3�Ɏ��Ă邩��A����̉��ǔł݂����Ȃ��̂��낤�Ɨ\�z���Ă��邾��
�����琮�����\�Ɋւ�����ς��Ȃ��\���̕������������ȂƎv������
�N���b�N������̐��\���A���Ȃ��Ƃ�K6-3�ȉ��ɂȂ邱�Ƃ͂Ȃ����낤���ˁB
�����킩��������E�E�E���x���Ȃ����������Ă�
���O�͒~���@���H
���O�͒~���@���H
AMD��CPU�͍��x�͂��������Ȍ`�ɂȂ邨�I
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/002.html
> �Ƃ������ƂŁA�����I�ɂ̓v���Z�T�������Ɏ��s�ł��閽�ߐ��𑝂₷�ƍ���
> �\�ɂȂ�悤�Ɏv���邪�A����̃v���Z�T�̎������\���グ��ɂ́A����
> ���s���ߐ��𑝂₷�����A1���߂����s�ł��Ȃ�(���s���Ă����������
> �P�[�X���܂�)�T�C�N�������炷���Ƃ̕����d�v�ł���B
> �Ƃ������ƂŁA�����I�ɂ̓v���Z�T�������Ɏ��s�ł��閽�ߐ��𑝂₷�ƍ���
> �\�ɂȂ�悤�Ɏv���邪�A����̃v���Z�T�̎������\���グ��ɂ́A����
> ���s���ߐ��𑝂₷�����A1���߂����s�ł��Ȃ�(���s���Ă����������
> �P�[�X���܂�)�T�C�N�������炷���Ƃ̕����d�v�ł���B
���������s���ߐ��𑝂₷�����A1���߂����s�ł��Ȃ�(���s���Ă����������P�[�X���܂�)�T�C�N�������炷���Ƃ̕����d�v
�ȂႱ���
(���s���Ă����������P�[�X�j�������C�R�[������Ȃ��̂�����H�iCPU�I�ȈӖ������Ƃ��Ắj
�����1�p�C�v���C�����́u1���߂����s�ł��Ȃ��T�C�N���v������Ă�����
�������s�̂��߂̃p�C�v���C�����₷���Ƃ�����簐i���Đ��ʏグ�Ă�̂�GPU����Ȃ����ˁi�C���I�[�_��SIMD�p�C�v���\����݂����ȁj
�Ⴄ�̂���
�ȂႱ���
(���s���Ă����������P�[�X�j�������C�R�[������Ȃ��̂�����H�iCPU�I�ȈӖ������Ƃ��Ắj
�����1�p�C�v���C�����́u1���߂����s�ł��Ȃ��T�C�N���v������Ă�����
�������s�̂��߂̃p�C�v���C�����₷���Ƃ�����簐i���Đ��ʏグ�Ă�̂�GPU����Ȃ����ˁi�C���I�[�_��SIMD�p�C�v���\����݂����ȁj
�Ⴄ�̂���
������ƒ��ׂĂ݂���
�C�X���G���̂ق���CPU�Ő�����2�{����3�{�ɂȂ����̂���
����ς��ł����ۂł�������
����Ƀf�R�[�_�������āA���ɂ����[�v��p�L���b�V���t������F�X����
����SSE�������������\�オ��Ȃ������C������
�����Ȃ�Ƃ�����������̃l�b�N�Ƃ������A�v���O�����̂ق��ŏ���������Ă��ł͂Ȃ����Ǝv�����
Bull�͓��@�X���b�h��炩����������
��������̓��@���s�܂ŕʃR�A�ł���i�m��ǁj�ƂȂ�Ƃ���Ƀp�C�v���C���{���̉��l�����܂���E�E�E
�C�X���G���̂ق���CPU�Ő�����2�{����3�{�ɂȂ����̂���
����ς��ł����ۂł�������
����Ƀf�R�[�_�������āA���ɂ����[�v��p�L���b�V���t������F�X����
����SSE�������������\�オ��Ȃ������C������
�����Ȃ�Ƃ�����������̃l�b�N�Ƃ������A�v���O�����̂ق��ŏ���������Ă��ł͂Ȃ����Ǝv�����
Bull�͓��@�X���b�h��炩����������
��������̓��@���s�܂ŕʃR�A�ł���i�m��ǁj�ƂȂ�Ƃ���Ƀp�C�v���C���{���̉��l�����܂���E�E�E
�܂����@�l�^���[�v��������
�p�C�v���C���X�g�[���̎����낊��
��������\�N���OAMD������4�{��CPU���������ō���Ă��炵���ȁB
���\�͏�肭������5%���オ�邪���̓f�R�[�_�[���{�g���l�b�N�ɂȂ���
���܂�ς��Ȃ��Ƃ��B����ƃu���̃A�[�L�e�N�`���̊T�v�͂��Ȃ�x86CPU��
�����`�ȂƎv�����H�������N�ȓ���Intel���Ǐ]����Ǝv���B
��������\�N���OAMD������4�{��CPU���������ō���Ă��炵���ȁB
���\�͏�肭������5%���オ�邪���̓f�R�[�_�[���{�g���l�b�N�ɂȂ���
���܂�ς��Ȃ��Ƃ��B����ƃu���̃A�[�L�e�N�`���̊T�v�͂��Ȃ�x86CPU��
�����`�ȂƎv�����H�������N�ȓ���Intel���Ǐ]����Ǝv���B
���[
>�p�C�v���C���X�g�[���̎����낊��
��327����
>�p�C�v���C���X�g�[���̎����낊��
��327����
>>331
�����>327�̂ǂ��ɑ��Č����Ă������̂����E�E�E
���܂����p�C�v���C���{���ɂ�����
�������s���ߐ��𑝂₷���Ɓi�A�E�g�I�u�I�[�_��L���b�V���������j��
�X�g�[�����ŗV��ł郊�\�[�X�����炷���Ƃ���
�����>327�̂ǂ��ɑ��Č����Ă������̂����E�E�E
���܂����p�C�v���C���{���ɂ�����
�������s���ߐ��𑝂₷���Ɓi�A�E�g�I�u�I�[�_��L���b�V���������j��
�X�g�[�����ŗV��ł郊�\�[�X�����炷���Ƃ���
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/002.html
�r���̌��_�����ǂނ���Ȃ������ĂȂ��Ȃ��́H
�r���̌��_�����ǂނ���Ȃ������ĂȂ��Ȃ��́H
> �������s���ߐ��𑝂₷���Ɓi�A�E�g�I�u�I�[�_��L���b�V���������j
>>326�̋L���ł�
���Z��𑝂₷ �� �������s���ߐ��𑝂₷�Ȃ�
>>326�̋L���ł�
���Z��𑝂₷ �� �������s���ߐ��𑝂₷�Ȃ�
�ǂނ̖ʓ|�L����������
���Z��𑝂₷ �� �������s���ߐ��𑝂₷ �� 1���߂����s�ł��Ȃ�(���s���Ă����������P�[�X���܂�)�T�C�N�������炷
�Ȃ̂��O���t�B�b�N�v���Z�b�T����A�Ƃ������Ƃ�����>327�ɏ������̂���
CPU�ɂ͕�����s�̂��߂̋@�\�i�A�E�g�I�u�I�[�_��L���b�V�����j���[���Ȃ�����
�������߂ɂ͈ˑ��W�������̂ł����p�C�v���C���{���͕K�v������
�s�����W���̂�GPU�ƕς��Ȃ��Ǝv��
���Z��𑝂₷ �� �������s���ߐ��𑝂₷ �� 1���߂����s�ł��Ȃ�(���s���Ă����������P�[�X���܂�)�T�C�N�������炷
�Ȃ̂��O���t�B�b�N�v���Z�b�T����A�Ƃ������Ƃ�����>327�ɏ������̂���
CPU�ɂ͕�����s�̂��߂̋@�\�i�A�E�g�I�u�I�[�_��L���b�V�����j���[���Ȃ�����
�������߂ɂ͈ˑ��W�������̂ł����p�C�v���C���{���͕K�v������
�s�����W���̂�GPU�ƕς��Ȃ��Ǝv��
���s�����W����
���Ȃ�ςȏ����������Ă��܂������ǁA�u���Z��𑝂₷���X�g�[�������炷�v�̌���
���Ȃ�ςȏ����������Ă��܂������ǁA�u���Z��𑝂₷���X�g�[�������炷�v�̌���
>>335
���҂~�X���Ă����B
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/002.html
���炶��Ȃ��āA���̑O��
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/001.html
�ɁA
���܂��A���̃O���t��SPARC64 V��VI�̔�r���s���Ă���A�ڍׂɌ���Ɠ���͑����قȂ��Ă��邪�A
���S�̓I��CPI�Ƃ��Ă͂قړ����ł��邱�Ƃ������Ă���B�ƌ�����V����VI�ʼn��P�������悤�ł��邪�A
���N���b�N�����シ��ƃ������̃A�N�Z�X�Ɋ|����T�C�N�����͑�������̂ŁA
���V�X�e���N����CPI�������Ƃ������Ƃ�2���L���b�V���̃~�X���͌������Ă��锤�ł���A
�����̑��̓_�ł�CPI���ێ�����ɂ͑����̉��P�w�͂��s���Ă���ƍl������B
�ƁA�����Ă���B
���ƁAGPU�͓��ӂƂ���̈悪�����Ă������A���̌���ꂽ�̈�Ȃ�A
GPU�̃A�v���[�`�̕����ǂ����Ă����̘b�ł���H
���҂~�X���Ă����B
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/002.html
���炶��Ȃ��āA���̑O��
http://journal.mycom.co.jp/articles/2006/12/11/sparc64/001.html
�ɁA
���܂��A���̃O���t��SPARC64 V��VI�̔�r���s���Ă���A�ڍׂɌ���Ɠ���͑����قȂ��Ă��邪�A
���S�̓I��CPI�Ƃ��Ă͂قړ����ł��邱�Ƃ������Ă���B�ƌ�����V����VI�ʼn��P�������悤�ł��邪�A
���N���b�N�����シ��ƃ������̃A�N�Z�X�Ɋ|����T�C�N�����͑�������̂ŁA
���V�X�e���N����CPI�������Ƃ������Ƃ�2���L���b�V���̃~�X���͌������Ă��锤�ł���A
�����̑��̓_�ł�CPI���ێ�����ɂ͑����̉��P�w�͂��s���Ă���ƍl������B
�ƁA�����Ă���B
���ƁAGPU�͓��ӂƂ���̈悪�����Ă������A���̌���ꂽ�̈�Ȃ�A
GPU�̃A�v���[�`�̕����ǂ����Ă����̘b�ł���H
>>318
> �f�R�[�_��4-way�Ƃ����̂̓��W���[��������̘b���낤�H
> 2�{�̃p�C�v*2�R�A�ɑΉ����邽�߂ɑ��₵���̂ł����āA
> �f�R�[�_�d���̐v�ɂ������Ď�����Ȃ��B
�u2�{�̃p�C�v*2�R�A�ɑΉ����邽�߁v�ł����
�P����2Way�f�R�[�_��2�ςނق����y
���ʂɎ��������4Way�f�R�[�_��2Way�f�R�[�_�ɑ���
�N���e�B�J���p�X��2�{�ɐL�тĂ��܂����A�N���b�N����̏�Q�ɂȂ邩���
����ł�4Way�f�R�[�_��ς�ł����̂�
�����X���b�h���������T�[�o�[�p�r�ł�2x2Way�f�R�[�_�����Ƃ��ē�����
�����X���b�h�������W���[���� �ƂȂ邱�Ƃ������ł��낤
PC�i�����ʂ�Personal�ȁj�p�r�ł�4Way�f�R�[�_�Ƃ��ē������Ƃ�
IPC����i��������ALU�����̑��E�j��_���Ă����Ȃ����ȁH
�i�l�I�ɂ�Netburst�̃g���[�X�L���b�V����Nehalem��LSD�݂����Ȏd�g�݂�������
�f�R�[�_��ʂ��Ȃ��ł��ޏꍇ�������Ȃ�悤�ȍ\���ɂȂ��Ă����Ȃ�����
�v���Ă��邯�ǁA����͊��S�ɍ����̂Ȃ��ϑz�j
> �f�R�[�_��4-way�Ƃ����̂̓��W���[��������̘b���낤�H
> 2�{�̃p�C�v*2�R�A�ɑΉ����邽�߂ɑ��₵���̂ł����āA
> �f�R�[�_�d���̐v�ɂ������Ď�����Ȃ��B
�u2�{�̃p�C�v*2�R�A�ɑΉ����邽�߁v�ł����
�P����2Way�f�R�[�_��2�ςނق����y
���ʂɎ��������4Way�f�R�[�_��2Way�f�R�[�_�ɑ���
�N���e�B�J���p�X��2�{�ɐL�тĂ��܂����A�N���b�N����̏�Q�ɂȂ邩���
����ł�4Way�f�R�[�_��ς�ł����̂�
�����X���b�h���������T�[�o�[�p�r�ł�2x2Way�f�R�[�_�����Ƃ��ē�����
�����X���b�h�������W���[���� �ƂȂ邱�Ƃ������ł��낤
PC�i�����ʂ�Personal�ȁj�p�r�ł�4Way�f�R�[�_�Ƃ��ē������Ƃ�
IPC����i��������ALU�����̑��E�j��_���Ă����Ȃ����ȁH
�i�l�I�ɂ�Netburst�̃g���[�X�L���b�V����Nehalem��LSD�݂����Ȏd�g�݂�������
�f�R�[�_��ʂ��Ȃ��ł��ޏꍇ�������Ȃ�悤�ȍ\���ɂȂ��Ă����Ȃ�����
�v���Ă��邯�ǁA����͊��S�ɍ����̂Ȃ��ϑz�j
�f�R�[�_���₵�Ď��s�p�C�v�̕�U�A�Ƃ����������͖̂���
Bull�̃f�R�[�_�̓����O�ƃV���[�g�H���������ɏo���邩��ő�8�f�R�[�h�Ƃ��ߋ��X���ɂ�����
�ߏ�Ȃ�Ǝv�������Ƃ��邯��
���L���͒P�Ɂu�f�R�[�h�s���Ŏ��s�p�C�v���Ɂv�u�f�R�[�h�ߏ�v�Ƃ����s�ލ����Ȏ��Ԃ�
2�R�A�ւ̔z���Ńo�����X������Ă����̂��Ƃ���Ȃ����Ǝv��
���[�v��p�g���[�X�L���b�V���t���Ȃ�]�v�o�����X���ꂻ������
Bull�̃f�R�[�_�̓����O�ƃV���[�g�H���������ɏo���邩��ő�8�f�R�[�h�Ƃ��ߋ��X���ɂ�����
�ߏ�Ȃ�Ǝv�������Ƃ��邯��
���L���͒P�Ɂu�f�R�[�h�s���Ŏ��s�p�C�v���Ɂv�u�f�R�[�h�ߏ�v�Ƃ����s�ލ����Ȏ��Ԃ�
2�R�A�ւ̔z���Ńo�����X������Ă����̂��Ƃ���Ȃ����Ǝv��
���[�v��p�g���[�X�L���b�V���t���Ȃ�]�v�o�����X���ꂻ������
340 �F,,�E�L�́M�E,,�j��-�������F2010/02/18(��) 13:23:04 ID:Re/rOMyD
�܂�ALU�łǂꂾ������x�҂�������ʓI�ȃ��[�N���[�h�̃v���O������
�L���b�V���A�N�Z�X�ɑ��x���x�z������ł����ǂ�
Sandy Bridge�̑f����AVX��t�������ȊO��Nehalem/Westmere���x�[�X��
LSU�����Ƃ�cmp+jcc�̑Ώۊg��Ƃ��A�����i���Ƃ�����
���ƕێ�I�ȃA�[�L�e�N�`���ɂȂ邱�Ƃ������_�ł킩���Ă���B
���ႠBulldozer���ǂ��܂őR�ł��邩�Ƃ����ƁE�E�E
L1�̍\���͐��������ł��ȁB
�X���b�h����16KB��L1�f�[�^�����A2�X���b�h�v32KB�̂ق����A�e�X���b�h�̕��ɉ�����
�L���Ɏg����̂͊m��I�ɖ��炩�B
�L���b�V�����X���b�h���ɓƗ����Ă��镪2�X���b�h���v�ł̑ш�͉҂��₷���ʂ͂���̂���
Sandy Bridge�����[�h���߂̓������s����2�{�ɂȂ��Ă���̂ŁA�P����L1�̑ш揟���ł���
�K�������L���ł͂Ȃ��B
L2�͂Ƃ����ƁA�܂��e�ʓI�ɂ�2�̓Ɨ�L1�f�[�^�L���b�V���ƃf�[�^����������̂�
�N���X�o�[�X�C�b�`���K�v�ɂȂ背�C�e���V�̖ʂł͕s����������̃I�[�o�[�w�b�h����������B
���̂ւ��Intel��Core 2 Duo�Œʂ������ł͂��邯�ǁAL1D��32KB��8Way Set Associative
�Ɣ�r�I�X���b�V���O�̕p�x�͏��Ȃ��\�����Ƃ��Ă����B
L1D���e�X���b�h16KB��4Way Set Associative��Bulldozer�͂���������������B
��Nehalem��ŐV���ɑg�܂ꂽ�R�[�h����������������CPU��Sandy Bridge�̂ق��ł��傤�B
���������R�A���E���N���b�N���Ȃ�̘b�B���|�I�ȍ��N���b�N�œ˂�������Ȃ�b�͕ς���Ă���B
�L���b�V���A�N�Z�X�ɑ��x���x�z������ł����ǂ�
Sandy Bridge�̑f����AVX��t�������ȊO��Nehalem/Westmere���x�[�X��
LSU�����Ƃ�cmp+jcc�̑Ώۊg��Ƃ��A�����i���Ƃ�����
���ƕێ�I�ȃA�[�L�e�N�`���ɂȂ邱�Ƃ������_�ł킩���Ă���B
���ႠBulldozer���ǂ��܂őR�ł��邩�Ƃ����ƁE�E�E
L1�̍\���͐��������ł��ȁB
�X���b�h����16KB��L1�f�[�^�����A2�X���b�h�v32KB�̂ق����A�e�X���b�h�̕��ɉ�����
�L���Ɏg����̂͊m��I�ɖ��炩�B
�L���b�V�����X���b�h���ɓƗ����Ă��镪2�X���b�h���v�ł̑ш�͉҂��₷���ʂ͂���̂���
Sandy Bridge�����[�h���߂̓������s����2�{�ɂȂ��Ă���̂ŁA�P����L1�̑ш揟���ł���
�K�������L���ł͂Ȃ��B
L2�͂Ƃ����ƁA�܂��e�ʓI�ɂ�2�̓Ɨ�L1�f�[�^�L���b�V���ƃf�[�^����������̂�
�N���X�o�[�X�C�b�`���K�v�ɂȂ背�C�e���V�̖ʂł͕s����������̃I�[�o�[�w�b�h����������B
���̂ւ��Intel��Core 2 Duo�Œʂ������ł͂��邯�ǁAL1D��32KB��8Way Set Associative
�Ɣ�r�I�X���b�V���O�̕p�x�͏��Ȃ��\�����Ƃ��Ă����B
L1D���e�X���b�h16KB��4Way Set Associative��Bulldozer�͂���������������B
��Nehalem��ŐV���ɑg�܂ꂽ�R�[�h����������������CPU��Sandy Bridge�̂ق��ł��傤�B
���������R�A���E���N���b�N���Ȃ�̘b�B���|�I�ȍ��N���b�N�œ˂�������Ȃ�b�͕ς���Ă���B
341 �F,,�E�L�́M�E,,�j��-�������F2010/02/18(��) 13:25:44 ID:Re/rOMyD
�~L2�͂Ƃ����ƁA�܂��e�ʓI�ɂ�
��L2�͂Ƃ����ƁA�܂��e�ʓI�ɂ�1MB�Ƒ��߂ɂƂ��Ă͂��邪
��L2�͂Ƃ����ƁA�܂��e�ʓI�ɂ�1MB�Ƒ��߂ɂƂ��Ă͂��邪
���Z2pipe������A���߂�2way�ƌ������Ƃ͖����ȁB
load/store���܂߂��4pipe����
reg/reg���Z�̔䗦���l����ƃo�����X���Ă��邩��
�ˑ��W��蓯��N���b�N�ŏ����ł��Ȃ����Z������̂�
��������ёւ��Ē��x�����Ƃ�������������
���߂̐�o���͒������ω����₷�����߃Z�b�g�Ȃ̂ŁA
���ϒl�ł��ꂮ�炢�Ƃ��A�Ƃ��閽�߂̑g�ݍ��킹�Ȃ�
�����Ƃ����ς��Ƃ��A�������̓����
load/store���܂߂��4pipe����
reg/reg���Z�̔䗦���l����ƃo�����X���Ă��邩��
�ˑ��W��蓯��N���b�N�ŏ����ł��Ȃ����Z������̂�
��������ёւ��Ē��x�����Ƃ�������������
���߂̐�o���͒������ω����₷�����߃Z�b�g�Ȃ̂ŁA
���ϒl�ł��ꂮ�炢�Ƃ��A�Ƃ��閽�߂̑g�ݍ��킹�Ȃ�
�����Ƃ����ς��Ƃ��A�������̓����
343 �F,,�E�L�́M�E,,�j��-�������F2010/02/18(��) 13:30:00 ID:Re/rOMyD
�����I�ɂ�4�̉ϒ����߂�1�̖��ߗ��o������2�̖��ߗ�̂ق������₷����B
>>343
����Ȃ̓�����O���̃N���b�J�[
�Z���N�^��H�̂������݂����ɂȂ�̂ŁAn^2�I�[�_�ȏ�̕��ׂ������邾�낤�ˁB
���������{���ŁA�Q���߂��f�R�[�h���ĂP�N���b�N�S���ߐ�o���ł��������炢��������
����Ȃ̓�����O���̃N���b�J�[
�Z���N�^��H�̂������݂����ɂȂ�̂ŁAn^2�I�[�_�ȏ�̕��ׂ������邾�낤�ˁB
���������{���ŁA�Q���߂��f�R�[�h���ĂP�N���b�N�S���ߐ�o���ł��������炢��������
L1���ʂȂ͓̂Ɨ�����TransientTransactionCache�������đ��x���҂��邩��
L1-L2�Ԃ�WriteCoalescingCache�Ń��C�e���V�B��
L3�̓}���`Way�σu���b�N�̕ϑԎd�l
L1-L2�Ԃ�WriteCoalescingCache�Ń��C�e���V�B��
L3�̓}���`Way�σu���b�N�̕ϑԎd�l
AMD��Intel�ɔ�ׂăL���b�V�����c�Ƃ������z���������ǁA
AMD�̃L���b�V���\�����ϑԉ߂����ȁB
�����ȋZ�p�~�ς��Ȃ��Ƃ��܂̃L���b�V���\���͖����B
AMD�̃L���b�V���\�����ϑԉ߂����ȁB
�����ȋZ�p�~�ς��Ȃ��Ƃ��܂̃L���b�V���\���͖����B
�ʂɕϑԂł���������
�L���b�V���]�X�͐��\�ŗ���Ă���Ęb����
�L���b�V���]�X�͐��\�ŗ���Ă���Ęb����
>>340
����̃t���{�b�R�ɂ���܂����Ԃ�
���N�匴�������Ă����L���b�V���̍��炵������ȁB
>���|�I�ȍ��N���b�N�œ˂�������Ȃ�b�͕ς���Ă���B
3G�㔼�͏o���邾�낤��
����ȍ~�A4G���̐��i�|���|���o����̂��H�ƂȂ�Ɩ��������ȁB
���Ǎ��Ɠ���������H���ɗ��������̂��ˁB
����̃t���{�b�R�ɂ���܂����Ԃ�
���N�匴�������Ă����L���b�V���̍��炵������ȁB
>���|�I�ȍ��N���b�N�œ˂�������Ȃ�b�͕ς���Ă���B
3G�㔼�͏o���邾�낤��
����ȍ~�A4G���̐��i�|���|���o����̂��H�ƂȂ�Ɩ��������ȁB
���Ǎ��Ɠ���������H���ɗ��������̂��ˁB
�x���`�ɂ́A����
AMD��CPU��INTEL�Ɣ�ׂĂ�����肷����̂ł͌����ĂȂ���B
�������A�`�b�v�Z�b�g�Ɋւ��Ă͕ʂȂ�˂��B
INTEL�Ɣ�ׂăn�C�G���h�}�U�[������ڂ������A�Ƃ������n�C�G���h�����݂��Ȃ��Ƃ�������B
X58��20000�~�`39800�~�N���X�̃}�U�[���~�����Ă��R���V���[�}�����ɂ͑��݂����A�G���^�[�v���C�Y�����̍����ȃ}�U�[�킴��Ȃ��̂Ńg�[�^���R�X�g�ƃj�[�Y���ӂ݂����ʁAINTEL�Ɍ�w������B
Thuban�ł͗��ނ���INTEL��X�N���X�̃`�b�v�Z�b�g�o���Ă���A����AMD�Ń������X���b�g*6 PCIe x16*3 SATA 3Gbps *10�̃}�U�[���~�����A�������K�����i�łˁB
�������A�`�b�v�Z�b�g�Ɋւ��Ă͕ʂȂ�˂��B
INTEL�Ɣ�ׂăn�C�G���h�}�U�[������ڂ������A�Ƃ������n�C�G���h�����݂��Ȃ��Ƃ�������B
X58��20000�~�`39800�~�N���X�̃}�U�[���~�����Ă��R���V���[�}�����ɂ͑��݂����A�G���^�[�v���C�Y�����̍����ȃ}�U�[�킴��Ȃ��̂Ńg�[�^���R�X�g�ƃj�[�Y���ӂ݂����ʁAINTEL�Ɍ�w������B
Thuban�ł͗��ނ���INTEL��X�N���X�̃`�b�v�Z�b�g�o���Ă���A����AMD�Ń������X���b�g*6 PCIe x16*3 SATA 3Gbps *10�̃}�U�[���~�����A�������K�����i�łˁB
>>351
CPU����Dual CH�Ȃ̂Ƀ������X���b�g��6�{�����Ă��Ȃ��c�B
CPU����Dual CH�Ȃ̂Ƀ������X���b�g��6�{�����Ă��Ȃ��c�B
CPU�̔{�̒l�i�̃}�U�[�Ƃ������킯�Ȃ���
���[�J�[��AMD�̃n�C�G���h�}�U�[���C�Ȃ�����d���Ȃ�
���[�U�[��AMD=�����Ƃ����C���[�W������A���\�W�Ȃ����i���������_�őI�����ɂ����Ȃ�
�n�C�G���h�~�������Opteron�����Ƃ�
���[�U�[��AMD=�����Ƃ����C���[�W������A���\�W�Ȃ����i���������_�őI�����ɂ����Ȃ�
�n�C�G���h�~�������Opteron�����Ƃ�
����������Ȃ�uIntel�̌�o��q���v�ł͂Ȃ��̂��B���������e���v���Ȃ��݁B
�i�ꉞ������������w������Ƃ����p�Ⴊ�ς��ƌ����������j
AM3����DDR3��1ch������3DIMM�i2ch��6DIMM�j���ăT�|�[�g���Ă������H
������������Ă��A���ڂ�����ݒ�ɂ����Ȃ��ƃ_����A���Ɣ����B
PCIe x16*3�͐l�ɂ���Ă͎g�����낤���ǁA
�R���V���[�}�p�r��SATA10�|�[�g�t���Ė����ƑʖځA�Ȑl�͋ɂ߂ď��Ȃ����낤�B
��p���m�ۂ����߂�͕̂��̃P�[�X���������A����d�͂����Ĕn���ɂȂ��B
�����܂ł��l�̓G���^�[�v���C�Y�����̃}�U�[��SAS�̃J�[�h�t����C���[�W���ȁB
���Y�R�X�g�����Ď��v���Ȃ��}�U�[�Ȃ�A�K�����iw�͍����Ȃ邾�낤�Ȃ��B
�u���ꂻ�����Ȃ�������Ȃ��v���Ă̂�����Ȃ��́H
�i�ꉞ������������w������Ƃ����p�Ⴊ�ς��ƌ����������j
AM3����DDR3��1ch������3DIMM�i2ch��6DIMM�j���ăT�|�[�g���Ă������H
������������Ă��A���ڂ�����ݒ�ɂ����Ȃ��ƃ_����A���Ɣ����B
PCIe x16*3�͐l�ɂ���Ă͎g�����낤���ǁA
�R���V���[�}�p�r��SATA10�|�[�g�t���Ė����ƑʖځA�Ȑl�͋ɂ߂ď��Ȃ����낤�B
��p���m�ۂ����߂�͕̂��̃P�[�X���������A����d�͂����Ĕn���ɂȂ��B
�����܂ł��l�̓G���^�[�v���C�Y�����̃}�U�[��SAS�̃J�[�h�t����C���[�W���ȁB
���Y�R�X�g�����Ď��v���Ȃ��}�U�[�Ȃ�A�K�����iw�͍����Ȃ邾�낤�Ȃ��B
�u���ꂻ�����Ȃ�������Ȃ��v���Ă̂�����Ȃ��́H
AMD�ɂ܂Ƃ��Ȓm�\������Ƃ����O��ɗ��Ă�
Bulldozer�̊J���������ȂƂ��ɁA�킴�킴�L���̊J�����\�[�X��������
����Œu����������K10�̉��ǂ���s���čs���킯���Ȃ��B
���ۂɂ́AAMD��K10����������C�܂�܂�Ȃ���A
Bulldozer�͗ǂ��ăT�[�o����̃X���[�v�b�g�R�A�A
��������ΊJ�����~���B
Bulldozer�̊J���������ȂƂ��ɁA�킴�킴�L���̊J�����\�[�X��������
����Œu����������K10�̉��ǂ���s���čs���킯���Ȃ��B
���ۂɂ́AAMD��K10����������C�܂�܂�Ȃ���A
Bulldozer�͗ǂ��ăT�[�o����̃X���[�v�b�g�R�A�A
��������ΊJ�����~���B
��ʘ_�Ƃ��āA�C���e���ɂ�����
�E�L���b�V�����x��
�EIPC������
�E�ȏ�ɂ��g�����W�X�^�����������i�ʐς�����̐��\�ŗ��j
�Ă����̂͂܂��������ȁB���̕��ቿ�i�����A���i�тƐ��\����
�l������������ł͂��邩�炻��Ȃ�Ɏ��v������킯�ŁB
�E�L���b�V�����x��
�EIPC������
�E�ȏ�ɂ��g�����W�X�^�����������i�ʐς�����̐��\�ŗ��j
�Ă����̂͂܂��������ȁB���̕��ቿ�i�����A���i�тƐ��\����
�l������������ł͂��邩�炻��Ȃ�Ɏ��v������킯�ŁB
IPC��AMD�̕����ザ��Ȃ������H
>>356
���́u����Ă���v�͂��̃L���b�V���\���ɂ���āA
�T�[�o�[�s��ɓ��݂Ƃǂ܂ꂽ����AAMD�͐����������B
�ǂ����u�n�������v�ȂH
>>357
���̖ϑz����������Ƃ����ȁB
���́u����Ă���v�͂��̃L���b�V���\���ɂ���āA
�T�[�o�[�s��ɓ��݂Ƃǂ܂ꂽ����AAMD�͐����������B
�ǂ����u�n�������v�ȂH
>>357
���̖ϑz����������Ƃ����ȁB
>>357��eDRAM�N���H
>>360
�����́u����Ă���v�͂��̃L���b�V���\���ɂ���āA
���T�[�o�[�s��ɓ��݂Ƃǂ܂ꂽ����AAMD�͐����������B
�r���L���b�V���\���Ő����������Ȃ�ď������ȁB
Barton���ォ�疳�p�̒�����������Ă��̂ɁB
����Ȃ炻�̍u�]�̃\�[�X�����B���ꂩ��ʓI�ɐ������Ă���B
���߂Č������A�r���L���b�V���͌��݂ł͔n������
���C�e���V�������グ�p�C�v���C����V���钣�{�l
�����́u����Ă���v�͂��̃L���b�V���\���ɂ���āA
���T�[�o�[�s��ɓ��݂Ƃǂ܂ꂽ����AAMD�͐����������B
�r���L���b�V���\���Ő����������Ȃ�ď������ȁB
Barton���ォ�疳�p�̒�����������Ă��̂ɁB
����Ȃ炻�̍u�]�̃\�[�X�����B���ꂩ��ʓI�ɐ������Ă���B
���߂Č������A�r���L���b�V���͌��݂ł͔n������
���C�e���V�������グ�p�C�v���C����V���钣�{�l
���݂����ȑ命���ȕ����ɑ����Ă邢���ς�ҁ[�ہ[��2�R�A�ŏ\���Ȃ�Ȃ�
780G�̐��\�ɂ�����Ɗ���������������A
llano�̓���GPU���y���݁B
llano�̓���GPU���y���݁B
�r���L���b�V��
�E�����b�g
�L���b�V���e�ʂɖ��ʂ��Ȃ�
LV1�`3��C���������Ԃ̑��x�����ɂ₩
(�L���b�V���̋��ڂł����x�͋}���ɕς��Ȃ�����A
�Q�[���⓮��Ƃ��ň����������J�N�J�N�Ƃ����ɂ����B)
�E�f�����b�g
���C�e���V���C���N���[�V�u�^�C�v���傫������x��
�L���b�V���̓R�A��X���b�h�ӂ�2M������Ώ\���Ȃ�ŁA������Ȃ����͗L���Ȏ�i���Ǝv���B
�l�I�ɂ͑����x���Ă����삪���肵�đ���AMD�̔r���L���b�V���͍D�����ȁB
�E�����b�g
�L���b�V���e�ʂɖ��ʂ��Ȃ�
LV1�`3��C���������Ԃ̑��x�����ɂ₩
(�L���b�V���̋��ڂł����x�͋}���ɕς��Ȃ�����A
�Q�[���⓮��Ƃ��ň����������J�N�J�N�Ƃ����ɂ����B)
