Intel�̎�����CPU�ɂ��Č�낤 31
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 30
ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 3�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1160039483/
Intel uPs Info 2
ttp://pc11.2ch.net/test/read.cgi/mac/1159817811/l
Intel�̎�����CPU�ɂ��Č�낤 30
ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 3�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1160039483/
Intel uPs Info 2
ttp://pc11.2ch.net/test/read.cgi/mac/1159817811/l
|
|
|
���ߋ��X��
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
21 ttp://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
>>1
����
����
penryn�o��܂ł��Ɖ��X������邩�Ȃ��B
penryn�͂₭�łĂ���[
Intel Developer Forum
September 18--20, 2007 | San Francisco | Moscone Center West
http://www.intel.com/idf/us/fall2007/index.htm
September 18--20, 2007 | San Francisco | Moscone Center West
http://www.intel.com/idf/us/fall2007/index.htm
�����H�������@�f�X�N�g�b�v��
Intel����10����l�T��?45mm
�b���11�����T�����?Penryn
http://www.hkepc.com/?id=127
���@�Ǝҕ\���C�|���폱�� Intel ���ݘ��� 10 ����l�T������?�V��� 45 �ޕę|����C
���a�v�� 11 �����T�?�C�������� 45 �ޕĐ���C
���� 45 �ޕ�?�ʙ|���훒�l�j�S Yorkfield �y Xeon DP �l�j�S Harpertown �B
�b���11�����T�����?Penryn
http://www.hkepc.com/?id=127
���@�Ǝҕ\���C�|���폱�� Intel ���ݘ��� 10 ����l�T������?�V��� 45 �ޕę|����C
���a�v�� 11 �����T�?�C�������� 45 �ޕĐ���C
���� 45 �ޕ�?�ʙ|���훒�l�j�S Yorkfield �y Xeon DP �l�j�S Harpertown �B
9 �FSocket774�F2007/09/14(��) 11:24:46 ID:Ia7Hdk2z
age
core���j�S ���B
BCN�A�m�[�gPC��7�J���A���ōD���Ȕ���グ���ێ��`A4/B5�Ƃ���Core 2 Duo�̓��ڂ��g��
http://pc.watch.impress.co.jp/docs/2007/0914/bcn.htm
A4�^�C�v�̓���CPU��Celeron M�������������������B
�����āACore 2 Duo��31.9%�̃V�F�A���l�����AIntel��CPU�̃V�F�A��83.3%�ƂȂ����B
B5�^�C�v�ł́ACore 2 Duo��63.7%���߁AIntel�͂ق�100%�̃V�F�A���ێ����Ă���B
http://pc.watch.impress.co.jp/docs/2007/0914/bcn.htm
A4�^�C�v�̓���CPU��Celeron M�������������������B
�����āACore 2 Duo��31.9%�̃V�F�A���l�����AIntel��CPU�̃V�F�A��83.3%�ƂȂ����B
B5�^�C�v�ł́ACore 2 Duo��63.7%���߁AIntel�͂ق�100%�̃V�F�A���ێ����Ă���B
���j��San Francisco�֏o�����[
���N���Ƃ������Ȃ���A�S�R�R�������Ȃ��Ȃ�
���N�ɂȂ邩����
���N�ɂȂ邩����
�����IDF�܂ł͉���������������
IDF�łǁ[��ƂłĂ��邩���ȁB
�₫���������čw������t���X�g���[�V������킩��
Intel Plans to Boost Desktop Processor System Bus to 1600MHz.
Intel Readies New Enthusiast-Class Intel X48 Chipset
http://www.xbitlabs.com/news/chipsets/display/20070915151123.html
Intel Readies New Enthusiast-Class Intel X48 Chipset
http://www.xbitlabs.com/news/chipsets/display/20070915151123.html
���悢��x�[����E��Intel�̎���CPU�uNehalem�v
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm
����݂�ƃT�[�o�[�̃����R����DDR3�̃g���v���`�����l����FB-DIMM�͊��S�Ɏ��S�̗\���B
���Ƃ̓f�X�N�g�b�v�Ń����R���ڂ͂����l�^�̉\�����o�Ă����ˁB�܂����[�G���h��DDR2
���g�����߂Ƀ`�b�v�Z�b�g�o�R�Ƃ����\�������邪�B
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm
����݂�ƃT�[�o�[�̃����R����DDR3�̃g���v���`�����l����FB-DIMM�͊��S�Ɏ��S�̗\���B
���Ƃ̓f�X�N�g�b�v�Ń����R���ڂ͂����l�^�̉\�����o�Ă����ˁB�܂����[�G���h��DDR2
���g�����߂Ƀ`�b�v�Z�b�g�o�R�Ƃ����\�������邪�B
8MB���LL2�L���b�V���E�E�E�E32Way�ɂ���̂��E�E�E
Intel�͐����Ȃ��B
Intel�͐����Ȃ��B
��������3���}�����f�t�H�ɂȂ�̂�
�f�X�N�g�b�v�ł�64Bit������ɕ��y���Ȃ�����
3��3G�͂��傤�ǂ��������B
3��3G�͂��傤�ǂ��������B
6���}�������҂��ėǂ��\��w
AMD��IPC per Watt�Ƃ������Ă��Ȃ�㍘�����A
�㓡����̋L���̕\���ʂ��TDP�ōs���̂Ȃ�
intel�̓V���O���X���b�h���\���߂ĂȂ��\���B
Parrot�Ɣߊ��Speculative Multithreading�����ҁB
�����ȒP��Memory wall�͔j��Ȃ����낤���A����̗\���@�\���͗]�����͂��낤���B
AMD��IPC per Watt�Ƃ������Ă��Ȃ�㍘�����A
�㓡����̋L���̕\���ʂ��TDP�ōs���̂Ȃ�
intel�̓V���O���X���b�h���\���߂ĂȂ��\���B
Parrot�Ɣߊ��Speculative Multithreading�����ҁB
�����ȒP��Memory wall�͔j��Ȃ����낤���A����̗\���@�\���͗]�����͂��낤���B
�������{�C�ɂȂ���Intel�͋����Ȃ��A�Ȃ����킭�킭���Ă���B
����Ɉ�������AMD�̑̂��炭�U��Ƃ�����������Ă��˂��E�E�E
����Ɉ�������AMD�̑̂��炭�U��Ƃ�����������Ă��˂��E�E�E
24 �FSocket774�F2007/09/17(��) 04:04:44 ID:XB6ysBVy
C2D��K�ڂɎg���Ă���PenD�@�����芷����̂Ɏ����Ă�����TDP����Ȃ��ł���
�܂��܂��ς��Ă��炤��PenD��
�܂��܂��ς��Ă��炤��PenD��
����ς蔚�M�Ȃ̂�(�ߘm
>19
32way�Ăǂ��ɏ����Ă���́H
32way�Ăǂ��ɏ����Ă���́H
�Ă��͂₭OC�c�[���o���Ă���
TDP�Ɋւ��ẮA�̂̋L���ł�4core����ɂȂ�����܂������E(130W)�ɒB����Ƃ͌����Ă��悤�ł��ˁB
BTX���ǂ��\�����[�V�����ɂȂ��?��
���������������E�ŗ���ȏ�A�R������Ȃ��Ǝv���A
���Ƀn�C�G���h�Ό��͍������f�R�ʔ����Ȃ肻���B
AMD�̐V�R�A���\��ʂ�o��Ƃ����O��ŁB
�悭�悭�l������AParrot������Gesher���ォ�ȁA�C�X���G�����̔엿�����B
BTX���ǂ��\�����[�V�����ɂȂ��?��
���������������E�ŗ���ȏ�A�R������Ȃ��Ǝv���A
���Ƀn�C�G���h�Ό��͍������f�R�ʔ����Ȃ肻���B
AMD�̐V�R�A���\��ʂ�o��Ƃ����O��ŁB
�悭�悭�l������AParrot������Gesher���ォ�ȁA�C�X���G�����̔엿�����B
>>18
>�܂����[�G���h��DDR2 ���g�����߂Ƀ`�b�v�Z�b�g�o�R�Ƃ����\�������邪�B
�f�X�N�g�b�v��Nehalem�𓊓�����2009�N1���ɂ�DDR3�̉��i��DDR2�̂Q�������炢�܂�
�����Ă���͂��B����ł�DDR2���g��Ȃ��Ă͂����Ȃ��قǃ��[�G���h�Ȃ�Wolfdale��
�������������B
���o�C���s��͂܂��ʂ̘b�����f�X�N�g�b�v�͂��ׂă����R�������ōs�����낤�B
>�܂����[�G���h��DDR2 ���g�����߂Ƀ`�b�v�Z�b�g�o�R�Ƃ����\�������邪�B
�f�X�N�g�b�v��Nehalem�𓊓�����2009�N1���ɂ�DDR3�̉��i��DDR2�̂Q�������炢�܂�
�����Ă���͂��B����ł�DDR2���g��Ȃ��Ă͂����Ȃ��قǃ��[�G���h�Ȃ�Wolfdale��
�������������B
���o�C���s��͂܂��ʂ̘b�����f�X�N�g�b�v�͂��ׂă����R�������ōs�����낤�B
LGA 1366�\�P�b�gwktk
>Fusion�Ȃ�ăl�^CPU
GPU������intel��Nehalem�Ōv�悵�Ă��鎖����
GPU������intel��Nehalem�Ōv�悵�Ă��鎖����
���ꂩ�琬�c����B�j�������Ă̂ɂ�[�B
IDF�ɍs���ė���Ƃ������ł�
>>18
�o�����[�`���C���X�g���[���Z�O�����g�ł�Tylersburg�Ȃ�č����Ďg���܂���
�ǂ����݂�DDR2�͎g���܂���
http://pc.watch.impress.co.jp/docs/2007/0607/ubiq188_04.jpg
�o�����[�`���C���X�g���[���Z�O�����g�ł�Tylersburg�Ȃ�č����Ďg���܂���
�ǂ����݂�DDR2�͎g���܂���
http://pc.watch.impress.co.jp/docs/2007/0607/ubiq188_04.jpg
{kind=link}
CPU�ւ̃����R�������̓T�[�o�[�����݂̂ƂȂ�
http://blog.livedoor.jp/amd646464/archives/51032343.html
MCM�ɂ��CPU�ւ�GPU�����Ɋւ���Intel�͂���قǖ{�C�ł͂Ȃ��A��AMD Fusion���ӎ������u���t�ł���B
http://microboy.seesaa.net/article/37769795.html
http://blog.livedoor.jp/amd646464/archives/51032343.html
MCM�ɂ��CPU�ւ�GPU�����Ɋւ���Intel�͂���قǖ{�C�ł͂Ȃ��A��AMD Fusion���ӎ������u���t�ł���B
http://microboy.seesaa.net/article/37769795.html
DDR3�̏����̉��i�ɂ��Ă͂��Ȃ�s�������Ǝv���B
���̂Ƃ��̎����ɑ傫�����E������Ȃ����B
�C���e�������̕ӕ������ĂāA���X�N�͂��܂���������悤�ɍl���Ă���͂��B
���̂Ƃ��̎����ɑ傫�����E������Ȃ����B
�C���e�������̕ӕ������ĂāA���X�N�͂��܂���������悤�ɍl���Ă���͂��B
�f�X�N�g�b�v��Nehalem�A�[�L�����y���͂��߂�2009�N���ɂ�
DDR2/DDR3�����ʂ̓N���X���Ă�
DDR2/DDR3�����ʂ̓N���X���Ă�
>>39
���O�͖����l���H
���O�͖����l���H
http://journal.mycom.co.jp/articles/2007/05/16/idf15/images/Photo04l.jpg
http://journal.mycom.co.jp/articles/2007/05/16/idf15/images/Photo12l.jpg
{kind=link}
http://journal.mycom.co.jp/articles/2007/05/16/idf15/images/Photo12l.jpg
{kind=link}
>>18
�������₱��������
Nehalem��GPU���������̂����m���A���炩���A��
�㓡��l�ő����ł�����
�x�[����E�����r�[�ɁuGPU�����v��G�̎����o�Ă��Ȃ��Ȃ�̂�
�������Ȃ��c
�������₱��������
Nehalem��GPU���������̂����m���A���炩���A��
�㓡��l�ő����ł�����
�x�[����E�����r�[�ɁuGPU�����v��G�̎����o�Ă��Ȃ��Ȃ�̂�
�������Ȃ��c
�����ł���قǗD�G��GPU�������B
>>42
�ǂ����ɓ]��ł�IDF��ɒp�����������Ȃ��Ƃ����ނȂ�̃��X�N�����
�ǂ����ɓ]��ł�IDF��ɒp�����������Ȃ��Ƃ����ނȂ�̃��X�N�����
>>35
��������B
���ݐ��c�̃A�N�Z�X�|�C���g����ƌo�R�ŏ������ݒ��B
���n�ɂ͒������Ċό����邩��A�܂��䖝�ł��邩�Ȃ��Ċ����ŁB
��������B
���ݐ��c�̃A�N�Z�X�|�C���g����ƌo�R�ŏ������ݒ��B
���n�ɂ͒������Ċό����邩��A�܂��䖝�ł��邩�Ȃ��Ċ����ŁB
Goto �u�����AMD Fusion ���C�N��GPU�����v�����̘b�肪����܂���ł����v
Gelsinger �uNehalem�ł̓v���b�g�t�H�[�����x���ŁA�}�C�N���A�[�L�e�N�`�����x���ŏ_��ȍ\�����Ƃ��B�������CPU�\�P�b�g�ւ́A�܂��_�C���x���ł�GPU�������\���v
Goto �u��̓I�Ȑ��i���A�����͌��܂��Ă���̂ł��傤���H�v
Gelsinger �u�c�O�Ȃ��猻�݂̃��[�h�}�b�v��ɂ͂Ȃ��B�������ڋq����̗v�]������Ό����������v
Gelsinger �uNehalem�ł̓v���b�g�t�H�[�����x���ŁA�}�C�N���A�[�L�e�N�`�����x���ŏ_��ȍ\�����Ƃ��B�������CPU�\�P�b�g�ւ́A�܂��_�C���x���ł�GPU�������\���v
Goto �u��̓I�Ȑ��i���A�����͌��܂��Ă���̂ł��傤���H�v
Gelsinger �u�c�O�Ȃ��猻�݂̃��[�h�}�b�v��ɂ͂Ȃ��B�������ڋq����̗v�]������Ό����������v
fusion�Ȃ�ċ߂���������Ȃ����Ė����̘b����
��������������ǂ����������Ȃ�āA�L���̗���͂Ȃ�����
��������������ǂ����������Ȃ�āA�L���̗���͂Ȃ�����
�C���e���A�����G���W����Havok�Ђ�
http://japanese.engadget.com/2007/09/17/havok-intel/
http://japanese.engadget.com/2007/09/17/havok-intel/
���X
��X�͌ڋq�̗v�]�ɉ����āA�I�v�V������GPU�lj���������
�p�ӂ���\�������
�Ɖ]���b�����̂������߂���
Nehalem�ɂ�GPU�����������I��
�㓡�O�������Ă邾���B
GPU��������Nehalem�Ȃ�ďo�Ȃ���B
��X�͌ڋq�̗v�]�ɉ����āA�I�v�V������GPU�lj���������
�p�ӂ���\�������
�Ɖ]���b�����̂������߂���
Nehalem�ɂ�GPU�����������I��
�㓡�O�������Ă邾���B
GPU��������Nehalem�Ȃ�ďo�Ȃ���B
GPU�˂�����
>>21
1ch������2DIMM����Ȃ����������B
�����Nehalem�̂���ɂ�DDR3��2Gbit�������Ȃ��Ă邩��2�X���b�g��8GB���\�ɂȂ邩��64bit�ɂȂ��ˁ[�́B
1ch������2DIMM����Ȃ����������B
�����Nehalem�̂���ɂ�DDR3��2Gbit�������Ȃ��Ă邩��2�X���b�g��8GB���\�ɂȂ邩��64bit�ɂȂ��ˁ[�́B
DDR3��nonReg����1ch������2DIMM�܂ő}���������H
���ȃ��X
1�`���l��2�X���b�g�ɕύX�ɂȂ����ƌ㓡�̉ߋ��L���ɂ������BDDR3-1366�܂ł͈ꉞnonReg�ł��Q���h��
�����������B
1�`���l��2�X���b�g�ɕύX�ɂȂ����ƌ㓡�̉ߋ��L���ɂ������BDDR3-1366�܂ł͈ꉞnonReg�ł��Q���h��
�����������B
�����łȂ������Ă��ˁ[��Ȃ�
2���Ƃ���������
�����ɂ�1���}���ł��������Ȃ��P�[�X���قƂ�ǂ�1000�ɯ�
�����ɂ�1���}���ł��������Ȃ��P�[�X���قƂ�ǂ�1000�ɯ�
56 �FSocket774�F2007/09/17(��) 20:11:22 ID:AKD2QZd3
���J
��肎���ĂȂɂ��������́H
�L���b�V��
�����ĂȂɂ��������́H
60 �FSocket774�F2007/09/17(��) 20:47:03 ID:AKD2QZd3
unix
Havok������Larabee��PC�ɔ��荞�ވׂ��낤�ȁB
�������Z��GPGPU�̗L���ȗp�r��Havok��Nvidia�AAMD������GPU�ɑΉ����Ă���
���o�[�W�����ł�GPU��Ή��ɂ���Ă��܂����낤�B
�����Nvidia�AAMD�A����Fusion�ɂ͑傫���Ɏ�ƂȂ�B
�������Z��GPGPU�̗L���ȗp�r��Havok��Nvidia�AAMD������GPU�ɑΉ����Ă���
���o�[�W�����ł�GPU��Ή��ɂ���Ă��܂����낤�B
�����Nvidia�AAMD�A����Fusion�ɂ͑傫���Ɏ�ƂȂ�B
���ł�AGEIA���S���S�B
�, ��, 冂̎O��������t�B��鰂ƌ��Ɋ������ꂽ���_�Ńp���[�o�����X�����������
�Ⴆ��Ȃ�� = Intel , �� = AMD , � = NVIDIA, �t�B�k�� = Havok(�܂�ISV�A��) , �t�B�암 = ATI
�Ⴆ��Ȃ�� = Intel , �� = AMD , � = NVIDIA, �t�B�k�� = Havok(�܂�ISV�A��) , �t�B�암 = ATI
冂�AMD���Ċ������Ȃ��B
������Ƃ������������͍��߂邽�߂ɖk�����J��Ԃ����A�ǒn��ʼn��x�����Ă�
�吨�ɉe�����Ȃ��Ƃ����߂����B
������Ƃ������������͍��߂邽�߂ɖk�����J��Ԃ����A�ǒn��ʼn��x�����Ă�
�吨�ɉe�����Ȃ��Ƃ����߂����B
>>61
>�v���X�����[�X�ɂ���Havok�̓C���e���ɋz�����ꂽ����]���̃I�y���[�V�������ێ���
>�đS�v���b�g�t�H�[�������̐��i�����Ƃ̂��ƁB
>�v���X�����[�X�ɂ���Havok�̓C���e���ɋz�����ꂽ����]���̃I�y���[�V�������ێ���
>�đS�v���b�g�t�H�[�������̐��i�����Ƃ̂��ƁB
Larrabee��Havok�Ŕ��낤�Ȃ�Ďv���Ă���Ȃ�
PhysX�̂Q�̕���
PhysX�̂Q�̕���
�uNehalem�v��3�`���l��DDR3�������̔閧
http://pc.watch.impress.co.jp/docs/2007/0918/kaigai387.htm
�g45nm�h���L�[���[�h��AMD���}������Intel
�`Duo�h�A�gQuad�h�Ȃǂ̃T�u�u�����h�p�~�v��͓P��
http://pc.watch.impress.co.jp/docs/2007/0918/ubiq196.htm
http://pc.watch.impress.co.jp/docs/2007/0918/kaigai387.htm
�g45nm�h���L�[���[�h��AMD���}������Intel
�`Duo�h�A�gQuad�h�Ȃǂ̃T�u�u�����h�p�~�v��͓P��
http://pc.watch.impress.co.jp/docs/2007/0918/ubiq196.htm
>>65
�ŏ��͂��������̂͂�����܂��A��������Ȃ�M����z�͂��Ȃ��B
���u�S�v���b�g�t�H�[�������v�Ƃ����\���ł͉���\���Ă�̂���ؕs���B
>>66
PhysX��p�`�b�v�Ɣėpx86��Larabee���ׂ邱�Ǝ��̃A�z�炵���B
�ŏ��͂��������̂͂�����܂��A��������Ȃ�M����z�͂��Ȃ��B
���u�S�v���b�g�t�H�[�������v�Ƃ����\���ł͉���\���Ă�̂���ؕs���B
>>66
PhysX��p�`�b�v�Ɣėpx86��Larabee���ׂ邱�Ǝ��̃A�z�炵���B
�J�[�h���̂�PhysX��p�����A���̃`�b�v��Cell�݂�����
�ėp�R�A�{���������_�ɓ�����������PE
�ėp�R�A�{���������_�ɓ�����������PE
>>66
����
����
x86�ƌ����NJ����̃\�t�g�������������킯�ł͂Ȃ�
�V�K�\�t�g���K�v
������ΖӒ�
�V�K�\�t�g���K�v
������ΖӒ�
����̓z���}���`���ꏏ�B
�ŁA�����܂ŕ��o����p�r�Ȃ�
Larrabee�̕����y���Ɍ����Ă���B
�ŁA�����܂ŕ��o����p�r�Ȃ�
Larrabee�̕����y���Ɍ����Ă���B
�ǂ������Larrabee�y������̂��낤�E�E�E
��������̃\�t�g�̍������]�X�Ƃ������z���邯��
�}���`�R�A�ǂ��납SSE�Ƃ��N�A�b�h��f���A���ł���
�����̃\�t�g�Ȃ�č��������ĂȂ��Ƃ����̂͂ǂ��v���Ă�낤���B
�����̃\�t�g�̍������͕��y�ɕK�v�ȏ����ł��Ȃ�ł��Ȃ�����
����ȓ˂����݂͈Ӗ��������Ȃ��B
�}���`�R�A�ǂ��납SSE�Ƃ��N�A�b�h��f���A���ł���
�����̃\�t�g�Ȃ�č��������ĂȂ��Ƃ����̂͂ǂ��v���Ă�낤���B
�����̃\�t�g�̍������͕��y�ɕK�v�ȏ����ł��Ȃ�ł��Ȃ�����
����ȓ˂����݂͈Ӗ��������Ȃ��B
��ʓI��CPU�̓N���b�N���オ�������
���������]�߂邵���������̃\�t�g�����ʂɑ���B
�V�����@�\���\�t�g�������ł͎g����킯���B
GPU�̏ꍇ�����l�B
����Larrabee�́E�E�E�ƂȂ��
��PhysX�Ɏ��Ă��܂��B
���������]�߂邵���������̃\�t�g�����ʂɑ���B
�V�����@�\���\�t�g�������ł͎g����킯���B
GPU�̏ꍇ�����l�B
����Larrabee�́E�E�E�ƂȂ��
��PhysX�Ɏ��Ă��܂��B
>GPU�̏ꍇ�����l�B
>
>����Larrabee�́E�E�E�ƂȂ��
>��PhysX�Ɏ��Ă��܂��B
�L�`�K�C�F�肳��Ă��v�����Ȃ��B
>
>����Larrabee�́E�E�E�ƂȂ��
>��PhysX�Ɏ��Ă��܂��B
�L�`�K�C�F�肳��Ă��v�����Ȃ��B
>>67�̌㓡�̍Ō��DDR2-1066�̘b�A�s�m��Ƃ����N���G��Ȃ��̂ˁB
���ꂾ���@���Ă����̂�
���ꂾ���@���Ă����̂�
���Ǖ��ʂ�DDR2�Ƃ��Ă͕W�����͂���Ȃ�������ł���
���F�j�b�`�ō�����OC�������͒N������肽�����̂ł͂Ȃ��Ƃ������Ƃł�
���F�j�b�`�ō�����OC�������͒N������肽�����̂ł͂Ȃ��Ƃ������Ƃł�
DDR3�̂��Ƃ��I
�Ƃ�������肽���Ă����Ȃ���Ȃ����B
DDR2-1066�����郁�[�J�[�Ȃ�A�����o�ăv���~�A�t���Ŕ���邩��A�W�����Ɏ^���̂͂��B
�܂��ł��ADDR�̂Ƃ����{��DDR333�܂ł̂͂����A�C���e���̂킪�܂܂ŋ}�400���o�����ƂɂȂ��āA
DDR2��533����X�^�[�g�ɂȂ����o�܂������āA���ꂪ������800�܂ł����킯�����ǁA
�����1066���o���ƂȂ�ƁADDR3�́A�܂�1333����X�^�[�g�ɂȂ�킯�ŁA
��������ƍ��x��DDR3-2400�܂ōs�������Ƃ�CPU���[�J�[�������o������������A���ꂪ�|���̂�������Ȃ��ˁB
DDR2-1066�����郁�[�J�[�Ȃ�A�����o�ăv���~�A�t���Ŕ���邩��A�W�����Ɏ^���̂͂��B
�܂��ł��ADDR�̂Ƃ����{��DDR333�܂ł̂͂����A�C���e���̂킪�܂܂ŋ}�400���o�����ƂɂȂ��āA
DDR2��533����X�^�[�g�ɂȂ����o�܂������āA���ꂪ������800�܂ł����킯�����ǁA
�����1066���o���ƂȂ�ƁADDR3�́A�܂�1333����X�^�[�g�ɂȂ�킯�ŁA
��������ƍ��x��DDR3-2400�܂ōs�������Ƃ�CPU���[�J�[�������o������������A���ꂪ�|���̂�������Ȃ��ˁB
�ǂ�������DDR3�̗����グ���x���̂��������Ă̂��{�����낤�B
��荂����DDR2�ɓ������Ă���Micron��AMD�Ƒg��őʁX�����˂����ǁA
����ς蔽�Α����ŃI�v�V������������Č�d�����Ƃ����I�`�B
��荂����DDR2�ɓ������Ă���Micron��AMD�Ƒg��őʁX�����˂����ǁA
����ς蔽�Α����ŃI�v�V������������Č�d�����Ƃ����I�`�B
����DDR3��ϋɓI�Ɏg�����R���Ȃ�����ȁBDDR����DDR2�ւ̈ڍs�Ɠ����ŁA�܂��͏���d�͓I��
�Â݂̂��郂�o�C������������ڍs���ȁB
�Â݂̂��郂�o�C������������ڍs���ȁB
����ɂ��Ă��A�ŏ�ʃ��f�������s���i�Ɠ���3GHz�Ȃ̂͂Ȃ����낤�B
�]�T�Ȃ̂��ȁB
�]�T�Ȃ̂��ȁB
Penryn��Prescott���̑厸�s�ƌ����\��������ɂ͂��邪�B�B�B
�]�T�Ȃ낤�ˁB
�]�T�Ȃ낤�ˁB
�G���n���X�h�z���g�p���[��Q6600��27w�Ȃ̂�
���[�N������15w�قǂȂ甃�������ȂƂ������Ă���B
���Ă䂤��45nm��Hi-k�̎��͂��݂����Ⴈ�����ȁ`����
�o�Ă���Ƃ������Ă���B
�����c2d�͏����X�e�b�s���O�Ȃ̂�22w�������ł�
���[�N������15w�قǂȂ甃�������ȂƂ������Ă���B
���Ă䂤��45nm��Hi-k�̎��͂��݂����Ⴈ�����ȁ`����
�o�Ă���Ƃ������Ă���B
�����c2d�͏����X�e�b�s���O�Ȃ̂�22w�������ł�
���s�H�@�@�@�ˁ[��
�������������Ƃ�����A�ŋ߂�Intel�̃}�[�P�e�B���O�g�[�N�����Ă���ƂȂ��Ȃ������[���B
���ŋ߁AIntel�̊����������邲�ƂɌ��L�[���[�h�����́g45nm�h�Ȃ̂��B
���V���[���E�}���[�j�㋉���В���COMPUTEX TAIPEI�ł̊�u���A
��Intel 3�V���[�Y�`�b�v�Z�b�g���\��ł̃��`���[�h�E�}���m�E�X�L�[���В��̍u���A
�����{�ł̃N���C�A���g���M�����[�A�b�v�f�[�g�A������ɂ����Ă�
���g45nm�h�Ƃ����L�[���[�h���������A�Ă���Ƃ����V�[����M�҂͉��x���ڌ������B
�����ꂪ�Ӗ����邱�Ƃ́AIntel�����N�㔼�̃}�[�P�e�B���O�̏d�v�ȃL�[���[�h��
���g45nm�h��I�����A�����Ĕ��\��Ȃǂł��ꂪ���s����Ă���A�����������Ƃ��낤�B
��
��45nm�v���Z�X���[���Ő��������Core 2 Extreme QX9650�̓�����O�|������̂�
������������ƍl����g���R�ȗ���h�ƌ�����̂ł͂Ȃ����낤���B
�������Ă���́A�ȑO�̋L���ł��ӂꂽ�悤�ɁAIntel��45nm�v���Z�X���[����
�����ɏ����ɗ����オ���Ă���Ƃ����b�̏ؖ��ł�����B
�������������Ƃ�����A�ŋ߂�Intel�̃}�[�P�e�B���O�g�[�N�����Ă���ƂȂ��Ȃ������[���B
���ŋ߁AIntel�̊����������邲�ƂɌ��L�[���[�h�����́g45nm�h�Ȃ̂��B
���V���[���E�}���[�j�㋉���В���COMPUTEX TAIPEI�ł̊�u���A
��Intel 3�V���[�Y�`�b�v�Z�b�g���\��ł̃��`���[�h�E�}���m�E�X�L�[���В��̍u���A
�����{�ł̃N���C�A���g���M�����[�A�b�v�f�[�g�A������ɂ����Ă�
���g45nm�h�Ƃ����L�[���[�h���������A�Ă���Ƃ����V�[����M�҂͉��x���ڌ������B
�����ꂪ�Ӗ����邱�Ƃ́AIntel�����N�㔼�̃}�[�P�e�B���O�̏d�v�ȃL�[���[�h��
���g45nm�h��I�����A�����Ĕ��\��Ȃǂł��ꂪ���s����Ă���A�����������Ƃ��낤�B
��
��45nm�v���Z�X���[���Ő��������Core 2 Extreme QX9650�̓�����O�|������̂�
������������ƍl����g���R�ȗ���h�ƌ�����̂ł͂Ȃ����낤���B
�������Ă���́A�ȑO�̋L���ł��ӂꂽ�悤�ɁAIntel��45nm�v���Z�X���[����
�����ɏ����ɗ����オ���Ă���Ƃ����b�̏ؖ��ł�����B
IDF Fall 2007�O�����|�[�g
http://pc.watch.impress.co.jp/docs/2007/0919/idf00.htm
http://pc.watch.impress.co.jp/docs/2007/0919/idf00.htm
45nm�����A�s�[������|�C���g�������悤�ł���
�n���H CPU�̐��\�̔����̓v���Z�X�̗ǂ������Ō��܂��ł����B
266MHz�ō쓮�o���郁�����͏��Ȃ����낤��
���܂���C�O�T�C�g��IDF���|�[�g�̎��Ԃł���B
Intel shows off 32 nanometre wafer, talks Nehalem
http://www.theinquirer.net/?article=42431
�E32nm�E�F�n��������
�EPenryn��11/12�ɔ��\
�ENehalem�̓��W�����[�\��
�ENehalem�͈ꃖ���O�ɃV���R�������Ă�
Intel shows off 32 nanometre wafer, talks Nehalem
http://www.theinquirer.net/?article=42431
�E32nm�E�F�n��������
�EPenryn��11/12�ɔ��\
�ENehalem�̓��W�����[�\��
�ENehalem�͈ꃖ���O�ɃV���R�������Ă�
>>92
�ŏ��ɖڂɂ������͂�
>The next 32 generation will have the second version of Hafnium gates,
>and he showed off a 32 inch wafer.
�ł��ǂ낢��w
81�Z���`�E�F�n����A�ƁB
�ŏ��ɖڂɂ������͂�
>The next 32 generation will have the second version of Hafnium gates,
>and he showed off a 32 inch wafer.
�ł��ǂ낢��w
81�Z���`�E�F�n����A�ƁB
����͉����v������
>And 45 nanometre graphics integrated with the CPU will be available next year
Otellini unveils Nehalem
http://www.bit-tech.net/news/2007/09/18/otellini_unveils_nehalem/1
�_�C�ʐ^����
http://www.bit-tech.net/news/2007/09/18/otellini_unveils_nehalem/1
�_�C�ʐ^����
Intel Developer Forum 2007 - Day 1: Nehalem, Intel's GPUs, 32nm and More
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3101
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3101
>>96
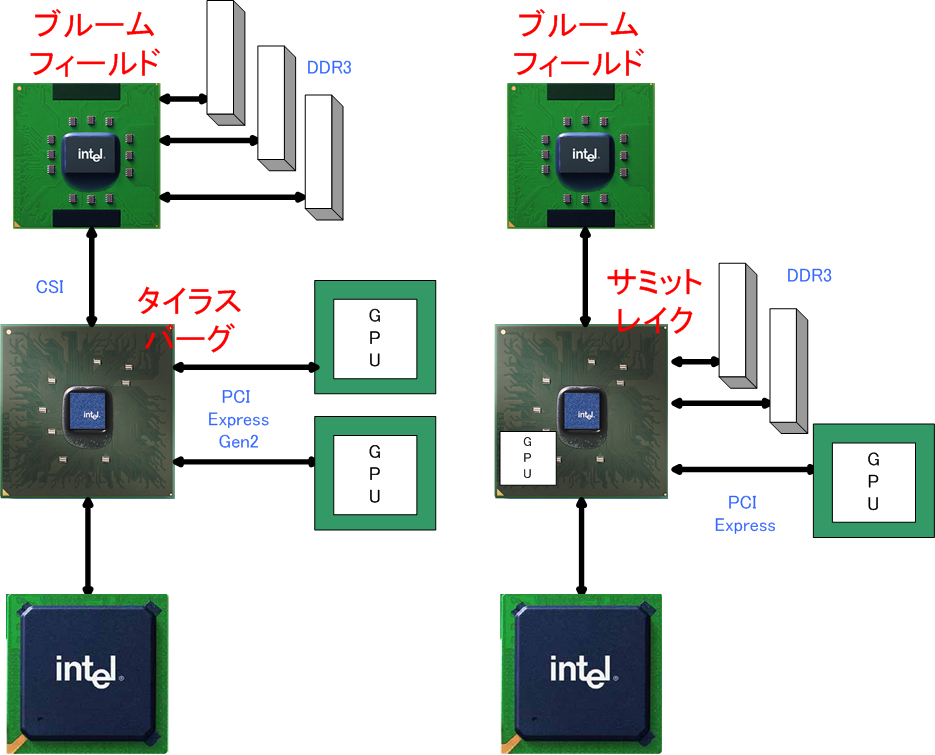
�㑤��DRAM�p�b�h�ō��E��CSI���Ƃ�QuickPath���낤���B
�R�A�̃��C�A�E�g��Penryn�Ƃ����Ԃ�Ⴄ�悤�Ɍ�����˂��B
�L���b�V������ɂ��Ĕ�ׂĂ݂Ă��R�A�����Ȃ�傫���悤�Ɍ�����B
�Ə����ĂĎv���o�������ǁA�L���b�V������L3�܂ł���������B
��ԉ��̂��ŏI���x���̃L���b�V���Ɍ����邯�ǁA���ꂪL3���Ƃ����L2�͂ǂ����낤�B
���ƃR�A�����E��2�����ׂĂ���̂��s�v�c�Ȋ����B
�^���N���X�o�[�Ƃ��̗ނ��Ǝv�����ǁA�����ɗאڂ��ĂȂ��R�A������B
����Ƃ��N���X�o�[�͐^���c�ɑ����Ă�����Ȃ��Ăǂ������ɂł������Ă�̂��ȁB
�E�F�n�ʐ^���琄�����Ă݂���Nehalem�̃_�C�T�C�Y�͂�������280mm2���炢�H
Barcelona�Ƃقړ����T�C�Y�Ȃ̂͋����[���ȁB
�㑤��DRAM�p�b�h�ō��E��CSI���Ƃ�QuickPath���낤���B
�R�A�̃��C�A�E�g��Penryn�Ƃ����Ԃ�Ⴄ�悤�Ɍ�����˂��B
�L���b�V������ɂ��Ĕ�ׂĂ݂Ă��R�A�����Ȃ�傫���悤�Ɍ�����B
�Ə����ĂĎv���o�������ǁA�L���b�V������L3�܂ł���������B
��ԉ��̂��ŏI���x���̃L���b�V���Ɍ����邯�ǁA���ꂪL3���Ƃ����L2�͂ǂ����낤�B
���ƃR�A�����E��2�����ׂĂ���̂��s�v�c�Ȋ����B
�^���N���X�o�[�Ƃ��̗ނ��Ǝv�����ǁA�����ɗאڂ��ĂȂ��R�A������B
����Ƃ��N���X�o�[�͐^���c�ɑ����Ă�����Ȃ��Ăǂ������ɂł������Ă�̂��ȁB
�E�F�n�ʐ^���琄�����Ă݂���Nehalem�̃_�C�T�C�Y�͂�������280mm2���炢�H
Barcelona�Ƃقړ����T�C�Y�Ȃ̂͋����[���ȁB
>>97
��������ł�Ԃɑ��B
Penryn��410M�ɑ���Nehalem��731M�B
��G�c�Ȍv�Z�ł͂��邯�ǃL���b�V���ȊO�̃g�����W�X�^�̐���
Merom��65M
Penryn��70M
Nehalem��278M
�ŃR�A����2�{�Ƃ͌���Nehalem���_���g�c�ɑ����B
��͂胁���R����QuickPath�̉e�����B
Yorkfield��5.5GHz�������������B
�Ƃ��Ƃ�IDF��Super PI���o�Ă������c�B
Larrabee�̓O���t�B�b�N���o���܂���A�ƁB
����Larrabee��GPU���S������̂��H
��������ł�Ԃɑ��B
Penryn��410M�ɑ���Nehalem��731M�B
��G�c�Ȍv�Z�ł͂��邯�ǃL���b�V���ȊO�̃g�����W�X�^�̐���
Merom��65M
Penryn��70M
Nehalem��278M
�ŃR�A����2�{�Ƃ͌���Nehalem���_���g�c�ɑ����B
��͂胁���R����QuickPath�̉e�����B
Yorkfield��5.5GHz�������������B
�Ƃ��Ƃ�IDF��Super PI���o�Ă������c�B
Larrabee�̓O���t�B�b�N���o���܂���A�ƁB
����Larrabee��GPU���S������̂��H
Nehalem�̃_�C�����������ȁE�E�E�B�����Ă����������B
CPU-GPU�����ALarrabee��Graphics�������\�B
�K�������Ĕے肵�������z��o�ė�����
�K�������Ĕے肵�������z��o�ė�����
Nehalem's chief architect, Glenn Hinton, also revealed
that the processor will incorporate technology to better help it handle single-threaded applications,
�V���O���X���b�h�̃^�[�{���[�h��
Enhanced Dynamic Acceleration�݂����Ȃ̂���
that the processor will incorporate technology to better help it handle single-threaded applications,
�V���O���X���b�h�̃^�[�{���[�h��
Enhanced Dynamic Acceleration�݂����Ȃ̂���
>>101
�㓡�L����d�g���p���ĕK�������Ĕے肵�Ă��z��̂��Ƃ��v���o���Ə������ݏグ�Ă��邗
�㓡�L����d�g���p���ĕK�������Ĕے肵�Ă��z��̂��Ƃ��v���o���Ə������ݏグ�Ă��邗
>>97
�_�C�ʐ^�������Ăďd�v�Ȃ��ƂɋC�Â��Ȃ������B
Nehalem: Single die, 8-cores, 731M transistors, 16 threads, memory controller, graphics, amazing.
�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�I�I�I�I�I�I�I
�Ƃ����킯��Nehalem��Native 8core�o�[�W����������݂����ł��B
�_�C�ʐ^��E�F�n�͊Ԃɍ���Ȃ��������ۂ����ǁB
4core��731M tansistors�Ȃ̂ɂ��ꂪ8core�ɂȂ�Ƃǂꂾ���c�c�B
���ƁA�ʐϓI�ɂ�QuickPath�̕���HT���傫�����ȋC������ȁB
������4core�ł��x���̂��ȁH
���Ƃ��Ă�8core�łł����N���ɓ������ꂩ�˂�ȁB
AMD��Sandtiger��2009�N�㔼���ۂ����AAMD���悢�������c�B
Shanghai���炷����MCM 8core�o���Ȃ��ƃ}�W������B
���ɂ���AIntel��AMD����邱�Ƃ����Ă����Ȃ��Ċ����ł��ˁB
�_�C�ʐ^�������Ăďd�v�Ȃ��ƂɋC�Â��Ȃ������B
Nehalem: Single die, 8-cores, 731M transistors, 16 threads, memory controller, graphics, amazing.
�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�G�I�I�I�I�I�I�I
�Ƃ����킯��Nehalem��Native 8core�o�[�W����������݂����ł��B
�_�C�ʐ^��E�F�n�͊Ԃɍ���Ȃ��������ۂ����ǁB
4core��731M tansistors�Ȃ̂ɂ��ꂪ8core�ɂȂ�Ƃǂꂾ���c�c�B
���ƁA�ʐϓI�ɂ�QuickPath�̕���HT���傫�����ȋC������ȁB
������4core�ł��x���̂��ȁH
���Ƃ��Ă�8core�łł����N���ɓ������ꂩ�˂�ȁB
AMD��Sandtiger��2009�N�㔼���ۂ����AAMD���悢�������c�B
Shanghai���炷����MCM 8core�o���Ȃ��ƃ}�W������B
���ɂ���AIntel��AMD����邱�Ƃ����Ă����Ȃ��Ċ����ł��ˁB
���Ⴀ��������
Intel announced that in its largest configuration, Nehalem (2H 2008, 45nm) will
feature 8 cores on a single die, each core supporting 2 threads per core
(welcome back Hyper Threading) for a total of 16 threads per physical chip.
8 cores on a single die
Intel announced that in its largest configuration, Nehalem (2H 2008, 45nm) will
feature 8 cores on a single die, each core supporting 2 threads per core
(welcome back Hyper Threading) for a total of 16 threads per physical chip.
8 cores on a single die
1�_�C����500mm2�Ƃ��ɂȂ肻��������
�ɎE���C���낤���B
�ɎE���C���낤���B
�o�Ă�MP���낤��
Anandtech��Harpertown vs. Barcelona�L�����B
http://www.anandtech.com/IT/showdoc.aspx?i=3099
�@�@---------------------
�@�@Intel has made some successful changes to the quad-core Xeon that have helped it achieve
�@�@as much as a 56% lead in performance over the 2.0GHz Barcelona part.
�@�@---------------------
�N���b�N��ȏ�̐��\�����o�Ă邷�B
http://www.anandtech.com/IT/showdoc.aspx?i=3099
�@�@---------------------
�@�@Intel has made some successful changes to the quad-core Xeon that have helped it achieve
�@�@as much as a 56% lead in performance over the 2.0GHz Barcelona part.
�@�@---------------------
�N���b�N��ȏ�̐��\�����o�Ă邷�B
TheINQ�ɂ��A����������ʓI�ȃx���`���B����NDA����ł�L�҂��������ˁB�B�B
http://www.theinquirer.net/?article=42423
http://www.theinquirer.net/?article=42423
113 �FSocket774�F2007/09/19(��) 07:05:40 ID:wufzuCcM
>>37,42,47,49,75,77
���炵����
���炵����
�������TechReport��Hapertown vs. Barcelona�BBarcelona/2.5GHz������ăf�X�N�g�b�v�x���`�}�[�N
���s���Ă��邷�B
http://www.techreport.com/articles.x/13224/1
���s���Ă��邷�B
http://www.techreport.com/articles.x/13224/1
������㓡��intel�̏�w���ƃp�C�v�����Ă邩�猈��I�ȊԈႢ�͂��Ȃ�����
���x�����������낤���B
���x�����������낤���B
�ȑO�̋L���ł�8�R�A��MCM������
1�_�C�Ƃ����̂�anandtech�̃g�o�V����Ȃ����Ȃ�
1�_�C�Ƃ����̂�anandtech�̃g�o�V����Ȃ����Ȃ�
����ANehalem�������˂��H����Penryn���~��������
Nehalem�����������ȁE�E�E�B
Penryn������Westmere������
Nehalem�����āASandyBridge�������������Y�ނ�
AMD�Ɋ撣���Ă����Ȃ��ƁA����͌������ȁB
Penryn������Westmere������
Nehalem�����āASandyBridge�������������Y�ނ�
AMD�Ɋ撣���Ă����Ȃ��ƁA����͌������ȁB
Nehalem�̓T�[�o�p�Ƃ��Ă͂��������ǃf�X�N�g�b�v�ł����܂Ő��\���K�v��
�^��Ȃ�
�^��Ȃ�
���\�s�v�Ȑl�͒@�������Ԃ�AMD�А�CPU�ŗǂ���Ȃ���?
�����Ȃ�AMD
�����Ȃ�AMD
���\���L���č��鎖�͂Ȃ��B
H.264�G���R�Ȃ��፡�ł������
H.264�G���R�Ȃ��፡�ł������
���\���߂Ȃ��l�͂����ɂ����Ⴂ���Ȃ��̂ł������ɂ��A�肭��������
http://pc11.2ch.net/test/read.cgi/jisaku/1190122267/
http://pc11.2ch.net/test/read.cgi/jisaku/1189437911/
http://pc11.2ch.net/test/read.cgi/jisaku/1190122267/
http://pc11.2ch.net/test/read.cgi/jisaku/1189437911/
��[�@���������s�e��������
Nehalem�̐��\���t���Ɉ����o���ɂ�16�X���b�h�ȏ����Ń������ш���ނ�����g��
�A�v�����K�v�Ȃ킯����B
�f�X�N�g�b�v�ł��������A�v���͂����ꕔ����B�T�[�o�HPC�ł͕��ʂɂ��邪�B
Nehalem�̐��\���t���Ɉ����o���ɂ�16�X���b�h�ȏ����Ń������ш���ނ�����g��
�A�v�����K�v�Ȃ킯����B
�f�X�N�g�b�v�ł��������A�v���͂����ꕔ����B�T�[�o�HPC�ł͕��ʂɂ��邪�B
8�R�A�̓T�[�o�HPC������
�f�X�N�g�b�v��4�R�A�~�܂�Ȃ�BEE�ŏo����������ǁB
�f�X�N�g�b�v��4�R�A�~�܂�Ȃ�BEE�ŏo����������ǁB
>>125
�Q�[�����Ȃ��BHavoc�����������Ȃ��B
�Q�[�����Ȃ��BHavoc�����������Ȃ��B
>124
��[�G���R�[�_]
��[�G���R�[�_]
>>124
�����Quad�R�A�����Ă���ȃA�v���͂����ꕔ���낗
�����o��Ό�X�\�t�g�����Ă���B����ł�������Ȃ����B
�ł��A8�R�ANehalem�̓}�W�ŗ~�����ȁc�B
>>121&>>123
�����A�ɂ��A�~�͂��Ȃ��ŗ~�����Ƃ���B
�U������Ȃ点�߂�C7�X���ɂł������B
�����Quad�R�A�����Ă���ȃA�v���͂����ꕔ���낗
�����o��Ό�X�\�t�g�����Ă���B����ł�������Ȃ����B
�ł��A8�R�ANehalem�̓}�W�ŗ~�����ȁc�B
>>121&>>123
�����A�ɂ��A�~�͂��Ȃ��ŗ~�����Ƃ���B
�U������Ȃ点�߂�C7�X���ɂł������B
�Ȃ��havok�E�E�E�E�E
���l���Ă�H���̃R�v���͕������Z�H
���l���Ă�H���̃R�v���͕������Z�H
����d�͓I�Ƀ��o�C�����ƌ��������B���o�C���̃��[�h�}�b�v��Penryn�iMontevina)�ȍ~�A�܂��������\��
���[�N���Ȃ����Ƃ�����APenryn�p���̉\���������\���B
���[�N���Ȃ����Ƃ�����APenryn�p���̉\���������\���B
Intel�ASkulltrail��Nehalem�̎����f���Ȃǂ������J
�ENVIDIA��SLI�Ƃ̑g�ݍ��킹�œ��삵�Ă����gSkulltrail�h
�E���삵�Ă���Nehalem�̃V�X�e��(2�\�P�b�g��8�R�A�ASMT��16�R�A)
http://pc.watch.impress.co.jp/docs/2007/0919/idf01.htm
�ENVIDIA��SLI�Ƃ̑g�ݍ��킹�œ��삵�Ă����gSkulltrail�h
�E���삵�Ă���Nehalem�̃V�X�e��(2�\�P�b�g��8�R�A�ASMT��16�R�A)
http://pc.watch.impress.co.jp/docs/2007/0919/idf01.htm
Silverthorne +SSD�ł悭��>���o�C��
>>130
��d���ł͂����ƌ�ŏo���Ȃ����H
>>132
����ł��������A�p���[���~�����ꍇ�ɂ́A
����ς�f�X�N�g�b�v�Ɠ���CPU���~�����Ƃ��낾�B
Silverthorne���m�[�g�pCPU�Ɠ������x�̐��\�Ȃ�A
���قǖ��͂Ȃ����B
��d���ł͂����ƌ�ŏo���Ȃ����H
>>132
����ł��������A�p���[���~�����ꍇ�ɂ́A
����ς�f�X�N�g�b�v�Ɠ���CPU���~�����Ƃ��낾�B
Silverthorne���m�[�g�pCPU�Ɠ������x�̐��\�Ȃ�A
���قǖ��͂Ȃ����B
http://www.intel.com/pressroom/kits/events/idffall_2007/BriefingSmith45nm.pdf
��18�y�[�W�ŁAFSB��1600��3.2GHz��Harpertown���ƁASPECfp2006rate�ł��A
���肬��Barcelona2.5GHz����悤���B2.6GHz���o���炷�������ꂻ�������A3.2GHz�����ł邩�킩��ǁB
��18�y�[�W�ŁAFSB��1600��3.2GHz��Harpertown���ƁASPECfp2006rate�ł��A
���肬��Barcelona2.5GHz����悤���B2.6GHz���o���炷�������ꂻ�������A3.2GHz�����ł邩�킩��ǁB
>>115
�M�ҕK�����ȁB�㓡���͂�����AMD�̓��W�����[������]�X�������Ă������B
Nehalem�̓��W�����[���Ƃ����Ă����̂ɁA�S���Ƃ肠�����Ȃ������B
�M�ҕK�����ȁB�㓡���͂�����AMD�̓��W�����[������]�X�������Ă������B
Nehalem�̓��W�����[���Ƃ����Ă����̂ɁA�S���Ƃ肠�����Ȃ������B
>>134
3GHz��E5472��TDP 80w������3.2GHz��2360 SE�Ɠ���TDP120w�Ȃ炷���o���邾�낤�B
FSB1600��Xeon��E5472��E5462�݂̂������̂�2360 SE�̔N���o�ꂪ�����܂�Ă��������̃l�^������A
����Intel�̃��[�h�}�b�v�͏����������Ă��邩���m��Ȃ��B
3GHz��E5472��TDP 80w������3.2GHz��2360 SE�Ɠ���TDP120w�Ȃ炷���o���邾�낤�B
FSB1600��Xeon��E5472��E5462�݂̂������̂�2360 SE�̔N���o�ꂪ�����܂�Ă��������̃l�^������A
����Intel�̃��[�h�}�b�v�͏����������Ă��邩���m��Ȃ��B
�Ă������A�㓡�����ϋɓI�ɂƂ�グ��Z�p���đ�̂������ȁB
Prescott, PS3, Bercelona, Fusion
Core 2��Nehalem�̓A�[�L�e�N�`���̏ڍׂ��ł�܂ŁA���[�h�}�b�v���x��
�b�����܂Ɏ��グ���邵���Ȃ��������ǁc�B
Prescott, PS3, Bercelona, Fusion
Core 2��Nehalem�̓A�[�L�e�N�`���̏ڍׂ��ł�܂ŁA���[�h�}�b�v���x��
�b�����܂Ɏ��グ���邵���Ȃ��������ǁc�B
���������⑫�B
FSB1600��Xeon�̋L���B���t��8��23��
http://www.vr-zone.com/articles/1600FSB_Harpertown_To_Counter_Barcelona_In_Q4_'07/5187.html
2360 SE�N�������̋L���B���t��9��11���B
http://pc.watch.impress.co.jp/docs/2007/0911/amd2.htm
FSB1600��Xeon�̋L���B���t��8��23��
http://www.vr-zone.com/articles/1600FSB_Harpertown_To_Counter_Barcelona_In_Q4_'07/5187.html
2360 SE�N�������̋L���B���t��9��11���B
http://pc.watch.impress.co.jp/docs/2007/0911/amd2.htm
��̕��ŋS�̎����������̂悤�Ɋ��ł�A�t�H�������
Integrated Graphics �͂����܂Łuplan�v
��AMD���݂����Ă̌���
anandtech�́uLarrabee would be Intel's discrete GPU�v
�L�q��Anand�̍앶����
http://www.pcper.com/article.php?aid=453
��Otellini �u�����r�[�v���W�F�N�g���ō��̃R���s���[�e�B���O�A�������Z�A
������ш�ÃA�v���P�[�V�����̐��E�ŗp�r��������Ɨ\�����܂��v
Integrated Graphics �͂����܂Łuplan�v
��AMD���݂����Ă̌���
anandtech�́uLarrabee would be Intel's discrete GPU�v
�L�q��Anand�̍앶����
http://www.pcper.com/article.php?aid=453
��Otellini �u�����r�[�v���W�F�N�g���ō��̃R���s���[�e�B���O�A�������Z�A
������ш�ÃA�v���P�[�V�����̐��E�ŗp�r��������Ɨ\�����܂��v
>anandtech�́uLarrabee would be Intel's discrete GPU�v
>�L�q��Anand�̍앶����
�I�b�e���[�j�̔������Ă̋L�q�B
>While discussing the processor, Otellini noted that it will "move us into discrete graphics".
http://www.theregister.co.uk/2007/09/18/intel_discrete_graphics_larrabee/
>�L�q��Anand�̍앶����
�I�b�e���[�j�̔������Ă̋L�q�B
>While discussing the processor, Otellini noted that it will "move us into discrete graphics".
