Intelの次世代CPUについて語ろう 33
■前スレ
Intelの次世代CPUについて語ろう 32
ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
■関連スレ
【Penryn】次世代モバイルCPU雑談スレ 4【Nehalem】
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
Intelの次世代CPUについて語ろう 32
ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
■関連スレ
【Penryn】次世代モバイルCPU雑談スレ 4【Nehalem】
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 3
ttp://pc11.2ch.net/test/read.cgi/mac/1190013206/
|
|
|
■過去スレ
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
■過去スレ その2
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
↓CPU関連スレの参考テンプレ
------------------------------------------
http://1rg.org/up/6010.html
秋 葉 原 の パ ー ツ シ ョ ッ プ で 出 回 っ て い る
C P U 買 い 替 え の 見 極 め 確 認 用 動 画
------------------------------------------
------------------------------------------
http://1rg.org/up/6010.html
秋 葉 原 の パ ー ツ シ ョ ッ プ で 出 回 っ て い る
C P U 買 い 替 え の 見 極 め 確 認 用 動 画
------------------------------------------
>>4はNG推奨
最近150Wとか170Wとか頭悪いんじゃないかと思うわ
SunのRockは16コアの2.3GHzで250Wだ。それに比べたら常識の範囲内。
さっさと15WのCPU出さんかい
Nehalemって何W位になるの?
Bloomfield TDP130W
Lynnfield TDP95W
Havendale TDP95W以下
Lynnfield TDP95W
Havendale TDP95W以下
Yorkfieldと変わらないんだな
GPU内蔵でもそれで収まるのか
GPU内蔵でもそれで収まるのか
>>13
内蔵はDual CoreのHavendaleだけだよ。
内蔵はDual CoreのHavendaleだけだよ。
もっとも、Nehalemは、Core MAと比べるとCPUコアのサイズが大きい。
このことは、CPUの中でロジック部分が大きいことを意味している。
CPUの中のSRAM部分は、電力的にはリーク電流(Leakage)に対する影響が大きい。
それに対してロジック部分は、アクティブ電力への影響が大きい。
つまり、Nehalemは、原理的にはTDP(Thermal Design Power:熱設計消費電力)が高くなりやすい。
このことは、CPUの中でロジック部分が大きいことを意味している。
CPUの中のSRAM部分は、電力的にはリーク電流(Leakage)に対する影響が大きい。
それに対してロジック部分は、アクティブ電力への影響が大きい。
つまり、Nehalemは、原理的にはTDP(Thermal Design Power:熱設計消費電力)が高くなりやすい。
>>9
いやそれむしろ1コアあたりのTDPで15.625Wだからすげー効率いいと思うぞ
いやそれむしろ1コアあたりのTDPで15.625Wだからすげー効率いいと思うぞ
Rockは1コア10Wだ、組み込み専用プロセッサとTukwilaを比べるのはナンセンスだが
Yonahだろうが45nmだろうがTDP上げまくってるIntelにTDPは関係ないのかもしれない
Yonahだろうが45nmだろうがTDP上げまくってるIntelにTDPは関係ないのかもしれない
まぁアーキテクチャを大きく拡張・変更した直後って
たいていエンドユーザー的には美味しくないバランスの悪いシロモノになるから(386しかりPenProしかり)
E8500買ってNehalemの次世代待ちがいいような希ガス
たいていエンドユーザー的には美味しくないバランスの悪いシロモノになるから(386しかりPenProしかり)
E8500買ってNehalemの次世代待ちがいいような希ガス
待っても高過ぎて買えないが正解。
旧来のMCHの機能を内蔵して、クアッドコアでTDP95Wてのは、これはこれでたいしたものじゃまいか。
>>20
まだ動作クロックが不明だからなんともいえん罠。
まだ動作クロックが不明だからなんともいえん罠。
クロックよりは最終的な性能が重要なのであ?
Nehalemの効率自体はかなり凄い事になるんじゃないかと思うが、
どの程度クロックが伸びるかによってはK8初期と同じような状況に陥る事態もありうるな。
たとえ本当にPenryn比でIPC150%以上になっても2GHz後半止まりだとPenryn-1600と大して変わらん。
どちらにせよ消費電力と製造コストの問題で45nm世代ではPen!!!とPen4みたいに暫く住み分けるという予想に賛成。
デスクトップ
エンスージアスト…Core3Extreme(Blooomfield)
パフォーマンス…Core3Quad上位(Bloomfield)
アッパーミドル…Core3Quad下位(Lynnfield)・Core2Quad(Yorkfield-12M) 併売
ミドルロー…Core3Duo(Havendale)・Core2Duo上位(Wolfdale-6M) 併売
ローエンド…Core2Duo下位(Wolfdale-3M)
エントリー…Celeron(Allendale-512K or Wolfdale-1M?1536K?)
モバイル
エンスージアスト…Core3Extreme(Clarksfield)
パフォーマンス…Core3Quad(Clarkefield)・Core3Duo上位(Auburndale) 併売
ミドル…Core3Duo下位(Auburndale)・Core2Duo上位(Penryn-6M) 併売
ローエンド…Core2Duo下位(Penryn-3M)
エントリー…Celeron(Penryn-SC?)
09'Q2時点でこんなもんじゃなかろうか。
どの程度クロックが伸びるかによってはK8初期と同じような状況に陥る事態もありうるな。
たとえ本当にPenryn比でIPC150%以上になっても2GHz後半止まりだとPenryn-1600と大して変わらん。
どちらにせよ消費電力と製造コストの問題で45nm世代ではPen!!!とPen4みたいに暫く住み分けるという予想に賛成。
デスクトップ
エンスージアスト…Core3Extreme(Blooomfield)
パフォーマンス…Core3Quad上位(Bloomfield)
アッパーミドル…Core3Quad下位(Lynnfield)・Core2Quad(Yorkfield-12M) 併売
ミドルロー…Core3Duo(Havendale)・Core2Duo上位(Wolfdale-6M) 併売
ローエンド…Core2Duo下位(Wolfdale-3M)
エントリー…Celeron(Allendale-512K or Wolfdale-1M?1536K?)
モバイル
エンスージアスト…Core3Extreme(Clarksfield)
パフォーマンス…Core3Quad(Clarkefield)・Core3Duo上位(Auburndale) 併売
ミドル…Core3Duo下位(Auburndale)・Core2Duo上位(Penryn-6M) 併売
ローエンド…Core2Duo下位(Penryn-3M)
エントリー…Celeron(Penryn-SC?)
09'Q2時点でこんなもんじゃなかろうか。
IPCが150%以上なんてどこの情報?
以前あったHKEPCの情報でも、マルチスレッドで1.2〜2倍、シングルスレッドは1.1〜1.25倍と、
ポラックの法則通りのかなり現実味のある数字しか出てないと思うんだが。
以前あったHKEPCの情報でも、マルチスレッドで1.2〜2倍、シングルスレッドは1.1〜1.25倍と、
ポラックの法則通りのかなり現実味のある数字しか出てないと思うんだが。
そもそもIPC伸びても性能あがる事にはならんだろ。
ただ単にデコードされたμOPが増えただけってことだし。
ただ単にデコードされたμOPが増えただけってことだし。
ボラックの法則なんて経験則だろ
内部命令じゃない実IPCはもう限界に近い
でもまだ上がるんだろうな
内部命令じゃない実IPCはもう限界に近い
でもまだ上がるんだろうな
>>17
10W位のU9300とかと比べて性能良いの?
10W位のU9300とかと比べて性能良いの?
Intelの中の人が「Nehalemでは電力効率がさらにうpする。比較対象はPenrynで」とかいってたな。
まあ8コア+HTで倍ドン、で最大16スレッドもあればそりゃ、と考えられなくもないが、さすがに半信半疑だわな。
まあ8コア+HTで倍ドン、で最大16スレッドもあればそりゃ、と考えられなくもないが、さすがに半信半疑だわな。
糖で動くプロセサキボン
電力効率が極まったら今度はどこで勝負するんだろうね。
最終的にはダイサイズ勝負になってしまうのかな。
最終的にはダイサイズ勝負になってしまうのかな。
PC用途でマルチスレッドが何処まで有効か疑問
最終勝負はやはり一般ユーザに,如何に魅力的な提案をできるか,だろう。
オーバークロックww
CPUどうこうより、それを使っていかに有益な人生を送れるかに注力したほうが
使い方なんかそれぞれの好きにすればいいだろ
そういう俺は裏面キャパシタ配置のセンスでCPU選んでた時期がありました
そういう俺は裏面キャパシタ配置のセンスでCPU選んでた時期がありました
渋いな
グロいな
>>38
キャパシタ職人の朝は早い(ry
キャパシタ職人の朝は早い(ry
41 :Socket774:2008/02/17(日) 03:06:25 ID:o1J3FetU
She has a bottom like a "bloom field".
http://www.tcmagazine.com/comments.php?id=18172&catid=2
http://forums.vr-zone.com/showthread.php?t=237309
http://www.tcmagazine.com/comments.php?id=18172&catid=2
http://forums.vr-zone.com/showthread.php?t=237309
電極の形状を長方形にして、電極密度を上げてるかな。
キャパシタはこれまでより若干小さいものかな?
キャパシタはこれまでより若干小さいものかな?
SilverthorneのパフォーマンスはDothan以上
http://pc.watch.impress.co.jp/docs/2008/0218/kaigai419.htm
http://pc.watch.impress.co.jp/docs/2008/0218/kaigai419.htm
>>43
トランジスタを多くするとリーク電流が大きくなるから、少ないトランジスタを
高速で動作させた方が、電力効率が良くなるって事か。
Silverthorneの1.86GHzでのシングルスレッドの性能が、Stealeyの800MHzと同等
かそれ以上って事は、Isaiahの1.8GHzには全く勝てない話になるな。
トランジスタを多くするとリーク電流が大きくなるから、少ないトランジスタを
高速で動作させた方が、電力効率が良くなるって事か。
Silverthorneの1.86GHzでのシングルスレッドの性能が、Stealeyの800MHzと同等
かそれ以上って事は、Isaiahの1.8GHzには全く勝てない話になるな。
2GHzで2W以下を目指すSilverthorneと、
2GHzでTDP20WくらいになりそうなIsaiahを比べてもなぁ……。
2GHzでTDP20WくらいになりそうなIsaiahを比べてもなぁ……。
デスクトップ向けの2ダイMCMなモノなら、10W以上になるだろうし4スレッド実行が
有利になるから、結構比べ物になるかと。
有利になるから、結構比べ物になるかと。
ならん
Diamondville-SCは4W、DCは8Wと後藤記事にはある。
それだけ消費電力が違うと業務用では別種だろうけれど、性能的にはC7X2ってとこだろうから、
実際にITXなM/Bが出れば、リテールではIsaiah搭載EPIAと競合するかもしれない。
それだけ消費電力が違うと業務用では別種だろうけれど、性能的にはC7X2ってとこだろうから、
実際にITXなM/Bが出れば、リテールではIsaiah搭載EPIAと競合するかもしれない。
値段も安くしてほしいよね。
Isaiahとはパフォーマンス的に競合できない
>>51
D201スレ見てると
「性能段違いだけどD201は熱処理ムズイ(密閉系静穏ケースやブック形ケースは実質不可)からEPIAでいいや」ってのが結構居る。
今のEPIAとD201系の立場が逆転すると考えればなかなか面白いことになると思う
D201スレ見てると
「性能段違いだけどD201は熱処理ムズイ(密閉系静穏ケースやブック形ケースは実質不可)からEPIAでいいや」ってのが結構居る。
今のEPIAとD201系の立場が逆転すると考えればなかなか面白いことになると思う
SilverthorneってIntel64対応だったんだなあ。
in-orderで64bit命令を実行するなんて、単気筒1000ccのエンジンみたいな
違和感があるな。
まあレジスタが倍増するから、2命令同時実行のチャンスが増える筈だし、x32の
時よりもin-orderとの相性は良いのかも?
in-orderで64bit命令を実行するなんて、単気筒1000ccのエンジンみたいな
違和感があるな。
まあレジスタが倍増するから、2命令同時実行のチャンスが増える筈だし、x32の
時よりもin-orderとの相性は良いのかも?
>>53
元々OoOなCPUでも、64bit化でのレジスタ倍増による、命令の同時実行の可能性の増大は
有る訳だから、in-orderのCPUの場合に、OoOより性能アップ度合いが高くなるかどうかが
興味深いかな?
VLIWなCPUだと、コンパイラによる命令コードの最適配置が、性能に大きく易経するから、
in-orderなCPUも、64bit化による同時実行可能な命令コードの配置が増えた場合の、性能
アップがOoOなCPUよりも大きくなりそうな気がしますが。
元々OoOなCPUでも、64bit化でのレジスタ倍増による、命令の同時実行の可能性の増大は
有る訳だから、in-orderのCPUの場合に、OoOより性能アップ度合いが高くなるかどうかが
興味深いかな?
VLIWなCPUだと、コンパイラによる命令コードの最適配置が、性能に大きく易経するから、
in-orderなCPUも、64bit化による同時実行可能な命令コードの配置が増えた場合の、性能
アップがOoOなCPUよりも大きくなりそうな気がしますが。
>>52
IsaiahはC7から熱設計を変更する必要はない
IsaiahはC7から熱設計を変更する必要はない
57 :Socket774:2008/02/19(火) 21:36:33 ID:FJ2qewBM
【半導体】欧州委員会、不公正取引の疑いでインテル(Intel)の事業所に立ち入り検査[08/02/14]
http://news24.2ch.net/test/read.cgi/bizplus/1203307296/
http://news24.2ch.net/test/read.cgi/bizplus/1203307296/
58 :Socket774:2008/02/20(水) 04:44:26 ID:kyqs1u+9
オレゴンに期待する雑音哀れwwwwwwwwwwwwwwwwwwwwww
>>57-58
うぜぇ。オレゴンの失敗に期待する方が哀れだわ。
うぜぇ。オレゴンの失敗に期待する方が哀れだわ。
オレゴンが失敗して得することなんて何も無いんだけどな。
どんだけ卑屈なんだか。
どんだけ卑屈なんだか。
オレゴンがどうとかいってる奴らも含めて楽しみじゃないですか、Nehalem。
出し惜しみみたいになるのが最悪のシナリオ。
出し惜しみみたいになるのが最悪のシナリオ。
地球温暖化に拍車をかけるNehalemはもういいよ
Sandy Bridgeに期待している
Sandy Bridgeに期待している
地球温暖化に拍車をかける(笑)
地球温暖化はあきらかに電気製品の販促の為に騒いでるものだな
どちらにせよ地球にとって人間は害虫だな
と、寄生獣が2ちゃんをする時代がやってきました
67 :Socket774:2008/02/21(木) 01:23:57 ID:trRofOJw
つーかさー微細化にも限界があるでしょ?今でも原子数個分の壁しかないんでしょ?
MicroSDに1TBとかありえんふつう
MicroSDに1TBとかありえんふつう
68 :Socket774:2008/02/21(木) 01:26:10 ID:trRofOJw
影響を与えル程売れるといいね(プ
>68
Diamondvilleはデスクトップ向けだから消費電力が上がって当然。
Diamondvilleはデスクトップ向けだから消費電力が上がって当然。
ケコーン。コケコケ。
>>69
それは45nmから絶縁膜にハフニウムを使うことで解決済み。
なので、スケールダウンをしてムーアの法則を当分維持できると去年のIDFで言っていた。
ただ、これでリーク電流は抑えられたけど、電源電圧がスケーリング則に従わなくなって
しまった事によりシュリンクしても電力は下がらなくなってしまったという問題は何か別の
手段で解決しないといけないけど。
それは45nmから絶縁膜にハフニウムを使うことで解決済み。
なので、スケールダウンをしてムーアの法則を当分維持できると去年のIDFで言っていた。
ただ、これでリーク電流は抑えられたけど、電源電圧がスケーリング則に従わなくなって
しまった事によりシュリンクしても電力は下がらなくなってしまったという問題は何か別の
手段で解決しないといけないけど。
正しくは「ゲートリークは抑えられた」。
サブスレッショルドリークを抑えるのはHigh-kでも無理。
サブスレッショルドリークは電源電圧を下げられない要因のひとつ。
サブスレッショルドリークを抑えるのはHigh-kでも無理。
サブスレッショルドリークは電源電圧を下げられない要因のひとつ。
しょんべんを我慢するときにどうするか。もちろん締め付けるよね。
緩めたら漏れちゃうから。しかし、一旦出始めたものを再び締め付けで
抑えるのは難しい。だからそうなる前に、カテーテルで抜き取るのが
一番良い訳だ。
緩めたら漏れちゃうから。しかし、一旦出始めたものを再び締め付けで
抑えるのは難しい。だからそうなる前に、カテーテルで抜き取るのが
一番良い訳だ。
Intel touts Larrabee at GDC
http://www.tgdaily.com/content/view/36158/118/
http://www.tgdaily.com/content/view/36158/118/
[GDC 2008#21]ゲームに使えるリアルタイムレイトレーシング最前線
ttp://www.4gamer.net/games/047/G004713/20080222012/
ttp://www.4gamer.net/games/047/G004713/20080222012/
レイトレっていうのはちょっと飛躍しすぎだとは思うけど、
脱GPU化が進んでいくのは明らかだよね。
脱GPU化が進んでいくのは明らかだよね。
なんかショボくなった
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
まずLarrabeeの32コア版を投入、その1年後に、48コアのプロセス微細化版を投入する
↓
http://www.tgdaily.com/content/view/36159/135/
最初は12の小さなコアからなるもので、そのうちに16コアのもの24コアのものが出てくる
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
まずLarrabeeの32コア版を投入、その1年後に、48コアのプロセス微細化版を投入する
↓
http://www.tgdaily.com/content/view/36159/135/
最初は12の小さなコアからなるもので、そのうちに16コアのもの24コアのものが出てくる
何時もの事じゃないか
そして何時の間にか無かったことに
そして何時の間にか無かったことに
コストを完全に無視できる軍事用途に喰い込めなかったんだとか。
IntelがSUNに提示しているロードマップとのことす。
http://at.sun.com/sunnews/events/2008/jan/sun_intel_breakfast/pdf/Sun_Intel_Road%20Show_Austria.pdf
■Dunnington (次期Xeon MP) p14参照
- 既報通りPenryn(L2: 3M) x 3 + 16MB Shared L3
- TDP <= 130W
- 2008下半期にリリース予定
■Nehalem-EP (8-core/2-socket)の性能予測 p16参照
- SPECint_rate_base2006: Xeon5160/3GHzの2.8倍 (〜170)
- SPECfp_rate_base2006: Xeon5160/3GHzの3.8倍 (〜160)
- Intelわ2008年末のAMDの状況を次のように予測している
動作クロック: 最高2.8GHz
SPECint_rate_base: 〜120
SPECfp_rate_base: 〜120
http://at.sun.com/sunnews/events/2008/jan/sun_intel_breakfast/pdf/Sun_Intel_Road%20Show_Austria.pdf
■Dunnington (次期Xeon MP) p14参照
- 既報通りPenryn(L2: 3M) x 3 + 16MB Shared L3
- TDP <= 130W
- 2008下半期にリリース予定
■Nehalem-EP (8-core/2-socket)の性能予測 p16参照
- SPECint_rate_base2006: Xeon5160/3GHzの2.8倍 (〜170)
- SPECfp_rate_base2006: Xeon5160/3GHzの3.8倍 (〜160)
- Intelわ2008年末のAMDの状況を次のように予測している
動作クロック: 最高2.8GHz
SPECint_rate_base: 〜120
SPECfp_rate_base: 〜120
以前出回っていたNehalem画像すけど、持ち主のコメント付の投稿がXtremeSystems掲示板に
出ていたす。
http://www.xtremesystems.org/forums/showpost.php?p=2792298&postcount=139
出ていたす。
http://www.xtremesystems.org/forums/showpost.php?p=2792298&postcount=139
>>74
>それは45nmから絶縁膜にハフニウムを使うことで解決済み。
してません。
>スケールダウンをしてムーアの法則を当分維持できると去年のIDFで言っていた。
22nmでもう怪しいです。
>電源電圧がスケーリング則に従わなくなって しまった事によりシュリンクしても電力は下がらなくなってしまったという問題
以前から従っていません。
ゲート長をシュリンクできなくて困ってます。
今は等価スケーリングという事をやっていますがそれも限界です。
さて22nmプロセスはどうなるのでしょう?
>それは45nmから絶縁膜にハフニウムを使うことで解決済み。
してません。
>スケールダウンをしてムーアの法則を当分維持できると去年のIDFで言っていた。
22nmでもう怪しいです。
>電源電圧がスケーリング則に従わなくなって しまった事によりシュリンクしても電力は下がらなくなってしまったという問題
以前から従っていません。
ゲート長をシュリンクできなくて困ってます。
今は等価スケーリングという事をやっていますがそれも限界です。
さて22nmプロセスはどうなるのでしょう?
22nmって4年後じゃんw
>>84のPDF文書わ削除されたす。Dunningtonの構成なんて今更隠すようなモノでも無いと思うすけど。。。
http://pc.watch.impress.co.jp/docs/2007/1018/kaigai394.htm
http://pc.watch.impress.co.jp/docs/2007/1018/kaigai394.htm
22nmで限界っつーことで、そのプロセスルールに
最適なアーキテクチャを考えよう
最適なアーキテクチャを考えよう
デスクトップ版Silverthorne, "Diamondville"のマザーボード写真す。
http://www.hkepc.com/?id=813&fs=c1h
http://www.hkepc.com/?id=813&fs=c1h
1945年、戦闘機のほとんどはレシプロで
最大速度は700km程度だった
それがわずか10年後にはマッハ2!
人々はマッハ3もすぐと考えた
60年代には人は月の大地を踏んだ
ボーイング747は世界をぐっと狭くした
70年代以降は。。。
人は物理法則に支配されている
テクノロジーの進歩には限界がある
CPUクロック10GHzはすぐとみんな考えていたけど
今のところ5GHzがやっとだ
2と2が並ぶ22nm
これが神が定めたプロセスルールの限界なのだ!
ムーアの法則は去った
フリーランチは終わった
スキルのないSEの代わりら中国人だ
ギャルはPCでなく携帯でネットする
実は何より配線遅延
太い配線のほうが信号の伝わる速度が速いのた!
細い配線処女のマンコの如し!
最大速度は700km程度だった
それがわずか10年後にはマッハ2!
人々はマッハ3もすぐと考えた
60年代には人は月の大地を踏んだ
ボーイング747は世界をぐっと狭くした
70年代以降は。。。
人は物理法則に支配されている
テクノロジーの進歩には限界がある
CPUクロック10GHzはすぐとみんな考えていたけど
今のところ5GHzがやっとだ
2と2が並ぶ22nm
これが神が定めたプロセスルールの限界なのだ!
ムーアの法則は去った
フリーランチは終わった
スキルのないSEの代わりら中国人だ
ギャルはPCでなく携帯でネットする
実は何より配線遅延
太い配線のほうが信号の伝わる速度が速いのた!
細い配線処女のマンコの如し!
とオチも構成もないダブンすいません
プロセスルールはもういいからもっと根本的なところでブレイクスルー
な技術が生まれればいいな。
な技術が生まれればいいな。
パラダイムシフトはCMOSが限界に達して、ビジネスに深刻な影響が出てから起きるだろう。
バイポーラからCMOSへの移行のときもそうだった。
バイポーラからCMOSへの移行のときもそうだった。
某オタによれば配線遅延は問題にならないほど小さいらしいから微細化はまだまだ続くだろう。
最適化の結果として問題を抑え込めてるだけで小さいわけじゃないで…
処女のマンコが気になった
なんで配線遅延が問題にならないほど小さいの?
根拠は?
根拠は?
これからは人海戦術の時代。
つまり!中国が世界の派遣を握る!!
つまり!中国が世界の派遣を握る!!
プロセス微細化鈍化→三次元構造→CNT使用などの超高速半導体
光パスCPUの実現は後数年なんだよな
intelのお偉いさんがいってた記憶がある
intelのお偉いさんがいってた記憶がある
>>98,100
根拠はオタに聞いてくれ。
22 名前:MACオタ>21 さん[sage] 投稿日:2008/01/04(金) 01:20:48 ID:ZHS6RxJo
>>21
若干誤解もあるようなので。。。
----------------
GriffinはK10やMeromみたいにより大きなユニット単位でクロックゲーティングが適用される
ことは十分考えられるな。
----------------
クロックゲーティングに関して、大きなユニット単位で行うのわ既に常識化しているし設計コストも
安いす。設計が大変なのわ、より細粒度化した"Fine grain clock-gating"というヤツす。
----------------
ultra low-kは配線遅延に効くんだからクロックには効果あるでしょ。
----------------
今時配線遅延がボトルネックという話わ聞かないす。ましてIBM/AMDのプロセスわ配線層が多い
Intelと比べても既に配線遅延の問題わ影響が小さいす。
根拠はオタに聞いてくれ。
22 名前:MACオタ>21 さん[sage] 投稿日:2008/01/04(金) 01:20:48 ID:ZHS6RxJo
>>21
若干誤解もあるようなので。。。
----------------
GriffinはK10やMeromみたいにより大きなユニット単位でクロックゲーティングが適用される
ことは十分考えられるな。
----------------
クロックゲーティングに関して、大きなユニット単位で行うのわ既に常識化しているし設計コストも
安いす。設計が大変なのわ、より細粒度化した"Fine grain clock-gating"というヤツす。
----------------
ultra low-kは配線遅延に効くんだからクロックには効果あるでしょ。
----------------
今時配線遅延がボトルネックという話わ聞かないす。ましてIBM/AMDのプロセスわ配線層が多い
Intelと比べても既に配線遅延の問題わ影響が小さいす。
105 :Socket774:2008/02/26(火) 12:55:54 ID:sURjl/wn
>>某オタによれば配線遅延は問題にならないほど小さいらしいから
ここまで正しいと仮定して
>>微細化はまだまだ続くだろう。
これが正しいとは限らんわな
微細化の障害が「配線遅延ただ一つのみ」って言うなら話は別だがw
ここまで正しいと仮定して
>>微細化はまだまだ続くだろう。
これが正しいとは限らんわな
微細化の障害が「配線遅延ただ一つのみ」って言うなら話は別だがw
DunningtonよりNehalen4コアの方が速いなんて落ちはないよね?
TulsaとWoodcrestってどっちが速かったっけ
インテルの6コア「Dunnington」、次第に正体が明らかに
http://japan.cnet.com/news/ent/story/0,2000056022,20368138,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20368138,00.htm
>>90
http://www.hkepc.com/database/images/2007111216585737.jpg
http://image.blog.livedoor.jp/materialistica/imgs/c/d/cd8b9478.JPG
どう見てもD201GLY2です
ありがとうございました
http://www.hkepc.com/database/images/2007111216585737.jpg
{kind=link}
http://image.blog.livedoor.jp/materialistica/imgs/c/d/cd8b9478.JPG
{kind=link}
どう見てもD201GLY2です
ありがとうございました
ソケット(とは言わないのか?BGAだと)違うんだから使いまわせる訳無いじゃん
112 :MACオタ>100 さん:2008/02/26(火) 21:27:19 ID:Qu9idi6X
>>100
問題にならないなんてトンデモを書いているのわ>>97さんす(笑)
ただし抵抗と静電容量による純粋な配線遅延の微細化による悪化わ、設計の改善である程度回避
できるのわ古くから知られているす。
http://csg.csail.mit.edu/6.884/handouts/lectures/L04-Wires.pdf
この結果、動作クロックに影響するパイプラインステージの一段の中のようなローカルな領域でわ、
微細化ともに遅延を減らせることが判っているす。
http://www.nistep.go.jp/achiev/ftx/jpn/stfc/stt057j/0512_03_feature_articles/200512_fa02/0512fa02chart/chart04.gif
ただしこの図にもあるように、チップ全体のような大きな領域(図中の「Global配線遅延」)わ、未だに
難しい問題があるようで、コアのサイズをやたらに大きく出来ない原因にも繋がっているす。
問題にならないなんてトンデモを書いているのわ>>97さんす(笑)
ただし抵抗と静電容量による純粋な配線遅延の微細化による悪化わ、設計の改善である程度回避
できるのわ古くから知られているす。
http://csg.csail.mit.edu/6.884/handouts/lectures/L04-Wires.pdf
この結果、動作クロックに影響するパイプラインステージの一段の中のようなローカルな領域でわ、
微細化ともに遅延を減らせることが判っているす。
http://www.nistep.go.jp/achiev/ftx/jpn/stfc/stt057j/0512_03_feature_articles/200512_fa02/0512fa02chart/chart04.gif
{kind=link}
ただしこの図にもあるように、チップ全体のような大きな領域(図中の「Global配線遅延」)わ、未だに
難しい問題があるようで、コアのサイズをやたらに大きく出来ない原因にも繋がっているす。
113 :MACオタ>110 さん:2008/02/26(火) 21:28:05 ID:Qu9idi6X
>>110
情報感謝するす。
情報感謝するす。
は を わって書く奴見ると無性に腹が立つ
あぼーんすることをお勧めする
ttp://en.expreview.com/2008/02/26/nehalem-and-qx9770-comparison-and-tylersburgs-debut/
思ったよりは小さい感じだな。
思ったよりは小さい感じだな。
釣り?
信憑性が高くない情報だけど
◇SPECint_rate_base2006
・Nehalem-EP xxxGHz:169
・Shanghai 2.80GHz:118
・Xeon X5482:117
・Barcelona 2.30GHz:88
・Xeon X5365:95
◇SPECfp_rate_base2006
・Nehalem-EP xxxGHz:171
・Shanghai 2.80GHz:127
・Xeon X5482:84
・Barcelona 2.30GHz:80
・Xeon X5365:65
http://blogs.zdnet.com/Ou/?p=1025
◇SPECint_rate_base2006
・Nehalem-EP xxxGHz:169
・Shanghai 2.80GHz:118
・Xeon X5482:117
・Barcelona 2.30GHz:88
・Xeon X5365:95
◇SPECfp_rate_base2006
・Nehalem-EP xxxGHz:171
・Shanghai 2.80GHz:127
・Xeon X5482:84
・Barcelona 2.30GHz:80
・Xeon X5365:65
http://blogs.zdnet.com/Ou/?p=1025
119 :MACオタ>118 さん:2008/02/27(水) 08:18:26 ID:0rj98mcp
SPECのrateだからな。SMTの8スレッドが効いてる可能性が高いかと。
Nehalemのクロックがわからないので仮にX5482と同クロックだったら、
SMTで30%アップとして、1スレッドの性能はHarpertownと比べて大体10%くらいじゃないだろうか?
SMTがそこまで効かなくてもっと良いかもしれないし、クロックが3.2GHzより下の可能性もあるけど。
Nehalemのクロックがわからないので仮にX5482と同クロックだったら、
SMTで30%アップとして、1スレッドの性能はHarpertownと比べて大体10%くらいじゃないだろうか?
SMTがそこまで効かなくてもっと良いかもしれないし、クロックが3.2GHzより下の可能性もあるけど。
shanghaiって、もう動くサンプルとかあんのかね?
"Nehalem-EP"と"Shanghai"の4コア対決は
圧倒的に"Nehalem-EP"が勝利なのか?
ただ、AMDは"Montreal"が8コアであるみたいだし、
登場時期によっては…どちらにしろこの結果からすると、
8コアでないと4コアの"Nehalem-EP"と対等に戦えないな。
このまま沈むか…?
圧倒的に"Nehalem-EP"が勝利なのか?
ただ、AMDは"Montreal"が8コアであるみたいだし、
登場時期によっては…どちらにしろこの結果からすると、
8コアでないと4コアの"Nehalem-EP"と対等に戦えないな。
このまま沈むか…?
Montrealはよほど早くでないとNehalem-EP以外に8コアのNehalem-EXとも
ぶつかりそうだけど。
ぶつかりそうだけど。
>>124
Nehalem-EXってQ4 2009じゃないっけ?
Nehalem-EXってQ4 2009じゃないっけ?
Barcelona→Shanghaiで確実にIPCは上がってるな
POWER6の敵じゃなかったなw>涅槃
>>127
普段はIntel VS AMDで顔真っ赤にしてるけど、そう言われると(知らないので反論する材料もないが)反論してしまうのが自作板住人
普段はIntel VS AMDで顔真っ赤にしてるけど、そう言われると(知らないので反論する材料もないが)反論してしまうのが自作板住人
何時の世も
IBMに勝る
ものはなし
IBMに勝る
ものはなし
POWERって、実際触ってみるとアレ、アレレってな性能の出なさがあるんだよな、クロックの割りに。NetBustもそうだけど・・・
頭でっかちが肝心な部分をすっぽかして理詰めでつくっているような感触がする。
頭でっかちが肝心な部分をすっぽかして理詰めでつくっているような感触がする。
131 :sage:2008/02/29(金) 18:25:00 ID:rX55FAOt
Powerは高いんで論外
涅槃なら4ソケット16コアでも1000万でお釣りがくるが
Power6 64コアはどう考えても1億以上
TPC-C.ORGとかで値段確認したわけじゃないけど
涅槃なら4ソケット16コアでも1000万でお釣りがくるが
Power6 64コアはどう考えても1億以上
TPC-C.ORGとかで値段確認したわけじゃないけど
athlonXP 3200+からC2Dに乗り換えたけど、体感で速くなったと思えない。
3GまでOCしてるのにフォルダの表示程度でもたつく
人間ってのはどうしてもリズムに支配されてるから、体感速度を語る上では絶対値として
表された速度ってのはそれほど重要じゃないんだよな。
様々なシチュエーションでの応答速度の平均からズレが少ない、いわゆる偏差の少ない
応答の安定度の方が体感では支配的になる。
・・・と言っても、全体がある程度以上遅くなると、偏差が少なくても耐えられなくなるが。
その点ではNetBurst系はかなり酷かったが、Core系は相当良くなってるよな。
P6/K7系のフィーリングに良く似た感じで使いにくいと感じる部分は少ない。
K8の体感速度は、P6/K7系のそれを更に突き詰めた感じがするな。
その分、ピークは抑え目になってるんだろうけど。
速度が与えるインパクトの強さでは、波の荒いNetBurst系が一番強烈ではあるが。w
あと64bit系WindowsでもX2の方が有利だし
しかも仮想ではさらにC2Dにとって絶望的なほどの差がつく
C2D厨は非常に都合の悪いデータが出るととたんに黙り込むな
馬鹿どもが 起動時間が遅いとやっぱりもっさりだろw Intel厨房は
メモリ周りとチップセット周りが遅いのを自覚してるから火病ってるんでしょうな。もっさりはFSBの構造だけじゃなく、調停ロジックも関係ありそうだな。
調停の方式としては、先に要求を出したデバイスを問答無用で優先する・優先順位の高いデバイス優先する・
各デバイスに順番に優先権を与える・・・等、色々な方法があるが、Bi-Directional方式でバスの利用効率を
考えた場合、出来るだけ同じデバイスがバスを占有する時間を長くして、切り替えのオーバーヘッド
減らした方が効率がいいから、「占有時間の長い要求を持つデバイスを優先する」方法なのかもしれん。
だとすると、マウス入力やキーボード入力のように散発的で低速かつ情報量の少ない要求なんかは、
大量のメモリアクセスが頻発するようなエンコードとかが動いてると、かなり優先順位を落とされそうだな。
3GまでOCしてるのにフォルダの表示程度でもたつく
人間ってのはどうしてもリズムに支配されてるから、体感速度を語る上では絶対値として
表された速度ってのはそれほど重要じゃないんだよな。
様々なシチュエーションでの応答速度の平均からズレが少ない、いわゆる偏差の少ない
応答の安定度の方が体感では支配的になる。
・・・と言っても、全体がある程度以上遅くなると、偏差が少なくても耐えられなくなるが。
その点ではNetBurst系はかなり酷かったが、Core系は相当良くなってるよな。
P6/K7系のフィーリングに良く似た感じで使いにくいと感じる部分は少ない。
K8の体感速度は、P6/K7系のそれを更に突き詰めた感じがするな。
その分、ピークは抑え目になってるんだろうけど。
速度が与えるインパクトの強さでは、波の荒いNetBurst系が一番強烈ではあるが。w
あと64bit系WindowsでもX2の方が有利だし
しかも仮想ではさらにC2Dにとって絶望的なほどの差がつく
C2D厨は非常に都合の悪いデータが出るととたんに黙り込むな
馬鹿どもが 起動時間が遅いとやっぱりもっさりだろw Intel厨房は
メモリ周りとチップセット周りが遅いのを自覚してるから火病ってるんでしょうな。もっさりはFSBの構造だけじゃなく、調停ロジックも関係ありそうだな。
調停の方式としては、先に要求を出したデバイスを問答無用で優先する・優先順位の高いデバイス優先する・
各デバイスに順番に優先権を与える・・・等、色々な方法があるが、Bi-Directional方式でバスの利用効率を
考えた場合、出来るだけ同じデバイスがバスを占有する時間を長くして、切り替えのオーバーヘッド
減らした方が効率がいいから、「占有時間の長い要求を持つデバイスを優先する」方法なのかもしれん。
だとすると、マウス入力やキーボード入力のように散発的で低速かつ情報量の少ない要求なんかは、
大量のメモリアクセスが頻発するようなエンコードとかが動いてると、かなり優先順位を落とされそうだな。
こいつ何時アク禁になるの?
>>127
確かにPOWER6の8コアわSPECrate2006下記のような結果でNehalemの2008年末段階での予想値を
上回っているす。
SPECint_rate2006 (base): 206
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01103.html
SPECfp_rate2006 (base): 189
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01102.html
しかしこちらわデュアルコアチップすから、同じ2ソケットで比較すると半分す。
SPECint_rate2006 (base): 106
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01100.html
SPECfp_rate2006 (base): 102
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01101.html
IBMにしてもNehalemに対抗するにわ45nmのPOWER6+待ちということす。
確かにPOWER6の8コアわSPECrate2006下記のような結果でNehalemの2008年末段階での予想値を
上回っているす。
SPECint_rate2006 (base): 206
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01103.html
SPECfp_rate2006 (base): 189
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01102.html
しかしこちらわデュアルコアチップすから、同じ2ソケットで比較すると半分す。
SPECint_rate2006 (base): 106
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01100.html
SPECfp_rate2006 (base): 102
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070518-01101.html
IBMにしてもNehalemに対抗するにわ45nmのPOWER6+待ちということす。
45nmはクワッドコアなの?