�E�f�����b�g
���C�e���V���C���N���[�V�u�^�C�v���傫������x��
�L���b�V���̓R�A��X���b�h�ӂ�2M������Ώ\���Ȃ�ŁA������Ȃ����͗L���Ȏ�i���Ǝv���B
�l�I�ɂ͑����x���Ă����삪���肵�đ���AMD�̔r���L���b�V���͍D�����ȁB
> �Q�[���⓮��Ƃ��ň����������J�N�J�N�Ƃ����ɂ���
��̓����c�c�Ƃ�����ŁA���M�ł��B
��̓����c�c�Ƃ�����ŁA���M�ł��B
http://www.theinquirer.net/inquirer/news/1561981/amd-sample-chips
> AMD will sample chips early next year
����Ȃ��Ƃ������Ă��킯�ł����A������2�����B
�����炢�܂ł�early�Ȃ�ł��傤���˂��B
> AMD will sample chips early next year
����Ȃ��Ƃ������Ă��킯�ł����A������2�����B
�����炢�܂ł�early�Ȃ�ł��傤���˂��B
>>366
�悭����Șb��M���Ă�Ȃ�
�悭����Șb��M���Ă�Ȃ�
���C�e���V���傫���Ȃ�Ƃ��͑��̐v�v�f�Ƃ̃g���[�h�I�t�����肻��
����ł�K8�ł����č̗p�����������郌�x���ł͖����Ǝv��
�{���Ƀf�����b�g���傫���Ȃ��Ă����̂̓}���`�R�A����ɓ����Ă��Ă��炶��Ȃ�����
����S�R�A��L1L2�L���b�V�����X�k�[�v���Ȃ��Ⴂ���Ȃ��̂̓{�g���l�b�N�ɂȂ��Ă�C������
����ł�K8�ł����č̗p�����������郌�x���ł͖����Ǝv��
�{���Ƀf�����b�g���傫���Ȃ��Ă����̂̓}���`�R�A����ɓ����Ă��Ă��炶��Ȃ�����
����S�R�A��L1L2�L���b�V�����X�k�[�v���Ȃ��Ⴂ���Ȃ��̂̓{�g���l�b�N�ɂȂ��Ă�C������
eDRAM�̐l��GPU�X���Ƃ��\��Ă�10240Bit�̐l�Ȃ�E�E�E��
����͉�����
AMD��GPU��10240bit�Ȃ͕̂ς��Ȃ�
intel��many core��vliw�͂�������߂��Ă�߂��悤����
AMD��GPU��10240bit�Ȃ͕̂ς��Ȃ�
intel��many core��vliw�͂�������߂��Ă�߂��悤����
Fermi����������
�g�������Ȃ��̂ɐ��ߕ��̂͂��낻�됸�_�I�ɃL�c����Ȃ�
�g�������Ȃ��̂ɐ��ߕ��̂͂��낻�됸�_�I�ɃL�c����Ȃ�
�ׂ�GPU�Ȃ�ĉ�ʕ\�����ł���Ή��ł������킯����
���������ȃn�[�h�����Ŏg�����ɂȂ�Ȃ����Ƃ��g�����R������
����S3����\���̂���A�[�L�e�N�`�����Ă�fermi�ȊO���������킯����
�ǂ��ł�������
AMD�M�҃X���͕����̓����ł��ǂ��i�ނ�
�N�x���Ȃ̂�
��قljɂȂ̂�
����Ƃ������̉�S�̏W��Ȃ̂�
���������ȃn�[�h�����Ŏg�����ɂȂ�Ȃ����Ƃ��g�����R������
����S3����\���̂���A�[�L�e�N�`�����Ă�fermi�ȊO���������킯����
�ǂ��ł�������
AMD�M�҃X���͕����̓����ł��ǂ��i�ނ�
�N�x���Ȃ̂�
��قljɂȂ̂�
����Ƃ������̉�S�̏W��Ȃ̂�
2~10*10
2�i�@��10�i�@�̃n�C�u���b�h
�������E�ɓS�i�q�̌��������̐��E��������悤�Ȃ���
2�i�@��10�i�@�̃n�C�u���b�h
�������E�ɓS�i�q�̌��������̐��E��������悤�Ȃ���
������
�g�������Ȃ��̂ɐ��ߕ��̂͂��낻�됸�_�I�ɃL�c����Ȃ��̂�
�g�������Ȃ��̂ɐ��ߕ��̂͂��낻�됸�_�I�ɃL�c����Ȃ��̂�
eDRAM���ڂ��Ȃ�Bulldozer�Ɋ��҂���̂���
���낻�됸�_�I�ɋ�s����Ȃ����H
���낻�됸�_�I�ɋ�s����Ȃ����H
ID�ς����@�����낻�됸�_�I�ɃL�c����Ȃ��̂�
�G���͂��ꂵ��������̂�
Bulldozer��K10�����������Ƃ���
���͍��܂łP�������˂�
Power7�`�[���ɂ���Ԃɕ������ł��̏�Ԃ���
���͍��܂łP�������˂�
Power7�`�[���ɂ���Ԃɕ������ł��̏�Ԃ���
���ς�炸���͂ȓd�g��
�M�҂��đ�ς��敳�A�[�L�e�N�`���ł�
�f���炵�����ĐM�����܂Ȃ��Ƃ����Ȃ���
�f���炵�����ĐM�����܂Ȃ��Ƃ����Ȃ���
�T���v���ł��o���Ȃ����葬�x�Ȃ�Čv��Ȃ��������E�ɂ�
���̓d�g�͋��߂���̂ő��}�Ɏ���ł�������
����Ő��E�͋~����
���̓d�g�͋��߂���̂ő��}�Ɏ���ł�������
����Ő��E�͋~����
10240bit�N���ǂ��^�C�~���O�ŏ���
eDRAM�N���▭�ȃ^�C�~���O�Ō����
eDRAM�N���▭�ȃ^�C�~���O�Ō����
�M�҂Ƃ����Ίm���ɉɂ���ȁB�uAMD�̎�����CPU�ɂ��Č��v�����̃X���ɁA
�킴�킴Intel�ׂ���������B�X���̎�|���킩��Ȃ��ׂ����ɒɂ��ɂ��B
�킴�킴Intel�ׂ���������B�X���̎�|���킩��Ȃ��ׂ����ɒɂ��ɂ��B
�ʂɔے�I����������̂����傤���Ȃ��Ƃ͎v�����E�E�E
�������ۂɒ��点�Ă݂�ƂقƂ�ǂ��G���ɂ��R�s�y���m�ᔭ�����Ƃ�������
�C���������ȊO�ɉ�������
�������ۂɒ��点�Ă݂�ƂقƂ�ǂ��G���ɂ��R�s�y���m�ᔭ�����Ƃ�������
�C���������ȊO�ɉ�������
�����ĖY�ꂽ����ɒc�q�������A�������ʏ�^�]
�r�N�e�B���L���b�V���ƃC���N���[�W�����L���b�V��
http://journal.mycom.co.jp/column/architecture/177/index.html
http://journal.mycom.co.jp/column/architecture/177/index.html
>>382
�����ƁA�l�n�����̈����͂����܂ł��I
�����ƁA�l�n�����̈����͂����܂ł��I
390 �FSocket774�F2010/02/19(��) 16:41:23 ID:+JbR+U19
��������Z-RAM�͂ǂ��Ȃ����H
�ŋ߁A�S�R�b���Ȃ���
�ŋ߁A�S�R�b���Ȃ���
T-RAM���ĉ����낤�H�@�O�O�b�Ă����܂�������Ȃ����B
65nm ����ȍ~�A�ł���ʓI�ɗp����肢��6T-SRAM�͑����̖��ɒ��ʂ��Ă���B
�����ŁA��X��6T-SRAM�ɑ���SRAM���������Ă���B����A�o���N�V���R���E�G�n�[��p���āA
�T�C���X�^��SRAM(Static Random Access Memory)�Z���ɉ��p���邱�Ƃ����݂��B����Bulk Thyristor-RAM(BT-RAM)�́A
�o���N�V���R���E�G�n�[��p���Ă��邽�߂ɁA�R�X�g��}���邱�Ƃ��ł����ɍ��ڃf�o�C�X�Ƃ̑������悢�B
�����100ps�̍�����������/�ǂݏo�����\�A�I���d���ƃI�t�d���̔䂪10^8�ȏ�A�X�^���o�C�d����0.5nA/cell�ȉ��Ɣ��ɗǍD�ȓ������������B
�܂��A�A�m�[�h�̈�ɑI���G�s�^�L�V�����Z�p��p���邱�ƂŁA���z�Z���T�C�Y��30F^2(F�̓f�T�C�����[��)�Ə]���^��6T-SRAM �̖�1/4�̃T�C�Y�ɂȂ��Ă���B
���̂悤��BT-RAM�͌���SRAM�̒��ʂ��Ă�������������A65nm����ȍ~�ɗL�]�ȃf�o�C�X�ł��邱�Ƃ��킩�����B
http://ci.nii.ac.jp/naid/110006272863
�T�C���X�^
http://ja.wikipedia.org/wiki/%E3%82%B5%E3%82%A4%E3%83%AA%E3%82%B9%E3%82%BF
�����ŁA��X��6T-SRAM�ɑ���SRAM���������Ă���B����A�o���N�V���R���E�G�n�[��p���āA
�T�C���X�^��SRAM(Static Random Access Memory)�Z���ɉ��p���邱�Ƃ����݂��B����Bulk Thyristor-RAM(BT-RAM)�́A
�o���N�V���R���E�G�n�[��p���Ă��邽�߂ɁA�R�X�g��}���邱�Ƃ��ł����ɍ��ڃf�o�C�X�Ƃ̑������悢�B
�����100ps�̍�����������/�ǂݏo�����\�A�I���d���ƃI�t�d���̔䂪10^8�ȏ�A�X�^���o�C�d����0.5nA/cell�ȉ��Ɣ��ɗǍD�ȓ������������B
�܂��A�A�m�[�h�̈�ɑI���G�s�^�L�V�����Z�p��p���邱�ƂŁA���z�Z���T�C�Y��30F^2(F�̓f�T�C�����[��)�Ə]���^��6T-SRAM �̖�1/4�̃T�C�Y�ɂȂ��Ă���B
���̂悤��BT-RAM�͌���SRAM�̒��ʂ��Ă�������������A65nm����ȍ~�ɗL�]�ȃf�o�C�X�ł��邱�Ƃ��킩�����B
http://ci.nii.ac.jp/naid/110006272863
�T�C���X�^
http://ja.wikipedia.org/wiki/%E3%82%B5%E3%82%A4%E3%83%AA%E3%82%B9%E3%82%BF
���͂�T-RAM�����Œ��t�]��_�����������Ȃ��Ă����ȁB
�u���h�[�U�́B
�u���h�[�U�́B
PenD��Core2��Corei7��eDRAM��T-RAM
�_����I�ȏu���̏�芷��
�_����I�ȏu���̏�芷��
>>354
������K�����i�ŗ~�������Č����Ă邶��Ȃ��AIstanbul�������Ƃ��N�ɂ̓��W�J���Ȏv�l�͂Ȃ��̂����H�c�_�ɂȂ�Ȃ��悗
>>351>>355
����A�K�v���ǂ����N�̎�ςŌ���Ă��ˁB
�����ł���Intel���p�ӂ��Ă������AMD�����߂đI�����̂ЂƂ��ăG���h���[�U�[�ɒ��ׂ��ł���B
���Ȃ݂Ɏ�ςŌ��Ȃ�l��S����4U���b�N�}�E���g���g���Ă���̂�SATA�͂����炠���Ă�����Ȃ��B
������K�����i�ŗ~�������Č����Ă邶��Ȃ��AIstanbul�������Ƃ��N�ɂ̓��W�J���Ȏv�l�͂Ȃ��̂����H�c�_�ɂȂ�Ȃ��悗
>>351>>355
����A�K�v���ǂ����N�̎�ςŌ���Ă��ˁB
�����ł���Intel���p�ӂ��Ă������AMD�����߂đI�����̂ЂƂ��ăG���h���[�U�[�ɒ��ׂ��ł���B
���Ȃ݂Ɏ�ςŌ��Ȃ�l��S����4U���b�N�}�E���g���g���Ă���̂�SATA�͂����炠���Ă�����Ȃ��B
�v��
�uIntel�̓n�C�G���h�}�U�{��SSD����Ċ��S�ȓz������AMD���^������v
�uIntel�̓n�C�G���h�}�U�{��SSD����Ċ��S�ȓz������AMD���^������v
�o��O���珟�������������������Ă�̂��Q�n�]�B
�ӂӁA���̒��x�͏��̌��B
���ꂩ��^�̃Q�[���]�̋��|�𖡍��킹�Ă��B
���ꂩ��^�̃Q�[���]�̋��|�𖡍��킹�Ă��B
������R�A�����{������ɂ���A�N���b�N��6GHz�ɂȂ�ɂ���
�O���������Ƃ̃M���b�v���ɘa���邽�߂ɁA�I���_�C�������͔��ɏd�v
�O���������Ƃ̃M���b�v���ɘa���邽�߂ɁA�I���_�C�������͔��ɏd�v
Intel�̃}�U�[�̃n�C�G���h����10GbE�Ƃ�BBU+�L���b�V����RAID�ł��t���Ă�́H
�����l�i������������ˁH
�����l�i������������ˁH
���邦��Ƃ������z�́A�A�{�����₷���悤�ɓd�g����Ă���Ă��邾���}�V���ȁB
�}���`�R�A�Ƃ�L3�L���b�V���Ƃ�GPU�����Ƃ����s������
����CPU�̑傫�����ێ������i�������Ȃ����烁����������邾�낤��
����CPU�̑傫�����ێ������i�������Ȃ����烁����������邾�낤��
>>406
�ǂ����낤�H�@����ɂ���ėv�����\���ǂ�ǂ�オ���Ă�������A
CPU�ɓ�������郁�����ʂ͑����邾�낤���ǁA�O�t���������͖����Ȃ�Ȃ��Ǝv�����B
�ǂ����낤�H�@����ɂ���ėv�����\���ǂ�ǂ�オ���Ă�������A
CPU�ɓ�������郁�����ʂ͑����邾�낤���ǁA�O�t���������͖����Ȃ�Ȃ��Ǝv�����B
���̗v�����\�ɑς�����ш����������̂�����킯�����A�O����������������
�����v���Z�X���i��ł��_�C�T�C�Y�͂قڈ��A�܂�PAD�����
����ɑ��đg�ݍ��܂�鉉�Z��͑�������
intel�ł�sandy bridge����ł����ς������ς�����
�����v���Z�X���i��ł��_�C�T�C�Y�͂قڈ��A�܂�PAD�����
����ɑ��đg�ݍ��܂�鉉�Z��͑�������
intel�ł�sandy bridge����ł����ς������ς�����
>>407
���̓���GPU�ƊO�t��GPU�݂����ɓ��O���p�ɂȂ邩�����Ă��Ƃ���ˁH
���̓���GPU�ƊO�t��GPU�݂����ɓ��O���p�ɂȂ邩�����Ă��Ƃ���ˁH
AMD��eDRAM�Ȃ�64MB���ڂł��Ȃ���
2012�N�ɉ�Ђ��������
T-RAM�Ȃ�256MB�ȏ㓋�ڂ��Ȃ���
�����オ�Ȃ��Ȃ�B
���Ɏ؋����ł��Ȃ��Ȃ��āA���E����
2012�N�ɉ�Ђ��������
T-RAM�Ȃ�256MB�ȏ㓋�ڂ��Ȃ���
�����オ�Ȃ��Ȃ�B
���Ɏ؋����ł��Ȃ��Ȃ��āA���E����
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
�����������̔g��SoC�Ő�s���Ă���ARM����ŁA
x86�܂ŗ���͍̂Ōォ�ƁB
�ėp�������̃r�b�g�P�����������āA�����ɓ��ݐ��Ă���p�Ό��ʈ������B
x86�܂ŗ���͍̂Ōォ�ƁB
�ėp�������̃r�b�g�P�����������āA�����ɓ��ݐ��Ă���p�Ό��ʈ������B
OS�����������������������A
�x���`�}�[�N�\�t�g�̂��߂�MSDOS�ɋt�߂肩��
�{���]�|�ł͂Ȃ����H
�x���`�}�[�N�\�t�g�̂��߂�MSDOS�ɋt�߂肩��
�{���]�|�ł͂Ȃ����H
�����܂Ŗ߂�Ȃ��Ă����B
64MB�����UNIX�͓����B���p�I�ȃ��C����256MB���B
�v����Ɍg�ы@�ł��B
64MB�����UNIX�͓����B���p�I�ȃ��C����256MB���B
�v����Ɍg�ы@�ł��B
PC�̔łȂ�őg�ݍ��݂̘b���Ă�́H
������߂��ĊW�����b�肵���o���Ȃ����
�{���͂���Ȏ��͉������Ȃ����̂���
���̃X���⑼����o�����Ă���A���͈Ⴄ
�{���͂���Ȏ��͉������Ȃ����̂���
���̃X���⑼����o�����Ă���A���͈Ⴄ
�����PGB�ڂ�悤�ɂȂ��BCPU�p�b�P�[�W�ɁB
�ŁA���������݂̂��߂ɂSCPU�}�U�[���d���B
�ŁA���������݂̂��߂ɂSCPU�}�U�[���d���B
���������݂��āA�R�q�[�����V�́H
>>417
2011�N�܂ł̃��[�h�}�b�v�i��\���j�Ɍv�悪�Ȃ�����
���N�Ɨ��N�͂܂����肦�Ȃ�
K7(1999) -> K8(2003) -> K10(2007) -> Bulldozer(2011)
�݂����ɃA�[�L�e�N�`���̕ύX�͒ʏ�4�N�������Ă�����
�����Ă�2013�N�Ƀ}�C�i�[�`�F���W���f���𓊓����A
���L���b�V���A�[�L�e�N�`�������ǂ���ۂ�
eDRAM��T-RAM��������邢��DRAM���̂��̂�
MCM���ڂ��ăL���b�V���Ƃ��Ďg���̂���������
���������f����ύX����Ȃ炻�ꂱ��2015�N���^�[�Q�b�g�ɂȂ�
�A�[�L�e�N�`���I�ɂ�GPU�����邾����Liano��
ATI��(2006�N)���Ă�����̖ڂ�����܂�5�N�����肻������
�r����swift��������2009�N��ڎw���Ă������ۂ�����
���ǎ��������œڍ��������ۂ���
�E�E�E�Ƃ���ł������Ă����͉̂��N��̘b���H
2011�N�܂ł̃��[�h�}�b�v�i��\���j�Ɍv�悪�Ȃ�����
���N�Ɨ��N�͂܂����肦�Ȃ�
K7(1999) -> K8(2003) -> K10(2007) -> Bulldozer(2011)
�݂����ɃA�[�L�e�N�`���̕ύX�͒ʏ�4�N�������Ă�����
�����Ă�2013�N�Ƀ}�C�i�[�`�F���W���f���𓊓����A
���L���b�V���A�[�L�e�N�`�������ǂ���ۂ�
eDRAM��T-RAM��������邢��DRAM���̂��̂�
MCM���ڂ��ăL���b�V���Ƃ��Ďg���̂���������
���������f����ύX����Ȃ炻�ꂱ��2015�N���^�[�Q�b�g�ɂȂ�
�A�[�L�e�N�`���I�ɂ�GPU�����邾����Liano��
ATI��(2006�N)���Ă�����̖ڂ�����܂�5�N�����肻������
�r����swift��������2009�N��ڎw���Ă������ۂ�����
���ǎ��������œڍ��������ۂ���
�E�E�E�Ƃ���ł������Ă����͉̂��N��̘b���H
>>419
7�N���炢�j�[�g����Ă�݂��������ǁA���O�������͉̂��N��̘b���H�@�G�@���@��B
7�N���炢�j�[�g����Ă�݂��������ǁA���O�������͉̂��N��̘b���H�@�G�@���@��B
���s�H
"���s"�Ƃ�����"����"����˂��́H
�Ƃ������BeDRAM������l�^���A���Ŗʔ����Ȃ��Ȃ��B
�Ƃ������BeDRAM������l�^���A���Ŗʔ����Ȃ��Ȃ��B
SRAM��eDRAM��ڑ���������ɂ��Ȃ���
������
������
>>423
�܂��Ƃ��Ȉӌ�������Ȃ��z�ɁA�Ȃ�ł܂��Ƃ��Ȉӌ��������K�v�����H
�܂��Ƃ��Ȉӌ�������Ȃ��z�ɁA�Ȃ�ł܂��Ƃ��Ȉӌ��������K�v�����H
����� ��(�L�[�M)��
T-RAM��eDRAM�̏��x�ɔ]���ɐN�����đ卬���̎G���m�I��Q��
�Ƃ肠�����AAMD�Ƀ��C�Z���X������炵��T-RAM�͂Ƃ�����
DRAM�������ɓ������Ȃ�Intel���ɍl���Ă݂�Ƃ���
�L���b�V������Intel����
�Ƃ肠�����AAMD�Ƀ��C�Z���X������炵��T-RAM�͂Ƃ�����
DRAM�������ɓ������Ȃ�Intel���ɍl���Ă݂�Ƃ���
�L���b�V������Intel����
GPU��������ꍇ�AT-RAM��eDRAM�Ȃ���
�܂����x���łȂ�
�܂����x���łȂ�
�������ƁA���N�����N�����N���قƂ�ǖ���365�����S���X�ȏサ�ĂāA
���̃��X��99�p�[�Z���g�ȏオ�˂����ݏ����ڂ��A�P���ȉR���A�ϑz���A�ǂ����̏��̌�ǂ��A�P�Ȃ��排������ŁA
�X�ɕ�������g���Ď����A�Ȃ肷�܂������Ȃ���A���_�݂肫�Ő�ɊԈႢ��F�߂Ȃ��āA
�������������g���Ă郂�m�����̃X���Ń}���Z�[���Ă�Ηǂ����̂��A�������g���Ă��郂�m�ȊO�̃��[�J�[�̊֘A�X���ł��������A
���Đl�̑����������������̂̓����h�N�T�C�̂�B�F�B
�ق��Ƃ��Ί��S���X��H��Ԃōr�炵��邵�B
�����獡�����ɓ������i�v�A�N�ւɂȂ邩�t��ŗ~������B
���̃��X��99�p�[�Z���g�ȏオ�˂����ݏ����ڂ��A�P���ȉR���A�ϑz���A�ǂ����̏��̌�ǂ��A�P�Ȃ��排������ŁA
�X�ɕ�������g���Ď����A�Ȃ肷�܂������Ȃ���A���_�݂肫�Ő�ɊԈႢ��F�߂Ȃ��āA
�������������g���Ă郂�m�����̃X���Ń}���Z�[���Ă�Ηǂ����̂��A�������g���Ă��郂�m�ȊO�̃��[�J�[�̊֘A�X���ł��������A
���Đl�̑����������������̂̓����h�N�T�C�̂�B�F�B
�ق��Ƃ��Ί��S���X��H��Ԃōr�炵��邵�B
�����獡�����ɓ������i�v�A�N�ւɂȂ邩�t��ŗ~������B
�������邩�K�������ē�����킩��Ȃ��֎�
��������i7 920�Ɏh�����Ă�9600GT 128bit �̒��q�͂ǂ������H�E�E�E�EeDRAM�N
��������i7 920�Ɏh�����Ă�9600GT 128bit �̒��q�͂ǂ������H�E�E�E�EeDRAM�N
�A���J�[�����Ń��X����������Ă܂������Ⴂ�͖����Ǝv����
���̌����Ă�m�I��Q�҂Ƃ͖ܘ_ID:d4jGDU/f�ł͂Ȃ�ID:EmyWqqc/�̂ق�
T-RAM��eDRAM�̋�̓I�Ȑ��\�͕s��������
�k�X�̃R������Ɓ�DRAM���̗e�ʂ��҂��āA���x��SRAM��
��T-RAM�̂ق����������ǂ��炵��
�Ȃ̂�>410�ł�T-RAM��eDRAM��4�{���K�v���Ƃ������Ă���
���̕ӂׂ͂ɂ����̕����@���������x���ł͂Ȃ��\�[�X�����o��Ζ����ȂƂ�����
���̃\�[�X�o�����ɂ��܂ł�eDRAMeDRAM10240bit10240bit�t�F�b�`���v���t�F�b�`�A�Ă��Ă邩��
����͖��炩�ɂ��Ԕ��̕���ł�
���̌����Ă�m�I��Q�҂Ƃ͖ܘ_ID:d4jGDU/f�ł͂Ȃ�ID:EmyWqqc/�̂ق�
T-RAM��eDRAM�̋�̓I�Ȑ��\�͕s��������
�k�X�̃R������Ɓ�DRAM���̗e�ʂ��҂��āA���x��SRAM��
��T-RAM�̂ق����������ǂ��炵��
�Ȃ̂�>410�ł�T-RAM��eDRAM��4�{���K�v���Ƃ������Ă���
���̕ӂׂ͂ɂ����̕����@���������x���ł͂Ȃ��\�[�X�����o��Ζ����ȂƂ�����
���̃\�[�X�o�����ɂ��܂ł�eDRAMeDRAM10240bit10240bit�t�F�b�`���v���t�F�b�`�A�Ă��Ă邩��
����͖��炩�ɂ��Ԕ��̕���ł�
T-RAM�@�ʐς�6T-SRAM���1/4
eDRAM(IBM)�@�@���@1/3
���x�͒m���
eDRAM(IBM)�@�@���@1/3
���x�͒m���
eDRAM���߂��ۂ�
T-RAM�����������݂���
T-RAM�����������݂���
>>433
���m�O����|�ւ����Ă�˂��悗
���m�O����|�ւ����Ă�˂��悗
1T-RAM�Ȃ�āADRAM�ƌ����͓����B(�������Z���̍l��������)
�Ⴂ�͂ł������}�g���b�N�X���g��DRAM�̑���ɏ�����DRAM���ʂɎg���_�B
�g���[�h�I�t�Ƃ��Ă�(��Ƃ���1TRAM����݂�)
1) 1T-RAM�̃L���p�V�^�e�ʂ͏��Ȃ��Ă悢�B�i�z�����Z���Ċe�ʂ�����̂Łj
2) �Z���X�A���v�Ȃǂ̉�H�͑����Ȃ�(�}�g���N�X���������̂ŁA�����K�v)
3) ���W�b�NLSI�Ƒ������ǂ�(���L���p�V�^��H�͎g��Ȃ��ĉ��Ƃ�����)
4) �G���[�̂��郁�����Z���̓���ւ������₷��(�������������̑��Ȃ̂ŁA�]�v�ɍ���Ċۂ��Ǝ��ւ�)
5) ���t���b�V���͕K�v
���ɁAMDRAM������̋Z�p�����p���A���t���b�V���B����H���g����
�[���p�C�v���C��SRAM�Ƃ��Ďg�p�ł���
DRAM�ƕς��Ȃ��Z���X�A���v�Ƃ��g���̂ŁA�T�C�N���^�C���͂���Ȃɑ����Ȃ��Ǝv����
CPU�ɏ悹��悤�Ȃ��̂ł͓�Ǝv�����ȁ[�@�ł��A1GB���炢������邱�Ƃ��o�����
���Ȃ肷�������Ƃ��o�������B
�Ⴂ�͂ł������}�g���b�N�X���g��DRAM�̑���ɏ�����DRAM���ʂɎg���_�B
�g���[�h�I�t�Ƃ��Ă�(��Ƃ���1TRAM����݂�)
1) 1T-RAM�̃L���p�V�^�e�ʂ͏��Ȃ��Ă悢�B�i�z�����Z���Ċe�ʂ�����̂Łj
2) �Z���X�A���v�Ȃǂ̉�H�͑����Ȃ�(�}�g���N�X���������̂ŁA�����K�v)
3) ���W�b�NLSI�Ƒ������ǂ�(���L���p�V�^��H�͎g��Ȃ��ĉ��Ƃ�����)
4) �G���[�̂��郁�����Z���̓���ւ������₷��(�������������̑��Ȃ̂ŁA�]�v�ɍ���Ċۂ��Ǝ��ւ�)
5) ���t���b�V���͕K�v
���ɁAMDRAM������̋Z�p�����p���A���t���b�V���B����H���g����
�[���p�C�v���C��SRAM�Ƃ��Ďg�p�ł���
DRAM�ƕς��Ȃ��Z���X�A���v�Ƃ��g���̂ŁA�T�C�N���^�C���͂���Ȃɑ����Ȃ��Ǝv����
CPU�ɏ悹��悤�Ȃ��̂ł͓�Ǝv�����ȁ[�@�ł��A1GB���炢������邱�Ƃ��o�����
���Ȃ肷�������Ƃ��o�������B
SIMM�N�ɂ�EDORAM�����������ނƎv�����
����Œ����Ƃ�������Y�͑����A�z���낗
�F��ȈӖ��Ō��ł���
�F��ȈӖ��Ō��ł���
�Ȃ�CPU������IGP�Ő��\���o���K�v������Ɗ��Ⴂ���Ă���
���Ԕ�������炵�����Ƃ͂킩�����B
���Ԕ�������炵�����Ƃ͂킩�����B
T-RAM�̓T�C���X�^�[RAM�B
1T-SRAM��SRAM�C���^�t�F�[�X��DRAM�ŁA�������Z����
DRAM�Ɠ����B
1T-SRAM��SRAM�C���^�t�F�[�X��DRAM�ŁA�������Z����
DRAM�Ɠ����B
Z-RAM�ł�T-RAM�ł��A�����ėe�ʂ����������A�ǂ���AMD��ȁB
442 �F,,�E�L�́M�E,,�j��-�������F2010/02/20(�y) 19:14:41 ID:O3dj1pkY
>>437
�킯���킩�����������
�킯���킩�����������
�c�q�����A�f���^�������́H
�������A�s�q�`�l���ăT�C���X�^���������B
�ł��T�C���X�^���āA�o�C�|�[���f�q�Ȃ̂Ń��[�N�d���ǂ���łȂ�
�n�m���Ă���Ƃ��ɂ͓d���Ȃ��Ȃ��Ă͂Ȃ�Ȃ��C������B
����d�͖ʂő��v�Ȃ̂��ȁH
�ł��T�C���X�^���āA�o�C�|�[���f�q�Ȃ̂Ń��[�N�d���ǂ���łȂ�
�n�m���Ă���Ƃ��ɂ͓d���Ȃ��Ȃ��Ă͂Ȃ�Ȃ��C������B
����d�͖ʂő��v�Ȃ̂��ȁH
���A�I�茠�̌�c�q����\�ɏo�v���Ăĕ�����
Intel�ł����悤�ȋC�����Ă���
�Ȃɂ����܂���
�N���v�����Ȃ������Ƃ����̂͂悭���邱��
�����͋Z�p�̐i���Ŗ��_���u���[�N�X���[�������B
452 �F,,�E�L�́M�E,,�j��-�������F2010/02/21(��) 01:34:07 ID:rewDbUvq
Flash�̃u���E�U�Q�[����Ă�ƃV���O���X���b�h���\�܂��܂��~�������Ďv����
Flash���}���`�X���b�h�Ή������炢����ˁH
������Ă���X�N���v�g���V���O���X���b�h�O��Ȃ̂�
���������Flash�̂Ă�̂Ɠ��`
���������Flash�̂Ă�̂Ɠ��`
�A�N�V�����X�N���v�g���ăC���^�v���^����Ȃ��́H
IBM��PPE/PX�J���̎�C�A�[�L�e�N�g�ŗ�̖\�I�{��������Daivid Sippy ��
����AMD�ɍݐE���Ƃ̂��ƁB
�\�[�X�̓P���^�b�L�[��w�ł̍u���̏Љ�L�����B
http://www.engr.uky.edu/news/article.php?idnum=852
�@�@---------------------
�@�@Today, Shippy works for AMD, another processor maker. In addition to the
�@�@PowerPC-based processors in the Xbox 360 and PlayStation 3, he also had a
�@�@hand in designing the chips in Nintendo�fs Wii console. He also spent time with
�@�@Intrinsity, a microprocessor development company that helped Samsung create
�@�@highly efficient chips to power the company�fs media-rich smartphones. His
�@�@work in designing high-performance computer chip technology also encompasses
�@�@microprocessor designs for notebook computers, desktop computers, high-end
�@�@servers and mainframes that have helped change the way people play, work and live.
�@�@---------------------
����AMD�ɍݐE���Ƃ̂��ƁB
�\�[�X�̓P���^�b�L�[��w�ł̍u���̏Љ�L�����B
http://www.engr.uky.edu/news/article.php?idnum=852
�@�@---------------------
�@�@Today, Shippy works for AMD, another processor maker. In addition to the
�@�@PowerPC-based processors in the Xbox 360 and PlayStation 3, he also had a
�@�@hand in designing the chips in Nintendo�fs Wii console. He also spent time with
�@�@Intrinsity, a microprocessor development company that helped Samsung create
�@�@highly efficient chips to power the company�fs media-rich smartphones. His
�@�@work in designing high-performance computer chip technology also encompasses
�@�@microprocessor designs for notebook computers, desktop computers, high-end
�@�@servers and mainframes that have helped change the way people play, work and live.