http://www.theregister.co.uk/2007/09/18/intel_discrete_graphics_larrabee/
>>139
�܂��p���炵������C�Ȃ̂���
������x�����Ă݂Ă���B
Intel��CPU-GPU�����Ȃ�Ă��Ȃ��i�j
Larrabee��Glaphic����Ȃ��i�j
�S���㓡�̖ϑz�i�j
�ǂ��l���Ă����O���L�`�K�C�ł���
�܂��p���炵������C�Ȃ̂���
������x�����Ă݂Ă���B
Intel��CPU-GPU�����Ȃ�Ă��Ȃ��i�j
Larrabee��Glaphic����Ȃ��i�j
�S���㓡�̖ϑz�i�j
�ǂ��l���Ă����O���L�`�K�C�ł���
�������ɁAGlaphic����Ȃ���w
>>141
���w���͑����Q��
���w���͑����Q��
���̃L�`�K�C�ł��������������Ȃ������
�������v���Ă�낤����
�������v���Ă�낤����
graphic���Ă��Q�[�}�[�ɂ͊W�Ȃ��Ɩ����삾����ǂ��ł�����
http://pc.watch.impress.co.jp/docs/2007/0920/idf03.htm
> ���̃f���́A�uIntel X38�v��Penryn�x�[�X�̃N�A�b�h�R�ACPU�uYorkfield�v�𗘗p�������́B
> Yorkfield�͐�q����11��12���ɔ��\�����Penryn�x�[�X��CPU��1�ŁA�{���A�����b�N
> ��Ԃŏo�ׂ����Ƃ����B
�{���A�����b�N���Ă܂�����B MMX Pentium�ȗ��������H
> ���̃f���́A�uIntel X38�v��Penryn�x�[�X�̃N�A�b�h�R�ACPU�uYorkfield�v�𗘗p�������́B
> Yorkfield�͐�q����11��12���ɔ��\�����Penryn�x�[�X��CPU��1�ŁA�{���A�����b�N
> ��Ԃŏo�ׂ����Ƃ����B
�{���A�����b�N���Ă܂�����B MMX Pentium�ȗ��������H
>>146
�͂��H
�͂��H
ttp://pc.watch.impress.co.jp/docs/2007/0920/idf03.htm
�C���v���X�Ŋ�u���̓��e���ڂ�����
>�O���t�B�b�N�����^�`�b�v�Z�b�g�ɂ����Ă����y���ꂽ�B
>Intel��1����܂���2����O�̃v���Z�X�Z�p��p����
>�`�b�v�Z�b�g�����邱�Ƃ͍L���m���Ă���B
>2009�N�ɂ�45nm�v���Z�X���O���t�B�b�N�@�\�ւ���������邪�A
>����̓O���t�B�b�N��CPU���������̂ƂȂ�A
>130nm���ォ��6 �{�̃p�t�H�[�}���X�ƂȂ�B
�����炭���̕�����
Nehalem��GPU������������
�����ς炩�犨�Ⴂ���Ă�A�t�H�����鈫���@>>101=103
�C���v���X�Ŋ�u���̓��e���ڂ�����
>�O���t�B�b�N�����^�`�b�v�Z�b�g�ɂ����Ă����y���ꂽ�B
>Intel��1����܂���2����O�̃v���Z�X�Z�p��p����
>�`�b�v�Z�b�g�����邱�Ƃ͍L���m���Ă���B
>2009�N�ɂ�45nm�v���Z�X���O���t�B�b�N�@�\�ւ���������邪�A
>����̓O���t�B�b�N��CPU���������̂ƂȂ�A
>130nm���ォ��6 �{�̃p�t�H�[�}���X�ƂȂ�B
�����炭���̕�����
Nehalem��GPU������������
�����ς炩�犨�Ⴂ���Ă�A�t�H�����鈫���@>>101=103
by impress ���a�c
��IA�x�[�X�̃��j�C�R�ACPU�uLarrabee�v
���I�b�e���[�j���̓��j�C�R�ACPU�ł���Larrabee�ɂ��Ă����y
��IA�x�[�X�̃��j�C�R�ACPU�uLarrabee�v
���I�b�e���[�j���̓��j�C�R�ACPU�ł���Larrabee�ɂ��Ă����y
�ȑO���[�N����pdf���甲��
http://kjm.kir.jp/pc/?p=42578.jpg
�B��Ă��镔��
http://kjm.kir.jp/pc/?p=42579.jpg
http://kjm.kir.jp/pc/?p=42578.jpg
{kind=link}
�B��Ă��镔��
http://kjm.kir.jp/pc/?p=42579.jpg
{kind=link}
http://download.intel.com/pressroom/kits/events/idffall_2007/TranscriptOtelliniKeynote.pdf
�S���ǂނ̖ʓ|�������̂ŁALarrabee�Ō����������ӂ�ǂ��ǁALarrabee��GPU�ł���悤�Ȃ��Ƃ�
�����ĂȂ��ˁB
�S���ǂނ̖ʓ|�������̂ŁALarrabee�Ō����������ӂ�ǂ��ǁALarrabee��GPU�ł���悤�Ȃ��Ƃ�
�����ĂȂ��ˁB
�^�Q�[���@�p�Ƃ��ē���CPU��GPU��ڎw���č���āA���ʍ��܂�����������
�^���p�N����́ASACD�Đ��⓮��f�S�[�h�A��×p�摜�����u���[�h�T�[�o�ňꕔ�]����������ƓI�ɑ厸�s
���[�ƁA�Ȃ����H
�܁A����͂����Ƃ���Larrabee�͑����J�����~�ɂ���ׂ����Ǝv����
�^���p�N����́ASACD�Đ��⓮��f�S�[�h�A��×p�摜�����u���[�h�T�[�o�ňꕔ�]����������ƓI�ɑ厸�s
���[�ƁA�Ȃ����H
�܁A����͂����Ƃ���Larrabee�͑����J�����~�ɂ���ׂ����Ǝv����
Larrabee���Ă��̂������������Ă�ȁc�B
>>141
���������Ă܂�����ǂ�ł�
Intel�����ɗ͂����Ă���̂��悭�����邩��
http://www.intel.com/pressroom/kits/events/idffall_2007/KeynoteGelsinger.pdf
http://www.intel.com/pressroom/kits/events/idffall_2007/BriefingSmith45nm.pdf
http://www.intel.com/pressroom/kits/events/idffall_2007/BriefingSilicon&TechManufacturing.pdf
���������Ă܂�����ǂ�ł�
Intel�����ɗ͂����Ă���̂��悭�����邩��
http://www.intel.com/pressroom/kits/events/idffall_2007/KeynoteGelsinger.pdf
http://www.intel.com/pressroom/kits/events/idffall_2007/BriefingSmith45nm.pdf
http://www.intel.com/pressroom/kits/events/idffall_2007/BriefingSilicon&TechManufacturing.pdf
45nm 820M�g�����W�X�^��Yorkfield��TDP 120W
45nm 731M�~2����TDP�����ɂȂ��
45nm 731M�~2����TDP�����ɂȂ��
�t��K�{
Intel��Nehalem�̊T�v�\�A�����f�������J
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388.htm
��Nehalem��CPU�R�A�̃}�C�N���A�[�L�e�N�`���́A
�����S�ɐV�v�ŁACore MA�̊g���ł͂Ȃ��Ƃ����B
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388.htm
��Nehalem��CPU�R�A�̃}�C�N���A�[�L�e�N�`���́A
�����S�ɐV�v�ŁACore MA�̊g���ł͂Ȃ��Ƃ����B
>>157
���P����邾��B������v���Ⴄ����B
���P����邾��B������v���Ⴄ����B
�Q����������������ȁA����Ɣ��\�ł������B
�㓡�]�X���AHyperThreading���Swww�Ƃ������Ă��A���̂ق����S�z���B
�㓡�]�X���AHyperThreading���Swww�Ƃ������Ă��A���̂ق����S�z���B
>>161
���̂�NetBurst�ł����āAHTT�����S�����킯����Ȃ������̂ɂȁB
���̂�NetBurst�ł����āAHTT�����S�����킯����Ȃ������̂ɂȁB
�J�i�_�̃I���^
Netburst�ł�HTT�̎����ɐƎ㐫����������ŁASMT��ʂ̖��Ƃ͈Ⴄ����ȁB
Intel�{�点��Ƃ��킢�ȁE�E�E�B
AMD�ǂ��l�߂�ꂽ��������ȁB
AMD�ǂ��l�߂�ꂽ��������ȁB
http://pc.watch.impress.co.jp/docs/2007/0920/kaigai388_01l.gif
�㓡�ł���
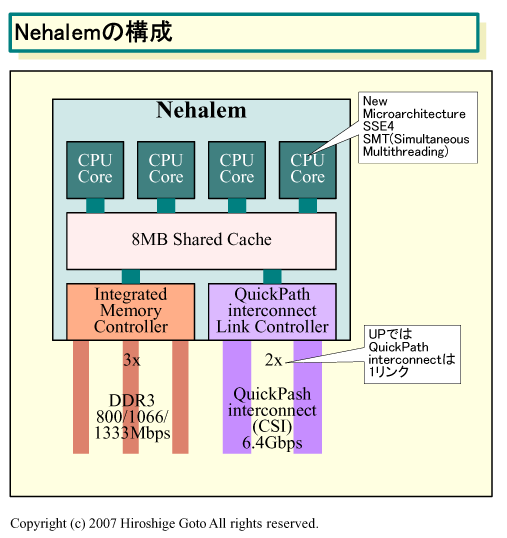
���ꂪ�uNehalem�̍\���v�Ə��������P������
GPU�����b�͂����I���ɂ���
{kind=link}
�㓡�ł���
���ꂪ�uNehalem�̍\���v�Ə��������P������
GPU�����b�͂����I���ɂ���
>>167
���H
Nehalem�͐���̖��O�ł����ȍ\���̃o�[�W������������
GPU�����o�[�W�������m��Ȃ̂����B
���܂���GPU�����o�[�W�����͂Ȃ��Ƃ���������Ȃ̂��H�H
���H
Nehalem�͐���̖��O�ł����ȍ\���̃o�[�W������������
GPU�����o�[�W�������m��Ȃ̂����B
���܂���GPU�����o�[�W�����͂Ȃ��Ƃ���������Ȃ̂��H�H
>167
����̂�����Ə�ɏ�����Ă��鎖���ǂ߂Ȃ��́H
IDF�ł́A����ɉ����āANehalem�ɒlj������V���߂�A
�}�C�N���A�[�L�e�N�`����Core MA�Ɠ��l��4�C�V���[/
�T�C�N���ł��邱�ƁA64-bit�ɍœK�����ꂽ�v�ɂȂ邱�ƁA
GPU�R�A��CPU�̃_�C(�����̖{��)�ɓ�������邱�ƁA�}���`
�v���Z�b�T(MP)�łł�QuickPath interconnect(CSI)��4�����N
�ɂȂ邱�ƂȂǂ����炩�ɂ��ꂽ�B
����̂�����Ə�ɏ�����Ă��鎖���ǂ߂Ȃ��́H
IDF�ł́A����ɉ����āANehalem�ɒlj������V���߂�A
�}�C�N���A�[�L�e�N�`����Core MA�Ɠ��l��4�C�V���[/
�T�C�N���ł��邱�ƁA64-bit�ɍœK�����ꂽ�v�ɂȂ邱�ƁA
GPU�R�A��CPU�̃_�C(�����̖{��)�ɓ�������邱�ƁA�}���`
�v���Z�b�T(MP)�łł�QuickPath interconnect(CSI)��4�����N
�ɂȂ邱�ƂȂǂ����炩�ɂ��ꂽ�B
�����͂܂�����b�ŁANehalem�̉����邩��₤�̂͂��̒i�K�ł͂قƂ�Ǖs�\���ƁB
�����ɂȂ�܂����X�Ƃ��ăQ��������Ă����Ǝv�����B
��
�㓡���Ɋ���
�����ɂȂ�܂����X�Ƃ��ăQ��������Ă����Ǝv�����B
��
�㓡���Ɋ���
Larrabee�̈ʒu�t���ŝ��߂Ă�݂��������ǁA����̘b����ɊԈ���Ă��Ȃ��悤�Ɏv���邷�B
http://pc.watch.impress.co.jp/docs/2007/0920/idf03.htm
�@�@-------------------------
�@�@�����Ēh��ɂ͐�T�̋��j����Intel���������邱�Ƃ\����Havok�̃W�F�t�E�C�G�C�c����A
�@�@�Q�[���f�x���b�p�ł���PANDEMIC�̃W���V���E���X�j�N���炪�o�d�B�N�A�b�h�R�A���Q�[���J����
�@�@������V�����X�^���_�[�h�ƂȂ鑶�݂ł���Ƃ��A�Q�[���ɂ���ɕ��G�ȕ������Z��g�ݍ��ނ��Ƃ�
�@�@�\�ƂȂ�ł��낤Larrabee�Ɋ��҂����B
�@�@-------------------------
CELL B.E.�R���Ă��ƂŁB
http://pc.watch.impress.co.jp/docs/2007/0920/idf03.htm
�@�@-------------------------
�@�@�����Ēh��ɂ͐�T�̋��j����Intel���������邱�Ƃ\����Havok�̃W�F�t�E�C�G�C�c����A
�@�@�Q�[���f�x���b�p�ł���PANDEMIC�̃W���V���E���X�j�N���炪�o�d�B�N�A�b�h�R�A���Q�[���J����
�@�@������V�����X�^���_�[�h�ƂȂ鑶�݂ł���Ƃ��A�Q�[���ɂ���ɕ��G�ȕ������Z��g�ݍ��ނ��Ƃ�
�@�@�\�ƂȂ�ł��낤Larrabee�Ɋ��҂����B
�@�@-------------------------
CELL B.E.�R���Ă��ƂŁB
Dailytech��UMPC����̐��i�ɂ��Ă̋L�����B
http://www.dailytech.com/Intel+Details+Next+Generation+Menlow+MID+UMPC+Platform/article8959.htm
�܂�������ɂ��Ă�A����Ȋ����B
�@�@------------------------------
�@�@The McCaslin platform uses 90 nanometer Stealey 600MHz (A100) and 800MHz (A110)
�@�@processors coupled with the 945GU Express chipset and ICH7U southbridge.
�@�@------------------------------
�������Silverthome���i�̍\����A�����Ȃ�Ƃ̂��Ƃ��B
�@�@------------------------------
�@�@Menlow, on the other hand, will use new 45 nanometer Hi-k low-power Silverthorne processors
�@�@and the Poulsbo chipset. Other features included on the Menlow platform are 802.11n wireless
�@�@technology, 3G and WiMAX for extended broadband coverage.
�@�@------------------------------
http://www.dailytech.com/Intel+Details+Next+Generation+Menlow+MID+UMPC+Platform/article8959.htm
�܂�������ɂ��Ă�A����Ȋ����B
�@�@------------------------------
�@�@The McCaslin platform uses 90 nanometer Stealey 600MHz (A100) and 800MHz (A110)
�@�@processors coupled with the 945GU Express chipset and ICH7U southbridge.
�@�@------------------------------
�������Silverthome���i�̍\����A�����Ȃ�Ƃ̂��Ƃ��B
�@�@------------------------------
�@�@Menlow, on the other hand, will use new 45 nanometer Hi-k low-power Silverthorne processors
�@�@and the Poulsbo chipset. Other features included on the Menlow platform are 802.11n wireless
�@�@technology, 3G and WiMAX for extended broadband coverage.
�@�@------------------------------
>>66
����
����
intel��GPU�g�����ق����I����͗L���Ǝv�������ȁB
FB-DMM�����ʖڂ炵������Q�[���p�Ɏg���Ƃ�����債�����y�����ǁB
�x���`���ʂ͖ʔ������B
Havok�����q��Љ��łȂɂ����Ă���̂����C�ɂȂ�ˁBAgeia��AMD������������
���āB����GPU�܂ߑS��CPU���[�J�[�������W�J�ɂȂ�̂��ȁB
FB-DMM�����ʖڂ炵������Q�[���p�Ɏg���Ƃ�����債�����y�����ǁB
�x���`���ʂ͖ʔ������B
Havok�����q��Љ��łȂɂ����Ă���̂����C�ɂȂ�ˁBAgeia��AMD������������
���āB����GPU�܂ߑS��CPU���[�J�[�������W�J�ɂȂ�̂��ȁB
AMD���̂��̂����������\���������Ȃ��́H
Intel��G�ɉĂ����v�Ȋ�Ƃ��Ă̂������Ă��邯�ǂ��B
Intel��G�ɉĂ����v�Ȋ�Ƃ��Ă̂������Ă��邯�ǂ��B
http://www.4gamer.net/games/032/G003263/20070919044/
���̋L�����ƁA�����G���W���̃}���`�R�A�Ή��̍œK�����Ă̂�����ˁB
Nehalem���ƃ��C���X�g���[����4�R�A�ɂȂ�\�������邩��A����ɔ����ă}���`�R�A�Ή��A�v������
���₷���߂̏�������Ȃ����ȁB
���̋L�����ƁA�����G���W���̃}���`�R�A�Ή��̍œK�����Ă̂�����ˁB
Nehalem���ƃ��C���X�g���[����4�R�A�ɂȂ�\�������邩��A����ɔ����ă}���`�R�A�Ή��A�v������
���₷���߂̏�������Ȃ����ȁB
�ʰ�݂��Ӻ݂�DDR3��ذ�Ȃ̂��H
DDR2�ł�����~����
�Ƃ͂����Ă��o��̂����N�㔼������DDR3�����Ă邩
DDR2�ł�����~����
�Ƃ͂����Ă��o��̂����N�㔼������DDR3�����Ă邩
Nehalem���҂���������
���N�̉Ă�PenD�ŏ����Ă��
���N�̉Ă�PenD�ŏ����Ă��
����Ȏ������Ă�ƁA���ݏo�Ă��u�ǂ���������SandyBridge�܂ő҂I�v���ďɂȂ肩�˂��
��PC�������Ǝv���Ă�z�A���͔�����!����������
�߂�������������낗
Nehalem�͗~�����ȁB4�R�A��8�X���b�h�Ƃ��̌��������B
���܂�C2D�ł��Ȃ��s���������킯�����c�B
>>180�͔��������Ƃ��B
���܂�C2D�ł��Ȃ��s���������킯�����c�B
>>180�͔��������Ƃ��B
Nehalem�~�����B���ƂP�N�キ�炢����
��������ӂƎv���o�������A�̉��Ƃ�����SGI��ONYX��8CPU��
�v�Z�������CPU�g�p���̃o�[��8�{�Y���[�b�ƐL�т�̂��������̂������ȁB
�����̂̐i���������B
�v�Z�������CPU�g�p���̃o�[��8�{�Y���[�b�ƐL�т�̂��������̂������ȁB
�����̂̐i���������B
188 �FSocket774�F2007/09/20(��) 20:51:45 ID:aOkGW0TQ
�Ƃ肠����P35+C2D�������f���ŔN������A
Penryn�ɍڂ������Ĕ��N�g���ANeharem��wktk����̂����̏����g�p�^�[���H
Penryn�ɍڂ������Ĕ��N�g���ANeharem��wktk����̂����̏����g�p�^�[���H
�����ōl���邱�Ƃ̏o���Ȃ��z�͊m���ɕ����g���Ǝv�����ǁB
190 �FSocket774�F2007/09/20(��) 22:18:43 ID:1YAzVbzu
>188
Penryn���āA���N�����t���O�V�b�v����Ȃ��́H�@���ꂶ��Z�������.....����L���ŁANehalem��2009�N����
�ƌ����C�����邯�ǁA�ǂ��Ȃ�H
Penryn���āA���N�����t���O�V�b�v����Ȃ��́H�@���ꂶ��Z�������.....����L���ŁANehalem��2009�N����
�ƌ����C�����邯�ǁA�ǂ��Ȃ�H
�T�~�b�g���C�N�̓o��͒x������
�f�X�N�g�b�v�i���p�t�H�[�}���X�сj�ł�Penryn���Ԃ��Ȃ蒷����
�f�X�N�g�b�v�i���p�t�H�[�}���X�сj�ł�Penryn���Ԃ��Ȃ蒷����
����penryn�t�@�~���[�̉��i���m�肽����
�����4�R�A�͂����[�̂���
�����4�R�A�͂����[�̂���
�y�����
>>190
Core Duo�����̔��N���Core 2 Duo��������������\������
Core Duo�����̔��N���Core 2 Duo��������������\������
>>172
GP-GPU�R����c�B���Q�ڂ��Ă��B
GP-GPU�R����c�B���Q�ڂ��Ă��B
����
CPU�K���\
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�S�b�h�B������_
QX6850�E�E�E�E�E�E���g���}��
QX6700�E�E�E�E�E���F�������[�b�g��
�i����̕ǁj
Q6700�E�E�E�E�E�E�c��
FX74�E�E�E�E�E�E�E�哝��
Q6600�E�E�E�E�E�E�r���E�Q�C�c
E6850�E�E�E�E�E�E���t������b
E6700�E�E�E�E�E�E���w��������
E6600�E�E�E�E�E�E���ʂ����
6000+�E�E�E�E�E�E����
E6400�E�E�E�E�E�E����
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�`���p���W�[�̂��������
E4300�E�E�E�E�E���i�[
3500�{�E�E�E�E�k�R
PenD�E�E�E�E�E�l�Y�~
Pen4�E�E�E�E�E�E�U���K�j
AthlonXP�E�E�E�E�_���S���V
Pen�V�E�E�E�E�E�A�I�~�h��
Athlon�E�E�E�E�E�咰��
Pen�U�E�E�E�E�E�N���~�W�A
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�S�b�h�B������_
QX6850�E�E�E�E�E�E���g���}��
QX6700�E�E�E�E�E���F�������[�b�g��
�i����̕ǁj
Q6700�E�E�E�E�E�E�c��
FX74�E�E�E�E�E�E�E�哝��
Q6600�E�E�E�E�E�E�r���E�Q�C�c
E6850�E�E�E�E�E�E���t������b
E6700�E�E�E�E�E�E���w��������
E6600�E�E�E�E�E�E���ʂ����
6000+�E�E�E�E�E�E����
E6400�E�E�E�E�E�E����
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�`���p���W�[�̂��������
E4300�E�E�E�E�E���i�[
3500�{�E�E�E�E�k�R
PenD�E�E�E�E�E�l�Y�~
Pen4�E�E�E�E�E�E�U���K�j
AthlonXP�E�E�E�E�_���S���V
Pen�V�E�E�E�E�E�A�I�~�h��
Athlon�E�E�E�E�E�咰��
Pen�U�E�E�E�E�E�N���~�W�A
���w����������K���\�H
�Ñ�A�X�e�J�̊K���\�����
�ǂ����U���K�j�ł�
�Ȃ�Ń[�b�g�����E���g���}���̕�����Ȃ�
>>202
�����^
�����^
�t�Z�I���Z�p��32nm�v���Z�X��ڎw��Intel
http://pc.watch.impress.co.jp/docs/2007/0921/hot506.htm
http://pc.watch.impress.co.jp/docs/2007/0921/hot506.htm
�������g�̖����L���c
�N���͂����
207 �F ��O47sMVBmgM �F2007/09/21(��) 05:47:27 ID:LntuXoQR
Intel planning quad-core notebook CPUs for 3Q08
http://www.digitimes.com/systems/a20070919PD211.html
http://www.digitimes.com/systems/a20070919PD211.html
�l�n�����̏������ĎI���������R������
�f�X�N�g�b�v�͌ォ�����
����̓\�P�b�g423�̈������F�Z�������悤
�f�X�N�g�b�v�͌ォ�����
����̓\�P�b�g423�̈������F�Z�������悤
>>208
�m���ɕY���ȁB
32nm�ɂȂ�����f�X�N�g�b�v�������R�������Ƃ��ɂȂ肻�������ǂȁB
�܂������R�������Ɣ�����ł̐��\�����������ȁB
�V���O���\�P�b�g���Ƃ��܂荷���o�Ȃ��̂��ȁH
�m���ɕY���ȁB
32nm�ɂȂ�����f�X�N�g�b�v�������R�������Ƃ��ɂȂ肻�������ǂȁB
�܂������R�������Ɣ�����ł̐��\�����������ȁB
�V���O���\�P�b�g���Ƃ��܂荷���o�Ȃ��̂��ȁH
FSB��CSI�ʼn��P������H
�`�b�v�Z�b�g���̃������R���g���[����DDR2�ɑΉ�����낤���H
�Ή�����Ȃ炻��Ȃ�Ƀf�X�N�g�b�v�p�r�Ƃ��Ă̈Ӗ��͂��肻�������B
�`�b�v�Z�b�g���̃������R���g���[����DDR2�ɑΉ�����낤���H
�Ή�����Ȃ炻��Ȃ�Ƀf�X�N�g�b�v�p�r�Ƃ��Ă̈Ӗ��͂��肻�������B
211 �F ��O47sMVBmgM �F2007/09/21(��) 12:41:43 ID:LntuXoQR
Skulltrail�ƃ��o�C��Penryn�̃x���`�}�[�N���ʂ����\
http://pc.watch.impress.co.jp/docs/2007/0921/idf07.htm
http://pc.watch.impress.co.jp/docs/2007/0921/idf07.htm
212 �FSocket774�F2007/09/21(��) 12:51:08 ID:feqFg0ra
Phenom FX�̔��\�̂��Ƃ�intel�̔��\���b�V���͂������ˁB
�Ȃ҂������������ˁB�Ă��A32nm�Ƃ��o�Ă�������Ă����ق��
�ǂ��[���Ăȋ�B
�����܂ł���ł�����AMD�͂����Ƃ₩�ɂȂ������炢����Ȃ��́H
�ق�Ǝア���́E�E�E����Ȃ��Ēx��CPU�������߂���B
�͂�����݂ĂĂ��ق�Ƃ��킢�����ɂȂ��Ă���E�E�E
�Ȃ҂������������ˁB�Ă��A32nm�Ƃ��o�Ă�������Ă����ق��
�ǂ��[���Ăȋ�B
�����܂ł���ł�����AMD�͂����Ƃ₩�ɂȂ������炢����Ȃ��́H
�ق�Ǝア���́E�E�E����Ȃ��Ēx��CPU�������߂���B
�͂�����݂ĂĂ��ق�Ƃ��킢�����ɂȂ��Ă���E�E�E
213 �FSocket774�F2007/09/21(��) 12:57:54 ID:feqFg0ra
���͂��������ꂷ��������͂����������ЂƂ͌����Ǝv���B
���܂�ɂ������i2����x�ꂮ�炢�H�j��������Ă��������܂��B
���܂�ɂ������i2����x�ꂮ�炢�H�j��������Ă��������܂��B
�M�ҕ�|���߂��ł���
penryn�łƂ��Ƃ��m�[�g�ł��y�ɃG���R�ł��鎞�オ����̂�
>>216
��Merom���o�Ă����Ƃ��ɂ��v�����ȁB
��Merom���o�Ă����Ƃ��ɂ��v�����ȁB
�m�[�g��CPU����HDD�Ƃ��O�I�v�����n�ゾ����Ȃǂ����˂�
AMD����T�x��ɂȂ����܂���CPU���l�オ�肷��̂��S�z�A�̂̃A�z�݂����Ȓl�i�Ŕ����̂͂�������
���傤���Ȃ��̂ʼn���AMD�̎菕��������A���N�ɂ��ʰ�݂�100�{����CPU��10�h���ŏo����
AMD����T�x��ɂȂ����܂���CPU���l�オ�肷��̂��S�z�A�̂̃A�z�݂����Ȓl�i�Ŕ����̂͂�������
���傤���Ȃ��̂ʼn���AMD�̎菕��������A���N�ɂ��ʰ�݂�100�{����CPU��10�h���ŏo����
32nm�Ńg���C�Q�[�g�g�����W�X�^�g��Ȃ��̂�
�����g����A22nm�ł͎g�����
�����g����A22nm�ł͎g�����
>>218
���̐VCPU�Ϳ�939�ŏo���Ă���
���̐VCPU�Ϳ�939�ŏo���Ă���
>>218
�ŋ߂̃C���e���́A�u���\���グ�Ȃ��v�Ƃ����I��������Ă�
Core2 Extreme 3.2GHz���o���Ȃ������̂̓N���b�N���グ���Ȃ�Quad�̂��߂����邪�A�ʂɏo���Ȃ��Ă����肪�A���Ȃ̂Ŗ��Ȃ�����B
�R�n���Ȃ�Quad�͖�薳�����A����Athlon X2��Core2 2.93GHz�Ɠ����ȏゾ������A3.2GHz���o���Ă����낤����
45nm������
11���̎��_�ŁA3.33GHz+�͗e�ՂȂ͂�����3GHz�ǂ܂�B
Xeon���������ȁA2006�N6���̎��_�Ńf���A��3GHz��B�����Ă���킯�ŁA
3.16GHz�ɂ���̂́u2.93GHz����P�N�ŁA���������オ���Ă���Core2�v�Ƃ͈ꏏ�ɂł��Ȃ��ƁB
Core2�����N�܂��オ�邯�ǂ�
���f���i���o�[�݂Ă��ACore2 QX9650��3GHz�Ƃ������Ƃ�QX9950/3.5GHz�ŏI���B�����Core3�̂��߂��Ǝv���Ώ\�������B
QX9700��3GHz/FSB1.6GHz���Ƃ���AQX9900 3.4GHz/1.6GHz���Ōォ��
�ŋ߂̃C���e���́A�u���\���グ�Ȃ��v�Ƃ����I��������Ă�
Core2 Extreme 3.2GHz���o���Ȃ������̂̓N���b�N���グ���Ȃ�Quad�̂��߂����邪�A�ʂɏo���Ȃ��Ă����肪�A���Ȃ̂Ŗ��Ȃ�����B
�R�n���Ȃ�Quad�͖�薳�����A����Athlon X2��Core2 2.93GHz�Ɠ����ȏゾ������A3.2GHz���o���Ă����낤����
45nm������
11���̎��_�ŁA3.33GHz+�͗e�ՂȂ͂�����3GHz�ǂ܂�B
Xeon���������ȁA2006�N6���̎��_�Ńf���A��3GHz��B�����Ă���킯�ŁA
3.16GHz�ɂ���̂́u2.93GHz����P�N�ŁA���������オ���Ă���Core2�v�Ƃ͈ꏏ�ɂł��Ȃ��ƁB
Core2�����N�܂��オ�邯�ǂ�
���f���i���o�[�݂Ă��ACore2 QX9650��3GHz�Ƃ������Ƃ�QX9950/3.5GHz�ŏI���B�����Core3�̂��߂��Ǝv���Ώ\�������B
QX9700��3GHz/FSB1.6GHz���Ƃ���AQX9900 3.4GHz/1.6GHz���Ōォ��
Skulltrail 3.4GHz
Skulltrail�\���ł���悤�ɂȂ�܂ő҂�
DivX Codec 6.7
�V�@�\
* ���K�� 1080HD �v���t�@�C�����T�|�[�g
* 1080i �r�f�I�̈��k���\�̌���
* HDV�ADVCPRO HD�AAVCHD �ň�ʓI�ȏc�����lj��T�|�[�g
* �e�Ղȉ摜�t�H�[�}�b�g�ϊ�
* ���Ѝő��� DivX �r�f�I�f�R�[�_
�ŐV��DivX�R�[�f�b�N�̐V�����@�\
* �f�R�[�f�B���O���x�̍ő� 12% �̍������ɂ�芊�炩�ȓ���Đ�������
* �m�ł��D�ꂽ�i���n���[�h�̃G���R�[�f�B���O���x�� 10% �ȏ�A�b�v
* �m�ő��n���[�h�̈��k�����ő� 7% �A�b�v�����𑜓x�L���v�`���ɑΉ�
* �V���� Intel CPU �Ɏ�������� SSE4 �������I�ɃT�|�[�g
����݂���ӂŎg������������
�V�@�\
* ���K�� 1080HD �v���t�@�C�����T�|�[�g
* 1080i �r�f�I�̈��k���\�̌���
* HDV�ADVCPRO HD�AAVCHD �ň�ʓI�ȏc�����lj��T�|�[�g
* �e�Ղȉ摜�t�H�[�}�b�g�ϊ�
* ���Ѝő��� DivX �r�f�I�f�R�[�_
�ŐV��DivX�R�[�f�b�N�̐V�����@�\
* �f�R�[�f�B���O���x�̍ő� 12% �̍������ɂ�芊�炩�ȓ���Đ�������
* �m�ł��D�ꂽ�i���n���[�h�̃G���R�[�f�B���O���x�� 10% �ȏ�A�b�v
* �m�ő��n���[�h�̈��k�����ő� 7% �A�b�v�����𑜓x�L���v�`���ɑΉ�
* �V���� Intel CPU �Ɏ�������� SSE4 �������I�ɃT�|�[�g
����݂���ӂŎg������������
WiMAX��Moorestown�ōL���郂�o�C���f�o�C�X�̍s����
http://plusd.itmedia.co.jp/pcuser/articles/0709/21/news023.html
�Ɠd����SoC�ACanmore(�P�[�����A)
http://pc.watch.impress.co.jp/docs/2007/0921/ubiq197.htm
http://plusd.itmedia.co.jp/pcuser/articles/0709/21/news023.html
�Ɠd����SoC�ACanmore(�P�[�����A)
http://pc.watch.impress.co.jp/docs/2007/0921/ubiq197.htm
CPU�K���\
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�㋉�叫
QX6850�E�E�E�E�E�叫
QX6700�E�E�E�E�E����
�i����̕ǁj
Q6700�E�E�E�E�E�E����
FX74�E�E�E�E�E�E�E�y��
Q6600�E�E�E�E�E�E�卲
E6850�E�E�E�E�E�E����
E6700�E�E�E�E�E�E����
E6600�E�E�E�E�E�E���
6000+�E�E�E�E�E�E����
E6400�E�E�E�E�E�E����
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�y��
E4300�E�E�E�E�E����
3500�{�E�E�E�E�R��
PenD�E�E�E�E�E�ޒ�
Pen4�E�E�E�E�E�E����
AthlonXP�E�E�E�E�㓙��
Pen�V�E�E�E�E�E�ꓙ��
Athlon�E�E�E�E�E��
Pen�U�E�E�E�E�E�O����
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�㋉�叫
QX6850�E�E�E�E�E�叫
QX6700�E�E�E�E�E����
�i����̕ǁj
Q6700�E�E�E�E�E�E����
FX74�E�E�E�E�E�E�E�y��
Q6600�E�E�E�E�E�E�卲
E6850�E�E�E�E�E�E����
E6700�E�E�E�E�E�E����
E6600�E�E�E�E�E�E���
6000+�E�E�E�E�E�E����
E6400�E�E�E�E�E�E����
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�y��
E4300�E�E�E�E�E����
3500�{�E�E�E�E�R��
PenD�E�E�E�E�E�ޒ�
Pen4�E�E�E�E�E�E����
AthlonXP�E�E�E�E�㓙��
Pen�V�E�E�E�E�E�ꓙ��
Athlon�E�E�E�E�E��
Pen�U�E�E�E�E�E�O����
soket939
���n�g�ł��B
Intel Fellow�ɂ��Shop Talk�ł�GPU�����̎���ɑ����
�����炳�܂ɂ���������Ă��܂����B
Intel Fellow�ɂ��Shop Talk�ł�GPU�����̎���ɑ����
�����炳�܂ɂ���������Ă��܂����B
�����IDF�ł�Nehalem��Larrabee�ł���ڍׂ͖�������Ȃ������̂ɂ��̐�̌v��Ȃ�ċ����Ă��炦��킯���Ȃ��
�����������\�����{�Ƃ�����d�͂���%���Ƃ��������x���̓������낤
�ł��Ɠd������Canmore�œ�������Ƃ��Ă���ȏ㑽��PC�ł����낤��
�����������\�����{�Ƃ�����d�͂���%���Ƃ��������x���̓������낤
�ł��Ɠd������Canmore�œ�������Ƃ��Ă���ȏ㑽��PC�ł����낤��
232 �FSocket774�F2007/09/21(��) 17:38:42 ID:PyfEa1pT
soket939
�ǂ��݂Ă����m�����x��
�ǂ��݂Ă����m�����x��
3500+(939)�������肵�ĂĒx������w
234 �FSocket774�F2007/09/21(��) 17:59:21 ID:0FBWSJ0y
CPU�K���\
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�Ј���
QX6850�E�E�E�E�E�
QX6700�E�E�E�E�E�В�
�i����̕ǁj
Q6700�E�E�E�E�E�E����
FX74�E�E�E�E�E�E�E�ꖱ
Q6600�E�E�E�E�E�E�햱
E6850�E�E�E�E�E�E���
E6700�E�E�E�E�E�E����
E6600�E�E�E�E�E�E����
6000+�E�E�E�E�E�E�ے�
E6400�E�E�E�E�E�E�ے��㗝
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�W��
E4300�E�E�E�E�E �W���㗝
3500�{�E�E�E�E �ǒ�
PenD�E�E�E�E�E ��C
Pen4�E�E�E�E�E�E���Ј�
AthlonXP�E�E�E�E�_��Ј�
Pen�V�E�E�E�E�E�V���Ј��i���K�����j
Athlon�E�E�E�E�E�p�[�g
Pen�U�E�E�E�E�E�A���o�C�g
2007�N9�����݁i�K���͐����ϓ����܂��j
soket939�E�E�E�E�E�Ј���
QX6850�E�E�E�E�E�
QX6700�E�E�E�E�E�В�
�i����̕ǁj
Q6700�E�E�E�E�E�E����
FX74�E�E�E�E�E�E�E�ꖱ
Q6600�E�E�E�E�E�E�햱
E6850�E�E�E�E�E�E���
E6700�E�E�E�E�E�E����
E6600�E�E�E�E�E�E����
6000+�E�E�E�E�E�E�ے�
E6400�E�E�E�E�E�E�ے��㗝
�i�L�h�S���ǁj
5000�{�E�E�E�E�E�W��
E4300�E�E�E�E�E �W���㗝
3500�{�E�E�E�E �ǒ�
PenD�E�E�E�E�E ��C
Pen4�E�E�E�E�E�E���Ј�
AthlonXP�E�E�E�E�_��Ј�
Pen�V�E�E�E�E�E�V���Ј��i���K�����j
Athlon�E�E�E�E�E�p�[�g
Pen�U�E�E�E�E�E�A���o�C�g
���낻��E�U��
����ɉ���PenM�������ĂȂ�����Ȃ���
�Г��Ɏ���̕ǂƂ��L�h�S���Ƃ�����������A�d�����ɂ��������Ȃ��B
��������UMPC�v���b�g�t�H�[���ł���Moorestown�ł�GPU���������Ă邵�A2010�N�ɃO���t�B�b�N���\��10�{��
���邽�߂�CPU�Ɠ�������32nm�v���Z�X�̗p�Ƃ������Ƃ�����APC�ł��x���Ƃ�2010�N�ɂ�GPU���_�C�ɓ������Ă���
���낤�B
���邽�߂�CPU�Ɠ�������32nm�v���Z�X�̗p�Ƃ������Ƃ�����APC�ł��x���Ƃ�2010�N�ɂ�GPU���_�C�ɓ������Ă���
���낤�B
���j�C�R�A�A�w�e���W�j�A�X�R�A�̃v���O���~���O����
http://pc.watch.impress.co.jp/docs/2007/0920/idf04.htm
x87���܂��h��̂��H
http://pc.watch.impress.co.jp/docs/2007/0920/idf04.htm
x87���܂��h��̂��H
���W�X�^���݂��Ă鎞�_�ł����R�v���Ƃ����Ȃ�����[��
���j�C�R�A�A�w�e���W�j�A�X�R�A�̃v���O���~���O����
http://pc.watch.impress.co.jp/docs/2007/0920/idf04.htm
x87���܂��h��̂��H
http://pc.watch.impress.co.jp/docs/2007/0920/idf04.htm
x87���܂��h��̂��H
>>226
���܂ǂ�DivX�ȂN���g��Ȃ��̂�
���܂ǂ�DivX�ȂN���g��Ȃ��̂�
���ǂ��͉��������߁H
�\�[�X�̓A�j���ȊO�̏ꍇ��
�\�[�X�̓A�j���ȊO�̏ꍇ��
>>243
Final Cut Pro
Final Cut Pro
���܂ő����Asoket��
>>243
�����̋Z�p�f���B�g���g��Ȃ��͂܂������W�Ȃ��B
�����̋Z�p�f���B�g���g��Ȃ��͂܂������W�Ȃ��B
�܂����\�g���Ă�l���Ȃ����H
���C���X�g���[�����ǂ����ǁA�➙��ܸö�ȉ��B
�������i�łȂ����ȁB�B�B
�������i�łȂ����ȁB�B�B
Intel��GPU������Ȃ�MCH�̕�����B
http://pc.watch.impress.co.jp/docs/2007/0921/idf06.htm
http://journal.mycom.co.jp/articles/2007/09/20/idf04/002.html
Silverthorn��������
�O���t���炷��ƁA�ʏ�0.1W�A�s�[�N0.4W
�Ă�����R���Ő���オ���Ă�Ǝv�����̂ɐG�ꂽ�̂�>>250��������E�E�E
http://journal.mycom.co.jp/articles/2007/09/20/idf04/002.html
Silverthorn��������
�O���t���炷��ƁA�ʏ�0.1W�A�s�[�N0.4W
�Ă�����R���Ő���オ���Ă�Ǝv�����̂ɐG�ꂽ�̂�>>250��������E�E�E
�܂��A����������
�̊���P3_1Ghz+���炢�ŗǂ�����A�V�X�e���S�̂�10W�ʂ�PC���ق�����B
�n�C�G���h�Q�[�����Ȃ�����ˁB
�n�C�G���h�Q�[�����Ȃ�����ˁB
1995/12-2004/4 P5 120MHz
200/4-2007/1 Klamath 266MHz
�� �͓�800EB
����܂Ŏg��������̂��|���V�[�Ȃ��
200/4-2007/1 Klamath 266MHz
�� �͓�800EB
����܂Ŏg��������̂��|���V�[�Ȃ��
>>254
C7�ł������B
C7�ł������B
>>252
�V�������ł��̂ˁB
�����A��k�݂����Ȃ́[��PC����Ăق����B
��{�\���͋➙�Ƃ����̎�芪���Ȃ��ǁA
��������1Ghz�ȏ��łāA
�Ȃ�ׂ��ŐV�̃��o�C��GPU�i����d�͂ɂ������āI�j����łāA
USB�Ȃ��[�����ĂāB���ŁB
����ŁA➑̂̔����ȏオ�o�b�e���[�Ȃ́B�i���蕶��͈��̏[�d��24���Ԃ����܂��I�@����ނ肩�ȁB�j
�����A4�́[��PC���ǂ���������Ă���Ȃ������҂��Ă�B
�m�[�g�^�����ǁA�t�������͊O�����Ă�������Ȃ��Ǝv���Ă�B
���������A�v���O���������āA���C�g��MMO�����Ȃ��āA�l�b�g�T�[�t�B�����Ă����A
�����͈̔͂ł͖����Ȃ��̂��o����Ǝv���B
���̍ہA���̃t���[�`���[�ł����ă��b�`�ɂ����헪�����肾�Ƃ�������B
�V�������ł��̂ˁB
�����A��k�݂����Ȃ́[��PC����Ăق����B
��{�\���͋➙�Ƃ����̎�芪���Ȃ��ǁA
��������1Ghz�ȏ��łāA
�Ȃ�ׂ��ŐV�̃��o�C��GPU�i����d�͂ɂ������āI�j����łāA
USB�Ȃ��[�����ĂāB���ŁB
����ŁA➑̂̔����ȏオ�o�b�e���[�Ȃ́B�i���蕶��͈��̏[�d��24���Ԃ����܂��I�@����ނ肩�ȁB�j
�����A4�́[��PC���ǂ���������Ă���Ȃ������҂��Ă�B
�m�[�g�^�����ǁA�t�������͊O�����Ă�������Ȃ��Ǝv���Ă�B
���������A�v���O���������āA���C�g��MMO�����Ȃ��āA�l�b�g�T�[�t�B�����Ă����A
�����͈̔͂ł͖����Ȃ��̂��o����Ǝv���B
���̍ہA���̃t���[�`���[�ł����ă��b�`�ɂ����헪�����肾�Ƃ�������B
����ȃ`�b�v�Z�b�g�ƃ�������GPU������100W�߂������p�\�R����0.4W��CPU��ς�ʼn��̈Ӗ���������H
>>255
�͓����A���������b�ɂȂ�����B�������ꂾ����1Ghz�ŁI
�����A�����ɂ����u�ԁA���Ղ肪�����������Ă��A�ʂ̂Ƃ���ɂ߂������悤�ɂȂ�����B
���͂Ƃ�����A���̕ӂ̎���̂��̂͂������̂����������Ǝv�����疖�i���g���Ăق����ˁB
>>256
C7�͍ŋߒǂ������ĂȂ�����ǂ��Ȃ��Ă�̂��ȁB
�ꎞ���Ђ���Ă���B�ł��➙�͂����ƈ������B
�͓����A���������b�ɂȂ�����B�������ꂾ����1Ghz�ŁI
�����A�����ɂ����u�ԁA���Ղ肪�����������Ă��A�ʂ̂Ƃ���ɂ߂������悤�ɂȂ�����B
���͂Ƃ�����A���̕ӂ̎���̂��̂͂������̂����������Ǝv�����疖�i���g���Ăق����ˁB
>>256
C7�͍ŋߒǂ������ĂȂ�����ǂ��Ȃ��Ă�̂��ȁB
�ꎞ���Ђ���Ă���B�ł��➙�͂����ƈ������B
>>258
����ȋ����ȍ\�����ȁB
�`�b�v�Z�b�g��5W�ʂ����A��������1�`�b�v��1W���Đ̓ǂ̂����Ǎŋ߂͈Ⴄ�̂��ȁB
�ʂɍő�����Ȃ��Ă��e�ʂ����m�ۂł���Ζ��Ȃ��������B
GPU�͂�����Ɩ��m���Ń��o�C���ł��Ƃǂꂭ�炢�H���̂��킩��Ȃ���ˁB
���Ă������`�b�v�Z�b�g��PCI-E�������Ă邩���킩��Ȃ��B
�ł����܂����V�X�e���S�̂�40�`65W���炢�ɂȂ�ȁ[�Ƃ������Ă�B
����ȋ����ȍ\�����ȁB
�`�b�v�Z�b�g��5W�ʂ����A��������1�`�b�v��1W���Đ̓ǂ̂����Ǎŋ߂͈Ⴄ�̂��ȁB
�ʂɍő�����Ȃ��Ă��e�ʂ����m�ۂł���Ζ��Ȃ��������B
GPU�͂�����Ɩ��m���Ń��o�C���ł��Ƃǂꂭ�炢�H���̂��킩��Ȃ���ˁB
���Ă������`�b�v�Z�b�g��PCI-E�������Ă邩���킩��Ȃ��B
�ł����܂����V�X�e���S�̂�40�`65W���炢�ɂȂ�ȁ[�Ƃ������Ă�B
DDR2��1����6�`8W���炢���邺
DDR3�͏������Ȃ�����
DDR3�͏������Ȃ�����
>>234
����������
���̊K���\���Ă��ڂ�
4004�ƃN���b�h�Ƃ���ׂ�Ȃ�܂����͂����낤����
P2�ƃN���b�h���Đ��\�{���炢��˂���
����������
���̊K���\���Ă��ڂ�
4004�ƃN���b�h�Ƃ���ׂ�Ȃ�܂����͂����낤����
P2�ƃN���b�h���Đ��\�{���炢��˂���
1�`�b�v7W�Ƃ��A�ǂ�ȃG�A�_�X�^�[��p�I�[�o�[�N���b�N�ł����B
���R1���W���[���ł��Ă��Ƃ���B
�ł��`�b�v�Z�b�g��GPU�����Ȃ�d�C�H����B
���ꂼ��30W��40W���炢���ȁB
���R1���W���[���ł��Ă��Ƃ���B
�ł��`�b�v�Z�b�g��GPU�����Ȃ�d�C�H����B
���ꂼ��30W��40W���炢���ȁB
40�`65W���č��̃��o�C���m�[�gPC�Ŋ��ɒB������Ă邩��ACPU�̕���GPU�ɂ�����
�������炢�����̂͂ł����Ȃ��́HGPU�͂��Ȃ肵��ڂ��̂ɂȂ�Ǝv�����B
�d�ʋ]���ɂ��Ă������݂���������A���[�J�[�̌����o�b�e���[���{���Ƃ�
�m�[�g�p�̊O�t���o�b�e���[��������Ď��������Ί�1�����Ȃ�Ƃ��Ή��ł������B
�������炢�����̂͂ł����Ȃ��́HGPU�͂��Ȃ肵��ڂ��̂ɂȂ�Ǝv�����B
�d�ʋ]���ɂ��Ă������݂���������A���[�J�[�̌����o�b�e���[���{���Ƃ�
�m�[�g�p�̊O�t���o�b�e���[��������Ď��������Ί�1�����Ȃ�Ƃ��Ή��ł������B
�܂��v����ɒP�O���d�r2�{��2�T�Ԏ������200LX���~������
>>264
��������˂��B�i��
�➙�p�̃`�b�v�Z�b�g�́I���Ă���H���ʂ̂��������B��������_�u���V���b�N�B�B�B
�������Ǝ��J�����Ă�̂������C��������ǁA�܁[������B
�ŁIGPU���u���b�N�{�b�N�X�I�I�ƁB�`�b�v���[�J�[�̐l�A�����I�������I�I
>>265
�������A�d�ʂ̂��Ǝ��O���Ă��B�����Ȃ�ƌ��\�d��������˂��B
���ƁAGF8600�̃��o�C���ł��Ăǂꂭ�炢�H���̂��Ȃ��B
��������˂��B�i��
�➙�p�̃`�b�v�Z�b�g�́I���Ă���H���ʂ̂��������B��������_�u���V���b�N�B�B�B
�������Ǝ��J�����Ă�̂������C��������ǁA�܁[������B
�ŁIGPU���u���b�N�{�b�N�X�I�I�ƁB�`�b�v���[�J�[�̐l�A�����I�������I�I
>>265
�������A�d�ʂ̂��Ǝ��O���Ă��B�����Ȃ�ƌ��\�d��������˂��B
���ƁAGF8600�̃��o�C���ł��Ăǂꂭ�炢�H���̂��Ȃ��B
Menlow�v���b�g�t�H�[����Montevina�v���b�g�t�H�[���ŋ��ʂȂ̂�
Wi-Fi�ƃ��o�C��WiMAX�@�\���������ꂽ�R���{���W���[��Echo Peak
���o�C��WiMAX�͂��Ȃ�{�C���[�h
http://journal.mycom.co.jp/news/2007/09/18/043/index.html
���[�U�[�̌��̌�����ĈӖ��ł͂���ς��ꂪ��Ԃ̖ڋ�
Wi-Fi�ƃ��o�C��WiMAX�@�\���������ꂽ�R���{���W���[��Echo Peak
���o�C��WiMAX�͂��Ȃ�{�C���[�h
http://journal.mycom.co.jp/news/2007/09/18/043/index.html
���[�U�[�̌��̌�����ĈӖ��ł͂���ς��ꂪ��Ԃ̖ڋ�
>>266
���͒m��܂��ǁA����Ȋ������ۂ��ł��ˁB
�ł��➙����̃R���Z�v�g�͉���������߂Ȃ��Ƃ��������Ɏ����͂Ƃ��Ă�B�i�ł����C���̏������x�͑Ë����Ă邯�ǁB�j
ܸö���Ƃ܂�܂���I�I
���͒m��܂��ǁA����Ȋ������ۂ��ł��ˁB
�ł��➙����̃R���Z�v�g�͉���������߂Ȃ��Ƃ��������Ɏ����͂Ƃ��Ă�B�i�ł����C���̏������x�͑Ë����Ă邯�ǁB�j
ܸö���Ƃ܂�܂���I�I
GPU����ɂ���ƁA���ꂾ���œd�C�H������A
GPU����邩�A�ȓd�͂���邩�̂ǂ������ɂȂ�B
GPU����邩�A�ȓd�͂���邩�̂ǂ������ɂȂ�B
>>270
�����ł���˂��B
�ꉞVista�̍œK���ł����������ۂ�����GPU�͑g�ݍ��݂ł����������ǂ������m��Ȃ��ł��ˁB
�����^������ł����NJ��҂��Ă݂悤���ȁB
�����ł���˂��B
�ꉞVista�̍œK���ł����������ۂ�����GPU�͑g�ݍ��݂ł����������ǂ������m��Ȃ��ł��ˁB
�����^������ł����NJ��҂��Ă݂悤���ȁB
���������Q�܂��ˁB
���肪�Ƃ��ł��B
���肪�Ƃ��ł��B
>>243
�ėp���ōŋ��Ȃ̂�Divx����
�ėp���ōŋ��Ȃ̂�Divx����
�ނ��덡���Ƃ����邭�炢�G���R���z�̕���
Divx��WMV�Ō���ێ���x264�Ȃ�Ċᒆ�ɂȂ������肷��
Divx��WMV�Ō���ێ���x264�Ȃ�Ċᒆ�ɂȂ������肷��
DivX�͉ƓdDVD�v���[���[��g�ѓd�b���Ή����Ă�
277 �FSocket774�F2007/09/22(�y) 02:12:09 ID:8pl9ri2O
>>252
���̒��x�̐��\�Ńs�[�N0.4W�A�ʏ�0.1W�āA�ʂɂ������Ȃ���H
�Ⴆ��Ȃ�
Athlon64 X2 2.8GHz��������
���̐��\��125W����
�Ă�����R���Ő���オ��Ǝv�����̂ɐG�ꂽ�̂�>>252��������E�E�E
����Ȃ���
���̒��x�̐��\�Ńs�[�N0.4W�A�ʏ�0.1W�āA�ʂɂ������Ȃ���H
�Ⴆ��Ȃ�
Athlon64 X2 2.8GHz��������
���̐��\��125W����
�Ă�����R���Ő���オ��Ǝv�����̂ɐG�ꂽ�̂�>>252��������E�E�E
����Ȃ���
�Ⴆ��������
Athlon64 X2 2.8GHz��������
���̐��\��125W����
�u���̐��\�ł�������125W����v
�ɂ��ׂ���������
Pentium D����Ȃɍ����\�Ȃ̂�150W���x�I
�ł�������
���̐��\��125W����
�u���̐��\�ł�������125W����v
�ɂ��ׂ���������
Pentium D����Ȃɍ����\�Ȃ̂�150W���x�I
�ł�������
>>277��Silverthorn�̐��\�����S�ɔc�����Ă���悤�ł��B
Silverthorne�̏ڍׂ͂悭�킩��A
http://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
�㓡���̐����ɂ��ƁACPU�R�A��P6�N���X�̃_�C�T�C�Y��L2��512KB�AFSB��533MHz������A
���̂�������G�c�����A2GHz��Tualatin�����̐��\��0.4W�ƍl����Ό��\�����C���B
http://pc.watch.impress.co.jp/docs/2007/0919/amd.htm
�ŋߏo�����f���i���o�[���疳������肵�Đ��\�̋߂�����AMD��Athlon64 2000+�ł�TDP8W�����ˁB
http://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
�㓡���̐����ɂ��ƁACPU�R�A��P6�N���X�̃_�C�T�C�Y��L2��512KB�AFSB��533MHz������A
���̂�������G�c�����A2GHz��Tualatin�����̐��\��0.4W�ƍl����Ό��\�����C���B
http://pc.watch.impress.co.jp/docs/2007/0919/amd.htm
�ŋߏo�����f���i���o�[���疳������肵�Đ��\�̋߂�����AMD��Athlon64 2000+�ł�TDP8W�����ˁB
�f���������ȏ㋉
���炨�O��������H���Ă�J���i
���N���X�C���e����SSD���o��炵����
���N���X�C���e����SSD���o��炵����
�����đ�����Ηe�ʂ͏��Ȃ��Ă���
�݂��RAID0����킯����
�݂��RAID0����킯����
�Q�[�����Ȃ烁���R�������Ɍ��邩��Ȃ��B�Ȃ�ŃC���e���͑��������R������
�i�߂Ȃ��̂��̂��B
�i�߂Ȃ��̂��̂��B
0.4W���쎞��800MHz�Ƃ����̕ӑ������ď����ĂȂ��H
IPC�������\��������A500MHz�ӂ肩������Ȃ����ǁB
2GHz�Ƃ����̂́A�����܂ł��̐��\���o����Ƃ��������ł����āA
����d�͂͑S�R�Ⴄ���ƂɂȂ�Ǝv���B
����ł�6W�Ƃ����̒��x���Ǝv�����ǁB
VIA��CPU�͒����d�͂ł��A�N���b�N������̐��\���������Ⴍ�āA���\����I�Ǝv������B
�܂Ƃ��Ȓ����d��CPU���o�Ă��ė~�����ˁB
IPC�������\��������A500MHz�ӂ肩������Ȃ����ǁB
2GHz�Ƃ����̂́A�����܂ł��̐��\���o����Ƃ��������ł����āA
����d�͂͑S�R�Ⴄ���ƂɂȂ�Ǝv���B
����ł�6W�Ƃ����̒��x���Ǝv�����ǁB
VIA��CPU�͒����d�͂ł��A�N���b�N������̐��\���������Ⴍ�āA���\����I�Ǝv������B
�܂Ƃ��Ȓ����d��CPU���o�Ă��ė~�����ˁB
�n�[�h���͂����[��s���ă\�t�g��������
�N���b�N������̐��\�Ȃ͂ǂ��ł��������ǂˁB����d�͓�����̐��\��������B
>>283
SSD���āA�C���e�����{�C�o���č�����炷�����̂ł��������Ȃ��B
�v���Z�X�Z�p�̎���͂���NAND�����������B�i�t���b�V�����������͒m��Ȃ����B�j
SSD���āA�C���e�����{�C�o���č�����炷�����̂ł��������Ȃ��B
�v���Z�X�Z�p�̎���͂���NAND�����������B�i�t���b�V�����������͒m��Ȃ����B�j
>>290
32nm�v���Z�X�̎���́ASRAM�������炵�����B
32nm�v���Z�X�̎���́ASRAM�������炵�����B
Intel�̃v���Z�X�̎���͂����Ă�SRAM�̋C�͂��邪
���߂�B�L������Ă������B
�ǂ��Ō��������ȁB�B�B�ق�Ƃ��߂�B
�ǂ��Ō��������ȁB�B�B�ق�Ƃ��߂�B
32nm�v���Z�X�̍���̎���́A�����I�ɑ������������łȂ��A�Z���ʐς̏k������������
�i65nm->45nm��66���A����52.9���j�A�n�[�h���͒Ⴉ���������ˁB
�h���C��45nm����Ă邩��A32nm�͉t�Z�Ή������łn�j�H
�t�Z���\�Z�p�́A32nm��鎞�ɂ͏[�����Ȃ�Ă邾�낤���B
�������AIDF�ł͍\�����ǂ��Ȃ��Ă邩�Ƃ��͎�����ĂȂ������ȁE�E�E�B
�E�F�n�͏o���Ă�̂ɁA�f�ʎʐ^�͔閧�B
�����IDF�A�R�}�[�V�����Șb�͂���Ȃ�ɂ��������ǁANeharem�̏ڍׂƂ��A�˂����b
�͂���܂�Ȃ����B
��ŁALarrabee��2010�N���HLarrabee����Ȃɏo��̒x�������������B
�i65nm->45nm��66���A����52.9���j�A�n�[�h���͒Ⴉ���������ˁB
�h���C��45nm����Ă邩��A32nm�͉t�Z�Ή������łn�j�H
�t�Z���\�Z�p�́A32nm��鎞�ɂ͏[�����Ȃ�Ă邾�낤���B