136 :MACオタ>135 さん:2008/03/01(土) 18:27:46 ID:/2XypY9l
>>135
一応、リーク資料を含むIBMのロードマップでわPOWER6+世代で同一筐体のコア数を2倍にすることに
なっているす。
最近IBMわ高密度実装に凝っているすから、デュアルコアのままでソケット数を増やすのかもしれないすけど。。。
一応、リーク資料を含むIBMのロードマップでわPOWER6+世代で同一筐体のコア数を2倍にすることに
なっているす。
最近IBMわ高密度実装に凝っているすから、デュアルコアのままでソケット数を増やすのかもしれないすけど。。。
なるほど
45nm版Core 2の品薄が深刻化、完成PCもXeonを代替採用
http://www.watch.impress.co.jp/akiba/hotline/20080301/etc_45nmxeon.html
なんだか、在庫不足が長引いてるな。
歩留問題でもあるのか?
http://www.watch.impress.co.jp/akiba/hotline/20080301/etc_45nmxeon.html
なんだか、在庫不足が長引いてるな。
歩留問題でもあるのか?
あmdのせい
POWER6やPOWER6+やらの価格帯はいくらなんだ?
Itaniumよりネハレンがライバルになるの?
Itaniumよりネハレンがライバルになるの?
143 :MACオタ>141 さん:2008/03/02(日) 14:43:40 ID:Rb6z5yls
>>141
IBMのブレードサーバーBladeCenterにわ、Xeon , Opteron, POWER6それぞれのモデルがあるすから、
ちょうど比較できるす。
http://www-03.ibm.com/systems/bladecenter/hardware/
JS22 (POWER6) 4GHz x 4core/2socket $6,129-
HS20 (Xeon) 3GHz x 8core/2socket $6,235-
LS21 (Opteron) 2.4GHz x 4core/2socket $2,826.75- (セール中)
IBMのブレードサーバーBladeCenterにわ、Xeon , Opteron, POWER6それぞれのモデルがあるすから、
ちょうど比較できるす。
http://www-03.ibm.com/systems/bladecenter/hardware/
JS22 (POWER6) 4GHz x 4core/2socket $6,129-
HS20 (Xeon) 3GHz x 8core/2socket $6,235-
LS21 (Opteron) 2.4GHz x 4core/2socket $2,826.75- (セール中)
OSがAIXだとアプリもWin,Linuxより高くなる
ソケット単位で課金するアプリなら
本体以外も含めたトータルコストで
xeonが圧勝だな
ソケット単位で課金するアプリなら
本体以外も含めたトータルコストで
xeonが圧勝だな
問題は使う人間が扱えるかどうかだな
何はともあれコンパイル速度が上がるんなら歓迎だぜ
ALUの性能も大幅にupするっぽいし、4コア8スレッドの性能を早く享受したいもんだ
今のAthlon64X2-4200+の何倍の速度が出るんだろう…
ALUの性能も大幅にupするっぽいし、4コア8スレッドの性能を早く享受したいもんだ
今のAthlon64X2-4200+の何倍の速度が出るんだろう…
>>144
この手のものは、「CPUパワーのためにシステムとアプリを買う」というより
「アプリも含めたシステムを買ったらCPUがこれになる」ってパターンが多いからな。
カバーする市場の性格がかなり違う。
この手のものは、「CPUパワーのためにシステムとアプリを買う」というより
「アプリも含めたシステムを買ったらCPUがこれになる」ってパターンが多いからな。
カバーする市場の性格がかなり違う。
ISSCC 2008 - Intelの巨大チッププロセサ「Tukwila」
http://journal.mycom.co.jp/articles/2008/03/02/isscc1/index.html
http://journal.mycom.co.jp/articles/2008/03/02/isscc1/index.html
ウィルコム、Atomプロセッサー搭載のモバイル端末を開発
http://k-tai.impress.co.jp/cda/article/news_toppage/38783.html
http://k-tai.impress.co.jp/cda/article/news_toppage/38783.html
152 :Socket774:2008/03/03(月) 17:41:13 ID:N1tnHh3I
【PC】Intel、超低消費電力(0.6〜2.5ワット)のモバイル向けCPU「Atom」を発表(08/03/03)
http://news24.2ch.net/test/read.cgi/bizplus/1204511406/
http://news24.2ch.net/test/read.cgi/bizplus/1204511406/
0.6Wが超低消費電力に見えるのは65Wとかにならされてるからか
インテル製品を使うメリットはx86使えるだけ。
でもチップとして高ければ採用されない。
とはいえインテルはCPUを高く売っているわけだから・・・
それに組み込み用もなあ・・・
でもチップとして高ければ採用されない。
とはいえインテルはCPUを高く売っているわけだから・・・
それに組み込み用もなあ・・・
Atom を24時間回りっぱなしのファイルサーバーに使えるかな?
完全ファンレスのファイルサーバーができると結構いいんだけど・・・
システム全体で30W以下とかなったら結構いける
完全ファンレスのファイルサーバーができると結構いいんだけど・・・
システム全体で30W以下とかなったら結構いける
http://www.dailytech.com/Intel+Reveals+4+Watt+Diamondville+Processor+Details/article10876.htm
Atomの方はたぶんUMPCやMID用で自作には回ってこないんじゃないかな?
TDP高くなるけど4WのDiamondvilleの方なら、リファレンスのM/Bの写真がすでにある。
PCIスロット、DIMMスロット1本という拡張性はほぼないやつだけど。
Atomの方はたぶんUMPCやMID用で自作には回ってこないんじゃないかな?
TDP高くなるけど4WのDiamondvilleの方なら、リファレンスのM/Bの写真がすでにある。
PCIスロット、DIMMスロット1本という拡張性はほぼないやつだけど。
TheINQの信頼度不明の噂す。Intelわ22nm世代で450mmウェハを使うんだとか。。。
http://www.theinquirer.net/gb/inquirer/news/2008/03/03/intel-450-sheepdog
http://www.theinquirer.net/gb/inquirer/news/2008/03/03/intel-450-sheepdog
時期的には必然的に22nmになるんじゃないの?
http://strj-jeita.elisasp.net/pdf_ws_2005nendo/9H_WS2005Economy_Osada_J450mm.pdf
http://techon.nikkeibp.co.jp/article/NEWS/20060512/117045/
http://techon.nikkeibp.co.jp/article/NEWS/20070720/136482/
http://techon.nikkeibp.co.jp/article/NEWS/20071031/141638/
http://www.eetimes.jp/contents/200711/28325_1_20071122200604.cfm
>米Intel Corp.をはじめとするLSIメーカーは2012〜2014年にも量産化したい考え
http://strj-jeita.elisasp.net/pdf_ws_2005nendo/9H_WS2005Economy_Osada_J450mm.pdf
http://techon.nikkeibp.co.jp/article/NEWS/20060512/117045/
http://techon.nikkeibp.co.jp/article/NEWS/20070720/136482/
http://techon.nikkeibp.co.jp/article/NEWS/20071031/141638/
http://www.eetimes.jp/contents/200711/28325_1_20071122200604.cfm
>米Intel Corp.をはじめとするLSIメーカーは2012〜2014年にも量産化したい考え
相変わらずマクオタはプロセスに疎いな。
Intelがやりたいと言っても装置一式変えないといかんからな。
装置メーカーにそこまでの開発余力があるのか。
300mmの効率化の方が優先したいメーカーも多い。
やるにしても開発はすぐにでも始めないとなあ。
装置メーカーにそこまでの開発余力があるのか。
300mmの効率化の方が優先したいメーカーも多い。
やるにしても開発はすぐにでも始めないとなあ。
450mmなんて実現するわけないじゃんwww
バカじゃね?
バカじゃね?
ATOMを並列でいっぱい積んで処理させ・・・られないか。
シングルスレッドアプリが足引っ張るよなあ
シングルスレッドアプリが足引っ張るよなあ
それなんてLarrabee?
168 :Socket774:2008/03/04(火) 12:35:58 ID:S5O9m5Gl
Manyコアと言っても25mmじゃ8コアで200mmだもんな。それプラスクロスバーなりリングバスのトランジスタ領域が
必要になるわけだから・・・。
必要になるわけだから・・・。
>>167
Larrabeeのx86化には、当然ながらAtomコアが使われると思うが。
Larrabeeのx86化には、当然ながらAtomコアが使われると思うが。
ATOMコアはないだろ
SMT不要なのとダイサイズがまだでかすぎるのとで
SMT不要なのとダイサイズがまだでかすぎるのとで
173 :Socket774:2008/03/04(火) 20:17:51 ID:S5O9m5Gl
ヘテロジニアスマルチコア世代のラージコアはNehalem or Sandy Bridge
でシンプルコアはLarrabee or Atom・・・外れたら冴えない(ry
でシンプルコアはLarrabee or Atom・・・外れたら冴えない(ry
174 :Socket774:2008/03/05(水) 13:57:24 ID:4Ugt8/2R
atomの処理能力についての情報が全然見つからないんだが
リーク情報が見当たらないところを見ると、本気でたいしたこと無いのだろう
A110以下な処理も多数あるだろうし
A110以下な処理も多数あるだろうし
もともとモバイル系はリーク情報なんてほとんど出ないよ
メインストリームのCPUならともかく、これだけ用途が特化
されたものだと、ニュース屋も興味の対象にならないと思ってるのか
単に情報自体が出回らないのか理由は知らんけどね
メインストリームのCPUならともかく、これだけ用途が特化
されたものだと、ニュース屋も興味の対象にならないと思ってるのか
単に情報自体が出回らないのか理由は知らんけどね
搭載機が出たら回す人もいるだろうから、それに期待する。
ちょ
http://www.techreport.com/r.x/amd-780g/ep2.gif
http://www.techreport.com/r.x/amd-780g/power-idle.gif
http://www.techreport.com/r.x/amd-780g/ep2.gif
{kind=link}
http://www.techreport.com/r.x/amd-780g/power-idle.gif
{kind=link}
CPUに対してチップセットはゴミだな
4gamerが無茶苦茶なマザボベンダのコメントを掲載しているす。
http://www.4gamer.net/games/047/G004749/20080305042/
------------------
P35マザーボードは,現時点ですでにX38マザーボードよりも高い性能を示している。
------------------
結局PCサーバー向けと一般向けのチップセット開発を事業部ごと分離したのが祟って、
開発リソースが足りなくなってるんじゃないすかね。。。
http://www.4gamer.net/games/047/G004749/20080305042/
------------------
P35マザーボードは,現時点ですでにX38マザーボードよりも高い性能を示している。
------------------
結局PCサーバー向けと一般向けのチップセット開発を事業部ごと分離したのが祟って、
開発リソースが足りなくなってるんじゃないすかね。。。
http://www.atmarkit.co.jp/fsys/kaisetsu/010new845chipset/new845chipset01.html
----------------------------
2002年に入って、IntelのEnterprise Platforms Group(EPG:サーバ/ワークステーション向け製品
グループ)によるチップセット開発は、Desktop Platforms Group(DPG:デスクトップPC向け製品グ
ループ)から完全に独立したもようだ。それを裏付けるかのように、チップセットの型番の命名則が
変わっている。
----------------------------
----------------------------
2002年に入って、IntelのEnterprise Platforms Group(EPG:サーバ/ワークステーション向け製品
グループ)によるチップセット開発は、Desktop Platforms Group(DPG:デスクトップPC向け製品グ
ループ)から完全に独立したもようだ。それを裏付けるかのように、チップセットの型番の命名則が
変わっている。
----------------------------
HKEPCがデュアルコアAtomベースのミニPCが3Qに登場すると報じているす。
http://www.hkepc.com/?id=847
・1.87GHz, TDP 12W, 533MHz FSB
・BGAパッケージ
・945GC ノースブリッジ + ICH7
・BOX945GCLF "Little Falls" (シングルコア) および BOX945GCLF2 "Little Falls 2" (デュアルコア)
http://www.hkepc.com/?id=847
・1.87GHz, TDP 12W, 533MHz FSB
・BGAパッケージ
・945GC ノースブリッジ + ICH7
・BOX945GCLF "Little Falls" (シングルコア) および BOX945GCLF2 "Little Falls 2" (デュアルコア)
12Wとかどんだけ爆熱だよ
>TDP 12W
( ゚д゚)
( ゚д゚)・・・
(;゚д゚;)
( ゚д゚)
( ゚д゚)・・・
(;゚д゚;)
185 :Socket774:2008/03/06(木) 00:45:08 ID:1FZkXxt/
デスクトップや組み込み向けのTDPが情報が出るたびに高くなってるね。
モバイル向けは超選別という可能性もあるね。
モバイル向けは超選別という可能性もあるね。
65nmのCore 2 Duo ULVでさえTDP10Wなのに
マザボ自体ダサいけどな
メモリはMAXで2Gか、できれば3G積みたいんだが・・・
あとRAID付けて欲しい、ん、想定外?
あとRAID付けて欲しい、ん、想定外?
DIMMスロット1本か。拡張スロットの方はチップセット内蔵で大抵間に合うけど、
DIMM1本だと2GBが最大か。
DIMM1本だと2GBが最大か。
あんまし無茶な要求すんな
>>182
かわいい(;´Д`)ハァハァ
かわいい(;´Д`)ハァハァ
Mini-ITXだからDIMM1本は仕方ないんだろうな。
MicroATX版が出れば2本期待できるが、あまり出そうな感じがしない。
MicroATX版が出れば2本期待できるが、あまり出そうな感じがしない。
945GCって1GBメモリまでしか対応してなかったんじゃ・・・と思って調べてみたら
2GBメモリもおkな奴もあるのか、勉強になった
2GBメモリもおkな奴もあるのか、勉強になった
Isaiahに完敗決定
トランジスタ数が半分でIn-OrderなAtomにIsaiahが負けたら、
VIAのCPU設計チームは無能すぎるんだが。
VIAのCPU設計チームは無能すぎるんだが。
これだけTDPが高いATOMの方が無能に見える
Atomの性能レベルだと、ノースサウス統合で1W切るのもあるからな
CPUのみで、堂々と「たったの8W!」て言われてもなw
CPUのみで、堂々と「たったの8W!」て言われてもなw
まあ、0.5〜2WだったはずのTDPが発表時に0.6〜2.5Wに増えてるのは
intelらしいけどw
DiamondvilleのTDPがあがったのは、歩留まり上げるためだけじゃなくて、
TDP4WのシングルコアだとAtomじゃなくてDiamondvilleがUMPCで採用されるから
わざとスペックダウンしたんじゃないかって気もする。
intelなら高い方を売りつけるためにやりかねない。
intelらしいけどw
DiamondvilleのTDPがあがったのは、歩留まり上げるためだけじゃなくて、
TDP4WのシングルコアだとAtomじゃなくてDiamondvilleがUMPCで採用されるから
わざとスペックダウンしたんじゃないかって気もする。
intelなら高い方を売りつけるためにやりかねない。
なんかアホが混じってるな。Atomといってもブランドなんだから
実際のラインナップは複数ある。>>182 は省電力デスクトップやミニPC向けだろ
そしてモバイル機向けのAtom(ULV扱い?)は、Intelの言うように
TDP2.5W以下なんだろう。普通に考えるとIsaiahの完敗だ
>>198
すごね、まだベンチも出てないのに性能が分かるんだね
実際のラインナップは複数ある。>>182 は省電力デスクトップやミニPC向けだろ
そしてモバイル機向けのAtom(ULV扱い?)は、Intelの言うように
TDP2.5W以下なんだろう。普通に考えるとIsaiahの完敗だ
>>198
すごね、まだベンチも出てないのに性能が分かるんだね
LVって普通は選別品だろ?
今まで声高に宣伝してたTDPは実は選別品のものですか?
今まで声高に宣伝してたTDPは実は選別品のものですか?
>>201
お前はアホか
>モバイル機向けのAtom(ULV扱い?)
というのは、従来ULVで扱われていたカテゴリのCPUか? という意味だ
それが選別品かどうかは本質から外れる話題だし、仮にそうだとしても現時点でそれが
わかるわけがないことくらい常識でわかるだろ
そもそも、ATOMにはSilverthorneとDiamondvilleがあり、さらに
デュアルコアとシングルコアがあることは知ってるか?
それぞれ用途も違うし、それがわかってたら、そんなマヌケなレスは書けないはずだ
お前はアホか
>モバイル機向けのAtom(ULV扱い?)
というのは、従来ULVで扱われていたカテゴリのCPUか? という意味だ
それが選別品かどうかは本質から外れる話題だし、仮にそうだとしても現時点でそれが
わかるわけがないことくらい常識でわかるだろ
そもそも、ATOMにはSilverthorneとDiamondvilleがあり、さらに
デュアルコアとシングルコアがあることは知ってるか?
それぞれ用途も違うし、それがわかってたら、そんなマヌケなレスは書けないはずだ
なんだ?他人を攻撃したい年頃か?
ATOMのベンチは既に出てるから、探すといいぞ。
ATOMのベンチは既に出てるから、探すといいぞ。
>>202
どちらにしろ12Wは多い。
どちらにしろ12Wは多い。
206 :Socket774:2008/03/06(木) 14:18:57 ID:fOoUqTAR
E8400と5000+BE(OC3.1G)を使っていますので感想を。
結論は5000+BEをお奨めします。
負荷の重い作業を長時間継続してするような場合、(例えば動画エンコードや3Dゲーム)
ならE8400が断然早いです。
ベンチマークでの結果もスーパーπ1万桁の数字で16秒と29秒という差です。
ところが、(私もSleipnir使いなのですが)、軽いアプリを複数起動して行ったり来たりする
使い方では、E8400は立ち上がりで一瞬立ち止まるような遅さを感じます。
よく「もっさり」とか「引っかかる」と表現されるものなのかはわかりませんが、
2台並べて使い比べるとE8400ではいらいらするほどです。
(4GにOCしても変わりません)
結論は5000+BEをお奨めします。
負荷の重い作業を長時間継続してするような場合、(例えば動画エンコードや3Dゲーム)
ならE8400が断然早いです。
ベンチマークでの結果もスーパーπ1万桁の数字で16秒と29秒という差です。
ところが、(私もSleipnir使いなのですが)、軽いアプリを複数起動して行ったり来たりする
使い方では、E8400は立ち上がりで一瞬立ち止まるような遅さを感じます。
よく「もっさり」とか「引っかかる」と表現されるものなのかはわかりませんが、
2台並べて使い比べるとE8400ではいらいらするほどです。
(4GにOCしても変わりません)
>>203
Atom1.6GHzでSuperPi 1Mが108秒ってやつでしょ?
あれだけで何が分かるのかって気がするが・・・
SuperPiだけで判断していいんなら
同クロックのC7よりはるかに小さいTDPで
2〜3倍の性能ってことになるよ?
Atom1.6GHzでSuperPi 1Mが108秒ってやつでしょ?
あれだけで何が分かるのかって気がするが・・・
SuperPiだけで判断していいんなら
同クロックのC7よりはるかに小さいTDPで
2〜3倍の性能ってことになるよ?
>>206
マルチ氏ね
マルチ氏ね
pi 1M108秒ってgeode以下じゃねえの?
penM 780なら30秒くらいだぞ
penM 780なら30秒くらいだぞ
おいおい、ベンチが出てないって言うから示唆しただけなのに
そこを突っ込むのかよw
そこを突っ込むのかよw
http://pc11.2ch.net/test/read.cgi/notepc/1201872977/6-7
AtomとTDPがかぶるLXには圧勝。
DiamondvilleだとTDPがかぶるNXは中身AthlonXPだから、互角かちょっと負けって感じだな。
AtomとTDPがかぶるLXには圧勝。
DiamondvilleだとTDPがかぶるNXは中身AthlonXPだから、互角かちょっと負けって感じだな。
>>209
GeodeNX1750(TDP14W)と同じか速いくらいだ
ちなみにTDP6WのGeodeNX1500は1分半くらいかかる
例のベンチはSilverthorneだからTDPはIntelの言うのがほんとなら2.5Wだ
PenM780は確かに速いね。でもTDPは27W
GeodeNX1750(TDP14W)と同じか速いくらいだ
ちなみにTDP6WのGeodeNX1500は1分半くらいかかる
例のベンチはSilverthorneだからTDPはIntelの言うのがほんとなら2.5Wだ
PenM780は確かに速いね。でもTDPは27W
つうかπは今時の実アプリの目安には全くならん
シングルスレッドの性能評価で一番あてになるベンチって何?
んーしょっぱい
90mmのC7・ドタンや130nmのGeodeLXと比べられてる時点で・・・・
90mmのC7・ドタンや130nmのGeodeLXと比べられてる時点で・・・・
何を期待してたのやら。
昨日から開催されているIntelの投資家向けの報告会の資料が面白いす。
http://intel_im.edgesuite.net/2008/index.htm
特に興味深い点わ、Otellini CEOのプレゼン資料の解説付Nehalem画像で今までの謎が解けたす。
http://intel_im.edgesuite.net/2008/200618/IM2008_Otellini.pdf (p.34参照)
- 公開されたダイ写真の下1/3を占めるキャッシュ部分わ共有L3だった
- コアの下側、内寄りの領域がちゃんとL2キャッシュに見える。まず確実に独立L2す。(512KB程度か?)
IDFで公開されたダイ写真わスクランブルがかけられていたということで。。。
http://intel_im.edgesuite.net/2008/index.htm
特に興味深い点わ、Otellini CEOのプレゼン資料の解説付Nehalem画像で今までの謎が解けたす。
http://intel_im.edgesuite.net/2008/200618/IM2008_Otellini.pdf (p.34参照)
- 公開されたダイ写真の下1/3を占めるキャッシュ部分わ共有L3だった
- コアの下側、内寄りの領域がちゃんとL2キャッシュに見える。まず確実に独立L2す。(512KB程度か?)
IDFで公開されたダイ写真わスクランブルがかけられていたということで。。。
>Atom1.6GHzでSuperPi 1Mが108秒ってやつでしょ?
Pen4 1.6Gで試してみたら121秒だ、何をやってもだめだなPen4は・・・
Pen4 1.6Gで試してみたら121秒だ、何をやってもだめだなPen4は・・・
悪いM780定格で測ったら35秒だったわ
ocしてるから消費電力はセレロン440辺りと大差ねえんだろうな
ocしてるから消費電力はセレロン440辺りと大差ねえんだろうな
>>220
Dynamic Power Management
Dynamic Power Management
いやその一言だけだろ
比較グラフデータとかないじゃん
比較グラフデータとかないじゃん
223 :Socket774:2008/03/06(木) 18:44:02 ID:1FZkXxt/
次のIDFを待てBy Intel
224 :Socket774:2008/03/06(木) 18:47:46 ID:7oK7PLJJ
ICH11、G55、P55は、いつごろ?
ttp://journal.mycom.co.jp/articles/2008/03/06/cebit04/002.html
↑スゲー、遂にAMDが暴挙に出た。
High-k使わずにむしろlow-k、しかもUltra-low-k
というか何故にIBMと組むのかが解りません。
ただ頑張ってntelの独走を許さないでくれ。
お値段が心配なのよ。
↑スゲー、遂にAMDが暴挙に出た。
High-k使わずにむしろlow-k、しかもUltra-low-k
というか何故にIBMと組むのかが解りません。
ただ頑張ってntelの独走を許さないでくれ。
お値段が心配なのよ。
涅槃は熱湯婆以来のもっさりアクセラレータと化すか。
>>225の知恵遅れがやばい
釣られてる約2名はIE使いなのか・・
メアドで文通とか縦読みとかはVIPでやってくれ
ところで、実際に>>225のリンク先の記事がトンデモなのわ無視すか?
---------------------------
同社の45nmプロセスでは、ゲート絶縁膜材料の誘電体にUltra-low-Kを用いることで低消費電力を
実現している。
---------------------------
ゲート絶縁膜にlow-kって(笑)
---------------------------
同社の45nmプロセスでは、ゲート絶縁膜材料の誘電体にUltra-low-Kを用いることで低消費電力を
実現している。
---------------------------
ゲート絶縁膜にlow-kって(笑)
>>232
読み方によってはそれほどとんでもないな
読み方によってはそれほどとんでもないな
笠原ってこんなにレベル低かったのか。 ショック。
笠原違いじゃね?
親子かもしれんが。
親子かもしれんが。
名前が違ったww 勘違いしてすまん。
2008年6月 重大な危機が訪れる
http://pc.watch.impress.co.jp/docs/2008/0307/ubiq211.htm
http://pc.watch.impress.co.jp/docs/2008/0307/ubiq211.htm
>>何故にIBMと組むのかが解りません。
から
>新プロセスを一社で頑張ってるのはIntelだけ。
>他の会社普通に連合を組んでやってる。
頭の良いやつは違うな、IBMと組む理由に疑問に思っただけで
一社でやれよと解釈できる回転の速さに感服するよ。
好意的に解釈してもゲート絶縁膜にlow-kはおかしいと思うんだが
まあ知恵遅れなんだな、俺は。
から
>新プロセスを一社で頑張ってるのはIntelだけ。
>他の会社普通に連合を組んでやってる。
頭の良いやつは違うな、IBMと組む理由に疑問に思っただけで
一社でやれよと解釈できる回転の速さに感服するよ。
好意的に解釈してもゲート絶縁膜にlow-kはおかしいと思うんだが
まあ知恵遅れなんだな、俺は。
IBM様にすがる、だろ?
実際資金面から言っても
AMD連合じゃなくてIBMとその他の連合だしな
AMD連合じゃなくてIBMとその他の連合だしな
BTとnyを同時に起動したままで、たまにAV見たり、PSエミュをしたりするんですが
DuoとQuad、どちらがおすすめですか?
DuoとQuad、どちらがおすすめですか?
|
J
. 。
>><,,,,,,,,,(゚>゚
J
. 。
>><,,,,,,,,,(゚>゚
>>241
今はDuoでじゅうぶん
今はDuoでじゅうぶん
まずはCeleron 420で半年間修行しろ
>>217の続きす。翌日分のプレゼン資料も公開されているす。
面白げな話わ下記の通りす。
■Perlmutterプレゼン http://intel_im.edgesuite.net/2008/2-1230766/IM2008_Perlmutter.pdf
・モジュラ設計による開発期間の短縮 (p.19)
Merom 4M L2 -> Merom 2M L2 (4.5ヶ月), Merom 4M L2 -> MCM (3.5ヶ月)
⇒ Penryn 6M L2 -> Penryn 3M L2 (5週間), Penryn MCM Quad-> Penryn Dual (3週間)
これを書くと、またアム虫の火病出そうすけど、モジュラ設計を謳いながら未だに専用ダイの
デュアルコア製品が出せないAMDとわ大違いと言いたそうす。
・デュアルコアNehalemわ、すぐ出そう (p.20)
・組込向けSoCの作り分け (p.23)
- Canmore: IA core, Graphics, Audio, Video, IO, MCH
- Tolapai: IA core, Micro-Engines, MCH, IO
- Lincroft: IA core, Graphics & Display, MCH, Video
- Diamodville: IA coreのみ
■サーバーロードマップ http://intel_im.edgesuite.net/2008/2-1030879/IM2008_Skaugen.pdf
・Enterprise SSD
- 50x IOPS, 4.5x低消費電力
- standared HDD form factor, SATA 3.0Gb/s
面白げな話わ下記の通りす。
■Perlmutterプレゼン http://intel_im.edgesuite.net/2008/2-1230766/IM2008_Perlmutter.pdf
・モジュラ設計による開発期間の短縮 (p.19)
Merom 4M L2 -> Merom 2M L2 (4.5ヶ月), Merom 4M L2 -> MCM (3.5ヶ月)
⇒ Penryn 6M L2 -> Penryn 3M L2 (5週間), Penryn MCM Quad-> Penryn Dual (3週間)
これを書くと、またアム虫の火病出そうすけど、モジュラ設計を謳いながら未だに専用ダイの
デュアルコア製品が出せないAMDとわ大違いと言いたそうす。
・デュアルコアNehalemわ、すぐ出そう (p.20)
・組込向けSoCの作り分け (p.23)
- Canmore: IA core, Graphics, Audio, Video, IO, MCH
- Tolapai: IA core, Micro-Engines, MCH, IO
- Lincroft: IA core, Graphics & Display, MCH, Video
- Diamodville: IA coreのみ
■サーバーロードマップ http://intel_im.edgesuite.net/2008/2-1030879/IM2008_Skaugen.pdf
・Enterprise SSD
- 50x IOPS, 4.5x低消費電力
- standared HDD form factor, SATA 3.0Gb/s
■モバイルロードマップ http://intel_im.edgesuite.net/2008/2-1230766/IM2008_Eden.pdf
・2008 2H クアドコアモバイルチップ (p.18)
・2009 Nehalem based モバイル (p.21)
アム虫の爆熱願望がかなえられる事わ無さそうす。
・Montevina (Mid 2008) (p.22)
- バッテリ駆動でHDビデオ再生2.5時間
- メインストリームで25W TDP、58%小さいパッケージ
・純正SSD (1.8" & 2.5", 32-80GB) (p.26)
■MIDロードマップ http://intel_im.edgesuite.net/2008/2-1230766/IM2008_Chandrasekher.pdf
・性能 (EEMBC Suite v1.1) (p.11)
Silverthorne/1.6GHz HT: 270
Silverthorne/1.2GHz no HT: 150
ARM Cortex-A8/1GHz (est.): 120
ARM Cortex-A8/600MHz (est.): 70
ARM11/400MHz with GCC: 20
・Moorestown
- アイドル消費電力: Menlowの1/10 (p.14)
- LINCROFT CPU (p.21)
LPIA Core + Graphic & Display + Memory Controller + Video Encode + Video Decode
- LANGWELL I/O Controller
System Controller, SSD Controller, Multiple I/O blocks
- PMIC power management IC
- EVANS PEAK 無線コントローラ
- Lincroft, Langwell共に13mm x 13mm程度のパッケージ (p.22)
- クレジットカードより小さいマザーボード
・2008 2H クアドコアモバイルチップ (p.18)
・2009 Nehalem based モバイル (p.21)
アム虫の爆熱願望がかなえられる事わ無さそうす。
・Montevina (Mid 2008) (p.22)
- バッテリ駆動でHDビデオ再生2.5時間
- メインストリームで25W TDP、58%小さいパッケージ
・純正SSD (1.8" & 2.5", 32-80GB) (p.26)
■MIDロードマップ http://intel_im.edgesuite.net/2008/2-1230766/IM2008_Chandrasekher.pdf
・性能 (EEMBC Suite v1.1) (p.11)
Silverthorne/1.6GHz HT: 270
Silverthorne/1.2GHz no HT: 150
ARM Cortex-A8/1GHz (est.): 120
ARM Cortex-A8/600MHz (est.): 70
ARM11/400MHz with GCC: 20
・Moorestown
- アイドル消費電力: Menlowの1/10 (p.14)
- LINCROFT CPU (p.21)
LPIA Core + Graphic & Display + Memory Controller + Video Encode + Video Decode
- LANGWELL I/O Controller
System Controller, SSD Controller, Multiple I/O blocks
- PMIC power management IC
- EVANS PEAK 無線コントローラ
- Lincroft, Langwell共に13mm x 13mm程度のパッケージ (p.22)
- クレジットカードより小さいマザーボード
>>245-246 まとめ乙
248 :Socket774:2008/03/07(金) 22:53:12 ID:OnTAmuv4
2012年までTick-Tockモデル継続するのか・・・。
プロセス開発で躓くとTick-Tockがリスク要因にもなる?
250 :MACオタ>249 さん:2008/03/07(金) 23:08:23 ID:LqYE/3dN
>>249
新コアと新プロセスを同時投入しないので、リスクを減らすことができるすけど。。。
新コアと新プロセスを同時投入しないので、リスクを減らすことができるすけど。。。
今回の45nm Core2の遅れがCore3に響かないのがいいな
Core2は新製品投入が遅すぎるんだよね・・・2006年からほとんどかわっちゃいない
Core2は新製品投入が遅すぎるんだよね・・・2006年からほとんどかわっちゃいない
Itaniumは45nmで出さないのか
もったいない
もったいない
結局L3は搭載するみたいだな
Tick-Tockが一瞬Tick! Tack!に見えた俺、ギャルゲ脳
クソゲー脳の間違いだろ?
Nehalemは人生
Nehalemがモバイルに投入されるから爆熱じゃないって?
Pentium4ですらモバイルに投入したIntelなのに、
幸せ回路発動しすぎだろ。
Nehalemが爆熱になるかどうかは判断しかねるが、
少なくとも現行より省電力であると推測できる材料は、いままで皆無だろ。
Pentium4ですらモバイルに投入したIntelなのに、
幸せ回路発動しすぎだろ。
Nehalemが爆熱になるかどうかは判断しかねるが、
少なくとも現行より省電力であると推測できる材料は、いままで皆無だろ。
HKMGの熟成。
ttp://aceshardware.freeforums.org/finally-an-image-of-shanghai-t405-15.html#5302
ttp://chip-architect.com/news/Shanghai_Nehalem.jpg
ttp://chip-architect.com/news/Shanghai_Nehalem.jpg
{kind=link}
ロジック部分の大きさの違いが印象的だな。
Shanghaiの方がL3の容量小さいのにダイで占める面積は多そうだ。
262 :MACオタ>261 さん:2008/03/08(土) 17:39:28 ID:xLYlIju9
>>261
画像の作者のVries氏もそこに注目しているみたいす。
Nehalem
-------------------
L3 cache tiles: 5.7mm2/MB (excl.tags)
-------------------
Shanghai
-------------------
L3 cache tiles: 7.5mm2/MB
-------------------
画像の作者のVries氏もそこに注目しているみたいす。
Nehalem
-------------------
L3 cache tiles: 5.7mm2/MB (excl.tags)
-------------------
Shanghai
-------------------
L3 cache tiles: 7.5mm2/MB
-------------------
Shanghai は高速冗長な設計になっているんだろうか?
L2は、512Kbと大きいな
マとしての直感で
シングルスレッドアプリケーション
Shanghai < Nehalem
マルチスレッドアプリケーション
Nehalem < Shanghai
と見た
L2は、512Kbと大きいな
マとしての直感で
シングルスレッドアプリケーション
Shanghai < Nehalem
マルチスレッドアプリケーション
Nehalem < Shanghai
と見た
マルチスレッドなら並列度にもよるけどSMT搭載のNehalemにShanghaiが敵う事は無いと思うが…
265 :Socket774:2008/03/08(土) 18:52:59 ID:j1dPWdUH
Nehalemは32nm世代のWestmereでもダイにGPU統合しない予感。
>>265
Nehalem以外にコアがあるから、そちらに乗せるのでは?
Nehalem以外にコアがあるから、そちらに乗せるのでは?
>>265
エコサイクルとしてのコストパフォーマンスが激悪化するからGPGPUの確実な使い道が確定して
メインストリームに取り込まれるまではダイに統合はしないんじゃないの?
幸いIntelの場合はMCMでも出来のいい統合が出来るんだし
エコサイクルとしてのコストパフォーマンスが激悪化するからGPGPUの確実な使い道が確定して
メインストリームに取り込まれるまではダイに統合はしないんじゃないの?
幸いIntelの場合はMCMでも出来のいい統合が出来るんだし
アム厨悲惨
GMAを統合したNehalemは
ジサカー達にとっては積極的に避けるべき対象
ジサカー達にとっては積極的に避けるべき対象
>>264
出てみるまではわからんけど、ネハレンはヤバイ予感がしすぎる。
開発プロジェクトが二転三転しているであろう事は外目にも想像がつくし、正直期待していないです。
逆に自分の想像をぶっちぎって超高性能なら、ちょっと見直す。
出てみるまではわからんけど、ネハレンはヤバイ予感がしすぎる。
開発プロジェクトが二転三転しているであろう事は外目にも想像がつくし、正直期待していないです。
逆に自分の想像をぶっちぎって超高性能なら、ちょっと見直す。
>>270
基本性能は高いとおもう。ただ、Pen4のHTTのように、
特定ソフトでしか高い性能を発揮しないとかの危険性はある。
だけどHTTだってだいぶ改良もされているだろうし、
基本性能も悪い事はないだろう。
基本性能は高いとおもう。ただ、Pen4のHTTのように、
特定ソフトでしか高い性能を発揮しないとかの危険性はある。
だけどHTTだってだいぶ改良もされているだろうし、
基本性能も悪い事はないだろう。
>>270
そういう意見が自分にはさっぱり分からんね…
Pen4と違って物凄く真っ当な作りのコアにしか見えんよ
プロジェクトが二転三転する要素が見当たらん
ま、マの人にとっては積極的なマルチスレッドプログラミングを強いる嫌なコアに見えるかもしれんがね
そういう意見が自分にはさっぱり分からんね…
Pen4と違って物凄く真っ当な作りのコアにしか見えんよ
プロジェクトが二転三転する要素が見当たらん
ま、マの人にとっては積極的なマルチスレッドプログラミングを強いる嫌なコアに見えるかもしれんがね
Nehalemの道筋は正しいでしょ
ネイティブクアッド、FSB→PQIで帯域大幅増大とシリアル化、メモコン統合、ノース統合、64bit最適化
と、ボトルネックを潰していってるわけで
ネイティブクアッド、FSB→PQIで帯域大幅増大とシリアル化、メモコン統合、ノース統合、64bit最適化
と、ボトルネックを潰していってるわけで
ただ初モノ技術が多いから避けたがる気持ちがわからないでもない
オレは特攻するけどな
たまには熱いCPUを入れてやらないと水冷システムが完全に無駄になる
オレは特攻するけどな
たまには熱いCPUを入れてやらないと水冷システムが完全に無駄になる
>>273
それは本当にボトルネックなのか?
一度そこから見直す必要があると思うんだよ、古い考え方に従ってただ計算して、ここがボトルネックだって言っているような
そんな予感がしてならないんだよ、そもそも「正しい」と考えられているだけで良いのなら悪夢ネトバがそれではないのか?
それは本当にボトルネックなのか?
一度そこから見直す必要があると思うんだよ、古い考え方に従ってただ計算して、ここがボトルネックだって言っているような
そんな予感がしてならないんだよ、そもそも「正しい」と考えられているだけで良いのなら悪夢ネトバがそれではないのか?
なんというゆとり脳
次世代スレとは思えないカス発言だな・・・
CPU関係のサイトをググって見るだけでも分かるようなことを
言ってるあたりMACオタより遥かに有害だな
次世代スレとは思えないカス発言だな・・・
CPU関係のサイトをググって見るだけでも分かるようなことを
言ってるあたりMACオタより遥かに有害だな
たとえば、先頭に上げられるネイティブクアッドを実現したら、何か決定的な高性能化はあるか?
絶対ないね、そこに挙げられている要素は、すべて枝葉末節だ。
絶対ないね、そこに挙げられている要素は、すべて枝葉末節だ。
>>275
あんまり根本的なことを言われても困るが
一般的にはボトルネックであろうと思われてる部分じゃないのかな
まあ多分サーバー用途に強くなるよう強化してるんだろなって印象がある。
「単一処理で速くなる」、よりも「同時多重負荷に対して遅くならない」ことを目指してるんじゃないかな
ああ、それとボトルネック潰しで浮動小数点も大幅強化してるね。
あんまり根本的なことを言われても困るが
一般的にはボトルネックであろうと思われてる部分じゃないのかな
まあ多分サーバー用途に強くなるよう強化してるんだろなって印象がある。
「単一処理で速くなる」、よりも「同時多重負荷に対して遅くならない」ことを目指してるんじゃないかな
ああ、それとボトルネック潰しで浮動小数点も大幅強化してるね。
>>271
他社のSMT見たことある?