�@�@---------------------
>>450
���[�A�����ăT�C���X�^���ėv�̓��b�`���ׁH
���b�`���˂ăf�[�^�ێ����悤�Ȃ�Ă��Ƃ���ӂ�ĂȂ����H
>>451
�܂��A���������b�Ȃ�[���������ǂ�
���[�A�����ăT�C���X�^���ėv�̓��b�`���ׁH
���b�`���˂ăf�[�^�ێ����悤�Ȃ�Ă��Ƃ���ӂ�ĂȂ����H
>>451
�܂��A���������b�Ȃ�[���������ǂ�
�Ȃ�AMD������X���b�h�ł���N�O�̘b�肾����T-RAM�l�^���������Ă��ł����H
http://pc11.2ch.net/test/read.cgi/jisaku/1240713914/581
�@�@--------------------
�@�@581 ���O�FSocket774 ���e���F2009/05/19(��) 16:53:35 ID:1p866YQ2
�@�@�@�@T-RAM and GlobalFoundries team up for Thyristor-RAM development
�@�@�@�@http://www.tcmagazine.com/comments.php?shownews=26563&catid=6
�@�@--------------------
���Ȃ݂ɍX�ɑO�̎��̃J�L�R�~��SOI���p��FBC (Floating Body Cell)�̖��_�ɂ���
�����Ă��܂����B
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/12
�@�@--------------------
�@�@12 ���O�FMAC�I�^ ���e���F2008/01/03(��) 19:04:51 ID:0OGEg5J1
�@�@�@�@�ȒP�ɂ܂Ƃ߂�ƁA������Z-RAM�̖��_�펟�̂悤�ȃ��m���B
�@�@�@�@�@�ESOI�w���L���p�V�^�Ƃ��Ďg�p���邱�Ƃŏ\���ȗe�ʂ�҂��郂�m�́A�X�C�b�`���O�g�����W�X�^
�@�@�@�@�@�@�̓d���e�ʂ������Ƌ��ɒቺ���邱�Ƃ����ɂȂ�
�@�@�@�@�@�@�EPD-SOI�ɂ����K�p�ł��Ȃ�
�@�@--------------------
Z-RAM�� Innovative Silicon �Ђ͑���Z-RAM�Ŋo�C�|�[���g�����W�X�^��
���p���邱�Ƃő�d���𗬂���悤�ɂ���Ƃ������m�ł������AT-RAM�͓������X�C�b�`���O
�g�����W�X�^�̑�d�����ɃT�C���X�^���g�p����Ƃ����̂��|�C���g���ƁB
�T�C���X�^�͎��m�̂悤�ɑ�d���X�C�b�`���O�Ɏg�p�����f�q�ł��B
http://pc11.2ch.net/test/read.cgi/jisaku/1240713914/581
�@�@--------------------
�@�@581 ���O�FSocket774 ���e���F2009/05/19(��) 16:53:35 ID:1p866YQ2
�@�@�@�@T-RAM and GlobalFoundries team up for Thyristor-RAM development
�@�@�@�@http://www.tcmagazine.com/comments.php?shownews=26563&catid=6
�@�@--------------------
���Ȃ݂ɍX�ɑO�̎��̃J�L�R�~��SOI���p��FBC (Floating Body Cell)�̖��_�ɂ���
�����Ă��܂����B
http://pc11.2ch.net/test/read.cgi/jisaku/1199338832/12
�@�@--------------------
�@�@12 ���O�FMAC�I�^ ���e���F2008/01/03(��) 19:04:51 ID:0OGEg5J1
�@�@�@�@�ȒP�ɂ܂Ƃ߂�ƁA������Z-RAM�̖��_�펟�̂悤�ȃ��m���B
�@�@�@�@�@�ESOI�w���L���p�V�^�Ƃ��Ďg�p���邱�Ƃŏ\���ȗe�ʂ�҂��郂�m�́A�X�C�b�`���O�g�����W�X�^
�@�@�@�@�@�@�̓d���e�ʂ������Ƌ��ɒቺ���邱�Ƃ����ɂȂ�
�@�@�@�@�@�@�EPD-SOI�ɂ����K�p�ł��Ȃ�
�@�@--------------------
Z-RAM�� Innovative Silicon �Ђ͑���Z-RAM�Ŋo�C�|�[���g�����W�X�^��
���p���邱�Ƃő�d���𗬂���悤�ɂ���Ƃ������m�ł������AT-RAM�͓������X�C�b�`���O
�g�����W�X�^�̑�d�����ɃT�C���X�^���g�p����Ƃ����̂��|�C���g���ƁB
�T�C���X�^�͎��m�̂悤�ɑ�d���X�C�b�`���O�Ɏg�p�����f�q�ł��B
����ȋL������������Ȃ�����
�yIEDM�zSOI�g���L���p�V�^���XDRAM�C�����⍂�����Ői�W
http://techon.nikkeibp.co.jp/article/NEWS/20051207/111444/
�R�����u�X�̗��������̂��A�Ȃ�炩�̃u���[�N�X���[���������̂�
�yIEDM�zSOI�g���L���p�V�^���XDRAM�C�����⍂�����Ői�W
http://techon.nikkeibp.co.jp/article/NEWS/20051207/111444/
�R�����u�X�̗��������̂��A�Ȃ�炩�̃u���[�N�X���[���������̂�
>>455
Flash�������o���Ƃ��Ɉꉞ�R���p�C������邯�ǁA
�O���Ƀe�L�X�g��AS�t�@�C�������Ă��肷�邩��A
�����ǂ����������Ȃ낤���H
Flash�������o���Ƃ��Ɉꉞ�R���p�C������邯�ǁA
�O���Ƀe�L�X�g��AS�t�@�C�������Ă��肷�邩��A
�����ǂ����������Ȃ낤���H
Flash�̓���Ƃ��Q�[�����Ĉٗl�ɏd����ˁB
���̎�y�ɂł���Flash MMORPG�̐����X�y�b�N��
Core2 1.8GHz�ȏ�Ƃ���
���̎�y�ɂł���Flash MMORPG�̐����X�y�b�N��
Core2 1.8GHz�ȏ�Ƃ���
����Ȃ̂���̂��悗
������������
������������
>>460
�p�u���b�V��
�p�u���b�V��
>>462
http://fragoria.acquire.co.jp/startup/spec.php
�悭������1.8GHz�Ƃ͏����ĂȂ����ǁA
������������2GB,Pentium Core2�ȏ�B
2ch�̃X���ł��d������Ƃ�������
http://fragoria.acquire.co.jp/startup/spec.php
�悭������1.8GHz�Ƃ͏����ĂȂ����ǁA
������������2GB,Pentium Core2�ȏ�B
2ch�̃X���ł��d������Ƃ�������
5���������Ƃ��낻��A���[�N���o�Ă������̂�
X6�̃l�^�����łȂ��ȁB����ᔭ���������H
X6�̃l�^�����łȂ��ȁB����ᔭ���������H
>>465
������H�@�ǂ��炩�Ƃ����ƁA���O���͂������ɂł����������Ȃ����H
������H�@�ǂ��炩�Ƃ����ƁA���O���͂������ɂł����������Ȃ����H
���f���i���o�[�ƃN���b�N�̊W�͂܂��͂����肵�ĂȂ��͂�
��������6�R�AOp�������Ă�ȏ�����R������Ȃlj�������
��������6�R�AOp�������Ă�ȏ�����R������Ȃlj�������
����ƁA���Ƃ͂����ǂ��ł����炢����Ŕ��邩���炢
>>465
�n���H
�n���H
>>458
>�Ȃ�AMD������X���b�h�ł���N�O�̘b�肾����T-RAM�l�^���������Ă��ł����H
����Bulldozer�̐��\�����ϑz����l�^���Ȃ��B
����IBM�A���ESOI�q�����POWER7�ɂ�eDRAM�ڂ��Ă����A�݂����ȁB
>�Ȃ�AMD������X���b�h�ł���N�O�̘b�肾����T-RAM�l�^���������Ă��ł����H
����Bulldozer�̐��\�����ϑz����l�^���Ȃ��B
����IBM�A���ESOI�q�����POWER7�ɂ�eDRAM�ڂ��Ă����A�݂����ȁB
471 �F,,�E�L�́M�E,,�j��-�������F2010/02/21(��) 13:51:12 ID:rewDbUvq
>>462
atgames�Ƃ��l������炢��Ƃ����o�C��˃A��
atgames�Ƃ��l������炢��Ƃ����o�C��˃A��
T-RAM��eDRAM�̖ϑz�ő�\�ꂵ�Ă�͎̂G������
>>470���G������B
Bulldozer��������ďo�Ȃ���
X6��5���ɂłȂ���A��芷�����ق���������ˁH
X6��5���ɂłȂ���A��芷�����ق���������ˁH
>>474
"Bulldozer"����͓䂾������Ȃ�ɏ��͊J������Ă���ȁB
�����܂ň�N�߂����邩���̕��������������ǂ��B
�̐S�ȂƂ��������Ȃ�����A�ϑz�\����ԂŊy�����X���ɂȂ��Ă��邯�ǂ�
�u��芷���v��Intel���w���Ȃ�A�������ƕς��������������낤�B
AMD��Intel���啝�ύX�\�肪"���NQ1�\��"�Ȃ킯�ŁA
Intel��"Sandy Bridge"�����N�ɂ͂ł��Ⴄ����A�ς���Ȃ炢�܂̂�������H
"Bulldozer"����͓䂾������Ȃ�ɏ��͊J������Ă���ȁB
�����܂ň�N�߂����邩���̕��������������ǂ��B
�̐S�ȂƂ��������Ȃ�����A�ϑz�\����ԂŊy�����X���ɂȂ��Ă��邯�ǂ�
�u��芷���v��Intel���w���Ȃ�A�������ƕς��������������낤�B
AMD��Intel���啝�ύX�\�肪"���NQ1�\��"�Ȃ킯�ŁA
Intel��"Sandy Bridge"�����N�ɂ͂ł��Ⴄ����A�ς���Ȃ炢�܂̂�������H
CPU�����i�����������̂����͐́B
�ʂ�Sandy�o��܂ő҂��悵�B
Bulldozer�����N�o��Ƃ����ۏ��Ȃ����B
�ʂ�Sandy�o��܂ő҂��悵�B
Bulldozer�����N�o��Ƃ����ۏ��Ȃ����B
TDP�ƕ����������Ă邾����
�����̂�
�����̂�
Bulldozer�͗��N�łȂ��ł���
TRAM���ڂ��邽�߂ɉ�������ł���
TRAM���ڂ��邽�߂ɉ�������ł���
�u�����\��ʂ�o�邩�͕ʂƂ���T-RAM�܂ňꏏ�ɂ͏o���Ă��Ȃ�����
�a��^���Ȃ��ł�������
���̃X���̓o��l����N��������Ă���
�N�ƒN�����Ő���Ă�̂������ς�킩���
�N�ƒN�����Ő���Ă�̂������ς�킩���
�E�G��
�@�O�A�E���R
�@MAD�I�^
�@LL�T�C�Y
�@�ӌ��c
�@�A���~
�@������
�@�@�@�@�@�i�ȏ�R�s�y���d�g�O���[�v�j
�E���̑�Intel�h
�EAMD�h
�@�O�A�E���R
�@MAD�I�^
�@LL�T�C�Y
�@�ӌ��c
�@�A���~
�@������
�@�@�@�@�@�i�ȏ�R�s�y���d�g�O���[�v�j
�E���̑�Intel�h
�EAMD�h
>>476
Sandy�����N�o�邩�ۏ͂Ȃ����ǂȁB
Sandy�����N�o�邩�ۏ͂Ȃ����ǂȁB
PhenomII�{�����x�̐��\�ł���������V�������N����
����d�͉����Ă��ꂽ�炻��ł�����B
����d�͉����Ă��ꂽ�炻��ł�����B
>>483
Sandy�͗��N��ɏo���
����ES�̑O�i�̃R�A���������Ă�
�����Ȃ�B
�u���͗\��ǂ���y�[�p�[������
��ɗ��N�o�邱�Ƃ͂Ȃ�����w
Sandy�͗��N��ɏo���
����ES�̑O�i�̃R�A���������Ă�
�����Ȃ�B
�u���͗\��ǂ���y�[�p�[������
��ɗ��N�o�邱�Ƃ͂Ȃ�����w
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
Bulldozer���J�����~�ɂȂ��Ă��A32nm�̉��ǔ�K10��8/16�R�A������āA
���i���\��̈�����ɁA�����������葱���鍡�̓��X��
�Ȃ�ƂȂ�������Ȃ����낤���B
���i���\��̈�����ɁA�����������葱���鍡�̓��X��
�Ȃ�ƂȂ�������Ȃ����낤���B
�����̃V���R�����オ���Ă邩�琻�i���X�P�W���[���ʂ�o����Č����Ȃ�
Fermi�͂ǂ��Ȃ��Ă��܂��낤�ȁ[
�A���Ɣ�ׂ�͍̂������ATimna��Larrabee�i��1����j���đO����Ȃ��͂Ȃ��B
�V���R���̂���I�ڂ��ĂȂ�Bulldozer�̕���������ɂȂ肻���ƌ����̂͑Ó������B
Fermi�͂ǂ��Ȃ��Ă��܂��낤�ȁ[
�A���Ɣ�ׂ�͍̂������ATimna��Larrabee�i��1����j���đO����Ȃ��͂Ȃ��B
�V���R���̂���I�ڂ��ĂȂ�Bulldozer�̕���������ɂȂ肻���ƌ����̂͑Ó������B
Bulldozer�͗��N�̖ڋʏ��i������T�d�Ɏ���i�߂Ă���낤
�������@�f�����o���郌�x���ɂȂ�܂ł͂Ђ��B���ȋC������
AMD�̍���̃}�[�P�e�B���O�́ALlano��O�ʂɏo����APU�̒m���x�����32nm�̏��������A�s�[�����ĂƂ��낶��Ȃ����ȁB
�������@�f�����o���郌�x���ɂȂ�܂ł͂Ђ��B���ȋC������
AMD�̍���̃}�[�P�e�B���O�́ALlano��O�ʂɏo����APU�̒m���x�����32nm�̏��������A�s�[�����ĂƂ��낶��Ȃ����ȁB
���\���ǂ����ǂ�ǂ[�N�����A�����I�ȈӖ����܂߂�
�}�X�N���o���Ă��ǂ�ǂ[�N�����ALarrabee���܂߂�
>>489
����͐�ɂ��蓾�Ȃ��B�ǂꂭ�炢
�����ԃy�[�p�[�Ō떂�����āA������
�X�e�b�s���O�グ�āA�떂�����Ă�����
���̌J��Ԃ��ł����Ȃ��B�܂����ꂾ��
�؋�����CPU�J�����ẮA�؋���
�����̗��ꂾ��Hw
����͐�ɂ��蓾�Ȃ��B�ǂꂭ�炢
�����ԃy�[�p�[�Ō떂�����āA������
�X�e�b�s���O�グ�āA�떂�����Ă�����
���̌J��Ԃ��ł����Ȃ��B�܂����ꂾ��
�؋�����CPU�J�����ẮA�؋���
�����̗��ꂾ��Hw
PenD��Core2��Corei7��eDRAM��T-RAM�����
�ŋ߂�GPU�݂����ɁA����ӂ�ȉ\���x�Ȃ��̂͑������痬���āA�^�̃X�y�b�N�͒��O�܂Ō��\�������Ǝv����B
Fermi 3/26
NV�͂܂������T�������Ƃ����悤�ł�
NV�͂܂������T�������Ƃ����悤�ł�
>>492
HD4770��40nm�v���Z�X�m�F���A�Đv(HD5***)�����悤��
Llano�́AGF fab1��32nm�v���Z�X���m�F����Bulldozer&fab2��
���Ƃ����ރe�X�g�I�Ӗ��������傫���Ǝv����
�S�ẮANY fab2�{�ғ��̏����̂悤�ȋC���������
HD4770��40nm�v���Z�X�m�F���A�Đv(HD5***)�����悤��
Llano�́AGF fab1��32nm�v���Z�X���m�F����Bulldozer&fab2��
���Ƃ����ރe�X�g�I�Ӗ��������傫���Ǝv����
�S�ẮANY fab2�{�ғ��̏����̂悤�ȋC���������
>495
���l�[���e�N�m���W�[(R)�ƌ����ANV�͂����I�I�J�~���N����
���l�[���e�N�m���W�[(R)�ƌ����ANV�͂����I�I�J�~���N����
���܂�l�������Ȃ��̂�
Bulldozer�̎��`�b�v���z�肵���p�t�H�[�}���X���o���Ȃ����ďꍇ����
������̖�肶��Ȃ��A���̐v���Ƃ���σ_�����Č��_�������ŏo�Ă��܂�����
���ɂ���C�͂���
Bulldozer�̎��`�b�v���z�肵���p�t�H�[�}���X���o���Ȃ����ďꍇ����
������̖�肶��Ȃ��A���̐v���Ƃ���σ_�����Č��_�������ŏo�Ă��܂�����
���ɂ���C�͂���
>>498
�������ɂ���́A�V�~�����[�V�������ĉ�H�v���Ă�Ǝv��������ww
�iPower�n�ɋ߂��v������V�~�����[�V�������₷�����낤���j
���́AAMD���z�肵�Ă�SW�̃g�����h��Bulldozer�ƍ��v���Ă�̘b������
�������ɂ���́A�V�~�����[�V�������ĉ�H�v���Ă�Ǝv��������ww
�iPower�n�ɋ߂��v������V�~�����[�V�������₷�����낤���j
���́AAMD���z�肵�Ă�SW�̃g�����h��Bulldozer�ƍ��v���Ă�̘b������
>>499
phenom�Anehalem�n�ɍœK�������\�t�g�ł͐U���Ȃ����낤�ˁB
�ł�Core2�n�A����C2Q�ɍœK�����Ă���z�ł͐��\�o��������ˁH
phenom�Anehalem�n�ɍœK�������\�t�g�ł͐U���Ȃ����낤�ˁB
�ł�Core2�n�A����C2Q�ɍœK�����Ă���z�ł͐��\�o��������ˁH
>>490
CPU�n�ł����������̂��āA�O�����܂�ɕ�������C2D�n�����o�����Ȃ����ǁc�B
>>500
�Ȃ�ŁH�@C2Q�n�Ƃ͑S���Ⴄ�f�U�C�����Ǝv�����ǁH
CPU�n�ł����������̂��āA�O�����܂�ɕ�������C2D�n�����o�����Ȃ����ǁc�B
>>500
�Ȃ�ŁH�@C2Q�n�Ƃ͑S���Ⴄ�f�U�C�����Ǝv�����ǁH
>>499
���̂����܂�b��ɂȂ�Ȃ����ǁA
���Ȃ��Ƃ�����INT/FPU�̍\����Bulldozer�����ɍœK�����ꂽ
�R�[�h�łȂ���ΐ��\���o�ɂ����Ǝv�����B
Intel�n�ɍœK�����ꂽ�R�[�h����̃R���V���[�}�]�[����
�ǂ�����Ă��������낤�����Ďv���B
���̂����܂�b��ɂȂ�Ȃ����ǁA
���Ȃ��Ƃ�����INT/FPU�̍\����Bulldozer�����ɍœK�����ꂽ
�R�[�h�łȂ���ΐ��\���o�ɂ����Ǝv�����B
Intel�n�ɍœK�����ꂽ�R�[�h����̃R���V���[�}�]�[����
�ǂ�����Ă��������낤�����Ďv���B
>>501
2�R�A���Ƃɋ��L��L2������������肭�d�Ȃ肻���Ɏv����
2�R�A���Ƃɋ��L��L2������������肭�d�Ȃ肻���Ɏv����
AMD begins shipping "Magny-Cours" Opteron
http://www.techspot.com/news/37972-AMD-begins-shipping-MagnyCours-Opteron.html
http://www.techspot.com/news/37972-AMD-begins-shipping-MagnyCours-Opteron.html
>>503
���ꂾ���ňꏏ�Ȃ�ΈႤCPU���đ��݂��Ȃ��ȁB
���ꂾ���ňꏏ�Ȃ�ΈႤCPU���đ��݂��Ȃ��ȁB
Core 2�̃L���b�V���T�C�Y�ɍœK�����Ă���A�v������16kB�����Ȃ�L1���_�Ńq�b�g���Ȃ�����
���Ȃ�}�Y�[���ȁB
���Ȃ�}�Y�[���ȁB
�Ƃ��낪intel�œK���R���p�C������L1D��16KB�����Ȃ�
CoreDuo��Nehalem��16KB������
CoreDuo��Nehalem��16KB������
>>502
> ���̂����܂�b��ɂȂ�Ȃ����ǁA
> ���Ȃ��Ƃ�����INT/FPU�̍\����Bulldozer�����ɍœK�����ꂽ
> �R�[�h�łȂ���ΐ��\���o�ɂ����Ǝv�����B
�b��ɂȂ�Ȃ��͓̂�����O����ˁH �R��͊y�ϓI����B
����CPU�ւ̍œK���̖]�݂�����AMD���A�������l���������Ԃ͂����Ղ肠����������
�����R�[�h�₱�ꂩ��̃g�����h���l������ŃA���ŗǂ��Ɣ��f�������炱���̍\������B
��������AMD�́uBulldozer�œK���R�[�h�v�Ȃ�Ė�������闧�ꂶ��Ȃ��B
�����R�[�h�𑖂点���ꍇ�Ɍ������N���b�N���A���Ƃ��Ăł�K10�����鐫�\���o���Ȃ��ƍ��Ӗ��������B
�łȂ��ƒN�������Ă���Ȃ����́B�Ƃ������A�������̃A�[�L�e�N�g�W�߂Ƃ��ĉ����Ƃ��l���ɂ���
���������̂Ȃ�P�Ȃ锜��ȋ��Ǝ��Ԃ̖��ʁBK10���V�������N�����ق��������B
> ���̂����܂�b��ɂȂ�Ȃ����ǁA
> ���Ȃ��Ƃ�����INT/FPU�̍\����Bulldozer�����ɍœK�����ꂽ
> �R�[�h�łȂ���ΐ��\���o�ɂ����Ǝv�����B
�b��ɂȂ�Ȃ��͓̂�����O����ˁH �R��͊y�ϓI����B
����CPU�ւ̍œK���̖]�݂�����AMD���A�������l���������Ԃ͂����Ղ肠����������
�����R�[�h�₱�ꂩ��̃g�����h���l������ŃA���ŗǂ��Ɣ��f�������炱���̍\������B
��������AMD�́uBulldozer�œK���R�[�h�v�Ȃ�Ė�������闧�ꂶ��Ȃ��B
�����R�[�h�𑖂点���ꍇ�Ɍ������N���b�N���A���Ƃ��Ăł�K10�����鐫�\���o���Ȃ��ƍ��Ӗ��������B
�łȂ��ƒN�������Ă���Ȃ����́B�Ƃ������A�������̃A�[�L�e�N�g�W�߂Ƃ��ĉ����Ƃ��l���ɂ���
���������̂Ȃ�P�Ȃ锜��ȋ��Ǝ��Ԃ̖��ʁBK10���V�������N�����ق��������B
�܂��L�~�͊y�ϓI�ł�AMD�̒��̐l�͊y�ϓI����Ȃ����낤�ȁB
>����CPU�ւ̍œK���̖]�݂�����AMD���A�������l���������Ԃ͂����Ղ肠����������
>�����R�[�h�₱�ꂩ��̃g�����h���l������ŃA���ŗǂ��Ɣ��f�������炱���̍\������B
�l���������Ԃ͂����Ղ肠�����Ƃ����Ď��{��`��n���ɂ��Ă�̂��ƁB���Ԃ͋������B
����ȓۋC�ȃ��[�J�[�Ȃ�č��̕s���̒��A�����ŏ������邼�B
���ꂩ��v���Z�b�T�̊J���ɂ͉��N��������悤�����B
�ǂ������Ă�����ۂɂ��̂����ɂł�܂ʼn��N��������B
Bulldozer�͐V�����`�[�����J�������낤���AIntel�ɍœK�����ꂽ�A�v�����s��ɂ��ӂ�Ă���
���������ɂ͂����ĂȂ������̂��AAMD���������Ƃ�ĂȂ������̂��A�^��Ɏv����ȁB
>����CPU�ւ̍œK���̖]�݂�����AMD���A�������l���������Ԃ͂����Ղ肠����������
>�����R�[�h�₱�ꂩ��̃g�����h���l������ŃA���ŗǂ��Ɣ��f�������炱���̍\������B
�l���������Ԃ͂����Ղ肠�����Ƃ����Ď��{��`��n���ɂ��Ă�̂��ƁB���Ԃ͋������B
����ȓۋC�ȃ��[�J�[�Ȃ�č��̕s���̒��A�����ŏ������邼�B
���ꂩ��v���Z�b�T�̊J���ɂ͉��N��������悤�����B
�ǂ������Ă�����ۂɂ��̂����ɂł�܂ʼn��N��������B
Bulldozer�͐V�����`�[�����J�������낤���AIntel�ɍœK�����ꂽ�A�v�����s��ɂ��ӂ�Ă���
���������ɂ͂����ĂȂ������̂��AAMD���������Ƃ�ĂȂ������̂��A�^��Ɏv����ȁB
>>509
�C�\�e����32kB�������Ǝv�������A16kB������?
�C�\�e����32kB�������Ǝv�������A16kB������?
INT/FPU�������N���ē����킯����Ȃ���
�ǂ������R�[�h��z�肵�Ă�̂��S�R�킩��Ȃ���
�ǂ������R�[�h��z�肵�Ă�̂��S�R�킩��Ȃ���
>Intel�n�ɍœK�����ꂽ�R�[�h����̃R���V���[�}�]�[����
>�ǂ�����Ă��������낤�����Ďv���B
�����y�U�Ő키�C������Ȃ�
���炩�̎�͑ł��Ă���͂��������S�ɕ��u�v���C
���������ǂ�����Đ키�A�Ȃ�Ď��͍l���ĂȂ�������
�Z�O�����g���炵�Ă�������Ȃ��悤�ɔ���B
����������������Ǝv�����B
>�ǂ�����Ă��������낤�����Ďv���B
�����y�U�Ő키�C������Ȃ�
���炩�̎�͑ł��Ă���͂��������S�ɕ��u�v���C
���������ǂ�����Đ키�A�Ȃ�Ď��͍l���ĂȂ�������
�Z�O�����g���炵�Ă�������Ȃ��悤�ɔ���B
����������������Ǝv�����B
���[�����\����
cpu1:
int x2, ldx1, stx1 fp-mltx1 fp-addx1
cpu2:
int x2, ldx1, stx1 fp-mltx1 fp-addx1
���[�����\���ɕς�����Ƃ���
cpu1:
int x2, ldx1, stx1
cpu2:
int x2, ldx1, stx1
cpu1/2:(share)
fp-mltx2 fp-addx2
fpu�̃t���X�s�[�h����m���ƁA
���G�Ȃ��Ƃ������Ƃɂ��f�����b�g��
�g���[�h�I�t���ǂ̒��x�̂��̂ł��邩����
cpu1:
int x2, ldx1, stx1 fp-mltx1 fp-addx1
cpu2:
int x2, ldx1, stx1 fp-mltx1 fp-addx1
���[�����\���ɕς�����Ƃ���
cpu1:
int x2, ldx1, stx1
cpu2:
int x2, ldx1, stx1
cpu1/2:(share)
fp-mltx2 fp-addx2
fpu�̃t���X�s�[�h����m���ƁA
���G�Ȃ��Ƃ������Ƃɂ��f�����b�g��
�g���[�h�I�t���ǂ̒��x�̂��̂ł��邩����
>>513
>>Intel�n�ɍœK�����ꂽ�R�[�h����̃R���V���[�}�]�[����
>>�ǂ�����Ă��������낤�����Ďv���B
���܂܂Œʂ�Ɂu�œK���v����Ă��ĂȂ��Ă��A
�����Ə����ł���悤�ɐv����Ă����B
AMD�n��CPU�ɍœK�����ꂽ�R�[�h�Ȃ�āA
�������Ȃ��������ɁA����������Ȃ�̐��юc���Ă��邵�B
Intel�̂悤�ɍœK�����O���CPU�v�ł͂Ȃ��̂��낤�B
�����Ƃ��œK�����ꂽ�猋�\�Ȃ����ǂȁB
�I�n�̃x���`�Ȃǂ��݂Ă�Ƃ킩�邱�Ƃ����ǂˁB
>>Intel�n�ɍœK�����ꂽ�R�[�h����̃R���V���[�}�]�[����
>>�ǂ�����Ă��������낤�����Ďv���B
���܂܂Œʂ�Ɂu�œK���v����Ă��ĂȂ��Ă��A
�����Ə����ł���悤�ɐv����Ă����B
AMD�n��CPU�ɍœK�����ꂽ�R�[�h�Ȃ�āA
�������Ȃ��������ɁA����������Ȃ�̐��юc���Ă��邵�B
Intel�̂悤�ɍœK�����O���CPU�v�ł͂Ȃ��̂��낤�B
�����Ƃ��œK�����ꂽ�猋�\�Ȃ����ǂȁB
�I�n�̃x���`�Ȃǂ��݂Ă�Ƃ킩�邱�Ƃ����ǂˁB
���[��A��K7�̎���ɂ́A�ӂ��̃A�v����Intel�����ɂɍœK������Ă��邩��
AMD�ɍœK�������AMD�̕����f�R�͂₢�AAMD�͕s���ȏœ����Ă�����Ă���
�F�����嗬�������̂ɂ�����y�ώ�`�҂��������낤�ȁB
Bulldozer��Sandy Bridge�ł�K7vsP6�̈Ⴂ�ǂ���ł͂Ȃ����B
AMD�ɍœK�������AMD�̕����f�R�͂₢�AAMD�͕s���ȏœ����Ă�����Ă���
�F�����嗬�������̂ɂ�����y�ώ�`�҂��������낤�ȁB
Bulldozer��Sandy Bridge�ł�K7vsP6�̈Ⴂ�ǂ���ł͂Ȃ����B
�l�I�ɂ͈�т���Bulldozer�̓T�[�o�����Ƃ��������Ȃ̂ŁA
�R���V���[�}�ŕ��y����Ǝv���Ă��Ȃ��̂ŁA�܂��R���V���[�}�ł����y����h
�̂��Ƃ��l��������̘b�Ȃ��ǁB
�R���V���[�}�ŕ��y����Ǝv���Ă��Ȃ��̂ŁA�܂��R���V���[�}�ł����y����h
�̂��Ƃ��l��������̘b�Ȃ��ǁB
Intel�œK���ɑΉ�����CPU���Ƃ����̂�
����IntelCPU�̊��S�R�s�[�����ƌ����Ă�悤�Ȃ�����
�n���n�������b��
����IntelCPU�̊��S�R�s�[�����ƌ����Ă�悤�Ȃ�����
�n���n�������b��
�����Ȃ��Ƃ�����OS�́A�_���v���Z�b�T�ƕ����v���Z�b�T(�}���`�R�A)�̌��������炢�͂��Ă邩��A
�܂�MS��Bulldozer��FPU�͘_���I��2�����ǁAINT�͕����I��2�ɋ߂��A�ł����E���͔����Ƃ���
�����ɑΉ����Ă���邩�ǂ�������������B
�܂�MS��Bulldozer��FPU�͘_���I��2�����ǁAINT�͕����I��2�ɋ߂��A�ł����E���͔����Ƃ���
�����ɑΉ����Ă���邩�ǂ�������������B
�����Ƃ��ȒP�ȗ�Ř_���v���Z�b�T�̐��ƕ����v���Z�b�T�̐����V�X�e������擾����
���ʂɉ���������������悤�ȃv���O�����Ŋ��ɕs���ɂȂ�\���傾�ȁB
���ʂɉ���������������悤�ȃv���O�����Ŋ��ɕs���ɂȂ�\���傾�ȁB
>>518
���������Ȃ��Ƃ����ĂȂ�����B��Q�ϑz���B
AMD�̓R���p�C����p�ӂł��铖�Ă�����̂��Ƃ������ƂƁA
Bulldozer�͊�����x86�v���Z�b�T�ƒ������قȂ�v���Ƃ������Ƃ����Ȃ킯�ŁA
K10�x�[�X�Ȃ���߂ċC�ɂ����肶��Ȃ��B�[���A������Llano�h�Ȃ�ŁB
���������Ȃ��Ƃ����ĂȂ�����B��Q�ϑz���B
AMD�̓R���p�C����p�ӂł��铖�Ă�����̂��Ƃ������ƂƁA
Bulldozer�͊�����x86�v���Z�b�T�ƒ������قȂ�v���Ƃ������Ƃ����Ȃ킯�ŁA
K10�x�[�X�Ȃ���߂ċC�ɂ����肶��Ȃ��B�[���A������Llano�h�Ȃ�ŁB
>>516-517
���[�c���������Ă��邩�����ς�킩��Ȃ��B
���������cx86�n�̏ꍇ��CPU�̍��ق�OS�����z�����邩��A
�{���ɍœK������Ă���\�t�g�ȊO�͑傫�ȍ����o�Ȃ��Ǝv�����H
Linux�n�Ŏ��̓R���p�C��������A�g���Ă��Ȃ����߃Z�b�g���ꂽ��B
�����܂ō�������\�t�g�E�F�A�łȂ��ƂȁB
���[�c���������Ă��邩�����ς�킩��Ȃ��B
���������cx86�n�̏ꍇ��CPU�̍��ق�OS�����z�����邩��A
�{���ɍœK������Ă���\�t�g�ȊO�͑傫�ȍ����o�Ȃ��Ǝv�����H
Linux�n�Ŏ��̓R���p�C��������A�g���Ă��Ȃ����߃Z�b�g���ꂽ��B
�����܂ō�������\�t�g�E�F�A�łȂ��ƂȁB
���オ��������̂��ȁB
�̂�K7��p�ɍœK��������3�{�����Ƃ������ǂ����̉�Ђ�
�l�^���b��ɂȂ������炢�Ȃ̂ɁB
�̂�K7��p�ɍœK��������3�{�����Ƃ������ǂ����̉�Ђ�
�l�^���b��ɂȂ������炢�Ȃ̂ɁB
>>523
����cPen4 Xeon�́c����B
����cPen4 Xeon�́c����B
�R�e�͑��������ځ[�Ă��ł��O�炪�������Ă邩������Ȃ��B
>>525
�܂��債�����Ƃ͌����ĂȂ�����C�ɂ����
�܂��債�����Ƃ͌����ĂȂ�����C�ɂ����
MS�ɗ��ݍ���ŁAIntel��AMD���ꂼ��œK�������R�[�h��f���o��
VisualC++������Ă��炦������łȂ������H
�A���A�o�C�g�f�[�^�͔{�ɂȂ邯�ǁE�E�E
VisualC++������Ă��炦������łȂ������H
�A���A�o�C�g�f�[�^�͔{�ɂȂ邯�ǁE�E�E
���X���ő���ɂ��Ă��炦�Ȃ����猋�ǂ��̃X���ɖ߂��Ă����킯��
>>527
���ꂾ�ƌ��ɓ�{�̎��Ԃ�������B�ȒP�Ɍ����Γ�{�̗\�Z��������B
������CPU�����ゲ�Ƃɂ킩���̂ŁA���؎��ԂƗ\�Z����Z�����B
�c�Ȃ̂Ō��ǖ{�̕����́u����Ȃ�v�ɓ������̂������o���̂���ԁB
�ŁA�����I�ȃv���O�C���Ȃǂœ���CPU�Ɂu�œK���v������̂���B
CPU�������I�ɂǂ��ł���A����͕ς��Ȃ��B
�{���ɍœK���ł���̂̓V�X�e����Ŕ[�i�ł���T�[�o�[�Ȃǂ̃n�C�G���h�����B
���ꂾ�ƌ��ɓ�{�̎��Ԃ�������B�ȒP�Ɍ����Γ�{�̗\�Z��������B
������CPU�����ゲ�Ƃɂ킩���̂ŁA���؎��ԂƗ\�Z����Z�����B
�c�Ȃ̂Ō��ǖ{�̕����́u����Ȃ�v�ɓ������̂������o���̂���ԁB
�ŁA�����I�ȃv���O�C���Ȃǂœ���CPU�Ɂu�œK���v������̂���B
CPU�������I�ɂǂ��ł���A����͕ς��Ȃ��B
�{���ɍœK���ł���̂̓V�X�e����Ŕ[�i�ł���T�[�o�[�Ȃǂ̃n�C�G���h�����B
Bulldozer�͂ǂ���琫�\��K10.5����
��ɂȂ�悤�����A���ʂɌ�����������
�N���A�����ꍇ�Ɍ��肳��邻����
Bulldozer�Ή��̐�p�R���p�C���Ńr���h
�����o�C�i���̂ݍ����ɂȂ���Ă�
����ȊO�́AAthlonXP�܂ōő�Ő��\
�ቺ����炵��
��ɂȂ�悤�����A���ʂɌ�����������
�N���A�����ꍇ�Ɍ��肳��邻����
Bulldozer�Ή��̐�p�R���p�C���Ńr���h
�����o�C�i���̂ݍ����ɂȂ���Ă�
����ȊO�́AAthlonXP�܂ōő�Ő��\
�ቺ����炵��
Bulldozer�́AAMD�� AVX�i128-bit�����낤���ǁj�ςނ���intel�ɍœK�����ꂽ�R�[�h�Ȃ�
��r�I�œK�������Ⴀ��܂����H
3DNow!�̓�̕��͓��݂����Ȃ����낤��
��r�I�œK�������Ⴀ��܂����H
3DNow!�̓�̕��͓��݂����Ȃ����낤��
>>532
Intel�Ɗe���߂̃N���b�N�S���قȂ�̂�
icc�g���č����ɂȂ邱�Ƃ�������
gcc�⑼�̃R���p�C���g���Ă�����͐�Ες��Ȃ��B
Intel�Ɗe���߂̃N���b�N�S���قȂ�̂�
icc�g���č����ɂȂ邱�Ƃ�������
gcc�⑼�̃R���p�C���g���Ă�����͐�Ες��Ȃ��B
>>533
�Ȃ�Ŗ��O�R�e���O���́H
�Ȃ�Ŗ��O�R�e���O���́H
>>534
���`�H���Ɏ��₷���ˁ[��
���`�H���Ɏ��₷���ˁ[��
This paper was presented at the 16th IEEE Symposium on High-Performance Computer Architecture (2010) and describes the compiler Intermediate Representation, WHIRL. It discusses a number of compilation concepts in Open64 and provides examples.
�����䂤������Ȃ����������Ă��邩��
Intel�ɑ傫���a�����������
�킩��H
�����䂤������Ȃ����������Ă��邩��
Intel�ɑ傫���a�����������
�킩��H
Agena�ő厸�s���Ă邩��A���̋��P��������Ζ���Ɏd�オ�邾��B
���m���o�Ă���܂ł͉��Ƃł�������B
���m���o�Ă���܂ł͉��Ƃł�������B
538 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 03:56:18 ID:QutNOdX2
>>503
�A�z��
�A�z��
>>503
���ق�
���ق�
�؋����މ�₂Ƃ��s�i�A���Ƃ��M�Җϑz�A���Ƃ�
���������M���M���́u������v������Intel�����ł���
���������M���M���́u������v������Intel�����ł���
AMD�̃}�U�[���Ċv�V�����Ȃ�
�D��������Ȃ�
690G���牽���ω��Ȃ���
�D��������Ȃ�
690G���牽���ω��Ȃ���
�G���搶���͂悤�������܂�
>>541
Intel�̃`�b�v�Z�b�g���ĉ����u�v�V�I�v�ȃ��m�������������H
Intel�̃`�b�v�Z�b�g���ĉ����u�v�V�I�v�ȃ��m�������������H
Direct-X���T�|�[�g���Ȃ����Ă����v�V�����������ȁB
�\�t�g�G�~���łȂ��A�n�[�h�`�ʋ@�\����������ĂȂ����ĈӖ��łˁB
���܂��ɁA���o�C���헪�Ŏ����̍�����u�����h�ɂ͎����̃`�b�v�Z�b�g���g���Ƃ������B
�Q�[�����Ȃ��Ƃ��AFlash�Ȃł̂����������x�ȕ`�ʎg��Ȃ���������ǁA
�g�����u�ԂɎg�����ɂȂ�Ȃ��Z�b�g�ɂȂ�B
�\�t�g�G�~���łȂ��A�n�[�h�`�ʋ@�\����������ĂȂ����ĈӖ��łˁB
���܂��ɁA���o�C���헪�Ŏ����̍�����u�����h�ɂ͎����̃`�b�v�Z�b�g���g���Ƃ������B
�Q�[�����Ȃ��Ƃ��AFlash�Ȃł̂����������x�ȕ`�ʎg��Ȃ���������ǁA
�g�����u�ԂɎg�����ɂȂ�Ȃ��Z�b�g�ɂȂ�B
���XUSB1.1�Ƀo�O�d���ނ�����͊v�V�I������
http://ux.getuploader.com/mosa/download/33/athlon2-i5.wmv
�v�V�I�Ȓx�����ȁ[
�v�V�I�Ȓx�����ȁ[
547 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 14:11:03 ID:QutNOdX2
���x���̒Ⴂ�g�������Ƀn�b�X�����ăR�e���Ă�����Ăǂ������
549 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 14:14:52 ID:QutNOdX2
DirectX
���i�͂`�l�c�͕����Ƃ����f�I���̓J�X���Ƃ��A�������ɗ��ł���
�����͊Ԉ���ĂȂ�����L�����s�ło�b�V���b�v�Œ�������
�a�s�n�Z�b�g��i7 920�}�V���̃r�f�I�J�[�ނ̒lj��I�v�V������
9600�f�s��I��ōw��������128bit�g���b�v�������Ƃ������
���얯�Ƃ��ăA�E�g���Z�[�t���B�ǂ�����
�����͊Ԉ���ĂȂ�����L�����s�ło�b�V���b�v�Œ�������
�a�s�n�Z�b�g��i7 920�}�V���̃r�f�I�J�[�ނ̒lj��I�v�V������
9600�f�s��I��ōw��������128bit�g���b�v�������Ƃ������
���얯�Ƃ��ăA�E�g���Z�[�t���B�ǂ�����
BTO�̎��_�ō̓_�ΏۊO��
(�L�E�t�E�M)
BTO�Ȃ̂ŎQ�l�_�ɂȂ邪�A����ł��A�E�g���Ȃ�
�ςȏ@�����������Ⴄ�I������ԕs�����B
�ςȏ@�����������Ⴄ�I������ԕs�����B
�t�F�b�`���v���t�F�b�`�ȃJ�����̂��Ƃ͒m���
���{��ł͂���Ȋ���
�т傤�]����k�x�E�]�l�y�`�ʁz
�m���n(�X��)���̌`���ԁA�S�Ɋ��������ƂȂǂ��A���t�E�G��E���y�Ȃǂɂ���Ďʂ�����킷���ƁB�u��i���\����v�u�S���\�v
���{��ł͂���Ȋ���
�т傤�]����k�x�E�]�l�y�`�ʁz
�m���n(�X��)���̌`���ԁA�S�Ɋ��������ƂȂǂ��A���t�E�G��E���y�Ȃǂɂ���Ďʂ�����킷���ƁB�u��i���\����v�u�S���\�v
555 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 14:46:00 ID:QutNOdX2
�`��irender�j�ƕ`�ʁidepict�j�͉p��ł���S���ʂ̈Ӗ�
Intel �I���{�͂��A�ǂ����Q�[���̓V���{���ă��N�ɏo���Ȃ����炳�ADirectX�͖��Ή���GDI�ƍĐ��x�������Ή����Ă������ˁH
���߂Ă܂Ƃ���Dx10.1�Ή��o����悤�ɂȂ��Ă���������������B
���߂Ă܂Ƃ���Dx10.1�Ή��o����悤�ɂȂ��Ă���������������B
�������ɂ���͑ʖڂ���E�E�E
�܂�Ńe�w���c���d���݂���Ă�悤�ȉ��蕳������H�씭���B
�܂�Ńe�w���c���d���݂���Ă�悤�ȉ��蕳������H�씭���B
558 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 14:56:54 ID:QutNOdX2
��Flash�̍Đ���GPU�]�X�����Ă鎞�_�Ŏg�������Ɩ�������
GPU�Đ��x���ɑΉ������t�H�[�}�b�g�Ȃ�ĂقƂ�Ǎ̗p����ĂȂ����B
GPU�Đ��x���ɑΉ������t�H�[�}�b�g�Ȃ�ĂقƂ�Ǎ̗p����ĂȂ����B
559 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 15:13:45 ID:QutNOdX2
�_�E���O���[�h���g����Windows XP�}�V����V�K�������郆�[�U�[���瑽���̂�
DX10.1���ǂ��Ƃ������̂͂ˁE�E�E
API�Ȃ�Č��ǕK�v�ȃ\�t�g���Ή����Ȃ��������Ȃ�ł���B
SSE��4.2��AES-NI�܂őΉ��������i���s��ɏo�Ă�̂ɁA�iVIA Nano�ł���Ή��ς݂ȁjSSSE3����
�Ή����ĂȂ�CPU���炠�邾��H����ɑ��āA�uAMD��CPU���ȁv�Ȃ�Č����邩�H
DX10.1���ǂ��Ƃ������̂͂ˁE�E�E
API�Ȃ�Č��ǕK�v�ȃ\�t�g���Ή����Ȃ��������Ȃ�ł���B
SSE��4.2��AES-NI�܂őΉ��������i���s��ɏo�Ă�̂ɁA�iVIA Nano�ł���Ή��ς݂ȁjSSSE3����
�Ή����ĂȂ�CPU���炠�邾��H����ɑ��āA�uAMD��CPU���ȁv�Ȃ�Č����邩�H
����....