�������AIDF�ł͍\�����ǂ��Ȃ��Ă邩�Ƃ��͎�����ĂȂ������ȁE�E�E�B
�E�F�n�͏o���Ă�̂ɁA�f�ʎʐ^�͔閧�B
�����IDF�A�R�}�[�V�����Șb�͂���Ȃ�ɂ��������ǁANeharem�̏ڍׂƂ��A�˂����b
�͂���܂�Ȃ����B
��ŁALarrabee��2010�N���HLarrabee����Ȃɏo��̒x�������������B
�ǂ�����QX9650�̃x���`�̂��ĂȂ��ł����H�@QX6850�Ɣ�ׂĂǂ���������E�E
�ԍ���6850�����C��9650�܂Ŕ��ł邩�炳�������������낤�Ȃ��E�E
�ԍ���6850�����C��9650�܂Ŕ��ł邩�炳�������������낤�Ȃ��E�E
������SSE4�Ή��\�t�g���ƍő�Ő��\��2�{�ȏ�ɒ��ˏオ���Ă�B
>>296
�ǂ����ɂ��������ǖY�ꂽ
�ǂ����ɂ��������ǖY�ꂽ
���W�b�N�v���Z�X�̎����SRAM�Ɍ��܂��Ƃ�B
Flash�Ƃ̓v���Z�X���S�R�Ⴄ�B
Flash�Ƃ̓v���Z�X���S�R�Ⴄ�B
QX9650�����\��̐l���܂����H
�Ő��Mooly Eden�̃C���^�r���[��
http://www.tgdaily.com/content/view/33958/136/
���ς�炸�A�u�i�������A���Ŗʔ�������B
�@�E���ʃm�[�g��4-core�͂���Ȃ���
�@�E64-bit�Ȃ�ĒN���g���́H
�@�EPenryn��Mobile K10�R�ŊJ�������̂ɁAGriffin�Ȃ�ďo���Ă��đ��
�@�E������J���̌㔼�͑��}�Ƀ����[�X���邱�Ƃ������ڕW�ɂȂ����B
�@�E�m�[�g�p�v���Z�b�T�ōł��d�v�Ȃ̂̓X���[�v���
�@�E�iFusion�ɂ��Ă̎����)�ǂ��A�C�f�A���BTimna���̂��̂̃p�N�������ǂˁB
���X
http://www.tgdaily.com/content/view/33958/136/
���ς�炸�A�u�i�������A���Ŗʔ�������B
�@�E���ʃm�[�g��4-core�͂���Ȃ���
�@�E64-bit�Ȃ�ĒN���g���́H
�@�EPenryn��Mobile K10�R�ŊJ�������̂ɁAGriffin�Ȃ�ďo���Ă��đ��
�@�E������J���̌㔼�͑��}�Ƀ����[�X���邱�Ƃ������ڕW�ɂȂ����B
�@�E�m�[�g�p�v���Z�b�T�ōł��d�v�Ȃ̂̓X���[�v���
�@�E�iFusion�ɂ��Ă̎����)�ǂ��A�C�f�A���BTimna���̂��̂̃p�N�������ǂˁB
���X
�������Justin Ratner�̃C���^�r���[��
http://www.extremetech.com/article2/0,1697,2185865,00.asp
�@�E�������R���g���[�������ɂ�Z�p�I�ȃg���[�h�I�t������ANehalem�����[�X�̃^�C�~���O���œK�ƐM����
�@�E45-nm�v���Z�X�ł̃��^���Q�[�g�̗̍p��A�����̎j�����I�Ȑi��
�@�ESilverthone�̃R�A"Bonnell"�퉼�z������SSE�܂őS�����B�����d�͂ł�IA����d�l�헎�Ƃ��Ȃ�
http://www.extremetech.com/article2/0,1697,2185865,00.asp
�@�E�������R���g���[�������ɂ�Z�p�I�ȃg���[�h�I�t������ANehalem�����[�X�̃^�C�~���O���œK�ƐM����
�@�E45-nm�v���Z�X�ł̃��^���Q�[�g�̗̍p��A�����̎j�����I�Ȑi��
�@�ESilverthone�̃R�A"Bonnell"�퉼�z������SSE�܂őS�����B�����d�͂ł�IA����d�l�헎�Ƃ��Ȃ�
���@�E�������R���g���[�������ɂ�Z�p�I�ȃg���[�h�I�t������ANehalem�����[�X�̃^�C�~���O���œK�ƐM����
�I�����AMD���V�F�A���͕̂s�\�Ƃ�����ꂽ�̂ɂ���͖������
�I�����AMD���V�F�A���͕̂s�\�Ƃ�����ꂽ�̂ɂ���͖������
�I�����AMD���V�F�A����ꂽ�̂́A
�C���e�����l�b�g�o�[�X�g��FB-DIMM�Ƃ��A���������炾��B
�C���e�����l�b�g�o�[�X�g��FB-DIMM�Ƃ��A���������炾��B
����Ȃ��Ƃ͑S�R�Ȃ��B
���͗��ł̓A���u�̐Ζ�����
�A���u�̃A�u�����H
�C�X���G����
C2D��������X����EXCEL�}�N���̏������x��r��X2��C2D�ł��Ă����ǂ��E�E�E
�Ȃ��C2D��X2����{���x����������ˁB
���̎�����t�������ăA���~���r��Ă邩�璍�ӂ���悤�ɁE�E�E
�Ȃ��C2D��X2����{���x����������ˁB
���̎�����t�������ăA���~���r��Ă邩�璍�ӂ���悤�ɁE�E�E
�����A���~�Ƃ������Ă�̂��O��������
�l�n�[�����̃_�C�����܂�L���C�łȂ��̂��C�ɂȂ�B���\�I�ɐ��������Ƃ��Ă���͂����d�͂�������
�Ȃ����Ƃ������O������ˁB
�Ȃ����Ƃ������O������ˁB
�ʐ^�Ȃ�ĎB��悤�ɂ���Ăǂ��ɂł��o����
���̉ł��ʐ^�ʂ�͐����悩����
�������悭�H��
���̉ł��ʐ^�ʂ�͐����悩����
�������悭�H��
���N�I�ł����W���}�C�J
>>312
�S�R�����[�悗
�S�R�����[�悗
315 �FSocket774�F2007/09/25(��) 06:54:19 ID:imhYnrd9
732 �F���͌��c�� [��] �F2007/09/24(��) 23:48:29 ID:lBueDY8X
�H�쉳>>309
�H�쉳>>309
http://journal.mycom.co.jp/photo/articles/2007/09/24/idf01/images/Photo02l.jpg
wolfdale��yorkfield�炵�����ǁA�_�C�̐��@�A���Ȃ��H
�ʐ^�̓s�����H����Ƃ������Ƃ͈ႤCPU����Ɏ���Ă�̂��낤���H
����CPU�͐����`�ɋ߂��_�C��65nm Conroe�̂悤�ɂ��v����B
{kind=link}
wolfdale��yorkfield�炵�����ǁA�_�C�̐��@�A���Ȃ��H
�ʐ^�̓s�����H����Ƃ������Ƃ͈ႤCPU����Ɏ���Ă�̂��낤���H
����CPU�͐����`�ɋ߂��_�C��65nm Conroe�̂悤�ɂ��v����B
���ہA���ɂ��ABloomfiled�̍ŏ��̐��i��TDP��130W�ƁA
���s�̃N�A�b�h�R�A�Ɠ������x���ɂȂ��Ă���(���ۂɂ̓������R���g���[������������Ă���̂ŁA
���s�̃N�A�b�h�R�A���͉������Ă���ƌ����邩������Ȃ����c�c)�B
http://pc.watch.impress.co.jp/docs/2007/0925/ubiq198.htm
8�R�A200W���ڂ�
���s�̃N�A�b�h�R�A�Ɠ������x���ɂȂ��Ă���(���ۂɂ̓������R���g���[������������Ă���̂ŁA
���s�̃N�A�b�h�R�A���͉������Ă���ƌ����邩������Ȃ����c�c)�B
http://pc.watch.impress.co.jp/docs/2007/0925/ubiq198.htm
8�R�A200W���ڂ�
Core2�̍ŏ���4�R�A�Ɠ����ŁA8�R�A��Nehalem��4�R�A�ł��1���قǃN���b�N�����āATDP150W���炢�œo�ꂶ��Ȃ����ȁB
���ް���
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
���i�̓��������́uNehalem���O�ɂȂ邩������Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://blog.livedoor.jp/amd646464/archives/51060099.html
2010�N�ɐ��i�������
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
���i�̓��������́uNehalem���O�ɂȂ邩������Ȃ��v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://blog.livedoor.jp/amd646464/archives/51060099.html
2010�N�ɐ��i�������
2010�N��������ACPU���R�A���ǂ����Ă������ȁB
���x�C�X���G���̐V�A�[�LCPU���o�ꂷ�鎟�������A
>AMD��3DLabs�̃G���W�j�A�𐔕S�l�ق����Ƃ���
���̑OAMD�����߂�ATI�������B
���x�C�X���G���̐V�A�[�LCPU���o�ꂷ�鎟�������A
>AMD��3DLabs�̃G���W�j�A�𐔕S�l�ق����Ƃ���
���̑OAMD�����߂�ATI�������B
���ް���Ĕ�������Ă���ʂɂ͗��ʂ��Ȃ���Ȃ���
2008�N�A2009�N�Ȃ�Ƃ������A2010�N���ƁA�v���Z�X�ڍs�������Ȃ�CPU��32nm����ɂȂ��Ă��ȁB
�P���ɔ{�����Ă���Ȃ�A32nm��16�R�A���炢���낤���B
Larrabee���ȑO32�R�A�Ƃ���������������A�A�N�Z�����[�^�{�[�h�������낤����A
�Ȃ�Ƃ�������Ȃ��́H���܂荂������Ȃ���������Ȃ����ǁB
�P���ɔ{�����Ă���Ȃ�A32nm��16�R�A���炢���낤���B
Larrabee���ȑO32�R�A�Ƃ���������������A�A�N�Z�����[�^�{�[�h�������낤����A
�Ȃ�Ƃ�������Ȃ��́H���܂荂������Ȃ���������Ȃ����ǁB
HKEPC��Penryn���r���[���B
http://www.hkepc.com/?id=171
�����i���C���i�b�v
�@Nov. 2007
�@�@QX9650/Quad 3GHz/12MB L2/1333MHz FSB�@�@$999-
�@Jan. 2008
�@�@Q9550/Quad 2.83GHz/12MB L2/1333MHz FSB�@$530-
�@�@Q9450/Quad 2.66GHz/12MB L2/1333MHz FSB�@$316-
�@�@Q9300/Quad 2.50GHz/6MB L2/1333MHz �@FSB�@$266-
�@�@E8500/Dual 3.16GHz/6MB L2/1333MHz �@FSB�@$266-
�@�@E8400/Dual 3.00GHz/6MB L2/1333MHz �@FSB�@$183-
�@�@E8300/Dual 2.83GHz/6MB L2/1333MHz �@FSB�@-----
�@�@E8200/Dual 2.66GHz/6MB L2/1333MHz �@FSB�@$163-
���x���`�}�[�N
�@http://www.hkepc.com/?id=171&page=3
������d��
�@�@�@�@�@�@�@�@�@�@�@�@Idol Pwr�@�@�@Idol Temp�@�@�@�@Max Pwr�@�@�@Max Temp
�@�@�@�@�@�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]
QX6850/2.33GHz�@�@�@72�@�@�@�@�@�@�@43�@�@�@�@�@�@�@�@�@95�@�@�@�@�@�@�@�@57
Yorkfield/2.33GHz�@�@57�@�@�@�@�@�@�@35�@�@�@�@�@�@�@�@�@79�@�@�@�@�@�@�@�@46
http://www.hkepc.com/?id=171
�����i���C���i�b�v
�@Nov. 2007
�@�@QX9650/Quad 3GHz/12MB L2/1333MHz FSB�@�@$999-
�@Jan. 2008
�@�@Q9550/Quad 2.83GHz/12MB L2/1333MHz FSB�@$530-
�@�@Q9450/Quad 2.66GHz/12MB L2/1333MHz FSB�@$316-
�@�@Q9300/Quad 2.50GHz/6MB L2/1333MHz �@FSB�@$266-
�@�@E8500/Dual 3.16GHz/6MB L2/1333MHz �@FSB�@$266-
�@�@E8400/Dual 3.00GHz/6MB L2/1333MHz �@FSB�@$183-
�@�@E8300/Dual 2.83GHz/6MB L2/1333MHz �@FSB�@-----
�@�@E8200/Dual 2.66GHz/6MB L2/1333MHz �@FSB�@$163-
���x���`�}�[�N
�@http://www.hkepc.com/?id=171&page=3
������d��
�@�@�@�@�@�@�@�@�@�@�@�@Idol Pwr�@�@�@Idol Temp�@�@�@�@Max Pwr�@�@�@Max Temp
�@�@�@�@�@�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]
QX6850/2.33GHz�@�@�@72�@�@�@�@�@�@�@43�@�@�@�@�@�@�@�@�@95�@�@�@�@�@�@�@�@57
Yorkfield/2.33GHz�@�@57�@�@�@�@�@�@�@35�@�@�@�@�@�@�@�@�@79�@�@�@�@�@�@�@�@46
E6850�ł��v������Dual�ŏ�ʂ�E8500�̂�����������������
Quad���Đ��\���㗦������
���������A���\/���b�g��Dual�ɔ�ׂĈ������
Quad��������̂��ăG���R��������
�w�ǂ̃Q�[���ł܂�Quad�̂��u���炩�Ɂv�����Ƃ�������
�}���`�X���b�h�Ή��̃��X�v���Ƃ��̃��[�e�N�Q�[���ł���
�R�A�P�ʂ�CPU���p���͒Ⴂ�A�R�A����������Α�����ق�
CPU���p����������Ƃ��������X�d�l
Quad���Đ��\���㗦������
���������A���\/���b�g��Dual�ɔ�ׂĈ������
Quad��������̂��ăG���R��������
�w�ǂ̃Q�[���ł܂�Quad�̂��u���炩�Ɂv�����Ƃ�������
�}���`�X���b�h�Ή��̃��X�v���Ƃ��̃��[�e�N�Q�[���ł���
�R�A�P�ʂ�CPU���p���͒Ⴂ�A�R�A����������Α�����ق�
CPU���p����������Ƃ��������X�d�l
�������ACave�̃e�X�g����т��̃X�e�[�W�ȊO��
�}���`�R�A�̈Ӗ����w�ǖ����Ƃ�����
�}���`�R�A�̈Ӗ����w�ǖ����Ƃ�����
>>325
�z���g���悱��A
����ȏ���d�́A���x�������Ȃ̂��H
���ꂪ45nm�̃p���[�Ȃ̂��B
�f���A���R�A�̃x���`��ׂ͂Ȃ��̂��H
�z���g���悱��A
����ȏ���d�́A���x�������Ȃ̂��H
���ꂪ45nm�̃p���[�Ȃ̂��B
�f���A���R�A�̃x���`��ׂ͂Ȃ��̂��H
�@�@�@�@�@�@�@�@�@�@�@�@Idol Pwr�@�@�@Idol Temp�@�@�@�@Max Pwr�@�@�@Max Temp
�@�@�@�@�@�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]
��QX6850/2.33GHz�@�@�@72�@�@�@�@�@�@�@43�@�@�@�@�@�@�@�@�@95�@�@�@�@�@�@�@�@57
���ꏋ������
QX6850/2.33GHz�@�@�@60�@�@�@�@�@�@�@33�@�@�@�@�@�@�@�@�@80�@�@�@�@�@�@�@�@45
���ۂ͂�������
�@�@�@�@�@�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]�@�@�@�@�@�@�@�@[W]�@�@�@�@�@�@�@[C]
��QX6850/2.33GHz�@�@�@72�@�@�@�@�@�@�@43�@�@�@�@�@�@�@�@�@95�@�@�@�@�@�@�@�@57
���ꏋ������
QX6850/2.33GHz�@�@�@60�@�@�@�@�@�@�@33�@�@�@�@�@�@�@�@�@80�@�@�@�@�@�@�@�@45
���ۂ͂�������
�����������̂��悭������Ȃ���
�L�`�K�C�͕����Ă���
�@�@Q9550/Quad 2.83GHz/12MB L2/1333MHz FSB�@$530-
�@�@Q9450/Quad 2.66GHz/12MB L2/1333MHz FSB�@$316-
0.17GHz�̈Ⴂ�ŁA$214�c�I
�Ȃ�Ƃ��������
�@�@Q9450/Quad 2.66GHz/12MB L2/1333MHz FSB�@$316-
0.17GHz�̈Ⴂ�ŁA$214�c�I
�Ȃ�Ƃ��������
0.17GHz�̈Ⴂ�ŁA$214down�c�I
�Ȃ�Ƃ����_���
�Ȃ�Ƃ����_���
0.17x4��0.68GHz�̈Ⴂ�ƍl����I
���l
�`�L�V���[����
9550���{�b�^�N���Ȃ�������ˁ[����
Tigerton��Yorkfield�͔���C���������Ȃ��c
>�G���R����
�\�[�X�̃R���p�C���Ƃ��J���p�r�ł����ɗ����܂��恄��
���N���b�N�̃V���O���R�A��3����1���炢�ɂȂ�܂�
�\�[�X�̃R���p�C���Ƃ��J���p�r�ł����ɗ����܂��恄��
���N���b�N�̃V���O���R�A��3����1���炢�ɂȂ�܂�
���O�{�C����R���p�C����r���h���Ɉꕞ����ˁ[��
����Ȃɑ����I�������T�{��˂�����S���@
����Ȃɑ����I�������T�{��˂�����S���@
>>339
�ō����C�C�I���Đl�͉䖝�ł��Ȃ����낤����
�ō����C�C�I���Đl�͉䖝�ł��Ȃ����낤����
nehalem���ăx�[�X�N���b�N�����ɂȂ��
���N�̂P���ɐV����CPU���o����Ă����L���������C�������
�ǂ��CPU������킩�����Ȃ����H
�ǂ��CPU������킩�����Ȃ����H
�Y�����Y���������
QX9650��QX6850�Ɣ�r���Ăǂ̂��炢���\�������Ă�́H
2800���オ���Ă�
>>348
�}�W���X����Ɠ��N���b�N�Ȃ琫�\�A�b�v��5%���x
�}�W���X����Ɠ��N���b�N�Ȃ琫�\�A�b�v��5%���x
SSE4���g��Ȃ��ꍇ�́A�ˁB
�g������A�T�����炢�����Ȃ鎖������炵���B
�g������A�T�����炢�����Ȃ鎖������炵���B
���������Nehalem��܂����B
ttp://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
����ς�8�R�A��MCM����Ȃ��ăl�C�e�B�u�Ȃ̂��ȁB
ttp://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
����ς�8�R�A��MCM����Ȃ��ăl�C�e�B�u�Ȃ̂��ȁB
>L2��L3�͕����I�ɂ͓����L���b�V��SRAM�ŁA���R���t�B�M�����u���ɃG���A���Ďg�������Ă���̂�������Ȃ��B
����������x���������B
����SRAM���ƁA���C�e���V�̖�肪�c���Ă��܂��C������B
L0�ƌĂ�������l�I���Ғl�傗
����������x���������B
����SRAM���ƁA���C�e���V�̖�肪�c���Ă��܂��C������B
L0�ƌĂ�������l�I���Ғl�傗
2-way��SMT������L1��2�̃X���b�h�ŋ��L
�����܂��I���S���g����炩���Ȃ����S�z�ł�
8�R�A�Ƃ������L����킟
�I���S�������Ԃ�āA�Г��I�ɂ͂��łɃC�X���G���Ɠ��i�������ď����Ă������ȁB
���x�_���Ȃ炳��[�Ȃ炾�낤�B
���x�_���Ȃ炳��[�Ȃ炾�낤�B
�l�C�e�B�u8�R�A�̓��X�N���傫������C�����邪�Ȃ��c
4�R�A�ɍi���ăX�P�[�������b�g�ŃS���������������݂�ȍK���ɂȂ��C���������
4�R�A�ɍi���ăX�P�[�������b�g�ŃS���������������݂�ȍK���ɂȂ��C���������
45nm�Ńl�C�e�B�u8�R�A�́A�ł����Ƃ��Ă�����B
����Ȃ�܂ł͍s���Ȃ��Ǝv�����A���S�ɃC�X���G���̕⍲���ɂȂ�낤�ˁB
�C�X���G���������CPU���A�V�������N���āA���ߒlj����āA�I�N�^�R�A�����āA�������i�v�ɌJ��Ԃ��c�c
�C�X���G���������CPU���A�V�������N���āA���ߒlj����āA�I�N�^�R�A�����āA�������i�v�ɌJ��Ԃ��c�c
>>355����, >>357����, >>360����
�A�����̊�]�ɉ߂��Ȃ��Ƃ�v�������ǁA�Ő�[�̃v���Z�b�T�v�Ɍg�����̗����Y�ތ{�̂悤��
�^�����g�W�c���A�u��炩���v���u����[�Ȃ�v���u�⍲���ɂȂ�v���Ɣ�]����q�g���ĉ��҂�����(��)
��������ł���Z�p�ɑ���h�ӂ���������Ƃ肳���̃J�L�R�~������Ƃ������Ԃɂ�A���ƈ��W
�Ƃ����C���ɂȂ邷�B
�A�����̊�]�ɉ߂��Ȃ��Ƃ�v�������ǁA�Ő�[�̃v���Z�b�T�v�Ɍg�����̗����Y�ތ{�̂悤��
�^�����g�W�c���A�u��炩���v���u����[�Ȃ�v���u�⍲���ɂȂ�v���Ɣ�]����q�g���ĉ��҂�����(��)
��������ł���Z�p�ɑ���h�ӂ���������Ƃ肳���̃J�L�R�~������Ƃ������Ԃɂ�A���ƈ��W
�Ƃ����C���ɂȂ邷�B
�I���S���̋K�͂�m��Ȃ��~�[�ǂ��ɉ��������Ă�����
�Q�����j������������ȁB
�I���S���҂͋v�����炸
�I���S���͕���������
�C�X���G���͋��̗����Y��
���ꂾ���̂��Ƃ��B
�C�X���G���͋��̗����Y��
���ꂾ���̂��Ƃ��B
ttp://www.4gamer.net/games/030/G003078/20070926042/
nVIDIA�ǂ��{���ĂB
���ƃI���S���̒����U��͖��炩���ȁB�l�o�̎��̋P���͔��ꂽ�B
�������͊Ԉ���Ă����Ƃ��Ă������Ă��ꂽ�r�W�����͊��������̂ɁB
������K8�̃p�`������肩��B
nVIDIA�ǂ��{���ĂB
���ƃI���S���̒����U��͖��炩���ȁB�l�o�̎��̋P���͔��ꂽ�B
�������͊Ԉ���Ă����Ƃ��Ă������Ă��ꂽ�r�W�����͊��������̂ɁB
������K8�̃p�`������肩��B
AMD��Intel��ǂ�����������A������B
�f�B�Y�j�[�Ə�����˂̊G���Ă��Ƃ��B
�f�B�Y�j�[�Ə�����˂̊G���Ă��Ƃ��B
>>366
CPU�o�X���C�Z���X�ƌ�������
���ėv�����Ă�Ǝv����
Intel���o�X���C�Z���X�̍X�V�◿���ŏa�����ĂȂ����
50$���ӂ������Ȃ��̂́AAMD��������ᖾ��
CPU�o�X���C�Z���X�ƌ�������
���ėv�����Ă�Ǝv����
Intel���o�X���C�Z���X�̍X�V�◿���ŏa�����ĂȂ����
50$���ӂ������Ȃ��̂́AAMD��������ᖾ��
AMD�̃v���b�g�t�H�[���ł��ASLI�Ή��Ȃ̂�NVIDIA�̃`�b�v�Z�b�g���������B
CrossFire�̕����嗬�ɂȂ�ANVIDIA��SLI�̃��C�Z���X�ɐϋɓI�ɂȂ邾�낤�B
CrossFire�̕����嗬�ɂȂ�ANVIDIA��SLI�̃��C�Z���X�ɐϋɓI�ɂȂ邾�낤�B
2005�N 2�R�A
2007�N 4�R�A
2009�N 8�R�A
2011�N 16�R�A
2013�N 32�R�A
2015�N 64�R�A
2017�N 128�R�A
2019�N 256�R�A
2021�N 512�R�A
2023�N 1024�R�A
2025�N 2048�R�A
2027�N 4096�R�A
2029�N 8192�R�A
2007�N 4�R�A
2009�N 8�R�A
2011�N 16�R�A
2013�N 32�R�A
2015�N 64�R�A
2017�N 128�R�A
2019�N 256�R�A
2021�N 512�R�A
2023�N 1024�R�A
2025�N 2048�R�A
2027�N 4096�R�A
2029�N 8192�R�A
>>370
2�R�A��2001�N���낤��
2�R�A��2001�N���낤��
�{�{�Q�[���̋��낵��
10000�N�ɂ͂����ɂȂ��Ă�
���̑O�ɁA�g�����W�X�^�����������E�ɒB���邩����S���Ƃ��B
10���ɂ͏o��́H
�Ȃɂ��H
E8500/Dual 3.16GHz/6MB L2/1333MHz �@FSB�@$266-
E6850������w�������킯�����c
E6850������w�������킯�����c
E8500���X���[����Nehalem�܂ő҂ĂC�C����Ȃ����B
�l�K���ĂȂ���6850�����\���Ă�����Ⴂ(�l*�L��`)
�l�K���ĂȂ���6850�����\���Ă�����Ⴂ(�l*�L��`)
379 �FSocket774�F2007/09/29(�y) 17:15:46 ID:DGxxZJ2D
�p�\�R���V���b�v�ŋ������N
http://want-pc.com
http://want-pc.com
��[�����ӂ��[��ǂ���45nm�Ȃ́H
381 �FSocket774�F2007/09/30(��) 04:06:54 ID:aR072ZUM
>>371
�����@>>370��x86�����m��Ȃ���BPower�Ƃ�Sparc�Ȃ�ĂȂ�̂��Ƃ���
�m��Ȃ�����PC�[�B
�ƌ�������Power��Sparc�Ȃ�Ďg�������ƂȂ����ǂˁB
���Â�Sparc���[�N�X�e�[�V�����������Ə����v���Ă邪�A���ɗ����������Ȃ�
��(�P�Ȃ郂�m���������珊�L����������)
�����@>>370��x86�����m��Ȃ���BPower�Ƃ�Sparc�Ȃ�ĂȂ�̂��Ƃ���
�m��Ȃ�����PC�[�B
�ƌ�������Power��Sparc�Ȃ�Ďg�������ƂȂ����ǂˁB
���Â�Sparc���[�N�X�e�[�V�����������Ə����v���Ă邪�A���ɗ����������Ȃ�
��(�P�Ȃ郂�m���������珊�L����������)
2001�N 2�R�A�iHTT�j �| 180nm�i�i�m�j
2003�N 2�R�A�iHTT�j �| 130nm
2005�N 2�R�A �| 90nm
2007�N 4�R�A �| 65nm
2009�N 8�R�A �| 45nm
2011�N 16�R�A �| 32nm
2013�N 32�R�A �| 22.5nm
2015�N 64�R�A �| 16nm
2017�N 128�R�A �| 11.25nm
2019�N 256�R�A �| 8nm
2021�N 512�R�A �| 5.625nm
2023�N 1024�R�A �| 4nm
2025�N 2048�R�A �| 2.8125nm
2027�N 4096�R�A �| 2nm
2029�N 8192�R�A �| 1.40625nm
2031�N 16384�R�A �| 1nm
2033�N 32769�R�A �| 703.125pm�i�s�R�j
2035�N 65536�R�A �| 500pm
2037�N 131072�R�A �| 351.5625pm
2039�N 262144�R�A �| 250pm
2041�N 524288�R�A �| 175.78125pm
2043�N 1048576�R�A �| 125pm
2045�N 2097152�R�A �| 87.890625pm
2047�N 4194304�R�A �| 62.5pm
2049�N 8388608�R�A �| 43.9453125pm
2051�N 16777216�R�A �| 31.25pm
2053�N 33554432�R�A �| 21.97265625pm
2055�N 67108864�R�A �| 15.625pm
2057�N 134217728�R�A �| 10.986328125pm
2059�N 268435456�R�A �| 7.8125pm
�g�����W�X�^�������̌��E�͂ǂ̂��炢���H
2003�N 2�R�A�iHTT�j �| 130nm
2005�N 2�R�A �| 90nm
2007�N 4�R�A �| 65nm
2009�N 8�R�A �| 45nm
2011�N 16�R�A �| 32nm
2013�N 32�R�A �| 22.5nm
2015�N 64�R�A �| 16nm
2017�N 128�R�A �| 11.25nm
2019�N 256�R�A �| 8nm
2021�N 512�R�A �| 5.625nm
2023�N 1024�R�A �| 4nm
2025�N 2048�R�A �| 2.8125nm
2027�N 4096�R�A �| 2nm
2029�N 8192�R�A �| 1.40625nm
2031�N 16384�R�A �| 1nm
2033�N 32769�R�A �| 703.125pm�i�s�R�j
2035�N 65536�R�A �| 500pm
2037�N 131072�R�A �| 351.5625pm
2039�N 262144�R�A �| 250pm
2041�N 524288�R�A �| 175.78125pm
2043�N 1048576�R�A �| 125pm
2045�N 2097152�R�A �| 87.890625pm
2047�N 4194304�R�A �| 62.5pm
2049�N 8388608�R�A �| 43.9453125pm
2051�N 16777216�R�A �| 31.25pm
2053�N 33554432�R�A �| 21.97265625pm
2055�N 67108864�R�A �| 15.625pm
2057�N 134217728�R�A �| 10.986328125pm
2059�N 268435456�R�A �| 7.8125pm
�g�����W�X�^�������̌��E�͂ǂ̂��炢���H
>>382
�\���߂��������B
ttp://japan.cnet.com/news/ent/story/0,2000056022,20062349,00.htm
16nm�Ō��E�炵���B
2013�N�ĈӊO�Ƃ�������Ȃ��B
�\���߂��������B
ttp://japan.cnet.com/news/ent/story/0,2000056022,20062349,00.htm
16nm�Ō��E�炵���B
2013�N�ĈӊO�Ƃ�������Ȃ��B
2007�N2��23��
Intel����CPU���J�����ƌ������\�B
��CPU�͏]����CPU�̖�10�{�̑�����100����1�̃R�X�g�Ő������邱�Ƃ��ł���B
��3�N�ŏ��i���\��B
http://ja.wikipedia.org/wiki/CPU%E5%B9%B4%E8%A1%A8
Intel����CPU���J�����ƌ������\�B
��CPU�͏]����CPU�̖�10�{�̑�����100����1�̃R�X�g�Ő������邱�Ƃ��ł���B
��3�N�ŏ��i���\��B
http://ja.wikipedia.org/wiki/CPU%E5%B9%B4%E8%A1%A8
��CPU���Ă܂Ƃ��ȃ\�[�X�������Ɩ������B
wiki�Ƃ��e���r�Ō����Ƃ�����Ȃ̂�����B
wiki�Ƃ��e���r�Ō����Ƃ�����Ȃ̂�����B
>>383
�����U�N��ł��\�t�g�̃}���`�X���b�h�Ή����o���Ă邩���������
�����U�N��ł��\�t�g�̃}���`�X���b�h�Ή����o���Ă邩���������
Si���q�̑傫�����l�����16nm�`8nm�ӂ肪���E���낤�ȁB
�����A�ϑw����Z�p���o�Ă��Ă邩��g�����W�X�^���͂��̌�����₹��Ǝv�����ǁB
�����A�ϑw����Z�p���o�Ă��Ă邩��g�����W�X�^���͂��̌�����₹��Ǝv�����ǁB
�O�������A�g�����W�X�^�̍\���E�f�ނ�ς���Ȃ肵�Ē���������Ɍ������\���B
���̏��Ă�ƁA�R�A���𑝂₵�܂�������ɐi�݂��������ǂȁB
���܂ŔM���Ȃ�Â���̂��B
���܂ŔM���Ȃ�Â���̂��B
nehalem���ƁA�R�A���𑝂₳����1�R�A������̃T�C�Y��1.5�{�ɂȂ��Ă��邯�ǁA
�T�C�Y�𑝂₵�A�R�A���𑝂₵����R�X�g���|���肷�����ˁH
�T�C�Y�𑝂₵�A�R�A���𑝂₵����R�X�g���|���肷�����ˁH
���̂��߂Ƀv���Z�X�Z�p��i�������Ă���B
nehalem��4�R�A�ɂȂ����̂́A����ŏ\���o�ϐ�������������B
���Ȃ݂ɁAConroe�Ńl�C�e�B�u�N�A�b�h�R�A�����ɂ͍���65nm�����Z�p�ł��\���Ȃ��ǁA�l�C�e�B�u�N�A�b�h�R�A�̐v���Ԃɍ���Ȃ��Č���̃f���A���~�Q�\���ɂȂ����B
nehalem��4�R�A�ɂȂ����̂́A����ŏ\���o�ϐ�������������B
���Ȃ݂ɁAConroe�Ńl�C�e�B�u�N�A�b�h�R�A�����ɂ͍���65nm�����Z�p�ł��\���Ȃ��ǁA�l�C�e�B�u�N�A�b�h�R�A�̐v���Ԃɍ���Ȃ��Č���̃f���A���~�Q�\���ɂȂ����B
���ꂪWhitefield����
Nehalem��8�R�A�܂őΉ��B
http://blog.livedoor.jp/amd646464/archives/51065032.html
�ɂ���MCM�̉\�����o�Ă������ǁB
���L���ɂ́u8�R�A���i��4�R�A�̃_�C��2���ׂ��`��ɂȂ�v�Ƃ���̂ŁASmithfield�̂悤��
1�_�C������MCM��ԂȂ̂��APaxville�݂����ɃC���^�[�t�F�C�X�������L���ĉ\��������B
http://blog.livedoor.jp/amd646464/archives/51065032.html
�ɂ���MCM�̉\�����o�Ă������ǁB
���L���ɂ́u8�R�A���i��4�R�A�̃_�C��2���ׂ��`��ɂȂ�v�Ƃ���̂ŁASmithfield�̂悤��
1�_�C������MCM��ԂȂ̂��APaxville�݂����ɃC���^�[�t�F�C�X�������L���ĉ\��������B
CPU���m�̐�p�����N(QuickPath)������A
MCM���낤��Native���낤�ƊW�Ȃ��C��������A�ǂ��Ȃ낤���B
MCM���낤��Native���낤�ƊW�Ȃ��C��������A�ǂ��Ȃ낤���B
������300mm�V���R���E�F�n1����1CPU�̋���v���Z�b�T�����Ă݂����ȁB
������H������w
������H������w
397 �FSocket774�F2007/09/30(��) 13:20:24 ID:B6qkYRnP
�`�b�v�Z�b�g����}�}���S���v���Ȃ��Ƃ����Ȃ�����炩����낤�Ȃ�
���Ă݂͂�������
���Ă݂͂�������
2013�N �l�ޖŖS
>398
�C�`���[�̃��[�U�[�I�[�o�[�N���b�N�Ől�ޖŖS�Ƃ��z������
�C�`���[�̃��[�U�[�I�[�o�[�N���b�N�Ől�ޖŖS�Ƃ��z������
>>395
�������R���g���[�������ĂȂ�����CPU�̃������A�N�Z�X�͒x���Ȃ��Ȃ��́H
�܂��A���ł�Opteron�ň����}�U�[���Ƃ��������̂�����ǁB
�������R���g���[�������ĂȂ�����CPU�̃������A�N�Z�X�͒x���Ȃ��Ȃ��́H
�܂��A���ł�Opteron�ň����}�U�[���Ƃ��������̂�����ǁB
>>401
�g���v���o�X�̏ꍇ���ƁA�Q�{�P�o�X�̌`�ŕ��U����슛�H
�g���v���o�X�̏ꍇ���ƁA�Q�{�P�o�X�̌`�ŕ��U����슛�H
����
Yorkfiled�ăl�C�e�B�uQuad Core��������ˁH
�j�R�C�`���������H
Yorkfiled�ăl�C�e�B�uQuad Core��������ˁH
�j�R�C�`���������H
>>403
Wolfdale2���ׂ��j�R�C�`
Wolfdale2���ׂ��j�R�C�`
>>404
AMD�ɗ���邩������('A`)
AMD�ɗ���邩������('A`)
>>405
�ʂɃj�R�C�`�����u�����v�Ƃ������Ƃł��Ȃ���B
�v���X�R�̃j�R�C�`�ň����C���[�W����������ǁA�ł��̈����q�̃j�R�C�`��
�ł��̂悢�q�̃j�R�C�`�ł͑�Ⴂ�����A�����܂���ǂ��Ȃ邵�ˁB
�ʂɃj�R�C�`�����u�����v�Ƃ������Ƃł��Ȃ���B
�v���X�R�̃j�R�C�`�ň����C���[�W����������ǁA�ł��̈����q�̃j�R�C�`��
�ł��̂悢�q�̃j�R�C�`�ł͑�Ⴂ�����A�����܂���ǂ��Ȃ邵�ˁB
>>405
�l�C�e�B�uQuad���~�����Ȃ��AMD�ɁB
�ł��A���قNjC�ɂ���قǐ��\���������[���B
�ނ���N���b�N�̕�Yorkfiled�̕������\�o���邾��B
����ƁABalcerona�̏������r�W�����͏���K8�Ɣ��c�B
�l�C�e�B�uQuad���~�����Ȃ��AMD�ɁB
�ł��A���قNjC�ɂ���قǐ��\���������[���B
�ނ���N���b�N�̕�Yorkfiled�̕������\�o���邾��B
����ƁABalcerona�̏������r�W�����͏���K8�Ɣ��c�B
�o�Ă�����������̂ɁB
AMD��11����('A`)
Intel�����N��1����������('A`)
X38����Ȃ�ȁE�E�E
X48��8�N��Q1�����炵����
Intel�����N��1����������('A`)
X38����Ȃ�ȁE�E�E
X48��8�N��Q1�����炵����
�������ďo����܂������悭��
�Ȃ�ł������Ȃ���
�Ȃ�ł������Ȃ���
X9650�����Ă���������ɂ͍��N���b�N�ł�X���o��낤�ȁc�����ɔ����\�肾�������ǖ�����
�ł���ˁ[
Intel�̃Q���V���K�[���������ACPU�̋Z�p���������
http://opentechpress.jp/enterprise/07/10/01/031206.shtml
>Nehalem�Ɏ�������閽�߃Z�b�g�uSSE4.2�v�́A1�̖��߂œ�����256�̔�r���\�ɂȂ邽�߁A���ߐ���75���팸�����3�{�̐��\���オ��������Ƃ����B
http://opentechpress.jp/enterprise/07/10/01/031206.shtml
>Nehalem�Ɏ�������閽�߃Z�b�g�uSSE4.2�v�́A1�̖��߂œ�����256�̔�r���\�ɂȂ邽�߁A���ߐ���75���팸�����3�{�̐��\���オ��������Ƃ����B
�^�[�Q�b�g�͎��XML�����̏�������
�j�R�C�`�ɂ��Ƃ��Εs���_�̃g���v���R�A�Ȃ�ďo�����ɍςނ�
Penryn����ŃV���O���_�C����Harpertown��������Ȃ�������
Penryn����ŃV���O���_�C����Harpertown��������Ȃ�������
256�̔�r����bitwise�Ȃ낤�����ʂ͂ǂ��ɂǂ��i�[�����
ATA�Ƃ������O��������ɂ͊����̃��\�[�X�̊g���◬�p�ł͂Ȃ��Ɨ�������̋@�\�u���b�N�ɂȂ�Ǝv����
418 �F�E�M�́L�E�j��-���R:�c-�F2007/10/02(��) 01:28:55 ID:U6H56/cf
����XMM���W�X�^16�{�̈���
�x���`�X������ƐV�����̂��~�����Ȃ邪�A���i��CPU�g�p���݂��E6300�ł��\�����ȂƎv���Ă��܂�
E6300�Ȃ�\������[
>>416
Intel(R) SSE4 Programming Reference
ttp://download.intel.com/design/processor/manuals/D91561.pdf
Page.51
5.3.1.7 Diagram Comparison and Aggregation Process
������
Intel(R) SSE4 Programming Reference
ttp://download.intel.com/design/processor/manuals/D91561.pdf
Page.51
5.3.1.7 Diagram Comparison and Aggregation Process
������
http://pc.watch.impress.co.jp/docs/2007/1002/kaigai390.htm
���\�V���������ȁB
8�\�P�b�g�ł�GPU��CPU�ɓ����̗���ɂȂ��Ă���Ƃ��B
�m�[�g�E�f�X�N�g�b�v�ł̓n�C�G���h�ȊO�̓`�b�v�Z�b�g�̃����R�����g���Ƃ����b���������ǁA
Nehalem����őS�Ă̗̈��CPU�̃����R�����g���Ƃ������ƂɂȂ邩���B
���\�V���������ȁB
8�\�P�b�g�ł�GPU��CPU�ɓ����̗���ɂȂ��Ă���Ƃ��B
�m�[�g�E�f�X�N�g�b�v�ł̓n�C�G���h�ȊO�̓`�b�v�Z�b�g�̃����R�����g���Ƃ����b���������ǁA
Nehalem����őS�Ă̗̈��CPU�̃����R�����g���Ƃ������ƂɂȂ邩���B
�ӂށc���C���X�g���[�����������R���g���[���������Ęb���o�Ă�ˁB
�`�b�v�x���_�ł�����C���e���I�ɂ͂ǂ����ł�������Ȃ��̂��ȁB
> �������A���C���X�g���[��������Nehalem�́ATylersburg�n�Ƃ͈قȂ�`�b�v�Z�b�g�ŃJ�o�[����B
> ��胍�[�R�X�g�ȃv���b�g�t�H�[����p�ӂ��Ă���B
> ������́A�]����3�`�b�v�\�����[�V����(CPU+MCH+ICH)�ł͂Ȃ��A
> 2�`�b�v�\�����[�V����(CPU+IOH)�ɂȂ�ƌ����Ă���B
�`�b�v�x���_�ł�����C���e���I�ɂ͂ǂ����ł�������Ȃ��̂��ȁB
> �������A���C���X�g���[��������Nehalem�́ATylersburg�n�Ƃ͈قȂ�`�b�v�Z�b�g�ŃJ�o�[����B
> ��胍�[�R�X�g�ȃv���b�g�t�H�[����p�ӂ��Ă���B
> ������́A�]����3�`�b�v�\�����[�V����(CPU+MCH+ICH)�ł͂Ȃ��A
> 2�`�b�v�\�����[�V����(CPU+IOH)�ɂȂ�ƌ����Ă���B
Penryn���������m��
Yorkfield��������A���炭�͔���������K�v�Ȃ��ȁB
���́APenryn�̃N���b�N���ǂ��܂ł��������B
AMD�̂���莟�悾���ǁB
AMD�̂���莟�悾���ǁB
AMD�̃N���b�N��3GHz�����Ȃ�������AYorkfield��3.4GHz(FSB1600�ł�Ƃ��āj�ŏI������Ȃ����ȁB
Nehalem�̓R�A�����ł������甭�M�̊W�ŃN���b�N�グ�ɂ����������B
Nehalem�̓R�A�����ł������甭�M�̊W�ŃN���b�N�グ�ɂ����������B
�n�C�G���h�ƃ��[�G���h��3ch��2ch�̃}�U�[�ɕ����ꂽ�肷�邩�ȁH
�X�P�[���u���Ȑv�����ɂ͍œK�Ȏs��ɍœK�ȃ^�C�~���O�œ����ł��Ȃ���Ӗ����Ȃ�
�v�͈�u�ŏI����Ă��o���f�[�V������10�`12����
���ڔ�r����悤�Ȃ��Ƃł͂Ȃ����ǁA���̐v�ʂł̎��R�x�́uNetBurst�̏_��v�̘b���v���N����
�ł��A�V�K�v���Z�X�J���ɔ���ȋ��������鍡�ƂȂ��Ă̓��X�N�}�l�W�����g�̊ϓ_����A
�厸�s�ł��Ȃ������X�P�[���r���e�B�����W�����[���͕K�R�Ȃ낤��
�v�͈�u�ŏI����Ă��o���f�[�V������10�`12����
���ڔ�r����悤�Ȃ��Ƃł͂Ȃ����ǁA���̐v�ʂł̎��R�x�́uNetBurst�̏_��v�̘b���v���N����
�ł��A�V�K�v���Z�X�J���ɔ���ȋ��������鍡�ƂȂ��Ă̓��X�N�}�l�W�����g�̊ϓ_����A
�厸�s�ł��Ȃ������X�P�[���r���e�B�����W�����[���͕K�R�Ȃ낤��
���W�����[������Ό��̊��Ԃ��Z���čς�
Linux Kernel�Ɠ�����
Linux Kernel�Ɠ�����
Eden���R�����g�̍s�Ԃ��珟��ɂ����ǂݎ����
�u���o�C����Nehalem���Penryn�̕����������v
Special Sizing Techniques�v�}���Z�[
�u���o�C����Nehalem���Penryn�̕����������v
Special Sizing Techniques�v�}���Z�[
�ŁA�_�C��GPU�����͊m��ŊԈႢ�Ȃ��̂��ˁH
http://pc.watch.impress.co.jp/docs/article/20000825/kgi3_6.jpg
http://www.watch.impress.co.jp/akiba/tmp/blog/20070610/f070610i1.jpg
{kind=link}
http://www.watch.impress.co.jp/akiba/tmp/blog/20070610/f070610i1.jpg
{kind=link}
�������ANehalem�̃_�C��1��ނł͂Ȃ��AIntel��2009�N�ɂ́A�R�A�̃R���t�B�M�����[�V�������قȂ�_�C���A���Ȃ��Ƃ������3��ޓ�������B
�f���A���R�A�A�I�N�^�R�A�AGPU�����ƁA�f���A���R�A�ƍ��킹�č��v��4�n���̃R�A�R���t�B�M�����[�V��������������B
�f���A���R�A�A�I�N�^�R�A�AGPU�����ƁA�f���A���R�A�ƍ��킹�č��v��4�n���̃R�A�R���t�B�M�����[�V��������������B
����胍�[�R�X�g�ȃv���b�g�t�H�[����p�ӂ��Ă���B
��������́A�]����3�`�b�v�\�����[�V����(CPU+MCH+ICH)�ł͂Ȃ��A
��2�`�b�v�\�����[�V����(CPU+IOH)�ɂȂ�ƌ����Ă���B
��Nehalem�̃��C���X�g���[���ւ̐Z���́ANehalem��GPU�R�A�����ł̌v��Ƃ�����ł���B
����ƌ����f�X�N�g�b�v�ł�GPU�R�A�����ł��K�v�ɂȂ�B
3�`�b�v�\�����[�V�����iPenryn+GMCH+ICH�j����
2�`�b�v�\�����[�V�����iGPU����2�R�A��Nehalem+IOH�j�ɂȂ��Ă�
�V�X�e���R�X�g�͓������炢�A����d�͂͂��傢�オ�肻���ȋC������B
��������́A�]����3�`�b�v�\�����[�V����(CPU+MCH+ICH)�ł͂Ȃ��A
��2�`�b�v�\�����[�V����(CPU+IOH)�ɂȂ�ƌ����Ă���B
��Nehalem�̃��C���X�g���[���ւ̐Z���́ANehalem��GPU�R�A�����ł̌v��Ƃ�����ł���B
����ƌ����f�X�N�g�b�v�ł�GPU�R�A�����ł��K�v�ɂȂ�B
3�`�b�v�\�����[�V�����iPenryn+GMCH+ICH�j����
2�`�b�v�\�����[�V�����iGPU����2�R�A��Nehalem+IOH�j�ɂȂ��Ă�
�V�X�e���R�X�g�͓������炢�A����d�͂͂��傢�オ�肻���ȋC������B
����PC�̔M���́ACPU��GPU������A����d�͂��オ���Ă���p�͊y�ɂȂ�C������B
���o�C���m�[�g�Ƃ��́A�M������J���Ɍł܂�Ƌt�ɐv���Â炢��������Ȃ����ǂˁB
���o�C���m�[�g�Ƃ��́A�M������J���Ɍł܂�Ƌt�ɐv���Â炢��������Ȃ����ǂˁB
GPU�����͂Ȃ��ƌ����Ă��l�B�̌�����͂܂����B
>�V�X�e���R�X�g�͓������炢
���ӁB�Ƃ�����Intel��Nehalem�Œ�R�X�g����_���ĂȂ����B
>����d�͂͂��傢�オ�肻��
GMCH������TDP�����u���Ȃ畁�ʂɍl����Ή�����㩁B
���ӁB�Ƃ�����Intel��Nehalem�Œ�R�X�g����_���ĂȂ����B
>����d�͂͂��傢�オ�肻��
GMCH������TDP�����u���Ȃ畁�ʂɍl����Ή�����㩁B
���C�o���s�݂�����
Nehalem x2 \30,000�`\60,000
Nehalem x4 \50,000�`\120,000
Nehalem x8 \150,000�`
�Ƃ��ŁA�o�Ă��邩���ȁB
Nehalem x2 \30,000�`\60,000
Nehalem x4 \50,000�`\120,000
Nehalem x8 \150,000�`
�Ƃ��ŁA�o�Ă��邩���ȁB
�T�[�o��n�C�G���h�f�X�N�g�b�v�ł͂������A
���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
�X�P�[���r���e�B�����܂萶�����Ȃ��B
�~�h���ȉ��N���X�ł̏œ_�́A
GPU���ǂ���ɂ�������̂��H ��������Ƃ����牽�H ���炢���B
>>439
�킵�̂��Ƃ��ȁB
Intel�����̗l�X�Ȕ��������鍡�ł��C�������������v���Ă�B
�̂̓����R���E�k���@�\����CPU�̂��ƂȂǓ��ɂȂ������B
�tIDF��Nehalem��o�����Ă���͂�����ƍl���������B
74 �FSocket774 [sage] �F2007/03/30(��) 20:58:23 ID:hLKHH8dP
��GMCH���S������o�����[�f�X�N�g�b�v��o�C���s��B
�����R����MCH����CPU�Ɉڂ�ƃ������ւ̃A�N�Z�X�������ɂȂ�̂ŁA
����Ȃ烁���R�����X�ŏ�����CPU�ɂ������悤�A�Ƃ������Ƃ͍l���Ă��邩���B
���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
�X�P�[���r���e�B�����܂萶�����Ȃ��B
�~�h���ȉ��N���X�ł̏œ_�́A
GPU���ǂ���ɂ�������̂��H ��������Ƃ����牽�H ���炢���B
>>439
�킵�̂��Ƃ��ȁB
Intel�����̗l�X�Ȕ��������鍡�ł��C�������������v���Ă�B
�̂̓����R���E�k���@�\����CPU�̂��ƂȂǓ��ɂȂ������B
�tIDF��Nehalem��o�����Ă���͂�����ƍl���������B
74 �FSocket774 [sage] �F2007/03/30(��) 20:58:23 ID:hLKHH8dP
��GMCH���S������o�����[�f�X�N�g�b�v��o�C���s��B
�����R����MCH����CPU�Ɉڂ�ƃ������ւ̃A�N�Z�X�������ɂȂ�̂ŁA
����Ȃ烁���R�����X�ŏ�����CPU�ɂ������悤�A�Ƃ������Ƃ͍l���Ă��邩���B
>>443
�̂��A1�`2�N�O�A�ɓǂ݂����Ă�����
�̂��A1�`2�N�O�A�ɓǂ݂����Ă�����
>>444
�Ӗ��킩��˂�
CPU�Ƀ����R����������20�N�A�m�[�X�u���b�W�ۂ��Ɠ�������10�N�ȏ�o���Ă̂ɁA�Ȃ�1-2�N�O�ɓ��ɖ���������
�R�X�g��J���̖ʂł��������ɂȂ�����A�C���e�����̗p����̂��킩�肫���Ă��b������
�Ӗ��킩��˂�
CPU�Ƀ����R����������20�N�A�m�[�X�u���b�W�ۂ��Ɠ�������10�N�ȏ�o���Ă̂ɁA�Ȃ�1-2�N�O�ɓ��ɖ���������
�R�X�g��J���̖ʂł��������ɂȂ�����A�C���e�����̗p����̂��킩�肫���Ă��b������
�����o�C���ł��A���Ȃ��Ƃ��f���A���R�A�ł́A�]����TDP���x���𑵂���Ɛ��������B
���K�R�I�ɁANehalem�ł̓A�N�e�B�u�d�͂����������ނ��߂̏ȓd�͐v������ɐi�߂邩�A
��CPU����N���b�N������ɗ}���邱�ƂɂȂ�B
�]�����_�C�T�C�Y��1.4�{�傫�����N���b�N��}����TDP�𑵂���E�E�E�E
�@�@�@/�@ �_,, ,,�^ �@�@�@|
�@�@�@|�@�i���j �i���j|||�@ |
�@�@�@| �@/�P�܁P�R�@U.| �@�@�E�E�E�E�E����B
���K�R�I�ɁANehalem�ł̓A�N�e�B�u�d�͂����������ނ��߂̏ȓd�͐v������ɐi�߂邩�A
��CPU����N���b�N������ɗ}���邱�ƂɂȂ�B
�]�����_�C�T�C�Y��1.4�{�傫�����N���b�N��}����TDP�𑵂���E�E�E�E
�@�@�@/�@ �_,, ,,�^ �@�@�@|
�@�@�@|�@�i���j �i���j|||�@ |
�@�@�@| �@/�P�܁P�R�@U.| �@�@�E�E�E�E�E����B
>>442
����ϐ^���̃A�z�������ȁc
����ϐ^���̃A�z�������ȁc
>�T�[�o��n�C�G���h�f�X�N�g�b�v�ł͂������A
>���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
>�X�P�[���r���e�B�����܂萶�����Ȃ��B
Intel�̌����X�P�[���r���e�B�̈Ӗ������Ⴆ�Ă�ȁB
�T�[�o�[���烂�o�C���܂ŏ_��ɍ\����ς��Đ����ł���_���X�P�[���u���Ƃ����Ă���̂ł����āB
>���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
>�X�P�[���r���e�B�����܂萶�����Ȃ��B
Intel�̌����X�P�[���r���e�B�̈Ӗ������Ⴆ�Ă�ȁB
�T�[�o�[���烂�o�C���܂ŏ_��ɍ\����ς��Đ����ł���_���X�P�[���u���Ƃ����Ă���̂ł����āB
>>448
�X�P�[���r���e�B�̃����b�g���ŏ��\���ł͎����āA�ނ���
�p�t�H�[�}���X��̃f�����b�g�������c��Ƃ����ӌ�������A
������Ⴆ�Ă�Ƃ������z�͎����Ȃ��B
���o�C���������Ɓunehalem ���� penryn �����������邩���v
������[�㓡����̖ϑz�̗��t���ɂȂ��Ă�]�����_������Ă�
�����ł���H
�X�P�[���r���e�B�̃����b�g���ŏ��\���ł͎����āA�ނ���
�p�t�H�[�}���X��̃f�����b�g�������c��Ƃ����ӌ�������A
������Ⴆ�Ă�Ƃ������z�͎����Ȃ��B
���o�C���������Ɓunehalem ���� penryn �����������邩���v
������[�㓡����̖ϑz�̗��t���ɂȂ��Ă�]�����_������Ă�
�����ł���H
2��45W���Ă����L���������\���邩��1�ɂ��Ă�TDP�͔����ɂ͂Ȃ�Ȃ���
TDP�������Ϗ���d�͂̕����d�v�B
453 �F�E�M�́L�E�j��-���R:�c-�F2007/10/03(��) 01:19:18 ID:UgwGfELV
�S�͉ғ����d�����Ƃ��������Ȃ����ɂ�TDP�����W�˂�
�t�@�[�X�g�V���R�����o�Ă����̎��_�̔��������ǂ��Ȃ邩�킩����
�p�t�H�[�}���X�ێ��̂���TDP������OEM�e�Ђ��ߖ��グ��\��������
�p�t�H�[�}���X�ێ��̂���TDP������OEM�e�Ђ��ߖ��グ��\��������
>>439
������Ȃǂ��Ȃ�
�ނ��뉽�x�ł����킹�Ă�������
GPU�������͂Ȃ��I �i�����ς�
�Ƃ�����Silverthorne���ڋ@�͔����\��
������Ȃǂ��Ȃ�
�ނ��뉽�x�ł����킹�Ă�������
GPU�������͂Ȃ��I �i�����ς�
�Ƃ�����Silverthorne���ڋ@�͔����\��
����Ȃ�����
���̎���SoC�������͔���
���̎���SoC�������͔���
http://www.4gamer.net/games/038/G003822/20070926019/
����݂�ƁA�ꉞ45nm�����GPU�R�A��2009�N�ɂ͓o�ꂷ��炵������ANehalem��
��������͖̂����ł͂Ȃ��悤���B
�����AGPU�R�A��������悤�����ǁA��������GPU�ɂ���āA2��ނ�GPU����CPU���o��낤���B
����݂�ƁA�ꉞ45nm�����GPU�R�A��2009�N�ɂ͓o�ꂷ��炵������ANehalem��
��������͖̂����ł͂Ȃ��悤���B
�����AGPU�R�A��������悤�����ǁA��������GPU�ɂ���āA2��ނ�GPU����CPU���o��낤���B
458 �F�E�M�́L�E�j��-���R:�c-�F2007/10/03(��) 02:26:08 ID:UgwGfELV
2�R�A�{Larrabee16�R�A��]
�ʂɓ������Ă��ǂ����ǁA
Nehalem�Ƃ��ċ���������͈̂���R�A�̕����ł�����
�A���R�A�̕����͂�����������Ȃ��ǁA�I�}�P�B
���ɑf�G�ȃI�}�P���݂���Ă��ƂŁA���̍D���������c�_���Ă����傤���Ȃ��B
Nehalem�Ƃ��ċ���������͈̂���R�A�̕����ł�����
�A���R�A�̕����͂�����������Ȃ��ǁA�I�}�P�B
���ɑf�G�ȃI�}�P���݂���Ă��ƂŁA���̍D���������c�_���Ă����傤���Ȃ��B
�Ȃ�ł�����ł���������̂����s�݂����ɂȂ��Ă��������
������MPU���D���ȉ��Ƃ��Ă͂��ɂ����
������MPU���D���ȉ��Ƃ��Ă͂��ɂ����
���̂Ƃ����Intel��GPU�����ł�����ŁAAMD�݂����Ƀf�X�N�g�b�v��GPU��������{�Ƃ����̂Ƃ͈Ⴄ���ƁB
>>460
���Ɏn�܂������Ƃł���
���Ɏn�܂������Ƃł���
�ߊϓI�ӌ����肾�Ȃ���
�Ő�[�𑖂�V�ˏW�c������Ă邩��S�z�����
�@�bhttp://www.bit-tech.net/news/2007/09/18/otellini_unveils_nehalem/1
�@�b���ƁA���̋L�������Ĕ��������Ƃ́ANehalem��chief-architect�ɂ�Glenn Hinton��
�@�b�����邱�ƁB���̐l��P6��NetBurst�̂Ƃ���chief-architect�ʼn�����Pentium 4��
�@�b�_���̃g�b�v�ɖ��O�������Ă���l�Ȃ��ǁB�����AOR���Ȃ��ƁB
�@�b
�@�bftp://download.intel.co.jp/jp/developer/jpdoc/2001q1_art02_j.pdf
�@�b����NetBurst���Ԃ�clock�����`��Douglas M. Carmean����Larrabee�ɂ������B
