AMD�̎�����CPU�ɂ��Č�낤 5������
���������[�h�}�b�v
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
�yCRISC�zCPU�A�[�L�e�N�`���ɂ��Č��yEPIC�z3
http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Intel�̎�����CPU�ɂ��Č�낤 25
http://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���i���[�h�}�b�v �i�Z���j
ttp://www.amdcompare.com/prodoutlook/
�e�N�m���W�E���[�h�}�b�v �i3�N�j
ttp://www.amdcompare.com/techoutlook/
���O�X��
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
�yCRISC�zCPU�A�[�L�e�N�`���ɂ��Č��yEPIC�z3
http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Intel�̎�����CPU�ɂ��Č�낤 25
http://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
|
|
|
Rev. F�̎��̎��ɗ���AMD�̎�����R�A�uHound�v
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
�g�傪�i��AMD�̃R�v���Z�b�T�\�z
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
�v�̃��W�����[���Ŏs��ɍœK������CPU�R�A���`AMD�̐V�헪(1)
http://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
��������������ۂ��L���͂��Ƃ��B
�O�X���ɃA�h���X�\��Ȃ�����orz
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
�g�傪�i��AMD�̃R�v���Z�b�T�\�z
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
�v�̃��W�����[���Ŏs��ɍœK������CPU�R�A���`AMD�̐V�헪(1)
http://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
��������������ۂ��L���͂��Ƃ��B
�O�X���ɃA�h���X�\��Ȃ�����orz
4 �F�E�́E�j��-������ ��toBASh.... �F2006/06/16(��) 02:55:00 ID:7kGcJ0Bt
998 ���O�FSocket774[sage] ���e���F2006/06/16(��) 02:42:37 ID:15wyeOAX
>>996
uOPs�ɕ������ꂽ���ʂ́A��������B
�������A����ł������I��閽�߂̓p�C�v���C���̒��Ŏ��Ԃ��o�̂�҂��Ă�B
999 ���O�FSocket774[sage] ���e���F2006/06/16(��) 02:43:49 ID:15wyeOAX
>>997
�X�g�A���߂������ꍇ�͈ˑ��邷��B
�ˑ����Ȃ��悤�ɃR�[�h��g�ނ̂����߃��x�������Ă�����ł����H
�Ƃ肠�����u���^�C�A�X�e�[�W�v�̖ړI��������Ă���B
GR��FP/MM�̎��s�p�C�v���C���i���̈Ⴂ������ƕ�����s�ł��Ȃ����R���ȁB
�Ƃ�����VTune��CodeAnalist�g�������Ɩ�������h�V���g��
��CodeAnalist
�A�i���̒B�l�ł����H��
�A�i���̒B�l�ł����H��
�ˑ��̂Ȃ��悤�ɑg�ނƌ����Ă��Ȃ��A�ςȑg�ݕ�������Ԉ�������ʂ̂ł�CPU�͗v��Ȃ����Ȃ��B
�ˑ��̂���g�ݕ������璀�����s����邾������B
���v���H
���v���H
��T�ɂ����Ƃ������Ȃ��B
�܂��o�ĂȂ�CPU�ł��ꂱ�ꌾ���̂��Ȃ��A�A�A
�v���X�R�Ȃ�Netburst�Ƃ����d�͂ɔ���ꂽ�����CPU��������
K8L�������Ȃ�Ȃ����Ƃ��F�邵���Ȃ��B
�܂��o�ĂȂ�CPU�ł��ꂱ�ꌾ���̂��Ȃ��A�A�A
�v���X�R�Ȃ�Netburst�Ƃ����d�͂ɔ���ꂽ�����CPU��������
K8L�������Ȃ�Ȃ����Ƃ��F�邵���Ȃ��B
AMD�ׂ̂����̗���
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
>999 ���O�FSocket774[sage] ���e���F2006/06/16(��) 02:43:49 ID:15wyeOAX
>>>997
>�X�g�A���߂������ꍇ�͈ˑ��邷��B
���n���̖��߂��������Ă��Ƃ́A���̑��������߂́A���ԂɎ��s����邾���ŁA
�ǂ��z���͖����ł���
�����������ł���
>>>997
>�X�g�A���߂������ꍇ�͈ˑ��邷��B
���n���̖��߂��������Ă��Ƃ́A���̑��������߂́A���ԂɎ��s����邾���ŁA
�ǂ��z���͖����ł���
�����������ł���
> �v�̃��W�����[���Ŏs��ɍœK������CPU�R�A
> ttp://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
�e��H�̃��W�����[�����i��ł���ׁAAMD�͊ȒP�Ƀ��W���[���̊g�����\���Ƃ������e�B
�ŁA���̐��ʂ�FPU��128bit���E�E�E
�悭����ƁE�E�E64bit x 2�E�E�E�E������ăv���X�R�b�g��32bit x 2�œ��삵�Ă���Ƃ������đ����ł����̂Ɏ��Ă�B
K8L�͂ǂ����p�b�`�����̂悤�ł���B
> ttp://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
�e��H�̃��W�����[�����i��ł���ׁAAMD�͊ȒP�Ƀ��W���[���̊g�����\���Ƃ������e�B
�ŁA���̐��ʂ�FPU��128bit���E�E�E
�悭����ƁE�E�E64bit x 2�E�E�E�E������ăv���X�R�b�g��32bit x 2�œ��삵�Ă���Ƃ������đ����ł����̂Ɏ��Ă�B
K8L�͂ǂ����p�b�`�����̂悤�ł���B
����ς�R�v���Z�b�T�͑��Ђ܂�����
����Intel��AMP�̎���ƕ]�����I���Ă�̂ɑ��v�Ȃ낤��
����Intel��AMP�̎���ƕ]�����I���Ă�̂ɑ��v�Ȃ낤��
>>11��Phil Hester(�t�B���E�փX�^�[)���̐^�̎ʐ^�i����͎���ł͂���܂���j
> http://i-bbs.sijex.net/imageDisp.jsp?id=ups1&file=1150407427793o.jpg
> http://i-bbs.sijex.net/imageDisp.jsp?id=ups1&file=1150407427793o.jpg
{kind=link}
15 �F�E�́E�j��-������ ��toBASh.... �F2006/06/16(��) 07:00:51 ID:7kGcJ0Bt
ID:15wyeOAX�͘^���搶�Ȃ̂�
��[���A��������iPhil Hester�j�́A���W�����[���̓��������Ċ撣�邼�B
�j�W��FPU���W���[���������ЂƂ��ɂ������āE�E�E�E
�Е��̃X�P�W���[���͂Ԃ��āA�Е��̂���Ƃ�����Ȃ��ŁE�E�E�E�E
�����A��肭�����Ȃ��E�E�E�E�E�����A�����ƊȒP�ɊȒP�ɁE�E�E�_�u���Ŏ�荞�߂E�E�E�E
�ŁA�ł����P�Q�WbitFPU���j�b�g�����Ł[���A����Ő��\�͂Q�{����(�܂��m�F���ĂȂ����ǁE�E)
��[���A���ꔭ�\�����Ⴆ!!!
�j�W��FPU���W���[���������ЂƂ��ɂ������āE�E�E�E
�Е��̃X�P�W���[���͂Ԃ��āA�Е��̂���Ƃ�����Ȃ��ŁE�E�E�E�E
�����A��肭�����Ȃ��E�E�E�E�E�����A�����ƊȒP�ɊȒP�ɁE�E�E�_�u���Ŏ�荞�߂E�E�E�E
�ŁA�ł����P�Q�WbitFPU���j�b�g�����Ł[���A����Ő��\�͂Q�{����(�܂��m�F���ĂȂ����ǁE�E)
��[���A���ꔭ�\�����Ⴆ!!!
17 �FSocket774�F2006/06/16(��) 07:19:33 ID:hu4M5CSB
http://pc7.2ch.net/test/read.cgi/jisaku/1150010642/
872 ���O�FSocket774[sage] ���e���F2006/06/16(��) 00:09:52 ID:15wyeOAX
�G���h���[�U�[�ɂƂ��Ă݂�A��ɋ������A�����g�݂Ȃ��ʼn��i�������萫�\���������シ��̂��]�܂����B
�������A����͖ڐ�̗������ł���A�������������R�X�g�������㏸�����v���o�Ȃ��̂ł���A��Ƃ͋�������߂Ă��܂��B
�ׂ���ʂ̂ɑ��z�̃R�X�g�𓊉����闝�R���Ȃ��Ȃ邩�炾�ȁB
�܂�A��ɋ������ė~������Ώ����g�݂ɏ\���ȗ��v����邵���Ȃ��B
1�N����4�N���x��INTEL�̈�l�����ŗǂ��̂��낤��B
�����̂��镶�̂ł��Ȃ�
�ނ��������Ă�l�ɂ͂킩��܂���ˁH
�ق����݂Ȃ��猩����Ă����܂��傤
872 ���O�FSocket774[sage] ���e���F2006/06/16(��) 00:09:52 ID:15wyeOAX
�G���h���[�U�[�ɂƂ��Ă݂�A��ɋ������A�����g�݂Ȃ��ʼn��i�������萫�\���������シ��̂��]�܂����B
�������A����͖ڐ�̗������ł���A�������������R�X�g�������㏸�����v���o�Ȃ��̂ł���A��Ƃ͋�������߂Ă��܂��B
�ׂ���ʂ̂ɑ��z�̃R�X�g�𓊉����闝�R���Ȃ��Ȃ邩�炾�ȁB
�܂�A��ɋ������ė~������Ώ����g�݂ɏ\���ȗ��v����邵���Ȃ��B
1�N����4�N���x��INTEL�̈�l�����ŗǂ��̂��낤��B
�����̂��镶�̂ł��Ȃ�
�ނ��������Ă�l�ɂ͂킩��܂���ˁH
�ق����݂Ȃ��猩����Ă����܂��傤
18 �F�E�́E�j��-������ ��toBASh.... �F2006/06/16(��) 07:20:35 ID:7kGcJ0Bt
�uINTEL�v�i�j
19 �FT.A. ��Vr3ZLNzp5. �F2006/06/16(��) 08:20:41 ID:stT2yzCR
���ʁA���߂̈ˑ��W���`�F�b�N���āA�ˑ��W�̂Ȃ����߂����s�p�C�v�ɕ�������̂�
�X�P�W���[���̖����������悤�ȁE�E�E�����Out-Of-Order�̊�{�T�O�ŕʂ�K8�Ǝ��̂��̂���Ȃ����B
NetBurst��ALU�͔{�����s�̂������ŁA�������s�p�C�v�ɓ�������閽�߂Ȃ��邢�ˑ��W��
���e�������������H
�܂��ANetBurst�̖�����o�߂Ȃ��̂��ȁH
�X�P�W���[���̖����������悤�ȁE�E�E�����Out-Of-Order�̊�{�T�O�ŕʂ�K8�Ǝ��̂��̂���Ȃ����B
NetBurst��ALU�͔{�����s�̂������ŁA�������s�p�C�v�ɓ�������閽�߂Ȃ��邢�ˑ��W��
���e�������������H
�܂��ANetBurst�̖�����o�߂Ȃ��̂��ȁH
>>15�̓}�ł悭����~�[
���O���^���Ɠ����X�e�[�W�����Ă��ƂɁi ߄D߁j�C�Â���
���O���^���Ɠ����X�e�[�W�����Ă��ƂɁi ߄D߁j�C�Â���
21 �FSocket774�F2006/06/16(��) 10:06:25 ID:sMW4nYqo
�}����Ȃ��ă�����
�������łȂ�����������
�m���������W���C���t�M�����S�}����
�l�g�i�����M�ꁨ�������i���p�����u���t�M��
���J��Ԃ����X�L���ɂȂ��Ă���z
�m�[�g�����̂��߂Ɏ�������Ȃ��܂����Ă����̂͋L���ɌÂ�
����ȓz�������ɗ���Ȃ�āAM��Ƃ��^�Ƃ�5�̏d�͂Ɉ�����ꂽ�̂��H
�m���������W���C���t�M�����S�}����
�l�g�i�����M�ꁨ�������i���p�����u���t�M��
���J��Ԃ����X�L���ɂȂ��Ă���z
�m�[�g�����̂��߂Ɏ�������Ȃ��܂����Ă����̂͋L���ɌÂ�
����ȓz�������ɗ���Ȃ�āAM��Ƃ��^�Ƃ�5�̏d�͂Ɉ�����ꂽ�̂��H
K8L�̃_�C�t�H�g�̉�͂��������ł́AFP�n���j�b�g�͑S��64bit�Â�
���E�ɕ�����Ă�悤�Ɍ�������B
�uSSE1�����v�����܂œ��l�A�Ɨ�����2��m64���j�b�g�Ƃ��Ă�
2���킹��1��m128i���j�b�g���Ƃ��Ă������t���L�V�u���d�l�Ȃ�
�����悤�ɕ��ׂ��Ă镂�������n���j�b�g���Ɨ����ē��������Ƃ�
�o���Ă��s�v�c����Ȃ��B�ނ���ȒP�ɏo���������B
�܂�SSE*�X�J����x87���Z�ɂ����ĉ����Z���m�E�ώZ���m�ł̕�����s��
�\�ɂ��邱�ƂŁACore�A�[�L�ɑ��鋭�݂ɂȂ�B
�������128bit�~2�̃��[�h�ш�������B
���������ߑш�̔��肪���邩��A�����܂Ńs�[�N���\���o����̂�
128bitFP�����Z�{�ώZ�̕�����s�̎��Ǝv���B
SSE*�������j�b�g�����Ȃ��Ƃ���A���c�q�̎w�E�ǂ���
64bit���[�h�ł̔ėp�����̊��p�ŏ\���ȃX���[�v�b�g��
�o����悤�ɂ��邩��Ǝv���B
���������i�Œ菬���Ƃ��āj�p�b�N�h�������g���̂͂����ŋ߂̃Q�[����
�G���R�[�_�ł͗��s��Ȃ����A���������Ƀt�H�[�J�X�����ق���
�S�̂Ƃ��Ă͗L���ɂȂ锤�B
������ɂ��Ă�K8L���o��܂ł�SSE�Ή��\�t�g�ł�Core2�̂ق���
���|�I�ɗD�����낤����AAMD�I���͂���܂łǂ����邩�A����ȁB
�K��Intel��Core2�̑�����ւ��ɂ͎��Ԃ�v���A�b���~�b�h�����W�ȉ��ł�
NetBurst�̍Ɉ�|�Z�[��������A�ቿ�i�тł͏\���킦��B
�}���`�v���Z�b�T�\���̎I�Ȃ�Opteron�̗D�ʂ�h�邪���ɂ͂܂�����Ȃ��͂��B
���E�ɕ�����Ă�悤�Ɍ�������B
�uSSE1�����v�����܂œ��l�A�Ɨ�����2��m64���j�b�g�Ƃ��Ă�
2���킹��1��m128i���j�b�g���Ƃ��Ă������t���L�V�u���d�l�Ȃ�
�����悤�ɕ��ׂ��Ă镂�������n���j�b�g���Ɨ����ē��������Ƃ�
�o���Ă��s�v�c����Ȃ��B�ނ���ȒP�ɏo���������B
�܂�SSE*�X�J����x87���Z�ɂ����ĉ����Z���m�E�ώZ���m�ł̕�����s��
�\�ɂ��邱�ƂŁACore�A�[�L�ɑ��鋭�݂ɂȂ�B
�������128bit�~2�̃��[�h�ш�������B
���������ߑш�̔��肪���邩��A�����܂Ńs�[�N���\���o����̂�
128bitFP�����Z�{�ώZ�̕�����s�̎��Ǝv���B
SSE*�������j�b�g�����Ȃ��Ƃ���A���c�q�̎w�E�ǂ���
64bit���[�h�ł̔ėp�����̊��p�ŏ\���ȃX���[�v�b�g��
�o����悤�ɂ��邩��Ǝv���B
���������i�Œ菬���Ƃ��āj�p�b�N�h�������g���̂͂����ŋ߂̃Q�[����
�G���R�[�_�ł͗��s��Ȃ����A���������Ƀt�H�[�J�X�����ق���
�S�̂Ƃ��Ă͗L���ɂȂ锤�B
������ɂ��Ă�K8L���o��܂ł�SSE�Ή��\�t�g�ł�Core2�̂ق���
���|�I�ɗD�����낤����AAMD�I���͂���܂łǂ����邩�A����ȁB
�K��Intel��Core2�̑�����ւ��ɂ͎��Ԃ�v���A�b���~�b�h�����W�ȉ��ł�
NetBurst�̍Ɉ�|�Z�[��������A�ቿ�i�тł͏\���킦��B
�}���`�v���Z�b�T�\���̎I�Ȃ�Opteron�̗D�ʂ�h�邪���ɂ͂܂�����Ȃ��͂��B
32B Instruction Fetch
���c�q
������
������
26 �FPowerPC�I�^�F2006/06/16(��) 19:47:14 ID:R7l8o1QE
>>19
>NetBurst��ALU�͔{�����s�̂������ŁA�������s�p�C�v�ɓ�������閽�߂Ȃ��邢�ˑ��W��
>���e�������������H
���ʂɃ��W�X�^���l�[�~���O���Ă��ˁ[�́H
>NetBurst��ALU�͔{�����s�̂������ŁA�������s�p�C�v�ɓ�������閽�߂Ȃ��邢�ˑ��W��
>���e�������������H
���ʂɃ��W�X�^���l�[�~���O���Ă��ˁ[�́H
27 �FSocket774�F2006/06/16(��) 21:08:50 ID:VErJGTFT
�C���e����Core2 XE�͏���d�͂����߂��A���b�g���\���Ⴂ�̂ɂ���ׂāA
AMD�Ђ̈ꕔ�̃f���A���R�A�v���Z�b�T�͏���d�͂��C���e���̃V���O���R�A��Core Solo�����ƂȂ��Ă���A
�C���e���Ђ�CPU�͂����g�����ɂȂ�Ȃ����オ�������Ă���܂��B
�����g�̓��[�J�[���ɂ�����炸�ǂ������h�������̂ł����A
�����C���e�����i�͔����Ȃ��قǁA�C���e���͑����Ă��܂��܂����B
AMD�͕s����ƌ����l���Ȃ��ɂ͂��܂����A����̓`�b�v�Z�b�g���[�J�̑Ӗ��ł��� �A
AMD�͗ǂ��v���Z�b�T�݂̂���葱����E�l�h�ł���Ƃ����܂� �BAMD�͒��ړI�ɂ͊W����܂���B
���������唼�̕s��̓��[�U�[���]���ɓ�������Ή����ł�����̂���ł��B
Intel�̐��i����IA-64��AMD64�ɂƂ��Ă�����A�͂����肢���čő������͂���܂���B
�C���e�����悤�Ȃ�
AMD�Ђ̈ꕔ�̃f���A���R�A�v���Z�b�T�͏���d�͂��C���e���̃V���O���R�A��Core Solo�����ƂȂ��Ă���A
�C���e���Ђ�CPU�͂����g�����ɂȂ�Ȃ����オ�������Ă���܂��B
�����g�̓��[�J�[���ɂ�����炸�ǂ������h�������̂ł����A
�����C���e�����i�͔����Ȃ��قǁA�C���e���͑����Ă��܂��܂����B
AMD�͕s����ƌ����l���Ȃ��ɂ͂��܂����A����̓`�b�v�Z�b�g���[�J�̑Ӗ��ł��� �A
AMD�͗ǂ��v���Z�b�T�݂̂���葱����E�l�h�ł���Ƃ����܂� �BAMD�͒��ړI�ɂ͊W����܂���B
���������唼�̕s��̓��[�U�[���]���ɓ�������Ή����ł�����̂���ł��B
Intel�̐��i����IA-64��AMD64�ɂƂ��Ă�����A�͂����肢���čő������͂���܂���B
�C���e�����悤�Ȃ�
>>27
�ȂɁH�@���̃R�s�y���s���Ă�́H
�ȂɁH�@���̃R�s�y���s���Ă�́H
K8L��K8����̊g���AL2��conflict�̏����ɐ�O���l�����ăL���b�V���\���̉������l���Ă݂��B
L1��L3���r���ł���A���Ƃ��R�A1��L1�ɓǂݍ��܂��Ƌ��LL3�ɂ̓f�[�^�͂Ȃ��Ȃ�B
������A���̍ۃR�A2-4��L2�ɃR�A1�Ƀf�[�^���ǂݍ��܂ꂽ���Ƃ��L�^�����Ȃ����ȁB
�R�A1�́AL3�Ƀf�[�^���������ޏꍇ�́A������L2�ɂ��̂��Ƃ��L�^����B
����L2�̐��̂́A�������Ă����f�[�^�̃A�h���X�݂̂��L�^���邽�߂̂��̂ł���B
�����l����ƁAL1,L2,L3�̂��ׂĂɑ��ē����Ƀ��N�G�X�g���������ˁH
�R�A1��L1,L2,L3�Ƀ��N�G�X�g���āAL2�Ńq�b�g�������̓q�b�g���Ȃ������ꍇ�͈ȉ��̂悤�ɂȂ�̂��ȁH
L2�Ƀq�b�g���Y���R�A�ɃA�N�Z�X�����̃R�A��L1,L2�Ƀ��N�G�X�g��L1�Ƀq�b�g���R�A1�Ƀf�[�^�𑗂�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��L2�Ƀq�b�g���R�A1��L3�̃A�h���X�𑗂遨�R�A1��L3�Ƀ��N�G�X�g
�q�b�g�Ȃ������C���������ɃA�N�Z�X��L1�ɒ��ړǂݍ��݁��R�A2-4��L2�ɂ��̂��Ƃ��L�^�H
L1��L3���r���ł���A���Ƃ��R�A1��L1�ɓǂݍ��܂��Ƌ��LL3�ɂ̓f�[�^�͂Ȃ��Ȃ�B
������A���̍ۃR�A2-4��L2�ɃR�A1�Ƀf�[�^���ǂݍ��܂ꂽ���Ƃ��L�^�����Ȃ����ȁB
�R�A1�́AL3�Ƀf�[�^���������ޏꍇ�́A������L2�ɂ��̂��Ƃ��L�^����B
����L2�̐��̂́A�������Ă����f�[�^�̃A�h���X�݂̂��L�^���邽�߂̂��̂ł���B
�����l����ƁAL1,L2,L3�̂��ׂĂɑ��ē����Ƀ��N�G�X�g���������ˁH
�R�A1��L1,L2,L3�Ƀ��N�G�X�g���āAL2�Ńq�b�g�������̓q�b�g���Ȃ������ꍇ�͈ȉ��̂悤�ɂȂ�̂��ȁH
L2�Ƀq�b�g���Y���R�A�ɃA�N�Z�X�����̃R�A��L1,L2�Ƀ��N�G�X�g��L1�Ƀq�b�g���R�A1�Ƀf�[�^�𑗂�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��L2�Ƀq�b�g���R�A1��L3�̃A�h���X�𑗂遨�R�A1��L3�Ƀ��N�G�X�g
�q�b�g�Ȃ������C���������ɃA�N�Z�X��L1�ɒ��ړǂݍ��݁��R�A2-4��L2�ɂ��̂��Ƃ��L�^�H
����AL3�����̍\�����Ƃ�邱�Ƃ���
>>29
����Ȃɒx�����Ăǂ�����C��(��
����Ȃɒx�����Ăǂ�����C��(��
���ς�炸�ǂݓ���������C�Ő��ꗬ����Ă�X���ł��ˁB
>>26
�^�̈ˑ����̓��W�X�^���l�[�~���O��������ł��Ȃ�
�{��ALU�͂��̂��߂̍H�v�ł͂���
�Q�l�F���́u�n�U�[�h�ƃ��l�[�~���O�v
http://ja.wikipedia.org/wiki/%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF%E3%83%BB%E3%83%AA%E3%83%8D%E3%83%BC%E3%83%9F%E3%83%B3%E3%82%B0
�R��̓����b�g�̏������iOoO-CPU��RAW�Ђ�������܂���̃v���O�������Ăǂ�ȂH�j�ɔ�ׂ�
�f�����b�g�i�N���b�N���{�̕�������邽�߂ɓd�́����j���傫�����Ǝv������
�^�̈ˑ����̓��W�X�^���l�[�~���O��������ł��Ȃ�
�{��ALU�͂��̂��߂̍H�v�ł͂���
�Q�l�F���́u�n�U�[�h�ƃ��l�[�~���O�v
http://ja.wikipedia.org/wiki/%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF%E3%83%BB%E3%83%AA%E3%83%8D%E3%83%BC%E3%83%9F%E3%83%B3%E3%82%B0
�R��̓����b�g�̏������iOoO-CPU��RAW�Ђ�������܂���̃v���O�������Ăǂ�ȂH�j�ɔ�ׂ�
�f�����b�g�i�N���b�N���{�̕�������邽�߂ɓd�́����j���傫�����Ǝv������
�v�́AL1��L3�̊W�͍��܂Œʂ�B�����AL3�̗e�ʑ���Ƌ��L�ɂ���ă��C�e���V���������邩��
L1��L3���r���ł��邩��A����̃R�A���f�[�^�������čs���ƁA���̃R�A���Q�Ƃ����ꍇ�ɍ���
�ǂ̃R�A�������čs�������L�^���Ƃ��A�S���̃R�A�ɖ₢���킹�Ȃ��Ă����ނ��烌�C�e���V�����邵�A�W�Ȃ��R�A������܂���邱�Ƃ��Ȃ�
����Ȃ�A���Ȃ��Ƃ����\�̒ቺ�͂Ȃ��̂�
�ȉ��A���ᔻ���ǂ�����
L1��L3���r���ł��邩��A����̃R�A���f�[�^�������čs���ƁA���̃R�A���Q�Ƃ����ꍇ�ɍ���
�ǂ̃R�A�������čs�������L�^���Ƃ��A�S���̃R�A�ɖ₢���킹�Ȃ��Ă����ނ��烌�C�e���V�����邵�A�W�Ȃ��R�A������܂���邱�Ƃ��Ȃ�
����Ȃ�A���Ȃ��Ƃ����\�̒ቺ�͂Ȃ��̂�
�ȉ��A���ᔻ���ǂ�����
>>34
���x�����킹��ȁA�x���Ȃ邾�����B
���x�����킹��ȁA�x���Ȃ邾�����B
36 �FT.A. ��Vr3ZLNzp5. �F2006/06/18(��) 01:15:39 ID:HkL0ytwq
AMD�̓R�����[�o�Ă���܂ł́A���牿�i�𗎂Ƃ��K�v�͂Ȃ��Ɣ��f���Ă���̂ł��傤�B
�R�����[�O��2.8G������āA�R�����[�o����AFX�߂Ă�����3G�ɂ��āA
2.8G�܂ł͑R�o����(���Y�o���邾���̗ʂ������)���i�܂ʼn�����B
65nm�����グ�܂ł͐��Y�ʑ����܂���A���̃V�F�A�L�[�v�ł��傤�ˁB
65nm�����オ�������_�ŁA�N���b�NUP�ƒቿ�i�ōU���J�n�BHound�Œnj����ĂƂ���ł��傤���B
�L���b�V���ʂ́A�������[IF�̃��C�e���V���팸����v�Ȃ̂ŁA����܂�ڂ��Ă����ʂ͔����ł��傤�B
�ނ���AIntel��AMD�ɑR���邽�߂ɑ�ʂ̃L���b�V���𓋍ڂ�����Ȃ��Ȃ��Ă�ƌ���ׂ��B
�R�����[�O��2.8G������āA�R�����[�o����AFX�߂Ă�����3G�ɂ��āA
2.8G�܂ł͑R�o����(���Y�o���邾���̗ʂ������)���i�܂ʼn�����B
65nm�����グ�܂ł͐��Y�ʑ����܂���A���̃V�F�A�L�[�v�ł��傤�ˁB
65nm�����オ�������_�ŁA�N���b�NUP�ƒቿ�i�ōU���J�n�BHound�Œnj����ĂƂ���ł��傤���B
�L���b�V���ʂ́A�������[IF�̃��C�e���V���팸����v�Ȃ̂ŁA����܂�ڂ��Ă����ʂ͔����ł��傤�B
�ނ���AIntel��AMD�ɑR���邽�߂ɑ�ʂ̃L���b�V���𓋍ڂ�����Ȃ��Ȃ��Ă�ƌ���ׂ��B
����CPU�R�A���\�ł��L���b�V���̗e�ʁ����\�ł��AIntel�ɑR�����i��
�s�������Ă̂�����Ȃ̂��ȁB
�n�C�G���h�T�[�o�[�͓������v���Ƃ�����A���Ƃ̓f�X�N�g�b�v�����o�C��
�����A�����f�X�N�g�b�v�ƃ��o�C���p��PCI-Ex4�ix2�ł��H�j������CPU�Ȃ�
�Ăǂ����Ȃ��H
GPU���o����ΐ��\�i����UMA���j�ŗL���ɂȂ邵�A�m��HT���m�[�X�^�T�E�X
�ڑ��Ɏg���Ă�nVidia�̃T�E�X�`�b�v�����̂܂g���邵�B�m��AMD�̕��j�Ƃ�
�Ă�mobile�͕ʃR�A�ɂ��锤������A����ɂ���PCI-E���ڂ���Ȃ�s�s���͖���
���B
���̓��[�G���h�f�X�N�g�b�v���A�~�b�h���n�C�G���h�f�X�N�g�b�v�ƕ�MB��
�Ȃ�Ƃ����ASocket754/939 �̖����Č������˂Ȃ��_���ȁH
�s�������Ă̂�����Ȃ̂��ȁB
�n�C�G���h�T�[�o�[�͓������v���Ƃ�����A���Ƃ̓f�X�N�g�b�v�����o�C��
�����A�����f�X�N�g�b�v�ƃ��o�C���p��PCI-Ex4�ix2�ł��H�j������CPU�Ȃ�
�Ăǂ����Ȃ��H
GPU���o����ΐ��\�i����UMA���j�ŗL���ɂȂ邵�A�m��HT���m�[�X�^�T�E�X
�ڑ��Ɏg���Ă�nVidia�̃T�E�X�`�b�v�����̂܂g���邵�B�m��AMD�̕��j�Ƃ�
�Ă�mobile�͕ʃR�A�ɂ��锤������A����ɂ���PCI-E���ڂ���Ȃ�s�s���͖���
���B
���̓��[�G���h�f�X�N�g�b�v���A�~�b�h���n�C�G���h�f�X�N�g�b�v�ƕ�MB��
�Ȃ�Ƃ����ASocket754/939 �̖����Č������˂Ȃ��_���ȁH
���ǂ��l����ƁuAMD EfficeonII�v���ȁA�R�����B�i��
Conroe��OC�ϐ��͐����A���4GHz���\���B
AMD��65nm�ŏ��X�N���b�N���グ�����x�ł͑S���ǂ��t���Ȃ��B
> ttp://www.xtremesystems.org/forums/showthread.php?t=103381
Conroe�̂SGHz��AMD�Ђ̍ŐVCPU�̂TGHz�ɕC�G����B
AMD��65nm�ŏ��X�N���b�N���グ�����x�ł͑S���ǂ��t���Ȃ��B
> ttp://www.xtremesystems.org/forums/showthread.php?t=103381
Conroe�̂SGHz��AMD�Ђ̍ŐVCPU�̂TGHz�ɕC�G����B
�����L�ۂ݂ɂ��ėx�炳���l�̓T�^�B
>>38
http://www.atitech.ca/products/mobilityradeonx1800/specs.html
�bNative PCI Express x16 bus interface
Mobile�ł��n�C�G���h���܂߂�ɂ́Ax16���K�v���Ď��ł��ˁB
���\�̒ႢGPU���� x8 �� x4 �ł��[�����ǂ����A���̂��X�y�b�N�łɍڂ���
�Ȃ������ł����A�t���ғ����Ȃ��ꍇ�̏ȃG�l����Ƃ��āAx4��x8����i��
�����̓X�^���o�C������j�́ACPU�ŕK�v�����ȋC�����܂��B
http://www.atitech.ca/products/mobilityradeonx1800/specs.html
�bNative PCI Express x16 bus interface
Mobile�ł��n�C�G���h���܂߂�ɂ́Ax16���K�v���Ď��ł��ˁB
���\�̒ႢGPU���� x8 �� x4 �ł��[�����ǂ����A���̂��X�y�b�N�łɍڂ���
�Ȃ������ł����A�t���ғ����Ȃ��ꍇ�̏ȃG�l����Ƃ��āAx4��x8����i��
�����̓X�^���o�C������j�́ACPU�ŕK�v�����ȋC�����܂��B
AMD���̎��ゾ��
�܂��������N�ꂵ�ݑ����Ă����C���e�����v���܂��}�V��
�܂��������N�ꂵ�ݑ����Ă����C���e�����v���܂��}�V��
>>44
>>37
�S�R���̎��ザ��Ȃ����C���e���̂悤�ɂЂǂ����i���L���͂����Ŕ���悤�Ȃ��Ƃ͏o���Ȃ��B
�Ȃ��Ȃ�AMD�ɂ͐��\�I�ɗ����̂ł��ӐM���Ĕ����悤�Ȑ~�ȃt�@�������Ȃ�����B
64�V���[�Y�͒n���Ɍ�������҂𖡕��ɂ��Ĕ���グ��L���Ă����B
AMD���낤���C���e�����낤���A�悢���̂���������ڂ����������̂����Ȃ̂ł���B
�ւ��Ȑ��i���o���Ȃ�܂���������Ȃ����낤�B
�܂��AAM2�ƃR�����[���ׂ�AMD���I������Ƃ����o�J�����邪�����ł͂Ȃ��B
AM2�͒P��DDR2�����̂��߂̃}�C�i�[�`�F���W��CPU�I�ɂ͉��̕ω����Ȃ��B
����ł���d����ቿ�i�A���łɏ������Ă�����̂ɂƂ��Ă�DDR2�����p�ł���Ȃǖ��͂������B
�R�����[�͍��܂ł��ł��D�ꂽCPU�ł͂Ȃ����ƌ����Ă���PentiumM�̃j�R�C�`�̐i���`�B
�C���e���͍ň���CPU�ƂȂ��Ă��܂���Pentium4���悤�₭�̂āA�܂������V�����H���ŋN����_�����̂ł���B
�܂�A�܂��������炵�Ă��Ȃ��R�����[�ƌ��s��AM2���ׂ�̂͊ԈႢ�B
AMD�����ɏo���Ă���65nm���i��Hound�Ɣ�r���ׂ����̂ł���B
>>37
�S�R���̎��ザ��Ȃ����C���e���̂悤�ɂЂǂ����i���L���͂����Ŕ���悤�Ȃ��Ƃ͏o���Ȃ��B
�Ȃ��Ȃ�AMD�ɂ͐��\�I�ɗ����̂ł��ӐM���Ĕ����悤�Ȑ~�ȃt�@�������Ȃ�����B
64�V���[�Y�͒n���Ɍ�������҂𖡕��ɂ��Ĕ���グ��L���Ă����B
AMD���낤���C���e�����낤���A�悢���̂���������ڂ����������̂����Ȃ̂ł���B
�ւ��Ȑ��i���o���Ȃ�܂���������Ȃ����낤�B
�܂��AAM2�ƃR�����[���ׂ�AMD���I������Ƃ����o�J�����邪�����ł͂Ȃ��B
AM2�͒P��DDR2�����̂��߂̃}�C�i�[�`�F���W��CPU�I�ɂ͉��̕ω����Ȃ��B
����ł���d����ቿ�i�A���łɏ������Ă�����̂ɂƂ��Ă�DDR2�����p�ł���Ȃǖ��͂������B
�R�����[�͍��܂ł��ł��D�ꂽCPU�ł͂Ȃ����ƌ����Ă���PentiumM�̃j�R�C�`�̐i���`�B
�C���e���͍ň���CPU�ƂȂ��Ă��܂���Pentium4���悤�₭�̂āA�܂������V�����H���ŋN����_�����̂ł���B
�܂�A�܂��������炵�Ă��Ȃ��R�����[�ƌ��s��AM2���ׂ�̂͊ԈႢ�B
AMD�����ɏo���Ă���65nm���i��Hound�Ɣ�r���ׂ����̂ł���B
> �Ȃ��Ȃ�AMD�ɂ͐��\�I�ɗ����̂ł��ӐM���Ĕ����悤�Ȑ~�ȃt�@�������Ȃ�����B
2ch�̎���ɏZ�ݒ����A���~������B
AM2��Conroe�������|�I�ɐ��\�������͖̂������A�ł�������͂���w
2ch�̎���ɏZ�ݒ����A���~������B
AM2��Conroe�������|�I�ɐ��\�������͖̂������A�ł�������͂���w
CPU�P�̂̐��\�ł͊��S�ɍ���intel�^�[�����ȁB
���X�A���݂��������ꂽ�����ŃA�[�L�e�N�`�����X�V���Ă邩�瓖�R�̌��ʂł͂��邪�B
�����A���ƓI�ɂ͂ǂ����낤�ȁB
Opteron�̖��i�AAMD64�̗̍p�A�d�͌���&�}���`�R�A�ւ̘H���]��etc�E�E�E�Ɗ�Ɛ헪�Ƃ��Ă�
���S��intel�͌��ɉ���Ă邵�AFab36�̉ғ��Ŕ��������ƍ��������𗼗��ł���̐����o�����B
�Ɛ�֎~�@�֘A��intel�ւ̌��������������������ė��Ă�B
���̏œ����Ƃ��ǂ�������������������E�E�E
���X�A���݂��������ꂽ�����ŃA�[�L�e�N�`�����X�V���Ă邩�瓖�R�̌��ʂł͂��邪�B
�����A���ƓI�ɂ͂ǂ����낤�ȁB
Opteron�̖��i�AAMD64�̗̍p�A�d�͌���&�}���`�R�A�ւ̘H���]��etc�E�E�E�Ɗ�Ɛ헪�Ƃ��Ă�
���S��intel�͌��ɉ���Ă邵�AFab36�̉ғ��Ŕ��������ƍ��������𗼗��ł���̐����o�����B
�Ɛ�֎~�@�֘A��intel�ւ̌��������������������ė��Ă�B
���̏œ����Ƃ��ǂ�������������������E�E�E
> ���X�A���݂��������ꂽ�����ŃA�[�L�e�N�`�����X�V���Ă邩�瓖�R�̌��ʂł͂��邪�B
AMD��Athlon64���\�ȗ��w�ǐi�����Ă��Ȃ��̂����E�E�E
AMD��Athlon64���\�ȗ��w�ǐi�����Ă��Ȃ��̂����E�E�E
>>48
SSE3�Ή��AHyperTransport2.0�ADualCore���ADDR2�Ή��͐i������Ȃ��̂��H
���Ƃ�����ANetBurst��2000�N11���̔��\�ȗ��A�傫�ȕω���Prescott�����ł���ȊO��
FSB�N���b�N����ƃL���b�V�����ʂƂ����͋Z�Ői���Ƃ͌�����ȁB
�����Č����Ȃ�HyperThreading���炢�����A������ŏ�����g�ݍ��܂�Ă��@�\��ON�ɂ���������
OFF�̂܂܂̒��r���[�Ȃ��̂킳�ꂽ�A�����o�J�����������ɉ߂���B
Prescott��SSE3�������Ήʂ����ĉ��ǂƂ����邩�ǂ����E�E�E����Ӗ��A���ꂪNetBurst�Ƀg�h�����h�����Ƃ������邵�ȁB
���̕���ł͊��ɂ���Ƃ͂����ADualCore�Ƃ����\���I�ɂ��傫�ȕω������镪�A�܂��i���ƌ�����Ǝv�����ȁB
������ɂ���A��{�A�[�L�e�N�`���̊J�����s��ւ̓����������ǁ��E�E�E�Ƃ����T�C�N���͂قڔ������ꂾ����A
���炭��AMD�����܂łƓ����悤�ɂ͂����낤���E�E�EK8�Ńo�X�����^����ɉ��ǂ��Ă������̂͐������낤�ȁB
SSE3�Ή��AHyperTransport2.0�ADualCore���ADDR2�Ή��͐i������Ȃ��̂��H
���Ƃ�����ANetBurst��2000�N11���̔��\�ȗ��A�傫�ȕω���Prescott�����ł���ȊO��
FSB�N���b�N����ƃL���b�V�����ʂƂ����͋Z�Ői���Ƃ͌�����ȁB
�����Č����Ȃ�HyperThreading���炢�����A������ŏ�����g�ݍ��܂�Ă��@�\��ON�ɂ���������
OFF�̂܂܂̒��r���[�Ȃ��̂킳�ꂽ�A�����o�J�����������ɉ߂���B
Prescott��SSE3�������Ήʂ����ĉ��ǂƂ����邩�ǂ����E�E�E����Ӗ��A���ꂪNetBurst�Ƀg�h�����h�����Ƃ������邵�ȁB
���̕���ł͊��ɂ���Ƃ͂����ADualCore�Ƃ����\���I�ɂ��傫�ȕω������镪�A�܂��i���ƌ�����Ǝv�����ȁB
������ɂ���A��{�A�[�L�e�N�`���̊J�����s��ւ̓����������ǁ��E�E�E�Ƃ����T�C�N���͂قڔ������ꂾ����A
���炭��AMD�����܂łƓ����悤�ɂ͂����낤���E�E�EK8�Ńo�X�����^����ɉ��ǂ��Ă������̂͐������낤�ȁB
>>49
�S�R�Ƃ������A�S���i���Ƃ͌����Ȃ��B
�S�R�Ƃ������A�S���i���Ƃ͌����Ȃ��B
�S�F��ςŌ��ߕt����
>>50
�Ȃ�Conroe���S���i�����ĂȂ��ƌ����ׂ����ȁB
�X�e�b�s���O�������ʂ�A�P�Ȃ�P6�̉��ǂɉ߂���B
�o�X�̓N���b�N�����グ�Ă邪NetBurst�̗��p�����AComplexDecoder+SimpleDecoder�Ƃ����\����
�p�C�v���C���̊�{�\����P6���̂��́B
���ǂ��i������Ȃ��Ȃ�AP6vsK7�͐̂��牽���ς��Ȃ����ƂɂȂ�B
��x�ANetBurst�ɐi��(�l�I�ɂ͑މ������E�E�E)���Ă����Ȃ���AP6�ɕ����߂��Ă��Ă����މ������ȁB
�Ȃ�Conroe���S���i�����ĂȂ��ƌ����ׂ����ȁB
�X�e�b�s���O�������ʂ�A�P�Ȃ�P6�̉��ǂɉ߂���B
�o�X�̓N���b�N�����グ�Ă邪NetBurst�̗��p�����AComplexDecoder+SimpleDecoder�Ƃ����\����
�p�C�v���C���̊�{�\����P6���̂��́B
���ǂ��i������Ȃ��Ȃ�AP6vsK7�͐̂��牽���ς��Ȃ����ƂɂȂ�B
��x�ANetBurst�ɐi��(�l�I�ɂ͑މ������E�E�E)���Ă����Ȃ���AP6�ɕ����߂��Ă��Ă����މ������ȁB
>�p�C�v���C���̊�{�\��
����͏ڍה��\���ꂽ��ł���?
�ǂ���Ώڍ׃L�{���B
����͏ڍה��\���ꂽ��ł���?
�ǂ���Ώڍ׃L�{���B
P6��K7�͌Z��݂����Ȃ��ƌ����l�����邩��ˁB
Conroe�̉��Ǔ_�������炵�����ʂƂ����̂́A���̂܂�K8�ɂ��K�p�ł���B
���̂�����͊w��ȂŃA�C�f�A���̂��̂͐̂��炠����̂��قƂ�ǂŁA�����ɂ�
�������̌������̂Ƃ������������t���ɂ������B
���Ƃ͍������̖�肾�ȁB
�s�[�N�d���ɂȂ肪����intel�ƕ��ϒl��Œ�l�̒�グ���d������AMD�ł͂��̂������
���Ȃ�Ⴄ����ˁB
Conroe�̉��Ǔ_�������炵�����ʂƂ����̂́A���̂܂�K8�ɂ��K�p�ł���B
���̂�����͊w��ȂŃA�C�f�A���̂��̂͐̂��炠����̂��قƂ�ǂŁA�����ɂ�
�������̌������̂Ƃ������������t���ɂ������B
���Ƃ͍������̖�肾�ȁB
�s�[�N�d���ɂȂ肪����intel�ƕ��ϒl��Œ�l�̒�グ���d������AMD�ł͂��̂������
���Ȃ�Ⴄ����ˁB
> P6��K7�͌Z��݂����Ȃ��ƌ����l�����邩��ˁB
�Ƃ������AK7��P6�̐^�����q�ɉ߂��Ȃ����AK8��K7���g�������o�[�W�������B
���̊g���͌��\�D��Ă������AK8L�͋}���̎Y���ł����Ȃ������ŗ\�肵�Ă�����̐��ʂ͓�����낤�ȁB
�Ƃ������AK7��P6�̐^�����q�ɉ߂��Ȃ����AK8��K7���g�������o�[�W�������B
���̊g���͌��\�D��Ă������AK8L�͋}���̎Y���ł����Ȃ������ŗ\�肵�Ă�����̐��ʂ͓�����낤�ȁB
>>54
�ǂ������k�قȂ��B
K8��SSE3�Ή��A�}���`�R�A���ADDR2�Ή��Ȃǂ̈�A�̉��ǂ�i������Ȃ��ƌ�������Ȃ�A
NetBurst��Banias�n�̓��l�̉��ǂ��i������Ȃ��ƌ������ƂɂȂ�͓̂��R����Ȃ����B
�ǂ������k�قȂ��B
K8��SSE3�Ή��A�}���`�R�A���ADDR2�Ή��Ȃǂ̈�A�̉��ǂ�i������Ȃ��ƌ�������Ȃ�A
NetBurst��Banias�n�̓��l�̉��ǂ��i������Ȃ��ƌ������ƂɂȂ�͓̂��R����Ȃ����B
58 �FSocket774�F2006/06/20(��) 12:19:06 ID:6GrIxX1M
�ǂ��ł�����
3�N�O�ɒx��ɒx��ďo����3200+��AP4 3.2GHz�𖢂��ɍ��l�Ŕ��葱����AMD��Intel��DQN���Ă��Ƃł�����
���͂ǂ��炪��ɂ��̏�E���邩�A��
3�N�O�ɒx��ɒx��ďo����3200+��AP4 3.2GHz�𖢂��ɍ��l�Ŕ��葱����AMD��Intel��DQN���Ă��Ƃł�����
���͂ǂ��炪��ɂ��̏�E���邩�A��
AMD�ƃC���e���A������������Ă��Ėʔ���
���Ƃ��Ɖ�Ђ̋K�͂╶�����炵�ĈႤ���A�����Ǝv��
AMD�̃R�v�����ǂ��܂ŕ��y���邩������
���Ƃ��Ɖ�Ђ̋K�͂╶�����炵�ĈႤ���A�����Ǝv��
AMD�̃R�v�����ǂ��܂ŕ��y���邩������
L1��L3�ƂŃ��C�e���V�̍����L��AL3�����p�AL1���R�A���ƂɕʂƂ����\���Ȃ�A
L1��L3�Ƃ�r���ɂ��邱�Ƃ���߂�����B
�r���ɂ��Ȃ����A�ǂ��Ƃœ��e���ς�邱�Ƃ���������ǂƂ��̃^�O�t
�͗v��Ȃ��Ȃ�B�P���ɁA�������Ƃ��ɁA�ǂ̃R�A���������������̃^�O�t��
���邾���ł悢�A�ǂރR�A�������ȊO�̃^�O��������ēx�ǂݒ����Ƃ����P����
���삾���ōςށB
L1��L3�Ƃ�r���ɂ��邱�Ƃ���߂�����B
�r���ɂ��Ȃ����A�ǂ��Ƃœ��e���ς�邱�Ƃ���������ǂƂ��̃^�O�t
�͗v��Ȃ��Ȃ�B�P���ɁA�������Ƃ��ɁA�ǂ̃R�A���������������̃^�O�t��
���邾���ł悢�A�ǂރR�A�������ȊO�̃^�O��������ēx�ǂݒ����Ƃ����P����
���삾���ōςށB
>>56
����x86�nCPU���̂��ARISC�n�v���Z�b�T�Ƃ����Ƃ����ɒʉ߂����Z�p�̗��p�ɉ߂��Ȃ�����A
�^�����ǂ��̂ƌ����͖̂��Ӗ��B
����x86�nCPU���̂��ARISC�n�v���Z�b�T�Ƃ����Ƃ����ɒʉ߂����Z�p�̗��p�ɉ߂��Ȃ�����A
�^�����ǂ��̂ƌ����͖̂��Ӗ��B
62 �FSocket774�F2006/06/20(��) 12:56:37 ID:6GrIxX1M
>>61
����Ȃ�āA��̒��̊^�̏Z���Ȃ���˂����Ⴉ�킢������
����Ȃ�āA��̒��̊^�̏Z���Ȃ���˂����Ⴉ�킢������
�V�F�A�����Ȃ��̂ɉ������V�F�A�����Ă�Ɗ��Ⴂ����l�����č���B
1�T�ԑO�̘R��Ƃ�(�@߁��)<�߯�߰
1�T�ԑO�̘R��Ƃ�(�@߁��)<�߯�߰
>>57
> K8��SSE3�Ή��A�}���`�R�A���ADDR2�Ή��Ȃǂ̈�A�̉��ǂ�i������Ȃ��ƌ�������
�i���ł͂Ȃ��ȁB
SSE3�Ή��́A�g�����߃Z�b�g�ւ̑Ή��ł����Ȃ��B
�}���`�R�A���͌��X�̐v���}���`�R�A�O����i���Ƃ͌����Ȃ��B
DDR2�Ή����A�P�ɐV�������ւ̑Ή��ɉ߂��Ȃ��B
�i���̌��Ђ���Ȃ��B
> K8��SSE3�Ή��A�}���`�R�A���ADDR2�Ή��Ȃǂ̈�A�̉��ǂ�i������Ȃ��ƌ�������
�i���ł͂Ȃ��ȁB
SSE3�Ή��́A�g�����߃Z�b�g�ւ̑Ή��ł����Ȃ��B
�}���`�R�A���͌��X�̐v���}���`�R�A�O����i���Ƃ͌����Ȃ��B
DDR2�Ή����A�P�ɐV�������ւ̑Ή��ɉ߂��Ȃ��B
�i���̌��Ђ���Ȃ��B
����v�����u�`�ɑΉ����������v��i������Ȃ��ƌ����Ȃ�
����i���Ƃ����ړx�ɓ����낤�c
����i���Ƃ����ړx�ɓ����낤�c
�펯�I�ɂ͎���H�̑�����V���Ȑv��i���Ƃ����̂��낤�ˁB
�A���~�͂͐M�҂���������펯���ʂ��Ȃ��č���ȁB
�A���~�͂͐M�҂���������펯���ʂ��Ȃ��č���ȁB
�Ӂ[��B�܂�����ŗǂ���ˁB
���͐M�ғ��m�̑Ό����Ă�̂��y������������ƓK���Șb��Ő���オ���ĂĂ���B
���͐M�ғ��m�̑Ό����Ă�̂��y������������ƓK���Șb��Ő���オ���ĂĂ���B
>>60
����͓ǂݍ��݂ɍs���Ƃ��͏��L3�܂Ŋm�F���ɍs���Ƃ������Ƃ��H
����͓ǂݍ��݂ɍs���Ƃ��͏��L3�܂Ŋm�F���ɍs���Ƃ������Ƃ��H
K8L��L3�L���b�V���ɂ��Č����A���݂܂ł̋c�_�𑍍�����ƁA
�O�X����809�ȏ�ɍ����\�ȃL���b�V���ɂȂ锭���͑S���o�Ă��Ȃ��ȁB
�����Ƃ��A�O�X����809���Ȃ���ăL���b�V���ł����Ȃ����ǂȁB
> AMD�̎�����CPU�ɂ��Č�낤 4������
> http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/809
����܂ł̂܂Ƃ߁B
K8L��L3��L1L2�Ɗ��S�Ȕr���\���ƂȂ�B
�r���\���Ƃ��闝�R��L1L2���r���\���Ŋe�R�A���ɓƗ������L���b�V����������AL3��ς�ł�L1L2�𑖍�������ɁA
���R�A�ւ�L1L2�̏Ɖ�(�R�q�[�����V����̈�)��K�v�Ƃ��邩��AL3�͏o���邾��L1L2�Ɣr���ȃL���b�V���ł�������������ǂ��Ȃ邩�炾�B
�s���S�Ȕr���\���̋^�f��>>801�ɏ�����Ă��邪�A��L�̂悤��L1L2�̑�����ɕK�����R�A�ւ̏Ɖ����ׁAL3�͊��S�r���\�����ێ��ł���B
���ɁAL3�̓_�[�e�B�L���b�V��(�j�����Ƀ������ւ̏������݂��K�v�ȃL���b�V��)���܂܂Ȃ��B
�_�[�e�B�L���b�V���̏������݂�L2���j�������Ƃ��ɍs����B
����ɂ��AL3�̓��������ێ�����f�[�^�̎ʂ��ł���q�b�g�������Ȃ�Ƀ��C�e���V�����シ��Ƃ������������B
���X���b�g��L3�Ƃ̃R�q�[�����V����͌����ł���K�v���Ȃ�(�_�[�e�B�L���b�V�����܂܂Ȃ����A���L�����L1L2�݂̂ŗǂ�)�Ɖ�p�P�b�g�͑���Ȃ��\�����Ǝv����B
���ׁ̈AL3�Ǝ��������͓����ɃA�N�Z�X�\�ƂȂ�B
�Ӂ[����Ɖ�͏I���E�E�E�����������B
�O�X����809�ȏ�ɍ����\�ȃL���b�V���ɂȂ锭���͑S���o�Ă��Ȃ��ȁB
�����Ƃ��A�O�X����809���Ȃ���ăL���b�V���ł����Ȃ����ǂȁB
> AMD�̎�����CPU�ɂ��Č�낤 4������
> http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/809
����܂ł̂܂Ƃ߁B
K8L��L3��L1L2�Ɗ��S�Ȕr���\���ƂȂ�B
�r���\���Ƃ��闝�R��L1L2���r���\���Ŋe�R�A���ɓƗ������L���b�V����������AL3��ς�ł�L1L2�𑖍�������ɁA
���R�A�ւ�L1L2�̏Ɖ�(�R�q�[�����V����̈�)��K�v�Ƃ��邩��AL3�͏o���邾��L1L2�Ɣr���ȃL���b�V���ł�������������ǂ��Ȃ邩�炾�B
�s���S�Ȕr���\���̋^�f��>>801�ɏ�����Ă��邪�A��L�̂悤��L1L2�̑�����ɕK�����R�A�ւ̏Ɖ����ׁAL3�͊��S�r���\�����ێ��ł���B
���ɁAL3�̓_�[�e�B�L���b�V��(�j�����Ƀ������ւ̏������݂��K�v�ȃL���b�V��)���܂܂Ȃ��B
�_�[�e�B�L���b�V���̏������݂�L2���j�������Ƃ��ɍs����B
����ɂ��AL3�̓��������ێ�����f�[�^�̎ʂ��ł���q�b�g�������Ȃ�Ƀ��C�e���V�����シ��Ƃ������������B
���X���b�g��L3�Ƃ̃R�q�[�����V����͌����ł���K�v���Ȃ�(�_�[�e�B�L���b�V�����܂܂Ȃ����A���L�����L1L2�݂̂ŗǂ�)�Ɖ�p�P�b�g�͑���Ȃ��\�����Ǝv����B
���ׁ̈AL3�Ǝ��������͓����ɃA�N�Z�X�\�ƂȂ�B
�Ӂ[����Ɖ�͏I���E�E�E�����������B
>>64
���i���̌��Ђ���Ȃ��B
�悭�����������ƌ�����ˁB�N��AMD�̊����������炻���͂��Ȃ������A�Ƃł���������H
�[���A���������i���Ȃ�Č��t�͂��̃h�b�O�C���[�ȋƊE�ɂ͑傰���������B������₷���i���ł�����B
���́u�`�ɑΉ����������v�ł��\���Ȑi�����Ǝv�����B
���i���̌��Ђ���Ȃ��B
�悭�����������ƌ�����ˁB�N��AMD�̊����������炻���͂��Ȃ������A�Ƃł���������H
�[���A���������i���Ȃ�Č��t�͂��̃h�b�O�C���[�ȋƊE�ɂ͑傰���������B������₷���i���ł�����B
���́u�`�ɑΉ����������v�ł��\���Ȑi�����Ǝv�����B
�����A���l��Athlon64�̊J���`�[���ɂ�����Ƃ����̐̂ɐi�����Ă���ȁB
�܂��́A�f���A���R�A����������O�ɂȂ�Ȃ�r���L���b�V����p�~�������\��L2���L�L���b�V�����J������ˁB
�܂��́A�f���A���R�A����������O�ɂȂ�Ȃ�r���L���b�V����p�~�������\��L2���L�L���b�V�����J������ˁB
>>71=64
���፡����ł��x���Ȃ��A���Ђ��Ă���B���ނ�
���፡����ł��x���Ȃ��A���Ђ��Ă���B���ނ�
����ȕ��ȉ�Ђɂ̓w�b�h�n���g����Ă��s���Ȃ���B
�N�̏ꍇ�̓w�b�h����Ȃ��ăe�[���Ƃ�����
(�g�J�Q)�e�[���J�b�g
(�g�J�Q)�e�[���J�b�g
>>75
�ǂ��œd�g�E�������m��Ȃ���FX��3GHz���o�����Ƃ����E6600�ɂ��珟�ĂȂ��͖̂����Ȃ�B
�ǂ��œd�g�E�������m��Ȃ���FX��3GHz���o�����Ƃ����E6600�ɂ��珟�ĂȂ��͖̂����Ȃ�B
�܁A�L���b�V���������狭�����Ă�I/O�ɂ͌����Ȃ�����ȁE�E�E
����`�b�v���̃R�q�[�����V����Ŏ�L���Ȓ��x�ŁA�\�P�b�g�Ԃ̃R�q�[�����V����ɂ͂قƂ�ǖ����A
�\�P�b�g�Ԃł������L���ĂȂ��f�[�^�ł��L���b�V�������L�ɂȂ��Ă邨�����ŁA���L�f�[�^���Q�Ƃ��Ă��Ȃ�
���W�ȃR�A���R�q�[�����V����Ɋ������܂��Ƃ����Ƃ��납�B
����`�b�v���̃R�q�[�����V����Ŏ�L���Ȓ��x�ŁA�\�P�b�g�Ԃ̃R�q�[�����V����ɂ͂قƂ�ǖ����A
�\�P�b�g�Ԃł������L���ĂȂ��f�[�^�ł��L���b�V�������L�ɂȂ��Ă邨�����ŁA���L�f�[�^���Q�Ƃ��Ă��Ȃ�
���W�ȃR�A���R�q�[�����V����Ɋ������܂��Ƃ����Ƃ��납�B
K8L��L3���L�L���b�V���́A�R�q�[�����V����ɂ͑S�����b�Ȃ����ǂȁB
���R�A����L1L2�ŃL���b�V���G���[�̂Ƃ��͑��R�A�S�ĂŏƉ�(L1L2����)���K�v�B
�����Ƃ��A���n�܂������Ƃł͂Ȃ��O���炸���Ƃ����ǂȁB
�ŁA�L���b�V�����\����������L2�̑��������Ԃ���������ƁE�E�E
���R�A����L1L2�ŃL���b�V���G���[�̂Ƃ��͑��R�A�S�ĂŏƉ�(L1L2����)���K�v�B
�����Ƃ��A���n�܂������Ƃł͂Ȃ��O���炸���Ƃ����ǂȁB
�ŁA�L���b�V�����\����������L2�̑��������Ԃ���������ƁE�E�E
>>78
������������H
���x���x�u�����v�ƌ����Ă�l�����A���O�̗������Ă���u�����v���Ă̂́A��̓I�ɉ�������Ă�H
�L���b�V���ɑ��āu�����v����Ƃ����̂��ǂ����C���[�W�o���Ȃ���ŁA�������ށB
������������H
���x���x�u�����v�ƌ����Ă�l�����A���O�̗������Ă���u�����v���Ă̂́A��̓I�ɉ�������Ă�H
�L���b�V���ɑ��āu�����v����Ƃ����̂��ǂ����C���[�W�o���Ȃ���ŁA�������ށB
>>78
L1L2�ŃL���b�V���G���[���N�����R�A�����L���b�V�����t���b�V������Ⴂ����������ˁH
���̃R�A�͂��̂܂ܑ���B
L1L2�ŃL���b�V���G���[���N�����R�A�����L���b�V�����t���b�V������Ⴂ����������ˁH
���̃R�A�͂��̂܂ܑ���B
���o��������Ȃ����ǁAK8L
ttp://www.theinquirer.net/?article=32424
ttp://www.chip-architect.com/news/K8L_floorplan.jpg
ttp://www.theinquirer.net/?article=32424
ttp://www.chip-architect.com/news/K8L_floorplan.jpg
{kind=link}
�Ȃɂ��̂��₶
COMPUTEX TAIPEI 2006 - AMD�̎�����e�N�m���W��T��ACTO�EPhil Hester���C���^�r���[
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/
�匴�Y��ƌ㓡�O�Ƃ̋����C���^�r���[�������ł���B
���݂̏o�Ă���̊m�F���Ă��ł��˂��B
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/
�匴�Y��ƌ㓡�O�Ƃ̋����C���^�r���[�������ł���B
���݂̏o�Ă���̊m�F���Ă��ł��˂��B
K8 �� L3 �̈��������Ă�C���e���[�́AItanium (Montecito) �̈��������Ă�
���Ƃɂ��Ȃ���Ȃ��B
Montecito �� L2 �͕����AL3 �͋��L�B�����Ƃ� Montecito �̏ꍇ�� L3 ��
�ԈႢ�Ȃ� Inclusive ���낤���ǁB
�������A�C���e���[���J��Ԃ������Ă�
> ���R�A����L1L2�ŃL���b�V���G���[�̂Ƃ��͑��R�A�S�ĂŏƉ�(L1L2����)���K�v�B
���Ă䂤�̂� Montecito �ł������B
�ʂɂ���͔r���L���b�V���̓�������Ȃ���B
�V���O���X���b�h���\���d�v�ȃf�X�N�g�b�v�ł́AL2 ���L�͓��R�̉������ǁA
�T�[�o�̏ꍇ�͂����Ƃ�������Ȃ��̂˂��B
���Ƃɂ��Ȃ���Ȃ��B
Montecito �� L2 �͕����AL3 �͋��L�B�����Ƃ� Montecito �̏ꍇ�� L3 ��
�ԈႢ�Ȃ� Inclusive ���낤���ǁB
�������A�C���e���[���J��Ԃ������Ă�
> ���R�A����L1L2�ŃL���b�V���G���[�̂Ƃ��͑��R�A�S�ĂŏƉ�(L1L2����)���K�v�B
���Ă䂤�̂� Montecito �ł������B
�ʂɂ���͔r���L���b�V���̓�������Ȃ���B
�V���O���X���b�h���\���d�v�ȃf�X�N�g�b�v�ł́AL2 ���L�͓��R�̉������ǁA
�T�[�o�̏ꍇ�͂����Ƃ�������Ȃ��̂˂��B
�ʂɈ����͌����ĂȂ��A�������Ă��邾�����B
Inclusive��L3���L�L���b�V����L���Ă���ꍇ�AL1L2L3�ŃL���b�V���G���[�Ȃ瓯��\�P�b�g���̃R�A�ւ̏Ɖ�͕s�v���B
Inclusive��L3���L�L���b�V����L���Ă���ꍇ�AL1L2L3�ŃL���b�V���G���[�Ȃ瓯��\�P�b�g���̃R�A�ւ̏Ɖ�͕s�v���B
�A�z���B
�ʃR�A�� L1 �� dirty �ȃf�[�^�������Ă���A���� L1 ��
�Ɖ�邵���Ȃ��낤�B
Write Thorugh �L���b�V�������Ȃ�������̂��Ⴀ��܂����A
Write Back �L���b�V����������O�̌���ł́A�ʃR�A��
L1, L2 �ɏƉ��K�v������̂́AMontecito ���낤���A
Core Duo ���낤�������B
���܂ł��Q�������������ĂāA�p���������Ȃ��̂��H
�ʃR�A�� L1 �� dirty �ȃf�[�^�������Ă���A���� L1 ��
�Ɖ�邵���Ȃ��낤�B
Write Thorugh �L���b�V�������Ȃ�������̂��Ⴀ��܂����A
Write Back �L���b�V����������O�̌���ł́A�ʃR�A��
L1, L2 �ɏƉ��K�v������̂́AMontecito ���낤���A
Core Duo ���낤�������B
���܂ł��Q�������������ĂāA�p���������Ȃ��̂��H
>>87
�A�z�͂��Ow
Inclusive��L3���L�L���b�V����L���Ă���̂�����AL3�L���b�V���G���[�̎��_�œ���\�P�b�g���L1L2�̑S�Ă��L���b�V���ێ�����Ă��Ȃ����Ƃ��������Ă���B
�A�z�͂��Ow
Inclusive��L3���L�L���b�V����L���Ă���̂�����AL3�L���b�V���G���[�̎��_�œ���\�P�b�g���L1L2�̑S�Ă��L���b�V���ێ�����Ă��Ȃ����Ƃ��������Ă���B
�ŁA���� L3 �L���b�V���ɂ��邱�Ƃ�����������A���ꂩ�� L1 �� L2 ��
�₢���킹����킯�H
��������ƁAL3 �q�b�g���̃��C�e���V�́AL3 �₢���킹 + L1/L2 �₢���킹
�ɂȂ�킯���B������Ēx�������B
���C�e���V�̂��Ƃ������ƍl���č��AL3 �ւ̖₢���킹�� L1/L2 �ւ�
�₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B��������AL3 �~�X�q�b�g�����A
L3 �q�b�g���������͕ς���B�r���L���b�V�����낤���A�����łȂ��낤���A
���x�͕ς���B
���ꂮ�炢�̂��Ƃ��������́H
�{���ɃA�z�H
�₢���킹����킯�H
��������ƁAL3 �q�b�g���̃��C�e���V�́AL3 �₢���킹 + L1/L2 �₢���킹
�ɂȂ�킯���B������Ēx�������B
���C�e���V�̂��Ƃ������ƍl���č��AL3 �ւ̖₢���킹�� L1/L2 �ւ�
�₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B��������AL3 �~�X�q�b�g�����A
L3 �q�b�g���������͕ς���B�r���L���b�V�����낤���A�����łȂ��낤���A
���x�͕ς���B
���ꂮ�炢�̂��Ƃ��������́H
�{���ɃA�z�H
>>89
> �ŁA���� L3 �L���b�V���ɂ��邱�Ƃ�����������A���ꂩ�� L1 �� L2 ��
> �₢���킹����킯�H
> ��������ƁAL3 �q�b�g���̃��C�e���V�́AL3 �₢���킹 + L1/L2 �₢���킹
> �ɂȂ�킯���B������Ēx�������B
�ق��A���̂Ƃ���B
> ���C�e���V�̂��Ƃ������ƍl���č��AL3 �ւ̖₢���킹�� L1/L2 �ւ�
> �₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B
����Ȕn���Ȃ��Ƃ͂��Ȃ��A�t�ɒx���Ȃ��Ă��܂��B
L3���L�L���b�V���͕֗������AL1L2���x�����ƑO��Őv����Ă���B
> ���ꂮ�炢�̂��Ƃ��������́H
> �{���ɃA�z�H
�A�z�͂��O�����Ă�w
> �ŁA���� L3 �L���b�V���ɂ��邱�Ƃ�����������A���ꂩ�� L1 �� L2 ��
> �₢���킹����킯�H
> ��������ƁAL3 �q�b�g���̃��C�e���V�́AL3 �₢���킹 + L1/L2 �₢���킹
> �ɂȂ�킯���B������Ēx�������B
�ق��A���̂Ƃ���B
> ���C�e���V�̂��Ƃ������ƍl���č��AL3 �ւ̖₢���킹�� L1/L2 �ւ�
> �₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B
����Ȕn���Ȃ��Ƃ͂��Ȃ��A�t�ɒx���Ȃ��Ă��܂��B
L3���L�L���b�V���͕֗������AL1L2���x�����ƑO��Őv����Ă���B
> ���ꂮ�炢�̂��Ƃ��������́H
> �{���ɃA�z�H
�A�z�͂��O�����Ă�w
> > ���C�e���V�̂��Ƃ������ƍl���č��AL3 �ւ̖₢���킹�� L1/L2 �ւ�
> > �₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B
> ����Ȕn���Ȃ��Ƃ͂��Ȃ��A�t�ɒx���Ȃ��Ă��܂��B
> L3���L�L���b�V���͕֗������AL1L2���x�����ƑO��Őv����Ă���B
�͂��H
�x���Ȃ�킯�Ȃ������B
��Ɍ��ʂ���������̌��ʂ������p���āA�x��Ă������ʂ͎̂Ă��
��������B�{���̃o�J�ł��Ȃ��B
���ہAConroe �̃L���b�V���̐�`���ڂɂ��� Direct L1 to L1 cache
transfer ���āA�܂��ɂ��������Z�p����B
�C���e���[���āA�C���e���̋Z�p���m���̂��B
> > �₢���킹�͕���ɍs�Ȃ��悤�ɍ��͂��B
> ����Ȕn���Ȃ��Ƃ͂��Ȃ��A�t�ɒx���Ȃ��Ă��܂��B
> L3���L�L���b�V���͕֗������AL1L2���x�����ƑO��Őv����Ă���B
�͂��H
�x���Ȃ�킯�Ȃ������B
��Ɍ��ʂ���������̌��ʂ������p���āA�x��Ă������ʂ͎̂Ă��
��������B�{���̃o�J�ł��Ȃ��B
���ہAConroe �̃L���b�V���̐�`���ڂɂ��� Direct L1 to L1 cache
transfer ���āA�܂��ɂ��������Z�p����B
�C���e���[���āA�C���e���̋Z�p���m���̂��B
�b��K8��L2���[�h���C�e���V����r�I�������Ƃ�O��ɂ��Ă鎞�_�ŐQ������ȁB
�ʏ�A���[�h���C�e���V�̓L���b�V���ɑ��ăA�h���X�̏Ɖ���s���A�q�b�g�����f�[�^�̃��[�h�����܂�
�̎��Ԃ�����A�A�h���X�Ɖ�܂łŃq�b�g��������Α債�����Ԃ͂������B
L2=512KByte/Mem=512MByte��O������Ƃ����ꍇ�Ȃ�A�L���b�V������������̃f�[�^��ێ����Ă���
�m����1/1024������A�Ɖ�Ń��[�h���C�e���V�Ɠ����̎��Ԃ��K�v�ɂȂ�P�[�X�ȂNjɋ͂����B
�ʏ�A���[�h���C�e���V�̓L���b�V���ɑ��ăA�h���X�̏Ɖ���s���A�q�b�g�����f�[�^�̃��[�h�����܂�
�̎��Ԃ�����A�A�h���X�Ɖ�܂łŃq�b�g��������Α債�����Ԃ͂������B
L2=512KByte/Mem=512MByte��O������Ƃ����ꍇ�Ȃ�A�L���b�V������������̃f�[�^��ێ����Ă���
�m����1/1024������A�Ɖ�Ń��[�h���C�e���V�Ɠ����̎��Ԃ��K�v�ɂȂ�P�[�X�ȂNjɋ͂����B
> �b��K8��L2���[�h���C�e���V����r�I�������Ƃ�O��ɂ��Ă鎞�_�ŐQ������ȁB
�O��ɂȂǂ��Ă��Ȃ��A���ׂ̈Ɋ��đ����Ə����Ă���B
����̓q�b�g���Ȃ��ꍇ���������ƑO��Ƃ��Ă���B
�O��ɂȂǂ��Ă��Ȃ��A���ׂ̈Ɋ��đ����Ə����Ă���B
����̓q�b�g���Ȃ��ꍇ���������ƑO��Ƃ��Ă���B
>>87 ���āA�ǂ������������H
L3 �Ƀq�b�g�����ꍇ�AL1 �� L2 �ɖ₢���킹�āA�_�[�e�B�ȃf�[�^��
�����Ă邩�ǂ����m�F���Ȃ��Ⴂ���Ȃ��̂͊m������ˁB
L3 �Ƀq�b�g�����ꍇ�AL1 �� L2 �ɖ₢���킹�āA�_�[�e�B�ȃf�[�^��
�����Ă邩�ǂ����m�F���Ȃ��Ⴂ���Ȃ��̂͊m������ˁB
> �ʏ�A���[�h���C�e���V�̓L���b�V���ɑ��ăA�h���X�̏Ɖ���s���A�q�b�g�����f�[�^�̃��[�h�����܂�
> �̎��Ԃ�����A�A�h���X�Ɖ�܂łŃq�b�g��������Α債�����Ԃ͂������B
> L2=512KByte/Mem=512MByte��O������Ƃ����ꍇ�Ȃ�A�L���b�V������������̃f�[�^��ێ����Ă���
> �m����1/1024������A�Ɖ�Ń��[�h���C�e���V�Ɠ����̎��Ԃ��K�v�ɂȂ�P�[�X�ȂNjɋ͂����B
����ׂ����_���Ԉ���Ă���B
�L���b�V���G���[�ɂ��Ɖ�������邱�ƂŁA�e�R�A�ɑ傫�ȕ��S���|�邱�Ƃ�Y��Ă���B
�P�R�A�����̃��[�h���C�e���V�����Ă���_������w
�S�ẴR�A���ғ���Ԃɂ���Ƃ��̕��ׂ��C�ɂ��Ă����B
> �̎��Ԃ�����A�A�h���X�Ɖ�܂łŃq�b�g��������Α債�����Ԃ͂������B
> L2=512KByte/Mem=512MByte��O������Ƃ����ꍇ�Ȃ�A�L���b�V������������̃f�[�^��ێ����Ă���
> �m����1/1024������A�Ɖ�Ń��[�h���C�e���V�Ɠ����̎��Ԃ��K�v�ɂȂ�P�[�X�ȂNjɋ͂����B
����ׂ����_���Ԉ���Ă���B
�L���b�V���G���[�ɂ��Ɖ�������邱�ƂŁA�e�R�A�ɑ傫�ȕ��S���|�邱�Ƃ�Y��Ă���B
�P�R�A�����̃��[�h���C�e���V�����Ă���_������w
�S�ẴR�A���ғ���Ԃɂ���Ƃ��̕��ׂ��C�ɂ��Ă����B
>>95
87��86�ɑ��Ă̔����Ƃ��Ă͕s�K�����A����͊���>>88�ɏ����Ă���B
>>88�����O�������l��������B
���łɂ����ƁA>>89��>>86�̎��Ԃ����܂����ׂɏ�����Ă���ƌ���̂����ʂ���w
87��86�ɑ��Ă̔����Ƃ��Ă͕s�K�����A����͊���>>88�ɏ����Ă���B
>>88�����O�������l��������B
���łɂ����ƁA>>89��>>86�̎��Ԃ����܂����ׂɏ�����Ă���ƌ���̂����ʂ���w
�����������͍ŏ��̏������݂� Inclusive ���ď����Ă����A
>>88�����O����Ȃ�Ă��Ƃ��s�\�Ȃ͖̂������Ǝv���̂����B
L3 �ւ̖₢���킹�� L1/L2 �ւ̖₢���킹����čs�Ȃ��A
>>88 �̃P�[�X�ł����C�e���V�̈����Ȃǂ͋N���Ȃ����A�܂�
�������ĂȂ��̂��B
�ŁA���� >>91 �ɂ͂܂Ƃ��Ȕ��_���v�����Ȃ�����m�\����߂����
�������邵���肪�Ȃ��킯�ˁB���킢�����ȓz���Ȃ��B
>>88�����O����Ȃ�Ă��Ƃ��s�\�Ȃ͖̂������Ǝv���̂����B
L3 �ւ̖₢���킹�� L1/L2 �ւ̖₢���킹����čs�Ȃ��A
>>88 �̃P�[�X�ł����C�e���V�̈����Ȃǂ͋N���Ȃ����A�܂�
�������ĂȂ��̂��B
�ŁA���� >>91 �ɂ͂܂Ƃ��Ȕ��_���v�����Ȃ�����m�\����߂����
�������邵���肪�Ȃ��킯�ˁB���킢�����ȓz���Ȃ��B
>>99
���R�A�ւ̏Ɖ�������邱�Ƃ����O�͖������Ă���B
���R�A����̏Ɖ��������ƁA���R�A�̍�Ƃ��~�߂Đ�ɏƉ�ɑ���ԐM���s��˂����Ȃ��B
���ꂪ�A4�R�A�����ɔ������邱�ƂƂȂ蕉�ׂ͑傫���Ȃ�B
��������O�͎��O���Ă���B
�ŁAL1L2�͊e�R�A�Ɨ����Ă���AL1L2�Ńq�b�g�����ꍇ�́A���L�t���O�������Ă��Ȃ���Α��R�A�ւ̏Ɖ�͕s�v���B
L3���L�L���b�V���𓋍ڂ���ړI�Ƃ��ăL���b�V���G���[���̏Ɖ�p�P�b�g�����炷�ړI�����邱�Ƃ�Y��Ȃ��ł���B
�e�R�A�̊�{�L���b�V����L1L2�ł��邱�Ƃ���������Ɨ������Ă����B
�ł��AK8L�̏ꍇ�́AL3��L1L2�Ɗ��S�r���\���ɂ���̂��s���������B
�ł��̏ꍇ�AL3�ƃ������[�͓����A�N�Z�X���\�ƂȁB
���̂悤�ȓ����ɂȂ邪�A�R�q�[�����V�̌y���ɂ͑S�����ɗ����Ȃ����̂ł���ƌ����Ă邾�����B
���̈Ӗ��ŁA�Ȃ���ċ��L�L���b�V���ƂȂ�B
���R�A�ւ̏Ɖ�������邱�Ƃ����O�͖������Ă���B
���R�A����̏Ɖ��������ƁA���R�A�̍�Ƃ��~�߂Đ�ɏƉ�ɑ���ԐM���s��˂����Ȃ��B
���ꂪ�A4�R�A�����ɔ������邱�ƂƂȂ蕉�ׂ͑傫���Ȃ�B
��������O�͎��O���Ă���B
�ŁAL1L2�͊e�R�A�Ɨ����Ă���AL1L2�Ńq�b�g�����ꍇ�́A���L�t���O�������Ă��Ȃ���Α��R�A�ւ̏Ɖ�͕s�v���B
L3���L�L���b�V���𓋍ڂ���ړI�Ƃ��ăL���b�V���G���[���̏Ɖ�p�P�b�g�����炷�ړI�����邱�Ƃ�Y��Ȃ��ł���B
�e�R�A�̊�{�L���b�V����L1L2�ł��邱�Ƃ���������Ɨ������Ă����B
�ł��AK8L�̏ꍇ�́AL3��L1L2�Ɗ��S�r���\���ɂ���̂��s���������B
�ł��̏ꍇ�AL3�ƃ������[�͓����A�N�Z�X���\�ƂȁB
���̂悤�ȓ����ɂȂ邪�A�R�q�[�����V�̌y���ɂ͑S�����ɗ����Ȃ����̂ł���ƌ����Ă邾�����B
���̈Ӗ��ŁA�Ȃ���ċ��L�L���b�V���ƂȂ�B
> ���R�A�ւ̏Ɖ�������邱�Ƃ����O�͖������Ă���B
> ���R�A����̏Ɖ��������ƁA���R�A�̍�Ƃ��~�߂Đ�ɏƉ�ɑ����
> �M���s��˂����Ȃ��B
����͒P���ɊԈႢ�B
�Ђ���Ƃ��ă\�t�g�E�F�A�G���W�j�A�Ńn�[�h�E�F�A�̂��Ƃ�S���m��Ȃ��l�H
�\�t�g�E�F�A�̏ꍇ�A����X���b�h����Ƃ��s�Ȃ��Ă���Ԃ́A���̃X���b�h��
���̍�Ƃ��s�Ȃ����Ƃ��ł��Ȃ��B
�������A�n�[�h�E�F�A�Ȃ�A�����I�Ƀg�����W�X�^��z���������₹�A
���̍�Ƃ��~�߂邱�ƂȂ��A����ɍ�Ƃ��s�Ȃ����Ƃ��ł���B
�\�t�g�E�F�A�ŃX���b�h�𑝂₷�̂Ɠ������Ƃ����B
> ���R�A����̏Ɖ��������ƁA���R�A�̍�Ƃ��~�߂Đ�ɏƉ�ɑ����
> �M���s��˂����Ȃ��B
����͒P���ɊԈႢ�B
�Ђ���Ƃ��ă\�t�g�E�F�A�G���W�j�A�Ńn�[�h�E�F�A�̂��Ƃ�S���m��Ȃ��l�H
�\�t�g�E�F�A�̏ꍇ�A����X���b�h����Ƃ��s�Ȃ��Ă���Ԃ́A���̃X���b�h��
���̍�Ƃ��s�Ȃ����Ƃ��ł��Ȃ��B
�������A�n�[�h�E�F�A�Ȃ�A�����I�Ƀg�����W�X�^��z���������₹�A
���̍�Ƃ��~�߂邱�ƂȂ��A����ɍ�Ƃ��s�Ȃ����Ƃ��ł���B
�\�t�g�E�F�A�ŃX���b�h�𑝂₷�̂Ɠ������Ƃ����B
> ����͒P���ɊԈႢ�B
����ᐦ��w
��������������Ă��܂������B
�ŁA���܂��̖ϑz�����Ă���B
����ᐦ��w
��������������Ă��܂������B
�ŁA���܂��̖ϑz�����Ă���B
�P�ɔz�������邾���̘b����B
�܂� Conroe �̐�`������������悤�Ƃ���ƁAL1 �̃|�[�g���𑝂₷
�K�v������̂ŁA����͂���Ȃ�ɑ�ςȘb�����A����� K8L �̘b�Ȃ�A
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/001.html
�̐}2������Ε�����ʂ�A����R�A����AL3 �ւ̖₢���킹��
�ʂ̃R�A�� L1/L2 �ւ̖₢���킹�́A�N���X�o�[�Ɍo�R�ŕʂ̌o�H��
�ʂ�̂ŁA����ɔ��s���Ă����̖����Ȃ����Ƃ�������B
�z���͂����Ƃ���킯�B
�܂�A�������AAMD �̐v�w�̕��������ƁB
������܂������ǂˁB
�܂� Conroe �̐�`������������悤�Ƃ���ƁAL1 �̃|�[�g���𑝂₷
�K�v������̂ŁA����͂���Ȃ�ɑ�ςȘb�����A����� K8L �̘b�Ȃ�A
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/001.html
�̐}2������Ε�����ʂ�A����R�A����AL3 �ւ̖₢���킹��
�ʂ̃R�A�� L1/L2 �ւ̖₢���킹�́A�N���X�o�[�Ɍo�R�ŕʂ̌o�H��
�ʂ�̂ŁA����ɔ��s���Ă����̖����Ȃ����Ƃ�������B
�z���͂����Ƃ���킯�B
�܂�A�������AAMD �̐v�w�̕��������ƁB
������܂������ǂˁB
���āA�A�z�N�͕��u�ŁE�E�E
>>84
> COMPUTEX TAIPEI 2006 - AMD�̎�����e�N�m���W��T��ACTO�EPhil Hester���C���^�r���[
> ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/
> --�Ƃ����L2�L���b�V���̃T�C�Y��1MB����512KB�Ɍ������킯�ł����A����͉��̂ł��傤?