��Q�ϑz�Ɠ˂����܂�Ă����������Ȃ�����������
��Q�ϑz�Ɠ˂����܂�Ă����������Ȃ�����������
561 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 15:25:50 ID:QutNOdX2
����GMA��DirectX�̑Ή����݂��ċƊE�̑������������Ă���ė����͊m���ɂ���Ǝv����B
����ł�GPU�s��̃V�F�A�𑝂₵�Ă�B����55%����H
DirectX���Ė{���ɕK�v�Ȃ́H
�uSSE�Ή���x�点�ċƊE�̑����Ђ��ς�AMD�v���ċc�_�������Ȃ��̂��s�v�c�łȂ��B
�����Ƃ��A���s�V�F�A���ƈ�������O�Ɏs��Ɍ��������i���ݐi�s�`�j�Ǝv�����ǂˁB
SSE�������v���ł͂Ȃ����A�Ή���x�点�����i���V�F�A�������Ă鎖���͊m���ɂ���ł��B
����ł�GPU�s��̃V�F�A�𑝂₵�Ă�B����55%����H
DirectX���Ė{���ɕK�v�Ȃ́H
�uSSE�Ή���x�点�ċƊE�̑����Ђ��ς�AMD�v���ċc�_�������Ȃ��̂��s�v�c�łȂ��B
�����Ƃ��A���s�V�F�A���ƈ�������O�Ɏs��Ɍ��������i���ݐi�s�`�j�Ǝv�����ǂˁB
SSE�������v���ł͂Ȃ����A�Ή���x�点�����i���V�F�A�������Ă鎖���͊m���ɂ���ł��B
�܂�GMA��AMD���Ή����Ȃ��v�V����������Ď������
���Ɋ��ݕt���Ă��́H
���Ɋ��ݕt���Ă��́H
Sandy�ł�10.1�Ή�����炵���������ς�K�v�Ȃ�A����
564 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 15:36:37 ID:QutNOdX2
���Ή����Ȃ��v�V��
NVIDIA�͂��炵���ł���
NVIDIA�͂��炵���ł���
GMA�̏ꍇ�AGPU�̃V�F�A�ƌ������`�b�v�Z�b�g�̃V�F�A�Ɋ܂܂����̂���B
�P�̂��ᔄ�蕨�ɂ���Ȃ�Ȃ����̂��A�u�C�Â���������Ă܂����v�ĂȊ�����
�V�F�A�̔������߂Ă���āA����Ӗ����̐[����肾��ȁB
�P�̂��ᔄ�蕨�ɂ���Ȃ�Ȃ����̂��A�u�C�Â���������Ă܂����v�ĂȊ�����
�V�F�A�̔������߂Ă���āA����Ӗ����̐[����肾��ȁB
NVIDIA�͊i�ʂ��������Ō����Ă���
�뎚�ɐ���Ɋ��ݕt���Ă�Ȃ��B
���x�������ނƂ����A�킴�ƌ뎚���������Ƃ����B
���x�������ނƂ����A�킴�ƌ뎚���������Ƃ����B
568 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 15:48:10 ID:QutNOdX2
>>565
���ꂱ���R���f�B�e�B���̍ł��镨�ŁA�����Ă����ŏ\�����Ǝs��̑啔�����F�����Ă����Ԃ�
�V�F�A�Ɍ���Ă�킯��
�O�t���̍����\���i����ʑ�O�ɔ��킹�邾���̃R���e���c���܂��s�݁B
���ꂱ���R���f�B�e�B���̍ł��镨�ŁA�����Ă����ŏ\�����Ǝs��̑啔�����F�����Ă����Ԃ�
�V�F�A�Ɍ���Ă�킯��
�O�t���̍����\���i����ʑ�O�ɔ��킹�邾���̃R���e���c���܂��s�݁B
����544��ے肵�Ƃ�Ȃ�
�������ɗ�����
�������ɗ�����
����Ȃ̂ɖ���O����肻���ɂȂ�����
571 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 16:05:37 ID:QutNOdX2
>>569
�ے肷��������뎚�ȑO�̖�肶���
�ے肷��������뎚�ȑO�̖�肶���
���������̂Ȃ����g������ȁA�A��
[�ތ�]�u�c�Ƃ����ӂ��ɕ`�ʂ���v�̈Ӗ��ł�describe�������Ƃ���ʓI.
portray�͓���́i���ɂ悭�Ȃ��j�C���[�W����������悤�Ȃ�����,
depict�͓��ɏ������t��, �Ώۂ̐������p��`����悤�ׂ����`�ʂ��邱��.
�قȂ錾��ԂŊ��S�ɃC�R�[���ɂȂ�悤�ȒP��͒������̂��n���̌��t����
�f�[�^���^�X�N���ƌ��t�̈Ӗ����p��̂ق����D�悳��Ă��܂��s�v�c
portray�͓���́i���ɂ悭�Ȃ��j�C���[�W����������悤�Ȃ�����,
depict�͓��ɏ������t��, �Ώۂ̐������p��`����悤�ׂ����`�ʂ��邱��.
�قȂ錾��ԂŊ��S�ɃC�R�[���ɂȂ�悤�ȒP��͒������̂��n���̌��t����
�f�[�^���^�X�N���ƌ��t�̈Ӗ����p��̂ق����D�悳��Ă��܂��s�v�c
574 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 16:09:41 ID:QutNOdX2
>>572
������肪�Ȃ��Ǝv�����_�œ����悤�Ȏv�l�Ȃ낤��
������肪�Ȃ��Ǝv�����_�œ����悤�Ȏv�l�Ȃ낤��
���Ȃ݂�>554>573��Yahoo!���������p
���������̖������ؖ��ł����M���ɂ�G��Ȃ��Ƃ͎v��
577 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 16:15:04 ID:QutNOdX2
�������ˁA�����_�̃R���e���c�̕s�݂Ԃ�l�����DX10.1�Ή����悤�����܂����������Ȃ���
578 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 16:15:44 ID:QutNOdX2
describe�i�j
����ł�3D�v���̂قƂ�ǂ��I�����C���Q�[��������ȁB
�n�C�G���hPC�Q�[���͎��v�͂��邯�ǃj�b�`�B
�I�����C���Q�[���̏ꍇ�͕~���������邱�Ƃ��c�Ɖۑ��
�Ȃ邩��ADX11�Ȃ�Ę_�O�BDX10.1�ł��猙����B
������Ƃ����đΉ����Ȃ��Ă����Ƃ͎v��Ȃ����ǂˁB
�n�C�G���hPC�Q�[���͎��v�͂��邯�ǃj�b�`�B
�I�����C���Q�[���̏ꍇ�͕~���������邱�Ƃ��c�Ɖۑ��
�Ȃ邩��ADX11�Ȃ�Ę_�O�BDX10.1�ł��猙����B
������Ƃ����đΉ����Ȃ��Ă����Ƃ͎v��Ȃ����ǂˁB
�~���̍�����Intel�����߂�
Intel�����[�i�_
MMO�͕��ʃQ�[������G���W���ō����
Unreal�G���W���Ƃ���
�����`�ɂ̓O���t�B�b�N�G���W�������ǁA���ۂ�MMO����L�b�g
MMO�����Ђ͂��̃G���W������MMO����邩��A���̃G���W����DX10��11�ɑΉ����Ȃ���
DX10��11�̃Q�[���̐�����n�܂�Ȃ�
Unreal�G���W���Ƃ���
�����`�ɂ̓O���t�B�b�N�G���W�������ǁA���ۂ�MMO����L�b�g
MMO�����Ђ͂��̃G���W������MMO����邩��A���̃G���W����DX10��11�ɑΉ����Ȃ���
DX10��11�̃Q�[���̐�����n�܂�Ȃ�
�܂�9�Ȃ̂�
5000�����X�v���O���}���Ƃ������
5000�����X�v���O���}���Ƃ������
Unreal�G���W���Ȃg�����獂�����ď����ɂȂ�Ȃ���B
��ʓI�Ɏg���Ă�̂͊؍����̈����t���[�����[�N�B
�Q�[���V�X�e���܂ł�����x�g�ݍ��܂�Ă邩��A�ǂ��
�݂ȓ����悤�ȃQ�[�����ɂȂ�B
��ʓI�Ɏg���Ă�̂͊؍����̈����t���[�����[�N�B
�Q�[���V�X�e���܂ł�����x�g�ݍ��܂�Ă邩��A�ǂ��
�݂ȓ����悤�ȃQ�[�����ɂȂ�B
�K�v��������Ή����Ȃ�
�Ȃ�Ă̂�HD3870/3850���o��������łЂ�����Ȃ���NVIDIA�������Ă����Ƃ���
�ŁA���Ԃ����킯����
��������ȉ���Ȃ����@���Ŋ�^���Ԃɂ��ĘA���X�딚��
����σA�X�y�����҂͋C���������˃E���R���I������
�Ȃ�Ă̂�HD3870/3850���o��������łЂ�����Ȃ���NVIDIA�������Ă����Ƃ���
�ŁA���Ԃ����킯����
��������ȉ���Ȃ����@���Ŋ�^���Ԃɂ��ĘA���X�딚��
����σA�X�y�����҂͋C���������˃E���R���I������
����͓��{(�Ɗ؍�)�ŗ��s���Ă�MMO�̘b�����?
AMD�̕������̈ӎu����ɐ̂�����قȓ��{��PC�Q�[������Ȃ�Ċᒆ�ɂ���͂����Ȃ����B
AMD�̕������̈ӎu����ɐ̂�����قȓ��{��PC�Q�[������Ȃ�Ċᒆ�ɂ���͂����Ȃ����B
SSE�̘b���o������
AMD��CPU��SSSE3��4�ɑΉ�����̂ƁAIntel��GPU��DX10.1�ɑΉ�����̂͂ǂ����̃n�[�h���������������
AMD�͏o���邯�ǃ����b�g�����Ȃ����炵�Ȃ��AIntel�͖���������o���Ȃ����Ǝv����
����Ƃ��x�N�g�����j�b�g��SSE5��AVX�Ή��ɕύX����̂�������̂�SSE4�Ή��Ƃ����̂�
AMD��CPU��SSSE3��4�ɑΉ�����̂ƁAIntel��GPU��DX10.1�ɑΉ�����̂͂ǂ����̃n�[�h���������������
AMD�͏o���邯�ǃ����b�g�����Ȃ����炵�Ȃ��AIntel�͖���������o���Ȃ����Ǝv����
����Ƃ��x�N�g�����j�b�g��SSE5��AVX�Ή��ɕύX����̂�������̂�SSE4�Ή��Ƃ����̂�
�Ȃŋ߂�MMO�̓A�N�V�����F��������
�O�������Ȃ���サ�Ă邩�炱��܂ňȏ�ɃX�y�b�N���v������邩��
�I���{�V�F�A50%�ȏ゠��̂ɂ��������Ȃ���Ȃ�
�܂����̂ւ��Llano�������Ɋ��҂��Ƃ���
�O�������Ȃ���サ�Ă邩�炱��܂ňȏ�ɃX�y�b�N���v������邩��
�I���{�V�F�A50%�ȏ゠��̂ɂ��������Ȃ���Ȃ�
�܂����̂ւ��Llano�������Ɋ��҂��Ƃ���
�Ȃ��SSSE3��4�ɑΉ����Ȃ����ƂɂȂ��Ă���̂��Ӗ��킩���B
Llano�͌͂�ď������Ȃ���K10�n�R�A�̊g���łŒ�R�X�g�A
�łȂ�����ATI�n�̃O���t�B�b�N�Ƃ����茘���\���ŁA
�d�͊Ǘ���Intel�ɑ啪����������A�ߔN��AMD��CPU�̒��ł�
���\���������|�W�V�����ɂ��邾�낤�ȁB
�d�͏��Ȃ�����ꂾ�������\�̌���ɂȂ��邵�A
�Ԃ����Ⴏ�V�A�[�L�e�N�`������Ȃ���ʖڂ��݂����Ȏv�z�ɂ��܂��Ă�W�W�C�͊����B
�łȂ�����ATI�n�̃O���t�B�b�N�Ƃ����茘���\���ŁA
�d�͊Ǘ���Intel�ɑ啪����������A�ߔN��AMD��CPU�̒��ł�
���\���������|�W�V�����ɂ��邾�낤�ȁB
�d�͏��Ȃ�����ꂾ�������\�̌���ɂȂ��邵�A
�Ԃ����Ⴏ�V�A�[�L�e�N�`������Ȃ���ʖڂ��݂����Ȏv�z�ɂ��܂��Ă�W�W�C�͊����B
AMD��Llano�܂�K7�n�̃A�[�L�e�N�`�������X�Ђ��Â��Ă���Ƃ����̂Ȃ�A
Intel�͋ɒ[�Șb�A�Ԃ�NB�Ƃ������̂������ƁA
P6�n�̃A�[�L�e�N�`�������X�Ђ��Â��Ă���킯�ŁA���XAMD�������N���X�^�[�h�ȂǂƂ���
��ύX����������������������R���V���[�}�ɕ��y������K�v�͂Ȃ��B
�ނ���GPU�̓����ɒ��͂���K10�n���g�����Ȃ��瓬�������������ȁB
Intel�͋ɒ[�Șb�A�Ԃ�NB�Ƃ������̂������ƁA
P6�n�̃A�[�L�e�N�`�������X�Ђ��Â��Ă���킯�ŁA���XAMD�������N���X�^�[�h�ȂǂƂ���
��ύX����������������������R���V���[�}�ɕ��y������K�v�͂Ȃ��B
�ނ���GPU�̓����ɒ��͂���K10�n���g�����Ȃ��瓬�������������ȁB
>>587
�A���̉B���ʂŎ����ł��邱�Ƃ��m�F�ł���܂ł͊g�����Ă��邱�Ƃ��B���Ă����B
�����̃`�F�b�N�ȂǂɂQ�N���炢�̃X�p���͂���Ȃ̂ŁA���N��ɏo�܂��[�ƌ����Ă��A
���̗y���O�Ɍ��߂Ď������Ă���B
�ł����āA��������ɂ͒��O�ɋ����āA�I�}�C���A�R�����T�|�[�g�ł��ĂȂ����炤���̂b�o�t�����z���z��
�Ȃ�Č����Ă���B
�t�ɁA�����Ȋg�����`�l�c�����������Ƃ��ɂ́A�K���������邵�ȁB
�A���̉B���ʂŎ����ł��邱�Ƃ��m�F�ł���܂ł͊g�����Ă��邱�Ƃ��B���Ă����B
�����̃`�F�b�N�ȂǂɂQ�N���炢�̃X�p���͂���Ȃ̂ŁA���N��ɏo�܂��[�ƌ����Ă��A
���̗y���O�Ɍ��߂Ď������Ă���B
�ł����āA��������ɂ͒��O�ɋ����āA�I�}�C���A�R�����T�|�[�g�ł��ĂȂ����炤���̂b�o�t�����z���z��
�Ȃ�Č����Ă���B
�t�ɁA�����Ȋg�����`�l�c�����������Ƃ��ɂ́A�K���������邵�ȁB
AMD��Bulldozer�����PC�s��ŕ��y������C�͂���܂�Ȃ��Ǝv��
����ɁA�N���X�^�[�A�[�L�e�N�`���Ȃ̂�K10�����g�����W�X�^������ǂ����悤�Ƃ������ʂ��낤
�f���A���R�A�قǑ傫���Ȃ��AHTT�قnj������������Ȃ����\�ǂ������ȍ\�����Ǝv��
�ʂɌ������Ă���킯�ł��Ȃ��AAPU��O��Ƃ����ꍇ�ɁA
CPU�R�A���𐮐����Z�����̃}���`�R�A�ɂ���K�v�����邩��A
�F�X���������炱�̌`�ɂȂ����������낤�B
����ɁA�N���X�^�[�A�[�L�e�N�`���Ȃ̂�K10�����g�����W�X�^������ǂ����悤�Ƃ������ʂ��낤
�f���A���R�A�قǑ傫���Ȃ��AHTT�قnj������������Ȃ����\�ǂ������ȍ\�����Ǝv��
�ʂɌ������Ă���킯�ł��Ȃ��AAPU��O��Ƃ����ꍇ�ɁA
CPU�R�A���𐮐����Z�����̃}���`�R�A�ɂ���K�v�����邩��A
�F�X���������炱�̌`�ɂȂ����������낤�B
AMD��SSSE3��SSSE4.1�A4.2�ɑΉ�����C���Ȃ���Ȃ��́H
�Ή�����C����Ȃ�ASSE4A�Ȃ�ēƎ��ɂ��Ȃ����낤���B
�Ǝ��H����SSE5��߂����ǁAIntel��AVX�ɂȂ����߂�AMD���~�����̂́A
XOP�ȂǂœƎ��Ɏ������Ă��邵�B
�Ή�����C����Ȃ�ASSE4A�Ȃ�ēƎ��ɂ��Ȃ����낤���B
�Ǝ��H����SSE5��߂����ǁAIntel��AVX�ɂȂ����߂�AMD���~�����̂́A
XOP�ȂǂœƎ��Ɏ������Ă��邵�B
>>594
�Ή��͂����Ȃ��H�@�Ή�����ɂ��������Ƃ͂Ȃ����B
�����A���܂܂ł͖��������������ŁB
�l������̂́A�Ή�����ɂ͂�����x�ȏ��
�R�A��M��K�v������������Ƃ��H
�Ή��͂����Ȃ��H�@�Ή�����ɂ��������Ƃ͂Ȃ����B
�����A���܂܂ł͖��������������ŁB
�l������̂́A�Ή�����ɂ͂�����x�ȏ��
�R�A��M��K�v������������Ƃ��H
�Ǝ��K�i�͎g���Ȃ����Ă̂�AMD�̎咣�Ȃ̂ɂ�
�[���ALlano�̊J������SSE5�̂��肾��������
SSSE3, SSE4���Ԃɍ���Ȃ�������������B
Bulldozer�͎d�蒼�����Ēx�点������Ԃɍ������B
�����ABull�̕���SSSE3, SSE4���Ή����Ă�Ǝv���ˁB
�ԂƂ���AVX�����Ƃ����ƐF�X�s���������B
SSSE3, SSE4���Ԃɍ���Ȃ�������������B
Bulldozer�͎d�蒼�����Ēx�点������Ԃɍ������B
�����ABull�̕���SSSE3, SSE4���Ή����Ă�Ǝv���ˁB
�ԂƂ���AVX�����Ƃ����ƐF�X�s���������B
�l�\�z�ł�SSSE3�`AVX�ł�K10�R�A���J�����ł��������Ȃ��Ǝv���B
"���邦��"�͂���������B����l�^�Ƃ��Ėʔ��݂��Ȃ�����B
�d�g����Ȃ�����Ɩʔ��������ɔ���Ă�B
�d�g����Ȃ�����Ɩʔ��������ɔ���Ă�B
���[��A���Ⴀ�����t�ɊÂ��ĐV��̑�l�^���łĂ��Ȃ��̂ł��炭�͋x�Ƃ����B
601 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 21:36:52 ID:QutNOdX2
>>587
�܂��A���̂ւ�̖��߂��̂��̂���������̂͂���Ȃɓ�Փx�����Ȃ��ł��傤�B
��OPs�����f���o���ĉ��T�C�N���������Ăł����s�o����A�����������ƂɂȂ邩��ˁB
�u�����Ɏ��s�o��������ɂ���v���Ă��ƂɂȂ�Ǝ��ۖ�薳���ł���B
SSE4���g����Ńp�t�H�[�}���X�̗v�ɂȂ�̂́ASIMD���W�X�^/GPR�Ԃ̘A�g�B
���Ƃ��Ε������SIMD���Z���j�b�g�ł�点����Ƃ��ł���悤�ɂȂ����B
SIMD���W�X�^�̊e�v�f���r���ĕ�������t���O���X�V���閽�߂��lj����ꂽ��
�f�[�^�������߂��啝�Ɋg�[����Ă���B
�����AMD��SIMD�̎����͂ƌ����ƁA�E�E�E
SSE2�܂łɎ�������Ă�movd xmm, r32�ł��牽�T�C�N�����v����B�`���̕��U�N���X�^�\���̏h���B
�Ȃ��Ȃ�A�����I�Ƀ��W�X�^�t�@�C���E���s�p�C�v���C��������Ă����ɁA�����Ƃ�Ȃ��Ƃ����Ȃ�����B
Shanghai�ł��炱��ȍ�������������ˁB
> 979 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.42ns= 1.00c
> 980 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 1.18ns= 2.83c
> 981 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 4.79ns= 11.5c T: 1.08ns= 2.58c
http://www.freeweb.hu/instlatx64/
Intel��CPU�����C�e���V1�ł���Ă鏈���ɂ��ꂾ������������A���肷���XMM���W�X�^�ɓ]�����邾����
���\���X�ɂȂ肩�˂Ȃ��B
�����U�N���X�^�Z�p�ł��̒��x�̎��������o���Ȃ�AMD�̃m�E�n�E��������
�@Bulldozer��2�̐����N���X�^��A�g����Reverse-HT�i�ϑz�j���Ƃ�
�@�Ƃ��������A�܂������������l�ɕڂ͑łC�͂Ȃ�
���ꂩ�瓖����O������AVX���̂�Intel�̂��̂����x����B
Intel�̂��̂�1�R�A������256�r�b�gSIMD�_���Z�p���߂�3����/clk���s�ł��邪
AMD�̂�128�r�b�gSIMD���j�b�g�~2������ˁB
�܂��A���̂ւ�̖��߂��̂��̂���������̂͂���Ȃɓ�Փx�����Ȃ��ł��傤�B
��OPs�����f���o���ĉ��T�C�N���������Ăł����s�o����A�����������ƂɂȂ邩��ˁB
�u�����Ɏ��s�o��������ɂ���v���Ă��ƂɂȂ�Ǝ��ۖ�薳���ł���B
SSE4���g����Ńp�t�H�[�}���X�̗v�ɂȂ�̂́ASIMD���W�X�^/GPR�Ԃ̘A�g�B
���Ƃ��Ε������SIMD���Z���j�b�g�ł�点����Ƃ��ł���悤�ɂȂ����B
SIMD���W�X�^�̊e�v�f���r���ĕ�������t���O���X�V���閽�߂��lj����ꂽ��
�f�[�^�������߂��啝�Ɋg�[����Ă���B
�����AMD��SIMD�̎����͂ƌ����ƁA�E�E�E
SSE2�܂łɎ�������Ă�movd xmm, r32�ł��牽�T�C�N�����v����B�`���̕��U�N���X�^�\���̏h���B
�Ȃ��Ȃ�A�����I�Ƀ��W�X�^�t�@�C���E���s�p�C�v���C��������Ă����ɁA�����Ƃ�Ȃ��Ƃ����Ȃ�����B
Shanghai�ł��炱��ȍ�������������ˁB
> 979 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.42ns= 1.00c
> 980 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 1.18ns= 2.83c
> 981 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 4.79ns= 11.5c T: 1.08ns= 2.58c
http://www.freeweb.hu/instlatx64/
Intel��CPU�����C�e���V1�ł���Ă鏈���ɂ��ꂾ������������A���肷���XMM���W�X�^�ɓ]�����邾����
���\���X�ɂȂ肩�˂Ȃ��B
�����U�N���X�^�Z�p�ł��̒��x�̎��������o���Ȃ�AMD�̃m�E�n�E��������
�@Bulldozer��2�̐����N���X�^��A�g����Reverse-HT�i�ϑz�j���Ƃ�
�@�Ƃ��������A�܂������������l�ɕڂ͑łC�͂Ȃ�
���ꂩ�瓖����O������AVX���̂�Intel�̂��̂����x����B
Intel�̂��̂�1�R�A������256�r�b�gSIMD�_���Z�p���߂�3����/clk���s�ł��邪
AMD�̂�128�r�b�gSIMD���j�b�g�~2������ˁB
����������
�ԍ�����т���
604 �F,,�E�L�́M�E,,�j��-�������F2010/02/24(��) 21:47:12 ID:QutNOdX2
>>597
AVX�d�l���ɂ�SSE4.2�܂ł�VEX�G���R�[�f�B���O�ł��܂܂�Ă邩��
AMD�������I����Ȃ��Ƀt���Z�b�g��AVX���T�|�[�g����Ƃ����Ȃ炻�̂ւ���T�|�[�g�Ȃ�ł���B
AES-NI/PCLMULQDQ�Ɋւ��Ă�AVX�Ə������肪�Ɨ����Ă邩�炻�̌���ł͂Ȃ����ǂˁB
45nm��Bulldozer���_�ł�SSSE3���悤�₭�T�|�[�g�\�肾�����B
���ƈꕔSSE4.1�̖��߂��܂܂�Ă���
AVX�d�l���ɂ�SSE4.2�܂ł�VEX�G���R�[�f�B���O�ł��܂܂�Ă邩��
AMD�������I����Ȃ��Ƀt���Z�b�g��AVX���T�|�[�g����Ƃ����Ȃ炻�̂ւ���T�|�[�g�Ȃ�ł���B
AES-NI/PCLMULQDQ�Ɋւ��Ă�AVX�Ə������肪�Ɨ����Ă邩�炻�̌���ł͂Ȃ����ǂˁB
45nm��Bulldozer���_�ł�SSSE3���悤�₭�T�|�[�g�\�肾�����B
���ƈꕔSSE4.1�̖��߂��܂܂�Ă���
AMD�������Z�p��Intel�Ɉ���x��Ă�̂��l����ƁA�ǂ��������Ȃ��Ⴂ���Ȃ��͎̂d���������낤��
K10�R�A���ƁA128bit��SIMD���j�b�g���R�A��1/4���߂�
���ꂪ256bit�Ȃ�1/3�A512bit�Ȃ�1/2�ɂ��Ȃ�
�R�A�̃T�C�Y�����d�͂��l������SIMD���j�b�g�����̂���Ԍ��ʓI
K10�R�A���ƁA128bit��SIMD���j�b�g���R�A��1/4���߂�
���ꂪ256bit�Ȃ�1/3�A512bit�Ȃ�1/2�ɂ��Ȃ�
�R�A�̃T�C�Y�����d�͂��l������SIMD���j�b�g�����̂���Ԍ��ʓI
��ڽ�q�ڂɂ�SIMM��SIMD�̊��Ⴂ����������I�u�Ԃ̃��O�i�G�����h�^���h�ƌĂ�Ă�������̃��O�j
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
>>605
���A����ȂɃf�P�G�́H
�J���J���ɍœK�����Ȃ��ƃX�J�X�J���Ƃ�
GPU���Ⴀ�S�Ď�������đS�ăX�J�����j�b�g�ɂ����Ƃ�����
�\��SIMD���j�b�g���H
�ق�Ɨv��Ȃ��q���ۂ���
���A����ȂɃf�P�G�́H
�J���J���ɍœK�����Ȃ��ƃX�J�X�J���Ƃ�
GPU���Ⴀ�S�Ď�������đS�ăX�J�����j�b�g�ɂ����Ƃ�����
�\��SIMD���j�b�g���H
�ق�Ɨv��Ȃ��q���ۂ���
GPU�őS���X�J���Ȃ�đ��݂��邩�H
SIMD�̓T�^�Ⴞ�Ǝv����
SIMD�̓T�^�Ⴞ�Ǝv����
ttp://pc.watch.impress.co.jp/docs/2008/0707/kaigai_02l.gif
ttp://www.4gamer.net/games/050/G005004/20080614003/
AMD��VLIW�ɂ�������
NV�́ux86�R�A��ALU�ł̕��Z�v�݂����ȏ��������Ă���炵��
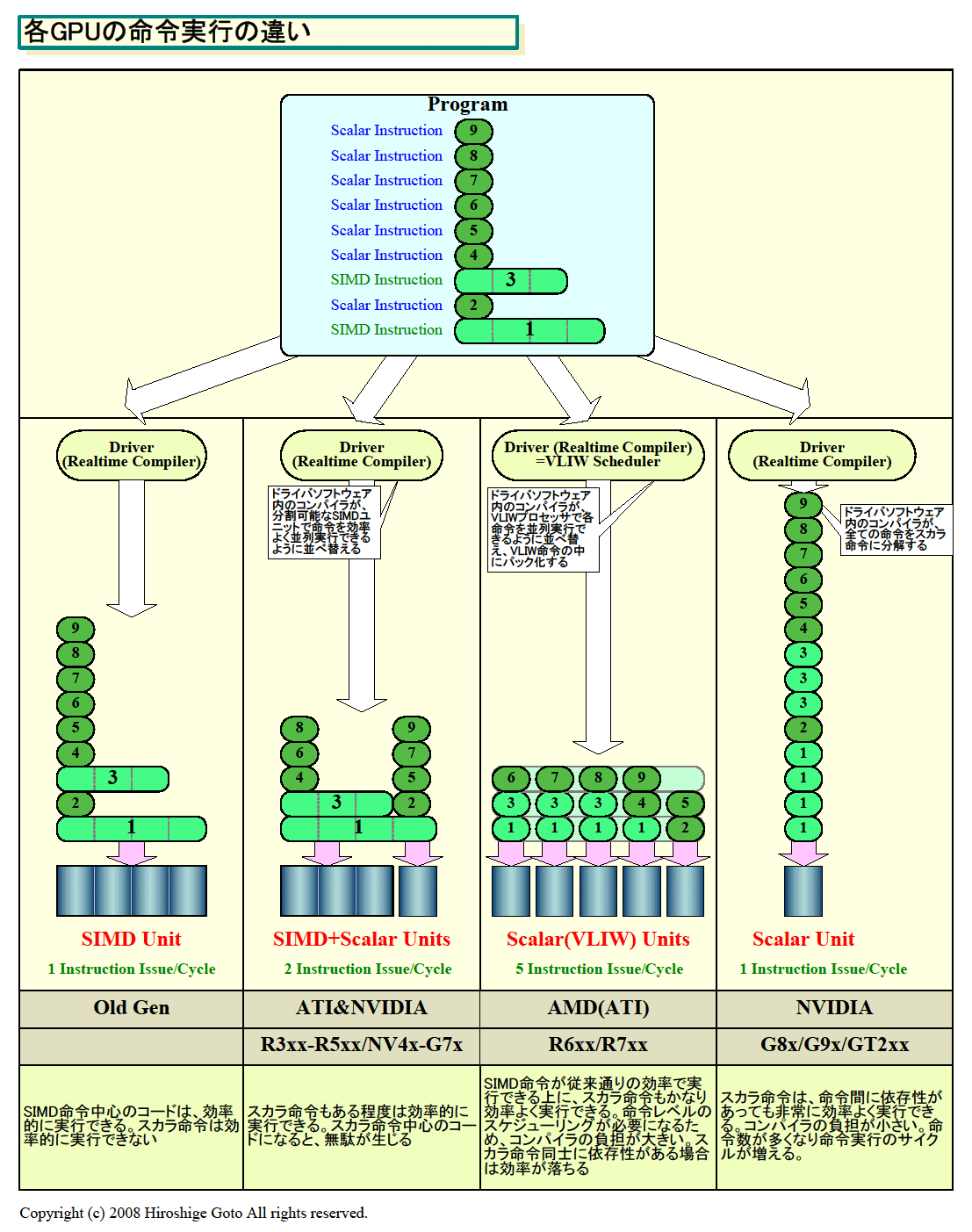{kind=link}
ttp://www.4gamer.net/games/050/G005004/20080614003/
AMD��VLIW�ɂ�������
NV�́ux86�R�A��ALU�ł̕��Z�v�݂����ȏ��������Ă���炵��
>>590
�h���\���������h�|�W�V�����ǂ��납���N�̑�{������
Bulldozer��蔄���v�f�Ă���B
����Athlon II�̉��i�тœ���������ԈႢ�Ȃ������B
�h���\���������h�|�W�V�����ǂ��납���N�̑�{������
Bulldozer��蔄���v�f�Ă���B
����Athlon II�̉��i�тœ���������ԈႢ�Ȃ������B
����܂ł̎��т���AAVX�Ƃ��g�����߂��傫�����y���邱�Ƃ�
�Ȃ����������ǁA����Ԃ����ꂭ�炢�����ł��邱�Ƃ��Ȃ��Ȃ����B
�����������Ƃł���B�R�A���̂��̂̉��ǂ�g���ł͑傫�����\��
�����グ��悤�ȋZ�p�͂قڏo�s�����āA�v���Z�X�k�����炢����
�c���ĂȂ��B
�Ȃ����������ǁA����Ԃ����ꂭ�炢�����ł��邱�Ƃ��Ȃ��Ȃ����B
�����������Ƃł���B�R�A���̂��̂̉��ǂ�g���ł͑傫�����\��
�����グ��悤�ȋZ�p�͂قڏo�s�����āA�v���Z�X�k�����炢����
�c���ĂȂ��B
>>608
�t����B
SIMD��VLIW�g���Ă�GPU�Ȃ�ĕ��������������B
16bit���Z���32bit���Z���SIMD�̂���SSE5�ł���Ǝ����������B
�t����B
SIMD��VLIW�g���Ă�GPU�Ȃ�ĕ��������������B
16bit���Z���32bit���Z���SIMD�̂���SSE5�ł���Ǝ����������B
GPU��SIMD���j�b�g�̌ł܂�Ȃ��ǁA����Ȋ�{�I�Ȃ��Ƃ�
�킩���ĂȂ�>>613�͏��w�����H
�킩���ĂȂ�>>613�͏��w�����H
�Ƃ肠����GPU��SIMD���Ƃ����L�������Ă���
AMD
ttp://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
Nvidia
ttp://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
AMD
ttp://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
Nvidia
ttp://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
SIMD��VLIW���g���ĂȂ�GPU��T���ق�����ρi�ŋ߂́j
�u�X�J���v���Z�b�T��SIMD�\���v�̌���>610����ςނ���
i5 650
981 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.13ns= 0.44c
982 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.12ns= 0.40c
983 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 1.19ns= 4.0c T: 0.17ns= 0.58c
nano
979 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.62ns= 1.00c
980 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.62ns= 1.00c
981 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 4.33ns= 7.0c T: 0.62ns= 1.00c
phenom2
973 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.33ns= 1.00c
974 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.94ns= 2.83c
975 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 3.83ns= 11.5c T: 0.64ns= 1.92c
981 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.13ns= 0.44c
982 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.12ns= 0.40c
983 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 1.19ns= 4.0c T: 0.17ns= 0.58c
nano
979 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.62ns= 1.00c
980 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.62ns= 1.00c
981 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 4.33ns= 7.0c T: 0.62ns= 1.00c
phenom2
973 SSE2 :MOVD r32, xmm L: [diff. reg. set] T: 0.33ns= 1.00c
974 SSE2 :MOVD xmm, r32 L: [diff. reg. set] T: 0.94ns= 2.83c
975 SSE2 :MOVD r32, xmm+MOVD xmm, r32 L: 3.83ns= 11.5c T: 0.64ns= 1.92c
�����E�E�E
�m���ɂ��ꂶ��x���`�ō����t�����
����Sandra�����肶��
�m���ɂ��ꂶ��x���`�ō����t�����
����Sandra�����肶��
AMD�����l�[�����@��߂Ă�����Ƃ���
CPU����Ȃ�
CPU����Ȃ�
�T���h����FPU�Ȃ̓}�W�Ő�]�I�ȍ������Ă邩���
i7��Phenom�U����ׂĂ݂�Ƃ����˥��
i7��Phenom�U����ׂĂ݂�Ƃ����˥��
CPU�Ń��l�[���Ƃ�������
���W�X�^���l�[�~���O�����
���W�X�^���l�[�~���O�����
���W�X�^���l�[���ł��Ȃ��b�o�t�͌��ׂb�o�t�ƌĂ�ł��ߌ�����Ȃ��Ȃ�
Bulldozer�͔����̊֘A�ɓ������Ă���
��ƂȂ��x���ړI�łł����グ�Ă���
����������A���ۂɏo��킯�������B
��������ȃA�[�L�e�N�`���̐��i���o�ׂ����
���\�Ȃ�Đ�ł�킯���Ȃ��B
�����d�d�Ƃ������傾��Bulldozer�Ȃ��
��ƂȂ��x���ړI�łł����グ�Ă���
����������A���ۂɏo��킯�������B
��������ȃA�[�L�e�N�`���̐��i���o�ׂ����
���\�Ȃ�Đ�ł�킯���Ȃ��B
�����d�d�Ƃ������傾��Bulldozer�Ȃ��
�G���搶���Ƃ߂���J�l�ł��B
�ŏ��͖{���ɐ��\���o��A�[�L�e�B�N�`���̗\��ō��n�߂��낤����
�ŏ������x�����肾���������d�d�ƈꏏ�ɂ���̂͂ǂ����ƁB
�܂����ۂɂ�>>601
> �����U�N���X�^�Z�p�ł��̒��x�̎��������o���Ȃ�AMD�̃m�E�n�E��������
> �@Bulldozer��2�̐����N���X�^��A�g����Reverse-HT�i�ϑz�j���Ƃ�
���������A���̒�����Ă݂Ȃ��Ƃ킩��Ȃ����Ƃ�����A�Ƃ������Ƃ��B
�ŏ������x�����肾���������d�d�ƈꏏ�ɂ���̂͂ǂ����ƁB
�܂����ۂɂ�>>601
> �����U�N���X�^�Z�p�ł��̒��x�̎��������o���Ȃ�AMD�̃m�E�n�E��������
> �@Bulldozer��2�̐����N���X�^��A�g����Reverse-HT�i�ϑz�j���Ƃ�
���������A���̒�����Ă݂Ȃ��Ƃ킩��Ȃ����Ƃ�����A�Ƃ������Ƃ��B
nano�����̂�
>618
��������Đ����o�����Ƃ������Ƃ�������ȁi��j
��������Đ����o�����Ƃ������Ƃ�������ȁi��j
��������������
"�ނ���`�ƌ�����"�I
�_�O���t�̏o�Ԃ���Ȃ���
"�ނ���`�ƌ�����"�I
�_�O���t�̏o�Ԃ���Ȃ���
���Ȃ݂ɁA���ɏo����Ă�nano�̓v���t�F�b�`��������
�����Ŕ�r���Ă���̂�肳��ɒx��
ttp://www.viatech.co.jp/jp/products/processors/nano/
�i������X���C�h���Ń��U���U�v���t�F�b�`�L���Ƃ������Ă�j
C3�X�����Ⴞ���ԑO��MSR��������
�L���ɂ�����@���������Ă邯��
�����Ŕ�r���Ă���̂�肳��ɒx��
ttp://www.viatech.co.jp/jp/products/processors/nano/
�i������X���C�h���Ń��U���U�v���t�F�b�`�L���Ƃ������Ă�j
C3�X�����Ⴞ���ԑO��MSR��������
�L���ɂ�����@���������Ă邯��
SSE�ɗ͓��ꂽ���Ȃ���ATi��������Ȃ����H
GPGPU�����H���͂ǂ����m��I����������
GPU��V�K�J������̗̖͂���AMD�͔����Ƃ����`�ɂȂ��������ł�
�����I�Ȋϓ_���厖�����nj���Z���I�Ɍ��ʂ��o�Ă��������ł����
GPU��V�K�J������̗̖͂���AMD�͔����Ƃ����`�ɂȂ��������ł�
�����I�Ȋϓ_���厖�����nj���Z���I�Ɍ��ʂ��o�Ă��������ł����
CPU����ɔ�ׂ���GPU�̔���͔��X������̂��B
����Ȃ̂�ATI�����ɔ���Ȋz�����Ă�����������͖������낤�B
����Ȃ̂�ATI�����ɔ���Ȋz�����Ă�����������͖������낤�B