�@�bhttp://journal.mycom.co.jp/articles/2007/09/24/idf01/003.html
�@�bPhoto24:Conroe/Penryn�Ɣ�ׂ�ƁA���Ȃ�G�R�Ƃ�����ہB
�@�b���傤��Willamette/Northwood��Prescott������ׂ��Ƃ��̈�ۂɋ߂��B
�Ő�[�𑖂�V�ˏW�c������Ă邩��S�z�����
�@�bhttp://www.bit-tech.net/news/2007/09/18/otellini_unveils_nehalem/1
�@�b���ƁA���̋L�������Ĕ��������Ƃ́ANehalem��chief-architect�ɂ�Glenn Hinton��
�@�b�����邱�ƁB���̐l��P6��NetBurst�̂Ƃ���chief-architect�ʼn�����Pentium 4��
�@�b�_���̃g�b�v�ɖ��O�������Ă���l�Ȃ��ǁB�����AOR���Ȃ��ƁB
�@�b
�@�bftp://download.intel.co.jp/jp/developer/jpdoc/2001q1_art02_j.pdf
�@�b����NetBurst���Ԃ�clock�����`��Douglas M. Carmean����Larrabee�ɂ������B
�@�bhttp://journal.mycom.co.jp/articles/2007/09/24/idf01/003.html
�@�bPhoto24:Conroe/Penryn�Ɣ�ׂ�ƁA���Ȃ�G�R�Ƃ�����ہB
�@�b���傤��Willamette/Northwood��Prescott������ׂ��Ƃ��̈�ۂɋ߂��B
�p�C�v���C���̐[���ɂ͂܂������ӂ�Ȃ��̂�
>>463
�������E�E�E�S�z�ł�
�������E�E�E�S�z�ł�
�匴����w
>>449
�X�P�[���r���e�B�̃����b�g����ԑ傫���̂��ŏ��\���Ǝv������
���܂ł̃��[�G���h�̓L���b�V���������HT�������
�V���R����ɂ͂��邯�ǖ������ăp�^�[��������
����d�͂�V���R���̖��ʂ��Ȃ��Ȃ�
����Ƀ��W�����[���ɂ��p�t�H�[�}���X�_�E����
���W���[�����������������Ȃ�Ǝv���̂���
�X�P�[���r���e�B�̃����b�g����ԑ傫���̂��ŏ��\���Ǝv������
���܂ł̃��[�G���h�̓L���b�V���������HT�������
�V���R����ɂ͂��邯�ǖ������ăp�^�[��������
����d�͂�V���R���̖��ʂ��Ȃ��Ȃ�
����Ƀ��W�����[���ɂ��p�t�H�[�}���X�_�E����
���W���[�����������������Ȃ�Ǝv���̂���
>>467
����A�X�P�[���r���e�B���ێ����邽�߂ɁA�ŏ��\��������
�l����Εs�v�ȃ��W�b�N���V���R�����K�v�ɂȂ邵�A
�œK���ɐ�������Ő��\�͂��т��ƒቺ����
�X�P�[���r���e�B�̃����b�g�͊ȈՂɃ��W���[����lj��ł���
�悤�ɂȂ邱�ƂȂ��ǁA���̂��߂ɂ̓��W���[����
�C���^�t�F�[�X�̋��ʉ��Ƃ����K�v�ɂȂ��čœK���ɐ���
����邵�A�ŏ��\�������Ȃ�s�v�ȃ��W���[���ԃC���^�t�F�[�X��
�e�R�A�ɗ\�ߗp�ӂ��Ƃ��K�v������ł���B
����A�X�P�[���r���e�B���ێ����邽�߂ɁA�ŏ��\��������
�l����Εs�v�ȃ��W�b�N���V���R�����K�v�ɂȂ邵�A
�œK���ɐ�������Ő��\�͂��т��ƒቺ����
�X�P�[���r���e�B�̃����b�g�͊ȈՂɃ��W���[����lj��ł���
�悤�ɂȂ邱�ƂȂ��ǁA���̂��߂ɂ̓��W���[����
�C���^�t�F�[�X�̋��ʉ��Ƃ����K�v�ɂȂ��čœK���ɐ���
����邵�A�ŏ��\�������Ȃ�s�v�ȃ��W���[���ԃC���^�t�F�[�X��
�e�R�A�ɗ\�ߗp�ӂ��Ƃ��K�v������ł���B
�܁A�C���e���I�ɂ͎I������AMD��ׂ���̂ŁA����ł�����Ȃ����낤���B
�ӂ[�̐l�́A32nm�������Ȃ�A�V�������N�ł�Nehalem��Gesher��҂Ă����킯�ŁB
TDP�Ƃ��̘b�́AAMD��Nehalem�Ɲh�R����CPU���o���Ă������ɖ��ɂȂ��Ă��邾�����낤�B
�ǂ݂̂����\�����ŃR�A���E�܂ŃN���b�N�����Ă��ė��Д��M���ƁB
�ӂ[�̐l�́A32nm�������Ȃ�A�V�������N�ł�Nehalem��Gesher��҂Ă����킯�ŁB
TDP�Ƃ��̘b�́AAMD��Nehalem�Ɲh�R����CPU���o���Ă������ɖ��ɂȂ��Ă��邾�����낤�B
�ǂ݂̂����\�����ŃR�A���E�܂ŃN���b�N�����Ă��ė��Д��M���ƁB
����Ȃ�AMD�����߂�Ȃ�B
>>461
AMD��GPU��������{�Ƃ͈ꌾ�������Ė������c�B
AMD��GPU��������{�Ƃ͈ꌾ�������Ė������c�B
���W�����[�[�Ă������R�A��L���b�V���CSI������R���̕��т��������B
1�R�A����4�R�A�܂œ���R�A�v�ŕ�����ނ̃}�X�N�����܂���ƁB
�����R�����ڂȂ̂�Xeon��XE�����Ȏ��_�ŁA�܂��킩�����悤�Ȃ��́B
�l�C�e�B�u4�R�A�̓n�C�G���h�I�����[�ŁA�~�b�h�����W�ȉ���2�R�A�܂��͂���MCM�B
1�R�A����4�R�A�܂œ���R�A�v�ŕ�����ނ̃}�X�N�����܂���ƁB
�����R�����ڂȂ̂�Xeon��XE�����Ȏ��_�ŁA�܂��킩�����悤�Ȃ��́B
�l�C�e�B�u4�R�A�̓n�C�G���h�I�����[�ŁA�~�b�h�����W�ȉ���2�R�A�܂��͂���MCM�B
���̂���HDD����w�h���C�u���b�o�t�ɓ����ɂȂ�̂��ȁB
>>473
���̍��ɂ͌��w�h���C�u�͍���FDD�݂����ɂ���Ȃ��Ȃ��Ă��������ǂ�
���̍��ɂ͌��w�h���C�u�͍���FDD�݂����ɂ���Ȃ��Ȃ��Ă��������ǂ�
>���W�����[�[�Ă������R�A��L���b�V���CSI������R���̕��т��������B
�܂���������������ȁB
���Z�����P�ʂŕ������Ă�킯���ᖳ������B
Java�A�N�Z�����[�^��Í���ǃR�v�����ڂ���
�w�e���W�j�A�X�\���ɂȂ��
�㓡������炪�����Ă��L�������邪
���ۖ��A����ȃ��W�����[�\���͏����Ƃ��Đ������Ȃ�����B
�i��Ԋ|���肷���j
�܂���������������ȁB
���Z�����P�ʂŕ������Ă�킯���ᖳ������B
Java�A�N�Z�����[�^��Í���ǃR�v�����ڂ���
�w�e���W�j�A�X�\���ɂȂ��
�㓡������炪�����Ă��L�������邪
���ۖ��A����ȃ��W�����[�\���͏����Ƃ��Đ������Ȃ�����B
�i��Ԋ|���肷���j
Intel's Silverthorne processor to run at up to 1.7 GHz
http://www.tgdaily.com/content/view/34160/135/
http://www.tgdaily.com/content/view/34160/135/
>>442
���o������Œ��̊��������Ȃ�ď��F����Ȃ���
http://blog.livedoor.jp/amd646464/archives/51067296.html
���͂܂����B����̕��̏�ŗx�炳���t�F�[�Y���Ă�����
���o������Œ��̊��������Ȃ�ď��F����Ȃ���
http://blog.livedoor.jp/amd646464/archives/51067296.html
���͂܂����B����̕��̏�ŗx�炳���t�F�[�Y���Ă�����
GPU�������āC���ϊj��Timna���C�X���G���ɍ�点�邾������B
��FGPU���� = Timna = �C�X���G��
���FGPU���� �� Timna = �C�X���G��
���FGPU���� �� Timna = �C�X���G��
���E�܂ŃR���p�N�g�ɍ��̂��C�X���G�����B
������Timna��RDRAM�����R���I���Ŏ��s�B
�������W�����[�����Ă�����A���SDRAM�����R���ɕύX����Z�ʂ��������̂��낤���H
http://pc.watch.impress.co.jp/docs/article/20000825/kaigai03.htm
�E�����̃��j�b�g��������Ƃ����������ŁA�܂����j�b�g�������炵�Ĕz�������炵��
�ECPU�̊e�Z����Ƀu���b�N�Ԃ̔z�����C���[��z�u���邱�ƂŁA�u���b�N�Ԃ̔z���ʐς����炵��
�E���������e�N�m���W�ɂ���āATimna�ł�CPU��̔z���ʐς�50%������
�E����ɁA�Q�[�g�T�C�Y�����炷���Ƃł���ɋ@�\�u���b�N�̖ʐς�20%���炵��
>>459-460
����PC�ŁA���C���{�[�h�ɕ�������\�P�b�g�ɑ}���u�c��I�����邱�Ƃ͊y�����B
���W�����[�v�ɂ���ڋq�ɑ��ăJ�X�^�����C�hCPU������Ȃ�y�����A�����ۂ͖����B
���������Ӗ���CPU�R�A/�A���R�A�̑g�ݍ��킹�Q�[���͂��܂苻�����킩�Ȃ��B
������Timna��RDRAM�����R���I���Ŏ��s�B
�������W�����[�����Ă�����A���SDRAM�����R���ɕύX����Z�ʂ��������̂��낤���H
http://pc.watch.impress.co.jp/docs/article/20000825/kaigai03.htm
�E�����̃��j�b�g��������Ƃ����������ŁA�܂����j�b�g�������炵�Ĕz�������炵��
�ECPU�̊e�Z����Ƀu���b�N�Ԃ̔z�����C���[��z�u���邱�ƂŁA�u���b�N�Ԃ̔z���ʐς����炵��
�E���������e�N�m���W�ɂ���āATimna�ł�CPU��̔z���ʐς�50%������
�E����ɁA�Q�[�g�T�C�Y�����炷���Ƃł���ɋ@�\�u���b�N�̖ʐς�20%���炵��
>>459-460
����PC�ŁA���C���{�[�h�ɕ�������\�P�b�g�ɑ}���u�c��I�����邱�Ƃ͊y�����B
���W�����[�v�ɂ���ڋq�ɑ��ăJ�X�^�����C�hCPU������Ȃ�y�����A�����ۂ͖����B
���������Ӗ���CPU�R�A/�A���R�A�̑g�ݍ��킹�Q�[���͂��܂苻�����킩�Ȃ��B
�}�U�[��ɃR�v���Ƃ�2���L���b�V���̃\�P�b�g��������������������C������B
Timna��RDRAM�I�����s�����������A
����ȏ�Ɍ��וi��MCH����肾�����B
MCH�ɖ�肪�Ȃ���Ƃ肠�����o����Ȃ����Ȃ��H
>>481
�C������c���B�ӁB�����N���Ƃ��Ă��܂����ȁB
����ȏ�Ɍ��וi��MCH����肾�����B
MCH�ɖ�肪�Ȃ���Ƃ肠�����o����Ȃ����Ȃ��H
>>481
�C������c���B�ӁB�����N���Ƃ��Ă��܂����ȁB
�Ή���������DDR�ɕϊ�����`�b�v�������Ȃ������̂��ŏI�I�Ȍ����Ƃ���Ă����ǁA�ǂ��Ȃ�ȁB
����ӂ�ȋL���Ō��̂͂悵�����������Ǝv�����ǁB
�������͂Ƃ�ł��Ȃ����Ⴂ�����Ă����BSilverthorne����ManyCore����̃V���v���R�A��������I
UMPC�ł̗��R�̓t�F�C�N�ɉ߂��Ȃ��BIntel����ׂ��E�E�E�B
�O�ꂽ��Ⴆ�Ȃ��W���[�N�Ƃ��ď��ė~�����B
UMPC�ł̗��R�̓t�F�C�N�ɉ߂��Ȃ��BIntel����ׂ��E�E�E�B
�O�ꂽ��Ⴆ�Ȃ��W���[�N�Ƃ��ď��ė~�����B
�C���e���A�uItanium�v�v���Z�b�T�̒P��R�A������̃p�t�H�[�}���X������v��
http://japan.cnet.com/news/ent/story/0,2000056022,20357972,00.htm
�C���e���AMoorestown�ȂǍŐV�e�N�m���W�[���Љ�
http://enterprise.watch.impress.co.jp/cda/topic/2007/10/04/11301.html
http://japan.cnet.com/news/ent/story/0,2000056022,20357972,00.htm
�C���e���AMoorestown�ȂǍŐV�e�N�m���W�[���Љ�
http://enterprise.watch.impress.co.jp/cda/topic/2007/10/04/11301.html
�X�p�R���́A�P��R�A������̐��\����߂ă��j�[�R�A�ɑ�������A���ȏ�ɐi�����鎖���o���Ȃ��Ȃ邩��ȁB
Itanium�łP�R�A�̐��\���グ��w�͂�D�悷��͓̂��R�B
Itanium�łP�R�A�̐��\���グ��w�͂�D�悷��͓̂��R�B
http://pc.watch.impress.co.jp/docs/article/20001002/kaigai01.htm
Timna���|�V�������͈̂�PC�����������̂Ɉ����Ȃ�Ȃ���������B
Celeron+i810E�ɕ���������B
���������g���u���v���ƂȂ���MTH�EMPT��p�ӂ��Ȃ�������Ȃ��Ȃ����̂�
���{��RDRAM��I�����Ă��܂������ƂɋN������B
Nehalem�Ń��W�����[���ɑ������̂́u����̓R�P�܂����v�錾�B
Intel���ڎw��Nehalem�ł�GPU��CPU�̓���
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
Timna���|�V�������͈̂�PC�����������̂Ɉ����Ȃ�Ȃ���������B
Celeron+i810E�ɕ���������B
���������g���u���v���ƂȂ���MTH�EMPT��p�ӂ��Ȃ�������Ȃ��Ȃ����̂�
���{��RDRAM��I�����Ă��܂������ƂɋN������B
Nehalem�Ń��W�����[���ɑ������̂́u����̓R�P�܂����v�錾�B
Intel���ڎw��Nehalem�ł�GPU��CPU�̓���
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
����̑�����
���̐l���H
���{�E�E
���̐l���H
���{�E�E
�v��ƃ����R����CPU�Ɉڂ��ł���ɍ��킹��
�`�b�v�Z�b�g����CPU��GPU�@�\���ڂ������Ă��H
�ŁA����ȍ~�̓`�b�v�Z�b�g����GPU���������͖����B
�܂��AAMD��Fusion�̂悤��stream processor�Ƃ��Ă͊��҂ł�����̂ł͂Ȃ��B
�����܂œ����`�b�v�Z�b�g��GPU��CPU�Ɉڂ���������Timna�ł���B
�`�b�v�Z�b�g����CPU��GPU�@�\���ڂ������Ă��H
�ŁA����ȍ~�̓`�b�v�Z�b�g����GPU���������͖����B
�܂��AAMD��Fusion�̂悤��stream processor�Ƃ��Ă͊��҂ł�����̂ł͂Ȃ��B
�����܂œ����`�b�v�Z�b�g��GPU��CPU�Ɉڂ���������Timna�ł���B
>�܂��A�}�[�P�e�B���O��(�̓���)�ƁA�^�̓�������ʂ���K�v������(��)�B
>�}���`�`�b�v�p�b�P�[�W��(GPU��CPU�p�b�P�[�W��)���ꂽ�Ƃ��悤�B
>����̓`�b�v�̎����ʐς����炷���A�v�V�I���Ƃ����ƁA�����ł͂Ȃ��B
>�����V���R����(CPU��GPU��)���ꂽ�ꍇ�́A����͊v�V���v
����͂ǂ��ȂȂ��E�E
���႟�A�����ς���ĉ����o����悤�ɂȂ����̂��ĕ�������Ȃ�ē������B
>�}���`�`�b�v�p�b�P�[�W��(GPU��CPU�p�b�P�[�W��)���ꂽ�Ƃ��悤�B
>����̓`�b�v�̎����ʐς����炷���A�v�V�I���Ƃ����ƁA�����ł͂Ȃ��B
>�����V���R����(CPU��GPU��)���ꂽ�ꍇ�́A����͊v�V���v
����͂ǂ��ȂȂ��E�E
���႟�A�����ς���ĉ����o����悤�ɂȂ����̂��ĕ�������Ȃ�ē������B
Pentium D�����o�Ă�肵��(���{)�Ȑl������c
Tulsa��Paxville������قNJv�V�I����Ȃ������[��
Tulsa��Paxville������قNJv�V�I����Ȃ������[��
�F�X�ȋL����ǂތ���ANehalem����͖`���̐�����ۂ��Ȃ��B
���܂܂ł���Ă������̑S�Ă������鎖�ƁA
�����CPU�ւ̔��W�݂����Ȋ���������B
���܂܂ł���Ă������̑S�Ă������鎖�ƁA
�����CPU�ւ̔��W�݂����Ȋ���������B
FUSION�����Ė`���̏����i�K�Ŗ�������
�ȉ����X�R�s�y �i����܂Ȃ炠�ځ[���j
�ȉ����X�R�s�y �i����܂Ȃ炠�ځ[���j
257 �FSocket774 [sage] �F2007/04/19(��) 01:54:23 ID:zEEcQS/A
129 �FSocket774 �F2007/04/19(��) 01:39:01 ID:H9HpQLsK
Fusion�͑S�R�Z�����Ă��Ȃ��v
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
130 �FSocket774 �F2007/04/19(��) 01:41:21 ID:hJW7H+yL
Fusion�����������ƂȂ�������
�I���{VGA�������̂邾���Ŋ��҂͂���ȗ\��
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
283 �FSocket774 [sage] �F2007/04/20(��) 03:04:42 ID:3M2UfOSS
>>257
single-die����MCM�̂ق����_��������Ƃ��āA���̗�Ƃ��āA
DX10�����`�b�v�쐻���DX11�ɂ��悤�Ƃ����犮�S�ɍĐv�ɂȂ��Ă��܂����A
MCM�Ȃ��GPU��������芷����ςނƂ����B
���N��\�z
single-die����MCM�̂ق����_��������Ƃ��āA���̗�Ƃ��āA
DX11�����`�b�v�쐻���DX12�ɂ��悤�Ƃ����犮�S�ɍĐv�ɂȂ��Ă��܂����A
MCM�Ȃ��GPU��������芷����ςނƂ����B
129 �FSocket774 �F2007/04/19(��) 01:39:01 ID:H9HpQLsK
Fusion�͑S�R�Z�����Ă��Ȃ��v
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
130 �FSocket774 �F2007/04/19(��) 01:41:21 ID:hJW7H+yL
Fusion�����������ƂȂ�������
�I���{VGA�������̂邾���Ŋ��҂͂���ȗ\��
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
283 �FSocket774 [sage] �F2007/04/20(��) 03:04:42 ID:3M2UfOSS
>>257
single-die����MCM�̂ق����_��������Ƃ��āA���̗�Ƃ��āA
DX10�����`�b�v�쐻���DX11�ɂ��悤�Ƃ����犮�S�ɍĐv�ɂȂ��Ă��܂����A
MCM�Ȃ��GPU��������芷����ςނƂ����B
���N��\�z
single-die����MCM�̂ق����_��������Ƃ��āA���̗�Ƃ��āA
DX11�����`�b�v�쐻���DX12�ɂ��悤�Ƃ����犮�S�ɍĐv�ɂȂ��Ă��܂����A
MCM�Ȃ��GPU��������芷����ςނƂ����B
���̊Ԃɂ��uFUSION�v���A�������蒆�g�̖���
�ȃu�����h�l�[���^�}�[�P�e�B���O�p��ɂȂ��Ă��܂����B
http://techon.nikkeibp.co.jp/article/NEWS/20061026/122718/
��Advanced Micro Devices�CInc.�iAMD�Ёj�̓O���t�B�b�N�X�`���H��CPU�R�A��
1�`�b�v��ɏW�ς���86�n�}�C�N���v���Z�T�uFusion�v�i�J���R�[�h���j��
2008�N���`2009�N���߂����h�ɊJ������
��
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
�uFUSION�́A�A�N�Z�����[�g�^�R���s���[�e�B���O�ɂ��Ă̑S�Ă��J�o�[����B
������A�V�X�e���I���`�b�v(SoC)�̃����`�b�v�\���Ɍ��炸�A�����`�b�v�ɂ��
�V�X�e�����x���ł̃w�e���W�j�A�X�\����FUSION�Ɋ܂�ł���B
�܂��A�g�ѓd�b�r�W�l�X�����̂��܂��܂ȋ@�\�v�f�̓���(���i)����A
PC�����̃n�C�p�t�H�[�}���X�̃N���C�A���gCPU�܂ŁA�S�Ă�FUSION�ɒ�`���Ă���v
http://www.geocities.jp/andosprocinfo/wadai07/20070804.htm
2009�N��CPU�ł�GPU��������郏���`�b�v��Fusion����߁C�摗�肵���悤�ł��B
���C���X�g���[���ł́C�p�b�P�[�W��Fusion�ɕύX����Ă���CCPU��GPU��
�}���`�`�b�v�p�b�P�[�W�ɓ��ڂ���A�v���[�`�ɂȂ�Ǝv���܂��B
�ȃu�����h�l�[���^�}�[�P�e�B���O�p��ɂȂ��Ă��܂����B
http://techon.nikkeibp.co.jp/article/NEWS/20061026/122718/
��Advanced Micro Devices�CInc.�iAMD�Ёj�̓O���t�B�b�N�X�`���H��CPU�R�A��
1�`�b�v��ɏW�ς���86�n�}�C�N���v���Z�T�uFusion�v�i�J���R�[�h���j��
2008�N���`2009�N���߂����h�ɊJ������
��
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
�uFUSION�́A�A�N�Z�����[�g�^�R���s���[�e�B���O�ɂ��Ă̑S�Ă��J�o�[����B
������A�V�X�e���I���`�b�v(SoC)�̃����`�b�v�\���Ɍ��炸�A�����`�b�v�ɂ��
�V�X�e�����x���ł̃w�e���W�j�A�X�\����FUSION�Ɋ܂�ł���B
�܂��A�g�ѓd�b�r�W�l�X�����̂��܂��܂ȋ@�\�v�f�̓���(���i)����A
PC�����̃n�C�p�t�H�[�}���X�̃N���C�A���gCPU�܂ŁA�S�Ă�FUSION�ɒ�`���Ă���v
http://www.geocities.jp/andosprocinfo/wadai07/20070804.htm
2009�N��CPU�ł�GPU��������郏���`�b�v��Fusion����߁C�摗�肵���悤�ł��B
���C���X�g���[���ł́C�p�b�P�[�W��Fusion�ɕύX����Ă���CCPU��GPU��
�}���`�`�b�v�p�b�P�[�W�ɓ��ڂ���A�v���[�`�ɂȂ�Ǝv���܂��B
http://japan.cnet.com/news/biz/story/0,2000056020,20352860-2,00.htm
��i�����ł́APC�s�ꂪ�}���ɐ��n������A�E�H�[���X�g���[�g���ł��D��
�������͐L�єY��ł���B���̌��ʁAIntel��AMD���APC���܂��w�����Ă��Ȃ�
�c��Ȑ��̐l�X������̗��v���Ƃ��čl���Ă���B���Ђɂ͂���𐢊E���~��
���߂̐l���I���g�݂ɂ������l�������邪�A����炪���v�����߂Ă���B
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
��X���A���݁AFUSION�Ő^���ɍl���Ă���̂͂��̉��B���C���X�g���[��
�m�[�gPC�s��ƁA�G�}�[�W���O�s�ꂾ�B����2�s��ɁA���Ȃ�t�H�[�J�X���Ă���B
(�����`�b�v��)FUSION�́A���C���X�g���[���m�[�gPC�s��ɕϊv�������炵�A
(PC�ȊO��)�f�o�C�X�ɂ��G�}�[�W���O�s��̌@��N�����̉\�����J�����炾�B
��X�̃r�W�����ɂ���FUSION�́A���C���X�g���[����PC�s����������łȂ��B
�ނ���50x15(2015�N�܂łɐ��E�l����50%�ɁA�����ȃC���^�[�l�b�g�ڑ��ƃR���s��
�[�e�B���O�����C�j�V�A�`�u)�s��ɐZ�����A�R���o�[�W�F���X�f�o�C�X��
�s���x86 CPU�ŗ����グ�Ax86 CPU���n���h�w���h��DTV�ɂ����炷���߂̂��̂��B
�܂�AFUSION�̓V���O���|�C���g�Ƀt�H�[�J�X�����헪�ł͂Ȃ��A�L�Ăȃr���[���v
���G�}�[�W���O�s��Ƃ͐����������i�K�ɂ��鍑��n��̎s��̂��Ƃ������܂��B
�@�@�o�ϓI�ɔ��W�r��ł���A����āA����A�W�A�A�C���h�A�����A���V�A�A�����ȂǁB
��i�����ł́APC�s�ꂪ�}���ɐ��n������A�E�H�[���X�g���[�g���ł��D��
�������͐L�єY��ł���B���̌��ʁAIntel��AMD���APC���܂��w�����Ă��Ȃ�
�c��Ȑ��̐l�X������̗��v���Ƃ��čl���Ă���B���Ђɂ͂���𐢊E���~��
���߂̐l���I���g�݂ɂ������l�������邪�A����炪���v�����߂Ă���B
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
��X���A���݁AFUSION�Ő^���ɍl���Ă���̂͂��̉��B���C���X�g���[��
�m�[�gPC�s��ƁA�G�}�[�W���O�s�ꂾ�B����2�s��ɁA���Ȃ�t�H�[�J�X���Ă���B
(�����`�b�v��)FUSION�́A���C���X�g���[���m�[�gPC�s��ɕϊv�������炵�A
(PC�ȊO��)�f�o�C�X�ɂ��G�}�[�W���O�s��̌@��N�����̉\�����J�����炾�B
��X�̃r�W�����ɂ���FUSION�́A���C���X�g���[����PC�s����������łȂ��B
�ނ���50x15(2015�N�܂łɐ��E�l����50%�ɁA�����ȃC���^�[�l�b�g�ڑ��ƃR���s��
�[�e�B���O�����C�j�V�A�`�u)�s��ɐZ�����A�R���o�[�W�F���X�f�o�C�X��
�s���x86 CPU�ŗ����グ�Ax86 CPU���n���h�w���h��DTV�ɂ����炷���߂̂��̂��B
�܂�AFUSION�̓V���O���|�C���g�Ƀt�H�[�J�X�����헪�ł͂Ȃ��A�L�Ăȃr���[���v
���G�}�[�W���O�s��Ƃ͐����������i�K�ɂ��鍑��n��̎s��̂��Ƃ������܂��B
�@�@�o�ϓI�ɔ��W�r��ł���A����āA����A�W�A�A�C���h�A�����A���V�A�A�����ȂǁB
968 �FMAC�I�^ [sage] �F2007/08/22(��) 08:03:03 ID:Gs+EEEm/
Hot Chips��Phil Hestor��"Fusion�탍�[�G���h������SoC"�I�Ȃ��Ƃ�������炵�����BMediaGX�̍ė������H
http://news.com.com/8301-10784_3-9763693-7.html
�@�@----------------------
�@�@That's the plan for Fusion. It's not going to replace high-end discrete graphics chips coveted
�@�@by gamers, and it's not going to deliver the ultimate in CPU performance, Hester said. But
�@�@AMD thinks that integrating the GPU will be essential around the end of the decade because
�@�@so many applications--games and videos, for starters--will want to latch onto the GPU
�@�@architecture and because the relative performance of a GPU is way beyond the CPU right now,
�@�@he said.
�@�@----------------------
Hot Chips��Phil Hestor��"Fusion�탍�[�G���h������SoC"�I�Ȃ��Ƃ�������炵�����BMediaGX�̍ė������H
http://news.com.com/8301-10784_3-9763693-7.html
�@�@----------------------
�@�@That's the plan for Fusion. It's not going to replace high-end discrete graphics chips coveted
�@�@by gamers, and it's not going to deliver the ultimate in CPU performance, Hester said. But
�@�@AMD thinks that integrating the GPU will be essential around the end of the decade because
�@�@so many applications--games and videos, for starters--will want to latch onto the GPU
�@�@architecture and because the relative performance of a GPU is way beyond the CPU right now,
�@�@he said.
�@�@----------------------
>Fusion�탍�[�G���h������SoC"�I�Ȃ��Ƃ�������炵�����B
>MediaGX�̍ė������H
�O���t�B�b�N�����`�b�v�Z�b�g�̌㊘�I���i�Ƃ���
�����ۂ���܂邩��ȁ@>Fusion
GPU����CPU���̋��c��
>AMD��GPU�R�A��ėp�Ɏg�����Ƃ�ړI�Ƃ��ē������悤�Ƃ��Ă���B
�Ƃ������Ă邯��
�P�Ȃ����PC�������ނƊ���������������I�B
�܂����ꂾ���L���������������
���X�������݂��Ȃ����낤���ǥ��
>MediaGX�̍ė������H
�O���t�B�b�N�����`�b�v�Z�b�g�̌㊘�I���i�Ƃ���
�����ۂ���܂邩��ȁ@>Fusion
GPU����CPU���̋��c��
>AMD��GPU�R�A��ėp�Ɏg�����Ƃ�ړI�Ƃ��ē������悤�Ƃ��Ă���B
�Ƃ������Ă邯��
�P�Ȃ����PC�������ނƊ���������������I�B
�܂����ꂾ���L���������������
���X�������݂��Ȃ����낤���ǥ��
�p�\�R���͂ǂ�ǂ�R���f�e�B�����Ă܂�Ȃ��Ȃ��Ă���
���������ԑO����܂�Ȃ�����
������x86�݊�CPU���[�J�[��O���t�B�b�N�X�x���_��������
PC�p�[�c����������悵�Ă���10�N�O�Ɣ�ׂ��
������x86�݊�CPU���[�J�[��O���t�B�b�N�X�x���_��������
PC�p�[�c����������悵�Ă���10�N�O�Ɣ�ׂ��
AMD�̏ꍇCPU-GPU�̖��߃Z�b�g���x���ł̓�����SSE5�łȂ����킯����
�C�X���G���Ȃ�n�C�G���hGPU���̃������ш�����Ƃ����_�Ƃ������Ă��ꂻ�����B
���̓h���C�o���ȁA�O��͂���œP�ނ������������
http://www.4gamer.net/games/038/G003822/20070926019/
I����Nehalem�ɓ��������45nm�����GPU�R�A��
�u�ƒ�p�Q�[���@���x����3D�O���t�B�b�N�X�@�\���T�|�[�g�v�炵���̂ŁAG70�AR500�����
�~�h�������W�N���X���낤���B
�h���C�o�ɂ��Ă͌݊���������撣��炵�����ǁAG965��DirectX10�Ή���2008�N��Q2�����A
NVIDIA��AMD�قǂɂ͂܂����҂ł������ɂȂ��B
I����Nehalem�ɓ��������45nm�����GPU�R�A��
�u�ƒ�p�Q�[���@���x����3D�O���t�B�b�N�X�@�\���T�|�[�g�v�炵���̂ŁAG70�AR500�����
�~�h�������W�N���X���낤���B
�h���C�o�ɂ��Ă͌݊���������撣��炵�����ǁAG965��DirectX10�Ή���2008�N��Q2�����A
NVIDIA��AMD�قǂɂ͂܂����҂ł������ɂȂ��B
>>505
���݂́u�������ǂ�������������v���x�����ƔߎS�����邯�ǁA
���̃��x���̃O���t�B�b�N�`�b�v���W���œ��������悤�ɂȂ�����A
�l�g�Q�[������ɍL�����ˁB
���݂́u�������ǂ�������������v���x�����ƔߎS�����邯�ǁA
���̃��x���̃O���t�B�b�N�`�b�v���W���œ��������悤�ɂȂ�����A
�l�g�Q�[������ɍL�����ˁB
�Ƃ���Ń��W�����[�v�Ńl�n�[�����̃f���A���R�A�ł������L2�͔�����4MB�ɂȂ�Ȃ��H
>>507
���W�����[�v�Ƃ��W�Ȃ��A4MB�ł�����4MB�ɂȂ邾������Ȃ��̂��H
���W�����[�v�Ƃ��W�Ȃ��A4MB�ł�����4MB�ɂȂ邾������Ȃ��̂��H
>>505
PS�ESS���x���Ƃ͌���Ȃ����C��������DC, �����Ƃ�Wii�N���X����ˁH
PS�ESS���x���Ƃ͌���Ȃ����C��������DC, �����Ƃ�Wii�N���X����ˁH
���[���BWii��������A�]�T��PS2�͉z���Ă邼�[�E�E�E�E�E�E
AMD�X�����]�����Ԕ����J�Ȑl��������ł��Ă�����
512 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 02:15:09 ID:ciMKYx9v
FF11��XGA�ŏo�����Xbox�͉z���邾�낤
360�͖������������
360�͖������������
Pentium M��1.4GHz����Core 2 Extreme QX9650�Ɍ�������Ə������x��
���{���炢�ɂȂ�H�i�P���Ƀp�C�ĂƂ��Łj
���{���炢�ɂȂ�H�i�P���Ƀp�C�ĂƂ��Łj
3�{�`4�{
�V���O���^�X�N����2.5�{���炢���H
�G���R�[�_�[�J���ҁ�������SSE4�Ɋւ��鏊��
http://www.marumo.ne.jp/db2007_9.htm#19
http://www.marumo.ne.jp/db2007_a.htm#3
http://www.marumo.ne.jp/db2007_9.htm#19
http://www.marumo.ne.jp/db2007_a.htm#3
519 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 14:54:37 ID:ciMKYx9v
�����A���̃T�C�g�ɂł�SSE4�l�^�����Ă�����
pshufb�̃��C�e���V3��1�͂��߂�
pshufb�̃��C�e���V3��1�͂��߂�
�{���ɃG���R�[�_�[�J�������̂��������ȃR�����g���ȁE�E�E�B
�m���������������āANehalem����B
�m���������������āANehalem����B
�X�y���~�X���炢���邾��B
������Ȃ��g��������ĂȂ��œ��e�ɓ˂����߂�B
������Ȃ��g��������ĂȂ��œ��e�ɓ˂����߂�B
522 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 15:04:22 ID:ciMKYx9v
SSSE3��H.264�ɂ͂��܂�g���Ȃ����Č����Ă��Ȕ�
SSE2�܂łŖ��߃Z�b�g�͎�����قڊ������Ă����A�������߂������Ȃ鎖�͂����Ă�
�V���߂Ō��I�ɑ����Ȃ鎖�͂܂��Ȃ��B
SSE2�܂łŖ��߃Z�b�g�͎�����قڊ������Ă����A�������߂������Ȃ鎖�͂����Ă�
�V���߂Ō��I�ɑ����Ȃ鎖�͂܂��Ȃ��B
�g�����߂��[��������O��L2�L���b�V���Ƃ����ӂ₹�ƁB
524 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 15:17:51 ID:ciMKYx9v
����́AAMD�ɑ��Ă����Ă�̂��H
�[���A�\�t�g���ɂ͂������낢���߂��Ȃ����āA�����͉̂R�B
�G���R�[�_���ɂ͂������낢���߂��������Ă�������B
�͂����肢����Intel��Whitepaper�����łȂ��ō��XIDF�̏���
�ǂ����������Ă郌�x���̃R�[�h�����̓R�[�h���������Ă�Ⴂ���B
�����Ȃ�Ă킩������Ȃ��B
�G���R�[�_���ɂ͂������낢���߂��������Ă�������B
�͂����肢����Intel��Whitepaper�����łȂ��ō��XIDF�̏���
�ǂ����������Ă郌�x���̃R�[�h�����̓R�[�h���������Ă�Ⴂ���B
�����Ȃ�Ă킩������Ȃ��B
�킩��Ȃ��Ă���
�I���̓t���[�����`��H��
�I���̓t���[�����`��H��
527 �FMAC�I�^���c�q �����F2007/10/06(�y) 16:38:40 ID:CLRn0sLW
>>519
�@�@---------------
�@�@pshufb�̃��C�e���V3��1�͂��߂�
�@�@---------------
Apple�ƕt�������悤�ɂȂ������b�Ǝv�������ǁAvector permute�n���߂̃��C�e���V�Z�k�ɒ���
���Ă���Ƃ����Ӗ���Intel��w�����Ă���x���������邷�B
����Ő܊p��vperm���߂̃��C�e���V���ǂ�ǂ����Ă���IBM��VMX�̎����ɂ����ʂĂ邷�B
CELL BE��SPE ISA�ł�4 cycle�����B�B�B
�@�@---------------
�@�@pshufb�̃��C�e���V3��1�͂��߂�
�@�@---------------
Apple�ƕt�������悤�ɂȂ������b�Ǝv�������ǁAvector permute�n���߂̃��C�e���V�Z�k�ɒ���
���Ă���Ƃ����Ӗ���Intel��w�����Ă���x���������邷�B
����Ő܊p��vperm���߂̃��C�e���V���ǂ�ǂ����Ă���IBM��VMX�̎����ɂ����ʂĂ邷�B
CELL BE��SPE ISA�ł�4 cycle�����B�B�B
���̓n�[�h�������炢�����A�ŋ߂̃\�t�g���͎��삪�����z���������B
�������g���Ȃ��Ǝv�������߂͂ǂ�ȃ\�t�g�ł����ɗ����Ȃ��̂悤�Ȃ��Ƃ�����ɂ����ȁB
������\�t�g�������邲�Ƃ��̃X�L��������Ȉ̂����̂ɂȂ����낤�ȁB
>�I���`�b�v�������R���g���[���Ƃ� HT �����Ƃ����ʂ�
> PC ���[�U�I�ɂ͖ʔ����l�^�Ȃ�[����
������SSE4���킩�邩��PC���[�U�����ゾ�Ƃ��������̂��낤���c�B
�n�[�h�I���`�̔��z�͗����ł���Ȃ��B
�������g���Ȃ��Ǝv�������߂͂ǂ�ȃ\�t�g�ł����ɗ����Ȃ��̂悤�Ȃ��Ƃ�����ɂ����ȁB
������\�t�g�������邲�Ƃ��̃X�L��������Ȉ̂����̂ɂȂ����낤�ȁB
>�I���`�b�v�������R���g���[���Ƃ� HT �����Ƃ����ʂ�
> PC ���[�U�I�ɂ͖ʔ����l�^�Ȃ�[����
������SSE4���킩�邩��PC���[�U�����ゾ�Ƃ��������̂��낤���c�B
�n�[�h�I���`�̔��z�͗����ł���Ȃ��B
�͂��͂��۽�۽
530 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 16:53:26 ID:ciMKYx9v
vector permute���߂�AES�̃A�N�Z�����[�V�����ɂ��Ȃ�g����悤��
http://www.mail-archive.com/[email protected]/msg00899.html
�������p�b�`
http://patchwork.ozlabs.org/cbe-oss-dev/patch?id=11684
http://www.mail-archive.com/[email protected]/msg00899.html
�������p�b�`
http://patchwork.ozlabs.org/cbe-oss-dev/patch?id=11684
531 �FMAC�I�^���⑫�F2007/10/06(�y) 16:53:56 ID:CLRn0sLW
SIMD�̖���A�w�������x�N�g�����W�X�^�̒P�ʂɕ��בւ���K�v������x�Ƃ����_�ɐs���邷�B
http://jun.artcompsci.org/articles/future_sc/note008.html#rdocsect7
�������������ɂ�A
�@�wvector permute���^�_���R�̌v�Z�R�X�g�Ŏ��s�ł���x
�Ƃ������Ƃ����ɑ厖�ɂȂ邷�B
http://jun.artcompsci.org/articles/future_sc/note008.html#rdocsect7
�������������ɂ�A
�@�wvector permute���^�_���R�̌v�Z�R�X�g�Ŏ��s�ł���x
�Ƃ������Ƃ����ɑ厖�ɂȂ邷�B
�n�[�h���̓\�t�g���ƒ��������\�t�g���̓n�[�h���ƒ�������
�`���݂����ɂȂ��ċƊE�����Ɣ����݂����ɂȂ��Ă�̂��H
�����ɋ��������������Ă邩�C�����Ȃ��낤���B
�`���݂����ɂȂ��ċƊE�����Ɣ����݂����ɂȂ��Ă�̂��H
�����ɋ��������������Ă邩�C�����Ȃ��낤���B
533 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 17:02:44 ID:ciMKYx9v
VMX: vperm+vsel
SPU: shufb�{selb
SSE5: pperm�{pcmov
���āAIntel�����ǁApshufb��pand/pandn/por�ł��Ƃ������Ēx���Ȃ肻���B
�ނ���pinsrb+pextrb���g�������B
SPU: shufb�{selb
SSE5: pperm�{pcmov
���āAIntel�����ǁApshufb��pand/pandn/por�ł��Ƃ������Ēx���Ȃ肻���B
�ނ���pinsrb+pextrb���g�������B
>>530
PadLock�ɏ��Ă܂����H
PadLock�ɏ��Ă܂����H
>>532
�N������Ȃ��Ƃ͂����ĂȂ����ǁB�ŋ߂̃\�t�g���͂��߂Ȃ���������̂͊m���B
�������R���g���[����HT���݂āA(Nehalem��)���ʂ�PC���[�U�ɂ͂������낭�Ă�
�\�t�g���ɂ͊W�Ȃ���(��
�Ǝv���̂͊����ӕ��i�����Ă���n�[�h���̑��݂�Y��Ă���
����o�Ă��镶�͂���ȁB
�A�Z���u������Ă��܂ł���Ȃ��Ƃ��̂��܂��Ƃ�
����̋����\�t�g�������B���Ă���B
�N������Ȃ��Ƃ͂����ĂȂ����ǁB�ŋ߂̃\�t�g���͂��߂Ȃ���������̂͊m���B
�������R���g���[����HT���݂āA(Nehalem��)���ʂ�PC���[�U�ɂ͂������낭�Ă�
�\�t�g���ɂ͊W�Ȃ���(��
�Ǝv���̂͊����ӕ��i�����Ă���n�[�h���̑��݂�Y��Ă���
����o�Ă��镶�͂���ȁB
�A�Z���u������Ă��܂ł���Ȃ��Ƃ��̂��܂��Ƃ�
����̋����\�t�g�������B���Ă���B
�����܂œǂ�ł킩����
ID:o5cgVy4S �̎���͋���
ID:o5cgVy4S �̎���͋���
���낤�ˁB
539 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 17:46:39 ID:ciMKYx9v
�A�[�L�e�N�`���͑��l���̈�r�Ȃ��用�Ⴂ�̐l�Ԃ̂������ƂȂ�Ă��������C�ɂ��Ȃ�
������ɃA�[�L�e�N�g���Ȃ߂�ςȋ�C���Y���Ă�̂͊m�����ȁB
��
NetBurst�͕�
�I���S���͕�
AMD�͕�
AndyGlew�̓X�p�C��
��
NetBurst�͕�
�I���S���͕�
AMD�͕�
AndyGlew�̓X�p�C��
541 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 17:49:40 ID:ciMKYx9v
����Cell�̐v�����l�͓���������
542 �FMAC�I�^���c�q �����F2007/10/06(�y) 19:50:11 ID:CLRn0sLW
>>541
���̃R�����g��A���ԂɎ����̈��������I���邾�����Ǝv�������ǁB�B�B
�v��g���[�h�I�t�̐ςݏd�˂�����A�����̎v���ʂ�̕��j���I������Ȃ���������ƌ�����
�w�_���Ȑv�x�Ǝ咣����̂�A�Z���v�l���B
�Ⴆ�Ύ���>>527��CELL BE�̐v��ᔻ���Ă��邷���ǁA
�@�@------------------
�@�@����Ő܊p��vperm���߂̃��C�e���V���ǂ�ǂ����Ă���IBM��VMX�̎����ɂ����ʂĂ邷�B
�@�@CELL BE��SPE ISA�ł�4 cycle�����B�B�B
�@�@------------------
CELL�̏ꍇ��A�i���Ȃ��Ƃ�LS���ł�)SIMD�œK�����{���ꂽ�f�[�^�z�u�ɂȂ��Ă���Ƃ����O���
vector permute�ɏd�_���u����Ă��Ȃ��Ƃ����w�I���x���Ȃ���Ă���Ǝv���邷�B
���̃R�����g��A���ԂɎ����̈��������I���邾�����Ǝv�������ǁB�B�B
�v��g���[�h�I�t�̐ςݏd�˂�����A�����̎v���ʂ�̕��j���I������Ȃ���������ƌ�����
�w�_���Ȑv�x�Ǝ咣����̂�A�Z���v�l���B
�Ⴆ�Ύ���>>527��CELL BE�̐v��ᔻ���Ă��邷���ǁA
�@�@------------------
�@�@����Ő܊p��vperm���߂̃��C�e���V���ǂ�ǂ����Ă���IBM��VMX�̎����ɂ����ʂĂ邷�B
�@�@CELL BE��SPE ISA�ł�4 cycle�����B�B�B
�@�@------------------
CELL�̏ꍇ��A�i���Ȃ��Ƃ�LS���ł�)SIMD�œK�����{���ꂽ�f�[�^�z�u�ɂȂ��Ă���Ƃ����O���
vector permute�ɏd�_���u����Ă��Ȃ��Ƃ����w�I���x���Ȃ���Ă���Ǝv���邷�B
3�s�ł܂Ƃ߂�
���肪�Ƃ��������܂���
>>543
���̂̐v�͂��ꂼ��Ɏv�f��v�z������
���ꂪ�C�ɓ���Ȃ�����Ƃ����Ĕᔻ����̂�
�@���Ȃ��̂�
���z�͑S�Ăɂ����Ċ��S�Ȃ��̂���
����Ȃ��͖̂��̂܂���
�����ł͉����������o������ʼn������]���ɂ��Ȃ���Ȃ��
���̂̐v�͂��ꂼ��Ɏv�f��v�z������
���ꂪ�C�ɓ���Ȃ�����Ƃ����Ĕᔻ����̂�
�@���Ȃ��̂�
���z�͑S�Ăɂ����Ċ��S�Ȃ��̂���
����Ȃ��͖̂��̂܂���
�����ł͉����������o������ʼn������]���ɂ��Ȃ���Ȃ��
IBM��Intel��(Freescale���H)�ACell�̂悤�ɉ����ɂ��ꂽ�莎���I�ɐF�X�ł��鋭�݂����邩���
548 �FSocket774�F2007/10/06(�y) 20:57:54 ID:5P/FIC0t
Nehalem�̂W�R�A�͖��͓I���ȁB
�Q�O�O�X�N�̎n�߂ɂ͔�������Ă��邾�낤�B
�Q�O�O�X�N�̎n�߂ɂ͔�������Ă��邾�낤�B
549 �FSocket774�F2007/10/06(�y) 21:13:58 ID:5P/FIC0t
�Q�O�P�T�N�ɂ̓��[�A�̖@�������E�ɂȂ�Ɨ\������Ă��܂��B
�����ŗʎq�R���s���[�^�ł��ˁB����ŗʎq�R���s���[�^������Ă݂����B
�����ŗʎq�R���s���[�^�ł��ˁB����ŗʎq�R���s���[�^������Ă݂����B
1971�N 1�R�A 108kHz �| 10��m�i�}�C�N���j
1974�N 1�R�A 2MHz �| 6��m
1976�N 1�R�A 5MH�� �| 3��m
1982�N 1�R�A 6MHz �| 1.5��m
1990�N 1�R�A 25MH�� �| 1��m
1992�N 1�R�A 50MHz �| 0.8��m
1994�N 1�R�A 75MHz �| 0.6��m
1995�N 1�R�A 120MHz �| 0.35��m
1998�N 1�R�A 266MHz �| 0.25��m
1999�N 1�R�A 500MHz�| 180nm�i�i�m�j
2001�N 2�R�A�iHTT�j �| 180nm�i�i�m�j
2001�N 2�R�A
2003�N 2�R�A�iHTT�j1.60GHz �| 130nm
2004�N 2�R�A (SMT 4�X���b�h)
2005�N 2�R�A 2.66GHz �| 90nm
2007�N 4�R�A �| 65nm
2009�N 8�R�A �| 45nm
2011�N 16�R�A �| 32nm
2013�N 32�R�A �| 22.5nm
2015�N 64�R�A �| 16nm
2003�N ��CPU
20??�N �ʎq�R���s���[�^
20??�N DNA�R���s���[�^
1974�N 1�R�A 2MHz �| 6��m
1976�N 1�R�A 5MH�� �| 3��m
1982�N 1�R�A 6MHz �| 1.5��m
1990�N 1�R�A 25MH�� �| 1��m
1992�N 1�R�A 50MHz �| 0.8��m
1994�N 1�R�A 75MHz �| 0.6��m
1995�N 1�R�A 120MHz �| 0.35��m
1998�N 1�R�A 266MHz �| 0.25��m
1999�N 1�R�A 500MHz�| 180nm�i�i�m�j
2001�N 2�R�A�iHTT�j �| 180nm�i�i�m�j
2001�N 2�R�A
2003�N 2�R�A�iHTT�j1.60GHz �| 130nm
2004�N 2�R�A (SMT 4�X���b�h)
2005�N 2�R�A 2.66GHz �| 90nm
2007�N 4�R�A �| 65nm
2009�N 8�R�A �| 45nm
2011�N 16�R�A �| 32nm
2013�N 32�R�A �| 22.5nm
2015�N 64�R�A �| 16nm
2003�N ��CPU
20??�N �ʎq�R���s���[�^
20??�N DNA�R���s���[�^
551 �FSocket774�F2007/10/06(�y) 22:25:05 ID:OCFvOAQA
>>542
�߂��炵��MAC�I�^���܂Ƃ��Ȃ��Ƃ������Ă���@��3�s�����ǂ�łȂ�����
�߂��炵��MAC�I�^���܂Ƃ��Ȃ��Ƃ������Ă���@��3�s�����ǂ�łȂ�����
���\�͗ʎq�R���s���[�^�������z�����Ȃ��ǁ�����DNA�R���s���[�^�������z�����Ȃ��ǁ������m�C�}���^�R���s���^�B
>>550
�~2003�N ��CPU
��2010�N ��CPU
2010�N ��CPU 1�R�A
2012�N ��CPU 2�R�A
2014�N ��CPU 4�R�A
2016�N ��CPU 8�R�A
2018�N ��CPU 16�R�A
2020�N ��CPU 32�R�A
2022�N ��CPU 64�R�A
2024�N ��CPU 128�R�A
2026�N ��CPU 256�R�A
2028�N ��CPU 512�R�A
2030�N ��CPU 1024�R�A
�~2003�N ��CPU
��2010�N ��CPU
2010�N ��CPU 1�R�A
2012�N ��CPU 2�R�A
2014�N ��CPU 4�R�A
2016�N ��CPU 8�R�A
2018�N ��CPU 16�R�A
2020�N ��CPU 32�R�A
2022�N ��CPU 64�R�A
2024�N ��CPU 128�R�A
2026�N ��CPU 256�R�A
2028�N ��CPU 512�R�A
2030�N ��CPU 1024�R�A
�ʎq�R���s���[�^���
����ʎq���ق���
����ʎq���ق���
541 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 17:49:40 ID:ciMKYx9v �@[sage]
����Cell�̐v�����l�͓���������
�w�_���Ȑv�x�Ǝ咣����̂́A�Z���v�l�Ȃ̂�������Ȃ����A
�v�̓g���[�h�I�t�̐ςݏd�˂�����A�A�[�L�e�N�g�̎v���ʂ�̕]�����s��œ����Ȃ����Ƃ�����B
�Ƃ������A���ۓ����Ȃ������B
�������z�ɑ��郊�^�[�����ӂ݂�ƁuCell���J���w�������l�͓����������v�͐^�B
����Cell�̐v�����l�͓���������
�w�_���Ȑv�x�Ǝ咣����̂́A�Z���v�l�Ȃ̂�������Ȃ����A
�v�̓g���[�h�I�t�̐ςݏd�˂�����A�A�[�L�e�N�g�̎v���ʂ�̕]�����s��œ����Ȃ����Ƃ�����B
�Ƃ������A���ۓ����Ȃ������B
�������z�ɑ��郊�^�[�����ӂ݂�ƁuCell���J���w�������l�͓����������v�͐^�B
>>549
2015�N�Ɏg�����ɂȂ郂�m���o���Ă���Ȃ�
Cell�́A�u�v�����l�v�ƈꊇ��ɂ���̂͂�����ƈႤ���낤���ǁA
���̃��[�J���������\�����������Ă̂͏O�ڂ̈�v���鏊����Ȃ��̂��H
2015�N�Ɏg�����ɂȂ郂�m���o���Ă���Ȃ�
Cell�́A�u�v�����l�v�ƈꊇ��ɂ���̂͂�����ƈႤ���낤���ǁA
���̃��[�J���������\�����������Ă̂͏O�ڂ̈�v���鏊����Ȃ��̂��H
�����������蕪��ł͐��\�o�Ă�̂�CELL�����Ƃ������
���ꂪ�Q�[���pCPU�Ƃ��ėǂ��Ƃ����z���n���B
���ꂪ�Q�[���pCPU�Ƃ��ėǂ��Ƃ����z���n���B
�ʎq�R���s���[�^�̎������u
http://www.nhk.or.jp/professional/backnumber/060214/photo/photo02.jpg
http://www.nhk.or.jp/professional/backnumber/060214/index.html
http://www.nhk.or.jp/professional/backnumber/060214/photo/photo02.jpg
{kind=link}
http://www.nhk.or.jp/professional/backnumber/060214/index.html
560 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 22:46:53 ID:ciMKYx9v
>>557
�Q�[����SCE��IP���������
�Q�[����������ł��������ʓ�������Ȃ�L�肾�낤����
�܂�SCE�����ɑ̂ɂȂ����͉̂���Cell�����̂�������Ȃ����ǂ�
�Q�[����SCE��IP���������
�Q�[����������ł��������ʓ�������Ȃ�L�肾�낤����
�܂�SCE�����ɑ̂ɂȂ����͉̂���Cell�����̂�������Ȃ����ǂ�
���k����f�R�[�h
��×p�摜�f�f
��������
��������
�����5000���~�i����2000���~�j������ł͂����Ȃ�
��×p�摜�f�f
��������
��������
�����5000���~�i����2000���~�j������ł͂����Ȃ�
Optical computer
http://en.wikipedia.org/wiki/Optical_computer
http://en.wikipedia.org/wiki/Optical_computer
�L���m���T�C�G���X���{ ���R���s���[�^
http://www.canon.co.jp/technology/s_labo/light/004/04.html
http://www.canon.co.jp/technology/s_labo/light/004/04.html
���ς�炸CELL BE�@�����Ђǂ������ǁACELL BE�̗L�����p�ɍ��{�I�ȃv���O�����v�̌�����
���K�v�Ȃ��Ƃ�A�ŏ����画���Ă����b���B
1�N���炸�Ń\�t�g���o�Ă���̂��x������ƌ����Ē@���̂�A���܂�ɂ��C���������邷�B
���K�v�Ȃ��Ƃ�A�ŏ����画���Ă����b���B
1�N���炸�Ń\�t�g���o�Ă���̂��x������ƌ����Ē@���̂�A���܂�ɂ��C���������邷�B
�������̌��R���s���[�^�[�Ɍ����A���́u�����v�ɐ���
http://wiredvision.jp/archives/200511/2005110401.html
http://wiredvision.jp/archives/200511/2005110401.html
566 �F�R�E�L�́M�E,,�j�����������������F2007/10/06(�y) 23:42:25 ID:ciMKYx9v
567 �FMAC�I�^���c�q �����F2007/10/06(�y) 23:48:27 ID:CLRn0sLW
�D�ꂽ�����������X�C�b�`�p�K���X���J��
http://www.agc.co.jp/news/1998/0910.html
http://www.agc.co.jp/news/1998/0910.html
��N���炸���낤�������낤���ACell/B.E.�̃\�t�g�E�F�A�ʂ͔ᔻ����Ă�����ׂ��B
�ʏ�ł���Γ��R�A�\�t�g�E�F�A�E�J�����Ƃ����v�f���݂�
�o�c���f�A�������f�A�J���v����s��Ȃ�������Ȃ��B
Intel��Larrabee���ɏo���ƁA�\�t�g�E�F�A�ʂ���Ɉӎ����Ă��邱�Ƃ��킩��B
