�yRDF�z�Z�}���e�B�b�N�E�F�u�y���^���z
1 �FName_Not_Found�F
�Z�}���e�B�b�N�E�F�u�Ȃ�ď��F�ϑz�Ȃ�ł��傤���B
[���^���ƃZ�}���e�B�b�N�E�E�F�u]
http://www.kanzaki.com/docs/sw/
[RSS]
http://rss-jp.net/
[���^���ƃZ�}���e�B�b�N�E�E�F�u]
http://www.kanzaki.com/docs/sw/
[RSS]
http://rss-jp.net/
|
|
|
2 �FName_Not_Found�F03/07/09 01:33 ID:???
�ϑz�ł��B
�����������������I��������������������
�����������������I��������������������
3 �FName_Not_Found�F03/07/09 01:57 ID:???
�i�@�L_�T`�j̰�
4 �FName_Not_Found�F03/07/09 04:52 ID:???
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
----------------�ĊJ-------------------
----------------�I��-------------------
5 �FName_Not_Found�F03/07/09 10:09 ID:???
�Z�}���e�B�b�N�E�F�u���ĉ��H
6 �FName_Not_Found�F03/07/09 10:23 ID:???
�閧����(*߄t�) ��߯�@
7 �FName_Not_Found�F03/07/09 19:46 ID:???
�炪���鈫��
8 �FName_Not_Found�F03/07/10 02:44 ID:???
���̊ԂɃX�����c
����͂��Ă����A�����������N���B
[SemanticWeb.org]
http://www.semanticweb.org/
[W3C Semantic Web]
http://www.w3c.org/2001/sw/
[Dublin Core]
http://dublincore.org/
����͂��Ă����A�����������N���B
[SemanticWeb.org]
http://www.semanticweb.org/
[W3C Semantic Web]
http://www.w3c.org/2001/sw/
[Dublin Core]
http://dublincore.org/
9 �FName_Not_Found�F03/07/10 02:44 ID:???
�X�}���e�b�N
10 �FName_Not_Found�F03/07/10 02:45 ID:???
�Ƃ������Z�}���e�B�b�N�E�E�F�u�����X���ł�����ˁB
11 �FName_Not_Found�F03/07/10 02:49 ID:???
RDF������Ă��܂��B
12 �FName_Not_Found�F03/07/10 21:43 ID:???
MS�������������Ȃ�Web�Z�p�͑S���ϑz�B
13 �FName_Not_Found�F03/07/11 07:38 ID:???
M$�͖��W�B�Z�}���e�B�b�N�E�F�u�̍ő�̕ǂ�
���Ղɏ�����SEO��ɑ��鐧��҂Ȃ̂ŁB
���Ղɏ�����SEO��ɑ��鐧��҂Ȃ̂ŁB
14 �FName_Not_Found�F03/07/11 14:56 ID:???
�Z�}���e�B�b�N�E�F�u�̗���ĉ�������H
RSS��P3P��FOAF�ƁH
RSS��P3P��FOAF�ƁH
15 �FName_Not_Found�F03/07/11 23:04 ID:???
16 �FName_Not_Found�F03/07/11 23:46 ID:t4HtwUxt
�Ђ��[���Ղ����
17 �FName_Not_Found�F03/07/12 00:21 ID:???
�J�g�`�����n�b�P�[��
18 �FName_Not_Found�F03/07/12 00:24 ID:???
�I�}���e�B�b�N�E�F�[�u
19 �F�i�P���P�G�F03/07/12 12:26 ID:???
���A�����X������
20 �FName_Not_Found�F03/07/12 18:26 ID:???
�I���g���W�[���ĕ������
21 �FName_Not_Found�F03/07/12 18:26 ID:???
sw�ɋ��������l���Ă���Ȃɂ��Ȃ��̂�
22 �FName_Not_Found�F03/07/12 19:46 ID:???
23 �FName_Not_Found�F03/07/13 18:47 ID:???
�@__�ȁQ��_
�@|�i�@�@�O�O �j|�@���Q��ہi�O�O�j
�@|�_�܁܁܁_
�@�_ |�܁܁�~|�@�@�@�@�@�@�@�@�@�R���
�@�@ ~�P�P�P�P
25 �FName_Not_Found�F03/07/22 18:16 ID:???
���O�炿���Ƃ��age!
26 �FName_Not_Found�F03/07/22 23:42 ID:???
>13
���ꌾ���Ă�Ȃ��B
�f�l���� Google�Ăт����ɖ��������ȃR�[�h�����Ă͌f���Œ�\���₵�܂���Ƃ�
�ŋ߂������Ă��Ȃ��������B
���ꌾ���Ă�Ȃ��B
�f�l���� Google�Ăт����ɖ��������ȃR�[�h�����Ă͌f���Œ�\���₵�܂���Ƃ�
�ŋ߂������Ă��Ȃ��������B
27 �FName_Not_Found�F03/07/23 08:00 ID:???
RDF���܂Ƃ��ɋ@�\���͂��߂��
�u���Ԃɖ��ɂȂ�̂̓��^���̍��̂��낤�ȁB
�u���Ԃɖ��ɂȂ�̂̓��^���̍��̂��낤�ȁB
28 �FName_Not_Found�F03/07/23 10:13 ID:???
���݂�� 2 �y�Ӗ��_�z
�ksemantics�l
(1)�k���l ����̈Ӗ����ۂ��������镪��B�Ӗ��̖{���T���A�Ӗ��\���̕��́A�Ӗ��ω��̌����E�ތ^�̕��͂Ȃǂ��s���B�Ӌ`�w�B
(2)�k�_�l �L���_�̈ꕪ�ȁB�L���Ƃ��ꂪ�w�������Ώۂ⎖�ԂƂ̊Ԃ̊W����舵���B���ɘ_���w�ł́A�L���̉��߂Ɛ^���T�O������������w���B
���\���_
����p�_
�ksemantics�l
(1)�k���l ����̈Ӗ����ۂ��������镪��B�Ӗ��̖{���T���A�Ӗ��\���̕��́A�Ӗ��ω��̌����E�ތ^�̕��͂Ȃǂ��s���B�Ӌ`�w�B
(2)�k�_�l �L���_�̈ꕪ�ȁB�L���Ƃ��ꂪ�w�������Ώۂ⎖�ԂƂ̊Ԃ̊W����舵���B���ɘ_���w�ł́A�L���̉��߂Ɛ^���T�O������������w���B
���\���_
����p�_
29 �FName_Not_Found�F03/07/23 10:16 ID:???
Resource Description Framework
�@WWW�𗘗p����A�v���P�[�V�����Ԃł�
���ʓI�ȃf�[�^�������\�ɂ��邽�߂̃��^�f�[�^�t���[�����[�N�B
�@RDF�ł́A���^�f�[�^�̃v���p�e�B���`�\�ɂ��A
�قȂ�A�v���P�[�V�������m���AWWW��ʂ��ăf�[�^�̌������s�Ȃ���悤�ɂ���B
���̃v���p�e�B�Z�b�g�𗘗p���邱�ƂŁA�قȂ�A�v���P�[�V�����ԂŐl�Ԃ����ʉ\�ȏ�ԂŃf�[�^������������A
�\�t�g�E�F�A�����߉\�Ȍ`�Ńf�[�^������������ł���悤�ɂȂ�B
�@����RDF�́AW3C��RDF���[�L���O�O���[�v�ɂ����Ďd�l�Ă̍��肪�i��ł���B
W3C�̊T�v�����ɂ��A�T�C�g�}�b�v��[�e�B���O�A�X�g���[���`�����l���̒�`�A�T�[�`�G���W���A�F�̔��s�Ȃǂ�
RDF�̋Z�p�����������Ƃ��Ă���B
�@WWW�𗘗p����A�v���P�[�V�����Ԃł�
���ʓI�ȃf�[�^�������\�ɂ��邽�߂̃��^�f�[�^�t���[�����[�N�B
�@RDF�ł́A���^�f�[�^�̃v���p�e�B���`�\�ɂ��A
�قȂ�A�v���P�[�V�������m���AWWW��ʂ��ăf�[�^�̌������s�Ȃ���悤�ɂ���B
���̃v���p�e�B�Z�b�g�𗘗p���邱�ƂŁA�قȂ�A�v���P�[�V�����ԂŐl�Ԃ����ʉ\�ȏ�ԂŃf�[�^������������A
�\�t�g�E�F�A�����߉\�Ȍ`�Ńf�[�^������������ł���悤�ɂȂ�B
�@����RDF�́AW3C��RDF���[�L���O�O���[�v�ɂ����Ďd�l�Ă̍��肪�i��ł���B
W3C�̊T�v�����ɂ��A�T�C�g�}�b�v��[�e�B���O�A�X�g���[���`�����l���̒�`�A�T�[�`�G���W���A�F�̔��s�Ȃǂ�
RDF�̋Z�p�����������Ƃ��Ă���B
30 �FName_Not_Found�F03/07/23 12:48 ID:???
http://www.semblog.org/archives/000103.html
���b���RSS�A���e�i���������B
���b���RSS�A���e�i���������B
31 �FName_Not_Found�F03/07/24 12:23 ID:???
���{��œǂ߂�Ղ���RDF����͂Ȃ��ł����B
32 �FName_Not_Found�F03/07/24 13:49 ID:???
>31
�Ղ����Ȃ����ǎ�荇�����_�莁�̂Ƃ��낪����Ƃ��Ă͒�ԁB
�Ղ����Ȃ����ǎ�荇�����_�莁�̂Ƃ��낪����Ƃ��Ă͒�ԁB
33 �FName_Not_Found�F03/07/24 16:00 ID:???
RDF���g����\�t�g���Ăǂ��������̂ɂȂ�H
�u���E�U�[�Ŏg�������Ȃ��̂��ȁH
�u���E�U�[�Ŏg�������Ȃ��̂��ȁH
34 �FName_Not_Found�F03/07/24 16:39 ID:???
35 �FName_Not_Found�F03/07/24 18:12 ID:???
Web�ł̗��p��ł͂Ȃ������
Mozilla�͌��\�F�X�ȃA�v���P�[�V��������RDF�ŊǗ����Ă��ˁB
Mozilla�͌��\�F�X�ȃA�v���P�[�V��������RDF�ŊǗ����Ă��ˁB
36 �FName_Not_Found�F03/07/24 22:07 ID:???
>35
RDF�͌��\���p�Ⴀ��Ǝv�����B
RSS�Ƃ�DoblinCoreMetadata�Ƃ�FoaF�Ƃ��B
RDF�͌��\���p�Ⴀ��Ǝv�����B
RSS�Ƃ�DoblinCoreMetadata�Ƃ�FoaF�Ƃ��B
37 �FName_Not_Found�F03/07/24 22:49 ID:???
�K���ɉp�ꌗ��Blog���߂Ă݂�����RSS��p�ӂ��Ă�Ƃ��둽���ˁB
����Blog tool���o�͂���̂����̂܂g���Ă�ۂ�����
�菑���̐l�������肷��B
����Blog tool���o�͂���̂����̂܂g���Ă�ۂ�����
�菑���̐l�������肷��B
38 �FName_Not_Found�F03/07/25 00:58 ID:???
39 �FName_Not_Found�F03/07/25 01:31 ID:yTfG6fLO
RDF���g����\�t�g����...
SharpReader�Ƃ� NetNewsWire�݂����ȃj���[�X���[�_�͂ǂ��H
�������֗����Ǝv�����ǂȁB
SharpReader�Ƃ� NetNewsWire�݂����ȃj���[�X���[�_�͂ǂ��H
�������֗����Ǝv�����ǂȁB
41 �FName_Not_Found�F03/07/25 02:18 ID:???
>38
�����Ȃ�قǁB
RSS�A���e�i�Ƃ��͂ǂ��X���B
�����Ȃ�قǁB
RSS�A���e�i�Ƃ��͂ǂ��X���B
42 �FName_Not_Found�F03/07/25 12:32 ID:???
RNA�悳������
43 �FName_Not_Found�F03/07/26 21:22 ID:???
FOAF���Ăǂ��ǂ�ł�H
44 �FName_Not_Found�F03/07/26 22:34 ID:???
�ӂ��[��
45 �FName_Not_Found�F03/07/26 23:04 ID:???
�ӂ�����
46 �FName_Not_Found�F03/07/26 23:27 ID:???
̫���(��
47 �FName_Not_Found�F03/07/26 23:50 ID:???
FOAF�͎��̂����Ȃ肳��Ƃ������Ƃ��E�E�E�B
48 �FName_Not_Found�F03/07/27 13:12 ID:???
(*���)̫���!!
49 �FName_Not_Found�F03/07/27 13:32 ID:???
RSS���ĂقƂ��Blog���̍X�V������Ɏg���Ă邯��
������čX�V���Ƃ���������Ȃ���
���ʂɃT�C�g���̋L���ꗗ�Ƃ��Ďg���Ă��ǂ���ˁH
������čX�V���Ƃ���������Ȃ���
���ʂɃT�C�g���̋L���ꗗ�Ƃ��Ďg���Ă��ǂ���ˁH
50 �FName_Not_Found�F03/07/27 19:51 ID:???
XSLT��RSS��HTML�ɂ���̂����s���Ă�݂��������ǁA
RSS���ꂩ�������C�̋N���Ȃ����Ƃ��ẮA�ނ���
HTML�̐��^��HTML��RSS�ɕύX����XSLT���L�{���k�B
�ڸځ`�B
RSS���ꂩ�������C�̋N���Ȃ����Ƃ��ẮA�ނ���
HTML�̐��^��HTML��RSS�ɕύX����XSLT���L�{���k�B
�ڸځ`�B
51 �FName_Not_Found�F03/07/27 22:03 ID:???
����RSS���������������Ǝv�����B
52 �FName_Not_Found�F03/07/28 18:58 ID:???
�T�C�g�}�b�v��RDF�ŕ\������ƃ��T�Q�B
�C�}�C�`�ȕ��ޕ��@�g���Ă�Ə�肭�\�����ł��Ȃ����
���ƂȂ��u�ǂ��T�C�g�\���v���ēz�̕��ɂȂ肻���B
�C�}�C�`�ȕ��ޕ��@�g���Ă�Ə�肭�\�����ł��Ȃ����
���ƂȂ��u�ǂ��T�C�g�\���v���ēz�̕��ɂȂ肻���B
53 �FName_Not_Found�F03/07/28 19:27 ID:???
>>52
���̘b���Ă���H
�T�C�g�}�b�v�ARDF/XML
http://members.jcom.home.ne.jp/jintrick/Personal/d20032f.html#d3_2
���̘b���Ă���H
�T�C�g�}�b�v�ARDF/XML
http://members.jcom.home.ne.jp/jintrick/Personal/d20032f.html#d3_2
54 �FName_Not_Found�F03/07/28 20:29 ID:???
>53
���₻��͒m������B
�Ă����̃T�C�g���\�����[���L�������ȁc
���₻��͒m������B
�Ă����̃T�C�g���\�����[���L�������ȁc
55 �FName_Not_Found�F03/07/29 11:28 ID:???
�͂Ăȃ_�C�A���[����RSS���o��
http://antipop.zapto.org/id_798.php#articles
�ŁA�����lolipop�p�ɉ���
http://dac.lolipop.jp/diary/200307.html#d20030728
http://antipop.zapto.org/id_798.php#articles
�ŁA�����lolipop�p�ɉ���
http://dac.lolipop.jp/diary/200307.html#d20030728
56 �FName_Not_Found�F03/07/31 10:11 ID:???
���{��FOAF�̍ŐV�����`���Ă���l��������URL�m�肽������
57 �FName_Not_Found�F03/08/01 23:21 ID:???
���̕���͓��ʂ������肾�Ǝv���Ă݂�e�X�g
58 �FName_Not_Found�F03/08/01 23:43 ID:???
�ނ̓I�s�j�I�����[�_�[�ł��ȁB
�i�O�O�j
60 �FName_Not_Found�F03/08/03 23:56 ID:hvCLnE84
application/rdf+xml����MIME�^�C�v���Ăǂ���B
�����Ƃ���text/xml��application/xml�ōς܂��Ă�T�C�g�������āA
����ł������̂��Ǝv���͂��߂Ă���B
������MovableType�̃e���v���[�g����ƁAmeta�v�f��RSS��MIME�^�C�v��
application/rss+xml���Ďw�肵�Ă��邵�B
�����ǂ��Ȃ��Ă�����B
�����Ƃ���text/xml��application/xml�ōς܂��Ă�T�C�g�������āA
����ł������̂��Ǝv���͂��߂Ă���B
������MovableType�̃e���v���[�g����ƁAmeta�v�f��RSS��MIME�^�C�v��
application/rss+xml���Ďw�肵�Ă��邵�B
�����ǂ��Ȃ��Ă�����B
61 �FName_Not_Found�F03/08/04 00:37 ID:???
RSS1.0�ł͍��̂Ƃ���application/xml�����ŁARDF�p(�܂���RSS�p)��MIME Type���o�^���ꂽ��
������g���ׂ��A�Ƃ��邪�B
������g���ׂ��A�Ƃ��邪�B
62 �FName_Not_Found�F03/08/04 01:06 ID:???
63 �FName_Not_Found�F03/08/04 01:18 ID:???
�o�^���ꂽ�̂��H
64 �FName_Not_Found�F03/08/04 01:38 ID:???
�o�^�����̂Ƃ��̏��Web�ɍڂ�^�C�~���O�ɍ��ق����邩�͕�����Ȃ����ǁA
http://www.iana.org/assignments/media-types/application/
�ɂ͂܂��Ȃ��ˁB
http://www.iana.org/assignments/media-types/application/
�ɂ͂܂��Ȃ��ˁB
65 �FName_Not_Found�F03/08/04 02:28 ID:???
>>60
application/xml���ƁA
IE6��xml�̂悤�Ƀu���E�U��ʂŕ\���ł��邩��A���͂������Ă�B
application/rdf+xml���ƃ_�E�����[�h��ʂɁE�E�E�B
��T�̐l�͂���ȓK���ȗ��R�������肷���Ȃ����낤���iw
���������Mime Type���o�^����Ă��Ȃ����Ă̂����邾�낤���ǁB
application/xml���ƁA
IE6��xml�̂悤�Ƀu���E�U��ʂŕ\���ł��邩��A���͂������Ă�B
application/rdf+xml���ƃ_�E�����[�h��ʂɁE�E�E�B
��T�̐l�͂���ȓK���ȗ��R�������肷���Ȃ����낤���iw
���������Mime Type���o�^����Ă��Ȃ����Ă̂����邾�낤���ǁB
66 �FName_Not_Found�F03/08/04 20:34 ID:???
60
RSS��p�N���C�A���g�őΉ����Ă�����̂���낤��
RSS��p�N���C�A���g�őΉ����Ă�����̂���낤��
67 �FName_Not_Found�F03/08/06 11:14 ID:???
�����A�]���f�[�^���_���v����c�[���Ƃ���
���𑗂��Ă��邩���Ē��ׂĂ݂���H
���𑗂��Ă��邩���Ē��ׂĂ݂���H
68 �FName_Not_Found�F03/08/06 13:22 ID:???
�Ђゥ�����Ղ�����I
�@�@�@ (��V��)
�@�@�@�� �O �O �������ꂩ����l���������ĉ������ˁi�O�O�j�B
�@�@��|�@�@�@�@|��
�@�@�@�i�Q�j�i�Q�j�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R��p��
�@�@�@�� �O �O �������ꂩ����l���������ĉ������ˁi�O�O�j�B
�@�@��|�@�@�@�@|��
�@�@�@�i�Q�j�i�Q�j�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R��p��
70 �FName_Not_Found�F03/08/17 01:58 ID:???
�{���ɐL�тȂ��c �O����O�旈����B
71 �FName_Not_Found�F03/08/17 03:49 ID:???
�R��͉p��ア�w�^���Ȃ�Ő_�肽��ł��B
72 �FName_Not_Found�F03/08/19 09:09 ID:???
RSS1.0��2.0��0.91���}�C�i�[��������
���O��͂ǂ̃o�[�W�����������Ă��܂���
���O��͂ǂ̃o�[�W�����������Ă��܂���
73 �FName_Not_Found�F03/08/19 16:31 ID:???
>>72
RSS 1.0
RSS 1.0
74 �FName_Not_Found�F03/08/19 17:28 ID:???
�N����1.0���}�C�i�[�Ȃ�Ă����Ă���
2.0�͕�
2.0�͕�
75 �FName_Not_Found�F03/08/19 23:58 ID:???
��������Ȃ�����?
@IT W3C/XML Watch - 8����
http://www.atmarkit.co.jp/fxml/column/w3c2003/08.html
> RSS 2.0�̏��L�����ړ����ACreative Commons���C�Z���X�Œ�
>
> �ŋߊe��Web�T�C�g��RSS�̃o�i�[����������悤�ɂȂ�܂����B
> RSS�̓T�C�g�ɂ������XML�`���Œ��邽�߂ɂ���܂��B
> ���́�IT�ł��V���L����RSS�t�B�[�h�Œ��Ă��܂��B����RSS�̘b��ł��B
>
> UserLand Software��RSS 2.0�̏��L����Berkman Center�ֈړ�����Ɣ��\������܂����B
> �ړ��ɔ����A�e�������R�ɕ����◘�p���ł���Creative Commons���C�Z���X�Œ���Ƃ̂��Ƃł��B
>
> ���Ȃ݂�RSS�͌����_�ł�0.9x�n�A1.0�A2.0���������Ă����Ԃł��B
> RSS�͑傫���������2�ʂ肠��܂��B�܂�RSS 0.9��1.0�B
> ������RDF(Resource Description Framework)���x�[�X�Ƃ���RDF Site Summary�Ƃ����Ӗ����Ƃ����Ă��܂��B
> ��������RSS 0.9x��2.0�B������RDF���g�p�����A
> Rich Site Summary�܂���Really Simple Syndication�Ƃ����Ӗ��ɂȂ邻���ł��B
> �����_�ł�RSS 0.91���L���̗p����Ă���Ƃ����Ă��܂��B
> �����0.91�̗̍p�܂���2.0�ւ̈ڍs���i�ނ̂��A1.0�������Ԃ��̂��A
> ���͕��z���ǂ��ς�邩��������Ƃ���ł��B
@IT W3C/XML Watch - 8����
http://www.atmarkit.co.jp/fxml/column/w3c2003/08.html
> RSS 2.0�̏��L�����ړ����ACreative Commons���C�Z���X�Œ�
>
> �ŋߊe��Web�T�C�g��RSS�̃o�i�[����������悤�ɂȂ�܂����B
> RSS�̓T�C�g�ɂ������XML�`���Œ��邽�߂ɂ���܂��B
> ���́�IT�ł��V���L����RSS�t�B�[�h�Œ��Ă��܂��B����RSS�̘b��ł��B
>
> UserLand Software��RSS 2.0�̏��L����Berkman Center�ֈړ�����Ɣ��\������܂����B
> �ړ��ɔ����A�e�������R�ɕ����◘�p���ł���Creative Commons���C�Z���X�Œ���Ƃ̂��Ƃł��B
>
> ���Ȃ݂�RSS�͌����_�ł�0.9x�n�A1.0�A2.0���������Ă����Ԃł��B
> RSS�͑傫���������2�ʂ肠��܂��B�܂�RSS 0.9��1.0�B
> ������RDF(Resource Description Framework)���x�[�X�Ƃ���RDF Site Summary�Ƃ����Ӗ����Ƃ����Ă��܂��B
> ��������RSS 0.9x��2.0�B������RDF���g�p�����A
> Rich Site Summary�܂���Really Simple Syndication�Ƃ����Ӗ��ɂȂ邻���ł��B
> �����_�ł�RSS 0.91���L���̗p����Ă���Ƃ����Ă��܂��B
> �����0.91�̗̍p�܂���2.0�ւ̈ڍs���i�ނ̂��A1.0�������Ԃ��̂��A
> ���͕��z���ǂ��ς�邩��������Ƃ���ł��B
76 �FName_Not_Found�F03/08/25 15:52 ID:???
77 �FName_Not_Found�F03/08/25 16:03 ID:???
RDF�������߂�
78 �FName_Not_Found�F03/08/26 17:31 ID:o2Cb2eoH
RSS���[�_�[
http://pc2.2ch.net/test/read.cgi/software/1055962775/
RSS���Ăǂ���H
http://pc.2ch.net/test/read.cgi/pcnews/1061109526/
http://pc2.2ch.net/test/read.cgi/software/1055962775/
RSS���Ăǂ���H
http://pc.2ch.net/test/read.cgi/pcnews/1061109526/
79 �FName_Not_Found�F03/08/28 13:42 ID:???
>76
���V���ł��̋L�����Ă����abbr(�܂���acronym)�͑���Ȃƈ�l�[�����Ă��܂����B
���V���ł��̋L�����Ă����abbr(�܂���acronym)�͑���Ȃƈ�l�[�����Ă��܂����B
80 �FName_Not_Found�F03/08/29 11:29 ID:???
�ǂ��ł��������ǁA���������܂ŁAWordNet��WorldNet���Ǝv���Ă��c
81 �FName_Not_Found�F03/09/04 10:42 ID:???
Top > Insider.NET > ���W > �T�C�g�̍X�V�������W������RSS
http://www.atmarkit.co.jp/fdotnet/special/rss/rss_01.html
http://www.atmarkit.co.jp/fdotnet/special/rss/rss_01.html
82 �FName_Not_Found�F03/09/09 10:38 ID:???
�Z�}���e�B�b�N���~�܂�Ȃ�
83 �FName_Not_Found�F03/09/09 11:25 ID:???
̯ �Ƃ܂�Ȃ�
84 �FName_Not_Found�F03/09/09 16:22 ID:???
�@�@ �^�_�Q�Q�^�_
�@�@�i�@�@�P�́P�@�@�j
�@�@�i�@�@�@�@�@�@�@�@ �j
�@�@�b �@�@�b�@�@ �@|
�@�@�i_�Q�Q_�j_�Q�Q_�j
85 �FName_Not_Found�F03/09/10 23:05 ID:???
86 �FName_Not_Found�F03/09/27 01:02 ID:???
11����W3CDay��TimbernnersLee������Ƃ����\��������
87 �FName_Not_Found�F03/09/27 22:28 ID:???
http://www.w3.org/2003/11/14-W3CDay-Japan/
��ʐl���Q���ł���̂ˁB
��ʐl���Q���ł���̂ˁB
88 �Fhttp://www.w3.org/2003/11/14-W3CDay-Japan/�F03/10/06 18:16 ID:kYquyrTz
89 �FName_Not_Found�F03/10/15 08:49 ID:gngTrbN4
http://www.net.intap.or.jp/INTAP/s-web/data/conference2003/index.html
�uSemanticWeb�J���t�@�����X�v
���ɂ����W3C Day�Ɠ���������B
�uSemanticWeb�J���t�@�����X�v
���ɂ����W3C Day�Ɠ���������B
90 �FName_Not_Found�F03/10/15 11:36 ID:???
�ǂ�����c��`�m��wSFC���������ւ���Ă�ˁB
�c�h���������H
�c�h���������H
91 �FName_Not_Found�F03/10/15 12:09 ID:???
>>89
> ���ɂ����W3C Day�Ɠ���������B
�Ⴄ�����B
>>90
�I�}�G���m�F�����B
�c�܂�����͂��Ă����A�����̐^�����ԂƂ͂����w���������c
�s���Ă݂悤���Ȃ��c�B
> ���ɂ����W3C Day�Ɠ���������B
�Ⴄ�����B
>>90
�I�}�G���m�F�����B
�c�܂�����͂��Ă����A�����̐^�����ԂƂ͂����w���������c
�s���Ă݂悤���Ȃ��c�B
92 �FName_Not_Found�F03/10/15 12:26 ID:???
�C�������c
93 �FName_Not_Found�F03/11/13 23:02 ID:???
���Ă܂��ȁB
�ێ����ɁA�}�C�i�[�Șb����B
����DCMI Document��PR�ł���
Expressing Dublin Core in HTML/XHTML meta and link elements
��Public Comment Period�ł��B
��������v���Ƃ��낪������͂ǂ����B
http://dublincore.org/documents/2003/10/31/dcq-html/
http://dublincore.org/news/communications/public-comment.shtml
�ێ����ɁA�}�C�i�[�Șb����B
����DCMI Document��PR�ł���
Expressing Dublin Core in HTML/XHTML meta and link elements
��Public Comment Period�ł��B
��������v���Ƃ��낪������͂ǂ����B
http://dublincore.org/documents/2003/10/31/dcq-html/
http://dublincore.org/news/communications/public-comment.shtml
94 �FName_Not_Found�F03/11/16 10:57 ID:???
>>93
�Ƃ���ŁA���ꂪ����?�@���F?�@�ɂȂ�����A
RFC2731 �� replace ���� RFC ���o��̂���?
# prefix �� property name �̋��͌��ǃs���I�h���g��������
# ���ꂳ���̂���?�@�R�����͔F�߂Ȃ��݂����ˁB
�Ƃ���ŁA���ꂪ����?�@���F?�@�ɂȂ�����A
RFC2731 �� replace ���� RFC ���o��̂���?
# prefix �� property name �̋��͌��ǃs���I�h���g��������
# ���ꂳ���̂���?�@�R�����͔F�߂Ȃ��݂����ˁB
95 �FName_Not_Found�F03/11/16 22:21 ID:???
>>94
�ǂ��Ȃ낤�B�l�I�ɂ͏o�����ȗ\���B
�R�����]�X�̘b�̓��[�����O���X�g�ɂ������ˁB
�����̕��̈ӌ�����ɁA
http://www.jiscmail.ac.uk/cgi-bin/wa.exe?A2=ind0306&L=dc-architecture&P=3109
Andy����(���Y�����̍쐬��)���P�āA�s���I�h�̂ق��ɗ��ꂪ�X������A
DC-2003���abstract model�̘b��Ɉ��ݍ��܂�Ă��܂��A
���̊Ԃɂ�proposed recommendation�ɂȂ���public comment�A
�݂����Ȋ������B(�ڂ����ǂ�łȂ��̂ňႤ�����B)
�ǂ��Ȃ낤�B�l�I�ɂ͏o�����ȗ\���B
�R�����]�X�̘b�̓��[�����O���X�g�ɂ������ˁB
�����̕��̈ӌ�����ɁA
http://www.jiscmail.ac.uk/cgi-bin/wa.exe?A2=ind0306&L=dc-architecture&P=3109
Andy����(���Y�����̍쐬��)���P�āA�s���I�h�̂ق��ɗ��ꂪ�X������A
DC-2003���abstract model�̘b��Ɉ��ݍ��܂�Ă��܂��A
���̊Ԃɂ�proposed recommendation�ɂȂ���public comment�A
�݂����Ȋ������B(�ڂ����ǂ�łȂ��̂ňႤ�����B)
>>95
���A�|�C���^���肪�Ƃ��B�Q�l�ɂȂ��B
�������A�s���I�h�ƃR�����͕����ł悩�����Ǝv�����ǂˁc�B
XML Namespace �� QName �Ƃ̍����]�X���Č������ǁA
�ނ��� XML Namespace �ɂ��킹�������̕����킩��₷���Ă�������Ȃ��B
�܂��ǂ����ł�����������ǂ����ł��������ǂ��B
���A�l�I�ɂ͂���Ȃ̂�� case-insensitive �Ȃ̂��ǂ��ɂ����ė~�����B
HTML4 �ł̖��ߍ��݂�O���ɒu���Ă������ŕK�R�I��
�����Ȃ���������낤���ǁAHTML4 �� Dublin Core ���ߍ���ł��Ȃ��c�B
�܂��A���X�ύX�̂��悤���Ȃ����낤���ǂ��B
���A�|�C���^���肪�Ƃ��B�Q�l�ɂȂ��B
�������A�s���I�h�ƃR�����͕����ł悩�����Ǝv�����ǂˁc�B
XML Namespace �� QName �Ƃ̍����]�X���Č������ǁA
�ނ��� XML Namespace �ɂ��킹�������̕����킩��₷���Ă�������Ȃ��B
�܂��ǂ����ł�����������ǂ����ł��������ǂ��B
���A�l�I�ɂ͂���Ȃ̂�� case-insensitive �Ȃ̂��ǂ��ɂ����ė~�����B
HTML4 �ł̖��ߍ��݂�O���ɒu���Ă������ŕK�R�I��
�����Ȃ���������낤���ǁAHTML4 �� Dublin Core ���ߍ���ł��Ȃ��c�B
�܂��A���X�ύX�̂��悤���Ȃ����낤���ǂ��B
97 �FName_Not_Found�F03/11/21 06:14 ID:???
���Ȃ����̌c���̂�A�������ЂƂ��܂����H
�ǂ�Ȃ����H�ʔ����b�������H
�ǂ�Ȃ����H�ʔ����b�������H
98 �FName_Not_Found�F03/11/25 06:54 ID:???
>>97
W3C Day �Ƃ͈���āA�ǂ��炩�Ƃ����Ǝ������̘b�����S�ł������ǁA
�����[���������Ƃ͊m���ł��B
OWL �� N-Triples �ɕϊ����āA���������Ɏ��R����܂���
�_�����ɕϊ����ďo�͂���uRDF Analyzer�v(SFC ��)�Ƃ��A
�u�������v���Ċ����ł����ˁB
�����ŕ������Ă��Ă��A����ς����������Ɗ������ЂƂ���(w
���ƁA���Ȃ����X���h�Řb��ɂȂ��Ă��x�m�ʂ�
�u�q���[�}���i���b�W�i�r�Q�[�^�[�v�����\�ʔ��������ł��B
http://slashdot.jp/article.pl?sid=03/11/18/0128244
���̑��A�v���O�����S�̂ɂ��ẮA���L�� weblog ���ڂ����Ǝv���܂��B
http://www.chimimo.com/mt/archives/000247.html
W3C Day �Ƃ͈���āA�ǂ��炩�Ƃ����Ǝ������̘b�����S�ł������ǁA
�����[���������Ƃ͊m���ł��B
OWL �� N-Triples �ɕϊ����āA���������Ɏ��R����܂���
�_�����ɕϊ����ďo�͂���uRDF Analyzer�v(SFC ��)�Ƃ��A
�u�������v���Ċ����ł����ˁB
�����ŕ������Ă��Ă��A����ς����������Ɗ������ЂƂ���(w
���ƁA���Ȃ����X���h�Řb��ɂȂ��Ă��x�m�ʂ�
�u�q���[�}���i���b�W�i�r�Q�[�^�[�v�����\�ʔ��������ł��B
http://slashdot.jp/article.pl?sid=03/11/18/0128244
���̑��A�v���O�����S�̂ɂ��ẮA���L�� weblog ���ڂ����Ǝv���܂��B
http://www.chimimo.com/mt/archives/000247.html
99 �FName_Not_Found�F03/12/01 00:15 ID:eR2Askyc
����ȃX�����������Ƃ�...
W3C Day�̃��|��
http://www.cybergarden.net/w3c_day_japan_2003.html
�ɂ������
�����s�����������B�B�B
> �Z�}���e�B�b�NWeb�̗�
PICS�iPlatform for Internet Content Selection�j�Ȃ��Z�}���e�B�b�N�E�F�u�ɋ߂����ȁH
W3C Day�̃��|��
http://www.cybergarden.net/w3c_day_japan_2003.html
�ɂ������
�����s�����������B�B�B
> �Z�}���e�B�b�NWeb�̗�
PICS�iPlatform for Internet Content Selection�j�Ȃ��Z�}���e�B�b�N�E�F�u�ɋ߂����ȁH
100 �FName_Not_Found�F03/12/01 00:18 ID:???
���APICS����RDF�̑O�g����Ȃ������́H
101 �FName_Not_Found�F03/12/01 01:36 ID:???
>>100
��������܂���i����o���j
�Z�}���e�B�b�N�E�F�u�ɂ��ĕ������Ƃ���
P3P��PICS�̏Љ����Ă������̂�...
�L�����B���������̂Łu�߂��v�Ƃ����\���ɂ��Ă݂܂����B
�����ƒ��ׂĂ��珑���ׂ��ł����ˁi����
��������܂���i����o���j
�Z�}���e�B�b�N�E�F�u�ɂ��ĕ������Ƃ���
P3P��PICS�̏Љ����Ă������̂�...
�L�����B���������̂Łu�߂��v�Ƃ����\���ɂ��Ă݂܂����B
�����ƒ��ׂĂ��珑���ׂ��ł����ˁi����
102 �FName_Not_Found�F03/12/01 16:13 ID:???
103 �FName_Not_Found�F03/12/02 10:21 ID:???
���c�̓i�E�Z�}���e�B�b�N
104 �FName_Not_Found�F03/12/07 00:15 ID:???
����������
105 �FName_Not_Found�F03/12/11 00:38 ID:???
�Ƃ肠�����B
Expressing Dublin Core in HTML/XHTML meta and link elements
��DCMI Recommendation�Ȃ����͗l�B
http://dublincore.org/documents/2003/11/30/dcq-html/
�Ƃ������Apublic comment���Ԓ��A���[�����O���X�g�Ɉ���R�����g�����ĂȂ�������I
�����̂�����ŁADublin Core�B
�Öق̎^���Ƃ������ƂȂ̂�����Ƃ��c
Expressing Dublin Core in HTML/XHTML meta and link elements
��DCMI Recommendation�Ȃ����͗l�B
http://dublincore.org/documents/2003/11/30/dcq-html/
�Ƃ������Apublic comment���Ԓ��A���[�����O���X�g�Ɉ���R�����g�����ĂȂ�������I
�����̂�����ŁADublin Core�B
�Öق̎^���Ƃ������ƂȂ̂�����Ƃ��c
106 �FName_Not_Found�F03/12/16 23:26 ID:???
(�E�́E)��!!�A�N�Z�X���g���Ă܂��ˁB
107 �FName_Not_Found�F03/12/17 18:58 ID:???
RDF/OWL������̎d�l���܂Ƃ߂�PR�ɂȂ��Ă�Ȃ��c
108 �FName_Not_Found�F03/12/19 17:08 ID:MRwuh8GL
�͂ĂȃA���e�i�ɓ������ꂽ��
109 �FName_Not_Found�F03/12/19 21:06 ID:???
�����ƑS���������X�̂悤���B
110 �FName_Not_Found�F03/12/20 02:19 ID:???
OWL�ɏڂ������y���Ă���{��h�L�������g(���L�ł����ł��ǂ�)����
�_���݂Ƃ��ȊO�ɂǂ�������H
�_���݂Ƃ��ȊO�ɂǂ�������H
111 �FName_Not_Found�F03/12/22 17:58 ID:EEBOGztx
112 �FName_Not_Found�F04/01/07 16:17 ID:f/TOTCS4
113 �FName_Not_Found�F04/01/13 19:19 ID:???
>111-112
�x�ꂽ���LJd�N�X�B
�x�ꂽ���LJd�N�X�B
114 �FName_Not_Found�F04/01/23 04:40 ID:peulll+/
�������͂��܂肨���ɗ����Ȃ��ł��傤���H
http://www.w3.org/Consortium/Translation/Japanese
http://www.w3.org/Consortium/Translation/Japanese
115 �FName_Not_Found�F04/02/11 09:28 ID:???
RDF/OWL�������ɂȂ�܂����B
RDF/XML Syntax Specification (Revised)
http://www.w3.org/TR/rdf-syntax-grammar/
RDF Vocabulary Description Language 1.0: RDF Schema
http://www.w3.org/TR/rdf-schema/
RDF Semantics
http://www.w3.org/TR/rdf-mt/
RDF Primer
http://www.w3.org/TR/rdf-primer/
RDF Test Cases
http://www.w3.org/TR/rdf-testcases/
Resource Description Framework (RDF): Concepts and Abstract Syntax
http://www.w3.org/TR/rdf-concepts/
OWL Web Ontology Language Overview
http://www.w3.org/TR/owl-features/
OWL Web Ontology Language Guide
http://www.w3.org/TR/owl-guide/
OWL Web Ontology Language Reference
http://www.w3.org/TR/owl-ref/
OWL Web Ontology Language Semantics and Abstract Syntax
http://www.w3.org/TR/owl-semantics/
OWL Web Ontology Language Test Cases
http://www.w3.org/TR/owl-test/
OWL Web Ontology Language Use Cases and Requirements
http://www.w3.org/TR/webont-req/
RDF/XML Syntax Specification (Revised)
http://www.w3.org/TR/rdf-syntax-grammar/
RDF Vocabulary Description Language 1.0: RDF Schema
http://www.w3.org/TR/rdf-schema/
RDF Semantics
http://www.w3.org/TR/rdf-mt/
RDF Primer
http://www.w3.org/TR/rdf-primer/
RDF Test Cases
http://www.w3.org/TR/rdf-testcases/
Resource Description Framework (RDF): Concepts and Abstract Syntax
http://www.w3.org/TR/rdf-concepts/
OWL Web Ontology Language Overview
http://www.w3.org/TR/owl-features/
OWL Web Ontology Language Guide
http://www.w3.org/TR/owl-guide/
OWL Web Ontology Language Reference
http://www.w3.org/TR/owl-ref/
OWL Web Ontology Language Semantics and Abstract Syntax
http://www.w3.org/TR/owl-semantics/
OWL Web Ontology Language Test Cases
http://www.w3.org/TR/owl-test/
OWL Web Ontology Language Use Cases and Requirements
http://www.w3.org/TR/webont-req/
116 �FName_Not_Found�F04/02/11 23:21 ID:???
�����Ƀv���X�����[�X���o�Ă���܂��B
http://www.w3.org/2004/01/sws-pressrelease
http://www.w3.org/2004/01/sws-pressrelease
117 �FName_Not_Found�F04/02/23 16:48 ID:u1EX2A95
�_�莁�ɍ���遨�Z�}���e�B�b�NWeb���ɂ킩�I�ɕ����遨����Č���������B
118 �FName_Not_Found�F04/02/25 03:53 ID:???
>>117
���
���
119 �FName_Not_Found�F04/02/25 03:55 ID:???
���ׂ�Β��ׂ�قǁA�I�����ăA�^�}�����ȁ`�ƟT�ɂȂ�i��
�킩�����悤�ȋC�ɂȂ���blog�����U�炩���ق����K���i��
�킩�����悤�ȋC�ɂȂ���blog�����U�炩���ق����K���i��
120 �FName_Not_Found�F04/02/26 05:17 ID:???
>>120
���������Ă��炦��Ƃ��̂��������ꂵ���ł��B
���݂��撣��܂��傤�B�B
�Z�p�I�Șb�͂܂������ɂ̓����ł����A
�Z�}���e�B�b�NWeb�ł́A�E�F�u�y�[�W�̃��^�f�[�^��
�N���t�^����̂���Ԗ]�܂����ƍl�����Ă����ł��傤���B
�@�쐬�ҁ�RDF/XML�̋L�q������ł́H(�I�[�T�����O�c�[��������ǂ��B�B)
�A�����ҁ��쐬�҂̈Ӑ}�Ƃ̂���́H
�@�@�@�@�@���̍����Ҋ�(�����T�[�r�X�ԁj�Ƃ̂���́H
�@�@�@�@�@
���������Ă��炦��Ƃ��̂��������ꂵ���ł��B
���݂��撣��܂��傤�B�B
�Z�p�I�Șb�͂܂������ɂ̓����ł����A
�Z�}���e�B�b�NWeb�ł́A�E�F�u�y�[�W�̃��^�f�[�^��
�N���t�^����̂���Ԗ]�܂����ƍl�����Ă����ł��傤���B
�@�쐬�ҁ�RDF/XML�̋L�q������ł́H(�I�[�T�����O�c�[��������ǂ��B�B)
�A�����ҁ��쐬�҂̈Ӑ}�Ƃ̂���́H
�@�@�@�@�@���̍����Ҋ�(�����T�[�r�X�ԁj�Ƃ̂���́H
�@�@�@�@�@
122 �FName_Not_Found�F04/02/26 20:01 ID:???
����Ă������A����͐l�Ԃ��K���K����������Ȃ��Ǝv����c�B
��b�̒�`(URI)����͂����炻��ɉ�����UI������āA����ɓ��͂��Ă������Ń��^�f�[�^��
����Ƃ����̂���������Ȃ�
��b�̒�`(URI)����͂����炻��ɉ�����UI������āA����ɓ��͂��Ă������Ń��^�f�[�^��
����Ƃ����̂���������Ȃ�
123 �FName_Not_Found�F04/02/26 20:07 ID:???
���A�K���K�������Ă�l�Ԃ������Ɉ�l�c�c�B
124 �FName_Not_Found�F04/02/27 00:53 ID:???
���H�K���K���������̂���Ȃ��́c�H
125 �FName_Not_Found�F04/02/27 11:27 ID:???
�t�H�[���ɋL�����邾���łł�������悤�ɂȂ�̂�҂ׂ�����
�Ȃ�قǁB�B�t�H�[���ɋL�����Ă͔̂��ɏ�����܂��ˁB
��͂�쐬�҂����^�f�[�^��t�^����̂���Ԗ]�܂�����ł��傤���ˁB
�����҂̏ꍇ�A���Ɂwsubject(���)�x�Ƃ������v�f��t�^����̂���������B
����RDF Analyzer��INTAP�̃y�[�W�Ŏg����Ƃ����̂�����ł����A
�T�����������̂��ǂ��ɂ���̂��킩��Ȃ���ł���ˁB�Ȃ��̂��ȁH
��͂�쐬�҂����^�f�[�^��t�^����̂���Ԗ]�܂�����ł��傤���ˁB
�����҂̏ꍇ�A���Ɂwsubject(���)�x�Ƃ������v�f��t�^����̂���������B
����RDF Analyzer��INTAP�̃y�[�W�Ŏg����Ƃ����̂�����ł����A
�T�����������̂��ǂ��ɂ���̂��킩��Ȃ���ł���ˁB�Ȃ��̂��ȁH
����Ȃ��ƌ����Ƃ��āA���͉���RSS�������ŏ����Ă邯�ǂ��B
CC�̃��C�Z���X�Ȃ̓_�C�A���O�ɓ����Ă��������Ń��^�f�[�^���ł���悤�ɂȂ��Ă邵�A���������̂����z�̈���Ǝv���B
CC�̃��C�Z���X�Ȃ̓_�C�A���O�ɓ����Ă��������Ń��^�f�[�^���ł���悤�ɂȂ��Ă邵�A���������̂����z�̈���Ǝv���B
128 �FName_Not_Found�F04/02/28 12:55 ID:???
���^�f�[�^�������ŏ������Ă̂͂ǂ��Ȃ́B
�T�C�g���X�V�����玩���Ń��^�f�[�^���X�V�����̂����R���Ǝv�����ǁB
���Ԃ�A�����ōX�V����郁�^�f�[�^�̎����s�����Ă��ƂȂ�ˁB
�ǂ�ȂƂ��낪�s���Ȃ낤�B
�T�C�g���X�V�����玩���Ń��^�f�[�^���X�V�����̂����R���Ǝv�����ǁB
���Ԃ�A�����ōX�V����郁�^�f�[�^�̎����s�����Ă��ƂȂ�ˁB
�ǂ�ȂƂ��낪�s���Ȃ낤�B
129 �FName_Not_Found�F04/02/28 19:09 ID:???
�����I�ɍX�V����郁�^�f�[�^���āA
�ǂ�ȃ��^�v�f���t�^������ł��傤���B�B
�Ⴆ�A�L�[���[�h�Ƃ������A�T�O�I�ȗv�f���ƁA
�����̈Ӑ}�ƈ������Ƃ����s���̎�ɂȂ��ł��傤���ˁB
���ƁARDF Validation �T�[�r�X��2�o�C�g�R�[�h�������
�O���t���̕����������������Ă��܂���ł��B�B
UTF-8�ł��O���t���̕��������������Ă��܂��܂��B
�Z�}���e�B�b�NWeb��Phase2�ɓ������̂͌��\�Ȃ�ł����A
����ȏ����I�Ȃ��Ƃł܂Â��Ă鎩���ɂ́A
�A���Ă����Ȃ��B�B
�ǂ�ȃ��^�v�f���t�^������ł��傤���B�B
�Ⴆ�A�L�[���[�h�Ƃ������A�T�O�I�ȗv�f���ƁA
�����̈Ӑ}�ƈ������Ƃ����s���̎�ɂȂ��ł��傤���ˁB
���ƁARDF Validation �T�[�r�X��2�o�C�g�R�[�h�������
�O���t���̕����������������Ă��܂���ł��B�B
UTF-8�ł��O���t���̕��������������Ă��܂��܂��B
�Z�}���e�B�b�NWeb��Phase2�ɓ������̂͌��\�Ȃ�ł����A
����ȏ����I�Ȃ��Ƃł܂Â��Ă鎩���ɂ́A
�A���Ă����Ȃ��B�B
130 �FName_Not_Found�F04/02/29 13:30 ID:???
131 �FName_Not_Found�F04/02/29 14:44 ID:???
RDF/RSS�ɑ��闝�����A���{�I�ɊԈ���Ă���悤�ȁB
132 �FName_Not_Found�F04/02/29 22:06 ID:???
���^�f�[�^�̎����ĉ�? ����validation�ŕ�����������̂͂���[���Ȃ��C�����܂��B
�����ŕt�������̂��āAmeta�v�f��author���x�����Ȃ��C�����邯�ǁB
�����ŕt�������̂��āAmeta�v�f��author���x�����Ȃ��C�����邯�ǁB
>>132
�������������Ⴄ���̂Ȃ�ł��ˁB�B�ǂ������肪�Ƃ��������܂��B
���N�̉ĂɎg�����Ƃ��͕����������Ȃ������悤�ȋC�����āA
���̑O�v���Ԃ�Ɏg�����當���������ĂĂт����肵�܂����B
>>130
�����I�ȃ��^�f�[�^�t�^�A���ۂ�������Ƃ��Ȃ��̂Ŏ����킩��܂���B
�߂����ɂ����܂��傤�B�B
�������������Ⴄ���̂Ȃ�ł��ˁB�B�ǂ������肪�Ƃ��������܂��B
���N�̉ĂɎg�����Ƃ��͕����������Ȃ������悤�ȋC�����āA
���̑O�v���Ԃ�Ɏg�����當���������ĂĂт����肵�܂����B
>>130
�����I�ȃ��^�f�[�^�t�^�A���ۂ�������Ƃ��Ȃ��̂Ŏ����킩��܂���B
�߂����ɂ����܂��傤�B�B
134 �FName_Not_Found�F04/03/11 17:04 ID:???
1�T�Ԉȏ�o�̂ɂ܂������������݂��Ȃ��̂͂��݂����Ȃ��B
DCMES�̂ق��ɁA�E�F�u�y�[�W�����炱���K�v�ȃ��^�f�[�^���āA
�ǂ�Ȃ̂���������Ǝv���܂����H�H
���́A�u���̃��\�[�X�̑����͌f���I�v�Ƃ��A
����̃��\�[�X�̑����̓��[�����M�t�H�[���I��Ƃ��A
���������E�F�u�y�[�W�̢������̗l�Ȃ��̂��������^�f�[�^�������āA
�@�B������������Ɨ����ł����
���̒���炵�₷���Ȃ�悤�ȋC�������ł����ǁA�A
�ƁA�ꂵ����ɘb�������Ă݂���ł����A
�݂�ȋ����Ȃ����Ȃ��B�B��
DCMES�̂ق��ɁA�E�F�u�y�[�W�����炱���K�v�ȃ��^�f�[�^���āA
�ǂ�Ȃ̂���������Ǝv���܂����H�H
���́A�u���̃��\�[�X�̑����͌f���I�v�Ƃ��A
����̃��\�[�X�̑����̓��[�����M�t�H�[���I��Ƃ��A
���������E�F�u�y�[�W�̢������̗l�Ȃ��̂��������^�f�[�^�������āA
�@�B������������Ɨ����ł����
���̒���炵�₷���Ȃ�悤�ȋC�������ł����ǁA�A
�ƁA�ꂵ����ɘb�������Ă݂���ł����A
�݂�ȋ����Ȃ����Ȃ��B�B��
135 �FName_Not_Found�F04/03/22 13:17 ID:???
>134
Annotea Project
http://www.w3.org/2001/Annotea/
Global Document Annotation
http://i-content.org/gda/
���͂̍\���E��b���̃}�[�N�t���B
�����I�Ȏ������ƁA�@�B�|��̐��x����Ɨv��o�͂Ɋ��҂��Ă�
�i�f����������ł͊��҂ł���Ǝv�����j�B
Annotea Project
http://www.w3.org/2001/Annotea/
Global Document Annotation
http://i-content.org/gda/
���͂̍\���E��b���̃}�[�N�t���B
�����I�Ȏ������ƁA�@�B�|��̐��x����Ɨv��o�͂Ɋ��҂��Ă�
�i�f����������ł͊��҂ł���Ǝv�����j�B
136 �FName_Not_Found�F04/03/23 02:43 ID:???
>>135
�@�B�|���v��Ƃ������ʂ��猩�Ă����̂��ʔ����ł��ˁB
���[�U�[�{�ʂ̃A�m�e�[�V����������ǂ̂悤�ɑ����̂����A�����[���ł��B
Annotea Project�̕��́A���Ƃł�������ǂ�ł݂܂��B
(�p��A���Ȃ̂ŁA�A)
������ɂ���A�����͏���̂��Ƃ��炢�����c�����Ă��Ȃ������̂ŁA
�ƂĂ��h�����܂����B�ǂ������肪�Ƃ��������܂��B
����ȕ��ɁA�F���Z�}���e�B�b�N�E�F�u�֘A�̋Z�p�ɑ��āA
�ǂ̂悤�Ȃ��Ƃ����҂��Ă���̂��A�ƂĂ��m�肽���ł��B
�@�B�|���v��Ƃ������ʂ��猩�Ă����̂��ʔ����ł��ˁB
���[�U�[�{�ʂ̃A�m�e�[�V����������ǂ̂悤�ɑ����̂����A�����[���ł��B
Annotea Project�̕��́A���Ƃł�������ǂ�ł݂܂��B
(�p��A���Ȃ̂ŁA�A)
������ɂ���A�����͏���̂��Ƃ��炢�����c�����Ă��Ȃ������̂ŁA
�ƂĂ��h�����܂����B�ǂ������肪�Ƃ��������܂��B
����ȕ��ɁA�F���Z�}���e�B�b�N�E�F�u�֘A�̋Z�p�ɑ��āA
�ǂ̂悤�Ȃ��Ƃ����҂��Ă���̂��A�ƂĂ��m�肽���ł��B
137 �FName_Not_Found�F04/03/29 16:20 ID:???
137 ���O�FName_Not_Found[sage] ���e���F04/03/25 15:16 ID:???
RDF����HeadLineEditor�ŏ�����magpierss�ŕ\�����ėV��ł邾���ł͂��߂ł����H
RDF����HeadLineEditor�ŏ�����magpierss�ŕ\�����ėV��ł邾���ł͂��߂ł����H
138 �FName_Not_Found�F04/03/29 16:20 ID:???
138 ���O�FName_Not_Found[sage] ���e���F04/03/25 15:26 ID:???
>>137
�������������Ȑςݏd�˂����̂������d�v�Ȃ�ł��B
���Б����Ă��������B
>>137
�������������Ȑςݏd�˂����̂������d�v�Ȃ�ł��B
���Б����Ă��������B
139 �FName_Not_Found�F04/03/29 16:20 ID:???
139 ���O�F>>137[sage] ���e���F04/03/25 17:45 ID:???
�T���N�X
�l�B��XOOPS�̃j���[�X���W���[���ŁA�t�B�[�h����\��ł��B
���̑��̏��ɂ̓w�b�h���C���G�f�B�^��AMovable Type��ݒu�����̂ł�����
���M���Ă���Ɠ��������Ă����ł����A�܂��n�܂��ĂȂ��ł��B
���������g�����������Ǝv���Ă��ł����ǁA�Ԉ���ĂȂ������݂����B
���������邼���`�`�`
�T���N�X
�l�B��XOOPS�̃j���[�X���W���[���ŁA�t�B�[�h����\��ł��B
���̑��̏��ɂ̓w�b�h���C���G�f�B�^��AMovable Type��ݒu�����̂ł�����
���M���Ă���Ɠ��������Ă����ł����A�܂��n�܂��ĂȂ��ł��B
���������g�����������Ǝv���Ă��ł����ǁA�Ԉ���ĂȂ������݂����B
���������邼���`�`�`
140 �F137�F04/04/10 11:02 ID:9MhudWsq
>>139
�]�L���肪�Ƃ��������܂��B
�����ʂŎn�܂�悤�ł��B
Movable Type�Ɋe�{�݂��瓊�e���Ă�����āA������D������Ƀy�[�W��
�\�������܂��B
���Ƃ͐Ƒ䓌��������ȁB
�]�L���肪�Ƃ��������܂��B
�����ʂŎn�܂�悤�ł��B
Movable Type�Ɋe�{�݂��瓊�e���Ă�����āA������D������Ƀy�[�W��
�\�������܂��B
���Ƃ͐Ƒ䓌��������ȁB
141 �FName_Not_Found�F04/04/25 23:23 ID:???