>>633
IT�֘A��Ƃ���Ɖ��l�i�������z�j�ō�����������ɔ������������
�����A�������Ȃ������猻��AMD�����݂��ĂȂ�������������Ȃ��c
IT�֘A��Ƃ���Ɖ��l�i�������z�j�ō�����������ɔ������������
�����A�������Ȃ������猻��AMD�����݂��ĂȂ�������������Ȃ��c
�V�K�ɋ����͂̂���GPU���J������̂�����Ȃ̂́A
Intel�̎S������Ă��A�����ɂȂ��Ă錻�݂̃O���t�B�b�N�`�b�v�s������Ă����炩�B
�����ɑ喇�͂������͎̂��������A����ATI�����ĂȂ����
���������Ƌꋫ�ɗ�������Ă������낤�ȁB
Intel�̎S������Ă��A�����ɂȂ��Ă錻�݂̃O���t�B�b�N�`�b�v�s������Ă����炩�B
�����ɑ喇�͂������͎̂��������A����ATI�����ĂȂ����
���������Ƌꋫ�ɗ�������Ă������낤�ȁB
>>633
x86SIMDvsGPGPU�̐킢�͂��ꂩ�炾
x86SIMDvsGPGPU�̐킢�͂��ꂩ�炾
637 �FSocket774�F2010/02/25(��) 15:12:02 ID:455fafEZ
>>579
�������MMO��MO�͌��\64bit��Windows�V�ɑΉ����Ă���Ή��\�肾�����肷�邼�BVista����Ƃ͂��炢�Ⴂ��w
FF11�ARO�A���l�Q�AGNO3�B���ƕۏ��ĂȂ����Ǒ�q�C��PSU
64bit�V�ɑΉ�����̂�DirectX11�ɑΉ����Ȃ��̂��ς��Ǝv����
�܂��X�y�b�N�����ł�����MMO��11�͂����11�ɑΉ��͂��ĂĂ����܂ł����Ă��Œ�C����9.0c�Ȃ͕̂K�R�ƌ������w
�������MMO��MO�͌��\64bit��Windows�V�ɑΉ����Ă���Ή��\�肾�����肷�邼�BVista����Ƃ͂��炢�Ⴂ��w
FF11�ARO�A���l�Q�AGNO3�B���ƕۏ��ĂȂ����Ǒ�q�C��PSU
64bit�V�ɑΉ�����̂�DirectX11�ɑΉ����Ȃ��̂��ς��Ǝv����
�܂��X�y�b�N�����ł�����MMO��11�͂����11�ɑΉ��͂��ĂĂ����܂ł����Ă��Œ�C����9.0c�Ȃ͕̂K�R�ƌ������w
64bit��Win7�œ����悤�C�����Ă��邾���ŁA64bit�l�C�e�B�u�ɏ��������Ă���̂Ƃ͈Ⴄ��Ȃ��́H
Vista����Ƃ́c����
Vista�̍���POL�����Ή�������������
��������N���C�A���g�X�V����Ε��ʂɓ�������
���g��32bit�����炻���܂�Vista�œ�������
Vista�œ�����7�œ����Ȃ��Ȃ邱�Ƃ��Ȃ��낤
Vista�̍���POL�����Ή�������������
��������N���C�A���g�X�V����Ε��ʂɓ�������
���g��32bit�����炻���܂�Vista�œ�������
Vista�œ�����7�œ����Ȃ��Ȃ邱�Ƃ��Ȃ��낤
48�R�ACPU�@Many-core
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/1.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/2.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/6.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/7.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/12.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/1.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/2.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/6.jpg
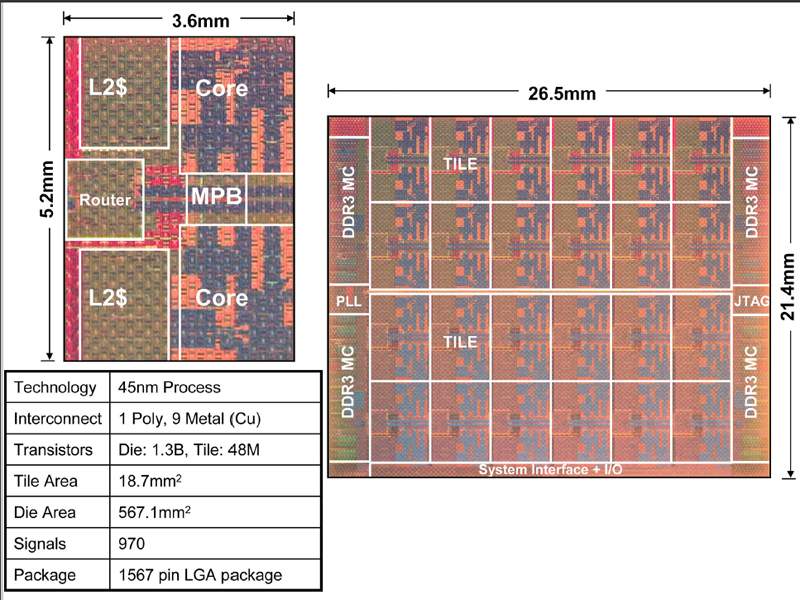{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/7.jpg
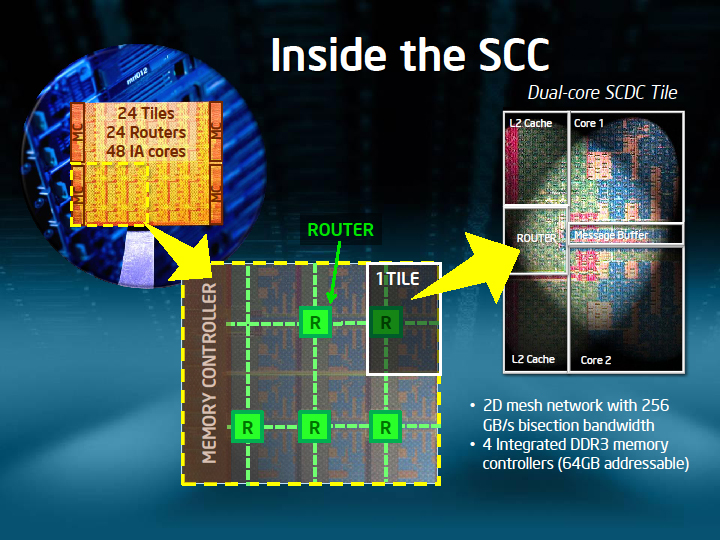{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/349/232/12.jpg
{kind=link}
������ƕ����Ă����
�܂�AMD���z���𐂂ꗬ���n�߂���
�U�R�A��4���ɔ��\����Ƃ��R�����n�߂���
�܂�AMD���z���𐂂ꗬ���n�߂���
�U�R�A��4���ɔ��\����Ƃ��R�����n�߂���
�G���N���u�[�������������Ɏ����ɓ˂��h�����������Ȃ��Ă������
���x���x�̌J��Ԃ��Ńu�[�������𓊂���̂��ʓ|�������Ȃ������H
���x���x�̌J��Ԃ��Ńu�[�������𓊂���̂��ʓ|�������Ȃ������H
���́[AMD��CPU���_�����ăX���ǂ��ł��������H
�����d�g�E�E�E
6�R�A�͔����ς�
6�R�A�͔����ς�
�����ł���
���i��r�T�C�g���m��Ȃ��Ȃ�ċC�������߂���
���ꌩ�ď��ł��Ă��炢��������
ttp://www.coneco.net/specList.asp?FREE_WORD=&DISPLAY=20&SPEC_ORDER=DEF&LOWPRICE=&HIPRICE=&MAKER_NAME=&OP1=Opteron&OP2=&OP3=&OP4=&OP5=&SPEC=1&ORDER=&CATEGORY1=0150&CATEGORY2=10&CATEGORY3=10&SID=CO&SHOP_ID=&LIST_KIND=0
���ꌩ�ď��ł��Ă��炢��������
ttp://www.coneco.net/specList.asp?FREE_WORD=&DISPLAY=20&SPEC_ORDER=DEF&LOWPRICE=&HIPRICE=&MAKER_NAME=&OP1=Opteron&OP2=&OP3=&OP4=&OP5=&SPEC=1&ORDER=&CATEGORY1=0150&CATEGORY2=10&CATEGORY3=10&SID=CO&SHOP_ID=&LIST_KIND=0
�E�C���X�T�C�g�\���
NOD32�Ŗh��
NOD���ᖳ�����낗
���x�̓u���N���ނ̂��H
NOD32�Ȃ���S
NOD32�Ȃ���S
Magny-Cours���낵��������
AMD�͏œy��������Ȃ̂���
AMD�͏œy��������Ȃ̂���
Opteron�̃V�F�A����ςȂ��ƂɂȂ��Ă邩���
���肪Beckton���ƍl����Ƃ���ł��L�c�C��Ȃ���
���肪Beckton���ƍl����Ƃ���ł��L�c�C��Ȃ���
Opteron�̃V�F�A�Ȃ�č����̂�
1%���Ȃ�����
�o�J���x����Ĕ������̂Ƒ��ꌈ�܂��Ă���w
1%���Ȃ�����
�o�J���x����Ĕ������̂Ƒ��ꌈ�܂��Ă���w
�����͈̂�N�O�̃`�b�v�̃j�R�C�`�����炾��B
�m�n�c�R�Q�g���Ă�o�J�Ȃ�Ă܂�����́H
>>662
�������Ė��߂ł����H
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
�������Ė��߂ł����H
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
���肪�Ƃ��O�O
eDRAM�̏ڂ�����킩�邩�炤�ꂵ����
eDRAM�̏ڂ�����킩�邩�炤�ꂵ����
�{�������ɗ���z����
���������Ȃ���Ȃ�w
���Ɛ���Ă����w
���������Ȃ���Ȃ�w
���Ɛ���Ă����w
�����Ő���Ă�z�͒N�ЂƂ肢�Ȃ���O�O
i7 920�a�s�n�}�V����GF9600GT�@�h128bit�h�̐_�I�v�V������I�����čw�������C�P�k�}����C
��������̉��d�g�𐂂ꗬ���Ă�݂���������
i7 920�a�s�n�}�V����GF9600GT�@�h128bit�h�̐_�I�v�V������I�����čw�������C�P�k�}����C
��������̉��d�g�𐂂ꗬ���Ă�݂���������
>>666
�N���悻��w
�N���悻��w
>>667
����H�@�����̃l�^�ɖ����o�Ȃ́H
����H�@�����̃l�^�ɖ����o�Ȃ́H
��������^�X���ŃC�P�k�}�ɔF���ł��Ȃ�����������ċ�������C������
�{�l�͂悭�킩���Ă�͂�������GF9600GT�n��������҂͂��Ȃ��ł����H���ĕ����Ă݂�Ƃ�����
>>669
Xeon����Ȃ��Ƃ����Ȃ����R���Ă���́Hi7�Ƃ��n�R�l�̎������H����ϒᐫ�\�Ȃ́H
�悭�킩��Ȃ�����Xeon�Ƃ̔�r�ŋ����Ă���Ȃ��H
Xeon����Ȃ��Ƃ����Ȃ����R���Ă���́Hi7�Ƃ��n�R�l�̎������H����ϒᐫ�\�Ȃ́H
�悭�킩��Ȃ�����Xeon�Ƃ̔�r�ŋ����Ă���Ȃ��H
�E�ۏI��
9600GT128bit�ƎG����������R�[�����Ă�����������
���݂̓S�~����
676 �FSocket774�F2010/02/26(��) 01:12:07 ID:GgLocYBh
�����r�[�݂����ɁAK6�����܂̃v���Z�X�ō��Έ�_�C�ɉ����H
���\�����낤���ǁE�E�E
�����̃}���`�R�ACPU�̖��̓f�[�^�̐���������Ȃ����ȁH
Fermi����r�[�����Ă�ƁA��ʂ̃R�A�ƕ��U�L���b�V�����o�X�Ōq���ƁA�������d�C�ƃV���R����n�����Ă�悤�ȋC������
���Z��̕����ł͏���d�̗͂\�����~�X������͂��Ȃ��Ǝv������A���͂����Ȃ�Ȃ�����
Bulldozer��2�R�A��1���W���[�����Ă̂́A�o�X�̐��𑝂₳���ɃR�A�̐��𑝂₷���߂̂��̂���Ȃ��������ċC������
�����̃}���`�R�ACPU�̖��̓f�[�^�̐���������Ȃ����ȁH
Fermi����r�[�����Ă�ƁA��ʂ̃R�A�ƕ��U�L���b�V�����o�X�Ōq���ƁA�������d�C�ƃV���R����n�����Ă�悤�ȋC������
���Z��̕����ł͏���d�̗͂\�����~�X������͂��Ȃ��Ǝv������A���͂����Ȃ�Ȃ�����
Bulldozer��2�R�A��1���W���[�����Ă̂́A�o�X�̐��𑝂₳���ɃR�A�̐��𑝂₷���߂̂��̂���Ȃ��������ċC������
>>677
��U�̗p���������O�o�X���A���̎g�����͂������ʎ̂Ă��݂�����
���Z�@�����łȂ��o�X���܂߂đ��R�A���ł̃V���R��/�d�͂̌�������}�������ʂ��Ă��Ƃ��ȁH
��U�̗p���������O�o�X���A���̎g�����͂������ʎ̂Ă��݂�����
���Z�@�����łȂ��o�X���܂߂đ��R�A���ł̃V���R��/�d�͂̌�������}�������ʂ��Ă��Ƃ��ȁH
K-6�@350nm�@162mm2
�P���v�Z����ƁA45nm�ŃR����������ꍇ�A�ʐς͂��悻�U�O���̂P�A�܂�2.7mm2�B
���P���v�Z��270mm2�i��17mm�p�j�̃_�C�ɂP�O�O���B
�P���v�Z����ƁA45nm�ŃR����������ꍇ�A�ʐς͂��悻�U�O���̂P�A�܂�2.7mm2�B
���P���v�Z��270mm2�i��17mm�p�j�̃_�C�ɂP�O�O���B
�g�����W�X�^��2237��i4004��40���R�A��45nm 300mm2
���O��D�����ȁB���炩�ɓ��������X�Ȃ̂ɁB
>>676
�P���Ɍ��s�v���Z�X�ɃV�������N���āA
�R���V���[�}�[�����ŋ��e�����_�C�T�C�Y�ɕ~���l�߂��炢���ڂ���ĂȂ�>>679
�ܘ_�����Ȃ��̂ʼn��̈Ӗ����Ȃ��B
�e�R�A��K6�x�[�X�̃}���`�R�A�i���j�C�R�A�jCPU���Ȃ�
���R�A���炢�̂�����̂��ĈӖ��Ȃ�A����肩�Ȃ�T���߂ɂ��Ȃ��ƒ��╔�����j�]����B
Intel��48�R�A����`�b�v�݂����ȑS���قȂ����A�v���[�`�������K�v�B
>>676
�P���Ɍ��s�v���Z�X�ɃV�������N���āA
�R���V���[�}�[�����ŋ��e�����_�C�T�C�Y�ɕ~���l�߂��炢���ڂ���ĂȂ�>>679
�ܘ_�����Ȃ��̂ʼn��̈Ӗ����Ȃ��B
�e�R�A��K6�x�[�X�̃}���`�R�A�i���j�C�R�A�jCPU���Ȃ�
���R�A���炢�̂�����̂��ĈӖ��Ȃ�A����肩�Ȃ�T���߂ɂ��Ȃ��ƒ��╔�����j�]����B
Intel��48�R�A����`�b�v�݂����ȑS���قȂ����A�v���[�`�������K�v�B
�ߋ���CPU�Ń��j�[�R�A���Ƃ�����AthlonXP���炢����Ȃ��́B
�����180nm��12x16mm���炢����������45nm�ɂ����16�R�A
���炢�͌y����肻�����B
�����180nm��12x16mm���炢����������45nm�ɂ����16�R�A
���炢�͌y����肻�����B
���������̂܂�����ŁA�y�������Ă邾������Ȃ��̂��H
�펯�ӂ��Ɍ��̂͒p��������
�펯�ӂ��Ɍ��̂͒p��������
�z���w���v�Z�ɓ���Ȃ��ƂȁB
k6�͂T�w���������Bphenom�͉��w�������B
k6�͂T�w���������Bphenom�͉��w�������B
�|���b�N�̖@���ƃV���v���R�A��A�Ă��Ă��듚����͂ǂ�������
686 �FSocket774�F2010/02/26(��) 02:20:02 ID:6nio2p+y
��
>>601�̃T�C�g�eop�̎��s���Ԃ��������ĕ֗�����
movupd�̎g�����������Ȃ��������ǁA
���ꌩ�ĉ��߂�movapd�����o���Ă��������ȂƎv������
movupd�̎g�����������Ȃ��������ǁA
���ꌩ�ĉ��߂�movapd�����o���Ă��������ȂƎv������
�}�j�N������4ch������2G��8�R�A�ł��p�r���悶��{�̃p�t�H�[�}���X���������
�܂�MCM�Ń����R���{�������
�u�p���������ނ̐^����AMD��������v�Ȃ�Ęb�ʼn��Ő���オ���Ă�́H
�C���e���̒p���������j�R�C�`�b�o�t�̃}�l������Magny-Cours���o������B
Hypertransport��FSB�Ɣ�ׂ�͉̂��z��
DT�����ŏ����_�C�T�C�Y�ɗ]�T�̂���������r���Ńj�R�C�`�������̒p��������
�܂��m���ɏ����͐^�����Ă�Ȃ�
�܂��m���ɏ����͐^�����Ă�Ȃ�
Core2Quad���j�R�C�`����ˁB
Intel��CPU�Ԑڑ���P2P�ɂȂ��āA�}���`�v���Z�b�T�\���ł̕s�����Ȃ��Ȃ邾�낤
����_�C��XeonMP�ɑR����ɂ́A
AMD�Ƃ��Ă�MCM��1�p�b�P�[�W�ӂ�̃R�A�����₷�̂��A�����I��������Ȃ��́H
Nehalem-EX�͈Ⴄ���ǁAIntel�̃C���h�E�o���K���[���`�[���݂����ɁA
�I�p�ɔh���_�C����ƃ`�[����ʂɍ��]�T�Ȃ�ĂȂ����낤���B
����_�C��XeonMP�ɑR����ɂ́A
AMD�Ƃ��Ă�MCM��1�p�b�P�[�W�ӂ�̃R�A�����₷�̂��A�����I��������Ȃ��́H
Nehalem-EX�͈Ⴄ���ǁAIntel�̃C���h�E�o���K���[���`�[���݂����ɁA
�I�p�ɔh���_�C����ƃ`�[����ʂɍ��]�T�Ȃ�ĂȂ����낤���B
�_�C�̋��剻���Ă���܂�悭�Ȃ����ƂȂ��ǂˁB
�悭�Ȃ��ƒm����G�ȃg���[�h�I�t���s�������ʂ�
�����Ȃ�̂ł����āB
�����l�����ɋ���`�b�v��v���āA���N����o��o��
�ƌ����ĂP�N�x�����Ă����Ђ�����݂����ł����ˁB
�悭�Ȃ��ƒm����G�ȃg���[�h�I�t���s�������ʂ�
�����Ȃ�̂ł����āB
�����l�����ɋ���`�b�v��v���āA���N����o��o��
�ƌ����ĂP�N�x�����Ă����Ђ�����݂����ł����ˁB
100mm2���x�̃`�b�v��MCM�Ȃ�A�ЂƂ̃_�C�ō��Ȃ��ق��������������A
400mm2�N���X�̃`�b�v��MCM�Ȃ�d�����Ȃ��Ǝv�����B
����������Ȃ�A900mm2�N���X�̃`�b�v�������I�Ȓl�i�ō���Ƃ����������B
�l�I�ɂ́A�����_��4core�ȏ�*2 ��MCM�͂��傤���Ȃ��Ǝv���Ă�B
400mm2�N���X�̃`�b�v��MCM�Ȃ�d�����Ȃ��Ǝv�����B
����������Ȃ�A900mm2�N���X�̃`�b�v�������I�Ȓl�i�ō���Ƃ����������B
�l�I�ɂ́A�����_��4core�ȏ�*2 ��MCM�͂��傤���Ȃ��Ǝv���Ă�B
�ǂ�����������Ƀv���O��������蒼���̂�����
�������ƒ��߂�NUMA�ɂ��ė~����
�������ƒ��߂�NUMA�ɂ��ė~����
>>693
>�ꂵ����͑o���������낤���ǁB
���ЂƂ�
���̎����Ɂu�������ꂵ���o���Ȃ��v�Ɣ����ȃ����o���Ă���悩
���N��ɂ����Ƃ����̏o���ė~������ȁB
����}���`�R�A���v���N�����Ă�킯�ł��Ȃ��̂ɁB
>�ꂵ����͑o���������낤���ǁB
���ЂƂ�
���̎����Ɂu�������ꂵ���o���Ȃ��v�Ɣ����ȃ����o���Ă���悩
���N��ɂ����Ƃ����̏o���ė~������ȁB
����}���`�R�A���v���N�����Ă�킯�ł��Ȃ��̂ɁB
�ʂ�
�ǂ���������Ƃ������_�������������������Ƃ�
intel��C2Q�܂ł�MCM�̓}���`�R�A�ȑO�ɑш悪�N�����Ă�������6core�ł�����������
magny-cours�͂����ł͂Ȃ�
���ꂾ���̂���
�ǂ���������Ƃ������_�������������������Ƃ�
intel��C2Q�܂ł�MCM�̓}���`�R�A�ȑO�ɑш悪�N�����Ă�������6core�ł�����������
magny-cours�͂����ł͂Ȃ�
���ꂾ���̂���
�v���O���~���O���f���͒ʏ�̃}���`�R�A�H����Ƃ��}���`�\�P�b�g���C�N�H
GPGPU�ł̃}���`�X���b�h�́AGPU���ŃX���b�h�Ǘ����s���̂�
CPU���͂܂������ӎ�����K�v�͂Ȃ��B�R���t���N�g��GPU�ŊǗ�
����B�Ă������傫���f�[�^���R�A���ƂɊ���U���ĕ���v�Z����
�̂�GPGPU�Ȃ̂ŃR���t���N�g���悤���Ȃ��B
CPU�Ō����}���`�X���b�h�Ƃ͂܂������T�O���Ⴄ�B
CPU���͂܂������ӎ�����K�v�͂Ȃ��B�R���t���N�g��GPU�ŊǗ�
����B�Ă������傫���f�[�^���R�A���ƂɊ���U���ĕ���v�Z����
�̂�GPGPU�Ȃ̂ŃR���t���N�g���悤���Ȃ��B
CPU�Ō����}���`�X���b�h�Ƃ͂܂������T�O���Ⴄ�B
���W�X�^�����S�R�Ⴄ����
2�R�C�`�R�A������������
>>705
���N�͋�Ȃ����狖���Ă����āI
�ꉞ�R�A�Ԃ�HT�������������A
���������o���̃R�A�̃����R�����g����
4�`�����l�����������Ă��邵�I
���N�͋�Ȃ����狖���Ă����āI
�ꉞ�R�A�Ԃ�HT�������������A
���������o���̃R�A�̃����R�����g����
4�`�����l�����������Ă��邵�I
>>706
�킩����
�킩����
708 �FSocket774�F2010/02/27(�y) 02:27:24 ID:9oXm7K+l
�ȂA�C���e����i3�Ƃ��́APC���ނ���g�ݍ��ݗp�r�Ƃ��ăz�[���I�[�g���[�V�����̃Z���^�[�Ɏg�p���ꂻ���Ȑ��i���ȁB
�R���s���[�^�[���[�J�[�͉ƒ�ɂ���}�C�N���R���g���[���[�����т����������Ȃ��A�D���������Ď��s���Ă����B
AMD�ł́A�ǂꂪ���̃N���X�ɂȂ�H
�R���s���[�^�[���[�J�[�͉ƒ�ɂ���}�C�N���R���g���[���[�����т����������Ȃ��A�D���������Ď��s���Ă����B
AMD�ł́A�ǂꂪ���̃N���X�ɂȂ�H
�N�A�b�h�R�A�ł������烁�����W�{�g�킹�Ăق����Ȃ��B
MB�̎����ʐς����������B
MB�̎����ʐς����������B
http://enthusiast.hardocp.com/image.html?image=MTI0Mzg5MDcxM1hIaUNtcm9ZTjFfMV8xX2wuanBn
������g���B
������g���B
�m���p���j����}�}���͂����������邩�炫�炢�ł�
>>708
Intel�ł�i3�ł͂Ȃ���ATOM�n�����ꂾ��B
���܂͑��݂��Ȃ���AMD�ł͗��N�o��Bobcat���ȁH
i3��i5�N���X���R�Ȃ�Llano������B
Intel�ł�i3�ł͂Ȃ���ATOM�n�����ꂾ��B
���܂͑��݂��Ȃ���AMD�ł͗��N�o��Bobcat���ȁH
i3��i5�N���X���R�Ȃ�Llano������B
6�R�A���Ă����9�����炢����́H
3~4���O�ゾ��
870������ɂԂ���낤��
870������ɂԂ���낤��
�ŏ�����3��4�o����
25k�`45k�ʂ���Ȃ��������I��
25k�`45k�ʂ���Ȃ��������I��
�S���͂Ȃ��B
Phenom II X4 965BE��17K���炢������A����1.5�{��25k���Ǝv���B
Phenom II X4 965BE��17K���炢������A����1.5�{��25k���Ǝv���B
Hex Core��3����������5�N�U��ɃV�X�e���ꎮ�����ւ���B
���傹���N�O�̎ICPU�̃}�C�i�[�`�F���W�ł���B
�T���ȏ�͐�ɂ��肦�Ȃ��B
������32k�B
�T���ȏ�͐�ɂ��肦�Ȃ��B
������32k�B
719��Itanium2��100��������Ēm�����甭�����������Ȃ�
DT���p�A�[�L��6�R�AOp�ł�30�����邪
>>719�̗~�������i�ƌ����͈Ⴄ����Ȃ��B
�����S����3���f�����邩��A���ʂł�3.2���N���X�͂��肻���B
�����S����3���f�����邩��A���ʂł�3.2���N���X�͂��肻���B
���ʂ�3.2��������Ȃ�AIntel�����ł���
>>719�͕ς���>717�݂����Ȍv�Z�ō����Ă邾��
Opteron��8�R�A�̉��ʃ��f����309�h��������ɂȂ�炵������
Phenom��6�R�A�Ȃ炩�Ȃ胊�[�Y�i�u������
Phenom��6�R�A�Ȃ炩�Ȃ胊�[�Y�i�u������
�l�C�e�B�u�ɂ������4�R�A���Ȃ��MCM�ō��Ȃ������낤�H
MCM�Ɋւ���m�E�n�E��������������
>>726
�u�����q��������MCM�Ȃ�ȒP�v�����ǁA
���\���o�������Ȃ���ǂ�������K�v�����������炾��B
4�R�A�Ɋւ��Ă̓_�C�T�C�Y�I�ɍs����Ɣ��f�����̂ł́H
�u�����q��������MCM�Ȃ�ȒP�v�����ǁA
���\���o�������Ȃ���ǂ�������K�v�����������炾��B
4�R�A�Ɋւ��Ă̓_�C�T�C�Y�I�ɍs����Ɣ��f�����̂ł́H
���Ђ�65nm�v���Z�X�̏o���������Ɨǂ����̂��Ɠ���ł����낤��
AMD��65nm�AIntel��90nm�̏o�����������������
���Ƃ���FSB��2�̃_�C���o�X�ڑ��ł���Pentium4�ƈ���āA
�����R��������K10�́u�q�������v�Ƃ����킯�ɂ͂����Ȃ�����A
MCM�ŃN���b�h�Ƃ����I�����͂Ƃ�Ȃ������B
Magny-Cours������͓����ŁA�_�C1��Lisbon�Ƃ̓\�P�b�g���ς���Ă��܂��B
�����R��������K10�́u�q�������v�Ƃ����킯�ɂ͂����Ȃ�����A
MCM�ŃN���b�h�Ƃ����I�����͂Ƃ�Ȃ������B
Magny-Cours������͓����ŁA�_�C1��Lisbon�Ƃ̓\�P�b�g���ς���Ă��܂��B
���ނ͉���1�R�A*48MCM����Ȃ��́H
���̔��z�͂Ȃ�����
>>732
���܂�ɔ�����ŋ���������A�p�b�P�[�W�T�C�Y����剻�������邩��B
���܂�ɔ�����ŋ���������A�p�b�P�[�W�T�C�Y����剻�������邩��B
������Fushion����ˁ[�[�́I�I
>>735
�Ȃɂ���H
�Ȃɂ���H
738 �FSocket774�F2010/03/01(��) 05:20:07 ID:4e4In82v
>>714
> 6�R�A���Ă����9�����炢����́H
�ǂ����낤?�A�R�A�����������������͐������Z���\��2/3����6�R�A���v�ł�4�R�A�����ł����Ȃ����ƁE�E�E
128bitSSE��2���j�b�g��2�R�A�ŋ��L���邩��6�R�A���v�ł�6���j�b�g�������ڂ���Ă��Ȃ��E�E�E
���_���猾���č��z���i�ɂ͂Ȃ肦�Ȃ��Ǝv�����E�E�E
> 6�R�A���Ă����9�����炢����́H
�ǂ����낤?�A�R�A�����������������͐������Z���\��2/3����6�R�A���v�ł�4�R�A�����ł����Ȃ����ƁE�E�E
128bitSSE��2���j�b�g��2�R�A�ŋ��L���邩��6�R�A���v�ł�6���j�b�g�������ڂ���Ă��Ȃ��E�E�E
���_���猾���č��z���i�ɂ͂Ȃ肦�Ȃ��Ǝv�����E�E�E
�܂������ƂȂ��m�I��Q��
>>738
> > 6�R�A���Ă����9�����炢����́H
> �ǂ����낤?�A�R�A�����������������͐������Z���\��2/3����6�R�A���v�ł�4�R�A�����ł����Ȃ����ƁE�E�E
����ȒP���Ȃ���Ȃ���
�������Z���\�͍\���̈Ⴂ�ɂ�链��s����͂��邾�낤�������I�ɃR�A������̐��\�͌���ێ��ɗ��܂邾�낤
> 128bitSSE��2���j�b�g��2�R�A�ŋ��L���邩��6�R�A���v�ł�6���j�b�g�������ڂ���Ă��Ȃ��E�E�E
Intel��SSE��1�R�A1���j�b�g�����瓯������
(AVX��2�R�A1���j�b�g�ɂȂ邩�琫�\�����ɂȂ��ĕs��������)
> > 6�R�A���Ă����9�����炢����́H
> �ǂ����낤?�A�R�A�����������������͐������Z���\��2/3����6�R�A���v�ł�4�R�A�����ł����Ȃ����ƁE�E�E
����ȒP���Ȃ���Ȃ���
�������Z���\�͍\���̈Ⴂ�ɂ�链��s����͂��邾�낤�������I�ɃR�A������̐��\�͌���ێ��ɗ��܂邾�낤
> 128bitSSE��2���j�b�g��2�R�A�ŋ��L���邩��6�R�A���v�ł�6���j�b�g�������ڂ���Ă��Ȃ��E�E�E
Intel��SSE��1�R�A1���j�b�g�����瓯������
(AVX��2�R�A1���j�b�g�ɂȂ邩�琫�\�����ɂȂ��ĕs��������)
256bit��128bit
�ɏ������c
�ɏ������c
���̃��C�A�E�g�Ƃ͑傫���قȂ�A����傫�߂�Llano�_�C���C�A�E�g�ʐ^�����o���Ă��邱�ƁB
����̉摜�Ȃ��H
����̉摜�Ȃ��H
�����̔��\���������̂�
�T�v�������������B
�T�v�������������B
744 �FSocket774�F2010/03/01(��) 08:00:18 ID:4e4In82v
>>740
�܂萮�������6�R�A��Bulldozer��4�R�A��Sandy Bridge�ɐ��\�ŏ��ĂȂ��Ƃ������_�����o�Ă��܂���ȁE�E�E
�܂萮�������6�R�A��Bulldozer��4�R�A��Sandy Bridge�ɐ��\�ŏ��ĂȂ��Ƃ������_�����o�Ă��܂���ȁE�E�E
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
>>745
����ȓd�g�u���O�N���S��������
����ȓd�g�u���O�N���S��������
749 �FSocket774�F2010/03/01(��) 09:25:31 ID:J7JRO6wZ
X4 965�͕s�{�ӂɃR���������i���Ƃ��Ă��܂�kakaku�Ŕ����1�ʂ͈����o���������B
����CPU���R�A�����肵�Ď�`���Ă����ɂ������S�҂�AMD���x����Ȃ��Ȃ����ˁB
C2D,C2Q�̍��͑S�Ăɂ�����intel�Ɋ��S�s�k�����̂͂킩�邪
�n������Corei�ɂȂ��Ă�����܂�ŏ��Ă�v�f�����ȁB
����CPU���R�A�����肵�Ď�`���Ă����ɂ������S�҂�AMD���x����Ȃ��Ȃ����ˁB
C2D,C2Q�̍��͑S�Ăɂ�����intel�Ɋ��S�s�k�����̂͂킩�邪
�n������Corei�ɂȂ��Ă�����܂�ŏ��Ă�v�f�����ȁB
>>749
���̊���Intel�V�F�A���Ƃ��Ă��˂�
���̊���Intel�V�F�A���Ƃ��Ă��˂�
�قډ�������
�ŁA�v��Xeon�̃V�F�A�͔�age
�ŁA�v��Xeon�̃V�F�A�͔�age
�G�����܂��N�������B
�ǂ������H�܂���e�Ɂu���ނ�Ȃ�����...�v���Č���ꂽ�̂��H
�ǂ������H�܂���e�Ɂu���ނ�Ȃ�����...�v���Č���ꂽ�̂��H
>>740
ttp://www.realworldtech.com/includes/images/articles/merom-2.gif
ttp://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:AMD_A64_Opteron_arch.svg
��SSE
Core2�͐����ƃZ�b�g(?)��3���j�b�g
K8�͏����_�ƃZ�b�g(?)��2���j�b�g
ttp://www.realworldtech.com/includes/images/articles/merom-2.gif
{kind=link}
ttp://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:AMD_A64_Opteron_arch.svg
{kind=link}
��SSE
Core2�͐����ƃZ�b�g(?)��3���j�b�g
K8�͏����_�ƃZ�b�g(?)��2���j�b�g
Xeon�̃V�F�A���݂̃j���[�X��3�N�O4�N�O�̕������Ȃ����c
�G������ڽ��g����SIMM�������Ă�����������i�����Ă��Ȃ���
�G������ڽ��g����SIMM�������Ă�����������i�����Ă��Ȃ���
top500�Ƃ����Č�������ˁH
>top500
�����A���ꂩ�B
�V�F�A��Intel�����������\��AMD�̕�������Ă���B
�����A���ꂩ�B
�V�F�A��Intel�����������\��AMD�̕�������Ă���B
�l�n����Xeon���{���J�X�߂���Opteron�̑����ɂ��y�Ȃ�Top500��
758 �FSocket774�F2010/03/02(��) 23:38:25 ID:Auz7fpIY
a
�܂��M�Ҕ]��
�M�Ҕ]�͊m���ɒɂ��ȁBTOP500�̌��ʂƂ��N�ł��ς���̂ɁA
�K���ɂ����ے肵�悤�Ƃ���z�����邩��ȁB
�K���ɂ����ے肵�悤�Ƃ���z�����邩��ȁB
�l�n���ĂȂ��Opteron�ɂ��珟�ĂȂ���H
QPI��CPU�{�̂����M���H�����邩�炩�ˁH
QPI��CPU�{�̂����M���H�����邩�炩�ˁH
>>761
�����P�Ɋ��S�ɍœK�����ꂽ�V�X�e�����o�Ă��Ȃ������ł́H
Nehalem��Opteron�V�X�e����萫�\�͍����Ǝv�����c�B
�����P�Ɋ��S�ɍœK�����ꂽ�V�X�e�����o�Ă��Ȃ������ł́H
Nehalem��Opteron�V�X�e����萫�\�͍����Ǝv�����c�B
����Ȋ����ɂȂ�炵���c��͉���Ȃ̂ŒN���C�����I
ttp://www.xbitlabs.com/news/mobile/display/20100301223005_AMD_s_Sabine_Platform_Takes_Nearly_Final_Shape.html
���������c�����둗�M����B�͂��˂���I�I�I�I
���������c�����둗�M����B�͂��˂���I�I�I�I
>>764
�ߓǂݖ|��
�ő�4�R�A�ATDP20-59W�ADX11�Ή��AUSB3.0�A�o���N�[�o(GPU)
3,4�R�A�@TDP35W-59W
2�R�A �@TDP20W
GPU�ɂ��Ă������Ⴒ���Ꮡ���Ă��邪�A�Z�߂�̂��ʓ|
��͔C����
>released in Q1 2011
����������A�Ԃɍ����̂��ˁH
�ߓǂݖ|��
�ő�4�R�A�ATDP20-59W�ADX11�Ή��AUSB3.0�A�o���N�[�o(GPU)
3,4�R�A�@TDP35W-59W
2�R�A �@TDP20W
GPU�ɂ��Ă������Ⴒ���Ꮡ���Ă��邪�A�Z�߂�̂��ʓ|
��͔C����
>released in Q1 2011
����������A�Ԃɍ����̂��ˁH
�I���̐E��ɃT�[�o�[�����邪Xeon�̃V�[�����Đ\������x�̑傫�������Ȃ���
1.5�����~2�������炢���낤��
�������A�T�[�o�[����̔p�M�͂������B
�h���C���[�̎キ�炢�o�Ă���ۂ��B
1.5�����~2�������炢���낤��
�������A�T�[�o�[����̔p�M�͂������B
�h���C���[�̎キ�炢�o�Ă���ۂ��B
Sabine�Ƃ����P������邽�тɃT�[�o�C���Ɠǂ�ł��܂��B
>>761
�L���b�V�����\��SSE�Ńx���`���l���҂��d�l������B
�L���b�V�������ꂽ��SSE�W�Ȃ���ΓI�Ȑ��\���v�������ƃw�^���B
�����F-1�̃l�n�Ƀg���b�N�̃I�v�B
�L���b�V�����\��SSE�Ńx���`���l���҂��d�l������B
�L���b�V�������ꂽ��SSE�W�Ȃ���ΓI�Ȑ��\���v�������ƃw�^���B
�����F-1�̃l�n�Ƀg���b�N�̃I�v�B
770 �FSocket774�F2010/03/03(��) 01:09:37 ID:JDQsgmTj
>>769
> �L���b�V�������ꂽ��SSE�W�Ȃ���ΓI�Ȑ��\���v�������ƃw�^���B
�������A�N�Z�X���\���l�n�̕��������\���Ǝv����?