�\���̕ω����炷��ƁA�����ă����[�X���}��������������T�d�ɂȂ��Ă��邱�Ƃ��킩��B
http://www.intel.co.jp/jp/intel/pr/press2007/070417.htm
��Larrabee�́A�����̑����̃\�t�g�E�F�A���g�����v���O���~���O���\
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
�����������ɂ��Ắu������CPU�wNehalem(�l�w�[����)�x���O�ɂȂ邩������Ȃ��v
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
http://www.xbitlabs.com/news/video/display/20070919151611.html
��In 2010 Intel will release its code-named Larrabee processor
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
�ʏ�ł���Γ��R�A�\�t�g�E�F�A�E�J�����Ƃ����v�f���݂�
�o�c���f�A�������f�A�J���v����s��Ȃ�������Ȃ��B
Intel��Larrabee���ɏo���ƁA�\�t�g�E�F�A�ʂ���Ɉӎ����Ă��邱�Ƃ��킩��B
�\���̕ω����炷��ƁA�����ă����[�X���}��������������T�d�ɂȂ��Ă��邱�Ƃ��킩��B
http://www.intel.co.jp/jp/intel/pr/press2007/070417.htm
��Larrabee�́A�����̑����̃\�t�g�E�F�A���g�����v���O���~���O���\
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
�����������ɂ��Ắu������CPU�wNehalem(�l�w�[����)�x���O�ɂȂ邩������Ȃ��v
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
http://www.xbitlabs.com/news/video/display/20070919151611.html
��In 2010 Intel will release its code-named Larrabee processor
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
570 �FMAC�I�^��569 �����F2007/10/06(�y) 23:58:36 ID:CLRn0sLW
���R���s���[�^�[������ڎw���āF���W�ω�H�����ւ̏d�v�Ȉ��
http://wiredvision.jp/archives/200111/2001111902.html
http://wiredvision.jp/archives/200111/2001111902.html
DNA�R���s���[�^�@�ā@�S�W��vs���J�S�W���ɏo�Ă��B
>>570
�ʂɎ��Ԃ̘b�͂��ĂȂ��B
569�ł�"�\�t�g�E�F�A�ʂ̏���"��"�����[�X�����̔��f"�Ƃ������ƂɊւ��鑊�֊W�������������B
�ʂɎ��Ԃ̘b�͂��ĂȂ��B
569�ł�"�\�t�g�E�F�A�ʂ̏���"��"�����[�X�����̔��f"�Ƃ������ƂɊւ��鑊�֊W�������������B
���R���s���[�^���ĂȂɂ����ȂH
NTT�A�؎�T�C�Y�ŗe��1GB�̌��������̎���ɐ��� - 2005�N�̐��i����
http://journal.mycom.co.jp/news/2004/02/12/016.html
http://journal.mycom.co.jp/news/2004/02/12/016.html
577 �FMAC�I�^��573 �����F2007/10/07(��) 00:12:10 ID:00wOqcSE
>>573
�����팾���Ă��A���j�C�R�A�ɑΉ����邽�߂ɂ�傫�ȃv���O���~���O�p���_�C���̕ύX���K�v�ɂȂ邷�B
Intel��������撣���Ă�10�N���Ct��C��C++��u�������Ă���Ƃ��v���Ȃ������ǁB�B�B
http://pc.watch.impress.co.jp/docs/2007/0925/idf10.htm
https://intel.wingateweb.com/us/published/TCRS003/TCRS003_100s.pdf
�����팾���Ă��A���j�C�R�A�ɑΉ����邽�߂ɂ�傫�ȃv���O���~���O�p���_�C���̕ύX���K�v�ɂȂ邷�B
Intel��������撣���Ă�10�N���Ct��C��C++��u�������Ă���Ƃ��v���Ȃ������ǁB�B�B
http://pc.watch.impress.co.jp/docs/2007/0925/idf10.htm
https://intel.wingateweb.com/us/published/TCRS003/TCRS003_100s.pdf
���R���s���[�^�����[�A���p���ȂƂ������Ƃ��āA�\�Z�Ԃ��肽���l��
�撣������l�^���Ǝv���ˁB
Intel������Ă�̂͂����܂ŃV���R���ł̌��Ɠd�C�M���̕ϊ����낤�H
�撣������l�^���Ǝv���ˁB
Intel������Ă�̂͂����܂ŃV���R���ł̌��Ɠd�C�M���̕ϊ����낤�H
>>577
���������p���_�C�����ω�����Ƃ��v���Ȃ����A�ω�����Ȃ炻��܂ő҂����Ȃ��B
����Ct�₻�̑��̃\�t�g�E�F�A�J���̐V���ȃA�v���[�`����肭�����Ȃ��Ȃ�
�e���X�P�[���R���s���[�e�B���O�v��͎���i��ςݏd�˂Ă��邸�鉄��������܂ł��B
���������p���_�C�����ω�����Ƃ��v���Ȃ����A�ω�����Ȃ炻��܂ő҂����Ȃ��B
����Ct�₻�̑��̃\�t�g�E�F�A�J���̐V���ȃA�v���[�`����肭�����Ȃ��Ȃ�
�e���X�P�[���R���s���[�e�B���O�v��͎���i��ςݏd�˂Ă��邸�鉄��������܂ł��B
580 �FMAC�I�^��579 �����F2007/10/07(��) 00:36:15 ID:00wOqcSE
>>579
�@�@--------------
�@�@����܂ő҂����Ȃ��B
�@�@--------------
�����Ȗ\�_���ˁB32-bit�v���Z�b�T�̎������������ꂽ�����Ɛ��̃\�t�g�E�F�A���Ή�����悤��
�Ȃ��������Ƃ̍����v���o���ׂ����Ǝv�����B
�������A�h���X��Ԃ����̖��ŁA���ꂷ����B�B�B
�@�@--------------
�@�@����܂ő҂����Ȃ��B
�@�@--------------
�����Ȗ\�_���ˁB32-bit�v���Z�b�T�̎������������ꂽ�����Ɛ��̃\�t�g�E�F�A���Ή�����悤��
�Ȃ��������Ƃ̍����v���o���ׂ����Ǝv�����B
�������A�h���X��Ԃ����̖��ŁA���ꂷ����B�B�B
������Intel�́A�[������J�����߂Đ��N��Ɏ��p���A�Ȃ�Ă������Ƃ������Ȃ��悤��
��Ɣ������܂߂�R&D�ɖc��ȋ���������ł�B�n�[�h�E�\�t�g�̗��ւɑ��āB
�@����̔�p�������Ɠ���ł邩�炾�B��ɕی��͂����Ă�B
��Ɣ������܂߂�R&D�ɖc��ȋ���������ł�B�n�[�h�E�\�t�g�̗��ւɑ��āB
�@����̔�p�������Ɠ���ł邩�炾�B��ɕی��͂����Ă�B
>>579
Cell���܂�PS3�́A�Q�[���R���\�[���̐���ω��̃^�C�~���O�ł���ɋ߂����Ƃ���낤�Ƃ����킯����ȁB
���̂��ɊJ�����ƃ��C�u�����ƃh�L�������g�̒��ȉ����ŁA�����グ���Ƀf�x���b�p�[�����܂�W�߂��Ȃ������̂���_�B
����ƃR�X�g�R���g���[���̊�_�ݒ��������̂���_�B
�ėp�v���Z�b�T���Ă�����Ȃ��āu����PS�̃R�A�Ɏg���v�Ƃ����O��ŊJ���Ɋւ���Ă��ŁA
����܂�SCE�Ƃ��Ď��s����ȁB
Cell���܂�PS3�́A�Q�[���R���\�[���̐���ω��̃^�C�~���O�ł���ɋ߂����Ƃ���낤�Ƃ����킯����ȁB
���̂��ɊJ�����ƃ��C�u�����ƃh�L�������g�̒��ȉ����ŁA�����グ���Ƀf�x���b�p�[�����܂�W�߂��Ȃ������̂���_�B
����ƃR�X�g�R���g���[���̊�_�ݒ��������̂���_�B
�ėp�v���Z�b�T���Ă�����Ȃ��āu����PS�̃R�A�Ɏg���v�Ƃ����O��ŊJ���Ɋւ���Ă��ŁA
����܂�SCE�Ƃ��Ď��s����ȁB
>>570
�����ƋL����
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
Intel�̃��j�C�R�A�v���W�F�N�g�𗦂���Jim Held��(Intel Fellow & Director of Intel Tera-scale Computing Research, Intel)
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
Intel��Stephen L. Smith(�X�e�B�[�u�EL�E�X�~�X)��(Vice President, Director, Digital Enterprise Group Operations, Intel)
�����ƋL����
���u�\�t�g�E�F�A�R�~���j�e�B�̓v���O������̕��G�����������Ƃ͖]��ł��Ȃ��v
Intel�̃��j�C�R�A�v���W�F�N�g�𗦂���Jim Held��(Intel Fellow & Director of Intel Tera-scale Computing Research, Intel)
���uLarrabee�̃\�t�g�E�F�A�̏����������܂łɂ́A���炭���Ԃ������邾�낤�v
Intel��Stephen L. Smith(�X�e�B�[�u�EL�E�X�~�X)��(Vice President, Director, Digital Enterprise Group Operations, Intel)
�������̌��R���s���[�^�[�Ɍ����A���́u�����v�ɐ���
http://wiredvision.jp/archives/200511/2005110401.html
���d�q�ƌ��q�̗������\���v�f�Ɏ����A����d�q�I�ɂ����w�I�ɂ�
�������ł��镡���^�V���R���`�b�v�̎������A��C�ɋ߂Â����̂��B
����ȍ\���̂b�o�t��z�������B
������������������
������������������
���� �����W�X�^ ����
������������������
�����@��CPU�@�@����
�����@�@�R�A�@�@ .����
����(RISC����).����
������������������
�������L���b�V��.| ��L0�L���b�V��
������������������
���@�@�@�@ ���ϊ��@ ��
������������������
�����d�q��CPU����
�����@�@�R�A�@�@ .����
����(CISC����).����
������������������
���� �L���b�V�� .����L1�L���b�V��
������������������
������������������
���� �L���b�V�� .����L2�L���b�V��
������������������
������������������
�@�@�@���@ ����������
�@�@�@���@ �� ������ ��
�@�@�@���@ ����������
�@�@�@��
�@�@�@���o�X
http://wiredvision.jp/archives/200511/2005110401.html
���d�q�ƌ��q�̗������\���v�f�Ɏ����A����d�q�I�ɂ����w�I�ɂ�
�������ł��镡���^�V���R���`�b�v�̎������A��C�ɋ߂Â����̂��B
����ȍ\���̂b�o�t��z�������B
������������������
������������������
���� �����W�X�^ ����
������������������
�����@��CPU�@�@����
�����@�@�R�A�@�@ .����
����(RISC����).����
������������������
�������L���b�V��.| ��L0�L���b�V��
������������������
���@�@�@�@ ���ϊ��@ ��
������������������
�����d�q��CPU����
�����@�@�R�A�@�@ .����
����(CISC����).����
������������������
���� �L���b�V�� .����L1�L���b�V��
������������������
������������������
���� �L���b�V�� .����L2�L���b�V��
������������������
������������������
�@�@�@���@ ����������
�@�@�@���@ �� ������ ��
�@�@�@���@ ����������
�@�@�@��
�@�@�@���o�X
��������������������������������
��������������������������������
���� �����W�X�^ ���� �����W�X�^ ����
��������������������������������
�����@��CPU�@�@�����@��CPU�@�@����
�����@�@�R�A�@�@ .�����@�@�R�A�@�@ .����
����(RISC����).����(RISC����).����
��������������������������������
�������L���b�V��.|�@|.���L���b�V������L0�L���b�V��
��������������������������������
���@�@�@�@ ���ϊ��@�@�@�@�@ .���ϊ��@ ��
��������������������������������
�����d�q��CPU�����d�q��CPU����
�����@�@�R�A�@�@ .�����@�@�R�A�@�@ .����
����(CISC����).����(CISC����).����
��������������������������������
���� �L���b�V�� .���� �L���b�V�� .����L1�L���b�V��
��������������������������������
��������������������������������
�����@�@�@�@���L�L���b�V���@�@�@�@ ����L2�L���b�V��
��������������������������������
��������������������������������
�@�@�@�@�@�@���@�@�@�@�@ ����������
�@�@�@�@�@�@���@�@�@�@�@ �� ������ ��
�@�@�@�@�@�@���@�@�@�@�@ ����������
�@�@�@�@�@�@��
�@�@�@�@�@�@���o�X
��������������������������������
���� �����W�X�^ ���� �����W�X�^ ����
��������������������������������
�����@��CPU�@�@�����@��CPU�@�@����
�����@�@�R�A�@�@ .�����@�@�R�A�@�@ .����
����(RISC����).����(RISC����).����
��������������������������������
�������L���b�V��.|�@|.���L���b�V������L0�L���b�V��
��������������������������������
���@�@�@�@ ���ϊ��@�@�@�@�@ .���ϊ��@ ��
��������������������������������
�����d�q��CPU�����d�q��CPU����
�����@�@�R�A�@�@ .�����@�@�R�A�@�@ .����
����(CISC����).����(CISC����).����
��������������������������������
���� �L���b�V�� .���� �L���b�V�� .����L1�L���b�V��
��������������������������������
��������������������������������
�����@�@�@�@���L�L���b�V���@�@�@�@ ����L2�L���b�V��
��������������������������������
��������������������������������
�@�@�@�@�@�@���@�@�@�@�@ ����������
�@�@�@�@�@�@���@�@�@�@�@ �� ������ ��
�@�@�@�@�@�@���@�@�@�@�@ ����������
�@�@�@�@�@�@��
�@�@�@�@�@�@���o�X
�ϊ��R�X�g�������������ȁ[�B
���̋L�����m���Ȃ�A�ŋ߂�INTEL��CPU��RISC�ϊ�����ĂȂ��͂��B�͂��B�B�B
���̋L�����m���Ȃ�A�ŋ߂�INTEL��CPU��RISC�ϊ�����ĂȂ��͂��B�͂��B�B�B
587 �FMAC�I�^��492 �����F2007/10/07(��) 08:37:46 ID:00wOqcSE
>>492
�@�@---------------------
�@�@Tulsa��Paxville������قNJv�V�I����Ȃ������[��
�@�@---------------------
Tulsa��V���O���_�C�Ȃ��ǁB�B�B
http://images.dailytech.com/nimage/1660_tulsa_die.png
�@�@---------------------
�@�@Tulsa��Paxville������قNJv�V�I����Ȃ������[��
�@�@---------------------
Tulsa��V���O���_�C�Ȃ��ǁB�B�B
http://images.dailytech.com/nimage/1660_tulsa_die.png
{kind=link}
588 �F���다�L ��W/mVP3FtOs �F2007/10/07(��) 09:40:02 ID:0UNIcA0g
>>584
CPU��������Ȃ��o�X�C���^�[�t�F�C�X�̂ق������
���������
>>580
�����DOS�Ƃ������n�I��OS�̂�������
HIMEM.sys��EMM386.exe�Ƃ����킯�̂킩���h���C�o��
���������g������DOS�Ƃ͔��ɁA
RISC_UNIX��32bit��64bit���̓X���[�Y��������
����A�v���O�����ł��Ȃ�����킩��Ȃ����ǁA
OpenMP�̃R�X�g���[���A�قȂ�v���Z�X�ԓ��m�̃������R�s�[��
�u�ԓI�ɂł���Ƃ��Ă��A����v���O���~���O���ē����?
��������Ȃ��Ƃ����烁�j�[�R�A�̖��́A�\�t�g�E�F�A����Ȃ���
�n�[�h���Ă��ƂɂȂ���
CPU��������Ȃ��o�X�C���^�[�t�F�C�X�̂ق������
���������
>>580
�����DOS�Ƃ������n�I��OS�̂�������
HIMEM.sys��EMM386.exe�Ƃ����킯�̂킩���h���C�o��
���������g������DOS�Ƃ͔��ɁA
RISC_UNIX��32bit��64bit���̓X���[�Y��������
����A�v���O�����ł��Ȃ�����킩��Ȃ����ǁA
OpenMP�̃R�X�g���[���A�قȂ�v���Z�X�ԓ��m�̃������R�s�[��
�u�ԓI�ɂł���Ƃ��Ă��A����v���O���~���O���ē����?
��������Ȃ��Ƃ����烁�j�[�R�A�̖��́A�\�t�g�E�F�A����Ȃ���
�n�[�h���Ă��ƂɂȂ���
589 �FMAC�I�^�����다�L �����F2007/10/07(��) 10:04:30 ID:00wOqcSE
>>588
�@�@------------------
�@�@����v���O���~���O���ē����?
�@�@------------------
�A���_�[���̖@���ƌ�������E�̂��߂ɁA���x���グ��̂�������B
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
�@�@------------------
�@�@����v���O���~���O���ē����?
�@�@------------------
�A���_�[���̖@���ƌ�������E�̂��߂ɁA���x���グ��̂�������B
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%A0%E3%83%80%E3%83%BC%E3%83%AB%E3%81%AE%E6%B3%95%E5%89%87
�v�b �A���_�[���̖@�������Ă�����
���ʂ̃}�̓f�b�h���b�N��R���{�C���������Ȃ�����
���ʂ̃}�̓f�b�h���b�N��R���{�C���������Ȃ�����
��IBM�C���̑��x��300����1�Ɍ����ł���V���R���f�q���J��
http://itpro.nikkeibp.co.jp/article/USNEWS/20051104/224053/
http://itpro.nikkeibp.co.jp/article/USNEWS/20051104/224053/
593 �FMAC�I�^��590 �����F2007/10/07(��) 12:52:35 ID:00wOqcSE
>>590
����ł�A�������̉���킨�C�����邷�B
>>588 �����A���z�I�ȓ����Ԃł̘b�����]�݂̂悤�������̂ŁA����@�������������ʂ���̘b
�Ƃ������ƂŁB�B�B
����ł�A�������̉���킨�C�����邷�B
>>588 �����A���z�I�ȓ����Ԃł̘b�����]�݂̂悤�������̂ŁA����@�������������ʂ���̘b
�Ƃ������ƂŁB�B�B
������ɖ��o����Z�p�@�ڎ�
http://itpro.nikkeibp.co.jp/article/COLUMN/20070605/273706/?ST=ittrend
������ɖ��o����Z�p�i�O�ҁj
http://itpro.nikkeibp.co.jp/members/NBY/techsquare/20050412/158864/?ST=ittrend
������ɖ��o����Z�p�i��ҁj
http://itpro.nikkeibp.co.jp/members/NBY/techsquare/20050412/158865/?ST=ittrend
http://itpro.nikkeibp.co.jp/article/COLUMN/20070605/273706/?ST=ittrend
������ɖ��o����Z�p�i�O�ҁj
http://itpro.nikkeibp.co.jp/members/NBY/techsquare/20050412/158864/?ST=ittrend
������ɖ��o����Z�p�i��ҁj
http://itpro.nikkeibp.co.jp/members/NBY/techsquare/20050412/158865/?ST=ittrend
�ȏ�n�Q�ǂ��̑����ł���
�܂��A��CPU�̖{�i�I�Ȑ��i����2020�N�ȍ~���낤�Ǝv���B
CMOS�̔��������E�ɒB���Ă��A���炭�̓_�C�T�C�Y�g���3D�����ʼn������邾�낤���B
CMOS�̔��������E�ɒB���Ă��A���炭�̓_�C�T�C�Y�g���3D�����ʼn������邾�낤���B
http://pc11.2ch.net/test/read.cgi/mac/1190013206/50
> 50 ���O�F���̖��ݒ�[sage] ���e���F2007/10/08(��) 00:43:41 ID:GdLbrKvV0
> Nehalem�_�C��͂���
> http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
> 50 ���O�F���̖��ݒ�[sage] ���e���F2007/10/08(��) 00:43:41 ID:GdLbrKvV0
> Nehalem�_�C��͂���
> http://chip-architect.com/news/Nehalem_at_1st_glance_.jpg
{kind=link}
598 �F�R�E�L�́M�E,,�j�����������������F2007/10/08(��) 06:28:46 ID:wd4n7JNm
�L���b�V����������B�܂�������
�R�A���Ƀ��C����5�{�ɕ�����Ă�̂͊m���Ɉ�a�������������ꂪL2��L3�������Ƃ�
�R�A���Ƀ��C����5�{�ɕ�����Ă�̂͊m���Ɉ�a�������������ꂪL2��L3�������Ƃ�
599 �FMAC�I�^��597 �����F2007/10/08(��) 07:50:59 ID:npbht7O+
600 �FMAC�I�^���⑫�F2007/10/08(��) 08:09:02 ID:npbht7O+
Hans de Vries�����R�A�����ɉ��炩��L2->L1�Ԃ̃o�b�t�@������Ƃ����ӌ��݂������B
http://aceshardware.freeforums.org/viewtopic.php?p=2307#2307
�@�@-----------------
�@�@The greenish trapezoids did caught my attention. This area should
�@�@contain bus/cache interface stuff like read and write buffers but I
�@�@played with L1 D related options as well. The wires obscure everything
�@�@in this area.
�@�@-----------------
���̈ӌ��킱����B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/201-204
http://aceshardware.freeforums.org/viewtopic.php?p=2307#2307
�@�@-----------------
�@�@The greenish trapezoids did caught my attention. This area should
�@�@contain bus/cache interface stuff like read and write buffers but I
�@�@played with L1 D related options as well. The wires obscure everything
�@�@in this area.
�@�@-----------------
���̈ӌ��킱����B
http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/201-204
601 �FMAC�I�^���⑫2�F2007/10/08(��) 09:50:18 ID:npbht7O+
���"greenish trapezoids"�̌������ǁA���ʃ_�C�ʐ^�ŕ��s�l�ӌ`�Ɍ����镔�����Ă����̂�A
FPU���Ƃ����b�����⑫���Ă������B
FPU���Ƃ����b�����⑫���Ă������B
>>600
297 ���O�FMAC�I�^��294 ����[sage] ���e���F2007/10/06(�y) 23:43:20 ID:CLRn0sLW
>>294
�@�@---------------
�@�@��������chip-architect�͂��܂�M�p���Ė������A
�@�@---------------
Hans de Vries���̘b��AAcesHardware��RealWorldTech�̌f���ł����Γǂ߂邷���ǁA
�M���ł���l�����Ǝv�����B
297 ���O�FMAC�I�^��294 ����[sage] ���e���F2007/10/06(�y) 23:43:20 ID:CLRn0sLW
>>294
�@�@---------------
�@�@��������chip-architect�͂��܂�M�p���Ė������A
�@�@---------------
Hans de Vries���̘b��AAcesHardware��RealWorldTech�̌f���ł����Γǂ߂邷���ǁA
�M���ł���l�����Ǝv�����B
�l�ɂ͐M�p�ł���Ƃ������Ƃ��Ă��炢���s����`���ȁB
Intel�����̃_�C�v���b�g�Ɣ�r���Ă��Ⴄ�̂ɁB
chip-arcitect�͂�����ۂ������ŐM�ߐ��͂��܂����ł���B
Intel�����̃_�C�v���b�g�Ɣ�r���Ă��Ⴄ�̂ɁB
chip-arcitect�͂�����ۂ������ŐM�ߐ��͂��܂����ł���B
604 �FMAC�I�^��602-603 �����F2007/10/08(��) 13:51:40 ID:npbht7O+
>�M�Ɩ@�G�������ނ��Ȃ�����
�����MAC�I�^�̂��Ƃ���B
�匴�L���ƈ����L����\��t���Ă�Έ��S�Ƃ����B
�����MAC�I�^�̂��Ƃ���B
�匴�L���ƈ����L����\��t���Ă�Έ��S�Ƃ����B
606 �FMAC�I�^��605 �����F2007/10/08(��) 14:10:31 ID:npbht7O+
>>605
�����匴����������̈ӌ���ᔻ�������Ƃ������Ǝv���Ă��邷���H
����A��b�𗝉����Ă���q�g�Ƃ�c�_���\�����ǁASF��ϑz�ƋZ�p�̋�ʂ����Ȃ��q�g�Ƃ�
�b�ɂȂ�Ȃ��Ƃ����������B
�����匴����������̈ӌ���ᔻ�������Ƃ������Ǝv���Ă��邷���H
����A��b�𗝉����Ă���q�g�Ƃ�c�_���\�����ǁASF��ϑz�ƋZ�p�̋�ʂ����Ȃ��q�g�Ƃ�
�b�ɂȂ�Ȃ��Ƃ����������B
�匴�L���͓\��t���Ă͂����Ȃ����ނɑ�����Ǝv���̂����B
������肷���B
������肷���B
608 �FMAC�I�^��607 �����F2007/10/08(��) 15:30:12 ID:npbht7O+
>>607
�@�@------------------
�@�@�匴�L���͓\��t���Ă͂����Ȃ�����
�@�@------------------
�����Ԃ�A�����ɏW�܂��Ă��邷����A�����Ƌ��S�n���ǂ��Ǝv����(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1188093841/l50
�@�@------------------
�@�@�匴�L���͓\��t���Ă͂����Ȃ�����
�@�@------------------
�����Ԃ�A�����ɏW�܂��Ă��邷����A�����Ƌ��S�n���ǂ��Ǝv����(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1188093841/l50
609 �F ��47o/marumo �F2007/10/08(��) 16:14:19 ID:jPINgKpd
�т݂�[�Ƀ^�C�~���O���O���Ă���̂ŃX���[���悤���v�����̂����ǁB
>>520
�w�E���肪�ƁA���ƂŒ����Ƃ��B
>>522
SSSE3 �͂���Ȃ�ɕ]�����Ă���B�g�����������Ƃ����Ă�̂� SSE3 �̕��B
����n���ƕ��������_���g�����Ƃ��Ȃ��̂ŁASSE3 �Ŏg����̂� LDDQU ����
�ɂȂ���ǁAPentium 4 �ȊO�ł� MOVDQU �̃G�C���A�X�ɂȂ��Ă邩��
�g���Ă��Ӗ����Ȃ��̂�B
>>525
���́[�uSSE4.2 �ɂ̓G���R�[�h���I�ɐS�䂩��閽�߂��Ȃ��v�Ə����Ă�
�u�I���`�b�v�������R���g���[���Ƃ� HT �����Ƃ����ʂ� PC ���[�U�I�ɂ�
�ʔ����l�^�Ȃ�[���ǁA�\�t�g���I�ɂ͓��Ɉӎ�����悤�Ȃ��Ƃ���Ȃ��v
�ƕʂ̂��Ƃ������Ă���B
�ECRC32 �� POPCNT �╶�����r�̎g�������G���R�[�h���ɂ͂Ȃ��B
�@(����� 525�ł����ӂ��Ƃ�Ă�Ɖ���)
�E�������R���g���[���̈ʒu��HT�̗L�����\�t�g�����ӎ����Ȃ���R�[�h
�@�����K�v�͖����B(������Ɋւ��Ă͓��ӂƂ�Ă邩����)
�Ə����Ă邾�������H ����Ȃ��݂��悤�ȓ��e���H
Penryn �͑Ή��R�[�h�������Đ��\�̕ω����m�F����K�v�����邯�ǁA
Nehalem �͂��̕K�v���Ȃ� (�̂Ŏ�����낤�Ƃ͎v��Ȃ�) ���[������
���ƂŁANehalem ���� Penryn ���D��Ă���Ƃ���������͂Ȃ����B
>>520
�w�E���肪�ƁA���ƂŒ����Ƃ��B
>>522
SSSE3 �͂���Ȃ�ɕ]�����Ă���B�g�����������Ƃ����Ă�̂� SSE3 �̕��B
����n���ƕ��������_���g�����Ƃ��Ȃ��̂ŁASSE3 �Ŏg����̂� LDDQU ����
�ɂȂ���ǁAPentium 4 �ȊO�ł� MOVDQU �̃G�C���A�X�ɂȂ��Ă邩��
�g���Ă��Ӗ����Ȃ��̂�B
>>525
���́[�uSSE4.2 �ɂ̓G���R�[�h���I�ɐS�䂩��閽�߂��Ȃ��v�Ə����Ă�
�u�I���`�b�v�������R���g���[���Ƃ� HT �����Ƃ����ʂ� PC ���[�U�I�ɂ�
�ʔ����l�^�Ȃ�[���ǁA�\�t�g���I�ɂ͓��Ɉӎ�����悤�Ȃ��Ƃ���Ȃ��v
�ƕʂ̂��Ƃ������Ă���B
�ECRC32 �� POPCNT �╶�����r�̎g�������G���R�[�h���ɂ͂Ȃ��B
�@(����� 525�ł����ӂ��Ƃ�Ă�Ɖ���)
�E�������R���g���[���̈ʒu��HT�̗L�����\�t�g�����ӎ����Ȃ���R�[�h
�@�����K�v�͖����B(������Ɋւ��Ă͓��ӂƂ�Ă邩����)
�Ə����Ă邾�������H ����Ȃ��݂��悤�ȓ��e���H
Penryn �͑Ή��R�[�h�������Đ��\�̕ω����m�F����K�v�����邯�ǁA
Nehalem �͂��̕K�v���Ȃ� (�̂Ŏ�����낤�Ƃ͎v��Ȃ�) ���[������
���ƂŁANehalem ���� Penryn ���D��Ă���Ƃ���������͂Ȃ����B
�ł��Acache�\���▽�߃��C�e���V���S�R������Ă��肵�āB
�����т̎���͏I������B
���܂�������H��������C���߂Ă����H�ނ����ł��p�ӂ���B
���܂�������H��������C���߂Ă����H�ނ����ł��p�ӂ���B
Cell�͂��̐��܂���ׂ����낤�ȁB�������ׂ��y�U���ԈႦ���̂�����B
���߂���iPod�p�ɊJ�����Ă�����听�����Ă����̂ɁB
���߂���iPod�p�ɊJ�����Ă�����听�����Ă����̂ɁB
970����Ȃ���750VX��������ǂ�����
?
>>612
�A�t�H�ł����H
�A�t�H�ł����H
���肷��Ȃ�
http://journal.mycom.co.jp/articles/2007/10/10/idf01/index.html
�匴����IDF���|�[�g�̐V�����̂������B
���XIDF�Ō��J���ꂽ����Ȃ��̂Ő��������������̂͂��傤���Ȃ����A
�匴�����_�C�̉���SRAM������L3�ƌ��Ă�͗l�B
Nehalem�ŏ���8�R�A�͓����_�C����ׂ�QPI2�����N�Őڑ��ł͂Ɨ\�z���Ă���B
���̒ʂ�Ȃ�A�p�b�P�[�W�̋Z�p���m�������A32nm����ł̓l�C�e�B�u8�R�A�AMCM��16�R�A�ƂȂ肻�����B
�匴����IDF���|�[�g�̐V�����̂������B
���XIDF�Ō��J���ꂽ����Ȃ��̂Ő��������������̂͂��傤���Ȃ����A
�匴�����_�C�̉���SRAM������L3�ƌ��Ă�͗l�B
Nehalem�ŏ���8�R�A�͓����_�C����ׂ�QPI2�����N�Őڑ��ł͂Ɨ\�z���Ă���B
���̒ʂ�Ȃ�A�p�b�P�[�W�̋Z�p���m�������A32nm����ł̓l�C�e�B�u8�R�A�AMCM��16�R�A�ƂȂ肻�����B
���o��������Ȃ������ǁA�N����1600MHz FSB���f����Harpertown/Wolfdale���o�邷�ˁB
http://www.vr-zone.com/articles/New_Harpertown_Model_%26_Pricing_Updated/5300.html
��FSB 1600MHz Xeon
�@- Quad-Core (Harpertown)
�@X5472/3.0GHz, TDP: 120W, $958, Nov. 2007
�@E5472/3.0GHz, TDP: 80W, $1022, Nov. 2007
�@E5462/2.8GHz, TDP: 80W, $797, Nov. 2007
�@- Dual-Core (Wolfdale)
�@X5272/2.4GHz, TDP: 80W, $1172, Nov. 2007
http://www.vr-zone.com/articles/New_Harpertown_Model_%26_Pricing_Updated/5300.html
��FSB 1600MHz Xeon
�@- Quad-Core (Harpertown)
�@X5472/3.0GHz, TDP: 120W, $958, Nov. 2007
�@E5472/3.0GHz, TDP: 80W, $1022, Nov. 2007
�@E5462/2.8GHz, TDP: 80W, $797, Nov. 2007
�@- Dual-Core (Wolfdale)
�@X5272/2.4GHz, TDP: 80W, $1172, Nov. 2007
619 �FMAC�I�^�������F2007/10/10(��) 19:32:21 ID:KeJwjuRb
X5272�̓���N���b�N�ԈႦ�����B
�@�@X5272/3.4GHz, TDP: 80W, $1172, Nov. 2007
�@�@X5272/3.4GHz, TDP: 80W, $1172, Nov. 2007
Wolfdale�܂���3.4�f�����̂s�c�o80�v?
���\����Ȃ���
�܁A�I�@���C�͂Ȃ�����
���\����Ȃ���
�܁A�I�@���C�͂Ȃ�����
C2D��3.4GHz���҂��������ȁB
>>620
3.4GHz�Ȃ�65W�����R���Ǝv������
3.4GHz�Ȃ�65W�����R���Ǝv������
X6800(3.00GHz)�c75��
E6850(3.00GHz)�c65��
E8500(3.16GHz)�c65��
�@
�Ó�������Ó��Ȑ��������ǁA3.4GHz��80������Penryn�����4GHz�͌��������c(�L��֥`)
E6850(3.00GHz)�c65��
E8500(3.16GHz)�c65��
�@
�Ó�������Ó��Ȑ��������ǁA3.4GHz��80������Penryn�����4GHz�͌��������c(�L��֥`)
>>623
E6850��65W�ɂȂ����悤�ɁA���ǂ͍s���邾�낤
Penryn 3.06GHz/1066MHz��4�R�A��TDP45W�炵������A3.06GHz/25W�͂����邩������Ȃ�
�f�X�N�g�b�v�͓d�����������낤���ǁA3GHz�Ŏ���45W���x�͂������Ȃ���
E6850��65W�ɂȂ����悤�ɁA���ǂ͍s���邾�낤
Penryn 3.06GHz/1066MHz��4�R�A��TDP45W�炵������A3.06GHz/25W�͂����邩������Ȃ�
�f�X�N�g�b�v�͓d�����������낤���ǁA3GHz�Ŏ���45W���x�͂������Ȃ���
���Ă�����4�R�A3GHz��80w������Ȃ�2�R�A3.4GHz��80w�͖��炩�Ƀn�Y���i�g���Ă邾��E�E�E
�n�Y���i��15���~�̒l�D�t�����Ⴄ�ӂ肪Intel�̗]�T��@���Ɍ����Ă�ȁ`
�f���A���R�A��Barcelona���x��܂����Ă邩�炵�傤���Ȃ����ǂ�
�n�Y���i��15���~�̒l�D�t�����Ⴄ�ӂ肪Intel�̗]�T��@���Ɍ����Ă�ȁ`
�f���A���R�A��Barcelona���x��܂����Ă邩�炵�傤���Ȃ����ǂ�
4GHz�I�[�o�[�͂����������B
TDP�̃����W��1�����邾���ŁA���ۂ̏���d�͂͌̂ɂ���č����o�Ă��邾��B
TDP���ǂ��܂Ō����Ɏg���Ă�̂��m��Ȃ����A�C�[���h�ɂ��e�����Ă��邾�낤���B
TDP���ǂ��܂Ō����Ɏg���Ă�̂��m��Ȃ����A�C�[���h�ɂ��e�����Ă��邾�낤���B
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
���͂̕��͓��ɂ������낢�̂͂Ȃ��AGPU�ɂ��ẮA����EU�̌����{�����āA�N���b�N��1.5�`2�{�ɂȂ�Ȃ�A
3DMark06�ɂ��ẮAHD2400��8400GS���炢�̐��\�ɂȂ肻���ŁA
IDF�ł�45nm�̓���GPU���ƒ�p�Q�[���R���\�[�����ɂȂ���Ă̂ɍ����������Ȃ��Ă��炢�B
�ނ���ACore MA��Nehalem�̃X�P�[���r���e�B�̐}�ɂ���MPSever������1�_�C6�R�A�̃R�A�͈�̂Ȃ낤w
1�_�C4�R�A�ł��V���Ȃ̂�6�R�A����w
���͂̕��͓��ɂ������낢�̂͂Ȃ��AGPU�ɂ��ẮA����EU�̌����{�����āA�N���b�N��1.5�`2�{�ɂȂ�Ȃ�A
3DMark06�ɂ��ẮAHD2400��8400GS���炢�̐��\�ɂȂ肻���ŁA
IDF�ł�45nm�̓���GPU���ƒ�p�Q�[���R���\�[�����ɂȂ���Ă̂ɍ����������Ȃ��Ă��炢�B
�ނ���ACore MA��Nehalem�̃X�P�[���r���e�B�̐}�ɂ���MPSever������1�_�C6�R�A�̃R�A�͈�̂Ȃ낤w
1�_�C4�R�A�ł��V���Ȃ̂�6�R�A����w
�㓡�������������ް�̏��o�Ă��������肩�狻�����Ė\���C��������
�b�����Ɍ�������������
�b�����Ɍ�������������
GPGPU�I��
>>630
���ް�̺����̫��ݽ���ǂꂮ�炢���o�Ȃ����Ƃɂ͉��Ƃ������Ȃ�
���ް�̺����̫��ݽ���ǂꂮ�炢���o�Ȃ����Ƃɂ͉��Ƃ������Ȃ�
GPGPU�Ή��̃\�t�g���łȂ���ᐫ�\�͂ǂ������Ă�Larrabee�̈�l�����ł���
Intel�������Ă�̂͂����������Ƃ�
Intel�������Ă�̂͂����������Ƃ�
�����Larrabee���ꏏ
Larrabee����x86�Ȃ̂��H
����͒ɂ��c
������ǂ������
Larrabee�y������̂��ƁE�E�E
Larrabee�y������̂��ƁE�E�E
(�L��`) ��CPU�~�������������ް�ꏏ�ɔ����ĂˁA�łȂ��Ɣ���Ȃ���B
(�L��`) �����߾�ė~�������������ް�ꏏ�ɔ����ĂˁA�łȂ��Ɣ���Ȃ���B
(�L��`) �����ް�~�������������ް����������ĂˁA�ł��i����
(�L��`) �����߾�ė~�������������ް�ꏏ�ɔ����ĂˁA�łȂ��Ɣ���Ȃ���B
(�L��`) �����ް�~�������������ް����������ĂˁA�ł��i����
�S���͈ꌩ��
http://kjm.kir.jp/pc/?p=44138.jpg
http://kjm.kir.jp/pc/?p=44138.jpg
{kind=link}
���с[�̓C���X�g���N�V�����Z�b�g��x86�ƌ݊����Ă����b�炵���B
>>640
CPU���S�ɒu������������Ă邯�ǁA�s�\�ł͂Ȃ��낤���A���N��̘b���낤���B�B�B
CPU���S�ɒu������������Ă邯�ǁA�s�\�ł͂Ȃ��낤���A���N��̘b���낤���B�B�B
Larrabee��Nehalem�������̂����Ȃ��āAHPC�����ɂ�Larrabee���g���Ă���Ƃ������Ƃ���B
Larrabee�̓A�N�Z�����[�^�J�[�h�Ƃ��ďo����Ęb�����邵�A�f�X�N�g�b�v���Ƃ̈�ʓI��
�I�Ƃ��ɂ͊W�Ȃ����낤�B
Intel�Ƃ��Ă͏����I�ɂ́A�]���^�̑傫�߂̃R�A��Larrabee�̃R�A�̂悤�ȓ����^�̏��^�R�A�Ƃ�
���킹�����j�[�R�A�֍s�������낤���ǂˁB
Larrabee�̓A�N�Z�����[�^�J�[�h�Ƃ��ďo����Ęb�����邵�A�f�X�N�g�b�v���Ƃ̈�ʓI��
�I�Ƃ��ɂ͊W�Ȃ����낤�B
Intel�Ƃ��Ă͏����I�ɂ́A�]���^�̑傫�߂̃R�A��Larrabee�̃R�A�̂悤�ȓ����^�̏��^�R�A�Ƃ�
���킹�����j�[�R�A�֍s�������낤���ǂˁB
>�f�X�N�g�b�v���Ƃ̈�ʓI�ȎI�Ƃ��ɂ͊W�Ȃ�
Intel Revolutionizes Gaming With Real-Time RayTracing
http://www.dailytech.com/article.aspx?newsid=9005
If his engine succeeds, it has the potential to shatter a 10+ year tradition of rendering monotony by ditching the old--rasterization--for the new--ray-tracing.
Intel Revolutionizes Gaming With Real-Time RayTracing
http://www.dailytech.com/article.aspx?newsid=9005
If his engine succeeds, it has the potential to shatter a 10+ year tradition of rendering monotony by ditching the old--rasterization--for the new--ray-tracing.
�A�N�Z�����[�^���B���[��BPhsyX�Ƃ��쒀�����Ⴄ�낤���B
�g�`�������摜�����������ɂ��C���I���Ă��ƂɂȂ����炿����Ƃ������ˁB
�g�`�������摜�����������ɂ��C���I���Ă��ƂɂȂ����炿����Ƃ������ˁB
�Q�[���̂��Ƃ͖Y��Ă��B�m���ɁA�f�X�N�g�b�v�ɂ�������x�W����ȁB
�f�X�N�g�b�v�ł��ŏ����痘�p����邱�Ƃ�O��Ƃ���Ȃ�ALarrabee�͌��\�����o��̂��낤���B
�f�X�N�g�b�v�ł��ŏ����痘�p����邱�Ƃ�O��Ƃ���Ȃ�ALarrabee�͌��\�����o��̂��낤���B
������GPU�������̂���Ƃ͓���v�����B
DirectX���g�p����Ȃ�p�t�H�[�}���X�I�Ɋ��҂ł���
DirectX���g�p���Ȃ��Ȃ�\�t�g���[�J�[����̓Ǝ�API�̃T�|�[�g�����҂ł��Ȃ��B
DirectX���g�p����Ȃ�p�t�H�[�}���X�I�Ɋ��҂ł���
DirectX���g�p���Ȃ��Ȃ�\�t�g���[�J�[����̓Ǝ�API�̃T�|�[�g�����҂ł��Ȃ��B
Larrabee��GPU��ւ�Intel���g���l���ĂȂ����낤�B
��ւ���Ƃ��Ă��A���ꂱ���Ƃ��Ȃ�悩�ƁB
��������Havok�����������A�����G���W���Ƃ�����Ȃ����낤���B
�f�X�N�g�b�v�ɊW����Ƃ��āA�ꕔ�̃��[�U�[��������Ȃ����ƁB
���C����HPC���Ǝv���邵�B
��ւ���Ƃ��Ă��A���ꂱ���Ƃ��Ȃ�悩�ƁB
��������Havok�����������A�����G���W���Ƃ�����Ȃ����낤���B
�f�X�N�g�b�v�ɊW����Ƃ��āA�ꕔ�̃��[�U�[��������Ȃ����ƁB
���C����HPC���Ǝv���邵�B
>>647
������Ə����B
���с[�̘H���Ȃ�AGPU�̃}�l�S�g��FPU���₹�ΓK���Ȑ��\�͏o�����Ȋ������ȁ[�B����ɔėp���Ŕ����Ă���B
�P�_�C�ɂǂꂾ���l�߂�邩�͒m��Ȃ����B
����GPU���x�N�g���v���Z�b�T���ۂ����̂����A�ǂ����ŃN���X���邩���B�����B
������Ə����B
���с[�̘H���Ȃ�AGPU�̃}�l�S�g��FPU���₹�ΓK���Ȑ��\�͏o�����Ȋ������ȁ[�B����ɔėp���Ŕ����Ă���B
�P�_�C�ɂǂꂾ���l�߂�邩�͒m��Ȃ����B
����GPU���x�N�g���v���Z�b�T���ۂ����̂����A�ǂ����ŃN���X���邩���B�����B
Larrabee�̖����͕������Z�ւ̓����ł���GPU�Ƃ��Ă͒ᑬ�Ή�
�p�r
1)�Q�[�}�ւ�(CPU+Larrabee����)+�����\GPU�ɂĕ������Z�@�\��������n�C�X�y�b�N�Q�[��PC
2)CPU+Larrabee�ɂ�HPC����
����Ȋ�������Ȃ�����?
AMD�̍\�z�ƑS���Ⴄ�̂�Larrabee��MIMD�ł���AMD�̂�SIMD�ł���_
AMD�̍\�z���ƑΉ��\�t�g�͖w�ǔ�������Ȃ��\�����傫�����s�����Intel�͍l���AAMD�͏����̑Ή��\�t�g�ŃC���p�N�g�_��?
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
�p�r
1)�Q�[�}�ւ�(CPU+Larrabee����)+�����\GPU�ɂĕ������Z�@�\��������n�C�X�y�b�N�Q�[��PC
2)CPU+Larrabee�ɂ�HPC����
����Ȋ�������Ȃ�����?
AMD�̍\�z�ƑS���Ⴄ�̂�Larrabee��MIMD�ł���AMD�̂�SIMD�ł���_
AMD�̍\�z���ƑΉ��\�t�g�͖w�ǔ�������Ȃ��\�����傫�����s�����Intel�͍l���AAMD�͏����̑Ή��\�t�g�ŃC���p�N�g�_��?
http://pc.watch.impress.co.jp/docs/2007/1011/kaigai392.htm
�����A���PhysX�}���ɂ��������B�g�b�v�_�E�����Ċ����ɂȂ�ȁB
AMD�́A�\�z���͈̂����Ȃ����ǁAXML�����u�[�X�g���Ă����͊�Ȃ��ȁB�I������Ȃ����B
AMD�́A�\�z���͈̂����Ȃ����ǁAXML�����u�[�X�g���Ă����͊�Ȃ��ȁB�I������Ȃ����B
���Ƃ��Ă�Larrabee�̕������ǂ��Ǝv���Ă�B
�僁�����̑������炵�Ă�MIMDk���������������낤�ȁA
�ǂ�ȂɊ撣���Ă�SIMD�n���Ǝ僁�����̑��������ނ��獂���\GPU�ɕC�G������̂͌��ƍ��Ȃ����E�E�E
�僁�����̑������炵�Ă�MIMDk���������������낤�ȁA
�ǂ�ȂɊ撣���Ă�SIMD�n���Ǝ僁�����̑��������ނ��獂���\GPU�ɕC�G������̂͌��ƍ��Ȃ����E�E�E
�܁[�����_�� top500 �Ƃ����Ă��A�N���X�^������������Ȃ����ˁB
MIMD���Ĉ�̃f�[�^��������̂ɂ������ߔ��s���邱�Ƃ��Ƃ������Ă��B
�悭�l�����炻�����MISD���ȁB���l���Ă���B�B�B
�������с[�̃A�v���[�`�͂����Ǝv���B
�����A�r������lj����邩�ƌ����Ƃ�����Ɣ����B�����I�ɐ旧���̂��Ȃ��B��
������A�o���I�ƏՌ��̂�����̂����҂������ˁB�R���ɂނ��炢���B
�悭�l�����炻�����MISD���ȁB���l���Ă���B�B�B
�������с[�̃A�v���[�`�͂����Ǝv���B
�����A�r������lj����邩�ƌ����Ƃ�����Ɣ����B�����I�ɐ旧���̂��Ȃ��B��
������A�o���I�ƏՌ��̂�����̂����҂������ˁB�R���ɂނ��炢���B
�s��I�Ɍ����ꍇ
Intel(MIMD�n)����GPU�Ƃ̋��������ł���AAMD(SIMD)���ƑΗ�����
AMD(SIMD)�̕�����GPU�V�F�A�̑傫�����N���X��GPU���������ނ��ƂɂȂ邩��E�E�E
Intel(MIMD�n)����GPU�Ƃ̋��������ł���AAMD(SIMD)���ƑΗ�����
AMD(SIMD)�̕�����GPU�V�F�A�̑傫�����N���X��GPU���������ނ��ƂɂȂ邩��E�E�E
>>647
>������GPU�������̂���Ƃ͓���v�����B
>>644���
���A���^�C�����C�g���[�V���O�͍������Z���\��K�v�Ƃ���B
���A���^�C�����C�g���[�V���O�̓��X�^���C�[�[�V���������Ƃ���\������ɂ��Ȃ��B
���A���^�C�����C�g���[�V���O�̓^�X�N�̕������e�ՂłقڃR�A���ɔ�Ⴕ�Đ��\���L�т�B
Intel�̐��i���郊�A���^�C�����C�g���[�V���O�̓��X�^���C�[�[�V�������n�[�h�E�F�A�Ŏ��������]����GPU��u��������\��������B
>������GPU�������̂���Ƃ͓���v�����B
>>644���
���A���^�C�����C�g���[�V���O�͍������Z���\��K�v�Ƃ���B
���A���^�C�����C�g���[�V���O�̓��X�^���C�[�[�V���������Ƃ���\������ɂ��Ȃ��B
���A���^�C�����C�g���[�V���O�̓^�X�N�̕������e�ՂłقڃR�A���ɔ�Ⴕ�Đ��\���L�т�B
Intel�̐��i���郊�A���^�C�����C�g���[�V���O�̓��X�^���C�[�[�V�������n�[�h�E�F�A�Ŏ��������]����GPU��u��������\��������B
>>655
ATI�H�����̂͂悩�����̂��A���������̂��B���\�[�X���镪��������������Ȃ��B
����͂������B
>>656
�A�ʏ������K�v�Ȃ�����˂��B���C�L���X�g���āA���˂��ăJ�����ɓ��������C��\�����邾��������B
�Ƃ�����A�����I�Ƀf�B�X�v���C�̋@�\���̂ɉe�����邩���ˁB
GPU���ISPU���IPPU���I�쒀�I�I�Ȃ�ĂˁB
����ˁI
ATI�H�����̂͂悩�����̂��A���������̂��B���\�[�X���镪��������������Ȃ��B
����͂������B
>>656
�A�ʏ������K�v�Ȃ�����˂��B���C�L���X�g���āA���˂��ăJ�����ɓ��������C��\�����邾��������B
�Ƃ�����A�����I�Ƀf�B�X�v���C�̋@�\���̂ɉe�����邩���ˁB
GPU���ISPU���IPPU���I�쒀�I�I�Ȃ�ĂˁB
����ˁI
HPC�s��́A���Ȃ��Ƃ�������5�N��
GPGPU��Larrabee�n�͈����A�j�b�`�ł���Â���ƒf�����悤�B
Larrabee��������\��������̂̓����_�����OWS�A���C�g���[�V���O�B
�ł����A���^�C�����C�g���Q�[�����y���߂�Ƃ����ϑz�͕������Ⴞ�߁B
http://www.hc.ic.i.u-tokyo.ac.jp/~kaki/SIGGRAPH2002/Panel_RT_vs_RAS.html
GPGPU��Larrabee�n�͈����A�j�b�`�ł���Â���ƒf�����悤�B
Larrabee��������\��������̂̓����_�����OWS�A���C�g���[�V���O�B
�ł����A���^�C�����C�g���Q�[�����y���߂�Ƃ����ϑz�͕������Ⴞ�߁B
http://www.hc.ic.i.u-tokyo.ac.jp/~kaki/SIGGRAPH2002/Panel_RT_vs_RAS.html
2002�N�Ƃ������j�[�R�A�̃��̎����o�Ă��ĂȂ������C������
�X���[�v�b�g�R���s���[�e�B���O�̃X�̎����o�Ă��ĂȂ������C������
���N���b�N�u����Presscott��Tejas�����݂������C������
�X���[�v�b�g�R���s���[�e�B���O�̃X�̎����o�Ă��ĂȂ������C������
���N���b�N�u����Presscott��Tejas�����݂������C������
�����A���C�g���[�V���O���č��̕S�{�����Ȃ��Ă�
���A���^�C���ɂ͏[������Ȃ���ˁE�E�E�E
���A���^�C���ɂ͏[������Ȃ���ˁE�E�E�E
���ɂ���DirectX�B
MS�i�a�l�j�����������Ƃ���Ηǂ����E�E
>>658�����ǂݕ�thx
>CPU�͍���������Ȃ邾�낤���AGPU������������ȏ�̃y�[�X�ő����Ȃ�v
>�i������ACPU�ł̃��C�g���[�V���O�����X�^������u�������邱�Ƃ͂Ȃ��j
GPU�łȂ炢���Ȃ̂����B
>Q�F�@GPU�Ń��C�g���[�V���O���ł���̂�CPU�ɂ������̂͂ǂ����Ă��H
>Philipp Slusallek�F�@���C�g���[�V���O������n�[�h�E�F�A�́ACPU�ł�GPU�ł��\��Ȃ��B
>�@�@�@�@�@�@�@�@�@�@�@�@�@�i���̉ŁA�قڍ���̃p�l���̌��_�����܂��Ă��܂����悤�Ɋ������j
�ǂ��悤���B
�����I��DX9���o���Ƃ����B
MS�i�a�l�j�����������Ƃ���Ηǂ����E�E
>>658�����ǂݕ�thx
>CPU�͍���������Ȃ邾�낤���AGPU������������ȏ�̃y�[�X�ő����Ȃ�v
>�i������ACPU�ł̃��C�g���[�V���O�����X�^������u�������邱�Ƃ͂Ȃ��j
GPU�łȂ炢���Ȃ̂����B
>Q�F�@GPU�Ń��C�g���[�V���O���ł���̂�CPU�ɂ������̂͂ǂ����Ă��H
>Philipp Slusallek�F�@���C�g���[�V���O������n�[�h�E�F�A�́ACPU�ł�GPU�ł��\��Ȃ��B
>�@�@�@�@�@�@�@�@�@�@�@�@�@�i���̉ŁA�قڍ���̃p�l���̌��_�����܂��Ă��܂����悤�Ɋ������j
�ǂ��悤���B
�����I��DX9���o���Ƃ����B
���߂̎d�����Ėʔ����Ȃ��B
>>660
>Now Daniel Pohl has shown that with modern quad-core gaming machines, high performance ray-traced graphics is achievable at acceptable frame rates.
>>661
>�@����N�Ƃ��āA�X�g���[�~���O�����i���݂̃��X�^�����n�[�h�̏����`�ԁj�����C�g���[�V���O�Ƀx�X�g�Ȃ̂��ǂ����A�Ƃ����_��������ꂽ�B
����͗]�k������Larrabee�̃u���b�N�_�C�A�O�����ɂ�Texture Sampler�Ȃ���̂�������
���ǂǂ���ɍœK�����ꂽ�p�C�v���C�����H�Ƃ������Ƃ���
>Now Daniel Pohl has shown that with modern quad-core gaming machines, high performance ray-traced graphics is achievable at acceptable frame rates.