> �L���b�V���V�X�e���̃��f�����O���s���āA�e�R�A���ǂ̂��炢�̃T�C�Y��L2���������Ƃ���
> �ł��ǂ��V�X�e���p�t�H�[�}���X���ł��邩�����������B���̌��ʁA
> L2��1MB�𓋍ڂ����(�eL2�̃R�q�[�����V�m�ۂ̂��߂�)L3��N���X�o�[�̕��ׂ����܂�Ƃ������_���o�Ă���B
�ʔ������Ƃ�������Ă���B
L2�����������������A�R�q�[�����V����ŗL���Ƃ�����|�ł���B
����͉����L2��傫�����āA�Ɖ�p�P�b�g�ɂ��q�b�g������́AL2������������L3�֓f���o��(�_�[�e�B���̓������ւ��f���o�����ƂŃN���[��������)
L2�ł̓q�b�g������L3�ł̃q�b�g�̂ق����L���Ƃ̔������B
���̂悤��CTO�EPhil Hester�����܂��A�R�q�[�����V�̈������C�ɂ��Ă���̂ł���B
�����炪�A�Ȃ����L3���L�L���b�V���̐^���Ƃ����邩����w
>>84
> COMPUTEX TAIPEI 2006 - AMD�̎�����e�N�m���W��T��ACTO�EPhil Hester���C���^�r���[
> ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/
> --�Ƃ����L2�L���b�V���̃T�C�Y��1MB����512KB�Ɍ������킯�ł����A����͉��̂ł��傤?
> �L���b�V���V�X�e���̃��f�����O���s���āA�e�R�A���ǂ̂��炢�̃T�C�Y��L2���������Ƃ���
> �ł��ǂ��V�X�e���p�t�H�[�}���X���ł��邩�����������B���̌��ʁA
> L2��1MB�𓋍ڂ����(�eL2�̃R�q�[�����V�m�ۂ̂��߂�)L3��N���X�o�[�̕��ׂ����܂�Ƃ������_���o�Ă���B
�ʔ������Ƃ�������Ă���B
L2�����������������A�R�q�[�����V����ŗL���Ƃ�����|�ł���B
����͉����L2��傫�����āA�Ɖ�p�P�b�g�ɂ��q�b�g������́AL2������������L3�֓f���o��(�_�[�e�B���̓������ւ��f���o�����ƂŃN���[��������)
L2�ł̓q�b�g������L3�ł̃q�b�g�̂ق����L���Ƃ̔������B
���̂悤��CTO�EPhil Hester�����܂��A�R�q�[�����V�̈������C�ɂ��Ă���̂ł���B
�����炪�A�Ȃ����L3���L�L���b�V���̐^���Ƃ����邩����w
> ����͉����L2��傫�����āA�Ɖ�p�P�b�g�ɂ��q�b�g�������
�u�eL2�̃R�q�[�����V�m�ۂ̂��߂Ɂv���Ă̂��A�P�ɏƉ�̃R�X�g�Ɠǂނ킯�ˁB
�Ⴄ��˂��H
L2 �ŋ��L���Ă��郉�C���̓�������邽�߂̃R�X�g����˂��́H
K8L �R�A�̓}���`�\�P�b�g�ɂ����̂܂ܑΉ������R�A�ŁA�Ɖ���Ȃ�A
�ʂɍ���̘b�Ɍ��炸�AHT �o�R�ŕp�ɂɗ��Ă�͂��B�}���`�\�P�b�g�����
�Ɖ�ɑς����� L3 ��N���X�o�[���A���������̃R�A����̏Ɖ��
�ς����Ȃ��킯���Ȃ��B
�u�eL2�̃R�q�[�����V�m�ۂ̂��߂Ɂv���Ă̂��A�P�ɏƉ�̃R�X�g�Ɠǂނ킯�ˁB
�Ⴄ��˂��H
L2 �ŋ��L���Ă��郉�C���̓�������邽�߂̃R�X�g����˂��́H
K8L �R�A�̓}���`�\�P�b�g�ɂ����̂܂ܑΉ������R�A�ŁA�Ɖ���Ȃ�A
�ʂɍ���̘b�Ɍ��炸�AHT �o�R�ŕp�ɂɗ��Ă�͂��B�}���`�\�P�b�g�����
�Ɖ�ɑς����� L3 ��N���X�o�[���A���������̃R�A����̏Ɖ��
�ς����Ȃ��킯���Ȃ��B
> ����R�A����AL3 �ւ̖₢���킹��
> �ʂ̃R�A�� L1/L2 �ւ̖₢���킹�́A�N���X�o�[�Ɍo�R�ŕʂ̌o�H��
> �ʂ�̂ŁA����ɔ��s���Ă����̖����Ȃ����Ƃ�������B
�������A�z�N��������A���R�AL1L2�ւ̏Ɖ��L3�y�у������̃A�N�Z�X���ɉ\�Ƃ̂��o�J��������яo���܂������
����͔��ɕ|���B
���R�A��L2����ׁ̈A�_�[�e�B�L���b�V�����������֏������ޓ���ƁA���R�A�����R�A�ւ�L2�Ɖ�ƃ��������[�h�������A�N�Z�X����P�[�X��
�l���Ă݂悤�B
���R�A�̃��������[�h�����R�A�̃������X�g�A����ɔ�э��P�[�X�B
���̃P�[�X�̂Ƃ��ɑ��R�A����̕ԐM���L���b�V���ێ��ƂȂ��Ă�ۏ�͂ǂ��ɂ��Ȃ��B
> �ʂ̃R�A�� L1/L2 �ւ̖₢���킹�́A�N���X�o�[�Ɍo�R�ŕʂ̌o�H��
> �ʂ�̂ŁA����ɔ��s���Ă����̖����Ȃ����Ƃ�������B
�������A�z�N��������A���R�AL1L2�ւ̏Ɖ��L3�y�у������̃A�N�Z�X���ɉ\�Ƃ̂��o�J��������яo���܂������
����͔��ɕ|���B
���R�A��L2����ׁ̈A�_�[�e�B�L���b�V�����������֏������ޓ���ƁA���R�A�����R�A�ւ�L2�Ɖ�ƃ��������[�h�������A�N�Z�X����P�[�X��
�l���Ă݂悤�B
���R�A�̃��������[�h�����R�A�̃������X�g�A����ɔ�э��P�[�X�B
���̃P�[�X�̂Ƃ��ɑ��R�A����̕ԐM���L���b�V���ێ��ƂȂ��Ă�ۏ�͂ǂ��ɂ��Ȃ��B
> L2 �ŋ��L���Ă��郉�C���̓�������邽�߂̃R�X�g����˂��́H
���������R�X�g�Ȃ�傫���������|�I�ɗL���Ȃ̂����E�E�E
���������R�X�g�Ȃ�傫���������|�I�ɗL���Ȃ̂����E�E�E
> �������A�z�N��������A���R�AL1L2�ւ̏Ɖ��L3�y�у������̃A�N�Z�X���ɉ\
���̋L�q�ɂ́A�������A�N�Z�X�̂��Ƃ͈ꌾ�������ĂȂ��킯�����A
�ǂ������ڂ����́H �C�ł��������H
> ���R�A�̃��������[�h�����R�A�̃������X�g�A����ɔ�э��P�[�X�B
���R��ѐ�����͂���ł���B
�܂����A�������Ȃ��Ǝ咣���Ă�Ɠǂ킯�H
�ǂ��l�߂���ƁA�����܂ŋ�z���������Ȃ��ł��ˁB
����ȊO�̋L�q�����낢��ς����ǂˁB
> ���R�A��L2����ׁ̈A�_�[�e�B�L���b�V�����������֏������ޓ���ƁA
L2 ���������A����������Ȃ��āAL3 �ɏ������ނł���B
> ���R�A�����R�A�ւ�L2�Ɖ�ƃ��������[�h�������A�N�Z�X����P�[�X
���������[�h���ɔ��s����Ƃ͉��͈ꌾ�������ĂȂ��킯�����B
�������̃o���h���͌����Ă�̂ŁA�����܂ł͂��Ȃ���łȂ��́H
�������̏ꍇ�A�ǂ���100�N���b�N�߂�������킯�ŁA�L���b�V���A�N�Z�X
�Ɠ����ɔ��s���Ă��A�B���ł��郌�C�e���V�̓������A�N�Z�X�S�̂�
�R�X�g�ɔ�ׂď��Ȃ�����ˁB
���̋L�q�ɂ́A�������A�N�Z�X�̂��Ƃ͈ꌾ�������ĂȂ��킯�����A
�ǂ������ڂ����́H �C�ł��������H
> ���R�A�̃��������[�h�����R�A�̃������X�g�A����ɔ�э��P�[�X�B
���R��ѐ�����͂���ł���B
�܂����A�������Ȃ��Ǝ咣���Ă�Ɠǂ킯�H
�ǂ��l�߂���ƁA�����܂ŋ�z���������Ȃ��ł��ˁB
����ȊO�̋L�q�����낢��ς����ǂˁB
> ���R�A��L2����ׁ̈A�_�[�e�B�L���b�V�����������֏������ޓ���ƁA
L2 ���������A����������Ȃ��āAL3 �ɏ������ނł���B
> ���R�A�����R�A�ւ�L2�Ɖ�ƃ��������[�h�������A�N�Z�X����P�[�X
���������[�h���ɔ��s����Ƃ͉��͈ꌾ�������ĂȂ��킯�����B
�������̃o���h���͌����Ă�̂ŁA�����܂ł͂��Ȃ���łȂ��́H
�������̏ꍇ�A�ǂ���100�N���b�N�߂�������킯�ŁA�L���b�V���A�N�Z�X
�Ɠ����ɔ��s���Ă��A�B���ł��郌�C�e���V�̓������A�N�Z�X�S�̂�
�R�X�g�ɔ�ׂď��Ȃ�����ˁB
>>108
���O�������ĂȂ��Ă�AMD��L3�ƃ������͓����A�N�Z�X����ƌ����Ă���B
���O�������ĂȂ��Ă�AMD��L3�ƃ������͓����A�N�Z�X����ƌ����Ă���B
�������FID:qfDm/Dlb�@���@�^��
�������FID:fcZeb4m3�@���@�G���S���̋�
> ���������R�X�g�Ȃ�傫���������|�I�ɗL���Ȃ̂����E�E�E
�����ʐς������Ă��āAL2 �� L3 ��`�b�v��ɍڂ��邱�Ƃ�
�l����ƁA�����Ƃ͌���Ȃ��ł���B
�������Ƃ낤�Ƃ���ƃL���b�V�����C���S�̂��܂�܂�]������K�v��
����킯�ŁA���Ȃ蒷���Ԃ�����B���ꂮ�炢�Ȃ�AL3 �̗e�ʂ�傫��
���ċ��L�����܂����������������ł���B
�����ʐς������Ă��āAL2 �� L3 ��`�b�v��ɍڂ��邱�Ƃ�
�l����ƁA�����Ƃ͌���Ȃ��ł���B
�������Ƃ낤�Ƃ���ƃL���b�V�����C���S�̂��܂�܂�]������K�v��
����킯�ŁA���Ȃ蒷���Ԃ�����B���ꂮ�炢�Ȃ�AL3 �̗e�ʂ�傫��
���ċ��L�����܂����������������ł���B
>>112
��?
L3��S�r���ɂ���̂���?
���̃P�[�X�͍l�����邪�A���܂�ǂ�����Ƃ͎v���Ȃ��B
�����Ƃ��A��ԒP���Ȋg���ōςނ��炻�̉\���͍������ǂȁB
L3��S�r���Ƃ���̂Ȃ�112�̗�����OK�����A�����Ȃ��L3�L���b�V���̃q�b�g�����͈�������B
��?
L3��S�r���ɂ���̂���?
���̃P�[�X�͍l�����邪�A���܂�ǂ�����Ƃ͎v���Ȃ��B
�����Ƃ��A��ԒP���Ȋg���ōςނ��炻�̉\���͍������ǂȁB
L3��S�r���Ƃ���̂Ȃ�112�̗�����OK�����A�����Ȃ��L3�L���b�V���̃q�b�g�����͈�������B
> ���O�������ĂȂ��Ă�AMD��L3�ƃ������͓����A�N�Z�X����ƌ����Ă���B
���A�����Ȃ̂��H
�|�C���^���ڂ�B
�܂��ǂ����ɂ��Ă� >>106 �����낢��ςȂ͕̂ς��Ȃ����ǂˁB
��: ��ѐ����䂵�Ȃ��Ɖ���AL2�������������������
���A�����Ȃ̂��H
�|�C���^���ڂ�B
�܂��ǂ����ɂ��Ă� >>106 �����낢��ςȂ͕̂ς��Ȃ����ǂˁB
��: ��ѐ����䂵�Ȃ��Ɖ���AL2�������������������
>>111
���̔F�����Ƙ^���͂��������̂������Ȃ��͂��B�@����ăn�Y�����������B�@���܂�ˁB
�Ƃ������Ƃ́A���܂��A�{���i�g���b�v�͖Y�ꂽ�j����H
���̔F�����Ƙ^���͂��������̂������Ȃ��͂��B�@����ăn�Y�����������B�@���܂�ˁB
�Ƃ������Ƃ́A���܂��A�{���i�g���b�v�͖Y�ꂽ�j����H
> L3��S�r���ɂ���̂���?
���͂����v���Ă��B
���������A�����̃R�A���狤�L����̂ɁA���S�r���ɂ���̂�
���Ȃ�ʓ|�ł���B
> �����Ȃ��L3�L���b�V���̃q�b�g�����͈�������B
�����Ȃ�ˁB
�����̓g���[�h�I�t�����ǁA����ł��\��L3�̌��ʂ͂���Ǝv����B
���͂����v���Ă��B
���������A�����̃R�A���狤�L����̂ɁA���S�r���ɂ���̂�
���Ȃ�ʓ|�ł���B
> �����Ȃ��L3�L���b�V���̃q�b�g�����͈�������B
�����Ȃ�ˁB
�����̓g���[�h�I�t�����ǁA����ł��\��L3�̌��ʂ͂���Ǝv����B
> �|�C���^���ڂ�B
�����ŒT���B
> �܂��ǂ����ɂ��Ă� >>106 �����낢��ςȂ͕̂ς��Ȃ����ǂˁB
> ��: ��ѐ����䂵�Ȃ��Ɖ���AL2�������������������
�v�l��~���Đ���������̂͗ǂ��Ȃ��B
�����ŒT���B
> �܂��ǂ����ɂ��Ă� >>106 �����낢��ςȂ͕̂ς��Ȃ����ǂˁB
> ��: ��ѐ����䂵�Ȃ��Ɖ���AL2�������������������
�v�l��~���Đ���������̂͗ǂ��Ȃ��B
> > �|�C���^���ڂ�B
> �����ŒT���B
���[�B
AMD �X���݂̂�ȁB�I���Ƀ|�C���^���Ă���I
# ���낻���Ѝs��
> �����ŒT���B
���[�B
AMD �X���݂̂�ȁB�I���Ƀ|�C���^���Ă���I
# ���낻���Ѝs��
�T���X����Montecito�͔LL3
���LL3�Ȃ̂�Tlusa��
���LL3�Ȃ̂�Tlusa��
MAC�I�^,�@Come�@on�@�I
MAC�I�^�Ȃ�i��
MAC�I�^�Ȃ�i��
>>116
> ���͂����v���Ă��B
> ���������A�����̃R�A���狤�L����̂ɁA���S�r���ɂ���̂�
> ���Ȃ�ʓ|�ł���B
�ʓ|�Ƃ������A���ʂ͊��S�r���ɂ��邯�ǂȁB
AMD�Ђ̔��\���Ă�����A���S�r���ɂ�����J�����Ԃ��D�悳��Ă���Ǝv����B
�܂��A�S�r�����낤��w
> �����̓g���[�h�I�t�����ǁA����ł��\��L3�̌��ʂ͂���Ǝv����B
����܂薳���̂ł͂Ȃ�����?
�������AL3���������̓}�V�����A�N���[���L���b�V�������ێ��o���Ȃ��\���͒ɂ����A�S�R�A����L2�Ƌ��L�����m���͍����Ȃ邩��QMB�ł͗e�ʂ��s�����ȁB
> ���͂����v���Ă��B
> ���������A�����̃R�A���狤�L����̂ɁA���S�r���ɂ���̂�
> ���Ȃ�ʓ|�ł���B
�ʓ|�Ƃ������A���ʂ͊��S�r���ɂ��邯�ǂȁB
AMD�Ђ̔��\���Ă�����A���S�r���ɂ�����J�����Ԃ��D�悳��Ă���Ǝv����B
�܂��A�S�r�����낤��w
> �����̓g���[�h�I�t�����ǁA����ł��\��L3�̌��ʂ͂���Ǝv����B
����܂薳���̂ł͂Ȃ�����?
�������AL3���������̓}�V�����A�N���[���L���b�V�������ێ��o���Ȃ��\���͒ɂ����A�S�R�A����L2�Ƌ��L�����m���͍����Ȃ邩��QMB�ł͗e�ʂ��s�����ȁB
K8L��L3���L�L���b�V�����S�r���������ꍇ�́A�Ȃ����L3���L�L���b�V��������E�����A
�x���`�}�[�N��pL3���L�L���b�V���ɂȂ��Ă��܂����낤�B
���R�A��L1L2�ɕێ�����Ă���L���b�V����L3���L�L���b�V���ɑ��݂��Ă��Ă�����͖��Ӗ��B
���R�A��L1L2�ŃL���b�V���~�X��ɁA���R�A��L1L2�Ɖ�����̂ł����Ńq�b�g����B
�܂�S�r���������ꍇ�͎g�������Ȃ��L���b�V�����ʂɕێ�����\���ł���Ӌ`�͏������B
�������A�x���`�}�[�N��p�ƌ����̂Ȃ�A���̌��_���\�ʉ����邱�Ƃ͏��Ȃ��̂ł���Ȃ�ɗǂ����ʂƂȂ邾�낤�B
�������E�E�EK8L�͂Ƃ�ł���CPU�ɂȂ肻���ȗ\��������͉̂�������?
�x���`�}�[�N��pL3���L�L���b�V���ɂȂ��Ă��܂����낤�B
���R�A��L1L2�ɕێ�����Ă���L���b�V����L3���L�L���b�V���ɑ��݂��Ă��Ă�����͖��Ӗ��B
���R�A��L1L2�ŃL���b�V���~�X��ɁA���R�A��L1L2�Ɖ�����̂ł����Ńq�b�g����B
�܂�S�r���������ꍇ�͎g�������Ȃ��L���b�V�����ʂɕێ�����\���ł���Ӌ`�͏������B
�������A�x���`�}�[�N��p�ƌ����̂Ȃ�A���̌��_���\�ʉ����邱�Ƃ͏��Ȃ��̂ł���Ȃ�ɗǂ����ʂƂȂ邾�낤�B
�������E�E�EK8L�͂Ƃ�ł���CPU�ɂȂ肻���ȗ\��������͉̂�������?
���ʂɐ��\������ʂ����Ǝv����
�܂�Core�ɂ͋y�Ȃ����낤���Ă̂͂킩�肫�������Ƃ���
������ӂ�4x4�őR����Ƃ������Ƃł���
���i����ł̓n�[�p�[�^�E���������Ęb�ɂȂ肻��������
�܂�Core�ɂ͋y�Ȃ����낤���Ă̂͂킩�肫�������Ƃ���
������ӂ�4x4�őR����Ƃ������Ƃł���
���i����ł̓n�[�p�[�^�E���������Ęb�ɂȂ肻��������
�����ŔM���c�_���Ă鍁��t�́A����ς���W�̋ƊE�ɂ���́H
����x���ł��������c�_�ł���l���Ă���܌��Ȃ���Łc
����x���ł��������c�_�ł���l���Ă���܌��Ȃ���Łc
���̂��낤�BID:qfDm/Dlb�̂������Ɍ�����B
�S�p�p���Ƃ��g�����炾�낤���B
����Ƃ����e�𗝉������ɏ����Ă�悤�Ɍ����邩�炾�낤���B
�S�p�p���Ƃ��g�����炾�낤���B
����Ƃ����e�𗝉������ɏ����Ă�悤�Ɍ����邩�炾�낤���B
>>125
�ǂ̂�����ɋ^�₪����̂������Ă݂�w
�S�r���ɂ����ꍇ�AL2�Ƃ����ł͂Ȃ�L1�Ƃ��S�ɂ��邵���Ȃ����Ƃ������o���Ă�����?
���S�r���̏ꍇ�́AL3�ւ̒lj����폜�������𗎂Ƃ����ƂȂ��s���|�C���g�����邪�A�S�r���̏ꍇ�ɂ͂��ꂪ�Ȃ��B
���ǂ̂Ƃ���AL2�j������L3�փN���[���L���b�V����lj����邾���ƂȂ�AL3�����t�Ȃ�g�p���̈����Â��L���b�V���ƒu�������邾�����B
�������A����L1�֎�荞�܂�X�V����_�[�e�B�L���b�V���ɂȂ�O�̃L���b�V���܂Ő������ꂸ��L3�Ɏc�葱���Ă���Ƃ������肳�܂Ȃ�B
���̓ǂ܂��ƕs�����L���b�V����L3��ǂޑO�ɑ��R�A�ւ̏Ɖ�̌���L1L2�Ńq�b�g���邩���肱���Ȃ����ȁB
������ɂ܂�Ȃ����̂ł����Ȃ���B
�x���`�}�[�N��p�L���b�V���Ƃ͂悭���������̂�w
�ǂ̂�����ɋ^�₪����̂������Ă݂�w
�S�r���ɂ����ꍇ�AL2�Ƃ����ł͂Ȃ�L1�Ƃ��S�ɂ��邵���Ȃ����Ƃ������o���Ă�����?
���S�r���̏ꍇ�́AL3�ւ̒lj����폜�������𗎂Ƃ����ƂȂ��s���|�C���g�����邪�A�S�r���̏ꍇ�ɂ͂��ꂪ�Ȃ��B
���ǂ̂Ƃ���AL2�j������L3�փN���[���L���b�V����lj����邾���ƂȂ�AL3�����t�Ȃ�g�p���̈����Â��L���b�V���ƒu�������邾�����B
�������A����L1�֎�荞�܂�X�V����_�[�e�B�L���b�V���ɂȂ�O�̃L���b�V���܂Ő������ꂸ��L3�Ɏc�葱���Ă���Ƃ������肳�܂Ȃ�B
���̓ǂ܂��ƕs�����L���b�V����L3��ǂޑO�ɑ��R�A�ւ̏Ɖ�̌���L1L2�Ńq�b�g���邩���肱���Ȃ����ȁB
������ɂ܂�Ȃ����̂ł����Ȃ���B
�x���`�}�[�N��p�L���b�V���Ƃ͂悭���������̂�w
�����B�����AID:qfDm/Dlb������K8L�̐v�҂������̂�
�w�A�z�N�͂ق��Ƃ��āx�Ƃ��A�w�m�\���Ⴗ�����i�����x�Ƃ��������ǁA
���̒��ɂ͉��̂悤�ȃo�J������̂ŁA
4gamer�̋L���̗l�ɁA���C�h�Ő������Ă���Ȃ��።��
���̒��ɂ͉��̂悤�ȃo�J������̂ŁA
4gamer�̋L���̗l�ɁA���C�h�Ő������Ă���Ȃ��።��
�����Ƃ��ߎS�Ȃ̂�ID:qfDm/Dlb���������q�ׂĂ���̂��A
�R���ς������Ă���̂���������Ȃ����Ƃ��B
�E�E�E���͂قƂ�Ǘ����ł��Ȃ�orz
�R���ς������Ă���̂���������Ȃ����Ƃ��B
�E�E�E���͂قƂ�Ǘ����ł��Ȃ�orz
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/001.html
|--����ɂ��AL3��Main Memory�ɓ����ɃA�N�Z�X���邱�ƂŃ��������C�e���V��}����킯�ł���?
|���̒ʂ肾�B
|--����ɂ��AL3��Main Memory�ɓ����ɃA�N�Z�X���邱�ƂŃ��������C�e���V��}����킯�ł���?
|���̒ʂ肾�B
�����Ɍ�����̂́A�����̂ގp���ƁA�u�C���e���̂�邱�Ƃ͑f���炵���āAAMD�̂�邱�Ƃ�
�܂�Ȃ��v���Č��_�ȊO�F�߂Ȃ��_���W�J����B
�������݂̎��Ԃ����n��Ō��Ă��ƁA���̋c�_�Ŕނ̐l���������ɘQ���Ă��邩���킩��B
�c�_�̑��肪��Ђɍs�����肵�Ă���̂ƑΏƓI�Ɂc
�܂�Ȃ��v���Č��_�ȊO�F�߂Ȃ��_���W�J����B
�������݂̎��Ԃ����n��Ō��Ă��ƁA���̋c�_�Ŕނ̐l���������ɘQ���Ă��邩���킩��B
�c�_�̑��肪��Ђɍs�����肵�Ă���̂ƑΏƓI�Ɂc
��芸�����AID:qfDm/Dlb�̏������݂͓Ǝ��p��Ƃ��������ė���s�\�Ȃ̂�����B
�O�_�O�_�Ɨ���s�\�ȒP�����ׂ��A�X�p���Ƙ_����H�}�ł��`���Ăǂ�����UP���Ă���B
���Ƃ��ẮA���ʂɒ�����������肻�����̕�������Ղ��ď�����B
(���R�����A�_����H�ɂ�MIL�L���Ƃ���������Ƃ����K�i�����邩��A�Ǝ��L���͖����łȁB)
�L���b�V���̓������邭�炢������A���ꂭ�炢�͂�������p����H
�O�_�O�_�Ɨ���s�\�ȒP�����ׂ��A�X�p���Ƙ_����H�}�ł��`���Ăǂ�����UP���Ă���B
���Ƃ��ẮA���ʂɒ�����������肻�����̕�������Ղ��ď�����B
(���R�����A�_����H�ɂ�MIL�L���Ƃ���������Ƃ����K�i�����邩��A�Ǝ��L���͖����łȁB)
�L���b�V���̓������邭�炢������A���ꂭ�炢�͂�������p����H
���ƈ�C�ɂȂ������AID:qfDm/Dlb�̌����L���b�V���́u�����v���ĂȂH
�P�ꂩ����ۂ��ƁAC�����for���̂悤�ɃL���b�V����1line���������Ă���悤�Ȋ��������B
K8����L1/L2�͋���64Byte/line������AL1��1024line�EL2=512KByte�ł�8192line��������H
����Ȃ̂Łu�����v�Ȃ��Ă���L���b�V��������������������E�E�E
�P�ꂩ����ۂ��ƁAC�����for���̂悤�ɃL���b�V����1line���������Ă���悤�Ȋ��������B
K8����L1/L2�͋���64Byte/line������AL1��1024line�EL2=512KByte�ł�8192line��������H
����Ȃ̂Łu�����v�Ȃ��Ă���L���b�V��������������������E�E�E
�Z�p����鎖���u�ړI�v����Ȃ��āu��i�v�ɂȂ��Ă邩��Ȃ�
�ǂ�Ȃɐ����������������k�قɂ��������Ȃ��
�ǂ�Ȃɐ����������������k�قɂ��������Ȃ��
>>130
������āA�}1�ƈႢ�A�}2�ł́A�������A�N�Z�X�̃p�X��
L3 �A�N�Z�X�̃p�X���N���X�o�[���猩�ĕ�������Ă���
�����ɕ��ăA�N�Z�X�ł�����Č����Ă邾���ł́H
>>109 �́A>>108 �ւ̕ԓ�������AL3 �A�N�Z�X����ۂɂ�
��Ƀ������ɂ����ăA�N�Z�X����Ǝ咣���Ă���悤�ȁB
������Ă��Ȃ�ߌ��Ȏ咣���Ǝv�����ǁB
L3 �̓����������͂邩�Ƀo���h������������A�������[�g��
�A�N�Z�X����ƁA�������̑��̃o���h�������ĂƂĂ�������
���ƂɂȂ�͂�����B
������āA�}1�ƈႢ�A�}2�ł́A�������A�N�Z�X�̃p�X��
L3 �A�N�Z�X�̃p�X���N���X�o�[���猩�ĕ�������Ă���
�����ɕ��ăA�N�Z�X�ł�����Č����Ă邾���ł́H
>>109 �́A>>108 �ւ̕ԓ�������AL3 �A�N�Z�X����ۂɂ�
��Ƀ������ɂ����ăA�N�Z�X����Ǝ咣���Ă���悤�ȁB
������Ă��Ȃ�ߌ��Ȏ咣���Ǝv�����ǁB
L3 �̓����������͂邩�Ƀo���h������������A�������[�g��
�A�N�Z�X����ƁA�������̑��̃o���h�������ĂƂĂ�������
���ƂɂȂ�͂�����B
>>133
���O�̓X�L�����Ƃ����P��ŁA��������Ɖ��߂��S�L���b�V�����C����S�ēǂނƗ��������̂�?
��������͂���w
��ʐl���x�̒m���ƒm��������A�X�L��������L���b�V�����C���̓A�h���X�ɂ��_�C���N�g�Ɍ��܂邱�Ƃ𗝉��o���邾�낤���A
�X�L������Way���ōςނ��Ƃ������ł���̂����E�E���O�ɂ����v������͖̂�������w
>>135
�d�g���Ă܂���?
���O�̓X�L�����Ƃ����P��ŁA��������Ɖ��߂��S�L���b�V�����C����S�ēǂނƗ��������̂�?
��������͂���w
��ʐl���x�̒m���ƒm��������A�X�L��������L���b�V�����C���̓A�h���X�ɂ��_�C���N�g�Ɍ��܂邱�Ƃ𗝉��o���邾�낤���A
�X�L������Way���ōςނ��Ƃ������ł���̂����E�E���O�ɂ����v������͖̂�������w
>>135
�d�g���Ă܂���?
>��������͂���w
�����A���̕ӂ̓��{��̕s���R���������Ɍ�����̂�������Ȃ��B
�����A���̕ӂ̓��{��̕s���R���������Ɍ�����̂�������Ȃ��B
L3 �Ǝ��������ւ̃A�N�Z�X���A��ɓ����ɍs�Ȃ����Ď咣�̕���
�d�g���Ǝv�����ǁB
�d�g���Ǝv�����ǁB
>>137
�s���R�Ȃ̂�?
�n��Ȕ��z�Ȃ�w
>>138
���[�h���͕��s���ăA�N�Z�X�����B
�������AL3�Ńq�b�g����������ւ̃A�N�Z�X�͑ł�����(���͔j��)���ǂȁB
���C�e���V�B���̊�{�I�Ȏ�@�̈����B
�s���R�Ȃ̂�?
�n��Ȕ��z�Ȃ�w
>>138
���[�h���͕��s���ăA�N�Z�X�����B
�������AL3�Ńq�b�g����������ւ̃A�N�Z�X�͑ł�����(���͔j��)���ǂȁB
���C�e���V�B���̊�{�I�Ȏ�@�̈����B
L3 �A�N�Z�X���� L2 �����A�N�Z�X�݂����ɁA�������K�w�̐���
�����ɃA�N�Z�X����Ȃ�A�Ȃ�Ƃ��Ȃ邾�낤���ǁc
L3 �A�N�Z�X���� D-RAM �����A�N�Z�X�̂悤�ɁA�������K�w�̐[������
�����ɃA�N�Z�X���悤�Ƃ���ƁA�o���h�����������A���C�e���V�͑傫��
�Ȃ邩��A���܂������Ȃ��ł���B
L3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x�� D-RAM �ɃA�N�Z�X���悤�Ƃ���ƁA
�A�N�Z�X�v�������ŁA�������o�X���O�a����̂ł́H
����ɁAcache �ɂ��Ă̓J�X�^�����W�b�N������A�����̒��f�Ƃ���
���R�ɒ�`�ł��邯�ǁADDR2 �ɁAREAD �R�}���h�̈�ʓI�ȃA�{�[�g�@�\����
�Ȃ��̂ł́H �������̏������d�Ȃ����ꍇ�ɂ͕ʂ� READ �R�}���h��
��銄�荞�݂����͂ł���݂��������ǁA���傫���̂ŁA��������
���ɒP�Ƀ������A�N�Z�X��ł���Ƃ����킯�ɂ͂����Ȃ��̂ł́H
�����ɃA�N�Z�X����Ȃ�A�Ȃ�Ƃ��Ȃ邾�낤���ǁc
L3 �A�N�Z�X���� D-RAM �����A�N�Z�X�̂悤�ɁA�������K�w�̐[������
�����ɃA�N�Z�X���悤�Ƃ���ƁA�o���h�����������A���C�e���V�͑傫��
�Ȃ邩��A���܂������Ȃ��ł���B
L3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x�� D-RAM �ɃA�N�Z�X���悤�Ƃ���ƁA
�A�N�Z�X�v�������ŁA�������o�X���O�a����̂ł́H
����ɁAcache �ɂ��Ă̓J�X�^�����W�b�N������A�����̒��f�Ƃ���
���R�ɒ�`�ł��邯�ǁADDR2 �ɁAREAD �R�}���h�̈�ʓI�ȃA�{�[�g�@�\����
�Ȃ��̂ł́H �������̏������d�Ȃ����ꍇ�ɂ͕ʂ� READ �R�}���h��
��銄�荞�݂����͂ł���݂��������ǁA���傫���̂ŁA��������
���ɒP�Ƀ������A�N�Z�X��ł���Ƃ����킯�ɂ͂����Ȃ��̂ł́H
>>142
�ց[�����Ȃ�w
���Ⴛ���������Ƃɂ��Ă�������?
L3��ςނƁA���������[�h��L3�̑�����ƂȂ邩�炻�̕��x���Ȃ���Ă��Ƃʼn��Ƃ��Ă͂���ł��\��Ȃ���B
K8L���Ĉ����Ȃ�������w
�ց[�����Ȃ�w
���Ⴛ���������Ƃɂ��Ă�������?
L3��ςނƁA���������[�h��L3�̑�����ƂȂ邩�炻�̕��x���Ȃ���Ă��Ƃʼn��Ƃ��Ă͂���ł��\��Ȃ���B
K8L���Ĉ����Ȃ�������w
> ����ƁA�ł���Ȃ��ꍇ����������j���Ə����Ă��B
���Ƃ���ƁA�܂��� >>135 �� >>140 �ŏ������Ƃ���ɁA
���ʓI�� L3 �Ƀq�b�g���邩�疳�ʂɂȂ郁�����A�N�Z�X�����ŁA
�������o�X�����S�ɖO�a����킯�ŁA���ɂ܂����ł��傤�B
> L3��ςނƁA���������[�h��L3�̑�����ƂȂ邩�炻�̕��x���Ȃ���Ă���
���̗������ƁAL2 ��ςނƃ��������[�h�� L2 �̑�����ƂȂ邩�炻�̕�
�x���Ȃ���Ă��ƂɂȂ邯�ǁc
�������K�w�������������ʔ�₳��郌�C�e���V�����A���̃������K�w��
���L���b�V�����ʂ̕����傫������A�������K�w�𑝂₷�킯�Łc
������Ȃ�ł��A���������͍l���Ă���Ԏ������������������Ǝv���܂���B
���Ƃ���ƁA�܂��� >>135 �� >>140 �ŏ������Ƃ���ɁA
���ʓI�� L3 �Ƀq�b�g���邩�疳�ʂɂȂ郁�����A�N�Z�X�����ŁA
�������o�X�����S�ɖO�a����킯�ŁA���ɂ܂����ł��傤�B
> L3��ςނƁA���������[�h��L3�̑�����ƂȂ邩�炻�̕��x���Ȃ���Ă���
���̗������ƁAL2 ��ςނƃ��������[�h�� L2 �̑�����ƂȂ邩�炻�̕�
�x���Ȃ���Ă��ƂɂȂ邯�ǁc
�������K�w�������������ʔ�₳��郌�C�e���V�����A���̃������K�w��
���L���b�V�����ʂ̕����傫������A�������K�w�𑝂₷�킯�Łc
������Ȃ�ł��A���������͍l���Ă���Ԏ������������������Ǝv���܂���B
>>144
�܂�ʔ������ȁB
�c�t�߂����B
���̏ꍇ�̓����́A���R�̂��Ƃ����Ǔ��삪��������܂ő҂��Ȃ����Ă������B
>>145
�S�R�s�����Ȃ��AL3�͏��F�I�u�U�[�o�[�q�b�g�����烉�b�L�[���Ē��x�ł����Ȃ��B
���Ȃ݂�L1L2�������A�N�Z�X�����B
�܂�ʔ������ȁB
�c�t�߂����B
���̏ꍇ�̓����́A���R�̂��Ƃ����Ǔ��삪��������܂ő҂��Ȃ����Ă������B
>>145
�S�R�s�����Ȃ��AL3�͏��F�I�u�U�[�o�[�q�b�g�����烉�b�L�[���Ē��x�ł����Ȃ��B
���Ȃ݂�L1L2�������A�N�Z�X�����B
����ɂ��łȐ��������Ă����ƁA�������̃��[�h���߂͊���(�����[�h�����܂�)����܂Ō��\�����҂������B
����ɔ�ׂāA�L���b�V�������͑������烁�������[�h�̗v���͒��߂Ă����o�b�t�@���p�ӂ���Ă���B
�A�����[�h�̏ꍇ�A���������[�h�҂��o�b�t�@����t�ɂȂ�܂Ő�s�ł���d�g�݂��B
�ŁA���̃��[�h�҂��o�b�t�@�ɑ��݂��Ă��鎞�́A�����j���܂��͎��������Ƃ��\�ɂȂ��Ă���B
����ɔ�ׂāA�L���b�V�������͑������烁�������[�h�̗v���͒��߂Ă����o�b�t�@���p�ӂ���Ă���B
�A�����[�h�̏ꍇ�A���������[�h�҂��o�b�t�@����t�ɂȂ�܂Ő�s�ł���d�g�݂��B
�ŁA���̃��[�h�҂��o�b�t�@�ɑ��݂��Ă��鎞�́A�����j���܂��͎��������Ƃ��\�ɂȂ��Ă���B
> �S�R�s�����Ȃ�
�o�X���O�a���Ă���ł́A�����������N�G�X�g���o���Ȃ���ł����A
���������ĕ������ĂȂ��ł����H
> ���Ȃ݂�L1L2�������A�N�Z�X�����B
>>99 �ŁAID:FYZQm2Nx ���AL3 �� L1/L2 �ւ̖₢���킹����čs�Ȃ�����
�����Ă��Ƃ��ɂ́A>>100 �Ŏv��������ے肵�Ă����݂����ł����c
>>100 �̂����g�̔����͌�肾�����Ƃ������Ƃł��傤���H
�o�X���O�a���Ă���ł́A�����������N�G�X�g���o���Ȃ���ł����A
���������ĕ������ĂȂ��ł����H
> ���Ȃ݂�L1L2�������A�N�Z�X�����B
>>99 �ŁAID:FYZQm2Nx ���AL3 �� L1/L2 �ւ̖₢���킹����čs�Ȃ�����
�����Ă��Ƃ��ɂ́A>>100 �Ŏv��������ے肵�Ă����݂����ł����c
>>100 �̂����g�̔����͌�肾�����Ƃ������Ƃł��傤���H
����A����͑S�R���ɂȂ��ĂȂ���ł����c
���Ȃ������͑S���n�[�h�E�F�A�𗝉�����ĂȂ����Ƃ��A���ɂ�
�͂����蕪����܂����̂ŁA�����������݂܂��B
�����������������A���肪�Ƃ��������܂����B
�ł͂ł́B
���Ȃ������͑S���n�[�h�E�F�A�𗝉�����ĂȂ����Ƃ��A���ɂ�
�͂����蕪����܂����̂ŁA�����������݂܂��B
�����������������A���肪�Ƃ��������܂����B
�ł͂ł́B
�����A���������i���Ăǂ����ɍs���Ă��܂����悤�ł���B
�ǂ����A�S�R�����ɂȂ��Ă��Ȃ��̂����������ł��ˁB
L3�ւ̃A�N�Z�X�v���ƃ������[�ւ̃��[�h�v�����������s�ɔ������Ă��邱�Ƃ��܂������ł��܂���?
������L3���q�b�g����A���[�h�҂��o�b�t�@��j������Ηǂ������B
���Ƀ����R���֎w�ߍς݂œǂݏo����Ԃł����Ă��\��Ȃ��B
�ǂݍ��܂�ė����i�K�Ń��[�h�҂��o�b�t�@���m�F���邽���Ŕj���o���܂�����ˁB
�ǂ����A�S�R�����ɂȂ��Ă��Ȃ��̂����������ł��ˁB
L3�ւ̃A�N�Z�X�v���ƃ������[�ւ̃��[�h�v�����������s�ɔ������Ă��邱�Ƃ��܂������ł��܂���?
������L3���q�b�g����A���[�h�҂��o�b�t�@��j������Ηǂ������B
���Ƀ����R���֎w�ߍς݂œǂݏo����Ԃł����Ă��\��Ȃ��B
�ǂݍ��܂�ė����i�K�Ń��[�h�҂��o�b�t�@���m�F���邽���Ŕj���o���܂�����ˁB
>>151
���Ⴀ���O�͏��������B���߂łƂ��B�����Ɩ��ₗ
���Ⴀ���O�͏��������B���߂łƂ��B�����Ɩ��ₗ
������
> --������BAMD��K7��K8��L1��L2��Victim Cache�̍\����������킯�ł����A
> �V�R�A���܂�L1��L2��Victim Cache�̍\���ł��傤��? �����L3�͂ǂ��Ȃ�܂���?
> �������₾���A�����̂Ƃ���͊o���Ă��Ȃ��BChuck Moore(AMD Senior Fellow)�Ɋm�F���Ă���Ԏ��������B
�������ɁA�s���S�r���Ƃ͑������h�炩�����낤�ȁB
�o���Ă��Ȃ��Ȃ�āA����Ȃ̂��肦�˂��B
> �V�R�A���܂�L1��L2��Victim Cache�̍\���ł��傤��? �����L3�͂ǂ��Ȃ�܂���?
> �������₾���A�����̂Ƃ���͊o���Ă��Ȃ��BChuck Moore(AMD Senior Fellow)�Ɋm�F���Ă���Ԏ��������B
�������ɁA�s���S�r���Ƃ͑������h�炩�����낤�ȁB
�o���Ă��Ȃ��Ȃ�āA����Ȃ̂��肦�˂��B
>>136
>�厫�� ���� �i�O�ȓ��j
>������ �y�����z<
>�i���j�X��
>�e���r�W������t�@�N�V�~���ȂǂŁA���M�̍ۂɁA�摜�𑽂��̓_�ɕ������A���ꂼ��̓_�̖��ÂȂǂ�d�C�M���ɕϊ����邽�߂ɁA
>���̏����Ŋe�_�����ǂ邱�ƁB�܂��A��M�̍ۂɁA�d�C�M����_�̏W���ɕϊ����ĉ摜���\�����鑀��B�X�L�����B
�u���̏����Ŋe�_�����ǂ邱�Ɓv�����������H
��ʐl���x�̒m���ƒm��������A�܂��ŏ��ɓ��ɕ����Ԃ̂͌ꌹ�ʂ�̓��삾�ȁB
���m�����������G���W�j�A�Ȃ珮�X�������B
��芸�����A�O����P�Ă����B
����ρA��H�}�����Ȃ��Ă�����B����܂ł��Ȃ�����B
>>154
�d�v�ȃ|�C���g���B����Ă邩�瑦�����Ȃ�������Ȃ��̂��H
�C���^�r���[�̓��e��intel�̎��ɂ�����\�����������B
>�厫�� ���� �i�O�ȓ��j
>������ �y�����z<
>�i���j�X��
>�e���r�W������t�@�N�V�~���ȂǂŁA���M�̍ۂɁA�摜�𑽂��̓_�ɕ������A���ꂼ��̓_�̖��ÂȂǂ�d�C�M���ɕϊ����邽�߂ɁA
>���̏����Ŋe�_�����ǂ邱�ƁB�܂��A��M�̍ۂɁA�d�C�M����_�̏W���ɕϊ����ĉ摜���\�����鑀��B�X�L�����B
�u���̏����Ŋe�_�����ǂ邱�Ɓv�����������H
��ʐl���x�̒m���ƒm��������A�܂��ŏ��ɓ��ɕ����Ԃ̂͌ꌹ�ʂ�̓��삾�ȁB
���m�����������G���W�j�A�Ȃ珮�X�������B
��芸�����A�O����P�Ă����B
����ρA��H�}�����Ȃ��Ă�����B����܂ł��Ȃ�����B
>>154
�d�v�ȃ|�C���g���B����Ă邩�瑦�����Ȃ�������Ȃ��̂��H
�C���^�r���[�̓��e��intel�̎��ɂ�����\�����������B
> �u���̏����Ŋe�_�����ǂ邱�Ɓv�����������H
Set Associative������A�^�O�A���C�������������邩��X�L�����Ő������B
Set Associative������A�^�O�A���C�������������邩��X�L�����Ő������B
>>146
>���삪��������܂ő҂��Ȃ����Ă������B
���H�@��������҂��Ȃ����āH
�����Ƌؓ��𗧂Ăď����Ă���B
�f�҂��Ȃ����Ɓf�Ɓf�����f�͕ʂ̈Ӗ��ł��B
�����w���O�ɁA�����ƌ��t�������܂��傤�B
>���삪��������܂ő҂��Ȃ����Ă������B
���H�@��������҂��Ȃ����āH
�����Ƌؓ��𗧂Ăď����Ă���B
�f�҂��Ȃ����Ɓf�Ɓf�����f�͕ʂ̈Ӗ��ł��B
�����w���O�ɁA�����ƌ��t�������܂��傤�B
>>157
�c�t���ɂ��A��B
�c�t���ɂ��A��B
�c���ɓ����g������ʂ��Ȃ���B
���{��ł���
���{��������Ǝg���ĂȂ��l�Ɍ����Ă��ȁB
�M���Ȃ��Ǝv���Č��Ă���ɂ������̐l�������̂�
���̈������ɂ͂悭�킩���b������ǂ��ł�������
�������l���Č������E�ł͊m���ɂ������l���������Ă�낤�Ȃ�
���̈������ɂ͂悭�킩���b������ǂ��ł�������
�������l���Č������E�ł͊m���ɂ������l���������Ă�낤�Ȃ�
AMD�̒��̐l����������L3�ɂ͓����ɃA�N�Z�X������Č����Ă�̂ɃC�`�������t����͉̂��łȂH
���Ȃ݂ɁA���̂��Ƃ�CTO��Phil Hester�����łȂ�Senior Fellow��Charles Moore�������Ă�B
���Ȃ݂ɁA���̂��Ƃ�CTO��Phil Hester�����łȂ�Senior Fellow��Charles Moore�������Ă�B
������A����� L3 �ƃ������̃A�N�Z�X�p�X���Ɨ����Ă��āA
�����ɃA�N�Z�X���u�ł���v�Ƃ����Ӗ��ł́H
ID:qfDm/Dlb ���咣���Ă���悤�ȁAL3 �A�N�Z�X�̍ہA���
�������ɂ��A�N�Z�X�����݂���Ă����̂́A����Ƃ͑S�R�Ⴄ���A
�������������s�\�ł��傤�B
���̎����s�\���Ă̂�������Ȃ��̂́A������S�R�Ⴄ�Ӗ���
���߂��邱�ƂɂȂ�̂ŁA������ƃ��o���Ǝv���B
�����ɃA�N�Z�X���u�ł���v�Ƃ����Ӗ��ł́H
ID:qfDm/Dlb ���咣���Ă���悤�ȁAL3 �A�N�Z�X�̍ہA���
�������ɂ��A�N�Z�X�����݂���Ă����̂́A����Ƃ͑S�R�Ⴄ���A
�������������s�\�ł��傤�B
���̎����s�\���Ă̂�������Ȃ��̂́A������S�R�Ⴄ�Ӗ���
���߂��邱�ƂɂȂ�̂ŁA������ƃ��o���Ǝv���B
ID:dnp8WgFi = �A�z ��FA?
> ��X�̃}�C�N���v���Z�T�͎�L���̃R���g���[����H���������̂ŁC3���L���b�V��
> �Ƀq�b�g���Ȃ������Ƃ��̃y�i���e�B�����Ȃ��B2���L���b�V�����q�b�g���Ȃ������ۂɁC
> 3���L���b�V���Ǝ�L�����ɃA�N�Z�X���āC3���L���b�V�����q�b�g�����ۂɎ�L��
> �ւ̃A�N�Z�X�𒆎~����������炾�B
by Charles Moore
������������K8�ł�L2�ƃ������͓����ɃA�N�Z�X���ɂ�����ł���B
> �Ƀq�b�g���Ȃ������Ƃ��̃y�i���e�B�����Ȃ��B2���L���b�V�����q�b�g���Ȃ������ۂɁC
> 3���L���b�V���Ǝ�L�����ɃA�N�Z�X���āC3���L���b�V�����q�b�g�����ۂɎ�L��
> �ւ̃A�N�Z�X�𒆎~����������炾�B
by Charles Moore
������������K8�ł�L2�ƃ������͓����ɃA�N�Z�X���ɂ�����ł���B
�����ɃA�N�Z�X����
ID:dnp8WgFi�̓��̒�
Start========>L3�ǂݍ��݊���
Start========>�������ǂݍ��݊���
��ʂ̐l�̗���
Start========>L3======>�ǂݍ��݊���
Start========>������===============================================================================>�ǂݍ��݊���
ID:dnp8WgFi�̓��̒�
Start========>L3�ǂݍ��݊���
Start========>�������ǂݍ��݊���
��ʂ̐l�̗���
Start========>L3======>�ǂݍ��݊���
Start========>������===============================================================================>�ǂݍ��݊���
169 �FID:dnp8WgFi�F2006/06/21(��) 21:35:15 ID:/X8BiUNN
>>167
������A����� L3 �ƃ������̃A�N�Z�X�p�X���Ɨ����Ă��āA
�����ɃA�N�Z�X���u�ł���v�Ƃ����Ӗ��ł́H
Charles Moored�����咣���Ă���悤�ȁAL3 �A�N�Z�X�̍ہA���
�������ɂ��A�N�Z�X�����݂���Ă����̂́A����Ƃ͑S�R�Ⴄ���A
�������������s�\�ł��傤�B
���̎����s�\���Ă̂�������Ȃ��̂́A������S�R�Ⴄ�Ӗ���
���߂��邱�ƂɂȂ�̂ŁA������ƃ��o���Ǝv���B
������A����� L3 �ƃ������̃A�N�Z�X�p�X���Ɨ����Ă��āA
�����ɃA�N�Z�X���u�ł���v�Ƃ����Ӗ��ł́H
Charles Moored�����咣���Ă���悤�ȁAL3 �A�N�Z�X�̍ہA���
�������ɂ��A�N�Z�X�����݂���Ă����̂́A����Ƃ͑S�R�Ⴄ���A
�������������s�\�ł��傤�B
���̎����s�\���Ă̂�������Ȃ��̂́A������S�R�Ⴄ�Ӗ���
���߂��邱�ƂɂȂ�̂ŁA������ƃ��o���Ǝv���B
���o���ēǂ�ł݂��B
ID:dnp8WgFi = �A�z ��FA
ID:dnp8WgFi = �A�z ��FA
���ꂩ�B
ttp://itpro.nikkeibp.co.jp/article/COLUMN/20060518/238286/
������ď��Ȃ��Ƃ� DDR2 ����ł� >>140 �ɏ��������R����A
�s�\���Ǝv�����ǂȁB
�܂��������R���g���[������ D-RAM �ɃR�}���h�s�������
�O�ɁA���f���Ԃɍ����Ή\�����ǁB���������Ӗ��Ȃ̂��ȁH
>>168
�����ł́A�������o�X�� L3 �����o���h�����������߂ɖ�������
�����b�����Ă���̂� (>>140 �Q��)�A���̐}�ł͔��_�ɂȂ��ĂȂ��B
�Ƃ������A���C�e���V�̐}�ł͔��_�ɂȂ�Ȃ����Ă��Ƃ�������Ȃ�
�̂̓��o���B
ID �ŕ�����Ǝv�����ǁA>>169 �͉�����Ȃ���B
ttp://itpro.nikkeibp.co.jp/article/COLUMN/20060518/238286/
������ď��Ȃ��Ƃ� DDR2 ����ł� >>140 �ɏ��������R����A
�s�\���Ǝv�����ǂȁB
�܂��������R���g���[������ D-RAM �ɃR�}���h�s�������
�O�ɁA���f���Ԃɍ����Ή\�����ǁB���������Ӗ��Ȃ̂��ȁH
>>168
�����ł́A�������o�X�� L3 �����o���h�����������߂ɖ�������
�����b�����Ă���̂� (>>140 �Q��)�A���̐}�ł͔��_�ɂȂ��ĂȂ��B
�Ƃ������A���C�e���V�̐}�ł͔��_�ɂȂ�Ȃ����Ă��Ƃ�������Ȃ�
�̂̓��o���B
ID �ŕ�����Ǝv�����ǁA>>169 �͉�����Ȃ���B
Charles Moored����dnp8WgFi�̂ǂ��炪��������?
Charles Moored���͉R�f���ł���?
Charles Moored���͉R�f���ł���?
>>173
>>171 �ɏ������悤�ɁA�������R���g���[�����A�������o�X��
�R�}���h���o���O�ɒ��f���ł���Ȃ�ACharles Moore����
���t�ǂ���̂��Ƃ��ADDR2 �ł������ł���Ƃ͎v����B
>>147 ��A>>168 �ł́A�o�X���O�a����Ƃ����w�E�ɑ���
�܂��������_�ɂȂ��ĂȂ��A�܂�A���̔����҂̓n�[�h�E�F�A��
�������ĂȂ����Ƃ́A���ɏq�ׂ��Ƃ���B
>>171 �ɏ������悤�ɁA�������R���g���[�����A�������o�X��
�R�}���h���o���O�ɒ��f���ł���Ȃ�ACharles Moore����
���t�ǂ���̂��Ƃ��ADDR2 �ł������ł���Ƃ͎v����B
>>147 ��A>>168 �ł́A�o�X���O�a����Ƃ����w�E�ɑ���
�܂��������_�ɂȂ��ĂȂ��A�܂�A���̔����҂̓n�[�h�E�F�A��
�������ĂȂ����Ƃ́A���ɏq�ׂ��Ƃ���B
> L3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x�� D-RAM �ɃA�N�Z�X���悤�Ƃ���ƁA
> �A�N�Z�X�v�������ŁA�������o�X���O�a����̂ł́H
dnp8WgFi���A�z�Ȃ̂́AL3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x��D-RAM�ɃA�N�Z�X�v�������߂����Ǝv���Ă���Ƃ���B
�A�z����ł���B
> �A�N�Z�X�v�������ŁA�������o�X���O�a����̂ł́H
dnp8WgFi���A�z�Ȃ̂́AL3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x��D-RAM�ɃA�N�Z�X�v�������߂����Ǝv���Ă���Ƃ���B
�A�z����ł���B
> L3 �A�N�Z�X�̃��N�G�X�g�Ɠ����p�x��D-RAM�ɃA�N�Z�X�v�������߂����Ǝv��
> �Ă���Ƃ���B
����A����� ID:qfDm/Dlb �̎咣�ŁA���̎咣�́u����Ȃ��Ƃ͎����s�\���v
���Ă��ƂȂ��ǁB
�ǂ߂Ε�����Ǝv�����ǂ˂��B
> �Ă���Ƃ���B
����A����� ID:qfDm/Dlb �̎咣�ŁA���̎咣�́u����Ȃ��Ƃ͎����s�\���v
���Ă��ƂȂ��ǁB
�ǂ߂Ε�����Ǝv�����ǂ˂��B
�O�a���Č����Ă�L3�������������܂ł�L3�ւ̃A�N�Z�X�Ɠ����p�x�Ń����R���ւ̗v�����������킯�����Ȃ��B
4�R�A�ɂȂ��Ă���Ȃ�ɋ����͂���Ă�낤���B
4�R�A�ɂȂ��Ă���Ȃ�ɋ����͂���Ă�낤���B
qfDm/Dlb�͗v�����A������ꍇ>>147�ɏ����Ă�悤�ɁAD-RAM�ւ͎��ۂɃA�N�Z�X�v���͔��߂���Ȃ��Ɨ������Ă���悤������
>>177
�������R���g���[����ʂ��ă������o�X�ɗv�����o���ꍇ�A
���R�A���̗v���̉̓������o�X�̃o���h���ɐ��������B
ID:qfDm/Dlb �̎咣�́AL3 �� D-RAM �ɓ����̗v����
���s�ł���Ƃ������Ƃ��Ӗ����Ă��āAL3 �ƃ������o�X��
�o���h���ɈႢ������ȏ�A����Ȃ��Ƃ͓��R�s�\�Ȃ킯�B
�������R���g���[����ʂ��ă������o�X�ɗv�����o���ꍇ�A
���R�A���̗v���̉̓������o�X�̃o���h���ɐ��������B
ID:qfDm/Dlb �̎咣�́AL3 �� D-RAM �ɓ����̗v����
���s�ł���Ƃ������Ƃ��Ӗ����Ă��āAL3 �ƃ������o�X��
�o���h���ɈႢ������ȏ�A����Ȃ��Ƃ͓��R�s�\�Ȃ킯�B
>>179
���������A���������Ȃ��ƌ����Ȃ�B
���͂���Ȃ��ƈꌾ�������ĂȂ����B
�ȂA�X�����L�тĂ�Ǝv���ė��Ă݂��疳���ꒃ�����₪���āA���̃{�P�B
���O������ɁA���[�h�v���ƃ����R����t�ƃ����R������D-RAM�ւ̃��[�h�w�߂��������Ă���Ɖ��߂��Ă��邾�����낤���B
����ȒP���\���ł��������𗝉��ł��Ȃ��悤�Ȓm�\���������Ă��Ȃ����牴�̔�������ǂ��Ă��˂��̂��B
���AqfDm/Dlb�ȁB
���������A���������Ȃ��ƌ����Ȃ�B
���͂���Ȃ��ƈꌾ�������ĂȂ����B
�ȂA�X�����L�тĂ�Ǝv���ė��Ă݂��疳���ꒃ�����₪���āA���̃{�P�B
���O������ɁA���[�h�v���ƃ����R����t�ƃ����R������D-RAM�ւ̃��[�h�w�߂��������Ă���Ɖ��߂��Ă��邾�����낤���B
����ȒP���\���ł��������𗝉��ł��Ȃ��悤�Ȓm�\���������Ă��Ȃ����牴�̔�������ǂ��Ă��˂��̂��B
���AqfDm/Dlb�ȁB
Hammer�̎�������
ttp://www.amd.com/us-en/assets/content_type/DownloadableAssets/MPF_Hammer_Presentation.PDF
�P8,�P9�y�[�W���Q�Ƃ���
>151
>L3�ւ̃A�N�Z�X�v���ƃ������[�ւ̃��[�h�v�����������s�ɔ������Ă��邱�Ƃ��܂������ł��܂���?
>������L3���q�b�g����A���[�h�҂��o�b�t�@��j������Ηǂ������B
�����܂ł͂�����
>���Ƀ����R���֎w�ߍς݂œǂݏo����Ԃł����Ă��\��Ȃ��B
�����������Ă��Ƃ���?
ttp://www.amd.com/us-en/assets/content_type/DownloadableAssets/MPF_Hammer_Presentation.PDF
�P8,�P9�y�[�W���Q�Ƃ���
>151
>L3�ւ̃A�N�Z�X�v���ƃ������[�ւ̃��[�h�v�����������s�ɔ������Ă��邱�Ƃ��܂������ł��܂���?
>������L3���q�b�g����A���[�h�҂��o�b�t�@��j������Ηǂ������B
�����܂ł͂�����
>���Ƀ����R���֎w�ߍς݂œǂݏo����Ԃł����Ă��\��Ȃ��B
�����������Ă��Ƃ���?
>>178
���A�������B>>147 �͂��������Ӗ��������̂��B�ǂ݊ԈႦ�Ă��B
���܂�B>>150 �͎������B>>147 �͂܂Ƃ��Ȕ������B
�������A>>148 �̌㔼�ŏ��������ƁA���Ȃ킿 ID:qfDm/Dlb ���A
>>100 ���� >>148 �܂ł̊ԂŁA�ӌ��𐳔��ɕς����Ƃ���
�����͎c�邪�B
���A�������B>>147 �͂��������Ӗ��������̂��B�ǂ݊ԈႦ�Ă��B
���܂�B>>150 �͎������B>>147 �͂܂Ƃ��Ȕ������B
�������A>>148 �̌㔼�ŏ��������ƁA���Ȃ킿 ID:qfDm/Dlb ���A
>>100 ���� >>148 �܂ł̊ԂŁA�ӌ��𐳔��ɕς����Ƃ���
�����͎c�邪�B
>>146
>���̏ꍇ�̓����́A���R�̂��Ƃ����Ǔ��삪��������܂ő҂��Ȃ����Ă������B
���̏ꍇ�́f�����f�́AL3�A�N�Z�X�̃t�F�C�Y�ƃ������A�N�Z�X�̃t�F�C�Y���d�Ȃ��Ă���Ƃ���
�Ӗ��ŁA�������Ă���Ƃ����Ӗ��ł͖����ƌ����ׂ��B
���������肶��ˁH
>���̏ꍇ�̓����́A���R�̂��Ƃ����Ǔ��삪��������܂ő҂��Ȃ����Ă������B
���̏ꍇ�́f�����f�́AL3�A�N�Z�X�̃t�F�C�Y�ƃ������A�N�Z�X�̃t�F�C�Y���d�Ȃ��Ă���Ƃ���
�Ӗ��ŁA�������Ă���Ƃ����Ӗ��ł͖����ƌ����ׂ��B
���������肶��ˁH
�Ō��ǂ��A�L���b�V�������MOESI��MESI�Ȃ̂��ǂ����ȂH
�������������Ĉ�X����̂͂߂�ǂ�
�������������Ĉ�X����̂͂߂�ǂ�
�������������b�͕��������ȁB
���Ȃ݂�POWER4��2���L���b�V����MESI���g������7��ԂŊǗ����Ă�炵���B
K8L�̏ꍇ�A����\�P�b�g���ł̋��L�Ƃ����\�P�b�g�Ԃł̋��L�Ƃ��̋�ʂ����肻���ȋC������B
���Ȃ݂�POWER4��2���L���b�V����MESI���g������7��ԂŊǗ����Ă�炵���B
K8L�̏ꍇ�A����\�P�b�g���ł̋��L�Ƃ����\�P�b�g�Ԃł̋��L�Ƃ��̋�ʂ����肻���ȋC������B
>>186
> K8L�̏ꍇ�A����\�P�b�g���ł̋��L�Ƃ����\�P�b�g�Ԃł̋��L�Ƃ��̋�ʂ����肻���ȋC������B
�S���Ȃ��Ƃ������A��ʂ���K�v���Ȃ��B
����́A�Ȃ����L3���L�L���b�V���̉��b�Ƃł�������̂�������Ȃ����ǂȁB
L3���L�L���b�V���ɕt���Ă̓R�q�[�����V����͑S������Ă��Ȃ��Ƃ������ł��Ȃ��B
> K8L�̏ꍇ�A����\�P�b�g���ł̋��L�Ƃ����\�P�b�g�Ԃł̋��L�Ƃ��̋�ʂ����肻���ȋC������B
�S���Ȃ��Ƃ������A��ʂ���K�v���Ȃ��B
����́A�Ȃ����L3���L�L���b�V���̉��b�Ƃł�������̂�������Ȃ����ǂȁB
L3���L�L���b�V���ɕt���Ă̓R�q�[�����V����͑S������Ă��Ȃ��Ƃ������ł��Ȃ��B
>>185
����ǂ��ł������b���ȁB
���J����Ă���A����Ȃ�Ɋy���߂邾�낤���L���b�V���\���̈Ⴂ���瑽���̃A�����W�͂���̂����ʂ��B
�R�q�[�����V����Ō����AK8L�͉��̖ʔ��݂��Ȃ��B
Woodcrest���́AL1�̃R�q�[�����V�����L2���L�L���b�V���̃R�q�[�����V���䂪�قȂ邩�炻��Ȃ�ɃA�����W���Ă݂�Ɗy���߂邾�낤�B
���̏ꍇ�AL2���L�L���b�V���̃R�q�[�����V�͑��\�P�b�g��L2���L�L���b�V���ԂƂōs���̂��������ǂ����ƂɂȂ�B
�܂�A�P�\�P�b�g�����Ȃ�L2�̃R�q�[�����V����͕s�v�ƂȂ���Exclusive�̏�Ԃł̃L���b�V���ێ��ƂȂ�B
����ǂ��ł������b���ȁB
���J����Ă���A����Ȃ�Ɋy���߂邾�낤���L���b�V���\���̈Ⴂ���瑽���̃A�����W�͂���̂����ʂ��B
�R�q�[�����V����Ō����AK8L�͉��̖ʔ��݂��Ȃ��B
Woodcrest���́AL1�̃R�q�[�����V�����L2���L�L���b�V���̃R�q�[�����V���䂪�قȂ邩�炻��Ȃ�ɃA�����W���Ă݂�Ɗy���߂邾�낤�B
���̏ꍇ�AL2���L�L���b�V���̃R�q�[�����V�͑��\�P�b�g��L2���L�L���b�V���ԂƂōs���̂��������ǂ����ƂɂȂ�B
�܂�A�P�\�P�b�g�����Ȃ�L2�̃R�q�[�����V����͕s�v�ƂȂ���Exclusive�̏�Ԃł̃L���b�V���ێ��ƂȂ�B
�����Ō������L��MESI�ł�Shared�ł����ċ��L�L���b�V���̂��Ƃ���Ȃ��B
����\�P�b�g�̑��R�A�Ƃ����f�[�^�����L���Ă邱�Ƃ�������킴�킴���\�P�b�g��Invalid�v�����o���K�v���������B
����\�P�b�g�̑��R�A�Ƃ����f�[�^�����L���Ă邱�Ƃ�������킴�킴���\�P�b�g��Invalid�v�����o���K�v���������B
WriteThrough�Ȃ番���邯��WriteBack�Ȃ瑼�\�P�b�g��L2�Ԃ�snoop���Ă��Ӗ��Ȃ���B
L1��DirtyCache�����邩�������B
���ǁA�ǂݍ��ނƂ��͑��\�P�b�g��L1�܂ŏƉ�邱�ƂɂȂ�H
���Ă�����L1��WriteThrough�Ȃ̂��ȁB
L1��DirtyCache�����邩�������B
���ǁA�ǂݍ��ނƂ��͑��\�P�b�g��L1�܂ŏƉ�邱�ƂɂȂ�H
���Ă�����L1��WriteThrough�Ȃ̂��ȁB
������X���ɒ���t���Č����Ɩϑz����ʂł������������ƃu�c�u�c�����Ă����������j�[�g������̂͂����ł����H
�ŁA���ۂǂ����Ȃ̂�B
���̉��������������j�[�g�Ƃ��ǂ��ł���������A�^����m�肽���B
���������ڍׂ���ʃ��x���ɓ`����Ă���̂��AL3�L���b�V���@�\�ɂ��āB
���̉��������������j�[�g�Ƃ��ǂ��ł���������A�^����m�肽���B
���������ڍׂ���ʃ��x���ɓ`����Ă���̂��AL3�L���b�V���@�\�ɂ��āB
>>185
AMD�̎����ɂ���L1-DataCache��MOESI�v���g�R���T�|�[�g�ƂȂ��Ă�B
(�����̃A�h���X�͎����PC�ɂ��邩��A��A���Ɏ����B)
���ۂ̐���̏ڍׂ͋L�ڂ���ĂȂ����A�l�I�ɂ�Modified,Owned,Invalid�̊ebit��
Shared��Exclusive������3bit�̃J�E���^�ɂ�鐧��ƍl���Ă�B(0��Exclusive,1�`7��Shared)
���ꂾ�ƁA���R�A����̃��[�h�v���ŊY���A�h���X�̃f�[�^���������ꍇ�AShared�J�E���^���C���N�������g����
�f�[�^��Ԃ��A��M����Shared�J�E���^�ƗL�����������`�F�b�N���ĊȒP�ȃG���[�`�F�b�N���o����B
L1/L2���狤�L�f�[�^���j��(�܂���WriteBack)�����ꍇ�́A�j���v���𑼃R�A�ɑ��M���A��M���͊Y���A�h���X��
Shared�J�E���^���f�N�������g����B
���ꂾ�ƁA�P���ȃJ�E���^���䂾����Exclusive��Shared�̏�ԑJ�ڂ��X���[�Y�ɐ���ł��邵�A���R�A�̋��L��
������x�����c���ł���B
���sK8��DualCore�ł��_��8�R�A�܂ł����T�|�[�g���Ȃ��̂��A���̃J�E���^��3bit�܂ł����Ȃ��ƍl����Δ[���ł���B
AMD�̎����ɂ���L1-DataCache��MOESI�v���g�R���T�|�[�g�ƂȂ��Ă�B
(�����̃A�h���X�͎����PC�ɂ��邩��A��A���Ɏ����B)
���ۂ̐���̏ڍׂ͋L�ڂ���ĂȂ����A�l�I�ɂ�Modified,Owned,Invalid�̊ebit��
Shared��Exclusive������3bit�̃J�E���^�ɂ�鐧��ƍl���Ă�B(0��Exclusive,1�`7��Shared)
���ꂾ�ƁA���R�A����̃��[�h�v���ŊY���A�h���X�̃f�[�^���������ꍇ�AShared�J�E���^���C���N�������g����
�f�[�^��Ԃ��A��M����Shared�J�E���^�ƗL�����������`�F�b�N���ĊȒP�ȃG���[�`�F�b�N���o����B
L1/L2���狤�L�f�[�^���j��(�܂���WriteBack)�����ꍇ�́A�j���v���𑼃R�A�ɑ��M���A��M���͊Y���A�h���X��
Shared�J�E���^���f�N�������g����B
���ꂾ�ƁA�P���ȃJ�E���^���䂾����Exclusive��Shared�̏�ԑJ�ڂ��X���[�Y�ɐ���ł��邵�A���R�A�̋��L��
������x�����c���ł���B
���sK8��DualCore�ł��_��8�R�A�܂ł����T�|�[�g���Ȃ��̂��A���̃J�E���^��3bit�܂ł����Ȃ��ƍl����Δ[���ł���B
8�R�A�܂łȂ̂�HT��Node�Ǘ���3bit�����炶��Ȃ��́H
>>195
>>84�̃����N��ǂ�Ō�����������HyperTransport���̂��̂̐����ł͂Ȃ��͂����B
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/002.html
��--�ʂ̕����������܂��BHyperTransport V1�ł�Node��3bit�̃J�E���^�ŊǗ����Ă��܂����B�Ȃ̂ŁA8Node���ő�ł����BHyperTransport V3�ł͂ǂ��ł��傤?
�����̃J�E���^�͑��₷�B���݂�8�����A�����̃A�h���X�g���Ȃǂɔ����Ċg������B
��--�ǂ��܂ő��₷�̂ł��傤?
������̓C���v�������g�Ɉˑ�����BHyperTransport�ł͂����܂ŋK�肵�Ă��Ȃ��B
���́u�C���v�������g�Ɉˑ�����B�v�ƌ����������q���g�ɂȂ��Ďv���������ǂȁB
HyperTransport�̃m�[�h�Ǘ������Ȃ�3bit�Ȃ�đ債���T�C�Y����Ȃ����A���������l����
�ŏ�����8bit�Ƃ������ƃL���̂������ɋK�肵�Ă����Ă��ǂ������͂����B
�����A�L���b�V������̃C���v�������g�ɉe������ƂȂ��1bit���₷�����Ł~���C������
�T�C�Y�������邩�炻��������ɂ͂����Ȃ�����ȁB
>>84�̃����N��ǂ�Ō�����������HyperTransport���̂��̂̐����ł͂Ȃ��͂����B
ttp://journal.mycom.co.jp/articles/2006/06/20/computex01/002.html
��--�ʂ̕����������܂��BHyperTransport V1�ł�Node��3bit�̃J�E���^�ŊǗ����Ă��܂����B�Ȃ̂ŁA8Node���ő�ł����BHyperTransport V3�ł͂ǂ��ł��傤?
�����̃J�E���^�͑��₷�B���݂�8�����A�����̃A�h���X�g���Ȃǂɔ����Ċg������B
��--�ǂ��܂ő��₷�̂ł��傤?
������̓C���v�������g�Ɉˑ�����BHyperTransport�ł͂����܂ŋK�肵�Ă��Ȃ��B
���́u�C���v�������g�Ɉˑ�����B�v�ƌ����������q���g�ɂȂ��Ďv���������ǂȁB
HyperTransport�̃m�[�h�Ǘ������Ȃ�3bit�Ȃ�đ債���T�C�Y����Ȃ����A���������l����
�ŏ�����8bit�Ƃ������ƃL���̂������ɋK�肵�Ă����Ă��ǂ������͂����B
�����A�L���b�V������̃C���v�������g�ɉe������ƂȂ��1bit���₷�����Ł~���C������
�T�C�Y�������邩�炻��������ɂ͂����Ȃ�����ȁB
�܂��A�ςȂ̂��N���Ă�����w
�Ƃ肠����
ID:vo5salCs=�A�z?
�Ƃ肠����
ID:vo5salCs=�A�z?
���e�ɑ���c�b�R�~�����ŁA�A�z���̓��{��ŁA���́A�����l���Ė����l��
���X�͎~�߂��ȁB���ꂵ���B
���X�͎~�߂��ȁB���ꂵ���B
>>197�̓I�^�ɒm���őR�ł��Ȃ��A���݂������Ȃ�
�����ɂ���̂�CPU�̃A�[�L�e�N�`���I�^�H
>>196
����r�b�g���\��Ă���݂Ȃ��Ȃ��Ƃ͂悭���邵�A
ARM��Thumb���߂݂����Ȍ`�ŃR�}���h���`����A
�o�X����ς���K�v�����܂�Ȃ���Ȃ�?
����͂����ƁA��Ώ̐������R�A+���W���[�����Ȃ�āA�܂��܂��ǂ�����CELL�݂���
����r�b�g���\��Ă���݂Ȃ��Ȃ��Ƃ͂悭���邵�A
ARM��Thumb���߂݂����Ȍ`�ŃR�}���h���`����A
�o�X����ς���K�v�����܂�Ȃ���Ȃ�?
����͂����ƁA��Ώ̐������R�A+���W���[�����Ȃ�āA�܂��܂��ǂ�����CELL�݂���
>>185
�����P.255�ɋL�ڂ�����B
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
>>201
�Ȃ�قǁA������l�����邩�E�E�E
�ꉞ�A�J�E���^�������ƈ�����b�g���l������B
Exclusive��Shared��2��Ԃ����ŊǗ�����ꍇ�A�j���v����������R�A�͑ΏۃA�h���X�̃f�[�^��
Shared����Exclusive�ɂ��邩�AShared�̂܂c�����肵�Ȃ���Ȃ�Ȃ��Ȃ邪�A���̂��߂ɂ͎��R�A�ȊO��
�����f�[�^�����L���Ă���R�A�����邩�ǂ����₢���킹�Ȃ���Ȃ�Ȃ��B
�J�E���^�����Ȃ�A��Ɏ��R�A�ȊO�̃R�A�����������f�[�^�����L���Ă��邩�킩�邩��A�₢���킹�̕K�v��
�Ȃ��Ȃ�B(�P�ɃJ�E���^���f�N�������g����0�ɂȂ����炻�ꂪExclusive�ł��邱�Ƃ��Ӗ�����B)
���X�A�g�����W�X�^���������@�����AHyperTransport��ʉ߂���p�P�b�g�������炷�ɂ͗L�����Ǝv���B
�����P.255�ɋL�ڂ�����B
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
>>201
�Ȃ�قǁA������l�����邩�E�E�E
�ꉞ�A�J�E���^�������ƈ�����b�g���l������B
Exclusive��Shared��2��Ԃ����ŊǗ�����ꍇ�A�j���v����������R�A�͑ΏۃA�h���X�̃f�[�^��
Shared����Exclusive�ɂ��邩�AShared�̂܂c�����肵�Ȃ���Ȃ�Ȃ��Ȃ邪�A���̂��߂ɂ͎��R�A�ȊO��
�����f�[�^�����L���Ă���R�A�����邩�ǂ����₢���킹�Ȃ���Ȃ�Ȃ��B
�J�E���^�����Ȃ�A��Ɏ��R�A�ȊO�̃R�A�����������f�[�^�����L���Ă��邩�킩�邩��A�₢���킹�̕K�v��
�Ȃ��Ȃ�B(�P�ɃJ�E���^���f�N�������g����0�ɂȂ����炻�ꂪExclusive�ł��邱�Ƃ��Ӗ�����B)
���X�A�g�����W�X�^���������@�����AHyperTransport��ʉ߂���p�P�b�g�������炷�ɂ͗L�����Ǝv���B
�f�l�������ȁB
>>202
�J�E���^�����͂����߂��Ȃ��B
���_�����������ŁA�������������炾�B
���������A���L��Ԃɂ���f�[�^�͔��ɏ��Ȃ��Ƃ����O������O���Ă���B
�ق�̋͂�����̋��L�f�[�^�ׂ̈ɁA�J�E���^�̓����̓��_���B
>>202
�J�E���^�����͂����߂��Ȃ��B
���_�����������ŁA�������������炾�B
���������A���L��Ԃɂ���f�[�^�͔��ɏ��Ȃ��Ƃ����O������O���Ă���B
�ق�̋͂�����̋��L�f�[�^�ׂ̈ɁA�J�E���^�̓����̓��_���B
��AMD�ɉB�����͂���̂��ˁH
���\�����ȓd�͕����ł����ė~������
���\�����ȓd�͕����ł����ė~������
�ȓd�͋Z�p��AMD���Intel�̂ق����i��ł邩��Ȃ��B
AMD�͍��܂Ńf�X�N�g�b�v�͂悩���������o�C�����S�R�_������������c�P������Ă�����
>>203
�������H
MOESI�v���g�R������Modified,Owned,Exclusive,Shared,Invalid��5��Ԃ��Ǘ�����̂�
�Œ�ł�3bit�K�v�����A�J�E���^�����Ȃ�Exclusive��Shared�̊Ǘ���3bit�A�c��3��Ԃ�
2bit�����点������2bit��������B
��ԑJ�ڂɂ��Ă��A5��Ԃ̑g�����ɂȂ��ԑJ�ډ�H�𐧌䂷����A3��Ԃ̑g�����{
�P���J�E���^�̕����͂邩�ɊȒP���Ǝv�����H
2Way���x�Ȃ�債�����ʂ͂Ȃ��낤���AK8L���^�[�Q�b�g�Ƃ���32Way��64Way�ł̓p�P�b�g��
�팸�͐[���Ȗ�肾�Ǝv�����ȁB
�������H
MOESI�v���g�R������Modified,Owned,Exclusive,Shared,Invalid��5��Ԃ��Ǘ�����̂�
�Œ�ł�3bit�K�v�����A�J�E���^�����Ȃ�Exclusive��Shared�̊Ǘ���3bit�A�c��3��Ԃ�
2bit�����点������2bit��������B
��ԑJ�ڂɂ��Ă��A5��Ԃ̑g�����ɂȂ��ԑJ�ډ�H�𐧌䂷����A3��Ԃ̑g�����{
�P���J�E���^�̕����͂邩�ɊȒP���Ǝv�����H
2Way���x�Ȃ�債�����ʂ͂Ȃ��낤���AK8L���^�[�Q�b�g�Ƃ���32Way��64Way�ł̓p�P�b�g��
�팸�͐[���Ȗ�肾�Ǝv�����ȁB
> 2bit�����点������2bit��������B
�����A�Œ��ꒃ�Șb������Ă������B
���O�́A�J�E���^�[�������������ʂ��肩?
���ꂽ�ǁA��Ԃ�K�ɔc�����邱�Ƃ͕s�\���B
����ɁA���ꂩ��}���`�R�A�����i�݁A�S�\�P�b�g�ł��Œ�Sx�S=16�R�A�ȏ�ɂȂ�ƌ����̂Ɏ��g�����������L�t���O��������7bit?
���ʂ��A���ʂ��B
�����A�Œ��ꒃ�Șb������Ă������B
���O�́A�J�E���^�[�������������ʂ��肩?
���ꂽ�ǁA��Ԃ�K�ɔc�����邱�Ƃ͕s�\���B
����ɁA���ꂩ��}���`�R�A�����i�݁A�S�\�P�b�g�ł��Œ�Sx�S=16�R�A�ȏ�ɂȂ�ƌ����̂Ɏ��g�����������L�t���O��������7bit?
���ʂ��A���ʂ��B
��������CPU�ł�����
�����\�͂Ȃ�Pen4 2.8CGX4�����x�]�T�ŏo���邵
�����\�͂Ȃ�Pen4 2.8CGX4�����x�]�T�ŏo���邵
210 ���O�F Socket774 [sage] ���e���F 2006/06/23(��) 10:15:25 ID:gibFrwTZ
>>207
�ǂ��Ǝv�����炱���ɏ�����ŁA�����\�����Ă��������̂ɁB
>>207
�ǂ��Ǝv�����炱���ɏ�����ŁA�����\�����Ă��������̂ɁB
���C�ɋC�ɏ�邱�Ƃ��������J�i�H�@�J�i�H
�C���^�r���[���̃J�E���^���ĎQ�ƃJ�E���^�̂���?
ID���Ƃ��i���o�����O���Ƃ��������̈Ӗ��ő����Ă��B
ID���Ƃ��i���o�����O���Ƃ��������̈Ӗ��ő����Ă��B
>>208
������K8L�ł�bit���𑝂₷��H
�K�v�ȃg�����W�X�^���������邱�Ƃ��f�����b�g�ł͂��邪�A�Z�p�I�ɂ͂Ȃ�獢��͂Ȃ������ȒP�Ȋg�����B
�R�q�[�����V����̃p�P�b�g��HyperTransport�ɂ����镉�ׂ̖���K8�v����������_�Ƃ���Ă�������������ȁB
K8L�ōX�ɂ��̕��ׂ��y�����邽�߂ɁA���g�����W�X�^��K�v�Ƃ��鋤�LL3��lj�����ʂ�����A���̒��x�̊�{�I��
�p�P�b�g�팸��i�͍ŏ������������Ă��Ă����������Ȃ��B
�J�E���^�̃C���N�������g�E�f�N�������g�Ȃ�āA�_����H�̏����̖��W�Ő^����Ɉ������x�̊ȒP�ȉ�H�����A
�����1�N���b�N�Ŋ������鍂���Ȃ��̂�����A���x�ʂł����G�ȏ�ԑJ�ډ�H���L�����B
130nm�̏���K8�ł̓_�C�T�C�Y�ւ̉e�����[������������A�K�v�ŏ����ɗ��߂��낤���A65nm����L2���ʂƂȂ�
K8L�Ȃ��C��8bit�ʂ܂Ŋg�����Ă��A�_�C��ŕK�v�Ȗʐς͂ނ��댸��B
�p�P�b�g�팸�̃����b�g�Ɠ����Ƀg�����W�X�^���ʂ̃f�����b�g�����鎖�ʂ́A������ł��ŏ�����F�����Ă���A
����ȊO�ɉ����f�����b�g������u��̓I�v�ɉ�����Ă���B
���ق�̋͂�����̋��L�f�[�^�ׂ̈ɁA�J�E���^�̓����̓��_���B
���ꂱ���A���LL2�̕������ʂ��ȁB
���L���ƈ��������Ƀ��C�e���V�̑����Ƃ����f�����b�g�Ƃ̃g���[�h�I�t�����H
�͂�����̋��L�f�[�^�ׂ̈ɁA��ʂ̔L�f�[�^�▽�߂̃��[�h���C�e���V���������������ۂǖ��ʁB
>>210
����A�����{�[���Ǝ������߂Ȃ���ł��v�������x�̂��Ƃ�����A�����l�����z�͂��邾��B
������K8L�ł�bit���𑝂₷��H
�K�v�ȃg�����W�X�^���������邱�Ƃ��f�����b�g�ł͂��邪�A�Z�p�I�ɂ͂Ȃ�獢��͂Ȃ������ȒP�Ȋg�����B
�R�q�[�����V����̃p�P�b�g��HyperTransport�ɂ����镉�ׂ̖���K8�v����������_�Ƃ���Ă�������������ȁB
K8L�ōX�ɂ��̕��ׂ��y�����邽�߂ɁA���g�����W�X�^��K�v�Ƃ��鋤�LL3��lj�����ʂ�����A���̒��x�̊�{�I��
�p�P�b�g�팸��i�͍ŏ������������Ă��Ă����������Ȃ��B
�J�E���^�̃C���N�������g�E�f�N�������g�Ȃ�āA�_����H�̏����̖��W�Ő^����Ɉ������x�̊ȒP�ȉ�H�����A
�����1�N���b�N�Ŋ������鍂���Ȃ��̂�����A���x�ʂł����G�ȏ�ԑJ�ډ�H���L�����B
130nm�̏���K8�ł̓_�C�T�C�Y�ւ̉e�����[������������A�K�v�ŏ����ɗ��߂��낤���A65nm����L2���ʂƂȂ�
K8L�Ȃ��C��8bit�ʂ܂Ŋg�����Ă��A�_�C��ŕK�v�Ȗʐς͂ނ��댸��B
�p�P�b�g�팸�̃����b�g�Ɠ����Ƀg�����W�X�^���ʂ̃f�����b�g�����鎖�ʂ́A������ł��ŏ�����F�����Ă���A
����ȊO�ɉ����f�����b�g������u��̓I�v�ɉ�����Ă���B
���ق�̋͂�����̋��L�f�[�^�ׂ̈ɁA�J�E���^�̓����̓��_���B
���ꂱ���A���LL2�̕������ʂ��ȁB
���L���ƈ��������Ƀ��C�e���V�̑����Ƃ����f�����b�g�Ƃ̃g���[�h�I�t�����H
�͂�����̋��L�f�[�^�ׂ̈ɁA��ʂ̔L�f�[�^�▽�߂̃��[�h���C�e���V���������������ۂǖ��ʁB
>>210
����A�����{�[���Ǝ������߂Ȃ���ł��v�������x�̂��Ƃ�����A�����l�����z�͂��邾��B
>>214
���O�A������킴�Ɣ����Ă邾��w
> ���O�́A�J�E���^�[�������������ʂ��肩?
> ���ꂽ�ǁA��Ԃ�K�ɔc�����邱�Ƃ͕s�\���B
���O�A������킴�Ɣ����Ă邾��w
> ���O�́A�J�E���^�[�������������ʂ��肩?
> ���ꂽ�ǁA��Ԃ�K�ɔc�����邱�Ƃ͕s�\���B
> ���ꂱ���A���LL2�̕������ʂ��ȁB
> ���L���ƈ��������Ƀ��C�e���V�̑����Ƃ����f�����b�g�Ƃ̃g���[�h�I�t�����H
> �͂�����̋��L�f�[�^�ׂ̈ɁA��ʂ̔L�f�[�^�▽�߂̃��[�h���C�e���V���������������ۂǖ��ʁB
���O�A���ɂ��������Ⴂ�˂��ȁA�Ƃ�����������蔽�_��?
���L�L���b�V���̌��\�́A���O���v���Ă����肸���Ƌ��͂��A�������Conroe��L2�L���b�V���̘b�����ȁB
���LL2��L���邱�ƂŁA�V�K���[�h���ɑ��R�A�֏Ɖ�p�P�b�g�𑗂�Ȃ��čςށB
����ɁA�P�X���b�h����L2�̑S�Ă��g����B
�}���`�X���b�h���̏Ɖ��L1�����ōςށB
���̂悤�ȗ��_�ƁA�{�����_�ł���͂��̃��C�e���V�̑�����Intel�̋Z�p�͂ŗ}������ł��鐦�܂������ɍ����\�ȃL���b�V���Ȃ�B
> ���L���ƈ��������Ƀ��C�e���V�̑����Ƃ����f�����b�g�Ƃ̃g���[�h�I�t�����H
> �͂�����̋��L�f�[�^�ׂ̈ɁA��ʂ̔L�f�[�^�▽�߂̃��[�h���C�e���V���������������ۂǖ��ʁB
���O�A���ɂ��������Ⴂ�˂��ȁA�Ƃ�����������蔽�_��?
���L�L���b�V���̌��\�́A���O���v���Ă����肸���Ƌ��͂��A�������Conroe��L2�L���b�V���̘b�����ȁB
���LL2��L���邱�ƂŁA�V�K���[�h���ɑ��R�A�֏Ɖ�p�P�b�g�𑗂�Ȃ��čςށB
����ɁA�P�X���b�h����L2�̑S�Ă��g����B
�}���`�X���b�h���̏Ɖ��L1�����ōςށB
���̂悤�ȗ��_�ƁA�{�����_�ł���͂��̃��C�e���V�̑�����Intel�̋Z�p�͂ŗ}������ł��鐦�܂������ɍ����\�ȃL���b�V���Ȃ�B
>>215
�E�E�E�����I�܂�
>���ꂽ��
���˂����݂ǂ��낾�����̂��A�C���t�������B
�Ƃ肠�������{����K���Ă��痈���B�ƌ����Ă������B
>16�R�A�ȏ�ɂȂ�ƌ����̂Ɏ��g�����������L�t���O��������7bit?
�E�E�E���sK8��z�肵����Łu3bit�v�Ə����Ă�͂������H
�ǂ�����u7bit�v�Ȃ�ďo�Ă����H
�܁A64�R�A�ł�6bit�ő���邪�ȁB
2�i�������ł�����K���ė����B
�E�E�E�����I�܂�
>���ꂽ��
���˂����݂ǂ��낾�����̂��A�C���t�������B
�Ƃ肠�������{����K���Ă��痈���B�ƌ����Ă������B
>16�R�A�ȏ�ɂȂ�ƌ����̂Ɏ��g�����������L�t���O��������7bit?
�E�E�E���sK8��z�肵����Łu3bit�v�Ə����Ă�͂������H
�ǂ�����u7bit�v�Ȃ�ďo�Ă����H
�܁A64�R�A�ł�6bit�ő���邪�ȁB
2�i�������ł�����K���ė����B
�����X�Ő\����Ȃ���
>>216
CPU�A�[�L�e�B�`���f�l�̑f�p�ȋ^��Ȃ��ǂ��A
>�P�X���b�h����L2�̑S�Ă��g����
���̂�����͒N�����䂷��낤�BCPU���HOS�H
>>216
CPU�A�[�L�e�B�`���f�l�̑f�p�ȋ^��Ȃ��ǂ��A
>�P�X���b�h����L2�̑S�Ă��g����
���̂�����͒N�����䂷��낤�BCPU���HOS�H
>>217
�ւցA�܂肨�O�́A��Ԃ̕ێ��ȂǂȂ��ŒP��Shared�J�E���^�����ŗǂ��ƌ����Ă����?
�܂��A�������͂�����Ƃ���B
���\�ґ���ɂ���̂͂����Ƃ�����邩�猙���Ȃ��B
�ւցA�܂肨�O�́A��Ԃ̕ێ��ȂǂȂ��ŒP��Shared�J�E���^�����ŗǂ��ƌ����Ă����?
�܂��A�������͂�����Ƃ���B
���\�ґ���ɂ���̂͂����Ƃ�����邩�猙���Ȃ��B
>>221
��{�I�ɂ����Ȃ�B
��{�I�ɂ����Ȃ�B
>>219
�ŏ��ɏ������ʂ�AMOESI�v���g�R���̏�Ԑ���݂̂Ɍ��肵���ꍇ��
Modified,Owned,Invalid��3��ԁ{Exclusive,Shared�̊Ǘ��J�E���^�����H
����ȊO�̏�ԕێ���MOESI�v���g�R���ɂ͒��ڊW���Ȃ����낤�Ƃ������ƂŖ���������ł̘b���B
���������A�A�h���X�Ǘ����炵��K8��K8L�ł�40bit����48bit�֊g�������炵������ȁB
�ŁA�f�����b�g�̉���͂܂����H
�ŏ��ɏ������ʂ�AMOESI�v���g�R���̏�Ԑ���݂̂Ɍ��肵���ꍇ��
Modified,Owned,Invalid��3��ԁ{Exclusive,Shared�̊Ǘ��J�E���^�����H
����ȊO�̏�ԕێ���MOESI�v���g�R���ɂ͒��ڊW���Ȃ����낤�Ƃ������ƂŖ���������ł̘b���B
���������A�A�h���X�Ǘ����炵��K8��K8L�ł�40bit����48bit�֊g�������炵������ȁB
�ŁA�f�����b�g�̉���͂܂����H
>>222
���肪�ƁB
�f�l�l�������ǁA���̂�����̊m�ۂ���\�����n�Y�����ꍇ�Ƃ�
�����ɑ������X���b�h�̓��e�ɂ���ẮA�r�������������Ȃ�ꍇ�Ȃ��H
����ł��\����L2���x�m�ۂ��Ă邩����Q�͂Ȃ��̂�������Ȃ����ǁB
���肪�ƁB
�f�l�l�������ǁA���̂�����̊m�ۂ���\�����n�Y�����ꍇ�Ƃ�
�����ɑ������X���b�h�̓��e�ɂ���ẮA�r�������������Ȃ�ꍇ�Ȃ��H
����ł��\����L2���x�m�ۂ��Ă邩����Q�͂Ȃ��̂�������Ȃ����ǁB
>>225
�L���b�V�����C���ɂ���ẮA�����̃R�A�ŋ���(��荇��)����P�[�X���o�Ă���B
�ߓx�ȋ����̓L���b�V�����\��ቺ�����錴���ɂ��Ȃ�B
Conroe�́A�L���b�V�����C�����ߓx�Ɏ�荇��ʂ悤�ɂ���@�\���g�ݍ��܂�Ă���B
�L���b�V�����C�����ň�莞�Ԗ��Ɋe�R�A�̎g�p�����J�E���g���A������8Way���ɕ������Ă������E���e�R�A�̎���ɉ�����0��16Way�܂ŕω������Ă���B
���̋@�\�ɂ���āA��莞�ԓ��͋��E��ύX���Ȃ����ƂŁA�ߓx�̋������������Ă���킯���B
�悭�l����ꂽ�d�g�݂ƂȂ��Ă���B
�L���b�V�����C���ɂ���ẮA�����̃R�A�ŋ���(��荇��)����P�[�X���o�Ă���B
�ߓx�ȋ����̓L���b�V�����\��ቺ�����錴���ɂ��Ȃ�B
Conroe�́A�L���b�V�����C�����ߓx�Ɏ�荇��ʂ悤�ɂ���@�\���g�ݍ��܂�Ă���B
�L���b�V�����C�����ň�莞�Ԗ��Ɋe�R�A�̎g�p�����J�E���g���A������8Way���ɕ������Ă������E���e�R�A�̎���ɉ�����0��16Way�܂ŕω������Ă���B
���̋@�\�ɂ���āA��莞�ԓ��͋��E��ύX���Ȃ����ƂŁA�ߓx�̋������������Ă���킯���B
�悭�l����ꂽ�d�g�݂ƂȂ��Ă���B
>>226
�ق��ق��B�ʔ����ˁB������ƕ����Ă����
�ق��ق��B�ʔ����ˁB������ƕ����Ă����
�����ƁA�e��Ԃ�������ON�ɂȂ蓾�鎖��z��ɓ����̂�Y��Ă��ȁB
Modified,Owned,Invalid�Ɋe1bit��3bit�AShared��Exclusive�͓�����ON�ɂȂ�Ȃ��̂�1bit��ON/OFF��
�\�������������4bit���ȁB
�J�E���^�����ł͍ŏ���3bit�͓����ŁA�J�E���^��0�`7��3bit�A���v6bit���ȁB(���sK8�O��ł̘b)
�E�E�E����ς�2bit����������H
�ǂ������v�Z�Ȃ�2bit��NG�ɂȂ�̂��A�����낵���B
���ƁA�f�����b�g�̉�����ȁB
���ꂩ��d���Ȃ�ŁA���Ɍ��鎞�܂łɗ��ނ��A�u�{���v����Bw
Modified,Owned,Invalid�Ɋe1bit��3bit�AShared��Exclusive�͓�����ON�ɂȂ�Ȃ��̂�1bit��ON/OFF��
�\�������������4bit���ȁB
�J�E���^�����ł͍ŏ���3bit�͓����ŁA�J�E���^��0�`7��3bit�A���v6bit���ȁB(���sK8�O��ł̘b)
�E�E�E����ς�2bit����������H
�ǂ������v�Z�Ȃ�2bit��NG�ɂȂ�̂��A�����낵���B
���ƁA�f�����b�g�̉�����ȁB
���ꂩ��d���Ȃ�ŁA���Ɍ��鎞�܂łɗ��ނ��A�u�{���v����Bw
>>228
> �J�E���^��0�`7��3bit
�������Ԉ���Ă���Ƃ��낾�B
���̃J�E���^�[�͊e�R�A�Ƃ�Shared��Ԃ�ۑ�����̂�����A�V�R�A�Ȃ�7bit�K�v�B
�����ƕ����Ă��瓊�e����B
> �J�E���^��0�`7��3bit
�������Ԉ���Ă���Ƃ��낾�B
���̃J�E���^�[�͊e�R�A�Ƃ�Shared��Ԃ�ۑ�����̂�����A�V�R�A�Ȃ�7bit�K�v�B
�����ƕ����Ă��瓊�e����B
>>218
>>�P�X���b�h����L2�̑S�Ă��g����
>���̂�����͒N�����䂷��낤�BCPU���HOS�H
�p�ɂɃL���b�V���������������錋�ʁA��L�X���b�h�Ɋւ���L���b�V���̊�������������Ă��Ƃł���B
�ނ��葝�₷�킯����Ȃ��Ǝv���B
>>�P�X���b�h����L2�̑S�Ă��g����
>���̂�����͒N�����䂷��낤�BCPU���HOS�H
�p�ɂɃL���b�V���������������錋�ʁA��L�X���b�h�Ɋւ���L���b�V���̊�������������Ă��Ƃł���B
�ނ��葝�₷�킯����Ȃ��Ǝv���B
�����̓�l���B
�������āA�����̌���w
��߂Ƃ��Ⴂ���̂�
��߂Ƃ��Ⴂ���̂�
�E�E�E�����A�Ȃ�قǂˁB�@�����ȊO�̃R�A�Ɋebit��Ή������Ă邩��7bit�Ȃ̂��B
����Ȃɂ�����E�E�E�����ȊO�̃R�A�����������f�[�^���Q�Ƃ��Ă��邩�����ێ�����Ώ[�����B
�j���v�����o���Ƃ��ɁA�L���b�V�����C���̃A�h���X�ƃJ�E���^�̒l���ꏏ�Ɋi�[���邾���ł����B
(1)�j���v���p�P�b�g���Ŋ�̂ǂꂩ1�R�A�ɓ]���B
(2)�v������M�����R�A�͊Y���A�h���X������AShared�J�E���^���f�N�������g����Ɠ�����
��M�p�P�b�g�Ɋi�[���ꂽ�J�E���^���f�N�������g����B(�Ȃ�����̂܂܁B)
(3)��M�p�P�b�g���X�ɕʃR�A�ɓ]���B
(4)�ȉ��A(2)�E(3)���J��Ԃ��A�p�P�b�g���̃J�E���^��0�ɂȂ������_�œ]�����~�B
����Ȃ�A1�̔j���v���p�P�b�g���e�R�A�̊Ԃŏ����]�����邾���ōςނ��A�r���ŃJ�E���^��0�ɂȂ�����
����ȏ�̓]�����K�v�Ȃ��B
WriteBack�̎���WriteBack�����f�[�^���p�P�b�g�ɍڂ��ē]������ŐV�̃f�[�^�������ɔ��f�ł���B
���ł�Owned�t���O���ꏏ�ɓ]�����āA�J�E���^��0�ɂ����R�A�̋��L�f�[�^���V����Owned�ɂȂ�悤�ɂ���A
Owned�̏��n����������B
�킩��₷�������Ή݂����Ȃ������ȁB
���_������Ƃ���A�����]�����邱�Ƃŏ����J�n���珈�������܂Ŏ��Ԃ������邱�Ƃ����E�E�E
L1/L2����j���܂���WriteBack����鋤�L�f�[�^�͎Q�Ɨ�������ԌÂ�����j���EWriteBack��������
�������Ԃ��������Ă����͋ɂ߂ď��Ȃ��B(���܂��ܓ����A�N�Z�X���������ꍇ�ɂ�����Ƒ҂�������x�B)
�܁A�������Ԃ�D�悷��ꍇ�͔j���EWriteBack�p�P�b�g��S�R�A�ɖ������ɑ��M����Ƃ������@�����邪�A
���̏ꍇ��Shared�J�E���^�̒l�͕K�v�Ȃ�����Ƀp�P�b�g���͑����邪�ȁB
������ɂ���A�������c�����Ă�Ηp�͑����ȁB
����Ȃɂ�����E�E�E�����ȊO�̃R�A�����������f�[�^���Q�Ƃ��Ă��邩�����ێ�����Ώ[�����B
�j���v�����o���Ƃ��ɁA�L���b�V�����C���̃A�h���X�ƃJ�E���^�̒l���ꏏ�Ɋi�[���邾���ł����B
(1)�j���v���p�P�b�g���Ŋ�̂ǂꂩ1�R�A�ɓ]���B
(2)�v������M�����R�A�͊Y���A�h���X������AShared�J�E���^���f�N�������g����Ɠ�����
��M�p�P�b�g�Ɋi�[���ꂽ�J�E���^���f�N�������g����B(�Ȃ�����̂܂܁B)
(3)��M�p�P�b�g���X�ɕʃR�A�ɓ]���B
(4)�ȉ��A(2)�E(3)���J��Ԃ��A�p�P�b�g���̃J�E���^��0�ɂȂ������_�œ]�����~�B
����Ȃ�A1�̔j���v���p�P�b�g���e�R�A�̊Ԃŏ����]�����邾���ōςނ��A�r���ŃJ�E���^��0�ɂȂ�����
����ȏ�̓]�����K�v�Ȃ��B
WriteBack�̎���WriteBack�����f�[�^���p�P�b�g�ɍڂ��ē]������ŐV�̃f�[�^�������ɔ��f�ł���B
���ł�Owned�t���O���ꏏ�ɓ]�����āA�J�E���^��0�ɂ����R�A�̋��L�f�[�^���V����Owned�ɂȂ�悤�ɂ���A
Owned�̏��n����������B
�킩��₷�������Ή݂����Ȃ������ȁB
���_������Ƃ���A�����]�����邱�Ƃŏ����J�n���珈�������܂Ŏ��Ԃ������邱�Ƃ����E�E�E
L1/L2����j���܂���WriteBack����鋤�L�f�[�^�͎Q�Ɨ�������ԌÂ�����j���EWriteBack��������
�������Ԃ��������Ă����͋ɂ߂ď��Ȃ��B(���܂��ܓ����A�N�Z�X���������ꍇ�ɂ�����Ƒ҂�������x�B)
�܁A�������Ԃ�D�悷��ꍇ�͔j���EWriteBack�p�P�b�g��S�R�A�ɖ������ɑ��M����Ƃ������@�����邪�A
���̏ꍇ��Shared�J�E���^�̒l�͕K�v�Ȃ�����Ƀp�P�b�g���͑����邪�ȁB
������ɂ���A�������c�����Ă�Ηp�͑����ȁB
>>233
���O�A�}�W�ŃA�z����?w
���O�A�}�W�ŃA�z����?w
��ꂽ�^���e�[�v
���ꂾ�������ǂ݂Â炢�������݂��Â��Ă��邪�A���ɗ��b�̓[���B
�₽��p��������܂����ē���b�����Ă���悤�����A���w�����x���̊ԈႢ����Œ��g���[���B
���ꂪ���̃X���̃N�I���e�B�B
�₽��p��������܂����ē���b�����Ă���悤�����A���w�����x���̊ԈႢ����Œ��g���[���B
���ꂪ���̃X���̃N�I���e�B�B
����A�����l�|�������Ȃ��B
�{���͂܂Ƃ��ȃ��x���̐l�����l���ɂ��͂��B
�ł�������Ă��܂��B
�{���͂܂Ƃ��ȃ��x���̐l�����l���ɂ��͂��B
�ł�������Ă��܂��B
���̃X��������Ȃɂ����̂͑S�Ĉ��~�ł��i�m
�܂�����Reverse HT�̕��ꃋ�[�}�[�����サ�Ă��������ǁA�����������Ă�q�g��
�F���ł������肵����(��)
�F���ł������肵����(��)
AMD Socket AM2 has a secret weapon
http://www.theinquirer.net/?article=32589
Reverse HT(HyperThreading)�ɂ��āB
�����铮�I�}���`�X���b�h�Z�p�ŁAAM2�\�P�b�g��Athlon X2�ʼnB���@�\�Ƃ��Ď�������Ă���B
�\�t�g�E�G�A������Dual Core��Single Core�Ɍ����Ă�
(=Single Thread�I�Ƀ}���`�X���b�h�����Ȃ�����s����Ƃ�����)
���Ƃɂ���āA6����/cycle�̍�IPC�������B
http://www.theinquirer.net/?article=32589
Reverse HT(HyperThreading)�ɂ��āB
�����铮�I�}���`�X���b�h�Z�p�ŁAAM2�\�P�b�g��Athlon X2�ʼnB���@�\�Ƃ��Ď�������Ă���B
�\�t�g�E�G�A������Dual Core��Single Core�Ɍ����Ă�
(=Single Thread�I�Ƀ}���`�X���b�h�����Ȃ�����s����Ƃ�����)
���Ƃɂ���āA6����/cycle�̍�IPC�������B
AMD to Boost Single-Threading Performance on Multi-Core Chips, Say Sources.
http://www.xbitlabs.com/news/cpu/display/20060622143710.html
xbit�͍X�ɏڂ����B
http://www.xbitlabs.com/news/cpu/display/20060622143710.html
xbit�͍X�ɏڂ����B
To activate it customers will �gonly need to update the processor driver and the mainboard BIOS,�h
they say. Microsoft Corp. will reportedly even release a corresponding patch for the operating systems
that will allow recognizing two cores of the Athlon 64 X2 as a single one.
Reverse HT����Combined Mode��L���ɂ���ɂ́A�V�����v���Z�b�T�h���C�o�A�V����BIOS���K�v�B
MS��Dual Core��P��v���Z�b�T�Ƃ��ĔF�������邽��OS�̃p�b�`��p�ӁB
they say. Microsoft Corp. will reportedly even release a corresponding patch for the operating systems
that will allow recognizing two cores of the Athlon 64 X2 as a single one.
Reverse HT����Combined Mode��L���ɂ���ɂ́A�V�����v���Z�b�T�h���C�o�A�V����BIOS���K�v�B
MS��Dual Core��P��v���Z�b�T�Ƃ��ĔF�������邽��OS�̃p�b�`��p�ӁB
243 �FMAC�I�^��241 �����F2006/06/24(�y) 01:33:05 ID:E43Y3/ZJ
>>241
Reverse HT��n�[�h�E�F�A�I�Ȏ����Ƃ��Ă핅�ꃋ�[�}�[�̗̈悷���ǁA���p���Ă���
xbotlabs�̋L���ɂ���悤��
�@�@------------------------
�@�@Microsoft Corp. will reportedly even release a corresponding patch for the
�@�@operating systems that will allow recognizing two cores of the Athlon 64 X2
�@�@as a single one.
�@�@------------------------
(�ŋ߂�Efficeon �̔̔������������)���N�̐K�r�߂̍b�゠���āAMicrosoft ����
OS�I�f���A���R�A�T�|�[�g�����������\����A���邩�Ǝv���邷�B
Reverse HT��n�[�h�E�F�A�I�Ȏ����Ƃ��Ă핅�ꃋ�[�}�[�̗̈悷���ǁA���p���Ă���
xbotlabs�̋L���ɂ���悤��
�@�@------------------------
�@�@Microsoft Corp. will reportedly even release a corresponding patch for the
�@�@operating systems that will allow recognizing two cores of the Athlon 64 X2
�@�@as a single one.
�@�@------------------------
(�ŋ߂�Efficeon �̔̔������������)���N�̐K�r�߂̍b�゠���āAMicrosoft ����
OS�I�f���A���R�A�T�|�[�g�����������\����A���邩�Ǝv���邷�B
xbit�ǂݒ�������S�R����Ă��B
Combined Mode�ł́A2�R�A���̃��\�[�X�A�Ⴆ��2�Z�b�g���̃f�R�[�_��1�R�A�̂��߂����Ɏg����(=6 inst./cycle)
�Ƃ����������b�ŁA���I�}���`�X���b�h�Z�p�̗ނł͂Ȃ��悤���B
Combined Mode�ƒʏ�̃��[�h�͓��I�ɐ�ւ��\�B�Ȃ��Ȃ��������낢�B
Combined Mode�ł́A2�R�A���̃��\�[�X�A�Ⴆ��2�Z�b�g���̃f�R�[�_��1�R�A�̂��߂����Ɏg����(=6 inst./cycle)
�Ƃ����������b�ŁA���I�}���`�X���b�h�Z�p�̗ނł͂Ȃ��悤���B
Combined Mode�ƒʏ�̃��[�h�͓��I�ɐ�ւ��\�B�Ȃ��Ȃ��������낢�B
Reverse HT�łǂ̒��x�V���O���X���b�h���\���A�b�v����낤�B
Intel���Ǝ��H���ōD���������Ă邩��MS�Ƃ��Ă�AMD�������Ɍ��܂��Ă邾�낤�B
MS�����P�c�̂��Ȃ��Ɗ��Ⴂ���Ă�̂��B
MS�����P�c�̂��Ȃ��Ɗ��Ⴂ���Ă�̂��B
>>244
> �Ⴆ��2�Z�b�g���̃f�R�[�_��1�R�A�̂��߂����Ɏg����(=6 inst./cycle)
������w�ljR�݂����Ȃ��̂ŁA����Ȃ�v���V�[�{���ʂ�_�����k�ق��낤�ȁB
���ۂ́ACombined Mode�ŕЕ��̃R�A�̓d����OFF�ɂ��邱�ƂƁA�N���b�NUP(�{���𑝂₷ x9��x10)�������낤�ȁB
���X�f���A���R�A�̓V���O���R�A�Ɣ�r���ĂP�V%���x�Ⴂ�N���b�N�œ��삳���Ă���B
�Б��̃R�A�̓d����芮�S��~�������ƂŌ�����P�V%���x�̃N���b�N�A�b�v���\�ɂȂ���Ă����̘b���B
MS�ɂ��Ă��A�Е��̃R�A���~������x�̂��ƂȂ�A���Ƀ}���`�\�P�b�g�ł̏�Q����@�\��CPU�藣��(CPU���蓖�ĕύX��ɐ藣��)����
�����ς݂�����ȒP�ȃp�b�`��p�ӂ��邾���őΉ��͉\���B
����ɂ��Ă��A�l�^�����������ƒ��Șb�ŏ����x�̂��Ƃł����Ȃ��B
�܂��A����ł��V���O���R�A����ɂȂ�Ƃ͂���17%���x�̃N���b�N�A�b�v���ʂ�AMD�Ɏ��Δ��ɗL�p���낤�B
Conroe�ɐ�ΓI�ȍ���t�����Ă������Ƃ��v���A17%�A�b�v�͕������ł������Ƃ��Ă����������AMD��CPU���������~�����ƂɂȂ�B
> �Ⴆ��2�Z�b�g���̃f�R�[�_��1�R�A�̂��߂����Ɏg����(=6 inst./cycle)
������w�ljR�݂����Ȃ��̂ŁA����Ȃ�v���V�[�{���ʂ�_�����k�ق��낤�ȁB
���ۂ́ACombined Mode�ŕЕ��̃R�A�̓d����OFF�ɂ��邱�ƂƁA�N���b�NUP(�{���𑝂₷ x9��x10)�������낤�ȁB
���X�f���A���R�A�̓V���O���R�A�Ɣ�r���ĂP�V%���x�Ⴂ�N���b�N�œ��삳���Ă���B
�Б��̃R�A�̓d����芮�S��~�������ƂŌ�����P�V%���x�̃N���b�N�A�b�v���\�ɂȂ���Ă����̘b���B
MS�ɂ��Ă��A�Е��̃R�A���~������x�̂��ƂȂ�A���Ƀ}���`�\�P�b�g�ł̏�Q����@�\��CPU�藣��(CPU���蓖�ĕύX��ɐ藣��)����
�����ς݂�����ȒP�ȃp�b�`��p�ӂ��邾���őΉ��͉\���B
����ɂ��Ă��A�l�^�����������ƒ��Șb�ŏ����x�̂��Ƃł����Ȃ��B
�܂��A����ł��V���O���R�A����ɂȂ�Ƃ͂���17%���x�̃N���b�N�A�b�v���ʂ�AMD�Ɏ��Δ��ɗL�p���낤�B
Conroe�ɐ�ΓI�ȍ���t�����Ă������Ƃ��v���A17%�A�b�v�͕������ł������Ƃ��Ă����������AMD��CPU���������~�����ƂɂȂ�B
xbit�̐����������āu�l�^���J�����ꂽ�v�Ƃ������Ă�ɂ��l�����܂�
���̍������Ȃ��̂Ɂ`���낤�ȁB�Ƃ�����������Ă�ɂ��~�����܂�
>>247
�፡�܂ł���f���A���\�P�b�g�ȃ}�V����
>���Ƀ}���`�\�P�b�g�ł̏�Q����@�\��CPU�藣��(CPU���蓖�ĕύX��ɐ藣��)����
>�����ς݂�����ȒP�ȃp�b�`��p�ӂ��邾���őΉ��͉\���B
����Ă݁H�ȒP�Ȃ�H����������
Windows�ł�Linux�ł�Solaris�ł��ł���������B��ł��̊ȒP�ȃp�b�`�������Ă݁H
�፡�܂ł���f���A���\�P�b�g�ȃ}�V����
>���Ƀ}���`�\�P�b�g�ł̏�Q����@�\��CPU�藣��(CPU���蓖�ĕύX��ɐ藣��)����
>�����ς݂�����ȒP�ȃp�b�`��p�ӂ��邾���őΉ��͉\���B
����Ă݁H�ȒP�Ȃ�H����������
Windows�ł�Linux�ł�Solaris�ł��ł���������B��ł��̊ȒP�ȃp�b�`�������Ă݁H
http://pc7.2ch.net/test/read.cgi/jisaku/1150872014/721
721 �FSocket774�F2006/06/23(��) 22:54:32 ID:0WhA3Ykz
��������Ȃ�AAnti-HT�ɂ͎��]�����Ƃ��������Ȃ�
ttp://www.intel.co.jp/jp/developer/technology/magazine/research/EPI-throttling-1005.htm
���K�C�V���c�ł���
721 �FSocket774�F2006/06/23(��) 22:54:32 ID:0WhA3Ykz
��������Ȃ�AAnti-HT�ɂ͎��]�����Ƃ��������Ȃ�
ttp://www.intel.co.jp/jp/developer/technology/magazine/research/EPI-throttling-1005.htm
���K�C�V���c�ł���
>>248-250
���O���A���ł���ȂɕK���Ȃ�w
�����Ƃ������A�f���A���R�A�����z�I�ɂP�R�A�ɂ�����x�ŃN���b�N������̐��\������I�ɐL�т�悤�Ȃ��Ƃ͍l����B
����ȂɊȒP�ɐ��\���オ��Ȃ�N����J�͂��Ȃ����A���ɂ����ƍ����\�ɂȂ��Ă���B
�܂�AMD�Ђ̌������Ƃ́A�Ƃ�ł��Ȃ��^�킵���R�ɏ[�����Ă���ƁA������x�̒m��������l�B�ɂ͎v���Ă��܂��킯���B
�܂��A���O���͖��m�̂悤������AMD�Ђ̍L���^�Ɏăv���V�[�{���ʂƃN���b�N�A�b�v���ʂŊ��ł�������B
���O���A���ł���ȂɕK���Ȃ�w
�����Ƃ������A�f���A���R�A�����z�I�ɂP�R�A�ɂ�����x�ŃN���b�N������̐��\������I�ɐL�т�悤�Ȃ��Ƃ͍l����B
����ȂɊȒP�ɐ��\���オ��Ȃ�N����J�͂��Ȃ����A���ɂ����ƍ����\�ɂȂ��Ă���B
�܂�AMD�Ђ̌������Ƃ́A�Ƃ�ł��Ȃ��^�킵���R�ɏ[�����Ă���ƁA������x�̒m��������l�B�ɂ͎v���Ă��܂��킯���B
�܂��A���O���͖��m�̂悤������AMD�Ђ̍L���^�Ɏăv���V�[�{���ʂƃN���b�N�A�b�v���ʂŊ��ł�������B
>>252
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=69544&threadid=69522&roomid=11
ttp://img154.imageshack.us/img154/8774/1194mp5zlusr4uni9bc.png
�Ȃ��قɂ�Core Multiplexing �Ȃ���̂�����炵�����E�E�E
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=69544&threadid=69522&roomid=11
ttp://img154.imageshack.us/img154/8774/1194mp5zlusr4uni9bc.png
{kind=link}
�Ȃ��قɂ�Core Multiplexing �Ȃ���̂�����炵�����E�E�E
�l�I�ɂ͋������邯�ǂȁAR-HTT�B
�܂��A����AM2�Ɏ�������Ă�Ƃ��͂Ƃ������Ƃ��āB
�́AHTT���o���Ƃ��ɁA�ŏI�I�ɂ͊e���s���j�b�g��Ɨ������A
�K�v�ɉ����Ă����𑩂˂Ę_��CPU���\������悤�Ȏd�g�݂ɂȂ鎞�オ����̂��ȁA
�Ȃ�Ėϑz���������Ƃ�����B
��������A�V���O���X���b�h�ŋ쓮�ł��镽�ϓI�ȃ��j�b�g��������s���j�b�g��
�������Ă��A�g����Ȃ��ꍇ�͕ʂ̘_��CPU���\�����Ďg���Ƃ��A����Ȋ����Ńg�[�^����
���Ă̐��\�����コ������̂��ȁA�Ƃ��B
�܂��A����Ȃ̂̓X�P�W���[�����O�Ƃ��o���Ȃ��Ǝv����ŁA�����Ȗϑz���Ƃ͎v�����ǁA
�Ȃ�ƂȂ��A�H���������悤�ȋC�������ŁA�ǂ��Ȃ邩�����A���B
�܂��A����AM2�Ɏ�������Ă�Ƃ��͂Ƃ������Ƃ��āB
�́AHTT���o���Ƃ��ɁA�ŏI�I�ɂ͊e���s���j�b�g��Ɨ������A
�K�v�ɉ����Ă����𑩂˂Ę_��CPU���\������悤�Ȏd�g�݂ɂȂ鎞�オ����̂��ȁA
�Ȃ�Ėϑz���������Ƃ�����B
��������A�V���O���X���b�h�ŋ쓮�ł��镽�ϓI�ȃ��j�b�g��������s���j�b�g��
�������Ă��A�g����Ȃ��ꍇ�͕ʂ̘_��CPU���\�����Ďg���Ƃ��A����Ȋ����Ńg�[�^����
���Ă̐��\�����コ������̂��ȁA�Ƃ��B
�܂��A����Ȃ̂̓X�P�W���[�����O�Ƃ��o���Ȃ��Ǝv����ŁA�����Ȗϑz���Ƃ͎v�����ǁA
�Ȃ�ƂȂ��A�H���������悤�ȋC�������ŁA�ǂ��Ȃ邩�����A���B
>�́AHTT���o���Ƃ��ɁA�ŏI�I�ɂ͊e���s���j�b�g��Ɨ������A
>�K�v�ɉ����Ă����𑩂˂Ę_��CPU���\������悤�Ȏd�g�݂ɂȂ鎞�オ����̂��ȁA
>�Ȃ�Ėϑz���������Ƃ�����B
HTT���炻��Ȗϑz���ł���Ȃ�Ă���������c�˔\�ł���
>�K�v�ɉ����Ă����𑩂˂Ę_��CPU���\������悤�Ȏd�g�݂ɂȂ鎞�オ����̂��ȁA
>�Ȃ�Ėϑz���������Ƃ�����B
HTT���炻��Ȗϑz���ł���Ȃ�Ă���������c�˔\�ł���
>>254
INTEL��HT�e�N�m���W�́A��r�I�y���v���Z�X�������������s������ʂł̃X���[�v�b�g���オ��ȖړI���B
Sun�̃i�C�A�K���ƃR���Z�v�g�͕ς����B
INTEL��HT�e�N�m���W�́A��r�I�y���v���Z�X�������������s������ʂł̃X���[�v�b�g���オ��ȖړI���B
Sun�̃i�C�A�K���ƃR���Z�v�g�͕ς����B
>>253
Intel�����������̂��̂Ƃ��ẮA�V���O���X���b�h�v���Z�X�I�Ƀ}���`�X���b�h�v���Z�X�Ɏ����ϊ������s���邱�Ƃł̐��\���ゾ�B
�������A���̂悤�Ȋ�b�����ɂ����Ă����Ɍ��E�͌����Ă����ł��̃v���Z�X���̂̃A�[�L�e�N�`�������ς��Ȃ�����������߂�͓̂���B
�����Ō��݂ł́A�����\�Ȕėp�����W���[���ɍi���Č���������Ă�����B
���̔ėp�����W���[���́A�R���p�C���ł̑g���ƁA�C���^�[�v���^�`���ł̎����̗��ʂŌ�������Ă��邪�A�܂��܂������̒i�K�ł����Ȃ��B
�ėp�����������ƕ��̌��㗦�͉�����̂��l�b�N(������O�̘b����)�ł���A�V���Ȕ��z�̏o����҂ƌ������悤�Ȃ��̂ł����Ȃ��B
�����͔��Ɍ������̂�B
Intel�����������̂��̂Ƃ��ẮA�V���O���X���b�h�v���Z�X�I�Ƀ}���`�X���b�h�v���Z�X�Ɏ����ϊ������s���邱�Ƃł̐��\���ゾ�B
�������A���̂悤�Ȋ�b�����ɂ����Ă����Ɍ��E�͌����Ă����ł��̃v���Z�X���̂̃A�[�L�e�N�`�������ς��Ȃ�����������߂�͓̂���B
�����Ō��݂ł́A�����\�Ȕėp�����W���[���ɍi���Č���������Ă�����B
���̔ėp�����W���[���́A�R���p�C���ł̑g���ƁA�C���^�[�v���^�`���ł̎����̗��ʂŌ�������Ă��邪�A�܂��܂������̒i�K�ł����Ȃ��B
�ėp�����������ƕ��̌��㗦�͉�����̂��l�b�N(������O�̘b����)�ł���A�V���Ȕ��z�̏o����҂ƌ������悤�Ȃ��̂ł����Ȃ��B
�����͔��Ɍ������̂�B
AMD�̉B���ʂƂ�炪������4�~4��HTX�o�X�����Ȃ̂͂킩����
x86�Ƃ�����IPC�͂����オ��Ȃ��Ƃ����펯���������̂ŁAK8�̓��C�e���V�팸�ŕ��ϓ_���グ�悤�Ƃ���
�ł�Banias�̓g�����W�X�^�𑝂₳���ɁA�Â��o�C�i����VLIW���݂̍�IPC���o���Ă݂���(���ʁA����Itanium�̎���i�߂�)
�������͂܂��������킯��
HTT�����Ȃ��g�����W�X�^�lj��ŋ^���f���A���R�A�̌��ʂ��o�����Z������
�������A���Z�͏o�s�����Ă͂��Ȃ�����
���ł��R�A�͔����̎��Ԃ��������ĂȂ����A�R�A���͂܂������Ă����̂�����A
�����R�A���g���ăV���O���X���b�h���\���グ�闠�Z�����邩������Ȃ�
1�R�A��2�R�A�Ɍ�����������A2�R�A��1�R�A�Ɍ���������ق����������Ȃ��Ǝv��
�ł�Banias�̓g�����W�X�^�𑝂₳���ɁA�Â��o�C�i����VLIW���݂̍�IPC���o���Ă݂���(���ʁA����Itanium�̎���i�߂�)
�������͂܂��������킯��
HTT�����Ȃ��g�����W�X�^�lj��ŋ^���f���A���R�A�̌��ʂ��o�����Z������
�������A���Z�͏o�s�����Ă͂��Ȃ�����
���ł��R�A�͔����̎��Ԃ��������ĂȂ����A�R�A���͂܂������Ă����̂�����A
�����R�A���g���ăV���O���X���b�h���\���グ�闠�Z�����邩������Ȃ�
1�R�A��2�R�A�Ɍ�����������A2�R�A��1�R�A�Ɍ���������ق����������Ȃ��Ǝv��
by �����ߌ㓡
Gesher�̓R�A�Ԃ̃C���^�[�R�l�N�g�ɓ���ȋZ�p���̗p���Ă���
�R�A�Ԃ͍��x�ɓ��������E�E�E�Ȃ�炩���
Gesher�̓R�A�Ԃ̃C���^�[�R�l�N�g�ɓ���ȋZ�p���̗p���Ă���
�R�A�Ԃ͍��x�ɓ��������E�E�E�Ȃ�炩���
ID:hEof9TqD�͊ԈႢ�Ȃ��G�����ȁB�悭���܂��A�����ϑz�����������^����
�悤�Ɍ�����E�E�E�E
1�̃R�A�~�߂Ă��̕�����1�̃R�A�N���b�N�A�b�v����Ƃ������o�J���Ƃ�����
����ƂȁA
>�����Ƃ������A�f���A���R�A�����z�I�ɂP�R�A�ɂ�����x�ŃN���b�N������̐��\������I�ɐL�т�悤�Ȃ��Ƃ͍l����B
>����ȂɊȒP�ɐ��\���オ��Ȃ�N����J�͂��Ȃ����A���ɂ����ƍ����\�ɂȂ��Ă���B
����Ȏ������Ă�悤���ᐔ�N�O�̍l���������B�S�����̃g�����h�ɏ��ĂȂ��B
�悤�Ɍ�����E�E�E�E
1�̃R�A�~�߂Ă��̕�����1�̃R�A�N���b�N�A�b�v����Ƃ������o�J���Ƃ�����
����ƂȁA
>�����Ƃ������A�f���A���R�A�����z�I�ɂP�R�A�ɂ�����x�ŃN���b�N������̐��\������I�ɐL�т�悤�Ȃ��Ƃ͍l����B
>����ȂɊȒP�ɐ��\���オ��Ȃ�N����J�͂��Ȃ����A���ɂ����ƍ����\�ɂȂ��Ă���B
����Ȏ������Ă�悤���ᐔ�N�O�̍l���������B�S�����̃g�����h�ɏ��ĂȂ��B
>>259
����Ȃ�ăX�[�p�[�X�J���H
����Ȃ�ăX�[�p�[�X�J���H
�����Ō����Ă���Z�p�Ƃ͊W�Ȃ��A
1�̃R�A�~�߂Ă��̕�����1�̃R�A���N���b�N�A�b�v�Ƃ����̂�
���肾�Ǝv���ȁB���̏ꍇ�A�M���x�����ɂȂ肻�������B
1�̃R�A�~�߂Ă��̕�����1�̃R�A���N���b�N�A�b�v�Ƃ����̂�
���肾�Ǝv���ȁB���̏ꍇ�A�M���x�����ɂȂ肻�������B
���@�I�}���`�X���b�f�B���O��Foxton�e�N�m���W���������Ȃ������ς��ł�
�A���~��AM2��10%�ȏ�̐��\������҂��Ă����킯�����A���ʂ͂����̂Ƃ���B
���ʂ�������悤�ɂȂ��Ă���w�ǂ̃A���~�́A�ŏ����炻��Ȃ̊��҂��Ă˂���ƌ����o�����킯�ŁA
�����Anti-HT�ɂ��Ă͐���Ƃ��A���~�̊��҂̒��𗦒��ɕ��������Ƃ����킯���B
���Ȃ݂ɁA���Ƃ��Ă͂U���߃f�R�[�h/�T�C�N���ɂȂ����Ƃ���Ő��\�͖w�Ǐオ�炷�A���X2�`3%���x�Ɨ\�z����B
Anti-HT���[�h���͑����̃N���b�N�A�b�v(10%)�������ɂ����Ƃ��ăg�[�^����1.03x1.1=13.3%���x�̐��\����ƌ���B
����A�A���~��������AMD�Ђ̍L��Ɋ��҂��Ă���l�̗\�z�������Ă���B
���ʂ�������悤�ɂȂ��Ă���w�ǂ̃A���~�́A�ŏ����炻��Ȃ̊��҂��Ă˂���ƌ����o�����킯�ŁA
�����Anti-HT�ɂ��Ă͐���Ƃ��A���~�̊��҂̒��𗦒��ɕ��������Ƃ����킯���B
���Ȃ݂ɁA���Ƃ��Ă͂U���߃f�R�[�h/�T�C�N���ɂȂ����Ƃ���Ő��\�͖w�Ǐオ�炷�A���X2�`3%���x�Ɨ\�z����B
Anti-HT���[�h���͑����̃N���b�N�A�b�v(10%)�������ɂ����Ƃ��ăg�[�^����1.03x1.1=13.3%���x�̐��\����ƌ���B
����A�A���~��������AMD�Ђ̍L��Ɋ��҂��Ă���l�̗\�z�������Ă���B
>>265
���O�ȏ�̃A���~�͂����ɂ͂��Ȃ���
���O�ȏ�̃A���~�͂����ɂ͂��Ȃ���
�������ĂȂ�A�����̊ԈႢ�B
>>266
�����Ƃ́A�A���~�͑S�����҂��ĂȂ����Ă��Ƃ���?
����Ȃ�ǂ����A�₽��ɑ����o�J���E�U�C�̂ő����Ȃ炿���Ɨ\�z�l���o���Ă݂���Ă��Ƃ��B
>>266
�����Ƃ́A�A���~�͑S�����҂��ĂȂ����Ă��Ƃ���?
����Ȃ�ǂ����A�₽��ɑ����o�J���E�U�C�̂ő����Ȃ炿���Ɨ\�z�l���o���Ă݂���Ă��Ƃ��B
�E�U�C���ǂ����͎�ς̑���B
�����猾�킹����O�̕����E�U�C�Ǝv���̂Ɠ����悤�ɂ��B
�K�Z���낤���Ȃ낤���l�^�ŗV�Ԃ̂͊�{���낗
�����猾�킹����O�̕����E�U�C�Ǝv���̂Ɠ����悤�ɂ��B
�K�Z���낤���Ȃ낤���l�^�ŗV�Ԃ̂͊�{���낗
�V�ԂȂ�A�\�z�l�\���Ă���ɂ�����Ă��Ƃ��ȁB
�������������ŁA����Ȃ̒m��˂��ƌ�Ō����Ă��ǂ��Ώ����Ă��������邩��ȁB
�܂��AAM2�̂Ƃ��̋��͔����̂��������ǂȁB
�������������ŁA����Ȃ̒m��˂��ƌ�Ō����Ă��ǂ��Ώ����Ă��������邩��ȁB
�܂��AAM2�̂Ƃ��̋��͔����̂��������ǂȁB
>>269
>�V�ԂȂ�A�\�z�l�\���Ă���ɂ�����Ă��Ƃ��ȁB
��������Ȃ����̂�ϑz���āA���܂��̒��ԂɂȂ�Ƃ������Ƃ��B
��Ȃ������B
>�V�ԂȂ�A�\�z�l�\���Ă���ɂ�����Ă��Ƃ��ȁB
��������Ȃ����̂�ϑz���āA���܂��̒��ԂɂȂ�Ƃ������Ƃ��B
��Ȃ������B
�ˑ��W(ry
���ӂ���>>R-HTT
���ӂ���>>R-HTT
>>269
����������Ώ��Ƃ������͂炢����������
�l�^��������m���������������
����ȂɎ������S�Řb���Ă��܂��ė~�����Ȃ�VIP�ɂŃX�����Ă낗
����������Ώ��Ƃ������͂炢����������
�l�^��������m���������������
����ȂɎ������S�Řb���Ă��܂��ė~�����Ȃ�VIP�ɂŃX�����Ă낗
Reverse-HT�A�Z�p�I�ɖʔ������ǂ������ȁB
�ǂ����x���`����X�R�A�オ��Ȃ����낤���������Ŋ��҂͂��ĂȂ��B
�ނ���A�A�v���P�[�V�������ɓ��삪��ւ�����Ƃ����������犴���B
�f���A���R�A�ւ̈ڍs�ɔ����p�t�H�[�}���X�̒ቺ���ŏ����ɂ��Ă���邾�낤���B
���Ă������ˁAIntel�Ȃ�Ƃ�����AMD������Ȃ̊J������Ȃ�ă}�W�M������B
���ƈꃖ���A�����Ƌ^��������ɈႢ�Ȃ��B
���̐�ɂ���̂͗��_���A����Ƃ��c�B
�ǂ����x���`����X�R�A�オ��Ȃ����낤���������Ŋ��҂͂��ĂȂ��B
�ނ���A�A�v���P�[�V�������ɓ��삪��ւ�����Ƃ����������犴���B
�f���A���R�A�ւ̈ڍs�ɔ����p�t�H�[�}���X�̒ቺ���ŏ����ɂ��Ă���邾�낤���B
���Ă������ˁAIntel�Ȃ�Ƃ�����AMD������Ȃ̊J������Ȃ�ă}�W�M������B
���ƈꃖ���A�����Ƌ^��������ɈႢ�Ȃ��B
���̐�ɂ���̂͗��_���A����Ƃ��c�B
�Ǝ����������Ă݂���������ł�����
�܂��AAMD�M�҂��W�����K�Z���Ǝv���Ă�낤���ǂ��ǂˁB
�����A�v�X�̖ʔ��l�^�����A����オ���Ă�������ˁH
�����A�v�X�̖ʔ��l�^�����A����オ���Ă�������ˁH
���߂̓��@���s�Ɏg���̂́H
�m���������e�R�A�Ɋ��蓖�Ă�悤�Ȏ���
�������œǂL��������̂ł���
�m���������e�R�A�Ɋ��蓖�Ă�悤�Ȏ���
�������œǂL��������̂ł���
���R�A��~&�N���b�N�A�b�v����Ԍ����I���Ȃ��B
�Ђ��B���ɂ��Ă����̂������邵�B
�Ђ��B���ɂ��Ă����̂������邵�B
���ʂ𗼕��Ƃ����s����Ƃ����͋Z�Ȃ�Itanium���������Ă�
�ŁA�v���Z�b�T������킩��Ƃ���R���p�C���̋��͂��K�v�s���Ȃ��AMD�ɂ͊��҂ł��Ȃ�
xbit�ɋL�����������Ǝv�����Дx�E���ăN���b�N�A�b�v���̕����܂������I�����A���ɂ��Ȃ��Ă���
�ŁA�v���Z�b�T������킩��Ƃ���R���p�C���̋��͂��K�v�s���Ȃ��AMD�ɂ͊��҂ł��Ȃ�
xbit�ɋL�����������Ǝv�����Дx�E���ăN���b�N�A�b�v���̕����܂������I�����A���ɂ��Ȃ��Ă���
>>275
�n�����Ȃ��A����オ��������������F�̔����T���܂Ŕ��������Ⴄ����Ȃ����B(w
�n�����Ȃ��A����オ��������������F�̔����T���܂Ŕ��������Ⴄ����Ȃ����B(w
>>281
�ނ���K�Z����Ȃ������Ƃ��̕����|���B
�ނ���K�Z����Ȃ������Ƃ��̕����|���B
����A����|���Ƃ��������ʂɏ펯�����邾��B
AMD�̃t�F���[����k�����ŁuAnti-HT�v�̘b�����Ă����́A�uAMD���ǂ��l�߂��Ă���Ȃ��A
�����������v�Ƃ̊��z����������Conroe�̔�����1���O�ɂ�������s����\�肾�����Ƃ͎Q�����ˁB
�ꉞ�́A�f�R�[�_������������Ēx�����邱�ƂȂ��X�P�W���[����uOPs����������悤������A�K�Z����Ȃ��̂��낤���ǁA
����ł̐��\����Ȃǖw�ǖ����ɂ��������A���N���b�N�𑽏��͏グ��悤�����炻�̂��Ƃ��B�����Ă��܂��邾�낤���ǁA
�܂Ƃ��Ȋ�Ƃ̂��邱�Ƃ���Ȃ���B
���ƁA�C�ɂȂ����̂́A���̎��̃t�F���[�̔����̒���FPU���j�b�g��2�{�̂悤�Ȑ���������Ă��Ǝv�����A
����͂ǂ����K8L�ƍ������Ă����悤���B
AMD�̃t�F���[����k�����ŁuAnti-HT�v�̘b�����Ă����́A�uAMD���ǂ��l�߂��Ă���Ȃ��A
�����������v�Ƃ̊��z����������Conroe�̔�����1���O�ɂ�������s����\�肾�����Ƃ͎Q�����ˁB
�ꉞ�́A�f�R�[�_������������Ēx�����邱�ƂȂ��X�P�W���[����uOPs����������悤������A�K�Z����Ȃ��̂��낤���ǁA
����ł̐��\����Ȃǖw�ǖ����ɂ��������A���N���b�N�𑽏��͏グ��悤�����炻�̂��Ƃ��B�����Ă��܂��邾�낤���ǁA
�܂Ƃ��Ȋ�Ƃ̂��邱�Ƃ���Ȃ���B
���ƁA�C�ɂȂ����̂́A���̎��̃t�F���[�̔����̒���FPU���j�b�g��2�{�̂悤�Ȑ���������Ă��Ǝv�����A
����͂ǂ����K8L�ƍ������Ă����悤���B
284 �FSocket774�F2006/06/25(��) 10:53:25 ID:VCccotti
>283
> �܂Ƃ��Ȋ�Ƃ̂��邱�Ƃ���Ȃ���B
�C���e�����AP4�̃p�C�v���C���i���𑝂₵�܂�����3GHz��CPU��������Ƃ���
���́A�����v�����B���\�͏オ�炸�ɁA����d�͂���Burst��������B
> �܂Ƃ��Ȋ�Ƃ̂��邱�Ƃ���Ȃ���B
�C���e�����AP4�̃p�C�v���C���i���𑝂₵�܂�����3GHz��CPU��������Ƃ���
���́A�����v�����B���\�͏オ�炸�ɁA����d�͂���Burst��������B
�q�ϓI�Ɍ���C�J�ꂽ��ЂȂ̂�INTEL��FA�H
> ���\�͏オ�炸��
P4�ɂȂ�A����Đ��\�͂�G���R�[�h���\�͔���I�ɍ����\��������B
AthlonXP�ł͍Ō�܂Œǂ��t���Ȃ������̂͋L���ɐV�����B
P4�ɂȂ�A����Đ��\�͂�G���R�[�h���\�͔���I�ɍ����\��������B
AthlonXP�ł͍Ō�܂Œǂ��t���Ȃ������̂͋L���ɐV�����B
���������M���͓���Đ��\�͂�G���R�[�h���\�����Ȑ�����
��������Έ����Ȃ�
��������Έ����Ȃ�
INTEL���g���AP4�͂��̂悤��CPU���ƍŏ�����f�����Ă�����ȁB
P4�ɏ�������̑����\�t�g�������œ������Ƃ����ق��������Ȓ������B
�l�b�g�o�[�X�g��ь������Ă���z�̖w�ǂ��A���ꓙ�̑O������𗝉������ɑ����ł��������Ȃ̂����m�������킯�����A
���͂����̘̂b�Ƃ��ĕЕt���ėǂ����������ȁB
P4�ɏ�������̑����\�t�g�������œ������Ƃ����ق��������Ȓ������B
�l�b�g�o�[�X�g��ь������Ă���z�̖w�ǂ��A���ꓙ�̑O������𗝉������ɑ����ł��������Ȃ̂����m�������킯�����A
���͂����̘̂b�Ƃ��ĕЕt���ėǂ����������ȁB
���̑O������𗝉��ł��Ȃ������̂ł͂Ȃ��A
���̑O����������ԂɎ�����Ȃ������A���Ă��Ƃ���ˁH
�܂��A���ƂȂ��Ă�intel���g������𗝉������A���ĈӖ��ł�
�Еt���Ă��ǂ��Ƃ͌����邩���ˁB
���́A����Ŗ�ɕ����ꂽ�l�g�o���A
���������ʂɓd�͂�M�ɕς��Ă�A���ăR�g�������B
���̑O����������ԂɎ�����Ȃ������A���Ă��Ƃ���ˁH
�܂��A���ƂȂ��Ă�intel���g������𗝉������A���ĈӖ��ł�
�Еt���Ă��ǂ��Ƃ͌����邩���ˁB
���́A����Ŗ�ɕ����ꂽ�l�g�o���A
���������ʂɓd�͂�M�ɕς��Ă�A���ăR�g�������B
��ʓI�ɂ͎�����Ĕ����I�ɔ��ꂽ�̂����E�E�E
INTEL�������Ǝs���c�����Ă������ʂ��B
�������A�v���X�R�b�g�͎��s�삾���ȁB(�����INTEL�͍ŏ�����F�߂��Ă�)
INTEL�������Ǝs���c�����Ă������ʂ��B
�������A�v���X�R�b�g�͎��s�삾���ȁB(�����INTEL�͍ŏ�����F�߂��Ă�)
293 �FSocket774�F2006/06/25(��) 12:22:19 ID:aorbaUnI
�Ȃ�ŎG���i��ID:Ay9E9Mu7�j�ƕ��ʂɉ�b���Ă�
P4��K���ɐ���������̂͂Ȃ��H���̈Ӗ�������́H
295 �FSocket774�F2006/06/25(��) 12:24:45 ID:aorbaUnI
�t�H���������ȁB
Intel�גɂ����Ďv�킹�邱�Ƃ��_��
Intel�גɂ����Ďv�킹�邱�Ƃ��_��
�K���ɐ��������ĉ���?
����������Ă��邾���ŁAP4�͂ǂ�Ȃ��̂ł��������ɏ������܂��Ȃ�ēd�g�Ȃ��ƌ������o���͂Ȃ����B
P4�̔����ŁAPC�ƊE�͕s������E�����̋Ǝ킪�����ݗ������ނȂ������ɐ��ڂ���������Y��Ă�����Ă͍���B
P4�ɂ��APC�œ���������̂���ʉ����A���݂ł͑�����PC��TV�`���[�i�[�����ڂ���A���̊ԂŎg���`�̑��ʈ�̌^PC
�܂Ń��C���i�b�v�����悤�ɂȂ����ƌ����Ă��ߌ��Ƃ͎v����B
����������Ă��邾���ŁAP4�͂ǂ�Ȃ��̂ł��������ɏ������܂��Ȃ�ēd�g�Ȃ��ƌ������o���͂Ȃ����B
P4�̔����ŁAPC�ƊE�͕s������E�����̋Ǝ킪�����ݗ������ނȂ������ɐ��ڂ���������Y��Ă�����Ă͍���B
P4�ɂ��APC�œ���������̂���ʉ����A���݂ł͑�����PC��TV�`���[�i�[�����ڂ���A���̊ԂŎg���`�̑��ʈ�̌^PC
�܂Ń��C���i�b�v�����悤�ɂȂ����ƌ����Ă��ߌ��Ƃ͎v����B
������Ȃ������Ƃ������AIntel���\�z��������
�������n�̎��v�����Ȃ��������Ċ������ȁB
���v�����Ȃ�����
�\�z�ȏ�ɃN���b�N������Ȃ�����
�I�ɂ͖�����������
����d�͖��
�܂������͐��ԓI�ɃN���b�N���Ɏ�`����������
�}�[�P�e�B���O�I�ɍ��N���b�N�\�ȃA�[�L�ɂ����̂����邩������B
>>293
�킩�����Ⴂ�邯�Ǔ��{��ʂ��邤���͂���
�������n�̎��v�����Ȃ��������Ċ������ȁB
���v�����Ȃ�����
�\�z�ȏ�ɃN���b�N������Ȃ�����
�I�ɂ͖�����������
����d�͖��
�܂������͐��ԓI�ɃN���b�N���Ɏ�`����������
�}�[�P�e�B���O�I�ɍ��N���b�N�\�ȃA�[�L�ɂ����̂����邩������B
>>293
�킩�����Ⴂ�邯�Ǔ��{��ʂ��邤���͂���
�܂���^���Ԃɂ��Đ��������Ƃ�E�E�E�ӯ
Pen4�̂������ŕs������E�����Ăǂꂾ���ϑz���������悗
�h�b�g�R���o�u�����e������A�����̕s�����K�ꂽ���Ƃ͖����ł��������ł����B
�h�b�g�R���o�u�����e������A�����̕s�����K�ꂽ���Ƃ͖����ł��������ł����B
���YCPU��낤���I
�`��������͋����ނ������A�Ă���͓���Ȃ�������Ƌ������
�������R�������{�͂��낻����E����
�`��������͋����ނ������A�Ă���͓���Ȃ�������Ƌ������
�������R�������{�͂��낻����E����
����ȂƂ����������S���݂���悤�ɂȂ�����A�����I��肾�Ǝv�����i�j
��[Super���]
�����ꂽ�E�E�E�[���A���Ȃ��intel���I���̗]�n���قƂ�ǖ����������ɍ��グ�����������ȁB
��p�̃R�v����������悤�Ƃ��Ă邭�炢������A�\�t�g�E�F�A�Ή����K�v������
���肦�Ȃ��Ƃ��͘b���Ⴄ�Ǝv���B
���肦�Ȃ��Ƃ��͘b���Ⴄ�Ǝv���B
�����������܂��ƁA�K���Ȃ�B
���Ԃ�B
���Ԃ�B
>>305
���{��ł�k
���{��ł�k
�E�֏��Z����k�X�Z���ł����璆�̃I�t�B�X�����@����������
�E�j���J���[�U�[���x���`��(ry
�EXeon�̏����\�͂�PenIII�x�[�X�̂Ɣ��(ry
�E�d����(ry
�E�j���J���[�U�[���x���`��(ry
�EXeon�̏����\�͂�PenIII�x�[�X�̂Ɣ��(ry
�E�d����(ry
����������������������`�b�v��CPU�𖼏�����Ⴂ�����
�G���R��p��AMD�̃T�u�\�P�b�g�ɓ���ĖႤ���炢����ɏo����l�g�o������������������
�M���ĒN���g��E�E�E
�G���R��p��AMD�̃T�u�\�P�b�g�ɓ���ĖႤ���炢����ɏo����l�g�o������������������
�M���ĒN���g��E�E�E
��������Ⴂ���Ȃ��Ƃ͑傫���o���ˁB
�l�g�o�́A5GHz�Ƃ��̍��N���b�N�ʼn���Ă���A
�ʂɈ����Ȃ�CPU�ɂȂ��Ă��͂��B
�N���b�N������̐��\�������͍̂��N���b�N�ɐU��������������B
����̃l�g�o�̈����_�́u�N���b�N�̒Ⴓ�v���B
�l�g�o�́A5GHz�Ƃ��̍��N���b�N�ʼn���Ă���A
�ʂɈ����Ȃ�CPU�ɂȂ��Ă��͂��B
�N���b�N������̐��\�������͍̂��N���b�N�ɐU��������������B
����̃l�g�o�̈����_�́u�N���b�N�̒Ⴓ�v���B
���ʁACPU���Ă̂̓R���p�C���̓f���o�����߂͂���
�A�[�L�e�B�N�`�������߂���ǁA
pentium4�͂��������(���[���Aintel�̃`�b�v�͂����Ă����������j
�N���b�N��������Α������낤(�z��)�A������pentium4�ɍœK��
���ꂽ�R���p�C�����o��(��]�I�ϑ�)�̌��ɊJ�����ꂽ���Ă̂�
���܂�����I�łȂ������̂ЂƂ���
�A�[�L�e�B�N�`�������߂���ǁA
pentium4�͂��������(���[���Aintel�̃`�b�v�͂����Ă����������j
�N���b�N��������Α������낤(�z��)�A������pentium4�ɍœK��
���ꂽ�R���p�C�����o��(��]�I�ϑ�)�̌��ɊJ�����ꂽ���Ă̂�
���܂�����I�łȂ������̂ЂƂ���
312 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/06/26(��) 03:38:53 ID:k3w/QMnN
Intel�͂���ȑŎZ�I�Ȃ��Ƃ͂��ĂȂ��B���А��R���p�C�������Ă邩�炗����
VC++��GCC�ɂ�������ƋZ�p���Ă邵�B
�ނ���Pen4�����ɍœK������ĂȂ��Â��R�[�h���x�������킯��
VC++��GCC�ɂ�������ƋZ�p���Ă邵�B
�ނ���Pen4�����ɍœK������ĂȂ��Â��R�[�h���x�������킯��
�L���b�V���T�C�Y�ł���������ł�K8�ɗ���Ă���Pen4
���R�ΏĂ��X�R�A���U���Ȃ���
���E�܂�OC�Ƃ��������ł͋t�]����Pen4�̂ق����������
�Α�����B����B��i�ł̓_���|���������ǂ�('A`)
���R�ΏĂ��X�R�A���U���Ȃ���
���E�܂�OC�Ƃ��������ł͋t�]����Pen4�̂ق����������
�Α�����B����B��i�ł̓_���|���������ǂ�('A`)
314 �F�E�́E�j��-������ ��toBASh.... �F2006/06/26(��) 03:43:43 ID:k3w/QMnN
����Intel���u2004�N����ɂ�600W�ɓ��B�v�Ȃ�ė\�����v���[�����Ă�����A
��p�����������Ζ{����600W��CPU�������肾�����낤�B
��p�����������Ζ{����600W��CPU�������肾�����낤�B
�p�C�v���C���o�u���̑傫������Netburst�̐^��������
�ǂ���ILP��4��5�őł��~�߂���
���̎�TLP(Netburst)�̎��オ����̂�EPIC(IA-64)������̂��͂킩��Ȃ�����
�Ǝ�������ۂ����Ə����Ă݂�
�ǂ���ILP��4��5�őł��~�߂���
���̎�TLP(Netburst)�̎��オ����̂�EPIC(IA-64)������̂��͂킩��Ȃ�����
�Ǝ�������ۂ����Ə����Ă݂�
316 �FSocket774�F2006/06/26(��) 04:57:22 ID:bKrKwimI
>>313
������������������Ȃ������͎̂��ゾ���
CPU�Ȃd�C�H���ē�����O�̕����Ȃ�
����5G�o������
�C���e�����������������̂͊ԈႢ�Ȃ��̂�
�ʔ����̂�GPU�����̐�ǂ��Ȃ邩�����
���̂��n�C�G���hGPU�Ɋւ��Ă�
�d�C�H���ē�����O���܂���ʂ��Ă���
VIA��CPU�ł�GPU�ł�����Ă邱�ƈꏏ�Ȃ̂��f�G��
������������������Ȃ������͎̂��ゾ���
CPU�Ȃd�C�H���ē�����O�̕����Ȃ�
����5G�o������
�C���e�����������������̂͊ԈႢ�Ȃ��̂�
�ʔ����̂�GPU�����̐�ǂ��Ȃ邩�����
���̂��n�C�G���hGPU�Ɋւ��Ă�
�d�C�H���ē�����O���܂���ʂ��Ă���
VIA��CPU�ł�GPU�ł�����Ă邱�ƈꏏ�Ȃ̂��f�G��
���ꂱ�� >314(600W �قǂ̐������������͊o���Ă��Ȃ���)��
�����Ă���悤�ȃL�`�K�C�����̐������{�C�ŐM���Ă����̂Ȃ�
���܂�ɂ������삾�낤�B
�ȃG�l��A�Ƃ�����������������Ȃ���B
�u�N���b�N�w�W�D��E���\�͂��̎�(�x���`�̓��e��������� OK)�v�Ƃ���
�}�[�P�e�B���O�̓s�����������Ă��Ȃ��̂͏���҂Ƃ��Ė�肠��
�����Ă���悤�ȃL�`�K�C�����̐������{�C�ŐM���Ă����̂Ȃ�
���܂�ɂ������삾�낤�B
�ȃG�l��A�Ƃ�����������������Ȃ���B
�u�N���b�N�w�W�D��E���\�͂��̎�(�x���`�̓��e��������� OK)�v�Ƃ���
�}�[�P�e�B���O�̓s�����������Ă��Ȃ��̂͏���҂Ƃ��Ė�肠��
�ł����ʂ̐l�ɂ͌������Ȃ����
>>314
���������A���x��COMPUTEX��1000W���̓d�����h�J�h�J�o�ċh��������
���������A���x��COMPUTEX��1000W���̓d�����h�J�h�J�o�ċh��������
�A��������f�t�H�ɂȂ�̂��낤���c
�C���e���uCore4��Athlon64 X4��140W�ɑ���������138W�ŁA����d�͂����Ȃ��Ă��ށB
1000W�Ȃ�Ďg���̂�AMD�v���b�g�t�H�[���������v
1000W�Ȃ�Ďg���̂�AMD�v���b�g�t�H�[���������v
AMD��AM2��\�P�b�gF�Ƃ͔�r�ɂȂ��ȁB
Woodcrest�̔����͐����B
> ���E���ŁA150 �Јȏ�̃V�X�e���E���[�J�[����A�����i�𓋍ڂ��� 200 �@��ȏ�̃T�[�o�[��[�N�X�e�[�V�����̔̔���\�肵�Ă��܂��B
> �܂��A���{�����ɂ����Ă��A��v�V�X�e���E���[�J�[����у`���l����Ɗe�Ђ��A
> �ŐV�̃f���A���R�A �C���e��R XeonR �v���Z�b�T�[ 5100 �ԑ�𓋍ڂ����T�[�o�[�ƃ��[�N�X�e�[�V�������A�������i������v��ł��B
�̗p��Ƃ���̃R�����g���������Ƃ�
> ttp://www.intel.co.jp/jp/intel/pr/press2006/060626b.htm
Woodcrest�̔����͐����B
> ���E���ŁA150 �Јȏ�̃V�X�e���E���[�J�[����A�����i�𓋍ڂ��� 200 �@��ȏ�̃T�[�o�[��[�N�X�e�[�V�����̔̔���\�肵�Ă��܂��B
> �܂��A���{�����ɂ����Ă��A��v�V�X�e���E���[�J�[����у`���l����Ɗe�Ђ��A
> �ŐV�̃f���A���R�A �C���e��R XeonR �v���Z�b�T�[ 5100 �ԑ�𓋍ڂ����T�[�o�[�ƃ��[�N�X�e�[�V�������A�������i������v��ł��B
�̗p��Ƃ���̃R�����g���������Ƃ�
> ttp://www.intel.co.jp/jp/intel/pr/press2006/060626b.htm
�}�C����IBM�̓��낷������
Microsoft-������AMD-������nVIDIa
�@�����@�@�i�����ɃP���J�j�@�@����
�@Intel-������Linux-������ATI
�@�����@�@�i�����ɃP���J�j�@�@����
�@Intel-������Linux-������ATI
�~�@Linux-������ATI
327 �FSocket774�F2006/06/29(��) 23:26:23 ID:jpH0EB8k
ttp://www.itmedia.co.jp/enterprise/articles/0606/29/news068.html
���̃X���ɂ͉��z���@�\���Z�L�����e�B��̋��ЂɂȂ�Ȃ���
�����Ă����z����R������Ȃ��B
���̃X���ɂ͉��z���@�\���Z�L�����e�B��̋��ЂɂȂ�Ȃ���
�����Ă����z����R������Ȃ��B
328 �FSocket774�F2006/06/30(��) 00:23:27 ID:niV7MX5M
�܂��������Ȃ���B����͉�X��2�N�O�ɔ��\�������̂ɑ���Ή��ł����Ȃ��B
330 �FSocket774�F2006/06/30(��) 10:46:59 ID:LTXKLRAp
>>329
���m�\���Ⴂ�����N���Ċy�����̂��H
���m�\���Ⴂ�����N���Ċy�����̂��H
�O���̒[������̌����Ȃ�킩���Ȃ�?
����Hound�̃L���b�V���͂ǂ��Ȃ�H
��jail�Ƃ�chroot���p���Ă邪327���Ȃ�ŋ��ЂȂ̂������E�E�E
�r�������炵�傤���Ȃ��B
335 �FSocket774�F2006/06/30(��) 23:28:57 ID:LTXKLRAp
>>333
jail��chroot�͊O���B�����鎖�Œ��ŋN�����������߂�@�\�B
�܂�A�O���U�������Ζ��́B
���z���@�\���O�̐��E������Ē�����O���B���ł���B
jail��chroot�͊O���B�����鎖�Œ��ŋN�����������߂�@�\�B
�܂�A�O���U�������Ζ��́B
���z���@�\���O�̐��E������Ē�����O���B���ł���B
>>332
����ɔr���I�ȋ��LL3���ďI���ł���B
����ɔr���I�ȋ��LL3���ďI���ł���B
���z���Z�p�A�݂������H�v
����
�M���O�̏I���@���̃M���O�͉������Ă��܂���B
�X���ɖ߂��ăM���O�̏�Ԃ��m�F����ɂ́A[�L�����Z��]���N���b�N���Ă��������B
�M���O�������ŏI�������ꍇ�́A�c�b�R�~����Ă��Ȃ��M���O��������\��������܂��B
�M���O���ɏI������ɂ́A[�����ɏI��]���N���b�N���Ă��������B
�������Ă��Ȃ��M���O�@���z���Z�p�A�݂������H�v.exe ���I�����邱�Ƃ�I�����܂����B
�M���O���������܂���B
���̖���Maccrosoft�ɕ��Ă��������B
���z���Z�p�A�݂������H�v.exe �̃G���[���쐬����܂����B
���Ђł́A���̕i�̉��P�ɖ𗧂Ă�ƂƂ��ɁA�����̋@�����Ƃ��Ĉ����܂��B
�G���[�Ɋ܂܂��f�[�^�̏ڍׁF�@���z���Z�p�A�݂������H�v
�G���[�̕@���̖�����Ă����������肪�Ƃ��������܂����B
�X���ɖ߂��ăM���O�̏�Ԃ��m�F����ɂ́A[�L�����Z��]���N���b�N���Ă��������B
�M���O�������ŏI�������ꍇ�́A�c�b�R�~����Ă��Ȃ��M���O��������\��������܂��B
�M���O���ɏI������ɂ́A[�����ɏI��]���N���b�N���Ă��������B
�������Ă��Ȃ��M���O�@���z���Z�p�A�݂������H�v.exe ���I�����邱�Ƃ�I�����܂����B
�M���O���������܂���B
���̖���Maccrosoft�ɕ��Ă��������B
���z���Z�p�A�݂������H�v.exe �̃G���[���쐬����܂����B
���Ђł́A���̕i�̉��P�ɖ𗧂Ă�ƂƂ��ɁA�����̋@�����Ƃ��Ĉ����܂��B
�G���[�Ɋ܂܂��f�[�^�̏ڍׁF�@���z���Z�p�A�݂������H�v
�G���[�̕@���̖�����Ă����������肪�Ƃ��������܂����B
> http://pc7.2ch.net/test/read.cgi/jisaku/1151802697/172 ���
> ���ꂩ��
> ��Read�S���R�A�����R�A�S�Ăɑ���L1L2�Ɖ�Ǝ�L3�A�N�Z�X�Ƒ��R�AL3�Ɖ�Ɠ����Ƀ������A�N�Z�X
> �͂ȂႤ�C������B
���Ȃ���A�A�N�Z�X�A�h���X�ɂ��S���R�A�����߂��Ă��邩�炱���Ɖ�Ɠ����Ƀ������A�N�Z�X���\�Ȃ�B
���LL3�̓��W�b�N�I�ɂ̓��������Ƃ��čl���āA�S���R�A�������C���u���b�N�P�ʂŒS���R�A�������ɊǗ�����B
���ꂾ�ƃ_�[�e�B�L���b�V���������邱�ƂɂȂ�B
�������A���S�r���͖������ȁB
> ���ꂩ��
> ��Read�S���R�A�����R�A�S�Ăɑ���L1L2�Ɖ�Ǝ�L3�A�N�Z�X�Ƒ��R�AL3�Ɖ�Ɠ����Ƀ������A�N�Z�X
> �͂ȂႤ�C������B
���Ȃ���A�A�N�Z�X�A�h���X�ɂ��S���R�A�����߂��Ă��邩�炱���Ɖ�Ɠ����Ƀ������A�N�Z�X���\�Ȃ�B
���LL3�̓��W�b�N�I�ɂ̓��������Ƃ��čl���āA�S���R�A�������C���u���b�N�P�ʂŒS���R�A�������ɊǗ�����B
���ꂾ�ƃ_�[�e�B�L���b�V���������邱�ƂɂȂ�B
�������A���S�r���͖������ȁB
Conroe�X������̈ړ�
��������>>173
���������A���̌��ʂ�Read�����R�A�Ɉ�U�W�߂���Ɉ˗����֕ԐM�����d�g�݂��B
�����ǂ�����c�BRead�S���R�A�ɂ͏W�߂����̂܂܈˗����ɕԂ��Ă���āB
���̐����͂���Ȋ���
Hound��z�肵�Ă邩��eCPU�͒����ŁB
CPU1���̎��R�AL1L2�Ƒ��R�AL1L2��Probe
�@��
CPU1���̋��LL3��Probe
������CPU1����CPU3�Ƀ������ǂݍ��ݗv�����o��
�@��
CPU3�͎��L���b�V���S�Ă̏Ɖ�ƃ������̓ǂݏo��������s��
������CPU0,1,2�ւ�Probe�v�����o��
�@��
CPU3�͎��L���b�V����Probe���ʂ�CPU1�ɕԐM
CPU0,2�͎��L���b�V���S�Ă�Probe���s��
�@��
CPU0,2��Probe���ʂ�CPU1�ɕԐM
�������̃f�[�^��DRAM����CPU3�ɓ͂�
�@��
CPU3��CPU0�Ƀ������̃f�[�^�𑗐M
�@��
CPU0��CPU3��SourceDone��ԐM
���̎������琄��������肱�ꂪ���R���Ǝv�����ǁB
�eCPU�͂��ꂼ�ꂪ��������Probe����킯�ŁB
���ꂪ�������̌��t�Ɉ��������������R�B
��������>>173
���������A���̌��ʂ�Read�����R�A�Ɉ�U�W�߂���Ɉ˗����֕ԐM�����d�g�݂��B
�����ǂ�����c�BRead�S���R�A�ɂ͏W�߂����̂܂܈˗����ɕԂ��Ă���āB
���̐����͂���Ȋ���
Hound��z�肵�Ă邩��eCPU�͒����ŁB
CPU1���̎��R�AL1L2�Ƒ��R�AL1L2��Probe
�@��
CPU1���̋��LL3��Probe
������CPU1����CPU3�Ƀ������ǂݍ��ݗv�����o��
�@��
CPU3�͎��L���b�V���S�Ă̏Ɖ�ƃ������̓ǂݏo��������s��
������CPU0,1,2�ւ�Probe�v�����o��
�@��
CPU3�͎��L���b�V����Probe���ʂ�CPU1�ɕԐM
CPU0,2�͎��L���b�V���S�Ă�Probe���s��
�@��
CPU0,2��Probe���ʂ�CPU1�ɕԐM
�������̃f�[�^��DRAM����CPU3�ɓ͂�
�@��
CPU3��CPU0�Ƀ������̃f�[�^�𑗐M
�@��
CPU0��CPU3��SourceDone��ԐM
���̎������琄��������肱�ꂪ���R���Ǝv�����ǁB
�eCPU�͂��ꂼ�ꂪ��������Probe����킯�ŁB
���ꂪ�������̌��t�Ɉ��������������R�B
���܂�A���Ԑꂾ�B
�܂��A�ӂɂł����X�����B
�܂��A�ӂɂł����X�����B
�����烌�X������
AMD silently launches Dual-Core Optimiser
http://www.theinquirer.net/default.aspx?article=32790
http://www.theinquirer.net/default.aspx?article=32790
347 �FSocket774�F2006/07/04(��) 08:40:03 ID:VQ1i3D8P
Conroe�X���苒�������B
Intel��L2��菬������������̋��LL3�Ȃɉ��l�Ȃnj��o���킯�Ȃ��
Intel��L2��菬������������̋��LL3�Ȃɉ��l�Ȃnj��o���킯�Ȃ��
>>346
AMD Dual Core Optimizer Released
ttp://www.tweakguides.com/
�}���`CPU���Ή��̃\�t�g�ł̕s������݂����Ȃ���
AMD Dual Core Optimizer Released
ttp://www.tweakguides.com/
�}���`CPU���Ή��̃\�t�g�ł̕s������݂����Ȃ���
���~��L2�L���b�V���ɑ���M�́A��l�ɂ͗����ł���c
�܂�AMD�����f���i���o�[�ō��ʉ����Ă�����
�܂�AMD�����f���i���o�[�ō��ʉ����Ă�����
>>347
�苒���āc���~ID:guWaYbJC������Ɋ����������낤����
�苒���āc���~ID:guWaYbJC������Ɋ����������낤����
�V�X�e���o�����X���R�X�g�o�����X���l�����ɁA�P�ɃL���b�V����������Ηǂ��Ǝv���Ă���z�͂ɂ킩�B
65nm�ɂȂ��ăN���b�N�グ����̂��Ȃ��B
�N���b�N������������
�v���Z�X�Ƃ�������3����c�݃V���R���ŏオ��\��B
��O����cSi�͂��łɎ�������Ă�Ƃ����b������B
�\�����[�N�d�����}�����Ă�Ȃ�A�����ŃN���b�N�͏オ��
�t�ɗ}�����Ȃ��ƃl�g�o�̂悤�ɔ������Ă��N���b�N�グ���Ȃ��B
65nm�ł̃��C���A�b�v���R�ꕷ�����Ă��鍠�ɂ͂킩���Ȃ�����
�t�ɗ}�����Ȃ��ƃl�g�o�̂悤�ɔ������Ă��N���b�N�グ���Ȃ��B
65nm�ł̃��C���A�b�v���R�ꕷ�����Ă��鍠�ɂ͂킩���Ȃ�����
NetBurst�͔M�̕ǂŃN���b�N���グ���Ȃ��������ǁAK8���������R�Ȃ̂��Ƃ����_������������B
OC���Ă�����قǐL�тȂ������B
OC���Ă�����قǐL�тȂ������B
65nm�̍ŏ��̃g�����W�X�^�͍Ō��90nm�̂���Ɠ�������AMD�������Ă���ȁBCTI�Ƃ�������B
������N���b�N�ϐ�����͔z���x���̕��������҂ł��Ȃ���Ȃ����ȁB
Vt�̈Ⴄ�g�����W�X�^���ǂ��g�����ł��ς�邾�낤���ǁB
������N���b�N�ϐ�����͔z���x���̕��������҂ł��Ȃ���Ȃ����ȁB
Vt�̈Ⴄ�g�����W�X�^���ǂ��g�����ł��ς�邾�낤���ǁB
�v�f�Ƃ��Ă͎����Ă����낤���ǁA�Q�[�g����≏�����Ƃ��܂ňꏏ���ǂ����Ȃ�Ă킩��Ȃ���ł́H
AMD��65nm���i���o�Ă���̂��܂��悾���B
AMD��65nm���i���o�Ă���̂��܂��悾���B
AMD��65nm�͐≏����1.3nm���ȁB
�v���Z�X�Ԃ̃g�����W�X�^�Z�p���L��STT���Ė��O�ł���B
65nm�ŃN���b�N�͐L���邩������Ȃ����ǁA����d�͂܂ŗ}�����邩�͂܂���������ˁB
�v���X���݂�����OC�ϐ��ǂ��Ă�����d�͑傫�������琻�i�̋����͂͗����Ă��܂��̂ŁA
�ŋ߂�AMD��90nm�ł�CTI�Ńg�����W�X�^�����ǂ��A��R��d���ȃg�����W�X�^�̊����𑝂₵��
�����d�͂��N���b�N���̂܂܂�"ENERGY EFFICIENT"������Ă���Ǝv���B
�g�����W�X�^�̉��ǂ̂قƂ�ǂ�����d�͉��Ɍ����Ă銴���H
���̕����܂肪�ǍD����65nm�ł̓N���b�N�ɂ��X�����邾�낤����A���҂��Ă����Ǝv���B
65nm�ŃN���b�N�͐L���邩������Ȃ����ǁA����d�͂܂ŗ}�����邩�͂܂���������ˁB
�v���X���݂�����OC�ϐ��ǂ��Ă�����d�͑傫�������琻�i�̋����͂͗����Ă��܂��̂ŁA
�ŋ߂�AMD��90nm�ł�CTI�Ńg�����W�X�^�����ǂ��A��R��d���ȃg�����W�X�^�̊����𑝂₵��
�����d�͂��N���b�N���̂܂܂�"ENERGY EFFICIENT"������Ă���Ǝv���B
�g�����W�X�^�̉��ǂ̂قƂ�ǂ�����d�͉��Ɍ����Ă銴���H
���̕����܂肪�ǍD����65nm�ł̓N���b�N�ɂ��X�����邾�낤����A���҂��Ă����Ǝv���B
362 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/05(��) 23:50:28 ID:J77r0n59
K7/K8��SIMD�������j�b�g�̃��C�e���V��2���Ă̂����|�I�Ɏ�_���ƁB
���j�b�g���X�g�[���Ȃ��ɉғ������悤�Ǝv������A4����ɂȂ�悤�ɃR�[�h���X�P�W���[�����O���Ȃ��Ƃ����Ȃ��B
Core 2�̂���̓��C�e���V1�ōς�łĂ������t��128bit�Ȃ̂ɁB
�����琫�\�̏o���₷���ɑ傫�ȍ����o��B
�����t��x87��X�J�����������ł͂����炩���͂��邩�ƁiSIMD���������͂܂�K8L�܂ł͒��߂�j
���j�b�g���X�g�[���Ȃ��ɉғ������悤�Ǝv������A4����ɂȂ�悤�ɃR�[�h���X�P�W���[�����O���Ȃ��Ƃ����Ȃ��B
Core 2�̂���̓��C�e���V1�ōς�łĂ������t��128bit�Ȃ̂ɁB
�����琫�\�̏o���₷���ɑ傫�ȍ����o��B
�����t��x87��X�J�����������ł͂����炩���͂��邩�ƁiSIMD���������͂܂�K8L�܂ł͒��߂�j
���ǂ��������Z�̂��ƂŗD�����Ă��Ȃ�
�����Ƌ��͂�FPU������
����10�{���炢�������
����10�{���炢�������
365 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/06(��) 00:59:01 ID:N4/pv/lW
������MPEG�G���R�[�_��Q�[���ł��p�b�N�h�������Z�͎g����
�����������Z�x�[�X�ł��}�X�N���Z�Ȃ�SIMD�������j�b�g�ł��
SSE4�Ő������Z�̋������s���Ă邩��A�g���@��͑�����Ǝv�ӁB
�قڃG���R�[�_��Í��������������ǁB
�����������Z�x�[�X�ł��}�X�N���Z�Ȃ�SIMD�������j�b�g�ł��
SSE4�Ő������Z�̋������s���Ă邩��A�g���@��͑�����Ǝv�ӁB
�قڃG���R�[�_��Í��������������ǁB
>���j�b�g���X�g�[���Ȃ��ɉғ������悤�Ǝv������A4����ɂȂ�悤�ɃR�[�h���X�P�W���[�����O���Ȃ��Ƃ����Ȃ��B
MMX��4������Ă��Ƃ�? 128bit����SIMD�Ȃ�2����ł����Ǝv�����B
MMX��4������Ă��Ƃ�? 128bit����SIMD�Ȃ�2����ł����Ǝv�����B
367 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/06(��) 01:10:49 ID:N4/pv/lW
>>366
���������Ӗ����������ǁA�����I�ɂ͏㔼���Ɖ������ɕ������ĕʁX�ɏ������邩��A�ˑ��W�Ƃ���
�X�P�W���[���̕��S���t�ɑ������肵�Č��ǐL�тȂ�������B
�������Ɓi�P�Q�W�r�b�gSIMD�x�[�X�j�������A���Ƃ���Core(Yonah)�Ȃ�P��Fused-��OP�Ƃ��Ĉ����邵�A
���C�e���V�P������������C�ɂ���K�v���̂������Ȃ�㩁B
���������Ӗ����������ǁA�����I�ɂ͏㔼���Ɖ������ɕ������ĕʁX�ɏ������邩��A�ˑ��W�Ƃ���
�X�P�W���[���̕��S���t�ɑ������肵�Č��ǐL�тȂ�������B
�������Ɓi�P�Q�W�r�b�gSIMD�x�[�X�j�������A���Ƃ���Core(Yonah)�Ȃ�P��Fused-��OP�Ƃ��Ĉ����邵�A
���C�e���V�P������������C�ɂ���K�v���̂������Ȃ�㩁B
�X�P�W���[���̕��S�����炷���߂ɁAK8L�Ő���SIMD��128bit�ɂȂ�̂��H
>364
��̉��Ɏg���C�Ȃ�ł����c
��̉��Ɏg���C�Ȃ�ł����c
�_���S���I���i���c�q�j�͒��������������Ǝv����
�@�����ǂ��Ă��܂��̂��낤�ȁB����
�@�����ǂ��Ă��܂��̂��낤�ȁB����
371 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/06(��) 03:03:52 ID:N4/pv/lW
�O�X����w�E���Ă����ƂȂ̂Ɂu�Y�������̗p�ӂȂ炠�邺�v���Č����܂ŕ����Ȃ������r��������
�Ă��A���̋�������Ղ茩�Ăđ���DQN���Ǝv���܂����B
�w�E��������Ȃ��Ⴛ�̂܂܈ᔽ���Ă�ꂽ�̂ɁA�������ȋ�s����Ă������B
�܂��A���͎��Ǝ����ł��B
�Ă��A���̋�������Ղ茩�Ăđ���DQN���Ǝv���܂����B
�w�E��������Ȃ��Ⴛ�̂܂܈ᔽ���Ă�ꂽ�̂ɁA�������ȋ�s����Ă������B
�܂��A���͎��Ǝ����ł��B
Hound��L3�͊��S�Ƀ������̃R�s�[���Ď咣���Ă��l�͌��Ǐ������̂��B
���ł���ȍl���ɂȂ����̂��m�肽�������̂����B
���ł���ȍl���ɂȂ����̂��m�肽�������̂����B
������������
�ǂ�����SIMM�Ƃ����ӋC�ɘA�Ă��Ă������N���o�������Ȉ���
�c�q�̓lj�͂ɂ����̊������o�����I
376 �FSocket774�F2006/07/06(��) 16:22:06 ID:iYyoH/cD
N�͒ɂ��V�l�ق����ȁB
377 �F���́��j��-------�F2006/07/06(��) 18:58:28 ID:NOfk0Izz
>>370 >>375
�����ƁA�����A�t�ɉ��̘b�����Ă�̂��T�b�p���ł���
�S�����肪�����ς�����߂���
�����ƁA���̃C���X�p�C��2006�����܂���̓a�l�ł��邤���́A
������Z�p�͂ň��|�ł��Ă��A�ނ₻�̎�芪�����C�ɓ���Ȃ����
�s�����Ă��Ƃ��炢�͕S�����m�ł���B
�Ȃ����a���Ȃǂ���C�͂Ȃ��B
����ł������ȁH
�����ƁA�����A�t�ɉ��̘b�����Ă�̂��T�b�p���ł���
�S�����肪�����ς�����߂���
�����ƁA���̃C���X�p�C��2006�����܂���̓a�l�ł��邤���́A
������Z�p�͂ň��|�ł��Ă��A�ނ₻�̎�芪�����C�ɓ���Ȃ����
�s�����Ă��Ƃ��炢�͕S�����m�ł���B
�Ȃ����a���Ȃǂ���C�͂Ȃ��B
����ł������ȁH
Sun and AMD to share common socket
http://www.theinquirer.net/default.aspx?article=32854
Opterons��Sparc���\�P�݊���
http://www.theinquirer.net/default.aspx?article=32854
Opterons��Sparc���\�P�݊���
379 �FSocket774�F2006/07/06(��) 20:42:44 ID:AmvGPAYu
amd
2008�N�̗\�肾����A�����炭Tukwila(CSI)�ւ̑R��
Sparc����Opteron�֍s���Ƃ���͂����Ă��A�t�͑��݂��Ȃ����낤��
�����l����Ƃ����Sparc�I���̂����Ďv��
�����l����Ƃ����Sparc�I���̂����Ďv��
Sun�̉�̂͒����ɐi��ł���
384 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/06(��) 23:15:10 ID:N4/pv/lW
IPF��Xeon�̃v���b�g�t�H�[�����ʉ��͋Ȃ���Ȃ�ɂ�x86�݊��ł���IPF�V�X�e����
�ቿ�i���ɂ���㩂�
�������A���܂���130nm�v���Z�X��������IPF����T����Ȃ�
�ቿ�i���ɂ���㩂�
�������A���܂���130nm�v���Z�X��������IPF����T����Ȃ�
Alpha AXP �� Slot B �� Athlon �� M/B ���ʂɏo����(�Ȃ��Ă�)
�Ȃf�W�����c
�Ȃf�W�����c
386 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/07(��) 01:41:24 ID:JqieHhRq
���ۖ��ASun�̐^��������Java�̎��s���x�ASolaris���Windows�ASPARC���Opteron�Ȃ̂ق�����������
>K7/K8��SIMD�������j�b�g�̃��C�e���V��2���Ă̂����|�I�Ɏ�_���ƁB
Conroe�̂ق����ǂ��͓̂�����O�����ǁA�\�t�g���ʂ̓w�͂ʼnB���ł�����x����
�����łȂ���ANetburst�Ńx���`�������ɓ����Ȃ�Ă��肦�Ȃ�����
Conroe�̂ق����ǂ��͓̂�����O�����ǁA�\�t�g���ʂ̓w�͂ʼnB���ł�����x����
�����łȂ���ANetburst�Ńx���`�������ɓ����Ȃ�Ă��肦�Ȃ�����
>>387
Netburst�̓N���b�N�̍���������������A
K8�ɂ��Ă݂��Netburst���N���b�N������̐��\��
������x�傫������K�v������B
Netburst�̓N���b�N�̍���������������A
K8�ɂ��Ă݂��Netburst���N���b�N������̐��\��
������x�傫������K�v������B
>>385
���ꂩ�E�E�E�@���̌�Alpha�́E�E�E�E
http://ascii24.com/news/i/hard/article/2003/04/01/642822-000.html
���ꂩ�E�E�E�@���̌�Alpha�́E�E�E�E
http://ascii24.com/news/i/hard/article/2003/04/01/642822-000.html
Transitive Emulator Ports Sparc/Solaris Apps to Linux on Xeon, Itanium
http://www.itjungle.com/breaking/bn062806-story02.html
http://www.itjungle.com/breaking/bn062806-story02.html
391 �FSocket774�F2006/07/07(��) 10:22:10 ID:p7XNEmG3
>>387-388
NetBurst��SIMD�͎��ۂ̂Ƃ���債�đ����Ȃ���ȁB
�����̓��j�b�g���N���b�N�̔��������128bit��2�N���b�N��������64bit��2�N���b�N��2����
�i���ʂƏ�ʂ�1�N���b�N�����炵���j
PenM��Athlon64��64bit�œ�����SIMD���j�b�g��2��B
Pen4�͎��N���b�N�����A�����̂����悻1.5�{���������Ă邪�ASIMD���j�b�g���x���ł̓X���[�v�b�g��0.75�{�ł����Ȃ��B
movaps/movapd/movdqa���g����Load/Store�̑ш悪���̂���������A����������ăg�[�^���̃X���[�v�b�g��
���邱�Ƃ��o����i�ꍇ������j�B������ɂ��Ă��ꂵ�����B
�{��ALU�̂ق��Ɍ����Ă�����ȁB�A�������������̊ԈႢ�����B
�A�������łǂꂾ���̃_�C�ʐςƓd�͂�����Ă��Ǝv���H
�t�ɃA�������������炱������SIMD�̃X���[�v�b�g���Ȃ�������ɂ���Ă��ʂ�����Ǝv���B
�p�b�N�h���������Ɋւ��ẮA������128�r�b�g�̔������j�b�g����
�������x87��X�J�����Z�ł͉����������g���Ȃ��̂�Athlon�D�ʁB
128�r�b�g�t���Ɏg���Ύ��N���b�N���̋��݂�L/S�ш��Pen4�D�ʁB
���̓_�ACore�}�C�N���A�[�L�e�N�`���́AMMX��x87�ł��\��Athlon�ɑR�ł��鐫�\���o���邾���̃��j�b�g���𓋍ڂ��Ă�B
�ނ�������A128bit�t���Ɏg���X���[�v�b�g�͔{�B
SPECint�ł̈��|�I�Ȑ�����ICC�̃I�[�g�x�N�g���C�Y�̌��ʂɂ����̂̉\���������B
�t�Ɍ����ƁAIntel C++��Vector C�Ȃǂ̎����x�N�g�����c�[�������g���A���̒��x�̃R�[�h�Ȃ疾���I�ɃR�[�h��
�L�q���Ȃ��Ă�SIMD�����Ă���邭�炢�A���\�������o�����߂̊J���҂̕��S�͌y���B
NetBurst��SIMD�͎��ۂ̂Ƃ���債�đ����Ȃ���ȁB
�����̓��j�b�g���N���b�N�̔��������128bit��2�N���b�N��������64bit��2�N���b�N��2����
�i���ʂƏ�ʂ�1�N���b�N�����炵���j
PenM��Athlon64��64bit�œ�����SIMD���j�b�g��2��B
Pen4�͎��N���b�N�����A�����̂����悻1.5�{���������Ă邪�ASIMD���j�b�g���x���ł̓X���[�v�b�g��0.75�{�ł����Ȃ��B
movaps/movapd/movdqa���g����Load/Store�̑ш悪���̂���������A����������ăg�[�^���̃X���[�v�b�g��
���邱�Ƃ��o����i�ꍇ������j�B������ɂ��Ă��ꂵ�����B
�{��ALU�̂ق��Ɍ����Ă�����ȁB�A�������������̊ԈႢ�����B
�A�������łǂꂾ���̃_�C�ʐςƓd�͂�����Ă��Ǝv���H
�t�ɃA�������������炱������SIMD�̃X���[�v�b�g���Ȃ�������ɂ���Ă��ʂ�����Ǝv���B
�p�b�N�h���������Ɋւ��ẮA������128�r�b�g�̔������j�b�g����
�������x87��X�J�����Z�ł͉����������g���Ȃ��̂�Athlon�D�ʁB
128�r�b�g�t���Ɏg���Ύ��N���b�N���̋��݂�L/S�ш��Pen4�D�ʁB
���̓_�ACore�}�C�N���A�[�L�e�N�`���́AMMX��x87�ł��\��Athlon�ɑR�ł��鐫�\���o���邾���̃��j�b�g���𓋍ڂ��Ă�B
�ނ�������A128bit�t���Ɏg���X���[�v�b�g�͔{�B
SPECint�ł̈��|�I�Ȑ�����ICC�̃I�[�g�x�N�g���C�Y�̌��ʂɂ����̂̉\���������B
�t�Ɍ����ƁAIntel C++��Vector C�Ȃǂ̎����x�N�g�����c�[�������g���A���̒��x�̃R�[�h�Ȃ疾���I�ɃR�[�h��
�L�q���Ȃ��Ă�SIMD�����Ă���邭�炢�A���\�������o�����߂̊J���҂̕��S�͌y���B
�ė��N��Hound�ɂȂ��Ă��債�����\����͊��҂ł��Ȃ����Ă̂��Ȃ�
4�R�A�Ȃ�ėv���
4�R�A�Ȃ�ėv���
�{���ɗ��N�̍����ł�Ȃ�f���������Ă��������낾���c
�͂āH
�͂āH
>>392
4�R�A�͕K�v����
8�R�A�͍��̊����Ƃ킩��Avista���悾��
����Dual CPU�g���Ă����Ȃ�����A�u2�R�A����˂������v���Č����Ă��̂Ɠ���
4�R�A�͕K�v����
8�R�A�͍��̊����Ƃ킩��Avista���悾��
����Dual CPU�g���Ă����Ȃ�����A�u2�R�A����˂������v���Č����Ă��̂Ɠ���
���͂ЂƂ܂�10�{������FPU��������16�R�A��CPU���~�����ł�
�p�r��3DCG�ł�
�p�r��3DCG�ł�
�f���A���R�AOp�g���Ă鉴���猾�킹���
������R�A�������Ă�����Ȃ��悤�ȋƖ��p�Ƃ��A�s�тȎ�Ȃ�Ƃ�����
�������ʂ̃p�\�R���p�r�ł�2�R�A�ł���
������Ɨp��PC�Ȃ�1�R�A�ŃC�i�t
������R�A�������Ă�����Ȃ��悤�ȋƖ��p�Ƃ��A�s�тȎ�Ȃ�Ƃ�����
�������ʂ̃p�\�R���p�r�ł�2�R�A�ł���
������Ɨp��PC�Ȃ�1�R�A�ŃC�i�t
>>397
��{�I�ɓ��ӁB
���lj�Ђɓ��������o�b�́A
�c�ƁE�����̓Z������������A
�����E�V�d�́A���͂����Ă��
�ɂȂ��Ă��܂��B
�ł��l�ł�3�R�A���炢�~�����B�Ȃ���d�����������̂ł�
��{�I�ɓ��ӁB
���lj�Ђɓ��������o�b�́A
�c�ƁE�����̓Z������������A
�����E�V�d�́A���͂����Ă��
�ɂȂ��Ă��܂��B
�ł��l�ł�3�R�A���炢�~�����B�Ȃ���d�����������̂ł�
�G���R�Ƃ��Q�[���Ƃ�����Ă݂����肾�ƁA4CPU�܂łȂ�g���Ă����\�t�g�͔�r�I����
8CPU�͊��S�Ƃ͌���Ȃ����ǁA�قږ��ʂ������B
�ꕔ�̃x���`��8CPU 100%�ɂȂ��������B
8CPU�͊��S�Ƃ͌���Ȃ����ǁA�قږ��ʂ������B
�ꕔ�̃x���`��8CPU 100%�ɂȂ��������B
>>396
�I�v�e�����̃\�P�b�g�Ŏg����Q�R�A��Cell���o��Ύ������������ȁB
�ł������R����RDRAM����HTT�Ή����v�邵�A�S�b�\���V�K�쐬���K�v���������B
�I�v�e�����̃\�P�b�g�Ŏg����Q�R�A��Cell���o��Ύ������������ȁB
�ł������R����RDRAM����HTT�Ή����v�邵�A�S�b�\���V�K�쐬���K�v���������B
>>400
�ǂ������Ƃ�����HTX�J�[�h�ł̒̕������������ȁB
�ǂ������Ƃ�����HTX�J�[�h�ł̒̕������������ȁB
>>398
3�R�A�Ƃ�����XBOX360CPU
3�R�A�Ƃ�����XBOX360CPU
403 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/08(�y) 01:45:42 ID:BFG5MP+c
Cell�̍������������̃X���[�v�b�g�Ȃ�ď��F�P���x�����ł���B
�������x�����߂Ȃ��Q�[����p�̐�
�������x�����߂Ȃ��Q�[����p�̐�
Cell�l�^��������ȷ��
405 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/08(�y) 02:39:13 ID:BFG5MP+c
���Ⴀ�AHound��Core2��L2��菬�������LL3�l�^�ĊJ
���W�b�N��H����������L2��128MB���炢�ς߂�����ˁI�H
���̖����������Ƃɂ��āI
�f���A���`�����l���������V�͂P�Q�W���������P�ʂŃA�N�Z�X���邱�Ƃ�
�Ȃ�Ǝv�����ǁA�L���b�V�����C���͂P�Q�W���������ɂȂ�́H
�Ȃ�Ǝv�����ǁA�L���b�V�����C���͂P�Q�W���������ɂȂ�́H
AMD�͊o���₷�����O�̃u�c�����ׂ���
410 �FSocket774�F2006/07/08(�y) 08:24:54 ID:2/H90wdM
���₢��AMD�́`ron�Ƃ����������[�����т��ׂ���
Athlon�A���������ْ[��
Athlon�A���������ْ[��
>>403
�ǂ��������\CPU�Ȃ�āA�Q�[�����炢�ɂ����g���ĂȂ����낤���B
�ǂ��������\CPU�Ȃ�āA�Q�[�����炢�ɂ����g���ĂȂ����낤���B
128byte = 1024bit!
413 �FSocket774�F2006/07/08(�y) 10:03:07 ID:cdm7YRMg
Conroe XE�@�@ 3.33GHz dual 4MB FSB1333MHz TDP 95W '06Q4 �@$1199 (Athlon64 X2 4.16GHz����)
Conroe E6900 3.20GHz dual 4MB FSB1066MHz TDP 65W '06Q4 �@$969�@(Athlon64 X2 4.00GHz����)
Conroe E6800 2.93GHz dual 4MB FSB1066MHz TDP 65W '06Q4 �@$749�@(Athlon64 X2 3.66GHz����)
Conroe E6700 2.67GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$529 �@(Athlon64 X2 3.34GHz����)
Athlon64 FX-64 3.00GHz dual �@1MBx2�@ TDP ???W AM2 '07Q1
Conroe E6600 2.40GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$309 �@(Athlon64 X2 3.00GHz����)
Conroe E6500 2.40GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$269 �@(Athlon64 X2 2.88GHz����)
Athlon64 FX-62 2.80GHz dual �@1MBx2�@ TDP 125W AM2 '06/6/6 $1236
Athlon64 5400+ 2.80GHz dual �@512KBx2 TDP ???W AM2 '07Q1
Athlon64 FX-60 2.60GHz dual �@1MBx2�@ TDP 110W 939 '06/1 �@�@$1031
Athlon64 5200+ 2.60GHz dual �@1MBx2�@ TDP�@89W AM2 '06Q3
Athlon64 5000+ 2.60GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $696
Conroe E6400 2.13GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$239 �@(Athlon64 X2 2.56GHz����)
Athlon64 4800+ 2.40GHz dual �@1MBx2�@ TDP�@89W AM2 '06/6/6 $645
Athlon64 4600+ 2.40GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $558
Conroe E6300 1.86GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$210 �@(Athlon64 X2 2.23GHz����)
Athlon64 4400+ 2.20GHz dual �@1MBx2�@�@TDP�@89W AM2 '06/6/6 $469
Athlon64 4200+ 2.20GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $365
Athlon64 3800+ 2.00GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $303
Conroe E6200 1.60GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$179 �@(Athlon64 X2 1.92GHz����)
Conroe E6100 1.33GHz dual 2MB FSB1066MHz TDP 35W '07Q1 �@$149 �@(Athlon64 X2 1.60GHz����)
Conroe E6900 3.20GHz dual 4MB FSB1066MHz TDP 65W '06Q4 �@$969�@(Athlon64 X2 4.00GHz����)
Conroe E6800 2.93GHz dual 4MB FSB1066MHz TDP 65W '06Q4 �@$749�@(Athlon64 X2 3.66GHz����)
Conroe E6700 2.67GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$529 �@(Athlon64 X2 3.34GHz����)
Athlon64 FX-64 3.00GHz dual �@1MBx2�@ TDP ???W AM2 '07Q1
Conroe E6600 2.40GHz dual 4MB FSB1066MHz TDP 65W '06Q3 �@$309 �@(Athlon64 X2 3.00GHz����)
Conroe E6500 2.40GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$269 �@(Athlon64 X2 2.88GHz����)
Athlon64 FX-62 2.80GHz dual �@1MBx2�@ TDP 125W AM2 '06/6/6 $1236
Athlon64 5400+ 2.80GHz dual �@512KBx2 TDP ???W AM2 '07Q1
Athlon64 FX-60 2.60GHz dual �@1MBx2�@ TDP 110W 939 '06/1 �@�@$1031
Athlon64 5200+ 2.60GHz dual �@1MBx2�@ TDP�@89W AM2 '06Q3
Athlon64 5000+ 2.60GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $696
Conroe E6400 2.13GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$239 �@(Athlon64 X2 2.56GHz����)
Athlon64 4800+ 2.40GHz dual �@1MBx2�@ TDP�@89W AM2 '06/6/6 $645
Athlon64 4600+ 2.40GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $558
Conroe E6300 1.86GHz dual 2MB FSB1066MHz TDP 65W '06Q3 �@$210 �@(Athlon64 X2 2.23GHz����)
Athlon64 4400+ 2.20GHz dual �@1MBx2�@�@TDP�@89W AM2 '06/6/6 $469
Athlon64 4200+ 2.20GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $365
Athlon64 3800+ 2.00GHz dual �@512KBx2 TDP�@89W AM2 '06/6/6 $303
Conroe E6200 1.60GHz dual 2MB FSB1066MHz TDP 65W '06Q4 �@$179 �@(Athlon64 X2 1.92GHz����)
Conroe E6100 1.33GHz dual 2MB FSB1066MHz TDP 35W '07Q1 �@$149 �@(Athlon64 X2 1.60GHz����)
>>406
���̓��W�b�N��H�͍���k�������Ǝv���Ă�B�������œ����A���M�ʏ������ȑf�ȃR�A
�łˁB���Anti-HT��HTT���������������̂ł͂Ȃ����ƁB��ŁA������L1,L2�ƃf�J�C
L3(���\M)�A�����8�R�A�ʂɂȂ��Ȃ����ȂƎv���B�ܘ_OS����Anti-HT�g��������
�\�͂̍����R�A��HTT�g���������\�͂̒Ⴂ�R�A�ʂł��Ȃ��Ƃ����Ȃ����B
�����}���`�R�A���ɍs���l�܂����炻�����̕����ɐi�ނ�Ȃ����ȁH
���̓��W�b�N��H�͍���k�������Ǝv���Ă�B�������œ����A���M�ʏ������ȑf�ȃR�A
�łˁB���Anti-HT��HTT���������������̂ł͂Ȃ����ƁB��ŁA������L1,L2�ƃf�J�C
L3(���\M)�A�����8�R�A�ʂɂȂ��Ȃ����ȂƎv���B�ܘ_OS����Anti-HT�g��������
�\�͂̍����R�A��HTT�g���������\�͂̒Ⴂ�R�A�ʂł��Ȃ��Ƃ����Ȃ����B
�����}���`�R�A���ɍs���l�܂����炻�����̕����ɐi�ނ�Ȃ����ȁH
�W�����������������~�W���������~�Q�����łP�Q�W��������
ttp://www.elpida.com/pdfs/J0876E20.pdf
�o�[�X�g���S(�o�[�X�g�`���b�v)�Ƃ����̂��g����
�U�S���������ŃA�N�Z�X�ł���́H
���O���炷��ƘA���łW�̃f�[�^������̂�
�Ԃ������Ă�Ǝv�����ǁA���\�͗ǂ��́H
ttp://www.elpida.com/pdfs/J0876E20.pdf
�o�[�X�g���S(�o�[�X�g�`���b�v)�Ƃ����̂��g����
�U�S���������ŃA�N�Z�X�ł���́H
���O���炷��ƘA���łW�̃f�[�^������̂�
�Ԃ������Ă�Ǝv�����ǁA���\�͗ǂ��́H
���W�b�N��H����������Itanium2�ݾ�
���͖w�ǒP���x�ōςނ�
�{���x�ɂ���������̑����������ĊF�����Ă�́H
�{���x�ɂ���������̑����������ĊF�����Ă�́H
�^�ʖڂȐ��l�v�Z�e�킢�낢��H
�ŏI�I�ȗL�������́A�����Ă��̏ꍇ�P���x�ł��\����͈͓�����
�v�����ǁA���������_���Z�̏ꍇ�A�v�Z�r���ŁA�L���������ǂ���
���邱�Ƃ����邩��A���S���ɐU��Ɣ{���x�ɂȂ��˂��H
�C��������Đ^�ʖڂɏ����ΒP���x�ł��ςނ��Ƃ������Ǝv�����ǁA
���Ȃ�ʓ|����Ȃ����Ȃ��B
���ƁACell�͔{���x�ł��������������炵����B
ttp://slashdot.jp/comments.pl?sid=322480&cid=969082
���������̌��ʌ����IA64�g���Ӗ��Ȃ��˂��B
AMD64�̕����������}�V�B
�ŏI�I�ȗL�������́A�����Ă��̏ꍇ�P���x�ł��\����͈͓�����
�v�����ǁA���������_���Z�̏ꍇ�A�v�Z�r���ŁA�L���������ǂ���
���邱�Ƃ����邩��A���S���ɐU��Ɣ{���x�ɂȂ��˂��H
�C��������Đ^�ʖڂɏ����ΒP���x�ł��ςނ��Ƃ������Ǝv�����ǁA
���Ȃ�ʓ|����Ȃ����Ȃ��B
���ƁACell�͔{���x�ł��������������炵����B
ttp://slashdot.jp/comments.pl?sid=322480&cid=969082
���������̌��ʌ����IA64�g���Ӗ��Ȃ��˂��B
AMD64�̕����������}�V�B
�P�D���H�傪TSUBAME�����J
7��4����@IT�ɐ�����C�������̒k�b�Ƃ��āC�u�\�z��20���~�A�d�C���T�|�[�g�G���W�j�A��p
�Ȃǂ̉^�c��ɔN��3���~�|�����Ă���B���D�Ŋe�Ђ��撣���Ă��ꂽ�̂ŁA�{���ł���ƂĂ�
���̒l�i�ō\�z�ł���V�X�e���ł͂Ȃ��B�v�Ə�����Ă��܂����C��ʂɒl�������傫����w���k
�Ƃ��Ă�����̔��l�ȉ��̊����ŁC���������_���s���O����邩��C�X�p�R���ׂ͖���Ȃ��C�ׂ����
������J����o�Ȃ��C�]���āC�J���G���W�j�A�����炳��ē��H��̑��Ɛ����̗p�ł��Ȃ��Ƃ���
���z�Ɋׂ��Ă��܂��܂��B��w�̐搶���C�l���āC������������������Ζ��C���Ƃ͂ǂ��Ȃ�
�Ă��\��Ȃ��Ƃ����Z���X�ł͍��������̂ł��B
7��4����@IT�ɐ�����C�������̒k�b�Ƃ��āC�u�\�z��20���~�A�d�C���T�|�[�g�G���W�j�A��p
�Ȃǂ̉^�c��ɔN��3���~�|�����Ă���B���D�Ŋe�Ђ��撣���Ă��ꂽ�̂ŁA�{���ł���ƂĂ�
���̒l�i�ō\�z�ł���V�X�e���ł͂Ȃ��B�v�Ə�����Ă��܂����C��ʂɒl�������傫����w���k
�Ƃ��Ă�����̔��l�ȉ��̊����ŁC���������_���s���O����邩��C�X�p�R���ׂ͖���Ȃ��C�ׂ����
������J����o�Ȃ��C�]���āC�J���G���W�j�A�����炳��ē��H��̑��Ɛ����̗p�ł��Ȃ��Ƃ���
���z�Ɋׂ��Ă��܂��܂��B��w�̐搶���C�l���āC������������������Ζ��C���Ƃ͂ǂ��Ȃ�
�Ă��\��Ȃ��Ƃ����Z���X�ł͍��������̂ł��B
�R�s�y����Ȃ���p�����炢������
>>418
CAD�Ȃ��ʂɗv��
���x��0.001�~���i�����_�ȉ�3���j���x�͕��ʂ����A
�v������̂̃T�C�Y��1���[�g���ȏ�Ȃ珬���_�ȏ��4���K�v
�Œ�ł�7���̐��x���v�邯�ǁA�P���x��6�������Ȃ�
CAD�Ȃ��ʂɗv��
���x��0.001�~���i�����_�ȉ�3���j���x�͕��ʂ����A
�v������̂̃T�C�Y��1���[�g���ȏ�Ȃ珬���_�ȏ��4���K�v
�Œ�ł�7���̐��x���v�邯�ǁA�P���x��6�������Ȃ�
>>419�̃����N��̃����N��̃o�[�N���[�̘_���ɂ���Op248�Ŏ���
�v���Z�b�T���������ĂȂ����A�����Ă��鐔�l���炷���1CPU�ł̒l���ۂ��B
K8L�N�A�b�h�R�AOp�Ƃ��ɂȂ�ƁA�{���x�ł̓x�N�^�Ƃ�Cell�Ƃ���Ȃ�ɐ킦�������Ȃ����B
x86�n��CPU�������܂Ő킦����[���Ƃɂ��������E�E�E
�v���Z�b�T���������ĂȂ����A�����Ă��鐔�l���炷���1CPU�ł̒l���ۂ��B
K8L�N�A�b�h�R�AOp�Ƃ��ɂȂ�ƁA�{���x�ł̓x�N�^�Ƃ�Cell�Ƃ���Ȃ�ɐ킦�������Ȃ����B
x86�n��CPU�������܂Ő킦����[���Ƃɂ��������E�E�E
�ł�Cell���A���s�̔ėpPowerPC�̕�������
>>422
CAD�Ŏg���Ă郆�[�U�[���A�ʂ����Ăǂꂾ������̂��B
�P���x�ŊԂɍ������[�U�[>>�������������������������������{���x���K�{�ȃ��[�U�[
IA32��CPU�������̔�IA32�ȑ�CPU���쒀���Ă��������j������A�P���Ȑ��
���\�����s��ł̏��s�����߂Ȃ��̂́A��ڗđR�ł��B
>>424
���̔ėp��PowerPC���o�b�p�ɃG���n���X���Ă���Ȃ��Ȃ�������AMAC��Intel
�ɈƑւ��������B
CAD�Ŏg���Ă郆�[�U�[���A�ʂ����Ăǂꂾ������̂��B
�P���x�ŊԂɍ������[�U�[>>�������������������������������{���x���K�{�ȃ��[�U�[
IA32��CPU�������̔�IA32�ȑ�CPU���쒀���Ă��������j������A�P���Ȑ��
���\�����s��ł̏��s�����߂Ȃ��̂́A��ڗđR�ł��B
>>424
���̔ėp��PowerPC���o�b�p�ɃG���n���X���Ă���Ȃ��Ȃ�������AMAC��Intel
�ɈƑւ��������B
�������H
�ނ��뉴�I�ɂ́A�Q�[���Ƃ��̕s�^�ʖځi�Ƃ����̂́A���炩������j��
����ȊO���Ⴀ�A���������_�����{���x�Ƃ����F���Ȃ�
�����g�A�Z�p�n�ƋƖ��n�̌o�������Ȃ���ł��ꂾ��
�Ԃ����Ⴏ�P���x���d���Ŏg�������Ƃ͈�x���Ȃ���
�ނ��뉴�I�ɂ́A�Q�[���Ƃ��̕s�^�ʖځi�Ƃ����̂́A���炩������j��
����ȊO���Ⴀ�A���������_�����{���x�Ƃ����F���Ȃ�
�����g�A�Z�p�n�ƋƖ��n�̌o�������Ȃ���ł��ꂾ��
�Ԃ����Ⴏ�P���x���d���Ŏg�������Ƃ͈�x���Ȃ���
���ʕ��������_�Ƃ�������{���x
�P���x�̓O���t�B�N�X�Ƃ���"�g���̂ď���" ��p���Ǝv���Ă�
�P���x�̓O���t�B�N�X�Ƃ���"�g���̂ď���" ��p���Ǝv���Ă�
GK��
AMD����ĂȂ������ł���
431 �FSocket774�F2006/07/10(��) 22:21:57 ID:uNADgyCx
�덷���ݐς���悤�Ȍv�Z�͔{���x����Ȃ��Ǝ��p�ɂȂ�Ȃ���B
�d�C�ł����̂ł��V�~�����[�V�������Ȃ�K���{���x�B
�d�C�ł����̂ł��V�~�����[�V�������Ȃ�K���{���x�B
Reverse Hyperthreading does not exist
http://www.theinquirer.net/default.aspx?article=32885
����σK�Z���������ۂ��ˁB
http://www.theinquirer.net/default.aspx?article=32885
����σK�Z���������ۂ��ˁB
433 �F ��DanGorION6 �F2006/07/11(��) 00:52:25 ID:VBEAkFC2
>>419
PPE�̓t���Z�b�g��PowerPC�����炻���FPU���ڂ��Ă邵�A
SPE�ł̓\�t�g����������K�v�����邪�A����ł�7�R�A�����邩��
�N���b�N���~�R�A���̗͋Z�ł���Ȃ�̐��\�͏o���Ă�݂���������
��
http://www.cs.berkeley.edu/~samw/projects/cell/CF06.pdf
Core2�̓p�b�N�h�{���x�𗘗p���邱�ƂłP�R�A������4DP/clock�̉��Z���\�B
���ꂪ�N���ɂ�4�R�A���ڂŁA���v16DP/clock�ɒB����B
2.66GHz�Ȃ�42GFlops����B�i�P���x�Ȃ炻�̔{�j
�Ȃ�ɂ���Cell�͐�p�̃R�A�v�����Ă��܂����̋���_�C�B���M�����Ȃ�̂��̂炵����
�����ߋ�̈���o�܂����B
��������ɂ��Ă�Itanium�͗v��Ȃ��q�ɂȂ��Ă��܂��ˁB
PPE�̓t���Z�b�g��PowerPC�����炻���FPU���ڂ��Ă邵�A
SPE�ł̓\�t�g����������K�v�����邪�A����ł�7�R�A�����邩��
�N���b�N���~�R�A���̗͋Z�ł���Ȃ�̐��\�͏o���Ă�݂���������
��
http://www.cs.berkeley.edu/~samw/projects/cell/CF06.pdf
Core2�̓p�b�N�h�{���x�𗘗p���邱�ƂłP�R�A������4DP/clock�̉��Z���\�B
���ꂪ�N���ɂ�4�R�A���ڂŁA���v16DP/clock�ɒB����B
2.66GHz�Ȃ�42GFlops����B�i�P���x�Ȃ炻�̔{�j
�Ȃ�ɂ���Cell�͐�p�̃R�A�v�����Ă��܂����̋���_�C�B���M�����Ȃ�̂��̂炵����
�����ߋ�̈���o�܂����B
��������ɂ��Ă�Itanium�͗v��Ȃ��q�ɂȂ��Ă��܂��ˁB
435 �F ��DanGorION6 �F2006/07/11(��) 01:17:45 ID:VBEAkFC2
>>434
�{���x�̘b�����Ă���ǁB�P���x�Ȃ�P���ɂ���2�{�ł����B
AltiVec�ł��{���x���T�|�[�g���ꂽ��ł����H�i�E�́E�j
�{���x�̘b�����Ă���ǁB�P���x�Ȃ�P���ɂ���2�{�ł����B
AltiVec�ł��{���x���T�|�[�g���ꂽ��ł����H�i�E�́E�j
AltiVec����
AltiVec�̐��\���Ă��A�ǂ����Ϙa(vA * vB + vC)���Z������
1�I�y���[�V�����łł��邩��2�~4��8SP/clock�Ƃ������Ă��B
���l��Cell��SPE�����낤���ǁB
��-����a-�ςȂ͂������2�I�y���[�V����������B
8SP���Ǝv���Ă���K�b�J�����邱�ƂɂȂ邾�낤�B
Core2�͒P���x�~�Sor�{���x�~�Q�̉����Z���j�b�g�ƐώZ���j�b�g��
���ꂼ��P��������A�ρ{�a�͂������ρ{���ł��A����ɂ͒P���x�̉��Z��
�{���x�̐ώZ�ł��A�����ɕ�����s�ł���B
AMD��K8L�ł���ɒǏ]����`���B
�Q�[���@�Ƃ��Ă��ґ�Ȑ����A�R���s���[�^�Ƃ��Ă݂�ACell�͌����Ă�قǍ����\����Ȃ��B
���ϐ��\���J�^���O�X�y�b�N��20����1�Ƃ���SCE�̓`���������ɖ������ȁB
1�I�y���[�V�����łł��邩��2�~4��8SP/clock�Ƃ������Ă��B
���l��Cell��SPE�����낤���ǁB
��-����a-�ςȂ͂������2�I�y���[�V����������B
8SP���Ǝv���Ă���K�b�J�����邱�ƂɂȂ邾�낤�B
Core2�͒P���x�~�Sor�{���x�~�Q�̉����Z���j�b�g�ƐώZ���j�b�g��
���ꂼ��P��������A�ρ{�a�͂������ρ{���ł��A����ɂ͒P���x�̉��Z��
�{���x�̐ώZ�ł��A�����ɕ�����s�ł���B
AMD��K8L�ł���ɒǏ]����`���B
�Q�[���@�Ƃ��Ă��ґ�Ȑ����A�R���s���[�^�Ƃ��Ă݂�ACell�͌����Ă�قǍ����\����Ȃ��B
���ϐ��\���J�^���O�X�y�b�N��20����1�Ƃ���SCE�̓`���������ɖ������ȁB
DSP �� CPU �̒��Ԃ��Ǝv���Ζʔ����Ȃ�Ȃ���?
>>438
�ʔ������ĈӖ�����A����ȏ�Ȃ�����Ȃ����ˁB
�����̎�Œ@���̂ɂ͂����Ǝv���B
�����A����ς�{���xFP���\������������Ƃ����
���������Ȃ��B
�ʔ������ĈӖ�����A����ȏ�Ȃ�����Ȃ����ˁB
�����̎�Œ@���̂ɂ͂����Ǝv���B
�����A����ς�{���xFP���\������������Ƃ����
���������Ȃ��B
GK�̋Y���Ȃ����K�v�Ȃ���B
Core2 Duo�Ƃ�CPU�A�[�L�e�N�`���X���ɂ�Cell�~���N���Ă����ȁB
Core2 Duo�Ƃ�CPU�A�[�L�e�N�`���X���ɂ�Cell�~���N���Ă����ȁB
PS2��CPU�����āA�֘a���Z��}�g���b�N�X���Z������
���낵���X���[�v�b�g���ւ��Ă����ł͂Ȃ����B
�����ɂ�(ry
���낵���X���[�v�b�g���ւ��Ă����ł͂Ȃ����B
�����ɂ�(ry
442 �F ��DanGorION6 �F2006/07/12(��) 00:18:15 ID:RKN7RHkO
���[�U�[�v���O���~���O�̗]�n�������Ƃ��邩�ǂ����ŕ]���͕����ꂻ���ȋC���B
PS3���p�\�R�������Č�������Ȃ�AMS�I�t�B�X�������Ƃ͌���Ȃ����ǁAGNOME�Ȃ�KDE�Ȃ肪
���p�I�ȑ��x�œ����͍̂Œ������ȁB
PPE�͂Ƃ�����SPE�͔{���x�̓n�[�h�ŃT�|�[�g���ĂȂ�����A�p�b�N�h��������g����
�\�t�g�I�ɏ������Ȃ��Ǝg���܂��B
���߃X�P�W���[�����O�Ƃ��ō����܂�鎖�ԈႢ�Ȃ��B
PS3���p�\�R�������Č�������Ȃ�AMS�I�t�B�X�������Ƃ͌���Ȃ����ǁAGNOME�Ȃ�KDE�Ȃ肪
���p�I�ȑ��x�œ����͍̂Œ������ȁB
PPE�͂Ƃ�����SPE�͔{���x�̓n�[�h�ŃT�|�[�g���ĂȂ�����A�p�b�N�h��������g����
�\�t�g�I�ɏ������Ȃ��Ǝg���܂��B
���߃X�P�W���[�����O�Ƃ��ō����܂�鎖�ԈႢ�Ȃ��B
Cell��������������Ȃ����Ă킩�肫���Ă�����A���O��X���[�����
����t�@�r������������A���X�ǂ����������Ȃ�ăA�t�H����
����t�@�r������������A���X�ǂ����������Ȃ�ăA�t�H����
�v���Ԃ�ɔ`���Ă݂��牽��Cell�̘b�ɂȂ��Ă�́H
Apple�ɂ����ꂸ�O�̂̌����݂���Ȃ��ASony�{�̂�����ʖڏo������Ă�o�����Ȃ��B
Apple�ɂ����ꂸ�O�̂̌����݂���Ȃ��ASony�{�̂�����ʖڏo������Ă�o�����Ȃ��B
�{���x�{���x�����ɂ�ɂ����邳����
>>428 >>431
���x���v�������v�Z�͔{���x�ł�����Ȃ��B
�{�i�I�ɃV�~�����[�V��������Ȃ�128bit�ȏ�g���ł���B
�t�ɗ]�萸�x���v������Ȃ��Ȃ�P���x�ő�T�Ԃɍ����B
���x���v�������v�Z�͔{���x�ł�����Ȃ��B
�{�i�I�ɃV�~�����[�V��������Ȃ�128bit�ȏ�g���ł���B
�t�ɗ]�萸�x���v������Ȃ��Ȃ�P���x�ő�T�Ԃɍ����B
���ō��ɃA�z
�p�b�N�h�{���x�u���߁v�Ȃ炠�邪���ڎ��s�ł���u���j�b�g�v�͂Ȃ��B
�}�C�N���R�[�h�����ŁA�����̐������Z�̑g�ݍ��킹�Ŏ��s�����B
�t�Ƀ\�t�g�ł�邩�炱��IEEE754�K��̐��x�ɏ]�����Ƃ��ł���B
���O�Ń\�t�g�������Ȃ��Ǝg���Ȃ��Ƃ����̂͌�肾���A�s�x�\�t�g��
�������Ă�����ق�����������������ȁB
�P���x�̂ق��͐��x�͓x�O���BIEEE�̃t�H�[�}�b�g���23bit��
�����������邪�A������̐��x��15bit���x�B
���̂ւ��SSE�ł������B
�p�b�N�h�{���x�u���߁v�Ȃ炠�邪���ڎ��s�ł���u���j�b�g�v�͂Ȃ��B
�}�C�N���R�[�h�����ŁA�����̐������Z�̑g�ݍ��킹�Ŏ��s�����B
�t�Ƀ\�t�g�ł�邩�炱��IEEE754�K��̐��x�ɏ]�����Ƃ��ł���B
���O�Ń\�t�g�������Ȃ��Ǝg���Ȃ��Ƃ����̂͌�肾���A�s�x�\�t�g��
�������Ă�����ق�����������������ȁB
�P���x�̂ق��͐��x�͓x�O���BIEEE�̃t�H�[�}�b�g���23bit��
�����������邪�A������̐��x��15bit���x�B
���̂ւ��SSE�ł������B
>>447�͖{���ɱ��Ȃ�
�܂������W�Ȃ�����
�A���`�\�j�[�̗�����Đ������
���i���ƂɑP�������L�邾�낤��
�A���`�\�j�[�̗�����Đ������
���i���ƂɑP�������L�邾�낤��
���́u�����v��\��Cell
�A���`Cell�Ȃ�A���`IBM�ɗ��ꂻ�������ǁc
��̊�Ƃ�IBM���_�Ă�̂��ASony�ɖ@���������Ȃ̂����f�����˂邪
��̊�Ƃ�IBM���_�Ă�̂��ASony�ɖ@���������Ȃ̂����f�����˂邪
���㓡�O��Weekly�C�O�j���[�X��
�R�v���Z�b�T�̎�����J���AAMD�́uTorrenza�v�C�j�V�A�`�u
ttp://pc.watch.impress.co.jp/docs/2006/0713/kaigai287.htm
AMD�̓R�A�̊J�����R�v���x���_���͂����ސ헪�ł����悤�ł�
�ǂ����݂����ɔ������J��Ԃ�����Ȃ�ł��傤��
�l�I�ɂ�PC�N���X�^�p�Ƀl�b�g���[�N�J�[�h��HTX�ɑ}���ăV�X�e���o�X�ɗ������߂��粲��
�R�v���Z�b�T�̎�����J���AAMD�́uTorrenza�v�C�j�V�A�`�u
ttp://pc.watch.impress.co.jp/docs/2006/0713/kaigai287.htm
AMD�̓R�A�̊J�����R�v���x���_���͂����ސ헪�ł����悤�ł�
�ǂ����݂����ɔ������J��Ԃ�����Ȃ�ł��傤��
�l�I�ɂ�PC�N���X�^�p�Ƀl�b�g���[�N�J�[�h��HTX�ɑ}���ăV�X�e���o�X�ɗ������߂��粲��
>>453
���̂��߂�infiniband�J�[�h�ƈꏏ�ɏo�Ă����̂�HTX��������B
���̂��߂�infiniband�J�[�h�ƈꏏ�ɏo�Ă����̂�HTX��������B
�ŋ߃G���R�������̂ŁA�G���R�p�R�v��������Ȃ��`
����ȊO�͂b�o�t���ׂقƂ�ǂȂ��̂��Ӗ��Ȃ�������
����ȊO�͂b�o�t���ׂقƂ�ǂȂ��̂��Ӗ��Ȃ�������
>>448
EE�Ɗ��Ⴂ���Ă邾��B
http://www.realworldtech.com/page.cfm?ArticleID=RWT021005084318&p=4
>Unlike the Emotion Engine, the SPE contains a double precision (DP) unit.
EE�Ɗ��Ⴂ���Ă邾��B
http://www.realworldtech.com/page.cfm?ArticleID=RWT021005084318&p=4
>Unlike the Emotion Engine, the SPE contains a double precision (DP) unit.
>>442 >>448
�ǂ����炻�̎��M�����Ղ�̔����������Ă���̂��\�[�X���~�����Ƃ���ł��ȁB
http://www.cs.berkeley.edu/~samw/projects/cell/CF06.pdf
���̕ӂ̘_�����������Cell�͔{���x�ł����������̑��x���o��悤�����ǁB
�ǂ����炻�̎��M�����Ղ�̔����������Ă���̂��\�[�X���~�����Ƃ���ł��ȁB
http://www.cs.berkeley.edu/~samw/projects/cell/CF06.pdf
���̕ӂ̘_�����������Cell�͔{���x�ł����������̑��x���o��悤�����ǁB
��n�OGK�̘A����
�u���������̐��\�v���Ă̂�8�R�A�iPS3�ł͎���7�R�A�j���ł��낗����
�v14.63GFlops�i�s�[�N���\�j���Ƃ�����Kentsfield���o���܂ł��Ȃ�
Conroe�̃��[�G���h�ɂ��������ȁB
�����������̒ᑬ��DP���j�b�g���ǂ�ȍ\���ɂȂ��Ă�̂��������Ă݂Ă���悗����
�����̔��e�����Ă邺�B
������ɂ��Ă��AKentsfield�Ɠ������ɏo���2004�N�̃V���O���R�A�A�[�L�e�N�`����
����ɔ�ׂĂ��Ӗ��̖����������B
PC�ɂ̓x�N�g�����E�p�����������ɂ������������d�v�ł�����
GPU�ɂł���点�Ă�������FP���\�i����������R�A�̍��v�l�j��
�I�i���Ă��Ӗ��Ȃ��B
�Ȃ�ɂ���A�n�ɑ��̂��ĂȂ��V�v��CPU���o���Ă��A�}�V�����Ƃ�
�V���ɃR�[�h�����������̂�������O�̃Q�[���Ȃ�Ƃ������A�����R�[�h
���Y�ł̃p�t�H�[�}���X���d������PC��T�[�o�s��Ŏ������R�͖���㩁B
�������Q�[���ł��炽������800MHz���x�̒ᑬCPU�ς}�V���ɂ��炵������
�\�ꂽ���Ȃ�C�������킩��Ȃ��ł��Ȃ����APC�̃R�v���Z�b�T�Ƃ��ė��p�Ƃ�
���H�ł����o���Ȃ�����A���̔I�ɂ͗v��Ȃ��q���ˁB
�u���������̐��\�v���Ă̂�8�R�A�iPS3�ł͎���7�R�A�j���ł��낗����
�v14.63GFlops�i�s�[�N���\�j���Ƃ�����Kentsfield���o���܂ł��Ȃ�
Conroe�̃��[�G���h�ɂ��������ȁB
�����������̒ᑬ��DP���j�b�g���ǂ�ȍ\���ɂȂ��Ă�̂��������Ă݂Ă���悗����
�����̔��e�����Ă邺�B
������ɂ��Ă��AKentsfield�Ɠ������ɏo���2004�N�̃V���O���R�A�A�[�L�e�N�`����
����ɔ�ׂĂ��Ӗ��̖����������B
PC�ɂ̓x�N�g�����E�p�����������ɂ������������d�v�ł�����
GPU�ɂł���点�Ă�������FP���\�i����������R�A�̍��v�l�j��
�I�i���Ă��Ӗ��Ȃ��B
�Ȃ�ɂ���A�n�ɑ��̂��ĂȂ��V�v��CPU���o���Ă��A�}�V�����Ƃ�
�V���ɃR�[�h�����������̂�������O�̃Q�[���Ȃ�Ƃ������A�����R�[�h
���Y�ł̃p�t�H�[�}���X���d������PC��T�[�o�s��Ŏ������R�͖���㩁B
�������Q�[���ł��炽������800MHz���x�̒ᑬCPU�ς}�V���ɂ��炵������
�\�ꂽ���Ȃ�C�������킩��Ȃ��ł��Ȃ����APC�̃R�v���Z�b�T�Ƃ��ė��p�Ƃ�
���H�ł����o���Ȃ�����A���̔I�ɂ͗v��Ȃ��q���ˁB
Conroe��2.4GHz�̔{���x����19.2GFlops���B
Pentium XE 965�i3.73GHz�j����14.93GFlops�ˁB
Cell�̔{���x���Z�̎d�g�݂͒m�肽���ȁB
Pentium XE 965�i3.73GHz�j����14.93GFlops�ˁB
Cell�̔{���x���Z�̎d�g�݂͒m�肽���ȁB
>>457
�P���x���j�b�g������A�P���x�v�Z�𐔉�J��Ԃ����ƂŔ{���x�v�Z�͉\���B
���Ă������A���͂����ł͂Ȃ��B
Cell�ɂ�SPE����32bit�̒P���x���j�b�g��4���ڂ���Ă͂��邪�A
64bit�̕��������_���Z��1�T�C�N���Ŏ��s�\�ȁu�{���x���j�b�g�v�͎�������Ă��Ȃ��̂���I
�{���x���j�b�g������A2���j�b�g*8�R�A*3.2GHz = 51.2GFLOPS�����_��\�ȃn�Y���B
�P���x���j�b�g������A�P���x�v�Z�𐔉�J��Ԃ����ƂŔ{���x�v�Z�͉\���B
���Ă������A���͂����ł͂Ȃ��B
Cell�ɂ�SPE����32bit�̒P���x���j�b�g��4���ڂ���Ă͂��邪�A
64bit�̕��������_���Z��1�T�C�N���Ŏ��s�\�ȁu�{���x���j�b�g�v�͎�������Ă��Ȃ��̂���I
�{���x���j�b�g������A2���j�b�g*8�R�A*3.2GHz = 51.2GFLOPS�����_��\�ȃn�Y���B
>>460
�P���x����Ŕ{���x���đ��������Ȃ��H
�܂Ƃ��ɔ{���x���ӎ������n�[�h�łȂ���
14.63GFlops�Ƃ����疳�����Ǝv�����ǁB
�P���x����Ŕ{���x���đ��������Ȃ��H
�܂Ƃ��ɔ{���x���ӎ������n�[�h�łȂ���
14.63GFlops�Ƃ����疳�����Ǝv�����ǁB
>>461
������/���T�C�N������HW�T�|�[�g�����ƃL�c�C��ŁE�E�E
Cell����SP�ŗ��_�l200GLOPS���炢�ŁADP�ɂȂ��7%���炢�Ɍ��������Ă邩��
�Ƃ肠����HW�ŗL���Ȕ{���x�T�|�[�g�������Ă�Ƃ͎v���Ȃ��Ȃ�
�{���x�T�|�[�g���Ă�Ȃ�50��100GFLOPS�����Ă��������Ȃ�
������/���T�C�N������HW�T�|�[�g�����ƃL�c�C��ŁE�E�E
Cell����SP�ŗ��_�l200GLOPS���炢�ŁADP�ɂȂ��7%���炢�Ɍ��������Ă邩��
�Ƃ肠����HW�ŗL���Ȕ{���x�T�|�[�g�������Ă�Ƃ͎v���Ȃ��Ȃ�
�{���x�T�|�[�g���Ă�Ȃ�50��100GFLOPS�����Ă��������Ȃ�
ttp://www.theinquirer.net/default.aspx?article=32978
>PS3 Cell yields are in the toilet
�Q�[���@�͂���PC�x�[�X�ɂ���Ηǂ���E�E�E
�d�l��OS����Microsoft�������
�n�[�h�͂�������������āB
MSX�����B
>PS3 Cell yields are in the toilet
�Q�[���@�͂���PC�x�[�X�ɂ���Ηǂ���E�E�E
�d�l��OS����Microsoft�������
�n�[�h�͂�������������āB
MSX�����B
�R�v��
HW�T�|�[�g��IEEE�{���x���������`���ƕ����̃p�b�N�h����/�P���x�Ƃ�
���ݕϊ���������Ȃ�Ƃ��Ȃ��K�X�B
�ǂ݂̂��{���x�֘A�̖��߂͒P���x�Ƃ̕ϊ��ȊO�͉����Z�ƐώZ�E�Ϙa�Z�����Ȃ��̂ŁA
����Ȃ����̂̓\�t�g������������㩁B
���A�ǂ����s�[�N���\����������Z�̐��\����B
��������32bit�����~2�~2�ɓW�J
��
�w���̑召��r
��
�������ق��̉��������������V�t�g
��
���ʂɐ�����(or��)�Z
��
���グ�ior�����j�̉��������������`���ւ̃p�b�L���O
����ʼn��̔]���ł�2DP/4clk���x�̃X���[�v�b�g�Ɏ��܂�Ǝv���Ă��
��Z�͕�����̐Ϙa�Z���K�v�ɂȂ�ȁB���53bit�������܂�����̂�
���������e�L�g�[�ł����C�����邪�ȁB
���ݕϊ���������Ȃ�Ƃ��Ȃ��K�X�B
�ǂ݂̂��{���x�֘A�̖��߂͒P���x�Ƃ̕ϊ��ȊO�͉����Z�ƐώZ�E�Ϙa�Z�����Ȃ��̂ŁA
����Ȃ����̂̓\�t�g������������㩁B
���A�ǂ����s�[�N���\����������Z�̐��\����B
��������32bit�����~2�~2�ɓW�J
��
�w���̑召��r
��
�������ق��̉��������������V�t�g
��
���ʂɐ�����(or��)�Z
��
���グ�ior�����j�̉��������������`���ւ̃p�b�L���O
����ʼn��̔]���ł�2DP/4clk���x�̃X���[�v�b�g�Ɏ��܂�Ǝv���Ă��
��Z�͕�����̐Ϙa�Z���K�v�ɂȂ�ȁB���53bit�������܂�����̂�
���������e�L�g�[�ł����C�����邪�ȁB
ttp://japan.cnet.com/news/ent/story/0,2000056022,20170387-2,00.htm
65nm�͍��N���ɏo�ׂ����݂������ȁB
������"AMD will start to ship chips"�����B
������������N���ɂ͏H�t�Ŏ�ɓ��邩���H
����45nm���t�Z���Ă̂͏��߂Ă̏��̂悤�ȁB
SRAM�����삵�����Ă����̂͂��łɏo�Ă������B
Intel�̓h���C�I�������ǁA�R�X�g�I�ɂ͂���ωt�Z�̕��������낤�Ȃ��B
"���א��͂��łɃh���C�I���Ɠ����x��"��ASML�͌����Ă��肷�邩������܂�͎����I�ɂ����ɂȂ肻���ɂ͂Ȃ����B
65nm�͍��N���ɏo�ׂ����݂������ȁB
������"AMD will start to ship chips"�����B
������������N���ɂ͏H�t�Ŏ�ɓ��邩���H
����45nm���t�Z���Ă̂͏��߂Ă̏��̂悤�ȁB
SRAM�����삵�����Ă����̂͂��łɏo�Ă������B
Intel�̓h���C�I�������ǁA�R�X�g�I�ɂ͂���ωt�Z�̕��������낤�Ȃ��B
"���א��͂��łɃh���C�I���Ɠ����x��"��ASML�͌����Ă��肷�邩������܂�͎����I�ɂ����ɂȂ肻���ɂ͂Ȃ����B
>>461
�ꔲ���̃A�z��������Ȃ��B
�����Ȃ�Ƃ������A���������_���̏ꍇ�A
�����������Čv�Z�Ȃ�Ăł���킯�˂����[�́B
packed�������ĉ��̂��Ƃ����m�炸�Ɍ����Ă�z�͋~���������A�z�B
�ꔲ���̃A�z��������Ȃ��B
�����Ȃ�Ƃ������A���������_���̏ꍇ�A
�����������Čv�Z�Ȃ�Ăł���킯�˂����[�́B
packed�������ĉ��̂��Ƃ����m�炸�Ɍ����Ă�z�͋~���������A�z�B
���������ACell��SPE�ɂ͔{���x���������_���Z������ڂ���Ă�����āA�S�R�m���Ă��Ȃ��ȁB
http://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765508.jpg.html
ISSCC�ł�Cell�̔{���x��Z��ɂ��Ę_�����\�����������Adie photo�ɂ����Ă̒ʂ�DP��������B
http://www.geocities.jp/andosprocinfo/wadai05/20050219.htm
�܁A�v�Z���x�����ɒx���̂ŁA�p�r�����Ȃ���肳�ꂻ�������ǁB
http://ascii24.com/news/i/tech/article/2005/02/10/imageview/images765508.jpg.html
{kind=link}
ISSCC�ł�Cell�̔{���x��Z��ɂ��Ę_�����\�����������Adie photo�ɂ����Ă̒ʂ�DP��������B
http://www.geocities.jp/andosprocinfo/wadai05/20050219.htm
�܁A�v�Z���x�����ɒx���̂ŁA�p�r�����Ȃ���肳�ꂻ�������ǁB
>>467
���҂��Ă����ʂ���B
AMD�Ђ����\���Ă���ŐV�̃��[�h�}�b�v����65nm�̋�����2007/1Q���炾���{�i������̂�2007/3Q�B
���̒i�K�ł��A���N���b�N�i��90nm������90nm�Ɠ����̃N���b�N�ɂȂ�͔̂N����t�|���肻���B
TDP��65W��90nm��EE�ƕς��Ȃ������\���S�������A�ω����Ă���̂̓_�C�T�C�Y��65W�̑I�ʂ��y�ɂȂ���x�B
����Ȓ��q������K8L��2007�N�ɔ��������ȂNJ��҂��Ȃ������������A���\�����҂��Ȃ������ǂ��B
> ttp://images.dailytech.com/nimage/2008_large_amd_q307.jpg
���҂��Ă����ʂ���B
AMD�Ђ����\���Ă���ŐV�̃��[�h�}�b�v����65nm�̋�����2007/1Q���炾���{�i������̂�2007/3Q�B
���̒i�K�ł��A���N���b�N�i��90nm������90nm�Ɠ����̃N���b�N�ɂȂ�͔̂N����t�|���肻���B
TDP��65W��90nm��EE�ƕς��Ȃ������\���S�������A�ω����Ă���̂̓_�C�T�C�Y��65W�̑I�ʂ��y�ɂȂ���x�B
����Ȓ��q������K8L��2007�N�ɔ��������ȂNJ��҂��Ȃ������������A���\�����҂��Ȃ������ǂ��B
> ttp://images.dailytech.com/nimage/2008_large_amd_q307.jpg
{kind=link}
���Ȃ�Ȃ̂���B
473 �FSocket774�F2006/07/14(��) 12:39:50 ID:WybS+67g
�v���Z�b�T�[���\�������ɂȂ��������A�d�v�Ȃ̂͐��\�������i��l�����ł͂Ȃ����낤���B
>463
����Ȃ�� XBOX?
����Ȃ�� XBOX?
AMD���v���Z�X�Œx���̂͂���Ӗ��K�R������ȁB
intel�̐��Y�I�����̕������AMD�̐��Y�J�n���̕�����
�炵������B
intel�̐��Y�I�����̕������AMD�̐��Y�J�n���̕�����
�炵������B
dailytech�̋L�����uAMD�Ђ����\���Ă���ŐV�̃��[�h�}�b�v�v�ƌ����̂͂ǂ����Ǝv�����E�E�E�B
R-HTT�̎����^�ɎĕK���ɔ��_���Ă��낤�Ȃ��B
R-HTT�̎����^�ɎĕK���ɔ��_���Ă��낤�Ȃ��B
477 �FSocket774�F2006/07/14(��) 13:43:47 ID:fvAeqCxH
�����畉����GK�iID:JBJ3+3bd �j�̓X���Ⴂ���Ă��Ⴂ�����痈��Ȃ���
�����\�����ǂ��ł���DP���Z�������炳�܂ɒx�����Ƃɕς��͖�������B
�C���I�[�_�����炻�̒ᑬ���Ղ�Ɍ㑱�̖��߂͑҂�������B
������u���b�N�{�b�N�X�Ƃ��Ă݂�ǂ��������Z���j�b�g�\�����낤��
�x�����̂͒x���A���ꂾ���B
���ӂ̒P���x���������ł���X�J�����\�Ō���ΐ��\���̂P���x�B
SPE�S���ɋψ�Ɋ���U���悤�ȒP���ȉ��Z�ł̃X���[�v�b�g�Ȃ��
�ėp�����Ȃ�������́B
256KB�̃A�h���X��Ԃɖ��߃R�[�h�ƃf�[�^�����܂邩���[�́B
���ꂪ�V�`�W���ăf�[�^�̏o�������S�����Ă��Ȃ��Ⴂ���Ȃ�
PPE�̕��S�ǂ��d����B
����PPE����2issue�ŃC���I�[�_�̕n��ȃR�A�����ȁB
��ʂ̕������Z���̃R�v���Ȃ�PhysX�����邵������͊���MS��DirectX��
�T�|�[�g��\�����Ă�BPC�p�r��Cell�̏o�開�͑S���������B
�Ƃɂ���Cell�Ȃ�Ď���ɂ͗v��Ȃ��N�YCPU������
�Q�n�ɂł��X�b�e�����B
�����\�����ǂ��ł���DP���Z�������炳�܂ɒx�����Ƃɕς��͖�������B
�C���I�[�_�����炻�̒ᑬ���Ղ�Ɍ㑱�̖��߂͑҂�������B
������u���b�N�{�b�N�X�Ƃ��Ă݂�ǂ��������Z���j�b�g�\�����낤��
�x�����̂͒x���A���ꂾ���B
���ӂ̒P���x���������ł���X�J�����\�Ō���ΐ��\���̂P���x�B
SPE�S���ɋψ�Ɋ���U���悤�ȒP���ȉ��Z�ł̃X���[�v�b�g�Ȃ��
�ėp�����Ȃ�������́B
256KB�̃A�h���X��Ԃɖ��߃R�[�h�ƃf�[�^�����܂邩���[�́B
���ꂪ�V�`�W���ăf�[�^�̏o�������S�����Ă��Ȃ��Ⴂ���Ȃ�
PPE�̕��S�ǂ��d����B
����PPE����2issue�ŃC���I�[�_�̕n��ȃR�A�����ȁB
��ʂ̕������Z���̃R�v���Ȃ�PhysX�����邵������͊���MS��DirectX��
�T�|�[�g��\�����Ă�BPC�p�r��Cell�̏o�開�͑S���������B
�Ƃɂ���Cell�Ȃ�Ď���ɂ͗v��Ȃ��N�YCPU������
�Q�n�ɂł��X�b�e�����B
�������{���x���^���K�������A����͂���Ŕ{���x��p�̃R�v����]�߂�
�ςޘb�W���}�C�J�B
Cell�o�ڂ̃R�v���͂���ŏ[���p�r�͂��邵�A���Ȃ��Ƃ��{���x�p�R�v��
���v���������R����邾�낤�B�����Ă����AMD�ւ̍v���x�����̍���
���Ȃ�B
�����AMD�̃R�v������̒��ł́A�ǂ��炪�D�G�Ƃ����b�͕s�тȘ_������
�v���B
�ςޘb�W���}�C�J�B
Cell�o�ڂ̃R�v���͂���ŏ[���p�r�͂��邵�A���Ȃ��Ƃ��{���x�p�R�v��
���v���������R����邾�낤�B�����Ă����AMD�ւ̍v���x�����̍���
���Ȃ�B
�����AMD�̃R�v������̒��ł́A�ǂ��炪�D�G�Ƃ����b�͕s�тȘ_������
�v���B
479 �FSocket774�F2006/07/14(��) 17:09:28 ID:fvAeqCxH
�{���x���x����������肶��Ȃ��B
SPE�����ڃ��C������������ǂݏ����ł��Ȃ��B
PPE���疾���I�ɓǂݏ������Ă��˂Ȃ炸�A���߁E�f�[�^���킹��
256K�Ɏ��߂Ȃ��Ƃ����Ȃ��B
256KB����A�|�P�X�e��h���J�X��VM�̃~�j�Q�[����������x����
�ƂĂ��ėp���Z�ɂ͕s����
����ɂ�32bit�Œ蒷���߂Ȃ̂Ƀ��W�X�^��w�肷��̂�
7�r�b�g���g���Ă邹���ŁA���߃Z�b�g�̊g��������B
�g���̂ăA�[�L�e�N�`���������Ƃ���B
SPE�����ڃ��C������������ǂݏ����ł��Ȃ��B
PPE���疾���I�ɓǂݏ������Ă��˂Ȃ炸�A���߁E�f�[�^���킹��
256K�Ɏ��߂Ȃ��Ƃ����Ȃ��B
256KB����A�|�P�X�e��h���J�X��VM�̃~�j�Q�[����������x����
�ƂĂ��ėp���Z�ɂ͕s����
����ɂ�32bit�Œ蒷���߂Ȃ̂Ƀ��W�X�^��w�肷��̂�
7�r�b�g���g���Ă邹���ŁA���߃Z�b�g�̊g��������B
�g���̂ăA�[�L�e�N�`���������Ƃ���B
480 �FSocket774�F2006/07/14(��) 17:19:02 ID:Dx8mC3Hh
�܂Ƃ߁B
2000�N�O��`�f���A���R�A���i���o�ꂵ�n�߂�B
���N��c
2005�N�`Athlon64 X2���o��B�u���ꂩ��̓f���A���R�A�̎��ゾ�I�v
�������ACell�����\�����B�d�l���݂�ƃs�[�N�ȊO�͂����������Ƃ��Ȃ��̂͂킩���Ă������A
�O�E�ɖڂ������Ȃ��������������u�W�R�A�v�̕����ɂ݂̂��܂��܌��Ă��܂��������A�������N�����B
1�N��c�������N�����ăt�@�r�����Ă����A�����uCell�͌��ǁ`�`�Ȃ���v�ƋC�Â��A���瑛�����N�������ɂ��ւ�炸�ACell�̘b����o���Ɠ{��o���B
�܂��A�����ɍ����ɖ߂�A�M�҂����͊O�E�ɖڂ������Ȃ��Ȃ邾�낤�B
�߂ł����A�߂ł����B
�ŁAAMD�̘b��́H���A��������Ă����Ȃ����i�����̂̓_���Ȃ�ł��������O�O�G�G�G�G��
2000�N�O��`�f���A���R�A���i���o�ꂵ�n�߂�B
���N��c
2005�N�`Athlon64 X2���o��B�u���ꂩ��̓f���A���R�A�̎��ゾ�I�v
�������ACell�����\�����B�d�l���݂�ƃs�[�N�ȊO�͂����������Ƃ��Ȃ��̂͂킩���Ă������A
�O�E�ɖڂ������Ȃ��������������u�W�R�A�v�̕����ɂ݂̂��܂��܌��Ă��܂��������A�������N�����B
1�N��c�������N�����ăt�@�r�����Ă����A�����uCell�͌��ǁ`�`�Ȃ���v�ƋC�Â��A���瑛�����N�������ɂ��ւ�炸�ACell�̘b����o���Ɠ{��o���B
�܂��A�����ɍ����ɖ߂�A�M�҂����͊O�E�ɖڂ������Ȃ��Ȃ邾�낤�B
�߂ł����A�߂ł����B
�ŁAAMD�̘b��́H���A��������Ă����Ȃ����i�����̂̓_���Ȃ�ł��������O�O�G�G�G�G��
���ꂩ��ϊv���炵������
Core2Duo��AM2�����������́H
�O�]�����ƃC���e���ɕ������肻�������ǁAAMD�ɑR��́H
Core2Duo��AM2�����������́H
�O�]�����ƃC���e���ɕ������肻�������ǁAAMD�ɑR��́H
�Œ�ł�2007�N�܂ł́A�`�l�c������ςȂ��B
�����Ȃc
�\�PA�����芷�������������ǁA�A���_�[�����䖝���Ă�����
�\�PA�����芷�������������ǁA�A���_�[�����䖝���Ă�����
>>480
ES�i���o�Ă��b��ɂ��Ă͑ʖڂł�
�����ɔ������Ă���łȂ��Ɠ{��l���������܂�����B
�܂���AMD�����͂������Ă����������Ȑl�͂��Ȃ��Ǝv���܂����ǂˁO�O�G
ES�i���o�Ă��b��ɂ��Ă͑ʖڂł�
�����ɔ������Ă���łȂ��Ɠ{��l���������܂�����B
�܂���AMD�����͂������Ă����������Ȑl�͂��Ȃ��Ǝv���܂����ǂˁO�O�G
>>471
������ăR�s�y�H
������ăR�s�y�H
AMD�����͔��\�O�ł�OK�q��B
�Ȃ��Ȃ炱����AMD������X���B
������Cell�G�k�X���ł̓i�C�B
�Ȃ��Ȃ炱����AMD������X���B
������Cell�G�k�X���ł̓i�C�B
�X���^�C���ǂ߂Ȃ��قǍ���͂��Ⴂ�A���ɂ���ȓ���b�������ł��������
Cell�͍ŋ��̎T���a���Ƃ������͂킩��܂���
AMD �� '4x4' Power Programs �� Conroe �ɔ���
http://www.pcmag.com/article2/0,1895,1989028,00.asp
>4x4 �v���b�g�t�H�[���̓}�U�{�ɓ�̕����I�ȃ\�P�b�g��z�u�A
>��̃\�P�b�g�� AMD �� Direct Connect �A�[�L�e�N�`���ɂ���Č݂��ɐڑ�����Ă���B
>AMD Athlon 64 X2 �v���Z�b�T�����\�P�b�g�ɓ��ڂ���A�v 4 �R�A�ɂȂ�B
>8 �R�A�� "8X8" �v���O�����̓o��� 2007 �N�B
>4 �̉��z�I�ȃv���Z�b�T�R�A������̕����I�ȃv���b�Z�b�T�ō\�������\��B
>4x4 �v���b�g�t�H�[���̓o�ꎞ���ɂ��Ă͂܂������ɖ�������Ă��Ȃ����A
>AMD �̍L��S���́u���������ɔ��\���܂��v�ƌ����A
>�C���e����������x�o���������Ƃ��ł��鎞���ɊԂɍ��킹��\�����ق̂߂������B
Athlon 64 x2 �P�̃V�X�e���Ɣ�r���āA�J������ 4x4 �v���b�g�t�H�[���ł�
Vista �̍ŐV beta ��� 3DMark 06 �� Maxon Cinebench R9.5 �A WinSAT �Ȃǂ�
�}���`�X���b�h�̃x���`�}�[�N�ŁA���� 80 %�@�̃p�t�H�[�}���X���オ������B
http://www.pcmag.com/article2/0,1895,1989028,00.asp
>4x4 �v���b�g�t�H�[���̓}�U�{�ɓ�̕����I�ȃ\�P�b�g��z�u�A
>��̃\�P�b�g�� AMD �� Direct Connect �A�[�L�e�N�`���ɂ���Č݂��ɐڑ�����Ă���B
>AMD Athlon 64 X2 �v���Z�b�T�����\�P�b�g�ɓ��ڂ���A�v 4 �R�A�ɂȂ�B
>8 �R�A�� "8X8" �v���O�����̓o��� 2007 �N�B
>4 �̉��z�I�ȃv���Z�b�T�R�A������̕����I�ȃv���b�Z�b�T�ō\�������\��B
>4x4 �v���b�g�t�H�[���̓o�ꎞ���ɂ��Ă͂܂������ɖ�������Ă��Ȃ����A
>AMD �̍L��S���́u���������ɔ��\���܂��v�ƌ����A
>�C���e����������x�o���������Ƃ��ł��鎞���ɊԂɍ��킹��\�����ق̂߂������B
Athlon 64 x2 �P�̃V�X�e���Ɣ�r���āA�J������ 4x4 �v���b�g�t�H�[���ł�
Vista �̍ŐV beta ��� 3DMark 06 �� Maxon Cinebench R9.5 �A WinSAT �Ȃǂ�
�}���`�X���b�h�̃x���`�}�[�N�ŁA���� 80 %�@�̃p�t�H�[�}���X���オ������B
>>486
> AMD �� '4x4' Power Programs �� Conroe �ɔ���
�ց[�A����ᐦ���ˁAINTEL���тт茞���Ă�Ǝv����B
�܂��A�����������ƂŁA����Conroe�����ĉ����璭�߂Ă��邩��K���K��w
> AMD �� '4x4' Power Programs �� Conroe �ɔ���
�ց[�A����ᐦ���ˁAINTEL���тт茞���Ă�Ǝv����B
�܂��A�����������ƂŁA����Conroe�����ĉ����璭�߂Ă��邩��K���K��w
�^���A�܂�1�����Q����H
����A����8X8�́c
�\�s�\����Ȃ��Ă��c��̂�����|�����ĉ����b�g�K�v�Ȃ�c
�\�s�\����Ȃ��Ă��c��̂�����|�����ĉ����b�g�K�v�Ȃ�c
http://enterprise.watch.impress.co.jp/cda/static/image/2005/04/22/fy05-048_dl585.jpg
http://h50146.www5.hp.com/products/servers/proliant/dl585_sh.html
1000�h���炢����ˁH
{kind=link}
http://h50146.www5.hp.com/products/servers/proliant/dl585_sh.html
1000�h���炢����ˁH
100W�N���X��GPU��4��8���ڂ����ƂȂ�ƁA����ǂ���ł͍ς܂Ȃ��E�E�E�E
>>495
�����N��̘b�ȁE�E�E��������镶���ŽϿ
�����N��̘b�ȁE�E�E��������镶���ŽϿ
�����̒�������������������G���X�[�W�A�X�gPC�a���̗\��
ttp://sources.redhat.com/ml/binutils-cvs/2006-07/msg00051.html
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/include/opcode/i386.h.diff?cvsroot=src&r1=1.68&r2=1.69
K8L�ɒlj������SSE���ߌQ��SSE4a�ƌĂ�Ă���悤���B
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/gas/config/tc-i386.c.diff?cvsroot=src&r1=1.218&r2=1.219
PROCESSOR_AMDFAM10�̒�`��CpuMNI�������Ă��Ȃ��̂�
MNI(SSE4)�͎g���Ȃ�����
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/include/opcode/i386.h.diff?cvsroot=src&r1=1.68&r2=1.69
K8L�ɒlj������SSE���ߌQ��SSE4a�ƌĂ�Ă���悤���B
ttp://sourceware.org/cgi-bin/cvsweb.cgi/src/gas/config/tc-i386.c.diff?cvsroot=src&r1=1.218&r2=1.219
PROCESSOR_AMDFAM10�̒�`��CpuMNI�������Ă��Ȃ��̂�
MNI(SSE4)�͎g���Ȃ�����
500 �FSocket774�F2006/07/16(��) 23:35:47 ID:tfBaYZQF
�������̃��x���̍����X���́B���O�炢�������ǂ��ł���Ȓm���g�ɒ����Ă����B
AMD�ɊW�Ȃ����Ƃ��w�ǂ���
>>500
�X���Ⴂ�Ȃ킯�����c
���L�� (www.reed-electronics.com) �̕���ǂނƁA�u�ǂ��� 10%�`20% �����A
logic redundancy ������A�����{�ɂł���BIBM �ȊO�ŁA(CPU �ɂ���?)
���������Ă�Ƃ��낪���邩�ǂ����͒m��Ȃ����v�Ƃ���̂ŁA�Ȃɂ��Ȃ���
10%�`20% �����AIBM �̗͂� 20% �` 40% �ɂ��Ă�Ƃ��ǂ߂���A�{���̒l��
���������ǂ���H
�X���Ⴂ�Ȃ킯�����c
���L�� (www.reed-electronics.com) �̕���ǂނƁA�u�ǂ��� 10%�`20% �����A
logic redundancy ������A�����{�ɂł���BIBM �ȊO�ŁA(CPU �ɂ���?)
���������Ă�Ƃ��낪���邩�ǂ����͒m��Ȃ����v�Ƃ���̂ŁA�Ȃɂ��Ȃ���
10%�`20% �����AIBM �̗͂� 20% �` 40% �ɂ��Ă�Ƃ��ǂ߂���A�{���̒l��
���������ǂ���H
���̃C���^�r���[�ł́Alogic redundancy���Ă̂́ASPE8�̂���7���g���������Ă��ƂŁA����Ń`�b�v�̕����܂�グ����
���Ă��Ǝ������Ă��Ȃ�����
���ƁA10�`20%���Ă̂��AIBM�ȊO�̉�ЂȂ�Cell���炢�̃T�C�Y�̃`�b�v������A���̒��x���������܂�オ��Ȃ����낤��
���Ċ����ŁA��ɂ��������Ȃ��C������
�{���͂����Ɨǂ��̂��A�����̂��͓䂾����
�u���O�̒���������E�\�������Ă�킯����Ȃ��āA�������ʂ̂Ƃ���ŁASPE8���̂܂g���d�l����37%���炢����˂���
����ɗ\�z���Ă��̂��AIBM�̃C���^�r���[��10�`20%���Ă��炢�Ⴂ�����������Ă邩��A������ɔ�т��������
��������
�܂�A�^�C�g�������ӓI�ŁA���e���ʋL�������Ȃ��Ƃ����Ɣc���ł��Ȃ��Ƃ������炵����������
���Ă��Ǝ������Ă��Ȃ�����
���ƁA10�`20%���Ă̂��AIBM�ȊO�̉�ЂȂ�Cell���炢�̃T�C�Y�̃`�b�v������A���̒��x���������܂�オ��Ȃ����낤��
���Ċ����ŁA��ɂ��������Ȃ��C������
�{���͂����Ɨǂ��̂��A�����̂��͓䂾����
�u���O�̒���������E�\�������Ă�킯����Ȃ��āA�������ʂ̂Ƃ���ŁASPE8���̂܂g���d�l����37%���炢����˂���
����ɗ\�z���Ă��̂��AIBM�̃C���^�r���[��10�`20%���Ă��炢�Ⴂ�����������Ă邩��A������ɔ�т��������
��������
�܂�A�^�C�g�������ӓI�ŁA���e���ʋL�������Ȃ��Ƃ����Ɣc���ł��Ȃ��Ƃ������炵����������
���ʂɂ��A10%�`20%�ɂȂ邪�Alogic redundancy���g���Ă��邩��37%�ɂȂ��Ă���
���Ă��Ƃ�
���Ă��Ƃ�
506 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 05:49:37 ID:zbUstSrv
��HPPE�P�{SPE7�ł̕����܂�Ɍ��܂��Ă邾��
�P�R�A�͖����ɂ��ďo�����Ƃ͌��܂��Ă�̂ɁA���őS�R�A�����삷��_�C�̕����܂�Ɍ��y����K�v�������
�P�R�A�͖����ɂ��ďo�����Ƃ͌��܂��Ă�̂ɁA���őS�R�A�����삷��_�C�̕����܂�Ɍ��y����K�v�������
507 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 06:10:41 ID:zbUstSrv
�u100mm�l���̃_�C���x�̕����܂�v�Ƃ͌������AIntel��AMD�̃��C���X�g���[���`�o�����[����
�_�C�́A90nm�l�����x�ŁA������X�Ɂulogic redundancy�v����Ă�킯�ŁB
���Ƃ���Yonah�ł���ΕЃR�A�������Ȃ����̂�Core Solo�A
����ɃL���b�V��������Celeron M 4xx�V���[�Y�ȂǂƂ������Ƀ��[�G���h�ł�
���Ƃɂ��A�t���Z�b�g�łƂ��Ă͊�����̃_�C��L�����p���邱�ƂŁA
���p�������グ�Ă���B
����ɁA�X�y�b�N�͌Œ�łȂ�����S��2.16GHz�œ����K�v�͖����A�N���b�N�ϐ���
�����Ē�N���b�N�̃R�A�Ƃ��邱�Ƃ��ł���B
Cell��100mm�l�������Ȃ�Intel��AMD��50mm�l�������ł����H
Cell�̕����܂�͏\�������ł��傤�ȁB
�_�C�́A90nm�l�����x�ŁA������X�Ɂulogic redundancy�v����Ă�킯�ŁB
���Ƃ���Yonah�ł���ΕЃR�A�������Ȃ����̂�Core Solo�A
����ɃL���b�V��������Celeron M 4xx�V���[�Y�ȂǂƂ������Ƀ��[�G���h�ł�
���Ƃɂ��A�t���Z�b�g�łƂ��Ă͊�����̃_�C��L�����p���邱�ƂŁA
���p�������グ�Ă���B
����ɁA�X�y�b�N�͌Œ�łȂ�����S��2.16GHz�œ����K�v�͖����A�N���b�N�ϐ���
�����Ē�N���b�N�̃R�A�Ƃ��邱�Ƃ��ł���B
Cell��100mm�l�������Ȃ�Intel��AMD��50mm�l�������ł����H
Cell�̕����܂�͏\�������ł��傤�ȁB
���L���̃C���^�r���[��IBM�̕��В��������Ă����A�R��ɂ��݂���Ă��c
Electronic News: What�fs the defining factor that makes some chips better than others?
Reeves: Defects. It becomes a bigger problem the bigger the chip is. With chips that are one-by-one and silicon germanium,
we can get yields of 95 percent. With a chip like the Cell processor, you�fre lucky to get 10 or 20 percent.
If you put logic redundancy on it, you can double that. It�fs a great strategy, and I�fm not sure anyone other than IBM is doing that with logic.
Everybody does it with DRAM. There are always extra bits in there for memory. People have not yet moved to logic block redundancy, though.
10�`20%���Đ����������Ă�Ƃ���̎���"you"������AIBM���g�̕����܂�ɂ��Ęb���ĂȂ��ł���B�����܂ň�ʘ_�݂��������ŁA
���Ђ�Cell�݂����ȃ`�b�v�������A10�`20%�������������낤���Č����Ă�B
�ŁA"you"��logic redundancy���g���A"you"�������܂��{�ɂł���A�ƕ��В��������Ă�킯���B
�ŁA���̌��logic�ɂ��Ă��AIBM�ȊO�ɏ璷�\������Ă邩�͒m��ADRAM���Ƃ���Ă�ˁ[�Blogic block redundancy
���ƁA�܂���ʓI����Ȃ��悤���ˁA��IBM�̕��В��������Ă���B
�Ƃ����킯�ŁA�L�҂̎���ɑ��A"logic redundancy"���g���̂������̃`�b�v�����̊̂��A��IBM�̕��В������Ă邾���ŁA
10�`20%���Đ��������ۂ�Cell�̕����܂肩�ǂ����́A�悭�킩���̂���Ȃ��́H
logic redundancy��SPE1�璷�̍\���A�Ƃ����b�Ɠǂ̂͘R�ꂾ����A�Ⴄ�Ƃ���ꂽ��A������������Ȃ���
Electronic News: What�fs the defining factor that makes some chips better than others?
Reeves: Defects. It becomes a bigger problem the bigger the chip is. With chips that are one-by-one and silicon germanium,
we can get yields of 95 percent. With a chip like the Cell processor, you�fre lucky to get 10 or 20 percent.
If you put logic redundancy on it, you can double that. It�fs a great strategy, and I�fm not sure anyone other than IBM is doing that with logic.
Everybody does it with DRAM. There are always extra bits in there for memory. People have not yet moved to logic block redundancy, though.
10�`20%���Đ����������Ă�Ƃ���̎���"you"������AIBM���g�̕����܂�ɂ��Ęb���ĂȂ��ł���B�����܂ň�ʘ_�݂��������ŁA
���Ђ�Cell�݂����ȃ`�b�v�������A10�`20%�������������낤���Č����Ă�B
�ŁA"you"��logic redundancy���g���A"you"�������܂��{�ɂł���A�ƕ��В��������Ă�킯���B
�ŁA���̌��logic�ɂ��Ă��AIBM�ȊO�ɏ璷�\������Ă邩�͒m��ADRAM���Ƃ���Ă�ˁ[�Blogic block redundancy
���ƁA�܂���ʓI����Ȃ��悤���ˁA��IBM�̕��В��������Ă���B
�Ƃ����킯�ŁA�L�҂̎���ɑ��A"logic redundancy"���g���̂������̃`�b�v�����̊̂��A��IBM�̕��В������Ă邾���ŁA
10�`20%���Đ��������ۂ�Cell�̕����܂肩�ǂ����́A�悭�킩���̂���Ȃ��́H
logic redundancy��SPE1�璷�̍\���A�Ƃ����b�Ɠǂ̂͘R�ꂾ����A�Ⴄ�Ƃ���ꂽ��A������������Ȃ���
�Ƃ肠����IBM��AMD��������܂�̃m�E�n�E�H����ɓ��ꂽ�炵������10�`20%�Ȃ�Ă��Ƃ͂Ȃ��Ǝv���B
AMD��Sempron�i���Ԃ�j��95%�̕����܂�炵������ȁB
AMD��Sempron�i���Ԃ�j��95%�̕����܂�炵������ȁB
�X���Ⴂ�𑱂��Ė{���ɐ\����Ȃ����A���������37%���Ď��Z�̐������APPE1�{SPE8����37%�ŁA
PPE1�{SPE7����69���ŁASPE7�ɂ���̂͌o�c�㐳�������Ęb�ŏo�Ă�������
�i�v�Z�̑O��́Ahttp://satoshi.blogs.com/life/2005/05/post_12.html�@�����Ă���j
���������10�`20%��37%�Ɣ�r���Ă邱�Ƃ���Alogic redundancy�ɂ��Ă�SPE�̏璷�\���Ɠǂ�ł�͗l
������ƌ����āA�R��̓ǂݕ��������Ă邩�͂܂��ʖ�肾���ȁ[
PPE1�{SPE7����69���ŁASPE7�ɂ���̂͌o�c�㐳�������Ęb�ŏo�Ă�������
�i�v�Z�̑O��́Ahttp://satoshi.blogs.com/life/2005/05/post_12.html�@�����Ă���j
���������10�`20%��37%�Ɣ�r���Ă邱�Ƃ���Alogic redundancy�ɂ��Ă�SPE�̏璷�\���Ɠǂ�ł�͗l
������ƌ����āA�R��̓ǂݕ��������Ă邩�͂܂��ʖ�肾���ȁ[
>>508
������₷������L���������܂���
������₷������L���������܂���
�璷���͎�v��PC���[�J�[�Ȃ���ɂ���Ă邵IBM�̂��ƌ|�ł����ł��Ȃ��B
INTEL�ɂ��Ă��璷�����₷���L���b�V����傫�����Ă������܂肪���܂舫�����Ȃ��̂͂����������Ƃ��B
INTEL�ɂ��Ă��璷�����₷���L���b�V����傫�����Ă������܂肪���܂舫�����Ȃ��̂͂����������Ƃ��B
>>513
�@����ɁAIntel�̃v���Z�b�T��SRAM�f�q�Ń��W�b�N���������Ă���A
���̂���PC���[�J�[����t���Ń��W�b�N�̏璷�����m�ۂ��邱�Ƃ�
�\�A�Ƃ���������|���Ǝv�����B
�܂��Ɏ����ゾ�ȁB���R���t�B�M�����u�������B
�@����ɁAIntel�̃v���Z�b�T��SRAM�f�q�Ń��W�b�N���������Ă���A
���̂���PC���[�J�[����t���Ń��W�b�N�̏璷�����m�ۂ��邱�Ƃ�
�\�A�Ƃ���������|���Ǝv�����B
�܂��Ɏ����ゾ�ȁB���R���t�B�M�����u�������B
>>479
SPE�ɉ��̂��߂�DMA�R���g���[��������Ă���̂��ƁB
�����������ς�炸�����̓A���`Cell�X�����Ȃ��B
�A���`���ɂ�������Ƃ͂��������m����t���Ă͔@���ł��傤���B
�X���ł���B
SPE�ɉ��̂��߂�DMA�R���g���[��������Ă���̂��ƁB
�����������ς�炸�����̓A���`Cell�X�����Ȃ��B
�A���`���ɂ�������Ƃ͂��������m����t���Ă͔@���ł��傤���B
�X���ł���B
�ǂ������X���Ⴂ
64bit�͋���Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
>>517
�����܂ł�32bit�Ɣ�r���Ă̘b������ACore x64����@�� K8 x64����@����
�b�ɂ͂Ȃ��ĂȂ��B
�܂�����̋L���Ƀl�^���c�����������낤����A���N�e�J���ă}�e�B
�����܂ł�32bit�Ɣ�r���Ă̘b������ACore x64����@�� K8 x64����@����
�b�ɂ͂Ȃ��ĂȂ��B
�܂�����̋L���Ƀl�^���c�����������낤����A���N�e�J���ă}�e�B
>>518
���̔�r�͂����Ӗ����Ȃ���Ȃ����ȁB���̂��܂�ɔߎS�Ȑ��������Ă��܂���
64bit�A�v���P�[�V�����𑖂点�邽�߂�Core���I��邱�Ƃ͂قƂ�ǂ��Ȃ��Ǝv����B
(32bit�ő��点���1.5�{����CPU�������Ēx��64bit�Ƃ��Ďg���̂͂��Ȃ�E�C������)
�����[���̂�64bit OS��ł�32bit�A�v���P�[�V�����̐��\���ȁB���ꂪ���������Ȃ��
�܂��Ȃ�Ƃ�64bit���[�h�̈Ӗ�������B
���ǁu�S���ʋy���AMD�v�Ɓu��_����Intel�v�Ƃ����\�}�͕ς���Ă��Ȃ���
�u���܂ł̃R�[�h������AMD�v�Ɓu�V�����������R�[�h������Intel�v�̍\�}��
64bit�̊ϓ_����͍��ׂƂȂ�����������Ȃ��B
���̔�r�͂����Ӗ����Ȃ���Ȃ����ȁB���̂��܂�ɔߎS�Ȑ��������Ă��܂���
64bit�A�v���P�[�V�����𑖂点�邽�߂�Core���I��邱�Ƃ͂قƂ�ǂ��Ȃ��Ǝv����B
(32bit�ő��点���1.5�{����CPU�������Ēx��64bit�Ƃ��Ďg���̂͂��Ȃ�E�C������)
�����[���̂�64bit OS��ł�32bit�A�v���P�[�V�����̐��\���ȁB���ꂪ���������Ȃ��
�܂��Ȃ�Ƃ�64bit���[�h�̈Ӗ�������B
���ǁu�S���ʋy���AMD�v�Ɓu��_����Intel�v�Ƃ����\�}�͕ς���Ă��Ȃ���
�u���܂ł̃R�[�h������AMD�v�Ɓu�V�����������R�[�h������Intel�v�̍\�}��
64bit�̊ϓ_����͍��ׂƂȂ�����������Ȃ��B
�ʂ�intel�т�������Ȃ����ǁAWoodcrest�̃x���`����OS��Win�Ix64��XPx64�����H
�����ƃx���`�e�X�g���������ɐ����������Ă��Ӗ��Ȃ����ȁ[
���ƃA�X�L�[�̃x���`�ł��i����̓x���`�����䂾���j�A64bit���܂�ׂ�Ȃ��x���Ȃ��Ă�Ȃ�Ƃ������A
64bit�̕��������̂�����̂ŁA���ǃR�[�h�̍œK���̘b�ŁAintel�R���p�C������64bit����32bit��肳���
�����Ȃ�܂�����āA�\�����Ȃ��ɂ������炸
�����ƃx���`�e�X�g���������ɐ����������Ă��Ӗ��Ȃ����ȁ[
���ƃA�X�L�[�̃x���`�ł��i����̓x���`�����䂾���j�A64bit���܂�ׂ�Ȃ��x���Ȃ��Ă�Ȃ�Ƃ������A
64bit�̕��������̂�����̂ŁA���ǃR�[�h�̍œK���̘b�ŁAintel�R���p�C������64bit����32bit��肳���
�����Ȃ�܂�����āA�\�����Ȃ��ɂ������炸
�܂�C���e����CPU�͂킴�킴�œK�����Ă��Ȃ��Ɖ����o���Ȃ��S�~���Ă���
>>520
�˂��Ƃ[���Ƃ̎�������R���p�C���̉��ǂ��]�X�ƌ���ꑱ���Ă������ɍ�������̂�
microoptimization�ɂ͊��҂��Ȃ������B�u64bit�̕����������̂�����v�Ƃ�����Ԃ���
�R���p�C���ɂ���āu64bit�̕����x�����̂�����v�Ƃ�����Ԃɂ܂Ŏ����Ă����͖̂����B
���̑O�ɐV�����R���p�C�����o�Ă��g���Ă��炦�Ȃ��Ƃ��������̐[���L���삪�c�c
�˂��Ƃ[���Ƃ̎�������R���p�C���̉��ǂ��]�X�ƌ���ꑱ���Ă������ɍ�������̂�
microoptimization�ɂ͊��҂��Ȃ������B�u64bit�̕����������̂�����v�Ƃ�����Ԃ���
�R���p�C���ɂ���āu64bit�̕����x�����̂�����v�Ƃ�����Ԃɂ܂Ŏ����Ă����͖̂����B
���̑O�ɐV�����R���p�C�����o�Ă��g���Ă��炦�Ȃ��Ƃ��������̐[���L���삪�c�c
�������A����Conroe�ɍ��킹���œK��������ƁA64bit�ɍ��킹��CPU��������Ƃ��́A�܂��œK���������Ȃ��Ɛ��\��
�łȂ��Ƃ������ƂɂȂ邾�낤��
������intel�̂��Ƃ���
���Ȃ݂ɁAWoodcrest�̕������\����ăO���t�����ǁAx64�̃x���`�����Ȃ��̂ł܂����������A64bit���ƃN���b�N�ӂ肾��
Opteron�Ƃقڌ݊p�̈�ۂ���
Hound����ł�����Ɛ��\�A�b�v���Ă���Ȃ�Aintel��DP�I�D���������������肢���Ƃ����Ȃ�������
�łȂ��Ƃ������ƂɂȂ邾�낤��
������intel�̂��Ƃ���
���Ȃ݂ɁAWoodcrest�̕������\����ăO���t�����ǁAx64�̃x���`�����Ȃ��̂ł܂����������A64bit���ƃN���b�N�ӂ肾��
Opteron�Ƃقڌ݊p�̈�ۂ���
Hound����ł�����Ɛ��\�A�b�v���Ă���Ȃ�Aintel��DP�I�D���������������肢���Ƃ����Ȃ�������
524 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/18(��) 23:28:42 ID:zOiEeD5j
32bit/64bit�Ɍ��炸�Ƃɂ����t�F�b�`�ш悪����Ȃ��Ǝv���B
9�o�C�g10�o�C�g�̖��߂Ȃ��SSE�g���Ă���K���K���g���̂ɁA�t�F�b�`�ш�l�b�N��
���Z���j�b�g�ɍs���͂��Ȃ����Ă̂��ň��̃p�^�[��
9�o�C�g10�o�C�g�̖��߂Ȃ��SSE�g���Ă���K���K���g���̂ɁA�t�F�b�`�ш�l�b�N��
���Z���j�b�g�ɍs���͂��Ȃ����Ă̂��ň��̃p�^�[��
���̐���͂��Ȃ���ҏo����������Ȃ��ł����H
>>521
���̐��̂ǂ�Ȃ��̂ł���������
���̐��̂ǂ�Ȃ��̂ł���������
>>524
���O�A�z����?
����Ȃ��ƌ����o������ACPU�Ȃ�ĉ�������������Ă��Ȃ���B
SSE�����͏\���ɍ����Ȃ̂ɂȂɂ��ق����Ă���B
���O�A�z����?
����Ȃ��ƌ����o������ACPU�Ȃ�ĉ�������������Ă��Ȃ���B
SSE�����͏\���ɍ����Ȃ̂ɂȂɂ��ق����Ă���B
Intel��Itanium������̂�
AMD�哱��x64�ɂ͂��܂�͂����Ă��Ȃ��̂��낤
AMD�哱��x64�ɂ͂��܂�͂����Ă��Ȃ��̂��낤
�N�}�[
>>528
�P���Ɏ��ԕs���������Ǝv�����ǂ�
IA-64�����邩��Ƃ������AHP�̎�O�̂Ă�킯�ɂ������Ȃ����A
�Ǝ���x86-64����낤�ɂ�MS����T�|���Ȃ��ƌ���ꂽ��������ł��Ȃ���
���ԕs���ƌ�����VT�̕��͂ǂ��Ȃ��Ă�낤�B
�P���Ɏ��ԕs���������Ǝv�����ǂ�
IA-64�����邩��Ƃ������AHP�̎�O�̂Ă�킯�ɂ������Ȃ����A
�Ǝ���x86-64����낤�ɂ�MS����T�|���Ȃ��ƌ���ꂽ��������ł��Ȃ���
���ԕs���ƌ�����VT�̕��͂ǂ��Ȃ��Ă�낤�B
531 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 23:07:37 ID:1bCHDZNj
>>527
���O�A�z����H
�t�����Ă݂�킩���邪�A�Œ�ł�4�o�C�g�AREX�t���Ȃ�5�o�C�g�͎g���B���[�h�E�X�g�A�����߂�8�o�C�g
CoreMA���炢���j�b�g�������b�`���ƃ��j�b�g�g����̂ɑS�R����ˁ[��B
���O�A�z����H
�t�����Ă݂�킩���邪�A�Œ�ł�4�o�C�g�AREX�t���Ȃ�5�o�C�g�͎g���B���[�h�E�X�g�A�����߂�8�o�C�g
CoreMA���炢���j�b�g�������b�`���ƃ��j�b�g�g����̂ɑS�R����ˁ[��B
532 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 23:09:53 ID:1bCHDZNj
�f�����邪�ACoreMA�ɉ��ǂ��Ȃ�����AMD��K8L�ň��|�I�ȋt�]�𐋂���B
64bit������������>>530�̌������z���Z�p���A���������r���[�Ȏ����Ȃ��
�ǂ��������ꂩ��{�ȋZ�p�Ȃ̂ɁE�E�E
32bit���ł͂�����������A�I�s��ł͔����ɂȂ��Ă��܂�
�ǂ��������ꂩ��{�ȋZ�p�Ȃ̂ɁE�E�E
32bit���ł͂�����������A�I�s��ł͔����ɂȂ��Ă��܂�
534 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 23:47:27 ID:1bCHDZNj
������₷���b������ƁACoreMA�͏�艺��v256�r�b�g��L1�ԓ]���ш��
128bit��load/store���e1�{���ɂ�������炸�AL1�̓ǂݏ����̃X���[�v�b�g��
�����̃P�[�X��NetBurst��256bit/clock�ɖ����Ȃ��B
�Ȃ����H
�t�F�b�`�ш悪����Ȃ�����B
K8L�͂�������Load/Store�e1�ɉ����A128bit��Load��2�A�������s�\�����A
16�o�C�g�̖��ߑш悶��g�����킯���Ȃ��B
K8L�̃t�F�b�`�ш��32byte�ւ̊g��͕K�R�Ƃ�����㩁B
128bit��load/store���e1�{���ɂ�������炸�AL1�̓ǂݏ����̃X���[�v�b�g��
�����̃P�[�X��NetBurst��256bit/clock�ɖ����Ȃ��B
�Ȃ����H
�t�F�b�`�ш悪����Ȃ�����B
K8L�͂�������Load/Store�e1�ɉ����A128bit��Load��2�A�������s�\�����A
16�o�C�g�̖��ߑш悶��g�����킯���Ȃ��B
K8L�̃t�F�b�`�ш��32byte�ւ̊g��͕K�R�Ƃ�����㩁B
������
�g������Ȃ��قǂ�unit���ڂ������R��������Ă���B
�g������Ȃ��قǂ�unit���ڂ������R��������Ă���B
������ɉ��ǂ͑�ςȂ̂Ŏア�Ƃ��납�珇�ɉ��ǂ��Ă�������B
�悭����ꂽ�R�[�h�������A�܂�ׂ�Ȃ����U��������
��̃��j�b�g�ɕ��ׂ��W�����鎖�̕��������̂�
�e�X�̃��j�b�g�ɗ]�T���������Ă����K�v�����邩��B
�f�R�[�_��2����/clock��Load/Store��3�̏ꍇ
���߂���f�R�[�_��3����/clock�ɂ��Ȃ�����A���o�����X�Ȃ�
�Ƃ����b�ɂȂ邪�A���ۂɂ�Load/Store�̑ш�A�t�F�b�`�̑ш�A
ALU�̐��AConroe�Ɍ�����悤�ȃf�R�[�_��uFusion�̓����A
�����ƍL���͈͂Ō����L1, L2�̑ш�ȂǗl�X�ȗv�����D�荬�����đ��x�����܂��Ă���B
�]���āA���炩�̃��j�b�g��2���Ə��Ȃ���3���Ǝg����Ȃ��A
�Ƃ������P���ɂ͊����Ȃ���ԂɂȂ��Ă���\�����l�����邩��B
�悭����ꂽ�R�[�h�������A�܂�ׂ�Ȃ����U��������
��̃��j�b�g�ɕ��ׂ��W�����鎖�̕��������̂�
�e�X�̃��j�b�g�ɗ]�T���������Ă����K�v�����邩��B
�f�R�[�_��2����/clock��Load/Store��3�̏ꍇ
���߂���f�R�[�_��3����/clock�ɂ��Ȃ�����A���o�����X�Ȃ�
�Ƃ����b�ɂȂ邪�A���ۂɂ�Load/Store�̑ш�A�t�F�b�`�̑ш�A
ALU�̐��AConroe�Ɍ�����悤�ȃf�R�[�_��uFusion�̓����A
�����ƍL���͈͂Ō����L1, L2�̑ш�ȂǗl�X�ȗv�����D�荬�����đ��x�����܂��Ă���B
�]���āA���炩�̃��j�b�g��2���Ə��Ȃ���3���Ǝg����Ȃ��A
�Ƃ������P���ɂ͊����Ȃ���ԂɂȂ��Ă���\�����l�����邩��B
537 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/20(��) 00:45:09 ID:4sGRX40G
�Ƃ肠����NetBurst���N���b�N���������邩��SIMD�̑����͋}���������̂ł��傤�ȁB
90nm��NetBurst�̎��s�����炩�ɂȂ�܂ł�CoreMA�̓��o�C���p�̃A�[�L�e�N�`���������̂�
SIMD���j�b�g��64bit�ŁASSE�̓�OPs�t���[�W�����ł����̂Ǝv���Ă܂����B
�Ȃ�ł���ȉ�������TDP34W���x(Merom)�Ɏ��܂�̂����������s�v�c�ł���B
�Ȃ�ɂ���A�g���[�X�L���b�V���̗p��{�C�ŐM���Ă܂����B
���܂��o�����X���Ƃ�Ώȓd�͋Z�p�ƍ����\�𗼗�����Z�p�ɂȂ肤��Ǝv����
���ۃI���S�����C�X���G�������̐����CPU�̓g���[�X�L���b�V���̗p�̂悤�ł����B
�Ȃ�ɂ���A1�X���b�h�̐��\���グ�邽�߂̋Z�p�͈��������K�v�ɂȂ�Ǝv���܂��B
�N���b�N���グ���Ȃ����珮�X�ˁB
90nm��NetBurst�̎��s�����炩�ɂȂ�܂ł�CoreMA�̓��o�C���p�̃A�[�L�e�N�`���������̂�
SIMD���j�b�g��64bit�ŁASSE�̓�OPs�t���[�W�����ł����̂Ǝv���Ă܂����B
�Ȃ�ł���ȉ�������TDP34W���x(Merom)�Ɏ��܂�̂����������s�v�c�ł���B
�Ȃ�ɂ���A�g���[�X�L���b�V���̗p��{�C�ŐM���Ă܂����B
���܂��o�����X���Ƃ�Ώȓd�͋Z�p�ƍ����\�𗼗�����Z�p�ɂȂ肤��Ǝv����
���ۃI���S�����C�X���G�������̐����CPU�̓g���[�X�L���b�V���̗p�̂悤�ł����B
�Ȃ�ɂ���A1�X���b�h�̐��\���グ�邽�߂̋Z�p�͈��������K�v�ɂȂ�Ǝv���܂��B
�N���b�N���グ���Ȃ����珮�X�ˁB
�_���S�̓A�t�H���肾�ȁB
K8L���Ɖ]�X�ƌ����B
������K8�̓_���S�̎v�f�ƈ����Conroe��萫�\�������A�_���S�Ɍ��킹��Ɛv�~�X�̋�CPU�ƂȂ�B
����ǁAK8L�͈Ⴄ�̌�������B
AMD�̍L���M���ċ^��ʂ͉̂��̂�?
K8L�̓_���S�Ɍ��킹��Ƌ�CPU�A����ȋ�CPU�������Ȃ�AMD�̍L������̐M���Ă���̂��������Ă���B
K8L���Ɖ]�X�ƌ����B
������K8�̓_���S�̎v�f�ƈ����Conroe��萫�\�������A�_���S�Ɍ��킹��Ɛv�~�X�̋�CPU�ƂȂ�B
����ǁAK8L�͈Ⴄ�̌�������B
AMD�̍L���M���ċ^��ʂ͉̂��̂�?
K8L�̓_���S�Ɍ��킹��Ƌ�CPU�A����ȋ�CPU�������Ȃ�AMD�̍L������̐M���Ă���̂��������Ă���B
K8��Conroe��萫�\��������K8�͐v�~�X�̋�CPU
K8������K8L����
�Ƃ����_�������łɔj�]���Ă��ǁA�����ē���_���Ō����̂Ȃ�
K8�̑����ɂ��y�Ȃ�������CPU��Netburst�������Ȃ�����Intel��
Conroe�ݏo���������������āA���ƂȂ�Ǝv�����ǂˁB
�܂����ɂ���A������������ˁH
�ǂ��̉�Ђ̊Ŕw�����Ă邩�ŁA�����̐��\���ς��킯�ł��Ȃ��B
K8������K8L����
�Ƃ����_�������łɔj�]���Ă��ǁA�����ē���_���Ō����̂Ȃ�
K8�̑����ɂ��y�Ȃ�������CPU��Netburst�������Ȃ�����Intel��
Conroe�ݏo���������������āA���ƂȂ�Ǝv�����ǂˁB
�܂����ɂ���A������������ˁH
�ǂ��̉�Ђ̊Ŕw�����Ă邩�ŁA�����̐��\���ς��킯�ł��Ȃ��B
540 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/20(��) 02:55:23 ID:4sGRX40G
���̎���ɂ��������̂���邾���ł��傤�B
CoreMA�ɂ����Ƒ����ɒ��肵�Ă��Ƃ��Ă�90nm�ō��Ă��Ƃ͎v���Ȃ��B
�V���O���R�A�ł������炭Tejas�Ȃ݂̋���_�C�ɂȂ��Ă��͂��B
Pentium D�����āA90nm����͈��|�I�ɕ����Ă�����
65nm�v���Z�X�ɂȂ���Athlon64 X2�Ƃ��߂͂�邾���̏���d�̓����W�ɗ��������A
���\�̏o����N���b�N�܂ŏグ����悤�ɂȂ��Ă�B
����Intel���v���Z�X�Ń��[�h���A�������V�A�[�L�����Ń��[�h���Ă邩�炱��������
�Ȃ��Ă邯�ǃv���Z�X���[���͌݊p�ɂȂ�A�V�A�[�L�������B
�㔭�̋��݂�AMD�����[�h�ɓ]���Ă�����s�v�c�͂Ȃ��B
K8L��K8�̊g���ɂ����Ȃ��Ȃ�ACMA��CPUID�������Ƃ���Pentium Pro�̊g���̊g���ł����B
�����ł̗D�ʂ͂ǂ���ɌX�����͔��������Ǖ��������͏\���t�]�\�ȃX�y�b�N�ł���B
CoreMA�ɂ����Ƒ����ɒ��肵�Ă��Ƃ��Ă�90nm�ō��Ă��Ƃ͎v���Ȃ��B
�V���O���R�A�ł������炭Tejas�Ȃ݂̋���_�C�ɂȂ��Ă��͂��B
Pentium D�����āA90nm����͈��|�I�ɕ����Ă�����
65nm�v���Z�X�ɂȂ���Athlon64 X2�Ƃ��߂͂�邾���̏���d�̓����W�ɗ��������A
���\�̏o����N���b�N�܂ŏグ����悤�ɂȂ��Ă�B
����Intel���v���Z�X�Ń��[�h���A�������V�A�[�L�����Ń��[�h���Ă邩�炱��������
�Ȃ��Ă邯�ǃv���Z�X���[���͌݊p�ɂȂ�A�V�A�[�L�������B
�㔭�̋��݂�AMD�����[�h�ɓ]���Ă�����s�v�c�͂Ȃ��B
K8L��K8�̊g���ɂ����Ȃ��Ȃ�ACMA��CPUID�������Ƃ���Pentium Pro�̊g���̊g���ł����B
�����ł̗D�ʂ͂ǂ���ɌX�����͔��������Ǖ��������͏\���t�]�\�ȃX�y�b�N�ł���B
�Ƃ肠����ʧʧ�ł�����������̈����҂Ƃ�����ݺނ̗\����wktk���Ƃ����B
�O������Ă߁[�̂���H���Ă�邩��ȁI
�O������Ă߁[�̂���H���Ă�邩��ȁI
�����܂ł̈�A�̔����ŁA�_���S���A�t�H�Œm�������Ȃ͖̂��炩���Ǝv�����A
�����Ƃ͌����A�ςȐ錾����̂͂�߂Ƃ��B
�����Ƃ͌����A�ςȐ錾����̂͂�߂Ƃ��B
ID:SzK9d2Cj ���A�t�H�Œm�������ł͖������������Ă���邻���ł��B
�ቴ�l���㗝�ŁA
�Ă߂���A��[�����̌������ۂ����ĕ�����B
K8L�ɑ���Ȗ������˂����A����ɂ��B
��H�𑝂₵�܂��Ƃ��A�@�\���グ�܂��Ƃ������Ă����ȁ`�A
���ꂪ�{���Ɏ��������̂��͕����o�Ă݂Ȃ����Ƃɂ͕������̂���B
�������A��H�𑝂₵����A�ꕔ�̐��\����グ���肷��ƁA�ǂ����ɂ��̂�����N����A�����ȒP�ɐ��\���オ���˂��B
������g���[�h�I�t�ƌ����̂���B
�_���S�̃A�t�H�͂���ȓ�����O�̂��Ƃ�����K8L���}���Z�[���Ă��邩��@�����B
���̒��Â��˂����A�����ƃV���L���Ƃ���A�V���b�L���ȁB
�Ă߂���A��[�����̌������ۂ����ĕ�����B
K8L�ɑ���Ȗ������˂����A����ɂ��B
��H�𑝂₵�܂��Ƃ��A�@�\���グ�܂��Ƃ������Ă����ȁ`�A
���ꂪ�{���Ɏ��������̂��͕����o�Ă݂Ȃ����Ƃɂ͕������̂���B
�������A��H�𑝂₵����A�ꕔ�̐��\����グ���肷��ƁA�ǂ����ɂ��̂�����N����A�����ȒP�ɐ��\���オ���˂��B
������g���[�h�I�t�ƌ����̂���B
�_���S�̃A�t�H�͂���ȓ�����O�̂��Ƃ�����K8L���}���Z�[���Ă��邩��@�����B
���̒��Â��˂����A�����ƃV���L���Ƃ���A�V���b�L���ȁB
Conroe�̓u�c������o���O�����ݾ����X���×����Ă��킯������
����ɂ���ȑf�l�Șb��莗��ł����ł��}�j�A�b�N�Șb�̂ق����ǂݎ�Ƃ��Ėʔ����B
K8L�ɂ��ăl�K�e�B�u�Ȍ������������A��ݺނ̃|�W�e�B�u�Ȉӌ��͖ʔ����B
���O�̃��X�͂܂��B
����ɂ���ȑf�l�Șb��莗��ł����ł��}�j�A�b�N�Șb�̂ق����ǂݎ�Ƃ��Ėʔ����B
K8L�ɂ��ăl�K�e�B�u�Ȍ������������A��ݺނ̃|�W�e�B�u�Ȉӌ��͖ʔ����B
���O�̃��X�͂܂��B
�u���\���オ��Ƃ͌���Ȃ��v���Č��������Ȃ甒�s�ł��o�����k�فB
SSE�����ŐG���Čo�������܂��Č���Ă鍁��t�ɉ�������q�ׂ���
�A�z�Ƃ����Ċ|�����Ă������͂������B
SSE�̃��j�b�g���{���ɂ�鉉�Z�X���[�v�b�g����ɍ��킹�A�t�F�b�`�ш���g�傷��̂͑Ó��B
���������[�h�t�����Z�̃l�b�N���������邽�߁A�����I�Ȗ��ߑш�͌��シ��B
����Ƀt�F�b�`�ш�̌����64�r�b�g�ėp���Z�̃X���[�v�b�g������͂����B
���Ƃ��� add r64, imm64 ��10�o�C�g�B�t�F�b�`�ш�16byte�Ȃ�3���ߎ�荞�ނ̂�
���������A32byte�Ȃ�]�T���B
Core2���L���b�V���e�ʂ͏��Ȃ����A�����R����HT�o�X�̑ш�͂���B
�����̃s�[�N���\�͍����Ȃ����낤���A�������߈��肵�����\�͓��₷���Ȃ�B
�Z�p�I�Ȗ��ł���AK7/K8��L1���߃L���b�V���Ƀt�F�b�`����ۂ�
�v���f�R�[�h���ς܂��Ă���̂ŁA�t�F�b�`��{�����₷���B
����ɁA�v���f�R�[�h����p���ăf�R�[�h�O�̒i�K�Ŕėp�����p�C�v��FP/SIMD�p�C�v��
�U�蕪���Ă��܂��̂ŁA�f�R�[�_�̕��S���y���A66H�v���t�B�b�N�X�Ȃǂ̖�������Ȃ��čςށB
Core2�̓t�F�b�`�ш��32byte�ɂ��Ȃ��������R�͑z���ɓ�Ȃ��B
Core2�̃v���f�R�[�h�̓t�F�b�`��Ȃ̂ŁA�t�F�b�`�ш�𑝂₵�Ă�
���x�̓v���f�R�[�h���j�b�g���l�b�N�ɂȂ邾�낤�B
�g���[�X�L���b�V���̔��z���̂�K7/K8�̃v���f�R�[�h���߃L���b�V�����
�i���̂ł������͂��Ȃ̂ɁAP6�ɑލs���Ă���B
�A���������B
���́A���ߒ��������Ȃ�ƃ�OPs�̋������ǂ����Ȃ��Ȃ�4issue���A
��胊�b�`�ȃI�y���[�V���������肵�ċ����̂ł���3issue��
�ǂ��������\���o���₷�������ȁB
SSE�����ŐG���Čo�������܂��Č���Ă鍁��t�ɉ�������q�ׂ���
�A�z�Ƃ����Ċ|�����Ă������͂������B
SSE�̃��j�b�g���{���ɂ�鉉�Z�X���[�v�b�g����ɍ��킹�A�t�F�b�`�ш���g�傷��̂͑Ó��B
���������[�h�t�����Z�̃l�b�N���������邽�߁A�����I�Ȗ��ߑш�͌��シ��B
����Ƀt�F�b�`�ш�̌����64�r�b�g�ėp���Z�̃X���[�v�b�g������͂����B
���Ƃ��� add r64, imm64 ��10�o�C�g�B�t�F�b�`�ш�16byte�Ȃ�3���ߎ�荞�ނ̂�
���������A32byte�Ȃ�]�T���B
Core2���L���b�V���e�ʂ͏��Ȃ����A�����R����HT�o�X�̑ш�͂���B
�����̃s�[�N���\�͍����Ȃ����낤���A�������߈��肵�����\�͓��₷���Ȃ�B
�Z�p�I�Ȗ��ł���AK7/K8��L1���߃L���b�V���Ƀt�F�b�`����ۂ�
�v���f�R�[�h���ς܂��Ă���̂ŁA�t�F�b�`��{�����₷���B
����ɁA�v���f�R�[�h����p���ăf�R�[�h�O�̒i�K�Ŕėp�����p�C�v��FP/SIMD�p�C�v��
�U�蕪���Ă��܂��̂ŁA�f�R�[�_�̕��S���y���A66H�v���t�B�b�N�X�Ȃǂ̖�������Ȃ��čςށB
Core2�̓t�F�b�`�ш��32byte�ɂ��Ȃ��������R�͑z���ɓ�Ȃ��B
Core2�̃v���f�R�[�h�̓t�F�b�`��Ȃ̂ŁA�t�F�b�`�ш�𑝂₵�Ă�
���x�̓v���f�R�[�h���j�b�g���l�b�N�ɂȂ邾�낤�B
�g���[�X�L���b�V���̔��z���̂�K7/K8�̃v���f�R�[�h���߃L���b�V�����
�i���̂ł������͂��Ȃ̂ɁAP6�ɑލs���Ă���B
�A���������B
���́A���ߒ��������Ȃ�ƃ�OPs�̋������ǂ����Ȃ��Ȃ�4issue���A
��胊�b�`�ȃI�y���[�V���������肵�ċ����̂ł���3issue��
�ǂ��������\���o���₷�������ȁB
>>546
���̈ӌ����������̂Ȃ�K8�͉��̂����Ȃ��Ă��Ȃ�?
K8��AMD64�̌��c�ł���w
����܂ł͏o���Ȃ��������ǁA���͏o������Ă�?
���̈ӌ����������̂Ȃ�K8�͉��̂����Ȃ��Ă��Ȃ�?
K8��AMD64�̌��c�ł���w
����܂ł͏o���Ȃ��������ǁA���͏o������Ă�?
�����Pentium M��64bit�Ή����Ȃ��������R���悤�Ȃ��̂��̂��B
�r������܂��B
�v���Z�X���[���̏k����X�e�b�s���O�̉��ǂɔ�����K8�͐i�����Ă���B
L/S�ш�̔{�����ASSE3�̗p���f���A���R�A�����AHT��1600MHz���B
130nm��90nm�̊Ԃɂǂꂾ���̉��ǂ��s��ꂽ�Ǝv���H
65nm�ł͂����������g�����o�����������\�̃X�y�b�N�����Ȃ����R��
����Ƃ����Ȃ�A�����Ă��炢�������̂����B
�r������܂��B
�v���Z�X���[���̏k����X�e�b�s���O�̉��ǂɔ�����K8�͐i�����Ă���B
L/S�ш�̔{�����ASSE3�̗p���f���A���R�A�����AHT��1600MHz���B
130nm��90nm�̊Ԃɂǂꂾ���̉��ǂ��s��ꂽ�Ǝv���H
65nm�ł͂����������g�����o�����������\�̃X�y�b�N�����Ȃ����R��
����Ƃ����Ȃ�A�����Ă��炢�������̂����B
AMD�͂����̊Ԃ܂ŁAK8�͊����Ŋg������Ƃ���ȂǂȂ��Ƃق����Ă����̂�Y�ꂽ��?
>>548
�����B������̂�3�N�B
�オ�킸���������X�ɐ��\�������悤�Ƃ��AAthlon64 3000+�ȂǁA2�N�߂��l�i���ς��Ȃ������B
AM2���o��܂ł͂���3000+�������\�̗���Ă���Sempron���AAthlon�ɂȂ炢���\���̂܂ܒl�i���̂܂܁B
K8�����N�A�ė��N�Ɖ��ǂ͂���Ă������낤�B
��������őR�ł���̂��H
�����B������̂�3�N�B
�オ�킸���������X�ɐ��\�������悤�Ƃ��AAthlon64 3000+�ȂǁA2�N�߂��l�i���ς��Ȃ������B
AM2���o��܂ł͂���3000+�������\�̗���Ă���Sempron���AAthlon�ɂȂ炢���\���̂܂ܒl�i���̂܂܁B
K8�����N�A�ė��N�Ɖ��ǂ͂���Ă������낤�B
��������őR�ł���̂��H
K8L�Ŋg�����Ă���̂̓��j�b�g�̃f�[�^���ł�����
K8�p�C�v���C���̍\�����̂��̂ł͖������Ă̂͂킩���Ă��ȁH
K8�p�C�v���C���̍\�����̂��̂ł͖������Ă̂͂킩���Ă��ȁH
>>550
����������Ȃ�Intel��2�N�߂��ɂ킽���Ă��������鐫�\�����o���Ȃ��������낗
�����������s��͒���邩��ȁB
�悤�₭Intel�������o�����u����d�͓����萫�\�v�Ȃ炩�Ȃ���サ�Ă�ȁB
Pentium 4�̓L���b�V�����ʂ��炢�����ł��Ȃ��������A����ɔ�������d�͂����������B
�悤�₭���������̂�65nm�ɂȂ��Ă���B
Intel��HyperTransport�R�̃o�X�A�[�L�e�N�`�����o����́H
Opteron�R�ɑR�ł��Ȃ�����A���j�[�R�A�헪�]�X��
�����Č��ʂ��͖��邭�Ȃ��ȁB
����������Ȃ�Intel��2�N�߂��ɂ킽���Ă��������鐫�\�����o���Ȃ��������낗
�����������s��͒���邩��ȁB
�悤�₭Intel�������o�����u����d�͓����萫�\�v�Ȃ炩�Ȃ���サ�Ă�ȁB
Pentium 4�̓L���b�V�����ʂ��炢�����ł��Ȃ��������A����ɔ�������d�͂����������B
�悤�₭���������̂�65nm�ɂȂ��Ă���B
Intel��HyperTransport�R�̃o�X�A�[�L�e�N�`�����o����́H
Opteron�R�ɑR�ł��Ȃ�����A���j�[�R�A�헪�]�X��
�����Č��ʂ��͖��邭�Ȃ��ȁB
Opteron�ɑR�ł��Ȃ�����A
Opteron��4�\�P�b�g�ȏ�Ŏ��Ě�����Ă�����B
�T�[�o�[�S�s���10%�ɂ������Ȃ��s��Ŋ撣���Ă���B
2�\�P�b�g�܂łȂ�HT�������R�������͖͂w�ǂȂ��Ȃ邩��ȁB
�T�[�o�[�S�s���10%�ɂ������Ȃ��s��Ŋ撣���Ă���B
2�\�P�b�g�܂łȂ�HT�������R�������͖͂w�ǂȂ��Ȃ邩��ȁB
>K8L��K8�̊g���ɂ����Ȃ��Ȃ�ACMA��CPUID�������Ƃ���Pentium Pro�̊g���̊g���ł����B
�g�����낤���Ȃ낤���A���\�ŏ��ĂȂ���܂��ɕ������̂Ȃ�Ƃ��B
K8L�ƑΛ�����ׂ�CPU��Nehalem�ɂȂ��ĂȂ����Ƃ��F�肽����A�{�C�ŁB
����A�����Ȃ������������ꍇ���l�����Ă�������@>Nehalem���s��www
NetBurst���������g���ς���Ă邵�ACore�ȗ��������Ȃ��Ƃ͌�����Ȃ����A
��͂茻�����o�Ă��Ȃ����̂��ǂ����������͉̂Ώ��̌��ł���A���ہB
�g�����낤���Ȃ낤���A���\�ŏ��ĂȂ���܂��ɕ������̂Ȃ�Ƃ��B
K8L�ƑΛ�����ׂ�CPU��Nehalem�ɂȂ��ĂȂ����Ƃ��F�肽����A�{�C�ŁB
����A�����Ȃ������������ꍇ���l�����Ă�������@>Nehalem���s��www
NetBurst���������g���ς���Ă邵�ACore�ȗ��������Ȃ��Ƃ͌�����Ȃ����A
��͂茻�����o�Ă��Ȃ����̂��ǂ����������͉̂Ώ��̌��ł���A���ہB
4�\�P�b�g�͒m���8�\�P�b�g�ȏ�ɂȂ�Ƒ����Itanium�ł����B
Xeon�Ɣ䂵�Ă��������̔@��RAS�@�\��8�\�P�b�g�ȏ�̃n�C�G���h�s���_���̂͂�����Ɩ��d�ł́B
�t��������ƁAIPF�Ƌ���������Ă��Ƃ�PPC��SPARC�Ƃ���������킯�ŁB
Xeon�Ɣ䂵�Ă��������̔@��RAS�@�\��8�\�P�b�g�ȏ�̃n�C�G���h�s���_���̂͂�����Ɩ��d�ł́B
�t��������ƁAIPF�Ƌ���������Ă��Ƃ�PPC��SPARC�Ƃ���������킯�ŁB
Opteron�����ꂩ�甄���s��́A4�\�P�b�g�ȏ�ł̎��삩�A������T�[�o�[�s�ꂾ���̂悤�ȁE�E
���A����������w�W��f���p�X�[�p�[�R���s���[�^��CPU���v������B
����ȂƂ��낾��B
��t�����đ�R�ׂ��Ă��������B
���A����������w�W��f���p�X�[�p�[�R���s���[�^��CPU���v������B
����ȂƂ��낾��B
��t�����đ�R�ׂ��Ă��������B
0.35��m, 180nm, 90nm�Ƃ��Ă��̃y�[�X�Ȃ玟�̒�؊���45nm���ȁB
���Ƃ��A�ǂ��������|�I�D�ʂȏ������Ƃ��n���������Ƃ͍l���Ȃ��B
���������������Ȃ��s��͒���邾�������Ęb�B
K8L���R�P��Core2�����l���肵���ق����������Ďv���l�͂���݂����ł����B
���Ƃ��A�ǂ��������|�I�D�ʂȏ������Ƃ��n���������Ƃ͍l���Ȃ��B
���������������Ȃ��s��͒���邾�������Ęb�B
K8L���R�P��Core2�����l���肵���ق����������Ďv���l�͂���݂����ł����B
K8L�͓]�����������͊������ȁB
Conroe�ɓ͂����A���z�Z�[�������҂���B
�Z�J���hPC�ɍœK���Ǝv���ˁB
���r���[�ɓ����\���ƁA�ǂ�������i�͉�����Ȃ����AK8L���D�G�������Ƃ��Ă�45nm�ɒ����ڍs����Intel��
�����ȒP�ɒl�������Ȃ�����낭�Ȃ��Ƃɂ͂Ȃ���B
Conroe�ɓ͂����A���z�Z�[�������҂���B
�Z�J���hPC�ɍœK���Ǝv���ˁB
���r���[�ɓ����\���ƁA�ǂ�������i�͉�����Ȃ����AK8L���D�G�������Ƃ��Ă�45nm�ɒ����ڍs����Intel��
�����ȒP�ɒl�������Ȃ�����낭�Ȃ��Ƃɂ͂Ȃ���B
>>556
Itanium������ł��錏�ɂ���
Itanium������ł��錏�ɂ���
>>556
Itanium��4socket���W�������B
Xeon�Ɠ���FSB�g���Ă邩��ȁB
��K�̓T�[�o��4way���Z�b�g�ɂ��ăZ�b�g�Ԃ��`�b�v�Z�b�g�Ōq���ł�B
����Sun��X4600��IA�T�[�o�ɂ�����Ȃ��Ȃ����S���������B
���C���t���[���s���N�H�ł���Ɩʔ������ǁB
Itanium��4socket���W�������B
Xeon�Ɠ���FSB�g���Ă邩��ȁB
��K�̓T�[�o��4way���Z�b�g�ɂ��ăZ�b�g�Ԃ��`�b�v�Z�b�g�Ōq���ł�B
����Sun��X4600��IA�T�[�o�ɂ�����Ȃ��Ȃ����S���������B
���C���t���[���s���N�H�ł���Ɩʔ������ǁB
>>560
IPF��3�����܂ł͊J�������肵�Ă��錏
>>561
ttp://www.geocities.jp/andosprocinfo/wadai06/20060715.htm
>X4600�̓��C���t���[���قǂ̌��S���͂���܂���
IPF��3�����܂ł͊J�������肵�Ă��錏
>>561
ttp://www.geocities.jp/andosprocinfo/wadai06/20060715.htm
>X4600�̓��C���t���[���قǂ̌��S���͂���܂���
�c�q�̐l��INTEL�h���F�����Ă邪�A�N������Ƃ͈����
�n�[�h�����ł��̍l���ĂȂ��������Ǝv�����B
�\�t�g�����Ẵn�[�h�����\�t�g�����_���猩��ƁA�����݂�C2D�̎�_�Č��\����B
���ɃT�[�o�s��ōl����ƂˁB
�n�[�h�����ł��̍l���ĂȂ��������Ǝv�����B
�\�t�g�����Ẵn�[�h�����\�t�g�����_���猩��ƁA�����݂�C2D�̎�_�Č��\����B
���ɃT�[�o�s��ōl����ƂˁB
�������� Opteron 32CPU ���������� Horus �͂ǂ��Ȃ�����?
�����ł��Ȃ��悤�Ȃӂ��Ȃ�ł����
�Ⴆ��Xen��HVM�g�����Ǝv�������A�����VT���Ǝg�����ɂȂ�Ȃ��B
AMD��SVT�ƈ���āA�����������I/O����G�~�����[�g���Ă���Ȃ�����B
���z���Z�p�̓����^���I�Ȃɂ��g���Ă��邵�A
��ƃx�[�X�ł����[�h�o�����V���O�Ɖ��z���Z�p��g�ݍ��킹��
�K�ȃ��\�[�X�z�u���邱�ƂŃR�X�g��}������B
���������Ӗ��Ō����CMA�̓T�[�o�s��ł͔��Ɋ낤���B
�܂�K8L���ė��N�ɐL�т�Ȃ�A����܂łɎ��ł��Ԃ͂���Ǝv�����B
�Ⴆ��Xen��HVM�g�����Ǝv�������A�����VT���Ǝg�����ɂȂ�Ȃ��B
AMD��SVT�ƈ���āA�����������I/O����G�~�����[�g���Ă���Ȃ�����B
���z���Z�p�̓����^���I�Ȃɂ��g���Ă��邵�A
��ƃx�[�X�ł����[�h�o�����V���O�Ɖ��z���Z�p��g�ݍ��킹��
�K�ȃ��\�[�X�z�u���邱�ƂŃR�X�g��}������B
���������Ӗ��Ō����CMA�̓T�[�o�s��ł͔��Ɋ낤���B
�܂�K8L���ė��N�ɐL�т�Ȃ�A����܂łɎ��ł��Ԃ͂���Ǝv�����B
567 �FMAC�I�^��546 �����F2006/07/20(��) 19:36:42 ID:opnP7RHY
>>546
�@�@-----------------------------
�@�@SSE�̃��j�b�g���{���ɂ�鉉�Z�X���[�v�b�g����ɍ��킹�A�t�F�b�`�ш���g�傷��̂͑Ó��B
�@�@-----------------------------
SIMD (Single Instruction Multiple Data)��C�����ʂ薽�߂�����̃f�[�^�����ʂ��グ���@���B
�Ȃ�SSE�̋��������߃t�F�b�`�ɒ�������B�B�B�Ȃ�ăg���f�������Ó��Ȃ�(��)
�@�@-----------------------------
�@�@SSE�̃��j�b�g���{���ɂ�鉉�Z�X���[�v�b�g����ɍ��킹�A�t�F�b�`�ш���g�傷��̂͑Ó��B
�@�@-----------------------------
SIMD (Single Instruction Multiple Data)��C�����ʂ薽�߂�����̃f�[�^�����ʂ��グ���@���B
�Ȃ�SSE�̋��������߃t�F�b�`�ɒ�������B�B�B�Ȃ�ăg���f�������Ó��Ȃ�(��)
>>567
K8L�ɂ����āA�\�z�����1clk������̃s�[�N�X���[�v�b�g�́A
��ʓI�Ȑ������Z��3���߁A����SIMD��2���߁A
80bitFPU�̉��Z��2���߁AFP��SIMD��2���߁B
�܂�A���ʂ̖��߂�SIMD���߂ŃX���[�v�b�g�͂��܂�ς��Ȃ��B
�����āA���ߒ�������Ȃɂ͈��Ȃ����A��͂�SIMD�̕��������B
> �����ʂ薽�߂�����̃f�[�^�����ʂ��グ���@���B
SSE�����ŁA���߂̃o�C�g��������̏������Ԃ͒Z���Ȃ����̂��B
�����疽�߃t�F�b�`�ш悪�d�v�ɂȂ�B
K8L�ɂ����āA�\�z�����1clk������̃s�[�N�X���[�v�b�g�́A
��ʓI�Ȑ������Z��3���߁A����SIMD��2���߁A
80bitFPU�̉��Z��2���߁AFP��SIMD��2���߁B
�܂�A���ʂ̖��߂�SIMD���߂ŃX���[�v�b�g�͂��܂�ς��Ȃ��B
�����āA���ߒ�������Ȃɂ͈��Ȃ����A��͂�SIMD�̕��������B
> �����ʂ薽�߂�����̃f�[�^�����ʂ��グ���@���B
SSE�����ŁA���߂̃o�C�g��������̏������Ԃ͒Z���Ȃ����̂��B
�����疽�߃t�F�b�`�ш悪�d�v�ɂȂ�B
����
���ߒ�(REX�Ƒ��l�͊܂܂Ȃ�)
x87: 2 Byte
SIMD-SP: 3 Byte
SIMD-DP: 4 Byte
�A�h���b�V���O�ɂ�閽�ߒ��̑���
[reg] +0 Byte
[reg +disp8] +1 Byte
[reg +reg*n] +1 Byte
[reg +reg*n +disp8] +2 Byte
[reg +disp32] +4 Byte
[reg +reg*n +disp32] +5 Byte
(n=1,2,4,8)
���ߒ�(REX�Ƒ��l�͊܂܂Ȃ�)
x87: 2 Byte
SIMD-SP: 3 Byte
SIMD-DP: 4 Byte
�A�h���b�V���O�ɂ�閽�ߒ��̑���
[reg] +0 Byte
[reg +disp8] +1 Byte
[reg +reg*n] +1 Byte
[reg +reg*n +disp8] +2 Byte
[reg +disp32] +4 Byte
[reg +reg*n +disp32] +5 Byte
(n=1,2,4,8)
>>557
���������A�����H��̃X�p�R������Opteron���ς�ł�����H
���������A�����H��̃X�p�R������Opteron���ς�ł�����H
Itanium�Ȃ�ĒN�����́H
http://enterprise.watch.impress.co.jp/cda/topic/2005/12/16/6853.html
�uItanium�x�[�X�̃V�X�e���̔���グ�́A�T����IBM�������Ă���̂ł��B
���ɓ��{�s��̓��C���t���[������̃��v���[�X��RISC����̃}�C�O���[�V����
�Ń��[�h���Ă��܂��BItanium�x�[�X�̃V�X�e���̔���グ�́ASPARC�x�[�X��
�V�X�e����1.6�{�ɁAPOWER�x�[�X�̃V�X�e����1.17�{�Ƃ����������o�Ă��܂��B�v
http://enterprise.watch.impress.co.jp/cda/topic/2006/02/07/7170.html
�uItanium�̓G���^�[�v���C�Y����щȊw�Z�p����ł̓����𒆐S�Ɋm���ɃV�F�A��
�L���Ă���v�u�ߔN��RISC����̈ڍs���������Ă���B�Ƃ�킯���{�ł�Sun��
SPARC�V�X�e������̈ڍs��160���AIBM��POWER�A�[�L�e�N�`���̃V�X�e��
����̈ڍs��117���ƁA���E�ɂ�����RISC����̈ڍs�g�����h���������Ă���v
http://enterprise.watch.impress.co.jp/cda/foreign/2006/02/21/7251.html
IDC�ɂ��ƁAItanium�T�[�o�[�̔F�m�x�͌��サ�Ă���A�w���ӎv��������Ƃ�
�����Ă���Ƃ����B�܂��A���p���̊�Ƃ̌ڋq�����x�������A�T���čD�ӓI�Ȕ���
�������Ƃ����B ���̂ق��AHP��PA-RISC�T�[�o�[�ڋq��3����2��Itanium�T�[�o�[
�ւ̈ڍs���������Ă��邱�Ƃ����������B�K�p����Ƃ��ẮAERP��CRM�Ȃǂ�
�~�b�V�����N���e�B�J������ł̗̍p����������Ƃ��낪�����Ƃ����B
http://enterprise.watch.impress.co.jp/cda/static/image/2006/04/07/intel654.jpg
{kind=link}
�uIDC�ɂ���Itanium�x�[�X�E�T�[�o�|�̏o���z��2004�N��14���h���ɑ���
2009�N�ɂ�66���h���܂Ő�������Ɨ\�����Ă���B�܂��A���{�ɂ����Ă��o�ׂ�
�L�тĂ���A2005�N�����ɂ����Ă�SPARC������o���z�������v
>>572
�ɂ킩�ɐM����B
�ɂ킩�ɐM����B
NEC�Ɠ������͓���Ă邩�炩�A���{�h�����hItanium�̃V�X�e��������Ă���
575 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/20(��) 22:50:53 ID:4sGRX40G
AMD��2�{��128bit���[�h���j�b�g����g���č��������悤�Ƃ��Ă����
�����L���Ɏg���ɂ�16�o�C�g����t�F�b�`�ш悪�s������B
���l��Core2����艺��v256k�̑ш�����ɂ����ł���ȁB
MMX���Ɩ��ߒ��͊�{3�o�C�g�������B
�����L���Ɏg���ɂ�16�o�C�g����t�F�b�`�ш悪�s������B
���l��Core2����艺��v256k�̑ш�����ɂ����ł���ȁB
MMX���Ɩ��ߒ��͊�{3�o�C�g�������B
�ց[�AK8L��L1�f�[�^�L���b�V�����ăX�Q�[�����B
�m��Ȃ�������B
�m��Ȃ�������B
577 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/20(��) 23:12:30 ID:4sGRX40G
�܂�128bit/clock�ł���BK8L�҂��ł��ȁB
�܂��A�����ōő���NetBurst�ł��傤�ȁB
�܂��A�����ōő���NetBurst�ł��傤�ȁB
>573
�L���̓��t���݂�Ɣ����ɒ��v�O��c
�L���̓��t���݂�Ɣ����ɒ��v�O��c
Itanium���ēs�s�`�����Ǝv���Ă��B
Itanium�ȂǑ��݂��Ȃ�
Itanium�̒��̐l�ȂǑ��݂��Ȃ�
�@�@����@�@�@�@�@�@�@�@�@�@�Ȃ�
�A���~�j�E���@�@�@�@�C�^�j�E��
���邠���S�ȁ@�@�g���r�A�̐�
����Ё`�X�̒��@�@�O���[���O���[��
�A���~�j�E���@�@�@�@�C�^�j�E��
���邠���S�ȁ@�@�g���r�A�̐�
����Ё`�X�̒��@�@�O���[���O���[��
�㓡�O��Weekly�C�O�j���[�X
�R�v���Z�b�T�ւ̕��U���i��AMD�̎�����CPU
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
��AMD��CPU�J���Ɩ��ڂɗ��ރR�v���Z�b�T�헪
���e�ЂňقȂ�T�u�v���Z�b�T�̓����̎d��
�����Ђ̃R�v���Z�b�T��AMD CPU�ɓ�������
��CPU�ɓ�������R�v���Z�b�T�͎s�ꂪ���߂�
���s�N����AMD�̔ėp�v���Z�b�T�R�A�̍���̔��W
���v���Z�b�T�R�A�̉��v�̓p�[�c�P�ʂōs�Ȃ��Ă䂭
���ėp�v���Z�b�T�R�A�W��R�v���Z�b�T���U�ւƕς��헪
�R�v���Z�b�T�ւ̕��U���i��AMD�̎�����CPU
http://pc.watch.impress.co.jp/docs/2006/0721/kaigai289.htm
��AMD��CPU�J���Ɩ��ڂɗ��ރR�v���Z�b�T�헪
���e�ЂňقȂ�T�u�v���Z�b�T�̓����̎d��
�����Ђ̃R�v���Z�b�T��AMD CPU�ɓ�������
��CPU�ɓ�������R�v���Z�b�T�͎s�ꂪ���߂�
���s�N����AMD�̔ėp�v���Z�b�T�R�A�̍���̔��W
���v���Z�b�T�R�A�̉��v�̓p�[�c�P�ʂōs�Ȃ��Ă䂭
���ėp�v���Z�b�T�R�A�W��R�v���Z�b�T���U�ւƕς��헪
K10�����œ�����K8L�̂܂܂��Ď���
6�N��ɂ�K11�̑������������Ă��邾�낤��
6�N��ɂ�K11�̑������������Ă��邾�낤��
�����͐Â��ł��ˁE�E�E
���炭Kxx���ĕ\�L�͖����Ȃ��ł͂Ȃ����Ȃ��ƁB
���m�ȃR�A�̐�����͍���͖����Ǝv���邵�B
���炭Kxx���ĕ\�L�͖����Ȃ��ł͂Ȃ����Ȃ��ƁB
���m�ȃR�A�̐�����͍���͖����Ǝv���邵�B
�����̃\�t�g�����鐫�\�𗎂Ƃ��Ȃ����߂�K8�R�A�ɂ́A�قƂ�ǎ�����Ȃ����Ă��Ƃ���
[PATCH] Add alignment to amd family 10 instruction tests
ttp://sourceware.org/ml/binutils/2006-07/msg00261.html
�t�F�b�`��32 Byte�����A���C�����g��16 Byte�ł����悤��
�Ƃ����AMD Family 10 = K10 = K8L �Ȃ̂��낤��
ttp://sourceware.org/ml/binutils/2006-07/msg00261.html
�t�F�b�`��32 Byte�����A���C�����g��16 Byte�ł����悤��
�Ƃ����AMD Family 10 = K10 = K8L �Ȃ̂��낤��
CPU�̋@�\�u���b�N�����W�����[������邩��
���m��Kxx������Č����͓̂���Ȃ邩�Ȃ��Ǝv�����B
Compute core���ς��ΐ�������Č����邩�ȁH
���m��Kxx������Č����͓̂���Ȃ邩�Ȃ��Ǝv�����B
Compute core���ς��ΐ�������Č����邩�ȁH
>>588
�܁A�������ɃR�A�͓����������̉��ǂ̂܂܂ł��A���Ƃ̓u�����h���悾��
�uAthlon64�v�u�����h�ɉ�����t����Ƃ�
�uAthlon�v�u�����h�ɂ��邩
����Ƃ��ʂ̃u�����h�ɂ���̂��B
�����AGeForce��Radeon�݂����ɁA�O����̃\�t�g���g���Ƒ��x���ቺ����Ƃ��N�����獢���
�܁A�������ɃR�A�͓����������̉��ǂ̂܂܂ł��A���Ƃ̓u�����h���悾��
�uAthlon64�v�u�����h�ɉ�����t����Ƃ�
�uAthlon�v�u�����h�ɂ��邩
����Ƃ��ʂ̃u�����h�ɂ���̂��B
�����AGeForce��Radeon�݂����ɁA�O����̃\�t�g���g���Ƒ��x���ቺ����Ƃ��N�����獢���
590 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/22(�y) 22:30:51 ID:s44Z1s9K
���낻��Athlon 65�o����
�ނ���Athlon'07
Athlon XP�ł���
Athlon Vis��
>>593
����A���{��ŃA�Z���u��������������
����A���{��ŃA�Z���u��������������
Athlon128 ����B
�v���t�B�b�N�X�𑝂₵�āA�ėp���W�X�^���S�{�̂U�S���炢�ɂ���A
�܂��܂����\�E�v���o�����������B
�v���t�B�b�N�X�𑝂₵�āA�ėp���W�X�^���S�{�̂U�S���炢�ɂ���A
�܂��܂����\�E�v���o�����������B
���\������N���b�N��f���i���o�[�ŕ\�����Ă����̂͏���҂Ƃ��Ă͕���₷���������ǁA
�R�v���Z�b�T�̐��\��������������₷���`�ŕ\������̂͂��Ȃ����ˁB
�ǂ�����낤�B
�R�v���Z�b�T�̐��\��������������₷���`�ŕ\������̂͂��Ȃ����ˁB
�ǂ�����낤�B
>>590
���N�܂ő҂Ă�w
���N�܂ő҂Ă�w
598 �FSocket774�F2006/07/24(��) 03:36:59 ID:f3ofoMCg
���҂�����
599 �FSocket774�F2006/07/24(��) 03:40:01 ID:t55PY74j
���̃A���h��
Athlon Conroe
Athlon Conroe
2007�NQ1 AMD�����65nm Intel��4�R�ACPU����
2007�N�� AMD�����4�R�ACPU���� Intel��45nm�v���Z�X��
2008�N AMD����ƐVCPU K8L����
2009�N Intel 8�R�ACPU���� 32nm�v���Z�X��
2007�N�� AMD�����4�R�ACPU���� Intel��45nm�v���Z�X��
2008�N AMD����ƐVCPU K8L����
2009�N Intel 8�R�ACPU���� 32nm�v���Z�X��
ATI�ƍ���������������ǁA������ċZ�p�I�Ȃ��̂ɂǂ̂��炢�e�����邩�ȁB
���ǂ̂Ƃ���CAMD���v�������Ƃ��ł����u�����v�R�v�����Ă̂�GPU�����������B�B�B��(��)
http://pc.watch.impress.co.jp/docs/2006/0725/amdati.htm
�@�@------------------------------
�@�@�yQ�z �����[�X�̒��ŏq�ׂ��Ă���CPU��GPU�̓����Ƃ����̂́A�_�C���x���ł̓�����
�@�@�@�@�Ӗ�����̂�
�@�@�yA�z �������B��X��1�̃_�C��CPU��GPU�����邱�Ƃ��v�悵�Ă���B���ׂĂ̎s���
�@�@�@�@�������������̂��������ɋ��߂��Ă���킯�ł͂Ȃ����A�j�[�Y�͂���B
�@�@------------------------------
http://pc.watch.impress.co.jp/docs/2006/0725/amdati.htm
�@�@------------------------------
�@�@�yQ�z �����[�X�̒��ŏq�ׂ��Ă���CPU��GPU�̓����Ƃ����̂́A�_�C���x���ł̓�����
�@�@�@�@�Ӗ�����̂�
�@�@�yA�z �������B��X��1�̃_�C��CPU��GPU�����邱�Ƃ��v�悵�Ă���B���ׂĂ̎s���
�@�@�@�@�������������̂��������ɋ��߂��Ă���킯�ł͂Ȃ����A�j�[�Y�͂���B
�@�@------------------------------
���̏ꍇ�A�R�v���ƌ�������
�g�ݍ������̓����v���Z�b�T�ł���i1�`�b�v�j
�R�v���͕ʂ̘H���ŁA���ꂩ��̌v��ł́H
�g�ݍ������̓����v���Z�b�T�ł���i1�`�b�v�j
�R�v���͕ʂ̘H���ŁA���ꂩ��̌v��ł́H
�����MAC���搶�������������琷��ɑ��R���Ă�����Ⴂ�܂��ˁB
���ꂩ�A���[�J�[���̑唼�͓����u�f�`������
�`�l�c�̏ꍇ�f�o�t�A�N�Z�X���b�o�t�o�R���ă������A�N�Z�X�ɂȂ邩��{�g���l�b�N�ɂȂ�
CPU+GPU�̂�ɂ���Β��ڃA�N�Z�X�ł���悤�ɂȂ邩������Ƃ������Ƃ��ȁH�H�H
�`�l�c�̏ꍇ�f�o�t�A�N�Z�X���b�o�t�o�R���ă������A�N�Z�X�ɂȂ邩��{�g���l�b�N�ɂȂ�
CPU+GPU�̂�ɂ���Β��ڃA�N�Z�X�ł���悤�ɂȂ邩������Ƃ������Ƃ��ȁH�H�H
�������낤�ˁB
�n�C�G���h���i�ɂ͑�e��&�L�ш�̃��������K�v�����A
CPU�ɃI���_�C��GPU���Ⴟ����Ɛ��\�s�����낤�ˁB
�I���_�C��GPU���g�p���A�ڑ���PCI-Express�Ȃ艽�Ȃ�A
�O���̃n�C�G���h��GPU���T�|�[�g����A�Ƃ����`�Ȃ�A
�I���_�C��GPU���̃A�N�Z�����[�g���]�߂�A�Ƃ����`�����z�I�ȗ\���B
�n�C�G���h���i�ɂ͑�e��&�L�ш�̃��������K�v�����A
CPU�ɃI���_�C��GPU���Ⴟ����Ɛ��\�s�����낤�ˁB
�I���_�C��GPU���g�p���A�ڑ���PCI-Express�Ȃ艽�Ȃ�A
�O���̃n�C�G���h��GPU���T�|�[�g����A�Ƃ����`�Ȃ�A
�I���_�C��GPU���̃A�N�Z�����[�g���]�߂�A�Ƃ����`�����z�I�ȗ\���B
���AHTX��GPU�ڑ��̖ڂ��łĂ��������ȁB
���̃n�C�G���hGPU���ƃ������ш��40GB/s���x�ł���B
���K8��DDR2-800�g����12.8GB/s�B
HT3.0�ł�20.8GB/s�����B
���ʂ�GPU������ɂ��Ă��n�C�G���h�͖������ˁB
�R�v�������ĉ��Z�������悤�Ǝv���Ă��ш�̖�肪�o�Ă���ȁB
�܂����Z��������e�ɂ���邾�낤���ǂ��B
���K8��DDR2-800�g����12.8GB/s�B
HT3.0�ł�20.8GB/s�����B
���ʂ�GPU������ɂ��Ă��n�C�G���h�͖������ˁB
�R�v�������ĉ��Z�������悤�Ǝv���Ă��ш�̖�肪�o�Ă���ȁB
�܂����Z��������e�ɂ���邾�낤���ǂ��B
610 �FSocket774�F2006/07/25(��) 10:27:18 ID:LXN9v78G
����������Ȃ���Ώo�����B
�V���R���ђʓd�ɂ��Q�O�O�W�N�ʂɎ��p�������B
���̑��ɖ������������邵�B
�����͂sbit/s���Ɏ��삵�Ă�B
�ڕW�͂obit/s������������ȁB
�V���R���ђʓd�ɂ��Q�O�O�W�N�ʂɎ��p�������B
���̑��ɖ������������邵�B
�����͂sbit/s���Ɏ��삵�Ă�B
�ڕW�͂obit/s������������ȁB
>>608
��ԑ������Ȃ̂́ACPU�Ɠ����\�P�b�g������GPU�G���W���ƁADVI�C���^�[�t�F�[�X
���ڂ���DVI�g���l���`�b�v���낤�ȁB
����Ȃ�v���b�g�t�H�[���͈�ōςނ��AGPU�ɕK�v�Ȑ��\���������ʂ������ւ�
�����Ŏ����o����B
��ԑ������Ȃ̂́ACPU�Ɠ����\�P�b�g������GPU�G���W���ƁADVI�C���^�[�t�F�[�X
���ڂ���DVI�g���l���`�b�v���낤�ȁB
����Ȃ�v���b�g�t�H�[���͈�ōςނ��AGPU�ɕK�v�Ȑ��\���������ʂ������ւ�
�����Ŏ����o����B
�v���Ԃ��MAC�I�^�Ȃ̂�
�ꃌ�X�ŏI��肩
�ꃌ�X�ŏI��肩
HTX�̕�����������B
�\�P�b�g���͓�N�͂�����B
�\�P�b�g���͓�N�͂�����B
���ǂ̂Ƃ���CMAC�I�^���v�������Ƃ��ł����u�P�`�v�̂������Ă̂�Pڽ�����������B�B�B��(��)
>>611
��������DVI�g���l���ŁA�ǂ̒��x�̑ш���̂��l�@���Ă݂��B
1920x1440(24BPP)����8MB�K�v������A�����85Hz�̃��t���b�V�����[�g
�ɊԂɍ����l�ɓ]������Ȃ�A705MB/S�@���BHyperTransport�̑ш�Ȃ�
�S�R���Ȃ��Ȃ��B
�Ȃ܂�UMA�݂����Ƀ��[�N�����������C���������Ɏ��Ȃ�����A���̕�
�y���Ȃ���B
�m�[�g�pCPU�ɂ́ADualCore�Ȃ����R�v��GPU���I���_�C�őg�ݍ���
�����m���������ǂ����ˁB
��������DVI�g���l���ŁA�ǂ̒��x�̑ш���̂��l�@���Ă݂��B
1920x1440(24BPP)����8MB�K�v������A�����85Hz�̃��t���b�V�����[�g
�ɊԂɍ����l�ɓ]������Ȃ�A705MB/S�@���BHyperTransport�̑ш�Ȃ�
�S�R���Ȃ��Ȃ��B
�Ȃ܂�UMA�݂����Ƀ��[�N�����������C���������Ɏ��Ȃ�����A���̕�
�y���Ȃ���B
�m�[�g�pCPU�ɂ́ADualCore�Ȃ����R�v��GPU���I���_�C�őg�ݍ���
�����m���������ǂ����ˁB
age
http://pc.watch.impress.co.jp/docs/2006/0725/amdati.htm
| �yQ�z ATI�͍���̌��ɂ��Ă��ł�Intel�ɘb�͂����̂��B
| �yA�z ����A���Ă��Ȃ��B
�����̂�? ����ŁB
| �yQ�z ATI�͍���̌��ɂ��Ă��ł�Intel�ɘb�͂����̂��B
| �yA�z ����A���Ă��Ȃ��B
�����̂�? ����ŁB
�˂����ނƂ���͂�������Ȃ�����?
> �yA�z ��X��Intel�ƈႢ�A�C���^�[�t�F�C�X�K�i���I�[�v���ɂ��Ă���B�Ⴆ�AIntel�̓`�b�v�Z�b�g���l�b�g���[�N�R���g���[����Intel���ł��邱�Ƃ�v������B����ɂ��A
> ���Ђ̃R���|�[�l���g��r�����Ă���B��X�͂������������Ƃ͂��Ȃ��B��X�̓C���^�[�t�F�C�X���I�[�v���ɂ��邱�ƂŁA�e�Ђ�AMD�G�R�V�X�e���ւ̎Q�����Ăт�����B
����g����Ș_���B
�C���^�[�t�F�C�X�̒��S��AMD�����邱�Ƃ�����������̂ł���A�����ăI�[�v���Ƃ͌���Ȃ��B
���s����`�̕������͂�����߂āAIntel����邩AMD����邩��Б���̑I���𔗂�ׂ����B
�G����̂Ȃ�O��I�ɂ���悢�̂ł����āA�s���̗ǂ��Ƃ��낾��Intel�𗘗p���悤�Ǝv��ʂ��Ƃ��B
�C���^�[�t�F�[�X����������INTEL��AMD�ŋ��L���͑S���Ȃ��悤�ɂ���͂����肷��B
> �yA�z ��X��Intel�ƈႢ�A�C���^�[�t�F�C�X�K�i���I�[�v���ɂ��Ă���B�Ⴆ�AIntel�̓`�b�v�Z�b�g���l�b�g���[�N�R���g���[����Intel���ł��邱�Ƃ�v������B����ɂ��A
> ���Ђ̃R���|�[�l���g��r�����Ă���B��X�͂������������Ƃ͂��Ȃ��B��X�̓C���^�[�t�F�C�X���I�[�v���ɂ��邱�ƂŁA�e�Ђ�AMD�G�R�V�X�e���ւ̎Q�����Ăт�����B
����g����Ș_���B
�C���^�[�t�F�C�X�̒��S��AMD�����邱�Ƃ�����������̂ł���A�����ăI�[�v���Ƃ͌���Ȃ��B
���s����`�̕������͂�����߂āAIntel����邩AMD����邩��Б���̑I���𔗂�ׂ����B
�G����̂Ȃ�O��I�ɂ���悢�̂ł����āA�s���̗ǂ��Ƃ��낾��Intel�𗘗p���悤�Ǝv��ʂ��Ƃ��B
�C���^�[�t�F�[�X����������INTEL��AMD�ŋ��L���͑S���Ȃ��悤�ɂ���͂����肷��B
�uAMD�G�R�V�X�e���v�̒��S��AMD������̂̓I�[�v������Ȃ��Ƃ����̂�
��Ȃɂ��Ă����������
��Ȃɂ��Ă����������
>>618
nForce for intel��intel�o�X��HyperTransport�̗����g���Ă邪�H
AMD�̌����I�[�v�����Ă̂͋�����邩���Ȃ����̈Ⴂ����B
�܂��A��Б�����Ώ����ɂ���Ȃ�A�T�[�h�p�[�e�B���S��intel���痣������̂�
�������ȁB
�����ł����Aintel�̐��i����v���b�g�t�H�[���\�z�͋ɘ_����uintel���i�ȊO�g���ȁB�v�Ƃ���
�Ɛ�I�\�z������ȁB
nForce for intel��intel�o�X��HyperTransport�̗����g���Ă邪�H
AMD�̌����I�[�v�����Ă̂͋�����邩���Ȃ����̈Ⴂ����B
�܂��A��Б�����Ώ����ɂ���Ȃ�A�T�[�h�p�[�e�B���S��intel���痣������̂�
�������ȁB
�����ł����Aintel�̐��i����v���b�g�t�H�[���\�z�͋ɘ_����uintel���i�ȊO�g���ȁB�v�Ƃ���
�Ɛ�I�\�z������ȁB
> �܂��A��Б�����Ώ����ɂ���Ȃ�A�T�[�h�p�[�e�B���S��intel���痣������͖̂������ȁB
����͂��肦�Ȃ��ȁB
�ǂ���ɕt�����́A�e�Ђ��ꂼ��̓s���Ō��܂�A���O�̖ϑz�ƈ�v���邱�Ƃ͂Ȃ��ȁB
����͂��肦�Ȃ��ȁB
�ǂ���ɕt�����́A�e�Ђ��ꂼ��̓s���Ō��܂�A���O�̖ϑz�ƈ�v���邱�Ƃ͂Ȃ��ȁB
intel�ƃ`�b�v�Z�b�g���[�J�[�̓����ɋ������邪�AAMD�Ƃ͒��ڋ����͂��Ȃ�����ȁB
�`�b�v�Z�b�g���[�J�[���m�̐킢�Ȃ�A�t�@�u���X�ł����Z�͂��邪�E�E�E
�o�X���C�Z���X�������Ă܂Ő����\�͂ł͑S�������ڂ̂Ȃ�����ɒ��ނقNJԔ����ȓz������Ƃ͎v���ȁB
�`�b�v�Z�b�g���[�J�[���m�̐킢�Ȃ�A�t�@�u���X�ł����Z�͂��邪�E�E�E
�o�X���C�Z���X�������Ă܂Ő����\�͂ł͑S�������ڂ̂Ȃ�����ɒ��ނقNJԔ����ȓz������Ƃ͎v���ȁB
cpu+gpu���Ă����̂�GPU���`GHz�œ��삷��Ƃ������ƂȂ̂ł����H
No
CPU�AGPU�����݂����͂��āA�ǂ��������Z�����Ƃ��ɂ͗V��łȂ��ŏ�������Ă����`�ɂȂ�Ζ��ʂ��Ȃ��̂ɂ�
���ƃ�������
���ƃ�������
AMD��ATI�̃v���Z�b�T��1�ɗZ������
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
http://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
>>623
����CPU�R�A�����Ċ�{�N���b�N�̂��{��������AGPU�������{�����Ď��
�g���Ă��邾�낤�B
VIA C3���l�w�~�A�ȑO��FPU����CPU�R�A��1/2�œ��삵�Ă����A�قȂ�{��
�̃��j�b�g���_�C�ɍڂ���̂́A�����薳���������B
����CPU�R�A�����Ċ�{�N���b�N�̂��{��������AGPU�������{�����Ď��
�g���Ă��邾�낤�B
VIA C3���l�w�~�A�ȑO��FPU����CPU�R�A��1/2�œ��삵�Ă����A�قȂ�{��
�̃��j�b�g���_�C�ɍڂ���̂́A�����薳���������B
1�`�b�v�Ɏ��߂�̂͂����Ƃ��āA�ǂ������p�r���ɂ�ł���낤�ˁB
>>628
�I���`�b�vVideo���g���Ă����l�ȗp�r���낤�ˁB
�m�[�g�o�b��ƒ�������[�J�[���o�b������B
�I�v�e��������64bitFP�Ή�������p�R�A��p�ӂ��āA�w�ǂ��Ȋw�v�Z�p�r��
�ꕔ��\�����u�ɉZ�i���ȁHFPU���j�b�g�̔��W�łƂ��ē���ւ������
�Ƃ���B
������������m�[�gPC��[�J�[��PC�����ł��AFPU���j�b�g�Ƃ̓���ւ���
���Ă��邩�������B�ǂ���64bitFP�Ȃ�Ĉ�ʗp�r�ł͖w�ǎg���ĂȂ��̂�
����A32bit���Q�ő�p���ď��X�x���Ȃ��Ă�32bitFP�������Ȃ當��͏o��
���낤���B
���ꂪ����ȃ��[�U�[�ɂ̓I�v�e�����킹��ςށB
�I���`�b�vVideo���g���Ă����l�ȗp�r���낤�ˁB
�m�[�g�o�b��ƒ�������[�J�[���o�b������B
�I�v�e��������64bitFP�Ή�������p�R�A��p�ӂ��āA�w�ǂ��Ȋw�v�Z�p�r��
�ꕔ��\�����u�ɉZ�i���ȁHFPU���j�b�g�̔��W�łƂ��ē���ւ������
�Ƃ���B
������������m�[�gPC��[�J�[��PC�����ł��AFPU���j�b�g�Ƃ̓���ւ���
���Ă��邩�������B�ǂ���64bitFP�Ȃ�Ĉ�ʗp�r�ł͖w�ǎg���ĂȂ��̂�
����A32bit���Q�ő�p���ď��X�x���Ȃ��Ă�32bitFP�������Ȃ當��͏o��
���낤���B
���ꂪ����ȃ��[�U�[�ɂ̓I�v�e�����킹��ςށB
��64bitFP
����Ȃ̐̂���x86�ɂ��邶���B
Core2��64bitFP�~4/32bitFP�~8�����H
���̎���̐l�Ԃ���B
����Ȃ̐̂���x86�ɂ��邶���B
Core2��64bitFP�~4/32bitFP�~8�����H
���̎���̐l�Ԃ���B
��������ėp�V�F�[�_�[�ʼn��Z�\�Ȃ��͔̂C����A�Ƃ����X�^���X�Ȃ�ł��傤�B
���ɃO���t�B�b�N�W�Ɍ��炸�B
���ɃO���t�B�b�N�W�Ɍ��炸�B
>>630
�����獡�_�C�ɍڂ��Ă�FPU�W��������`��GPU�Ɠ���ւ����Ⴆ�A�_�C�T�C�Y��
�J�����\�[�X�̐ߖ}�����Ęb����������Ȃ̂����B
���݂Ɏ���C7�iIsaiah�j�́AFPU�@�\��VSSE���j�b�g�Ɏ�荞��ł��܂��炵�����B
�����獡�_�C�ɍڂ��Ă�FPU�W��������`��GPU�Ɠ���ւ����Ⴆ�A�_�C�T�C�Y��
�J�����\�[�X�̐ߖ}�����Ęb����������Ȃ̂����B
���݂Ɏ���C7�iIsaiah�j�́AFPU�@�\��VSSE���j�b�g�Ɏ�荞��ł��܂��炵�����B
>>632
�����݂Ɏ���C7�iIsaiah�j�́AFPU�@�\��VSSE���j�b�g�Ɏ�荞��ł��܂��炵�����B
Intel�����N���O����Ƃ����ɂ���Ă邱�Ƃ����B
���s���i��64bit��FPU��128�r�b�g��SIMD�����������Z�݂����Ȃ��Ƃ���Ă�AMD���炷���
�ڐV�������Ƃ����m��B
�����݂Ɏ���C7�iIsaiah�j�́AFPU�@�\��VSSE���j�b�g�Ɏ�荞��ł��܂��炵�����B
Intel�����N���O����Ƃ����ɂ���Ă邱�Ƃ����B
���s���i��64bit��FPU��128�r�b�g��SIMD�����������Z�݂����Ȃ��Ƃ���Ă�AMD���炷���
�ڐV�������Ƃ����m��B
>>623
����GPU�N���b�N���Ȃ��Ȃ��オ��Ȃ��̂�ASIC�v���Z�X������
�܂����킴�킴�J�X�^����ASIC������������Ȃ�Ă��Ȃ����낤����
������ CPU+GPU �I���_�C�܂ł����Γ���v���Z�X���낤����
����GPU�N���b�N���Ȃ��Ȃ��オ��Ȃ��̂�ASIC�v���Z�X������
�܂����킴�킴�J�X�^����ASIC������������Ȃ�Ă��Ȃ����낤����
������ CPU+GPU �I���_�C�܂ł����Γ���v���Z�X���낤����
Isaiah��SSE��128bit�ɐ���܂��B
FPU��SSE�ƌ��p�B
�P���x���Z�Ȃ瓯����4�A�{���x���Z�Ȃ�2�����{�\�B
����Z�̍������⏜�Z/����������ōs����悤�ɂ���B
�����o��낤�E�E�E
���Ȃ݂ɁAIsaiah�ł悤�₭Out-of-Order��SuperScalar�����������B
�i���s��Intel,AMD�̃A�[�L�e�N�`���ɋ߂Â��B�j
FPU��SSE�ƌ��p�B
�P���x���Z�Ȃ瓯����4�A�{���x���Z�Ȃ�2�����{�\�B
����Z�̍������⏜�Z/����������ōs����悤�ɂ���B
�����o��낤�E�E�E
���Ȃ݂ɁAIsaiah�ł悤�₭Out-of-Order��SuperScalar�����������B
�i���s��Intel,AMD�̃A�[�L�e�N�`���ɋ߂Â��B�j
ttp://pc.watch.impress.co.jp/docs/2006/0609/comp09.htm
���̕ӓǂނ�ATi��GPU�ŕ������Z�ł���݂���������ACPU+GPU�����������A
PhysX�̎��S�͊m�肩�ȁB
����ɂ��Ă�
ttp://pc.watch.impress.co.jp/docs/2006/0606/comp02.htm
���U����Intel�̊�u�����Ńf�������Z�p���V���ɂ�AMD�̕��Ƃ����͉̂��Ƃ��͂�B
���̕ӓǂނ�ATi��GPU�ŕ������Z�ł���݂���������ACPU+GPU�����������A
PhysX�̎��S�͊m�肩�ȁB
����ɂ��Ă�
ttp://pc.watch.impress.co.jp/docs/2006/0606/comp02.htm
���U����Intel�̊�u�����Ńf�������Z�p���V���ɂ�AMD�̕��Ƃ����͉̂��Ƃ��͂�B
>>636
PhysX�͊���MS�������ɃT�|�[�g���Ă�B
AMD+ATI�͂܂����ꂩ��B�ǂ������Ƃ�����
AEGIA��SDK���o���Ă��炤�����m��Ȃ�����BCell�����������B
PhysX�͊���MS�������ɃT�|�[�g���Ă�B
AMD+ATI�͂܂����ꂩ��B�ǂ������Ƃ�����
AEGIA��SDK���o���Ă��炤�����m��Ȃ�����BCell�����������B
>>633
AMD��SSE���j�b�g��3Dnow!�����������Ă�������AFPU�܂ł͎肪���Ȃ���
���̃W���}�C�J�B
�ł����̂��A�Ő�pFPU���c��������Ȃ̂��A�m�����s�i�ł̕��������_���Z
�\�͂́AIntel����AMD�̕������������Ǝv�����B
�܂�Intel��SSE���C����FPU���\���d�����ĂȂ�����������������AAMD
�Ȃ�FPU���\�ł̗D�ʂ�ۂ��������낤����A��肭GPU��FPU�@�\����肱��
�̂����҂������B
AMD��SSE���j�b�g��3Dnow!�����������Ă�������AFPU�܂ł͎肪���Ȃ���
���̃W���}�C�J�B
�ł����̂��A�Ő�pFPU���c��������Ȃ̂��A�m�����s�i�ł̕��������_���Z
�\�͂́AIntel����AMD�̕������������Ǝv�����B
�܂�Intel��SSE���C����FPU���\���d�����ĂȂ�����������������AAMD
�Ȃ�FPU���\�ł̗D�ʂ�ۂ��������낤����A��肭GPU��FPU�@�\����肱��
�̂����҂������B
NetBurst��FPU�̓N���b�N�̔��������128bit SIMD���j�b�g�ŏ������Ă�
x87��SSE*�X�J�����Z�͔��������g���Ȃ��d�l�������B
�����ۂ�AMD�͓�����64bit���B
x87���g���Â��R�[�h�����́A�����������j�b�g�̎��N���b�N�Ԃ�
AMD�̂ق��������������A128�r�b�g�t���Ɏg��SIMD�ł́AAMD��2��������
�ʂ����ƂɂȂ�̂ŁAIntel�����|�I�ɗD�ʁB
Core�ł�128�r�b�g�E�����ɂȂ��Ă�̂ŁA�����ӂ�����x87��SSE*��
�X�J�����Z���\���瓯�N���b�N�œ����ASIMD�Ȃ�_�u���X�R�A���B
x64�ł�x87���SSE*��ϋɊ��p���邱�ƂɂȂ�̂ŁA64�r�b�g�\���ł�
���|�I�ɕs�����ȁB
K8L�ł�Core2��Ǐ]���邱�Ƃ͊m��̂悤�����B
>>638
��ŁA�ǂ������p�C�v���C���\���ɂ������̂��}�����Ă݂��B
���j�b�g�������₵�Ă����ߋ������ǂ����Ȃ���S�~���R�����B
x87��SSE*�X�J�����Z�͔��������g���Ȃ��d�l�������B
�����ۂ�AMD�͓�����64bit���B
x87���g���Â��R�[�h�����́A�����������j�b�g�̎��N���b�N�Ԃ�
AMD�̂ق��������������A128�r�b�g�t���Ɏg��SIMD�ł́AAMD��2��������
�ʂ����ƂɂȂ�̂ŁAIntel�����|�I�ɗD�ʁB
Core�ł�128�r�b�g�E�����ɂȂ��Ă�̂ŁA�����ӂ�����x87��SSE*��
�X�J�����Z���\���瓯�N���b�N�œ����ASIMD�Ȃ�_�u���X�R�A���B
x64�ł�x87���SSE*��ϋɊ��p���邱�ƂɂȂ�̂ŁA64�r�b�g�\���ł�
���|�I�ɕs�����ȁB
K8L�ł�Core2��Ǐ]���邱�Ƃ͊m��̂悤�����B
>>638
��ŁA�ǂ������p�C�v���C���\���ɂ������̂��}�����Ă݂��B
���j�b�g�������₵�Ă����ߋ������ǂ����Ȃ���S�~���R�����B
PC�̐��E�ŃI���`�b�v�������͗L�肦��̂���
HPC�̐l�����̓v���Z�X���i��X�N���b�`�p�b�h�������̓I���`�b�v��������
�ǂ�ǂ₹���Č����Ă邯��
HPC�̐l�����̓v���Z�X���i��X�N���b�`�p�b�h�������̓I���`�b�v��������
�ǂ�ǂ₹���Č����Ă邯��
�lj� 1000�Ƃ������ɂ����̂�O��炵������
>>639
> AMD��2�������� �ʂ����ƂɂȂ�̂ŁAIntel�����|�I�ɗD�ʁB
����64bit�Ɣ���128bit�Ȃ�݊p�����B
���łɁA�l�g�o��64bit����*2���B
�ނ��냌�C�e���V�Ȃǂ�AMD�L�������A
�N���b�N���ゾ����l�g�o�̏����B
> AMD��2�������� �ʂ����ƂɂȂ�̂ŁAIntel�����|�I�ɗD�ʁB
����64bit�Ɣ���128bit�Ȃ�݊p�����B
���łɁA�l�g�o��64bit����*2���B
�ނ��냌�C�e���V�Ȃǂ�AMD�L�������A
�N���b�N���ゾ����l�g�o�̏����B
�܂�K8L�ł͍ĂтԂ�������Ƃ����킯�ł��ˁH
�����ŏ����錾���邩
�Q�O�O�W�N�ɏo�Ă��Ă���A���߂�Ȃ�������̂�w
>>642
> �ނ��냌�C�e���V�Ȃǂ�AMD�L�������A
�ԈႢ�B���ۂ͕������邱�Ƃňˑ��W�`�F�C�����o���Č����������Ă���B
���r�W�������オ���ĉ��P����Ă������A���{�I�ȉ�����i��128�r�b�g���iK8L�j�Ȃ킯���B
�N���b�N���Ԃ�NetBurst�D�ʂƂ����̂͐������B
�N���b�N��L���Ă������x87��SSE�X�J�����������������ȏ��
�����Ă������肾�����낤�B
> �ނ��냌�C�e���V�Ȃǂ�AMD�L�������A
�ԈႢ�B���ۂ͕������邱�Ƃňˑ��W�`�F�C�����o���Č����������Ă���B
���r�W�������オ���ĉ��P����Ă������A���{�I�ȉ�����i��128�r�b�g���iK8L�j�Ȃ킯���B
�N���b�N���Ԃ�NetBurst�D�ʂƂ����̂͐������B
�N���b�N��L���Ă������x87��SSE�X�J�����������������ȏ��
�����Ă������肾�����낤�B
>>646
����������ˑ��W�͊ɂ��Ȃ��B
�i����̓l�g�o���������Ɓj
���ہA128bit������Core2�ł�
�V���b�t���Ȃǂ��x���Ȃ��Ă���B
64bit�̕�������肪�����Ă����̂��B
128bit���̓p���[�����邾���B
�܂��A�������ߐ��������邩��
�f�R�[�h�E�X�P�W���[���E���^�C���Ȃǂ�
���ׂ͍����Ȃ邯�ǂˁB
����������ˑ��W�͊ɂ��Ȃ��B
�i����̓l�g�o���������Ɓj
���ہA128bit������Core2�ł�
�V���b�t���Ȃǂ��x���Ȃ��Ă���B
64bit�̕�������肪�����Ă����̂��B
128bit���̓p���[�����邾���B
�܂��A�������ߐ��������邩��
�f�R�[�h�E�X�P�W���[���E���^�C���Ȃǂ�
���ׂ͍����Ȃ邯�ǂˁB
>>639
�Ƃ������́A������SSE�ɂ�镂�������_���Z�͊��p����ĂȂ����Ď��Ńt�@�H
������n�r��x64�ɂȂ��Ă��A�A�v���̕���x64�ɂȂ�̂͏����ゾ���A�܂���
�⍡�܂œ��삵�Ă����������_���Z�������ASSE�ŏ��������̂͂��̃R�X�g��
�z���o���邭�炢�̐��\�����K�v�����A�����܂ł̍��͖��������ȋC�����邪�B
�Ƃ������́A������SSE�ɂ�镂�������_���Z�͊��p����ĂȂ����Ď��Ńt�@�H
������n�r��x64�ɂȂ��Ă��A�A�v���̕���x64�ɂȂ�̂͏����ゾ���A�܂���
�⍡�܂œ��삵�Ă����������_���Z�������ASSE�ŏ��������̂͂��̃R�X�g��
�z���o���邭�炢�̐��\�����K�v�����A�����܂ł̍��͖��������ȋC�����邪�B
>>648 �⑫
Itanium �̎�����Ԃ�����A�\�[�X�����������Ė��Ή�����̂��A���̒���
���[�U�[���ǂꂾ���������Ă邩�̏؍����Ǝv���Ă鎖���A��̈ӌ��̑O��B
Itanium �̎�����Ԃ�����A�\�[�X�����������Ė��Ή�����̂��A���̒���
���[�U�[���ǂꂾ���������Ă邩�̏؍����Ǝv���Ă鎖���A��̈ӌ��̑O��B
�V���v���ȃR�[�h�����čœK���̓R���p�C���ɔC����
>>639
�̂����Ɍ������邪�ANetBurst��FPU�̓N���b�N�̔���������ĉ��H
�̂����Ɍ������邪�ANetBurst��FPU�̓N���b�N�̔���������ĉ��H
���̂܂܂̈Ӗ��B
3.6GHz����Ȃ�SIMD���j�b�g��1.8GHz����Ȃ킯�B
ALU���M�����邩��SIMD�����ł������œ������Ȃ��Ƃ炢���B
3.6GHz����Ȃ�SIMD���j�b�g��1.8GHz����Ȃ킯�B
ALU���M�����邩��SIMD�����ł������œ������Ȃ��Ƃ炢���B
P4��SIMD�͔��������AFPU�������H
FPU�̉��Z�̓X���[�v�b�g1����B
FPU�̉��Z�̓X���[�v�b�g1����B
ALU�͔{���Ȃ̂͒m���Ă����AFPU�͔����������̂��B
�ւ��B
�ւ��B
�܂����̘b�肩
�v���X�R�b�g��FP���Z�̃��C�e���V��������瓙������
�v���X�R�b�g��FP���Z�̃��C�e���V��������瓙������
��Ɖ������������݂ɓ����P�ɂȂ邾�낤
FPmul�͉�����������������Ȃ��݂��������B
FPmul�͉�����������������Ȃ��݂��������B
>>650
����ōςނȂ�x64�̓C������ȁBIA64��Itanium��64bit�s��𐧔e���Ă����B
����ōςނȂ�x64�̓C������ȁBIA64��Itanium��64bit�s��𐧔e���Ă����B
OS��CPU�ɍ��킹�čœK����������B
�l�Ԃ��R���s���[�^�ɍ��킹�čœK����������B
>>657
�ׂ���ˁ[��B
Centrino�Ƃ����A���̃v���b�g�t�H�[���\�z�Ƃ����A���В��ߏo���̈Ӑ}�ۏo���ɉ�����
�`�b�v�Z�b�g�̑��Y�̐����{�i��������Aintel��舳�|�I�Ɉ����Ȃ�����N���g���B
�f�B�X�J�E���g����ɂȂ���intel�ɏ��Ă�͂����Ȃ����ȁB
�����̊ԈႢ�ł��܂��ܔ��ꂽ�Ƃ��Ă��A����グ�ɔ�Ⴕ�ăo�X���C�Z���X����intel��
�����Ă���邾����intel���ׂ��邾���̘b���B
AMD�̕��̓o�X���C�Z���X�������A�`�b�v�Z�b�g����ĂȂ�����CPU�����Y������
�e�Ђ̃`�b�v�Z�b�g���K�R�I�Ɏ��v�������邩��ȁB
�D���Ő��Ŋ�ƗU�v���Ă�y�n�ƁA�₭���ɂ݂����ߗ������y�n�ŁA�ǂ������������₷����
�Ȃ�čl����܂ł��Ȃ��B
�ׂ���ˁ[��B
Centrino�Ƃ����A���̃v���b�g�t�H�[���\�z�Ƃ����A���В��ߏo���̈Ӑ}�ۏo���ɉ�����
�`�b�v�Z�b�g�̑��Y�̐����{�i��������Aintel��舳�|�I�Ɉ����Ȃ�����N���g���B
�f�B�X�J�E���g����ɂȂ���intel�ɏ��Ă�͂����Ȃ����ȁB
�����̊ԈႢ�ł��܂��ܔ��ꂽ�Ƃ��Ă��A����グ�ɔ�Ⴕ�ăo�X���C�Z���X����intel��
�����Ă���邾����intel���ׂ��邾���̘b���B
AMD�̕��̓o�X���C�Z���X�������A�`�b�v�Z�b�g����ĂȂ�����CPU�����Y������
�e�Ђ̃`�b�v�Z�b�g���K�R�I�Ɏ��v�������邩��ȁB
�D���Ő��Ŋ�ƗU�v���Ă�y�n�ƁA�₭���ɂ݂����ߗ������y�n�ŁA�ǂ������������₷����
�Ȃ�čl����܂ł��Ȃ��B
�ł���(�}�[�P�b�g�K��)���Ⴄ�c
�D���Ő��Ŋ�ƗU�v���Ă�x�R�̓y�n
�₭���ɂ݂����ߗ�����铌���̓y�n
�₭���ɂ݂����ߗ�����铌���̓y�n
���z�c�ꖇ�I
AMD�����`�b�v�Z�b�g�̏����v�ƁA
�o�X���C�Z���X����������intel�����`�b�v�Z�b�g�̏����v��
��̂ǂ��炪�����̂ł�����?
�o�X���C�Z���X����������intel�����`�b�v�Z�b�g�̏����v��
��̂ǂ��炪�����̂ł�����?
���̐l�����킩��Ȃ���W���}�C�J
�ł�Intel��IGP���ߎS����������m�[�g�Ō��\�o�Ă�������@��RadeonExpress
�������ǂ��炩�ƌ����ƃ~�h�������W�ӂ�ŁB965G���`���ʂ�ߎS�������烁�[�J�[�͔��݂��Ȃ�
�������ǂ��炩�ƌ����ƃ~�h�������W�ӂ�ŁB965G���`���ʂ�ߎS�������烁�[�J�[�͔��݂��Ȃ�
�m�[�g������chipset�͍��N�����ς����炢��945�̂܂�
������Aintel��VistaPremium��945�ł��������Ă��Ƃɂ�����A�ƑʁX�����˂�������Ȃ�����
������Aintel��VistaPremium��945�ł��������Ă��Ƃɂ�����A�ƑʁX�����˂�������Ȃ�����
>>663
���ƌ����Ă��Aintel�n��10%���x�̃V�F�A��AMD�n��50%�̃V�F�A�Ȃ�卷�Ȃ��B
965�����90nm�����������A�����Ȃ�Ƃ��悢��T�[�h�p�[�e�B���Ꮯ���ɂȂ��B
CPU�ł͊��ɑO����̃v���Z�X�����A�`�b�v�Z�b�g��90nm�Ȃ�đ��Ђɂ͖����B
intel�o�X�͎g�������AHyperTransport��CPU�ȊO�Ƃ̐ڑ��ł����R�Ɏg���邵�A
�������R���g���[����CPU����������A�_�C�T�C�Y�}�����Č��̎�Ԃ����邵�A
���т����ς߂T�[�o�[�����ɂ��H�����߂�\�������邵�ȁB
��Б���Ȃ�ăA�z�Ȃ��ƌ����o���Ƃ��v����A�ꉞ�A�ی����x��intel������
��邾�낤���A��{��AMD�������S�ɂȂ邾�낤�ȁB���T�[�h�p�[�e�B
���ƌ����Ă��Aintel�n��10%���x�̃V�F�A��AMD�n��50%�̃V�F�A�Ȃ�卷�Ȃ��B
965�����90nm�����������A�����Ȃ�Ƃ��悢��T�[�h�p�[�e�B���Ꮯ���ɂȂ��B
CPU�ł͊��ɑO����̃v���Z�X�����A�`�b�v�Z�b�g��90nm�Ȃ�đ��Ђɂ͖����B
intel�o�X�͎g�������AHyperTransport��CPU�ȊO�Ƃ̐ڑ��ł����R�Ɏg���邵�A
�������R���g���[����CPU����������A�_�C�T�C�Y�}�����Č��̎�Ԃ����邵�A
���т����ς߂T�[�o�[�����ɂ��H�����߂�\�������邵�ȁB
��Б���Ȃ�ăA�z�Ȃ��ƌ����o���Ƃ��v����A�ꉞ�A�ی����x��intel������
��邾�낤���A��{��AMD�������S�ɂȂ邾�낤�ȁB���T�[�h�p�[�e�B
Intel��North��90nm��South��130nm�B
VIA������9xx�����90nm��80nm�Ɉڂ�炵���B
SiS�͍��N110nm�ŁA���N80nm�Ƃ��B
TSMC��UMC�����邩��v���Z�X���̂͒���Ă邵�ȁB
���͂ǂ������\�肪���ĂɂȂ�Ƃ����B
VIA������9xx�����90nm��80nm�Ɉڂ�炵���B
SiS�͍��N110nm�ŁA���N80nm�Ƃ��B
TSMC��UMC�����邩��v���Z�X���̂͒���Ă邵�ȁB
���͂ǂ������\�肪���ĂɂȂ�Ƃ����B
Geforce6100/6150������90nm����Ȃ������H�@�܂�intel��������Ȃ����ǂˁB
���ƃT�E�X�͓d���̊W�Ŕ����͌����������B�`�b�v�Z�b�g��PCI MAC�A��t�� PCI PHY �Ƃ����Ȃ���
���ƃT�E�X�͓d���̊W�Ŕ����͌����������B�`�b�v�Z�b�g��PCI MAC�A��t�� PCI PHY �Ƃ����Ȃ���
>>672
�m�[�X������AGP��3.3V��1.5V���A��������DDR��2.5V�ADDR2��1.8V���g���Ă邪�B
�܂�PCI�̓��K�V�[�ɂȂ��Ă�������A�m���ɐ̂�ISA�݂����ɃA�_�v�^IC�͕K�v
��������A����̓m�[�X��GPU��Video�o�͂���̂Ɠ����ƍl����ςނ����B
�m�[�X������AGP��3.3V��1.5V���A��������DDR��2.5V�ADDR2��1.8V���g���Ă邪�B
�܂�PCI�̓��K�V�[�ɂȂ��Ă�������A�m���ɐ̂�ISA�݂����ɃA�_�v�^IC�͕K�v
��������A����̓m�[�X��GPU��Video�o�͂���̂Ɠ����ƍl����ςނ����B
>>673
PCI-Express(0.8V)��DDR2(1.5�`1.8V)�ASATA(0.5V)�Ɣ�ׂ�� IDE��PCI ��5V�͕ʎ���������B
�����AGP�̎��͂܂�130nm�Ƃ�180nm���������B
PCI-Express(0.8V)��DDR2(1.5�`1.8V)�ASATA(0.5V)�Ɣ�ׂ�� IDE��PCI ��5V�͕ʎ���������B
�����AGP�̎��͂܂�130nm�Ƃ�180nm���������B
chipset����d�������̓d���ŋ�������킯����Ȃ��B
intel��ICH8��PATA�͂Ȃ��������APCI�͎c���Ă�ȁB
���悢��ł��M���̓��x���R���o�[�^�łł����ނ��낤���APCIe�ڑ��Ƃ��ŊO�ɏo����Ă�����Ȗ��ł��Ȃ����낤�B
intel��ICH8��PATA�͂Ȃ��������APCI�͎c���Ă�ȁB
���悢��ł��M���̓��x���R���o�[�^�łł����ނ��낤���APCIe�ڑ��Ƃ��ŊO�ɏo����Ă�����Ȗ��ł��Ȃ����낤�B
90nm����3.3V�����̂͂��Ȃ������Ă����Ⴊ�����Ă��B
>>670
����Ȃ�AMD�����͉��i�����ė~������
�`�b�v�Z�b�g�ƃ}�U�{�͉��i����������Ƃ͎v��Ȃ����ǁB
����������Intel������10%�V�F�A������
AMD������50%�V�F�A�����ȒP�Ȃ�Ȃ�
����Ȃ�AMD�����͉��i�����ė~������
�`�b�v�Z�b�g�ƃ}�U�{�͉��i����������Ƃ͎v��Ȃ����ǁB
����������Intel������10%�V�F�A������
AMD������50%�V�F�A�����ȒP�Ȃ�Ȃ�
�T�[�h�p�[�e�B�[�݂͂�Ȃ��̍l����Intel�����ɎQ�����Ă�ł���B
�ł����ǂ�Intel����������A�ƁB
�ł����ǂ�Intel����������A�ƁB
�C���e������������Ƃ������A�o�X���C�Z���X�̖��ł���B
�C���e�����g�ō��ɂ̓��C�Z���X������Ȃ���������ł����肷��
���������Ђ���낤�Ƃ���ƁA���̃R�X�g���������Ă��܂��ׂ���Ȃ��B
ATi�������`�v�Z�g����Ă����������A�ߋ��̗Ⴉ��S�R���߂���
nVIDIA�̓_���_���A������͋��͂��Ă���邩����킩��Ȃ��B
�C���e�����g�ō��ɂ̓��C�Z���X������Ȃ���������ł����肷��
���������Ђ���낤�Ƃ���ƁA���̃R�X�g���������Ă��܂��ׂ���Ȃ��B
ATi�������`�v�Z�g����Ă����������A�ߋ��̗Ⴉ��S�R���߂���
nVIDIA�̓_���_���A������͋��͂��Ă���邩����킩��Ȃ��B
681 �FSocket774�F2006/08/02(��) 22:06:30 ID:WPr3kYOR
INTEL�����Ő�������̂̓G���g���[������
�����`�b�v�Z�b�g�̂�
���v�̑������C���X�g���[���`�n�C�G���h�̗̈��
�ق�100%�Ƃ����Ă������ق�INTEL�`�b�v��
���ߐs������Ă邵��(�L�E�ցE�M)
�����`�b�v�Z�b�g�̂�
���v�̑������C���X�g���[���`�n�C�G���h�̗̈��
�ق�100%�Ƃ����Ă������ق�INTEL�`�b�v��
���ߐs������Ă邵��(�L�E�ցE�M)
intel�̏ꍇ�A���ЂƓ���130nm��90nm�ł�����1�E2����O�̃v���Z�X������ȁE�E�E
���p�̐i�s�x���S�R�Ⴄ����R�X�g�����ɂȂ�����܂����Ă�B
���p�̐i�s�x���S�R�Ⴄ����R�X�g�����ɂȂ�����܂����Ă�B
�����������ȏ��Fab��300mm�E�F�n�������C���c
���������Aintel��Rambus�̃o�X���C�Z���X�͉������Ă����H
���������Aintel��Rambus�̃o�X���C�Z���X�͉������Ă����H
>>681
��[�Iܸ�]
��[�Iܸ�]
http://journal.mycom.co.jp/special/2006/conroe/
Conroe�x���`�Ȃ̂����A�O���̂��ꂼ���CPU�̊�{�I���\���͂̂Ƃ���������
K8�̑f�����ǂ��Ƃ̕]����
�_���S��K8�̎��̃R�A��L1�̑ш摝������Č����Ă������A���̒ʂ�Ȃ�A
32bit�œ������炢�A64bit�ł͑啝�ɂԂ��������Ă̂͂��蓾��������
Conroe�x���`�Ȃ̂����A�O���̂��ꂼ���CPU�̊�{�I���\���͂̂Ƃ���������
K8�̑f�����ǂ��Ƃ̕]����
�_���S��K8�̎��̃R�A��L1�̑ш摝������Č����Ă������A���̒ʂ�Ȃ�A
32bit�œ������炢�A64bit�ł͑啝�ɂԂ��������Ă̂͂��蓾��������
�啝�ɁA�Ƃ͂����Ȃ���������Ȃ����t�]�͂ł��邾�낤��
ttp://pc.watch.impress.co.jp/docs/2006/0703/kaigai286.htm
������ƕ����邪Hound�ł�128bit�~2
�f�R�[�h�ASSE���\���ǂ����Ȃ炠�Ƃ̓L���b�V�����悩�˂��B
64byte�ێ��Ń��C�e���V���������肵�Ȃ���s���邩�ȁB
������ƕ����邪Hound�ł�128bit�~2
�f�R�[�h�ASSE���\���ǂ����Ȃ炠�Ƃ̓L���b�V�����悩�˂��B
64byte�ێ��Ń��C�e���V���������肵�Ȃ���s���邩�ȁB
�����ɂ���}�����āAL1�̓f�[�^�L���b�V�������ш摝����̂��Ǝv���Ă�����
���߃L���b�V�������R�ш摝����Ǝv���ׂ��Ȃ̂���
���߃L���b�V�������R�ш摝����Ǝv���ׂ��Ȃ̂���
K8�̃f�R�[�h���̑f�����ǂ��̂͒P�Ƀv���f�R�[�h�L���b�V���̉��b�ł����Ȃ��B
K8�͔r���L���b�V���\���Ȃ̂�L1���߃L���b�V�����v���f�R�[�h�L���b�V���ɂ���̂͗e�Ղ�������L���Ă���B
�������ǂ��ʂ���ł��Ȃ����Ƃ��ӎ����Ă����K�v������B
>>685
���\���Ȃ��ш��{�����邱�Ƃ��\���͔��ɂ��₵���B
���ۂɏo���Ă݂Ȃ��ƕ]���ł��Ȃ��ȁB
K8�͔r���L���b�V���\���Ȃ̂�L1���߃L���b�V�����v���f�R�[�h�L���b�V���ɂ���̂͗e�Ղ�������L���Ă���B
�������ǂ��ʂ���ł��Ȃ����Ƃ��ӎ����Ă����K�v������B
>>685
���\���Ȃ��ш��{�����邱�Ƃ��\���͔��ɂ��₵���B
���ۂɏo���Ă݂Ȃ��ƕ]���ł��Ȃ��ȁB
>>684
ServerWorks�͊���Intel��������P�ނ��ċv�����BDDR2�Ή��`�b�v����Ȃ��B
ServerWorks�͊���Intel��������P�ނ��ċv�����BDDR2�Ή��`�b�v����Ȃ��B
����Hound�ŋt�]���Ă��������Nehalem�̋��|���c
�t�]���Ȃ��ꍇ������ȏ�̋��|�Ȃ̂��orz
�t�]���Ȃ��ꍇ������ȏ�̋��|�Ȃ̂��orz
2007�N��K8L��2008�N�ɂ�NewCore�����B
2008�N�́hcore update�h��������K�X�B
2008�N���Ղ�45nm�Ɉڍs�\��Ƃ��āA�ǂ��Łhcore update�h����낤�H
���ƁA�hDirect Con��ect Architecture 2.0�h�ŁA������xIntel��˂�������
�ǂ����̲���ޭ��Ō����Ă������ǁADCA2.0���ĺ���+�k����CPU�ɓ����H
2008�N���Ղ�45nm�Ɉڍs�\��Ƃ��āA�ǂ��Łhcore update�h����낤�H
���ƁA�hDirect Con��ect Architecture 2.0�h�ŁA������xIntel��˂�������
�ǂ����̲���ޭ��Ō����Ă������ǁADCA2.0���ĺ���+�k����CPU�ɓ����H
2008�N��NewCore�̓��o�C������ˁB
Hound�n���~��Ă���Ǝv���B
Hound�n���~��Ă���Ǝv���B
2008�N�̃��o�C����
Intel Core3 VS AMD ���o�C���R�A(K8)
�Ƃ����킯����
Intel Core3 VS AMD ���o�C���R�A(K8)
�Ƃ����킯����
FTC�A��Rambus�ɓƋ֖@�ᔽ�ْ̍�
ttp://enterprise.watch.impress.co.jp/cda/foreign/2006/08/03/8386.html
����ƓS�Ƃ������ꂽ���B����ŏ�����CPU��PC�̐��\�E�v�����Ղ��Ȃ�ȁB
ttp://enterprise.watch.impress.co.jp/cda/foreign/2006/08/03/8386.html
����ƓS�Ƃ������ꂽ���B����ŏ�����CPU��PC�̐��\�E�v�����Ղ��Ȃ�ȁB
697 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/03(��) 23:49:50 ID:5FmR8lKT
Core2����SSE�̃��j�b�g�͂����ς�������ǁA������x�̂Ƃ���܂ł�����
���߃t�F�b�`�ш悪�����������āA���\���ł��Ȃ̂�ˁB
Core2��SIMD�����ɔ�ׂĕ�����������r�I�L�тĂȂ��̂́A���������̂ق������C�e���V������
���[�h�E�X�g�A�̈ˑ��x���������炾�ƕ��͂���B
�ŁA�A�h���b�V���O�����߂łW�o�C�g���炢�g�����Ⴄ���獡�x�͑ш悪�l�b�N�ɂȂ�B
�����������A�[�L�e�N�`���ł͕��ϓI�Ɉ��|�I�Ȑ��\��������ǁA
�ꕔ�̖��߂̃X���[�v�b�g��NetBurst�������킯�ŁA����ς���P���ė~������ˁB
�g���[�X�L���b�V�����Ă����̂�������i�̂ЂƂł͂���Ƃ͎v�����ǁA���x�͔ėp����
�i�����̃�OPs�j�̊i�[������������B
�t�F�b�`��32byte/clock�����SSE������������64bit���߂��A�R���߃R���X�^���g�Ɏ�荞�߂�B
SSE�~�Ƃ��ẮA����128bit SIMD���j�b�g���ڂ�K8L�Ɋ��҂���Ƃ���͂���B
���s�A�[�L�e�N�`����32byte�̃t�F�b�`�ш�Ƃ�����Itanium2�������ł��傤�B
�܂��Œ蒷LIW�����ǁB
���߃t�F�b�`�ш悪�����������āA���\���ł��Ȃ̂�ˁB
Core2��SIMD�����ɔ�ׂĕ�����������r�I�L�тĂȂ��̂́A���������̂ق������C�e���V������
���[�h�E�X�g�A�̈ˑ��x���������炾�ƕ��͂���B
�ŁA�A�h���b�V���O�����߂łW�o�C�g���炢�g�����Ⴄ���獡�x�͑ш悪�l�b�N�ɂȂ�B
�����������A�[�L�e�N�`���ł͕��ϓI�Ɉ��|�I�Ȑ��\��������ǁA
�ꕔ�̖��߂̃X���[�v�b�g��NetBurst�������킯�ŁA����ς���P���ė~������ˁB
�g���[�X�L���b�V�����Ă����̂�������i�̂ЂƂł͂���Ƃ͎v�����ǁA���x�͔ėp����
�i�����̃�OPs�j�̊i�[������������B
�t�F�b�`��32byte/clock�����SSE������������64bit���߂��A�R���߃R���X�^���g�Ɏ�荞�߂�B
SSE�~�Ƃ��ẮA����128bit SIMD���j�b�g���ڂ�K8L�Ɋ��҂���Ƃ���͂���B
���s�A�[�L�e�N�`����32byte�̃t�F�b�`�ш�Ƃ�����Itanium2�������ł��傤�B
�܂��Œ蒷LIW�����ǁB
>>694-695
�ϑz�Ō��ȃn�Q�B
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/PhilHesterAMDAnalystDay.pdf
�ϑz�Ō��ȃn�Q�B
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/PhilHesterAMDAnalystDay.pdf
>>696
���܂ŒN���������Ă����낤�˂��B�i��
���܂ŒN���������Ă����낤�˂��B�i��
>>697
Core2�Ɍ��炸�A�����������Z���ă��C�e���V����������ł���
����32byte�̃t�F�b�`�ш���āAPPC�Ƃ�SPARC�Ƃ���RISC�`�b�v�ɖ������������H
Core2�Ɍ��炸�A�����������Z���ă��C�e���V����������ł���
����32byte�̃t�F�b�`�ш���āAPPC�Ƃ�SPARC�Ƃ���RISC�`�b�v�ɖ������������H
RMMA�̑��茋�ʂ��������납�����̂ŁA754pin��Athlon3400+�ł��������m���߂Ă݂����ǁA
�匴�L���ɂ��閽�߈ȊO�ł������X�����ł����ǁA
2byte���߂�MOV,ADD,OR���Ƃق�2byte/cycle�ALEA����1byte/cycle���炢�����łȂ�����
����͖��߂̐����ケ��Ȃ���Ȃ́H
�匴�L���ɂ��閽�߈ȊO�ł������X�����ł����ǁA
2byte���߂�MOV,ADD,OR���Ƃق�2byte/cycle�ALEA����1byte/cycle���炢�����łȂ�����
����͖��߂̐����ケ��Ȃ���Ȃ́H
702 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/06(��) 01:53:25 ID:fBFPpL3+
>>700
��������Œ蒷4byte�ł��ȁBPPC G5��4issue������16byte���x�ł��傤�B
VLIW�n��
Itanium 2 �E�E�E16byte�~2�i3*2issue����)
Efficeon �E�E�E32byte�~1(8issue����)
��������Œ蒷4byte�ł��ȁBPPC G5��4issue������16byte���x�ł��傤�B
VLIW�n��
Itanium 2 �E�E�E16byte�~2�i3*2issue����)
Efficeon �E�E�E32byte�~1(8issue����)
http://www.geocities.jp/andosprocinfo/wadai06/20060805.htm
���e��x���`�}�[�N��Core 2 Duo��Opteron�ɏ����Ă������́C�L���b�V�����܂߂��f�[�^�A�N�Z�X���\�������_
���ꂪ������Ȃ�A�����AMD�̕������͑吳���Ƃ������ƂɂȂ�ȁB
���e��x���`�}�[�N��Core 2 Duo��Opteron�ɏ����Ă������́C�L���b�V�����܂߂��f�[�^�A�N�Z�X���\�������_
���ꂪ������Ȃ�A�����AMD�̕������͑吳���Ƃ������ƂɂȂ�ȁB
704 �FSocket774�F2006/08/08(��) 11:48:22 ID:acfMu0pZ
�H
Z-RAM�ŋS�̗l��L3�ς�ł���Ȃ����ȁB�R�A4��L1-64k+64k L2-512k L3-128M�Ƃ��B
��������32MB���炢�����E���Ǝv��
�`�[�gCPU�����F�ł����B�B�B�B
http://pc7.2ch.net/test/read.cgi/jisaku/1154290759/
K8�͔��ɗD�����ŁA��������Ă����Ȃ����Ȃ���ۂŁA
����Core�͓���̏����ɓ������ă`���[�j���O�����Ă���
���͋C��������B
http://journal.mycom.co.jp/special/2006/conroe/006.html
http://pc7.2ch.net/test/read.cgi/jisaku/1154290759/
K8�͔��ɗD�����ŁA��������Ă����Ȃ����Ȃ���ۂŁA
����Core�͓���̏����ɓ������ă`���[�j���O�����Ă���
���͋C��������B
http://journal.mycom.co.jp/special/2006/conroe/006.html
�����N�挩�����R�����[�����ʕ����Ă���悤�ɂ͌����Ȃ��ȁB
K8���}�C�i�[�`�F���W����܂��܂��킦�邱�Ƃ͂킩�����B
K8���}�C�i�[�`�F���W����܂��܂��킦�邱�Ƃ͂킩�����B
>>707
����Ȃ��ƌ����Ă��Ȃ��A�T�N���G�f�B�^64bit�ƃ������ш�������w�ǂ̃x���`���ʂ�
�b������������AMD��CPU�����|���Ă邵�Ȃ��B
����Ȃ��ƌ����Ă��Ȃ��A�T�N���G�f�B�^64bit�ƃ������ш�������w�ǂ̃x���`���ʂ�
�b������������AMD��CPU�����|���Ă邵�Ȃ��B
L1 Hit�͈̔͂�K8��Core�͓����B
L1 Miss / L2 Hit�͈̔͂ł�Core��Latency�̕������Ȃ��B
L1 Miss / L2 Miss�͈̔͂ɐ���ƁA�����R����������K8�̕���Latency�����Ȃ��B
���Ď��ł���
L1 Miss / L2 Hit�͈̔͂ł�Core��Latency�̕������Ȃ��B
L1 Miss / L2 Miss�͈̔͂ɐ���ƁA�����R����������K8�̕���Latency�����Ȃ��B
���Ď��ł���
L1���ш悪�S���Ⴄ�B(Conroe��K8�̔{��)
L1����̓ǂݍ��ݑ҂���Conroe��K8�̓�{�̐��\�B
�L���b�V���~�X��O��ɍl����悤�ȃ\�t�g�͌��X����ᑬ���B
L1����̓ǂݍ��ݑ҂���Conroe��K8�̓�{�̐��\�B
�L���b�V���~�X��O��ɍl����悤�ȃ\�t�g�͌��X����ᑬ���B
���[���A������������c
�����烁�����ш�Ƃ��A����\���Ƃ��A�������������@�\�őΌ������Ă��Ӗ��Ȃ���B
���ʂ������S�āB
���Ƒ匴�͐����d�������Ǝv���A�ǂ����̓V�c�������݂ɁB
����Ń~�X���[�h���낤�ƂȂ낤�ƁAk8�͂܂��܂�������A�Ƃ�����]�I�ϑ���AMD�M�҂Ɍ��o����
Hound�Ɍq����܂ł̐S�̋��菊��������B
���ʂ������S�āB
���Ƒ匴�͐����d�������Ǝv���A�ǂ����̓V�c�������݂ɁB
����Ń~�X���[�h���낤�ƂȂ낤�ƁAk8�͂܂��܂�������A�Ƃ�����]�I�ϑ���AMD�M�҂Ɍ��o����
Hound�Ɍq����܂ł̐S�̋��菊��������B
���͑匴�Y��I���p�t�̓���͈ɒB����Ȃ������I
K8L�̖ϑz
�m���ɁAL1�̑ш��{�ɏグ�܂��ƌ��\���Ă���B
�������A�f���A���A�N�Z�X���\�ɂ���ƌ��\���Ă���B
���ꂾ������������ƈ�ʐl��M�҂͐����Ǝv���Ă��܂��B
�������A����ɂ͑傫�ȗ��Ƃ���������\���������B
����ƈ����ւ��ɁA���C�e���V�̈������z�肳��Ă��܂����炾�AAMD�͂��̂��Ƃɂ͌����ĐG��Ȃ��B
�������A�悭�悭�l���Ă݂��L1��L2�̐��\�͂����ȒP�ɂ͏オ��Ȃ��B
���\���ȒP�ɏグ����̂Ȃ�L1�͂����Ƌ���ŁA�����Ɛ��\���ǂ����̂ɂȂ��Ă���B
����łȂ��Ă�AMD��L1��Intel�̔{�̗e�ʂ�����A���\�����߂�̂͗e�Ղł͂Ȃ��B
�匴�͂���Ȃ��Ə��m�̔��ł��莩�g�ɓs���̗ǂ��Ƃ��낾��s���ǂ��܂Ƃ߂��ɉ߂��Ȃ��B
�������AuOPs�͂ǂ̂悤�ɂȂ��Ă��邩�s���ł���ƌ����Ȃ��炾�B
���_�Ƃ��āA����܂Ƃ��ɂ͕������Ă��Ȃ��B
�m���ɁAL1�̑ш��{�ɏグ�܂��ƌ��\���Ă���B
�������A�f���A���A�N�Z�X���\�ɂ���ƌ��\���Ă���B
���ꂾ������������ƈ�ʐl��M�҂͐����Ǝv���Ă��܂��B
�������A����ɂ͑傫�ȗ��Ƃ���������\���������B
����ƈ����ւ��ɁA���C�e���V�̈������z�肳��Ă��܂����炾�AAMD�͂��̂��Ƃɂ͌����ĐG��Ȃ��B
�������A�悭�悭�l���Ă݂��L1��L2�̐��\�͂����ȒP�ɂ͏オ��Ȃ��B
���\���ȒP�ɏグ����̂Ȃ�L1�͂����Ƌ���ŁA�����Ɛ��\���ǂ����̂ɂȂ��Ă���B
����łȂ��Ă�AMD��L1��Intel�̔{�̗e�ʂ�����A���\�����߂�̂͗e�Ղł͂Ȃ��B
�匴�͂���Ȃ��Ə��m�̔��ł��莩�g�ɓs���̗ǂ��Ƃ��낾��s���ǂ��܂Ƃ߂��ɉ߂��Ȃ��B
�������AuOPs�͂ǂ̂悤�ɂȂ��Ă��邩�s���ł���ƌ����Ȃ��炾�B
���_�Ƃ��āA����܂Ƃ��ɂ͕������Ă��Ȃ��B
717 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 02:28:13 ID:NIaDKxnG
>>715�̌㔼�͑s����k�ق��ȁB���������̂����邩��A���`�҂ސ~�͔n���ɂ�����B
K8��L1��Assosiativity��2Way�iPenM/Core��4Way)�ɗ��Ƃ���PenM��2�{�̗e�ʂĂ邾����
�ʂɖ����ł��Ȃ�ł��Ȃ��B
���[�h�ш�͒P�ɐM������{�ɂ�����������B
PenM��Core��L1���[�h�ш�͔{�����Ă邪���C�e���V��Assosiativity�͈�؋]���ɂ��ĂȂ��B
�v���Z�X�����������������Ă��Ȃ��s�v�c�͂Ȃ��B
���C�e���V�̑����Ƃ��A�z���点�B
K8��L1��Assosiativity��2Way�iPenM/Core��4Way)�ɗ��Ƃ���PenM��2�{�̗e�ʂĂ邾����
�ʂɖ����ł��Ȃ�ł��Ȃ��B
���[�h�ш�͒P�ɐM������{�ɂ�����������B
PenM��Core��L1���[�h�ш�͔{�����Ă邪���C�e���V��Assosiativity�͈�؋]���ɂ��ĂȂ��B
�v���Z�X�����������������Ă��Ȃ��s�v�c�͂Ȃ��B
���C�e���V�̑����Ƃ��A�z���点�B
718 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 02:32:06 ID:NIaDKxnG
Associativity
���߂�ˊ���Ȃ��p�P��g����
���߂�ˊ���Ȃ��p�P��g����
�܂���ʘ_�Ƃ��Ă͂ǂ���Ԉ���ĂȂ����ǁAL1�Ń��C�e���V���͍l���㩁B
>�������AuOPs�͂ǂ̂悤�ɂȂ��Ă��邩�s��
�Ƃ肠����>>715�͂���C�ɗǂ���������NE�B
>�������AuOPs�͂ǂ̂悤�ɂȂ��Ă��邩�s��
�Ƃ肠����>>715�͂���C�ɗǂ���������NE�B
>>71
Assosiativity��2Way�ɗ��Ƃ��Ă��e�ʂ�������킯�˂���w
Assosiativity��2Way�ɗ��Ƃ��Ă��e�ʂ�������킯�˂���w
���Ȃ݂�Way���ő傫�����C�e���V���ω�����̂�16Way���z����悤�ȏꍇ�ł���A2Way�`8Way�Ȃ�w�NJW�Ȃ��B
���e�ʂ�������ƁA�����e�ς������邱�ƂŃ��C�e���V�ɉe������B
�X�ɁA�M�����𑝂₹�ƌ����Ă��邪����ȒP���Ȃ��̂���˂���B
���e�ʂ�������ƁA�����e�ς������邱�ƂŃ��C�e���V�ɉe������B
�X�ɁA�M�����𑝂₹�ƌ����Ă��邪����ȒP���Ȃ��̂���˂���B
722 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 03:12:07 ID:NIaDKxnG
�T���̐[�x�����点��̂ŁALatency=3�͈̔͂Ŏ����ł��郁�����e�ʂ͑������ȁB
4Way��2Way���Ⴆ�炢�Ⴂ�ł����B
�������A�L���b�V�����C�����܂����ƃy�i���e�B���傫������A�u16�o�C�g�A�h���X���E���ׂ��Ȃ��v
�Ƃ�����������Ă�B
�ш悪������ƃ��[�h���C�e���V���������闝�R�������ƌ�����B�����͂��܂�łȂ����B
[�G���ɂ͂킩��Ȃ���������Ȃ��ۑ�]
Pentium 4��L2�̃��C�e���V���ُ�ɑ傫���������R���������
�q���g�F�L���b�V�����C��
4Way��2Way���Ⴆ�炢�Ⴂ�ł����B
�������A�L���b�V�����C�����܂����ƃy�i���e�B���傫������A�u16�o�C�g�A�h���X���E���ׂ��Ȃ��v
�Ƃ�����������Ă�B
�ш悪������ƃ��[�h���C�e���V���������闝�R�������ƌ�����B�����͂��܂�łȂ����B
[�G���ɂ͂킩��Ȃ���������Ȃ��ۑ�]
Pentium 4��L2�̃��C�e���V���ُ�ɑ傫���������R���������
�q���g�F�L���b�V�����C��
724 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 03:32:28 ID:NIaDKxnG
�͂��͂��A��������Ȃ�Core 2 Duo��8Way�ɂ��Ȃ��̂ł����H
��x�ɓǂݏ�������i�L���b�V�����C�����ׂ��Ȃ��j�f�[�^����������ƃ��C�e���V��������Ƃ���
�g���f�����_�̐������o���Ȃ��ȏ�A���������Ă������͂�����܂���B
��x�ɓǂݏ�������i�L���b�V�����C�����ׂ��Ȃ��j�f�[�^����������ƃ��C�e���V��������Ƃ���
�g���f�����_�̐������o���Ȃ��ȏ�A���������Ă������͂�����܂���B
726 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 03:48:20 ID:NIaDKxnG
��������8Way���ȁB�ǂ�łȂ������B
�������A�d�q�̈ړ��x���オ��Ȃ��Ɩ����ȉ��ǂł���B
2Way��8Way�Ȃ�]�v�ɒT���̃��C�e���V�̍�����㩁B
AMD��65nm���Ń��[�h�E�X�g�A�ш�𑝂₷�ƃ��C�e���V��������
����́A������������AMD�����炻�������ė~�������Ă����������Ȋ�]�I�ϑ�����Ȃ��̂��ȁH
�������A�d�q�̈ړ��x���オ��Ȃ��Ɩ����ȉ��ǂł���B
2Way��8Way�Ȃ�]�v�ɒT���̃��C�e���V�̍�����㩁B
AMD��65nm���Ń��[�h�E�X�g�A�ш�𑝂₷�ƃ��C�e���V��������
����́A������������AMD�����炻�������ė~�������Ă����������Ȋ�]�I�ϑ�����Ȃ��̂��ȁH
> ��x�ɓǂݏ�������i�L���b�V�����C�����ׂ��Ȃ��j�f�[�^����������ƃ��C�e���V��������Ƃ���
> �g���f�����_�̐������o���Ȃ��ȏ�A���������Ă������͂�����܂���B
���̔n�����������ɂ͂ǂ��������炢���̂�?
�L���b�V�����C�������D���Ȃ����傫������ƁA�L���b�V�����C���ׂ͌��Ȃ����烌�C�e���V�͑����Ȃ��̂ł����ł��Ƃł����������̂�?
L1�̂悤�Ȓ������ȃL���b�V���ɂȂ�ƃ��C�����̑傫�����瑬�x�ɉe�����邱�Ƃ𗝉����Ă���B
> �g���f�����_�̐������o���Ȃ��ȏ�A���������Ă������͂�����܂���B
���̔n�����������ɂ͂ǂ��������炢���̂�?
�L���b�V�����C�������D���Ȃ����傫������ƁA�L���b�V�����C���ׂ͌��Ȃ����烌�C�e���V�͑����Ȃ��̂ł����ł��Ƃł����������̂�?
L1�̂悤�Ȓ������ȃL���b�V���ɂȂ�ƃ��C�����̑傫�����瑬�x�ɉe�����邱�Ƃ𗝉����Ă���B
728 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 03:58:00 ID:NIaDKxnG
�ǂ����ǂ��ǂ݊ԈႦ������Ȃ�
�L���b�V�����C�����𑝂₷�Ȃ�Č����ĂȂ�����B���O�}�W�r������B
32Byte��1�L���b�V�����C����̃f�[�^�̓ǂݏ�����byte����aligned��16byte���ɂ����
�ǂ����ă��C�e���V��������̂��������Ɛ��������I�C
���Ȃ݂ɃL���b�V�����C���T�C�Y���������L/S�̃��C�e���V��������̂�L1����Ȃ���L2����B
Northwood��64byte�L���b�V�����C�e���V2�������B
�����킩�邾��A>>722�ɂ��������Ɠ����Ă���A�G���搶
�L���b�V�����C�����𑝂₷�Ȃ�Č����ĂȂ�����B���O�}�W�r������B
32Byte��1�L���b�V�����C����̃f�[�^�̓ǂݏ�����byte����aligned��16byte���ɂ����
�ǂ����ă��C�e���V��������̂��������Ɛ��������I�C
���Ȃ݂ɃL���b�V�����C���T�C�Y���������L/S�̃��C�e���V��������̂�L1����Ȃ���L2����B
Northwood��64byte�L���b�V�����C�e���V2�������B
�����킩�邾��A>>722�ɂ��������Ɠ����Ă���A�G���搶
729 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 03:58:48 ID:NIaDKxnG
8byte����aligned��16byte���ɂ����
�N���G���搶�Ȃ̂�?
���O��?
�ш�𑝂₷�̂������ȒP�Ȃ��Ƃ���˂���B
65nm�ɂȂ��Ă�����͂����Ƃ��ς��˂����A�ς��悤�Ƃ���Γ��ڂ���g�����W�X�^���\���ǂꂾ�������\���o���邩�Ȃ�B
�������������Ă��甭������ȁB
���O��?
�ш�𑝂₷�̂������ȒP�Ȃ��Ƃ���˂���B
65nm�ɂȂ��Ă�����͂����Ƃ��ς��˂����A�ς��悤�Ƃ���Γ��ڂ���g�����W�X�^���\���ǂꂾ�������\���o���邩�Ȃ�B
�������������Ă��甭������ȁB
731 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 04:07:09 ID:NIaDKxnG
64byte�L���b�V�����C���\����L1-L2�Ԃ̑ш悪���Ƃ��Ώ�艺��e8byte�Ȃ�
L2����1�L���b�V�����C�������[�h����̂ɁA32byte�L���b�V�����C���̂�����A
4�N���b�N�͑��߂ɂ�����i�P���v�Z�Łj
���ꂪ�L���b�V�����C���T�C�Y��傫�����邱�Ƃɂ�郌�C�e���V�̑�������B
���Ƃ��ƍ��N���b�N��_�����v������A1�N���b�N������̈ړ��x�̖������邯�ǂˁB
ID:R0NF0tOi�͎G���搶�̎咣�ƑS����������������
L2����1�L���b�V�����C�������[�h����̂ɁA32byte�L���b�V�����C���̂�����A
4�N���b�N�͑��߂ɂ�����i�P���v�Z�Łj
���ꂪ�L���b�V�����C���T�C�Y��傫�����邱�Ƃɂ�郌�C�e���V�̑�������B
���Ƃ��ƍ��N���b�N��_�����v������A1�N���b�N������̈ړ��x�̖������邯�ǂˁB
ID:R0NF0tOi�͎G���搶�̎咣�ƑS����������������
732 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 04:07:56 ID:NIaDKxnG
> ���Ƃ��ƍ��N���b�N��_�����v������A1�N���b�N������̈ړ��x�̖������邯�ǂˁB
�����NetBurst�̘b�B
�����NetBurst�̘b�B
> ���Ƃ��ƍ��N���b�N��_�����v������A1�N���b�N������̈ړ��x�̖������邯�ǂˁB
����Ƃ܂Ƃ��Ȃ��Ƃ�����������˂���w
�Ă߂��͎��Ԃ����肷���Ȃ�A���������B
���ǂ̂Ƃ������A��H�����b�`�ɂ��邱�ƂɐV�g�����W�X�^�̐��\���g�����܂��ƁA���x�̓N���b�N���グ��˂��B
����Ȃ���Ȃ�AMD�̔��\�͔��ɉ�������B
�o�Č��Ȃ����S���]���o���Ȃ����e�ƂȂ��Ă�����Ă��Ƃ��B
�����炻��ȂɊ��҂���̂͂ǂ����Ǝv�����B
����Ƃ܂Ƃ��Ȃ��Ƃ�����������˂���w
�Ă߂��͎��Ԃ����肷���Ȃ�A���������B
���ǂ̂Ƃ������A��H�����b�`�ɂ��邱�ƂɐV�g�����W�X�^�̐��\���g�����܂��ƁA���x�̓N���b�N���グ��˂��B
����Ȃ���Ȃ�AMD�̔��\�͔��ɉ�������B
�o�Č��Ȃ����S���]���o���Ȃ����e�ƂȂ��Ă�����Ă��Ƃ��B
�����炻��ȂɊ��҂���̂͂ǂ����Ǝv�����B
734 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 04:18:27 ID:NIaDKxnG
> ����Ȃ���Ȃ�AMD�̔��\�͔��ɉ�������B
�u����Ȃ���ȁv�ƑO�̕��͂Ƃ̌q���肪�s���B
�������Ǝv���̂͂Ă߂��̎�ςł����ċq�ϐ����Ȃ�㩁B
IBM��65nm SOI�͔��ɗD�G���Ƃ����b���܂����B
�c�q������Ȃ�A���Ԃ̖��ʂ���
���^�Ƃ͊�b�m���ɍ������肷���邩�炢���肪�����˂���
�s���������Ȃ�Ⴀ�u������҂����v�œ����邼��
���^�Ƃ͊�b�m���ɍ������肷���邩�炢���肪�����˂���
�s���������Ȃ�Ⴀ�u������҂����v�œ����邼��
>>734
IBM�̖��O�����o���Δ[�����Ă����Ƃł��v���Ă���̂�?
�����Intel�ł���A�S���E�ōł��D�ꂽ�ݔ��ƌ����@�ւƃV���R���Z�p��L���Ă���Intel�ȁB
��x������ďo�����Ă�����A�ڂ���B
>>735
���������ȁA���_���ƌ������Ƃ��������Ă�����B
IBM�̖��O�����o���Δ[�����Ă����Ƃł��v���Ă���̂�?
�����Intel�ł���A�S���E�ōł��D�ꂽ�ݔ��ƌ����@�ւƃV���R���Z�p��L���Ă���Intel�ȁB
��x������ďo�����Ă�����A�ڂ���B
>>735
���������ȁA���_���ƌ������Ƃ��������Ă�����B
�G������������イ�g�����t"�g�����W�X�^���\"�B
�ł����ꂪ��̓I�ɉ����w���Ă���̂��͕s���B
�܂��d���ʂł�������������MyCOM�̃��|�[�g�ł����Ă����A�ƁB
�ł����ꂪ��̓I�ɉ����w���Ă���̂��͕s���B
�܂��d���ʂł�������������MyCOM�̃��|�[�g�ł����Ă����A�ƁB
>>736
�b�ƊW�Ȃ����ǁAAMD��SOI��IBM�̂��̂Ȃ�
�b�ƊW�Ȃ����ǁAAMD��SOI��IBM�̂��̂Ȃ�
64bit��128bit���͒P���ɃA�N�Z�X���̖�肾���瑝�₵������Ƃ����ă��C�e���V�ɂ͒���
�e�����Ȃ��͂������ȁB
���X�p�������o�X�̗L���ȓ_�͂����Ȃ��B
�o�X���g��œ�Փx���オ��͓̂����z�����ȁB
���������K8L��65nm������Ă��Ƃ��ƁA���̂܂܂̉�H�ł̌��w�V�������N�Ȃ�P���Ƀo�X�z������
�ق�2/3�Ń��C�e���V�ʂł͗]�T���o���邩��A����ő��E����ă��C�e���V�͈ێ��ł��邾��B
Prescott�݂����ɃL���b�V���e�ʔ{�����ƁA�P���ɔz�������{�ɂȂ邩�烌�C�e���V�͑����邪�ȁB
�e�����Ȃ��͂������ȁB
���X�p�������o�X�̗L���ȓ_�͂����Ȃ��B
�o�X���g��œ�Փx���オ��͓̂����z�����ȁB
���������K8L��65nm������Ă��Ƃ��ƁA���̂܂܂̉�H�ł̌��w�V�������N�Ȃ�P���Ƀo�X�z������
�ق�2/3�Ń��C�e���V�ʂł͗]�T���o���邩��A����ő��E����ă��C�e���V�͈ێ��ł��邾��B
Prescott�݂����ɃL���b�V���e�ʔ{�����ƁA�P���ɔz�������{�ɂȂ邩�烌�C�e���V�͑����邪�ȁB
���C�e���V�������邱�Ƃɂ��Ȃ���
AMD�����s���邱�Ƃɂ��Ȃ���
�C�����܂�Ȃ��̂ł��B
�������C�e���V���Č��������������Ⴄ�ƁB
����肫�ŁA������点�Ă�Intel�͑f���炵���AAMD�͕��Ƃ��������Ȃ��B
�܂Ƃ��ɋZ�p�_����点�邾�����ʁB
AMD��L1�L���b�V���ɂ�����32B�L���b�V�����C����2�E�F�C�Z�b�g�A�\�V�G�C�e�B�u��
64KB+64KB�Ƃ����\���́A����K7�i0.25��m�j�̎��_�Ŋ��Ɏ������Ă������́B
(K6��32KB+32KB)
�ނ��낻�̊ԂɁAIntel��Pentium III��Pentium M�ŗe��2�{�ACore 2��8�E�F�C���B
K8�̃L���b�V���\���ɖ���������ƌ����Ȃ�AIntel�̂ق��������Ԗ������Ă邱�ƂɂȂ�B
�t�Ɍ����ƁAL1�L���b�V�����̂̐��\�����͍s����Ǝv�����ȁB
���C�e���V��2�ɂ�����e�ʂ�{������̂͋ꂵ����������A4�E�F�C�����炢��
���邩��������ȁB
AMD�����s���邱�Ƃɂ��Ȃ���
�C�����܂�Ȃ��̂ł��B
�������C�e���V���Č��������������Ⴄ�ƁB
����肫�ŁA������点�Ă�Intel�͑f���炵���AAMD�͕��Ƃ��������Ȃ��B
�܂Ƃ��ɋZ�p�_����点�邾�����ʁB
AMD��L1�L���b�V���ɂ�����32B�L���b�V�����C����2�E�F�C�Z�b�g�A�\�V�G�C�e�B�u��
64KB+64KB�Ƃ����\���́A����K7�i0.25��m�j�̎��_�Ŋ��Ɏ������Ă������́B
(K6��32KB+32KB)
�ނ��낻�̊ԂɁAIntel��Pentium III��Pentium M�ŗe��2�{�ACore 2��8�E�F�C���B
K8�̃L���b�V���\���ɖ���������ƌ����Ȃ�AIntel�̂ق��������Ԗ������Ă邱�ƂɂȂ�B
�t�Ɍ����ƁAL1�L���b�V�����̂̐��\�����͍s����Ǝv�����ȁB
���C�e���V��2�ɂ�����e�ʂ�{������̂͋ꂵ����������A4�E�F�C�����炢��
���邩��������ȁB
�x���̂͂��邾�낤�ȁB
�����Ă����Ȃ�����A�m���ɂ`�l�c�I���^�_(^o^)�^
�����Ă����Ȃ�����A�m���ɂ`�l�c�I���^�_(^o^)�^
�͂₭���q���g��CPU������ė~�����B
�d�q�g���Ȃ甭�M�ɓ���Y�܂��邱�ƂɂȂ�B
�d�q�g���Ȃ甭�M�ɓ���Y�܂��邱�ƂɂȂ�B
�͂₭�d�͎q���g��CPU������ė~�����B
���q�g���Ȃ狗�����ɓ���Y�܂��邱�ƂɂȂ�B
���q�g���Ȃ狗�����ɓ���Y�܂��邱�ƂɂȂ�B
�d�͎q�ł������͒����Ȃ��̂ł́H
�ʎq�R���s���[�^�[�܂����H������
��Ԃ�P���Ȃ��ċ������Ȃ����̂ł́H
���[���z�[���g�����ق��������ˁ`�H
>>736
���̃C���e����90nm�̃��[�N�d���ő厸�s�����̂́A�L���ɐV�����b�����B
���ꂪ�n�����g���������������e���́A�����o���Ȃ����炢�傫���Ǝv���B
���̃C���e����90nm�̃��[�N�d���ő厸�s�����̂́A�L���ɐV�����b�����B
���ꂪ�n�����g���������������e���́A�����o���Ȃ����炢�傫���Ǝv���B
�����č��x��AMD�̕���Գާ�����ɒu����Ă��܂��Ă���Ƃ��������c
orz
�{���Ɏc�O�����A���オ�ς���Ă��܂����B
K8L�ŋt�]������A�̘b�Ŕn���ɂ���Ȃ�Ă��Ƃ��Ȃ��Ă����ނ̂��ȁB
����͂����ƁA��̑Ό��A�N�����Ă��Ă����B
orz
�{���Ɏc�O�����A���オ�ς���Ă��܂����B
K8L�ŋt�]������A�̘b�Ŕn���ɂ���Ȃ�Ă��Ƃ��Ȃ��Ă����ނ̂��ȁB
����͂����ƁA��̑Ό��A�N�����Ă��Ă����B
750 �FSocket774�F2006/08/11(��) 17:19:05 ID:8vxTgi4M
�[���G���Ȃ�Ė{�\�Ȃ���K������悤�Ȃ���˂�����
�c�t�����ɂ`�u�ǂ�ǂ��Ă��
�c�t�����ɂ`�u�ǂ�ǂ��Ă��
751 �FSocket774�F2006/08/11(��) 17:35:46 ID:edvR+Ra+
�r���L���b�V���Ƃ����̂̓������[���烍�[�h�������ɂk�Q���o�R�����ɂk�P�Ɏ��߁A
�k�P����p�[�W���ꂽ��k�Q�Ɏ��߂�Ƃ�������ɂȂ�A�k�P�̃p�[�W���̏�����
���G�Ȋ����B�k�Q�����L�ɂ��悤�Ƃ�����K�R�I�ɔr���ɏo���Ȃ����������H
�k�P����p�[�W���ꂽ��k�Q�Ɏ��߂�Ƃ�������ɂȂ�A�k�P�̃p�[�W���̏�����
���G�Ȋ����B�k�Q�����L�ɂ��悤�Ƃ�����K�R�I�ɔr���ɏo���Ȃ����������H
��ŁA�m�[�g�ƃf�X�N�g�b�v�Ń}�C�N���A�[�L�̐v�����f�����킯���B
>>750
�c�t�����͂����ƃp�p�}�}�̃v�����X���������V�b�J�����Ă邩��I�P�B
���āA�X���Ⴂ�J�L�R���ȁB
>>752
�f�X�m�[�g�Ń}�C�R�̐g�̂����f�H
�c�t�����͂����ƃp�p�}�}�̃v�����X���������V�b�J�����Ă邩��I�P�B
���āA�X���Ⴂ�J�L�R���ȁB
>>752
�f�X�m�[�g�Ń}�C�R�̐g�̂����f�H
����Ϗ����I�ɂ̓R�A�������邾�����H
�V���O���X���b�h���i�i�ɑ����Ȃ�z�����Ăق�������
�V���O���X���b�h���i�i�ɑ����Ȃ�z�����Ăق�������
�X���b�h���ʂɓf��OS��A�v������]���Ă͂ǂ���
>754
����60�N���炢�҂��ĂĂ���
�v���I�ɑ����̂�p�ӂ��Ă�邩��
����60�N���炢�҂��ĂĂ���
�v���I�ɑ����̂�p�ӂ��Ă�邩��
�L���b�V���ƃ��������\���グ��悢�Ƃ������_�̓X���[���H
�ł�Itanium��PPC�͂����܂ő����Ȃ����c
�X���b�h���ʂɓf��OS��A�v������]���Ă͂ǂ���
�X���b�h���ʂɓf��OS��A�v������]���Ă͂ǂ���
>>758
2001�N�̃f���A���R�A�������ƃR�A���������A�N�A�b�h�R�APOWER5+�͂ǂ��Ȃ�H
2001�N�̃f���A���R�A�������ƃR�A���������A�N�A�b�h�R�APOWER5+�͂ǂ��Ȃ�H
>>746
�k�n�@��
�k�n�@��
�[���AAMD����Ƃ������Ă����āAAMD�ɒׂ�Ăق����̂�?
����AMD���ׂ�Ă��܂�����A�������Ȃ��Ȃ��đ�ςȂ��ƂɂȂ��Ȃ��̂�?
C2D������AMD�ɐ��\��ذ�ނ���ĂȂ�������A�o���Ȃ��������낤���B
����AMD���ׂ�Ă��܂�����A�������Ȃ��Ȃ��đ�ςȂ��ƂɂȂ��Ȃ��̂�?
C2D������AMD�ɐ��\��ذ�ނ���ĂȂ�������A�o���Ȃ��������낤���B
�{���ɒׂꂻ���ɂȂ����� IBM ���E���Ă���Ȃ�����
AMD����Ƃ������Ă����ķ����������H
AMD����Ƃ������Ă������l���ܯ�ق���Ȃ��O�O�G
>>764
intel�̎Ј��͏����g�����ǂ�
intel�̎Ј��͏����g�����ǂ�
���X�g�������̐l�͂����ł��Ȃ��悤�ł��B
�Ј��̕��Ϗ�����AMD�̕����ゾ������K�X�E�E�E
Intel�̂ق����H��Ƃ��̍�ƈ������������
�����J���v���͉�Ђ��傫������Ƃ͂����A��萔�Ŏ������
�t��AMD�͌����J���v������ЋK�͂̊��ɂ͑��������Ȃ���Intel�ɑR�ł���ȁB
�����J���v���͉�Ђ��傫������Ƃ͂����A��萔�Ŏ������
�t��AMD�͌����J���v������ЋK�͂̊��ɂ͑��������Ȃ���Intel�ɑR�ł���ȁB
�܂���AMD�͏������s�̃G���[�g�W�c
>>769
�ŁA�L�~�͍����H�����H
�ŁA�L�~�͍����H�����H
�܂��A��������ȁB
5���Ŕ�������Ȃ�Đ�����
773 �FSocket774�F2006/08/14(��) 21:50:48 ID:/5IHfuMX
>>770
�������Ȃ��܂��E�E�E
�������Ȃ��܂��E�E�E
�ȒP�Ȃ���
FlashRAM���ڂ���VLIW�^CPU�ɂ��Ă��܂�������ł���B
�N���[�\�[�^�̓��I�œK���|������
FlashRAM���ڂ���VLIW�^CPU�ɂ��Ă��܂�������ł���B
�N���[�\�[�^�̓��I�œK���|������
����z�̓o�J
VLIW��ISA�̖��Ȃ̂ɁA�Ȃ�ł��ꂪ�o�Ă���B
�m���ɕ��G��x86�̃f�R�[�_�̖��Ƃ̓I�T���o�ł��邯��
����͂��͂�x86CPU�Ƃ͂����Ȃ��㕨��
�m���ɕ��G��x86�̃f�R�[�_�̖��Ƃ̓I�T���o�ł��邯��
����͂��͂�x86CPU�Ƃ͂����Ȃ��㕨��
K8L���e�[�v�A�E�g�������B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~111541,00.html
�@�@---------------------------
�@�@ In addition to launching its Next-Generation AMD Opteron processors, AMD also
�@�@announced the completion of the design, or tape-out, of its native Quad-Core AMD
�@�@Opteron processors.
�@�@---------------------------
�_�C�̃��C�A�E�g�}�����ŐM�҂��x��������Ƃ�������E�p�ł������Ƃ�C�f���Ɋ��
�ׂ����Ǝv�����B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~111541,00.html
�@�@---------------------------
�@�@ In addition to launching its Next-Generation AMD Opteron processors, AMD also
�@�@announced the completion of the design, or tape-out, of its native Quad-Core AMD
�@�@Opteron processors.
�@�@---------------------------
�_�C�̃��C�A�E�g�}�����ŐM�҂��x��������Ƃ�������E�p�ł������Ƃ�C�f���Ɋ��
�ׂ����Ǝv�����B
>>778
�����Intel�������ł�H
�����Intel�������ł�H
�N���b�N�ƒx���`�ŐM�҂ǂ��납��ʃ��[�U�[�܂Ő��]��������̂��̓}�V���낤�Bw
�����Ƃ��A���̂������Ŏ����̎���i�߂Ă��܂������������邪�B
�����Ƃ��A���̂������Ŏ����̎���i�߂Ă��܂������������邪�B
K8L���ăV���O���R�A�ł����ʂɔ�����̂��ȁH
�}���`�R�A�ɓ�������悤�ɐv����Ă邩�炻��͂Ȃ��H
�}���`�R�A�ɓ�������悤�ɐv����Ă邩�炻��͂Ȃ��H
�Ă`�l�c�A������l�o�t��07�N����
ttp://www.nikkei.co.jp/news/main/20060816AT2M1600G16082006.html
ttp://www.nikkei.co.jp/news/main/20060816AT2M1600G16082006.html
783 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/16(��) 23:04:28 ID:thAe/y1Q
�P���Ɍ��s��K8�����w�V�������N�����1�R�A50mm^2���̂����ǁA
�������[�R���g���[���̕��͏k���ł��Ȃ��̂ŁA�L���b�V�������剻����Ȃ�
�R�A����������ׂ�Ȃ肵��100mm^2�l�����x�Ɏ��߂�K�v������Ƃ��B
���ꂱ��Core Duo�`���ŃV���O���R�AAthlon��X2�̕ЃR�A�����łƂ��ďo��������
�����I���낤�ˁB
Sempron�̓`�b�v�Z�b�g�Ƃ̃����`�b�v���Ƃ����o���Ɩʔ��������B
�������[�R���g���[���̕��͏k���ł��Ȃ��̂ŁA�L���b�V�������剻����Ȃ�
�R�A����������ׂ�Ȃ肵��100mm^2�l�����x�Ɏ��߂�K�v������Ƃ��B
���ꂱ��Core Duo�`���ŃV���O���R�AAthlon��X2�̕ЃR�A�����łƂ��ďo��������
�����I���낤�ˁB
Sempron�̓`�b�v�Z�b�g�Ƃ̃����`�b�v���Ƃ����o���Ɩʔ��������B
>>779
AMD�t�@���Ƃ��Ă�A��������Ă��Ȃ�K8L���e�[�v�A�E�g����Ă��b��ɂ��Ă킢���Ȃ��炵�����B
AMD�t�@���Ƃ��Ă�A��������Ă��Ȃ�K8L���e�[�v�A�E�g����Ă��b��ɂ��Ă킢���Ȃ��炵�����B
>>784
�����Intel�������ł�H
�����Intel�������ł�H
�C����������o�J�ۏo���̕��̂��܂˂ăA�z�̑���������
AMD�̃N�A�b�h�́A�N���b�N�ǂ̕ӂ肩�烊���[�X�����\��Ȃ�?
Socket F Opteron���ߎS�ȏo�����̂悤���ˁB�B�B
4-socket/8-core�ł�SPECint2000_rate�̔�r���B
�@Xeon 7041/3GHz: 114(base)/114(peak)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060710-06446.html
�@Opteron 8220SE/2.8GHz: 146(base)/166(base)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060721-06572.html
�@Xeon 7140M(3.4GHz): 161(base)/162(peak)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060724-06780.html
�A�����̐S�̋��菊�ł��遄2-socket�Ńl�b�g�o�[�X�gXeon�ɂ���ǂ������Ƃ�(��)
4-socket/8-core�ł�SPECint2000_rate�̔�r���B
�@Xeon 7041/3GHz: 114(base)/114(peak)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060710-06446.html
�@Opteron 8220SE/2.8GHz: 146(base)/166(base)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060721-06572.html
�@Xeon 7140M(3.4GHz): 161(base)/162(peak)
�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060724-06780.html
�A�����̐S�̋��菊�ł��遄2-socket�Ńl�b�g�o�[�X�gXeon�ɂ���ǂ������Ƃ�(��)
Tulsa ktkr!!
���炩��Intel�̓X�R�A�������ɂȂ�悤��L3�����Ă����Ȃ�
������base��160over���ăX�Q�[�ȁc
���炩��Intel�̓X�R�A�������ɂȂ�悤��L3�����Ă����Ȃ�
������base��160over���ăX�Q�[�ȁc
Xeon�ł����\���o���Ȃ���Ȃ����Ă̂͂킩�邪�A����͋������邩��ȁB
IBM��X-Series���ƁA�`�b�v�̊J��������3�N��1���h�����������Ă邵�B
IBM��X-Series���ƁA�`�b�v�̊J��������3�N��1���h�����������Ă邵�B
> ���炩��Intel�̓X�R�A�������ɂȂ�悤��L3�����Ă����Ȃ�
16MB on-chip L3 �L���b�V���̈З͂��ēz�ł����ˁB
> ������base��160over���ăX�Q�[�ȁc
base �� peak ���قƂ�Ǖς��Ȃ�����AIntel C compiler ���A
SPEC + Intel CPU �̑g���������ɁA������ƃ`���[�j���O����Ă����
���Ƃ���Ȃ��̂��ȁB
16MB on-chip L3 �L���b�V���̈З͂��ēz�ł����ˁB
> ������base��160over���ăX�Q�[�ȁc
base �� peak ���قƂ�Ǖς��Ȃ�����AIntel C compiler ���A
SPEC + Intel CPU �̑g���������ɁA������ƃ`���[�j���O����Ă����
���Ƃ���Ȃ��̂��ȁB
base�̈Ӌ`�͒N�ł���r�I�e�Ղɂ��̃X�R�A���o������ē_�ɂ���킯��
���́A���[�U�̎g���Ă�A�v���P�[�V�����Ő��\���o�邩�ł���B
Intel �R���p�C�����A�ǂ�ȃA�v���ł��œK�ȃR�[�h��f����ق�
������Ζ��Ȃ����ǁASPEC �̃x���`�}�[�N�Ώۂ�F�����ďo��
�R�[�h�����Ă�����Ӗ��Ȃ��B
base �� peak �ŁA�����܂ō����o�Ȃ��Ƃ���ƁA��҂̉\����
����Ȃ�ɂ��肤��̂ł́H �܂��A���ۂɂǂ���Ȃ̂��͉��Ƃ�
�����Ȃ����ǂ��B
���ƁA���̈�ۂ��ƁAgcc �g���� NetBurst �̕����x���Ȃ闦��
�����B�T�[�o���Ƃ���ς� Linux �����\�������ALinux ����
�J�[�l������A�v���܂őS�� gcc �ŃR���p�C������Ă邩��A����
Opteron �̕�������������B
Intel �R���p�C�����A�ǂ�ȃA�v���ł��œK�ȃR�[�h��f����ق�
������Ζ��Ȃ����ǁASPEC �̃x���`�}�[�N�Ώۂ�F�����ďo��
�R�[�h�����Ă�����Ӗ��Ȃ��B
base �� peak �ŁA�����܂ō����o�Ȃ��Ƃ���ƁA��҂̉\����
����Ȃ�ɂ��肤��̂ł́H �܂��A���ۂɂǂ���Ȃ̂��͉��Ƃ�
�����Ȃ����ǂ��B
���ƁA���̈�ۂ��ƁAgcc �g���� NetBurst �̕����x���Ȃ闦��
�����B�T�[�o���Ƃ���ς� Linux �����\�������ALinux ����
�J�[�l������A�v���܂őS�� gcc �ŃR���p�C������Ă邩��A����
Opteron �̕�������������B
SPEC�@���Ȃ�Regulation�ʒm���Ă����A�ƁB
�ȑO����SPEC�Ɍ����Xeon��Opteron���������肵�Ă��B
>>788�͋U������
>>788�͋U������
>�A�����̐S�̋��菊�ł��遄2-socket�Ńl�b�g�o�[�X�gXeon�ɂ���ǂ������Ƃ�(��)
�A�����̐S�̋��菊����8socket�ł���H
�A�����̐S�̋��菊����8socket�ł���H
>>795 ����
�@�@------------------------
�@�@�ȑO����SPEC�Ɍ����Xeon��Opteron���������肵�Ă��B
�@�@------------------------
���x�𑪂�SPEC2000�ƃX���[�v�b�g�𑪂�SPECrate_2000�̋�ʂ����Ȃ��q�g�������ɂ�
���������B�B�B�@���Ȃ݂�rate�̐��т�\�P�b�g�̐������������ш悪�����鉶�b�ŁC�V���O��
�R�A�̎��ォ��Opteron�L���Ƃ������ƂɂȂ��Ă������B
�@�E2004Q2����4-way (4-socket) SPECint_rate2000
�@�@Opteron850/2.4GHz: 63.4(base) / 68.5(peak)
�@�@Xeon MP/3.0GHz: 59.0(base) / 61.6 (peak)
>>796 ����
�@�@-------------------------
�@�@�A�����̐S�̋��菊����8socket�ł���H
�@�@-------------------------
����]���Ő��������Ă�������(��) >>554-561�ł��ǂݕԂ��Ɨǂ����Ǝv�����B
�@�@------------------------
�@�@�ȑO����SPEC�Ɍ����Xeon��Opteron���������肵�Ă��B
�@�@------------------------
���x�𑪂�SPEC2000�ƃX���[�v�b�g�𑪂�SPECrate_2000�̋�ʂ����Ȃ��q�g�������ɂ�
���������B�B�B�@���Ȃ݂�rate�̐��т�\�P�b�g�̐������������ш悪�����鉶�b�ŁC�V���O��
�R�A�̎��ォ��Opteron�L���Ƃ������ƂɂȂ��Ă������B
�@�E2004Q2����4-way (4-socket) SPECint_rate2000
�@�@Opteron850/2.4GHz: 63.4(base) / 68.5(peak)
�@�@Xeon MP/3.0GHz: 59.0(base) / 61.6 (peak)
>>796 ����
�@�@-------------------------
�@�@�A�����̐S�̋��菊����8socket�ł���H
�@�@-------------------------
����]���Ő��������Ă�������(��) >>554-561�ł��ǂݕԂ��Ɨǂ����Ǝv�����B
798 �FMAC�I�^���⑫�F2006/08/19(�y) 01:12:01 ID:WLa2cPcz
SPECint_rate2000 �̓o�^�f�[�^�̃����N���B
�@�E2004Q2����4-way (4-socket) SPECint_rate2000
�@�@Opteron850/2.4GHz: 63.4(base) / 68.5(peak)
�@�@�@�@�@�@http://www.spec.org/cpu/results/res2004q2/cpu2000-20040503-03009.html
�@�@Xeon MP/3.0GHz: 59.0(base) / 61.6 (peak)
�@�@�@�@�@�@http://www.spec.org/cpu/results/res2004q2/cpu2000-20040322-02934.html
�@�E2004Q2����4-way (4-socket) SPECint_rate2000
�@�@Opteron850/2.4GHz: 63.4(base) / 68.5(peak)
�@�@�@�@�@�@http://www.spec.org/cpu/results/res2004q2/cpu2000-20040503-03009.html
�@�@Xeon MP/3.0GHz: 59.0(base) / 61.6 (peak)
�@�@�@�@�@�@http://www.spec.org/cpu/results/res2004q2/cpu2000-20040322-02934.html
Pacifica�̎����l���Ă����ĉ������B
Mac���^�A�X���[�v�b�g�݂����Ȋ�{�I�ȒP����������ĂȂ��̂��B
�X���[�v�b�g���Ă����̂́A�P�ɒP�ʎ��Ԃ�����ɏ��������ʂ�
�������t�ŁA�V���O���R�A�A�V���O���X���b�h�ł��g������B
�m���� Sun �̌����X���[�v�b�g�R���s���[�e�B���O�́A�X�̃R�A��
�x���Ă��}���`�R�A�Ńg�[�^���ő�����Ηǂ��Ƃ������Ƃ�������`
���傾���A�ʂɃ}���`�X���b�h�łȂ��ƃX���[�v�b�g�Ƃ������t��
�g���Ȃ��킯�ł͂Ȃ��B
�X���[�v�b�g���Ă����̂́A�P�ɒP�ʎ��Ԃ�����ɏ��������ʂ�
�������t�ŁA�V���O���R�A�A�V���O���X���b�h�ł��g������B
�m���� Sun �̌����X���[�v�b�g�R���s���[�e�B���O�́A�X�̃R�A��
�x���Ă��}���`�R�A�Ńg�[�^���ő�����Ηǂ��Ƃ������Ƃ�������`
���傾���A�ʂɃ}���`�X���b�h�łȂ��ƃX���[�v�b�g�Ƃ������t��
�g���Ȃ��킯�ł͂Ȃ��B
>>800
�\�b�X�l
�\�b�X�l
�V�R�A�o������ɏ��ĂĂȂ���
�I����Ă�ƕ��ʂ͌������Ȃ�
�I����Ă�ƕ��ʂ͌������Ȃ�
quadcore�ɂȂ����Ƃ��āA�ǂ̂��炢���\�����シ��̂��B
>>802
���ȁB
������90nm�ȃl�g�o�́A���M�Ɋւ��ăC�L�i���ŏI���Ԃ��������B
�ł�K8L���o�����͂ǂ��Ȃ邩�A������ƃh�L�h�L�����B
���ȁB
������90nm�ȃl�g�o�́A���M�Ɋւ��ăC�L�i���ŏI���Ԃ��������B
�ł�K8L���o�����͂ǂ��Ȃ邩�A������ƃh�L�h�L�����B
��������tHyperThreading���Ăǂ��Ȃ����H
>>805
�ϑz�ŏI�������߲
�ϑz�ŏI�������߲
MAC�I�^�ɂ̓C���e�����������Ă���炵��4�~4�ƃR�v���ɂ��Č���Ă��炢������
809 �FMAC�I�^��808 �����F2006/08/19(�y) 17:23:38 ID:WLa2cPcz
>>808
http://pc7.2ch.net/test/read.cgi/mac/1121683774/727
�킽����C���Ȃ�������http://pc7.2ch.net/test/read.cgi/mac/1121683774/360-361��
�悤�Ȉُ�ȉ��i�̌n�Ɉق��ƂȂ��Ȃ����Ƃ���X�s�v�c�Ɏv���Ă��邷�B�B�B
http://pc7.2ch.net/test/read.cgi/mac/1121683774/727
�킽����C���Ȃ�������http://pc7.2ch.net/test/read.cgi/mac/1121683774/360-361��
�悤�Ȉُ�ȉ��i�̌n�Ɉق��ƂȂ��Ȃ����Ƃ���X�s�v�c�Ɏv���Ă��邷�B�B�B
>>809
������l�Ԃ��Ȃɂ����Ŕ��낤�����R�Ȃ�ŁB
������l�Ԃ��Ȃɂ����Ŕ��낤�����R�Ȃ�ŁB
�L�`�K�C�̑��������Ȃ�
4x4�́A�ꂵ����B
�\�P�b�g�^�C�v��GPU�i�R�v���j�͏o�Ȃ��B
DX10(10.1??)�����PCI-E�ڑ���GPU�ł���A����͊��ɃR�v���Ƃ݂Ȃ���B
�������A�����GPGPU�I�ȃ\�t�g������ď��߂Ď�������B
2�\�P�b�g�̕Б��ɂ�CPU���A�܂���GPU�ȊO�̃R�v����������邾�낤�B
ATI����ɓ��ꂽ���ƂŁAAMD��GPU(VPU)�̓����̈ӎv�͊��ɖ��炩�B
�܂��A��X��ʐl��2�\�P�b�g�}�U�[���g�p����K�R���͍�����������낤�B
��ʓI�ȗp�r�ł�GPU(VPU)�̉��p�ŁA�قڂ܂��Ȃ��������B
GPU(VPU)�������\�ȕ���Ȃ�p�t�H�[�}���X��CPU�����|����B
��X�������鐔���Ȃ���Ƃ���
�P��x���`�̌��ʁE�E�E
�����F��
ttp://w3cic.riken.go.jp/HPC/Symposium/2005/benchmark.pdf
�l�T�C�g
ttp://gpgpu.jp/article/17502609.html
�������3�����z���2�����z��ɂ��Ă��肷����
CPU�Ƃ̔�r�͂ǂ��Ȃ̂��Ȃ��ċC��������E�E�E
Microsoft���A�ǂ��������E�E�E
�\�P�b�g�^�C�v��GPU�i�R�v���j�͏o�Ȃ��B
DX10(10.1??)�����PCI-E�ڑ���GPU�ł���A����͊��ɃR�v���Ƃ݂Ȃ���B
�������A�����GPGPU�I�ȃ\�t�g������ď��߂Ď�������B
2�\�P�b�g�̕Б��ɂ�CPU���A�܂���GPU�ȊO�̃R�v����������邾�낤�B
ATI����ɓ��ꂽ���ƂŁAAMD��GPU(VPU)�̓����̈ӎv�͊��ɖ��炩�B
�܂��A��X��ʐl��2�\�P�b�g�}�U�[���g�p����K�R���͍�����������낤�B
��ʓI�ȗp�r�ł�GPU(VPU)�̉��p�ŁA�قڂ܂��Ȃ��������B
GPU(VPU)�������\�ȕ���Ȃ�p�t�H�[�}���X��CPU�����|����B
��X�������鐔���Ȃ���Ƃ���
�P��x���`�̌��ʁE�E�E
�����F��
ttp://w3cic.riken.go.jp/HPC/Symposium/2005/benchmark.pdf
�l�T�C�g
ttp://gpgpu.jp/article/17502609.html
�������3�����z���2�����z��ɂ��Ă��肷����
CPU�Ƃ̔�r�͂ǂ��Ȃ̂��Ȃ��ċC��������E�E�E
Microsoft���A�ǂ��������E�E�E
�V�������N�Ń_�C�T�C�Y���]��Ȃ烁�C�����������Ə�����Ă��ꂽ�炢���̂�
�]��ʂ��A�тɒZ���������ɒ����Ȃ̂�
����Ȃɑ������X���Ԃ��Ă���Ƃ͎v������E�E�E
��������ȁ@�S�����Ă�
>>809
�}���`�v���Z�b�T�Ή�CPU��������Ȃ��āA�V���O���v���Z�b�T�Ή�CPU�������Ƃ͍l���Ȃ��̂��H
PowerPC�n�ƈ����intel/AMD�̏ꍇ�A�l�b�g��[���ʂɂ����g��Ȃ��悤�ȃ��C�g���[�U�[��
�r�W�l�X�����N���C�A���g�A�m�[�gPC���V���O���v���Z�b�T�̎g�p�������̏�ł͈��|�I�ɑ����킯�����B
MP�����̓���ۏ�E���i�ݒ�ł���Ȃɑ�ʂɃV���O���Ŏg�����A�����琔�ʂŃf�B�X�J�E���g���Ă�
����ɂ����B
�ǂ����V���O���ł����g��Ȃ��̂Ȃ�AMP�����̃o���f�[�V�����R�X�g���Ȃ��Ĉ��������������[�J�[�����[�U�[��
�����邵�ȁB
�P�ɁA���v�̃o�����X�ɍ��킹�����i���C���i�b�v�Ɖ��i�ݒ�Ƃ��������̘b���Ǝv�����A����̂ǂ����ُ�ȂH
�}���`�v���Z�b�T�Ή�CPU��������Ȃ��āA�V���O���v���Z�b�T�Ή�CPU�������Ƃ͍l���Ȃ��̂��H
PowerPC�n�ƈ����intel/AMD�̏ꍇ�A�l�b�g��[���ʂɂ����g��Ȃ��悤�ȃ��C�g���[�U�[��
�r�W�l�X�����N���C�A���g�A�m�[�gPC���V���O���v���Z�b�T�̎g�p�������̏�ł͈��|�I�ɑ����킯�����B
MP�����̓���ۏ�E���i�ݒ�ł���Ȃɑ�ʂɃV���O���Ŏg�����A�����琔�ʂŃf�B�X�J�E���g���Ă�
����ɂ����B
�ǂ����V���O���ł����g��Ȃ��̂Ȃ�AMP�����̃o���f�[�V�����R�X�g���Ȃ��Ĉ��������������[�J�[�����[�U�[��
�����邵�ȁB
�P�ɁA���v�̃o�����X�ɍ��킹�����i���C���i�b�v�Ɖ��i�ݒ�Ƃ��������̘b���Ǝv�����A����̂ǂ����ُ�ȂH
���� ���̎���͂����I��낤�Ƃ��Ă���
>>817
�C���^�[�l�b�g���g�����[�U�[�Ȃ�A�f���A���v���Z�b�T�͏[���𗧂��B
�Z�L�����e�B�`�F�b�N�⓮��Đ��Ȃ́A�C���^�[�l�b�g�ł͓�����O�c�̃N���b�J�[
��Ԃ�����A�}���`�^�X�N�Ŏg���Ղ������ɂ̓f���A���v���Z�b�T���V�b�J�����p�o����B
�r�W�l�X�����ł��AOffice�n�\�t�g���`�}�`�}�g�������̗p�r�Ȃ�C�������낤���A����
���炻��������ɂ͂�����B�O���t�B�b�N�Ă����Windows Vista�ȂAOS����
���̂��}���`�^�X�N����O��ȍ��ɂȂ��Ă��������B
�C���^�[�l�b�g���g�����[�U�[�Ȃ�A�f���A���v���Z�b�T�͏[���𗧂��B
�Z�L�����e�B�`�F�b�N�⓮��Đ��Ȃ́A�C���^�[�l�b�g�ł͓�����O�c�̃N���b�J�[
��Ԃ�����A�}���`�^�X�N�Ŏg���Ղ������ɂ̓f���A���v���Z�b�T���V�b�J�����p�o����B
�r�W�l�X�����ł��AOffice�n�\�t�g���`�}�`�}�g�������̗p�r�Ȃ�C�������낤���A����
���炻��������ɂ͂�����B�O���t�B�b�N�Ă����Windows Vista�ȂAOS����
���̂��}���`�^�X�N����O��ȍ��ɂȂ��Ă��������B
821 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/20(��) 12:37:08 ID:RkvenfXh
���͂�A�u�V���O���\�P�b�g�v�u�f���A���\�P�b�g�v�̂ق�������Ȍ�����
>>819
> OS���̂��̂��}���`�^�X�N����O��ȍ��ɂȂ��Ă��������B
�}���`�^�X�N����Ȃ��ă}���`�X���b�h����B
�ȑO�uWin98�̓}���`�^�X�N���Ή��v�Ƃ������Ă��A�z���������A���܂����H
> OS���̂��̂��}���`�^�X�N����O��ȍ��ɂȂ��Ă��������B
�}���`�^�X�N����Ȃ��ă}���`�X���b�h����B
�ȑO�uWin98�̓}���`�^�X�N���Ή��v�Ƃ������Ă��A�z���������A���܂����H
>>822
OS/2�G���Ȃł�Win98�̃}���`�^�X�N�����̂����T����
�u�}���`�^�X�N�Ή��͕s���S�v�Ƃ��L���ɂ��Ă��ȁB�����B
OS/2�G���Ȃł�Win98�̃}���`�^�X�N�����̂����T����
�u�}���`�^�X�N�Ή��͕s���S�v�Ƃ��L���ɂ��Ă��ȁB�����B
Prescott�͂ǂ�����CPU���낤���B���M�ʂ������Ă��邱�Ƃ͊m�����B
���ׂ��������Ƃ���ɋ}���ȉ��x�㏸���݂��邵�A�������f�ł���B
��C�̗��ꂪ���݂��Ȃ��������44�����x������A�P�[�X�Ɏ���
�A��C�̗��ꂪ������������Ⴍ�Ȃ邾�낤�B
intel���������Ă���P�[�X���ʂ̋z�C�_�N�g������A�����������M�͗}����ꂻ�����B
��������ƁA���M���͂܂����v�Ƃ������ƂɂȂ�B
�e�X�g�Ɏg����Prescott�́A�ő��60A����d���������B
�ׂ��s����60A�ȏ�̓d�C�𗬂��Ȃ���Ȃ�Ȃ��B
��d���ɑς�����悤�AmPGA478����LGA775�ɂȂ�A�����Ƀs������p�b�h�ɕύX���Ă���B
�������ڑ��ʂ̂قƂ�ǂ��A�d���ɔ�₳��Ă���B
LGA775�ł����M�ʂ͑傫�����A���M�������サ�Ă���悤�ŔM�Ɋւ���g���u���͕����Ă��Ȃ��B
�p�C�v���C����31�i�ƂȂ�A��荂�N���b�N���삪�\�ɂȂ��Ă���B
LGA775�ɂ��d�����ӂ����P���A���x�������N���b�N��_�����Ƃ��Ă��A�����ŏ��߂āu���M���v���o�Ă���B
�N���b�N�����𗎂Ƃ��Ȃ�����A�O��I�ɃN���b�N���グ�A�s��ɃA�s�[������u�N���b�N�����`�v���������A������intel�͕��j��]���B
�f���A���R�A���������グ�邱�ƂɂȂ����B��������A����d�͂𗎂Ƃ����R�A(�N���b�N���������R�A)��2�g���Đ��\�����コ���邱�Ƃ��ł���B
intel��NetBurst(Pentium 4�n)��CPU�𒆎~���A�N���b�N�����S�̓I�ȏ����\�͌����ڎw�����ƂɂȂ����B
intel�̍l���܂ŕς�������Prescott�B����̓N���b�N�����`�̏I�����Ӗ����Ă���B
���͂������Ă܂Ő��i�낤�Ƃ���intel�́APrescott����̈��͂ɕ������̂�������Ȃ��B
����CPU�̗��j�̒��ŁAPrescott�͏������Ƃ��ł��Ȃ��d�v��CPU�ɂȂ邾�낤�B
���ׂ��������Ƃ���ɋ}���ȉ��x�㏸���݂��邵�A�������f�ł���B
��C�̗��ꂪ���݂��Ȃ��������44�����x������A�P�[�X�Ɏ���
�A��C�̗��ꂪ������������Ⴍ�Ȃ邾�낤�B
intel���������Ă���P�[�X���ʂ̋z�C�_�N�g������A�����������M�͗}����ꂻ�����B
��������ƁA���M���͂܂����v�Ƃ������ƂɂȂ�B
�e�X�g�Ɏg����Prescott�́A�ő��60A����d���������B
�ׂ��s����60A�ȏ�̓d�C�𗬂��Ȃ���Ȃ�Ȃ��B
��d���ɑς�����悤�AmPGA478����LGA775�ɂȂ�A�����Ƀs������p�b�h�ɕύX���Ă���B
�������ڑ��ʂ̂قƂ�ǂ��A�d���ɔ�₳��Ă���B
LGA775�ł����M�ʂ͑傫�����A���M�������サ�Ă���悤�ŔM�Ɋւ���g���u���͕����Ă��Ȃ��B
�p�C�v���C����31�i�ƂȂ�A��荂�N���b�N���삪�\�ɂȂ��Ă���B
LGA775�ɂ��d�����ӂ����P���A���x�������N���b�N��_�����Ƃ��Ă��A�����ŏ��߂āu���M���v���o�Ă���B
�N���b�N�����𗎂Ƃ��Ȃ�����A�O��I�ɃN���b�N���グ�A�s��ɃA�s�[������u�N���b�N�����`�v���������A������intel�͕��j��]���B
�f���A���R�A���������グ�邱�ƂɂȂ����B��������A����d�͂𗎂Ƃ����R�A(�N���b�N���������R�A)��2�g���Đ��\�����コ���邱�Ƃ��ł���B
intel��NetBurst(Pentium 4�n)��CPU�𒆎~���A�N���b�N�����S�̓I�ȏ����\�͌����ڎw�����ƂɂȂ����B
intel�̍l���܂ŕς�������Prescott�B����̓N���b�N�����`�̏I�����Ӗ����Ă���B
���͂������Ă܂Ő��i�낤�Ƃ���intel�́APrescott����̈��͂ɕ������̂�������Ȃ��B
����CPU�̗��j�̒��ŁAPrescott�͏������Ƃ��ł��Ȃ��d�v��CPU�ɂȂ邾�낤�B
����ׂ�����
>>826
�}���`�^�X�N�̒�`�́H
�}���`�^�X�N�̒�`�́H
>>827
��ttp://e-words.jp/w/E3839EE383ABE38381E382BFE382B9E382AF.html
OS�ɓƍٌ��̂Ȃ��m���v���G���v�e�B�u�Ȃ�ĕ��B����Ȍ��t�͂o�b��
�o�Ă���O�͑��݂��Ȃ������B�v����Ƀ}�[�P�e�B���O�̓s���ŏo�Ă���
��t�̒�`�ł����Ȃ��B
��ttp://e-words.jp/w/E3839EE383ABE38381E382BFE382B9E382AF.html
OS�ɓƍٌ��̂Ȃ��m���v���G���v�e�B�u�Ȃ�ĕ��B����Ȍ��t�͂o�b��
�o�Ă���O�͑��݂��Ȃ������B�v����Ƀ}�[�P�e�B���O�̓s���ŏo�Ă���
��t�̒�`�ł����Ȃ��B
�����ǂ��A���[�U�ɒ��Ă�����̓}���`�^�X�N�����B
���s�R���e�L�X�g��ۑ������܂܃A�v���P�[�V�������X�C�b�`�ł���DOSSHELL���}���`�^�X�N�����ȁB
���s�R���e�L�X�g��ۑ������܂܃A�v���P�[�V�������X�C�b�`�ł���DOSSHELL���}���`�^�X�N�����ȁB
830 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/21(��) 22:39:49 ID:s8DGGU8N
�u�s���S�ȃv���G���v�e�B�u�}���`�^�X�N�v
���S�ȃv���G���v�e�B�u���ǂ������ǂ����[�U�ɂƂ��Ẵ����b�g�ɂȂ���H
832 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/22(��) 00:28:12 ID:biYczle/
�A�v�����\�������OS�܂œ��A��ɂ���̂��f�����b�g�łȂ��Ƃ����Ȃ�
��������
��������
833 �FMAC�I�^���c�q �����F2006/08/22(��) 00:33:35 ID:sidVPKUa
>>832
�v���G���v�V������C�^�X�N�X�P�W���[�����O�̖��ł����āC�������ی�Ƃ�W���������ǁB�B�B
�v���G���v�V������C�^�X�N�X�P�W���[�����O�̖��ł����āC�������ی�Ƃ�W���������ǁB�B�B
834 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/22(��) 00:39:09 ID:biYczle/
���邾��B�t���b�s�[�̏��������ɑ��̍�Ƃ��ł��Ȃ��Ƃ��B
��ŁA���̃t���b�s�[��������Ă�Ɓi�ȉ���
��ŁA���̃t���b�s�[��������Ă�Ɓi�ȉ���
835 �FMAC�I�^���c�q �����F2006/08/22(��) 00:44:23 ID:sidVPKUa
>>834
�@�@------------------
�@�@���邾��B�t���b�s�[�̏��������ɑ��̍�Ƃ��ł��Ȃ��Ƃ��B
�@�@------------------
�����t�H�[�}�b�g�v���O�����������������B
co-operative�}���`�^�X�N��v���Z�b�T������L���Ɏg�p����Ƃ����_�Ńv���G���v�V�������
�D��Ă��邷���ǁC������炸�ɖ��ʂ�CPU������Ɛ肷��R�[�h��������Ɨ��_���Ԃ�
�ɂȂ���Ă����̘b���B
�@�@------------------
�@�@���邾��B�t���b�s�[�̏��������ɑ��̍�Ƃ��ł��Ȃ��Ƃ��B
�@�@------------------
�����t�H�[�}�b�g�v���O�����������������B
co-operative�}���`�^�X�N��v���Z�b�T������L���Ɏg�p����Ƃ����_�Ńv���G���v�V�������
�D��Ă��邷���ǁC������炸�ɖ��ʂ�CPU������Ɛ肷��R�[�h��������Ɨ��_���Ԃ�
�ɂȂ���Ă����̘b���B
836 �FMAC�I�^���⑫�F2006/08/22(��) 00:46:20 ID:sidVPKUa
���������CWindows386�Ƃ��̎��_��FD��2�������Ƀt�H�[�}�b�g����Ƃ����|���������
�����悤�ȋC�����邷���ǁC�����v���G���v�V�������ᖳ����(��)
�����悤�ȋC�����邷���ǁC�����v���G���v�V�������ᖳ����(��)
>>832
���������A�v�����\������Ƃ����C���M�����[�Ȏ��Ԃ�O��Ƃ���̂����������ˁH
���S�ȃv���G���v�e�B�u�}���`�^�X�N���������Ă���͂���NT�ł�BSOD�͋N���邵
���ꂻ��̐ӔC��OS�A��ɂ���Ƃ���������͘b�̂���ւ��łȂ��́H
�ʂɃm���v���G���v�e�B�u�̕����D��Ă���Č����Ă�킯����Ȃ�����B
���[�U�Ɂu�}���`�^�X�N�v����Ă��鎖���͕ς��Ȃ����ǁA���ꂪ
�ǂ̂悤�Ɂu�܂������́v�ł���̂��������Ă��傤�����ȁB
���������A�v�����\������Ƃ����C���M�����[�Ȏ��Ԃ�O��Ƃ���̂����������ˁH
���S�ȃv���G���v�e�B�u�}���`�^�X�N���������Ă���͂���NT�ł�BSOD�͋N���邵
���ꂻ��̐ӔC��OS�A��ɂ���Ƃ���������͘b�̂���ւ��łȂ��́H
�ʂɃm���v���G���v�e�B�u�̕����D��Ă���Č����Ă�킯����Ȃ�����B
���[�U�Ɂu�}���`�^�X�N�v����Ă��鎖���͕ς��Ȃ����ǁA���ꂪ
�ǂ̂悤�Ɂu�܂������́v�ł���̂��������Ă��傤�����ȁB
����>>823����Ȃ����ǁc
���������}���`�^�X�N(�v���Z�X)���Ă����̂̓��b�`�ɂȂ����v���Z�b�T�̃p���[���o���邾�����ʂɂ��Ȃ�(�V��ł鎞�Ԃ����Ȃ�����)���߂ɔ��Ă��ꂽ���B
�ŁA�X�̃v���Z�X���ʂ̃v���Z�X���ӎ����ē����Ȃ�Ė����ł���B
(�v���O���}���u�����̃A�v�����g���l�͂���ȃA�v�����g���ɈႢ�Ȃ��v�Ƃ��z�肵�Ȃ��炻���Ƃ̐e�a�������߂�w�͂����Ȃ��Ă͂Ȃ�Ȃ��B
���邢�͎����̔r���I��L���o���邾�����炷�Ƃ��B�{���]�|�����ǁB)
�܂�OS�ɂ����o���Ȃ��d����OS������������Ă邩�畴�������Ă��ƂȂ�Ȃ��́B
���������[�v�Ƃ����̕ӂ̃`�F�b�N���Â����ꂾ�ƃf�o�b�O�n���ɑ�����Ȃ�
�����X&�������܂�B
���������}���`�^�X�N(�v���Z�X)���Ă����̂̓��b�`�ɂȂ����v���Z�b�T�̃p���[���o���邾�����ʂɂ��Ȃ�(�V��ł鎞�Ԃ����Ȃ�����)���߂ɔ��Ă��ꂽ���B
�ŁA�X�̃v���Z�X���ʂ̃v���Z�X���ӎ����ē����Ȃ�Ė����ł���B
(�v���O���}���u�����̃A�v�����g���l�͂���ȃA�v�����g���ɈႢ�Ȃ��v�Ƃ��z�肵�Ȃ��炻���Ƃ̐e�a�������߂�w�͂����Ȃ��Ă͂Ȃ�Ȃ��B
���邢�͎����̔r���I��L���o���邾�����炷�Ƃ��B�{���]�|�����ǁB)
�܂�OS�ɂ����o���Ȃ��d����OS������������Ă邩�畴�������Ă��ƂȂ�Ȃ��́B
���������[�v�Ƃ����̕ӂ̃`�F�b�N���Â����ꂾ�ƃf�o�b�O�n���ɑ�����Ȃ�
�����X&�������܂�B
> co-operative�}���`�^�X�N��v���Z�b�T������L���Ɏg�p����Ƃ����_�Ńv
> ���G���v�V�������D��Ă��邷���ǁC
������
�����ŋ߂܂ŁAco-operative�ȃ}���`�^�X�NOS�����I�������Ȃ�����
���[�U�炵���ӌ����ȁB(w
�v���G���v�e�B�u�ȃJ�[�l���Ȃ�A���C�e���V����̌������v���Z�X��
�����D��x��^���Ă����A�����ł͂Ȃ��v���O�����ɂ͒Ⴂ�D��x��
�^����Ƃ��������Ƃ��ł���B�v���Z�b�T������L���Ɋ��p������Ă���
�̂́A�����������Ƃ������B
�Ⴆ�� I/O �𑽂��s�Ȃ��v���Z�X�ɍ����D��x��^����ƁA�V�X�e��
�S�̂̃X���[�v�b�g����������B���̎��A�������Ȃ��ꍇ�ɔ�ׂāACPU��
�A�C�h�����Ԃ͌���B���Ȃ킿�ACPU �������������I�Ɏg�����Ƃ��ł���B
co-operative �ȃ}���`�^�X�N�����T�|�[�g���ĂȂ��J�[�l�����ƁA
���������œK�� CPU ���蓖�Ă��A���������ł���B
> ���G���v�V�������D��Ă��邷���ǁC
������
�����ŋ߂܂ŁAco-operative�ȃ}���`�^�X�NOS�����I�������Ȃ�����
���[�U�炵���ӌ����ȁB(w
�v���G���v�e�B�u�ȃJ�[�l���Ȃ�A���C�e���V����̌������v���Z�X��
�����D��x��^���Ă����A�����ł͂Ȃ��v���O�����ɂ͒Ⴂ�D��x��
�^����Ƃ��������Ƃ��ł���B�v���Z�b�T������L���Ɋ��p������Ă���
�̂́A�����������Ƃ������B
�Ⴆ�� I/O �𑽂��s�Ȃ��v���Z�X�ɍ����D��x��^����ƁA�V�X�e��
�S�̂̃X���[�v�b�g����������B���̎��A�������Ȃ��ꍇ�ɔ�ׂāACPU��
�A�C�h�����Ԃ͌���B���Ȃ킿�ACPU �������������I�Ɏg�����Ƃ��ł���B
co-operative �ȃ}���`�^�X�N�����T�|�[�g���ĂȂ��J�[�l�����ƁA
���������œK�� CPU ���蓖�Ă��A���������ł���B
> ���������A�v�����\������Ƃ����C���M�����[�Ȏ��Ԃ�O��Ƃ���̂����������ˁH
�A�v���̖\���Ȃ�āA���ۂɂ́A��������イ�N������̂�����A
�����������Ԃ�O��Ƃ��Ȃ��������������B
> ���S�ȃv���G���v�e�B�u�}���`�^�X�N���������Ă���͂���NT�ł�BSOD�͋N���邵
����͂قڑS�āA�n�[�h�̕s�ǂ��A�f�o�C�X�h���C�o�̃o�O����B�b���Ⴄ�B
������ƌ�����ĂȂ��n�[�h��f�o�C�X�h���C�o���g���̂������B
�A�v���P�[�V���� �� �J�[�l�� �� �n�[�h �Ƃ����ˑ��W������킯������A
�E���ɂ�����̂قǁA���M���ł�����̂�I�Ԃׂ��B
���ƁA�Ȃ�����Ă���悤�����AWindows 98 ���A���[�U�v���Z�X��
�v���G���v�V�����́A�T�|�[�g���Ă��B
���������A�X�P�W���[�����O�I�ȈӖ��ł́AWindows 98 �͐^�̃}���`�^�X�N
OS �ƌ����ėǂ��B(������ MacOS 9 ������Ƃ̑傫�ȈႢ)
Windows 98 ���^�̃}���`�^�X�N����Ȃ����Ă����̂́A�������ی삪�s���S�ŁA
�\�������v���O�����∫�ӂ̃v���O�������A���̃v���O������J�[�l���̃�����
��Ԃ��u�`���Ƃ��ł������炾�ȁB
����ł� MacOS 9 �ɔ�ׂ�A�������ی�@�\�������ԃ}�V�ł͂���B
�܂��AWindows 98 �ɂ́A�������ߖ�̂��߂ɁA16bit ���ォ��̃��W���[����
�������g���Ă������߁A�g����V�X�e�����\�[�X�̐������������Ƃ��A
���ɂ����낢����͂��������B
�A�v���̖\���Ȃ�āA���ۂɂ́A��������イ�N������̂�����A
�����������Ԃ�O��Ƃ��Ȃ��������������B
> ���S�ȃv���G���v�e�B�u�}���`�^�X�N���������Ă���͂���NT�ł�BSOD�͋N���邵
����͂قڑS�āA�n�[�h�̕s�ǂ��A�f�o�C�X�h���C�o�̃o�O����B�b���Ⴄ�B
������ƌ�����ĂȂ��n�[�h��f�o�C�X�h���C�o���g���̂������B
�A�v���P�[�V���� �� �J�[�l�� �� �n�[�h �Ƃ����ˑ��W������킯������A
�E���ɂ�����̂قǁA���M���ł�����̂�I�Ԃׂ��B
���ƁA�Ȃ�����Ă���悤�����AWindows 98 ���A���[�U�v���Z�X��
�v���G���v�V�����́A�T�|�[�g���Ă��B
���������A�X�P�W���[�����O�I�ȈӖ��ł́AWindows 98 �͐^�̃}���`�^�X�N
OS �ƌ����ėǂ��B(������ MacOS 9 ������Ƃ̑傫�ȈႢ)
Windows 98 ���^�̃}���`�^�X�N����Ȃ����Ă����̂́A�������ی삪�s���S�ŁA
�\�������v���O�����∫�ӂ̃v���O�������A���̃v���O������J�[�l���̃�����
��Ԃ��u�`���Ƃ��ł������炾�ȁB
����ł� MacOS 9 �ɔ�ׂ�A�������ی�@�\�������ԃ}�V�ł͂���B
�܂��AWindows 98 �ɂ́A�������ߖ�̂��߂ɁA16bit ���ォ��̃��W���[����
�������g���Ă������߁A�g����V�X�e�����\�[�X�̐������������Ƃ��A
���ɂ����낢����͂��������B
���s�\��̃^�X�N���e�����O�ɂ�����x�킩���Ă���ꍇ��
co-operative�ł�pre-enptive�ł��卷�͂Ȃ��B
���������A���s���ɗD��x��ς��Ȃ�������Ȃ��悤�ȏɂ���Ƃ������Ƃ́A
�V�X�e���v���̂ɖ�肪����Ƃ�������B
�V�X�e���\���ɂ�����n�[�h�̃R�X�g�����ꂾ���������Ȃ��Ă��錻��ł�
pre-enptive�ȃJ�[�l���̕K�v���͂��܂�Ȃ��Ƃ�������B
�܁A�D�G�ȃV�X�}�l������Ƃ����O��̘b�ł�����ǂ��ˁB
co-operative�ł�pre-enptive�ł��卷�͂Ȃ��B
���������A���s���ɗD��x��ς��Ȃ�������Ȃ��悤�ȏɂ���Ƃ������Ƃ́A
�V�X�e���v���̂ɖ�肪����Ƃ�������B
�V�X�e���\���ɂ�����n�[�h�̃R�X�g�����ꂾ���������Ȃ��Ă��錻��ł�
pre-enptive�ȃJ�[�l���̕K�v���͂��܂�Ȃ��Ƃ�������B
�܁A�D�G�ȃV�X�}�l������Ƃ����O��̘b�ł�����ǂ��ˁB
>>841
���������A���s���ɗD��x��ς���̂́A�V�X�e���Ǘ��҂���Ȃ��āA
�J�[�l���Ȃ��ǁB
�܂Ƃ��ȃ}���`�^�X�N OS �́A�V�X�e���S�̂̃X���[�v�b�g���ő�ɂ���
���߂ɁA���I�Ƀv���Z�X�̗D��x���������Ă��B
������D�G�ȃV�X�e���Ǘ��҂����Ă��A���������J�[�l���̌����͂ł���B
���������A���s���ɗD��x��ς���̂́A�V�X�e���Ǘ��҂���Ȃ��āA
�J�[�l���Ȃ��ǁB
�܂Ƃ��ȃ}���`�^�X�N OS �́A�V�X�e���S�̂̃X���[�v�b�g���ő�ɂ���
���߂ɁA���I�Ƀv���Z�X�̗D��x���������Ă��B
������D�G�ȃV�X�e���Ǘ��҂����Ă��A���������J�[�l���̌����͂ł���B
843 �FSocket774�F2006/08/22(��) 02:51:21 ID:86DO07db
��������Vista���ƃJ�[�l�����[�h�Ɉʒu���Ă�GDI���ǂ����s������
���̕����肷��̂��ȁB
���̕����肷��̂��ȁB
>843
���A�悤�₭�����Ȃ�? (���Ă��������ʂ�?)
���A�悤�₭�����Ȃ�? (���Ă��������ʂ�?)
���̂����AD3D���J�[�l���̐[���܂ŐH�����ނ�
�Ӗ��i�X
�Ӗ��i�X
846 �FSocket774�F2006/08/22(��) 10:23:55 ID:4azQEBNd
4*4�҂̂�E6600������ō��g�ނ̂Ƃǂ����������Ȃ낤
���͓���AthlonXP2500+�ŕs���R���ĂȂ�
���͓���AthlonXP2500+�ŕs���R���ĂȂ�
AthlonXP2500+�ň���R�O�O�����N�G�X�g(�K��Ґ��T���l/��)�̂v�d�a�T�[�o�[���ʂɓ��삵�Ă邵�ȁB
�x���`�Ƃ�����AOp146�Ŗ��b�R���W�O�O�O���N�܂őΉ��\�������B
(3��8000���N�G�X�g/s�~������R�Q���W�R�Q�O�����N�G�X�g/��)
Op146��2Ghz��Athlon 64 3200+�����̃}�V���ŁA�����R�Q���W�R�O�O���l��html�y�[�W��1�������邱�Ƃ��ł���v�Z�B
����Ȃ�CPU���Ɏg���̂��ƁB�Ƃ��ɃT�[�o�[����ł́A�����\�̐��\���Ǝv���B
�x���`�Ƃ�����AOp146�Ŗ��b�R���W�O�O�O���N�܂őΉ��\�������B
(3��8000���N�G�X�g/s�~������R�Q���W�R�Q�O�����N�G�X�g/��)
Op146��2Ghz��Athlon 64 3200+�����̃}�V���ŁA�����R�Q���W�R�O�O���l��html�y�[�W��1�������邱�Ƃ��ł���v�Z�B
����Ȃ�CPU���Ɏg���̂��ƁB�Ƃ��ɃT�[�o�[����ł́A�����\�̐��\���Ǝv���B
�R�R�A�ȏ�K�v�ȁu�Ȃ���v��Ƃ́A
��PC�ł���������ǂ���Ȃ����ˁB
�܂�A���X�Q�R�A�ŏ\���B
�����Ƃ��A���ۂɎg���Ă݂Ȃ��ƕ�����Ȃ����ǂˁB
��PC�ł���������ǂ���Ȃ����ˁB
�܂�A���X�Q�R�A�ŏ\���B
�����Ƃ��A���ۂɎg���Ă݂Ȃ��ƕ�����Ȃ����ǂˁB
>>847
����Ȃ������̂ɂ���邾��B
�ÓIHTML��mod�����Ȃ炻��ł��\�����낤���ACGI��T�[�u���b�g����������
�����ɑ���Ȃ��Ȃ�㩁B
2ch�Ȃ��N���O���琔�\��̐������B
1��̐��\�グ����͕�����ŕ��ׂƃ��X�N�U�����ق��������ȁB
����Ȃ������̂ɂ���邾��B
�ÓIHTML��mod�����Ȃ炻��ł��\�����낤���ACGI��T�[�u���b�g����������
�����ɑ���Ȃ��Ȃ�㩁B
2ch�Ȃ��N���O���琔�\��̐������B
1��̐��\�グ����͕�����ŕ��ׂƃ��X�N�U�����ق��������ȁB
>>850
�x���`�p�����A�Ȃ��m��A
Athlon2500+�œ��i�r�̉摜������(�A�_���gHP�̃��t�[�I�ȃT�C�g)
���ʂɎ��e���Ă�CPU���ׂQ�O�����B
Apache�g���Ă�����́AOp175�ł����i�r���������W�O���ɂȂ��Ă���
WEB�T�[�o�[�\�t�g�ς�����Athlon�ł�������v�ɂȂ����B
��������P�O���l�̓A�N�Z�X����Ă�T�o��AthlonXP2500�œ����Ă���B
����ȏ�A�N�Z�X�����T�[�o�[������Ȃɐ��̒��ɂ���Ƃ͎v���B
SPEC�̃x���`�ŁA���b���\���̍ɏ����ł�����ăx���`�łĂ��A�����ƂȂ�Ƃ�����
���ʂ̉�Ђł���ȍ����\�ȃ}�V���K�v�Ȃ���ȁB(���b���\���̏������܂��K�v�����Ђ���̂���H)
�T�[�o�[����ł́A�����\�ȏ�̃I�[�o�[�X�y�b�N���Ǝv���B
(�p�\�R�����[�J�[�͐V���i����K�v�����邩�犩�߂�낤���A�@�l����ł͂���ȍ����\�Ȃ̂����v���)
>�x���`�p�K�`�K�`�ݒ��keepaliveON�ʼn�
3��8000rps�͊ԈႢ�������B
Requests per second: 48480.62 [#/sec] (mean)
�S���W�O�O�Orps�������B(�C���X�g�����̃f�t�H���g��Ԃ�)
keepaliveOFF��1��9974rps���ȁB�v�Z���Ȃ����ƁA41��8867���l�ɖ���html�y�[�W��\���ł���v�Z�B����Ȃɐl�Ԃ��ˁ[��
�x���`�p�����A�Ȃ��m��A
Athlon2500+�œ��i�r�̉摜������(�A�_���gHP�̃��t�[�I�ȃT�C�g)
���ʂɎ��e���Ă�CPU���ׂQ�O�����B
Apache�g���Ă�����́AOp175�ł����i�r���������W�O���ɂȂ��Ă���
WEB�T�[�o�[�\�t�g�ς�����Athlon�ł�������v�ɂȂ����B
��������P�O���l�̓A�N�Z�X����Ă�T�o��AthlonXP2500�œ����Ă���B
����ȏ�A�N�Z�X�����T�[�o�[������Ȃɐ��̒��ɂ���Ƃ͎v���B
SPEC�̃x���`�ŁA���b���\���̍ɏ����ł�����ăx���`�łĂ��A�����ƂȂ�Ƃ�����
���ʂ̉�Ђł���ȍ����\�ȃ}�V���K�v�Ȃ���ȁB(���b���\���̏������܂��K�v�����Ђ���̂���H)
�T�[�o�[����ł́A�����\�ȏ�̃I�[�o�[�X�y�b�N���Ǝv���B
(�p�\�R�����[�J�[�͐V���i����K�v�����邩�犩�߂�낤���A�@�l����ł͂���ȍ����\�Ȃ̂����v���)
>�x���`�p�K�`�K�`�ݒ��keepaliveON�ʼn�
3��8000rps�͊ԈႢ�������B
Requests per second: 48480.62 [#/sec] (mean)
�S���W�O�O�Orps�������B(�C���X�g�����̃f�t�H���g��Ԃ�)
keepaliveOFF��1��9974rps���ȁB�v�Z���Ȃ����ƁA41��8867���l�ɖ���html�y�[�W��\���ł���v�Z�B����Ȃɐl�Ԃ��ˁ[��
���N�G�X�g���Ă̂�ry
>>851
�^�X���̃R�s���Ă�����������ˁ[����������
�������A��146����Ȃ���148�Ȃ�������
���߂Ď����ʼnĂ��珑�����߂�B
�^�X���̃R�s���Ă�����������ˁ[����������
�������A��146����Ȃ���148�Ȃ�������
���߂Ď����ʼnĂ��珑�����߂�B
AMD's Next Generation Microarchitecture Preview: from K8 to K8L
http://www.xbitlabs.com/articles/cpu/display/amd-k8l.html
http://www.xbitlabs.com/articles/cpu/display/amd-k8l.html
>>851
�T�[�o�\�t�g�A���ɕς�����H
�T�[�o�\�t�g�A���ɕς�����H
856 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/23(��) 22:57:07 ID:EBosGeHL
LiteSpeed Web Server
�܂��ł������߁B
�܂��ł������߁B
>>856
�ǂ��B
搂�����͂����Ƃ���肾�ˁB
�ڍs���悤�Ƃ��ěƂ����i��ʼn�������j�b�ł�����Ηǂ����ǁA
���{��̉^�p���web��ɂ͂��܂�Ȃ��悤�Ɍ�����B
���� Apache �̌�p���������āA���L�̓����̒ʂ肩�Ȃ� Apache ���[�U���ӎ����Ă���B
�ÓI�R���e���c�̑��x�� Apache �� 6�`9�{
PHP �� Apache(+ mod_php) �� 1.5�{�ȏ�̑��x
Apache �̐ݒ�t�@�C���𗝉�����̂ňڍs���e��
�A�v��(CGI)�ڑ��p�̓Ǝ��̃v���g�R��(LSAPI) [PHP, Ruby/Rails]
CGI �� FastCGI �� JSP(AJP1.3) �Ƃ���T�̊O���A�v��������
SSL�AGZIP���k�A�ÓI���[�h�o�����T�AVirtualHost���g����
.htaccess �Ɍ݊�������̂͐���
�ǂ��B
搂�����͂����Ƃ���肾�ˁB
�ڍs���悤�Ƃ��ěƂ����i��ʼn�������j�b�ł�����Ηǂ����ǁA
���{��̉^�p���web��ɂ͂��܂�Ȃ��悤�Ɍ�����B
���� Apache �̌�p���������āA���L�̓����̒ʂ肩�Ȃ� Apache ���[�U���ӎ����Ă���B
�ÓI�R���e���c�̑��x�� Apache �� 6�`9�{
PHP �� Apache(+ mod_php) �� 1.5�{�ȏ�̑��x
Apache �̐ݒ�t�@�C���𗝉�����̂ňڍs���e��
�A�v��(CGI)�ڑ��p�̓Ǝ��̃v���g�R��(LSAPI) [PHP, Ruby/Rails]
CGI �� FastCGI �� JSP(AJP1.3) �Ƃ���T�̊O���A�v��������
SSL�AGZIP���k�A�ÓI���[�h�o�����T�AVirtualHost���g����
.htaccess �Ɍ݊�������̂͐���
858 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/24(��) 00:18:35 ID:4p7GxLNL
851�̒��̐l����Ȃ����ARuby on Rails�̏d���ɑς����˂�Mongrel�ƂƂ���
�����������Ă݂���₽�烌�X�|���X�ǂ����甏�q���������B
�����������Ă݂���₽�烌�X�|���X�ǂ����甏�q���������B
>>853
����A����x���`���ď������̉������B��������148�������B�{�l�ł����B
����A����x���`���ď������̉������B��������148�������B�{�l�ł����B
�������ϋɓI��Fab�헪�����ڂɏo��AMD���|�Y������
�����������M�o���̂��˂�
�����������M�o���̂��˂�
>860
�Ԃ����ƓƋ֖@�ō���Intel���M����₾��
�Ԃ����ƓƋ֖@�ō���Intel���M����₾��
MS(�Q�C�V?)��apple�̊��������Ă�A�Ƃ��������B
863 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/26(�y) 09:04:25 ID:4mZVtPah
90�N��ɃA�|�[�����ɍ������Ƃ��ɓ������Ă邩��ˁB
����̂����OS�̘b��ɂȂ�ƂƂ���ɑf�l�L���c�_�n�߂邯�ǁA
����������CPU�̘b�����̒��x�Ȃ́H
����������CPU�̘b�����̒��x�Ȃ́H
���g�ɂ��Ă͑f�l��������Ȃ��H
����OS�i�Ƃ������\�t�g�j�̘b�ɂȂ�ƃr�b�N������قǃ��[�g�s�A�Ȃ̂�������
���i��������Ńx���`�Ƃ邾���Ȃ�N�ł��ł��邵�Ȃ�
����OS�i�Ƃ������\�t�g�j�̘b�ɂȂ�ƃr�b�N������قǃ��[�g�s�A�Ȃ̂�������
���i��������Ńx���`�Ƃ邾���Ȃ�N�ł��ł��邵�Ȃ�
�X�y�b�N�~�ŁA���ǃp�\�R����L���ɗ��p���āA���̉����𐬂������邱�Ƃ����Ă��Ȃ�
�̘̂R�ꂪ�����������B�Ӗ��Ȃ��ȂƁE�E�E
�͂�orz
�̘̂R�ꂪ�����������B�Ӗ��Ȃ��ȂƁE�E�E
�͂�orz
>>864
��������I�Ȑ��E�Ȃ͕̂���������b����
��������I�Ȑ��E�Ȃ͕̂���������b����
AMD having trouble with 65nm stock voltage speed
ttp://www.theinquirer.net/default.aspx?article=33964
�ȑORev.G�ł����I�ɏ���d�͂�������킯�ł͂Ȃ��Ƃ������Ē@����Ă��l���������ǐ����������ˁB
ttp://www.theinquirer.net/default.aspx?article=33964
�ȑORev.G�ł����I�ɏ���d�͂�������킯�ł͂Ȃ��Ƃ������Ē@����Ă��l���������ǐ����������ˁB
���̎����ɂ��������b���o�Ă���̂͂܂�����˂��B
�����ƑO����65nm�̃E�F�n�͗����Ă�͂��Ȃ̂ɁB
����i���m��Ȃ�����ES�����ďo�Ă����B
�����N���ʎY�o�ׂ͖��������ˁB
�P���ȉ�H�̐v�~�X�Ƃ��Ȃ�ǂ����ǁB
AMD�̗��j
0.25um�@bad
0.18um�@good
0.13um�@bad
90nm�@good
65nm�@bad?
�����ƑO����65nm�̃E�F�n�͗����Ă�͂��Ȃ̂ɁB
����i���m��Ȃ�����ES�����ďo�Ă����B
�����N���ʎY�o�ׂ͖��������ˁB
�P���ȉ�H�̐v�~�X�Ƃ��Ȃ�ǂ����ǁB
AMD�̗��j
0.25um�@bad
0.18um�@good
0.13um�@bad
90nm�@good
65nm�@bad?
870 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/26(�y) 22:50:32 ID:4mZVtPah
�P���Ƀ_�C���������Ȃ邾���ł����n���͂����邾�낤����A�����͓͂�����̂ł�
871 �FMAC�I�^��868 �����F2006/08/26(�y) 23:54:09 ID:3iedCWVq
>>868
IBM,AMD,SONY�w�c���CSRAM�̒�d�������Intel�ɒx����Ƃ��Ă��邱�Ƃ�C���Ǝv�������ǁB�B�B
http://journal.mycom.co.jp/articles/2006/02/23/isscc/001.html
�@�@---------------------------
�@�@���x�A�O�̐Ȃɍ����Ă���IBM�Ђ�PPC970�̊J���҂ɁA�uIntel��SRAM�̓d����������
�@�@����̂ɁAIBM�͏グ�Ă���(��q��POWER6�̘_���Q��)�A����?�v�Ƙb����������A�u����
�@�@Intel����������̂�������Ȃ��B�Г��ł͉�����Ƃ����Ă��邪���X�������Ȃ��v
�@�@�Ƃ��������ŁA���̂���������Ȃ���Intel��SRAM�Z���͒�d���ł̈��萫���ǂ��悤�ł���B
�@�@---------------------------
IBM,AMD,SONY�w�c���CSRAM�̒�d�������Intel�ɒx����Ƃ��Ă��邱�Ƃ�C���Ǝv�������ǁB�B�B
http://journal.mycom.co.jp/articles/2006/02/23/isscc/001.html
�@�@---------------------------
�@�@���x�A�O�̐Ȃɍ����Ă���IBM�Ђ�PPC970�̊J���҂ɁA�uIntel��SRAM�̓d����������
�@�@����̂ɁAIBM�͏グ�Ă���(��q��POWER6�̘_���Q��)�A����?�v�Ƙb����������A�u����
�@�@Intel����������̂�������Ȃ��B�Г��ł͉�����Ƃ����Ă��邪���X�������Ȃ��v
�@�@�Ƃ��������ŁA���̂���������Ȃ���Intel��SRAM�Z���͒�d���ł̈��萫���ǂ��悤�ł���B
�@�@---------------------------
�ł��A�Z�p�͂�AMD�Ƃ�������̕��]���L�܂��Ă�̂�����B
���������Ɩ�������
NOR�^�t���b�V���������[�l��������
ttp://www.ednjapan.com/content/l_news/2006/08/l_news060817_0101.html
Spansion (AMD, Fujitsu)
���ł�NAND
ttp://www.ednjapan.com/content/l_news/2006/08/l_news060815_0301.html
ttp://www.ednjapan.com/content/l_news/2006/08/l_news060817_0101.html
Spansion (AMD, Fujitsu)
���ł�NAND
ttp://www.ednjapan.com/content/l_news/2006/08/l_news060815_0301.html
>>867
�Ó�
�}�j���Ń}�C�i�[�ȃX���ŁA�f�l�Ă�肵������ɐ��Ƃ��ۂ��̂Ԃ�
�̂͐����J�R�����C�B�����ɂ����Ă�������^�C�v�łB
>>869
90nm�ŃO�b�^�[�������̂́AIntel�����[�N�d���ň������̂��AAMD��SOI��
���������A������Ȃ��B
65nm�ł�SOI�̐_�ʗ͂��キ�Ȃ��āA���[�N�d���̈��e������r�I�傫���Ȃ���
���������W���}�C�J�B
>>871
Intel��90nm�ł̎��n�ɕK�������ASOI�ɗ���Ȃ��������ʂ̕��@�ŃK���K�b�e
��낤�ˁB�������N���O�̘b������A���낻��IBM�ɂ����Ƃ��Ȃ��Ăăz�X�C���B
�Ó�
�}�j���Ń}�C�i�[�ȃX���ŁA�f�l�Ă�肵������ɐ��Ƃ��ۂ��̂Ԃ�
�̂͐����J�R�����C�B�����ɂ����Ă�������^�C�v�łB
>>869
90nm�ŃO�b�^�[�������̂́AIntel�����[�N�d���ň������̂��AAMD��SOI��
���������A������Ȃ��B
65nm�ł�SOI�̐_�ʗ͂��キ�Ȃ��āA���[�N�d���̈��e������r�I�傫���Ȃ���
���������W���}�C�J�B
>>871
Intel��90nm�ł̎��n�ɕK�������ASOI�ɗ���Ȃ��������ʂ̕��@�ŃK���K�b�e
��낤�ˁB�������N���O�̘b������A���낻��IBM�ɂ����Ƃ��Ȃ��Ăăz�X�C���B
>>875
���̗��ꂾ����˂����ނ��ǁASOI��AMD�̂���肾�Ǝv���Ă�H
���̗��ꂾ����˂����ނ��ǁASOI��AMD�̂���肾�Ǝv���Ă�H
���ɂ͍Ō��IBM������ēǂ߂���
�����������Ⴂ���ł��邩
�����������Ⴂ���ł��邩
SPEC���CPU2006�x���`�}�[�N�����\
http://www.geocities.jp/andosprocinfo/wadai06/20060826.htm
SPEC CPU2006
http://www.spec.org/cpu2006
http://www.geocities.jp/andosprocinfo/wadai06/20060826.htm
SPEC CPU2006
http://www.spec.org/cpu2006
>>876
SOI�u���v�撣������Ȃ��āASOI�u�Łv�撣������������BSOI�Z�p���̂���
��IBM���肾�����Ǝv���Ă邪�B
>>877
�ʂ�IBM��SOI�Z�p��AMD�ꔄ�ɂ�����Ȃ����AIntel��������̗p���Ȃ�����
��������ȁB
SOI�����̃��X�N�Ό��ʂ��AIntel�͑ʖڂ��ƍl���āAAMD�͑��v���Ɣ��f����
���ʂł����Ȃ��B
SOI�u���v�撣������Ȃ��āASOI�u�Łv�撣������������BSOI�Z�p���̂���
��IBM���肾�����Ǝv���Ă邪�B
>>877
�ʂ�IBM��SOI�Z�p��AMD�ꔄ�ɂ�����Ȃ����AIntel��������̗p���Ȃ�����
��������ȁB
SOI�����̃��X�N�Ό��ʂ��AIntel�͑ʖڂ��ƍl���āAAMD�͑��v���Ɣ��f����
���ʂł����Ȃ��B
>>879�i�����j
�����č��XIntel��SOI������̂́A��s����AMD�ɑ��ĕs���ɂȂ邵�A
���X�̃f�����b�g�������A�������̃t�@�N�g���̐ݔ����ς��郊�X�N��
�c����B
����ɑ��̋Z�p�Ń��[�N�d����}����ڏ����L��������A65nm�ŗL����
���߂����̂��낤���A���ʂ��o�Ă�B���������Ӗ��ł͍���Intel��
SOI�����Ȃ������s�����A�����o���Ă�ƌ�����B
�����č��XIntel��SOI������̂́A��s����AMD�ɑ��ĕs���ɂȂ邵�A
���X�̃f�����b�g�������A�������̃t�@�N�g���̐ݔ����ς��郊�X�N��
�c����B
����ɑ��̋Z�p�Ń��[�N�d����}����ڏ����L��������A65nm�ŗL����
���߂����̂��낤���A���ʂ��o�Ă�B���������Ӗ��ł͍���Intel��
SOI�����Ȃ������s�����A�����o���Ă�ƌ�����B
�p���m�C�A��Intel��DST�����̗p�������Ȃ��������
AMD��90nmSOI�̓��g���[������Ȃ��������H
>>882
�t�A130n�̂����g���[����90n�̂�IBM
�t�A130n�̂����g���[����90n�̂�IBM
Intel��SOI�g��i���j�Ȃ������̂͑���
IBM���@�O�ȓ����g�p���ӂ������邩��B
IBM���@�O�ȓ����g�p���ӂ������邩��B
>>885
�����ʂɉ������b�Ȃ�d�����Ȃ����AP4�o�X�̃��C�Z���X���o���a���ăT�[�h
�p�[�e�B���̃`�b�v�Z�b�g��MB���[�J�[���Ղ߂āA�s�ꂩ��ǂ��o�����SIntel
�������������؍�������Ȃ���ȁB
�����ʂɉ������b�Ȃ�d�����Ȃ����AP4�o�X�̃��C�Z���X���o���a���ăT�[�h
�p�[�e�B���̃`�b�v�Z�b�g��MB���[�J�[���Ղ߂āA�s�ꂩ��ǂ��o�����SIntel
�������������؍�������Ȃ���ȁB
>>880
�������≺�L�̋L���������P4�� 6X1 �� 9xx �́A65nm�̂܂܂ŃX�e�b�s���O�ύX
������TDP��啝�ɉ����Ă��Ă邪�A�ǂ������Z�p�������낤�H
http://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
�܂��P���ȃv���Z�X���P�ŁA��d���i�������̂��l�ɂȂ���������������B
�������≺�L�̋L���������P4�� 6X1 �� 9xx �́A65nm�̂܂܂ŃX�e�b�s���O�ύX
������TDP��啝�ɉ����Ă��Ă邪�A�ǂ������Z�p�������낤�H
http://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
�܂��P���ȃv���Z�X���P�ŁA��d���i�������̂��l�ɂȂ���������������B
�g���l�����ʂ͐≏����������ƌ������邾����
>>887
Pentium D 960 ��sspec�łœd���ׂ����ASL9K7�F95W�^1.225V-1.312V �ŁA
SL9AP�F130W�^1.3V �������B
�d�������ʼn���������ł͂Ȃ�����������A��͂艽���V�Z�p�ȃv���Z�X����
�̉\�������������B�i�ܘ_�f�U�C���ύX�ɂ�镔�������邩���H�����B�j
Pentium D 960 ��sspec�łœd���ׂ����ASL9K7�F95W�^1.225V-1.312V �ŁA
SL9AP�F130W�^1.3V �������B
�d�������ʼn���������ł͂Ȃ�����������A��͂艽���V�Z�p�ȃv���Z�X����
�̉\�������������B�i�ܘ_�f�U�C���ύX�ɂ�镔�������邩���H�����B�j
P1265�L�^�[�Ǝv�������ǁAP1265����Pen4�̍����ȃg�����W�X�^�Ŏg����悤�Ȃ���Ȃ�������
����������ȃz���g
����������ȃz���g
891 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/28(��) 23:32:00 ID:gJ0GUKba
SantaRosa�����LV/ULV Merom�Ɏg����̂���H
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai298.htm
���W�Ȃ����ǁu1st dual core�v�ƁuQuad Core Module�v�̕����������
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai_12l.gif
���W�Ȃ����ǁu1st dual core�v�ƁuQuad Core Module�v�̕����������
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai_12l.gif
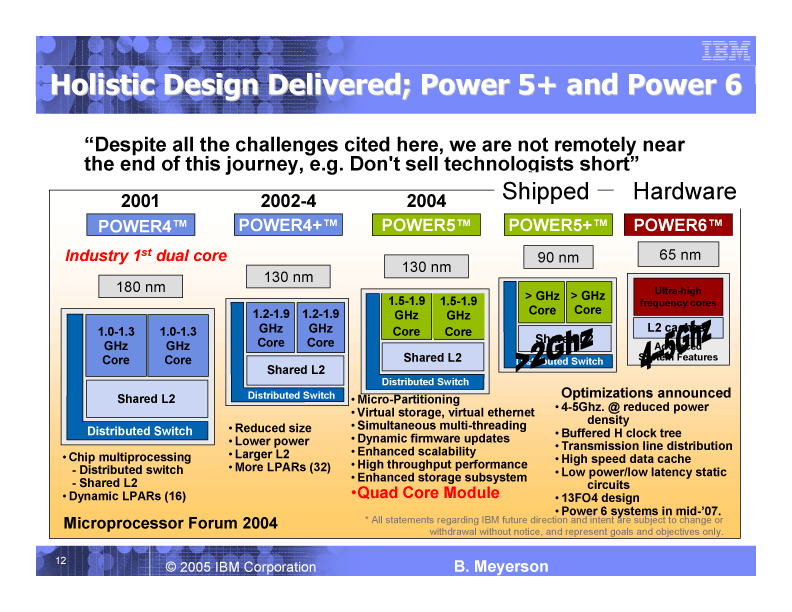{kind=link}
intel��65nm����͐������Ă�ȁB
AMD���K���K�b�e�ق����B
AMD���K���K�b�e�ق����B
>>890
P1265 �͕����̋Z�p�̏W�听�����A�g�ݍ��킹�����ނ���Ȃ��݂���������A
�����̂������獂����P4�p�ɂ��g����P�`�Q��ނ��A�R�A�S�̂���Ȃ��ĕ���
�I�ɓ��������̊��B
ttp://www.sijapan.com/breaking/0509/21ssi_intel050921.html
�b�����\�������d�͂ȃg�����W�X�^�A�c��Si�A8�wCu�z���A��U�d���iLow-k�j�≏�����̗p�����AP1265�͓��Ђ�65nm�v���Z�X
�b�Z�p�Ƃ��Ă͑�2����ɂȂ�B
�b90nm�v���Z�X���l�ɁA���Ђ͐V����65nm�v���Z�X�ł�3��ނ���4��ނ̔h���v���Z�X���J������B���̐V�����v���Z�X��2007�N
�b����ʎY�K�p�����\��B
P1265 �͕����̋Z�p�̏W�听�����A�g�ݍ��킹�����ނ���Ȃ��݂���������A
�����̂������獂����P4�p�ɂ��g����P�`�Q��ނ��A�R�A�S�̂���Ȃ��ĕ���
�I�ɓ��������̊��B
ttp://www.sijapan.com/breaking/0509/21ssi_intel050921.html
�b�����\�������d�͂ȃg�����W�X�^�A�c��Si�A8�wCu�z���A��U�d���iLow-k�j�≏�����̗p�����AP1265�͓��Ђ�65nm�v���Z�X
�b�Z�p�Ƃ��Ă͑�2����ɂȂ�B
�b90nm�v���Z�X���l�ɁA���Ђ͐V����65nm�v���Z�X�ł�3��ނ���4��ނ̔h���v���Z�X���J������B���̐V�����v���Z�X��2007�N
�b����ʎY�K�p�����\��B
Intel�̃X�e�b�s���O������\���Ă邩���Ȃ��B
AMD�̃��r�W�����͉�H�v���������ǁB
�v���Z�X�̉��ǂ��X�e�b�s���O�̕ύX�Ɋ܂߂�Ȃ�AIntel��AMD�݂����Ɍp���I�Ƀv���Z�X�̉��ǂ��n�߂����Ď����������B
�ł������̍H���Copy Exactly�����s���鎖���l����Ƃ���ȃt���L�V�u���ɂ͉��Ǐo���Ȃ��C������B
�ƂȂ�Ƃ�͂��H�v����v�����ȁB
���Aggressive��Clock Gating����悤�ɂȂ����Ƃ��A��d���œ��삵�₷�������Ƃ����l�����邩�B
PentiumD��Specification Updates����������D-0�Ɋւ����ች���L�q�����������Ȃ��B
AMD�̃��r�W�����͉�H�v���������ǁB
�v���Z�X�̉��ǂ��X�e�b�s���O�̕ύX�Ɋ܂߂�Ȃ�AIntel��AMD�݂����Ɍp���I�Ƀv���Z�X�̉��ǂ��n�߂����Ď����������B
�ł������̍H���Copy Exactly�����s���鎖���l����Ƃ���ȃt���L�V�u���ɂ͉��Ǐo���Ȃ��C������B
�ƂȂ�Ƃ�͂��H�v����v�����ȁB
���Aggressive��Clock Gating����悤�ɂȂ����Ƃ��A��d���œ��삵�₷�������Ƃ����l�����邩�B
PentiumD��Specification Updates����������D-0�Ɋւ����ች���L�q�����������Ȃ��B
���X�̂Ă�\��̃l�b�g�o�[�X�g�ȃA�[�L�e�B�N�`���ɁA��Ԍ������đ傫�ȃf�U�C��
�ύX�͂��ĂȂ��̃W���}�C�J�B
�v���Z�X��̂̕ύX�Ȃ�A�R�A�A�[�L�����ֈڍs���Ă����̂܂܃m�E�n�E���g���邩��A
�R�X�g�Ό��ʂ��傫�����B
90nm�������d�́����M�������Ȃ����͎̂�Ƀ��[�N�d���̖�肾����A�g�����W�X�^
���������ĕύX���ꗥ�ɍs���₷��L2�L���b�V���ɁA���[�N�d����̃v���Z�X��
�����ƍl����ƁA���\����͍��������H
�܂��h�f�l�̓��Ă����ۂ��Ȑ����Ȃ̂ŁA�b�����ȉ��œǂ�Ŗ��Ȃ��ƍ��邪�B�i�m
�ύX�͂��ĂȂ��̃W���}�C�J�B
�v���Z�X��̂̕ύX�Ȃ�A�R�A�A�[�L�����ֈڍs���Ă����̂܂܃m�E�n�E���g���邩��A
�R�X�g�Ό��ʂ��傫�����B
90nm�������d�́����M�������Ȃ����͎̂�Ƀ��[�N�d���̖�肾����A�g�����W�X�^
���������ĕύX���ꗥ�ɍs���₷��L2�L���b�V���ɁA���[�N�d����̃v���Z�X��
�����ƍl����ƁA���\����͍��������H
�܂��h�f�l�̓��Ă����ۂ��Ȑ����Ȃ̂ŁA�b�����ȉ��œǂ�Ŗ��Ȃ��ƍ��邪�B�i�m
�i�����j
L2�L���b�V���Ȃ�A�f�U�C���I�ɂ���{�I�ɃR�A�A�[�L�Ƒ傫�ȍ����Ȃ���������A
������m�E�n�E�̗��p�����Ղ������b�g���L�邵�B
L2�L���b�V���Ȃ�A�f�U�C���I�ɂ���{�I�ɃR�A�A�[�L�Ƒ傫�ȍ����Ȃ���������A
������m�E�n�E�̗��p�����Ղ������b�g���L�邵�B
898 �FMAC�I�^��889 �����F2006/08/29(��) 21:37:25 ID:Z9LUK9DC
>>889
�@�@----------------------
�@�@�d�������ʼn���������ł͂Ȃ�����������A��͂艽���V�Z�p�ȃv���Z�X����
�@�@�̉\�������������B
�@�@----------------------
��������SSPEC�܂Ŋm�F����������C"Supported Features"�̍��ڂ��m���߂�Ηǂ�����
�Ǝv�����B
�@SL9AP: http://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@SL9K7: http://processorfinder.intel.com/details.aspx?sSpec=SL9K7
http://www.watch.impress.co.jp/AKIBA/hotline/20060701/etc_petiumdc1.html
�@�@----------------------
�@�@�d�������ʼn���������ł͂Ȃ�����������A��͂艽���V�Z�p�ȃv���Z�X����
�@�@�̉\�������������B
�@�@----------------------
��������SSPEC�܂Ŋm�F����������C"Supported Features"�̍��ڂ��m���߂�Ηǂ�����
�Ǝv�����B
�@SL9AP: http://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@SL9K7: http://processorfinder.intel.com/details.aspx?sSpec=SL9K7
http://www.watch.impress.co.jp/AKIBA/hotline/20060701/etc_petiumdc1.html
���ŁA�ŋ߂͂ǂ̃v���Z�X�܂�ArF���\�O���t�B�ōs���́H32nm�H
�������������̂��T�b�p���������l������ȁB
���Ⴂ���Ă邾�����낤���B
>>896
�m���ɂ킴�킴������邩�ȂƂ͎v�������ǁA������Intel�̃}���p���[���ȂƁB
Celeron�ł͂��炭�g�����ATulsa�������ƊJ�������ė��Ă����炻��̐��ʂ��t�B�[�h�o�b�N���Ă�\��������B
>>899
TSMC��32nm�܂�ArF�t�Z�ōs�����Č����Ă�ˁB
EUV�ƌ�����Intel�����ǁAEUV�Ԃɍ����̂��ȁB
���ƁA�ŋ�IBM��ArF�t�Z�Ő���29.9nm���𑜂��Ă�B
���Ƃ��Ȃ肻���ȋC�����Ȃ��ł��Ȃ��Ȃ��B
�����Y���ۑ�݂��������ǁB
�ň��AArF�t�Z�œ�d�I�����ĕ��@������B
���ח����}�����邩�ǂ������������ǁB
���Ⴂ���Ă邾�����낤���B
>>896
�m���ɂ킴�킴������邩�ȂƂ͎v�������ǁA������Intel�̃}���p���[���ȂƁB
Celeron�ł͂��炭�g�����ATulsa�������ƊJ�������ė��Ă����炻��̐��ʂ��t�B�[�h�o�b�N���Ă�\��������B
>>899
TSMC��32nm�܂�ArF�t�Z�ōs�����Č����Ă�ˁB
EUV�ƌ�����Intel�����ǁAEUV�Ԃɍ����̂��ȁB
���ƁA�ŋ�IBM��ArF�t�Z�Ő���29.9nm���𑜂��Ă�B
���Ƃ��Ȃ肻���ȋC�����Ȃ��ł��Ȃ��Ȃ��B
�����Y���ۑ�݂��������ǁB
�ň��AArF�t�Z�œ�d�I�����ĕ��@������B
���ח����}�����邩�ǂ������������ǁB
>>892
AMD���C���e����n���ɂ��Ă�̂��A�h���P�c�����݂����ŏ����
AMD���C���e����n���ɂ��Ă�̂��A�h���P�c�����݂����ŏ����
65nm�����������ȁB
1.4V�Ȃ�ו������Ă��Ӗ��˂���B
1.4V�Ȃ�ו������Ă��Ӗ��˂���B
�d���͂����ȒP�ɉ�����Ȃ��A�ᑬ�Ȃ�ʂ���w
�b�o�t2���ׂ�2�{�̐��\�ɂȂ�Ȃ��͖̂��炩�ɖ��ʂ����Ă�Ǝv���͉̂��������낤��
���ۃR�����Ƃ��ł�1.4�{�Ə�����Ă邪
�q-�g�s�s�̗L���ȂƂ����1�Ɍ����č��܂ł̃A�v�������2�{�ɋ߂Â����߂̃R�[�h�ł͂Ȃ����Ǝv��
2�R�A��p�ŏ�����Ă�̂�����ɑ����͂Ȃ�Ȃ��Ǝv��
���ۃR�����Ƃ��ł�1.4�{�Ə�����Ă邪
�q-�g�s�s�̗L���ȂƂ����1�Ɍ����č��܂ł̃A�v�������2�{�ɋ߂Â����߂̃R�[�h�ł͂Ȃ����Ǝv��
2�R�A��p�ŏ�����Ă�̂�����ɑ����͂Ȃ�Ȃ��Ǝv��
1�R�A��2�R�A�ɑ����Đ��\���{�ɂȂ�\�t�g�͑��݂��邼�B
>�q-�g�s�s�̗L���ȂƂ����1�Ɍ����č��܂ł̃A�v�������2�{�ɋ߂Â����߂̃R�[�h�ł͂Ȃ����Ǝv��
�Z�p�͂�AMD�����ˁB
�Z�p�͂�AMD�����ˁB
R-HTT�ŃV���O���X���b�h�̐��\�A�b�v�͂ǂ�ȂɊy�ϓI�Ɍ��Ă�2�{�ǂ��납�A1�C2�����炢�������҂ł��Ȃ���ˁH
���������ȒP��1�X���b�h���̃R�A�Ɋ���U���̂Ȃ�A�R���p�C���̕������ȒP�Ƀ}���`�R�A�ɑΉ��ł��邱�ƂɂȂ�B
���ɁA���Z���j�b�g���̃R�A�ŋ��L���Ď��s����Ƃ��Ă��A1�X���b�h����3���߂��閽�߂𒊏o�ł���@��́A
����ȂɂȂ����낤�B
�ǂ�������������Ă邩�̏��Ȃ��̂ɁAR-HTT��2�{�Ƃ��͂������ɂ��߂ł�������Ǝv�����B
���������ȒP��1�X���b�h���̃R�A�Ɋ���U���̂Ȃ�A�R���p�C���̕������ȒP�Ƀ}���`�R�A�ɑΉ��ł��邱�ƂɂȂ�B
���ɁA���Z���j�b�g���̃R�A�ŋ��L���Ď��s����Ƃ��Ă��A1�X���b�h����3���߂��閽�߂𒊏o�ł���@��́A
����ȂɂȂ����낤�B
�ǂ�������������Ă邩�̏��Ȃ��̂ɁAR-HTT��2�{�Ƃ��͂������ɂ��߂ł�������Ǝv�����B
�n�[�h�E�F�A�ŕ����o����̂͌������������邩��DLP��TLP�Ȃ킯��
909 �FMAC�I�^��904-907 �����F2006/08/30(��) 19:19:50 ID:GEjlkWxL
>>904-907
�@�@-------------------
�@�@�q-�g�s�s�́B�B�B
�@�@-------------------
�Ƃ��Ƃ����ꃋ�[�}�[�ɂ܂��v����Ă̂�C�����ɂ��A�����炵���ƌ����ׂ��Ȃ���(��)
�@�@-------------------
�@�@�q-�g�s�s�́B�B�B
�@�@-------------------
�Ƃ��Ƃ����ꃋ�[�}�[�ɂ܂��v����Ă̂�C�����ɂ��A�����炵���ƌ����ׂ��Ȃ���(��)
910 �FMAC�I�^���⑫�F2006/08/30(��) 19:40:13 ID:GEjlkWxL
�}���`�R�A����Ɍ����āC�V���O���X���b�h�A�v�����}���`�R�A�Ŏ��s����Ƃ����w�͂�
�i�s�������ǁC�����Ă��鐬�ʂ��Ă̂�C���̒��x���B
SPECfp2000 Peak �Ɍ���}���`�X���b�h���̌���
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=0&v=1&ncf=2&nct=256&cpcf=1&cpct=2&mf=200&mt=3800&o=0&o=1&start=80
�@�EPOWER5+/2.1GHz: 3321 -> 4051 (2-chip/4-core)
�@�EOpteron/3GHz: 2497 -> 3538 (4-chip/4-core)
�@�EOpteron/2.8GHz: 2344 -> 2518 (2-chip/2-core)
�@�EUltraSPARC III/1.2GHz: 1118 -> 1344 (2-chip/2-core)
�ǂ����Ă��������ш������̌��ʂ������Ă��邾��������C�������ш悪�����Ȃ��f���A���R�A
�͌��ʂ����J�ł���悤�ȑ㕨���ᖳ�����Ă��Ƃ��B���R�������\�Ƃ̑��ւ��傫��SPECint��
�͂����������ʂ��o�Ȃ��̂Ō��J����Ă��Ȃ����B
�}���`�v���Z�b�T��p�ɃR���p�C�����Ă��̒��x������C�u�����̃A�v���������������v���Ęb��
������C���ȊO�ɂ͎��m�̂��Ƃ��B
�i�s�������ǁC�����Ă��鐬�ʂ��Ă̂�C���̒��x���B
SPECfp2000 Peak �Ɍ���}���`�X���b�h���̌���
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=0&v=1&ncf=2&nct=256&cpcf=1&cpct=2&mf=200&mt=3800&o=0&o=1&start=80
�@�EPOWER5+/2.1GHz: 3321 -> 4051 (2-chip/4-core)
�@�EOpteron/3GHz: 2497 -> 3538 (4-chip/4-core)
�@�EOpteron/2.8GHz: 2344 -> 2518 (2-chip/2-core)
�@�EUltraSPARC III/1.2GHz: 1118 -> 1344 (2-chip/2-core)
�ǂ����Ă��������ш������̌��ʂ������Ă��邾��������C�������ш悪�����Ȃ��f���A���R�A
�͌��ʂ����J�ł���悤�ȑ㕨���ᖳ�����Ă��Ƃ��B���R�������\�Ƃ̑��ւ��傫��SPECint��
�͂����������ʂ��o�Ȃ��̂Ō��J����Ă��Ȃ����B
�}���`�v���Z�b�T��p�ɃR���p�C�����Ă��̒��x������C�u�����̃A�v���������������v���Ęb��
������C���ȊO�ɂ͎��m�̂��Ƃ��B
�ŏ��̈�s�Ō���������Ƃ͂����A���܂�R-HTT��M���Ă�Ǝv���Ă�̂�w
���͏��Ȃ��Ƃ�K8L�܂ŁAR-HTT��f�i������悤�Ȑ��\����Z�p�͎�������Ă���\���͒Ⴂ�Ǝv���Ă���B
������A4x4�ŃR�A�������ȊO�ɁA�ǂ�����Đ��\������A�s�[���������Ȃ̂��ɂ͋�������B
���͏��Ȃ��Ƃ�K8L�܂ŁAR-HTT��f�i������悤�Ȑ��\����Z�p�͎�������Ă���\���͒Ⴂ�Ǝv���Ă���B
������A4x4�ŃR�A�������ȊO�ɁA�ǂ�����Đ��\������A�s�[���������Ȃ̂��ɂ͋�������B
912 �FMAC�I�^��911 �����F2006/08/30(��) 20:09:43 ID:GEjlkWxL
>>911
�@�@---------------------
�@�@���܂�R-HTT��M���Ă�Ǝv���Ă�̂�w
�@�@---------------------
����������ł��Ȃ������ǁC��{�I�ȑf�{������ɂ�������炸�_���Ȃ��̂��_���ƌ�����
�Ȃ��������݂ɂ헎�_�������B
�@�@---------------------
�@�@���܂�R-HTT��M���Ă�Ǝv���Ă�̂�w
�@�@---------------------
����������ł��Ȃ������ǁC��{�I�ȑf�{������ɂ�������炸�_���Ȃ��̂��_���ƌ�����
�Ȃ��������݂ɂ헎�_�������B
>>913
>>898�͔n������B
�ȓd�͋@�\��EIST��Enhanced HALT State�́ATDP:130W��SL9AP�̃X�e�b�s���O��
��������Ă邩��ASL9K7��TDP:95W�ɗ��������R�ɂȂ��ĂȂ��B
TDP���ł͕̂��ׂ��������Ă鎞�ɕK�v�ȗ�p���\������A�A�C�h�����Ɍ���EIST
��Enhanced HALT State ��TDP��傫����������ʂ������̂́A���ʂɍl�����
�킩��b�Ȃ̂ɁB
>>898�͔n������B
�ȓd�͋@�\��EIST��Enhanced HALT State�́ATDP:130W��SL9AP�̃X�e�b�s���O��
��������Ă邩��ASL9K7��TDP:95W�ɗ��������R�ɂȂ��ĂȂ��B
TDP���ł͕̂��ׂ��������Ă鎞�ɕK�v�ȗ�p���\������A�A�C�h�����Ɍ���EIST
��Enhanced HALT State ��TDP��傫����������ʂ������̂́A���ʂɍl�����
�킩��b�Ȃ̂ɁB
>>900
������Intel�Ƀ}���p���[������Ƃ����Ă��A�f�U�C������ɂ͂���Ȃɗ]�T��
�����C�����邪�B�i�v���Z�X�����Y����Ɋւ��Ă͊m���Ƀ_���g�c�����B�j
�Ƃ肠����Intel�Ƃ��Ă̓R�A�A�[�L�ɑ��Ă̂S�R�A����64bit�����\���ɁA
�f�U�C������̃}���p���[���D��I�ɕK�v���낤���B�����łȂ��Ɨ��v����
�ǂ��T�[�o�[�����ŁAAMD�ɑR�o���Ȃ����B
>>897 �Ɋւ��ẮA������ƒ����B
�R�A�A�[�L�ƃl�g�o�A�[�L���ƁACPU����N���b�N��1GHz���炢�Ⴄ�̂ŁA�Ⴆ
L2�L���b�V����SRAM�Ŋ�{�I�Ƀf�U�C���������ł��A���ۂɂ͂��Ȃ����Ă���
���Ă�\���������C�����܂��B
�܂�����ł������d�͂ȃv���Z�X������m�E�n�E��ɂ́A��ԍD�s��
�Ȕ��Ȃ̂͊m���ł��傤���ǁB
������Intel�Ƀ}���p���[������Ƃ����Ă��A�f�U�C������ɂ͂���Ȃɗ]�T��
�����C�����邪�B�i�v���Z�X�����Y����Ɋւ��Ă͊m���Ƀ_���g�c�����B�j
�Ƃ肠����Intel�Ƃ��Ă̓R�A�A�[�L�ɑ��Ă̂S�R�A����64bit�����\���ɁA
�f�U�C������̃}���p���[���D��I�ɕK�v���낤���B�����łȂ��Ɨ��v����
�ǂ��T�[�o�[�����ŁAAMD�ɑR�o���Ȃ����B
>>897 �Ɋւ��ẮA������ƒ����B
�R�A�A�[�L�ƃl�g�o�A�[�L���ƁACPU����N���b�N��1GHz���炢�Ⴄ�̂ŁA�Ⴆ
L2�L���b�V����SRAM�Ŋ�{�I�Ƀf�U�C���������ł��A���ۂɂ͂��Ȃ����Ă���
���Ă�\���������C�����܂��B
�܂�����ł������d�͂ȃv���Z�X������m�E�n�E��ɂ́A��ԍD�s��
�Ȕ��Ȃ̂͊m���ł��傤���ǁB
916 �FMAC�I�^��913-914 �����F2006/08/30(��) 22:14:06 ID:GEjlkWxL
>>913-914
�@�@----------------------
�@�@�ȓd�͋@�\��EIST��Enhanced HALT State�́ATDP:130W��SL9AP�̃X�e�b�s���O��
�@�@��������Ă邩��ASL9K7��TDP:95W�ɗ��������R�ɂȂ��ĂȂ��B
�@�@----------------------
�����N����ǂ���(��)
SL9AP: http://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@�@======================
�@�@Supported Features:
�@�@- Dual Core
�@�@- Execute Disable Bit
�@�@- Intel EM64T
�@�@- Intel Virtualization Technology
�@�@======================
SL9K7: http://processorfinder.intel.com/details.aspx?sSpec=SL9K7
�@�@======================
�@�@Supported Features:
�@�@- Dual Core
�@�@- Enhanced Intel Speedstep? Technology
�@�@- Execute Disable Bit
�@�@- Intel EM64T
�@�@- Intel Virtualization Technology
�@�@======================
�@�@----------------------
�@�@�ȓd�͋@�\��EIST��Enhanced HALT State�́ATDP:130W��SL9AP�̃X�e�b�s���O��
�@�@��������Ă邩��ASL9K7��TDP:95W�ɗ��������R�ɂȂ��ĂȂ��B
�@�@----------------------
�����N����ǂ���(��)
SL9AP: http://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@�@======================
�@�@Supported Features:
�@�@- Dual Core
�@�@- Execute Disable Bit
�@�@- Intel EM64T
�@�@- Intel Virtualization Technology
�@�@======================
SL9K7: http://processorfinder.intel.com/details.aspx?sSpec=SL9K7
�@�@======================
�@�@Supported Features:
�@�@- Dual Core
�@�@- Enhanced Intel Speedstep? Technology
�@�@- Execute Disable Bit
�@�@- Intel EM64T
�@�@- Intel Virtualization Technology
�@�@======================
Opteron 1000 �픭�\����2�T�Ԃŏ��ł����炵����(��)
�@�E���i���\�@http://pc.watch.impress.co.jp/docs/2006/0815/amd.htm
�@�EAMD�ŐV���i�\ http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_609,00.html
�O�_�O�_���ˁB�B�B
�@�E���i���\�@http://pc.watch.impress.co.jp/docs/2006/0815/amd.htm
�@�EAMD�ŐV���i�\ http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_609,00.html
�O�_�O�_���ˁB�B�B
�}���`�R�A�����Ƀv���O�������Ȃ��Ă������AR-HTT�ɂ��Ă����̗L����
�������o���ɂ́AR-HTT�����Ƀv���O��������K�v������Ƃ������Ƃ�OK?
�}���`�R�A�����Ƀv���O��������ɂ��AR-HTT�����Ƀv���O��������ɂ��l�Ԃ�
�]�ɂ͕s�����Ș_���I�v�l���K�v�Ȃ̂Ō�����������ɂ����Ƃ������Ƃ͂��邵�B
���ʊW��������̂��ƁA�����������ʂ��o��O�Ɏ��s���\�ɗ]�͂������Ă����ʂ�
�Ȃ�ƁB�����Ȃ�͕̂ʂƂ��āA�P�ʎ��Ԃ�����ɂł��鏈�������b�`�ɂȂ�Ƃ���
�̂ł�����Ȃ��́B�����A�v���̍������łQ�{�̏������o����킯�ł͂Ȃ�����
�P�O�����x�ł������Ȃ�Ȃ炢�����Ƃ��B
�}���`�R�A��R-HTT�����ʂƂ����ɂ͂܂���������B
�P��̃\�t�g����ł͂Ȃ��ł�����ˁB�Ȃ����ƂȂ���}���`�R�A�̂ق���
���K�����ǁA�}���`HDD�ɂ���RAID0+1�Ƃ��ōœK���Ƃ������ł��Ă���Ȃ����ȂƁB
�����������ȊO�ւ̃A�N�Z�X���Ǘ�����̂�AMD�̕������Ƃ��Ă���̂��ȁB
�������o���ɂ́AR-HTT�����Ƀv���O��������K�v������Ƃ������Ƃ�OK?
�}���`�R�A�����Ƀv���O��������ɂ��AR-HTT�����Ƀv���O��������ɂ��l�Ԃ�
�]�ɂ͕s�����Ș_���I�v�l���K�v�Ȃ̂Ō�����������ɂ����Ƃ������Ƃ͂��邵�B
���ʊW��������̂��ƁA�����������ʂ��o��O�Ɏ��s���\�ɗ]�͂������Ă����ʂ�
�Ȃ�ƁB�����Ȃ�͕̂ʂƂ��āA�P�ʎ��Ԃ�����ɂł��鏈�������b�`�ɂȂ�Ƃ���
�̂ł�����Ȃ��́B�����A�v���̍������łQ�{�̏������o����킯�ł͂Ȃ�����
�P�O�����x�ł������Ȃ�Ȃ炢�����Ƃ��B
�}���`�R�A��R-HTT�����ʂƂ����ɂ͂܂���������B
�P��̃\�t�g����ł͂Ȃ��ł�����ˁB�Ȃ����ƂȂ���}���`�R�A�̂ق���
���K�����ǁA�}���`HDD�ɂ���RAID0+1�Ƃ��ōœK���Ƃ������ł��Ă���Ȃ����ȂƁB
�����������ȊO�ւ̃A�N�Z�X���Ǘ�����̂�AMD�̕������Ƃ��Ă���̂��ȁB
919 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/30(��) 23:35:41 ID:I4aUwYgG
�P��2�{�ɂł���̂̓u���b�N�Í��̃u���[�g�t�H�[�X�A�^�b�N���炢����B
>>916
�����web��ł̃~�X���ۂ����B������920~950���G���b�^�̂�����EIST��
�Ȃ������ׂɁAsspec�łŋL�ڂ��ĂȂ������̂��A���̂܂܃R�s�y����
�C���R�ꂵ���\���������C���B
http://www.watch.impress.co.jp/AKIBA/hotline/20060107/etc_presler.html
���ۂɉ��L��DataSheet��update���݂Ă��AEIST�̗L����130W��95W�̈Ⴂ��
���R�Ƃ́A�����ɂ�������ĂȂ��B���������ꍇ�Aweb����pdf�̋L�ڂ�M�p
���ׂ������B
http://www.intel.com/design/Pentiumxe/datashts/310306.htm
http://developer.intel.com/design/Pentiumxe/specupdt/310307.htm
�����web��ł̃~�X���ۂ����B������920~950���G���b�^�̂�����EIST��
�Ȃ������ׂɁAsspec�łŋL�ڂ��ĂȂ������̂��A���̂܂܃R�s�y����
�C���R�ꂵ���\���������C���B
http://www.watch.impress.co.jp/AKIBA/hotline/20060107/etc_presler.html
���ۂɉ��L��DataSheet��update���݂Ă��AEIST�̗L����130W��95W�̈Ⴂ��
���R�Ƃ́A�����ɂ�������ĂȂ��B���������ꍇ�Aweb����pdf�̋L�ڂ�M�p
���ׂ������B
http://www.intel.com/design/Pentiumxe/datashts/310306.htm
http://developer.intel.com/design/Pentiumxe/specupdt/310307.htm
>>916
���̂��A���X�̘b���Pen4 6x1�iPenD 9xx�������j�̃X�e�b�s���O��C-1����D-0�ɕύX
�ɂȂ������Ƃɂ��TDP�̌����ɂ��ĂȂ킯�B
ttp://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
ttp://pc.watch.impress.co.jp/docs/2006/0615/intel.htm
�ŁA�X�e�b�s���O�̕ϑJ�͈ȉ��̒ʂ�iCPUID�Ƃ̊W���L�q�j
0F62h = B-1�@�G���b�^�ɂ��EIST����
0F64h = C-1�@EIST�L���@����ɔ����HTDP����
0F65h = D-0�@TDP����
ttp://pc.watch.impress.co.jp/docs/2006/0201/intel.htm
ttp://pc.watch.impress.co.jp/docs/2006/0217/intel.htm
�����Œ��ڂ�SL9AP�����Ă݂��
ttp://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@Core Stepping�@-
�@CPUID�@String�@0F62h
�Ƃ����킯��>>898�͉������������̂��Ӗ��s�����Ă��ƁB
���̂��A���X�̘b���Pen4 6x1�iPenD 9xx�������j�̃X�e�b�s���O��C-1����D-0�ɕύX
�ɂȂ������Ƃɂ��TDP�̌����ɂ��ĂȂ킯�B
ttp://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
ttp://pc.watch.impress.co.jp/docs/2006/0615/intel.htm
�ŁA�X�e�b�s���O�̕ϑJ�͈ȉ��̒ʂ�iCPUID�Ƃ̊W���L�q�j
0F62h = B-1�@�G���b�^�ɂ��EIST����
0F64h = C-1�@EIST�L���@����ɔ����HTDP����
0F65h = D-0�@TDP����
ttp://pc.watch.impress.co.jp/docs/2006/0201/intel.htm
ttp://pc.watch.impress.co.jp/docs/2006/0217/intel.htm
�����Œ��ڂ�SL9AP�����Ă݂��
ttp://processorfinder.intel.com/details.aspx?sSpec=SL9AP
�@Core Stepping�@-
�@CPUID�@String�@0F62h
�Ƃ����킯��>>898�͉������������̂��Ӗ��s�����Ă��ƁB
>>918
Intel��I/OAT��CPU�ɂ�����d�������炻���Ƃ����l���݂��������ǁB
1���̃`�b�v�ɂł��邱�Ƃɂ͌��肪����킯�ʼn��ł�����ł��l�ߍ��ނ̂͗ǂ��Ȃ��Ǝv���B
Intel��I/OAT��CPU�ɂ�����d�������炻���Ƃ����l���݂��������ǁB
1���̃`�b�v�ɂł��邱�Ƃɂ͌��肪����킯�ʼn��ł�����ł��l�ߍ��ނ̂͗ǂ��Ȃ��Ǝv���B
R-HTT�����ƃ}���`�R�A�����̃v���O�������Ă킴�킴�킯��Ӗ����ĉ��H
���������AR-HTT�͏]���̃V���O���X���b�h�̃v���O�������������s�ł�����Ęb����Ȃ������H
�����R-HTT�����ɂ̓v���O���������������Ȃ��Ƃ����Ȃ��̂Ȃ�A10%���x�����������
�}���`�R�A�����v���O���������ł������ƁB
����ɁAR-HTT���̂��ǂ��������Ȏ���������Ȃ̂ɁA��������̃v���O�����Ƃ������o����Ă�
�킯�킩���̂����B
���������AR-HTT�͏]���̃V���O���X���b�h�̃v���O�������������s�ł�����Ęb����Ȃ������H
�����R-HTT�����ɂ̓v���O���������������Ȃ��Ƃ����Ȃ��̂Ȃ�A10%���x�����������
�}���`�R�A�����v���O���������ł������ƁB
����ɁAR-HTT���̂��ǂ��������Ȏ���������Ȃ̂ɁA��������̃v���O�����Ƃ������o����Ă�
�킯�킩���̂����B
>>921
������web�̃~�X�W���}�C�J���Č����Ă邾��B�͂����茾�����A���܂ł�
web��pdf�̖����͌����������邪�A����web���̃~�X���B
ttp://download.intel.com/design/PentiumXE/specupdt/31030711.pdf
�bSL9AP C1 2M x 2 0F64h 960 3.60GHz/800MHz 775-Land LGA
���炭���������������������̂����ŁA�Ⴆ��MB���[�J�[���Ԉ�����v
�����đ��Q�������Ƃ��Ă��Apdf�Ȏ��������ɂ��Ȃ������ꍇ�͑i�ׂł�
���ĂȂ��Ǝv���B
������web�̃~�X�W���}�C�J���Č����Ă邾��B�͂����茾�����A���܂ł�
web��pdf�̖����͌����������邪�A����web���̃~�X���B
ttp://download.intel.com/design/PentiumXE/specupdt/31030711.pdf
�bSL9AP C1 2M x 2 0F64h 960 3.60GHz/800MHz 775-Land LGA
���炭���������������������̂����ŁA�Ⴆ��MB���[�J�[���Ԉ�����v
�����đ��Q�������Ƃ��Ă��Apdf�Ȏ��������ɂ��Ȃ������ꍇ�͑i�ׂł�
���ĂȂ��Ǝv���B
�����炻�̃~�X������ł��낤�y�[�W�������o���Ă��ē��ӂ��Ɍ���Ă��邩��
�������������̂��킩��Ȃ����Ă��炩������������B
����EIST�L���ɂ��TDP�̌��������Č������������������炻�̐����������܂ł̂��ƁB
�������������̂��킩��Ȃ����Ă��炩������������B
����EIST�L���ɂ��TDP�̌��������Č������������������炻�̐����������܂ł̂��ƁB
AMD man has poetic mission
ttp://www.theinquirer.net/default.aspx?article=34046
>(It's a possibly amusing quirk that Boswell never speaks the name of "our competitor". Is Intel, like Voldemort, too evil to name?)
���O�������Ă͂����Ȃ����̐l�����X��
�|�G�}�[���Ȃ�
ttp://www.theinquirer.net/default.aspx?article=34046
>(It's a possibly amusing quirk that Boswell never speaks the name of "our competitor". Is Intel, like Voldemort, too evil to name?)
���O�������Ă͂����Ȃ����̐l�����X��
�|�G�}�[���Ȃ�
�]�k����Cyrix�̍��ȂApdf�Ȏ����ɂ���ԈႢ�▵�����������肵��
��J��������B�i�ꃂ�[�h�j
������pdf��web�ɂ���ڂ��ĂȂ�����CPU���A�X���ɏo���̂����ʂ��������B
�i�V�~�W�~�j
��J��������B�i�ꃂ�[�h�j
������pdf��web�ɂ���ڂ��ĂȂ�����CPU���A�X���ɏo���̂����ʂ��������B
�i�V�~�W�~�j
929 �FMAC�I�^��921 �����F2006/08/31(��) 00:49:42 ID:vdIUiipz
>>921
�����̈��p�����\�[�X��ǂ�ł邷���H
http://pc.watch.impress.co.jp/docs/2006/0201/intel.htm
�@�@--------------------------
�@�@�傫�ȕύX�_�Ƃ��āA�uEnhanced HALT State�v�ƁA�uEnhanced Intel SpeedStep Technology�v
�@�@(EIST)���L���ƂȂ�APentium D 940(3.20GHz)�̃}�U�[�{�[�h�v�K�C�h���C����130W�g����
�@�@95W�g�֕ύX�����\��B
�@�@--------------------------
130W -> 95W �̕ύX��EIST�ɂ����̂��Ƃ����_��C���ׂĂ̎����ň�v���Ă��邷�B
�����̈��p�����\�[�X��ǂ�ł邷���H
http://pc.watch.impress.co.jp/docs/2006/0201/intel.htm
�@�@--------------------------
�@�@�傫�ȕύX�_�Ƃ��āA�uEnhanced HALT State�v�ƁA�uEnhanced Intel SpeedStep Technology�v
�@�@(EIST)���L���ƂȂ�APentium D 940(3.20GHz)�̃}�U�[�{�[�h�v�K�C�h���C����130W�g����
�@�@95W�g�֕ύX�����\��B
�@�@--------------------------
130W -> 95W �̕ύX��EIST�ɂ����̂��Ƃ����_��C���ׂĂ̎����ň�v���Ă��邷�B
>>929
�܂��A���̋C�����������t�g����
�܂��A���̋C�����������t�g����
��n�O�����X���[�Ńy�j�X
>>929
�����������\�[�X��ǂ�ł�̂��H
���̋L����B-1����C-1�ւ̃X�e�b�s���O�ύX��EIST���L���ɂȂ���ċL���B
�iEIST���L���ɂȂ���TDP��������Ă̂��l�I�ɂ͗����ł��Ȃ�������͂����Ă����j
�ŁA�b��ɂ��Ă��̂�C-1����D-0�ւ̕ύX��TDP�������Ă���Ă��ƁB
�����ł���H
�����������\�[�X��ǂ�ł�̂��H
���̋L����B-1����C-1�ւ̃X�e�b�s���O�ύX��EIST���L���ɂȂ���ċL���B
�iEIST���L���ɂȂ���TDP��������Ă̂��l�I�ɂ͗����ł��Ȃ�������͂����Ă����j
�ŁA�b��ɂ��Ă��̂�C-1����D-0�ւ̕ύX��TDP�������Ă���Ă��ƁB
�����ł���H
>>930
���ɓ˂����߂Ȃ����i�j
���ɓ˂����߂Ȃ����i�j
�����ƁA�����ʼnؗ�ɃX���[! (AA��
���}���`�v���Z�b�T��p�ɃR���p�C�����Ă��̒��x
�܂��v���O���~���O���������Ă݂��炢����Ȃ����Ȃ�
�܂��v���O���~���O���������Ă݂��炢����Ȃ����Ȃ�
936 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/01(��) 00:48:05 ID:KiFsgqNN
ICC�̎����X���b�h�����I�v�V��������ˁ[�́H
NetBurst�H�������Nehalem�����@�X���b�f�B���O���g���܂�����̂������炵����
������ď]���^�A�[�L�e�N�`���x�[�X�̃}���`�R�A�ɂ��ȒP�ɉ��p�ł��郂�m�Ȃ̂��낤��
NetBurst�H�������Nehalem�����@�X���b�f�B���O���g���܂�����̂������炵����
������ď]���^�A�[�L�e�N�`���x�[�X�̃}���`�R�A�ɂ��ȒP�ɉ��p�ł��郂�m�Ȃ̂��낤��
intel�l�g�o�̃N���b�N�ȏ�����F���グ�Ȃ��̂��ȁH
AMD�����̂܂܂���o���Ӗ��Ȃ����ȁB
intel�����̂܂���Ɉ�l��������Ǝv���H
����3.8Ghz�̕ǂ�j���ė~�������B
65nm�ł͂ł���̂��ȁH
AMD�����̂܂܂���o���Ӗ��Ȃ����ȁB
intel�����̂܂���Ɉ�l��������Ǝv���H
����3.8Ghz�̕ǂ�j���ė~�������B
65nm�ł͂ł���̂��ȁH
���ꂩ��}���`�R�A�����i�ނ̂ɃN���b�N���グ��悤�ȋ����Ȃ��Ƃ͂��Ȃ����낤�H
�グ�Ă��ق�̏�������B
�グ�Ă��ق�̏�������B
Power6�Ȃ�cPower6�Ȃ炫���ƂȂ�Ƃ����Ă����c
Power6��TDP�͂ǂ̒��x�Ȃ낤?
Power6�̊J���͒x��ɒx��Ă��邩��Ȃ��A���Ƃ������Ȃ��B
�����Conroe��3.6GHz���x�Ȃ獡�ł���pOC�\�����APower6���o�Ă��鍠�ɂ͑債�ăN���b�N�̍������������肵�����B
�������OC���Ă̘b�A�}���`�R�A����i�߂Ă��邩����N���b�N�͂��܂�グ�Ȃ����j�̂悤�����ȁB
�����Conroe��3.6GHz���x�Ȃ獡�ł���pOC�\�����APower6���o�Ă��鍠�ɂ͑債�ăN���b�N�̍������������肵�����B
�������OC���Ă̘b�A�}���`�R�A����i�߂Ă��邩����N���b�N�͂��܂�グ�Ȃ����j�̂悤�����ȁB
Power4���f���A���R�A���o�����Ƃ��AAMD��Athlon�@1.33GHz���炢�������H
AMD�u�I�[�o�[�M�K�w���c�̎���I�v�Ȃǂƌ����Ă��ȁB
�܂�Power4���M�K�w���c�I�[�o�[����������
�����AAMD��C���e��Pentium4�Ƀ��N�e�J���Ă��A���́A�ǂ����Ă����낤
����Ƃ��A�}���`�R�A�̑��݂���m��Ȃ��������낤���B
AMD�u�I�[�o�[�M�K�w���c�̎���I�v�Ȃǂƌ����Ă��ȁB
�܂�Power4���M�K�w���c�I�[�o�[����������
�����AAMD��C���e��Pentium4�Ƀ��N�e�J���Ă��A���́A�ǂ����Ă����낤
����Ƃ��A�}���`�R�A�̑��݂���m��Ȃ��������낤���B
���̓����̓f���A���R�A�S���s�v���낤��B
Intel��AMD�̎�͂͌l������CPU�AIBM�Ƃ͏Z�ގs�ꂪ�Ⴄ�B
���\�����サ�Ɩ��p�Ƃł��g����悤�ɂȂ�s�ꂪ�d�Ȃ��ʂ������Ȃ��Ă͂��邪�A��͂�x�[�X�͈Ⴄ�B
Intel��AMD�̎�͂͌l������CPU�AIBM�Ƃ͏Z�ގs�ꂪ�Ⴄ�B
���\�����サ�Ɩ��p�Ƃł��g����悤�ɂȂ�s�ꂪ�d�Ȃ��ʂ������Ȃ��Ă͂��邪�A��͂�x�[�X�͈Ⴄ�B
POWER���f���A�����N���b�h�ɂ�������̂͐��\���V���{�C����
AMD�t�@�������ꂩ��̓I�[�o�[�M�K�w���c
��IBM���M�K�w���c�Ɠ����Ƀ}���`�R�A�����i�߂��
��AMD�t�@�����Ȃɂ���H���܂��́H
AMD�t�@�����f���A���R�A�͋ƊE�̃g�����h
��IBM���܂��ȁB�����ɍ��N���b�N�������
��AMD�t�@����������Ă����N���b�N���グ��͎̂���Ƌt�s����
��IBM��TDP��POWER5�Ɠ��������A���łɃN�A�b�h��������Ȃ��BAMD���N���b�N���グ���Ȃ���������H
��AMD�t�@�����E�E�E�E�E�E�N���b�N���グ��̂́i����
��IBM���M�K�w���c�Ɠ����Ƀ}���`�R�A�����i�߂��
��AMD�t�@�����Ȃɂ���H���܂��́H
AMD�t�@�����f���A���R�A�͋ƊE�̃g�����h
��IBM���܂��ȁB�����ɍ��N���b�N�������
��AMD�t�@����������Ă����N���b�N���グ��͎̂���Ƌt�s����
��IBM��TDP��POWER5�Ɠ��������A���łɃN�A�b�h��������Ȃ��BAMD���N���b�N���グ���Ȃ���������H
��AMD�t�@�����E�E�E�E�E�E�N���b�N���グ��̂́i����
947 �FMAC�I�^���c�q �����F2006/09/02(�y) 13:07:59 ID:QRapaI75
>>936
�@�@------------------------
�@�@ICC�̎����X���b�h�����I�v�V��������ˁ[�́H
�@�@------------------------
icc for Solaris��PowerPC��icc�����݂��Ȃ������ǁB�B�B (>>910�Q��)
�@�@------------------------
�@�@ICC�̎����X���b�h�����I�v�V��������ˁ[�́H
�@�@------------------------
icc for Solaris��PowerPC��icc�����݂��Ȃ������ǁB�B�B (>>910�Q��)
948 �FMAC�I�^��921 �����F2006/09/02(�y) 13:17:18 ID:QRapaI75
>>921
�]���ϑz�̔�I��C���������ɂ��ė~�������B�B�B
�@�@--------------------
�@�@���̂��A���X�̘b���Pen4 6x1�iPenD 9xx�������j�̃X�e�b�s���O��C-1����D-0�ɕύX
�@�@�ɂȂ������Ƃɂ��TDP�̌����ɂ��ĂȂ킯�B
�@�@--------------------
Pentium D 9xx ��C1->D0�X�e�b�s���O�ύX�ɂ��TDP�̕ϑJ
�@�E945: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9QB
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9QQ
�@�E925: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9D9
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9KA
�@�E915: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9DA
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9KB
�ǂ�TDP���������Ă�����(��)
�]���ϑz�̔�I��C���������ɂ��ė~�������B�B�B
�@�@--------------------
�@�@���̂��A���X�̘b���Pen4 6x1�iPenD 9xx�������j�̃X�e�b�s���O��C-1����D-0�ɕύX
�@�@�ɂȂ������Ƃɂ��TDP�̌����ɂ��ĂȂ킯�B
�@�@--------------------
Pentium D 9xx ��C1->D0�X�e�b�s���O�ύX�ɂ��TDP�̕ϑJ
�@�E945: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9QB
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9QQ
�@�E925: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9D9
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9KA
�@�E915: 95W (C1) -> 95W (D0)
�@�@C1: http://processorfinder.intel.com/details.aspx?sSpec=SL9DA
�@�@D0: http://processorfinder.intel.com/details.aspx?sSpec=SL9KB
�ǂ�TDP���������Ă�����(��)
�킴�킴URL�\���Ă���̂ɉ��Ō��Ȃ��낤�ˁB
����Ƃ��}�W�Ō����ĂȂ��̂��ȁB
ttp://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
> �@�ΏۂƂȂ�̂́APentium 4 631(3GHz)�A��641(3.2GHz)�A��651(3.4GHz)�A��661
> (3.6GHz)�ŁA�X�e�b�s���O��C-1����D-0�ɕύX�����B�o������631/641��
> 2007�N1��22���A651/661��2006�N11��22���B
>
> �@����ɂ��ACPUID��F64����F65�ɂȂ�ATDP(Thermal Design Power)��86W����
> 65W�Ɉ�����������B
ttp://pc.watch.impress.co.jp/docs/2006/0615/intel.htm
> �@�ΏۂƂȂ�̂́AOEM�����̉��z���Z�p�uVT�v�t��Pentium D 960(3.60GHz)/
> 950(3.40GHz)�A�����VT�Ȃ���Pentium D 945(3.4GHz)/925(3GHz)/
> 915(2.80GHz)�ŁA�X�e�b�s���O��C-1����D-0�ɕύX�����B
>
> �@CPUID��F64����F65�ɂȂ����ق��APentium D 960��FMB���ύX����A�]����
> 130W(2005 Performance FMB)����95W(2005 Mainstream FMB)�Ɉ���������ꂽ�B
����Ƃ��}�W�Ō����ĂȂ��̂��ȁB
ttp://pc.watch.impress.co.jp/docs/2006/0828/intel.htm
> �@�ΏۂƂȂ�̂́APentium 4 631(3GHz)�A��641(3.2GHz)�A��651(3.4GHz)�A��661
> (3.6GHz)�ŁA�X�e�b�s���O��C-1����D-0�ɕύX�����B�o������631/641��
> 2007�N1��22���A651/661��2006�N11��22���B
>
> �@����ɂ��ACPUID��F64����F65�ɂȂ�ATDP(Thermal Design Power)��86W����
> 65W�Ɉ�����������B
ttp://pc.watch.impress.co.jp/docs/2006/0615/intel.htm
> �@�ΏۂƂȂ�̂́AOEM�����̉��z���Z�p�uVT�v�t��Pentium D 960(3.60GHz)/
> 950(3.40GHz)�A�����VT�Ȃ���Pentium D 945(3.4GHz)/925(3GHz)/
> 915(2.80GHz)�ŁA�X�e�b�s���O��C-1����D-0�ɕύX�����B
>
> �@CPUID��F64����F65�ɂȂ����ق��APentium D 960��FMB���ύX����A�]����
> 130W(2005 Performance FMB)����95W(2005 Mainstream FMB)�Ɉ���������ꂽ�B
Power6���p�C�v���C�����ו���������4GHz�I�[�o�[����
����ȓs���悭�������̂Ȃ�ł���
����ȓs���悭�������̂Ȃ�ł���
�ڂ����́A���߂���IBM�ցB
>>948
TDP�͔��M�̐�Βl����Ȃ��ėv����p���\�Ȃ̂�����A���\�̒Ⴂ�N���X��
TDP������ȏ㉺���闝�R���Ȃ�����BTDP���܂܂ɂ���Ε����܂肪�オ
��̂����B
����Ȏ���CPU�̔��M�ɊS�������V�Ȃ�A�قڏ펯���Ǝv���̂����B
��Ԋ̐S�ȁA��������b��ɂ��Ă�960�ɑ��锽�Ȃ蔽�_�Ȃ�������ȁB
TDP�͔��M�̐�Βl����Ȃ��ėv����p���\�Ȃ̂�����A���\�̒Ⴂ�N���X��
TDP������ȏ㉺���闝�R���Ȃ�����BTDP���܂܂ɂ���Ε����܂肪�オ
��̂����B
����Ȏ���CPU�̔��M�ɊS�������V�Ȃ�A�قڏ펯���Ǝv���̂����B
��Ԋ̐S�ȁA��������b��ɂ��Ă�960�ɑ��锽�Ȃ蔽�_�Ȃ�������ȁB
>>952
�������Ă��Ȃ�TDP���u���������v�ƌ����Ă��܂������ɂ��ẮH
�������Ă��Ȃ�TDP���u���������v�ƌ����Ă��܂������ɂ��ẮH
>>950
�������Ԃ̑������߂����uOPs������B
����ŁA�i���𑝂₳����4GHz��5GHz�ғ���CPU�v���\�ɂȂ�B
��)
�������Ԃ̑������߂�A�A���ʂ�B�A�x�����߂�C�Ƃ���B
����܂ł̐v����B�����uOPs�����Ă��A�����A�����uOPs������ƒi���𑝂₳���ɍ��N���b�N���o����B
B�̖��߂�1��uOP�ɕ�������̂���{�Ƃ����ꍇ�B
A�̖��߂�1��uOP�ɕ��������B
B�̖��߂�1��uOP�ɕ��������B
C�̖��߂�2��uOP�ɕ��������B
���v4��uOP���o����B
A�̖��߂�1��uOP�ɕ�������̂���{�Ƃ����ꍇ�B
A�̖��߂�1��uOP�ɕ��������B
B�̖��߂�2��uOP�ɕ��������B
C�̖��߂�4��uOP�ɕ��������B
���v7��uOP���o����B
A�̖��߂𑽗p����\�t�g����IBM-Power6�͍��N���b�N�̃����b�g�𑶕��ɐ����������������B
B�̖��߂𑽗p����\�t�g����IBM-Power6�̍��N���b�N�̃����b�g�͑�����uOP�ɂ�葊�E���ꍂ��������Ȃ��B
C�̖��߂𑽗p����\�t�g����IBM-Power6�̍��N���b�N�̃����b�g�͂���ȏ�ɑ����鑝����uOP�ɂ�葊�E����t�ɒᑬ�������B
�������Ԃ̑������߂����uOPs������B
����ŁA�i���𑝂₳����4GHz��5GHz�ғ���CPU�v���\�ɂȂ�B
��)
�������Ԃ̑������߂�A�A���ʂ�B�A�x�����߂�C�Ƃ���B
����܂ł̐v����B�����uOPs�����Ă��A�����A�����uOPs������ƒi���𑝂₳���ɍ��N���b�N���o����B
B�̖��߂�1��uOP�ɕ�������̂���{�Ƃ����ꍇ�B
A�̖��߂�1��uOP�ɕ��������B
B�̖��߂�1��uOP�ɕ��������B
C�̖��߂�2��uOP�ɕ��������B
���v4��uOP���o����B
A�̖��߂�1��uOP�ɕ�������̂���{�Ƃ����ꍇ�B
A�̖��߂�1��uOP�ɕ��������B
B�̖��߂�2��uOP�ɕ��������B
C�̖��߂�4��uOP�ɕ��������B
���v7��uOP���o����B
A�̖��߂𑽗p����\�t�g����IBM-Power6�͍��N���b�N�̃����b�g�𑶕��ɐ����������������B
B�̖��߂𑽗p����\�t�g����IBM-Power6�̍��N���b�N�̃����b�g�͑�����uOP�ɂ�葊�E���ꍂ��������Ȃ��B
C�̖��߂𑽗p����\�t�g����IBM-Power6�̍��N���b�N�̃����b�g�͂���ȏ�ɑ����鑝����uOP�ɂ�葊�E����t�ɒᑬ�������B
�G����intel�̓N���b�N���グ�Ă����Ƃ����Ă��������B
130W�ɂȂ�܂ŏグ��̂��ȁH
�N���b�N�グ�Ȃ��Ɛ��\�オ��Ȃ��āA�i�����~�܂��Ă��܂��܂����B
AMD���R���Ă��Ȃ��ƐV�������̂����Ȃ����ȁH
130W�ɂȂ�܂ŏグ��̂��ȁH
�N���b�N�グ�Ȃ��Ɛ��\�オ��Ȃ��āA�i�����~�܂��Ă��܂��܂����B
AMD���R���Ă��Ȃ��ƐV�������̂����Ȃ����ȁH
>>955
���ۂ����Ȃ�ˁB
�}�[�P�e�B���O�ł́u�N���b�N���グ��K�v�͂Ȃ��v�Ƃ��������Ȃ��킯��
Core2��3.2GHz�܂ŏグ�����ƁA�ǂ����邩�͂����
4�R�A�̂�2.66GHz�炵������A�����2.93GHz������܂ŏグ��]�T�͂��邾�낤
Core2 1.86GHz��Athlon64 3000+�̂悤�ɁA���܂�l�i���ς�炸���N�����ς����炢�܂Ŕ����邱�ƂɂȂ邩��
���ۂ����Ȃ�ˁB
�}�[�P�e�B���O�ł́u�N���b�N���グ��K�v�͂Ȃ��v�Ƃ��������Ȃ��킯��
Core2��3.2GHz�܂ŏグ�����ƁA�ǂ����邩�͂����
4�R�A�̂�2.66GHz�炵������A�����2.93GHz������܂ŏグ��]�T�͂��邾�낤
Core2 1.86GHz��Athlon64 3000+�̂悤�ɁA���܂�l�i���ς�炸���N�����ς����炢�܂Ŕ����邱�ƂɂȂ邩��
80���b�g�̃v���Z�b�T�Ńx�[�X1.5V�Ƃ����
60A���̓d��������Ă�̂��H
�v���ʂ���Ȃ���
60A���̓d��������Ă�̂��H
�v���ʂ���Ȃ���
Intel�̘cSi �������z�����Ȃ��ǁ����� AMD�̘cSi
Woodcres��2000�V���[�Y�̃x���`��r���킩��Ղ��ڂ��Ă�Ƃ��Ȃ��H
����ƁATyan�@Thunder n6650W�iSAS�Ȃ��j�������H
����ƁATyan�@Thunder n6650W�iSAS�Ȃ��j�������H
960 �FMAC�I�^��959 �����F2006/09/02(�y) 23:11:37 ID:QRapaI75
961 �FMAC�I�^��957 �����F2006/09/02(�y) 23:15:42 ID:QRapaI75
>>957
�@�@----------------
�@�@60A���̓d��������Ă�̂��H �v���ʂ���Ȃ���
�@�@----------------
�v���ʂ�C�͂邩�ɏ������Ƃ������Ƃ��o���Ă����Ɨǂ����Ǝv�����B
http://www.eccj.or.jp/qanda/he_qa/elec/d0104.html
�@�@================
�@�@��@�l�̋@�\�̒������Ƀ_���[�W����킯�ł��ˁB���߂Ċ��d�̋��낵����F�����܂����B
�@�@�@�@���̐S���ד��ǂ�����d�C�I���l�Ȃǂ́A�킩���Ă���̂ł��傤���B
�@�@���@�����ɁA���낢�날��܂����A��ʘ_�Ō����A�S���ד��́A����܂��͎葫�̊Ԃ̒ʓd
�@�@�@�@�ł́A100mA�ŋN���蓾��Ƃ����Ă��܂��B
�@�@================
�@�@----------------
�@�@60A���̓d��������Ă�̂��H �v���ʂ���Ȃ���
�@�@----------------
�v���ʂ�C�͂邩�ɏ������Ƃ������Ƃ��o���Ă����Ɨǂ����Ǝv�����B
http://www.eccj.or.jp/qanda/he_qa/elec/d0104.html
�@�@================
�@�@��@�l�̋@�\�̒������Ƀ_���[�W����킯�ł��ˁB���߂Ċ��d�̋��낵����F�����܂����B
�@�@�@�@���̐S���ד��ǂ�����d�C�I���l�Ȃǂ́A�킩���Ă���̂ł��傤���B
�@�@���@�����ɁA���낢�날��܂����A��ʘ_�Ō����A�S���ד��́A����܂��͎葫�̊Ԃ̒ʓd
�@�@�@�@�ł́A100mA�ŋN���蓾��Ƃ����Ă��܂��B
�@�@================
AMD�ł�INTEL�ł��A����N���b�N������̏����\�͂����コ���邱�Ƃ��ē����ˁH
AMD Virtualization�@�v�iAMD-V�j ���Ă���܂���ʂȂ��̂��ȁH
���܂̂Ƃ���A�ǂ̋L���݂Ă�Woodcrest�Ɋ��s�ۂ��ˁB
�܂��A51�~�~��FBDIMM�̍����̂����ł�3���Ԉȏ��
���̂��ƁA�}�U�[���ƂԂ���т��������ǁB
���܂̂Ƃ���A�ǂ̋L���݂Ă�Woodcrest�Ɋ��s�ۂ��ˁB
�܂��A51�~�~��FBDIMM�̍����̂����ł�3���Ԉȏ��
���̂��ƁA�}�U�[���ƂԂ���т��������ǁB
>>964
AMD-V��VT�����Ȃ̂������ĂȂ�����E�E�E
AMD-V��VT�����Ȃ̂������ĂȂ�����E�E�E
>>966
Xen�֘A���ׂĂ݂�Ƃ킩���B
�����㍡��VT���ē����Ϗ��̂����肵����^���ĂȂ�����
�̐S��I/O���������肤�܂����Ȃ��Ɖ��z��������ł̃p�t�H�[�}���X����ɂ͔����B
Xen�֘A���ׂĂ݂�Ƃ킩���B
�����㍡��VT���ē����Ϗ��̂����肵����^���ĂȂ�����
�̐S��I/O���������肤�܂����Ȃ��Ɖ��z��������ł̃p�t�H�[�}���X����ɂ͔����B
�Q��O�ɒNjL�B
���z�����邾���Ȃ獡�̂܂܂ŏ\���Ƃ������AVMWare�ł�������Ȃ��ł������Ǝv���B
�n�[�h�E�F�A���z�����Ă���Ƀp�t�H�[�}���X�����߂�Ȃ�A����VT����(�L��֥`)
HVM�iVT�j�g�����\�t�g���z����DomainU�g�������A5�{���炢��������E�E�E
INTEL������VT�J�����炵�����ǁB
Win�x�[�X��HVM��������̂�����Win�炵�����ǂ��B
���z�����邾���Ȃ獡�̂܂܂ŏ\���Ƃ������AVMWare�ł�������Ȃ��ł������Ǝv���B
�n�[�h�E�F�A���z�����Ă���Ƀp�t�H�[�}���X�����߂�Ȃ�A����VT����(�L��֥`)
HVM�iVT�j�g�����\�t�g���z����DomainU�g�������A5�{���炢��������E�E�E
INTEL������VT�J�����炵�����ǁB
Win�x�[�X��HVM��������̂�����Win�炵�����ǂ��B
PCI-E��5GHz�ɂȂ�Ȃ���VT��
���ہAVMware �Ȃ�A���̂Ƃ��� VT �ɗ�����\�t�g�����ʼn��z������
�����ނ��둬���炵�����ˁB�܂��A���ꂾ�� VMware �̃f�L���������Ƃ�
���Ԃ��Ȃ킯�����B
�����ނ��둬���炵�����ˁB�܂��A���ꂾ�� VMware �̃f�L���������Ƃ�
���Ԃ��Ȃ킯�����B
���Ă��Ƃ�Woodcres�Ɋ��s����Ȃ��H
vmware �� Xen �͉��z���̕��j�E�g�������܂������Ⴄ��
VT �� Pacifica �͂ǂ��炩�Ƃ����� Xen �Ɍ����Ă���
�b����Ȃ����ȁ[
������ Xen �I�Ȍ����ł� Pacifica �̕���
�����x�������ǂ����ł͂Ȃ����A���Ęb���Ǝv��
�������������
VT �� Pacifica �͂ǂ��炩�Ƃ����� Xen �Ɍ����Ă���
�b����Ȃ����ȁ[
������ Xen �I�Ȍ����ł� Pacifica �̕���
�����x�������ǂ����ł͂Ȃ����A���Ęb���Ǝv��
�������������
�b�x��
�v���Ԃ�̏Ă��T���ł��B�X�C�����b�^�C�i�C�E�E�E�E�B
http://headlines.yahoo.co.jp/hl?a=20060903-00000002-yom-soci&kz=soci
�v���Ԃ�̏Ă��T���ł��B�X�C�����b�^�C�i�C�E�E�E�E�B
http://headlines.yahoo.co.jp/hl?a=20060903-00000002-yom-soci&kz=soci
>>953
TDP�����������u960�v�̘b������A�Ɖ��x�����킩��̂��B
TDP�����������u960�v�̘b������A�Ɖ��x�����킩��̂��B
MAC�I�^���r���ŊԈႢ�ɋC�Â��ē����o���Ă邭�炢�������u���Ƃ��B
976 �FMAC�I�^��956-957 �����F2006/09/03(��) 14:34:11 ID:uauwyV9b
>>956-975
�����錾�����l��(��)
�V�X�e�b�s���O�ɑ���Z�p���������J������>>889�̐��_���g���f���Ȃ̂햾�炩�ɂȂ��
�v�����B�������������ɔ����Ă��邷����B
�����錾�����l��(��)
�V�X�e�b�s���O�ɑ���Z�p���������J������>>889�̐��_���g���f���Ȃ̂햾�炩�ɂȂ��
�v�����B�������������ɔ����Ă��邷����B
977 �FMAC�I�^��962-963 �����F2006/09/03(��) 16:07:44 ID:uauwyV9b
>>962-963
�@�@-------------------------
�@�@����N���b�N������̏����\�͂����コ���邱�Ƃ��ē����ˁH
�@�@-------------------------
�J�Ԍ����邲�Ƃ��u���͂�i�����̃v���Z�X�̔����ɂ��)�^�_�т����҂ł��Ȃ��v�Ƃ���
�펯�܂��ċc�_��i�߂�̂�C���\�Șb���B
�������C���o�C���v���Z�b�T�N���X�̏���d�͂ƃg�����W�X�^���Ŏ���IPC��啝�Ɍ��コ����
Core�A�[�L�e�N�`���̓o���ڑO�ɂ������C�����������z���������ނƂ������z�͂ǂ��Ȃ��ˁB�B�B
�Q�����˂�̒m����������̓��e���C�d�q�H�w�̋�������Ђ��ĂȂ������ȃ��C�^�[
�̎G����f���ɐM���āC�ڂ̑O�ɂ��錻���Ƃ̖����������Ȃ��q�g�����邱�Ƃɕs���������邷�B
�@�@-------------------------
�@�@����N���b�N������̏����\�͂����コ���邱�Ƃ��ē����ˁH
�@�@-------------------------
�J�Ԍ����邲�Ƃ��u���͂�i�����̃v���Z�X�̔����ɂ��)�^�_�т����҂ł��Ȃ��v�Ƃ���
�펯�܂��ċc�_��i�߂�̂�C���\�Șb���B
�������C���o�C���v���Z�b�T�N���X�̏���d�͂ƃg�����W�X�^���Ŏ���IPC��啝�Ɍ��コ����
Core�A�[�L�e�N�`���̓o���ڑO�ɂ������C�����������z���������ނƂ������z�͂ǂ��Ȃ��ˁB�B�B
�Q�����˂�̒m����������̓��e���C�d�q�H�w�̋�������Ђ��ĂȂ������ȃ��C�^�[
�̎G����f���ɐM���āC�ڂ̑O�ɂ��錻���Ƃ̖����������Ȃ��q�g�����邱�Ƃɕs���������邷�B
978 �F�E�́E�j��-�������V���I�i����Mac���^���� ��DanGorION6 �F2006/09/03(��) 16:38:15 ID:iy3y8THw
�n�C�G���hRISC�p�̃R���p�C����MPI�Ή��I�v�V�����͎�������Ăē��R�B�B
SPEC�̃\�[�X�R�[�h�������Ɩ�������B
�}���`�X���b�h������\�[�X�R�[�h���x���ŋL�q�����OS�ˑ��ɂȂ邵�ȁB
SPEC�̃\�[�X�R�[�h�������Ɩ�������B
�}���`�X���b�h������\�[�X�R�[�h���x���ŋL�q�����OS�ˑ��ɂȂ邵�ȁB
979 �FMAC�I�^���c�q �����F2006/09/03(��) 17:20:04 ID:uauwyV9b
>>978
�@�@--------------------
�@�@�n�C�G���hRISC�p�̃R���p�C����MPI�Ή��I�v�V�����͎�������Ăē��R�B�B
�@�@--------------------
OpenMP���Č����������������HMPI�����\�[�X�R�[�h���x���ł̑Ή����K�v�����ǁB�B�B
����킻��Ƃ��āC1000�ȏ゠��SPECfp�̓o�^�̒���"Parallel=Yes"�̃f�[�^�������������
�����̂Ɂu���R�v���Č������Ă��܂������H�H
�@�@--------------------
�@�@�n�C�G���hRISC�p�̃R���p�C����MPI�Ή��I�v�V�����͎�������Ăē��R�B�B
�@�@--------------------
OpenMP���Č����������������HMPI�����\�[�X�R�[�h���x���ł̑Ή����K�v�����ǁB�B�B
����킻��Ƃ��āC1000�ȏ゠��SPECfp�̓o�^�̒���"Parallel=Yes"�̃f�[�^�������������
�����̂Ɂu���R�v���Č������Ă��܂������H�H
980 �F�E�́E�j��-�������V���I�i����Mac���^���� ��DanGorION6 �F2006/09/03(��) 18:11:53 ID:iy3y8THw
�������������B
GPL�̃R�[�h���܂ނƂ����Ă�̂ɂ��̃��C�Z���X�͈ᔽ�Ȃ�ōR�c����ׂ��Ȃ�
�Ȃ�ɂ��Ă��\�[�X�R�[�h���Ȃ����Ƃɂ͉����ł��������
GPL�̃R�[�h���܂ނƂ����Ă�̂ɂ��̃��C�Z���X�͈ᔽ�Ȃ�ōR�c����ׂ��Ȃ�
�Ȃ�ɂ��Ă��\�[�X�R�[�h���Ȃ����Ƃɂ͉����ł��������
MAC�I�^���l�i�U���Ɉڂ��Ă�̂͘_���I�ɊԈ���Ă��
�F�߂�悤�Ȃ���ł���B������̔s�k�錾�ł���
�N�ɂł�����悤�ȐԂ��p�������甼�N���炢�p��������
����ȃ}�C�i�[�X�����Ⴛ���ł��Ȃ���łȂ����Ȃ���
�F�߂�悤�Ȃ���ł���B������̔s�k�錾�ł���
�N�ɂł�����悤�ȐԂ��p�������甼�N���炢�p��������
����ȃ}�C�i�[�X�����Ⴛ���ł��Ȃ���łȂ����Ȃ���
�N���b�N������̌������グ���Ȃ�������N���b�N���グ�邵���Ȃ�����Ȃ�����B
�}���`�R�A���ł��オ�邯�ǁB
CPU�̐i���~�܂����݂������ȁB
130W���Ƃ܂��@����邵�B
P3��Athlon�̎��̂悤�ɗ��҂̃N���b�N���グ�������n�܂�����ʔ������ǁB
�ŋ߁A�݊p�Ȑ킢���ł��Ă��Ȃ���B
�}���`�R�A���ł��オ�邯�ǁB
CPU�̐i���~�܂����݂������ȁB
130W���Ƃ܂��@����邵�B
P3��Athlon�̎��̂悤�ɗ��҂̃N���b�N���グ�������n�܂�����ʔ������ǁB
�ŋ߁A�݊p�Ȑ킢���ł��Ă��Ȃ���B
983 �FMAC�I�^���c�q �����F2006/09/03(��) 18:41:49 ID:uauwyV9b
>>980
�@�@---------------------
�@�@GPL�̃R�[�h���܂ނƂ����Ă�̂ɂ��̃��C�Z���X�͈ᔽ�Ȃ�ōR�c����ׂ��Ȃ�
�@�@---------------------
SPEC CPU�Ɋ܂܂��R�[�h��C���ׂĂǂ����Ń\�[�X���J����Ă��郂�m���肷�B
http://gcc.gnu.org/ml/gcc/2001-10/msg01310.html
�@�@=====================
�@�@The parts of spec2000 that are free software already exist on FTP sites, but
�@�@anyone attempting to post the tests that use that software (what part to compile,
�@�@what input data to use, how to compute the result) would necessarily violate their
�@�@license agreement with the spec people. It's legal for the spec people to do this�@
�@�@(use GPL software in a proprietary context) because of the GPL's "mere
�@�@aggregation" clause: the testbench is proprietary even though it uses free code;
�@�@the free code is always in separate programs.
�@�@=====================
�@�@---------------------
�@�@GPL�̃R�[�h���܂ނƂ����Ă�̂ɂ��̃��C�Z���X�͈ᔽ�Ȃ�ōR�c����ׂ��Ȃ�
�@�@---------------------
SPEC CPU�Ɋ܂܂��R�[�h��C���ׂĂǂ����Ń\�[�X���J����Ă��郂�m���肷�B
http://gcc.gnu.org/ml/gcc/2001-10/msg01310.html
�@�@=====================
�@�@The parts of spec2000 that are free software already exist on FTP sites, but
�@�@anyone attempting to post the tests that use that software (what part to compile,
�@�@what input data to use, how to compute the result) would necessarily violate their
�@�@license agreement with the spec people. It's legal for the spec people to do this�@
�@�@(use GPL software in a proprietary context) because of the GPL's "mere
�@�@aggregation" clause: the testbench is proprietary even though it uses free code;
�@�@the free code is always in separate programs.
�@�@=====================
984 �F�E�́E�j��-�������V���I�i����Mac���^���� ��DanGorION6 �F2006/09/03(��) 19:01:12 ID:iy3y8THw
���ꂪ��肾���[�Ă�
GPL�ɂ܂��10�̌��
ttp://opentechpress.jp/opensource/06/08/31/0233200.shtml
ttp://opentechpress.jp/opensource/06/08/31/0233200.shtml
>>963
SPEC �̓o�C�i���z�z�͂��ĂȂ����AGPL�ȃv���O�����ɂ��Ă̓\�[�X��
���ς����ĂȂ�����A�Ĕz�z�̋`�������������������Ȃ��Ǝv����B
SPEC �̓o�C�i���z�z�͂��ĂȂ����AGPL�ȃv���O�����ɂ��Ă̓\�[�X��
���ς����ĂȂ�����A�Ĕz�z�̋`�������������������Ȃ��Ǝv����B
���[��A������ƈႤ���BGPL�����ɂ��ẮA���ς�炸�Ĕz�z�̋`���������A
���ۍĔz�z���邱�Ƃ͂ł��邪�AGPL�ȃ\�t�g�ƒ��ڃ����N����Ȃ�testsuite
�����ɂ��Ă�GPL�̓K�p���Ȃ����Ă��Ƃ��ȁB
���ۍĔz�z���邱�Ƃ͂ł��邪�AGPL�ȃ\�t�g�ƒ��ڃ����N����Ȃ�testsuite
�����ɂ��Ă�GPL�̓K�p���Ȃ����Ă��Ƃ��ȁB
ttp://pc.watch.impress.co.jp/docs/2006/0518/hot425.htm
�p���I�L������VT�̗L��Ɩ����ł̐��\���ڂ��Ă�
�p���I�L������VT�̗L��Ɩ����ł̐��\���ڂ��Ă�
AMD�ɂ͉��̊W���Ȃ��L������
�X���Ⴂ����������
�X���Ⴂ����������
>>990
�@�@--------------------
�@�@AMD�ɂ͉��̊W���Ȃ��L������
�@�@�X���Ⴂ����������
�@�@--------------------
���������q�g���āCAMD�̃v���Z�b�T��ǂ��d�C�œ����Ă��āCIntel�̃v���Z�b�T�툫���d�C��
�����Ă���Ė{�C�ŐM���Ă�������(��)
�@�@--------------------
�@�@AMD�ɂ͉��̊W���Ȃ��L������
�@�@�X���Ⴂ����������
�@�@--------------------
���������q�g���āCAMD�̃v���Z�b�T��ǂ��d�C�œ����Ă��āCIntel�̃v���Z�b�T�툫���d�C��
�����Ă���Ė{�C�ŐM���Ă�������(��)
�N��>>976�ɂ͂����܂Ȃ��ˁB
�����X��4649
���������u������v�X���b�h��Intel��AMD�ɕ�����K�v�����邷���H
�Z�p�����̂�C����������̈Ⴂ���������B���R�C�������[�J�[���Ⴄ�ƕ����@���܂�
�ς��Ȃ�ăg���f���Ȃ��Ƃ��������B
�܂��Z�p�_�p�̃X���b�h�Ɩϑz�p�̃X���b�h����Ƃ��C�l�ԗp�ƒ��p�ŕ�������Ă̂�
�A���Ȃ̂�������Ȃ������ǁC���������ȕ��u���p�̃X���b�h��@���̕ӂő���Ă������B
�@�u�C���e���̐��ނ� AMD�̔ɉhPART39�v
�@http://pc7.2ch.net/test/read.cgi/jisaku/1156786255/l50
�@�u�C���e���̍Č���AMD�̒�� Part1�v
�@http://pc7.2ch.net/test/read.cgi/jisaku/1152040033/
�Z�p�����̂�C����������̈Ⴂ���������B���R�C�������[�J�[���Ⴄ�ƕ����@���܂�
�ς��Ȃ�ăg���f���Ȃ��Ƃ��������B
�܂��Z�p�_�p�̃X���b�h�Ɩϑz�p�̃X���b�h����Ƃ��C�l�ԗp�ƒ��p�ŕ�������Ă̂�
�A���Ȃ̂�������Ȃ������ǁC���������ȕ��u���p�̃X���b�h��@���̕ӂő���Ă������B
�@�u�C���e���̐��ނ� AMD�̔ɉhPART39�v
�@http://pc7.2ch.net/test/read.cgi/jisaku/1156786255/l50
�@�u�C���e���̍Č���AMD�̒�� Part1�v
�@http://pc7.2ch.net/test/read.cgi/jisaku/1152040033/
��������ȂƎv���Ă�̂��m��A���[�J�[���Ⴆ�ΐv�͈Ⴄ����B
�d�l�����[�N������͂��邯�ǖ��O�����ĂȂ������肷�邩��u������v�Ƃ���
�����������Ă���ɉ߂��Ȃ��Ǝv�����B
�d�l�����[�N������͂��邯�ǖ��O�����ĂȂ������肷�邩��u������v�Ƃ���
�����������Ă���ɉ߂��Ȃ��Ǝv�����B
���������X���[�����c
�l�X�Ǝ��X���ł����ĂĂ݂�
AMD�̎�����CPU�ɂ��Č�낤 6������
http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
AMD�̎�����CPU�ɂ��Č�낤 6������
http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
999
(���փ�)��̥��1000get�E�E�E
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/