> �L���b�V�������ꂽ��SSE�W�Ȃ���ΓI�Ȑ��\���v�������ƃw�^���B
�������A�N�Z�X���\���l�n�̕��������\���Ǝv����?
�X�p�R��TOP500�ŏ�ʂɂȂ�ɂ́A��K�͂ȈČ��ō̗p����Ȃ��Ƃǂ����悤���Ȃ�����ˁB
���ƁAXeon��Nehalem�ɂȂ�܂ł̓v���Z�b�T�ڑ���FSB�őʖڑʖڂ��������B
ORNL�͎���Opteron�g���悤�����ǁACray��Intel��CPU�g�����X�p�R�������悤�ɂȂ�����A
���܂ł݂����ɏ�ʂ�Opteron�������ď���ς�邩������Ȃ��B
���ƁAXeon��Nehalem�ɂȂ�܂ł̓v���Z�b�T�ڑ���FSB�őʖڑʖڂ��������B
ORNL�͎���Opteron�g���悤�����ǁACray��Intel��CPU�g�����X�p�R�������悤�ɂȂ�����A
���܂ł݂����ɏ�ʂ�Opteron�������ď���ς�邩������Ȃ��B
�X�p�R���̐v���Đ��N�P�ʂŊ|���邩��
�����ȒP�ɃA�[�L�e�N�`���̕ύX�͖�����Ȃ��H
Intel����ʂɐH�����ނɂ́A�����ȃo�b�N�A�b�v(Intel����̎����o���j
�������ƌ������C������
�����ȒP�ɃA�[�L�e�N�`���̕ύX�͖�����Ȃ��H
Intel����ʂɐH�����ނɂ́A�����ȃo�b�N�A�b�v(Intel����̎����o���j
�������ƌ������C������
1000����ɂ��B����IA�T�[�o�s��S�̂��猩��A�X�p�R���́g�j�b�`�h�����ȁB
���݊����~����AMD�ɂ̓X�p�R���͏���Ȃ���邾���A
Intel�ɂ��Ă݂�u�X�p�R���ɂ��g����Ȃ�ǂ��������R�Ɂv���炢�̂���Ȃ����B
�[��Opteron�ɂ́ASPARC64VIIIfx�݂����ɃX�p�R�������̃J�X�^���d�l������̂���?
�ʔ����Ǝv�����B
���݊����~����AMD�ɂ̓X�p�R���͏���Ȃ���邾���A
Intel�ɂ��Ă݂�u�X�p�R���ɂ��g����Ȃ�ǂ��������R�Ɂv���炢�̂���Ȃ����B
�[��Opteron�ɂ́ASPARC64VIIIfx�݂����ɃX�p�R�������̃J�X�^���d�l������̂���?
�ʔ����Ǝv�����B
���������A�N�Z�X���\���l�n�̕��������\���Ǝv����?
���������A�N�Z�X���\���l�n�̕��������\���Ǝv����?
��Ȗ������Ă���̂�2���܂���
���������A�N�Z�X���\���l�n�̕��������\���Ǝv����?
��Ȗ������Ă���̂�2���܂���
775 �FMAC�I�^��772 �����F2010/03/03(��) 04:57:37 ID:3CqODviD
>>772
�@�@-----------------
�@�@�����ȒP�ɃA�[�L�e�N�`���̕ύX�͖�����Ȃ��H
�@�@-----------------
2�N�O��Intel�ւ̈ڍs�����肵�āA�J�����i�߂��Ă��܂��B
http://www2.cray.com/global_pages/news_jp/Intel.html
�@�@==================
�@�@Cray�̎В���CEO�APeter Ungaro�͎��̂悤�ɏq�ׂĂ��܂��B�uIntel�̍��x��
�@�@�����̋Z�p�Ɋւ�����m����Cray�̋ƊE�̃g�b�v�X�P�[���u��HPC�V�X�e����
�@�@�Z�p���ЂƂɂȂ����Ƃ��̉\���ɋ������Ă��܂��BCray�͍ł��v�V�I��
�@�@�X�[�p�[�R���s���[�e�B���O�V�X�e������Ă���Ǝ������Ă���A�����ACray��
�@�@�ڋq�͂�蕝�L���v���Z�b�T�e�N�m���W��I���ł���悤�ɂȂ�܂��B���̒�g�ɂ��A
�@�@HPC�s��́A���ł��A���E���ōł��X�P�[���u���ȃX�[�p�[�R���s���[�^�ɋ���
�@�@����őP�̃}�C�N���v���Z�b�T����ɓ���邱�Ƃ��ł���悤�ɂȂ�܂��B����ɁA
�@�@2012�N��Cascade�Ɍ�����Cray�̋ƊE�����[�h����A�_�v�e�B�u�X�[�p�[�R���s���[
�@�@�e�B���O�\�z����������܂��B�v
�@�@==================
AMD�ɔ�����̂͗��N�ł��I���B
Cray�̎�����X�[�p�[�R���s���[�^�A"cascade"�Ɋւ���v���Z�b�T�ڍs�̓^����
���Ă͂�����̋L�����ǂ����B
http://www.geocities.jp/andosprocinfo/wadai08/20080503.htm
�@�@==================
�@�@Cray��IBM�́C���z$500M��DARPA��HPCS�v���W�F�N�g�̍ŏI�t�F�[�Y�̌_��҂�
�@�@�Ȃ��Ă���CCray��AMD��Opteron���g���� XT-5�̌�p�@�𒆐S�Ƃ���Cascade�Ƃ���
�@�@�V�X�e�����Ă��Ă���ƌ����Ă��܂����C����Cascade�Ɋւ��āCIntel CPU�ɕύX
�@�@��������DARPA�ɐ\������Ă���Ƃ̂��Ƃł��B
�@�@==================
�@�@-----------------
�@�@�����ȒP�ɃA�[�L�e�N�`���̕ύX�͖�����Ȃ��H
�@�@-----------------
2�N�O��Intel�ւ̈ڍs�����肵�āA�J�����i�߂��Ă��܂��B
http://www2.cray.com/global_pages/news_jp/Intel.html
�@�@==================
�@�@Cray�̎В���CEO�APeter Ungaro�͎��̂悤�ɏq�ׂĂ��܂��B�uIntel�̍��x��
�@�@�����̋Z�p�Ɋւ�����m����Cray�̋ƊE�̃g�b�v�X�P�[���u��HPC�V�X�e����
�@�@�Z�p���ЂƂɂȂ����Ƃ��̉\���ɋ������Ă��܂��BCray�͍ł��v�V�I��
�@�@�X�[�p�[�R���s���[�e�B���O�V�X�e������Ă���Ǝ������Ă���A�����ACray��
�@�@�ڋq�͂�蕝�L���v���Z�b�T�e�N�m���W��I���ł���悤�ɂȂ�܂��B���̒�g�ɂ��A
�@�@HPC�s��́A���ł��A���E���ōł��X�P�[���u���ȃX�[�p�[�R���s���[�^�ɋ���
�@�@����őP�̃}�C�N���v���Z�b�T����ɓ���邱�Ƃ��ł���悤�ɂȂ�܂��B����ɁA
�@�@2012�N��Cascade�Ɍ�����Cray�̋ƊE�����[�h����A�_�v�e�B�u�X�[�p�[�R���s���[
�@�@�e�B���O�\�z����������܂��B�v
�@�@==================
AMD�ɔ�����̂͗��N�ł��I���B
Cray�̎�����X�[�p�[�R���s���[�^�A"cascade"�Ɋւ���v���Z�b�T�ڍs�̓^����
���Ă͂�����̋L�����ǂ����B
http://www.geocities.jp/andosprocinfo/wadai08/20080503.htm
�@�@==================
�@�@Cray��IBM�́C���z$500M��DARPA��HPCS�v���W�F�N�g�̍ŏI�t�F�[�Y�̌_��҂�
�@�@�Ȃ��Ă���CCray��AMD��Opteron���g���� XT-5�̌�p�@�𒆐S�Ƃ���Cascade�Ƃ���
�@�@�V�X�e�����Ă��Ă���ƌ����Ă��܂����C����Cascade�Ɋւ��āCIntel CPU�ɕύX
�@�@��������DARPA�ɐ\������Ă���Ƃ̂��Ƃł��B
�@�@==================
776 �FMAC�I�^���⑫�F2010/03/03(��) 05:09:03 ID:3CqODviD
�Q�l�܂łɁA�ŐV��Cray CTO, Steve Scott ���� "Cascade" �Ɋւ���R�����g��
�E���Ă��܂����BPRIMEUR Weekly ���̃C���^�r���[���B
http://enterthegrid.com/primeur/09/articles/weekly/AE-PR-09-09-52.html
�@�@--------------------
�@�@(Scott:)
�@�@We are continuing to work on Cascade which is our DARPA-HPCS programme s
�@�@ystem. That will be coming out in 2012. It will have, for the first time since the
�@�@introduction of the the XT line, a whole new infrastructure: New cabinets, new
�@�@cooling designs, a hybrid optical interconnect. There will be electrical links within
�@�@a couple of cabinets and optical links everywhere else. And we will also develop
�@�@by that time Intel processors. Now we sell Intel processors already in the CX1,
�@�@the desk side system. With the next generation network that we are doing for
�@�@Cascade we will have a PCI-Express based processor interface and we will also
�@�@come out with an Intel based board.
�@�@Primeur: What is the largest Intel system that you have now?
�@�@Scott: The biggest one is in the CX-1, the desk side system. We also have some
�@�@clusters we did for customers. But for our main product line it is AMD until we get
�@�@to 2012.
�@�@--------------------
AMD�Ƃ́A2012�N�ł�����c�ƁB
�E���Ă��܂����BPRIMEUR Weekly ���̃C���^�r���[���B
http://enterthegrid.com/primeur/09/articles/weekly/AE-PR-09-09-52.html
�@�@--------------------
�@�@(Scott:)
�@�@We are continuing to work on Cascade which is our DARPA-HPCS programme s
�@�@ystem. That will be coming out in 2012. It will have, for the first time since the
�@�@introduction of the the XT line, a whole new infrastructure: New cabinets, new
�@�@cooling designs, a hybrid optical interconnect. There will be electrical links within
�@�@a couple of cabinets and optical links everywhere else. And we will also develop
�@�@by that time Intel processors. Now we sell Intel processors already in the CX1,
�@�@the desk side system. With the next generation network that we are doing for
�@�@Cascade we will have a PCI-Express based processor interface and we will also
�@�@come out with an Intel based board.
�@�@Primeur: What is the largest Intel system that you have now?
�@�@Scott: The biggest one is in the CX-1, the desk side system. We also have some
�@�@clusters we did for customers. But for our main product line it is AMD until we get
�@�@to 2012.
�@�@--------------------
AMD�Ƃ́A2012�N�ł�����c�ƁB
2012�N�����Intel�������܂���Ƃ���������AMD�ƃI�T���o����킯����Ȃ�
�ŋߍ����G34�v���b�g�t�H�[����Bulldozer16�R�A�uInterlagos�v�����ʂɃT�|�[�g���Ă�������
Cray��GPGPU�ɂ��Ăǂꂾ���͂�����邩�ɂ����AMD�̗D��x�͕ς�邾�낤����
�ŋߍ����G34�v���b�g�t�H�[����Bulldozer16�R�A�uInterlagos�v�����ʂɃT�|�[�g���Ă�������
Cray��GPGPU�ɂ��Ăǂꂾ���͂�����邩�ɂ����AMD�̗D��x�͕ς�邾�낤����
ORNL�ɍ̗p�������H��Magny Cours
779 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 08:17:59 ID:0NfHtkGH
>>740
Intel��Core 2���炸����1�R�A������SIMD ALU�~3�����H
Intel��Core 2���炸����1�R�A������SIMD ALU�~3�����H
�܂��C���������̂�
SIMM�Ȃ̂�SIMD�Ȃ̂��͂����肵�悤��
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
782 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 08:36:09 ID:0NfHtkGH
>>777
�i�킸���Ȃ���jIntel�u���v�����Ă���Ă̂͌���̂��Ƃł����āA
����͕����ʂ��K�͈Č���Intel���C���ɂȂ���Ęb�Ȃ�
> Cray��GPGPU�ɂ��Ăǂꂾ���͂�����邩�ɂ����
GPGPU��D�悷��Ȃ珮�XAMD�͂Ȃ����낤�B�{���x�̎������\�҂��Ȃ��Ƃ����Ȃ��̂ɁB
�����I�ɂ�28nm�v���Z�X�ȍ~��Fermi�A�[�L���炢���H
�Ă��Ȃ�ł���ŁyCPU�܂ŁzAMD��I�Ȃ��Ƃ����Ȃ�����
����FireStream��I�ԂƂ��Ă�Xeon�ł����킯����
�i�킸���Ȃ���jIntel�u���v�����Ă���Ă̂͌���̂��Ƃł����āA
����͕����ʂ��K�͈Č���Intel���C���ɂȂ���Ęb�Ȃ�
> Cray��GPGPU�ɂ��Ăǂꂾ���͂�����邩�ɂ����
GPGPU��D�悷��Ȃ珮�XAMD�͂Ȃ����낤�B�{���x�̎������\�҂��Ȃ��Ƃ����Ȃ��̂ɁB
�����I�ɂ�28nm�v���Z�X�ȍ~��Fermi�A�[�L���炢���H
�Ă��Ȃ�ł���ŁyCPU�܂ŁzAMD��I�Ȃ��Ƃ����Ȃ�����
����FireStream��I�ԂƂ��Ă�Xeon�ł����킯����
Opteron+FireStream���ƒl�i�������܂���A����Ȃ���
HyperTranport��Y��Ă܂���c�q����B
Intel�x�[�X����Fermi���w�e���W�j�A�X��interconnect��
���ɂ����Ȃ�悤�ȁB
Intel�x�[�X����Fermi���w�e���W�j�A�X��interconnect��
���ɂ����Ȃ�悤�ȁB
Cray�̂̓����r�[���O��łȂ���
786 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 08:52:25 ID:0NfHtkGH
����̘b�������GPGPU�Ή���Cray CX1��Xeon�{Tesla��
HT���ڑ��łȂ��Ɛ��\���o�Ȃ��ƂȂ��QPI�����C�Z���X����Ηǂ������̘b�Ȃ̂�
2012�N���_��AMD���ǂ��̂����͖̂����ȁB
Intel�Ƃ��Ă�1�\�P�b�g������QPI����4�{�o�Ă�XeonMP��HPC�����ɔ���ɂ͗ǂ��@��ƂȂ�
HT���ڑ��łȂ��Ɛ��\���o�Ȃ��ƂȂ��QPI�����C�Z���X����Ηǂ������̘b�Ȃ̂�
2012�N���_��AMD���ǂ��̂����͖̂����ȁB
Intel�Ƃ��Ă�1�\�P�b�g������QPI����4�{�o�Ă�XeonMP��HPC�����ɔ���ɂ͗ǂ��@��ƂȂ�
ORNL�̎����オHT��fermi��magni-cours���Ƃ����\�������ǁA
�����悤��Firestream�ł���邾��
Fermi���|�V�������ꍇ�̑�ֈĂƂ��ė��œ����Ă����ȋC������
�����40nm�ł���O�_�O�_�Ȃ̂�28nm��Fermi�Ƃ���������
����ƁA�����̔{���x�̐��\��AMD�����|���Ă����
�����悤��Firestream�ł���邾��
Fermi���|�V�������ꍇ�̑�ֈĂƂ��ė��œ����Ă����ȋC������
�����40nm�ł���O�_�O�_�Ȃ̂�28nm��Fermi�Ƃ���������
����ƁA�����̔{���x�̐��\��AMD�����|���Ă����
788 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:00:31 ID:0NfHtkGH
������ƁA�����̔{���x�̐��\��AMD�����|���Ă����
Fermi�͔{���x�̃X���[�v�b�g���P���x��1/2�Ȃ̂ň��|���N�\���Ȃ�
> �����40nm�ł���O�_�O�_�Ȃ̂�28nm��Fermi�Ƃ���������
TSMC��28nm��HKMG�̗p�����瑽���}�V�ɂȂ�
Fermi�͔{���x�̃X���[�v�b�g���P���x��1/2�Ȃ̂ň��|���N�\���Ȃ�
> �����40nm�ł���O�_�O�_�Ȃ̂�28nm��Fermi�Ƃ���������
TSMC��28nm��HKMG�̗p�����瑽���}�V�ɂȂ�
789 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:02:14 ID:0NfHtkGH
���Ȃ݂Ɍ�FireStream�̔{���x�͒P���x��1/5
>>786
AMD��QPI���C�Z���X����́H
AMD���Ή�����Ƃ͓���v�����
����Ƃ�Fermi�x�[�X��Tesla��QPI�ς�ł��炤�́H
�m�[�}���ł̊J������O�_�O�_�Ȃ̂ɁA����ȃJ�X�^�����Ȃ�Ė���
AMD��QPI���C�Z���X����́H
AMD���Ή�����Ƃ͓���v�����
����Ƃ�Fermi�x�[�X��Tesla��QPI�ς�ł��炤�́H
�m�[�}���ł̊J������O�_�O�_�Ȃ̂ɁA����ȃJ�X�^�����Ȃ�Ė���
�I�������ǃX�p�R���̓o�O�Ɋւ��ăV�r�A��
�o�O�ƌ�����Intel�����ǂ���͒u���Ƃ��Ƃ��Ă�
���܂ł�GPU�͕`�悵���l���ĂȂ��ă������Ȃ̃o�O�h�~�̋@�\������Ȃ�����
�X�p�R���Ɏg���Ȃ��Ƃ��ǂ����Ō�����
������ނ͂ǂ��Ȃ�
Fermi�͂����ɂ��������炵������AMDATi�̂ق��͍�firestream��radeon�ō������������Ȃ��炢����
�o�O�ƌ�����Intel�����ǂ���͒u���Ƃ��Ƃ��Ă�
���܂ł�GPU�͕`�悵���l���ĂȂ��ă������Ȃ̃o�O�h�~�̋@�\������Ȃ�����
�X�p�R���Ɏg���Ȃ��Ƃ��ǂ����Ō�����
������ނ͂ǂ��Ȃ�
Fermi�͂����ɂ��������炵������AMDATi�̂ق��͍�firestream��radeon�ō������������Ȃ��炢����
792 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:07:25 ID:0NfHtkGH
�܂����ʂɍl�����PCIe Gen3���낤��
Fermi���\��ʂ�o�Ă��琦���������ǁA
�����܂�Ⴂ�A���M�A������d�́A�J����q�炵������ˁA�������߂��
�����܂�Ⴂ�A���M�A������d�́A�J����q�炵������ˁA�������߂��
>>788
��������������E�E�EFe��mi�̌���������ƌ��Ă݂��
40nm�ł��琻�i�Ƃ��Đ������邩�ǂ����̐��ˍۂ̍U�h������Ă��
ATi�����Ă܂�܂�1���������40�ȉ��̃m�E�n�E�ς�łT�������������[�X���Ă�̂�
28nm��Fermi����������g���u���������ɏo����Ǝv���Ă�̂��H
��������������E�E�EFe��mi�̌���������ƌ��Ă݂��
40nm�ł��琻�i�Ƃ��Đ������邩�ǂ����̐��ˍۂ̍U�h������Ă��
ATi�����Ă܂�܂�1���������40�ȉ��̃m�E�n�E�ς�łT�������������[�X���Ă�̂�
28nm��Fermi����������g���u���������ɏo����Ǝv���Ă�̂��H
795 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:08:38 ID:0NfHtkGH
�s�s���ȓ��e�ɂ͊�ȂɐS������q
797 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:12:44 ID:0NfHtkGH
��������AVX�����GPGPU���Đ����c���Ă�̂�����
CPU�����̃x�N�^�G���W���̃X���[�v�b�g�̓��[�A�̖@���ȏ�̃T�C�N���ŃX�P�[���ł���
���Ɣ{���x�Ɍ���Γd�͌����I�ɂ��t�]���邾�낤
CPU�����̃x�N�^�G���W���̃X���[�v�b�g�̓��[�A�̖@���ȏ�̃T�C�N���ŃX�P�[���ł���
���Ɣ{���x�Ɍ���Γd�͌����I�ɂ��t�]���邾�낤
798 �F,,�E�L�́M�E,,�j��-�������F2010/03/03(��) 09:13:25 ID:0NfHtkGH
>>794
40nm��HKMG�����Ή�������Q�l�ɂȂ�Ȃ�
40nm��HKMG�����Ή�������Q�l�ɂȂ�Ȃ�
HD 5870�E�E�E�P���x���������_���Z��2.72TFLOPS�@�{���x544GFLOPS
HD 4870�E�E�E�P���x���������_���Z��1.20TFLOPS�@�{���x240GFLOPS
HD 4870�E�E�E�P���x���������_���Z��1.20TFLOPS�@�{���x240GFLOPS
>>791
> �I�������ǃX�p�R���̓o�O�Ɋւ��ăV�r�A��
> �o�O�ƌ�����Intel�����ǂ���͒u���Ƃ��Ƃ��Ă�
> ���܂ł�GPU�͕`�悵���l���ĂȂ��ă������Ȃ̃o�O�h�~�̋@�\������Ȃ�����
> �X�p�R���Ɏg���Ȃ��Ƃ��ǂ����Ō�����
> ������ނ͂ǂ��Ȃ�
> Fermi�͂����ɂ��������炵������AMDATi�̂ق��͍�firestream��radeon�ō������������Ȃ��炢����
�����̓V��1���Ƃ����X�p�R����HD4870x2���ڂ�Top5�Ƀ����N�C�����Ă��邩����Ȃ���
HD5xxx�����ECC�ɂ��Ή����邵��
ttp://pc.watch.impress.co.jp/docs/news/20091116_329389.html
�V�͈ꍆ��Xeon�Ɠ�����Radeon HD 4870�𓋍ڂ��A���5�ʂ̒���GPU�ɂ�鉉�Z���s�Ȃ��B��̃V�X�e���B
> �I�������ǃX�p�R���̓o�O�Ɋւ��ăV�r�A��
> �o�O�ƌ�����Intel�����ǂ���͒u���Ƃ��Ƃ��Ă�
> ���܂ł�GPU�͕`�悵���l���ĂȂ��ă������Ȃ̃o�O�h�~�̋@�\������Ȃ�����
> �X�p�R���Ɏg���Ȃ��Ƃ��ǂ����Ō�����
> ������ނ͂ǂ��Ȃ�
> Fermi�͂����ɂ��������炵������AMDATi�̂ق��͍�firestream��radeon�ō������������Ȃ��炢����
�����̓V��1���Ƃ����X�p�R����HD4870x2���ڂ�Top5�Ƀ����N�C�����Ă��邩����Ȃ���
HD5xxx�����ECC�ɂ��Ή����邵��
ttp://pc.watch.impress.co.jp/docs/news/20091116_329389.html
�V�͈ꍆ��Xeon�Ɠ�����Radeon HD 4870�𓋍ڂ��A���5�ʂ̒���GPU�ɂ�鉉�Z���s�Ȃ��B��̃V�X�e���B
HKMG�ȑO�̊�{�I�Ȑv�̃��x���ł����Ă�̂�Fermi�����Ă�̂ɁE�E�E�E
>>798
HKMG�����Ή��Ȃ̂ɃO�_�O�_�Ȃ�w
��Փx���オ��28nm�ŃX���[�Y�ɊJ���o����Ƃ͎v�����
�c�O�����Ǖ��ʂ�AMD����s���Ď~�߂���������
HKMG�����Ή��Ȃ̂ɃO�_�O�_�Ȃ�w
��Փx���オ��28nm�ŃX���[�Y�ɊJ���o����Ƃ͎v�����
�c�O�����Ǖ��ʂ�AMD����s���Ď~�߂���������
>>800
ECC�����O���t�B�b�N���������G���b�^100�l�ł��邩��Xeon�Łu���Ȃ��v�͖�����Ȃ���
ECC�����O���t�B�b�N���������G���b�^100�l�ł��邩��Xeon�Łu���Ȃ��v�͖�����Ȃ���
�m���Ɍ����鎖��
40nm�Ɍ��ݐi�s�`�Ŏl�ꔪ�ꂵ��28nm�ǂ���łȂ�Fermi������Ă邎V
40nm�����Ɏs������Č��ݐi�s�`��28nm���i�̊J�����i��ł�ATi
40nm�Ɍ��ݐi�s�`�Ŏl�ꔪ�ꂵ��28nm�ǂ���łȂ�Fermi������Ă邎V
40nm�����Ɏs������Č��ݐi�s�`��28nm���i�̊J�����i��ł�ATi
�c�q�͋t�_�ɂȂ����\��
�u�a�_���Ă͂����肢���Ă���
5-way��VLIW��GPGPU����!? �o�J�o�J����! ���͕����ɖ߂邼!
���u�I������͕�������Ȃ��̂�I�o�Ă��Ȃ����I
�ڂ��h��������
�\�߃G���b�^���킩���Ă���A�v���I�Ȃ̂͐��������Ƃ��ė\�ߔ������邩��A
���Ȃ���Ȃ��́H
�^�p���Ă���A�v���I�Ȃ̂��o�Ă���ƍ��邾�낤���ǁB
���Ȃ���Ȃ��́H
�^�p���Ă���A�v���I�Ȃ̂��o�Ă���ƍ��邾�낤���ǁB
811 �FSocket774�F2010/03/03(��) 11:26:26 ID:JDQsgmTj
�^�p���Ă���A�v���I�Ȃ̂��o�Ă���͍̂ŋ߂���AMD�����ȁB
812 �F��������������v���������������������������F2010/03/03(��) 11:57:08 ID:fdVmpcqA
�Ƃ����������Ă��������̔N��5000���̍ݓ��؍��l40�B�̂ЂƂ育��
�N��Opteron�Ńv���_�N�V�����V�X�e�����^�p���Ă��Ȃ���ǂ��Ƃ������Ƃ͂Ȃ�
Intel�̃G���b�^�̓n���p�Ȃ������
�V�F�A�m�ۂɂǂ����ƈ��͂��g���Ă����̂��
�V�F�A�m�ۂɂǂ����ƈ��͂��g���Ă����̂��
��̓I�ɂǂ̃G���b�^�H
816 �F��������������v���������������������������F2010/03/03(��) 12:26:18 ID:fdVmpcqA
i7
���m�G���b�^���́AC0��108���̓�D0��fix���ꂽ�̂�16�A�c��92���͕��u
http://download.intel.com/design/processor/specupdt/320836.pdf
C2Q
�X�e�b�s���O�ύX��fix���ꂽ���́E�V���ȃG���b�^�A���킹��78��
http://download.intel.com/design/processor/specupdt/318727.pdf
C2D
�X�e�b�s���O�ύX��fix���ꂽ���́E�V���ȃG���b�^�A���킹��76��
http://download.intel.com/design/processor/specupdt/318733.pdf
AM3�̊��m�G���b�^���F34
http://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/41322.pdf
���m�G���b�^���́AC0��108���̓�D0��fix���ꂽ�̂�16�A�c��92���͕��u
http://download.intel.com/design/processor/specupdt/320836.pdf
C2Q
�X�e�b�s���O�ύX��fix���ꂽ���́E�V���ȃG���b�^�A���킹��78��
http://download.intel.com/design/processor/specupdt/318727.pdf
C2D
�X�e�b�s���O�ύX��fix���ꂽ���́E�V���ȃG���b�^�A���킹��76��
http://download.intel.com/design/processor/specupdt/318733.pdf
AM3�̊��m�G���b�^���F34
http://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/41322.pdf
817 �FSocket774�F2010/03/03(��) 12:49:38 ID:JDQsgmTj
>>816
����ǂ������{�I�Ɏ��Q�Ȃ������w
�^�p���Ă���A�v���I�Ȃ̂��o�Ă���͍̂ŋ߂���AMD�����ȁB
�m���Q�x����������ȁA�v�Z�~�X��TLB�j����?
����ǂ������{�I�Ɏ��Q�Ȃ������w
�^�p���Ă���A�v���I�Ȃ̂��o�Ă���͍̂ŋ߂���AMD�����ȁB
�m���Q�x����������ȁA�v�Z�~�X��TLB�j����?
>817
���܂�...�n�����낤w
TLB�͓e���p�A�v�Z�~�X�͂��܂��̃g�J�Q���݂̔]�݂��̕����낤w
�n���Ȑe���琶�܂��ƃK�L���n���Ȃ�ww
���܂�...�n�����낤w
TLB�͓e���p�A�v�Z�~�X�͂��܂��̃g�J�Q���݂̔]�݂��̕����낤w
�n���Ȑe���琶�܂��ƃK�L���n���Ȃ�ww
819 �FSocket774�F2010/03/03(��) 12:56:45 ID:JDQsgmTj
>>818 ����Ȃ��ƌ����Ă��ً}�ɕԕi����Ă������w
http://www.fudzilla.com/index.php?option=com_content&task=view&id=10707&Itemid=35
i7�ɂ�TLB�G���b�^������ǂ˂�
�N���e�B�J���i�G���b�^�̓C���e����AMD�����ʂ�Fix���邾��A���ق���ˁ[�́H
i7�ɂ�TLB�G���b�^������ǂ˂�
�N���e�B�J���i�G���b�^�̓C���e����AMD�����ʂ�Fix���邾��A���ق���ˁ[�́H
>>820 �����炻��͎��Q�Ȃ������w ������AMD�ƌ���I�ɈႤ�Ƃ��낾��?
���Q���o��o�Ȃ���i7�͔����������炻�������G���b�^���o��g��������Ȃ��Č��\����������Ă����̂͂Ȃ�����
�G���b�^�̂��鐻�i���o���ċ������Ă邾���Ȃ̂ɂ�����ւ��Ă���
�G���b�^�̂��鐻�i���o���ċ������Ă邾���Ȃ̂ɂ�����ւ��Ă���
>>822
������̂ł͂��ꂪ�i�����Ă��Ƃ���?�A�Ⴄ�̂���w
���݂���G���b�^�Ȃ�Ă��̂͂��������Ȓ����������ĂȂ���Ί��ł����点��̂͏펯����?
AMD���D�G�����猰�݉������G���b�^�����Ȃ��Ƃ͎v���Ȃ��ˁB�P�Ɏ蔲������A�\�Z�Ȃ����E�E�E
������̂ł͂��ꂪ�i�����Ă��Ƃ���?�A�Ⴄ�̂���w
���݂���G���b�^�Ȃ�Ă��̂͂��������Ȓ����������ĂȂ���Ί��ł����点��̂͏펯����?
AMD���D�G�����猰�݉������G���b�^�����Ȃ��Ƃ͎v���Ȃ��ˁB�P�Ɏ蔲������A�\�Z�Ȃ����E�E�E
�~������̂ł͂��ꂪ�i�����Ă��Ƃ���?�@��������̂ł͂Ȃ����ꂪ�i�����Ă��Ƃ���?
�܂��A��������>820�̕��͂�ǂ߂�A����CPU�͉��̉��P�����Ȃ��܂܂���H���ꂪ�i�����Č���������H
��������Ƃ͌ゾ����BIOS���x���ŃG���b�^�̊Y������A�h���X�ϊ��o�b�t�@�ɐ��������Ă邾�������B
�������AMD��TLB�G���b�^�̑Ώ��Ɖ����Ⴄ�́H�����i���H�Q�ڂ��Ă�́H
��������Ƃ͌ゾ����BIOS���x���ŃG���b�^�̊Y������A�h���X�ϊ��o�b�t�@�ɐ��������Ă邾�������B
�������AMD��TLB�G���b�^�̑Ώ��Ɖ����Ⴄ�́H�����i���H�Q�ڂ��Ă�́H
���������X���`���ȁA�R���������邩�炨�܂��炨�ƂȂ����s��ł���
AMD�fs Sabine Platform Takes Nearly Final Shape.
http://www.xbitlabs.com/news/mobile/display/20100301223005_AMD_s_Sabine_Platform_Takes_Nearly_Final_Shape.html
AMD�fs Sabine Platform Takes Nearly Final Shape.
http://www.xbitlabs.com/news/mobile/display/20100301223005_AMD_s_Sabine_Platform_Takes_Nearly_Final_Shape.html
���[�A����������G���̌������Ƃ͑S���������搳�`����B
����Ă邳�����[�A����ς���Ă邪�����ˁI
����ł�����H�A�z����
����Ă邳�����[�A����ς���Ă邪�����ˁI
����ł�����H�A�z����
>>825
> ��������Ƃ͌ゾ����BIOS���x���ŃG���b�^�̊Y������A�h���X�ϊ��o�b�t�@�ɐ��������Ă邾�������B
> �������AMD��TLB�G���b�^�̑Ώ��Ɖ����Ⴄ�́H�����i���H�Q�ڂ��Ă�́H
��������Q�����邩�������̈Ⴂ����?�AIntel�̂͏��u����܂��ƌ�Ő��\�ɖw�LjႢ���Ȃ��E�E�E
����ɑ�AMD�̂͏���قǂɐ��\�����������ň��ȃP�[�X����1/2�܂Ő��\�ቺ����w
> ��������Ƃ͌ゾ����BIOS���x���ŃG���b�^�̊Y������A�h���X�ϊ��o�b�t�@�ɐ��������Ă邾�������B
> �������AMD��TLB�G���b�^�̑Ώ��Ɖ����Ⴄ�́H�����i���H�Q�ڂ��Ă�́H
��������Q�����邩�������̈Ⴂ����?�AIntel�̂͏��u����܂��ƌ�Ő��\�ɖw�LjႢ���Ȃ��E�E�E
����ɑ�AMD�̂͏���قǂɐ��\�����������ň��ȃP�[�X����1/2�܂Ő��\�ቺ����w
�������Ԃ���G���͌��C����
���ׂ������Ă����u�����Ђ̕��i���X�p�R���Ɏg�����Ώ������Ђ̕��i�g�������Ă����̘b�Ȃ̂ɁA
JDQsgmTj�͂ȂɕK���ɂȂ��Ă�́H
JDQsgmTj�����u�v���C�D����M
�ȍ~���u�ł�
JDQsgmTj�͂ȂɕK���ɂȂ��Ă�́H
JDQsgmTj�����u�v���C�D����M
�ȍ~���u�ł�
Intel�E�E�����O�ɓ��O��validate�����{���Ă���v���I�Ȗ�肪���������琻�i�Ƃ��ďo�ׂ��Ȃ��̐��ƂȂ��Ă�
AMD�E�E�����O�ɓK����validate�����{���Ă���v���I�Ȗ������߂����P�[�X�������ŋ�2�x�����������B�M�����ɋ^�₠��
AMD�E�E�����O�ɓK����validate�����{���Ă���v���I�Ȗ������߂����P�[�X�������ŋ�2�x�����������B�M�����ɋ^�₠��
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
Llano��TDP59W���ăf�X�N�g�b�v���܂܂�Ă��ȁH
���\���ꂽ�̂̓m�[�g�����Ȃ̂��H
���\���ꂽ�̂̓m�[�g�����Ȃ̂��H
AMD��Bulldozer�ł܂�����Ă��ꂻ���ȋC�z������s��ɏo�����S���m�F����Ă���̍w���ɂ��������悢���낤�B
���\�͊��҂ł��Ȃ����ǂȁB
���\�͊��҂ł��Ȃ����ǂȁB
Intel�̂ق������O��Validate���Ă���Ă̂͂��̒ʂ肾�낤
�䂦�ɁAP55��USB�Ƃ��������ĂĂ����Ĕ������Ƃ�������
�䂦�ɁAP55��USB�Ƃ��������ĂĂ����Ĕ������Ƃ�������
>>162�ɂ���
���������ďW���ăG���b�^�T�����̂�AMDCPU
���i���[�U�[�Ƃ�������ɎG���j�Ɋ���ďW���ăG���b�^�����t����̂�IntelCPU
���������ďW���ăG���b�^�T�����̂�AMDCPU
���i���[�U�[�Ƃ�������ɎG���j�Ɋ���ďW���ăG���b�^�����t����̂�IntelCPU
�G���b�^���ɉ��P����AMD�ƕ��u��intel
P55�̃G���b�^�̑�ver�͂ǂ�����w
H55�ُ̈픭�M�͂ǂ�����w
�����ł��܂Ƃ��Ȑ_�o���Ă���o�O���炯��Intel�Ȃ͎g��Ȃ���w
�ŋ߂�AMD�̈��芴�Ƃ�����ُ�ɍ������獢��
P55�̃G���b�^�̑�ver�͂ǂ�����w
H55�ُ̈픭�M�͂ǂ�����w
�����ł��܂Ƃ��Ȑ_�o���Ă���o�O���炯��Intel�Ȃ͎g��Ȃ���w
�ŋ߂�AMD�̈��芴�Ƃ�����ُ�ɍ������獢��
>>833
> Llano��TDP59W���ăf�X�N�g�b�v���܂܂�Ă��ȁH
> ���\���ꂽ�̂̓m�[�g�����Ȃ̂��H
�m�[�g�������Ǝv���܂��ˁA��{�I�Ƀp���[�Q�[�e�B���O�@�\�ł������肵�����������E�E�E
���������̕��ȓd�͐��\��Intel���݂ɂȂ�Ǝv����BGPU��DirectX 11�Ή����������̂ł͂Ȃ�����?