>>661
>�@����N�Ƃ��āA�X�g���[�~���O�����i���݂̃��X�^�����n�[�h�̏����`�ԁj�����C�g���[�V���O�Ƀx�X�g�Ȃ̂��ǂ����A�Ƃ����_��������ꂽ�B
����͗]�k������Larrabee�̃u���b�N�_�C�A�O�����ɂ�Texture Sampler�Ȃ���̂�������
���ǂǂ���ɍœK�����ꂽ�p�C�v���C�����H�Ƃ������Ƃ���
�\�t�g�V���h�E�Ƃ��ǂ������B
���U���C�g���[�V���O�ł�����̂��H
���U���C�g���[�V���O�ł�����̂��H
AMD�̌v��́u�������ł�GPU�����Z�Ɏg���Ă���v�ł͂Ȃ��āA
�u���Z�ɂ��g�����v���Ē��x�̔��z����Ȃ��̂��Ƌ^���Ă�B
���ǎg������Larrabee�Ƒ債�č����Ȃ��\���B
�d�͂�Q��镪�g�����͏��Ȃ��������c�B
�u���Z�ɂ��g�����v���Ē��x�̔��z����Ȃ��̂��Ƌ^���Ă�B
���ǎg������Larrabee�Ƒ債�č����Ȃ��\���B
�d�͂�Q��镪�g�����͏��Ȃ��������c�B
Larrabee�́u���Z�Ɏg���Ă���AGPU�Ƃ��Ă��g���邩����H�v������S�R�Ⴄ�B
�X�p�R������HPC�N���X�^�A�I�[�v�����̗���̒��ŁA
�V�X�e�����i������x86�T�[�o�[�̃N���X�^�V�X�e�����}�L���Ă����B
�����Ă��̗��ꂪ����������B������Larrabee��x86��I�B
����������̓��C���X�g���[����x86�v���Z�b�T�Ɛ키���Ƃ��Ӗ�����B
Merom�ANehalem�ASandy Bridge�E�E�E�E�AK8�AK10�AK11�E�E�E�E
�c��ȊJ�����\�[�X�𒍂����݁A�ő�̗ʎY���ʂ邱���Ɛ킦��̂��낤���H
�V�X�e�����i������x86�T�[�o�[�̃N���X�^�V�X�e�����}�L���Ă����B
�����Ă��̗��ꂪ����������B������Larrabee��x86��I�B
����������̓��C���X�g���[����x86�v���Z�b�T�Ɛ키���Ƃ��Ӗ�����B
Merom�ANehalem�ASandy Bridge�E�E�E�E�AK8�AK10�AK11�E�E�E�E
�c��ȊJ�����\�[�X�𒍂����݁A�ő�̗ʎY���ʂ邱���Ɛ킦��̂��낤���H
����
���̂�PowerPC 4x0
670 �FMAC�I�^ [sage] �F2007/06/26(��) 22:25:47 ID:E+b+TZBO
Blue Gene/P�̃v���X�����[�X���B
http://www-03.ibm.com/press/us/en/pressrelease/21791.wss
�@�@---------------------
�@�@Four IBM (850 MHz) PowerPC 450 processors are integrated on a single Blue Gene/P
�@�@chip. Each chip is capable of 13.6 billion operations per second.
�@�@---------------------
�@�EPPC450: Quad 850MHz PPC440 core with "Double Hummer" FP-APU
�@�E1 petaflops at 294,912-processor
�@�Eup to 884,736-processor
�@�Eoptical rack-to-rack interconnect
671 �FMAC�I�^���⑫ [sage] �F2007/06/26(��) 22:35:03 ID:E+b+TZBO
�Ƃ肠����884,736-processor�̍ő�\����2-PetaFlops�풴���邷�B����PPC44x�x�[�X��
�R�A��90nm�o���NCMOS��2GHz���邱�Ƃ��\�Ȃ��Ƃ��ؖ�����Ă��邷����(>>392�Q��)�A
Blue Gene��A���̂܂܂̐v�ł����N�ȓ���5-PetaFlops���郍�[�h�}�b�v�팻���I���B
���̂�PowerPC 4x0
670 �FMAC�I�^ [sage] �F2007/06/26(��) 22:25:47 ID:E+b+TZBO
Blue Gene/P�̃v���X�����[�X���B
http://www-03.ibm.com/press/us/en/pressrelease/21791.wss
�@�@---------------------
�@�@Four IBM (850 MHz) PowerPC 450 processors are integrated on a single Blue Gene/P
�@�@chip. Each chip is capable of 13.6 billion operations per second.
�@�@---------------------
�@�EPPC450: Quad 850MHz PPC440 core with "Double Hummer" FP-APU
�@�E1 petaflops at 294,912-processor
�@�Eup to 884,736-processor
�@�Eoptical rack-to-rack interconnect
671 �FMAC�I�^���⑫ [sage] �F2007/06/26(��) 22:35:03 ID:E+b+TZBO
�Ƃ肠����884,736-processor�̍ő�\����2-PetaFlops�풴���邷�B����PPC44x�x�[�X��
�R�A��90nm�o���NCMOS��2GHz���邱�Ƃ��\�Ȃ��Ƃ��ؖ�����Ă��邷����(>>392�Q��)�A
Blue Gene��A���̂܂܂̐v�ł����N�ȓ���5-PetaFlops���郍�[�h�}�b�v�팻���I���B
>>665
AMD�̍l�����́A���͖������d�����Ă�l�Ȃ��̂�Z�߂āA�������j�b�g��
���s���Ă��܂��݂����Ȋ����ł́H
FPU��SSE��GPU���j�b�g�Řd���A�݂����ȁB
AMD�̍l�����́A���͖������d�����Ă�l�Ȃ��̂�Z�߂āA�������j�b�g��
���s���Ă��܂��݂����Ȋ����ł́H
FPU��SSE��GPU���j�b�g�Řd���A�݂����ȁB
IBM�͌��X�n�C�G���h�����G����Ȃ��B
Larrabee�Ɠ�������Westmere MCM16�R�A���o����[�̂�����܂�
MIMD��Larrabee��SIMD��GPU�̐킢
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
����Ⴀ�����͉�����
Larrabee�̐��ۂ́A�C���e���̔�������悾�ȁB
Nehahlem�ŁA�T�v���C�Y��Larrabee�̃R�A���Z�������ɂ��P�R�A�ڂ�����Ȃ�A���y�i�\�t�g���������ĈӖ�����Ȃ����j�͂���B
���A���y����Larrabee��Unified Shader�ɖ��m�ɕ����Ă������A���US�p�\�t�g�����y����m�����A����͍����B
��������ALarrabee��US�Ɋ��S�ɒu������鎖�͂Ȃ����낤�BUS�p�ɍ�����\�t�g���A�ȒP�Ƀx���_���̂Ă�Ƃ͎v���Ȃ��B
�����AUS�p�\�t�g����ɏo������ALarrabee��US�Ƌ������铹��͍����邵���Ȃ��Ȃ�Ǝv���B
Nehahlem�ŁA�T�v���C�Y��Larrabee�̃R�A���Z�������ɂ��P�R�A�ڂ�����Ȃ�A���y�i�\�t�g���������ĈӖ�����Ȃ����j�͂���B
���A���y����Larrabee��Unified Shader�ɖ��m�ɕ����Ă������A���US�p�\�t�g�����y����m�����A����͍����B
��������ALarrabee��US�Ɋ��S�ɒu������鎖�͂Ȃ����낤�BUS�p�ɍ�����\�t�g���A�ȒP�Ƀx���_���̂Ă�Ƃ͎v���Ȃ��B
�����AUS�p�\�t�g����ɏo������ALarrabee��US�Ƌ������铹��͍����邵���Ȃ��Ȃ�Ǝv���B
�ށ[���̕ӘR��̈ӌ��͂����ƈႤ�B
Unified Shader �����R�[�h (���x�I�ɗL�ӂ�) ��������l�ԂȂ�
Larrabee �����R�[�h�������̂͂���Ȃɋ�ɂ��Ȃ��B
�Ȃ̂ŁA�s�[�N���x�� 2 �{�Ƃ��A�v�Z��/����d�͂Ŕ����Ƃ���
�����b�g������Δނ�� Larrabee �����R�[�h���������낤�B
���� Larrabee �̃A�[�L�e�N�`�� (x86 �݊�) �I�ɏ�L���\��
�B���͖������ۂ����[�Ƃ��Ȃ��ǂˁB
Unified Shader �����R�[�h (���x�I�ɗL�ӂ�) ��������l�ԂȂ�
Larrabee �����R�[�h�������̂͂���Ȃɋ�ɂ��Ȃ��B
�Ȃ̂ŁA�s�[�N���x�� 2 �{�Ƃ��A�v�Z��/����d�͂Ŕ����Ƃ���
�����b�g������Δނ�� Larrabee �����R�[�h���������낤�B
���� Larrabee �̃A�[�L�e�N�`�� (x86 �݊�) �I�ɏ�L���\��
�B���͖������ۂ����[�Ƃ��Ȃ��ǂˁB
�ǂ���GPGPU�p�̃A�v���Ȃ�ĂقƂ�Ǐo�Ȃ�����W�Ȃ���
�ǂ���Larrabee���̕��y���Ȃ�����W�Ȃ���
GPGPU�͊J�����Ǝ��s�����o���o���Ȃ̂��ɂ��ȁB
�Ƃɂ�������������n�C�G���h�͂Ƃ������A��ʂ�GPGPU�����y����͓̂��������B
DirectX�Ƃ�OpenGL�݂�����GPGPU�̃X�^���_�[�h�������āAUS�𗘗p�����A�v����
�����Ă���PC�ő���A�Ƃ����Ȃ�g��Ȃ���͖������Ęb�ɂȂ邾�낤���B
�Ƃɂ�������������n�C�G���h�͂Ƃ������A��ʂ�GPGPU�����y����͓̂��������B
DirectX�Ƃ�OpenGL�݂�����GPGPU�̃X�^���_�[�h�������āAUS�𗘗p�����A�v����
�����Ă���PC�ő���A�Ƃ����Ȃ�g��Ȃ���͖������Ęb�ɂȂ邾�낤���B
>>675
Intel�����N�̏t�ɂ�����v���[������Larrabee��2010�N��2 SP TFlops, 1 DP TFlops������GPU�Ƒ卷�����͂�
Intel�����N�̏t�ɂ�����v���[������Larrabee��2010�N��2 SP TFlops, 1 DP TFlops������GPU�Ƒ卷�����͂�
>>679
2010�N����GPU�����̐��\�Ȃ�A���Ęb�����ʂ����Ăǂ��Ȃ낤�H
2010�N����GPU�����̐��\�Ȃ�A���Ęb�����ʂ����Ăǂ��Ȃ낤�H
681 �FSocket774�F2007/10/12(��) 21:29:31 ID:EcH4zVyD
�����l���Ă݂��B�����͑��2012�`2014�N���炢�B
CPU�ɂ͂ǂ��܂Ŏ�荞�߂邩�B
�@�E�}���`�R�ACPU(�R�A���܂ł͂킩��Ȃ��A4or8�R�A?)
�@�EGPU(���тł����ł�������B3DMark06��10000over�ʂ̃X�y�b�N�A���N�O�̃f�B�X�N���[�gGPU����)
�@�E�m�[�X�u���b�W
�@�E�T�E�X�u���b�W
�����ł�����u���ɂ̃������v���o����Ă���Ƃ���B
�@���ɂ̃������FDRAM���݂̏W�ϓx�ASRAM���݂̃A�N�Z�X���x�A�t���b�V���Ɠ��l�̕s������(���������ϋv���͖�����)
�@���A�����ɑ�ʐ��Y����Ă��邱�ƁB(�Ⴆ��1TB��\100000�ʂƂ��A���R���܂��܂ȗe�ʂ̂��̂�����B1/4/16/64/256/1024GB�Ȃ�)
�@�������̂���DIMM��SD�J�[�h�T�C�Y���Ƃ���B
����ƁA�}�U�{�ɂ�CPU�\�P�b�g�Ɠ����������p�X���b�g���S���炢�A�O���������p�X���b�g���������S���炢�B
HDD�͂Ȃ��Ȃ�B�i���C�����������p�œ������݃X���b�g�Ɏh�������j���w�h���C�u���s�v�B�i�o�b�N�A�b�v�p�r�ɂ�SD�J�[�h�T�C�Y�̃��������g�������A
�ǂ����Ă�DVD���������l�͕ʓr�O�����݂�������j
�X����\�t�g�̋�����SD�J�[�h�T�C�Y�̃������ōs���B(�C�V����DS�������ȃC���[�W�j
PCI-Express�ɂ�����̂́A�����̑z���͂ł̓T�E���h�J�[�h�ƃr�f�I�L���v�`���J�[�h���炢�����v�����Ȃ�����Ax1 or x4���Q�X���b�g���炢�B
�}�U�{�͌��I�ɏ������Ȃ�BDTX�Ȃ�Ă���Ȃ��B�P�[�X���T�C���`�x�C�s�v�A3.5�C���`�x�C�s�v�B
���K�V�[�f�o�C�X�͓��R�S�p�B
�p�\�R�����g�ݗ��Ă悤�Ƃ���������A�}�U�{��CPU�A�K�v�Ȃ����̃������A�P�[�X�Ɠd���B�ȏ�I���B
�i���A�}�E�X�ƃL�[�{�[�h���������j
�E�E�E�Ȃ�Ă��ƂɂȂ��Ăق����B
CPU�ɂ͂ǂ��܂Ŏ�荞�߂邩�B
�@�E�}���`�R�ACPU(�R�A���܂ł͂킩��Ȃ��A4or8�R�A?)
�@�EGPU(���тł����ł�������B3DMark06��10000over�ʂ̃X�y�b�N�A���N�O�̃f�B�X�N���[�gGPU����)
�@�E�m�[�X�u���b�W
�@�E�T�E�X�u���b�W
�����ł�����u���ɂ̃������v���o����Ă���Ƃ���B
�@���ɂ̃������FDRAM���݂̏W�ϓx�ASRAM���݂̃A�N�Z�X���x�A�t���b�V���Ɠ��l�̕s������(���������ϋv���͖�����)
�@���A�����ɑ�ʐ��Y����Ă��邱�ƁB(�Ⴆ��1TB��\100000�ʂƂ��A���R���܂��܂ȗe�ʂ̂��̂�����B1/4/16/64/256/1024GB�Ȃ�)
�@�������̂���DIMM��SD�J�[�h�T�C�Y���Ƃ���B
����ƁA�}�U�{�ɂ�CPU�\�P�b�g�Ɠ����������p�X���b�g���S���炢�A�O���������p�X���b�g���������S���炢�B
HDD�͂Ȃ��Ȃ�B�i���C�����������p�œ������݃X���b�g�Ɏh�������j���w�h���C�u���s�v�B�i�o�b�N�A�b�v�p�r�ɂ�SD�J�[�h�T�C�Y�̃��������g�������A
�ǂ����Ă�DVD���������l�͕ʓr�O�����݂�������j
�X����\�t�g�̋�����SD�J�[�h�T�C�Y�̃������ōs���B(�C�V����DS�������ȃC���[�W�j
PCI-Express�ɂ�����̂́A�����̑z���͂ł̓T�E���h�J�[�h�ƃr�f�I�L���v�`���J�[�h���炢�����v�����Ȃ�����Ax1 or x4���Q�X���b�g���炢�B
�}�U�{�͌��I�ɏ������Ȃ�BDTX�Ȃ�Ă���Ȃ��B�P�[�X���T�C���`�x�C�s�v�A3.5�C���`�x�C�s�v�B
���K�V�[�f�o�C�X�͓��R�S�p�B
�p�\�R�����g�ݗ��Ă悤�Ƃ���������A�}�U�{��CPU�A�K�v�Ȃ����̃������A�P�[�X�Ɠd���B�ȏ�I���B
�i���A�}�E�X�ƃL�[�{�[�h���������j
�E�E�E�Ȃ�Ă��ƂɂȂ��Ăق����B
682 �FSocket774�F2007/10/12(��) 21:37:25 ID:eIbOos5H
�ŐV�s�̃p�\�R�����R�N�o�ĂΕ��ɂȂ�̂ɁE�E�E
684 �FSocket774�F2007/10/12(��) 22:39:00 ID:eIbOos5H
�l�n�[�������o��܂ő҂āB
XML�A�N�Z�����[�V�����ŁA
Intel - Oracle
vs
AMD - MS SQL Server
vs
IBM - DB2
�Ȃ�Ă��ƂɁB
���ƕς��ˁ[
Intel - Oracle
vs
AMD - MS SQL Server
vs
IBM - DB2
�Ȃ�Ă��ƂɁB
���ƕς��ˁ[
>>486-487
Itanium�叟���̗\��
Itanium�叟���̗\��
���j�C�R�A��Itanium�ڂ�����̂͂��蓾�Ȃ��̂��ˁB���������B
Itanium����́AAMD�ȏ�̒x���Ƃӂ������肾����u�v��v�ł͉��̈Ӗ����Ȃ��B
IA64�͊�n�E����n�͂��Ƃ��
HPC�p�r�ł����ɍD��
http://ia.topicmaker.com/manager/server/20060605/1.html
http://techon.nikkeibp.co.jp/article/NEWS/20050418/103861/
http://www.computerworld.jp/news/plf/61509.html
HPC�p�r�ł����ɍD��
http://ia.topicmaker.com/manager/server/20060605/1.html
http://techon.nikkeibp.co.jp/article/NEWS/20050418/103861/
http://www.computerworld.jp/news/plf/61509.html
Cell��Larrabee���̑��C�Ӗ��̂ɒu�����Ă��ǂ݉�����
512 �F�叫 [] �F2006/09/22(��) 02:34:16 ID:5BcAUztB0
��[
cell�̓X�p�R���ƊE���ᗬ�s��Ȃ���Ȃ����ˁB
���ǐ����̏�ł�spec�Ǝ��ۂ�spec�̘�������������������ˁB
linpack�ŋS�̂悤�ȃX�R�A���o��BlueGene�������łǂꂾ�������Ă邩�m���Ă邩?
�l�̒m�����A���ӂ��1����������B�i�����ۂ͐������x�j
�Ƃ��낪�A>>1�̃T�C�g�itarusan�j�ŎU�X�@����Ă�Itanium2�x�[�X�̃X�p�R���Ȃ��
�����Ŏ��ʂقǔ[�����т�����B
�ш悾�̃s�[�N���\�Ȃ��Ŏ��ۂ̌v�Z���o���郏�P����Ȃ���
�Ȋw�҂��g��̓v���O�����������ɑ����v�Z�o���邩�����Ȃ�B
���̓_��Itanium�͔��ɗD�G�ł����āAcell���ǂ��Ȃ̂��͖��m���B
���Ȃ��Ƃ��E�`���ߕӂł�cell�͘b��ɂ��Ȃ�Ȃ��B
���i�ΐ��\��ł͂܂������A�P�̐��\�̔�r�ł͔�ׂ�܂ł������Ǝv���B
512 �F�叫 [] �F2006/09/22(��) 02:34:16 ID:5BcAUztB0
��[
cell�̓X�p�R���ƊE���ᗬ�s��Ȃ���Ȃ����ˁB
���ǐ����̏�ł�spec�Ǝ��ۂ�spec�̘�������������������ˁB
linpack�ŋS�̂悤�ȃX�R�A���o��BlueGene�������łǂꂾ�������Ă邩�m���Ă邩?
�l�̒m�����A���ӂ��1����������B�i�����ۂ͐������x�j
�Ƃ��낪�A>>1�̃T�C�g�itarusan�j�ŎU�X�@����Ă�Itanium2�x�[�X�̃X�p�R���Ȃ��
�����Ŏ��ʂقǔ[�����т�����B
�ш悾�̃s�[�N���\�Ȃ��Ŏ��ۂ̌v�Z���o���郏�P����Ȃ���
�Ȋw�҂��g��̓v���O�����������ɑ����v�Z�o���邩�����Ȃ�B
���̓_��Itanium�͔��ɗD�G�ł����āAcell���ǂ��Ȃ̂��͖��m���B
���Ȃ��Ƃ��E�`���ߕӂł�cell�͘b��ɂ��Ȃ�Ȃ��B
���i�ΐ��\��ł͂܂������A�P�̐��\�̔�r�ł͔�ׂ�܂ł������Ǝv���B
>>681
�w���̓d�q�u���b�N�̂悤�Ȏ���p�\�R�����~����
http://www.otonanokagaku.net/products/kit/ex150/detail.html
�w���̓d�q�u���b�N�̂悤�Ȏ���p�\�R�����~����
http://www.otonanokagaku.net/products/kit/ex150/detail.html
�ǂ����ɂ��둽�R�A���R���V���[�}�ɂ͂�点�悤�Ƃ���̂͂܂��܂��V�������R�Z�p���Ȃ��߂��B
2020�N�ʂɂȂ�������Ȃ�Ȃ����B
2020�N�ʂɂȂ�������Ȃ�Ȃ����B
693 �FSocket774�F2007/10/13(�y) 00:09:24 ID:uQkOUTvm
��{�I�ɊC�O�L���̏E���������A�킴�Ɨv�_����ނ��Đ�̂Ă�B
http://nueda.main.jp/blog/
http://nueda.main.jp/blog/
FSB1600MHz��Core2 Extreme�͎��g��3.20GHz��TDP��136W�B
http://northwood.blog60.fc2.com/blog-entry-1324.html
http://northwood.blog60.fc2.com/blog-entry-1324.html
>>681
�ŁA���݂͂���ʼn������������B
VIA EPIA PX ��Aopen i945GMt-FA��2.5�C���`SSD�ڑ����������Ȃ��B
���ƁAPCI-Express��2�X���b�g�̎��_��mini-DTX�ɂ����Ȃ�Ȃ����B
�ŁA���݂͂���ʼn������������B
VIA EPIA PX ��Aopen i945GMt-FA��2.5�C���`SSD�ڑ����������Ȃ��B
���ƁAPCI-Express��2�X���b�g�̎��_��mini-DTX�ɂ����Ȃ�Ȃ����B
���傤�ǂ��̃X���b�h��GPGPU�Ő���オ���Ă���݂������ˁB
AMD��nVidia�̎���GPU��A�X�Ȃ�GPGPU�@�\�̍��x���Ɍ������Ă���Ƃ̂��Ƃ��B
http://www.theinquirer.net/gb/inquirer/news/2007/10/11/g92-rv670-gpgpu-monsters
�@�@--------------------
�@�@This change will not affect 3D performance, so you might want to skip the talk about higher
�@�@3Dmark scores. This change touches on the GPGPU (General Purpose computing on GPUs)
�@�@concept.
�@�@--------------------
Larrabee���ǂ��Ȃ邩��m��Ȃ������ǁA���̕��삪�z�b�g�Ȃ��Ƃ�m�����Ǝv���邷�B
�Ƃ����SMID��MIMD��Η��T�O���ᖳ��(�Ⴆ��CELL BE��SIMD�v���Z�b�T�̃}���`�R�A)�̂ɁA
>>672�̂悤�Ȑ���L�����������C�^�[������Ĉ��������H
AMD��nVidia�̎���GPU��A�X�Ȃ�GPGPU�@�\�̍��x���Ɍ������Ă���Ƃ̂��Ƃ��B
http://www.theinquirer.net/gb/inquirer/news/2007/10/11/g92-rv670-gpgpu-monsters
�@�@--------------------
�@�@This change will not affect 3D performance, so you might want to skip the talk about higher
�@�@3Dmark scores. This change touches on the GPGPU (General Purpose computing on GPUs)
�@�@concept.
�@�@--------------------
Larrabee���ǂ��Ȃ邩��m��Ȃ������ǁA���̕��삪�z�b�g�Ȃ��Ƃ�m�����Ǝv���邷�B
�Ƃ����SMID��MIMD��Η��T�O���ᖳ��(�Ⴆ��CELL BE��SIMD�v���Z�b�T�̃}���`�R�A)�̂ɁA
>>672�̂悤�Ȑ���L�����������C�^�[������Ĉ��������H
MAC�I�^���Ă����\�[�X�\��Ȃ��瑼�l��@�����Ƃ����ł��Ȃ��Ȃ��Ă��܂����ȁB
�Ǝ�������V�����ӌ��������āA���ɂ͓����Ă���B
����̕��σ��x�����������Ă��܂�������A�����R�e�Ȃ̂��Ă鉿�l�������낤���ǂˁB
�m���ɍ���̌㓡�̋L���̏������͂ǂ����Ƃ��������ǂ��B
�Ǝ�������V�����ӌ��������āA���ɂ͓����Ă���B
����̕��σ��x�����������Ă��܂�������A�����R�e�Ȃ̂��Ă鉿�l�������낤���ǂˁB
�m���ɍ���̌㓡�̋L���̏������͂ǂ����Ƃ��������ǂ��B
�܂��g������肾�B
�ǂ����Ă��㓡��@���Ȃ���C���ς܂�̂��B
�ǂ����Ă��㓡��@���Ȃ���C���ς܂�̂��B
699 �FMAC�I�^��668 �����F2007/10/13(�y) 12:52:49 ID:FgAu8YUJ
>>668
�c�O�Ȃ���Blue Gene���p�v�Z�@�̈���o�Ȃ�������A�����ȑg�������v���Z�b�T�ł���
PPC4xx�̏����Ƃ����̂�l�����炢���B
�ėp�v���Z�b�T�ɂ��R�X�g�_�E�����ʂ�A���ɑ傫�����B���傤�ǂ��̃u���O�ōŋߌ_��̑�^
�v�Z�@��TFLOPS�P�����܂Ƃ߂Ă��邷�B
http://rblog-tech.japan.cnet.com/petaflops/2007/10/1700_ed63.html�@�@
�@�EBlue Gene/P (PPC450)�@\10,79M/FLOPS
�@�EXtreme-X (Barcelona)�@\9.25M/FLOPS
�c�O�Ȃ���Blue Gene���p�v�Z�@�̈���o�Ȃ�������A�����ȑg�������v���Z�b�T�ł���
PPC4xx�̏����Ƃ����̂�l�����炢���B
�ėp�v���Z�b�T�ɂ��R�X�g�_�E�����ʂ�A���ɑ傫�����B���傤�ǂ��̃u���O�ōŋߌ_��̑�^
�v�Z�@��TFLOPS�P�����܂Ƃ߂Ă��邷�B
http://rblog-tech.japan.cnet.com/petaflops/2007/10/1700_ed63.html�@�@
�@�EBlue Gene/P (PPC450)�@\10,79M/FLOPS
�@�EXtreme-X (Barcelona)�@\9.25M/FLOPS
HKEPC��X48�`�b�v�Z�b�g��B
http://www.hkepc.com/?id=220
���g��A1600MHz FSB & DDR3-1600�Ή���X38�Ƃ̂��Ƃ��B
�Ή��v���Z�b�T��Yorkfield XE�Ƃ��ďo�Ă���Ƃ̂��Ƃ��B
http://www.hkepc.com/?id=220
���g��A1600MHz FSB & DDR3-1600�Ή���X38�Ƃ̂��Ƃ��B
�Ή��v���Z�b�T��Yorkfield XE�Ƃ��ďo�Ă���Ƃ̂��Ƃ��B
>>700
ASUS�ƋY���DDR-3�ł�X38��FSB1600�Ή����Ă邵���̂܂g����z��������
ASUS�ƋY���DDR-3�ł�X38��FSB1600�Ή����Ă邵���̂܂g����z��������
�Â��L�������ǁACELL BE�^�̃A�[�L�e�N�`�������C�g���[�V���O�ɂ����Ĕėp�v���Z�b�T��GPGPU
���D��Ă���Ƃ����b�肷�B
http://gametomorrow.com/blog/index.php/2007/09/05/cell-vs-g80/
�L�����ł����y����Ă��邷����Larrabee���A���̕ӂ̐��\��ڎw�����v���Ǝv���邷�B
���D��Ă���Ƃ����b�肷�B
http://gametomorrow.com/blog/index.php/2007/09/05/cell-vs-g80/
�L�����ł����y����Ă��邷����Larrabee���A���̕ӂ̐��\��ڎw�����v���Ǝv���邷�B
���ł�Cell�Ɣ�r��������z: �㓡�AMAC�I�^ �͐~�[
704 �FMAC�I�^���⑫�F2007/10/13(�y) 15:25:23 ID:FgAu8YUJ
>>699�̃����N��̉��i���ς̌��A�u���^�����b�N�̐_�v�q�쎁����R�����g�����Ă���̂ŁA
�ӔC��Љ�邷�B
http://grape.mtk.nao.ac.jp/~makino/journal/journal-2007-10.html#11
�@�@---------------------------
�@�@�@# �A���u���O �B���ς�炸���X�������ꏏ�݂����ȕ��͂��A�A�ACapacity Computing���Ă̂�
�@�@�v����Ɉ����p�\�R�����ׂ邾���̂��̂ŏ����ȃW���u���ʂɗ����A�Ƃ����Ӗ��Ȃ������
�@�@�͓̂�����O�ł͂Ȃ����B�ŁA 4 �\�P�b�g�m�[�h�� 288 �|�[�g�X�C�b�`�łȂ�����Ƃ���A
�@�@���ۂɂ� 144�m�[�h�܂ł� SU �Ƃ��̂��Ă���P�ʂɎg���݂����Ȋ��������B�܂��A���������g��
�@�@�Ȃ�����288�|�[�g�̃X�C�b�`2�K�w�ɂ��đS���Ȃ����Ƃ��ł���̂��ȁB�Ȃ����Ƃ����
�@�@��m�[�h���ł����ȃA�v���P�[�V���������邩�ǂ����͂Ȃ��Ȃ�������ǁB
�@�@�@�Ƃ������ACapacity Computing �Ȃ̂ɂȂ�2�K�w IB �X�C�b�`�H�Ƃ����̂͂������^��ŁA����
�@�@�ӂȂg����Ȃ�g�������A�Ƃ����̂͂���낤���ǁB�t�ɂ����� Capacity Computing ��
�@�@�����Ă������Ƃő�K�͌v�Z������Ȃ��������̌������p�ӂ��Ă���킯���B���������V�X�e��
�@�@�ƁA��K�͌v�Z������悤�ɍ�����͂��̃V�X�e�����ׂĂ��A�A�A
�@�@---------------------------
������ɂ���u���E�ŋ��v��ڎw���ᖳ�����[�U�[������HPC�N���X�^�Ƃ��āu�ėp�v���Z�b�T��
���������v�Ƃ����_�Ɉ٘_�����܂�Ă���ᖳ�����B
�ӔC��Љ�邷�B
http://grape.mtk.nao.ac.jp/~makino/journal/journal-2007-10.html#11
�@�@---------------------------
�@�@�@# �A���u���O �B���ς�炸���X�������ꏏ�݂����ȕ��͂��A�A�ACapacity Computing���Ă̂�
�@�@�v����Ɉ����p�\�R�����ׂ邾���̂��̂ŏ����ȃW���u���ʂɗ����A�Ƃ����Ӗ��Ȃ������
�@�@�͓̂�����O�ł͂Ȃ����B�ŁA 4 �\�P�b�g�m�[�h�� 288 �|�[�g�X�C�b�`�łȂ�����Ƃ���A
�@�@���ۂɂ� 144�m�[�h�܂ł� SU �Ƃ��̂��Ă���P�ʂɎg���݂����Ȋ��������B�܂��A���������g��
�@�@�Ȃ�����288�|�[�g�̃X�C�b�`2�K�w�ɂ��đS���Ȃ����Ƃ��ł���̂��ȁB�Ȃ����Ƃ����
�@�@��m�[�h���ł����ȃA�v���P�[�V���������邩�ǂ����͂Ȃ��Ȃ�������ǁB
�@�@�@�Ƃ������ACapacity Computing �Ȃ̂ɂȂ�2�K�w IB �X�C�b�`�H�Ƃ����̂͂������^��ŁA����
�@�@�ӂȂg����Ȃ�g�������A�Ƃ����̂͂���낤���ǁB�t�ɂ����� Capacity Computing ��
�@�@�����Ă������Ƃő�K�͌v�Z������Ȃ��������̌������p�ӂ��Ă���킯���B���������V�X�e��
�@�@�ƁA��K�͌v�Z������悤�ɍ�����͂��̃V�X�e�����ׂĂ��A�A�A
�@�@---------------------------
������ɂ���u���E�ŋ��v��ڎw���ᖳ�����[�U�[������HPC�N���X�^�Ƃ��āu�ėp�v���Z�b�T��
���������v�Ƃ����_�Ɉ٘_�����܂�Ă���ᖳ�����B
��̕���Larrabee�Ń��C�g���Q�[���������邩�̂悤�Șb���o�Ă�����
�P�`�Q�N�O�̃Q�n��Cell�X���̐~�ϑz�����Ă��邩�̂悤�ȃf�W���u
CG�������Ɩ��p�A�N�Z�����[�^�Ƃ��Č����ꍇ�͂ǂ����낤
MAYA�A3dsMAX�̃A�N�Z�����[�^�Ƃ���Cell�����p����Ă��鐢�E�͓������Ȃ�����
�����V�X�e���V����add-on�J�[�h�y������͍̂���
�P�`�Q�N�O�̃Q�n��Cell�X���̐~�ϑz�����Ă��邩�̂悤�ȃf�W���u
CG�������Ɩ��p�A�N�Z�����[�^�Ƃ��Č����ꍇ�͂ǂ����낤
MAYA�A3dsMAX�̃A�N�Z�����[�^�Ƃ���Cell�����p����Ă��鐢�E�͓������Ȃ�����
�����V�X�e���V����add-on�J�[�h�y������͍̂���
661 �FSocket774 [��] �F2007/10/11(��) 22:13:25 ID:tNQg6Jek
���ɂ���DirectX�B
MS�i�a�l�j�����������Ƃ���Ηǂ����E�E
>>658�����ǂݕ�thx
>CPU�͍���������Ȃ邾�낤���AGPU������������ȏ�̃y�[�X�ő����Ȃ�v
>�i������ACPU�ł̃��C�g���[�V���O�����X�^������u�������邱�Ƃ͂Ȃ��j
GPU�łȂ炢���Ȃ̂����B
>Q�F�@GPU�Ń��C�g���[�V���O���ł���̂�CPU�ɂ������̂͂ǂ����Ă��H
>Philipp Slusallek�F�@���C�g���[�V���O������n�[�h�E�F�A�́ACPU�ł�GPU�ł��\��Ȃ��B
>�@�@�@�@�@�@�@�@�@�@�@�@�@�i���̉ŁA�قڍ���̃p�l���̌��_�����܂��Ă��܂����悤�Ɋ������j
�ǂ��悤���B
�����I��DX9���o���Ƃ����B
���ɂ���DirectX�B
MS�i�a�l�j�����������Ƃ���Ηǂ����E�E
>>658�����ǂݕ�thx
>CPU�͍���������Ȃ邾�낤���AGPU������������ȏ�̃y�[�X�ő����Ȃ�v
>�i������ACPU�ł̃��C�g���[�V���O�����X�^������u�������邱�Ƃ͂Ȃ��j
GPU�łȂ炢���Ȃ̂����B
>Q�F�@GPU�Ń��C�g���[�V���O���ł���̂�CPU�ɂ������̂͂ǂ����Ă��H
>Philipp Slusallek�F�@���C�g���[�V���O������n�[�h�E�F�A�́ACPU�ł�GPU�ł��\��Ȃ��B
>�@�@�@�@�@�@�@�@�@�@�@�@�@�i���̉ŁA�قڍ���̃p�l���̌��_�����܂��Ă��܂����悤�Ɋ������j
�ǂ��悤���B
�����I��DX9���o���Ƃ����B
707 �FMAC�I�^��705 �����F2007/10/13(�y) 17:47:17 ID:FgAu8YUJ
>>705
�@�@-----------------
�@�@MAYA�A3dsMAX�̃A�N�Z�����[�^�Ƃ���Cell�����p����Ă��鐢�E�͓������Ȃ�����
�@�@-----------------
�w�������Ȃ������x���āB�B�B�ǂꂾ���C�����������B
�ނ���o���N��҂�����CELL BE�n�̃`�b�v��PC�ɓ��ڂ��ꂽ���Ƃ��������ƁB
http://trendy.nikkeibp.co.jp/article/ceatec/20071003/1003206/
�@�@=================
�@�@CEATEC�̓��Ńu�[�X�ɂ́A�\�j�[�E�R���s���[�^�G���^�e�C�������g�̉ƒ�p�Q�[���@�u�v���C�X
�@�@�e�[�V����3�v�iPS3�j�̃v���Z�b�T�uCell Broadband Engine�v�iCell/B.E.�j��SPE�R�A��p�����V�^
�@�@���f�B�A�X�g���[�~���O�v���Z�b�T�uSpursEngine�v�𓋍ڂ����uQosmio�v���Q�l�W�����Ă���B
�@�@=================
�@�@-----------------
�@�@MAYA�A3dsMAX�̃A�N�Z�����[�^�Ƃ���Cell�����p����Ă��鐢�E�͓������Ȃ�����
�@�@-----------------
�w�������Ȃ������x���āB�B�B�ǂꂾ���C�����������B
�ނ���o���N��҂�����CELL BE�n�̃`�b�v��PC�ɓ��ڂ��ꂽ���Ƃ��������ƁB
http://trendy.nikkeibp.co.jp/article/ceatec/20071003/1003206/
�@�@=================
�@�@CEATEC�̓��Ńu�[�X�ɂ́A�\�j�[�E�R���s���[�^�G���^�e�C�������g�̉ƒ�p�Q�[���@�u�v���C�X
�@�@�e�[�V����3�v�iPS3�j�̃v���Z�b�T�uCell Broadband Engine�v�iCell/B.E.�j��SPE�R�A��p�����V�^
�@�@���f�B�A�X�g���[�~���O�v���Z�b�T�uSpursEngine�v�𓋍ڂ����uQosmio�v���Q�l�W�����Ă���B
�@�@=================
�������Cell�~��Larrabee�~�ɈƑւ���
�X���̃��x�����ǂ�ǂ���
�X���̃��x�����ǂ�ǂ���
Cell����SPE4�W����
710 �FMAC�I�^��709 �����F2007/10/13(�y) 17:58:31 ID:FgAu8YUJ
>>709
SPE�̌����A���ċv���ǖ؎��̌�������[�h�}�b�v�ʂ�Ȃ�ŁA�\�肳��Ă������Ƃ��ƁB�B�B
http://techon.nikkeibp.co.jp/article/NEWS/20051027/110194/?SS=imgview&FD=-740149408
SPE�̌����A���ċv���ǖ؎��̌�������[�h�}�b�v�ʂ�Ȃ�ŁA�\�肳��Ă������Ƃ��ƁB�B�B
http://techon.nikkeibp.co.jp/article/NEWS/20051027/110194/?SS=imgview&FD=-740149408
>>708
�u�������_���\�v�͐l�����l�ւƑ��点�閂�͂������
�u�������_���\�v�͐l�����l�ւƑ��点�閂�͂������
SPE4�{�G���R�[�_�[+�f�R�[�_�[=SpursEngine
SPE��DSP�ւ�H
PPE�͗v��܂��H
SPE��DSP�ւ�H
PPE�͗v��܂��H
713 �FMAC�I�^��697 �����F2007/10/13(�y) 19:02:21 ID:oZktu19s
>>697
�@�@-----------------
�@�@���l��@�����Ƃ����ł��Ȃ��Ȃ��Ă��܂����ȁB
�@�@-----------------
�ʔ��������̂ŁA������ɂ��\�点�Ă����������B�N���w�@�����Ƃ����ł��Ȃ��x���B�B�B
http://hissi.dyndns.ws/read.php/jisaku/20071013/bmZHNzNJaTE.html
�@�@-----------------
�@�@���l��@�����Ƃ����ł��Ȃ��Ȃ��Ă��܂����ȁB
�@�@-----------------
�ʔ��������̂ŁA������ɂ��\�点�Ă����������B�N���w�@�����Ƃ����ł��Ȃ��x���B�B�B
http://hissi.dyndns.ws/read.php/jisaku/20071013/bmZHNzNJaTE.html
>>705
Cell�̏ꍇ�̓\�j�[�̃\�t�g�E�G�A�T�|�[�g���_���_������������������A
Intel���V�b�J���T�|�[�g����Ȃ�ACell�ƑS��������̕��ɂ͐���Ȃ���
�v���B
����������Ƃ����ĕK��Intel������������Ęb�ł��������B
>>707
SpursEngine�͍��̂Ƃ������p�r����������A�Q�[���@�ł���PS3�Ɣ�ׂĂ�
�����w�Ǐo�Ȃ��C���B
�܂�����p�r�̂����́A�\�t�g�T�|�[�g������I�ōςނ��牽�Ƃ��Ȃ���ǁB
>>712
���̂Ƃ���͔ėp���̂���DSP�̈��ł��傤�ˁB
Cell�̏ꍇ�̓\�j�[�̃\�t�g�E�G�A�T�|�[�g���_���_������������������A
Intel���V�b�J���T�|�[�g����Ȃ�ACell�ƑS��������̕��ɂ͐���Ȃ���
�v���B
����������Ƃ����ĕK��Intel������������Ęb�ł��������B
>>707
SpursEngine�͍��̂Ƃ������p�r����������A�Q�[���@�ł���PS3�Ɣ�ׂĂ�
�����w�Ǐo�Ȃ��C���B
�܂�����p�r�̂����́A�\�t�g�T�|�[�g������I�ōςނ��牽�Ƃ��Ȃ���ǁB
>>712
���̂Ƃ���͔ėp���̂���DSP�̈��ł��傤�ˁB
715 �FMAC�I�^��714 �����F2007/10/13(�y) 19:12:05 ID:oZktu19s
>>714
�@�@------------------
�@�@SpursEngine�͍��̂Ƃ������p�r����������A�Q�[���@�ł���PS3�Ɣ�ׂĂ�
�@�@�����w�Ǐo�Ȃ��C���B
�@�@------------------
ISA�������ǂ��납�A�R�A��SPE���̂��̂��B
�@�usilverthrone�͓���p�r����������PC�Ɣ�ׂ�Ɛ����o�Ȃ��C���v
�Ƃǂ��Ⴄ�����ˁB�B�B
�@�@------------------
�@�@SpursEngine�͍��̂Ƃ������p�r����������A�Q�[���@�ł���PS3�Ɣ�ׂĂ�
�@�@�����w�Ǐo�Ȃ��C���B
�@�@------------------
ISA�������ǂ��납�A�R�A��SPE���̂��̂��B
�@�usilverthrone�͓���p�r����������PC�Ɣ�ׂ�Ɛ����o�Ȃ��C���v
�Ƃǂ��Ⴄ�����ˁB�B�B
������A����
469 �FSocket774 �F2007/10/12(��) 22:06:01 ID:HcvW86ff
�g�����͐��i����Ă���l���邩���薳
476 �FSocket774 �F2007/10/12(��) 23:15:35 ID:R4g1hWe8
�ŏ�����g�������߂Ă�����Ȃ��������@PhysX
�g���������߂܂������ƁE�E�E�E�E�E(�G�O�ցO)
http://www.4gamer.net/games/032/G003263/20070919044/
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
��HAVOK���̂́ALarrabee�̂悤�ȍ��X���b�h����n�[�h�E�F�A�Ɍ����������͓��ӂł͂Ȃ�
(�G�L�t�M)
469 �FSocket774 �F2007/10/12(��) 22:06:01 ID:HcvW86ff
�g�����͐��i����Ă���l���邩���薳
476 �FSocket774 �F2007/10/12(��) 23:15:35 ID:R4g1hWe8
�ŏ�����g�������߂Ă�����Ȃ��������@PhysX
�g���������߂܂������ƁE�E�E�E�E�E(�G�O�ցO)
http://www.4gamer.net/games/032/G003263/20070919044/
http://pc.watch.impress.co.jp/docs/2007/1012/kaigai393.htm
��HAVOK���̂́ALarrabee�̂悤�ȍ��X���b�h����n�[�h�E�F�A�Ɍ����������͓��ӂł͂Ȃ�
(�G�L�t�M)
>>714
SpursEngine���ă���������DDR2�ɂ��邩�Ǝv������XDR DRAM�Ȃ�
PC�i���C������������Ȃ����ǁj��XDR�ڂ�̂��ď��߂āH���`�k�k
SpursEngine���ă���������DDR2�ɂ��邩�Ǝv������XDR DRAM�Ȃ�
PC�i���C������������Ȃ����ǁj��XDR�ڂ�̂��ď��߂āH���`�k�k
���߂ĂȂ�Ȃ��́H
nvidia��XDR���ڂ̃O���{����Ă����ǂ���͎���i����
nvidia��XDR���ڂ̃O���{����Ă����ǂ���͎���i����
�������̂���SpursEngine��PC-FX�{�[�h�ɂł����Ă��܂�������(�G�O�ցO)
SPE4��1.5Ghz����PS3��Cell���x���Ȃ��Ă�́H
>>705
CG�������̃A�N�Z�����[�^�͑��Â̐̂�����x�ƂȂ��o�Ă��
���܂�Ƀj�b�`�߂��Ĕ���Ȃ������y���Ȃ���ȁB
���ʂ̃p�\�R�����ׂăt�@�[���ɂ����ق����͂����茾���Ď����葁�����B
���X�^�̃��v���[�X�Ń��A���^�C�����C�g���[�V���O�Ȃ�Ėϑz�Ƃ����z�̃��x���Ƃ����v���Ȃ���
�Ӗ����Ȃ����B
���̃I�t���C�������_���[�͖ړI��i���D��̕��G�Ȏ����ɂȂ��Ă�
SSE���獡���ɂ낭�ɗL�����p���ĂȂ���Ԃ���
����Gerato�݂�����GPU�����_���[�����邵�B
CG�������̃A�N�Z�����[�^�͑��Â̐̂�����x�ƂȂ��o�Ă��
���܂�Ƀj�b�`�߂��Ĕ���Ȃ������y���Ȃ���ȁB
���ʂ̃p�\�R�����ׂăt�@�[���ɂ����ق����͂����茾���Ď����葁�����B
���X�^�̃��v���[�X�Ń��A���^�C�����C�g���[�V���O�Ȃ�Ėϑz�Ƃ����z�̃��x���Ƃ����v���Ȃ���
�Ӗ����Ȃ����B
���̃I�t���C�������_���[�͖ړI��i���D��̕��G�Ȏ����ɂȂ��Ă�
SSE���獡���ɂ낭�ɗL�����p���ĂȂ���Ԃ���
����Gerato�݂�����GPU�����_���[�����邵�B
Gelato�������Ͽ�ꉞ
>>721-722
Intel���J�����Ă�̂̓Q�[���G���W��
Intel���J�����Ă�̂̓Q�[���G���W��
Visual Computing Group�̂��Ƃ�
����͋�ATI��3Dlabs��PowerVR�̔p�ނ��E���ɂ���ꏊ
����͋�ATI��3Dlabs��PowerVR�̔p�ނ��E���ɂ���ꏊ
�Q�[���G���W�������Ȃ̂�����킩���ĂȂ��l���K����FUD���Ă����Ƃ������Ƃ�
Intel�̗]���v���W�F�N�g�ł��ꂾ������オ��邨�܂���Ɋ��t
�Q�[���G���W���i�j
>>723
����Șb�o�Ă������H
�}���`�R�A����̃Q�[���G���W���v��"�[��"�͂��Ă邯�ǂȁB
http://journal.mycom.co.jp/articles/2005/09/10/cedec1/
>>724
�I�t�B�V������VCG�y�[�W�͂��傱���傱�L�q���ς�邵�A
���ۓI�Ȑ����ŃC�}�C�`��̓I�ɉ��̎d�����Ă�̂��悭�킩��Ȃ��B
�@639 �FSocket774 [sage] �F2007/02/21(��) 21:16:55 ID:KVzbsmwV
�@http://www.intel.com/jobs/careers/visualcomputing/
�@�T���^�N�����`�[���́uGPU silicon development with a broad range of silicon design opportunities�v
�@�q���Y�o���`�[���́uproduct software (e.g. OpenGL, and Video), marketing, and validation�v
�����������2007�N�H�B
discrete GPU�Ɋւ��Ă͂���������o���o�����\�ɋC�t�����[�b�B
Intel gaming GPU due out in fall 2007
http://www.techreport.com/onearticle.x/10549
Intel hiring staff for 'leading edge graphics'
http://www.techreport.com/onearticle.x/10564
3Dlabs staff was hired by Intel
http://www.techreport.com/onearticle.x/10597
Intel seeks more employees for GPU project
http://www.techreport.com/onearticle.x/11411
Intel career page confirms discrete GPU plans
http://www.techreport.com/onearticle.x/11683
Intel to launch its first gaming GPU in 2008-2009
http://www.techreport.com/onearticle.x/11794
Intel is hiring discrete graphic experts
http://forums.vr-zone.com/showthread.php?t=169845
����Șb�o�Ă������H
�}���`�R�A����̃Q�[���G���W���v��"�[��"�͂��Ă邯�ǂȁB
http://journal.mycom.co.jp/articles/2005/09/10/cedec1/
>>724
�I�t�B�V������VCG�y�[�W�͂��傱���傱�L�q���ς�邵�A
���ۓI�Ȑ����ŃC�}�C�`��̓I�ɉ��̎d�����Ă�̂��悭�킩��Ȃ��B
�@639 �FSocket774 [sage] �F2007/02/21(��) 21:16:55 ID:KVzbsmwV
�@http://www.intel.com/jobs/careers/visualcomputing/
�@�T���^�N�����`�[���́uGPU silicon development with a broad range of silicon design opportunities�v
�@�q���Y�o���`�[���́uproduct software (e.g. OpenGL, and Video), marketing, and validation�v
�����������2007�N�H�B
discrete GPU�Ɋւ��Ă͂���������o���o�����\�ɋC�t�����[�b�B
Intel gaming GPU due out in fall 2007
http://www.techreport.com/onearticle.x/10549
Intel hiring staff for 'leading edge graphics'
http://www.techreport.com/onearticle.x/10564
3Dlabs staff was hired by Intel
http://www.techreport.com/onearticle.x/10597
Intel seeks more employees for GPU project
http://www.techreport.com/onearticle.x/11411
Intel career page confirms discrete GPU plans
http://www.techreport.com/onearticle.x/11683
Intel to launch its first gaming GPU in 2008-2009
http://www.techreport.com/onearticle.x/11794
Intel is hiring discrete graphic experts
http://forums.vr-zone.com/showthread.php?t=169845
�o�J��Y�A�Ⴄ����
���[�}�[�𗘗p���ăl�^���Ă���邩�炱��
���̓s�x�������~�[���]���k�`�Ő���オ���
NVIDIA�~ vs AMDATi�~ �X�������킩�邾��
�����ǂ���������ς��ނ�邩��
���[�}�[�𗘗p���ăl�^���Ă���邩�炱��
���̓s�x�������~�[���]���k�`�Ő���オ���
NVIDIA�~ vs AMDATi�~ �X�������킩�邾��
�����ǂ���������ς��ނ�邩��
730 �FMAC�I�^��728 �����F2007/10/14(��) 11:32:16 ID:Nd7fT4Az
>>728
�@�@-----------------
�@�@�C�}�C�`��̓I�ɉ��̎d�����Ă�̂��悭�킩��Ȃ��B
�@�@-----------------
�`�b�v�Z�b�g����������ɓ����ƁA������ Intel��ő��GPU�x���_������A�����Ǝd��������
���邱�Ƃ�m�����B
SoC�Ɏ���o���̂��m�肷����A�d���푝���Ă����邱�Ƃ햳�����B
�@�@-----------------
�@�@�C�}�C�`��̓I�ɉ��̎d�����Ă�̂��悭�킩��Ȃ��B
�@�@-----------------
�`�b�v�Z�b�g����������ɓ����ƁA������ Intel��ő��GPU�x���_������A�����Ǝd��������
���邱�Ƃ�m�����B
SoC�Ɏ���o���̂��m�肷����A�d���푝���Ă����邱�Ƃ햳�����B
�̂���Larrabee�ے�h�͕K�����������ǁE�E�A
�������AGPU�ɂȂ���Ď��m�肵�ĉ��������낤�˂�
�������AGPU�ɂȂ���Ď��m�肵�ĉ��������낤�˂�
GPU����Ŋ撣��̂�GMA�a�ł�
�������Ă����ĉ����� ����
http://www.4gamer.net/games/038/G003822/20070926019/SS/010.jpg
http://www.4gamer.net/games/038/G003822/20070926019/SS/011.jpg
http://www.4gamer.net/games/038/G003822/20070926019/SS/014.jpg
�������Ă����ĉ����� ����
http://www.4gamer.net/games/038/G003822/20070926019/SS/010.jpg
{kind=link}
http://www.4gamer.net/games/038/G003822/20070926019/SS/011.jpg
{kind=link}
http://www.4gamer.net/games/038/G003822/20070926019/SS/014.jpg
{kind=link}
���j�[�R�A�Ő��\���ǂ�ǂ�L�т�̂����������낤��
���s���j�b�g���ڂŃs�[�N���\�������̂�GPGPU�~�̐S�̋��菊�������݂��������炗
���s���j�b�g���ڂŃs�[�N���\�������̂�GPGPU�~�̐S�̋��菊�������݂��������炗
>>731
�ϑz���E�Z�l��
�ϑz���E�Z�l��
Larrabee���v�V���肦��v�f��3D�_�C�X�^�b�L���O�ɂ�钴�L�ш惁�������B
���܂�ɂ���x���ɂ���A���̃v���Z�X�̎��p���̐���Ō��܂��Ȃ������H
���܂�ɂ���x���ɂ���A���̃v���Z�X�̎��p���̐���Ō��܂��Ȃ������H
2008�N��1tflops���Ⴈ�b�ɂȂ�Ȃ�
740 �FMAC�I�^��739 �����F2007/10/14(��) 12:05:16 ID:Nd7fT4Az
>>739
�w���Ɣ�ׂāx���b�ɂȂ�Ȃ������H
�w���Ɣ�ׂāx���b�ɂȂ�Ȃ������H
>>732
�Ȃ�Ă�����GPU�V�F�ANo.1�������
G965�Œɂ��ڌ���G3x�ł͏C����}���Ă�������
����������ƃh���C�o�̊����x�A����d�͐��\���ǂ��ɂ����Ăق���
�Ȃ�Ă�����GPU�V�F�ANo.1�������
G965�Œɂ��ڌ���G3x�ł͏C����}���Ă�������
����������ƃh���C�o�̊����x�A����d�͐��\���ǂ��ɂ����Ăق���
45nm�̏o�����Ăǂ��Ȃ낤�B
QX9770��3.2GHz/FSB1600MHz��TDP136W�B
QX9775��TDP150W�B
�����TDP����65nm�Ɣ�ׂĂ������ȒP�ɃN���b�N�グ���Ȃ��C������̂����B
�������65nm��G�X�e�b�v�݂����ɏ���TDP�͌���낤���ǂ��B
FSB����H�炢������ȁB
QX9770��3.2GHz/FSB1600MHz��TDP136W�B
QX9775��TDP150W�B
�����TDP����65nm�Ɣ�ׂĂ������ȒP�ɃN���b�N�グ���Ȃ��C������̂����B
�������65nm��G�X�e�b�v�݂����ɏ���TDP�͌���낤���ǂ��B
FSB����H�炢������ȁB
High-K�͏���d�͂������H
http://blog.livedoor.jp/amd646464/archives/51059931.html
�N���b�N�オ��Ƃ��ꂪ����������̂��ȁH
http://blog.livedoor.jp/amd646464/archives/51059931.html
�N���b�N�オ��Ƃ��ꂪ����������̂��ȁH
XeonDP��3.16GHz��TDP120W������AXeon����3.2GHz��120W�̂܂܂̉\���͍����Ǝv���B
����Ŕ��M�̂����������Ȃ����ȁH
Xeon�̕��ɂ͏o���̗ǂ��̉āA�f�X�N�g�b�v�����͏o���̈����̂��Ƃ��B
����Ŕ��M�̂����������Ȃ����ȁH
Xeon�̕��ɂ͏o���̗ǂ��̉āA�f�X�N�g�b�v�����͏o���̈����̂��Ƃ��B
>737
3D�_�C�X�^�b�L���O�ɂ�钴�L�ш悪�ł�����A�{���Ɋv�����Ǝv������
����܂肻������z����CPU�A�[�L�e�N�`���̗\����Ă݂Ȃ���ˁBLarrabee���炢���B
IBM�Ȃ��A�X�^�b�L���O�����������x���łł��Ă���Ă����Ă��C�����邯�ǁA
����ȊO����ܘb�ɂłĂ��Ȃ����Ă��Ƃ́A�܂�10�N���炢�͂łĂ������ɂȂ��̂��ˁB
3D�_�C�X�^�b�L���O�ɂ�钴�L�ш悪�ł�����A�{���Ɋv�����Ǝv������
����܂肻������z����CPU�A�[�L�e�N�`���̗\����Ă݂Ȃ���ˁBLarrabee���炢���B
IBM�Ȃ��A�X�^�b�L���O�����������x���łł��Ă���Ă����Ă��C�����邯�ǁA
����ȊO����ܘb�ɂłĂ��Ȃ����Ă��Ƃ́A�܂�10�N���炢�͂łĂ������ɂȂ��̂��ˁB
>>728
���ǂނƏ����
���̎�̃l�^�L�������o�J�ƒނ���o�J�͎���łق���
http://www.techreport.com/onearticle.x/10549
Intel gaming GPUs will be based on Imagination Technologies' PowerVR architecture,
and now they're saying the chips will come out in the late summer or early fall of 2007.