���́A����Ȃ�ł����ǁA���̃T�[�`�G���W������
RDF/XML�ŋL�q���ꂽ���^�f�[�^���ǂ̂��炢�d�v�����Ă��ł��傤���H�H
(HTML�̃w�b�_�̃��^���͂قƂ�ǖ�������Ă��ł���ˁH�H)
���A���݂܂���A�A�E�������킩��Ȃ����S�҂ł��B�B
RDF/XML�ŋL�q���ꂽ���^�f�[�^���ǂ̂��炢�d�v�����Ă��ł��傤���H�H
(HTML�̃w�b�_�̃��^���͂قƂ�ǖ�������Ă��ł���ˁH�H)
���A���݂܂���A�A�E�������킩��Ȃ����S�҂ł��B�B
142 �FName_Not_Found�F04/04/26 18:39 ID:???
>>141
���͂܂�����قǏd�����ĂȂ��̂ł͂Ȃ����ƁB
����L�p��RDF/XML���^�f�[�^��������Ώd�v�������悤�ɂȂ邾�낤����
������ĕ�SEO�����������META�v�f���l�̉^����H�邾�낤�B
���҂ɂ�郁�^�f�[�^�͋��U�̐\�������ɗe�ՂȂ̂�
Web��ʂł̊��p�͂Ȃ��Ȃ�����悤�Ɏv���B
���͂܂�����قǏd�����ĂȂ��̂ł͂Ȃ����ƁB
����L�p��RDF/XML���^�f�[�^��������Ώd�v�������悤�ɂȂ邾�낤����
������ĕ�SEO�����������META�v�f���l�̉^����H�邾�낤�B
���҂ɂ�郁�^�f�[�^�͋��U�̐\�������ɗe�ՂȂ̂�
Web��ʂł̊��p�͂Ȃ��Ȃ�����悤�Ɏv���B
>>142
���݂̃T�[�`�G���W�������^�f�[�^���ǂ������Ă���̂��A
�����c���ł��Ă��Ȃ������̂ŁA�ƂĂ��Q�l�ɂȂ�܂����A
�R�����g�ǂ������肪�Ƃ��������܂��I
�����ł���ˁA������META�v�f�����\���I��
���^�f�[�^�̋L�q��RDF/XML�ɂ���ĉ\�ł������Ƃ��Ă��A
����������l�Ԃ������̓��e���L�q���Ă�����META�v�f�̓�̕��ɂȂ�܂���ˁB
�����l����ƁA��͂�O������̃��^�f�[�^�̕t�^���s����
�Ȃ�̂ł��傤���B�B���[��B�B
���݂̃T�[�`�G���W�������^�f�[�^���ǂ������Ă���̂��A
�����c���ł��Ă��Ȃ������̂ŁA�ƂĂ��Q�l�ɂȂ�܂����A
�R�����g�ǂ������肪�Ƃ��������܂��I
�����ł���ˁA������META�v�f�����\���I��
���^�f�[�^�̋L�q��RDF/XML�ɂ���ĉ\�ł������Ƃ��Ă��A
����������l�Ԃ������̓��e���L�q���Ă�����META�v�f�̓�̕��ɂȂ�܂���ˁB
�����l����ƁA��͂�O������̃��^�f�[�^�̕t�^���s����
�Ȃ�̂ł��傤���B�B���[��B�B
144 �FName_Not_Found�F04/04/28 22:05 ID:???
���̗��������ɁA�_�莁�̃������Ƃ��Ă��^�C�����[�Ȃ̂ŏ����Ƃ��B
�l�X��RDF����������Semantic Web Search
ttp://www.kanzaki.com/memo/2004/04/27-1
�x�[�^�i�K�œ��{��ʂ�Ȃ��炵�����A�ʔ������ȗ\��
�l�X��RDF����������Semantic Web Search
ttp://www.kanzaki.com/memo/2004/04/27-1
�x�[�^�i�K�œ��{��ʂ�Ȃ��炵�����A�ʔ������ȗ\��
145 �FName_Not_Found�F04/04/30 23:53 ID:???
�X���Ⴂ�������������݂����ACool URIs don't change������Ă�����c�B
���ʂ̂͊��فBxrea�œƎ��h���C������Ĉꐶ�������Ă���B
���́A���낻��t�@�C�������S���t���Ԑ��Ɉڍs���܂��B
ttp://www.kanzaki.com/memo/2004/04/06-1
��are dates in URIs actually useful? �Ƃ����^��𓊂������Ă���A
������ɑ��Ăǂ�Ȉӌ����o�Ă���̂��͂�����Ɩʔ������B
���ʂ̂͊��فBxrea�œƎ��h���C������Ĉꐶ�������Ă���B
���́A���낻��t�@�C�������S���t���Ԑ��Ɉڍs���܂��B
ttp://www.kanzaki.com/memo/2004/04/06-1
��are dates in URIs actually useful? �Ƃ����^��𓊂������Ă���A
������ɑ��Ăǂ�Ȉӌ����o�Ă���̂��͂�����Ɩʔ������B
146 �F�����������F04/05/06 06:28 ID:3MWHdtxt
147 �FName_Not_Found�F04/05/06 23:32 ID:???
>>146
RDF�t�@�C��"��"�H
RDF�t�@�C��"��"�H
148 �F�����������F04/05/07 21:53 ID:???
149 �FName_Not_Found�F04/05/07 23:47 ID:???
150 �FName_Not_Found�F04/05/15 19:48 ID:???
���̎��_�ŁA�ǂ̂悤�ȃ��^�f�[�^���ǂ̂��炢����Ă��邩���Ă���������
�Ȃ���ł��傤���B
���{�ƊC�O�ňႢ�Ƃ�����̂��ȁ[�B�B
�Ȃ���ł��傤���B
���{�ƊC�O�ňႢ�Ƃ�����̂��ȁ[�B�B
151 �FName_Not_Found�F04/05/17 01:12 ID:???
rss�Ȃ�rss�T�[�`�Ƃ����邯�ǂˁB
���ۂ̏��͂ǂ��Ȃ낤���c�B
���ۂ̏��͂ǂ��Ȃ낤���c�B
152 �FName_Not_Found�F04/05/17 19:30 ID:???
153 �FName_Not_Found�F04/05/18 16:30 ID:pPj0g4RG
FOAF Explorer�ɂȂ���Ȃ��݂��������ǁA�C�̂������ȁH
http://xml.mfd-consult.dk/foaf/explorer/
http://xml.mfd-consult.dk/foaf/explorer/
154 �FName_Not_Found�F04/05/19 12:24 ID:???
>>153
�Ȃ���������[�B
FOAF�̃A�C�R���́A�F�Ⴂ��4�̊���ĂȂӖ�����̂��ȁB
�l�Ƃ��Ă�RDF Validation�T�[�r�X�ŃO���t������Ă�2�o�C�g�R�[�h��
�����������Ă��܂��̂��Ƃ��Ă��߂����ł��B
�Ȃ���������[�B
FOAF�̃A�C�R���́A�F�Ⴂ��4�̊���ĂȂӖ�����̂��ȁB
�l�Ƃ��Ă�RDF Validation�T�[�r�X�ŃO���t������Ă�2�o�C�g�R�[�h��
�����������Ă��܂��̂��Ƃ��Ă��߂����ł��B
155 �FName_Not_Found�F04/06/08 23:24 ID:???
�Z�}���e�B�b�NWeb�ŏ��@���A�g����@�x�m�ʌ����J��
http://www.itmedia.co.jp/news/articles/0406/08/news083.html
�Ƃ̂��Ƃł��B
semweb�̉��b������ł��関�����߂��H
http://www.itmedia.co.jp/news/articles/0406/08/news083.html
�Ƃ̂��Ƃł��B
semweb�̉��b������ł��関�����߂��H
156 �FName_Not_Found�F04/06/21 18:33 ID:???
http://www.iana.org/assignments/media-types/application/
IANA��application/rdf+xml���o�ꂵ�Ă��܂����B
RFC���ԋ߂ł��ˁB
IANA��application/rdf+xml���o�ꂵ�Ă��܂����B
RFC���ԋ߂ł��ˁB
157 �FName_Not_Found�F04/07/04 19:01 ID:tuPrpDmA
���Ă�̂ŏグ�Ă݂�B
rdf:about�̒l��
����XML���͒���ID���t���Ă��Ȃ��t���O�����g���w�肷����@���č��̂Ƃ��떳���H
�d�l���͈ꉞ�ǂ��ǁA������Ȃ������B
�Ⴆ�u<rdf:RDF>���܂��Ă���v�f�v�ɂ��Ă���<rdf:RDF>�ŏq�ׂ悤�Ǝv������
rdf:about�ɂ͂Ȃ�ď����Ηǂ��낤�B
Xpath�݂�����rdf:about=".."�Ƃ�������Ίy�Ȃ��ǁA
���ƕ�܂��Ă���v�f��ID��U���ĎQ�Ƃ��Ȃ��Ɩ����Ȃ̂��ȁB
rdf:about�̒l��
����XML���͒���ID���t���Ă��Ȃ��t���O�����g���w�肷����@���č��̂Ƃ��떳���H
�d�l���͈ꉞ�ǂ��ǁA������Ȃ������B
�Ⴆ�u<rdf:RDF>���܂��Ă���v�f�v�ɂ��Ă���<rdf:RDF>�ŏq�ׂ悤�Ǝv������
rdf:about�ɂ͂Ȃ�ď����Ηǂ��낤�B
Xpath�݂�����rdf:about=".."�Ƃ�������Ίy�Ȃ��ǁA
���ƕ�܂��Ă���v�f��ID��U���ĎQ�Ƃ��Ȃ��Ɩ����Ȃ̂��ȁB
158 �FName_Not_Found�F04/07/04 21:07 ID:???
>>158
Xpointer�ł����B�Ȃ�قǁB
�ƂȂ�Ƃ܂����p�I�ł͖��������ł��ˁB
����ɂ��Ă��AXpointer�̂����b�������Ƃ������̂͋C�̂������낤���E�E�E�B
Xpointer�ł����B�Ȃ�قǁB
�ƂȂ�Ƃ܂����p�I�ł͖��������ł��ˁB
����ɂ��Ă��AXpointer�̂����b�������Ƃ������̂͋C�̂������낤���E�E�E�B
160 �FName_Not_Found�F04/07/06 00:25 ID:???
���I�ɂ�XPointer�Ă܂����̏�̘b���Ċ��������炻������R�ȋC������Ȃ�
161 �FName_Not_Found�F04/07/13 15:33 ID:ZSsFP0WK
���݂܂����Ŏ��₵�Ă����̂��ǂ����킩��܂��E�E
blog����������rdf���āAblog�Ŏ��Ԃ�CMT+9:00�ɍ��킹�ĂĂ�
rdf�̒��ɂ͂��̓��{����+9:00�Ə�������ł����
blog��A�Ƃ����G���g���[��10���ɓ��e���Ă�
RSS���[�_�[�ł�19���ɓ��e���ꂽ�ƕ\��������ł��B
����͂����������Ȃ�ł����H
blog����������rdf���āAblog�Ŏ��Ԃ�CMT+9:00�ɍ��킹�ĂĂ�
rdf�̒��ɂ͂��̓��{����+9:00�Ə�������ł����
blog��A�Ƃ����G���g���[��10���ɓ��e���Ă�
RSS���[�_�[�ł�19���ɓ��e���ꂽ�ƕ\��������ł��B
����͂����������Ȃ�ł����H
162 �FName_Not_Found�F04/07/13 15:38 ID:???
163 �FName_Not_Found�F04/07/13 16:01 ID:???
�ǂ����ł�
������ւ����Ă݂܂�
������ւ����Ă݂܂�
164 �FName_Not_Found�F04/08/15 19:21 ID:???
RSS�Ƃ�RDF�Ƃ�XML�̃o�i�[�摜���āA�����̂��̂�����́H
�����̃T�C�g���I�����W�̏����������`�̉摜���g���Ă���悤�ŁA
���ꂪ�����̃��m���Ǝv�������A���̉摜�̔z�z���Ƃ����̂�
���낢��O�O���Ă��o�Ă��Ȃ��B
�����̃T�C�g���I�����W�̏����������`�̉摜���g���Ă���悤�ŁA
���ꂪ�����̃��m���Ǝv�������A���̉摜�̔z�z���Ƃ����̂�
���낢��O�O���Ă��o�Ă��Ȃ��B
165 �FName_Not_Found�F04/08/15 19:50 ID:???
>>164
XML
http://archive.scripting.com/2000/12/15
RDF
http://www.ilrt.bristol.ac.uk/people/cmdjb/2001/04/rdf-icon/
�������Ǝv���B
RSS�͒m���B
XML
http://archive.scripting.com/2000/12/15
RDF
http://www.ilrt.bristol.ac.uk/people/cmdjb/2001/04/rdf-icon/
�������Ǝv���B
RSS�͒m���B
166 �FName_Not_Found�F04/08/15 19:53 ID:???
�I�����W���Ă̂͂���ł���
http://minimalverbosity.com/2003/May/19/buttons.htm
http://kalsey.com/tools/buttonmaker/
http://minimalverbosity.com/2003/May/19/buttons.htm
http://kalsey.com/tools/buttonmaker/
Headline-Editor Lite
http://www.infomaker.jp/editorlite/
���̃c�[����>>165�̃A�C�R�����g���Ă邩��A
���̂����ōL�܂��Ă���̂����B
http://www.infomaker.jp/editorlite/
���̃c�[����>>165�̃A�C�R�����g���Ă邩��A
���̂����ōL�܂��Ă���̂����B
169 �FName_Not_Found�F04/08/19 03:49 ID:???
>>168
�I���V���C���ƌ����ȁB
�I���V���C���ƌ����ȁB
170 �FName_Not_Found�F04/09/13 16:26:35 ID:???
xpointer����mozilla�ŕ����I�ɂƂ͂�����������Ă��̂��B
XSLT��xpointer�v���Z�b�T���Ȃ����ȁB
XSLT��xpointer�v���Z�b�T���Ȃ����ȁB
171 �FName_Not_Found�F04/09/19 22:27:58 ID:???
���Ɛ����Ŋ�����Ƃ����Ƃ���ł悤�₭RFC���o�܂����B
application/rdf+xml Media Type Registration
urn:ietf:rfc:3870
application/rdf+xml Media Type Registration
urn:ietf:rfc:3870
172 �FName_Not_Found�F04/09/22 10:05:49 ID:???
Dublin Core (DCMI Metadata Terms) �Ɍ�b���lj�����܂����B
���O: provenance
URI: http://purl.org/dc/terms/provenance
��`: http://dublincore.org/documents/dcmi-terms/#provenance
���܂����g������������Ȃ��Ǝv���Ă����Ƃ���A�g�p�Ⴊ����܂����B
http://dublincore.org/dcregistry/detailServlet?reqType=detail&item=http%3A%2F%2Fpurl.org%2Fdc%2Fterms%2Fprovenance
���O: provenance
URI: http://purl.org/dc/terms/provenance
��`: http://dublincore.org/documents/dcmi-terms/#provenance
���܂����g������������Ȃ��Ǝv���Ă����Ƃ���A�g�p�Ⴊ����܂����B
http://dublincore.org/dcregistry/detailServlet?reqType=detail&item=http%3A%2F%2Fpurl.org%2Fdc%2Fterms%2Fprovenance
173 �FName_Not_Found�F04/09/22 23:15:07 ID:???
����ł��킩��Ȃ��B�B
174 �FName_Not_Found�F04/09/22 23:40:21 ID:???
>>173
���\�[�X�̍쐬���ꂽ��A���̏��L�҂�Ǘ����ǂ̂悤�ɑJ�ڂ��������L�^�����b�A
�Ƃ������Ƃ��Ǝv���܂��B
��Ɍ`�̂��郊�\�[�X (�G��⒤���Ȃ�) �̊Ǘ��Ɏg�p���邱�Ƃ�z�肵�Ă���̂ł��傤�ˁB
���\�[�X�̍쐬���ꂽ��A���̏��L�҂�Ǘ����ǂ̂悤�ɑJ�ڂ��������L�^�����b�A
�Ƃ������Ƃ��Ǝv���܂��B
��Ɍ`�̂��郊�\�[�X (�G��⒤���Ȃ�) �̊Ǘ��Ɏg�p���邱�Ƃ�z�肵�Ă���̂ł��傤�ˁB
175 �FName_Not_Found�F04/09/23 15:32:27 ID:???
>>174
�e�Ȑl���Ă����ł��ˁi�����j�E�E
�Ȃ�قǁI�m���ɔ��p�i�̏ꍇ�ɂ͏����ق��ǂ�ǂ�ς���Ă����܂�����ˁI
���ɂȂ�܂����[�I
�e�Ȑl���Ă����ł��ˁi�����j�E�E
�Ȃ�قǁI�m���ɔ��p�i�̏ꍇ�ɂ͏����ق��ǂ�ǂ�ς���Ă����܂�����ˁI
���ɂȂ�܂����[�I
176 �FName_Not_Found�F04/10/05 00:47:41 ID:kNd0gwYI
����ȂɍD�����������g�������������������Ɗ�����悤�ɂȂ��Ă���21�̏��H
�Z�}���e�B�b�N�E�F�u�̍��͂ǂ��Ȃ��Ă���̂��낤��
�グ�Ă݂Ċm�F���Ă݂悤
���Ă���A���̔��Ăق�Ɛl���Ȃ��Ȃ�����
�Z�}���e�B�b�N�E�F�u�̍��͂ǂ��Ȃ��Ă���̂��낤��
�グ�Ă݂Ċm�F���Ă݂悤
���Ă���A���̔��Ăق�Ɛl���Ȃ��Ȃ�����
177 �FName_Not_Found�F04/10/05 09:41:12 ID:???
�����ƃ��`���Ă����ǘb�肪�Ȃ��̂�c�c�B
178 �FName_Not_Found�F04/10/05 22:48:43 ID:???
179 �FName_Not_Found�F04/10/06 20:55:30 ID:???
�����R�R�����ƌ��Ă܂���[�I
���Ă��_�莁�{������
���Ă��_�莁�{������
180 �FName_Not_Found�F04/10/07 02:03:13 ID:???
>>179
RDF/OWL����i���j
ttp://www.kanzaki.com/book/rdf/
> �Z�}���e�B�b�N�E�E�F�u�̔w�i����ARDF�̃f�[�^���f���A
> RDF�X�L�[�}�AOWL�A�����RDF���������N�G����
> ���_�܂ł����グ�ĉ�����܂��B
> �N���A��������2005�N���ɏo�ŗ\��ł��B
���
RDF/OWL����i���j
ttp://www.kanzaki.com/book/rdf/
> �Z�}���e�B�b�N�E�E�F�u�̔w�i����ARDF�̃f�[�^���f���A
> RDF�X�L�[�}�AOWL�A�����RDF���������N�G����
> ���_�܂ł����グ�ĉ�����܂��B
> �N���A��������2005�N���ɏo�ŗ\��ł��B
���
182 �FName_Not_Found�F04/10/07 22:47:31 ID:???
183 �FName_Not_Found�F04/10/08 00:05:33 ID:???
184 �FName_Not_Found�F04/10/08 00:17:57 ID:???
������ƑO�͎g���Ă���ł����A�܂��g���Ȃ��Ȃ��Ă܂��ˁB
ttp://www.ilrt.bris.ac.uk/discovery/chatlogs/rdfig/2004-09-27.html#T10-25-36
ttp://www.w3.org/RDF/Validator/ARPServlet.tmp/servlet_33244.png
ttp://www.ilrt.bris.ac.uk/discovery/chatlogs/rdfig/2004-09-27.html#T10-25-36
ttp://www.w3.org/RDF/Validator/ARPServlet.tmp/servlet_33244.png
{kind=link}
����B
�����m�F�����̂̓e�L�X�g�G���A����̓��͂ł����B
�m��2004-09-28�`30�����̋C���B
�����m�F�����̂̓e�L�X�g�G���A����̓��͂ł����B
�m��2004-09-28�`30�����̋C���B
186 �Far�F04/10/09 17:21:54 ID:E+oo4Xeb
������Ǝ��₪����܂��B
�_�肳��Ƃ��� http://kanzaki.com/memo/2004/04/17-1 ��ǂނƁA
>> body�Ƃ��ăR�����g�{���܂Ŗ��ߍ��ނƂ����̂́A���^�f�[�^�Ƃ������V���W�P�[�V�����̔��z�ɋ߂��i���ꂪ�K�{�ɂȂ��Ă���̂͋�����j�B
�Ə�����Ă��āA�m���ɖ{���͋L���̃��^�f�[�^����Ȃ���Ȃ��Ǝv���Ƃ���͂����ł��B
�ł��ARSS1.0��Content���W���[��
http://web.resource.org/rss/1.0/modules/content/
�͖{�������̂܂ܔz�M�i�G���R�[�h���Ăł����j���郂�m�Ȃ̂ɁARDF�Ń��^�f�[�^��������Ă邶��Ȃ��ł����B
���҂ɖ���������悤�ȋC�������ł����A����RDF�ŋL���̖{����z�M����̂�NG�Ȃ�ł��傤���H
���������uRDF�̓��^�f�[�^��z�M���邽�߂����̂��́v�Ƃ��������̔F�����Ԉ���Ă���̂ł��傤���H
blog�̋L�����g���b�N�o�b�N��R�����g�S�Ă��Ђ�����߂Ĉ��RDF�ɖ��ߍ���ł݂悤�Ɩϑz���Ă��ł����A
�Ԉ���Ă�̂��ǂ�������킩��܂��� orz
�_�肳��Ƃ��� http://kanzaki.com/memo/2004/04/17-1 ��ǂނƁA
>> body�Ƃ��ăR�����g�{���܂Ŗ��ߍ��ނƂ����̂́A���^�f�[�^�Ƃ������V���W�P�[�V�����̔��z�ɋ߂��i���ꂪ�K�{�ɂȂ��Ă���̂͋�����j�B
�Ə�����Ă��āA�m���ɖ{���͋L���̃��^�f�[�^����Ȃ���Ȃ��Ǝv���Ƃ���͂����ł��B
�ł��ARSS1.0��Content���W���[��
http://web.resource.org/rss/1.0/modules/content/
�͖{�������̂܂ܔz�M�i�G���R�[�h���Ăł����j���郂�m�Ȃ̂ɁARDF�Ń��^�f�[�^��������Ă邶��Ȃ��ł����B
���҂ɖ���������悤�ȋC�������ł����A����RDF�ŋL���̖{����z�M����̂�NG�Ȃ�ł��傤���H
���������uRDF�̓��^�f�[�^��z�M���邽�߂����̂��́v�Ƃ��������̔F�����Ԉ���Ă���̂ł��傤���H
blog�̋L�����g���b�N�o�b�N��R�����g�S�Ă��Ђ�����߂Ĉ��RDF�ɖ��ߍ���ł݂悤�Ɩϑz���Ă��ł����A
�Ԉ���Ă�̂��ǂ�������킩��܂��� orz
���`�A�A�z�Ȃ��Ƃ������Ă��܂��܂����B
W3C�� Resource Description Framework (RDF) Model and Syntax Specification�i�M��ł����j��ǂ�ł����A
���_�̂Ƃ����
>>RDF�̓��^�f�[�^���������邽�߂̊�b
���ď����Ă���܂��ˁB
�������A��������_����ł����A���p�̈�̈��
>>(5)�_���I�ɒP��ȁu�h�L�������g�v��\���ЂƂ܂Ƃ܂�̃y�[�W���L�q���邱�Ƃɂ�����
�Ƃ���̂ŁAblog�̖{����R�����g�A�g���b�N�o�b�N�S�Ă���̃h�L�������g�ƍl�����Ȃ�A
�R�����g�̖{�����O�ɒǂ��o���K�v�͖����C�����܂��B
��l�ŏ���ɐi�߂ĂăX�~�}�Z���B
W3C�� Resource Description Framework (RDF) Model and Syntax Specification�i�M��ł����j��ǂ�ł����A
���_�̂Ƃ����
>>RDF�̓��^�f�[�^���������邽�߂̊�b
���ď����Ă���܂��ˁB
�������A��������_����ł����A���p�̈�̈��
>>(5)�_���I�ɒP��ȁu�h�L�������g�v��\���ЂƂ܂Ƃ܂�̃y�[�W���L�q���邱�Ƃɂ�����
�Ƃ���̂ŁAblog�̖{����R�����g�A�g���b�N�o�b�N�S�Ă���̃h�L�������g�ƍl�����Ȃ�A
�R�����g�̖{�����O�ɒǂ��o���K�v�͖����C�����܂��B
��l�ŏ���ɐi�߂ĂăX�~�}�Z���B
188 �FName_Not_Found�F04/10/10 06:38:14 ID:s+VjnURb
DC Wordnet cc VCARD etc
�F��ȏ��Ō�b������Ă�݂��������ǂ��A�N���܂Ƃ߂Ĉꗗ�݂����Ȃ̍���Ă���Ȃ�����
��������Ώ����₷������
�K�������Č�b���`���Ă݂����Łu���������è�g���Ηǂ������̂��c�v�Ȃ�Ďv�����������Ȃ�悤�ȋC������
�Ͽ �����Ă邩��܂Ƃ܂�Ȃ���w
�F��ȏ��Ō�b������Ă�݂��������ǂ��A�N���܂Ƃ߂Ĉꗗ�݂����Ȃ̍���Ă���Ȃ�����
��������Ώ����₷������
�K�������Č�b���`���Ă݂����Łu���������è�g���Ηǂ������̂��c�v�Ȃ�Ďv�����������Ȃ�悤�ȋC������
�Ͽ �����Ă邩��܂Ƃ܂�Ȃ���w
189 �F188�F04/10/10 11:31:12 ID:s+VjnURb
���������߂܂���
��Ȃ��狰�낵�������������ȁc
��Ȃ��狰�낵�������������ȁc
190 �FName_Not_Found�F04/10/10 14:35:54 ID:???
>>189
Wordnet��VCARD�͕����邯�ǁADC��cc�͉��̗��H
Wordnet��VCARD�͕����邯�ǁADC��cc�͉��̗��H
191 �FName_Not_Found�F04/10/10 16:57:16 ID:???
RDF���Ă̂͊����̂��̂ɕW�������ꂽ����I�ȃ}�[�N�A�b�v�����Ă������Ƃ������̂ł���
�ŁA����ɂ���ĈقȂ��������ԂŃf�[�^�̗��ʂ��e�ՂɂȂ���Ă̂��Z�}���e�B�b�N�E�F�u�̍l����
�R�����g�ɑ��A�����̓R�����g�ł���`��Ƃ����Ӗ��t���ň͂��̂͂Ȃ���Ԉ���ĂȂ���B
RSS��RDF����������ɂȂ��ĂȂ��H
�RDF�̓��^�f�[�^���������邽�߂̊�b��A�Ƃ��������ł̢���^��f�[�^���Ă̂�
�����̓R�����g�Ȃ�ł��棂Ƃ������A���Ȃ킿�͂��Ă���}�[�N�A�b�v�̂��Ƃ��w���Ă���
���āARSS�͖{���f�[�^�{�̂̃R���e�i�t�H�[�}�b�g�ł͂Ȃ��A�ڎ��f�[�^�ł������B
������Ō����Ƃ���̃��^�f�[�^�́A���ۂ̕��̓t�@�C���̖ڎ������܂Ƃ߂�RSS�t�@�C�����A���̕��͂ɂƂ��ă��^�ȃf�[�^���Ƃ����Ӗ��Ō����Ă���
�ŁA����ɂ���ĈقȂ��������ԂŃf�[�^�̗��ʂ��e�ՂɂȂ���Ă̂��Z�}���e�B�b�N�E�F�u�̍l����
�R�����g�ɑ��A�����̓R�����g�ł���`��Ƃ����Ӗ��t���ň͂��̂͂Ȃ���Ԉ���ĂȂ���B
RSS��RDF����������ɂȂ��ĂȂ��H
�RDF�̓��^�f�[�^���������邽�߂̊�b��A�Ƃ��������ł̢���^��f�[�^���Ă̂�
�����̓R�����g�Ȃ�ł��棂Ƃ������A���Ȃ킿�͂��Ă���}�[�N�A�b�v�̂��Ƃ��w���Ă���
���āARSS�͖{���f�[�^�{�̂̃R���e�i�t�H�[�}�b�g�ł͂Ȃ��A�ڎ��f�[�^�ł������B
������Ō����Ƃ���̃��^�f�[�^�́A���ۂ̕��̓t�@�C���̖ڎ������܂Ƃ߂�RSS�t�@�C�����A���̕��͂ɂƂ��ă��^�ȃf�[�^���Ƃ����Ӗ��Ō����Ă���
>>191
���X���肪�Ƃ��������܂��B
>>�RDF�̓��^�f�[�^���������邽�߂̊�b��A�Ƃ��������ł̢���^��f�[�^���Ă̂�
>>�����̓R�����g�Ȃ�ł��棂Ƃ������A���Ȃ킿�͂��Ă���}�[�N�A�b�v�̂��Ƃ��w���Ă���
RDF��F��Framework�ł����ˁA��ʂ育������ɂȂ��Ă܂����B
�܂��Ȃ�ƂȂ��ł����A�킩�����C�����܂��B
���肪�Ƃ��������܂����B
���X���肪�Ƃ��������܂��B
>>�RDF�̓��^�f�[�^���������邽�߂̊�b��A�Ƃ��������ł̢���^��f�[�^���Ă̂�
>>�����̓R�����g�Ȃ�ł��棂Ƃ������A���Ȃ킿�͂��Ă���}�[�N�A�b�v�̂��Ƃ��w���Ă���
RDF��F��Framework�ł����ˁA��ʂ育������ɂȂ��Ă܂����B
�܂��Ȃ�ƂȂ��ł����A�킩�����C�����܂��B
���肪�Ƃ��������܂����B
193 �FName_Not_Found�F04/10/10 19:09:39 ID:???
>>190
189����Ȃ����ǁA
DC�̓_�u�����R�A�ACC�̓N���G�C�e�B�u�R�����Y����Ȃ�����
�Ƃ������A���̃X���b�h�}�Ɋ��C�Â����Ȃ��c
�_�莁���ʂ��H�H
189����Ȃ����ǁA
DC�̓_�u�����R�A�ACC�̓N���G�C�e�B�u�R�����Y����Ȃ�����
�Ƃ������A���̃X���b�h�}�Ɋ��C�Â����Ȃ��c
�_�莁���ʂ��H�H
�lj�
�������܂��Ɂu���^�f�[�^�v�̌��t�̒�`���킩��Ȃ���ˁc
�����ȈӖ��Ŏg���Ă邩�炨���Ȏ��͍��������
�������܂��Ɂu���^�f�[�^�v�̌��t�̒�`���킩��Ȃ���ˁc
�����ȈӖ��Ŏg���Ă邩�炨���Ȏ��͍��������
195 �FName_Not_Found�F04/10/10 21:18:52 ID:???
>>188
SchemaWeb���ǂ��B
ttp://www.schemaweb.info/
����Ȃ̂��B
Kissology �N���N�ɃL�X���������L�^�����b
ttp://www.gnowsis.org/ont/kissology.html
�����ō���Ă����āA��œ����̌��������炻����Ȃ��̂Ƃ��Č��ѕt���Ă��悵�B
SchemaWeb���ǂ��B
ttp://www.schemaweb.info/
����Ȃ̂��B
Kissology �N���N�ɃL�X���������L�^�����b
ttp://www.gnowsis.org/ont/kissology.html
�����ō���Ă����āA��œ����̌��������炻����Ȃ��̂Ƃ��Č��ѕt���Ă��悵�B
>>195
���肪�Ƃ�
Kissology�̓A�������ǁA�����Œ�`������b�𑼂ɒ���̂��y����������
���̓��^�f�[�^��\���̂��y�����Ȃ��Ă�����Ԃ�����A���������̍���Ċ���Ă����̂͗ǂ�����
FOAF�Ń����N�W�݂����Ȃ̍���Ă���ǁA
�����N��T�C�g�̊Ǘ��҂͒m�荇���ł͖�������A���̕ӂ�́u���h�v��u�����v���ǂ���`���悤���l���Ă�
FOAF�Ƃ͈Ⴄ�̂��ȂƎv���Ă݂���
���肪�Ƃ�
Kissology�̓A�������ǁA�����Œ�`������b�𑼂ɒ���̂��y����������
���̓��^�f�[�^��\���̂��y�����Ȃ��Ă�����Ԃ�����A���������̍���Ċ���Ă����̂͗ǂ�����
FOAF�Ń����N�W�݂����Ȃ̍���Ă���ǁA
�����N��T�C�g�̊Ǘ��҂͒m�荇���ł͖�������A���̕ӂ�́u���h�v��u�����v���ǂ���`���悤���l���Ă�
FOAF�Ƃ͈Ⴄ�̂��ȂƎv���Ă݂���
197 �FName_Not_Found�F04/10/10 23:20:49 ID:???
Kissology
�l�I�ɂ͍D������
�l�I�ɂ͍D������
198 �FName_Not_Found�F04/10/10 23:37:40 ID:???
199 �FName_Not_Found�F04/10/13 11:56:18 ID:???
RDF�N�G�������WD���o�܂����B
SPARQL (Simple Protocol And RDF Query Language) �Ə�����
�X�p�[�N���Ɠǂނ����ł� (ttp://www.w3.org/News/2004#item159)�B
SPARQL Query Language for RDF
ttp://www.w3.org/TR/rdf-sparql-query/
SPARQL (Simple Protocol And RDF Query Language) �Ə�����
�X�p�[�N���Ɠǂނ����ł� (ttp://www.w3.org/News/2004#item159)�B
SPARQL Query Language for RDF
ttp://www.w3.org/TR/rdf-sparql-query/
RDF/OWL�{�͂���ɉ������Ă��܂��̂ł��傤���B
��͂菑�ЂōŐV�Z�p��ǂ��̂͌��E������܂��ˁc�B
��͂菑�ЂōŐV�Z�p��ǂ��̂͌��E������܂��ˁc�B
201 �FName_Not_Found�F04/10/14 02:28:35 ID:???
>>200
2�����o�������B10���ł�20���ł����N��u�N�Ŕ�������̂������B
2�����o�������B10���ł�20���ł����N��u�N�Ŕ�������̂������B
202 �FName_Not_Found�F04/10/14 07:30:06 ID:???
����͂�����ƁB
203 �FName_Not_Found�F04/10/14 08:07:23 ID:???
��2�ł��o���悳���B
204 �FName_Not_Found�F04/10/14 22:00:04 ID:???
2ch�ɃN���G�C�e�B�u�R�����Y�̃X�����Ă���H
205 �FName_Not_Found�F04/10/14 22:36:10 ID:???
>>204
����Ƃ�����@�w���Ȃ��c�Ǝv���ĒT������A
����ɂ͂��������c�B
�w���쌠�x�@�N���G�C�e�B�u�R�����Y
http://academy3.2ch.net/test/read.cgi/jurisp/1093612569/l50
����Ƃ�����@�w���Ȃ��c�Ǝv���ĒT������A
����ɂ͂��������c�B
�w���쌠�x�@�N���G�C�e�B�u�R�����Y
http://academy3.2ch.net/test/read.cgi/jurisp/1093612569/l50
206 �FName_Not_Found�F04/10/15 04:09:14 ID:???
>>205
���Ȃ��������Ƃɂ�����w
������ML���Ȃ����ȕ��͋C�����A
Hotwired������Ƃ���Ȃ�ɘb���l�^
�����肻���ȋC������B
���̔ɗ��Ă�̂̓_���H
���Ȃ��������Ƃɂ�����w
������ML���Ȃ����ȕ��͋C�����A
Hotwired������Ƃ���Ȃ�ɘb���l�^
�����肻���ȋC������B
���̔ɗ��Ă�̂̓_���H
207 �FName_Not_Found�F04/10/15 04:13:35 ID:3j8o6Gx9
>>206
cc�P�Ƃ̽ڂ͂ǂ�����
���^���̑����ڂł��邱�̽�(�����Ȃ��?)������オ���ĂȂ��킯����
���̽ڂł�����Ȃ�?cc�Ȃ�Ƃ����₷�����A�����t�������邗
cc�P�Ƃ̽ڂ͂ǂ�����
���^���̑����ڂł��邱�̽�(�����Ȃ��?)������オ���ĂȂ��킯����
���̽ڂł�����Ȃ�?cc�Ȃ�Ƃ����₷�����A�����t�������邗
208 �FName_Not_Found�F04/10/15 20:26:57 ID:???
CC�ƃ��^�f�[�^�͑S���W�Ȃ����낤
���^�f�[�^�Z�p�ɂ͋����A���A������
�N���G�C�e�B�u�R�����Y�ɂ͉��狻�������̂�
�����ł���Ă��������Ⴄ�̂����c
���^�f�[�^�Z�p�ɂ͋����A���A������
�N���G�C�e�B�u�R�����Y�ɂ͉��狻�������̂�
�����ł���Ă��������Ⴄ�̂����c
209 �FName_Not_Found�F04/10/15 20:41:31 ID:???
>>208
�ł����Acc�̐���Ƃ�cc���̂��̂̉�b���Ă�����肩�Acc�����^�f�[�^��
���ڂ��Ă��āA������ǂ�����ē`�d�����邩���Ęb���Ȃ�A�����ł������悤��
�����Ȃ��ǁA�ǂ��H
���̃X���̑��x���x������������Acc�̃��^�f�[�^�̏�������������Ȃ��Ƃ��A
���������b��������Ȃ����Ǝv���B
�ł����Acc�̐���Ƃ�cc���̂��̂̉�b���Ă�����肩�Acc�����^�f�[�^��
���ڂ��Ă��āA������ǂ�����ē`�d�����邩���Ęb���Ȃ�A�����ł������悤��
�����Ȃ��ǁA�ǂ��H
���̃X���̑��x���x������������Acc�̃��^�f�[�^�̏�������������Ȃ��Ƃ��A
���������b��������Ȃ����Ǝv���B
210 �FName_Not_Found�F04/10/15 21:19:25 ID:???
CC�̃��^�f�[�^�I�Șb�B
http://www.kanzaki.com/docs/sw/ccm.html
http://www.kanzaki.com/docs/sw/ccm.html
211 �FName_Not_Found�F04/10/15 21:35:08 ID:???
>>208
�Ƃ���ƃ��C�Z���X��GPL�h�H
�Ƃ���ƃ��C�Z���X��GPL�h�H
212 �FName_Not_Found�F04/10/15 21:37:19 ID:???
���������Ƃł��Ȃ����B
213 �FName_Not_Found�F04/10/15 22:05:11 ID:???
>>211
GPL�����āAXML�Œ�`��������̂ł́H
GPL�����āAXML�Œ�`��������̂ł́H
214 �FName_Not_Found�F04/10/16 11:08:28 ID:???
215 �FName_Not_Found�F04/10/17 05:26:13 ID:???
>>214
cc��GPL��URL�������ā[
cc��GPL��URL�������ā[
216 �FName_Not_Found�F04/10/17 21:42:08 ID:???
�������₿����ƑO�ɁADublin Core��dcterms:license���������ˁB
�����cc:license�Ƃ͓����Ȃ낤���B
��������������b���m�̊W���L�q�E���Ă����T�[�r�X���o�Ă���낤�ȁB
�����cc:license�Ƃ͓����Ȃ낤���B
��������������b���m�̊W���L�q�E���Ă����T�[�r�X���o�Ă���낤�ȁB
217 �FName_Not_Found�F04/10/20 05:53:25 ID:???
kanzaki�����Ăǂ����̑�w�̐搶�H
�E�F�u���Ă̍u���Ƃ�����Ȃ畷�������[
�E�F�u���Ă̍u���Ƃ�����Ȃ畷�������[
218 �FName_Not_Found�F04/10/20 21:54:37 ID:???
semweb�ɗ������������߂̊�b�m����g�ɕt���悤�ƁA�_���w�̓��发��ǂ�ł݂�����܁B
1�K�̏q��_���ɂ��H��t���܂���B���ȓ�B
1�K�̏q��_���ɂ��H��t���܂���B���ȓ�B
219 �FName_Not_Found�F04/10/20 22:45:00 ID:eENSDVNb
�_���w�����B�ǂ�ł݂邩�ȁB
���͂Ƃɂ����F��Ȏ��������ް��ɂ��ď������K�����Ă��
��ɓ���܂��銴��
Notation 3�������Ă݂�̂����ɂȂ�
�_�莁�̻�Ăɉ��������� /docs/sw/n3
���͂Ƃɂ����F��Ȏ��������ް��ɂ��ď������K�����Ă��
��ɓ���܂��銴��
Notation 3�������Ă݂�̂����ɂȂ�
�_�莁�̻�Ăɉ��������� /docs/sw/n3
220 �FName_Not_Found�F04/10/20 23:02:37 ID:???
RDF�̎d�l����ǂ�ł݂āA����͐��w�␔���_���w�̒m�����v��ȂƎv��������ł��B
�Ⴆ��Concepts and Abstract Syntax�ɂ�����������Ȃ��̂�����܂��ȁB
�ȉ��A�{���̈ꕔ��|��B�i����܂蕪�����ĂȂ��̂Ŗ�̂ق��͐M�p�ł��܂���j
6.3 Graph Equivalence
6.3 �O���t�̓�����
Two RDF graphs G and G' are equivalent if there is a bijection M between the sets of nodes of the two graphs, such that:
RDF�O���tG��G'�́A���O���t�̃m�[�h�W���ԂɑS�P��M������ꍇ�ɓ����ƂȂ�B
�@1. M maps blank nodes to blank nodes.
�@1. M�͋m�[�h����m�[�h�ւ̊��ł���B
�@2. M(lit)=lit for all RDF literals lit which are nodes of G.
�@2. M(lit)=lit ���ׂĂ�RDF���e�����ɂ��āAG�̃m�[�h�ł���悤��lit�B
�@3. M(uri)=uri for all RDF URI references uri which are nodes of G.
�@3. M(uri)=uri ���ׂĂ�RDF��URI�Q�Ƃɂ��āAG�̃m�[�h�ł���悤��uri�B
�@4. The triple ( s, p, o ) is in G if and only if the triple ( M(s), p, M(o) ) is in G'
�@4. �g���v��( s, p, o )��G�Ɋ܂܂�� ↔ �g���v��( M(s), p, M(o) )��G'�Ɋ܂܂��B
With this definition, M shows how each blank node in G can be replaced with a new blank node to give G'.
���̒�`�ŁAG�̊e�m�[�h���ʂ̋m�[�h�ɒu���������AG'���^������Ƃ���M�̓�����������B
����Ȃ̂������ς��o�Ă���RDF Semantics�ȂƂĂ����̒m���ł͓ǂ߂܂���c�B
�Ⴆ��Concepts and Abstract Syntax�ɂ�����������Ȃ��̂�����܂��ȁB
�ȉ��A�{���̈ꕔ��|��B�i����܂蕪�����ĂȂ��̂Ŗ�̂ق��͐M�p�ł��܂���j
6.3 Graph Equivalence
6.3 �O���t�̓�����
Two RDF graphs G and G' are equivalent if there is a bijection M between the sets of nodes of the two graphs, such that:
RDF�O���tG��G'�́A���O���t�̃m�[�h�W���ԂɑS�P��M������ꍇ�ɓ����ƂȂ�B
�@1. M maps blank nodes to blank nodes.
�@1. M�͋m�[�h����m�[�h�ւ̊��ł���B
�@2. M(lit)=lit for all RDF literals lit which are nodes of G.
�@2. M(lit)=lit ���ׂĂ�RDF���e�����ɂ��āAG�̃m�[�h�ł���悤��lit�B
�@3. M(uri)=uri for all RDF URI references uri which are nodes of G.
�@3. M(uri)=uri ���ׂĂ�RDF��URI�Q�Ƃɂ��āAG�̃m�[�h�ł���悤��uri�B
�@4. The triple ( s, p, o ) is in G if and only if the triple ( M(s), p, M(o) ) is in G'
�@4. �g���v��( s, p, o )��G�Ɋ܂܂�� ↔ �g���v��( M(s), p, M(o) )��G'�Ɋ܂܂��B
With this definition, M shows how each blank node in G can be replaced with a new blank node to give G'.
���̒�`�ŁAG�̊e�m�[�h���ʂ̋m�[�h�ɒu���������AG'���^������Ƃ���M�̓�����������B
����Ȃ̂������ς��o�Ă���RDF Semantics�ȂƂĂ����̒m���ł͓ǂ߂܂���c�B
222 �FName_Not_Found�F04/10/21 00:07:51 ID:???
����Ȃ���?
�@1. M maps blank nodes to blank nodes.
�@1. M�͋m�[�h���m�[�h�ւƑΉ��t����B
�@2. M(lit)=lit for all RDF literals lit which are nodes of G.
�@2. M(lit)=lit (lit��G�̑S�Ă�RDF���e�����ł���m�[�h)
�@3. M(uri)=uri for all RDF URI references uri which are nodes of G.
�@3. M(uri)=uri (uri��G�̑S�Ă�RDF URI�Q�Ƃł���m�[�h)
�@4. The triple ( s, p, o ) is in G if and only if the triple ( M(s), p, M(o) ) is in G'
�@4. �g���v��( s, p, o )��G�Ɋ܂܂�� ↔ �g���v��( M(s), p, M(o) )��G'�Ɋ܂܂��B
With this definition, M shows how each blank node in G can be replaced with a new blank node to give G'.
���̒�`�ŁAG�̊e�m�[�h���ʂ̋m�[�h�ɒu���������AG'���^������Ƃ���M�̓�����������B
�@1. M maps blank nodes to blank nodes.
�@1. M�͋m�[�h���m�[�h�ւƑΉ��t����B
�@2. M(lit)=lit for all RDF literals lit which are nodes of G.
�@2. M(lit)=lit (lit��G�̑S�Ă�RDF���e�����ł���m�[�h)
�@3. M(uri)=uri for all RDF URI references uri which are nodes of G.
�@3. M(uri)=uri (uri��G�̑S�Ă�RDF URI�Q�Ƃł���m�[�h)
�@4. The triple ( s, p, o ) is in G if and only if the triple ( M(s), p, M(o) ) is in G'
�@4. �g���v��( s, p, o )��G�Ɋ܂܂�� ↔ �g���v��( M(s), p, M(o) )��G'�Ɋ܂܂��B
With this definition, M shows how each blank node in G can be replaced with a new blank node to give G'.
���̒�`�ŁAG�̊e�m�[�h���ʂ̋m�[�h�ɒu���������AG'���^������Ƃ���M�̓�����������B
223 �FName_Not_Found�F04/10/21 00:26:31 ID:???
>>222
for all �́͂̂��Ƃ���ˁH
M(lit)=lit �͉��Ȃ낤�B�C�ӂ�RDF���e�����������Ƃ��Ċ�M�ɓ˂����ނƁA
G�̃m�[�h�ł��郊�e�������Ԃ��Ă���Ƃ������ƂȂ납�B
for all �́͂̂��Ƃ���ˁH
M(lit)=lit �͉��Ȃ낤�B�C�ӂ�RDF���e�����������Ƃ��Ċ�M�ɓ˂����ނƁA
G�̃m�[�h�ł��郊�e�������Ԃ��Ă���Ƃ������ƂȂ납�B
224 �FName_Not_Found�F04/10/21 00:44:31 ID:???
M(lit)=lit
�Ƃ����̂�M��lit�ɂ��Ă͂�������̂܂ܕԂ���Ƃ����Ӗ��B
for all...�Ƃ����̂�lit���Ȃ�ł��邩�������Ă���B
"x^2 > 0 for all real numbers x"
�u�S�Ă̎���x�ɂ���x^2 > 0�v
�Ɠ����悤�Ȃ��́B
�Ƃ����̂�M��lit�ɂ��Ă͂�������̂܂ܕԂ���Ƃ����Ӗ��B
for all...�Ƃ����̂�lit���Ȃ�ł��邩�������Ă���B
"x^2 > 0 for all real numbers x"
�u�S�Ă̎���x�ɂ���x^2 > 0�v
�Ɠ����悤�Ȃ��́B
225 �FName_Not_Found�F04/10/21 05:03:23 ID:???
M �� G �̋�, ���e����, URI�Q�ƃm�[�h�� G' �̃m�[�h�֎ʂ��P���ʑ�
�Ƃ��������߂ł����̂��낤���B
1. M(blank node) = blank node
2. M([lit]) = [lit]�@(��[lit] �� {[lit]��RDF literals | [lit] ��G�̃m�[�h})
3. M([uri]) = [uri]�@(��[uri] �� {[uri]��RDF URI | [uri] ��G�̃m�[�h})
4. (s, p, o)��G ��(M(s), p, M(o))��G'
�Ƃ��B
�Ƃ��������߂ł����̂��낤���B
1. M(blank node) = blank node
2. M([lit]) = [lit]�@(��[lit] �� {[lit]��RDF literals | [lit] ��G�̃m�[�h})
3. M([uri]) = [uri]�@(��[uri] �� {[uri]��RDF URI | [uri] ��G�̃m�[�h})
4. (s, p, o)��G ��(M(s), p, M(o))��G'
�Ƃ��B
226 �FName_Not_Found�F04/10/21 08:12:44 ID:???
�����A�F����ڂ����ˁB
M(x)�Ƃ��邱�Ƃ�x��G�ɂ���m�[�h���ƌ��肵�Ă���̂��B
�q��Ɋւ��Ă͂�����������͗v��Ȃ��낤���B
�Ⴆ�A
:subject1 :predicate1 :object1 . ��
:subject1 :predicate2 :object1 . �͂�������ł͂Ȃ���ˁB
M(x)�Ƃ��邱�Ƃ�x��G�ɂ���m�[�h���ƌ��肵�Ă���̂��B
�q��Ɋւ��Ă͂�����������͗v��Ȃ��낤���B
�Ⴆ�A
:subject1 :predicate1 :object1 . ��
:subject1 :predicate2 :object1 . �͂�������ł͂Ȃ���ˁB
227 �FName_Not_Found�F04/10/21 14:18:41 ID:???
229 �FName_Not_Found�F04/11/01 20:23:22 ID:???
�`�i������Web�` �Z�}���e�B�b�NWeb
ttp://www.justsystem.co.jp/book/pc/semantic.html
---
����Ȃ��̂��������B
ttp://www.justsystem.co.jp/book/pc/semantic.html
---
����Ȃ��̂��������B
230 �FName_Not_Found�F04/11/01 21:55:55 ID:???
>>229
�N���ǂl����H ���z�L�{���B
������ ttp://www.amazon.com/o/ASIN/0262062321/ (2002-11-15���s) �̂悤�ł��ˁB
�N���ǂl����H ���z�L�{���B
������ ttp://www.amazon.com/o/ASIN/0262062321/ (2002-11-15���s) �̂悤�ł��ˁB
231 �FName_Not_Found�F04/11/02 21:41:12 ID:???
>>229
�����ǂ݂��Ă��܂����B
�ڂ����ǂ�ł͂��܂��A�|��͑��v�����ł��B
���e�͂��������ASemantic Web���������悤�Ƃ���Z�p�ɂ�
�ǂ̂悤�Ȃ��̂����邩�Ƃ����ϓ_����́A�F�X��semweb�Z�p�Љ�{�Ƃ��������ł��B
�X�̋Z�p�ɂ��Ă͏ڂ����������Ă���Ǝv���܂��B
�Ώۓǎ҂͂�͂�semweb�̃A�v���P�[�V�����쐬�ȂǂɊւ��Z�p�҂ȂǂŁA
�G���h���[�U�̗�������]�n������Ƃ���A�Z�p�҂���ǂ̂悤�ȃr�W������������邩�A
�ǂ̂悤�ȃA�v���P�[�V������̊��ł��邩�A�Ƃ����Ƃ���œo�ꂷ��ϏO�����炢�ł��ˁB
���ʂ�web���[�U���ǂނ��̂ł͂Ȃ��ł����A
semweb�ɋ����������Ă��郌�x���̃��[�U�ɂƂ��ẮA
��semweb�̋Z�p�ҒB����������Ă���̂����T�ςł���{�A�Ƃ����Ƃ���ł��傤���B
5000�~�Ƃ����l�i�ɂ��ẮA�Z�p�Ҍ����ł��芎�|��̂��߁A�����ȂƂ��낾�Ǝv���܂��B
�����ǂ݂��Ă��܂����B
�ڂ����ǂ�ł͂��܂��A�|��͑��v�����ł��B
���e�͂��������ASemantic Web���������悤�Ƃ���Z�p�ɂ�
�ǂ̂悤�Ȃ��̂����邩�Ƃ����ϓ_����́A�F�X��semweb�Z�p�Љ�{�Ƃ��������ł��B
�X�̋Z�p�ɂ��Ă͏ڂ����������Ă���Ǝv���܂��B
�Ώۓǎ҂͂�͂�semweb�̃A�v���P�[�V�����쐬�ȂǂɊւ��Z�p�҂ȂǂŁA
�G���h���[�U�̗�������]�n������Ƃ���A�Z�p�҂���ǂ̂悤�ȃr�W������������邩�A
�ǂ̂悤�ȃA�v���P�[�V������̊��ł��邩�A�Ƃ����Ƃ���œo�ꂷ��ϏO�����炢�ł��ˁB
���ʂ�web���[�U���ǂނ��̂ł͂Ȃ��ł����A
semweb�ɋ����������Ă��郌�x���̃��[�U�ɂƂ��ẮA
��semweb�̋Z�p�ҒB����������Ă���̂����T�ςł���{�A�Ƃ����Ƃ���ł��傤���B
5000�~�Ƃ����l�i�ɂ��ẮA�Z�p�Ҍ����ł��芎�|��̂��߁A�����ȂƂ��낾�Ǝv���܂��B
���łɁA�l�I�ɂ́A�}���قň�x�ǂ߂���������ς��ɂȂ�{���Ɗ����܂��B
�h�b�O�C���[�Ȑ��E�̐�[�̕����ł�����A���X�ƐV�Z�p���o�ꂵ�Ă���ł��傤���A
2002�N����semweb�Z�p�̃X�i�b�v�V���b�g�A�Ƃ��������ł��傤���B
�������A���̖{�̒��ɍ���d��Ȋ�ՂƂȂ��b�Z�p���܂܂�Ă������ǂ����܂ł�
�F���ł��Ă��܂��� (���Ȃ��Ƃ�RDF�Ɋւ��Ă͐��y�[�W���x�����Љ��Ă��Ȃ������Ǝv���܂�)�B
�Ȃ�ɂ��旧���ǂ݂̊��z�Ȃ̂ŁA�Q�l�ȉ��Ƃ������ƂŁc�B
�h�b�O�C���[�Ȑ��E�̐�[�̕����ł�����A���X�ƐV�Z�p���o�ꂵ�Ă���ł��傤���A
2002�N����semweb�Z�p�̃X�i�b�v�V���b�g�A�Ƃ��������ł��傤���B
�������A���̖{�̒��ɍ���d��Ȋ�ՂƂȂ��b�Z�p���܂܂�Ă������ǂ����܂ł�
�F���ł��Ă��܂��� (���Ȃ��Ƃ�RDF�Ɋւ��Ă͐��y�[�W���x�����Љ��Ă��Ȃ������Ǝv���܂�)�B
�Ȃ�ɂ��旧���ǂ݂̊��z�Ȃ̂ŁA�Q�l�ȉ��Ƃ������ƂŁc�B
233 �FName_Not_Found�F04/11/03 00:32:57 ID:???
>>231
���r���[���肪�Ƃ��B
������Ƌ��߂Ȃ̂����ˁA�|�����炩�B
�_�莁�̂Ɣ�ׂĂ���ǂ����������߂����Ǝv���܂��B
�������͂Ȃ����ۂɏ����l�������ۂ����͋C�c�c�B
���r���[���肪�Ƃ��B
������Ƌ��߂Ȃ̂����ˁA�|�����炩�B
�_�莁�̂Ɣ�ׂĂ���ǂ����������߂����Ǝv���܂��B
�������͂Ȃ����ۂɏ����l�������ۂ����͋C�c�c�B
234 �FName_Not_Found�F04/11/03 11:14:33 ID:???
�_�肳��̃��^�f�[�^�̊ȈՐ����t�H�[��������
����Ȃӂ��ɊȒP�ɍ쐬�ł���悤�ɂȂ�̂����z�Ȃ��
�����܂Ƃ�Č��Ă������ް����J���Ă黲Ă�������
������������semweb�ɋ߂Â��Ă�?
����Ȃӂ��ɊȒP�ɍ쐬�ł���悤�ɂȂ�̂����z�Ȃ��
�����܂Ƃ�Č��Ă������ް����J���Ă黲Ă�������
������������semweb�ɋ߂Â��Ă�?
235 �FName_Not_Found�F04/11/03 12:38:49 ID:???
>>234
�ǂ��H
�ǂ��H
236 �FName_Not_Found�F04/11/03 14:28:52 ID:???
237 �FName_Not_Found�F04/11/03 16:05:24 ID:???
>>236
thx
thx
238 �FName_Not_Found�F04/11/03 17:42:26 ID:???
> �����܂Ƃ�Č��Ă������ް����J���Ă黲Ă�������
�u�����܂Ƃ�āv���Ăǂ��H
�u�����܂Ƃ�āv���Ăǂ��H
239 �FName_Not_Found�F04/11/03 21:27:51 ID:???