�������Bulldozer�ƈ���Ă���Ȃ�ɔ���邩���m��Ȃ��ˁB
> Llano��TDP59W���ăf�X�N�g�b�v���܂܂�Ă��ȁH
> ���\���ꂽ�̂̓m�[�g�����Ȃ̂��H
�m�[�g�������Ǝv���܂��ˁA��{�I�Ƀp���[�Q�[�e�B���O�@�\�ł������肵�����������E�E�E
���������̕��ȓd�͐��\��Intel���݂ɂȂ�Ǝv����BGPU��DirectX 11�Ή����������̂ł͂Ȃ�����?
�������Bulldozer�ƈ���Ă���Ȃ�ɔ���邩���m��Ȃ��ˁB
> �ŋ߂�AMD�̈��芴�Ƃ�����ُ�ɍ������獢��
������?�A����OC����ƒ����ɕs����ɂȂ邪�E�E�E
������?�A����OC����ƒ����ɕs����ɂȂ邪�E�E�E
>>831
��Intel�E�E�����O�ɓ��O��validate�����{���Ă���v���I�Ȗ�肪���������琻�i�Ƃ��ďo�ׂ��Ȃ��̐��ƂȂ��Ă�
����A������i7��TLB�G���b�^�͖��C���ō��ł��o�ׂ��Ă邵�A�����AMD�Ɠ����悤��BIOS����fix���Ă邾���B
����ς���Ă���Ă��������A����Ă�Ȃ炤�����ł���䂤�ł�����B
��Intel�E�E�����O�ɓ��O��validate�����{���Ă���v���I�Ȗ�肪���������琻�i�Ƃ��ďo�ׂ��Ȃ��̐��ƂȂ��Ă�
����A������i7��TLB�G���b�^�͖��C���ō��ł��o�ׂ��Ă邵�A�����AMD�Ɠ����悤��BIOS����fix���Ă邾���B
����ς���Ă���Ă��������A����Ă�Ȃ炤�����ł���䂤�ł�����B
Intel�E�E�����O�ɓ��O��validate�����{���Ă���v���I�Ȗ�肪����������u�t�@�C���ړ��v�̂悤�Ƀ��[�U�[�̒m�\��v���I�ɂ��Č�����I����������̐��ƂȂ��Ă�
���̏؋����肦��̂��G��
���̏؋����肦��̂��G��
fix���Đ��\��������Ȃ��Ȃ炻��Ŗ��Ȃ��悤�ȁc
>Intel�̂͏��u����܂��ƌ�Ő��\�ɖw�LjႢ���Ȃ�
���ꂪ�{���Ȃ��
�����莟����X���Ƃ͎v���Ȃ��C���������Ȃ�
2���قNJY���X���Ɉړ����Ă���Ȃ�����
>Intel�̂͏��u����܂��ƌ�Ő��\�ɖw�LjႢ���Ȃ�
���ꂪ�{���Ȃ��
�����莟����X���Ƃ͎v���Ȃ��C���������Ȃ�
2���قNJY���X���Ɉړ����Ă���Ȃ�����
>>840
> ����A������i7��TLB�G���b�^�͖��C���ō��ł��o�ׂ��Ă邵�A�����AMD�Ɠ����悤��BIOS����fix���Ă邾���B
> ����ς���Ă���Ă��������A����Ă�Ȃ炤�����ł���䂤�ł�����B
���O����̉��ɍS���Ă���̂������ł��Ȃ��A��{�I��BIOS�őΉ��o���Ă���̂Ȃ牽�����͂Ȃ��B
�������AMD�̂悤�ȍň�1/2�ɐ��\�����鎖��͏����B
> ����A������i7��TLB�G���b�^�͖��C���ō��ł��o�ׂ��Ă邵�A�����AMD�Ɠ����悤��BIOS����fix���Ă邾���B
> ����ς���Ă���Ă��������A����Ă�Ȃ炤�����ł���䂤�ł�����B
���O����̉��ɍS���Ă���̂������ł��Ȃ��A��{�I��BIOS�őΉ��o���Ă���̂Ȃ牽�����͂Ȃ��B
�������AMD�̂悤�ȍň�1/2�ɐ��\�����鎖��͏����B
>>842
�������ȁA������X���ň��̌��s�i��AMD��1����O�̐��i�̃G���b�^�̘b�Ȃ�Ă�����߂�B
�������ȁA������X���ň��̌��s�i��AMD��1����O�̐��i�̃G���b�^�̘b�Ȃ�Ă�����߂�B
>>842
�n�[�h�E�F�A�G���b�^�E�E�E�\�t�g�E�F�A�ł͉����o���Ȃ��̂ʼn��}���u�ŋ@�\���~�߂邭�炢�B����m���͍���
�\�t�g�E�F�A�G���b�^�E�E�E�}�C�N���R�[�h��������������ςނ����̕�����������ł��P�Ƀo�O�������ֈڂ��������ȉ\��������
�Ƃ܂�����Ȋ����̔��f��
�]�ɒv���I�ȃG���b�^������Ă���ƑS���o����
��ɏ��C������������̂��G���Ȃ킯����
�n�[�h�E�F�A�G���b�^�E�E�E�\�t�g�E�F�A�ł͉����o���Ȃ��̂ʼn��}���u�ŋ@�\���~�߂邭�炢�B����m���͍���
�\�t�g�E�F�A�G���b�^�E�E�E�}�C�N���R�[�h��������������ςނ����̕�����������ł��P�Ƀo�O�������ֈڂ��������ȉ\��������
�Ƃ܂�����Ȋ����̔��f��
�]�ɒv���I�ȃG���b�^������Ă���ƑS���o����
��ɏ��C������������̂��G���Ȃ킯����
AMD�ɕs���Ȃ��Ƃ�������ƁA�����G���Ă�肷��z�̂ق����C����������
���b�e�������l�i�ے�ȊO�Ŕ��_�����
���b�e�������l�i�ے�ȊO�Ŕ��_�����
�m�I��Q�҂�����PC�ɂǂꂾ�����邩���l�����
���̔̒m�I��Q�ҁ��G���@�Ɣ��f���č����x���Ȃ���Ȃ����H
���̔̒m�I��Q�ҁ��G���@�Ɣ��f���č����x���Ȃ���Ȃ����H
>>779
> Intel��Core 2���炸����1�R�A������SIMD ALU�~3�����H
�������ˁA����128bitSSE���j�b�g�ƌ����Ă�AMD�̂�SIMD ALU�~2��Intel�̂�SIMD ALU�~3�̈Ⴂ������B
Bulldozer��SIMD ALU�~2��128bitSSE���j�b�g��2���ڂ�2�R�A�ŋ��L����`���ɂȂ邩��ꉞ��1�R�A���쎞��128bitSSEx2�̐��\������B
����ɑ�Sandy Bridge��SIMD ALU�~2��256bitSSE���j�b�g��1�R�A�ɕt��1�䓋�ڂ���B
���ꂾ�������Ă����R�A���Ό�����Bulldozer��Sandy Bridge��肩�Ȃ萫�\����������R�A���ŏ������邵���Ȃ��B
Sandy Bridge��4�R�A�ɑ�Bulldozer��6�R�A�ł����ĂȂ����낤�ȁE�E�E
�X�Ɍ����ΐ������Z���\�ł�Bulldozer��Sandy Bridge�ɏ��ĂȂ�����A��͂����ȓd�͏������������������E�E�E
> Intel��Core 2���炸����1�R�A������SIMD ALU�~3�����H
�������ˁA����128bitSSE���j�b�g�ƌ����Ă�AMD�̂�SIMD ALU�~2��Intel�̂�SIMD ALU�~3�̈Ⴂ������B
Bulldozer��SIMD ALU�~2��128bitSSE���j�b�g��2���ڂ�2�R�A�ŋ��L����`���ɂȂ邩��ꉞ��1�R�A���쎞��128bitSSEx2�̐��\������B
����ɑ�Sandy Bridge��SIMD ALU�~2��256bitSSE���j�b�g��1�R�A�ɕt��1�䓋�ڂ���B
���ꂾ�������Ă����R�A���Ό�����Bulldozer��Sandy Bridge��肩�Ȃ萫�\����������R�A���ŏ������邵���Ȃ��B
Sandy Bridge��4�R�A�ɑ�Bulldozer��6�R�A�ł����ĂȂ����낤�ȁE�E�E
�X�Ɍ����ΐ������Z���\�ł�Bulldozer��Sandy Bridge�ɏ��ĂȂ�����A��͂����ȓd�͏������������������E�E�E
����
���������Ȍ��Ɂu�m�I��Q�ҁv�ƌ������Ƃ�������������
�����������Ȃ�u�ŏd�x�m�I��Q�ҁv���������̒m�\���G���@����
���������Ȍ��Ɂu�m�I��Q�ҁv�ƌ������Ƃ�������������
�����������Ȃ�u�ŏd�x�m�I��Q�ҁv���������̒m�\���G���@����
�ǂ����Ă�ID:9jfob2PR���m�I��Q�ҁ��G���ɂ��������܂���E�E�E�E
NG�ɓ˂����̂ł����A���͌����Ȃ�
I����D:JDQsgmTj���G������Ȃ��Ȃ�R�e�t���ė~������
>>835
> Intel�̂ق������O��Validate���Ă���Ă̂͂��̒ʂ肾�낤
���O����AMD��Intel�ɍ��͂Ȃ���
�V�F�A���͂Ƃ�����Cray��IBM�Ƌ��͂���HPC��T�[�o�[���i�J�����Ă�����
Top10�Ȃ͂ǂ�������x���ʼn^�p���Ă邩��ȁA���Ԃ������Ă����邱�Ƃ�z�肵�Ď������炢���Ă�
> �䂦�ɁAP55��USB�Ƃ��������ĂĂ����Ĕ������Ƃ�������
�Œ�̊�Ƃ���ȁA�����ɂ��قǂ�����w
Fix����Ver�����N���ɏo���Ƃ������Ă��̂ɂ܂��o���ĂȂ���������Ȃ���
> Intel�̂ق������O��Validate���Ă���Ă̂͂��̒ʂ肾�낤
���O����AMD��Intel�ɍ��͂Ȃ���
�V�F�A���͂Ƃ�����Cray��IBM�Ƌ��͂���HPC��T�[�o�[���i�J�����Ă�����
Top10�Ȃ͂ǂ�������x���ʼn^�p���Ă邩��ȁA���Ԃ������Ă����邱�Ƃ�z�肵�Ď������炢���Ă�
> �䂦�ɁAP55��USB�Ƃ��������ĂĂ����Ĕ������Ƃ�������
�Œ�̊�Ƃ���ȁA�����ɂ��قǂ�����w
Fix����Ver�����N���ɏo���Ƃ������Ă��̂ɂ܂��o���ĂȂ���������Ȃ���
���߂�ID:JDQsgmTj�͎G��������
�X�������ς݂܂���ł���
�X�������ς݂܂���ł���
791 Socket774 sage 2010/03/03(��) 14:36:12 ID:JDQsgmTj
>>788
> AM2��������5600+��E6600���ĂƂ��낾��B
5600+��E4700�ɂ��畉���Ă���悤�����ǁE�E�E
http://www.anandtech.com/bench/default.aspx?p=30&p2=63&c=1
>>788
> AM2��������5600+��E6600���ĂƂ��낾��B
5600+��E4700�ɂ��畉���Ă���悤�����ǁE�E�E
http://www.anandtech.com/bench/default.aspx?p=30&p2=63&c=1
�܂����[�v������
>>849�̘b���炵���Ԕ����ّ��̍��}�Ȃ�u�X���̃��[�v�v�ɂ͂Ȃ�낤
�uAMD�͏����_�ƃx�N�^���i�ƒ�������H�jGPGPU�Ɉڂ��\��v���ĕ�����
�\�[�X�����Ō����Ă�ȊO�͓��{�꒝���Ă邩�ǂ������s���Ȃ��炢�ŒN���H�����Ȃ���
�z�̔]�����[�v����ꂽ�^���e�[�v�͂����̂��Ƃ���
�uAMD�͏����_�ƃx�N�^���i�ƒ�������H�jGPGPU�Ɉڂ��\��v���ĕ�����
�\�[�X�����Ō����Ă�ȊO�͓��{�꒝���Ă邩�ǂ������s���Ȃ��炢�ŒN���H�����Ȃ���
�z�̔]�����[�v����ꂽ�^���e�[�v�͂����̂��Ƃ���
���܂Ȃ�Athlon�����X���Ƃ����፬���ɂȂ��Ă�Ƃ����>>858������
�܂�����I���ċC���ɂȂ���
�܂�����I���ċC���ɂȂ���
>>856
�����g�������Ƃ�����l�Ɍ��킹���
E6600�̓x���`��SSE�n�������������וi
�������penD����͈��|�I�ɑ����Ȃ邪X2 5600+�ɂ͋y�Ȃ�
����p�r(Office��u���E�U)���ƁA����4800+�ɂ��珟�Ă邩�ǂ����ȑ㕨�ł����Ȃ�
�����g�������Ƃ�����l�Ɍ��킹���
E6600�̓x���`��SSE�n�������������וi
�������penD����͈��|�I�ɑ����Ȃ邪X2 5600+�ɂ͋y�Ȃ�
����p�r(Office��u���E�U)���ƁA����4800+�ɂ��珟�Ă邩�ǂ����ȑ㕨�ł����Ȃ�
>>856
����ɃR�s�y���Ȃ��ʼn������B
>>858
> E4700 > 5600+ �̍��ڐ��P�S
�������ǂ߂Ă܂���ALower is Better�̍��ڂ��������邱�Ƃ�������Ă�ˁB
E4700 > 5600+ �̍��ڐ��͂Q�W�ł��B
����ɃR�s�y���Ȃ��ʼn������B
>>858
> E4700 > 5600+ �̍��ڐ��P�S
�������ǂ߂Ă܂���ALower is Better�̍��ڂ��������邱�Ƃ�������Ă�ˁB
E4700 > 5600+ �̍��ڐ��͂Q�W�ł��B
�킴�킴���̃X���܂ŗ��ĉ����Ă�̂��Ǝv���G���b�^�Ɣ��M�B���ɖz������
�S�߂ȓz�炾
�S�߂ȓz�炾
�u���h�[�U�[��8�R�A�ł�300�o2�ȉ��ɂȂ邾�낤����
12�R�A���炢�����ė��邩����
12�R�A���炢�����ė��邩����
>>858
Lower is Better�̍��ڂ�Higher is Better�̍��ڂ�����B
>>856�̔�r��5600+�������Ă���̂́��̂������ȁB
WinRAR 3.8 Compression - 300MB Archive
Fallout 3 - 1680 x 1050 - Medium Quality
Left 4 Dead - 1680 x 1050 - Max Settings (No AA/AF/Vsync)
Lower is Better�̍��ڂ�Higher is Better�̍��ڂ�����B
>>856�̔�r��5600+�������Ă���̂́��̂������ȁB
WinRAR 3.8 Compression - 300MB Archive
Fallout 3 - 1680 x 1050 - Medium Quality
Left 4 Dead - 1680 x 1050 - Max Settings (No AA/AF/Vsync)
�������Ƌ�CID�o�^
ID:JDQsgmTj��NG�ɂ��܂���
�������X���͕��a�ł��O�O
�������X���͕��a�ł��O�O
�Ԃ����Ⴏ�t�F���~��胉���r�[�̕����g������ˁH
���N32nm�Ɉڍs����܂ŁA�b�o�t�ƃ}�U�[�{�[�h�̍X�V�͂��a�����ȁE�E�E
>>839
i5�Ń\�P�b�g�Ă�����i3�Ń����R���Ă���Intel���܂�����
i5�Ń\�P�b�g�Ă�����i3�Ń����R���Ă���Intel���܂�����
�h�c�Ԃ��z�A�S���G��������NG-ID�ɂԂ����߂Ε��a����
��^���ԂɂȂ�܂Ŏ��_�������Ⴎ���ጾ���܂���z�͑S���G���ł����悗����
��^���ԂɂȂ�܂Ŏ��_�������Ⴎ���ጾ���܂���z�͑S���G���ł����悗����
���_����ׂ�͕̂��ʂ̐l��
�펞�d�g����o�Ȃ̂��G��
�펞�d�g����o�Ȃ̂��G��
���߂�A�d�g������ƘR�炵���������
���o ID:JDQsgmTj (17��)
12�R�A�ɍœK�����邾������ˁH
���肦�˂��E�E�E
�K���`�F�b�J�[
http://hissi.org/read.php/jisaku/20100303/ZmRWbXBjcUE.html
���o ID:fdVmpcqA (38��)
���e���e��������
http://hissi.org/read.php/jisaku/20100303/ZmRWbXBjcUE.html
���o ID:fdVmpcqA (38��)
���e���e��������
>>876
���s���s�X���b�h���𑝂₷�̂̓R�X�g��������A
�V�F�A�̏��Ȃ�CPU�����̍œK���͂Ȃ��Ȃ��Ȃ���Ȃ��A�Ƃ����̂���_�B
�\�t�g�E�F�A�̍œK���ł͂ǂ��ɂ��Ȃ�Ȃ������E�r������̃��X�������Ă����A
�Ƃ����̂���_�B
transactional memory���̑��X���b�h�����Z�p�͈ˑR�Ƃ��ăn�[�h�E�\�t�g�Ƃ�
���p�i�K�ɂ͂Ȃ��A8�R�A����̂͂��܂���������͂Ȃ����ƁB
���s���s�X���b�h���𑝂₷�̂̓R�X�g��������A
�V�F�A�̏��Ȃ�CPU�����̍œK���͂Ȃ��Ȃ��Ȃ���Ȃ��A�Ƃ����̂���_�B
�\�t�g�E�F�A�̍œK���ł͂ǂ��ɂ��Ȃ�Ȃ������E�r������̃��X�������Ă����A
�Ƃ����̂���_�B
transactional memory���̑��X���b�h�����Z�p�͈ˑR�Ƃ��ăn�[�h�E�\�t�g�Ƃ�
���p�i�K�ɂ͂Ȃ��A8�R�A����̂͂��܂���������͂Ȃ����ƁB
>>879
�ǂ���ɂ���ACPU���o���Ă��܂��Ώ͕ς��ł���
Intel�����ĒǏ]�����
�ǂ݂̂��A����̃T�[�o�V�X�e���ł́A�_�[�X�P�ʂ̃R�A�͒������Ȃ��Ȃ邩��
�\�t�g�E�F�A���œK������Ă����ł���
64bit�ڍs���̗l�ɂ�
�ǂ���ɂ���ACPU���o���Ă��܂��Ώ͕ς��ł���
Intel�����ĒǏ]�����
�ǂ݂̂��A����̃T�[�o�V�X�e���ł́A�_�[�X�P�ʂ̃R�A�͒������Ȃ��Ȃ邩��
�\�t�g�E�F�A���œK������Ă����ł���
64bit�ڍs���̗l�ɂ�
�Ή��͂���邯�ǍœK���͂���Ȃ��E�E�E���ꂪ����
���ƁA�T�[�o�[�̐�ɂ͑����̎g�p�҂����邩�炻����œK���̍����ɂ���̂͂�����Ƃ�������
���ƁA�T�[�o�[�̐�ɂ͑����̎g�p�҂����邩�炻����œK���̍����ɂ���̂͂�����Ƃ�������
Intel�͈ˑR�Ƃ��ăR�A�������V���O���X���b�h���\���d�v�����Ă���B
�������ȏ�ɃR�A���𑝂₻���Ƃ���AMD�̓����ɒǏ]�͂��Ă��Ȃ��B
�������ȏ�ɃR�A���𑝂₻���Ƃ���AMD�̓����ɒǏ]�͂��Ă��Ȃ��B
SSE�����ōœK������Ȃ琫�\���͏o�邩������Ȃ���
�������Z��䂾�ƍœK�����Ă�5%�Ⴆ�Ί�Ղ��ă��x�������B
�R�[�h���r���h���鎞�_�ŃO���[�o���ȍœK���͂��Ă����ŁA
�C���e�������̍œK���������Ă�SSE�ȊO�ł͖ڂ��������͏o�Ȃ��B
�������Z��䂾�ƍœK�����Ă�5%�Ⴆ�Ί�Ղ��ă��x�������B
�R�[�h���r���h���鎞�_�ŃO���[�o���ȍœK���͂��Ă����ŁA
�C���e�������̍œK���������Ă�SSE�ȊO�ł͖ڂ��������͏o�Ȃ��B
884 �FSocket774�F2010/03/04(��) 03:53:22 ID:BBmjbmaq
�@���s��Ibexpeak�̃}�U�[�{�[�h�ł�Sandy Bridge-DC/QC�̓T�|�[�g����Ȃ��B
�Ƃ����̂��ACPU�\�P�b�g���قȂ��Ă��邩�炾�B
�x���_�[�̏��ɂ��AIntel��Couger Point����œ�������CPU�\�P�b�g�́A
Socket H2(�\�P�b�g�G�C�`�c�[)�Ƃ����J���R�[�h�l�[��������ꂽ���̂ɂȂ�A
�s���������s��LGA1156(Socket H)����1�s��������1,155�s���ɂȂ�̂��Ƃ����B
�i�����j
�@����ɂ��A�]����CPU�ł���Lynnfield�AClarkdale��Couger Point�}�U�[�{�[�h�ł͗��p�ł��Ȃ��B
�t�ɁASandy Bridge��Ibexpeak�}�U�[�{�[�h�ł͗��p�ł��Ȃ��B
�@�Ȃ��AIntel�̓T�[�o�[/���[�N�X�e�[�V�����s��ł��V����CPU�\�P�b�g������B
OEM���[�J�[�̏��ɂ��ASocket B2�ASocket R�Ƃ����̂����ꂾ�B
Socket B2�͂��̖��̒ʂ�ABloomfiled(�ŏ���Core i7�̊J���R�[�h�l�[��)�p�Ƃ���
�J�����ꂽSocket B(LGA1366)�̉��ǔłŁA�������10�s��������1,356�s���ƂȂ�B
�i�����j
�@Sandy Bridge����ŐV�������������Socket R��2,011�s���ƂȂ�A
Sandy Bridge-EP�ASandy Bridge-EX�ƌĂ�����K�͂�
�T�[�o�[/���[�N�X�e�[�V���������̃v���Z�b�T�ŃT�|�[�g�����B
�E�\�[�X
Sandy Bridge��Socket H2��2011�N��1�l�����ɓo��
http://pc.watch.impress.co.jp/docs/column/ubiq/20100304_352469.html
�C���e���~���܂����ˁI
�Ƃ����̂��ACPU�\�P�b�g���قȂ��Ă��邩�炾�B
�x���_�[�̏��ɂ��AIntel��Couger Point����œ�������CPU�\�P�b�g�́A
Socket H2(�\�P�b�g�G�C�`�c�[)�Ƃ����J���R�[�h�l�[��������ꂽ���̂ɂȂ�A
�s���������s��LGA1156(Socket H)����1�s��������1,155�s���ɂȂ�̂��Ƃ����B
�i�����j
�@����ɂ��A�]����CPU�ł���Lynnfield�AClarkdale��Couger Point�}�U�[�{�[�h�ł͗��p�ł��Ȃ��B
�t�ɁASandy Bridge��Ibexpeak�}�U�[�{�[�h�ł͗��p�ł��Ȃ��B
�@�Ȃ��AIntel�̓T�[�o�[/���[�N�X�e�[�V�����s��ł��V����CPU�\�P�b�g������B
OEM���[�J�[�̏��ɂ��ASocket B2�ASocket R�Ƃ����̂����ꂾ�B
Socket B2�͂��̖��̒ʂ�ABloomfiled(�ŏ���Core i7�̊J���R�[�h�l�[��)�p�Ƃ���
�J�����ꂽSocket B(LGA1366)�̉��ǔłŁA�������10�s��������1,356�s���ƂȂ�B
�i�����j
�@Sandy Bridge����ŐV�������������Socket R��2,011�s���ƂȂ�A
Sandy Bridge-EP�ASandy Bridge-EX�ƌĂ�����K�͂�
�T�[�o�[/���[�N�X�e�[�V���������̃v���Z�b�T�ŃT�|�[�g�����B
�E�\�[�X
Sandy Bridge��Socket H2��2011�N��1�l�����ɓo��
http://pc.watch.impress.co.jp/docs/column/ubiq/20100304_352469.html
�C���e���~���܂����ˁI
Bulldozer��AM3������
Llano�͂ǂ��Ȃ��H
Llano�͂ǂ��Ȃ��H
AMD���d������̂̓R�A���W�b�N
Inel���d������̂̓L���b�V����SIMD���j�b�g
Intel��SMT�̕������p�C�v���C�������ɑ������ׂ��邪
�ǂ����o�O���Ă�̂ł��܂�Ӗ�������
Inel���d������̂̓L���b�V����SIMD���j�b�g
Intel��SMT�̕������p�C�v���C�������ɑ������ׂ��邪
�ǂ����o�O���Ă�̂ł��܂�Ӗ�������
> AMD���d������̂̓R�A���W�b�N
����AMD�����Ő��l���Z���\��2/3�Ɍ��炷�̂�����s�\�B
�v���ÏL���ƂĂ��d�����Ă���Ƃ͎v���Ȃ��B
����AMD�����Ő��l���Z���\��2/3�Ɍ��炷�̂�����s�\�B
�v���ÏL���ƂĂ��d�����Ă���Ƃ͎v���Ȃ��B
�ŋ߃R�e���Ȃ��̂�
�G���Ђ����߁A�N�\�`����
Barcelona�̃u���b�N�}
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai06l.gif
����!���̕s�����ɂ܂�Ȃ���H�\���AAGU��3������̂ɓ����ɓ���\�Ȃ̂�2�ł����Ȃ��B
����Ȃ��������Ȑv������Barcelona�̐^���������̂ł���B
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai06l.gif
{kind=link}
����!���̕s�����ɂ܂�Ȃ���H�\���AAGU��3������̂ɓ����ɓ���\�Ȃ̂�2�ł����Ȃ��B
����Ȃ��������Ȑv������Barcelona�̐^���������̂ł���B
> AGU��3������̂ɓ����ɓ���\�Ȃ̂�2�ł����Ȃ�
���̐}����́A�ǂݎ��Ȃ�����
���̐}����́A�ǂݎ��Ȃ�����
>>880
�}���`�X���b�h�ɂ����E������B879�������Ă邪�r���̃��b�N�Ȃ��l�b�N
�ɂȂ��ăR�A����������ƃ{�g���l�b�N�ɂȂ�B�܂����ɂ������͂���炵����
�ڂ����͒m��Ȃ�w
�f�[�^�x�[�X�T�[�o�[�ł�������16�R�A�ɑΉ��������ă��x�������ˁB
�}���`�X���b�h�ɂ����E������B879�������Ă邪�r���̃��b�N�Ȃ��l�b�N
�ɂȂ��ăR�A����������ƃ{�g���l�b�N�ɂȂ�B�܂����ɂ������͂���炵����
�ڂ����͒m��Ȃ�w
�f�[�^�x�[�X�T�[�o�[�ł�������16�R�A�ɑΉ��������ă��x�������ˁB
�R�A����������ƃL���b�V���R�q�[�����V�ێ��Ƀ��\�[�X�H������ˁA���ꂪ�����ĂȂ��Ƃł���B
128�R�ASMP�ȃ}�V�������̒��ɂ͂��邺��
�����Ă����s�����͗ǂ��Ȃ��̂������w
896 �FSocket774�F2010/03/04(��) 10:18:50 ID:wBgHAtZJ
>>887
3���s��intel���Ȃ�HT�𓋍ڂ��Ă���̂��A�l���Ă݂Ȃ͂�
3���s��intel���Ȃ�HT�𓋍ڂ��Ă���̂��A�l���Ă݂Ȃ͂�
32�̘b�H
������ ID:Xc/rYEvr��>>878���鐨���ɂ���\�肩�ȁB
bull�̎��ۂ̐��\�͏o�Ă���܂ŕ�����Ȃ��Ȃ��B
bull�̎��ۂ̐��\�͏o�Ă���܂ŕ�����Ȃ��Ȃ��B
���ʂɃV���O���X���b�h���\���]���ɃR�A�𑝂₵��CMT���Ǝv����B
�����̂̏ꍇ�̓g�����W�X�^���̐����邩��A
�A�C�f�B�A��Ŗ��@�̂悤�ɉ�������A�Ȃ�Ă��Ƃ͂܂����肦�Ȃ��B
�����̂̏ꍇ�̓g�����W�X�^���̐����邩��A
�A�C�f�B�A��Ŗ��@�̂悤�ɉ�������A�Ȃ�Ă��Ƃ͂܂����肦�Ȃ��B
�\�[�X��2ch����
K7�n�̃X�P�W���[���͈ˑ��W���N�ɒ��ׂ����ʂȉ��Z�𑝂₷�̂�
4����ɂ��Ă�5%�قǐ��\�オ��炵����
Core�n�̃X�P�W���[���Ȃ�2�ŏ[������
K7�n�̃X�P�W���[���͈ˑ��W���N�ɒ��ׂ����ʂȉ��Z�𑝂₷�̂�
4����ɂ��Ă�5%�قǐ��\�オ��炵����
Core�n�̃X�P�W���[���Ȃ�2�ŏ[������
AMD�̓l�C�e�B�u2/4�R�ACPU�Ő�s������GPU������Ă邵�ŁA�}���`�R�ACPU�̓����̐ڑ��̃m�E�n�E�����܂��Ă�
���̌o������A�N���X�o�[�X�C�b�`�ő傫���ȃy�i���e�B�[�����ɖ������\�Ȍ��E��4�`6�R�A�܂ł��ė\���𗧂Ă���Ȃ�����
Bulldozer��2�R�A��1���W���[���ɂ��邱�ƂŁA�N���X�o�[�X�C�b�`�̐ڑ���4�`6�ɗ}�����܂ܑ����̃R�A�����̂��ő�̖ړI�Ȃ�Ȃ���
���̌o������A�N���X�o�[�X�C�b�`�ő傫���ȃy�i���e�B�[�����ɖ������\�Ȍ��E��4�`6�R�A�܂ł��ė\���𗧂Ă���Ȃ�����
Bulldozer��2�R�A��1���W���[���ɂ��邱�ƂŁA�N���X�o�[�X�C�b�`�̐ڑ���4�`6�ɗ}�����܂ܑ����̃R�A�����̂��ő�̖ړI�Ȃ�Ȃ���
>901 ���O�FSocket774[sage] ���e���F2010/03/04(��) 11:54:24 ID:hqQPCMfZ
>�\�[�X��2ch����
���͂�a�C���x��
>�\�[�X��2ch����
���͂�a�C���x��
�܂�Bulldozer�̃T���v�����o���Ώ����͏�R��Ă��邾�낤�B
Sandy�R�Ȃ炻�낻��Ȃ�Ȃ����B
�T���v�����o���Ȃ���c�c�ފݍs�����ȁB
Larrabee��Rock�����U���đ҂��Ă���B
Sandy�R�Ȃ炻�낻��Ȃ�Ȃ����B
�T���v�����o���Ȃ���c�c�ފݍs�����ȁB
Larrabee��Rock�����U���đ҂��Ă���B
�ފ݂ɓn��ɂ��D�̓t�F���Ȃ�Ƃ�����ɏ���ďo�q���Ă�̂Ŕފ݂ɓn��Ȃ��B
�C���e����IPC3�̐v�Ńp�C�v���C���ߐ�Ȃ�����
HTT�������B�܂�IPC3�Ńf�R�[�h�E���s�ł����Ƃ��Ă�
�g����͓̂���B
������AMD�̓R�A���y�A�ŃX���b�h���\���グ�AIPC4�̋��L
�f�R�[�_�����ĕ���x�����߂����ɁA�����p�C�v��2/3
�ɂ��ăR�A������̃��\�[�X�͗}�������BHTT�݂����Ȃ��Ƃ�
���Ȃ��Ǝg����Ȃ��̂Ȃ�A2/3�ɂ��Ă��e���͏��Ȃ���
���f�����낤�ˁB
HTT�������B�܂�IPC3�Ńf�R�[�h�E���s�ł����Ƃ��Ă�
�g����͓̂���B
������AMD�̓R�A���y�A�ŃX���b�h���\���グ�AIPC4�̋��L
�f�R�[�_�����ĕ���x�����߂����ɁA�����p�C�v��2/3
�ɂ��ăR�A������̃��\�[�X�͗}�������BHTT�݂����Ȃ��Ƃ�
���Ȃ��Ǝg����Ȃ��̂Ȃ�A2/3�ɂ��Ă��e���͏��Ȃ���
���f�����낤�ˁB
���p�C�v���C���ߐ�Ȃ�����HTT������
HTT=HyperTransporT�@�̌��͂����Ƃ��Ƃ���
�v���O�����Ȃ�ď�ɕ��ϒl�I�Ȃ��̂œ����킯�ł͂Ȃ�����
�u�ˑ�����Ń��\�[�X�]��܂���u�ԁv�Ȃ�Ă��̂�����
���i�͖��p�ł����̎��Ɏg�����߂�HT��p�ӂ���̂͂����������Ƃł͂Ȃ�
�ł����ۂŐ����X�J�����\���ǂ̒��x�オ�������Ŕ��f���ׂ�
�������u�قƂ�Ǖς���ĂȂ������͂��v�ƈȑO�����Ē�������Ȃ������킯�Ȃ��
��ۂł͉ߏ肾�����낤�ˁA���s�p�C�v���f�R�[�_��
HTT=HyperTransporT�@�̌��͂����Ƃ��Ƃ���
�v���O�����Ȃ�ď�ɕ��ϒl�I�Ȃ��̂œ����킯�ł͂Ȃ�����
�u�ˑ�����Ń��\�[�X�]��܂���u�ԁv�Ȃ�Ă��̂�����
���i�͖��p�ł����̎��Ɏg�����߂�HT��p�ӂ���̂͂����������Ƃł͂Ȃ�
�ł����ۂŐ����X�J�����\���ǂ̒��x�オ�������Ŕ��f���ׂ�
�������u�قƂ�Ǖς���ĂȂ������͂��v�ƈȑO�����Ē�������Ȃ������킯�Ȃ��
��ۂł͉ߏ肾�����낤�ˁA���s�p�C�v���f�R�[�_��
�C���e����HTT���������̂́A�O�������A�N�Z�X���Ă���Œ��Ƀp�C�v���C����������J�����炾��B
��{�Ƃ��āA1st-cache�Ƀq�b�g���Ȃ�����p�C�v���C���̋͏o��B
1st-cache��hit���܂���A���܂�͏o�Ȃ����̂̂������͗]�肠����Ē��x����B
��{�Ƃ��āA1st-cache�Ƀq�b�g���Ȃ�����p�C�v���C���̋͏o��B
1st-cache��hit���܂���A���܂�͏o�Ȃ����̂̂������͗]�肠����Ē��x����B
L1�̓��C�e���V�ŒZ�ɂ��邽�߂ɃT�C�Y�͏������Ȃ��ŁA
���L1�Ƀq�b�g��������Ƃ����͍̂l���ɂ����ȁB
�����Ńp�C�v���C�����u�Ԃ��ǂ����߂Č������グ�邩
�Ƃ����b�ɂȂ�B
�C���e���͉��zCPU�Ŏ��s���j�b�g�̋߂�B
AMD�͂ǂ����Ȃ�X���b�h���𑝂₻���Ƃ����v�z�B
�܂��ǂ����������Ƃ������̂ł͂Ȃ��v�z�̈Ⴂ�����牽�Ƃ�
�����Ȃ��ȁB�������o�Ă��Ă���̂��y���݂��낤�B
���L1�Ƀq�b�g��������Ƃ����͍̂l���ɂ����ȁB
�����Ńp�C�v���C�����u�Ԃ��ǂ����߂Č������グ�邩
�Ƃ����b�ɂȂ�B
�C���e���͉��zCPU�Ŏ��s���j�b�g�̋߂�B
AMD�͂ǂ����Ȃ�X���b�h���𑝂₻���Ƃ����v�z�B
�܂��ǂ����������Ƃ������̂ł͂Ȃ��v�z�̈Ⴂ�����牽�Ƃ�
�����Ȃ��ȁB�������o�Ă��Ă���̂��y���݂��낤�B
��Core�}�C�N���A�[�L�e�N�`���̃v���Z�b�T�ł����Ă��A�n�C�p�[�X���b�f�B���O�E�e�N�m���W�[�������t���O��1�i�L���j�������Ă���B
���������A���z�v���Z�b�T����1�ł��邽�߁A�n�C�p�[�X���b�f�B���O�E�e�N�m���W�[������Ă��Ȃ��̂Ɠ����ł���B�i�E�B�L�y�uHT�v�j
�u����x�͏[���Ńp�C�v���C���̓M���E�M���E�A�������L���b�V���̓s����ǂ����Ă����Ԃ��o����v�����߂邽�߂�����HT���g���̂Ȃ�
Core2�ł�����Ă���Ȃ����H���������ۂ�i7����
�u�܂��܂����ł��邩��f�R�[�_�ƃp�C�v���C�����₵���v�u������HT�����Ă����Č��ʖ����v
�Ȃǂƍl���A�o�O���X�ɑ�����Ȃǂ̃f�����b�g���l���Ă�߂��\��������
���������A���z�v���Z�b�T����1�ł��邽�߁A�n�C�p�[�X���b�f�B���O�E�e�N�m���W�[������Ă��Ȃ��̂Ɠ����ł���B�i�E�B�L�y�uHT�v�j
�u����x�͏[���Ńp�C�v���C���̓M���E�M���E�A�������L���b�V���̓s����ǂ����Ă����Ԃ��o����v�����߂邽�߂�����HT���g���̂Ȃ�
Core2�ł�����Ă���Ȃ����H���������ۂ�i7����
�u�܂��܂����ł��邩��f�R�[�_�ƃp�C�v���C�����₵���v�u������HT�����Ă����Č��ʖ����v
�Ȃǂƍl���A�o�O���X�ɑ�����Ȃǂ̃f�����b�g���l���Ă�߂��\��������
IBM��SUM��AMD�����\����ɋ^������Ă�HTT�g���̂͂����P�Ƀx���`�}�[�N
��Ȃ�������B
��Ȃ�������B
>>915
AMD��HTT�͎g��Ȃ����cSMT�͎g�����ǁB
AMD��HTT�͎g��Ȃ����cSMT�͎g�����ǁB
Wikipedia�ɂ��ƁA
Sun��2005�N��UltaraSPARC T1����
IBM��2004�N��POWER5����
���ꂼ��SMT�̗p���Ă�݂��������ǁH