他社のSMT見たことある?
CeBITで展示されていたらしいSilverthorneのウェハす。
http://www.theinquirer.net/gb/inquirer/news/2008/03/08/intel-talk-mobile-toys
http://www.theinquirer.net/gb/inquirer/news/2008/03/08/intel-talk-mobile-toys
ここでこけるんじゃないかとか、
悪夢のネトバの再来じゃないかと不安そうな発言を繰り返している奴らが、
一番こけてほしいと心の中では思ってるんだからなあ。
自作板特有の病的な反応にはつくづく嫌気がさすわ。
悪夢のネトバの再来じゃないかと不安そうな発言を繰り返している奴らが、
一番こけてほしいと心の中では思ってるんだからなあ。
自作板特有の病的な反応にはつくづく嫌気がさすわ。
ネハレンのSPECrate値がすでに流出してるだろ
それから適当に推測すると、
シングルスレッド→C2D同等
マルチスレッド→C2Dの30〜50%アップ
くらいの感じじゃね?
SMT以外、性能アップはあんまないと思う
あとマルチソケットの性能と
それから適当に推測すると、
シングルスレッド→C2D同等
マルチスレッド→C2Dの30〜50%アップ
くらいの感じじゃね?
SMT以外、性能アップはあんまないと思う
あとマルチソケットの性能と
>>281
物が出れば決定するよ、時間が結果を出してくれるから待っていろ。
物が出れば決定するよ、時間が結果を出してくれるから待っていろ。
パクマン = 釣り糸
キミらネハレン好きだねー
Intelはプロセッサ数*2MBのL2量を基本にしているが
本格的にマルチスレッドアプリケーションが登場して、共有L3キャッシュであるなら
L3使用量は、プロセッサの数*2MBより減ってくると推定しているんだよ、同じデータを参照する確率が上がるからね。
ならL2の容量が大きいほうが有利だろう、とまぁそんな風に考えた訳。
それと
>Shanghaiの方がL3の容量小さいのにダイで占める面積は多そうだ。
もちょっと気になった、AMDの技術力が低くて大量に面積を食ってしまったとは思えなかったので、高速化でもしたかなと…
それ以外の部分についての性能アップは誤差の範囲に落ち着くだろうと予想した訳。
シングルプロセッサでの処理はC2DにはAMDが勝てそうになさそうなのでC2D勝利と。
Intelはプロセッサ数*2MBのL2量を基本にしているが
本格的にマルチスレッドアプリケーションが登場して、共有L3キャッシュであるなら
L3使用量は、プロセッサの数*2MBより減ってくると推定しているんだよ、同じデータを参照する確率が上がるからね。
ならL2の容量が大きいほうが有利だろう、とまぁそんな風に考えた訳。
それと
>Shanghaiの方がL3の容量小さいのにダイで占める面積は多そうだ。
もちょっと気になった、AMDの技術力が低くて大量に面積を食ってしまったとは思えなかったので、高速化でもしたかなと…
それ以外の部分についての性能アップは誤差の範囲に落ち着くだろうと予想した訳。
シングルプロセッサでの処理はC2DにはAMDが勝てそうになさそうなのでC2D勝利と。
>逆に自分の想像をぶっちぎって超高性能なら、ちょっと見直す。
基準がよくわからんが、上海比は今はお楽しみだが、
Core2比でもぶっちぎりの超高性能なんてことはとりあえずないって。
そりゃrateは速くなるだろうけど、デスクトップ用途ではそんなかわらんはず。
後藤記事にあまり洗脳されない方がいいぞ。
Nehalemって、つなぎとメモリ周りはようやっとモダンになって移行リスクが増加していながら、
所詮はコアはCore2の焼き直しっぽい。
基準がよくわからんが、上海比は今はお楽しみだが、
Core2比でもぶっちぎりの超高性能なんてことはとりあえずないって。
そりゃrateは速くなるだろうけど、デスクトップ用途ではそんなかわらんはず。
後藤記事にあまり洗脳されない方がいいぞ。
Nehalemって、つなぎとメモリ周りはようやっとモダンになって移行リスクが増加していながら、
所詮はコアはCore2の焼き直しっぽい。
Core2の焼き直しも何もP6ですよ
ただSSE4.2とATAに最適化した際の性能向上は恐らくnotably
ただSSE4.2とATAに最適化した際の性能向上は恐らくnotably
intelにしろAMDにしろ今できることはとりあえずやりました感があるな、NehalemとShanghai
まあ得手不得手あるにしろIPCはあまり変わらなくなってくるんじゃなかろうか。
結局クロック周波数の勝負になってきそうな気がする。
まあ得手不得手あるにしろIPCはあまり変わらなくなってくるんじゃなかろうか。
結局クロック周波数の勝負になってきそうな気がする。
IntelのSRAMが他社より異常に集積度が高いのは一般常識かと思ったがそうでもないようだな。
>>289
だがSMTがある分Nehalemのが早いだろ。
対C2DではたぶんShanghaiの方が早い。
"同クロックならば"という注釈が付き、
現状を見るとあんまり上昇しないだろうな。
>>290
一般常識じゃないけど、このスレでは
普通に知っているんじゃない? みんな。
だがSMTがある分Nehalemのが早いだろ。
対C2DではたぶんShanghaiの方が早い。
"同クロックならば"という注釈が付き、
現状を見るとあんまり上昇しないだろうな。
>>290
一般常識じゃないけど、このスレでは
普通に知っているんじゃない? みんな。
別にずば抜けて集積度は高くも無いはずだが。。。
SOIは集積度を高めにくいという話をどこかで聞いた気もする。
とはいえL2同士で比べるとそこまで大きな差も無いからどうだろ。
SOIは集積度を高めにくいという話をどこかで聞いた気もする。
とはいえL2同士で比べるとそこまで大きな差も無いからどうだろ。
>対C2DではたぶんShanghaiの方が早い。
何をどう考えるとこんな妄想ができるのかわからん。
E4xxx比なら速いだろう、ということか。
何をどう考えるとこんな妄想ができるのかわからん。
E4xxx比なら速いだろう、ということか。
それくらいの性能は無いと困るけどな。競争的な意味で。
『ゲート絶縁膜材料の誘電体にUltra-low-K』で笑いを取ったMYCOMの笠原光氏すけど、
http://journal.mycom.co.jp/articles/2008/03/06/cebit04/002.html
この経歴じゃ仕方がないのかもしれないす(笑)
http://job.mycom.co.jp/08/pc/visitor/search/corp50857/obog8/obog.html
-------------------
笠原 光
2005年入社
経営学部 第二経営学科 卒業
毎日コミュニケーションズ 出版事業本部 マイコミジャーナル編集部
IT系情報サイトの編集
-------------------
安藤氏の記事とコレが並ぶMYCOMの玉石混交っぷりって。。。
http://journal.mycom.co.jp/articles/2008/03/06/cebit04/002.html
この経歴じゃ仕方がないのかもしれないす(笑)
http://job.mycom.co.jp/08/pc/visitor/search/corp50857/obog8/obog.html
-------------------
笠原 光
2005年入社
経営学部 第二経営学科 卒業
毎日コミュニケーションズ 出版事業本部 マイコミジャーナル編集部
IT系情報サイトの編集
-------------------
安藤氏の記事とコレが並ぶMYCOMの玉石混交っぷりって。。。
2ちゃんねるでいつも冷静で的確なレスを発表されている
MACオタさんの経歴をぜひ知りたいです><
MACオタさんの経歴をぜひ知りたいです><
297 :MACオタ>296 さん:2008/03/09(日) 09:17:46 ID:lSXgkkSe
それは素晴らしいギャグですね
1行目と2行目に明らかな矛盾があるね
鬼の首を取ったかのように騒いでるのを見てるとなんか恥ずかしくなってくる。
Atomの詳細な処理能力はまだ発表されてないのか?
EeePCの新型がこれを積むみたいだから情報が欲しいわ。
EeePCの新型がこれを積むみたいだから情報が欲しいわ。
>それわ、匿名掲示板の趣旨から外れているかと思うす。
おいおい、なんだこの無責任っぷりは…。
自分は安全な匿名掲示板に引きこもって、名指しで人を罵倒するだけなら
どんな能なしでも出来る。
おいおい、なんだこの無責任っぷりは…。
自分は安全な匿名掲示板に引きこもって、名指しで人を罵倒するだけなら
どんな能なしでも出来る。
303 :MACオタ>302 さん:2008/03/09(日) 13:24:57 ID:lSXgkkSe
304 :貧乏博士(白紙) ◆LOX0z7Scgs :2008/03/09(日) 16:59:59 ID:59tPOWN2
IntelがISSCC2008のSilverthorne論文を公開していたす。
ftp://download.intel.com/corporate/pressroom/emea/deu/fotos/08-03-CeBIT/Texte/TechnicalPaper_45nm_Silverthorne.pdf
ftp://download.intel.com/corporate/pressroom/emea/deu/fotos/08-03-CeBIT/Texte/TechnicalPaper_45nm_Silverthorne.pdf
Golem..deがSilverthorneのCPU-Z画像と1.33GHzでのVista CPUインデックスの値を掲載しているす。
http://www.golem.de/0803/58212.html
-------------------
Vistas eigener Benchmark "WEI" ergab fu"r den 1,3-GHz-Atom einen Wert von 1,7 im
Prozessortest. Intels Kleinster liegt damit in etwa auf dem Niveau eines Celeron-M
(Banias-Kern) mit 1 GHz.
-------------------
CPUインデックス1.7でBaniasコアのCelerom M/1GHzと同程度とか。
http://www.golem.de/0803/58212.html
-------------------
Vistas eigener Benchmark "WEI" ergab fu"r den 1,3-GHz-Atom einen Wert von 1,7 im
Prozessortest. Intels Kleinster liegt damit in etwa auf dem Niveau eines Celeron-M
(Banias-Kern) mit 1 GHz.
-------------------
CPUインデックス1.7でBaniasコアのCelerom M/1GHzと同程度とか。
これじゃ、x86以外の利点無しだな
むしろ発熱がでかすぎてそのメリットさえ失われる
しかもただのCPU以外の機能が無いし
かといって、発熱を無視できる環境だともっといい性能のを安価に使えるわけで
むしろ発熱がでかすぎてそのメリットさえ失われる
しかもただのCPU以外の機能が無いし
かといって、発熱を無視できる環境だともっといい性能のを安価に使えるわけで
>>307はAtomやDiamondvilleの値段がいくらになるか知っているのか。
309 :貧乏博士(白紙) ◆LOX0z7Scgs :2008/03/09(日) 17:33:24 ID:59tPOWN2
個人的には拡張された部分でどれくらい性能を伸ばせるのか
6年間での足回りの進化に注目したい
6年間での足回りの進化に注目したい
310 :Socket774:2008/03/09(日) 17:35:26 ID:fuMTdWAK
AtomもNehalemも来月のIDFには詳細が判明するでしょ。それまでのお楽しみということで。
406 :名刺は切らしておりまして :2008/03/04(火) 23:44:38 ID:AwnxgWhf
Baniasセレロン(L2 512KB、4800万トランジスタ)を
45nmで作った方が同電力高性能な予感
Baniasセレロン(L2 512KB、4800万トランジスタ)を
45nmで作った方が同電力高性能な予感
viaのIsaiahがそんな感じになるだろ
313 :Socket774:2008/03/09(日) 18:38:55 ID:fuMTdWAK
スマートフォンで単体プロセッサが2.5Wて致命的じゃね?
>>312
Isaiahは65nmで9,500万トランジスタだから、全然比較にならないと思われ。
まあ現行のC7のTDP範囲内で性能ウプを目指した設計だから、狙いが全然違う
訳だけど。
>>314
TDP別に3種類くらい製品シリーズが出ると思われ。
Isaiahは65nmで9,500万トランジスタだから、全然比較にならないと思われ。
まあ現行のC7のTDP範囲内で性能ウプを目指した設計だから、狙いが全然違う
訳だけど。
>>314
TDP別に3種類くらい製品シリーズが出ると思われ。
大雑把にシュリンク係数0.6としてL2 1MB Baniasを45nmに
83平方mm * 0.6 * 0.6 * 0.6 = 18平方mm
さすがにこんな都合よく行かないか
83平方mm * 0.6 * 0.6 * 0.6 = 18平方mm
さすがにこんな都合よく行かないか
そんなありえないぐらい順調なシュリンクが出来るわけねえだろ
それにBaniasを45nmにして省電力機構を足したところで1W切るTDPは
どうみても無理だしな
それにBaniasを45nmにして省電力機構を足したところで1W切るTDPは
どうみても無理だしな
x86である以上、微細化しても、もうどうしようもないでしょ。
トランジスタ構造の見直しとか、抜本的な改革がないと駄目だろうな。
トランジスタ構造の見直しとか、抜本的な改革がないと駄目だろうな。
ということはワンチップになるのもその流れか
原発並みの熱密度だっけ、だから無制限にシュリンクだけをするということはできないということか
60mm2以下のx86CPUをなかなか見ないと思ったらすでに小さくできているけど仕方なく量を増して熱を分散してるのね
ARMの組み込みであるマイコンのCortex-M3が 0.86mm2 ということを考えるとそこまで行く前に行き詰ると
60mm2以下のx86CPUをなかなか見ないと思ったらすでに小さくできているけど仕方なく量を増して熱を分散してるのね
ARMの組み込みであるマイコンのCortex-M3が 0.86mm2 ということを考えるとそこまで行く前に行き詰ると
未だに45nmプロセスに夢見てる奴いるんだ
intelの45nmって90nm同様失敗?
>>326
CPU「のみ」で1Wを大きく超えるAtomみればわからないか?
桁違いの爆熱なんだが
もしx86でなければ、同じトランジスタでそれ以上の性能や機能を実装できる
同じ消費電力なら、それ以上の性能を実現できる
x86はほんとインテルに生まれて幸せ者だよ
CPU「のみ」で1Wを大きく超えるAtomみればわからないか?
桁違いの爆熱なんだが
もしx86でなければ、同じトランジスタでそれ以上の性能や機能を実装できる
同じ消費電力なら、それ以上の性能を実現できる
x86はほんとインテルに生まれて幸せ者だよ
>>325
High-k採用で大成功って感じでアピールしてるけどね、Intel自身は。
ただ自作市場に流通不足なのはどういうこっちゃ?って感じだが、PCメーカー向け
とかで引っ張りだこなのかな。
>>326
命令コード体系が複雑で、デコーダその他にどうしてもトランジスタその他が
多く必要になるからでしょ。
そのお陰で一時期はRISCプロセッサが持て囃された訳だけど、命令コード量の
多さがメモリアクセス量を増やしてしまう問題が露見して、コード量が少ない
CISCが見直された経緯がある。
しかし今は命令デコードでの非効率さが、処理能力や消費電力のネックになって
きていて、それをIntelはx86で儲けた資本力で培った、設計能力&製造能力を
フルに使ってカバーしようとしてるだけだし。
High-k採用で大成功って感じでアピールしてるけどね、Intel自身は。
ただ自作市場に流通不足なのはどういうこっちゃ?って感じだが、PCメーカー向け
とかで引っ張りだこなのかな。
>>326
命令コード体系が複雑で、デコーダその他にどうしてもトランジスタその他が
多く必要になるからでしょ。
そのお陰で一時期はRISCプロセッサが持て囃された訳だけど、命令コード量の
多さがメモリアクセス量を増やしてしまう問題が露見して、コード量が少ない
CISCが見直された経緯がある。
しかし今は命令デコードでの非効率さが、処理能力や消費電力のネックになって
きていて、それをIntelはx86で儲けた資本力で培った、設計能力&製造能力を
フルに使ってカバーしようとしてるだけだし。
>CPU「のみ」で1Wを大きく超えるAtomみればわからないか?
知りたいのは結論ではなく原因なんですが・・・・
知りたいのは結論ではなく原因なんですが・・・・
低発熱な組み込み向けはx86みたいに豊富な機能を持ってないし
ハイエンドだと処理能力でも消費電力でも構造でも大差ないでしょ。
この手の話でx86をクサす人は組み込み向けとハイエンドを故意に混同してる。
ハイエンドだと処理能力でも消費電力でも構造でも大差ないでしょ。
この手の話でx86をクサす人は組み込み向けとハイエンドを故意に混同してる。
それはどの辺なんだろうな、命令セット程度なら置換だけだし大した事はなさそうな気がしてならない
過去の遺産となっているセグメントとかその辺りが効いているのだろうか・・・・
過去の遺産となっているセグメントとかその辺りが効いているのだろうか・・・・
>>329
過去に膨大な遺産を抱えているために、命令セットが肥大化している。
それを処理するための回路が複雑化してしまっている。
いくらCPUを小さくしようとしても過去の遺産が邪魔をして、
それを妨げている。
だったよーな。
過去に膨大な遺産を抱えているために、命令セットが肥大化している。
それを処理するための回路が複雑化してしまっている。
いくらCPUを小さくしようとしても過去の遺産が邪魔をして、
それを妨げている。
だったよーな。
>>327
同じトランジスタで同等以上の性能を持つCPUを挙げてくれ。
同じトランジスタで同等以上の性能を持つCPUを挙げてくれ。
その、命令セットがx86であるが故のオーバーヘッドって
直感的ではなく、定量的に議論されたのを見たことある?
直感的ではなく、定量的に議論されたのを見たことある?
>>334
定量的と言ってもそんな数字だせないし、仮に出しても
その値にどれだけ信用性があることやら
ただし、定量的に表しにくいと言っても、x86命令のデコーダ部分が
完璧にオーバーヘッドになっているのは事実。そうするとデコードに
掛かる時間がオーバーヘッドの定量値なるかと言うとそうでもない
デコードから先のスケーラ部分でも、既存プログラムを高速に動作
させるためにx86命令の癖や発行順序に依存している事もあるからね
定量的と言ってもそんな数字だせないし、仮に出しても
その値にどれだけ信用性があることやら
ただし、定量的に表しにくいと言っても、x86命令のデコーダ部分が
完璧にオーバーヘッドになっているのは事実。そうするとデコードに
掛かる時間がオーバーヘッドの定量値なるかと言うとそうでもない
デコードから先のスケーラ部分でも、既存プログラムを高速に動作
させるためにx86命令の癖や発行順序に依存している事もあるからね
>>334
>>328の後半の文章が現在の状況をそのまま表してるよ
x86だからオーバーヘッドが大きいんじゃなくて
CISCだから非効率なだけ
そもそもCISCはもはやIAアーキのプロセッサ以外存在しないぐらい壊滅的
CISCのほうが電力効率と性能向上曲線がRISCより優秀なら
そんな状況にはなってないよ
そのIAプロセッサですら中身はほとんどRISCプロセッサだしね
コストと消費電力に対する要求度合いが大きく、Windowsが動かなくてもいい
組み込み向けや携帯機器向けの場合、ほぼ100%RISCプロセッサ
>>328の後半の文章が現在の状況をそのまま表してるよ
x86だからオーバーヘッドが大きいんじゃなくて
CISCだから非効率なだけ
そもそもCISCはもはやIAアーキのプロセッサ以外存在しないぐらい壊滅的
CISCのほうが電力効率と性能向上曲線がRISCより優秀なら
そんな状況にはなってないよ
そのIAプロセッサですら中身はほとんどRISCプロセッサだしね
コストと消費電力に対する要求度合いが大きく、Windowsが動かなくてもいい
組み込み向けや携帯機器向けの場合、ほぼ100%RISCプロセッサ
逆だろ。
命令や機能が限定される組み込み用途でしかRISCは生き残れなかった。
命令や機能が限定される組み込み用途でしかRISCは生き残れなかった。
あとはIBMみたいにOSからアプリからシステム全部をガチガチに固めることで生き残ったか
それにしたって、POWERプロセッサの進化が鈍ってしまえば、何時HPやSUNの二の舞に
なるかも分からんけど
それにしたって、POWERプロセッサの進化が鈍ってしまえば、何時HPやSUNの二の舞に
なるかも分からんけど
逆にかんがえるんだ
X86は、それほど複雑な命令セットじゃないから生き残れたんだ
ピュアスタックとか直行性が完璧とかだったら
死んでたと思う
X86は、それほど複雑な命令セットじゃないから生き残れたんだ
ピュアスタックとか直行性が完璧とかだったら
死んでたと思う
>>338
命令が限定されるというよりも・・・
R3000の後継プロセッサを見ていると、RISCが後継難になるのは
パイプラインが直接露出してしまった事だと思ったよ
ハードウェアに近すぎるがゆえに、よりハイパフォーマンスを狙って新しい技術を実装しようとすると互換が困難になる
そのためR4000以降ボロボロのアーキテクチャになってしまった、古くは6502から65816でも実感したな。
6502は8bitRISCチップで、ほぼ究極の命令セットだったと思う、対して65816は16bit最低の命令セットになっていた。
おれは、この一点が純粋RISCが生き残れなかった理由になったと思ったよ。
>>328
>そのお陰で一時期はRISCプロセッサが持て囃された訳だけど、命令コード量の
>多さがメモリアクセス量を増やしてしまう問題が露見して、コード量が少ない
>CISCが見直された経緯がある
.NETやJavaに見られる、バイトコードが恐ろしくコンパクトなので、あれをマイクロ命令に変換して実行したら
大幅な帯域圧縮になりそうな気がする、しかも命令はプログラム中でよくつかわれるパターンを凝縮したようなコード体系だし
大量に出現する命令をより速くするという方針にも向いていてJITが、マイクロコード用メモリ収まるようなら
イカした結果をだすのではないかと思う今日この頃です。
命令が限定されるというよりも・・・
R3000の後継プロセッサを見ていると、RISCが後継難になるのは
パイプラインが直接露出してしまった事だと思ったよ
ハードウェアに近すぎるがゆえに、よりハイパフォーマンスを狙って新しい技術を実装しようとすると互換が困難になる
そのためR4000以降ボロボロのアーキテクチャになってしまった、古くは6502から65816でも実感したな。
6502は8bitRISCチップで、ほぼ究極の命令セットだったと思う、対して65816は16bit最低の命令セットになっていた。
おれは、この一点が純粋RISCが生き残れなかった理由になったと思ったよ。
>>328
>そのお陰で一時期はRISCプロセッサが持て囃された訳だけど、命令コード量の
>多さがメモリアクセス量を増やしてしまう問題が露見して、コード量が少ない
>CISCが見直された経緯がある
.NETやJavaに見られる、バイトコードが恐ろしくコンパクトなので、あれをマイクロ命令に変換して実行したら
大幅な帯域圧縮になりそうな気がする、しかも命令はプログラム中でよくつかわれるパターンを凝縮したようなコード体系だし
大量に出現する命令をより速くするという方針にも向いていてJITが、マイクロコード用メモリ収まるようなら
イカした結果をだすのではないかと思う今日この頃です。
R3000は386やVAX8700の1/3のトランジスタで
3倍以上速かった
これがRISC伝説を産んだ
でもR4000は。。。
3倍以上速かった
これがRISC伝説を産んだ
でもR4000は。。。
>>341
.NETは良く知らんから置いとくけど、Javaバイトコードをネイティブで動かすCPUを
開発してた時期もあったし、そこらあたりの最適化や実行効率はかなりよさげだね
問題はJavaでそこまでする需要があるかどうかだけど、、、
.NETは良く知らんから置いとくけど、Javaバイトコードをネイティブで動かすCPUを
開発してた時期もあったし、そこらあたりの最適化や実行効率はかなりよさげだね
問題はJavaでそこまでする需要があるかどうかだけど、、、
少なくともMSは.NETを主力にしたいと考えているし、WEBの進化でバイトコードやインタプリタ形式のプログラムが増えてくんじゃない
JAVAや.NETなどバイトコードをJustInCompileする言語はキャッシュ容量やデュアルコアは有効なのかな?
JAVAや.NETなどバイトコードをJustInCompileする言語はキャッシュ容量やデュアルコアは有効なのかな?
blackfinマンセー
http://www.computerbase.de/news/hardware/prozessoren/intel/2008/maerz/intel_6-core_dunnington_die-shot/
XenonCPUみたい。
画像の元ネタはInvesterMeeting2008のSkaugenのスライド。
XenonCPUみたい。
画像の元ネタはInvesterMeeting2008のSkaugenのスライド。
>>344
スタックマシンは構造が簡単で、超が付くほどの小規模回路でも実現できるが、それをやっては駄目だ。
並列度が取れず全くパフォーマンスはでない、当時のJavaマシンはそういう物だった。
スタックマシンは、一旦レジスターマシンに変換しないと駄目だ。
またスタックマシンのコードは、結果の依存関係を機械的に把握しやすく、暗にオプティマイズのヒントを多く含んでいる。
その為OoOを行う時の強力なヒントをコードストリームから得やすいと思われる、レジスター概念がないため
コード変換後のレジスター数は実行する側の自由になる、ここでレジスターはパイプラインの深さに依存して必要本数が変わってくるが
パイプラインの深さの決定権をハード側が持っていると、Atomのようなケースにも柔軟に対応できると思われる。
レジスターマシンにしてしまうと、レジスターはコードによって固定されてしまいがちになってしまう。
スタックマシンは構造が簡単で、超が付くほどの小規模回路でも実現できるが、それをやっては駄目だ。
並列度が取れず全くパフォーマンスはでない、当時のJavaマシンはそういう物だった。
スタックマシンは、一旦レジスターマシンに変換しないと駄目だ。
またスタックマシンのコードは、結果の依存関係を機械的に把握しやすく、暗にオプティマイズのヒントを多く含んでいる。
その為OoOを行う時の強力なヒントをコードストリームから得やすいと思われる、レジスター概念がないため
コード変換後のレジスター数は実行する側の自由になる、ここでレジスターはパイプラインの深さに依存して必要本数が変わってくるが
パイプラインの深さの決定権をハード側が持っていると、Atomのようなケースにも柔軟に対応できると思われる。
レジスターマシンにしてしまうと、レジスターはコードによって固定されてしまいがちになってしまう。
>>341
> R3000の後継プロセッサを見ていると、RISCが後継難になるのは
> パイプラインが直接露出してしまった事だと思ったよ
ディレイドスロットとか、特定のインプリメンテーションに依存しすぎてたよなー
> .NETやJavaに見られる、バイトコードが恐ろしくコンパクトなので、あれをマイクロ命令に変換して実行したら
> 大幅な帯域圧縮になりそうな気がする、しかも命令はプログラム中でよくつかわれるパターンを凝縮したようなコード体系だし
でもこのへんのバイトコードってスタックマシンじゃない?今のCPUもレジスタリネーミング
程度はしているけど、スタックマシンのコード --> 物理レジスタやりくりの最適化、ましてや
今ソフトウェアのJITがやっているように、一度実行させてトレースを取って2度目以降から
最適化なんてのをCPUにインプリするとなるとかなり大変そうだが、どうなのかねえ?
> R3000の後継プロセッサを見ていると、RISCが後継難になるのは
> パイプラインが直接露出してしまった事だと思ったよ
ディレイドスロットとか、特定のインプリメンテーションに依存しすぎてたよなー
> .NETやJavaに見られる、バイトコードが恐ろしくコンパクトなので、あれをマイクロ命令に変換して実行したら
> 大幅な帯域圧縮になりそうな気がする、しかも命令はプログラム中でよくつかわれるパターンを凝縮したようなコード体系だし
でもこのへんのバイトコードってスタックマシンじゃない?今のCPUもレジスタリネーミング
程度はしているけど、スタックマシンのコード --> 物理レジスタやりくりの最適化、ましてや
今ソフトウェアのJITがやっているように、一度実行させてトレースを取って2度目以降から
最適化なんてのをCPUにインプリするとなるとかなり大変そうだが、どうなのかねえ?
350 :Socket774:2008/03/11(火) 05:58:30 ID:8LPKQr1x
Atomの価格が出てるね
http://northwood.blog60.fc2.com/blog-entry-1770.html#more
1.6GHz、TDP2Wで44ドル
1.6GHz、TDP4Wで29ドル
この価格差だとTDP4WのDiamondvilleを選んでしまうね。
http://northwood.blog60.fc2.com/blog-entry-1770.html#more
1.6GHz、TDP2Wで44ドル
1.6GHz、TDP4Wで29ドル
この価格差だとTDP4WのDiamondvilleを選んでしまうね。
567 :Socket774 [↓] :2008/03/11(火) 07:08:45 ID:pYAxCyLe
■笠原一輝のユビキタス情報局■
立ち上がるネットトップ/ネットブック市場
ttp://pc.watch.impress.co.jp/docs/2008/0311/ubiq212.htm
ttp://pc.watch.impress.co.jp/docs/2008/0311/ubiq06.jpg
CLEVOのTN70M。Silverthorneと推定されるIntelの次世代CPUを採用し、
7型タッチパネルワイド液晶(1,024×600ドットないしは800×480ドット)を搭載している。
1.8インチのHDDかSSDを搭載可能
ttp://xs224.xs.to/xs224/08055/mm3500636.jpg
C7より遅いです
本当にありがとうございました
■笠原一輝のユビキタス情報局■
立ち上がるネットトップ/ネットブック市場
ttp://pc.watch.impress.co.jp/docs/2008/0311/ubiq212.htm
ttp://pc.watch.impress.co.jp/docs/2008/0311/ubiq06.jpg
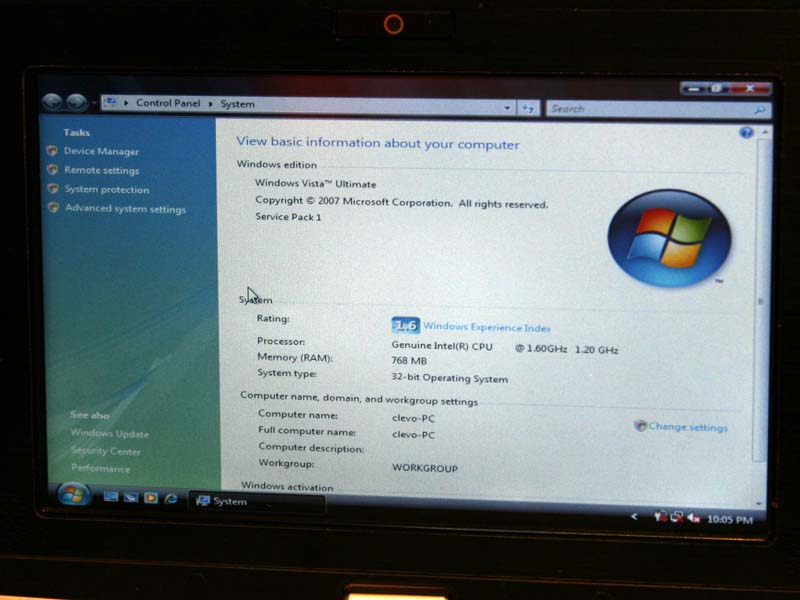{kind=link}
CLEVOのTN70M。Silverthorneと推定されるIntelの次世代CPUを採用し、
7型タッチパネルワイド液晶(1,024×600ドットないしは800×480ドット)を搭載している。
1.8インチのHDDかSSDを搭載可能
ttp://xs224.xs.to/xs224/08055/mm3500636.jpg
{kind=link}
C7より遅いです
本当にありがとうございました
>>245-246でもIntelのSSDへの入れ込みが理解できるすけど、このCNET記事によると価格面でも
攻勢をかけるとのことす。
http://blogs.cnet.com/8301-13924_1-9888760-64.html
-------------------
Winslow [marketing manager for the NAND Products Group] said. "And in 2009, a 50 percent reduction,
then again in 2010."
-------------------
Intelが業界を良い方向に導くために短期的利益率を捨てる企業ということを、ここ2年で証明することに
なるかもしれないす。
攻勢をかけるとのことす。
http://blogs.cnet.com/8301-13924_1-9888760-64.html
-------------------
Winslow [marketing manager for the NAND Products Group] said. "And in 2009, a 50 percent reduction,
then again in 2010."
-------------------
Intelが業界を良い方向に導くために短期的利益率を捨てる企業ということを、ここ2年で証明することに
なるかもしれないす。
>351
Silverthorneは1.2GHzで動いているように見えるが……。
定格の1.6GHzだともうちょっとスコア上がるっしょ。
Silverthorneは1.2GHzで動いているように見えるが……。
定格の1.6GHzだともうちょっとスコア上がるっしょ。
どっちにしろwktkしすぎてはいかんということやろね。
あげちゃった orz
TDP2W程度でその性能が出るっつーのがポイントなんだろうな。
比較相手のC7はEstherだから1.5GHzだと10W以上食ってそうだし。
TDP2W程度でその性能が出るっつーのがポイントなんだろうな。
比較相手のC7はEstherだから1.5GHzだと10W以上食ってそうだし。
VIAの戦える市場がどんどんintelに食われていくだろうな。
性能がDiamondvilleの方がC7より多少低くても、Diamondvilleの方が安く売れるだろうし、
新コアのIsaiahは性能的にCeleron400、500シリーズが対抗馬。
TDP下げるためにクロック下げれば、Diamondvilleとの性能差が縮まるし、
TDP10〜20Wクラスしか積極的に売り込める場所ないんじゃないか?
性能がDiamondvilleの方がC7より多少低くても、Diamondvilleの方が安く売れるだろうし、
新コアのIsaiahは性能的にCeleron400、500シリーズが対抗馬。
TDP下げるためにクロック下げれば、Diamondvilleとの性能差が縮まるし、
TDP10〜20Wクラスしか積極的に売り込める場所ないんじゃないか?
>>344
トランスメタが生き残っていれば、コードモーフィングを活用出来たかも知れないのにね。
トランスメタが生き残っていれば、コードモーフィングを活用出来たかも知れないのにね。
>>349
|今ソフトウェアのJITがやっているように、一度実行させてトレースを取って2度目以降から
|最適化なんてのをCPUにインプリするとなるとかなり大変そうだが、どうなのかねえ?
正にコードモーフィングそのものです。
>>356
フェノムで躓いたAMDが、780GとHybrid Graphicsでちょっと復活しかかってる様に、
VIAもVideo内蔵チップで対抗するしか無いと思われ。
DX10サポートのChrome 400を最新プロセスで製造するなら、性能的にも消費電力的
にも充分対抗出来ると思う。
Intelは廉価PCにはDirectX9対応の旧くて130umな945Gを廃物?利用するみたいだし、
UMPCに使う最新のVideo内蔵チップセットは、商品展開上組み込み向けや廉価PCには
使えないだろうから。
|今ソフトウェアのJITがやっているように、一度実行させてトレースを取って2度目以降から
|最適化なんてのをCPUにインプリするとなるとかなり大変そうだが、どうなのかねえ?
正にコードモーフィングそのものです。
>>356
フェノムで躓いたAMDが、780GとHybrid Graphicsでちょっと復活しかかってる様に、
VIAもVideo内蔵チップで対抗するしか無いと思われ。
DX10サポートのChrome 400を最新プロセスで製造するなら、性能的にも消費電力的
にも充分対抗出来ると思う。
Intelは廉価PCにはDirectX9対応の旧くて130umな945Gを廃物?利用するみたいだし、
UMPCに使う最新のVideo内蔵チップセットは、商品展開上組み込み向けや廉価PCには
使えないだろうから。
デスクトップで鯖もどきを作る分には、2Wだろうが4Wだろうがファンレスにできるよね。
361 :Socket774:2008/03/11(火) 15:00:40 ID:8LPKQr1x
http://pc.watch.impress.co.jp/docs/2008/0311/intel.htm
ところで2009/10←Impressはこれを2009年10月と解釈してるわけだが、2009年or2010年だよね?
Moorestownの項目なんだが・・・。
ところで2009/10←Impressはこれを2009年10月と解釈してるわけだが、2009年or2010年だよね?
Moorestownの項目なんだが・・・。
つぅか、DX10の必要がない。
廉価PC向けならOSはHome Basic、もしくはLinuxになるだろう。
廉価PC向けならOSはHome Basic、もしくはLinuxになるだろう。
ロードマップ見て思ったけど光CPUはどうなったの
数年後
>>187
それファンがついてるのは945GCだよ。
真ん中がICH7で一番左のがDiamondville。
なんつってみたりしてな。
でもDiamondvilleって大きさが一円玉よりわずかに大きいぐらい(22x22mm、一辺がSATAコネクタ一個半程度)なんで。
通常の845GC(37.5x37.5mm)やICH7(31x31mm)より小さいんだよな。
ありえない話でもないかもしれない。
それファンがついてるのは945GCだよ。
真ん中がICH7で一番左のがDiamondville。
なんつってみたりしてな。
でもDiamondvilleって大きさが一円玉よりわずかに大きいぐらい(22x22mm、一辺がSATAコネクタ一個半程度)なんで。
通常の845GC(37.5x37.5mm)やICH7(31x31mm)より小さいんだよな。
ありえない話でもないかもしれない。
性能優位だけで戦えるほど甘くないでしょ。
VIAは安泰だ。
VIAは安泰だ。
そうだね。最後に勝つのはブランド力のあるほうだ
>>367
AMD<なんだと
AMD<なんだと
VIAにブランド力など
立ち上がるネットトップ/ネットブック市場
http://pc.watch.impress.co.jp/docs/2008/0311/ubiq212.htm
|現時点ではデュアルコア版のDiamondvilleがどのような形になっているのか(つまりMCMなのか、
|それともネイティブでデュアルコアなのか)は明らかではないが、Silverthorneはモジュラー
|デザインになっており、デュアルコア版を作るのもそんなに大変ではないと考えられるので、
|おそらくネイティブでデュアルコアという形になっているのではないだろうか。
これってどうなんでしょう?
PentiumDみたいに単に2コアを1ダイにしただけなら、MCMの方がSingleダイ
の有効利用が可能なのでコスト的に安くすみそうだけど。
もしC2DみたいにL2を共有して1MBにする場合だと、性能的な優位がかなり
出てくる訳ですが、このコアではUMPC向けにはTDP的に使えないからコスト
ダウンには不利だし。
http://pc.watch.impress.co.jp/docs/2008/0311/ubiq212.htm
|現時点ではデュアルコア版のDiamondvilleがどのような形になっているのか(つまりMCMなのか、
|それともネイティブでデュアルコアなのか)は明らかではないが、Silverthorneはモジュラー
|デザインになっており、デュアルコア版を作るのもそんなに大変ではないと考えられるので、
|おそらくネイティブでデュアルコアという形になっているのではないだろうか。
これってどうなんでしょう?
