Intel Larrabee 2�R�A
Intel��Larrabee(�����r�[)�ɂ��Č��X���ł��B
���O�X��
Intel Larrabee 1�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
���J�ŗ���Ă�����
�E�}���`�R�A�łȂ����j�[�R�A�ƌĂт܂�
�EPentium�x�[�X��x86�R�A�𑽐��~�l�߂�GPU
�EGPU�Ƃ��Ă̏o�ח\���2009�N�㔼�`2010�N
�EDirectX�AOpenGL�ɑΉ�
�E�����I�ɂ�GPU�ȊO�̎s��(����R���s���[�e�B���O��)���_���Ă�
���̑��A�lj����ڂ� >>2-10 ��
���O�X��
Intel Larrabee 1�R�A
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/
���J�ŗ���Ă�����
�E�}���`�R�A�łȂ����j�[�R�A�ƌĂт܂�
�EPentium�x�[�X��x86�R�A�𑽐��~�l�߂�GPU
�EGPU�Ƃ��Ă̏o�ח\���2009�N�㔼�`2010�N
�EDirectX�AOpenGL�ɑΉ�
�E�����I�ɂ�GPU�ȊO�̎s��(����R���s���[�e�B���O��)���_���Ă�
���̑��A�lj����ڂ� >>2-10 ��
|
|
|
�����܂Ńe���v��
3 �FSocket774�F2009/03/27(��) 20:41:37 ID:3CWlSFJT
��
4 �F,,�E�L�́M�E,,�j��-�������F2009/03/27(��) 20:41:57 ID:dpz/20w5
���Ԃ�IDF�Ŕ��\������Ǝv����
�������Ă���J�߂Ă���
http://dango.chu.jp/tripper/20090326.html
http://dango.chu.jp/tripper/20090325.html
�������Ă���J�߂Ă���
http://dango.chu.jp/tripper/20090326.html
http://dango.chu.jp/tripper/20090325.html
Intel�̒P�̃Q�[�~���OGPU��2007�N�ā`�H���ɓo��
http://techreport.com/discussions.x/10549
Intel�̒P��VGA(Larrabee)��2008�N�O���ɓo�ꂵ
2008�N�̒P��VGA���o�חʂ�20�`30%���߂�A���i��$300�ȉ�
http://www.digitimes.com/mobos/a20070606VL207.html
�u2008�N�ɂ�Larrabee�̓���f�������J����v
���i�̓��������ɂ��Ắu2008�N���`2009�N�v
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Larrabee�̊J���Ҍ����{�[�h��2008�N11���ɓo�ꂷ��
http://en.hardspell.com/doc/showcont.asp?news_id=3793
Larrabee�v���Z�b�T�̑��w�́C2009�N�I��肩��2010�N���߂ɂ����ēo��
http://itpro.nikkeibp.co.jp/article/NEWS/20080805/312163/
1���ɏo��Ɨ\�z����Ă����V���R�����X��6�����x��
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
Larrabee���s��֓����ł���̂͑����Ă�2010�N�㔼
http://www.4gamer.net/games/085/G008505/20090217033/
http://techreport.com/discussions.x/10549
Intel�̒P��VGA(Larrabee)��2008�N�O���ɓo�ꂵ
2008�N�̒P��VGA���o�חʂ�20�`30%���߂�A���i��$300�ȉ�
http://www.digitimes.com/mobos/a20070606VL207.html
�u2008�N�ɂ�Larrabee�̓���f�������J����v
���i�̓��������ɂ��Ắu2008�N���`2009�N�v
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
Larrabee�̊J���Ҍ����{�[�h��2008�N11���ɓo�ꂷ��
http://en.hardspell.com/doc/showcont.asp?news_id=3793
Larrabee�v���Z�b�T�̑��w�́C2009�N�I��肩��2010�N���߂ɂ����ēo��
http://itpro.nikkeibp.co.jp/article/NEWS/20080805/312163/
1���ɏo��Ɨ\�z����Ă����V���R�����X��6�����x��
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
Larrabee���s��֓����ł���̂͑����Ă�2010�N�㔼
http://www.4gamer.net/games/085/G008505/20090217033/
6 �FSocket774�F2009/03/27(��) 21:41:49 ID:ywNfSRJl
>>5
�N�P�ʂŒx�����Ă���ȁB
�N�P�ʂŒx�����Ă���ȁB
589 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/15(��) 11:04:00 ID:mvyTBgoL0
>>588
SIMD�����^x86�̃��j�[�R�A�A�]��x86�R�A��SIMD�����^x86�R�A�̍����R�A�ɂ��Ă�
Intel��2005�N�����肩�猾�y���Ă邵�A�����J���͂���ȑO�������Ă邾�낤�B
���ꂪGPU�̔�����Ԃ������̂��Ƃ͂��̎��_�ł͖�������Ȃ��������ǂˁB
AMD��Fusion�̂��Ƃ�������̂�ATI�����ザ��ˁH
Torrenza�\�z�����o�����̂���2006�N�̉č��B
AMD������Ă̂͂��������B
590 �F����������K������ [sage] �F2009/03/15(��) 13:11:38 ID:05Tc8pI10
�܂��̓e���X�P�[���R���s���[�e�B���O�̎��オ����������ƌ�����80�R�A�̎���v���Z�b�T�����A
���̓r�W���A���R���s���[�e�B���O�����s�邩��ƌ����ă����r�[�v����u�`�グ��B
�ȂJ���`�[���������B�̃v���W�F�N�g�Ɍp�����ė\�Z�����Ă��炤���߂ɁA
��w�����x���炩���āu�����ɂȂ��邷�������Ƃ���Ă܂��v�ȋ�C���o���Ă邾���Ȋ����B
����܂Ŕ���Ȕ�p�𓊂��Ă��邪�A������R&D�Ȃ�Ƃ������A�R�[�h�l�[���\����
���炩�̐��i���o���Ƃ��Ă�ȏ�A���v���o���̂��g���B���R������2009�N3�����ݗ��v�̓[���B
���������A���̐V�������j�[�R�A�v���W�F�N�g���\�A���������E�E�E���������M�ᐫ�\�ő厸�s�B
201x�N�ɂ͍���Itanium�̂Ԃ��@�����ȏ�̔l�|�̑ΏۂɂȂ��Ă鈫���B
591 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/15(��) 13:23:34 ID:mvyTBgoL0
�܁A���i���o���܂ł͗��v���o���Ȃ����炳�B
�����v�����𗧂Ă����ƂƑ����v�ɂȂ���̂������Ȃ���ƂƁA
���̂ւꗬ�Ɠ̋��ڂȂ�ˁH
Intel�̓n�[�h���o���O�ɁA�}���`�R�A�J���x���\�t�g�E�F�A�ő������ł߂���B
Threading Building Blocks��Pallarel Studio�����ꂾ�B
>>588
SIMD�����^x86�̃��j�[�R�A�A�]��x86�R�A��SIMD�����^x86�R�A�̍����R�A�ɂ��Ă�
Intel��2005�N�����肩�猾�y���Ă邵�A�����J���͂���ȑO�������Ă邾�낤�B
���ꂪGPU�̔�����Ԃ������̂��Ƃ͂��̎��_�ł͖�������Ȃ��������ǂˁB
AMD��Fusion�̂��Ƃ�������̂�ATI�����ザ��ˁH
Torrenza�\�z�����o�����̂���2006�N�̉č��B
AMD������Ă̂͂��������B
590 �F����������K������ [sage] �F2009/03/15(��) 13:11:38 ID:05Tc8pI10
�܂��̓e���X�P�[���R���s���[�e�B���O�̎��オ����������ƌ�����80�R�A�̎���v���Z�b�T�����A
���̓r�W���A���R���s���[�e�B���O�����s�邩��ƌ����ă����r�[�v����u�`�グ��B
�ȂJ���`�[���������B�̃v���W�F�N�g�Ɍp�����ė\�Z�����Ă��炤���߂ɁA
��w�����x���炩���āu�����ɂȂ��邷�������Ƃ���Ă܂��v�ȋ�C���o���Ă邾���Ȋ����B
����܂Ŕ���Ȕ�p�𓊂��Ă��邪�A������R&D�Ȃ�Ƃ������A�R�[�h�l�[���\����
���炩�̐��i���o���Ƃ��Ă�ȏ�A���v���o���̂��g���B���R������2009�N3�����ݗ��v�̓[���B
���������A���̐V�������j�[�R�A�v���W�F�N�g���\�A���������E�E�E���������M�ᐫ�\�ő厸�s�B
201x�N�ɂ͍���Itanium�̂Ԃ��@�����ȏ�̔l�|�̑ΏۂɂȂ��Ă鈫���B
591 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/15(��) 13:23:34 ID:mvyTBgoL0
�܁A���i���o���܂ł͗��v���o���Ȃ����炳�B
�����v�����𗧂Ă����ƂƑ����v�ɂȂ���̂������Ȃ���ƂƁA
���̂ւꗬ�Ɠ̋��ڂȂ�ˁH
Intel�̓n�[�h���o���O�ɁA�}���`�R�A�J���x���\�t�g�E�F�A�ő������ł߂���B
Threading Building Blocks��Pallarel Studio�����ꂾ�B
592 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/03/15(��) 13:33:03 ID:mvyTBgoL0
�����オ����������ƌ�����
����͌N�̖ϑz���B
Intel�͌N���v���Ă�ȏ�Ƀ\�t�g�d���ŁA�\�t�g�����Ă��Ȃ���ΈӖ����Ȃ���
Cell��GPGPU����闧��ɂ���B
�J���ҕs�݂̃��j�[�R�A�قǖ��ʂȂ��͖̂�������ȁB
Core i7��3�R�A�~�߂�1�R�A�̃I�[�o�[�N���b�N����@�\�Ȃ�ĕt���Ă�̂́A
�\�t�g�J���҂��\�����Ă��ĂȂ������c�����Ă邩�炱���̂��́B
���̈Ӗ��ŁA�o���ɂ��Ă��^�C�~���O�����v����Ă����Ƃ�����_���Ă��邾�낤�B
�����s���Ă�Atom�����āA���Ƃ��Ƃ̓��j�[�R�A�Ƃ��Đv����Ă�
�R�A�v���V���O���R�A�ɃJ�b�g�_�E���������̂ŁA
�|�V�������J���v��ł��Z�p�]�p�͐ϋɓI�ɍs���Ă��B
593 �F����������K������ [sage] �F2009/03/15(��) 13:36:24 ID:RiYi+c5g0
>>590
Intel������Larrabee�ƐS�����悤�Ǝv���Ă�قǃA�z����Ȃ�
Sandy�ȍ~�̃��C�X�g���[���v���Z�b�T�̃��[�h�}�b�v�����킩��
Larrabee��x86�ł̃x�N�^�g���ƃR�A������̎������u
����LNI�������c��Ό�̎��Ƃ������Ƃ���ł���
594 �F����������K������ [sage] �F2009/03/15(��) 15:29:30 ID:q2KEKfTT0
>>593
LNI�Ƃ͉��ł��傤���B
���₵�Ă��݂܂���B
595 �F����������K������ [sage] �F2009/03/15(��) 15:34:35 ID:RiYi+c5g0
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai470.htm
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
�����オ����������ƌ�����
����͌N�̖ϑz���B
Intel�͌N���v���Ă�ȏ�Ƀ\�t�g�d���ŁA�\�t�g�����Ă��Ȃ���ΈӖ����Ȃ���
Cell��GPGPU����闧��ɂ���B
�J���ҕs�݂̃��j�[�R�A�قǖ��ʂȂ��͖̂�������ȁB
Core i7��3�R�A�~�߂�1�R�A�̃I�[�o�[�N���b�N����@�\�Ȃ�ĕt���Ă�̂́A
�\�t�g�J���҂��\�����Ă��ĂȂ������c�����Ă邩�炱���̂��́B
���̈Ӗ��ŁA�o���ɂ��Ă��^�C�~���O�����v����Ă����Ƃ�����_���Ă��邾�낤�B
�����s���Ă�Atom�����āA���Ƃ��Ƃ̓��j�[�R�A�Ƃ��Đv����Ă�
�R�A�v���V���O���R�A�ɃJ�b�g�_�E���������̂ŁA
�|�V�������J���v��ł��Z�p�]�p�͐ϋɓI�ɍs���Ă��B
593 �F����������K������ [sage] �F2009/03/15(��) 13:36:24 ID:RiYi+c5g0
>>590
Intel������Larrabee�ƐS�����悤�Ǝv���Ă�قǃA�z����Ȃ�
Sandy�ȍ~�̃��C�X�g���[���v���Z�b�T�̃��[�h�}�b�v�����킩��
Larrabee��x86�ł̃x�N�^�g���ƃR�A������̎������u
����LNI�������c��Ό�̎��Ƃ������Ƃ���ł���
594 �F����������K������ [sage] �F2009/03/15(��) 15:29:30 ID:q2KEKfTT0
>>593
LNI�Ƃ͉��ł��傤���B
���₵�Ă��݂܂���B
595 �F����������K������ [sage] �F2009/03/15(��) 15:34:35 ID:RiYi+c5g0
http://pc.watch.impress.co.jp/docs/2008/1006/kaigai470.htm
http://pc.watch.impress.co.jp/docs/2008/1217/kaigai481.htm
�듚�\���
10 �FSocket774�F2009/03/28(�y) 08:53:27 ID:mgXxdVsL
11 �FMAC�I�^���c�q �����F2009/03/28(�y) 10:50:10 ID:cu35dzXH
>>4
���w���ł����AIntel�������������Ă���͓ǂ߂܂���ł������H
http://software.intel.com/en-us/articles/prototype-primitives-guide/
�@�@------------------
�@�@Math utility functions DO NOT CORRESPOND DIRECTRY TO LARRABEE NEW
�@�@INSTRUCTIONS, but are added for programming support.
�@�@[��������MAC�I�^�t�L]
�@�@------------------
�}�C�N���A�[�L�e�N�`���AISA�APE (programming environments)�ƒ��ۓx�����߂Ă����̂�
���������j�Ȃ̂ł����āA�S���n�[�h�E�F�A�����ƍl����̂͑�ԈႢ���Ɓc
���w���ł����AIntel�������������Ă���͓ǂ߂܂���ł������H
http://software.intel.com/en-us/articles/prototype-primitives-guide/
�@�@------------------
�@�@Math utility functions DO NOT CORRESPOND DIRECTRY TO LARRABEE NEW
�@�@INSTRUCTIONS, but are added for programming support.
�@�@[��������MAC�I�^�t�L]
�@�@------------------
�}�C�N���A�[�L�e�N�`���AISA�APE (programming environments)�ƒ��ۓx�����߂Ă����̂�
���������j�Ȃ̂ł����āA�S���n�[�h�E�F�A�����ƍl����̂͑�ԈႢ���Ɓc
�g�v���Z�b�T�p���[�ɂ��Ȃ������ς��h�̐��ɑ���̓��C�g���[�V���O
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
���U�������āA�����Ƀ��C�g���[�V���O�ʂ����v�������Ȃ��@by Intel
http://hiroshicom.blog.so-net.ne.jp/2007-10-23
Intel��Neoptica�ƌ�����Ђ������Ƃ����b
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
NVIDA��mental ray�ł�����݂�Mental Images��
http://blog.livedoor.jp/polo702/archives/51212966.html
NVIDIA�A���C�g���[�V���O�Z�p�J����RayScale����
http://japan.cnet.com/news/biz/story/0,2000056020,20373923,00.htm
Intel�C�Q�[���f�x���b�p��Offset Software��
http://www.4gamer.net/games/021/G002195/20080221047/
�mGDC 2008�n�Q�[���Ɏg���郊�A���^�C�����C�g���[�V���O�őO��
http://www.4gamer.net/games/047/G004713/20080222012/
�������C�g���[�V���O�Z�p�AApple Intel NVIDIA ATI Autodesk�o�g�҂炪�J��
http://blog.goo.ne.jp/cadboy/e/fabef5f77e8cdc68bb297b5fc6bcb9c8
�mGDC 2009�nOTOY�ALightStage���g����Ruby�̐V�샀�[�r�[�𐧍�
http://www.4gamer.net/games/080/G008082/20090327045/
http://www.itmedia.co.jp/news/articles/0402/20/news047_2.html
���U�������āA�����Ƀ��C�g���[�V���O�ʂ����v�������Ȃ��@by Intel
http://hiroshicom.blog.so-net.ne.jp/2007-10-23
Intel��Neoptica�ƌ�����Ђ������Ƃ����b
http://masafumi.cocolog-nifty.com/masafumis_diary/2007/11/post_ebc6.html
NVIDA��mental ray�ł�����݂�Mental Images��
http://blog.livedoor.jp/polo702/archives/51212966.html
NVIDIA�A���C�g���[�V���O�Z�p�J����RayScale����
http://japan.cnet.com/news/biz/story/0,2000056020,20373923,00.htm
Intel�C�Q�[���f�x���b�p��Offset Software��
http://www.4gamer.net/games/021/G002195/20080221047/
�mGDC 2008�n�Q�[���Ɏg���郊�A���^�C�����C�g���[�V���O�őO��
http://www.4gamer.net/games/047/G004713/20080222012/
�������C�g���[�V���O�Z�p�AApple Intel NVIDIA ATI Autodesk�o�g�҂炪�J��
http://blog.goo.ne.jp/cadboy/e/fabef5f77e8cdc68bb297b5fc6bcb9c8
�mGDC 2009�nOTOY�ALightStage���g����Ruby�̐V�샀�[�r�[�𐧍�
http://www.4gamer.net/games/080/G008082/20090327045/
13 �F,,�E�L�́M�E,,�j��-�������F2009/03/28(�y) 13:36:21 ID:D0rPPE4r
>>11
���������Ă邾�낗��
> ���\�ʂłǂ����������A�A�Z���u�������g�ݍ��݊����x���ŏ����₷�����Ƃ��d�������̂����m��Ȃ��B
���������Ă邾�낗��
> ���\�ʂłǂ����������A�A�Z���u�������g�ݍ��݊����x���ŏ����₷�����Ƃ��d�������̂����m��Ȃ��B
14 �FMAC�I�^���c�q �����F2009/03/28(�y) 13:43:54 ID:cu35dzXH
>>13
ISA�ɓ����Ă��Ȃ���������Ȃ��Ə����Ă���킯�ł�����A
�@�@-----------------
�@�@�A�Z���u�������
�@�@-----------------
�������͈Ⴄ�Ǝv���܂���B
ISA�ɓ����Ă��Ȃ���������Ȃ��Ə����Ă���킯�ł�����A
�@�@-----------------
�@�@�A�Z���u�������
�@�@-----------------
�������͈Ⴄ�Ǝv���܂���B
Larrabee: A Many-Core x86 Architecture for Visual Computing
http://download.intel.com/technology/architecture-silicon/Siggraph_Larrabee_paper.pdf
http://www2.computer.org/portal/web/csdl/doi/10.1109/MM.2009.9
http://portal.acm.org/citation.cfm?id=1360612.1360617
Larry Seiler�@ Intel Corporation
Doug Carmean�@ Intel Corporation
Eric Sprangle�@ Intel Corporation
Tom Forsyth�@ Intel Corporation
Michael Abrash�@ RAD Game Tools
Pradeep Dubey�@ Intel Corporation
Stephen Junkins�@ Intel Corporation
Adam Lake�@ Intel Corporation
Jeremy Sugerman�@ Stanford University
Robert Cavin�@ Intel Corporation
Roger Espasa�@ Intel Corporation
Ed Grochowski�@ Intel Corporation
Toni Juan�@ Intel Corporation
Pat Hanrahan�@ Stanford University
Pixomatic��2005�N�̏I����Intel�ɂ���Ĕ�������܂���
http://www.radgametools.com/jp/pixomain.htm
http://software.intel.com/en-us/articles/michael-abrash-biography/
>Michael Abrash is a programmer at RAD Game Tools, working with Intel on the Larrabee project. He is co-author of the Pixomatic software renderer. He worked on Quake at id Software and on Windows NT and Xbox at Microsoft.
Tom Forsyth�̃o�b�N�O�����h�̓\�t�g�E�F�A�����_�����O�A��3Dlabs
http://www.sgi.co.jp/company_info/press_releases/archives/20080820.html
http://s08.idav.ucdavis.edu/forsyth-larrabee-graphics-architecture.pdf
http://software.intel.com/en-us/articles/tom-forsyth-bio/
>he has written animation middleware for RAD Game Tools, game graphics engines for Muckyfoot Productions and Direct3D video card drivers for 3DLabs.
http://download.intel.com/technology/architecture-silicon/Siggraph_Larrabee_paper.pdf
http://www2.computer.org/portal/web/csdl/doi/10.1109/MM.2009.9
http://portal.acm.org/citation.cfm?id=1360612.1360617
Larry Seiler�@ Intel Corporation
Doug Carmean�@ Intel Corporation
Eric Sprangle�@ Intel Corporation
Tom Forsyth�@ Intel Corporation
Michael Abrash�@ RAD Game Tools
Pradeep Dubey�@ Intel Corporation
Stephen Junkins�@ Intel Corporation
Adam Lake�@ Intel Corporation
Jeremy Sugerman�@ Stanford University
Robert Cavin�@ Intel Corporation
Roger Espasa�@ Intel Corporation
Ed Grochowski�@ Intel Corporation
Toni Juan�@ Intel Corporation
Pat Hanrahan�@ Stanford University
Pixomatic��2005�N�̏I����Intel�ɂ���Ĕ�������܂���
http://www.radgametools.com/jp/pixomain.htm
http://software.intel.com/en-us/articles/michael-abrash-biography/
>Michael Abrash is a programmer at RAD Game Tools, working with Intel on the Larrabee project. He is co-author of the Pixomatic software renderer. He worked on Quake at id Software and on Windows NT and Xbox at Microsoft.
Tom Forsyth�̃o�b�N�O�����h�̓\�t�g�E�F�A�����_�����O�A��3Dlabs
http://www.sgi.co.jp/company_info/press_releases/archives/20080820.html
http://s08.idav.ucdavis.edu/forsyth-larrabee-graphics-architecture.pdf
http://software.intel.com/en-us/articles/tom-forsyth-bio/
>he has written animation middleware for RAD Game Tools, game graphics engines for Muckyfoot Productions and Direct3D video card drivers for 3DLabs.
Tera-scale Computing
http://www.intel.com/technology/itj/2007/v11i3/4-environment/11-authors.htm
>Doug Carmean is a Senior Principal Engineer with Intel's Visual Computing Group in Oregon. Doug was one of the key architects responsible for definition of the Intel Pentium 4 processor.
> He has been with Intel for 18 years, working on IA-32 processors from the 80486 to the Intel Pentium 4 processor and beyond.
>Anwar Rohillah is currently working as a VCG architect focusing on performance analysis and simulation. He has also worked on the Intel Pentium 4 processor family developing hardware prefetchers and doing performance analysis.
>Eric Sprangle is a Principal Engineer with Intel's Visual Computing Group in Austin. Eric has been with Intel for eight years, working on the IntelR PentiumR 4 processor family, and he is currently one of the lead architects on the Larrabee project.
http://japan.zdnet.com/news/hardware/story/0,2000056184,20378365,00.htm
>Larry Seiler���́A��T�T���t�����V�X�R�ōs��ꂽLarrabee�̐�����ŁA
>�u�����ɕK�v�Ȃ̂́ACPU�̊��S�ȃv���O�����\���ƁA�O���t�B�b�N�X
>�v���Z�b�T�̕����Ȃǂ̓Ǝ��̋@�\��g�ݍ��킹���A�[�L�e�N�`�����B
>�����āA���̃A�[�L�e�N�`����Larrabee���v�Əq�ׂ��B
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
>Larrabee�̃O���t�B�b�N�X�T�C�h�̃A�[�L�e�N�g�ł���Larry Seiler����
>��ATI Technologies�B�܂��A�r�W���A���R���s���[�e�B���O�ɂ��Ă�
>�uChalk Talk�v�ɂ́ANVIDIA�ŃV�F�[�f�B���O����uCg�v�������William
>(Bill) R. Mark�����o�ꂵ���BMark����NVIDIA��Ƀe�L�T�X��w�I�[�X
>�e�B���Z�Ɉڂ������A���݂�Intel�̃��T�[�`�Z���^�[�ɏ������Ă���Ƃ����B
When Will Ray-Tracing Replace Rasterization?�@�u�t�FLarry Seiler�iATI)
http://www.hc.t.u-tokyo.ac.jp/~kaki/SIGGRAPH2002/Panel_RT_vs_RAS.html
http://www.intel.com/technology/itj/2007/v11i3/4-environment/11-authors.htm
>Doug Carmean is a Senior Principal Engineer with Intel's Visual Computing Group in Oregon. Doug was one of the key architects responsible for definition of the Intel Pentium 4 processor.
> He has been with Intel for 18 years, working on IA-32 processors from the 80486 to the Intel Pentium 4 processor and beyond.
>Anwar Rohillah is currently working as a VCG architect focusing on performance analysis and simulation. He has also worked on the Intel Pentium 4 processor family developing hardware prefetchers and doing performance analysis.
>Eric Sprangle is a Principal Engineer with Intel's Visual Computing Group in Austin. Eric has been with Intel for eight years, working on the IntelR PentiumR 4 processor family, and he is currently one of the lead architects on the Larrabee project.
http://japan.zdnet.com/news/hardware/story/0,2000056184,20378365,00.htm
>Larry Seiler���́A��T�T���t�����V�X�R�ōs��ꂽLarrabee�̐�����ŁA
>�u�����ɕK�v�Ȃ̂́ACPU�̊��S�ȃv���O�����\���ƁA�O���t�B�b�N�X
>�v���Z�b�T�̕����Ȃǂ̓Ǝ��̋@�\��g�ݍ��킹���A�[�L�e�N�`�����B
>�����āA���̃A�[�L�e�N�`����Larrabee���v�Əq�ׂ��B
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
>Larrabee�̃O���t�B�b�N�X�T�C�h�̃A�[�L�e�N�g�ł���Larry Seiler����
>��ATI Technologies�B�܂��A�r�W���A���R���s���[�e�B���O�ɂ��Ă�
>�uChalk Talk�v�ɂ́ANVIDIA�ŃV�F�[�f�B���O����uCg�v�������William
>(Bill) R. Mark�����o�ꂵ���BMark����NVIDIA��Ƀe�L�T�X��w�I�[�X
>�e�B���Z�Ɉڂ������A���݂�Intel�̃��T�[�`�Z���^�[�ɏ������Ă���Ƃ����B
When Will Ray-Tracing Replace Rasterization?�@�u�t�FLarry Seiler�iATI)
http://www.hc.t.u-tokyo.ac.jp/~kaki/SIGGRAPH2002/Panel_RT_vs_RAS.html
Ray Tracing and Gaming - Quake 4: Ray Traced Project
http://www.pcper.com/article.php?aid=334&type=expert&pid=1
http://software.intel.com/en-us/articles/quake-wars-gets-ray-traced/
>Daniel Pohl started researching real-time ray tracing for games in 2004 during his study of computer science at the Erlangen-Nuernberg University in Germany. he joined Intel�fs ray-tracing group.
Stephen Junkins
http://mrl.nyu.edu/publications/gdc-tutorial2001/
>He is a senior software architect in the Graphics and 3D Technologies group in the Intel Architecture Labs.
Pradeep Dubey
http://techresearch.intel.com/articles/Top-Links/1603.htm
>He was one of the principal architects of the AltiVec multimedia extension to Power PC architecture.
Adam Lake, Intel Graphics Media Accelerator 900 Series Software Developer's Guide
http://software.intel.com/en-us/articles/intel-graphics-media-accelerator-900-series-software-developers-guide/
Robert Cavin, Computer Architect at Intel Corporation, SANTA CLARA, CA
http://www.linkedin.com/pub/5/649/606
Roger Espasa, Adding a vector unit to a superscalar processor
http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/e/Espasa:Roger.html
Ed Grochowski
http://software.intel.com/en-us/videos/ed-grochowski-bio/
>I joined Intel Corporation in Santa Clara, California in 1986 and have worked there ever since. I was a member of the design teams for four microprocessors, some of which you've probably owned: the 486, Pentium, Pentium II, and Itanium.
Toni Juan, Data caches for superscalar processors
http://citeseer.ist.psu.edu/old/134846.html
Jeremy Sugerman, I'm working on various GPU programming notions including Brook
http://www-graphics.stanford.edu/~yoel/
Pat Hanrahan, Graphics Systems and Architectures.
http://www-graphics.stanford.edu/~hanrahan/
http://www.pcper.com/article.php?aid=334&type=expert&pid=1
http://software.intel.com/en-us/articles/quake-wars-gets-ray-traced/
>Daniel Pohl started researching real-time ray tracing for games in 2004 during his study of computer science at the Erlangen-Nuernberg University in Germany. he joined Intel�fs ray-tracing group.
Stephen Junkins
http://mrl.nyu.edu/publications/gdc-tutorial2001/
>He is a senior software architect in the Graphics and 3D Technologies group in the Intel Architecture Labs.
Pradeep Dubey
http://techresearch.intel.com/articles/Top-Links/1603.htm
>He was one of the principal architects of the AltiVec multimedia extension to Power PC architecture.
Adam Lake, Intel Graphics Media Accelerator 900 Series Software Developer's Guide
http://software.intel.com/en-us/articles/intel-graphics-media-accelerator-900-series-software-developers-guide/
Robert Cavin, Computer Architect at Intel Corporation, SANTA CLARA, CA
http://www.linkedin.com/pub/5/649/606
Roger Espasa, Adding a vector unit to a superscalar processor
http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/e/Espasa:Roger.html
Ed Grochowski
http://software.intel.com/en-us/videos/ed-grochowski-bio/
>I joined Intel Corporation in Santa Clara, California in 1986 and have worked there ever since. I was a member of the design teams for four microprocessors, some of which you've probably owned: the 486, Pentium, Pentium II, and Itanium.
Toni Juan, Data caches for superscalar processors
http://citeseer.ist.psu.edu/old/134846.html
Jeremy Sugerman, I'm working on various GPU programming notions including Brook
http://www-graphics.stanford.edu/~yoel/
Pat Hanrahan, Graphics Systems and Architectures.
http://www-graphics.stanford.edu/~hanrahan/
�mGDC 2009��30�n���Ƀ\�t�g�J���Ҍ��������o�Ă����uLarrabee�v
http://www.4gamer.net/games/049/G004963/20090328006/
http://www.4gamer.net/games/049/G004963/20090328006/
����œ������[�߂��낤��
���\�o��܂ł̕ǂ���������B
���\�o��܂ł̕ǂ���������B
20 �F,,�E�L�́M�E,,�j��-�������F2009/03/29(��) 23:13:03 ID:GVhM6U0P
IDF���܂��Ȃ�
http://blog.livedoor.jp/amd646464/archives/51333715.html
��Intel��GDC 2009�ɂ�C++ Larrabee prototype library�̏ڍׂ\���܂���
������͎��ۂ�Larrabee�ŃR�[�h�𑖂点��킯�ł͂Ȃ��A
��Larrabee���G�~�����[�g���ăV�X�e���̃v���C�}��CPU
���ɂăR�[�h���R���p�C���E���s����Ƃ̂��Ƃł�
�ˁ[�ˁ[�c�q����c�q����
�T���v�������삷��V���R�������Ă���
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
518 �FSocket774 [sage] �F2009/02/08(��) 20:41:32 ID:oV5466gY
�����ADreamWorks�����łɎg�p���Ă���āH
���uLarrabee�́A����ꂪ�B���ł�����E��2�{��3�{�ǂ��납20�{�ɂ������グ�Ă����v
���̕]���͎��̏�ł̃V�~�����[�V����
���Ȃ݂ɃX�[�p�[�{�[����CM��Opteron�ō�������̂ł�
519 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/08(��) 20:42:15 ID:bDqzIbh7
�ϑz��
��Intel��GDC 2009�ɂ�C++ Larrabee prototype library�̏ڍׂ\���܂���
������͎��ۂ�Larrabee�ŃR�[�h�𑖂点��킯�ł͂Ȃ��A
��Larrabee���G�~�����[�g���ăV�X�e���̃v���C�}��CPU
���ɂăR�[�h���R���p�C���E���s����Ƃ̂��Ƃł�
�ˁ[�ˁ[�c�q����c�q����
�T���v�������삷��V���R�������Ă���
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
518 �FSocket774 [sage] �F2009/02/08(��) 20:41:32 ID:oV5466gY
�����ADreamWorks�����łɎg�p���Ă���āH
���uLarrabee�́A����ꂪ�B���ł�����E��2�{��3�{�ǂ��납20�{�ɂ������グ�Ă����v
���̕]���͎��̏�ł̃V�~�����[�V����
���Ȃ݂ɃX�[�p�[�{�[����CM��Opteron�ō�������̂ł�
519 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/08(��) 20:42:15 ID:bDqzIbh7
�ϑz��
22 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 06:18:09 ID:CPSTJJC2
��Intel��GDC 2009�ɂ�C++ Larrabee prototype library�̏ڍׂ\���܂���
������͎��ۂ�Larrabee�ŃR�[�h�𑖂点��킯�ł͂Ȃ��A
��Larrabee���G�~�����[�g���ăV�X�e���̃v���C�}��CPU
���ɂăR�[�h���R���p�C���E���s����Ƃ̂��Ƃł�
���̃��C�u���������Ă邯�ǂ�
�Ă��N�ł��g���邯�ǂ�
�����Ȃ݂ɃX�[�p�[�{�[����CM��Opteron�ō�������̂ł�
���t�H���[��������
Quad Core Opteron�Ɏ��]����Intel�iXeon�j�ɒu��������ꂽ�����ł��B
������͎��ۂ�Larrabee�ŃR�[�h�𑖂点��킯�ł͂Ȃ��A
��Larrabee���G�~�����[�g���ăV�X�e���̃v���C�}��CPU
���ɂăR�[�h���R���p�C���E���s����Ƃ̂��Ƃł�
���̃��C�u���������Ă邯�ǂ�
�Ă��N�ł��g���邯�ǂ�
�����Ȃ݂ɃX�[�p�[�{�[����CM��Opteron�ō�������̂ł�
���t�H���[��������
Quad Core Opteron�Ɏ��]����Intel�iXeon�j�ɒu��������ꂽ�����ł��B
�܂�larrabee����Ȃ���
24 �FSocket774�F2009/03/30(��) 06:59:01 ID:WZAOIXr6
Intel��GDC��Larrabee�̖��߃Z�b�g�̊T�v�����J
http://pc.watch.impress.co.jp/docs/2009/0330/kaigai498.htm
http://pc.watch.impress.co.jp/docs/2009/0330/kaigai498.htm
GeForce7�Ŕ]�݂����~�܂��āA�ŋ߂̃j���[�X�����Ă��
����3�ЂƂ�������ŖŒ��ꒃ�݂������ȁB
���N�ė��N������ŖŒ��ꒃ�̂܂�CPU�ɓ�������āA
MMX�݂�����CPU�̋@�\�̈�Ƃ��Ă��̂܂ܖY�ꋎ��ꂻ�����ȁB
���ȉ������r�[�q��֎~�B
����3�ЂƂ�������ŖŒ��ꒃ�݂������ȁB
���N�ė��N������ŖŒ��ꒃ�̂܂�CPU�ɓ�������āA
MMX�݂�����CPU�̋@�\�̈�Ƃ��Ă��̂܂ܖY�ꋎ��ꂻ�����ȁB
���ȉ������r�[�q��֎~�B
����͂��O���n���Ȃ�������
���ǃN���b�N2GH���߂��Ȃ�悤�œd�͌����̈����͂ǂ��ɂ��Ȃ�Ȃ�������
���������A�����������s���ꍇ�v���O���}�u���ȉ�H�͌Œ��H��500�`2000�{�̓d�C����
CPU�̃R�v���Ƃ��Ă͗ǂ���������GPU�Ƃ��Ďg���ɂ͌�����������
���������A�����������s���ꍇ�v���O���}�u���ȉ�H�͌Œ��H��500�`2000�{�̓d�C����
CPU�̃R�v���Ƃ��Ă͗ǂ���������GPU�Ƃ��Ďg���ɂ͌�����������
Atom��2GHz��TDP2.4W����
Atom������肾���Ăǂ�����A�C�t��
�v��I�ɗ��p����̂�
# ���̘b���H
# ���̘b���H
>>24
�����O�o�X�����h�O���h���R�A��n�{�ł��̏��͂Ȃ���
�����O�o�X�����h�O���h���R�A��n�{�ł��̏��͂Ȃ���
ttp://game.watch.impress.co.jp/docs/series/3dcg/20090330_80150.html
����P�i��3D�Q�[���t�@���̂��߂�Intel�ELarrabee�u��
3D�O���t�B�b�N�X��v���BIntel�ELarrabee��DirectX��GPU���Ԃ����킷�̂�
����P�i��3D�Q�[���t�@���̂��߂�Intel�ELarrabee�u��
3D�O���t�B�b�N�X��v���BIntel�ELarrabee��DirectX��GPU���Ԃ����킷�̂�
intel�V����肷���ĕ��Љ�
MS�V����肷���ĕ��Љ�
35 �FSocket774�F2009/03/30(��) 17:41:38 ID:yn5FA+IQ
Cell2 B.E. + Larrabee
36 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 21:04:04 ID:CPSTJJC2
�����p�N���������B
����̋�_�҂͖ق��Ă��ق����g�̂��߂����B
http://pc12.2ch.net/test/read.cgi/tech/1232817361/
649 ���O�FMAC�I�^���c�q ����[sage] ���e���F2009/03/30(��) 19:41:31
>>638
�@�@--------------
�@�@Cell�Ȃ炻�̂܂�[x, y, z, *]���낤�B
�@�@--------------
�܂��㓡�O�Ε��݂̃g���f������(��)
16-way SIMD���ǂ����߂邩�Ƃ�������10�N�O��Altivec���ʉ߂������ł��B
http://www.freescale.com/webapp/sps/site/overview.jsp?nodeId=0162468rH3bTdGmKqW5Nf2F9DHMbVXVDcM
�����̃L���[�A�v����RGB�̊e�v�f1-byte�̉摜�����ŁA���݂̃L���[�A�v����xyz��
�e�v�f4-byte FP��3D�������Ƃ��������̈Ⴂ�Ȃ̂ł́H
AIM��vector permute��I�сAIntel�͂��Â�scatter/gather��I�Ƃ����͓̂����̘b��
�ʂɂ��Ă������[���b�ł��B
650 ���O�F�y�j�X�͋A��[sage] ���e���F2009/03/30(��) 19:53:41
�܂���̒��̊^�̎c�O�Ȏq��������B
GeForce��LSU�ł���scatter/gather���T�|�[�g���Ă�̂ɁB
651 ���O�F�f�t�H���g�̖���������[sage] ���e���F2009/03/30(��) 20:09:43
SPU�̏ꍇ�ALSU��shuffle�AMFCIO������Odd�p�C�v������
���ς��]�𑽗p���Ȃ��Ȃ�Permute������128�r�b�g�A���C�����ꂽ
3(4)�x�N�g���Ƃ��Ďg��������������
����̋�_�҂͖ق��Ă��ق����g�̂��߂����B
http://pc12.2ch.net/test/read.cgi/tech/1232817361/
649 ���O�FMAC�I�^���c�q ����[sage] ���e���F2009/03/30(��) 19:41:31
>>638
�@�@--------------
�@�@Cell�Ȃ炻�̂܂�[x, y, z, *]���낤�B
�@�@--------------
�܂��㓡�O�Ε��݂̃g���f������(��)
16-way SIMD���ǂ����߂邩�Ƃ�������10�N�O��Altivec���ʉ߂������ł��B
http://www.freescale.com/webapp/sps/site/overview.jsp?nodeId=0162468rH3bTdGmKqW5Nf2F9DHMbVXVDcM
�����̃L���[�A�v����RGB�̊e�v�f1-byte�̉摜�����ŁA���݂̃L���[�A�v����xyz��
�e�v�f4-byte FP��3D�������Ƃ��������̈Ⴂ�Ȃ̂ł́H
AIM��vector permute��I�сAIntel�͂��Â�scatter/gather��I�Ƃ����͓̂����̘b��
�ʂɂ��Ă������[���b�ł��B
650 ���O�F�y�j�X�͋A��[sage] ���e���F2009/03/30(��) 19:53:41
�܂���̒��̊^�̎c�O�Ȏq��������B
GeForce��LSU�ł���scatter/gather���T�|�[�g���Ă�̂ɁB
651 ���O�F�f�t�H���g�̖���������[sage] ���e���F2009/03/30(��) 20:09:43
SPU�̏ꍇ�ALSU��shuffle�AMFCIO������Odd�p�C�v������
���ς��]�𑽗p���Ȃ��Ȃ�Permute������128�r�b�g�A���C�����ꂽ
3(4)�x�N�g���Ƃ��Ďg��������������
601 �F,,�E�L�́M�E,,�j��-������ [sage] �F2009/02/06(��) 07:50:39 ID:36Q+eCpY
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
����Larrabee�̃T���v����Dreamworks�ŕ]������Ă�悤����
38 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 21:35:32 ID:CPSTJJC2
TOMS�̎��肾�������H
http://www.tomshardware.com/news/intel-larrabee-graphics,5847.html
http://www.tomshardware.com/news/intel-larrabee-graphics,5847.html
39 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 21:39:51 ID:CPSTJJC2
���Ƃ��ASPE��4�̃o���o���̃A�h���X����32�r�b�g�f�[�^���E���Ă���
128�r�b�g�Ƀp�b�N����̂ɂ�����T�C�N�����͂����ł��傤���H
�]�݂��ɃE���R���܂��Ă�l��scatter/gather�͋���������Ĕn���ɂ������悤�����A
�c�O�Ȃ��Ƃ�Cell�̎������\�͖{���ɔߎS�ł���B
�܂�����v�Z���Ă݂�킩��܂��B
128�r�b�g�Ƀp�b�N����̂ɂ�����T�C�N�����͂����ł��傤���H
�]�݂��ɃE���R���܂��Ă�l��scatter/gather�͋���������Ĕn���ɂ������悤�����A
�c�O�Ȃ��Ƃ�Cell�̎������\�͖{���ɔߎS�ł���B
�܂�����v�Z���Ă݂�킩��܂��B
>>38
���Ƃ��艳
���Ƃ��艳
>>38
�T���v�������炩�̌����� �����E�G�ꂽ�E�ʓd���삳���� �̗ނ̕����͂܂�����������ĂȂ���
�T���v�������炩�̌����� �����E�G�ꂽ�E�ʓd���삳���� �̗ނ̕����͂܂�����������ĂȂ���
42 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 22:02:00 ID:CPSTJJC2
SSE5�����N�\��i�j�Ȃ���܂�����������
Tom's�Ɠ����̋L��
http://news.cnet.com/8301-10784_3-9985989-7.html
�����ɂ�"Monsters vs. Aliens"��DreamWorks��Intel�̒�g�̍ŏ���
���ʂł���Ə����Ă��邾����Larrabee���g����Ƃ͏����ĂȂ��B
�܂�Tom's�̓��̕��͂͊ԈႢ�B
�ł��{������Larrabee��2009�N�㔼�����[�X�\��Ə�����Ă�
����A3�����J�̉f��Ɏg���郂�m���H�Ƌ^���̂����ʁB
�Ƃ��낪���c�q�͂�������Ȃ��B
���̏�ɓ����邱�Ƃ������ɁA����ɃT���v���Ȃ��
�����ϑz�����o���̂��c�q�]�B
http://news.cnet.com/8301-10784_3-9985989-7.html
�����ɂ�"Monsters vs. Aliens"��DreamWorks��Intel�̒�g�̍ŏ���
���ʂł���Ə����Ă��邾����Larrabee���g����Ƃ͏����ĂȂ��B
�܂�Tom's�̓��̕��͂͊ԈႢ�B
�ł��{������Larrabee��2009�N�㔼�����[�X�\��Ə�����Ă�
����A3�����J�̉f��Ɏg���郂�m���H�Ƌ^���̂����ʁB
�Ƃ��낪���c�q�͂�������Ȃ��B
���̏�ɓ����邱�Ƃ������ɁA����ɃT���v���Ȃ��
�����ϑz�����o���̂��c�q�]�B
44 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 22:30:52 ID:CPSTJJC2
������\���낗��
�T���v�����Ă͖̂��_�\�t�g�E�F�A�i�V�~�����[�^���܂߂āj�̘b�ł��傤�B
���������ʂ�Intel�͊���������B
AVX�̃V�~�����[�^�Ȃ狎�N�̒i�K�ł���o�Ă���B
�i�s���葽���Ɍ��J����Ă�SDE�̂ق��̓N���b�N�A�L�����[�g�ł͂Ȃ����j
���Ƃ������ǁA�ꕔ�ŏ���ɏo����Ă邯�ǁuTAT�v�݂����ȃc�[������
���Ƃ��ƃp�[�g�i�[�����̃c�[���Ȃ��B
�����܂߂Ă��܂��炪�S�Ă�m��͂����Ȃ���
�T���v�����Ă͖̂��_�\�t�g�E�F�A�i�V�~�����[�^���܂߂āj�̘b�ł��傤�B
���������ʂ�Intel�͊���������B
AVX�̃V�~�����[�^�Ȃ狎�N�̒i�K�ł���o�Ă���B
�i�s���葽���Ɍ��J����Ă�SDE�̂ق��̓N���b�N�A�L�����[�g�ł͂Ȃ����j
���Ƃ������ǁA�ꕔ�ŏ���ɏo����Ă邯�ǁuTAT�v�݂����ȃc�[������
���Ƃ��ƃp�[�g�i�[�����̃c�[���Ȃ��B
�����܂߂Ă��܂��炪�S�Ă�m��͂����Ȃ���
45 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 22:37:35 ID:CPSTJJC2
Dreamworks�̃����_�����O�N���X�^��Intel���Z�p���͂����̂́A�ǂ������Ƃ����ƃ\�t�g�E�F�A�Z�p�����B
Xeon�������Ă�悤�����B
�܂�AMD�Ƃ̌��ʂɑ����V�݂����Ȃ��B
Xeon�������Ă�悤�����B
�܂�AMD�Ƃ̌��ʂɑ����V�݂����Ȃ��B
���`���A���������Ȃ�
47 �FMAC�I�^���c�q �����F2009/03/30(��) 22:59:58 ID:Da0yd18P
>>45
�Ƃ肠����������F�߂�C�ɂȂ����̂͌��\�Șb�ł��B
���̕ӂ̔l�i�G�����ӂ��Ă������ق����ǂ��̂ł́H
http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/898-903
�Ƃ肠����������F�߂�C�ɂȂ����̂͌��\�Șb�ł��B
���̕ӂ̔l�i�G�����ӂ��Ă������ق����ǂ��̂ł́H
http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/898-903
48 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:04:26 ID:CPSTJJC2
���x�ł������Ă���
898 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/02/17(��) 20:26:10 ID:x/bBLQwK
Demerjian�i�j
�����Ԃ�����̗͂L��\�[�X���Ȃ�����
898 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/02/17(��) 20:26:10 ID:x/bBLQwK
Demerjian�i�j
�����Ԃ�����̗͂L��\�[�X���Ȃ�����
49 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:05:40 ID:CPSTJJC2
�ނ������ɂ�Penryn��HyperThreading�����ڂ���Ă�炵�����B
�]���X�ɃE���R���l�܂��Ă�l�͐M��̑Ώۂ��E���R�Ȃ��B
�]���X�ɃE���R���l�܂��Ă�l�͐M��̑Ώۂ��E���R�Ȃ��B
�V�~�����[�^���T���v����������Ȃ�đO�㖢���I
�������c�q����
�[��
�������c�q����
�[��
51 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:06:47 ID:CPSTJJC2
�\�t�g�E�F�A���܂߂āA�J���ɂ��������̂̓T���v���ł��傤�B
�n�[�h�E�F�A���Ȃ�ĉ����������H
�n�[�h�E�F�A���Ȃ�ĉ����������H
52 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:09:58 ID:CPSTJJC2
http://kishinkan.jugem.jp/?day=20081105
�u�����̍����v�炵���ł���
���Ƃ���ł���N�̌��t���������ȁH
> TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ� �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷�B ...
�u�����̍����v�炵���ł���
���Ƃ���ł���N�̌��t���������ȁH
> TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ� �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷�B ...
�����y����������c�q
54 �FMAC�I�^���c�q �����F2009/03/30(��) 23:10:58 ID:Da0yd18P
>>48
�ł�FUDzilla�͐M����c�q����(��)
�@�@-----------------
�@�@929 ���O�F,,�E�L�́M�E,,�j��-������ ���e���F2009/02/19(��) 00:06:51 ID:yEXM5r22
�@�@�@�@intel Larrabee�ɂ�Windows XP�p�h���C�o���p�ӂ���Ȃ�
�@�@�@�@http://a96sj096.cocolog-nifty.com/weblog/2008/11/intel-larrabeew.html
�@�@�@�@������O������DirectX9�܂ł̕`�惁�\�b�h�ɂ͋������Ȃ��݂����ŁB
�@�@-----------------
�|�ꃋ�[�}�[�T�C�g�̃\�[�X�͂�����B
http://www.fudzilla.com/index.php?option=com_content&task=view&id=10349&Itemid=1
�ł�FUDzilla�͐M����c�q����(��)
�@�@-----------------
�@�@929 ���O�F,,�E�L�́M�E,,�j��-������ ���e���F2009/02/19(��) 00:06:51 ID:yEXM5r22
�@�@�@�@intel Larrabee�ɂ�Windows XP�p�h���C�o���p�ӂ���Ȃ�
�@�@�@�@http://a96sj096.cocolog-nifty.com/weblog/2008/11/intel-larrabeew.html
�@�@�@�@������O������DirectX9�܂ł̕`�惁�\�b�h�ɂ͋������Ȃ��݂����ŁB
�@�@-----------------
�|�ꃋ�[�}�[�T�C�g�̃\�[�X�͂�����B
http://www.fudzilla.com/index.php?option=com_content&task=view&id=10349&Itemid=1
�����v�����A�R������cell�̗R�s�[����Ȃ��́H
56 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:12:29 ID:CPSTJJC2
�]���X�̃E���R���l�܂����l�̏�����FUDZILLA�͐M�p�ł��邾��
57 �FMAC�I�^���c�q �����F2009/03/30(��) 23:16:51 ID:Da0yd18P
>>56
���̃q�g�͌�TheINQ���Ēm���Ă܂�����
http://www.google.com/search?q=Fuad-Abazovic+site%3Atheinquirer.net�@(��)
���̃q�g�͌�TheINQ���Ēm���Ă܂�����
http://www.google.com/search?q=Fuad-Abazovic+site%3Atheinquirer.net�@(��)
58 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:20:05 ID:CPSTJJC2
fuckin' hate.
�T���v�����V���R���T���v��
���w���̂�����
�l��Ƃ͏Z�ސ��E���Ⴄ�c�q����ɂƂ��Ă͂���Ȃ̂͒ʗp���Ȃ���ł��ˁI
�������c�q����
�[��
���w���̂�����
�l��Ƃ͏Z�ސ��E���Ⴄ�c�q����ɂƂ��Ă͂���Ȃ̂͒ʗp���Ȃ���ł��ˁI
�������c�q����
�[��
60 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:45:47 ID:CPSTJJC2
�n�����ˁB
�V���R���T���v���Ȃ�ăn�[�h�x���_�[�ɓn������Ń\�t�g���ɒ��ڒ������ł͂Ȃ��B
�\�t�g������ɂ̓\�t�g�E�F�A�x�[�X�̃V�~�����[�^�ŏ[���T���v���Ƃ��Ď��p�ɂȂ���B
Cell�̂���������B�N���b�N�T�C�N���A�L�����[�g�Ȃ���B
�V���R���T���v���Ȃ�ăn�[�h�x���_�[�ɓn������Ń\�t�g���ɒ��ڒ������ł͂Ȃ��B
�\�t�g������ɂ̓\�t�g�E�F�A�x�[�X�̃V�~�����[�^�ŏ[���T���v���Ƃ��Ď��p�ɂȂ���B
Cell�̂���������B�N���b�N�T�C�N���A�L�����[�g�Ȃ���B
61 �F,,�E�L�́M�E,,�j��-�������F2009/03/30(��) 23:46:33 ID:CPSTJJC2
����DW���n�[�h���ɂȂ�����ł����H
62 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 00:00:02 ID:YbyWNvCs
> TheINQ��Charlie "Groo" Demerjian��Larrabee�̃T���v�������N�̏H�ɂ�
> �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷
�����ł̊J���҂��y�\�t�g�́z�J���҂̂��Ƃ��w���Ă邱�ƂɋC�Â��Ăق����B
�n�[�h�J���҂�Intel�������B
�����āu�T���v���v�Ƃ͈�ʊJ���Ҍ����ɂ�protorype primitive�̂��ƁB
�m���ɂ���̌��J�͔ނ̌������Ƃ���N�x��̍��N3���ɂȂ����B
�n�[�h���Ǝv���Ĉ���J���Ă��̂͂��܂��炾������
> �J���Ҍ����ɔz�z�����Ɠ`���Ă��邷
�����ł̊J���҂��y�\�t�g�́z�J���҂̂��Ƃ��w���Ă邱�ƂɋC�Â��Ăق����B
�n�[�h�J���҂�Intel�������B
�����āu�T���v���v�Ƃ͈�ʊJ���Ҍ����ɂ�protorype primitive�̂��ƁB
�m���ɂ���̌��J�͔ނ̌������Ƃ���N�x��̍��N3���ɂȂ����B
�n�[�h���Ǝv���Ĉ���J���Ă��̂͂��܂��炾������
63 �FMAC�I�^���c�q �����F2009/03/31(��) 00:09:28 ID:3FaCOFUY
>>62
"silicon"���ď����Ă���̂ł����H
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
�@�@---------------------
�@�@the Taiwanese were expecting silicon in January.
�@�@---------------------
Intel�̓`�b�v�̊J�����[�J�[�ł����āA�r�f�I�J�[�h��}�U�[�{�[�h�̊J�����[�J�[�͕ʓr���܂���B
"silicon"���ď����Ă���̂ł����H
http://www.realworldtech.com/forums/index.cfm?action=detail&id=96437&threadid=96378&roomid=2
�@�@---------------------
�@�@the Taiwanese were expecting silicon in January.
�@�@---------------------
Intel�̓`�b�v�̊J�����[�J�[�ł����āA�r�f�I�J�[�h��}�U�[�{�[�h�̊J�����[�J�[�͕ʓr���܂���B
64 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 00:11:09 ID:YbyWNvCs
�܂��F������d�g�ł��E������ł���B
�Ȃނ�Penryn�ɂ�HyperThreading����������Ă���B
�Ȃނ�Penryn�ɂ�HyperThreading����������Ă���B
65 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 00:17:38 ID:YbyWNvCs
Demakasejan�̍��b���������b�̂悤�Ɍ���Ă��f�v�������܂���
http://www.xbitlabs.com/news/video/display/20080117222433_Intel_Promises_to_Sample_Larrabee_Processors_in_Late_2008.html
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
������F������̓d�g���������
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
������F������̓d�g���������
67 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 00:20:15 ID:YbyWNvCs
http://www.theinquirer.net/inquirer/news/419/1030419/penryn-to-have-ht
�܂��A�R��100�x�����Ζ{���ɂȂ鐢�E�̐l�ł���B
���p���˔]���X�ɃE���R���l�܂��Ă�l�́B
�܂��A�R��100�x�����Ζ{���ɂȂ鐢�E�̐l�ł���B
���p���˔]���X�ɃE���R���l�܂��Ă�l�́B
68 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 00:39:42 ID:YbyWNvCs
http://www.intel.com/pressroom/archive/releases/20080804fact.htm
Intel�̌������\�͂���B
09�N�ɂȂ邩10�N�ɂȂ邩���m�Ȏ����������ĂȂ����̂̃V���R���T���v����08�N���ɏo���邾�H
�ʎY�o�ׂ̔��N�O���炢�ɏo����Ǝv�������B
���ǁu�J���Ҍ����T���v���v�̐��̂��n�[�h�E�F�A�Ȃ̂��\�t�g�E�F�A�Ȃ̂�����
��ʂ��t���ĂȂ��L�҂�������B
���{�ɂ��u80�R�A�v�Ȃ�ď������Ⴄ�L�҂����邭�炢�����A�ާ��L�҂����Ⴂ����̂�����Ӗ����R�B
Intel�̌������\�͂���B
09�N�ɂȂ邩10�N�ɂȂ邩���m�Ȏ����������ĂȂ����̂̃V���R���T���v����08�N���ɏo���邾�H
�ʎY�o�ׂ̔��N�O���炢�ɏo����Ǝv�������B
���ǁu�J���Ҍ����T���v���v�̐��̂��n�[�h�E�F�A�Ȃ̂��\�t�g�E�F�A�Ȃ̂�����
��ʂ��t���ĂȂ��L�҂�������B
���{�ɂ��u80�R�A�v�Ȃ�ď������Ⴄ�L�҂����邭�炢�����A�ާ��L�҂����Ⴂ����̂�����Ӗ����R�B
> �ʎY�o�ׂ̔��N�O���炢�ɏo����Ǝv�������B
�V�K�A�[�L�e�N�`���Ȃ�ʎY�̈�N�ȏ�O�Ƀt�@�[�X�g�V���R���Ȃ�Ă͓̂�����O�̘b�����B
�V�K�A�[�L�e�N�`���Ȃ�ʎY�̈�N�ȏ�O�Ƀt�@�[�X�g�V���R���Ȃ�Ă͓̂�����O�̘b�����B
����͂��������������ꂻ���ł��ˁc
>>69
1st�V���R����OEM�ɏo���Ƃ��Ȃ�����E�E�E
1st�V���R����OEM�ɏo���Ƃ��Ȃ�����E�E�E
72 �FMAC�I�^��71 �����F2009/03/31(��) 01:10:02 ID:3FaCOFUY
>>71
>>66�̈��p���̈�s�ڂ��ǂ����B
"first silicon should be late this year IN TERMS OF SAMPLES" [��: ������MAC�I�^]
>>66�̈��p���̈�s�ڂ��ǂ����B
"first silicon should be late this year IN TERMS OF SAMPLES" [��: ������MAC�I�^]
1st�V���R�����p�[�g�i�[�����̃T���v���Ƃ��ďo���Ƃ����܂ł��������H
Paul Otellini�̏o�����ǂ����m��Ȃ�����͂�����Ƃ͌����Ȃ���
���ʂɊ��Ⴂ���Ǝv����
Paul Otellini�̏o�����ǂ����m��Ȃ�����͂�����Ƃ͌����Ȃ���
���ʂɊ��Ⴂ���Ǝv����
74 �FMAC�I�^��73 �����F2009/03/31(��) 01:22:53 ID:3FaCOFUY
>>73
�p������w�ŏ���[�G���W�j�A�����O�T���v���p]�V���R���x�Ɠǂނׂ����ƁB
�@�@------------------
�@�@Paul Otellini�̏o�����ǂ����m��Ȃ�
�@�@------------------
�c�q������̃q�g��������l�H
�p������w�ŏ���[�G���W�j�A�����O�T���v���p]�V���R���x�Ɠǂނׂ����ƁB
�@�@------------------
�@�@Paul Otellini�̏o�����ǂ����m��Ȃ�
�@�@------------------
�c�q������̃q�g��������l�H
wikipedia������
ttp://en.wikipedia.org/wiki/Paul_Otellini
����A����ς�Z�p���̐l����Ȃ��̂�
>>74
���̕���ES�Ɠǂނ̂͂�����Ƃǂ��Ȃ낤��
ttp://en.wikipedia.org/wiki/Paul_Otellini
����A����ς�Z�p���̐l����Ȃ��̂�
>>74
���̕���ES�Ɠǂނ̂͂�����Ƃǂ��Ȃ낤��
76 �FMAC�I�^��75 �����F2009/03/31(��) 01:33:24 ID:3FaCOFUY
>>75
�@�@------------------
�@�@���̕���ES�Ɠǂނ̂͂�����Ƃǂ��Ȃ낤��
�@�@------------------
http://lise.me.sophia.ac.jp/kktm/Essay/term_in_terms_of.htm
�@�@===================
�@�@�@�hin terms of �`�h�́Cby �`, with �`, by �` using �`, by the use of �`�̂悤�ɖ�
�@�@�\��Ȃ��ꍇ�������ł��D���ɂ́Ccontext�u�����v�ɂ���āC�u�`�Ƃ����_�ŁC�`�Ƃ����_
�@�@����C�`�Ƃ����ϓ_����v�ƖĂ��悢�ꍇ������܂��D�A���C�u�`�Ƃ����ϓ_����v���t
�@�@�ɉp��ꍇ�C�hfrom the viewpoint of �`�h�Ƃ���ƁC�hin terms of �`�h���班���u����
�@�@�Ă��܂��܂��D
�@�@===================
�@�@------------------
�@�@���̕���ES�Ɠǂނ̂͂�����Ƃǂ��Ȃ낤��
�@�@------------------
http://lise.me.sophia.ac.jp/kktm/Essay/term_in_terms_of.htm
�@�@===================
�@�@�@�hin terms of �`�h�́Cby �`, with �`, by �` using �`, by the use of �`�̂悤�ɖ�
�@�@�\��Ȃ��ꍇ�������ł��D���ɂ́Ccontext�u�����v�ɂ���āC�u�`�Ƃ����_�ŁC�`�Ƃ����_
�@�@����C�`�Ƃ����ϓ_����v�ƖĂ��悢�ꍇ������܂��D�A���C�u�`�Ƃ����ϓ_����v���t
�@�@�ɉp��ꍇ�C�hfrom the viewpoint of �`�h�Ƃ���ƁC�hin terms of �`�h���班���u����
�@�@�Ă��܂��܂��D
�@�@===================
����ES�����̗p����Ƃ��āA���x��2009�`2010�N�ƈٗl�ɕ��̂���\������
�ʏ��Intel�̃��[�h�}�b�v����2H09�Ƃ�1H10�Ƃ��̕\��������������
late 08��ES���o��Č���(>>66)�Ȃ�mid 09�ɗʎY�o�ׂƂ������Ă����͂��Ȃ̂�
���ꂪ1st�V���R���Ȃ炻��ȍ~�̃f�o�b�O���Ԃ�14�`18����������
��S�I�Ȑv���ƒx�����܂܂���̂ŃR���T�o�e�B�u�ȗ\����2009�`2010�N�̕\���ŗǂ��Ǝv���Ă����̂���
�ʏ��Intel�̃��[�h�}�b�v����2H09�Ƃ�1H10�Ƃ��̕\��������������
late 08��ES���o��Č���(>>66)�Ȃ�mid 09�ɗʎY�o�ׂƂ������Ă����͂��Ȃ̂�
���ꂪ1st�V���R���Ȃ炻��ȍ~�̃f�o�b�O���Ԃ�14�`18����������
��S�I�Ȑv���ƒx�����܂܂���̂ŃR���T�o�e�B�u�ȗ\����2009�`2010�N�̕\���ŗǂ��Ǝv���Ă����̂���
78 �FMAC�I�^��77 �����F2009/03/31(��) 01:53:05 ID:3FaCOFUY
>>77
�L���̓��t������Ɨǂ����ƁB
�L���̓��t������Ɨǂ����ƁB
>>78
�������������̂��킩��܂���[
�������������̂��킩��܂���[
80 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 04:35:38 ID:YbyWNvCs
�����c�Y��
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
sampling "it" to developers���w�����̂͂��������A
"Larrabee first silicon"�ł͂Ȃ�"Larrabee"�Ȃ�Ȃ��̂��H
"First silicon of Larrabee �`"�Ȃ�܂�������ǂȁB
����ς�Mac�I�^�͔]���X�ɃE���R�l�܂��Ă邩��p�ꂪ�ǂ߂Ȃ��ȁB
so fool.
> �gLarrabee first silicon should be late this year in terms of samples
> and we�fll start playing with it and sampling it to developers and I
> still think we are on track for a product in late �f09, 2010 timeframe,�h
> said Paul Otellini, chief executive officer of Intel.
sampling "it" to developers���w�����̂͂��������A
"Larrabee first silicon"�ł͂Ȃ�"Larrabee"�Ȃ�Ȃ��̂��H
"First silicon of Larrabee �`"�Ȃ�܂�������ǂȁB
����ς�Mac�I�^�͔]���X�ɃE���R�l�܂��Ă邩��p�ꂪ�ǂ߂Ȃ��ȁB
so fool.