���ǂނƏ����
���̎�̃l�^�L�������o�J�ƒނ���o�J�͎���łق���
http://www.techreport.com/onearticle.x/10549
Intel gaming GPUs will be based on Imagination Technologies' PowerVR architecture,
and now they're saying the chips will come out in the late summer or early fall of 2007.
747 �FMAC�I�^��746 �����F2007/10/14(��) 14:39:27 ID:Nd7fT4Az
>>746
���ǂނƁALarrabee�̉���Ƃ���PowerVR�̃^�C�������_�����O�̘b�肪�o�Ă����Ƃ������������邷���ǁB�B�B
���ǂނƁALarrabee�̉���Ƃ���PowerVR�̃^�C�������_�����O�̘b�肪�o�Ă����Ƃ������������邷���ǁB�B�B
Larrabee��3D Stacking�g���Ă邾�Ȃ�ď����c�i�E�́E�j
749 �FMAC�I�^��u �����F2007/10/14(��) 14:51:15 ID:Nd7fT4Az
>>748
�����܂�polaris��Larrabee�̎����f�����Ƃ������Ƃ��O�B
�R�����������CELL/BE�̓�Ԑ�����_�����^�C���v���Z�b�T�ɉ߂��Ȃ����ƁB�B�B
�����܂�polaris��Larrabee�̎����f�����Ƃ������Ƃ��O�B
�R�����������CELL/BE�̓�Ԑ�����_�����^�C���v���Z�b�T�ɉ߂��Ȃ����ƁB�B�B
>>748
Larrabee��3D Stacking�ł͖����Ǝv���B�قڊm���ɁB�����I�ɂ������B
Polaris�͂���Cell���C�N�����ǁALarrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�㓡�����Ԉ�����u���b�N�}�������Ă��邯�ǁA
�e�R�A��Local Store����Ȃ���L1 Cache�Ȃ̂ŁB
Larrabee��3D Stacking�ł͖����Ǝv���B�قڊm���ɁB�����I�ɂ������B
Polaris�͂���Cell���C�N�����ǁALarrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�㓡�����Ԉ�����u���b�N�}�������Ă��邯�ǁA
�e�R�A��Local Store����Ȃ���L1 Cache�Ȃ̂ŁB
>>742
�V���O������150W�`200W�����̌��E�Ƃ������ăN���b�N��}���Ă�������
�}���`�R�A�͕��U���Ă邩��200W�ł��R�A������50W�Ȃ̂ŃN���b�N�������Əグ����̂ł́H
�V���O������150W�`200W�����̌��E�Ƃ������ăN���b�N��}���Ă�������
�}���`�R�A�͕��U���Ă邩��200W�ł��R�A������50W�Ȃ̂ŃN���b�N�������Əグ����̂ł́H
Cell�����������ɏo���̂��낻�눣�ꂾ���玫�߂Ȃ����H
>>752
http://news.zdnet.co.uk/hardware/0,1000000091,39154677,00.htm
"We could not ship desktop and notebook processors at 150 watts. We just couldn't do it."
http://news.zdnet.co.uk/hardware/0,1000000091,39154677,00.htm
"We could not ship desktop and notebook processors at 150 watts. We just couldn't do it."
755 �FMAC�I�^��u �����F2007/10/14(��) 15:13:36 ID:Nd7fT4Az
>>751
�@�@------------------
�@�@Larrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�@�@------------------
�S�����J����Ă��Ȃ��������ǁA����ϑz���Ă��邷���H
�@�@------------------
�@�@Larrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�@�@------------------
�S�����J����Ă��Ȃ��������ǁA����ϑz���Ă��邷���H
>>755
����Ax86�x�[�X��SSE��512bit�Ɋg�������Ƃł��ϑz���Ă݂�e�X�g�B
����Ax86�x�[�X��SSE��512bit�Ɋg�������Ƃł��ϑz���Ă݂�e�X�g�B
>>752
���A�N�}�[
���A�N�}�[
�㓡�i�]���j�ƊE�W�ҏ����\�[�X�ɂ���̂̓A������
���������A�ŏ��ɓo�ꂷ��̂́u�����Ă݂�g���K�Łh�A�܂��{�i�I�Ȑ��i�Ƃ͌����Ȃ��v(�ƊE�W��)
���uLarrabee�ɂ��Ă͔��ɒ����Ԃ̃��T�[�`���s�Ȃ�ꂽ�B�J���`�[���̕Ґ����ς��A
���A�[�L�e�N�`������������蒼���ꂽ�B���߃Z�b�g�ɂ��Ă��A���܂��܂Ȍ������s�Ȃ�ꂽ�悤�����A
���ŏI�I��x86�A�[�L�e�N�`���̊g���ɗ����������v�Ƃ���ƊE�W�҂͌��B
�Q�������́u2008�N�f������v�ƌJ��Ԃ������Ă�B
�������Ă�͔̂�������Ȃ��ăf���B
���������ǁA���݂��A�[�L�e�N�`����
����������蒼
���A���鎞�_�̃f�U�C���ŃV���R�������Ĉꉞ2008�N�Ƀf���B
���̗��ň������������J���B
����ȃI�`�ɂȂ鈫���B
���������A�ŏ��ɓo�ꂷ��̂́u�����Ă݂�g���K�Łh�A�܂��{�i�I�Ȑ��i�Ƃ͌����Ȃ��v(�ƊE�W��)
���uLarrabee�ɂ��Ă͔��ɒ����Ԃ̃��T�[�`���s�Ȃ�ꂽ�B�J���`�[���̕Ґ����ς��A
���A�[�L�e�N�`������������蒼���ꂽ�B���߃Z�b�g�ɂ��Ă��A���܂��܂Ȍ������s�Ȃ�ꂽ�悤�����A
���ŏI�I��x86�A�[�L�e�N�`���̊g���ɗ����������v�Ƃ���ƊE�W�҂͌��B
�Q�������́u2008�N�f������v�ƌJ��Ԃ������Ă�B
�������Ă�͔̂�������Ȃ��ăf���B
���������ǁA���݂��A�[�L�e�N�`����
����������蒼
���A���鎞�_�̃f�U�C���ŃV���R�������Ĉꉞ2008�N�Ƀf���B
���̗��ň������������J���B
����ȃI�`�ɂȂ鈫���B
759 �FMAC�I�^��758 �����F2007/10/14(��) 15:31:36 ID:Nd7fT4Az
760 �FMAC�I�^���⑫�F2007/10/14(��) 15:37:10 ID:Nd7fT4Az
�t��������ƁA��A�̋L��(http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm �Ȃ�)��
�㓡���̔]���ł�Polaris��Larrabee�̋�ʂ����Ă��Ȃ��炵�����Ƃ������Ă��邷���ǁA
���̂�������A�����瓯�ꎋ���������������Ă����ۂ��邷�B
���̏���Intel�Ȃ̂��A���܂莿�̗ǂ����������ȃu���[���̃q�g�Ȃ̂�����肷���ǁB�B�B
�㓡���̔]���ł�Polaris��Larrabee�̋�ʂ����Ă��Ȃ��炵�����Ƃ������Ă��邷���ǁA
���̂�������A�����瓯�ꎋ���������������Ă����ۂ��邷�B
���̏���Intel�Ȃ̂��A���܂莿�̗ǂ����������ȃu���[���̃q�g�Ȃ̂�����肷���ǁB�B�B
737 ���O�FMAC�I�^[sage] ���e���F2007/10/14(��) 11:48:57 ID:Nd7fT4Az
Larrabee���v�V���肦��v�f��3D�_�C�X�^�b�L���O�ɂ�钴�L�ш惁�������B
���܂�ɂ���x���ɂ���A���̃v���Z�X�̎��p���̐���Ō��܂��Ȃ������H
748 ���O�Fu[sage] ���e���F2007/10/14(��) 14:48:32 ID:Vcf5EqG/
Larrabee��3D Stacking�g���Ă邾�Ȃ�ď����c�i�E�́E�j
Polaris��Larrabee�̋�ʂ����ĂȂ���H
Larrabee���v�V���肦��v�f��3D�_�C�X�^�b�L���O�ɂ�钴�L�ш惁�������B
���܂�ɂ���x���ɂ���A���̃v���Z�X�̎��p���̐���Ō��܂��Ȃ������H
748 ���O�Fu[sage] ���e���F2007/10/14(��) 14:48:32 ID:Vcf5EqG/
Larrabee��3D Stacking�g���Ă邾�Ȃ�ď����c�i�E�́E�j
Polaris��Larrabee�̋�ʂ����ĂȂ���H
762 �FMAC�I�^��761 �����F2007/10/14(��) 15:54:48 ID:Nd7fT4Az
�㓡�L�����������ǁALarrabee�Ɋւ��Ă͂��̃X����Part 29�ł�
�ǂݕԂ��Ă���l�����ق�����낵�����Ɓc�B����ȏ�ɏ[���������͂łĂȂ���ŁB
GPU��IEEE754�̔{���x�T�|�[�g����炵�����A�ǂ�ǂ�ėp�����Ă����ŁA
�����GPU�Ɣ�r����Larrabee��GPU�Ȃ̂��Ƃ����c�_��������ƁB
����PC�ɂ�����n�C�G���hGPU���Ď��p���l����Ɩw�ǂ̃��[�U�ɂ͂������������B
�ǂݕԂ��Ă���l�����ق�����낵�����Ɓc�B����ȏ�ɏ[���������͂łĂȂ���ŁB
GPU��IEEE754�̔{���x�T�|�[�g����炵�����A�ǂ�ǂ�ėp�����Ă����ŁA
�����GPU�Ɣ�r����Larrabee��GPU�Ȃ̂��Ƃ����c�_��������ƁB
����PC�ɂ�����n�C�G���hGPU���Ď��p���l����Ɩw�ǂ̃��[�U�ɂ͂������������B
�ėp�������M��
���ꂩ��Œ�@�\�ւ̗h��߂�������
���ꂩ��Œ�@�\�ւ̗h��߂�������
�l�I�Ȉӌ��Ȃ̂����E�E�E
GPU���ėp�I�ȕ����ɐi������̂͂ǂ����Ǝv���Ă�B
����������������Ȃ̂Ŋ��҂��Ă��Ȃ��B
GPU���ėp�I�ȕ����ɐi������̂͂ǂ����Ǝv���Ă�B
����������������Ȃ̂Ŋ��҂��Ă��Ȃ��B
766 �FMAC�I�^��u �����F2007/10/14(��) 16:22:54 ID:Nd7fT4Az
>>763
������v���[�������ЂƂ��l�^�ł�H
IA�v���Z�b�T��3D�_�C�X�^�b�L���O�l�^�ł�A����Ș_����@�������H
http://www.cc.gatech.edu/~loh/Papers/micro2006-3d.pdf
�@�@------------------
�@�@In this research, we study the performance advantages and thermal challenges of two forms
�@�@of die stacking: Stacking a large DRAM or SRAM cache on a microprocessor and dividing a
�@�@traditional microarchitecture between two die in a stack.
�@�@------------------
������v���[�������ЂƂ��l�^�ł�H
IA�v���Z�b�T��3D�_�C�X�^�b�L���O�l�^�ł�A����Ș_����@�������H
http://www.cc.gatech.edu/~loh/Papers/micro2006-3d.pdf
�@�@------------------
�@�@In this research, we study the performance advantages and thermal challenges of two forms
�@�@of die stacking: Stacking a large DRAM or SRAM cache on a microprocessor and dividing a
�@�@traditional microarchitecture between two die in a stack.
�@�@------------------
>>765
����҂̐��i��PC���[�J�[�̐��j��Intel�ɓ͂��Ă�
���[�G���h��SiS/Mirage�ɔC����
http://arena.nikkeibp.co.jp/winpc/col/02/web_road_intel.pdf
Q35�EG33�͏���d�͂̏��Ȃ�Gen3.5����̃R�A�����
http://pc.watch.impress.co.jp/docs/2007/0318/cebit10.htm
http://pc.watch.impress.co.jp/docs/2007/0607/comp08.htm
http://www.4gamer.net/games/038/G003822/20070926019/
��2�i�K�ȍ~�͓�ɕ���B��́C���DirectX 10�̓����^�V�F�[�_
�A�[�L�e�N�`���I�ȃA�v���[�`�Ői������������ŁC���̎�@�̓O���t�B�b�N�X
�@�\�Ɛ��\�����߂����ŁC����d�͂傳���镾�Q������B
�����ł�����C�����d�̓v���b�g�t�H�[�������ɂ́CG33�Ȃǂō̗p����Ă���
�uGMA 3100�v�Ȃǂ̂悤�ɁC�Œ�@�\�̔䗦�����߂邱�Ƃŏ���d�͂�}����
���������p�ӂ���Ă���B
����҂̐��i��PC���[�J�[�̐��j��Intel�ɓ͂��Ă�
���[�G���h��SiS/Mirage�ɔC����
http://arena.nikkeibp.co.jp/winpc/col/02/web_road_intel.pdf
Q35�EG33�͏���d�͂̏��Ȃ�Gen3.5����̃R�A�����
http://pc.watch.impress.co.jp/docs/2007/0318/cebit10.htm
http://pc.watch.impress.co.jp/docs/2007/0607/comp08.htm
http://www.4gamer.net/games/038/G003822/20070926019/
��2�i�K�ȍ~�͓�ɕ���B��́C���DirectX 10�̓����^�V�F�[�_
�A�[�L�e�N�`���I�ȃA�v���[�`�Ői������������ŁC���̎�@�̓O���t�B�b�N�X
�@�\�Ɛ��\�����߂����ŁC����d�͂傳���镾�Q������B
�����ł�����C�����d�̓v���b�g�t�H�[�������ɂ́CG33�Ȃǂō̗p����Ă���
�uGMA 3100�v�Ȃǂ̂悤�ɁC�Œ�@�\�̔䗦�����߂邱�Ƃŏ���d�͂�}����
���������p�ӂ���Ă���B
>>766
���̘_���͌����B���������Ŗܘ_�ǂ�łȂ��B
3D Stacking��Tera Tera Tera���݂Ă��ǂ߂�悤�ɁA
Sandy Bridge�ȍ~�̌v�悶��Ȃ��̂���(����Ɏv���Ă�)�B
�R���V���[�}�s��ɂ����Ă�Future Mark�݂����ȉ�ЂɁA
Ray-Tracing Mark���Physics Mark�݂����Ȃ̂���ꂹ������Ȃ����ƁB
�Q�[�����Ȃ��̂�CPU��GPU�͂Ƃ肠�����n�C�G���h������A
3D Mark�x���`�̃X�R�A�ő�������ƁA�P�Ȃ�u���W�����������̂�����̐��E�Ȃ킯�ŁB
���W���[�ȃx���`�ʼn����Ԃ��������Ύ��p���͕ʂƂ��Ă����s�邩���B
���̘_���͌����B���������Ŗܘ_�ǂ�łȂ��B
3D Stacking��Tera Tera Tera���݂Ă��ǂ߂�悤�ɁA
Sandy Bridge�ȍ~�̌v�悶��Ȃ��̂���(����Ɏv���Ă�)�B
�R���V���[�}�s��ɂ����Ă�Future Mark�݂����ȉ�ЂɁA
Ray-Tracing Mark���Physics Mark�݂����Ȃ̂���ꂹ������Ȃ����ƁB
�Q�[�����Ȃ��̂�CPU��GPU�͂Ƃ肠�����n�C�G���h������A
3D Mark�x���`�̃X�R�A�ő�������ƁA�P�Ȃ�u���W�����������̂�����̐��E�Ȃ킯�ŁB
���W���[�ȃx���`�ʼn����Ԃ��������Ύ��p���͕ʂƂ��Ă����s�邩���B
���ϑO��"Tera Tera Tera"�v���[�����������̂ŏ����Ă������B
http://xtreview.com/images/davis.pdf
http://xtreview.com/images/davis.pdf
770 �F���ϑz�A�����E���_�A�֒��\���͓K�x�ɁB�F2007/10/14(��) 17:02:56 ID:v8nszUq4
Larrabee�l�^�̓X����S/N���ቺ�����܂�
�V���R�������ăf����܂ŋ֎~�E�E�Ƃ͌����܂����l���ĉ�����
�V���R�������ăf����܂ŋ֎~�E�E�Ƃ͌����܂����l���ĉ�����
���ƁA�]�k�����A
http://pc.watch.impress.co.jp/docs/2007/0518/kaigai359.htm
���̋L���⍡��̌㓡�L�����݂Ă���ƁA�㓡����MIMD���Ă����p��̎g���������������B
�����SIMD�������̕���x�ł�������GPU���Larrabee�̕����ゾ�Ǝv���̂����A
SIMD vs MIMD�Ȃ�ĊԈႢ�܂���̔�r���L���ɂ��ĂĂ悢�̂��ƁB
http://pc.watch.impress.co.jp/docs/2007/0518/kaigai359.htm
���̋L���⍡��̌㓡�L�����݂Ă���ƁA�㓡����MIMD���Ă����p��̎g���������������B
�����SIMD�������̕���x�ł�������GPU���Larrabee�̕����ゾ�Ǝv���̂����A
SIMD vs MIMD�Ȃ�ĊԈႢ�܂���̔�r���L���ɂ��ĂĂ悢�̂��ƁB
�㓡����Ȃ��ă��g�i�[�Ɍ���
�����������̓��g�i�[���B
�ʂ�MIMD�ƌĂԂ̂͂������APenD�ȍ~��MIMD������B
�ŁANehalem�ł�8 core�ȏ�s���̂ɁALarrabee����SIMD�g��
�Ő��\�҂��ł�̂��ő�̃L�����낤�ƁB
�܁A�����҂�Larrabee�l�^�͂���������B
�ʂ�MIMD�ƌĂԂ̂͂������APenD�ȍ~��MIMD������B
�ŁANehalem�ł�8 core�ȏ�s���̂ɁALarrabee����SIMD�g��
�Ő��\�҂��ł�̂��ő�̃L�����낤�ƁB
�܁A�����҂�Larrabee�l�^�͂���������B
>>771
�㓡�M�҈ȊO��A�����v���Ă���Ǝv�����B(>>696-698 �Q��)
>>770
�����S�O�������A�����̚n�D�𑼐l�ɉ����t���邠�Ȃ��̐l�����S�z�Ȃ��ǁB�B�B
�㓡�M�҈ȊO��A�����v���Ă���Ǝv�����B(>>696-698 �Q��)
>>770
�����S�O�������A�����̚n�D�𑼐l�ɉ����t���邠�Ȃ��̐l�����S�z�Ȃ��ǁB�B�B
Intel�ɂƂ��ĂȂ��Ă͂Ȃ�Ȃ��l������
Rattner �� ��������Y
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
5�N��i2009�N�j�ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B
Rattner �� ��������Y
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
5�N��i2009�N�j�ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B
���H���ꂪLarrabee�̂��Ƃł���H
�I�b�e���[�j�������IDF��Larrabee�ōŏ��̃��j�[�R�A�]�X�ƌ����Ă���
�I�b�e���[�j�������IDF��Larrabee�ōŏ��̃��j�[�R�A�]�X�ƌ����Ă���
777 �FMAC�I�^��775 �����F2007/10/14(��) 18:09:43 ID:Nd7fT4Az
>>775
2007�N�̍����A����100�R�A���̃v���Z�b�T�푶�݂��邷���ǁH
http://www.rapportincorporated.com/kilocore/kc256.html
http://www.tilera.com/products/processors.php
2007�N�̍����A����100�R�A���̃v���Z�b�T�푶�݂��邷���ǁH
http://www.rapportincorporated.com/kilocore/kc256.html
http://www.tilera.com/products/processors.php
>>776
Larrabee��������Ȃ�������B
Larrabee�ȊO�ɂ����i���ł��Ȃ����s�v���W�F�N�g������������
���Ƃ����Y��Ȃ��B
Larrabee��������Ȃ�������B
Larrabee�ȊO�ɂ����i���ł��Ȃ����s�v���W�F�N�g������������
���Ƃ����Y��Ȃ��B
780 �FMAC�I�^��779 �����F2007/10/14(��) 18:18:27 ID:Nd7fT4Az
>>779
Rattner�̃R�����g��ǂݒ����ė~�������B
�@�@-----------------
�@�@�yRattner���z �����Ȃ邾�낤�B����10�R�A���x�̘b�����Ă��邪�A5�N��ɂ́A�����A100�R�A�ȏオ
�@�@����ɓ����Ă��邾�낤�B�������Ĉ����Ă����悤�ȁA��K��SMP�V�X�e���������`�b�v�Ɏ��܂�
�@�@�悤�ɂȂ�B
�@�@-----------------
�����āA���Ȃ��Ƃ�Tilea��SMP���B
http://www.tilera.com/products/processors.php
�@�@================
�@�@Each tile is a complete full-featured processor, including integrated L1 & L2 cache and a
�@�@non-blocking switch that connects the tile into the mesh. This means that each tile can
�@�@independently run a full operating system, or multiple tiles taken together can run a multi-
�@�@processing operating system like SMP Linux.
�@�@================
Rattner�̃R�����g��ǂݒ����ė~�������B
�@�@-----------------
�@�@�yRattner���z �����Ȃ邾�낤�B����10�R�A���x�̘b�����Ă��邪�A5�N��ɂ́A�����A100�R�A�ȏオ
�@�@����ɓ����Ă��邾�낤�B�������Ĉ����Ă����悤�ȁA��K��SMP�V�X�e���������`�b�v�Ɏ��܂�
�@�@�悤�ɂȂ�B
�@�@-----------------
�����āA���Ȃ��Ƃ�Tilea��SMP���B
http://www.tilera.com/products/processors.php
�@�@================
�@�@Each tile is a complete full-featured processor, including integrated L1 & L2 cache and a
�@�@non-blocking switch that connects the tile into the mesh. This means that each tile can
�@�@independently run a full operating system, or multiple tiles taken together can run a multi-
�@�@processing operating system like SMP Linux.
�@�@================
>>770
�����ɒቺ���Ă���܂� �i�����F�j
�����ɒቺ���Ă���܂� �i�����F�j
782 �FSocket774�F2007/10/14(��) 18:53:47 ID:WkOMMTTZ
���������ǁATDP�㏸���S�z�����Yorkfield XE�Ƃ팾��ES����Ŋ���4.5GHz�œ����Ă���Ƃ����b�B
http://forum.coolaler.com/showpost.php?p=1875925&postcount=98
http://forum.coolaler.com/showpost.php?p=1879353&postcount=118
http://forum.coolaler.com/showpost.php?p=1875925&postcount=98
http://forum.coolaler.com/showpost.php?p=1879353&postcount=118
>>728
�}�[�P�e�B���O��������ȁA���̃v���Z�b�T�Ɩ��炩�ɈႤ����
discrete GPU��high throughput computing�̗��ʂŒނ��ė���
���̐l���F�X����Ă邱�Ƃ͊ԈႢ�Ȃ���
���[�}�[�ɗ������͂��Ȃ�R���g���[������Ă�
AMD�ւ̌����ANVIDIA�Ƃ̎�����J�[�h�ɗ��p����Ӑ}��������
�܂�����ȉ��l���ނ莅�ŗx�炳�������
�}�[�P�e�B���O��������ȁA���̃v���Z�b�T�Ɩ��炩�ɈႤ����
discrete GPU��high throughput computing�̗��ʂŒނ��ė���
���̐l���F�X����Ă邱�Ƃ͊ԈႢ�Ȃ���
���[�}�[�ɗ������͂��Ȃ�R���g���[������Ă�
AMD�ւ̌����ANVIDIA�Ƃ̎�����J�[�h�ɗ��p����Ӑ}��������
�܂�����ȉ��l���ނ莅�ŗx�炳�������
�㓡��
SIMD VS MIND������������
�̂̃x�N�g���^�X�p�R�� VS ������@��
�ǂ������v���O�����̎��R�x���������ʂłĂ����
GPGPU�͌��E�����Ă�̂͊ԈႢ�Ȃ�
SIMD VS MIND������������
�̂̃x�N�g���^�X�p�R�� VS ������@��
�ǂ������v���O�����̎��R�x���������ʂłĂ����
GPGPU�͌��E�����Ă�̂͊ԈႢ�Ȃ�
>>770
�l�̉��߂ɂ����Signal�Ɋ�������Noise�Ɋ�������A�l�X�Ȃ�B
������GPU�n�ȃ��[�}�[���͒H���Ă����Əo����vr-zone��forum��������A
beyond3d��forum��������Ainquirer��������Afudzilla��������A
�E�E�E�E�܂�͂����������ƁB
�����ł̕s�тʼn���Ȃ��c�_�́A
��w�̍u���Ŏg������̃X���C�h��IDF�Ȃ�w��Ő��ꗬ���ΏI���b�B
�ł���������Ȃ�or�ł��Ȃ��B�����ߍ���Intel�l�����ƁB
�l�̉��߂ɂ����Signal�Ɋ�������Noise�Ɋ�������A�l�X�Ȃ�B
������GPU�n�ȃ��[�}�[���͒H���Ă����Əo����vr-zone��forum��������A
beyond3d��forum��������Ainquirer��������Afudzilla��������A
�E�E�E�E�܂�͂����������ƁB
�����ł̕s�тʼn���Ȃ��c�_�́A
��w�̍u���Ŏg������̃X���C�h��IDF�Ȃ�w��Ő��ꗬ���ΏI���b�B
�ł���������Ȃ�or�ł��Ȃ��B�����ߍ���Intel�l�����ƁB
larrabee�͂��̂��o�ĂȂ���ŁA�]�����悤���Ȃ����Ă̂����ۂ̂Ƃ��낾���
�l�I�ɂ�X86�݊����Ă̂ɑ�������������Ǝv��
1000���g�����W�X�^�N���X�Ȃ�X86�ł��Œ蒷�ł�����ܕς��Ȃ����낤����
���j�[�R�A�ł���H
���̓_�����ސl�����Ȃ��̂͂Ȃ�łȂH
�l�I�ɂ�X86�݊����Ă̂ɑ�������������Ǝv��
1000���g�����W�X�^�N���X�Ȃ�X86�ł��Œ蒷�ł�����ܕς��Ȃ����낤����
���j�[�R�A�ł���H
���̓_�����ސl�����Ȃ��̂͂Ȃ�łȂH
788 �FSocket774�F2007/10/14(��) 21:12:06 ID:qJ4W83H5
L2�M�҂ł͂Ȃ�����
���@L2 6M�@�̎��́@8M�@12M�@8M����ȁH�H
���@L2 6M�@�̎��́@8M�@12M�@8M����ȁH�H
>>787
"1000���g�����W�X�^�N���X"���ĉ��̘b�H
"1000���g�����W�X�^�N���X"���ĉ��̘b�H
>larrabee�͂��̂��o�ĂȂ���ŁA�]�����悤���Ȃ����Ă̂����ۂ̂Ƃ��낾���
��������̂�������CPU�X���Ȃ̂ł�??
�Ȃ����[�}�[���ɑ��ĐT�d���Ă������A�����悭�킩��Ȃ�����
�Ƃ肠�����@���Ă��邾���̓z�����������Ɍ�����c�B
��������̂�������CPU�X���Ȃ̂ł�??
�Ȃ����[�}�[���ɑ��ĐT�d���Ă������A�����悭�킩��Ȃ�����
�Ƃ肠�����@���Ă��邾���̓z�����������Ɍ�����c�B
http://pc.watch.impress.co.jp/docs/2007/0418/idf03.htm
��IA�x�[�X�Ƃ������Ƃ������ċƊE����̊��҂��傫�����ŁA
����͑��a�c�������Ă邾���Ŏ��ۂ̊��ғx�͕s�������A
Larrabee�Ɋ��҂��Ă����@�l���[�U�[���炵�Ă݂���
Havok�ŕ������Z�ݾ��ȏHIDF���\���݂ăY�b�R�P�Ă�̂ł͂܂����H
���[�}�[�̏����Ă�ʂ�ɂȂ�����Ȃ����ŁA�ꕔ�ڋq����̐M�p���āB
���[�}�[�𗘗p����ɂ��悵�Ȃ��ɂ���A
�N�Ԕ���グ$35Billion�̏���ƂƂ��Ă̎��o�������Ď��Ƃ�i�߂Ăق����B
>>768 >>790
���[�}�[���Ɋ��e�ɂȂ�A���p���͕ʂƂ��ė��s�邩������Ȃ����́A
�Ɋ��҂�����ŋc�_���d�˂Ă����̂����̃X���̐������݂���Ȃ킯�ł��ˁH
��IA�x�[�X�Ƃ������Ƃ������ċƊE����̊��҂��傫�����ŁA
����͑��a�c�������Ă邾���Ŏ��ۂ̊��ғx�͕s�������A
Larrabee�Ɋ��҂��Ă����@�l���[�U�[���炵�Ă݂���
Havok�ŕ������Z�ݾ��ȏHIDF���\���݂ăY�b�R�P�Ă�̂ł͂܂����H
���[�}�[�̏����Ă�ʂ�ɂȂ�����Ȃ����ŁA�ꕔ�ڋq����̐M�p���āB
���[�}�[�𗘗p����ɂ��悵�Ȃ��ɂ���A
�N�Ԕ���グ$35Billion�̏���ƂƂ��Ă̎��o�������Ď��Ƃ�i�߂Ăق����B
>>768 >>790
���[�}�[���Ɋ��e�ɂȂ�A���p���͕ʂƂ��ė��s�邩������Ȃ����́A
�Ɋ��҂�����ŋc�_���d�˂Ă����̂����̃X���̐������݂���Ȃ킯�ł��ˁH
Intel��2008�N��1�l������FSB 1,600MHz�Ή����i�𓊓�
http://pc.watch.impress.co.jp/docs/2007/1015/ubiq202.htm
http://pc.watch.impress.co.jp/docs/2007/1015/ubiq202.htm
>>791
������
�����ăN�\�}�W���ɂ���Ă���܂�Ȃ������
AMD�G�k�X����̂̃Q�n��Cell�X���݂����ɔ]������S�J�ł��Ԕ���˂�����̂��y����
NVIDIA�~ vs AMDATi�~ �Ƃ��ԂƂ�S3�~�݂����ȍH�썇��X�����y����
�����ƃ��x���������Ă���������������
������
�����ăN�\�}�W���ɂ���Ă���܂�Ȃ������
AMD�G�k�X����̂̃Q�n��Cell�X���݂����ɔ]������S�J�ł��Ԕ���˂�����̂��y����
NVIDIA�~ vs AMDATi�~ �Ƃ��ԂƂ�S3�~�݂����ȍH�썇��X�����y����
�����ƃ��x���������Ă���������������
794 �FSocket774�F2007/10/14(��) 23:59:18 ID:L9sQOMoo
�l�n�[�����W�R�A��҂��Ă��鉴�͏����g�B
�T�u���~�i���FLarrabee��HPC���o�g�̃��g�i�[���v�b�V�����Ă��܂�
GRAPE��GRAPE-DR�ʼn��p�͈͍L���Đ����c��(�\�Z�l��)�ɕK��(���s����v���W�F�N�g�I��)
Larrabee�����p�͈͍L���Đ����c��(�V�F�A�l��)�ɕK��(���s�����Itanic��XScale�̓�̕�)
GRAPE��GRAPE-DR�ʼn��p�͈͍L���Đ����c��(�\�Z�l��)�ɕK��(���s����v���W�F�N�g�I��)
Larrabee�����p�͈͍L���Đ����c��(�V�F�A�l��)�ɕK��(���s�����Itanic��XScale�̓�̕�)
>>793
�N�A����ł�����
�N�A����ł�����
797 �FSocket774�F2007/10/15(��) 00:10:27 ID:c3Sy8xcl
�W�R�A���������ɂȂ�Ȃ����ȁB
���s����100��$��������邱�ƂɂȂ�����ł��ˁi�j
��Intel�C��HP�C�x�m�ʂȂ�9�ЁCItanium�̕��y���i��100���h���̎����𓊓�
http://itpro.nikkeibp.co.jp/article/COLUMN/20060303/231680/
Itanium���ڃT�[�o�A����x�[�X�̃V�F�A������RISC�T�[�o��6�������Ɋg��
http://www.rbbtoday.com/news/20070301/39100.html
��Intel�C��HP�C�x�m�ʂȂ�9�ЁCItanium�̕��y���i��100���h���̎����𓊓�
http://itpro.nikkeibp.co.jp/article/COLUMN/20060303/231680/
Itanium���ڃT�[�o�A����x�[�X�̃V�F�A������RISC�T�[�o��6�������Ɋg��
http://www.rbbtoday.com/news/20070301/39100.html
Itanium��Larrabee���ᓊ���̋K�͂��Ⴄ�B
Larrabee���Č��X�j�b�`���ʂ��˂���Ă邶���B
Larrabee���Č��X�j�b�`���ʂ��˂���Ă邶���B
��Ɛ헪������������XScale�����Ď��s�Ƃ͌���Ȃ�����
Larrabee�͂����������i
- ����Ă����l���g���悤�Ȑ��i�ł͂Ȃ�
- ��GPU�ł��ėpCPU�ł��Ȃ����A�ǂ���Ƃ����܂苣�����Ȃ�
- Intel�I�ɂ͔���Ȃ��Ă����܂�ɂ��Ȃ�
- ���Ȃ��Ƃ��ŏ��͑����R�A�̘b�萫�d��
���͍ŏ��ɉ\���o�������璆�g�͕ς���ĂȂ��B
GPU��CPU���̃J�e�S���C�Y���b��̒��S�ɂȂ肷���āA���g���悭�݂��ĂȂ������l
�����������B�P��x86�̃x�N�g���g���ŕ��Z�������Ă�������B
- ����Ă����l���g���悤�Ȑ��i�ł͂Ȃ�
- ��GPU�ł��ėpCPU�ł��Ȃ����A�ǂ���Ƃ����܂苣�����Ȃ�
- Intel�I�ɂ͔���Ȃ��Ă����܂�ɂ��Ȃ�
- ���Ȃ��Ƃ��ŏ��͑����R�A�̘b�萫�d��
���͍ŏ��ɉ\���o�������璆�g�͕ς���ĂȂ��B
GPU��CPU���̃J�e�S���C�Y���b��̒��S�ɂȂ肷���āA���g���悭�݂��ĂȂ������l
�����������B�P��x86�̃x�N�g���g���ŕ��Z�������Ă�������B
>>798
���E�ł�Itanium�T�[�o�[�̎s��K�͂͂�������11���h��(2006�N)�B
���N�R�����h�ɐV���ɊJ�݂���300�l�̃f�U�C���Z���^�[�ێ����邱�Ƃ���o���܂���B
�J���� 1���h��(300 x 33���h��)
�T�[�o�[�x���_��Itanium�̔���グ 7.7���h��(11���h�� x 0.7)
Intel��Itanium�̏o�ח� 7.7����(7.7���h�� / 1���h��)
Intel��Itanium�̔���グ 1.54���h��(77000 x 2000�h��)
Itanium��Intel�I�ɂ͑厸�s�B
�Ǝ��Ƀv���Z�b�T���J���������Ȃ��T�[�o�x���_���v���Z�b�T����Intel���甃���@���Ĕ���OS�Ŗׂ��Ă���̂�����B
�ł�Intel��POWER��SPARC�ɑ���J�[�h���~�������T�[�o�[�x���_�Ƃ̂Ȃ���̂��߂ɂ����߂Ȃ��B
���E�ł�Itanium�T�[�o�[�̎s��K�͂͂�������11���h��(2006�N)�B
���N�R�����h�ɐV���ɊJ�݂���300�l�̃f�U�C���Z���^�[�ێ����邱�Ƃ���o���܂���B
�J���� 1���h��(300 x 33���h��)
�T�[�o�[�x���_��Itanium�̔���グ 7.7���h��(11���h�� x 0.7)
Intel��Itanium�̏o�ח� 7.7����(7.7���h�� / 1���h��)
Intel��Itanium�̔���グ 1.54���h��(77000 x 2000�h��)
Itanium��Intel�I�ɂ͑厸�s�B
�Ǝ��Ƀv���Z�b�T���J���������Ȃ��T�[�o�x���_���v���Z�b�T����Intel���甃���@���Ĕ���OS�Ŗׂ��Ă���̂�����B
�ł�Intel��POWER��SPARC�ɑ���J�[�h���~�������T�[�o�[�x���_�Ƃ̂Ȃ���̂��߂ɂ����߂Ȃ��B
�x���_�Ƃ̌q���肪���邩�狤���Ŏ������o���Ă����
Larrabee�����ĒP�ꕔ��Ō��ĐԂł����̈ʒu�܂ł��ǂ蒅������
Larrabee�����ĒP�ꕔ��Ō��ĐԂł����̈ʒu�܂ł��ǂ蒅������
>>789
1000���g�����W�X�^�N���X���Ă̂�
1�R�A������̏W�ϓx
larrab���o��͓̂����悾��
�d�l����܂��ĂȂ����낤���A�A�v���P�[�V�����������ĂȂ�
1000���g�����W�X�^�N���X���Ă̂�
1�R�A������̏W�ϓx
larrab���o��͓̂����悾��
�d�l����܂��ĂȂ����낤���A�A�v���P�[�V�����������ĂȂ�
>�x���_�Ƃ̌q���肪���邩�狤���Ŏ������o���Ă����
�Ⴂ�܂��B
�x���_�͎��Ђ̂��߂ɂ����������܂���B
Itanium�ł͂Ȃ��u(Itanium��ς�)���Ђ̃T�[�o�[�v�ɓ�������̂ł��B
������Itanium���̂̊J���Ɛ����Ɣ̔��̔�p�͑S��Intel�����B
�T�[�o�x���_�̓����́u���ЃT�[�o�[�́v�}�[�P�e�B���O, �~�h���E�F�A, �o���f�[�V�����ւ̓����B
(����ǂ�ł킩�����Ǝv������100���h�������̂��Ȃ�̕�����������I�Ȏg���������Ă��邱�Ƃ��킩��͂��B
�v���Z�b�T�̐�������OS�܂Ŏ��Ђł���Ă�IBM�Ƃ͈Ⴄ�BSIer�A���̎�_���I�悵���`�B)
���A�`�b�v�Z�b�g��Ǝ��ŊJ�����Ă���Ƃ���͂���ւ̓������B
�E�E�E�� �����܂ł��炾�珑���Ă������ǁB
Gelato ICE�̃X�|���T�[�������Itanium���̂��̂ɓ������Ă�̂�HP��Intel�������Ƃ킩�肻���Ȃ��́B
100�ȏ�Ƃ�����ISA�̃����o�[�͂قƂ�Ǖs�Q���B���ꂪ�����B
�Ⴂ�܂��B
�x���_�͎��Ђ̂��߂ɂ����������܂���B
Itanium�ł͂Ȃ��u(Itanium��ς�)���Ђ̃T�[�o�[�v�ɓ�������̂ł��B
������Itanium���̂̊J���Ɛ����Ɣ̔��̔�p�͑S��Intel�����B
�T�[�o�x���_�̓����́u���ЃT�[�o�[�́v�}�[�P�e�B���O, �~�h���E�F�A, �o���f�[�V�����ւ̓����B
(����ǂ�ł킩�����Ǝv������100���h�������̂��Ȃ�̕�����������I�Ȏg���������Ă��邱�Ƃ��킩��͂��B
�v���Z�b�T�̐�������OS�܂Ŏ��Ђł���Ă�IBM�Ƃ͈Ⴄ�BSIer�A���̎�_���I�悵���`�B)
���A�`�b�v�Z�b�g��Ǝ��ŊJ�����Ă���Ƃ���͂���ւ̓������B
�E�E�E�� �����܂ł��炾�珑���Ă������ǁB
Gelato ICE�̃X�|���T�[�������Itanium���̂��̂ɓ������Ă�̂�HP��Intel�������Ƃ킩�肻���Ȃ��́B
100�ȏ�Ƃ�����ISA�̃����o�[�͂قƂ�Ǖs�Q���B���ꂪ�����B
intel���āAx86�ȊO�ς��Ƃ��Ȃ����
iAPX486,i860,i960,ARM,Itaniam
�����獂���\�ȃv���Z�b�T������Ă��A���o���Ȃ���
��p�v���Z�b�T���Ȃ��̂́Ai860,i960�ŏؖ��ς�
i960�Ȃ�ăZ�K�̊�ՂƂ�RAID�R���g���[���[�Ƃ����낢��g���Ă���
iAPX486,i860,i960,ARM,Itaniam
�����獂���\�ȃv���Z�b�T������Ă��A���o���Ȃ���
��p�v���Z�b�T���Ȃ��̂́Ai860,i960�ŏؖ��ς�
i960�Ȃ�ăZ�K�̊�ՂƂ�RAID�R���g���[���[�Ƃ����낢��g���Ă���
>�����獂���\�ȃv���Z�b�T������Ă��A���o���Ȃ���
>��p�v���Z�b�T���Ȃ��̂́Ai860,i960�ŏؖ��ς�
i860�͍����\����Ȃ�����B
�����\�ɂ������ō�������ǐv�����Ő��\�����ہB
������CPU�Ƃ��č̗p����WS����������N�{�^���o���Ă���
�G���̃x���`�Řb�ɂȂ�Ȃ��X�R�A�������L��������B
>��p�v���Z�b�T���Ȃ��̂́Ai860,i960�ŏؖ��ς�
i860�͍����\����Ȃ�����B
�����\�ɂ������ō�������ǐv�����Ő��\�����ہB
������CPU�Ƃ��č̗p����WS����������N�{�^���o���Ă���
�G���̃x���`�Řb�ɂȂ�Ȃ��X�R�A�������L��������B
i960���������Ō�����
Itanium��2013�`2015�N�̃��[�h�}�b�v�܂ł���킯����
http://japan.cnet.com/news/ent/story/0,2000056022,20350934,00.htm
http://www.techworld.com/opsys/features/index.cfm?featureID=3503&pagtype=all
>>800
PXA�AIOP�AIXP�A���Ƀ`�b�v�͊e���Ŏg���Ă���
��Ђ�Dell�IRAID�J�[�h��IOP��
http://japan.cnet.com/news/ent/story/0,2000056022,20350934,00.htm
http://www.techworld.com/opsys/features/index.cfm?featureID=3503&pagtype=all
>>800
PXA�AIOP�AIXP�A���Ƀ`�b�v�͊e���Ŏg���Ă���
��Ђ�Dell�IRAID�J�[�h��IOP��
���ꂩ��Itanium�ɂP���~�ȏ����������̂��B
����͂���Ŋm���ɂ������ȁB
����͂���Ŋm���ɂ������ȁB
812 �FSocket774�F2007/10/15(��) 21:38:16 ID:0ljw4f7n
���������~�ƃh���̉��l���Ⴂ�����鎞��ɂȂɂ�����
����>>813�݂����ȓ��������ȃ��X�����肰�Ȃ��ł���悤�ɂȂ肽��
>>809
�{���ɂ��C������Ȃ�Itanium�ł�������uarch�̕ύX�܂߂ɂ��ƁB
Tick-Tock�قǂ̈ٗl�ȃn�C�y�[�X�ł��Ƃ͌���Ȃ�����POWER�ɒx��Ȃ����x�ɂ͂���ė~�����B
Montecito��65nm��(�{����Montvale)�̓L�����Z�����ꂽ��Tukwila��45nm�ł����[�h�}�b�v�ɂȂ������B
8�N��܂ł̃��[�h�}�b�v�Ȃ�ėv��Ȃ�����B�ǂ����r���ʼn�����������ύX�ɂȂ���B
����POWER��x86������2010�N�܂ł����Ȃ������B�o���o�����\�Ƃ������Ă����傤���Ȃ���ˁB
�{���ɂ��C������Ȃ�Itanium�ł�������uarch�̕ύX�܂߂ɂ��ƁB
Tick-Tock�قǂ̈ٗl�ȃn�C�y�[�X�ł��Ƃ͌���Ȃ�����POWER�ɒx��Ȃ����x�ɂ͂���ė~�����B
Montecito��65nm��(�{����Montvale)�̓L�����Z�����ꂽ��Tukwila��45nm�ł����[�h�}�b�v�ɂȂ������B
8�N��܂ł̃��[�h�}�b�v�Ȃ�ėv��Ȃ�����B�ǂ����r���ʼn�����������ύX�ɂȂ���B
����POWER��x86������2010�N�܂ł����Ȃ������B�o���o�����\�Ƃ������Ă����傤���Ȃ���ˁB
>>816
Itanium�������I�ɃA���ŁA�Ƃ肠�������[�h�}�b�v�͎����Ȃ��Ƃ����Ȃ��������Ă�A�Ƃ����̂͌����Ă邪
Itanium�f���A���R�A�������N�������H
POWER�f���A���R�A��5�N�x��Ă邾������Ȃ��A�V���i���\�̑��x������������Ȃ�
Itanium�������I�ɃA���ŁA�Ƃ肠�������[�h�}�b�v�͎����Ȃ��Ƃ����Ȃ��������Ă�A�Ƃ����̂͌����Ă邪
Itanium�f���A���R�A�������N�������H
POWER�f���A���R�A��5�N�x��Ă邾������Ȃ��A�V���i���\�̑��x������������Ȃ�
818 �FMAC�I�^��817 �����F2007/10/15(��) 23:01:32 ID:WHqL7U1/
>>817
�@�@---------------
�@�@Itanium�f���A���R�A�������N�������H
�@�@---------------
Itanium�������̂펩�R�����ǁA�A���~���݂̖ϑz�튨�ق��ė~�������B
http://www.golem.de/0502/36134-montecito-die.jpg
�@�@---------------
�@�@Itanium�f���A���R�A�������N�������H
�@�@---------------
Itanium�������̂펩�R�����ǁA�A���~���݂̖ϑz�튨�ق��ė~�������B
http://www.golem.de/0502/36134-montecito-die.jpg
{kind=link}
Montecito�͒x�ꂽ����T�[�o�[�̏o�J�n�͋��N��9�����炾��B
�ł�mx2�����邩��f���A���R�A����2004�N�ł������C������B
�ł�mx2�����邩��f���A���R�A����2004�N�ł������C������B
�x�N�g���@�}���Z�[FUSION�}���Z�[�ł��Ȃ���tarusan�V�L��
�n���V�~���ւ̖������炽�炾��
�n�D�ɍ���Ȃ�Larrabee��(��)�Ɛ��Ď̂ĂĂ邨
�n���V�~���ւ̖������炽�炾��
�n�D�ɍ���Ȃ�Larrabee��(��)�Ɛ��Ď̂ĂĂ邨
>>818
�L���b�V���̊C�ɔ�э��݂���
�L���b�V���̊C�ɔ�э��݂���
822 �FSocket774�F2007/10/16(��) 08:45:26 ID:etWfhVN/
�ǂ��ł��������ǁAMac�I�^����̓��{�ꂪ�C���������Ǝv���Ă���̂́A�����������H
>>822
�U�X���o
�U�X���o
���̒m�����7�N�O����U�X���o
825 �F822�F2007/10/16(��) 10:03:12 ID:etWfhVN/
����������Ȃ�������ł��ˁcί
TheINQ��IDF��k���|�[�g���B
http://www.theinquirer.net/gb/inquirer/news/2007/10/16/idf-taiwan-2007-intel-penryn
�@�E�Ⓚ�@��p�ɂ��X9772/3.2GHz��6GHz OC�f��
�@�ELN2��p�ɂ��X6750/3GHz�́�6GHz OC�f��
�@�ETDP 45W�̃��o�C������Penryn/2.66GHz�̃f��
�������hkepc��SkullTrail��Yorkfield XE�ɂ��Ă̋L�����B
http://www.hkepc.com/?id=238
�@�ESkullTrail: Socket771 x 2, 5400 chipset, 1600MHz FSB, FB-DIMM 800�T�|�[�g, Max. 8GB, QuadSLI�T�|�[�g
�@�EQX9755/3.2GHz: Socket771(���̂�Harpertown��) $1,499-
�@�EQX9750/3.2GHz: Socket775 $1,399-
http://www.theinquirer.net/gb/inquirer/news/2007/10/16/idf-taiwan-2007-intel-penryn
�@�E�Ⓚ�@��p�ɂ��X9772/3.2GHz��6GHz OC�f��
�@�ELN2��p�ɂ��X6750/3GHz�́�6GHz OC�f��
�@�ETDP 45W�̃��o�C������Penryn/2.66GHz�̃f��
�������hkepc��SkullTrail��Yorkfield XE�ɂ��Ă̋L�����B
http://www.hkepc.com/?id=238
�@�ESkullTrail: Socket771 x 2, 5400 chipset, 1600MHz FSB, FB-DIMM 800�T�|�[�g, Max. 8GB, QuadSLI�T�|�[�g
�@�EQX9755/3.2GHz: Socket771(���̂�Harpertown��) $1,499-
�@�EQX9750/3.2GHz: Socket775 $1,399-
>>822
�X���I�^�ꂪ�ꍑ��̓y�l�����炵����������
�X���I�^�ꂪ�ꍑ��̓y�l�����炵����������
Nehalem looks set to deliver a real big performance jump
http://www.theinquirer.net/gb/inquirer/news/2007/10/16/idf-taipei-nehalem-real-big
Kirk Skaugen, Intel's Digital Enterprise Group VP and GM of Server Platforms Group
CPU core performance jump from the same process Core 2 (Penryn) to Nehalem would be
higher than the jump for Netburst to Core 2 itself
�������c
http://www.theinquirer.net/gb/inquirer/news/2007/10/16/idf-taipei-nehalem-real-big
Kirk Skaugen, Intel's Digital Enterprise Group VP and GM of Server Platforms Group
CPU core performance jump from the same process Core 2 (Penryn) to Nehalem would be
higher than the jump for Netburst to Core 2 itself
�������c
�������R�A�̕����͔閧�@�\�̎����������Ă����������Ȃ��قǂ̊g���ƕ����B
����eneble�����̂��͒m��Ȃ����ǁA�y���݂ɂȂ��Ă܂���܂����B
Nehalem�̓A���R�A�ɂ��Ă̘b�肪��s���Ă邯�ǁA�����R�A�̏ڍׂ��m�肽���B
����eneble�����̂��͒m��Ȃ����ǁA�y���݂ɂȂ��Ă܂���܂����B
Nehalem�̓A���R�A�ɂ��Ă̘b�肪��s���Ă邯�ǁA�����R�A�̏ڍׂ��m�肽���B
Intel�̐V�@�\���čň�������ɂȂ�Ȃ��ƗL���ɂ���Ȃ�����Ȃ��B
������INQUIRER�̋L����������c�B
������INQUIRER�̋L����������c�B
>>829
���܂肷����Nehalem���ƘmP4��ԂɂȂ�킯����
���܂肷����Nehalem���ƘmP4��ԂɂȂ�킯����
�������������āA���ꂪ��Ԃ������ȁB
> �e���v���͑O����46.9%����52.4%�ɃA�b�v�����B
> �e���v���͂���Ɍ��サ�A57���O��ɂȂ錩�ʂ����B
> �e���v���͑O����46.9%����52.4%�ɃA�b�v�����B
> �e���v���͂���Ɍ��サ�A57���O��ɂȂ錩�ʂ����B
Netburst����CoreMA�ֈڍs���āA��荂������邩�炾�낤���ˁB
XeonMP�ȂATulsa����435mm2�ōŏ��1,980�h�����ATigerton�Ɉڍs�ŁA
143mm2*2��2,301�h���Ŕ������B�����E�G�n1���������CPU�̐��͔{�ǂ��낶��Ȃ����낤�B
XeonMP�ȂATulsa����435mm2�ōŏ��1,980�h�����ATigerton�Ɉڍs�ŁA
143mm2*2��2,301�h���Ŕ������B�����E�G�n1���������CPU�̐��͔{�ǂ��낶��Ȃ����낤�B
>>833
�ł����ɎI�pCPU���Ə����ɍ����Ă��i���щ��i�ɖ�����邾�낤���j�^�p���Ɍ����Ă��܂���
���ꂮ�炢�̂����͂��������Ȃ����
Netburst��CoreMA�ӂ蕝���ʂƂł����������́H
�ł����ɎI�pCPU���Ə����ɍ����Ă��i���щ��i�ɖ�����邾�낤���j�^�p���Ɍ����Ă��܂���
���ꂮ�炢�̂����͂��������Ȃ����
Netburst��CoreMA�ӂ蕝���ʂƂł����������́H
��������intel�`�b�v�̉��i���ǐ�̉��i����Ɛ艿�i�ֈڍs���Ă䂭�̂ł���
Inq�̓K���Ȑ��������ǁA
PentiumD 3.73GHz��Core2 2.93GHz��30~80%���\���A�b�v�����̂ƁA
Core2�̍Ō��Extreme�ł�3.6GHz ,FSB1600MHz������A
Core2 3.6GHz * 1.3~1.8����H�E�E�E�ق�Ƃ���
PentiumD 3.73GHz��Core2 2.93GHz��30~80%���\���A�b�v�����̂ƁA
Core2�̍Ō��Extreme�ł�3.6GHz ,FSB1600MHz������A
Core2 3.6GHz * 1.3~1.8����H�E�E�E�ق�Ƃ���
��ʐl�ɂ͂���ȃn�C�X�y�b�R�Ȃ��͕̂K�v�Ȃ�
AMD�i�j�̈����ŏ\��
AMD�i�j�̈����ŏ\��
TheINQ��Tukwila�̃_�C�ʐ^���f�ڂ��Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2007/10/17/idf-taiwan-itanium-news
�@�@------------------------
�@�@so, while single thread core performance might not jump up too much,
�@�@large jobs should scale much better.
�@�@------------------------
���p���̒ʂ�C��{�I�ɂ�Montecito�̃R�A�P���Ă���悤�Ɍ����邷�B
Montecito�̃_�C�ʐ^ http://en.wikipedia.org/wiki/Image:Montecito_micrograph.jpg
http://www.theinquirer.net/gb/inquirer/news/2007/10/17/idf-taiwan-itanium-news
�@�@------------------------
�@�@so, while single thread core performance might not jump up too much,
�@�@large jobs should scale much better.
�@�@------------------------
���p���̒ʂ�C��{�I�ɂ�Montecito�̃R�A�P���Ă���悤�Ɍ����邷�B
Montecito�̃_�C�ʐ^ http://en.wikipedia.org/wiki/Image:Montecito_micrograph.jpg
{kind=link}
���������o���� "Tukwila dies!" ��
Silverthorne���S���b��ɏo�܂���ˁB
http://pc.watch.impress.co.jp/docs/2007/1018/ubiq203.htm
���o�C���pPC�v���b�g�t�H�[���Ƃ��āA���͊��҂��Ă���B
http://pc.watch.impress.co.jp/docs/2007/1018/ubiq203.htm
���o�C���pPC�v���b�g�t�H�[���Ƃ��āA���͊��҂��Ă���B
�����p�t�H�[�}���X�����W���Ⴗ����̂�
������CPU�Ƃ��������͂⌻�s����ɋ߂�����ł́H
INTEL���g��Vista�������Ƃ�ړI�Ƃ��Ă��Ȃ����Č����Ă邵��
������CPU�Ƃ��������͂⌻�s����ɋ߂�����ł́H
INTEL���g��Vista�������Ƃ�ړI�Ƃ��Ă��Ȃ����Č����Ă邵��
Core 2 Duo T7300 �� Core 2 Quad Q6600
�Ŗ����Ă���ǒP���ɃR�A�����������삪�����ƍl���Ă����́H
�Ŗ����Ă���ǒP���ɃR�A�����������삪�����ƍl���Ă����́H
���̓�Ŗ������R���킩���
T���ăm�[�g�p�������H
>>842
�ŁA���̓�̑I�����u������CPU�X���v�̘b��ɉ����W����́H�@
�ŁA���̓�̑I�����u������CPU�X���v�̘b��ɉ����W����́H�@
Moorestown�̂���Ɏ���32nm�̗p������UMPC�p��CPU���f���A���R�A������낤���B
http://pc.watch.impress.co.jp/docs/2007/1018/kaigai394.htm
�ȑO�̋L���ŁACoreMA��MP�ł�6�R�A�Ƃ����̂͂ǂ��������Ƃ��낤���Ǝv���Ă������A
����̋L����Dunnington�͖{����6�R�A�炵���B�����AL2��3�R�A���̋��L�������̂��A
2�R�A���̋��L�Ə�ς���Ă���B
�܂��ANehalem��8�R�A��Beckton�͌㓡���̏��8�R�A��LLC��24MB�ŋ��L�炵���A
TechOn�ł�4�R�A�_�C����ׂ��`��Ƃ������ƈقȂ��Ă���悤�Ɏv����B
Nehalem�̃L���b�V���W�̏���4�R�A�����łȂ�8�R�A���������Ă����w
�ȑO�̋L���ŁACoreMA��MP�ł�6�R�A�Ƃ����̂͂ǂ��������Ƃ��낤���Ǝv���Ă������A
����̋L����Dunnington�͖{����6�R�A�炵���B�����AL2��3�R�A���̋��L�������̂��A
2�R�A���̋��L�Ə�ς���Ă���B
�܂��ANehalem��8�R�A��Beckton�͌㓡���̏��8�R�A��LLC��24MB�ŋ��L�炵���A
TechOn�ł�4�R�A�_�C����ׂ��`��Ƃ������ƈقȂ��Ă���悤�Ɏv����B
Nehalem�̃L���b�V���W�̏���4�R�A�����łȂ�8�R�A���������Ă����w
848 �FSocket774�F2007/10/18(��) 16:09:51 ID:RNJmu5nw
�U�R�A�͔���Ȃ�����
3�R�A���͔����C������B
8way 128�X���b�h ����
852 �FSocket774�F2007/10/18(��) 17:44:58 ID:RoXEh2xC
���{��`�͂��������I��邩���͂Ȃ�
>>867 Nehalem��8 Way MP�\����@�����ɂ��₵���}�BEva���́B
>>867
ܸö!!
ܸö!!
�����玟�X�����MP�T�[�o�`�b�v�Ƃ͂����A�܂��ɉ��������ȁd
FSB��QPI�ɂȂ������ꂩ��MCM�̈З͑S�J�̂͂��������̂ɁE�E�E������
>>847
�Z�t�B���g�̎��c
�Z�t�B���g�̎��c
����o����Itanium�͗m���H
��ɂ�
45nm�������Ƃ�����
Nehalem��QPI�̎�����
45nm�������Ƃ�����
Nehalem��QPI�̎�����
MCM���~�߂闝�R�͓d�͌����������Ȃ邩��ł����ˁB
��p�����N�Ƃ���QP���ł���̂Ȃ�AI���������Z�p���Ǝv�����ǂȁB
��p�����N�Ƃ���QP���ł���̂Ȃ�AI���������Z�p���Ǝv�����ǂȁB
�\�P�b�g������̃R�A�����A���ȏ�ɑ��₵�Ă����������x��
����Ȃ����Ă̂�mcm�~�߂闝�R����
��p�̖������邵
����Ȃ����Ă̂�mcm�~�߂闝�R����
��p�̖������邵
���Ƃ�AMD�݂����ɃR�A���ɂ�L���b�V�����ɂ̑I�ʗ����i���A���R�A�i��
���L���b�V���i�Ƃ��Đ��i�ɂ��Ղ����Ă̂��L�肻���B
���L���b�V���i�Ƃ��Đ��i�ɂ��Ղ����Ă̂��L�肻���B
XeonMP�̃}���`�R�A�́APaxville�ATulsa�AWhitefield�ƃV���O���_�C�ōs���͂����A
Whitefield���s��Tigerton����MCM�ɂȂ��������ƌ�������������Ȃ��́H
XeonDP�A�f�X�N�g�b�v��MCM���Ȃ��Ƃ܂����܂����킯����Ȃ����������B
Whitefield���s��Tigerton����MCM�ɂȂ��������ƌ�������������Ȃ��́H
XeonDP�A�f�X�N�g�b�v��MCM���Ȃ��Ƃ܂����܂����킯����Ȃ����������B
MCM���n�C�G���h�Ɏ����čs�����Ƃ���ƁA�ǂ����Ă�1�_�C���キ�Ȃ邩���
�l�i�����������Ƃ͂����A���Ƃ���Core2��1�_�C�ȂǁA1�N�ȏ�o���Ă�2.93GHz��3GHz�̐��\���サ���Ȃ�
������AQX6850���o�����߂�
�������邯�ǁATDP130W���f�����V���O���A�f���A���X���b�h���\�ł�1�_�C�Ɠ����̐��\���o�����邽�߁B
�������A���E���肬��܂ł�邱�Ƃ͂Ȃ��낤���A
�u1�_�C������̐��\���A�����E�̔����܂ł����������Ȃ��v
�Ƃ����헪�͂�߂Ăق�������
�l�i�����������Ƃ͂����A���Ƃ���Core2��1�_�C�ȂǁA1�N�ȏ�o���Ă�2.93GHz��3GHz�̐��\���サ���Ȃ�
������AQX6850���o�����߂�
�������邯�ǁATDP130W���f�����V���O���A�f���A���X���b�h���\�ł�1�_�C�Ɠ����̐��\���o�����邽�߁B
�������A���E���肬��܂ł�邱�Ƃ͂Ȃ��낤���A
�u1�_�C������̐��\���A�����E�̔����܂ł����������Ȃ��v
�Ƃ����헪�͂�߂Ăق�������
>>864
����̓V���O���`�b�v�ł��}���`�`�b�v�ł��ς��Ȃ��ˁH
����̓V���O���`�b�v�ł��}���`�`�b�v�ł��ς��Ȃ��ˁH
�P�ɔz���Z�p���m������Ė����������Ǝv��
QuickPath�̓s��������̓]�����[�g��4�{�ȏ�ɂȂ��Ă�킯��
>>863
Whitefield��MCM�������Ƃ����\�������
QuickPath�̓s��������̓]�����[�g��4�{�ȏ�ɂȂ��Ă�킯��
>>863
Whitefield��MCM�������Ƃ����\�������
>>864
865�Ɠ�����1�_�C�}���`�R�A�ł�MCM�ł��A�R�A���������ɃN���b�N���킹��Ȃ瓯�����Ǝv���B
>>866
�]���̃p�������o�X����Ȃ�����A���̉\��������������ˁB
Intel�̂��Ƃ�����1�_�C8�R�A��������Ȃ��āAMCM���o�b�N�A�b�v�v�����Ƃ��Ă���Ă�͂����낤���B
����Whitefield��MCM�������Ƃ����\�̃\�[�X���Ăǂ����ȁH
�\���Ƃ��Ă�����ƒႢ�C��������ǁBWhitefield��FSB������QPI�Ɉڍs����͂�������CPU�����B
865�Ɠ�����1�_�C�}���`�R�A�ł�MCM�ł��A�R�A���������ɃN���b�N���킹��Ȃ瓯�����Ǝv���B
>>866
�]���̃p�������o�X����Ȃ�����A���̉\��������������ˁB
Intel�̂��Ƃ�����1�_�C8�R�A��������Ȃ��āAMCM���o�b�N�A�b�v�v�����Ƃ��Ă���Ă�͂����낤���B
����Whitefield��MCM�������Ƃ����\�̃\�[�X���Ăǂ����ȁH
�\���Ƃ��Ă�����ƒႢ�C��������ǁBWhitefield��FSB������QPI�Ɉڍs����͂�������CPU�����B
>>867
���߂�A���Ⴂ���Ă�
8�R�A MCM�̉\���������̂�Harpertown��
���̉\��45nm�̂�������Harpertown�̓l�C�e�B�u�N�@�b�h����?�Ƃ������Ă�����
���߂�A���Ⴂ���Ă�
8�R�A MCM�̉\���������̂�Harpertown��
���̉\��45nm�̂�������Harpertown�̓l�C�e�B�u�N�@�b�h����?�Ƃ������Ă�����
>>868
�m����Harpertown�̓l�C�e�B�u�N�A�b�h�ł͂��ă��X�͌��\�������ˁB
���͂ނ���Caneland�̃X�k�[�v�t�B���^�̗e�ʂ�64MB������l�C�e�B�u�N�A�b�h�͏o�邩�ǂ���
�^�⎋���Ă����B
Penryn����Ȃ�Tulsa�݂����ȍ\���ɂȂ邩��AL2��6MB*2�ɑ���L3��16MB�܂ł���
�ڂ����Ȃ����Ă̂̓o�����X������Ȃ��Ă��ƂŁB
����Ƃ���Dunnington��L2����L3��16MB���Ǝv�������A6�R�A�Ȃ�ė\���ł��Ȃ���w
�m����Harpertown�̓l�C�e�B�u�N�A�b�h�ł͂��ă��X�͌��\�������ˁB
���͂ނ���Caneland�̃X�k�[�v�t�B���^�̗e�ʂ�64MB������l�C�e�B�u�N�A�b�h�͏o�邩�ǂ���
�^�⎋���Ă����B
Penryn����Ȃ�Tulsa�݂����ȍ\���ɂȂ邩��AL2��6MB*2�ɑ���L3��16MB�܂ł���
�ڂ����Ȃ����Ă̂̓o�����X������Ȃ��Ă��ƂŁB
����Ƃ���Dunnington��L2����L3��16MB���Ǝv�������A6�R�A�Ȃ�ė\���ł��Ȃ���w
>���͂ނ���Caneland�̃X�k�[�v�t�B���^�̗e�ʂ�64MB������l�C�e�B�u�N�A�b�h�͏o�邩�ǂ���
>�^�⎋���Ă����B
>Penryn����Ȃ�Tulsa�݂����ȍ\���ɂȂ邩��AL2��6MB*2�ɑ���L3��16MB�܂ł���
>�ڂ����Ȃ����Ă̂̓o�����X������Ȃ��Ă��ƂŁB
����ˁB�ǂ�����IDF���|�[�g��SF 128MB���ĕ����Ƃ���L3 32MB�Ńl�C�e�B�u������?�Ǝv�������nj�������B
>����Ƃ���Dunnington��L2����L3��16MB���Ǝv�������A6�R�A�Ȃ�ė\���ł��Ȃ���w
���������ӂ�
>�^�⎋���Ă����B
>Penryn����Ȃ�Tulsa�݂����ȍ\���ɂȂ邩��AL2��6MB*2�ɑ���L3��16MB�܂ł���
>�ڂ����Ȃ����Ă̂̓o�����X������Ȃ��Ă��ƂŁB
����ˁB�ǂ�����IDF���|�[�g��SF 128MB���ĕ����Ƃ���L3 32MB�Ńl�C�e�B�u������?�Ǝv�������nj�������B
>����Ƃ���Dunnington��L2����L3��16MB���Ǝv�������A6�R�A�Ȃ�ė\���ł��Ȃ���w
���������ӂ�
����45nm��ArF�h���C�I���̃_�u���p�^�[�j���O�ł���B
�����A�t�Z��߂��B
Intel�͑O����45nm����g���ƌ����Ă��C�����邪
193nm�h���C�ł����ЂƊ撣��
193nm�h���C�ł����ЂƊ撣��
�_�u���p�^�[�j���O�ł���Ȃ���
������ł̓_�u���p�^�[�j���O�͉t�Z���X���[�v�b�g���Ⴂ����̗p����킯������
������ł̓_�u���p�^�[�j���O�͉t�Z���X���[�v�b�g���Ⴂ����̗p����킯������
4�R�A�A8�R�A���o���̂͗ǂ����ǃV���O�����N���b�N���o���ė~�����B
CoreSolo 6Ghz�Ƃ��o���āB
CoreSolo 6Ghz�Ƃ��o���āB
����LAN�Ƃ��d�q�����W�Ƃ̊������ĉ������ꂽ�����H
6ghz�т͂ނ�����Ȃ��������B
6ghz�т͂ނ�����Ȃ��������B
�W�Ȃ��Ǝv�����B�B
>>875
single core ��6GHz�o���Ȃ�����A�}���`�R�A�Ō떂�����Ă�����B
����Hf�n�Q�[�g��EOT�ƕ��������̏ڍׂ������Ȃ����牽�Ƃ������Ȃ����i�����m��Ȃ������j
4GHz����������ǂ��ˈʂ��낤�Ȃ��B
single core ��6GHz�o���Ȃ�����A�}���`�R�A�Ō떂�����Ă�����B
����Hf�n�Q�[�g��EOT�ƕ��������̏ڍׂ������Ȃ����牽�Ƃ������Ȃ����i�����m��Ȃ������j
4GHz����������ǂ��ˈʂ��낤�Ȃ��B
�V���O���Ȃ�4G�͍s�����낤���ǁA������N�A�b�h��3.5G�̕��������ƍ�������邩��Ȃ��B
>>880
�����臒l�������āA����d�͂�����Ƃ����Ӗ��H
�I���͌����I�Ȕ͈͂œ�������������B
���N���b�N�u���́A�N���b�N�ɑ��Ă̏���d�͂������I�ł͂Ȃ�����
�}���`�R�A�u�����L�߂悤�ƃ��[�J�[����N�ɂȂ��Ă����Ȃ��́H
���܂Œʂ�N���b�N���グ����A�N���b�N�グ�Ă���ł���B
���ꂪ���Ƃ��}���`�R�A�̕����D�ʂł������Ƃ��Ă��B
�����臒l�������āA����d�͂�����Ƃ����Ӗ��H
�I���͌����I�Ȕ͈͂œ�������������B
���N���b�N�u���́A�N���b�N�ɑ��Ă̏���d�͂������I�ł͂Ȃ�����
�}���`�R�A�u�����L�߂悤�ƃ��[�J�[����N�ɂȂ��Ă����Ȃ��́H
���܂Œʂ�N���b�N���グ����A�N���b�N�グ�Ă���ł���B
���ꂪ���Ƃ��}���`�R�A�̕����D�ʂł������Ƃ��Ă��B
������������6Ghz��single���邩������Ȃ����ǐ�Δ���Ȃ�����
>>881
����͂ǂ�����
����Ƀ}���`�R�A��x86�v���Z�b�T���̗p�����̂�
�͂����肢���ē��Ƒ��Ђ̐��i�ɔ�ׂđ啪�x�����Ă����Ă��������炢����
���������V���O���R�A�ŃN���b�N�グ��̂ɂ͌��E��������Ă��Ƃ�
�啪�O���番�����Ă����Ƃ�����
����͂ǂ�����
����Ƀ}���`�R�A��x86�v���Z�b�T���̗p�����̂�
�͂����肢���ē��Ƒ��Ђ̐��i�ɔ�ׂđ啪�x�����Ă����Ă��������炢����
���������V���O���R�A�ŃN���b�N�グ��̂ɂ͌��E��������Ă��Ƃ�
�啪�O���番�����Ă����Ƃ�����
>>882
�����͉��i���悾�Ǝv��
�����͉��i���悾�Ǝv��
>>883
�}���`�R�A�����x�������̂́A�N���b�N���E��
�F�����Â��������炾�ƃI���͎v���Ă���B
�����N���b�N�Ɍ��E�����������Ƃ��Ă���ł��}���`�R�A�𐄂��i�߂����͋^��B
���[�U�ɕ��������ԍl�����琔���グ���ق����Z�[���X���y�����B
High-k�g���Ă�����d�͂��ω��Ȃ�����A
����̓R�A��=�Z�[���X�ƂȂ邱�Ƃ͊ԈႢ�Ȃ����������ǁB
>>882
>875��Y��Ȃ��ł��������B
�}���`�R�A�����x�������̂́A�N���b�N���E��
�F�����Â��������炾�ƃI���͎v���Ă���B
�����N���b�N�Ɍ��E�����������Ƃ��Ă���ł��}���`�R�A�𐄂��i�߂����͋^��B
���[�U�ɕ��������ԍl�����琔���グ���ق����Z�[���X���y�����B
High-k�g���Ă�����d�͂��ω��Ȃ�����A
����̓R�A��=�Z�[���X�ƂȂ邱�Ƃ͊ԈႢ�Ȃ����������ǁB
>>882
>875��Y��Ȃ��ł��������B
>>881
�]���ɂ���̂͏���d�͂łȂ��Ƃ����܂�Ȃ����낤
�f�R�[�_�[�̐��ł��L���b�V���̗e�ʂł������͂�
�������������X�]���ɂ���6GHz��B������Ӗ��͂���̂��Ƃ�������
#���������V���O���R�A�����N���b�N�����Ă��ǂ���SMT�ŕ����X���b�h���点�邩��PG�̕��S�̓}���`�R�A�Ƒ卷�Ȃ��킯��
�]���ɂ���̂͏���d�͂łȂ��Ƃ����܂�Ȃ����낤
�f�R�[�_�[�̐��ł��L���b�V���̗e�ʂł������͂�
�������������X�]���ɂ���6GHz��B������Ӗ��͂���̂��Ƃ�������
#���������V���O���R�A�����N���b�N�����Ă��ǂ���SMT�ŕ����X���b�h���点�邩��PG�̕��S�̓}���`�R�A�Ƒ卷�Ȃ��킯��
�A�J�L�R
�R�A�̑啝�Ȋg�����Ȃ���A�_�C�ʐς������Ȃ��킯��
�f���A���R�A�܂ł͕K�R�������Ǝv��
�N���b�N�������ɂ����鐢�E�������Ƃ��Ă�AMD���f���A���R�A�o����
Intel���R�Ńf���A���������̂ł͂Ȃ�����
�R�A�̑啝�Ȋg�����Ȃ���A�_�C�ʐς������Ȃ��킯��
�f���A���R�A�܂ł͕K�R�������Ǝv��
�N���b�N�������ɂ����鐢�E�������Ƃ��Ă�AMD���f���A���R�A�o����
Intel���R�Ńf���A���������̂ł͂Ȃ�����
AMD���A���N���b�N��IPC��CPU��K9�Ƃ��ďo�����Ƃ��Ă��B
���ꂪ�A�����I�ɕs�\�Ȏ����������ăf���A���R�A�ɕύX�ɂȂ����B
���ꂪ�A�����I�ɕs�\�Ȏ����������ăf���A���R�A�ɕύX�ɂȂ����B
8�R�A�~8�\�P�b�g��64�R�A128�X���b�h�́uBeckton�v
http://pc.watch.impress.co.jp/docs/2007/1022/kaigai395.htm
http://pc.watch.impress.co.jp/docs/2007/1022/kaigai395.htm
��IPC���͂킩��B��K9
K8��������IPC�グ������ĂȂ��Ƃ������Ă����ȁB
K8��������IPC�グ������ĂȂ��Ƃ������Ă����ȁB
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
2003�N��MPF�p�̃X���C�h���炷��ƁAK9�őS�������肾�������킩��Ȃ����A
���N���b�N�A��IPC�o���_���Ă����\��������ˁB
2003�N��MPF�p�̃X���C�h���炷��ƁAK9�őS�������肾�������킩��Ȃ����A
���N���b�N�A��IPC�o���_���Ă����\��������ˁB
Xenon���ď���d�͂������́H
ES7000�Ƃ�Altix XE�Ƃ��͂��������낤��
K8�͊J����������Dual Core��������ł����킯�����E�E�E
Italy�����邩��
K8�͊J����������Dual Core��������ł����킯�����E�E�E
�ƂȂ�Ȃ�
Montecito��Paxville�����邩��
Netburst��P7���J����������Dual Core��������ł����킯�����E�E�E
�ƂȂ邗
�o�X�C���^�[�t�F�C�X�̓������ăv���Z�b�T�R�A�̃}�C�N���A�[�L�e�N�`���ƊW����킯�H
K9��K10�������Ė��������炻���CMP���Ă���Ȃ��́H
K8�͊J����������Dual Core��������ł����킯�����E�E�E
�ƂȂ�Ȃ�
Montecito��Paxville�����邩��
Netburst��P7���J����������Dual Core��������ł����킯�����E�E�E
�ƂȂ邗
�o�X�C���^�[�t�F�C�X�̓������ăv���Z�b�T�R�A�̃}�C�N���A�[�L�e�N�`���ƊW����킯�H
K9��K10�������Ė��������炻���CMP���Ă���Ȃ��́H
�n�߂���K8��K8�f���A���R�A�ƍl�����Ă��킯����Ȃ��ăo�b�N�A�b�v�v�����������낤�B
�ł�K8���f���A���R�A���l�����Đv����Ă����̂��܂������B
http://journal.mycom.co.jp/special/2003/opteron/003.html
�ł�K8���f���A���R�A���l�����Đv����Ă����̂��܂������B
http://journal.mycom.co.jp/special/2003/opteron/003.html
���Ȃ݂Ƀo�X�C���^�[�t�F�[�X�̓������Ă̂��}�C�N���A�[�L�e�N�`���Ɩ��ڂɊW���Ă�Ǝv�����B
AMD��Hyper Transport��IMC�������������͂��ꂩ���r�I�����g�p�����V�X�e���A�[�L�e�N�`���ɂȂ�Ƃ�������������
���̎����猻�݂Ɏ���܂Ńv���Z�b�T�R�A�̍��V������Ȃ����������ُ펖�ԂȂ̂ł�����
��K8���f���A���R�A���l�����Đv����Ă���
�Ӂ[��CK9�ł�K10�ł��Ȃ���
���̎����猻�݂Ɏ���܂Ńv���Z�b�T�R�A�̍��V������Ȃ����������ُ펖�ԂȂ̂ł�����
��K8���f���A���R�A���l�����Đv����Ă���
�Ӂ[��CK9�ł�K10�ł��Ȃ���
>>899
Hammer���f���A���R�A���ӎ����Đv����Ă����̂͗L�����낤���B
Hammer���f���A���R�A���ӎ����Đv����Ă����̂͗L�����낤���B
AMD�̃f���A���R�A�͕ی��������낤����
OPTERON,ATHLON64��HT�ƃR�A�Ԃɂ̓X�C�b�`������Ƃ���
���W���[���\���ő��A�[�L�e�N�`�����
�f���A���R�A���e��
OPTERON,ATHLON64��HT�ƃR�A�Ԃɂ̓X�C�b�`������Ƃ���
���W���[���\���ő��A�[�L�e�N�`�����
�f���A���R�A���e��
902 �FSocket774�F2007/10/22(��) 12:49:21 ID:LEPoeKG+
>>899
��o��������Dual�R�A�Ƃ��ď��o�Ă���B
���������̂̂��Ƃ����ǁADaiki PC Info�Ƃ��ӂ�ŐF�X�o�Ă��A�����������B
���������đO���I�̘b�������肵�Ȃ����H
��o��������Dual�R�A�Ƃ��ď��o�Ă���B
���������̂̂��Ƃ����ǁADaiki PC Info�Ƃ��ӂ�ŐF�X�o�Ă��A�����������B
���������đO���I�̘b�������肵�Ȃ����H
���̃X���͂����� AMD�̉ߋ���CPU�ɂ��Č�낤 �X���ɂȂ����̂��ƁB
Hammer�͕ی��ł��Ȃ��āA��������_���Ă�Ȃ��́H
���Ԃ����d�͓��ɉ����̂߂ǂ��������炷����邽�߂ɁB
���ꂪ�ی��Ƃ����Εی������B
CMP�ӂ�͖����Ȃ���K9�ӂ�ŗ\�肳��Ă����̂����ˁB
���Ԃ����d�͓��ɉ����̂߂ǂ��������炷����邽�߂ɁB
���ꂪ�ی��Ƃ����Εی������B
CMP�ӂ�͖����Ȃ���K9�ӂ�ŗ\�肳��Ă����̂����ˁB
{kind=link}
>>905
POWER4��1�_�C2�R�A��L2�����L�Ȃ��ǁA�ǂ̕�����PenD�����ȂH
POWER4��1�_�C2�R�A��L2�����L�Ȃ��ǁA�ǂ̕�����PenD�����ȂH
PenD�����̓c�C���R�A���Č����Ă����c����B
�����R������������MCM����Ȃ��˂���
PenD������Opteron�����̑傫�ȈႢ��
PenD�����̂ق����ƁA�L���V���X�k�[�v�Ń������AI/O�ш悪�Ƃ��Ă��܂�����
Op������1�\�P�b�g�Ȃ�A�x���`�b�v�O�o�X�ɐM���o�����L���b�V���X�k�[�v���ł�����ĂƂ�
PenD�����̂ق����ƁA�L���V���X�k�[�v�Ń������AI/O�ш悪�Ƃ��Ă��܂�����
Op������1�\�P�b�g�Ȃ�A�x���`�b�v�O�o�X�ɐM���o�����L���b�V���X�k�[�v���ł�����ĂƂ�
>>883
���ꌾ�����������A�iAMD�E�j���f���A���R�AAthlon64 X2�t�@���ܖڂ���Ȃ����c
���ꌾ�����������A�iAMD�E�j���f���A���R�AAthlon64 X2�t�@���ܖڂ���Ȃ����c
911 �FSocket774�F2007/10/22(��) 18:59:46 ID:0gbhTnXh
>>370
�Q�O�Q�X�N�܂ŃZ��D�Ő키
�Q�O�Q�X�N�܂ŃZ��D�Ő키
>550 �����O�o�b�N�p�X�B���͖���DEC
1992 200MHz EV4 / 50MHz
1995 333MHz EV5 / 120MHz
2000 731MHz EV6 / 800Hz-1.5GHz
2001 1GHz EV7/ 1.5-2.2GHz
4�{�����[�h����Ă���Intel�̉������Ղ肪������
1992 200MHz EV4 / 50MHz
1995 333MHz EV5 / 120MHz
2000 731MHz EV6 / 800Hz-1.5GHz
2001 1GHz EV7/ 1.5-2.2GHz
4�{�����[�h����Ă���Intel�̉������Ղ肪������
800MH����M��������
EV6�܂ł͂����Ƃ�
EV7�ł��g�b�v�N���X
EV8�͗\��ʂ�łĂ��Ƃ��Ă�
���̃v���Z�b�T�Ƌ����ł��Ȃ��㕨
�Ō�̂��8issue 4way SMT�Ƃ����������ł���
EV7�ł��g�b�v�N���X
EV8�͗\��ʂ�łĂ��Ƃ��Ă�
���̃v���Z�b�T�Ƌ����ł��Ȃ��㕨
�Ō�̂��8issue 4way SMT�Ƃ����������ł���
>>910
���B���̕���BAMD�~���A�~�����g���ĂȂ����肾��ˁB
���B���̕���BAMD�~���A�~�����g���ĂȂ����肾��ˁB
916 �FSocket774�F2007/10/23(��) 02:06:08 ID:ZhnPJN8S
�J�b�R���X
http://www.youtube.com/watch?v=VI5GCsZCgeo
http://www.youtube.com/watch?v=VI5GCsZCgeo
Opteron 2360 SE + PGI Compiler + SmartHeap Library
http://www.spec.org/cpu2006/results/res2007q4/cpu2006-20070908-01997.html
[-fast] SSE���܂߂����܂��܂ȍœK�����s���B
[-Mipa=inline] ���̃C�����C�������s���Ăяo���̃I�[�o�[�w�b�h���팸����B
[barcelona] K10�A�[�L�e�N�`�����^�[�Q�b�g�ɂ����R�[�h�������s���B
[-Mipa] �v���V�[�W���Ԃ̃O���[�o���ȍœK���̂��߂ɉ�͂��s���B
[-Bstatic_pgi] �����^�C�����C�u�����ƃX�^�e�B�b�N�Ƀ����N������B
[-fb] �v���Z�b�T�����̃p�t�H�[�}���X�J�E���^����T���v�����O�����f�[�^����ɍœK�����s���B
Xeon X5355 + GCC Compiler
http://www.spec.org/cpu2006/results/res2007q4/cpu2006-20070913-02007.html
[-O3] ���܂��܂ȍœK�����s���BSSE�͗��p���Ȃ��B
[-fno-inline-functions] ���̃C�����C�������s��Ȃ��B
*Opteron + GCC Compiler��Xeon + PGI Compiler + SmartHeap Library�̐��т͌��ݒ��Ă���܂���B
Sponsorrd by �Ɛ��Ɛ���tel�Ɛ키���`��AMD
http://www.spec.org/cpu2006/results/res2007q4/cpu2006-20070908-01997.html
[-fast] SSE���܂߂����܂��܂ȍœK�����s���B
[-Mipa=inline] ���̃C�����C�������s���Ăяo���̃I�[�o�[�w�b�h���팸����B
[barcelona] K10�A�[�L�e�N�`�����^�[�Q�b�g�ɂ����R�[�h�������s���B
[-Mipa] �v���V�[�W���Ԃ̃O���[�o���ȍœK���̂��߂ɉ�͂��s���B
[-Bstatic_pgi] �����^�C�����C�u�����ƃX�^�e�B�b�N�Ƀ����N������B
[-fb] �v���Z�b�T�����̃p�t�H�[�}���X�J�E���^����T���v�����O�����f�[�^����ɍœK�����s���B
Xeon X5355 + GCC Compiler
http://www.spec.org/cpu2006/results/res2007q4/cpu2006-20070913-02007.html
[-O3] ���܂��܂ȍœK�����s���BSSE�͗��p���Ȃ��B
[-fno-inline-functions] ���̃C�����C�������s��Ȃ��B
*Opteron + GCC Compiler��Xeon + PGI Compiler + SmartHeap Library�̐��т͌��ݒ��Ă���܂���B
Sponsorrd by �Ɛ��Ɛ���tel�Ɛ키���`��AMD
AMD�~�ɂ��r�炵���i��ōr�p���Ă�Ȃ��E�E�E�E�B
>>908
�̃L���[�u�^Dual Opteron��݂��Ă̂����������A
�Е���CPU�ɂ������������Ԃ牺�����ĂȂ������B
������A���x�I�ɂ̓l�C�e�B�u�ɃR�A���q�������
�x���Ȃ邩������Ȃ����AMCM�ɂ���͓̂�����Ď��͖�������B
�����I�ɃR�A�ƃR�A��QPI�łȂ��������������B
�ނ���MCM�����₷���Ȃ�����Ȃ��̂��ȁH
>>918
���̒��x���u���v����AMD������CPU�X���͂ǂ��Ȃ���B
�������ɗN���A�~�̃L���T�͖{�������H
�̃L���[�u�^Dual Opteron��݂��Ă̂����������A
�Е���CPU�ɂ������������Ԃ牺�����ĂȂ������B
������A���x�I�ɂ̓l�C�e�B�u�ɃR�A���q�������
�x���Ȃ邩������Ȃ����AMCM�ɂ���͓̂�����Ď��͖�������B
�����I�ɃR�A�ƃR�A��QPI�łȂ��������������B
�ނ���MCM�����₷���Ȃ�����Ȃ��̂��ȁH
>>918
���̒��x���u���v����AMD������CPU�X���͂ǂ��Ȃ���B
�������ɗN���A�~�̃L���T�͖{�������H
Intel��Nehalem�����FB-DIMM���t�F�C�h�A�E�g�̕�����
http://pc.watch.impress.co.jp/docs/2007/1023/kaigai396.htm
http://pc.watch.impress.co.jp/docs/2007/1023/kaigai396.htm
FB-DIMM��Intel�̈Í��j�ɒlj����ȁB
MP�͈ꕔ�T�[�o�x���_�œƎ��Ɏ������Ă��������o�b�t�@�������ł������K�{�ɂȂ������ď�Ԃ��ˁB
AMD�̏ꍇ�AG3MX��2P�A8P�ǂ����ł��g���邵�A�ʂɎg��Ȃ��Ă��������ǁA
Intel��MP�����ŕK�{���Ă̂��Ⴂ���ˁB
AMD�̏ꍇ�AG3MX��2P�A8P�ǂ����ł��g���邵�A�ʂɎg��Ȃ��Ă��������ǁA
Intel��MP�����ŕK�{���Ă̂��Ⴂ���ˁB
����ς�Intel�ɂƂ���RAMBUS�͋S�傩�c
�{�l�����͕��̐S�Z���낤���Ǔ����S�����Ă܂Ƃ��ɏ������Ă��Ƃ��ז�����Љ�̊Q�������
���������@�����Ēʂ��ċ쒀���ė~������
���������@�����Ēʂ��ċ쒀���ė~������
�����͏d�v�����炻�̌��ɂ��Ă͉����C�������A
RAMBUS�͂��܂肤�܂�������Ȃ��B
RAMBUS�͂��܂肤�܂�������Ȃ��B
���ۂɐ��i�ɏo���Ȃ��Ƃ���͓��������Ӗ��������B���i�������Ă����̓�������B
���ۂɂ͓����ŋZ�p��ی삵�Ȃ��ƃ_���Ȃ낤���ǁA
���̓�����������Z�p�����ЂŎg�����A
���ЂɎg�킹�ċ�����邩�ł͈�ۂ��S���Ⴄ�ȁB
���̓�����������Z�p�����ЂŎg�����A
���ЂɎg�킹�ċ�����邩�ł͈�ۂ��S���Ⴄ�ȁB
>>926
���܂Ƃ��ɏ������Ă���
���������̊�Ƃ��A�g�����ĂȂǑS���Ȃ����́A
�h�q�E�����Ȃǂ��܂߂Ėc��Ȑ����擾���Ă���킯����
���܂Ƃ��ɏ������Ă���
���������̊�Ƃ��A�g�����ĂȂǑS���Ȃ����́A
�h�q�E�����Ȃǂ��܂߂Ėc��Ȑ����擾���Ă���킯����
���ʂɍl���āA�����̏��Ő��i�����Ȃ������ɓ����}���Ă�A�Ȃ�Ă̂�
�h�܂Ƃ��ɏ������Ă��Ɓh�i��T�͑��Ɓj����肽�������Ă�B
���̏ꍇ�͌������Ɠ��m�ɂȂ邩��A�j���[�X�ɂȂ炸
�i�Ȃ��Ă��h��g�h�j�ڗ����Ȃ������B
�����ƂƏ����ȃx���`���[���Ƙb�萫�����邩��ڗ��B
�����S���Ƃ����_�ł́A����Ă邱�Ƃ͂���܂肩���Ȃ��B
�h�܂Ƃ��ɏ������Ă��Ɓh�i��T�͑��Ɓj����肽�������Ă�B
���̏ꍇ�͌������Ɠ��m�ɂȂ邩��A�j���[�X�ɂȂ炸
�i�Ȃ��Ă��h��g�h�j�ڗ����Ȃ������B
�����ƂƏ����ȃx���`���[���Ƙb�萫�����邩��ڗ��B
�����S���Ƃ����_�ł́A����Ă邱�Ƃ͂���܂肩���Ȃ��B
�����S���Ƃ����̂͑i�ׂ��{��
���X�N�����Ŗׂ��邱�Ƃ����l���ĂȂ�
Intel�ɂ���MS�ɂ��悫����ƃ��X�N���ď������Ă�
Xbox��Itanium�����Ă�킩�邾�낤��
���X�N�����Ŗׂ��邱�Ƃ����l���ĂȂ�
Intel�ɂ���MS�ɂ��悫����ƃ��X�N���ď������Ă�
Xbox��Itanium�����Ă�킩�邾�낤��
���������W���[���Ƀq�[�g�V���N�������Ď��_��
FB DIMM�̎��s�͖ڂɂ݂��Ă�����
�悭�l������ADRAM�����M�̖��ō������ł��Ȃ����オ���������
������ĈӊO�������ȗ\��
FB DIMM�̎��s�͖ڂɂ݂��Ă�����
�悭�l������ADRAM�����M�̖��ō������ł��Ȃ����オ���������
������ĈӊO�������ȗ\��
���i�Y���邱�Ƃɂ̓��X�N�����邪
�����ɂȂ�悤�Ȓm�b�E�m���ݏo���ߒ��ɂ����X�N�͂��邼
�ǂ����ă��X�N�[�����Ǝv�����
�����ɂȂ�悤�Ȓm�b�E�m���ݏo���ߒ��ɂ����X�N�͂��邼
�ǂ����ă��X�N�[�����Ǝv�����
���̗��_����ARM�̂悤��IP��Ƃ͂��������Ƃ����b�ɂȂ�B
���Ȃ��Ƃ��A�����J�ł͓����Ȃ�ăK�L�̎v�����Ŏ�ꂿ�Ⴄ�����
http://ja.wikipedia.org/wiki/%E3%83%88%E3%82%A4%E3%83%AC%E3%81%AE%E9%A0%86%E7%95%AA%E3%82%92%E6%B1%BA%E3%82%81%E3%82%8B%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0%E3%81%AE%E7%89%B9%E8%A8%B1
http://ja.wikipedia.org/wiki/%E3%83%88%E3%82%A4%E3%83%AC%E3%81%AE%E9%A0%86%E7%95%AA%E3%82%92%E6%B1%BA%E3%82%81%E3%82%8B%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0%E3%81%AE%E7%89%B9%E8%A8%B1
>>926
�ߋ���intel�Ȃ�āA���Ђ̖W�Q�������ړI�̖��Ӗ��ȑi�ׂ��܂��肾��
�ߋ���intel�Ȃ�āA���Ђ̖W�Q�������ړI�̖��Ӗ��ȑi�ׂ��܂��肾��
�������悤
�@�����ɂȂ�悤�Ȓm�b�E�m��
���܂Ƃ��ɏ������Ă����Ƃɉe����^����悤�Ȓm�b�E�m��
�@�����ɂȂ�悤�Ȓm�b�E�m��
���܂Ƃ��ɏ������Ă����Ƃɉe����^����悤�Ȓm�b�E�m��
�������Ēm�I���Y�̕ی�̂ЂƂɉ߂��Ȃ���
���ۂɓ����Ƃ������Љ�ɗL�v���ǂ������Ă̂̓x�c��������
���ۂɓ����Ƃ������Љ�ɗL�v���ǂ������Ă̂̓x�c��������
���������܂��������
Intel�ɂȂɂ�����ƃA�����������̂했�x�̂��Ƃ����ǁAIBM��POWER�T�[�o�[�ł�
POWER4/POWER5->POWER6�̒i�K�ō���b��̃������o�b�t�@(SMI�`�b�v)���}�U�[�{�[�h
�ォ��DIMM�Ɉړ����������B
�������Ń}�U�[�{�[�h�̎������x�����サ�āA�ő哋�ڃ������̑����Ɋ�^���Ă��邷�B
http://www.nevicare.nl/aix/uif077.pdf
(p.5�Q�ƁB�Ȃ��\��Fully Buffered DIMM�ƌ����̂�JEDEC�K�i��FB-DIMM���ᖳ����)
���Ȃ݂�SMI�`�b�v�탁�����R���g���[��-�o�b�t�@�Ԃ����N���b�N�̋����p�������Ō��ԂƂ���
�_�ŁA����b���Intel��micro-buffer�v��Ɣ��ɋ߂����B
POWER4/POWER5->POWER6�̒i�K�ō���b��̃������o�b�t�@(SMI�`�b�v)���}�U�[�{�[�h
�ォ��DIMM�Ɉړ����������B
�������Ń}�U�[�{�[�h�̎������x�����サ�āA�ő哋�ڃ������̑����Ɋ�^���Ă��邷�B
http://www.nevicare.nl/aix/uif077.pdf
(p.5�Q�ƁB�Ȃ��\��Fully Buffered DIMM�ƌ����̂�JEDEC�K�i��FB-DIMM���ᖳ����)
���Ȃ݂�SMI�`�b�v�탁�����R���g���[��-�o�b�t�@�Ԃ����N���b�N�̋����p�������Ō��ԂƂ���
�_�ŁA����b���Intel��micro-buffer�v��Ɣ��ɋ߂����B
DIMM��ɍ����A���@�\�ȃn�u���ڂ�����Ă̂�
RUMBUS�̓�������ʂ�̑O�ɋZ�p�I�ɔj�]���Ă�
FB DIMM����DIMM�Ƀq�[�g�V���N�̂��Ă�
�X���b�g��אڂ������Ȃ���
RUMBUS�̓�������ʂ�̑O�ɋZ�p�I�ɔj�]���Ă�
FB DIMM����DIMM�Ƀq�[�g�V���N�̂��Ă�
�X���b�g��אڂ������Ȃ���
>>934
�������A���X�N�̑傫���̈Ⴂ����⌅�O��ł���
>>930-931�̊ԈႢ�͓������ʂɎ擾���邱�Ƃ����Ƃ݂Ȃ��Ă��邱�Ƃ���
�擾���������ŏW����s�����Ƃ����Ȃ̂��Ɖ��̂킩��Ȃ��낤��
�����S�����W����s�����߂ɓ������ʂɎ擾(�Ƃ���������)���s���Ă��邩��
�܂Ƃ��Ȋ�Ƃ̂���������Ɍ����Ă�낤����
�������A���X�N�̑傫���̈Ⴂ����⌅�O��ł���
>>930-931�̊ԈႢ�͓������ʂɎ擾���邱�Ƃ����Ƃ݂Ȃ��Ă��邱�Ƃ���
�擾���������ŏW����s�����Ƃ����Ȃ̂��Ɖ��̂킩��Ȃ��낤��
�����S�����W����s�����߂ɓ������ʂɎ擾(�Ƃ���������)���s���Ă��邩��
�܂Ƃ��Ȋ�Ƃ̂���������Ɍ����Ă�낤����
>937
�܂Ƃ��ɏ������Ă���^�Q�[���\�t�g��Ђɂ�鏤�W���l
�Ȃ�Ęb���������ȁB
�܂Ƃ��ɏ������Ă���^�Q�[���\�t�g��Ђɂ�鏤�W���l
�Ȃ�Ęb���������ȁB
IBM�̃n�C�G���h��PC�T�[�o�[����
�����Ƃ���p�Ƃ����Ⴄ�����r���Ă��Ӗ��Ȃ��Ǝv����
IBM Power6����CPU4000�s���ȏゾ��H(�z��)
Power4��3000�s���Ƃ���������
80�w�Z���~�b�N��Ղ�8�w������Ղ��ᐢ�E���Ⴄ
�����Ƃ���p�Ƃ����Ⴄ�����r���Ă��Ӗ��Ȃ��Ǝv����
IBM Power6����CPU4000�s���ȏゾ��H(�z��)
Power4��3000�s���Ƃ���������
80�w�Z���~�b�N��Ղ�8�w������Ղ��ᐢ�E���Ⴄ
947 �FMAC�I�^��945 �����F2007/10/23(��) 23:12:50 ID:ZuczVhpi
>>945
�@�@-------------------
�@�@�����Ƃ���p�Ƃ����Ⴄ�����r���Ă��Ӗ��Ȃ�
�@�@-------------------
�������������[�X�����POWER6�u���[�h��AIA�Ɠ���BladeCenter S➑̂Ɏ��܂�\�肷�B
http://www.itjungle.com/bns/bns100407-story01.html
�@�@====================
�@�@The one thing IBM is not ready to talk about is the forthcoming JS12 and JS22 blade servers.
�@�@But the word on the street is that the Power6-based blade server launch is imminent. The
�@�@JS22 is definitely a Power6 blade, but the exact speeds and feeds are unknown.
�@�@====================
�@�@-------------------
�@�@�����Ƃ���p�Ƃ����Ⴄ�����r���Ă��Ӗ��Ȃ�
�@�@-------------------
�������������[�X�����POWER6�u���[�h��AIA�Ɠ���BladeCenter S➑̂Ɏ��܂�\�肷�B
http://www.itjungle.com/bns/bns100407-story01.html
�@�@====================
�@�@The one thing IBM is not ready to talk about is the forthcoming JS12 and JS22 blade servers.
�@�@But the word on the street is that the Power6-based blade server launch is imminent. The
�@�@JS22 is definitely a Power6 blade, but the exact speeds and feeds are unknown.
�@�@====================
>>943
�g�����ĂȂǑS���Ȃ����́A�Ă̂�����ɓǂݔ���Ȃ��悤��
�������̔���
����قǃ��X�N�̍����s�ׂ����������Ȃ��͂�����
�g�����ĂȂǑS���Ȃ����́A�Ă̂�����ɓǂݔ���Ȃ��悤��
�������̔���
����قǃ��X�N�̍����s�ׂ����������Ȃ��͂�����
>>948
�ǂݔ���ĂȂ�
�����̑�ʎ擾�ɖ��͖���
�W���ړI�Ƃ��������̊��p�ɖ�肪����
�Ȃ����X�N���傫���Ƃ������̊z���������萫�I�Șb�����Ă���݂���������
�����N�Q�𖼖ڂƂ��đ��Ƃ������i�ׂ��N�������Ƃ̓��[���X�N�n�C���^�[���̂���������
����͖��m�Ȏ���
�ǂݔ���ĂȂ�
�����̑�ʎ擾�ɖ��͖���
�W���ړI�Ƃ��������̊��p�ɖ�肪����
�Ȃ����X�N���傫���Ƃ������̊z���������萫�I�Șb�����Ă���݂���������
�����N�Q�𖼖ڂƂ��đ��Ƃ������i�ׂ��N�������Ƃ̓��[���X�N�n�C���^�[���̂���������
����͖��m�Ȏ���
���Ƃ̒�����ԁA�O�~�����ƃx���`���[�̈�{�ނ�A�s���|�C���g����
�����_���Ń��X�N�������̂͂ނ����҂���B
�Ƃ������@v5WXly3h�@�̓��X�N�̑傫������Ȃ�������ɂ��Ă��B
�����ł͋C�Â��ĂȂ��悤�����B
�l�I�ȉ��l�ς��A���������q�ρA�����ł��邩�̂悤�Ɍ���Ă�B
�����_���Ń��X�N�������̂͂ނ����҂���B
�Ƃ������@v5WXly3h�@�̓��X�N�̑傫������Ȃ�������ɂ��Ă��B
�����ł͋C�Â��ĂȂ��悤�����B
�l�I�ȉ��l�ς��A���������q�ρA�����ł��邩�̂悤�Ɍ���Ă�B
ID:g7dhiEvb��
�����@�����Ă��o����Ă��������@�ʼn�����Ă���Ƃ����q�ϓI��������ڂ����ނ��Ă���킯����
�����@�����Ă��o����Ă��������@�ʼn�����Ă���Ƃ����q�ϓI��������ڂ����ނ��Ă���킯����
���܂��炪�o�b�t�@�o�b�t�@��������}�}�����6�����ڂ��Ă݂�
http://sylphys.ddo.jp/upld2nd/pc2/src/1193151057742.jpg
http://sylphys.ddo.jp/upld2nd/pc2/src/1193151057742.jpg
{kind=link}
>>951
�N�����@�����p���Ă������A�����C���[�W�ő�������
�N�����@�����p���Ă������A�����C���[�W�ő�������
955 �F�R�E�L�́M�E,,�j�����������������F2007/10/24(��) 02:43:58 ID:Gk6tXf/m
>>944
���W���l���Ē�Y���炢�����v�������Ȃ�
���W���l���Ē�Y���炢�����v�������Ȃ�
Transmeta
958 �FSocket774�F2007/10/25(��) 18:40:18 ID:NOueZfk0
p
959 �F ��O47sMVBmgM �F2007/10/25(��) 19:18:48 ID:B45fzJPo
Intel brings chips to the desert
http://www.theinquirer.net/gb/inquirer/news/2007/10/25/intel-brings-chips-desert
http://www.theinquirer.net/gb/inquirer/news/2007/10/25/intel-brings-chips-desert
960 �FSocket774�F2007/10/25(��) 23:57:41 ID:WODUrHnw
�l�n�[�����Ō��܂肾��H
Intel�Łu8x4�v�ōL����2008�N��CPU���[�h�}�b�v
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397.htm
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397.htm
���VCPU�́A�n�C�p�t�H�[�}���X�̑�^�_�C�œo�ꂵ�A�v���Z�X�Z�p����������ɏ]����
�����C���X�g���[���_�C�A�o�����[�_�C�ւƐ��ڂ��čs���B�E�H�[�^�t�H�[���ƌĂ��헪���B
���Ƃ��낪�ACore MA�ł͓����v���Z�X�Z�p�̒��Łi���j3.5�{�̃_�C�̃X�P�[���r���e�B������B
CoreMA�ł�6�R�A+16MB L3��Dunnington���\�肳��Ă邵
�ʂɃ��W�����[�v����Ȃ��Ă��X�P�[���r���e�B�����ł��Ă���Ă��Ƃ��
�����C���X�g���[���_�C�A�o�����[�_�C�ւƐ��ڂ��čs���B�E�H�[�^�t�H�[���ƌĂ��헪���B
���Ƃ��낪�ACore MA�ł͓����v���Z�X�Z�p�̒��Łi���j3.5�{�̃_�C�̃X�P�[���r���e�B������B
CoreMA�ł�6�R�A+16MB L3��Dunnington���\�肳��Ă邵
�ʂɃ��W�����[�v����Ȃ��Ă��X�P�[���r���e�B�����ł��Ă���Ă��Ƃ��
963 �F�R�E�L�́M�E,,�j�����������������F2007/10/26(��) 00:18:55 ID:lI4MoesY
�L���b�V����������Gallatin, Tulsa������ł�����Ă����Ƃ����ˁ[
Itanium���Ƃ���Ă�T���^�N�������炷��Γ�����O�̎d�������B
Itanium���Ƃ���Ă�T���^�N�������炷��Γ�����O�̎d�������B
�_�C���������Ɖ����ƗZ�ʂ��������Ă�����
>>962-964
����AIntel�������Ă�̂͐v�̗e�Ղ��̂��Ƃ�����
Madison-9M��Madison��1.5�N�ゾ��Dunnington��Clorvertown(3�����O�|���̂��Ƃ��l�����Ă�)��1.7�N��
Tulsa�͗�O�I�ɑ������ǂ����Tulsa���̂�3�����O�|������Ă邵Dempsey��FB-DIMM�Ŕ��N�x�ꂽ�����
����AIntel�������Ă�̂͐v�̗e�Ղ��̂��Ƃ�����
Madison-9M��Madison��1.5�N�ゾ��Dunnington��Clorvertown(3�����O�|���̂��Ƃ��l�����Ă�)��1.7�N��
Tulsa�͗�O�I�ɑ������ǂ����Tulsa���̂�3�����O�|������Ă邵Dempsey��FB-DIMM�Ŕ��N�x�ꂽ�����
>>467
�V���R���ʂɂ��Ȃ������W�J���W�����[�v
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397_07l.gif
286mm2 Kentsfield
143mm2 Conroe
111mm2 Allendale
77mm2�@Celeron M
�V���R���ʂɂ��Ȃ������W�J���W�����[�v
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397_07l.gif
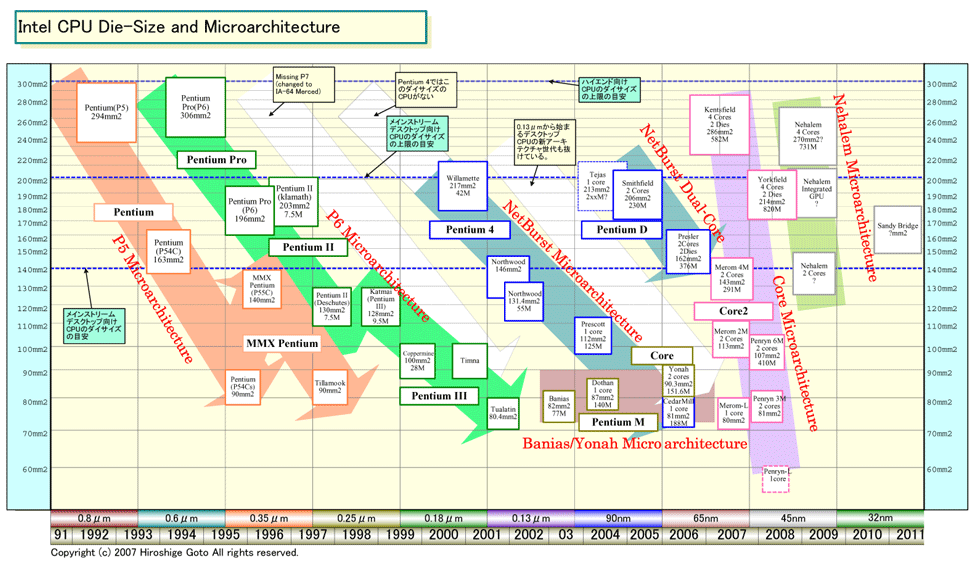{kind=link}
286mm2 Kentsfield
143mm2 Conroe
111mm2 Allendale
77mm2�@Celeron M
967 �F�R�E�L�́M�E,,�j�����������������F2007/10/26(��) 03:41:57 ID:lI4MoesY
>>966
Conroe��Allendale�͂�������L2�̔��������Ԃ������������̐v���B
Kentsfield�͂�����Conroe�~2�����B
�}���`�R�A�ɃV�t�g���đ��ΓI�ɂP�R�A���������Ȃ��Ă邩��
�R�A�v���x���Ń��W�����[������Ӗ��͍��̂Ƃ���Ȃ��B
���Ă�AMD�͉̂�H�v�c�[��������ڂ���K�X�B
Conroe��Allendale�͂�������L2�̔��������Ԃ������������̐v���B
Kentsfield�͂�����Conroe�~2�����B
�}���`�R�A�ɃV�t�g���đ��ΓI�ɂP�R�A���������Ȃ��Ă邩��
�R�A�v���x���Ń��W�����[������Ӗ��͍��̂Ƃ���Ȃ��B
���Ă�AMD�͉̂�H�v�c�[��������ڂ���K�X�B
�n�C�G���h�ƃ��[�G���h�E���o�C���̓��������̃Y����
Core2�����胂�W�����[������Nehalem����̕����傫���Ȃ肻��
Core2�����胂�W�����[������Nehalem����̕����傫���Ȃ肻��
>>966
Celelon M��CMA����Ȃ���
Celelon M��CMA����Ȃ���
970 �FSocket774�F2007/10/26(��) 07:32:29 ID:eRSgyaHI
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
969 ���O�FSocket774[sage] ���e���F2007/10/26(��) 07:08:08 ID:9JFzpz6Y
>>966
Celelon M��CMA����Ȃ���
�ŁA���qBASE�̗ʎq�R���s���[�^�Ɏg����CPU�͉������\�����̂���
>>969
m9(^�D^)�߷ެ����
m9(^�D^)�߷ެ����
>>972
���́A���H�Ƃ���{�f�q���ő̂̒��ɏW�ς���Z�p���������炾�߂���B
���́A���H�Ƃ���{�f�q���ő̂̒��ɏW�ς���Z�p���������炾�߂���B
�ʂɗʎq������g��Ȃ������āA�g�Ƃ��ďd�˂邱�Ƃ��ł�����畁�ʂɌ��g����
�d�q�Ȃ̔䂶��Ȃ����ǂˁB
�܂��A���Ɛ��N�őf�q���x���ɂȂ��ĂȂ��ƃR���s���[�^�̔��W�͏I��邱�ƊԈႢ�Ȃ��B
�d�q�Ȃ̔䂶��Ȃ����ǂˁB
�܂��A���Ɛ��N�őf�q���x���ɂȂ��ĂȂ��ƃR���s���[�^�̔��W�͏I��邱�ƊԈႢ�Ȃ��B
>>975
������A�R�q�[�����X���ړ�������Ƃ�����Șb�ȑO�Ȃ́B
������A�R�q�[�����X���ړ�������Ƃ�����Șb�ȑO�Ȃ́B
>969
CeleronM��4xx����Yonah(CoreMA)����(�E�L��`�E)
5xx�����Merom����
CeleronM��4xx����Yonah(CoreMA)����(�E�L��`�E)
5xx�����Merom����
����A�R�q�[�����X���ď�Ԃ�\���p�ꂶ��Ȃ����ēx��������ˁB
�R�ꂪ�����Ă�̂͌��ʎq�R���s���[�^����Ȃ����āA�P�Ȃ���R���s���[�^�B
�܁[�A���炭�͓��������͔����̂��s���낤���ǁA�������A�N�Z�X�Ƃ���
WDM�ɂ����Ȃ��̂��ˁB
�[���AMRAM�͂܂����B
�R�ꂪ�����Ă�̂͌��ʎq�R���s���[�^����Ȃ����āA�P�Ȃ���R���s���[�^�B
�܁[�A���炭�͓��������͔����̂��s���낤���ǁA�������A�N�Z�X�Ƃ���
WDM�ɂ����Ȃ��̂��ˁB
�[���AMRAM�͂܂����B
>>977
Core��CMA����Ȃ���BCore2��CMA
Core��CMA����Ȃ���BCore2��CMA
980 �FSocket774�F2007/10/27(�y) 11:16:17 ID:PRsVoc2b
>>624
wiki��
wiki��
>>978
2000�N�ʂ���Intel��AMD���������Ă�݂��������ǁA����d�C�ɕϊ�����̂�
�܂�����܂菬�����o���Ȃ��炵���B�ł����낻��o�Ă��邩���ˁB
2000�N�ʂ���Intel��AMD���������Ă�݂��������ǁA����d�C�ɕϊ�����̂�
�܂�����܂菬�����o���Ȃ��炵���B�ł����낻��o�Ă��邩���ˁB
�������A���̌����ɐ��������Ƃ��A����͏\�N�ȓ��Ɏ������邩�H
NTT�̕�����b��������1�i�m�b���x�̒x���ɐ������Ă��B���݂�CPU��
3�N���b�N���ʂ����瑊���Ȃ��B�����Ƃ��A���ꂶ�ᑫ��Ȃ����ǂ��B
3�N���b�N���ʂ����瑊���Ȃ��B�����Ƃ��A���ꂶ�ᑫ��Ȃ����ǂ��B
988 �FSocket774�F2007/10/28(��) 23:43:22 ID:YLPUJsQN
���Z���j�b�g�̐���Athlon64�̔{����̂ɁA
�������炢��������Athlon64�ɕ����Ƃ����̂�
���炩�ɕ��������_���Z�\�͂�Athlon64�̔����Ƃ�������
�������炢��������Athlon64�ɕ����Ƃ����̂�
���炩�ɕ��������_���Z�\�͂�Athlon64�̔����Ƃ�������
4��������QuadChannel�H
>>988
�]�~�\�̂�����Ă郌�X�ɐ���������������
�]�~�\�̂�����Ă郌�X�ɐ���������������
991 �F�R�E�L�́M�E,,�j�����������������F2007/10/29(��) 01:02:10 ID:vjmDbN68
���Z���j�b�g���͓��������ȁB
SIMD�����ł���f�[�^����2�{�ɂȂ��������ŁB
SIMD�̓f�[�^�X���[�v�b�g���オ��Ȃ��Ɛ��\�͌��サ�Ȃ��B
SIMD�����ł���f�[�^����2�{�ɂȂ��������ŁB
SIMD�̓f�[�^�X���[�v�b�g���オ��Ȃ��Ɛ��\�͌��サ�Ȃ��B
������ނ�ł�����͂ˁ[��