PentiumDみたいに単に2コアを1ダイにしただけなら、MCMの方がSingleダイ
の有効利用が可能なのでコスト的に安くすみそうだけど。
もしC2DみたいにL2を共有して1MBにする場合だと、性能的な優位がかなり
出てくる訳ですが、このコアではUMPC向けにはTDP的に使えないからコスト
ダウンには不利だし。
デュアルコアをネイティブに作っても、今年だとDiamondvilleにしか使えないしな〜。
ネイティブにした方が、FSBの利用頻度下がるのでシステム全体の消費電力は下がるだろうけど、
Diamondvilleはそこまでシビアな用途は想定されてないだろうし…。
ネイティブで出てきたら、SoCで統合する他のプラットフォーム用のテストを兼ねてだろうか。
ネイティブにした方が、FSBの利用頻度下がるのでシステム全体の消費電力は下がるだろうけど、
Diamondvilleはそこまでシビアな用途は想定されてないだろうし…。
ネイティブで出てきたら、SoCで統合する他のプラットフォーム用のテストを兼ねてだろうか。
>>370
開発コストはMCMの方が安いが、製造コストはMCMの方が高くつく
ATOMは安くて大量に売るCPUだから、MCMじゃないほうがより儲かる
というかMCMなんて事をしてたら、あそこまで安くはできんと思う
開発コストはMCMの方が安いが、製造コストはMCMの方が高くつく
ATOMは安くて大量に売るCPUだから、MCMじゃないほうがより儲かる
というかMCMなんて事をしてたら、あそこまで安くはできんと思う
>>341
なるほど。
R4000以降でMIPSアーキティクチャが、組み込み向けにすらARMに駆逐されてしまった
のを不思議に思ってたけど、そういう理由が有ったんですね。
>>343 が書いてる様に、R3000の頃は絶賛されてたのに何故なのか、ずっと疑問だった
ので、ちょっとスッキリしました。
最近の組み込み向けCPUは、CISCのコード量の少なさとRISCのデコーダーの単純さを、
バランス良く設計してる様に思われる(例:ルネサスの次期CPU:RXシリーズ等)けど、
ARMもそういう感じなのでしょうか?
なるほど。
R4000以降でMIPSアーキティクチャが、組み込み向けにすらARMに駆逐されてしまった
のを不思議に思ってたけど、そういう理由が有ったんですね。
>>343 が書いてる様に、R3000の頃は絶賛されてたのに何故なのか、ずっと疑問だった
ので、ちょっとスッキリしました。
最近の組み込み向けCPUは、CISCのコード量の少なさとRISCのデコーダーの単純さを、
バランス良く設計してる様に思われる(例:ルネサスの次期CPU:RXシリーズ等)けど、
ARMもそういう感じなのでしょうか?
>>373
ARMは面白いよ。全命令にコンディショナル実行ができたり、Thumbモードがあったり
http://ja.wikipedia.org/wiki/ARM%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3#.E8.A8.AD.E8.A8.88.E3.81.AB.E3.81.A4.E3.81.84.E3.81.A6
ARMは面白いよ。全命令にコンディショナル実行ができたり、Thumbモードがあったり
http://ja.wikipedia.org/wiki/ARM%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3#.E8.A8.AD.E8.A8.88.E3.81.AB.E3.81.A4.E3.81.84.E3.81.A6
>>374
コンディショナル実行で分岐を減らす、ってのは面白いなあ。
昔アセンブラで組み込みソフトを作っていた頃、分岐を減らす為に分岐条件を
一つのbit列に纏めて、最後に判定する様な処理を作った事があるよ。
でも他人がトレースする時は分かりにくくて不評だったけど、コンパイラで展開
して自動生成する分には関係無いからオケだね。
ThumbってのはIAのx32→x64の拡張の逆パターンみたいな感じですね。
コンディショナル実行で分岐を減らす、ってのは面白いなあ。
昔アセンブラで組み込みソフトを作っていた頃、分岐を減らす為に分岐条件を
一つのbit列に纏めて、最後に判定する様な処理を作った事があるよ。
でも他人がトレースする時は分かりにくくて不評だったけど、コンパイラで展開
して自動生成する分には関係無いからオケだね。
ThumbってのはIAのx32→x64の拡張の逆パターンみたいな感じですね。
http://intel_im.edgesuite.net/2008/123085/IM2008_Mentzer.pdf
バラ色未来な資料作る前にG965、G35、G45をどうにかしれ
ユーザーは泣いてるぞ
http://pc11.2ch.net/test/read.cgi/jisaku/1204308230/
バラ色未来な資料作る前にG965、G35、G45をどうにかしれ
ユーザーは泣いてるぞ
http://pc11.2ch.net/test/read.cgi/jisaku/1204308230/
>>373
ルネサスのRXはコテコテのCISCだと思う
そうでなかったら、予告しているコード・サイズの達成は無理
3オペランドで、オペランドにメモリとレジスタの
両方取れるんだから、どういう命令フォーマットであろうが
最大級に複雑な命令なことは確実
ルネサスのRXはコテコテのCISCだと思う
そうでなかったら、予告しているコード・サイズの達成は無理
3オペランドで、オペランドにメモリとレジスタの
両方取れるんだから、どういう命令フォーマットであろうが
最大級に複雑な命令なことは確実
>>337
個人的には、G45はG33より消費電力が下がってくれたら他に文句なし
個人的には、G45はG33より消費電力が下がってくれたら他に文句なし
380 :Socket774:2008/03/12(水) 22:49:57 ID:aDT0xSGb
C2DのT9300とT7800ってどっちの方が高性能なの?
381 :Socket774:2008/03/12(水) 22:54:12 ID:lAq67N28
元麻布春男氏の記事だが、L3が2コアにしか共有されてないというのは間違いでは?
あとは以前の情報だとメモコンはHavendaleだと非統合(GMCHのMCM)だったような・・・。
さらにPCI-EがCPUからではなく、System Controllerが出てるのも以前のリーク情報と
違うような・・・。
あとは以前の情報だとメモコンはHavendaleだと非統合(GMCHのMCM)だったような・・・。
さらにPCI-EがCPUからではなく、System Controllerが出てるのも以前のリーク情報と
違うような・・・。
RXは
頻繁に使う処理を1バイト命令で実行とか言ってるんだから、
16レジスタ中4レジスタを可視にして
6bitを命令、2bitをレジスタ
4bitを命令、4bitを2bitレジスタ×2オペランド
4bitを命令、2bitを2bitレジスタ、2bit即値(インクリメント、デクリメント)で
命令は
命令長判別もしくは命令長切り替えと、
加算、減算、乗算、比較、分岐、AND、OR、右シフト、左シフト、ロード、ストア
レジスタ切り替え(4レジスタ×4)かレジスタ間コピー
あたりではないかと。
SuperHの陰に隠れてるが三菱側のM32Rは命令セットが綺麗で理解しやすかったな。
IA-64もPredicateで分岐ペナルティを隠蔽してたな。
頻繁に使う処理を1バイト命令で実行とか言ってるんだから、
16レジスタ中4レジスタを可視にして
6bitを命令、2bitをレジスタ
4bitを命令、4bitを2bitレジスタ×2オペランド
4bitを命令、2bitを2bitレジスタ、2bit即値(インクリメント、デクリメント)で
命令は
命令長判別もしくは命令長切り替えと、
加算、減算、乗算、比較、分岐、AND、OR、右シフト、左シフト、ロード、ストア
レジスタ切り替え(4レジスタ×4)かレジスタ間コピー
あたりではないかと。
SuperHの陰に隠れてるが三菱側のM32Rは命令セットが綺麗で理解しやすかったな。
IA-64もPredicateで分岐ペナルティを隠蔽してたな。
>>382
あとちょっとでVLIWだったのにInstructionが足りないぞ。
あとちょっとでVLIWだったのにInstructionが足りないぞ。
職人芸的神コーディングは後々の保守が面倒なんだ。
特にドキュメンテーションが不備だと地獄。
特にドキュメンテーションが不備だと地獄。
>>382
M32Rって元々はTRONだったからでは?
M32Rって元々はTRONだったからでは?
386 :Socket774:2008/03/14(金) 11:57:42 ID:gkbIgqIt
アフィ厨乙
PowerPCはRiscというよりCiscに近いのでは?
PowerPCがCISCなんて言い出したらきりがない
例えばPentiumProは普通はCISCに分類されるだろ
元の設計思想がRISCならRISC、CISCならCISC、実装は二の次でいい
つまりPowerPCは元のPOWERがRISCで、さらに設計的にはRISCだから
RISCということで良い
例えばPentiumProは普通はCISCに分類されるだろ
元の設計思想がRISCならRISC、CISCならCISC、実装は二の次でいい
つまりPowerPCは元のPOWERがRISCで、さらに設計的にはRISCだから
RISCということで良い
PowerPCは、命令セットはRISC的だけれど、ハードウェアアーキテクチャはCISC的だね。
ネトバはこの反対。
ネトバはこの反対。
http://www.intel.co.jp/jp/personal/campaign/promotion/index.htm?iid=jpOAD+Mar08_IPCpromo_cm_b?/match/#/match/
intelお得のfudベンチ?
intelお得のfudベンチ?
スタックマシンは遅いからダメ
Pen4までX86の浮動小数点演算がおそかったのは
スタックアーキのせい
Pen4までX86の浮動小数点演算がおそかったのは
スタックアーキのせい
スタックアーキテクチャの一番の利点は
Cとか高級言語で書かれたプログラムを簡単にコンパイルできること
ALGOLというCの遠い祖先の言語で、
まともに動く最初のコンパイラが出たのは
バローズB5000というスタックマシンだっ
Cとか高級言語で書かれたプログラムを簡単にコンパイルできること
ALGOLというCの遠い祖先の言語で、
まともに動く最初のコンパイラが出たのは
バローズB5000というスタックマシンだっ
高級言語というか、自由文脈文法を持つ言語であれば
構文木を辿ったらそのまま言語処理完了、この時に計算データは後入れ後出しだからね。
だから、フォートランとかだとスタックマシンがうまく行かない。
>>395
スタックマシンはその処理の構造上、演算対象は唯一スタックの先頭になる。
直前の計算が完了するまで次の計算に進めない、例えばパイプライン10段のCPUなら、同クロック性能が1/10になってしまう。
レジスタマシンは、適当にパイプラインを組めば、パイプラインの段数分同時演算ができる。
スタックマシンでもパイプラインを作れなくもないのだが、作っているうちに、いっそレジスタマシンに変換したほうが簡単となってしまう事多々あり。
サンマイクロシステムズがSPARCを作った時、このアーキテクチャは、この点についてものすごく意識していると思った。
Javaを作って動かす事を最初から考えていたのだろうな。
構文木を辿ったらそのまま言語処理完了、この時に計算データは後入れ後出しだからね。
だから、フォートランとかだとスタックマシンがうまく行かない。
>>395
スタックマシンはその処理の構造上、演算対象は唯一スタックの先頭になる。
直前の計算が完了するまで次の計算に進めない、例えばパイプライン10段のCPUなら、同クロック性能が1/10になってしまう。
レジスタマシンは、適当にパイプラインを組めば、パイプラインの段数分同時演算ができる。
スタックマシンでもパイプラインを作れなくもないのだが、作っているうちに、いっそレジスタマシンに変換したほうが簡単となってしまう事多々あり。
サンマイクロシステムズがSPARCを作った時、このアーキテクチャは、この点についてものすごく意識していると思った。
Javaを作って動かす事を最初から考えていたのだろうな。
>>396THX
なるほどそっか
なるほどそっか
>>396
いや、SPARCのほうが古いしJavaとは関係ないよ。
いや、SPARCのほうが古いしJavaとは関係ないよ。
日本語を読めない方がいらっしゃいました。
>>399
じゃ解説して
じゃ解説して
なるほどパイプラインですか。
同クロック性能が1/10でも、1/10の規模で作れるならいいじゃない?
というわけには行かないもんですよな。
同クロック性能が1/10でも、1/10の規模で作れるならいいじゃない?
というわけには行かないもんですよな。
俺も>>396の最後2行の意味が良く分からん
http://www.itmedia.co.jp/news/articles/0803/18/news030.html
> またIntel命令セットの次のステップとして、「Intel AVX(
> Advanced Vector Extensions)」も紹介した。これはソフトウ
> ェアプログラマー向けのもので、浮動小数点演算、メディア、
> 処理能力を要するソフトの性能を高める。電力効率を高めるこ
> ともでき、既存のIntelプロセッサと互換性を持つ。主な特徴と
> しては、ベクターが128ビットから256ビットに拡大した点や、
> データ再配列の強化などがある。Intelは4月初めに上海で開く
> Intel Developer Forum(IDF)でAVXの詳細な仕様を公開する予定。
> AVXは2010年にコードネームで「Sandy Bridge」と呼ばれる
> マイクロアーキテクチャに実装される。
> またIntel命令セットの次のステップとして、「Intel AVX(
> Advanced Vector Extensions)」も紹介した。これはソフトウ
> ェアプログラマー向けのもので、浮動小数点演算、メディア、
> 処理能力を要するソフトの性能を高める。電力効率を高めるこ
> ともでき、既存のIntelプロセッサと互換性を持つ。主な特徴と
> しては、ベクターが128ビットから256ビットに拡大した点や、
> データ再配列の強化などがある。Intelは4月初めに上海で開く
> Intel Developer Forum(IDF)でAVXの詳細な仕様を公開する予定。
> AVXは2010年にコードネームで「Sandy Bridge」と呼ばれる
> マイクロアーキテクチャに実装される。
http://www.intel.com/pressroom/archive/releases/20080317fact.htm
Nehalem:
L1命令キャッシュ:32KB
L1データキャッシュ:32KB
L2キャッシュ:256KB
L3キャッシュ:最大8MB
Nehalem:
L1命令キャッシュ:32KB
L1データキャッシュ:32KB
L2キャッシュ:256KB
L3キャッシュ:最大8MB
Ex-Transmeta CEO Ditzel joins - wait for it - Intel
ttp://www.theregister.co.uk/2008/03/08/ditzel_intel/
Transmeta創業者のDave Ditzel氏がIntelに入社
ttp://www.theregister.co.uk/2008/03/08/ditzel_intel/
Transmeta創業者のDave Ditzel氏がIntelに入社
>>402
つまり「SPARCのアーキテクチャは後々スタックマシンを高速に実行するのに
適した作りに最初からなっている。その頃から、Java VIMのようなのを作る
つもりだったんだろうな」てことかなという所まで読んだ。
つまり「SPARCのアーキテクチャは後々スタックマシンを高速に実行するのに
適した作りに最初からなっている。その頃から、Java VIMのようなのを作る
つもりだったんだろうな」てことかなという所まで読んだ。
>>405
マジか。なんか凄いことになりそうだな。
マジか。なんか凄いことになりそうだな。
先々週の話題じゃん
intelのSSEは4.1までで、次からはIntel AVXに名称変更だろうか。
Intel Altivec
http://download.intel.com/pressroom/archive/reference/Smith_briefing_0308.pdf
AVXは3オペランド形式の命令セットになるらしい
AVXは3オペランド形式の命令セットになるらしい
SSE5互換か?
Nehalemのホワイトペーパー
http://www.intel.com/pressroom/archive/reference/whitepaper_Nehalem.pdf
読んで気が付いたところ
・out-of-orderウィンドウの拡大
・LOCK prefixやXCHGといった同期プリミティブの高速化
・分岐予測ミス時のペナルティを減少
・ハードウェアプリフェッチ、ロード・ストアのスケジューリングの向上
・2次BTBを新設
・renamed return stack bufferを新設し、リターン命令の分岐予測ミスを減少。
・512エントリのTLBを追加
http://www.intel.com/pressroom/archive/reference/whitepaper_Nehalem.pdf
読んで気が付いたところ
・out-of-orderウィンドウの拡大
・LOCK prefixやXCHGといった同期プリミティブの高速化
・分岐予測ミス時のペナルティを減少
・ハードウェアプリフェッチ、ロード・ストアのスケジューリングの向上
・2次BTBを新設
・renamed return stack bufferを新設し、リターン命令の分岐予測ミスを減少。
・512エントリのTLBを追加
SSEの名前やめちゃうのか。
80x86も5からPentiumになったし、
Pentiumも4までだったし、
SSEも名前の変え時じゃないか?
Pentiumも4までだったし、
SSEも名前の変え時じゃないか?
SSE5はAMDに盗られたからな
AVXも目指してるところは同じだろうし
これもメインはLarrabee(コプロ)向けの命令って事に成るんじゃないのけ?
で、当然こっちが普及するわけでSSE5は3dnowと同じ運命か?
VIAはAVXいくだろうな
nvidiaはどうするのかね?
AVXも目指してるところは同じだろうし
これもメインはLarrabee(コプロ)向けの命令って事に成るんじゃないのけ?
で、当然こっちが普及するわけでSSE5は3dnowと同じ運命か?
VIAはAVXいくだろうな
nvidiaはどうするのかね?
AMD社、マルチコアに向けたプログラミング手法を開発へ 2008/02/14
ttp://www.eetimes.jp/contents/200802/31205_1_20080214191118.cfm
↓
マイクロソフトとインテル、マルチコア用プログラミングで共同研究イニシアチブ発足へ 2008/03/18
ttp://japan.cnet.com/news/ent/story/0,2000056022,20369612,00.htm
ttp://www.eetimes.jp/contents/200802/31205_1_20080214191118.cfm
↓
マイクロソフトとインテル、マルチコア用プログラミングで共同研究イニシアチブ発足へ 2008/03/18
ttp://japan.cnet.com/news/ent/story/0,2000056022,20369612,00.htm
> IntelはNehalemでキャッシュ構造に関してAMDのアプローチを採用する。
> つまり、非共有のL1, L2と共有のL3という構造になる。
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
> つまり、非共有のL1, L2と共有のL3という構造になる。
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
>>418
排他キャッシュというわけではないんでしょ?
排他キャッシュというわけではないんでしょ?
排他L2は高速、と言及してるけれどどちらともつかず。
インテル、新しいグラフィックチップ「Larrabee」の追加情報を公開
http://japan.cnet.com/news/ent/story/0,2000056022,20369631,00.htm
GMAシリーズで手こずっているのが嘘のように
LarrabeeではDirectX対応が上手く行yps:jjh4きp5rj
http://japan.cnet.com/news/ent/story/0,2000056022,20369631,00.htm
GMAシリーズで手こずっているのが嘘のように
LarrabeeではDirectX対応が上手く行yps:jjh4きp5rj
人間の振り方で何とかなるかもよ。
ララビーはストリーミングプロセッサになるんかな。
CPUみたいな分岐予測をしないやつになるんかな。
しかし、インテル一社で全部まかないそうな勢いだね。
あ、あっちだったら、引き抜きゃ良いのか。。。
ララビーはストリーミングプロセッサになるんかな。
CPUみたいな分岐予測をしないやつになるんかな。
しかし、インテル一社で全部まかないそうな勢いだね。
あ、あっちだったら、引き抜きゃ良いのか。。。
>>421
対応ドライバまだdfapiejfaijf
対応ドライバまだdfapiejfaijf
複数の大学参加する調査を5年間実施して
成果が見えてくるのはいったい・・・・・
成果が見えてくるのはいったい・・・・・
マルチコアなんて飾りです
偉い人にはそれが・・・
偉い人にはそれが・・・
だからItaniumのデュアルコアはPOWERに6年も遅れたのか
この記事ではグラフィックプロセッサになっちゃってるのな。
GPUとでもしないと普及しないよ
これ
これ
http://intel_im.edgesuite.net/2008/2-1030879/IM2008_Kilroy.pdf p16
エンプラグループはエンプラグループで
金融、資源採掘、CADをターゲットにしてる
そんなあれもこれも出来る都合のいいものになるのでしょうか
エンプラグループはエンプラグループで
金融、資源採掘、CADをターゲットにしてる
そんなあれもこれも出来る都合のいいものになるのでしょうか
分岐予測を強化するより分岐の必要のないプログラムを書かせた方が早くね?
>>431
無理だから。そんなのどんだけコードが…。
無理だから。そんなのどんだけコードが…。
“Larrabee”のx86命令はCore2やPhenomのそれとは異なるものとなる。
http://northwood.blog60.fc2.com/blog-entry-1795.html
http://northwood.blog60.fc2.com/blog-entry-1795.html
NehalemでL2レイテンシが河童並に戻ってくれたらうれしいお
グラフィックもベクタプロセッサとしても使えるPCI-Expressに接続できるボードとして提供し、後でワンシリコンかMCMでCPUに統合って線だな
初期のlalabeeはグラボと見た目は変わらなさそう
初期のlalabeeはグラボと見た目は変わらなさそう
普通のCPUもPCI-Expressで提供すれば超高密度サーバーが実現するのに。
PCI-E(2.0)*16なら双方向16GB/sだし、ボード上にXDRメモリを使えば100GB/s
程度のメモリ帯域を確保出来る。
PCI-E(2.0)*16なら双方向16GB/sだし、ボード上にXDRメモリを使えば100GB/s
程度のメモリ帯域を確保出来る。
>>431
条件付き実行命令
条件付き実行命令
ほう、intel思い切った作戦だな。
SSEの名前はAMDにくれてやるんだな、太っ腹w
一度ケチのついた名前wには興味はありませんって感じ。
SSEの名前はAMDにくれてやるんだな、太っ腹w
一度ケチのついた名前wには興味はありませんって感じ。
Intel AVXに名前を変えたのは単なる販売戦略的理由からだけだろ。
64bit MMX
128bit SSE
256bit AVX
ってことで、このタイミングで名前変えるのもいいと思うけどな。
128bit SSE
256bit AVX
ってことで、このタイミングで名前変えるのもいいと思うけどな。
Altivecで良いんじゃね
次のは512bitになるんかいね
GPUやItaniumだとコンパイラレベルで最適化したり
分岐も予測じゃなく真偽両方計算しといて
正解だけ採用するんじゃないっけか?
分岐も予測じゃなく真偽両方計算しといて
正解だけ採用するんじゃないっけか?
新たに256bitレジスタを追加するなら
OSのサポートがいることになるけど、
Vista SP2以降のみサポートとかなったりして。
OSのサポートがいることになるけど、
Vista SP2以降のみサポートとかなったりして。
Sandy Bridge、Bulldozerが2010年に登場するのでそれに合わせてWindows7も2010年に登場します。
AVX : 256-bit vector extension to SSE for FP intensive applications
としてあるから、SSEレジスタの上位に128bit足すような感じなんだろうね。
もちろん、ユーザープログラムがAVX使うなら、256bitレジスタ保存に対応した
コンテクストスイッチを持つOSは居るだろうから、>>446の言うとおり
Vista SP2(?) か Windows 7必須ってことになるはず。
としてあるから、SSEレジスタの上位に128bit足すような感じなんだろうね。
もちろん、ユーザープログラムがAVX使うなら、256bitレジスタ保存に対応した
コンテクストスイッチを持つOSは居るだろうから、>>446の言うとおり
Vista SP2(?) か Windows 7必須ってことになるはず。
2010年のCPUだし、さすがにXPは対応できないだろ。
Win95を考えれば
徐々に見えてくるNehalem──8Mバイトの3次キャッシュは「みんなで使う」
http://plusd.itmedia.co.jp/pcuser/articles/0803/19/news094.html
排他キャッシュではない
http://plusd.itmedia.co.jp/pcuser/articles/0803/19/news094.html
排他キャッシュではない
>>445
conditional moveならx86にも既にあるが。SSEにはないけど。
conditional moveならx86にも既にあるが。SSEにはないけど。
>SSEにはないけど
SSE4.1にある
SSE4.1にある
マイクロアーキテクチャーの革新はないということでFA?チックタックモデルと言いながら、これじゃK8→K10もといK8Lと進んだAMDと同じだな。
例えるならK7→K8
さすがはAMDのcopycat
>>456
とりあえずお前が"copy cat"と言いたいだけってのはわかった。
とりあえずお前が"copy cat"と言いたいだけってのはわかった。
L2が共有じゃなく、256kと容量も少ないのが気になるな。
ここで足を引張られなければいいけど。
ここで足を引張られなければいいけど。
L2は容量が減ってレイテンシも小さくなってるんじゃないかな。
むしろ、4コアで共有のL3がどれだけ速いかの方が重要な気が。
K10と違って排他じゃないし、L3が速ければL2独立でも問題ないと思うけど。
むしろ、4コアで共有のL3がどれだけ速いかの方が重要な気が。
K10と違って排他じゃないし、L3が速ければL2独立でも問題ないと思うけど。
L2までのつくりは、Phenomと割と似てるからここのグラフ1みたいになりそうだな
と思ったんだ
http://www.4gamer.net/games/039/G003983/20071223001/
2スレッドまではcore2のほうがいいからな。
と思ったんだ
http://www.4gamer.net/games/039/G003983/20071223001/
2スレッドまではcore2のほうがいいからな。
階層こそPhenomと似てるけど、キャッシュの特性は全然違うんだからあんまり参考にならんよ。
K10はK8のL2の外側にL3くっつけたようなもんだが、
NehalemはPenrynのL1とL2の間にL1.5を挟みこんだようなもんだからな。
NehalemはPenrynのL1とL2の間にL1.5を挟みこんだようなもんだからな。
笑える
L3が速ければ、L3からL2に繰上だろう
たしかにL3の速度は重要だよね。PenrynのL2より遅く、BarcelonaのL3より速いというのは間違いないだろうが。
466 :Socket774:2008/03/21(金) 10:19:25 ID:qjDKz2ja
お前らL5だろ
■後藤弘茂のWeekly海外ニュース■
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
>>468
|共有されるのは、最下層のL3だけだ。
|従来のキャッシュ階層の下にL3を加えたのではなく、従来のL2とL1の間に1階層挟み込んで、
|その結果が3階層キャッシュとなったのだろう。
なんだツマラン。ごく普通の話じゃないか。
|共有されるのは、最下層のL3だけだ。
|従来のキャッシュ階層の下にL3を加えたのではなく、従来のL2とL1の間に1階層挟み込んで、
|その結果が3階層キャッシュとなったのだろう。
なんだツマラン。ごく普通の話じゃないか。
L1が増えてるのだから、L2がそのままだと持たないのだろう。
L2が新たなもっさり機構として挟まっただけ。
L2が新たなもっさり機構として挟まっただけ。
>>470
"もっさり機構"って何? 弱い子はどっか逝ってくれ。
"もっさり機構"って何? 弱い子はどっか逝ってくれ。
L1が増えたって何が増えたんだ?
容量はPenrynとNehalemで全く同じなのに。何か新しい情報でも持ってるのか?
容量はPenrynとNehalemで全く同じなのに。何か新しい情報でも持ってるのか?
>>470
やっぱレイテンシも増えるのかなぁ
やっぱレイテンシも増えるのかなぁ
後藤の予想はストレージ階層がどんどん深くなるという半紙だけだったな
そりゃあ容量が増えればレイテイシはどんどん増えるだろうて
増えないならL1だけにしてどんどん容量増やせばいいんだしな
増えないならL1だけにしてどんどん容量増やせばいいんだしな
>>472
マジだね。64K+64Kかと思ったら32K+32Kだってよ。
おもったより余計にひどいや。HTするのこれで?
CMAの性能はL1が少ないことで制限されているが、制限があることで
急激な負荷を避けられるから高クロックで回る。つまりわざともっさりさせている。
オレゴンチームの研究でもFPのユニット自体の性能は十分なメモリを確保すれば倍ぐらい
なんだろ。
涅槃で制限を取っ払うから。256Kから溢れさせることで負荷の軽減をさせる必要があるのかと。
L2が多いほうが有利なGAMEもあることだし、ボトルネックにはなるしょ。L3がCore2のL2と
等速ならまだしも。それが出来ないことが増やした理由だし。
http://www.4gamer.net/games/030/G003078/20071023010/
AMDでも1Mから512Kに減らしたことで相当性能差が出てる。AthlonのL2が1Mあることを前提に開発された
GAMEがあるなら。今のCORE2に最適化されて開発しているGAMEはL2が2Mないと話にならんのじゃないか。
マジだね。64K+64Kかと思ったら32K+32Kだってよ。
おもったより余計にひどいや。HTするのこれで?
CMAの性能はL1が少ないことで制限されているが、制限があることで
急激な負荷を避けられるから高クロックで回る。つまりわざともっさりさせている。
オレゴンチームの研究でもFPのユニット自体の性能は十分なメモリを確保すれば倍ぐらい
なんだろ。
涅槃で制限を取っ払うから。256Kから溢れさせることで負荷の軽減をさせる必要があるのかと。
L2が多いほうが有利なGAMEもあることだし、ボトルネックにはなるしょ。L3がCore2のL2と
等速ならまだしも。それが出来ないことが増やした理由だし。
http://www.4gamer.net/games/030/G003078/20071023010/
AMDでも1Mから512Kに減らしたことで相当性能差が出てる。AthlonのL2が1Mあることを前提に開発された
GAMEがあるなら。今のCORE2に最適化されて開発しているGAMEはL2が2Mないと話にならんのじゃないか。
477 :Socket774:2008/03/21(金) 19:07:22 ID:lXP+Gbqa
仕様もろくに読めなかったヤツがくやしまぎれに長文か
もっさり信者は性能に対する感性が研ぎ澄まされてるのだなぁ
ってお前出鱈目言ってるだけじゃねーか
ってお前出鱈目言ってるだけじゃねーか
intelプロセッサは伝統的に多way
低レイテンシの高効率、高速だけど
低容量L1だ
他は計128kBのdirect or 2-way L1が多い
低レイテンシの高効率、高速だけど
低容量L1だ
他は計128kBのdirect or 2-way L1が多い
あとFPの性能は原則メモリ帯域だよ
SPEC95_fpはそれがはげしかったし
姫野ベンチだと単純に帯域比例だ
Crayは言った、
"Supur computing,it's band width."
一番帯域のあるPowerシリーズがあんま速くない
っつー反証はあるけどな
SPEC95_fpはそれがはげしかったし
姫野ベンチだと単純に帯域比例だ
Crayは言った、
"Supur computing,it's band width."
一番帯域のあるPowerシリーズがあんま速くない
っつー反証はあるけどな
L1帯域とL2のway数が気になります
>一番帯域のあるPowerシリーズがあんま速くないっつー反証はあるけどな
かつてそうだったんだろう、理由も分る気がするよ。
ウソではないと思う、当時は。
かつてそうだったんだろう、理由も分る気がするよ。
ウソではないと思う、当時は。
>>479
つまりdata,Instructionそれぞれ64kb 16wayなIsaiahは最強だと?
つまりdata,Instructionそれぞれ64kb 16wayなIsaiahは最強だと?
NehalemもわりとCSI以外は手堅い進歩で収まってる。
AMDまじでおわった企業だな。VIAの方がまだおもしろいしましだよ。
AMDまじでおわった企業だな。VIAの方がまだおもしろいしましだよ。
487 :Socket774:2008/03/22(土) 02:55:09 ID:nMJCD8LJ
XDRってXDR2じゃなくXDRで既に3GHzでしょ
しかもランバスならデュアルチャンネルとかリニアに性能上がる
高いといっても何世代も一番重要な足周りが低性能なPC買わされてる事に疑問を持たない人ってどうなの
今はメモリ屋の儲けしか考えられてないって事だよ
しかもランバスならデュアルチャンネルとかリニアに性能上がる
高いといっても何世代も一番重要な足周りが低性能なPC買わされてる事に疑問を持たない人ってどうなの
今はメモリ屋の儲けしか考えられてないって事だよ
>>485
手堅いのか?あまりまっとうな気がしないけど。
手堅いのか?あまりまっとうな気がしないけど。
Intel AVX(Advanced Vector Extensions)はアポーの要望に応えてのものですか 。
まあfp SIMDについてはもともとAltiVecは単精度のみだから...
整数は完成度高いけどね
整数は完成度高いけどね
NeharemのベースはCore2って話がではじめてるな
実行ユニットをリッチにしたかんじだな、こりゃ
実行ユニットをリッチにしたかんじだな、こりゃ
core2ベースなら尚更失敗の可能性が少なくなってる気がするが
新アーキテクチャじゃないとどこぞに負けてしまう!、とかいう世界の住人でもない限り
あまり気にする部分でもないかと。
実際に重要なのは、消費電力と性能。
新アーキテクチャじゃないとどこぞに負けてしまう!、とかいう世界の住人でもない限り
あまり気にする部分でもないかと。
実際に重要なのは、消費電力と性能。
Nehalemは素直にcore2ベースでしょ。それ以外の何者でもない。
P6(PentiumPro)→Pentium2→Pentium3→PentiumM(Merom)→Core(Yonah)→Core2→Core3(Nehalem)
で実に順当な進化をしてきてるだけ。
Intelは毎度「刷新した設計のコアで」なんちゃらとマーケティングの都合で言ってるけど、
本音はCPUIDにあるfamily 6
てかいい加減この話題止めようぜ…当たり前の事話しても何も面白くない
P6(PentiumPro)→Pentium2→Pentium3→PentiumM(Merom)→Core(Yonah)→Core2→Core3(Nehalem)
で実に順当な進化をしてきてるだけ。
Intelは毎度「刷新した設計のコアで」なんちゃらとマーケティングの都合で言ってるけど、
本音はCPUIDにあるfamily 6
てかいい加減この話題止めようぜ…当たり前の事話しても何も面白くない
まるっきりK7->K8の流れだな
>>487
一度メモリーの性能を落として、足回りを悪くしてどの程度の性能ダウンがあるか
いまどきのCPUで試してみたら分るんじゃね
オレはその上で、あまり意味はなくなってきているかも・・・と結論した。
もちろん足回りだって性能が高いに越した事はないが、いまどきの壮絶なCPUとの性能ギャップでは
ちょっと性能が高いとか低いとかでは、無影響になってしまったんだと思ったよ。
一度メモリーの性能を落として、足回りを悪くしてどの程度の性能ダウンがあるか
いまどきのCPUで試してみたら分るんじゃね
オレはその上で、あまり意味はなくなってきているかも・・・と結論した。
もちろん足回りだって性能が高いに越した事はないが、いまどきの壮絶なCPUとの性能ギャップでは
ちょっと性能が高いとか低いとかでは、無影響になってしまったんだと思ったよ。
Nehalem(32nm)でL2が512KB、L3が12〜16MBに増加されるんでしょう?
どんなにNehalemがCore2ベースだろうが、今までの技術の総結集だろうが、まるっきりWillamette -> Northwoodの流れなんだが・・・。
どんなにNehalemがCore2ベースだろうが、今までの技術の総結集だろうが、まるっきりWillamette -> Northwoodの流れなんだが・・・。
intelの中の人以外はWestmereがどうなるかなんてわからないだろ、ここで聞いても。
それに、Willamette>Northwoodの流れっていうのもL2だけ見た感想なんだから、
そんな近視眼的なものに意味があるとは思えないんだが。
プロセスシュリンクでL2増量と少しの改善だと、Core2の65nm>45nmも同じ流れだし。
それに、Willamette>Northwoodの流れっていうのもL2だけ見た感想なんだから、
そんな近視眼的なものに意味があるとは思えないんだが。
プロセスシュリンクでL2増量と少しの改善だと、Core2の65nm>45nmも同じ流れだし。
Intelは長い歴史の中で一般人に対してはクロック周波数神話を創り出し、
同時に自作erに対してはキャッシュ量神話を創り出した。
同時に自作erに対してはキャッシュ量神話を創り出した。
結局何が起こっているのかというと
昔、仮想記憶で少ないメモリーをディスク装置とページング機能を使って大量に見せかけていたのが
今は、それなりに大きくなったが実用には余りに小容量なL2-L3キャッシュの内容をDRAMに退避して使っているという事になっているのかと。
昔の実験段階を超え商業利用的に実用的とされるメインフレーム(初めてのマシンはIBM360あたり?)のメモリーがやっと1MB超程度で、これが丸ごとキャッシュに収まった頃あたりから
ちょっと変化してきた感がした。
昔、仮想記憶で少ないメモリーをディスク装置とページング機能を使って大量に見せかけていたのが
今は、それなりに大きくなったが実用には余りに小容量なL2-L3キャッシュの内容をDRAMに退避して使っているという事になっているのかと。
昔の実験段階を超え商業利用的に実用的とされるメインフレーム(初めてのマシンはIBM360あたり?)のメモリーがやっと1MB超程度で、これが丸ごとキャッシュに収まった頃あたりから
ちょっと変化してきた感がした。
同一アーキ内でシュリンクして全体の拡張は控えめにしてキャッシュ増量されるって
典型的なTick TockモデルのTockってだけじゃん
典型的なTick TockモデルのTockってだけじゃん
これから求められるのはソフトウェア側の軽量化だな。
Tock Tockモデルでも性能が出てればオールオケw
ところでいつものように隠し機能が載ってると思うのだが、みんなで予想してみないか?
ところでいつものように隠し機能が載ってると思うのだが、みんなで予想してみないか?
結局本当の意味での刷新にはsandy bridge待たなければいけないわけか
〜ベース、と言ってもその程度・基準は人それぞれ(中の人にとっても、外の人にとっても)
永久に水掛け論
http://journal.mycom.co.jp/news/2003/03/13/43.html
--確かに何もないところからMicroProcessorを作るのには時間がかかります。ただ、Pentium MはPentium IIIをベースにしているので、普通ならそれほど時間が掛からないように思うのですが、いかがでしょう?
なぜかというと、Pentium IIIをベースにしていないからだ(笑)
--Timnaは確かKatmaiコアをベースにしていたと思うのですが、Baniasはそうではない、と(笑)
Baniasはモバイルのための新設計だ。
永久に水掛け論
http://journal.mycom.co.jp/news/2003/03/13/43.html
--確かに何もないところからMicroProcessorを作るのには時間がかかります。ただ、Pentium MはPentium IIIをベースにしているので、普通ならそれほど時間が掛からないように思うのですが、いかがでしょう?
なぜかというと、Pentium IIIをベースにしていないからだ(笑)
--Timnaは確かKatmaiコアをベースにしていたと思うのですが、Baniasはそうではない、と(笑)
Baniasはモバイルのための新設計だ。
>〜ベース、と言ってもその程度・基準は人それぞれ(中の人にとっても、外の人にとっても)
そういう話をしてるんじゃないだろ。Nehalemは今までの新マイクロアーキテクチャを
うたった進化と比較しても、たいしたことはないと。もちろん、CSI等を除いた話だけど。
そういう話をしてるんじゃないだろ。Nehalemは今までの新マイクロアーキテクチャを
うたった進化と比較しても、たいしたことはないと。もちろん、CSI等を除いた話だけど。
PentiumM(Banias/Dothan)→Core(Yonah)→Core2(Merom)
完全に一から再設計なんて、ネトバだってしてないだろw
どこからが完全設計か、によるが、x86 CPUである限りは完全100%新設計はやらんだろ
どこからが完全設計か、によるが、x86 CPUである限りは完全100%新設計はやらんだろ
IntelのOoO x86はP6(Pentium Pro)から始まったわけで
そういう意味ではどれだけ改良した所でOoOならfamily 6でもおかしくはない
そういう意味ではどれだけ改良した所でOoOならfamily 6でもおかしくはない
Merom系の32nmも出るのかね?