81 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 04:40:28 ID:YbyWNvCs
���p������w�ŏ���[�G���W�j�A�����O�T���v���p]�V���R���x�Ɠǂނׂ����ƁB
�ǂ����߂������ȓd�g�ȉ��߂ɂȂ������
�E���R�l�܂肷�������e���[������
�]�S�E�o���낗����
�ǂ����߂������ȓd�g�ȉ��߂ɂȂ������
�E���R�l�܂肷�������e���[������
�]�S�E�o���낗����
82 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 04:50:38 ID:YbyWNvCs
����ES���w���Ȃ炱���������낤��
Engineering sample of Larrabee, silicon should be late this year in terms of samples
(�ȉ���
��������"developer"���n�[�h�x���_�[���Ƃ͎v���ĂȂ��킯�����B
�������̋L����Demakasejan��"devs"���ĕ\�����Ă邯�ǁAdev��
��Ƀ\�t�g�E�F�A�̊J����(softwawe developer)�̂��Ƃ��w�����t�ł���
��������device�ł͂Ȃ�
Engineering sample of Larrabee, silicon should be late this year in terms of samples
(�ȉ���
��������"developer"���n�[�h�x���_�[���Ƃ͎v���ĂȂ��킯�����B
�������̋L����Demakasejan��"devs"���ĕ\�����Ă邯�ǁAdev��
��Ƀ\�t�g�E�F�A�̊J����(softwawe developer)�̂��Ƃ��w�����t�ł���
��������device�ł͂Ȃ�
83 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 05:12:06 ID:YbyWNvCs
Anton Shilov�̋L�����낢��ǂ�ł݂����ǁA
�������ƑS�ĉR���炯��Demakasejan�قǂɂ͓d�g�������Ȃ��B
�������ƑS�ĉR���炯��Demakasejan�قǂɂ͓d�g�������Ȃ��B
Intel�̊O�ɓn���錻�������݂���Ƃ͎v����Ȃ�
�_�C�S�̂̎d�l�܂��ł܂��ĂȂ�����
�_�C�S�̂̎d�l�܂��ł܂��ĂȂ�����
85 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 05:49:48 ID:YbyWNvCs
GDC�̃v���[�������̈ꕔ��Intel�����ɂ������Ă邼�B
�ǂ��ł������L�҂ǂ��̖ϑz�L���Ȃ�����ۂǓǂމ��l����l�^�����o����Ă�킯�����B
�ǂ��ł������L�҂ǂ��̖ϑz�L���Ȃ�����ۂǓǂމ��l����l�^�����o����Ă�킯�����B
�c�q�����p����4�s�ڂɋC�t���Ă��܂����悤�Ȃ̂ŁA���͖ʔ�������܂���B
�����������������Ǝv�����̂�>>73�̕����䖳���ɂ��Ă��܂����悤�Łc
�����������������Ǝv�����̂�>>73�̕����䖳���ɂ��Ă��܂����悤�Łc
87 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 07:20:32 ID:YbyWNvCs
���Ƃ����N�̃W�����v�Ɍf�ڂ��ꂽ�h���N�G�X�̔������Ő���オ��邩�H
���܂���̂���Ă�̂͂���ȉ��ŁA�uDQ5�ŃG�X�^�[�N�����ԂɂȂ�v���x���ȁB
������l�^�ł���ȑO�ɗ������ĂȂ��A�Ƃ������T���ĝs���B
MAC���^�̐M��f�}�j����͐̂��炱�����������ł���
> 801 �FSocket774[sage]�F2008/09/05(��) 04:37:50 ID:Kupns0iS
> �f�X�N�g�b�v�p��GPU�Ɋւ���L���������Ă�Charlie Demerjian�ēz��
> �L���ȓz�����u�F�l�ɂ��Ɓv�Ƃ��u���̍l���ł́v���ĂȖϑz�L���������z����
> �C�O�̃t�H�[�����T�C�g�ł͑���ɂ���Ȃ����x���̓z
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
�M�����ʂ��R�m�U�}����
http://www.theinquirer.net/inquirer/news/419/1030419/penryn-to-have-ht
http://www.theinquirer.net/inquirer/news/724/1002724/penryn-does-not-have-ht
By Charlie Demerjian
���܂���̂���Ă�̂͂���ȉ��ŁA�uDQ5�ŃG�X�^�[�N�����ԂɂȂ�v���x���ȁB
������l�^�ł���ȑO�ɗ������ĂȂ��A�Ƃ������T���ĝs���B
MAC���^�̐M��f�}�j����͐̂��炱�����������ł���
> 801 �FSocket774[sage]�F2008/09/05(��) 04:37:50 ID:Kupns0iS
> �f�X�N�g�b�v�p��GPU�Ɋւ���L���������Ă�Charlie Demerjian�ēz��
> �L���ȓz�����u�F�l�ɂ��Ɓv�Ƃ��u���̍l���ł́v���ĂȖϑz�L���������z����
> �C�O�̃t�H�[�����T�C�g�ł͑���ɂ���Ȃ����x���̓z
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
�M�����ʂ��R�m�U�}����
http://www.theinquirer.net/inquirer/news/419/1030419/penryn-to-have-ht
http://www.theinquirer.net/inquirer/news/724/1002724/penryn-does-not-have-ht
By Charlie Demerjian
88 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 07:23:32 ID:YbyWNvCs
�[��
�ŏ����猩�Ă邪�H��
�����Œ��������ƂȂ�債�ē��ĂɂȂ�Ȃ���B
�����ԈႢ�͑傢�ɂ��蓾�邵
�ŏ����猩�Ă邪�H��
�����Œ��������ƂȂ�債�ē��ĂɂȂ�Ȃ���B
�����ԈႢ�͑傢�ɂ��蓾�邵
89 �F,,�E�L�́M�E,,�j��-�������F2009/03/31(��) 07:25:41 ID:YbyWNvCs
�ނ���܊p�g�ݍ��݊��̃v���g�^�C�v�����J����Ă���琶�Y���̂��邱�Ƃ������H
90 �FMAC�I�^���c�q �����F2009/03/31(��) 07:52:48 ID:3FaCOFUY
>>88
�@�@--------------
�@�@�����ԈႢ�͑傢�ɂ��蓾�邵
�@�@--------------
���ꃋ�[�}�[���ȒP�ɐM����q�g���đf���ł���(��)
���͋^��[�����āc
http://www.google.com/search?q=Otellini+Larrabee+first-silicon
�@�@--------------
�@�@�����ԈႢ�͑傢�ɂ��蓾�邵
�@�@--------------
���ꃋ�[�}�[���ȒP�ɐM����q�g���đf���ł���(��)
���͋^��[�����āc
http://www.google.com/search?q=Otellini+Larrabee+first-silicon
Intel�͋��N�̒i�K�ł́A2010�N�����ς��܂�45nm���i����������\�肾������B
���N�ɓ����āA32nm�ւ̈ڍs�𑁂߂����ɁAHavendale�̓L�����Z���Ƃ����v��ɂȂ����B
32nm�ւ̋}�]���̗����Larrabee��45nm�ł��̂��̂��L�����Z�����ꂽ�\���������B
�V�������N���x���Ȃ�܂���������BItan(ry
���N�ɓ����āA32nm�ւ̈ڍs�𑁂߂����ɁAHavendale�̓L�����Z���Ƃ����v��ɂȂ����B
32nm�ւ̋}�]���̗����Larrabee��45nm�ł��̂��̂��L�����Z�����ꂽ�\���������B
�V�������N���x���Ȃ�܂���������BItan(ry
Itanium�͗\�Z�J�b�g�Œx�����܂��肾����E�E�E
Doug Carmean�݂����ȑ�䏊���Q�����Ă���Larrabee�`�[���͂�����t������Ă������B
Doug Carmean�݂����ȑ�䏊���Q�����Ă���Larrabee�`�[���͂�����t������Ă������B
Larrabee��NVIDIA��IP�����ƍ��Ȃ��Ȃ�炵����
�Ȃ�Ō�Pentium4�Ƃ���Itanium�Ƃ��̒n���g���������Ă��
����P�i��3D�Q�[���t�@���̂��߂�Intel�ELarrabee�u��
http://game.watch.impress.co.jp/docs/series/3dcg/20090330_80150.html
http://game.watch.impress.co.jp/docs/series/3dcg/20090330_80150.html
����3D�Q�[���̃����_�����O�̓p�t�H�[�}���X�Ⴍ�Ďg���Ȃ��āA����R���s���[�e�B���O�ɂ����g���Ȃ����Ď�����
������v���O�����̏��������K�{���Ă��ƂŁ����ꂪ������}���Z�[�������Ƃ���
Dx11����̃Q�[�������C�g���[�V���O�`�ʂɂȂ邱�Ƃ�nVIDIA����ԍŏ��ɗ\�����Ă邵�A��������z������ł�GPGPU�̓����Ȃ��
����R���s���[�e�B���O�ł�GPGPU�̂ق����R�X�p����ۂ���
Larrabee�͂ǂ����~�h�������W�Ƃ����[�G���h�����̃I���{������̔F�m�ɂȂ肻�������
������v���O�����̏��������K�{���Ă��ƂŁ����ꂪ������}���Z�[�������Ƃ���
Dx11����̃Q�[�������C�g���[�V���O�`�ʂɂȂ邱�Ƃ�nVIDIA����ԍŏ��ɗ\�����Ă邵�A��������z������ł�GPGPU�̓����Ȃ��
����R���s���[�e�B���O�ł�GPGPU�̂ق����R�X�p����ۂ���
Larrabee�͂ǂ����~�h�������W�Ƃ����[�G���h�����̃I���{������̔F�m�ɂȂ肻�������
�ŏI�I�Ƀ��j�[�R�A�̃~�j�R�A�Ƃ��ē������āAGPU�Ƃ��ē������Ȃ��Ƃ��͂�����x86�R�A�Ƃ���
���p������Ă���Ȃ�Ȃ��́H
���p������Ă���Ȃ�Ȃ��́H
�g���g��Ȃ����R�[�h�ɂ���ċɒ[�ɈႤFP���SSE������R�A���番������̂�
�ŏI�ڕW�Ȃ�ˁ[���Ǝv���Ă����B
�ŏI�ڕW�Ȃ�ˁ[���Ǝv���Ă����B
>>96
�܂��Ń��C�g���[�V���O����ʂ̃Q�[���ł��g����悤�ɂȂ�낤���H
��������d�͏グ���Ƀp�t�H�[�}���X�グ��́A���낻����E�Ȃ�Ȃ��́H
�����v���Z�X��11nm���炢�Ŏ~�܂���Ęb����Ȃ����������H
�܂��Ń��C�g���[�V���O����ʂ̃Q�[���ł��g����悤�ɂȂ�낤���H
��������d�͏グ���Ƀp�t�H�[�}���X�グ��́A���낻����E�Ȃ�Ȃ��́H
�����v���Z�X��11nm���炢�Ŏ~�܂���Ęb����Ȃ����������H
���Ȃ��Ƃ����[�U�[���̎��v�͂قƂ�ǂȂ����낤
�����_�ł�HD�@�͔��ꂸ�ɔC�V�����������Ă�n��
�����_�ł�HD�@�͔��ꂸ�ɔC�V�����������Ă�n��
���ǎ����Ƃ��̔����̂��������肽������������˂�
����Ⴛ����
��ʃ��[�U�ɂ�Đ��x�����`�b�v�Z�b�g+Atom or C7�ŏ\��
��ʃ��[�U�ɂ�Đ��x�����`�b�v�Z�b�g+Atom or C7�ŏ\��
���̓��[�U�[������ɋC�Â����鎖
�ڂ����Ƃ��Ă�ƃX�p�R���ƊE������Ȃ��Intel��
���N��1T��300w�œo�ꂾ�����H
�����ɋ�̓I�Ȑ��l���o�����Ƃ͖���
�ߋ���IBM�̃X���C�h�ɂ�90W��1200Gflops�Ƃ�����
�ߋ���IBM�̃X���C�h�ɂ�90W��1200Gflops�Ƃ�����
�������̎�ނ�o���h�����܂����܂��ĂȂ��̂��ق��Ă��邾����
108 �F,,�E�L�́M�E,,�j��-�������F2009/04/03(��) 02:19:17 ID:AmgSe0xb
>>105
���[��A�����Ƃ͓��g����B
�P���xFMA�~16����~16�R�A�~2GH����1024GFLOPS�����B
����300W�������Ƃ��Ă݁H
�P����16�Ŋ����Ă�1�R�A������16W�������B����Core 2�Ȃ݂̏���d�͂Ȃ��B
����������SIMD���Z���j�b�g���̂��̂͂���Ȃɏ���d�͍͂����Ȃ��B
���Ƃ��f�AAtom�̒P���x�����������Z�̍ő�X���[�v�b�g��
���N���b�N��Core 2�Ɠ����B
Atom��2GHz�E16�R�A�ŒP���v�Z��512GFLOPS�ɂȂ邪
2.5�`4W�A�P����16�{����40�`64W���x�����B
���Ȃ݂�Atom��128bit FADD+FMUL or �X�J��2������s
Larrabee��FMA�ɑΉ�����512bit SIMD���j�b�g�ɉ����Ĕ�Ώ̂̃X�J�����Z�����킹��
���v2����Ŏ��s�ł���̂݁B
�ǂ����ς����Ă�1�R�A������̏���d�͂�Atom�̔{�������낤�B
32nm�v���Z�X�Ő�������邱�Ƃ��l����Ƃ�����X�ɗ�����i�{�Œ�n�[�h�EVRAM�j
�������ς����Ă�16�R�A1TFLOPS��100W�z�����ǂ����̃��x���B
���[��A�����Ƃ͓��g����B
�P���xFMA�~16����~16�R�A�~2GH����1024GFLOPS�����B
����300W�������Ƃ��Ă݁H
�P����16�Ŋ����Ă�1�R�A������16W�������B����Core 2�Ȃ݂̏���d�͂Ȃ��B
����������SIMD���Z���j�b�g���̂��̂͂���Ȃɏ���d�͍͂����Ȃ��B
���Ƃ��f�AAtom�̒P���x�����������Z�̍ő�X���[�v�b�g��
���N���b�N��Core 2�Ɠ����B
Atom��2GHz�E16�R�A�ŒP���v�Z��512GFLOPS�ɂȂ邪
2.5�`4W�A�P����16�{����40�`64W���x�����B
���Ȃ݂�Atom��128bit FADD+FMUL or �X�J��2������s
Larrabee��FMA�ɑΉ�����512bit SIMD���j�b�g�ɉ����Ĕ�Ώ̂̃X�J�����Z�����킹��
���v2����Ŏ��s�ł���̂݁B
�ǂ����ς����Ă�1�R�A������̏���d�͂�Atom�̔{�������낤�B
32nm�v���Z�X�Ő�������邱�Ƃ��l����Ƃ�����X�ɗ�����i�{�Œ�n�[�h�EVRAM�j
�������ς����Ă�16�R�A1TFLOPS��100W�z�����ǂ����̃��x���B
109 �F,,�E�L�́M�E,,�j��-�������F2009/04/03(��) 02:21:15 ID:AmgSe0xb
> Atom��2GHz�E16�R�A�ŒP���v�Z��512GFLOPS�ɂȂ邪
������128GFLOPS�������B���܂�
������128GFLOPS�������B���܂�
110 �F,,�E�L�́M�E,,�j��-�������F2009/04/03(��) 02:27:21 ID:AmgSe0xb
���ꖔ�ԈႦ��
(4 FMUL + 4 FADD)�~2 �~16 = 256GFLOPS
�Q�������orz
(4 FMUL + 4 FADD)�~2 �~16 = 256GFLOPS
�Q�������orz
111 �F,,�E�L�́M�E,,�j��-�������F2009/04/03(��) 02:35:31 ID:AmgSe0xb
���ݎ���ktkr
2 FMUL + 4 FADD��192GFLOPS��FA
orz
2 FMUL + 4 FADD��192GFLOPS��FA
orz
GDC2009�̃X���C�h���������Ă�
http://software.intel.com/en-us/articles/intel-at-gdc/
http://software.intel.com/en-us/articles/intel-at-gdc/
Larrabee�P�̂���Ȃ���GDDR�₻�̑��̕��i���݂ŁA�O���{���̊g���J�[�h�̏�Ԃ�MAX300w���Ă��Ƃ��낤
X86�Ή��ŐF�X�ƗZ�ʂ������Ď��s���\�����̐��l�Ȃ璆�X�D�G����Ȃ����H
�Ƃ���ŁASIMD���j�b�g���d�͌������悢���͔���
�Ƃ͌����Ă��APowerPC G4�̐v�ŁA128bit��SIMD�̓��ڂ��ڂ���ꍇ
SIMD�t��500Mhz��SIMD����700Mhz����������d�͂Ƃ������ʂ�����
���ꂩ�����d�͂̔��P���Ɍv�Z�����
500Mhz�iSIMD���j�F500Mhz�iSIMD�L�j�F700Mhz�iSIMD���j�F700Mhz�iSIMD�L�j��1�F2�F2�F4
�d�͏���ȏ�Ƀs�[�N���\�͉҂��Ă͂��邩��d�͌����ł͗D�G
�Ƃ͌����Ă��A����Ȃ�ɂ͓d�C��
X86�Ή��ŐF�X�ƗZ�ʂ������Ď��s���\�����̐��l�Ȃ璆�X�D�G����Ȃ����H
�Ƃ���ŁASIMD���j�b�g���d�͌������悢���͔���
�Ƃ͌����Ă��APowerPC G4�̐v�ŁA128bit��SIMD�̓��ڂ��ڂ���ꍇ
SIMD�t��500Mhz��SIMD����700Mhz����������d�͂Ƃ������ʂ�����
���ꂩ�����d�͂̔��P���Ɍv�Z�����
500Mhz�iSIMD���j�F500Mhz�iSIMD�L�j�F700Mhz�iSIMD���j�F700Mhz�iSIMD�L�j��1�F2�F2�F4
�d�͏���ȏ�Ƀs�[�N���\�͉҂��Ă͂��邩��d�͌����ł͗D�G
�Ƃ͌����Ă��A����Ȃ�ɂ͓d�C��
2�s�ڂ́w���s���\���x�͂����̏����Y��
�P�̂�200W�͒����邾��
���ƂȂ�����
���ƂȂ�����
Intel���܂Ƃ��ɐ��\�Œ��荇�����Ƃ���̂Ȃ�n�C�G���h��200W�����Ă��邾�낤��
���������ꂾ���d�͏���č������\���������Ă���̂�����
���������ꂾ���d�͏���č������\���������Ă���̂�����
Ati��Q3��40n�ANvidia��Q4��40n�Ȃ̂�
Larrabee�͗��N��45n������
���������̎�������������
Larrabee�͗��N��45n������
���������̎�������������
�R�A������������������A�����v���Z�X�����炩�ɂȂ��Ă��Ȃ��̂����B
�܁A������2010�N�̌㔼�Ȃ�Tukwila���̃_�C�T�C�Y�ł��Ȃ�����32nm���낤���ǂˁB
�܁A������2010�N�̌㔼�Ȃ�Tukwila���̃_�C�T�C�Y�ł��Ȃ�����32nm���낤���ǂˁB
119 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 15:15:47 ID:Xs52YYB6
�㓡�������ɂ�XDR2����Ȃ��������H
���̂Ƃ���ő�ڋq�s�݂̃y�[�p�[�K�i�B
��������PS4���悩�B
���̂Ƃ���ő�ڋq�s�݂̃y�[�p�[�K�i�B
��������PS4���悩�B
PS4���ő�̌����W����
121 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 17:10:04 ID:Xs52YYB6
���A������
NVIDIA�Ƀv���b�V���[�����������邾���ł�Intel�Ƃ��Ă̓����b�g�͂���̂��낤���B
�܂��㓡��Larrabee��CPU��GPU�@�\�����鎞��ւ̒ʉߓ_���Ă��ƂɋC�Â��Ă�悤�����B
NVIDIA�Ƀv���b�V���[�����������邾���ł�Intel�Ƃ��Ă̓����b�g�͂���̂��낤���B
�܂��㓡��Larrabee��CPU��GPU�@�\�����鎞��ւ̒ʉߓ_���Ă��ƂɋC�Â��Ă�悤�����B
122 �FSocket774�F2009/04/04(�y) 18:39:14 ID:9i/m86yt
���܂łł���Core2Quad��5��Ƃ��q���ăG���R���Ă��H
����ȏ��ł���ӂ̃^�[�Q�b�g��
PCI-E�̌��E300W�H�g���Ă���Ɍ��܂��Ă邾��
����ȏ��ł���ӂ̃^�[�Q�b�g��
PCI-E�̌��E300W�H�g���Ă���Ɍ��܂��Ă邾��
123 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 18:48:03 ID:Xs52YYB6
�}�V��1�䂠����̃G���R�������グ��ɂ͂ǂ������Ƃ����Ɖ��Z���j�b�g��胁�����[���K�v�B
��ŁA���̂��߂ɂ̓��C����������GB���炢�g����悤��64�r�b�g�����i�܂Ȃ��Ƒʖڂ���B
��ŁAVista��64�r�b�g�Ɉڍs����ƌ��z���đ�ʐ��Y�����̂�
���܂��炪XP 32�r�b�g�ɗ��܂��Ă邩��DRAM���[�J�[���s���`�Ȃ��B
��ŁA���̂��߂ɂ̓��C����������GB���炢�g����悤��64�r�b�g�����i�܂Ȃ��Ƒʖڂ���B
��ŁAVista��64�r�b�g�Ɉڍs����ƌ��z���đ�ʐ��Y�����̂�
���܂��炪XP 32�r�b�g�ɗ��܂��Ă邩��DRAM���[�J�[���s���`�Ȃ��B
�����āA�v��Ȃ�����
125 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 19:38:26 ID:Xs52YYB6
�v��Ȃ��Ȃ�v��Ȃ��ŗǂ���B
Fixstars��Cell�Ń��A���^�C���G���R�������Ă����ǂ����GigaAccel 180��ł���Ă�B
�z�X�gOS����Ɨ��������������64�r�b�g��Linux�������Ă��̏�ŃG���R�[�_�������Ă�B
��������DDR2�f���A���`���l����4GB���x�B
�X��PCIe�����z�C�[�T�[�l�b�g�Ƃ��Ďg�����ƂŃz�X�g�Ƃ̍����ʐM���ł���iLinux�̏ꍇ�j
Larrabee�̃J�[�h���ɂ͂���ȂɃ������͐ς܂Ȃ��Ǝv������
�ǂ������Ƃ����ƃz�X�g���̃��������K�v���ȁB
Fixstars��Cell�Ń��A���^�C���G���R�������Ă����ǂ����GigaAccel 180��ł���Ă�B
�z�X�gOS����Ɨ��������������64�r�b�g��Linux�������Ă��̏�ŃG���R�[�_�������Ă�B
��������DDR2�f���A���`���l����4GB���x�B
�X��PCIe�����z�C�[�T�[�l�b�g�Ƃ��Ďg�����ƂŃz�X�g�Ƃ̍����ʐM���ł���iLinux�̏ꍇ�j
Larrabee�̃J�[�h���ɂ͂���ȂɃ������͐ς܂Ȃ��Ǝv������
�ǂ������Ƃ����ƃz�X�g���̃��������K�v���ȁB
�_���S�͐����Ƃ��̘b�̓_���݂��������疳���Ɍ��Ȃ��ėǂ�
DDJ��LRBni����L�����A�e���߂����ꂢ�ɐ}�����Ă��ĕ�����₷���������ƁB
http://www.ddj.com/hpc-high-performance-computing/216402188
http://www.ddj.com/hpc-high-performance-computing/216402188
128 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 20:44:19 ID:Xs52YYB6
���̎����Ă鎑���ɍڂ��Ă邵������
����肾��
����肾��
129 �F,,�E�L�́M�E,,�j��-�������F2009/04/04(�y) 21:21:23 ID:Xs52YYB6
http://www.rambus.com/jp/products/xdr2/xdr2_vs_gddr5.html
GDDR5��1Gbps������0.5W���H���ˁB
http://d.hatena.ne.jp/cjohn/20090301/1235902584
Radeon HD4870�̓������́u�]���v�����ōő�58W���炢�H���悤���B
������x�̗e�ʂ̃L���b�V��������A�^�C�������_�����O���邱�Ƃ�
����d�͂�}���邱�Ƃ��\����Ȃ����A�ƁB
�^�C���̓���ւ��̎��ɂ����������g���t�B�b�N�͔������Ȃ�����ˁB
GDDR5��1Gbps������0.5W���H���ˁB
http://d.hatena.ne.jp/cjohn/20090301/1235902584
Radeon HD4870�̓������́u�]���v�����ōő�58W���炢�H���悤���B
������x�̗e�ʂ̃L���b�V��������A�^�C�������_�����O���邱�Ƃ�
����d�͂�}���邱�Ƃ��\����Ȃ����A�ƁB
�^�C���̓���ւ��̎��ɂ����������g���t�B�b�N�͔������Ȃ�����ˁB
130 �F,,�E�L�́M�E,,�j��-�������F2009/04/05(��) 04:13:58 ID:Drqasbi/
GDC�̍u�����̂��̂̃r�f�I�͂���������ǂ���
http://software.intel.com/en-us/videos/gdc-session-overview-simd-programming-on-larrabee/
����L�҂̊��Ⴂ�ɉ�������ĂȂ����̏�����ł��܂���B
http://software.intel.com/en-us/videos/gdc-session-overview-simd-programming-on-larrabee/
����L�҂̊��Ⴂ�ɉ�������ĂȂ����̏�����ł��܂���B
131 �F,,�E�L�́M�E,,�j��-�������F2009/04/05(��) 04:40:50 ID:Drqasbi/
INTEL��NV�ɏ��i����Larrabee�J�����~��1���߿
NV��INTEL�ɏ��i���Ĕp��čs����2���߿
NV��INTEL�ɏ��i���Ĕp��čs����2���߿
���{�̃��[�J�����j�[�R�A�̃v���Z�b�T���J����������������Ȃ���
134 �FMAC�I�^���c�q �����F2009/04/05(��) 13:53:15 ID:rdFTsbY1
>>130
����u���̃r�f�I���Ⴀ��܂����(��)�@
http://software.intel.com/en-us/blogs/2009/04/03/videos-posted-from-gdc-more-coming/
�@�@------------------------
�@�@(full session video to be posted in one month - stay tuned)
�@�@------------------------
>>85��intel�̎������Љ�����肾�����悤�ł����A���ۂ�Larrabee�֘A�̃v���[�����A�b�v���[�h
���ꂽ�̂�>>112�̍��ł����B
�m�������U��͒p�������������Ɓc
����u���̃r�f�I���Ⴀ��܂����(��)�@
http://software.intel.com/en-us/blogs/2009/04/03/videos-posted-from-gdc-more-coming/
�@�@------------------------
�@�@(full session video to be posted in one month - stay tuned)
�@�@------------------------
>>85��intel�̎������Љ�����肾�����悤�ł����A���ۂ�Larrabee�֘A�̃v���[�����A�b�v���[�h
���ꂽ�̂�>>112�̍��ł����B
�m�������U��͒p�������������Ɓc
�@�@�@ �@ �@ �@ �@�@ �@�@__�]`'�L''"'�}�@�@�@�@�@�@�@�@�@�@____�_ �@�@�[�]�� �@�@ |��
�@ �@ �@ �@ �@�@ �@�@ �@ Z.�@�@�@ __�M�T �@�@�@�@�@�@�@ �@�_�@ �@�@�@�@ɁL�@ �@���k
�@�ȁ@�@�@ �@ �^|�@�@�@ޘ��l������g=��-�_�@�@�@�@�@�@�_ �@�@ �[�]�� �@ ,�^
/ �@ �Ɂ_�^ �@ |�@�@�@�@�ML,.��,� u }� Ɂ@�@ �_�@�@�@�@�@�@,>�@�@�@ɁL�@�@�@�_
�@�@�@�@�@�@�@�@�@|_�Q�@�@�@�@�Y.!_�^�^ i | �@ �@ l�A �@ �@ ��.�@�@�@�[�]���@�|�
�[�]���@�|��R�R�@/�@�@u'�@�_�R�]'�L�@�@!|�@ �@�@ Ĥ�@ �@�@ �_ �@�@,ɁL�@ �P���m
�@ɁL�@ �@Ɂ@���@�@/_____, �@}j �@�n� �@�R �R,�Q�Q_/�@�@�@�@�^ �@�[�]���@ ���]�R�R
�[�]���@ �j|�j. �@ �@ �^�@___�m�@�^�__,��/ u �l.�@�@�@�^ �@�@�@ ,ɁL�@�@ Ɂ@��
�@ɁL�@�@ ���k�@�@�@���@�@{��r݁L�@ ,��..�^ �^�@�R�R �@ �_�@�@�@�@|�b�@�@�j|�j
�[�]���@�@|�@�@�@�@ �^�@�@ �P �@ �m{��,�@�^,�V�@ �@!|�@�@�@ �_ �@�@��E�@�@ ���k
�@ɁL�@�@�@l.__�m�@�@ �_�@ �@�@�@,.��@!l�MT�L | / �@ �@ |:|�@ �@�@�@/�@�@�@�@�@�@ |
�[�]���@�[�];:�]�@�@�@�@�_ �@�@// �@ �@l�@ |�@�@�@ �@|_|�@�@�@��.�A�@�@�@�@ �@ l.__�m
�@ɁL�@�@�@�i�Q,�@�@ �@ �^ �@�@�_�[--��Q|��____,�mj���@�@�@ /�@�@�@ �@ �@ ���]
�[�]�� �@ �^ �@ �@ �^�@�@�@�@ �_�P�_�[`�g�-���@�@�@�@�^ �@ �@ �@ �@�@ Ɂ@��
�@ɁL�@�@�@�_ �@ �@ �_�@�@�@�@�@�@�_�@ �R�@ �_�@�@�R�@�@�@�P�P|
�@| |�@�@�@�z.___�@�@�@�@>�@�@�@�@�@�@ �_. �R.�@�@�R �@ ���@�@�@�@ �@|�^l �@ �^|�@�@�ȁ@ /�_
�@��E�@�@ /|�@�i_,�@�@�^ �@�@ �@�@�@ �@�@ �j�@l�R�@�@ ',�@ l�A�@�@�@�@�@�@|�^ �@ |�@/ �@ �u
�@�@ �@ �@ ���]�@�@�@�_�@�@�@�@�@�@ , �C�_,��ʁ@�@ } �@���@�@�@�@�@�@�@�@�@ |/
�@�@�@�@ �@Ɂ@���@�@ �@ �_ �@�@ �@(����='''"�L�@,��,__�m/
�@�@�@ �@�@���]�R�@�@�@ �^ �@�@�@�@�@�@�@�@�@�@�щ�i�/
�@�@�@ �@�@� ���g�@�@�� �@�@ �@�@�@ �@�@�@ �@�@ �M�N�N�N�L
�@ �@ �@�@ �@ �@ �@�@ �@ �_
�@ �@ �@ �@ �@�@ �@�@ �@ Z.�@�@�@ __�M�T �@�@�@�@�@�@�@ �@�_�@ �@�@�@�@ɁL�@ �@���k
�@�ȁ@�@�@ �@ �^|�@�@�@ޘ��l������g=��-�_�@�@�@�@�@�@�_ �@�@ �[�]�� �@ ,�^
/ �@ �Ɂ_�^ �@ |�@�@�@�@�ML,.��,� u }� Ɂ@�@ �_�@�@�@�@�@�@,>�@�@�@ɁL�@�@�@�_
�@�@�@�@�@�@�@�@�@|_�Q�@�@�@�@�Y.!_�^�^ i | �@ �@ l�A �@ �@ ��.�@�@�@�[�]���@�|�
�[�]���@�|��R�R�@/�@�@u'�@�_�R�]'�L�@�@!|�@ �@�@ Ĥ�@ �@�@ �_ �@�@,ɁL�@ �P���m
�@ɁL�@ �@Ɂ@���@�@/_____, �@}j �@�n� �@�R �R,�Q�Q_/�@�@�@�@�^ �@�[�]���@ ���]�R�R
�[�]���@ �j|�j. �@ �@ �^�@___�m�@�^�__,��/ u �l.�@�@�@�^ �@�@�@ ,ɁL�@�@ Ɂ@��
�@ɁL�@�@ ���k�@�@�@���@�@{��r݁L�@ ,��..�^ �^�@�R�R �@ �_�@�@�@�@|�b�@�@�j|�j
�[�]���@�@|�@�@�@�@ �^�@�@ �P �@ �m{��,�@�^,�V�@ �@!|�@�@�@ �_ �@�@��E�@�@ ���k
�@ɁL�@�@�@l.__�m�@�@ �_�@ �@�@�@,.��@!l�MT�L | / �@ �@ |:|�@ �@�@�@/�@�@�@�@�@�@ |
�[�]���@�[�];:�]�@�@�@�@�_ �@�@// �@ �@l�@ |�@�@�@ �@|_|�@�@�@��.�A�@�@�@�@ �@ l.__�m
�@ɁL�@�@�@�i�Q,�@�@ �@ �^ �@�@�_�[--��Q|��____,�mj���@�@�@ /�@�@�@ �@ �@ ���]
�[�]�� �@ �^ �@ �@ �^�@�@�@�@ �_�P�_�[`�g�-���@�@�@�@�^ �@ �@ �@ �@�@ Ɂ@��
�@ɁL�@�@�@�_ �@ �@ �_�@�@�@�@�@�@�_�@ �R�@ �_�@�@�R�@�@�@�P�P|
�@| |�@�@�@�z.___�@�@�@�@>�@�@�@�@�@�@ �_. �R.�@�@�R �@ ���@�@�@�@ �@|�^l �@ �^|�@�@�ȁ@ /�_
�@��E�@�@ /|�@�i_,�@�@�^ �@�@ �@�@�@ �@�@ �j�@l�R�@�@ ',�@ l�A�@�@�@�@�@�@|�^ �@ |�@/ �@ �u
�@�@ �@ �@ ���]�@�@�@�_�@�@�@�@�@�@ , �C�_,��ʁ@�@ } �@���@�@�@�@�@�@�@�@�@ |/
�@�@�@�@ �@Ɂ@���@�@ �@ �_ �@�@ �@(����='''"�L�@,��,__�m/
�@�@�@ �@�@���]�R�@�@�@ �^ �@�@�@�@�@�@�@�@�@�@�щ�i�/
�@�@�@ �@�@� ���g�@�@�� �@�@ �@�@�@ �@�@�@ �@�@ �M�N�N�N�L
�@ �@ �@�@ �@ �@ �@�@ �@ �_
136 �F,,�E�L�́M�E,,�j��-�������F2009/04/05(��) 19:04:25 ID:Drqasbi/
>>133
��[DAPDNA]
�����K�́E�ᐫ�\�̃v���Z�b�T�G�������g�I�ɍč\�����ĉ�H���\������B
PE�͒P�̂ʼn��Z���j�b�g�E�������E�l�b�g���[�N�@�\�����B
�����_�ł����Ƃ��j���[�����l�b�g�ɋ߂��n�[�h��������Ȃ��B
http://www.ipflex.com/jp/1-products/3_dd2_arch.html
��[DAPDNA]
�����K�́E�ᐫ�\�̃v���Z�b�T�G�������g�I�ɍč\�����ĉ�H���\������B
PE�͒P�̂ʼn��Z���j�b�g�E�������E�l�b�g���[�N�@�\�����B
�����_�ł����Ƃ��j���[�����l�b�g�ɋ߂��n�[�h��������Ȃ��B
http://www.ipflex.com/jp/1-products/3_dd2_arch.html
137 �F,,�E�L�́M�E,,�j��-�������F2009/04/05(��) 19:12:05 ID:Drqasbi/
MAC���^�͉p�ꂪ�������Ȃ��������킢�����Ȏq�����Ă��Ƃ��킩����
138 �F,,�E�L�́M�E,,�j��-�������F2009/04/06(��) 02:49:55 ID:gOw9+ozd
512�r�b�g�x�N�g���ɑ���S�Ă�load/store����ɂ�non-temporal��t���邱�Ƃ��ł���B
scatter/gather��swizzle���܂߁B
scatter/gather��swizzle���܂߁B
�^�C���ɂ�������Larrabee���x�̃L���b�V������SD�𑜓x���炢�ł������ɂ��������
�ǂ����̃X���ŋ����Ă�����낤���A�n���c�q�B
�������グ��̂̓������ʂ���Ȃ��ē]���ш悾���B
�l�R�̊z�قǂ̍L�������Ȃ��L���b�V���Ȃ�Ĉ�u�Ŏg�����āA���Ǔ]�����x�����ɂȂ�B
�{���Ȃ�Read�o�X2�{+Write�o�X��3�n���ق����Ƃ��낾�B
�ǂ����̃X���ŋ����Ă�����낤���A�n���c�q�B
�������グ��̂̓������ʂ���Ȃ��ē]���ш悾���B
�l�R�̊z�قǂ̍L�������Ȃ��L���b�V���Ȃ�Ĉ�u�Ŏg�����āA���Ǔ]�����x�����ɂȂ�B
�{���Ȃ�Read�o�X2�{+Write�o�X��3�n���ق����Ƃ��낾�B
140 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 03:11:59 ID:iiFWVgMc
�����烍�[�e�[�V��������́B
�e�^�C���ɑ��ăL���b�V�������T�C�N�������蓖�Ă���Ă��ƂɈӖ�������B
���蓖�đ�����킯�ł͂Ȃ����A�݃T�C�N���P�ʂŃC���^�[���[�u����킯�ł��Ȃ�
���낱��C���^�[���[�u����]��GPU�Ƃ̈Ⴂ�B
�����܂Ƃ��ɓǂ�łȂ�����B
L2������ͷ�����ł����Ľ�ׯ��߯����ł͂Ȃ���
�e�^�C���ɑ��ăL���b�V�������T�C�N�������蓖�Ă���Ă��ƂɈӖ�������B
���蓖�đ�����킯�ł͂Ȃ����A�݃T�C�N���P�ʂŃC���^�[���[�u����킯�ł��Ȃ�
���낱��C���^�[���[�u����]��GPU�Ƃ̈Ⴂ�B
�����܂Ƃ��ɓǂ�łȂ�����B
L2������ͷ�����ł����Ľ�ׯ��߯����ł͂Ȃ���
141 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 04:39:23 ID:iiFWVgMc
�܂��A60fps�ʼn�ʏ�������̂ɉ���^�C�������ւ���������l���Ă݂�����B
�s�N�Z���P�ʂœǂ�ł͏����߂�����GPU�͖��ʂȃf�[�^�t���[�����������B
����GPU���āA�ǂɃy���L��h��̂ɕ����̒��S�ɂ���y���L�̓������o�P�c��
�ړ������ɁA���тɏ��ʂ̃y���L����܂��邽�߂Ƀo�P�c�܂ʼn����������Ă�悤�ȏ�Ԃ���B
�h��ʂɉ����ăo�P�c���ړ���������Ƃ����u���C�N�X���[����낤�Ƃ��Ă�̂�Intel�B
�����āu�o�P�c�������ĕ����̂͏d�����I�ȁv�A�z�Ȍ����|���肪>>139
�s�N�Z���P�ʂœǂ�ł͏����߂�����GPU�͖��ʂȃf�[�^�t���[�����������B
����GPU���āA�ǂɃy���L��h��̂ɕ����̒��S�ɂ���y���L�̓������o�P�c��
�ړ������ɁA���тɏ��ʂ̃y���L����܂��邽�߂Ƀo�P�c�܂ʼn����������Ă�悤�ȏ�Ԃ���B
�h��ʂɉ����ăo�P�c���ړ���������Ƃ����u���C�N�X���[����낤�Ƃ��Ă�̂�Intel�B
�����āu�o�P�c�������ĕ����̂͏d�����I�ȁv�A�z�Ȍ����|���肪>>139
���������{�̌��ɖ݂͖݉��Ƃ����̂�����킯��
143 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 07:03:35 ID:iiFWVgMc
�������B���E�ʼnߔ�����GPU�V�F�A�������Ă���̂�Intel�ł��B
Larrabee��
�l�n�����ƃ����r�̃L���b�V���\�����Ď��Ă��ˁA�Ȃ�ƂȂ�
�l�n������SMT����4�X���b�h��LRBni�lj����āA
�l�n����1�R�A4GHz�{�����r15�R�A2GHz�{4MBL3�̘_���R�A64��CPU�Ƃ��ł������
�l�n������SMT����4�X���b�h��LRBni�lj����āA
�l�n����1�R�A4GHz�{�����r15�R�A2GHz�{4MBL3�̘_���R�A64��CPU�Ƃ��ł������
�^�C�������_���̂�360��CoD4�Ȃł��t���[�����[�g�҂����߂�eDRAM����g���Ă���Ă邪��
�d�̖͂������邵���C��VRAM�̑ш�𑝂₷�����̊g���͌������Ȃ���Ȃ��B
�d�̖͂������邵���C��VRAM�̑ш�𑝂₷�����̊g���͌������Ȃ���Ȃ��B
DirectX�̃����_�����O�p�C�v���C����������3D�`��Ɉˑ�������
�o�[�W���������łނ���API�̎��R�x���S�\���Ɓu�����Ȃ��Ɓv���������Ă�
�o�[�W���������łނ���API�̎��R�x���S�\���Ɓu�����Ȃ��Ɓv���������Ă�
>>141
�Ђǂ����Ⴂ������悤�����ALarrabee�Ƀu���C�N�X���[�Ȃ�Ė�����B
����GPU�ɔ�r���Ėڗ��v�f�͂Ȃɂ��Ȃ��B>>147�̌������R�x�͂����邯�ǁB
�c�q���咣����^�C�����̃��[�e�[�V�������̃L���b�V�����̂͊��Ɏ�������Ă�B
�y���L�̘b��ɏ�������Ă��Ȃ�A500ml�̃o�P�c��20���炢�p�ӂ��āu�����ǂ�Ɨ����I�v��
����ł�̂�Larrabee�B�o�P�c�ɂ̓y���L�ȊO�Ƀj�X��������邺�A���\����I�H���Ċ����B
�o�P�c�Ƀy���L���c���Ă��邤���͑��̐l�ƃo�P�c��������������̂ňꌩ�������悳������
�����邯�ǁA����������ƕǂ�20���Ĉʂ̍L����������30�F�g�����Ƃ��v�����ꂽ�B
����Ȃ��F���o��̂Œ��g�������Ƀ��`���`�����̎q�������g���ɂł�B
�o�P�c�̗e�ʂ�����Ȃ��������ς肨�g���ɉ��x������B
���F�g����̂͌������̉�����h����x�ł������ăI�`�B
�Ђǂ����Ⴂ������悤�����ALarrabee�Ƀu���C�N�X���[�Ȃ�Ė�����B
����GPU�ɔ�r���Ėڗ��v�f�͂Ȃɂ��Ȃ��B>>147�̌������R�x�͂����邯�ǁB
�c�q���咣����^�C�����̃��[�e�[�V�������̃L���b�V�����̂͊��Ɏ�������Ă�B
�y���L�̘b��ɏ�������Ă��Ȃ�A500ml�̃o�P�c��20���炢�p�ӂ��āu�����ǂ�Ɨ����I�v��
����ł�̂�Larrabee�B�o�P�c�ɂ̓y���L�ȊO�Ƀj�X��������邺�A���\����I�H���Ċ����B
�o�P�c�Ƀy���L���c���Ă��邤���͑��̐l�ƃo�P�c��������������̂ňꌩ�������悳������
�����邯�ǁA����������ƕǂ�20���Ĉʂ̍L����������30�F�g�����Ƃ��v�����ꂽ�B
����Ȃ��F���o��̂Œ��g�������Ƀ��`���`�����̎q�������g���ɂł�B
�o�P�c�̗e�ʂ�����Ȃ��������ς肨�g���ɉ��x������B
���F�g����̂͌������̉�����h����x�ł������ăI�`�B
3D�������f�[�^��
�@�E�W�I���g���i�`��)�f�[�^�B�����P�ʂ̒��_�A�e�N�X�`�����W�A�J���[���ȂǁB
�@�E�V�F�[�f�B���O�i�A�e�j�f�[�^�B�s�N�Z�����̉��Z�����B���C�g���������B
�@�E�t���[���o�b�t�@��e�N�X�`���f�[�^�A�A���t�@�l�Ȃǂ̃C���[�W�f�[�^�B
���C�g���ł�Z-Buffer�ł������͕ς�炸�K�v�ȃf�[�^�����A���ꂪ�ǂꂾ���̗ʂɂȂ邩�l��������B
����GPU�ł͂���珈�����ƂɁi�����I�ɂ́j�ʂ̑�����p�ӂ��Ă���B
NV��ATI�̃X�g���[���v���Z�b�T�����ɒu�����L���b�V����Larrabee�̂��̂Ɠ��l�ɋ��L������A
ATI�̏ꍇ�͕ʂ�SP�A���C�Ƃ̋��L�p�L���b�V�����u�����B
�������C���^�[�t�F�C�X�̓s�N�Z���I�y���[�V�����ł̃^�C�������ɕ�����4�Ȃ���8���x�������Ēu����A
������ꂼ��ɃL���b�V�����������B
Larrabee��Intel���������������ɔ��\���Ă�����e�́AIntel�ɂƂ��ĉ���I�Ȃ�����
�u�����ē��R�v�u�Ȃɂ����X�v�̓��e�ł����Ȃ��B
�@�E�W�I���g���i�`��)�f�[�^�B�����P�ʂ̒��_�A�e�N�X�`�����W�A�J���[���ȂǁB
�@�E�V�F�[�f�B���O�i�A�e�j�f�[�^�B�s�N�Z�����̉��Z�����B���C�g���������B
�@�E�t���[���o�b�t�@��e�N�X�`���f�[�^�A�A���t�@�l�Ȃǂ̃C���[�W�f�[�^�B
���C�g���ł�Z-Buffer�ł������͕ς�炸�K�v�ȃf�[�^�����A���ꂪ�ǂꂾ���̗ʂɂȂ邩�l��������B
����GPU�ł͂���珈�����ƂɁi�����I�ɂ́j�ʂ̑�����p�ӂ��Ă���B
NV��ATI�̃X�g���[���v���Z�b�T�����ɒu�����L���b�V����Larrabee�̂��̂Ɠ��l�ɋ��L������A
ATI�̏ꍇ�͕ʂ�SP�A���C�Ƃ̋��L�p�L���b�V�����u�����B
�������C���^�[�t�F�C�X�̓s�N�Z���I�y���[�V�����ł̃^�C�������ɕ�����4�Ȃ���8���x�������Ēu����A
������ꂼ��ɃL���b�V�����������B
Larrabee��Intel���������������ɔ��\���Ă�����e�́AIntel�ɂƂ��ĉ���I�Ȃ�����
�u�����ē��R�v�u�Ȃɂ����X�v�̓��e�ł����Ȃ��B
�����F�g����̂͌������̉�����h����x�ł������ăI�`�B
SD���x�̉掿�Ȃ�ŋ����Ă��Ƃ�
SD���x�̉掿�Ȃ�ŋ����Ă��Ƃ�
>>150
SD���x�̉掿�Ȃ�ő�����Ȃ��Ƃ��Ă��A
UnifiedShader�Ȃɔ�ׂėy���ɍ������R�x�ƁAx86�n�v���O���}�̏n���x���Ă������݂���
�ŋ��ɂ͂Ȃ�邩���B
����d�͂���W���x�ɗ}������Ȃ�A
Windows7�������X�}�[�g�t�H���p�v���b�g�z�[���Ƃ���Qualcomm��MSM7xxxx���쒀�ł��邩���H��
SD���x�̉掿�Ȃ�ő�����Ȃ��Ƃ��Ă��A
UnifiedShader�Ȃɔ�ׂėy���ɍ������R�x�ƁAx86�n�v���O���}�̏n���x���Ă������݂���
�ŋ��ɂ͂Ȃ�邩���B
����d�͂���W���x�ɗ}������Ȃ�A
Windows7�������X�}�[�g�t�H���p�v���b�g�z�[���Ƃ���Qualcomm��MSM7xxxx���쒀�ł��邩���H��
�ŁALarrabee�̃������ш�̃\�[�X�͂ǂ��H
����͏ڂ����c�q�������Ă����Ȃ��H
Larrabee�̃L���b�V���Ɍ��z�����Ă�c�q�ɑ��A
> Larrabee���x�̃L���b�V������SD�𑜓x���炢�ł������ɂ�������
�[�̂����̎咣�����B
Larrabee�̃L���b�V���Ɍ��z�����Ă�c�q�ɑ��A
> Larrabee���x�̃L���b�V������SD�𑜓x���炢�ł������ɂ�������
�[�̂����̎咣�����B
>>148-149
�^�C�������_�́AZ�o�b�t�@��RW�����S�ɃI���`�b�v�L���b�V���ōs���� �� �ш�P�`���
����ɁA�������|�����������O��Z�o�b�t�@�������ăe�N�Z���Q�Ƃ����1�s�N�Z���ɂ�1��Ɍ��� �� �ш�P�`���
�����64*64�^�C�����x�̓K�ȒP�ʂŎ�������ɂ́A������x�̃I���`�b�v�L���b�V���̑傫�����K�v�ɂȂ��Ă���
�^�C�������_�́AZ�o�b�t�@��RW�����S�ɃI���`�b�v�L���b�V���ōs���� �� �ш�P�`���
����ɁA�������|�����������O��Z�o�b�t�@�������ăe�N�Z���Q�Ƃ����1�s�N�Z���ɂ�1��Ɍ��� �� �ш�P�`���
�����64*64�^�C�����x�̓K�ȒP�ʂŎ�������ɂ́A������x�̃I���`�b�v�L���b�V���̑傫�����K�v�ɂȂ��Ă���
>>153
�ł�Intel�͉𑜓x�������Ȃ�قǃL���b�V���ɂ���ă������ւ�
�A�N�Z�X�����炷���Ƃ��o����ƌ����Ă����͂�
�L���b�V���̓q�b�g��100%����Ȃ��ƈӖ������̂�? ��������?
�ł�Intel�͉𑜓x�������Ȃ�قǃL���b�V���ɂ���ă������ւ�
�A�N�Z�X�����炷���Ƃ��o����ƌ����Ă����͂�
�L���b�V���̓q�b�g��100%����Ȃ��ƈӖ������̂�? ��������?
>>154
�܂�Z-Buffer�@�̏ꍇ�B
�I�u�W�F�N�g�͂���O���[�v�P�ʂɐ蕪���邱�Ƃ��\�����炱��͏�����������悢�B
���C�g���[�V���O�Ɣ�r���đ�ʂ̃I�u�W�F�N�g���ł����Ȃ��L���b�V���ł��܂�����B
���������̃I�u�W�F�N�g���ǂ̃t���[���̈���߂邩�͊��S�Ƀ����_���ł���A
Z-buffer�@�̐��i��ABGRA����Z-Buffer���͕p�ɂɓǂݍ���-��r-�����o�����s����B
�^�C�����ŏ�������ꍇ�͂�������ăL���b�V���ɕێ����邱�ƂɂȂ邪�A
�K�v�ȃL���b�V���ʂ��ǂ̂��炢�ɂȂ邩�͊ȒP�Ɍv�Z�ł���ł���B
> �𑜓x�̘b�Ȃ�ASD�ōŋ��Ȃ̂��U���ς߂g�c�܂ł�������Ă��Ƃ���B
�܂��v�����SLI����CrossFire�����Ă��Ƃ��ˁB
���C�g���[�V���O�̏ꍇ�B
�s�N�Z�����ɒ��ڂ��邽�߃t���[���̈�͈ꕔ���L���b�V���ɏ���Ă�������B
���̓_��Z-Buffer���ɔ�ׁA�����𑜓x�ł��K�v�ȃL���b�V���ʂ͏������Ă悭�Ȃ�B
����ŁA���C�g���[�V���O�̏ꍇ�����ƌ�������I�u�W�F�N�g��S�Č�������K�v������B
�I�u�W�F�N�g�̍\���v�f�͍Œ�ł� X,Y,Z���W�Ɠ��ߗ��A���˗��A���ܗ��A������ RGB�B
�ꍇ�ɂ���Ă̓e�N�X�`�����W�iU,V)���K�v�B1�g���C�A���O��������72�`132�o�C�g�B
�S�ẴR�A�ł��̃f�[�^�͋��L�\�Ȃ���Larrabee�̏ꍇL2�Ƀh�J���Ƃ̂��Ă����������ǁA
���ڂł���f�[�^�ʂɑ��I�u�W�F�N�g�����ǂ̒��x�ɂȂ��Ă��܂����͊ȒP�ɑz�����ł���B
SD�𑜓x�Ȃ琔��|���S���ōς܂����邯�ǁA�𑜓x�����Ȃ��Ă����炻��Ȃ�ɕ������Ȃ���
�r�����ڗ��B
�����ɉ����ĕ�����Texture�C���[�W������FSAA�p�̍������s���A
����ɃC���X�g���N�V�����p�ɃL���b�V����Ȃ��Ƃ����Ȃ��B
�܂�Z-Buffer�@�̏ꍇ�B
�I�u�W�F�N�g�͂���O���[�v�P�ʂɐ蕪���邱�Ƃ��\�����炱��͏�����������悢�B
���C�g���[�V���O�Ɣ�r���đ�ʂ̃I�u�W�F�N�g���ł����Ȃ��L���b�V���ł��܂�����B
���������̃I�u�W�F�N�g���ǂ̃t���[���̈���߂邩�͊��S�Ƀ����_���ł���A
Z-buffer�@�̐��i��ABGRA����Z-Buffer���͕p�ɂɓǂݍ���-��r-�����o�����s����B
�^�C�����ŏ�������ꍇ�͂�������ăL���b�V���ɕێ����邱�ƂɂȂ邪�A
�K�v�ȃL���b�V���ʂ��ǂ̂��炢�ɂȂ邩�͊ȒP�Ɍv�Z�ł���ł���B
> �𑜓x�̘b�Ȃ�ASD�ōŋ��Ȃ̂��U���ς߂g�c�܂ł�������Ă��Ƃ���B
�܂��v�����SLI����CrossFire�����Ă��Ƃ��ˁB
���C�g���[�V���O�̏ꍇ�B
�s�N�Z�����ɒ��ڂ��邽�߃t���[���̈�͈ꕔ���L���b�V���ɏ���Ă�������B
���̓_��Z-Buffer���ɔ�ׁA�����𑜓x�ł��K�v�ȃL���b�V���ʂ͏������Ă悭�Ȃ�B
����ŁA���C�g���[�V���O�̏ꍇ�����ƌ�������I�u�W�F�N�g��S�Č�������K�v������B
�I�u�W�F�N�g�̍\���v�f�͍Œ�ł� X,Y,Z���W�Ɠ��ߗ��A���˗��A���ܗ��A������ RGB�B
�ꍇ�ɂ���Ă̓e�N�X�`�����W�iU,V)���K�v�B1�g���C�A���O��������72�`132�o�C�g�B
�S�ẴR�A�ł��̃f�[�^�͋��L�\�Ȃ���Larrabee�̏ꍇL2�Ƀh�J���Ƃ̂��Ă����������ǁA
���ڂł���f�[�^�ʂɑ��I�u�W�F�N�g�����ǂ̒��x�ɂȂ��Ă��܂����͊ȒP�ɑz�����ł���B
SD�𑜓x�Ȃ琔��|���S���ōς܂����邯�ǁA�𑜓x�����Ȃ��Ă����炻��Ȃ�ɕ������Ȃ���
�r�����ڗ��B
�����ɉ����ĕ�����Texture�C���[�W������FSAA�p�̍������s���A
����ɃC���X�g���N�V�����p�ɃL���b�V����Ȃ��Ƃ����Ȃ��B
��BGRA����Z-Buffer���͕p�ɂɓǂݍ���-��r-�����o�����s����
��������S�ɃI���`�b�v�L���b�V���ŏ������A1/60�b��1���ŏI�\�����ʂ�VRAM�ɏ����o���̂��^�C�������_
������GPU�̓L���b�V�������Ă�Ƃ͌����A1�|���`�斈��VRAM�Ƀt���b�V�����ɂႢ����悤�Ȃ���
��������S�ɃI���`�b�v�L���b�V���ŏ������A1/60�b��1���ŏI�\�����ʂ�VRAM�ɏ����o���̂��^�C�������_
������GPU�̓L���b�V�������Ă�Ƃ͌����A1�|���`�斈��VRAM�Ƀt���b�V�����ɂႢ����悤�Ȃ���
>>155
> �����64*64�^�C�����x�̓K�ȒP�ʂŎ�������ɂ́A������x�̃I���`�b�v�L���b�V���̑傫�����K�v�ɂȂ��Ă���
�����������ƁB
���Ƃ���24�̈������ 64x64�T�C�Y�̃^�C����\�������ꍇ�A
�����Ɉ�����t���[���̈��512x192���x�ł����Ȃ��B
>>156
> �ł�Intel�͉𑜓x�������Ȃ�قǃL���b�V���ɂ���ă������ւ�
> �A�N�Z�X�����炷���Ƃ��o����ƌ����Ă����͂�
�C���e���͂����������������Ń|�J���s���B�������͕������Ă����x���B
��ʂ̃I�u�W�F�N�g���X�J�X�J�̋�Ԓ���������忂��Ă邾���Ȃ�A�u���ϓI�Ɍ����ꍇ�v�������B
����A��ʂ̃I�u�W�F�N�g�����Ֆ�����ԂɎU����Ă����ꍇ�A�S�Ă̗̈��
�A�N�Z�X���U���I�ɔ�������B�܂����Ȃ��I�u�W�F�N�g�ł���ʂ����ς���
�h�A�b�v�ŕ\�������悤�ȏꍇ�A�S�Ă̗̈�ɘA�������A�N�Z�X����������B
�����̏ꍇ�A�L���b�V���̓���ւ���Ƃ��p�ɂɔ������͂��߂�B
���ʂǂ��������Ƃ������邩�Ƃ����ƁA�s�[�N���\�͍����Ă�����������ŋɒ[�ɐ��\��������A
�܂�t���[�����[�g�������Ȃ�ቺ����Ƃ�������������B�v����ɁA�u��������vGPU�̒a���B
> �����64*64�^�C�����x�̓K�ȒP�ʂŎ�������ɂ́A������x�̃I���`�b�v�L���b�V���̑傫�����K�v�ɂȂ��Ă���
�����������ƁB
���Ƃ���24�̈������ 64x64�T�C�Y�̃^�C����\�������ꍇ�A
�����Ɉ�����t���[���̈��512x192���x�ł����Ȃ��B
>>156
> �ł�Intel�͉𑜓x�������Ȃ�قǃL���b�V���ɂ���ă������ւ�
> �A�N�Z�X�����炷���Ƃ��o����ƌ����Ă����͂�
�C���e���͂����������������Ń|�J���s���B�������͕������Ă����x���B
��ʂ̃I�u�W�F�N�g���X�J�X�J�̋�Ԓ���������忂��Ă邾���Ȃ�A�u���ϓI�Ɍ����ꍇ�v�������B
����A��ʂ̃I�u�W�F�N�g�����Ֆ�����ԂɎU����Ă����ꍇ�A�S�Ă̗̈��
�A�N�Z�X���U���I�ɔ�������B�܂����Ȃ��I�u�W�F�N�g�ł���ʂ����ς���
�h�A�b�v�ŕ\�������悤�ȏꍇ�A�S�Ă̗̈�ɘA�������A�N�Z�X����������B
�����̏ꍇ�A�L���b�V���̓���ւ���Ƃ��p�ɂɔ������͂��߂�B
���ʂǂ��������Ƃ������邩�Ƃ����ƁA�s�[�N���\�͍����Ă�����������ŋɒ[�ɐ��\��������A
�܂�t���[�����[�g�������Ȃ�ቺ����Ƃ�������������B�v����ɁA�u��������vGPU�̒a���B
>>159
���₢��c�^�C�������_�ł͊e�^�C���̏����́u�Ɨ��v���Ă��H
�����̏I������^�C���͎��̏����^�C���ɓ���ւ���Ηǂ������A1�^�C����1�R�A���蓖�ĂƂ��Ύ~
���₢��c�^�C�������_�ł͊e�^�C���̏����́u�Ɨ��v���Ă��H
�����̏I������^�C���͎��̏����^�C���ɓ���ւ���Ηǂ������A1�^�C����1�R�A���蓖�ĂƂ��Ύ~
> ������GPU�̓L���b�V�������Ă�Ƃ͌����A1�|���`�斈��VRAM�Ƀt���b�V�����ɂႢ����悤�Ȃ���
����͑����ȑO��GPU�̘b�ł����āA���sGPU�̓I���`�b�v�L���b�V���ɍڂ�����ŏ��������B
�������L���b�V���ɏ���Ȃ������̓������Ɠ���ւ�����������B
1/60���ōς܂����邩�ǂ�����Larrabee��NV��ATI���ς���B
����͑����ȑO��GPU�̘b�ł����āA���sGPU�̓I���`�b�v�L���b�V���ɍڂ�����ŏ��������B
�������L���b�V���ɏ���Ȃ������̓������Ɠ���ւ�����������B
1/60���ōς܂����邩�ǂ�����Larrabee��NV��ATI���ς���B
>>160
�N�͂�������>157�𗝉������ق������� ;-)
�N�͂�������>157�𗝉������ق������� ;-)
����c���́c�h���L���X�̃������\�����Ēm���Ă܂��H�� �^�C�������_�̊T�O�킩��܂��H
>>161
>1/60���ōς܂����邩�ǂ�����Larrabee��NV��ATI���ς���B
���Ⴀ�������̃o���h���ƃL���b�V���T�C�Y�����킹�Ę_�c���Ȃ���Ȃ�Ȃ��̂ł́H
>1/60���ōς܂����邩�ǂ�����Larrabee��NV��ATI���ς���B
���Ⴀ�������̃o���h���ƃL���b�V���T�C�Y�����킹�Ę_�c���Ȃ���Ȃ�Ȃ��̂ł́H
GT200�Ƃ����W�X�^������2MB�゠���Ȃ���������
����Ƃ͕ʂɗp�r���ɃL���b�V�����ς�ł���
����Ƃ͕ʂɗp�r���ɃL���b�V�����ς�ł���
>>163
�����A����������KYRO�Ȃ̓z�������Ă�H
����A�P�Ȃ�Z-Sort�̔��W�ł��B�̈悲�ƂɃ|���S���\�[�g���Ď�O�����`��B
�ȑO�c�q�ɂ͐����������ǂȁB���R�����ǁANV�ł�ATI�ł����܂�UnifiedShader�Ȃ�Č��\�B
���܂��ꂪ�g���Ȃ��̂́A
�@�E�����|���S���̏��������G�ɂȂ萳�����\�����s���Ȃ��A
�@�@�������̓|���S���������������x�Ƀy�i���e�B����������
�@�E�����������s���Ȃ��A����Ȓlj��������K�v�ƂȂ�
�Ƃ����v���I�Ȍ��ׂ����邩��B
�����A����������KYRO�Ȃ̓z�������Ă�H
����A�P�Ȃ�Z-Sort�̔��W�ł��B�̈悲�ƂɃ|���S���\�[�g���Ď�O�����`��B
�ȑO�c�q�ɂ͐����������ǂȁB���R�����ǁANV�ł�ATI�ł����܂�UnifiedShader�Ȃ�Č��\�B
���܂��ꂪ�g���Ȃ��̂́A
�@�E�����|���S���̏��������G�ɂȂ萳�����\�����s���Ȃ��A
�@�@�������̓|���S���������������x�Ƀy�i���e�B����������
�@�E�����������s���Ȃ��A����Ȓlj��������K�v�ƂȂ�
�Ƃ����v���I�Ȍ��ׂ����邩��B
>>159
>���ʂǂ��������Ƃ������邩�Ƃ����ƁA�s�[�N���\�͍����Ă�����������ŋɒ[�ɐ��\��������A
>�܂�t���[�����[�g�������Ȃ�ቺ����Ƃ�������������B
������Č��s��GPU�ł��������Ƃ��N���Ă���...
>���ʂǂ��������Ƃ������邩�Ƃ����ƁA�s�[�N���\�͍����Ă�����������ŋɒ[�ɐ��\��������A
>�܂�t���[�����[�g�������Ȃ�ቺ����Ƃ�������������B
������Č��s��GPU�ł��������Ƃ��N���Ă���...
���L���b�V���ɏ���Ȃ������̓������Ɠ���ւ�����������
�^�C�������_�̏ꍇ�A�L���b�V���ɏ���Ȃ��i���ʂ��ςȁj��ȃf�[�^�͒��_�f�[�^�ƂȂ�
�e�N�Z���Q�Ƃ́A64*64�^�C���Ȃ�K���Œ��4096���������� �i�����������j
�^�C�������_�̏ꍇ�A�L���b�V���ɏ���Ȃ��i���ʂ��ςȁj��ȃf�[�^�͒��_�f�[�^�ƂȂ�
�e�N�Z���Q�Ƃ́A64*64�^�C���Ȃ�K���Œ��4096���������� �i�����������j
>>164
> ���Ⴀ�������̃o���h���ƃL���b�V���T�C�Y�����킹�Ę_�c���Ȃ���Ȃ�Ȃ��̂ł́H
�����������Ƃł��B
�^�C�������_���邩��L���b�V����ꂨ�����œK�ɕ`��ł�����Ă����̂͌��z�ł���ŁA
���Ǒ���肪�d�v�ɂȂ��Ă����ł��B�ƁA>139�Ő\���Ă���܂�^^
>>168
���̒��_�f�[�^�������_�����O�r���ʼnςƂ������ɖ��Ȍ��ۂ���������B
�e�N�Z���������ڂ��Ă͂�����Ƃ����̂�>157�̃��C�g���̕��ʼn�������B
> ���Ⴀ�������̃o���h���ƃL���b�V���T�C�Y�����킹�Ę_�c���Ȃ���Ȃ�Ȃ��̂ł́H
�����������Ƃł��B
�^�C�������_���邩��L���b�V����ꂨ�����œK�ɕ`��ł�����Ă����̂͌��z�ł���ŁA
���Ǒ���肪�d�v�ɂȂ��Ă����ł��B�ƁA>139�Ő\���Ă���܂�^^
>>168
���̒��_�f�[�^�������_�����O�r���ʼnςƂ������ɖ��Ȍ��ۂ���������B
�e�N�Z���������ڂ��Ă͂�����Ƃ����̂�>157�̃��C�g���̕��ʼn�������B
>>166
Z�\�[�g�H Z�o�b�t�@���ɑS�|���ōX�V���āA1�s�N�Z����1��̃e�N�Z���Q�Ƃ�Ή��t���Ă����
Z�\�[�g�H Z�o�b�t�@���ɑS�|���ōX�V���āA1�s�N�Z����1��̃e�N�Z���Q�Ƃ�Ή��t���Ă����
>>169
�ʂɖ���Ȃ��Ǝv�����ǁc���ɕK�v�ȃ|���̒��_�f�[�^�͂킩���Ă���珇���v���t�F�b�`���邾��
�ʂɖ���Ȃ��Ǝv�����ǁc���ɕK�v�ȃ|���̒��_�f�[�^�͂킩���Ă���珇���v���t�F�b�`���邾��
>>169
�^�C�������_�Ȃ烁�����̃o���h����ߖ�ł�����Ă̂����z�Ȃ�?
�^�C�������_�Ȃ烁�����̃o���h����ߖ�ł�����Ă̂����z�Ȃ�?
�uZ�o�b�t�@�͓����A�h���X��p�ɂɍX�V����̂őS���L���b�V�����Ă����܂��傤�v
�u�����t���[���o�b�t�@��̃s�N�Z�������x���h��͖̂��ʂȂ̂ŁA1���K�v�ȐF��h��悤�ɍH�v���܂��傤�v
�����K�ȃg�����W�X�^���Ŏ�������̂��^�C�������_���Ă����̘b
�܂��m���ɒ��_�f�[�^�̎Q�Ƃ͏璷�ɂȂ�ˁA�ł��s�N�Z�������̏璷���Ƃǂ������ǂ�����
�u�����t���[���o�b�t�@��̃s�N�Z�������x���h��͖̂��ʂȂ̂ŁA1���K�v�ȐF��h��悤�ɍH�v���܂��傤�v
�����K�ȃg�����W�X�^���Ŏ�������̂��^�C�������_���Ă����̘b
�܂��m���ɒ��_�f�[�^�̎Q�Ƃ͏璷�ɂȂ�ˁA�ł��s�N�Z�������̏璷���Ƃǂ������ǂ�����
>>170
�N�̂����^�C�������_��������Ɛ������Ă݁H
DreamCast�Ƃ����L�[���[�h���o�Ă�������KYRO�A�����Ƃ�����PowerVR�̂��Ƃ��Ǝv������ ;-)
���߂��PowerVR�Ȃ猳���̐l�Ȃ�ł��B
> �ʂɖ���Ȃ��Ǝv�����ǁc���ɕK�v�ȃ|���̒��_�f�[�^�͂킩���Ă���珇���v���t�F�b�`���邾��
��������|���S���̑O��W���ł���߂ɂȂ��Ă��悯��ˁB
�������\�����s���ꍇ�A���������Ń|���S�������Ă����������s�����߁A
�|���S���X�L�������ŏ��ɍs�����_�ŐV�����|���S�����������A���_�f�[�^���V�����Ȃ�܂��B
>>172
> �^�C�������_�Ȃ烁�����̃o���h����ߖ�ł�����Ă̂����z�Ȃ�?
�t���[���o�b�t�@�����݂���ߖ�ɂȂ�܂����ǁA3D�������Ă��ꂾ������Ȃ��ł�����˂��c�B
���Ƃ���HD�𑜓x��64x64�ŕ��������ہA1���g���C�A���O�����Ȃ߂�̂ɂ�����g���t�B�b�N����
�ǂ̂��炢�ɂȂ�Ǝv���܂��H�@510�p�X�ɂȂ�킯�ł����ǁB
�N�̂����^�C�������_��������Ɛ������Ă݁H
DreamCast�Ƃ����L�[���[�h���o�Ă�������KYRO�A�����Ƃ�����PowerVR�̂��Ƃ��Ǝv������ ;-)
���߂��PowerVR�Ȃ猳���̐l�Ȃ�ł��B
> �ʂɖ���Ȃ��Ǝv�����ǁc���ɕK�v�ȃ|���̒��_�f�[�^�͂킩���Ă���珇���v���t�F�b�`���邾��
��������|���S���̑O��W���ł���߂ɂȂ��Ă��悯��ˁB
�������\�����s���ꍇ�A���������Ń|���S�������Ă����������s�����߁A
�|���S���X�L�������ŏ��ɍs�����_�ŐV�����|���S�����������A���_�f�[�^���V�����Ȃ�܂��B
>>172
> �^�C�������_�Ȃ烁�����̃o���h����ߖ�ł�����Ă̂����z�Ȃ�?