>>238
�������̕ӂ�ł͂Ȃ����ƁB
ttp://ike.s33.xrea.com/
ttp://www.geocities.co.jp/SiliconValley-SantaClara/1308/
ttp://www.geocities.co.jp/Milano-Kotto/1366/
ttp://stardustcrown.com/link/csssite.html
�������̕ӂ�ł͂Ȃ����ƁB
ttp://ike.s33.xrea.com/
ttp://www.geocities.co.jp/SiliconValley-SantaClara/1308/
ttp://www.geocities.co.jp/Milano-Kotto/1366/
ttp://stardustcrown.com/link/csssite.html
�o�悾����URL�\��Ȃ��̂ͽϿ�����A
���@���@�Ł@���@���@���@��@��@w
���̒��̋Z�p�n��ĈȊO�����ް������J���Ă黲Ă��������̂�
���O�Y�ꂽ��
�A����痚�����Ă݂�
���@���@�Ł@���@���@���@��@��@w
���̒��̋Z�p�n��ĈȊO�����ް������J���Ă黲Ă��������̂�
���O�Y�ꂽ��
�A����痚�����Ă݂�
241 �FName_Not_Found�F04/11/03 22:35:30 ID:???
>>239
CSS�����Ă�T�C�g�ŁA�J�X�C�P���c�Bthx
CSS�����Ă�T�C�g�ŁA�J�X�C�P���c�Bthx
242 �FName_Not_Found�F04/11/03 23:54:14 ID:???
�_�莁�̃��^�f�[�^�����t�H�[�������ˁI
������������m�����
������������m�����
�����c�������ĐZ�����ĂȂ��̂��B����͈���������
�����A��Ȃ��Ȃ�������URL���\��Ȃ������c
���Ԃ�3110.net�ĂƂ��ł��B����Ă��炲�߂�
�����A��Ȃ��Ȃ�������URL���\��Ȃ������c
���Ԃ�3110.net�ĂƂ��ł��B����Ă��炲�߂�
244 �FName_Not_Found�F04/11/04 00:43:38 ID:???
>>243
�Ⴄ�悤����B�\�[�X�ɂ͂���炵���\�L�͌�����Ȃ��B
ttp://3110.net/
ttp://3110.net/sample/sample.htm
���ƁA235����Ȃ���234�ȋC��������A���v���H
���@��@��@�Ɓ@�d�@���@���@��@�B�@w
�Ⴄ�悤����B�\�[�X�ɂ͂���炵���\�L�͌�����Ȃ��B
ttp://3110.net/
ttp://3110.net/sample/sample.htm
���ƁA235����Ȃ���234�ȋC��������A���v���H
���@��@��@�Ɓ@�d�@���@���@��@�B�@w
>>244
���̊ԈႢ�Ŏv���o����
ttp://3110.net/�łȂ���"3110.net"�Ļ�Ė��Ȃ�
�ԈႢ�Ȃ��Ǝv���B�����̈�������
> ���Ƥ235����Ȃ���234�ȋC�����������v��?�� �� �� �� �d �� �� �� � w
���������j���̖钆�Ɏd��������?ϼނŌ����Ă�?
���@�́@�ʁ@��@���@��@orz
���̊ԈႢ�Ŏv���o����
ttp://3110.net/�łȂ���"3110.net"�Ļ�Ė��Ȃ�
�ԈႢ�Ȃ��Ǝv���B�����̈�������
> ���Ƥ235����Ȃ���234�ȋC�����������v��?�� �� �� �� �d �� �� �� � w
���������j���̖钆�Ɏd��������?ϼނŌ����Ă�?
���@�́@�ʁ@��@���@��@orz
��i�u�����͔��x�Ƃ��Ă�����v
�R��u��-(AAry�v
�A��x�x�����ē����ƎG�k��
��i�u���߂�����ώc���āv
�R��u�ܱ����(AAry�v
�ȈՐ���̫�т͕ۑ����Ľ����ď��������Ďg���Ă܂�
�ςȗ���Ɏ����čs���Ă��܂����̂����U��
���̽ڂɂ�����Ď������ް������Ă�Ǝv�����ǁA��������ɗ��p���Ă�?
�����֗��ȗ��p�@�������狳���Ă�������
�R��u��-(AAry�v
�A��x�x�����ē����ƎG�k��
��i�u���߂�����ώc���āv
�R��u�ܱ����(AAry�v
�ȈՐ���̫�т͕ۑ����Ľ����ď��������Ďg���Ă܂�
�ςȗ���Ɏ����čs���Ă��܂����̂����U��
���̽ڂɂ�����Ď������ް������Ă�Ǝv�����ǁA��������ɗ��p���Ă�?
�����֗��ȗ��p�@�������狳���Ă�������
247 �FName_Not_Found�F04/11/04 17:52:12 ID:???
>>246
�X�N���v�g�̉������āAkanzaki���̃��^�f�[�^�ɉ����������A
�����̕K�v�ȃ��^�f�[�^����͂ł���悤�ɒlj��������Ă��ƁH
����͉��̃��^�f�[�^�H
�X�N���v�g�̉������āAkanzaki���̃��^�f�[�^�ɉ����������A
�����̕K�v�ȃ��^�f�[�^����͂ł���悤�ɒlj��������Ă��ƁH
����͉��̃��^�f�[�^�H
>>247
���콷�ς̒lj��Ƃ�����
foaf:Person���ɗv�f��lj�������foaf:name��foaf:nick�ɕύX������(��Ă͑I�����Đؑւ���)�F�X
�[�������̂͂ł��ĂȂ����ǂ�
���콷�ς̒lj��Ƃ�����
foaf:Person���ɗv�f��lj�������foaf:name��foaf:nick�ɕύX������(��Ă͑I�����Đؑւ���)�F�X
�[�������̂͂ł��ĂȂ����ǂ�
249 �FName_Not_Found�F04/11/05 09:14:29 ID:???
�y�b�g�̃��^�f�[�^����������
250 �FName_Not_Found�F04/11/07 02:18:44 ID:B4QI6ica
���Z�Q������o��
ttp://www.kanzaki.com/memo/#item2004-11-05-1
>�o���Ȃ�12�����{�܂ŁA���ꂪ�����Ȃ�1�����{���Ƃ������Ƃ�...
��ַ�ַ��---
ttp://www.kanzaki.com/memo/#item2004-11-05-1
>�o���Ȃ�12�����{�܂ŁA���ꂪ�����Ȃ�1�����{���Ƃ������Ƃ�...
��ַ�ַ��---
251 �FName_Not_Found�F04/11/07 22:25:58 ID:???
�o�Ŏ���?
252 �FName_Not_Found�F04/11/08 02:28:35 ID:???
>>249�������Ă��邵�A�ꉞ�Q�l�ɂȂ郊�\�[�X�\���Ă�������
�y�b�g�L�q�{�L���u����
ttp://www.kanzaki.com/memo/2004/04/21-1
�y�b�g�E�{�L���u�����X�V
ttp://www.kanzaki.com/memo/2004/04/25-1
Pet-a-Matic
ttp://ideagraph.net/xmlns/pets/pet-a-matic.htm
�Ƃɂ̓y�b�g���Ȃ����ǂ�w
�y�b�g�L�q�{�L���u����
ttp://www.kanzaki.com/memo/2004/04/21-1
�y�b�g�E�{�L���u�����X�V
ttp://www.kanzaki.com/memo/2004/04/25-1
Pet-a-Matic
ttp://ideagraph.net/xmlns/pets/pet-a-matic.htm
�Ƃɂ̓y�b�g���Ȃ����ǂ�w
254 �FName_Not_Found�F04/11/10 23:31:16 ID:???
Japan.internet.com Web�e�N�m���W�[ - �����R���e���c�ɂƂǂ܂�Ȃ� RSS �̗��p�@
ttp://japan.internet.com/webtech/20041108/10.html
�����֗��Ȃ�������Ȃ����A�N��������Ă���Ȃ����낤���B
ttp://japan.internet.com/webtech/20041108/10.html
�����֗��Ȃ�������Ȃ����A�N��������Ă���Ȃ����낤���B
255 �FName_Not_Found�F04/11/11 04:05:41 ID:???
>>254
RSS���悭�킩��Ȃ��������X�I
�E�|�b�h�L���X�g�Ƃ����Z�p�i���@�j������܂����BiPod�ƊW������Z�p�ł��B
�ERSS��enclosure�v�f�͕������ȊO�́A
�@���Ƃ��Ή摜��特�y���̃��\�[�X���w��i�L�q�j�ł���v�f�ł��B
�@�Q�l�Fen�Eclo�Esure ���� n. �͂�
�E�|�b�h�L���X�g�i�Z�p�j�ł́A�u�|�b�h�L���X�g�Ή��̃\�t�g���A
�@enclosure�v�f�ɏ����Ă��鉹���t�@�C����URI��ǂݍ��ށv
�@�Ƃ������ƂɂȂ��Ă��܂��B
�E�|�b�h�L���X�g�Ή����Ă����̂́A�i��ɏ����Ă��鍀�ڂ���\�z�����悤�ɁA�j
�@�uenclosure�v�f�𗝉����āA�����v���[���@��̊Ǘ��@�\�������\�t�g�ƘA�����邱�Ɓv���w���܂��B
�@�i�܂�Aenclosure�v�f�ɂ͒P�ɉ����t�@�C����URI�Ƃ������ȊO�ɉ����������Ă��邩������Ȃ��i�H�j
�@�@�c�Ǝv�������ǁA����͑����Ⴄ���ۂ��B�j�@
�@���̓��������v���O���������̋L���ł́e�擾�v���O�����f�ƌĂԁB
�E���́e�擾�v���O�����f��iPod�ȊO�̃v���[���[�ƒ��ǂ��Ȃ��Ă����A
�@�F��ȃv���[���[�Ń|�b�h�L���X�g�Ƃ����Z�p���g���邩���ˁB
���܂�|�b�h�L���X�g���Ă������O�t�������ǁA�P��RSS���̉����t�@�C���w��@�\����Ȃ����B
�EBlogMatrix���Ă����\�t�g�ł́Aenclosure�v�f��ǂݍ���ŁA�����ɏ����Ă���
�@�����t�@�C����URI����t�@�C�����_�E�����[�h���Ă��̃_�E�����[�h�������
�@�ʂ̍Đ��\�t�g�ɓn�����Ƃ��o�����B�i���̈�A�̓�����|�b�h�L���X�g�Z�p�ȂǂƌĂԂ炵���j
�E���̃\�t�g�͗��p�Ґ����������ǁA�|�b�h�L���X�g�̕����g���Ă郆�[�U�̐��Ȃ\�t�g��҂ͼ�ȁB
�E����ʼn����z�M�Ƃ�����z�M�ł���ˁH
�E���Ƃ��A�V���i���o���Ƃ��āA�����RSS�ɍڂ��āA���Ă�RSS�̂������������������v�f�̒���
�@���̐V���i�̃r�f�I�N���b�v��URI�����Ă����A�E�n�E�n����ˁH
�E�\�t�g�E�F�A�̃A�b�v�f�[�g�v���O�������������ׁB���Ȃ�E�B���X������邯�ǂȂ�����
�����Ƃ��ẮA�܂�Ńx���`���[��Ƃł��B�����Đ����킩��ɂ����L���ł����B�ň��ł��B
RSS���悭�킩��Ȃ��������X�I
�E�|�b�h�L���X�g�Ƃ����Z�p�i���@�j������܂����BiPod�ƊW������Z�p�ł��B
�ERSS��enclosure�v�f�͕������ȊO�́A
�@���Ƃ��Ή摜��特�y���̃��\�[�X���w��i�L�q�j�ł���v�f�ł��B
�@�Q�l�Fen�Eclo�Esure ���� n. �͂�
�E�|�b�h�L���X�g�i�Z�p�j�ł́A�u�|�b�h�L���X�g�Ή��̃\�t�g���A
�@enclosure�v�f�ɏ����Ă��鉹���t�@�C����URI��ǂݍ��ށv
�@�Ƃ������ƂɂȂ��Ă��܂��B
�E�|�b�h�L���X�g�Ή����Ă����̂́A�i��ɏ����Ă��鍀�ڂ���\�z�����悤�ɁA�j
�@�uenclosure�v�f�𗝉����āA�����v���[���@��̊Ǘ��@�\�������\�t�g�ƘA�����邱�Ɓv���w���܂��B
�@�i�܂�Aenclosure�v�f�ɂ͒P�ɉ����t�@�C����URI�Ƃ������ȊO�ɉ����������Ă��邩������Ȃ��i�H�j
�@�@�c�Ǝv�������ǁA����͑����Ⴄ���ۂ��B�j�@
�@���̓��������v���O���������̋L���ł́e�擾�v���O�����f�ƌĂԁB
�E���́e�擾�v���O�����f��iPod�ȊO�̃v���[���[�ƒ��ǂ��Ȃ��Ă����A
�@�F��ȃv���[���[�Ń|�b�h�L���X�g�Ƃ����Z�p���g���邩���ˁB
���܂�|�b�h�L���X�g���Ă������O�t�������ǁA�P��RSS���̉����t�@�C���w��@�\����Ȃ����B
�EBlogMatrix���Ă����\�t�g�ł́Aenclosure�v�f��ǂݍ���ŁA�����ɏ����Ă���
�@�����t�@�C����URI����t�@�C�����_�E�����[�h���Ă��̃_�E�����[�h�������
�@�ʂ̍Đ��\�t�g�ɓn�����Ƃ��o�����B�i���̈�A�̓�����|�b�h�L���X�g�Z�p�ȂǂƌĂԂ炵���j
�E���̃\�t�g�͗��p�Ґ����������ǁA�|�b�h�L���X�g�̕����g���Ă郆�[�U�̐��Ȃ\�t�g��҂ͼ�ȁB
�E����ʼn����z�M�Ƃ�����z�M�ł���ˁH
�E���Ƃ��A�V���i���o���Ƃ��āA�����RSS�ɍڂ��āA���Ă�RSS�̂������������������v�f�̒���
�@���̐V���i�̃r�f�I�N���b�v��URI�����Ă����A�E�n�E�n����ˁH
�E�\�t�g�E�F�A�̃A�b�v�f�[�g�v���O�������������ׁB���Ȃ�E�B���X������邯�ǂȂ�����
�����Ƃ��ẮA�܂�Ńx���`���[��Ƃł��B�����Đ����킩��ɂ����L���ł����B�ň��ł��B
256 �FName_Not_Found�F04/11/11 04:09:29 ID:???
�܂�A�ꌾ�ł����A
�uRSS�̒��ʼn��ł��������enclosure�v�f�ŋ��`���I�I�v
���Ă������Ƃł���B�����Ă��߂�ˁB�Ԉ���Ă���w�E���āB�ԈႢ���Ǝv�������B
�uRSS�̒��ʼn��ł��������enclosure�v�f�ŋ��`���I�I�v
���Ă������Ƃł���B�����Ă��߂�ˁB�Ԉ���Ă���w�E���āB�ԈႢ���Ǝv�������B
257 �FName_Not_Found�F04/11/11 07:27:05 ID:???
���[��A>>254�́A���������Ă��邩�͕������ĕ����Ă����Ȃ����Ȃ��B
����ŁA���̋L���ɂ���Ⴊ�A254�ɂƂ��ĕ֗��Ɗ������Ȃ��Ƃ�����|�ł͂Ȃ��̂��낤���c�B
����ŁA���̋L���ɂ���Ⴊ�A254�ɂƂ��ĕ֗��Ɗ������Ȃ��Ƃ�����|�ł͂Ȃ��̂��낤���c�B
258 �FName_Not_Found�F04/11/11 07:30:51 ID:???
s/��/�u/;
259 �FName_Not_Found�F04/11/11 20:14:09 ID:???
>>255
�����܂���A���肪�Ƃ��������܂����B
1�������炢�O�Ɉȉ��̋L�����������̂ł����A���̎��͂���𗝉��ł����A
���炭�Y��Ă����̂ł����A��x�ڂ̑����������̂ł��̋@��Ɏ��₵�܂����B
Wired News - �l�b�g������iPod�Œ����w�|�b�h�L���X�e�B���O�x - : Hotwired
http://hotwired.goo.ne.jp/news/technology/story/20041013301.html
>>257
���܂܂�RSS�Ńo�C�i���[�R���e���c���w��ł���͓̂�����O����
�v���Ă����ikanzaki���̎ʐ^�̃��^�f�[�^�̂悤�ȁj�̂ŁA�ǂ���
�j���[�X�Ȃ̂��悭������Ȃ������̂ŁA������܂����Bthx!
�ʐ^/�摜�ƃ��^�f�[�^ -- EXIF�𗘗p����JPEG��RDF�̘A�� (Image-metadata integration with Exif)
ttp://www.kanzaki.com/docs/sw/photo-rdf.html
�����܂���A���肪�Ƃ��������܂����B
1�������炢�O�Ɉȉ��̋L�����������̂ł����A���̎��͂���𗝉��ł����A
���炭�Y��Ă����̂ł����A��x�ڂ̑����������̂ł��̋@��Ɏ��₵�܂����B
Wired News - �l�b�g������iPod�Œ����w�|�b�h�L���X�e�B���O�x - : Hotwired
http://hotwired.goo.ne.jp/news/technology/story/20041013301.html
>>257
���܂܂�RSS�Ńo�C�i���[�R���e���c���w��ł���͓̂�����O����
�v���Ă����ikanzaki���̎ʐ^�̃��^�f�[�^�̂悤�ȁj�̂ŁA�ǂ���
�j���[�X�Ȃ̂��悭������Ȃ������̂ŁA������܂����Bthx!
�ʐ^/�摜�ƃ��^�f�[�^ -- EXIF�𗘗p����JPEG��RDF�̘A�� (Image-metadata integration with Exif)
ttp://www.kanzaki.com/docs/sw/photo-rdf.html
260 �FName_Not_Found�F04/11/12 08:55:30 ID:???
Welkin�g���Ă݂��������炵�Ⴂ�܂����H
����ς�A�����������Ɏ��o������Ă���ƁA������Ƃ������낢�ł���ˁB
�����I��GUI������̂Ȃ�A���Ɛ���RDF�I�u�W�F�N�g�ɏ]���ĕς���Ƃ��c
����H�����IsaViz�łł��܂��������H
����ς�A�����������Ɏ��o������Ă���ƁA������Ƃ������낢�ł���ˁB
�����I��GUI������̂Ȃ�A���Ɛ���RDF�I�u�W�F�N�g�ɏ]���ĕς���Ƃ��c
����H�����IsaViz�łł��܂��������H
261 �FName_Not_Found�F04/11/12 13:08:54 ID:???
RDF�I�u�W�F�N�g���ĉ��H
262 �FName_Not_Found�F04/11/12 15:07:53 ID:???
�g���v���̍l�����A�I�u�W�F�N�g�Ƃ��đ����������������肭��̂ł����Ă�ł��܂��������ł��B
�ꌾ�Ō����ƁArdf:about��rdf:resource�Ardf:ID�Ȃǂ̒l(���̌��������������Ȃ��c)�ɂȂ��Ă���URI�̂��Ƃł��B
�ꌾ�Ō����ƁArdf:about��rdf:resource�Ardf:ID�Ȃǂ̒l(���̌��������������Ȃ��c)�ɂȂ��Ă���URI�̂��Ƃł��B
263 �FName_Not_Found�F04/11/12 15:09:46 ID:???
264 �FName_Not_Found�F04/11/17 02:27:15 ID:???
�Z�}���e�B�b�NWeb����
ttp://ssl.ohmsha.co.jp/cgi-bin/menu.cgi?ISBN=4-274-07979-1
---
����Ȃ��̂��������A���̂Q�B
���ێ�Ɏ���ĂȂ�����킩��Ȃ����ǁA>>229�̖{���͐V�����ŁA
�_�莁�̖{�ƃR���Z�v�g�����Ă���\���BRDF/OWL�{�̂悤���B
ttp://ssl.ohmsha.co.jp/cgi-bin/menu.cgi?ISBN=4-274-07979-1
---
����Ȃ��̂��������A���̂Q�B
���ێ�Ɏ���ĂȂ�����킩��Ȃ����ǁA>>229�̖{���͐V�����ŁA
�_�莁�̖{�ƃR���Z�v�g�����Ă���\���BRDF/OWL�{�̂悤���B
265 �FName_Not_Found�F04/11/17 11:08:18 ID:???
>>264
���̖{DAML+OIL�̋L������������OWL�̋L�������������悤�ȋC������
���̖{DAML+OIL�̋L������������OWL�̋L�������������悤�ȋC������
266 �FName_Not_Found�F04/11/18 04:09:14 ID:???
�ڎ�����������OWL����悤�Ȃ��ǁB
>>266
�����ȂB�Ͽ�B�Ȃ�ʂ̖{�ƊԈႦ���炵��
11��������semweb�̏��Ђł��������̂�������
�Ȃ̂�������Ȃ�
XMLNS�g����RDF&XHTML�݂����ɏ����Ă�l���܂���?
�ǂ������ް����̧�قɂ��Ă̂��ʓ|�Ɋ����Ă��܂�
head��address���璊�o�����ł͖���X(HT)ML���ɂ��̂܂����Ă��܂�����
DC��tableofContents�Ȃ�Ă��̂܂g���邾�낤��
�������̂��Ƃ���p�ɒ�`������Ă��܂������Ǝv���Ă����
�����ȂB�Ͽ�B�Ȃ�ʂ̖{�ƊԈႦ���炵��
11��������semweb�̏��Ђł��������̂�������
�Ȃ̂�������Ȃ�
XMLNS�g����RDF&XHTML�݂����ɏ����Ă�l���܂���?
�ǂ������ް����̧�قɂ��Ă̂��ʓ|�Ɋ����Ă��܂�
head��address���璊�o�����ł͖���X(HT)ML���ɂ��̂܂����Ă��܂�����
DC��tableofContents�Ȃ�Ă��̂܂g���邾�낤��
�������̂��Ƃ���p�ɒ�`������Ă��܂������Ǝv���Ă����
268 �FName_Not_Found�F04/11/18 15:50:20 ID:???
>>229�̂�DAML+OIL���ۂ����ǁH
269 �FName_Not_Found�F04/11/21 01:38:18 ID:???
ttp://www.flickr.com/creativecommons/
�Ⴆ�����ɂ���CCPL��BY:�����̎ʐ^���g���ꍇ�A�ǂ̂悤��
�ʐ^�̌����҂���������̂ł��傤���H
HTML�Ƀ^�O�ŏ��������ŁA�u���E�U��ł͒��ڌ����Ȃ��ėǂ��̂�
�u���E�U�ł�������悤�ɖ��L����̂�CCPL�̎g������������܂���B
�u���E�U�Œ��ڌ����錩���Ȃ����킸�A�^�O�̏������������Ă��������B
�Ⴆ�����ɂ���CCPL��BY:�����̎ʐ^���g���ꍇ�A�ǂ̂悤��
�ʐ^�̌����҂���������̂ł��傤���H
HTML�Ƀ^�O�ŏ��������ŁA�u���E�U��ł͒��ڌ����Ȃ��ėǂ��̂�
�u���E�U�ł�������悤�ɖ��L����̂�CCPL�̎g������������܂���B
�u���E�U�Œ��ڌ����錩���Ȃ����킸�A�^�O�̏������������Ă��������B
270 �FName_Not_Found�F04/11/21 02:41:11 ID:???
���ߍ���ł���RDF���g��������Ȃ��H
> ���Ȃ��̏]���ׂ������͈ȉ��̒ʂ�ł��B
> �A��. ���Ȃ��͌�����҂̃N���W�b�g��\�����Ȃ���Ȃ�܂���B
���ꂩ��A�ꉞ�u���E�U�Ō����Ȃ���Αʖڂ��Ƃ�������B������RDF+����Җ��ƃ����N�łǂ����ȁH
�@���W���Z�}���e�B�b�N�E�F�u���ڂ����Ȃ����������̂��Ȃ��ǂ��B
> ���Ȃ��̏]���ׂ������͈ȉ��̒ʂ�ł��B
> �A��. ���Ȃ��͌�����҂̃N���W�b�g��\�����Ȃ���Ȃ�܂���B
���ꂩ��A�ꉞ�u���E�U�Ō����Ȃ���Αʖڂ��Ƃ�������B������RDF+����Җ��ƃ����N�łǂ����ȁH
�@���W���Z�}���e�B�b�N�E�F�u���ڂ����Ȃ����������̂��Ȃ��ǂ��B
271 �FName_Not_Found�F04/11/21 17:58:01 ID:???
>>270
���肪�Ƃ��������܂��B
�N���W�b�g�̕\����RDF�����ŗǂ��̂��A�u���E�U�Ō����Ȃ���Ȃ�Ȃ��̂�
������Ȃ���ł���ˁB
�Ⴆ�ABY:�����̎ʐ^��������ĉ�W�Ƃ��ăR�}�[�V�������[�Y�i�̔��j����Ȃ�A
������҂����邽�߂ɂ͎��Ɉ�����邵���Ȃ��̂ŁA����͕�����̂ł����A
�E�F�u�Ŏg�p����̂�RDF�Œ�`���āA����Ƀu���E�U�Ō�����悤�ɂ���
�K�v������̂��^��Ɏv���܂����B
�����������̕��̈ӌ������������Ǝv���܂��B
���肪�Ƃ��������܂��B
�N���W�b�g�̕\����RDF�����ŗǂ��̂��A�u���E�U�Ō����Ȃ���Ȃ�Ȃ��̂�
������Ȃ���ł���ˁB
�Ⴆ�ABY:�����̎ʐ^��������ĉ�W�Ƃ��ăR�}�[�V�������[�Y�i�̔��j����Ȃ�A
������҂����邽�߂ɂ͎��Ɉ�����邵���Ȃ��̂ŁA����͕�����̂ł����A
�E�F�u�Ŏg�p����̂�RDF�Œ�`���āA����Ƀu���E�U�Ō�����悤�ɂ���
�K�v������̂��^��Ɏv���܂����B
�����������̕��̈ӌ������������Ǝv���܂��B
272 �FName_Not_Found�F04/11/21 18:16:07 ID:???
273 �FName_Not_Found�F04/11/22 08:17:41 ID:???
>>267
RDF&XHTML������H
ttp://www.w3.org/MarkUp/2004/02/xhtml-rdf.html
���Ƃ���ƁA�������荞��XHTML 2.0��҂����ق������������B
�������̂����� (XHTML�ɂ��RDF�\��) �͂܂��܂������I�Ȋ�K�X�B
��������RDF/A�Ƃ������̂��������ˁB
ttp://www.formsplayer.com/notes/rdf-a.html
�ǂ�łȂ��̂ʼn����V�����̂��͒m��Ȃ����ǁc�B
RDF&XHTML������H
ttp://www.w3.org/MarkUp/2004/02/xhtml-rdf.html
���Ƃ���ƁA�������荞��XHTML 2.0��҂����ق������������B
�������̂����� (XHTML�ɂ��RDF�\��) �͂܂��܂������I�Ȋ�K�X�B
��������RDF/A�Ƃ������̂��������ˁB
ttp://www.formsplayer.com/notes/rdf-a.html
�ǂ�łȂ��̂ʼn����V�����̂��͒m��Ȃ����ǁc�B
274 �FName_Not_Found�F04/11/22 09:49:46 ID:???
�Ȃ��̗ǃX����
275 �FName_Not_Found�F04/11/22 18:00:57 ID:???
>>272
���A�����Ă��܂����̂� (�������������̂�����)�B
���̖{�A�l�I�ɂ͂ǂ����Ȃ��ƁB
�ڎ�������Əڂ��������Ă���悤�Ɍ����邯�ǁA
���ꂼ��̃Z�N�V�����ŏq�ׂ��Ă���ʂ͏��Ȃ��A��G�c�B
�S�̂Ƃ��Ă��e�͂Ƃ��Ă��A�̌n�I�Ȑ����Ƃ������͒f�Ђ̏W�ςƂ��������B
���ɁARDF/OWL�̏͂Ɋւ��ẮA������x�̊�Ղ̂���l�łȂ��ƁA
���܂����S�e���͂߂������ł��Ȃ��̂ł͂Ȃ����Ɗ뜜����B
RDF�̏͂Ɋւ��āArdf:about/rdf:resource��QName���g����A�Ƃ��A
RDF�� (�v���[�����e������) �f�t�H���g���ꂪ�p��ł���A�ȂǂƏ����Ă��� (����R����ˁH)�B
���̑�RDF�̖{���E�{����������������ȋL�q��A�Ȃ��˂����݂����Ȃ�������L�q�ȂǁB
OWL�͎������m��Ȃ����ʂȂ̂Ő��m���ɂ��Ă̓R�����g�ł��Ȃ����ǁA
���S�������҂�RDF�̏͂Ɠ����l�Ȃ̂Ŕ����ɂȂ��Ă��܂��Ȃ��B
�������A�ǂ�Ŏ���̍L���镔�������� (�Ǝv��) �̂ŁA�����Ĉ����Ƃ܂ł͌���Ȃ����ǁA
�w�����������Ă���l�́A�_�肳���RDF/OWL�{��҂��������K�������B
���A�����Ă��܂����̂� (�������������̂�����)�B
���̖{�A�l�I�ɂ͂ǂ����Ȃ��ƁB
�ڎ�������Əڂ��������Ă���悤�Ɍ����邯�ǁA
���ꂼ��̃Z�N�V�����ŏq�ׂ��Ă���ʂ͏��Ȃ��A��G�c�B
�S�̂Ƃ��Ă��e�͂Ƃ��Ă��A�̌n�I�Ȑ����Ƃ������͒f�Ђ̏W�ςƂ��������B
���ɁARDF/OWL�̏͂Ɋւ��ẮA������x�̊�Ղ̂���l�łȂ��ƁA
���܂����S�e���͂߂������ł��Ȃ��̂ł͂Ȃ����Ɗ뜜����B
RDF�̏͂Ɋւ��āArdf:about/rdf:resource��QName���g����A�Ƃ��A
RDF�� (�v���[�����e������) �f�t�H���g���ꂪ�p��ł���A�ȂǂƏ����Ă��� (����R����ˁH)�B
���̑�RDF�̖{���E�{����������������ȋL�q��A�Ȃ��˂����݂����Ȃ�������L�q�ȂǁB
OWL�͎������m��Ȃ����ʂȂ̂Ő��m���ɂ��Ă̓R�����g�ł��Ȃ����ǁA
���S�������҂�RDF�̏͂Ɠ����l�Ȃ̂Ŕ����ɂȂ��Ă��܂��Ȃ��B
�������A�ǂ�Ŏ���̍L���镔�������� (�Ǝv��) �̂ŁA�����Ĉ����Ƃ܂ł͌���Ȃ����ǁA
�w�����������Ă���l�́A�_�肳���RDF/OWL�{��҂��������K�������B
276 �FName_Not_Found�F04/11/25 13:28:25 ID:???
kanzaki����RDF/OWL����̏ڍזڎ������܂����B
RDF/OWL����F�ڍזڎ�
ttp://www.kanzaki.com/book/rdf/toc-detail.html
RDF/OWL����F�ڍזڎ�
ttp://www.kanzaki.com/book/rdf/toc-detail.html
277 �FName_Not_Found�F04/12/04 16:10:03 ID:???
278 �FName_Not_Found�F04/12/05 11:37:11 ID:c1ecC3ag
>>277
��������news��age�����I
��������news��age�����I
279 �FName_Not_Found�F04/12/05 20:39:54 ID:???
OWL��|�Ă���l�����B����Ō����ւ̒�������₷���Ȃ�܂��ȁB
OWL�E�F�u�E�I���g���W�[����T�v
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-features-20040210.html
OWL�E�F�u�E�I���g���W�[����K�C�h
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-guide-20040210.html
OWL�E�F�u�E�I���g���W�[���ꃊ�t�@�����X
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-ref-20040210.html
OWL�E�F�u�E�I���g���W�[����Z�}���e�B�N�X����ђ��ۍ\��
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-semantics-20040210/
OWL�E�F�u�E�I���g���W�[���ꃆ�[�X�P�[�X����їv��
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-webont-req-20040210.html
OWL�E�F�u�E�I���g���W�[����T�v
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-features-20040210.html
OWL�E�F�u�E�I���g���W�[����K�C�h
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-guide-20040210.html
OWL�E�F�u�E�I���g���W�[���ꃊ�t�@�����X
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-ref-20040210.html
OWL�E�F�u�E�I���g���W�[����Z�}���e�B�N�X����ђ��ۍ\��
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-owl-semantics-20040210/
OWL�E�F�u�E�I���g���W�[���ꃆ�[�X�P�[�X����їv��
ttp://www.asahi-net.or.jp/~ax2s-kmtn/internet/rec-webont-req-20040210.html
280 �FName_Not_Found�F04/12/09 01:07:23 ID:???
�ێ�
�_�莁�̖{���o��܂ł�����������?
�Ȃʔ��C��RDF���ϋ����Ă݂�͔̂@����
���ŏЉ��Ă�Kissology�݂�����
�_�莁�̖{���o��܂ł�����������?
�Ȃʔ��C��RDF���ϋ����Ă݂�͔̂@����
���ŏЉ��Ă�Kissology�݂�����
281 �FName_Not_Found�F04/12/09 01:12:03 ID:???
�����������^�^�O����͂���̂��ʓ|�����A�X�V�͂���ɍ���Ȃ��ǁA
�{���ɃZ�}���e�B�b�Nweb���Ď�������̂��ȁ[�B
�ȂZ�p�I�ȃu���C�N�X���[���Ȃ��ƌ���ł͖����ł́H�I
�{���ɃZ�}���e�B�b�Nweb���Ď�������̂��ȁ[�B
�ȂZ�p�I�ȃu���C�N�X���[���Ȃ��ƌ���ł͖����ł́H�I
282 �FName_Not_Found�F04/12/09 01:13:08 ID:???
RDF�͐l�Ԃ���ŏ����ɂ͖ʓ|���吙�Ȃ�ȁB
283 �FName_Not_Found�F04/12/09 08:12:04 ID:???
�m���ɁB�o���邱�Ƃ����c���Ǝv��
284 �FName_Not_Found�F04/12/09 17:46:13 ID:???
�ǂ�ȃ��^�f�[�^�G�f�B�^�E���[�e�B���e�B����������֗��H
285 �FName_Not_Found�F04/12/09 20:25:59 ID:???
>>284
DCMI�Ή�
DCMI�Ή�
286 �FName_Not_Found�F04/12/10 01:13:01 ID:???
>>284
�E���ʂɃt�@�C����ҏW���Ă��邾���ŁA�������Ȃ��Ă����^�f�[�^���E�X�V���Ă����B
�@(�Ⴆ�A�t�@�C���̕ۑ����Ƀo�b�N�O���E���h�ł��̃C�x���g�����m����
�@���^�f�[�^���X�V���Ă����O���A�v���Ȃ�)
�Edc:subject�Ȃǂ̃L�[���[�h�t����Ǘ�����y�E��I�ɂł���B
�@(�F�X�ȓ�����b�𗘗p���āA�L�[���[�h���ꗗ����I��������A
�@�֘A���\�[�X�̏W���ɑ��Ĉꊇ���ăL�[���[�h�̒lj��E�C���E�폜���ł��A
�@�L�[���[�h���̂ɂ��Ă��F�X�W���`�ł����肵�āA
�@���܂��ɃL�[���[�h�Ɋ�Â������\�[�X�Ԃ̊W���O���t�B�J���ɕ\�����Ă����Ɗ������A�Ȃ�)
�E��������邾���ŁA���^�f�[�^�̐����E�X�V�E�Ǘ�����Web�ւ�PUT�AWeb��ł̃��^�f�[�^�ւ�
�@�A�N�Z�X�ɂ�����C���^�[�t�F�[�X�Ȃǂ��܂Ƃ߂Ă���Ă���郁�^�f�[�^�����Ǘ��X�C�[�g�B
���₠�A�����ꂾ�B
�E���ʂɃt�@�C����ҏW���Ă��邾���ŁA�������Ȃ��Ă����^�f�[�^���E�X�V���Ă����B
�@(�Ⴆ�A�t�@�C���̕ۑ����Ƀo�b�N�O���E���h�ł��̃C�x���g�����m����
�@���^�f�[�^���X�V���Ă����O���A�v���Ȃ�)
�Edc:subject�Ȃǂ̃L�[���[�h�t����Ǘ�����y�E��I�ɂł���B
�@(�F�X�ȓ�����b�𗘗p���āA�L�[���[�h���ꗗ����I��������A
�@�֘A���\�[�X�̏W���ɑ��Ĉꊇ���ăL�[���[�h�̒lj��E�C���E�폜���ł��A
�@�L�[���[�h���̂ɂ��Ă��F�X�W���`�ł����肵�āA
�@���܂��ɃL�[���[�h�Ɋ�Â������\�[�X�Ԃ̊W���O���t�B�J���ɕ\�����Ă����Ɗ������A�Ȃ�)
�E��������邾���ŁA���^�f�[�^�̐����E�X�V�E�Ǘ�����Web�ւ�PUT�AWeb��ł̃��^�f�[�^�ւ�
�@�A�N�Z�X�ɂ�����C���^�[�t�F�[�X�Ȃǂ��܂Ƃ߂Ă���Ă���郁�^�f�[�^�����Ǘ��X�C�[�g�B
���₠�A�����ꂾ�B
287 �FName_Not_Found�F04/12/10 03:01:36 ID:???
�����T�C�g�G�f�B�^����āA
���^�f�[�^�����@�\�t���Ă����Ή��͂�����c
�ł��Ȃ��͂Ȃ��������ȁB
�������A�T�C�g�Ɋւ��鐢�̒��̎�ȗv�]�Ȃǂ�T���āA
���������܂��܂Ƃ߂�悤�ȍ\���ɂ���K�v�����邪�c�B
���I�R���e���c���l�b�N�B
���^�f�[�^�����@�\�t���Ă����Ή��͂�����c
�ł��Ȃ��͂Ȃ��������ȁB
�������A�T�C�g�Ɋւ��鐢�̒��̎�ȗv�]�Ȃǂ�T���āA
���������܂��܂Ƃ߂�悤�ȍ\���ɂ���K�v�����邪�c�B
���I�R���e���c���l�b�N�B
288 �FName_Not_Found�F04/12/13 04:26:40 ID:???
RSS�AFOAF�ȊO�Ɏ��p�I�ȏ�Ԃɂ���RDF���ĉ�������H
289 �FName_Not_Found�F04/12/13 07:23:10 ID:???
>>288
���o�����ǁAAnnotea�Ȃ͎g��������ŐF�X�Ƃł������B
�֑��Ƃ��āA������"RDF"�łȂ���"��b"�Ƃ������ق����悢�ˁc�B
RDF�łȂ��Ă�FOAF��RSS�̌�b�͎g���܂����B
�܂��AFOAF���ꎩ�̖̂ړI�͎��p�Ƃ������͂��V�т̕��ł��ˁB
���o�����ǁAAnnotea�Ȃ͎g��������ŐF�X�Ƃł������B
�֑��Ƃ��āA������"RDF"�łȂ���"��b"�Ƃ������ق����悢�ˁc�B
RDF�łȂ��Ă�FOAF��RSS�̌�b�͎g���܂����B
�܂��AFOAF���ꎩ�̖̂ړI�͎��p�Ƃ������͂��V�т̕��ł��ˁB
290 �FName_Not_Found�F04/12/13 14:48:10 ID:???
291 �FName_Not_Found�F04/12/13 17:29:12 ID:???
ttp://www.morikita.co.jp/cgi-bin/kensaku-bunya2.cgi?is=ISBN4-627-82931-0
�o�ŎЂ̃y�[�W(��)���Ɖ��i����E�ꌎ���s�Ȃ��ǁB
�o�ŎЂ̃y�[�W(��)���Ɖ��i����E�ꌎ���s�Ȃ��ǁB
292 �FName_Not_Found�F04/12/14 04:35:25 ID:???
�ǂ��ł��������ǃ��A���_�肽��ɂ����Ă݂���
293 �FName_Not_Found�F04/12/14 07:23:54 ID:???
>>291
�\���t�̂ق���12���c�ǂ������B
����ɂ��Ă��ꗗ�y�[�W�ƌʃy�[�W�ʼn��i���Ⴄ���B
�Q�����ς���Ă���悤���B
ttp://www.esbooks.co.jp/books/search_result?publisher=%BF%B9%CB%CC%BD%D0%C8%C7
2005�N12�������\�� 3,360�~(�ō�)
ttp://www.esbooks.co.jp/books/detail?accd=R0041140
�����\���: 2004�N12�����{, �̔����i: 2,940�~�i�ō��j
�\���t�̂ق���12���c�ǂ������B
����ɂ��Ă��ꗗ�y�[�W�ƌʃy�[�W�ʼn��i���Ⴄ���B
�Q�����ς���Ă���悤���B
ttp://www.esbooks.co.jp/books/search_result?publisher=%BF%B9%CB%CC%BD%D0%C8%C7
2005�N12�������\�� 3,360�~(�ō�)
ttp://www.esbooks.co.jp/books/detail?accd=R0041140
�����\���: 2004�N12�����{, �̔����i: 2,940�~�i�ō��j
294 �FName_Not_Found�F04/12/14 10:43:09 ID:???
>>292
���炱��c
���炱��c
295 �FName_Not_Found�F04/12/14 11:23:22 ID:???
�_�肽��� R�ED�EF�I R�ED�EF�I �Ƃ݂�ȂŔ����Ă݂���
296 �FName_Not_Found�F04/12/14 11:46:26 ID:???
���_�I��ɂɂ��T�C�g������ꂽ��ǂ������
297 �FName_Not_Found�F04/12/14 16:08:00 ID:???
�_�莁�͎��̒��ł��łɐ_�i�����Ă��B�B
298 �FName_Not_Found�F04/12/14 17:46:09 ID:???
�F�̐S�̒��ɐ����Ă�B����ł�������Ȃ����B
299 �FName_Not_Found�F04/12/14 18:12:35 ID:???
>>297
����Ɋւ��Ă͉�����������
����Ɋւ��Ă͉�����������
300 �FName_Not_Found�F04/12/14 19:11:23 ID:???
ttp://www.kanzaki.com/memo/2004/12/14-2
amazon�Ŕ��������Ǝv������\��Ȃ��̂��B
��Ƀ`�F�b�N����K�v������ȁc�B
amazon�Ŕ��������Ǝv������\��Ȃ��̂��B
��Ƀ`�F�b�N����K�v������ȁc�B
301 �FName_Not_Found�F04/12/14 20:02:30 ID:???
RDF/OWL�{�͔N�����肬��Ɋ��s
ttp://kanzaki.com/memo/2004/12/14-2
�������ȁB�I�����C�����X���ő��Ƃ��B
���ƕ\���摜�o�Ă܂��B
ttp://kanzaki.com/memo/2004/12/14-2
�������ȁB�I�����C�����X���ő��Ƃ��B
���ƕ\���摜�o�Ă܂��B
302 �FName_Not_Found�F04/12/14 22:55:30 ID:???
>>296
���O�͐_�肽��̂��Ƃ��킩�����Ⴂ�˂��b�B
�_�肽���DNA���x���Ń��\�[�X��URI�̉i���������܂�Ă���I
�T�[�o�ɂ������������̒p���������ʐ^���������Ƃ�
�������o���Ċ��Ԃ�߂�_�邽��ʧʧ�i�L�D�M�G�j
���O�͐_�肽��̂��Ƃ��킩�����Ⴂ�˂��b�B
�_�肽���DNA���x���Ń��\�[�X��URI�̉i���������܂�Ă���I
�T�[�o�ɂ������������̒p���������ʐ^���������Ƃ�
�������o���Ċ��Ԃ�߂�_�邽��ʧʧ�i�L�D�M�G�j
303 �FName_Not_Found�F04/12/14 23:02:37 ID:???
>>300-301
�H
�H
305 �FName_Not_Found�F04/12/15 05:43:28 ID:???
�u�Z�}���e�B�b�NWeb�R���t�@�����X2005�v�̈ē������Ă܂����B
http://www.intap.or.jp/INTAP/whatsnew/16-20050210_swc/index.html
����: 2005�N2��10���i�j�@10�F00�`18�F00
���: �c����O�c�L�����p�X
���: ���3,000�~�A�w���y�ъW�҂͖���
�O��̗l�q�ɂ��Ă� >>98 ��������ǂ����B
http://www.intap.or.jp/INTAP/whatsnew/16-20050210_swc/index.html
����: 2005�N2��10���i�j�@10�F00�`18�F00
���: �c����O�c�L�����p�X
���: ���3,000�~�A�w���y�ъW�҂͖���
�O��̗l�q�ɂ��Ă� >>98 ��������ǂ����B
306 �FName_Not_Found�F04/12/15 06:54:34 ID:???
>>304
�킩��Ȃ��c �������e����Ȃ��́c�H
�킩��Ȃ��c �������e����Ȃ��́c�H
307 �FName_Not_Found�F04/12/15 07:50:39 ID:???
www�����ĂȂ��I�܂���ĂȂ��I
>>306
�܂������^��Ɏv���Ă�̂����Ӗ��s������
>�Ȃ�amazon.co.jp�ł́A
>����͗\��ł͂Ȃ��o�ב��̔��Ƃ����`�ɂȂ�Ƃ̂��ƁB
>�ł�����N���܂ł͌f�ڂ���܂���
�܂������^��Ɏv���Ă�̂����Ӗ��s������
>�Ȃ�amazon.co.jp�ł́A
>����͗\��ł͂Ȃ��o�ב��̔��Ƃ����`�ɂȂ�Ƃ̂��ƁB
>�ł�����N���܂ł͌f�ڂ���܂���
309 �FName_Not_Found�F04/12/15 11:29:07 ID:???
>>308
����A�Ȃ��301��300�� (�w���Ă�����e��) �����A�h���X��
����300�����݂��Ă��Ȃ����̂悤�Ȍ`�ŏ����Ă���̂��낤�ƁB
���łɁA���̈��p�̈Ӑ}���킩��Ȃ��c�B
����A�Ȃ��301��300�� (�w���Ă�����e��) �����A�h���X��
����300�����݂��Ă��Ȃ����̂悤�Ȍ`�ŏ����Ă���̂��낤�ƁB
���łɁA���̈��p�̈Ӑ}���킩��Ȃ��c�B
�܂艴���������ꂽ�Ƃł��H
������>>307���^�B
������>>307���^�B
311 �FName_Not_Found�F04/12/15 13:28:18 ID:0SbC2+R6
�Z�}���e�B�b�NWeb�R���t�@�����X2005
���������B�B
���������B�B
313 �FName_Not_Found�F04/12/15 19:58:14 ID:???
����ŋC�Â������ǁA�_�肳��̃T�C�g�̃��^�f�[�^�Ŏg�p�����URI�Q�Ƃ�
"www"���肾������Ȃ��������肷��̂����ǁA����͂����̂��낤���c�B
�Ⴆ�� /memo/2004/12/14-2 �ɂ��āA
�ǂ����"www"�����URI�Q��: ttp://www.kanzaki.com/memo/2004/12/14-2
ttp://www.kanzaki.com/info/memo.rdf
ttp://kanzaki.com/info/memo.rdf
�ǂ����"www"�Ȃ���URI�Q��: ttp://kanzaki.com/memo/2004/12/14-2
ttp://www.kanzaki.com/memo/2004/12/14-2?mode=rdf
ttp://kanzaki.com/memo/2004/12/14-2?mode=rdf
�܂�ARDF�ɂ������ꂪ"www"����ƂȂ���2�p�^�[�������ĖF�����Ȃ��悤�ȋC���B
owl:sameAs������ʼn����Ȃ̂�������Ȃ����ǁc�B
�܂��A�u���̃����̍P�v�y�[�W�v���Awww���肨��тȂ��ŃA�N�Z�X�����ꍇ��
���ꂼ��www����ƂȂ���2�p�^�[���ɂȂ��Ă��܂��悤�ŁB
ttp://kanzaki.com/memo/
ttp://www.kanzaki.com/memo/
�̊e�u���̃����̍P�v�y�[�W�v�����N�ɒ��ځB
�����ŁA�h���C�������Ă���l�A"www"����ƂȂ��A�ǂ���ɂ��Ă܂����H
�܂��A�P�v�I��URI�ɂ��Ăǂ̂悤�Ȑv�����Ă܂����H
"www"���肾������Ȃ��������肷��̂����ǁA����͂����̂��낤���c�B
�Ⴆ�� /memo/2004/12/14-2 �ɂ��āA
�ǂ����"www"�����URI�Q��: ttp://www.kanzaki.com/memo/2004/12/14-2
ttp://www.kanzaki.com/info/memo.rdf
ttp://kanzaki.com/info/memo.rdf
�ǂ����"www"�Ȃ���URI�Q��: ttp://kanzaki.com/memo/2004/12/14-2
ttp://www.kanzaki.com/memo/2004/12/14-2?mode=rdf
ttp://kanzaki.com/memo/2004/12/14-2?mode=rdf
�܂�ARDF�ɂ������ꂪ"www"����ƂȂ���2�p�^�[�������ĖF�����Ȃ��悤�ȋC���B
owl:sameAs������ʼn����Ȃ̂�������Ȃ����ǁc�B
�܂��A�u���̃����̍P�v�y�[�W�v���Awww���肨��тȂ��ŃA�N�Z�X�����ꍇ��
���ꂼ��www����ƂȂ���2�p�^�[���ɂȂ��Ă��܂��悤�ŁB
ttp://kanzaki.com/memo/
ttp://www.kanzaki.com/memo/
�̊e�u���̃����̍P�v�y�[�W�v�����N�ɒ��ځB
�����ŁA�h���C�������Ă���l�A"www"����ƂȂ��A�ǂ���ɂ��Ă܂����H
�܂��A�P�v�I��URI�ɂ��Ăǂ̂悤�Ȑv�����Ă܂����H
314 �FName_Not_Found�F04/12/15 20:27:31 ID:???
www������80�Ԃ�@���ꂽ�Ƃ��́Awww��301�Ń��_�C���N�g���Ă�B
���Ƃ͊g���q����ăR���e���g�l�S�V�G�[�V�������ȁB
���Ƃ͊g���q����ăR���e���g�l�S�V�G�[�V�������ȁB
315 �FName_Not_Found�F04/12/15 20:34:02 ID:???
��藧�Ăđ�͂��ĂȂ�����ǁA�T�C�g���̋L�q��www����Ɍ��肵�Ă܂��B
�K��www�Ȃ��̕��փA�N�Z�X�͂قƂ�ǂȂ��̂ŁA��̕K�v���̂Ȃ��Ƃ�����ԁB
�K��www�Ȃ��̕��փA�N�Z�X�͂قƂ�ǂȂ��̂ŁA��̕K�v���̂Ȃ��Ƃ�����ԁB
316 �FName_Not_Found�F04/12/15 20:40:37 ID:???
��������A>>145����͊��S���t���Ԃ�URI�Ɉڍs�����̂��ȁH
���Ƃ�����F�X��ς��������ǁB
�Q�l: �u�f�B���N�g���\���ǂ����Ă�H�v�X��
http://pc5.2ch.net/test/read.cgi/hp/1030814119/179-
���Ƃ�����F�X��ς��������ǁB
�Q�l: �u�f�B���N�g���\���ǂ����Ă�H�v�X��
http://pc5.2ch.net/test/read.cgi/hp/1030814119/179-
317 �FName_Not_Found�F04/12/15 21:11:25 ID:???
�Ȃ�قǁAwww����̂ق����嗬�Ȃ̂��ȁB
���ӌ����肪�Ƃ��B������ƌ������Ă݂܂��B
���ӌ����肪�Ƃ��B������ƌ������Ă݂܂��B
318 �FName_Not_Found�F04/12/15 23:38:15 ID:???
>>317
�ǂ��炩����ɌŒ肵�āA�����ւ̃��N�G�X�g��
���_�C���N�g����悤�ɂ��Ă����ǂ����ł�������Ȃ��������B
���� >>314 �ɓ����ɂ��Ă�B
�ǂ��炩����ɌŒ肵�āA�����ւ̃��N�G�X�g��
���_�C���N�g����悤�ɂ��Ă����ǂ����ł�������Ȃ��������B
���� >>314 �ɓ����ɂ��Ă�B
319 �FName_Not_Found�F04/12/16 02:36:51 ID:???
>>317
��ʓI�Ƃ���ʓI�łȂ��Ƃ����Ęb�ł͂Ȃ�����
ftp.kanzaki.com�Ƃ����[���T�[�o�Ƃ����낢�땪����K�v������Ȃ�
Web�T�[�o��URL�������ق����Ǘ���s���������Ă��������
www�p�r��URL�����v��Ȃ��̂ł���AWWW�͖������Ă�����
�����ق����X�}�[�g�ȋC�������
��ʓI�Ƃ���ʓI�łȂ��Ƃ����Ęb�ł͂Ȃ�����
ftp.kanzaki.com�Ƃ����[���T�[�o�Ƃ����낢�땪����K�v������Ȃ�
Web�T�[�o��URL�������ق����Ǘ���s���������Ă��������
www�p�r��URL�����v��Ȃ��̂ł���AWWW�͖������Ă�����
�����ق����X�}�[�g�ȋC�������
320 �FName_Not_Found�F04/12/16 07:44:18 ID:???
URI�v�̊ϓ_���猩��ƁA
���́Awww�t����URI��Web�̎������Ďg�p����邩�ۂ����ȁB
����A�����Ȃ�����HTTP��O��ɂ������ʎq���̂��i���Z���X�ɂȂ邩�B
URN����IDN�g���Ȃ�������ˊm�� (���ݓo�^����Ă���NID�̒��ł�)�B
�܁A����Ȃ��Ƃ܂ŐS�z����K�v���Ȃ����B
���́Awww�t����URI��Web�̎������Ďg�p����邩�ۂ����ȁB
����A�����Ȃ�����HTTP��O��ɂ������ʎq���̂��i���Z���X�ɂȂ邩�B
URN����IDN�g���Ȃ�������ˊm�� (���ݓo�^����Ă���NID�̒��ł�)�B
�܁A����Ȃ��Ƃ܂ŐS�z����K�v���Ȃ����B
>>318-319
���X�ǂ����ł��B���́Awww������ł��Ȃ��ł��ǂ���ł������Ƃ������Ƃ��A
���ꂪ�G�C���A�X�Ƃ��ĊǗ���֗̕��̂��߂Ɏg�p����Ă��邱�Ƃ��m���Ă�����ł����A
�F����̍D�݂��ǂ��炩��m�肽���Ď��₵�܂����B
�����s���ł����܂���B
���X�ǂ����ł��B���́Awww������ł��Ȃ��ł��ǂ���ł������Ƃ������Ƃ��A
���ꂪ�G�C���A�X�Ƃ��ĊǗ���֗̕��̂��߂Ɏg�p����Ă��邱�Ƃ��m���Ă�����ł����A
�F����̍D�݂��ǂ��炩��m�肽���Ď��₵�܂����B
�����s���ł����܂���B
322 �FName_Not_Found�F04/12/16 15:10:55 ID:???
���p��x�Ⴊ�Ȃ��̂ł���Ό��ڂŌ��߂����Ă����W���}�C�J
323 �FName_Not_Found�F04/12/16 17:04:22 ID:???
�܂��܂��B
324 �FName_Not_Found�F04/12/16 22:18:43 ID:???
>>320
> URN����IDN�g���Ȃ�������ˊm�� (���ݓo�^����Ă���NID�̒��ł�)�B
urn:publicid �Ƃ��g���Έꉞ�\���Ǝv�����ǁA
�܂��]�茻���I�ł͂Ȃ��B
> URN����IDN�g���Ȃ�������ˊm�� (���ݓo�^����Ă���NID�̒��ł�)�B
urn:publicid �Ƃ��g���Έꉞ�\���Ǝv�����ǁA
�܂��]�茻���I�ł͂Ȃ��B
325 �FName_Not_Found�F04/12/16 23:26:10 ID:???
owner��IDN��URI��hostname���Adescription�ɏ���path component�Ă͂߂�ƁB
class�́cXML������DOCUMENT�ōs����̂��H
SGML�͂悭�������B
class�́cXML������DOCUMENT�ōs����̂��H
SGML�͂悭�������B
>>325
XML �����̃N���X�� SGML ���ȁB
�Ⴆ�� +//IDN www.2ch.com//SGML Home Page of 2ch//JA �Ȃ�
urn:publicid:+:IDN+www.2ch.com:SGML+Home+Page+of+2ch:JA
�݂����Ȋ����������Ǝv���B
�܂��A�قƂ�LjӖ��͂Ȃ����ǂ��B
XML �����̃N���X�� SGML ���ȁB
�Ⴆ�� +//IDN www.2ch.com//SGML Home Page of 2ch//JA �Ȃ�
urn:publicid:+:IDN+www.2ch.com:SGML+Home+Page+of+2ch:JA
�݂����Ȋ����������Ǝv���B
�܂��A�قƂ�LjӖ��͂Ȃ����ǂ��B
327 �FName_Not_Found�F04/12/17 01:37:19 ID:???