ソケットそのものがねじ止めでバックプレート付きとは‥
ソケット側のピンがよっぽど細かくなってるんだろうな。
ソケット側のピンがよっぽど細かくなってるんだろうな。
伝説のソケットごとスッポンが
バックプレート外すだけで簡単に出来るようになるのか
バックプレート外すだけで簡単に出来るようになるのか
バックプレート採用になったのは熱対策なんじゃないかと思う。
LGA775のソケットカバーはマザー裏面へのハンダ付けがほとんどだったから
金属製のソケットカバーを伝ってかなりの熱量がマザー裏面に回ってた。
LGA775以降にやたらと裏面の冷却が強化されたマザーが出てきたのはそのせい。
今回は熱的に厳しくなるところにメモリの配線がくるから、熱の影響を避けるために
バックプレートで熱の逃げ道を作ったんだろう。
ヒートシンクの固定方式はLGA775と同じみたいだから、このバックプレートのサイズじゃ
マザーの歪み防止にはならんだろうし。
LGA775のソケットカバーはマザー裏面へのハンダ付けがほとんどだったから
金属製のソケットカバーを伝ってかなりの熱量がマザー裏面に回ってた。
LGA775以降にやたらと裏面の冷却が強化されたマザーが出てきたのはそのせい。
今回は熱的に厳しくなるところにメモリの配線がくるから、熱の影響を避けるために
バックプレートで熱の逃げ道を作ったんだろう。
ヒートシンクの固定方式はLGA775と同じみたいだから、このバックプレートのサイズじゃ
マザーの歪み防止にはならんだろうし。
よく見たら、ソケット部とソケットカバー部が物理的に分かれてて、ソケットカバー部が
ねじ止めなのな。ソケットに負荷をかけない構造でもあるな。
ねじ止めなのな。ソケットに負荷をかけない構造でもあるな。
775のプッシュ式のクーラーを考案した奴は脳が腐ってる
もういいかげんにソケット諦めたほうがいいと思うんだけど。
むしろコストが上がっているような気がすんですよ。
むしろコストが上がっているような気がすんですよ。
>>520
ソケットをあきらめてどうするだよ…。
ソケットをあきらめてどうするだよ…。
>>520
SECC(pentium2あたりのカセットみたいなの)復活か?
SECC(pentium2あたりのカセットみたいなの)復活か?
スロットで端子数四桁とかどんだけ長いパッケージになるんだw
SLI/Crossfireと同じ向きにすれば、廃熱もできるぞ
完全に1から設計してるのはIA-64とその昔のRiscの860 960ぐらいじゃない。
.: : : : : : : : :: :::: :: :: : :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
. . : : : :: : : :: : ::: :: : :::: :: ::: ::: :::::::::::::::::::::::::::::::::::::
. . .... ..: : :: :: ::: :::::: :::::::::::: : :::::::::::::::::::::::::::::::::::::::::::::
Λ_Λ . . . .: : : ::: : :: ::::::::: ::::::::::::::::::::::::::::
/:彡ミ゛ヽ;)ー、 . . .: : : :::::: ::::::::::::::::::::::::::::::::
/ :::/:: ヽ、ヽ、 ::i . .:: :.: ::: . ::::::::::::::::::::::::::::::::::::::
/ :::/;;: ヽ ヽ ::l . :. :. .:: : :: :: :::::::: : ::::::::::::::::
 ̄ ̄ ̄(_,ノ  ̄ ̄ ̄ヽ、_ノ ̄
. . : : : :: : : :: : ::: :: : :::: :: ::: ::: :::::::::::::::::::::::::::::::::::::
. . .... ..: : :: :: ::: :::::: :::::::::::: : :::::::::::::::::::::::::::::::::::::::::::::
Λ_Λ . . . .: : : ::: : :: ::::::::: ::::::::::::::::::::::::::::
/:彡ミ゛ヽ;)ー、 . . .: : : :::::: ::::::::::::::::::::::::::::::::
/ :::/:: ヽ、ヽ、 ::i . .:: :.: ::: . ::::::::::::::::::::::::::::::::::::::
/ :::/;;: ヽ ヽ ::l . :. :. .:: : :: :: :::::::: : ::::::::::::::::
 ̄ ̄ ̄(_,ノ  ̄ ̄ ̄ヽ、_ノ ̄
529 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/25(火) 03:12:20 ID:lnVjw8iv
AVX使えば団子焼きが2倍速くなることだけは理解した
530 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/25(火) 03:17:25 ID:lnVjw8iv
L2を共有すると、同時にL2にアクセスしたときにスループットが落ちる。
共有数が増えるほど甚大になる。
4コア8スレッドとしては3階層が妥当でしょ。
同じ3階層でもVictim cacheとInclusive cacheじゃ、特性はだいぶ違う。
共有数が増えるほど甚大になる。
4コア8スレッドとしては3階層が妥当でしょ。
同じ3階層でもVictim cacheとInclusive cacheじゃ、特性はだいぶ違う。
531 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/25(火) 03:36:12 ID:lnVjw8iv
>>448
むしろ独立したレジスタとしてAV0〜AV15(仮)を加えるように思えたんだが。
【AVXの命令フォーマット予想】
(66h) (REX) 0Fh 3Ch-3Fh Opcode3 ModRM (SIB) (disp) (imm8)
Opcode3 の 0-2ビット目がDest
64ビットでの時はREX.WがDestの上位ビットの代わり。
どうみても妄想です本当にありがとうございました。
SSSE3とSSE4のOpcode空間ってF2, F3プリフィックスも使ってないんだが
AVXだとここにも何かしらのニーモニックが割り当てられる気がする。
むしろ独立したレジスタとしてAV0〜AV15(仮)を加えるように思えたんだが。
【AVXの命令フォーマット予想】
(66h) (REX) 0Fh 3Ch-3Fh Opcode3 ModRM (SIB) (disp) (imm8)
Opcode3 の 0-2ビット目がDest
64ビットでの時はREX.WがDestの上位ビットの代わり。
どうみても妄想です本当にありがとうございました。
SSSE3とSSE4のOpcode空間ってF2, F3プリフィックスも使ってないんだが
AVXだとここにも何かしらのニーモニックが割り当てられる気がする。
いち早くL3を導入しているのに、Phenomは何で遅いのだろうか。着眼点は
Intelより何時も半歩早いのに、気が付くと二歩戻っているという。
Intelより何時も半歩早いのに、気が付くと二歩戻っているという。
533 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/25(火) 04:04:56 ID:lnVjw8iv
コンシューマ向け製品でオンダイのL3載ったのってPentium4EEが初じゃないの?
4スレッドのCPUとしてはTulsaが初だね。
4スレッドのCPUとしてはTulsaが初だね。
>着眼点は Intelより何時も半歩早いのに
AMDのマーケティングが成功している良い明石じゃないかw
これからも精進してくだしあ><
AMDのマーケティングが成功している良い明石じゃないかw
これからも精進してくだしあ><
そんなこと言い出したらキャッシュは全て遅くならないための物だぞ。
HDDとバスの速度をCPUの100倍速くしろよ
そうすりゃメモリもキャッシュもいらんだろ
そうすりゃメモリもキャッシュもいらんだろ
もうレジスタだけでいいよ
それはすばらしいベクタマシンですね
L3キャッシュ1GBくらい積めばおk
>>532
Phenomは遅くなってねーだろ。ありゃ単にクロックが低すぎるだけだ。
>>540
ダイサイズがとんでもない事になりそうだな。
それともアレか? 昔懐かしP5世代のように、
M/Bにメモリチップでも直付けするか?
Phenomは遅くなってねーだろ。ありゃ単にクロックが低すぎるだけだ。
>>540
ダイサイズがとんでもない事になりそうだな。
それともアレか? 昔懐かしP5世代のように、
M/Bにメモリチップでも直付けするか?
いっそメモリボードにCPUを搭載してマルチCPUにすればいいんじゃね?
Phenomに最適化したプログラムを書かせないと。
>>530
同時にL2にアクセスするとどうしてスループットが落ちるの?
同時にL2にアクセスするとどうしてスループットが落ちるの?
>>544
どうなんだろ?
L3無しはコアが多いとそれなりに足かせになる気がする。
むしろ上位では勝てない事は確定しているから、
低価格向けに出して、シェアを確保する道具にするつもりじゃないのかな?
クロックも上がれば、C2Qともそれなりに戦える可能性もあるし。
ただ、どうも付け焼き刃的な発想の気がしないでもない…。
どうなんだろ?
L3無しはコアが多いとそれなりに足かせになる気がする。
むしろ上位では勝てない事は確定しているから、
低価格向けに出して、シェアを確保する道具にするつもりじゃないのかな?
クロックも上がれば、C2Qともそれなりに戦える可能性もあるし。
ただ、どうも付け焼き刃的な発想の気がしないでもない…。
結構前にクロック競争諦めて多コアに移行するって方針打ち出したじゃない
それでクロック上げろってのも矛盾してるな、コア増やしても思ったようにリニアに性能上がらないからかもしらんが
それでクロック上げろってのも矛盾してるな、コア増やしても思ったようにリニアに性能上がらないからかもしらんが
http://pc.watch.impress.co.jp/docs/2008/0326/kaigai428.htm
次のWestmereは6コアでキャッシュ容量もコア数に比例して増えるくらいらしい。
クロックはあまりあがらないのかな?
上の記事とは関係ないけど、Nehalemはコアの利用状況とか見て、
クロックアップするらしいので、アプリのマルチコア対応が進まないうちは、これで
しのぐんじゃないかな。
次のWestmereは6コアでキャッシュ容量もコア数に比例して増えるくらいらしい。
クロックはあまりあがらないのかな?
上の記事とは関係ないけど、Nehalemはコアの利用状況とか見て、
クロックアップするらしいので、アプリのマルチコア対応が進まないうちは、これで
しのぐんじゃないかな。
549 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 02:39:14 ID:4weY/39z
>>545
Core 2の共有L2はね、L1の半分のL/S帯域しかないのをFIFO制御で2コアで共有してアクセスしてんのよ。
だから、L2にアクセスするコア数が増えれば増えるほど、1コアあたりの帯域が減るんだよ。
32K+32KじゃそもそもL1キャッシュミスの頻度はかなり高い。
L2共有キャッシュMeromはもともと
NehalemはL2までを独立にしてL3に容量を割くことにしたようだが、流石に
256KBになれば32K+32Kでミスする頻度よりよっぽど少ないはずだ。
同時となれば特にそうでしょう。
Core 2の共有L2はね、L1の半分のL/S帯域しかないのをFIFO制御で2コアで共有してアクセスしてんのよ。
だから、L2にアクセスするコア数が増えれば増えるほど、1コアあたりの帯域が減るんだよ。
32K+32KじゃそもそもL1キャッシュミスの頻度はかなり高い。
L2共有キャッシュMeromはもともと
NehalemはL2までを独立にしてL3に容量を割くことにしたようだが、流石に
256KBになれば32K+32Kでミスする頻度よりよっぽど少ないはずだ。
同時となれば特にそうでしょう。
550 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 02:43:00 ID:4weY/39z
途中送信しちゃった
L2共有キャッシュのMeromはもともとモバイル向けの設計でパフォーマンスを狙った設計じゃない。
AMDの排他キャッシュもアクセス性能を狙ったものじゃないし、実効帯域自体が狭いから
相対的にIntelのほうが「マシ」なだけで本当はパフォーマンス設計としては欠点は多い。
L2共有キャッシュのMeromはもともとモバイル向けの設計でパフォーマンスを狙った設計じゃない。
AMDの排他キャッシュもアクセス性能を狙ったものじゃないし、実効帯域自体が狭いから
相対的にIntelのほうが「マシ」なだけで本当はパフォーマンス設計としては欠点は多い。
>>547
消費電力が無理に上がらない範囲でクロックアップならアリでしょ。
多コア対応アプリが増えない限り、ある程度クロックがあった方が良いし、
多コア対応アプリが増えても、クロックが高い方が有利だし。
消費電力が無理に上がらない範囲でクロックアップならアリでしょ。
多コア対応アプリが増えない限り、ある程度クロックがあった方が良いし、
多コア対応アプリが増えても、クロックが高い方が有利だし。
>>551
日大じゃキツかろう
日大じゃキツかろう
ここの住人は凄い理系だなおい。
555 :どうていだいまおう:2008/03/26(水) 19:09:51 ID:y2aRAYM/
団子褒めるやつ初めて見たw
もちろんおれは団子以下だけどな
もちろんおれは団子以下だけどな
まあ、団子でも京大卒なくらいだからな。
>4コア8スレッドとしては3階層が妥当でしょ。
Core2のL1→L2のスループット低下防止というメリットに言及しながら、
共有しないことによりL2キャッシュ容量が256MBに減少するという
デメリットについて言及してない時点で意味がわかってないと推定
できます。
インテルがL3共有にしたという事実に対して、適当な後付理由をくっつけた
だけでしょ。
Core2のL1→L2のスループット低下防止というメリットに言及しながら、
共有しないことによりL2キャッシュ容量が256MBに減少するという
デメリットについて言及してない時点で意味がわかってないと推定
できます。
インテルがL3共有にしたという事実に対して、適当な後付理由をくっつけた
だけでしょ。
256MB L2ホスィ
256KBですね。失礼
>>532
>いち早くL3を導入しているのに、Phenomは何で遅いのだろうか。着眼点は
Intelより何時も半歩早いのに、気が付くと二歩戻っているという。
L3”だけ”でCPUができてるわけじゃないでしょうに。
>>537
>HDDとバスの速度をCPUの100倍速くしろよ
>そうすりゃメモリもキャッシュもいらんだろ
高速転送、待ち時間と容量はトレードオフ。
>いち早くL3を導入しているのに、Phenomは何で遅いのだろうか。着眼点は
Intelより何時も半歩早いのに、気が付くと二歩戻っているという。
L3”だけ”でCPUができてるわけじゃないでしょうに。
>>537
>HDDとバスの速度をCPUの100倍速くしろよ
>そうすりゃメモリもキャッシュもいらんだろ
高速転送、待ち時間と容量はトレードオフ。
>>537
そんな事をしたら読み取りヘッドが大量に必要になって
50年前の洗濯機みたいなハードディスクになるから嫌だ
電源を入れて回転が安定するまで一時間弱、ジャンプでも読みながらのんびり待つ時代に戻るのも良いという人も居そうだが。
そんな事をしたら読み取りヘッドが大量に必要になって
50年前の洗濯機みたいなハードディスクになるから嫌だ
電源を入れて回転が安定するまで一時間弱、ジャンプでも読みながらのんびり待つ時代に戻るのも良いという人も居そうだが。
562 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 21:18:27 ID:4weY/39z
キャッシュ構成の違いだよ。
Inclusive Cacheだと下位層でヒットしたときに上位にロードするときの手続きが簡素で済むんだよ。
AMDのVictim Cacheは、容量あたりの効率はいいが、レイテンシが長くなりがち。
AMDのはL1とL2のキャッシュラインが重複しないように制御してるので
L1ミスヒット・L2ヒットのときに、L2からL1にロードするだけでなくて
L1からL2に書き戻す処理が常に発生する。
L3はもっと複雑で、全コアのL1・L2とも重複しない部分をL3に格納するというテラカオス。
こんなことをしてもキャッシュコントローラが複雑になる上に性能が上がらない。
AMDとしてはプロセスルールで水を空けられてるので、いかにSRAMをけちるかに命を懸けてる
ようにみえるが、はっきり言って本末転倒なんじゃないのかなと。
あとNehalemがL2のサイズを256KBにした理由だけど
非共有のキャッシュは容量は小さいほうがスヌープのオーバーヘッドは小さいし、
ヒットレイテンシも小さく設計できる。
Inclusive Cacheだと下位層でヒットしたときに上位にロードするときの手続きが簡素で済むんだよ。
AMDのVictim Cacheは、容量あたりの効率はいいが、レイテンシが長くなりがち。
AMDのはL1とL2のキャッシュラインが重複しないように制御してるので
L1ミスヒット・L2ヒットのときに、L2からL1にロードするだけでなくて
L1からL2に書き戻す処理が常に発生する。
L3はもっと複雑で、全コアのL1・L2とも重複しない部分をL3に格納するというテラカオス。
こんなことをしてもキャッシュコントローラが複雑になる上に性能が上がらない。
AMDとしてはプロセスルールで水を空けられてるので、いかにSRAMをけちるかに命を懸けてる
ようにみえるが、はっきり言って本末転倒なんじゃないのかなと。
あとNehalemがL2のサイズを256KBにした理由だけど
非共有のキャッシュは容量は小さいほうがスヌープのオーバーヘッドは小さいし、
ヒットレイテンシも小さく設計できる。
>あとNehalemがL2のサイズを256KBにした理由だけど
>非共有のキャッシュは容量は小さいほうがスヌープのオーバーヘッドは小さいし、
>ヒットレイテンシも小さく設計できる。
それはそうだけど、実際そうなるかは不明だし、それがL2共有によるメリット
を超えるメリットを持つかどうかわからない。
現状はあくまで、3層構造を共有するメリットとデメリットを書く
にとどめるべきですね。メリットデメリットを含む定性的な話から、
メリットを導き出す目的はなんでしょうか?
X>0 Y<0→X+Y>0ですか?
>非共有のキャッシュは容量は小さいほうがスヌープのオーバーヘッドは小さいし、
>ヒットレイテンシも小さく設計できる。
それはそうだけど、実際そうなるかは不明だし、それがL2共有によるメリット
を超えるメリットを持つかどうかわからない。
現状はあくまで、3層構造を共有するメリットとデメリットを書く
にとどめるべきですね。メリットデメリットを含む定性的な話から、
メリットを導き出す目的はなんでしょうか?
X>0 Y<0→X+Y>0ですか?
564 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 21:40:59 ID:4weY/39z
L1ミスヒット・L2ヒット時の挙動について詳細書いておくか
【AMDの場合】
入れ替え対象となるL1上のキャッシュラインの内容をVictim Bufferに退避
↓
ロード対象のラインをL2からL1に移動
↓
Victim Buffer上にコピーしたラインをL2の、さっきデータをL1にうつした跡んとこに移動。
#ちなみにVictim Bufferの転送が済まない内にL1ミスが起きると、Victim Bufferが空になるまで
#一連の制御ができなくて、20クロック程度も待たされる。
#これではNetBurstの分岐予測ミスのペナルティすら笑えない。
これがL3だと、言葉で説明しづらいくらいもっと複雑。
【Intelの場合(っていうか広く一般で使われてるInclusive Cacheの場合)】
L1上にあるキャッシュラインのコピーはL2上にも常にあるため、
L1からL2に退避する必要があるのは、ラインが変更された場合だけでいい。
(変更されてなければ破棄するだけでいい)
ラインの重複を許している分、Victim Bufferみたいな仕組みが原理的に必要ない。
でも今の性能差は、キャッシュよりももっと根本的なところの設計が違う気がするんだがな。
AMDはK7以降実行パイプラインの基本構造を実質ほとんど変えてないが、Intelは地道にマイナーチェンジを重ねてきたからね。
【AMDの場合】
入れ替え対象となるL1上のキャッシュラインの内容をVictim Bufferに退避
↓
ロード対象のラインをL2からL1に移動
↓
Victim Buffer上にコピーしたラインをL2の、さっきデータをL1にうつした跡んとこに移動。
#ちなみにVictim Bufferの転送が済まない内にL1ミスが起きると、Victim Bufferが空になるまで
#一連の制御ができなくて、20クロック程度も待たされる。
#これではNetBurstの分岐予測ミスのペナルティすら笑えない。
これがL3だと、言葉で説明しづらいくらいもっと複雑。
【Intelの場合(っていうか広く一般で使われてるInclusive Cacheの場合)】
L1上にあるキャッシュラインのコピーはL2上にも常にあるため、
L1からL2に退避する必要があるのは、ラインが変更された場合だけでいい。
(変更されてなければ破棄するだけでいい)
ラインの重複を許している分、Victim Bufferみたいな仕組みが原理的に必要ない。
でも今の性能差は、キャッシュよりももっと根本的なところの設計が違う気がするんだがな。
AMDはK7以降実行パイプラインの基本構造を実質ほとんど変えてないが、Intelは地道にマイナーチェンジを重ねてきたからね。
565 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 21:46:22 ID:4weY/39z
Nehalemの場合、占有キャッシュと言っても、SMTがあるから、2スレッドで共有してるキャッシュだからね。
4コア8スレッドでL1ミスヒットのときにいちいち唯一のL2のFIFOに要求かけて、果たして性能出せるかな?
その意味じゃ、L1とL2の間に、小容量低レイテンシの占有キャッシュを挟んだってイメージのほうが捉えやすいかなと思うけど。
4コア8スレッドでL1ミスヒットのときにいちいち唯一のL2のFIFOに要求かけて、果たして性能出せるかな?
その意味じゃ、L1とL2の間に、小容量低レイテンシの占有キャッシュを挟んだってイメージのほうが捉えやすいかなと思うけど。
>Nehalemの場合、占有キャッシュと言っても、SMTがあるから、2スレッドで共有してるキャッシュだからね。
4コア8スレッドでL1ミスヒットのときにいちいち唯一のL2のFIFOに要求かけて、果たして性能出せるかな?
今のL1→L2帯域が飽和してるならそうでしょうね。
しかし、飽和してるかどうかはわからないでしょう。
それとHTはあくまで仮想ですから、実際に帯域をそれほど必要
としないと予測できます。
仮説ばかりで結論を急いでも意味ないでしょうね。
4コア8スレッドでL1ミスヒットのときにいちいち唯一のL2のFIFOに要求かけて、果たして性能出せるかな?
今のL1→L2帯域が飽和してるならそうでしょうね。
しかし、飽和してるかどうかはわからないでしょう。
それとHTはあくまで仮想ですから、実際に帯域をそれほど必要
としないと予測できます。
仮説ばかりで結論を急いでも意味ないでしょうね。
>>565
SMTは実質1スレッドだと思ってたんだけどな、いってみれば極端なタイムスライス
リソースロックをして失敗したらスレッド切り替えというのが、命令単位で行われているというか・・・
だから、単一のスレッドでもしっかりチューンしてしまうと2スレッド走らせても効果が出ないというチューン野郎に思わぬ副作用あり。
SMTは実質1スレッドだと思ってたんだけどな、いってみれば極端なタイムスライス
リソースロックをして失敗したらスレッド切り替えというのが、命令単位で行われているというか・・・
だから、単一のスレッドでもしっかりチューンしてしまうと2スレッド走らせても効果が出ないというチューン野郎に思わぬ副作用あり。
568 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 22:21:58 ID:4weY/39z
確かに仮想だけど、1スレッドだけで使うより、2スレッドで共有してる方が遙かにL1ミスの頻度は高くなるよ。
増えてないからねコアあたりのL1容量が。Meromアーキと変わらず32K+32Kだ。
スレッド毎の利用状況に応じた動的配分なんかはL1+L2にも必要になってくるんだよね。
まあオレゴンチームはNetBurstで既に経験してるんだけどさ
増えてないからねコアあたりのL1容量が。Meromアーキと変わらず32K+32Kだ。
スレッド毎の利用状況に応じた動的配分なんかはL1+L2にも必要になってくるんだよね。
まあオレゴンチームはNetBurstで既に経験してるんだけどさ
570 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 22:29:00 ID:4weY/39z
>>567
そのへんはNetBurstの時に学んだよ
こと、並列化に関しては命令レベルでどうこうやるよりはOoO/レジスタリネーミングの機構にうまくハマる
コードを書いた方が性能のばしやすい。
インオーダのAtomはまた別の方針が必要になりそうだけど。
そのへんはNetBurstの時に学んだよ
こと、並列化に関しては命令レベルでどうこうやるよりはOoO/レジスタリネーミングの機構にうまくハマる
コードを書いた方が性能のばしやすい。
インオーダのAtomはまた別の方針が必要になりそうだけど。
571 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 22:31:21 ID:4weY/39z
>>569
いや、レイテンシの隠蔽にはSMTは有効だけど、L2を独立にしたのはレイテンシじゃなくて、スループットの問題じゃないの。
いや、レイテンシの隠蔽にはSMTは有効だけど、L2を独立にしたのはレイテンシじゃなくて、スループットの問題じゃないの。
4issueでも平均同時命令実行数は
2程度なんで、メモリウェイトなくても
SMTで性能あがるだろ
なんでL2 256kBか?って分かるわけ
ねーだろ!
個人的にはitaniumのL2が長いこと
256kBだったんで、よくはわからんが
適正容量なんだとおもう
2程度なんで、メモリウェイトなくても
SMTで性能あがるだろ
なんでL2 256kBか?って分かるわけ
ねーだろ!
個人的にはitaniumのL2が長いこと
256kBだったんで、よくはわからんが
適正容量なんだとおもう
毎度ながらL2よりL1が少ないのが気にかかる。
データベースとか、キャッシュミスが
当たり前の処理だと、メモリレイテンシ
隠蔽の効果は高い
当たり前の処理だと、メモリレイテンシ
隠蔽の効果は高い
>>573
L2がL1より小さかったらL2の存在意義、やるべき仕事が・・・
L2がL1より小さかったらL2の存在意義、やるべき仕事が・・・
>なんでL2 256kBか?って分かるわけ
ねーだろ!
L1-L2がネックだからL3共有という主張を否定してるだけで、
L2が256kBということに突っ込んでるわけではないでしょう。
ねーだろ!
L1-L2がネックだからL3共有という主張を否定してるだけで、
L2が256kBということに突っ込んでるわけではないでしょう。
メモリ階層の上のほうが小容量なのは
当然
これ当はまんないのは昔のDuronとかだけ
SMTの本来の目的はWide Issueのため
遊んでいる演算器を回すため
レイテンシ隠蔽が主目的って誰が
言いはじめたんだ?
当然
これ当はまんないのは昔のDuronとかだけ
SMTの本来の目的はWide Issueのため
遊んでいる演算器を回すため
レイテンシ隠蔽が主目的って誰が
言いはじめたんだ?
579 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 22:46:47 ID:4weY/39z
俺の論旨
「L1ミス→即4コア共有キャッシュだとスループットの問題が発生するので、
各コア独立で、共有キャッシュへのアクセス頻度をある程度減らせる程度の容量のL2を間に挟んだ」
AMDのL3の機構は俺もよく理解できてないので口を挟むのは辞める。
「L1ミス→即4コア共有キャッシュだとスループットの問題が発生するので、
各コア独立で、共有キャッシュへのアクセス頻度をある程度減らせる程度の容量のL2を間に挟んだ」
AMDのL3の機構は俺もよく理解できてないので口を挟むのは辞める。
>>580
アレはメモコン統合している上に、65nmでネイティブ4コアっていう
バカでっかいコアサイズとキャッシュとのトレードオフからの2MBなんだろ。
メモコンを統合するNehalemでもL3は8MBだし、
AMDの45nm ShanghaiではL3は6MBだから、
キャッシュサイズに関しては大して差があるわけではない。
アレはメモコン統合している上に、65nmでネイティブ4コアっていう
バカでっかいコアサイズとキャッシュとのトレードオフからの2MBなんだろ。
メモコンを統合するNehalemでもL3は8MBだし、
AMDの45nm ShanghaiではL3は6MBだから、
キャッシュサイズに関しては大して差があるわけではない。
>L1ミス→即4コア共有キャッシュだとスループットの問題が発生するので
発生するのは確かだけど、”どの程度”発生するの?ってさっきから
わからないんだけど?
たとえば、農家ばかりの土地で1時間1台しか車が通らないなら、交通量が
8倍になっても問題ないよね?
で?L1-L2が現状でどの程度アップアップなの?そこがボトルネックで
”アーキを変える必要性があるほど”全体の性能に影響を与えるもの
になると思う根拠が誰にも示されてないでしょう。
”アーキを変える必要性があるほど”全体の性能に影響を与えるもの
なら、それを理由にL3を共有にしたという主張を行う価値があるでしょう。
発生するのは確かだけど、”どの程度”発生するの?ってさっきから
わからないんだけど?
たとえば、農家ばかりの土地で1時間1台しか車が通らないなら、交通量が
8倍になっても問題ないよね?
で?L1-L2が現状でどの程度アップアップなの?そこがボトルネックで
”アーキを変える必要性があるほど”全体の性能に影響を与えるもの
になると思う根拠が誰にも示されてないでしょう。
”アーキを変える必要性があるほど”全体の性能に影響を与えるもの
なら、それを理由にL3を共有にしたという主張を行う価値があるでしょう。
>>581
Power5は、2way SMTで50%
開発中止になったAlpha21464は
4way SMTで150%性能あがる
レイテンシ隠蔽だけじゃこんな性能
あがらないよ
演算器が並列性の限界で遊んでいるっ
てのは些細なことじゃない
Power5は、2way SMTで50%
開発中止になったAlpha21464は
4way SMTで150%性能あがる
レイテンシ隠蔽だけじゃこんな性能
あがらないよ
演算器が並列性の限界で遊んでいるっ
てのは些細なことじゃない
>>582
完全に趣味だよね…。でもキャッシュの速さは異常。
でも64bit OSが主流になるとL1キャッシュのサイズが、
少し不安になってくる気がするんだが…。
それでもコアの拡張分でかなり高速化はされるんだろうけどさ。
余程の事がない限り、あと数年はIntelの上位は安泰だ。
完全に趣味だよね…。でもキャッシュの速さは異常。
でも64bit OSが主流になるとL1キャッシュのサイズが、
少し不安になってくる気がするんだが…。
それでもコアの拡張分でかなり高速化はされるんだろうけどさ。
余程の事がない限り、あと数年はIntelの上位は安泰だ。
>>585
50%とか目茶目茶嘘臭いwww
50%とか目茶目茶嘘臭いwww
588 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:02:36 ID:4weY/39z
逆に、L1ミス頻度がそんなに少ないなら、L2のレイテンシが大きくてもそんなに問題にならないことになるはず。
Pentium IIIからPentium MあたりまでずっとL2のレイテンシの短さを大事にしてきたのは
L1は高頻度でミスヒットするものという前提で設計してきたからで。
AMDは逆にL1の容量命。
Pentium IIIからPentium MあたりまでずっとL2のレイテンシの短さを大事にしてきたのは
L1は高頻度でミスヒットするものという前提で設計してきたからで。
AMDは逆にL1の容量命。
Coreがスバラシイというのは認めるとして、ここらで Shanghai には頑張ってほしい
Intelの独走を止めるんだAMD
Intelの独走を止めるんだAMD
kentsfieldには勝てるよね?
>逆に、L1ミス頻度がそんなに少ないなら、L2のレイテンシが大きくてもそんなに問題にならないことになるはず。
Pentium IIIからPentium MあたりまでずっとL2のレイテンシの短さを大事にしてきたのは
<高頻度ミスヒット>→<L1→L2帯域が詰まるの?>
で、”高”って何に比べて高いの?相対の”高”に比較対象がない理由は?
今の話だと”帯域をいっぱいいっぱい”にするぐらいって言いたげ
だけど。
関係のありそうで、ない話を持ち出してきたので、自分でも良くわかって
なかったのでしょう。
Pentium IIIからPentium MあたりまでずっとL2のレイテンシの短さを大事にしてきたのは
<高頻度ミスヒット>→<L1→L2帯域が詰まるの?>
で、”高”って何に比べて高いの?相対の”高”に比較対象がない理由は?
今の話だと”帯域をいっぱいいっぱい”にするぐらいって言いたげ
だけど。
関係のありそうで、ない話を持ち出してきたので、自分でも良くわかって
なかったのでしょう。
593 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:16:46 ID:4weY/39z
>>590
その割にはQ6600が未だに人気だね
>>592
LUTっていうんんだけど、L2程度にすっぽり収まるようなサイズのテーブルを使って結果を
ランダムルックアップする高速化手法があってだな。
長年Intelアーキテクチャが得意としてきたんだけど、それがもし、4コアで同時に共有キャッシュにアクセスしてみ?
格段に性能落ちるんだわ。
ちなみに、Core 2の2コア共有でも、そういう兆候は確認できてる。
その割にはQ6600が未だに人気だね
>>592
LUTっていうんんだけど、L2程度にすっぽり収まるようなサイズのテーブルを使って結果を
ランダムルックアップする高速化手法があってだな。
長年Intelアーキテクチャが得意としてきたんだけど、それがもし、4コアで同時に共有キャッシュにアクセスしてみ?
格段に性能落ちるんだわ。
ちなみに、Core 2の2コア共有でも、そういう兆候は確認できてる。
594 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:22:39 ID:4weY/39z
Core 2におけるL2のデータスループットは2コアの「合計で」 各L1の半分程度ですね
理解力がないと切れるよ?
あぼーんするだけだけどさ。
理解力がないと切れるよ?
あぼーんするだけだけどさ。
>LUTっていうんんだけど、L2程度にすっぽり収まるようなサイズのテーブルを使って結果を
ランダムルックアップする高速化手法があってだな。
大抵の人は素人なので、特定の人にしかわからないことを書くべきでは
ないですよ。
そういう話で結論するなら、こちらから言うことは何もないですね。
言ってることの正統性を判断できないですから。
ランダムルックアップする高速化手法があってだな。
大抵の人は素人なので、特定の人にしかわからないことを書くべきでは
ないですよ。
そういう話で結論するなら、こちらから言うことは何もないですね。
言ってることの正統性を判断できないですから。
>Core 2におけるL2のデータスループットは2コアの「合計で」 各L1の半分程度ですね
では早いキャッシュと遅いキャッシュの帯域を比べて何したいんでしょ?
相変わらず言いたいことがわかりません。
貴方にとって”理解力がある”のは貴方の意見を鵜呑みにする人
だけでしょ。
FSBやHDDは帯域足りなさすぎるのかなー。(キャッシュに比べて)
では早いキャッシュと遅いキャッシュの帯域を比べて何したいんでしょ?
相変わらず言いたいことがわかりません。
貴方にとって”理解力がある”のは貴方の意見を鵜呑みにする人
だけでしょ。
FSBやHDDは帯域足りなさすぎるのかなー。(キャッシュに比べて)
597 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:35:34 ID:4weY/39z
何が言いたいんだか
これは別に特殊なアルゴリズムでもなんでもない。
SSE4.1で、L1にロードせずに直にxmmレジスタに読み込むmovntdqaみたいな命令を用意してきたこと自体が
そういう需要にこたえた結果なんだから。
正規表現マッチングなんかでよく使われるFAや、ウィルス検索に用いるマルチパターンマッチングなんかも
LUTを適用した身近な例だ。
あくまでごくごく一般的に使われてる手法。
これは別に特殊なアルゴリズムでもなんでもない。
SSE4.1で、L1にロードせずに直にxmmレジスタに読み込むmovntdqaみたいな命令を用意してきたこと自体が
そういう需要にこたえた結果なんだから。
正規表現マッチングなんかでよく使われるFAや、ウィルス検索に用いるマルチパターンマッチングなんかも
LUTを適用した身近な例だ。
あくまでごくごく一般的に使われてる手法。
このスレに来て何言ってんだ
>あくまでごくごく一般的に使われてる手法。
”一般的”の意味をワザとずらして書いても話はかみ合わんでしょ。
”一般的”の意味をワザとずらして書いても話はかみ合わんでしょ。
10年くらいまえのインテルのイベントでゲッツしたインテル宇宙人人形が出てきたぜ
これオクで売れないかな。
これオクで売れないかな。
601 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:42:02 ID:4weY/39z
>FSBやHDDは帯域足りなさすぎるのかなー。(キャッシュに比べて)
当 た り 前 だ ろ
さらに言うとCPUから見てFSBにアクセス投げるのはオンダイの最終レベルのキャッシュのミスヒット後になるので
仮にキャッシュより速くてもどうしようもない。
当 た り 前 だ ろ
さらに言うとCPUから見てFSBにアクセス投げるのはオンダイの最終レベルのキャッシュのミスヒット後になるので
仮にキャッシュより速くてもどうしようもない。
FSB→メモリです。
604 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:47:20 ID:4weY/39z
やれやれ、キャッシュがFSBアクセス頻度減らしてくれてるから、という発想がないのか・・・
>やれやれ、キャッシュがFSBアクセス頻度減らしてくれてるから、という発想がないのか・・・
ですから遅いほうの帯域と早いほうの帯域を単純比較する意味は
ないと思うんだけど?
2倍だから?って話にいきつくんだよね。
ですから遅いほうの帯域と早いほうの帯域を単純比較する意味は
ないと思うんだけど?
2倍だから?って話にいきつくんだよね。
ID:61VwMTm1 は自分があまりにも無知なくせに背伸びして
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。
607 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 23:52:52 ID:4weY/39z
だから、LUTが何かそもそもわかってないだろ
L1ミスのペナルティ被っても、L2からの1回のロード程度ですむなら
L1でこね回すより速いケースが多いんだよ。
L1ミスのペナルティ被っても、L2からの1回のロード程度ですむなら
L1でこね回すより速いケースが多いんだよ。
L1のおかげでL2のアクセス頻度は減るんじゃないかなー
>ID:61VwMTm1 は自分があまりにも無知なくせに背伸びして
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。
背伸びというか、普通に読んで理解できないから聞いてる
だけですよ。
>だから、LUTが何かそもそもわかってないだろ
さー初めて(今日3回目)聞いた。
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。
背伸びというか、普通に読んで理解できないから聞いてる
だけですよ。
>だから、LUTが何かそもそもわかってないだろ
さー初めて(今日3回目)聞いた。
>>609
このスレに来ておいて
>普通に読んで理解できないから
>さー初めて(今日3回目)聞いた。
と書きなぐるのは、自分があまりにも無知なくせに背伸びして
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。 (コピペ)
L1+共有L2 対 L1+L2+共有L3 の話からどんどんそれていってるのも見苦しい
このスレに来ておいて
>普通に読んで理解できないから
>さー初めて(今日3回目)聞いた。
と書きなぐるのは、自分があまりにも無知なくせに背伸びして
恥かいてることを自覚したほうがよい。傍から見てても痛々しい。 (コピペ)
L1+共有L2 対 L1+L2+共有L3 の話からどんどんそれていってるのも見苦しい
>長年Intelアーキテクチャが得意としてきたんだけど、それがもし、4コアで同時に共有キャッシュにアクセスしてみ?