�t���[���o�b�t�@�����݂���ߖ�ɂȂ�܂����ǁA3D�������Ă��ꂾ������Ȃ��ł�����˂��c�B
���Ƃ���HD�𑜓x��64x64�ŕ��������ہA1���g���C�A���O�����Ȃ߂�̂ɂ�����g���t�B�b�N����
�ǂ̂��炢�ɂȂ�Ǝv���܂��H�@510�p�X�ɂȂ�킯�ł����ǁB
�H�H�HZ�o�b�t�@�Ȃ̂ɂȂ�Ō�������|���S���̑O��W�Ȃ�Ęb���o�Ă����H
���������_��Deferred Rendering�̏ȃ������ł��Ă����̘b�Ȃ̂�
���������_��Deferred Rendering�̏ȃ������ł��Ă����̘b�Ȃ̂�
�����Ȃ�ł���
ttp://www.z-z-z.jp/BLOG/log/eid264.html
>Larabee�́A��ꐢ��̂��̂́AATI��NVIDIA�̃n�C�G���hGPU�ɂ͑S���y�Ȃ��p�t�H�[�}���X�Ƃ����Ă���B
>�e�N�X�`�����j�b�g�ɕ��ׂ�������ƃ����O�o�X���p���N���Ďv�����قǃp�t�H�[�}���X���łȂ��炵���B
ttp://www.z-z-z.jp/BLOG/log/eid264.html
>Larabee�́A��ꐢ��̂��̂́AATI��NVIDIA�̃n�C�G���hGPU�ɂ͑S���y�Ȃ��p�t�H�[�}���X�Ƃ����Ă���B
>�e�N�X�`�����j�b�g�ɕ��ׂ�������ƃ����O�o�X���p���N���Ďv�����قǃp�t�H�[�}���X���łȂ��炵���B
177 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 20:01:13 ID:iiFWVgMc
�Ƃ����RadeonHD 4800�V���[�Y����SIMD�R�A���Ƃ�L1�L���b�V����16KB�����Ȃ���ł���������
200SP��16KB�ł���B��Ȫ�B
L2�̂ق��͔���J�����A3800�̂Ƃ��̓e�N�X�`���L���b�V�����_�C�S�̂�256KB��
����ȂɃ_�C�T�C�Y���傫���Ȃ��ĂȂ����Ƃ���z���ɓ�Ȃ��B
GeForce�̂ق��́A1SM������64KB�̃R���X�^���g�������i���߃o�b�t�@�����˂�j��16KB
����Ń������ш�̃Z�[�u�Ƃ��A������ς�����B
��̃R�A��L1 32KB�{32KB��L2 256KB�~�R�A�����Ă����ԑш�Z�[�u�ł��邺�B
�ɂ��ނ̓^�C���̃T�C�Y��256KB���Ǝv������ł�悤�����ǁA
Larrabee�̃L���b�V���͕��U�^�ł͂��邯�Nj��L�L���b�V���ł��B
���Ƃ́A�킩��܂��ˁH
���ƁA���߂̃T�C�Y�̌������ǂ�
���j�A�ɃA�h���b�V���O�o���郌�W�X�^�t�@�C���̋K�͂���
���ߒ��ɂ��������邾��H��
��ŁA����GeForce���ă��W�X�^���ĉ��{�����������H
32�r�b�g���W�X�^��8192�{���邢��16384�{�������H
���āA1���߂̒����͉��o�C�g�ɂȂ�ł��傤���H��
Radeon�̂ق��̓l�C�e�B�u���߃Z�b�g���J����Ă邯�ǁA��僂���ł���
����Ȃ�ł悭General Purpose�Ƃ������������ł��B
200SP��16KB�ł���B��Ȫ�B
L2�̂ق��͔���J�����A3800�̂Ƃ��̓e�N�X�`���L���b�V�����_�C�S�̂�256KB��
����ȂɃ_�C�T�C�Y���傫���Ȃ��ĂȂ����Ƃ���z���ɓ�Ȃ��B
GeForce�̂ق��́A1SM������64KB�̃R���X�^���g�������i���߃o�b�t�@�����˂�j��16KB
����Ń������ш�̃Z�[�u�Ƃ��A������ς�����B
��̃R�A��L1 32KB�{32KB��L2 256KB�~�R�A�����Ă����ԑш�Z�[�u�ł��邺�B
�ɂ��ނ̓^�C���̃T�C�Y��256KB���Ǝv������ł�悤�����ǁA
Larrabee�̃L���b�V���͕��U�^�ł͂��邯�Nj��L�L���b�V���ł��B
���Ƃ́A�킩��܂��ˁH
���ƁA���߂̃T�C�Y�̌������ǂ�
���j�A�ɃA�h���b�V���O�o���郌�W�X�^�t�@�C���̋K�͂���
���ߒ��ɂ��������邾��H��
��ŁA����GeForce���ă��W�X�^���ĉ��{�����������H
32�r�b�g���W�X�^��8192�{���邢��16384�{�������H
���āA1���߂̒����͉��o�C�g�ɂȂ�ł��傤���H��
Radeon�̂ق��̓l�C�e�B�u���߃Z�b�g���J����Ă邯�ǁA��僂���ł���
����Ȃ�ł悭General Purpose�Ƃ������������ł��B
178 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 20:16:28 ID:iiFWVgMc
�⑫����ƁA�����܂ł��������L���b�V�����C����1�G���g��32�o�C�g���x��
�u�L���b�V���v
�Ȃ���A�㏑�����Ȃ��s�N�Z���܂ŃL���b�V���Ɏ�荞�ޕK�v�͂Ȃ���ł���B
��`���̃s�N�Z�����������L���b�V����H�����ĔF���͌��B
�����ł����ԃ������g���t�B�b�N���点�܂���B
http://software.intel.com/file/15542
�u�L���b�V���v
�Ȃ���A�㏑�����Ȃ��s�N�Z���܂ŃL���b�V���Ɏ�荞�ޕK�v�͂Ȃ���ł���B
��`���̃s�N�Z�����������L���b�V����H�����ĔF���͌��B
�����ł����ԃ������g���t�B�b�N���点�܂���B
http://software.intel.com/file/15542
���e�N�X�`�����j�b�g�ɕ��ׂ�������ƃ����O�o�X���p���N
�����e�N�X�`�����j�b�g�̏����ŋl�܂��Ă邾�����ĂȂ�A
�R�A�ăe�N�X�`�����j�b�g���G�~�����[�g���Ă���ǂ����
�ق�ƂɃ����O�o�X���p���N���Ă�Ȃ�ǂ�������Ȃ����ǂ�
�����e�N�X�`�����j�b�g�̏����ŋl�܂��Ă邾�����ĂȂ�A
�R�A�ăe�N�X�`�����j�b�g���G�~�����[�g���Ă���ǂ����
�ق�ƂɃ����O�o�X���p���N���Ă�Ȃ�ǂ�������Ȃ����ǂ�
��������������AA���ǂ�����̂����ĉۑ�͂ǂ����Ă��c���ȁ[
4xSSAA�Ƃ��Ȃ�A�S�`���(0,0)�E(0,0.5)�E(0.5,0)�E(0.5,0.5)���炵��4��`���ĕ��ώ��Ƃ��ł��������
4xSSAA�Ƃ��Ȃ�A�S�`���(0,0)�E(0,0.5)�E(0.5,0)�E(0.5,0.5)���炵��4��`���ĕ��ώ��Ƃ��ł��������
181 �F,,�E�L�́M�E,,�j��-�������F2009/04/07(��) 20:51:09 ID:iiFWVgMc
�\�[�X��FUDzillla�����̎ア�f�}�J�Z�W�����搶����
�������G�C�v�����t�[��
�������G�C�v�����t�[��
Wii 5,000�����DS 1����͔C�V���ɂƂ��ĉ����Ӗ�����̂�
ttp://pc.watch.impress.co.jp/docs/2009/0408/kaigai499.htm
ttp://pc.watch.impress.co.jp/docs/2009/0408/kaigai499.htm
�c�q��Intel��D��������ȁA�ӖړI�ɐM�p���đ��������ĂȂ��Ȃ�
>>178��PDF�A40�y�[�W���炢����ǂ߂A�|���S���T�C�Y�ɂ���Ă��Ƃ��ȒP�ɔj�]���邱�Ƃ�������̂ɁB
�^�C�������_�����O�ɂ���ĉ҂���̂͏����̏��T�C�Y�|���S�������݂��Ă���Ƃ������ŁA
���̑O�����Ƃ܂Ƃ��ɋ@�\���Ȃ���������ڂ����ނ������Ă�B
���łɏ����Ă����Ȃ����Ƃ��������Ⴄ�ϑz�Ȃ̂��܂�����
>>178��PDF�A40�y�[�W���炢����ǂ߂A�|���S���T�C�Y�ɂ���Ă��Ƃ��ȒP�ɔj�]���邱�Ƃ�������̂ɁB
�^�C�������_�����O�ɂ���ĉ҂���̂͏����̏��T�C�Y�|���S�������݂��Ă���Ƃ������ŁA
���̑O�����Ƃ܂Ƃ��ɋ@�\���Ȃ���������ڂ����ނ������Ă�B
���łɏ����Ă����Ȃ����Ƃ��������Ⴄ�ϑz�Ȃ̂��܂�����
>>178�̎�������Intel�̌����^�C�������_�����O���������`����킯�����ǁA
���ǂ̂Ƃ���h���L���X�͂܂������W�Ȃ��A>>157�O���Ő������ꂽZ-Buffer�̔��W�ɉ߂��Ȃ��B
�S�Ẵ^�C�������킯�ł͂Ȃ��A���ڂ��镔���̂݃L���b�V�����Ă����Ƃ����Ⴂ�͂�����̂́A
����͂����܂�Larrabee�̃L���b�V���\���ɂ��킹�������̃p�f�B���O�����킹�邾���̌��ʂ����Ȃ����āA
���X�^�I�y���[�V�����Ńp�f�B���O���O�ꂽ�������̈�ɃA�N�Z�X���Ė��ʂȃg���t�B�b�N�����������
�L���b�V�����C�����ɕ������ăg���t�B�b�N���������ق����}�V�A���čl�����B
���R�قȂ�|���S������������ۂɂ͕ʂ̃������̈�ɃA�N�Z�X����K�v�����邵�A
�|���S���T�C�Y���傫���Ȃ���̕��A�N�Z�X���郁�����̈悪�傫���Ȃ邽�߁A
�L���b�V�����Ɏ��܂�Ȃ�Ă����̂͊����ȉR�����A�������g���t�B�b�N��������Ă����̂��R�B
�P�Ɂu���ʂȃg���t�B�b�N�����点��v�����B
�ŁALBRni�ł͂��̗̈�ʂ��邽�߂̗Ő��v�Z�ƔF���������I�Ɏ����ł�����Ă��������B
���ǂ̂Ƃ���h���L���X�͂܂������W�Ȃ��A>>157�O���Ő������ꂽZ-Buffer�̔��W�ɉ߂��Ȃ��B
�S�Ẵ^�C�������킯�ł͂Ȃ��A���ڂ��镔���̂݃L���b�V�����Ă����Ƃ����Ⴂ�͂�����̂́A
����͂����܂�Larrabee�̃L���b�V���\���ɂ��킹�������̃p�f�B���O�����킹�邾���̌��ʂ����Ȃ����āA
���X�^�I�y���[�V�����Ńp�f�B���O���O�ꂽ�������̈�ɃA�N�Z�X���Ė��ʂȃg���t�B�b�N�����������
�L���b�V�����C�����ɕ������ăg���t�B�b�N���������ق����}�V�A���čl�����B
���R�قȂ�|���S������������ۂɂ͕ʂ̃������̈�ɃA�N�Z�X����K�v�����邵�A
�|���S���T�C�Y���傫���Ȃ���̕��A�N�Z�X���郁�����̈悪�傫���Ȃ邽�߁A
�L���b�V�����Ɏ��܂�Ȃ�Ă����̂͊����ȉR�����A�������g���t�B�b�N��������Ă����̂��R�B
�P�Ɂu���ʂȃg���t�B�b�N�����点��v�����B
�ŁALBRni�ł͂��̗̈�ʂ��邽�߂̗Ő��v�Z�ƔF���������I�Ɏ����ł�����Ă��������B
185 �FSocket774�F2009/04/08(��) 04:03:21 ID:3Qlt9f5Y
����Geforce�ɂ͂��ꂾ�����ʂȃg���t�B�b�N�������Ƃ������Ƃł��ˁB�킩��܂��B
���̕����������Ă���ˁBG80�Ȃ� 64bit x 6����BNV770�Ȃ� 32bit x 8����B
Larrabee�������R��4���炢�ς�� Unganged Mode�ŃA�N�Z�X������A�����͂܂Ƃ��ɂȂ邩���˂�
Larrabee�������R��4���炢�ς�� Unganged Mode�ŃA�N�Z�X������A�����͂܂Ƃ��ɂȂ邩���˂�
9�y�[�W(>>178)�̐}�����ۂ̐��i�̃_�C�A�O�������Ǝv���Ă���C�^�C�q�ł����H
����͖͎��}������킩��₷�����邽�߂ɂ��������Ă���̂ł����āA�����R������ɂȂ邩�͖����s���Ȃ̂����B
����͖͎��}������킩��₷�����邽�߂ɂ��������Ă���̂ł����āA�����R������ɂȂ邩�͖����s���Ȃ̂����B
�ŁA�����Ȃ�̂��H
�\�[�X�͂��܂��������A�R�P���[�ȋC�����Ă�����
�\�[�X�͂��܂��������A�R�P���[�ȋC�����Ă�����
�����R���������ɂȂ����Ƃ��Ă������O�o�X�Ɍq���������
�����O�o�X�������ɂȂ��Ȃ��́H
�����O�o�X�������ɂȂ��Ȃ��́H
>>178
�����O�o�X����Ȃ��Ȃ�����S3��Chrome400���Ȃ���
�����O�o�X����Ȃ��Ȃ�����S3��Chrome400���Ȃ���
�c�q���̍��~�߂�ꂽ��
>>184,186
�����ш�𑝂₷���Ă̂́A���{�I�ɓd�͌����������v���ȁB
���Ȃ݂�PC�Q�[���̓��[�G���hPC�ł������̂�O��ɍ�邩��
�n�C�G���h�ɂ��킹�ă|���S���͑��₹�Ȃ��B
�e�N�X�`���̕i�ʂ�V�F�[�_�ō��ʉ�����B
�𑜓x��������قǗL���ɂȂ���Ă̂́A�v����Ƀ^�C��������̃|���S�����͌�����Ă��ƁB
�𑜓x���ƂɕʁX�̃|���S�����f����p�ӂ���H
�ǂ��̊J���҂�����Ȗ��ʋ�������́H
CRISIS�ł��炽������200���|�����x�ł���B
�����ш�𑝂₷���Ă̂́A���{�I�ɓd�͌����������v���ȁB
���Ȃ݂�PC�Q�[���̓��[�G���hPC�ł������̂�O��ɍ�邩��
�n�C�G���h�ɂ��킹�ă|���S���͑��₹�Ȃ��B
�e�N�X�`���̕i�ʂ�V�F�[�_�ō��ʉ�����B
�𑜓x��������قǗL���ɂȂ���Ă̂́A�v����Ƀ^�C��������̃|���S�����͌�����Ă��ƁB
�𑜓x���ƂɕʁX�̃|���S�����f����p�ӂ���H
�ǂ��̊J���҂�����Ȗ��ʋ�������́H
CRISIS�ł��炽������200���|�����x�ł���B
�𑜓x���Ƃł͂Ȃ��ɂ���LOD��DX11����̃e�b�Z���[�^���g�����
�����I�ɒ��_�͑������
���ƁA�𑜓x��������ᓖ�R��������^�C����������킯������
���ǗL���ɂ͂Ȃ��
�����I�ɒ��_�͑������
���ƁA�𑜓x��������ᓖ�R��������^�C����������킯������
���ǗL���ɂ͂Ȃ��
194 �FSocket774�F2009/04/08(��) 10:25:28 ID:mfmrx+Hs
����͎�ɗ֊s���������炩�ɂ���̂��ړI�ł����ĕ`�悵�Ȃ��s�N�Z���̈�܂ŃL���b�V���ɂ̂��Ȃ��Ă����͕̂ς��Ȃ�
>>187
���Ȃ��������Ă����Ȃ������������Ⴄ�ɂ��q�ł����H
�����Ȃ��G�Ɛ���Ă�ЂƂ������Ȃ���
����肪�ǂ��Ȃ邩�s�������烁���R��4���炢�ς�܂Ƃ��ɂȂ邩���ˁA���Č����Ă邾���ł���B
64bit���̃o�X��{�����Ȃ�A�܂����[�G���h�����m��ł��傤���ǁB
>>189
�����O�p�P�b�g����������Ȃ��Ƃ��Ȃ茵�����ł����A�R�A�Ɠ��������߂� 1/2����
����Ȃ�ɃX���[�v�b�g�͊m�ۂł��܂��B
���Ď����͂ǂ��Ȃ�ł��傤�H
>>192
> �𑜓x��������قǗL���ɂȂ���Ă̂́A�v����Ƀ^�C��������̃|���S�����͌�����Ă��ƁB
�_�E�g�B
�S�̂̃^�C������������i���Ƃ���20->192)�ƕ��ꂪ�傫���Ȃ���
���ς̃^�C��������|���S����������Ƃ����������g�����떂�����B
�𑜓x�̍���Ɋւ�炸�������Ȃ���Ȃ�Ȃ��|���S���̐��͕ς�炸�A
���A�𑜓x��������ق�1�̃|���S������߂�^�C�����������邽�߁A
�������g���t�B�b�N�͂��̂܂ܑ������܂��B
�|���S�����V�[����1�����Ȃ���A�����̏I������^�C���͗p�ς݂ł��傤��
���ۂ̓|���S���͑�ʂɑ��݂��邽�ߏ����̏I������^�C���͈�T�ɗp�ς݂Ƃ͌����܂���B
���Ƀ^�C�������̏ꍇ�A����^�C�����Ƀ|���S�����������荞�މ\���������Ȃ�܂��B
> CRISIS�ł��炽������200���|�����x�ł���B
����200���|���S�����������瑊���ł����āB
RADEON9000�AGeForce3���x���� 60FPS�ŏ����ł��܂���ȁB
�e�N�Z��������60���e�N�Z��/sec�ʂ͂ق����̂ŁAGeForce9600GT�ł���Ƃ��ĂƂ���ł����B
Larrabee���ƃW�I���g���f�[�^�����ŃL���b�V�����ӂ�Ă��܂��܂�����A
����ς胁�����o�X�͋��͂Ȃ��̂��ق����ł��˂�
���Ȃ��������Ă����Ȃ������������Ⴄ�ɂ��q�ł����H
�����Ȃ��G�Ɛ���Ă�ЂƂ������Ȃ���
����肪�ǂ��Ȃ邩�s�������烁���R��4���炢�ς�܂Ƃ��ɂȂ邩���ˁA���Č����Ă邾���ł���B
64bit���̃o�X��{�����Ȃ�A�܂����[�G���h�����m��ł��傤���ǁB
>>189
�����O�p�P�b�g����������Ȃ��Ƃ��Ȃ茵�����ł����A�R�A�Ɠ��������߂� 1/2����
����Ȃ�ɃX���[�v�b�g�͊m�ۂł��܂��B
���Ď����͂ǂ��Ȃ�ł��傤�H
>>192
> �𑜓x��������قǗL���ɂȂ���Ă̂́A�v����Ƀ^�C��������̃|���S�����͌�����Ă��ƁB
�_�E�g�B
�S�̂̃^�C������������i���Ƃ���20->192)�ƕ��ꂪ�傫���Ȃ���
���ς̃^�C��������|���S����������Ƃ����������g�����떂�����B
�𑜓x�̍���Ɋւ�炸�������Ȃ���Ȃ�Ȃ��|���S���̐��͕ς�炸�A
���A�𑜓x��������ق�1�̃|���S������߂�^�C�����������邽�߁A
�������g���t�B�b�N�͂��̂܂ܑ������܂��B
�|���S�����V�[����1�����Ȃ���A�����̏I������^�C���͗p�ς݂ł��傤��
���ۂ̓|���S���͑�ʂɑ��݂��邽�ߏ����̏I������^�C���͈�T�ɗp�ς݂Ƃ͌����܂���B
���Ƀ^�C�������̏ꍇ�A����^�C�����Ƀ|���S�����������荞�މ\���������Ȃ�܂��B
> CRISIS�ł��炽������200���|�����x�ł���B
����200���|���S�����������瑊���ł����āB
RADEON9000�AGeForce3���x���� 60FPS�ŏ����ł��܂���ȁB
�e�N�Z��������60���e�N�Z��/sec�ʂ͂ق����̂ŁAGeForce9600GT�ł���Ƃ��ĂƂ���ł����B
Larrabee���ƃW�I���g���f�[�^�����ŃL���b�V�����ӂ�Ă��܂��܂�����A
����ς胁�����o�X�͋��͂Ȃ��̂��ق����ł��˂�
196 �FSocket774�F2009/04/08(��) 10:49:34 ID:mfmrx+Hs
�ϑz�������ǃQ�[���̐��\����Ƀr�W�l�X�I���H�͂Ȃ�
�G���X�[�Q�[�}�[�Ȃ�Đ�ΐ��͏��Ȃ��B
�����GPGPU�����C���A�v���ɂȂ�B�Ƃ�����N�͂����������B
�G���X�[�Q�[�}�[�Ȃ�Đ�ΐ��͏��Ȃ��B
�����GPGPU�����C���A�v���ɂȂ�B�Ƃ�����N�͂����������B
���j�^�̉𑜓x���オ���Ă����̂Ƀ|���S�����������Ȃ���A�|���S���������^�C���ɂ܂����銄���͋t�ɑ������Ⴄ����
>>196
���炠��A������CRISIS�Əo���Ă����ăQ�[�����\�W�Ȃ��Ƃ������o�����������A���̎q
���炠��A������CRISIS�Əo���Ă����ăQ�[�����\�W�Ȃ��Ƃ������o�����������A���̎q
�ǂ��ł�������Crysis���Ǝv��
�Q�[���̐��\��グ�̂��߂ɂ���Q�[�����K�v�Ƃ������Ƃ���
���Ȃ��Ƃ�N��GPGPU�͂��������ʒu�t��
���Ȃ��Ƃ�N��GPGPU�͂��������ʒu�t��
�܂��m���ɁA���̂���͊J���������������100���{�����Ă��Ԏ��ɂȂ�P�[�X���o�Ă�����
�܂�܂����ǂ̂Ƃ���>>151���Ă��Ƃ���Ȃ��ł����H
�`�b�v�Z�b�g�̎x���Ȃ���OS����A�v���A�����E�r�f�I�E�ȒP��3D�`�揈���܂ŏo�����
Intel�Ƃ��Ă̓T�[�h�p�[�e�B�r�����ł��Ă��ꂵ����ˁB
���̂��炢�Ȃ烁�����ш�債�ĐH��Ȃ�����I���L���b�V������Ȃ��Ă������ł��邵��
�`�b�v�Z�b�g�̎x���Ȃ���OS����A�v���A�����E�r�f�I�E�ȒP��3D�`�揈���܂ŏo�����
Intel�Ƃ��Ă̓T�[�h�p�[�e�B�r�����ł��Ă��ꂵ����ˁB
���̂��炢�Ȃ烁�����ш�債�ĐH��Ȃ�����I���L���b�V������Ȃ��Ă������ł��邵��
Larrabee�̃������o�X�����ɒ[�ɋ���
�O��Ō��ID:L7T7q90v�͂Ȃ�Ȃ�
Intel�̒��̐l�����Đ��\�]�����炢����Ă邾��
�O��Ō��ID:L7T7q90v�͂Ȃ�Ȃ�
Intel�̒��̐l�����Đ��\�]�����炢����Ă邾��
�L���b�V�������邩�烁�����ш�͐ߖ�ł���Ƃ����咣�ɑ���c�b�R�~�Ȃ̂ł́H
> Larrabee�̃������o�X�����ɒ[�ɋ���
> �O��Ō��ID:L7T7q90v�͂Ȃ�Ȃ�
�ǂ��ł���Ȕ��������̂���������
> �O��Ō��ID:L7T7q90v�͂Ȃ�Ȃ�
�ǂ��ł���Ȕ��������̂���������
>>207
Larrabee�̃A�v���P�[�V�����Ƃ��ėL���ȕ������������������ł����āA
������������Ă��Ȃ�����A������a���ɂ����Ⴂ�����˂��Ęb�����Ă��邾���ł����H
Cache���\�_��W�J����ق�������ۂlj����B
Larrabee�̃A�v���P�[�V�����Ƃ��ėL���ȕ������������������ł����āA
������������Ă��Ȃ�����A������a���ɂ����Ⴂ�����˂��Ęb�����Ă��邾���ł����H
Cache���\�_��W�J����ق�������ۂlj����B
���ǂ̂Ƃ���
���킩���Ă���̂�
Larrabee�̓��C���������Ƃ�Byte/Flops��������x�܂ł�
�Ⴂ���Ƃ����e�ł���n�[�h�E�F�A�A�[�L�e�N�`��
�Ƃ������Ƃł�����
����͊����̐��i�Ƃ̔�r�ł�
�R�X�g�I�d�͌����I�ȃA�h�o���e�[�W�ł���Ǝv���邪
�f�B�X�N���[�g�O���t�B�b�N�X�Ƃ��Ď��ۂɎs��Ő������邩��
�V�F�[�_�̎�����烁�����o�X����狣�����鐻�i�̏o�����
���ɂ��x�z�I�ȗv���������Ă����ς�킩��Ȃ��킯
>>208
>���̂��炢�Ȃ烁�����ш�債�ĐH��Ȃ�����I���L���b�V������Ȃ��Ă������ł��邵��
���킩���Ă���̂�
Larrabee�̓��C���������Ƃ�Byte/Flops��������x�܂ł�
�Ⴂ���Ƃ����e�ł���n�[�h�E�F�A�A�[�L�e�N�`��
�Ƃ������Ƃł�����
����͊����̐��i�Ƃ̔�r�ł�
�R�X�g�I�d�͌����I�ȃA�h�o���e�[�W�ł���Ǝv���邪
�f�B�X�N���[�g�O���t�B�b�N�X�Ƃ��Ď��ۂɎs��Ő������邩��
�V�F�[�_�̎�����烁�����o�X����狣�����鐻�i�̏o�����
���ɂ��x�z�I�ȗv���������Ă����ς�킩��Ȃ��킯
>>208
>���̂��炢�Ȃ烁�����ш�債�ĐH��Ȃ�����I���L���b�V������Ȃ��Ă������ł��邵��
>>209
> �܂�܂����ǂ̂Ƃ���>>151���Ă��Ƃ���Ȃ��ł����H
> ����d�͂���W���x�ɗ}������Ȃ�A
> Windows7�������X�}�[�g�t�H���p�v���b�g�z�[���Ƃ���Qualcomm��MSM7xxxx���쒀�ł��邩���H��
> �܂�܂����ǂ̂Ƃ���>>151���Ă��Ƃ���Ȃ��ł����H
> ����d�͂���W���x�ɗ}������Ȃ�A
> Windows7�������X�}�[�g�t�H���p�v���b�g�z�[���Ƃ���Qualcomm��MSM7xxxx���쒀�ł��邩���H��
��قlj������Ęb�������ĂȂ��̂�������Ȃ����ǂ�
�@Qualcomm MSM7xxx�R�Ƃ��Ă�Larabee���l�����ꍇ�������ш�͂���قǕK�v�Ȃ�
�Ƃ����b�����Ă�킯�ŁA���ʊW���S���t�B
�@Qualcomm MSM7xxx�R�Ƃ��Ă�Larabee���l�����ꍇ�������ш�͂���قǕK�v�Ȃ�
�Ƃ����b�����Ă�킯�ŁA���ʊW���S���t�B
>>ID:g7ggsR1Y = ID:L7T7q90v
���Ⴀ������
>>148
>�����邯�ǁA����������ƕǂ�20���Ĉʂ̍L����������30�F�g�����Ƃ��v�����ꂽ�B
>����Ȃ��F���o��̂Œ��g�������Ƀ��`���`�����̎q�������g���ɂł�B
>�o�P�c�̗e�ʂ�����Ȃ��������ς肨�g���ɉ��x������B
>
>���F�g����̂͌������̉�����h����x�ł������ăI�`�B
#�������u���͍����pID:g7ggsR1Y����Ȃ��v
#�Ǝ咣���Ă���Ă����܂�Ȃ�
���Ⴀ������
>>148
>�����邯�ǁA����������ƕǂ�20���Ĉʂ̍L����������30�F�g�����Ƃ��v�����ꂽ�B
>����Ȃ��F���o��̂Œ��g�������Ƀ��`���`�����̎q�������g���ɂł�B
>�o�P�c�̗e�ʂ�����Ȃ��������ς肨�g���ɉ��x������B
>
>���F�g����̂͌������̉�����h����x�ł������ăI�`�B
#�������u���͍����pID:g7ggsR1Y����Ȃ��v
#�Ǝ咣���Ă���Ă����܂�Ȃ�
�Ȃ�ł���ȓ��{��̉�����Ȃ��Ⴂ����̂���B������������ȁB
>>212
>>140-141�́u�L���b�V��������o�P�c�܂ʼn����������Ȃ��ł����v�Ƃ����b�ɑ���
����Ȏ�������u���F�g����̂͌������̉�����h����x�ł������ăI�`�v�����Ă����b���낪�B
>>212
>>140-141�́u�L���b�V��������o�P�c�܂ʼn����������Ȃ��ł����v�Ƃ����b�ɑ���
����Ȏ�������u���F�g����̂͌������̉�����h����x�ł������ăI�`�v�����Ă����b���낪�B
�ǂ̃|���S�����ǂ̃^�C���ɑ����Ă邩���O�ɑS���\�[�g���Ƃ��Ⴆ���b���Ⴂ�܂���
1��1�|���S���������璀���^�C���ƃR�A�̊��蓖�ĕύX����́H���ʂ�����
1��1�|���S���������璀���^�C���ƃR�A�̊��蓖�ĕύX����́H���ʂ�����
������Č���VGA�Ƃ���PCIE�Ɏh���Ďg����
��قnj��肳�ꂽ�p�r���\�t�g���Ή�����悤�Ƀv���O���������������Ȃ��ƈӖ����K������
�łȂ��ƌ��ǐ[��A�j���̃G���R������ɂ����g���Ȃ�����
��p�\�t�g���t������
��قnj��肳�ꂽ�p�r���\�t�g���Ή�����悤�Ƀv���O���������������Ȃ��ƈӖ����K������
�łȂ��ƌ��ǐ[��A�j���̃G���R������ɂ����g���Ȃ�����
��p�\�t�g���t������
216 �FSocket774�F2009/04/08(��) 16:33:57 ID:iv1TLkc4
Gpu�Ƃ��č����\����Ȃ��ƕ��y�͂��Ȃ�����B
���̗p�r�͂����܂ŃI�}�P�@�\�ł����Ȃ����B
���N�o���Ƃ��āA1�`2���~��HD4770��HD5850������ƌ݊p�ȏ�̐��\���ł�̂��H
���̗p�r�͂����܂ŃI�}�P�@�\�ł����Ȃ����B
���N�o���Ƃ��āA1�`2���~��HD4770��HD5850������ƌ݊p�ȏ�̐��\���ł�̂��H
>>216
��Ȉ�����Ȃ����낗
�ŏ���Larrabee�̓\�t�g�J���Ҍ����̊J���L�b�g�̂悤�Ȃ��̂ŁA���炭�����B
����2010�N�ɏo���Ƃ��āA���̎��_�ŃO���t�B�b�N�{�[�h�Ƃ��Ă����g�������Ȃ�A
nVidia��AMD�̃n�C�G���h�̂��ق����A�����l�i�ō��p�t�H�[�}���X�Ȃ̂�
��ɓ���BLarrabee�̏_������s�̂̃\�t�g�Ȃ�ē��ʊF�����낤���A
�����ŃR�[�h�����Ȃ��l�ȊO�ɂ͍��������ŕ�̎�������B
�r�f�I�G���R�[�h����肽���l�́A���낻�땷�����Ă��邾�낤Sandy Bridge�̂ق���
�����I�ȑI�����ɂȂ�͂��B�]���̃G���R�[�h�\�t�g�̈ꕔ��AVX���g�������̂��A
Larrabee�����̂��̂�葁���A��ނ��o�Ă���B
����v�Z���̂��̂�A�O���t�B�b�N���A�����V�~�����[�V������A�o�C�I�C���t�H�Ȃǂ�
����������Ă�l�ȊO������ɂ���悤�Ȃ��̂���Ȃ��B
�{����PS4�ɍ̗p�����Ȃ�i�Ȃ��Ǝv�����ǁj�A�Q�[���J���҂��g�����ƂɂȂ邾�낤���ǁB
��Ȉ�����Ȃ����낗
�ŏ���Larrabee�̓\�t�g�J���Ҍ����̊J���L�b�g�̂悤�Ȃ��̂ŁA���炭�����B
����2010�N�ɏo���Ƃ��āA���̎��_�ŃO���t�B�b�N�{�[�h�Ƃ��Ă����g�������Ȃ�A
nVidia��AMD�̃n�C�G���h�̂��ق����A�����l�i�ō��p�t�H�[�}���X�Ȃ̂�
��ɓ���BLarrabee�̏_������s�̂̃\�t�g�Ȃ�ē��ʊF�����낤���A
�����ŃR�[�h�����Ȃ��l�ȊO�ɂ͍��������ŕ�̎�������B
�r�f�I�G���R�[�h����肽���l�́A���낻�땷�����Ă��邾�낤Sandy Bridge�̂ق���
�����I�ȑI�����ɂȂ�͂��B�]���̃G���R�[�h�\�t�g�̈ꕔ��AVX���g�������̂��A
Larrabee�����̂��̂�葁���A��ނ��o�Ă���B
����v�Z���̂��̂�A�O���t�B�b�N���A�����V�~�����[�V������A�o�C�I�C���t�H�Ȃǂ�
����������Ă�l�ȊO������ɂ���悤�Ȃ��̂���Ȃ��B
�{����PS4�ɍ̗p�����Ȃ�i�Ȃ��Ǝv�����ǁj�A�Q�[���J���҂��g�����ƂɂȂ邾�낤���ǁB
218 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 20:21:03 ID:W7bdOxGx
�܁A�Q�[�����n�C�G���hVGA���������邱�Ƃ͂Ȃ���
�ǂ̉�Ђ���v�����������Ǝv�����B
�Q�[�������f�B�X�N���[�gGPU�Ȃ�Đ��ގs�ꂾ���B
���͉��x�������Ă��K�X����AIntel�����́u�j�b�`�s��v�ɎQ������Ӗ���
GPGPU�E���Ɠ�����HPC�����̃A�N�Z�����[�^�B����CPU�{GPU��������Ɍ����Ă̎����B
Intel��NVIDIA��ATI�̃n�C�G���h�ɃQ�[������VGA�Ƃ��ď����ɍs���C�ȂǍX�X�����B
�~�b�h�����W�N���X���x�̐��\���o��Q�[���ɂ��\���g���邵
�����ŏ��߂�GPGPU���}�V�ȃA�N�Z�����[�^�Ƃ��ĕ]���邱�Ƃ��ł���B
�n�C�G���h�H���̉�Ђ͎��X�k�����邢�͌o�c�j�]�B
FF11��l�[�W���݂����ȃm�[�g�ŏ\���ȃl�g�Q�͂܂��܂������B
���̏łǂ��̃\�t�g��Ђ��A�⏕�d���K�{�̔��M�O���{�v������Q�[���o�����Ǝv���B
�R���V���[�}�@�̂�������ڐA���ւ̎R����B
�L���b�V���̊��p�ɂ���ē�����d�͌�����j�]�����Ă܂Ŋ���GPU��
�����̃X�y�b�N�v���ɍ��킹��K�v�͂Ȃ����
�����Ƃ��u�{���̖ړI�v�ł���X�g���[���v���Z�b�T�Ƃ��č���Ȃ����x�ɂ�
���ш�̃C���^�[�R�l�N�g�o�X�͔����Ă��邾�낤���ǁAHPC�����j���O�R�X�g��
����d�͂ɔ�Ⴗ�邩��ˁB
�ǂ̉�Ђ���v�����������Ǝv�����B
�Q�[�������f�B�X�N���[�gGPU�Ȃ�Đ��ގs�ꂾ���B
���͉��x�������Ă��K�X����AIntel�����́u�j�b�`�s��v�ɎQ������Ӗ���
GPGPU�E���Ɠ�����HPC�����̃A�N�Z�����[�^�B����CPU�{GPU��������Ɍ����Ă̎����B
Intel��NVIDIA��ATI�̃n�C�G���h�ɃQ�[������VGA�Ƃ��ď����ɍs���C�ȂǍX�X�����B
�~�b�h�����W�N���X���x�̐��\���o��Q�[���ɂ��\���g���邵
�����ŏ��߂�GPGPU���}�V�ȃA�N�Z�����[�^�Ƃ��ĕ]���邱�Ƃ��ł���B
�n�C�G���h�H���̉�Ђ͎��X�k�����邢�͌o�c�j�]�B
FF11��l�[�W���݂����ȃm�[�g�ŏ\���ȃl�g�Q�͂܂��܂������B
���̏łǂ��̃\�t�g��Ђ��A�⏕�d���K�{�̔��M�O���{�v������Q�[���o�����Ǝv���B
�R���V���[�}�@�̂�������ڐA���ւ̎R����B
�L���b�V���̊��p�ɂ���ē�����d�͌�����j�]�����Ă܂Ŋ���GPU��
�����̃X�y�b�N�v���ɍ��킹��K�v�͂Ȃ����
�����Ƃ��u�{���̖ړI�v�ł���X�g���[���v���Z�b�T�Ƃ��č���Ȃ����x�ɂ�
���ш�̃C���^�[�R�l�N�g�o�X�͔����Ă��邾�낤���ǁAHPC�����j���O�R�X�g��
����d�͂ɔ�Ⴗ�邩��ˁB
�܂�A���s����
220 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 20:30:10 ID:W7bdOxGx
���d�͌�������x86�x�[�X�̉��Z�A�N�Z�����[�^��HPC�s�ꂪ�����Ƃ��]��ł���̂���
�����R�X�g��胉�j���O�R�X�g�̂ق��������邩��ˁB
�o��팸������鍡�����炱���d�͌��������߂���B
�܂����N����ɂ�Celeron��CPU�R�A�ׂ̗ɍڂ������Ă邾�낤��
�����R�X�g��胉�j���O�R�X�g�̂ق��������邩��ˁB
�o��팸������鍡�����炱���d�͌��������߂���B
�܂����N����ɂ�Celeron��CPU�R�A�ׂ̗ɍڂ������Ă邾�낤��
221 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 20:33:35 ID:W7bdOxGx
PCIe x16�̑ш���\�����p�ł���A�v���P�[�V�����̓Q�[������Ȃ��������Ă��Ƃ�
Pixomatic 4�i���j����肽������RAD�[�̖���
ATI��NV�E������Intel�̖�S���g�ݍ��킳�������ʂ�
�n�C�p�[�t�@���^�W�[�y�[�p�[�v���Z�b�T �����x�[
ATI��NV�E������Intel�̖�S���g�ݍ��킳�������ʂ�
�n�C�p�[�t�@���^�W�[�y�[�p�[�v���Z�b�T �����x�[
�����ŋ߂̒c�q�̃n�[�h���������Ђǂ�w��
224 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 20:51:01 ID:W7bdOxGx
�ŏ����猾���Ă�Ǝv�����B
�ӊO�ɂ��d�͌����Ƀt�H�[�J�X�����A�[�L�e�N�`���Ƃ������Ƃ����炩�ɂȂ����̂�
GPU�Ƃ��Ă��\��������Ǝv�����B
�~�b�h�����WGPU���݂̐��\���~�b�h�����WGPU���݂̏���d�͂Ŏ����ł���Ȃ爫���Ȃ�����B
���Ȃ݂Ƀr�b�g�C���^�[���[�u���߂��邯�ǁA���Ɏg��������܂����H
�킩��ˁ[���낤�ȁB
�q���g�F���[�h�E�X�g�A����
�ӊO�ɂ��d�͌����Ƀt�H�[�J�X�����A�[�L�e�N�`���Ƃ������Ƃ����炩�ɂȂ����̂�
GPU�Ƃ��Ă��\��������Ǝv�����B
�~�b�h�����WGPU���݂̐��\���~�b�h�����WGPU���݂̏���d�͂Ŏ����ł���Ȃ爫���Ȃ�����B
���Ȃ݂Ƀr�b�g�C���^�[���[�u���߂��邯�ǁA���Ɏg��������܂����H
�킩��ˁ[���낤�ȁB
�q���g�F���[�h�E�X�g�A����
���т�тł����̓~�h�������W�N���X��GPU�̐��\�͌��킸�����ȁ`
NV��AMD�̓\�t�g�J�����撣��������`
NV��AMD�̓\�t�g�J�����撣��������`
226 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 21:07:52 ID:W7bdOxGx
Pentium 4�������肾�ˁB
TDP���E�������Ă��܂��������[�N�d���ŃV�������N���Ă�����d�͉�����Ȃ�
1KW�⏕�d���ł��p�ӂ��Ȃ��ƍ��܂ł̃y�[�X�Ői���ł��Ȃ��ˁH������
TDP���E�������Ă��܂��������[�N�d���ŃV�������N���Ă�����d�͉�����Ȃ�
1KW�⏕�d���ł��p�ӂ��Ȃ��ƍ��܂ł̃y�[�X�Ői���ł��Ȃ��ˁH������
227 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 21:14:26 ID:W7bdOxGx
40nm����ł�GTX260�N���X���~�b�h�����W�̏���d�͑сi�⏕�d���v�E�s�v�̋��E������j
�ɍ~��Ă���Ƃ����F���ł������ǁA���������Ȃ��悤��
�ɍ~��Ă���Ƃ����F���ł������ǁA���������Ȃ��悤��
�Ƃ������A���~�h���̎�͐��i��GTS250�ł���A�����ׂ��ƁA�O�N�O��
8800GTX����ɂ��������꒷��Z�Ȃ킯�ŁE�E�E�B�Ȃ��N�����ς���
���[�h�}�b�v�����ۂ����B
8800GTX����ɂ��������꒷��Z�Ȃ킯�ŁE�E�E�B�Ȃ��N�����ς���
���[�h�}�b�v�����ۂ����B
�Ƃ���ƃr�b�O�`�b�v��NVIDIA���͂͂₭���E����
230 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 21:32:04 ID:W7bdOxGx
Intel�͐����L���p�̌���r�b�O�`�b�v�H�����Ǝv������
�N���b�N�Q�[�e�B���O�E�p���[�Q�[�e�B���O�Ɋ�����
��������d�͂𗎂Ƃ����낤��
�Ƃ������A�Q�[���f�x���b�p�[���E�����ĂȂ����H
�R���V���[�}�ɓ�������A��Ђ��̂��̂��Ȃ��Ȃ�����
�����܂ł��Q�[�������Ȃ�Ƃ͎v��Ȃ������B
�N���b�N�Q�[�e�B���O�E�p���[�Q�[�e�B���O�Ɋ�����
��������d�͂𗎂Ƃ����낤��
�Ƃ������A�Q�[���f�x���b�p�[���E�����ĂȂ����H
�R���V���[�}�ɓ�������A��Ђ��̂��̂��Ȃ��Ȃ�����
�����܂ł��Q�[�������Ȃ�Ƃ͎v��Ȃ������B
���{�ɂ͂܂��G���Q������W���}�C�J
JK�݂͂�Ȍg�т�100�~�A200�~�P�ʂ̃Q�[��������Ă��^^
233 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 22:13:03 ID:W7bdOxGx
GDC�ł͐����Ȃ������悤�����ǁA�r�b�g�C���^�[���[�u�̓q���x���g�Ȑ��p���������ȁB
�u�n�b�J�[�̂��̂��݁v�ɂ��ڂ��Ă�
���Ȃ݂�punpcklbw�{pmovmskb�Ƃ��Ő�������~�e�N�Ƃ������邯��
�u�n�b�J�[�̂��̂��݁v�ɂ��ڂ��Ă�
���Ȃ݂�punpcklbw�{pmovmskb�Ƃ��Ő�������~�e�N�Ƃ������邯��
�唼�̃��[�U�[��PS2�N���X�̃Q�[���Ŗ������Ă�
235 �F,,�E�L�́M�E,,�j��-�������F2009/04/08(��) 22:26:01 ID:W7bdOxGx
���[�����R���s���[�^�����ŋ���Bonanza���ăq���x���g�Ȑ��g���Ă��ˁB
Larrabee��AI�Ɏg������āA���������Ӗ��Ȃ�
�Ǝv���܂����B
Intel�v���Z�b�T���H���ɏ��Ă鎞�オ����Ȃ炻��͂���Ŗʔ�������Ȃ���
Larrabee��AI�Ɏg������āA���������Ӗ��Ȃ�
�Ǝv���܂����B
Intel�v���Z�b�T���H���ɏ��Ă鎞�オ����Ȃ炻��͂���Ŗʔ�������Ȃ���
�����G���W���Ŕ������L�����̂����ς������A���ɗh����Ȃ甃���Ă���Ă�������
�����G���W������Ƃ����o���������悢
http://www.teck.co.jp/gj/products/himebo/anime/anime.html
http://www.teck.co.jp/gj/products/himebo/anime/anime.html
���{�̃G���G�t�͐_�B
���鐫�\���o���ꍇ
���b�g�p�t�H�[�}���X��Njy���N���b�N�͉����A���̕��`�b�v�T�C�Y��傫�����ĕ⊮
�R�X�g�p�t�H�[�}���X��Nj����`�b�v�T�C�Y�����������A���̑���ɃN���b�N���グ�ăJ�o�[
���b�g�p�t�H�[�}���X��Njy���N���b�N�͉����A���̕��`�b�v�T�C�Y��傫�����ĕ⊮
�R�X�g�p�t�H�[�}���X��Nj����`�b�v�T�C�Y�����������A���̑���ɃN���b�N���グ�ăJ�o�[
240 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 00:50:32 ID:ZFwVKAEX
�ȓd�͉��̕������Ȃ�ˁB
���Ƃ���Atom Z550��2GHz�����TDP2.5W�����ǁA��H���V���v���ɂ���̂Ɠ����ɁA
���Z�N���X�^���ɃN���b�N�Q�[�e�B���O�E�p���[�Q�[�e�B���O�̉�H��lj����A
�Ȗ��ȓd�͊Ǘ������邱�ƂŎ������Ă���B
GPU�͂��������d�͂̍œK���Ƃ͂قlj����Ƃ���ɂ���B
���Ă������A�܂Ƃ��ɂ���ĂȂ��Ǝv���B
���Ƃ������ǁALarrabee�̃}�X�N���Z�̖{���͂ȂƎv���H
�}���`�v���N�T���g���ĉ��Z���ʂ��f�X�e�B�l�[�V�����t�B�[���h�Ƀu�����f�B���O�H�ہB
�G�������g���ɃR���g���[���t���[�E�f�[�^�t���[���Ւf����
�u���Z���̂��́v���}�X�N���邱�Ƃ��ł���B
���ƁA�X�J������肭�g�����ƂŃf�[�^�t���[�̍팸������Ă�B
�����x�N�g�����̃��[�h�E�X�g�A�A�h���X�̎Z�o�Ȃ�ăX�J�����W�X�^�ł����������B
�Ƃ��낪�x�N�g���^�̃v���Z�b�T���Ă̂́A�x�N�g���̑S�v�f�œ������Z���₪���ˁB
��ެȰ�?
���Ƃ���Atom Z550��2GHz�����TDP2.5W�����ǁA��H���V���v���ɂ���̂Ɠ����ɁA
���Z�N���X�^���ɃN���b�N�Q�[�e�B���O�E�p���[�Q�[�e�B���O�̉�H��lj����A
�Ȗ��ȓd�͊Ǘ������邱�ƂŎ������Ă���B
GPU�͂��������d�͂̍œK���Ƃ͂قlj����Ƃ���ɂ���B
���Ă������A�܂Ƃ��ɂ���ĂȂ��Ǝv���B
���Ƃ������ǁALarrabee�̃}�X�N���Z�̖{���͂ȂƎv���H
�}���`�v���N�T���g���ĉ��Z���ʂ��f�X�e�B�l�[�V�����t�B�[���h�Ƀu�����f�B���O�H�ہB
�G�������g���ɃR���g���[���t���[�E�f�[�^�t���[���Ւf����
�u���Z���̂��́v���}�X�N���邱�Ƃ��ł���B
���ƁA�X�J������肭�g�����ƂŃf�[�^�t���[�̍팸������Ă�B
�����x�N�g�����̃��[�h�E�X�g�A�A�h���X�̎Z�o�Ȃ�ăX�J�����W�X�^�ł����������B
�Ƃ��낪�x�N�g���^�̃v���Z�b�T���Ă̂́A�x�N�g���̑S�v�f�œ������Z���₪���ˁB
��ެȰ�?
Atom�Ƀp���[�Q�[�e�B���O�E�E�E���ƁE�E�E�H
242 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 01:00:17 ID:ZFwVKAEX
��HPower Gating�͂܂����������ȁH
http://www.anandtech.com/showdoc.aspx?i=3230&p=4
Clock gating (sending the clock signal through a logic gate that can disable it on the fly,
thus shutting off whatever the clock connects to) is an obvious aspect of Silverthorne's design.
All Intel processors use clock gating; Silverthorne simply uses it more aggressively
- the clock going to every "power zone" is gated, something that isn't the case in
mobile Core 2. Each logic cluster (205 total) in Silverthorne is referred to as a Functional
Unit Block (FUB) and the entire chip uses what Intel calls a sea of FUB design.
Each FUB is clock gated and can be disabled independently to optimize for
power consumption.
The cache in Silverthorne is in its own FUB, which apparently isn't the case in mobile Core 2.
GPU������͂��������d�͐���̃m�E�n�E�̘b�������Ƃ��Ȃ��ȁB
http://www.anandtech.com/showdoc.aspx?i=3230&p=4
Clock gating (sending the clock signal through a logic gate that can disable it on the fly,
thus shutting off whatever the clock connects to) is an obvious aspect of Silverthorne's design.
All Intel processors use clock gating; Silverthorne simply uses it more aggressively
- the clock going to every "power zone" is gated, something that isn't the case in
mobile Core 2. Each logic cluster (205 total) in Silverthorne is referred to as a Functional
Unit Block (FUB) and the entire chip uses what Intel calls a sea of FUB design.
Each FUB is clock gated and can be disabled independently to optimize for
power consumption.
The cache in Silverthorne is in its own FUB, which apparently isn't the case in mobile Core 2.
GPU������͂��������d�͐���̃m�E�n�E�̘b�������Ƃ��Ȃ��ȁB
������GPU�Ȃ�N���b�N�Q�[�e�B���O�͕��ʂł���
244 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 01:13:29 ID:ZFwVKAEX
�N���b�N�P�ʂ���Ȃ���msec�P�ʂ����ǂȁB
245 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 01:21:32 ID:ZFwVKAEX
GPU�̎��̃N���b�N�Q�[�e�B���O�������܂ł̃^�C�����O��
Atom��C1,C2�������܂ł̎��Ԃ��Ăǂ������Z���낤��
MONITOR/MWAIT���߂��ăN���b�N�P�ʂŐ���ł��邼�B
Atom��C1,C2�������܂ł̎��Ԃ��Ăǂ������Z���낤��
MONITOR/MWAIT���߂��ăN���b�N�P�ʂŐ���ł��邼�B
�n�[�h�E�F�A����ƃ\�t�g�E�F�A������������ĂȂ����H
�N���b�N�Q�[�e�B���O��C1/C2�X�e�[�g�͓����x���̘b����Ȃ��ł���B
�N���b�N�Q�[�e�B���O��C1/C2�X�e�[�g�͓����x���̘b����Ȃ��ł���B
Larrabee���Č���MS�ɂ��\�j�[�ɂ�������ꂽ�炵���B
248 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 02:00:35 ID:ZFwVKAEX
>>246
msec�P�ʂ���\�t�g�����������������
msec�P�ʂ���\�t�g�����������������
�ǂ�����Ď��ԑ������낤
CPU�Ō���EIST��C'n'Q�݂����Ȃ̂Ɗ��Ⴂ���ĂȂ����H
����͑J�ڎ��ԑ̊��ł��邩��msec�ƌ����̂������邪
CPU�Ō���EIST��C'n'Q�݂����Ȃ̂Ɗ��Ⴂ���ĂȂ����H
����͑J�ڎ��ԑ̊��ł��邩��msec�ƌ����̂������邪
250 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 02:15:36 ID:ZFwVKAEX
http://benchmarkreviews.com/index.php?option=com_content&task=view&id=179&Itemid=72&limit=1&limitstart=13
> The GPU also has clock-gating circuitry, which effectively "shuts down" blocks of the
> GPU which are not being used at a particular time (where time is measured in milliseconds),
> further reducing power during periods of non-peak GPU utilization.
�ĊO�A�\�t�g���䂶��ˁ[�́H��
> The GPU also has clock-gating circuitry, which effectively "shuts down" blocks of the
> GPU which are not being used at a particular time (where time is measured in milliseconds),
> further reducing power during periods of non-peak GPU utilization.
�ĊO�A�\�t�g���䂶��ˁ[�́H��
251 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 02:17:32 ID:ZFwVKAEX
Intel �� Pat Gelsinger ���AIDF �� Larrabee �� Nehalem EX �Ȃǐ���
http://japan.internet.com/webtech/20090408/4.html
http://japan.internet.com/webtech/20090408/4.html
����Intel�I���{���^�C�������_�����O
�^�C�������_�̂Ƃ����ă^�C�����Ƃ�VS�S���v�Z���Ȃ����́H
Xbox360���ƕ��������ő�4�Ȃ̂ōŏ��̃p�X�Ń^�O������炵�����ǁA
Larrabee�Ƃ����Ⴛ�������̂͌����I����Ȃ���ȁB
���Ƃ����ă������ɏ����o���̂��Ȃ��Ǝv�����B
Xbox360���ƕ��������ő�4�Ȃ̂ōŏ��̃p�X�Ń^�O������炵�����ǁA
Larrabee�Ƃ����Ⴛ�������̂͌����I����Ȃ���ȁB
���Ƃ����ă������ɏ����o���̂��Ȃ��Ǝv�����B
254 �F,,�E�L�́M�E,,�j��-�������F2009/04/09(��) 21:11:41 ID:ZFwVKAEX
�Ȃ�̂��߂̋��L�L���b�V������
���̒��ԃo�b�t�@�ǂ����璲�B����H
�e�N�X�`���f�[�^���ʉ߂���x��CPU�����̃f�[�^���U�b�N���N���A����鋤�L�L���b�V���f���炵�X
257 �F,,�E�L�́M�E,,�j��-�������F2009/04/10(��) 04:19:24 ID:oP/L+sZX
�S�Ẵ��[�h�E�X�g�A���߂Ƀm���e���|�����i�L���b�V���������Ȃ��j�w����t���ł�����ǂˁB
1���g��Ȃ��f�[�^�݂͂�ȃm���e���|�����Ń��[�h���邱�ƂɂȂ��B
1���g��Ȃ��f�[�^�݂͂�ȃm���e���|�����Ń��[�h���邱�ƂɂȂ��B
258 �F,,�E�L�́M�E,,�j��-�������F2009/04/10(��) 06:29:13 ID:oP/L+sZX
�]�ڂ��Ă�����
> Intel Gets Ready to Push Ct Out of the Lab
> ttp://www.hpcwire.com/features/Intel-Gets-Ready-to-Push-Ct-Out-of-the-Lab-42634332.html
> Ct�̓x�[�^�ł��N���ɏo��B�ŏ��̐��i�ł�2010�N���ɏo��B
> Ct���g���ő�̗��_�́ACt�̍��x�Ȓ��ۉ��ɂ���ă}�b�s���O�����ߓI�ɍs���邽�߂ɁA
> �v���O���}�[���x�N�^���j�b�g��v���Z�b�T�R�A�𑀍삵����f�[�^�\�����}�b�v����K�v���Ȃ��ƌ������Ƃ��B
> �܂��A���̋Z�p�͌���_�Ɋ�Â��Ă���̂ŋ�����f�b�h���b�N�̖�������邱�Ƃ��o����B
> ����v�Z�ɂ́u�������̊m�ہv�Ɓu�X�P�[���r���e�B�v�Ƃ�����̍������Ct�͂������������邱�Ƃ�ڕW�ɂ��Ă���B
> Ct��C++��STL�̗����P����`�ł̊g���ɂ���Ď�������Ă���A
> Ct�̒���f�[�^�^�C�v�ƃI�y���[�^��p���Ċ����̃R�[�h���������邱�ƂŁA
> �R�[�h�̃f�[�^���x���̕��������o�����Ƃ��o����B
> Ct�̒����I�Ȗژ_���̓f�x���b�p�Ƀ��j�[�R�A�փ\�t�g�E�F�A���V�[�����X�ɈڐA�����邱�Ƃł���B
> �]���āA�����ASSE4�ɂ���ăf�[�^����v�Z���s��Nehalem���^�[�Q�b�g�ɍ��ꂽ�A�v���P�[�V�����́A
> Larrabee(LRBni)��SandyBridge(AVX)�Ή��̃A�v���P�[�V�����ɂȂ邾�낤�B
C++��֗��ɂ����悤�Ȍ����SSE�E�}���`�R�A��p�����A�v�������������J���ł��āA
�C��������AVX�ɂ�Larrabee�ɂ��Ή����Ă��A���Ă̂�ڎw���Ă�̂��낤��
OpenCL�͏I�����ۂ���
> Intel Gets Ready to Push Ct Out of the Lab
> ttp://www.hpcwire.com/features/Intel-Gets-Ready-to-Push-Ct-Out-of-the-Lab-42634332.html
> Ct�̓x�[�^�ł��N���ɏo��B�ŏ��̐��i�ł�2010�N���ɏo��B
> Ct���g���ő�̗��_�́ACt�̍��x�Ȓ��ۉ��ɂ���ă}�b�s���O�����ߓI�ɍs���邽�߂ɁA
> �v���O���}�[���x�N�^���j�b�g��v���Z�b�T�R�A�𑀍삵����f�[�^�\�����}�b�v����K�v���Ȃ��ƌ������Ƃ��B
> �܂��A���̋Z�p�͌���_�Ɋ�Â��Ă���̂ŋ�����f�b�h���b�N�̖�������邱�Ƃ��o����B
> ����v�Z�ɂ́u�������̊m�ہv�Ɓu�X�P�[���r���e�B�v�Ƃ�����̍������Ct�͂������������邱�Ƃ�ڕW�ɂ��Ă���B
> Ct��C++��STL�̗����P����`�ł̊g���ɂ���Ď�������Ă���A
> Ct�̒���f�[�^�^�C�v�ƃI�y���[�^��p���Ċ����̃R�[�h���������邱�ƂŁA
> �R�[�h�̃f�[�^���x���̕��������o�����Ƃ��o����B
> Ct�̒����I�Ȗژ_���̓f�x���b�p�Ƀ��j�[�R�A�փ\�t�g�E�F�A���V�[�����X�ɈڐA�����邱�Ƃł���B
> �]���āA�����ASSE4�ɂ���ăf�[�^����v�Z���s��Nehalem���^�[�Q�b�g�ɍ��ꂽ�A�v���P�[�V�����́A
> Larrabee(LRBni)��SandyBridge(AVX)�Ή��̃A�v���P�[�V�����ɂȂ邾�낤�B
C++��֗��ɂ����悤�Ȍ����SSE�E�}���`�R�A��p�����A�v�������������J���ł��āA
�C��������AVX�ɂ�Larrabee�ɂ��Ή����Ă��A���Ă̂�ڎw���Ă�̂��낤��
OpenCL�͏I�����ۂ���
�Ƃ��������݂��B
260 �F,,�E�L�́M�E,,�j��-�������F2009/04/10(��) 07:21:08 ID:oP/L+sZX
������OpenCL�i�j���Ď���GPGPU��p���ꂶ���B
�������CPU�����̊J���ɂ��u�g����v�̂͒m���Ă邪�A���̏ꍇ��"able"�ł�����"useful"�ł͂Ȃ�
N88BASIC��Ajax�ł��܂����Č����Ă������b�g���v�������Ȃ��̂Ɠ����B
MS�Ɏx������ĂȂ����_��Windows�ł̕W�����͖�������
�t��Intel�̒���g����ivec/fvec/dvec�݂����Ȕ�����SIMD�N���X���C�u�����܂�
VC++�W���Ŏ�荞�̂�MS�B
�i���܂�ɔ���������SSE3�ȍ~�̊��̓��b�v����ĂȂ����j
�������CPU�����̊J���ɂ��u�g����v�̂͒m���Ă邪�A���̏ꍇ��"able"�ł�����"useful"�ł͂Ȃ�
N88BASIC��Ajax�ł��܂����Č����Ă������b�g���v�������Ȃ��̂Ɠ����B
MS�Ɏx������ĂȂ����_��Windows�ł̕W�����͖�������
�t��Intel�̒���g����ivec/fvec/dvec�݂����Ȕ�����SIMD�N���X���C�u�����܂�
VC++�W���Ŏ�荞�̂�MS�B
�i���܂�ɔ���������SSE3�ȍ~�̊��̓��b�v����ĂȂ����j
�m�������Ă�ȁB�ƂĂ��d�������v�Z�̎��v�ɑΉ����Ă������E�ł�
Windows���}�C�i�[���������A���̉e��������Ȃɑ����ɏ�����킯���Ȃ�
Windows���}�C�i�[���������A���̉e��������Ȃɑ����ɏ�����킯���Ȃ�
�c�q�Ƃ�������CPU�I�y�R�[�h���^�����
Larrabee�͒P�ɕ��y�x�����Ō����AIntel��CPU�ƍ��ڂ�����Č����Ă����ԈႢ�Ȃ����y�͂���
�ł��P�̂̊g���J�[�h�Ƃ��Ĕ���邩�ǂ����̓L���[�A�v�����������낤��
���̂Ƃ���Larrabee���g�������Ȃ̂�HPC�������Q�[���E�G���R�E�摜�n�̃r�W�l�X�p�r
�r�W�l�X�p�r�̓p�C�����Ȃ����A�G���R�Ɏ����Ă͊C�O�ł͂�������TV��^�悷�镶�����̂�����
����Intel�����̂̓Q�[�����[�J�[�Ɏ��e��������Larrabee�œK���Q�[�����o�����鎖����
�Ԃ����ႯXbox�ɍ̗p�����邱�Ƃɐ�������`�F�b�N���C�g�����E�E�E
�܂�MS�͐헪�セ��͂��Ȃ����낤��
�ł��P�̂̊g���J�[�h�Ƃ��Ĕ���邩�ǂ����̓L���[�A�v�����������낤��
���̂Ƃ���Larrabee���g�������Ȃ̂�HPC�������Q�[���E�G���R�E�摜�n�̃r�W�l�X�p�r
�r�W�l�X�p�r�̓p�C�����Ȃ����A�G���R�Ɏ����Ă͊C�O�ł͂�������TV��^�悷�镶�����̂�����
����Intel�����̂̓Q�[�����[�J�[�Ɏ��e��������Larrabee�œK���Q�[�����o�����鎖����
�Ԃ����ႯXbox�ɍ̗p�����邱�Ƃɐ�������`�F�b�N���C�g�����E�E�E
�܂�MS�͐헪�セ��͂��Ȃ����낤��
264 �FSocket774�F2009/04/10(��) 17:03:24 ID:Jj2Ldl+x
Larrabee���̂͂ǂ�����ALNI�͐V�����X�^���_�[�h�ɂȂ���Ď��ł��ˁB
NV�Ǝ��e�����ɂȂ�Q�[�����ɔ��������W�J�B
���������e�̌��ʂ��o���ɂ́A�n�C�G���h�`�b�v���烍�[�G���h�܂Ń��C���i�b�v���K�v�ł́H
�~�h�������W���`�b�v���������̂ɍœK�����Ă��܂��ƃ��[�U�[������B
NV�Ǝ��e�����ɂȂ�Q�[�����ɔ��������W�J�B
���������e�̌��ʂ��o���ɂ́A�n�C�G���h�`�b�v���烍�[�G���h�܂Ń��C���i�b�v���K�v�ł́H
�~�h�������W���`�b�v���������̂ɍœK�����Ă��܂��ƃ��[�U�[������B
�Ȃ�Ȃ�
�����r�����̊Ԃɂ�16�R�A�ɂȂ��Ă�
�����Ԃ�ڂ��Ȃ�����
�����Ԃ�ڂ��Ȃ�����
267 �F,,�E�L�́M�E,,�j��-�������F2009/04/10(��) 20:45:50 ID:oP/L+sZX
16�R�A�͍ŏ��\���ł��B�⏕�d�������œ������ǂ����̃��C���́B
�n�C�G���h�͂��ꂾ�끨http://pc11.2ch.net/test/read.cgi/jisaku/1235460118/758
���n�]�ʂ�2GHz�Ȃ�16�R�A�ŗ��_�s�[�N1TFLOPS�ŁAGPGPU�Ƃ��Ă�GTX280����ˁB
�iGPU�Ɣ�r���āj��e�ʂ̃L���b�V����ς�ł镪�ėp���͈��|�I�ɏゾ�낤��
�܂��A�������Q�[���pGPU�Ƃ��Ă̐��\�ɋ^�╄�������Ă̂͊m���ɓ��ӂ�����Ȃ��B
�{���Ȃ�Tesla�i���邢��FireStream�j�Ɣ�ׂ�ׂ��㕨���낤
Tesla��炩���GPU�Ƃ��Ă̌Œ��H��o�͌n���͔r������Ă�Larrabee�͎����Ă邪
����͗���̈Ⴂ���Ǝv���̂ł��B
Larrabee�́uGPU�@�\�����C����CPU�R�A�v�Ƃ��āA�ǂ����l�b�N�ɂȂ�̂��A
�s����g���Ē���������K�v�����邩��ȁB
Celeron�Ƃ̍��ڂ͂��̎��̒i�K�B
�t��Tesla��GPU�@�\�������i�����ɂ���̂ŁA���˂�K�v���Ȃ��B
�K�v�Ȃ�Quadro���Ă���ƁB
�n�C�G���h�͂��ꂾ�끨http://pc11.2ch.net/test/read.cgi/jisaku/1235460118/758
���n�]�ʂ�2GHz�Ȃ�16�R�A�ŗ��_�s�[�N1TFLOPS�ŁAGPGPU�Ƃ��Ă�GTX280����ˁB
�iGPU�Ɣ�r���āj��e�ʂ̃L���b�V����ς�ł镪�ėp���͈��|�I�ɏゾ�낤��
�܂��A�������Q�[���pGPU�Ƃ��Ă̐��\�ɋ^�╄�������Ă̂͊m���ɓ��ӂ�����Ȃ��B
�{���Ȃ�Tesla�i���邢��FireStream�j�Ɣ�ׂ�ׂ��㕨���낤
Tesla��炩���GPU�Ƃ��Ă̌Œ��H��o�͌n���͔r������Ă�Larrabee�͎����Ă邪
����͗���̈Ⴂ���Ǝv���̂ł��B
Larrabee�́uGPU�@�\�����C����CPU�R�A�v�Ƃ��āA�ǂ����l�b�N�ɂȂ�̂��A
�s����g���Ē���������K�v�����邩��ȁB
Celeron�Ƃ̍��ڂ͂��̎��̒i�K�B
�t��Tesla��GPU�@�\�������i�����ɂ���̂ŁA���˂�K�v���Ȃ��B
�K�v�Ȃ�Quadro���Ă���ƁB
268 �FSocket774�F2009/04/10(��) 21:20:19 ID:mQ2l8oN+
Intel Larrabee 2009�N�㔼�܂���2010�N�O���ɓo�ꂪ�Z���H
http://happinesslife120.blog31.fc2.com/blog-entry-1744.html
�o��o�鍼�\�ɂȂ�Ȃ����Ƃ��F��
���͂Ȃ��Ƃ�Ct�̃f�L����Ȃ̂��낤�Ȃ�����
1�̃v���O�������_�C�i�~�b�N���R���p�C���ɂ���Ăǂ��܂Ń}���`�R�A�X�P�[���r���e�B���o����̂�
1�̃v���O�������_�C�i�~�b�N���R���p�C���ɂ���Ăǂ��܂Ń}���`�R�A�X�P�[���r���e�B���o����̂�
Itanium����1�i�̃`�b�v�͒��V���{���������
�f�x���b�p�[�ɃT���v���Ƃ��Ĕz�����v���g�^�C�v�̗]����s��ɏo��������������
�f�x���b�p�[�ɃT���v���Ƃ��Ĕz�����v���g�^�C�v�̗]����s��ɏo��������������
Larrabee��45nm-8�R�A��300�o2�A16�R�A��600�o2�N���X��
32nm-16�R�A����300�o2�A22nm-16�R�A����140�o2�Ŏ��܂�
�ŏI�`��22nm-48�R�A�炵������A430�o2�ŏ����\��3�`4T���ĂƂ��납
32nm-16�R�A����300�o2�A22nm-16�R�A����140�o2�Ŏ��܂�
�ŏI�`��22nm-48�R�A�炵������A430�o2�ŏ����\��3�`4T���ĂƂ��납
Larrabee��600mm2�Ə����Ă�t�����X�̃T�C�g���ƁA45nm����48�R�A�A
32nm����64�R�A�����Đ������Ă邯�ǁB
Intel�����N140mm2��Merom���炢��Larrabee����10�R�A���炢�ƌv�Z���Ă�����A
45nm��300mm2��8�R�A���Ă̂͂�����Ȃ�ł��A�R�A�����Ȃ�����Ǝv�����B
32nm����64�R�A�����Đ������Ă邯�ǁB
Intel�����N140mm2��Merom���炢��Larrabee����10�R�A���炢�ƌv�Z���Ă�����A
45nm��300mm2��8�R�A���Ă̂͂�����Ȃ�ł��A�R�A�����Ȃ�����Ǝv�����B
�_���ǂ�łȂ��̂�
10�R�A+4MB��L2�L���b�V����140mm^2����
Penryn��L2�L���b�V����6.0mm^2/MB�Ȃ̂�
16�R�A+4MB��L2�L���b�V������185.6mm^2�ʂɂȂ�v�Z
>Larrabee��45nm-8�R�A��300�o2�A16�R�A��600�o2�N���X��
������Penryn���̃��b�`�R�A��
10�R�A+4MB��L2�L���b�V����140mm^2����
Penryn��L2�L���b�V����6.0mm^2/MB�Ȃ̂�
16�R�A+4MB��L2�L���b�V������185.6mm^2�ʂɂȂ�v�Z
>Larrabee��45nm-8�R�A��300�o2�A16�R�A��600�o2�N���X��
������Penryn���̃��b�`�R�A��
10�N�O�͖��߃��x���̕���Nj�����
���̓f�[�^���x���̕���Nj�����Ƃ�
���@�̃R���p�C������i�Ƃ��̑����ԃ��C���[����j�����āI
�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`
�]���̃X�[�p�[�E�X�P�[��RISC�ł́C�����\���ǂ����̓v���Z�b�T���Ŕ��f����Ă����B
���̂��߃v���Z�b�T�����Ŗ��ߓ��e����͂���K�v������C���ꂪ�v���Z�b�T�������\������
��ł̑傫�ȕǂɂȂ��Ă����B�܂��C�����\���ۂ��̓R�[�h�̔z��ɂ��ˑ�����B
���̂��߃v���O�����ɂ���Ă͕����̌��ʂ��ő���ɔ����ł��Ȃ��Ƃ������������Ă����B
����ɑ���EPIC�ł̓v���O�������R���p�C�������͂��C�������ł������I�ɍs����R�[�h������B
���̂��߃v���Z�b�T�͕����\���ۂ�����͂���K�v���Ȃ��C�R���p�C�����쐬���������\
�ȃR�[�h�����s���邾���ł����B�܂�n�[�h�E�G�A�i�v���Z�b�T�j�Ɋ��S�Ɉˑ�����̂ł͂Ȃ��C
�n�[�h�E�G�A�ƃ\�t�g�E�G�A�i�R���p�C���j�������S����̂ł���B�����̕��@���ǂ����邩�́C
�\�t�g�E�G�A�ɔC�����������s���̌����������C��荂�x�Ȏ�@���������₷���B�n�[�h�E�G�A��
���V���v���ȍ\���ɂ���āC�^����ꂽ���߂������ɏ������邱�Ƃɐ�O�ł���̂��B
���̂悤�ȃA�v���[�`�ɂ���āC�C���e�� Itanium 2 �v���Z�b�T�̓X�[�p�[�E�X�P�[��RISC���͂邩��
���킷������\�͂����������B��v��RISC�v���Z�b�T�ł́C1�T�C�N���œ������s�ł��閽�ߐ�
�͍ő�ł�4���߁B����ɑ��ăC���e�� Itanium 2 �v���Z�b�T�́C�����_�ōő�6���߂����s�ł���B
���̓f�[�^���x���̕���Nj�����Ƃ�
���@�̃R���p�C������i�Ƃ��̑����ԃ��C���[����j�����āI
�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`
�]���̃X�[�p�[�E�X�P�[��RISC�ł́C�����\���ǂ����̓v���Z�b�T���Ŕ��f����Ă����B
���̂��߃v���Z�b�T�����Ŗ��ߓ��e����͂���K�v������C���ꂪ�v���Z�b�T�������\������
��ł̑傫�ȕǂɂȂ��Ă����B�܂��C�����\���ۂ��̓R�[�h�̔z��ɂ��ˑ�����B
���̂��߃v���O�����ɂ���Ă͕����̌��ʂ��ő���ɔ����ł��Ȃ��Ƃ������������Ă����B
����ɑ���EPIC�ł̓v���O�������R���p�C�������͂��C�������ł������I�ɍs����R�[�h������B
���̂��߃v���Z�b�T�͕����\���ۂ�����͂���K�v���Ȃ��C�R���p�C�����쐬���������\
�ȃR�[�h�����s���邾���ł����B�܂�n�[�h�E�G�A�i�v���Z�b�T�j�Ɋ��S�Ɉˑ�����̂ł͂Ȃ��C
�n�[�h�E�G�A�ƃ\�t�g�E�G�A�i�R���p�C���j�������S����̂ł���B�����̕��@���ǂ����邩�́C
�\�t�g�E�G�A�ɔC�����������s���̌����������C��荂�x�Ȏ�@���������₷���B�n�[�h�E�G�A��
���V���v���ȍ\���ɂ���āC�^����ꂽ���߂������ɏ������邱�Ƃɐ�O�ł���̂��B
���̂悤�ȃA�v���[�`�ɂ���āC�C���e�� Itanium 2 �v���Z�b�T�̓X�[�p�[�E�X�P�[��RISC���͂邩��
���킷������\�͂����������B��v��RISC�v���Z�b�T�ł́C1�T�C�N���œ������s�ł��閽�ߐ�
�͍ő�ł�4���߁B����ɑ��ăC���e�� Itanium 2 �v���Z�b�T�́C�����_�ōő�6���߂����s�ł���B
�R���p�C���������ł���Ɗ��Ⴂ���Ăł����̂�EPIC
Ct�ł̓}�����������撣���
CELL��CUDA�̗l�Ȕ�l���I�ȗv���͂��Ȃ��Ƃ���������
Ct�ł̓}�����������撣���
CELL��CUDA�̗l�Ȕ�l���I�ȗv���͂��Ȃ��Ƃ���������
>>270
�ǂ�ȃR�A���A�L���b�V���T�C�Y�A�������o���h���A�x�N�^���ł�
�X�P�[���r���e�B�������o����Daynamically reoptimaize�Ɋ��҂��܂��傤�O�O
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai_10.jpg
���C���e���W�F���X�Ȓ��ۉ��@�\�������ɍœK�����Ă���܂��O�O
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai_11.jpg
�ǂ�ȃR�A���A�L���b�V���T�C�Y�A�������o���h���A�x�N�^���ł�
�X�P�[���r���e�B�������o����Daynamically reoptimaize�Ɋ��҂��܂��傤�O�O
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai_10.jpg
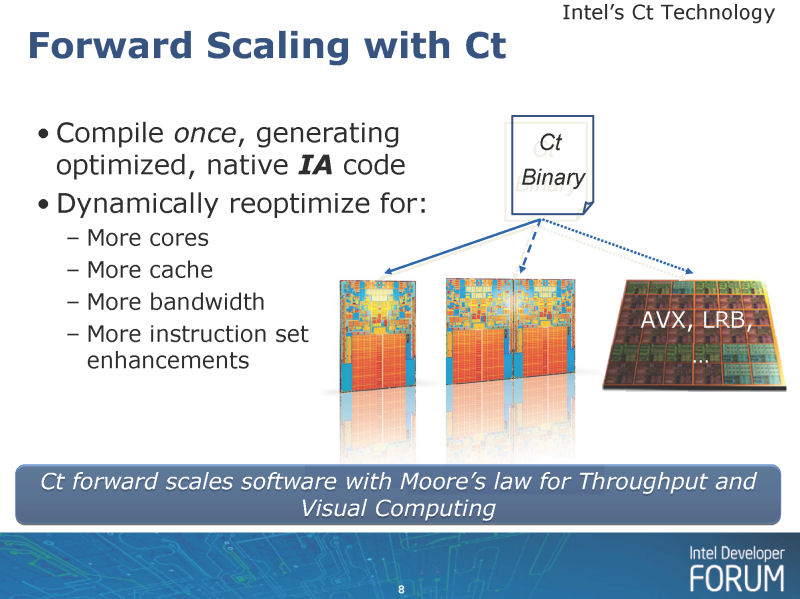{kind=link}
���C���e���W�F���X�Ȓ��ۉ��@�\�������ɍœK�����Ă���܂��O�O
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai_11.jpg
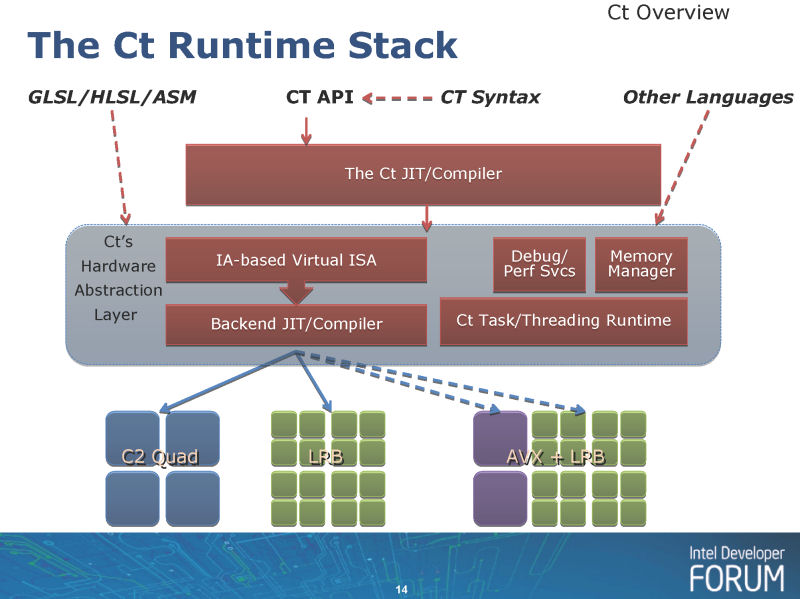{kind=link}
�������O��AnVIDIA�l���Ƃ��Ƃ�VIA��H���Ē�������CPU���o���Ă���邱�Ƃ��F���Ƃɖ߂��
nv�ׂ͒�邾������
ION�v���b�g�t�H�[�������ւɂȂ����ȏ�K�v�Ȃ�����B
x86�s���intel�ȊO�ׂ͖���Ȃ��d�g�݂ɂȂ��Ă邩��ȁB
x86�s���intel�ȊO�ׂ͖���Ȃ��d�g�݂ɂȂ��Ă邩��ȁB
281 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 16:21:46 ID:4rAUMB1v
CUDA�͂ˁA
SIMD�̊e�G�������g��Thread�Ƃ����T�O�ɒ��ۉ�����̂͂����̂���
switch���Ƃ��r��return�Ƃ��������N�\�x����
���nj��̃n�[�h�E�F�A��SIMD�ł��ĂȂ��Ƃ������Ƃ��ӎ����Ȃ��Ƃ����Ȃ�
�ӎ����ď����Ȃ���CPU�̔����̐��\���܂܂Ȃ�Ȃ��㕨
�Ƃ������ƁB
Intel�̓x�N�g���Ƃ����T�O���B�������Ȃ��B
STL�ōs�Z�Ƃ���������Ƃ���l�Ȃ璼���I�Ɏg�����Ƃ��ł��邾�낤
����d�l�Ƃ��Ă�Ct�̂ق��������Ȃ����ۉ����Ă�B
SIMD�̊e�G�������g��Thread�Ƃ����T�O�ɒ��ۉ�����̂͂����̂���
switch���Ƃ��r��return�Ƃ��������N�\�x����
���nj��̃n�[�h�E�F�A��SIMD�ł��ĂȂ��Ƃ������Ƃ��ӎ����Ȃ��Ƃ����Ȃ�
�ӎ����ď����Ȃ���CPU�̔����̐��\���܂܂Ȃ�Ȃ��㕨
�Ƃ������ƁB
Intel�̓x�N�g���Ƃ����T�O���B�������Ȃ��B
STL�ōs�Z�Ƃ���������Ƃ���l�Ȃ璼���I�Ɏg�����Ƃ��ł��邾�낤
����d�l�Ƃ��Ă�Ct�̂ق��������Ȃ����ۉ����Ă�B
>>273
��140mm2��Merom���炢��Larrabee����10�R�A���炢
�����I/O������o�X�AGPU�Ƃ��Ă̌㏈�����j�b�g�̕�����������
�����ȉ��Z���j�b�g���������ł̘b�ł���
�ėp����t�^���邽�߂ɑ��ʂ̃g�����W�X�^���g����X86�Ή���H�A�ʐό����̈���MIMD�A�����O�o�X�i������16�R�A�ȏ�ł�2�K�w�j��
�g���ď�600mm2��48�R�A�˂����߂�ƂȂ�ƁA�P���v�Z�Ńg�����W�X�^������̌����͊���GPU�̐��{�ɂȂ�
���ꂶ��s�[�N���\�͒Ⴂ���ėp���ɗD�ꂽ�E�E�E�Ȃǂƌ����b�͐�����Ԃ�
��140mm2��Merom���炢��Larrabee����10�R�A���炢
�����I/O������o�X�AGPU�Ƃ��Ă̌㏈�����j�b�g�̕�����������
�����ȉ��Z���j�b�g���������ł̘b�ł���
�ėp����t�^���邽�߂ɑ��ʂ̃g�����W�X�^���g����X86�Ή���H�A�ʐό����̈���MIMD�A�����O�o�X�i������16�R�A�ȏ�ł�2�K�w�j��
�g���ď�600mm2��48�R�A�˂����߂�ƂȂ�ƁA�P���v�Z�Ńg�����W�X�^������̌����͊���GPU�̐��{�ɂȂ�
���ꂶ��s�[�N���\�͒Ⴂ���ėp���ɗD�ꂽ�E�E�E�Ȃǂƌ����b�͐�����Ԃ�
��GPU�Ƃ��Ă̌㏈�����j�b�g
����Ȃ���́H �e�N�X�`�����˂��˃��j�b�g��������ˌŒ�Ȃ�
����Ȃ���́H �e�N�X�`�����˂��˃��j�b�g��������ˌŒ�Ȃ�
>�e�N�X�`�����˂��˃��j�b�g��������ˌŒ�Ȃ�
���̒ʂ�B
���̒ʂ�B
285 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 21:41:09 ID:4rAUMB1v
>>282
���̂��[�A�Q�[������肽���Ȃ�Q�[���pGPU���������W�����B
�l�炻�������̋��߂ĂȂ����炳�B
48�R�A��3TFLOPS�ł�������Ă��Ǝ��̂��A�d�͌����̍����̏ؖ��ɂȂ��Ă���B
�Öق�300W����̔��肪���邩��ˁB
GTX295�Ȃ��1.5TFLOPS���x����B
���̂��[�A�Q�[������肽���Ȃ�Q�[���pGPU���������W�����B
�l�炻�������̋��߂ĂȂ����炳�B
48�R�A��3TFLOPS�ł�������Ă��Ǝ��̂��A�d�͌����̍����̏ؖ��ɂȂ��Ă���B
�Öق�300W����̔��肪���邩��ˁB
GTX295�Ȃ��1.5TFLOPS���x����B
�����I
���ʂ�RVxxx��GTxxx�����܂�
���ʂ�RVxxx��GTxxx�����܂�
GPU�͒P���ɃV�F�[�_�[�����Ƀg�����W�X�^�S����������Ă킯�ɂ�����ˁ[
ROP��������ʁE�o���h���Ȃ��o�����X�ǂ����b�`�ɂ��ɂႢ����
ROP��������ʁE�o���h���Ȃ��o�����X�ǂ����b�`�ɂ��ɂႢ����
288 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 21:56:05 ID:4rAUMB1v
��GPGPU�p�r�ň���������Ă̂͑�O��ŃQ�[���͓�̎��ł��傤
���オ�\�t�g�����_�ɂȂ�̂�҂݂����ȁB
�Q�[���Ȃ̂��߂�GPU�̐����ɐ��艺����C�͂Ȃ��ł��傤�B���炩�ɁB
�t�ɂ��AGT300�Ƃ��K�v�ȃQ�[���Ƃ����ďo��́H
�}�b�v��I�u�W�F�N�g�̃f�[�^�ǂݏo�����l�b�N������A�X�g���[�W�ɋ��������ق����}�V�ɂȂ肻�������ǁB
���オ�\�t�g�����_�ɂȂ�̂�҂݂����ȁB
�Q�[���Ȃ̂��߂�GPU�̐����ɐ��艺����C�͂Ȃ��ł��傤�B���炩�ɁB
�t�ɂ��AGT300�Ƃ��K�v�ȃQ�[���Ƃ����ďo��́H
�}�b�v��I�u�W�F�N�g�̃f�[�^�ǂݏo�����l�b�N������A�X�g���[�W�ɋ��������ق����}�V�ɂȂ肻�������ǁB
Memory I/F������ȂɃg�����W�X�^����
GPU�̃g�����W�X�^����͑f�l�ɂ͕���Â炢�ȁB��GT200��SP�������
���W�X�^��4�{�ɂȂ��Ăǂꂭ�炢�g�����W�X�^������̂��Ƃ��悭�킩���
���W�X�^��4�{�ɂȂ��Ăǂꂭ�炢�g�����W�X�^������̂��Ƃ��悭�킩���
291 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 22:25:14 ID:4rAUMB1v
������I/F�̓g�����W�X�^�͐H�u���v�Ȃ�����������Ȃ����ȁB
�M���x���傫���Ȃ邩��
�M���x���傫���Ȃ邩��
R600�̃����O�o�X�͂Q�������ł���
293 �FMAC�I�^���c�q �����F2009/04/11(�y) 22:40:21 ID:beOBX2xO
>>291
�@�@----------------
�@�@�M���x���傫���Ȃ邩��
�@�@----------------
�ǂ��ł���ȃg���f�������o���Ă������c
http://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765504.jpg.html
�@�@----------------
�@�@�M���x���傫���Ȃ邩��
�@�@----------------
�ǂ��ł���ȃg���f�������o���Ă������c
http://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765504.jpg.html
{kind=link}
294 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 22:41:08 ID:4rAUMB1v
Larrabee�̃����O��Cell��EIB�Ɠ����x���낤���ǂˑш�I�ɂ�
R600�������O�Ȃ͔̂M�̕��U�ׂ̈�����̂�
296 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 22:43:19 ID:4rAUMB1v
Cell�i�j�i�j�i�j�i�j�i�j�i�j
���Ȃ݂�GPU�̃������ш�ˑ��x��CPU��Cell�Ɣ�ׂ��̂ɂȂ�Ȃ���
���Ȃ݂�GPU�̃������ш�ˑ��x��CPU��Cell�Ɣ�ׂ��̂ɂȂ�Ȃ���
297 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 22:45:41 ID:4rAUMB1v
�g�����W�X�^������Ȃ��ăR�X�g���낤�B
�L���b�V���͔M���x���Ⴂ���APentium M�ł͂��ꎩ�̂�
�q�[�g�X�v���b�_�Ƃ��Ă̕���p�����҂���L2��傫�������ӂ�������B
�L���b�V���͔M���x���Ⴂ���APentium M�ł͂��ꎩ�̂�
�q�[�g�X�v���b�_�Ƃ��Ă̕���p�����҂���L2��傫�������ӂ�������B
298 �FMAC�I�^���c�q �����F2009/04/11(�y) 22:50:14 ID:beOBX2xO
>>296
�@�@-------------
�@�@���Ȃ݂�GPU�̃������ш�ˑ��x��CPU��Cell�Ɣ�ׂ��̂ɂȂ�Ȃ���
�@�@-------------
�m����GPU�̉��x/�M���z�̃f�[�^���������Ƃ͂Ȃ��ł��ˁB
���̂�������������Љ�܂��傤�B
�@�@-------------
�@�@���Ȃ݂�GPU�̃������ш�ˑ��x��CPU��Cell�Ɣ�ׂ��̂ɂȂ�Ȃ���
�@�@-------------
�m����GPU�̉��x/�M���z�̃f�[�^���������Ƃ͂Ȃ��ł��ˁB
���̂�������������Љ�܂��傤�B
299 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 23:07:16 ID:4rAUMB1v
RAMBUS�������ɂ̓������]���ш擖�������d�͂�Gbit������0.5W
300 �F,,�E�L�́M�E,,�j��-�������F2009/04/11(�y) 23:07:32 ID:4rAUMB1v
GDDR5�̂�
301 �FMAC�I�^���c�q �����F2009/04/11(�y) 23:57:24 ID:beOBX2xO
>>297
�@�@--------------
�@�@�L���b�V���͔M���x���Ⴂ���A
�@�@--------------
�M���x���Ⴂ�̂́A�A�N�Z�X�p�x��������"L2"�ȍ~�̃L���b�V������̘b�ł��B
L1�L���b�V���̏���d�͔͂��ɑ傫���̂ł���B
�ÓT�I�ȎQ�l�����ł����ATable 1�Ƃ����ǂ����B
ftp://ftp.cs.utexas.edu/pub/techreports/tr03-20.pdf
�@�@--------------
�@�@�L���b�V���͔M���x���Ⴂ���A
�@�@--------------
�M���x���Ⴂ�̂́A�A�N�Z�X�p�x��������"L2"�ȍ~�̃L���b�V������̘b�ł��B
L1�L���b�V���̏���d�͔͂��ɑ傫���̂ł���B
�ÓT�I�ȎQ�l�����ł����ATable 1�Ƃ����ǂ����B
ftp://ftp.cs.utexas.edu/pub/techreports/tr03-20.pdf
302 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 00:05:38 ID:/CCtSOFj
�펯�B�Ȃɂӂ��ɁB
���ڃA�h���b�V���O�ł���_��Intel�A�[�L��L1��GPU�̃��W�X�^�t�@�C���Ǝ����悤�ȃ��������B
���ڃA�h���b�V���O�ł���_��Intel�A�[�L��L1��GPU�̃��W�X�^�t�@�C���Ǝ����悤�ȃ��������B
>>285
Larrabee�̐��\�����Ȃ�Ęb�͂��ĂȂ���
45nm�����600mm2�̃`�b�v��48�R�A�l�ߍ��߂�Ƃ���Ə����\�͂�3T�O��
����͐��\�����܂�ɂ��g��������h���Č����Ă��
GT200��45nm�ɃV�������N����600mm2�܂Ŋg�����Ă�2T�O��ɂ����Ȃ�Ȃ�
�Ȃ̂Ƀs�[�N���\���ėp���ɏd�_��u����Larrabee��3T�H
�悤�����>>273�́w45nm-600mm2�̃`�b�v��48�R�A�ڂ��Ă邩���`��x
���ė\���͊��҂���������Ȃ����H���Ă���
�ʂ�Larrabee�����Ȃ��Ă�ᖳ��
Larrabee�̐��\�����Ȃ�Ęb�͂��ĂȂ���
45nm�����600mm2�̃`�b�v��48�R�A�l�ߍ��߂�Ƃ���Ə����\�͂�3T�O��
����͐��\�����܂�ɂ��g��������h���Č����Ă��
GT200��45nm�ɃV�������N����600mm2�܂Ŋg�����Ă�2T�O��ɂ����Ȃ�Ȃ�
�Ȃ̂Ƀs�[�N���\���ėp���ɏd�_��u����Larrabee��3T�H
�悤�����>>273�́w45nm-600mm2�̃`�b�v��48�R�A�ڂ��Ă邩���`��x
���ė\���͊��҂���������Ȃ����H���Ă���
�ʂ�Larrabee�����Ȃ��Ă�ᖳ��
305 �FMAC�I�^���c�q �����F2009/04/12(��) 00:33:55 ID:A0Wr6FLY
>>302
�@�@----------------
�@�@���ڃA�h���b�V���O�ł���_��
�@�@----------------
������Ɩϑz�����Ă���悤�ȁc
�������A�h���X�������Ɏ��邱�Ƃ�������L1���u���ڃA�h���V���O�ł���v�Ƃ͌���Ȃ��̂ł́H
�@�@----------------
�@�@���ڃA�h���b�V���O�ł���_��
�@�@----------------
������Ɩϑz�����Ă���悤�ȁc
�������A�h���X�������Ɏ��邱�Ƃ�������L1���u���ڃA�h���V���O�ł���v�Ƃ͌���Ȃ��̂ł́H
306 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 00:42:03 ID:/CCtSOFj
http://www.overclockers.com.ua/news/hardware/2009-04-10/103617/
> �B��-�r����������, �����p�|�� �y�x�r�u�����~�� ���q ���r�u�|�y���u�~�y�y
> �r���x�}���w�~���s�� �{���|�y���u�����r�p ���t�u�� ���������r���s�� �s���p���y���u���{���s��
> ���y���p Intel Larrabee �� 40-48 �t�� 64 �������{.
> �B��-�r����������, �����p�|�� �y�x�r�u�����~�� ���q ���r�u�|�y���u�~�y�y
> �r���x�}���w�~���s�� �{���|�y���u�����r�p ���t�u�� ���������r���s�� �s���p���y���u���{���s��
> ���y���p Intel Larrabee �� 40-48 �t�� 64 �������{.
307 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 00:44:23 ID:/CCtSOFj
>>306
Atom�ɂ���L1 Read��p�̃X�e�[�W������̂��m��Ȃ��̂�
�����������m��Ȃ��̂�
����ƁA���W�X�^�I�Ɏg������Ă̂�Intel�̒��̐l���g�̌��t����
����Larrabee�̏ꍇ�L���b�V�����C���̃T�C�Y�ƃx�N�^����32�o�C�g�ň�v���Ă�
Atom�ɂ���L1 Read��p�̃X�e�[�W������̂��m��Ȃ��̂�
�����������m��Ȃ��̂�
����ƁA���W�X�^�I�Ɏg������Ă̂�Intel�̒��̐l���g�̌��t����
����Larrabee�̏ꍇ�L���b�V�����C���̃T�C�Y�ƃx�N�^����32�o�C�g�ň�v���Ă�
308 �FMAC�I�^���c�q �����F2009/04/12(��) 00:48:48 ID:A0Wr6FLY
>>306
����\�[�X��>>273�̕������p���Ă���t�����X�̃T�C�g�ł���B
�@�@-----------------
�@�@�I���������~�y�{:
�@�@HardWare France
�@�@-----------------
�ǂ߂Ȃ��̂Ȃ�C�O�T�C�g�����p����ƒp�������܂����B
����\�[�X��>>273�̕������p���Ă���t�����X�̃T�C�g�ł���B
�@�@-----------------
�@�@�I���������~�y�{:
�@�@HardWare France
�@�@-----------------
�ǂ߂Ȃ��̂Ȃ�C�O�T�C�g�����p����ƒp�������܂����B
309 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 00:49:53 ID:/CCtSOFj
> �uLarrabee�ł�L1�L���b�V�������W�X�^�̉����ƍl���邱�Ƃ��ł���v��Intel��Tom Forsyth���͐�������B
http://pc.watch.impress.co.jp/docs/2009/0330/kaigai498.htm
http://pc.watch.impress.co.jp/docs/2009/0330/kaigai498.htm
310 �FMAC�I�^���c�q �����F2009/04/12(��) 00:55:20 ID:A0Wr6FLY
>>309
�u���ڃA�h���V���O�ł���v�Ƃ����̂Ƃ͈Ӗ��������Ⴄ�悤�ȁc
CELL�ɂ�����128�̃��W�X�^��L0-cache�ł���Ƃ����̂Ɠ����悤�ɁA�g�����̘b��ł���B
�u���ڃA�h���V���O�ł���v�Ƃ����̂Ƃ͈Ӗ��������Ⴄ�悤�ȁc
CELL�ɂ�����128�̃��W�X�^��L0-cache�ł���Ƃ����̂Ɠ����悤�ɁA�g�����̘b��ł���B
311 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 01:07:16 ID:/CCtSOFj
���x�ł������Ă�邪L1���[�h�̓p�C�v���C���ɑg�ݍ��܂�Ă��B
addps v1, v2, [mem]��1�N���b�N�T�C�N���̃X���[�v�b�g�ł��Ȃ���
addps v1, v2, [mem]��1�N���b�N�T�C�N���̃X���[�v�b�g�ł��Ȃ���
312 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 01:16:46 ID:/CCtSOFj
SPU��shufb�Ń��b�N�A�b�v�\�ȃe�[�u����2�{�̃��W�X�^�Ɏ��܂�32byte���������A
Larrabee�̏ꍇ��32KB��L1�L���b�V���S�̂�
��������T�C�N���������Ă����Ȃ�AL1�Ɏ��܂�K�v���Ȃ�����
>>307��64�o�C�g�̊ԈႢ��
Larrabee�̏ꍇ��32KB��L1�L���b�V���S�̂�
��������T�C�N���������Ă����Ȃ�AL1�Ɏ��܂�K�v���Ȃ�����
>>307��64�o�C�g�̊ԈႢ��
313 �FMAC�I�^���c�q �����F2009/04/12(��) 01:26:05 ID:A0Wr6FLY
>>311-312
���߂ĈӖ��𗝉����ď����Ă���Ǝv�������̂ł����c
���߂ĈӖ��𗝉����ď����Ă���Ǝv�������̂ł����c
314 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 01:35:15 ID:/CCtSOFj
������load���߂Ɖ��Z���߂ɕ�������ď��������Ǝv������ł���ȁi�j
315 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 05:08:51 ID:/CCtSOFj
GT200�̃��W�X�^�t�@�C���̃��C�e���V��64KB�������肷�邯�ǂ��̕����C�e���V�͑傫����
���W�X�^������L���b�V����葬���Ȃ�ČŒ�ϔO�͎̂Ăĉ�������
���W�X�^������L���b�V����葬���Ȃ�ČŒ�ϔO�͎̂Ăĉ�������
316 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 05:16:25 ID:/CCtSOFj
�~GT200�̃��W�X�^�t�@�C���̃��C�e���V��64KB�������肷�邯��
��GT200�̃��W�X�^�t�@�C����64KB�������肷�邯��
��GT200�̃��W�X�^�t�@�C����64KB�������肷�邯��
317 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 05:19:08 ID:/CCtSOFj
318 �FMAC�I�^���c�q �����F2009/04/12(��) 08:51:04 ID:A0Wr6FLY
>>317
�@�@-------------------
�@�@GeForce�̔ߎS�ȃ��W�X�^���[�h���C�e���V�̘b��
�@�@-------------------
�Ӗ����������Ă��܂����H�ш敝�̖��̂悤�ł��B
�@�@===================
�@�@- operand gather:
�@�@Input operands from registers are read sequentially from the same bank(s) of the register file.
�@�@Takes from 2 cycles (1 32-bit input operand) to 12 cycles (3 64-bit input operands).
�@�@(actually 1 to 6 cycles as the RF clock is half the shader clock)
�@�@===================
�ǂʂ�A�ŏ��P�ʂ̃f�[�^�ł̓��W�X�^�̓���N���b�N(�V�F�[�_�[���j�b�g�̔���)���Z��
�V���O���T�C�N���Ƃ̂��ƁB
�@�@-------------------
�@�@GeForce�̔ߎS�ȃ��W�X�^���[�h���C�e���V�̘b��
�@�@-------------------
�Ӗ����������Ă��܂����H�ш敝�̖��̂悤�ł��B
�@�@===================
�@�@- operand gather:
�@�@Input operands from registers are read sequentially from the same bank(s) of the register file.
�@�@Takes from 2 cycles (1 32-bit input operand) to 12 cycles (3 64-bit input operands).
�@�@(actually 1 to 6 cycles as the RF clock is half the shader clock)
�@�@===================
�ǂʂ�A�ŏ��P�ʂ̃f�[�^�ł̓��W�X�^�̓���N���b�N(�V�F�[�_�[���j�b�g�̔���)���Z��
�V���O���T�C�N���Ƃ̂��ƁB
��l������b���Ă�̂������ς蕪����ǂ�
�i�ǂ������������̂����킩���j
�n�b�L�������Ė��f�ł��B
���ɒc�q�͂��̃X���Ɍ���Ȃ����ǂ����A�����܂��邵
��Â��������Ă����Ɋ���I�ɂȂ邵�������ꂵ�����
�Ƃɂ������Ҏ��d���Ă�������
�i�ǂ������������̂����킩���j
�n�b�L�������Ė��f�ł��B
���ɒc�q�͂��̃X���Ɍ���Ȃ����ǂ����A�����܂��邵
��Â��������Ă����Ɋ���I�ɂȂ邵�������ꂵ�����
�Ƃɂ������Ҏ��d���Ă�������
�z���W�j�A�X�̑����R�A�v���Z�b�T���āA�����܂�ǂ����������
17�R�A�Ă��Ƃ��ăS�~����1�I�t����Ⴈ�����Ċm���������Ȃ�
17�R�A�Ă��Ƃ��ăS�~����1�I�t����Ⴈ�����Ċm���������Ȃ�
>>319
���X�������Ă����ʁB��l�������ڂƂ�
���X�������Ă����ʁB��l�������ڂƂ�
322 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 17:05:17 ID:/CCtSOFj
>>318
�킩������H
������A��ʓI��CPU�̃��W�X�^�Ɠ����ړx�Ń��W�X�^������CPU�̃L���b�V����葬��
�Ȃ�Ďv�����ނ͖̂��Ӗ����ƁB
���Ȃ݂�Larrabee�͊e�R�A������{����SIMD���W�X�^����̃��W�X�^���[�h�ш��192B/clk�ŁA
L1����ł�64B/clk�͍Œ����
���N8�����_�ł��������Ă邵�B
�킩������H
������A��ʓI��CPU�̃��W�X�^�Ɠ����ړx�Ń��W�X�^������CPU�̃L���b�V����葬��
�Ȃ�Ďv�����ނ͖̂��Ӗ����ƁB
���Ȃ݂�Larrabee�͊e�R�A������{����SIMD���W�X�^����̃��W�X�^���[�h�ш��192B/clk�ŁA
L1����ł�64B/clk�͍Œ����
���N8�����_�ł��������Ă邵�B
323 �FMAC�I�^��319 �����F2009/04/12(��) 19:25:38 ID:A0Wr6FLY
>>319
�@�@----------------
�@�@��l������b���Ă�̂������ς蕪����ǂ�
�@�@�i�ǂ������������̂����킩���j
�@�@----------------
�����͓��{�ꌗ�̐l�B�ɉ�����ꂽ�A���J�̌f���ł��B�����͈̔͂������ɈقȂ�l��
���邱�Ƃ͓��R�Ȃ�ł���B
��������Ȃ����Ƃ�����A�q�˂Ă���������Ή��A���Ă����ł�����܂��B
������Ƃ����`���`������͕ʂɂ��āA�������e������e�͗����ł���悤�ɂȂ��đ��͖������ƁB
�@�@----------------
�@�@��l������b���Ă�̂������ς蕪����ǂ�
�@�@�i�ǂ������������̂����킩���j
�@�@----------------
�����͓��{�ꌗ�̐l�B�ɉ�����ꂽ�A���J�̌f���ł��B�����͈̔͂������ɈقȂ�l��
���邱�Ƃ͓��R�Ȃ�ł���B
��������Ȃ����Ƃ�����A�q�˂Ă���������Ή��A���Ă����ł�����܂��B
������Ƃ����`���`������͕ʂɂ��āA�������e������e�͗����ł���悤�ɂȂ��đ��͖������ƁB
324 �FMAC�I�^���c�q �����F2009/04/12(��) 19:32:18 ID:A0Wr6FLY
>>322
�@�@---------------
�@�@�킩������H
�@�@---------------
�S�R�B
GPU�̂悤�ȃ��j�C�R�A�V�X�e���ŁA�o�X��(=�z��)���P�`���č\�����V���v���ɂ��邱�Ƃ�
�P�Ȃ�v��̃g���[�h�I�t�ł��B���C�e���V�I�Ƀo�X�����̃f�[�^���V���O���T�C�N����
�ǂݏ������邱�Ƃ́A�A�h���X�ϊ���K�v�Ƃ���L1�L���b�V���ɂ͖����ł��B
���傤�ǃf�o�C�X�h���C�o�o�R�ł̃A�N�Z�X���K�v��HDD��̉��z���������u�����������Ɠ����v
�Ƌ��ق���̂Ɠ������Ƃ��Ǝv���܂��H
�@�@---------------
�@�@�킩������H
�@�@---------------
�S�R�B
GPU�̂悤�ȃ��j�C�R�A�V�X�e���ŁA�o�X��(=�z��)���P�`���č\�����V���v���ɂ��邱�Ƃ�
�P�Ȃ�v��̃g���[�h�I�t�ł��B���C�e���V�I�Ƀo�X�����̃f�[�^���V���O���T�C�N����
�ǂݏ������邱�Ƃ́A�A�h���X�ϊ���K�v�Ƃ���L1�L���b�V���ɂ͖����ł��B
���傤�ǃf�o�C�X�h���C�o�o�R�ł̃A�N�Z�X���K�v��HDD��̉��z���������u�����������Ɠ����v
�Ƌ��ق���̂Ɠ������Ƃ��Ǝv���܂��H
325 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 19:39:03 ID:/CCtSOFj
GeForce�̎������\�̒Ⴓ�͌듚����w�E���Ă��
http://pc.watch.impress.co.jp/docs/2008/0707/kaigai452.htm
GPU���L�̃g���[�h�I�t�i�j��������܂ܔėp�v���Z�b�V���O���ǂ��Ƃ�
�}�̑Ώۂɂ����Ȃ�܂��B
> ���C�e���V�I�Ƀo�X�����̃f�[�^���V���O���T�C�N����
> �ǂݏ������邱�Ƃ́A�A�h���X�ϊ���K�v�Ƃ���L1�L���b�V���ɂ͖����ł��B
1�T�C�N���͗��ɏo����Ƃ͎v��Ȃ����AGPU�̃��W�X�^�t�@�C���݂����Ȓ��x��
�����ŗǂ��Ȃ�\���\���ƌ����Ă�킯�����B
����͂����ƁA������Tera�~3�ł́ALarrabee��L1�̃��C�e���V�͂P����Ȃ��������ȁH
�ܘ_�M���Ă͂��Ȃ��B
http://pc.watch.impress.co.jp/docs/2008/0707/kaigai452.htm
GPU���L�̃g���[�h�I�t�i�j��������܂ܔėp�v���Z�b�V���O���ǂ��Ƃ�
�}�̑Ώۂɂ����Ȃ�܂��B
> ���C�e���V�I�Ƀo�X�����̃f�[�^���V���O���T�C�N����
> �ǂݏ������邱�Ƃ́A�A�h���X�ϊ���K�v�Ƃ���L1�L���b�V���ɂ͖����ł��B
1�T�C�N���͗��ɏo����Ƃ͎v��Ȃ����AGPU�̃��W�X�^�t�@�C���݂����Ȓ��x��
�����ŗǂ��Ȃ�\���\���ƌ����Ă�킯�����B
����͂����ƁA������Tera�~3�ł́ALarrabee��L1�̃��C�e���V�͂P����Ȃ��������ȁH
�ܘ_�M���Ă͂��Ȃ��B
326 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 19:41:17 ID:/CCtSOFj
327 �FMAC�I�^���c�q �����F2009/04/12(��) 19:47:44 ID:A0Wr6FLY
>>325
�@�@-----------------
�@�@GeForce�̎������\�̒Ⴓ�͌듚����w�E���Ă��
�@�@-----------------
>>302����ǂݒ����ė~�����̂ł����A�N��GPU�̃��C�e���V���肵�Ă���̂ł͂Ȃ��A
�u���ڃA�h���V���O�ł��邩�v��₤�Ă���̂ł����H
�@�@-----------------
�@�@GeForce�̎������\�̒Ⴓ�͌듚����w�E���Ă��
�@�@-----------------
>>302����ǂݒ����ė~�����̂ł����A�N��GPU�̃��C�e���V���肵�Ă���̂ł͂Ȃ��A
�u���ڃA�h���V���O�ł��邩�v��₤�Ă���̂ł����H
328 �F,,�E�L�́M�E,,�j��-�������F2009/04/12(��) 19:58:45 ID:/CCtSOFj
���͑ш�ƃ��C�e���V�������ɂ��ĂȂ���
TLB���Q�Ƃ��ăL���b�V���̃^�O���E�E�E�]�X�͎��p�I�ȃN���b�N�ŏo����̂Ȃ牽�̖����Ȃ�
�w�ǂ̖��߂̈�̃��W�X�^�I�y�����h��ModRM + SIB + DISP + imm8�ɂ�郁�����Q�Ƃ�
�u�������邱�Ƃ��o����_�Ŏg������̖ʂł͑S�R���ɂȂ�Ȃ��킯����
�i�ނ��냁��������̃��[�h����Numeric Convert�o����_�ŗe�ʌ����I�ɋ��僌�W�X�^�t�@�C�����D�ʐ�������j
TLB���Q�Ƃ��ăL���b�V���̃^�O���E�E�E�]�X�͎��p�I�ȃN���b�N�ŏo����̂Ȃ牽�̖����Ȃ�
�w�ǂ̖��߂̈�̃��W�X�^�I�y�����h��ModRM + SIB + DISP + imm8�ɂ�郁�����Q�Ƃ�
�u�������邱�Ƃ��o����_�Ŏg������̖ʂł͑S�R���ɂȂ�Ȃ��킯����
�i�ނ��냁��������̃��[�h����Numeric Convert�o����_�ŗe�ʌ����I�ɋ��僌�W�X�^�t�@�C�����D�ʐ�������j
Tera Tera Tera�̃R�A��������̗ʂ���@�����
������Larrabee��2008�N�̔�����2009�N�̓��ɂ͏o���v�悾������˂�����
�܁[�������猾���邱�Ƃ���
������Larrabee��2008�N�̔�����2009�N�̓��ɂ͏o���v�悾������˂�����
�܁[�������猾���邱�Ƃ���
�e�[�v�A�E�g�͂܂����ˁH
332 �FMAC�I�^���c�q �����F2009/04/13(��) 21:10:05 ID:yLL+D6e+
>>328
�@�@-----------------
�@�@�i�ނ��냁��������̃��[�h����Numeric Convert�o����_�ŗe�ʌ����I�ɋ��僌�W�X�^
�@�@�t�@�C�����D�ʐ�������j
�@�@-----------------
���[�h����scatter/gather��conversion���L���Ȃ͔̂ے肵�܂��ADDJ�L��
(http://www.ddj.com/architect/216402188)�ɂ����āA"currently a two(multi)-instruction
sequence. "�Ƃ����������U������邱�Ƃ��猩�Ă��A�ŏ���Larrabee�̎����ɂ����Ă��̋@�\��
�P�Ȃ郍�[�h�E�X�g�A�Ɠ������C�e���V�œ��삷��Ƃ͎v��Ȃ��ق����ǂ����ƁB
�@�@-----------------
�@�@�i�ނ��냁��������̃��[�h����Numeric Convert�o����_�ŗe�ʌ����I�ɋ��僌�W�X�^
�@�@�t�@�C�����D�ʐ�������j
�@�@-----------------
���[�h����scatter/gather��conversion���L���Ȃ͔̂ے肵�܂��ADDJ�L��
(http://www.ddj.com/architect/216402188)�ɂ����āA"currently a two(multi)-instruction
sequence. "�Ƃ����������U������邱�Ƃ��猩�Ă��A�ŏ���Larrabee�̎����ɂ����Ă��̋@�\��
�P�Ȃ郍�[�h�E�X�g�A�Ɠ������C�e���V�œ��삷��Ƃ͎v��Ȃ��ق����ǂ����ƁB
333 �F,,�E�L�́M�E,,�j��-�������F2009/04/13(��) 21:31:09 ID:GQw4NMmU
������O
�t�ɁANumeric Convert�����Ȃ����܂ł���̂Ɠ������C�e���V�ɂȂ��Ă͍��邵
�ߏ�ȃI�y���[�V�������x�̒Nj��͔M���x�����߁A���ʓI�ɐ��\����̑��g��
�Ȃ肩�˂Ȃ�
�t�ɁANumeric Convert�����Ȃ����܂ł���̂Ɠ������C�e���V�ɂȂ��Ă͍��邵
�ߏ�ȃI�y���[�V�������x�̒Nj��͔M���x�����߁A���ʓI�ɐ��\����̑��g��
�Ȃ肩�˂Ȃ�
334 �FMAC�I�^���c�q �����F2009/04/13(��) 21:58:57 ID:yLL+D6e+
>>333
�Ԏ����Ԃ��Ă���x�ɁA�{���ɈӖ��𗝉����Ă��炦�Ă���̂��s���ɂȂ�̂ł����c
�@�@--------------
�@�@�ߏ�ȃI�y���[�V�������x�̒Nj��͔M���x�����߁A���ʓI�ɐ��\����̑��g��
�@�@�Ȃ肩�˂Ȃ�
�@�@--------------
���̎v�����݂Ƌt�ɁAIntel�̕��́w�����͒P�ꖽ�߂ɂ������x�Əq�ׂĂ���̂ł�����ǁA
�����Ă��܂����H�Ⴆ�A
http://www.ddj.com/architect/216402188?pgno=4
�@�@===============
�@�@Figure 12: vgatherd v1 {k1}, [rbx + v2*4]. This is a simplified representation of what is
�@�@currently a hardware-assisted multi-instruction sequence, but will become a single
�@�@instruction in the future.
�@�@===============
�Ԏ����Ԃ��Ă���x�ɁA�{���ɈӖ��𗝉����Ă��炦�Ă���̂��s���ɂȂ�̂ł����c
�@�@--------------
�@�@�ߏ�ȃI�y���[�V�������x�̒Nj��͔M���x�����߁A���ʓI�ɐ��\����̑��g��
�@�@�Ȃ肩�˂Ȃ�
�@�@--------------
���̎v�����݂Ƌt�ɁAIntel�̕��́w�����͒P�ꖽ�߂ɂ������x�Əq�ׂĂ���̂ł�����ǁA
�����Ă��܂����H�Ⴆ�A
http://www.ddj.com/architect/216402188?pgno=4
�@�@===============
�@�@Figure 12: vgatherd v1 {k1}, [rbx + v2*4]. This is a simplified representation of what is
�@�@currently a hardware-assisted multi-instruction sequence, but will become a single
�@�@instruction in the future.
�@�@===============
Larrabee�L���b�V���ł����������^
>>139�͂ǂ�����?���̂�?
>>139�͂ǂ�����?���̂�?
336 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 02:39:46 ID:WBJWfhIq
vgatherd���}�C�N���R�[�h�������Ă̂́@�y����8���ɗ\�������Ƃ���z�@���낗
���Z���j�b�g���ŕ�������Ƃ������Ă��n�������邪�B
�ő�16��̃}�X�N��vloadd �ɓW�J�����낤
�ǂ��ł��āA�Ƃ肠�����̓f�R�[�_����ˁH
������̍ۂɃ}�X�N���W�X�^�̓\�t�g����͌����Ȃ��V���h�E���W�X�^��������g�����ƂɂȂ邾�낤
�ł������Core MA�̂悤�ɏ��Z�푤�œƎ��Ƀ��[�v���܂킵�ď�����������Ȃ��H
���͏����̎������Ă̂�Core MA�ɓ��������ꍇ�̎����Ɏv���Ďd����������
�C���I�[�_�^�v���Z�b�T�ɂ͒P���OP������i�K�ł͂Ȃ��B
>>335
���[�X�g�P�[�X���낢��l���Ă݂����ǁA�ő�T�C�Y�Ȃ�1080p���炢�Ȃ�Ƃ��Ȃ肻�������
���Ԃ�4k���������Ƃ��C�`�����������Ŗ����H��
���Z���j�b�g���ŕ�������Ƃ������Ă��n�������邪�B
�ő�16��̃}�X�N��vloadd �ɓW�J�����낤
�ǂ��ł��āA�Ƃ肠�����̓f�R�[�_����ˁH
������̍ۂɃ}�X�N���W�X�^�̓\�t�g����͌����Ȃ��V���h�E���W�X�^��������g�����ƂɂȂ邾�낤
�ł������Core MA�̂悤�ɏ��Z�푤�œƎ��Ƀ��[�v���܂킵�ď�����������Ȃ��H
���͏����̎������Ă̂�Core MA�ɓ��������ꍇ�̎����Ɏv���Ďd����������
�C���I�[�_�^�v���Z�b�T�ɂ͒P���OP������i�K�ł͂Ȃ��B
>>335
���[�X�g�P�[�X���낢��l���Ă݂����ǁA�ő�T�C�Y�Ȃ�1080p���炢�Ȃ�Ƃ��Ȃ肻�������
���Ԃ�4k���������Ƃ��C�`�����������Ŗ����H��
337 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 02:40:34 ID:WBJWfhIq
���@�ł������Core MA�̏��Z��̂悤��ALU���œƎ��Ƀ��[�v���܂킵�ď�����������Ȃ��H
338 �FMAC�I�^���c�q �����F2009/04/14(��) 05:17:30 ID:emmzXgAm
>>336
�@�@----------------
�@�@vgatherd���}�C�N���R�[�h�������Ă̂́@�y����8���ɗ\�������Ƃ���z�@���낗
�@�@----------------
������Ɠ����̋c�_��ǂ�ł݂܂������A���ꂠ�Ȃ��Ƌc�_���Ă����q�g�B�̋��ʔF��������
�悤�ł����H
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/388
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/400
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/402
�����A�Ō�̃q�g��@�����������Ǝv���܂����A�w�������߂ɕ��������̂́A�L���b�V�����C����
�܂����ꍇ�x�Ƃ����F���͊Ԉ���Ă��Ȃ��悤�ł��B
�@�@----------------
�@�@vgatherd���}�C�N���R�[�h�������Ă̂́@�y����8���ɗ\�������Ƃ���z�@���낗
�@�@----------------
������Ɠ����̋c�_��ǂ�ł݂܂������A���ꂠ�Ȃ��Ƌc�_���Ă����q�g�B�̋��ʔF��������
�悤�ł����H
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/388
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/400
http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/402
�����A�Ō�̃q�g��@�����������Ǝv���܂����A�w�������߂ɕ��������̂́A�L���b�V�����C����
�܂����ꍇ�x�Ƃ����F���͊Ԉ���Ă��Ȃ��悤�ł��B
339 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 05:46:43 ID:WBJWfhIq
�����̓������߂ɕ��������Ȃ�f�R�[�_�ŕ������Ă̂������B
340 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 05:54:05 ID:WBJWfhIq
���[�X�g�P�[�X��16�T�C�N�����Ă̂͋t�ɂ�����Permute/Numeric Conver����у}�X�N��
�[���R�X�g�i���C�e���V�͂Ƃ������X���[�v�b�g�I�ɂ́j���Ă��ƂȁB
�[���R�X�g�i���C�e���V�͂Ƃ������X���[�v�b�g�I�ɂ́j���Ă��ƂȁB
341 �FMAC�I�^���c�q �����F2009/04/14(��) 06:55:44 ID:emmzXgAm
>>339-340
�ׂ������Ƃł����A
�@�@--------------
�@�@�����̓������߂ɕ��������Ȃ�
�@�@--------------
���̂Ƃ���LRBni�̖��߂́w�������߁x�ł͖����A�w(������)���̖��߁x�ɕ�������邾���ł��B
�V����ISA�ł�����A���i�K�ł͖��߂ƃn�[�h�E�F�A�̑Ή��W���ۂ���Ă���̂����R���ƁB
�@�@---------------
�@�@���[�X�g�P�[�X��16�T�C�N��
�@�@---------------
intel�́w16��̃L���b�V���A�N�Z�X���K�v�ɂȂ�x�Əq�ׂĂ��邾���ŁA�T�C�N�����͌��y����
���Ȃ������̂ł́H
http://software.intel.com/en-us/articles/game-physics-performance-on-larrabee/
�@�@================
�@�@The speedup of gather/scatter is limited by the cache, which can usually access
�@�@one cache line per cycle, which may result in 16 accesses to the cache in the worst case.
�@�@================
�ׂ������Ƃł����A
�@�@--------------
�@�@�����̓������߂ɕ��������Ȃ�
�@�@--------------
���̂Ƃ���LRBni�̖��߂́w�������߁x�ł͖����A�w(������)���̖��߁x�ɕ�������邾���ł��B
�V����ISA�ł�����A���i�K�ł͖��߂ƃn�[�h�E�F�A�̑Ή��W���ۂ���Ă���̂����R���ƁB
�@�@---------------
�@�@���[�X�g�P�[�X��16�T�C�N��
�@�@---------------
intel�́w16��̃L���b�V���A�N�Z�X���K�v�ɂȂ�x�Əq�ׂĂ��邾���ŁA�T�C�N�����͌��y����
���Ȃ������̂ł́H
http://software.intel.com/en-us/articles/game-physics-performance-on-larrabee/
�@�@================
�@�@The speedup of gather/scatter is limited by the cache, which can usually access
�@�@one cache line per cycle, which may result in 16 accesses to the cache in the worst case.
�@�@================
342 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:01:18 ID:WBJWfhIq
����ς�{�݂����ȓ��ȂȁB���̘b���Ǝv���Ă�B
http://software.intel.com/file/2093
The VPU instruction set also includes gather and scatter support,
that is, loads and stores from non-contiguous addresses. Instead of
loading a 16-wide vector from a single address, 16 elements are
loaded from or stored to up to 16 different addresses that are
specified in another vector register. This allows 16 shader
instances to be run in parallel, each of which appears to run
serially, even when performing array accesses with computed
indices. The speed of gather/scatter is limited by the cache, which
typically only accesses one cache line per cycle. However, many
workloads have highly coherent access patterns, and therefore
take much less than 16 cycles to execute.
�@�@�@�@�@�@�@~~~~~~~~~~~~~~~~~~~~~
http://software.intel.com/file/2093
The VPU instruction set also includes gather and scatter support,
that is, loads and stores from non-contiguous addresses. Instead of
loading a 16-wide vector from a single address, 16 elements are
loaded from or stored to up to 16 different addresses that are
specified in another vector register. This allows 16 shader
instances to be run in parallel, each of which appears to run
serially, even when performing array accesses with computed
indices. The speed of gather/scatter is limited by the cache, which
typically only accesses one cache line per cycle. However, many
workloads have highly coherent access patterns, and therefore
take much less than 16 cycles to execute.
�@�@�@�@�@�@�@~~~~~~~~~~~~~~~~~~~~~
343 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:06:35 ID:WBJWfhIq
�����̂Ƃ���LRBni�̖��߂́w�������߁x�ł͖����A�w(������)���̖��߁x�ɕ�������邾���ł��B
���߃Z�b�g�Ƃ��Č��J����ĂȂ����̃}�X�N���W�X�^���g�����߂���
�������߂łȂ��ĂȂ�
�n������
���߃Z�b�g�Ƃ��Č��J����ĂȂ����̃}�X�N���W�X�^���g�����߂���
�������߂łȂ��ĂȂ�
�n������
344 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:11:24 ID:WBJWfhIq
�����������̂��߂́u�f�R�[�h�v����
�V�K�̖��߂��낤���v���t�B�b�N�X�̃G���R�[�f�B���O���ς����������x86���̂��̂��B
POWER�]�͋���
�V�K�̖��߂��낤���v���t�B�b�N�X�̃G���R�[�f�B���O���ς����������x86���̂��̂��B
POWER�]�͋���
345 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:16:33 ID:WBJWfhIq
P5�܂ł�x86�̕��������ꂽ���߂�"Instructions"�ƌ����̂ɑ�
�������߂�P��"Operations" (OPs)�ƌĂ�ł��B
P6�ł͂�����X�ɕ������邩��"Micro-Operations"�i��OPs�j�Ȃ킯��
�������߂�P��"Operations" (OPs)�ƌĂ�ł��B
P6�ł͂�����X�ɕ������邩��"Micro-Operations"�i��OPs�j�Ȃ킯��
346 �FMAC�I�^���c�q �����F2009/04/14(��) 07:18:40 ID:emmzXgAm
>>342
����̓L���b�V������̓]���ɕK�v�ȃT�C�N�����̂��ƂŁA���߂̃X���[�v�b�g�^���C�e���V��
�����������ᖳ�����Ƃ͓ǂ߂Δ��邩�ƁB
>>343
����̓��[�h�^�X�g�A�L���[�́w���e�x�ł����āA�����W�X�^�Ƃ͌ĂȂ��Ǝv���܂���B
����̓L���b�V������̓]���ɕK�v�ȃT�C�N�����̂��ƂŁA���߂̃X���[�v�b�g�^���C�e���V��
�����������ᖳ�����Ƃ͓ǂ߂Δ��邩�ƁB
>>343
����̓��[�h�^�X�g�A�L���[�́w���e�x�ł����āA�����W�X�^�Ƃ͌ĂȂ��Ǝv���܂���B
347 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:27:44 ID:WBJWfhIq
������A���߃Z�b�g�Ƃ���k0�`k7�Ƃ͕ʂ̃}�X�N���W�X�^���K�v���B
���[�h�����l���ǂ�����č�������H
�r���Ŋ��荞�݂���������ǂ�����ď�Ԃ�Ҕ�����H
���������ʂ̖��߂ɒu����������demerjian��̖ϑz�̃\�[�X�͂ǂ��ł����H
�f�R�[�_��ʂ�ȏ�V���v�����߂��낤���������߂���B
x86���̂܂܂̃G���R�[�h�`�Ԃ̂܂܃f�R�[�_��ʉ߂��閽�߂ȂǁA�Ȃ��B
����P54C�̃}�j���A�������Ă�����ȋL�q�͌����Ȃ�
���[�h�����l���ǂ�����č�������H
�r���Ŋ��荞�݂���������ǂ�����ď�Ԃ�Ҕ�����H
���������ʂ̖��߂ɒu����������demerjian��̖ϑz�̃\�[�X�͂ǂ��ł����H
�f�R�[�_��ʂ�ȏ�V���v�����߂��낤���������߂���B
x86���̂܂܂̃G���R�[�h�`�Ԃ̂܂܃f�R�[�_��ʉ߂��閽�߂ȂǁA�Ȃ��B
����P54C�̃}�j���A�������Ă�����ȋL�q�͌����Ȃ�
348 �FMAC�I�^���c�q �����F2009/04/14(��) 07:31:48 ID:emmzXgAm
>>347
�@�@--------------
�@�@�f�R�[�_��ʂ�ȏ�V���v�����߂��낤���������߂���B
�@�@--------------
�c�q����̔F���ł�RISC�ɂ̓f�R�[�_���������ƂɂȂ��Ă���̂ł����H
�@�@--------------
�@�@�f�R�[�_��ʂ�ȏ�V���v�����߂��낤���������߂���B
�@�@--------------
�c�q����̔F���ł�RISC�ɂ̓f�R�[�_���������ƂɂȂ��Ă���̂ł����H
349 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 07:40:16 ID:WBJWfhIq
�ϒ����߂قǂɕ��G�ȃ��W�b�N�͕K�v�Ȃ��A�̈ꌾ���ȁB
�\���猩���閽�߂ł͂Ȃ�
���ە\���猩���閽�߂ł͑���Ȃ����Ƃ��킩��B
haddps��Pentium 4�̓���RISC�ł̓V���b�t���~2�Ɖ��Z��3���߂���x86����ł�
�����闠���W�X�^���g����i���Ȃ�
�\���猩���閽�߂ł͂Ȃ�
���ە\���猩���閽�߂ł͑���Ȃ����Ƃ��킩��B
haddps��Pentium 4�̓���RISC�ł̓V���b�t���~2�Ɖ��Z��3���߂���x86����ł�
�����闠���W�X�^���g����i���Ȃ�
350 �FMAC�I�^���c�q �����F2009/04/14(��) 07:46:56 ID:emmzXgAm
>>349
�@�@---------------
�@�@�ϒ����߂قǂɕ��G�ȃ��W�b�N�͕K�v�Ȃ�[���A��͂�������߂ł��邱�Ƃɕς�薳��]
�@�@---------------
�Ƃ������Ƃł�����A�P�Ȃ�\���̈Ⴂ�Ȃ̂Ŋ��ݕt�����؍����͖����ł��ˁB
�@�@---------------
�@�@haddps
�@�@---------------
LRBni�ɂ��̖��߂͌�������܂���B>>341�Ŏ�舵���Ă���b���LRBni�Ǝ����̊W�ł��B
�@�@---------------
�@�@�ϒ����߂قǂɕ��G�ȃ��W�b�N�͕K�v�Ȃ�[���A��͂�������߂ł��邱�Ƃɕς�薳��]
�@�@---------------
�Ƃ������Ƃł�����A�P�Ȃ�\���̈Ⴂ�Ȃ̂Ŋ��ݕt�����؍����͖����ł��ˁB
�@�@---------------
�@�@haddps
�@�@---------------
LRBni�ɂ��̖��߂͌�������܂���B>>341�Ŏ�舵���Ă���b���LRBni�Ǝ����̊W�ł��B
�������߂̒��Ԓl�̃X�g�A�����Ɏg���邢���闠���W�X�^�Ȃ�8086�̎��ォ��m���Ă��B
���Ȃ݂�SSE3��HADDPS�̗�Ȃ�ĕs���̃e���|�������W�X�^��p���镡�����߂�SIMD�ɉ��p�����T�^��
������W�Ȃ��b���Ǝv�����Ⴄ��������s������
������W�Ȃ��b���Ǝv�����Ⴄ��������s������
353 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 20:36:52 ID:WBJWfhIq
���Ă������A�f�R�[�h���ꂽ���߂��u�������߁v����Ȃ���Ȃ�Ȃ́H����������
354 �FMAC�I�^���c�q �����F2009/04/14(��) 21:07:22 ID:emmzXgAm
>>353
�@�@------------------
�@�@���Ă������A�f�R�[�h���ꂽ���߂��u�������߁v����Ȃ���Ȃ�Ȃ�
�@�@------------------
�w���߁x�����Z���s���̂ł͖����A�w�_����H�x�����Z���s���̂ł��B
�@�@------------------
�@�@���Ă������A�f�R�[�h���ꂽ���߂��u�������߁v����Ȃ���Ȃ�Ȃ�
�@�@------------------
�w���߁x�����Z���s���̂ł͖����A�w�_����H�x�����Z���s���̂ł��B
355 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 21:40:31 ID:WBJWfhIq
ALU�͉��Z�E���Z�E�r�b�g�_�����Z��S����ł��̂ł��B
������`���Ă��̂͂�͂�������߂ł���B
����Ƃ��A���ߖ��ɕʁX�̉�H��ʂ��Ă�Ƃł��v���Ă�̂��H��
������`���Ă��̂͂�͂�������߂ł���B
����Ƃ��A���ߖ��ɕʁX�̉�H��ʂ��Ă�Ƃł��v���Ă�̂��H��
356 �FMAC�I�^���c�q �����F2009/04/14(��) 22:01:08 ID:emmzXgAm
>>355
�@�@--------------
�@�@���ߖ��ɕʁX�̉�H��ʂ��Ă�Ƃł��v���Ă�̂��H
�@�@--------------
���̒ʂ�ł���B
���Z��H�Ƃ���Z��H�Ƃ����������Ƃ͂���܂��H
http://journal.mycom.co.jp/column/architecture/070/index.html
http://journal.mycom.co.jp/column/architecture/078/index.html
�@�@--------------
�@�@���ߖ��ɕʁX�̉�H��ʂ��Ă�Ƃł��v���Ă�̂��H
�@�@--------------
���̒ʂ�ł���B
���Z��H�Ƃ���Z��H�Ƃ����������Ƃ͂���܂��H
http://journal.mycom.co.jp/column/architecture/070/index.html
http://journal.mycom.co.jp/column/architecture/078/index.html
357 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 22:12:05 ID:WBJWfhIq
�n��������������������Ō���H��������
�Ӗ��𗝉������
�uALU�v�͎Z�p���Z���_�����Z���ʓ|���܂�����ă��j�b�g��
���O�̘_�����ƌ��Z��_���a�E�_���ςȂNJe�I�y���[�V�������ƂɃ��j�b�g���K�v�ɂȂ邾�낗
�펯�ōl����
�Ӗ��𗝉������
�uALU�v�͎Z�p���Z���_�����Z���ʓ|���܂�����ă��j�b�g��
���O�̘_�����ƌ��Z��_���a�E�_���ςȂNJe�I�y���[�V�������ƂɃ��j�b�g���K�v�ɂȂ邾�낗
�펯�ōl����
358 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 22:15:47 ID:WBJWfhIq
http://www.is.titech.ac.jp/~ohshima/TA/architecture/ohshima/7/node9.html
�Ȃ�ł������v�Z�@�Ȋw�̊�b���������ĂȂ��l�Ԃ�������
����Ƃ��A�������yMAC�̂�����邢�z�̂��H
���߂�������
�Ȃ�ł������v�Z�@�Ȋw�̊�b���������ĂȂ��l�Ԃ�������
����Ƃ��A�������yMAC�̂�����邢�z�̂��H
���߂�������
359 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 22:20:12 ID:WBJWfhIq
360 �FMAC�I�^���c�q �����F2009/04/14(��) 22:25:05 ID:emmzXgAm
>>358
����"ALU"�̒��ɂ́A>>357�ň�������������Ă���悤�ȉ�H�������Ă���̂ł���B
���Ȃ݂ɏ�Z��̃y�[�W�̕�������A��Z��ɂ͉��Z��ƃV�t�^���܂܂�Ă��邱�Ƃ���
������悤�ɁA���S�ɓƗ����Ă���Ƃ�����ł��Ȃ��A���̓|�[�g���ւ��Ĕėp������������
���Ƃ��\�ł��B
������ɂ���A�p�C�v���C����̂ǂ����̒i�K�Łw���߁x�͐���M���ɕϊ�����邱�ƂɂȂ�܂��B
����"ALU"�̒��ɂ́A>>357�ň�������������Ă���悤�ȉ�H�������Ă���̂ł���B
���Ȃ݂ɏ�Z��̃y�[�W�̕�������A��Z��ɂ͉��Z��ƃV�t�^���܂܂�Ă��邱�Ƃ���
������悤�ɁA���S�ɓƗ����Ă���Ƃ�����ł��Ȃ��A���̓|�[�g���ւ��Ĕėp������������
���Ƃ��\�ł��B
������ɂ���A�p�C�v���C����̂ǂ����̒i�K�Łw���߁x�͐���M���ɕϊ�����邱�ƂɂȂ�܂��B
361 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 22:43:20 ID:WBJWfhIq
���߃f�R�[�_�����̂�Opcode��Operand�̐��K���ł����ē������߂͕����ʂ�̖��߂�
362 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 23:15:15 ID:WBJWfhIq
MAC���^�̐ق��ϑz�ɔ����āAIntel�͉��Z���j�b�g�ɑ�
���̃_�C�i�~�b�N�R���t�B�M�����[�V������p���邱�Ƃ�
���ߖ��ɐ�p��H��p�ӂ���K�v���Ȃ��悤�ɂ��Ă�킯����
���Ƃ���SSE��PSADBW��SIMD��Z�̍ŏI�i���g���Ă�ƌ����Ă���
���̃_�C�i�~�b�N�R���t�B�M�����[�V������p���邱�Ƃ�
���ߖ��ɐ�p��H��p�ӂ���K�v���Ȃ��悤�ɂ��Ă�킯����
���Ƃ���SSE��PSADBW��SIMD��Z�̍ŏI�i���g���Ă�ƌ����Ă���
363 �FMAC�I�^���c�q �����F2009/04/14(��) 23:23:34 ID:emmzXgAm
>>361
�@�@-----------------
�@�@�������߂͕����ʂ�̖��߂�
�@�@-----------------
�����>>348�ŁwRISC�́H�x�Ɩ₤���̂ł����H
�܂����|���_�Ɋׂ�̂��n���炵���̂ŁA�V���v����RISC�̈��Ƃ���AVR32�̃}�j���A�����B
http://www.atmel.com/dyn/resources/prod_documents/doc32001.pdf (p.22)
�@�@---------------------
�@�@3.3 Decode unit
�@�@The decode unit generates the necessary signals in order for the instruction to execute
�@�@correctly. The ID stage accepts one instruction each clock cycle from the prefetch unit.
�@�@This instruction is then decoded, and control signals and register file addresses are generated.
�@�@---------------------
>>360�̍Ō�̍s�ɏ������ʂ�̓��e�ł��B
�@�@-----------------
�@�@�������߂͕����ʂ�̖��߂�
�@�@-----------------
�����>>348�ŁwRISC�́H�x�Ɩ₤���̂ł����H
�܂����|���_�Ɋׂ�̂��n���炵���̂ŁA�V���v����RISC�̈��Ƃ���AVR32�̃}�j���A�����B
http://www.atmel.com/dyn/resources/prod_documents/doc32001.pdf (p.22)
�@�@---------------------
�@�@3.3 Decode unit
�@�@The decode unit generates the necessary signals in order for the instruction to execute
�@�@correctly. The ID stage accepts one instruction each clock cycle from the prefetch unit.
�@�@This instruction is then decoded, and control signals and register file addresses are generated.
�@�@---------------------
>>360�̍Ō�̍s�ɏ������ʂ�̓��e�ł��B
364 �F,,�E�L�́M�E,,�j��-�������F2009/04/14(��) 23:39:19 ID:WBJWfhIq
P54C��RISC�ł͂Ȃ��B
������POWER�]�͋���
������POWER�]�͋���
�c�q�͔ے�̂��߂̔ے�����Ă銴������
���ł����ł���
���ł����ł���
366 �F,,�E�L�́M�E,,�j��-�������F2009/04/15(��) 05:07:10 ID:+VkfR7Ie
���Z��H�ƌ��Z��H�̓}���`�v���N�T�ɂ���ĉ�H���g���܂킵��ւ��邱�ƂŎ����ł����
http://www.ie.u-ryukyu.ac.jp/~wada/digcir05/alu.html
�����ł͐G��ĂȂ����A�X�ɉ��Z���Carry in/out���̂Ă�Θ_����(AND)�A
carry out��`�d�������ɏo�͂Ɏg����XOR�ɂȂ�B
���łɁASIMD�����Z�̖{�����ĉ����킩��H
���グ�̓`�d��r���Œf�����Ă邾������B
���ɁA��Z��݂����ȋK�͂̑傫�ȉ�H�������悤��CPU�Ȃ�A�Ȃ�Ƃ�����
��H�����߂Ɏg���܂킹��悤�ɂ��悤�ƍl����킯�ŁB
CPU�ɂ���ĉ��Z���j�b�g�E��Z���j�b�g��������Ă̂͊m���ɂ�������
�����Ă��ꂼ����Z���ߐ�p��H�Ə�Z���ߐ�p��H�ł͂Ȃ��B
���߂��ƂɕʁX�̉��Z��H��p�ӂ���A���Ȃ킿���Z��p��H�ƌ��Z��p��H��
�����Ȃ�Č����̈������Ƃ͂��܂ǂ��A����A�ŏ�����A���ĂȂ����Ă��Ƃ���B
�n�b�L���������Ƃ�����B�z�͑�w����o�ĂȂ��ˁB
�Ԃ����ႯALU�̎����̒m���͗��惌�x���B
http://www.ie.u-ryukyu.ac.jp/~wada/digcir05/alu.html
�����ł͐G��ĂȂ����A�X�ɉ��Z���Carry in/out���̂Ă�Θ_����(AND)�A
carry out��`�d�������ɏo�͂Ɏg����XOR�ɂȂ�B
���łɁASIMD�����Z�̖{�����ĉ����킩��H
���グ�̓`�d��r���Œf�����Ă邾������B
���ɁA��Z��݂����ȋK�͂̑傫�ȉ�H�������悤��CPU�Ȃ�A�Ȃ�Ƃ�����
��H�����߂Ɏg���܂킹��悤�ɂ��悤�ƍl����킯�ŁB
CPU�ɂ���ĉ��Z���j�b�g�E��Z���j�b�g��������Ă̂͊m���ɂ�������
�����Ă��ꂼ����Z���ߐ�p��H�Ə�Z���ߐ�p��H�ł͂Ȃ��B
���߂��ƂɕʁX�̉��Z��H��p�ӂ���A���Ȃ킿���Z��p��H�ƌ��Z��p��H��
�����Ȃ�Č����̈������Ƃ͂��܂ǂ��A����A�ŏ�����A���ĂȂ����Ă��Ƃ���B
�n�b�L���������Ƃ�����B�z�͑�w����o�ĂȂ��ˁB
�Ԃ����ႯALU�̎����̒m���͗��惌�x���B
367 �F,,�E�L�́M�E,,�j��-�������F2009/04/15(��) 05:35:36 ID:+VkfR7Ie
�������߂�Opcode�̓}���`�v���N�T�̐���p���̓r�b�g�̏W���ł���B
�܁A�n���͂��ȂȂ��ᒼ��Ȃ����낤��
�܁A�n���͂��ȂȂ��ᒼ��Ȃ����낤��
45nm��600�`700mm2�Ƃ������Ă邯�ǖ{�C�łǂ��ɔ���C�Ȃ�
�Ă����ꂶ�Ⴝ���̃x�N�^�v���Z�b�T�����
�Ă����ꂶ�Ⴝ���̃x�N�^�v���Z�b�T�����
>>368
�x�N�^�}�V���̐S�����Ƃ��Ă͒��r���[����BXeon�a�����̃}�V����
�З͂�����悤�Ȍv�Z�����Ă���l�ɂ͏d��邩������A
�������o���h�����m�[�h�Ԍ����������Ƒ����Ȃ���b�ɂȂ��Ƃ���
�v�Z����肽�������҂���������킯��
�x�N�^�}�V���̐S�����Ƃ��Ă͒��r���[����BXeon�a�����̃}�V����
�З͂�����悤�Ȍv�Z�����Ă���l�ɂ͏d��邩������A
�������o���h�����m�[�h�Ԍ����������Ƒ����Ȃ���b�ɂȂ��Ƃ���
�v�Z����肽�������҂���������킯��
370 �F,,�E�L�́M�E,,�j��-�������F2009/04/15(��) 06:41:23 ID:+VkfR7Ie
��K�͌v�Z�@���a�����̃N���X�^���d��邱�̎���ɂ��܂��ɂ���Ȍ����҂���́H
���ꂽ���P�ɖ��̕������ł��ĂȂ������Ȃ�Ȃ��́H
���ꂽ���P�ɖ��̕������ł��ĂȂ������Ȃ�Ȃ��́H
371 �FMAC�I�^���c�q �����F2009/04/15(��) 08:00:55 ID:acQvN9EB
>>366-367
�@�@----------------
�@�@�}���`�v���N�T�ɂ���ĉ�H���g���܂킵��
�@�@----------------
�Ȃ��X�S���Ƃ���Ɋ��ݕt����āA�����Ă��܂��B
�}���`�v���N�T���āw�ؑցx���s�����Z��ł��B�d�q��H�Ƃ��ĉ����ւ��Ă����
�v���܂����H
�@�@----------------
�@�@�������߂�Opcode�̓}���`�v���N�T�̐���p���̓r�b�g�̏W���ł���B
�@�@----------------
���̔F�����ƁA�s��̉��Z�킪�S���قȂ鐮�����Z�ƕ��������_���Z�Ƃ��̃R�[�h��
�d�Ȃ��Ă��܂��܂���(��)
�@�@----------------
�@�@�}���`�v���N�T�ɂ���ĉ�H���g���܂킵��
�@�@----------------
�Ȃ��X�S���Ƃ���Ɋ��ݕt����āA�����Ă��܂��B
�}���`�v���N�T���āw�ؑցx���s�����Z��ł��B�d�q��H�Ƃ��ĉ����ւ��Ă����
�v���܂����H
�@�@----------------
�@�@�������߂�Opcode�̓}���`�v���N�T�̐���p���̓r�b�g�̏W���ł���B
�@�@----------------
���̔F�����ƁA�s��̉��Z�킪�S���قȂ鐮�����Z�ƕ��������_���Z�Ƃ��̃R�[�h��
�d�Ȃ��Ă��܂��܂���(��)
372 �FMAC�I�^�������F2009/04/15(��) 08:05:12 ID:acQvN9EB
���ꂩ�炱��A
�@�@----------------
�@�@�������߂�Opcode�̓}���`�v���N�T�̐���p���̓r�b�g�̏W���ł���B
�@�@----------------
>>361�Œc�q���咣���Ă���
�@�@================
�@�@���߃f�R�[�_�����̂�Opcode��Operand�̐��K���ł����ē������߂͕����ʂ�̖��߂�
�@�@================
�Ɩ������܂��B
�@�@----------------
�@�@�������߂�Opcode�̓}���`�v���N�T�̐���p���̓r�b�g�̏W���ł���B
�@�@----------------
>>361�Œc�q���咣���Ă���
�@�@================
�@�@���߃f�R�[�_�����̂�Opcode��Operand�̐��K���ł����ē������߂͕����ʂ�̖��߂�
�@�@================
�Ɩ������܂��B
�c�q�ɕ֏悷��悤����
�y�j�X��x86�����X�}�C�N���R�[�h�x�[�X��CISC�����Ă��Ƃ�m��Ȃ��̂��A�m���ĂĂȂ�
�������߂̊T�O������Ȃ��^���̔n���̂��A�ǂ������ˁH
����łȂ��Ƃ�2Way�ȏ�̃X�[�p�[�X�J���ɂ����ăf�R�[�h��̖��߂��L���[�C���O������
�X�P�W���[���ʼn��Z���j�b�g�U�蕪����̂ɓ������ߕ\�����K�v�Ȃ��Ƃ��炢�A�킩�邾�낤�ɁB
�y�j�X��x86�����X�}�C�N���R�[�h�x�[�X��CISC�����Ă��Ƃ�m��Ȃ��̂��A�m���ĂĂȂ�
�������߂̊T�O������Ȃ��^���̔n���̂��A�ǂ������ˁH
����łȂ��Ƃ�2Way�ȏ�̃X�[�p�[�X�J���ɂ����ăf�R�[�h��̖��߂��L���[�C���O������
�X�P�W���[���ʼn��Z���j�b�g�U�蕪����̂ɓ������ߕ\�����K�v�Ȃ��Ƃ��炢�A�킩�邾�낤�ɁB
��������(�}�C�N���R�[�h)��ALU�̑I���y��ALU�̃R���t�B�M�����[�V�����̂��߂̃r�b�g�W�����R�[�h�̌n���������̂��Ă̂͐���
�Ƃ������A�f�B�W�^����H1�N���̓z�ł�����
����ȓ�����O�̃��x���̋c�_����ł��c
����ȓ�����O�̃��x���̋c�_����ł��c
NVIDIA��Chief Scientist��Larrabee��ᔻ
http://www.xbitlabs.com/news/video/display/20090413143345_Intel_Larrabee_s_x86_Compatibility_Is_Drawback__Chief_Scientist_of_Nvidia.html
http://www.xbitlabs.com/news/video/display/20090413143345_Intel_Larrabee_s_x86_Compatibility_Is_Drawback__Chief_Scientist_of_Nvidia.html
nVidia��ᔻ���������炢
nVidia�����]���� ���@�ƂĂ��ǂ���
x86��GPU�������̗��ꂪ�C�ɓ���Ȃ���������
AMD�������l������
45nm�v���Z�X�������オ������2007�N
Intel�ɂƂ��Ă�Larrabee�̗ʎY���J�n���鍡�N�㔼?�ɂ�
45nm�v���Z�X�͂������ɐ�[�v���Z�X����Ȃ����
Intel�ɂƂ��Ă�Larrabee�̗ʎY���J�n���鍡�N�㔼?�ɂ�
45nm�v���Z�X�͂������ɐ�[�v���Z�X����Ȃ����
������4GHz��GDDR5�𓋍ڂ���������ш��256GB/s�ƂȂ肩�Ȃ�L���ł����A
��512bit�ƂȂ�Ɗ�����G�ƂȂ邽�߂��R�X�g��������܂�
���̃_�C�̂ł������烁�����o�X512bit����
��512bit�ƂȂ�Ɗ�����G�ƂȂ邽�߂��R�X�g��������܂�
���̃_�C�̂ł������烁�����o�X512bit����
���߂�20���炵����
Tukwila���̃g�����W�X�^���I�H
>>376
�^����킯�Ȃ�����B����Ȃ��Ƃ����炨�I������B
�^����킯�Ȃ�����B����Ȃ��Ƃ����炨�I������B
���N�̓o��ł��邱�Ƃ��l����Ə��Ȃ����炢����
����ϋ�����v���Z�X�̌����߂Ɏg���H�����Ɗ��҂ł��Ȃ��B
IntelCPU���v���Z�X��s�������̗��R�̑唼�Ȗ������ザ��b�ɂȂ��B
����ϋ�����v���Z�X�̌����߂Ɏg���H�����Ɗ��҂ł��Ȃ��B
IntelCPU���v���Z�X��s�������̗��R�̑唼�Ȗ������ザ��b�ɂȂ��B
�v���Z�X�Ő�s���Ă��邩�炠�̃_�C�T�C�Y��45nm�Ȃ̂����B
6���e�[�v�A�E�g�ƌ�����GT300�̃_�C�T�C�Y��Larrabee���Ȃ�55nm���낤�B
6���e�[�v�A�E�g�ƌ�����GT300�̃_�C�T�C�Y��Larrabee���Ȃ�55nm���낤�B
�H
Graphic Processable General Purpose Unit
391 �F,,�E�L�́M�E,,�j��-�������F2009/04/15(��) 21:48:50 ID:+VkfR7Ie
����v�̃v���Z�b�T�Ȃ����d�͂̓N���b�N�̂R��ɔ�Ⴗ��Ƃ����@�����t��ɂƂ���
�N���b�N��7���ɗ}���ăR�A����3�{�ɂ���Ώ���d�͐����u���ŃX���[�v�b�g�͖�2�{
�N���b�N��7���ɗ}���ăR�A����3�{�ɂ���Ώ���d�͐����u���ŃX���[�v�b�g�͖�2�{
�����͂��������ǂȁB
393 �F,,�E�L�́M�E,,�j��-�������F2009/04/16(��) 05:14:23 ID:svKHknEt
1.7GHz�`2.5GHz���Ă����Ԃ��L��ȂƎv�������
��ŁA16�R�A��2.5GHz��48�R�A��1.7GHz����̓������炢�̏���d�͂��Ă��ƂɂȂ�̂��ȁH
�Ǝv������B
���ƁA�R�A�����������1�R�A������̃^�C���̃X���b�v�̕p�x�����邩��
���𑜓x�ł̓d�͌����͍X�ɏ㏸����E�E�E��������Ȃ��B
��ŁA16�R�A��2.5GHz��48�R�A��1.7GHz����̓������炢�̏���d�͂��Ă��ƂɂȂ�̂��ȁH
�Ǝv������B
���ƁA�R�A�����������1�R�A������̃^�C���̃X���b�v�̕p�x�����邩��
���𑜓x�ł̓d�͌����͍X�ɏ㏸����E�E�E��������Ȃ��B
Tera*3��2006�N������45nm�v���Z�X�ł����m�ȗ\���͓�������̂��낤�B
��������Tera*3�ł̃R�A����16�`24���������܂ł̊܈ӂ͂Ȃ��Ǝv���B
��������Tera*3�ł̃R�A����16�`24���������܂ł̊܈ӂ͂Ȃ��Ǝv���B
�ėp��H�̓d�͌����͐�p��H��1/500�`1/2000�ɂ����Ȃ���
��p��H���g�킸�ėp��H�ő�ւ���A���̕��ėp���j�b�g�𑽂��ς߂邩��Z�p���Z�ł͗ǂ���
GPU�̂悤�Ȍ��܂����ߒ��̑������̂Ŏg���ɂ͓d�͌����������邯�ǂ�
��p��H���g�킸�ėp��H�ő�ւ���A���̕��ėp���j�b�g�𑽂��ς߂邩��Z�p���Z�ł͗ǂ���
GPU�̂悤�Ȍ��܂����ߒ��̑������̂Ŏg���ɂ͓d�͌����������邯�ǂ�
>>395
�����낷��
�����낷��
����[���A�ǂ����ʂȃX���ł��̕������o����������
���܂ǂ���GPU�ɐ�p��H�Ȃ�Ĕ������Ȃ��B���r���[�ɔėp�ȃv���O���}�u���V�F�[�_���啔�����߂�B
�Ƃ肠��������d�͂��N���b�N�̎O��ɔ�Ⴗ��Ȃ�Ă̂�
�P�������������Ⴞ���炻��Ŏ�����z�肷��̂͂�߂�
�P�������������Ⴞ���炻��Ŏ�����z�肷��̂͂�߂�
�@�@|�@� �@ �
�@�@|�m�Q�m�@�@�@
�@�@|� �D�)�@���@400
�@�@|�@ /�@�@�@�@
�@�@| /
�@�@|�m�Q�m�@�@�@
�@�@|� �D�)�@���@400
�@�@|�@ /�@�@�@�@
�@�@| /
401 �F,,�E�L�́M�E,,�j��-�������F2009/04/16(��) 21:31:11 ID:svKHknEt
���{�������������߂Ƃ������[�����ȁB
�\�t�g�E�F�A�ŏ_��Ƀ����_�ł����Ȃ�A�uA-Buffer�v�̗p�ł��Ȃ��̂���
�^�C�������_�Ƃ��������ǂ��Ǝv���̂�����
�^�C�������_�Ƃ��������ǂ��Ǝv���̂�����
�q���g 256KB��L2
>>403
�H VRAM�ɊO�o�������ǂ������AVRAM����Ȃ��Ȃ����烁�C���������ɏo���Ηǂ�
����ɉϒ������ǁA���������H�v�����1�^�C�����̔������s�N�Z���o�b�t�@�ł�����Ǝv����
�H VRAM�ɊO�o�������ǂ������AVRAM����Ȃ��Ȃ����烁�C���������ɏo���Ηǂ�
����ɉϒ������ǁA���������H�v�����1�^�C�����̔������s�N�Z���o�b�t�@�ł�����Ǝv����
405 �F,,�E�L�́M�E,,�j��-�������F2009/04/17(��) 03:39:04 ID:6kUq0iu/
����ł��A�K�v�ȃs�N�Z�����܂ރL���b�V�����C���������t�F�b�`����������
�������ш悠����̐��\�ł͂��Ȃ�D�ʂ��Ǝv���
�������ш悠����̐��\�ł͂��Ȃ�D�ʂ��Ǝv���
����͎������郁�����ш��胊���O�o�X�̕��Ńl�b�N�ɂȂ�̂ł��ꂷ������B
�\�[�X�͑P�i�̖ϑz�u���O
��ʓI�c�_�̏o���Ȃ��z�̈ӌ���
���w���̊w���������Ȋw�]�_�̂悤�Ȃ��́B
���w���̊w���������Ȋw�]�_�̂悤�Ȃ��́B
409 �F,,�E�L�́M�E,,�j��-�������F2009/04/17(��) 22:50:54 ID:6kUq0iu/
Chrome���D�ꂽ�d�͌������������Ă闝�R��������邾����
��ݼް�̖ϑz�͔ے�ł���
��ݼް�̖ϑz�͔ے�ł���
�����\��ڎw���Γd�͌�����������͎̂d���Ȃ�
�����r�͒N�ł��u���b�V���A�b�v���ꂽ2����ڂ��炪�{�ԂƎv���Ă邾��
�{������������������
�����Ă����Ă��f�B�X�N���[�g��GPU�͖łԂ�
�{������������������
�����Ă����Ă��f�B�X�N���[�g��GPU�͖łԂ�
412 �F,,�E�L�́M�E,,�j��-�������F2009/04/18(�y) 05:37:02 ID:Yeeg3jSz
����A�P�Ƀ_�C��傫���o���Ȃ���������Ȃ��̂��H
�L���b�V����������Ƀ������R���g���[���ɃK���K�����ׂ�����v�ɂ��Ă����A�d�͌����͈����Ȃ邪
SRAM�Ƀg�����W�X�^�H��ꂸ�ɍςނ���ȁB
�ʐς�����̐��\���A�d�͌������̃g���[�h�I�t�Ȃ�B
�t�Ɍ����ƁA600mm²���鋐��_�C���R�X�g�ō���Intel���炷��Γd�͌����ɐU�邱�Ƃ��o����B
�e�R�A256KB��L2�L���b�V�������蓖�Ă��Ă�Larrabee�ɂ́A�����R���ɃK���K�����ׂ�����K�v���Ȃ��킯���B
�L���b�V����������Ƀ������R���g���[���ɃK���K�����ׂ�����v�ɂ��Ă����A�d�͌����͈����Ȃ邪
SRAM�Ƀg�����W�X�^�H��ꂸ�ɍςނ���ȁB
�ʐς�����̐��\���A�d�͌������̃g���[�h�I�t�Ȃ�B
�t�Ɍ����ƁA600mm²���鋐��_�C���R�X�g�ō���Intel���炷��Γd�͌����ɐU�邱�Ƃ��o����B
�e�R�A256KB��L2�L���b�V�������蓖�Ă��Ă�Larrabee�ɂ́A�����R���ɃK���K�����ׂ�����K�v���Ȃ��킯���B
Chrome���āAS3��Chrome�H
�܂����A�c�q������D�]���̌��t���o��Ƃ͎v��Ȃ������B
���ہA���f�B�A���˂����A�[�L�e�N�`���ɂ��Ď�ނ����L�����Ȃ���
S3���̂��ڂ����������o���Ă��Ȃ���ŁA�\���ɂ��Ă͂܂������̓�B
������T�C�g�ɏ�����A���̃u���b�N�}�ŐF�X�ϑz���邵���Ȃ�����
ttp://img144.imageshack.us/img144/3791/0005929201aeb476buz6.jpg
DXSDK�̃T���v���Ƃ������Ă݂�����ƁAGS������Ƃ�
GPU�ŌJ��Ԃ����Z����悤�Ȃ�́A�������ӂ݂����B
ttp://www.youtube.com/watch?v=pGnrBu3N2QE
���̃X���ɒ�����GPUBench�̌��ʂ̓o�O���ۂ��C���傢�ɂ��邪
���ɐM���Ă݂��ATI,nVIDIA�Ƃ͈Ⴄ�ȁA�Ƃ����C�͂���ˁB
Cache Hit Fetch Cost
540GTX
ttp://xs538.xs.to/xs538/09165/fetchcost_single743.png
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/fetchcost_single.png
Streaming Access Fetch Cost
540GTX
ttp://xs138.xs.to/xs138/09165/fetchcost_seq387.png
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/fetchcost_seq.png
�͂��߂�0-30 inst������̌X�����Ⴄ
�����Areadback,download�͌������iCPU��nano������H�j
intel,ATI,nVIDIA�ɒ��ڂ��W�܂钆�A�N��������ڂ���Ȃ��Ƃ����
�ȂS�j���S�j������Ă�S3
�s�C���ȃ_�[�N�z�[�X�E�E
�܂����A�c�q������D�]���̌��t���o��Ƃ͎v��Ȃ������B
���ہA���f�B�A���˂����A�[�L�e�N�`���ɂ��Ď�ނ����L�����Ȃ���
S3���̂��ڂ����������o���Ă��Ȃ���ŁA�\���ɂ��Ă͂܂������̓�B
������T�C�g�ɏ�����A���̃u���b�N�}�ŐF�X�ϑz���邵���Ȃ�����
ttp://img144.imageshack.us/img144/3791/0005929201aeb476buz6.jpg
{kind=link}
DXSDK�̃T���v���Ƃ������Ă݂�����ƁAGS������Ƃ�
GPU�ŌJ��Ԃ����Z����悤�Ȃ�́A�������ӂ݂����B
ttp://www.youtube.com/watch?v=pGnrBu3N2QE
���̃X���ɒ�����GPUBench�̌��ʂ̓o�O���ۂ��C���傢�ɂ��邪
���ɐM���Ă݂��ATI,nVIDIA�Ƃ͈Ⴄ�ȁA�Ƃ����C�͂���ˁB
Cache Hit Fetch Cost
540GTX
ttp://xs538.xs.to/xs538/09165/fetchcost_single743.png
{kind=link}
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/fetchcost_single.png
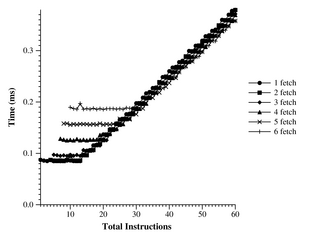{kind=link}
Streaming Access Fetch Cost
540GTX
ttp://xs138.xs.to/xs138/09165/fetchcost_seq387.png
{kind=link}
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/fetchcost_seq.png
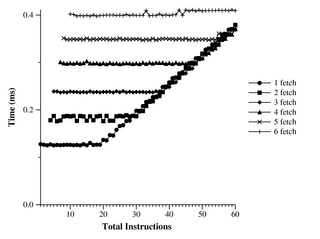{kind=link}
�͂��߂�0-30 inst������̌X�����Ⴄ
�����Areadback,download�͌������iCPU��nano������H�j
intel,ATI,nVIDIA�ɒ��ڂ��W�܂钆�A�N��������ڂ���Ȃ��Ƃ����
�ȂS�j���S�j������Ă�S3
�s�C���ȃ_�[�N�z�[�X�E�E
414 �F,,�E�L�́M�E,,�j��-�������F2009/04/18(�y) 06:04:30 ID:Yeeg3jSz
�uLarrabee��Chrome�Ɏ��Ă�v�Ƃ����ӌ��̓��A���ł��悭�������B
���Ă������AGDDR5��4GHz�Ƃ�����d�͂���Ȫ
�n�͂͗L��ɉz�������Ƃ͂Ȃ����ǁA�L���b�V���Ɏ��܂�悤�ȉ��Z�ɑ��Ă܂�
���ׂ�����v�ɂ���ׂ�����Ȃ��ˁB
���Ă������AGDDR5��4GHz�Ƃ�����d�͂���Ȫ
�n�͂͗L��ɉz�������Ƃ͂Ȃ����ǁA�L���b�V���Ɏ��܂�悤�ȉ��Z�ɑ��Ă܂�
���ׂ�����v�ɂ���ׂ�����Ȃ��ˁB
�o���ACPU����������
�Ȃɂ����玗���v�z������̂�������܂���ˁB
�Ȃɂ����玗���v�z������̂�������܂���ˁB
Intel�ł�600mm²�̃_�C�͒�R�X�g�������
HKMG��AMD��CPU��SOI���̓R�X�g�p�t�H�[�}���X���ǂ����A���Ƃ�����GPU�̃o���N���͍���
�������A����`�b�v�ł���ʂ̃R�A�ō\�������`�Ȃ�A���������ł����i�Ƃ��Ďg���邩��
�܂������g�����ɂȂ�Ȃ��`�b�v�͏��Ȃ��Ȃ邩��A�R�X�g�p�t�H�[�}���X�͏グ����
�v����ɁgIntel�Ȃ�h����Ȃ��āgLarrabee�Ȃ�h�A��r�I��R�X�g�ō���\��������
HKMG��AMD��CPU��SOI���̓R�X�g�p�t�H�[�}���X���ǂ����A���Ƃ�����GPU�̃o���N���͍���
�������A����`�b�v�ł���ʂ̃R�A�ō\�������`�Ȃ�A���������ł����i�Ƃ��Ďg���邩��
�܂������g�����ɂȂ�Ȃ��`�b�v�͏��Ȃ��Ȃ邩��A�R�X�g�p�t�H�[�}���X�͏グ����
�v����ɁgIntel�Ȃ�h����Ȃ��āgLarrabee�Ȃ�h�A��r�I��R�X�g�ō���\��������
nvidia��gt200�Ń��W�X�^���₵�����Ă��Ƃ�������
����S3��Chrome400/500�ł̓��W�X�^���₵�Ă�炵��
���ԂE�ň�ԓI�m��400/500�ɂ��Ĕc�����Ă�T�C�g
ttp://translate.google.co.jp/translate?u=http://it-daily.ru/AlgoNetGetNews.action.php%3FID%3D9645&hl=ja&ie=UTF-8&sl=ru&tl=en
>Growth in productivity, however, say in the S3, is achieved mainly by a quantitative increase in the registers.
�i����excalibur E1��128bit,E2��256bit�Ƃ��̏�E�E�j
�ŁA���̌���
ttp://www.youtube.com/watch?v=b32iKtPF15Q
�܂��A�N���b�N���������Ă���ǁAsp��1100MHz����1025MHz��75MHz�ق�
�ԉ�CPU������Ȃ�ŁA���ꂾ���ǁE�E
����ɉ��Z���j�b�g���₷���A���W�X�^��L���b�V�����₵���������ʓI�Ȃ̂����ˁB
����S3��Chrome400/500�ł̓��W�X�^���₵�Ă�炵��
���ԂE�ň�ԓI�m��400/500�ɂ��Ĕc�����Ă�T�C�g
ttp://translate.google.co.jp/translate?u=http://it-daily.ru/AlgoNetGetNews.action.php%3FID%3D9645&hl=ja&ie=UTF-8&sl=ru&tl=en
>Growth in productivity, however, say in the S3, is achieved mainly by a quantitative increase in the registers.
�i����excalibur E1��128bit,E2��256bit�Ƃ��̏�E�E�j
�ŁA���̌���
ttp://www.youtube.com/watch?v=b32iKtPF15Q
�܂��A�N���b�N���������Ă���ǁAsp��1100MHz����1025MHz��75MHz�ق�
�ԉ�CPU������Ȃ�ŁA���ꂾ���ǁE�E
����ɉ��Z���j�b�g���₷���A���W�X�^��L���b�V�����₵���������ʓI�Ȃ̂����ˁB
>����S3��Chrome400/500�ł̓��W�X�^���₵�Ă�炵��
���������ȂႤ��
400����500�ł̓��W�X�^�����ʂ���Ă���Ă��Ƃ�
���������ȂႤ��
400����500�ł̓��W�X�^�����ʂ���Ă���Ă��Ƃ�
GPU��x86�݂����Ɍ݊����ɔ����Ă��Ȃ�����
�L���̈�̊K�w�����r�I���R�Ƀf�U�C���ł��邵��
�L���̈�̊K�w�����r�I���R�Ƀf�U�C���ł��邵��
�K�w���@���@�K�w�\��
421 �F,,�E�L�́M�E,,�j��-�������F2009/04/18(�y) 21:38:43 ID:Yeeg3jSz
>>419
x86���݊����ɔ����ċL���̈�����R�ɂł��Ȃ���������Ă��������H
Pentium 4�ł�8�{�̘_�����W�X�^�����z�����A128�{����Ȃ郌�W�X�^�t�@�C���I�Ɋ��蓖�ĂĂ������B
x86���݊����ɔ����ċL���̈�����R�ɂł��Ȃ���������Ă��������H
Pentium 4�ł�8�{�̘_�����W�X�^�����z�����A128�{����Ȃ郌�W�X�^�t�@�C���I�Ɋ��蓖�ĂĂ������B
Larrabee���o������A�����������u�n�[�h���̃G�S�v��
�n�[�h�E�F�A�̎d�l���B��������Ȃ�
�����������̂Ă���V�i���I�����蓾��Ǝv��
�n�[�h�E�F�A�̎d�l���B��������Ȃ�
�����������̂Ă���V�i���I�����蓾��Ǝv��
423 �F,,�E�L�́M�E,,�j��-�������F2009/04/18(�y) 21:49:57 ID:Yeeg3jSz
NVIDIA�̂��Ƃł��ˁB�킩��܂��B
600mm²���Č����Ă�2������������150mm²������ȁB
�����ɍs���A2011�N���ɏo����B
PS4�ɂ͏\���Ԃɍ���������B
�����ɍs���A2011�N���ɏo����B
PS4�ɂ͏\���Ԃɍ���������B
Intel���Ă���Ȃɐh��������������?
Intel�Ƃ��Ă�PS4�Ɏg���Ă��炢�����Ȃ��ł���B
�܂��A�����C���[�W�������˂Ȃ�����B
�܂��A�����C���[�W�������˂Ȃ�����B
G80����SP��8KB(32/8*2048)��GT200�Ŕ{������16KB���H
���̂Ƃ���Larrabee�͍����\�H���̉ƒ�p�Q�[����GPU�Ƃ��Ă͊��Ҕ��B
����ς菭�XGPU�p�t�H�[�}���X�����Ă������`�b�v�Z�b�g����orCPU�����ŕ��y������
�R�[�h�~�ς���HPC�_���Ƃ����̂����C���V�i���I���Ǝv���B
����ς菭�XGPU�p�t�H�[�}���X�����Ă������`�b�v�Z�b�g����orCPU�����ŕ��y������
�R�[�h�~�ς���HPC�_���Ƃ����̂����C���V�i���I���Ǝv���B
429 �F,,�E�L�́M�E,,�j��-�������F2009/04/19(��) 11:12:05 ID:fMaQCdsb
�Q�[���ō����\�H�����̂��̂����Ҕ��Ȃ�ł����ǂˁB
�g�ѓd�b��DS�������ׂ����Ă��Ȃ��ł����B
�g�ѓd�b��DS�������ׂ����Ă��Ȃ��ł����B
����͂����Ȃ���PS�n���ăE�����n�C�X�y�H��������Ȃ����Ȃ����낤�Ȃ�w
�����͍����G���R�Ńn�C�X�y�A�s�[���Ƃ��H
�掿�𗎂Ƃ���1����BD��xx���Ԃ��^��ł���I�݂�����
�掿�𗎂Ƃ���1����BD��xx���Ԃ��^��ł���I�݂�����
PC�Q�[�����Đ��������ŏk�����Ă���Ęb�����B
�\�t�g������ƒ�p�Q�[���@�Ƃ̃}���`�O��ł̊J���ł���B
DX11���o�ꂵ�Ă��قƂ�Ǎ̗p����Q�[���������Ȃ�Ď������肦�邵�ˁB
������XBOX720�Ƃ����o�邮��܂Ő扄���ɂ������������ˁH
�\�t�g������ƒ�p�Q�[���@�Ƃ̃}���`�O��ł̊J���ł���B
DX11���o�ꂵ�Ă��قƂ�Ǎ̗p����Q�[���������Ȃ�Ď������肦�邵�ˁB
������XBOX720�Ƃ����o�邮��܂Ő扄���ɂ������������ˁH
433 �F,,�E�L�́M�E,,�j��-�������F2009/04/19(��) 13:04:49 ID:fMaQCdsb
PC�Q�[�����̂͂܂��܂��p�C�͑傫���B
FF11�����܂��ɐl�C�Ȃ̂̓u�����g����̂������Ȃ̂͊m��I�ɖ��炩�B
���Ă������A�n�C�G���h�H���̃f�x���b�p�[�������ݒE�����Ă�B
�|�X�gCrysis���̃Q�[���������ɏo�ĂȂ��B
���Ă��������A���掿�~���Đ��͑傫�����ɋ��͗��Ƃ��Ȃ���ˁB
�u����H�g�уQ�[���ŏ\���ׂ���Ȃ琘���u���EPC�Q�[����Ȃ��ˁH�v��������
Intel�Ƃ��Ă̓f�B�X�N���[�g�yGame Processing Unit�z�̎s��͐[���肷��C�͂Ȃ����Ă̂��{�����Ǝv����
�ق��Ƃ��Ă���ł���s�ꂾ���B
�����炱��NVIDIA��ATI�����ėp�v���Z�b�T���ɐU���Ă�B
FF11�����܂��ɐl�C�Ȃ̂̓u�����g����̂������Ȃ̂͊m��I�ɖ��炩�B
���Ă������A�n�C�G���h�H���̃f�x���b�p�[�������ݒE�����Ă�B
�|�X�gCrysis���̃Q�[���������ɏo�ĂȂ��B
���Ă��������A���掿�~���Đ��͑傫�����ɋ��͗��Ƃ��Ȃ���ˁB
�u����H�g�уQ�[���ŏ\���ׂ���Ȃ琘���u���EPC�Q�[����Ȃ��ˁH�v��������
Intel�Ƃ��Ă̓f�B�X�N���[�g�yGame Processing Unit�z�̎s��͐[���肷��C�͂Ȃ����Ă̂��{�����Ǝv����
�ق��Ƃ��Ă���ł���s�ꂾ���B
�����炱��NVIDIA��ATI�����ėp�v���Z�b�T���ɐU���Ă�B
MMORPG�������d�����Ȃ��Ă�����ok
AION�Ƃ�TERA�Ƃ�
AION�Ƃ�TERA�Ƃ�
����doom�̍�����č����R��2�l3�r�Ői�����Ă���FPS
�ǂ����������͕ČR�̃T�W��������
�ǂ����������͕ČR�̃T�W��������
>>433
FF�]�T�͒������gMMO�Q�[�����H
FF�]�T�͒������gMMO�Q�[�����H
437 �F,,�E�L�́M�E,,�j��-�������F2009/04/19(��) 16:15:02 ID:fMaQCdsb
�͂��͂��ؗ��l�g�Q�ŋ��ؗ��l�g�Q�ŋ�
���������l�g�Q�����z����
440 �F,,�E�L�́M�E,,�j��-�������F2009/04/19(��) 16:22:27 ID:fMaQCdsb
���߂�A���l��RO�}���Z�[�Ȑl���Ǝv����
FF11�̌��߂��č��YMMO�Ƃ��Ĉ�Ԑ��������Q�[���ł���Ɠ�����
�㔭�̃Q�[���̎s��܂ŐH���Ă��܂������Ƃɂ���Ǝv���Ă邪�B
�[���A��{�����i�A�C�e���ۋ��j���ċ���̍Ǝv�����ǂȁB
FF11�̌㊘�̊m���̓X�N�G�j���g�����s���Ă�
FF11�̌��߂��č��YMMO�Ƃ��Ĉ�Ԑ��������Q�[���ł���Ɠ�����
�㔭�̃Q�[���̎s��܂ŐH���Ă��܂������Ƃɂ���Ǝv���Ă邪�B
�[���A��{�����i�A�C�e���ۋ��j���ċ���̍Ǝv�����ǂȁB
FF11�̌㊘�̊m���̓X�N�G�j���g�����s���Ă�
�C���e���͍��܂ŃQ�[���@�s��ɐH������łȂ���������A
���v���قƂ�Ǐo�Ȃ��Ă��A�g���ė~�����͂��B
���C�o���iIBM�AAMD�AnVIDIA�j���ꂵ�߂��邾���ł������b�g������B
���v���قƂ�Ǐo�Ȃ��Ă��A�g���ė~�����͂��B
���C�o���iIBM�AAMD�AnVIDIA�j���ꂵ�߂��邾���ł������b�g������B
�Ȃɂ��̍r�炵��
443 �FMAC�I�^��441 �����F2009/04/19(��) 17:35:58 ID:I2gA3WYZ
>>441
�ꉞ�A�c�_�ɂ͐����������F�����K�v�ł��̂Łc
�@�@---------------
�@�@�C���e���͍��܂ŃQ�[���@�s��ɐH������łȂ���������A
�@�@---------------
http://jibun.atmarkit.co.jp/ljibun01/rensai/gyoukai/015/01.html
�@�@===============
�@�@Xbox�̓y���e�B�A�� III 733MHz�ɉ����āA�}�C�N���\�t�g��NVIDIA�̗��Ђ������v����
�@�@�J�X�^���`�b�v�𓋍ڂ��Ă���B
�@�@===============
�ꉞ�A�c�_�ɂ͐����������F�����K�v�ł��̂Łc
�@�@---------------
�@�@�C���e���͍��܂ŃQ�[���@�s��ɐH������łȂ���������A
�@�@---------------
http://jibun.atmarkit.co.jp/ljibun01/rensai/gyoukai/015/01.html
�@�@===============
�@�@Xbox�̓y���e�B�A�� III 733MHz�ɉ����āA�}�C�N���\�t�g��NVIDIA�̗��Ђ������v����
�@�@�J�X�^���`�b�v�𓋍ڂ��Ă���B
�@�@===============
����������Xbox��Celeron�������ˁB
�n�C�O�����v�Ȃ��Ȃ�Ƃ�����A
�����\�v���Z�b�T���v���������ˁH
�A�L�o�Ƃ�������
�����\�v���Z�b�T���v���������ˁH
�A�L�o�Ƃ�������
�n�C�O���Q�[�����ă��m���ǂ̂��炢�l�����Ă邩����Ȃ����ǁA
������߂�ƃf�U�C�i�[�A�G���W�j�A�A�����X�g������}����B
������߂�ƃf�U�C�i�[�A�G���W�j�A�A�����X�g������}����B
�n�C�O���́u�X���v���ς��A�Ƃ������ł͂Ȃ�����
�ܘ_�������Ɏ��v������A����Intel�����哱���Ă��
�ܘ_�������Ɏ��v������A����Intel�����哱���Ă��
PC������Windows7���s�m�����낤���A
�����T�C�Y�����������k�����Ă����̂��˂��H
�����T�C�Y�����������k�����Ă����̂��˂��H
XP�̉E��ɃA�i���O���ĕ\����������̂�
�T�|�[�g�ł���ł�����v���b�V���[��
�e���b�v�ł�����v���b�V���[�݂����Ȃ��̂��낤
�e���b�v�ł�����v���b�V���[�݂����Ȃ��̂��낤
3D�Q�[���Ȃ�Ă݂�ȂقƂ�ǂ���ĂȂ������ł���B
����ł��Ȃ�Ńn�C�G���h�̃r�f�I�J�[�h������Ă������Č�����
3DMARK�Ƃ����L���[�A�v�������������炳�B
����ł��Ȃ�Ńn�C�G���h�̃r�f�I�J�[�h������Ă������Č�����
3DMARK�Ƃ����L���[�A�v�������������炳�B
3DMark���L���[�A�v���Ƃ���
�c���\����������
�c���\����������
�œK�������͂���vantage�����������c�O�Ȃ��̂ɏI��������
nvidia�̓O�_�O�_�Ȃ�ł���
�킩��܂�
nvidia�̓O�_�O�_�Ȃ�ł���
�킩��܂�
PC�Q�[�����k�����Ă�͓̂��{�ŗL�̘b����
���u���^�Q�[���@�̎s��������͏k�����Ă���B
456 �F,,�E�L�́M�E,,�j��-�������F2009/04/20(��) 03:15:02 ID:mmxDY20t
>>454
�C�̌������ł̓��A���ő��f�x���b�p�[�����p���̗��ł���
���C�g�ȃI���Q�����s���Ă�̂��ē��{�����̘b���Ⴀ��܂���
�C�̌������ł̓��A���ő��f�x���b�p�[�����p���̗��ł���
���C�g�ȃI���Q�����s���Ă�̂��ē��{�����̘b���Ⴀ��܂���
PC�Q�[���͊C���ł̂����Ŏ��v������ɔ��f����ɂ���
DOOM�ȍ~������Ƌɒ[�Ȃ��炢FPS�ɓ����������Ă��܂������炾�낤�ȁB
����O������́B
����O������́B
���{�̃}�X�R�~�͉����n��S�ʂɑ��ă}�C�i�X�C���[�W�����藬��
460 �F,,�E�L�́M�E,,�j��-�������F2009/04/20(��) 19:51:37 ID:mmxDY20t
�}�C�i�X�C���[�W���܂߂Đ�`�ɂȂ��Ă�Ƃ���㩁B
2ch�̃l�I���Ɠ��l�ɂ�
�Ƃ���ʼn���ID������Intel�����ĂˁH
2ch�̃l�I���Ɠ��l�ɂ�
�Ƃ���ʼn���ID������Intel�����ĂˁH
461 �F,,�E�L�́M�E,,�j��-�������F2009/04/20(��) 19:54:26 ID:mmxDY20t
�D�j���匕�U��Ď����̑��݂ɔY�݂Ȃ��琢�E���~���Q�[���������̂����{�̃R�A�Q�[���s�ꂗ
���T���}�b�`���̃I�b�T���͍D�܂�Ȃ�
���T���}�b�`���̃I�b�T���͍D�܂�Ȃ�
�C�OPC�Q�[�́AMMO�Ȃ�1000���I�[�o�[��WoW�̈�l����(���ɂ�100���l�K�͂̂���������o�Ă��Ă邯��)
�Q�[���z�M�v���b�g�t�H�[���Ȃ�ASteam��2000���I�[�o�[�ŁA
Counter-Strike�e��̍��v�̃s�[�N�l����20�����x���邵�A���̃}���`�v���C�Q�[�������K�́B���Д̔��c�[��������͂���
EA�ł���Q���B���ɂ��AFacebook�ł̃Q�[���z�M��A�����̃J�W���A���Q�[�z�M�A�̔��T�C�g�Ȃ����邩��A���͋������������A
�ƃQ�[�ƑS���Ⴄ�����ɍs���Ă�̂��悭�킩��B
�Q�[���z�M�v���b�g�t�H�[���Ȃ�ASteam��2000���I�[�o�[�ŁA
Counter-Strike�e��̍��v�̃s�[�N�l����20�����x���邵�A���̃}���`�v���C�Q�[�������K�́B���Д̔��c�[��������͂���
EA�ł���Q���B���ɂ��AFacebook�ł̃Q�[���z�M��A�����̃J�W���A���Q�[�z�M�A�̔��T�C�g�Ȃ����邩��A���͋������������A
�ƃQ�[�ƑS���Ⴄ�����ɍs���Ă�̂��悭�킩��B
Crysis�݂����ȋZ�p������I�\�t�g�́A�������Ăт���Ȃ��̂��ˁH
������PC���������́A�������Ȃ��Ƃ������ĂȂ����������H
������PC���������́A�������Ȃ��Ƃ������ĂȂ����������H
Crysis�͊��texture�\��t�����邩���āE�E
���{��PC-88����Ɍo���������Ƃ�AT�݊��@�ɂ��N���Ă邾���B
�܂��x���`�}�[�N�\�t�g���������r�f�I�J�[�h�͔����ł���B
�܂��x���`�}�[�N�\�t�g���������r�f�I�J�[�h�͔����ł���B
>>462
���̔����ȏオ�Ǝ҂Ɖˋ�A�J�E���g����
���̔����ȏオ�Ǝ҂Ɖˋ�A�J�E���g����
WoW��2000��������
RO������ł�800��
���Ȃ݂ɉ��Ă�MMO�͌��z�ۋ������S�Ŋ�{�������A�C�e���ۋ��͏��Ȃ�
�Ǝ҂�ˋ�A�J�E���g�̓A�W�A�����S����
RO������ł�800��
���Ȃ݂ɉ��Ă�MMO�͌��z�ۋ������S�Ŋ�{�������A�C�e���ۋ��͏��Ȃ�
�Ǝ҂�ˋ�A�J�E���g�̓A�W�A�����S����
�ł����āA������MMO�n�͊m���ɕ��ׂ͌y����
������Ƃ����Ă����̃v���C���[���I���{������P�̃J�[�h�ōς܂����Ȃ�
���E�ł��AMMO�̉^�c�ɐ��\�s���ɋN������₢���킹������͓̂��{�̂�
�C�O�ł�PC�̏�������܂߂Ċy���ނ���
���ƁA��������PC�Q�[���̃x�[�X�̓e�[�u���g�[�N������A
�e�[�u���g�[�N����̂���������������Q�[�}�[�����ʂɋ��邗
������Ƃ����Ă����̃v���C���[���I���{������P�̃J�[�h�ōς܂����Ȃ�
���E�ł��AMMO�̉^�c�ɐ��\�s���ɋN������₢���킹������͓̂��{�̂�
�C�O�ł�PC�̏�������܂߂Ċy���ނ���
���ƁA��������PC�Q�[���̃x�[�X�̓e�[�u���g�[�N������A
�e�[�u���g�[�N����̂���������������Q�[�}�[�����ʂɋ��邗
�c�b�R�~���ꂽ������Larrabee�̃X�����������Ȃ�
�b���Larrabee�ɖ߂��Ƃ�����
Larrabee�̃q�b�g�Ɍ��т��悤��PC�Q�[���͏o�����@�Ƃ����H
�b���Larrabee�ɖ߂��Ƃ�����
Larrabee�̃q�b�g�Ɍ��т��悤��PC�Q�[���͏o�����@�Ƃ����H
OFFSET�G���W���H���������̊J����Д������ĂȂ����������H
�������Z�p�f�������˂��Q�[���o����Ȃ��H
�l�I�ɂ͉f��g�C�E�X�g�[���[�����̂܂܂̃N�I���e�B�œ����܂��B
���炢�̃C���p�N�g���~�����ˁB
�������Z�p�f�������˂��Q�[���o����Ȃ��H
�l�I�ɂ͉f��g�C�E�X�g�[���[�����̂܂܂̃N�I���e�B�œ����܂��B
���炢�̃C���p�N�g���~�����ˁB
�N�I���e�B�[�ʂŁA���������ɏo��GPU�ɖ��m�ȃA�h�o���e�[�W�����Ă���̉��Z�\�͂̍��͖����ł���
�������PhysX�̂悤�Ȓlj����ʂ�A��ʂ̌Q�W���ʂɓ������悤�ȏ����̗v��Q�[����������Ȃ���
���̕����Ȃ�ň��AGPU�Ƃ��Ă͔���Ȃ��Ă��ACPU�ɑ����ăQ�[���Ƀ��b�`�Ȍ��ʂ�t�^����ׂ̃J�[�h�Ƃ��Ĕ���邩��
PhysX�ƈ����CPU�̃R�v���Ƃ��ē�������Ȃ�Ή��Q�[����������������
�������PhysX�̂悤�Ȓlj����ʂ�A��ʂ̌Q�W���ʂɓ������悤�ȏ����̗v��Q�[����������Ȃ���
���̕����Ȃ�ň��AGPU�Ƃ��Ă͔���Ȃ��Ă��ACPU�ɑ����ăQ�[���Ƀ��b�`�Ȍ��ʂ�t�^����ׂ̃J�[�h�Ƃ��Ĕ���邩��
PhysX�ƈ����CPU�̃R�v���Ƃ��ē�������Ȃ�Ή��Q�[����������������
>>471
�������Z��p�J�[�h�Ƃ������킯�Ȃ�����B
GPU�Ƃ��Đ������邩�́AAMD��NVIDIA��Larrabee�R�Ƃ��Ăǂ�Ȑ��i���o�����ɂ��ˁB
���������悤�Ȑ��i�����o���Ă��Ȃ�������A�����v���Z�X���i��ł镪�A�C���e�����L�����Ǝv�����ǁB
�ł��ŏI�I�ɂ̓w�g���W�j�A�XCPU�ɓ�������邩��A�������i���ǂ��Ƃ��W�Ȃ��Ȃ�Ǝv����B
�������Z��p�J�[�h�Ƃ������킯�Ȃ�����B
GPU�Ƃ��Đ������邩�́AAMD��NVIDIA��Larrabee�R�Ƃ��Ăǂ�Ȑ��i���o�����ɂ��ˁB
���������悤�Ȑ��i�����o���Ă��Ȃ�������A�����v���Z�X���i��ł镪�A�C���e�����L�����Ǝv�����ǁB
�ł��ŏI�I�ɂ̓w�g���W�j�A�XCPU�ɓ�������邩��A�������i���ǂ��Ƃ��W�Ȃ��Ȃ�Ǝv����B
NVIDIA��ATI��40nm���o�������
45nm�ŏo���Ă���Intel���L���ƂȁH�H
45nm�ŏo���Ă���Intel���L���ƂȁH�H
�N��45nm��Larrabee�̂��ƂƂ͌����Ă��Ȃ��B
600mm2�̃`�b�v����ǂ����悤���Ȃ����낤�B
600mm2�̃`�b�v����ǂ����悤���Ȃ����낤�B
>>472
��p�J�[�h�ɂ���K�v�͂Ȃ�
GPU�Ƃ��Ĕ����A�����Ď��Ԃ��o���đ�����ނ�����ł��A�Q�[���̕������Z��G���R�A���邢��CPU��
�A�N�Z�����[�^�[�Ƃ��Ďg����Ȃ�A�̂Ă�ꂸ�ɁA�V�����悹����GPU�̉��̃X���b�g�ő��̐l���𑗂��
���ڗ������オ��Ε������Z�̃I�v�V�������悹��Q�[���������邵�A
�܂��������Z�̃I�v�V�������悹���Q�[����������A�ꖇ��GPU�ƕ������Z�����Ȃ�Larrabee�������悤�ɂȂ�
PhysX�Ǝ����悤�ȕ������A��������͔ėp�����������낤������Ղ��͗L�邾�낤
��p�J�[�h�ɂ���K�v�͂Ȃ�
GPU�Ƃ��Ĕ����A�����Ď��Ԃ��o���đ�����ނ�����ł��A�Q�[���̕������Z��G���R�A���邢��CPU��
�A�N�Z�����[�^�[�Ƃ��Ďg����Ȃ�A�̂Ă�ꂸ�ɁA�V�����悹����GPU�̉��̃X���b�g�ő��̐l���𑗂��
���ڗ������オ��Ε������Z�̃I�v�V�������悹��Q�[���������邵�A
�܂��������Z�̃I�v�V�������悹���Q�[����������A�ꖇ��GPU�ƕ������Z�����Ȃ�Larrabee�������悤�ɂȂ�
PhysX�Ǝ����悤�ȕ������A��������͔ėp�����������낤������Ղ��͗L�邾�낤
���悢�旈�T�o�ꂾ���I���i��$99�I�I
http://northwood.blog60.fc2.com/blog-entry-2777.html
http://northwood.blog60.fc2.com/blog-entry-2783.html
http://northwood.blog60.fc2.com/blog-entry-2777.html
http://northwood.blog60.fc2.com/blog-entry-2783.html
Larrabee���Ƃ��Ƃ��o���̂��Ǝv��������Ȃ���w
>>475
��GPU�Ƃ��Ĕ����A�����Ď��Ԃ��o���đ�����ނ�����ł�
���̍��ɂ͂����Ɠd�̓p�t�H�[�}���X�̂������i���o�ĂĂ������ƈ��ނ���
��GPU�Ƃ��Ĕ����A�����Ď��Ԃ��o���đ�����ނ�����ł�
���̍��ɂ͂����Ɠd�̓p�t�H�[�}���X�̂������i���o�ĂĂ������ƈ��ނ���
�Ƃ肠���������o�āA�����O�o�X���ǂꂭ�炢�{�g���l�b�N�ɂȂ�̂��m�肽���ȁB
�ƂĂ�����Ȃ��������_���A�N�Z�X�ɑς����Ȃ�
�����A�\����Ă�GT300�͂Ȃɂ��V�A�[�L�̂悤��
nVidia's GT300 specifications revealed - it's a cGPU!
ttp://www.brightsideofnews.com/news/2009/4/22/nvidias-gt300-specifications-revealed---its-a-cgpu!.aspx
����ɑ�ATI�͂ǂ�����̂���
nVidia's GT300 specifications revealed - it's a cGPU!
ttp://www.brightsideofnews.com/news/2009/4/22/nvidias-gt300-specifications-revealed---its-a-cgpu!.aspx
����ɑ�ATI�͂ǂ�����̂���
ATI��GPGPU����Ȃ���AMD�Ƃ���SocketF�p��HT3.0�Ōq����StreamProcessor�o���Ăق����Ȃ��B
Larrabee��GPU�Ƃ��Ă���Ȃ���QPI�łȂ���LGA1366�ɍڂ����܂������̂ɁB
Larrabee��GPU�Ƃ��Ă���Ȃ���QPI�łȂ���LGA1366�ɍڂ����܂������̂ɁB
�\�P�b�g�ɍ����ƃ������ш悪�����ȉ��ɂȂ邩��A���\���������Ⴄ��Ȃ��́H
SocketG34����4ch������256bit�œ����ɂȂ邯�ǁA�N���b�N��GDDR�n�Ɣ�ׂ�Ƃ����ƒႢ���B
SocketG34����4ch������256bit�œ����ɂȂ邯�ǁA�N���b�N��GDDR�n�Ɣ�ׂ�Ƃ����ƒႢ���B
ATI�͊O��SSE���j�b�g�ɂȂ��Ȃ���
��̓���CPU��PCI-e���܂ނ炵����
��̓���CPU��PCI-e���܂ނ炵����
SocketF�ł�LGA1366�ł��A���[�J���Ɏ��O�̃��������q���邵
QPI/HT�o�R�ŕʃv���Z�b�T�̃��������ʑш�ŃA�N�Z�X�ł��邩��ш悪�����Ƃ���������Ȃ���ˁB
DDR3-1600������PC3-12800�Ȃ�ш��12.8GB/s�ALGA1366�Ȃ炻�ꂪ3�{��38.4GB/sec.
QPI��{��25.6GB/sec.��2�{���v���Z�b�T�Ԑڑ��Ɏg���� 51.2GB/sec.���v89.6GB/sec.�̃������ш悪����B
4�v���Z�b�T�\����3�{�g������ 76.8GB/sec. + 38.4GB/sec.�� 115.2GB/sec.�B
����2GHz�̃f�[�^���[�g������GDDR3��256bit�Őڑ�����HD4850�̃������ш��64GB/sec�A
�f�[�^���[�g3.6GHz��GDDR5���q��HD4870�ł悤�₭115.2GB/sec.�A
2.2GHz��GDDR3��512bit�Ōq�� GTX280��140GB/sec.�B
�ł����Z�\�[�X�ƌ��ʂ̓��C���������������肵�Ȃ��Ă͂����Ȃ��āA
������PCI-Express2.0 16���[���� 16GB/sec.�B
�������ш悪�v���I�ɂȂ�قǑ�K�͂ȉ��Z�ɂȂ�Ȃ�قǃ\�P�b�g�^�C�v�̂ق����L������ˁH
QPI/HT�o�R�ŕʃv���Z�b�T�̃��������ʑш�ŃA�N�Z�X�ł��邩��ш悪�����Ƃ���������Ȃ���ˁB
DDR3-1600������PC3-12800�Ȃ�ш��12.8GB/s�ALGA1366�Ȃ炻�ꂪ3�{��38.4GB/sec.
QPI��{��25.6GB/sec.��2�{���v���Z�b�T�Ԑڑ��Ɏg���� 51.2GB/sec.���v89.6GB/sec.�̃������ш悪����B
4�v���Z�b�T�\����3�{�g������ 76.8GB/sec. + 38.4GB/sec.�� 115.2GB/sec.�B
����2GHz�̃f�[�^���[�g������GDDR3��256bit�Őڑ�����HD4850�̃������ш��64GB/sec�A
�f�[�^���[�g3.6GHz��GDDR5���q��HD4870�ł悤�₭115.2GB/sec.�A
2.2GHz��GDDR3��512bit�Ōq�� GTX280��140GB/sec.�B
�ł����Z�\�[�X�ƌ��ʂ̓��C���������������肵�Ȃ��Ă͂����Ȃ��āA
������PCI-Express2.0 16���[���� 16GB/sec.�B
�������ш悪�v���I�ɂȂ�قǑ�K�͂ȉ��Z�ɂȂ�Ȃ�قǃ\�P�b�g�^�C�v�̂ق����L������ˁH
>483-484
�������`�b�v���ڂ������j�b�g���\�P�b�g�ɁB
���������ꂾ�Ɨe�ʂ�����Ȃ����낤�ȁB
�������`�b�v���ڂ������j�b�g���\�P�b�g�ɁB
���������ꂾ�Ɨe�ʂ�����Ȃ����낤�ȁB
>>486
����̓\�P�b�g1�݂̂��������A�N�Z�X�̕K�v�ȏ������s��
�\�P�b�g2�`3�̓������A�N�Z�X�̕K�v�ȏ������s���Ă��Ȃ��ꍇ�ɂ̂ݏo�鐔�l����
�����ɂ̓��[�J���Ɍq���郁�����ł���A����CPU����̌Ăяo���v�������荞���
�ш悪������
����̓\�P�b�g1�݂̂��������A�N�Z�X�̕K�v�ȏ������s��
�\�P�b�g2�`3�̓������A�N�Z�X�̕K�v�ȏ������s���Ă��Ȃ��ꍇ�ɂ̂ݏo�鐔�l����
�����ɂ̓��[�J���Ɍq���郁�����ł���A����CPU����̌Ăяo���v�������荞���
�ш悪������
4�\�P�b�g�Ƃ��A�����܂ŃR�X�g������115.2GB/sec�Ƃ������ȑш�o���Ă����傤���Ȃ��ł���B
���ʂ�256bit��GDDR5�q����A�����ш悪������̂ɁE�E�E�B
���ʂ�256bit��GDDR5�q����A�����ш悪������̂ɁE�E�E�B
490 �F,,�E�L�́M�E,,�j��-�������F2009/04/24(��) 06:45:27 ID:u3vDkKH6
>>473
TSMC��40nm�i���[�N�d�������R��j��Intel��45nm(HKMG)����d�͌����ł͌�җL�����낊��
���Ƃ́A�_�C�T�C�Y������̒P�����炢�H
Intel�ɂƂ��Ă͌������p�̏I������v���Z�X�ł���Ƃ����R�X�g�ʂł̗D�ʐ�������B
TSMC��40nm�i���[�N�d�������R��j��Intel��45nm(HKMG)����d�͌����ł͌�җL�����낊��
���Ƃ́A�_�C�T�C�Y������̒P�����炢�H
Intel�ɂƂ��Ă͌������p�̏I������v���Z�X�ł���Ƃ����R�X�g�ʂł̗D�ʐ�������B
�g�����W�X�^�P�̂̐��\�A�܂��Ă���P���ꂽ��������Ȃ��\�����ɁA
���i�̓d�͌���������Ă����Ӗ����낊��
�������\�̏o���͒c�q�̑�D����Demakasejan�Ȃ���
http://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
���i�̓d�͌���������Ă����Ӗ����낊��
�������\�̏o���͒c�q�̑�D����Demakasejan�Ȃ���
http://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
492 �F,,�E�L�́M�E,,�j��-�������F2009/04/24(��) 07:17:55 ID:u3vDkKH6
�o���N��HKMG�����Ȃ��Ń��[�N�d����}���閂�@������́H
���@�Ȃ�ĕK�v�Ȃ�
�S�Ă̓o�����X�̎����Ō��܂�
�S�Ă̓o�����X�̎����Ō��܂�
���傹��480gflops��312flops��搂����ƁA35.2gflops�ɗ���ʂ����X����A��n�Ђɂ͊��҂ł��Ȃ�
495 �F,,�E�L�́M�E,,�j��-�������F2009/04/24(��) 07:37:20 ID:u3vDkKH6
HKMG������32nm���炾���A�ޗ����ς��ĂȂ��̂ɉ��P�����킯���Ȃ��ł��B
����ATSMC��40nm���咣����D�ʐ��͂����܂œ��Ђ�55nm�A45nm�ɑ������
���Ă��Ƃ��l���Ȃ��Ƃ����܂���
http://pc.watch.impress.co.jp/docs/2007/1212/iedm03.htm
> High-k/Metal gate�Ő�������45nm�g�����W�X�^�̃Q�[�g���[�N�́A65nm�����
> ��ׂ�ƌ��I�ɒቺ�����Bn�`�����l��FET�̃Q�[�g���[�N��25����1�ȉ��ɁA
> p�`�����l��FET�̃Q�[�g���[�N��1,000����1�ȉ��ɂȂ����B�g�����W�X�^��
> �쓮�d����n�`�����l��FET��65nm����ɔ�ׂ�12%���サ�Ap�`�����l��FET�ł�
> 65nm����ɔ�ׂ�51%�����サ���B
�g�����W�X�^���x���ł̓d�͌����Ɋւ��Ă̓o���N�E��HKMG�ɑ��Ă��Ȃ蒙���������ԂȂ̂ł́H
2GHz�œ����C���I�[�_��x86�R�A�̏���d�͂��ǂ�Ȃ���Ȃ̂����Ă̂́AAtom�Ƃ�����Ⴊ����܂��ł��ˁB
���ƁA�L���b�V�������p�����ق���VRAM�̃������ш�i����d�́j���Z�[�u�ł���̂��ȂƁB
����ATSMC��40nm���咣����D�ʐ��͂����܂œ��Ђ�55nm�A45nm�ɑ������
���Ă��Ƃ��l���Ȃ��Ƃ����܂���
http://pc.watch.impress.co.jp/docs/2007/1212/iedm03.htm
> High-k/Metal gate�Ő�������45nm�g�����W�X�^�̃Q�[�g���[�N�́A65nm�����
> ��ׂ�ƌ��I�ɒቺ�����Bn�`�����l��FET�̃Q�[�g���[�N��25����1�ȉ��ɁA
> p�`�����l��FET�̃Q�[�g���[�N��1,000����1�ȉ��ɂȂ����B�g�����W�X�^��
> �쓮�d����n�`�����l��FET��65nm����ɔ�ׂ�12%���サ�Ap�`�����l��FET�ł�
> 65nm����ɔ�ׂ�51%�����サ���B
�g�����W�X�^���x���ł̓d�͌����Ɋւ��Ă̓o���N�E��HKMG�ɑ��Ă��Ȃ蒙���������ԂȂ̂ł́H
2GHz�œ����C���I�[�_��x86�R�A�̏���d�͂��ǂ�Ȃ���Ȃ̂����Ă̂́AAtom�Ƃ�����Ⴊ����܂��ł��ˁB
���ƁA�L���b�V�������p�����ق���VRAM�̃������ш�i����d�́j���Z�[�u�ł���̂��ȂƁB
>>495
HKMG�̓Q�[�g���[�N�͗}�����Ă��A90nm�ő傢�ɖ��ɂȂ���
�T�u�X���b�V�����h���[�N�͗}�����Ȃ�
����Ƃ����ŏo�Ă���쓮�d���̌���͘cSi�ɂ�鐬�ʂł����āA
HKMG�̓����ł̓Q�[�g�e�ʂ������Đ��\�ɂ̓}�C�i�X
����Ƀ`�b�v�̐��\�ɂ�RC�x���Ȃ��W���Ă���
�v���Z�X��]������ꍇ�͑S�̂����Ȃ���
>>496
�܂����̒ʂ肾��
�����炱�����\�����コ���邽�߂Ɋe��e�N�j�b�N���K�v�ɂȂ��Ă���킯��
��������ƍ��x�̓R�X�g�̖�肪�o�Ă��邩��Y�܂�����
HKMG�̓Q�[�g���[�N�͗}�����Ă��A90nm�ő傢�ɖ��ɂȂ���
�T�u�X���b�V�����h���[�N�͗}�����Ȃ�
����Ƃ����ŏo�Ă���쓮�d���̌���͘cSi�ɂ�鐬�ʂł����āA
HKMG�̓����ł̓Q�[�g�e�ʂ������Đ��\�ɂ̓}�C�i�X
����Ƀ`�b�v�̐��\�ɂ�RC�x���Ȃ��W���Ă���
�v���Z�X��]������ꍇ�͑S�̂����Ȃ���
>>496
�܂����̒ʂ肾��
�����炱�����\�����コ���邽�߂Ɋe��e�N�j�b�N���K�v�ɂȂ��Ă���킯��
��������ƍ��x�̓R�X�g�̖�肪�o�Ă��邩��Y�܂�����
Intel��90nm�v���Z�X�Ŗ��ɂȂ����̂̓Q�[�g���[�N�������Ǝv�����E�E�E
����Intel�͗ʎY�v���Z�X�ɓK�p�\�ȃg���C�Q�[�g�g�����W�X�^�̊J�����������Ă��邪
�����45nm�v���Z�X�ł�32nm�v���Z�X�ł��̗p���Ȃ��������Ƃ���
(Intel�ɂƂ��Ă�)����قǃN���e�B�J���Ȗ�肶��Ȃ����� �Ƃ������Ƃ��Ɣ��f���Ă���
>>�I�t���[�N
����Intel�͗ʎY�v���Z�X�ɓK�p�\�ȃg���C�Q�[�g�g�����W�X�^�̊J�����������Ă��邪
�����45nm�v���Z�X�ł�32nm�v���Z�X�ł��̗p���Ȃ��������Ƃ���
(Intel�ɂƂ��Ă�)����قǃN���e�B�J���Ȗ�肶��Ȃ����� �Ƃ������Ƃ��Ɣ��f���Ă���
>>�I�t���[�N
>>485
�{�C�Ō����Ă�H
����ARadeon�ł̓l�C�e�B�uVLIW�̓��I�R���p�C�������ł�CPU�Ń\�t�g�E�F�A�������Ă����
���s��SSE�ɂ�VLIW�̃R���p�C����蒷�����Ԃ�����悤�Ȗ��߂Ȃ�Ă܂��Ȃ�
��Ԏ��Ԃ̂����鏜�Z�ł��琔�\�T�C�N��
���߃��x���œ����悤�Ƃ��Ă�̂Ȃ�{���]�|
�����n�b�^���ł͂Ȃ����p�ɂȂ郌�x���ʼn��Z�S���Ƃ���Ζ���(SSE)�P�ʂ���Ȃ���
�v���V�[�W���E�X���b�h�P�ʂŊۓ������郂�f�����ȁB
���Ȃ킿�}�̃X�L����J�͂�Cell(��)�Ɠ�����������X�ɏオ�v�������
���̈Ӗ���CPU�Ƃ̖��߃Z�b�g�̈Ⴂ���ӎ����Ȃ��ėǂ�Larrabee����ԃ}�V�ȑI���ɂȂ�
�{�C�Ō����Ă�H
����ARadeon�ł̓l�C�e�B�uVLIW�̓��I�R���p�C�������ł�CPU�Ń\�t�g�E�F�A�������Ă����
���s��SSE�ɂ�VLIW�̃R���p�C����蒷�����Ԃ�����悤�Ȗ��߂Ȃ�Ă܂��Ȃ�
��Ԏ��Ԃ̂����鏜�Z�ł��琔�\�T�C�N��
���߃��x���œ����悤�Ƃ��Ă�̂Ȃ�{���]�|
�����n�b�^���ł͂Ȃ����p�ɂȂ郌�x���ʼn��Z�S���Ƃ���Ζ���(SSE)�P�ʂ���Ȃ���
�v���V�[�W���E�X���b�h�P�ʂŊۓ������郂�f�����ȁB
���Ȃ킿�}�̃X�L����J�͂�Cell(��)�Ɠ�����������X�ɏオ�v�������
���̈Ӗ���CPU�Ƃ̖��߃Z�b�g�̈Ⴂ���ӎ����Ȃ��ėǂ�Larrabee����ԃ}�V�ȑI���ɂȂ�
AMD��UMC��40nm���g������������
������GPU��CPU�Ɠ���SSE5���ڂ����Ȃ��̂�
SSE5�͂����������̂���Ȃ�����
�@# ���̘b�艽��ڂ�?
�@# ���̘b�艽��ڂ�?
�ǂ��������́H
AMD�͏��������CPU�ŃA�N�Z�����[�^�[�𓋍ڂ���Ƃ��Ă���
����ōŏ��Ɏv�����̂́E�E�E
����CPU�̓X�J�����j�b�g�{�x�N�^���j�b�g��1�ō\�������ėp�R�A�����ڂ��Ă���킯����
������̔ėp�R�A�{�Ɨ������x�N�^���j�b�g�Q�ɐ���������������
�Ⴆ�A�ėp�R�A�~4�{�x�N�^���j�b�g�Q�~1�Ƃ����č\���ɂȂ��Ȃ����H
AMD�̃��[�h�}�b�v�ɁASMT��R�A����SIMD���j�b�g�̊g���̗\�肪�����̂͂�������������
����ōŏ��Ɏv�����̂́E�E�E
����CPU�̓X�J�����j�b�g�{�x�N�^���j�b�g��1�ō\�������ėp�R�A�����ڂ��Ă���킯����
������̔ėp�R�A�{�Ɨ������x�N�^���j�b�g�Q�ɐ���������������
�Ⴆ�A�ėp�R�A�~4�{�x�N�^���j�b�g�Q�~1�Ƃ����č\���ɂȂ��Ȃ����H
AMD�̃��[�h�}�b�v�ɁASMT��R�A����SIMD���j�b�g�̊g���̗\�肪�����̂͂�������������
�Ȃ�2,3�N�O�̘b����J��Ԃ��Ă�悤�ȁc
>>498
�T�u�X���b�V�����h���[�N�ō����Ă�
�g���C�Q�[�g�g�����W�X�^���g��Ȃ��̂̓R�X�g�ƃ��X�N���傫������ł���
�����̋Z�p�̉��ǂōςނȂ炻�ꂪ���
>>498
�T�u�X���b�V�����h���[�N�ō����Ă�
�g���C�Q�[�g�g�����W�X�^���g��Ȃ��̂̓R�X�g�ƃ��X�N���傫������ł���
�����̋Z�p�̉��ǂōςނȂ炻�ꂪ���
�T�u�X���b�V�����h���[�N�̓V�~�����[�V�����Ƃ�����r�I�����Ɋm�����Ă�����ȁ`���O�\��30%�̃��[�N�d����60%�܂ő��������Ƃ̐����Ƃ��Ă͐����͂�����Ȃ��C������
>>501
��������
SSE5�Œ���閽�߂́AFP�Ϙa��1���߂�����ő�8�I�y���[�V����
GPU�͐��S�I�y���[�V�����P�ʂł̕�����s�����ł��Ȃ��̂ŁA�S�R�ʕ�
CPU��GPU�̃x�N�g�����Z�P�ʂ̃M���b�v�߂�ɂ�
CPU���ɂ�512�r�b�g�Ƃ�����ȏ�̃x�N�g�����̐V����SIMD���߂��K�v����
GPU����VLIW�����߂Ė��߂�����̕���x�������Ȃ��Ƃ����Ȃ��B
�K�R�I�ɍs�������̂�Larrabee�Ƃ��������B
�N���v���Ă�Ӗ���CPU�̌����肪�ł���GPU��Larrabee���B�ꂾ�B
���ASSE5��GPU����ʂ��Ă��{�l��AMD����Ǖ�����āAFusion�̍\�z���́A�傫����ނ��Ă܂����B
��������
SSE5�Œ���閽�߂́AFP�Ϙa��1���߂�����ő�8�I�y���[�V����
GPU�͐��S�I�y���[�V�����P�ʂł̕�����s�����ł��Ȃ��̂ŁA�S�R�ʕ�
CPU��GPU�̃x�N�g�����Z�P�ʂ̃M���b�v�߂�ɂ�
CPU���ɂ�512�r�b�g�Ƃ�����ȏ�̃x�N�g�����̐V����SIMD���߂��K�v����
GPU����VLIW�����߂Ė��߂�����̕���x�������Ȃ��Ƃ����Ȃ��B
�K�R�I�ɍs�������̂�Larrabee�Ƃ��������B
�N���v���Ă�Ӗ���CPU�̌����肪�ł���GPU��Larrabee���B�ꂾ�B
���ASSE5��GPU����ʂ��Ă��{�l��AMD����Ǖ�����āAFusion�̍\�z���́A�傫����ނ��Ă܂����B
GPU�Ƃ��čl���邩�炨������
CPU��SSE5���j�b�g��GPU�ɂ̂�ƍl����
CPU��SSE5���j�b�g��GPU�ɂ̂�ƍl����
GT200�Ƃ�����D3D�����Ă��邾�����ƑS�R�g���Ȃ�
��H�����\�L���Ȃ��́H
��H�����\�L���Ȃ��́H
�t��GPU��VLIW��SSE5�ɍ��킹��128bit�ɂ��킹����AGPU�Ƃ��Ă̐��\������Ȃ��H
���Ȃ��Ƃ��A����Radeon�Ƃ͂��Ȃ�Ⴄ�\���ɕύX����K�v������Ǝv�����ǁc�B
SSE5�̃��j�b�g��GPU�ɒP�ɑ��݂��邾���Ȃ�ACPU��SSE���j�b�g����������������������B
���Ȃ��Ƃ��A����Radeon�Ƃ͂��Ȃ�Ⴄ�\���ɕύX����K�v������Ǝv�����ǁc�B
SSE5�̃��j�b�g��GPU�ɒP�ɑ��݂��邾���Ȃ�ACPU��SSE���j�b�g����������������������B
VLIW���痣��Ă݂悤��
���Ȃ݂Ɍ��݂ł�shader 1�ɔ��s�����͍̂ő�32bit 5�v�f+����
���Ȃ݂Ɍ��݂ł�shader 1�ɔ��s�����͍̂ő�32bit 5�v�f+����
>>509
�g���Ȃ���H�͂Ȃ����ǁA�ғ����̒Ⴂ��H�͂���Ǝv���B
�Ƃ������AD3D�Ƃ��Ďg���ƁA�V�F�[�_�[���j�b�g�̉ғ����͔����ȉ�����B
�����ł��������ш悪�l�b�N�ɂȂ��Ă�B
�Ƃ������A�������ш悪�L�єY��ł邩��A�ėp�����ɑǂ���Ă�B
�g���Ȃ���H�͂Ȃ����ǁA�ғ����̒Ⴂ��H�͂���Ǝv���B
�Ƃ������AD3D�Ƃ��Ďg���ƁA�V�F�[�_�[���j�b�g�̉ғ����͔����ȉ�����B
�����ł��������ш悪�l�b�N�ɂȂ��Ă�B
�Ƃ������A�������ш悪�L�єY��ł邩��A�ėp�����ɑǂ���Ă�B
���f�̓V�F�[�_�R�A1��ɑ��f�R�[�_�t�����g�G���h1��Ȃ�Ƃ������A
���\��̃V�F�[�_��1��̃f�R�[�_�œ������߂��u���[�h�L���X�g����
������SIMD�\����������Ȃ�B
����AMD��NVIDIA�̂悤�ȃr�b�O�`�b�v�H���͏I��肾�Ƃ��猾���Ă�B
Fusion��SSE5�͂ǂ������Ƃ�����DX11�̘_���p�C�v���C���̑O��������CPU��GPU�̕⏕�I�Ɏg�����߂̋Z�p����Ȃ����ˁB
�]��CPU�R�A���V�F�[�_���C�N�Ɋ��p���邽�߂́B
���\��̃V�F�[�_��1��̃f�R�[�_�œ������߂��u���[�h�L���X�g����
������SIMD�\����������Ȃ�B
����AMD��NVIDIA�̂悤�ȃr�b�O�`�b�v�H���͏I��肾�Ƃ��猾���Ă�B
Fusion��SSE5�͂ǂ������Ƃ�����DX11�̘_���p�C�v���C���̑O��������CPU��GPU�̕⏕�I�Ɏg�����߂̋Z�p����Ȃ����ˁB
�]��CPU�R�A���V�F�[�_���C�N�Ɋ��p���邽�߂́B
>>513
NVIDIA�̃r�b�O�`�b�v�H�������E�����ǁB
�i�ǂ���̂Ƃ͌���Ȃ����j�}���`�`�b�v�H�������܂肤�܂������Ȃ�������B
GPU�̏����͒����������ǁA�o�͐�̃t���[���o�b�t�@��1�����Ȃ��̂����B
�ŋ߂�CF�SLI�̓t���[���P�ʂŕ��������Ă邯�ǁA
���x�̓t���[���P�ʂŒx�����������邩��A�Q�[���p�r�ɂ̓f�����b�g���傫���B
NVIDIA�̃r�b�O�`�b�v�H�������E�����ǁB
�i�ǂ���̂Ƃ͌���Ȃ����j�}���`�`�b�v�H�������܂肤�܂������Ȃ�������B
GPU�̏����͒����������ǁA�o�͐�̃t���[���o�b�t�@��1�����Ȃ��̂����B
�ŋ߂�CF�SLI�̓t���[���P�ʂŕ��������Ă邯�ǁA
���x�̓t���[���P�ʂŒx�����������邩��A�Q�[���p�r�ɂ̓f�����b�g���傫���B
�}���`�`�b�v�Ƃ����Ă����̂�
�������̋��L�������A�P��CF,SLI����
�������̋��L�������A�P��CF,SLI����
�ł����̏�����RV770�ōs���Ă��
�W�Ȃ��ǁA���v����larrabee���ۂ��Ȃ���
ttp://www.yusuke-ohara.com/weblog2/archive/2008/01/r700.html
�W�Ȃ��ǁA���v����larrabee���ۂ��Ȃ���
ttp://www.yusuke-ohara.com/weblog2/archive/2008/01/r700.html
Cell���܂�GPU�̕⏕�ł͂��邪�A�ڂ��ڂ����ʂ����Ă邯�ǁA
���̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
�]���ȉ�H������ĂĐς߂�R�A�����菭�Ȃ��Ȃ��Ă��܂��āA
�������N���b�N���L�тȂ��ƂȂ��Larrabee�o�開�Ȃ��Ȃ��B
Intel�̓n�[�h�ɂ���ȏ㓊�������Ȃ��āA�S���\�t�g�ɂ܂킷�ׂ����Ǝv���B
�������̕����ꔲ���ɑ�ςł��傤�BMS�ɓ������Ĕ���ȋ��������炢�łȂ��ƁB
��Ԃ����̂�MS��Larrabee���ۂ��Ɣ��蕥���Ă��܂����ƁB
�K�͓I�ɊJ���ł������Ȃ̂�MS���炢�����Ȃ��B
���̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
�]���ȉ�H������ĂĐς߂�R�A�����菭�Ȃ��Ȃ��Ă��܂��āA
�������N���b�N���L�тȂ��ƂȂ��Larrabee�o�開�Ȃ��Ȃ��B
Intel�̓n�[�h�ɂ���ȏ㓊�������Ȃ��āA�S���\�t�g�ɂ܂킷�ׂ����Ǝv���B
�������̕����ꔲ���ɑ�ςł��傤�BMS�ɓ������Ĕ���ȋ��������炢�łȂ��ƁB
��Ԃ����̂�MS��Larrabee���ۂ��Ɣ��蕥���Ă��܂����ƁB
�K�͓I�ɊJ���ł������Ȃ̂�MS���炢�����Ȃ��B
�ǂ����c�ǂ݁H
Larrabee�̃R�A�ł�����H
x86�R�A������Ȃ�Ƃ��Ȃ�Ƃ����������B
x86�R�A������Ȃ�Ƃ��Ȃ�Ƃ����������B
�ł����Ă������A痂�������Ăق���
522 �F,,�E�L�́M�E,,�j��-�������F2009/04/25(�y) 08:13:19 ID:NgQ/o9lJ
��Cell���܂�GPU�̕⏕�ł͂��邪�A�ڂ��ڂ����ʂ����Ă邯�ǁA
�v���̂ĂR���[�J���̘b�Ȃ�Ăǂ��ł������ł��B�r�W�l�X�ɂȂ��ĂȂ�����B
�����̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
DirectX 11(SM5.0)����ł̓����_���A�N�Z�X�@�\�͎d�l�ł��B�c�O�ł����ˁB
�����ڂ��x����Ƃ��̃��x������Ȃ���ł��B
����Ƃ�Wii�Ɠ����͂ꂽ�Z�p�H���̘b�ł����H���ꂱ���C�V���ɏ��Ă����Ȃ������B
�ǂ݂̂�VAIO�ɂ���g���Ă��炦�Ȃ�Cell�Ɏg�����͂Ȃ��ł���B
128�r�b�gSIMD��p�Ȃ�āA������2010�N��ɂ͊��ɉ��ł���B
��MS�ɓ������Ĕ���ȋ��������炢�łȂ��ƁB
���v�ɂȂ�Ȃ����Ƃ����K�v���ǂ��ɂ����ł��傤���H
����ȐԎ��o���Ă܂ŃQ�[�����Ƒ����Ă�\�j�[�͂Ԃ����Ⴏ�ُ킾���A
����Ɠ������o�ł��̂�����Ă�����܂����BIntel�͖��ʋ������̂͌����ȉ�Ђł���B
Itanium�͂��낤���č����o���Ă邩�����Ă邯�ǁA�N�X�������Ȃ��Ă邩��
�J���\�Z�͂ǂ�ǂ����Ă�悤�����ˁB
������������ǁAIntel�̓Q�[�}�[�̂��߂Ƀv���Z�b�T����Ă��Ȃ���ł���B
�����ԃ��[�J�[��F1�̂��߂Ɏ����ԍ���Ă��Ȃ��̂Ɠ������ƁB
Larrabee��x86�̖��߃Z�b�g�x�[�X�̉Ȋw�Z�p�v�Z�p�A�N�Z�����[�^�ŁA�Ȃ������ꎩ�̂�
�ėp���j�[�R�A�v���Z�b�T�Ƃ��Ă��g������̂ł����BWeb�T�[�o��RDB����������ł���B
�X��CPU��Larrrabee�i�Ɍ��炸���j�[�R�ACPU�j�Ƃ����n������t���[�����[�N�Ƃ���TBB��Ct��p�ӂ��Ă�B
Intel�̓n�[�h�邽�߂̃\�t�g�̊J���ɂ͔���Ȏ��ԁE��p�������Ă���B
�����܂�CPU�̉��������Larrabee������B
GPU�@�\�Ȃ��SIMD����������łɕt�����悤�Ȃ����A�f�����ėp�v���Z�b�T������
DirectX��OpenGL���o�R�����ɏ_��Ƀ~�h���E�F�A���N�������Ƃ��ł���B
GPU�́u�ėp�v���O���t�B�b�N�p�r�̂��łɉ߂��Ȃ��̂Ƃ܂������t�̗��ꂾ�ȁB
GPU�s��ɂ����āALarrabee���ėp�I�߂��āA�O���t�B�b�N�ɓ������ꂽGPU�Ƃ͐킦�Ȃ����Ă����̂Ȃ�
�ėp�ƃO���t�B�b�N��p�͑��e��Ȃ����̂��Ă��ƂɂȂ�킯�ŁA�܂������������R��GPGPU��
�^�̈Ӗ��Ŕėp���ł��Ȃ��B
�v���̂ĂR���[�J���̘b�Ȃ�Ăǂ��ł������ł��B�r�W�l�X�ɂȂ��ĂȂ�����B
�����̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
DirectX 11(SM5.0)����ł̓����_���A�N�Z�X�@�\�͎d�l�ł��B�c�O�ł����ˁB
�����ڂ��x����Ƃ��̃��x������Ȃ���ł��B
����Ƃ�Wii�Ɠ����͂ꂽ�Z�p�H���̘b�ł����H���ꂱ���C�V���ɏ��Ă����Ȃ������B
�ǂ݂̂�VAIO�ɂ���g���Ă��炦�Ȃ�Cell�Ɏg�����͂Ȃ��ł���B
128�r�b�gSIMD��p�Ȃ�āA������2010�N��ɂ͊��ɉ��ł���B
��MS�ɓ������Ĕ���ȋ��������炢�łȂ��ƁB
���v�ɂȂ�Ȃ����Ƃ����K�v���ǂ��ɂ����ł��傤���H
����ȐԎ��o���Ă܂ŃQ�[�����Ƒ����Ă�\�j�[�͂Ԃ����Ⴏ�ُ킾���A
����Ɠ������o�ł��̂�����Ă�����܂����BIntel�͖��ʋ������̂͌����ȉ�Ђł���B
Itanium�͂��낤���č����o���Ă邩�����Ă邯�ǁA�N�X�������Ȃ��Ă邩��
�J���\�Z�͂ǂ�ǂ����Ă�悤�����ˁB
������������ǁAIntel�̓Q�[�}�[�̂��߂Ƀv���Z�b�T����Ă��Ȃ���ł���B
�����ԃ��[�J�[��F1�̂��߂Ɏ����ԍ���Ă��Ȃ��̂Ɠ������ƁB
Larrabee��x86�̖��߃Z�b�g�x�[�X�̉Ȋw�Z�p�v�Z�p�A�N�Z�����[�^�ŁA�Ȃ������ꎩ�̂�
�ėp���j�[�R�A�v���Z�b�T�Ƃ��Ă��g������̂ł����BWeb�T�[�o��RDB����������ł���B
�X��CPU��Larrrabee�i�Ɍ��炸���j�[�R�ACPU�j�Ƃ����n������t���[�����[�N�Ƃ���TBB��Ct��p�ӂ��Ă�B
Intel�̓n�[�h�邽�߂̃\�t�g�̊J���ɂ͔���Ȏ��ԁE��p�������Ă���B
�����܂�CPU�̉��������Larrabee������B
GPU�@�\�Ȃ��SIMD����������łɕt�����悤�Ȃ����A�f�����ėp�v���Z�b�T������
DirectX��OpenGL���o�R�����ɏ_��Ƀ~�h���E�F�A���N�������Ƃ��ł���B
GPU�́u�ėp�v���O���t�B�b�N�p�r�̂��łɉ߂��Ȃ��̂Ƃ܂������t�̗��ꂾ�ȁB
GPU�s��ɂ����āALarrabee���ėp�I�߂��āA�O���t�B�b�N�ɓ������ꂽGPU�Ƃ͐킦�Ȃ����Ă����̂Ȃ�
�ėp�ƃO���t�B�b�N��p�͑��e��Ȃ����̂��Ă��ƂɂȂ�킯�ŁA�܂������������R��GPGPU��
�^�̈Ӗ��Ŕėp���ł��Ȃ��B
Geforce��SP����Radeon��菭�Ȃ����炤��ʂ�ʂ�
���������l���v���o������
���������l���v���o������
524 �F,,�E�L�́M�E,,�j��-�������F2009/04/25(�y) 09:25:56 ID:NgQ/o9lJ
Atom���x�̐��\��x86��16�R�A�����čX��SIMD�����������牽���o���邩
�l������l�ɂ͍ō��̃f�o�C�X�ɂȂ肻�������ǂ�
��Atom���x�A���Č����Ă�Cell�i�j�Ȃ̃X�J�����Z���\�͂��̃��x���ɂ���B���ĂȂ�
�l������l�ɂ͍ō��̃f�o�C�X�ɂȂ肻�������ǂ�
��Atom���x�A���Č����Ă�Cell�i�j�Ȃ̃X�J�����Z���\�͂��̃��x���ɂ���B���ĂȂ�
�R�A��������قǃv���O���~���O������Ȃ���Č������ǁA
�R�A���P�O�O�����炢��������t�ɊȒP�ɂȂ肻���ȋC�����Ȃ��ł��Ȃ��B
�R�A���P�O�O�����炢��������t�ɊȒP�ɂȂ肻���ȋC�����Ȃ��ł��Ȃ��B
AMD��6�R�ACPU�̎ʐ^���o�����ǁA�z������߂�ʐς����Ȃ肠���
>>522
�Q�[���@�̘b�͂Ƃ�����
���Ȋw�Z�p�v�Z�p�A�N�Z�����[�^
�������Ŕ{���x�ł�Cell������̂͂ǂ����āH�r�W�l�X�ɂȂ��Ă��
�Q�[���@�̘b�͂Ƃ�����
���Ȋw�Z�p�v�Z�p�A�N�Z�����[�^
�������Ŕ{���x�ł�Cell������̂͂ǂ����āH�r�W�l�X�ɂȂ��Ă��
��[�ǂ��ȁ[�i�j
>>522
> �����̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
>
> DirectX 11(SM5.0)����ł̓����_���A�N�Z�X�@�\�͎d�l�ł��B�c�O�ł����ˁB
> �����ڂ��x����Ƃ��̃��x������Ȃ���ł��B
DX11�̃����_���A�N�Z�X�@�\���d�l����w
��d�Ɋ��Ⴂ���Ă邼�B
����͂����Ă����ă^�C�������_�����O���̗p����LRB���܂���
�u�����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@�v�����B
> 128�r�b�gSIMD��p�Ȃ�āA������2010�N��ɂ͊��ɉ��ł���B
���Ƃ�����Ȃ��Ă��B
DLP�ɐU�邩TLP�ɐU�邩���Ă��Ƃ����B
����ɂ�512bitSIMD�̓R�A�����グ���Ȃ�LRB�̋���̍�ɂ����݂��Ȃ��ȁB
> �����̂܂܃����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@���m������Ă�����
>
> DirectX 11(SM5.0)����ł̓����_���A�N�Z�X�@�\�͎d�l�ł��B�c�O�ł����ˁB
> �����ڂ��x����Ƃ��̃��x������Ȃ���ł��B
DX11�̃����_���A�N�Z�X�@�\���d�l����w
��d�Ɋ��Ⴂ���Ă邼�B
����͂����Ă����ă^�C�������_�����O���̗p����LRB���܂���
�u�����_���A�N�Z�X�𐂂ꗬ���Ȃ��R�A�����̎�@�v�����B
> 128�r�b�gSIMD��p�Ȃ�āA������2010�N��ɂ͊��ɉ��ł���B
���Ƃ�����Ȃ��Ă��B
DLP�ɐU�邩TLP�ɐU�邩���Ă��Ƃ����B
����ɂ�512bitSIMD�̓R�A�����グ���Ȃ�LRB�̋���̍�ɂ����݂��Ȃ��ȁB
���x�����L������
����J�̃A�Z���u������
�S������Ȃ��L���b�V��
�ł����ł���������Ƃɂ�����R�X���b�h���点������ł��ˁB�킩��܂��B
����J�̃A�Z���u������
�S������Ȃ��L���b�V��
�ł����ł���������Ƃɂ�����R�X���b�h���点������ł��ˁB�킩��܂��B
����ADX11���ォ��̓����_���A�N�Z�X���~�����Ȃ�̂�
ttp://game.watch.impress.co.jp/docs/series/3dcg/20090325_79920.html
ttp://game.watch.impress.co.jp/img/gmw/docs/079/920/3dd1110.jpg
>DirectX 11�́A��q����DirectX���Z�V�F�[�_�[�ւ̑Ή��ɃV���N������`�ŁAGPGPU�I�ȃ|�e���V�������s�N�Z���V�F�[�_�[�ɂ��^������B
>���ꂪDirectX 11�̃s�N�Z���V�F�[�_�[�ɐV�@�\�Ƃ��ė^������uUnordered Access View�v�iUAV�j�Ƃ����V�T�O���B
>
>Unordered Access�Ƃ́A�܂�̓����_���A�N�Z�X�̂��ƁB
>
>�Ȃ�ƁA�s�N�Z���V�F�[�_�[����r�f�I�������ւ̃����_���A�N�Z�X���\�ƂȂ�̂��B
>����܂Ńs�N�Z���V�F�[�_�[�́A���炩���߂��̃s�N�Z�����W�ɑΉ�����
>�r�f�I�������ɏ������݁i�o�́j�����ł��Ȃ��������A���̐���蕥����̂��B
>�s�N�Z���V�F�[�_�[��DirectX���Z�V�F�[�_�[�ŁA�����_���������A�N�Z�X���ł���悤�ɂȂ��Ă��܂����W��
>�ʓ|�ɂȂ�̂��A�����X���b�h����̓��ꃁ�����A�h���X�A�N�Z�X�̊Ǘ����B
>���s�^�C�~���O�ɂ���ă������̓��e���ς���Ă��Ă��܂��\�����łĂ���킯�ŁA
>����̓}���`�X���b�h�v���O�����ŋN���肤��f�o�b�N����Ȍ��ۂ݂��˂Ȃ��B
>������DirectX 11�ɂ�����s�N�Z���V�F�[�_�[��DirectX���Z�V�F�[�_�[�ł�
>Atomic Operation�i�s������j�ɑΉ��������߂��T�|�[�g����Ă���B
nvidia,s3,intel�͂����������Ă���������
ati�͂ǂ����ȁE�E
ttp://game.watch.impress.co.jp/docs/series/3dcg/20090325_79920.html
ttp://game.watch.impress.co.jp/img/gmw/docs/079/920/3dd1110.jpg
{kind=link}
>DirectX 11�́A��q����DirectX���Z�V�F�[�_�[�ւ̑Ή��ɃV���N������`�ŁAGPGPU�I�ȃ|�e���V�������s�N�Z���V�F�[�_�[�ɂ��^������B
>���ꂪDirectX 11�̃s�N�Z���V�F�[�_�[�ɐV�@�\�Ƃ��ė^������uUnordered Access View�v�iUAV�j�Ƃ����V�T�O���B
>
>Unordered Access�Ƃ́A�܂�̓����_���A�N�Z�X�̂��ƁB
>
>�Ȃ�ƁA�s�N�Z���V�F�[�_�[����r�f�I�������ւ̃����_���A�N�Z�X���\�ƂȂ�̂��B
>����܂Ńs�N�Z���V�F�[�_�[�́A���炩���߂��̃s�N�Z�����W�ɑΉ�����
>�r�f�I�������ɏ������݁i�o�́j�����ł��Ȃ��������A���̐���蕥����̂��B
>�s�N�Z���V�F�[�_�[��DirectX���Z�V�F�[�_�[�ŁA�����_���������A�N�Z�X���ł���悤�ɂȂ��Ă��܂����W��
>�ʓ|�ɂȂ�̂��A�����X���b�h����̓��ꃁ�����A�h���X�A�N�Z�X�̊Ǘ����B
>���s�^�C�~���O�ɂ���ă������̓��e���ς���Ă��Ă��܂��\�����łĂ���킯�ŁA
>����̓}���`�X���b�h�v���O�����ŋN���肤��f�o�b�N����Ȍ��ۂ݂��˂Ȃ��B
>������DirectX 11�ɂ�����s�N�Z���V�F�[�_�[��DirectX���Z�V�F�[�_�[�ł�
>Atomic Operation�i�s������j�ɑΉ��������߂��T�|�[�g����Ă���B
nvidia,s3,intel�͂����������Ă���������
ati�͂ǂ����ȁE�E
DX11��AMD�ׂ����肶��Ȃ������H
��{�I��DX�̋K�i��MS��GPU�e�Ђ̋��c�Ō��܂�͂�
ATI�ׂ�����Ǝv���Ă������́A�e�b�Z���[�^�̎d�l��XBOX360�̂��̂ɋ߂�����
����ƁAfetch4���W���T�|�[�g�ɂȂ������Ƃ��炢��
���̂ق��Ɋւ��ẮA�ǂ����Ƃ������f�͂ł��Ȃ�
ATI�ׂ�����Ǝv���Ă������́A�e�b�Z���[�^�̎d�l��XBOX360�̂��̂ɋ߂�����
����ƁAfetch4���W���T�|�[�g�ɂȂ������Ƃ��炢��
���̂ق��Ɋւ��ẮA�ǂ����Ƃ������f�͂ł��Ȃ�
�̂̋L���F���Ă�����C�ɂȂ���̂�
ttp://game.watch.impress.co.jp/docs/20060514/ageia.htm
>�܂��A���������_���Z���\��58GFLOPS�������ŁA�܂����ߎ��s���[�g�͖��b220���̎��s���\�ƌ������ƂɂȂ��Ă���B
ttp://pc.watch.impress.co.jp/docs/2006/0412/kaigai260.htm
>�u��X�̃v���Z�b�T��(GPU�̂悤��)�X�g���[�~���O�v���Z�b�T�ł͂Ȃ��B
>�t�B�W�b�N�X�ł̓X�g���[�~���O�^�̃f�[�^�\���ł͂Ȃ����炾�B
>�Ⴆ�A�I���`�b�v�̃������ш悪�d�v�ƂȂ�B
>
>���Z�Ŏg���f�[�^�̓I���`�b�v�ɍڂ���(���Ƃō�������}���Ă���)����ŁA
>PPU�ł�2Tbit/sec�̓����������ш�����v
>
>��AGEIA��Manju Hegde��(Co-Founder, Chairman and CEO)�͌��B
>GPU��Programmable Shader�̉��Z�R�A���̂̕����I�Ȏ������A
>����ł̓t�B�W�b�N�X�V�~�����[�V�����̂悤��GPGPU�Ɍ����Ă��Ȃ���Hegde���͎w�E����B
>�uGPU�ł�(Programmable Shader��)�ėp���W�X�^�̐����ɂ߂ď��Ȃ��B
>����́A�t�B�W�b�N�X�̂悤�ɁA���G�ȃf�[�^�\���ɑ��āA�قȂ镡���̃A���S���Y���ŏ������s�Ȃ��ꍇ�ɂ́A���ɖ��ƂȂ�B
>PPU�ł́A���̂��߂ɑ���(�̃��W�X�^)������Ă���v��Hegde���͎w�E����B
�ĊO540GTX�̂��̒l�͒P�ɃX�J�E�^�[�̌̏�i�x���`�̃G���[�j�Ƃ͌����Ȃ��̂�������Ȃ��ˁE�E
����A�m���
Stanford GPUBench
Streaming: Basic Throughput
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/streamthroughput.png
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/streamthroughputbytes.png
4870
ttp://xs138.xs.to/xs138/09161/streamthroughput332.png
ttp://xs138.xs.to/xs138/09161/streamthroughputbytes603.png
540GTX
ttp://xs538.xs.to/xs538/09161/streamthroughput357.png
ttp://xs138.xs.to/xs138/09161/streamthroughputbytes432.png
ttp://game.watch.impress.co.jp/docs/20060514/ageia.htm
>�܂��A���������_���Z���\��58GFLOPS�������ŁA�܂����ߎ��s���[�g�͖��b220���̎��s���\�ƌ������ƂɂȂ��Ă���B
ttp://pc.watch.impress.co.jp/docs/2006/0412/kaigai260.htm
>�u��X�̃v���Z�b�T��(GPU�̂悤��)�X�g���[�~���O�v���Z�b�T�ł͂Ȃ��B
>�t�B�W�b�N�X�ł̓X�g���[�~���O�^�̃f�[�^�\���ł͂Ȃ����炾�B
>�Ⴆ�A�I���`�b�v�̃������ш悪�d�v�ƂȂ�B
>
>���Z�Ŏg���f�[�^�̓I���`�b�v�ɍڂ���(���Ƃō�������}���Ă���)����ŁA
>PPU�ł�2Tbit/sec�̓����������ш�����v
>
>��AGEIA��Manju Hegde��(Co-Founder, Chairman and CEO)�͌��B
>GPU��Programmable Shader�̉��Z�R�A���̂̕����I�Ȏ������A
>����ł̓t�B�W�b�N�X�V�~�����[�V�����̂悤��GPGPU�Ɍ����Ă��Ȃ���Hegde���͎w�E����B
>�uGPU�ł�(Programmable Shader��)�ėp���W�X�^�̐����ɂ߂ď��Ȃ��B
>����́A�t�B�W�b�N�X�̂悤�ɁA���G�ȃf�[�^�\���ɑ��āA�قȂ镡���̃A���S���Y���ŏ������s�Ȃ��ꍇ�ɂ́A���ɖ��ƂȂ�B
>PPU�ł́A���̂��߂ɑ���(�̃��W�X�^)������Ă���v��Hegde���͎w�E����B
�ĊO540GTX�̂��̒l�͒P�ɃX�J�E�^�[�̌̏�i�x���`�̃G���[�j�Ƃ͌����Ȃ��̂�������Ȃ��ˁE�E
����A�m���
Stanford GPUBench
Streaming: Basic Throughput
8800
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/streamthroughput.png
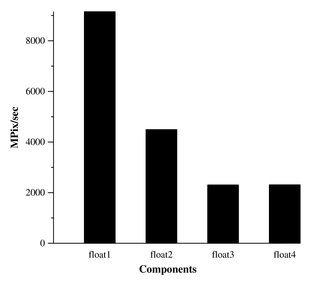{kind=link}
ttp://graphics.stanford.edu/projects/gpubench/results/8800GTX-0003/streamthroughputbytes.png
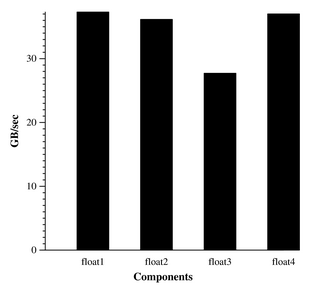{kind=link}
4870
ttp://xs138.xs.to/xs138/09161/streamthroughput332.png
{kind=link}
ttp://xs138.xs.to/xs138/09161/streamthroughputbytes603.png
{kind=link}
540GTX
ttp://xs538.xs.to/xs538/09161/streamthroughput357.png
{kind=link}
ttp://xs138.xs.to/xs138/09161/streamthroughputbytes432.png
{kind=link}
536 �F,,�E�L�́M�E,,�j��-�������F2009/04/25(�y) 22:45:29 ID:NgQ/o9lJ
>>530
�́H������H
GeForce��32�����SIMD�i����SIMT�j�ARadeon��RV700�n��5(+1)�����VLIW�̍X��40�����SIMD�����ǁH
Cell�͖��ߊԂ̃��C�e���V���傫�����āA���߃��x�������ł��Ȃ���������点��ƃN���b�N�����̎d������ł��Ȃ���
����Ƃ͕ʂ̗��R�ŕ���̋��i�j
�Ȃ�Ȃ�AAtom 1.6GHz����Cell SPE 3.2GHz�Ƃ����ߎS�ȃx���`���ʂ������o�������H��
�́H������H
GeForce��32�����SIMD�i����SIMT�j�ARadeon��RV700�n��5(+1)�����VLIW�̍X��40�����SIMD�����ǁH
Cell�͖��ߊԂ̃��C�e���V���傫�����āA���߃��x�������ł��Ȃ���������点��ƃN���b�N�����̎d������ł��Ȃ���
����Ƃ͕ʂ̗��R�ŕ���̋��i�j
�Ȃ�Ȃ�AAtom 1.6GHz����Cell SPE 3.2GHz�Ƃ����ߎS�ȃx���`���ʂ������o�������H��
537 �F,,�E�L�́M�E,,�j��-�������F2009/04/25(�y) 23:30:06 ID:NgQ/o9lJ
Cell�̃p�t�H�[�}���X��128�r�b�gSIMD��3.2GHz�ł͂Ȃ��A1024�r�b�gSIMD��400MHz���x���Ǝv���Ă��������B
DMA��1024�r�b�g�P�ʂłȂ��ƌ����I�ɂł��Ȃ��̂ƁAIntel�v���Z�b�T�Ɣ�ׂĂ�
�e���ߊԂ̃��C�e���V���ُ�ɑ傫�����ƁA����ɐs���܂��ȁB
DMA��1024�r�b�g�P�ʂłȂ��ƌ����I�ɂł��Ȃ��̂ƁAIntel�v���Z�b�T�Ɣ�ׂĂ�
�e���ߊԂ̃��C�e���V���ُ�ɑ傫�����ƁA����ɐs���܂��ȁB
������CellCell�����l�����₽�Ȃ���
����Ȏ��s��Ɣ�ׂ���intel���߂������낤
����Ȏ��s��Ɣ�ׂ���intel���߂������낤
539 �F,,�E�L�́M�E,,�j��-�������F2009/04/25(�y) 23:39:27 ID:NgQ/o9lJ
>>528
���Ȃ݂ɂ��������ʂ�IBM���g�����̂Ă�ƌ��Ă�
�����^����Ȃ�Intel�v���Z�b�T�ł�AVX�̗̍p�ŕ����������Z�̃X���[�v�b�g���X�ɔ{�ɂȂ�̂�
�����ȃA�N�Z�����[�^�ł͑����ł��ł��Ȃ��Ȃ�B
���������g�b�v500�ɓ���X�p�R����Intel�v���Z�b�T����ʂɂ���Ă邱�Ǝ��́A�����������Z�̃X���[�v�b�g������
���߂��Ă�킯����Ȃ����Ƃ̏؍��ł���������
���Ȃ݂ɂ��������ʂ�IBM���g�����̂Ă�ƌ��Ă�
�����^����Ȃ�Intel�v���Z�b�T�ł�AVX�̗̍p�ŕ����������Z�̃X���[�v�b�g���X�ɔ{�ɂȂ�̂�
�����ȃA�N�Z�����[�^�ł͑����ł��ł��Ȃ��Ȃ�B
���������g�b�v500�ɓ���X�p�R����Intel�v���Z�b�T����ʂɂ���Ă邱�Ǝ��́A�����������Z�̃X���[�v�b�g������
���߂��Ă�킯����Ȃ����Ƃ̏؍��ł���������
����A�f�W���u
542 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 02:40:44 ID:Ft3gm9E8
�������LINPACK�����Ōv��Ȃ����\������̂͊m������
���������ȊO�̐��\���Ƃ܂��܂�x86�̐��\�����|���Ă��܂����Ă̂������ȂƂ���Ȃ��B
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2615776
���A�R�X�g���Ĉ�ԏd�v����
�X�p�R���̏ꍇ�́A�����R�X�g��������d�͂��܂߂����j���O�R�X�g���d�������킯�����B
���ƁA�v���O�����g�݂ɂ����Đ��\���o���Ȃ���Ԃ��Ă̂��ғ����̃R�X�g�p�t�H�[�}���X��
��������v���ɂȂ邩��A�g����\�t�g���Y��������Ă̂��厖�Ȃ��B
���������ȊO�̐��\���Ƃ܂��܂�x86�̐��\�����|���Ă��܂����Ă̂������ȂƂ���Ȃ��B
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2615776
���A�R�X�g���Ĉ�ԏd�v����
�X�p�R���̏ꍇ�́A�����R�X�g��������d�͂��܂߂����j���O�R�X�g���d�������킯�����B
���ƁA�v���O�����g�݂ɂ����Đ��\���o���Ȃ���Ԃ��Ă̂��ғ����̃R�X�g�p�t�H�[�}���X��
��������v���ɂȂ邩��A�g����\�t�g���Y��������Ă̂��厖�Ȃ��B
Linpack�ȊO�����������_�ȊO
���݂�top500��W/flops�����Ȃ���ʂ�x86�n�ł͂Ȃ�Power�n
�P�Ɂh���Y�h�ƌ������疢���̂��̂͊܂܂Ȃ��B
�X�p�R���̗��p��30�N�ȏ�
�@top500�̔����ȏオN�v���Z�b�T�ȉ�
�@93�@98�@003�@2008�@�N
�@08�@64�@256�@4096�@N
x86���a�����}�V�����X�p�R�����[�U�[�ɂƂ��Ă͐V�Q
�ǂ��݂Ă����i�K�̃X�p�R���������Y�őa����x86�ɖ��m�ȗD�ʂ͂Ȃ��B
���݂�top500��W/flops�����Ȃ���ʂ�x86�n�ł͂Ȃ�Power�n
�P�Ɂh���Y�h�ƌ������疢���̂��̂͊܂܂Ȃ��B
�X�p�R���̗��p��30�N�ȏ�
�@top500�̔����ȏオN�v���Z�b�T�ȉ�
�@93�@98�@003�@2008�@�N
�@08�@64�@256�@4096�@N
x86���a�����}�V�����X�p�R�����[�U�[�ɂƂ��Ă͐V�Q
�ǂ��݂Ă����i�K�̃X�p�R���������Y�őa����x86�ɖ��m�ȗD�ʂ͂Ȃ��B
PowerPC�n�̂��Ƃ�Power�n�Ƃ͌���Ȃ�����
545 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 08:43:43 ID:Ft3gm9E8
����N���}���ɐL�тĂ�̂��ے��I���ˁB
2008�N�ɂ�Intel������75���AAMD���܂߂�Ύ���90���߂���x86���̗p����Ă�B
���ǂ̂Ƃ���u�X�p�R���Ȃ�ł͂̎��Y�v�ȂǑ債���E�F�C�g�͐�߂ĂȂ���
�R���p�C����C�u����������Ă��Ƃ��B
�����݂�top500��W/flops�����Ȃ���ʂ�x86�n�ł͂Ȃ�Power�n
�܁A�������\��A�E�g�I�u�I�[�_�Ȃ��W/flops�Ɋ�^���Ȃ�����ȁB
�u�P���x�Ȃ珟��I�v���đ����r����l�����邾�낤���ǁA
x86�̋��݂͂ނ��됮�����Z���\�ɂ���B
>>542�ŗᎦ������`�q��͖��Ȃ��D��B
�\�[�X�R�[�h����Ή��邯�ǎ���SIMD�������Z��́B
�g�b�v500�̂Ȃ���Power/Cell�A�[�L�e�N�`����[�����Ă�Ǝ҂���IBM���炢����
IBM���K�`��"Goodbye PA"����Ȃ��Ȃ��̃V�F�A����������ł���B
2008�N�ɂ�Intel������75���AAMD���܂߂�Ύ���90���߂���x86���̗p����Ă�B
���ǂ̂Ƃ���u�X�p�R���Ȃ�ł͂̎��Y�v�ȂǑ債���E�F�C�g�͐�߂ĂȂ���
�R���p�C����C�u����������Ă��Ƃ��B
�����݂�top500��W/flops�����Ȃ���ʂ�x86�n�ł͂Ȃ�Power�n
�܁A�������\��A�E�g�I�u�I�[�_�Ȃ��W/flops�Ɋ�^���Ȃ�����ȁB
�u�P���x�Ȃ珟��I�v���đ����r����l�����邾�낤���ǁA
x86�̋��݂͂ނ��됮�����Z���\�ɂ���B
>>542�ŗᎦ������`�q��͖��Ȃ��D��B
�\�[�X�R�[�h����Ή��邯�ǎ���SIMD�������Z��́B
�g�b�v500�̂Ȃ���Power/Cell�A�[�L�e�N�`����[�����Ă�Ǝ҂���IBM���炢����
IBM���K�`��"Goodbye PA"����Ȃ��Ȃ��̃V�F�A����������ł���B
���R���p�C����C�u����������Ă��Ƃ��B
�����A���蓮�x�N�g��������MPP����̕�������B��҂̕������j���B
������܂����i�K��x86�a�����ɖ��m�ȗD�ʂ͂Ȃ��B
�Ȋw�Z�p�v�Z����Ńo�C�i���݊��ɉ��̗D�ʂ��Ȃ����͌����܂ł��Ȃ��B
�P���x�Ȃ�Ƃ����Ă�̂�GPU��ʓ������Ă�l
��`�q�f�[�^�x�[�X�����H
���̈�`�q�f�[�^���`���\�����킩��Ȃ��ᗘ�p�Ɍ��т��Ȃ��B
�f�[�^�x�[�X�ւ̎��v�ɔ�Ⴕ�č\���̂��߂̎������Z���v��������
�����A���蓮�x�N�g��������MPP����̕�������B��҂̕������j���B
������܂����i�K��x86�a�����ɖ��m�ȗD�ʂ͂Ȃ��B
�Ȋw�Z�p�v�Z����Ńo�C�i���݊��ɉ��̗D�ʂ��Ȃ����͌����܂ł��Ȃ��B
�P���x�Ȃ�Ƃ����Ă�̂�GPU��ʓ������Ă�l
��`�q�f�[�^�x�[�X�����H
���̈�`�q�f�[�^���`���\�����킩��Ȃ��ᗘ�p�Ɍ��т��Ȃ��B
�f�[�^�x�[�X�ւ̎��v�ɔ�Ⴕ�č\���̂��߂̎������Z���v��������
547 �FMAC�I�^���c�q �����F2009/04/26(��) 14:30:29 ID:H+1rk+x7
>>545
�@�@-----------------
�@�@>>542�ŗᎦ������`�q��͖��Ȃ��D��B
�@�@-----------------
������ĕ����ʂ�ėpSIMD ISA�̐�삾����Altivec�̓��ӕ��삾������ł����A
�c�q���咣������A���Ԃɑ傫�ȃC���p�N�g��^�������ǂ����́c�H
http://eshop.macsales.com/images/Items/PowerMacG5_Perf_WP_071503.pdf (p.13-14)
�@�@-----------------
�@�@>>542�ŗᎦ������`�q��͖��Ȃ��D��B
�@�@-----------------
������ĕ����ʂ�ėpSIMD ISA�̐�삾����Altivec�̓��ӕ��삾������ł����A
�c�q���咣������A���Ԃɑ傫�ȃC���p�N�g��^�������ǂ����́c�H
http://eshop.macsales.com/images/Items/PowerMacG5_Perf_WP_071503.pdf (p.13-14)
548 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 14:43:18 ID:Ft3gm9E8
AltiVec�Ȃ�đS�R���ӂł��Ȃ�ł��Ȃ���
549 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 14:44:55 ID:Ft3gm9E8
>>546
��������܂����i�K��x86�a�����ɖ��m�ȗD�ʂ͂Ȃ��B
���Ȋw�Z�p�v�Z����Ńo�C�i���݊��ɉ��̗D�ʂ��Ȃ����͌����܂ł��Ȃ��B
�D�ʂ��Ȃ��̂�9���߂��V�F�A�Ă���
����ς萫�\����Ȃ��́i�j
��������܂����i�K��x86�a�����ɖ��m�ȗD�ʂ͂Ȃ��B
���Ȋw�Z�p�v�Z����Ńo�C�i���݊��ɉ��̗D�ʂ��Ȃ����͌����܂ł��Ȃ��B
�D�ʂ��Ȃ��̂�9���߂��V�F�A�Ă���
����ς萫�\����Ȃ��́i�j
�č��̌������Ƃ�����IBM�ɋ�������₷���H
200 �F���h�͐炵�Ă���܂��� [] �F2009/03/11(��) 12:54:24 ID:TQXBEJ9B
>>196
���f�p�ȋ^��Ȃ̂����A�Ȃ�LINPACK���AHPC�̐��\�𑪂�W���I�ȃx���`�}�[�N�ɂȂ��Ă��܂����낤�B
�����ɐ����I�Ȗ��ł��B
LINPACK�x���`�}�[�N������`��TOP500������`�̓A�����J�̍���Ȃ킯�ł��B
>>198
�������B�̓s�������������E�̓s��
�A�����J�̍��v���ǂ��ł��悢�����E�̑���
208 �F���h�͐炵�Ă���܂��� [sage] �F2009/03/16(��) 00:21:21 ID:oORgBQwI
>>154
�A�����J��IT�o�u��������2000�N�ȍ~�o�C�I�e�N�m���W�[�ɑǂ��Ƃ���
��`�q��V��œ������܂��葼�����o�������헪
�����ĕ��q�v�Z�̓X�J���@�Ƀ}�b�`�����i�����Ċj����V�~���ɂ��}�b�`�j
�����_�����ƌ����n�߂�LINPACK�x���`�}�[�N�������c�����͕̂č��̈ӌ��������킯
����Ȃ킯�ŕč��̒c�́E�@�ւ���̂ƂȂ��čs���Ă���
�^���p�N����̓v���W�F�N�g�̗ނɎ����̌v�Z�@�������g�킹��悤�Ȃ��Ƃ͔����Ă���
219 �F���h�͐炵�Ă���܂��� [] �F2009/03/22(��) 17:41:51 ID:tnJqbrXC
>>217
�A�����J�͂�����킩���Ă��č��\��LINPACK�x���`�}�[�N�O�~�����𑱂��Ă���B
222 �F���h�͐炵�Ă���܂��� [sage] �F2009/03/22(��) 20:25:12 ID:4urJOpxf
>>48
�����������Ƃ͕Đ��{��IBM�Ɍ����Ă��B
���[�h�����i�[�������B�j����̃V�~�����[�V�����Ƃ��B
�܂������S����������B
200 �F���h�͐炵�Ă���܂��� [] �F2009/03/11(��) 12:54:24 ID:TQXBEJ9B
>>196
���f�p�ȋ^��Ȃ̂����A�Ȃ�LINPACK���AHPC�̐��\�𑪂�W���I�ȃx���`�}�[�N�ɂȂ��Ă��܂����낤�B
�����ɐ����I�Ȗ��ł��B
LINPACK�x���`�}�[�N������`��TOP500������`�̓A�����J�̍���Ȃ킯�ł��B
>>198
�������B�̓s�������������E�̓s��
�A�����J�̍��v���ǂ��ł��悢�����E�̑���
208 �F���h�͐炵�Ă���܂��� [sage] �F2009/03/16(��) 00:21:21 ID:oORgBQwI
>>154
�A�����J��IT�o�u��������2000�N�ȍ~�o�C�I�e�N�m���W�[�ɑǂ��Ƃ���
��`�q��V��œ������܂��葼�����o�������헪
�����ĕ��q�v�Z�̓X�J���@�Ƀ}�b�`�����i�����Ċj����V�~���ɂ��}�b�`�j
�����_�����ƌ����n�߂�LINPACK�x���`�}�[�N�������c�����͕̂č��̈ӌ��������킯
����Ȃ킯�ŕč��̒c�́E�@�ւ���̂ƂȂ��čs���Ă���
�^���p�N����̓v���W�F�N�g�̗ނɎ����̌v�Z�@�������g�킹��悤�Ȃ��Ƃ͔����Ă���
219 �F���h�͐炵�Ă���܂��� [] �F2009/03/22(��) 17:41:51 ID:tnJqbrXC
>>217
�A�����J�͂�����킩���Ă��č��\��LINPACK�x���`�}�[�N�O�~�����𑱂��Ă���B
222 �F���h�͐炵�Ă���܂��� [sage] �F2009/03/22(��) 20:25:12 ID:4urJOpxf
>>48
�����������Ƃ͕Đ��{��IBM�Ɍ����Ă��B
���[�h�����i�[�������B�j����̃V�~�����[�V�����Ƃ��B
�܂������S����������B
551 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 14:57:35 ID:Ft3gm9E8
http://blog.goo.ne.jp/topography/e/32b297c79eb33bd1d8338e5f9fc0929e
�̂��̈�ԉ���Smith-Waterman�������ʂ̍����Ƃ���A�v���P�[�V�������Ă�
�N������̑�D����IBM�̃��|�[�g�ł��悗
��ł����Ĕ�r�Ɏg�����A�v���P�[�V������Q6600��PS3���S�s���Ă���>>542�Ɠ�����ۂ��ˁB
�i���̎~�܂���AltiVec�Ȃ�č���x86�ɋy�Ԃ͂����Ȃ�
���c�ɂ��Ԃ蓢���ɂ���Ă��܂��܂����ˁB
�̂��̈�ԉ���Smith-Waterman�������ʂ̍����Ƃ���A�v���P�[�V�������Ă�
�N������̑�D����IBM�̃��|�[�g�ł��悗
��ł����Ĕ�r�Ɏg�����A�v���P�[�V������Q6600��PS3���S�s���Ă���>>542�Ɠ�����ۂ��ˁB
�i���̎~�܂���AltiVec�Ȃ�č���x86�ɋy�Ԃ͂����Ȃ�
���c�ɂ��Ԃ蓢���ɂ���Ă��܂��܂����ˁB
552 �FMAC�I�^���c�q �����F2009/04/26(��) 15:20:04 ID:H+1rk+x7
>>551
�@�@----------------
�@�@�i���̎~�܂���AltiVec�Ȃ�č���x86�ɋy�Ԃ͂����Ȃ�
�@�@----------------
�Ӑ}�I�Ɍ떂�����Ă���̂��ǂ����͔���܂��A����������܂��ˁB
�@1. SPE ISA��Altivec�͕ʕ�
�@2. 2000�N��O���ɍŋ��̈�`�q�T���̃v���b�g�t�H�[���ł�����PowerMac��Top500��
�@�@���W���[�ɂȂ邱�Ƃ����������̂ɁA���̂�x86��Top500�ő傫�ȃV�F�A���߂闝�R��
�@�@��`�q�T���A�v���̐��\�Ȃ̂��H
�@�@----------------
�@�@�i���̎~�܂���AltiVec�Ȃ�č���x86�ɋy�Ԃ͂����Ȃ�
�@�@----------------
�Ӑ}�I�Ɍ떂�����Ă���̂��ǂ����͔���܂��A����������܂��ˁB
�@1. SPE ISA��Altivec�͕ʕ�
�@2. 2000�N��O���ɍŋ��̈�`�q�T���̃v���b�g�t�H�[���ł�����PowerMac��Top500��
�@�@���W���[�ɂȂ邱�Ƃ����������̂ɁA���̂�x86��Top500�ő傫�ȃV�F�A���߂闝�R��
�@�@��`�q�T���A�v���̐��\�Ȃ̂��H
553 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:24:10 ID:Ft3gm9E8
1�DSPE��SIMD���j�b�g����т��̂��߂̖��߃Z�b�g��AltiVec�iVMX�j�����ɂ��Ă���͖̂��炩�ł́H
�@�������swps3��Cell��PPE���g���Ă܂���
�Q�DIBM��Cell�̗D�ʐ���1��Ƃ��Ď������A�v���P�[�V������x86�ɎS�s���Ă�Ƃ����������d�v�ł�
�@PPE1�@��AltiVec������x86-SSE2�ɏ��Ă�ƕ@�����r�����Ă��̂ɁA�ǂ�ȃU�}�ł���
�@�������swps3��Cell��PPE���g���Ă܂���
�Q�DIBM��Cell�̗D�ʐ���1��Ƃ��Ď������A�v���P�[�V������x86�ɎS�s���Ă�Ƃ����������d�v�ł�
�@PPE1�@��AltiVec������x86-SSE2�ɏ��Ă�ƕ@�����r�����Ă��̂ɁA�ǂ�ȃU�}�ł���
554 �FMAC�I�^���⑫�F2009/04/26(��) 15:26:12 ID:H+1rk+x7
>>542�̕��ł����A�{���ɓǂ�ł����CELL/B.E.�̐��\��̖��Ƃ��Ďw�E����Ă���_��
�wAltivec�Ƃ̈Ⴂ�x�ɋN�����邱�Ƃ����锤�ł��B���̌��ʂ�������Altivec��@�����Ⴄ�̂���(��)
�@�@------------------
�@�@On the other hand, the performances of the Cell/BE are limited by its sparse vector
�@�@instruction set. For instance, the lack of support for 8-bit integer vectors restrains
�@�@performance on short, unrelated sequences with low scores, which constitute the largest
�@�@portion of the benchmark dataset.
�@�@------------------
�wAltivec�Ƃ̈Ⴂ�x�ɋN�����邱�Ƃ����锤�ł��B���̌��ʂ�������Altivec��@�����Ⴄ�̂���(��)
�@�@------------------
�@�@On the other hand, the performances of the Cell/BE are limited by its sparse vector
�@�@instruction set. For instance, the lack of support for 8-bit integer vectors restrains
�@�@performance on short, unrelated sequences with low scores, which constitute the largest
�@�@portion of the benchmark dataset.
�@�@------------------
555 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:27:12 ID:Ft3gm9E8
��������Cell�̐��\�ʂ̗D�ʐ��Ȃ��PS3���������ꂽ2006�N�����_�Ŋ��ɖ��������B
556 �FMAC�I�^���c�q �����F2009/04/26(��) 15:28:02 ID:H+1rk+x7
>>553
1.�ٖ̕��͒p�̏�h�肾�����悤�ł��ˁB���߂Ĉ��p�Ώۂ͒��g��ǂ�ł�����܂��傤(��)
1.�ٖ̕��͒p�̏�h�肾�����悤�ł��ˁB���߂Ĉ��p�Ώۂ͒��g��ǂ�ł�����܂��傤(��)
557 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:31:20 ID:Ft3gm9E8
���Ⴀswps3��POWER�Ńr���h���ē������Ă����悗����
PPC/AltiVec�p�œ��������Əo���邾��B
�܁A��������POWER�i�j�Ȃ�Ēᐫ�\�͂��Ăт���Ȃ��B
Celeron�f���A���R�A�Ƒ����ĂȂ������Ă��ƂŁB
PPC/AltiVec�p�œ��������Əo���邾��B
�܁A��������POWER�i�j�Ȃ�Ēᐫ�\�͂��Ăт���Ȃ��B
Celeron�f���A���R�A�Ƒ����ĂȂ������Ă��ƂŁB
558 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:35:00 ID:Ft3gm9E8
�܂Ƃ܂����ɂ��L������茳�̃}�V���ł��̃x���`�Ƃ��Ă݂�������
PPE 3.2GHz�Ƃ̔�r�ɂ�Atom 1.6GHz�������������ȁH
POWER(��)�̑���Ȃ��Core MA�ɂ͖�s���ł��傤
PPE 3.2GHz�Ƃ̔�r�ɂ�Atom 1.6GHz�������������ȁH
POWER(��)�̑���Ȃ��Core MA�ɂ͖�s���ł��傤
559 �FMAC�I�^���c�q �����F2009/04/26(��) 15:38:06 ID:H+1rk+x7
>>557
�@�@----------------
�@�@���Ⴀswps3��POWER�Ńr���h���ē������Ă����悗����
�@�@PPC/AltiVec�p�œ��������Əo���邾��B
�@�@----------------
�{����>>542��ǂ݂܂������H�v���b�g�t�H�[�����Ƃ̍œK���ɂ��ďq�ׂ��Ă��āA
�u�r���h���ē������Ă����悗���� �v�Ƃ����b�ł͖����̂ł����H�H
�@�@----------------
�@�@���Ⴀswps3��POWER�Ńr���h���ē������Ă����悗����
�@�@PPC/AltiVec�p�œ��������Əo���邾��B
�@�@----------------
�{����>>542��ǂ݂܂������H�v���b�g�t�H�[�����Ƃ̍œK���ɂ��ďq�ׂ��Ă��āA
�u�r���h���ē������Ă����悗���� �v�Ƃ����b�ł͖����̂ł����H�H
560 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:40:55 ID:Ft3gm9E8
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2615776
�������瓮������y�j�X�N
���x����������AltiVec�ɑ���SPE�̎�_�]�X�ȑO�̍��ł�
6+1�R�A��g����4�R�A�ɑ卷�t�����Ă��
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2615776&rendertype=figure&id=F1
�������瓮������y�j�X�N
���x����������AltiVec�ɑ���SPE�̎�_�]�X�ȑO�̍��ł�
6+1�R�A��g����4�R�A�ɑ卷�t�����Ă��
http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2615776&rendertype=figure&id=F1
561 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:45:17 ID:Ft3gm9E8
�����y�j�X����
�܂����r���h���@���킩��Ȃ��Ƃ������Ȃ�H
http://www.inf.ethz.ch/personal/sadam/swps3/
����\�[�X�R�[�h���Ƃ��Ă���
make -f Makefile.altivec
���������H
PPC-Altivec��p�Ńr���h����̂�Cell�S���W�Ȃ����B
�܂����r���h���@���킩��Ȃ��Ƃ������Ȃ�H
http://www.inf.ethz.ch/personal/sadam/swps3/
����\�[�X�R�[�h���Ƃ��Ă���
make -f Makefile.altivec
���������H
PPC-Altivec��p�Ńr���h����̂�Cell�S���W�Ȃ����B
�A�����ꂵ��
563 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 15:59:58 ID:Ft3gm9E8
�̌���`�̒c�q����́A�܂��{�苶����������܂��c
�n�C�G���h�v���Z�b�T�ɂ������`�q�T���R�[�h�̐��\��r�͂�SPECint2006��HMMer��
�܂܂�Ă��܂��̂ŁA����̃R�[�h�̐��\�]���ɂ͎g���܂��B
http://www.spec.org/cpu2006/Docs/456.hmmer.html
�@�@-----------------
�@�@Benchmark Description
�@�@�@Profile Hidden Markov Models (profile HMMs) are statistical models of multiple sequence
�@�@alignments, which are used in computational biology to search for patterns in DNA sequences.
�@�@�@The technique is used to do sensitive database searching, using statistical descriptions
�@�@of a sequence family's consensus. It is used for protein sequence analysis.
�@�@-----------------
�n�C�G���h�v���Z�b�T�ɂ������`�q�T���R�[�h�̐��\��r�͂�SPECint2006��HMMer��
�܂܂�Ă��܂��̂ŁA����̃R�[�h�̐��\�]���ɂ͎g���܂��B
http://www.spec.org/cpu2006/Docs/456.hmmer.html
�@�@-----------------
�@�@Benchmark Description
�@�@�@Profile Hidden Markov Models (profile HMMs) are statistical models of multiple sequence
�@�@alignments, which are used in computational biology to search for patterns in DNA sequences.
�@�@�@The technique is used to do sensitive database searching, using statistical descriptions
�@�@of a sequence family's consensus. It is used for protein sequence analysis.
�@�@-----------------
565 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 16:12:54 ID:Ft3gm9E8
> Project Leader - Kaivalya M. Dixit (IBM)
> - Alan MacKay (IBM)
�i�j
����������POWER(��)�̏o�開�����ȁB
Cell�͌��킸������
> - Alan MacKay (IBM)
�i�j
����������POWER(��)�̏o�開�����ȁB
Cell�͌��킸������
566 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 16:15:46 ID:Ft3gm9E8
567 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 16:16:47 ID:Ft3gm9E8
������������
>542
Q6600��PS3��茋�ʂ̗ǂ��x���`��������������łȂ�����ȂɊ�ׂ�̂��H
PS3
�@2006Nov �V�X�e���Ł@\50k-\6xk
�@2007Dec�@�V�X�e���Ł@\40k-\55k
Q6600
�@2007Jan�@CPU�P�̂Ł@\110k
�@2007Jul�@CPU�P�̂Ł@\37k
>549
>541
Q6600��PS3��茋�ʂ̗ǂ��x���`��������������łȂ�����ȂɊ�ׂ�̂��H
PS3
�@2006Nov �V�X�e���Ł@\50k-\6xk
�@2007Dec�@�V�X�e���Ł@\40k-\55k
Q6600
�@2007Jan�@CPU�P�̂Ł@\110k
�@2007Jul�@CPU�P�̂Ł@\37k
>549
>541
�c�q�������̐��E�ɓ����ď����錾���n�߂��悤�ł���(��)
���ۂɃx���`�}�[�N���ʂ�8�R�A�Ŕ�r����Ɖ��L�̒ʂ�B
�V�������̂قǏ����ɗǂ��Ȃ�Ƃ����b�ŁA���{���Ⴄ�Ƃ����l�^�ɂ͂Ȃ�Ȃ����ƁB
��456.hmmer�̔�r(8-core)
�@�EShanghai/2.9GHz: 258(peak)/160(base) [2009Q2, cpu2006-20090330-06865.html]
�@�ENehalem/3.2GHz: 245(peak)/191(base) [2009Q2, cpu2006-20090216-06529.html]
�@�ECore2/3.33GHz: 225(peak)/176(base) [2008Q4, cpu2006-20080915-05367.html]
�@�EPOWER6/4.7GHz: 204(peak)/167(base) [2007Q2, cpu2006-20070518-01103.html]
���ۂɃx���`�}�[�N���ʂ�8�R�A�Ŕ�r����Ɖ��L�̒ʂ�B
�V�������̂قǏ����ɗǂ��Ȃ�Ƃ����b�ŁA���{���Ⴄ�Ƃ����l�^�ɂ͂Ȃ�Ȃ����ƁB
��456.hmmer�̔�r(8-core)
�@�EShanghai/2.9GHz: 258(peak)/160(base) [2009Q2, cpu2006-20090330-06865.html]
�@�ENehalem/3.2GHz: 245(peak)/191(base) [2009Q2, cpu2006-20090216-06529.html]
�@�ECore2/3.33GHz: 225(peak)/176(base) [2008Q4, cpu2006-20080915-05367.html]
�@�EPOWER6/4.7GHz: 204(peak)/167(base) [2007Q2, cpu2006-20070518-01103.html]
570 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 16:50:55 ID:Ft3gm9E8
���\�����N���b�N�{SMT�ɐU�邩�A�R�A���ɐU�邩�͕��j�̈Ⴂ���Ă��ƂŁA
����16�\�P�b�g���m�̔�r�ŕ���Ȃ���ȁH��
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
IBM Corporation IBM Power 570 ( 4.2 GHz, 32 core, RedHat)
456.hmmer 883/667
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
Unisys Corporation Unisys ES7000 Model 7600R, Intel Xeon X7460, 2.66GHz
456.hmmer 1800/1440
����Ƃ�8�\�P�b�g48�R�A�̂ق����ǂ��������H
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06231.html
456.hmmer 900/720
����16�\�P�b�g���m�̔�r�ŕ���Ȃ���ȁH��
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
IBM Corporation IBM Power 570 ( 4.2 GHz, 32 core, RedHat)
456.hmmer 883/667
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
Unisys Corporation Unisys ES7000 Model 7600R, Intel Xeon X7460, 2.66GHz
456.hmmer 1800/1440
����Ƃ�8�\�P�b�g48�R�A�̂ق����ǂ��������H
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06231.html
456.hmmer 900/720
571 �FMAC�I�^���c�q �����F2009/04/26(��) 16:54:07 ID:H+1rk+x7
>>570
�p�ꂪ�ǂ߂Ȃ���ł�����A����������_�����ƁB
����32�R�A��96�R�A�̔�r�ł���(��)
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
�@�@------------------
�@�@32 cores, 16 chips, 2 cores/chip, 2 threads/core
�@�@------------------
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
�@�@------------------
�@�@96 cores, 16 chips, 6 cores/chip
�@�@------------------
�p�ꂪ�ǂ߂Ȃ���ł�����A����������_�����ƁB
����32�R�A��96�R�A�̔�r�ł���(��)
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081003-05500.html
�@�@------------------
�@�@32 cores, 16 chips, 2 cores/chip, 2 threads/core
�@�@------------------
http://spec.org/cpu2006/results/res2008q4/cpu2006-20081208-06233.html
�@�@------------------
�@�@96 cores, 16 chips, 6 cores/chip
�@�@------------------
572 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 16:54:26 ID:Ft3gm9E8
>>568
�������Ȃ����ǂȁB���Ă������X���b�h������Ă�A�v������Atom�Ɨǂ������Ȃ��ǂǂ��Ȃ́H>>563
���Ȃ݂�D945GCLF2 ����8000�~�iAtom 330���ځj
�������Ȃ����ǂȁB���Ă������X���b�h������Ă�A�v������Atom�Ɨǂ������Ȃ��ǂǂ��Ȃ́H>>563
���Ȃ݂�D945GCLF2 ����8000�~�iAtom 330���ځj
573 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 17:07:12 ID:Ft3gm9E8
>>571
�Ȃ�Ń\�P�b�g�P�ʂ̔�r�����Ⴂ���Ȃ��̂�����
1�\�P�b�g������̏���d�͂�POWER6�̂ق����H���Ă����
2�R�A�ł�XeonMP 6�R�A���̐��\�������Ă����肾��H��
�V�X�e���S�̂ł̃g�[�^�����\��d�͌������������Č��܂�̂ł�����
�R�A������Ō��߂邨�O���[�J���̃��[���͐��E�̂ǂ��ɍs���Ă��ʗp���Ȃ���A�y�j�X�N�B
�Ȃ�Ń\�P�b�g�P�ʂ̔�r�����Ⴂ���Ȃ��̂�����
1�\�P�b�g������̏���d�͂�POWER6�̂ق����H���Ă����
2�R�A�ł�XeonMP 6�R�A���̐��\�������Ă����肾��H��
�V�X�e���S�̂ł̃g�[�^�����\��d�͌������������Č��܂�̂ł�����
�R�A������Ō��߂邨�O���[�J���̃��[���͐��E�̂ǂ��ɍs���Ă��ʗp���Ȃ���A�y�j�X�N�B
�R�[�h���œK�����Ȃ��l�ԂɑS����͂Ȃ��S���v������������Cell
�V�X�e���̐v�v�z�ɔ�͂Ȃ��a�����ɍœK�����Ȃ��l�Ԃ��������a����MPP
���̕ӂ�̃_�u�X�^�A�����͘_���ł͂Ȃ��M�ɐ����Ă���
�����m���Őg���Z���Ă��邾���ɂ����݂��Ȃ���
�V�X�e���̐v�v�z�ɔ�͂Ȃ��a�����ɍœK�����Ȃ��l�Ԃ��������a����MPP
���̕ӂ�̃_�u�X�^�A�����͘_���ł͂Ȃ��M�ɐ����Ă���
�����m���Őg���Z���Ă��邾���ɂ����݂��Ȃ���
575 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 17:27:34 ID:Ft3gm9E8
�t�ɂ��A�������̃x�X�g�\�����[�V�������ĉ���H��
�ǂ̂ւ�őa�Ɩ����Ă�̂������ł��Ȃ����B
Cell���̑e�����^�}���`�R�A����
�ǂ̂ւ�őa�Ɩ����Ă�̂������ł��Ȃ����B
Cell���̑e�����^�}���`�R�A����
576 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 17:31:55 ID:Ft3gm9E8
���R�[�h���œK�����Ȃ��l�ԂɑS����͂Ȃ��S���v����������
�n�����ȁB��K�̓V�X�e���ɂ�����u�œK���v���Ă̂́A���{�I�Ɍ����ĂȂ��v���Z�b�T�����O���邱�ƂɂȂ��B
�d�̖͂��ʂ������
�n�����ȁB��K�̓V�X�e���ɂ�����u�œK���v���Ă̂́A���{�I�Ɍ����ĂȂ��v���Z�b�T�����O���邱�ƂɂȂ��B
�d�̖͂��ʂ������
577 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 17:36:15 ID:Ft3gm9E8
�N���X�^�̃����b�g�́A�m�[�h�P�ʂł̓���ւ����ł��邱�ƁB
578 �FMAC�I�^���c�q �����F2009/04/26(��) 17:37:26 ID:H+1rk+x7
>>573
�@�@---------------
�@�@�Ȃ�Ń\�P�b�g�P�ʂ̔�r�����Ⴂ���Ȃ��̂�����
�@�@---------------
�ȒP�ɂ܂Ƃ߂�Ɖ��L�̂悤�ɂȂ�܂��B
�@1. �A�[�L�e�N�`�����v���Z�X����̉e����傫����
�@2. HMMer�̓����Ƃ��āA�������t�b�g�v�����g��������L2�܂ł̃L���b�V���̃q�b�g��������
�@�@�x���`�}�[�N�̂��߁A�A���R�A�̉e����������
�@3. ��L�ɂ��A���R�A���Ƀg�����W�X�^���₵�Ă���v���Z�b�T�͕s���ɂȂ�B
�@4. ����ŁA�A���R�A���Ƀg�����W�X�^���₵�Ă���v���Z�b�T�͂���K�͂�SMP�\����
�@�@�\�ɂȂ邽�߁A�ő�K�͂ł̐�ΐ��\�͍����Ȃ�B
�@�@����͂���ŁA�ЂƂ́u���\��̗D�ʁv�B
�@�@(��: SPARC64 VII/2.52GHz: 2530(peak)/2530(base) [2008Q3, cpu2006-20080711-04737.html])
�@�@�@�@�@
�ŏ��̘b���炢�͏펯���Ɗ��҂����̂ł����H
�@�@---------------
�@�@�Ȃ�Ń\�P�b�g�P�ʂ̔�r�����Ⴂ���Ȃ��̂�����
�@�@---------------
�ȒP�ɂ܂Ƃ߂�Ɖ��L�̂悤�ɂȂ�܂��B
�@1. �A�[�L�e�N�`�����v���Z�X����̉e����傫����
�@2. HMMer�̓����Ƃ��āA�������t�b�g�v�����g��������L2�܂ł̃L���b�V���̃q�b�g��������
�@�@�x���`�}�[�N�̂��߁A�A���R�A�̉e����������
�@3. ��L�ɂ��A���R�A���Ƀg�����W�X�^���₵�Ă���v���Z�b�T�͕s���ɂȂ�B
�@4. ����ŁA�A���R�A���Ƀg�����W�X�^���₵�Ă���v���Z�b�T�͂���K�͂�SMP�\����
�@�@�\�ɂȂ邽�߁A�ő�K�͂ł̐�ΐ��\�͍����Ȃ�B
�@�@����͂���ŁA�ЂƂ́u���\��̗D�ʁv�B
�@�@(��: SPARC64 VII/2.52GHz: 2530(peak)/2530(base) [2008Q3, cpu2006-20080711-04737.html])
�@�@�@�@�@
�ŏ��̘b���炢�͏펯���Ɗ��҂����̂ł����H
579 �FMAC�I�^���⑫�F2009/04/26(��) 17:38:43 ID:H+1rk+x7
SPEC2006�ɂ����郁�������v�ʂɊւ��鎑���ł��B
http://www.spec.org/cpu2006/publications/SIGARCH-2007-03/05_cpu2006_wss.pdf
http://www.spec.org/cpu2006/publications/SIGARCH-2007-03/05_cpu2006_wss.pdf
580 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 17:44:44 ID:Ft3gm9E8
���@1. �A�[�L�e�N�`�����v���Z�X����̉e����傫����
�v���Z�X����̒x�ꂻ�̂��̂��A�[�L�e�N�`���̖��͂�ጸ������v���ł�
���Ƃ͎w�E���Ă������d�͌�������ڂ�w�����k�قȂ̂ŁA�ǂދC�����Ȃ��B
XeonMP�͎����Ƃ��čő�96�R�A�̃X�P�[���r���e�B�������Ă�킯��
����͑��̃x���`�}�[�N���ڂ�������炩���ȁB
�v���Z�X����̒x�ꂻ�̂��̂��A�[�L�e�N�`���̖��͂�ጸ������v���ł�
���Ƃ͎w�E���Ă������d�͌�������ڂ�w�����k�قȂ̂ŁA�ǂދC�����Ȃ��B
XeonMP�͎����Ƃ��čő�96�R�A�̃X�P�[���r���e�B�������Ă�킯��
����͑��̃x���`�}�[�N���ڂ�������炩���ȁB
Top500�ł�7���ȏ�̃V�F�A������Ă��Ȃ���d�͌����ł͂قƂ�Ǐ�ʂɓ����Ă��Ȃ��B
�v���Z�X����ł�Intel����Ԑi��ł���ɂ�������炸�B
����Larrabee�������Ă���Ƃ��ꂪ�ǂ��ω����邩�ʔ������B
http://www.green500.org/lists/listdisplay.php?month=11&year=2008&list=green500_200811.csv&start=1&line=50
�v���Z�X����ł�Intel����Ԑi��ł���ɂ�������炸�B
����Larrabee�������Ă���Ƃ��ꂪ�ǂ��ω����邩�ʔ������B
http://www.green500.org/lists/listdisplay.php?month=11&year=2008&list=green500_200811.csv&start=1&line=50
582 �F,,�E�L�́M�E,,�j��-�������F2009/04/26(��) 21:51:27 ID:Ft3gm9E8
���Ȃ݂ɂ��Ɏ�����XeonMP�V�X�e���̏���d�͂�1�Z���i4�\�P�b�g�j������1.5KW�Ȃ��
Unisys��MP�T�[�o��16�\�P�b�g��96�R�A�ō��v6KW���x����
http://www.unisys.co.jp/news/NR_080916_es7000_1.pdf
�\�[�X�͊����Ď����Ȃ����ǁAPOWER6��16�\�P�b�g���ǂ���H�炢���m���Ă���
1�R�A���m�Ŕ�r���ׂ��Ȃ�Č����Ă������Ȃ��ˁB
���ۂ̏���d�͂�ڂ̓�����ɂ�����A����16�\�P�b�g���m�̔�r���Ó����ƌ������Ӗ������ł������o�����B
����łȂ��Ƃ��y64�X���b�h�z�ł�����4GHz���鍂�N���b�N�Ȏ��_�ŁA�n���f��^����ƌ����闧��ł͂Ȃ��B
10�i���Z�����͖��G�Ȃ��炻�������ʂ����ɒ��͂��Ă��낵��
>>581
�����܂�LINPACK��̓d�͌��������炻�̂ւ�͉��^�I���B
���ۂ̗��p�V�[���f���ĂȂ����B
SPEC�l����Penryn����Nehalem�ɒu�������邱�ƂŁAHT�Ή��Ȃǂɂ�蓯�N���b�N�ł�
�������\��1.5�`2�{���x�ɂȂ邪�ALINPACK��ł�1�������܂�L�тȂ������肷�邵�B
�܁ACell��BlueGene�݂����ȖړI�����^����T�Ɉ����Ƃ͌����
���ʂȃv���O���}�r���e�B���K�v�ȗp�r�ɂ�Core MA�ɏ���\�����[�V�����͂Ȃ����낤�B
Unisys��MP�T�[�o��16�\�P�b�g��96�R�A�ō��v6KW���x����
http://www.unisys.co.jp/news/NR_080916_es7000_1.pdf
�\�[�X�͊����Ď����Ȃ����ǁAPOWER6��16�\�P�b�g���ǂ���H�炢���m���Ă���
1�R�A���m�Ŕ�r���ׂ��Ȃ�Č����Ă������Ȃ��ˁB
���ۂ̏���d�͂�ڂ̓�����ɂ�����A����16�\�P�b�g���m�̔�r���Ó����ƌ������Ӗ������ł������o�����B
����łȂ��Ƃ��y64�X���b�h�z�ł�����4GHz���鍂�N���b�N�Ȏ��_�ŁA�n���f��^����ƌ����闧��ł͂Ȃ��B
10�i���Z�����͖��G�Ȃ��炻�������ʂ����ɒ��͂��Ă��낵��
>>581
�����܂�LINPACK��̓d�͌��������炻�̂ւ�͉��^�I���B
���ۂ̗��p�V�[���f���ĂȂ����B
SPEC�l����Penryn����Nehalem�ɒu�������邱�ƂŁAHT�Ή��Ȃǂɂ�蓯�N���b�N�ł�
�������\��1.5�`2�{���x�ɂȂ邪�ALINPACK��ł�1�������܂�L�тȂ������肷�邵�B
�܁ACell��BlueGene�݂����ȖړI�����^����T�Ɉ����Ƃ͌����
���ʂȃv���O���}�r���e�B���K�v�ȗp�r�ɂ�Core MA�ɏ���\�����[�V�����͂Ȃ����낤�B
>576�@���Ƃ�����
Science�������Ă���ۑ�̎�ޕʔ䗦�ɑ��đa����MPP�̐ݒu������
���炩�ɑ������錻��́A�����A�������Ȃ�������Ȃ��ȁB
�~�����ĂȂ��v���Z�b�T
�������ĂȂ��V�X�e��
Science�������Ă���ۑ�̎�ޕʔ䗦�ɑ��đa����MPP�̐ݒu������
���炩�ɑ������錻��́A�����A�������Ȃ�������Ȃ��ȁB
�~�����ĂȂ��v���Z�b�T
�������ĂȂ��V�X�e��
584 �FMAC�I�^���c�q �����F2009/04/26(��) 22:31:34 ID:H+1rk+x7
>>582
�@�@----------------
�@�@�\�[�X�͊����Ď����Ȃ����ǁAPOWER6��16�\�P�b�g���ǂ���H�炢���m���Ă���
�@�@----------------
�T�[�o�[�̏���d�͂����ɂȂ��Ă�������B�\�[�X�Ȃ�Ă�����ł�(��)
http://www.green500.org/lists/listdisplay.php?month=11&year=2008&list=green500_200811.csv&start=101&line=201
166-168�ʂ�����B
���ɂ͉�����R���鏇�ʂ��ƁB
�@�@----------------
�@�@�\�[�X�͊����Ď����Ȃ����ǁAPOWER6��16�\�P�b�g���ǂ���H�炢���m���Ă���
�@�@----------------
�T�[�o�[�̏���d�͂����ɂȂ��Ă�������B�\�[�X�Ȃ�Ă�����ł�(��)
http://www.green500.org/lists/listdisplay.php?month=11&year=2008&list=green500_200811.csv&start=101&line=201
166-168�ʂ�����B
���ɂ͉�����R���鏇�ʂ��ƁB
585 �FMAC�I�^���⑫�F2009/04/26(��) 22:49:25 ID:H+1rk+x7
Green500�̓V�X�e���\�������肸�炢�̂ŁATop500�̓o�^����d�̓f�[�^���B
http://www.top500.org/list/2008/11/100
�@38�� POWER6/4.7GHz x 4896-core: 782.48 [kW]
�@83�� Xeon 54xx/3.0GHz x 4584-core: 510.61 [kW]
http://www.top500.org/list/2008/11/100
�@38�� POWER6/4.7GHz x 4896-core: 782.48 [kW]
�@83�� Xeon 54xx/3.0GHz x 4584-core: 510.61 [kW]
�X�p�R���ő��ʂȃv���O���}�r���e�B�͕��ʂ͕K�v�Ȃ����
587 �FMAC�I�^��586 �����F2009/04/27(��) 01:27:58 ID:yuRUEY7Y
>>586
�����������o���Č��݂����X�[�p�[�R���s���[�^�͗l�X�ȗp�r�Ɏg�����Ƃ�O��ɂ��܂��̂ŁA
����������ɂ͂����܂���B
���ɃN���X�^�́A�K���ɐ蕪���ď��K�͂ȃW���u�𗬂����Ƃ������̂�PC���[�N�X�e�[�V������
�����x���̃v���O���}�r���e�B�͕K�v�ɂȂ�܂��B
�ǂ��������g������z�肵�Ďd�l�����߂Ă��邩�́A���̎����Ƃ��B
http://accc.riken.jp/HPC/Symposium/2008/kurokawa.pdf
�����������o���Č��݂����X�[�p�[�R���s���[�^�͗l�X�ȗp�r�Ɏg�����Ƃ�O��ɂ��܂��̂ŁA
����������ɂ͂����܂���B
���ɃN���X�^�́A�K���ɐ蕪���ď��K�͂ȃW���u�𗬂����Ƃ������̂�PC���[�N�X�e�[�V������
�����x���̃v���O���}�r���e�B�͕K�v�ɂȂ�܂��B
�ǂ��������g������z�肵�Ďd�l�����߂Ă��邩�́A���̎����Ƃ��B
http://accc.riken.jp/HPC/Symposium/2008/kurokawa.pdf
588 �F,,�E�L�́M�E,,�j��-�������F2009/04/27(��) 03:01:33 ID:xE7gHVrV
����DP����B
Xeon MP��DP�����m�[�h������̐��\�͍����A�R�A������̓d�͌����͍X�ɏ���s���Ă���B
�P���ɃN���b�N��}���ăR�A�𑝂₵�Ă镪�ǂ��Ȃ��ē�����O�Ȃ̂���
����Unisys��16�\�P�b�g96�R�A�Ɣ�r����POWER 570 4.2GHz��16�\�P�b�g��
> IBM Power 570�̌��ʂ́A16�`�b�v�A32�R�A�A����уR�A������2�X���b�h�̃V�X�e���ɂ����̂ŁA
> Result�iPeak�j��832�ł����B�T�C�g�E�v�����j���O�ɐ��������ő�d�͎g�p�ʂ́A5600���b�g�ł��B
http://www-06.ibm.com/systems/jp/power/benchmark/570/
�Ƃ܂��A����16�\�P�b�g�ł̏���d�͂��قړ����Ɏ��܂��Ă�킯�����B
Unisys��1.5KVA/cell���Ă̂��ǂ����d���̒�i����d�͂ȋC�������̂ŁA
���ۂ̏���d�͂f�������m�Ȑ��l���~�����Ƃ��낾���B
������Top500��Xeon MP�����܂�g���Ȃ��̂́ADP���V�K���i���o��̂��x�����炩�ˁB
Xeon MP��DP�����m�[�h������̐��\�͍����A�R�A������̓d�͌����͍X�ɏ���s���Ă���B
�P���ɃN���b�N��}���ăR�A�𑝂₵�Ă镪�ǂ��Ȃ��ē�����O�Ȃ̂���
����Unisys��16�\�P�b�g96�R�A�Ɣ�r����POWER 570 4.2GHz��16�\�P�b�g��
> IBM Power 570�̌��ʂ́A16�`�b�v�A32�R�A�A����уR�A������2�X���b�h�̃V�X�e���ɂ����̂ŁA
> Result�iPeak�j��832�ł����B�T�C�g�E�v�����j���O�ɐ��������ő�d�͎g�p�ʂ́A5600���b�g�ł��B
http://www-06.ibm.com/systems/jp/power/benchmark/570/
�Ƃ܂��A����16�\�P�b�g�ł̏���d�͂��قړ����Ɏ��܂��Ă�킯�����B
Unisys��1.5KVA/cell���Ă̂��ǂ����d���̒�i����d�͂ȋC�������̂ŁA
���ۂ̏���d�͂f�������m�Ȑ��l���~�����Ƃ��낾���B
������Top500��Xeon MP�����܂�g���Ȃ��̂́ADP���V�K���i���o��̂��x�����炩�ˁB
589 �FMAC�I�^���c�q �����F2009/04/27(��) 03:25:45 ID:yuRUEY7Y
>>588
�@�@--------------
�@�@����DP����B
�@�@--------------
Xeon 54xx���ăf���A���R�A���i������Ǝv���̂Ȃ璲�ׂĂ݂Ă͂������ł���(��)
http://processorfinder.intel.com/List.aspx?ParentRadio=All&ProcFam=528&SearchKey=
�V�X�e���S�̂̏���d�̘͂b��ł����A�v���Z�b�T�̊����͂���قǑ傫�Ȃ��̂ł͂���܂���B
�������N�X�A���̊����͒ቺ������܂��B���L�̎�����p4-5���ǂ����B
http://www.ecmwf.int/newsevents/meetings/workshops/2008/ModellingSummit/presentations/Winchell.pdf
�@�@--------------
�@�@����DP����B
�@�@--------------
Xeon 54xx���ăf���A���R�A���i������Ǝv���̂Ȃ璲�ׂĂ݂Ă͂������ł���(��)
http://processorfinder.intel.com/List.aspx?ParentRadio=All&ProcFam=528&SearchKey=
�V�X�e���S�̂̏���d�̘͂b��ł����A�v���Z�b�T�̊����͂���قǑ傫�Ȃ��̂ł͂���܂���B
�������N�X�A���̊����͒ቺ������܂��B���L�̎�����p4-5���ǂ����B
http://www.ecmwf.int/newsevents/meetings/workshops/2008/ModellingSummit/presentations/Winchell.pdf
590 �FMAC�I�^���⑫�F2009/04/27(��) 03:29:37 ID:yuRUEY7Y
���ł�Green500�̏���d�͒l�ł����A�c�q����̑�D���Ȏ����l�ł���B
http://www.green500.org/faq.php
�@�@----------------
�@�@At publication time, will you be specific as to which form of power was used?
�@�@Yes. We will use "measured power" if a formal submission is made here and if the
�@�@number makes sense relative to the peak power rating. Furthermore, the list will
�@�@indeed explicitly show whether measured or peak power was used. (Since "measured
�@�@power" will be less than "peak power", it is advantageous to make a formal Green500
�@�@submission.)
�@�@----------------
http://www.green500.org/faq.php
�@�@----------------
�@�@At publication time, will you be specific as to which form of power was used?
�@�@Yes. We will use "measured power" if a formal submission is made here and if the
�@�@number makes sense relative to the peak power rating. Furthermore, the list will
�@�@indeed explicitly show whether measured or peak power was used. (Since "measured
�@�@power" will be less than "peak power", it is advantageous to make a formal Green500
�@�@submission.)
�@�@----------------
591 �F,,�E�L�́M�E,,�j��-�������F2009/04/27(��) 07:23:54 ID:xE7gHVrV
�uXeon DP�v�̈Ӗ����킩��Ȃ������̂��y�j�X�]�́B5000�ԑ���Č���Ȃ��Ɨ����ł��Ȃ����ȁH
��̓I�Ɍ�����Penryn����ł�����Harpertown�̂��Ƃ��B
4�R�A�~2�\�P�b�g��1�m�[�h8�R�A�B������N���X�^������ɂ�Infiniband�ő��ݐڑ����邾��H
�ǂ�����d�͐H���H
�܂肻���������Ƃ��B�p���������z���B
Xeon MP��Dunnington�̂ق����B7000�ԑ��
Xeon DP��FSB��1066/1333/1600MHz�A������Dunnington ��FSB��1066MHz
���\����I���Ďv�����z�͑f�l�BX7460�ł�130W��TDP�Ɏ��܂�̂��B������2.66GHz�B
�������[�ш�͑�e��L3�L���b�V���ŃZ�[�u����̂ő傫�Ȗ��͐����Ȃ�
�������Ȃ���O���A�N�Z�����[�^���t�����p����̂ɂ͂��܂�����Ȃ��ȁB
��̓I�Ɍ�����Penryn����ł�����Harpertown�̂��Ƃ��B
4�R�A�~2�\�P�b�g��1�m�[�h8�R�A�B������N���X�^������ɂ�Infiniband�ő��ݐڑ����邾��H
�ǂ�����d�͐H���H
�܂肻���������Ƃ��B�p���������z���B
Xeon MP��Dunnington�̂ق����B7000�ԑ��
Xeon DP��FSB��1066/1333/1600MHz�A������Dunnington ��FSB��1066MHz
���\����I���Ďv�����z�͑f�l�BX7460�ł�130W��TDP�Ɏ��܂�̂��B������2.66GHz�B
�������[�ш�͑�e��L3�L���b�V���ŃZ�[�u����̂ő傫�Ȗ��͐����Ȃ�
�������Ȃ���O���A�N�Z�����[�^���t�����p����̂ɂ͂��܂�����Ȃ��ȁB
Dunnington�̓l�C�e�B�u��96�R�A�����邪
�t�ɂ��̂�����MS�����������ƂɂȂ����B
2008����܂ł�Windows��64�_���v���Z�b�T�܂ł����g���Ȃ����������
�t�ɂ��̂�����MS�����������ƂɂȂ����B
2008����܂ł�Windows��64�_���v���Z�b�T�܂ł����g���Ȃ����������
�Ȃ��Larrabee�̃X����Xeon�k�`�ɂȂ��Ă�́H
�X���b�h�̕���x�Ƃ��Ă�Larrabee��XeonMP���Ȃ�ȁB
�e�ʂ͏��Ȃ���
�e�ʂ͏��Ȃ���
>>588
>Xeon MP�����܂�g���Ȃ��̂�
MP�ł��������邩�炾��B��ʐl���P�̂Ŕ�����悤��
����Xeon��2�\�P�b�g�ł������ʂ��ĂȂ����AOpteron��2xxx��8xxx��
���i���Ƃ���܂�ς���͂������牿�i��r�T�C�g�Ō��Ă݂��낵
>Xeon MP�����܂�g���Ȃ��̂�
MP�ł��������邩�炾��B��ʐl���P�̂Ŕ�����悤��
����Xeon��2�\�P�b�g�ł������ʂ��ĂȂ����AOpteron��2xxx��8xxx��
���i���Ƃ���܂�ς���͂������牿�i��r�T�C�g�Ō��Ă݂��낵
���[�ԈႦ���ȁ@�ʂɈ�ʐl�ł������鏊�ł������Ă�
597 �F,,�E�L�́M�E,,�j��-�������F2009/04/27(��) 21:09:36 ID:xE7gHVrV
�b�̍��𝆂�ł��܂ALarrabee��opcode���Č��J����Ă�H
599 �F,,�E�L�́M�E,,�j��-�������F2009/04/30(��) 19:30:51 ID:toL+Zzqj
�������Ƃ���ʼn����ł����B
�����A�����o���Ȃ��̂��B
�����A�����o���Ȃ��̂��B
600 �FSocket774�F2009/05/01(��) 00:08:58 ID:ls5mjusB
�@�@�@�@�@ .,,-�]''"~~�P��'''��,
�@�@�@ .,�^'�@ �U���J�E�B�@ �R�@http://aliennationreport.com/SHOSEIKODA.wmv
�@�@ ,,i�L�@�@�@�@�@�@�@�@�@�@�@�@�R
�@�@ |�@�Q,,,;---�]�]�]---�,____�@ |�@�@�@�@�@���c���� �� NVIDIA
�@�@|�]''�^�@�@�@�@�@�@�@�@�@�_�''�|
�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@|�@ |�@�@�@�@�U���J�E�B �� INTEL
�@ �i ./�@,;;iiilllllllliii;;,,;;iiillllllllii;;,, |�@ �j
�@�@.| | �@��E��/| | ��E��@.|�@/
�@�@ | |�_�@ ~~//�@ |�@~~~ �^| /
�@ �@ | |�@|�@./ .L;....;J �R�@|�@//�@�@�����P�ނ̗v������{���f��������
�@�@�@.| �R�,,;;iiill|||||||||lllii;;, �^.|
�@�@�@ �R �@ |'"~�--�]~��'''|�@/�@�@�@�@���c�ؐ��́A��������̌Y�I
�@�@�@�@�@|�@ �'''�----�]''"�@|
�@ _�Q_�^�_�@�@�@�@�@ r'"�P`��'"��`�܁�'�[�_ �@
�^�@�@|�@�@�@�_�Q�Q.r'�@�@�@�@�@ ���c �@�@�@�@�@�R
�@�@�@�@�@�@�@�@�@�@�i�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M�T
�@�@�@�@�@�@�@�@�@ �i;;;;;;;;;;;;;;;;;�l�Q�i�_!�i(^i_/�R�::*::: }
�@�@�@�@�@�@�@�@�@�@| �@�@�@/*-''�P�@:;;�P''-�@�@ i�@�@�
�@�@�@�@�@�@�@�@�@�@| �@�@�\���s;,�;�t�i �@ r�s;,�;�t� |�@.�@|
�@�@�@�@�@�@�@�@�@ �@@ i ;;;;;; �@�@ |�@�@�@::::�@�@ | �@�@|
�@�@�@�@�@�@�@�@ �@�@}�@�@<́@:;;;;; Ɂ@:::�@�@�@/;; >�@�@i
�@ �@�@�@�@��د�@�@ |�@�@|:::l:;;;;;;;*`;;�[;;`�R:�@l::::|�@�@ |
�܁܁R�@�@ �@ �@�c�M';:;�@�R:::;;; l l=��=��R�@::/�@ ��
�@��@�@�j�P}�P�P�P�P�P�S�@;; |�'^Y^',,|:::�^|�@/�@�@�@�@�@��������I�I
�_�l_,Ɂ�)}���� �@ �@.,,;:':;}#;�_��;;;-'�^ �@| �i
�@�@�Q,,�m�L�@�@��������;�;�;'��:��@�@�@�@ j,/
r�]'�L �����c�������c','/�G;����@�@ �@�@�_
�@�@�@ .,�^'�@ �U���J�E�B�@ �R�@http://aliennationreport.com/SHOSEIKODA.wmv
�@�@ ,,i�L�@�@�@�@�@�@�@�@�@�@�@�@�R
�@�@ |�@�Q,,,;---�]�]�]---�,____�@ |�@�@�@�@�@���c���� �� NVIDIA
�@�@|�]''�^�@�@�@�@�@�@�@�@�@�_�''�|
�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@|�@ |�@�@�@�@�U���J�E�B �� INTEL
�@ �i ./�@,;;iiilllllllliii;;,,;;iiillllllllii;;,, |�@ �j
�@�@.| | �@��E��/| | ��E��@.|�@/
�@�@ | |�_�@ ~~//�@ |�@~~~ �^| /
�@ �@ | |�@|�@./ .L;....;J �R�@|�@//�@�@�����P�ނ̗v������{���f��������
�@�@�@.| �R�,,;;iiill|||||||||lllii;;, �^.|
�@�@�@ �R �@ |'"~�--�]~��'''|�@/�@�@�@�@���c�ؐ��́A��������̌Y�I
�@�@�@�@�@|�@ �'''�----�]''"�@|
�@ _�Q_�^�_�@�@�@�@�@ r'"�P`��'"��`�܁�'�[�_ �@
�^�@�@|�@�@�@�_�Q�Q.r'�@�@�@�@�@ ���c �@�@�@�@�@�R
�@�@�@�@�@�@�@�@�@�@�i�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M�T
�@�@�@�@�@�@�@�@�@ �i;;;;;;;;;;;;;;;;;�l�Q�i�_!�i(^i_/�R�::*::: }
�@�@�@�@�@�@�@�@�@�@| �@�@�@/*-''�P�@:;;�P''-�@�@ i�@�@�
�@�@�@�@�@�@�@�@�@�@| �@�@�\���s;,�;�t�i �@ r�s;,�;�t� |�@.�@|
�@�@�@�@�@�@�@�@�@ �@@ i ;;;;;; �@�@ |�@�@�@::::�@�@ | �@�@|
�@�@�@�@�@�@�@�@ �@�@}�@�@<́@:;;;;; Ɂ@:::�@�@�@/;; >�@�@i
�@ �@�@�@�@��د�@�@ |�@�@|:::l:;;;;;;;*`;;�[;;`�R:�@l::::|�@�@ |
�܁܁R�@�@ �@ �@�c�M';:;�@�R:::;;; l l=��=��R�@::/�@ ��
�@��@�@�j�P}�P�P�P�P�P�S�@;; |�'^Y^',,|:::�^|�@/�@�@�@�@�@��������I�I
�_�l_,Ɂ�)}���� �@ �@.,,;:':;}#;�_��;;;-'�^ �@| �i
�@�@�Q,,�m�L�@�@��������;�;�;'��:��@�@�@�@ j,/
r�]'�L �����c�������c','/�G;����@�@ �@�@�_
TSMC confirms 40-nm yield issues, gives predictions
ttp://www.eetimes.com/news/semi/rss/showArticle.jhtml?articleID=217201043&cid=RSSfeed_eetimes_semiRSS
TSMC's 40nm problem revealed
ttp://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/635
ttp://www.eetimes.com/news/semi/rss/showArticle.jhtml?articleID=217201043&cid=RSSfeed_eetimes_semiRSS
TSMC's 40nm problem revealed
ttp://www.theinquirer.net/inquirer/news/878/1050878/tsmc-40nm-revealed
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/635
DDJ�L���A��2�e�B"Rasterization on Larrabee"
http://www.ddj.com/hpc-high-performance-computing/217200602
http://www.ddj.com/hpc-high-performance-computing/217200602
603 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 18:32:30 ID:0tvPTLzo
SCEA�̃p�[�g�i�[��ƃC���\���j�A�b�N�Q�[���Y��Larrabee�ɂ��Ē�����
�\�[�X�͉�
�\�[�X�͉�
������Ⴄ�Ǝv���܂�
�딚
Cell���S��
607 �FMAC�I�^���c�q �����F2009/05/04(��) 19:40:38 ID:wON4Wxya
>>603
�c�q����̂��Ƃł�����A���ꃋ�[�}�[�Ɉ����������Ă���\�����ے�ł��܂��A
Larrabee��Intel��CELL/B.E.�ł�����A���̕s�v�c�������c�Ƃ������x�̐M�ߐ��͂����
���傤���H
�c�q����̂��Ƃł�����A���ꃋ�[�}�[�Ɉ����������Ă���\�����ے�ł��܂��A
Larrabee��Intel��CELL/B.E.�ł�����A���̕s�v�c�������c�Ƃ������x�̐M�ߐ��͂����
���傤���H
608 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 19:42:47 ID:0tvPTLzo
��Intel��CELL/B.E.
�ӂӁA�����Ɍ����Ă�̂��n����
�܂�Cell��GPU�ł͂Ȃ��B
�ӂӁA�����Ɍ����Ă�̂��n����
�܂�Cell��GPU�ł͂Ȃ��B
>>603
�\�[�X��"��"�͒N���H
�\�[�X��"��"�͒N���H
610 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 19:47:24 ID:0tvPTLzo
���M���͂����܂�dango.chu.jp����
16�R�A���x���ƁA�s�N�Z�������ɂ����āA���X�^���C�Y�@�ł����C�g���[�V���O�@�ł���������Ȃ���
612 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 19:53:28 ID:0tvPTLzo
�����炭45nm��600mm^2����_�C�T�C�Y�Ȃ̂ɁA16�R�A�Ȃ킯���Ȃ����낤
613 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 19:57:22 ID:0tvPTLzo
firewall.insomniacgames.com / Squid [10.0.1.9]
�܁A�Ȃ�ł��ǂ����ǂȉ��́B
����Intel���Q�[���ƊE�ɔ���Ȃ畉���Ȃ������v���X�e����Ȃ���Xbox�V���[�Y�̌�p�@���낤�B
NVIDIA�ȊO��OpenGL�������Ĕ��������邵�B
�܁A�Ȃ�ł��ǂ����ǂȉ��́B
����Intel���Q�[���ƊE�ɔ���Ȃ畉���Ȃ������v���X�e����Ȃ���Xbox�V���[�Y�̌�p�@���낤�B
NVIDIA�ȊO��OpenGL�������Ĕ��������邵�B
614 �FMAC�I�^���c�q �����F2009/05/04(��) 20:07:28 ID:wON4Wxya
>>613
����͂�����Ȃ�ł����ӎ��ߏ�Ƃ������c�ł́H
����͂�����Ȃ�ł����ӎ��ߏ�Ƃ������c�ł́H
615 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 20:11:16 ID:0tvPTLzo
���e���ᖡ�����ɂ���Ȃ��Ƃ�������̂���
�܂��A�y���݂ɂ��Ă����Ɨǂ���
�܂��A�y���݂ɂ��Ă����Ɨǂ���
512bit���ƁA32bit16way������
GPU���ZLarrabee1�R�A16sp���Ď��ɂȂ�̂��ȁH
����
600mm^2�@Atom���Z24�R�A
24�R�A*16sp=384sp�i2Ghz�j
�g���C�A���O���Z�b�g�A�b�v���T���Ă����ǐ��\�ł����H
�Ƃ��������\�łĂ�́H
GPU���ZLarrabee1�R�A16sp���Ď��ɂȂ�̂��ȁH
����
600mm^2�@Atom���Z24�R�A
24�R�A*16sp=384sp�i2Ghz�j
�g���C�A���O���Z�b�g�A�b�v���T���Ă����ǐ��\�ł����H
�Ƃ��������\�łĂ�́H
618 �FMAC�I�^���c�q �����F2009/05/04(��) 20:25:29 ID:wON4Wxya
>>615
�@�@----------------
�@�@���e���ᖡ�����ɂ���Ȃ��Ƃ�������̂���
�@�@----------------
����Ȃ��ƌ����Ă��A�y�[�W�{������������e���ᖡ�ł���̂͒c�q�����Ȗ��(��)
�@�@----------------
�@�@���e���ᖡ�����ɂ���Ȃ��Ƃ�������̂���
�@�@----------------
����Ȃ��ƌ����Ă��A�y�[�W�{������������e���ᖡ�ł���̂͒c�q�����Ȗ��(��)
619 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 20:33:44 ID:0tvPTLzo
>>616
> 600mm^2�@Atom���Z24�R�A
�������Ƃ��������Ƃ������܂�������B
�������̌v�Z�ɂ͏d��Ȍ�肪����B
Atom�̃_�C��40���߂���FSB�C���^�[�t�F�C�X�ɐH���A���Ƃ͓d�͐���p�̃u���b�N�Ƃ����H���Ă�B
L2��512KB�ƁALarrabee��256KB/core���������B
Atom��P6��P5�̒��ԓI�ȃp�C�v���C���\������
Larrabee��P5�x�[�X�Ńp�C�v���C����Atom���V���v���Ȃ��̂��B
512�r�b�g�~2�̃����O�o�X��Cell��EIB���������債���_�C�T�C�Y�͐H��Ȃ��Ǝv����
�Ƃ������Ƃ�48�R�A���x�Ȃ�ς߂�̂ł́H
> 600mm^2�@Atom���Z24�R�A
�������Ƃ��������Ƃ������܂�������B
�������̌v�Z�ɂ͏d��Ȍ�肪����B
Atom�̃_�C��40���߂���FSB�C���^�[�t�F�C�X�ɐH���A���Ƃ͓d�͐���p�̃u���b�N�Ƃ����H���Ă�B
L2��512KB�ƁALarrabee��256KB/core���������B
Atom��P6��P5�̒��ԓI�ȃp�C�v���C���\������
Larrabee��P5�x�[�X�Ńp�C�v���C����Atom���V���v���Ȃ��̂��B
512�r�b�g�~2�̃����O�o�X��Cell��EIB���������債���_�C�T�C�Y�͐H��Ȃ��Ǝv����
�Ƃ������Ƃ�48�R�A���x�Ȃ�ς߂�̂ł́H
Larrabee:A Many-Core x86 Architecture for Visual Computing����600sqmm�Ȃ�40�R�A���Ɨ\�z���Ă���
48�R�A�Ȃ�650sqmm����Ǝv��
������̃E�F�n�̎ʐ^����_�C�T�C�Y�𐳊m�ɑ���͓̂����������48�R�A�ł��S�R���������͂Ȃ�
48�R�A�Ȃ�650sqmm����Ǝv��
������̃E�F�n�̎ʐ^����_�C�T�C�Y�𐳊m�ɑ���͓̂����������48�R�A�ł��S�R���������͂Ȃ�
622 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 20:49:04 ID:0tvPTLzo
���������ʂ͔��o���d�v���Ƃ͎v���Ă��Ȃ��B�����܂�x86�x�[�X�̃A�N�Z�����[�^������B
�݂͖݉��Ƃ����ł͂Ȃ����B
�f�B�X�N���[�g�ł��o���{���͂����܂�GPGPU�ɑ���\�h�����B
�܂��Q�[���R���\�[���ɍڂ�Ƃ��Ă�2011�N�ȍ~�̘b�ɂȂ邾�낤����
�Q�[���@�̗̍p�𑫂�����ɕ��y������Ƃ����J�[�h�͂ǂ݂̂��g���Ȃ��B
�݂͖݉��Ƃ����ł͂Ȃ����B
�f�B�X�N���[�g�ł��o���{���͂����܂�GPGPU�ɑ���\�h�����B
�܂��Q�[���R���\�[���ɍڂ�Ƃ��Ă�2011�N�ȍ~�̘b�ɂȂ邾�낤����
�Q�[���@�̗̍p�𑫂�����ɕ��y������Ƃ����J�[�h�͂ǂ݂̂��g���Ȃ��B
Larrabee�̓o���GPGPU�͂ǂ��Ȃ����Ⴄ��^p^
624 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 20:55:12 ID:0tvPTLzo
�������ш�l�b�N�ʼn��Z���j�b�g�����ė]����ԂŁA�ėp�R���s���[�e�B���O�Ŋ��H�����o�����Ƃ��Ă�
������݂�ƁAGPU�ɓ��������n�[�h���Ă̂͋t�ɖ��ʂ��������A�e�R�A���ɍ����A�N�Z�X�ł���
���[�J���L���b�V���������̂̓p�t�H�[�}���X�v��t�ɗL����������Ȃ��ˁB
������݂�ƁAGPU�ɓ��������n�[�h���Ă̂͋t�ɖ��ʂ��������A�e�R�A���ɍ����A�N�Z�X�ł���
���[�J���L���b�V���������̂̓p�t�H�[�}���X�v��t�ɗL����������Ȃ��ˁB
>>620
�O�q�����_���ɂ���
1GHz��10�R�A��1600*1200 AAx4��Half Life 2 ep.2��FPS60�炸�ɓ����݂�������
������Ăǂ��Ȃ̂�H�Ƌt����
�Q�[�����Ȃ����炳���ς�킩���̂���
�O�q�����_���ɂ���
1GHz��10�R�A��1600*1200 AAx4��Half Life 2 ep.2��FPS60�炸�ɓ����݂�������
������Ăǂ��Ȃ̂�H�Ƌt����
�Q�[�����Ȃ����炳���ς�킩���̂���
626 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 21:01:50 ID:0tvPTLzo
Larrabee��Intel��Cell�Ȃ�ē��̈������Ɩ����Ɍ����Ă�z�����邪
Cell��SCE��Niagara����i�j
�ƁA������Niagara�Ƃ̈Ⴂ���w�E���Ă������B
���ꂪ���̂܂��Larrabee��Cell�̌���I�ȈႢ�ɂȂ�B
>>625
http://pc11.2ch.net/test/read.cgi/mac/1214461149/166-167
Cell��SCE��Niagara����i�j
�ƁA������Niagara�Ƃ̈Ⴂ���w�E���Ă������B
���ꂪ���̂܂��Larrabee��Cell�̌���I�ȈႢ�ɂȂ�B
>>625
http://pc11.2ch.net/test/read.cgi/mac/1214461149/166-167
627 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 21:20:19 ID:0tvPTLzo
�����ɂ�2�N��3�{�Ȃ�ăy�[�X�ŐL�тĂȂ����A8800GTX��2�N�߂����g�b�v�ɌN�Ղ��Ă�����ȕNJ��Y��
GPU�̌���B
�L���[�^�C�g����������Crysis�����B
GPU�̌���B
�L���[�^�C�g����������Crysis�����B
�L���[�^�C�g���u�x���l�b�^�v�ɂȂ�ƐM���Ă�
629 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 21:34:20 ID:0tvPTLzo
TheINQ�̘A���Ȃ�A�����u�C���\���j�A�b�N�Q�[���Y�̓z��Larrabee�ɂ��Ē��ׂĂ��v���ď��𗬂���
�f�G�ɋr�F���ăf�}�L������Ă����낤���H
Demakasejan�搶�̑n��Ɋ��҉������B
�f�G�ɋr�F���ăf�}�L������Ă����낤���H
Demakasejan�搶�̑n��Ɋ��҉������B
�l�I�ɃO���t�B�b�N�X�ʂł����҂��Ă��
����ȂɌ������̂���
ttp://game.watch.impress.co.jp/img/gmw/docs/080/150/html/lrb08.jpg.html
texture unit�ȊO�ɂ��Œ�@�\���j�b�g������悤����
�ǂ̒��x�̋@�\����ł�̂���
����ȂɌ������̂���
ttp://game.watch.impress.co.jp/img/gmw/docs/080/150/html/lrb08.jpg.html
{kind=link}
texture unit�ȊO�ɂ��Œ�@�\���j�b�g������悤����
�ǂ̒��x�̋@�\����ł�̂���
�ߋ���Intel GPU�֘A�̃\�t�g�Ɋւ�����l�Ԃ�����ł��炱����
Intel�ސ��R���p�C�����MKL���̃G�[�X�����S����������� ����
Intel�ސ��R���p�C�����MKL���̃G�[�X�����S����������� ����
���̒c�q�̕�������Ղ�͒p���������B
633 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:21:00 ID:0tvPTLzo
�ʂɁB
������C�ӂ̃L�[���[�h��24���Ԉȓ��Ƀy�[�W�����N�Ńg�b�v�ɂ�����@�v�������B
������C�ӂ̃L�[���[�h��24���Ԉȓ��Ƀy�[�W�����N�Ńg�b�v�ɂ�����@�v�������B
634 �FMAC�I�^��630 �����F2009/05/04(��) 23:32:50 ID:wON4Wxya
>>630
GDC2009��Michael Abrash�̃v���[��������p.11�Ŏ��̂悤�ɏ�����Ă��܂��B
http://software.intel.com/file/15542
�@�@--------------------
�@�@- Fixed-function texture sampler units
�@�@- Also a per-core cache-management unit
�@�@- No other fixed-function units
�@�@--------------------
GDC2009��Michael Abrash�̃v���[��������p.11�Ŏ��̂悤�ɏ�����Ă��܂��B
http://software.intel.com/file/15542
�@�@--------------------
�@�@- Fixed-function texture sampler units
�@�@- Also a per-core cache-management unit
�@�@- No other fixed-function units
�@�@--------------------
635 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:38:58 ID:0tvPTLzo
�y�j�X����ɓ�����
�e�N�X�`�����j�b�g�ȊO��SIMD������x86�R�A�ȊO�̋@�\�͓��ɍڂ��ĂȂ��ƌ��Ă���B
�������ш�l�b�N�i������������悤�Ƃ���Ə���d�́E�M���x���l�b�N�ɂȂ�j�̑ŊJ���
�L���b�V���̓��ڂ���ё�e�ʉ����炢�����Ȃ��B
���̈Ӗ��ł̗D�ʐ��͂���Ǝv����B
DX11�ŕW���d�l�ɐ��荞�܂��e�b�Z���[�^���\�t�g�������Ăǂ�Ȑ��\���o��̂��͌v�肩�˂邪�B
�e�N�X�`�����j�b�g�ȊO��SIMD������x86�R�A�ȊO�̋@�\�͓��ɍڂ��ĂȂ��ƌ��Ă���B
�������ш�l�b�N�i������������悤�Ƃ���Ə���d�́E�M���x���l�b�N�ɂȂ�j�̑ŊJ���
�L���b�V���̓��ڂ���ё�e�ʉ����炢�����Ȃ��B
���̈Ӗ��ł̗D�ʐ��͂���Ǝv����B
DX11�ŕW���d�l�ɐ��荞�܂��e�b�Z���[�^���\�t�g�������Ăǂ�Ȑ��\���o��̂��͌v�肩�˂邪�B
���ׂĂ����ăC���^�[�l�b�g�����ł��傗���H
�g�D�i���o�[3�̒c�q����Ȃ炲���m���Ǝv������
���������ꍇ��NDA����ŏ����J�������B
�Ő��\�����炢�L�q���ꂽ�h�L�������g�����B
�ŁA�����i�K�ł͕����̃x���_�[�ɑ��ē������Ƃ����
�ǂꂪ������������߂�B
�g�D�i���o�[3�̒c�q����Ȃ炲���m���Ǝv������
���������ꍇ��NDA����ŏ����J�������B
�Ő��\�����炢�L�q���ꂽ�h�L�������g�����B
�ŁA�����i�K�ł͕����̃x���_�[�ɑ��ē������Ƃ����
�ǂꂪ������������߂�B
637 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:53:10 ID:0tvPTLzo
���͑g�D��No.3�Ȃ�Č��������Ƃ͂Ȃ��ȁB
�ʂ̂Ƃ���ł͑g�D�g�b�v�����B
�ʂ̂Ƃ���ł͑g�D�g�b�v�����B
�c�q����͑g�D�̎l�V���̈�l�ł���
639 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:56:19 ID:0tvPTLzo
640 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:57:03 ID:0tvPTLzo
>>638
�������g�b�v�̓A�K�T���m��
�������g�b�v�̓A�K�T���m��
>>638
�c�q3�Z��
�c�q3�Z��
642 �F,,�E�L�́M�E,,�j��-�������F2009/05/04(��) 23:58:00 ID:0tvPTLzo
> �Ő��\�����炢�L�q���ꂽ�h�L�������g�����B
> �ŁA�����i�K�ł͕����̃x���_�[�ɑ��ē������Ƃ����
> �ǂꂪ������������߂�B
�ǂ��SCE�̉��������ƒf�łł��邱�Ƃł͂Ȃ��ȁB
> �ŁA�����i�K�ł͕����̃x���_�[�ɑ��ē������Ƃ����
> �ǂꂪ������������߂�B
�ǂ��SCE�̉��������ƒf�łł��邱�Ƃł͂Ȃ��ȁB
643 �FSocket774�F2009/05/05(��) 00:22:11 ID:UmEykTr2
�ׂ������Ƃ͂ǂ��ł��ǂ���������Ă��o���H
�Ԃ��a���̋t�P�݂����ɂ݂�ȋ������\����H
�Ԃ��a���̋t�P�݂����ɂ݂�ȋ������\����H
644 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 00:24:16 ID:YebxnnTm
�������N���[�Y�h��Larrabee SDK�����݂��邱�Ƃ͒m���Ă��B
���N�����肩��ꕔ��ƌ����ɏ��͏o�Ă�B
���N�����肩��ꕔ��ƌ����ɏ��͏o�Ă�B
�C���\���j�A�b�N�͓Ɨ��n�Ȃ���A��낤�Ǝv���ΒP�Ƃ�NDA���ׂ�ł���B
�Ⴆ��Larrabee�ɍœK�������Q�[�������[���`���ɔ�������ȂǂŁB
�c�q�����đg�D�̃g�b�v�Ȃ�Intel��NDA����ŏ��Q�b�g�ł����Ȃ���
�N��������Larrabee�̎d�l��m���ă\�t�g�����͂��߂���Ȃ�Ė{�]����Ȃ��́B
�ő��̃g���b�v���������܂����I��
�Ⴆ��Larrabee�ɍœK�������Q�[�������[���`���ɔ�������ȂǂŁB
�c�q�����đg�D�̃g�b�v�Ȃ�Intel��NDA����ŏ��Q�b�g�ł����Ȃ���
�N��������Larrabee�̎d�l��m���ă\�t�g�����͂��߂���Ȃ�Ė{�]����Ȃ��́B
�ő��̃g���b�v���������܂����I��
646 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 00:37:38 ID:YebxnnTm
����Ȃ̂Œނ��̂�NotarinVIDIA���炢���B
�ꉞ���Ƙb���������Ƃ��̖��`�͉������Ǝ刵���ł����B
�ꉞ���Ƙb���������Ƃ��̖��`�͉������Ǝ刵���ł����B
>NotarinVIDIA
�����������
�����������
648 �FMAC�I�^���c�q �����F2009/05/05(��) 00:42:07 ID:q7/3GqkF
>>644
�@�@--------------
�@�@�N���[�Y�h��Larrabee SDK�����݂��邱�Ƃ͒m���Ă��B
�@�@--------------
���ꃋ�[�}�[�T�C�g��ǂނ��Ƃ́w�m���Ă���x�Ƃ͌���Ȃ�����(��)
�@�@--------------
�@�@�N���[�Y�h��Larrabee SDK�����݂��邱�Ƃ͒m���Ă��B
�@�@--------------
���ꃋ�[�}�[�T�C�g��ǂނ��Ƃ́w�m���Ă���x�Ƃ͌���Ȃ�����(��)
649 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 00:50:40 ID:YebxnnTm
>>642
WWS�̓���ɂ��Ēm��Ȃ��̂��͂����肵���B�ǂ������B
WWS�̓���ɂ��Ēm��Ȃ��̂��͂����肵���B�ǂ������B
651 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 02:11:25 ID:YebxnnTm
>>650
��[�H
SCE�̃\�t�g�J���p�[�g�i�[��Ƃ̗����������Ă邱�Ǝ��̂͒N�ł��m���Ă邾��B
PS3���n�܂����Ƃ����炶��Ȃ����B
��[�H
SCE�̃\�t�g�J���p�[�g�i�[��Ƃ̗����������Ă邱�Ǝ��̂͒N�ł��m���Ă邾��B
PS3���n�܂����Ƃ����炶��Ȃ����B
�������ˁBGDC����悩�����̂ɂˁB
653 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 02:30:14 ID:YebxnnTm
GDC�ł̃v���[�������Ȃ�Web�ɏo�Ă邾��
�C���\���j�A�b�N��PS3���Ȃ�Ƃ��}�V�Ɏg�����Ɠw�͂��Ă�̂����͒m���Ă邪
����ȏ�͋����Ȃ���B
�C���\���j�A�b�N��PS3���Ȃ�Ƃ��}�V�Ɏg�����Ɠw�͂��Ă�̂����͒m���Ă邪
����ȏ�͋����Ȃ���B
654 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 02:34:22 ID:YebxnnTm
���܂̃n�C�G���h�w���̃f�x���b�p�[�́A���������Y��ɂ��Ă��C�V���ɏ��ĂȂ��̂�
�����Ԃʂȓw�͂��Ă�ȂƂ�����ۂ����Ȃ��B
PS1�����̏��Ă��̂����ꂷ��Y��Ă銴���B
���A�p���b�p�̏��Y����̐V��͊y���݂ɂ��Ă��B
�����Ԃʂȓw�͂��Ă�ȂƂ�����ۂ����Ȃ��B
PS1�����̏��Ă��̂����ꂷ��Y��Ă銴���B
���A�p���b�p�̏��Y����̐V��͊y���݂ɂ��Ă��B
655 �FMAC�I�^���c�q �����F2009/05/05(��) 02:34:46 ID:q7/3GqkF
656 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 02:46:03 ID:YebxnnTm
������IEEE��ACM���炢�����ǂދC�͂Ȃ��ȁB
�ꉞ�E��o�R�ŊJ���҃J���t�@�����X�s�����Ƃ͂����Ă��Q�[���֘A�Ƃ͑S���W�Ȃ����B
�ꉞ�E��o�R�ŊJ���҃J���t�@�����X�s�����Ƃ͂����Ă��Q�[���֘A�Ƃ͑S���W�Ȃ����B
657 �FMAC�I�^���c�q �����F2009/05/05(��) 02:59:03 ID:q7/3GqkF
>>656
�@�@----------------
�@�@������IEEE��ACM���炢�����ǂދC�͂Ȃ��ȁB
�@�@----------------
�ǂ�����w��̖��O�ŁA�_�����̖��O���ᖳ���̂ł���(��)
��������IEEE���ǂ�قǂ̐��̎G���s���Ă��邌���Ƃ��c
�@�@----------------
�@�@������IEEE��ACM���炢�����ǂދC�͂Ȃ��ȁB
�@�@----------------
�ǂ�����w��̖��O�ŁA�_�����̖��O���ᖳ���̂ł���(��)
��������IEEE���ǂ�قǂ̐��̎G���s���Ă��邌���Ƃ��c
658 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 03:08:23 ID:YebxnnTm
�w������͉�ЂŎ���Ă邪�A�w��̂��̂̎Q���͂����������ȁB
���������w��Ȃ�Ĕ��\����l�^�������Ă��ĂȂ��l�Ԃ��Q�����郂������Ȃ���B
�܂��Ċw���ǂ�œ��e�𗝉��o���Ȃ��l�Ԃ��Q�����ė����o����C�x���g�ł��Ȃ��B
�J���҃J���t�@�����X���̂��̂͌ق���̉�ЂƂ���MS��ẪC�x���g�ɂ��܂ɐ��������邭�炢�B
��Ђ̉c�ƃg�b�v�̐l��MSKK�̔������ƕ���ł�ʐ^�݂��Ă��ꂽ��B
���̒��x�̕t�������B
���l�ł���Ă���͖^N���ŏ��ōŌゾ��B���Ő������������̂����܂��ɂ킩���B
���������w��Ȃ�Ĕ��\����l�^�������Ă��ĂȂ��l�Ԃ��Q�����郂������Ȃ���B
�܂��Ċw���ǂ�œ��e�𗝉��o���Ȃ��l�Ԃ��Q�����ė����o����C�x���g�ł��Ȃ��B
�J���҃J���t�@�����X���̂��̂͌ق���̉�ЂƂ���MS��ẪC�x���g�ɂ��܂ɐ��������邭�炢�B
��Ђ̉c�ƃg�b�v�̐l��MSKK�̔������ƕ���ł�ʐ^�݂��Ă��ꂽ��B
���̒��x�̕t�������B
���l�ł���Ă���͖^N���ŏ��ōŌゾ��B���Ő������������̂����܂��ɂ킩���B
���������S�X�e�[�^�X���ۂ��Ċ������c�q�ł�����
660 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 05:54:16 ID:YebxnnTm
���Ȃ݂�>>645�I�Ȏ��v�ōs����
���l�̃\�t�g�Ȃ�Larrabee C++ Intrinsics�ւ̈ڐA�Ȃ�Ƃ����ɏI����Ă邵�A
�l�C�e�B�u�A�Z���u���R�[�h����NASM�̍\���ŏ����I���Ă邩��ȁB
4�X���b�h������̂�1�X���b�h������ėp���W�X�^16�{�{SIMD���W�X�^32�{�͏\��������
���W�X�^�]�肷���ċt�ɉ��Ɏg������������ԁB
�ł��܂��A���݃y�[�p�[�v���Z�b�T�����R��Larrabee�ɍ\���K�v�Ȃ��ł���B
�茳�ɂ�����Ƃ����ʔ����f�o�C�X���茳�ɂ���̂ł������ɖv�����ł���B
���ł邩����Ȃ��A�[�L��҂������g������̂ŋZ�p�̒~�ς�������L�Ӌ`���B
�܁A����ł�Cell�i�j�͑S�����ɗ����Ȃ����ȁB
����͂���Ƃ��āALarrabee��PS4�ɍ̗p���Ă̂͒c�q�₳��I�ɂ����܂芽�}�ł��Ȃ���
�������Cell�ƐS�����Ă�����������
�Ƃ������AIntel�̌o�c�w��Wii�����Ȃ�ӎ����Ă�悤�ŁALarrabee���̊��w���̃Q�[���@�ɍ̗p���������Ƃ����Ă��B
�����n�ɏ�肽���Ǝv���̂�Intel�Ƃē������B
http://www.inside-games.jp/news/332/33233.html
���̕ӂ̐����u���Q�[���@2�ʑ����i�j�̉��V���ĂĂ��킩��ł���
���̊��ɋy��ŔC�V���n�[�h�Ƃ͕ʎ������ƌ�������\�j�[�ƁA�Â�Wii�̐�����J��
���\�����ł͖����R���e���c�͂��d�v�ł��邱�Ƃ����MS�B
SCE�̓g�b�v�����ꂾ����A����PS�w�c�̐l�́A�f���\�������オ��ΊS���W�߂����
�ӖړI�ɐM���Ă銴��������B�Ă��A���������l�����c���ĂȂ��C������B
�i�܁A�o�����X���d������360�̕������ʓI�ɍ����f���\�����o���Ă�̂�����Ȃ����j
����JK�����Ă����B�Q�[���Ȃ�Čg�т̉�ʒ��x�ł��v���Ƀ}�b�`����Ζv���ł����ł��B
���l�̃\�t�g�Ȃ�Larrabee C++ Intrinsics�ւ̈ڐA�Ȃ�Ƃ����ɏI����Ă邵�A
�l�C�e�B�u�A�Z���u���R�[�h����NASM�̍\���ŏ����I���Ă邩��ȁB
4�X���b�h������̂�1�X���b�h������ėp���W�X�^16�{�{SIMD���W�X�^32�{�͏\��������
���W�X�^�]�肷���ċt�ɉ��Ɏg������������ԁB
�ł��܂��A���݃y�[�p�[�v���Z�b�T�����R��Larrabee�ɍ\���K�v�Ȃ��ł���B
�茳�ɂ�����Ƃ����ʔ����f�o�C�X���茳�ɂ���̂ł������ɖv�����ł���B
���ł邩����Ȃ��A�[�L��҂������g������̂ŋZ�p�̒~�ς�������L�Ӌ`���B
�܁A����ł�Cell�i�j�͑S�����ɗ����Ȃ����ȁB
����͂���Ƃ��āALarrabee��PS4�ɍ̗p���Ă̂͒c�q�₳��I�ɂ����܂芽�}�ł��Ȃ���
�������Cell�ƐS�����Ă�����������
�Ƃ������AIntel�̌o�c�w��Wii�����Ȃ�ӎ����Ă�悤�ŁALarrabee���̊��w���̃Q�[���@�ɍ̗p���������Ƃ����Ă��B
�����n�ɏ�肽���Ǝv���̂�Intel�Ƃē������B
http://www.inside-games.jp/news/332/33233.html
���̕ӂ̐����u���Q�[���@2�ʑ����i�j�̉��V���ĂĂ��킩��ł���
���̊��ɋy��ŔC�V���n�[�h�Ƃ͕ʎ������ƌ�������\�j�[�ƁA�Â�Wii�̐�����J��
���\�����ł͖����R���e���c�͂��d�v�ł��邱�Ƃ����MS�B
SCE�̓g�b�v�����ꂾ����A����PS�w�c�̐l�́A�f���\�������オ��ΊS���W�߂����
�ӖړI�ɐM���Ă銴��������B�Ă��A���������l�����c���ĂȂ��C������B
�i�܁A�o�����X���d������360�̕������ʓI�ɍ����f���\�����o���Ă�̂�����Ȃ����j
����JK�����Ă����B�Q�[���Ȃ�Čg�т̉�ʒ��x�ł��v���Ƀ}�b�`����Ζv���ł����ł��B
SCE�̂��l�͐悪�����ĂȂ��̂͂������A����l�ԂƂ��Ăǂ��Ȃ̂�Ȕ����������̂���
��������x�ɂ��̉�Ђ̐��i�͔����悤�Ǝv�킹��͂�����
��������x�ɂ��̉�Ђ̐��i�͔����悤�Ǝv�킹��͂�����
�ł�Wii�̔���グ�}���ɗ�������������
�X�N�G�j�~���Y�̐V��Ȃ��600�{��������Ȃ��������ǂ������
�X�N�G�j�~���Y�̐V��Ȃ��600�{��������Ȃ��������ǂ������
�{�̂̕��͖O�a��Ԃ����ǃ\�t�g�̔���グ���ߎS�Ȃ̂������ˁB
���W���}�W�E�}�[�`�Ȃ�600�{��������ĂȂ���
���̓��������ǎ҃v���[���g�݂��������B
���W���}�W�E�}�[�`�Ȃ�600�{��������ĂȂ���
���̓��������ǎ҃v���[���g�݂��������B
664 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 08:38:46 ID:YebxnnTm
�܁A�|���J�[�{�l�C�g�̉~�Ղ�����悤���n�[�h�E�F�A���̃r�W�l�X�ɂ͂Ȃ�Ȃ��̂�B
�C�V���͎�ҋ~�ς֗̕��ȉ�Ђł͂Ȃ��Ƃ������Ƃ��B
Intel�I��Wii�̕������ŊS������̂̓����R���Ƃ��A����PS3�i�j�ȏ�ɔ���Ă锒��
�u�ł��v�Ƃ��A�܂�n�[�h�E�F�A����B
���̂ւ�̉����ɕ������Z�̎��v�����N�ł��Ȃ����Ɗ��҂��Ă���킯���B
Intel�̓��[�V�����Ɋւ��ẮAWii�����R���݂����ȃf�o�C�X���g�킸EyeToy�݂����ȃJ������
�\�t�g���Z�Ń��[�V���������o���悤�Ƃ��Ă���B
���A���^�C���摜��͂��ȁB
�킴�킴�����G���W������Havok�������Ӗ��������ɂ���B
�Ƃ������A����Ƃ͕ʂɃI�������ȂƋ�����WiiFit��PC�ł��̂��̂Ȍ��N���̋K�i����낤�Ƃ��Ă邪�B
�C�V���͎�ҋ~�ς֗̕��ȉ�Ђł͂Ȃ��Ƃ������Ƃ��B
Intel�I��Wii�̕������ŊS������̂̓����R���Ƃ��A����PS3�i�j�ȏ�ɔ���Ă锒��
�u�ł��v�Ƃ��A�܂�n�[�h�E�F�A����B
���̂ւ�̉����ɕ������Z�̎��v�����N�ł��Ȃ����Ɗ��҂��Ă���킯���B
Intel�̓��[�V�����Ɋւ��ẮAWii�����R���݂����ȃf�o�C�X���g�킸EyeToy�݂����ȃJ������
�\�t�g���Z�Ń��[�V���������o���悤�Ƃ��Ă���B
���A���^�C���摜��͂��ȁB
�킴�킴�����G���W������Havok�������Ӗ��������ɂ���B
�Ƃ������A����Ƃ͕ʂɃI�������ȂƋ�����WiiFit��PC�ł��̂��̂Ȍ��N���̋K�i����낤�Ƃ��Ă邪�B
�܂����N�U���ȁB
�ł�Intel�����͈Ⴄ�Ǝv���Ă����Ȃ��B
Corei7�R�P���ʂŐ������ˁB
��Larrabee�̂������B
�ł�Intel�����͈Ⴄ�Ǝv���Ă����Ȃ��B
Corei7�R�P���ʂŐ������ˁB
��Larrabee�̂������B
��
��
C
��
��
C
��
���܂���
�Ƃɕ��������ĂȂ���
�ꂶ��[�ɒr��
�Ƃɕ��������ĂȂ���
�ꂶ��[�ɒr��
���W���[���Ă̂͗]�ɂ��ĈӖ���
�]�ɂɍs���A���ĉ�������
�]�ɂɍs���A���ĉ�������
669 �F,,�E�L�́M�E,,�j���`[���q�q�q] �F2009/05/05(��) 15:34:57 ID:YebxnnTm
�����̂ڂ肾��
�D���ȃx���_������c�Ƃ����̂͌��w�S�ɂȂ���܂����爫�����Ƃ��ᖳ���Ǝv���܂����A
�C�ɓ���Ȃ��x���_��@�������Ƃ����~���́A��������Ŗڂ�܂点�邱�Ƃɂ����Ȃ�Ȃ�
�Ǝv���܂����c���āB
>>658
�@�@------------------
�@�@�w��Ȃ�Ĕ��\����l�^�������Ă��ĂȂ��l�Ԃ��Q�����郂������Ȃ���B
�@�@------------------
�w������ɎQ�������q�g���������Ȃ̂Ŋw����ɋ����܂������A�C�O�ł͍u���Ɏ��^������
�t������͓̂�����O�ŁA�ʔ���������������d������邱�Ƃ������ł��B
���������ΏE���Ă����v�֘A��transcript�ł��AQ&A�̕����ɖʔ��������ł��傤�H
�C�ɓ���Ȃ��x���_��@�������Ƃ����~���́A��������Ŗڂ�܂点�邱�Ƃɂ����Ȃ�Ȃ�
�Ǝv���܂����c���āB
>>658
�@�@------------------
�@�@�w��Ȃ�Ĕ��\����l�^�������Ă��ĂȂ��l�Ԃ��Q�����郂������Ȃ���B
�@�@------------------
�w������ɎQ�������q�g���������Ȃ̂Ŋw����ɋ����܂������A�C�O�ł͍u���Ɏ��^������
�t������͓̂�����O�ŁA�ʔ���������������d������邱�Ƃ������ł��B
���������ΏE���Ă����v�֘A��transcript�ł��AQ&A�̕����ɖʔ��������ł��傤�H
671 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 16:30:45 ID:YebxnnTm
���C�ɓ���Ȃ��x���_��@�������Ƃ����~���́A��������Ŗڂ�܂点�邱�Ƃɂ����Ȃ�Ȃ�
���̈�Ⴊ�y�j�X�搶�ł��ˁB�킩��܂��B
�����������ΏE���Ă����v�֘A��transcript�ł��AQ&A�̕����ɖʔ��������ł��傤�H
���l�̎���̕ԓ����E���Ă��Ċy���ނ����̉���Ȃ��l�Ԃɂ͂Ȃ肽���Ȃ����̂��ȁB
�܂�����SONY�l�������Z�̃V���[�y���J�`�J�`�͖ʔ������Ė���킹�Ă�����Ă邪
���̈�Ⴊ�y�j�X�搶�ł��ˁB�킩��܂��B
�����������ΏE���Ă����v�֘A��transcript�ł��AQ&A�̕����ɖʔ��������ł��傤�H
���l�̎���̕ԓ����E���Ă��Ċy���ނ����̉���Ȃ��l�Ԃɂ͂Ȃ肽���Ȃ����̂��ȁB
�܂�����SONY�l�������Z�̃V���[�y���J�`�J�`�͖ʔ������Ė���킹�Ă�����Ă邪
672 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 16:32:01 ID:YebxnnTm
�S�͂Œ�������B�{�[���y���ł���ƁB
�C���e���������r�݂����ȓd�͐H���̔n���ł����`�b�v�����đ��v�H
Apple���J�����Ă�Ǝ��v���Z�b�T��iPhone��iPod�t�@�~���[�Ɍ����ݍڂ���ꂽ���ςȂ��ƂɂȂ邼�B
Apple���J�����Ă�Ǝ��v���Z�b�T��iPhone��iPod�t�@�~���[�Ɍ����ݍڂ���ꂽ���ςȂ��ƂɂȂ邼�B
�^�[�Q�b�g���S�R�Ⴄ�̂ɃA�z�ł��傤���H
apple��cpu�v�Ƃ��Ӗ��킩��Ȃ�����
�����ǂԂɎ̂Ă�悤�Ȃ���
�����ǂԂɎ̂Ă�悤�Ȃ���
����ATI�̐l��Apple�Ɉڂ��č��̂�iphone�悤�̃��f�B�A�v���Z�b�T
677 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 19:01:38 ID:YebxnnTm
P.A.semi����B
PPC970�Ɩ��߃Z�b�g�݊��̏ȓd�̓v���Z�b�TPA6T��������Z�p�͖͂{������B
�I���W�i����PPC970���ǂ����悤���Ȃ����������ɁB
Intel��Larrabee�ȊO�ɂ�MID�p�̓Ǝ�GPU���J�����Ă邪�B
PPC970�Ɩ��߃Z�b�g�݊��̏ȓd�̓v���Z�b�TPA6T��������Z�p�͖͂{������B
�I���W�i����PPC970���ǂ����悤���Ȃ����������ɁB
Intel��Larrabee�ȊO�ɂ�MID�p�̓Ǝ�GPU���J�����Ă邪�B
678 �FMAC�I�^���c�q �����F2009/05/05(��) 19:17:45 ID:q7/3GqkF
>>677
���؎�`��W�Ԃ��銄�ɁA
�@�@----------------
�@�@�ȓd�̓v���Z�b�TPA6T��������Z�p�͖͂{������B
�@�@----------------
�������Ɩ����㕨�ɁA�����������Ə������Ⴄ�̂�����Ȃ���ł���(��)
���؎�`��W�Ԃ��銄�ɁA
�@�@----------------
�@�@�ȓd�̓v���Z�b�TPA6T��������Z�p�͖͂{������B
�@�@----------------
�������Ɩ����㕨�ɁA�����������Ə������Ⴄ�̂�����Ȃ���ł���(��)
679 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 19:19:16 ID:YebxnnTm
���������Ɩ����㕨�ɁA
���O���������Ƃ��Ȃ���ł��ˁB�킩��܂��B
NEC�̃X�g���[�W�A���C�ɂ��̗p����Ă��B
���킢�����ɁB
���O���������Ƃ��Ȃ���ł��ˁB�킩��܂��B
NEC�̃X�g���[�W�A���C�ɂ��̗p����Ă��B
���킢�����ɁB
680 �FMAC�I�^���c�q �����F2009/05/05(��) 19:30:25 ID:q7/3GqkF
>>679
(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/797
�@�@----------------------
�@�@797 ���O�FMAC�I�^ ���e���F2008/01/16(��) 01:53:52 ID:1O/FEDl+
�@�@�@�@�v���Ԃ��PowerPC�̘b��������悤�ȋC�����邷���ǁANEC���X�g���[�W�V�X�e���̃R���g���[��
�@�@�@�@�Ƃ��āAP.A. Semi��PWRficient�`�b�v���̗p����Ƃ̂��Ƃ��B
�@�@�@�@http://www.pasemi.com/news/pr_2008_01_10.html
�@�@----------------------
http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/711
�@�@======================
�@�@711 ���O�F�E�́E�j��-������ ���e���F2007/04/28(�y) 03:36:20 ID://+RcVJg
�@�@�@�@�����Ƃ��ꂾ�B������PPC���̂Ă���Ȃ��}�J�[���B
�@�@�@�@PWRficient�͊m���ɂ��Ȃ�䂩�����̂����邪
�@�@�@�@ES��700�h���A�]���L�b�g��8500�h��������悤�ȑ㕨����
�@�@�@�@�o�����ɂ͈����Ȃ�̂��H
�@�@======================
(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/797
�@�@----------------------
�@�@797 ���O�FMAC�I�^ ���e���F2008/01/16(��) 01:53:52 ID:1O/FEDl+
�@�@�@�@�v���Ԃ��PowerPC�̘b��������悤�ȋC�����邷���ǁANEC���X�g���[�W�V�X�e���̃R���g���[��
�@�@�@�@�Ƃ��āAP.A. Semi��PWRficient�`�b�v���̗p����Ƃ̂��Ƃ��B
�@�@�@�@http://www.pasemi.com/news/pr_2008_01_10.html
�@�@----------------------
http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/711
�@�@======================
�@�@711 ���O�F�E�́E�j��-������ ���e���F2007/04/28(�y) 03:36:20 ID://+RcVJg
�@�@�@�@�����Ƃ��ꂾ�B������PPC���̂Ă���Ȃ��}�J�[���B
�@�@�@�@PWRficient�͊m���ɂ��Ȃ�䂩�����̂����邪
�@�@�@�@ES��700�h���A�]���L�b�g��8500�h��������悤�ȑ㕨����
�@�@�@�@�o�����ɂ͈����Ȃ�̂��H
�@�@======================
������Ȃ����̈������荇���͂Ƃ������A�ҁ[���[���݂̘A����ARM�݊�������Ă���͕̂ł������悤�ȋC���B
ARM����炳��Ă���ƕ����Ă������肵���L��������B
������iphone��Power�ɂ��Ă����悩�����̂ɁB
ARM����炳��Ă���ƕ����Ă������肵���L��������B
������iphone��Power�ɂ��Ă����悩�����̂ɁB
682 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 20:02:28 ID:YebxnnTm
�m����m��Ȃ�������PA6T�œ����R�[�h���������Ƃ����邵�i�j
683 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 20:10:24 ID:YebxnnTm
�����Ƃ��{�ԈȊO��x86�z�X�g�ŃN���X�R���p�C������Ă����ǂ�
PA6T�͗ǂ������������C�e���V�E�X���[�v�b�g�̓�����7450��64�r�b�g�œI�Ȑ��\���B
PA6T�͗ǂ������������C�e���V�E�X���[�v�b�g�̓�����7450��64�r�b�g�œI�Ȑ��\���B
684 �FMAC�I�^��681 �����F2009/05/05(��) 20:24:17 ID:q7/3GqkF
>>681
ARM���n��������Apple�̌����������A�[�L�e�N�`���ł�����A�ߊς���K�v�͖����Ǝv���܂���B
http://www.ot1.com/arm/armchap1.html
�@�@----------------
�@�@A new company was set up with Apple, Acorn and VLSI Technology as founding partners.