Sun��2005�N��UltaraSPARC T1����
IBM��2004�N��POWER5����
���ꂼ��SMT�̗p���Ă�݂��������ǁH
T1�̃}���`�X���b�h��SMT����Ȃ���FGMT����Ȃ��̂�
HT��Intel�̃}�[�P�e�B���O���ꂾ��
IBM��Power7��4way��SMT���������Ă���������Intel������ق�SMT��L���ƍl���Ă����ȁB
Sun�̃}���`�X���b�h�ւ̌X�|�͐����s�v�Ȃ��炢�����B
Sun�̃}���`�X���b�h�ւ̌X�|�͐����s�v�Ȃ��炢�����B
Intel���̗p���Ă���SMT�ł���"HTT"�ƁA
AMD���̗p����SMT�ł���"Cluster based"�Ƃ͍��{�I�ɈႤ����c�B
AMD���̗p����SMT�ł���"Cluster based"�Ƃ͍��{�I�ɈႤ����c�B
�����ڂ������C�������Ȃ�܂������ǁABulldozer��Netburst�̌Z��ł��邱�Ƃ�
�����������̃A���������̉Εa���Ղ�͊y���݂Ȃ悤�ȁc
�����������̃A���������̉Εa���Ղ�͊y���݂Ȃ悤�ȁc
�������ŎU�X�uBull���i�M�����Ȃ����炢���ʂɐ[���p�C�v���C���Ƃ�����L1I�̖����j�l�g�o�v�Ƃ����d�g�����Ă��̂͂�͂�m�I��Q�ҎG���ł���
MAC�I�^�͂����������N�ƊE���E�H�b�`���Ă���
Bull��NB�̌Z��ȂǂƂ����f���p���Ƃ��Ȃ���Ȃ�Ȃ��̂��낤���B
�ނ���I�^���S�͂ŎӍ߂��邱�ƂɂȂ邾��B
Bull��NB�̌Z��ȂǂƂ����f���p���Ƃ��Ȃ���Ȃ�Ȃ��̂��낤���B
�ނ���I�^���S�͂ŎӍ߂��邱�ƂɂȂ邾��B
���̃X���ɂ͒N���Z�ݒ����Ă���̂��悭�������
�N���������
�N���������
�e�w
MAC�I�^
�c�q
����
�A���~
Inteler
AMDer
MAC�I�^
�c�q
����
�A���~
Inteler
AMDer
����Ɗe�R�e�̃E�H�b�`���[
�ނ���A�[�L�e�N�`���̖ʂł�Bulldozer��Netburst�̌Z��ł��邱�ƂɊ��҂��Ă��
Netburst�Ƀp���[�Q�[�g�t����SIMD���j�b�g���AHT�͖����A�f�R�[�_�[�͔{���ߔ��s��
�������Z�݂̂�{���ɂ��čĐv���Č���̃A���R�A�t������f���炵�����\�ɂȂ邾��
Netburst�Ƀp���[�Q�[�g�t����SIMD���j�b�g���AHT�͖����A�f�R�[�_�[�͔{���ߔ��s��
�������Z�݂̂�{���ɂ��čĐv���Č���̃A���R�A�t������f���炵�����\�ɂȂ邾��
�ނ���f�l�l���Ȃ�IBM�n�̐l�ނ�����Ă�Bulldozer�ƃN���b�N�d���ɂȂ���Power��
�N���b�N�d���߂��ă_��������Netburst�Ƃ��A�z�Q�[�����ɂȂ��肻�����B
������Ƃ����ē��������ʂ�Ƃ͌���Ȃ��̂����B
�N���b�N�d���߂��ă_��������Netburst�Ƃ��A�z�Q�[�����ɂȂ��肻�����B
������Ƃ����ē��������ʂ�Ƃ͌���Ȃ��̂����B
�}�C�N���R�[�h�d���A�f�R�[�h���uOp�L���b�V���AOutOfOrder���@���s�L��
���Ă�����̓l�g�o�Ɏ��ĂȂ����Ȃ�
�ł������Q�ނقǔn���ł͂Ȃ��낤
���łɂ���Ȃ�ł܂���
ttp://www.freepatentsonline.com/y2010/0058078.html
����6�R�A�ɓ��ڂ����Ƃ���C�X�e�[�g�p�t�H�[�}���X�u�[�X�g�֘A�H
���Ă�����̓l�g�o�Ɏ��ĂȂ����Ȃ�
�ł������Q�ނقǔn���ł͂Ȃ��낤
���łɂ���Ȃ�ł܂���
ttp://www.freepatentsonline.com/y2010/0058078.html
����6�R�A�ɓ��ڂ����Ƃ���C�X�e�[�g�p�t�H�[�}���X�u�[�X�g�֘A�H
932 �F,,�E�L�́M�E,,�j��-�������F2010/03/04(��) 23:59:18 ID:nE/pVmb8
>>891
�ǂ߂Ȃ��Ȃ�A�[�L�e�N�`���̘b�͓���̂ł�
���Ƃ�����T�C�N����3����ɓ������Ƃ��Ă�
Load/Store���j�b�g��2����Ȃ�����ǂݏ����A�h���X�Ƃ��ĎJ����̂�2�I�y���[�V�����܂ł�
���̃T�C�N���ɂ�1��̓X�g�[������B
>>913
�����L1D��16KB��4 Way Set Associative�Ȃ琢�b������BNehalem 1�R�A�̔����~2�����H
���Ƃ���Nehalem��HPC�A�v���P�[�V������HT�g���Ƃ������Đ��\������Ƃ������v���́A1�X���b�h�������L1D�e�ʂ����邩��Ȃ�ˁB
��l1�l�̂�L���闁���ɍő�2�l�܂œ���̂Ɣ����̗e�ς̗�����2����̂ƁA�ǂ��������K���l���Ă݂�����B
2��L1D�̃p�P�b�g�J���Ȃ��Ƃ����Ȃ�����A�[�r�^�̕�L2�̃��C�e���V���傫���Ȃ邵�X�k�[�v���K�v�ɂȂ邾��B
CbMT�͗��_�I�ɂ͖ʔ������������x���̃X�y�b�N����ɐ��\�ʂł̃f�����b�g��傫���z����悤�ȃ����b�g���v�������Ȃ��B
64KB�~2�Ƃ���������ӌ��͈�������ǂˁB
�ǂ߂Ȃ��Ȃ�A�[�L�e�N�`���̘b�͓���̂ł�
���Ƃ�����T�C�N����3����ɓ������Ƃ��Ă�
Load/Store���j�b�g��2����Ȃ�����ǂݏ����A�h���X�Ƃ��ĎJ����̂�2�I�y���[�V�����܂ł�
���̃T�C�N���ɂ�1��̓X�g�[������B
>>913
�����L1D��16KB��4 Way Set Associative�Ȃ琢�b������BNehalem 1�R�A�̔����~2�����H
���Ƃ���Nehalem��HPC�A�v���P�[�V������HT�g���Ƃ������Đ��\������Ƃ������v���́A1�X���b�h�������L1D�e�ʂ����邩��Ȃ�ˁB
��l1�l�̂�L���闁���ɍő�2�l�܂œ���̂Ɣ����̗e�ς̗�����2����̂ƁA�ǂ��������K���l���Ă݂�����B
2��L1D�̃p�P�b�g�J���Ȃ��Ƃ����Ȃ�����A�[�r�^�̕�L2�̃��C�e���V���傫���Ȃ邵�X�k�[�v���K�v�ɂȂ邾��B
CbMT�͗��_�I�ɂ͖ʔ������������x���̃X�y�b�N����ɐ��\�ʂł̃f�����b�g��傫���z����悤�ȃ����b�g���v�������Ȃ��B
64KB�~2�Ƃ���������ӌ��͈�������ǂˁB
intel������X���Řb�������������낤����
NetBurst�̓p�C�v���C���̒��Z�ɍ��E����Ȃ��A�[�L�e�N�`���Ȃ̂�
�I���߂���intel�̈̂��l�������Ă���
�g���[�X�L���b�V���̃A�C�f�B�A���f�R�[�_����̏���d�͂�������̂ɂ��L������
���x�̓N���b�N�����d�̓^&�g�����W�X�^�����ōœK�������
�ǂ��������C�����܂���A�Ƃ������A�����Ăق���
���܂ł�P3���ǂł̓E�H�b�`���[�Ƃ��Ėʔ����Ȃ�
NetBurst�̓p�C�v���C���̒��Z�ɍ��E����Ȃ��A�[�L�e�N�`���Ȃ̂�
�I���߂���intel�̈̂��l�������Ă���
�g���[�X�L���b�V���̃A�C�f�B�A���f�R�[�_����̏���d�͂�������̂ɂ��L������
���x�̓N���b�N�����d�̓^&�g�����W�X�^�����ōœK�������
�ǂ��������C�����܂���A�Ƃ������A�����Ăق���
���܂ł�P3���ǂł̓E�H�b�`���[�Ƃ��Ėʔ����Ȃ�
934 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 00:07:36 ID:ISFY9aIm
���g���[�X�L���b�V���̃A�C�f�B�A���f�R�[�_����̏���d�͂�������̂ɂ��L������
�f�R�[�h�σ�OPs���i�[���邽�߂�SRAM�̃R�X�g�����ɂȂ�Ȃ�����
����ލs�i�{�Ǐ����[�v�����L���b�V���j��������������킯�ŁB
�f�R�[�h�R�X�g�����ŃA�[�L�e�N�`���̗D���܂�Ȃ狌��RISC�͂����������C�������낤��
�f�R�[�h�σ�OPs���i�[���邽�߂�SRAM�̃R�X�g�����ɂȂ�Ȃ�����
����ލs�i�{�Ǐ����[�v�����L���b�V���j��������������킯�ŁB
�f�R�[�h�R�X�g�����ŃA�[�L�e�N�`���̗D���܂�Ȃ狌��RISC�͂����������C�������낤��
������Z-RAM�ŃJ�o�[�B�Ƃ�����]�������
�L���b�V���e�ʂɂ��Ă�intel�Ƌ������Ă���ȏ��LL1���ʁA���LL2���ʂ��ĕ����Ɍ����킴��Ȃ����ǂ�
Balcerona��L1D��64KB�����Ȃ���L2�ɗ����Ȃ��������512KB�����Ȃ��Ƌ��LL3�Ƀf�[�^�������Ȃ�
�����Đ�LL1D��L2D�ɑ��R�A����A�N�Z�X����ƃy�i���e�B�����[�Ȃ�
�ĂƂ����˂���ĕ����R�A�ŋ�����Ƃ���A�v���̐��\�����Č����Ă����ʂ�����킯��
Balcerona��L1D��64KB�����Ȃ���L2�ɗ����Ȃ��������512KB�����Ȃ��Ƌ��LL3�Ƀf�[�^�������Ȃ�
�����Đ�LL1D��L2D�ɑ��R�A����A�N�Z�X����ƃy�i���e�B�����[�Ȃ�
�ĂƂ����˂���ĕ����R�A�ŋ�����Ƃ���A�v���̐��\�����Č����Ă����ʂ�����킯��
Jazelle�Ƃ͌���Ȃ����AJava VM/CLR�̃n�[�h�E�F�A�x�����ߒlj��͂���̂��ˁB
x86���ᖢ�J��̕��삾���A���z�����l�ɑΏۂ����Ă邩��A
���������̓����ł��������̌��ʂ������߂�Ǝv�����B
x86���ᖢ�J��̕��삾���A���z�����l�ɑΏۂ����Ă邩��A
���������̓����ł��������̌��ʂ������߂�Ǝv�����B
Java�݂����ȓ���̃A�v���P�[�V�����ɍi���������A�b�v�Ȃ��
�Ӗ��Ȃ����낤�B
�Ӗ��Ȃ����낤�B
32nm�ւ̈ڍs���Ă��H
����l1�l�̂�L���闁���ɍő�2�l�܂œ���̂Ɣ����̗e�ς̗�����2����̂ƁA�ǂ��������K���l���Ă݂�����B
�����Ⴑ���
�܂��u�L���b�V��������Ɛ��\������v���Ċ����ɗ����̂�
�����Ⴑ���
�܂��u�L���b�V��������Ɛ��\������v���Ċ����ɗ����̂�
>>941
�ǂ��ǂ炻���Ȃ�
�ǂ��ǂ炻���Ȃ�
943 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 08:00:15 ID:ISFY9aIm
�����Ȃ�����������l�Ȃ�łق��Ƃ��ĉ�����
��ʂɂ͔�Q�ϑz���Ă����܂�
��ʂɂ͔�Q�ϑz���Ă����܂�
�u�t�F�b�`���v���t�F�b�`�v�Ƃ����܂ŎU�X�d�g�����܂����Ƃ��č��X�ق��Ƃ��ĉ������Ƃ������C����������
���������C����Ƃ��G�����z���Ȃ��Ƃ��l����Ώ�̂�
�u���C�ɒj���m2�l�œ����Ă��ق�������ق����C���������Ɍ��܂��Ă�I�v
���Č��������낤�Ȃ����ƁE�E�E
L1��ItoD�ŕ�����Ă邤���ɃR�A���L�����Ȃ����Ƃ��l�����
���{�l�́u�ꏊ�������Ă����l�Ɣ����G�����͂����v�Ƃ������l�ςƂ�������ʂ��Ă������ł͂��邪
���������C����Ƃ��G�����z���Ȃ��Ƃ��l����Ώ�̂�
�u���C�ɒj���m2�l�œ����Ă��ق�������ق����C���������Ɍ��܂��Ă�I�v
���Č��������낤�Ȃ����ƁE�E�E
L1��ItoD�ŕ�����Ă邤���ɃR�A���L�����Ȃ����Ƃ��l�����
���{�l�́u�ꏊ�������Ă����l�Ɣ����G�����͂����v�Ƃ������l�ςƂ�������ʂ��Ă������ł͂��邪
�L����
>>936
��������K10�̎d�l1���琺�o���ēǂݒ����Ă����B
��������K10�̎d�l1���琺�o���ēǂݒ����Ă����B
947 �FSocket774�F2010/03/05(��) 11:43:11 ID:eM/HPAJk
�u���h�[�U�[��AM3�ȊO�͖����H
��������AM3�����������o�����H
890�Ō݊����������Ȃ����H���ă��x�������
890�Ō݊����������Ȃ����H���ă��x�������
��������4�`���l���ɂȂ�Ƃ��A�����������啝�ȕύX����������
AM3���\�P�̌`��ς���K�v�͖�������
AM3���\�P�̌`��ς���K�v�͖�������
�\�P�b�g�����{����ς���Ȃ�A�uAM3r2�v�Ȃ�Ė��̂ɂ͂��Ȃ�����B
�����t���X�y�b�N�o�������Ȃ�ARD800�n���K�{�ɂȂ�\���͂���ȁB
�����t���X�y�b�N�o�������Ȃ�ARD800�n���K�{�ɂȂ�\���͂���ȁB
>MAC�I�^
Bulldozer�̃��C�e���V��{����������NetBurst(�Ă�POWER6)�̌Z��m�肾����
Fake�������͌Â����̉\���͂Ȃ��̂���?
Bulldozer�̃��C�e���V��{����������NetBurst(�Ă�POWER6)�̌Z��m�肾����
Fake�������͌Â����̉\���͂Ȃ��̂���?
�u�����Ă����V���R������́H
���o�Ă�890GX�n�}�U�[��AM3R2�Ȃ̂��H
AM3����
NetBurst�E�E�E�M�Ń��N�ɃN���b�N�オ��Ȃ��̂ɉߏ�ɐ[���p�C�v���C��
�@�@�@�@�@�@�@�@�I�ړI�Ƃ������́���₤���߂����ɉߏ�ɋ������ꂽ����\���i����ŕ₦�����ǂ����j
�@�@�@�@�@�@�@�@L1I����
POWER6�E�E�EIPC��胏�b�g�p�t�H�[�}���X�ɐU�邽�߁i�J���Ғk�H�j�̃C���I�[�_
Bulldozer�E�E�EBobcat�̌Z��
�@�@�@�@�@�@�@�@�I�ړI�Ƃ������́���₤���߂����ɉߏ�ɋ������ꂽ����\���i����ŕ₦�����ǂ����j
�@�@�@�@�@�@�@�@L1I����
POWER6�E�E�EIPC��胏�b�g�p�t�H�[�}���X�ɐU�邽�߁i�J���Ғk�H�j�̃C���I�[�_
Bulldozer�E�E�EBobcat�̌Z��
�l�g�o�͖k�X���v���X�R�Ńg�����W�X�^�{���������̂�
IPC�S���オ��Ȃ������̂��ő�̎��s�_
�l�g�o�̍��{�I�ȃA�[�L�Ƃ͕ʎ����̏��Ŏ��s����
IPC�S���オ��Ȃ������̂��ő�̎��s�_
�l�g�o�̍��{�I�ȃA�[�L�Ƃ͕ʎ����̏��Ŏ��s����
Netburst�Ƃ�����
intel��90nm�̓��[�N�d�������ɂЂǂ����������
Dothan�����o�C���p���������悤�ȌX������
intel��90nm�̓��[�N�d�������ɂЂǂ����������
Dothan�����o�C���p���������悤�ȌX������
>>955
�����"Bulldozer"��"Bobcat"��AMD������ȁc�B
�����"Bulldozer"��"Bobcat"��AMD������ȁc�B
���A���ꏑ���̖Y��Ă�
>955�ɕt������
POWER6�E�E�E�C���I�[�_�ŃX�J�X�J�i�ƌ����ׂ����HCPU�g�p���Ō�����100%�ɂ��Ȃ邯�ǁj�ȃp�C�v���C����ʃX���b�h�Ŗ��߂邽�߂�SMT
>955�ɕt������
POWER6�E�E�E�C���I�[�_�ŃX�J�X�J�i�ƌ����ׂ����HCPU�g�p���Ō�����100%�ɂ��Ȃ邯�ǁj�ȃp�C�v���C����ʃX���b�h�Ŗ��߂邽�߂�SMT
������\�������Ă邩�����
Bull��Bobcat���Z����Ă̂͂����߂�����
�]�Z��Ƃ������炢���炢����ˁH
Bull��Bobcat���Z����Ă̂͂����߂�����
�]�Z��Ƃ������炢���炢����ˁH
>>955
L1���߃L���b�V���������āc
L1���߃L���b�V���������āc
>>960
���߂ɌZ����Č��t�g�����̂�>951������^������������
Bull�����N���b�N�^�A�[�L���Ƃ��Ă����Ђ̂������Bob�̂ق������Ă�͂�
Atom�R���猩��������ƍ��ׂ�����
�̎Z���l����l�b�g�u�b�N����ŎI��DT�ɂ����p���Ȃ��悤�Ȃ����
Intel�ɔ�ׂĈ��|�I�ɏ�����AMD�����S�V�v���邭�炢�Ȃ炳�����ƒ��~���ׂ�����
�ɂ�������炸Bull�ƕ��������킹�ď������Ă�Ƃ������Ƃ͑������ʂ����v�Ȃ͂�
���߂ɌZ����Č��t�g�����̂�>951������^������������
Bull�����N���b�N�^�A�[�L���Ƃ��Ă����Ђ̂������Bob�̂ق������Ă�͂�
Atom�R���猩��������ƍ��ׂ�����
�̎Z���l����l�b�g�u�b�N����ŎI��DT�ɂ����p���Ȃ��悤�Ȃ����
Intel�ɔ�ׂĈ��|�I�ɏ�����AMD�����S�V�v���邭�炢�Ȃ炳�����ƒ��~���ׂ�����
�ɂ�������炸Bull�ƕ��������킹�ď������Ă�Ƃ������Ƃ͑������ʂ����v�Ȃ͂�
���܂��炨����
�����j��Pen4�����X�����Ԃ��Ă����傤���Ȃ��Ǝv�����B
>>960
Bull�͏o���������Ă�AM3�ێ��ŁA
8�R�A�A6�R�A������ق��ĂĂ��M�ҒB�������B
�o���Ɗ����x�������قǁA���X�ƐV���f���o���Ĕ����������i����B
���Â鎮�Ɏ��X�Ɣ����ւ������鎖���o����B
Bobcat��atom�Ƃ������ƑΌ����ăV�F�A�D��Ȃ��Ƃ����Ȃ�����A
�o�����ǂ������x�������B
�o���Ɗ����x�������ƁA�Ώۂ��M�҂���Ȃ��̂Ŏ��s�ɏI���B
���҂�Bobcat���ȁB
�o���̈�������A����グ���̐M�ґ����Bull�ƁA
��ʃ��[�U�[����̎��s�͋�����Ȃ��^��������Bobcat
Bobcat���ȁBBobcat��AMD�̐^�̋Z�p�͂��E�E�B
Bull�͏o���������Ă�AM3�ێ��ŁA
8�R�A�A6�R�A������ق��ĂĂ��M�ҒB�������B
�o���Ɗ����x�������قǁA���X�ƐV���f���o���Ĕ����������i����B
���Â鎮�Ɏ��X�Ɣ����ւ������鎖���o����B
Bobcat��atom�Ƃ������ƑΌ����ăV�F�A�D��Ȃ��Ƃ����Ȃ�����A
�o�����ǂ������x�������B
�o���Ɗ����x�������ƁA�Ώۂ��M�҂���Ȃ��̂Ŏ��s�ɏI���B
���҂�Bobcat���ȁB
�o���̈�������A����グ���̐M�ґ����Bull�ƁA
��ʃ��[�U�[����̎��s�͋�����Ȃ��^��������Bobcat
Bobcat���ȁBBobcat��AMD�̐^�̋Z�p�͂��E�E�B
�͂��͂��G���G��
�����͂ނ���Llano
Agena�ŋ�J�������獡�x�͗l�q���邺�B�Ƃ͂����Ă�
�\���2011�����ǁB�C���e�������Ă�������������
�܂Ŕ���������̂͂������ɏo��ł����B
�\���2011�����ǁB�C���e�������Ă�������������
�܂Ŕ���������̂͂������ɏo��ł����B
Bull�͔����J�n��A��N�ȓ��ɁA
Bull2�́A�����V���O���X���b�h���\���啝���A
PhenomII�����鐮���V���O���X���b�h���\�B���B
�͂��͂��ABull������@�����ɔ������l�B�A�c�O�ł����B��
�B���d���݃l�^������\���B
Bull2�́A�����V���O���X���b�h���\���啝���A
PhenomII�����鐮���V���O���X���b�h���\�B���B
�͂��͂��ABull������@�����ɔ������l�B�A�c�O�ł����B��
�B���d���݃l�^������\���B
>>964
���v
�uCPU�\���̋ߎ��̓��C�e���V�݂̂Ō��܂�v���Ƃ�
���������d�g����ɏo���Ă�G���ȊO�͊F�����痎�������Ă�
�t�ɎG���ɂ͉������Ă�����
���v
�uCPU�\���̋ߎ��̓��C�e���V�݂̂Ō��܂�v���Ƃ�
���������d�g����ɏo���Ă�G���ȊO�͊F�����痎�������Ă�
�t�ɎG���ɂ͉������Ă�����
���܂������������Ă�Ƃ������Ȃ悗
istanbul �� nehalem �̃V���O���\�P�b�g���f���ł� SPEC2006�ł̔�r������
������Ȃ��A1.5�{�̃R�A���ł��琫�\�Œǂ������Ƃ����ڂ��Ȃ��n���B
bulldozer�����͂Ȃ��ƌ�����͎̂d���Ȃ���w
�@(base/peak)�@�@�@�@�@�@�@int�@�@�@�@�@�@�@fp�@�@�@�@�@�@�@int-rate�@�@�@�@fp-rate
Opteron 2435/2.6GHz�@�@18.0 / 21.1�@�@22.0 / 23.9�@�@82.0 / 104�@�@65.1 / 72.0
Xeon E5540/2.53GHz�@�@26.5 / 29.4�@�@31.8 / 33.8�@�@104 / 111�@�@84.8 / 87.6
[�Q�l]
�� Opteron 2435/2.6GHz (HP ProLiant DL165 G6)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07830.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07831.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07510.html
�� Xeon E5540/2.53GHz (Bull R440 E2)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07141.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07139.html
(��L��CINT2006, CFP2006�̓f���A���\�P�b�g���f���̌��ʂ����A���x���`��
�V���O���v���Z�X�̃x���`�}�[�N�ł���B)
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08785.html
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08784.html
������Ȃ��A1.5�{�̃R�A���ł��琫�\�Œǂ������Ƃ����ڂ��Ȃ��n���B
bulldozer�����͂Ȃ��ƌ�����͎̂d���Ȃ���w
�@(base/peak)�@�@�@�@�@�@�@int�@�@�@�@�@�@�@fp�@�@�@�@�@�@�@int-rate�@�@�@�@fp-rate
Opteron 2435/2.6GHz�@�@18.0 / 21.1�@�@22.0 / 23.9�@�@82.0 / 104�@�@65.1 / 72.0
Xeon E5540/2.53GHz�@�@26.5 / 29.4�@�@31.8 / 33.8�@�@104 / 111�@�@84.8 / 87.6
[�Q�l]
�� Opteron 2435/2.6GHz (HP ProLiant DL165 G6)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07830.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07831.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07510.html
�� Xeon E5540/2.53GHz (Bull R440 E2)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07141.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07139.html
(��L��CINT2006, CFP2006�̓f���A���\�P�b�g���f���̌��ʂ����A���x���`��
�V���O���v���Z�X�̃x���`�}�[�N�ł���B)
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08785.html
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08784.html
�`�l�c�X���ŃC���e���}���Z�[������G��
�C���e���X���ł��@�܂ݎ҂Ȃ̂ŃX���[���܂��傤
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
�C���e���X���ł��@�܂ݎ҂Ȃ̂ŃX���[���܂��傤
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
>>974 �M�����܂��X���[���邱�Ƃ��o���Ȃ���
�ق��Ă��ꂾ���\���Ă��������̂����H
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://pc11.2ch.net/test/read.cgi/jisaku/1266588505/123-140
�݂��߂�̂�ID:R26hs6fN
�݂��߂�̂�ID:R26hs6fN
978 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 19:30:05 ID:ISFY9aIm
Latency/Throughput��Ƃ����l�����������Ă���
3issue��2issue���x�Ɍ������̂ł���Ζ��߂̃��C�e���V��1.5�{�����ɂȂ��Ă�
�p�C�v���C���ғ����͂���ȂɈ������Ȃ�
����1.5�{�̃N���b�N�ʼn�邩�ǂ�������
3issue��2issue���x�Ɍ������̂ł���Ζ��߂̃��C�e���V��1.5�{�����ɂȂ��Ă�
�p�C�v���C���ғ����͂���ȂɈ������Ȃ�
����1.5�{�̃N���b�N�ʼn�邩�ǂ�������
979 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 19:33:38 ID:ISFY9aIm
�����ƁA1.5�{��������2.5�{������5�������ɒ�����
POWER6��5GHz�z�������Ή�邾�낤���ǁA����d�͂�}���閂�@���Ȃ�����
NetBurst�̍ė��Ƃ��������l���Ȃ�
NetBurst�̍ė��Ƃ��������l���Ȃ�
�P���j�b�g����5GHz�ʼnĂ��Ƃ͓d�͎~�߂�����B
x86���̂Ă����
POWER6��65nm�APhenom��1.5�{�̃_�C�T�C�Y��5GHz�O�ゾ��
���߂Đl���݂ɒm�\���グ�����
�������{���ɗ��N�o��̂��Ȃ��B
���g��肻�����̂��C�ɂȂ邗
���g��肻�����̂��C�ɂȂ邗
>>985
GF��32nm fab�̎d�オ�莟�悶��ˁH
GF��32nm fab�̎d�オ�莟�悶��ˁH
�V�v�`�b�v�������Ȃ�V�K�v���Z�X�ō��Ƃ����v�悪�܂����d�Ȃ��
�m��ƌ����Ă�����
���߂���2011�N�ɏo���C�Ȃ��̂�������Ȃ���
�m��ƌ����Ă�����
���߂���2011�N�ɏo���C�Ȃ��̂�������Ȃ���
988 �FSocket774�F2010/03/05(��) 20:48:28 ID:TjPO7vFm
bulldozer��5GHz�ʼn�����Ƃ��Ă����͂���Ƃ͎v��Ȃ��B
�m����SSE�n�͑����킯���������Sandy Bridge�Ɣ�ׂ�ƐF�Č�����B
�m����SSE�n�͑����킯���������Sandy Bridge�Ɣ�ׂ�ƐF�Č�����B
AMD: Nile-Plattform mit DX11, Fusion für AM3(?)
http://www.hardware-infos.com/news.php?news=3455
Llano��AM3���ȁ[�Ƃ����L��
http://www.hardware-infos.com/news.php?news=3455
Llano��AM3���ȁ[�Ƃ����L��
Sandy Bridge��AVX�����邩��SIMD�I�ȏ����̔\�͈͂��������邯��
���ׂ̈ɂ��Ƃ��Ɠd�C�H��������SIMD���j�b�g�̋K�͂��X�ɔ{�ɂȂ�
�d�͘g�������Ȃ�N���b�N�𗎂Ƃ��Ȃ��Ⴂ���Ȃ�
���ׂ̈ɂ��Ƃ��Ɠd�C�H��������SIMD���j�b�g�̋K�͂��X�ɔ{�ɂȂ�
�d�͘g�������Ȃ�N���b�N�𗎂Ƃ��Ȃ��Ⴂ���Ȃ�
992 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 21:13:26 ID:ISFY9aIm
SIMD���j�b�g���d�C�H���H�H�H�H�H
993 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 21:16:53 ID:ISFY9aIm
���Ȃ݂ɂ��̗�������Bulldozer�̂ق����X�ɃN���b�N�オ��Ȃ���
Sandy Bridge��SIMD�������j�b�g�̃X���[�v�b�g�{���͌���������
Bulldozer��IMAC��H�����邩���
Sandy Bridge��SIMD�������j�b�g�̃X���[�v�b�g�{���͌���������
Bulldozer��IMAC��H�����邩���
�m�I��Q�҂̓d�g���o���������Ȃ��Ă����̂�
�Ƃ肠�����\���x���̂��܂߉��̒m�����ł̌������E��Bull�܂Ƃ�
K10��SSE1�R�A2���j�b�g�ɑ�Bull��1���W���[��2���j�b�g
FPU�̃��C�e���V�Ȃǂ��܂߁AGPGPU���l���Ă����Ȃ�̎蔲��
L1D�̃��C�e���V��5�炵���̂�L1I��5���Ƃ���
�f�R�[�_��1�ŃV���[�g�ƃ����O��2���Ƀf�R�[�h�o����Ƃ�����������
�����������Ƃ��āi���[�v��p�H�j�g���[�X�L���b�V���̂��Ƃ��l�����
2�X���b�h�t���ғ����ł��f�R�[�_�͉ߏ肩������Ȃ�
L1D��way�����{�ɂȂ��������C�e���V��3��5�ŗe�ʂ�1/4
�f�[�^�̋Ǐ����₻�̑��̐��\���W�͂��邯�ǂ���ł�L1���\���̂�K10�Ɣ�ׂĂ��Ȃ茵��������
�������܂��AL1L2L3�ŗ͂����킹�ă��������[�h�����Ȃ�����̂��{���̖ړI�Ȃ���
�F�X�o�����X����ĉ��Ƃ�����낤
�Ƃ肠�����\���x���̂��܂߉��̒m�����ł̌������E��Bull�܂Ƃ�
K10��SSE1�R�A2���j�b�g�ɑ�Bull��1���W���[��2���j�b�g
FPU�̃��C�e���V�Ȃǂ��܂߁AGPGPU���l���Ă����Ȃ�̎蔲��
L1D�̃��C�e���V��5�炵���̂�L1I��5���Ƃ���
�f�R�[�_��1�ŃV���[�g�ƃ����O��2���Ƀf�R�[�h�o����Ƃ�����������
�����������Ƃ��āi���[�v��p�H�j�g���[�X�L���b�V���̂��Ƃ��l�����
2�X���b�h�t���ғ����ł��f�R�[�_�͉ߏ肩������Ȃ�
L1D��way�����{�ɂȂ��������C�e���V��3��5�ŗe�ʂ�1/4
�f�[�^�̋Ǐ����₻�̑��̐��\���W�͂��邯�ǂ���ł�L1���\���̂�K10�Ɣ�ׂĂ��Ȃ茵��������
�������܂��AL1L2L3�ŗ͂����킹�ă��������[�h�����Ȃ�����̂��{���̖ړI�Ȃ���
�F�X�o�����X����ĉ��Ƃ�����낤
995 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 21:24:23 ID:ISFY9aIm
Pentium4��L1���߃L���b�V�����Ȃ����E�̐l��Bulldozer�Ȃ�ċ����Ȃ���
�W��������
ID:HZNagCPc���X�̂�����ʼn������Ȃ����X��2�x�قǏ����Ă��܂�����
�ܘ_ID:HZNagCPc�̂��Ƃ������Ă���킯�ł͂Ȃ�
ID:HZNagCPc���X�̂�����ʼn������Ȃ����X��2�x�قǏ����Ă��܂�����
�ܘ_ID:HZNagCPc�̂��Ƃ������Ă���킯�ł͂Ȃ�
SIMD���j�b�g�̓��b�g�p�t�H�[�}���X�A���Ƀs�[�N���̂���͂��Ȃ�ǂ���
�ł�����CPU�R�A�̒��ł͓d�͔n���H���̕���
�ł�����CPU�R�A�̒��ł͓d�͔n���H���̕���
998 �F,,�E�L�́M�E,,�j��-�������F2010/03/05(��) 21:34:34 ID:ISFY9aIm
�t�����g�G���h�قǂ���Ȃ���
Phenom II�Ȃ�256�r�b�g���ߗ�{100�r�b�g�v���f�R�[�h�^�O�T�C�N���ǂݏo���킯�������
x86���߂̐�o���͂���Ӗ�������x�N�g�����Z����
Phenom II�Ȃ�256�r�b�g���ߗ�{100�r�b�g�v���f�R�[�h�^�O�T�C�N���ǂݏo���킯�������
x86���߂̐�o���͂���Ӗ�������x�N�g�����Z����
http://www.hotchips.org/archives/hc21/2_mon/HC21.24.100.ServerSystemsI-Epub/HC21.24.110.Conway-AMD-Magny-Cours.pdf
Magny-Cours��Bul��FP1.75�{Int1.45�{
�R�A��12��16��1.33�{�������Ă����j�b�g�\���Ƃ�
�S�R�ʎ����̌����������ł�킯�ł���ȊO�̗v�f���s��������B
����FP���킯�킩���B
Magny-Cours��Bul��FP1.75�{Int1.45�{
�R�A��12��16��1.33�{�������Ă����j�b�g�\���Ƃ�
�S�R�ʎ����̌����������ł�킯�ł���ȊO�̗v�f���s��������B
����FP���킯�킩���B
>>987
NVIDIA�̂��Ƃ��[
NVIDIA�̂��Ƃ��[
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/