格段に性能落ちるんだわ。
まあ、これが正しいか正しくないか理解できんのでこれ以上話あっても無駄
だな。
正しいならインテルがL1→L2ネックを解消することを目的のひとつとして
L3キャッシュを採用する可能性があることはわかったけどね。
でもそれなら、単純にL1→L2帯域を増やせばいいような気もするけどね。
技術的にどうかは知らんけど。
格段に性能落ちるんだわ。
まあ、これが正しいか正しくないか理解できんのでこれ以上話あっても無駄
だな。
正しいならインテルがL1→L2ネックを解消することを目的のひとつとして
L3キャッシュを採用する可能性があることはわかったけどね。
でもそれなら、単純にL1→L2帯域を増やせばいいような気もするけどね。
技術的にどうかは知らんけど。
>データサイズがL1より大きかったら
ほぼ確実にL2アクセスになるよねー
あーなるほど、そういう状況なら足りんようになりそうだな。
>L1→L2キャッシュ帯域
ほぼ確実にL2アクセスになるよねー
あーなるほど、そういう状況なら足りんようになりそうだな。
>L1→L2キャッシュ帯域
やけにスレ伸びてるな。
難しくてよくわからん…
難しくてよくわからん…
>>614
わからんでいいと思うけどね。
言ってる本人も他人に説明できんのじゃ、詳しく理解はできてないんでしょ。
次世代スレだから云々とか言ってる人もいるけど、定性的な知識
を持ってるだけで、実際のところはわかってないんでしょう。
L1とL2の間がネックになる
わからんでいいと思うけどね。
言ってる本人も他人に説明できんのじゃ、詳しく理解はできてないんでしょ。
次世代スレだから云々とか言ってる人もいるけど、定性的な知識
を持ってるだけで、実際のところはわかってないんでしょう。
L1とL2の間がネックになる
616 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 00:29:29 ID:DzyQor8o
618 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 00:37:42 ID:DzyQor8o
>>615
CPIを使って説明するとこうなるようだ。
ttp://journal.mycom.co.jp/column/architecture/017/index.html
>巨大2次キャッシュを直結した場合のCPIは2.8〜4.6であるのに対して、
>巨大キャッシュを3次キャッシュとして中規模の2次キャッシュを介して
>接続する構成とすることにより、CPIを2.5〜3.8とし、
>性能を10〜20%改善することができる。
これはシングルスレッドでの話しみたいだが
マルチスレッド状況下で共有L2アクセス待ちが長くなるのを嫌って
L2でクッション+共有L3でミス率低減を図ってるんじゃないのかな。
CPIを使って説明するとこうなるようだ。
ttp://journal.mycom.co.jp/column/architecture/017/index.html
>巨大2次キャッシュを直結した場合のCPIは2.8〜4.6であるのに対して、
>巨大キャッシュを3次キャッシュとして中規模の2次キャッシュを介して
>接続する構成とすることにより、CPIを2.5〜3.8とし、
>性能を10〜20%改善することができる。
これはシングルスレッドでの話しみたいだが
マルチスレッド状況下で共有L2アクセス待ちが長くなるのを嫌って
L2でクッション+共有L3でミス率低減を図ってるんじゃないのかな。
620 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 00:46:46 ID:DzyQor8o
Core 2 QuadみたいにFSB経由でスヌープしてもオーバーヘッドはたかが知れてることが判明したしな
L2でキャッシュを共有するメリットも、そんなには無いんだよね。
L2の性能を4倍にするのは難しいが、4コアでそれぞれ独立のL2を持つことは容易だしそっちのほうが性能が出る。
L2でキャッシュを共有するメリットも、そんなには無いんだよね。
L2の性能を4倍にするのは難しいが、4コアでそれぞれ独立のL2を持つことは容易だしそっちのほうが性能が出る。
ID:61VwMTm1
ID:BvVBFGlJ
NG推奨 ヽ`∀´>っ-{}法{}曹{} ◆5OJ3YFv/hc
NG推奨 ヽ`∀´>っ-{}法{}曹{} ◆7idzB6JMx.
皆さんは、http://info.2ch.net/before.htmlの、特に一番下の項をよく読んで下さい。
内容の是非に関わらず、彼との会話・議論は毎回スレが荒れますので他所でお願いします。
彼の人格は、前スレ及び価○.comのQX9650のクチコミ辺りを読めば把握出来ると思います。
彼は自分のスレだから○○等と言ったりする妄想癖があるので構わないようにして下さい
ヽ`∀´>っ-{}法{}曹{} = モビルスーツガン○ム
最悪板⇒http://tmp7.2ch.net/test/read.cgi/tubo/1193932534/
価格COM最悪⇒http://bbs.kakaku.com/bbs/-/SortID=7161566/
ID:BvVBFGlJ
NG推奨 ヽ`∀´>っ-{}法{}曹{} ◆5OJ3YFv/hc
NG推奨 ヽ`∀´>っ-{}法{}曹{} ◆7idzB6JMx.
皆さんは、http://info.2ch.net/before.htmlの、特に一番下の項をよく読んで下さい。
内容の是非に関わらず、彼との会話・議論は毎回スレが荒れますので他所でお願いします。
彼の人格は、前スレ及び価○.comのQX9650のクチコミ辺りを読めば把握出来ると思います。
彼は自分のスレだから○○等と言ったりする妄想癖があるので構わないようにして下さい
ヽ`∀´>っ-{}法{}曹{} = モビルスーツガン○ム
最悪板⇒http://tmp7.2ch.net/test/read.cgi/tubo/1193932534/
価格COM最悪⇒http://bbs.kakaku.com/bbs/-/SortID=7161566/
L3のレイテンシは何サイクルなんだろう?
>>622
製品が出ないことには何とも言えないよね。
製品が出ないことには何とも言えないよね。
キャッシュ構造についてはインテルも十分シミュレーション
してるだろから、まあそれなりの効果はあるんだろ。
SMTのついては、マーケティングの材料のような気がするけどな。
少なくとも、これで見た目のコア数でまけることはなくなるから。
coreアーキテクチャはpen4ほどパイプラインが深くないから効果は低いと思うが。
まあクロック至上主義からコア至上主義に乗り換えたんだろうな。
してるだろから、まあそれなりの効果はあるんだろ。
SMTのついては、マーケティングの材料のような気がするけどな。
少なくとも、これで見た目のコア数でまけることはなくなるから。
coreアーキテクチャはpen4ほどパイプラインが深くないから効果は低いと思うが。
まあクロック至上主義からコア至上主義に乗り換えたんだろうな。
>2次キャッシュのアクセス待ち時間が大きく、1次キャッシュを
>ミスした場合のCPIが大きくなってしまう。このため、大容量の
>キャッシュは3次キャッシュとし、中間に2次キャッシュを挟む
>3階層のキャッシュが用いられる。
>例であるが、巨大2次キャッシュを直結した場合のCPIは2.8〜4.6
>であるのに対して、巨大キャッシュを3次キャッシュとして中規模
>の2次キャッシュを介して接続する構成とすることにより、CPIを
>2.5〜3.8とし、性能を10〜20%改善することができる。
これなら自然な話だね。
製造難度の問題ですから。
>ミスした場合のCPIが大きくなってしまう。このため、大容量の
>キャッシュは3次キャッシュとし、中間に2次キャッシュを挟む
>3階層のキャッシュが用いられる。
>例であるが、巨大2次キャッシュを直結した場合のCPIは2.8〜4.6
>であるのに対して、巨大キャッシュを3次キャッシュとして中規模
>の2次キャッシュを介して接続する構成とすることにより、CPIを
>2.5〜3.8とし、性能を10〜20%改善することができる。
これなら自然な話だね。
製造難度の問題ですから。
実際問題L1→L2の帯域の問題もあるんだろうけど、
そんな単純なレベルの話ならば、L1→L2帯域を増やせば
いいんでしょう。
団子の世界ではシミュレーションする必要なし?
そんな単純なレベルの話ならば、L1→L2帯域を増やせば
いいんでしょう。
団子の世界ではシミュレーションする必要なし?
628 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 01:01:06 ID:DzyQor8o
>少なくとも、これで見た目のコア数でまけることはなくなるから。
負けたことあったっけ?
実効2issue程度のNetBurstでのSMT以上には効果はありそうだけどな。
L3搭載の代わりにL2を小さくするのはDempseyに対するTulsaもそうだし
Harpertownに対するDunnington もそうだ。
技術的根拠はあるでしょ。
負けたことあったっけ?
実効2issue程度のNetBurstでのSMT以上には効果はありそうだけどな。
L3搭載の代わりにL2を小さくするのはDempseyに対するTulsaもそうだし
Harpertownに対するDunnington もそうだ。
技術的根拠はあるでしょ。
>4コア8スレッドに対応できるようなL1→L2帯域を実現しようとすれば
最低コア数倍の帯域を用意する必要があり、
うんうん、だからこの根拠はどこにも書いてないよね。
それがわかる?人はうらやましい。
最低コア数倍の帯域を用意する必要があり、
うんうん、だからこの根拠はどこにも書いてないよね。
それがわかる?人はうらやましい。
630 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 01:05:05 ID:DzyQor8o
631 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 01:12:06 ID:DzyQor8o
CPU-Zで確認したけどPenrynではキャッシュライン64byteに拡張されてんだな。
どのみちバスの並列化が困難なのは同じだけど。
どのみちバスの並列化が困難なのは同じだけど。
>>629
まだわからない?
L1ミス率5%でL2レイテンシが20サイクルだと
CPIの半分はL2アクセスに費やされる。
マルチスレッド条件下でL2アクセスが他のスレッドのロード待ちで
L2アクセスがL2レイテンシ*待ちロード数だけ増えると
CPIのうち、L2アクセスの占める割合が激増する。
そのぶん性能が低下する。
L2レイテンシを減らすかロード待ちを短縮するかL2アクセスそのものを減らすか、となるが
L2レイテンシを減らすのは無理ってかできるならやってる。
ロード待ちを短縮するには帯域を増やしてさっさとデータを流すしかない、従って帯域4倍と書いた、でも無理。
L2アクセスそのものを減らすためにL2+共有L3にしている。
まだわからない?
L1ミス率5%でL2レイテンシが20サイクルだと
CPIの半分はL2アクセスに費やされる。
マルチスレッド条件下でL2アクセスが他のスレッドのロード待ちで
L2アクセスがL2レイテンシ*待ちロード数だけ増えると
CPIのうち、L2アクセスの占める割合が激増する。
そのぶん性能が低下する。
L2レイテンシを減らすかロード待ちを短縮するかL2アクセスそのものを減らすか、となるが
L2レイテンシを減らすのは無理ってかできるならやってる。
ロード待ちを短縮するには帯域を増やしてさっさとデータを流すしかない、従って帯域4倍と書いた、でも無理。
L2アクセスそのものを減らすためにL2+共有L3にしている。
>レイテンシ隠蔽が主目的って誰が言いはじめたんだ?
あんたが疑問に思うのは勝手だが、多くのCPU開発者がそうだと言っているようだが…
http://pc.watch.impress.co.jp/docs/2003/1018/kaigai034.htm
http://pc.watch.impress.co.jp/docs/2005/0711/kaigai197.htm
後藤記事でも引っかかりますよヽ(´ー`)ノ
あんたが疑問に思うのは勝手だが、多くのCPU開発者がそうだと言っているようだが…
http://pc.watch.impress.co.jp/docs/2003/1018/kaigai034.htm
http://pc.watch.impress.co.jp/docs/2005/0711/kaigai197.htm
後藤記事でも引っかかりますよヽ(´ー`)ノ
634 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 01:30:16 ID:DzyQor8o
> Intelは次のように説明する。
>
> 「我々はキャッシュを極めてスケーラブルにしたかった。CPUコアを増やすにつれて、
> キャッシュ階層もスケールできるように。そのために、2-3の鍵となる要素がある。
>
> 1つは、(Nehalemでは)L2キャッシュの導入によって、L3キャッシュをバッファできる。
> CPUコア間で共有されるL3では、全てのコアがアクセスすることで、ボトルネックができる。
> それに対して、L2は各CPUコア占有で、非常にレイテンシが低く、実行エンジンにデータを
> うまく供給してくれる」
> こうして見ると、考え方としては、大容量化するマルチコア時代の共有キャッシュと、
> CPUコア内部のL1キャッシュの間に、新たに、中間のレイテンシと容量を持つキャッシュ
> 階層を挟み込んだと言えそうだ。実際に、Intelも「レベル2はブランドニューのキャッシュ」
> と表現する。つまり、3階層のうち、新たに加わったのはL3ではなくL2というニュアンスだ。
> 従来のキャッシュ階層の下にL3を加えたのではなく、従来のL2とL1の間に1階層挟み込んで、
> その結果が3階層キャッシュとなったのだろう。
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
今回は珍しく後藤弘茂と意見が一致したな
>
> 「我々はキャッシュを極めてスケーラブルにしたかった。CPUコアを増やすにつれて、
> キャッシュ階層もスケールできるように。そのために、2-3の鍵となる要素がある。
>
> 1つは、(Nehalemでは)L2キャッシュの導入によって、L3キャッシュをバッファできる。
> CPUコア間で共有されるL3では、全てのコアがアクセスすることで、ボトルネックができる。
> それに対して、L2は各CPUコア占有で、非常にレイテンシが低く、実行エンジンにデータを
> うまく供給してくれる」
> こうして見ると、考え方としては、大容量化するマルチコア時代の共有キャッシュと、
> CPUコア内部のL1キャッシュの間に、新たに、中間のレイテンシと容量を持つキャッシュ
> 階層を挟み込んだと言えそうだ。実際に、Intelも「レベル2はブランドニューのキャッシュ」
> と表現する。つまり、3階層のうち、新たに加わったのはL3ではなくL2というニュアンスだ。
> 従来のキャッシュ階層の下にL3を加えたのではなく、従来のL2とL1の間に1階層挟み込んで、
> その結果が3階層キャッシュとなったのだろう。
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
今回は珍しく後藤弘茂と意見が一致したな
>coreアーキテクチャはpen4ほどパイプラインが深くないから効果は低いと思うが。
メモリレイテンシの大幅な改良が見込まれないのですから
SMTによるメモリレイテンシ隠蔽の効果が増えるのでは?
メモリレイテンシの大幅な改良が見込まれないのですから
SMTによるメモリレイテンシ隠蔽の効果が増えるのでは?
>>632
うんうんちょっと理解するから待ってね。
うんうんちょっと理解するから待ってね。
637 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 01:44:32 ID:DzyQor8o
> Intelは次のように説明する。
>Intelも「レベル2はブランドニューのキャッシュ」
>と表現する。つまり、3階層のうち、新たに加わったのはL3ではなく
L2というニュアンスだ。
あーなんだインテルが言ってたことを書いてただけか。アホくさ。
>Intelも「レベル2はブランドニューのキャッシュ」
>と表現する。つまり、3階層のうち、新たに加わったのはL3ではなく
L2というニュアンスだ。
あーなんだインテルが言ってたことを書いてただけか。アホくさ。
別にこんなことが分かっても、CPU設計なんて一生関わらないだろうし、
プログラミングだって余程効率が求められるもの以外、そこまで関係ないよな。
プログラミングだって余程効率が求められるもの以外、そこまで関係ないよな。
642 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 06:50:42 ID:DzyQor8o
そこメモっとくわ
>今更な記事すら知らないで偉そうにしゃべっていた情報弱者の捨て台詞カコワル
こんなこと知ってても何の得にもならんでしょ。
で、団子があたかも自分が導きだしたかのように語ってるほうが
恥ずかしいとおもうけどね。
まあ雑音を発するしか脳のない輩に何言っても無駄だろうけど。
こんなこと知ってても何の得にもならんでしょ。
で、団子があたかも自分が導きだしたかのように語ってるほうが
恥ずかしいとおもうけどね。
まあ雑音を発するしか脳のない輩に何言っても無駄だろうけど。
>565 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/26(水) 21:46:22 ID:4weY/39z
>その意味じゃ、L1とL2の間に、小容量低レイテンシの占有キャッシュを挟んだって
>イメージのほうが捉えやすいかなと思うけど。
>Intelも「レベル2はブランドニューのキャッシュ」
> と表現する。
まんまでしょ。
で彼の意見のオリジナルはL1→L2キャッシュ帯域がネックになるという部分
のみ。説明できてなかったけどね。
>その意味じゃ、L1とL2の間に、小容量低レイテンシの占有キャッシュを挟んだって
>イメージのほうが捉えやすいかなと思うけど。
>Intelも「レベル2はブランドニューのキャッシュ」
> と表現する。
まんまでしょ。
で彼の意見のオリジナルはL1→L2キャッシュ帯域がネックになるという部分
のみ。説明できてなかったけどね。
まあアドバンスド・スマート・キャッシュでL1→L2の帯域が2倍になっている
ことからCore2Duoでも1倍ではL1→L2がネックになっていたと推察できる。
で、4コアだと確かにネックになる可能性が高いね。
こういう説明がわかりやすい説明なんだけどね。
ことからCore2Duoでも1倍ではL1→L2がネックになっていたと推察できる。
で、4コアだと確かにネックになる可能性が高いね。
こういう説明がわかりやすい説明なんだけどね。
>>562
cache構造がInclusiveだとメモリアクセスが遅く、Exclusiveだと
メモリアクセスが速い。Exclusive採用はキャッシュ容量を稼ぐため
とか勘違いしてるのはimpressだけで十分。
キャッシュ内だけで話を完結させたがるのがIntel。
メモリアクセスまで考慮してるのがAMD。
cache構造がInclusiveだとメモリアクセスが遅く、Exclusiveだと
メモリアクセスが速い。Exclusive採用はキャッシュ容量を稼ぐため
とか勘違いしてるのはimpressだけで十分。
キャッシュ内だけで話を完結させたがるのがIntel。
メモリアクセスまで考慮してるのがAMD。
煽るアホウに煽り入れるアホウ、同じアホなら鏡見て済ませってヤツか
そろそろ無限ループに入りそうだ
そろそろ無限ループに入りそうだ
Core2DuoE6300を使っているが、4GRAMのメモリで充分に快適で何の不満も感じない。
用途は、ネットとワ−プロとたまにフォトショップ7.0を使っている程度。
もう過剰な性能のCPUになっているのではないかと思う、このごろである。
用途は、ネットとワ−プロとたまにフォトショップ7.0を使っている程度。
もう過剰な性能のCPUになっているのではないかと思う、このごろである。
フォトショップでもフィルタガリガリかけたらまた違う感想になるだろ
ネットとワープロだけならそら既に過剰な域に達してるだろうけど
ネットとワープロだけならそら既に過剰な域に達してるだろうけど
フォトショ程度ならどうなんだろうね?
68040時代から使われているアプリだよ
最新版はもちろん最近のバージョンより
重いだろうけど、あんま性能不足を
感じることはないんじゃないかな?
3Dのほうも最新GPUとCPUなら飽和気味のような
OpenGLとCPUレンダリングだったり
レイトレだとまだまだ遅いんだろうけど
DirectXだと十分な日も近い
68040時代から使われているアプリだよ
最新版はもちろん最近のバージョンより
重いだろうけど、あんま性能不足を
感じることはないんじゃないかな?
3Dのほうも最新GPUとCPUなら飽和気味のような
OpenGLとCPUレンダリングだったり
レイトレだとまだまだ遅いんだろうけど
DirectXだと十分な日も近い
メーカーとしちゃもう十分なのを一般大衆に気づかれると終わるから
そういう気が起こらないように次々とハードもソフトも開発し続けてるんじゃないのか。
そういう気が起こらないように次々とハードもソフトも開発し続けてるんじゃないのか。
>>647
おいおい、容量を稼ぐためのアプローチとして
排他処理のメリットを長らく訴えてたのはAMD自身だぞ。
L2特盛りのBanias以降総容量でも劣勢が明らかになったあたりからトーンが弱くなったのが事実。
ちなみに全階層に同時に問合わせるする動作自体はそもそもExclusiveである必要はない。
上位層で該当ラインが見つかった場合は下位層への問い合わせ結果を破棄すればいい。
しかし現実にはキャッシュの上位階層から当たりをつけて順次アクセスしたほうが
無駄にバス帯域や電力を使わずにすむし、どこもやってない。
サーバ市場でのOpteronのいまの劣勢ぶりを見れば、殆ど役に立ってないのは明らかだろ。
おいおい、容量を稼ぐためのアプローチとして
排他処理のメリットを長らく訴えてたのはAMD自身だぞ。
L2特盛りのBanias以降総容量でも劣勢が明らかになったあたりからトーンが弱くなったのが事実。
ちなみに全階層に同時に問合わせるする動作自体はそもそもExclusiveである必要はない。
上位層で該当ラインが見つかった場合は下位層への問い合わせ結果を破棄すればいい。
しかし現実にはキャッシュの上位階層から当たりをつけて順次アクセスしたほうが
無駄にバス帯域や電力を使わずにすむし、どこもやってない。
サーバ市場でのOpteronのいまの劣勢ぶりを見れば、殆ど役に立ってないのは明らかだろ。
OSやアプリが重いから速くなってない
ってのは嘘で、ブラウザやOfficeも
速くなってる
IEだけなぜかめちゃくちゃ遅いが
Vista上でのWordの起動も、かつての
DOSエディタ並の速さだよ
ってのは嘘で、ブラウザやOfficeも
速くなってる
IEだけなぜかめちゃくちゃ遅いが
Vista上でのWordの起動も、かつての
DOSエディタ並の速さだよ
>雑音に雑音重ねてご苦労なこったなw
負け惜しみはさらにカコワルイですよm9(^Д^)
自分が無職だって、それを基準に人を非難しても意味ないでしょう。
OCスレの過去ログ読めばわかりますが、私は法科大学院にことし入学したので
今は休みですよ。
ですから将来は法曹です。
負け惜しみはさらにカコワルイですよm9(^Д^)
自分が無職だって、それを基準に人を非難しても意味ないでしょう。
OCスレの過去ログ読めばわかりますが、私は法科大学院にことし入学したので
今は休みですよ。
ですから将来は法曹です。
それはもはやマシンのスペックが関係ないような
IEが遅いのは
キャッシュファイルをHDDに溜め込むからでないの?
キャッシュファイルをHDDに溜め込むからでないの?
>>660
それもありそう
それもありそう
少し知識不足を感じたので今日少しCPUについて勉強。
1.デコーダー性能→K8>>Core>>NetBurst
L1の大きいK8がL1キャッシュミスヒットを起こすBlockSizeがCoreや
NetBurst大きい
NetBurstはL1だけでなくTrace Cacheにミスヒットするとデコーダー
能力が落ちるという点で、他と違う特徴を持っている。
CoreはL1キャッシュミスヒットをしてもL2が高速なため、デコーダー
能力が落ちが他より低い。
1.デコーダー性能→K8>>Core>>NetBurst
L1の大きいK8がL1キャッシュミスヒットを起こすBlockSizeがCoreや
NetBurst大きい
NetBurstはL1だけでなくTrace Cacheにミスヒットするとデコーダー
能力が落ちるという点で、他と違う特徴を持っている。
CoreはL1キャッシュミスヒットをしてもL2が高速なため、デコーダー
能力が落ちが他より低い。
↑馬鹿が無理すんなwww
もういい加減無視しろよ
3ヶ月ほどロムってもらわんと話にならんぞこりゃ
3ヶ月ほどロムってもらわんと話にならんぞこりゃ
ああ、阪大院さんか。
…こいつが出現してから既に3ヶ月過ぎてたっけ?
だとしたら根本的な所で頭悪いかもな。今後も厳しいかも。
…こいつが出現してから既に3ヶ月過ぎてたっけ?
だとしたら根本的な所で頭悪いかもな。今後も厳しいかも。
>…こいつが出現してから既に3ヶ月過ぎてたっけ?
このスレには昨日初めて来た。
このスレには昨日初めて来た。
匿名掲示板で、プロフィールを公開する奴=ろくなやつじゃない
2chで頭のレベルが違うといって許されるのは、東大理III、京大医レベルだけだ。
あと資産40億は余計だろ。関西対決か。
2chで頭のレベルが違うといって許されるのは、東大理III、京大医レベルだけだ。
あと資産40億は余計だろ。関西対決か。
妹が東大医だけどなw
>この程度のスレのレベルにはすぐ到達すると思うよ。
今はわからなくても、すぐにわかるようになる。
これは匿名掲示板で必要な心構えだよな〜。
アーキテクチャなんてそんな難しい分野じゃないし、
本当に理IIIレベルなら本を数冊かって1週間かけてよめば、
そのスレ住人なんて楽勝だろう。
しかし、普通の大学、大学院レベルではなかなか難しいと思うぞ。
今はわからなくても、すぐにわかるようになる。
これは匿名掲示板で必要な心構えだよな〜。
アーキテクチャなんてそんな難しい分野じゃないし、
本当に理IIIレベルなら本を数冊かって1週間かけてよめば、
そのスレ住人なんて楽勝だろう。
しかし、普通の大学、大学院レベルではなかなか難しいと思うぞ。
・メモリとキャッシュのレイテンシについて。
1.転送サイズがキャッシュからあふれない場合。
L1キャッシュミスヒットによりレイテンシが増加し始める転送サイズは、、。
当然NetBurst<Core<K8(L1の大きさの順)
L1ミスL2読みのレイテンシは
L2キャッシュのレイテンシ順つまり、
NetBurst>Core>K8(L1の大きさの順)
2.転送サイズが大きく、キャッシュから溢れる場合。
メモリコントローラーを内臓したK8が圧倒的。
1.転送サイズがキャッシュからあふれない場合。
L1キャッシュミスヒットによりレイテンシが増加し始める転送サイズは、、。
当然NetBurst<Core<K8(L1の大きさの順)
L1ミスL2読みのレイテンシは
L2キャッシュのレイテンシ順つまり、
NetBurst>Core>K8(L1の大きさの順)
2.転送サイズが大きく、キャッシュから溢れる場合。
メモリコントローラーを内臓したK8が圧倒的。
ちなみに>>663はたとえるなら頭の弱い小学生が包丁振り回していきがってるくらいのレベル。
ここらの連中には一目で知識がないとわかる。
どうせ多和田あたりのコラムでもちょっと読んできただけの理解だろうが
国語辞典を全部読みましたってくらい、何の役にも立ちません。
ここらの連中には一目で知識がないとわかる。
どうせ多和田あたりのコラムでもちょっと読んできただけの理解だろうが
国語辞典を全部読みましたってくらい、何の役にも立ちません。
謝れ!国語辞典に謝れ!
あれは通読したら半端ない知識がつくぞ。
とりあえず阪大院さんはこれ読みましょう
http://journal.mycom.co.jp/column/architecture/index.html
これ全部と色んなサイトのCPUのトレンド記事読めば(そして理解すれば)このスレの話題についていける様になるはず。
書き込むのはそれからでも遅くない。
つーかウゼェからそれまで消えててくれ
あれは通読したら半端ない知識がつくぞ。
とりあえず阪大院さんはこれ読みましょう
http://journal.mycom.co.jp/column/architecture/index.html
これ全部と色んなサイトのCPUのトレンド記事読めば(そして理解すれば)このスレの話題についていける様になるはず。
書き込むのはそれからでも遅くない。
つーかウゼェからそれまで消えててくれ
んで勘違いしてたけどトレースキャッシュはNetBurstのL1の一部にあたるんだな。
で、トレースキャッシュは容量が12KBではなく12KμOpsらしいが、これは12*1000個
のμOps命令を保存できるという意味。
で、L1の中には8KBのデーターキャッシュもあり、よく使うデータをココに保存する。
で、トレースキャッシュは容量が12KBではなく12KμOpsらしいが、これは12*1000個
のμOps命令を保存できるという意味。
で、L1の中には8KBのデーターキャッシュもあり、よく使うデータをココに保存する。
>>663>>673
メモは日記にでも書いとくか、頭の中に溜めておけ。
わざわざここに書きこむ必要なんて無いだろ。
このスレの過去ログも30ちょっとしか無いんだから
全部読む事をお勧めする。
それまで無駄な書き込みは不要。
メモは日記にでも書いとくか、頭の中に溜めておけ。
わざわざここに書きこむ必要なんて無いだろ。
このスレの過去ログも30ちょっとしか無いんだから
全部読む事をお勧めする。
それまで無駄な書き込みは不要。
679 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/27(木) 23:15:04 ID:DzyQor8o
>>667
ちなみに俺そういうのはGoogleノートブックにメモしてる。
#しかもぜんぜん違うし。
#L2レイテンシがL1のサイズと相関とか、どこをどうやったらそう理解できるんだwwww
しかし、3分クッキングを見てこだわりの日本料理を語るくらいの勢いの、アレな人だね。
モノを言うのは実践力だけだよ。
ちなみに俺そういうのはGoogleノートブックにメモしてる。
#しかもぜんぜん違うし。
#L2レイテンシがL1のサイズと相関とか、どこをどうやったらそう理解できるんだwwww
しかし、3分クッキングを見てこだわりの日本料理を語るくらいの勢いの、アレな人だね。
モノを言うのは実践力だけだよ。
>>676
トレースキャッシュというのはトレーススケジューリングという考えに基づいているんだよ。
トレーススケジューリングというのはVLIWのコンパイラ技術で出てきた考え方。
元々最適化技術ではプログラムを分岐単位で考える。VLIWコンパイラではプロセッサのリソースを
生かすために分岐を超えるより広域で最適化を行う技術が発展した。
分岐を超える場合、実行経路のなかでもっとも繰り返し頻度が高い(と思われる)経路に注力して
最適化処理すればもっとも効率がいい。トレースとはこの経路を抽出したもの。
トレースキャッシュはこの考えに基づいて、実行時に分岐予測器が導出した実行経路に従って
命令を格納していく点で通常の命令キャッシュとは異なる(目的は高バンド幅での命令フェッチ)。
あとはPen4での実現例でも調べればいい。
トレースケジューリングの考えをキャッシュに導入するというのは、Pen4のトレースキャッシュ以外でも
研究レベルでは似たようなのが結構あって名称も様々。
トレースキャッシュというのはトレーススケジューリングという考えに基づいているんだよ。
トレーススケジューリングというのはVLIWのコンパイラ技術で出てきた考え方。
元々最適化技術ではプログラムを分岐単位で考える。VLIWコンパイラではプロセッサのリソースを
生かすために分岐を超えるより広域で最適化を行う技術が発展した。
分岐を超える場合、実行経路のなかでもっとも繰り返し頻度が高い(と思われる)経路に注力して
最適化処理すればもっとも効率がいい。トレースとはこの経路を抽出したもの。
トレースキャッシュはこの考えに基づいて、実行時に分岐予測器が導出した実行経路に従って
命令を格納していく点で通常の命令キャッシュとは異なる(目的は高バンド幅での命令フェッチ)。
あとはPen4での実現例でも調べればいい。
トレースケジューリングの考えをキャッシュに導入するというのは、Pen4のトレースキャッシュ以外でも
研究レベルでは似たようなのが結構あって名称も様々。
ゴミのあまりの馬鹿っぷりに涙が。
釣りじゃなかったのか。
価格で教えて貰った知識をひけらかしてるし。
釣りじゃなかったのか。
価格で教えて貰った知識をひけらかしてるし。
階層化こそがNehalem MAの特徴
http://pc.watch.impress.co.jp/docs/2008/0328/kaigai429.htm
http://pc.watch.impress.co.jp/docs/2008/0328/kaigai429.htm
683 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/28(金) 00:12:58 ID:hRt4FTrn
大体にCPIが製造コスト云々とか言ってる時点でぜんぜん解ってないから。
キャッシュのパフォーマンス云々の「理屈」はこのへんに載ってる数式の意味でも理解してからいらっさいと。
http://www.csee.umbc.edu/~plusquel/611/
>>647が主張するような排他キャッシュの特性についても一応触れられてるね。
めぼしい反論はだいたい>>654で言いたいことは出尽くしてる気がするけど
サーバみたいなワークロードの性能改善策って、結局10や20変わるかどうかの小手先の
メモリレイテンシ削減よりも、マルチスレッド化のほうが効果大きかったんだよね。
キャッシュのパフォーマンス云々の「理屈」はこのへんに載ってる数式の意味でも理解してからいらっさいと。
http://www.csee.umbc.edu/~plusquel/611/
>>647が主張するような排他キャッシュの特性についても一応触れられてるね。
めぼしい反論はだいたい>>654で言いたいことは出尽くしてる気がするけど
サーバみたいなワークロードの性能改善策って、結局10や20変わるかどうかの小手先の
メモリレイテンシ削減よりも、マルチスレッド化のほうが効果大きかったんだよね。
それが、今回は、大幅に拡張するとはいえ、ハイファ設計のCore MAを、ヒルズボロのNehalemが継承することになる。
見方によっては、ハイファとヒルズボロの立場が逆転したとも言える。
IntelのDigital Enterprise Groupが、Nehalem設計について、“基本的にはフロムスクラッチだ”と強調する理由は、このあたりにありそうだ。
見方によっては、ハイファとヒルズボロの立場が逆転したとも言える。
IntelのDigital Enterprise Groupが、Nehalem設計について、“基本的にはフロムスクラッチだ”と強調する理由は、このあたりにありそうだ。
おまいら、文章で語るんじゃなくてVHDLでアーキテクチャを語って
みるのはどうかな?
みるのはどうかな?
686 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/28(金) 00:31:08 ID:hRt4FTrn
use bbs2ch.jisakupc.thread1202775674.res685.all;
>IntelのDigital Enterprise Groupが、Nehalem設計について、“基本的にはフロムスクラッチだ”と強調する理由は、このあたりにありそうだ。
イスラエルの人もP3じゃないよ、って言ったのと同じだろう。
どの程度が真実なのかは分からないけど、我々がファミリーナンバーで妄想してるよりは余程説得力はあると思われ。
今まで積み上げてきたものをちゃぶ台返すような事は、今後無理なんじゃない?
それこそがフロムスクラッチだという思想にこだわるのもいいけど、
結局は叩き出される性能次第なんだから。
フロムスクラッチで作り上げたものより、地道な改良が功を奏すのならそちらが正解だと思う。
イスラエルの人もP3じゃないよ、って言ったのと同じだろう。
どの程度が真実なのかは分からないけど、我々がファミリーナンバーで妄想してるよりは余程説得力はあると思われ。
今まで積み上げてきたものをちゃぶ台返すような事は、今後無理なんじゃない?
それこそがフロムスクラッチだという思想にこだわるのもいいけど、
結局は叩き出される性能次第なんだから。
フロムスクラッチで作り上げたものより、地道な改良が功を奏すのならそちらが正解だと思う。
半加算器やフリップフロップすら
よくわかんないんVHDLとか無理です
ごめんなさい
よくわかんないんVHDLとか無理です
ごめんなさい
マルチスレッドだと、サーバーでの
スループットはあがるけど、
1トランザクションっつーか、
ひとつの処理処理は短縮できない
SUNじゃないんで、スループットじゃなく
スピードが重要
スループットはあがるけど、
1トランザクションっつーか、
ひとつの処理処理は短縮できない
SUNじゃないんで、スループットじゃなく
スピードが重要
690 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/28(金) 00:56:26 ID:hRt4FTrn
メモリでいうとDDRも否定?
メモり・スループット・アップ→
シングル・スレッド・スピード・アップ
だからOK
シングル・スレッド・スピード・アップ
だからOK
いずれにしても、Core3はP6→Pen4ほどの変化は無いと思うよ。
あれは回路の設計にしても、自動設計を一部使用してるし、配置からしてこれまでとは全然違う構造だった。
(まぁ機能がゴチャゴチャ分散しててみにくかったわけだが)
Pen4ならフロムスクラッチと称しても全然問題ないと思う。
VHDL、ちょっとだけやったけどアーキテクチャについて語れるほどやってないな…
仕様については分かるけど、見ただけで性能の予測とか出来ません。
>>688
それぐらいなら簡単だから数時間で分かるよ。
CPUがどういう動きしてるか想像するのは楽しいから見とき。
デジタル回路の基礎はおもろいで。
機械系の俺オススメ
あれは回路の設計にしても、自動設計を一部使用してるし、配置からしてこれまでとは全然違う構造だった。
(まぁ機能がゴチャゴチャ分散しててみにくかったわけだが)
Pen4ならフロムスクラッチと称しても全然問題ないと思う。
VHDL、ちょっとだけやったけどアーキテクチャについて語れるほどやってないな…
仕様については分かるけど、見ただけで性能の予測とか出来ません。
>>688
それぐらいなら簡単だから数時間で分かるよ。
CPUがどういう動きしてるか想像するのは楽しいから見とき。
デジタル回路の基礎はおもろいで。
機械系の俺オススメ
Colwell氏によると、x86 CPUは、レガシーアーキテクチャを・・・
(途中省略)
・・・・泥沼状態となって開発が難航するという。
AMD死ね,氏ねじゃなく死ね。
というかさっさと潰れろとか,本気で思ってそうだ。
(途中省略)
・・・・泥沼状態となって開発が難航するという。
AMD死ね,氏ねじゃなく死ね。
というかさっさと潰れろとか,本気で思ってそうだ。
死ぬべきはMicrosoftじゃね?
>>694
誰が脆弱性の修正をするんだよwww
誰が脆弱性の修正をするんだよwww
俺達は排他的Windows教団の一人だからな
>>684
ぼーっとして読んでると読み違えるな。
それが、今回は、大幅に拡張するとはいえ、ハイファ設計のCore MAを、ヒルズボロのNehalemが継承することになる。
見方によっては、ファタハとヒズボラの立場が逆転したとも言える。
ぼーっとして読んでると読み違えるな。
それが、今回は、大幅に拡張するとはいえ、ハイファ設計のCore MAを、ヒルズボロのNehalemが継承することになる。
見方によっては、ファタハとヒズボラの立場が逆転したとも言える。
ぼーっとしていて修正し損ねた。
それが、今回は、大幅に拡張するとはいえ、ファタハ設計のCore MAを、ヒズボラのNehalemが継承することになる。
見方によっては、ファタハとヒズボラの立場が逆転したとも言える。
それが、今回は、大幅に拡張するとはいえ、ファタハ設計のCore MAを、ヒズボラのNehalemが継承することになる。
見方によっては、ファタハとヒズボラの立場が逆転したとも言える。
ガザ情勢解説乙w
なんだこの時事解説はwww
>>650
プログラム組む側からみると、32bitの限界である2Gbyte近傍でちょうどいいというのがエグイ
微妙にプログラムがめんどくさくなるんだよ。
できれば64bit化して16Gbyte程度とか、若干の余裕が欲しいところ。
パフォーマンスはもう充分な感じになってきたね。
プログラム組む側からみると、32bitの限界である2Gbyte近傍でちょうどいいというのがエグイ
微妙にプログラムがめんどくさくなるんだよ。
できれば64bit化して16Gbyte程度とか、若干の余裕が欲しいところ。
パフォーマンスはもう充分な感じになってきたね。
>>647
鯖用だったBartonをコスト度外視で北森にぶつけたりしたのが昔のAMD。
そのくらいAMDにとってキャッシュ総容量で負けることはあってはならなかったんだよ。
キャッシュ容量の有効利用が最大のメリットなのはAMD自身が言ってたことだからな。
キャッシュ容量が多い方がメモリーまで読みにいかなくてすむ確率が高くなることは当のAMDが一番よく知ってる。
だが今はIntelに対抗してキャッシュ増量したくても生産キャパに余裕がない状態だから論調を変えてるだけ。
鯖用だったBartonをコスト度外視で北森にぶつけたりしたのが昔のAMD。
そのくらいAMDにとってキャッシュ総容量で負けることはあってはならなかったんだよ。
キャッシュ容量の有効利用が最大のメリットなのはAMD自身が言ってたことだからな。
キャッシュ容量が多い方がメモリーまで読みにいかなくてすむ確率が高くなることは当のAMDが一番よく知ってる。
だが今はIntelに対抗してキャッシュ増量したくても生産キャパに余裕がない状態だから論調を変えてるだけ。
つーか未だにVHDLなの? Verilogじゃなくて?