�@�@The Acorn RISC Machine became the Advanced RISC Machine and Advanced RISC Machines
�@�@Ltd was born. Many of the original designers moved from Acorn to join the new company,
�@�@with others working in an advisory role. Additional expertise was provided by Apple and
�@�@new blood was recruited from around the world.
�@�@----------------
ARM���n��������Apple�̌����������A�[�L�e�N�`���ł�����A�ߊς���K�v�͖����Ǝv���܂���B
http://www.ot1.com/arm/armchap1.html
�@�@----------------
�@�@A new company was set up with Apple, Acorn and VLSI Technology as founding partners.
�@�@The Acorn RISC Machine became the Advanced RISC Machine and Advanced RISC Machines
�@�@Ltd was born. Many of the original designers moved from Acorn to join the new company,
�@�@with others working in an advisory role. Additional expertise was provided by Apple and
�@�@new blood was recruited from around the world.
�@�@----------------
685 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 20:25:37 ID:YebxnnTm
�C���������Ƃ��L���C�L���C
�n���w����̓����ӎ���������
�n���w����̓����ӎ���������
686 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 20:26:47 ID:YebxnnTm
�~�C��
������
������
��������C���\���j�A�b�N����
�X�p�C���E�U�E�h���S���V���[�Y��`�F�b�g�E�A���h�E�N�����N�V���[�Y
�̉�Ђ������H
�X�p�C���E�U�E�h���S���V���[�Y��`�F�b�g�E�A���h�E�N�����N�V���[�Y
�̉�Ђ������H
688 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 22:53:20 ID:YebxnnTm
Dobb's�̃T�C�g�̉�������̂܂��Intel���������Ƃ��č̗p���ꂽ�炵��
http://isdlibrary.intel-dispatch.com/isd/2494/drdobbs_042909_final.pdf
http://isdlibrary.intel-dispatch.com/isd/2494/drdobbs_042909_final.pdf
689 �FMAC�I�^���c�q �����F2009/05/05(��) 23:20:53 ID:q7/3GqkF
>>688
Abrash����Intel�Ј��Ȃ̂ŁA���Ԃ��t���ƁB
http://software.intel.com/en-us/articles/michael-abrash-biography/
Abrash����Intel�Ј��Ȃ̂ŁA���Ԃ��t���ƁB
http://software.intel.com/en-us/articles/michael-abrash-biography/
690 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 23:29:24 ID:YebxnnTm
drdobbs_042909_final.pdf
~~~~~~~~
��������B
�悭����ł����郂�m���B�p�̊T�O���Ȃ��́H
~~~~~~~~
��������B
�悭����ł����郂�m���B�p�̊T�O���Ȃ��́H
691 �FMAC�I�^���c�q �����F2009/05/05(��) 23:37:12 ID:q7/3GqkF
692 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 23:40:41 ID:YebxnnTm
������ȂH
�T�C�g�̓��e�ێʂ����Ƃ����Ă�̂��H
������ˁ[�Ȋw�����
�T�C�g�̓��e�ێʂ����Ƃ����Ă�̂��H
������ˁ[�Ȋw�����
693 �F,,�E�L�́M�E,,�j��-�������F2009/05/05(��) 23:46:18 ID:YebxnnTm
�܂�����������Ȃ̒p����������������ڂ炳���A�������蔽�Ȃ��Ă���
167 ���O�FMAC�I�^���c�q ����[sage] ���e���F2009/05/05(��) 19:21:28 ID:q7/3GqkF
>>166
�@�@------------------
�@�@�ጸ���ă}���`�X���b�h�����ĂȂ{�P
�@�@------------------
�C���I�[�_�[�ł��̂ŁA6�T�C�N���Ŏ��s�\�ȏ�����3�T�C�N���ɂȂ�A
2�X���b�h���s����OK�B
167 ���O�FMAC�I�^���c�q ����[sage] ���e���F2009/05/05(��) 19:21:28 ID:q7/3GqkF
>>166
�@�@------------------
�@�@�ጸ���ă}���`�X���b�h�����ĂȂ{�P
�@�@------------------
�C���I�[�_�[�ł��̂ŁA6�T�C�N���Ŏ��s�\�ȏ�����3�T�C�N���ɂȂ�A
2�X���b�h���s����OK�B
�ق�ƒ��ꋉ�̗g������肾��
695 �F,,�E�L�́M�E,,�j��-�������F2009/05/06(��) 00:01:31 ID:YebxnnTm
�Q�[��������̂�����
�Q�[��������̃A�N�Z�X���O�Ɉ���J���Ă�l������炵����
697 �F,,�E�L�́M�E,,�j��-�������F2009/05/06(��) 01:42:17 ID:YOaBKGUp
gatekeeper1.scei.jp�̃��O������Ă݂悤���ȂƎv����
���̑O���Ԏw��ŃA�N�Z�X���Ă��̂��ꂾ��B
�w��ǂ��肶��Ȃ���30���x�ꂽ��Ƃ����������ǂ�w
�������f�������H
�w��ǂ��肶��Ȃ���30���x�ꂽ��Ƃ����������ǂ�w
�������f�������H
699 �F,,�E�L�́M�E,,�j��-�������F2009/05/06(��) 02:38:44 ID:YOaBKGUp
�Q�n�ɃJ�L�R����X�N���v�g�d�������
700 �F,,�E�L�́M�E,,�j��-�������F2009/05/06(��) 02:57:04 ID:YOaBKGUp
�����A���Ȃ݂ɉR���B
���s�[�^�[�̗��K�ł�����*ntel.com�̂ق����������炢����
�iRSS���[�_�[�ɓo�^����Ă邩��X�V����x�ɏ��Ă���j
���s�[�^�[�̗��K�ł�����*ntel.com�̂ق����������炢����
�iRSS���[�_�[�ɓo�^����Ă邩��X�V����x�ɏ��Ă���j
701 �FSocket774�F2009/05/07(��) 01:40:08 ID:F2A2SuYO
�c�q����̓��ȊO�ɂ�������X�ˁE�E�E
702 �F,,�E�L�́M�E,,�j��-�������F2009/05/07(��) 23:07:31 ID:ZsasKbdo
scatter-prefetch�͂����[�ȁB�ő�16�̃L���b�V�����C�����o�b�N�O���E���h�ŃL���b�V����ɏW�߂邱�Ƃ��ł���B
��ŁA���܂���u���ꂭ�炢Cell��MFC DMA�ł��o����v���Č�������H
�킩���Ă˂��B�����킩���Ă˂��B
��ŁA���܂���u���ꂭ�炢Cell��MFC DMA�ł��o����v���Č�������H
�킩���Ă˂��B�����킩���Ă˂��B
703 �FSocket774�F2009/05/08(��) 02:18:34 ID:ytJHfmKx
�c�q����A�A�Z���u�����ɂ߂�����ł����A�������ЂȂ��ł����H
���͐ɂ��݂܂���
���͐ɂ��݂܂���
����ɂ��܂Ȃ��̂Ȃ�{�I�̒[����[�܂Ŕ����������
705 �FSocket774�F2009/05/08(��) 14:01:48 ID:ytJHfmKx
>>704
�ɂ��܂Ȃ����A�{���������������Ă��₠��Ⴕ��
�ɂ��܂Ȃ����A�{���������������Ă��₠��Ⴕ��
�@4004
707 �F,,�E�L�́M�E,,�j��-�������F2009/05/08(��) 20:19:59 ID:YH3MesOq
�eCPU�x���_���o���Ă�}�j���A���ȏ�̂��̂͂Ȃ��B
709 �F,,�E�L�́M�E,,�j��-�������F2009/05/09(�y) 23:14:20 ID:KAZA9i0l
���Ȃ݂Ƀl�M�U��V�~�����[�V�����Ńj�R�j�R�Z�p���f�r���[�l���Ă���
�c�q����̓X�L���͑��h�ł�����ǐl�i�ɓ�肾�Ǝv���B
>>710
�l�b�g�ƃ��A���͈Ⴄ�Ǝv���܂�
�l�b�g�ƃ��A���͈Ⴄ�Ǝv���܂�
712 �F,,�E�L�́M�E,,�j��-�������F2009/05/10(��) 01:01:20 ID:3H2ak24n
�������߂�̂ɔS�����ł��邱�Ƃ͑�O��ł���B
>>712
���̒ʂ�
���j�����̐l�ɂ��l�i�ɓ�L��̔S����������
�n���ƓV�ˎ���d�Ȃ̂�
���r���[�͂�����
��l�ϐl���ɂ߂�Ƃ���
���̒ʂ�
���j�����̐l�ɂ��l�i�ɓ�L��̔S����������
�n���ƓV�ˎ���d�Ȃ̂�
���r���[�͂�����
��l�ϐl���ɂ߂�Ƃ���
�����B���łɁA���̖������͉��ł��V�������̂͑S���ے肷��̂����R�Ǝv���Ă邪�A
���ꂶ�႟���҂ɂ͂Ȃ��B
�V�������̂����������莸�s����m���̂ق�����������A�O��Œ��߂Ă��邾���Ȃ�
�Ƃ肠�����S���ے肵�Ă�ق����C���͖�������邱�Ƃ��������A���ꂾ�����B
���ꂶ�႟���҂ɂ͂Ȃ��B
�V�������̂����������莸�s����m���̂ق�����������A�O��Œ��߂Ă��邾���Ȃ�
�Ƃ肠�����S���ے肵�Ă�ق����C���͖�������邱�Ƃ��������A���ꂾ�����B
�~ �S���ے�
�� �قƂ�ǔے�
�� �قƂ�ǔے�
��ʐl�ƈ̐l�̊ԂŐ��i�ɓ�̂��銄���ɍ��͂���̂��H
�ꏏ�Ɏd������Ȃ��l�ł��L�\�Ȃ�Ȃ�Ƃ����邪�v���C�x�[�g�͉�������B
�d����2ch���ɗ��Ă�킯�ł͂Ȃ����琫�i�j�]�R�e��NG�o�^
�d����2ch���ɗ��Ă�킯�ł͂Ȃ����琫�i�j�]�R�e��NG�o�^
�Ƃ�����Larrabee���Ċ�l�ϐl�ɉ䖝���Ȃ���Ȃ�Ȃ��قNJv�V�I��?
�܂�x86����Ƃ����v���̂����c
�܂�x86����Ƃ����v���̂����c
719 �F,,�E�L�́M�E,,�j��-�������F2009/05/10(��) 03:35:40 ID:3H2ak24n
P54C�Ƀ��C�hSIMD��������������R�A�P�ʂŌ���Ή��̐�i�����Ȃ��ȁB
���U���L�L���b�V��������NUMA�݂����Ȃ���
�܂��A�ėp�R���s���[�e�B���O�p�r�Ȃǔ��o���ӎ����č���ĂȂ��s�N�Z���V�F�[�f�B���O��
���������n�[�h�ŁA���{�I�Ɍ����ĂȂ����𐔂̖\�͂ɔC���ĉ������́A
�Z�p�̒~�ς̂���x86�̂ق����}�V�Ƃ͂����郌�x���ł͂���B
Larrabee���̂��̂��A�ėpCPU�Ƃ��Ă͐V����GPGPU�ɑ���A���`�e�[�[����B
x86�ł��X�g���[���ESIMD������������܂łł���I�ȁB
CPU���猩���ꡂ��ɑ����̃X���b�h�������ɓ������j�[�R�A�Ő�i�I��������Ȃ���
GPGPU�����猩��A���X�N������Č����ȃ\�����[�V������p�ӂ��Ă����������ȁB
���U���L�L���b�V��������NUMA�݂����Ȃ���
�܂��A�ėp�R���s���[�e�B���O�p�r�Ȃǔ��o���ӎ����č���ĂȂ��s�N�Z���V�F�[�f�B���O��
���������n�[�h�ŁA���{�I�Ɍ����ĂȂ����𐔂̖\�͂ɔC���ĉ������́A
�Z�p�̒~�ς̂���x86�̂ق����}�V�Ƃ͂����郌�x���ł͂���B
Larrabee���̂��̂��A�ėpCPU�Ƃ��Ă͐V����GPGPU�ɑ���A���`�e�[�[����B
x86�ł��X�g���[���ESIMD������������܂łł���I�ȁB
CPU���猩���ꡂ��ɑ����̃X���b�h�������ɓ������j�[�R�A�Ő�i�I��������Ȃ���
GPGPU�����猩��A���X�N������Č����ȃ\�����[�V������p�ӂ��Ă����������ȁB
����ȋ����������ɁA
���Z�p�̒~�ς̂���x86�̂ق����}�V�Ƃ͂����郌�x���ł͂���B
���̒��x�����A�h�o���e�[�W���Ȃ���ȁB
���������̐��̖\�͂��疞���Ɏg���Ȃ����b�`�R�A�d�l�ȏ�ɁA
���̑��吨�̃v���O���}�����g�킸�Ɏg����悤�ɂȂ���̍\�z�ɁA
���ꂩ��X�ɂǂꂾ�����z�����ނ����m���Ƃ����B
���Ȃ��Ƃ�����ȕ��̗i��ɓO��Ȃ������Ȃ���
���Z�p�̒~�ς̂���x86�̂ق����}�V�Ƃ͂����郌�x���ł͂���B
���̒��x�����A�h�o���e�[�W���Ȃ���ȁB
���������̐��̖\�͂��疞���Ɏg���Ȃ����b�`�R�A�d�l�ȏ�ɁA
���̑��吨�̃v���O���}�����g�킸�Ɏg����悤�ɂȂ���̍\�z�ɁA
���ꂩ��X�ɂǂꂾ�����z�����ނ����m���Ƃ����B
���Ȃ��Ƃ�����ȕ��̗i��ɓO��Ȃ������Ȃ���
>���Z�p�̒~�ς̂���x86�̂ق����}�V�Ƃ͂����郌�x���ł͂���B
>���̒��x�����A�h�o���e�[�W���Ȃ���ȁB
"�Z�p�̒~�ς̂���x86�̂ق����}�V"�Ƃ����͈̂��̃��g���b�N���낤
���̂܂����"���̒��x�����A�h�o���e�[�W���Ȃ�"�ƌ����̂͏�����������
Itanium�̎��s��ARM�l�b�g�u�b�N������ɗ��s��Ȃ����������x86�̎x�z�͂��킩��
>���̒��x�����A�h�o���e�[�W���Ȃ���ȁB
"�Z�p�̒~�ς̂���x86�̂ق����}�V"�Ƃ����͈̂��̃��g���b�N���낤
���̂܂����"���̒��x�����A�h�o���e�[�W���Ȃ�"�ƌ����̂͏�����������
Itanium�̎��s��ARM�l�b�g�u�b�N������ɗ��s��Ȃ����������x86�̎x�z�͂��킩��
Tim Sweeny���͑��^���Ă���܂�
DX11�����GPU���ǂ��Ȃ�̂��݂Ă݂Ȃ��ƁA�Ȃ�Ƃ������Ȃ�
nvidia�͂܂��啝�ɉ��҂���݂�������
ATI��R800����͊����H���ۂ����A�Ȃ�ƂȂ����̎��������larrabee�݊��ɑ��肻��
S3�͓ǂ߂Ȃ��ȁE�Echrome400/500��shader�͗D�G�Ȃ��A�����[�G���h����
�}���`GPU�Ƃ��ɂ���Ώ���o������������
�����AGPGPU�ɂ��Ă͈ꉞ�̃��W���[�K�iDXCS,OpenCL���o�����̂�
�ŏ�����Q�[���s��_���ĂȂ�S3�́A���邢�͑�����������ɕΌ��������K��GPU�Ƃ��邩��
nvidia�͂܂��啝�ɉ��҂���݂�������
ATI��R800����͊����H���ۂ����A�Ȃ�ƂȂ����̎��������larrabee�݊��ɑ��肻��
S3�͓ǂ߂Ȃ��ȁE�Echrome400/500��shader�͗D�G�Ȃ��A�����[�G���h����
�}���`GPU�Ƃ��ɂ���Ώ���o������������
�����AGPGPU�ɂ��Ă͈ꉞ�̃��W���[�K�iDXCS,OpenCL���o�����̂�
�ŏ�����Q�[���s��_���ĂȂ�S3�́A���邢�͑�����������ɕΌ��������K��GPU�Ƃ��邩��
>�d����2ch���ɗ��Ă�킯�ł͂Ȃ����琫�i�j�]�R�e��NG�o�^
�ŋ߂��̎�̏������ݗ��s���Ă�ȁB
�����A�c�q���X����݂����Ȃ��̃X���ł킴�킴
��{�N�����NG�o�^�����Ⴄ����ˁ`�
���Ȃ��Ⴂ���Ȃ��قǁA�c�q�ɐl���U���Ă���̂�?
NG�o�^�͖ق��Ă�����̂��B��������NG�o�^�Ȃ��
�R�e�ɂ��Ă݂��ǂ��ł������Ƃ������Ƃ���ǂ��ł��������炢��
�ǂ��ł������b�Ȃ��B
�ŋ߂��̎�̏������ݗ��s���Ă�ȁB
�����A�c�q���X����݂����Ȃ��̃X���ł킴�킴
��{�N�����NG�o�^�����Ⴄ����ˁ`�
���Ȃ��Ⴂ���Ȃ��قǁA�c�q�ɐl���U���Ă���̂�?
NG�o�^�͖ق��Ă�����̂��B��������NG�o�^�Ȃ��
�R�e�ɂ��Ă݂��ǂ��ł������Ƃ������Ƃ���ǂ��ł��������炢��
�ǂ��ł������b�Ȃ��B
>>724
������NG�o�^�ɉߏ蔽������̂����s���Ă�A�Ƃ�
������NG�o�^�ɉߏ蔽������̂����s���Ă�A�Ƃ�
��������������������������B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
�l�I�ɂ͐�p�u���E�U��NG�o�^�@�\�Ȃ�Đ��_�I�ɕs��p�Ȃ��q�l���g���@�\���Ǝv���Ă���B
�܂��Ă⋻�����Ȃ��A�C�ɐG������t�B���^���邽�߂̋@�\�ł���NG�o�^���s�����Ƃ���
���킴�킴�������݂��Ēm�点��Ȃ�Ă݂ĂĒp�������������߂Ă�����ẮB
���������������݂���Ԗ��ʂ��B�{�l�̔\�͂̒Ⴓ���e�Ղɑz���ł���B
�ȏ�A�ǎ҂̈ӌ��ł��B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
�l�I�ɂ͐�p�u���E�U��NG�o�^�@�\�Ȃ�Đ��_�I�ɕs��p�Ȃ��q�l���g���@�\���Ǝv���Ă���B
�܂��Ă⋻�����Ȃ��A�C�ɐG������t�B���^���邽�߂̋@�\�ł���NG�o�^���s�����Ƃ���
���킴�킴�������݂��Ēm�点��Ȃ�Ă݂ĂĒp�������������߂Ă�����ẮB
���������������݂���Ԗ��ʂ��B�{�l�̔\�͂̒Ⴓ���e�Ղɑz���ł���B
�ȏ�A�ǎ҂̈ӌ��ł��B
>>726
�e���u�[��������
�e���u�[��������
�N������Ȃ����Ƃ���ʂɐ������Ă���Ă���̂��B
��\����B�͂��肪�����v���Ȃ����B
�����f���͌l�̂��̂���Ȃ�����B�t�B���^��Ȃ��
�����͔n���ł��A�ƕ������݂��Ă���̂Ƃقړ��`�ł��B
��\����B�͂��肪�����v���Ȃ����B
�����f���͌l�̂��̂���Ȃ�����B�t�B���^��Ȃ��
�����͔n���ł��A�ƕ������݂��Ă���̂Ƃقړ��`�ł��B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
�����f���Ŏ����ɂƂ��Ă̋����̂Ȃ��b���
���R�ƃX���[�ł��Ȃ���͂������������f���Ɍ����ĂȂ��B
��������������
�v���Ԃ�Ɍ����ȃu�[��������������
>>720
���ǂꂾ�����z�����ނ�
���̌������ƓI�Ȑ��i�̂��̂��Ǝv������ǂ����낤���B
���E3��o�J�ƌ�����G�W�v�g�̃s���~�b�h���A���͔_�Պ��ɂ��̑��吨��
�d����^���ĐH�킹�邽�߂̌������Ƃ������Ƃ����������邭�炢����
���ǂꂾ�����z�����ނ�
���̌������ƓI�Ȑ��i�̂��̂��Ǝv������ǂ����낤���B
���E3��o�J�ƌ�����G�W�v�g�̃s���~�b�h���A���͔_�Պ��ɂ��̑��吨��
�d����^���ĐH�킹�邽�߂̌������Ƃ������Ƃ����������邭�炢����
732 �F,,�E�L�́M�E,,�j��-�������F2009/05/10(��) 13:02:46 ID:3H2ak24n
�M���X������
>>731
����Ȃ��Ƃ��Ȃ��Ă��f�X�}�͂��낲��]�����Ă��!
����Ȃ��Ƃ��Ȃ��Ă��f�X�}�͂��낲��]�����Ă��!
734 �F,,�E�L�́M�E,,�j��-�������F2009/05/10(��) 13:07:45 ID:3H2ak24n
>>720
> ���������̐��̖\�͂��疞���Ɏg���Ȃ����b�`�R�A�d�l�ȏ��
�uP54C�x�[�X�v���Ƃ������b�`�R�A���Č������Ⴄ�N�Ɋ��t�B
�O���o�X�R���g���[�����݂ł���Ȑ�������B
�܂�L2�L���b�V�����I�t�_�C�̎���Ȃ�ł��܂�Q�l�ɂȂ�Ȃ������m��Ȃ���
Pentium (P54C) : 330��
Pentium MMX (P55C) : 450��
�ǂ������R�A�̐����������Ă��邩�͒m��Ȃ����ASIMD��1�G�������g��1SP�Ƃ���GeForce�����̐���������
1�R�A��16SP�A48�R�A�Ȃ�768SP�������ˁB
> ���������̐��̖\�͂��疞���Ɏg���Ȃ����b�`�R�A�d�l�ȏ��
�uP54C�x�[�X�v���Ƃ������b�`�R�A���Č������Ⴄ�N�Ɋ��t�B
�O���o�X�R���g���[�����݂ł���Ȑ�������B
�܂�L2�L���b�V�����I�t�_�C�̎���Ȃ�ł��܂�Q�l�ɂȂ�Ȃ������m��Ȃ���
Pentium (P54C) : 330��
Pentium MMX (P55C) : 450��
�ǂ������R�A�̐����������Ă��邩�͒m��Ȃ����ASIMD��1�G�������g��1SP�Ƃ���GeForce�����̐���������
1�R�A��16SP�A48�R�A�Ȃ�768SP�������ˁB
���̖\�͂Ƃ͂܂���ATI
ttp://www.youtube.com/watch?v=pmBd9HQgTCQ
320SP��32SP�ɕ�������Ă����ƒN���M���Ȃ�����
���ە������ȁE�E
DX11����ł�����Ƃ͉��P���Ăق���
ttp://www.youtube.com/watch?v=pmBd9HQgTCQ
320SP��32SP�ɕ�������Ă����ƒN���M���Ȃ�����
���ە������ȁE�E
DX11����ł�����Ƃ͉��P���Ăق���
>>735
����A����\�͂ɂȂ��ĂȂ����炗
����A����\�͂ɂȂ��ĂȂ����炗
Larrabee�͂�����H
>�܂��A�ėp�R���s���[�e�B���O�p�r�Ȃǔ��o���ӎ����č���ĂȂ��s�N�Z���V�F�[�f�B���O��
>���������n�[�h�ŁA���{�I�Ɍ����ĂȂ����𐔂̖\�͂ɔC���ĉ������́A
�����̈��������A���𑝂₵�Č떂�����Ă�킯������
�܂�nvidia��9600GT(312gflops)������ł�
PPU(58gflops)�Ɠ���������Ȃ�physx��
>���������n�[�h�ŁA���{�I�Ɍ����ĂȂ����𐔂̖\�͂ɔC���ĉ������́A
�����̈��������A���𑝂₵�Č떂�����Ă�킯������
�܂�nvidia��9600GT(312gflops)������ł�
PPU(58gflops)�Ɠ���������Ȃ�physx��
���o����
ttp://isdlibrary.intel-dispatch.com/vc/2527/GamePhysicsOnLarrabee_paper.pdf
Game Physics
Performance on the
Larrabee Architecture
�ŏI�y�[�W�ɃX�P�[���r���e�B�[�ɂ��ď�����Ă邯��
(1GHz��0�`64core)�V�~�����[�V�����H
ttp://isdlibrary.intel-dispatch.com/vc/2527/GamePhysicsOnLarrabee_paper.pdf
Game Physics
Performance on the
Larrabee Architecture
�ŏI�y�[�W�ɃX�P�[���r���e�B�[�ɂ��ď�����Ă邯��
(1GHz��0�`64core)�V�~�����[�V�����H
740 �FSocket774�F2009/05/12(��) 21:49:14 ID:/EKUulqE
���āA���R�A���낤
ttp://www.pcgameshardware.com/aid,683947/Detailed-Larrabee-Die-shot-shown-by-Intel/News/
ttp://www.pcgameshardware.com/?menu=browser&article_id=683947&image_id=1127811
Detailed Larrabee Die shot shown by Intel
ttp://www.pcgameshardware.com/aid,683947/Detailed-Larrabee-Die-shot-shown-by-Intel/News/
ttp://www.pcgameshardware.com/?menu=browser&article_id=683947&image_id=1127811
Detailed Larrabee Die shot shown by Intel
48�R�A���ۂ�
������CPU�̃X���ɐ������̂��L�邯��32�R�A����
���Z���j�b�g�ȊO�̕������w�ǖ������Ă̂��s�v�c�Ȋ����������
���Z���j�b�g�ȊO�̕������w�ǖ������Ă̂��s�v�c�Ȋ����������
ATI�̓����O�o�X��߂���ʐϐߖ�ł������Č����ĂȂ���������
744 �F,,�E�L�́M�E,,�j��-�������F2009/05/12(��) 22:23:53 ID:f3YpA0AB
�R�A�̃��C�A�E�g��Atom�Ɏ��Ă����
745 �F,,�E�L�́M�E,,�j��-�������F2009/05/12(��) 22:28:10 ID:f3YpA0AB
�ǂ��݂Ă��R�A����ʂɍڂ���CPU�ł��B�{���ɂ��肪�Ƃ��������܂����B
beyond3d�����texture���낤���ǁA�͂Ȃ��ق�����
ttp://i41.tinypic.com/2hcdzja.png
ttp://i41.tinypic.com/2hcdzja.png
{kind=link}
747 �F,,�E�L�́M�E,,�j��-�������F2009/05/12(��) 22:41:05 ID:f3YpA0AB
xring�C���^�[�t�F�C�X���ȁH
748 �F,,�E�L�́M�E,,�j��-�������F2009/05/12(��) 22:44:52 ID:f3YpA0AB
�d���Ǘ����j�b�g����
���������
�_�C�T�C�Y�ǂꂭ�炢������H
751 �F,,�E�L�́M�E,,�j��-�������F2009/05/13(��) 01:23:58 ID:H+3wBFF6
�������E�E�E�傫���ł�
�c�q�̂��̐F���ĂȂ�ł��낱��ς���
���܂ɂ��т�Ƃ��H��
ttp://www.hardware-infos.com/news.php?news=2944&sprache=1
GT300�͈ꉞ40nm��490mm2�ȉ��Ƃ̉\�Ȃ��
larrabee��45nm�Ŋ��Ȃ̂��˂�beyond3d��900mm2?�Ƃ��\���Ă邪
GT300�͈ꉞ40nm��490mm2�ȉ��Ƃ̉\�Ȃ��
larrabee��45nm�Ŋ��Ȃ̂��˂�beyond3d��900mm2?�Ƃ��\���Ă邪
45nm��900mm2���Ƃ�����A����20���`30���~�R�[�X�A32nm����ł�10��������Ƃ�
�����Ȃ肻���ȋC�������I�ɂ��邯�ǁA�ǂ����낤�B
�����Ȃ肻���ȋC�������I�ɂ��邯�ǁA�ǂ����낤�B
IDF�ŏo��Larrabee�̃E�G�n���A�����32�H�R�A�̂�̃E�G�n�Ȃ�A
600�`700����mm���炢�ɂȂ��Ȃ����ȁB
600�`700����mm���炢�ɂȂ��Ȃ����ȁB
�Ȃ�Itanium�v���o���ȁc
900mm2�Ƃ������V���b�g�ŘI���o����̂��H
�㉺�̃������p�b�h�H����bit������̂���
�㉺�̃������p�b�h�H����bit������̂���
�Ȃ�ł���ȂɃ_�C���ł������
�������������˂�
�������������˂�
1TFLOPS����̂ɕK���Ȃ�ł���
1tflops�Ƃ����Ă�ATI��RV770�̂悤�ȕ�������ɗ�����
16�R�A2GHz��1TFlops������A32�R�A2GHz��2TFlops�̉\���������Ȃ����ȁB
�{���̂���Larrabee�l�^
ttp://dango.chu.jp/tripper/20090513.html
ttp://dango.chu.jp/tripper/20090513.html
764 �F,,�E�L�́M�E,,�j��-�������F2009/05/13(��) 21:42:35 ID:H+3wBFF6
900�Ȃ�48�R�A�Ő��\�_���g�c����
>>758
�X�e�b�p�̍ő傪21*21mm���炢�������C�����邩�疳������ˁH
�X�e�b�p�̍ő傪21*21mm���炢�������C�����邩�疳������ˁH
900�o2��48�R�A����16�R�A�ł�300�o2�������Ⴄ�����
���ꂾ��GPU�Ƃ��Ă̐��\�͎S�����ƂɂȂ邪�E�E�E
���ꂾ��GPU�Ƃ��Ă̐��\�͎S�����ƂɂȂ邪�E�E�E
���������̃����r�łP�U�R�A����܂��ȁB
�A�C�i�����Ę_���W�R�A�Ȃ��A��S�W�R�A�͂ق����B
�A�C�i�����Ę_���W�R�A�Ȃ��A��S�W�R�A�͂ق����B
�Ƃ�����900�o2�Ƃ����ĕ������ゾ�ƁA>>740�̎ʐ^�ŃR�A���Ƃɂ��鍕���ۂ������������ɂ�L2���ۂ������Ă������E�E�E
���̕�����256KB�̃L���b�V�����Ƃ���ƁA�䗦�I�ɃR�A1���Ƃ̃T�C�Y�ł����ˁH
���̕�����256KB�̃L���b�V�����Ƃ���ƁA�䗦�I�ɃR�A1���Ƃ̃T�C�Y�ł����ˁH
80486�x�[�X�ɂ���Ƃ���قnj������̂ɂ���
900�̓K�Z�����炗
���ۂ�600��
���ۂ�600��
600���P�Ȃ�\�ɉ߂����
772 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 06:44:30 ID:iuYvon+w
larrabee�����������Ɍ����Ȃ�������
ati�̂��ˑ��W�̖���shader���قƂ�ǎ��̂Ɠ�����
larrabee��soa���Ɩ��ʂ��������낤��
aos�ł�1/4�͎���
ati�̂��ˑ��W�̖���shader���قƂ�ǎ��̂Ɠ�����
larrabee��soa���Ɩ��ʂ��������낤��
aos�ł�1/4�͎���
�����������Ⴂ�܂����B
1���߂�AoS�ESoA�I�č\������Gather���߂�����Ă܂����B
�M���U�[�A�h���X���o�b�N�O���E���h�Ńv���t�F�b�`���閽�߂�������B
���̂������Tom Forsyth�̍u�������ɂ��ڂ��Ă���B�ǂ�łȂ��̂��H
�ނ���Radeon�̎�_��1���߃f�R�[�_�ɑ��ĉ��Z���j�b�g�����\���q�����Ă���ꐫ�ɂ���B
�I���R�A�̃��[�N�����������Ȃ��̂����_�B
1���߂�AoS�ESoA�I�č\������Gather���߂�����Ă܂����B
�M���U�[�A�h���X���o�b�N�O���E���h�Ńv���t�F�b�`���閽�߂�������B
���̂������Tom Forsyth�̍u�������ɂ��ڂ��Ă���B�ǂ�łȂ��̂��H
�ނ���Radeon�̎�_��1���߃f�R�[�_�ɑ��ĉ��Z���j�b�g�����\���q�����Ă���ꐫ�ɂ���B
�I���R�A�̃��[�N�����������Ȃ��̂����_�B
larrabee�̃p�C�v���C�����ĉ��i�H
Intel�̓��W�X�^�ԍ��݂����ȁu�������W�b�N�Ɂi�����I�Ɂj�e�����ł����Ȃ��́v���A
OP�̌��̂ق��ɒu���̂͋ɒ[�Ɍ������Ȃ��̂��ȁB�������ϑz�����ǁB
OP�̌��̂ق��ɒu���̂͋ɒ[�Ɍ������Ȃ��̂��ȁB�������ϑz�����ǁB
������512MIMD�炵���AGT300��
�����̃x�N�g���v���Z�b�T���������������ƂŊe�w�c�`�����X�������Ă����
�Â����������Ȃ�������Larrabee�̃p�C�v���C���̒i����Pentium�Ɠ�LV���Ď������E�E�E
6�i�`8�i����N���b�N��1Ghz�{���܂ł����オ��Ȃ���Ȃ����H
6�i�`8�i����N���b�N��1Ghz�{���܂ł����オ��Ȃ���Ȃ����H
780 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 21:12:05 ID:iuYvon+w
Atom���Z���͂Ȃ�Ƃ͌����Ă���8�i���Ƃ��ōςނ킯���Ȃ�����B
Larrabee��P5�݂����ɑ�܂��Ɍ�����SIMD���߂ƃX�J�����߂����݂ɕ��ׂȂ��ƃX�s�[�h���o�Ȃ��B
�p�C�v���C���̔�Ώ̐���P5��U/V�p�C�v���C�����C�N�Ȃ����B
P5�̃p�C�v���C���\�����̂��̂Ȃ킯���Ȃ��B
Atom��2�̃V���v���f�R�[�_�͑Ώ̂ŁA�f�R�[�h�������߂����������̃L���[�ɗ��߂�
�܂��X�ɉ��Z���j�b�g��U�蕪����B
�Ȃɂ��4Way��FGMT�Ȃ�Ńp�C�v���C�������邱�Ƃł̃y�i���e�B�����܂薳���B
Larrabee��P5�݂����ɑ�܂��Ɍ�����SIMD���߂ƃX�J�����߂����݂ɕ��ׂȂ��ƃX�s�[�h���o�Ȃ��B
�p�C�v���C���̔�Ώ̐���P5��U/V�p�C�v���C�����C�N�Ȃ����B
P5�̃p�C�v���C���\�����̂��̂Ȃ킯���Ȃ��B
Atom��2�̃V���v���f�R�[�_�͑Ώ̂ŁA�f�R�[�h�������߂����������̃L���[�ɗ��߂�
�܂��X�ɉ��Z���j�b�g��U�蕪����B
�Ȃɂ��4Way��FGMT�Ȃ�Ńp�C�v���C�������邱�Ƃł̃y�i���e�B�����܂薳���B
781 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 21:14:38 ID:iuYvon+w
���܂�㔼���Ӗ��s�����������ȁH
Atom���Z���Ȃ�K�R���ƁA10�i���邱�Ƃł̐��\�ւ̉e���ȁB
Atom��18�i��Core MA��葽���B
Atom���Z���Ȃ�K�R���ƁA10�i���邱�Ƃł̐��\�ւ̉e���ȁB
Atom��18�i��Core MA��葽���B
���₢��i����������Ȃ�ǂ����ǂ�
http://plusd.itmedia.co.jp/pcuser/articles/0808/05/news072.html
���p�C�v���C���̒i���ɂ��Ă��APentium�Ɠ��l�̃V���[�g�p�C�v���C�����ƃC���e���͐������Ă���B
���̂Ƃ��ł���̎����悤�Ȃ��Ƃ�������Ă邩��s�v�c�Ɏv���Ă�
����������ƁA��ԏ������Ԃ̒�������SIMD�G���W����1�N���b�N���삳����̂ɕK�v�Ȏ��Ԃ���ɍs���������
���̕�����7�i�Ƃ��ł��ǂ��Ƃ������ƂɎ��Ȃ̂��E�E�E�Ƃ��v���Ă�
http://plusd.itmedia.co.jp/pcuser/articles/0808/05/news072.html
���p�C�v���C���̒i���ɂ��Ă��APentium�Ɠ��l�̃V���[�g�p�C�v���C�����ƃC���e���͐������Ă���B
���̂Ƃ��ł���̎����悤�Ȃ��Ƃ�������Ă邩��s�v�c�Ɏv���Ă�
����������ƁA��ԏ������Ԃ̒�������SIMD�G���W����1�N���b�N���삳����̂ɕK�v�Ȏ��Ԃ���ɍs���������
���̕�����7�i�Ƃ��ł��ǂ��Ƃ������ƂɎ��Ȃ̂��E�E�E�Ƃ��v���Ă�
783 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 22:07:51 ID:iuYvon+w
�V���[�g���Ă֑̂͌�\�����B10�i�͗]�T�Œ�����̂͊m��I�ɖ��炩�B
P54C���Ă��A���߂̃v���t�B�N�X�E�G�X�P�[�v�o�C�g��1�o�C�g�������1�N���b�N�X�g�[�����Ă����B
1�o�C�gOpcode�̖��߂���2������s�ł��Ȃ��B
P55C��2�o�C�gOpcode�i0F xx /r�j�Ƃ����X�g�[���Ȃ��Ŏ��s�ł���悤�ɂȂ������A�i����1�i�������B
��ŁA�����ł���64�r�b�g�Ƃ��Ή����邾��HREX��͂��Ȃ���Ȃ�Ȃ��B
�X�ɁALarrabee�̐��\�̊̂ƂȂ�SIMD���߂͂�����X�ɒ������߂������B
�������p�C�v���C���n�U�[�h�Ȃ��ɉ�͂��Ȃ��Ⴂ���Ȃ����B
P54C�̃p�C�v���C�����̂܂�g����킯�ˁ[�����B
P54C���Ă��A���߂̃v���t�B�N�X�E�G�X�P�[�v�o�C�g��1�o�C�g�������1�N���b�N�X�g�[�����Ă����B
1�o�C�gOpcode�̖��߂���2������s�ł��Ȃ��B
P55C��2�o�C�gOpcode�i0F xx /r�j�Ƃ����X�g�[���Ȃ��Ŏ��s�ł���悤�ɂȂ������A�i����1�i�������B
��ŁA�����ł���64�r�b�g�Ƃ��Ή����邾��HREX��͂��Ȃ���Ȃ�Ȃ��B
�X�ɁALarrabee�̐��\�̊̂ƂȂ�SIMD���߂͂�����X�ɒ������߂������B
�������p�C�v���C���n�U�[�h�Ȃ��ɉ�͂��Ȃ��Ⴂ���Ȃ����B
P54C�̃p�C�v���C�����̂܂�g����킯�ˁ[�����B
784 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 22:09:26 ID:iuYvon+w
4Way�}���`�X���b�f�B���O������n�U�[�h�p�X�����ΓI�ɏ�������������ĈӖ����Ƃ�����
20�i���炢���邩����
20�i���炢���邩����
�s����Pentium��葽���͕̂�������
�ł��p�C�v���C���e�i�̏��v���Ԃ͈Ⴄ�ł���
�����i�͕������Ă��܂���1�i������̏��v���Ԃ͌��邩��N���b�N���グ����
�ł������ł��Ȃ��i�����邩��A�ŏI�I�ɂ͂������l�b�N�ɂȂ���
�Ⴆ��A-B-C-D�̍s��4�i���ꂼ��̏��v���Ԃ�1-2-8-4���Ƃ���
���̏ꍇC���{�g���l�b�N�ɂȂ邩��AC��C1��5�AC2��3��2�i�ɕ���
A-B-C1-C2-D��5�i�ɂ���A�e�i�̏��v���Ԃ�1-2-5-3-4�ƂȂ��āA�{�g���l�b�N�̏��v���Ԃ�5�ɂȂ�
����Ȃ�N���b�N��8/5��1.6�{�ɏグ����
�ł��AC�������ł��Ȃ��s����������E�E�E
�t��A��B�͂܂Ƃ߂Ă��܂��āAAB-C-D��3�i�ɂ��āA�e�i�̏��v���Ԃ�3-8-4�Ƃł���
���ꂾ�ƃN���b�N�͏オ��Ȃ����A�o�Ă���܂łɕK�v�ȃN���b�N����1���邵�A��������Ƃ��̃y�i���e�B�[������
Larrabee�ł��ASIMD�̕����̏��v���Ԃ�����Ȃ�A���̍s�������Ēi�������点���Ȃ��H
�ł��p�C�v���C���e�i�̏��v���Ԃ͈Ⴄ�ł���
�����i�͕������Ă��܂���1�i������̏��v���Ԃ͌��邩��N���b�N���グ����
�ł������ł��Ȃ��i�����邩��A�ŏI�I�ɂ͂������l�b�N�ɂȂ���
�Ⴆ��A-B-C-D�̍s��4�i���ꂼ��̏��v���Ԃ�1-2-8-4���Ƃ���
���̏ꍇC���{�g���l�b�N�ɂȂ邩��AC��C1��5�AC2��3��2�i�ɕ���
A-B-C1-C2-D��5�i�ɂ���A�e�i�̏��v���Ԃ�1-2-5-3-4�ƂȂ��āA�{�g���l�b�N�̏��v���Ԃ�5�ɂȂ�
����Ȃ�N���b�N��8/5��1.6�{�ɏグ����
�ł��AC�������ł��Ȃ��s����������E�E�E
�t��A��B�͂܂Ƃ߂Ă��܂��āAAB-C-D��3�i�ɂ��āA�e�i�̏��v���Ԃ�3-8-4�Ƃł���
���ꂾ�ƃN���b�N�͏オ��Ȃ����A�o�Ă���܂łɕK�v�ȃN���b�N����1���邵�A��������Ƃ��̃y�i���e�B�[������
Larrabee�ł��ASIMD�̕����̏��v���Ԃ�����Ȃ�A���̍s�������Ēi�������点���Ȃ��H
786 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 22:29:52 ID:iuYvon+w
���C�e���V�����炷���z�������C������B
�u4Way�̃}���`�X���b�f�B���O�Ȃ烌�C�e���V8�̖��߂�2�Ɍ�����v�Ƃ�
Forsyth��GDC�Ō����Ă�킯�Ȃ�
�t�Ɍ����ƁA�����������߂�������Ă��ƂȂ킯���ȁB
�u4Way�̃}���`�X���b�f�B���O�Ȃ烌�C�e���V8�̖��߂�2�Ɍ�����v�Ƃ�
Forsyth��GDC�Ō����Ă�킯�Ȃ�
�t�Ɍ����ƁA�����������߂�������Ă��ƂȂ킯���ȁB
787 �F,,�E�L�́M�E,,�j��-�������F2009/05/14(��) 22:33:13 ID:iuYvon+w
���C�e���V��8�Ƃ������Ă鎞�_��Execute���������ł��ꑊ���̒i���͂��邱�ƂɂȂ�B
Intel�̏ꍇ�A�p�C�v���C���i���̂��Ƃ������Ƃ��͊�{�I�Ƀn�U�[�h�p�X�Ȃ��
���������Ȃǂ̉��Z�H�����������߂͒i���ɓ���ĂȂ����Ƃ������̂����B
Intel�̏ꍇ�A�p�C�v���C���i���̂��Ƃ������Ƃ��͊�{�I�Ƀn�U�[�h�p�X�Ȃ��
���������Ȃǂ̉��Z�H�����������߂͒i���ɓ���ĂȂ����Ƃ������̂����B
Cell ���X�^���C�Y
http://journal.mycom.co.jp/articles/2006/09/14/cedec3/images/cedec_raster.wmv
Cell ���C�g���[�V���O
http://journal.mycom.co.jp/articles/2006/09/14/cedec3/images/cedec_raytrace.wmv
���ׁ[�͂������Y��ȉf�������ł���ˁH
����[���҂��Ă܂�
http://journal.mycom.co.jp/articles/2006/09/14/cedec3/images/cedec_raster.wmv
Cell ���C�g���[�V���O
http://journal.mycom.co.jp/articles/2006/09/14/cedec3/images/cedec_raytrace.wmv
���ׁ[�͂������Y��ȉf�������ł���ˁH
����[���҂��Ă܂�
Larrabee��2010�N�O���o��
http://www.tgdaily.com/html_tmp/content-view-42452-135.html
���C���i�b�v�ɂ��Ė�������Ă͂��܂��A���[�G���h�ŏ��Ȃ��Ƃ�8�R�A�A
�n�C�G���h�ŏ��Ȃ��Ƃ�32�R�A�ƂȂ邾�낤�Ƃ̂��Ƃł�
����N���b�N2GHz��32�R�A�Ńp�t�H�[�}���X��2TFlops�ƂȂ�Ƃ̂���
http://www.tgdaily.com/html_tmp/content-view-42452-135.html
���C���i�b�v�ɂ��Ė�������Ă͂��܂��A���[�G���h�ŏ��Ȃ��Ƃ�8�R�A�A
�n�C�G���h�ŏ��Ȃ��Ƃ�32�R�A�ƂȂ邾�낤�Ƃ̂��Ƃł�
����N���b�N2GHz��32�R�A�Ńp�t�H�[�}���X��2TFlops�ƂȂ�Ƃ̂���
32nm�ւ͂��ڍs����̂���
�ڍs�����Ƃ��āA�����Ȃ肱��Ȃł���������邩��
Larrabee
http://i40.tinypic.com/20iv3oj.png
����������L2-256kB���Ǝv�����A�L���b�V���Ƃ��̑��̕����̔䗦��1�F10���x
Phenom�U
http://pc.watch.impress.co.jp/img/pcw/docs/167/815/kaigai_6.jpg
L2-256kB��2�u���b�N��512KB
�����1�u���b�N�Ōv�Z����ƁAL2-256kB�Ƃ��̑��̕����̔䗦�͂�͂�1�F10���x
�X�J��������Pentium���ŏ�������������A512bitSIMD�֘A�̕���������Ȃ̂�
http://i40.tinypic.com/20iv3oj.png
{kind=link}
����������L2-256kB���Ǝv�����A�L���b�V���Ƃ��̑��̕����̔䗦��1�F10���x
Phenom�U
http://pc.watch.impress.co.jp/img/pcw/docs/167/815/kaigai_6.jpg
{kind=link}
L2-256kB��2�u���b�N��512KB
�����1�u���b�N�Ōv�Z����ƁAL2-256kB�Ƃ��̑��̕����̔䗦�͂�͂�1�F10���x
�X�J��������Pentium���ŏ�������������A512bitSIMD�֘A�̕���������Ȃ̂�
>>791
32nm�v���Z�X�͂��Ȃ�O�|������Ă��邩�琻���ʂł͗]�T���ۂ���
�f�U�C���ɂǂ̂��炢�̎��Ԃ�������̂��Ƃ�
�����J���n�߂�̂��킩��Ȃ�����ˁ[
>>792
�x�N�^�[���j�b�g�̓v���Z�b�T�R�A��1/3���x�炵��
����������L1�L���b�V���ł́H
32nm�v���Z�X�͂��Ȃ�O�|������Ă��邩�琻���ʂł͗]�T���ۂ���
�f�U�C���ɂǂ̂��炢�̎��Ԃ�������̂��Ƃ�
�����J���n�߂�̂��킩��Ȃ�����ˁ[
>>792
�x�N�^�[���j�b�g�̓v���Z�b�T�R�A��1/3���x�炵��
����������L1�L���b�V���ł́H
>>793
���������������̊m������킯�ł͂Ȃ��̂ł��܂Ȃ����ǁE�E�E
����������L1�Ȃ�32KB�ƌ������ɂȂ�
���̑���L2��512KB����Ă��邪�AL1�FL2��32KB�F512KB��1�F16
�܂�A����������L1�Ȃ炻�̑��̕����S�Ă�L2�ł��܂����܂�Ȃ���
���������������̊m������킯�ł͂Ȃ��̂ł��܂Ȃ����ǁE�E�E
����������L1�Ȃ�32KB�ƌ������ɂȂ�
���̑���L2��512KB����Ă��邪�AL1�FL2��32KB�F512KB��1�F16
�܂�A����������L1�Ȃ炻�̑��̕����S�Ă�L2�ł��܂����܂�Ȃ���
>>793
1�R�A��L2��512KB����Ȃ��āA256KB�����ǁB
���ƁAL1��L2�ł͗e�ʂ���������Ă���ʐς��Ⴄ����A�P���ɔ䗦�Ōv�Z���Ă��Ӗ����Ȃ��B
Nehalem�̃_�C�ʐ^�ł����Ă݂������BL2��L1�Ɣ�ׂėe�ʂقǖʐϐH���ĂȂ��̂킩�邩��B
1�R�A��L2��512KB����Ȃ��āA256KB�����ǁB
���ƁAL1��L2�ł͗e�ʂ���������Ă���ʐς��Ⴄ����A�P���ɔ䗦�Ōv�Z���Ă��Ӗ����Ȃ��B
Nehalem�̃_�C�ʐ^�ł����Ă݂������BL2��L1�Ɣ�ׂėe�ʂقǖʐϐH���ĂȂ��̂킩�邩��B
���X�ԈႦ���B
>>794�ˁB
>>794�ˁB
799 �FMAC�I�^��796 �����F2009/05/16(�y) 12:29:50 ID:1dwWUrwO
>>796
�@�@---------------
�@�@L1��L2�ł͗e�ʂ���������Ă���ʐς��Ⴄ
�@�@---------------
�ǎ҂̂��߂̎Q�l�Ƃ��āB
http://journal.mycom.co.jp/column/architecture/125/index.html
�@�@===============
�@�@��Ɏv���邩���m��Ȃ����A�g�����W�X�^���z���̕����ʐς�H���A��ʂɋL���Z����
�@�@�T�C�Y�̓g�����W�X�^�̐��ł͂Ȃ��A�����Ɛ����̔z���̖{���ŃT�C�Y�����܂�B�܂�A�}3.6
�@�@�̋L���Z���ł̓��[�h����1�{�A�r�b�g����2�{�Ŗʐς�2�P�ʂł��邪�A�}3.8�̃Z���ł̓��[�h
�@�@����2�{�A�r�b�g����4 �{�ŁA�ʐς�8�P�ʂɑ������Ă��܂��B
�@�@===============
�L���Z���ɓ����ǂݏ������s����悤�ɂȂ��Ă���(�}���`�|�[�g�\��)L1�͔z���̂�����
�ʐς����Ă��ƂŁB
�@�@---------------
�@�@L1��L2�ł͗e�ʂ���������Ă���ʐς��Ⴄ
�@�@---------------
�ǎ҂̂��߂̎Q�l�Ƃ��āB
http://journal.mycom.co.jp/column/architecture/125/index.html
�@�@===============
�@�@��Ɏv���邩���m��Ȃ����A�g�����W�X�^���z���̕����ʐς�H���A��ʂɋL���Z����
�@�@�T�C�Y�̓g�����W�X�^�̐��ł͂Ȃ��A�����Ɛ����̔z���̖{���ŃT�C�Y�����܂�B�܂�A�}3.6
�@�@�̋L���Z���ł̓��[�h����1�{�A�r�b�g����2�{�Ŗʐς�2�P�ʂł��邪�A�}3.8�̃Z���ł̓��[�h
�@�@����2�{�A�r�b�g����4 �{�ŁA�ʐς�8�P�ʂɑ������Ă��܂��B
�@�@===============
�L���Z���ɓ����ǂݏ������s����悤�ɂȂ��Ă���(�}���`�|�[�g�\��)L1�͔z���̂�����
�ʐς����Ă��ƂŁB
TechReport�̗\�z�ɂ��Larrabee��GPU�̐��\��r�B
http://www.techreport.com/discussions.x/16920
�M���x�͎Q�l���x�ł͂���܂����c
http://www.techreport.com/discussions.x/16920
�M���x�͎Q�l���x�ł͂���܂����c
�v�Z��̃s�[�N���\�Ȃ���i�v�Z�~�X���炢�͗L�邩���m��Ȃ����j�M���o�����Ȃ��H
�ƌ������A��r�Ώۂ�GT285��RD4890��65nm����i55nm�j�ŁALarrabee��45�i32?�jnm����Ȏ����l�����
����ł����Ȃ��C������
���ƁALarrabee�͌Œ��H�����Ȃ��āAGPU���������̍s����ėp��H�ŏ������Ȃ��Ⴂ���Ȃ������悤�ȁE�E�E
���̕����]�v�ɏ����\�͂����ꂻ�������A����ł����\�o��̂���
�ƌ������A��r�Ώۂ�GT285��RD4890��65nm����i55nm�j�ŁALarrabee��45�i32?�jnm����Ȏ����l�����
����ł����Ȃ��C������
���ƁALarrabee�͌Œ��H�����Ȃ��āAGPU���������̍s����ėp��H�ŏ������Ȃ��Ⴂ���Ȃ������悤�ȁE�E�E
���̕����]�v�ɏ����\�͂����ꂻ�������A����ł����\�o��̂���
802 �F,,�E�L�́M�E,,�j��-�������F2009/05/16(�y) 19:22:07 ID:8w+BcN0R
�ėp�����ƌŒ蕔���̃f�[�^�����̃I�[�o�[�w�b�h�����邩��
���Ȃ炸�����\�t�g�������s���Ƃ͌����Ȃ�
Lucille�̊J���ҁi�����܂ŃI�t���C��GI�����_���j�̎��肾���B
���Ȃ炸�����\�t�g�������s���Ƃ͌����Ȃ�
Lucille�̊J���ҁi�����܂ŃI�t���C��GI�����_���j�̎��肾���B
803 �F,,�E�L�́M�E,,�j��-�������F2009/05/16(�y) 19:35:16 ID:8w+BcN0R
http://software.intel.com/en-us/articles/intel-software-network-at-siggraph-2009/
�Ƃ肠����Twitter�ɒlj��������A��
�Ƃ肠����Twitter�ɒlj��������A��
8core��1�u���b�N����Ȃ�����
806 �F,,�E�L�́M�E,,�j��-�������F2009/05/16(�y) 21:32:36 ID:8w+BcN0R
�N���b�N���ɂ�鍷�ʉ��͂��ɂ�������L���R�A���������Ă���Ǝv����
32,24,16,8
�����O�o�X���O�a�����Ⴄ���
810 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 01:30:56 ID:bstP2wou
�����������ш摝�₹�����Ȃ�Ĕn���̂��邱��
�������ш悢�����Č������ɂ͑�����ۂ��B
64bit�ʼn䖝����
GT300��512bit��256GB/sec�m�ۂ���炵����
�����r�[�_�u���X�R�A�Ŋ��s����
�����r�[�_�u���X�R�A�Ŋ��s����
�J�^���O�X�y�b�N�͂��������ς��ł�
Cell��LS��낵���A�e���t����L2���ź�������������������Αш����͗}��������Ď��Ȃ̂���
>>810-814
>>139-
>>139-
GDDR5��512bit���Ƃ��ꂾ����100W�H���̂����B
�ˁ[��
819 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 16:56:44 ID:bstP2wou
>>815
�Ԃ����ႯNotarinVIDIA��GPU��SRAM�́ACUDA�Ŋ��蓖�Ă���ő吔��16Warp���x�܂킹��
1���[�v������1�`2KB per Warp���x�����Ȃ��B
�Ђ����烁�����ш摝�₳�Ȃ��Ɛ��\���o�Ȃ��B
�������˂Ƃ��������悤���Ȃ��B
��x�ɎJ�����[�N�Z�b�g�����Ȃ����AL2�ƌ��킸L1�����ł�ꡂ��ɃZ�[�u�ł���
�Ԃ����ႯNotarinVIDIA��GPU��SRAM�́ACUDA�Ŋ��蓖�Ă���ő吔��16Warp���x�܂킹��
1���[�v������1�`2KB per Warp���x�����Ȃ��B
�Ђ����烁�����ш摝�₳�Ȃ��Ɛ��\���o�Ȃ��B
�������˂Ƃ��������悤���Ȃ��B
��x�ɎJ�����[�N�Z�b�g�����Ȃ����AL2�ƌ��킸L1�����ł�ꡂ��ɃZ�[�u�ł���
non-temporal���ă����h��������ˁH
821 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 17:25:20 ID:bstP2wou
�ʂ�
���������̂��ăv���O���}���ӎ��������Ȃ��ˁH
823 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 17:31:27 ID:bstP2wou
Ct�Ƃ�OpenCL����͈ӎ�����K�v�Ȃ�����
824 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 17:42:06 ID:bstP2wou
GT300�i�j�͒P����SP���{��������ш���{�ɂ��Ȃ��Ƃ����Ȃ������B
�܂�����GTX295���V���O���_�C�ɂȂ��Ėт��������悤�Ȃ���
�G���K���g�ł��Ȃ�ł��Ȃ��B
�܂�����GTX295���V���O���_�C�ɂȂ��Ėт��������悤�Ȃ���
�G���K���g�ł��Ȃ�ł��Ȃ��B
�܂��ŁH
�܂��b�����ł����Ƃ���
�܂��b�����ł����Ƃ���
RV770��L2�L���b�V��4MB�݂����ɁA��ʂ̃������ςނ�ˁH
Larrabee�����Ċ�����GPU�Ɣ�r���ă}�V���Ă����Ń������̕ǂ͌����Ǝv�����ǂ˂�
TSV������Ζ������Ȃ낤��
TSV������Ζ������Ȃ낤��
828 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 21:51:36 ID:bstP2wou
�ėp�v���O�����������̂�1�`2KB�Ƃ��v���I�����邾��
�ǂ��̃Z�K�T�^�[������
�ǂ��̃Z�K�T�^�[������
�c�q�тт��Ă�˂�
GT300��Larrabee���ӂ�ڂ����ɂ���p���ڂɕ����Ԃ�
GT300��Larrabee���ӂ�ڂ����ɂ���p���ڂɕ����Ԃ�
830 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 22:01:10 ID:bstP2wou
�X�^�b�N�ċA���ł��Ȃ��N�\�v���Z�b�T����Ȃ��ł��B
�[�����L���ł����Ȃ�蓮�ŃX�^�b�N�m�ۂ���while�ōċA���ǂ��͂ł����BCPU�̃R�[�h���C�����C���W�J�Ƃ��̍œK���n�߂�Ƃ��������œK�����n�߂邱�ƂɂȂ�B
�Q�[���ő�����ǂ����ł�������
833 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 23:05:23 ID:bstP2wou
OCaml���g����悤�ɂ���B�b�͂��ꂩ�炾�B
Larrabee�̓R�[�h���ŏ����瑵���Ă��Ԃ��Ă̂͋��݂���
Larrabee�̓R�[�h���ŏ����瑵���Ă��Ԃ��Ă̂͋��݂���
�����O�o�X�ƃL���b�V���Ƃ������G�ȗv�������邩��A
���ۂɃ\�t�g�����܂ł͐��\�͕�����Ȃ��Ǝv���ȁB
�܂��A�V�F�[�_�[�����GPU�Ƃ��Č���Ȃ�A���\���������ш�ƌ����Ă��������낤���ǁB
���ۂɃ\�t�g�����܂ł͐��\�͕�����Ȃ��Ǝv���ȁB
�܂��A�V�F�[�_�[�����GPU�Ƃ��Č���Ȃ�A���\���������ш�ƌ����Ă��������낤���ǁB
�����������Ƃ��悭�킩���̂����A�X�^�b�N�̃�������new�Ŏ����Ă��ƂȂ�ނ���x���Ȃ邾��H
836 �F,,�E�L�́M�E,,�j��-�������F2009/05/17(��) 23:07:55 ID:bstP2wou
�������Z����ł���B
�Ȃ�̂��߂�PhysX��Havok����
���Ƃ���B�I�[�v���\�[�X�̕����G���W�����������炢���BGNU�哱�ŁB
�Ȃ�̂��߂�PhysX��Havok����
���Ƃ���B�I�[�v���\�[�X�̕����G���W�����������炢���BGNU�哱�ŁB
>>835
CUDA�Ƀq�[�v���X�^�b�N���Ȃ���B���ߑł��Ŕz������B�ċA��������[���Ȃ�����v���Z�X�������Ă��������ȁA�݂����ȁB�ň��n���O���ă��u�[�g�BCRT���R�����肵�Ȃ����痧�h�Ȃ��́B
CUDA�Ƀq�[�v���X�^�b�N���Ȃ���B���ߑł��Ŕz������B�ċA��������[���Ȃ�����v���Z�X�������Ă��������ȁA�݂����ȁB�ň��n���O���ă��u�[�g�BCRT���R�����肵�Ȃ����痧�h�Ȃ��́B
NV�͒i�X�r�W�l�X�p�C�v���C�������܂��Đ����̂�
�`�b�v�Z�b�g�����v���b�g�z�[������m�i�V�鍐
�`�b�v�Z�b�g�����v���b�g�z�[������m�i�V�鍐
ION������W���}�C�J
840 �F,,�E�L�́M�E,,�j��-�������F2009/05/18(��) 07:13:09 ID:2iM1oWiF
���ꂱ��Pineview�o��ŔN���ɏI���ł���B945GC���J������p�ς݂ł́H
32nm�Ɏ����Ă͒P�̔ł̗\�肷��Ȃ���������
32nm�Ɏ����Ă͒P�̔ł̗\�肷��Ȃ���������
�C�I�����i�G���W�����
843 �F,,�E�L�́M�E,,�j��-�������F2009/05/18(��) 20:15:58 ID:2iM1oWiF
�A�v���������G��悤�ȃ�������Ȃ����ǂ�
�ŏI�I�Ɏ��p�I�ȃA�v���Ŏg���Ȃ���Ӗ���������H
�܂��A��肢���ƃ��C�u��������g����悤�ɂ��Ă����B
�܂��A��肢���ƃ��C�u��������g����悤�ɂ��Ă����B
845 �F,,�E�L�́M�E,,�j��-�������F2009/05/18(��) 21:43:27 ID:2iM1oWiF
���ۉ��Ȃ�ď��F�떂����������ȁB
�n�[�h�̓����ʂ�ɂ��������Ȃ��B
�n�[�h�̓����ʂ�ɂ��������Ȃ��B
�摜�����Ƃ��̋Z�p���m�����Ă镪��Ȃ璊�ۉ�����肭�������낤���ǂˁB
847 �F,,�E�L�́M�E,,�j��-�������F2009/05/18(��) 21:56:12 ID:2iM1oWiF
Larrabee��x86�̔��킹�Ă�̂͐F��ȈӖ��Œׂ�����
�ڐA�ł��Ȃ��A�v����������Ȃ��B
�ڐA�ł��Ȃ��A�v����������Ȃ��B
�ڐA�̖������������ǂ��ɂ��Ȃ��̂��ˁH
����ς�VM�Ȃ��g���̂͒c�q�I�ɂ͉䖝�ł��Ȃ��́H
����ς�VM�Ȃ��g���̂͒c�q�I�ɂ͉䖝�ł��Ȃ��́H
849 �F,,�E�L�́M�E,,�j��-�������F2009/05/18(��) 22:05:17 ID:2iM1oWiF
�����ł͂Ȃ���
����Ő��\�o�Ȃ��Ȃ琢�b������
����Ő��\�o�Ȃ��Ȃ琢�b������
CUDA�̓n�[�h�������Č�����̂������Ƃ��낾��B
C�̎v�z���p���ł���B
C�̎v�z���p���ł���B
851 �F,,�E�L�́M�E,,�j��-�������F2009/05/19(��) 04:01:12 ID:opDui5O4
���Ȑ������肪�����Č����邪�ȁB
�̐S�̃l�C�e�B�u���߃��x���̃X���[�v�b�g�Ȃǂ̏ڍ��͌��J���ꂸ
�̐S�̃l�C�e�B�u���߃��x���̃X���[�v�b�g�Ȃǂ̏ڍ��͌��J���ꂸ
����Ȑ������Y��ɉ�����āA�����I�Ȑ��\���o���Ƃ��̍��g���ُ͈�B
CUDA�v���O���~���O���p�Y���Ƃ��čl����A������x�����������ق����������낢�B
�p�Y���ł��邱�Ƃ����ꂽ�Ȃ�ACUDA�ɐ��Y�������߂�̂͋؈Ⴂ�ł��邱�Ƃ��킩�邾�낤�B
CUDA�v���O���~���O���p�Y���Ƃ��čl����A������x�����������ق����������낢�B
�p�Y���ł��邱�Ƃ����ꂽ�Ȃ�ACUDA�ɐ��Y�������߂�̂͋؈Ⴂ�ł��邱�Ƃ��킩�邾�낤�B
�ǂ����̐������A�ǂ����̃p�Y�����A�ǂ����̐��Y���������������肾�Ǝv�����ǁA
�p�Y���������Ċy�������Ƃ����l�̐���larrabee>>cuda�ł��邱�Ƃ�x86��*�B��*�̗��_���Ǝv���ȁB
�p�Y���������Ċy�������Ƃ����l�̐���larrabee>>cuda�ł��邱�Ƃ�x86��*�B��*�̗��_���Ǝv���ȁB
�p�Y���ɕ��Ր���������C���ł邪
���s�̂̂悤�Ȏ����Ŗ��ɗ����Ȃ��Ȃ邩�����ꂸ
���s�̂̂悤�Ȏ����Ŗ��ɗ����Ȃ��Ȃ邩�����ꂸ
�����ėV�Ԃ̂��ړI�̃p�Y���Ƃ͈Ⴄ����
��Փx�͒Ⴂ�����ǂ��Ɍ��܂��Ă���
��Փx�͒Ⴂ�����ǂ��Ɍ��܂��Ă���
856 �F,,�E�L�́M�E,,�j��-�������F2009/05/19(��) 20:53:01 ID:opDui5O4
�p�Y���v�f�Ȃ�Cell�̂ق�������ۂǂ�肪������Ǝv�����ǂˁB
���߂̎d�l���S�������ĂāA���ׂ��Ƃ���ɓ������B
CUDA�i�j���Ă����̃u���b�N�{�b�N�X�����B
�Ȃɂ��A���m�Ȏ����o���C�������̂��C�ɓ����
���߂̎d�l���S�������ĂāA���ׂ��Ƃ���ɓ������B
CUDA�i�j���Ă����̃u���b�N�{�b�N�X�����B
�Ȃɂ��A���m�Ȏ����o���C�������̂��C�ɓ����
>>856
RPG�ł�������A�RD�_���W�����������}�b�s���O���Ă���邩���ᎆ�Ŏ蓮�}�b�s���O���Ȃ��Ⴂ���Ȃ����̍����ď����ȁH
�������ɕ��ᎆ�Ń}�b�v���C�͂͂����Ȃ��ȁB
RPG�ł�������A�RD�_���W�����������}�b�s���O���Ă���邩���ᎆ�Ŏ蓮�}�b�s���O���Ȃ��Ⴂ���Ȃ����̍����ď����ȁH
�������ɕ��ᎆ�Ń}�b�v���C�͂͂����Ȃ��ȁB
858 �F,,�E�L�́M�E,,�j��-�������F2009/05/19(��) 21:30:57 ID:opDui5O4
�����Ɛ��E���̖��{�̈����͂����܁i����
�������ɂ���ӂ���B
�������ɂ���ӂ���B
GT300�͂Ȃ��ƂĂ��А����������킳���Ƃ�ł���ȁB2.4TFLOPS�Ƃ��B
����ɁANvidia���������NQ1��28nm�v���Z�X�֑��߂Ɉڂ��Ă�����Ȃ�AGT300 X2�Ƃ��ł��A
����`�b�v��45nm��Larrabee�Ɠ����̏���d�͂��炢�ɂȂ��Ȃ����B
����������A�s�[�N���\�͔{�ȏ�̍��B
�ł��AIntel��32nm������������A�ڍs��������ǂ�����B
�]�k�����APS3�̓s�[�N���\��xbox360�̔{�����ԂŐ��ɏo�����A���ۂɎg���n�߂�ƁAxbox360��
�����g���₷���āA���ʁA���s���\��xbox360�̕�����Ȃ�ď����X�������B
Larrabee��GT300�̃s�[�N���\���A���Ƃ��{����Ă��ALarrabee�̕������\�ł₷���Ƃ��A�g���₷���Ȃ�ĂȂ�A
�s�[�N���\�Ȃ���܂�W�Ȃ��Ȃ邱�Ƃ����邩���ˁB�܂��A�t�Ɏg���ɂ����Ƃ����\�łȂ��āA�ڂ����Ă��Ȃ�
�Ȃ�Ă��Ƃ����邩������Ȃ����ǁB
����ɁANvidia���������NQ1��28nm�v���Z�X�֑��߂Ɉڂ��Ă�����Ȃ�AGT300 X2�Ƃ��ł��A
����`�b�v��45nm��Larrabee�Ɠ����̏���d�͂��炢�ɂȂ��Ȃ����B
����������A�s�[�N���\�͔{�ȏ�̍��B
�ł��AIntel��32nm������������A�ڍs��������ǂ�����B
�]�k�����APS3�̓s�[�N���\��xbox360�̔{�����ԂŐ��ɏo�����A���ۂɎg���n�߂�ƁAxbox360��
�����g���₷���āA���ʁA���s���\��xbox360�̕�����Ȃ�ď����X�������B
Larrabee��GT300�̃s�[�N���\���A���Ƃ��{����Ă��ALarrabee�̕������\�ł₷���Ƃ��A�g���₷���Ȃ�ĂȂ�A
�s�[�N���\�Ȃ���܂�W�Ȃ��Ȃ邱�Ƃ����邩���ˁB�܂��A�t�Ɏg���ɂ����Ƃ����\�łȂ��āA�ڂ����Ă��Ȃ�
�Ȃ�Ă��Ƃ����邩������Ȃ����ǁB
�s�[�N���\�F�@
Larrabee < Nvidia GPU
�R�X�g�p�t�H�[�}���X�F�@�v���Z�X���[���ƕ����܂�A����܂ł̃f�B�X�N���[�gGPU�s��ł̋����o�����l�����
Larrabee < Nvidia GPU ???
�Q�[���̎��s���\�F�Œ蕔���̊����A�������o���h���A�Q�[�����Ƃ̃L���b�V�������̈Ⴂ�����邱�Ƃ��l�����
Larrabee < Nvidia GPU ????
�Ȋw�Z�p�v�Z�̎��s���\�F���[�J���������̗ʁA�������o���h���A�J�������l�����
Larrabee > Nvidia GPU ?
HPC�p�ɊJ�������ǂꂾ���p�ӂ���̂��A�͂����Ă���̂���Larrabee�͖��m���B
Nvidia�́A�����Ă��A���傩��N���[�������邭�炢�A�������ւ̓����͂��Ă���B
Larrbee���ACt�p�ӂ�����A��������������A���Ȃ����Ă���݂����ł͂���B
Larrabee < Nvidia GPU
�R�X�g�p�t�H�[�}���X�F�@�v���Z�X���[���ƕ����܂�A����܂ł̃f�B�X�N���[�gGPU�s��ł̋����o�����l�����
Larrabee < Nvidia GPU ???
�Q�[���̎��s���\�F�Œ蕔���̊����A�������o���h���A�Q�[�����Ƃ̃L���b�V�������̈Ⴂ�����邱�Ƃ��l�����
Larrabee < Nvidia GPU ????
�Ȋw�Z�p�v�Z�̎��s���\�F���[�J���������̗ʁA�������o���h���A�J�������l�����
Larrabee > Nvidia GPU ?
HPC�p�ɊJ�������ǂꂾ���p�ӂ���̂��A�͂����Ă���̂���Larrabee�͖��m���B
Nvidia�́A�����Ă��A���傩��N���[�������邭�炢�A�������ւ̓����͂��Ă���B
Larrbee���ACt�p�ӂ�����A��������������A���Ȃ����Ă���݂����ł͂���B
�s�[�N���\�F�@
Larrabee < Nvidia GPU
�R�X�g�p�t�H�[�}���X�F�@�v���Z�X���[���ƕ����܂�A����܂ł̃f�B�X�N���[�gGPU�s��ł̋����o�����l�����
Larrabee < Nvidia GPU ???
�Q�[���̎��s���\�F�Œ蕔���̊����A�������o���h���A�Q�[�����Ƃ̃L���b�V�������̈Ⴂ�����邱�Ƃ��l�����
Larrabee < Nvidia GPU ????
�Ȋw�Z�p�v�Z�̎��s���\�F���[�J���������̗ʁA�������o���h���A�J�������l�����
Larrabee > Nvidia GPU ?
HPC�p�ɊJ�������ǂꂾ���p�ӂ���̂��A�͂����Ă���̂���Larrabee�͖��m���B
Nvidia�́A�����Ă��A���傩��N���[�������邭�炢�A�������ւ̓����͂��Ă���B
Larrbee���ACt�p�ӂ�����A��������������A���Ȃ����Ă���݂����ł͂���B
Larrabee < Nvidia GPU
�R�X�g�p�t�H�[�}���X�F�@�v���Z�X���[���ƕ����܂�A����܂ł̃f�B�X�N���[�gGPU�s��ł̋����o�����l�����
Larrabee < Nvidia GPU ???
�Q�[���̎��s���\�F�Œ蕔���̊����A�������o���h���A�Q�[�����Ƃ̃L���b�V�������̈Ⴂ�����邱�Ƃ��l�����
Larrabee < Nvidia GPU ????
�Ȋw�Z�p�v�Z�̎��s���\�F���[�J���������̗ʁA�������o���h���A�J�������l�����
Larrabee > Nvidia GPU ?
HPC�p�ɊJ�������ǂꂾ���p�ӂ���̂��A�͂����Ă���̂���Larrabee�͖��m���B
Nvidia�́A�����Ă��A���傩��N���[�������邭�炢�A�������ւ̓����͂��Ă���B
Larrbee���ACt�p�ӂ�����A��������������A���Ȃ����Ă���݂����ł͂���B
����Larrabee�̓\�t�g����library����Ă��炤���߂̂���Ό���ES�i������
���\�͂łȂ����A��ʎs��ł͂��܂蔄��Ȃ���B
���\�͂łȂ����A��ʎs��ł͂��܂蔄��Ȃ���B
������larra-bee ������larra-bee ����������
864 �F,,�E�L�́M�E,,�j��-�������F2009/05/21(��) 19:34:51 ID:m3faMz4i
������ASP��SFU�𗼕����������ꍇ�̃X���[�v�b�g�Ȃ��
�قƂ�LjӖ��ˁ[���āB
���[�h�E�X�g�A�ƕ�����s���邱�Ƃ��l��������SP��SFU���Ɏg����@��̂ق������Ȃ��B
�u1.6TFLOPS�{���v���炢�̔F����������
Cell�ł����������Ϙa�Z��Even�ƃ��[�h�E�X�g�A���߂�Odd�œ������s�o����悤�ɍ���Ă���B
�قƂ�LjӖ��ˁ[���āB
���[�h�E�X�g�A�ƕ�����s���邱�Ƃ��l��������SP��SFU���Ɏg����@��̂ق������Ȃ��B
�u1.6TFLOPS�{���v���炢�̔F����������
Cell�ł����������Ϙa�Z��Even�ƃ��[�h�E�X�g�A���߂�Odd�œ������s�o����悤�ɍ���Ă���B
>>840
Pineview�ŏI���Ȃ�������
������Atom�\�gPineview�h�̘b��
http://northwood.blog60.fc2.com/blog-entry-2852.html
���gPineview�h��NVIDIA���`�b�v�Z�b�g�ɑΉ��ł���B�Ȃ̂ŁA�V����́gION�h�v���b�g�t�H�[�����\�z���邱�Ƃ��\�ł���B
Pineview�ŏI���Ȃ�������
������Atom�\�gPineview�h�̘b��
http://northwood.blog60.fc2.com/blog-entry-2852.html
���gPineview�h��NVIDIA���`�b�v�Z�b�g�ɑΉ��ł���B�Ȃ̂ŁA�V����́gION�h�v���b�g�t�H�[�����\�z���邱�Ƃ��\�ł���B
>>865
�l�i�������ȏ�ɊJ�����ƂɂȂ邩�玀�S�Ȃ͕̂ς��ǂȁB
�l�i�������ȏ�ɊJ�����ƂɂȂ邩�玀�S�Ȃ͕̂ς��ǂȁB
�\�����ǃ����b�g���Ȃ���ŁA���������Ȃ�
�v�͂��ALarrabee����
���鉞�p�͈͂ł�Core2Quad��core i7�̉�����̐��\���Ĉʒu�t����
�������ɗ���Ȃ猋�\�������݃J����B
���鉞�p�͈͂ł�Core2Quad��core i7�̉�����̐��\���Ĉʒu�t����
�������ɗ���Ȃ猋�\�������݃J����B
�e�R�A��Windows���ʂɓ����Ȃ��Ȃ炽���������Ђł��Ȃ��B
��������larrabee�̃h���C�o�����AOS������
larrabee���Ǘ�����̂�larrabee 1core�������x�̃p�t�H�[�}���X�ŊԂɍ����̂���
larrabee���Ǘ�����̂�larrabee 1core�������x�̃p�t�H�[�}���X�ŊԂɍ����̂���
SMP = Symmetric Multi Processor = �Ώ̌^�}���`�v���Z�b�T
�Ǘ����ă}���`�������H
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai_08.jpg
�ihttp://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm�j
�\�t�g�Ɋւ��Ă͂��������ނ��̏���o�ĂȂ��̂ł́B������
�z�X�gCPU�Ȃ��Ŏg�����������Ƃ��Ă����Ȃ��ɂȂ邾�낤
{kind=link}
�ihttp://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm�j
�\�t�g�Ɋւ��Ă͂��������ނ��̏���o�ĂȂ��̂ł́B������
�z�X�gCPU�Ȃ��Ŏg�����������Ƃ��Ă����Ȃ��ɂȂ邾�낤
>>870
>873�̐}�Ō�����Larrabee��œ����̂�4�K�w�̍ʼn��w��������
>873�̐}�Ō�����Larrabee��œ����̂�4�K�w�̍ʼn��w��������
larrabee����R600�ł���Command Processor��Ultra Threaded Dispatch Processor�����݂��Ȃ��̂�
GPU�����̃X���b�h�Ǘ��Ƃ���larrabee���g(��core)����邵���Ȃ��̂���
�Ǝv������ł���
GPU�����̃X���b�h�Ǘ��Ƃ���larrabee���g(��core)����邵���Ȃ��̂���
�Ǝv������ł���
876 �F,,�E�L�́M�E,,�j��-�������F2009/05/25(��) 20:19:49 ID:HkUjpLWc
���̗����͐������B
�ł���́H�蓮�Ǘ��Ƃ��H
�C�����C���A�Z���u����pthread���o����
879 �F,,�E�L�́M�E,,�j��-�������F2009/05/25(��) 21:25:36 ID:HkUjpLWc
�ǂ������������ʂ�OS�ŏo���邱�Ƃ͂Ȃ�ł��ł�����x�̔ėp���͂���
���̓p�t�H�[�}���X
OpenMP�łł��邱�Ƃ͊�{�S���ł���ƌ����ۼ�ۂƁB
pthread IF������Ƃ邵�A����l�o API�̉��ł��ꂪ�g����ƍl����̂��Ó��ެϲ��B
����OpenMP 3.0 ��task ����܂ł�����Ǝ�������Ă���Ȃ�Alisp�ł������Ƃ�����
�ꃍ�[�W���[r�I�ȒP�ʂł̕����\�����A�������牞�p���L����B���
intel�����̓_���w���ă_�C�i�~�b�N��pipeline�̍\���Ƃ������Ă���̂��c�Ƃ����̂͐[�ǂ݂̂��������ۂ���
���O�����������Ȃ��Ȃ��_����ŁA���̂Ƃ���ʔ�����
pthread IF������Ƃ邵�A����l�o API�̉��ł��ꂪ�g����ƍl����̂��Ó��ެϲ��B
����OpenMP 3.0 ��task ����܂ł�����Ǝ�������Ă���Ȃ�Alisp�ł������Ƃ�����
�ꃍ�[�W���[r�I�ȒP�ʂł̕����\�����A�������牞�p���L����B���
intel�����̓_���w���ă_�C�i�~�b�N��pipeline�̍\���Ƃ������Ă���̂��c�Ƃ����̂͐[�ǂ݂̂��������ۂ���
���O�����������Ȃ��Ȃ��_����ŁA���̂Ƃ���ʔ�����
There Is No "Typical" Workload
ttp://i.i.com.com/cnwk.1d/i/bto/20080804/intel-larrabee-diagram-4-small-2.jpg
ttp://news.cnet.com/8301-13924_3-10006617-64.html?tag=nefd.top
�@�\�Œ�̃n�[�h�E�F�A���W�ς����@�ł̓^�C�g�����Ɏ��鉶�b������Ă��Ă��܂��Ƃ�����������
���܂ꂽ�̂� �\�t�g�E�F�A�Ń����_�����O�p�C�v���C������������Ƃ����A�C�f�B�A����
�O���t�B�b�N�X�w���̃n�[�h�E�F�A�Ŕėp�I�ȉ��Z���������Ƃ����v���ɂ���������̂���
���߂Ă݂�Ɣ��ɗǂ�����ꂽuArch���˂�
ttp://i.i.com.com/cnwk.1d/i/bto/20080804/intel-larrabee-diagram-4-small-2.jpg
{kind=link}
ttp://news.cnet.com/8301-13924_3-10006617-64.html?tag=nefd.top
�@�\�Œ�̃n�[�h�E�F�A���W�ς����@�ł̓^�C�g�����Ɏ��鉶�b������Ă��Ă��܂��Ƃ�����������
���܂ꂽ�̂� �\�t�g�E�F�A�Ń����_�����O�p�C�v���C������������Ƃ����A�C�f�B�A����
�O���t�B�b�N�X�w���̃n�[�h�E�F�A�Ŕėp�I�ȉ��Z���������Ƃ����v���ɂ���������̂���
���߂Ă݂�Ɣ��ɗǂ�����ꂽuArch���˂�
�Q�[�����Ƃɂ��ꂾ�����[�N���[�h������Ă���Ȃ�Œ�@�\���ڂł������
�Ǝv���Ă��܂��̂���
�Ǝv���Ă��܂��̂���
OpenMP�łł��邱�Ƃ��āc���x�������ł͔@���l�ɂ����߂ł��邶���B
Half-Life 2: Episode Two��4870 X2�Ȃ�A1920x1200 4xAA/8xAniso
�ŕ���fps��200�����Ă܂ȁB
�Q�[���p�Ɋ��҂����Ⴂ���Ȃ��ł���
�ŕ���fps��200�����Ă܂ȁB
�Q�[���p�Ɋ��҂����Ⴂ���Ȃ��ł���
888 �FSocket774�F2009/05/26(��) 17:32:04 ID:5Ujgpxkq
Larrabee��������Ȃ�
���܂ŏo���o�����\����Ă���
���܂ŏo���o�����\����Ă���
>>887
LRB�̓R�A����10�œ���N���b�N��1GHz����B
���i�ł�16�R�A�ȏ�Ƃ����b�����炠���܂ł��Q�l�l�ł���B
�Ƃ���ŁA�f���A��GPU�J�[�h���Đ͕̂]�������������Ǎ��͂���Ȃł��Ȃ��́H
LRB�̓R�A����10�œ���N���b�N��1GHz����B
���i�ł�16�R�A�ȏ�Ƃ����b�����炠���܂ł��Q�l�l�ł���B
�Ƃ���ŁA�f���A��GPU�J�[�h���Đ͕̂]�������������Ǎ��͂���Ȃł��Ȃ��́H
�Â�RageFuryMAXX�Ƃ�Voodoo5�Ƃ�����
��ׂ�Ȃ�c
��ׂ�Ȃ�c
3870 X2�Ƃ�4870 X2�Ƃ�7950 GX2�Ƃ�GTX 295�Ƃ���
PCI���u���b�W�̂�����OS����2��GPU�Ɍ�����CF/SLI����Ă邾��
��ق�FuryMAXX��Voodoo5�̕�����i�I
PCI���u���b�W�̂�����OS����2��GPU�Ɍ�����CF/SLI����Ă邾��
��ق�FuryMAXX��Voodoo5�̕�����i�I
nvidia�͍̂��ł��]������������
���ʂɂǂ�������
>>892
(��)
(��)
896 �F,,�E�L�́M�E,,�j��-�������F2009/05/30(�y) 14:14:54 ID:j8kyiVFL
> Intel����Investor Meeting�̃v���[���������_�E�����[�h�ł���B
> ttp://intelstudios.edgesuite.net/im/home.htm
> ��ʂ�ڂ�ʂ������A�����̂ł������C�ɂȂ����_���������B
>
> �E�������\�ƒ����o�b�e���[�̎������Ԃ������ł���Larrabee��Discrete Graphics�Ƃ��Ă͍ł��D�ꂽ�\�����[�V����
> ��Larrabee�̓��o�C���ł����������͗l
>�@�����̐��i���m�Ŕ�r�����Nehalem��Atom(Intel Architecture)�̓d�͊Ǘ���Geforce��Radeon��舳�|�I�ɋ���
>�@Calpella�̎��_��Clarksfield��GPU�������ăv���b�g�t�H�[���Ɍ����J���Ă���̂œ����͂��Ȃ葁���̂ł͂Ȃ���
>�@Clarksfield(or later) + Larrabee, Arrandale + GMA, Atom + GMA, Atom + PowerVR
>�@���N�O��PentiumM��GMA�݂̂��������o�C�����i�ɔ��ɕ����o�Ă���
> ttp://intelstudios.edgesuite.net/im/home.htm
> ��ʂ�ڂ�ʂ������A�����̂ł������C�ɂȂ����_���������B
>
> �E�������\�ƒ����o�b�e���[�̎������Ԃ������ł���Larrabee��Discrete Graphics�Ƃ��Ă͍ł��D�ꂽ�\�����[�V����
> ��Larrabee�̓��o�C���ł����������͗l
>�@�����̐��i���m�Ŕ�r�����Nehalem��Atom(Intel Architecture)�̓d�͊Ǘ���Geforce��Radeon��舳�|�I�ɋ���
>�@Calpella�̎��_��Clarksfield��GPU�������ăv���b�g�t�H�[���Ɍ����J���Ă���̂œ����͂��Ȃ葁���̂ł͂Ȃ���
>�@Clarksfield(or later) + Larrabee, Arrandale + GMA, Atom + GMA, Atom + PowerVR
>�@���N�O��PentiumM��GMA�݂̂��������o�C�����i�ɔ��ɕ����o�Ă���
�v��
���x���҂��Ă��l�S�����l�B
�܂����҂�������A�z�Ȃ��ǂ�
���Č����������Ă��Ƃ��B
���x���҂��Ă��l�S�����l�B
�܂����҂�������A�z�Ȃ��ǂ�
���Č����������Ă��Ƃ��B
898 �F,,�E�L�́M�E,,�j��-�������F2009/05/31(��) 18:06:45 ID:vMIWWUX3
�ǂ�������炻��Ȃ��߂ł������߂��o�����
�d�͊Ǘ���ɂ��Ă���̂͂܂��z��ł����B
�d�͊Ǘ���ɂ��Ă���̂͂܂��z��ł����B
���o�C�����ł߂Ă���̂��z��ł�����
N��A�̐����c����������֎q���Q�[�����I��肪�����Ă���
N��A�̐����c����������֎q���Q�[�����I��肪�����Ă���
�Ƃ������������E�E
901 �FSocket774�F2009/06/01(��) 16:12:20 ID:lpjlVVm9
N�̓v���b�g�t�H�[�����Ȃ�����I�Ɋo���Ȃ��Ȃ莀�S�m��B
I��A��V�݂͌��̃v���b�g�t�H�[���ŋ�������6:3:1�ŃV�F�A���邾�낤�ȁB
I��A��V�݂͌��̃v���b�g�t�H�[���ŋ�������6:3:1�ŃV�F�A���邾�낤�ȁB
VIA�叟��
������N��Q�����g��ł��ȁB
>>903
�����D��������Đ���Ƃ��ȁB
�����D��������Đ���Ƃ��ȁB
905 �F,,�E�L�́M�E,,�j��-�������F2009/06/03(��) 21:57:03 ID:xfJbAf1y
FF14�̃��[�h�v���b�g�t�H�[����������s�폟���ۂ��H
�����˂��[FF
907 �FSocket774�F2009/06/04(��) 21:08:18 ID:2xk6WdIM
Intel�̎咣�ł�NVIDIA��CUDA�͊m���ɑ傫�Ȑ��\����������炷���Ƃ��\����
�V�����v���O��������ł��邪�䂦�ɁA�J���҂ɕ��S�������邱�ƂɂȂ���
�ŏI�I�ɂ͏\�����\��������Ȃ��Ƃ��Ă��܂��B
���̈���ŁgLarrabee�h�͊�����x86���߂Ƃ̌݊������m�ۂ��邱�Ƃ�
�V��������̏K���Ƃ������S���J���҂ɋ����Ȃ��Əq�ׂĂ��܂��B
�m���ɑS���V���������S���V�����A�[�L�e�N�`�����[������o���Ȃ����J�͂����Ƃ�Ȃ��l���������镪��́A
���\�������ŗD��ł���ȊO�͑S�ē�̎��A�O�̎��ȃX�[�p�[�R���s���[�^�[�����Ȋw�v�Z���삾���ł��傤�B
����͍��܂ł����ꂩ����ς��Ȃ��ł��傤�B �n�[�h�̐i���͑����B
�ł��A�\�t�g�E�F�A�̐i���͒x���B����͗��j�������Ă܂��B
http://www.dailytech.com/Intel+Sheds+Light+on+Larrabee+Dismisses+NVIDIA+CUDA/article12256.htm
���������킯�ŁA�V��������̏K�����Ȃ��Ă����̂͂킩�����B�ŁA���\�́H
908 �FSocket774�F2009/06/04(��) 21:23:24 ID:4hf/swTx
Geforce256��
Larrabee�̃p�t�H�[�}���X��GeForce GTX 285����
http://blog.livedoor.jp/amd646464/archives/51355402.html
http://blog.livedoor.jp/amd646464/archives/51355402.html
910 �F,,�E�L�́M�E,,�j��-�������F2009/06/04(��) 23:00:01 ID:j0sST02h
������y���ޒ��x�ɂ͑S�R�����Ȃ��ˁB
���Ƃ͂ǂꂾ���^�[�Q�b�g�ɍœK������邩���낤
���Ƃ͂ǂꂾ���^�[�Q�b�g�ɍœK������邩���낤
���̃n�C�G���h�A�����̃A�b�p�[�~�h�������Ă��Ƃ�
�l�i���悾���ǃQ�[���p�Ƃ��đI�����ɓ����Ă���̂���
�l�i���悾���ǃQ�[���p�Ƃ��đI�����ɓ����Ă���̂���
�o������ɂ̓~�h���̒��`�キ�炢�͑_���邩�ȁH
��͏���d�͂��ȁB
��͏���d�͂��ȁB
128bit�̑g�ݍ��݊��ŏ��������̂�512bit�ŏ��������Ȃ��Ⴂ���Ȃ���B�����x�N�g�����ł��郋�[�v�Ȃ�ĊȒP��CUDA�ɈڐA�ł��邳�BopenMP�����̂܂g����Ȃ炻�̕��͗L���B
914 �FSocket774�F2009/06/04(��) 23:30:11 ID:q9Pji9xI
������Ɍ�����قǃX�s�[�h��������
�Ƃɂ����X�e�b�v���[�N���ݏd�Ō��Ă��Ȃ�
�n���h�X�s�[�h�A���ɃW���u�ƃX�g���[�g��Mayweather wannabe����
�E�A�b�p�[�ł͂Ȃ����A�b�p�[�ɗ����Ă��܂��̂�
�̂̃X�s�[�h�s���ɑ���{�l�̎��o������킵�Ă��邗
�Ƃɂ����X�e�b�v���[�N���ݏd�Ō��Ă��Ȃ�
�n���h�X�s�[�h�A���ɃW���u�ƃX�g���[�g��Mayweather wannabe����
�E�A�b�p�[�ł͂Ȃ����A�b�p�[�ɗ����Ă��܂��̂�
�̂̃X�s�[�h�s���ɑ���{�l�̎��o������킵�Ă��邗
915 �FSocket774�F2009/06/04(��) 23:32:07 ID:ackaH0Up
>>909
����������������������������������������������
45nm��600mm2���̒�����_�C�̂�����GTX285�������łˁ[�̂��悗��������������������������
�������������������������������������������
����������������������������������������������
45nm��600mm2���̒�����_�C�̂�����GTX285�������łˁ[�̂��悗��������������������������
�������������������������������������������
HD4770(RV740�j��136����mm
Evergreen(��R8xx)��180����mm��
GTX285�iGT200b�j��484mm2
GT300��495mm2
Larrabee�́i����
I��N�����h��
Evergreen(��R8xx)��180����mm��
GTX285�iGT200b�j��484mm2
GT300��495mm2
Larrabee�́i����
I��N�����h��
917 �FSocket774�F2009/06/04(��) 23:37:10 ID:ackaH0Up
R870��������
180mm2�Ƃ����|�I������
180mm2�Ƃ����|�I������
������A�����������\�Ɋ��҂ł������Ȃ����ẮB
�x���Ƃ��ł����Ƃ������Ă��͊��Ⴂ���Ă��B
�����Ɩ����ɋ��ق��Ă����͖��O�����B
�x���Ƃ��ł����Ƃ������Ă��͊��Ⴂ���Ă��B
�����Ɩ����ɋ��ق��Ă����͖��O�����B
Larrabee��PC�Q�[�}�[����ɏ�������C�Ȃ�Ă��炳�疳������
921 �F,,�E�L�́M�E,,�j��-�������F2009/06/05(��) 00:02:42 ID:j0sST02h
�����炳�܂ɃX�p�R�������A�N�Z�����[�^����
R870��GTX385��Larrabee�̂ǂꔃ�����A���P�[�g�Ƃ��Ă݂����ȁB
�ǂ������ɂ܂���āACell��GPU�ł�2010�N�ɓ����Ƃ����ꂽ��ʔ������ǂȁB
�܂��APS3�̏���A����킫��Ȃ����B
�܂��APS3�̏���A����킫��Ȃ����B
������@���o���\�肪�����ł��Ȃ��̂�GPU�����o���Ăǂ�����́H
�Q�[���̃g�����h�����C�g���嗬�ɂȂ�Ƃ����\����M���āA���łł���B
�N�̋��ŁH
IBM����GPU�ƊE�ɗ����Ƃ������ƂŁA�ǂ��ł��傤�B
T�����S����͂���ǂ���ł͂Ȃ��̂ŁB
���ŁA�\�j�[�͐����c���̂�
�܂������Ă�̂��H
�����A�����̕��傾���̔��ォ�B����ɂ��Ă��A�O�̐�Ƃ�
��������Ȃ��̂Ƃł͔���̈Ӗ����Ⴄ�Ǝv������
��������Ȃ��̂Ƃł͔���̈Ӗ����Ⴄ�Ǝv������
>>133
�挎�̃j���[�X������
http://techon.nikkeibp.co.jp/article/HONSHI/20090508/169818/
http://techon.nikkeibp.co.jp/article/HONSHI/20090508/169818/090518rp1.jpg
�挎�̃j���[�X������
http://techon.nikkeibp.co.jp/article/HONSHI/20090508/169818/
http://techon.nikkeibp.co.jp/article/HONSHI/20090508/169818/090518rp1.jpg
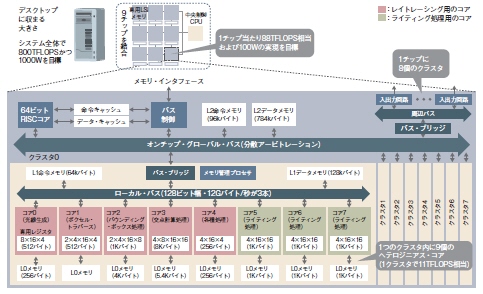{kind=link}
936 �FSocket774�F2009/06/08(��) 07:36:49 ID:bPrc+ceI
>>930
���ł͂��Ԃ�Cell�̃��C���̌����߂̂��߂�SSD�ɓ������Ă��ˁH
���ł͂��Ԃ�Cell�̃��C���̌����߂̂��߂�SSD�ɓ������Ă��ˁH
937 �FSocket774�F2009/06/08(��) 13:41:04 ID:PAGeRAu0
�@�@�@�@�@�@�@,�Q�Q�@�@ http://japanese.engadget.com/images/2006/06/kutaragi.jpg
�@ �@�@�@�����[�|� �_
�@�@�@�@/�_�@�@ -__ �Rʁ@�@�@�@�@�@�@ , -�\�\�\�\-��Q
�@�@�@ �o�_,=�@ � �L�M�@}_�!�@ �@ �@ �@ /�@�@�@�@�@�@�@//�Q;'��
�@�@�@�@{j�@ �T -�@,�R�@� �p �@ �@ �@ / __�@ __�@__�@ //��_�]��r'
�@�@�@�@ { �q ' �P�@ _�@ rɁ@�@�@�@ / /��_�q�@_�]/ //r'�]�/
�@�@�@�@�@�R�@���A�L�@�@ @�@�@�@ /�@ �@ �@ �@ �@ /�P�V� }
�@ �Q�Q_ __��-- ��@�@}� �Q__/�@ �@ �@ �@ �@ / �@ /�@/
/�L�@ �_�@�_�@ �_��/�_}�_ /�@ �@ �@ �@ �@ / �@ /}�@�q
|�@ �@ �@ �_�@�_�@�_ �_�rl�@/�@ �@ �@ �@ �@ / �@ /����v�_
|�@�@�@�@�@�@�_�@�_�@|�@|} |�@���P�P/�ܓ��)../}/ �M�[�\�r
|�@�@�@�@ �@ �@ �R�@ �R}�Q_j�Q ��'��@�@ �P�M�[' /�@�@ �@ /
|�@�@�@ , �C�L�P�P�P�@�@ �@ �@ �@ |�Q�Q�Q__.�^�@�@�@�@/
�_�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �Ɂ@|�@�@/�@�@�@�@�@/
�@}�_�@�@�@�@�@ �@ �@ �@ �@ �@ �@ /�@�@l�@ /�@�@ �@ �@ /
�@| �@ �_�Q�Q�Q�Q�Q__ cccc/�@ �@ |�_'�@�@�@�@�@/
. /�@�@�@�@�@�@�@�@�@ C/�@i�P �@ �@ �@ l �@�R.�Q__�^
{kind=link}
�@ �@�@�@�����[�|� �_
�@�@�@�@/�_�@�@ -__ �Rʁ@�@�@�@�@�@�@ , -�\�\�\�\-��Q
�@�@�@ �o�_,=�@ � �L�M�@}_�!�@ �@ �@ �@ /�@�@�@�@�@�@�@//�Q;'��
�@�@�@�@{j�@ �T -�@,�R�@� �p �@ �@ �@ / __�@ __�@__�@ //��_�]��r'
�@�@�@�@ { �q ' �P�@ _�@ rɁ@�@�@�@ / /��_�q�@_�]/ //r'�]�/
�@�@�@�@�@�R�@���A�L�@�@ @�@�@�@ /�@ �@ �@ �@ �@ /�P�V� }
�@ �Q�Q_ __��-- ��@�@}� �Q__/�@ �@ �@ �@ �@ / �@ /�@/
/�L�@ �_�@�_�@ �_��/�_}�_ /�@ �@ �@ �@ �@ / �@ /}�@�q
|�@ �@ �@ �_�@�_�@�_ �_�rl�@/�@ �@ �@ �@ �@ / �@ /����v�_
|�@�@�@�@�@�@�_�@�_�@|�@|} |�@���P�P/�ܓ��)../}/ �M�[�\�r
|�@�@�@�@ �@ �@ �R�@ �R}�Q_j�Q ��'��@�@ �P�M�[' /�@�@ �@ /
|�@�@�@ , �C�L�P�P�P�@�@ �@ �@ �@ |�Q�Q�Q__.�^�@�@�@�@/
�_�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �Ɂ@|�@�@/�@�@�@�@�@/
�@}�_�@�@�@�@�@ �@ �@ �@ �@ �@ �@ /�@�@l�@ /�@�@ �@ �@ /
�@| �@ �_�Q�Q�Q�Q�Q__ cccc/�@ �@ |�_'�@�@�@�@�@/
. /�@�@�@�@�@�@�@�@�@ C/�@i�P �@ �@ �@ l �@�R.�Q__�^
�n�܂�O�ɏI�����H
�����҂��B
It all indicates that the project will launch in 2010, most likely in 1H of 2010
if we don't see any further delays and we've heard that
software support and drivers are the number one reason of this delay.
if we don't see any further delays and we've heard that
software support and drivers are the number one reason of this delay.
941 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/21(��) 22:44:13 ID:aCSGhBhM
���߂�������
942 �FSocket774�F2009/06/22(��) 23:20:54 ID:mMwkv70i
>>920
��Larrabee��PC�Q�[�}�[����ɏ�������C�Ȃ�Ă��炳�疳������
�͂����肢����Intel�͒P��GPU�œV������낤�Ȃ�Ďv���ĂȂ��ł��傤�B
���łɃI���{�[�hGPU�Ƃ������W���[�ȕ����}���Ă���Intel���A
������j�b�`�ȕ���ɂȂ�悤�Ȃ��̂ɘJ�͂�������Ƃ͎v���Ȃ��B
���Ⴀ����Intel�͂킴�킴�����J�l��������Larrabee�̂悤�Ȃ��̂�����Ă���̂��H
����͍ŏI�I�ɂ�CPU�őS�Ă̏������s���Ă��܂��悤�ɂ��鎖�B
�ق��Ă����AGPGPU�Ɏ����玟�ւƎd����D���Ă��܂����O������̂��낤�ˁB
�h��荇����CPU��GPU�������p�b�P�[�W�ɂ��܂����h���x�̂��̂��A���N�o�Ă��邪�A
�����I�ɂ͑唼��PC���[�U�[�������ł��郌�x����GPU��CPU�Ɠ����̌��Ɏ��������ł��傤�B
�����Ȃ�A�g���J�[�h��GPU�Ȃ�Ĉꕔ�̂o�b�Q�[���^���炢��������Ȃ��悤�Ȏ������̃A�i�N���A�C�e���ɂȂ邱�Ƃł��傤�B
��Larrabee��PC�Q�[�}�[����ɏ�������C�Ȃ�Ă��炳�疳������
�͂����肢����Intel�͒P��GPU�œV������낤�Ȃ�Ďv���ĂȂ��ł��傤�B
���łɃI���{�[�hGPU�Ƃ������W���[�ȕ����}���Ă���Intel���A
������j�b�`�ȕ���ɂȂ�悤�Ȃ��̂ɘJ�͂�������Ƃ͎v���Ȃ��B
���Ⴀ����Intel�͂킴�킴�����J�l��������Larrabee�̂悤�Ȃ��̂�����Ă���̂��H
����͍ŏI�I�ɂ�CPU�őS�Ă̏������s���Ă��܂��悤�ɂ��鎖�B
�ق��Ă����AGPGPU�Ɏ����玟�ւƎd����D���Ă��܂����O������̂��낤�ˁB
�h��荇����CPU��GPU�������p�b�P�[�W�ɂ��܂����h���x�̂��̂��A���N�o�Ă��邪�A
�����I�ɂ͑唼��PC���[�U�[�������ł��郌�x����GPU��CPU�Ɠ����̌��Ɏ��������ł��傤�B
�����Ȃ�A�g���J�[�h��GPU�Ȃ�Ĉꕔ�̂o�b�Q�[���^���炢��������Ȃ��悤�Ȏ������̃A�i�N���A�C�e���ɂȂ邱�Ƃł��傤�B
943 �FSocket774�F2009/06/23(��) 00:21:42 ID:2zsDw3xM
>>932
�T���\��+�`�l�c+�\�j�[���������Ă��܂��C���e�������㍂�͏ォ�E�E�E�B
�C���e���ɑR���鐨�͂����ɂ͔��[�ȕ��@���Ⴈ��グ���x������ȁB
�C���e���̌����J������Ċm��48���h���������H�H
����������intel���b�o�t�s���Ɛ肵�Ă�肽�������炩���n�߂�̂�}������x��
�l�ł����Ƃł����ł���������C���e�����i�ɋ����ł��鐻�i��n�邽�߂�
�����҂ɂȂ��Ă�����Ăǂ����̋������[�J�[�ɂ�����Ă��炢������������������
�T���\��+�`�l�c+�\�j�[���������Ă��܂��C���e�������㍂�͏ォ�E�E�E�B
�C���e���ɑR���鐨�͂����ɂ͔��[�ȕ��@���Ⴈ��グ���x������ȁB
�C���e���̌����J������Ċm��48���h���������H�H
����������intel���b�o�t�s���Ɛ肵�Ă�肽�������炩���n�߂�̂�}������x��
�l�ł����Ƃł����ł���������C���e�����i�ɋ����ł��鐻�i��n�邽�߂�
�����҂ɂȂ��Ă�����Ăǂ����̋������[�J�[�ɂ�����Ă��炢������������������
���n�̃N�Y���̂�����{�̍s���ɂ͊��҂ł��Ȃ�
����
�̂������r�f�I�J�[�h�͂o�b�Q�[���^���������ĂȂ�����w
�����唼�̓Q�[��������ĂȂ�����
�̂������r�f�I�J�[�h�͂o�b�Q�[���^���������ĂȂ�����w
�����唼�̓Q�[��������ĂȂ�����
�̂̓r�f�I�J�[�h�Ȃ��ƊG���o�Ȃ��������B
949 �FSocket774�F2009/06/23(��) 12:25:23 ID:S4mu1KOO
��ʐl���r�f�I�J�[�h�����Ǝv���Ă�A�z���Ă܂�����E�E�E�r�f�I�J�[�h�̓I�^���������B
�@ �@�@�@�@�@�@�@,. -��k'��'�-�
�@�@�@�@�@�@�@,�m�@�@�@�@�@�@�@�@ �_
�@�@�@�@�@ �@/�@,r�]�ււ���'�ʤ�@ �R
�@�@�@�@�@�@ {�m ��.._�A ,,�^~`�@�@�r �@�p�@�@�@�@,r=-�
�@�@�@�@ �@�^�v�P`y'�NY�L�P�R�\}j=���@�@�@�@/,�~=/
�@�@�@�@�m�@/��'>-�q�Q�`�[�]'�@�@�,�} �@�@�@�V�@/
�@�@�@/�@_�� �;�G��r;==����'��;�@�V�@ �@ �V�@/
�@�@,/�@��' �m �_ �@ ���N�M�@�@�@ �m{�[--��V__/
�@ �l�Q_/�[�� ��-��Q_,,..�@�]'�L �V`�@�[��[�_
. /�@�@�@|�^�@|::::::|��@�@�@�@�@�@�@�V�@/:::::/ �@�@�@�R
/�@�@�@�b �@ |::::::|�_�_________�^' �@ /:::::/�V
! �@ �@�@l �@�@|::::::|�@�@�M�P�P�L �@�@�@|::::::|/
�@�@�@ �m�_�@|::::::| �@�@�@�@ �@�@�@ �@ |::::::|
�@ �@�@�@�@�@�@�@,. -��k'��'�-�
�@�@�@�@�@�@�@,�m�@�@�@�@�@�@�@�@ �_
�@�@�@�@�@ �@/�@,r�]�ււ���'�ʤ�@ �R
�@�@�@�@�@�@ {�m ��.._�A ,,�^~`�@�@�r �@�p�@�@�@�@,r=-�
�@�@�@�@ �@�^�v�P`y'�NY�L�P�R�\}j=���@�@�@�@/,�~=/
�@�@�@�@�m�@/��'>-�q�Q�`�[�]'�@�@�,�} �@�@�@�V�@/
�@�@�@/�@_�� �;�G��r;==����'��;�@�V�@ �@ �V�@/
�@�@,/�@��' �m �_ �@ ���N�M�@�@�@ �m{�[--��V__/
�@ �l�Q_/�[�� ��-��Q_,,..�@�]'�L �V`�@�[��[�_
. /�@�@�@|�^�@|::::::|��@�@�@�@�@�@�@�V�@/:::::/ �@�@�@�R
/�@�@�@�b �@ |::::::|�_�_________�^' �@ /:::::/�V
! �@ �@�@l �@�@|::::::|�@�@�M�P�P�L �@�@�@|::::::|/
�@�@�@ �m�_�@|::::::| �@�@�@�@ �@�@�@ �@ |::::::|
Larrabee����Pen4&ATOM�̌n���Ȃ̂���?
Pen4���Č��XCPU�Ƃ��Ă���ꂽ���̂���Ȃ����ĉ\��������ˁc
ttp://ameclub.com/cpu.html#p4secret
�ȂA�̂�i386�̃R�v�����Ă�悤�ʼn���������
Pen4���Č��XCPU�Ƃ��Ă���ꂽ���̂���Ȃ����ĉ\��������ˁc
ttp://ameclub.com/cpu.html#p4secret
�ȂA�̂�i386�̃R�v�����Ă�悤�ʼn���������
����P7������Ă����T���^�N������Merced�̊J���ɂȂ������A�I���S����Netburst�A
�C�X���G����Timna����Ă����낾���A����CPU���`�[�������Ȃ��悤�ȁB
�C�X���G����Timna����Ă����낾���A����CPU���`�[�������Ȃ��悤�ȁB
952 �FMAC�I�^��936 �����F2009/06/23(��) 17:24:42 ID:tntOpIdc
>>936
�@�@--------------------
�@�@���ł͂��Ԃ�Cell�̃��C���̌����߂̂��߂�SSD�ɓ������Ă��ˁH
�@�@--------------------
���W�b�N�v���Z�X�̍H���NAND���ł�����ăg���f�����́A�N�ɋ����܂�����(��)
�@�@--------------------
�@�@���ł͂��Ԃ�Cell�̃��C���̌����߂̂��߂�SSD�ɓ������Ă��ˁH
�@�@--------------------
���W�b�N�v���Z�X�̍H���NAND���ł�����ăg���f�����́A�N�ɋ����܂�����(��)
�����ł����A���Ƒ���Larrabee�L���B
http://www.pcpop.com/doc/0/411/411867.shtml
���ɐV���͖����悤�ȋC�����܂����c
http://www.pcpop.com/doc/0/411/411867.shtml
���ɐV���͖����悤�ȋC�����܂����c
Cell�Ƃ�PS3��GPU���ē��ł���B�̃t�@�u�����č���Ă�����H
������65nm�炵�����ǐݔ������͂ł����
������65nm�炵�����ǐݔ������͂ł����
GPU�̕��͒m��ǁACell��45nm�ł̐��Y���n�܂��Ă��B
�����Ȃ�
���̑O�o���V�{�̂��܂�65nm���������犨�Ⴂ����
���̑O�o���V�{�̂��܂�65nm���������犨�Ⴂ����
957 �FSocket774�F2009/06/23(��) 21:28:43 ID:2zsDw3xM
>>945-946�͂���Ӗ������B
GPU�̐��\�����́A������PC���[�U�[�ɂƂ��āu�{���́v�Ӗ��̂Ȃ����Ƃł��B
Geforce 7150 + nForce 630i�̑g�ݍ��킹��PC����GeForceGTX285���R�����ڂ���PC�ɑウ�Ă�
��ȗp�r�����[�h�ƃG�N�Z����E���[����Web�u���E�Y���x�Ȃ炽�����ĉ��K�ɂ͂Ȃ�܂���B���K�ɂȂ��O��PC�Q�[�����炢�̂��̂ł��B
�ނ���GPU�̂ނ�݂ȍ������́A����ȏ���d�͂ɔ����ܔM�n�����A��p�̂��߂̑����A�n���������҂̉��i�d�C��j�ւ̕��ׂ����߂܂��B
�N���������A�p�\�R����GPU�̑��x���\�������邱�Ƃɂ��������C�Â��͂��߂Ă��܂��B
����GPU�𓋍ڂ����}�V���̃f�J���A���邳���A�X�����⍂�������j���O�R�X�g��焈Ղ��͂��߂Ă��܂��B
�ǂ�Ȃɂ����ꂽ���\��GPU���ڂ��Ă��邩��Ƃ����āA����PC�ɔ��������邱�Ƃ͂��ꂩ��͂Ȃ��Ȃ��Ă����ł��傤�B
����GPU�p���[��K�v�Ƃ������I�ŏՌ��I�ȃA�v���P�[�V����������Ȃ�����͍���GPU�̎��v�͊��N�ł����A
���ʁAPC���̂��̂̔��������T�C�N���͏��X�ɗ����Ă������Ƃ͊ԈႢ�Ȃ��ł��傤�B
GPU�̐��\�����́A������PC���[�U�[�ɂƂ��āu�{���́v�Ӗ��̂Ȃ����Ƃł��B
Geforce 7150 + nForce 630i�̑g�ݍ��킹��PC����GeForceGTX285���R�����ڂ���PC�ɑウ�Ă�
��ȗp�r�����[�h�ƃG�N�Z����E���[����Web�u���E�Y���x�Ȃ炽�����ĉ��K�ɂ͂Ȃ�܂���B���K�ɂȂ��O��PC�Q�[�����炢�̂��̂ł��B
�ނ���GPU�̂ނ�݂ȍ������́A����ȏ���d�͂ɔ����ܔM�n�����A��p�̂��߂̑����A�n���������҂̉��i�d�C��j�ւ̕��ׂ����߂܂��B
�N���������A�p�\�R����GPU�̑��x���\�������邱�Ƃɂ��������C�Â��͂��߂Ă��܂��B
����GPU�𓋍ڂ����}�V���̃f�J���A���邳���A�X�����⍂�������j���O�R�X�g��焈Ղ��͂��߂Ă��܂��B
�ǂ�Ȃɂ����ꂽ���\��GPU���ڂ��Ă��邩��Ƃ����āA����PC�ɔ��������邱�Ƃ͂��ꂩ��͂Ȃ��Ȃ��Ă����ł��傤�B
����GPU�p���[��K�v�Ƃ������I�ŏՌ��I�ȃA�v���P�[�V����������Ȃ�����͍���GPU�̎��v�͊��N�ł����A
���ʁAPC���̂��̂̔��������T�C�N���͏��X�ɗ����Ă������Ƃ͊ԈႢ�Ȃ��ł��傤�B
>>943
���T���\��+�`�l�c+�\�j�[���������Ă��܂�
���̕��ʂ͌�������������ꂪ�����Ȃ����B
>932�͔����̕��傾���̔���ŁA��БS�̂̔���Ȃ�
�\�ʼn��ʂ̉�Ђ̂�������Intel����Ȃ킯����
���T���\��+�`�l�c+�\�j�[���������Ă��܂�
���̕��ʂ͌�������������ꂪ�����Ȃ����B
>932�͔����̕��傾���̔���ŁA��БS�̂̔���Ȃ�
�\�ʼn��ʂ̉�Ђ̂�������Intel����Ȃ킯����
>>957
�n�C�G���hGPU�Ƃ��A2�������A3�������Ȃ�ăQ�[�}�[�ł���ȑO�ɒP�Ȃ镨�D���Ȃ��?
3D�Q�[���l(������ق�Ƃɏ��X�ł͂��邪�ꉞ���̒��̈�l)�ł��A���������̃��[�U��
PC�̕��i�̎g��������C�ɂ��Ă���̂ŁA�ł���~�h���`���[�G���h��GPU�͐蔲�������Ƃ���Ȃ�B
�Ƃ������n�C�G���hGPU������邽�߂ɁA�n�C�G���h��3D�Q�[������Ă���Ƃ��������B
���̃Q�[��GPU�ɑ���v����������������₾�Ȃ��Ƃ��B
�܂�A�Q�[�}�[=������GPU�Ƃ����̂͒Z���I�����锭�z�B
�ނ���p�[�c�͎��p���Ƃ�����Ȃ��A�Ƃɂ����n�C�G���h�őg��ł���
�Ƃ������n�C�G���h����I�^�w�̕������������Ă���̂ł͂Ȃ����ƁB
�n�C�G���hGPU�Ƃ��A2�������A3�������Ȃ�ăQ�[�}�[�ł���ȑO�ɒP�Ȃ镨�D���Ȃ��?
3D�Q�[���l(������ق�Ƃɏ��X�ł͂��邪�ꉞ���̒��̈�l)�ł��A���������̃��[�U��
PC�̕��i�̎g��������C�ɂ��Ă���̂ŁA�ł���~�h���`���[�G���h��GPU�͐蔲�������Ƃ���Ȃ�B
�Ƃ������n�C�G���hGPU������邽�߂ɁA�n�C�G���h��3D�Q�[������Ă���Ƃ��������B
���̃Q�[��GPU�ɑ���v����������������₾�Ȃ��Ƃ��B
�܂�A�Q�[�}�[=������GPU�Ƃ����̂͒Z���I�����锭�z�B
�ނ���p�[�c�͎��p���Ƃ�����Ȃ��A�Ƃɂ����n�C�G���h�őg��ł���
�Ƃ������n�C�G���h����I�^�w�̕������������Ă���̂ł͂Ȃ����ƁB
3D�Q�[�Ȃ�ăG���Q�ȉ��̔���グ�̂��̍��Ńn�C�G���hGPU�������������̂�
������ƈُ킾���w
���̃X�e�C�^�X�Ƃ��Ĕ����Ă�z��������
������ƈُ킾���w
���̃X�e�C�^�X�Ƃ��Ĕ����Ă�z��������
����̏ꍇ��PC���������������Ă�A���v�ƃX�s�[�J�[����łĂ���T�E���h���A
PC�̑����ɑj�Q�����̂�����Ȃ�ȁB���{�̃I�^�N�ɂ͂��Ƒ����Ǝv���B
�R�A�Q�[�}�[�͔���ȃO���t�B�b�N�X�ݒ�����A���₷�����d���ŃO���t�B�N�X��ݒ肵����
����炵�����A���̃Q�[�}�[�����܂����ȃO���t�B�b�N�X�𒆐S�ɍl���Ă���킯����Ȃ��Ǝv���B
�܂��A����Ȃ�̐��\���Ȃ��Ɖ𑜓x�������Ȃ�������Ƃ��A�Q�[�����̃X�g���X�ɂ��Ȃ���킯�����B
�����āA�n�C�G���hGPU���K�v������Q�[�����������Ȃ��Ȃ�悤�ł͂��Ƃ������Ȃ��B
PC�̑����ɑj�Q�����̂�����Ȃ�ȁB���{�̃I�^�N�ɂ͂��Ƒ����Ǝv���B
�R�A�Q�[�}�[�͔���ȃO���t�B�b�N�X�ݒ�����A���₷�����d���ŃO���t�B�N�X��ݒ肵����
����炵�����A���̃Q�[�}�[�����܂����ȃO���t�B�b�N�X�𒆐S�ɍl���Ă���킯����Ȃ��Ǝv���B
�܂��A����Ȃ�̐��\���Ȃ��Ɖ𑜓x�������Ȃ�������Ƃ��A�Q�[�����̃X�g���X�ɂ��Ȃ���킯�����B
�����āA�n�C�G���hGPU���K�v������Q�[�����������Ȃ��Ȃ�悤�ł͂��Ƃ������Ȃ��B
�������f�X�N�g�b�vPC�ŃT�E���h�u���X�^�[�̑�������0.x���������H
�f�B�X�N���[�gGPU�������������܂ʼn�����̂ɂ͂܂�10�N�ȏォ���邾��
�f�B�X�N���[�gGPU�������������܂ʼn�����̂ɂ͂܂�10�N�ȏォ���邾��
964 �FSocket774�F2009/06/25(��) 00:26:04 ID:K2GEEYDR
>>944
�����n�̃N�Y���̂�����{�̍s���ɂ͊��҂ł��Ȃ�
�č��������悤�Ȃ��̂��B���[�K���ȑO�̃A�����J�Ȃ�AT&T������IBM�̎s����x���`���[��Ƃɉ��������
�����������̑勣������ɒa���������卑�u���ؐl�����a���v�̒a���ɂ��A�����J�͂��ĂȂ���@���������Ă���B
MS��intel���ǂꂾ���̃x���`���[��Ƃ̉��E�������A��̔ɉh����������邱�Ƃŕč����{�͐���t���E�E�E�B
�����邩���ʂ��ɂȂ�Ȃ�����X�N�̍�������Ȃǂ��Ȃ��̂��l�Ԃ��BNVIDIA��CUDA�͌��݂�PC�ɂ�����̑�Ȓ��킾�Ǝ^���������B
�������ቿ�i��PC�͑�Ȃ��̂������E��ς���͂����邪�A��������Z�p�͍����ȃn�C�G���h���i�����̕��Y���ł���B
�����𔗂�ꂽNVIDIA�̓J�[�h�ꖇ�̏�Ɏ��O�̃R���s���[�^�����B���������PCI�o�X��������ǂ��PC�̏�ł����点���邩��A����intel�ɓ��������Ȃ��Ă����B
���������̕��@��NVIDIA�̉�Ђ̋K�́i���㍂4��8110���h���j����l����ƁA�ƂĂ����藧���Ȃ��B
��������邵���Ȃ����A�o���Ȃ����NVIDIA�ɑ����̑I�����͂Ȃ��B
���ɋ����قǑf���炵���摜�������������Ăق����B5���~���x��DVD���R�[�_�[�����A���^�C����H.264�ϊ����o����̂ɁA
100���~�o���Ă�X86��CPU�ł͕ҏW�����N�ɂł��₵�Ȃ��BLarrabee�Ɛ키�̂͑�ς��낤����AXBOX360�̗l�ɂƂɂ��������ł������}�[�P�b�g�Ŏg���邱�Ƃ���Ԃ�
CELL�������ڎw���Ă������Ȃ̂ɂ��͂�SONY�͎��̂��낤�E�E�E�E�B
�͕̂��������\�j�[���i���炯�������̂��A���͂��ׂĂ��������ł��邱�Ƃ�^�ʖڂɍl����ƕ|���Ȃ�E�E�E�B
�����n�̃N�Y���̂�����{�̍s���ɂ͊��҂ł��Ȃ�
�č��������悤�Ȃ��̂��B���[�K���ȑO�̃A�����J�Ȃ�AT&T������IBM�̎s����x���`���[��Ƃɉ��������
�����������̑勣������ɒa���������卑�u���ؐl�����a���v�̒a���ɂ��A�����J�͂��ĂȂ���@���������Ă���B
MS��intel���ǂꂾ���̃x���`���[��Ƃ̉��E�������A��̔ɉh����������邱�Ƃŕč����{�͐���t���E�E�E�B
�����邩���ʂ��ɂȂ�Ȃ�����X�N�̍�������Ȃǂ��Ȃ��̂��l�Ԃ��BNVIDIA��CUDA�͌��݂�PC�ɂ�����̑�Ȓ��킾�Ǝ^���������B
�������ቿ�i��PC�͑�Ȃ��̂������E��ς���͂����邪�A��������Z�p�͍����ȃn�C�G���h���i�����̕��Y���ł���B
�����𔗂�ꂽNVIDIA�̓J�[�h�ꖇ�̏�Ɏ��O�̃R���s���[�^�����B���������PCI�o�X��������ǂ��PC�̏�ł����点���邩��A����intel�ɓ��������Ȃ��Ă����B
���������̕��@��NVIDIA�̉�Ђ̋K�́i���㍂4��8110���h���j����l����ƁA�ƂĂ����藧���Ȃ��B
��������邵���Ȃ����A�o���Ȃ����NVIDIA�ɑ����̑I�����͂Ȃ��B
���ɋ����قǑf���炵���摜�������������Ăق����B5���~���x��DVD���R�[�_�[�����A���^�C����H.264�ϊ����o����̂ɁA
100���~�o���Ă�X86��CPU�ł͕ҏW�����N�ɂł��₵�Ȃ��BLarrabee�Ɛ키�̂͑�ς��낤����AXBOX360�̗l�ɂƂɂ��������ł������}�[�P�b�g�Ŏg���邱�Ƃ���Ԃ�
CELL�������ڎw���Ă������Ȃ̂ɂ��͂�SONY�͎��̂��낤�E�E�E�E�B
�͕̂��������\�j�[���i���炯�������̂��A���͂��ׂĂ��������ł��邱�Ƃ�^�ʖڂɍl����ƕ|���Ȃ�E�E�E�B
> 5���~���x��DVD���R�[�_�[�����A���^�C����H.264�ϊ����o����̂ɁA
����͂����Ɛi��ł�B
�P�[�^�C�����`�b�v�Ń��A���^�C�������܂����B
http://www.itmedia.co.jp/promobile/articles/0904/24/news104.html
����͂����Ɛi��ł�B
�P�[�^�C�����`�b�v�Ń��A���^�C�������܂����B
http://www.itmedia.co.jp/promobile/articles/0904/24/news104.html
966 �FSocket774�F2009/06/25(��) 01:21:14 ID:K2GEEYDR
>>907
���m���ɑS���V���������S���V�����A�[�L�e�N�`�����[������o���Ȃ����J�͂����Ƃ�Ȃ��l���������镪��́A
�����\�������ŗD��ł���ȊO�͑S�ē�̎��A�O�̎��ȃX�[�p�[�R���s���[�^�[�����Ȋw�v�Z���삾���ł��傤�B
������͍��܂ł����ꂩ����ς��Ȃ��ł��傤�B �n�[�h�̐i���͑����B
���ł��A�\�t�g�E�F�A�̐i���͒x���B����͗��j�������Ă܂��B
�Ƃ������A���ꂪx86�̎����Ȃ�ȁB
�u�ߋ��̎��Y�𗬗p�ł��邩��vx86���g���Ă��钆�ŁA�u�킴�킴�ʂ̂������o����v�Ȃ�Ax86�Ȃ�Ďg���Ӗ���������ȁB
�����ƃn�b�L�������A�V�����v���O�������@���o����Ȃ�A������ɂ܂�Ȃ��ď����������Ȃ������x86�Ȃǂł͂Ȃ��A
�Q�[���@�Ɏg���Ă�ꍇ������PowerPC��g�тŎg����ARM��SuperH�V���[�Y�̕����A���������������B
�ƂȂ�ƁA���Łu�R�X�g�������Ă܂ŏK�����Ȃ���Ȃ�Ȃ��̂��v�Ƃ����b�ɂȂ�B
�܂��A���������킯�ŁA�ʂɃv���O���}�[�̐i�����x���Ƃ����킯�ł͂Ȃ��A��p�Ό��ʂ̘b���ȁB
ARM�̍œK���͋}���ɐi�ނ��A�Q�[���@��CPU�̎g�p�����}���ɏオ���Ă��邩��A
�v���O���}�[�̋Z�p���S�R�����Ƃ����킯�ł͂Ȃ���ȁB
���m���ɑS���V���������S���V�����A�[�L�e�N�`�����[������o���Ȃ����J�͂����Ƃ�Ȃ��l���������镪��́A
�����\�������ŗD��ł���ȊO�͑S�ē�̎��A�O�̎��ȃX�[�p�[�R���s���[�^�[�����Ȋw�v�Z���삾���ł��傤�B
������͍��܂ł����ꂩ����ς��Ȃ��ł��傤�B �n�[�h�̐i���͑����B
���ł��A�\�t�g�E�F�A�̐i���͒x���B����͗��j�������Ă܂��B
�Ƃ������A���ꂪx86�̎����Ȃ�ȁB
�u�ߋ��̎��Y�𗬗p�ł��邩��vx86���g���Ă��钆�ŁA�u�킴�킴�ʂ̂������o����v�Ȃ�Ax86�Ȃ�Ďg���Ӗ���������ȁB
�����ƃn�b�L�������A�V�����v���O�������@���o����Ȃ�A������ɂ܂�Ȃ��ď����������Ȃ������x86�Ȃǂł͂Ȃ��A
�Q�[���@�Ɏg���Ă�ꍇ������PowerPC��g�тŎg����ARM��SuperH�V���[�Y�̕����A���������������B
�ƂȂ�ƁA���Łu�R�X�g�������Ă܂ŏK�����Ȃ���Ȃ�Ȃ��̂��v�Ƃ����b�ɂȂ�B
�܂��A���������킯�ŁA�ʂɃv���O���}�[�̐i�����x���Ƃ����킯�ł͂Ȃ��A��p�Ό��ʂ̘b���ȁB
ARM�̍œK���͋}���ɐi�ނ��A�Q�[���@��CPU�̎g�p�����}���ɏオ���Ă��邩��A
�v���O���}�[�̋Z�p���S�R�����Ƃ����킯�ł͂Ȃ���ȁB
�\�j�[�̓��[�J�[�A�����͍�����
���ƂȂ���@���������Ă���悤�ŁAIBM��1991�N�̃��X�g���Ǝs��̖�������������
cuDA���^������A�����Ă��邱�Ƃ�����������B
�����A���n�ɂ����n�ɂ��Ȃ�Ȃ������l�Ȃ낤�ȁB
�����悤�ōL���ȓ��{�́A�܂��܂��F��Ȑl�فB
���ƂȂ���@���������Ă���悤�ŁAIBM��1991�N�̃��X�g���Ǝs��̖�������������
cuDA���^������A�����Ă��邱�Ƃ�����������B
�����A���n�ɂ����n�ɂ��Ȃ�Ȃ������l�Ȃ낤�ȁB
�����悤�ōL���ȓ��{�́A�܂��܂��F��Ȑl�فB
MAC�I�^���������������ǁA���̂͂邩����s����ނ��ȁc
IBM�̃��X�g���Ȃ�Ă������B
�x�����̃��X�g���Ȃ��ۂɎc���Ă邪
�x�����̃��X�g���Ȃ��ۂɎc���Ă邪
970 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/25(��) 07:10:51 ID:k0Bh9s7r
CUDA�i�j���ăz�X�g���L�b�N���Ă��Ȃ��Ƒ���Ȃ���
������x86�ˑ��A�Ƃ������R���p�C���^�[�Q�b�g�ˑ�
NVCC�ł�"Host"���̃R�[�h�͊e�^�[�Q�b�g�EOS�ɑ���l�C�e�B�u�R�[�h���̂��̂ɃR���p�C�������B
�ނ�����o���Ȃ����Z�����O�ł�邱�Ƃ͊��S�ɒ��߂Ă�̂�CUDA�B
�X�J�����Z�͂���������������e�R�A��Pentium�����i�ɖт����������x�j�̃X�J�����Z���j�b�g�������̂�Larrabee
������x86�ˑ��A�Ƃ������R���p�C���^�[�Q�b�g�ˑ�
NVCC�ł�"Host"���̃R�[�h�͊e�^�[�Q�b�g�EOS�ɑ���l�C�e�B�u�R�[�h���̂��̂ɃR���p�C�������B
�ނ�����o���Ȃ����Z�����O�ł�邱�Ƃ͊��S�ɒ��߂Ă�̂�CUDA�B
�X�J�����Z�͂���������������e�R�A��Pentium�����i�ɖт����������x�j�̃X�J�����Z���j�b�g�������̂�Larrabee
>>969
PC����͂����ɔ����Ă��܂��܂���
PC����͂����ɔ����Ă��܂��܂���
�������̂��Ƃ�
��������Ȃ����āA1990�N��n�߂ɉ��������������������ޯ�ؐ����ڂ���
����������
����������
>�u�ߋ��̎��Y�𗬗p�ł��邩��vx86���g���Ă��钆�ŁA
>�u�킴�킴�ʂ̂������o����v�Ȃ�Ax86�Ȃ�Ďg���Ӗ���������ȁB
Sun�X���ł����ł��Ă���B
���͑S���t�ł��B
x86�̃R�X�g�p�t�H�[�}���X���ǂ�����A
�킴�킴�݊������̂Ă��T�[�o�x���^�[��A
�݊����ɂ��Ƃ��Ƃ��܂肵���ĂȂ�HPC�ł�
x86���ǂ�ǂ��ɂ̂��Ă�B
���߃Z�b�g�̗D��͑債�����ł͂Ȃ��A���ǂ͐��̗͂Ȃ��B
>�u�킴�킴�ʂ̂������o����v�Ȃ�Ax86�Ȃ�Ďg���Ӗ���������ȁB
Sun�X���ł����ł��Ă���B
���͑S���t�ł��B
x86�̃R�X�g�p�t�H�[�}���X���ǂ�����A
�킴�킴�݊������̂Ă��T�[�o�x���^�[��A
�݊����ɂ��Ƃ��Ƃ��܂肵���ĂȂ�HPC�ł�
x86���ǂ�ǂ��ɂ̂��Ă�B
���߃Z�b�g�̗D��͑債�����ł͂Ȃ��A���ǂ͐��̗͂Ȃ��B
Apple����芷�����̂����ǃR�X�p�������
LRB�����̗͂̔g�ɏ��邩�ǂ�������ȁB
�x�N�g���v���Z�b�T���Ă̂͗v����ɃX�p�R���p��p�v���Z�b�T��1��ŁA
���̘_���Ŕėp�X�J���ɕ��������B
�Ⴆ�x�N�g��vs�X�J�����Ă̂̓K���͋Z�p�_���ۂ���
�X�p�R����p�vvs���̑��̗p�r�̔ėp�`�b�v���p
�̌o�ϖʂ̔�r�ł����Ȃ��Ƃ������A�͂��߂��炻���������_�ōl��������������ȁB
GPGPU��HPC�ł̗��p���Ă̂́AGPU�����Z��������������ǂ��������Ă̂����邪
PC�����Ɍ��X�����Ă���`�b�v�����̂܂�HPC�ɗ��p���悤�Ƃ��Ă���Ƃ���ɑ傫�ȈӖ�������B
������PC�ŃV�F�A���Ƃ�Ȃ��Ȃ�����ǂ�ǂ�X�p�R����p�v�`�b�v�ɋ߂Â��ē������H�Ɍ��������ǂˁB
LRB�������������ɐ��̗͂ɂ����Ă����邩�������ǂ���ł��B
�x�N�g���v���Z�b�T���Ă̂͗v����ɃX�p�R���p��p�v���Z�b�T��1��ŁA
���̘_���Ŕėp�X�J���ɕ��������B
�Ⴆ�x�N�g��vs�X�J�����Ă̂̓K���͋Z�p�_���ۂ���
�X�p�R����p�vvs���̑��̗p�r�̔ėp�`�b�v���p
�̌o�ϖʂ̔�r�ł����Ȃ��Ƃ������A�͂��߂��炻���������_�ōl��������������ȁB
GPGPU��HPC�ł̗��p���Ă̂́AGPU�����Z��������������ǂ��������Ă̂����邪
PC�����Ɍ��X�����Ă���`�b�v�����̂܂�HPC�ɗ��p���悤�Ƃ��Ă���Ƃ���ɑ傫�ȈӖ�������B
������PC�ŃV�F�A���Ƃ�Ȃ��Ȃ�����ǂ�ǂ�X�p�R����p�v�`�b�v�ɋ߂Â��ē������H�Ɍ��������ǂˁB
LRB�������������ɐ��̗͂ɂ����Ă����邩�������ǂ���ł��B
�Ȃ������ɂ͂܂������W�Ȃ��������Ƃ��G�������Ƃ��Ȃ��ʐ��E�̂ł����Ƃ��A
�����\���Ҍ������ɁA���邢�͂������������̍l�������������i���Ă��邩�̔@��������̂�
�����\���Ҍ������ɁA���邢�͂������������̍l�������������i���Ă��邩�̔@��������̂�
�\���҂݂�������Ȃ��āA�\���҂Ȃ�ł�(��炡
�������͂��܌��J����Ă�����̘g�̒����琄�@�����
�P�ɂ��̉�������̃}�}HPC�ɐi�o�������ςȋ�������Ǝv����B
�Ƃ��������Ԃ�g�����ɂȂ�Ȃ��Ǝv���B
���R�́c�����Ă��[���Ȃ���
���Ƃ��A���̕ӂł��ǂ�ŗސ����Ă��ꂽ�܂ցB
ttp://gimpo.2ch.net/test/read.cgi/scienceplus/1242298968/146
������͒��ڃ������̘b����Ȃ����ǁA�����ގ����̂���h�c�{�ɂ͂܂肻�����Ǝv���Ă���
�P�ɂ��̉�������̃}�}HPC�ɐi�o�������ςȋ�������Ǝv����B
�Ƃ��������Ԃ�g�����ɂȂ�Ȃ��Ǝv���B
���R�́c�����Ă��[���Ȃ���
���Ƃ��A���̕ӂł��ǂ�ŗސ����Ă��ꂽ�܂ցB
ttp://gimpo.2ch.net/test/read.cgi/scienceplus/1242298968/146
������͒��ڃ������̘b����Ȃ����ǁA�����ގ����̂���h�c�{�ɂ͂܂肻�����Ǝv���Ă���
>>978
���������āACPU����ڂŁA���J�̏���(���ߏ�)�ɓ��ꍞ��ł�Ƃ�
�딚���Ė\�I���������ޏ��N�������@����A��w���ނȗ\���҂���ł�
���J�͂قǂقǂɂȂ� ɼ
���������āACPU����ڂŁA���J�̏���(���ߏ�)�ɓ��ꍞ��ł�Ƃ�
�딚���Ė\�I���������ޏ��N�������@����A��w���ނȗ\���҂���ł�
���J�͂قǂقǂɂȂ� ɼ
981 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/25(��) 23:48:00 ID:k0Bh9s7r
�ގ����͔��o���Ȃ��ȁB
���Ƃ���Larrabee���r�b�O�G���f�B�A�����Ƃł��v���Ă�̂��H
���Ƃ���Larrabee���r�b�O�G���f�B�A�����Ƃł��v���Ă�̂��H
983 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/25(��) 23:54:43 ID:k0Bh9s7r
�uCt�v�̊T�v�������Ă�H
���ƁA�\�t�g�E�F�A�g�����U�N�V���i���������Ƃ�
���ǂ̓\�t�g���悾
������̃A�[�L�e�N�`�����R���p�C�����܂Ƃ��ȏ����R���p�C�������݂��Ȃ�
Opteron+Cell�݂����Ȃ��̂��ɏo���̂͒p����������B
���ƁA�\�t�g�E�F�A�g�����U�N�V���i���������Ƃ�
���ǂ̓\�t�g���悾
������̃A�[�L�e�N�`�����R���p�C�����܂Ƃ��ȏ����R���p�C�������݂��Ȃ�
Opteron+Cell�݂����Ȃ��̂��ɏo���̂͒p����������B
�Ƃ���ő�̂̃v���Z�b�T����ɋ@�\������}��Ƃ����̂�
����ς��ꂪ�͂���Ȃ̂����H
http://journal.mycom.co.jp/articles/2004/10/14/fpf/001.html
����ς��ꂪ�͂���Ȃ̂����H
http://journal.mycom.co.jp/articles/2004/10/14/fpf/001.html
>>983
��Ă͑厖�����A�������ł͂Ȃ��B���ɑ傴���ςɏ����ƁA
�V�X�e���S�̂ō����\��ڎw��HPC�ɑ��āA
������processor���R��R�q���ŒB����ڎw���c�Ƃ����헪��
�i���̑��H�����Ă��ƁB
�Ȃ��Ȃ���ɍ�������x�ł�����ƃX�P�[��������́A
linpack��FFT���n�߂Ƃ��Ď��̓\�t�g�Ƃ��Ă͏����h�ŁA
����䂥linpack��FFT�̂Ƃ��݂̂Ɏg���āA
����ȊO�̂�₱�����������Ƃ��Ƃ��ɂ́A���p�̒����c���ɗ����Ȃ�
���������i����ڎw���Ă��܂��ƌ������ƁB
���[�h�����i�[�͂����������H�ɕБ��˂������Ȃ̂�B
��Ă͑厖�����A�������ł͂Ȃ��B���ɑ傴���ςɏ����ƁA
�V�X�e���S�̂ō����\��ڎw��HPC�ɑ��āA
������processor���R��R�q���ŒB����ڎw���c�Ƃ����헪��
�i���̑��H�����Ă��ƁB
�Ȃ��Ȃ���ɍ�������x�ł�����ƃX�P�[��������́A
linpack��FFT���n�߂Ƃ��Ď��̓\�t�g�Ƃ��Ă͏����h�ŁA
����䂥linpack��FFT�̂Ƃ��݂̂Ɏg���āA
����ȊO�̂�₱�����������Ƃ��Ƃ��ɂ́A���p�̒����c���ɗ����Ȃ�
���������i����ڎw���Ă��܂��ƌ������ƁB
���[�h�����i�[�͂����������H�ɕБ��˂������Ȃ̂�B
�Ȃ�āA�_���S�ɐ����Ă����Ԃ̖��ʂ��c
�A�Z���u���Ƃ��@�B�ꃌ�x���̚n�D�ʼnۑ�ɑ���\�����[�V�����̑I����
�헪���]�X������ȁc
�́[�A���Ԃ̖��ʂ�ɼ
�A�Z���u���Ƃ��@�B�ꃌ�x���̚n�D�ʼnۑ�ɑ���\�����[�V�����̑I����
�헪���]�X������ȁc
�́[�A���Ԃ̖��ʂ�ɼ
987 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/26(��) 00:08:16 ID:CL3cLhy9
���Ȃ݂�Larrabee�ƕ��ʂ�x86�̖��߃Z�b�g�̈Ⴂ���ăl�C�e�B�u��SIMD���߂̃x�N�g�������炢������B
Ct�ɂ�����VIP�݂����Ȕ���SIMD���ۉ����C���[���g�����ƂŒ�R�X�g�ő��݈ڐA���ł���B
> ������processor���R��R�q���ŒB����ڎw���c�Ƃ����헪��
> �i���̑��H�����Ă��ƁB
�����ˁB��ɖŖS�����̂̓x�N�g���X�p�R������Ȃ���
Ct�ɂ�����VIP�݂����Ȕ���SIMD���ۉ����C���[���g�����ƂŒ�R�X�g�ő��݈ڐA���ł���B
> ������processor���R��R�q���ŒB����ڎw���c�Ƃ����헪��
> �i���̑��H�����Ă��ƁB
�����ˁB��ɖŖS�����̂̓x�N�g���X�p�R������Ȃ���
988 �FOOO-��(�L�́M�U�����|���F2009/06/26(��) 00:09:44 ID:el0yMclU
�[���A�X�p�R���̃V�~�����[�V�����v���O�����Ȃ�̏��������Ƃ��邪�A
HPC�T�C�h�̘b�肪�D���ȘA���͌����݃��x�����Ⴂ���B
��玩��嗬�h�̓G�ł͂Ȃ���(��炡
���̂��ꂽ�X�J��vs�x�N�g���_(��)�Ƃ��ꐶ����Ă����낵���B
HPC�T�C�h�̘b�肪�D���ȘA���͌����݃��x�����Ⴂ���B
��玩��嗬�h�̓G�ł͂Ȃ���(��炡
���̂��ꂽ�X�J��vs�x�N�g���_(��)�Ƃ��ꐶ����Ă����낵���B
989 �FOOO-��(�L�́M�U�����|���F2009/06/26(��) 00:11:42 ID:OEWTzDWN
�X�p�R���̃V�~�����[�V�����v���O�������Ă����Ƃ�����Ƃ�����̂Ƃ͈Ⴄ���A
�܂�������B
�[���A����Ȃ�A�[�L�X���̕��`���Ă���낱���B
�܂�������B
�[���A����Ȃ�A�[�L�X���̕��`���Ă���낱���B
>>987
�ǂ��������ł���B�ʁX�̗��R�łˁB
BG��[�h�����i�[�Ɋւ��Ă͂��̃R���Z�v�g����o��O������ɔ�H����Ă����悤�Ȃ��́B
�x�N�g������ɒ��q�����Ȃ������R�́c�����ōl���Ă��ꂽ�܂ցB
�X�J���[�����Ɛ��N�Ŕ�Ԃ�B����������ōl���Ă��ꂽ�܂ցB
���Ⴀ�A�C�C�q������A���������Ƃ������đ��߂ɂ˂Ȃ�Bɼ
�ǂ��������ł���B�ʁX�̗��R�łˁB
BG��[�h�����i�[�Ɋւ��Ă͂��̃R���Z�v�g����o��O������ɔ�H����Ă����悤�Ȃ��́B
�x�N�g������ɒ��q�����Ȃ������R�́c�����ōl���Ă��ꂽ�܂ցB
�X�J���[�����Ɛ��N�Ŕ�Ԃ�B����������ōl���Ă��ꂽ�܂ցB
���Ⴀ�A�C�C�q������A���������Ƃ������đ��߂ɂ˂Ȃ�Bɼ
991 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/26(��) 00:14:35 ID:CL3cLhy9
Ruby on Rails�i�����̃o�b�N�G���h�v���O�����j������������������扴��
���A�ځA���Ȃ݂�HPC�ɂ͂����Ȃ��̂ł����S���B
�����
�����
993 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/26(��) 00:16:00 ID:CL3cLhy9
�l�b�g�o�[�X�g���i�j���ȁH������
�܂��V���O���X���b�h���\�͑厖���ȁB
�܂��V���O���X���b�h���\�͑厖���ȁB
994 �FOOO-��(�L�́M�U�����|���F2009/06/26(��) 00:17:50 ID:OEWTzDWN
���炩���߂����Ă������A
PC�����̃v���Z�b�T���x�N�g���g�������悤�����܂����A
PC��T�[�o�����̃v���Z�b�T���ʎY���ʂŃR�X�g�p�t�H�[�}���X���o���Ă��邩��
�������Č��������B�X�J��vs�x�N�g���Ȃ�Ă���������̌����ō��̐��E�����̂͊Ԉ���Ă����B
�x�N�g���A�[�L�e�N�`�������烁�����ш悪�K�v�Ƃ��A�z���_�������̂�HPC�I�^�̓����B
PC�����̃v���Z�b�T���x�N�g���g�������悤�����܂����A
PC��T�[�o�����̃v���Z�b�T���ʎY���ʂŃR�X�g�p�t�H�[�}���X���o���Ă��邩��
�������Č��������B�X�J��vs�x�N�g���Ȃ�Ă���������̌����ō��̐��E�����̂͊Ԉ���Ă����B
�x�N�g���A�[�L�e�N�`�������烁�����ш悪�K�v�Ƃ��A�z���_�������̂�HPC�I�^�̓����B
995 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/26(��) 00:19:07 ID:CL3cLhy9
SPARC�Ȃ�Ď��v���Z�b�T�Ȃ̂Ɏ����グ�Ă�z�����邭�炢����
>>994
�������ǁA���̽ڂ�
>�x�N�g���A�[�L�e�N�`�������烁�����ш悪�K�v�Ƃ��A�z���_�������̂�HPC�I�^�̓����B
���̌��ɂӂ�Ă���̂́A�������������ϴ���������B
�����ɑ��͂��Ă���ȂɊy�������H�@��M���ȁc
�������ǁA���̽ڂ�
>�x�N�g���A�[�L�e�N�`�������烁�����ш悪�K�v�Ƃ��A�z���_�������̂�HPC�I�^�̓����B
���̌��ɂӂ�Ă���̂́A�������������ϴ���������B
�����ɑ��͂��Ă���ȂɊy�������H�@��M���ȁc
�������ǎ��ڗ��ĂƂ��您�O��B
�ڂ̓������̊J�����ɂ��ĂȂǁA�ɂ��ł����珑���������Ƃ�������ŁB
�ڂ͐Q�邩��B�����~���ȁB
�ڂ̓������̊J�����ɂ��ĂȂǁA�ɂ��ł����珑���������Ƃ�������ŁB
�ڂ͐Q�邩��B�����~���ȁB
>>995
����A�ӂ[�Ɏ��������Ă�
338 �F�s���ȃf�o�C�X���� [sage] �F2009/05/17(��) 13:20:15 ID:98rUAN+E
HPC�ł̎��тǂ��납�A���_���炯��SPARC����A�������ɊF����s���������̂ł��傤�B
737 �F�s���ȃf�o�C�X���� [sage] �F2009/06/10(��) 00:48:58 ID:64w/cXNS
�i�O���j �Ƃ����͕̂ʂɂ��Ă�SPARC�̒x���͊W�҂ɂ͒m��n���Ă邩�� �i�㗪�j
820 �F�s���ȃf�o�C�X���� [sage] �F2009/06/16(��) 21:15:32 ID:08YydSOx
�i�O���j �ނ���F��SPARC��HPC����ŁA�ᑬ�E�����i�̊��Ⴂ�@��ł��邾���� �i�㗪�j
����A�ӂ[�Ɏ��������Ă�
338 �F�s���ȃf�o�C�X���� [sage] �F2009/05/17(��) 13:20:15 ID:98rUAN+E
HPC�ł̎��тǂ��납�A���_���炯��SPARC����A�������ɊF����s���������̂ł��傤�B
737 �F�s���ȃf�o�C�X���� [sage] �F2009/06/10(��) 00:48:58 ID:64w/cXNS
�i�O���j �Ƃ����͕̂ʂɂ��Ă�SPARC�̒x���͊W�҂ɂ͒m��n���Ă邩�� �i�㗪�j
820 �F�s���ȃf�o�C�X���� [sage] �F2009/06/16(��) 21:15:32 ID:08YydSOx
�i�O���j �ނ���F��SPARC��HPC����ŁA�ᑬ�E�����i�̊��Ⴂ�@��ł��邾���� �i�㗪�j
999 �FOOO-��(�L�́M�U�����|���F2009/06/26(��) 00:25:30 ID:OEWTzDWN
���܂�B���J�b�Ƃ��������w ���͔��Ȃ��Ă���B
���̃X���͖T�ό��ߍ��ނ��肾�����̂ɉ䖝�ł��Ȃ������B
���X�������������܂Ȃ�������S���Ă���B
���̃X���͖T�ό��ߍ��ނ��肾�����̂ɉ䖝�ł��Ȃ������B
���X�������������܂Ȃ�������S���Ă���B
1000 �F,,�E�L�́M�E,,�j��-������ ��rFnQY4.id3Ix �F2009/06/26(��) 00:25:44 ID:CL3cLhy9
�m���Ă邩�珑���K�v�Ȃ�
AVX�Ή��̃R���p�C������茳�ɂ��鉴�l�Ȃ߂��
AVX�Ή��̃R���p�C������茳�ɂ��鉴�l�Ȃ߂��
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/