>>316
�Ԏ����x��܂������A���S���t����URI�ɂ��܂����B
�R���e���g�l�S�V�G�[�V�����ɂ����܂����B
root/yyyy/mm/dd-filename.extensions
���郊�\�[�X���̂̎�|����������肵�āA���̃��\�[�X�̍X�V����߂����Ȃ����Ƃ��A
�����Ɏ̂Ă��邩�炢���ˁB���̃��\�[�X�ɂ͐V�����łւ�
URI��������悤�Ȃ��̂����Ă����������B
�Ԏ����x��܂������A���S���t����URI�ɂ��܂����B
�R���e���g�l�S�V�G�[�V�����ɂ����܂����B
root/yyyy/mm/dd-filename.extensions
���郊�\�[�X���̂̎�|����������肵�āA���̃��\�[�X�̍X�V����߂����Ȃ����Ƃ��A
�����Ɏ̂Ă��邩�炢���ˁB���̃��\�[�X�ɂ͐V�����łւ�
URI��������悤�Ȃ��̂����Ă����������B
328 �FName_Not_Found�F04/12/17 08:12:00 ID:???
>>326
�����A�T���N�X�BSGML�ڂ����l�����̂ˁB�����Ȃ��B
>>327
�f���炵���ˁB
���͎�����������_���Ă��āA����v���Ƃ��낪������ǁA
1. �ł̊Ǘ��ɂ��Ă̍l��
�@ ��̓I�ɂ́A���݂̔łƍŐV�� (����щߋ��̔�) ������悤�ȃ��\�[�X (�d�l���Ȃǂ��T�^��)
�@ �ɁA���Ɍ��݂̔łƍŐV�łłǂ̂悤��URI�����蓖�Ă邩�̃K�C�h���C������H
2. ���\�[�X�Ԃ̃i�r�Q�[�V������\�[�X����
�@ �E�T�u�W�F�N�g���ŕ��ނ����c���[�\���ɂ��T�C�g�}�b�v��index�y�[�W�݂����Ȃ��̂�p�ӁH
�@ �E����Ƃ����t�f�B���N�g���\�������̂܂܊��������A���t�K�w�T�C�g�}�b�v�H
�@ �E�e�����ɉ��炩�̃L�[���[�h�ߍ��ނȂǂ��āA�T�C�g�����@�\��H
�@ �E����Ƃ��e���\�[�X��link�v�f�ߍ���ŁA�֘A���郊�\�[�X�̒��ڂ̌��т����s���H
3. ���\�[�X�Ǘ���
�@ �E���S���t���Ԃ̃f�B���N�g���\���ŁA�Ǘ���e�Ղɂ���c�[���݂����Ȃ��̂�����Ă�H
�@ �E�v��Ƃ�����A�����W���낤�� (�t�@�C�����ŒT���Ȃ�����c)�B
�����A�T���N�X�BSGML�ڂ����l�����̂ˁB�����Ȃ��B
>>327
�f���炵���ˁB
���͎�����������_���Ă��āA����v���Ƃ��낪������ǁA
1. �ł̊Ǘ��ɂ��Ă̍l��
�@ ��̓I�ɂ́A���݂̔łƍŐV�� (����щߋ��̔�) ������悤�ȃ��\�[�X (�d�l���Ȃǂ��T�^��)
�@ �ɁA���Ɍ��݂̔łƍŐV�łłǂ̂悤��URI�����蓖�Ă邩�̃K�C�h���C������H
2. ���\�[�X�Ԃ̃i�r�Q�[�V������\�[�X����
�@ �E�T�u�W�F�N�g���ŕ��ނ����c���[�\���ɂ��T�C�g�}�b�v��index�y�[�W�݂����Ȃ��̂�p�ӁH
�@ �E����Ƃ����t�f�B���N�g���\�������̂܂܊��������A���t�K�w�T�C�g�}�b�v�H
�@ �E�e�����ɉ��炩�̃L�[���[�h�ߍ��ނȂǂ��āA�T�C�g�����@�\��H
�@ �E����Ƃ��e���\�[�X��link�v�f�ߍ���ŁA�֘A���郊�\�[�X�̒��ڂ̌��т����s���H
3. ���\�[�X�Ǘ���
�@ �E���S���t���Ԃ̃f�B���N�g���\���ŁA�Ǘ���e�Ղɂ���c�[���݂����Ȃ��̂�����Ă�H
�@ �E�v��Ƃ�����A�����W���낤�� (�t�@�C�����ŒT���Ȃ�����c)�B
329 �FName_Not_Found�F04/12/17 08:12:46 ID:???
>>328��1.�̕⑫
�܂�A���ł��o���Ƃ��ɁA���ł�URI���ێ����� (����̉��ł����܂���)
�ŐV�ł�URI���~�����Ȃ�悤�ȏꍇ�B
�l������̂́A
1. ���ł̕����쐬�������ł�URI�ɂ���B
�@ ���ł��o����A���ŁE���ł�URI�Ƃ͕ʂɁA���炩�̓��t�ɂ��ŐV�ł�URI��p�ӁB
2. ���ł̕����쐬�����ŐV�ł�URI�ɂ���B
�@ ���ł��o����A���ŁE�ŐV�ł�URI�Ƃ͕ʂɁA���炩�̓��t�ɂ�鏉�ł�URI��p�ӁB
3. ���ō쐬���ɁA�ŐV��URI���p�ӂ��Ă����B���̂Ƃ������쐬���͂ǂ����URI�ɂȂ邩�B
4. ���������ŐV�ł̂��Ƃ͍l���Ȃ��B
���Ȃ��B
�܂�A���ł��o���Ƃ��ɁA���ł�URI���ێ����� (����̉��ł����܂���)
�ŐV�ł�URI���~�����Ȃ�悤�ȏꍇ�B
�l������̂́A
1. ���ł̕����쐬�������ł�URI�ɂ���B
�@ ���ł��o����A���ŁE���ł�URI�Ƃ͕ʂɁA���炩�̓��t�ɂ��ŐV�ł�URI��p�ӁB
2. ���ł̕����쐬�����ŐV�ł�URI�ɂ���B
�@ ���ł��o����A���ŁE�ŐV�ł�URI�Ƃ͕ʂɁA���炩�̓��t�ɂ�鏉�ł�URI��p�ӁB
3. ���ō쐬���ɁA�ŐV��URI���p�ӂ��Ă����B���̂Ƃ������쐬���͂ǂ����URI�ɂȂ邩�B
4. ���������ŐV�ł̂��Ƃ͍l���Ȃ��B
���Ȃ��B
330 �FName_Not_Found�F04/12/17 14:45:34 ID:???
331 �FName_Not_Found�F04/12/17 21:26:04 ID:???
>>330
�Ȃ�قǁA���������ˁB�����������I���B
�Ƃ͂����Acool URL's (��) �ɂ���悤�ɁA���O�⌾�t�̈Ӗ��̔�P�v�����l����Ƃ�����ƂȂ��c
�c�Ƃ����͕̂������Ȃ낤���ǁB
�܂��A�ɒ[�Ȑl�Ԃ̔]���F���Ƃ������ƂŃX���[���Ă���Ă��������B
�Ȃ�قǁA���������ˁB�����������I���B
�Ƃ͂����Acool URL's (��) �ɂ���悤�ɁA���O�⌾�t�̈Ӗ��̔�P�v�����l����Ƃ�����ƂȂ��c
�c�Ƃ����͕̂������Ȃ낤���ǁB
�܂��A�ɒ[�Ȑl�Ԃ̔]���F���Ƃ������ƂŃX���[���Ă���Ă��������B
332 �FName_Not_Found�F04/12/17 21:26:43 ID:???
�����ƁA�v���I�ȃ~�X���B s/URL/URI/
333 �FName_Not_Found�F04/12/17 22:26:36 ID:???
RDF/OWL�{�Aamazon�ŗ\��\�Ȃ悤�ł���B
�Ƃ肠�����\�܂����B
�����Ƃ��Aamazon�͗\��]�X�ł͕]���������悤�ł����B
ttp://www.amazon.co.jp/o/ASIN/4627829310/
�Ƃ肠�����\�܂����B
�����Ƃ��Aamazon�͗\��]�X�ł͕]���������悤�ł����B
ttp://www.amazon.co.jp/o/ASIN/4627829310/
334 �FName_Not_Found�F04/12/18 04:36:36 ID:???
���\��]�X�ł͕]��������
�Ƃ́H�O�]���̂���
�Ƃ́H�O�]���̂���
335 �FName_Not_Found�F04/12/18 05:00:39 ID:???
�\��Ŗ�肪����̂́A�l�C�̂�����������Ȃ��̂��ȁH
amazon�͓��א��ȏ�ɒ������t����̂ŗ\������Ƃ�����
�K�����������ɓ͂��킯�ł͂���܂���
amazon�͓��א��ȏ�ɒ������t����̂ŗ\������Ƃ�����
�K�����������ɓ͂��킯�ł͂���܂���
336 �FName_Not_Found�F04/12/18 09:55:13 ID:???
�����̒m�����ł́A>>335 + ���ꂪ�������� (?) �������ꍇ�ŁA
�ɂ��Ȃ��Ȃ��ė\�������I�ɃL�����Z�����ꂽ�]�X�œłÂ��Ă����l�������悤�ȋL�����B
���܂�amazon�Ńg���u���ɂ��������Ƃ͂Ȃ����A�܂��A�����ꕔ�̘b�ł��傤�ȁB
�ɂ��Ȃ��Ȃ��ė\�������I�ɃL�����Z�����ꂽ�]�X�œłÂ��Ă����l�������悤�ȋL�����B
���܂�amazon�Ńg���u���ɂ��������Ƃ͂Ȃ����A�܂��A�����ꕔ�̘b�ł��傤�ȁB
337 �FName_Not_Found�F04/12/18 18:55:25 ID:???
�_��^����AmazonID�擾����OWL�{�y�[�W�ɓ\���Ă��ꂽ��Q�������B
>>331
W3C�͎��ۂ�>>330�̌����悤�ɂ���Ă邵�A
�u�ŐV�Łv���ĈӖ��ł�URI�ƍl�������͂���ł����悤�ȋC������B
>>337
Amazon�̃A�t�F���G�C�gID�Ȃ炷�łɎ擾���Ă�݂�������B
ttp://www.amazon.co.jp/exec/obidos/ASIN/4627829310/thewebkanzaki-22
W3C�͎��ۂ�>>330�̌����悤�ɂ���Ă邵�A
�u�ŐV�Łv���ĈӖ��ł�URI�ƍl�������͂���ł����悤�ȋC������B
>>337
Amazon�̃A�t�F���G�C�gID�Ȃ炷�łɎ擾���Ă�݂�������B
ttp://www.amazon.co.jp/exec/obidos/ASIN/4627829310/thewebkanzaki-22
339 �FName_Not_Found�F04/12/18 21:49:31 ID:???
>>337
������iPod mini��_���ƁB
������iPod mini��_���ƁB
341 �FName_Not_Found�F04/12/24 20:47:38 ID:???
ttp://www.kanzaki.com/memo/2004/12/24-1
�������낻��B�������l����[�H
�������낻��B�������l����[�H
342 �FName_Not_Found�F04/12/24 20:53:29 ID:???
Amazon�̔z���\���������ƁA12/28�`12/30�ƂȂ��Ă�ˁB
�Ђ���Ƃ��ēX���̕���������ɓ���̂��Ȃ��c�B
�Ђ���Ƃ��ēX���̕���������ɓ���̂��Ȃ��c�B
343 �FName_Not_Found�F04/12/24 22:53:41 ID:???
����͐_�肽���n�������B���ꂩ���l�ŃC�u���߂�����
344 �FName_Not_Found�F04/12/24 23:02:25 ID:???
������
345 �FName_Not_Found�F04/12/24 23:06:58 ID:???
�c���Ȃ��B�X�g�[�J�[�ɔ��W���Ȃ����Ƃ��F�낤�B
346 �FName_Not_Found�F04/12/24 23:07:37 ID:???
���Ԃ���
347 �FName_Not_Found�F04/12/25 13:10:10 ID:???
�����A������n�����ꂽ���B�B
348 �FName_Not_Found�F04/12/25 13:25:07 ID:???
�L������
349 �FName_Not_Found�F04/12/25 13:46:56 ID:???
���Ⴀ�A���͐_�肽���RDF�������ŁB
350 �FName_Not_Found�F04/12/25 21:25:15 ID:???
���u����̂݁B
351 �FName_Not_Found�F04/12/25 21:45:28 ID:???
>350
�{�l�~��( ߄t�)!!
�{�l�~��( ߄t�)!!
�l�^�Ɍ��܂��Ă�corz=3
��̉��͒j���B
��̉��͒j���B
353 �FName_Not_Found�F04/12/25 21:56:18 ID:???
�L���C���玀��ł�
354 �FName_Not_Found�F04/12/25 22:04:28 ID:???
>353
�������您�O�c
�������您�O�c
355 �FName_Not_Found�F04/12/26 02:21:04 ID:???
�l�^�Ȃ̂͒N�����킩���Ă邵���O�������Ƃ��v���ĂȂ��B
�������̃l�^�̐U������L���C��A���Ęb���B
�������̃l�^�̐U������L���C��A���Ęb���B
356 �FName_Not_Found�F04/12/26 04:19:49 ID:???
�͂��B�ǂ��ł������ł��B���̘b��͏I���B
��������Ƃǂ���B
��������Ƃǂ���B
357 �FName_Not_Found�F04/12/28 02:59:25 ID:i3PJjBsA
ttp://www.kanzaki.com/ns/
FOAF�ɕK�v���������邩��Who's who description vocabulary���Ă̂͒��X
���N�͎d�����߂�����肾����������Ă݂邩��
�Ɩ�����茳�ʂ�̽ڐi�s�ɖ߂��Ă݂��B
�_�莁�̖{�������l���r���[���ڂ�
FOAF�ɕK�v���������邩��Who's who description vocabulary���Ă̂͒��X
���N�͎d�����߂�����肾����������Ă݂邩��
�Ɩ�����茳�ʂ�̽ڐi�s�ɖ߂��Ă݂��B
�_�莁�̖{�������l���r���[���ڂ�
358 �FName_Not_Found�F04/12/28 05:50:56 ID:???
FOAF�����Ⴂ���ĂȂ���?Friend of a Friend�̗�����?
�K�v�����Ă͉̂����Y�����邪(ȯĒm�l�ɏ�)���ȏЉ�����FOAF�͌��J���Ă�
Who's who description vocabulary�͒m��Ȃ������ȁB���̂낭�ł��Ȃ��v���t�Ȃ�ď����Ȃ����@orz
������b��������?
�K�v�����Ă͉̂����Y�����邪(ȯĒm�l�ɏ�)���ȏЉ�����FOAF�͌��J���Ă�
Who's who description vocabulary�͒m��Ȃ������ȁB���̂낭�ł��Ȃ��v���t�Ȃ�ď����Ȃ����@orz
������b��������?
359 �FName_Not_Found�F04/12/28 23:51:42 ID:???
�{�͗\�����ǂ܂��݂�����
�c�ɂɏZ��ł邩����i�������������ŕ|���B�B
�c�ɂɏZ��ł邩����i�������������ŕ|���B�B
360 �FName_Not_Found�F04/12/29 00:56:25 ID:???
���i���Ƃ������t�����Ⴂ���ĂȂ���?
361 �FName_Not_Found�F04/12/29 01:49:13 ID:???
ttp://www.amazon.co.jp/o/ASIN/4627829310
���݁Aamazon�ŁA�u�ɐ�v�Ɓu�����\�����F�ʏ�4�`6�T�Ԉȓ��v���������Ă��܂��B
(���E���h���r���ŐU�蕪���Ă���A�����������̂��߂Ǝv���܂��B)
�ǂ���ɂ��Ă��J�[�g�ɓ���悤�Ƃ���Ɠ���s�Əo��̂ŁA�ɐ�̏�Ԃ̂悤�ł��B
�\��̕��������m�� (��������) �̃��[���͖��������B
�\�̍ɂ͊m�ۂ���Ă���̂ł��傤���B
����Ƃ��A�P�ɔN���i�s�ŖZ���������Ȃ̂��c�B
���݁Aamazon�ŁA�u�ɐ�v�Ɓu�����\�����F�ʏ�4�`6�T�Ԉȓ��v���������Ă��܂��B
(���E���h���r���ŐU�蕪���Ă���A�����������̂��߂Ǝv���܂��B)
�ǂ���ɂ��Ă��J�[�g�ɓ���悤�Ƃ���Ɠ���s�Əo��̂ŁA�ɐ�̏�Ԃ̂悤�ł��B
�\��̕��������m�� (��������) �̃��[���͖��������B
�\�̍ɂ͊m�ۂ���Ă���̂ł��傤���B
����Ƃ��A�P�ɔN���i�s�ŖZ���������Ȃ̂��c�B
362 �FName_Not_Found�F04/12/29 02:57:31 ID:???
>>361
�Ǝv������A�������łɒ������͉̂\�ɂȂ��Ă��܂��B
�Ǝv������A�������łɒ������͉̂\�ɂȂ��Ă��܂��B
amazon�̗\��E�����Ŋ��ɓ��肳�ꂽ�����܂����H
�₢���킹�����Ă݂��Ƃ���A��͂���ב҂��̂悤�ŁA
���������f���Ă��炤�悤�ɗ���A�����\�����01/30 - 02/13�ɂȂ�܂����B
����������7�`10�����炢�҂��ƂɂȂ�ꍇ�����邻���ł����A����̓e���v���̗\���B
���X�Ŕ��������̂�҂�������������������܂���ˁc�B
�₢���킹�����Ă݂��Ƃ���A��͂���ב҂��̂悤�ŁA
���������f���Ă��炤�悤�ɗ���A�����\�����01/30 - 02/13�ɂȂ�܂����B
����������7�`10�����炢�҂��ƂɂȂ�ꍇ�����邻���ł����A����̓e���v���̗\���B
���X�Ŕ��������̂�҂�������������������܂���ˁc�B
364 �FName_Not_Found�F04/12/31 16:04:28 ID:Kzj2Tkvg
RDF/OWL�{�A�݂�����̒��̐l���������݂�������
�摜���Ղ���Ă�
��������̒����X�s�������ǖ���������@orz
���܂���ǂ����N��
�摜���Ղ���Ă�
��������̒����X�s�������ǖ���������@orz
���܂���ǂ����N��
365 �FName_Not_Found�F04/12/31 19:24:19 ID:???
�{�H
�c�c�d�l����ǂ߁A�J�X�ǂ��B���ق��w���o�̏������Z�p���ɗ����Ȃ��B
�c�c�d�l����ǂ߁A�J�X�ǂ��B���ق��w���o�̏������Z�p���ɗ����Ȃ��B
366 �FName_Not_Found�F04/12/31 22:57:42 ID:???
367 �FName_Not_Found�F05/01/03 01:31:34 ID:???
�V�h�I�ɍ����{�X�ɂāuRDF/OWL ����v�Q�b�g
�u�i������Web �Z�}���e�B�b�NWeb�v �A�u�Z�}���e�B�b�NWeb����v�ƈꏏ��
���ς݂ɂȂ��Ă܂���
�u�i������Web �Z�}���e�B�b�NWeb�v �A�u�Z�}���e�B�b�NWeb����v�ƈꏏ��
���ς݂ɂȂ��Ă܂���
368 �FName_Not_Found�F05/01/03 01:51:39 ID:???
369 �FName_Not_Found�F05/01/03 05:03:57 ID:???
�yFoaF�z���O��A���ȏЉ�ǂ����Ă�H�y100���z
http://pc5.2ch.net/test/read.cgi/hp/1104445716/l50
����1�͂��̽ڂ̏Z�l?
>>367
���r���[���ڂ�B���̍Ŋ��ł͂܂��������Ȃ���c
OWL�N���M�Ă���Ȃ����ȁB�I���W�i���ł��킩��Ȃ����͖������A����ϓ��{��œǂ݂���
http://pc5.2ch.net/test/read.cgi/hp/1104445716/l50
����1�͂��̽ڂ̏Z�l?
>>367
���r���[���ڂ�B���̍Ŋ��ł͂܂��������Ȃ���c
OWL�N���M�Ă���Ȃ����ȁB�I���W�i���ł��킩��Ȃ����͖������A����ϓ��{��œǂ݂���
>>369
���r���[�͊���
�����A�u���j�o�[�T��HTML/XHTML�v�Ɣ�ׂ�ƁA
���Ȃ������ɂ�����
�����ɗ\���m�����������炩�������
���r���[�͊���
�����A�u���j�o�[�T��HTML/XHTML�v�Ɣ�ׂ�ƁA
���Ȃ������ɂ�����
�����ɗ\���m�����������炩�������
371 �FName_Not_Found�F05/01/03 12:03:47 ID:???
372 �FName_Not_Found�F05/01/03 12:06:58 ID:???
�͒ʓǂ��đ�ӂ���A�����̓���ȏꏊ��₤�Ƃ��ɗL�p����ˁB
373 �FName_Not_Found�F05/01/03 21:05:48 ID:???
�Z�}���e�B�b�NWeb����Ƃǂ����������߂������ł������ė~�����B
>>373
�I���́u�Z�}���e�B�b�NWeb����v��ǂ�ł��Ȃ��̂ŁA���Ƃ������Ȃ�
�ǂ�ł����Ƃ��Ă��A�D���������Ă��ƂɂȂ肻�������Ȃ�
�I���́u�Z�}���e�B�b�NWeb����v��ǂ�ł��Ȃ��̂ŁA���Ƃ������Ȃ�
�ǂ�ł����Ƃ��Ă��A�D���������Ă��ƂɂȂ肻�������Ȃ�
375 �FName_Not_Found�F05/01/05 01:40:23 ID:???
�A�}�]���ŗ\���{�A����Ɣ������[����������[
376 �FName_Not_Found�F05/01/05 08:27:40 ID:???
>>375
���\���H
���\���H
378 �FName_Not_Found�F05/01/11 21:24:06 ID:???
RDF/OWL�{�w������
�����ǂ��������烌�r���[�͓�����ǁA
OWL�����܂����킩��Ȃ��l�̓I�X�X������
�v�������{�����[������̂ł�������w�ׂ���
�Ȃ���Ă�The Web Kanzaki���ĕ��n�߂��l�ɂ͓����Ă����₷��
�X���ɋ�������semweb�֘A�{�̒��ł͈ꉟ������
�����ǂ��������烌�r���[�͓�����ǁA
OWL�����܂����킩��Ȃ��l�̓I�X�X������
�v�������{�����[������̂ł�������w�ׂ���
�Ȃ���Ă�The Web Kanzaki���ĕ��n�߂��l�ɂ͓����Ă����₷��
�X���ɋ�������semweb�֘A�{�̒��ł͈ꉟ������
379 �FName_Not_Found�F05/01/12 00:39:36 ID:???
���z�c �����ƁARDF/OWL�֘A�ő��̓��发���o�Ă������K�v�Ȃ��B
�Ƃ��������ケ�����{�͏o�Ȃ��ł��傤�B
�R���e�i��reification��b�̈Ӗ��Ƃ��Aclass extension�Ƃ��̘b�܂ŐG����Ă��邵�A
(������) �d�l����ǂ�Ō����Ƃ��Ă����A�₤�ׂ��m������������������A
�ׂ₩�Ŏ����s������Ƃ��������B
(�l�I�ɂ́A��b�̐v�̏͂�HashSlashIssue (HashVsSlash)
�ɂ��G��ė~�����������ǁA�܂��A�債�����ł͂Ȃ��̂��ȁc�B)
�Ƃɂ����ARDF/OWL�Ɏ���o���Ȃ�K�g�̏��B
���Ȃ݂�>>264�̖{�Ɋւ��ẮA6�͂��������ǂ݂����OK�B
(5�͂̓c�[���ނɋ����̂���l�����B���͕̏͂s�v)�B
�Ƃ��������ケ�����{�͏o�Ȃ��ł��傤�B
�R���e�i��reification��b�̈Ӗ��Ƃ��Aclass extension�Ƃ��̘b�܂ŐG����Ă��邵�A
(������) �d�l����ǂ�Ō����Ƃ��Ă����A�₤�ׂ��m������������������A
�ׂ₩�Ŏ����s������Ƃ��������B
(�l�I�ɂ́A��b�̐v�̏͂�HashSlashIssue (HashVsSlash)
�ɂ��G��ė~�����������ǁA�܂��A�債�����ł͂Ȃ��̂��ȁc�B)
�Ƃɂ����ARDF/OWL�Ɏ���o���Ȃ�K�g�̏��B
���Ȃ݂�>>264�̖{�Ɋւ��ẮA6�͂��������ǂ݂����OK�B
(5�͂̓c�[���ނɋ����̂���l�����B���͕̏͂s�v)�B
380 �FName_Not_Found�F05/01/12 00:51:51 ID:???
���ƁA�C�Â������ׂ�typo�F
P129�̍Ō�̒i����s/dc:related/dc:relation/�ł��ˁB
�����Ƃǂ��ł��������ǁAP191�ɂ���Ӗ��K����2�̒i�������A
�Ō�̕��̌��ɋ�_���t���Ă��� (�ȏォ��Ȃ�K���ł����͍Ō�̕����ɋ�_�͂Ȃ�)
�̂ŁA�t�����Ǝv���܂� (�{���ɂǂ��ł������ł����c)�B
P129�̍Ō�̒i����s/dc:related/dc:relation/�ł��ˁB
�����Ƃǂ��ł��������ǁAP191�ɂ���Ӗ��K����2�̒i�������A
�Ō�̕��̌��ɋ�_���t���Ă��� (�ȏォ��Ȃ�K���ł����͍Ō�̕����ɋ�_�͂Ȃ�)
�̂ŁA�t�����Ǝv���܂� (�{���ɂǂ��ł������ł����c)�B
381 �FName_Not_Found�F05/01/12 00:55:17 ID:???
������AP203��
��ԏ�̕\�̉E��ɂ���uC�lj�����g���v���v�����̕\�Ɣ�ׂ�ƌ��H
��ԏ�̕\�̉E��ɂ���uC�lj�����g���v���v�����̕\�Ɣ�ׂ�ƌ��H
382 �FName_Not_Found�F05/01/12 15:17:31 ID:???
���r���[�ǂ����ł��B
�Ȃ�[���A�o��O����u�_�肳��̖{�����甃���v�Ƃ����������悭�����āA
�ق�Ƃ���Ǝv���Ă܂������A�{�����ۂ��ł��ˁB�������_�肳��B
�s���̏��X�ɂ����ς茩����Ȃ��̂ŁA�������Ăł��������Ǝv���܂��B
>>380-381
���̕ӂ͏o�ŎЂ��_�肳��Ƀ��[��Ƃ������ƁB
�Ȃ�[���A�o��O����u�_�肳��̖{�����甃���v�Ƃ����������悭�����āA
�ق�Ƃ���Ǝv���Ă܂������A�{�����ۂ��ł��ˁB�������_�肳��B
�s���̏��X�ɂ����ς茩����Ȃ��̂ŁA�������Ăł��������Ǝv���܂��B
>>380-381
���̕ӂ͏o�ŎЂ��_�肳��Ƀ��[��Ƃ������ƁB
�s���ɂȂ��Ƃ������Ă����Ȃ��炳������w�����Ō����܂����B
���������Ă����̂ŁA���ꂩ��ǂ܂��Ă��������܂��ł��B
���������Ă����̂ŁA���ꂩ��ǂ܂��Ă��������܂��ł��B
384 �FName_Not_Found�F05/01/14 06:11:36 ID:???
RDF Author�g���Ă���ǁA�C���|�[�g�����X�L�[�}��ۑ����Ă����Ȃ��̂Ɉނ�
�O���t�̂܂܍�ꂽ��y���ȂƎv���Ă�����A����ς肱�������c�[���͂����
��RDF/OWL�{�����ĂȂ����ց�
RDF Author
ttp://rdfweb.org/people/damian/RDFAuthor/
�I���g���W�[�G�f�B�^Protege
ttp://protege.stanford.edu/
# �ǂ�����vJavaVM
�O���t�̂܂܍�ꂽ��y���ȂƎv���Ă�����A����ς肱�������c�[���͂����
��RDF/OWL�{�����ĂȂ����ց�
RDF Author
ttp://rdfweb.org/people/damian/RDFAuthor/
�I���g���W�[�G�f�B�^Protege
ttp://protege.stanford.edu/
# �ǂ�����vJavaVM
385 �FName_Not_Found�F05/01/16 00:49:49 ID:???
�O���t���x���̕ҏW���ĕ֗��H
386 �FName_Not_Found�F05/01/16 07:28:23 ID:???
�����Ŏ����Ă݂��炢���̂�
387 �FName_Not_Found�F05/01/16 21:34:01 ID:???
�����v��Ȃ����畷���Ă���
388 �FName_Not_Found�F05/01/16 21:45:49 ID:???
�܂��l���ꂼ��ł��傤�B
389 �FName_Not_Found�F05/01/16 21:50:22 ID:???
�m����
�_�肳��Ƃ����ARSS1.1�̃h���t�g���o���݂��������ˁB
http://www.kanzaki.com/memo/2005/01/19-1
http://inamidst.com/rss1.1/
rdf:RDF�v�f�Ŋ����ĂȂ��̂��ȂςȊ����B
http://www.kanzaki.com/memo/2005/01/19-1
http://inamidst.com/rss1.1/
rdf:RDF�v�f�Ŋ����ĂȂ��̂��ȂςȊ����B
391 �FName_Not_Found�F05/01/19 13:52:55 ID:???
���O���c����orz
392 �FName_Not_Found�F05/01/20 23:17:13 ID:???
1.1�̘b�Ȃ�B
http://hail2u.net/blog/rss/rss_11.html
http://webweaver.g.hatena.ne.jp/kotastyle/20050118
http://hail2u.net/blog/rss/rss_11.html
http://webweaver.g.hatena.ne.jp/kotastyle/20050118
393 �F384�F05/01/22 02:21:47 ID:jX53S5sI
�ێ�
�_�莁�̖{���o���̂ɐ���オ��Ȃ���
>>385
�l�I�ɂ̓O���t���x���̕ҏW�́A����Ȏ�����Ă��邩���Ă��炢�ʓ|
����Web�f�U�w�Z�̍u�t�̃o�C�g����Ă���ǁA�����XML�n�Z�p�̍u����RDF/XML�̐����Ɏg������������
�e�[�u�����C�A�E�g���̕���f�l��d�l����ǂ܂Ȃ��X�g���N�^�[�ɂ͐}�������
�u�`�ł��Ă݂����ARSS�ɂ͂��������S�������݂���
RSS�����ă��[�_�ɓǂ܂���܂ł�����������u�������v�Ɛ���オ����
�ł��ꂩ��o����C�͖������낤�ȁB�����\�ȃG�f�B�^�̓o�ꂪ�҂���������
�_�莁�̖{���o���̂ɐ���オ��Ȃ���
>>385
�l�I�ɂ̓O���t���x���̕ҏW�́A����Ȏ�����Ă��邩���Ă��炢�ʓ|
����Web�f�U�w�Z�̍u�t�̃o�C�g����Ă���ǁA�����XML�n�Z�p�̍u����RDF/XML�̐����Ɏg������������
�e�[�u�����C�A�E�g���̕���f�l��d�l����ǂ܂Ȃ��X�g���N�^�[�ɂ͐}�������
�u�`�ł��Ă݂����ARSS�ɂ͂��������S�������݂���
RSS�����ă��[�_�ɓǂ܂���܂ł�����������u�������v�Ɛ���オ����
�ł��ꂩ��o����C�͖������낤�ȁB�����\�ȃG�f�B�^�̓o�ꂪ�҂���������
394 �FName_Not_Found�F05/01/23 00:43:38 ID:???
TabletPC�ŊW�}���i�`�������ɕҏW�ł���\�t�g�Ƃ�����Ɩʔ��������ȁB
395 �FName_Not_Found�F05/01/27 04:13:10 ID:+VMPlWUL
�z�[���y�[�W���쉤���g���A��A�̏����͏u�ԓI�ɉ����ł���B
�z�[���y�[�W���쉤���A�M���̃E�F�u�\�z�����I�ɐi�������邱�Ƃ����B
COMDEX����߂�21���I�̐��E��B���̏̍��͈ɒB�ł͂Ȃ��̂��B
�z�[���y�[�W���쉤���A�M���̃E�F�u�\�z�����I�ɐi�������邱�Ƃ����B
COMDEX����߂�21���I�̐��E��B���̏̍��͈ɒB�ł͂Ȃ��̂��B
396 �FName_Not_Found�F05/01/29 08:35:00 ID:???
>>395
�ʂ�Web�y�[�W����Ȃ��āARDB�̊Ǘ��Ƃ������������ǂ�
�ނ���v���W�F�N�g���̂̊Ǘ��A�_��W�̑��֊m�F�Ƃ�
�v���W�F�N�g�̐i�s��֘A�̖����Ɏg�����Ǝv���Ă����B
���������̏o����H
�ʂ�Web�y�[�W����Ȃ��āARDB�̊Ǘ��Ƃ������������ǂ�
�ނ���v���W�F�N�g���̂̊Ǘ��A�_��W�̑��֊m�F�Ƃ�
�v���W�F�N�g�̐i�s��֘A�̖����Ɏg�����Ǝv���Ă����B
���������̏o����H
397 �FName_Not_Found�F05/01/29 20:48:23 ID:???
>>396
����͈�A��age���ł��̂ŕ��u�肢�܂��B
����͈�A��age���ł��̂ŕ��u�肢�܂��B
398 �FName_Not_Found�F05/02/01 21:25:32 ID:Y1ztuw0x
�S�ĉ\�ł���B�z�[���y�[�W���쉤�ɕs�\�͂Ȃ��B
399 �FName_Not_Found�F05/02/02 18:15:03 ID:???
�N�����^�f�[�^���p�����T�C�g����������Ă���Ȃ�����
���ł��������g����������L�܂�悤�ȋC������
���ł��������g����������L�܂�悤�ȋC������
400 �FName_Not_Found�F05/02/02 18:42:26 ID:???
�����o�����̖@������
401 �FName_Not_Found�F05/02/02 20:42:01 ID:???
402 �FName_Not_Found�F05/02/02 22:18:10 ID:???
�ʂɃr�W�l�X���̒��҂���Ȃ����Ȃ��B
����ɁA�N�����Ȃ��Ȃ玩���ł�邵���Ȃ�����B
����ɁA�N�����Ȃ��Ȃ玩���ł�邵���Ȃ�����B
404 �FName_Not_Found�F05/02/03 18:26:48 ID:???
>>403
400�͉��Ȃ�
�A���J�[�̊ԈႢ�ʼn��Ɏ��₵�Ă��?��������c
�������Ă̂͗Ꭶ�ŁA���^�f�[�^�̔���₷���֗��Ȏg����(RSS�݂�����)���~�����ȂƎv�����Ď�����������
�딚�������玁��
400�͉��Ȃ�
�A���J�[�̊ԈႢ�ʼn��Ɏ��₵�Ă��?��������c
�������Ă̂͗Ꭶ�ŁA���^�f�[�^�̔���₷���֗��Ȏg����(RSS�݂�����)���~�����ȂƎv�����Ď�����������
�딚�������玁��
405 �FName_Not_Found�F05/02/03 20:09:53 ID:???
ITmedia�j���[�X�F�mWSJ�n �g�\�[�V�����^�M���O�h��Google���邩
http://www.itmedia.co.jp/news/articles/0502/02/news062.html
http://www.itmedia.co.jp/news/articles/0502/02/news062.html
>>404
����400�͉��Ȃ��c�c���O��399����Ȃ����H
����400�͉��Ȃ��c�c���O��399����Ȃ����H
407 �FName_Not_Found�F05/02/04 16:17:28 ID:???
imona�Ʒ��ޥJane�Ŋm�F������ڽ�Ԃ��S���Ⴄ�@orz
�킯�킩��Ȃ��̂Ŏӂ��Ă����܂��B���߂�Ȃ���
�ŁA���̓T�C�g�������]�X�Ə�����17�̏��q�����ł���낵��
�킯�킩��Ȃ��̂Ŏӂ��Ă����܂��B���߂�Ȃ���
�ŁA���̓T�C�g�������]�X�Ə�����17�̏��q�����ł���낵��
408 �FName_Not_Found�F05/02/04 16:44:55 ID:???
���ʂɃu���E�U�ŊJ���B���ƃp���c�ʐ^����������B
409 �FName_Not_Found�F05/02/05 00:17:31 ID:???
>>408
���O�͓]��ł������ł͂����Ȃ��z���ۂ��Ȃ�
���O�͓]��ł������ł͂����Ȃ��z���ۂ��Ȃ�
410 �FName_Not_Found�F05/02/08 07:01:51 ID:TlErer03
�z�[���y�[�W���쉤�Ȃ�A�p���c�ʐ^�����J�ł���B
411 �FName_Not_Found�F05/02/23 19:18:00 ID:???
RDF�͍D�������ARDF/XML�͌������B
412 �FName_Not_Found�F05/02/23 19:20:03 ID:???
���ɋL�q���@�����������H
413 �FName_Not_Found�F05/02/23 19:30:12 ID:???
Notation3, NTriples, Turtle, TriG, TriX, RXR...
414 �FName_Not_Found�F05/02/26 06:07:46 ID:???
415 �FName_Not_Found�F05/02/26 06:11:23 ID:???
>>411
�R��ARDF/XML���āA������XML�t�H�[�}�b�g�ɂ��傱���ƕt�������邾����RDF�O���t�����o����悤�ɂ��邽�߂̂��̂��Ǝv���Ă�����ǁA�Ⴄ���Ȃ��c�H
�R��ARDF/XML���āA������XML�t�H�[�}�b�g�ɂ��傱���ƕt�������邾����RDF�O���t�����o����悤�ɂ��邽�߂̂��̂��Ǝv���Ă�����ǁA�Ⴄ���Ȃ��c�H
416 �FName_Not_Found�F05/02/26 15:40:41 ID:???
�_�肳��Ƃ���RDF�����̃X�N���v�g���邯�ǁA
���ǂ�����ǂ������́H
RDF�Ȃ̗��_�Ƃ��g�����Ƃ����ڂ�
���ǂ�����ǂ������́H
RDF�Ȃ̗��_�Ƃ��g�����Ƃ����ڂ�
417 �FName_Not_Found�F05/02/26 16:01:07 ID:???
>>416
JavaScript�H
JavaScript�H
>>191
���o�f�X�^�A�X�}�\
���o�f�X�^�A�X�}�\
420 �FName_Not_Found�F05/02/26 17:56:48 ID:???
�Z�}���e�B�b�N�E�F�u�Ƃ�������m�����̂ŁA���̖ϑz�ɕt���������Ǝv�����B
�������E�E�E
�������E�E�E
422 �FName_Not_Found�F05/02/27 04:18:17 ID:???
�V����URI�X�L�[�����h���t�g��(���̂���RFC��)�o���炵��
���Ԏ����g��URI�X�L�[���Atag:��RFC��
http://www.kanzaki.com/memo/2005/02/25-1
The 'tag' URI scheme
http://www.taguri.org/07/draft-kindberg-tag-uri-07.html
cool URI�̘b�͒m��Ȃ����ǁA�N�ł���邱�Ƃ��ł��āA�Փ˂����Ȃ����Č����ɍl����ƒP������Ȃ��Ȃ�̂���
���Ԏ����g��URI�X�L�[���Atag:��RFC��
http://www.kanzaki.com/memo/2005/02/25-1
The 'tag' URI scheme
http://www.taguri.org/07/draft-kindberg-tag-uri-07.html
cool URI�̘b�͒m��Ȃ����ǁA�N�ł���邱�Ƃ��ł��āA�Փ˂����Ȃ����Č����ɍl����ƒP������Ȃ��Ȃ�̂���
423 �FName_Not_Found�F05/02/28 12:28:19 ID:???
Cool URIs(�ȉ���)�͎Љ�̃q�G�����L�[�\���ւ̒���ł��ȁB
���Ă����A�b��ɏ�����̂�tag�X�L�[���̏����ł��B
�Etag�Ƃ������O���ǂ����Bduri����ʖڂȂ̂��B�܂��A�����Ή��ł������̂�������Ȃ����ǁB
�E��������IRI���o������Atags SHOULD NOT be minted with percent-encoded parts
�Ȃ�Č���Ȃ��ŁA���߂�UTF-8�̃I�N�e�b�g����G���R�[�h�����ꍇ�̂�MAY���炢�ɂ��ė~�����B
�Ƃ͂����Atag���g���R���e�L�X�g���l����AURI�ւ̃}�b�s���O�������v��Ȃ��̂��Ȃ��B
�E���t�̌�/�����ȗ������Ƃ���01�Ɖ��߂����̂ɁA�������t�ŏȗ������̂Ƃ��Ȃ��̂�
�����łȂ� (���ʎq�Ƃ��ĈقȂ�) �Ƃ����̂͞B������������Ȃ��낤���B
UTC�Ɍ��肵�Ă܂ł���̂����A���������t��YYYY-MM-DD�Œ�̕����ǂ��̂ł́B
(�o���₷���̂��߂ɏȗ���F�߂Ă���悤�����ǁA���Ԃ̈Ӑ}�Ŏg�p���郆�[�U�����̗\��)
�E�\����authorityName�����K���������ƌ��߂Ă���̂ɁA����ɍ��v���Ȃ��Ă�
MUST NOT reject�Ƃ���������A��قǂ̃p�[�Z���g�G���R�[�h���A�\���㋖�����̂�
SHOULD NOT�ƌ������肷���т��Ȃ��X�^���X�͉��Ƃ��B���ꂼ��A�C�����͕�����Ȃ����Ȃ����B
�E���g��http��mailto�Ŏ��ʂ���邱�ƂɈ�a�����o����l�ł����
�u����tag����Ȃ��v�Ƃ��u����2005�N�ɂ������ʂ����悤�ȕ�������Ȃ��v
�Ƃ��������������҂����B�̂͋C�̂������B���Ă����tag�X�L�[���̖��ł͂Ȃ����B
�E�����A�J�E���g�����L���Ă������ԓ��ł̂ݓ��t���w��ł��邽��
���[���A�h���X��h���C���̏��L�҂��ς���Ă����v�Ƃ̂��Ƃ����ǁA
���͂�g��Ȃ��Ȃ��� (�ꍇ�ɂ���Ă͑��l�̂��̂ɂȂ���) �h���C������
���[���A�h���X�𗘗p���Ă܂ōP�v������������U���͒Ⴛ���ȋC���B
����ɁA���݂̏��L�҂������������ (���{��������u���쌠�N�Q�v�Ƃ�����ꂽ�肵��)�B
�l��URI��ς��邱�Ƃ�O��Ƃ���Web�f�U�C�����ĂȂ����̂��c�B
�}�t���߂̕s�����肾���ǁA��{�I�ȃA�C�f�B�A�͗ǂ��Ǝv����B
�Ƃ肠�����ARFC�ɂȂ�����A�����̃��[�J�����\�[�X�̎��ʎq������Ɏg�������Ȃ��c�B
���Ă����A�b��ɏ�����̂�tag�X�L�[���̏����ł��B
�Etag�Ƃ������O���ǂ����Bduri����ʖڂȂ̂��B�܂��A�����Ή��ł������̂�������Ȃ����ǁB
�E��������IRI���o������Atags SHOULD NOT be minted with percent-encoded parts
�Ȃ�Č���Ȃ��ŁA���߂�UTF-8�̃I�N�e�b�g����G���R�[�h�����ꍇ�̂�MAY���炢�ɂ��ė~�����B
�Ƃ͂����Atag���g���R���e�L�X�g���l����AURI�ւ̃}�b�s���O�������v��Ȃ��̂��Ȃ��B
�E���t�̌�/�����ȗ������Ƃ���01�Ɖ��߂����̂ɁA�������t�ŏȗ������̂Ƃ��Ȃ��̂�
�����łȂ� (���ʎq�Ƃ��ĈقȂ�) �Ƃ����̂͞B������������Ȃ��낤���B
UTC�Ɍ��肵�Ă܂ł���̂����A���������t��YYYY-MM-DD�Œ�̕����ǂ��̂ł́B
(�o���₷���̂��߂ɏȗ���F�߂Ă���悤�����ǁA���Ԃ̈Ӑ}�Ŏg�p���郆�[�U�����̗\��)
�E�\����authorityName�����K���������ƌ��߂Ă���̂ɁA����ɍ��v���Ȃ��Ă�
MUST NOT reject�Ƃ���������A��قǂ̃p�[�Z���g�G���R�[�h���A�\���㋖�����̂�
SHOULD NOT�ƌ������肷���т��Ȃ��X�^���X�͉��Ƃ��B���ꂼ��A�C�����͕�����Ȃ����Ȃ����B
�E���g��http��mailto�Ŏ��ʂ���邱�ƂɈ�a�����o����l�ł����
�u����tag����Ȃ��v�Ƃ��u����2005�N�ɂ������ʂ����悤�ȕ�������Ȃ��v
�Ƃ��������������҂����B�̂͋C�̂������B���Ă����tag�X�L�[���̖��ł͂Ȃ����B
�E�����A�J�E���g�����L���Ă������ԓ��ł̂ݓ��t���w��ł��邽��
���[���A�h���X��h���C���̏��L�҂��ς���Ă����v�Ƃ̂��Ƃ����ǁA
���͂�g��Ȃ��Ȃ��� (�ꍇ�ɂ���Ă͑��l�̂��̂ɂȂ���) �h���C������
���[���A�h���X�𗘗p���Ă܂ōP�v������������U���͒Ⴛ���ȋC���B
����ɁA���݂̏��L�҂������������ (���{��������u���쌠�N�Q�v�Ƃ�����ꂽ�肵��)�B
�l��URI��ς��邱�Ƃ�O��Ƃ���Web�f�U�C�����ĂȂ����̂��c�B
�}�t���߂̕s�����肾���ǁA��{�I�ȃA�C�f�B�A�͗ǂ��Ǝv����B
�Ƃ肠�����ARFC�ɂȂ�����A�����̃��[�J�����\�[�X�̎��ʎq������Ɏg�������Ȃ��c�B
424 �FName_Not_Found�F05/02/28 12:39:21 ID:???
>�l��URI��ς��邱�Ƃ�O��Ƃ���Web�݂��ĂȂ����̂��c�
�����������ł������܂����̖�Y
�����������ł������܂����̖�Y
425 �FName_Not_Found�F05/02/28 15:15:05 ID:???
���[���A�h���X�̐����K����"+"�������ĂȂ��݂���������
Gmail�̃G�C���A�X���g���Ȃ��̂��ȁB
Gmail�̃G�C���A�X���g���Ȃ��̂��ȁB
426 �FName_Not_Found�F05/03/03 13:36:41 ID:???
�Ⴆ�Ή摜��RDF�Amp3��RDF��������Ƃ���
������ǂ��g��������ł����H
hoge.png�ɂ�������hoge.png.rdf�Ƃ��ɂ��Ă����Ε֗��H
RDF�̗��O�݂����͕̂����邯�ǁA
���̎����Ƃ������g�������̂�������Ȃ��B
������ǂ��g��������ł����H
hoge.png�ɂ�������hoge.png.rdf�Ƃ��ɂ��Ă����Ε֗��H
RDF�̗��O�݂����͕̂����邯�ǁA
���̎����Ƃ������g�������̂�������Ȃ��B
427 �FName_Not_Found�F05/03/03 14:52:00 ID:???
RDF�����Ƃ������A���̃t�@�C���̃��^�f�[�^��RDF�ŕ\������A�̕����K����?
�g�����Ƃ����ƁA��������Ƃ��ɉ摜�Ȃ�t�@�C���������łȂ��T�C�Y�Ƃ��F�[�x�ŒT����Ƃ��B
�ܘ_�����̏���^�f�[�^������Ă��邱�Ƃ��O��ŁB
�����������Č����Ƃ��ꗗ�Ƃ�����Ƃ��ɏ��𑽂�������̂ŕ֗��Ȃ낤�Ȃ�
�Ƃ������炢�̗����������Ă��Ȃ��R��B���҂̎w�E�E���ӌ���҂B
�g�����Ƃ����ƁA��������Ƃ��ɉ摜�Ȃ�t�@�C���������łȂ��T�C�Y�Ƃ��F�[�x�ŒT����Ƃ��B
�ܘ_�����̏���^�f�[�^������Ă��邱�Ƃ��O��ŁB
�����������Č����Ƃ��ꗗ�Ƃ�����Ƃ��ɏ��𑽂�������̂ŕ֗��Ȃ낤�Ȃ�
�Ƃ������炢�̗����������Ă��Ȃ��R��B���҂̎w�E�E���ӌ���҂B
428 �FName_Not_Found�F05/03/03 19:43:51 ID:???
���^�f�[�^���З͂�����̂́A��ʂ̃f�[�^���t�B���^�����O���鎞�Ȗ�ŁB
���ʂ̃f�[�^�Ƀ|�c�|�c�ƃ��^�f�[�^��t���Ă��A
���ꂾ���ʼn�������I�Ȏ����o�����ł͂Ȃ��ł���B
�݂�Ȃ����^�f�[�^���L�q�����
�u2004�N�ȑO�ɔ��\���ꂽCC���C�Z���X�̊C�̎ʐ^�v
�Ƃ��w�肵��UA�ɒT��������悤�ɂȂ邩���m��Ȃ��B
�c�c�ƌ����b���Ǝv���Ă܂B
���ʂ̃f�[�^�Ƀ|�c�|�c�ƃ��^�f�[�^��t���Ă��A
���ꂾ���ʼn�������I�Ȏ����o�����ł͂Ȃ��ł���B
�݂�Ȃ����^�f�[�^���L�q�����
�u2004�N�ȑO�ɔ��\���ꂽCC���C�Z���X�̊C�̎ʐ^�v
�Ƃ��w�肵��UA�ɒT��������悤�ɂȂ邩���m��Ȃ��B
�c�c�ƌ����b���Ǝv���Ă܂B
429 �FName_Not_Found�F05/03/03 21:32:59 ID:???
�E�E�ERDF�����̂�߂邩�B
430 �FName_Not_Found�F05/03/03 23:03:36 ID:???
���������āAURN���r�炳�ꂽ���Ȃ����������̂���
431 �FName_Not_Found�F05/03/03 23:09:09 ID:???
>>429
> �E�E�ERDF�����̂�߂邩�B
�R����ǂ����悤����
�܂��n�b�L���Ƃ������̂͏o�Ă��Ȃ����A�����}�����Ƃ��Ȃ�
������������p��Ă��܂���������Ȃ���
> �E�E�ERDF�����̂�߂邩�B
�R����ǂ����悤����
�܂��n�b�L���Ƃ������̂͏o�Ă��Ȃ����A�����}�����Ƃ��Ȃ�
������������p��Ă��܂���������Ȃ���
432 �FName_Not_Found�F05/03/04 00:58:57 ID:???
�Ă������܂��Z�}���e�B�b�N�Ȃ�č\�z�i�K�������Ƃ��Ȃ���
���������Ă��Ȃ���! ���I�ɂ̓u���[���X�g�[�~���O���ł���
���������Ă��Ȃ���! ���I�ɂ̓u���[���X�g�[�~���O���ł���
433 �FName_Not_Found�F05/03/04 19:37:01 ID:???
RDF�ɏ�������炢�E���Ă����H
434 �FName_Not_Found�F05/03/07 12:20:53 ID:???
���b�c�Q�b�g �i�E�Z�}���e�B�b�N
435 �FName_Not_Found�F05/03/07 19:57:21 ID:???
���c�̓i�E�Z�}���e�B�b�N
436 �FName_Not_Found�F2005/03/23(��) 23:22:00 ID:???
tag�X�L�[�����ċ�̓I�ɂ�����RFC�ɂȂ邩���ăA�i�E���X�����̂���?
�g���Ă݂������LjꉞRFC�ɂȂ�܂ő҂Ƃ����Ǝv���āB
�g���Ă݂������LjꉞRFC�ɂȂ�܂ő҂Ƃ����Ǝv���āB
437 �FName_Not_Found�F2005/03/24(��) 00:14:49 ID:???
�C�F�[�C�I�Z�}���e�B�b�N�x�C�x�[
438 �FName_Not_Found�F2005/03/24(��) 19:18:47 ID:???
>>243 �̂� ttp://3110.sunnyday.jp/ ���ˁB
���ׂẴ��\�[�X�Ƀ��^�f�[�^�t���Ă�T�C�g�͏��߂Č����B
�f�U�C�����������A���̃T�C�g������ȕ��ɂ��������̂��B
���ׂẴ��\�[�X�Ƀ��^�f�[�^�t���Ă�T�C�g�͏��߂Č����B
�f�U�C�����������A���̃T�C�g������ȕ��ɂ��������̂��B
439 �FName_Not_Found�F2005/03/24(��) 22:23:31 ID:???
duri���ΏۂƂȂ鎞�Ԃ����肹�����\�[�X�̐�Ύ����w���悤�ɂȂ�̂Ɋ��҂��Ă����B
���ǁAduri�ɂ��Ă̓A�[�J�C�u����Ď��ۂɎQ�Əo���Ȃ��Ƒʖڂȕ����H
���ǁAduri�ɂ��Ă̓A�[�J�C�u����Ď��ۂɎQ�Əo���Ȃ��Ƒʖڂȕ����H
440 �FName_Not_Found�F2005/03/24(��) 22:27:49 ID:???
441 �FName_Not_Found�F2005/03/25(��) 00:29:02 ID:???
442 �FName_Not_Found�F2005/03/25(��) 07:19:34 ID:???
XLink�ͽڈႢ�����AXLink�ذ��ӱ��ع���ݖʔ�����
���A����܂�N���̂͂�߂悤��
���d���A��̘R�ꂪ��sڽ���Ă�邩��������
>>1-435�@�Ӂ[��
>>436�@�@�߁X����B���Ɏg���Ă�炵����
>>437�@�@Yeah baby!! kiss my ass.
>>438�@�@����܂莝���グ�ĎN���Ǝ������Ǝv���邼
>>439�@�@�ߋ��͂ǂ��ł������̂��Btag�������Ă���
>>440�@�@�@���Ă��Ȃ�B�܂��[�肵��
>>441�@�@2�����˂�̻�Ă��B���̽ڌ��Ă�?
���Ⴀ���x�݁B11���ɏo�Ђ����ǂȁ@orz
���A����܂�N���̂͂�߂悤��
���d���A��̘R�ꂪ��sڽ���Ă�邩��������
>>1-435�@�Ӂ[��
>>436�@�@�߁X����B���Ɏg���Ă�炵����
>>437�@�@Yeah baby!! kiss my ass.
>>438�@�@����܂莝���グ�ĎN���Ǝ������Ǝv���邼
>>439�@�@�ߋ��͂ǂ��ł������̂��Btag�������Ă���
>>440�@�@�@���Ă��Ȃ�B�܂��[�肵��
>>441�@�@2�����˂�̻�Ă��B���̽ڌ��Ă�?
���Ⴀ���x�݁B11���ɏo�Ђ����ǂȁ@orz
444 �FName_Not_Found�F2005/03/30(��) 22:28:23 ID:???
445 �FName_Not_Found�F2005/03/31(��) 00:34:46 ID:0JRUQEqC
>>444
����B�����Ď��X�V����Ƃ��ꏏ�ɂ���������āB�ԈႢ��F�߂�
<q>�������Ńe�X�g����(���Ă��炤)�ׂɃA�b�v���[�h���Ă��镶���ŁA����̂���͖�����ł���B</q>���Ă�
>>445
������w
����B�����Ď��X�V����Ƃ��ꏏ�ɂ���������āB�ԈႢ��F�߂�
<q>�������Ńe�X�g����(���Ă��炤)�ׂɃA�b�v���[�h���Ă��镶���ŁA����̂���͖�����ł���B</q>���Ă�
>>445
������w
447 �FName_Not_Found�F2005/03/31(��) 01:30:42 ID:???
�g�b�v�y�[�W���烊���N����Ă�̂ˁc
�|��͏�肢�̂� (���ނ��������)
ttp://mlv.lolipop.jp/W3C/docs/Potential.html
�|��͏�肢�̂� (���ނ��������)
ttp://mlv.lolipop.jp/W3C/docs/Potential.html
448 �FName_Not_Found�Flivedoor06/04/01(��) 22:05:09 ID:???
>>445
ttp://kanzaki.com/info/disclaimer#rights��
�u�I�����C���Ĕz�z�͂ł��܂���v���ĂȂ��Ă邩��A�ǂ��Ȃ��Ȃ��B
������Presented by�ŁA�����̊Ǘ��l�����Ă邱�ƂɂȂ��Ă�͍̂�������B
���������_�肳��ɒm�点���Ƃ���ŁA�Ώ�����]�T�Ȃ�Ă���̂��ȁB
�ɂ��Ă��A���[�������͂��ڂ��銄�Ƀy�[�W�͌��Â炢�ȁB
ttp://kanzaki.com/info/disclaimer#rights��
�u�I�����C���Ĕz�z�͂ł��܂���v���ĂȂ��Ă邩��A�ǂ��Ȃ��Ȃ��B
������Presented by�ŁA�����̊Ǘ��l�����Ă邱�ƂɂȂ��Ă�͍̂�������B
���������_�肳��ɒm�点���Ƃ���ŁA�Ώ�����]�T�Ȃ�Ă���̂��ȁB
�ɂ��Ă��A���[�������͂��ڂ��銄�Ƀy�[�W�͌��Â炢�ȁB
449 �FName_Not_Found�Flivedoor06/04/02(�y) 00:15:32 ID:???
�g�b�v�y�[�W���瓰�X�ƃp�N�������J���Ă�̂ȁB�����������Ƃ����v���Ȃ��B
����Ȏ����Ă�z���|����J���ĂĂ��M������B�|����S���p�N�����Ǝv���Ă��܂��B
����Ȏ����Ă�z���|����J���ĂĂ��M������B�|����S���p�N�����Ǝv���Ă��܂��B
450 �FName_Not_Found�F2005/04/03(��) 15:15:54 ID:???
�����ˁA�_�肳��Z���������ˁB���ꁫ
ESWC 2005 :: 2nd European Semantic Web Conference 2005
www.eswc2005.org
�Ɉψ���̈�l�Ƃ��ĎQ������݂����B
�Z�}���e�B�b�N�E�F�u�Ɋւ���v���O���~���O���[�N�V���b�v�̃y�[�W�ɏ����Ă��遫
tp://www.semanticscripting.org/SFSW2005/
ESWC 2005 :: 2nd European Semantic Web Conference 2005
www.eswc2005.org
�Ɉψ���̈�l�Ƃ��ĎQ������݂����B
�Z�}���e�B�b�N�E�F�u�Ɋւ���v���O���~���O���[�N�V���b�v�̃y�[�W�ɏ����Ă��遫
tp://www.semanticscripting.org/SFSW2005/
451 �FName_Not_Found�F2005/04/03(��) 15:21:58 ID:???
����H�ԈႦ���H
�ψ���̈�l�Ƃ��ĎQ������̂̓��[�N�V���bp�̕��ŁA
���ꂪESWC�Ƌ��ɂ����ۂ�
�ψ���̈�l�Ƃ��ĎQ������̂̓��[�N�V���bp�̕��ŁA
���ꂪESWC�Ƌ��ɂ����ۂ�
452 �FName_Not_Found�F2005/04/03(��) 19:23:05 ID:???
���̃X��������������������
�݂�Ȃ�2ch�̌�b��v���Ă݂Ȃ���?
foo��bar��baz�̘a�W�����Ƃ�
�Ⴆ��
<owl:Class rdf:ID="����">
<owl:sameClassAs rdf:resourse="&wn;Intercourse"/>
</owl:Class>
�݂����ȁB&wn;��Wordnet�̖��O���
���ɂȂ��Ă����Ǝv�����ǂ�?
�݂�Ȃ�2ch�̌�b��v���Ă݂Ȃ���?
foo��bar��baz�̘a�W�����Ƃ�
�Ⴆ��
<owl:Class rdf:ID="����">
<owl:sameClassAs rdf:resourse="&wn;Intercourse"/>
</owl:Class>
�݂����ȁB&wn;��Wordnet�̖��O���
���ɂȂ��Ă����Ǝv�����ǂ�?
453 �FName_Not_Found�F2005/04/06(��) 19:03:51 ID:???
�l�^�ɒN������Ă��Ȃ����炢��ꂽ�̂��c
���̔��̐l���Ȃ��Ȃ�����
���������̉�������2�T�𗘗p�������������̂ɋC�t����
���̔��̐l���Ȃ��Ȃ�����
���������̉�������2�T�𗘗p�������������̂ɋC�t����
454 �FName_Not_Found�F2005/04/06(��) 23:27:15 ID:???
���������ʂɂ܂��
455 �FName_Not_Found�F2005/04/07(��) 00:49:42 ID:???
>>454
����ϼ��(ry
����ϼ��(ry
456 �FName_Not_Found�F2005/04/07(��) 03:24:46 ID:???
�_�肽��̖{�����B
�_�肽��Ɏv�O�𑗂����B
�_�肽��Ɏv�O�𑗂����B
457 �FName_Not_Found�F2005/04/24(��) 02:40:22 ID:???
�_�莁�̓��������h�X�P�[�v�ʔ����ȁ[
��������Ȃ̍���Ă݂�����B�l�^������
��������Ȃ̍���Ă݂�����B�l�^������
458 �FName_Not_Found�F2005/04/24(��) 14:14:37 ID:???
>>457
�Ȃɂ���?
�Ȃɂ���?
459 �FName_Not_Found�F2005/04/25(��) 14:52:26 ID:???
460 �FName_Not_Found�F2005/05/15(��) 03:33:24 ID:???
�_�莁�̂�����Ƃ����������X�V����Ă��
461 �FName_Not_Found�F2005/06/19(��) 00:35:01 ID:y7h1ONnL
�uRDF�ƃZ�}���e�B�b�N��E�F�u�̌��݁v�X���C�h
ttp://www.kanzaki.com/works/2005/pub/0519ipsj.html
���炭�Ԃ�̍X�V�E�E�E
�l�^���Ȃ��E�E�E
ttp://www.kanzaki.com/works/2005/pub/0519ipsj.html
���炭�Ԃ�̍X�V�E�E�E
�l�^���Ȃ��E�E�E
462 �FName_Not_Found�F2005/06/19(��) 15:58:29 ID:???
������ƃl�^�����l������ɂ͂��邪�N�����Ȃ����
�����������m���������l��������
�d�l���o�����ĂȂ������p�I�ȗp�@�����܂薳�����炾�낤����
��{�I�Ƀc�[�����g���ď������̂�����c�[���̃��r���[�����������������
�����������m���������l��������
�d�l���o�����ĂȂ������p�I�ȗp�@�����܂薳�����炾�낤����
��{�I�Ƀc�[�����g���ď������̂�����c�[���̃��r���[�����������������
463 �FName_Not_Found�F2005/07/06(��) 01:15:20 ID:S/sOJ+fl BE:24102825-#
RDBMS�̃f�[�^�x�[�X�A�e�[�u���������̓��R�[�h��\���悤��
URI�̃X�L�[�����Ă����ł��傤���H
IANA�ɓo�^����Ă�����͓̂��e�Ȃ̂ł����A
���K�I�� X- �ړ��������Ďg���Ă���X�L�[���Ƃ��B
RDF �Œm����\������Ƃ��ARDF���\�[�X�Ƃ���
�f�[�^�x�[�X���̃��R�[�h���w���������Ƃ��ł���Ε֗����ȁA�Ǝv���āB
URI�̃X�L�[�����Ă����ł��傤���H
IANA�ɓo�^����Ă�����͓̂��e�Ȃ̂ł����A
���K�I�� X- �ړ��������Ďg���Ă���X�L�[���Ƃ��B
RDF �Œm����\������Ƃ��ARDF���\�[�X�Ƃ���
�f�[�^�x�[�X���̃��R�[�h���w���������Ƃ��ł���Ε֗����ȁA�Ǝv���āB
464 �FName_Not_Found�F2005/07/06(��) 01:45:06 ID:???
���ʂ�http�ł�����Ȃ��H
����ŁA����URI���瓖�Y���R�[�h����������o���X�N���v�g�ł��Ăяo���Ƃ��B
���łɎQ�l
�ߏ��URI�X�L�[���͗L�Q�ł���
ttp://www.kanzaki.com/memo/2004/02/28-3
����ŁA����URI���瓖�Y���R�[�h����������o���X�N���v�g�ł��Ăяo���Ƃ��B
���łɎQ�l
�ߏ��URI�X�L�[���͗L�Q�ł���
ttp://www.kanzaki.com/memo/2004/02/28-3
465 �FName_Not_Found�F2005/07/06(��) 12:46:25 ID:S/sOJ+fl
>>464�@�����Ă݂���������Ȃ��B
�X�L�[����HTTP��URI���g���Ƃ��A�C�����Ȃ���
����URI��HTTP�ł������Ă��G���[�ɂȂ�̂��C���������B
����Ⴛ��URI�ɂȂ����ƃR���e���c�Ȃ�d�|����
�u���Ă����������ǂ��B
�܂����O��ԂƂ��Ďg���Ƃ��ɂ�HTTP���v���g�R�������Ă̂�
�Y��Ă邩�炢�����ǁA�ł��S��I�ɂ�HTTP�Ŏn�܂��
HTTP�ł������ɂ��������Ȃ��ˁB
�t�ɁAHTTP�[�v���g�R���Ɖ��̊W���Ȃ��̂�
HTTP�Ŏn�܂�URI���g�����Ă̂ɒ�R�����āB���������H
�X�L�[����HTTP��URI���g���Ƃ��A�C�����Ȃ���
����URI��HTTP�ł������Ă��G���[�ɂȂ�̂��C���������B
����Ⴛ��URI�ɂȂ����ƃR���e���c�Ȃ�d�|����
�u���Ă����������ǂ��B
�܂����O��ԂƂ��Ďg���Ƃ��ɂ�HTTP���v���g�R�������Ă̂�
�Y��Ă邩�炢�����ǁA�ł��S��I�ɂ�HTTP�Ŏn�܂��
HTTP�ł������ɂ��������Ȃ��ˁB
�t�ɁAHTTP�[�v���g�R���Ɖ��̊W���Ȃ��̂�
HTTP�Ŏn�܂�URI���g�����Ă̂ɒ�R�����āB���������H
466 �FName_Not_Found�F2005/07/06(��) 12:55:33 ID:S/sOJ+fl BE:57845838-#
�������A�����ɉ��炩�̃h�L�������g�Ȃ�d�|���Ȃ��HTTP��
�������Ƃ��ł�����Ă������Ƃ́A���̖��O��Ԃ�������
�m�ۂ��Ă������Č����ؖ��ɂȂ��Ȃ��B
�[���Ƃ́A����ς�HTTP�Ŏn�܂�URI���g���Ȃ�
�����ɉ��炩�̃h�L�������g�Ȃ�d�|����u���Ă����ׂ����B
�������Ƃ��ł�����Ă������Ƃ́A���̖��O��Ԃ�������
�m�ۂ��Ă������Č����ؖ��ɂȂ��Ȃ��B
�[���Ƃ́A����ς�HTTP�Ŏn�܂�URI���g���Ȃ�
�����ɉ��炩�̃h�L�������g�Ȃ�d�|����u���Ă����ׂ����B
467 �FName_Not_Found�F2005/07/06(��) 12:57:03 ID:S/sOJ+fl
��W���̂��̂��Ă�������Ȃ��B
http://suika.fam.cx/~wakaba/-temp/wiki/wiki?URI%20scheme
�m���ɂ���Ȋ����ő��B������������E���Ȃ��Ȃ��ȁB
������IANA���Ǘ����Ȃ���Ȃ�Ȃ����Ă̂͂킩�邯�ǁA
����IANA�ŕW���Ƃ���Ă���X�L�[�����A�u�����v
���Ă̂����\����B���̂ւ�A�ǂ��l�����Ă���낤�B
http://suika.fam.cx/~wakaba/-temp/wiki/wiki?URI%20scheme
�m���ɂ���Ȋ����ő��B������������E���Ȃ��Ȃ��ȁB
������IANA���Ǘ����Ȃ���Ȃ�Ȃ����Ă̂͂킩�邯�ǁA
����IANA�ŕW���Ƃ���Ă���X�L�[�����A�u�����v
���Ă̂����\����B���̂ւ�A�ǂ��l�����Ă���낤�B
468 �FName_Not_Found�F2005/07/06(��) 13:06:45 ID:???
>>465
�m���ɐS��I�ɂ͓��ӁB
URI�̗��O�Ƃ��͂��Ă����A��͂�http��URI���g���Ƃ��́A
��\�[�X�Ȃ�200�Ŗ{�� or �X�N���v�g�o�R��DB�̒��g���A
����ȊO�̃��\�[�X�Ȃ�303�Ŋ֘A�����擾�ł���悤�ɂ��āA
HTTP�o�R�ŏ�����Ƃ������Ƃ��m���ɂ��Ă����ׂ����Ǝv���B
���̕K�v���Ȃ����tag�X�L�[�����Ȃ��B�܂�RFC�ɂ͂Ȃ��ĂȂ������B
�m���ɐS��I�ɂ͓��ӁB
URI�̗��O�Ƃ��͂��Ă����A��͂�http��URI���g���Ƃ��́A
��\�[�X�Ȃ�200�Ŗ{�� or �X�N���v�g�o�R��DB�̒��g���A
����ȊO�̃��\�[�X�Ȃ�303�Ŋ֘A�����擾�ł���悤�ɂ��āA
HTTP�o�R�ŏ�����Ƃ������Ƃ��m���ɂ��Ă����ׂ����Ǝv���B
���̕K�v���Ȃ����tag�X�L�[�����Ȃ��B�܂�RFC�ɂ͂Ȃ��ĂȂ������B
�����ƁA���̊Ԃɂ�2�������X���c�B466����Ɣ���Ă��܂��܂����ȁB
470 �FName_Not_Found�F2005/07/06(��) 14:39:12 ID:S/sOJ+fl
�ق��A���ꂩ�B����m������B
http://www.kanzaki.com/memo/2005/02/25-1
��������Aoai�@�X�L�[������W���ȂȁB
http://www.kanzaki.com/memo/2005/02/25-1
��������Aoai�@�X�L�[������W���ȂȁB
471 �FName_Not_Found�F2005/07/09(�y) 16:44:45 ID:???
472 �FName_Not_Found�F2005/07/11(��) 13:39:30 ID:+kvQxwz7
���{�̒n�����/�n�����Ɋւ���I���g���W�[���Ă������H
���ł�OWL�ŋL�q����Ă�����̂�����Ȃ�A
�n���������^�ɂ���ɂ������Ă��̓�����ӂ��g�����Ǝv�����ǁB
���ł�OWL�ŋL�q����Ă�����̂�����Ȃ�A
�n���������^�ɂ���ɂ������Ă��̓�����ӂ��g�����Ǝv�����ǁB
473 �FName_Not_Found�F2005/07/11(��) 14:13:40 ID:+kvQxwz7
�I���g���W�[�A�V�\�[���X�A�����W�ڕ\�̈Ⴂ���A
���ꂩ�܂Ƃ߂Ă���B
���ꂩ�܂Ƃ߂Ă���B
474 �FName_Not_Found�F2005/07/11(��) 14:40:00 ID:+kvQxwz7
http://www.bekkoame.ne.jp/~y_usui/search/sub_note.html
�Ƃ肠��������Ȋ����Ő������Ă���T�C�g�������Ă��ꂨ�܂���B
�R��݂����ȃv���O���}�ɁA�}���ُ��w����̐��p��
�o���o���̎d�l�������Ȃ�n����Ă��킩���E�E�E�E
�Ƃ肠��������Ȋ����Ő������Ă���T�C�g�������Ă��ꂨ�܂���B
�R��݂����ȃv���O���}�ɁA�}���ُ��w����̐��p��
�o���o���̎d�l�������Ȃ�n����Ă��킩���E�E�E�E
475 �FName_Not_Found�F2005/07/11(��) 15:44:38 ID:???
�����Ȃ��Ǝv�� or �ނ����ق����悢�Ǝv���B
�v���O���}�Ȃ玩���Œ��ׂ邱�Ƃ��炢�o���邾�낤�B
�v���O���}�Ȃ玩���Œ��ׂ邱�Ƃ��炢�o���邾�낤�B
476 �FName_Not_Found�F2005/07/12(��) 18:48:50 ID:???
XMLNews�ɂ��ē��{��ł킩��₷��������Ă�T�C�g���Ă���H
�ނ������ǂ悤�킩�����
�ނ������ǂ悤�킩�����
477 �FName_Not_Found�F2005/07/12(��) 21:17:53 ID:???
478 �FName_Not_Found�F2005/07/16(�y) 17:19:04 ID:???
479 �FName_Not_Found�F2005/07/27(��) 07:00:59 ID:???
���܂����I��10���[�߂��ł���Ă������
�����悩����orz
��10����v���O�����F�Z�}���e�B�b�N�E�F�u�ƃI���g���W�[������
http://www.jaist.ac.jp/ks/labs/kbs-lab/sig-swo/programs/A501.htm
�����悩����orz
��10����v���O�����F�Z�}���e�B�b�N�E�F�u�ƃI���g���W�[������
http://www.jaist.ac.jp/ks/labs/kbs-lab/sig-swo/programs/A501.htm
480 �FName_Not_Found�F2005/07/30(�y) 10:44:02 ID:???
FOAF�X�L�[�}���X�V���ꂽ��
��������OWL�������ς��c
FOAF Vocabulary Specification
http://xmlns.com/foaf/0.1/
��������OWL�������ς��c
FOAF Vocabulary Specification
http://xmlns.com/foaf/0.1/
481 �FName_Not_Found�F2005/08/01(��) 19:17:57 ID:???
482 �FName_Not_Found�F2005/08/02(��) 19:47:26 ID:???
�u���O��̈ӌ���^��W���v�ȃj���A���X����Ȃ��H��
483 �FName_Not_Found�F2005/08/02(��) 21:42:31 ID:???
�m���ɂȁA
�Ȃ�ML�̕��ł͒����X���b�h�������Ă�݂�������
�Ȃ�ML�̕��ł͒����X���b�h�������Ă�݂�������
484 �FName_Not_Found�F2005/08/16(��) 10:55:16 ID:???
microformats�͂ǂ���H
485 �FName_Not_Found�F2005/08/16(��) 13:43:30 ID:???
�L���[�A�v�����o�Ȃ���A�A�[���[�A�_�v�^�̊ߋ��Ȃ����Ȃ��B
486 �FName_Not_Found�F2005/08/16(��) 13:44:53 ID:???
���āA����͂ǂ̋Z�p�ł��������B
487 �FName_Not_Found�F2005/08/16(��) 20:29:54 ID:???
strict�X���ł悭������Aid/class������HTML�ɂƂ��Ă̈Ӗ���A
���邢��RDF�� intended meaning �ɂ��Ă��A
���� shared meaning (�Ӗ��̋��L (�̒��x)) �����m�������̂ȂƎv�������N���B
���邢��RDF�� intended meaning �ɂ��Ă��A
���� shared meaning (�Ӗ��̋��L (�̒��x)) �����m�������̂ȂƎv�������N���B
488 �FName_Not_Found�F2005/08/20(�y) 16:10:47 ID:???
�܂��������̒ʂ�Ȃ̂����A
�����͖����Ɏ����~�X�������A�Ӗ��̋��L�ȑO�̖�肪�܂�����
�Ƃɂ���RSS�͓���I�Ȗ������ʂ����Ă��ꂽ���ǁA�����ƕʂ̖���age�Ă��܂����悤�Ȗ����c
�����͖����Ɏ����~�X�������A�Ӗ��̋��L�ȑO�̖�肪�܂�����
�Ƃɂ���RSS�͓���I�Ȗ������ʂ����Ă��ꂽ���ǁA�����ƕʂ̖���age�Ă��܂����悤�Ȗ����c
489 �FName_Not_Found�F2005/08/21(��) 02:10:18 ID:???
RSS 2.0�Ɉ��������A3.0��RDF�x�[�X����Ȃ��ȁB
�܂����^�f�[�^���ӎ����ď����ꂽRSS�Ȃ�ĊF����������Ȃ����B
�܂����^�f�[�^���ӎ����ď����ꂽRSS�Ȃ�ĊF����������Ȃ����B
490 �FName_Not_Found�F2005/08/21(��) 02:17:55 ID:???
3.0���ăl�^�̂����Ȃ��āH
491 �FName_Not_Found�F2005/08/25(��) 18:26:46 ID:???
Arron���̖���������A�O�O���ăg�b�v�̂���l�^�������H
492 �FName_Not_Found�F2005/08/25(��) 18:27:50 ID:???
�����āA���ꖼ�O���c
s/Arron/Swartz/
s/Arron/Swartz/
493 �FName_Not_Found�F2005/09/09(��) 11:35:22 ID:???
���A�{���Ƀl�^����Ȃ�3.0���Ă���̂ˁB�m������B2.0�̌�p�Ȃ̂��B
494 �FName_Not_Found�F2005/09/24(�y) 07:38:05 ID:???
>>493
�����Ȃ́H
�����Ȃ́H
495 �FName_Not_Found�F2005/10/08(�y) 21:48:41 ID:???
�I���g���W�Z�p����@�E�F�u�I���g���W�Ƃn�v�k
ttp://www.tdupress.jp/cgi-bin/html.cgi?i=ISBN4-501-54010-9
����Ȗ{���o�Ă���̂ɂ��Â����̂�����ǁA�N�����r���[���ڂ�B
�킵�͐_�肳��̖{�����ŏ���������Ȃ��Ĉ݂������ꂽ...
ttp://www.tdupress.jp/cgi-bin/html.cgi?i=ISBN4-501-54010-9
����Ȗ{���o�Ă���̂ɂ��Â����̂�����ǁA�N�����r���[���ڂ�B
�킵�͐_�肳��̖{�����ŏ���������Ȃ��Ĉ݂������ꂽ...
496 �FName_Not_Found�F2005/10/08(�y) 22:01:21 ID:???
497 �FName_Not_Found�F2005/10/19(��) 01:14:20 ID:???
�R���e���g�E�l�S�V�G�[�V������RDF��URI�Q�Ƃɏڂ����l���܂��H
URI�Q�Ƃ͂��ꂪ�ЂƂ̃��\�[�X�����ʂ��邱�ƂɂȂ��Ă���Ǝv���̂ł����A
�R���e���g�E�l�S�V�G�[�V�����ł͂ЂƂ�URI�ɕ����̕��������т��邱�Ƃ��ł��܂��B
http://example.jp/doc �́Adoc.ja.html, doc.ja.xml, doc.en.html, doc.en.xml�̎l����I���Ƃ��A
dc:language��dc:format�Adcq:isFormatOf�Ȃǂ͂ǂ̂悤�ɋL�q����̂��]�܂����̂ł��傤���B
URI�Q�Ƃ͂��ꂪ�ЂƂ̃��\�[�X�����ʂ��邱�ƂɂȂ��Ă���Ǝv���̂ł����A
�R���e���g�E�l�S�V�G�[�V�����ł͂ЂƂ�URI�ɕ����̕��������т��邱�Ƃ��ł��܂��B
http://example.jp/doc �́Adoc.ja.html, doc.ja.xml, doc.en.html, doc.en.xml�̎l����I���Ƃ��A
dc:language��dc:format�Adcq:isFormatOf�Ȃǂ͂ǂ̂悤�ɋL�q����̂��]�܂����̂ł��傤���B
498 �FName_Not_Found�F2005/10/19(��) 13:51:12 ID:???
>>497
> URI�Q�Ƃ͂��ꂪ�ЂƂ̃��\�[�X�����ʂ��邱�ƂɂȂ��Ă���Ǝv��
���ʂ���u���\�[�X�v�͂ЂƂł����́u���\�[�X�v�̓��e����ɓ���ł���K�v�͂Ȃ��B
�����������炻�������ꍇ�͂�������dc:language�Ȃǂ��w�肵�Ȃ��Ǝv���B
> URI�Q�Ƃ͂��ꂪ�ЂƂ̃��\�[�X�����ʂ��邱�ƂɂȂ��Ă���Ǝv��
���ʂ���u���\�[�X�v�͂ЂƂł����́u���\�[�X�v�̓��e����ɓ���ł���K�v�͂Ȃ��B
�����������炻�������ꍇ�͂�������dc:language�Ȃǂ��w�肵�Ȃ��Ǝv���B
499 �FName_Not_Found�F2005/10/20(��) 12:25:51 ID:???
>>497
URI�Ƃ���ɑΉ����郊�\�[�X�͑��Α�����B
�܂����͈�Έꂾ���ǂˁB
��Α��Ȃ�R���e���g�l�S�V�G�[�V�������A
���Έ�Ȃ�~���[����Ƃ��ċ������邩�ȁB
URI�Ƃ���ɑΉ����郊�\�[�X�͑��Α�����B
�܂����͈�Έꂾ���ǂˁB
��Α��Ȃ�R���e���g�l�S�V�G�[�V�������A
���Έ�Ȃ�~���[����Ƃ��ċ������邩�ȁB
500 �FName_Not_Found�F2005/10/22(�y) 16:21:09 ID:???
>>499
����͕����I�Șb�ŁA�_���I�ɂ͈��URI�͈�̃��\�[�X�݂̂����ʂ����B
����͕����I�Șb�ŁA�_���I�ɂ͈��URI�͈�̃��\�[�X�݂̂����ʂ����B
501 �FName_Not_Found�F2005/10/25(��) 07:36:10 ID:x2B2hdU7
RDF�Ƃ������AXML���̂��̂Ɋւ��鎿��Ȃ�ł����E�E�E
(X)HTML�Ő錾����Ă�����̎Q�Ƃ�import����ɂ͂ǂ�����悢�̂ł��傤���H
�Ƃ����̂��A�t�@�C������ ♥ �Ȃǂ��܂܂�Ă����
�u���錾�̎��̂��Q�Ƃ��悤�Ƃ��܂����v�ƂȂ邩��ł��B
& �� �������ς����� & �ɒu�������邱�Ƃ�
�Ƃ肠�����G���[�͉���ł����ł����A��͂肠��̂܂܂̃e�L�X�g��\�����������̂ŁB
(X)HTML�Ő錾����Ă�����̎Q�Ƃ�import����ɂ͂ǂ�����悢�̂ł��傤���H
�Ƃ����̂��A�t�@�C������ ♥ �Ȃǂ��܂܂�Ă����
�u���錾�̎��̂��Q�Ƃ��悤�Ƃ��܂����v�ƂȂ邩��ł��B
& �� �������ς����� & �ɒu�������邱�Ƃ�
�Ƃ肠�����G���[�͉���ł����ł����A��͂肠��̂܂܂̃e�L�X�g��\�����������̂ŁB
502 �FName_Not_Found�F2005/10/25(��) 11:17:43 ID:???
HTML4 �Ɋւ��Ă͂��� http://www.w3.org/TR/html4/sgml/entities.html
503 �FName_Not_Found�F2005/10/25(��) 11:21:58 ID:???
>>501
������amp;�ɒu��������͈̂Ӗ����S������Ă��܂��̂ł�߂����������B
(���ꂾ�ƃn�[�g�}�[�N����Ȃ���"��hearts;"�Ƃ����������\�����Ă邱�ƂɂȂ�)
�P�Ƀn�[�g�}�[�N��\�����������Ȃ�A���l�����Q�Ƃɂ���̂��ȒP�B
��hearts; �� ��#9829; �ƈꏏ�B
http://www.eris.ais.ne.jp/~haza/html/numref
�������́AUTF-8�Ȃ當���������Ȃ����璼�ɏ����Ă����͂Ȃ���B
������amp;�ɒu��������͈̂Ӗ����S������Ă��܂��̂ł�߂����������B
(���ꂾ�ƃn�[�g�}�[�N����Ȃ���"��hearts;"�Ƃ����������\�����Ă邱�ƂɂȂ�)
�P�Ƀn�[�g�}�[�N��\�����������Ȃ�A���l�����Q�Ƃɂ���̂��ȒP�B
��hearts; �� ��#9829; �ƈꏏ�B
http://www.eris.ais.ne.jp/~haza/html/numref
�������́AUTF-8�Ȃ當���������Ȃ����璼�ɏ����Ă����͂Ȃ���B
504 �FName_Not_Found�F2005/10/25(��) 11:24:59 ID:???
>>501
�������傢�⑫�B�ꉞ����̒ʂ�̕��@�ł��\�ŁA�`����
<!DOCTYPE RDF [
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1 for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent"> %HTMLlat1;
<!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
<!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent"> %HTMLspecial;
]>
�Ƃ������u�d�l��́v��hearts;�Ƃ����g����悤�ɂȂ��B
�������A���ۂɊO��DTD��ǂݍ���ł��炦�邩��
�v���Z�b�T�̎����Ɉˑ����邩�炠�܂肨���߂��Ȃ��B
�������傢�⑫�B�ꉞ����̒ʂ�̕��@�ł��\�ŁA�`����
<!DOCTYPE RDF [
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1 for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent"> %HTMLlat1;
<!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
<!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent"> %HTMLspecial;
]>
�Ƃ������u�d�l��́v��hearts;�Ƃ����g����悤�ɂȂ��B
�������A���ۂɊO��DTD��ǂݍ���ł��炦�邩��
�v���Z�b�T�̎����Ɉˑ����邩�炠�܂肨���߂��Ȃ��B
505 �F501�F2005/10/28(��) 11:49:22 ID:EuavcBC7
>>504
���肪�Ƃ��������܂��B
�قƂ�ǂ�RSS���[�_�[�́A���̋L�q�������邱�Ƃœ����Ă���܂����B
------------------------------------
<!DOCTYPE rdf:RDF [
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1 for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent"> %HTMLlat1;
<!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
<!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent"> %HTMLspecial;
]>
------------------------------------
�����A�ꕔ��RSS���[�_�[�ł�
�u�s����XML�ł��B
�v�f 'rdf:RDF' �͎g�p����Ă��܂����ADTD �܂��̓X�L�[�}�ł͐錾����Ă��܂���B�v
�Ƃ����G���[���������܂��B�ǂ����A
�u�h�L�������g�^�C�v���錾����Ă���(=���`��XML�ł͂Ȃ�)�̂ɁA
���̒��� rdf:RDF �Ɋւ��镶�@���K�肳��ĂȂ�����A�����͕s�����I�v
�Ɣ��f����Ă���炵���ł��B
�Ƃ����킯�ŁA�ꕔ�̃��[�_�[���x���x���[��������(���������ꓖ����I�ȉ����͍D������Ȃ��ł���)
���@������܂�����A�����Ă��������B���肢���܂��B
���肪�Ƃ��������܂��B
�قƂ�ǂ�RSS���[�_�[�́A���̋L�q�������邱�Ƃœ����Ă���܂����B
------------------------------------
<!DOCTYPE rdf:RDF [
<!ENTITY % HTMLlat1 PUBLIC "-//W3C//ENTITIES Latin 1 for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-lat1.ent"> %HTMLlat1;
<!ENTITY % HTMLsymbol PUBLIC "-//W3C//ENTITIES Symbols for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-symbol.ent"> %HTMLsymbol;
<!ENTITY % HTMLspecial PUBLIC "-//W3C//ENTITIES Special for XHTML//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml-special.ent"> %HTMLspecial;
]>
------------------------------------
�����A�ꕔ��RSS���[�_�[�ł�
�u�s����XML�ł��B
�v�f 'rdf:RDF' �͎g�p����Ă��܂����ADTD �܂��̓X�L�[�}�ł͐錾����Ă��܂���B�v
�Ƃ����G���[���������܂��B�ǂ����A
�u�h�L�������g�^�C�v���錾����Ă���(=���`��XML�ł͂Ȃ�)�̂ɁA
���̒��� rdf:RDF �Ɋւ��镶�@���K�肳��ĂȂ�����A�����͕s�����I�v
�Ɣ��f����Ă���炵���ł��B
�Ƃ����킯�ŁA�ꕔ�̃��[�_�[���x���x���[��������(���������ꓖ����I�ȉ����͍D������Ȃ��ł���)
���@������܂�����A�����Ă��������B���肢���܂��B
506 �FName_Not_Found�F2005/10/28(��) 12:26:32 ID:???
>>505
���낻��XML�X���ֈړ����邱�Ƃ������߂��悤�B
XML�g���̃X�� 2.0
http://pc8.2ch.net/test/read.cgi/hp/1057198990/
���낻��XML�X���ֈړ����邱�Ƃ������߂��悤�B
XML�g���̃X�� 2.0
http://pc8.2ch.net/test/read.cgi/hp/1057198990/
507 �FName_Not_Found�F2005/12/04(��) 06:09:50 ID:kzYBuS0U
�N������RDF�̃N�G�����ꋳ���Ă���B�����SPARQL�H
508 �FName_Not_Found�F2005/12/08(��) 13:02:44 ID:???
tag scheme��RFC4151�ɂȂ��Ă��̂��B
authorityName�Ɠ��t�̋�肪�R���}���Ă̂��ߑR�Ƃ��Ȃ��B
authorityName�Ɠ��t�̋�肪�R���}���Ă̂��ߑR�Ƃ��Ȃ��B
509 �FName_Not_Found�F2005/12/27(��) 21:18:13 ID:???
���ɊՎU�Ƃ��Ă܂��ȁB
510 �FName_Not_Found�F2005/12/27(��) 21:30:06 ID:???
�l�����̂��B
511 �FName_Not_Found�F2005/12/27(��) 21:34:45 ID:???
���ɑ̂ł͂���܂����B
512 �FName_Not_Found�F2006/01/03(��) 20:36:36 ID:Cgnf4KoK
application/rss+xml��������W���H
IANA�ɂ�application/atom+xml��application/rdf+xml�����Ȃ�����
W3C��Home�ł͓��X��application/rss+xml�g���Ă�ˁB
IANA�ɂ�application/atom+xml��application/rdf+xml�����Ȃ�����
W3C��Home�ł͓��X��application/rss+xml�g���Ă�ˁB
513 �FName_Not_Found�F2006/01/06(��) 21:06:09 ID:???
Protégé�g���Ă�l����H
http://protege.stanford.edu/
�A�v���� C# �ŏ����������ǁA
Protégé���Ƃ� SOAP �������Őڑ����邵���Ȃ��̂��ȁH
�����Ƃ���y�ɂȂ����@�Ȃ��H
http://protege.stanford.edu/
�A�v���� C# �ŏ����������ǁA
Protégé���Ƃ� SOAP �������Őڑ����邵���Ȃ��̂��ȁH
�����Ƃ���y�ɂȂ����@�Ȃ��H
514 �FName_Not_Found�F2006/01/06(��) 21:14:35 ID:???
515 �FName_Not_Found�F2006/01/06(��) 21:21:30 ID:???
>>514 �ʂɖڐV�������e�ł͂Ȃ��Ǝv�����B
����A�ł��Ȃ��Z�}�E�F�u�̂��ƌ�����Ă�l�������C����������c
517 �FName_Not_Found�F2006/01/06(��) 21:38:32 ID:???
���𗝗R�ɁH ���ɂ��̃X���ŁB
518 �FName_Not_Found�F2006/01/06(��) 21:42:27 ID:???
>>517 �܂����������B
519 �FName_Not_Found�F2006/01/06(��) 21:55:53 ID:???
�܂�514�Ɍ����т��Ă������Ă��ƂŁB
���[
�m���ɂ��̃X���ł�����͂�̂͂ւт������������Ă���
����A
�X�}�\
�m���ɂ��̃X���ł�����͂�̂͂ւт������������Ă���
����A
�X�}�\
521 �FName_Not_Found�F2006/01/07(�y) 00:06:01 ID:???
�ւт����H
522 �FName_Not_Found�F2006/01/07(�y) 01:20:51 ID:???
�֑��H
523 �FName_Not_Found�F2006/01/07(�y) 19:39:32 ID:???
�ŋ߂̃K�L�͎֑����m��Ȃ��̂��B
�Ǝv������A�ϊ��ł����ɏo�Ă��Ȃ��ȁH
�u�w�r�A���v���ĉ�����E�E�E
�Ǝv������A�ϊ��ł����ɏo�Ă��Ȃ��ȁH
�u�w�r�A���v���ĉ�����E�E�E
524 �FName_Not_Found�F2006/01/07(�y) 21:57:16 ID:???
�ȂZ�}�E�F�u��
525 �FName_Not_Found�F2006/01/07(�y) 22:00:15 ID:???
�ւт����̂��Ƃ���B
526 �FName_Not_Found�F2006/01/08(��) 06:48:32 ID:???
�ւт����i���Ȃ����ϊ��ł��Ȃ���
���Ⴛ���i���Ȃ����ϊ��ł��Ȃ���
�������i���Ȃ����ϊ��ł��邗
���Ⴛ���i���Ȃ����ϊ��ł��Ȃ���
�������i���Ȃ����ϊ��ł��邗
527 �FName_Not_Found�F2006/01/13(��) 19:48:08 ID:3JH+HxXl
http://xmlns.com/wordnet/1.6/
�����̖��O��Ԃɍڂ��Ă�P��ꗗ�݂����̂��Č���Ȃ��̂���
�����̖��O��Ԃɍڂ��Ă�P��ꗗ�݂����̂��Č���Ȃ��̂���
528 �FName_Not_Found�F2006/01/15(��) 04:07:55 ID:???
>>527
Wordnet�C���X�g�[��������?
Wordnet�C���X�g�[��������?
529 �FName_Not_Found�F2006/01/27(��) 12:44:09 ID:QyM9Xbmg
OWL�ɂ�����N���X�̑��d�p���̓T�^�I�ȗ���Ă���܂��H
530 �FName_Not_Found�F2006/01/27(��) 16:04:19 ID:???
>>529
���d�p���Ƃ����p��͂Ȃ������C�����邯�ǁA
���ʂ�rdfs:subClassOf�������A�˂�Ƃ��A���������̂Ƃ��B
ttp://www.w3.org/TR/2004/REC-owl-guide-20040210/#ComplexClasses
���d�p���Ƃ����p��͂Ȃ������C�����邯�ǁA
���ʂ�rdfs:subClassOf�������A�˂�Ƃ��A���������̂Ƃ��B
ttp://www.w3.org/TR/2004/REC-owl-guide-20040210/#ComplexClasses
531 �FName_Not_Found�F2006/01/28(�y) 00:23:31 ID:???
�C�_���I������������SW�Ɋւ�邱�Ƃ��Ȃ��Ȃ�
SW�̓}�W�Ŏ���ł���
SW�̓}�W�Ŏ���ł���
532 �FName_Not_Found�F2006/01/28(�y) 11:05:48 ID:???
���������B���̌������ʂ������J���Ď���ł���B
533 �FName_Not_Found�F2006/01/28(�y) 11:14:35 ID:NwIFECR5
�������̂ӂ�������
�ł����M�����ׂ�
��������Ȃ����I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_ʁ@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@('(߁�߁��@�Ȃ����I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�@�@�q�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�R_)
�ł����M�����ׂ�
��������Ȃ����I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_ʁ@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@('(߁�߁��@�Ȃ����I
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�@�@�q�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�R�R_)
534 �FName_Not_Found�F2006/01/28(�y) 13:57:06 ID:???
�����������ʂ𗬗p�i���p�j���Ă�邩����J����
535 �FName_Not_Found�F2006/03/14(��) 13:11:11 ID:???
RDF/OWL�������ɂȂ��Ă���2�N���c�B
536 �FName_Not_Found�F2006/03/25(�y) 10:23:29 ID:yBVxOdqW
�W�W
537 �FName_Not_Found�F2006/03/25(�y) 21:33:17 ID:???
Image Annotation on the Semantic Web�@- W3C Working Draft 22 March 2006
http://www.w3.org/TR/2006/WD-swbp-image-annotation-20060322/
http://www.w3.org/TR/2006/WD-swbp-image-annotation-20060322/
538 �FName_Not_Found�F2006/03/26(��) 00:33:12 ID:???
539 �FName_Not_Found�F2006/03/26(��) 09:00:14 ID:sQzDw1iC
C++ �ŃZ�}���e�B�b�N�E�F�u��������̂ɕ֗��ȃ��C�u�������ĉ��H
540 �FName_Not_Found�F2006/03/26(��) 10:54:25 ID:???
Java�~���炢������Ȃ�
541 �FName_Not_Found�F2006/03/26(��) 11:13:53 ID:sQzDw1iC
Java �Ȃ炢�낢��ƕ֗����C�u����������ǂˁB
C++ �ł����肽�����Ƃ��������ŁB
C++ �ł����肽�����Ƃ��������ŁB
542 �FName_Not_Found�F2006/03/26(��) 20:38:58 ID:???
Objective-C�ł����肽�����č����̏u�Ԏv���Ă�B
543 �FName_Not_Found�F2006/03/27(��) 09:23:41 ID:???
544 �FName_Not_Found�F2006/03/27(��) 13:16:18 ID:???
currently C#, Java, Perl, PHP, Obj-C, Python, Ruby and Tcl.
���āE�E�E C# �܂ł���̂� C/C++ �͖����̂���B
���āE�E�E C# �܂ł���̂� C/C++ �͖����̂���B
545 �FName_Not_Found�F2006/03/27(��) 13:18:49 ID:???
Modular, object based libraries written in C.
>>543 �͂�����N���X���C�u�����ɂ܂Ƃ߂Ă�����Č����Ă��ł́H
>>543 �͂�����N���X���C�u�����ɂ܂Ƃ߂Ă�����Č����Ă��ł́H
547 �FName_Not_Found�F2006/04/03(��) 15:30:17 ID:???
Obj-C����̂��A�g���Ă݂悤���ȁB
548 �FName_Not_Found�F2006/04/03(��) 21:05:50 ID:???
���ȊO��Objective-C�g���z������ȉߑa�X���ɂ���Ƃ͎v������B
549 �FName_Not_Found�F2006/04/04(��) 13:41:06 ID:???
>>548
�ǂ������w�����Ƃ���D���x�ȘA�����M���Ă�Ƃ������Ƃ��������c
�ǂ������w�����Ƃ���D���x�ȘA�����M���Ă�Ƃ������Ƃ��������c
550 �FName_Not_Found�F2006/04/07(��) 16:40:55 ID:???
SPARQL Query Language for RDF - W3C Candidate Recommendation 6 April 2006
http://www.w3.org/TR/2006/CR-rdf-sparql-query-20060406/
SPARQL Specifications Are W3C Candidate Recommendations 2006-04-06:
W3C is pleased to announce the advancement of the SPARQL specifications
to Candidate Recommendations.
http://www.w3.org/TR/2006/CR-rdf-sparql-query-20060406/
SPARQL Specifications Are W3C Candidate Recommendations 2006-04-06:
W3C is pleased to announce the advancement of the SPARQL specifications
to Candidate Recommendations.
551 �FName_Not_Found�F2006/04/08(�y) 17:06:22 ID:???
>>550
RDF�ɑ���N�G�����đ��ɂ���������Ă������������H
RDF�ɑ���N�G�����đ��ɂ���������Ă������������H
552 �FName_Not_Found�F2006/04/12(��) 17:52:52 ID:???
librdf ���� Windows �ł��g�����̂��B
553 �FName_Not_Found�F2006/05/15(��) 14:21:14 ID:???
�l�I�ȃI���g���W�[�̖��O��ԂƂ���
�ǂ��URI���g�����Y�ނ��Ƃ����������ǁA
tag URI �� RFC �ɂȂ��ĔY�ޕK�v���Ȃ��Ȃ����B
�����Ƒf�Ў��ʎq # ���݂Ƃ߂��Ă���̂�
IRI���݂Ƃ߂��Ă��邩��Protege �Ȃ�
�I���g���W�[�ҏW�c�[���ł��g���邵�B
�ǂ��URI���g�����Y�ނ��Ƃ����������ǁA
tag URI �� RFC �ɂȂ��ĔY�ޕK�v���Ȃ��Ȃ����B
�����Ƒf�Ў��ʎq # ���݂Ƃ߂��Ă���̂�
IRI���݂Ƃ߂��Ă��邩��Protege �Ȃ�
�I���g���W�[�ҏW�c�[���ł��g���邵�B
554 �FName_Not_Found�F2006/05/15(��) 14:40:31 ID:???
>>553
���̌l�I�ȃI���g���W�[�����Д��\���Ă���B
���̌l�I�ȃI���g���W�[�����Д��\���Ă���B
555 �FName_Not_Found�F2006/05/15(��) 14:44:17 ID:???
>>554 �p���������I�^�N�˂��̌�b�W�Ȃ̂Ńp�X
556 �FName_Not_Found�F2006/05/15(��) 14:46:20 ID:???
>>554 �Ȃ̂Ŏ��ۂ̕������ł͌�b������킷 URI ��
�n�b�V������ urn:md5:�Ȃ�Ƃ� �Ŗ��ߍ���ł�B
�܂���b�����Ȃ�����Փ˂͋N�����ĂȂ����ǁA
�Փ˂��N�������Ƃ��ɂǂ����邩�͖���B
�n�b�V������ urn:md5:�Ȃ�Ƃ� �Ŗ��ߍ���ł�B
�܂���b�����Ȃ�����Փ˂͋N�����ĂȂ����ǁA
�Փ˂��N�������Ƃ��ɂǂ����邩�͖���B
557 �FName_Not_Found�F2006/05/17(��) 22:27:38 ID:???
>>555
�ǂ����n�H
�ǂ����n�H
558 �FName_Not_Found�F2006/06/04(��) 01:55:23 ID:???
�����ǂ�ł邾�낤���ǁA�u������Ƃ������� - Dublin Core��RDF���f���V�d�l�āv
ttp://www.kanzaki.com/memo/2006/06/04-1
valueString�͂�����Ɩʓ|�������B
ttp://www.kanzaki.com/memo/2006/06/04-1
valueString�͂�����Ɩʓ|�������B
559 �FName_Not_Found�F2006/06/04(��) 10:22:36 ID:h1O59m2k
>>558
���������ǂ�������͂͂��Ȃ���
�W�F�l���[�^���Ȃ碕ʂ̑��ģ�̕����y�Ƃ�������
���ꂩ����l���č��ύX��������͎̂^���ł���
���Ȃ烊�[�_�[���Ή�������̑��吨�͏]�����낤
����ϖʓ|����c���X�ς���Ȃ�c�Ƃ����̂��{������
���������ǂ�������͂͂��Ȃ���
�W�F�l���[�^���Ȃ碕ʂ̑��ģ�̕����y�Ƃ�������
���ꂩ����l���č��ύX��������͎̂^���ł���
���Ȃ烊�[�_�[���Ή�������̑��吨�͏]�����낤
����ϖʓ|����c���X�ς���Ȃ�c�Ƃ����̂��{������
560 �FName_Not_Found�F2006/06/04(��) 23:47:49 ID:???
>���������ǂ�������͂͂��Ȃ���
RSS���V�R�V�R����͂��Ă��鉴
RSS���V�R�V�R����͂��Ă��鉴
561 �FName_Not_Found�F2006/06/08(��) 14:49:23 ID:???
FOAF �̌�b�̒��ɂ� vCard RDF Representation
http://www.w3.org/TR/vcard-rdf
�̌�b�ɑ���������̂�����킯�Ȃ��ǁA
���݂Ƃ����\�H�l�ԂɊւ���������L�q�����ŁA
�����ȃ{�L���u�����[�𗘗p�\�H
�����ŗp�ӂ��� OWL �ŋL�q������b�Ƃ����B
http://www.w3.org/TR/vcard-rdf
�̌�b�ɑ���������̂�����킯�Ȃ��ǁA
���݂Ƃ����\�H�l�ԂɊւ���������L�q�����ŁA
�����ȃ{�L���u�����[�𗘗p�\�H
�����ŗp�ӂ��� OWL �ŋL�q������b�Ƃ����B
562 �FName_Not_Found�F2006/06/08(��) 15:14:32 ID:???
http://www.ietf.org/rfc/rfc4287.txt
������������� extensionElement ��
�F�߂��Ă��邩����v���Ǝv�����ǁA
���Ƃ���
<atom:Person foaf:gender="male">
�@�@�Ȃ�Ƃ�����Ƃ�
</atom:Person>
�Ȃ�ċL�q�͔F�߂���̂��ȁH����Ƃ�
<atom:Person>
�@�@�Ȃ�Ƃ�����Ƃ�
<foaf:gender>male</foaf:gender>
</atom:Person>
���ċL�q���Ȃ���Ȃ�Ȃ��̂��ȁH
������������� extensionElement ��
�F�߂��Ă��邩����v���Ǝv�����ǁA
���Ƃ���
<atom:Person foaf:gender="male">
�@�@�Ȃ�Ƃ�����Ƃ�
</atom:Person>
�Ȃ�ċL�q�͔F�߂���̂��ȁH����Ƃ�
<atom:Person>
�@�@�Ȃ�Ƃ�����Ƃ�
<foaf:gender>male</foaf:gender>
</atom:Person>
���ċL�q���Ȃ���Ȃ�Ȃ��̂��ȁH
563 �FName_Not_Found�F2006/06/08(��) 17:00:35 ID:???
SPARQL��CONSTRUCT����RDF�O���t�̈ꕔ�𒊏o������x�̎������ł��Ȃ��̂ł��傤��
�Ⴆ��XQuery�̂悤�ȍ\���ϊ��͕s�\�H
�Ⴆ��XQuery�̂悤�ȍ\���ϊ��͕s�\�H
564 �FName_Not_Found�F2006/06/11(��) 18:30:20 ID:Ofcyc8uB
>>561-562
XML���x���ō�����̂��ARDF���x���ō�����̂��ňقȂ邪�A
��{�I�ɂ��̂̌�b���G�[�W�F���g���������ĂȂ��Ə��������Ă���Ȃ��B
FOAF��RDF�̌�b������A�܂�Atom��RDF�\�����Ȃ��Ƃ����Ȃ��͂��B
�܂��P�Ȃ�^�O�Ƃ��Ďg�����Ƃ��o���Ȃ��͂Ȃ����낤���B�B
FOAF�AvCard RDF Representation�A�����ŗp�ӂ��� OWL �ŋL�q������b�́A���݂��\�B
OWL��SWRL�ł����̊W���L�q���Ă��āA�c�[�������_��������Ă���Ȃ�A�����I�ɕϊ����Ă����B
XML���x���ō�����̂��ARDF���x���ō�����̂��ňقȂ邪�A
��{�I�ɂ��̂̌�b���G�[�W�F���g���������ĂȂ��Ə��������Ă���Ȃ��B
FOAF��RDF�̌�b������A�܂�Atom��RDF�\�����Ȃ��Ƃ����Ȃ��͂��B
�܂��P�Ȃ�^�O�Ƃ��Ďg�����Ƃ��o���Ȃ��͂Ȃ����낤���B�B
FOAF�AvCard RDF Representation�A�����ŗp�ӂ��� OWL �ŋL�q������b�́A���݂��\�B
OWL��SWRL�ł����̊W���L�q���Ă��āA�c�[�������_��������Ă���Ȃ�A�����I�ɕϊ����Ă����B
565 �FName_Not_Found�F2006/07/09(��) 00:14:48 ID:???
������Ƃ������� - Dublin Core�̐V�d�l�Ăɑ���p�u���b�N�E�R�����g
ttp://www.kanzaki.com/memo/2006/07/08-1
ttp://www.kanzaki.com/memo/2006/07/08-1
566 �FName_Not_Found�F2006/07/21(��) 23:10:16 ID:R/Du3U6v
FOAF �݂����� RDF �x�[�X�̋L�q���āA XSL �ł͊ȒP��
�ϊ��ł��Ȃ��ł����HFOAF �� vCard/RDF �̊Ԃ�
�ϊ�����肽���̂ł����E�E�E
�ϊ��ł��Ȃ��ł����HFOAF �� vCard/RDF �̊Ԃ�
�ϊ�����肽���̂ł����E�E�E
567 �FName_Not_Found�F2006/07/22(�y) 00:58:58 ID:???
568 �FName_Not_Found�F2006/07/22(�y) 01:20:00 ID:???
>>567 �����������Ǝv���܂��B���̃X�L���s�����Ǝv���܂��B
RDF ���Ɠ������e�ł��L�q���@����������̂ŁA
XPath �����܂������Ȃ���ł��B�d���Ȃ��̂�
RDF �̃p�[�T���ǂ��������āA�g���v���ɕ������āA
boost::graph �Ɏ��o���Ă���}�j�s�����[�g����悤�ɂ��܂����B
RDF ���Ɠ������e�ł��L�q���@����������̂ŁA
XPath �����܂������Ȃ���ł��B�d���Ȃ��̂�
RDF �̃p�[�T���ǂ��������āA�g���v���ɕ������āA
boost::graph �Ɏ��o���Ă���}�j�s�����[�g����悤�ɂ��܂����B
569 �FName_Not_Found�F2006/08/02(��) 19:51:01 ID:ERjRIqq9
�ߎ��q
570 �FName_Not_Found�F2006/08/02(��) 21:07:05 ID:???
>>568
*�C�ӂ�* RDF �� XSLT �ŕύX����̂͂��Ȃ薳�d�ł��D
����̃A�v�����f�������RDF/XML����������Ȃ�XSLT�ł����ł��傤����
�C�ӂ�RDF/XML�����������Ȃ�RDF/XML�̃p�[�U�g���ď����������������ł��D
# ���Ă�RDF/XML �� XML �Ƃ��Ĉ������Ƃ��Ă����܂�K���ɂ͂Ȃ�Ȃ��Ǝv����...
*�C�ӂ�* RDF �� XSLT �ŕύX����̂͂��Ȃ薳�d�ł��D
����̃A�v�����f�������RDF/XML����������Ȃ�XSLT�ł����ł��傤����
�C�ӂ�RDF/XML�����������Ȃ�RDF/XML�̃p�[�U�g���ď����������������ł��D
# ���Ă�RDF/XML �� XML �Ƃ��Ĉ������Ƃ��Ă����܂�K���ɂ͂Ȃ�Ȃ��Ǝv����...
571 �FName_Not_Found�F2006/08/03(��) 01:04:13 ID:???
�Z�}���e�B�b�N�Ă����ƁA�V�}���e�b�N�̐e�ʂ݂������i��
�m�[�g���搶���l�������_�݂����ȃC���[�W���i��
�m�[�g���搶���l�������_�݂����ȃC���[�W���i��
572 �FName_Not_Found�F2006/08/03(��) 10:58:48 ID:???
�V���^�b�N�X�ƃV�}���e�b�N�X
573 �FName_Not_Found�F2006/10/07(�y) 01:06:15 ID:???
���ݔR���L�q�t���[�����[�N
574 �FName_Not_Found�F2006/10/10(��) 19:23:54 ID:???
�Q�����Ԃ�̏������݂����ꂩ�悗
575 �FName_Not_Found�F2006/12/14(��) 00:11:39 ID:???
MR3�g���Ă�ƁA���܂ɉ��̑O�G����Ȃ�������E�E�Eorz
576 �FName_Not_Found�F2006/12/14(��) 19:51:55 ID:???
��[��A���_��SemanticWeb�ɂ��ď������ƂɂȂ����������B
577 �FName_Not_Found�F2006/12/16(�y) 00:58:16 ID:???
���Ⴀ�A�����ɕ��y�����邩���e�[�}�ɂ��ď����Ă���B
578 �FName_Not_Found�F2006/12/25(��) 17:42:15 ID:???
����Ȃ��Ƃ��ł���Ȃ炢�܂���V�����낤��
579 �FName_Not_Found�F2006/12/26(��) 00:55:30 ID:???
�������R�ŕ��y���Ȃ��̂��ȁH��������Ȃ̂��ȁH
���y������A�����֗����Ǝv�����ǂȁB
kanzaki����̎��������Ă��炻���v���Ă����B
ttp://www.kanzaki.com/works/talks.html
���y������A�����֗����Ǝv�����ǂȁB
kanzaki����̎��������Ă��炻���v���Ă����B
ttp://www.kanzaki.com/works/talks.html
580 �FName_Not_Found�F2006/12/28(��) 19:31:43 ID:???
>>579
�Z�p�͂̂Ȃ��wWEB�f�U�C�i�[�x�ǂ����Ҕ������Ă邩�炗
�Z�p�͂̂Ȃ��wWEB�f�U�C�i�[�x�ǂ����Ҕ������Ă邩�炗
581 �FName_Not_Found�F2006/12/30(�y) 15:18:25 ID:???
582 �FName_Not_Found�F2007/01/01(��) 06:47:49 ID:???
���H
583 �FName_Not_Found�F2007/02/10(�y) 21:21:01 ID:???
�@�@�@�ySemantic Web�R�c���z
�@�@�@�@�@�@�@�@_,,..,,,,_ �@ _,,..,,,,_
�@�@�@�@ _,,..,,,_/ �E�ցE�R/�E�ցE �R,..,,,,_
�@�@�@ ./�@�E��_,,..,,,,_�@ l�@_,,..,,,,_/�ցE �R
�@�@�@�b�@�@ / �@�@�E�R /�E �@�@�R�@�@�@ l�@���G�[�W�F���g
�@�@�@ `'�--l�@�@ �@�@ ll�@�@ �@�@ l---�]�L
�@�@�@�@�@�@�@`'�---�]�L`'�---�]�L
584 �FName_Not_Found�F2007/02/17(�y) 00:33:49 ID:???
�@�@�@rdfs:Class_,,.,,,,_���@_,,..,,,,_�̃N���X�́H
�@�@�@�@�@ _,,..,,_/ �E�ցE�R/�E�ցE �R,..,,,,_�@�@��
�@�@�@�@./�@�E��_,,..,,,,_�@ l�@_,,..,,,,_/�ցE �R
�@�@���b�@ �@ / �@�@�E�R /�E �@�@�R�@�@�@ l�@rdfs:Class
�@�@�@�@ `'�--l�@�@ �@�@ll�@�@ �@�@ l---�]�L�@��
�̃N���X�́H'�---�]�L`'�---�]�L�̃N���X�́H
�@�@�@�@���@�@�@�@rdfs:Class�@�@��
585 �FName_Not_Found�F2007/03/22(��) 01:40:15 ID:???
XHTML�X������U�����ꂽ410�����ǁA���������Ă邱�Ƃ��Ă����Ă�?
586 �FName_Not_Found�F2007/04/05(��) 14:54:03 ID:???
�ǂ��̃X���̂��Ƃ������Ă���H
587 �FName_Not_Found�F2007/04/05(��) 19:15:56 ID:???
588 �FName_Not_Found�F2007/04/05(��) 20:50:27 ID:???
�����Ƃ����܂�W�Ȃ��悤�ȋC�����Ȃ��ł��Ȃ��B
589 �FName_Not_Found�F2007/04/05(��) 21:41:47 ID:???
���������A����ł���
>>>412 >>413
>��������ƒ��ׂĂ݂�����Atom���t�B�[�h��������Ȃ����Ă����̂́A
>RSS�Ƃ͈���ăE�F�u���\�[�X���o�ł���AtomAPI��������Ă�������?
>
>����RSS�̃o�[�W�������������Ă�����Ă����̂́A
>RSS1.0��RSS2.0���S�R�֘A���ĂȂ����Ă�����?
>>>412 >>413
>��������ƒ��ׂĂ݂�����Atom���t�B�[�h��������Ȃ����Ă����̂́A
>RSS�Ƃ͈���ăE�F�u���\�[�X���o�ł���AtomAPI��������Ă�������?
>
>����RSS�̃o�[�W�������������Ă�����Ă����̂́A
>RSS1.0��RSS2.0���S�R�֘A���ĂȂ����Ă�����?
590 �FName_Not_Found�F2007/04/05(��) 23:47:24 ID:???
�P�ɋK�i���������Ă���A�������ꂾ���̘b�B�D��Ă�Ƃ��D��ĂȂ��Ƃ��ǂ��ł��B
Atom/RDF����������H
���ƁAAtomPP��RPC�̘b������X���Ⴂ�B
�Ƃ����킯�ŁA�������̃X���ł������Ă��Ǝv����
��[ttp://www.w3.org/RDF/#specs]
��[ttp://www.ietf.org/rfc/rfc4287]
Atom/RDF����������H
���ƁAAtomPP��RPC�̘b������X���Ⴂ�B
�Ƃ����킯�ŁA�������̃X���ł������Ă��Ǝv����
��[ttp://www.w3.org/RDF/#specs]
��[ttp://www.ietf.org/rfc/rfc4287]
591 �FName_Not_Found�F2007/04/11(��) 01:10:27 ID:???
Atom/RDF���Ă̂͂܂�Atom��RDF�ɑ����ċL�q����Ă���̂��H
592 �FName_Not_Found�F2007/04/22(��) 18:26:46 ID:???
Semantic Web���Z�����Ȃ��������ĉ����Ǝv���H
593 �FName_Not_Found�F2007/04/22(��) 18:56:38 ID:???
����̋�_�����炶���
594 �FName_Not_Found�F2007/04/22(��) 20:59:02 ID:???
Strict HTML�ł������y���Ȃ�����ˁB
(�d�l������)�c�[���ɂ��x�����Ȃ��Ɛ�Ζ����B
(�d�l������)�c�[���ɂ��x�����Ȃ��Ɛ�Ζ����B
595 �FName_Not_Found�F2007/04/23(��) 22:07:01 ID:???
596 �FName_Not_Found�F2007/04/24(��) 14:06:32 ID:???
���̂��߂�Trust�w�Ȃ�Ȃ��̂��H
�c�c�Ǝ����ŏ����ĂČӎU�L���Ȃ��Ă���
�c�c�Ǝ����ŏ����ĂČӎU�L���Ȃ��Ă���
597 �FName_Not_Found�F2007/05/05(�y) 01:18:14 ID:???
>>592
�Z�}���e�B�b�N�ɂȂ����Ȃɕ֗��ł���\�Ƃ������f����N����̓I�ɒł��Ȃ�����B
�Z�}���e�B�b�N�ɂȂ����Ȃɕ֗��ł���\�Ƃ������f����N����̓I�ɒł��Ȃ�����B
598 �FName_Not_Found�F2007/05/05(�y) 06:26:44 ID:???
�ǂ��炩�Ƃ����ƁA�͂��Ă�悤�Ɍ����邯�ǁA
���̋�̈Ă��ǂ��l���Ă������ł��Ȃ��i��Ƀ��^�f�[�^���y�̕ǁj�B
���̋�̈Ă��ǂ��l���Ă������ł��Ȃ��i��Ƀ��^�f�[�^���y�̕ǁj�B
599 �FName_Not_Found�F2007/05/05(�y) 22:54:20 ID:???
RDF�]�X�̘b����Ȃ��āA
Semantic Web���̂��̂̊T�v�����܂��܂Ƃ߂Ă�{���Ă���H
Semantic Web���̂��̂̊T�v�����܂��܂Ƃ߂Ă�{���Ă���H
600 �FName_Not_Found�F2007/05/05(�y) 23:25:01 ID:???
�Z�}���e�B�b�N�E�F�u�Ȃ�Č��ł�
601 �FName_Not_Found�F2007/05/06(��) 11:09:33 ID:???
�A�C�������h���̒�����RDF�����G���W��
ttp://slashdot.jp/article.pl?sid=07/05/05/2054225
�����A���������ق�����낤���B
ttp://slashdot.jp/article.pl?sid=07/05/05/2054225
�����A���������ق�����낤���B
602 �FName_Not_Found�F2007/05/06(��) 15:39:37 ID:PieIFiyG
�{��CD�̔������Ƃ��A�A�[�e�B�X�g��TV�o�����Ȃ�iCal�Ƃ�RDFical�Ŕz�M����ė~�����Ǝv���B
RSS�ł����������V���̍X�V�����o����Ă��A
���ۊ��p����ƂȂ�ƃJ�����_�[�Ƃ��ďo���������֗��Ȃ킯�����B
���v�͍݂�Ǝv�����ǂȂ��B
RSS�ł����������V���̍X�V�����o����Ă��A
���ۊ��p����ƂȂ�ƃJ�����_�[�Ƃ��ďo���������֗��Ȃ킯�����B
���v�͍݂�Ǝv�����ǂȂ��B
603 �FName_Not_Found�F2007/05/07(��) 13:39:42 ID:???
�����ΏۂƂȂ�R���e���c���Ȃ��̂ɒ����������G���W�����c
�Ȃ��ȁc
�Ȃ��ȁc
604 �FName_Not_Found�F2007/05/07(��) 14:13:33 ID:???
�Ƃ������ĂĂ����傤���Ȃ����Ƃ肠����
�����̃f�[�^�x�[�X��RDF���f���������G���W��
�݂����ȃ��f���ʼn����֗��Ȃ��̂͂ł��Ȃ����ˁc�H
CDDB��RDF DB�� >>601 ��RDF�����G���W��
�݂����ȁ[�H
�����̃f�[�^�x�[�X��RDF���f���������G���W��
�݂����ȃ��f���ʼn����֗��Ȃ��̂͂ł��Ȃ����ˁc�H
CDDB��RDF DB�� >>601 ��RDF�����G���W��
�݂����ȁ[�H
605 �FName_Not_Found�F2007/05/08(��) 00:02:03 ID:???
DB���č\�z����K�v�͂Ȃ���ˁH
SPARQL�ɉ����ł���悤�ȃC���^�[�t�F�C�X�����B
�����Ō����Ăė����ł��Ȃ����B
SPARQL�ɉ����ł���悤�ȃC���^�[�t�F�C�X�����B
�����Ō����Ăė����ł��Ȃ����B
606 �FName_Not_Found�F2007/05/08(��) 02:00:12 ID:???
>>604
SquirrelRDF�Ƃ��ǂ���
SquirrelRDF�Ƃ��ǂ���
607 �FName_Not_Found�F2007/05/08(��) 11:57:43 ID:???
>>605
SPARCLE�Ȃ�RDQL�Ȃ�ō����Ɍ����ł���Ȃ炻��ł��������ǂ�
SPARCLE�Ȃ�RDQL�Ȃ�ō����Ɍ����ł���Ȃ炻��ł��������ǂ�
608 �FName_Not_Found�F2007/05/21(��) 23:07:27 ID:???
microformats���Ăǂ��ł����H
���������肻���Ȋ����ł�����
���������肻���Ȋ����ł�����
609 �FName_Not_Found�F2007/07/02(��) 23:47:22 ID:???
Semantic Web�Ɍ��������^�f�[�^�̎��������̉\���ɂ��ďq�ׂ��_�����Ă���H
610 �FName_Not_Found�F2007/07/15(��) 00:07:57 ID:???
���_�H
611 �FName_Not_Found�F2007/07/17(��) 22:07:13 ID:ERYUdJNE
>>609
�T���X�����������
������Semantic Web��烁�^�f�[�^�ɂ��Ę_���������Ǝv���Ă鏊�B
����������Ă݂����Ǝv�����������Ƃ��Ƃ����ɂ���Ă��ȁB
�Ȃ��[��̂����Ă��Ȃ�������ĂȂ����ȁB
�T���X�����������
������Semantic Web��烁�^�f�[�^�ɂ��Ę_���������Ǝv���Ă鏊�B
����������Ă݂����Ǝv�����������Ƃ��Ƃ����ɂ���Ă��ȁB
�Ȃ��[��̂����Ă��Ȃ�������ĂȂ����ȁB
612 �FName_Not_Found�F2007/07/23(��) 14:48:27 ID:???
�ŋ߃l�^�Ȃ������H
613 �FName_Not_Found�F2007/08/11(�y) 09:36:31 ID:???
Semantic Web�P�̂ŗ��_�I�Ș_����W�J����͓̂���Ȃ����ȁB
���͂◝�_�͏o���s�����ꂽ�������邵�A�ŋ߂͎����̘b�������݂��������ȁB
�c���ꂽ�\���Ƃ��ẮA����̈�ɍi���Ę_��W�J���銴���ɂȂ邾�낤�ȁB
���ƁA�ŋ߂�Social Tagging���g����
Semantic Web���������悤�Ƃ����ӌ�������݂��������B
�����ǂ��Ȃ낤�ȁB
���͂◝�_�͏o���s�����ꂽ�������邵�A�ŋ߂͎����̘b�������݂��������ȁB
�c���ꂽ�\���Ƃ��ẮA����̈�ɍi���Ę_��W�J���銴���ɂȂ邾�낤�ȁB
���ƁA�ŋ߂�Social Tagging���g����
Semantic Web���������悤�Ƃ����ӌ�������݂��������B
�����ǂ��Ȃ낤�ȁB
614 �FName_Not_Found�F2007/08/11(�y) 20:04:56 ID:???
Semantic Web�Ƃ����Ă����^�f�[�^����l�H�m�\�܂ŐF�X���邩��ȁB
615 �FName_Not_Found�F2007/08/16(��) 10:53:52 ID:???
�_���̃l�^�������Ă����p�I�ȃA�v���P�[�V�����͂������Əo���Ă��Ȃ������c
616 �FName_Not_Found�F2007/08/19(��) 01:30:21 ID:???
�N��microformats�݂����Ȗʓ|�Ȃ��Ƃ͂���Ă���Ȃ�����A
�����̃f�[�^���ʂ�RDF�ϊ�����h���C�o�����܂��܂Ə��������Ȃ��ȁB
�����̃f�[�^���ʂ�RDF�ϊ�����h���C�o�����܂��܂Ə��������Ȃ��ȁB
617 �Fhelba�F2007/08/21(��) 22:15:01 ID:MU1MFK36
���H�I�ȃA�v���P�[�V�����Ƃ����A�uPiggy Bank�v������܂����ǂ��ł��傤���H
ttp://simile.mit.edu/wiki/Piggy_Bank
���
ttp://opentechpress.jp/desktop/05/09/06/0242226.shtml?topic=1
ttp://simile.mit.edu/wiki/Piggy_Bank
���
ttp://opentechpress.jp/desktop/05/09/06/0242226.shtml?topic=1
618 �FName_Not_Found�F2007/08/21(��) 23:59:43 ID:???
619 �Fhelba�F2007/08/22(��) 02:12:59 ID:O+yq/IEP
620 �FName_Not_Found�F2007/08/22(��) 02:18:46 ID:???
>>619
���� �������ɂ���́c�c �Ȃ�čL��Ȏ��쎩��
���� �������ɂ���́c�c �Ȃ�čL��Ȏ��쎩��
621 �FName_Not_Found�F2007/08/22(��) 04:00:08 ID:???
�����ɗ��Ă� Name_Not_Found ����͂����ƃ��^�f�[�^�ɋ�������Ǝv�����
622 �FName_Not_Found�F2007/08/23(��) 09:53:42 ID:???
Name_Not_Found����͂��̔���L��������ȁB���O�ƈ���āB
623 �FName_Not_Found�F2007/08/25(�y) 13:10:33 ID:???
��O�҃T�[�r�X�������̃f�[�^�������RDF������Ƃ����͍̂l�������Ƃ��邪�A
������肪�������Ǝv�������B
�T�[�r�X���͕ϊ��@�\�������A���[�U�Ƀf�[�^��RDF���E��������������c�̂��H
������肪�������Ǝv�������B
�T�[�r�X���͕ϊ��@�\�������A���[�U�Ƀf�[�^��RDF���E��������������c�̂��H
624 �FName_Not_Found�F2007/08/25(�y) 17:30:16 ID:???
>>623
�c�[�������p�ӂ��ă��[�U�Ƀ{�^����������������B
�f�[�^�̌l�I�ȗ��p���F�߂��鑽���̃P�[�X�ł͖��Ȃ��Ǝv���B
�c�[�������p�ӂ��ă��[�U�Ƀ{�^����������������B
�f�[�^�̌l�I�ȗ��p���F�߂��鑽���̃P�[�X�ł͖��Ȃ��Ǝv���B
625 �FName_Not_Found�F2007/09/15(�y) 17:00:02 ID:pRUjerOq
�����v���Ԃ�ɂ��̃X�������Ă݂��B�قڎ���ł�ȁB
Google�̓��^�f�[�^�����ɋ�������Ǝv���Ă����ǁA�����ɓ����������͕̂s�����ȁB
�������Ɏ�����̋Z�p�ł͂Ȃ��͂��Ȃ��B���K�͂ł�������Labs�ł���Ă���ˁB
����Ȃ̗v��Ȃ����炳�B
ttp://www.google.com/experimental/
�S�Ẵ��\�[�X�Ƀ��^�f�[�^��t�^����A�C�f�A�ɂ�����ł��o�Ă��Ȃ����A����10�N���ᖳ�����ˁB
Google�̓��^�f�[�^�����ɋ�������Ǝv���Ă����ǁA�����ɓ����������͕̂s�����ȁB
�������Ɏ�����̋Z�p�ł͂Ȃ��͂��Ȃ��B���K�͂ł�������Labs�ł���Ă���ˁB
����Ȃ̗v��Ȃ����炳�B
ttp://www.google.com/experimental/
�S�Ẵ��\�[�X�Ƀ��^�f�[�^��t�^����A�C�f�A�ɂ�����ł��o�Ă��Ȃ����A����10�N���ᖳ�����ˁB
626 �FName_Not_Found�F2007/11/09(��) 04:05:06 ID:BZmJTSsM
�ŋ�Google�����\����OpenSocial�͖ʔ���������Ȃ��H
FOAF�����p�ł���悤�ɂȂ�Ȃ����Ȃ��Ɩϑz���Ă���B
FOAF�����p�ł���悤�ɂȂ�Ȃ����Ȃ��Ɩϑz���Ă���B
627 �FName_Not_Found�F2007/11/13(��) 15:42:10 ID:???
����Google�͉ߋ���Microsoft��l�X�P�Ȃ݂ɓƎ��H��������Ȃ�
�Z�a���悤�Ƃ��邭�炢�Ȃ�ŏ���������̋K�i�ɍ��킹�Ă��������̂�
�Z�a���悤�Ƃ��邭�炢�Ȃ�ŏ���������̋K�i�ɍ��킹�Ă��������̂�
628 �FName_Not_Found�F2007/11/13(��) 15:56:16 ID:???
Google��Microsoft���o���o���̉c���Nj���ƁB
Google�̕����A�v���[�`�����_���Ȃ����ŁE�E�E�B
Google�̕����A�v���[�`�����_���Ȃ����ŁE�E�E�B
629 �FName_Not_Found�F2007/11/13(��) 20:15:59 ID:Srz+MxJ+
���_�̃l�^�ł����̂Ȃ��H�Ȃ��Ȃ��Ȃ��B
�ꉞRDF/XML�͕������̂����E�E�E
�ꉞRDF/XML�͕������̂����E�E�E
630 �FName_Not_Found�F2007/11/13(��) 20:21:16 ID:???
�������Ȃ�킩�邾��
�Z�}���e�B�N�X�͖ϑz���������Ă��Ƃ�
�Z�}���e�B�N�X�͖ϑz���������Ă��Ƃ�
631 �FName_Not_Found�F2007/11/13(��) 20:58:15 ID:???
��Ղ��������y���ɓ���Z�}���e�B�b�NWeb
ttp://www.atmarkit.co.jp/news/200711/09/nri.html
���[���b�p��IST�� 2006�N1���ɁuNEPOMUK�v�ƌĂ��
�I�[�v���\�[�X�\�t�g�E�F�A�v���W�F�N�g���J�n�B
1150�����[��(��18��2535���~)��2�N�̌������Ԃ������ĊJ�����A
Linux�f�X�N�g�b�v���́uKDE4�v�Ɏ�������A
�s��������Ƃ���(����KDE4�̓x�[�^�ł�����Ă���)�B
ttp://www.atmarkit.co.jp/news/200711/09/nri.html
���[���b�p��IST�� 2006�N1���ɁuNEPOMUK�v�ƌĂ��
�I�[�v���\�[�X�\�t�g�E�F�A�v���W�F�N�g���J�n�B
1150�����[��(��18��2535���~)��2�N�̌������Ԃ������ĊJ�����A
Linux�f�X�N�g�b�v���́uKDE4�v�Ɏ�������A
�s��������Ƃ���(����KDE4�̓x�[�^�ł�����Ă���)�B
632 �FName_Not_Found�F2007/11/13(��) 21:02:45 ID:???
>>631
> �g�}�N���t�H�[�}�b�g�h�imicroformats�j
> �g�}�N���t�H�[�}�b�g�h�imicroformats�j
633 �FName_Not_Found�F2007/11/15(��) 15:09:46 ID:VhUzMENa
634 �FName_Not_Found�F2007/11/15(��) 19:25:58 ID:???
>>632
�������
�������
635 �FName_Not_Found�F2007/11/18(��) 19:56:08 ID:???
>>629
�ǂ�������������Ă�́H
�ǂ�������������Ă�́H
636 �FName_Not_Found�F2007/11/18(��) 20:43:53 ID:???
ttp://gihyo.jp/book/2007/978-4-7741-3242-6
���̖{���Ăǂ��H
���̖{���Ăǂ��H
637 �FName_Not_Found�F2007/11/19(��) 14:00:57 ID:yYyAS7O8
638 �FName_Not_Found�F2007/11/19(��) 20:44:43 ID:???
���N�̎O���H�����炶��x�����܂���
639 �FName_Not_Found�F2007/11/19(��) 21:04:06 ID:???
���_���Ĉꃖ����������Ώ\���W����
640 �FName_Not_Found�F2007/11/19(��) 21:45:51 ID:???
���{�̑�w�I������ȁB
641 �FName_Not_Found�F2007/11/19(��) 21:56:18 ID:???
���{�̑�w�ő�w�ƌĂ�ł������̂Ȃ�Đ��p�[�Z���g�����Ȃ���
642 �FName_Not_Found�F2007/11/19(��) 22:23:13 ID:???
���Z���������
643 �FName_Not_Found�F2007/11/20(��) 10:19:46 ID:???
>>637
���N�x�������
���N�x�������
644 �FName_Not_Found�F2007/11/20(��) 10:48:10 ID:j5JYXyJh
>>643
���܂��͏����ĂȂ���
���܂��͏����ĂȂ���
645 �FName_Not_Found�F2007/11/20(��) 21:58:41 ID:???
����Ȏ����܂ő����̃e�[�}�����߂�ꂸ�ɂ�����2ch�Ńl�^�T�����Ă�
�悤�Ȋw���͂�����N���炢�w������Ă��������ׂ̈��Ǝv����H
�悤�Ȋw���͂�����N���炢�w������Ă��������ׂ̈��Ǝv����H
646 �FName_Not_Found�F2007/11/20(��) 22:59:58 ID:???
�܂��������Ă��Ȃ�M2�͂ǂ���������ł���
4���ɏA�E�悪���܂��Ă��牽���i�߂Ă܂���
4���ɏA�E�悪���܂��Ă��牽���i�߂Ă܂���
647 �FName_Not_Found�F2007/11/25(��) 21:38:35 ID:4uFnyTGj
�h���X�e�B�b�N�ȃV�X�e�����\�z�����ł�
�ꍇ�ɂ���Ă͗L�p�ȊT�O�ł���Z�p���Ǝv�����ǁA
����ς�[��ǂ킢�ǂȋK�͂ł̃Z�}���e�B�b�NWeb�Ƃ����̂�
�������肷�����Ďv���Ă��܂��B
�I���g���W�̍\�z�Ȃ�Ė��̂܂����E�E�E�B
�ꍇ�ɂ���Ă͗L�p�ȊT�O�ł���Z�p���Ǝv�����ǁA
����ς�[��ǂ킢�ǂȋK�͂ł̃Z�}���e�B�b�NWeb�Ƃ����̂�
�������肷�����Ďv���Ă��܂��B
�I���g���W�̍\�z�Ȃ�Ė��̂܂����E�E�E�B
648 �FName_Not_Found�F2007/11/25(��) 21:58:55 ID:???
���N�̘b�����Ă��Ȃ��A�O�\�N��̘b�����Ă��
649 �FName_Not_Found�F2007/11/26(��) 20:58:49 ID:???
�Z�}���e�B�b�NWeb�̃A�v���[�`�̓��[�J���ȃV�X�e���ł̂�
�g������̂ɂȂ����Ⴄ�����ˁB
���\���������Ŏg���Ă�݂��������B
�I���g���W���A���̃V�X�e�����Ɍ���Δ��I�ȃ{�����[���ɂ͂Ȃ�Ȃ��B
WWW�̐��E�ł̓t�H�[�N�\�m�~�[�I�ȃA�v���[�`�̕��������Ă�B
�g������̂ɂȂ����Ⴄ�����ˁB
���\���������Ŏg���Ă�݂��������B
�I���g���W���A���̃V�X�e�����Ɍ���Δ��I�ȃ{�����[���ɂ͂Ȃ�Ȃ��B
WWW�̐��E�ł̓t�H�[�N�\�m�~�[�I�ȃA�v���[�`�̕��������Ă�B
650 �FName_Not_Found�F2007/12/01(�y) 22:18:38 ID:30R+gRt+
�Z�}���e�B�b�NWeb�ɂ͊��҂��Ă���ǂȁB�B�B
���������̔ɂ����Ă��d���Ȃ��X�����B
���������̔ɂ����Ă��d���Ȃ��X�����B
651 �FName_Not_Found�F2007/12/01(�y) 22:47:59 ID:???
���Ƃ����Ăǂ��̔Ȃ炢���낤�c
�ǂ��ɂ��ߑa���Ă��Ȃ��[�B
Protege���{�ꉻ�p�b�`�Ƃ��ˁ[�̂���('A`)
�p��͎v�l��H����ւ�邩���肾
�ǂ��ɂ��ߑa���Ă��Ȃ��[�B
Protege���{�ꉻ�p�b�`�Ƃ��ˁ[�̂���('A`)
�p��͎v�l��H����ւ�邩���肾
652 �FName_Not_Found�F2007/12/02(��) 00:31:37 ID:???
�l�^���Ȃ���ǂ̔ɂ����Ă��ߑa�邾�낤��c
653 �FName_Not_Found�F2007/12/02(��) 12:33:53 ID:???
�F�ARDF�����Ă邩���B
654 �FName_Not_Found�F2007/12/02(��) 15:26:16 ID:???
����SW�l�^�ō��Z�̑��_�����Ă��B
655 �FName_Not_Found�F2007/12/02(��) 15:36:37 ID:???
>>651
�p��ŋ��۔��������Ă� rdf �X���ɂ�����āc
�p��ŋ��۔��������Ă� rdf �X���ɂ�����āc
656 �FName_Not_Found�F2007/12/22(�y) 17:34:15 ID:/1K2Trxq
�Ȃ�[���A��������ȃS�e�S�e�����d�g�݂͂���Ȃ��悤�ȁE�E�E
657 �FName_Not_Found�F2007/12/27(��) 12:52:04 ID:???
GRDDL��link�^�O��href�͒��ڔz�z����URL���g���Ă������́H
�_�E�����[�h���Ďg�����́H
�_�E�����[�h���Ďg�����́H
658 �FName_Not_Found�F2007/12/31(��) 23:54:16 ID:???
>>657
���̂܂Q�Ƃ��������B
�R�s�[���Ďg���ꍇ�́A���J���Ƀ��C�Z���X�\�����������ɏ]���A
�Ȃ���Ίm�F���Ƃ�K�v������B
�����_�ł́A(�߂������Ƃ�)���ׂ�����������Ȃ����낤���A�O�҂ł悢�Ǝv����B
���Ă����A����2008�N�ɂȂ�܂���B
���낻��{������ĉ����^������semweb�A�v����邩�Ȃ��c�B
���̂܂Q�Ƃ��������B
�R�s�[���Ďg���ꍇ�́A���J���Ƀ��C�Z���X�\�����������ɏ]���A
�Ȃ���Ίm�F���Ƃ�K�v������B
�����_�ł́A(�߂������Ƃ�)���ׂ�����������Ȃ����낤���A�O�҂ł悢�Ǝv����B
���Ă����A����2008�N�ɂȂ�܂���B
���낻��{������ĉ����^������semweb�A�v����邩�Ȃ��c�B
659 �FName_Not_Found�F2008/01/07(��) 01:31:06 ID:???
�N�z�����O�ɂ���Ȃ��ƍl���Ă�Ƃ͉ɂȂ����
660 �FName_Not_Found�F2008/01/07(��) 20:00:39 ID:???
���������������d���H
661 �FName_Not_Found�F2008/01/13(��) 18:23:01 ID:???
>>658
�x���Ȃ������ǂ��肪�Ƃ��I�I
�x���Ȃ������ǂ��肪�Ƃ��I�I
662 �FName_Not_Found�F2008/01/18(��) 09:33:41 ID:???
GRDDL����SPARQL���̂悭�킩���d�l���ǂ�ǂ�����邵�A���Ă䂯�Ȃ��B
SW�̏����āA�݂�Ȃǂ��Ŏd����Ă�H
SW�̏����āA�݂�Ȃǂ��Ŏd����Ă�H
663 �FName_Not_Found�F2008/01/18(��) 12:03:33 ID:???
���̒��x�̏��Ȃ� W3C �̃g�b�v�y�[�W�ŏ\������
664 �FName_Not_Found�F2008/01/18(��) 18:51:50 ID:???
���{�ꂾ��
ttp://www.kanzaki.com/
ttp://www.w3.org/2005/11/Translations/Lists/ListLang-ja.html
ttp://www.techscore.com/tech/SemanticWeb/about.html
ttp://web.g.hatena.ne.jp/vantguarde/
��ւ�D(techscore�͏d��������)
���Ƃ́��̃T�C�g�Œm�����P����O�O�����肷��D
���̐l�͂ǂ�����Ă낤�D
ttp://www.kanzaki.com/
ttp://www.w3.org/2005/11/Translations/Lists/ListLang-ja.html
ttp://www.techscore.com/tech/SemanticWeb/about.html
ttp://web.g.hatena.ne.jp/vantguarde/
��ւ�D(techscore�͏d��������)
���Ƃ́��̃T�C�g�Œm�����P����O�O�����肷��D
���̐l�͂ǂ�����Ă낤�D
665 �FName_Not_Found�F2008/01/19(�y) 15:26:31 ID:???
�_���Ƃ��B
666 �FName_Not_Found�F2008/01/19(�y) 23:20:44 ID:???
������Ĉ�ʐl�ł��ǂ߂�H
667 �FName_Not_Found�F2008/01/19(�y) 23:28:50 ID:???
ggrks^^
668 �FName_Not_Found�F2008/01/20(��) 11:43:26 ID:???
�_���Ƃ��O�O�������ƂȂ���������
�u�Z�}���e�B�b�Nweb filetype:pdf�v�Ƃ��ŏo�Ă������ȂȁI
�т����肵���I
�Ȃ�肢������Ƃ����Ă���H
�u�Z�}���e�B�b�Nweb filetype:pdf�v�Ƃ��ŏo�Ă������ȂȁI
�т����肵���I
�Ȃ�肢������Ƃ����Ă���H
669 �FName_Not_Found�F2008/01/20(��) 13:08:25 ID:???
site:.edu
site:.ac.jp
site:.ac.jp
670 �FName_Not_Found�F2008/01/20(��) 13:11:58 ID:???
�ނ��� filetype:rdf
671 �FName_Not_Found�F2008/01/20(��) 15:10:06 ID:???
���ň�C�o�J���������Ă�A���S�҃X���ł���
672 �FName_Not_Found�F2008/01/20(��) 17:08:56 ID:swYesGle
Google Scholer
673 �FName_Not_Found�F2008/01/21(��) 08:14:51 ID:???
�v���O�������CGRDDL�Ŏw�肳�ꂽlink��URL�������ɊW�̂���t�@�C�����ǂ���
������������@���Ă���܂����H
XSLT�ȊO�̕ϊ��X�N���v�g���w�肵�Ă������ƂɂȂ��Ă�݂����Ȃ̂ŁC
�S�Ă�URL�����Ղ�XSLT�����n�ɗ����̂͂܂����C�����邵�C
���[�U�͕����w�肵�Ă������玩���ɊW�̂���XSLT�����������������������������Ǝv���܂��D
������ƍl�������x����C�������N���Ă������URL���߂����ŏ�������C
���炢�����v�������т܂���c�D
������������@���Ă���܂����H
XSLT�ȊO�̕ϊ��X�N���v�g���w�肵�Ă������ƂɂȂ��Ă�݂����Ȃ̂ŁC
�S�Ă�URL�����Ղ�XSLT�����n�ɗ����̂͂܂����C�����邵�C
���[�U�͕����w�肵�Ă������玩���ɊW�̂���XSLT�����������������������������Ǝv���܂��D
������ƍl�������x����C�������N���Ă������URL���߂����ŏ�������C
���炢�����v�������т܂���c�D
674 �FName_Not_Found�F2008/01/25(��) 21:23:27 ID:IYZieHT0
XLink�̊g�������N��RDF�Ɠ������e��\���܂����A
���҂̎g�������͂ǂ�����ׂ��Ȃ�ł��傤���H
XLink�ɂ͐U�镑�������Ƃ����邩��A
���Ƃ��Ώ����ȃf�[�^�Ƃ���RDF�������āA������u���E�U�p�ɕϊ�����XHTML+SVG+Xlink+etc�������Ƃ��A
����Ȋ����ł��傤���H
���҂̎g�������͂ǂ�����ׂ��Ȃ�ł��傤���H
XLink�ɂ͐U�镑�������Ƃ����邩��A
���Ƃ��Ώ����ȃf�[�^�Ƃ���RDF�������āA������u���E�U�p�ɕϊ�����XHTML+SVG+Xlink+etc�������Ƃ��A
����Ȋ����ł��傤���H
675 �FName_Not_Found�F2008/02/03(��) 14:45:35 ID:IEJf4Dm3
Social Graph API��FoaF�����p�����킯�����B
http://jp.techcrunch.com/archives/googles-gathers-social-graph-information-from-the-web-launches-api/
http://jp.techcrunch.com/archives/googles-gathers-social-graph-information-from-the-web-launches-api/
676 �FName_Not_Found�F2008/02/03(��) 19:47:36 ID:???
���̃X���I�ɂ͊W�������}�C�N���t�H�[�}�b�g�̕���
�d�ꂻ���ȁ�Social Graph API
�d�ꂻ���ȁ�Social Graph API
677 �FName_Not_Found�F2008/02/03(��) 21:04:31 ID:???
>>673
�����m���ɂ����@�͂Ȃ��Ǝv���B
type�����Ń��f�B�A�^�C�v���w�肵�Ă����������ǁA
���Ă����͂قƂ�nj������Ȃ��B
���Ƃ�HEAD�Ń��f�B�A�^�C�v�ׂ�Ƃ��B
(������T�[�o�ł�����Ɛݒ肵�Ă��Ȃ����Ƃ��悭����B)
�t�@�C�����Ɋg���q�������������ɔ��f����������B
>>674
�g���A�v���P�[�V������v���b�g�t�H�[������ł́B
XLink����Ɏg���悤�ɂȂ��Ă��������g���������A
���\�[�X�L�q�ɂ�RDF����т��Ďg���Ƃ����X�^���X�����邾�낤�B
���҂̕ϊ��@�\��p�ӂ��Ă��Α��݉^�p�����m�ۂł���B
��ɂ����Ă���悤�Ȏg�����ł��ʂɂ悢�Ǝv���B
�����m���ɂ����@�͂Ȃ��Ǝv���B
type�����Ń��f�B�A�^�C�v���w�肵�Ă����������ǁA
���Ă����͂قƂ�nj������Ȃ��B
���Ƃ�HEAD�Ń��f�B�A�^�C�v�ׂ�Ƃ��B
(������T�[�o�ł�����Ɛݒ肵�Ă��Ȃ����Ƃ��悭����B)
�t�@�C�����Ɋg���q�������������ɔ��f����������B
>>674
�g���A�v���P�[�V������v���b�g�t�H�[������ł́B
XLink����Ɏg���悤�ɂȂ��Ă��������g���������A
���\�[�X�L�q�ɂ�RDF����т��Ďg���Ƃ����X�^���X�����邾�낤�B
���҂̕ϊ��@�\��p�ӂ��Ă��Α��݉^�p�����m�ۂł���B
��ɂ����Ă���悤�Ȏg�����ł��ʂɂ悢�Ǝv���B
>>677
���肪�Ƃ��������܂��D
link�v�f�́utype="text/xsl"�v�Ɓu�g���q�v ������ň��ł��G���[�͖h�������ł��ˁD
������class������x-application-hoge���w�肳��Ă����炻�ꂾ���ǂށC
�Ƃ��l������ł����ǃL���C�ł����ˁc�D
���肪�Ƃ��������܂��D
link�v�f�́utype="text/xsl"�v�Ɓu�g���q�v ������ň��ł��G���[�͖h�������ł��ˁD
������class������x-application-hoge���w�肳��Ă����炻�ꂾ���ǂށC
�Ƃ��l������ł����ǃL���C�ł����ˁc�D
679 �FName_Not_Found�F2008/02/05(��) 01:25:24 ID:???
>>678
�ɂ�肫��B�Ȍ��Ɍ����A
GRDDL�Ή��̃h�L�������g��p�ӂ��Ă���郆�[�U������ɓ��ӂ���
class��t���Ă������ł���Ή\(�����C���g���ł̋K��Ƃ�)�B
Web��ʂŃ��[�U�ɂ����v������̂͂܂������B
�ɂ�肫��B�Ȍ��Ɍ����A
GRDDL�Ή��̃h�L�������g��p�ӂ��Ă���郆�[�U������ɓ��ӂ���
class��t���Ă������ł���Ή\(�����C���g���ł̋K��Ƃ�)�B
Web��ʂŃ��[�U�ɂ����v������̂͂܂������B
680 �FName_Not_Found�F2008/02/05(��) 01:29:48 ID:???
foaf�ʔ������Ȃ��ǁA�l�b�g�E�̗F�B���Ȃ�����E�E߁E(�D�M)�E߁E
����Ƃ��Ȃ���Ȃ�߁E(�D�M)�E߁E
����Ƃ��Ȃ���Ȃ�߁E(�D�M)�E߁E
681 �FName_Not_Found�F2008/02/05(��) 01:30:26 ID:???
682 �FName_Not_Found�F2008/02/05(��) 01:37:48 ID:???
>>680
�܂���b���̏��Ȃ����ꂾ���炻�������̂����邩��������A
�ʂɂ���ȊO�ł��g�����͂��邩��ȁB���̂�ʂ��Đl���q���邱�Ƃ�����B
�܂���b���̏��Ȃ����ꂾ���炻�������̂����邩��������A
�ʂɂ���ȊO�ł��g�����͂��邩��ȁB���̂�ʂ��Đl���q���邱�Ƃ�����B
683 �FName_Not_Found�F2008/02/05(��) 12:29:14 ID:???
>>680
���A�����扴�I
���A�����扴�I
684 �FName_Not_Found�F2008/02/05(��) 15:59:38 ID:???
�Ȃ�ŃP�[�^�C�Ƃ��e�탁�[���\�t�g�Ƃ��̃A�h���X����
�`����FOAF�œ��ꂵ�Ȃ��낤�˂��D
�`����FOAF�œ��ꂵ�Ȃ��낤�˂��D
685 �FName_Not_Found�F2008/02/05(��) 16:00:11 ID:???
��������Cicalender �� XML �łȂ�
���̊Ԃɂ� internet draft ��������Ă������D
���̊Ԃɂ� internet draft ��������Ă������D
686 �FName_Not_Found�F2008/02/05(��) 19:26:23 ID:???
�ȂɁARDFical�����邳
���������̓����̏璷�I�ȕ\�����͂ǂ����������肱�Ȃ�
ical�݊�������^�C���]�[���K�{�Ȃ낤���ǂȂ��AW3CDTF�ł��������
���������̓����̏璷�I�ȕ\�����͂ǂ����������肱�Ȃ�
ical�݊�������^�C���]�[���K�{�Ȃ낤���ǂȂ��AW3CDTF�ł��������
687 �FName_Not_Found�F2008/02/05(��) 20:16:55 ID:???
>>684
�A�v���̃f�[�^�t�H�[�}�b�g��FOAF�Ƃ����肦�Ȃ�����c
FOAF�ł̃G�N�X�|�[�g&�C���|�[�g�ł���@�\�͂ق����Ƃ͎v����
�A�v���̃f�[�^�t�H�[�}�b�g��FOAF�Ƃ����肦�Ȃ�����c
FOAF�ł̃G�N�X�|�[�g&�C���|�[�g�ł���@�\�͂ق����Ƃ͎v����
688 �FName_Not_Found�F2008/02/05(��) 22:25:43 ID:???
>>686
(X)HTML�̂����ŁAW3CDTF�ɂ͗ǂ���ۂ��Ȃ��c�c�B
(X)HTML�̂����ŁAW3CDTF�ɂ͗ǂ���ۂ��Ȃ��c�c�B
689 �FName_Not_Found�F2008/02/05(��) 23:01:50 ID:???
(X)HTML����DTF�ɂȂW���Ă������H
690 �FName_Not_Found�F2008/02/05(��) 23:07:41 ID:???
���ႠISO8601��
691 �FName_Not_Found�F2008/02/05(��) 23:32:13 ID:???
>>689
<ins>�Ƃ�<del>�Ƃ��Ɏg�����ǁA�d�l��A
> [ISO8601] allows many options and variations in the representation of dates and times.
> The current specification uses one of the formats described in the profile [DATETIME] for
> its definition of legal date/time strings ( %Datetime in the DTD).
>
> The format is:
>
> YYYY-MM-DDThh:mm:ssTZD
�ƃ^�C�v����������Ă��邹���Ŏg���Â炭�Ďd���Ȃ��B
<ins>�Ƃ�<del>�Ƃ��Ɏg�����ǁA�d�l��A
> [ISO8601] allows many options and variations in the representation of dates and times.
> The current specification uses one of the formats described in the profile [DATETIME] for
> its definition of legal date/time strings ( %Datetime in the DTD).
>
> The format is:
>
> YYYY-MM-DDThh:mm:ssTZD
�ƃ^�C�v����������Ă��邹���Ŏg���Â炭�Ďd���Ȃ��B
692 �FName_Not_Found�F2008/02/06(��) 00:00:32 ID:???
YYYY-MM-DDThh:mm:ssTZD��W3CDTF�̈�`���ł����āA
W3CDTF���̂ɂȂ�����ہH
W3CDTF���̂ɂȂ�����ہH
693 �FName_Not_Found�F2008/02/06(��) 00:02:42 ID:???
����Ƃ��C���[�W�݂����Ȃ��̂ɗ��R�Ȃ�ĂȂ���Ȃ��́H
�u�V�呞�����U���܂ő����v�̂��������Ƃ͎v�����ǁB
�u�V�呞�����U���܂ő����v�̂��������Ƃ͎v�����ǁB
694 �FName_Not_Found�F2008/02/06(��) 07:05:33 ID:???
���ꌾ������RDF�Ȃ�Č`���I����̉�˂�����
695 �FName_Not_Found�F2008/02/06(��) 07:10:02 ID:???
>>691
ical�Ȃ�Ă���ɁuYYYYMMDDThhmmss�v�����g���Ȃ�����
ical�Ȃ�Ă���ɁuYYYYMMDDThhmmss�v�����g���Ȃ�����
696 �FName_Not_Found�F2008/02/06(��) 07:49:10 ID:???
�N�����菑���Ń^�O������HTML�Ƃ͈���āA
RDF��^�f�[�^�̋L�q�͂ǂ����Ă��\�t�g�E�F�A�̃T�|�[�g�������ȁB
���������ǂ̏�ǂ̃v���p�e�B���Ȃ�Ă̂��菑���ł���Ă����
���[�U������Ƃ͎v���Ȃ�(�A�[���[�A�_�v�^�͂��Ă���)�B
���̈Ӗ��ł́AGRDDL�Ȃ��\�t�g�E�F�A�T�|�[�g���肫�̑��݂���Ȃ�
RDF��^�f�[�^�̋L�q�͂ǂ����Ă��\�t�g�E�F�A�̃T�|�[�g�������ȁB
���������ǂ̏�ǂ̃v���p�e�B���Ȃ�Ă̂��菑���ł���Ă����
���[�U������Ƃ͎v���Ȃ�(�A�[���[�A�_�v�^�͂��Ă���)�B
���̈Ӗ��ł́AGRDDL�Ȃ��\�t�g�E�F�A�T�|�[�g���肫�̑��݂���Ȃ�
697 �FName_Not_Found�F2008/02/06(��) 08:19:51 ID:???
�������Ă�l�Ԃ����������ق������z�I���Ǝv�����ǂ� HTML ���Ă��
698 �FName_Not_Found�F2008/02/06(��) 13:34:09 ID:???
�m���ɁAWEB�u���E�U�̂悤�Ƀ��^�����\�t�g�E�F�A�Ǝ��ɉ��߂��ꂽ�獢�邵��
�~����������̂ł���A�^�O�⊮�Ƃ��������̂ł͂Ȃ��ARDFAuthor�̂悤�ɃO���t�B�J���Ȃ��̂���
�Ƃ������A�����̏Z�l��RDF�����ۂȂɂɗ��p���Ă���H
�N���[�����܂��܂����y���Ă��Ȃ����ARSS���炢�����v�����Ȃ���
�~����������̂ł���A�^�O�⊮�Ƃ��������̂ł͂Ȃ��ARDFAuthor�̂悤�ɃO���t�B�J���Ȃ��̂���
�Ƃ������A�����̏Z�l��RDF�����ۂȂɂɗ��p���Ă���H
�N���[�����܂��܂����y���Ă��Ȃ����ARSS���炢�����v�����Ȃ���
699 �FName_Not_Found�F2008/02/06(��) 13:40:47 ID:???
RSS�菑�����Ă鉴�����܂�����
700 �FName_Not_Found�F2008/02/06(��) 18:56:14 ID:???
>>697
���������B�����炱���A�ςȃ\�[�X�̔×���h�����߂ɂ�
�\�t�g�E�F�A�ɂ�鐳�����o�͂̕⏕���K�v�Ȃ�Ȃ����ƁB
# �����Ƃ��A���̃\�t�g�E�F�A���s�v�c�}�[�N�A�b�v�Ȃ��
# �s�v�c�O���t��f�����肵��
���̕ӂ�CMS����肭����Ă����Ɗ��҂��Ă���c�B
>>698
���p�͂قڂȂ��ȁB
�̂�Web�y�[�W�̓��e��S��RDF�����Ă݂���Ƃ��ςȎ�����
�F�X����Ă������A�ŋ߂͂��܂�B
���������B�����炱���A�ςȃ\�[�X�̔×���h�����߂ɂ�
�\�t�g�E�F�A�ɂ�鐳�����o�͂̕⏕���K�v�Ȃ�Ȃ����ƁB
# �����Ƃ��A���̃\�t�g�E�F�A���s�v�c�}�[�N�A�b�v�Ȃ��
# �s�v�c�O���t��f�����肵��
���̕ӂ�CMS����肭����Ă����Ɗ��҂��Ă���c�B
>>698
���p�͂قڂȂ��ȁB
�̂�Web�y�[�W�̓��e��S��RDF�����Ă݂���Ƃ��ςȎ�����
�F�X����Ă������A�ŋ߂͂��܂�B
701 �FName_Not_Found�F2008/02/06(��) 19:16:09 ID:???
>>698
�u���O�̌ʃy�[�W�̃��^�f�[�^��RDF/XML�ŏo�͂��Ă�B����RSS��FOAF�B
�u���O�̌ʃy�[�W�̃��^�f�[�^��RDF/XML�ŏo�͂��Ă�B����RSS��FOAF�B
702 �FName_Not_Found�F2008/02/06(��) 19:42:51 ID:???
�l�I�Ɏv���`��(�ϑz����)semweb���W�̃V�i���I�B
1. ����RDF�T�C�g
Web�ɏo����Ă���A���p���l�̍���RDF���ł������Ńf�[�^��
�����RDF������SPARQL�G���h�|�C���g�Ō��J����T�C�g���o��B
2. RDF�̊��p�T�C�g
���̃G���h�|�C���g��F�X�g�ݍ��킹�ď���E�v�������
�Ȃǂ����銈�p�T�C�g���o��B
1��2�͔M�S��SW���i�҂����Ԃ�����҂����Ɋ撣���č��B
���̕ӂŃA�[���[�A�_�v�^�w��RDF�͕֗��������ƋC�Â��A
���ʂ̐l�X�͂����̃c�[�����d�g�݂�m��Ȃ��܂܊��p����B
3. semweb�G�f�B�^
��^�I�ȃf�[�^��e�Ղ�RDF���ł���悤�Ȏd�g�݂�������c�[���o��B
4. semweb�Ή��T�C�g�ƃc�[���̑��B
����RDF�T�C�g��������B�莝���̃f�[�^��RDF�����Č��J����l���o�Ă���B
�V�����Q�����Ă����l�������A���ǂ��ꂽsemweb�G�f�B�^�����J����B
1. ����RDF�T�C�g
Web�ɏo����Ă���A���p���l�̍���RDF���ł������Ńf�[�^��
�����RDF������SPARQL�G���h�|�C���g�Ō��J����T�C�g���o��B
2. RDF�̊��p�T�C�g
���̃G���h�|�C���g��F�X�g�ݍ��킹�ď���E�v�������
�Ȃǂ����銈�p�T�C�g���o��B
1��2�͔M�S��SW���i�҂����Ԃ�����҂����Ɋ撣���č��B
���̕ӂŃA�[���[�A�_�v�^�w��RDF�͕֗��������ƋC�Â��A
���ʂ̐l�X�͂����̃c�[�����d�g�݂�m��Ȃ��܂܊��p����B
3. semweb�G�f�B�^
��^�I�ȃf�[�^��e�Ղ�RDF���ł���悤�Ȏd�g�݂�������c�[���o��B
4. semweb�Ή��T�C�g�ƃc�[���̑��B
����RDF�T�C�g��������B�莝���̃f�[�^��RDF�����Č��J����l���o�Ă���B
�V�����Q�����Ă����l�������A���ǂ��ꂽsemweb�G�f�B�^�����J����B
703 �FName_Not_Found�F2008/02/06(��) 19:43:41 ID:???
5. ��Ƃ̎Q��
����RDF�̃f�[�^���ƂȂ�����Ƃ������RDF�����J����悤�ɂȂ�B
�ꍇ�ɂ���Ă͑��n����RDF����T�C�g�͕��ɒǂ����܂��B
���ʂ̐l�X���c�[����p����RDF�Ή��̃T�C�g�����J����悤�ɂȂ�B
6. �M�p��@
RDF��̂����K�I���l�������A��������p������̂�
�����B�d�q������M������������d�g�݂��L�܂�B
7. semweb�̑����Ɛ���
�U���^�f�[�^�ARDF�X�p���ȂǁA���܂��܂Ȗ�������Ȃ����
semweb�͎����I�ɔ��W����B
���������������Ă܂��A�������Ă܂��B�ϑz�ł��B
����RDF�̃f�[�^���ƂȂ�����Ƃ������RDF�����J����悤�ɂȂ�B
�ꍇ�ɂ���Ă͑��n����RDF����T�C�g�͕��ɒǂ����܂��B
���ʂ̐l�X���c�[����p����RDF�Ή��̃T�C�g�����J����悤�ɂȂ�B
6. �M�p��@
RDF��̂����K�I���l�������A��������p������̂�
�����B�d�q������M������������d�g�݂��L�܂�B
7. semweb�̑����Ɛ���
�U���^�f�[�^�ARDF�X�p���ȂǁA���܂��܂Ȗ�������Ȃ����
semweb�͎����I�ɔ��W����B
���������������Ă܂��A�������Ă܂��B�ϑz�ł��B
704 �FName_Not_Found�F2008/02/06(��) 19:48:51 ID:???
705 �FName_Not_Found�F2008/02/06(��) 21:46:18 ID:???
������RSS���菑���A���ȁB
���Ƃ́A�R���e���c��CreativeCommons���C�Z���X�ɂ��Ă�W�ŁA���C�Z���X����
RDF/XML�ŏ����Ă����Ă���B�u���E�U������XSLT�����XHTML�ɂ��ĕ\�����Ă邯�ǂˁB
���Ƃ́A�R���e���c��CreativeCommons���C�Z���X�ɂ��Ă�W�ŁA���C�Z���X����
RDF/XML�ŏ����Ă����Ă���B�u���E�U������XSLT�����XHTML�ɂ��ĕ\�����Ă邯�ǂˁB
706 �FName_Not_Found�F2008/02/07(��) 05:41:56 ID:???
�菑�����B�݂�ȁARDF�G�f�B�^���Ďg���Ă�H��Ԃ�RDFAuthor��IsaViz��
�Ȃ������Ďg���ɂ��������BMR3�͂�����������Ȃ��Ǝv��������ǁA�����
���`������Ă�����Emacs�ŃS���S�������Ă������ق��������Ƒ���������B
�S�R�W�Ȃ����AIsaViz�̃X�N���[���V���b�g�́u�X�L��������Ă�����A
������ăJ�X�C�P�T�C�g�v���ƂĂ��C�ɂȂ�B
http://www.w3.org/2001/11/IsaViz/images/isv8.png
�J�X�C�P�c�H
�Ȃ������Ďg���ɂ��������BMR3�͂�����������Ȃ��Ǝv��������ǁA�����
���`������Ă�����Emacs�ŃS���S�������Ă������ق��������Ƒ���������B
�S�R�W�Ȃ����AIsaViz�̃X�N���[���V���b�g�́u�X�L��������Ă�����A
������ăJ�X�C�P�T�C�g�v���ƂĂ��C�ɂȂ�B
http://www.w3.org/2001/11/IsaViz/images/isv8.png
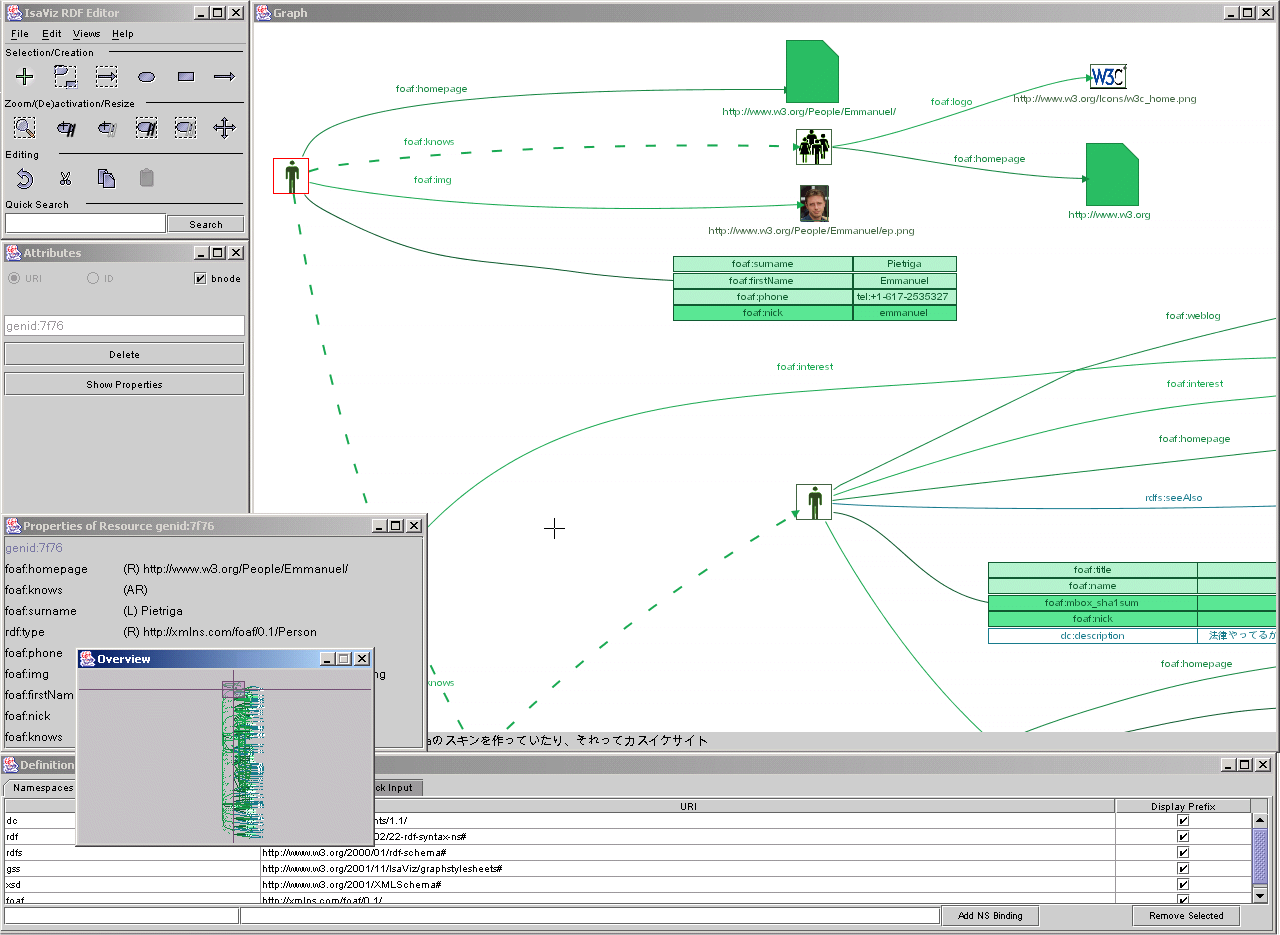{kind=link}
�J�X�C�P�c�H
�Ղ�Ă������Ă�H
���ƁCGoogle Base �݂����Ȃ̂Ńg���v�����荞���
SPARQL �Ō��������Ă����悤�Ȃ������������
����Ȃ����Ȃ��C�O�O��
���ƁCGoogle Base �݂����Ȃ̂Ńg���v�����荞���
SPARQL �Ō��������Ă����悤�Ȃ������������
����Ȃ����Ȃ��C�O�O��
708 �FName_Not_Found�F2008/02/07(��) 08:22:54 ID:???
RDF�G�f�B�^���Ăǂ�ȃC���^�[�t�F�[�X���g���₷���낤�ȁB
709 �FName_Not_Found�F2008/02/07(��) 15:03:49 ID:???
>>708
�p�r�ɂ����Ǝv�����ǁA�v���_�E���`���ō��ڂ�I�����āA
�l�������ŏ������ށi�ݒ肳�ꂽ�ȊO�̃t�H�[�}�b�g�̓G���[�j���Ċ������ȁH
�ł��A���������>>706�������Ă���悤��
������x�m���Ă郄�c�́A�K���ȃe���v���[�g������Ď����ŏ����Ă���������������ˁB
������vi�h�����ǂ�
�p�r�ɂ����Ǝv�����ǁA�v���_�E���`���ō��ڂ�I�����āA
�l�������ŏ������ށi�ݒ肳�ꂽ�ȊO�̃t�H�[�}�b�g�̓G���[�j���Ċ������ȁH
�ł��A���������>>706�������Ă���悤��
������x�m���Ă郄�c�́A�K���ȃe���v���[�g������Ď����ŏ����Ă���������������ˁB
������vi�h�����ǂ�
710 �FName_Not_Found�F2008/02/07(��) 19:31:14 ID:???
vi�Ƃ͂����Ԃ�X�g�C�b�N���Ȃ�
�悭����O���t�`�����̂܂܂�ҏW���Ă͕̂�����₷���낤���ǁA
�g���������Ƃ���Ƒ������Ȃ���ɂ����Ǝv����ˁB
���������X�g�R���g���[���Ɏ��E�q��E�ړI���3���p�ӂ���
�e�s���ƂɃ��\�[�X���L�q����Ƃ��A�v�������r�W�l�X���C�N��
�f�U�C���̂ق����邩�������B
�悭����O���t�`�����̂܂܂�ҏW���Ă͕̂�����₷���낤���ǁA
�g���������Ƃ���Ƒ������Ȃ���ɂ����Ǝv����ˁB
���������X�g�R���g���[���Ɏ��E�q��E�ړI���3���p�ӂ���
�e�s���ƂɃ��\�[�X���L�q����Ƃ��A�v�������r�W�l�X���C�N��
�f�U�C���̂ق����邩�������B
711 �FName_Not_Found�F2008/02/07(��) 20:40:26 ID:???
RDF/XML�Ȃ�ăq���[�}�����[�_�r���e�B�[�����C�^�r���e�B�[���Ⴂ�t�H�[�}�b�g
�ǂ��l���Ă��c�[���Ŏ����������Ďg�����̂���c
# �Ƃ�������ł�RSS���炢�����T�|�[�g�c�[�����Ȃ���˂�
# �c�[�����Ȃ��ƕ��y���Ȃ������y���Ȃ��ƃc�[��������Ȃ����c
�ǂ��l���Ă��c�[���Ŏ����������Ďg�����̂���c
# �Ƃ�������ł�RSS���炢�����T�|�[�g�c�[�����Ȃ���˂�
# �c�[�����Ȃ��ƕ��y���Ȃ������y���Ȃ��ƃc�[��������Ȃ����c
712 �FName_Not_Found�F2008/02/08(��) 09:02:46 ID:???
Web�y�[�W��RDF/XML�Ȃ�A���ƒ�^�I�ɁA���ꂱ��GRDDL�Ő����ł����������ȁB
713 �FName_Not_Found�F2008/02/08(��) 09:18:43 ID:???
�{�̃��r���[��RDF�ō��T�[�r�X�͂ǂ��H
1.�薼����Җ��Ō���
2.Amazon�̌������ʕ\��
3.���r���[�������������i��I���i����Ŏ���URN:ISBN�Adc:title�Ȃǂ��Z�b�g�j
4.�u���O�̃R�����g�����o�Ń��r���[�������݁idc:description�ɃZ�b�g�j
5.���M�iRDF�̃f�[�^�x�[�X�ɕۑ��j
���Ƃ�RDF�Ƃ��Č����B�u���E�U���猟������XHTML�ɕϊ��\���B��p�\�t�g�ɂ�RDF�ڑ��M�B
���y�Ȃ�A�I���̎��_�Ŏ���MusicBrainz�̒l����������A�o�^���Ȃ��ꍇ��MusicBrainz��Amazon��
������������f�[�^�������o�^�������MusicBrainz�̒l�������B
����Ȃ�RDF�̓���ɐG�ꂸ�ɒN�ł�RDF���g�����H
��b�͍�������}���ق������L�q�p�̌�b��`����Ă邩��A��������p����Ηǂ��B
�����g�͎����̃T�C�g�ŁA�Ǐ����z��RDF/XML�Ŏ菑�����Ă�B
1.�薼����Җ��Ō���
2.Amazon�̌������ʕ\��
3.���r���[�������������i��I���i����Ŏ���URN:ISBN�Adc:title�Ȃǂ��Z�b�g�j
4.�u���O�̃R�����g�����o�Ń��r���[�������݁idc:description�ɃZ�b�g�j
5.���M�iRDF�̃f�[�^�x�[�X�ɕۑ��j
���Ƃ�RDF�Ƃ��Č����B�u���E�U���猟������XHTML�ɕϊ��\���B��p�\�t�g�ɂ�RDF�ڑ��M�B
���y�Ȃ�A�I���̎��_�Ŏ���MusicBrainz�̒l����������A�o�^���Ȃ��ꍇ��MusicBrainz��Amazon��
������������f�[�^�������o�^�������MusicBrainz�̒l�������B
����Ȃ�RDF�̓���ɐG�ꂸ�ɒN�ł�RDF���g�����H
��b�͍�������}���ق������L�q�p�̌�b��`����Ă邩��A��������p����Ηǂ��B
�����g�͎����̃T�C�g�ŁA�Ǐ����z��RDF/XML�Ŏ菑�����Ă�B
714 �FName_Not_Found�F2008/02/08(��) 16:55:08 ID:???
BOOKLOG�݂����ȃT�[�r�X�ɑg�ݍ��ނ�����
���y������Ȃ�����̃u���O�ɑg�ݍ��ނ̂���̎肾�Ǝv���B���ꂾ���̂��߂ɕʃV�X�e����p�ӂ���E�o�^����͎̂�Ԃ����A�l�I�Ɏ����̔��M���͈�ɂ܂Ƃ߂Ă�������
�ނ���SNS�Ȃ�A���r���[�������āA����ɋC�������l�Ƃ͂Ȃ����A�i�D�̔��M���Ȃ��ǂȁc
���y������Ȃ�����̃u���O�ɑg�ݍ��ނ̂���̎肾�Ǝv���B���ꂾ���̂��߂ɕʃV�X�e����p�ӂ���E�o�^����͎̂�Ԃ����A�l�I�Ɏ����̔��M���͈�ɂ܂Ƃ߂Ă�������
�ނ���SNS�Ȃ�A���r���[�������āA����ɋC�������l�Ƃ͂Ȃ����A�i�D�̔��M���Ȃ��ǂȁc
715 �FName_Not_Found�F2008/02/08(��) 18:25:22 ID:???
>>713
�����ˁA����������Ă��ꂗ
�Ƃ肠������Amazon�̃��r���[�����������Ă���RDF�Ō��J����悤�ȁA
RDF�v���L�V�H�T�[�r�X�ł���Ă݂�Ƃ���������邩�������B
�����ˁA����������Ă��ꂗ
�Ƃ肠������Amazon�̃��r���[�����������Ă���RDF�Ō��J����悤�ȁA
RDF�v���L�V�H�T�[�r�X�ł���Ă݂�Ƃ���������邩�������B
716 �FName_Not_Found�F2008/02/08(��) 18:44:10 ID:???
>>714
>�l�I�Ɏ����̔��M���͈�ɂ܂Ƃ߂Ă�������
�悭�����邻��B
�������̕ӂ͌����Web�Ɠ����悤�ɁA���[�U�̍D�݂ɂ����
�E����̎�ނ̏���p�T�C�g(�Ⴆ�Η����̃��V�s���e�T�C�g�Ƃ�)
�E�l�Ǘ����ꂽ�T�C�g�A�������͌ʗ̈�̊��蓖�Ă���O���T�[�r�X(�u���O�Ƃ�)
�Ő��ݕ��������Ȃ����ȁB
RDF�������悤�ɁA���e�T�C�g�ŏW���ۊǂ������̂�
�l�T�C�g�ŌʊǗ��������̂ɕ������B
�������܂������Č����T�[�r�X����������
(�����ė��v�̑唼�������Ă�����)�A�ƁB
>�l�I�Ɏ����̔��M���͈�ɂ܂Ƃ߂Ă�������
�悭�����邻��B
�������̕ӂ͌����Web�Ɠ����悤�ɁA���[�U�̍D�݂ɂ����
�E����̎�ނ̏���p�T�C�g(�Ⴆ�Η����̃��V�s���e�T�C�g�Ƃ�)
�E�l�Ǘ����ꂽ�T�C�g�A�������͌ʗ̈�̊��蓖�Ă���O���T�[�r�X(�u���O�Ƃ�)
�Ő��ݕ��������Ȃ����ȁB
RDF�������悤�ɁA���e�T�C�g�ŏW���ۊǂ������̂�
�l�T�C�g�ŌʊǗ��������̂ɕ������B
�������܂������Č����T�[�r�X����������
(�����ė��v�̑唼�������Ă�����)�A�ƁB
717 �FName_Not_Found�F2008/02/09(�y) 02:28:35 ID:???
718 �FName_Not_Found�F2008/02/09(�y) 18:27:43 ID:???
>>717
�Ǝ��͎g���Ă��܂���B����}���ق�DC-NDL�ł��i���L�j�B
ttp://www.ndl.go.jp/jp/standards/dcndl/index.html
��������}���ق͋C�������Ă�B
�Ǝ��͎g���Ă��܂���B����}���ق�DC-NDL�ł��i���L�j�B
ttp://www.ndl.go.jp/jp/standards/dcndl/index.html
��������}���ق͋C�������Ă�B
719 �FName_Not_Found�F2008/02/09(�y) 20:18:09 ID:???
����Ԃ�����Ȋ������邯�ǁA
OpenID���ă��[�U�ʂ�URI�Ȃ���Ardf:about�̒l�Ɏg����̂���
OpenID���ă��[�U�ʂ�URI�Ȃ���Ardf:about�̒l�Ɏg����̂���
720 �FName_Not_Found�F2008/02/09(�y) 20:41:53 ID:???
�ł����B���Ă�����URI�ł���Ή��ł��g����B
�ړI��ɂ���
[ a foaf:Person ] ex:openId <Your OpenID URI> .
�Ȃ�Ă̂����邩���ˁB
���č\�����������Ƃ��ċv�X��Turtle�̃y�[�W���悤�Ƃ�����A
�c������H
�ړI��ɂ���
[ a foaf:Person ] ex:openId <Your OpenID URI> .
�Ȃ�Ă̂����邩���ˁB
���č\�����������Ƃ��ċv�X��Turtle�̃y�[�W���悤�Ƃ�����A
�c������H
721 �FName_Not_Found�F2008/02/09(�y) 23:16:04 ID:???
�l��\��URI���Ăǂ�Ȃ̂��悢���ȁB
timbl��FOAF���g����(http://dig.csail.mit.edu/breadcrumbs/node/71)�́A
FOAF��URI���ς��ƌl��URI���ς���Ă��܂��̂ŁA�������B
tag�X�L�[�}�Ƃ��H
timbl��FOAF���g����(http://dig.csail.mit.edu/breadcrumbs/node/71)�́A
FOAF��URI���ς��ƌl��URI���ς���Ă��܂��̂ŁA�������B
tag�X�L�[�}�Ƃ��H
722 �FName_Not_Found�F2008/02/10(��) 01:02:41 ID:???
>>721
�X�L�[�}�ischema�j����Ȃ��ăX�L�[���ischeme�j�ˁB
tag�ł�������http�ł��������A�D���Ȃ��̂��g�p��������B
�����̒u���ꏊ�@����URI��ς������Ȃ���A
�������ő���URI�ł͂Ȃ����URI�ŎQ�Ƃ���悤�ɂ����
�悢�̂ł͂Ȃ����ƁB
�X�L�[�}�ischema�j����Ȃ��ăX�L�[���ischeme�j�ˁB
tag�ł�������http�ł��������A�D���Ȃ��̂��g�p��������B
�����̒u���ꏊ�@����URI��ς������Ȃ���A
�������ő���URI�ł͂Ȃ����URI�ŎQ�Ƃ���悤�ɂ����
�悢�̂ł͂Ȃ����ƁB
723 �FName_Not_Found�F2008/02/10(��) 01:19:54 ID:???
>>718
��������ƁA�Ώێ��̂ɒ��ڊ��z�������ѕt�������
���z���̂����\�[�X�ɂ����ق����Q�Ɖ\���������Ă悳���������A����Ȋ����H
<���z����URI>
�@dc:title "���z" ;
�@dc:description "�{��" ;
�@dc:relation <urn:isbn:4-627-82931-0> .
���邢�͊��z�̑Ώۂ����ɂ���
<urn:isbn:4-627-82931-0> dc:relation [
�@dc:title "���z" ;
�@dc:description "�{��"
] .
�Ƃ��H ���z�i���r���[�Ƃ��R�����g�H�j�N���X���~�����Ƃ��낾�ȁB
��������ƁA�Ώێ��̂ɒ��ڊ��z�������ѕt�������
���z���̂����\�[�X�ɂ����ق����Q�Ɖ\���������Ă悳���������A����Ȋ����H
<���z����URI>
�@dc:title "���z" ;
�@dc:description "�{��" ;
�@dc:relation <urn:isbn:4-627-82931-0> .
���邢�͊��z�̑Ώۂ����ɂ���
<urn:isbn:4-627-82931-0> dc:relation [
�@dc:title "���z" ;
�@dc:description "�{��"
] .
�Ƃ��H ���z�i���r���[�Ƃ��R�����g�H�j�N���X���~�����Ƃ��낾�ȁB
724 �FName_Not_Found�F2008/02/10(��) 02:00:44 ID:???
>>721
�撣����FOAF��u���ꏊ���P�v�I�ɂ���B
���ꂩ�A�悭��������@������
�l��http��URI���蓖�ĂāA�����FOAF������
���_�C���N�g����̂��悢��Ȃ����ȁB
�撣����FOAF��u���ꏊ���P�v�I�ɂ���B
���ꂩ�A�悭��������@������
�l��http��URI���蓖�ĂāA�����FOAF������
���_�C���N�g����̂��悢��Ȃ����ȁB
725 �FName_Not_Found�F2008/02/10(��) 11:14:03 ID:???
>>724
�l�Ԃɗ^����URI�Ŏ擾�����iHTTP StatusCode��200�j�̂͐l�Ԃ��̂��̂ł���ׂ��B
�Ȃ̂�SeeOther303���g����҂��������Ǝv���B�P�v���͕����I�ۑ�B
���������A�u�}�N�h�i���h�̃n���o�[�K�[��URI�v���u���E�U�Ń��N�G�X�g����ƃJ�^���O��303�œ���
���A�����]�����u�Ń��N�G�X�g����ƃ}�N�h�i���h�̃T�[�o�[����n���o�[�K�[��200�œ������邩���B
�Ƃ���ŁA��b��URI�����N�G�X�g���ꂽ�ꍇ�ɒ�`������Ԃ����A�����303����Ȃ����납�B
�u��b�v�͒��ە��ł���A�u��b�̒�`�v�͌�b��description�œ�������Ȃ��C������B
�l�Ԃɗ^����URI�Ŏ擾�����iHTTP StatusCode��200�j�̂͐l�Ԃ��̂��̂ł���ׂ��B
�Ȃ̂�SeeOther303���g����҂��������Ǝv���B�P�v���͕����I�ۑ�B
���������A�u�}�N�h�i���h�̃n���o�[�K�[��URI�v���u���E�U�Ń��N�G�X�g����ƃJ�^���O��303�œ���
���A�����]�����u�Ń��N�G�X�g����ƃ}�N�h�i���h�̃T�[�o�[����n���o�[�K�[��200�œ������邩���B
�Ƃ���ŁA��b��URI�����N�G�X�g���ꂽ�ꍇ�ɒ�`������Ԃ����A�����303����Ȃ����납�B
�u��b�v�͒��ە��ł���A�u��b�̒�`�v�͌�b��description�œ�������Ȃ��C������B
726 �FName_Not_Found�F2008/02/10(��) 11:55:19 ID:???
>>725
DC�Ȃ͌��URI�ɃA�N�Z�X����Ƃ����ƕ����Ƀ��_�C���N�g����ˁB
�܂����_�C���N�g�͋Z�p�I�Ȓm�����K�v������A
��ʂ̐l�X��RDF�� (�c�[���Ȃǂ�) ������Web�Ō��J����Ȃ�ďꍇ�́A
�n�b�V��URI���g�����ق����y���Ƃ͎v���B
�P�v������̎����Ă͓̂��ӂł���Ƃ���ł͂���ȁB
���\�[�X�̕��ނ�z�u�\���Ɩ��ڂɌ��т������݂�URI�������l����ƁA
URI���P�v�I�Ɉێ�����͔̂��I (�ł���Ȃ炻��ɉz�������Ƃ͂Ȃ���)�B
����́A���݂�Web��404 Not Found���ÎĂ���̂Ɠ��l�A
Semantic Web���܂�404 RDF Not Found���ÂĎ����ق��Ȃ�
���Ă����̘b���Ƃ͎v�����ǂ��B
DC�Ȃ͌��URI�ɃA�N�Z�X����Ƃ����ƕ����Ƀ��_�C���N�g����ˁB
�܂����_�C���N�g�͋Z�p�I�Ȓm�����K�v������A
��ʂ̐l�X��RDF�� (�c�[���Ȃǂ�) ������Web�Ō��J����Ȃ�ďꍇ�́A
�n�b�V��URI���g�����ق����y���Ƃ͎v���B
�P�v������̎����Ă͓̂��ӂł���Ƃ���ł͂���ȁB
���\�[�X�̕��ނ�z�u�\���Ɩ��ڂɌ��т������݂�URI�������l����ƁA
URI���P�v�I�Ɉێ�����͔̂��I (�ł���Ȃ炻��ɉz�������Ƃ͂Ȃ���)�B
����́A���݂�Web��404 Not Found���ÎĂ���̂Ɠ��l�A
Semantic Web���܂�404 RDF Not Found���ÂĎ����ق��Ȃ�
���Ă����̘b���Ƃ͎v�����ǂ��B
727 �FName_Not_Found�F2008/02/10(��) 21:22:30 ID:???
�P�v�I��URI�Ƃ�����purl.org�Ƃ��D
����urn:pin�Ƃ��������Ƃ��邯�ǁC�ǂ�����Ď�邩�̓��J���l�D
����urn:pin�Ƃ��������Ƃ��邯�ǁC�ǂ�����Ď�邩�̓��J���l�D
728 �FName_Not_Found�F2008/02/10(��) 22:02:31 ID:???
��http://www.ietf.org/rfc/rfc3043.txt
NSI�l�l
NSI�l�l
729 �FName_Not_Found�F2008/02/11(��) 10:37:27 ID:???
> Process of identifier assignment:
> Names are granted via Network Solutions
> proprietary registration procedures.
���Ă���ˁB���ł��o�^�ł���̂��ȁHNSI�̃y�[�W���������悭�킩���B
> Names are granted via Network Solutions
> proprietary registration procedures.
���Ă���ˁB���ł��o�^�ł���̂��ȁHNSI�̃y�[�W���������悭�킩���B
730 �FName_Not_Found�F2008/02/11(��) 11:11:50 ID:???
�m���ɕ������ˁBNSI�Ƀh���C���ڊǂ�������炦�Ȃ����ȁH
�ł��������ێ������ȁB���A�Ă�����.jp�����疳����w
�ł��������ێ������ȁB���A�Ă�����.jp�����疳����w
731 �FName_Not_Found�F2008/02/11(��) 12:58:59 ID:???
�܂��A�l��URI�͕��ʂ�http�ł�����ˁB
���_�C���N�g��t���O�����g���ʎq�����p�����
���\�[�X���ʂɉ����ď��擾���ł��Ĉꋓ�����B
���_�C���N�g��t���O�����g���ʎq�����p�����
���\�[�X���ʂɉ����ď��擾���ł��Ĉꋓ�����B
732 �FName_Not_Found�F2008/02/11(��) 18:06:25 ID:???
>>731
�^���B
�ŁA�Ԃ��Ă���̂͂����Ȃ�FOAF����Ȃ��A�u�O���v���t�B�[���v�݂����ȕ��������Ǝv���B
�ŁA�O���݂����Ȋe�T�[�r�X�ŁA�y�[�W����GRDDL��FOAF�𒊏o�ł���悤�ɂ���BFOAF�ɑΉ��̂Ȃ�
���e��rdfs:seeAlso�ŎQ�Ƃ�����B���̎Q�Ɛ�ɃA�t�B��t����AFOAF�����ƂȂ��e�Ђ̎�����
�m�ۂł��A�Ǝ��E�V�K�T�[�r�X�ւ̓������Ӗ�������̂ɂȂ�B
���[�U�[�͋��ʌ`���Ńv���t�������悤�ɂȂ藘�������シ��B
GRDDL+FOAF�ł݂�ȃn�b�s�[�ɂȂ�݂�`���Ă݂��B�N���_���ށB
�^���B
�ŁA�Ԃ��Ă���̂͂����Ȃ�FOAF����Ȃ��A�u�O���v���t�B�[���v�݂����ȕ��������Ǝv���B
�ŁA�O���݂����Ȋe�T�[�r�X�ŁA�y�[�W����GRDDL��FOAF�𒊏o�ł���悤�ɂ���BFOAF�ɑΉ��̂Ȃ�
���e��rdfs:seeAlso�ŎQ�Ƃ�����B���̎Q�Ɛ�ɃA�t�B��t����AFOAF�����ƂȂ��e�Ђ̎�����
�m�ۂł��A�Ǝ��E�V�K�T�[�r�X�ւ̓������Ӗ�������̂ɂȂ�B
���[�U�[�͋��ʌ`���Ńv���t�������悤�ɂȂ藘�������シ��B
GRDDL+FOAF�ł݂�ȃn�b�s�[�ɂȂ�݂�`���Ă݂��B�N���_���ށB
733 �FName_Not_Found�F2008/02/11(��) 18:55:26 ID:???
�
734 �FName_Not_Found�F2008/02/12(��) 23:14:22 ID:???
���̃X���̏Z�l��GRDDL�g���Ă���l�������݂��������ǁARDFa���Ăǂ��Ȃ́H
GRDDL�����邩��A���������Ă���Ȃ��q�H
GRDDL�����邩��A���������Ă���Ȃ��q�H
735 �FName_Not_Found�F2008/02/13(��) 00:58:01 ID:???
>>734
�ڂ����͒m��Ȃ����ǂ����Ǝd�l�ɖڂ�ʂ��ƁAXHTML���g�����Ă�悤���ȁB
���������X�L�[�}���x���̊g���͑�T��肭�����Ȃ��悤�ȋC��������c�B
�ڂ����͒m��Ȃ����ǂ����Ǝd�l�ɖڂ�ʂ��ƁAXHTML���g�����Ă�悤���ȁB
���������X�L�[�}���x���̊g���͑�T��肭�����Ȃ��悤�ȋC��������c�B
736 �FName_Not_Found�F2008/02/13(��) 01:23:16 ID:???
GRDDL�����y����C���܂��������Ȃ������ꂾ�����H
737 �FName_Not_Found�F2008/02/13(��) 22:33:34 ID:???
��͂肱���̓X�N���[���X�N���b�p�[
738 �FName_Not_Found�F2008/02/14(��) 19:27:46 ID:???
���̊Ԃɂ��ARDF/OWL�������o��4�N���o���Ă�B
�Ă�XML�ƒa���������Ȃ̂ˁB
�Ă�XML�ƒa���������Ȃ̂ˁB
739 �FName_Not_Found�F2008/02/14(��) 22:59:45 ID:???
���̗���́ARDF�������Ȃ菑���͖̂���������
RDF�ɂ��₷���f�[�^����낤���Ċ����Ȃ낤���ˁB
�Ƃ����Ă��U������g���v�������o����悤�Ȏd�g�݂́A
�p�ӂł��Ă��g��������ς��낤���A
�܂��͕\�Ƃ��̒�^�I�ȃf�[�^��RDF�ɂ���Ƃ��납��
�n�߂��ق����悢�C������ȁB
RDF�ɂ��₷���f�[�^����낤���Ċ����Ȃ낤���ˁB
�Ƃ����Ă��U������g���v�������o����悤�Ȏd�g�݂́A
�p�ӂł��Ă��g��������ς��낤���A
�܂��͕\�Ƃ��̒�^�I�ȃf�[�^��RDF�ɂ���Ƃ��납��
�n�߂��ق����悢�C������ȁB
740 �FName_Not_Found�F2008/02/14(��) 23:48:22 ID:???
�c���OWL���L�q���Ăǂ��L���Ɏg���邩����肩�B
741 �FName_Not_Found�F2008/02/15(��) 00:11:45 ID:???
�f�[�^�x�[�X�ɓ˂�����Ő��_�G���W���ɔC����������
742 �FName_Not_Found�F2008/02/15(��) 00:15:37 ID:???
�܂��̓f�[�^���W�߂�Ƃ��낾�ȁB
743 �FName_Not_Found�F2008/02/15(��) 00:28:06 ID:???
�����c�[����邩
�ł��Ȃ��C�܂��͌�b�����ꂳ��ĂȂ��g�i�D
���_���悤�ɂ��D
���āC���邮�郋�[�v����D
���_���悤�ɂ��D
���āC���邮�郋�[�v����D
745 �FName_Not_Found�F2008/02/16(�y) 00:36:59 ID:???
��b�͓��ꂷ��K�v�Ȃ���
���ꂪSW�̃����b�g
���ꂪSW�̃����b�g
746 �FName_Not_Found�F2008/02/16(�y) 00:55:41 ID:???
>>743
���B
���B
747 �FName_Not_Found�F2008/02/16(�y) 00:57:56 ID:???
���ˁD����Ƃ��ꂪsameAs���Ă����̂��ォ���`�����OK�̂͂��D
��b�͍�郂�`�x�[�V�����Ɛ������v�ł��Ă�̂����M�����ĂȂ����Ă̂������ˁD
��҂͎��Ⴊ��R�łĂ���ΎQ�l�ɏo���邩�炻�̂�����������낤���ǁC
�����悤�Ȍ�b���Ȃ��Ɗm�M�����ĂȂ��c�D
��b�͍�郂�`�x�[�V�����Ɛ������v�ł��Ă�̂����M�����ĂȂ����Ă̂������ˁD
��҂͎��Ⴊ��R�łĂ���ΎQ�l�ɏo���邩�炻�̂�����������낤���ǁC
�����悤�Ȍ�b���Ȃ��Ɗm�M�����ĂȂ��c�D
748 �FName_Not_Found�F2008/02/16(�y) 01:24:55 ID:???
749 �FName_Not_Found�F2008/02/16(�y) 02:43:17 ID:???
���܂����b�̕s���_�͉���H�o������
�� ttp://www.schemaweb.info/
�� ttp://www.daml.org/ontologies/
�� ttp://www.opencyc.org/
�� ttp://swoogle.umbc.edu/
�� ttp://www.schemaweb.info/
�� ttp://www.daml.org/ontologies/
�� ttp://www.opencyc.org/
�� ttp://swoogle.umbc.edu/
750 �FName_Not_Found�F2008/02/16(�y) 03:22:34 ID:???
���肪���Ȃ̂́A�����̌�b��g�ݍ��킹�Ďg����
���O��Ԑ錾����ʂɂȂ�̂ŁA�����������
�V���v���Ȉ�̖��O��ԂɎ������K�v�Ȃ��̂�����
����Ďg�����ėႾ�Ȃ����ƁB
�X�L�[�}��subClassOf�Ƃ�subPropertyOf�����Ă�����
������b�Ƃ��q�����邵�ȁB
# ���̑���n���ɋ@�B�������ώG�ɂȂ�㩁B
���O��Ԑ錾����ʂɂȂ�̂ŁA�����������
�V���v���Ȉ�̖��O��ԂɎ������K�v�Ȃ��̂�����
����Ďg�����ėႾ�Ȃ����ƁB
�X�L�[�}��subClassOf�Ƃ�subPropertyOf�����Ă�����
������b�Ƃ��q�����邵�ȁB
# ���̑���n���ɋ@�B�������ώG�ɂȂ�㩁B
751 �FName_Not_Found�F2008/02/16(�y) 08:28:03 ID:???
�l�Ԃ̉ǐ��ɔ�ׂ�@�B�����̔ώG���͌y���ł���Ǝv��
752 �FName_Not_Found�F2008/02/16(�y) 09:36:35 ID:???
�{���ɕ��U�ۊǂ��ꂽ�f�[�^�̓N�G���E�����R�X�g����������
�i���ɃC���^�[�l�b�g�z���ł́j����A��͂�google�̂悤��
�W���Ǘ��^��DB+�A�N�Z�X�|�C���g���s���ɂȂ��ȁB
�i���ɃC���^�[�l�b�g�z���ł́j����A��͂�google�̂悤��
�W���Ǘ��^��DB+�A�N�Z�X�|�C���g���s���ɂȂ��ȁB
753 �FName_Not_Found�F2008/02/16(�y) 11:42:16 ID:???
���O��C�u���_�v���ċ�̓I�ɂ͂ǂ�Ȃ��̂�z�肵�Ă�́H
�ꌾ�ł����Ηv��SPARQL�ʼn\�ȃN�G���̂��Ƃ��w���Ă���́H
�ꌾ�ł����Ηv��SPARQL�ʼn\�ȃN�G���̂��Ƃ��w���Ă���́H
754 �FName_Not_Found�F2008/02/16(�y) 11:48:21 ID:???
���[���ɂ�鉉㈂ł��傤�ˁB
755 �FName_Not_Found�F2008/02/16(�y) 11:59:18 ID:???
���_����Ď��O�ŃX�N���b�`����g��ł�́H
756 �FName_Not_Found�F2008/02/16(�y) 12:24:37 ID:???
��T�ɂǂ��Ƃ͌����Ȃ��̂ł́B
757 �FName_Not_Found�F2008/02/16(�y) 19:50:51 ID:???
�܂������͐F�X���낤��
758 �FName_Not_Found�F2008/02/17(��) 00:13:23 ID:???
�Ƃ���ŁARaptor���Ďg����H
759 �FName_Not_Found�F2008/02/18(��) 19:20:46 ID:???
�g�������ƂȂ�
RDF�̊J���p�c�[���g���Ă�l����H
RDF�̊J���p�c�[���g���Ă�l����H
760 �FName_Not_Found�F2008/02/21(��) 19:37:31 ID:???
�f�[�^�t�H�[�}�b�g�Ƃ��ẴO���t���Ă̂��قƂ�nj��Ȃ����
�O���t�͔ėp�I�ł͂��邯�ǂ��A
��ʓI�ȃf�[�^�i�[�t�H�[�}�b�g�Ƃ��Ă͐�i�I�߂���̂�
�O���t�͔ėp�I�ł͂��邯�ǂ��A
��ʓI�ȃf�[�^�i�[�t�H�[�}�b�g�Ƃ��Ă͐�i�I�߂���̂�
761 �FName_Not_Found�F2008/02/22(��) 21:22:49 ID:???
��������RDF�̃O���t�͉�������̃t�H�[�}�b�g�ł͂Ȃ���Ȃ��H
RDF/XML���f�[�^�t�H�[�}�b�g�Ƃ��Ďg���邩�Ƃ����Ȃ�c�_�ɂȂ邩��
����Ȃ����A�\���ɐ���Ɛ݂����Ƃ��Ă������Â炢�Ǝv���B
RDF/XML���f�[�^�t�H�[�}�b�g�Ƃ��Ďg���邩�Ƃ����Ȃ�c�_�ɂȂ邩��
����Ȃ����A�\���ɐ���Ɛ݂����Ƃ��Ă������Â炢�Ǝv���B
762 �FName_Not_Found�F2008/02/22(��) 22:43:50 ID:???
- RDF = �f�[�^���f��
- RDF/XML = �t�H�[�}�b�g
�ł��ˁB����RDF/XML�͎��R�x���������Ă悭�Ȃ��t�H�[�}�b�g���Ǝv����c
����RDF���f���������ȏ������ł�������Ă̂̓f�[�^���o�͂���̂͊y�ɂȂ���ǁA
�p�[�X���ď�������ق��̃v���O�����������ɂ����Ȃ邩��˂��c
���^�f�[�^���v�Z�@�ɂƂ��ĉǂɁA�����\�ɂ��悤���Ęb�Ȃ̂�
�p�[�T�����̂ɋ�J�����Ăǂ�����Ɓc
- RDF/XML = �t�H�[�}�b�g
�ł��ˁB����RDF/XML�͎��R�x���������Ă悭�Ȃ��t�H�[�}�b�g���Ǝv����c
����RDF���f���������ȏ������ł�������Ă̂̓f�[�^���o�͂���̂͊y�ɂȂ���ǁA
�p�[�X���ď�������ق��̃v���O�����������ɂ����Ȃ邩��˂��c
���^�f�[�^���v�Z�@�ɂƂ��ĉǂɁA�����\�ɂ��悤���Ęb�Ȃ̂�
�p�[�T�����̂ɋ�J�����Ăǂ�����Ɓc
763 �FName_Not_Found�F2008/02/22(��) 23:13:29 ID:???
>>761
�t�H�[�}�b�g�Ƃ������t�ɂ��Ă̌�p�_���Ƃ͎v�����ǂ��A
�ȉ��̊W���Ǝv���Ƃ悢�����B
���f�� -> ���ۍ\�� -> ��ۍ\��
�O���t -> RDF -> RDF/XML
�c���[ -> XML(��ۍ\�����܂�) -> XML(S���łƂ�)
�e�[�u�� -> RDB(�ƌ����ƌꕾ�����邪)
�Ƃ܂��[�������čl���Ȃ��Ă��悢���ǁA�v�����>>760��
(RDF�Ɍ��炸)�O���t�����f���ɍ̗p�����f�[�^�t�H�[�}�b�g���]�X
���Ă��Ƃ���ˁB
RDF�͂悢����Ȃ̂ł���Ɋ�Â��čl���Ă��炤�̂�
�S�ROK���Ƃ͎v���B
�t�H�[�}�b�g�Ƃ������t�ɂ��Ă̌�p�_���Ƃ͎v�����ǂ��A
�ȉ��̊W���Ǝv���Ƃ悢�����B
���f�� -> ���ۍ\�� -> ��ۍ\��
�O���t -> RDF -> RDF/XML
�c���[ -> XML(��ۍ\�����܂�) -> XML(S���łƂ�)
�e�[�u�� -> RDB(�ƌ����ƌꕾ�����邪)
�Ƃ܂��[�������čl���Ȃ��Ă��悢���ǁA�v�����>>760��
(RDF�Ɍ��炸)�O���t�����f���ɍ̗p�����f�[�^�t�H�[�}�b�g���]�X
���Ă��Ƃ���ˁB
RDF�͂悢����Ȃ̂ł���Ɋ�Â��čl���Ă��炤�̂�
�S�ROK���Ƃ͎v���B
764 �FName_Not_Found�F2008/02/22(��) 23:40:26 ID:???
RDF/XML���g���Â炢���Ƃ͓Ó���
765 �FName_Not_Found�F2008/02/23(�y) 02:42:12 ID:???
����͕ό`�\������������̂ȁB
����XML�ɑ���SGML���v���o���B
����XML�ɑ���SGML���v���o���B
766 �FName_Not_Found�F2008/02/23(�y) 05:38:53 ID:???
>>760
��i�I���������c
�P���ɃO���t�\���͏_����Lj����h������g���Ȃ��������낤�B
�f�[�^�̓��͂��ʓ|�����A�������ʓ|�����c
�V�X�e���̓����Ŏg�����ɂ͂������ǃ��[�U�[�Ƀf�[�^���f���Ƃ��ăO���t�\����
�ӎ������ăA�v���P�[�V�������g�킹��̂͌��\��ς���Ȃ����Ȃ��c
��i�I���������c
�P���ɃO���t�\���͏_����Lj����h������g���Ȃ��������낤�B
�f�[�^�̓��͂��ʓ|�����A�������ʓ|�����c
�V�X�e���̓����Ŏg�����ɂ͂������ǃ��[�U�[�Ƀf�[�^���f���Ƃ��ăO���t�\����
�ӎ������ăA�v���P�[�V�������g�킹��̂͌��\��ς���Ȃ����Ȃ��c
767 �FName_Not_Found�F2008/02/23(�y) 08:52:15 ID:???
�O���t���āA�����̓��͗p�R���g���[���i�t�H�[���Ƃ��j��
����������̂ɓK�����u�T�^�I�ȃR���g���[���v���Ȃ���ˁB
�\�Ȃ烊�X�g�r���[�A�؍\���Ȃ�c���[�r���[�����邯�ǂ��A
�O���t�͑����ǂ���̂Ȃ��`�����Ă��邩��A
�r�W�l�X�I��UI�ɗ��Ƃ����Ƃ�������A
�����I�Ȍ`��ۂ����܂܃V�[�P���V�����ȃe�L�X�g�`����
�\�L(�V���A���C�Y)���邱�Ƃ�����B
���͓K�ȃR���g���[���̎p���������肷��̂�������ǂ��c
����������̂ɓK�����u�T�^�I�ȃR���g���[���v���Ȃ���ˁB
�\�Ȃ烊�X�g�r���[�A�؍\���Ȃ�c���[�r���[�����邯�ǂ��A
�O���t�͑����ǂ���̂Ȃ��`�����Ă��邩��A
�r�W�l�X�I��UI�ɗ��Ƃ����Ƃ�������A
�����I�Ȍ`��ۂ����܂܃V�[�P���V�����ȃe�L�X�g�`����
�\�L(�V���A���C�Y)���邱�Ƃ�����B
���͓K�ȃR���g���[���̎p���������肷��̂�������ǂ��c
768 �FName_Not_Found�F2008/02/23(�y) 09:30:10 ID:???
769 �FName_Not_Found�F2008/02/25(��) 18:20:51 ID:???
http://www.semanticweb.org/ �����Ă�H�������O����Ȃ���Ȃ��B
770 �FName_Not_Found�F2008/02/25(��) 18:42:59 ID:???
www.semanticweb.org -> www.ontoworld.org -> wiki.ontoworld.org
�Ƃ��炢�܂킵�ɂ��ꂽ����� wiki.ontoworld.org ��DNS�����Ȃ��ˁc
�Ƃ��炢�܂킵�ɂ��ꂽ����� wiki.ontoworld.org ��DNS�����Ȃ��ˁc
771 �FName_Not_Found�F2008/03/05(��) 11:08:03 ID:???
���̃X���ȊO�ɓ��{���SW�ɂ��ċc�_������G�k������ł���
�R�~���j�e�B������H
�R�~���j�e�B������H
772 �FName_Not_Found�F2008/03/05(��) 12:25:03 ID:???
�S�̒��ɁC�����
773 �FName_Not_Found�F2008/03/14(��) 22:19:13 ID:3ntQ5qjS
Yahoo!�n�܂����ȁB
774 �FName_Not_Found�F2008/03/15(�y) 00:36:24 ID:???
775 �FName_Not_Found�F2008/03/15(�y) 08:04:00 ID:???
�T�|�[�g����f�[�^��������ȁB
�m��Ȃ��̂����邼
�m��Ȃ��̂����邼
776 �FName_Not_Found�F2008/03/15(�y) 14:09:25 ID:???
���x�A���Ń��t�[�I�W���p���̌����̃G���W�j�A�Ƙb���@�������ǁA�����邩�Ȃ�
777 �FName_Not_Found�F2008/03/15(�y) 14:14:07 ID:???
�������C�ӂ�RDF�X�L�[�}���i����
778 �FName_Not_Found�F2008/03/22(�y) 19:32:28 ID:???
microformats���ǂ������낤�B
779 �FName_Not_Found�F2008/03/26(��) 15:06:45 ID:1D4mEOz9
�I���g���W���p�����Z�}���e�B�b�NWeb�̎�����ĉ�������́H
780 �FName_Not_Found�F2008/03/26(��) 23:23:35 ID:???
>>779 �N��������ŏ��ɍ�����l�ԂɂȂ��B
781 �FName_Not_Found�F2008/03/27(��) 00:11:55 ID:???
�����̓I���g���W�[���Ă̂��悭�킩��Ȃ��B���C���[�P�[�L�͏�ɍs���ق�
����Ȃ�悤�ȁBLinked Data�݂����ȉ��̕��łł�����g�݂̂ق���
�������낢���ǂˁ[�B
����Ȃ�悤�ȁBLinked Data�݂����ȉ��̕��łł�����g�݂̂ق���
�������낢���ǂˁ[�B
782 �FName_Not_Found�F2008/03/28(��) 13:13:41 ID:dnjuSv1V
���{�ɂ����Ă͂��邠�鍼�\�B
����グ�����͕̂����邪�A
���p�i�K�ɓ������͌����߂��H
����グ�����͕̂����邪�A
���p�i�K�ɓ������͌����߂��H
783 �FName_Not_Found�F2008/03/28(��) 23:01:08 ID:???
784 �FName_Not_Found�F2008/03/31(��) 07:13:18 ID:???
�E�F�u�Ɍ��炸�Z�}���e�B�N�X�n�̏��ׂɗ��Ă݂����ǁA����܂萷��オ���ĂȂ��݂����H
�I���g���W�����i�J���Ƃ����Ƌ����͈͂łȂ���ۂɎg���Ă�炵�����ǁA
�\���������Ƃ��ďo�Ă��ĂȂ�����Ȃ��B
�܂��A�I���g���W�Ȃ�Ĉ�ʐl�ɂ͂Ȃ��Ȃ�����������������A
���ۂ͂����郆�r�L�^�X�Ȏ����ɂȂ�낤���ǁB
�I���g���W�����i�J���Ƃ����Ƌ����͈͂łȂ���ۂɎg���Ă�炵�����ǁA
�\���������Ƃ��ďo�Ă��ĂȂ�����Ȃ��B
�܂��A�I���g���W�Ȃ�Ĉ�ʐl�ɂ͂Ȃ��Ȃ�����������������A
���ۂ͂����郆�r�L�^�X�Ȏ����ɂȂ�낤���ǁB
785 �FName_Not_Found�F2008/04/04(��) 09:56:00 ID:???
XML�Ŏ菑���ŕ���������āA�����XHTML�ƃ��^�f�[�^�Ɏ����ϊ��A
���Ă������ɃT�C�g�\�z���������ǁA������Ăǂ������������ł���́H
XSLT�g���������ᖳ������ˁH
���N�̋^��ȂA�ǂ��������Ă��������B
��낵�����肢���܂��B
���Ă������ɃT�C�g�\�z���������ǁA������Ăǂ������������ł���́H
XSLT�g���������ᖳ������ˁH
���N�̋^��ȂA�ǂ��������Ă��������B
��낵�����肢���܂��B
786 �FName_Not_Found�F2008/04/04(��) 14:19:56 ID:???
>>785
���ʂ�XSLT�v���Z�b�T��XSLT��p�ӂ��ăI�t���C���ŏ�������XHTML�������������ˁH
�ǂ̕ӂŖ������Ǝv�����́H
���ʂ�XSLT�v���Z�b�T��XSLT��p�ӂ��ăI�t���C���ŏ�������XHTML�������������ˁH
�ǂ̕ӂŖ������Ǝv�����́H
787 �FName_Not_Found�F2008/04/04(��) 14:50:34 ID:???
>>785
cgi�Ƃ��X�N���v�g�g���ł���̂ł́H
cgi�Ƃ��X�N���v�g�g���ł���̂ł́H
>>786,787
���߂�A�}�[�N�A�b�v����ɂ͂�����x�ڂ�������ǁA�v���O���~���O����ɂ͑a���B
�uXSLT�v���Z�b�T�v���Ă����P��͏����������B
�������Ă݂�����ǁA������ăt�@�C����������������ϊ����Ȃ��ƃ_���Ȃ́H
������Č��\�߂�ǂ������ˁH
���ƁA>>785�̎g�����Ŏg�p����Ƃ�����A�ǂꂪ�����߁H
�p��ɂ��a���̂ŁA������₷������T�C�g��m���Ă����畹���ċ����Ă��炦��Ƃ��肪�����ł��B
���߂�A�}�[�N�A�b�v����ɂ͂�����x�ڂ�������ǁA�v���O���~���O����ɂ͑a���B
�uXSLT�v���Z�b�T�v���Ă����P��͏����������B
�������Ă݂�����ǁA������ăt�@�C����������������ϊ����Ȃ��ƃ_���Ȃ́H
������Č��\�߂�ǂ������ˁH
���ƁA>>785�̎g�����Ŏg�p����Ƃ�����A�ǂꂪ�����߁H
�p��ɂ��a���̂ŁA������₷������T�C�g��m���Ă����畹���ċ����Ă��炦��Ƃ��肪�����ł��B
789 �FName_Not_Found�F2008/04/04(��) 18:08:08 ID:???
���S�҃X���s����
�T�[�o�T�C�h�ŕϊ�����Ȃ� Webprog
�T�[�o�T�C�h�ŕϊ�����Ȃ� Webprog
790 �FName_Not_Found�F2008/04/04(��) 18:44:11 ID:???
�܂��A���������ɂ��ς˂邱�Ƃ��Ȃ��ł��傤�B
cgi�ł��Ȃ�Ruby���I�X�X���������B
cgi�ł��Ȃ�Ruby���I�X�X���������B
791 �FName_Not_Found�F2008/04/04(��) 19:09:06 ID:???
ruby�͂��̍\�����ǂ����c
792 �FName_Not_Found�F2008/04/04(��) 19:33:09 ID:???
�C�����͂킩��B
�ł�Perl��PHP����邮�炢�Ȃ玩����Ruby��I������B
�ł�Perl��PHP����邮�炢�Ȃ玩����Ruby��I������B
793 �FName_Not_Found�F2008/04/04(��) 20:49:25 ID:???
>>788
>>785�ǂ�ł��ʼn�����肽���̂�����܂悭�킩��Ȃ��������ǂ���������
�����������Ƃ���Ă����Web�A�v����T�[�r�X���Ȃ������Ă��ƁH
�ėp�̂��̂͌������ƂȂ����ǁc�N���m���Ă�H
>>785�ǂ�ł��ʼn�����肽���̂�����܂悭�킩��Ȃ��������ǂ���������
�����������Ƃ���Ă����Web�A�v����T�[�r�X���Ȃ������Ă��ƁH
�ėp�̂��̂͌������ƂȂ����ǁc�N���m���Ă�H
794 �FName_Not_Found�F2008/04/04(��) 22:08:15 ID:???
������python���낤�I
795 �FName_Not_Found�F2008/04/05(�y) 04:23:46 ID:???
>>793
XML�ɖ{���ƃ��^�f�[�^(�쐬�����A�X�V�����A�L�[���[�h�Aetc.)��������
�����āAXSLT��RDF�Ƃ����link�v�f�Ń����N����XHTML������悤��
���ƂȂ̂��ȂƎv�������ǁA����Ȃ�XSLT�����ăX�N���v�g�ł����点���
�ς݂����Ȃ̂ŁA�����>>785���������߂Ă���̂��悭�킩���ˁB
XML�ɖ{���ƃ��^�f�[�^(�쐬�����A�X�V�����A�L�[���[�h�Aetc.)��������
�����āAXSLT��RDF�Ƃ����link�v�f�Ń����N����XHTML������悤��
���ƂȂ̂��ȂƎv�������ǁA����Ȃ�XSLT�����ăX�N���v�g�ł����点���
�ς݂����Ȃ̂ŁA�����>>785���������߂Ă���̂��悭�킩���ˁB
796 �FName_Not_Found�F2008/04/05(�y) 11:37:58 ID:???
785��XSLT�͏����邪�X�N���v�g�͏����Ȃ��ƌ����B
797 �FName_Not_Found�F2008/04/05(�y) 18:03:57 ID:???
����������XML�x�[�X�Ńf�[�^�ۑ����鎞�ɁA
�����Ƃ��ĉ����q�v�f�Ƃ��邩�����������ǂ��A
���������K���݂����Ȃ̂��ĂȂ��̂��ȁB
�����Ƃ��ĉ����q�v�f�Ƃ��邩�����������ǂ��A
���������K���݂����Ȃ̂��ĂȂ��̂��ȁB
798 �FName_Not_Found�F2008/04/05(�y) 18:22:38 ID:???
XML�X���ɍs�������Ă�����Ȃ��H
799 �FName_Not_Found�F2008/04/05(�y) 18:37:39 ID:???
����ȏ����I�Ȏ��⏉�S�҃X���ł���
800 �FName_Not_Found�F2008/04/06(��) 10:04:58 ID:???
>>797
�R��͗^����ꂽ�X�L�[�}�ɏ]���ď�������������
�C�ɂ��ĂȂ��������ǁA�X�L�[�}��v����l��
�ǂ��ₔ���n�ڏƂ�낤�ˁB
�R��͗^����ꂽ�X�L�[�}�ɏ]���ď�������������
�C�ɂ��ĂȂ��������ǁA�X�L�[�}��v����l��
�ǂ��ₔ���n�ڏƂ�낤�ˁB
���t���炸�ł��݂܂���B
������肽���̂́A>>795�ɂ���悤�Ɉ��XML��������
RDF��XHTML�ARSS�Ȃǂ��Ɏ����쐬���邱�Ƃɂ����
�T�C�g���\�z���邱�ƂȂ̂ł��B
�������肽�����Ƃ́A�����̋L����L�������XML��������
�L�����Ƃɕ�����XHTML�t�@�C���ɕϊ�����Ƃ������ƂȂ̂ł����A
�����XSLT�����łȂ��v���O�������w�Ȃ��Ǝ����ł��܂����ˁH
>>796�ɂ���Ƃ���AXSLT�͂�����x�����܂����X�N���v�g�͑S���_���Ȃ̂ł��B
�����ė��������A
ttp://overknee.info/
�̂悤�Ȃ��Ƃ���肽���킯�ł��B
�X���������炵�܂����B
������肽���̂́A>>795�ɂ���悤�Ɉ��XML��������
RDF��XHTML�ARSS�Ȃǂ��Ɏ����쐬���邱�Ƃɂ����
�T�C�g���\�z���邱�ƂȂ̂ł��B
�������肽�����Ƃ́A�����̋L����L�������XML��������
�L�����Ƃɕ�����XHTML�t�@�C���ɕϊ�����Ƃ������ƂȂ̂ł����A
�����XSLT�����łȂ��v���O�������w�Ȃ��Ǝ����ł��܂����ˁH
>>796�ɂ���Ƃ���AXSLT�͂�����x�����܂����X�N���v�g�͑S���_���Ȃ̂ł��B
�����ė��������A
ttp://overknee.info/
�̂悤�Ȃ��Ƃ���肽���킯�ł��B
�X���������炵�܂����B
803 �FName_Not_Found�F2008/04/06(��) 21:08:43 ID:???
�Z�}���e�B�b�NWeb�̘b�ł͂Ȃ��ȁB
�܂��ߑa�X�������������B
�܂��ߑa�X�������������B
804 �FName_Not_Found�F2008/04/07(��) 01:15:03 ID:???
�A�����Ă��āASemantic Web�֘A�̌������ɏ������Ă���Ƃ����A������
��l���o������B�ĊO����Ă�Ƃ�����Ȃ��B
>>801
1�ڂɂ��āB
1��XML����T�[�o�T�C�h��XHTML�ɕϊ�������̂ł���A
HIMMEL�Ƃ������̂�����B
���u���ꂿ����Ă邯�ǎQ�l�ɂ͂Ȃ邩���B
ttp://www.arielworks.net/works/codeyard/himmel
2�ڂɂ��āB
xsltproc1���ŃT�N���Ƃ��Ƃ����̂Ȃ疳�����Ȃ��B
DOM�ŋL���𒊏o����Ȃǂ̎菇���K�v�B
�������uttp://overknee.info/latest �̂悤�Ȃ��Ɓv����̓I�ɂ킩��Ȃ��c�B
��l���o������B�ĊO����Ă�Ƃ�����Ȃ��B
>>801
1�ڂɂ��āB
1��XML����T�[�o�T�C�h��XHTML�ɕϊ�������̂ł���A
HIMMEL�Ƃ������̂�����B
���u���ꂿ����Ă邯�ǎQ�l�ɂ͂Ȃ邩���B
ttp://www.arielworks.net/works/codeyard/himmel
2�ڂɂ��āB
xsltproc1���ŃT�N���Ƃ��Ƃ����̂Ȃ疳�����Ȃ��B
DOM�ŋL���𒊏o����Ȃǂ̎菇���K�v�B
�������uttp://overknee.info/latest �̂悤�Ȃ��Ɓv����̓I�ɂ킩��Ȃ��c�B
805 �FName_Not_Found�F2008/04/07(��) 01:40:37 ID:???
>>801
�����炻�̐������̂܂�������Ȃ�XML����XHTML���o�͂���XSLT��
XML����RDF���o�͂���XSLT��������2��XSLT�v���Z�b�T���点��ł���b����H
���̏������T�[�o�[�T�C�h�ł�肽���Ƃ��茳�ł�肽���Ƃ����ꂱ��̃^�C�~���O�Ŏ�����
�����Ƃ������ƕʂ̗v��������悤�Ɍ�������c
�Ƃ���� http://overknee.info/latest �̓��_�C���N�g���Ă邾������˂��c
�����炻�̐������̂܂�������Ȃ�XML����XHTML���o�͂���XSLT��
XML����RDF���o�͂���XSLT��������2��XSLT�v���Z�b�T���点��ł���b����H
���̏������T�[�o�[�T�C�h�ł�肽���Ƃ��茳�ł�肽���Ƃ����ꂱ��̃^�C�~���O�Ŏ�����
�����Ƃ������ƕʂ̗v��������悤�Ɍ�������c
�Ƃ���� http://overknee.info/latest �̓��_�C���N�g���Ă邾������˂��c
806 �FName_Not_Found�F2008/04/07(��) 11:44:38 ID:???
�Ȃɂ��̒�x���ȗ���
>>804
HIMMEL�ɂ��Ă͎Q�l�ɂ��Ă݂܂��B
��͂�DOM���K�v�ł����A���肪�Ƃ��������܂��B
>>805
�����ł��A�T�[�o�[�T�C�h�ŏ�����������ł��B
�����ōX�V����̂�XML���������ŁA������T�[�o�[�ɃA�b�v�����
���Ƃ͎�����XHTML�ARDF�ARSS���쐬�����A���Ă����悤�ɂ�������ł��B
�����JavaScript�iDOM�j���w�K����Ή\�ɂȂ�̂ł��傤���H
>>806
���߂�Ȃ����A���Ǒ��Ɏ��₷�邽�߂̓K�ȏꏊ���v�����Ȃ���ł��B
������������ɏڂ������́A���̃X�����炢�ɂ������Ȃ����ȂƎv���܂��āB
�����K�ȃX�������ɂ���̂Ȃ�U�����肢���܂��B
HIMMEL�ɂ��Ă͎Q�l�ɂ��Ă݂܂��B
��͂�DOM���K�v�ł����A���肪�Ƃ��������܂��B
>>805
�����ł��A�T�[�o�[�T�C�h�ŏ�����������ł��B
�����ōX�V����̂�XML���������ŁA������T�[�o�[�ɃA�b�v�����
���Ƃ͎�����XHTML�ARDF�ARSS���쐬�����A���Ă����悤�ɂ�������ł��B
�����JavaScript�iDOM�j���w�K����Ή\�ɂȂ�̂ł��傤���H
>>806
���߂�Ȃ����A���Ǒ��Ɏ��₷�邽�߂̓K�ȏꏊ���v�����Ȃ���ł��B
������������ɏڂ������́A���̃X�����炢�ɂ������Ȃ����ȂƎv���܂��āB
�����K�ȃX�������ɂ���̂Ȃ�U�����肢���܂��B
808 �FName_Not_Found�F2008/04/07(��) 16:03:48 ID:???
�T�[�o�T�C�h�ŏ����������Ȃ�Ⴂ�A���[�J�����[������ǂ߂Ȃ��̂���
�������炢����������Ȃ��Ȃ珉�S�҃X���s�����ď�ŗU������Ă邶���
�������炢����������Ȃ��Ȃ珉�S�҃X���s�����ď�ŗU������Ă邶���
�����ł��ˁAWebprog�̏��S�җp�X���Ɉڂ邱�Ƃɂ��܂��B
���f���|���Ă��܂��āA�{���ɂ��݂܂���ł����B
���Ă������������A���肪�Ƃ��������܂����B
���f���|���Ă��܂��āA�{���ɂ��݂܂���ł����B
���Ă������������A���肪�Ƃ��������܂����B
810 �FName_Not_Found�F2008/04/08(��) 02:55:58 ID:???
�_��搶��metaprof�g���Ă���l����H�������낢���A�Љ�Ă���
�Ƃ��돭����Ȃ��B
�Ƃ��돭����Ȃ��B
811 �FName_Not_Found�F2008/04/10(��) 08:45:04 ID:???
812 �FName_Not_Found�F2008/04/10(��) 12:22:38 ID:???
���܂��O�Ɏ��ɂ܂���
813 �FName_Not_Found�F2008/04/10(��) 15:27:03 ID:???
>>812
�܂�Ŗ��ʂɌ��C�̌������̐��q�݂����B
�܂�Ŗ��ʂɌ��C�̌������̐��q�݂����B
814 �FName_Not_Found�F2008/04/12(�y) 20:20:56 ID:???
OWL 2���Ă̂��o�Ă�B����A1.1�́c�H
815 �FName_Not_Found�F2008/04/12(�y) 21:21:37 ID:???
OWL 2 (previously known as OWL 1.1)�E�E�E
�������Ȃ̂ŁA1.1��2�ɕς������
�������Ȃ̂ŁA1.1��2�ɕς������
816 �FName_Not_Found�F2008/04/18(��) 20:35:55 ID:???
OWL��DLL���Ă���̂��ȁB
�����I���g���W�G�f�B�^�n�͑��Java�ŏ�����Ăăl�C�e�B�u�̂��̂����܂�Ȃ��C�����邯�ǁB
�����I���g���W�G�f�B�^�n�͑��Java�ŏ�����Ăăl�C�e�B�u�̂��̂����܂�Ȃ��C�����邯�ǁB
817 �FName_Not_Found�F2008/04/18(��) 21:50:42 ID:???
>>816
���˂��BProtege �Ȃ� Java �����B
���˂��BProtege �Ȃ� Java �����B
818 �FName_Not_Found�F2008/04/18(��) 22:46:16 ID:???
>>816�@�� Redland �g�������
819 �FName_Not_Found�F2008/04/19(�y) 15:14:53 ID:???
�d�l���낭�ɗ����ł��ĂȂ����A�܂Ƃ��Ȃ���͍��Ȃ����낤���ǁA
�Ƃ肠����Jena�Ƃ��Q�l�ɂ��Ȃ������Ă݂邩�ȁB
�Ƃ肠����Jena�Ƃ��Q�l�ɂ��Ȃ������Ă݂邩�ȁB
820 �FName_Not_Found�F2008/04/20(��) 00:58:28 ID:???
�ǂ�ȃI���g���W��낤�Ƃ��Ă�́H
�Q�l�܂łɋ����āB
�Q�l�܂łɋ����āB
821 �FName_Not_Found�F2008/04/20(��) 19:03:54 ID:???
�Z�}���e�B�b�N�E�E�F�u�̐��̂����܂��ɂ悭�킩��Ȃ����ǁA
�Ⴆ�u�I�����C���V���b�vA,B,C,D�̒��ŏ��iX����Ԉ���������
����̂͂ǂꂩ�v�ׂ����Ǝv�����Ƃ��ɁA���͌����G���W���Ȃǂ�
�g���Ď����łǂ��������̂��������Ȃ��Ƃ����Ȃ��Ƃ�����A
�Z�}���e�B�b�N�E�E�F�u��������������������Ƃ�����A�v���P�[�V������
����ɒ��ׂē����������Ă����悤�ɂȂ���Ă����A����ȔF���ł����̂��ȁB
�Ⴆ�u�I�����C���V���b�vA,B,C,D�̒��ŏ��iX����Ԉ���������
����̂͂ǂꂩ�v�ׂ����Ǝv�����Ƃ��ɁA���͌����G���W���Ȃǂ�
�g���Ď����łǂ��������̂��������Ȃ��Ƃ����Ȃ��Ƃ�����A
�Z�}���e�B�b�N�E�E�F�u��������������������Ƃ�����A�v���P�[�V������
����ɒ��ׂē����������Ă����悤�ɂȂ���Ă����A����ȔF���ł����̂��ȁB
822 �FName_Not_Found�F2008/04/20(��) 20:12:45 ID:???
>>820
�ȒP�Ɍ�����UI�W�̏������I���g���W�ł�낤���Ęb�B
�E�F�u�Ƃ͂��܂�W�Ȃ�����X���`���Ă��Ⴂ���낤���ǁB
�Z�}���e�B�b�N�E�F�u���Ă̂́A���X�f�̕����������͂���̂͌��\����ǂ�����
�R���e���c���̂��������܂��傤��A���Ă����w�i�Ő��܂ꂽ�l���B
���^���t����Ӗ��\���������邱�Ƃŋ@�B�ɂ��킩��`�ɂ��悤���A���Ă��ƁB
�u�Z�}���e�B�b�N�E�F�u�v���Č��t���̂͋�̓I�ȋZ�p�E���_���w���Ă�킯����Ȃ��A
�����܂Ńp���_�C���Ƃ������A�l�����̈��B
�I�����C���V���b�v�]�X�̘b�́A�ł���ƌ����ł��邯�ǁA
�e�V���b�v�̈Ӗ����ꉻ�Ƃ��A�����ƍ�肱��ł����Ȃ��Ɠ���B
�i�Z�}���e�B�b�N�E�F�u�Ƃ����l�����Z�����Ȃ��Ǝ����͓���A
���ꂪ����ł͍ő�̖�肩������Ȃ��j
�܂��A����Ȋ������Ǝ����ł͎v���Ă�B�����E�⑫�Ƃ�������肢���܂��B
�ȒP�Ɍ�����UI�W�̏������I���g���W�ł�낤���Ęb�B
�E�F�u�Ƃ͂��܂�W�Ȃ�����X���`���Ă��Ⴂ���낤���ǁB
�Z�}���e�B�b�N�E�F�u���Ă̂́A���X�f�̕����������͂���̂͌��\����ǂ�����
�R���e���c���̂��������܂��傤��A���Ă����w�i�Ő��܂ꂽ�l���B
���^���t����Ӗ��\���������邱�Ƃŋ@�B�ɂ��킩��`�ɂ��悤���A���Ă��ƁB
�u�Z�}���e�B�b�N�E�F�u�v���Č��t���̂͋�̓I�ȋZ�p�E���_���w���Ă�킯����Ȃ��A
�����܂Ńp���_�C���Ƃ������A�l�����̈��B
�I�����C���V���b�v�]�X�̘b�́A�ł���ƌ����ł��邯�ǁA
�e�V���b�v�̈Ӗ����ꉻ�Ƃ��A�����ƍ�肱��ł����Ȃ��Ɠ���B
�i�Z�}���e�B�b�N�E�F�u�Ƃ����l�����Z�����Ȃ��Ǝ����͓���A
���ꂪ����ł͍ő�̖�肩������Ȃ��j
�܂��A����Ȋ������Ǝ����ł͎v���Ă�B�����E�⑫�Ƃ�������肢���܂��B
823 �FName_Not_Found�F2008/04/26(�y) 14:58:26 ID:???
TechCrunch�ɁA���̂܂��ʂ������Ȃ�����S�������̃L�[���[�h��������
�ǂ����Ȃ�����A����̓Z�}���e�B�b�N�Ȍ������K�v���낤��A���Ęb���ڂ��Ă�
ttp://jp.techcrunch.com/archives/20080425is-keyword-search-about-to-hit-its-breaking-point/
�ǂ����Ȃ�����A����̓Z�}���e�B�b�N�Ȍ������K�v���낤��A���Ęb���ڂ��Ă�
ttp://jp.techcrunch.com/archives/20080425is-keyword-search-about-to-hit-its-breaking-point/
824 �FName_Not_Found�F2008/04/27(��) 00:27:52 ID:???
���̂�����͂قƂ�ǂ̐l���C�t���Ă���Ƃ��낾��ˁB
�Ȃ��Ȃ��i�܂Ȃ��̂̓R���e���c�̃f�[�^�\����ς��Ȃ��Ƃ����Ȃ�����Ȃ낤���ǁA
���������ɂ͏��Ȃ��炸NLP���K�v�ɂȂ�B
�ł�NLP�����҂͑��Z�}���e�B�b�NWeb�Ƃ����^���Ƃ��ɂ͔ے�I�Ȃ�B
�Ȃ������Č�������NLP�����҂́A�����܂Ől�Ԃ͕��i�g���Ă���`�ŏ��������ׂ��ł����āA
�@�B�̂��߂ɐl�Ԃ����킹��̂͂��������Ƃ����X�^���X�ȂB
�i�l�Ԃ��@�B��������Ə����Ă����悤�Ƃ����Z�}���e�B�b�NWeb�̃X�^���X�Ƃ͈قȂ�j
�ŁA���v�z�̈قȂ�O���[�v�͍��{����ے肵������ȁB
������h���݂����Ȃ��̂����ǁA����Ȃ��Ƃ������āA���n���v���悤�ɂ����Ȃ��ꍇ�������B
�����g�͉��Ƃ��������Ǝv�����ǁA�Ȃ��Ȃ�����Ǝv���B
�Ȃ��Ȃ��i�܂Ȃ��̂̓R���e���c�̃f�[�^�\����ς��Ȃ��Ƃ����Ȃ�����Ȃ낤���ǁA
���������ɂ͏��Ȃ��炸NLP���K�v�ɂȂ�B
�ł�NLP�����҂͑��Z�}���e�B�b�NWeb�Ƃ����^���Ƃ��ɂ͔ے�I�Ȃ�B
�Ȃ������Č�������NLP�����҂́A�����܂Ől�Ԃ͕��i�g���Ă���`�ŏ��������ׂ��ł����āA
�@�B�̂��߂ɐl�Ԃ����킹��̂͂��������Ƃ����X�^���X�ȂB
�i�l�Ԃ��@�B��������Ə����Ă����悤�Ƃ����Z�}���e�B�b�NWeb�̃X�^���X�Ƃ͈قȂ�j
�ŁA���v�z�̈قȂ�O���[�v�͍��{����ے肵������ȁB
������h���݂����Ȃ��̂����ǁA����Ȃ��Ƃ������āA���n���v���悤�ɂ����Ȃ��ꍇ�������B
�����g�͉��Ƃ��������Ǝv�����ǁA�Ȃ��Ȃ�����Ǝv���B
825 �FName_Not_Found�F2008/04/27(��) 00:39:43 ID:???
������Ă����l�H�m�\�̃A�v���[�`���̂��̂��Ă��ƂȂ̂��H
�o�[�i�[�Y=���[��̘_���ł��������悤�ɁASemantic Web��
�䂭�䂭�͐l�H�m�\�I�ȗv�f��������邱�Ƃ͋��ۂ��Ȃ��Ǝv���̂����ǁA
�o���_���Ⴄ�Ƃ����̂��ȁB
�o�[�i�[�Y=���[��̘_���ł��������悤�ɁASemantic Web��
�䂭�䂭�͐l�H�m�\�I�ȗv�f��������邱�Ƃ͋��ۂ��Ȃ��Ǝv���̂����ǁA
�o���_���Ⴄ�Ƃ����̂��ȁB
826 �FName_Not_Found�F2008/04/27(��) 01:24:20 ID:???
���z�I�Ȍ`�Ƃ��ẮA�Ⴆ�G�f�B�^�ɓ��͂������͂��玩���I�ɕ�����
�ĉ��������^�f�[�^�����������悤�Ȃ��̂��낤���ǁA���x�����đz���ł��Ȃ��B
���������A�L�[���[�h�������I�ɕߑ�����
�i�܂��͉�͂��ďo�Ă������E�q��E�ړI��Ȃǂ���g���v���̗v�f������āj�A
���͎҂ɂǂ���ǂ̂悤�ɑg�ݍ��킹�邩�w�肵�Ă��炤�悤�ɂ��邵���Ȃ����낤���ǁA
���ꂾ�ƕs�ւȂ낤�ȁB
�ĉ��������^�f�[�^�����������悤�Ȃ��̂��낤���ǁA���x�����đz���ł��Ȃ��B
���������A�L�[���[�h�������I�ɕߑ�����
�i�܂��͉�͂��ďo�Ă������E�q��E�ړI��Ȃǂ���g���v���̗v�f������āj�A
���͎҂ɂǂ���ǂ̂悤�ɑg�ݍ��킹�邩�w�肵�Ă��炤�悤�ɂ��邵���Ȃ����낤���ǁA
���ꂾ�ƕs�ւȂ낤�ȁB
827 �FName_Not_Found�F2008/04/27(��) 18:41:31 ID:A93x78p8
�}�C�N���t�H�[�}�b�g�݂����Ɋ����R���e���c�ɃG���x�b�h������̂��A
�Z�}���e�B�b�N�E�F�u�ƌ�����H
���C���P�[�L�̉��w�ŃS�j���S�j�����Ă邾����
���̔��W�����Ȃ��Ƃ����ᔻ������̂�������B
�Z�}���e�B�b�N�E�F�u�ƌ�����H
���C���P�[�L�̉��w�ŃS�j���S�j�����Ă邾����
���̔��W�����Ȃ��Ƃ����ᔻ������̂�������B
828 �FName_Not_Found�F2008/04/27(��) 19:07:29 ID:???
��̎��݂ł͂���Ǝv����B��������sw�B
829 �FName_Not_Found�F2008/04/27(��) 20:46:16 ID:???
�ǂ��炩�Ƃ����A�c��ȃI���g���W�ɍ��x�Ȑ��_�G���W���A
�ꍇ�ɂ���Ă͌����́E�l���m�\�܂łɋy�Ԃ悤�ȃZ�}���e�B�b�NWeb���A
microformats�Ƃ��̕����\����������B
�ꍇ�ɂ���Ă͌����́E�l���m�\�܂łɋy�Ԃ悤�ȃZ�}���e�B�b�NWeb���A
microformats�Ƃ��̕����\����������B
830 �FName_Not_Found�F2008/04/27(��) 23:17:07 ID:???
���҂͑Η�������̂ł͂Ȃ��Ǝv�����B
831 �FName_Not_Found�F2008/04/29(��) 01:31:45 ID:NBMG3Kfh
>>829
microformats�ŕt����������GRDDL�Ŕ����Ă��ɂ傲�ɂ傷��̂������I�Ȋ���������B
�����A����microformats���ė��\�Ȃ̑������Bhreveiw�Ȃ�Ċ��z��blockquote�Ń}�[�N�A�b�v����Ƃ�
�킯�킩��B
microformats�ŕt����������GRDDL�Ŕ����Ă��ɂ傲�ɂ傷��̂������I�Ȋ���������B
�����A����microformats���ė��\�Ȃ̑������Bhreveiw�Ȃ�Ċ��z��blockquote�Ń}�[�N�A�b�v����Ƃ�
�킯�킩��B
832 �FName_Not_Found�F2008/04/29(��) 03:01:01 ID:???
���z��blockquote�Ń}�[�N�A�b�v�͍����ȁB
�����̌�b�̉��߂��ɕς��Ȃ���
�i���������\���ł����Ȃ��̂�����A�Ӗ���^���悤���Ȃ��Ƃ������j
class�����l�ňӖ���t������ق������R�Ɋ�����B
http://www.kanzaki.com/memo/2004/03/15-2
hReview�Ȃ́A���r���[���e�̂��߂̃T�C�g�ł����
���[�U�Ƀ��^�f�[�^��t�����邽�߂̃}�[�N�A�b�v�̋L�q�͕s�v���낤�Ȃ��B
��p�̃t�H�[����p�ӂ��Ă��������낤���B
�����̌�b�̉��߂��ɕς��Ȃ���
�i���������\���ł����Ȃ��̂�����A�Ӗ���^���悤���Ȃ��Ƃ������j
class�����l�ňӖ���t������ق������R�Ɋ�����B
http://www.kanzaki.com/memo/2004/03/15-2
hReview�Ȃ́A���r���[���e�̂��߂̃T�C�g�ł����
���[�U�Ƀ��^�f�[�^��t�����邽�߂̃}�[�N�A�b�v�̋L�q�͕s�v���낤�Ȃ��B
��p�̃t�H�[����p�ӂ��Ă��������낤���B
833 �FName_Not_Found�F2008/04/29(��) 11:41:55 ID:???
834 �FName_Not_Found�F2008/04/29(��) 12:32:12 ID:???
> hreveiw�Ȃ�Ċ��z��blockquote�Ń}�[�N�A�b�v����
class�Ƃ��̑����l���K�肷�邾���ŗv�f�܂ł͌��߂ĂȂ��Ǝv���Ă����ǂ�������Ȃ������̂�
class�Ƃ��̑����l���K�肷�邾���ŗv�f�܂ł͌��߂ĂȂ��Ǝv���Ă����ǂ�������Ȃ������̂�
835 �FName_Not_Found�F2008/04/29(��) 14:24:19 ID:???
�F�X�ƍD������ɂ��o���Ď��E�����Ȃ��Ȃ��Ă��Ȃ����ȁB
836 �FName_Not_Found�F2008/04/29(��) 17:53:24 ID:???
>>834
�d�l�ihttp://microformats.org/wiki/hreview�j�������
���z�ɂ��Ă�class�̎w�肪���邾����
blockquote�v�f���������Ă�߂͂Ȃ����B
�d�l�ihttp://microformats.org/wiki/hreview�j�������
���z�ɂ��Ă�class�̎w�肪���邾����
blockquote�v�f���������Ă�߂͂Ȃ����B
837 �FName_Not_Found�F2008/04/29(��) 23:05:06 ID:???
�A�E�g���C�����̕ҏW��ʂ�XHTML�������āADublin Core��Microformats��
��b�ߍ��߂āA�V������b�̒lj����ł��閳���̃G�f�B�^����������
�����ȂƖϑz�B
��b�ߍ��߂āA�V������b�̒lj����ł��閳���̃G�f�B�^����������
�����ȂƖϑz�B
838 �FName_Not_Found�F2008/04/30(��) 01:51:16 ID:???
�A�E�g���C�������āA�u���b�N�v�f�̕\���ɂ͍œK�Ȃ���
�C�����C���v�f�̕\��������̂�ˁB
�ߐڂ��ē���q�ɂȂ����v�f�̎��ʂƂ��A�����E�����l�̕\���Ƃ��A
�����v�f�̋̎�舵���Ƃ��B���̕ӂ̎d�l�͂ǂ��H
�C�����C���v�f�̕\��������̂�ˁB
�ߐڂ��ē���q�ɂȂ����v�f�̎��ʂƂ��A�����E�����l�̕\���Ƃ��A
�����v�f�̋̎�舵���Ƃ��B���̕ӂ̎d�l�͂ǂ��H
839 �FName_Not_Found�F2008/05/01(��) 01:20:13 ID:???
�C�����C���v�f�̕\���͓���ˁB�����̓v���p�e�B�_�C�A���O�Ȃǂ���
�ҏW����悳���������ǁA�v�f���ׂ荇���Ă���Ƃ��͂ǂ��\����
�I���ł���悤�ɂ��邩�́A���Ȃ���Ȗ�肩������Ȃ��B
���^�f�[�^�̖��ߍ��݂ɂ��Ă��ARDFa��eRDF�⎩��v���t�@�C����
���낢�날�邩��A���ʂ̃C���^�[�t�F�[�X�ō�Ƃł���悤��
����͍̂���B��[�ł��A���z�͂���Ȃɕς��Ȃ�����Ȃ�Ƃ�
�ł��邩�ȁB
�ҏW����悳���������ǁA�v�f���ׂ荇���Ă���Ƃ��͂ǂ��\����
�I���ł���悤�ɂ��邩�́A���Ȃ���Ȗ�肩������Ȃ��B
���^�f�[�^�̖��ߍ��݂ɂ��Ă��ARDFa��eRDF�⎩��v���t�@�C����
���낢�날�邩��A���ʂ̃C���^�[�t�F�[�X�ō�Ƃł���悤��
����͍̂���B��[�ł��A���z�͂���Ȃɕς��Ȃ�����Ȃ�Ƃ�
�ł��邩�ȁB
840 �FName_Not_Found�F2008/05/03(�y) 14:22:57 ID:???
�_�u�����E�R�A�̓I���g���W�Ƃ�����́H
841 �FName_Not_Found�F2008/05/03(�y) 20:04:12 ID:???
�ǂ��炩�Ƃ����ƃI���g���W���L�q����Ƃ��ɂ��g�����{��b
842 �FName_Not_Found�F2008/05/06(��) 16:21:23 ID:???
�Z�}���e�B�b�N�E�F�u���Ă̂́A�������Ń|�`�|�`�ł�����ō��i�H�j���Ă͖̂����H
843 �FName_Not_Found�F2008/05/06(��) 16:49:43 ID:???
����ł����B�̂̓o�C�i������œ��͂������炢������Ȃ�
844 �FName_Not_Found�F2008/05/06(��) 20:25:36 ID:???
CURIE����rdf:about�Ƃ�rdf:resource�Ƃ�xlink:arcrole�Ƃ�xlink:role�Ƃ��Ŏg����悤�ɂ��Ăق����ȁB
845 �FName_Not_Found�F2008/05/07(��) 18:36:22 ID:???
>>842
N3�Ȃ烁�����ŏ\���A�Ƃ�����N3�������̂ɕ֗��ȃG�f�B�^�͂Ȃ����B
���[�J����RDF/XML��N3�̍\���`�F�b�N���ł���c�[���͂Ȃ��̂��ȁB
�I�����C���Ȃ� http://www.rdfabout.com/demo/validator/ �Ƃ�
��������B�������v���O���~���O�ł�����낢���肽��
���̂͂�����A���Ɏ������悢�̂��B
N3�Ȃ烁�����ŏ\���A�Ƃ�����N3�������̂ɕ֗��ȃG�f�B�^�͂Ȃ����B
���[�J����RDF/XML��N3�̍\���`�F�b�N���ł���c�[���͂Ȃ��̂��ȁB
�I�����C���Ȃ� http://www.rdfabout.com/demo/validator/ �Ƃ�
��������B�������v���O���~���O�ł�����낢���肽��
���̂͂�����A���Ɏ������悢�̂��B
846 �FName_Not_Found�F2008/05/15(��) 16:34:29 ID:???
Powerset�͂������ȁB���R���ꏈ���ł����܂łł����Ȃ�
�Z�}���e�B�b�N�E�E�F�u�͂���Ȃ��C�����Ă����B
�Z�}���e�B�b�N�E�E�F�u�͂���Ȃ��C�����Ă����B
847 �FName_Not_Found�F2008/05/15(��) 23:56:06 ID:???
�܂��܂��Asemweb�̍ő�̗��_�́A�v���������Ȃ��f�[�^���m��
�g�ݍ��킳���Ďv���������Ȃ����l�����܂�邱�Ƃ�����B
���m�̏���T���D�ꂽ�����G���W���͂��ꎩ�̉��l�͂��邯�ǁA
semweb�ɓG������̂ł͂Ȃ��Ǝv����B
�g�ݍ��킳���Ďv���������Ȃ����l�����܂�邱�Ƃ�����B
���m�̏���T���D�ꂽ�����G���W���͂��ꎩ�̉��l�͂��邯�ǁA
semweb�ɓG������̂ł͂Ȃ��Ǝv����B
848 �FName_Not_Found�F2008/05/16(��) 04:58:54 ID:???
����A����Ȃ��͌����߂����ˁB�����I�ɖ����\�z�}���������̂�
�ڂ̑O�Ɍ���Ă�������S���Ă��܂����B�܂��APowerset��
�����Ώۂ�Wikipedia��freebase�Ɍ��肵�Ă��邩��A�u�v��
�\�Ȃ낤���ǁB
�Z�}���e�B�b�N�E�E�F�u�����������v�V�I�ȃA�v���P�[�V������
�o�ꂵ�Ȃ��ƔF�m�x�̒Ⴓ�͂ǂ��ɂ��Ȃ�Ȃ��悤�ȁB
�Z�}���e�B�b�N�E�E�F�u�̌����G���W�������낢�날�����A
Powerset�̂悤�Ɍ��������H�v����c�B
�ڂ̑O�Ɍ���Ă�������S���Ă��܂����B�܂��APowerset��
�����Ώۂ�Wikipedia��freebase�Ɍ��肵�Ă��邩��A�u�v��
�\�Ȃ낤���ǁB
�Z�}���e�B�b�N�E�E�F�u�����������v�V�I�ȃA�v���P�[�V������
�o�ꂵ�Ȃ��ƔF�m�x�̒Ⴓ�͂ǂ��ɂ��Ȃ�Ȃ��悤�ȁB
�Z�}���e�B�b�N�E�E�F�u�̌����G���W�������낢�날�����A
Powerset�̂悤�Ɍ��������H�v����c�B
849 �FName_Not_Found�F2008/05/21(��) 01:33:39 ID:???
�N�����ꁫ�̓��{��ł������Ă���Ȃ����ȁB
http://www4.wiwiss.fu-berlin.de/bizer/bookmashup/
http://www4.wiwiss.fu-berlin.de/bizer/bookmashup/
850 �FName_Not_Found�F2008/05/24(�y) 23:34:17 ID:???
�K���Z�}���e�B�b�N�ȃT�[�r�X��n��B
�ŏ��̓V���{����������Ȃ����B
���������S�ӋC�ł����B
�ŏ��̓V���{����������Ȃ����B
���������S�ӋC�ł����B
851 �FName_Not_Found�F2008/05/25(��) 01:00:42 ID:???
���������
852 �FName_Not_Found�F2008/05/26(��) 00:09:21 ID:???
�{���ɉ������Ă�����Ȃ牽�������Ă݂邪�A�����̓v���O���~���O��
VBA�����G�������Ƃ̂Ȃ��Ǒf�l�Ȃ̂ŁA������������̂��킩��Ȃ��B
Book Mashup�̓��C�u�������g����300�s��̃R�[�h�Ŏ�������Ă��邻��
������ ������Ƃł͂Ȃ��낤���ǁA���[��APHP�̏�������Amazon�E
Google�����Ă���API�ׂ����̂��Ȃ��B
LOD���p�ꌗ�̃f�[�^����Ȃ̂͂��������Ȃ���ˁB
VBA�����G�������Ƃ̂Ȃ��Ǒf�l�Ȃ̂ŁA������������̂��킩��Ȃ��B
Book Mashup�̓��C�u�������g����300�s��̃R�[�h�Ŏ�������Ă��邻��
������ ������Ƃł͂Ȃ��낤���ǁA���[��APHP�̏�������Amazon�E
Google�����Ă���API�ׂ����̂��Ȃ��B
LOD���p�ꌗ�̃f�[�^����Ȃ̂͂��������Ȃ���ˁB
853 �FName_Not_Found�F2008/05/26(��) 02:46:57 ID:???
�܂�������邩���߂Ȃ����B
�l�I�ɂ͂ł���Ȃ狦�͂��Ă݂�������ǁB
�l�I�ɂ͂ł���Ȃ狦�͂��Ă݂�������ǁB
854 �FName_Not_Found�F2008/05/26(��) 22:12:00 ID:???
�����ł��肰�ɉ����~�����̂������Ă݂�ƁAWeb�ォ��e��C�x���g���
(�Ղ�Ƃ��R���T�[�g�Ƃ����C�u�Ƃ���) ���W�߂Ă��� (���[�U�ɂ�铊�e�ł���)�A
iCalendar��RDFical��RSS (�͂�����ƌ�������) �Œ��Ă����T�[�r�X�B
������̃t�H�[�}�b�g(RDF)�ŏo���Ă����A
��̓Q�[�g�E�F�C�����Ƃ����Ă����A�Ƃ����������B
(�Ղ�Ƃ��R���T�[�g�Ƃ����C�u�Ƃ���) ���W�߂Ă��� (���[�U�ɂ�铊�e�ł���)�A
iCalendar��RDFical��RSS (�͂�����ƌ�������) �Œ��Ă����T�[�r�X�B
������̃t�H�[�}�b�g(RDF)�ŏo���Ă����A
��̓Q�[�g�E�F�C�����Ƃ����Ă����A�Ƃ����������B
855 �FName_Not_Found�F2008/05/26(��) 22:36:52 ID:???
�����ق������̂�>>854�Ǝ��ĂāA
�������D���ȍ�ƁA�V���[�Y���̖̂{�̔�������ʒm���Ă����T�[�r�X
�������D���ȍ�ƁA�V���[�Y���̖̂{�̔�������ʒm���Ă����T�[�r�X
856 �FName_Not_Found�F2008/05/27(��) 00:10:23 ID:???
>>854
������ǂ�����ăZ�}���e�B�b�N�Ɏ������邩�͕ʂɂ���
�����C�x���g��iCalendar�̏W��͂ƂĂ��~�����B
�e�C�x���g�Ƀ^�O�t�����či�荞�݂ł����肷��Ƒf�G�B
>>855
��Ƃ�{�Ȃ�Amazon�̃f�[�^�����ł����ʂɎ����ł��������ˁB
������ǂ�����ăZ�}���e�B�b�N�Ɏ������邩�͕ʂɂ���
�����C�x���g��iCalendar�̏W��͂ƂĂ��~�����B
�e�C�x���g�Ƀ^�O�t�����či�荞�݂ł����肷��Ƒf�G�B
>>855
��Ƃ�{�Ȃ�Amazon�̃f�[�^�����ł����ʂɎ����ł��������ˁB
857 �FName_Not_Found�F2008/05/27(��) 03:31:29 ID:???
������Book Mashup�݂����A���Ђ�URI��^���āA�u���E�U�̃��N�G�X�g��
�����HTML�y�[�W��RDF��Ԃ��T�[�r�X�̓��{��ł����肽���Ȃ��Ǝv����
����B���Ђ�urn:isbn�ł������N�ł��邯��ǃ��\�[�X���擾�ł��Ȃ��̂ŁA
LinkedData�I�ɂ��������Ȃ��B
�Ƃ肠����PHP�̖{�ł������Ă݂邩�ȁc�B
�����HTML�y�[�W��RDF��Ԃ��T�[�r�X�̓��{��ł����肽���Ȃ��Ǝv����
����B���Ђ�urn:isbn�ł������N�ł��邯��ǃ��\�[�X���擾�ł��Ȃ��̂ŁA
LinkedData�I�ɂ��������Ȃ��B
�Ƃ肠����PHP�̖{�ł������Ă݂邩�ȁc�B
858 �FName_Not_Found�F2008/05/27(��) 16:26:44 ID:???
859 �FName_Not_Found�F2008/05/28(��) 09:08:29 ID:???
KDE4��semweb�̋Z�p���g���ăt�@�C�����^�O�t�������蒍�߂�t������ł���
�炵���B�E�F�u�A�v���̂悤�Ȋ��o�Ŏg����̂��ȁB
http://www.w3.org/2001/sw/sweo/public/UseCases/Nepomuk/
�炵���B�E�F�u�A�v���̂悤�Ȋ��o�Ŏg����̂��ȁB
http://www.w3.org/2001/sw/sweo/public/UseCases/Nepomuk/
860 �FName_Not_Found�F2008/05/28(��) 21:24:56 ID:???
���������t�@�C���[���~�����ĐF�X�ƃA�C�f�B�A������Ă����B
�������Ȃ��Ă��N�����ȁA����ς�B
�������Ȃ��Ă��N�����ȁA����ς�B
861 �FName_Not_Found�F2008/06/02(��) 22:51:34 ID:???
Book Mashup�̓��{��ł��ق������ď�ŏ�������APHP�̃\�[�X��
�_�E�����[�h����".com"��".jp"�ɕς��������œ����悤�ɂȂ����B
�N���ݒu���Ĕ��i�v�I�ɊǗ����Ă���Ȃ����Ȃ��B���{�Ŕ��������
����قڑS�Ă̏��Ђ�URI��^�����Ă���RDF�̃f�[�^��������̂ŁA
���Ȃ�֗��ɂȂ�Ǝv�����ǁB
�_�E�����[�h����".com"��".jp"�ɕς��������œ����悤�ɂȂ����B
�N���ݒu���Ĕ��i�v�I�ɊǗ����Ă���Ȃ����Ȃ��B���{�Ŕ��������
����قڑS�Ă̏��Ђ�URI��^�����Ă���RDF�̃f�[�^��������̂ŁA
���Ȃ�֗��ɂȂ�Ǝv�����ǁB
862 �FName_Not_Found�F2008/06/05(��) 08:34:14 ID:???
����I�Ȃ�]���Ă��邪
���肵�ăT�[�r�X�o���邩�킩��Ȃ�����Ȃ�
���肵�ăT�[�r�X�o���邩�킩��Ȃ�����Ȃ�
863 �FName_Not_Found�F2008/06/05(��) 16:49:56 ID:???
�N�� Book Mashup �̂��炵���ɂ��ĉ�����Ă���
864 �FName_Not_Found�F2008/06/05(��) 17:54:34 ID:???
timbl��WWW����ɃO���t�Ƃ����`�Ői�����Ă������Č����Ă���B
�ŏ��̓C���^�[�l�b�g�������B�����ŋ����[���̂̓P�[�u���ł͂Ȃ��A
�R���s���[�^�B����WWW�A�����ŋ����[���̂̓R���s���[�^�ł͂Ȃ��A
�����������B���̎���GGG�A�����ŋ����[���͕̂����ł͂Ȃ����̂��ƁA
�N���ǂ�Ȃ��Ƃ������Ă���̂��A����ǂ̂��A�����������̂��cetc.
�ŁA������Ȃ��ł䂯�Α傫�ȃO���[�o���O���t(GGG)���`���邾�낤�ƁB
�Ǐ��͐l�X�̐����̒��ŏd�v�Ȉʒu���߂銈���A���݂�WWW�ł͓Ǐ���
�ւ��邢�낢��ȃT�[�r�X������Ă���B�ƂȂ�ƁA�Ǐ���GGG�ł�
�傫�ȕ������߂�v�f�ɂȂ�Ǝv���B���ꂼ��̖{��URI������A
���̖{��ǂA���̖{�ɂ��ă��r���[�����ȂǁA���낢�댾�����Ƃ�
�ł���B������Book Mashup�͕K�v�B
�������{�ɂ�urn:isbn:�`����URI�����邯��ǁA����ł̓����N����
�f�[�^�ɂȂ�Ȃ��Bhttp:��URI�Ȃ�RDF�Ƀ��_�C���N�g�����A�N���������̂��A
�ǂ��Ŕ����Ă���̂��Ȃǂ��q�ׂ邱�Ƃ��ł���B�܂�A�����N����
�f�[�^=GGG�̈ꕔ�ɂȂ��B
����Ȋ������Ȃ��B������O�̂��Ƃ��������ĂȂ��悤�ȋC�����邯�ǁB
�ŏ��̓C���^�[�l�b�g�������B�����ŋ����[���̂̓P�[�u���ł͂Ȃ��A
�R���s���[�^�B����WWW�A�����ŋ����[���̂̓R���s���[�^�ł͂Ȃ��A
�����������B���̎���GGG�A�����ŋ����[���͕̂����ł͂Ȃ����̂��ƁA
�N���ǂ�Ȃ��Ƃ������Ă���̂��A����ǂ̂��A�����������̂��cetc.
�ŁA������Ȃ��ł䂯�Α傫�ȃO���[�o���O���t(GGG)���`���邾�낤�ƁB
�Ǐ��͐l�X�̐����̒��ŏd�v�Ȉʒu���߂銈���A���݂�WWW�ł͓Ǐ���
�ւ��邢�낢��ȃT�[�r�X������Ă���B�ƂȂ�ƁA�Ǐ���GGG�ł�
�傫�ȕ������߂�v�f�ɂȂ�Ǝv���B���ꂼ��̖{��URI������A
���̖{��ǂA���̖{�ɂ��ă��r���[�����ȂǁA���낢�댾�����Ƃ�
�ł���B������Book Mashup�͕K�v�B
�������{�ɂ�urn:isbn:�`����URI�����邯��ǁA����ł̓����N����
�f�[�^�ɂȂ�Ȃ��Bhttp:��URI�Ȃ�RDF�Ƀ��_�C���N�g�����A�N���������̂��A
�ǂ��Ŕ����Ă���̂��Ȃǂ��q�ׂ邱�Ƃ��ł���B�܂�A�����N����
�f�[�^=GGG�̈ꕔ�ɂȂ��B
����Ȋ������Ȃ��B������O�̂��Ƃ��������ĂȂ��悤�ȋC�����邯�ǁB
865 �FName_Not_Found�F2008/06/05(��) 18:05:09 ID:???
>>864
���ǃ��]���o������Ηǂ���ˁH
���ǃ��]���o������Ηǂ���ˁH
866 �FName_Not_Found�F2008/06/05(��) 18:22:59 ID:???
���]���o���Č����ƁAURN���ǂ����ɖ��O��������悤�Ȃ��́H����Ƃ�
purl.org�݂����Ȃ�H
�ǂ�����ɂ��Ă��A�ǂ����ɃT�[�o�������āA�{�̕\���摜�⒘�҂ւ̃����N
���܂�RDF��Ԃ��悤�ɂȂ��Ă����ق����������낢�Ǝv���B
purl.org�݂����Ȃ�H
�ǂ�����ɂ��Ă��A�ǂ����ɃT�[�o�������āA�{�̕\���摜�⒘�҂ւ̃����N
���܂�RDF��Ԃ��悤�ɂȂ��Ă����ق����������낢�Ǝv���B
867 �FName_Not_Found�F2008/06/06(��) 01:40:04 ID:???
���̏ꍇ�K�v�Ȃ̂�ISBN��URN�Ŗ₢������Ƃ�RDF Book Mashup(����ѓ���̃T�[�r�X)��
���̖{�ɂ��Ă�URL��Ԃ��Ă����悤�ȃ��]���o�Ȃ�Ȃ����ˁH
���ꂪ RDF Book Mashup �̗l�ȃT�[�r�X���̂Ƃ͓Ɨ��ɂ��銴���ŁB
���[��c�������H
���̖{�ɂ��Ă�URL��Ԃ��Ă����悤�ȃ��]���o�Ȃ�Ȃ����ˁH
���ꂪ RDF Book Mashup �̗l�ȃT�[�r�X���̂Ƃ͓Ɨ��ɂ��銴���ŁB
���[��c�������H
868 �FName_Not_Found�F2008/06/07(�y) 01:12:43 ID:???
�����N����f�[�^�̌����̈��http:�X�L�[����URI���g�����Ƃ������A
��������O��ĐV�����V�X�e��������K�v�͂Ȃ��Ǝv���B
���{�ł�semweb����������Ă���l�͂������A���������l������
�T�[�o�^�c���Ă����Ƃ������B
��������O��ĐV�����V�X�e��������K�v�͂Ȃ��Ǝv���B
���{�ł�semweb����������Ă���l�͂������A���������l������
�T�[�o�^�c���Ă����Ƃ������B
869 �FName_Not_Found�F2008/06/12(��) 17:31:14 ID:???
RDF/XML, N3, Turtle, RDFa��RDF�O���t�����o���������c�[����
�Ȃ��̂��ȁHRDF/XML�I�����[�Ȃ�W3C�̂�����邪�c
�Ȃ��̂��ȁHRDF/XML�I�����[�Ȃ�W3C�̂�����邪�c
870 �FName_Not_Found�F2008/06/12(��) 18:27:41 ID:???
RDFa CR���܂�����BPrimer�����̂����o�邩�ȁH
871 �FName_Not_Found�F2008/06/12(��) 21:27:08 ID:???
>>869
�u���E�U���Ă킯����Ȃ�����
http://mr3.sourceforge.net/ja/
�ɂ� RDF/XML, N3, N-Triple, Turtle�̃C���|�[�g�@�\��������ۂ��B
�u���E�U���Ă킯����Ȃ�����
http://mr3.sourceforge.net/ja/
�ɂ� RDF/XML, N3, N-Triple, Turtle�̃C���|�[�g�@�\��������ۂ��B
872 �FName_Not_Found�F2008/06/12(��) 23:31:38 ID:???
�����A���̎肪���������B����RDFa��������Ƃ������ǁA�����
XSLT��RDF/XML�Ɉ�x�ϊ����邵���Ȃ��̂��ȁB
XSLT��RDF/XML�Ɉ�x�ϊ����邵���Ȃ��̂��ȁB
873 �FName_Not_Found�F2008/06/15(��) 23:01:03 ID:???
>>852
VBA�Ȃ�Ƃ肠����MSXML�ł�����Ă݂��炢����Ȃ����ȁB
�Q�Ɛݒ�Œlj��ł��āAXMLHTTP�ŒʐM���ł���B
�T���v���R�[�h��VBScript�g�����̂���������������͂��B
VBA�Ȃ�Ƃ肠����MSXML�ł�����Ă݂��炢����Ȃ����ȁB
�Q�Ɛݒ�Œlj��ł��āAXMLHTTP�ŒʐM���ł���B
�T���v���R�[�h��VBScript�g�����̂���������������͂��B
874 �FName_Not_Found�F2008/06/18(��) 02:04:24 ID:???
>>873
����Linux���Ɉڂ����̂�VBA�͎g���Ȃ��BPHP�ɒ��풆�B
�Ƃ肠�������̓t�H�[����������RDF/XML��RDF�O���t��
�摜�ŕ\���ł���悤�ɂȂ����B�����A��ł��G���[�������
Fatal error�Ńv���O�������~�܂��Ă��܂��̂ŁA�G���[�������Ă�
validator�݂����Ō�܂Ńp�[�X���ăG���[���b�Z�[�W��\������
�悤�ɂ������B�����RAP��������Ȃ��Ƃ����Ȃ��̂��ȁB
����Linux���Ɉڂ����̂�VBA�͎g���Ȃ��BPHP�ɒ��풆�B
�Ƃ肠�������̓t�H�[����������RDF/XML��RDF�O���t��
�摜�ŕ\���ł���悤�ɂȂ����B�����A��ł��G���[�������
Fatal error�Ńv���O�������~�܂��Ă��܂��̂ŁA�G���[�������Ă�
validator�݂����Ō�܂Ńp�[�X���ăG���[���b�Z�[�W��\������
�悤�ɂ������B�����RAP��������Ȃ��Ƃ����Ȃ��̂��ȁB
875 �FName_Not_Found�F2008/06/26(��) 05:03:44 ID:???
BBC�̌���������RDFa���ŋߔM���ˁBMicroformats��RDFa�̗���͗��邩�ȁH
�ł�RDFa�̎菑���͌��\�炢��Ȃ��B
�ł�RDFa�̎菑���͌��\�炢��Ȃ��B
876 �FName_Not_Found�F2008/07/26(�y) 17:19:01 ID:???
RDFa��a���ĉ��H
877 �FName_Not_Found�F2008/07/26(�y) 17:42:31 ID:???
attributes��a
�O�O��Ώo�邯��
�O�O��Ώo�邯��
878 �FName_Not_Found�F2008/08/27(��) 01:30:44 ID:???
Refuse Derived Fuel
879 �FName_Not_Found�F2008/10/03(��) 17:00:21 ID:???
HTML 5��GRDDL�g�������Ƃ���head�v�f��@profile�̑����link�v�f��
@rel="profile"���w�肷�銴���ɂ���݂������ˁBGRDDL�̎d�l�O�ɂȂ邯��
XHTML 2.0��@profile���Ȃ����瓯���悤�ɂ����ق��������̂����B
�\���I�ɂ��������̂ق������ꂢ�����A�Ƃ�����head�v�f��@profile�������
�Ă̂͌��\�䂾���B
�ł������Ǝ��������낤���BGRDDL�̕������������肷��̂��ˁ[�B
@rel="profile"���w�肷�銴���ɂ���݂������ˁBGRDDL�̎d�l�O�ɂȂ邯��
XHTML 2.0��@profile���Ȃ����瓯���悤�ɂ����ق��������̂����B
�\���I�ɂ��������̂ق������ꂢ�����A�Ƃ�����head�v�f��@profile�������
�Ă̂͌��\�䂾���B
�ł������Ǝ��������낤���BGRDDL�̕������������肷��̂��ˁ[�B
880 �FName_Not_Found�F2008/10/16(��) 17:15:28 ID:???
RDFa���������ꂽ�ˁB
RDFa in XHTML: Syntax and Processing
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/
RDFa in XHTML: Syntax and Processing
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/
881 �FName_Not_Found�F2008/11/30(��) 18:48:44 ID:???
Semantic Web�̌�����Ăǂ��Ȃ��Ă�́H
RDF/OWL�������ɂȂ������͎d�l���ǂ��b������肵�Ă݂����̂����ǁA
���͂�������a���Ɂc�B
����RDF Semantics��|�ꂽ�����B
http://www-kasm.nii.ac.jp/~koide/RDF%20Semantics-J.htm
�_�肳���RDF/OWL����ł̐����͂܂�������₷�������Ǝv�����ǁA
���T�͓��{��ɂȂ��Ă��ǂ߂�C�����Ȃ��B
RDF/OWL�������ɂȂ������͎d�l���ǂ��b������肵�Ă݂����̂����ǁA
���͂�������a���Ɂc�B
����RDF Semantics��|�ꂽ�����B
http://www-kasm.nii.ac.jp/~koide/RDF%20Semantics-J.htm
�_�肳���RDF/OWL����ł̐����͂܂�������₷�������Ǝv�����ǁA
���T�͓��{��ɂȂ��Ă��ǂ߂�C�����Ȃ��B
882 �FName_Not_Found�F2008/11/30(��) 20:15:59 ID:???
�������m�肽��.
semweb�ɊS��������Ƃ��������Ƃ����炢�����m��Ȃ��̂�.
semweb�ɊS��������Ƃ��������Ƃ����炢�����m��Ȃ��̂�.
883 �FName_Not_Found�F2009/02/09(��) 17:21:50 ID:???
RDFa��property�����Ƃ��͂��̊����ɂ����XHTML���O��Ԃɒlj����ꂽ���ĔF���ł����́H
884 �FName_Not_Found�F2009/02/10(��) 20:22:39 ID:???
���Ɍ����Ɍ��߂Ă��Ȃ��悤�ȋC������B
XHTML M12N�ɂ���Ċe�X�̃X�L�[�}��"http://www.w3.org/1999/xhtml"���g�����Ă�������A
�������O���URI�̉��ɂ��ꂼ��قȂ��b�����݂��Ă���A�Ƃ������Ƃɂ��Ȃ肻���ȁB
XHTML M12N�ɂ���Ċe�X�̃X�L�[�}��"http://www.w3.org/1999/xhtml"���g�����Ă�������A
�������O���URI�̉��ɂ��ꂼ��قȂ��b�����݂��Ă���A�Ƃ������Ƃɂ��Ȃ肻���ȁB
885 �FName_Not_Found�F2009/02/16(��) 14:27:59 ID:???
>>883
�Z�N�V����9��Appendix�����킹�Ă݂�ƁCXHTML+RDFa 1.0�̏ꍇ��
XHTML���O��ԁi�̗v�f�^�̋��j�ɑ����邱�ƂɂȂ邵�CXHTML�t�@�~���[�ł�
Common�����W���ɉ����炵���̂ŁC����ς�XHTML���O��Ԃɑ����邱�Ƃ�
�Ȃ�Ǝv���D
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/#s_metaAttributes
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/#a_xhtmlrdfa_dtd
GRDDL�̂ق��͖��O��Ԃ��͂������`���Ă�̂ɂ˂��D
�Z�N�V����9��Appendix�����킹�Ă݂�ƁCXHTML+RDFa 1.0�̏ꍇ��
XHTML���O��ԁi�̗v�f�^�̋��j�ɑ����邱�ƂɂȂ邵�CXHTML�t�@�~���[�ł�
Common�����W���ɉ����炵���̂ŁC����ς�XHTML���O��Ԃɑ����邱�Ƃ�
�Ȃ�Ǝv���D
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/#s_metaAttributes
http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014/#a_xhtmlrdfa_dtd
GRDDL�̂ق��͖��O��Ԃ��͂������`���Ă�̂ɂ˂��D
886 �FName_Not_Found�F2009/02/17(��) 20:47:31 ID:???
XHTML���O��Ԏ��̂��g������āAXHTML+RDFa�͌�b���t���ɗ��p�A
XHTML 1.1�͌���I�ɗ��p���Ă���A�Ƃł����߂��邩�B
�d�l���ɂ����Ə����Ă����Ăق����ˁB
XHTML Role Attribute Module�Ȃ͖������Ă���̂ŕ�����₷���B
http://www.w3.org/TR/2008/WD-xhtml-role-20080407/#docconf
XHTML 1.1�͌���I�ɗ��p���Ă���A�Ƃł����߂��邩�B
�d�l���ɂ����Ə����Ă����Ăق����ˁB
XHTML Role Attribute Module�Ȃ͖������Ă���̂ŕ�����₷���B
http://www.w3.org/TR/2008/WD-xhtml-role-20080407/#docconf
887 �FName_Not_Found�F2009/04/06(��) 20:17:23 ID:???
�_��搶���V�����{���o�������ł��ˁB
RDF�͂������育�����������ǁA�܂������Ă݂悤���ȁB
RDF�͂������育�����������ǁA�܂������Ă݂悤���ȁB
888 �FName_Not_Found�F2009/06/05(��) 08:12:21 ID:+Z8r6xO9
>>887
�{�̕]���͂ǂ��Ȃ�ł��傤���H
�ƌ����Ă��Z�}���e�B�b�N�E�F�u�W�̖{�͂��ꂭ�炢�����Ȃ��C�����邯�ǁc
�Z�p�I�ɂ܂����������ł��傤���H
�h�L�������g�̈Ӗ��t���ŔY��ł܂�
XML��XSLT�̑g�ݍ��킹�͕~���������̂ł����Ǝ�y�ȕ��@���Ȃ����̂��Ɓc
�{�̕]���͂ǂ��Ȃ�ł��傤���H
�ƌ����Ă��Z�}���e�B�b�N�E�F�u�W�̖{�͂��ꂭ�炢�����Ȃ��C�����邯�ǁc
�Z�p�I�ɂ܂����������ł��傤���H
�h�L�������g�̈Ӗ��t���ŔY��ł܂�
XML��XSLT�̑g�ݍ��킹�͕~���������̂ł����Ǝ�y�ȕ��@���Ȃ����̂��Ɓc
889 �FName_Not_Found�F2009/06/10(��) 02:27:41 ID:???
�_�肳���XHTML/RDFa�ɂ��Ă̖{���o�ĂĂ�����ǂ�ł݂�����
����̓l�b�g�ŗ����Ȃ��Ɛ�Ε��y���Ȃ��K�i����
���{���RDFa�̉�����Ă�y�[�W�Ȃ�ĂȂ������
���y���Ȃ��K�i��������ċ��������ł��Ȃ��c�c
����̓l�b�g�ŗ����Ȃ��Ɛ�Ε��y���Ȃ��K�i����
���{���RDFa�̉�����Ă�y�[�W�Ȃ�ĂȂ������
���y���Ȃ��K�i��������ċ��������ł��Ȃ��c�c
890 �FName_Not_Found�F2009/07/15(��) 23:00:55 ID:???
>>889
�{�ɂȂ��Ă�����֗��B��₱�₵������Q�]�����ēǂ݂������B��������XHTML+RDFa�̃y�[�W������Ă݂����B
�܂��A���݂����ɍH�w�n�̊w�Z�s���Ă��Ȃ���IT�ƊE�ɂ��W�Ȃ��l�Ŏ��RDFa�Ƃ��M���Ă�l����
���Ȃ��̂�������ǂ��B
�{�ɂȂ��Ă�����֗��B��₱�₵������Q�]�����ēǂ݂������B��������XHTML+RDFa�̃y�[�W������Ă݂����B
�܂��A���݂����ɍH�w�n�̊w�Z�s���Ă��Ȃ���IT�ƊE�ɂ��W�Ȃ��l�Ŏ��RDFa�Ƃ��M���Ă�l����
���Ȃ��̂�������ǂ��B
891 �FName_Not_Found�F2009/07/18(�y) 19:28:29 ID:???
���v�A��������
892 �FName_Not_Found�F2009/08/03(��) 23:20:11 ID:puzXDiJf
POWDER���āC�ȑO�����Ƃ��� http://www.w3.org/TR/2007/WD-powder-voc-20070925/
�݂�����RDF�̏�ɍ�銴���������̂ɁC���̂܂ɂ�
This document was made obsolete by the development of the POWDER XML Schema.
�Ƃ�������ĂāCXML Schema�����邩��RDF Schema������Ȃ����ƂɂȂ��Ă�݂��������ǁC�Ȃ�ŁH
POWDER-S����owl:Class��3������q�ɂȂ����肵�ĂċC�����������C
���ׂĂ�RDF��RDF/XML�Ȃ킯�ł͂Ȃ������H
RDF Schema���c���Ƃ��CRDF�ł�XML��ɍ�����Ǝ�����(POWDER)���炢�̃V���v�����ŏ������̂�
�킴�킴���G�ɂ���Ӗ����킩���D
�݂�����RDF�̏�ɍ�銴���������̂ɁC���̂܂ɂ�
This document was made obsolete by the development of the POWDER XML Schema.
�Ƃ�������ĂāCXML Schema�����邩��RDF Schema������Ȃ����ƂɂȂ��Ă�݂��������ǁC�Ȃ�ŁH
POWDER-S����owl:Class��3������q�ɂȂ����肵�ĂċC�����������C
���ׂĂ�RDF��RDF/XML�Ȃ킯�ł͂Ȃ������H
RDF Schema���c���Ƃ��CRDF�ł�XML��ɍ�����Ǝ�����(POWDER)���炢�̃V���v�����ŏ������̂�
�킴�킴���G�ɂ���Ӗ����킩���D
893 �FName_Not_Found�F2010/01/06(��) 00:52:00 ID:54cGCxAC
RDF�ƃJ�e�S���_�́A��{�R���Z�v�g�����ʂ��Ă�Ɗ�����B
�Ă������AInformation Flow Framework�Ƃ����邵�ˁB
�ǂ����ɁARDF���x�[�X�ɂ����J�e�S���_�̉���y�[�W�Ƃ��Ȃ�����ł����B
Information Flow Frame�y�[�W�͓�����Ă킩��Ȃ��ł��B
RDF���̑f�l�Ȃ��̂Ȃ̂ŁB
�Ă������AInformation Flow Framework�Ƃ����邵�ˁB
�ǂ����ɁARDF���x�[�X�ɂ����J�e�S���_�̉���y�[�W�Ƃ��Ȃ�����ł����B
Information Flow Frame�y�[�W�͓�����Ă킩��Ȃ��ł��B
RDF���̑f�l�Ȃ��̂Ȃ̂ŁB
894 �FName_Not_Found�F2010/01/06(��) 00:59:03 ID:54cGCxAC
�l�����܂Ƃ܂��Ă��Ȃ��ē��{�ꂪ�O�j���O�j���ł��ˁB�����܂���B
�Ƃ肠�����A���ƖړI������̑ΏۂƂ��A�q����˂ƍl���āA
RDF�g���v���̏W�c����̌��ƍl����Ηǂ��������Ǝv���Ă��܂��B
RDF�̎Q�l���́w�Z�}���e�B�N�E�E�F�u�̂��߂�RDF/OWL����x�Ƃ����{�ł��B
�Ƃ肠�����A���ƖړI������̑ΏۂƂ��A�q����˂ƍl���āA
RDF�g���v���̏W�c����̌��ƍl����Ηǂ��������Ǝv���Ă��܂��B
RDF�̎Q�l���́w�Z�}���e�B�N�E�E�F�u�̂��߂�RDF/OWL����x�Ƃ����{�ł��B
895 �FName_Not_Found�F2010/03/21(��) 11:28:39 ID:froOcMg+
RDFa��ID�U�肽���Ƃ����Ăǂ�����ł����H�iRDF��rdf:ID�݂����Ɂj
896 �FName_Not_Found�F2010/03/21(��) 13:00:56 ID:???
>>895
RDFa���g���Ȃ�u�Z�}���e�B�b�NHTML/XHTML�v�͓ǂق��������B280�y�[�W�ɓ���������B
RDFa���g���Ȃ�u�Z�}���e�B�b�NHTML/XHTML�v�͓ǂق��������B280�y�[�W�ɓ���������B
���肪�Ƃ��������܂��B
�_�邳��̖{�ł���ˁH�̔������͂��Ȃ�ł����s���s���Ȃ�ł���orz
����������̒����A���u�̖{�̎R�̒����Ǝv����ł����E�E�E�T���Ă݂܂��B
�_�邳��̖{�ł���ˁH�̔������͂��Ȃ�ł����s���s���Ȃ�ł���orz
����������̒����A���u�̖{�̎R�̒����Ǝv����ł����E�E�E�T���Ă݂܂��B
898 �FName_Not_Found�F2010/03/21(��) 17:15:33 ID:???
>>897
�_�肳��̖{�����ǂ���ȂɌÂ��Ȃ���(���N��5��)�B
�������������ƒP��"#me"�݂����ɏ��������B
<div>
<p rel="foaf:primaryTopic" resource="#me">���̖��O��<span property="foaf:name">���R�R�I�v</span>�ł��B
�a������<span property="foaf:birthday" content="02-11">2��11��</span>�ł��B
<span rel="foaf:knows" resource="#ozawa"><span property="foaf:name">�����Y</span>(�a������<span property="foaf:birthday" content="05-24">5��24��</span>)�Ƃ͒m�荇���ł��B</span></p>
<p about="#ozawa">�����Y�̃z�[���y�[�W��<a rel="foaf:homepage" href="http://www.ozawa-ichiro.jp/">http://www.ozawa-ichiro.jp/</a>�ł��B</p>
</div>
http://www.kanzaki.com/works/2009/pub/graph-draw �Ŋm�F�ł���B�m�F�p��DIV�v�f��t�����B
�_�肳��̖{�����ǂ���ȂɌÂ��Ȃ���(���N��5��)�B
�������������ƒP��"#me"�݂����ɏ��������B
<div>
<p rel="foaf:primaryTopic" resource="#me">���̖��O��<span property="foaf:name">���R�R�I�v</span>�ł��B
�a������<span property="foaf:birthday" content="02-11">2��11��</span>�ł��B
<span rel="foaf:knows" resource="#ozawa"><span property="foaf:name">�����Y</span>(�a������<span property="foaf:birthday" content="05-24">5��24��</span>)�Ƃ͒m�荇���ł��B</span></p>
<p about="#ozawa">�����Y�̃z�[���y�[�W��<a rel="foaf:homepage" href="http://www.ozawa-ichiro.jp/">http://www.ozawa-ichiro.jp/</a>�ł��B</p>
</div>
http://www.kanzaki.com/works/2009/pub/graph-draw �Ŋm�F�ł���B�m�F�p��DIV�v�f��t�����B
899 �FName_Not_Found�F2012/04/29(��) 08:32:53.82 ID:???
�Z�}���e�B�b�N�������
900 �FName_Not_Found�F2012/09/15(�y) 18:45:38.19 ID:???
�n������
�n������
�n������
�n�����ˁ@
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n�����ˁ@
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
�n������
901 �FName_Not_Found�F2013/04/23(��) 13:10:03.51 ID:uoN0Y/yh
�ŋ�LOD�Ƃ����s�肻�������A�ȂX���Ȃ����ȁ`�Ǝv�������ǂ��������Ȃ������E�E�E
902 �FName_Not_Found�F2013/04/23(��) 16:12:00.34 ID:???
10�N�O����S�����ł���
903 �FName_Not_Found�F2013/04/24(��) 03:13:45.13 ID:???
����ƈ�ʂɂ܂ŐZ�����n�߂��Ƃ��낶���
904 �FName_Not_Found�F2013/06/07(��) 13:57:43.43 ID:???
��ʂ��Č����Ă��Ȃ��Ȃ��l�T�C�g�܂ŐZ�����Ȃ����
�s����LOD�ɂ��Ă��������ē����͂��邪
�s����LOD�ɂ��Ă��������ē����͂��邪
905 �FName_Not_Found�F