やはり漢なら軍用であるVHDLで決まりなのですよ。SystemCやらVerilogやら
は漢の武器を作るに足らぬ軟弱者なのであります。
は漢の武器を作るに足らぬ軟弱者なのであります。
Thoroughbred 84平方mm
Barton 101平方mm
Northwood 131平方mm
Barton 101平方mm
Northwood 131平方mm
キャッシュも、そろそろどんなコードに対しても十分に効く容量になりつつあるし
頭を使って工夫しまくれば AMD にだって勝機はあると思うよ
一回成功して馬鹿の一つ覚えみたいにやっているなら足元をすくえる余地はある、絶対に。
頭を使って工夫しまくれば AMD にだって勝機はあると思うよ
一回成功して馬鹿の一つ覚えみたいにやっているなら足元をすくえる余地はある、絶対に。
相手が空回し芸で遊んでたときですら辛うじて互角程度でしかなかったのに
本気を出された後で勝負になるわけがない
本気を出された後で勝負になるわけがない
大丈夫、今は空回りチームのターンだw
>>705
その時期にはIntelは300mmウェハに移行してるな。
AMDが300に移行してから200mm^2オーバーのチップを量産できたことから考えても生産力には大きな開きがあった
当時のAMDにとっちゃCelelon上位モデルに毛が生えたような単価で出すには100mm^2程度でもきつい筈だよ。
その時期にはIntelは300mmウェハに移行してるな。
AMDが300に移行してから200mm^2オーバーのチップを量産できたことから考えても生産力には大きな開きがあった
当時のAMDにとっちゃCelelon上位モデルに毛が生えたような単価で出すには100mm^2程度でもきつい筈だよ。
SMTがリソース余りの現代OoOスーパースカラプロセッサの救世主だ
Power5,6の性能を見よ!
ねはれんの今リーク済みの性能も、SMT E nableしか考えられない
Power5,6の性能を見よ!
ねはれんの今リーク済みの性能も、SMT E nableしか考えられない
コンピュータの性能はfloatで測るのが真髄
そのfloatはメモリ・スループットと並列度で決まる
新SIMDとSMTによる2レベルの並列度アップと
DDR3チャンネルで、この真理は証明されるだろう
Intelまんせ-
あと分岐予測の強化も忘れてはいけない
初代Pentiumから常に分岐予測では最先端を走ってたのだから
超大型のループやオブジェクト指向にだって
intelの分岐よそくは菊のさ
そのfloatはメモリ・スループットと並列度で決まる
新SIMDとSMTによる2レベルの並列度アップと
DDR3チャンネルで、この真理は証明されるだろう
Intelまんせ-
あと分岐予測の強化も忘れてはいけない
初代Pentiumから常に分岐予測では最先端を走ってたのだから
超大型のループやオブジェクト指向にだって
intelの分岐よそくは菊のさ
イスラエル > AMD >>> 俺ゴン
>>682
この前まで
IntelもCELLの真似して
インオーダー型のヘテロジニアスマルチコアに舵を取る!と一人で騒いで
(“シンプルコア”に向かう次世代CPUアーキテクチャだっけか?)
結局こういう予定調和なオチを書くか 後藤弘茂。
虫の良いブレイクスルーなんてCPU業界には無いんだよ。
この前まで
IntelもCELLの真似して
インオーダー型のヘテロジニアスマルチコアに舵を取る!と一人で騒いで
(“シンプルコア”に向かう次世代CPUアーキテクチャだっけか?)
結局こういう予定調和なオチを書くか 後藤弘茂。
虫の良いブレイクスルーなんてCPU業界には無いんだよ。
記念カキコ♪
まあ、遊びたいのはわかるが、4月から授業始まったら、CPUの勉強なんて
やってる暇なんかないがなw
やれないことはないが、2年か3年どっちか知らないが、ちゃんとローの勉強もしろよw
あと阪大ローなんて、上位3割ならともかく下7割なんて大したことないんだから、
あんま阪大阪大言うなW
やってる暇なんかないがなw
やれないことはないが、2年か3年どっちか知らないが、ちゃんとローの勉強もしろよw
あと阪大ローなんて、上位3割ならともかく下7割なんて大したことないんだから、
あんま阪大阪大言うなW
どーでもいいけど学校名出して愚痴愚痴騒ぐなよ。
そんなに大学名出したければ学歴板でも逝け。
>>712
オレゴンは読みが悪いだけで、決して悪いチームじゃないと思うぞ。
読みが悪いから悪いチームなのかもしれないが…。
そんなに大学名出したければ学歴板でも逝け。
>>712
オレゴンは読みが悪いだけで、決して悪いチームじゃないと思うぞ。
読みが悪いから悪いチームなのかもしれないが…。
http://journal.mycom.co.jp/column/architecture/006/index.html
しばらくキャッシュの勉強。
・キャッシュというものの必要性が生まれた歴史的背景。
CPUクロックの低いころは、CPU1クロック辺りの時間に対して
メモリ1クロック辺りの時間は大差なかったため、メモリからの
情報待ちに対するペナルティーは問題にならなかった。
しかし、CPUのクロックが上がるにつれ、CPU1クロック辺りの
時間とメモリ1クロック辺りの時間の乖離が進む。
その結果メモリからの情報待ちによるペナルティが大きくなり、
この問題をなんとかする必要性が生じた。
しばらくキャッシュの勉強。
・キャッシュというものの必要性が生まれた歴史的背景。
CPUクロックの低いころは、CPU1クロック辺りの時間に対して
メモリ1クロック辺りの時間は大差なかったため、メモリからの
情報待ちに対するペナルティーは問題にならなかった。
しかし、CPUのクロックが上がるにつれ、CPU1クロック辺りの
時間とメモリ1クロック辺りの時間の乖離が進む。
その結果メモリからの情報待ちによるペナルティが大きくなり、
この問題をなんとかする必要性が生じた。
・キャッシュラインサイズと、キャッシュ性能はトレードオフ
データサイズの増加にともなうメリット
1.メモリとの転送の回数が減る。
2.メモリの領域を連続してアクセスするような場合が多い場合に良い。
3.管理のためのオーバーヘッドのハードウェアが減る。
データサイズの増加にともなうデメリット
1.キャッシュメモリの利用効率が悪化。
2.キャッシュに格納できるライン数が逆比例で減ってしまう。
データサイズの増加にともなうメリット
1.メモリとの転送の回数が減る。
2.メモリの領域を連続してアクセスするような場合が多い場合に良い。
3.管理のためのオーバーヘッドのハードウェアが減る。
データサイズの増加にともなうデメリット
1.キャッシュメモリの利用効率が悪化。
2.キャッシュに格納できるライン数が逆比例で減ってしまう。
・共有キャッシュのメリットデメリット。
・メリット
1.両方のプロセサで同一の命令コードを使う場合や、同じデータ
を参照する場合などは、一つのコピーを両者で利用できる。
2.シングルスレッド時、キャッシュを占有できるため効率的。
・デメリット
1.プロセサコアごとにアクセス要求を受け付けるFIFO(First In First Out)
のキュー待ち時間がかかる。
今日はここまで。
・メリット
1.両方のプロセサで同一の命令コードを使う場合や、同じデータ
を参照する場合などは、一つのコピーを両者で利用できる。
2.シングルスレッド時、キャッシュを占有できるため効率的。
・デメリット
1.プロセサコアごとにアクセス要求を受け付けるFIFO(First In First Out)
のキュー待ち時間がかかる。
今日はここまで。
実際きついんだろう?
きつくなかったら独禁法とか言い出すまい。
きつくなかったら独禁法とか言い出すまい。
724 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/29(土) 07:01:36 ID:bZZcdgWS
なんつーか昔のAMDがキャッシュ容量で優位性を訴えてたのは否定しようの無い現実なんだけどさ
こんな資料にすらAMDの思惑は良く現れてる。
http://www.amd.com/jp-ja/Processors/ProductInformation/0,,30_118_1260_759%5E1040,00.html
http://www.amd.com/jp-ja/Processors/ProductInformation/0,,30_118_1260_759%5E1151,00.html
> キャッシュ・アーキテクチャ: AMD Athlonプロセッサは、128K(Intel PentiumR IIIプロセッサの4倍)の
> L1 キャッシュと 256K のフルスピード・オンチップ L2 キャッシュ(*)、合わせて 384K のフルスピード・
> キャッシュををオンチップでサポートしています。この高性能キャッシュ・デザインにより、システム全体の
> パフォーマンスが大幅に向上します。
AMDのシングルコアでの排他キャッシュ以上に、Intelのマルチコアでの共有キャッシュは効率的なアプローチだ
こんな資料にすらAMDの思惑は良く現れてる。
http://www.amd.com/jp-ja/Processors/ProductInformation/0,,30_118_1260_759%5E1040,00.html
http://www.amd.com/jp-ja/Processors/ProductInformation/0,,30_118_1260_759%5E1151,00.html
> キャッシュ・アーキテクチャ: AMD Athlonプロセッサは、128K(Intel PentiumR IIIプロセッサの4倍)の
> L1 キャッシュと 256K のフルスピード・オンチップ L2 キャッシュ(*)、合わせて 384K のフルスピード・
> キャッシュををオンチップでサポートしています。この高性能キャッシュ・デザインにより、システム全体の
> パフォーマンスが大幅に向上します。
AMDのシングルコアでの排他キャッシュ以上に、Intelのマルチコアでの共有キャッシュは効率的なアプローチだ
725 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/29(土) 07:09:29 ID:bZZcdgWS
昔はCPUとキャッシュの性能がバランスした、
というのは嘘
少なくともメインフレームではね
レイテンシ1000nsという当時としては
高速なコアメモリが出たときでも、辛かった
マイクロプロセッサの初期に限れば正しいけれど、
メモリが速ければもっとクロックあげられたのも事実
i286で2サイクルでメモリアクセスできるようになる辺りから
メモリレイテンシがネックになる
というのは嘘
少なくともメインフレームではね
レイテンシ1000nsという当時としては
高速なコアメモリが出たときでも、辛かった
マイクロプロセッサの初期に限れば正しいけれど、
メモリが速ければもっとクロックあげられたのも事実
i286で2サイクルでメモリアクセスできるようになる辺りから
メモリレイテンシがネックになる
キャッシュアルゴリズムがどうこう言う以前に
容量とレイテンシでintelキャッシュが圧倒しているという現実
容量とレイテンシでintelキャッシュが圧倒しているという現実
x86最新の構造はIsaiahだけどな
では、この俺様がマルチコア時代を予言しよう
1.最終レベル共有キャッシュは飽和時代に入る、ただ増量するだけでは性能はでなくなる。
2.実行中のすべてのスレッドがいかに効率的に動くかが重要になり各スレッドの効率の重要度は下がる。
3.スレッド間同期処理の重要要素、test and set 系の処理の高速化が重要になってくる。
4.激しいスレッドスイッチにも耐えられる仕組みが重要になってくる、SMTが汎用のスレッドスイッチレベルになってくると時代は変化する。
5.帯域拡張よりも情報量圧縮が重要になってくる。
1.最終レベル共有キャッシュは飽和時代に入る、ただ増量するだけでは性能はでなくなる。
2.実行中のすべてのスレッドがいかに効率的に動くかが重要になり各スレッドの効率の重要度は下がる。
3.スレッド間同期処理の重要要素、test and set 系の処理の高速化が重要になってくる。
4.激しいスレッドスイッチにも耐えられる仕組みが重要になってくる、SMTが汎用のスレッドスイッチレベルになってくると時代は変化する。
5.帯域拡張よりも情報量圧縮が重要になってくる。
>>714
一応、団子は京都大学でてるんだよ。
つーか、理系博士や旧帝医以上でもないのに学歴を何度さらすのは
見てて恥ずかしいからやめてほしい。
ペーパーテストで高得点採るのと、研究や実務で成果をだすのとを同列のレベルで
考えないで欲しい。
一応、団子は京都大学でてるんだよ。
つーか、理系博士や旧帝医以上でもないのに学歴を何度さらすのは
見てて恥ずかしいからやめてほしい。
ペーパーテストで高得点採るのと、研究や実務で成果をだすのとを同列のレベルで
考えないで欲しい。
>>718
昔々386SXなPCを周辺機器&オプション(増設メモリ等)てんこ盛りで買ったら、
その二ヵ月後にマイナーチェンジで486SXになって、思いっきりムカついた事を
思い出した。
総額比較で数%程度しか値段が変らないのに、性能は数割アップだったからなあ。
昔々386SXなPCを周辺機器&オプション(増設メモリ等)てんこ盛りで買ったら、
その二ヵ月後にマイナーチェンジで486SXになって、思いっきりムカついた事を
思い出した。
総額比較で数%程度しか値段が変らないのに、性能は数割アップだったからなあ。
自作板に何年もいてて価格でも偉そうなこと言ってる割には無知で無理解だったのに
阪大卒とか言うと逆に恥ずかしくなってくる。
阪大卒とか言うと逆に恥ずかしくなってくる。
>>731
団子は神戸大ですよ。
で阪大大学院>>>>>神戸大。
仮に京大でも
阪大院>>>京大学部
どっちにしても負け犬なんだよね。
>ペーパーテストで高得点採るのと、研究や実務で成果をだすのとを同列のレベルで
考えないで欲しい。
で?彼何か研究成果出したっけ?TX(笑ですか?
団子は神戸大ですよ。
で阪大大学院>>>>>神戸大。
仮に京大でも
阪大院>>>京大学部
どっちにしても負け犬なんだよね。
>ペーパーテストで高得点採るのと、研究や実務で成果をだすのとを同列のレベルで
考えないで欲しい。
で?彼何か研究成果出したっけ?TX(笑ですか?
>自作板に何年もいてて価格でも偉そうなこと言ってる割には無知で無理解だったのに
阪大卒とか言うと逆に恥ずかしくなってくる。
虫けらが何か言ってるなw
低学歴というのが図星である傍証でしょ。
阪大卒とか言うと逆に恥ずかしくなってくる。
虫けらが何か言ってるなw
低学歴というのが図星である傍証でしょ。
なんだ?
503が湧いてるのか?
503が湧いてるのか?
>>734
旧帝の院卒なんてごく普通の学歴ですよ。
企業から見れば、単なるごく普通の社員でしかない。
社会にでればわかるが、今の日本企業はそれほど大学名は気にしてないよ。
学歴に執着すると痛い目に遭う。
旧帝の院卒なんてごく普通の学歴ですよ。
企業から見れば、単なるごく普通の社員でしかない。
社会にでればわかるが、今の日本企業はそれほど大学名は気にしてないよ。
学歴に執着すると痛い目に遭う。
学歴板にでも行けよwwww
>社会にでればわかるが、今の日本企業はそれほど大学名は気にしてないよ。
学歴に執着すると痛い目に遭う。
さー私が何時学歴に固執したっけ?
私の場合働かなくても君たちより年間金が入ってくるんだけどね。
学歴に執着すると痛い目に遭う。
さー私が何時学歴に固執したっけ?
私の場合働かなくても君たちより年間金が入ってくるんだけどね。
まあ、阪大院なんかよりは明らかに資産40億の方が自慢だわな。
資産40億様をなのった方が2ch受けが良いことは明らか。
資産40億様をなのった方が2ch受けが良いことは明らか。
簡単な話なんだね。
このスレの全員は私にとっては、労働力なんだね。
現実社会では君たちは私の金、社会的地位、学歴の前にひれ伏す
んだね。資本主義社会にいる以上私の支配からは逃れられない。
○○先生お願いします。>弁護士になる私に対して。
○○様>大金持ちの私の注文に対して。
で、私に逆らうということは社会法則に反する行為であるんだね。
このスレの全員は私にとっては、労働力なんだね。
現実社会では君たちは私の金、社会的地位、学歴の前にひれ伏す
んだね。資本主義社会にいる以上私の支配からは逃れられない。
○○先生お願いします。>弁護士になる私に対して。
○○様>大金持ちの私の注文に対して。
で、私に逆らうということは社会法則に反する行為であるんだね。
なわけねーだろ低能
大体、法科大学院行かなきゃならんほどオツムのよろしくないお前に手取り足取り教えてやるほど
このスレの住人は寛大じゃないっつの。
それにお前は俺達にとってのお客様でもなんでもない。
でかい態度取りたきゃまず金出せ。
大体、法科大学院行かなきゃならんほどオツムのよろしくないお前に手取り足取り教えてやるほど
このスレの住人は寛大じゃないっつの。
それにお前は俺達にとってのお客様でもなんでもない。
でかい態度取りたきゃまず金出せ。
Intelの次世代CPUについて語る場で全く関係ない話しかできない奴はどんな学歴だろうが知障。
>なわけねーだろ低能
>大体、法科大学院行かなきゃならんほどオツムのよろしくない
>お前に手取り足取り教えてやるほど このスレの住人は寛大じゃないっつの。
私を目の前にした場合どういう発言になるか考えてみた。(翻訳)
>おっしゃる通りです○○様
>阪大大学院まで行かれて、さらにその上を目指すとはさすが○○様
>です。
>わたくし如きに出来ることは限られていますが、何かできることがあれば
>何時でも助力させてください。
>大体、法科大学院行かなきゃならんほどオツムのよろしくない
>お前に手取り足取り教えてやるほど このスレの住人は寛大じゃないっつの。
私を目の前にした場合どういう発言になるか考えてみた。(翻訳)
>おっしゃる通りです○○様
>阪大大学院まで行かれて、さらにその上を目指すとはさすが○○様
>です。
>わたくし如きに出来ることは限られていますが、何かできることがあれば
>何時でも助力させてください。
お前ら揃って養護学校へ行けよ、専門学校だと迷惑がかかるってw
747 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/29(土) 16:58:33 ID:bZZcdgWS
よし、>>729の妄想に妄想で対抗だ!
>1.最終レベル共有キャッシュは飽和時代に入る、ただ増量するだけでは性能はでなくなる。
階層が深くなればなるほど、また容量が大きければ大きいほどヒットレイテンシは伸びる傾向があるから
理屈の上では正しい。
ただ、そこまで逝くと、どうかすればLast Levelをメインメモリとして使った方がよくないか?
DRAMはRAMディスク代わりでおk。
>2.実行中のすべてのスレッドがいかに効率的に動くかが重要になり各スレッドの効率の重要度は下がる。
スレッド分割にしやすい処理はそうなるだろうけど必ずしも皆そうはならない。
分割できずなおかつ計算量の多い処理がクリティカルパスになる。
引き続きシングルスレッドの性能向上は必要。
>3.スレッド間同期処理の重要要素、test and set 系の処理の高速化が重要になってくる。
んなもんたかが知れてるよ。
マルチコアってむしろ非同期での動作が一番性能が伸びるんだぜ。
>4.激しいスレッドスイッチにも耐えられる仕組みが重要になってくる、SMTが汎用のスレッドスイッチレベルになってくると時代は変化する。
コンテクストスイッチに使う待避領域はAVXなんかサポートしたら現行の倍くらいになっちゃうんだよね、ぶっちゃけ。
むしろ、SWスレッド数分だけコア・SWスレッドがあればスイッチ必要ないよね。
>5.帯域拡張よりも情報量圧縮が重要になってくる。
いんたねっつの話ですか?><
>1.最終レベル共有キャッシュは飽和時代に入る、ただ増量するだけでは性能はでなくなる。
階層が深くなればなるほど、また容量が大きければ大きいほどヒットレイテンシは伸びる傾向があるから
理屈の上では正しい。
ただ、そこまで逝くと、どうかすればLast Levelをメインメモリとして使った方がよくないか?
DRAMはRAMディスク代わりでおk。
>2.実行中のすべてのスレッドがいかに効率的に動くかが重要になり各スレッドの効率の重要度は下がる。
スレッド分割にしやすい処理はそうなるだろうけど必ずしも皆そうはならない。
分割できずなおかつ計算量の多い処理がクリティカルパスになる。
引き続きシングルスレッドの性能向上は必要。
>3.スレッド間同期処理の重要要素、test and set 系の処理の高速化が重要になってくる。
んなもんたかが知れてるよ。
マルチコアってむしろ非同期での動作が一番性能が伸びるんだぜ。
>4.激しいスレッドスイッチにも耐えられる仕組みが重要になってくる、SMTが汎用のスレッドスイッチレベルになってくると時代は変化する。
コンテクストスイッチに使う待避領域はAVXなんかサポートしたら現行の倍くらいになっちゃうんだよね、ぶっちゃけ。
むしろ、SWスレッド数分だけコア・SWスレッドがあればスイッチ必要ないよね。
>5.帯域拡張よりも情報量圧縮が重要になってくる。
いんたねっつの話ですか?><
748 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/29(土) 17:00:24 ID:bZZcdgWS
○むしろ、SWスレッド数分だけコア・ハードウェアスレッドがあればスイッチ必要ないよね。
749 :Socket774:2008/03/29(土) 17:11:37 ID:KZx7tHS7
おっ、きますたね
1番、微妙だからいいや、認めとく。
2番、正しいからいいや、認めとく。
3番、4番、最近のWindows、Windowsと限らずそうなのだが
プロセス間ジャンプが非常に増えてきている、これはモジュールの独立性が高くなったと好意的にとらえるも良し。
レガーシーシステム多すぎじゃゴラーと解釈してもよし。
さらには、当初あげたとおりである、現状のプログラムのスレッドの粒度はまだ大きいがこれは、今後どんどん小さくなっていくと容易に予想できる。
スレッド切り替えの性能さえ確保できているなら、その方がよりCPUパワーを吸いつくせるとか
DBなどではデッドロック問題を最小限に抑えるとか、ま、とにかく良いことずくめだからだ。
malloc が、オブジェクト指向のはやりとともに new になって恐ろしく確保粒度が細かくなったが、これがスレッドでも必ず起こるに違いないと思われる。
実行コンテクストの退避領域であるが、これは一番であまり必要なくなったらきっと適当に確保できるに違いないと楽観的。
5番、プロセッサ内でもだんだん遠距離通信もどきな状況になりつつあるような気がするんだ。
遠距離通信なら圧縮は基本だ!!
1番、微妙だからいいや、認めとく。
2番、正しいからいいや、認めとく。
3番、4番、最近のWindows、Windowsと限らずそうなのだが
プロセス間ジャンプが非常に増えてきている、これはモジュールの独立性が高くなったと好意的にとらえるも良し。
レガーシーシステム多すぎじゃゴラーと解釈してもよし。
さらには、当初あげたとおりである、現状のプログラムのスレッドの粒度はまだ大きいがこれは、今後どんどん小さくなっていくと容易に予想できる。
スレッド切り替えの性能さえ確保できているなら、その方がよりCPUパワーを吸いつくせるとか
DBなどではデッドロック問題を最小限に抑えるとか、ま、とにかく良いことずくめだからだ。
malloc が、オブジェクト指向のはやりとともに new になって恐ろしく確保粒度が細かくなったが、これがスレッドでも必ず起こるに違いないと思われる。
実行コンテクストの退避領域であるが、これは一番であまり必要なくなったらきっと適当に確保できるに違いないと楽観的。
5番、プロセッサ内でもだんだん遠距離通信もどきな状況になりつつあるような気がするんだ。
遠距離通信なら圧縮は基本だ!!
あっあげちゃった、ゴメン
751 :ヽ・´∀`・,,)っ━━━━━━┓:2008/03/29(土) 17:27:24 ID:bZZcdgWS
まあ、いずれにしろ、Linuxをこき下ろした多年バウム教授の時代が20年経ってようやく来つつあるのはわかる
Windowsは初期のマイクロカーネルの時代に回帰しつつある。
Windows CEもそのうちNTカーネルと統合するらしいね。
これでいよいよWindows CEと、Windows MEと、Windows NTが統合を果たすぜ!
あれ?カチカチに固まって動かないぞ
Windowsは初期のマイクロカーネルの時代に回帰しつつある。
Windows CEもそのうちNTカーネルと統合するらしいね。
これでいよいよWindows CEと、Windows MEと、Windows NTが統合を果たすぜ!
あれ?カチカチに固まって動かないぞ
LinuxとReactOS (Winクローン)もLinux Unified Kernelで統合されそうです><
空気も読めずにスレの雰囲気を悪くすることにしかその高い脳力を使えないO/OUQ1mD
空気を読まずにガシガシとスレをタイトル通り進めることに時間と頭を使う団子
所詮2chにきている者同士、、、だが生産性という面でこれだけ差が出る事が分りためになった。
空気を読まずにガシガシとスレをタイトル通り進めることに時間と頭を使う団子
所詮2chにきている者同士、、、だが生産性という面でこれだけ差が出る事が分りためになった。
>>744
なにそのツンデレ。変換機見直したほうがいいよ。
なにそのツンデレ。変換機見直したほうがいいよ。
マイクロカーネルって、30年前からQNXとかあるのにね。
なぜいまごろ気が付くかと>MS。
ちなみに昔、インテルもOS出していたですよ。iRMXていうの。
メモリ1MBでリアルタイムでがしがし動いておりました。
いまだとキャッシュの中にまるごと入ってしまうサイズですわね。
なぜいまごろ気が付くかと>MS。
ちなみに昔、インテルもOS出していたですよ。iRMXていうの。
メモリ1MBでリアルタイムでがしがし動いておりました。
いまだとキャッシュの中にまるごと入ってしまうサイズですわね。
>なぜいまごろ気が付くかと>MS。
パフォーマンスが悪すぎたから、らしい……
さらには、JavaのVMや.NET Framework 等が安全で有る事を使って
すべてをカーネルモードへ移行してオーバーヘッドを無くすという考え方も最近はあるらしい。
パフォーマンスが悪すぎたから、らしい……
さらには、JavaのVMや.NET Framework 等が安全で有る事を使って
すべてをカーネルモードへ移行してオーバーヘッドを無くすという考え方も最近はあるらしい。
コンテクストスイッチのオーバーヘッドを加味しても
今のようにメモリが遅い状況では、スレッドを細粒度にしたほうが
CPUパワーを有効に使えるらしい
どこかで読んだ
モダンプログラミングの欠点のひとつに
分岐先が分岐直前まで決まらないケースがってのがある
Intelみたいに間接分岐予測などを導入するのもいいけど
SMTで分岐ミスのストールを隠蔽する方が楽
今のようにメモリが遅い状況では、スレッドを細粒度にしたほうが
CPUパワーを有効に使えるらしい
どこかで読んだ
モダンプログラミングの欠点のひとつに
分岐先が分岐直前まで決まらないケースがってのがある
Intelみたいに間接分岐予測などを導入するのもいいけど
SMTで分岐ミスのストールを隠蔽する方が楽
ケースが→ケースが増える
>今のようにメモリが遅い状況では、スレッドを細粒度にしたほうが
>CPUパワーを有効に使えるらしい
チャッティーインターフェイスなどと呼ばれているのだが
厳しいタイプとヌルイタイプがあって厳しいタイプは、存在自体がやっぱ厳しいよ。
>CPUパワーを有効に使えるらしい
チャッティーインターフェイスなどと呼ばれているのだが
厳しいタイプとヌルイタイプがあって厳しいタイプは、存在自体がやっぱ厳しいよ。
見栄えばっかりにマシンパワー割り当てないで
完全マイクロカーネルに戻して(デバイスドライバーは全部ユーザー空間で動かすとか)
とにかく頑丈なOS作ってくれればちょっとは見直すけどね
完全マイクロカーネルに戻して(デバイスドライバーは全部ユーザー空間で動かすとか)
とにかく頑丈なOS作ってくれればちょっとは見直すけどね
や、vistaでまさにそれをやったからゲームのスコア落ちたと叩かれてるわけで。
しかも結局ドライバの出来が悪くて落ちたりしてるし。
しかも結局ドライバの出来が悪くて落ちたりしてるし。
VMを使ってユーザー,カーネルモード廃棄はちょっと夢だけどね、色々な問題がシンプルに解決して気持ちが良さそうだし
CPUエラッタの吸収を是非ここでやってもらいたいし、オールマネージド化計画は滞りなく進めてもらいたい。
CPUエラッタの吸収を是非ここでやってもらいたいし、オールマネージド化計画は滞りなく進めてもらいたい。
>>762
TLB関連のエラッタはVMこそ危ない
TLB関連のエラッタはVMこそ危ない
>>763
VMで危ないエラッタだったら、交換以外手段はないのと違うか?
VMで危ないエラッタだったら、交換以外手段はないのと違うか?
阪大院たんの今日の活動マダー??
MSがハイパバイザ作ってるらしいけど、VMのホストもやってくれんのかな。
■後藤弘茂のWeekly海外ニュース■
Intelの次期CPUインターコネクト「QPI」
ttp://pc.watch.impress.co.jp/docs/2008/0331/kaigai430.htm
●QPIは、実はシリアルではない
●レイテンシと帯域のバランスを取った結果
Intelの次期CPUインターコネクト「QPI」
ttp://pc.watch.impress.co.jp/docs/2008/0331/kaigai430.htm
●QPIは、実はシリアルではない
●レイテンシと帯域のバランスを取った結果
770 :Socket774:2008/03/31(月) 00:41:25 ID:/G9bEKa6
8ソケットの図がカオスだな
>>770
曼荼羅ですな。
曼荼羅ですな。
QPIってやたら実装がリッチなんだが、こんなもんノーパソに乗せるつもりなのか・・・?
>>772
Turionにすら似たようなのが載ってるんだし、いいんじゃね?
Turionにすら似たようなのが載ってるんだし、いいんじゃね?
ぱんつくらいはけよ
775 :Socket774:2008/03/31(月) 09:14:22 ID:jBoryPnc
4ソケット、8ソケットといったレベルで性能がでるように考えられているとしか思えない
一般向け1ソケットには、もはやなんの関係のない世界になっているような・・・
一般向け1ソケットには、もはやなんの関係のない世界になっているような・・・
GPU統合にQPIを使うようだけど、外部バスとしてはノートでは使われないんじゃあ?
>>775
当然だけどマルチソケットとシングルソケットで本数が違う。
そもそもノースブリッジを統合するだけの話なんで、特殊なもんでもないでしょ。
GPUからメインメモリを参照するときはCPUの内蔵ノースブリッジを経由する。
当然だけどマルチソケットとシングルソケットで本数が違う。
そもそもノースブリッジを統合するだけの話なんで、特殊なもんでもないでしょ。
GPUからメインメモリを参照するときはCPUの内蔵ノースブリッジを経由する。
>>776
Nehalemのモバイル版のGiloなら、イスラエルチームで独自にチューンするようだが。
ハイエンドノートにCellを積みたがってる東芝とかいるし
デスクトップと比べて非力だからこそハードウェアアクセラレータが必要という考え方もできる。
Nehalemのモバイル版のGiloなら、イスラエルチームで独自にチューンするようだが。
ハイエンドノートにCellを積みたがってる東芝とかいるし
デスクトップと比べて非力だからこそハードウェアアクセラレータが必要という考え方もできる。
>>778
PCIeを直に出すのね。まあ合理的だ。
PCIeを直に出すのね。まあ合理的だ。
Nehalemらしい性能を出すとすると、軽く100万円コースなんだろうな
Nehalemで強化された分野って今AMDがなんとか戦えてるHPC分野だろうから、
個人用途のアプリだと性能引き出せない可能性の方が高そうな。
個人用途のアプリだと性能引き出せない可能性の方が高そうな。
いやいや、ゲーマー向け8CPUプラットフォームを出してくれるに
違いないですよwwちょw電気無理www
違いないですよwwちょw電気無理www
電気無理なのが金無理になるだけで大差ない
コードネーム:曼陀羅
>>782
HPCまではいかないだろ。
HPCまではいかないだろ。
Handheld PC?
High Paformance Computingかな?
ブレーカーが落ちるという事でしょう
漢はやはり自宅に100A引き込むでしょう。
ロマンですね>8CPUマシン
これをIYHした漢は半年や一年は崇め奉られるでしょう。
ロマンですね>8CPUマシン
これをIYHした漢は半年や一年は崇め奉られるでしょう。
「崇める」と「祟る」は良く似てる。
なんだかもう、僕らを置いてどこか遠くへ行ってしまいそうな勢いだな
PS3みたいならなきゃいいが……
PS3みたいならなきゃいいが……
大丈夫だろ? Nehalemの上位はサーバー関連や
ハイエンドゲーマーなどのTDPを気にしない分野だろうし、
通常版は現在のTDPとさほど変わらないレンジなのでは?
ハイエンドゲーマーなどのTDPを気にしない分野だろうし、
通常版は現在のTDPとさほど変わらないレンジなのでは?
コードネームが涅槃で、8CPUだと曼荼羅ですからね、
人は神仏の領域に踏み込もうとしているのでしょうかね。
人は神仏の領域に踏み込もうとしているのでしょうかね。
その神仏も人が作ったんだけどね。
人に不可能なんてない!
かもしれない!
かもしれない!
既にプロセスシュリンクが原子サイズの範疇に届きかけてるから、ある意味その通りだろ。
もう限界まできてるんだろうな
原子単位制御となるとまだまだだな
原子単位レベルまでいくと、有機化学系に走っていくのかな、ナノチューブのペプチド巻きとかが発展したら
ナノチューブの管型FETとか究極のトランジスタになりそうな気がするし。
しかし、CPU一個が30万として8個で240万、CPUだけで・・・これを作ったら悟りが開けそうだ。
原子単位レベルまでいくと、有機化学系に走っていくのかな、ナノチューブのペプチド巻きとかが発展したら
ナノチューブの管型FETとか究極のトランジスタになりそうな気がするし。
しかし、CPU一個が30万として8個で240万、CPUだけで・・・これを作ったら悟りが開けそうだ。
10年たてばジャンク屋で100円で売ってそうだしな。
{kind=link}
>>803
32bitが酷すぎるな・・・x86-64拡張なんかしたからx86の呪縛から解き放たれない
32bitが酷すぎるな・・・x86-64拡張なんかしたからx86の呪縛から解き放たれない
>>803->>804
お前ら元記事読んでないだろ。そのグラフの意味がわかってる?
お前ら元記事読んでないだろ。そのグラフの意味がわかってる?
Intel AVX
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=88816&threadid=88816&roomid=2
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=88816&threadid=88816&roomid=2
>>806
256bitレジスタは>>448の言うように、xmmレジスタの上位に
128bit足したものが256bitのymmレジスタになるんだね。
あと、VEXプレフィックスを付けることで、従来からあるSSE命令も
3オペランド形式が使えるが、256bitのymmレジスタを使えるのは
fp命令だけで、int命令はxmmレジスタしか使えないようだね。
あと、fp命令は積和演算命令が追加されてる。
256bitレジスタは>>448の言うように、xmmレジスタの上位に
128bit足したものが256bitのymmレジスタになるんだね。
あと、VEXプレフィックスを付けることで、従来からあるSSE命令も
3オペランド形式が使えるが、256bitのymmレジスタを使えるのは
fp命令だけで、int命令はxmmレジスタしか使えないようだね。
あと、fp命令は積和演算命令が追加されてる。
>>804は何を思って「32bitが酷すぎる」って思ったんだろうか。
>>804はItanium信者
IDFで公開された「Nehalem」の内部アーキテクチャ
http://pc.watch.impress.co.jp/docs/2008/0403/kaigai433.htm
>命令を発行するポート数が、Core MAの5からNehalemでは6ポートに増える。
"store"が、store Address, store Dataになってる。
あと仮想化の拡張が
>「Virtual Processor ID (VPID)」と「Extended Page Table (EPT)」が実装された。
実際どのくらい効くのか気になる。
http://pc.watch.impress.co.jp/docs/2008/0403/kaigai433.htm
>命令を発行するポート数が、Core MAの5からNehalemでは6ポートに増える。
"store"が、store Address, store Dataになってる。
あと仮想化の拡張が
>「Virtual Processor ID (VPID)」と「Extended Page Table (EPT)」が実装された。
実際どのくらい効くのか気になる。
>>810
ヲィヲィ…。
こんな初歩的な間違いをしないでくれよ>後藤氏
>>命令を発行するポート数が、Core MAの5からNehalemでは6ポートに増える。
>"store"が、store Address, store Dataになってる。
Core MAの発行ポート数もport0〜port5の計6ポートだよ。
IntelのOptimization Reference Manualに書いてあることなのだが…。
Core MAの図ではStore addressとStore dataを分けて書かずに
1つのStoreと書いてあるものがあるけど、これは単に簡略化して描いているだけ。
ヲィヲィ…。
こんな初歩的な間違いをしないでくれよ>後藤氏
>>命令を発行するポート数が、Core MAの5からNehalemでは6ポートに増える。
>"store"が、store Address, store Dataになってる。
Core MAの発行ポート数もport0〜port5の計6ポートだよ。
IntelのOptimization Reference Manualに書いてあることなのだが…。
Core MAの図ではStore addressとStore dataを分けて書かずに
1つのStoreと書いてあるものがあるけど、これは単に簡略化して描いているだけ。
Mobile Internet Device(MID)ってしきりに連呼してるけど
携帯とモロ被りの分野だけに流行るんだろうか。
携帯とモロ被りの分野だけに流行るんだろうか。
>>812
ウィルコム端末には期待しています。
ウィルコム端末には期待しています。
携帯が無線LANに繋がれば万事解決なのになw
キャリアは許さないだろうけどな。
キャリアは許さないだろうけどな。
自販機の無線LANスポット化ってどうなったん?
結局CMAをほとんどいじってないってことだな。
64-bitモード時にもMacro-Fusionされるようになった。
SMT(Simultaneous Multithreading)の実装
とキャッシュの変更ぐらいだな。
64bitでのmacro-fusionってそんなに意味がないって話じゃなかったっけ。
64-bitモード時にもMacro-Fusionされるようになった。
SMT(Simultaneous Multithreading)の実装
とキャッシュの変更ぐらいだな。
64bitでのmacro-fusionってそんなに意味がないって話じゃなかったっけ。
>>816
アイディアはよかったけど、誰がホストとして契約するかって問題が未解決のように思う。
アイディアはよかったけど、誰がホストとして契約するかって問題が未解決のように思う。
820 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/03(木) 19:41:12 ID:k2YfPbQX
AVXのマニュアル一通り斜め読みした。
案の定、AVXの256ビットSIMDは浮動小数周り+αのみのサポートだな。
SandyBridgeの時点ではユニット自体は128ビットのままで、浮動小数演算のレイテンシ隠蔽のため
のサポートとみた。この辺の流れはSSEのときと同じ。
真のSIMD ALUの256ビット化はAVX2か3の時代になると思われる。
となると、7DPってのはFMA+DotProductかな?
整数でも3オペランド命令が使えるようになるのも美味しい。
NAND/NOR命令まだー?
案の定、AVXの256ビットSIMDは浮動小数周り+αのみのサポートだな。
SandyBridgeの時点ではユニット自体は128ビットのままで、浮動小数演算のレイテンシ隠蔽のため
のサポートとみた。この辺の流れはSSEのときと同じ。
真のSIMD ALUの256ビット化はAVX2か3の時代になると思われる。
となると、7DPってのはFMA+DotProductかな?
整数でも3オペランド命令が使えるようになるのも美味しい。
NAND/NOR命令まだー?
>>819
アンカーミスった。 816⇒817
アンカーミスった。 816⇒817
822 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/03(木) 19:45:58 ID:k2YfPbQX
FMAはimm8を4つ目のレジスタ指定に使うことで真の4オペランド演算をサポート。
その点じゃAMD SSE5の4オペランド(笑)は紛い物だからな。
その点じゃAMD SSE5の4オペランド(笑)は紛い物だからな。
サンプルコードにFMAを使っているものがないし
CPUIDのFeature FlagもAVXと独立しているから
FMAはオプションかもな
CPUIDのFeature FlagもAVXと独立しているから
FMAはオプションかもな
atomよさそうだなー。
各種バスやらchipのついたメインドメインと、
電気的に疎に結びついた大量のサブドメインマシンみたいなの作らないかな。
今でも評価ボードみたいなのあるけど、評価ボードじゃ実用的じゃないしな。。。
なによりマシンとして個別であることが重要なので、
各種バスやらchipのついたメインドメインと、
電気的に疎に結びついた大量のサブドメインマシンみたいなの作らないかな。
今でも評価ボードみたいなのあるけど、評価ボードじゃ実用的じゃないしな。。。
なによりマシンとして個別であることが重要なので、
binutilsのavx対応patch
ttp://sourceware.org/ml/binutils/2008-04/msg00045.html
ttp://sourceware.org/ml/binutils/2008-04/msg00045.html
えー、
新設計じゃなくてCore2の焼き直しかよー…
でも正直そっちの方が安心だけど
新設計じゃなくてCore2の焼き直しかよー…
でも正直そっちの方が安心だけど
>>824
atomは、24時間動作の超低消費電力簡易鯖として売り出してほしいな。
無停電電源、超小型モニタ、内臓で無線LANハブ、火壁、ファイル鯖、http鯖くらいを仕込んで
買って設置したらそのまま使えるぐらいの奴。
棚のサバが邪魔なんだ・・・
atomは、24時間動作の超低消費電力簡易鯖として売り出してほしいな。
無停電電源、超小型モニタ、内臓で無線LANハブ、火壁、ファイル鯖、http鯖くらいを仕込んで
買って設置したらそのまま使えるぐらいの奴。
棚のサバが邪魔なんだ・・・
IDFのスライド
Upcoming Intel(R) 64 Instruction Set Architecture Extensions
- Intel(R) Advanced Vector Extensions (Intel(R) AVX)
ttps://intel.wingateweb.com/SHchina/published/NGMS002/SP_NGMS002_100r_eng.pdf
Upcoming Intel(R) 64 Instruction Set Architecture Extensions
- Intel(R) Advanced Vector Extensions (Intel(R) AVX)
ttps://intel.wingateweb.com/SHchina/published/NGMS002/SP_NGMS002_100r_eng.pdf
>>826
Nehalemの開発はいったんPrescottの大コケでキャンセルされて、同じコードネームで再開って流れだから、
時間を考えると仕方ない。
Sandy Bridgeのさらに2世代後にはオレゴンチームの逆襲が拝めると思うw
Nehalemの開発はいったんPrescottの大コケでキャンセルされて、同じコードネームで再開って流れだから、
時間を考えると仕方ない。
Sandy Bridgeのさらに2世代後にはオレゴンチームの逆襲が拝めると思うw
真っ新からCPU開発なんてオナネタ無しでオナニーするようなもんだ
うんざりするだろ?
うんざりするだろ?
MeromはBaniasの次世代として開発されていたけど、その次は検討されてたんだろうな
>>831
100%ゼロから開発なんて、できないよな
NetBurstだって、完全なゼロから作ってなどいないとおもう
>>831
100%ゼロから開発なんて、できないよな
NetBurstだって、完全なゼロから作ってなどいないとおもう
>>820
以前から気になっていた事で、積和演算(=内積、畳み込み演算)系のサポートは強力なのだが
外積、グラスマン積、行列式系のサポートが全然強化されないのが気になる
内積系・外積の組み合わせである、クリフォード積等についても
高度な科学技術計算では内積、外積は表裏一体なので、こちらが手抜きなのはどうなのかとずっと思っているのですが・・・
あと演算の種類ももっと抽象化してみるといいように思う。
*、+ を xor or で置き換えるとか、正規表現のような演算で置き換えて文字列処理とか。
以前から気になっていた事で、積和演算(=内積、畳み込み演算)系のサポートは強力なのだが
外積、グラスマン積、行列式系のサポートが全然強化されないのが気になる
内積系・外積の組み合わせである、クリフォード積等についても
高度な科学技術計算では内積、外積は表裏一体なので、こちらが手抜きなのはどうなのかとずっと思っているのですが・・・
あと演算の種類ももっと抽象化してみるといいように思う。
*、+ を xor or で置き換えるとか、正規表現のような演算で置き換えて文字列処理とか。
一般人には意味が謎だと思うので、ちょっと解説を加えます。
*、+ を xor or で置き換えると、暗号化・乱数発生・駅スパートなどの経路の最適化等に使えるものができます。
*、+ を xor or で置き換えると、暗号化・乱数発生・駅スパートなどの経路の最適化等に使えるものができます。
あと要素入れ替えも代数学を意識して欲しい、任意置換・逆置換がきれいに作れない
置換を積、適当な交換法則を持つ演算を和として、前述の種類の抽象化を図るときれいになると思う
Rubyや、最近のC#でLINQという機能(Database向けライブラリ)があって Aggregate など、抽象化された積和演算のイメージそのままのライブラリもあって
うまくはまるように作れば、あまり知識のない人にも積極活用される可能性もあると思う。
割合最先端を突っ走っているHaskell等でもfoldlといった形で存在して、高度に研究されているので、それも意識してほしいな。
置換を積、適当な交換法則を持つ演算を和として、前述の種類の抽象化を図るときれいになると思う
Rubyや、最近のC#でLINQという機能(Database向けライブラリ)があって Aggregate など、抽象化された積和演算のイメージそのままのライブラリもあって
うまくはまるように作れば、あまり知識のない人にも積極活用される可能性もあると思う。
割合最先端を突っ走っているHaskell等でもfoldlといった形で存在して、高度に研究されているので、それも意識してほしいな。
833はマイクロプロセサがどのように動いているか理解したほうがいい。
>>836
一応知っているし、Verilogも書けますが何か?
一応知っているし、Verilogも書けますが何か?
FPGAとか使ってオナニーしてればいいんじゃね?
なんでもできるが、なんでも追加するっていうのは<汎用プロセッサ>向きではないな。
高速化しても一部の人にしか恩恵がないものは、専用プロセッサか、専用ハードを作って実現すべき。
演算機能追加されてもコスト二倍、周波数半分だったら嫌だろ。
Verilog書けるだけではC言語書けるのと変わらない、ゲート/配線遅延を制して高速化できないとな。
高速化しても一部の人にしか恩恵がないものは、専用プロセッサか、専用ハードを作って実現すべき。
演算機能追加されてもコスト二倍、周波数半分だったら嫌だろ。
Verilog書けるだけではC言語書けるのと変わらない、ゲート/配線遅延を制して高速化できないとな。
841 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/05(土) 14:22:43 ID:M0cgdLjG
自分の環境だと>>829はAdobe Readerの2D GPUアクセラレーションを
無効にしないと正常に表示できなかった
気になったこと
(p.2-3)
> 2009年 暗号アクセラレータ(Westmere)
> 2010年 AVX
> Future FMA
Sandy BridgeにFMAは搭載されないのか?
(p.9)
> 2nd load port
何だろうこれは?
無効にしないと正常に表示できなかった
気になったこと
(p.2-3)
> 2009年 暗号アクセラレータ(Westmere)
> 2010年 AVX
> Future FMA
Sandy BridgeにFMAは搭載されないのか?
(p.9)
> 2nd load port
何だろうこれは?
843 :Socket774:2008/04/05(土) 15:58:08 ID:LT1RsLX4
> 2nd load port
何だろうこれは?
Loadが2ポート発行になるとか?
何だろうこれは?
Loadが2ポート発行になるとか?
>>841
コードを書いてみると分るんだが、全然並列化しないんだよ
三次元くらいなら、まだ知れているんだが、四次元(グラスマン積)あたりになると・・・
このレベルができると、また色々面白い事になるんだ
例えばゲームの物理などで良く使われる、凸物体の衝突判定は一気に汎用化して凹凸無視の汎用当たり判定とかも夢ではなくなる。
分割が必要なくなればデータ量も減るし、帯域削減にも繋がる。
さらに、外積でも演算子を * + から xor or に置換するとまた面白い事が起こったりもするけど、暇があったら書いてみるよ。
コードを書いてみると分るんだが、全然並列化しないんだよ
三次元くらいなら、まだ知れているんだが、四次元(グラスマン積)あたりになると・・・
このレベルができると、また色々面白い事になるんだ
例えばゲームの物理などで良く使われる、凸物体の衝突判定は一気に汎用化して凹凸無視の汎用当たり判定とかも夢ではなくなる。
分割が必要なくなればデータ量も減るし、帯域削減にも繋がる。
さらに、外積でも演算子を * + から xor or に置換するとまた面白い事が起こったりもするけど、暇があったら書いてみるよ。
>コードを書いてみると分るんだが、全然並列化しないんだよ
あっ、いまちょっと気付いてしまった、OoOタイプのプロセッサだと余り意味無いかもしれない・・・
あっ、いまちょっと気付いてしまった、OoOタイプのプロセッサだと余り意味無いかもしれない・・・
846 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/05(土) 20:14:47 ID:jHh6ugbG
あのさー
float4 × float4の外積ってdest格納するのにレジスタ4つ要るじゃん。
そんなの汎用化できると思う?
少しは考えよう。
float4 × float4の外積ってdest格納するのにレジスタ4つ要るじゃん。
そんなの汎用化できると思う?
少しは考えよう。
847 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/05(土) 20:20:40 ID:jHh6ugbG
xmm0とxmm1の外積をxmm4. xmm5, xmm6, xmm7に格納
pshufd xmm4, xmm0, 0x00
mulps xmm4, xmm1
pshufd xmm5, xmm0, 0x55
mulps xmm5, xmm1
pshufd xmm6, xmm0, 0xAA
mulps xmm6, xmm1
pshufd xmm7, xmm0, 0xFF
mulps xmm7, xmm1
こんなんいちいち専用命令作るだけ無駄だよ
pshufd xmm4, xmm0, 0x00
mulps xmm4, xmm1
pshufd xmm5, xmm0, 0x55
mulps xmm5, xmm1
pshufd xmm6, xmm0, 0xAA
mulps xmm6, xmm1
pshufd xmm7, xmm0, 0xFF
mulps xmm7, xmm1
こんなんいちいち専用命令作るだけ無駄だよ
専用ハードの支援が無い拡張命令、て確かに意味無いわよな
そういうのどんどん増えてる気がするんだけど。
そして負の遺産ばかりが増えていくと。
そういうのどんどん増えてる気がするんだけど。
そして負の遺産ばかりが増えていくと。
849 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/06(日) 13:21:58 ID:lnQja0X9
haddpsとか意味なさ過ぎて何に使うんだと思ったが、一応マシにはなってきてるんだがねぇ
すくなくともSandyBridgeの頃までには1μOpで扱えるようになるのでは。
すくなくともSandyBridgeの頃までには1μOpで扱えるようになるのでは。
x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
>>850
Itaniumの存在意義がまた一つ減りそうだな。
Itaniumの存在意義がまた一つ減りそうだな。
もうねIA64一本にしてCPUもOSもリスタートした方がいいよ。
853 :Socket774:2008/04/07(月) 23:57:36 ID:7VKOsXDb
Core MAを6命令発行に訂正したな<後藤氏
>>852
AMD死亡だな
AMD死亡だな
>>852
いっそOSもIntelが開発してくれ・・・
いっそOSもIntelが開発してくれ・・・
互換性を維持しつつ新命令で性能を伸ばす
やっとまともな手段で落ち着いたか…
でも整数演算は頭打ちとは…残念
整数演算も性能伸びると思ってたんだが
やっとまともな手段で落ち着いたか…
でも整数演算は頭打ちとは…残念
整数演算も性能伸びると思ってたんだが
てかIntelはSIMDの性能上げると言ってるだけで
SIMD整数の性能上げないなんて言ってないよな。
SIMD整数の性能上げないなんて言ってないよな。
>>855
Linuxで良くね? moblinもlinux使ってるし…。
Linuxで良くね? moblinもlinux使ってるし…。
>>852
IA64で互換性無くすなら、POWERのほうが随分とマシな気がするが
IA64で互換性無くすなら、POWERのほうが随分とマシな気がするが
x86の256bitと言えばTransmeta、 今どうしてるのかな。
gcc,binutilsならCPUが出る前から対応してるけど、それじゃ不満?
CPU、チップセット、メモリ関連技術、SSD、Raidカード、NIC、無線、VGA、M/B、コンパイラ・・・
とこれだけ多方面の高い技術を持つインテルでもOSとなると、、、、
MSには勝てません
プラットフォームを一度支配してしまった企業はまさに特権階級です
とこれだけ多方面の高い技術を持つインテルでもOSとなると、、、、
MSには勝てません
プラットフォームを一度支配してしまった企業はまさに特権階級です
Windowsって新命令の対応遅かったことあったの?
ってああx64のことか、納得。
>>855
ソフトウェア基調講演レポート
http://pc.watch.impress.co.jp/docs/2008/0404/idf03.htm
コンパイラだけでなくアプリケーション・OSにも力を入れ始めてるね。
で,ドライバは?w
ソフトウェア基調講演レポート
http://pc.watch.impress.co.jp/docs/2008/0404/idf03.htm
コンパイラだけでなくアプリケーション・OSにも力を入れ始めてるね。
で,ドライバは?w
正直いまのIntel CPUって継ぎはぎだらけのパッチワーク状態で
嫌い
嫌い
x86だからしょうがない。MSやAMDやら周辺メーカーと協調して、
一気に変えてもらった方が遙かにいいな。
とくにMSと話し合いをすれば周りも従わざるおえないだろうし。
一気に変えてもらった方が遙かにいいな。
とくにMSと話し合いをすれば周りも従わざるおえないだろうし。
ライトユーザーって表現でいいのかわからんけど
いわゆる初めて層がWindows離れし出したらヤバイよな
ヲタク系とかはどうでもいいんだろうけど
いわゆる初めて層がWindows離れし出したらヤバイよな
ヲタク系とかはどうでもいいんだろうけど
>>856
AVX用の新命令群は、それまでのSIMD命令群を置き換え易いけど、整数演算系の
命令群までは難しいでしょ。
SIMD系は元々FPUやらMMXやらSSEやら、次々に新しくしてきた経緯があるし、Intel
とAMDで分かれてるせいもあって、ソフトが内部的に分かれてるから、AVXもその延長
で済むけど。
まあ64bitになってから、良く使われる命令のみに特化して高速化するくらいなら、
あるかもしれんが、それはItaniumみたいに32bit命令を遅くする犠牲が必要そうだから、
当分無理っぽい気が。
AVX用の新命令群は、それまでのSIMD命令群を置き換え易いけど、整数演算系の
命令群までは難しいでしょ。
SIMD系は元々FPUやらMMXやらSSEやら、次々に新しくしてきた経緯があるし、Intel
とAMDで分かれてるせいもあって、ソフトが内部的に分かれてるから、AVXもその延長
で済むけど。
まあ64bitになってから、良く使われる命令のみに特化して高速化するくらいなら、
あるかもしれんが、それはItaniumみたいに32bit命令を遅くする犠牲が必要そうだから、
当分無理っぽい気が。
872 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/08(火) 14:12:39 ID:HaA4JWsP
いや、そのうち高速化するんじゃないの?
まずFPの256bit化はレイテンシの隠蔽が目的だろうけどよ。
まあ整数のSIMDは効果少ないかもね。スカラ性能のほうが伸びて欲しい。
pshufbの256bit版とかは大歓迎なんだが。
AESに限らずブロック暗号のS-boxが大幅に高速化できる。
まずFPの256bit化はレイテンシの隠蔽が目的だろうけどよ。
まあ整数のSIMDは効果少ないかもね。スカラ性能のほうが伸びて欲しい。
pshufbの256bit版とかは大歓迎なんだが。
AESに限らずブロック暗号のS-boxが大幅に高速化できる。
>>873
それは既にコスト的に破綻した戦略だが。Itaniumの32bit互換でも失敗してるし。
それは既にコスト的に破綻した戦略だが。Itaniumの32bit互換でも失敗してるし。
昔、PC-8801DOってのがあってだな
877 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/08(火) 15:57:32 ID:HaA4JWsP
PARROTは旧トランスメタチームが作るんかな
コードモーフィングをうまく活用したら、面白いことになりそうだねぇ。
でもそれって、ハードにオプティマイザを乗っけるってことになるんかなぁ。
でもそれって、ハードにオプティマイザを乗っけるってことになるんかなぁ。
いっそのことOSとか低レベルのプログラム以外ネィテブコードをやめて.NETみたいにVMで動かしてハードウェアを仮想化してしまえば
命令セットもいじりやすくなる。命令セットはOSメーカと話し合って開発すればいい
いいかげんハードウェアを互換性を保つ負担を押し付けるのはもう終わりしてもいいのでは。
命令セットもいじりやすくなる。命令セットはOSメーカと話し合って開発すればいい
いいかげんハードウェアを互換性を保つ負担を押し付けるのはもう終わりしてもいいのでは。
MicrosoftがSingularityをやっているし
Intelの新命令はきれいな新命令、AMDの新命令は汚い新命令。
もっとも非常にきれいな命令群とは言えるIA64は残念なことになってしまっているし、
きれいなことがいいこととは限らないのが微妙ではある
もっとも非常にきれいな命令群とは言えるIA64は残念なことになってしまっているし、
きれいなことがいいこととは限らないのが微妙ではある
IA64 って Itanimum のことか?
きれいか?
きれいか?
>>882
Ubuntuはまだ3歳。moblinもまだ1歳。ロリコンにお勧めです。
Ubuntuはまだ3歳。moblinもまだ1歳。ロリコンにお勧めです。
>>886
それどっちもLinuxベースだし、年齢詐称じゃん
それどっちもLinuxベースだし、年齢詐称じゃん
年増園
おちん○○ランドなOSはどこですか?
わぁいw
ところでSandy Bridgeの開発はヒルズボロですか?
ところでSandy Bridgeの開発はヒルズボロですか?
>>889
超感じ・・・じゃないや、超漢字。
超感じ・・・じゃないや、超漢字。
>>890
ハイファですよ。
ハイファですよ。
>>885
x64よりはマシって程度じゃね?
x64よりはマシって程度じゃね?
なぜIntelはSandy Bridgeに「AVX」を実装するのか
http://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
http://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
x86ごとAMDその他を切り捨てるつもりだったし
継ぎ接ぎばっかりしてるからこの有様
過去の資産に拘るソフト会社の寄生虫どもはそろって死ね
過去の資産に拘るソフト会社の寄生虫どもはそろって死ね
AppleのようにOSとハードを握っていれば話は簡単だったろうな。
AppleのOS?
osx以外の時あたりでしょ。
OSXだって、Appleが「x86系に変えるから!」って言ったらあっさり変わっただろ?
Appleは握っているというよりむしろ縛られないようにしている、
というほうが。
というほうが。
Universal Binaryはx86とPowerPC両方のコードが入ってるので、エミュじゃない。
PowerPC用のアプリのときはRosettaでエミュだけど。
PowerPC用のアプリのときはRosettaでエミュだけど。
トップガン>>896様が新しい資産を作って下さるようです。
期待しましょう。
期待しましょう。
IDF Shanghai 2008 - Nehalem情報を総まとめ、コアの内部構造からプラットフォームまで
ttp://journal.mycom.co.jp/articles/2008/04/10/idf09/index.html
基本設計はCMAだが、いろいろいじくってんな。さすがヒルズボロだ。
ttp://journal.mycom.co.jp/articles/2008/04/10/idf09/index.html
基本設計はCMAだが、いろいろいじくってんな。さすがヒルズボロだ。
906 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/10(木) 22:47:27 ID:5enbwnkH
大原も後藤と同じくとんちんかんなこと書いてるな。
まあいつものことだが
まあいつものことだが
907 :Socket774:2008/04/10(木) 23:14:43 ID:4C93LYju
自分が正しいと思ってることは大抵間違いなんだよ
>>894
そのネタ、前回から通して見てるが
既存のx86に新しいSIMD命令を載っけるんだから
別にIntelは「x86からの脱却」なんて図ってないけどな。
CPU内部の拡張SIMDユニットを新命令セットで叩かせて
FP性能稼ぐのは、後藤弘茂の大好きなヘテロジニアス構成の
出る幕が無いって事なんだが。
まだ影も形も見えないAMDのFusionとやらに
一縷の望みを繋いでるのかしら?このオッサン。
そのネタ、前回から通して見てるが
既存のx86に新しいSIMD命令を載っけるんだから
別にIntelは「x86からの脱却」なんて図ってないけどな。
CPU内部の拡張SIMDユニットを新命令セットで叩かせて
FP性能稼ぐのは、後藤弘茂の大好きなヘテロジニアス構成の
出る幕が無いって事なんだが。
まだ影も形も見えないAMDのFusionとやらに
一縷の望みを繋いでるのかしら?このオッサン。
>>905
なんかphoto20の説明が無茶苦茶すぎるな
なんかphoto20の説明が無茶苦茶すぎるな
>AMDのFusionとやらに
>一縷の望みを繋いでるのかしら?このオッサン。
それは猫基地外の方のおっさん。
>一縷の望みを繋いでるのかしら?このオッサン。
それは猫基地外の方のおっさん。
Neharemのデュアルコア+Atom×n個ののメニィコアCPUとかどうだろうか?
Intelは、x86の資産に完全に縛られてしまってるな
x86のプログラムコードが多すぎて、変えることすら叶わない状態になってる
これをなんとかするには、昔PowerMacがやったようにエミュレーションで対応したらどうだろうかとはおもうが
UMPCやNetBookでの対応をみるに、IntelとMS、昔ほど仲が良くないからなあ
x86のプログラムコードが多すぎて、変えることすら叶わない状態になってる
これをなんとかするには、昔PowerMacがやったようにエミュレーションで対応したらどうだろうかとはおもうが
UMPCやNetBookでの対応をみるに、IntelとMS、昔ほど仲が良くないからなあ
>>910
確かに酷すぎ…。
確かに酷すぎ…。
後藤氏の場合は東スポを読んでるようなものなので多少の間違いは
笑って済ませられるけど、大原氏は技術解説のような体裁で大嘘を
書くから後藤氏より質が悪い。
笑って済ませられるけど、大原氏は技術解説のような体裁で大嘘を
書くから後藤氏より質が悪い。
揮発性の速報だということを理解せずに古い後藤記事を引用する馬鹿もいるからなあ
そもそもNVIDIAがGP GPUなんて寝言をほざくから世の中おかしくなっていった。
戯れ言は死んでから言えってことで。
戯れ言は死んでから言えってことで。
ヒント:普及するほどCUDAが使えるビデオカードが普及してない
920 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/11(金) 20:57:39 ID:qI1I6a2A
いいかげんVista対応せいや
CUDAエンコできるのか
ウンコできない
intel自体は過去の束縛に楽観的なんじゃないの?
新しい命令セット用のコア作って性能を伸ばしつつ、
x86命令は既存のコアをMCMでのっけて処理するとか、
なんとでもなるし。
新しい命令セット用のコア作って性能を伸ばしつつ、
x86命令は既存のコアをMCMでのっけて処理するとか、
なんとでもなるし。
>>921
H.264の場合はGPUの整数演算が遅すぎるのでCPUでやった方がマシ
PCIExpressのレイテンシが大きすぎるのも問題あり
ATIがX1000シリーズでH.264のエンコできるようにするって言ってたけど、β版のまま企画倒れっぽい
たぶんもう諦めたはず
H.264の場合はGPUの整数演算が遅すぎるのでCPUでやった方がマシ
PCIExpressのレイテンシが大きすぎるのも問題あり
ATIがX1000シリーズでH.264のエンコできるようにするって言ってたけど、β版のまま企画倒れっぽい
たぶんもう諦めたはず
大々的にGPGPU利用し続けてるのなんてソニー(PS3)くらいだもんな
は?
927 :Socket774:2008/04/12(土) 07:56:30 ID:XxWxvXLZ
ひ?
フッ
いいこと思いついた。おまえ俺の(ry
もうさ、VistaがどうこうとかLinuxがどうこうとかやめて、
・ローカルでWWWサーバーが動くならOSは何でもいい
・アプリは全部WWWアプリにしちまえ
という乱暴なMIDはいかがですか。
もうさ、VistaがどうこうとかLinuxがどうこうとかやめて、
・ローカルでWWWサーバーが動くならOSは何でもいい
・アプリは全部WWWアプリにしちまえ
という乱暴なMIDはいかがですか。
>>929
絶対無理。たとえば、電卓を使うのに、サーバーが混雑して起動に数十秒かかるとか、
鯖がダウンして動かせないなんてことは普通にありえるし。
他にもセキュリティは大丈夫なのかとか、途中で切断されたらどうするんだとか問題が大杉。
絶対無理。たとえば、電卓を使うのに、サーバーが混雑して起動に数十秒かかるとか、
鯖がダウンして動かせないなんてことは普通にありえるし。
他にもセキュリティは大丈夫なのかとか、途中で切断されたらどうするんだとか問題が大杉。
>>929
何をしたいんだ?
ローカルでhttpd動かす必要はないだろ
たぶん言いたいことはこういうことなんだろうけど↓
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=Web%E3%82%B5%E3%83%BC%E3%83%93%E3%82%B9
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=%E3%83%96%E3%83%A9%E3%82%A6%E3%82%B6%E3%83%99%E3%83%BC%E3%82%B9
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=SaaS
何をしたいんだ?
ローカルでhttpd動かす必要はないだろ
たぶん言いたいことはこういうことなんだろうけど↓
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=Web%E3%82%B5%E3%83%BC%E3%83%93%E3%82%B9
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=%E3%83%96%E3%83%A9%E3%82%A6%E3%82%B6%E3%83%99%E3%83%BC%E3%82%B9
http://www.google.co.jp/search?hl=ja&lr=lang_ja&q=SaaS
仕事を考えれば社内のデータ共有は必須なわけで、鯖が落ちてたら結局同じ事。
しかしサーバの能力が過大に必要になるのは欠点。
互換性はIE切り捨てでMacやLinnuxにも移植されてるブラウザを使うのが吉か。
しかしサーバの能力が過大に必要になるのは欠点。
互換性はIE切り捨てでMacやLinnuxにも移植されてるブラウザを使うのが吉か。
社内アプリはブラウザベースになってから異常にもっさり化した
サクサク動いてたコンソールエミュレータ時代に戻りたい
サクサク動いてたコンソールエミュレータ時代に戻りたい
ごめん言葉が足りなかったようだよ
まさに「ローカルで常にhttpd動かす」わけですよ。
ネットに繋がっていても切断しても操作性が全然同じなわけです。
googleのApp Engineでデータストアがローカルとサーバーで
自動的に同期できちゃうよ。みたいなの。
まさに「ローカルで常にhttpd動かす」わけですよ。
ネットに繋がっていても切断しても操作性が全然同じなわけです。
googleのApp Engineでデータストアがローカルとサーバーで
自動的に同期できちゃうよ。みたいなの。
ハードの高速化とソフトの低速化を並列に進めることで
最大の需要と雇用が得られる
最大の需要と雇用が得られる
AIR、Google Gears、Silverlight、Java FX、Prism
>>934
WUXGA液晶使っててターミナルを小さなフォントで開くと、
「こんな小さな画面でよく仕事出来てたもんだな」
ってしみじみしない?
うちの社内アプリは良く出来てるよ。何千件×何千件の所要量計算
とかやらせてもさくっと出てくる。昔はバッチで夜間に計算させてたのに
今はリアルタイムで分かってありがたいことです。
WUXGA液晶使っててターミナルを小さなフォントで開くと、
「こんな小さな画面でよく仕事出来てたもんだな」
ってしみじみしない?
うちの社内アプリは良く出来てるよ。何千件×何千件の所要量計算
とかやらせてもさくっと出てくる。昔はバッチで夜間に計算させてたのに
今はリアルタイムで分かってありがたいことです。
sage
941 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/17(木) 19:35:14 ID:xGjW3nob
SQLiteで
>>941
いや全然違いうだろ。Proxyはゲートウェイにすぎない
いや全然違いうだろ。Proxyはゲートウェイにすぎない
>>934
混み出すと露骨にレスポンスが悪くなるから。
んで結局
回線増強
ルータ増強
サーバ増強
と昔より桁違いに金が掛かって
しかも処理能力は昔と大して変わらない業務システムが出来るワケだが
(つーかウチの会社だ)
混み出すと露骨にレスポンスが悪くなるから。
んで結局
回線増強
ルータ増強
サーバ増強
と昔より桁違いに金が掛かって
しかも処理能力は昔と大して変わらない業務システムが出来るワケだが
(つーかウチの会社だ)
そうか
ネットゲームと同じ、ソフトの自動アップデート、サーバーでのデータ管理、クライアント側での実行でいいのでは。
それと、ソフト実行時に重そうな処理を検知して自動的にサーバーか分散コンピューティングで実行とか。
それと、ソフト実行時に重そうな処理を検知して自動的にサーバーか分散コンピューティングで実行とか。
>>946
1行目は20年以上前からある普通の業務アプリそのものだな
2行目は無駄。重いアプリかどうかなんて設計時に分かってるんだから
そういうのは最初から分散処理でアプリ組んだほうが楽だし速い
つーか、分散処理なんてのは最初からそう組んでなければ上手く動けん
動的に検知して勝手に分散とか夢のような世界はあと10年は来ないね
1行目は20年以上前からある普通の業務アプリそのものだな
2行目は無駄。重いアプリかどうかなんて設計時に分かってるんだから
そういうのは最初から分散処理でアプリ組んだほうが楽だし速い
つーか、分散処理なんてのは最初からそう組んでなければ上手く動けん
動的に検知して勝手に分散とか夢のような世界はあと10年は来ないね
業務アプリでPC起動時かソフト立ち上げ時に自動ダウンロード、自動アップデートされてるならなんで
Webアプリなんて必要なんだ?
Windowパソコンで使ってるソフトは手動インストールだし、ワークステーションで使うソフトはソフト本体が
ネットワーク上にあって常にネットワーク経由でしかやってこなくて帯域を無駄に使ってるんだが。
アプリが重いかどうかじゃなくて処理が重いかどうか。
データベースみたいに情報量が常に右肩上がり、どんなときも全データ処理なら分散処理しかないだろうが、
シミュレーションみたいにパラメーターを読み込んで実行してみた後、数分で終わりそうならそのまま1PCで
処理して時間がかかりそうなら分散処理に移行させるってことで、なんでもかんでもいきなり分散化したら
非効率なのでは。
Webアプリなんて必要なんだ?
Windowパソコンで使ってるソフトは手動インストールだし、ワークステーションで使うソフトはソフト本体が
ネットワーク上にあって常にネットワーク経由でしかやってこなくて帯域を無駄に使ってるんだが。
アプリが重いかどうかじゃなくて処理が重いかどうか。
データベースみたいに情報量が常に右肩上がり、どんなときも全データ処理なら分散処理しかないだろうが、
シミュレーションみたいにパラメーターを読み込んで実行してみた後、数分で終わりそうならそのまま1PCで
処理して時間がかかりそうなら分散処理に移行させるってことで、なんでもかんでもいきなり分散化したら
非効率なのでは。
分散コンピューティングとか逝ってるからスパコン・HPCの世界をイメージしてるんじゃね?
今話してる業務アプリとはちょっとずれてる
今話してる業務アプリとはちょっとずれてる
951 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/19(土) 20:57:05 ID:8Oo+Tdbj
サーバでバージョンやファイルを一元管理する程度なら最悪でもJavaでいいじゃん
なんでいまさらHTMLだよ。機密情報を扱うなら尚更だな。
なんでいまさらHTMLだよ。機密情報を扱うなら尚更だな。
>>950
同じ「分散」でもクラスタ的な水平分散じゃなくて
業務システムは機能分散だからな。
個人的にはクライアント側がこれだけ無駄に性能上がってるのに
サーバーに処理一元化させるのが
本当に効率の良いやり方なのか疑問だが。
同じ「分散」でもクラスタ的な水平分散じゃなくて
業務システムは機能分散だからな。
個人的にはクライアント側がこれだけ無駄に性能上がってるのに
サーバーに処理一元化させるのが
本当に効率の良いやり方なのか疑問だが。
>個人的にはクライアント側がこれだけ無駄に性能上がってるのに
>サーバーに処理一元化させるのが
>本当に効率の良いやり方なのか疑問だが。
純粋に性能だけみれば間違いなくサーバ側の処理は出来るだけしないほうがいいな。
それこそ機能的な問題だろうね……
>サーバーに処理一元化させるのが
>本当に効率の良いやり方なのか疑問だが。
純粋に性能だけみれば間違いなくサーバ側の処理は出来るだけしないほうがいいな。
それこそ機能的な問題だろうね……
分散化は一時期もてはやされたけど
結局企業で使う場合セキュリティの問題が大きすぎるから
また一元化するのに戻ってきたわけだが・・・
結局企業で使う場合セキュリティの問題が大きすぎるから
また一元化するのに戻ってきたわけだが・・・
956 :ヽ・´∀`・,,)っ━━━━━━┓:2008/04/20(日) 13:24:33 ID:Uvq3eT/r
Java, ActiveX, Ajax, .NET ・・・
仮想化→サーバ統合
セキュリティ対策→集中管理
そんなこんなで大型サーバやメインフレームへ回帰の流れ
セキュリティ対策→集中管理
そんなこんなで大型サーバやメインフレームへ回帰の流れ
16コアのx86サーバーでも2000年ぐらいの大型機を凌ぐ性能だろ
性能があがったから分散化じゃなくて、性能があがったから再び集中会では?
性能があがったから分散化じゃなくて、性能があがったから再び集中会では?
そうだね、分散化なんて処理能力が低いから必要なものであって
性能があがれば分散させる必要は無いからね。
性能があがれば分散させる必要は無いからね。
正直Windowsじゃなきゃヤダヤダ→分散化だろ
それがなくなったり、仮想化なんかでサーバでWindows動かしちまおうとかしてるからな
それがなくなったり、仮想化なんかでサーバでWindows動かしちまおうとかしてるからな
>>959
集中させることが可能なら逆に負荷平準化にもなったりするしね
集中させることが可能なら逆に負荷平準化にもなったりするしね
>>960
どこまでもWindows様についていきます、か
どこまでもWindows様についていきます、か
{kind=link}
げるたんw
{kind=link}
そんな・・・声まで変わって・・・!
変わりっぷりが福本級だ
阪急黄金時代の人か
>>968
あれは奇跡だよな・・・
あれは奇跡だよな・・・
チャンドラシーカタンは人気ないよね。
ゲルタンとか言い出したのも俺なんだがw
てかかなり前からあんま上層部は変わってないのかなー。
10年くらいじゃそう社会は変わるものじゃないんだろうか。
ゲルタンとか言い出したのも俺なんだがw
てかかなり前からあんま上層部は変わってないのかなー。
10年くらいじゃそう社会は変わるものじゃないんだろうか。
10年経てば俺10才だぜ。大変化だよ
親族の中で希望の星から10/2年で穀潰し扱いに零落余裕でした
974 :Socket774:2008/04/27(日) 12:49:53 ID:1IKQOmDG
ネタがないねぇ
元々実物が有る話じゃないし、釣りネタみたいな記事やレビューが無いと、
議論にすらならないからなあ。
議論にすらならないからなあ。
>>963 965
ゲルタン イメチェンでちょい悪オヤジが入ってるwww
ゲルタン イメチェンでちょい悪オヤジが入ってるwww
AtomやIsaiahのスレも、似た様な理由で過疎ってるよね。
えらくなると悪いこともしないとやってけないのさ
なーんてな
なーんてな
>>974
わらびーのことでも語ってよ
わらびーのことでも語ってよ
iMacにMontevinaか
まじだ、モデルチェンジの情報はあったけど2ヶ月すっ飛ばしか
てかMontevinaて6月予定だったよな?
G45, G43のRevision A2はMac向けだったって事か。
appleの優遇っぷりはすごいな。
MSの一極支配を打破しておきたいという戦略的な意味があるのかな。
MSの一極支配を打破しておきたいという戦略的な意味があるのかな。
Intelが常に意識してる相手はSamsungやMS
時価総額で韓国サムスン電子が米インテルを抜いたなんて信じたくありません><
>>988
25年前だろ? 1993年の時点だったら誰だってそうなると予想してたぞ
25年前だろ? 1993年の時点だったら誰だってそうなると予想してたぞ
>>987
光インターコネクトもAppleがいちはやく取り入れてくれたら世の中加速するのに
光インターコネクトもAppleがいちはやく取り入れてくれたら世の中加速するのに
xeonと普通のcore2は何が違うの?
Xeonでも3000系と5000系と7000系でけっこう違うと思うが
大雑把に言うとサーバやワークステーション向け
大雑把に言うとサーバやワークステーション向け
言い訳なんかしないで 二人だけにわかるキス
昔から何度も言っているがNehalemはcoreMAの基本設計を超えられはしない。というかcoreMAそのものだ。
intelが提唱するプロセスルールのチクタクモデルはNehalemのシュリンクを待たずにに崩れるだろう。断ずる。
86は昔からたいして変わっちゃいない。唯一NetBurstだけが違うアプローチを展開しただけ。
intelが提唱するプロセスルールのチクタクモデルはNehalemのシュリンクを待たずにに崩れるだろう。断ずる。
86は昔からたいして変わっちゃいない。唯一NetBurstだけが違うアプローチを展開しただけ。
coreMAのアーキテクト達は優秀だよ。一つ一つの選択を非常に吟味している。
そこには革新的であれという功名心などなくただ、効率という大儀の元にもてる全てを集約させる
が、それこそが取りもなをさず革新なのだと私は言ってあげたい。
まあNehalemというあほな猿真似アーキテクチャはシュリンクを待たずに頓挫、
coreMAの本流からGPUと密に統合されたブツが出てくる。
そこには革新的であれという功名心などなくただ、効率という大儀の元にもてる全てを集約させる
が、それこそが取りもなをさず革新なのだと私は言ってあげたい。
まあNehalemというあほな猿真似アーキテクチャはシュリンクを待たずに頓挫、
coreMAの本流からGPUと密に統合されたブツが出てくる。
999 :Socket774:2008/04/30(水) 17:24:32 ID:Ok2ZgNjP
999
それほどでもない
1001 :1001: