AMD�̎�����APU/CPU�ɂ��Č�낤187����
1 �FSocket774�F
������
���ꂾ��
���ꂾ��
|
|
|
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
ttp://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 71
http://anago.2ch.net/test/read.cgi/jisaku/1388229742/
CPU�A�[�L�e�N�`���ɂ��Č�� 25
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
��ARM�̎�����core, SoC�ɂ��Č��X�� #002��
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
2014 AMD at CES Highlights:
ttp://www.techpowerup.com/196536/amd-surrounds-2014-ces-visitors-with-breakthrough-visual-and-audio-experiences.html
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤186����
http://anago.2ch.net/test/read.cgi/jisaku/1391229653/
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂���
�r�炵��W�Ȃ��R�s�y�Ȑl��NG�ɓ���Ė������܂��傤�B
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g
ttp://amd.jisakuita.net/
Intel�̎�����CPU�ɂ��Č�낤 71
http://anago.2ch.net/test/read.cgi/jisaku/1388229742/
CPU�A�[�L�e�N�`���ɂ��Č�� 25
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
��ARM�̎�����core, SoC�ɂ��Č��X�� #002��
http://anago.2ch.net/test/read.cgi/jisaku/1362032148/
Your processor's IQ: An Intro to HSA
http://www.youtube.com/watch?v=i6BWzL12KMI
Revolutionizing computing with HSA-enabled APUs
http://www.youtube.com/watch?v=4YV6z6Fgw48
2014 AMD at CES Highlights:
ttp://www.techpowerup.com/196536/amd-surrounds-2014-ces-visitors-with-breakthrough-visual-and-audio-experiences.html
�O�X��
AMD�̎�����APU/CPU�ɂ��Č�낤186����
http://anago.2ch.net/test/read.cgi/jisaku/1391229653/
Intel��iGPU����ΑΉ����ׂ��Ȃ��
dGPU�̂������ł��ڂ肪����iGPU�̎g�����͌��\����
dGPU�̂������ł��ڂ肪����iGPU�̎g�����͌��\����
������������ȂɎ��v�͂���̂��Ƃ����b�͂��Ă����A
�v���b�g�t�H�[�����܂������R�[�h�����������Ȃ�OpenCL�ł����̂ł�
Intel��Broadwell��Skylake��1.2/2.0�Ή�����邾�낤��
�Ƃ͂����A�œK���̎�ԂƁA
���Ƃ���OpenCL�͒ᐅ���ŊJ�����߂�ǂ��������Ƃ��l�����
���ʂ̕��y�͌���I�ɂȂ��Ă����������Ȃ��Ƃ͎v������
�v���b�g�t�H�[�����܂������R�[�h�����������Ȃ�OpenCL�ł����̂ł�
Intel��Broadwell��Skylake��1.2/2.0�Ή�����邾�낤��
�Ƃ͂����A�œK���̎�ԂƁA
���Ƃ���OpenCL�͒ᐅ���ŊJ�����߂�ǂ��������Ƃ��l�����
���ʂ̕��y�͌���I�ɂȂ��Ă����������Ȃ��Ƃ͎v������
GPGPU�̕��y�̖W���̍ő�̌������A�R�q�[�����g�����Ȃ����Ƃƃ|�C���^���g���Ȃ����Ƃ�����
������AGPGPU�����ɐ�p�̌������������ĊJ���������Ԃ�ʓ|������
APU��hUMA�͂������������n�[�h�E�F�A�̎d�g�݂����AOpenCL2��HSA�͂�������p�ł�����ɂȂ�
hUMA��GPGPU�̊��p���l���Ă邠���郁�[�J�[���҂��]��ł���@�\������AIntel��NVIDIA�̔�Ή��Ƃ��W�Ȃ��A
�������ʂō̗p���i�ނ��낤��
������AGPGPU�����ɐ�p�̌������������ĊJ���������Ԃ�ʓ|������
APU��hUMA�͂������������n�[�h�E�F�A�̎d�g�݂����AOpenCL2��HSA�͂�������p�ł�����ɂȂ�
hUMA��GPGPU�̊��p���l���Ă邠���郁�[�J�[���҂��]��ł���@�\������AIntel��NVIDIA�̔�Ή��Ƃ��W�Ȃ��A
�������ʂō̗p���i�ނ��낤��
��������GPGPU������Ƃ����_���Ȃ���������̂�
7 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 07:51:49.40 ID:j8lUve94
�ȒP�Ƃ������Ƃɂ��Ă����Ȃ���
�u����ȕ��Z�p�ɑS�͂�AMD���߂ہv
�ƌ���Ȃ��Ƃ����Ȃ��Ȃ邩��
�u����ȕ��Z�p�ɑS�͂�AMD���߂ہv
�ƌ���Ȃ��Ƃ����Ȃ��Ȃ邩��
>>5
�R�q�[�����g�Ȃ�AnViaida��Maxwell�Ŏ���������
>>6
CPU�ł̊J����x�� 1 �Ƃ���ƁAGPGPU �� 10 �ւ������ 100 ���炢�Ȃ��
�ŁAHSA �Ŋy�ɂȂ�ƌ����Ă��A�����������炢
�R�q�[�����g�Ȃ�AnViaida��Maxwell�Ŏ���������
>>6
CPU�ł̊J����x�� 1 �Ƃ���ƁAGPGPU �� 10 �ւ������ 100 ���炢�Ȃ��
�ŁAHSA �Ŋy�ɂȂ�ƌ����Ă��A�����������炢
9 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 08:10:24.88 ID:j8lUve94
�����������[�J�[�̓A�N�Z�����[�^�Ƃ���Xeon Phi��Tesla�����p�ӂ��ĂȂ�����
AMD��GPU���g�������Ȃ�ĒN���v���ĂȂ���
AMD��GPU���g�������Ȃ�ĒN���v���ĂȂ���
�@�o�[�`�������ƁA���ǖ����I�ɐ��䂵�������ǂ����Ęb�ɂȂ�̂ł́H
11 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 08:13:42.43 ID:j8lUve94
CUDA6��cudaMemcpy���s�v�ɂȂ���C/C++ + OpenMP���
������Ɩʓ|���炢�̐��Y���ɂȂ�������
AMD��Bolt�i�j�̓T���v���ǂތ��菉����CUDA�̎���t���h������������炢
�v���I�ɐ��Y���������B�R�[�h�̃^�C�v�ʑ������B
������Ɩʓ|���炢�̐��Y���ɂȂ�������
AMD��Bolt�i�j�̓T���v���ǂތ��菉����CUDA�̎���t���h������������炢
�v���I�ɐ��Y���������B�R�[�h�̃^�C�v�ʑ������B
�t���X�y�b�Nmaxwell���y���݂�
���������tubame3.0�̃R�����g�����xeon phi�ɋ߂����j�[�R�A���ۂ��v����
�����cuda6.0�̃X���Cd
http://oi60.tinypic.com/25stz88.jpg
���������tubame3.0�̃R�����g�����xeon phi�ɋ߂����j�[�R�A���ۂ��v����
�����cuda6.0�̃X���Cd
http://oi60.tinypic.com/25stz88.jpg
{kind=link}
13 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 08:25:09.31 ID:j8lUve94
OpenCL�ɂ�SPIR�����邩��HSAIL�Ȃ�ėv��Ȃ�����
Apple��Intel��NVIDIA��SPIR�x��
Apple��Intel��NVIDIA��SPIR�x��
������A����CPU�A���\�Ⴗ��
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_geforce_dx.png
(�@߄t�)
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
{kind=link}
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
{kind=link}
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_geforce_dx.png
{kind=link}
(�@߄t�)
15 �FSocket774�F2014/02/07(��) 08:41:43.38 ID:t7ubaw4e
�����v�Z���Ƃɐ�pASIC�g�ق��������I�Ȃ�Ȃ��́H
�������ɂP�̌v�Z�ɐ�pASIC�g�ނ͔̂�����I�Ȃ̂ŁA
���Ƃ���1�̃_�C�ɂ悭������100��ނ̌v�Z��H�����āA
����̌v�Z�̂ݗL���ɂ����o�[�W�����o������A�S����������o�[�W�����o�����肷�������
�������ɂP�̌v�Z�ɐ�pASIC�g�ނ͔̂�����I�Ȃ̂ŁA
���Ƃ���1�̃_�C�ɂ悭������100��ނ̌v�Z��H�����āA
����̌v�Z�̂ݗL���ɂ����o�[�W�����o������A�S����������o�[�W�����o�����肷�������
4770K()
http://www.4gamer.net/games/234/G023477/20140203052/TN/004.gif
http://www.4gamer.net/games/234/G023477/20140203052/TN/006.gif
http://www.4gamer.net/games/234/G023477/20140203052/TN/004.gif
{kind=link}
http://www.4gamer.net/games/234/G023477/20140203052/TN/006.gif
{kind=link}
fpga��
http://cdn.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-benchmarks.gif
http://cdn2.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-latency.gif
http://cdn3.wccftech.com/wp-content/uploads/2014/02/bf4-beyond16.gif
geforce��directx�ł����C�e���V����������
{kind=link}
http://cdn2.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-latency.gif
{kind=link}
http://cdn3.wccftech.com/wp-content/uploads/2014/02/bf4-beyond16.gif
{kind=link}
geforce��directx�ł����C�e���V����������
>>15
�n�[�h�őg�ނƈÍ��Ƃ�CODEC�̃o�[�W�����A�b�v�ɑΉ��ł��Ȃ�����ȁBDSP�ɂ���Ύ��R�x�͏オ�邪����Ȃ�GPU�g�������������B
�n�[�h�őg�ނƈÍ��Ƃ�CODEC�̃o�[�W�����A�b�v�ɑΉ��ł��Ȃ�����ȁBDSP�ɂ���Ύ��R�x�͏オ�邪����Ȃ�GPU�g�������������B
20 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 08:54:42.07 ID:j8lUve94
��×p������C�������̏��ʐ��Y�̓���p�r���������\�v���Z�b�T��
20nm����ȍ~�͍���������FPGA����
20nm����ȍ~�͍���������FPGA����
>>8
�܂�������ĂȂ���H��
�܂�������ĂȂ���H��
22 �FSocket774�F2014/02/07(��) 09:01:56.22 ID:eccU+4Tn
������AMD�̎�����APU/CPU�ɂ��Č��X���ł�
intel�̐�`�p�̃X���ł͂���܂���̂�
intel�̐�`�͑��ł��Ă�������
AMD�̎���p����ł͂���܂���
AMD�Ȃ牽�ł�������ł�
intel�̐�`�p�̃X���ł͂���܂���̂�
intel�̐�`�͑��ł��Ă�������
AMD�̎���p����ł͂���܂���
AMD�Ȃ牽�ł�������ł�
23 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 09:02:13.54 ID:j8lUve94
http://www.anandtech.com/show/7515/nvidia-announces-cuda-6-unified-memory-for-cuda
���̒��x�̃V���v�����͗~�����ˁB
Bolt�i�j�ɑ���ӌ��͂ǂ��ɓ���������̂���
���̒��x�̃V���v�����͗~�����ˁB
Bolt�i�j�ɑ���ӌ��͂ǂ��ɓ���������̂���
Starswarm Benchmark���Ƌ�����GPU�ł�14.1���h���C�o�[��Mantle�̊��ł���ˁB
DirectX��FPS�h���b�v���Ă��V�[���ł��t���[�����[�g�ێ����ĂāA�Ȃ��Ȃ��X�S���B
DirectX��FPS�h���b�v���Ă��V�[���ł��t���[�����[�g�ێ����ĂāA�Ȃ��Ȃ��X�S���B
���Q�[���́H
���X�������Ă��ɖ��߂��Ă�
���̃X���ł��O������������ɂ��Ė��ߑ�����Ƃ�
���̃X���ł��O������������ɂ��Ė��ߑ�����Ƃ�
>>8
�ߋ��`���Ď��́AMaxwel�����������ꂽ�́H
�ߋ��`���Ď��́AMaxwel�����������ꂽ�́H
28 �FSocket774�F2014/02/07(��) 13:07:31.49 ID:NvkVv6+D
Battlefield 4 Mantle vs DirectX Image Quality Comparison
http://forum.hardwarepal.com/battlefield-4-mantle-vs-directx-image-quality-comparison/
�ǂ��������̂݁H
http://forum.hardwarepal.com/battlefield-4-mantle-vs-directx-image-quality-comparison/
�ǂ��������̂݁H
AMD Lands OpenMAX State Tracker In Mesa Gallium3D
ttp://www.phoronix.com/scan.php?page=news_item&px=MTU5NDc
ttp://www.phoronix.com/scan.php?page=news_item&px=MTU5NDc
>>28
�����炳�܂ɃI�u�W�F�N�g���������Ă�ȁA���̊�̍��o���낤���H
�����炳�܂ɃI�u�W�F�N�g���������Ă�ȁA���̊�̍��o���낤���H
DirectX���̃O���t�B�b�N���r�Ώۂ�Mantle�ł��炢�ɂ����
�Ђ���Ƃ���Mantle���FPS�҂����E�E�E
�Ђ���Ƃ���Mantle���FPS�҂����E�E�E
LINPACK�͉ߋ��̂��̂�
�V���ȃx���`�}�[�NHPCG
http://news.mynavi.jp/column/sc13/010/
�܂�ALINPACK�������Ă�����ƌ����̖��Ƃ͐������قȂ�ALINPACK���\���������Ƃ����A�v���̎��s���\��
�������Ƃɂ��܂�q����Ȃ��Ȃ��Ă��܂��Ă���B
�����Ȃ�ƁA����LINPACK���\��B������Top500��1�ʂ���낤�Ƃ����w�͂́A���p�I�ɂ͈Ӗ��̖����w�͂ŁA
Top500�̑��݂̓X�p�R���̔��W�Ƀv���X�ɂȂ�ǂ��납�A�Ԉ���������ɃX�p�R���̊J�������������Ă��܂�
�}�C�i�X�v���ɂȂ��Ă��܂��B
���̂悤�Ȍ��O����A�e�l�V�[���Jack Dongarra�������HPCG(High Performance Conjugate Gradient)�Ƃ���
�x���`�}�[�N�v���O�������J��������B
�Ȃ��AJack Dongarra�����́ATop500�̎�Î҂�1�l�ŁAHPL���J�����l���ł���B
http://news.mynavi.jp/photo/column/sc13/010/images/008l.jpg
���̐}�Ɏ����悤�ɁA32�m�[�h�̃V�X�e���̃s�[�N���Z���\��5000GFlops��ŁAHPL�ł�4000GFlops���ƃs�[�N��
80%�ȏ�̐��\���o�Ă��邪�AHPCG�̏ꍇ�́A0.5%���x�̐��\�����o�Ă��Ȃ��B�܂�AHPCG�ł͉��Z���Ԃ����A
��є�т̃������A�N�Z�X��m�[�h�Ԃ�MPI�ʐM�̎��Ԃ����\�ɑ傫���e�����Ă���B
���̂��߁AHPL�Ő��\�������V�X�e����HPCG�ł����\�������Ƃ͌���Ȃ��B
�܂��AHPCG�ō����\���o�����߂̋Z�p�̊J�����K�v�ƂȂ�B
�V���ȃx���`�}�[�NHPCG
http://news.mynavi.jp/column/sc13/010/
�܂�ALINPACK�������Ă�����ƌ����̖��Ƃ͐������قȂ�ALINPACK���\���������Ƃ����A�v���̎��s���\��
�������Ƃɂ��܂�q����Ȃ��Ȃ��Ă��܂��Ă���B
�����Ȃ�ƁA����LINPACK���\��B������Top500��1�ʂ���낤�Ƃ����w�͂́A���p�I�ɂ͈Ӗ��̖����w�͂ŁA
Top500�̑��݂̓X�p�R���̔��W�Ƀv���X�ɂȂ�ǂ��납�A�Ԉ���������ɃX�p�R���̊J�������������Ă��܂�
�}�C�i�X�v���ɂȂ��Ă��܂��B
���̂悤�Ȍ��O����A�e�l�V�[���Jack Dongarra�������HPCG(High Performance Conjugate Gradient)�Ƃ���
�x���`�}�[�N�v���O�������J��������B
�Ȃ��AJack Dongarra�����́ATop500�̎�Î҂�1�l�ŁAHPL���J�����l���ł���B
http://news.mynavi.jp/photo/column/sc13/010/images/008l.jpg
{kind=link}
���̐}�Ɏ����悤�ɁA32�m�[�h�̃V�X�e���̃s�[�N���Z���\��5000GFlops��ŁAHPL�ł�4000GFlops���ƃs�[�N��
80%�ȏ�̐��\���o�Ă��邪�AHPCG�̏ꍇ�́A0.5%���x�̐��\�����o�Ă��Ȃ��B�܂�AHPCG�ł͉��Z���Ԃ����A
��є�т̃������A�N�Z�X��m�[�h�Ԃ�MPI�ʐM�̎��Ԃ����\�ɑ傫���e�����Ă���B
���̂��߁AHPL�Ő��\�������V�X�e����HPCG�ł����\�������Ƃ͌���Ȃ��B
�܂��AHPCG�ō����\���o�����߂̋Z�p�̊J�����K�v�ƂȂ�B
����TOP500�̕��ł��p���_�C���V�t�g���N�����Ȃ���
ARM���T�[�o�V�X�e���̊�{�d�l�\
http://www.theregister.co.uk/2014/01/29/arm_standardization_sbsa/
ARM�x�[�X�̃T�[�oSoC�`�b�v���J�����Ă����Ђ���������C�v���Z�T�A�[�L�e�N�`���͓����ł����C
�ǂ̂悤�Ȏ��ӃR���g���[�����t���Ă��邩�C�������}�b�v���ǂ��Ȃ��Ă��邩�́C�e�Ђł܂��܂��ł��B
���̂��߁COS�������́C�n�[�h�E�F�A�ɋ߂��w���e�Ђ̃`�b�v�ɃJ�X�g�}�C�Y����K�v������C
��Ԃ��|����Ƃ����ɂȂ��Ă��܂��B
SBSA�̏ڍׂ͔��\����Ă��Ȃ��̂ł����C�����̎��ӂɊւ��āC�����ڑ�����Ă��邩��������菇��
�ڑ�����Ă�����ӂ̏���菇��W�������C�n�[�h�E�F�A�����ׂ��@�\��3���x���ɕW��������Ƃ̂��Ƃł��B
SBSA�̌����O���[�v�ɂ́CAMD, HP, Red Hat, AppliedMicro, Cavium, Broadcom, Texas Instruments,
Microsoft, and the Linaro Linux-on-ARM group,�Ȃǂ������Ă���Ƃ̂��Ƃł��B
http://www.theregister.co.uk/2014/01/29/arm_standardization_sbsa/
ARM�x�[�X�̃T�[�oSoC�`�b�v���J�����Ă����Ђ���������C�v���Z�T�A�[�L�e�N�`���͓����ł����C
�ǂ̂悤�Ȏ��ӃR���g���[�����t���Ă��邩�C�������}�b�v���ǂ��Ȃ��Ă��邩�́C�e�Ђł܂��܂��ł��B
���̂��߁COS�������́C�n�[�h�E�F�A�ɋ߂��w���e�Ђ̃`�b�v�ɃJ�X�g�}�C�Y����K�v������C
��Ԃ��|����Ƃ����ɂȂ��Ă��܂��B
SBSA�̏ڍׂ͔��\����Ă��Ȃ��̂ł����C�����̎��ӂɊւ��āC�����ڑ�����Ă��邩��������菇��
�ڑ�����Ă�����ӂ̏���菇��W�������C�n�[�h�E�F�A�����ׂ��@�\��3���x���ɕW��������Ƃ̂��Ƃł��B
SBSA�̌����O���[�v�ɂ́CAMD, HP, Red Hat, AppliedMicro, Cavium, Broadcom, Texas Instruments,
Microsoft, and the Linaro Linux-on-ARM group,�Ȃǂ������Ă���Ƃ̂��Ƃł��B
>>32�@kaveri�̏ꍇDirectX���Ɛݒ艺���Ă��������҂��Ȃ������
�܂��掿�����߂�l�͍��̏�APU���낤��Intel���낤���O���{�ς�łc�w�P�P�ł����Ă��Ƃ���
�܂��掿�����߂�l�͍��̏�APU���낤��Intel���낤���O���{�ς�łc�w�P�P�ł����Ă��Ƃ���
BF4���̖��A�S�̓I�Ƀt�H�O���������Ă�̂��C���Ώ�
39 �FSocket774�F2014/02/07(��) 16:04:10.33 ID:NvkVv6+D
�t�H�O��������ƃI�u�G�N�g������̂�
�����k�فA���O�c�q����
41 �FSocket774�F2014/02/07(��) 16:10:37.32 ID:NvkVv6+D
�k��
Windows 8.1 3930K��i+R9 290X
[��ݒ�]
DX11.1�y170fps�zhttp://i.imgur.com/oCnFvAkh.png
Mantle �y337fps�z http://i.imgur.com/rbcOEQfh.png
[���ݒ�]
DX11.1�y157fps�zhttp://i.imgur.com/if1VXuOh.png
Mantle �y277fps�z http://i.imgur.com/RelaPy0h.png
[���ݒ�]
DX11.1�y146fps�zhttp://i.imgur.com/xGTVnfih.png
Mantle �y196fps�z http://i.imgur.com/8fdObJ0h.png
[�ō��ݒ�]
DX11.1�y102fps�zhttp://i.imgur.com/VPw2gglh.png
Mantle �y144fps�z http://i.imgur.com/VrPM79Uh.png
Windows 8.1 3930K��i+R9 290X
[��ݒ�]
DX11.1�y170fps�zhttp://i.imgur.com/oCnFvAkh.png
{kind=link}
Mantle �y337fps�z http://i.imgur.com/rbcOEQfh.png
{kind=link}
[���ݒ�]
DX11.1�y157fps�zhttp://i.imgur.com/if1VXuOh.png
{kind=link}
Mantle �y277fps�z http://i.imgur.com/RelaPy0h.png
{kind=link}
[���ݒ�]
DX11.1�y146fps�zhttp://i.imgur.com/xGTVnfih.png
{kind=link}
Mantle �y196fps�z http://i.imgur.com/8fdObJ0h.png
{kind=link}
[�ō��ݒ�]
DX11.1�y102fps�zhttp://i.imgur.com/VPw2gglh.png
{kind=link}
Mantle �y144fps�z http://i.imgur.com/VrPM79Uh.png
{kind=link}
�Ƃ肠����directX11��mantle�̍s�����ɂ͍ċN�����K�v�ɂȂ邩��
���K��Ŋm�F���Ă݂�
��ʂ������ۂ����͑��̐��Ȃ�đS�R�ς����
http://www.rupan.net/uploader/download/1391757212.zip
������m�F���Ă݂邩
���K��Ŋm�F���Ă݂�
��ʂ������ۂ����͑��̐��Ȃ�đS�R�ς����
http://www.rupan.net/uploader/download/1391757212.zip
������m�F���Ă݂邩
Mantle�ŃI�u�W�F�N�g�̐����͕ς����
���Ă��ז��ȑ����͂炵�Ď��E�ǂĂ����Ȃ�ނ���劽�}����
���Ă��ז��ȑ����͂炵�Ď��E�ǂĂ����Ȃ�ނ���劽�}����
�t�H�O�������肷���ĉ����������Ȃ��Ƃ��H
��O
�t�H�O��������Ȃ��Ȃ����������fps�オ��̂�
�����M���Ȃ��
�����M���Ȃ��
�ǂ��ł������b�����ݒ�ŃI�u�W�F�N�g�̃I���I�t��ւ��o����̂��C�ɓ���Ȃ�
����ς蔒���ۂ��Ȃ�ȊO�͉���ς����
http://www.rupan.net/uploader/download/1391758239.zip
DirectX11��mantle��Őݒ�グ�������Ă�����̐����͕̂ς��Ȃ���
http://www.rupan.net/uploader/download/1391758239.zip
DirectX11��mantle��Őݒ�グ�������Ă�����̐����͕̂ς��Ȃ���
�������`�[�e�B�[�A�C
�t�H�O�̌��i���Ȃ̂ɓ܁j��DICE���o�O������C������ƌ����Ă���A�̔z�u�����l
https://twitter.com/repi/status/429985248995467265
https://twitter.com/repi/status/429985248995467265
�ɈႢ�Ȃ�Ă��邩�H
�ݒ�ς��ē����ꏊ�ɂ��Ă��Ⴂ�Ȃ�ĂȂ���
�ݒ�ς��ē����ꏊ�ɂ��Ă��Ⴂ�Ȃ�ĂȂ���
>>48
���ꍡ�B������H�����C������Ă���
���ꍡ�B������H�����C������Ă���
������������B�����z��
�t�H�O�̐ݒ肾������Ⴄ�̂�
�t�H�O�̐ݒ肾������Ⴄ�̂�
���C��MS��mantle�͌��Ȃ�Ȃ����H
PC�Q�[���̃v���b�g�t�H�[����DirectX�Ŏ����Ă���悤�Ȃ��̂�����
OS�̃V�F�A�����Ɉڂ��Ȃ����Ƒf�l�Ȃ���ɍl���Ă��܂����
PC�Q�[���̃v���b�g�t�H�[����DirectX�Ŏ����Ă���悤�Ȃ��̂�����
OS�̃V�F�A�����Ɉڂ��Ȃ����Ƒf�l�Ȃ���ɍl���Ă��܂����
�c�O�Ȃ̂͂��O�̔]����A���̏�悻��
�R��100��R�s�y����ΐ^���ɂȂ���ēz����
�{����Mantle�����ЂɂȂ��Ă���炵��
�{����Mantle�����ЂɂȂ��Ă���炵��
�����Ȃ��Ƃ��x���`�̐��l���o����Ă邱��̏��
��̖̐����ݒ�ŕς�������ݒ肪�L���߂��邩���
����ɖ��̂��̂͐�|���Ăق��Ƃ��Ύc�[�͏����邵
���ǃA�z���ނ�ꂽ��������
����ɖ��̂��̂͐�|���Ăق��Ƃ��Ύc�[�͏����邵
���ǃA�z���ނ�ꂽ��������
����̓��A���^�C���Ńv���V�[�W������������Ă�Ƃ����疈��Ⴄ����������
>>57
����̓`�[�e�B�[�A�[�C�̓`������
http://cdn.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-benchmarks.gif
http://cdn2.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-latency.gif
http://cdn3.wccftech.com/wp-content/uploads/2014/02/bf4-beyond16.gif
����Ȃ��̂����ЂɂȂ邩��
AMD���͒x�����傫���̂ł��̉�����ł����Ȃ�
�����܂œ��Д�ł������Ȃ�
����̓`�[�e�B�[�A�[�C�̓`������
http://cdn.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-benchmarks.gif
http://cdn2.wccftech.com/wp-content/uploads/2014/02/battlefield-4-mantle-latency.gif
http://cdn3.wccftech.com/wp-content/uploads/2014/02/bf4-beyond16.gif
����Ȃ��̂����ЂɂȂ邩��
AMD���͒x�����傫���̂ł��̉�����ł����Ȃ�
�����܂œ��Д�ł������Ȃ�
>>61
DirectX11��Mantle�͐ݒ�ύX���ɃN���C�A���g���ċN�����Ȃ��ƗL��������Ȃ���
�Ƃ肠����������������
�����_�������ł͂Ȃ������ꏊ�ɔz�u�����悤�ɂȂ��Ă邼
DirectX11��Mantle�͐ݒ�ύX���ɃN���C�A���g���ċN�����Ȃ��ƗL��������Ȃ���
�Ƃ肠����������������
�����_�������ł͂Ȃ������ꏊ�ɔz�u�����悤�ɂȂ��Ă邼
>>62
���{�I�ɂ킩���ĂȂ��̂�BF4�͏���MantleAPI�Ή��^�C�g���Ńv���g�^�C�v�������Ƃ���
�R���\�[���@�ł����Ƃ���̃��[���`�^�C�g���I�i�������ڐA���j�ȗ����ʒu�����Ă��Ƃ���
PS3�����̃^�C�g�����݂č�����PS3�̌����\���ł����Ƃł������̂���
���{�I�ɂ킩���ĂȂ��̂�BF4�͏���MantleAPI�Ή��^�C�g���Ńv���g�^�C�v�������Ƃ���
�R���\�[���@�ł����Ƃ���̃��[���`�^�C�g���I�i�������ڐA���j�ȗ����ʒu�����Ă��Ƃ���
PS3�����̃^�C�g�����݂č�����PS3�̌����\���ł����Ƃł������̂���
�͂��͂�
���҂��Ă��
���҂��Ă��
120Hz���j�^�łȂ�ׂ��x���o�����ɗV�ԂȂ�Intel6�R�A��290X����Ȃ��Ɩ���������
>>62
�܂�������
DX�ł�AA�|�����780Ti�ɏ��ĂĂ邵�AMantle�ň��������ɏo���܂ł��Ȃ���
http://www.purepc.pl/karty_graficzne/battlefield_4_mantle_vs_directx_11_test_r9_290x_vs_gtx_780_ti
�܂�������
DX�ł�AA�|�����780Ti�ɏ��ĂĂ邵�AMantle�ň��������ɏo���܂ł��Ȃ���
http://www.purepc.pl/karty_graficzne/battlefield_4_mantle_vs_directx_11_test_r9_290x_vs_gtx_780_ti
�����I�Ȋ��҂͂��Ă�邪�����_�ł͂����̃S�~���ȁB
�p�[�c�V���b�v�����̂��߂ɉR�������炽���������B
AMD���傰���Ɍ����̂͂܂��킩��B
����ǒǏ]���郉�C�^�[�͔n�����B
������PC���C�^�[�͂��Ȃ��ƌ����邪���̒ʂ肾�ȁB
�p�[�c�V���b�v�����̂��߂ɉR�������炽���������B
AMD���傰���Ɍ����̂͂܂��킩��B
����ǒǏ]���郉�C�^�[�͔n�����B
������PC���C�^�[�͂��Ȃ��ƌ����邪���̒ʂ肾�ȁB
>>68
http://www.amazon.com/AMD-AD785KXBJABOX-A10-7850K-APU/dp/B00H7Z7YMI
7850�l�C�͓��{�Ɍ��������Ƃł͂Ȃ��B
����͕č��A�}�]����A10-7850K�̔̔��y�[�W�B�č��ł��i���B
�A�}�]������20�h����������P�Ǝ҂����A�܂��ɂ�����悤�����A
�A�}�]�����̂̍ɂ͐�Ă���A�P�`�Q�������|��悤���B
http://www.amazon.com/AMD-AD785KXBJABOX-A10-7850K-APU/dp/B00H7Z7YMI
7850�l�C�͓��{�Ɍ��������Ƃł͂Ȃ��B
����͕č��A�}�]����A10-7850K�̔̔��y�[�W�B�č��ł��i���B
�A�}�]������20�h����������P�Ǝ҂����A�܂��ɂ�����悤�����A
�A�}�]�����̂̍ɂ͐�Ă���A�P�`�Q�������|��悤���B
7850K�͕����܂肪���������ȋC�����邯�ǂ�
7700K���ĕ����܂肪�܂Ƃ��Ȃ�A���̒l�i�E�X�y�b�N�ł͔���Ȃ����낤
7700K���ĕ����܂肪�܂Ƃ��Ȃ�A���̒l�i�E�X�y�b�N�ł͔���Ȃ����낤
�ŋ�VIP�̎���PC�X���ł��K���ȓz�������Ă����Ȃ�
72 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 19:31:02.31 ID:j8lUve94
>>33
����Ȃɂ���GPGPU�X�p�R���I���̂��m�点����ˁH
�܂�FirePro�̓X�p�R�������Ƃ��Ă͎n�܂��Ă���Ȃ�����ǂ��ł������낤��
Xeon Phi��PCIe�ł��\�P�b�g�ł̂ق����i�i�ɃX�R�A�����Ȃ肻������
����Ȃɂ���GPGPU�X�p�R���I���̂��m�点����ˁH
�܂�FirePro�̓X�p�R�������Ƃ��Ă͎n�܂��Ă���Ȃ�����ǂ��ł������낤��
Xeon Phi��PCIe�ł��\�P�b�g�ł̂ق����i�i�ɃX�R�A�����Ȃ肻������
����ŃN���X�^������В�
> 323 ���O�FSocket774[sage] ���e���F2014/02/07(��) 19:30:56.26 ID:PW7sqzef
> �y���̓S�V�S�V����ł��ς邩
http://www.youtube.com/user/5454doga
�@�@_n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ n_
�@�i�@l�@�@�@�@_�A_�@�@�@�@�@_�A_�@�@�@�@l�@�j
�@ �_ �_�@�i <_,`�@�j�@�i�@,_�` �j �@�^ �^
�@�@�@�R___�P�P�@ �j�@ (�@�@�P�P___�^
�@�@�@�@�@/ �@�@�@/�@�@�@�_�@�@ �_
> �y���̓S�V�S�V����ł��ς邩
http://www.youtube.com/user/5454doga
�@�@_n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ n_
�@�i�@l�@�@�@�@_�A_�@�@�@�@�@_�A_�@�@�@�@l�@�j
�@ �_ �_�@�i <_,`�@�j�@�i�@,_�` �j �@�^ �^
�@�@�@�R___�P�P�@ �j�@ (�@�@�P�P___�^
�@�@�@�@�@/ �@�@�@/�@�@�@�_�@�@ �_
�y�������قǂ̗ʂȂ�����w
>>72
Maxwell��Denver�̏��OS���ڂ��ĒP�̓��삷��悤�ɂȂ邾�낤����
���ǃ\�P�b�g�ł̂悤�Ȃ��̂ɂȂ���
AMD�͂Ƃ肠����HPC���C�Ȃ�������A�X���I�ɂ͒��ڊW���������Ȃ��b����
Maxwell��Denver�̏��OS���ڂ��ĒP�̓��삷��悤�ɂȂ邾�낤����
���ǃ\�P�b�g�ł̂悤�Ȃ��̂ɂȂ���
AMD�͂Ƃ肠����HPC���C�Ȃ�������A�X���I�ɂ͒��ڊW���������Ȃ��b����
>>75
�@�@�@�@�@�@�@ �,,� �@�@�@�@
�@�@�@�@�@ �@ �i߃�߁@�j-� �@�@���x�A�Z�����������݂̂�
�@�@�@�@�@ �@,(m�)�R �@�@i �@�@BF4���ǂ��܂Ŋy���߂邩��������܂��̂ł��y���݂�
�@�@ �@�@ �@/�@/�@�R �R�@�� �@�@
�P�P�P�@�i_,�m�P�@�R�_�m�P�@
�@�@�@�@�@�@�@ �,,� �@�@�@�@
�@�@�@�@�@ �@ �i߃�߁@�j-� �@�@���x�A�Z�����������݂̂�
�@�@�@�@�@ �@,(m�)�R �@�@i �@�@BF4���ǂ��܂Ŋy���߂邩��������܂��̂ł��y���݂�
�@�@ �@�@ �@/�@/�@�R �R�@�� �@�@
�P�P�P�@�i_,�m�P�@�R�_�m�P�@
78 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 19:58:22.89 ID:j8lUve94
�C���^�[�R�l�N�g�̖���B
Near Memory��16GB���ڂ���Xeon Phi��4�\�P�b�g�ɑ}����
64GB�̍��������������L�ł��邱�ƂɂȂ�B
PCIe����CPU�����̃C���^�[�R�l�N�g�ɏ��Ă�ł���
�܂��ꉞPCIe 3.0��x48�Ƃ��o�Ă邯��
Near Memory��16GB���ڂ���Xeon Phi��4�\�P�b�g�ɑ}����
64GB�̍��������������L�ł��邱�ƂɂȂ�B
PCIe����CPU�����̃C���^�[�R�l�N�g�ɏ��Ă�ł���
�܂��ꉞPCIe 3.0��x48�Ƃ��o�Ă邯��
>>77
�Ȃ邾���}���łˁI
�Ȃ邾���}���łˁI
80 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 20:02:31.16 ID:j8lUve94
https://www.facebook.com/Hpcwirejapan/posts/199986503502454
AMD��SeaMicro��Freedom Fabric + APU�T�[�o�ŃX�p�R���ڎw���Ƃ������Ă���
���Ȃ������W�Șb�ł��Ȃ��ł���B
�ꉞ�����ȃC���^�[�R�l�N�g�͍��x�̃X�p�R���x���`�ł͌��ɂȂ肻���ł����B
�܂��A1�m�[�h�̔\�͂ɖ��͂Ȃ����A�ƌ������O�_�͂���܂����ǂˁE�E�E
AMD��SeaMicro��Freedom Fabric + APU�T�[�o�ŃX�p�R���ڎw���Ƃ������Ă���
���Ȃ������W�Șb�ł��Ȃ��ł���B
�ꉞ�����ȃC���^�[�R�l�N�g�͍��x�̃X�p�R���x���`�ł͌��ɂȂ肻���ł����B
�܂��A1�m�[�h�̔\�͂ɖ��͂Ȃ����A�ƌ������O�_�͂���܂����ǂˁE�E�E
���������ŋߋƊE�i�j�̘b�������ĂȂ��˂��̃X����
����������OpenCL2.0��HSA���ǂ��̂����̂��Ęb���������ǁA���X2.0�͉��z���������L�@�\�Ƃ������̂�����̂�
OpenCL��HSA�ɑΉ����Ă������HSA�A�Ƃ�������UMA��OpenCL�ɑΉ����Ċ����݂���
�Ƃ肠����OpenCL�n�\�t�g�̃A�b�v�f�[�g�҂������ǁA�����͖ʔ����Ȃ肻��
����������OpenCL2.0��HSA���ǂ��̂����̂��Ęb���������ǁA���X2.0�͉��z���������L�@�\�Ƃ������̂�����̂�
OpenCL��HSA�ɑΉ����Ă������HSA�A�Ƃ�������UMA��OpenCL�ɑΉ����Ċ����݂���
�Ƃ肠����OpenCL�n�\�t�g�̃A�b�v�f�[�g�҂������ǁA�����͖ʔ����Ȃ肻��
Freedom Fabric���Ă���Ȃɂ�����������������H
������HPC�n�̃V�X�e���Ƃ������́AMoonshot�Ƃ����Ǝv���Ă�
Tesla�͂Ƃ肠�����APCI-E�����܂�����InfiniBand���}���ɂ͂Ȃ��łȂ�
�ߖT�̃v���Z�b�T�Ԃ̒ʐM�R�X�g���ǂꂮ�炢�̔�d�ɂȂ�̂��m���
�}���`�\�P�b�g��Xeon Phi�Ɣ�ׂĂǂ��Ȃ̂��́c�c
���тŐ����Ȃ�Cray�̃C���^�[�R�l�N�g�������Ă���Phi���ď��Ȃ̂��Ȃ�
������HPC�n�̃V�X�e���Ƃ������́AMoonshot�Ƃ����Ǝv���Ă�
Tesla�͂Ƃ肠�����APCI-E�����܂�����InfiniBand���}���ɂ͂Ȃ��łȂ�
�ߖT�̃v���Z�b�T�Ԃ̒ʐM�R�X�g���ǂꂮ�炢�̔�d�ɂȂ�̂��m���
�}���`�\�P�b�g��Xeon Phi�Ɣ�ׂĂǂ��Ȃ̂��́c�c
���тŐ����Ȃ�Cray�̃C���^�[�R�l�N�g�������Ă���Phi���ď��Ȃ̂��Ȃ�
GF�w�������H
http://sp.m.reuters.co.jp/news/newsBodyPI.php?url=http://jp.reuters.com/article/technologyNews/idJPTYEA1602S20140207
http://sp.m.reuters.co.jp/news/newsBodyPI.php?url=http://jp.reuters.com/article/technologyNews/idJPTYEA1602S20140207
Mantle��DX11�Ɠ����G���o����悤�ɂȂ��Ă��炾��
API���������掿��r���K�v���Ǝv���Ă��̂ɁA�ǂ��̃T�C�g������ĂȂ��ĕs�v�c������
API���������掿��r���K�v���Ǝv���Ă��̂ɁA�ǂ��̃T�C�g������ĂȂ��ĕs�v�c������
�ċN�������瓯���G�ɂȂ��Ȃ��́H
�ꎞ�͐��E��������Ƃ܂Ō����Ă�IBM���c
�����̐����Ƃ����Ȃ�Ęb�͐̂���o�Ă邩�甄���Ă��s�v�c�ł͖���
88 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 20:55:47.87 ID:j8lUve94
IBM��Fab�Ő�������Ă����i��������i���܂߂Ď�ɓ���Ȃ�
�܂��A�����낤��IBM���܂߂�TSMC�Ƃ�Intel�ɓ������Ȃ�����
�l�����邵�AIBM���o���Ă����̍Ő�[�v���Z�X�J���̔�p�̕��S��
GF�����S���Ȃ���Ȃ�Ȃ��Ȃ�̂ŕK���������������������Ƃ͌���������
�܂��A�����낤��IBM���܂߂�TSMC�Ƃ�Intel�ɓ������Ȃ�����
�l�����邵�AIBM���o���Ă����̍Ő�[�v���Z�X�J���̔�p�̕��S��
GF�����S���Ȃ���Ȃ�Ȃ��Ȃ�̂ŕK���������������������Ƃ͌���������
>>84
�������̝s���H��ʂ��Ȃ����炗
�������̝s���H��ʂ��Ȃ����炗
�Ȃ�Intel�́A���̃h���C�o�Ŋo��������Ă̂����[���Ƃ����
�Ō�܂Ŋo�����Ȃ�����IGP���v���o�����B
�Ō�܂Ŋo�����Ȃ�����IGP���v���o�����B
�����mantle
DirectX�ƕ`�悪��������悤�ɂȂ���܂�
http://www.extremetech.com/gaming/175998-battlefield-4-amds-mantle-causes-washed-out-foggy-graphics-compared-to-directx
DirectX�ƕ`�悪��������悤�ɂȂ���܂�
http://www.extremetech.com/gaming/175998-battlefield-4-amds-mantle-causes-washed-out-foggy-graphics-compared-to-directx
�����I�ɂ�Mantle�̂ق������b�`�ɏo�������Ȃ̂ɂˁB������Ă���B
�n�[�h�E�F�A�I�Ɏ������Ă��Ă�DirectX�ɂȂ����ߎg���Ȃ��@�\��@����悤�ɂȂ�Ƃ����ˁB
�n�[�h�E�F�A�I�Ɏ������Ă��Ă�DirectX�ɂȂ����ߎg���Ȃ��@�\��@����悤�ɂȂ�Ƃ����ˁB
95 �FSocket774�F2014/02/08(�y) 03:57:02.44 ID:LPP4wZqO
�@�@���@�@���@�@���@�@���@�@���@�@��
http://kohada.2ch.net/test/read.cgi/pc/1361040663/126
http://kohada.2ch.net/test/read.cgi/pc/1361040663/126
AMD shows Mantle,Oculus Rift with TrueAudio
ttp://www.ocaholic.ch/modules/news/article.php?storyid=9020
ttp://www.ocaholic.ch/modules/news/article.php?storyid=9020
>>91
���ʂ�GPU�_�C���N�g�̃}���g���̂ق����掿�͗ǂ��Ȃ��Ȃ��̂�
���ʂ�GPU�_�C���N�g�̃}���g���̂ق����掿�͗ǂ��Ȃ��Ȃ��̂�
dgpu����炢igpu�̐��\�グ�ė~����
���M�ł����܂��
���M�ł����܂��
>>97
���h���C�o�[�̎��т�]�����Ă��B
���h���C�o�[�̎��т�]�����Ă��B
100 �FSocket774�F2014/02/08(�y) 06:51:35.97 ID:G4DVJzdc
��>>91�̐^�U�͂ǂ��Ȃ�
�Q�t�H�~���Ă̂̓z���g�����������z�������Ȃ�
>>91
�M�҃t�B���^�[��ʂ��Ƃ��ꂪ�����G�Ɍ�����炵����
�M�҃t�B���^�[��ʂ��Ƃ��ꂪ�����G�Ɍ�����炵����
AMD Radeon R9 Series in Short Supply - More Due to Lack of Components than Extreme Demand
ttp://wccftech.com/amd-radeon-r9-series-short-supply-due-lack-skus-extreme-demand/
AMD serves up more hints on ARM on Opteron
ttp://www.pcper.com/news/General-Tech/AMD-serves-more-hints-ARM-Opteron
ttp://wccftech.com/amd-radeon-r9-series-short-supply-due-lack-skus-extreme-demand/
AMD serves up more hints on ARM on Opteron
ttp://www.pcper.com/news/General-Tech/AMD-serves-more-hints-ARM-Opteron
����AMD���āAGPU��APU����D�����
1-3�����̔��㌩�ʂ���-16%�����ǂ�
���Y�����[���甄��Ă���̂ɂ��̗\�����Ă̂́A���炩�̐ݔ������Ƃ��ȂŐ��Y�����i���Ă���̂��ȁH
AMD���̂�HSA���Mantle�Ɋ|���������ŁA���Y�ϑ���GF�͐V�v���Z�X���[���֍H��ݔ��ύX���Ƃ����H
AMD���̂�HSA���Mantle�Ɋ|���������ŁA���Y�ϑ���GF�͐V�v���Z�X���[���֍H��ݔ��ύX���Ƃ����H
>>100
DirectX-ultra
http://bbsimg03.kakaku.k-img.com/images/bbs/001/805/1805041_m.jpg
mantle-ultra
http://bbsimg03.kakaku.k-img.com/images/bbs/001/805/1805042_m.jpg
�I�u�W�F�N�g�������Ă�Ƃ����������̂ł͂Ȃ����Ǖ`�悪�قȂ�͎̂���
�ǂ��������R�Ō��ʂ��قȂ�̂��m�����DirectX�Ɠ����`��ɂȂ�Ƃ����˂��Ƃ����b
DirectX-ultra
http://bbsimg03.kakaku.k-img.com/images/bbs/001/805/1805041_m.jpg
{kind=link}
mantle-ultra
http://bbsimg03.kakaku.k-img.com/images/bbs/001/805/1805042_m.jpg
{kind=link}
�I�u�W�F�N�g�������Ă�Ƃ����������̂ł͂Ȃ����Ǖ`�悪�قȂ�͎̂���
�ǂ��������R�Ō��ʂ��قȂ�̂��m�����DirectX�Ɠ����`��ɂȂ�Ƃ����˂��Ƃ����b
>>107
PS4�┠1�̐��Y���ǂ����Ă�̂������ȏ������炭�i���Ȃ��
PS4�┠1�̐��Y���ǂ����Ă�̂������ȏ������炭�i���Ȃ��
110 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 09:03:11.22 ID:4IK07MtE
�uOpteron������ĂȂ��v�Ő������b�ł�
>>112
�ݒ�F���Ȃ̂ɐݒ�F�܂ɂȂ��Ă邾������
�ݒ�F���Ȃ̂ɐݒ�F�܂ɂȂ��Ă邾������
���������O����opteron����ĂȂ�����
PC�s�ꂪ�k�����Ă�������Ă邾������Ȃ��̂�
PC�s�ꂪ�k�����Ă�������Ă邾������Ȃ��̂�
���������܂ŏ��X�Â��Ă����������g����
{kind=link}
120 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 10:24:11.66 ID:4IK07MtE
1P��8�R�AOpteron�̌�p���Ȃ��Ȃ����B
������u���ꂩ���APU�T�[�o�̎��ゾ�I�v�Ƃ����Ă��A���܂Ŏg���Ă��ڋq��
CPU8�R�A����4�R�A�ɃO���[�h�_�E���ł���킯�ł͂Ȃ��̂ł��B
������u���ꂩ���APU�T�[�o�̎��ゾ�I�v�Ƃ����Ă��A���܂Ŏg���Ă��ڋq��
CPU8�R�A����4�R�A�ɃO���[�h�_�E���ł���킯�ł͂Ȃ��̂ł��B
�{�Ƃ�����O�ɃZ�~�J�X�^���̃X�^�[�g�_�b�V�����I��邾���ȋC�����邪
Kaveri�̓f�X�N�����ɏ��ʏo���������ŁARadeon�Ȃ���Ă��m��Ă邵
�Z�~�J�X�^���̃J���t�����ʂ�������O�ɂȂ�Ƃ��������Ƃ��낾
�ߋ��̃}�C�i�X�ł������Ă�����߂������ł������Q�[�����ǂ�
Kaveri�̓f�X�N�����ɏ��ʏo���������ŁARadeon�Ȃ���Ă��m��Ă邵
�Z�~�J�X�^���̃J���t�����ʂ�������O�ɂȂ�Ƃ��������Ƃ��낾
�ߋ��̃}�C�i�X�ł������Ă�����߂������ł������Q�[�����ǂ�
123 �FSocket774�F2014/02/08(�y) 10:33:38.73 ID:H3j+WqwR
�R�A��������opteron�������Ă���Ă���Ɠ��N���E�h�E���z�f�X�N�g�b�v�n�̃T�[�o���A
AMD��APU�T�[�o�Ȃ�Ă���ăR�A�����Ȃ�CPU�����C���ɂ��Ă����
�����Ă���Ȃ��Ȃ�͓̂��R����
�P���̍����T�[�o�pCPU���Ȃ��AMD�͏d�����Ȃ��̂��悭�킩���
AMD��APU�T�[�o�Ȃ�Ă���ăR�A�����Ȃ�CPU�����C���ɂ��Ă����
�����Ă���Ȃ��Ȃ�͓̂��R����
�P���̍����T�[�o�pCPU���Ȃ��AMD�͏d�����Ȃ��̂��悭�킩���
>>121
�l�K�L�����K������
�l�K�L�����K������
125 �FSocket774�F2014/02/08(�y) 10:35:20.84 ID:H3j+WqwR
�Ƃ肠����BF4��Mantle�̕`�悪���������̂́ADICE��BF4�̃o�O�����Ă����Ă邩��A
BF4�̃A�b�v�f�[�g���Č��ؑ҂�����
BF4�̃A�b�v�f�[�g���Č��ؑ҂�����
�T�[�o�[�d���������Ă�xeon�ɏ��ĂȂ�
���ꂪ�킩���Ă邩��
���ꂪ�킩���Ă邩��
����ARM A57�̃T�[�o�[��x86�ɑ��Ăǂ�ȃ����b�g������̂��^��
���LjႤ�R�[�h��ʂ�����A�������ς��͓̂��R�ł���B
OP��APU�ɂȂ�����}���`G��GPU���\���L����ȁB
�i����Ă��A����E�G�̗l�q�Ŏs��S�̂̔����͗ʂ��ł���B
�i����Ă��A����E�G�̗l�q�Ŏs��S�̂̔����͗ʂ��ł���B
130 �FSocket774�F2014/02/08(�y) 10:49:36.68 ID:H3j+WqwR
>>127
Intel���ŐVATOM��ŐVXeon�𓊓�����܂ł́A���b�g�p�t�H�[�}���X�ŗ��_��������
Xeon E3-1230L v3 �� Silvermont�̃��b�p���ǂ����āA���b�p�ł�Intel��I�Ԏ���ɂȂ���
Intel���ŐVATOM��ŐVXeon�𓊓�����܂ł́A���b�g�p�t�H�[�}���X�ŗ��_��������
Xeon E3-1230L v3 �� Silvermont�̃��b�p���ǂ����āA���b�p�ł�Intel��I�Ԏ���ɂȂ���
A57�̃����b�g�������ĂȂ��̂�Xeon�ɏ��ĂȂ��Ƃ�
126������̐���Ă�B
126������̐���Ă�B
�A�v����������A4�̈����[���Ƃ�����Ɨǂ��I�ŃV�X�e�����g�߂�B
>>131
�ŁA�����b�g�́H
�ŁA�����b�g�́H
>>133
www.kao.com/jp/merit/
www.kao.com/jp/merit/
�I����ł�4�R�A���Ⴞ�߂Ȃ�ł��A�R�A���~������ł�
�����悤�Ƀ��������~����
�ŒP�̐��\�͂����Ĉ����I���ł͂Ȃ�amd��
�^�p�ł�10��20��q���Čq�����Ƃ����Ƃ�
�����Ɛ������ς���
�ʁX�ł��s������̂����邪
����cpu���������̑傫�������ׂē����łȂ�������Ȃ�
�����Ď��삶�Ⴀ��܂����Acpu��I�Ԃ킯�ł͂Ȃ�
����Ȃ킯�ŁAopteron��Xeon���Ƃ����̂�
�I�Ԓi�K�ɂ͂Ȃ���
�����悤�Ƀ��������~����
�ŒP�̐��\�͂����Ĉ����I���ł͂Ȃ�amd��
�^�p�ł�10��20��q���Čq�����Ƃ����Ƃ�
�����Ɛ������ς���
�ʁX�ł��s������̂����邪
����cpu���������̑傫�������ׂē����łȂ�������Ȃ�
�����Ď��삶�Ⴀ��܂����Acpu��I�Ԃ킯�ł͂Ȃ�
����Ȃ킯�ŁAopteron��Xeon���Ƃ����̂�
�I�Ԓi�K�ɂ͂Ȃ���
10GbE�ڂ��Ă邵���������甚���I�ɐl�C�ɂȂ肻��
������1���~����
������1���~����
>�^�p�ł�10��20��q���Čq�����Ƃ����Ƃ�
>�����Ɛ������ς���
��Ԃł������͉c�Ƃ̔��荞�݂��Ǝv����
>�����Ɛ������ς���
��Ԃł������͉c�Ƃ̔��荞�݂��Ǝv����
8�R�A�͂�
139 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 12:41:21.24 ID:4IK07MtE
ARM�̓T�[�o�����Ƃ��Ẵ\�t�g���Y���Ȃ��Ƃ����_����
140 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 12:48:31.04 ID:4IK07MtE
Windows RT���Č���8.1�ł�ActiveDirectory��Ή��������킯������
ARM��Windows Server�Ȃ�ďo���đ��v���ȁ`�ƁB
�������̂��炯�Ō��Ǖs�]�Ƃ��������ɂȂ肻���ȋC���B
ARM��Windows Server�Ȃ�ďo���đ��v���ȁ`�ƁB
�������̂��炯�Ō��Ǖs�]�Ƃ��������ɂȂ肻���ȋC���B
>>108
����͂킩��₷���A�`��̐F���Ⴄ�����ŗƂ�����������Ȃ�������
����͂킩��₷���A�`��̐F���Ⴄ�����ŗƂ�����������Ȃ�������
>>141
�����������̘b�舵���Ă�Ƃ��ł̓|�X�g�v���Z�b�V���O�̃o�O���낤���ď����Ă���
��ު�Ķް�Ƃ���Ķް�Ƃ������Ă�̂�NV�~����
�����������̘b�舵���Ă�Ƃ��ł̓|�X�g�v���Z�b�V���O�̃o�O���낤���ď����Ă���
��ު�Ķް�Ƃ���Ķް�Ƃ������Ă�̂�NV�~����
ARM��WindowsServer��x86�݊����C����WOW64�ʂ͐ς�ł��Ȃ��́H
����x86�ł��������
�抸����nVIDIA�Ȃ�́AnVIDIA���V�^�C�^����AMD���x�q���X�����Ă���ŗǂ���B
WOW64��64Bit��Windows�p�̋@�\������Ȃ�
�Ƃ�����RT�͖{���ƌ����Ă���64BitARM�܂ł̂Ȃ��p��
�l�C�e�B�u�A�v���̓o���}���邽�߂ɃX�g�A�A�v�������g���Ȃ���Ԃ���
�Ƃ�����RT�͖{���ƌ����Ă���64BitARM�܂ł̂Ȃ��p��
�l�C�e�B�u�A�v���̓o���}���邽�߂ɃX�g�A�A�v�������g���Ȃ���Ԃ���
148 �FSocket774�F2014/02/08(�y) 14:30:20.50 ID:fAEPs0Hp
Google�݂����ɃT�[�o�p�̃\�t�g�S�����O�ł��܂��݂����ȉ�ЂɂƂ��Ă�
�T�[�o��ARM�ł��ׂɂ������낤���ǁA
�����̉�Ђ͎��O�ł�炸�ɊO���̂��g���킯������A
��͂�x86�����₷��
�T�[�o��ARM�ł��ׂɂ������낤���ǁA
�����̉�Ђ͎��O�ł�炸�ɊO���̂��g���킯������A
��͂�x86�����₷��
�T�[�o�����WindowsRT�ȊO�ɂ��I�����͂��邵
Linux�Ƃ��Ȃ猻���_�ł��\�t�g��ARM�Ńr���h�����Ⴆ���������薳������
�������\���R���p�C�����̗v�f��x86�ɑR�o���邩�����
Linux�Ƃ��Ȃ猻���_�ł��\�t�g��ARM�Ńr���h�����Ⴆ���������薳������
�������\���R���p�C�����̗v�f��x86�ɑR�o���邩�����
EPSON��Tenash�^�u�͂����B����������ƂŐ�̂����Œx��鏊�������B
�ʂ����Ď����̊�F�͎g����̂��H�������B
�ʂ����Ď����̊�F�͎g����̂��H�������B
����
2�����{����Ȃ������́H
�͂��������
2�����{����Ȃ������́H
�͂��������
���A�m�[�g�̃X���ƊԈႦ���B���܂�
���܂���clovertrail���݂̕��������킯���Ȃ�
InstantGo�ɂ��Ή����ĂȂ�
InstantGo�ɂ��Ή����ĂȂ�
���⏟��ȃ}�C���[���K�p����Ȃ�
����AAMD�̓m�[�g��g�ы@�p�ɂ�������APU�o���Ă����A
���R�Ȃ���b����ł���
�Ƃ������A���̒�ID:PIkvlu5z�̎v���ʂ�ɐ���킯���Ȃ�
���R�Ȃ���b����ł���
�Ƃ������A���̒�ID:PIkvlu5z�̎v���ʂ�ɐ���킯���Ȃ�
159 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 16:14:43.11 ID:4IK07MtE
RT��ActiveDirectory�̈ꌏ�͑Ή�������Đ錾���Ă�����
���ǑΉ��ł��Ȃ������Ⴞ����T�[�o�łǂ�ȋ@�\���I�~�b�g����邩
�킩��������Ȃ���
���ǑΉ��ł��Ȃ������Ⴞ����T�[�o�łǂ�ȋ@�\���I�~�b�g����邩
�킩��������Ȃ���
�i����Ȃ��ƌ�������A�X�p�R���b�ł����Ɛ���オ���Ă��邱�̃X���́j
>>160
���O�����Đ��̒������Ă���Ă��Ƃ�
���O�����Đ��̒������Ă���Ă��Ƃ�
���o�C�������A��������ɂ͏o����Ă邩��A��A����L�b�g�ŏo�����ғI�Șb�͂���ł���B
�����ɂ�C-60�A�������������Ƒ�8�ŗ������邵�B
���ŁAAMD�̓���Đ��x�X�g�ȃ\�t�g���ĉ��������H
Arcsoft�@TMT6�Ƃ��A�{��DL�Ŕ���Ȃ���_�����Ȃ��ƔY�ݒ��B
�g�p���́AJungle�ł��A�v�f����Ȃ������ă_���Ȃ�ŁB
�����ɂ�C-60�A�������������Ƒ�8�ŗ������邵�B
���ŁAAMD�̓���Đ��x�X�g�ȃ\�t�g���ĉ��������H
Arcsoft�@TMT6�Ƃ��A�{��DL�Ŕ���Ȃ���_�����Ȃ��ƔY�ݒ��B
�g�p���́AJungle�ł��A�v�f����Ȃ������ă_���Ȃ�ŁB
���҂���b�Ƃ��͂������ǁA�^�u���b�g���̘̂b�͔Ⴂ������
>>152�����o����
>>152�����o����
��ƌ����̎��v�Ŏd�l���߂āA��ʌ����͐Ԏ��o��̃T�[�r�X�̔������A�A���͂��悤���Ȃ���ȁB
>>�^�u���b�g���̘̂b�͔Ⴂ������
�Ⴂ�����ǁA����PC�̃T�u���j�^�[�I�ɁALive!�o�R��SmartGlass�Ȃǂ��g����^�u���b�g���ǂ���ȁB
�����[�g�v���C�p��RadeonSk���̋@�\���AAPU������CCC�����Ƃ��o���Ȃ��̂��˂��B
>>�^�u���b�g���̘̂b�͔Ⴂ������
�Ⴂ�����ǁA����PC�̃T�u���j�^�[�I�ɁALive!�o�R��SmartGlass�Ȃǂ��g����^�u���b�g���ǂ���ȁB
�����[�g�v���C�p��RadeonSk���̋@�\���AAPU������CCC�����Ƃ��o���Ȃ��̂��˂��B
�����́A�ǂ��₦��ˁB
A10-7850�@DDR3-2400 8GB�A��8.1
Asrock FM2A88XM ex4+�A��@��80�@750w�A���m�P�[�X
SSD 128GB��2�A�C��@2GB�A�Ł@3GB
�T�t�@260X�{HIS�@260X�@CFX
����11.8�x�@CPU���x�@Min19-Max30�x
�N���@155w
�A�C�h���@94w
�����@270w
A10-7850�@DDR3-2400 8GB�A��8.1
Asrock FM2A88XM ex4+�A��@��80�@750w�A���m�P�[�X
SSD 128GB��2�A�C��@2GB�A�Ł@3GB
�T�t�@260X�{HIS�@260X�@CFX
����11.8�x�@CPU���x�@Min19-Max30�x
�N���@155w
�A�C�h���@94w
�����@270w
��{�Ⴂ�̘b�������ĂȂ��悤�Ȃ�
>>163�@powerDVD�g���Ă邯�ǂ�������������ACPU�ł�GPU�ł��A�v�R���ł��邵
�����R�[�f�b�N�Ƃ���VLC�ɗ��̂����ꂾ���ǁc�c�G���R�ݒ肪�����̂���������powerDVD���Ɠǂ߂Ȃ�
>>163�@powerDVD�g���Ă邯�ǂ�������������ACPU�ł�GPU�ł��A�v�R���ł��邵
�����R�[�f�b�N�Ƃ���VLC�ɗ��̂����ꂾ���ǁc�c�G���R�ݒ肪�����̂���������powerDVD���Ɠǂ߂Ȃ�
>>167�@thx�@����ϒ�Ԃ���Ԃ��B�@13Ultra�A���C���X�g�[������������̂ŁA����Ȃ�����orz
���܂���opencl�\�t�g��kaveri�œ������ƁAhuma�Ń������R�s�[�������Ȃ��Ȃ�̂��H
����Ƃ��������R�s�[�͐�����̂��B��҂Ȃ�\�t�g���蒼���Ȃ��Ƃ����Ȃ����Ă��Ƃ���ȁB
����Ƃ��������R�s�[�͐�����̂��B��҂Ȃ�\�t�g���蒼���Ȃ��Ƃ����Ȃ����Ă��Ƃ���ȁB
A10 7850�͓d�͌�������������ȁB�R�X�p���ǂ��Ȃ��B28nm�̌��E���ȁB�B
>>169�@��蒼���Ȃ��ƃ_������
OpenCL��HSA�Ή���2��ނ����āA���Bolt���̂��g�������S��HSA�A�v��
�������OpenCL2.0�̉��z���������L�A��҂͂�GPU�ł��g���邯�ǂ�UMA�g���ƃ������R�s�[���v��Ȃ��Ȃ�
������z���������L�͂�VIDIA�ł�Intel�ł�������
APU����������������ĈӖ��őΉ������҂̃\�t�g�͏o�Ȃ����낤���ǁA���������L��
�N���A�ł���\�t�g�E�F�A�̖�肪����Ȃ�g���邾�낤���A�����Ȃ��APU�̉��b���������Ȃ����낤�ˁi�����j
OpenCL��HSA�Ή���2��ނ����āA���Bolt���̂��g�������S��HSA�A�v��
�������OpenCL2.0�̉��z���������L�A��҂͂�GPU�ł��g���邯�ǂ�UMA�g���ƃ������R�s�[���v��Ȃ��Ȃ�
������z���������L�͂�VIDIA�ł�Intel�ł�������
APU����������������ĈӖ��őΉ������҂̃\�t�g�͏o�Ȃ����낤���ǁA���������L��
�N���A�ł���\�t�g�E�F�A�̖�肪����Ȃ�g���邾�낤���A�����Ȃ��APU�̉��b���������Ȃ����낤�ˁi�����j
>>170
��蒼���Ȃ��Ƃ��߂Ȃ̂��B��Ԃ��������
OpenCL2.0���g���ĂȂ��\�t�g��huma�̉��b�Ȃ����Ă��ƂȂ̂��B
���ƁAIntel��HSA�͓��R���Ȃ����낤���AOpenCL2.0�̉��z���������L���g����
iGPU�Ń������R�s�[�s�v�����\����������Ă��Ƃ��B
��蒼���Ȃ��Ƃ��߂Ȃ̂��B��Ԃ��������
OpenCL2.0���g���ĂȂ��\�t�g��huma�̉��b�Ȃ����Ă��ƂȂ̂��B
���ƁAIntel��HSA�͓��R���Ȃ����낤���AOpenCL2.0�̉��z���������L���g����
iGPU�Ń������R�s�[�s�v�����\����������Ă��Ƃ��B
174 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 19:41:27.04 ID:4IK07MtE
���{�I�Ȗ��Ƃ��āAOpenCL�̒��Ԍ���Ƃ���SPIR������̂�
�Ȃ�HSAIL���g���K�v������̂�
�Ȃ�HSAIL���g���K�v������̂�
HSAIL�ォ���Wavefront�P�ʂł�SIMT���s�́AFinalizer�ɂ���ă}�b�v�����B
�n�[�h�E�F�A�̎��s���f����W�X�^���B�����邱�Ƃ́AAMD�ȊO�̃n�[�h�E�F�A
���܂ޑ��푽�l�ȃv���Z�b�T���T�|�[�g���邽�߂ɕK�v�Ȃ��Ƃ���AMD�͐�������B
�f�l�̉��ł����ƂȂ����������������ǁB�����ȂȁB
�َ�A�[�L�Ή��ׂ̈���
����ɂg�r�`�͂n���������������������̂͂͂��߂��番�����Ă�b�ł�������Ƃ�
����Ȃ�����B
�n�[�h�E�F�A�̎��s���f����W�X�^���B�����邱�Ƃ́AAMD�ȊO�̃n�[�h�E�F�A
���܂ޑ��푽�l�ȃv���Z�b�T���T�|�[�g���邽�߂ɕK�v�Ȃ��Ƃ���AMD�͐�������B
�f�l�̉��ł����ƂȂ����������������ǁB�����ȂȁB
�َ�A�[�L�Ή��ׂ̈���
����ɂg�r�`�͂n���������������������̂͂͂��߂��番�����Ă�b�ł�������Ƃ�
����Ȃ�����B
�ʂ�HSA�Ƃ��Ă���Ȃ���OpenCL�Ƃ��Ď�������Ă�@�\�Ȃ�HSAIL�g���ł�������ˁH
�܂�OpenCL2.0����AMD�����\�ւ���Ă�炵�����炻��ł������h�N�T�C�������������
��UMA���͍̂œK�����Ȃ��ł��g����A�������œK�����������p�t�H�[�}���X�͏o�邩��
����p�Ɉꉞ�p�ӂ�������Ȃ��́HHSAIL����Bolt���̂�
�œK�����Ȃ��ł���UMA������A������J�����͑��Ђ̎g���ĂˁO�O���Ă̂��Ȃ��ꂾ���Ȃ�
�܂�OpenCL2.0����AMD�����\�ւ���Ă�炵�����炻��ł������h�N�T�C�������������
��UMA���͍̂œK�����Ȃ��ł��g����A�������œK�����������p�t�H�[�}���X�͏o�邩��
����p�Ɉꉞ�p�ӂ�������Ȃ��́HHSAIL����Bolt���̂�
�œK�����Ȃ��ł���UMA������A������J�����͑��Ђ̎g���ĂˁO�O���Ă̂��Ȃ��ꂾ���Ȃ�
>>173�@2.0�̐V�@�\����ˁA����ȊO�ł��g���Ȃ�AMD�̊J�����ł��܂��傤���Ċ���
�܂�����OpenCL��AMD�̊�����J�����ĂȂ���ŁA�V�@�\������ĉ��߂ł����Ȃ����ǂ�
�܂�����OpenCL��AMD�̊�����J�����ĂȂ���ŁA�V�@�\������ĉ��߂ł����Ȃ����ǂ�
{kind=link}
>>175�@���XOpenCL�َ͈�A�[�L��z�肵�Ă��悤��
>>177
>����OpenCL��AMD�̊�����J�����ĂȂ����
�������B�ł��������낤�ȁB
OpenCL�͂ǂ��̊��������H�@�܂���Intel���Ă��Ƃ͂Ȃ����
���ƁA�悻��OpenCL���ŊJ�����āAIntel�ANv�AATi��GPU�ɑΉ������\�t�g����̂�
>����OpenCL��AMD�̊�����J�����ĂȂ����
�������B�ł��������낤�ȁB
OpenCL�͂ǂ��̊��������H�@�܂���Intel���Ă��Ƃ͂Ȃ����
���ƁA�悻��OpenCL���ŊJ�����āAIntel�ANv�AATi��GPU�ɑΉ������\�t�g����̂�
��
���������ȍ\���́H
���������ȍ\���́H
����Ȃ�����X���ŕ������Ƃ���Ȃ����낤��
3���őg��(�L��֥�M)�ϰ��PC 32���
http://anago.2ch.net/test/read.cgi/jisaku/1389853777/
5���őg��(߄D�)�ϰ��PC 8���
http://anago.2ch.net/test/read.cgi/jisaku/1351097763/
�N���������������ł����ς��肷��X��115
http://anago.2ch.net/test/read.cgi/jisaku/1381547980/
3���őg��(�L��֥�M)�ϰ��PC 32���
http://anago.2ch.net/test/read.cgi/jisaku/1389853777/
5���őg��(߄D�)�ϰ��PC 8���
http://anago.2ch.net/test/read.cgi/jisaku/1351097763/
�N���������������ł����ς��肷��X��115
http://anago.2ch.net/test/read.cgi/jisaku/1381547980/
>>180
OpenCL�Ƃ��Ď�������Ă�͈͂Ȃ琫�\�s������Ȃ�������ǂ�ł������A�ܘ_CPU��SIMD�ł�
�����A�J���ґ��őz�肵�Ă�����Ă̂͂���킯�ŁA��������Ƃ�VIDIA�̃O���{�ς�ǂ�������������`
�Ƃ������Ă������肪�����ˁACUDA��OpenCL�ɂ��Ή����ăp�^�[����������
�ܘ_�K�b�`�K�`�ɍœK������HSA�A�v��������OpenCL�Ȃ�Intel�{�Q�t�H�ł��g����
�����A��GPU��z�肵�č���ĂȂ��ꍇ�͂قƂ��CPU�����ŏ������邱�ƂɂȂ邩������Ȃ����ǂ�
���͂�GPU���z�肷�邩��HSA��GPGPU�J�����y�ɂȂ��`�Ƃ������Ă����̈Ӗ����Ȃ������肷��
OpenCL�Ƃ��Ď�������Ă�͈͂Ȃ琫�\�s������Ȃ�������ǂ�ł������A�ܘ_CPU��SIMD�ł�
�����A�J���ґ��őz�肵�Ă�����Ă̂͂���킯�ŁA��������Ƃ�VIDIA�̃O���{�ς�ǂ�������������`
�Ƃ������Ă������肪�����ˁACUDA��OpenCL�ɂ��Ή����ăp�^�[����������
�ܘ_�K�b�`�K�`�ɍœK������HSA�A�v��������OpenCL�Ȃ�Intel�{�Q�t�H�ł��g����
�����A��GPU��z�肵�č���ĂȂ��ꍇ�͂قƂ��CPU�����ŏ������邱�ƂɂȂ邩������Ȃ����ǂ�
���͂�GPU���z�肷�邩��HSA��GPGPU�J�����y�ɂȂ��`�Ƃ������Ă����̈Ӗ����Ȃ������肷��
>>108
���̃Q�[���đ��z���_�ɉB�ꂽ�肷��̂��H
���̃Q�[���đ��z���_�ɉB�ꂽ�肷��̂��H
>>180
�c�O�Ȃ���������ȈӖ���openCL��amd����
opencl�́A�����ς����amd,ncidia�̂ǂ���ł��������ǁA
nvidia�Ȃ�A��͂�CUDA�����邵�����炪����
���邹���Ȃ��A����amd�����������A
�Ƃ����Ƃ����炢��opencl�ő���
�ŏ�����openCL���Č����̂�
amd������������ł��Ȃ�撣���Ă�\�t�g
�c�O�Ȃ���������ȈӖ���openCL��amd����
opencl�́A�����ς����amd,ncidia�̂ǂ���ł��������ǁA
nvidia�Ȃ�A��͂�CUDA�����邵�����炪����
���邹���Ȃ��A����amd�����������A
�Ƃ����Ƃ����炢��opencl�ő���
�ŏ�����openCL���Č����̂�
amd������������ł��Ȃ�撣���Ă�\�t�g
�\���͌��z����
NVIDIA����OpenCL�Ń\�t�g��������牽�̂�RADEON���ƃG���[��f���Ƃ�
GPU�����ɍœK��������Intel��OpenCL�œ����Ȃ��Ƃ����ʂɋN����
NVIDIA����OpenCL�Ń\�t�g��������牽�̂�RADEON���ƃG���[��f���Ƃ�
GPU�����ɍœK��������Intel��OpenCL�œ����Ȃ��Ƃ����ʂɋN����
AMD�I�ɂ�OpenCL��(HSA�̋@�\��)�g���͉̂ߓn���Ƃ����l��������ł́��I���W�i���̒��ԑw
������������炎VIDIA�����ł��������Ƃ͋N���邵�Ȃ�
��VIDIA�ł����g���Ȃ��Ȃ�CUDA�̕��������킯�ŁA���f�ł������ƃe�X�g�͂��邾��ꉞ
�ׂ����n�[�h�w�肵�Ă����āAOpenCL�Ȃ̂Ƀ��f�̎w�肪�Ȃ��i���Ȃ玩�ȐӔC�j���ă\�t�g�����邯�ǂ�
��VIDIA�ł����g���Ȃ��Ȃ�CUDA�̕��������킯�ŁA���f�ł������ƃe�X�g�͂��邾��ꉞ
�ׂ����n�[�h�w�肵�Ă����āAOpenCL�Ȃ̂Ƀ��f�̎w�肪�Ȃ��i���Ȃ玩�ȐӔC�j���ă\�t�g�����邯�ǂ�
�����������s���ɒ��Ԍ�������ނƂ����l�����̂�����܂�M�p���ĂȂ������
Write once, run anywhere
http://ja.wikipedia.org/wiki/Write_once,_run_anywhere
Write once, run anywhere
http://ja.wikipedia.org/wiki/Write_once,_run_anywhere
������������nVIDIA�ł�AMD�ł����̐����\�ɍ��킹�Đݒ�M��Ȃ��Ɛ��\�����Ȃ��Ƃ������邵�A���ۉ������Ȃ���Ώ��Ȃ��قǂ��������̂͂܂܂��鎖���Ǝv�����B
���������Ӗ��ł�Mantle��7700K��290X��290�Ɍ��肳�ꂽ���������邯�ǁA����APU/GPU�ɂ����ꂼ��œK������Ă������琦�����ɂȂ邾�낤����ŁA�쐬���ł͂��̕ӂ�
��荞�݂����[�U�[�ۓ���(�F�X�Ȑݒ�l��݂���)�̂��A���쑤�ł�������œK�������ă��[�U�[�͉���M�炸�ɍςނ悤�ɂ���̂�����̑Ή��^�C�g���Q�ŋC�ɂȂ�ˁB
���������Ӗ��ł�Mantle��7700K��290X��290�Ɍ��肳�ꂽ���������邯�ǁA����APU/GPU�ɂ����ꂼ��œK������Ă������琦�����ɂȂ邾�낤����ŁA�쐬���ł͂��̕ӂ�
��荞�݂����[�U�[�ۓ���(�F�X�Ȑݒ�l��݂���)�̂��A���쑤�ł�������œK�������ă��[�U�[�͉���M�炸�ɍςނ悤�ɂ���̂�����̑Ή��^�C�g���Q�ŋC�ɂȂ�ˁB
>>190
�����[�U�[�ۓ���(�F�X�Ȑݒ�l��݂���)�̂��A
�����쑤�ł�������œK�������ă��[�U�[�͉���M�炸�ɍςނ悤�ɂ���̂�
�O�҂͂Ƃ������A��҂͊��S�ɂ͖������Ǝv���B
������������掿�ł̃Q�[����������x��������(���[�G���h)�Ȋ�����A
4k2k�T�C�Y�ł�����x���삪�o�����(SLI�܂���CFX)�܂őI����������̒��ŁA
�܂����������炸�Ƃ����̂ɂ͖���������B
���[�G���h�p�A�~�h�������W�p�A�n�C�G���h�p�ACFX�����SLI�p�ƒP��������̂�������������Ȃ����H
�����[�U�[�ۓ���(�F�X�Ȑݒ�l��݂���)�̂��A
�����쑤�ł�������œK�������ă��[�U�[�͉���M�炸�ɍςނ悤�ɂ���̂�
�O�҂͂Ƃ������A��҂͊��S�ɂ͖������Ǝv���B
������������掿�ł̃Q�[����������x��������(���[�G���h)�Ȋ�����A
4k2k�T�C�Y�ł�����x���삪�o�����(SLI�܂���CFX)�܂őI����������̒��ŁA
�܂����������炸�Ƃ����̂ɂ͖���������B
���[�G���h�p�A�~�h�������W�p�A�n�C�G���h�p�ACFX�����SLI�p�ƒP��������̂�������������Ȃ����H
>>165
������������ł�����
������������ł�����
>>179
�َ�A�[�L�g���邯�ǁA��86��ARM�p�Ƃ��͕ʁX�ɍ��Ȃ��ƃ_���������͂��B
HSA�͂ǂ����ł��g�������Ă̂������b�g�̈�@OS�͂����
�َ�A�[�L�g���邯�ǁA��86��ARM�p�Ƃ��͕ʁX�ɍ��Ȃ��ƃ_���������͂��B
HSA�͂ǂ����ł��g�������Ă̂������b�g�̈�@OS�͂����
>>191
SLI��Mantle�ɂ͖��W����B
���IntelCPU�������œK���͍s��Ȃ����낤�ȁB
����AMD���m�ł�CPU��FX�Ƃ��͊O����邩���B
APU��iGPU���g�ݍ��œK�����eGPU�p�ɗp�ӂ���̂����x���낤�ȁB
SLI��Mantle�ɂ͖��W����B
���IntelCPU�������œK���͍s��Ȃ����낤�ȁB
����AMD���m�ł�CPU��FX�Ƃ��͊O����邩���B
APU��iGPU���g�ݍ��œK�����eGPU�p�ɗp�ӂ���̂����x���낤�ȁB
>>193
Intel�͂�86����������openCL�ŗǂ����Ă��Ƃ���
Intel�͂�86����������openCL�ŗǂ����Ă��Ƃ���
Advanced Micro Devices (AMD) Outlook Generally Favourable - Trend Starts Recovering After Big Plummet
ttp://wccftech.com/advanced-micro-devices-amd-outlook-generally-favourable-trend-recovering-plummet/
ttp://wccftech.com/advanced-micro-devices-amd-outlook-generally-favourable-trend-recovering-plummet/
>>195
�ʂɎg�������A�v����ARM�f�o�C�X�œ������\�肪�Ȃ��Ȃ炻��ł�����������Ȃ���
�ʂɎg�������A�v����ARM�f�o�C�X�œ������\�肪�Ȃ��Ȃ炻��ł�����������Ȃ���
198 �FSocket774�F2014/02/09(��) 08:24:13.30 ID:rfvYGTKP
���������A�Ȃ��AMD��nvidia���AGPU�̃l�C�e�B�u�R�[�h�Ńv���O���~���O�����Ȃ���H
�l�C�e�B�u�R�[�h�Ńv���O���~���O�����ƂȂɂ��܂������R�ł�����̂��H
�l�C�e�B�u�R�[�h�Ńv���O���~���O�����ƂȂɂ��܂������R�ł�����̂��H
>>198
�݊������܂������Ȃ�
BIOS���}�U�[�{�[�h��GPU���ƂɈႤ�悤�ɁA
�A�v��������قǂł͂Ȃ����Ă��A�ʂɍ���Ĕz�z���Ȃ��Ă͂Ȃ�Ȃ���
�݊������܂������Ȃ�
BIOS���}�U�[�{�[�h��GPU���ƂɈႤ�悤�ɁA
�A�v��������قǂł͂Ȃ����Ă��A�ʂɍ���Ĕz�z���Ȃ��Ă͂Ȃ�Ȃ���
200 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 08:33:11.79 ID:ZfCA/xE3
ARM�ł�x86�ł������o�C�i���������i�j�Ƃ���GUI�͂ǂ�����́H
�܂���Java�݂�����GUI�܂Ń}���`�v���b�g�t�H�[���̎�����p�ӂ������H
��������
�܂���Java�݂�����GUI�܂Ń}���`�v���b�g�t�H�[���̎�����p�ӂ������H
��������
201 �FSocket774�F2014/02/09(��) 09:13:36.54 ID:rfvYGTKP
>>199
�݊��������Ă��ł��邾���p�t�H�[�}���X�o���������[�U�[�Ƃ��͂��邾�낤��
���Ƃ��ƁAHPC�n���[�U�[�̓X�p�R���ɍ��킹�ăR�[�h�g�ݒ����悤�ȃ��[�U�[����������
�ő���ɍœK���������l������͂�
�݊��������Ă��ł��邾���p�t�H�[�}���X�o���������[�U�[�Ƃ��͂��邾�낤��
���Ƃ��ƁAHPC�n���[�U�[�̓X�p�R���ɍ��킹�ăR�[�h�g�ݒ����悤�ȃ��[�U�[����������
�ő���ɍœK���������l������͂�
VLIW4��VLIW5��GCN�ƃA�[�L�e�N�`���ς�邽�тɍœK�����ς���đ�ςɂȂ邾��
203 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 09:16:56.96 ID:ZfCA/xE3
��VLIW�����CAL/IL�͍ŏ������̂ĂĂ܂��B�����Ȃ̂���WiiU���炢����B
204 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 09:19:30.51 ID:ZfCA/xE3
�}���`�v���b�g�t�H�[���ŃA�v����肽����HTML5���g��������
HTML5�Ȃ�webCL�̗��݂����邾��
�v����2000�ɏ���Ă�IE6�����Ă���͎g����Ǝv�����l�͑��������Ǝv��
207 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 09:29:55.72 ID:ZfCA/xE3
��������ǂȁB
�ʁX�Ƀl�C�e�B�u�A�v���������ق������Y��������B
�ʁX�Ƀl�C�e�B�u�A�v���������ق������Y��������B
208 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 09:31:09.30 ID:ZfCA/xE3
2000�̂�IE5
Me����������IE5.5
IE6��XP
Me����������IE5.5
IE6��XP
webCL�Ȃ�Ĉ��ӂ̂���g���������ꂽ��webGL�̔�ł͂Ȃ����炢�A�����Ǝv����
���҂̃Q�[���pAPI�uMantle�v���e�X�g�A���\�͍ő�1.8�{�AAPU�����ł�1.1�{
�uBF4�{�t��HD�v��APU�P�ƂłȂ�Ƃ��v���COK�ɁH
http://akiba-pc.watch.impress.co.jp/docs/sp/20140208_634290.html
�uBF4�{�t��HD�v��APU�P�ƂłȂ�Ƃ��v���COK�ɁH
http://akiba-pc.watch.impress.co.jp/docs/sp/20140208_634290.html
Mantle�͕`��[�܂��ăt���[�����[�g�҂��ł邾���ƃo�����悤����
����͍��� ��
http://forum.hardwarepal.com/battlefield-4-mantle-vs-directx-image-quality-comparison/
�}���g���Ȃ�ʃ{�P�g���͌��̎R�Ƃ��n�ʂɐ����Ă鑐�����Ă�
����͍��� ��
http://forum.hardwarepal.com/battlefield-4-mantle-vs-directx-image-quality-comparison/
�}���g���Ȃ�ʃ{�P�g���͌��̎R�Ƃ��n�ʂɐ����Ă鑐�����Ă�
�@� �@�@�@�@*.�@(_�R�@�@�@�@�@�@+�@�@�@�@�@�@�@�@�
�@'�@ *�@ �,,ʁ@| �b�@�@+�@�@ �@ �@�Z�������p�̓d���V���������[
�@�@ .�@�i ߃�߁@/ /�@�@�@�@�@�@�@��@�N���V�R �v���`�i�d�� KRPW-PT500W/92+
�@ + �@y'_�@�@�@ ��@�@�@�@*�@�@�@�@�@http://youtu.be/_pA4rhndE7Q
�@�@�@�q_,)l�@�@�@�b *�@�@�@�@�@�@�B
���� lll./�@/���@�b lll�@�@�@�@+
:::::::::::.:�@.:. . �,,,,,,,,,,� . . . .: ::::::::
:::::::: :.: . .�@/�c�~�J�R;)�R�A. ::: : ::�@�@�Ȃ��������n���p�Ȃ���A�A�A
::::::: :.: . . / :::/:: �R�A�R�Ai . .:: :.: :::�@����ς�d���ƃP�[�X�����͈�����������_�����A�A�A
�P�P�P�i_,�m �P�P�R�_�m�P
�@'�@ *�@ �,,ʁ@| �b�@�@+�@�@ �@ �@�Z�������p�̓d���V���������[
�@�@ .�@�i ߃�߁@/ /�@�@�@�@�@�@�@��@�N���V�R �v���`�i�d�� KRPW-PT500W/92+
�@ + �@y'_�@�@�@ ��@�@�@�@*�@�@�@�@�@http://youtu.be/_pA4rhndE7Q
�@�@�@�q_,)l�@�@�@�b *�@�@�@�@�@�@�B
���� lll./�@/���@�b lll�@�@�@�@+
:::::::::::.:�@.:. . �,,,,,,,,,,� . . . .: ::::::::
:::::::: :.: . .�@/�c�~�J�R;)�R�A. ::: : ::�@�@�Ȃ��������n���p�Ȃ���A�A�A
::::::: :.: . . / :::/:: �R�A�R�Ai . .:: :.: :::�@����ς�d���ƃP�[�X�����͈�����������_�����A�A�A
�P�P�P�i_,�m �P�P�R�_�m�P
�}���g�����蔲��������FPS�҂��d�l�������Ȃ�āc
���ǐ��\�������o����Ǝv�킹�ăJ���N�����������킯�ˁB
���ǐ��\�������o����Ǝv�킹�ăJ���N�����������킯�ˁB
Mantle��DirectX�̉掿��r�̂˂����o�����Ƃ����璆�̃X���ɒ���܂����Ă��
�R�ł�100���Ȃ�Ƃ����Ă��
�R�ł�100���Ȃ�Ƃ����Ă��
���A�v���ł͖��Ӗ��ȋ�API�R�[���𒆐S�ɂ����x���`�}�[�N��45%���\UP���I�`�������Ƃ͂ȁB
�l�͉ߋ��Ɍ���ꂽ�l�|�ꂵ���g���Ȃ��Ƃ悭������
�G����HD Graphics�i�j���蔲�������ƌ���ꂽ���Ƃ��䂪���Ƃ̂悤�ɋC�ɕa��ł�̂��낤��
�G����HD Graphics�i�j���蔲�������ƌ���ꂽ���Ƃ��䂪���Ƃ̂悤�ɋC�ɕa��ł�̂��낤��
>>215
�܂��_�j�ςݝs����
�܂��_�j�ςݝs����
218 �FSocket774�F2014/02/09(��) 13:03:48.98 ID:ynh69tNu
�C���e���k�r�A���͔n�����肾��w
Mantle�͉��������p�I�����ő傫�Ȑ��\���オ����ꂽ�̂��ǂ�����
CPU�l�b�N�ɂȂ�Ȃ����O���t�B�b�N�ݒ�̒�fps�тł͐��\������������
���F���d���ŃO���t�B�b�N�𗎂Ƃ��ăt���[�����[�g�҂��K�v�̂���}���`�v���C�ł͐������K�ɂȂ���
�����A60%�ȏ㐫�\���オ��Ȃ��Mantle�O��őg�܂ꂽ�悤�ȃQ�[�����炢����Ǝv���Ă���
DirectX�̌�����Ďv�������[�����Ȃƍl����ꂳ��邢���@�������
CPU�l�b�N�ɂȂ�Ȃ����O���t�B�b�N�ݒ�̒�fps�тł͐��\������������
���F���d���ŃO���t�B�b�N�𗎂Ƃ��ăt���[�����[�g�҂��K�v�̂���}���`�v���C�ł͐������K�ɂȂ���
�����A60%�ȏ㐫�\���オ��Ȃ��Mantle�O��őg�܂ꂽ�悤�ȃQ�[�����炢����Ǝv���Ă���
DirectX�̌�����Ďv�������[�����Ȃƍl����ꂳ��邢���@�������
MS���T�{���Ă��킯�ł͂Ȃ��I
�ڂ�悤�������]���ɂ������Ȃ������������E�E�E
�ڂ�悤�������]���ɂ������Ȃ������������E�E�E
221 �FSocket774�F2014/02/09(��) 13:58:19.78 ID:rfvYGTKP
4�R�AAMD�v���Z�b�T�{290X�̂悤�ȃn�C�G���hGPU�{�t��HD���x�̒ᕉ�ׂȊ��{�Q�[�����Œ��掿�ݒ�
���炢�̏ꍇ��Mantle�ł̐��\���オ�߂�����傫��������
DirectX/�O���t�B�b�N�h���C�o�ɂ��CPU���ׂ��{�g���l�b�N�ɂȂ镔���ł�
���\���オ�傫������
���炢�̏ꍇ��Mantle�ł̐��\���オ�߂�����傫��������
DirectX/�O���t�B�b�N�h���C�o�ɂ��CPU���ׂ��{�g���l�b�N�ɂȂ镔���ł�
���\���オ�傫������
�}���g���F�{�g���l�b�N�ƂȂ��Ă��鋤�ʂŎg������̂��̂Ăĉ��l�p�������
HSA:���ʂŎg������̂������(��)
�}���g���͏������܂�DirectX�Ɠ����悤�Ƀ{�g���l�b�N���Č�����悤�ɂȂ��Ȃ���
HSA:���ʂŎg������̂������(��)
�}���g���͏������܂�DirectX�Ɠ����悤�Ƀ{�g���l�b�N���Č�����悤�ɂȂ��Ȃ���
�p�C�Ă��قǎ��A�v���ɈӖ��̂���x���`�͑��݂��Ȃ������
�y�U�̈Ⴄ���̂��ׂāA�܂��������Ⴂ�ȍ����Ńl�K���Ă��A�{�g���l�b�N����p�Ƃ����A�����ʂ肾�ȁB�@�I�}�G��
>>222
����
2��G�݂̖{���́A���̂Ƃ��됳���Ȃ��
���o�C���e�Ђ��̗p�����̂�HSA�叟���I�Ƃ����̂ł����
1�Ђ̂������A�[�L�����API�Ȃ�ė��s��킯���Ȃ���
Mantle�͖��ʂ��̂ē������č������I�Ƃ����̂ł����
�l�X��CPU/GPU�œ����K�v�̂���HSA�ŗǂ����\���o��킯���Ȃ�
����
2��G�݂̖{���́A���̂Ƃ��됳���Ȃ��
���o�C���e�Ђ��̗p�����̂�HSA�叟���I�Ƃ����̂ł����
1�Ђ̂������A�[�L�����API�Ȃ�ė��s��킯���Ȃ���
Mantle�͖��ʂ��̂ē������č������I�Ƃ����̂ł����
�l�X��CPU/GPU�œ����K�v�̂���HSA�ŗǂ����\���o��킯���Ȃ�
>>227
�ʔ����悤�ɗ����̔F���ԈႦ�Ă邩�猋�_���ԈႦ�Ă�
�ʔ����悤�ɗ����̔F���ԈႦ�Ă邩�猋�_���ԈႦ�Ă�
>>227
�s���ȁB
�������O���������o�R�Ńf�[�^������肷��HSA���iGPU�̃L���b�V����CPU�����ڃA�N�Z�X�ł���̂����̕����{���I�ɑ������B
�s���ȁB
�������O���������o�R�Ńf�[�^������肷��HSA���iGPU�̃L���b�V����CPU�����ڃA�N�Z�X�ł���̂����̕����{���I�ɑ������B
>>226
�ނ�]�݂����{�g���l�b�N������c�O�Ȃ�����߂�L���b�v�������Ėό����ꗬ���Ȃ�
�ނ�]�݂����{�g���l�b�N������c�O�Ȃ�����߂�L���b�v�������Ėό����ꗬ���Ȃ�
>>227>>229
����`����͂Ђǂ��ȁB
�w�e���W�j�A�X�}���`�R�A�ɂ��Ĉ�x���������������ǂ���B
ttp://ja.wikipedia.org/wiki/%E3%83%98%E3%83%86%E3%83%AD%E3%82%B8%E3%83%8B%E3%82%A2%E3%82%B9%E3%83%9E%E3%83%AB%E3%83%81%E3%82%B3%E3%82%A2
�܂���Mantle�Ƃ́A�l�C�e�B�uC��C��ł��ꂼ�ꏑ���ꂽ�v���O�������������ꍇ�ɁA��蒊�ۉ����s�킸���ڃ�������CPU��@���Ă���l�C�e�B�uC�̕��������\�Ƃ����̂ɂ悭���Ă���B
����̔F���͐������B
�����AHSA��C��͒��ۉ��Ƃ����Ӗ��ł͑S���Ⴄ�B
���̒��ɂ�x64CPU,ARMCPU,GPU�Ƃ��ꂼ��Ⴄ�}�C�N���v���Z�b�T�����X�̓��ӕ���Ŋ��Ă���A����͂��Ȃ킿�}�C�N���v���Z�b�T���ɓ��ӕ���ƕs���ӕ��삪���鎖���Ӗ����Ă���B
HSA�Ƃ́A���ꂼ�꓾�ӕ��삪�قȂ�}�C�N���v���Z�b�T��g�ݍ��킹�Ĉ�Ƃ���"�w�e���W�j�A�X�}���`�R�A"�̊��ɂ����āA�v���O�����������Ƃ��Ɏ����ł��̃v���O�����̏��������ɂ���āA
�����œ��ӂȃ}�C�N���v���Z�b�T�����ʂ��A����ɂ����x64CPU��GPU���G�~�����[�g������Ax64CPU��ARMCPU���G�~�����[�g����悤�Ȓ��ۉ��������ɒ���CPU/GPU�ɏ��������蓖�Ă邱�Ƃ�
������������Ƃ����Z�p���B
����Ă���͍ŏ��ɏq�ׂ��悤��C������OS���܂���JAVA��������Ƃ����悤�Ȓ��ۉ��Ƃ͑S���Ⴄ�B
�ǂ��炩�ƌ����Β��ړ��ӂȃ}�C�N���v���Z�b�T�ɏ�����������Ƃ����Ӗ��ł̓l�C�e�B�uC��Mantle�̎v�z�ɂɋ߂��B
(�������{���̈Ӗ��ő��X�̃}�C�N���v���Z�b�T�����̏���������͒��ۉ��͂���Ă���Ƃ����Ӗ��ł͊m���ɒ��ۉ��͍s���Ă���)
����`����͂Ђǂ��ȁB
�w�e���W�j�A�X�}���`�R�A�ɂ��Ĉ�x���������������ǂ���B
ttp://ja.wikipedia.org/wiki/%E3%83%98%E3%83%86%E3%83%AD%E3%82%B8%E3%83%8B%E3%82%A2%E3%82%B9%E3%83%9E%E3%83%AB%E3%83%81%E3%82%B3%E3%82%A2
�܂���Mantle�Ƃ́A�l�C�e�B�uC��C��ł��ꂼ�ꏑ���ꂽ�v���O�������������ꍇ�ɁA��蒊�ۉ����s�킸���ڃ�������CPU��@���Ă���l�C�e�B�uC�̕��������\�Ƃ����̂ɂ悭���Ă���B
����̔F���͐������B
�����AHSA��C��͒��ۉ��Ƃ����Ӗ��ł͑S���Ⴄ�B
���̒��ɂ�x64CPU,ARMCPU,GPU�Ƃ��ꂼ��Ⴄ�}�C�N���v���Z�b�T�����X�̓��ӕ���Ŋ��Ă���A����͂��Ȃ킿�}�C�N���v���Z�b�T���ɓ��ӕ���ƕs���ӕ��삪���鎖���Ӗ����Ă���B
HSA�Ƃ́A���ꂼ�꓾�ӕ��삪�قȂ�}�C�N���v���Z�b�T��g�ݍ��킹�Ĉ�Ƃ���"�w�e���W�j�A�X�}���`�R�A"�̊��ɂ����āA�v���O�����������Ƃ��Ɏ����ł��̃v���O�����̏��������ɂ���āA
�����œ��ӂȃ}�C�N���v���Z�b�T�����ʂ��A����ɂ����x64CPU��GPU���G�~�����[�g������Ax64CPU��ARMCPU���G�~�����[�g����悤�Ȓ��ۉ��������ɒ���CPU/GPU�ɏ��������蓖�Ă邱�Ƃ�
������������Ƃ����Z�p���B
����Ă���͍ŏ��ɏq�ׂ��悤��C������OS���܂���JAVA��������Ƃ����悤�Ȓ��ۉ��Ƃ͑S���Ⴄ�B
�ǂ��炩�ƌ����Β��ړ��ӂȃ}�C�N���v���Z�b�T�ɏ�����������Ƃ����Ӗ��ł̓l�C�e�B�uC��Mantle�̎v�z�ɂɋ߂��B
(�������{���̈Ӗ��ő��X�̃}�C�N���v���Z�b�T�����̏���������͒��ۉ��͂���Ă���Ƃ����Ӗ��ł͊m���ɒ��ۉ��͍s���Ă���)
�S�V�S�V�N�A������H
�@�@�@�@�Q�Q�Q
�@�@�@�^�@ �_::/�_
�@�@�^�@�(��)::(��)��@�@�݂Ȃ���APU�Ō�̎����߂Â��ė��܂���
�@ �b::�@�@��(_�l_)߁b�@����7850K��mantleBF4�ŃZ��������1fps�ł�������悤�Ȏ��ɂȂ�����
�@�@�_ �@߁@`�܁L�^߁@�@APU�͊��S�ɐՌ`���Ȃ����ł��܂��A�A�A
�@�@�^ �܁R�P�P�Rߡ�@�@�����āAAPU�ւ̍Ō�̎h�q�Z������BF4��p�@�������ԋ߂ł�
�@ / _�Q�_ �_/�_ �_�@�@�ŏI�ō����_PC����͂�����ł��i�܂��P�[�u���͂܂Ƃ߂ĂȂ����ǂˁj
�@�ƁQ�Q)_�R_�� �R_�@�@http://youtu.be/XY-opq5OgJ4
������AMD������X���͏I���i�Ƃ����������I������j�A�A�A
�@�@�@�^�@ �_::/�_
�@�@�^�@�(��)::(��)��@�@�݂Ȃ���APU�Ō�̎����߂Â��ė��܂���
�@ �b::�@�@��(_�l_)߁b�@����7850K��mantleBF4�ŃZ��������1fps�ł�������悤�Ȏ��ɂȂ�����
�@�@�_ �@߁@`�܁L�^߁@�@APU�͊��S�ɐՌ`���Ȃ����ł��܂��A�A�A
�@�@�^ �܁R�P�P�Rߡ�@�@�����āAAPU�ւ̍Ō�̎h�q�Z������BF4��p�@�������ԋ߂ł�
�@ / _�Q�_ �_/�_ �_�@�@�ŏI�ō����_PC����͂�����ł��i�܂��P�[�u���͂܂Ƃ߂ĂȂ����ǂˁj
�@�ƁQ�Q)_�R_�� �R_�@�@http://youtu.be/XY-opq5OgJ4
������AMD������X���͏I���i�Ƃ����������I������j�A�A�A
>>229�@�����ׂ̈���Ȃ��Ăł��邱�Ƒ��₷�ׂ���ˁ[�́H
�܂�OpenCL2.0���̂ɉ��z���������L�@�\�����邵�A�������GPU�Ɣ�r���Ăǂ�������
��GPU���x���Ȃ�ǂ������S�~���悗
�܂�OpenCL2.0���̂ɉ��z���������L�@�\�����邵�A�������GPU�Ɣ�r���Ăǂ�������
��GPU���x���Ȃ�ǂ������S�~���悗
>>233
�S�V�̑�D���Z���{HD7750�{�}���g����7850K�P�̂ł̃}���g���ƍ����Ȃ��ƂȂ��
���O�A�Z���R�X�p�ŋ����ċ��삷���B
�S�V�̑�D���Z���{HD7750�{�}���g����7850K�P�̂ł̃}���g���ƍ����Ȃ��ƂȂ��
���O�A�Z���R�X�p�ŋ����ċ��삷���B
���܂�opebCL�ō�������̂�HSA�Ή���AMD�J�����ō�������̂�
���\��r�Ƃ�AMD�͏o���Ă��Ȃ��̂��B
AMD��HSA�̃A�s�[���x���`�f���F�X�o���ėǂ��Ǝv������
���\��r�Ƃ�AMD�͏o���Ă��Ȃ��̂��B
AMD��HSA�̃A�s�[���x���`�f���F�X�o���ėǂ��Ǝv������
AMD�ɂ͑���Carizzo������������������HSA�̓y��������ɑn��グ�A���̏�ōX�Ɏ��Ђ�ARMCPU�������������^�̃w�e���W�j�A�X�}���`�R�A�����������ė~�����ȁB
�����Ȃ�����MS��Windows8.1��WindowsRT�������Ċ��S�Ɉ��OS�Ƃ��A�ȓd�̓��[�h�ł�Metro�𒆐S�Ƃ����v���O������APU����ARM�nCPU�ŏ���������A
GPGPU�̏������K�v�Ȏ���APU����GPU�ŏ���������Ƃ����A�ȓd�́E�����E���掿�̎O�̗v�f���܂Ƃ߂�OS��APU���g�����Ŏ����\�ɂȂ�B
MS�͎��Ђ̃��[�h�}�b�v�Ƃ���2015�N��Windwos9����Windwos8.1��WindowsRT�AWindowsPhone�̎O�{�����������������Ă����Ƃ����͌v��\���Ă��邵�A
�����AMD��APU�Ńw�e���W�j�A�X�}���`�R�A���������Ȃ��炻��ɍ��킹�œK���E�x�����Ă����Ƃ����̂����z�I�ƌ�����B
�����Ȃ�����MS��Windows8.1��WindowsRT�������Ċ��S�Ɉ��OS�Ƃ��A�ȓd�̓��[�h�ł�Metro�𒆐S�Ƃ����v���O������APU����ARM�nCPU�ŏ���������A
GPGPU�̏������K�v�Ȏ���APU����GPU�ŏ���������Ƃ����A�ȓd�́E�����E���掿�̎O�̗v�f���܂Ƃ߂�OS��APU���g�����Ŏ����\�ɂȂ�B
MS�͎��Ђ̃��[�h�}�b�v�Ƃ���2015�N��Windwos9����Windwos8.1��WindowsRT�AWindowsPhone�̎O�{�����������������Ă����Ƃ����͌v��\���Ă��邵�A
�����AMD��APU�Ńw�e���W�j�A�X�}���`�R�A���������Ȃ��炻��ɍ��킹�œK���E�x�����Ă����Ƃ����̂����z�I�ƌ�����B
>>236
�@LibreOffice Calc�̓z���܂��ɂ����Ȃ̂ł́H
�@LibreOffice Calc�̓z���܂��ɂ����Ȃ̂ł́H
239 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 19:09:17.88 ID:ZfCA/xE3
NVIDIA��GPU��OpenCL���C for CUDA�̂ق����������Ă̂Ɠ�����������ˁ[��
�ƊE�i�j�ł͂ǂ����m���ʗp�ł̂�GPU�V�F�A�͂����܂ŕ��ĂȂ��킯��
CUDA�����Ή����Č����Ă����\���邯�ǂ�
HSA���܂������悤�Ȃ����炻��ȗ��s��Ȃ����낤���ǁA���������L���͖̂ʔ������Ȃ��
���ꂪ���ʂ���Ȃ炻�̕���ł��������g�����łˁH���z�łȂ�CPU�Ƃ�GPU�ł������悤�Ȃ��Ƃł���炵������
�������ł������b�g����Ȃ炾���ǂ�
CUDA�����Ή����Č����Ă����\���邯�ǂ�
HSA���܂������悤�Ȃ����炻��ȗ��s��Ȃ����낤���ǁA���������L���͖̂ʔ������Ȃ��
���ꂪ���ʂ���Ȃ炻�̕���ł��������g�����łˁH���z�łȂ�CPU�Ƃ�GPU�ł������悤�Ȃ��Ƃł���炵������
�������ł������b�g����Ȃ炾���ǂ�
>>233
���炭��Ԏ�����ȁ@���H�삵�Ȃ���ƂĂ�����Ȃ�������fps�ɐ���Ȃ������Ƃ݂��邗
7850k�ɂ̓}���g��+HD7750orR-250�̌���ω����܂���i�c���Ă�̂ɂ�
���炭��Ԏ�����ȁ@���H�삵�Ȃ���ƂĂ�����Ȃ�������fps�ɐ���Ȃ������Ƃ݂��邗
7850k�ɂ̓}���g��+HD7750orR-250�̌���ω����܂���i�c���Ă�̂ɂ�
>>241
7850K��dGPU��������AG1820+HD7750�Ƃ̉��i�����L�������Ⴄ�����
7850K��dGPU��������AG1820+HD7750�Ƃ̉��i�����L�������Ⴄ�����
>>241
(�O�t�O) ����A���ꂾ���ɐ�O���Ă�킯����Ȃ��ł�����
(�O�t�O) �]�������Ԃɏ����Âi�߂Ă邾��������
(�O�t�O) BF4�͖{���ɂ܂��Z�������ł͈�x�������グ�ĂȂ�����ǂ��fps�o�邩������܂���
> 7850k�ɂ̓}���g��+HD7750orR-250�̌���ω����܂���i�c���Ă�̂�
(�O�t�O) ���₻�����ė���Ȃ�l���\���l���܂���A��1.2Ͽ�̍\���ł�����
(�O�t�O) 7850K�̒l�i�ɍ��킹���Ƃ��Ă�1Ͽ�]�T���邵�A���������O���{�����Ȃ炳��ɗ]�T�ł��܂��̂�
(�O�t�O) ����A���ꂾ���ɐ�O���Ă�킯����Ȃ��ł�����
(�O�t�O) �]�������Ԃɏ����Âi�߂Ă邾��������
(�O�t�O) BF4�͖{���ɂ܂��Z�������ł͈�x�������グ�ĂȂ�����ǂ��fps�o�邩������܂���
> 7850k�ɂ̓}���g��+HD7750orR-250�̌���ω����܂���i�c���Ă�̂�
(�O�t�O) ���₻�����ė���Ȃ�l���\���l���܂���A��1.2Ͽ�̍\���ł�����
(�O�t�O) 7850K�̒l�i�ɍ��킹���Ƃ��Ă�1Ͽ�]�T���邵�A���������O���{�����Ȃ炳��ɗ]�T�ł��܂��̂�
>>242
�܂肱��Ŕ�r�͏\���ʂ��������Ď����ȁB
���Ȃ݂ɂ��̔�r����IntelCPU�̕����y���ɒl�i�������p�[�c���g���Ă���B
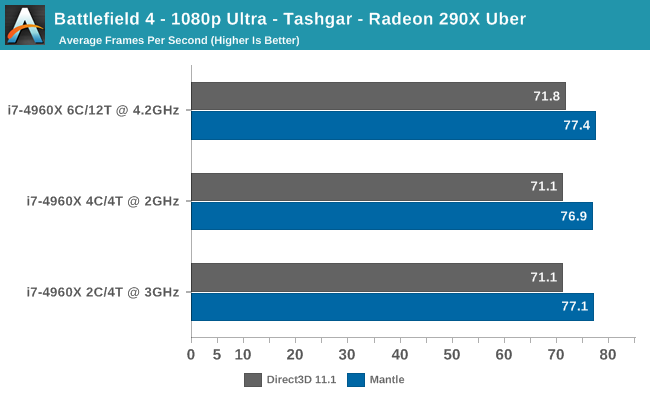
BattleFielde4 2560x1600 Ultra Setting 4xAA
R9-290X vs GTX780 and A10-7700K vs FX-8350 vs i5-4670K vs i7-4670X
ttp://cdn4.wccftech.com/wp-content/uploads/2014/02/Mantle-Battlefield-4-Performance-635x434.jpg
����
GPU���� R9-290X Mantle > R9-290X DirectX > GTX780 DirectX
CPU���� i7-4670X > A10-7700K > i5-4670K > FX-8350
BattleFielde4(�ō����אݒ�)
ttp://www.4gamer.net/games/032/G003251/20140114027/#bf4
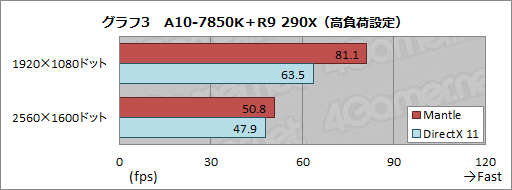
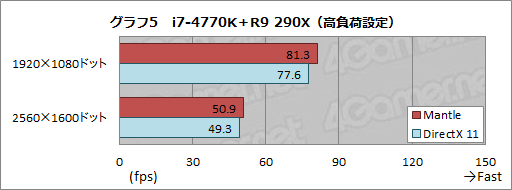
A10-7850K+R9 290X vs i7-4770K+R9 290X
ttp://www.4gamer.net/games/234/G023477/20140203052/TN/004.gif
ttp://www.4gamer.net/games/234/G023477/20140203052/TN/006.gif
����
A10-7850K+R9 290X �� i7-4770K+R9 290X
APU����Mantle�X�R�A���ɒ[�ɐL�т闝�R��APU��iGPU��dGPU�L�ł�Mantle���Ɏd�������Ă����
Kavari��AMD�������\������12�R�AAPU(CPU4�{GPU8)�Ƃ�����ł�
ttp://www.4gamer.net/games/234/G023477/20140203052/
>�����CAMD�̃A�s�[���ɔ�ׂāC�X�R�A���オ�肷���ȋC������B
>Mantle�ł́C�uAPU��GPU��g�ݍ��킹���Ƃ��ɁCAPU�^��GPU�R�A���|�X�g�G�t�F�N�g��p�Ŏg���v�Ƃ������������\���Ƃ������ƂȂ̂Łi�֘A�L���j�C
>�����ł̃X�R�A�́C�uMantle��CPU�̃{�g���l�b�N�����������v�����ł͂Ȃ��CAPU����GPU�R�A�ɁC�ꕔ�̏������I�t���[�h����œK�����K�p����Ă���\���͂��邩������Ȃ��B
�܂肱��Ŕ�r�͏\���ʂ��������Ď����ȁB
���Ȃ݂ɂ��̔�r����IntelCPU�̕����y���ɒl�i�������p�[�c���g���Ă���B
BattleFielde4 2560x1600 Ultra Setting 4xAA
R9-290X vs GTX780 and A10-7700K vs FX-8350 vs i5-4670K vs i7-4670X
ttp://cdn4.wccftech.com/wp-content/uploads/2014/02/Mantle-Battlefield-4-Performance-635x434.jpg
{kind=link}
����
GPU���� R9-290X Mantle > R9-290X DirectX > GTX780 DirectX
CPU���� i7-4670X > A10-7700K > i5-4670K > FX-8350
BattleFielde4(�ō����אݒ�)
ttp://www.4gamer.net/games/032/G003251/20140114027/#bf4
A10-7850K+R9 290X vs i7-4770K+R9 290X
ttp://www.4gamer.net/games/234/G023477/20140203052/TN/004.gif
ttp://www.4gamer.net/games/234/G023477/20140203052/TN/006.gif
����
A10-7850K+R9 290X �� i7-4770K+R9 290X
APU����Mantle�X�R�A���ɒ[�ɐL�т闝�R��APU��iGPU��dGPU�L�ł�Mantle���Ɏd�������Ă����
Kavari��AMD�������\������12�R�AAPU(CPU4�{GPU8)�Ƃ�����ł�
ttp://www.4gamer.net/games/234/G023477/20140203052/
>�����CAMD�̃A�s�[���ɔ�ׂāC�X�R�A���オ�肷���ȋC������B
>Mantle�ł́C�uAPU��GPU��g�ݍ��킹���Ƃ��ɁCAPU�^��GPU�R�A���|�X�g�G�t�F�N�g��p�Ŏg���v�Ƃ������������\���Ƃ������ƂȂ̂Łi�֘A�L���j�C
>�����ł̃X�R�A�́C�uMantle��CPU�̃{�g���l�b�N�����������v�����ł͂Ȃ��CAPU����GPU�R�A�ɁC�ꕔ�̏������I�t���[�h����œK�����K�p����Ă���\���͂��邩������Ȃ��B
>>244
�����������ł��ɂȂ��Ă�悤�ȃx���`��CPU�����������Ƃ������o������A�����̒��\�����
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
���ł��ɂȂ�Ȃ���ԂŔ�r�����
Corei3-4330�����{�g���l�b�N�ɂȂ��Ƃ�܂�����
�����������ł��ɂȂ��Ă�悤�ȃx���`��CPU�����������Ƃ������o������A�����̒��\�����
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
���ł��ɂȂ�Ȃ���ԂŔ�r�����
Corei3-4330�����{�g���l�b�N�ɂȂ��Ƃ�܂�����
���ł��ɂȂ�Ȃ���r������Ȃ�AR9-290XCFX������ׂ����Ď����H
2GPU�ł�4GPU�ȏ�ł��ǂ����ǂ���Ȃ炻��Ő����r���Ă���B
2GPU�ł�4GPU�ȏ�ł��ǂ����ǂ���Ȃ炻��Ő����r���Ă���B
����AMD�L����������`�@����
�d���ݒ�̃Q�[����FX��Sandy-E�Ɠ����I�I�݂����Ȃ��
�d���ݒ�̃Q�[����FX��Sandy-E�Ɠ����I�I�݂����Ȃ��
>>210�������Ȃ��A
>���ɁAKaveri����GPU�����\����ɉe�����Ă���Ƃ���A�`�D�ʂɂȂ�\��������B
>�œK�����K�p����Ă���\���͂��邩������Ȃ��B
�����炱��ȋL�����������悤�ɂȂ����H
�������AMD��EA/DICE�Ɋm�F���Ă��珑�����
>���ɁAKaveri����GPU�����\����ɉe�����Ă���Ƃ���A�`�D�ʂɂȂ�\��������B
>�œK�����K�p����Ă���\���͂��邩������Ȃ��B
�����炱��ȋL�����������悤�ɂȂ����H
�������AMD��EA/DICE�Ɋm�F���Ă��珑�����
>>245�@����H���������ƂU�O�����������Ă���ǁA�ǂ������������낤�ˁH
ttp://www.4gamer.net/games/234/G023477/20140203052/
���Ȃ݂�FF�P�S�t��HD�ō��ݒ�łP�P���I�[�o�[����
����GPU�œ��ł��ɂȂ��Ă���Ă��Ƃ́A���Ȃ��Ƃ�290X�����ł��ɂȂ���x�ɂ͂�GPU�����Ă���Ă��Ƃ���Ȃ��́H
���Ȃ��Ƃ���GPU���������\�͖��Ȃ����Ă��Ƃ��Ǝv�����ǁH
ttp://www.4gamer.net/games/234/G023477/20140203052/
���Ȃ݂�FF�P�S�t��HD�ō��ݒ�łP�P���I�[�o�[����
����GPU�œ��ł��ɂȂ��Ă���Ă��Ƃ́A���Ȃ��Ƃ�290X�����ł��ɂȂ���x�ɂ͂�GPU�����Ă���Ă��Ƃ���Ȃ��́H
���Ȃ��Ƃ���GPU���������\�͖��Ȃ����Ă��Ƃ��Ǝv�����ǁH
>>249
�o�[�c�\�����s�������瓖�R>>241=>>249�����X�ɍ����p�[�c�\�����Ŕ�r���Ă���낤�B
�������i�тŔ�r�������Ƃ���>>242�ɂƂ��Ă͂����Ă͂Ȃ�Ȃ���r���ˁB
�o�[�c�\�����s�������瓖�R>>241=>>249�����X�ɍ����p�[�c�\�����Ŕ�r���Ă���낤�B
�������i�тŔ�r�������Ƃ���>>242�ɂƂ��Ă͂����Ă͂Ȃ�Ȃ���r���ˁB
>>245
�Ƃ��������̃O���t���ƍŒ�fps�Ȃ̂�����fps�Ȃ̂��ō�fps�Ȃ̂��킩��Ȃ�����
��r�̈Ӗ��Ȃ��ˁH
�Œ�30fps�A�ō�100fps
�Œ�50fps�A�ō�80fps
�̔�r���ƕ��ςȂ痼��65fps�����ǁA��҂̂ق������炩�ɉ��K���Ǝv���̂���
�Ƃ��������̃O���t���ƍŒ�fps�Ȃ̂�����fps�Ȃ̂��ō�fps�Ȃ̂��킩��Ȃ�����
��r�̈Ӗ��Ȃ��ˁH
�Œ�30fps�A�ō�100fps
�Œ�50fps�A�ō�80fps
�̔�r���ƕ��ςȂ痼��65fps�����ǁA��҂̂ق������炩�ɉ��K���Ǝv���̂���
Core i7 4960X���g���Ȃ�AA10-4770K�ɂ�M/B�ƕ��������i���I��R9-290X2����]�v�ɍڂ���ׂ������A
Core i7 4770K���g���Ȃ�A���������i�I��VGA��R9-290���g���ׂ����B
Core i7 4770K���g���Ȃ�A���������i�I��VGA��R9-290���g���ׂ����B
>>249
intelCPU�ł������ƈ����œ��ł��ɂȂ��Ă�̂ɂ킴�킴����CPU�̕��ł�����r���ĂȂ��킯��
intelCPU�ł������ƈ����œ��ł��ɂȂ��Ă�̂ɂ킴�킴����CPU�̕��ł�����r���ĂȂ��킯��
>>252
�Ȃ������Ă�C������
�Ȃ������Ă�C������
>>253
�Ȃ�A>>244�̉��̕�������ԉ��i���������ˁB
ttp://cdn4.wccftech.com/wp-content/uploads/2014/02/Mantle-Battlefield-4-Performance-635x434.jpg
A10-7700K > i5-4670K
�Ȃ�A>>244�̉��̕�������ԉ��i���������ˁB
ttp://cdn4.wccftech.com/wp-content/uploads/2014/02/Mantle-Battlefield-4-Performance-635x434.jpg
A10-7700K > i5-4670K
�Q�t�H�~�����Ⴄ
pclab.pl�̂͌��L���̕��͂��ǂ߂Ȃ����牽�ł����Ȃ����̂������
����2�T�Ԃ�PS4�����������ƌ����̂�
>>255
�ł���������͑���덷�͈̔͂��낤��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
�����Ƃ��ł�4330�ł��łɓ��ł��ɂȂ��Ă邵
�ł���������͑���덷�͈̔͂��낤��
http://www.extremetech.com/wp-content/uploads/2014/02/BF4-Mantle-Overall.png
{kind=link}
�����Ƃ��ł�4330�ł��łɓ��ł��ɂȂ��Ă邵
>>253�@���Ⴀi3��290X�ςF���DirectX�̃X�R�A�o���Ă�
�ܘ_OpenCL��OpenGL�AMantle�Ȃ̃X�R�A�������
�܂��V���O��GPU�Ȃ�i3�ł����͈�������Ȃ��n�Y�����ǁA���ꂶ��Q�[���ȊO���g�����ɂȂ��
���Ȃ݂ɁA7850����ALU����͈ꉞOC��ivyi5�����ɒǂ�������
�����GPU�����_�����O��CPU��������������ĕ��ʂɍl������肦�Ȃ����
�ܘ_OpenCL��OpenGL�AMantle�Ȃ̃X�R�A�������
�܂��V���O��GPU�Ȃ�i3�ł����͈�������Ȃ��n�Y�����ǁA���ꂶ��Q�[���ȊO���g�����ɂȂ��
���Ȃ݂ɁA7850����ALU����͈ꉞOC��ivyi5�����ɒǂ�������
�����GPU�����_�����O��CPU��������������ĕ��ʂɍl������肦�Ȃ����
i3�ł���GPU�����ł��ɂȂ���Ă͕̂����邯�ǁA��������ă\�t�g�E�F�A�����_�����O�̔�r����
7850���������������Ă���ă��@�J����ˁ[�̂���
�����_�����O��GPU�ɓ�����O��̐v��CPU�ł�������Ȃ����ĉ����l���Đ����Ă�낤�H
GPU�K�v�Ȃ�O���{�ς߁I��Intel�Ƀ����`�b�v��������ł�x���`�Ȃɂ��������ƌ����邯�ǂ�
7850���������������Ă���ă��@�J����ˁ[�̂���
�����_�����O��GPU�ɓ�����O��̐v��CPU�ł�������Ȃ����ĉ����l���Đ����Ă�낤�H
GPU�K�v�Ȃ�O���{�ς߁I��Intel�Ƀ����`�b�v��������ł�x���`�Ȃɂ��������ƌ����邯�ǂ�
>>261
�����͎����Œ��ׂ邱�Ƃ��K�v����
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
i3-4330�@43.5
FX-6350�@39.4
G -3420�@35.2
G -3220�@33.1
�@7850K�@31.9
�����͎����Œ��ׂ邱�Ƃ��K�v����
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
i3-4330�@43.5
FX-6350�@39.4
G -3420�@35.2
G -3220�@33.1
�@7850K�@31.9
>>263
�����ȂA����͂��܂Ȃ�
�����ȂA����͂��܂Ȃ�
�Ƃ����킯�ő���ɂȂ肻���Ȃ̂�T���Ă�����
http://images.anandtech.com/graphs/graph7728/61058.png
ivy���ザ��2C4T��3GHz������Ⴂ�����Ă��Ƃ���
http://images.anandtech.com/graphs/graph7728/61058.png
{kind=link}
ivy���ザ��2C4T��3GHz������Ⴂ�����Ă��Ƃ���
����290X���g���Ă���̂�1920��1080�Ȃ�ĉ𑜓x�̌��ʂ����o���Ȃ��낤�H
GPU�̃����N�I��2560��1600�����ʂ���Ȃ��̂��H
GPU�̃����N�I��2560��1600�����ʂ���Ȃ��̂��H
����႟��r�Icpu�̍������Ղ��𑜓x�����炾��
����ȏ�̐ݒ��𑜓x�ł������cpu�͂قƂ�LjӖ��������̂��ꂿ�Ⴄ����ˁB
(�܂������Ӗ��������Ƃ͌����Ă��Ȃ�)
����ȏ�̐ݒ��𑜓x�ł������cpu�͂قƂ�LjӖ��������̂��ꂿ�Ⴄ����ˁB
(�܂������Ӗ��������Ƃ͌����Ă��Ȃ�)
CPU�����ł��Ȃ�Ӗ������邪�A���ł��ł��Ȃ��̂ɍ����o�Ȃ����Ă���Ⴄ����H
CPU��12�R�A�ł������o�Ȃ��̂��H
2.5K���x�ō����o�Ȃ��Ƃ�4K�o�͂�iGPU�ł���T�|�[�g���Ă����Ă��̌�����͂��������Ȃ����H
CPU��12�R�A�ł������o�Ȃ��̂��H
2.5K���x�ō����o�Ȃ��Ƃ�4K�o�͂�iGPU�ł���T�|�[�g���Ă����Ă��̌�����͂��������Ȃ����H
CPU�ɂ�GPU�ɂ��d����������API�R�[�������҂�������łȂ��ƃ}���g���̌��ʂ��o�Ȃ����炾�ˁB
�Z�������Ƃ������S�~CPU 6k+HD7750LP 13k
7850k 20k ����H����܂�ς���ȃR�X�g��
7850k 20k ����H����܂�ς���ȃR�X�g��
>>264
Pen��G3220�Ƃقړ������āA�Ȃ߂�����
Pen��G3220�Ƃقړ������āA�Ȃ߂�����
>>273
pen��6�炿�傢�A7850��2�������B
���z�P���S���pen��VGA������ς��Ȃ����ȋC������
290X�ł�7850��G3220�̔�r���Ă���̂�
pen��6�炿�傢�A7850��2�������B
���z�P���S���pen��VGA������ς��Ȃ����ȋC������
290X�ł�7850��G3220�̔�r���Ă���̂�
iGPU���D�G��APU�Ȃ̂ɁA
����CPU�����P�i�ł̔�r��dGPU���ڂ��肫�̔�r���肳��Ă��āA
�ǂ��ɂ�APU�ł���K�v�̔����푈�������Ă銴��������Ȃ��B(�T�ώ�)
�݂�ȁAITX�ɏ悹�悤ZE
����CPU�����P�i�ł̔�r��dGPU���ڂ��肫�̔�r���肳��Ă��āA
�ǂ��ɂ�APU�ł���K�v�̔����푈�������Ă銴��������Ȃ��B(�T�ώ�)
�݂�ȁAITX�ɏ悹�悤ZE
277 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 21:58:18.97 ID:ZfCA/xE3
HD7750�Ȃ烍�[�v���ł��邩��S�V�����Ƒg�ݍ��킹�Ă�Mini-ITX�P�[�X�Ɏ��܂邵
R-7 250oc�ł�R-7 250LP���i1�X��)�o��̂ɂ˂�
dGPU���肫��ITX�g�ނȂ�A�L���[�u�^�ŁA�ނ���LP�ɂ������K�v�������������肵�܂����ǂˁB
�d�v�Ȃ̂̓{�[�h���B
���[�v�������t���Ȃ��P�[�X�ɂ͂ނ�����B
������l�ɂ͕������Ă��炦��͂������A�u�����v���邗
U1�Ƃ�APU�ɍœK�ȃP�[�X���Ǝv�����ǂȂ��B
�d�v�Ȃ̂̓{�[�h���B
���[�v�������t���Ȃ��P�[�X�ɂ͂ނ�����B
������l�ɂ͕������Ă��炦��͂������A�u�����v���邗
U1�Ƃ�APU�ɍœK�ȃP�[�X���Ǝv�����ǂȂ��B
>>277
�g���X���b�g�̎g���Ȃ��P�[�X�������ł���I
�g���X���b�g�̎g���Ȃ��P�[�X�������ł���I
���[�v����mini-ITX����ML05�Ƃ���
����Ȃ̂�dGPU�������˂�
����Ȃ̂�dGPU�������˂�
>>275
ITX�Ȃ�Ăł������B���܂���NUC/BRIX����
ITX�Ȃ�Ăł������B���܂���NUC/BRIX����
���ꂩ��́AMintia�P�[�X�Ƀ}�C�R������̎��ォ�B
�g���X���b�g�������悤�ȏ������P�[�X��100W��APU���ꂽ���˂�
>>275
APU��iGPU��dGPU���ڊ��ł�Mantle��HSA�ł͋@�\����B
�����APU��12�w�e���W�j�A�X�}���`�R�A�v���Z�b�T�ł���AIntelCPU���Ⴆ4�R�A�ł�HT��8�X���b�h�ɑΉ����Ă����肷��̂ƈꏏ�B
APU��iGPU��dGPU���ڊ��ł�Mantle��HSA�ł͋@�\����B
�����APU��12�w�e���W�j�A�X�}���`�R�A�v���Z�b�T�ł���AIntelCPU���Ⴆ4�R�A�ł�HT��8�X���b�h�ɑΉ����Ă����肷��̂ƈꏏ�B
>>269
GPU�����ł����Ă̂��l���悤
GPU�����ł����Ă̂��l���悤
���O�痎������
���������Z������i3�g���n�R������290x�Ȃ�č����i�����킯��������
���X��7750���x���ւ̎R��
�t��iGPU�����p�ł��邩��7850k�g���ł�280x��290x���z�͂���
�Ƃ�����290x������z�������{�ʂ�7850k���Ă�����
�t�ɁA290x�g�����Z������i3���Ƃ͎v���Ȃ���
���������Z������i3�g���n�R������290x�Ȃ�č����i�����킯��������
���X��7750���x���ւ̎R��
�t��iGPU�����p�ł��邩��7850k�g���ł�280x��290x���z�͂���
�Ƃ�����290x������z�������{�ʂ�7850k���Ă�����
�t�ɁA290x�g�����Z������i3���Ƃ͎v���Ȃ���
��[�܂��m���ɁB
�Z��������i3��290X��g�ݍ��킹��l�Ԃ͕��ʋ��Ȃ���ȁB
�Z��������i3��290X��g�ݍ��킹��l�Ԃ͕��ʋ��Ȃ���ȁB
7750�����\�̊��Ɉ����ď�����ǂ���ȁ@HD4670�̍ė�
292 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 23:38:38.12 ID:ZfCA/xE3
Mantle��Ή��^�C�g���̂��Ƃ��l������290X��i5�ȏオ������
>>200
��{�ł���AGUI�͈���Ă��A�N�Z�X�ł��邱�Ƃ������A�Ƃ������ɂ������Ȃ�o�C�i���ł�����x�����ɂ��Ȃ��ƘJ�͂�������
��{�ł���AGUI�͈���Ă��A�N�Z�X�ł��邱�Ƃ������A�Ƃ������ɂ������Ȃ�o�C�i���ł�����x�����ɂ��Ȃ��ƘJ�͂�������
>>218
�C���e���͂��܂���Iris��Muntle�Ή���������̂ɂ�
Nvidia�ƈ���Ă܂��܂�Muntle�ɑΉ��d�l�Ǝv���ł���Ȃ̂�
>>238
����͑f���炵�������ˁA��������ς�MSOffice��OpenCL�ɑΉ������Ⴄ�Ƒ��݊��������Ȃ�Ƃ����̂����F�N���[���̈�����
�C���e���͂��܂���Iris��Muntle�Ή���������̂ɂ�
Nvidia�ƈ���Ă܂��܂�Muntle�ɑΉ��d�l�Ǝv���ł���Ȃ̂�
>>238
����͑f���炵�������ˁA��������ς�MSOffice��OpenCL�ɑΉ������Ⴄ�Ƒ��݊��������Ȃ�Ƃ����̂����F�N���[���̈�����
>>292
�m����APU290�����ʓI�����ǂ��AIntel��iGPU��Muntle�ɐ�ΑΉ����Ȃ����Ă̂��܂��킩��Ȃ������
�ނ���iGPU��ϋɓI�Ɋ��p���������n�C�G���h���Ă��炦�闝�R���ł���
�m����APU290�����ʓI�����ǂ��AIntel��iGPU��Muntle�ɐ�ΑΉ����Ȃ����Ă̂��܂��킩��Ȃ������
�ނ���iGPU��ϋɓI�Ɋ��p���������n�C�G���h���Ă��炦�闝�R���ł���
�@�����A�\�Z������Ηǂ�CPU��ςނɉz�������Ƃ͂Ȃ�����ǁA
Mantle�̕��y�x���オ��A�����\�Z�ŃQ�[�~���OPC��g�ޏꍇ�̗\�Z
�z���͊ԈႢ�Ȃ�GPU���ɂȂ�A�܂�Intel��CPU�Ƃ̑g�ݍ��킹�ł�
AMD�ׂ̖��͑�����킯���ȁB
Mantle�̕��y�x���オ��A�����\�Z�ŃQ�[�~���OPC��g�ޏꍇ�̗\�Z
�z���͊ԈႢ�Ȃ�GPU���ɂȂ�A�܂�Intel��CPU�Ƃ̑g�ݍ��킹�ł�
AMD�ׂ̖��͑�����킯���ȁB
LibreOffice Calc����humaHSA�Ή��Ȃ̂��A����Ƃ��P��opencl1.x�Ή����Ă��邾���H
>>295�@APU���[�U�[��MSoffice�̂Ă�LibreOffice���Ȃ��Ƃ��߂����
>>295�@APU���[�U�[��MSoffice�̂Ă�LibreOffice���Ȃ��Ƃ��߂����
>>298
MSOffice��HSA��OpenCL�ɑΉ����Ă��܂�����܂łȂ��E�E�E
MSOffice��HSA��OpenCL�ɑΉ����Ă��܂�����܂łȂ��E�E�E
MSOffice�͑���DX11��C++AMP�ɑΉ������Ȃ�����
�ʂɑ��ЋZ�p�Ȃg��Ȃ��Ă����ЋZ�p�őΉ��ł��邩���
LibreOffice��HSA���ʂ�MS���m���Ă邾�낤���AHSA��OpenCL�ADX11��C++AMP�̑S���ɐ[���ւ���Ă���AMD����Ă⋦�͂���Ƃ����AMS�����������ȋC�͂���
�ʂɑ��ЋZ�p�Ȃg��Ȃ��Ă����ЋZ�p�őΉ��ł��邩���
LibreOffice��HSA���ʂ�MS���m���Ă邾�낤���AHSA��OpenCL�ADX11��C++AMP�̑S���ɐ[���ւ���Ă���AMD����Ă⋦�͂���Ƃ����AMS�����������ȋC�͂���
�Ȃ��T�����Ⴊ�~��炵������A�S�V�S�V����ʼnɒׂ����B
Office�ō��������Ăق����̂��Ă���Ȃ���
1.����v���r���[
2.�O���t�̕`��
3.�v�Z���̍Čv�Z
4.DB�A�N�Z�X�ALookup�e�[�u���A�N�Z�X
1��3�͈�ӏ��̕ύX������ȍ~�̂��ׂĂɉe����^���邽�ߏ�����������������Ȃ�����x���̂ł�����HSA�͖��Ӗ��B
4�̓������A�N�Z�X����������HSA�͖��Ӗ��B
����HSA�ł��������̂���2�����Ȃ�Ȃ����ȁB
�ł��������DirectX�ł�������ˁB
1.����v���r���[
2.�O���t�̕`��
3.�v�Z���̍Čv�Z
4.DB�A�N�Z�X�ALookup�e�[�u���A�N�Z�X
1��3�͈�ӏ��̕ύX������ȍ~�̂��ׂĂɉe����^���邽�ߏ�����������������Ȃ�����x���̂ł�����HSA�͖��Ӗ��B
4�̓������A�N�Z�X����������HSA�͖��Ӗ��B
����HSA�ł��������̂���2�����Ȃ�Ȃ����ȁB
�ł��������DirectX�ł�������ˁB
����GPGPU�ł���Ȃ����
Office��Kaveri�͕s�v���Ă��Ƃ�
�G���R���Q�[������ʃ��[�U�[�̏d�������̑唼���낤��
�G���R���Q�[������ʃ��[�U�[�̏d�������̑唼���낤��
http://www.4gamer.net/games/999/G999902/20140208005/
GT3e�����������x�̃n���f�Ђ�����Ԃ���7850K�Ƃ����������Ăă����^
GT3e�����������x�̃n���f�Ђ�����Ԃ���7850K�Ƃ����������Ăă����^
���i�������ĂȂ����O�ɏ����ǂ�
307 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 09:04:20.52 ID:jLj49woF
CPU���̐��\�Əȓd�͐��l����Ή��i�Ɍ������Ă���
DDR3-2400�g��Ȃ��ƃt���ɐ��\�������Ȃ��̂ɂ��̃�����������Kaveri�͂ǂ��Ȃ�̂�
DDR3-2400�g��Ȃ��ƃt���ɐ��\�������Ȃ��̂ɂ��̃�����������Kaveri�͂ǂ��Ȃ�̂�
>>305
�ǂ�ȂɈ����Ă�5�`6������������
�ǂ�ȂɈ����Ă�5�`6������������
�����A���̐A���\�Ⴗ���A�A�A
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_geforce_dx.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
i3-4330�@43.5
FX-6350�@39.4
G -3420�@35.2
G -3220�@33.1
A10-7850K�@31.9 �� �ʼn��ʁi�j
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_mantle.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_geforce_dx.png
http://pclab.pl/zdjecia/artykuly/chaostheory/2014/02/mantle/charts/bf4_mp_cpu_radeon_dx.png
i3-4330�@43.5
FX-6350�@39.4
G -3420�@35.2
G -3220�@33.1
A10-7850K�@31.9 �� �ʼn��ʁi�j
>>308
�ŏ��4770R��4�����炢
�ŏ��4770R��4�����炢
�܂����������Ă�̂�
AMD��GPU�����̓Q�[���̂��߂�������Ȃ���
CPU�ƈꏏ�Ɏg���Ă������߂ɋ������Ă��
CPU�͂��̐�������\���オ�炯��GPU��2�N��1.5�{�ƌ����n�C�y�[�X�ł܂��܂��オ�邩��GPU���g����20�{�������ł���
AMD��GPU�����̓Q�[���̂��߂�������Ȃ���
CPU�ƈꏏ�Ɏg���Ă������߂ɋ������Ă��
CPU�͂��̐�������\���オ�炯��GPU��2�N��1.5�{�ƌ����n�C�y�[�X�ł܂��܂��オ�邩��GPU���g����20�{�������ł���
>>310
����CPU��������ˁH
����CPU��������ˁH
Intel�̃h���C�o�Ȃ�āAOS��GUI��web�u���E�U�A�I�t�B�X�A���悪���������ł���H
�ǂ����Q�[������z��dGPU������
�ǂ����Q�[������z��dGPU������
>>305
�����AMD���f����dGPU�܂œ��ڂ��Ă��
http://www.gigabyte.us/products/product-page.aspx?pid=4930#ov
���͂܂�Richland���ڂ��Ă邪Kaveri���ڂ�����DG�ł����
�����AMD���f����dGPU�܂œ��ڂ��Ă��
http://www.gigabyte.us/products/product-page.aspx?pid=4930#ov
���͂܂�Richland���ڂ��Ă邪Kaveri���ڂ�����DG�ł����
A10-7850K���$100�ȏ㍂���̂�
�S�V�S�V�N�����������Ⴄ��
�S�V�S�V�N�����������Ⴄ��
>>291
�㔭��Oland�̏o�������܂����Ȃ̂�240�A250��7750�ɔ�ׂĔ����Ȃ�ˁB
�㔭��Oland�̏o�������܂����Ȃ̂�240�A250��7750�ɔ�ׂĔ����Ȃ�ˁB
�T�OW�̍��ňꖜ�߂�ɂ͉����ԉғ�����Ⴂ���̂�
����������kaveri�̒ቿ�i�ł͂܂��Ȃ̂�
7850K�͏���d�͑����Ⴂ��
4Gamer�����ُ킾��
���ʂ̓s�[�N����90W�������Ȃ���
4Gamer�����ُ킾��
���ʂ̓s�[�N����90W�������Ȃ���
���Ȃ�������Ȃ��Ă����Ȃ�
>>320
24���ԉғ��Ȃ��1�N����
http://www.denki-keisan.info/?w=50&h=8&d=365&y=22
�����菬�^�ł����܂ł̐��\���o������Ă̂������b�g�ł���
Kaveri�������������f�����o���Ă����������ǂ܂�����
24���ԉғ��Ȃ��1�N����
http://www.denki-keisan.info/?w=50&h=8&d=365&y=22
�����菬�^�ł����܂ł̐��\���o������Ă̂������b�g�ł���
Kaveri�������������f�����o���Ă����������ǂ܂�����
>>322
�V�X�e���S�̂ŁH
�V�X�e���S�̂ŁH
�\�j�[��Microsoft��Intel�ɓ˂��������b�h�J�[�h
http://pc.watch.impress.co.jp/docs/column/ubiq/20140210_634526.html
������̕������{�I�Ȗ�肾���A�����PC���[�J�[���C�m�x�[�V�������N�����Ȃ��ő�̗��R��Microsoft�AIntel���g�ɂ���Ƃ����s�����B
PC�s��̐��ނ������������̂�Wintel��������
http://pc.watch.impress.co.jp/docs/column/ubiq/20140210_634526.html
������̕������{�I�Ȗ�肾���A�����PC���[�J�[���C�m�x�[�V�������N�����Ȃ��ő�̗��R��Microsoft�AIntel���g�ɂ���Ƃ����s�����B
PC�s��̐��ނ������������̂�Wintel��������
327 �FSocket774�F2014/02/10(��) 14:58:53.79 ID:ZUD053Ua
AMD�ASP��640��ōő�1GHz�쓮��Radeon R7 250X
http://pc.watch.impress.co.jp/docs/news/20140210_634512.html
http://pc.watch.impress.co.jp/docs/news/20140210_634512.html
>>326�@
���C�Z���X�t�B�[�������᎖�ƈێ��o���Ȃ��قǁA�����L�c�C���Ƃ������ȁB
MS,�����������̌��߂����ނ����g���Ȃ���A����᎗���悤�Ȑ��i������Ԃ�B
���C�Z���X�t�B�[�������᎖�ƈێ��o���Ȃ��قǁA�����L�c�C���Ƃ������ȁB
MS,�����������̌��߂����ނ����g���Ȃ���A����᎗���悤�Ȑ��i������Ԃ�B
������᎗���悤�Ȑ��i������Ԃ�B
�X�}�z���^�u���b�g����������
�X�}�z���^�u���b�g����������
�X�}�^�u�̘b�ȂA�m���w
�m�[�g�A���o�C������A�����i�Œ@���ƋU���������Ă�悤�����B
�m�[�g�A���o�C������A�����i�Œ@���ƋU���������Ă�悤�����B
�k�����Ă��ƊE��9�Ԏ�Ƃ�����P�ނ��ē��R����Ȃ���
�����͋؋�����̃\�j�[�M�҂�
�b�����ɕ����Ă���
�b�����ɕ����Ă���
333 �FSocket774�F2014/02/10(��) 15:29:16.75 ID:SdZ1Pcms
�����Ȃ艽�����Ă����H
�O���{�̘b�Ȃ��Ăˁ[��
�O���{�̘b�Ȃ��Ăˁ[��
PC�ł�intel cpu��������Ȃ���Ȃ�
amd������via��������
RT�ɂ���܂��I�����͍L����
OS��windows��������Ȃ�
linux��BSD������
�Ȃ����Ȃ����H
����Ȃ����炾
amd������via��������
RT�ɂ���܂��I�����͍L����
OS��windows��������Ȃ�
linux��BSD������
�Ȃ����Ȃ����H
����Ȃ����炾
336 �FSocket774�F2014/02/10(��) 15:37:27.31 ID:SdZ1Pcms
�c�Ƃ����肾����AMD������Ȃ��������i���̂͗͂͂���
Windows�̏ꍇ�Aintel�\���Ȃ烉�C�Z���X�t�B�[�����邪�AAMD�������Ȃ��B
��OS�̗p�ƂȂ�ƁA�R���V���[�}�[�Ɏ��v�͂Ȃ�����ABtB�����̃V�X�e���P�ʂ���ȁB
���ŁA7850k�ē��ׂ̗\����Ă݂����A�������肾�������B
��OS�̗p�ƂȂ�ƁA�R���V���[�}�[�Ɏ��v�͂Ȃ�����ABtB�����̃V�X�e���P�ʂ���ȁB
���ŁA7850k�ē��ׂ̗\����Ă݂����A�������肾�������B
CPU�̉��x�Ȃǂ����j�^�[����t���[�\�t�g���āA�ǂ���}���E�F�A������
��ȁB
��ȁB
�܁[�A�����悤�Ȑl�͕p�ɂɎg���\�t�g�����A
�n�[�h�E�F�A���x���܂Ō@�艺���Ă����匾��Ȃ��ǂ��납�A
���[�U�[����i��ŋ����Ă����\�t�g�����B
�܂������Ȃ��ق��������B
�n�[�h�E�F�A���x���܂Ō@�艺���Ă����匾��Ȃ��ǂ��납�A
���[�U�[����i��ŋ����Ă����\�t�g�����B
�܂������Ȃ��ق��������B
��̓I�ɂǂ�Ȉ��ӂ̂��铮�삷�邩��}���E�F�A���Č����Ă�H
PC���[�J�[��PC�n������P�ނ���ׂ͖̂���Ȃ�����
Microsoft��Intel�����ׂ����ĂȂ������
���ꂪ���ׂĂ̌���
PC���[�J�[���ׂ���Ȃ�ǂ����P�ނ͂��Ȃ�
�X�}�z�ł�Apple��Samsung�̓X�}�z�ő傫�ȗ��v���グ�Ă���
������\�j�[�̓X�}�z���Ƃ͂܂��̂ĂȂ�
���ꂾ���̘b
Microsoft��Intel�����ׂ����ĂȂ������
���ꂪ���ׂĂ̌���
PC���[�J�[���ׂ���Ȃ�ǂ����P�ނ͂��Ȃ�
�X�}�z�ł�Apple��Samsung�̓X�}�z�ő傫�ȗ��v���グ�Ă���
������\�j�[�̓X�}�z���Ƃ͂܂��̂ĂȂ�
���ꂾ���̘b
�n�����~
��������
��������
Google��W���u�Y�Ȃ�Apple���C�m�x�[�V�����N�����ĂȂ����ǂ�
�X�}�z�����v�オ��Ȃ��ēP�ނ��Ă��Ђ���܂����H
���ǃ\�j�[���_���Ȃ����ł���
���ǃ\�j�[���_���Ȃ����ł���
vaio�͉��i���Ȃ���
���ǒc�q���P�Ȃ���~�������̂��c�c����
>>346
�������X(�L�E�ցE`)
�������X(�L�E�ցE`)
348 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:16:37.51 ID:jLj49woF
>>341
iPod�ɕ����Ă�WALKMAN���Ă̂�����܂���
iPod�ɕ����Ă�WALKMAN���Ă̂�����܂���
350 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:26:07.54 ID:jLj49woF
>>326
SONY���g�������Ԃꂽ���Ƃ�F�߂����Ȃ��Ȃ����
�^�u���b�g��R���o�[�`�u��PC�̃A�C�f�B�A��ASUS�Ȃ̂ق���
����ۂǖʔ������̏o���Ă�B
VAIO���ʔ��������̂�2000�N�O��܂ł���B
���Ⴂ�M�҂��^�[�Q�b�g�ɂ����C�m�x�[�V�����Ƃ͒���������u�����h���@����
����ĂȂ�����B
���N��C1�̂悤�Ȑ�s�I�ȃ}�V�������Ȃ��Ȃ���SONY�ɉ��l�͂Ȃ��B
SONY���g�������Ԃꂽ���Ƃ�F�߂����Ȃ��Ȃ����
�^�u���b�g��R���o�[�`�u��PC�̃A�C�f�B�A��ASUS�Ȃ̂ق���
����ۂǖʔ������̏o���Ă�B
VAIO���ʔ��������̂�2000�N�O��܂ł���B
���Ⴂ�M�҂��^�[�Q�b�g�ɂ����C�m�x�[�V�����Ƃ͒���������u�����h���@����
����ĂȂ�����B
���N��C1�̂悤�Ȑ�s�I�ȃ}�V�������Ȃ��Ȃ���SONY�ɉ��l�͂Ȃ��B
�ʔ����A��������Ď��X�ɔے肵�Ă���������
�Ǘ������܂邾����
�Ƃ肠����ASUS�̎��͍m�肵����
��̎�̂Ђ�Ԃ����y���݂ɂ��Ă邺
�Ǘ������܂邾����
�Ƃ肠����ASUS�̎��͍m�肵����
��̎�̂Ђ�Ԃ����y���݂ɂ��Ă邺
ASUS�������Ƃ��Ӗ��������
�\�j�[���I��Ă�͓̂��{�̉Ɠd���[�J�[����������
�X�e���I�A�t���A�J����
���̕ӂ̍�荞�݂��O���n�̈����Ɣ�ׂđS�R�Ⴄ���炾��
�\�j�[���I��Ă�͓̂��{�̉Ɠd���[�J�[����������
�X�e���I�A�t���A�J����
���̕ӂ̍�荞�݂��O���n�̈����Ɣ�ׂđS�R�Ⴄ���炾��
ASUS�̗ǂ��ƌ�������A�l�i�A���ȁB
�L�[�{�[�h����������Acer���̓}�V�A�Ƃ����]���B
�܂��������o�C���m�[�g�ɕ����m�{�I��ł�l�Ԃ����ǂ��B
�L�[�{�[�h����������Acer���̓}�V�A�Ƃ����]���B
�܂��������o�C���m�[�g�ɕ����m�{�I��ł�l�Ԃ����ǂ��B
>>326
intel���g�������Ԃꂽ���Ƃ�F�߂����Ȃ��Ȃ����
HSA��}���g���̂悤�ȃA�C�f�B�A��AMD�Ȃ̂ق���
����ۂǖʔ������̏o���Ă�B
intel���ʔ��������̂�2000�N�O��܂ł���B
���Ⴂ�M�҂��^�[�Q�b�g�ɂ����C�m�x�[�V�����Ƃ͒���������u�����h���@����
����ĂȂ�����B
���N��i386�̂悤�Ȑ�s�I��CPU�����Ȃ��Ȃ���intel�ɉ��l�͂Ȃ��B
���Βc�q�R�s�y�ŗ��s�肻���ȕ��͂��ȁB�i���e�͓K���Ȃ�œ˂����܂Ȃ��Łj
intel���g�������Ԃꂽ���Ƃ�F�߂����Ȃ��Ȃ����
HSA��}���g���̂悤�ȃA�C�f�B�A��AMD�Ȃ̂ق���
����ۂǖʔ������̏o���Ă�B
intel���ʔ��������̂�2000�N�O��܂ł���B
���Ⴂ�M�҂��^�[�Q�b�g�ɂ����C�m�x�[�V�����Ƃ͒���������u�����h���@����
����ĂȂ�����B
���N��i386�̂悤�Ȑ�s�I��CPU�����Ȃ��Ȃ���intel�ɉ��l�͂Ȃ��B
���Βc�q�R�s�y�ŗ��s�肻���ȕ��͂��ȁB�i���e�͓K���Ȃ�œ˂����܂Ȃ��Łj
355 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:39:23.87 ID:jLj49woF
>>349
���{�ł�iPhone��iPad������Ă邩��ˁB
����炪iPod touch�̏�ʌ݊��ł���ȏ�͂킴�킴iPod touch��
�ʌɔ���Ȃ��ł���B
���Ȃ݂ɖk�Ă���iPod touch�̓X�}�z�������Ȃ��q�������ɂ悭����Ă�炵���B
����AXperia������Ă邩�Ƃ����ƁE�E�E
���{�ł�iPhone��iPad������Ă邩��ˁB
����炪iPod touch�̏�ʌ݊��ł���ȏ�͂킴�킴iPod touch��
�ʌɔ���Ȃ��ł���B
���Ȃ݂ɖk�Ă���iPod touch�̓X�}�z�������Ȃ��q�������ɂ悭����Ă�炵���B
����AXperia������Ă邩�Ƃ����ƁE�E�E
356 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:43:05.59 ID:jLj49woF
>>352
�������ራ������VAIO�̏o���i���ɃG���g���[���x���j�͊O���n�̈����ȉ�����
�Ȃ��̂ӂɂ�ӂɂ�^�b�`�̃L�[�{�[�h�́B
�������ራ������VAIO�̏o���i���ɃG���g���[���x���j�͊O���n�̈����ȉ�����
�Ȃ��̂ӂɂ�ӂɂ�^�b�`�̃L�[�{�[�h�́B
>>355
��H�v�����݂Ō��������Ɏ�����˂��t����ꂽ����A�X�}�z�b�ɐ�ւ����H
��H�v�����݂Ō��������Ɏ�����˂��t����ꂽ����A�X�}�z�b�ɐ�ւ����H
�L�[�{�[�h�̏o�������Ȃ��a������������ł����Thinkpad���
ASUS�Ƃ��Ȃ���
ASUS�Ƃ��Ȃ���
360 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:54:44.25 ID:jLj49woF
���邩�猾���Ă���B
�L�[�^�b�`����������B
���͊O�t���L�[�{�[�h��HHKB�����g��Ȃ����炢�L�[�{�[�h�ɂ͂�������Ă��
�L�[�^�b�`����������B
���͊O�t���L�[�{�[�h��HHKB�����g��Ȃ����炢�L�[�{�[�h�ɂ͂�������Ă��
361 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:55:17.24 ID:jLj49woF
>>359
�V����X1 Carbon�ɂ��Ĉꌾ�ǂ���
�V����X1 Carbon�ɂ��Ĉꌾ�ǂ���
>>359
�r�ꋶ���قnj��������ӁB
�r�ꋶ���قnj��������ӁB
>>361
X1�͂��т�������
X1�͂��т�������
364 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 19:58:43.18 ID:jLj49woF
>>358
�v�����݂���Ȃ��Ď�������B
iPod�̔̔��䐔�͏k���X������iPhone, iPad�ւ̈ڍs���i���ʂł�����
�ނ���iTunes�̃}�[�P�b�g�V�F�A�͊g�債�Ă���B
�v�����݂���Ȃ��Ď�������B
iPod�̔̔��䐔�͏k���X������iPhone, iPad�ւ̈ڍs���i���ʂł�����
�ނ���iTunes�̃}�[�P�b�g�V�F�A�͊g�債�Ă���B
�����̃v���Z�X�܂�킩��@�C���e������w�ԃv���Z�X�̗��j
http://ascii.jp/elem/000/000/864/864202/
http://ascii.jp/elem/000/000/864/864202/
�������
�~���ʁ@������
�c�q�̓��̈����ُ͈킾��ق�Ƃ�
�c�q�̓��̈����ُ͈킾��ق�Ƃ�
>>364
�u�܂��ے肠�肫�v�ł��̃X���ɏZ�ݒ����Ă邩��A���������Ή��ɂȂ����܂��悠�́B
>>366
���܂�A���X���`�����������܂����B
�u�܂��ے肠�肫�v�ł��̃X���ɏZ�ݒ����Ă邩��A���������Ή��ɂȂ����܂��悠�́B
>>366
���܂�A���X���`�����������܂����B
370 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 20:10:43.24 ID:jLj49woF
> ����Ȃ�SONY��Xperia�̃X�}�t�H��^�u���b�g�Ɉڍs���Ă��邶���
�ǂꂾ���䐔����Ă�悗����
iTunes�R��SONIC Stage�̃}�[�P�b�g�V�F�A�ǂ���H
��������iTunes�R�ƌ������_�Ŋ��ɓ�Ԑ����̃��W�b�N�Ɋׂ��Ă�
�����ăC�m�x�C�^�[�ł͂Ȃ�
�ǂꂾ���䐔����Ă�悗����
iTunes�R��SONIC Stage�̃}�[�P�b�g�V�F�A�ǂ���H
��������iTunes�R�ƌ������_�Ŋ��ɓ�Ԑ����̃��W�b�N�Ɋׂ��Ă�
�����ăC�m�x�C�^�[�ł͂Ȃ�
SONIC Stage? Music Unlimited����Ȃ��́H
372 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 20:13:17.56 ID:jLj49woF
���O�ς��Ă�����Ȃ����͔̂���܂���
G1610��A4����Phenom2x4�ɖ߂��Ă������lj������x��
�Z����������ԑ����BS-ATA6G�|�[�g��SSD�Ȃ����̂����邯��
�Z����������ԑ����BS-ATA6G�|�[�g��SSD�Ȃ����̂����邯��
>SonicStage�i�\�j�b�N�X�e�[�W�j�́A���ă\�j�[���J�����Ă���Windows�p���y�Ǘ��E�Đ��\�t�g�E�F�A�B���s�́ux-�A�v���v�̑O�g�ƂȂ����\�t�g�E�F�A�ɓ�����B
Windows�p�H�H�X�}�t�H��^�u���b�g�Ɉڍs�������Ęb����Ȃ������́H
Windows�p�H�H�X�}�t�H��^�u���b�g�Ɉڍs�������Ęb����Ȃ������́H
PC���[�J�[���C�m�x�[�V�������N�����Ȃ��̂�Wintel�������I
����Ȃ�AMD�M�҂ł�����Ȃ����x���̐ӔC�]��
����Ȃ�AMD�M�҂ł�����Ȃ����x���̐ӔC�]��
���������X���`�Ȃ�ő����͂����ł���B�E�҂Ȃ瑊�肵�Ă���邩��
Mantle�������Ȃ��r�f�I�J�[�h�g���Ă�A�z������
http://anago.2ch.net/test/read.cgi/jisaku/1391901409/
Mantle�������Ȃ��r�f�I�J�[�h�g���Ă�A�z������
http://anago.2ch.net/test/read.cgi/jisaku/1391901409/
377 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 20:20:16.85 ID:jLj49woF
���y�z�M�T�C�g���������B
WMP�ɂ��\�j�[�̃R���|�[�l���g���g��ꂽ����������
WMP�ɂ��\�j�[�̃R���|�[�l���g���g��ꂽ����������
378 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 20:24:18.60 ID:jLj49woF
iTMS�R��Web�T�[�r�X�Ƃ��Ă�mora���ȁB
���̃C�m�x�C�^�[�i�j�̓�Ԑ������@�̐^����
�㓡�������A�z��Ȃ�
���̃C�m�x�C�^�[�i�j�̓�Ԑ������@�̐^����
�㓡�������A�z��Ȃ�
379 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 20:37:55.82 ID:jLj49woF
>>375
��������イ�����Ă�悱�̃X��
��������イ�����Ă�悱�̃X��
���ꂪ�����������
>>376
DX�����S�ɗ��킵�Ă������Ă����c�c
DX�����S�ɗ��킵�Ă������Ă����c�c
�o�b���[�J�[�����z�𓊎����Ăo�b��鎞�オ����Ζʔ����Ȃ肻���Ȃ��ǂȁB
>>375
>PC���[�J�[���C�m�x�[�V�������N�����Ȃ��̂�Wintel�������I
����Ȃ���
PC���[�J�[���C�m�x�[�V�������N�����Ȃ��ő�̌�����AMD PC�����C���ɂ��Ȃ�����
�܂�PC���[�J�[����Ԉ����B
>PC���[�J�[���C�m�x�[�V�������N�����Ȃ��̂�Wintel�������I
����Ȃ���
PC���[�J�[���C�m�x�[�V�������N�����Ȃ��ő�̌�����AMD PC�����C���ɂ��Ȃ�����
�܂�PC���[�J�[����Ԉ����B
384 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 21:01:42.02 ID:jLj49woF
�\�j�[�͔F�߂��邽�߂̓w�͂�����Ȃ����낤
385 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 21:02:40.94 ID:jLj49woF
>>383
�Ȃ�Ȃ�AMD�������iPC��H
�Ȃ�Ȃ�AMD�������iPC��H
>>381
�c�w��Mantle�Ŋ��S�ɗ��킵�Ă��܂�����NVIDIA�����S�Ɏ��S�����Ⴄ�ł��傤���B
DICE���掿�]�X������Ă���Mantle�Ȃ�APU�ł�BF4�������܂����ăA�s�[��
�����ق����q�w�L����킯�����ȁA�n�C�G���h�@����Ȃ�DX�łłǂ������ăX�^���X
����B
�c�w��Mantle�Ŋ��S�ɗ��킵�Ă��܂�����NVIDIA�����S�Ɏ��S�����Ⴄ�ł��傤���B
DICE���掿�]�X������Ă���Mantle�Ȃ�APU�ł�BF4�������܂����ăA�s�[��
�����ق����q�w�L����킯�����ȁA�n�C�G���h�@����Ȃ�DX�łłǂ������ăX�^���X
����B
�����̐l�͉������C�ɂ��Ȃ��̂ŁA�X�}�z���g�щ��y�v���[���Ƃ��Ă��g���Ă�
�������C�ɂ��邲���ꕔ�̐l�́A�������^�C�v�̌g�щ��y�v���[����
���Čg�щ��y�v���[���������Ă��l�̑����́A�X�}�z�ōς܂��Ă��
�������C�ɂ��邲���ꕔ�̐l�́A�������^�C�v�̌g�щ��y�v���[����
���Čg�щ��y�v���[���������Ă��l�̑����́A�X�}�z�ōς܂��Ă��
>>384
���[�_�[�v�l�ł͂Ȃ����Ԏv�l�̃T�����[�}���В��ɐ��艺�������̂���������
�n�Ǝ҂̃��[�_�[�v�l�В��̂Ƃ��́A���̃A�b�v���݂����ȉ�Ђ��������ĕ��������Ƃ�����
�A�b�v���̃��[�_�[�̃W���u�X�͂Ȃ|�p��`�����Ċ����̓z�����������
�T�����[�}���v�l�Ƃ͑ɂȓz���Ċ���������
���[�_�[�v�l�ł͂Ȃ����Ԏv�l�̃T�����[�}���В��ɐ��艺�������̂���������
�n�Ǝ҂̃��[�_�[�v�l�В��̂Ƃ��́A���̃A�b�v���݂����ȉ�Ђ��������ĕ��������Ƃ�����
�A�b�v���̃��[�_�[�̃W���u�X�͂Ȃ|�p��`�����Ċ����̓z�����������
�T�����[�}���v�l�Ƃ͑ɂȓz���Ċ���������
�\�j�[��PS3������v��ǖ��X�R����������̂��ɂ������ȁB
����PS3�͋v��ǖ̑z��ǂ���̐��\�ƃR�X�g�ɗ��������A
�����o���ɂ����ƌ����Ă��p�t�H�[�}���X���g�����Ȃ��i��ň����o����悤�ɂȂ����B
���̊ԂɃX�g�����K�[������̐��Ŋ��S�ɕ������B
����PS3�͋v��ǖ̑z��ǂ���̐��\�ƃR�X�g�ɗ��������A
�����o���ɂ����ƌ����Ă��p�t�H�[�}���X���g�����Ȃ��i��ň����o����悤�ɂȂ����B
���̊ԂɃX�g�����K�[������̐��Ŋ��S�ɕ������B
�Ă��A��������PC���[�J�[��PC�ɋ������Ƃ�����R�X�p�ȊO��
�Ȃɂ�����H�H
������끫
�Ȃɂ�����H�H
������끫
>>391
�m�[�gPC��LCD��FHD�ɕς�����Ƃ����ʂ������
�m�[�gPC��LCD��FHD�ɕς�����Ƃ����ʂ������
>>390
�m�[�g��^�u���b�g�Ȃ烁�[�J�[�i�����Ȃ��B
�m�[�g��^�u���b�g�Ȃ烁�[�J�[�i�����Ȃ��B
>>390
�P�[�X�������ق���
�P�[�X�������ق���
>>386
���A����
���A����
396 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 21:35:57.06 ID:jLj49woF
����PC�ł����o���Ȃ����Ƃ����߂邯�ǂ�
���߂�Mac���������������Ă̂��uText to Speech������[�v�����������
���̓_�uVAIO�łȂ���Ȃ�Ȃ����R�v���ĂȂ�����ȁ[
���߂�Mac���������������Ă̂��uText to Speech������[�v�����������
���̓_�uVAIO�łȂ���Ȃ�Ȃ����R�v���ĂȂ�����ȁ[
�c�q�̔��������Ƃ��Ƃ�AMD�̎�����APU/CPU�ƊW�Ȃ���
ZUNE���v���o����walkman�Ƃ��͐������Ă����
���܂�sony��@�������C���A���Ă�Ȃ�B
>>390
��q����Ă��邪�A�����m�[�g�͂������Ƀ��[�J�[���ɂȂ�B
���o�C���m�[�g�ŃQ�[�����C�Ȃ����̂ŁA����d�͒ጸ�������̃C���e��CPU�ł����B
MSoffice�Ǝ����p�ʐ^�����A�u���E�W���O���x�ł����ǂˁA�ł��o��ʼn��K�ɃL�[�{�[�h�ł�������ł���B
>>390
��q����Ă��邪�A�����m�[�g�͂������Ƀ��[�J�[���ɂȂ�B
���o�C���m�[�g�ŃQ�[�����C�Ȃ����̂ŁA����d�͒ጸ�������̃C���e��CPU�ł����B
MSoffice�Ǝ����p�ʐ^�����A�u���E�W���O���x�ł����ǂˁA�ł��o��ʼn��K�ɃL�[�{�[�h�ł�������ł���B
400 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 22:03:27.21 ID:jLj49woF
��HHKB�����������Ă܂����E�E�E�E
USB�z�X�g�Ή��̃^�u���b�g���Ă̂͊���Əd������v�f����
USB�z�X�g�Ή��̃^�u���b�g���Ă̂͊���Əd������v�f����
�J�`���J�`�����邳���˂�
�c�q����MAC�I�^�������̂��H
�ԐM�����Ăтт������ǁA���o�C���n�͎���ł��Ȃ����ȁA�f�X�N�̃��[�J�[PC
�͂�͂薣�͂����Ȃ��낤�ȁB
�ԐM�����Ăтт������ǁA���o�C���n�͎���ł��Ȃ����ȁA�f�X�N�̃��[�J�[PC
�͂�͂薣�͂����Ȃ��낤�ȁB
403 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 22:35:46.72 ID:jLj49woF
OS�ɍS��Ȃ�ĂȂ���BUbuntu�̂��ꂪ�C�ɓ���Ȃ����yV2C�z 2.11.4 [R20131210] (L-0.7.0:x86)
�yJava�z [P]1.7.0_10-b18 (Oracle Corporation)
�yOS�z Windows Vista Service Pack 2 (x86)
�y�������z Total(Free)/Max.: 317(185)/493�@(Phys. Total/Avail.: 2037/726)�@[MB]
�y�s����e�z
�y�����@�z
�y�����ύ��ځz
�yJava�z [P]1.7.0_10-b18 (Oracle Corporation)
�yOS�z Windows Vista Service Pack 2 (x86)
�y�������z Total(Free)/Max.: 317(185)/493�@(Phys. Total/Avail.: 2037/726)�@[MB]
�y�s����e�z
�y�����@�z
�y�����ύ��ځz
404 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 22:36:19.18 ID:jLj49woF
�ȂςȂ̂ł�
http://www.youtube.com/watch?feature=player_embedded&v=npZ3_ILHVzs
����Ȃ�𓋍ڂ�����ł��Ȃ��̂��ˁH
����Ȃ�𓋍ڂ�����ł��Ȃ��̂��ˁH
���������ǂ��̉�Ђ��悪�Ȃ�
�X�}�z�Apc�͂����I��������i
���̂܂܂��Ɣ����������v�����Ȃ�
����͂ǂ̊�ƂɂƂ��Ă�������
�l�X�̐�����������K�W�F�b�g��
�ēx�����Ɛ��͐}���ς��
���̈Ӗ��ł́Asony�͂܂��킦��
�S�R���v��
�X�}�z�Apc�͂����I��������i
���̂܂܂��Ɣ����������v�����Ȃ�
����͂ǂ̊�ƂɂƂ��Ă�������
�l�X�̐�����������K�W�F�b�g��
�ēx�����Ɛ��͐}���ς��
���̈Ӗ��ł́Asony�͂܂��킦��
�S�R���v��
�C�m�x�[�V�������N�����Ȃ��̂́A�u�v���v���傫�ȗ��R��
�@�������APC���[�J�[�̑����炷��A���̃C�m�x�[�V������j�Q���Ă���̂�Microsoft��Intel���g�Ȃ̂��B
�Ⴆ�AMicrosoft��Intel���A���S�v���O�����ƌĂ��d�g�݂�p�ӂ��Ă���BPC�ɁuWindows�v��uCore�v�Ȃǂ�
�u�����h�V�[�����\���Ă���̂��������Ƃ�����l���������낤�B���̃V�[���̓}�[�P�e�B���O�L�����y�[����
��ɂȂ��Ă���A�V�[���i�ɓ\�邱�ƂŁAPC���[�J�[�ɂ͂��܂��܂ȓ��T(�����L�����y�[����}�[�P�e�B���O
�t�B�[�̒Ȃ�)������̂��B���̃��S�V�[����\�邽�߂ɂ͂��܂��܂ȏ��������K�v������̂����A
Microsoft�̗�Ō�����Windows Logo Program�ƌĂ��v���O�����̗v�������K�v������B
�����悤�Ȏd�g�݂�Intel�ɂ�����A�L���ȂƂ���ł�Ultrabook�𖼏�邽�߂̗v�����m���Ă���B
�@���́A���̗v�����班���ł��O���ƁA�r�[�ɓK�p�ł͖����Ȃ��Ă��܂����Ƃ��B�Ⴆ�A�\�j�[�̗�Ō����A
�uVAIO Z2�v�ƌĂ��2011/2012�N�^�̃n�C�G���hPC������̂����A2012�N10����Windows 8���������ꂽ��ɁA
Windows 8���ڃ��f���������[�X����邱�Ƃ͂Ȃ��A���Y�I���ɂȂ����B���̗��R�̓\�j�[�̊W�҂͌����Č����
����Ȃ��̂����AVAIO Z2�ɍ̗p���Ă���O���h�b�L���O�X�e�[�V�������ɓ��ڂ��Ă���f�B�X�N���[�gGPU���A
Windows 8�̃��S�v���ł͔F�߂��Ă��Ȃ��̂����R���ƍl�����Ă���B
�@�������APC���[�J�[�̑����炷��A���̃C�m�x�[�V������j�Q���Ă���̂�Microsoft��Intel���g�Ȃ̂��B
�Ⴆ�AMicrosoft��Intel���A���S�v���O�����ƌĂ��d�g�݂�p�ӂ��Ă���BPC�ɁuWindows�v��uCore�v�Ȃǂ�
�u�����h�V�[�����\���Ă���̂��������Ƃ�����l���������낤�B���̃V�[���̓}�[�P�e�B���O�L�����y�[����
��ɂȂ��Ă���A�V�[���i�ɓ\�邱�ƂŁAPC���[�J�[�ɂ͂��܂��܂ȓ��T(�����L�����y�[����}�[�P�e�B���O
�t�B�[�̒Ȃ�)������̂��B���̃��S�V�[����\�邽�߂ɂ͂��܂��܂ȏ��������K�v������̂����A
Microsoft�̗�Ō�����Windows Logo Program�ƌĂ��v���O�����̗v�������K�v������B
�����悤�Ȏd�g�݂�Intel�ɂ�����A�L���ȂƂ���ł�Ultrabook�𖼏�邽�߂̗v�����m���Ă���B
�@���́A���̗v�����班���ł��O���ƁA�r�[�ɓK�p�ł͖����Ȃ��Ă��܂����Ƃ��B�Ⴆ�A�\�j�[�̗�Ō����A
�uVAIO Z2�v�ƌĂ��2011/2012�N�^�̃n�C�G���hPC������̂����A2012�N10����Windows 8���������ꂽ��ɁA
Windows 8���ڃ��f���������[�X����邱�Ƃ͂Ȃ��A���Y�I���ɂȂ����B���̗��R�̓\�j�[�̊W�҂͌����Č����
����Ȃ��̂����AVAIO Z2�ɍ̗p���Ă���O���h�b�L���O�X�e�[�V�������ɓ��ڂ��Ă���f�B�X�N���[�gGPU���A
Windows 8�̃��S�v���ł͔F�߂��Ă��Ȃ��̂����R���ƍl�����Ă���B
�@�������Intel��Ultrabook�ɂ�����B�Ⴆ�A2013�N�^���f����Ultrabook�̗v���ɂ̓^�b�`�@�\���K�{�ƂȂ��Ă���B
�m���Ƀ^�b�`�@�\��Windows 8�𗘗p����ɂ͕K�{���Ǝv���̂����A�����A�����ł������������J���҂ɂƂ��Ă͌�����
�v���ł��邱�Ƃ͊ԈႢ�Ȃ��B���̌��ʂǂ����邩�ƌ����A�\�j�[�́uVAIO Pro�v��NEC PC�́uLaVie Z�v�̂悤�ɁA
�������f�����Ń^�b�`�ƃ^�b�`�����̃��f����p�ӂ���Ƃ����������𗘗p����Z���B������������܂��ǂ����A
�Ȃ��ꍇ�ɂ͂����������͓I�ȃ}�V����������Ƃ��Ă��A�����Ultrabook�Ƃ͖����Ȃ����ƂɂȂ�A
�J�e�S���I�ɂ�Ultrabook�ł������Ƃ��Ă����B
�@����Microsoft��Intel�̗v���ɓK�����Ȃ��}�V����v�����Ƃ��ɁAMicrosoft��Intel�������͂�������
�}�[�P�e�B���O��p�����Ă��������邾���̊o�傪�o�c�҂ɂ���̂��A�Ƃ����b�ɂȂ�B
���RPC���[�J�[�ɂƂ��Ă��������}�[�P�e�B���O��p���d�v�Ȏ����ɂȂ�̂ŁA�������炻������炦��悤�Ȑ��i��
����Ă͂ǂ����Ƃ����b���ɂȂ�A���������v���ɓ��Ă͂܂�Ȃ�PC�͊��i�K�Ń{�c�ɂȂ邱�Ƃ�������B
��������ƃG���W�j�A�͎��͂���ɊO��Ȃ��悤�Ȑv�����悤�ƐS������c�c���̌��ʂ͑ދ��ȃv���b�g�t�H�[���̊������B
�������PC���[�J�[�����`�����Ȃ����������Ƃ����l�������o���邪�A�����傫�ȉ�Ђł������قǂ��������`��������
�����Ȃ�Ƃ����̂͌Í������̐^�����낤�B
�m���Ƀ^�b�`�@�\��Windows 8�𗘗p����ɂ͕K�{���Ǝv���̂����A�����A�����ł������������J���҂ɂƂ��Ă͌�����
�v���ł��邱�Ƃ͊ԈႢ�Ȃ��B���̌��ʂǂ����邩�ƌ����A�\�j�[�́uVAIO Pro�v��NEC PC�́uLaVie Z�v�̂悤�ɁA
�������f�����Ń^�b�`�ƃ^�b�`�����̃��f����p�ӂ���Ƃ����������𗘗p����Z���B������������܂��ǂ����A
�Ȃ��ꍇ�ɂ͂����������͓I�ȃ}�V����������Ƃ��Ă��A�����Ultrabook�Ƃ͖����Ȃ����ƂɂȂ�A
�J�e�S���I�ɂ�Ultrabook�ł������Ƃ��Ă����B
�@����Microsoft��Intel�̗v���ɓK�����Ȃ��}�V����v�����Ƃ��ɁAMicrosoft��Intel�������͂�������
�}�[�P�e�B���O��p�����Ă��������邾���̊o�傪�o�c�҂ɂ���̂��A�Ƃ����b�ɂȂ�B
���RPC���[�J�[�ɂƂ��Ă��������}�[�P�e�B���O��p���d�v�Ȏ����ɂȂ�̂ŁA�������炻������炦��悤�Ȑ��i��
����Ă͂ǂ����Ƃ����b���ɂȂ�A���������v���ɓ��Ă͂܂�Ȃ�PC�͊��i�K�Ń{�c�ɂȂ邱�Ƃ�������B
��������ƃG���W�j�A�͎��͂���ɊO��Ȃ��悤�Ȑv�����悤�ƐS������c�c���̌��ʂ͑ދ��ȃv���b�g�t�H�[���̊������B
�������PC���[�J�[�����`�����Ȃ����������Ƃ����l�������o���邪�A�����傫�ȉ�Ђł������قǂ��������`��������
�����Ȃ�Ƃ����̂͌Í������̐^�����낤�B
INTEL�̓E���u�H�����̂Ă�ׂ����Ɖ��x������������
�ӌŒn�ɐ���߂��Ă��A���ǂ̓_���ɂȂ�̂�
�ӌŒn�ɐ���߂��Ă��A���ǂ̓_���ɂȂ�̂�
�Ƃ������C�O�m�x�[�V�����͂���������������
�y�ʉ��Ɖ��i�ቺ�ƏȃG�l���Ђ�������߂Ăق���
���łɃL�[�{�[�h��t���̏c����Ȃǐl�ԍH�w�ʂ�z�����Ă��炦��Ό������ƂȂ�
���i�j�X�ɐi�s���ēr�㍑��PC���s���n��ق������E�ς���
�y�ʉ��Ɖ��i�ቺ�ƏȃG�l���Ђ�������߂Ăق���
���łɃL�[�{�[�h��t���̏c����Ȃǐl�ԍH�w�ʂ�z�����Ă��炦��Ό������ƂȂ�
���i�j�X�ɐi�s���ēr�㍑��PC���s���n��ق������E�ς���
412 �FSocket774�F2014/02/10(��) 23:27:22.87 ID:sTHgoqvW
�{�����i�������i�f�U�C���ɉߓx�Ɍ����o���ׂ�����Ȃ�
���t���I���̃}�O���͎h�g�ȊO�ŐH���Ȃƌ����Ă�悤�Ȃ��̂�
���t���I���̃}�O���͎h�g�ȊO�ŐH���Ȃƌ����Ă�悤�Ȃ��̂�
413 �F,,�E�L�́M�E,,�j��-�������F2014/02/10(��) 23:36:23.40 ID:jLj49woF
>>410
��ΐ��Ȃ�APU�i�j��蔄��Ă邾��
��ΐ��Ȃ�APU�i�j��蔄��Ă邾��
>�}�[�P�e�B���O��p�����Ă��������邾���̊o��
���Ȃ��ւ���ł����Ă��Ƃ�
���Ȃ��ւ���ł����Ă��Ƃ�
�Q�C�c�u���������͎��ɔC���Ăق����v
>���i�ቺ
����͖��炩�ɏa���Ă��ˁA�{�����\�̐L�т��݉���������ultrabook�Ƃ������������ʂ̗v�f�ŕ���ĂƂ�Ƃ�ʂ�����Җڐ��Ȃ���
���炩�Ɋ����Ȓl�i�ݒ肗�A����ˁ[�A�͂������ł��˃R�[�X�܂�������
���̓_AMD�͈������Ȃ�������Ȃ��v�f���ڂŐS����?w
����͖��炩�ɏa���Ă��ˁA�{�����\�̐L�т��݉���������ultrabook�Ƃ������������ʂ̗v�f�ŕ���ĂƂ�Ƃ�ʂ�����Җڐ��Ȃ���
���炩�Ɋ����Ȓl�i�ݒ肗�A����ˁ[�A�͂������ł��˃R�[�X�܂�������
���̓_AMD�͈������Ȃ�������Ȃ��v�f���ڂŐS����?w
����ł��ǂ̊�Ƃł�������
���̏o����ƁA���܂���S���ق�Ƃ��Ɋ�����т邼
���̏o����ƁA���܂���S���ق�Ƃ��Ɋ�����т邼
����ς�BRIX Pro�ŃA���`����т��Ă����B
CPU���\��Intel���ゾ���A���セ��CPU���Ӗ����镝���u���čs���Ǝv�����ȁB
DDR3-2400�ő����Ȃ��̂̓t�F�A����Ȃ�����A�ݒ�ł��Ȃ��Ȃ�
���߂�1600���̃��C�e���V���l�߂���ł��Ȃ������̂��ȁB
����Intel�̕���AMD�قǃ������ш���グ�Ă��L�тȂ��B
CPU���\��Intel���ゾ���A���セ��CPU���Ӗ����镝���u���čs���Ǝv�����ȁB
DDR3-2400�ő����Ȃ��̂̓t�F�A����Ȃ�����A�ݒ�ł��Ȃ��Ȃ�
���߂�1600���̃��C�e���V���l�߂���ł��Ȃ������̂��ȁB
����Intel�̕���AMD�قǃ������ш���グ�Ă��L�тȂ��B
eDRAM��������DDR3-1600�ł������y�U�ɗ��Ă�������
AMD�Ƃ��Ă�HMC��TSV�̎��p����D�悵�����낤��
AMD�Ƃ��Ă�HMC��TSV�̎��p����D�悵�����낤��
���O��eDRAM�Ȃ牴��GDDR5�����ʯʯʂƂ����Ȃ��̂��ȁB
�ł���������ƃT�[�h��FM2+�}�U�[�̓�������ł��Ȃ�����A���炭���a�����ȁB
�ł���������ƃT�[�h��FM2+�}�U�[�̓�������ł��Ȃ�����A���炭���a�����ȁB
FM2�ł̓s���̊W�㖳�����낤
�_�C�ɒ[�q���͂����Ă��z������Ă��Ȃ��\��������
��p��BGA���f����p�ӂ��ĉ�������Ȃ炢���Ȃ����Ȃ����낤��
���Ǎ������Ȃ�
�_�C�ɒ[�q���͂����Ă��z������Ă��Ȃ��\��������
��p��BGA���f����p�ӂ��ĉ�������Ȃ炢���Ȃ����Ȃ����낤��
���Ǎ������Ȃ�
GDDR5M�����ꂽ����˂�
423 �FSocket774�F2014/02/11(��) 00:14:44.22 ID:7LWgqizX
��肠����DDR3 4ch���f���͂�
X1�̂́A��{OS���L���b�V���풓�����邽�߂̃���������
HSA�AVPU�p�r�ł͑�e�ʃo�[�X�g�]��������A���ʂ͗]�薳�����ė����ł���B
intel�̐^���������āA������������ĈӖ��Ȃ��B
HSA�AVPU�p�r�ł͑�e�ʃo�[�X�g�]��������A���ʂ͗]�薳�����ė����ł���B
intel�̐^���������āA������������ĈӖ��Ȃ��B
DDR4�ڍs����4ch�ɂ��邩�ǂ������ĂƂ������
�R�X�g�̂������鍂���}�U�[��4ch�z�������
�R�X�g�̂������鍂���}�U�[��4ch�z�������
����Intel��ARM�Q�����Ă���Ȃ����Ȃ�
���Ȃ�̃V�F�A����邾��
����҂ɂ������b�g���邵
�S��win-win�ɂȂ�Ǝv����
���Ȃ�̃V�F�A����邾��
����҂ɂ������b�g���邵
�S��win-win�ɂȂ�Ǝv����
�c�q�̔������[�h��
�����������ł����Ǝv���Ă�̂́ADRAM8GB����ʂɓ͂����i�т܂ŗ����Ă��āA
�Ȃ�SRAM2GB�������x�̒l�i�łł������Ȃ��A���̕ӂ�͂ǂ�JARO
�Ȃ�SRAM2GB�������x�̒l�i�łł������Ȃ��A���̕ӂ�͂ǂ�JARO
SRAM�͑�e�ʉ����ނ�������
�d�͏�������i������
�d�͏�������i������
SRAM��DRAM�Ɣ�ׂ�Ɛ��\�{�ʐς�H��
�Ƃ肠����SidePort���~������
feed the beast�Ƃ������ԑO���猾���Ă��̂������Ɍ����Ă�������
intel�͂��̂�����𑼎Ђɗ��炸���{�I�ɉ������悤�Ƃ���
AMD�͎��Ђ̓��ӂƂ���Ƃ���ʼn��Ƃ����낤�Ƃ����p��
���ɂ����N���b�N�̃������Ői���������邠������͂�͂肻���炵��
���Ђ͉������@�ɉ��炩�̎育�����Ă���悤������
NV�T���͂ǂ�����낤�ˁAAMD�H��(�ш�͑��ЋK�i�C��)�Ƃ����̂ł����
���AMD��荂���\�A���邢�́A���t�����l�̐��i���o���˂Ȃ�Ȃ��킯��
�l�i�ɑi���Ă��炤�̂�����ғI�ɂ͊���������������ˁA�Q�[�����Ȃ����ǂ�
intel�͂��̂�����𑼎Ђɗ��炸���{�I�ɉ������悤�Ƃ���
AMD�͎��Ђ̓��ӂƂ���Ƃ���ʼn��Ƃ����낤�Ƃ����p��
���ɂ����N���b�N�̃������Ői���������邠������͂�͂肻���炵��
���Ђ͉������@�ɉ��炩�̎育�����Ă���悤������
NV�T���͂ǂ�����낤�ˁAAMD�H��(�ш�͑��ЋK�i�C��)�Ƃ����̂ł����
���AMD��荂���\�A���邢�́A���t�����l�̐��i���o���˂Ȃ�Ȃ��킯��
�l�i�ɑi���Ă��炤�̂�����ғI�ɂ͊���������������ˁA�Q�[�����Ȃ����ǂ�
>>418
> ���セ��CPU���Ӗ����镝���u���čs���Ǝv�����ȁB
AMD�̃}�[�P�e�B���O���x���ꂷ���B
hQ��hUMA���ނ�̌����Ƃ����100%�������ꂽ�ꍇ�ł�GPU�p�Ƀv���O�����C�����Ȃ��Ƃ����Ȃ��͕̂ς��Ȃ���B
> ���セ��CPU���Ӗ����镝���u���čs���Ǝv�����ȁB
AMD�̃}�[�P�e�B���O���x���ꂷ���B
hQ��hUMA���ނ�̌����Ƃ����100%�������ꂽ�ꍇ�ł�GPU�p�Ƀv���O�����C�����Ȃ��Ƃ����Ȃ��͕̂ς��Ȃ���B
Intel�̕��͍��{�I�ȉ�������Ȃ��āA�p�b�`�I�ȉ����ɑ����Ă���悤�Ɏv��
AMD�ɔ�ׂăL���b�V������������������AeDRAM�i�v�̓L���b�V���ł���j�̂����Ă݂���
�L���b�V�����炠�ӂꂽ�Ƃ���ɐ��\��������̂��ڂɌ����Ă�
AMD�ɔ�ׂăL���b�V������������������AeDRAM�i�v�̓L���b�V���ł���j�̂����Ă݂���
�L���b�V�����炠�ӂꂽ�Ƃ���ɐ��\��������̂��ڂɌ����Ă�
>>433
> hQ��hUMA���ނ�̌����Ƃ����100%�������ꂽ�ꍇ�ł�GPU�p�Ƀv���O�����C�����Ȃ��Ƃ����Ȃ��͕̂ς��Ȃ���B
�n���͒m��Ȃ����낤���ǁAOpenCL2.0��hQ��hUMA�ɑΉ����邩���
Intel��k�r�ɂ��o�[�`�����A�h���X�Ƃ��ő��������b�g���邩��A����OpenCL�ŊJ�����Ă���Ƃ���͓��R�g�����A�V�K�䔭�������邾�낤��
> hQ��hUMA���ނ�̌����Ƃ����100%�������ꂽ�ꍇ�ł�GPU�p�Ƀv���O�����C�����Ȃ��Ƃ����Ȃ��͕̂ς��Ȃ���B
�n���͒m��Ȃ����낤���ǁAOpenCL2.0��hQ��hUMA�ɑΉ����邩���
Intel��k�r�ɂ��o�[�`�����A�h���X�Ƃ��ő��������b�g���邩��A����OpenCL�ŊJ�����Ă���Ƃ���͓��R�g�����A�V�K�䔭�������邾�낤��
>434
���̍l��������beast�̐H�~��}����(���������\�Ȃ��ɂ�)�K�v�����邾�Ǝv������
�v���ɂ���͉������@�������Ǝv��ꂗ
�p�b�`�I�Ɍ�����Ȃ炻��͂���ʼn��l�ς̈Ⴂ���˂�
����������Ȃ�����˂�
���̍l��������beast�̐H�~��}����(���������\�Ȃ��ɂ�)�K�v�����邾�Ǝv������
�v���ɂ���͉������@�������Ǝv��ꂗ
�p�b�`�I�Ɍ�����Ȃ炻��͂���ʼn��l�ς̈Ⴂ���˂�
����������Ȃ�����˂�
>>435
���₻��OpenCL�ŏ����Ă邵�B
OpenCL�����̂��Ďd�g�݂̓s����CUDA��肳��ɂ߂�ǂ����AOpenCL�g���Ă�ȏ�CPU��GPU�̋�ʂ������Ȃ�Ƃ����������B
���₻��OpenCL�ŏ����Ă邵�B
OpenCL�����̂��Ďd�g�݂̓s����CUDA��肳��ɂ߂�ǂ����AOpenCL�g���Ă�ȏ�CPU��GPU�̋�ʂ������Ȃ�Ƃ����������B
>>437
GPGPU�v���O�����̖ʓ|���̓|�C���^�̈�����CPU�ƈႤ���炾�����
hUMA��hQ�Ή���CPU�Ɠ����ɂȂ邩�炩�Ȃ�y�ɂȂ��A���ꂱ��CUDA�Ȃb�ɂȂ�Ȃ����炢��
GPGPU�v���O�����̖ʓ|���̓|�C���^�̈�����CPU�ƈႤ���炾�����
hUMA��hQ�Ή���CPU�Ɠ����ɂȂ邩�炩�Ȃ�y�ɂȂ��A���ꂱ��CUDA�Ȃb�ɂȂ�Ȃ����炢��
PS4�̋L����F�X���Ă���ƁAAPU + GDDR5�̑g�����̕]���͂��Ȃ荂����
�����\�����J�������₷���Ƃ����b���悭�o�Ă���
�R���������Ƒ�������A���̂����}�U�[�ɒ��t�����x�A�{�[���Ƃ��o���Ȃ�����
�����\�����J�������₷���Ƃ����b���悭�o�Ă���
�R���������Ƒ�������A���̂����}�U�[�ɒ��t�����x�A�{�[���Ƃ��o���Ȃ�����
>>436
GCN�ł�OpenCL�������ʔ������Ƃ����Ă��
���܂����ꉻ�ł��Ȃ���
GPGPU�݂����ȓ����v���O�����𑽐��̃f�[�^�ɓK�p����悤�ȏꍇ��
���̃f�[�^���������X���b�h�Ƃ��đ�ʂɗp�ӂ��Ă���
���̂����̃V�F�[�_�[���������X���b�h�𑖂点�͂��߂�B
�������A�N�Z�X���������ăX�g�[������܂Ńv���O���������s���ăX�g�[�������炻�̃X���b�h���T�X�y���h����
�������A�N�Z�X���������Ă��Ȃ��ʃX���b�h�ɐ�ւ��đ��点��B
���̃X���b�h���܂��X�g�[��������܂��ʂ̂ɐ�ւ���B
�ŃT�X�y���h���Ă����X���b�h�̃��������p�ӂł��Ă��炻����ĊJ����B
�Ƃ����悤�Ƀ������ш�̖��ʂ��ɗ͗}����悤�Ɏ�������Ă��āA����͖ʔ����Ȃ��Ǝv���Ă�
GCN�ł�OpenCL�������ʔ������Ƃ����Ă��
���܂����ꉻ�ł��Ȃ���
GPGPU�݂����ȓ����v���O�����𑽐��̃f�[�^�ɓK�p����悤�ȏꍇ��
���̃f�[�^���������X���b�h�Ƃ��đ�ʂɗp�ӂ��Ă���
���̂����̃V�F�[�_�[���������X���b�h�𑖂点�͂��߂�B
�������A�N�Z�X���������ăX�g�[������܂Ńv���O���������s���ăX�g�[�������炻�̃X���b�h���T�X�y���h����
�������A�N�Z�X���������Ă��Ȃ��ʃX���b�h�ɐ�ւ��đ��点��B
���̃X���b�h���܂��X�g�[��������܂��ʂ̂ɐ�ւ���B
�ŃT�X�y���h���Ă����X���b�h�̃��������p�ӂł��Ă��炻����ĊJ����B
�Ƃ����悤�Ƀ������ш�̖��ʂ��ɗ͗}����悤�Ɏ�������Ă��āA����͖ʔ����Ȃ��Ǝv���Ă�
>>438
��������炩�͊ȒP�ɂȂ邾�낤���ǁA����ł�GPU�����ɕύX���Ȃ��Ƃ����Ȃ�����������Ȃ�
Compute Core�Ƃ�������GPU�R�A��CPU�R�A�ꎋ����\���͌֒����Ǝv�����B
��������炩�͊ȒP�ɂȂ邾�낤���ǁA����ł�GPU�����ɕύX���Ȃ��Ƃ����Ȃ�����������Ȃ�
Compute Core�Ƃ�������GPU�R�A��CPU�R�A�ꎋ����\���͌֒����Ǝv�����B
>>440
����GPU�Ȃ畁�ʂł́c
����GPU�Ȃ畁�ʂł́c
>>441
�ǂ������Ƃ����Ɛ����R�A�Ǝ����R�A�ŗp�r�ɉ����Ďg���킯�悤�Ƃ����\���Ɍ������
�ǂ������Ƃ����Ɛ����R�A�Ǝ����R�A�ŗp�r�ɉ����Ďg���킯�悤�Ƃ����\���Ɍ������
>>443
���O�̂悤�ɂ����Ǝg���������K�v���Ɨ����ł���l�͕ʂɂ������ǁA
�����łȂ��l�ɂ킴�킴���������悤�ȕ\�����g���̂͐����ł͂Ȃ�����B
�܂��}�[�P�e�B���O�ɐ������͕K�{�ł͂Ȃ����B
���O�̂悤�ɂ����Ǝg���������K�v���Ɨ����ł���l�͕ʂɂ������ǁA
�����łȂ��l�ɂ킴�킴���������悤�ȕ\�����g���̂͐����ł͂Ȃ�����B
�܂��}�[�P�e�B���O�ɐ������͕K�{�ł͂Ȃ����B
>>430
SRAM��1�Z��������6Tr�ADRAM��1Tr+1C������ʐϔ�͐��\�{����Ȃ��Đ��{
SRAM��1�Z��������6Tr�ADRAM��1Tr+1C������ʐϔ�͐��\�{����Ȃ��Đ��{
DRAM�̓R���f���T��������Ȃ��́H
1T�t������1T-SRAM�ɂȂ�C��
1T�t������1T-SRAM�ɂȂ�C��
448 �FSocket774�F2014/02/11(��) 07:25:35.94 ID:MfMyHASX
250X�̃x���`�o�Ă�����
Battlefield 4
http://media.bestofmicro.com/K/4/421924/original/Battlefield4.png
Metro: Last Light
http://media.bestofmicro.com/K/9/421929/original/Metro.png
����ς�7770���낗
650Ti�E������
Battlefield 4
http://media.bestofmicro.com/K/4/421924/original/Battlefield4.png
{kind=link}
Metro: Last Light
http://media.bestofmicro.com/K/9/421929/original/Metro.png
{kind=link}
����ς�7770���낗
650Ti�E������
�S�V�N�̔�r�܂��[�H
>>448
����͂������̂�
����͂������̂�
http://www.gdm.or.jp/pressrelease/2014/0210/60025
>�Ȃ�PowerColor�ɂ��A�X�g���[���v���Z�b�T����512��Ƃ���A
>AMD�̌��̃X�y�b�N640���菭�Ȃ��_�ɂ͒��ӂ��K�v���B
http://pc.watch.impress.co.jp/img/pcw/docs/634/512/html/1.jpg.html
�c�O�Ȃ�����̃X�y�b�N�ŁhUp to 640�h�ƌ����Ă�̂ŁAAMD���F�ł�
���i���ƂɃX�y�b�N�̈Ⴄ�n���J�[�h�̔��a
>�Ȃ�PowerColor�ɂ��A�X�g���[���v���Z�b�T����512��Ƃ���A
>AMD�̌��̃X�y�b�N640���菭�Ȃ��_�ɂ͒��ӂ��K�v���B
http://pc.watch.impress.co.jp/img/pcw/docs/634/512/html/1.jpg.html
{kind=link}
�c�O�Ȃ�����̃X�y�b�N�ŁhUp to 640�h�ƌ����Ă�̂ŁAAMD���F�ł�
���i���ƂɃX�y�b�N�̈Ⴄ�n���J�[�h�̔��a
7700K���W���W�����ʂ����Ă邶���
http://www.coneco.net/SpecList/01501010/
http://www.coneco.net/SpecList/01501010/
���X�ܔ̔��f�[�^�A���̎��������L���O
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
AMD���ς�炸���ł��Ă܂��_(^o^)�^
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
AMD���ς�炸���ł��Ă܂��_(^o^)�^
454 �FSocket774�F2014/02/11(��) 08:52:30.40 ID:fKeclD8W
�����ē��\�����^�{���U���{�^�����\���ě������ē��\����
���ꂪ�Ȃ����Č�����z�͊�Ȏ�f������������
���ꂪ�Ȃ����Č�����z�͊�Ȏ�f������������
�����������H
������O�̎������S�V�S�V�̓R�X�p�����O�ɉ��̈����Ȃ̂����Œ�����o���������ǂ�
Intel Core i7-4770 Processor (8M Cache, up to 3.90 GHz)
ttp://ark.intel.com/ja/products/75122/
Intel Celeron Processor G1610 (2M Cache, 2.60 GHz)
ttp://ark.intel.com/ja/products/71072/
Intel Core i7-4770 Processor (8M Cache, up to 3.90 GHz)
ttp://ark.intel.com/ja/products/75122/
Intel Celeron Processor G1610 (2M Cache, 2.60 GHz)
ttp://ark.intel.com/ja/products/71072/
>>454
����Ȃ��Ȃ����ȃE�F�[�u�����n���p�Ȃ�
����Ȃ��Ȃ����ȃE�F�[�u�����n���p�Ȃ�
�A���}���Ƃ��A�ȑO����2ch�ɕp�o����ÓT�I�ȍ��o�V�т���
>>442
GPU�S�ʂ������Ȃ̂�
���Ƃ����GPGPU�I�ȃ������A�N�Z�X��CPU�Ƃ͂܂��ʎ�̃������A�N�Z�X�`�Ԃ�
�ނ��냁��������Ƀv���O�����������Ă���Ƃ���������
�������̕����������o�X�𐦂��L���Ɏg���Ă���Ǝv��
GPU�S�ʂ������Ȃ̂�
���Ƃ����GPGPU�I�ȃ������A�N�Z�X��CPU�Ƃ͂܂��ʎ�̃������A�N�Z�X�`�Ԃ�
�ނ��냁��������Ƀv���O�����������Ă���Ƃ���������
�������̕����������o�X�𐦂��L���Ɏg���Ă���Ǝv��
�������ш�ߖ�Ȃ��ă��C�e���V�B���̂��߂�����
�d���̃X�P�W���[������בւ��Ă����ʂ͌���Ȃ��A�Ƃ��������̘b
�������ǂ݂ɍs���Ă�ԕʂ̃X���b�h�����������Ă̂�intel��hyper threading�ł�����Ă�
����warp��wavefront�̒��g�����ւ������Ȃ牉�Z�̑��ʂ͌��点��ꍇ������
���܂ł̃n�[�h�X�P�W���[���ł͖������������ǃ\�t�g�X�P�W���[���Ȃ�\��������
dynamic warp formation
http://www.cs.rutgers.edu/~zhang.zheng/cs671_fall2013/lectures/thekkada_dwarpform.pdf
���܂ł̃n�[�h�X�P�W���[���ł͖������������ǃ\�t�g�X�P�W���[���Ȃ�\��������
dynamic warp formation
http://www.cs.rutgers.edu/~zhang.zheng/cs671_fall2013/lectures/thekkada_dwarpform.pdf
�^�C�^���t�H�[���̓}���g���Ή����Ȃ����낤�Ȃ�
>>447
�\�z��肸���ƖʐϐH���ȁB�s�v�c���B
�ł������͋L����ĂȂ��ȁB
SRAM�ɂ�����DRAM���[�J�������Ă�A�L���p�V�^�̍��w�r���͂���ȏ㖳��
�������������B
�\�z��肸���ƖʐϐH���ȁB�s�v�c���B
�ł������͋L����ĂȂ��ȁB
SRAM�ɂ�����DRAM���[�J�������Ă�A�L���p�V�^�̍��w�r���͂���ȏ㖳��
�������������B
>>463
HT���Ƃ�������2�̃X���b�h�ŁA����2�������������ǂ݂ɍs���ƌ��ǃX�g�[������
GCN���ƍő�256�̃X���b�h�����Ă��ꂼ��̃��������C�e���V���B������
�܂�2��256���Ă������̈Ⴂ�ł����Ȃ��ƌ������̂Ƃ���Ȃ��ǁA
���ʂƂ��ă��C�e���V�B�����ʂ͂��Ȃ�Ⴄ��Ȃ�����
HT���Ƃ�������2�̃X���b�h�ŁA����2�������������ǂ݂ɍs���ƌ��ǃX�g�[������
GCN���ƍő�256�̃X���b�h�����Ă��ꂼ��̃��������C�e���V���B������
�܂�2��256���Ă������̈Ⴂ�ł����Ȃ��ƌ������̂Ƃ���Ȃ��ǁA
���ʂƂ��ă��C�e���V�B�����ʂ͂��Ȃ�Ⴄ��Ȃ�����
Intel��SMT����2�X���b�h�������ɓ������Ƃ��Ă���́H
�d�g�ݍl����قړ�������B�Ӗ��I�Ƀp�C�v���C���̊e�X�e�[�W��1T�̂݁B
�X�g�[�����ɂ����G���R����i5��i7�ō������m�ɏo��B
�X�g�[�����ɂ����G���R����i5��i7�ō������m�ɏo��B
Haswell�͓������s�ł���p�^�[�������Ȃ葝���Ă�Ǝv����
471 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 15:38:50.10 ID:qr9HLeI3
CPU�ɂ͍����E��e�ʂ̃L���b�V���������ď��Ȃ��X���b�h���ł�
�p�C�v���C���ғ��������߂邱�Ƃ��ł���B
���X���b�h�Ń��C�e���V���B���i�j�Ƃ������ǃ��C�e���V���̂��̂�
�Z�k�ł��Ȃ���B
�s�N�Z���Ⓒ�_���Ԃ����ł���d��������点�Ȃ�GPU��CPU�Ƃ�
����������ē��R�����AGPU�ɓ�������d������������I�ɂȂ�
�p�C�v���C���ғ��������߂邱�Ƃ��ł���B
���X���b�h�Ń��C�e���V���B���i�j�Ƃ������ǃ��C�e���V���̂��̂�
�Z�k�ł��Ȃ���B
�s�N�Z���Ⓒ�_���Ԃ����ł���d��������点�Ȃ�GPU��CPU�Ƃ�
����������ē��R�����AGPU�ɓ�������d������������I�ɂȂ�
GPU�͕������ē��������𓊂�����Ǝv���B
473 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 15:48:53.20 ID:qr9HLeI3
�d�̖͂��ʂł��ȁB
�ǂ������邩�̓��[�U�̍D�݂��낤w
���͍����������������B
���͍����������������B
475 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 16:05:07.18 ID:qr9HLeI3
����͎��]�Ԃ��Ƃ邩�唪�Ԃ��Ƃ邩�̑I���ł���
�s���ɕs���ȗႦ�͎t���܂���w
����y�i���e�B�������Ȃ�P�[�X��������Ƃ��̂Ȃ̂ɁB
����y�i���e�B�������Ȃ�P�[�X��������Ƃ��̂Ȃ̂ɁB
477 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 16:24:33.24 ID:qr9HLeI3
ARM�݂����Ȓᐫ�\�̃v���Z�b�T�ł��番��\����̐��\�����
�v���f�B�P�[�g�͎g���Ȃ��Ȃ��Ă��Ă�̂����ǂ�
����̐���������Ǝw�����I�ɉ��Z�ʂ�������S�p�^�[�����Z�Ȃ��
���ʂ������Ƃ���B
��������GPU��CPU�Ɣ�ׂĒx���i�����ɏ����ł��鐔�����������j
�v���f�B�P�[�g�͎g���Ȃ��Ȃ��Ă��Ă�̂����ǂ�
����̐���������Ǝw�����I�ɉ��Z�ʂ�������S�p�^�[�����Z�Ȃ��
���ʂ������Ƃ���B
��������GPU��CPU�Ɣ�ׂĒx���i�����ɏ����ł��鐔�����������j
�\����10�N�O�Ɏ�������ăf�[�^�����邩��
������l�ɂȂ����̂ł�H
������l�ɂȂ����̂ł�H
�����牽�Ŏw���I�ɉ��Z�ʂ������镪���Ⴆ�ɏo����w
���͕���̑S�p�^�[���Ȃ�Č����ĂȂ����B
�\���͐��x���オ���Ă��\���B
���͕���̑S�p�^�[���Ȃ�Č����ĂȂ����B
�\���͐��x���オ���Ă��\���B
��p���Z�@�Ȃ\������Ȃ��Ďg�����̂�������Ė��������
481 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 16:47:27.78 ID:qr9HLeI3
����\���~�X�ɂ��p�C�v���C���ғ����̒ቺ�Ȃ�Ă��܂ǂ��̃A�[�L�e�N�`���ł�
����������肶��Ȃ����
�ŋ߂�Intel�R���p�C����cmov��f���Ȃ��Ȃ��Ă��Ă邵�B
����������肶��Ȃ����
�ŋ߂�Intel�R���p�C����cmov��f���Ȃ��Ȃ��Ă��Ă邵�B
��k�ŃZ���������������Ǐ�k����Ȃ����\��������
483 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 16:53:32.88 ID:qr9HLeI3
���߂̏o���p�x�͈�ʂ̃v���O�����ł�20%���x�Ƃ����Ă���B
����𗼕��̃p�X����������ƒP����2�{�̉��Z�킪�K�v�ɂȂ�B
�����ł܂���������̍X��2�{�B
��ǂ݂����悤�Ƃ������قǎg�����Z��̐����w�����I�ɑ����闝����B
�܂��v�����GPU�ɗ��Ƃ����߂�悤�ȗނ̉��Z���ď��F�u��ʓI�v�Ȃ̂��B
����𗼕��̃p�X����������ƒP����2�{�̉��Z�킪�K�v�ɂȂ�B
�����ł܂���������̍X��2�{�B
��ǂ݂����悤�Ƃ������قǎg�����Z��̐����w�����I�ɑ����闝����B
�܂��v�����GPU�ɗ��Ƃ����߂�悤�ȗނ̉��Z���ď��F�u��ʓI�v�Ȃ̂��B
�c�q���v���O�����]�X���Ƃ��͋�s
����������肶��Ȃ��Ƃ���ԑ�Ђ�����Ԃ��Ȃ�w
�Z�p�v�V���菬���ȉ��P�̐ςݏd�˂���̔��W����B
�����č���͏������Ȃ����B
���Ⴀ���͂����܂łȁB
�Z�p�v�V���菬���ȉ��P�̐ςݏd�˂���̔��W����B
�����č���͏������Ȃ����B
���Ⴀ���͂����܂łȁB
486 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:02:12.45 ID:qr9HLeI3
�s�k�錾�ł���
IDF�Ƃ��̔��\���Ă�ƁA���������������Ȑςݏd�˂������Ƃ��邱�Ƃ�A
�ꌩ�˔��q���Ȃ����Ƃ�n���Ɍ��r���Ă��̂ɂ���ߒ��Ȃǂ������āA
��邱�Ƃ���Ă�ȁ[�Ɗ������邼
�ꌩ�˔��q���Ȃ����Ƃ�n���Ɍ��r���Ă��̂ɂ���ߒ��Ȃǂ������āA
��邱�Ƃ���Ă�ȁ[�Ɗ������邼
488 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:07:47.30 ID:qr9HLeI3
Intel�͓��@�I�}���`�X���b�f�B���O�Ȃ�Ď��߂������
490 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:24:23.87 ID:qr9HLeI3
����̑唼�͉ߋ��̕�������9���ȏ�̃q�b�g���[�g�Ő��肷�邱�Ƃ��ł�����̂�
�唼�ŁA���S��50:50�Ő^�U�l�������_���Ȃ�Ă��̂͂قƂ�Ǒ��݂��Ȃ��̂�B
����ȍ��x�ȕ���\���@�\���Ȃ��Ă邩�炱��GPU�͉��Z���j�b�g���ʂɐς��
���ʏ������ł���킯��B
�ŏ������ʗp�r����߂Ă�B
�ł������Ȃ����Ƃ������o���邩�̂悤�Ɍ����̂̓n�b�^���ȊO�̂Ȃ�ł��Ȃ��B
�����Ă邩���d�v�Ȃ̂��B
�唼�ŁA���S��50:50�Ő^�U�l�������_���Ȃ�Ă��̂͂قƂ�Ǒ��݂��Ȃ��̂�B
����ȍ��x�ȕ���\���@�\���Ȃ��Ă邩�炱��GPU�͉��Z���j�b�g���ʂɐς��
���ʏ������ł���킯��B
�ŏ������ʗp�r����߂Ă�B
�ł������Ȃ����Ƃ������o���邩�̂悤�Ɍ����̂̓n�b�^���ȊO�̂Ȃ�ł��Ȃ��B
�����Ă邩���d�v�Ȃ̂��B
>>489
�D�G����AMD�Ɍ�������͂��Ȃ��Ĕp���C�������Ȃ��i'A`�j
�D�G����AMD�Ɍ�������͂��Ȃ��Ĕp���C�������Ȃ��i'A`�j
�C���e���͑��R�A�ɂ��ăN���b�N������Ɣ��ł���V���O�����\�������邩���
������H�ɓ����Ăǂ��ɂ��o���Ȃ������B
���j�b�g�ς�Ō떂�����Ă邯�ǂȁB
������H�ɓ����Ăǂ��ɂ��o���Ȃ������B
���j�b�g�ς�Ō떂�����Ă邯�ǂȁB
>>491
�����VESA�Ƃ��g��ł銴�����邩�炢���������
�����VESA�Ƃ��g��ł銴�����邩�炢���������
494 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:35:56.97 ID:qr9HLeI3
> ���R�A�ɂ��ăN���b�N������Ɣ��ł���V���O�����\�������邩���
Avoton�ɕ�����Opteron 33xx�V���[�Y�̈����͂����܂łɂ��悤��
Avoton�ɕ�����Opteron 33xx�V���[�Y�̈����͂����܂łɂ��悤��
�O�͐����v���Z�X�̌��E�́����Ƃ������Ă����ǒ����Ă邶���
�Ȃ�Ƃ��Ȃ���
�Ȃ�Ƃ��Ȃ���
�ړI�ʂ̃R�A�������w�e���W�[�j�A�X���ł��g�����W�X�^�����A�d�͌�����������B
�����������ɂ����Ȃ邩��A�����Ɉ����₷������̂����d�v�e�[�}�B
AMD�̓\�t�g�E�F�A�ʂł�HSA�A�n�[�h�E�F�A�ʂł�hUMA��hQ�𓋍ڂ���APU�A
�Ƃ��������o�����B
Intel�͉�������ĂȂ�
�����������ɂ����Ȃ邩��A�����Ɉ����₷������̂����d�v�e�[�}�B
AMD�̓\�t�g�E�F�A�ʂł�HSA�A�n�[�h�E�F�A�ʂł�hUMA��hQ�𓋍ڂ���APU�A
�Ƃ��������o�����B
Intel�͉�������ĂȂ�
497 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:40:05.01 ID:qr9HLeI3
Google�搶�ɁuIntel QuickAssist Technology�v�ŕ����Ă݂�Ƃ�����B
Xilinx��Altera��AMD���瓦���Ă����܂����B
Xilinx��Altera��AMD���瓦���Ă����܂����B
>>493
���҂������Ƃ����[
���҂������Ƃ����[
499 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 17:42:42.63 ID:qr9HLeI3
���o�C���ɓK����CPU�Ƃ�����̗p���Ă����x���_�[�Ɍb�܂�ĂȂ������
�����`�b�v�͂�
����Acer�Ɠ��ł�Dockport�̃v���g�^�C�v���s�̗p���ĂȂ�������
Acer��V5-122P��TI��Dockport�`�b�v���g���Ă���̂͊m��i��������I�v�V������HDMI�o�͋@�\�Ȃǂ�����炵�����A���{�Ŕ����Ă邩�͒m���j�A
���ł͒m��NJC�O�@���AMD�����ƍ̗p���邩�炠�邩���m���ȁB��Lenovo�����i�ł������C������B
���ł͒m��NJC�O�@���AMD�����ƍ̗p���邩�炠�邩���m���ȁB��Lenovo�����i�ł������C������B
>>488
Anaphase�F�E�E�E�E
Anaphase�F�E�E�E�E
Mac�ȊO�̃m�[�g�̏[�d�݂͂��DockPort�ɓ��ꂵ�Ă���B
Mini-ITX�}�U�[��DockPort���狋�d�ł���z�������Ă�������������Ȃ��B
Mini-ITX�}�U�[��DockPort���狋�d�ł���z�������Ă�������������Ȃ��B
������Œlj������L���b�V������������
4k8k�����t���V���x��Ȃ���DS�G���R�[�_�[�ʂ����߂̃L���b�V���ł���B
�{�̑��́A4Core�������Z�����A4-8CU�ςݑ����ŁAKaveri�Ƃ̍��͔����ȃ��x���ɗ������������݁B
4k8k�����t���V���x��Ȃ���DS�G���R�[�_�[�ʂ����߂̃L���b�V���ł���B
�{�̑��́A4Core�������Z�����A4-8CU�ςݑ����ŁAKaveri�Ƃ̍��͔����ȃ��x���ɗ������������݁B
�@�@�@�@�Q�Q�Q
�@�@�@�^�@ �_::/�_�@�@�݂Ȃ������APU�����S���ł��܂���
�@�@�^�@�(��)::(��)��@�@7850K��BF4�ŃZ�������Ƀ{���������܂���
�@ �b::�@�@��(_�l_)߁b�@�����ăZ��������mantle�Ŗ�P���̐��\������B���iDX��j
�@�@�_ �@߁@`�܁L�^߁@�@�Z��������mantle�̑������ǂ��ł�
�@�@�^ �܁R�P�P�Rߡ
�@ / _�Q�_ �_/�_ �_�@�@�I������A�A�AAPU�����S�ɏI������A�A�A
�@�ƁQ�Q)_�R_�� �R_��
�yG1820+HD7750��BF4����z�iWin8.1pro x64 driver14.1)
BF4 DX11 720p ���ݒ�
http://youtu.be/AK6h7bQQVHw
BF4 Mantle 720p ���ݒ�
http://youtu.be/kXobIk0_dns
�y����`��10�b�Ԃ�fps�z
DX11 �ō� 115fps�^�Œ� 59fps�^���� 81.7fps
Mantle �ō� 119fps�^�Œ� 67fps�^���� 89.0fps
�@�@�@�^�@ �_::/�_�@�@�݂Ȃ������APU�����S���ł��܂���
�@�@�^�@�(��)::(��)��@�@7850K��BF4�ŃZ�������Ƀ{���������܂���
�@ �b::�@�@��(_�l_)߁b�@�����ăZ��������mantle�Ŗ�P���̐��\������B���iDX��j
�@�@�_ �@߁@`�܁L�^߁@�@�Z��������mantle�̑������ǂ��ł�
�@�@�^ �܁R�P�P�Rߡ
�@ / _�Q�_ �_/�_ �_�@�@�I������A�A�AAPU�����S�ɏI������A�A�A
�@�ƁQ�Q)_�R_�� �R_��
�yG1820+HD7750��BF4����z�iWin8.1pro x64 driver14.1)
BF4 DX11 720p ���ݒ�
http://youtu.be/AK6h7bQQVHw
BF4 Mantle 720p ���ݒ�
http://youtu.be/kXobIk0_dns
�y����`��10�b�Ԃ�fps�z
DX11 �ō� 115fps�^�Œ� 59fps�^���� 81.7fps
Mantle �ō� 119fps�^�Œ� 67fps�^���� 89.0fps
�̂̃R�s�y����Lightningbolt���}����Ă����ǁADockPort�ɉ��߂āA�ĊO�����Ƃ���ɂ����܂肻�����ȁB
>>508
(߄t�) 250X��384sp��7750��艺�����甃���܂���
(߄t�) �ł�7850K+250��DG�Ƃ̑Ό��̂��߂ɂȂO���{���������ȂƔ��R�Ǝv���Ă܂�
(߄t�) 250X��384sp��7750��艺�����甃���܂���
(߄t�) �ł�7850K+250��DG�Ƃ̑Ό��̂��߂ɂȂO���{���������ȂƔ��R�Ǝv���Ă܂�
250X��640SP��
(߄t�) �����A�e�ɂ��肪��
�yMantle�܂Ƃ߁z
G1820+HD7750�Œ��ݒ��1����A��ݒ�Ȃ�2�����fps���オ������
�_�Ɋւ��Ă͑O�]���ʂ�ʼne�Ȃ��̂���i�S�V���ł��m�F�\�j
�_�ȊO�̉掿�ɂ��Ă͂Ƃ肠�����m�F�������̂͂Ȃ�
14.1�͊��S�Ȋj�n���h���C�o
BF4�N���ɃR�P�邵�A���j���[��ʂŋ����I��������A�Q�[�����ɕ`�旐�ꂽ��ߎS
����ŃQ�[���y���߂Ƃ������A�z����
�o���ȑO�̖��A�s����炯�A����h���C�o�o�Ȃ�����͎��Q�[�Ɏg���͖̂���
�Ƃ������P�Ō���mantle�͕��u����̂��g
G1820+HD7750�Œ��ݒ��1����A��ݒ�Ȃ�2�����fps���オ������
�_�Ɋւ��Ă͑O�]���ʂ�ʼne�Ȃ��̂���i�S�V���ł��m�F�\�j
�_�ȊO�̉掿�ɂ��Ă͂Ƃ肠�����m�F�������̂͂Ȃ�
14.1�͊��S�Ȋj�n���h���C�o
BF4�N���ɃR�P�邵�A���j���[��ʂŋ����I��������A�Q�[�����ɕ`�旐�ꂽ��ߎS
����ŃQ�[���y���߂Ƃ������A�z����
�o���ȑO�̖��A�s����炯�A����h���C�o�o�Ȃ�����͎��Q�[�Ɏg���͖̂���
�Ƃ������P�Ō���mantle�͕��u����̂��g
515 �FSocket774�F2014/02/11(��) 19:15:19.12 ID:ZuE/i/pU
HSA���������ǁASSE�Ƃ�AVX�̃x�N�^������GPU���ɓ�������悤�ɏo����ƐF�X�ƓW�J�v�ꂻ���ȋC������B
�ėp�Ɛ�p�̉��Z�@�̃n�C�u���b�h������
�ڑ������܂��������邢�́E�E�E����
�ڑ������܂��������邢�́E�E�E����
517 �Fsage�F2014/02/11(��) 19:22:43.93 ID:ZuE/i/pU
���\�������o���邩�͔��������ǁA����PC�s�ꂾ���Ɍ��肷��ƁASSE�EAVX�̕����g����P�[�X�͑����Ǝv�����E�E�E�B
SSE�͑������ǁAAVX�Q�Ƃ��ɑΉ����Ă�ŐV�Z�p�D���ȃ\�t�g��OpenCL�Ƃ��ɂ��Ή����Ă邱�Ƃ��������ǂ�
�ꉞC2Q����SSE����������A�͂ꂽ�\�t�g�̓���͖��Ȃ�����
�ꉞC2Q����SSE����������A�͂ꂽ�\�t�g�̓���͖��Ȃ�����
519 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 19:36:57.16 ID:qr9HLeI3
>>515
�P���ɓ����邾���Ő��S�T�C�N��������܂����ǂ���ł�낵���́H
512SP������4�`8SP���̏��������s���Ă��S�����������Ȃ��ł���B
�P���ɓ����邾���Ő��S�T�C�N��������܂����ǂ���ł�낵���́H
512SP������4�`8SP���̏��������s���Ă��S�����������Ȃ��ł���B
�������낤�Ƃ����CPU�R�A�����ɖc���SIMD���Z��ƈꏏ��TMU��ROP���ڂ��������v���Z�b�T�����Ȃ��Ɩ������Ǝv����
���ݒ���Ă̂����H�삾�˂��@>>506
PC�Ŏ����Ă���N�����`�������W����D�ݐݒ�@���ݒ�Ƃ�AA�Ƃ����ʊ|����Ǝv����
����������ɒ��ݒ�݂̂Ńx���`���������Ď��͂��������グ��Ε�������H��
�m��7850k+�}���g���Ȃ�80f�o�Ă�����i3��67f���@�ց`��
PC�Ŏ����Ă���N�����`�������W����D�ݐݒ�@���ݒ�Ƃ�AA�Ƃ����ʊ|����Ǝv����
����������ɒ��ݒ�݂̂Ńx���`���������Ď��͂��������グ��Ε�������H��
�m��7850k+�}���g���Ȃ�80f�o�Ă�����i3��67f���@�ց`��
�X�y�b�N���߂����ō����PSSL�ƈ���Ă�͂�Mantle�͕s����Ȃ�
���肷��܂ł̐��N�Ԃ͖�����PC�g�킸PS4�����ăQ�[������̂������
PS4�����Ă�AMD�ɂ͋������
���肷��܂ł̐��N�Ԃ͖�����PC�g�킸PS4�����ăQ�[������̂������
PS4�����Ă�AMD�ɂ͋������
���������Ύ������邩�ǂ����͂Ƃ���������Ȃ̂���������
Skylake Microarchitecture�̕�����?
http://microboy.seesaa.net/archives/201305-1.html
Skylake Microarchitecture�̕�����?
http://microboy.seesaa.net/archives/201305-1.html
>>524�@���Xbroadwell���_��OpenCL2.0�ɑΉ�������ĉ\�����邵�A��������̕��@��
iGPU���p���ˁ[�Ƃ��Ă̂�Intel���v���Ă邱�Ƃł���
����QSV�݂�����iGPU�A�N�e�B�u�ɂ��ĂȂ��Ǝg���܂���`�̓}�W�Ŋ��ق��Ăق����Avirtu���}�W�Ŏg���ˁ[��
���iiGPU�ł�GPU�̓����O�A�C�h���A�Q�[����GPGPU�̎��ɋN�����ā`�݂����Ȏg��������Intel���ƌ��������
�}���`GPU���z�肷��Ȃ����ϗ�������AMD�Ɋ��҂������������ǁA�Ƃ肠����carrizo�Ǝ�����GCN���悩��
iGPU���p���ˁ[�Ƃ��Ă̂�Intel���v���Ă邱�Ƃł���
����QSV�݂�����iGPU�A�N�e�B�u�ɂ��ĂȂ��Ǝg���܂���`�̓}�W�Ŋ��ق��Ăق����Avirtu���}�W�Ŏg���ˁ[��
���iiGPU�ł�GPU�̓����O�A�C�h���A�Q�[����GPGPU�̎��ɋN�����ā`�݂����Ȏg��������Intel���ƌ��������
�}���`GPU���z�肷��Ȃ����ϗ�������AMD�Ɋ��҂������������ǁA�Ƃ肠����carrizo�Ǝ�����GCN���悩��
526 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 20:16:01.73 ID:qr9HLeI3
�Ȃ�Ƃ��ł���Ȃ�256bit, 512bit�̐V���߂Ȃ�ĕs�v�ł��B
GPGPU������Ă�̂͐�������̉��z�}�V���p�̃R�[�h������
��������@�̃}�V���̃x�N�g�����Ƀ^�X�N�������ď������Ă���Ă���
�������f�[�^�Z�b�g�����ɑg�܂ꂽ�R�[�h��傫���f�[�^�Z�b�g�p��
���Z��Ŏ��s����Γ��R���ʂ��������܂���ȁB
GPGPU������Ă�̂͐�������̉��z�}�V���p�̃R�[�h������
��������@�̃}�V���̃x�N�g�����Ƀ^�X�N�������ď������Ă���Ă���
�������f�[�^�Z�b�g�����ɑg�܂ꂽ�R�[�h��傫���f�[�^�Z�b�g�p��
���Z��Ŏ��s����Γ��R���ʂ��������܂���ȁB
3DCG�Q�[�����Ƃ����āA���Ƃ��ΕW���ݒ�60fps�Œ�Ƃ����ƁA�ш���V�F�[�_�[�R�A���V�т܂����Ă���
������A���̗V��ł�ш��V�F�[�_�[�R�A�g���Čv�Z����]�n������܂���
�Ƃ��낪�A���掿�ݒ�Afps�Œ薳�����ƁA�ш�̓J�c�J�c�����V�F�[�_�[�R�A�͗V�т܂����Ă�
�ш���g��Ȃ��v�Z�Ȃ�K���K�����]�n������
������A���̗V��ł�ш��V�F�[�_�[�R�A�g���Čv�Z����]�n������܂���
�Ƃ��낪�A���掿�ݒ�Afps�Œ薳�����ƁA�ш�̓J�c�J�c�����V�F�[�_�[�R�A�͗V�т܂����Ă�
�ш���g��Ȃ��v�Z�Ȃ�K���K�����]�n������
528 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 20:33:47.57 ID:qr9HLeI3
>>524
Intel�̓��������͓����ƒ��ڊW�Ȃ��Ƃ���̗v���v����
�R������߂Ă��邺�B
���Ƃ���Larrabee��scatter/gather�̎����ɂ����������ł�
CPU�R�A��Out-Of-Order�Ƃ������ƂɂȂ��Ă���
���ۍ��ꂽ�̂�P54C�x�[�X�̃C���I�[�_�̃R�A�B
���m�ɏ����Ă��܂��ƑΏۂƂȂ�v���Z�b�T�̓����\�������O�ɘR�炷
���ƂɂȂ��Ă邩��ȁB
�{��GPU�ɂ���ׂ����j�b�g�́A�����ΏۂƂ͒��ڊW���Ȃ��̂�
����̓~�X���[�h�̂��߂̎d���݂ƍl����̂��Ó��B
Intel�̓��������͓����ƒ��ڊW�Ȃ��Ƃ���̗v���v����
�R������߂Ă��邺�B
���Ƃ���Larrabee��scatter/gather�̎����ɂ����������ł�
CPU�R�A��Out-Of-Order�Ƃ������ƂɂȂ��Ă���
���ۍ��ꂽ�̂�P54C�x�[�X�̃C���I�[�_�̃R�A�B
���m�ɏ����Ă��܂��ƑΏۂƂȂ�v���Z�b�T�̓����\�������O�ɘR�炷
���ƂɂȂ��Ă邩��ȁB
�{��GPU�ɂ���ׂ����j�b�g�́A�����ΏۂƂ͒��ڊW���Ȃ��̂�
����̓~�X���[�h�̂��߂̎d���݂ƍl����̂��Ó��B
>>525
Intel��GPGPU���p�͂��邾�낤����ȁB
���ꂪHSA�ł͂Ȃ��āAIntel�Ǝ������Ō����openCL���g���Ẳ\���͂��邾�낤�B
���ƁANv��Nv ARM�ł�HSA�g��Ȃ������ōs�����Ċ������낤�BApple��HSA����Ȃ�����Ǝ��̂������낤�Ǝv���B
Intel��GPGPU���p�͂��邾�낤����ȁB
���ꂪHSA�ł͂Ȃ��āAIntel�Ǝ������Ō����openCL���g���Ẳ\���͂��邾�낤�B
���ƁANv��Nv ARM�ł�HSA�g��Ȃ������ōs�����Ċ������낤�BApple��HSA����Ȃ�����Ǝ��̂������낤�Ǝv���B
��Âɍl���Ă݂�ƁA4way��8way�̃f�[�^�Z�b�g�ŁA���S�E����̉��Z���j�b�g�̉�߂�̂͂��Ȃ������ł��ˁB
�Ƃ������Ƃ́A����ς荡���APU�ł��ACPU����SIMD���Z���j�b�g�͎c�����܂܂���Ȃ��ƃ_���Ȃ̂��E�E�E�B
�Ƃ������Ƃ́A����ς荡���APU�ł��ACPU����SIMD���Z���j�b�g�͎c�����܂܂���Ȃ��ƃ_���Ȃ̂��E�E�E�B
>>526
���Ȃ�Ƃ��ł���Ȃ�256bit, 512bit�̐V���߂Ȃ�ĕs�v�ł��B
Intel�̕������ƃx�N�g�������Ȃ��Ƒ����Ȃ�Ȃ�����x�N�g�����߂��K�v��������Ȃ�����
GCN���ƃx�N�g�����������ĂȂ���B
clinfo���Ă���OpenCL�ɕt���Ă���R�}���h�Ńf�o�C�X���̐����x�N�g���T�C�Y���ׂ��邯��
Intel��double��4�Ƃ��ɂȂ��Ă���̂ɑ��AGCN����1�ɂȂ��Ă�B�܂�x�N�g�����͐������ĂȂ��B
HD6000�V���[�Y���x�N�g���x�[�X�������̂��������GCN�ł͒E�x�N�g�������Ă��邱�Ƃ���
������ProcessingUnit������GPU�ł̓x�N�g�����̈Ӗ����������Č������f�ȂƂ�������B
���Ȃ�Ƃ��ł���Ȃ�256bit, 512bit�̐V���߂Ȃ�ĕs�v�ł��B
Intel�̕������ƃx�N�g�������Ȃ��Ƒ����Ȃ�Ȃ�����x�N�g�����߂��K�v��������Ȃ�����
GCN���ƃx�N�g�����������ĂȂ���B
clinfo���Ă���OpenCL�ɕt���Ă���R�}���h�Ńf�o�C�X���̐����x�N�g���T�C�Y���ׂ��邯��
Intel��double��4�Ƃ��ɂȂ��Ă���̂ɑ��AGCN����1�ɂȂ��Ă�B�܂�x�N�g�����͐������ĂȂ��B
HD6000�V���[�Y���x�N�g���x�[�X�������̂��������GCN�ł͒E�x�N�g�������Ă��邱�Ƃ���
������ProcessingUnit������GPU�ł̓x�N�g�����̈Ӗ����������Č������f�ȂƂ�������B
532 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 21:34:43.68 ID:qr9HLeI3
����x�N�g���̈Ӗ��Ⴄ���
AoS-SoA�ϊ��̂��߂̍����ȃ��j�b�g����������Ă邩��
�\���̂Ƃ���AoS�\���ɂ���Ӗ��͂Ȃ����Ă�����
�ŏ������P�ʂ͂����炩�Ƃ�����AAVX�͒P���x8�v�f����
GCN�͒P���x64�v�f
AoS-SoA�ϊ��̂��߂̍����ȃ��j�b�g����������Ă邩��
�\���̂Ƃ���AoS�\���ɂ���Ӗ��͂Ȃ����Ă�����
�ŏ������P�ʂ͂����炩�Ƃ�����AAVX�͒P���x8�v�f����
GCN�͒P���x64�v�f
MS��Windows9��AVX2�K�{�ɂ��āA
Intel��Pentium/Celeron/ATOM�ɂ�AVX2�̂��Ă����Ƃ��ꂵ��
AVX2���S���f���ɍڂ�Ȃ������łȂ��Ȃ����y���Ȃ�
Intel��Pentium/Celeron/ATOM�ɂ�AVX2�̂��Ă����Ƃ��ꂵ��
AVX2���S���f���ɍڂ�Ȃ������łȂ��Ȃ����y���Ȃ�
534 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 21:37:09.31 ID:qr9HLeI3
Kaveri�g���Ȃ��Ȃ邯�ǁH
DirectX11�ȍ~��p��DirectCompute�K�{���炢�̂ق��������I���Ȃ�
Win8�͂ւ��ۂ�Atom��ARM���̂����ōŏ��v����DX9�~�܂�ɂȂ��Ă邵
Win8�͂ւ��ۂ�Atom��ARM���̂����ōŏ��v����DX9�~�܂�ɂȂ��Ă邵
���܂ł̂悤�ɏ]���R�[�h�����̂܂܂ő����Ȃ鎞��ƈ���āA
Haswell�́ASandy�ȍ~��Intel�v���Z�b�T�ɍœK�������R�[�h�������Ȃ�悤�ɂȂ��Ă�
AVX2�K�{�͂Ƃ������AWindows9��AVX�K�{�ɂ��āA
OS/���C�u����/�R���p�C�����f���R�[�h�Ƃ���Sandy�ȍ~��CPU�ɍœK������A
����Ȃ��CPU�̐i���̉��b�����
Haswell�́ASandy�ȍ~��Intel�v���Z�b�T�ɍœK�������R�[�h�������Ȃ�悤�ɂȂ��Ă�
AVX2�K�{�͂Ƃ������AWindows9��AVX�K�{�ɂ��āA
OS/���C�u����/�R���p�C�����f���R�[�h�Ƃ���Sandy�ȍ~��CPU�ɍœK������A
����Ȃ��CPU�̐i���̉��b�����
>>533
���ȁI�������̂���HSA�K�{�ɂ���Intel���쒀���悤����
���ȁI�������̂���HSA�K�{�ɂ���Intel���쒀���悤����
Windows8.1�ł���2006�N�ȍ~��CPU�Ȃ瓮�����x�ɗ��߂Ă����
AVX�K�{�͂��肦�Ȃ���
�Ƃ������ŋ߂�CPU�ł�Llano��Celeron�Ƃ��̂��Ƃ��l�����SSE3�K�{���x�����x�ł���
AVX�K�{�͂��肦�Ȃ���
�Ƃ������ŋ߂�CPU�ł�Llano��Celeron�Ƃ��̂��Ƃ��l�����SSE3�K�{���x�����x�ł���
��������������H����Mac�ɂł����҂��Ƃ�
Windows�ɂ͉����ł��Ăق�����
Windows�ɂ͉����ł��Ăق�����
>>532
GCN�̐�����AoS�Ƃ�SoA�Ƃ������L�q���̌������Ɩ������炻��������H�͎����ĂȂ��Ǝv��
�킴�킴�z��`���Ƀf�[�^�𐮌`�����ɂ��̂܂ܓ������Ă�Ǝv����
����AMD���o���Ă�OpenCL�̃K�C�h�ǂނƁA
�������A�N�Z�X��Channel�R���t���N�g���N���Ȃ��悤�ɃA�h���X���܂�ɂȂ�悤�ɃA�N�Z�X���邱�Ƃ𐄏����Ă���
���܂ł̏펯�i�A�������������A�N�Z�X�̕��������j���ʗp���Ȃ��A��Ȑ��E�ɂȂ��Ă�
GCN�̐�����AoS�Ƃ�SoA�Ƃ������L�q���̌������Ɩ������炻��������H�͎����ĂȂ��Ǝv��
�킴�킴�z��`���Ƀf�[�^�𐮌`�����ɂ��̂܂ܓ������Ă�Ǝv����
����AMD���o���Ă�OpenCL�̃K�C�h�ǂނƁA
�������A�N�Z�X��Channel�R���t���N�g���N���Ȃ��悤�ɃA�h���X���܂�ɂȂ�悤�ɃA�N�Z�X���邱�Ƃ𐄏����Ă���
���܂ł̏펯�i�A�������������A�N�Z�X�̕��������j���ʗp���Ȃ��A��Ȑ��E�ɂȂ��Ă�
Win8�ł悤�₭SSE2���K�{�ɂȂ������炢�ɁA
OS����CPU�g�����ߎg�p�͂��₩�Ȃ̂ɁA
����CPU�ł͕��C�Ŋg�����ߍ��Intel����AVX2�K�{���ȂǂƁA
�����݂����Ȃ��ƌ����Ă�̂�
OS����CPU�g�����ߎg�p�͂��₩�Ȃ̂ɁA
����CPU�ł͕��C�Ŋg�����ߍ��Intel����AVX2�K�{���ȂǂƁA
�����݂����Ȃ��ƌ����Ă�̂�
�唼�̃A�v������AVX�Ȃ�Ă����ĂȂ�����Ȃ�
����AVX2���g����Corei3��SSE4.2�܂ł�PentiumG����GFLOPS�l�����Ȃ�
�啝�ɍ������邪���ۂɂ��ꂪ���������A�v�����Ăǂꂾ�������
����AVX2���g����Corei3��SSE4.2�܂ł�PentiumG����GFLOPS�l�����Ȃ�
�啝�ɍ������邪���ۂɂ��ꂪ���������A�v�����Ăǂꂾ�������
>>542
������AHSA�\�t�g������Ȋ����ɂȂ邾�낤�ȂƎv���B
HSA�\�t�g�͑��C���ł͂Ȃ�HSA���[�U�[���F�X�ǂ��\�t�g������Č��J����HSA���i���Ȃ��Ƃ����Ȃ�
������AHSA�\�t�g������Ȋ����ɂȂ邾�낤�ȂƎv���B
HSA�\�t�g�͑��C���ł͂Ȃ�HSA���[�U�[���F�X�ǂ��\�t�g������Č��J����HSA���i���Ȃ��Ƃ����Ȃ�
SSE(128Bit)������Nehalem���ォ���FLOPs per cycle�X���C�h����������
http://images.anandtech.com/reviews/cpu/intel/Haswell/Architecture/avx2.jpg
http://images.anandtech.com/reviews/cpu/intel/Haswell/Architecture/avx2.jpg
{kind=link}
>>542
AMD64����SSE2���K�{����������A����Ȃ�ɕ��y�������ƂɂȂ�
>>543
��v�R���p�C���ƃ��C�u���������ׂ�AVX���T�|�[�g���Ă��邩��A
�m�炸�m�炸�Ɏg���Ă����
�G���R�Ȃǂ̓��ʂȃ\�t�g������AVX�Ή��Ƃ����킯����Ȃ�
AMD64����SSE2���K�{����������A����Ȃ�ɕ��y�������ƂɂȂ�
>>543
��v�R���p�C���ƃ��C�u���������ׂ�AVX���T�|�[�g���Ă��邩��A
�m�炸�m�炸�Ɏg���Ă����
�G���R�Ȃǂ̓��ʂȃ\�t�g������AVX�Ή��Ƃ����킯����Ȃ�
win9��2015�������H8�͂���������ȁA2015��20�����łĂ������邩
win9��DDR4�������[�Ɠ����ʕs�m��߂���Ǝv�����B
7�R�P8�R�P�ŃC���e�����ʖڂ͎����������Ȃ炠��̂�2016�N�ӂ�܂ł�
win8,2 win8,3(�v�����XPsp1,2,3)�ōs����Ȃ��낤��
7�R�P8�R�P�ŃC���e�����ʖڂ͎����������Ȃ炠��̂�2016�N�ӂ�܂ł�
win8,2 win8,3(�v�����XPsp1,2,3)�ōs����Ȃ��낤��
�l�b�g�L����ǂ�ł݂�ƁAGCN��HSA�ł́A�����I��SIMT�Ŏ��s����邩��A�x�N�^���͓��Ɉӎ�����K�v���Ȃ��A�Ƃ��������Ƃ�������Ă��܂��ˁB
Wavefront�̘_���x�N�^��64way���ӎ����ăv���O���~���O����A�������I�Ƀv���O������������A�Ƃ����������݂����B
Wavefront�̘_���x�N�^��64way���ӎ����ăv���O���~���O����A�������I�Ƀv���O������������A�Ƃ����������݂����B
Intel��celeron�AAtom��AVX���Ή�
AMD��Temash�ł���AVX�Ή�
AVX�����y�����獢��̂�Intel����
AMD��Temash�ł���AVX�Ή�
AVX�����y�����獢��̂�Intel����
552 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 23:58:20.25 ID:qr9HLeI3
�ʂɋ�����≺�ʂ�CPU�ŃT�|�[�g���ĂȂ�����Ƃ������R�ōŐV���߂�
�g���Ă͂����Ȃ����R�͂Ȃ����B
��T�|�[�g��CPU�𗝗R�ɂ��郔�@�J�͕������珑���Ȃ����@�J��
�A�s�[�����Ă���ɂ����Ȃ��B
������ŕK�{�ɂ��ė~�����̂͂ނ���MPX���ȁB
�g���Ă͂����Ȃ����R�͂Ȃ����B
��T�|�[�g��CPU�𗝗R�ɂ��郔�@�J�͕������珑���Ȃ����@�J��
�A�s�[�����Ă���ɂ����Ȃ��B
������ŕK�{�ɂ��ė~�����̂͂ނ���MPX���ȁB
�ʂɂ��܂�Ⴙ��
�{���ɕK�v�Ȃ�V����AVX�Ή���Celeron�o�����甃���Ă��������ŏI��肾��
�ނ��딃���ւ����v������Ȃ�
������AMD�̎��v�����N�����Ȃ�ĉ\���͂Ȃ���
�{���ɕK�v�Ȃ�V����AVX�Ή���Celeron�o�����甃���Ă��������ŏI��肾��
�ނ��딃���ւ����v������Ȃ�
������AMD�̎��v�����N�����Ȃ�ĉ\���͂Ȃ���
554 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 00:05:15.56 ID:qr9HLeI3
>>551
256�r�b�gSIMD���߂�2�T�C�N���ɕ������Ď��s���邾���Ȃ�
SSE�Ɣ�ׂē��ɗL���ƌ������Ƃ͂Ȃ��B
�ނ���Temash�̓�������1ch�����Ȃ���BayTrail���N���b�N���R�A��������Ă邵
���������ʂ��Ȃ��B
256�r�b�gSIMD���߂�2�T�C�N���ɕ������Ď��s���邾���Ȃ�
SSE�Ɣ�ׂē��ɗL���ƌ������Ƃ͂Ȃ��B
�ނ���Temash�̓�������1ch�����Ȃ���BayTrail���N���b�N���R�A��������Ă邵
���������ʂ��Ȃ��B
>>553
>AMD�̎��v�����N�����Ȃ�ĉ\���͂Ȃ���
���AAMD���[�U�[��������ɂ͓��ӁB
���N�����Ȃ�A���߁A�@�\�t���T�|�[�g��AMD���V�F�A20%�Ƃ����ď�Ȃ����ƂɂȂ�Ȃ����낤
>AMD�̎��v�����N�����Ȃ�ĉ\���͂Ȃ���
���AAMD���[�U�[��������ɂ͓��ӁB
���N�����Ȃ�A���߁A�@�\�t���T�|�[�g��AMD���V�F�A20%�Ƃ����ď�Ȃ����ƂɂȂ�Ȃ����낤
�ꉞ�AVEX�t�H�[�}�b�g�̉��b�ŁA�ăR���p�C������Γ���128bit�ł�SSE��萫�\����̉\���͂���݂����B
OpenCL�̎d�l�g�����Ă����`�ŋƊE�W�����i�W���Ă�̂�
�킴�킴HSA�Ή��ƌ����Ӗ��͂Ȃ����낤
ARM�n�̓\�t�g�E�F�A�X�^�b�N�𗬗p�ł��Ċ������̂����������
�킴�킴HSA�Ή��ƌ����Ӗ��͂Ȃ����낤
ARM�n�̓\�t�g�E�F�A�X�^�b�N�𗬗p�ł��Ċ������̂����������
558 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 00:15:42.85 ID:kt5jcB9L
MPX�̓G�A�{����Atom�ɂ��ڂ�炵�����玟��Windows�ł̏��E�W���@�\��
���荞�܂�邩�������ˁB
���荞�܂�邩�������ˁB
559 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 00:17:06.97 ID:kt5jcB9L
>>556
���炠���B3�I�y�����h�����B
�܂��A���\���㗦�Ȃ��1�����Ȃ����Ă̂������ȂƂ���B
�������ш�l�b�N�Ȃ�X�Ɏg����B
��������Jaguar����L2���x����ˁB
���炠���B3�I�y�����h�����B
�܂��A���\���㗦�Ȃ��1�����Ȃ����Ă̂������ȂƂ���B
�������ш�l�b�N�Ȃ�X�Ɏg����B
��������Jaguar����L2���x����ˁB
SSE�EAVX���߂̃x�N�^������GPU�n�[�h�E�F�A�ɓ�������悤�ɂ��悤�Ƃ����
�E�������A�N�Z�X�̃��C�e���V�����[�{�g���l�b�N
�E16way��SIMD���Z���j�b�g�߂��Ȃ��Ɓi�������߂̃f�[�^��16�X���b�h���p�ӂł��Ȃ��Ɓj���s�������{���{��
��������������OK�H
�E�������A�N�Z�X�̃��C�e���V�����[�{�g���l�b�N
�E16way��SIMD���Z���j�b�g�߂��Ȃ��Ɓi�������߂̃f�[�^��16�X���b�h���p�ӂł��Ȃ��Ɓj���s�������{���{��
��������������OK�H
561 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 00:25:32.82 ID:kt5jcB9L
�R�A�̃N���b�N�����l�����Ȃ��ƂˁB
3.7GHz��720MHz����Ⴂ������ł���
3.7GHz��720MHz����Ⴂ������ł���
�ׂ����������̂������������̂͐���y���ɓ��
x86�̃X�J�����߂���SIMD���߂ɕϊ�����ƌ����Ă�̂Ɠ���������
�ǂ����Ă����������A�v���[�`���������Ȃ�A��O�̒i�K�Ő����ς���̂��܂��}�V
�����璆�Ԍ����ݒ肵�ĉ��z�}�V����JIT�R���p�C������Ƃ����������b�ɂȂ�
JVM�Ƃ���
x86�̃X�J�����߂���SIMD���߂ɕϊ�����ƌ����Ă�̂Ɠ���������
�ǂ����Ă����������A�v���[�`���������Ȃ�A��O�̒i�K�Ő����ς���̂��܂��}�V
�����璆�Ԍ����ݒ肵�ĉ��z�}�V����JIT�R���p�C������Ƃ����������b�ɂȂ�
JVM�Ƃ���
���\�Ɍv�Z���Ă݂��
CPU:4�v�f�~2���j�b�g�~2module�@�~3700MHz=592���v�f
GPU:64�v�f�~8CU�~720MHz=3686.4���v�f
���ꂪ���_��̃s�[�N�����\�́i�Ϙa�]�X�͖����j
���āA�悭�l������A���������ɂ͑����Ȑ��̃f�[�^��SIMD���j�b�g�߂邽�߂̃X���b�h���o���K�v����B
������CPU�Ƃ̂���肪�E�E�E�B
�ǂ͂��Ȃ荂�����Ƃ������ł����E�E�E�B
CPU:4�v�f�~2���j�b�g�~2module�@�~3700MHz=592���v�f
GPU:64�v�f�~8CU�~720MHz=3686.4���v�f
���ꂪ���_��̃s�[�N�����\�́i�Ϙa�]�X�͖����j
���āA�悭�l������A���������ɂ͑����Ȑ��̃f�[�^��SIMD���j�b�g�߂邽�߂̃X���b�h���o���K�v����B
������CPU�Ƃ̂���肪�E�E�E�B
�ǂ͂��Ȃ荂�����Ƃ������ł����E�E�E�B
>�ʂɋ�����≺�ʂ�CPU�ŃT�|�[�g���ĂȂ�����Ƃ������R�ōŐV���߂�
�g���Ă͂����Ȃ����R�͂Ȃ����B
����̏��Ȃ����߂Ń\�t�g�����͈̂ꕔ�̃n�C�G���h���̋Ɩ��p�B
���ꂩ��n�C�G���h���̃\�t�g�����ɉ���Ă���\��������\�t�g��
������đO��̘b�ł����Ă�̂��H
�g���Ă͂����Ȃ����R�͂Ȃ����B
����̏��Ȃ����߂Ń\�t�g�����͈̂ꕔ�̃n�C�G���h���̋Ɩ��p�B
���ꂩ��n�C�G���h���̃\�t�g�����ɉ���Ă���\��������\�t�g��
������đO��̘b�ł����Ă�̂��H
�Q�[������x����������
FX��HD6850�Ń~�h���C�����������ǐ��\�s�����Ȃ�
FX��HD6850�Ń~�h���C�����������ǐ��\�s�����Ȃ�
�F��������
AVX vs GPGPU�Ƃ��i���Z���X�ɂ������L��
��������AMD��AVX�ɂ��Ή����Ă��邵�A�����AVX2��AVX512�ɂ��Ή����Ă���
�v�́A�ėp�I��AMD64
��C�e���V�ŗ��_FP���\���ႢAVX
�����C�e���V�ŗ��_FP���\������GPGPU
����3���ɉ����Ďg���킯�悤�Ƃ����̂��AOpenCL��HSA
AVX vs GPGPU�Ƃ��i���Z���X�ɂ������L��
��������AMD��AVX�ɂ��Ή����Ă��邵�A�����AVX2��AVX512�ɂ��Ή����Ă���
�v�́A�ėp�I��AMD64
��C�e���V�ŗ��_FP���\���ႢAVX
�����C�e���V�ŗ��_FP���\������GPGPU
����3���ɉ����Ďg���킯�悤�Ƃ����̂��AOpenCL��HSA
����́`�Ƃ��s�m��Ȃ��ƌ����o���Ȃ�
INTEL�������Mantle��HSA�ɑΉ����邩���Ȃ�����
INTEL�������Mantle��HSA�ɑΉ����邩���Ȃ�����
>>567
> ����́`�Ƃ��s�m��Ȃ��ƌ����o���Ȃ�
�s�m�肶��Ȃ����ǂȁA��ΑΉ����Ă���
> INTEL�������Mantle��HSA�ɑΉ����邩���Ȃ�����
����͐�Ζ�������w
> ����́`�Ƃ��s�m��Ȃ��ƌ����o���Ȃ�
�s�m�肶��Ȃ����ǂȁA��ΑΉ����Ă���
> INTEL�������Mantle��HSA�ɑΉ����邩���Ȃ�����
����͐�Ζ�������w
�����Ȃ������_��x64�Ɠ�����intel�̑�s�k���낗
�܂�AMD�ɒǏ]����̂��悗
�܂�AMD�ɒǏ]����̂��悗
�����ǐ������炠���Ƃ����ԂɁE�E�E
�Ȃ�ł��\���Ƃ������Ă��炨�Ԕ��ɂȂ�
�܂�Intel��GPU����ǂ��������Ă��ǂ�����鎖�͂Ȃ����������ǂ�
AMD64�́AMS����Ή�����Ɩ��߂��ꂽ���炵�Ԃ��ԑΉ���������
HSA�͕ʂɒN��������߂���Ȃ�����Ǐ]�Ȃ�Ă��Ȃ����낤
���ɒǏ]���悤�Ƃ�����A��b�J������n�߂Ȃ��Ƒʖڂ�����A�o�ꂷ��̂͑�����5�N�キ�炢����
�ǂ���Intel�̂��Ƃ�����X�J�C���[�N�̎��̎����炢�͍���Ă邩��A���̍X�Ɍ�ł̑Ή�����
5�N�������Kaveri���瑊����������邵�AdGPU��Mantle�Ƃ̘A�g�����肻��������A
�܂��A�����ɒx���ŁAIntel�͏o��܂ł��Ȃ��������낤
HSA�͕ʂɒN��������߂���Ȃ�����Ǐ]�Ȃ�Ă��Ȃ����낤
���ɒǏ]���悤�Ƃ�����A��b�J������n�߂Ȃ��Ƒʖڂ�����A�o�ꂷ��̂͑�����5�N�キ�炢����
�ǂ���Intel�̂��Ƃ�����X�J�C���[�N�̎��̎����炢�͍���Ă邩��A���̍X�Ɍ�ł̑Ή�����
5�N�������Kaveri���瑊����������邵�AdGPU��Mantle�Ƃ̘A�g�����肻��������A
�܂��A�����ɒx���ŁAIntel�͏o��܂ł��Ȃ��������낤
nv��mantle�ۂ��ʂ̂Ȃɂ��������������
>>575
> nv��mantle�ۂ��ʂ̂Ȃɂ��������������
���ɏo�����Ƃ��āADirectX��Mantle�̕��s�J���ɍX�ɕ��S�^����f�����b�g����ǂ�ȃ����b�g���L��H
Mantle��ps4����ڐA���₷�������\�ƈȏ�̃����b�g������Ƃ͎v���Ȃ�
��������Kepler��Maxwell�őS���Ⴄ�A�[�L�e�N�`���ɂȂ邩�痼���͕s�\�����A
Maxwell�����ɂ�����V�F�A�ň��|�I�ɗ�?��AKepler�����͏��������Ȃ�
> nv��mantle�ۂ��ʂ̂Ȃɂ��������������
���ɏo�����Ƃ��āADirectX��Mantle�̕��s�J���ɍX�ɕ��S�^����f�����b�g����ǂ�ȃ����b�g���L��H
Mantle��ps4����ڐA���₷�������\�ƈȏ�̃����b�g������Ƃ͎v���Ȃ�
��������Kepler��Maxwell�őS���Ⴄ�A�[�L�e�N�`���ɂȂ邩�痼���͕s�\�����A
Maxwell�����ɂ�����V�F�A�ň��|�I�ɗ�?��AKepler�����͏��������Ȃ�
>>574
�Ɩ��p���ĉ����������蓾�Ȃ��Ǝv����قǖ��ʂȂ��Ƃ��A
��w�Ȃ����������Ă������ɁA�債�Đ��ʂ��オ��Ȃ��悤�Ȃ��̂��g�����H
�����Ȃ�A���B��GT-R��800�������Ĕ���������Ƃ̓|���V�FGT-3������ɃR�[�X�ɍ��킹�Ă�������Z�b�e�B���O����B
�l�i�̍��قǁA�^�C���͐L�тȂ����A����Ȃ���B�܂�HSA�̓��[�N�X�e�[�V�����̐��E�Ŏg����Ǝv����B
�Ɩ��p���ĉ����������蓾�Ȃ��Ǝv����قǖ��ʂȂ��Ƃ��A
��w�Ȃ����������Ă������ɁA�債�Đ��ʂ��オ��Ȃ��悤�Ȃ��̂��g�����H
�����Ȃ�A���B��GT-R��800�������Ĕ���������Ƃ̓|���V�FGT-3������ɃR�[�X�ɍ��킹�Ă�������Z�b�e�B���O����B
�l�i�̍��قǁA�^�C���͐L�тȂ����A����Ȃ���B�܂�HSA�̓��[�N�X�e�[�V�����̐��E�Ŏg����Ǝv����B
TDP
TDP
�딚���܂��肾�E�E�E
�����Q��
�����Q��
�oTDP
AMD Publishes New Code For Open-Source VCE Video Encode
ttp://www.phoronix.com/scan.php?page=news_item&px=MTYwMTE
How to use a PS4 DualShock 4 to play PC games
ttp://www.extremetech.com/gaming/176263-how-to-use-a-dualshock-4-to-play-pc-games
ttp://www.phoronix.com/scan.php?page=news_item&px=MTYwMTE
How to use a PS4 DualShock 4 to play PC games
ttp://www.extremetech.com/gaming/176263-how-to-use-a-dualshock-4-to-play-pc-games
>575-576
GTX750Ti��786SP��650Ti���20%�قǍ���
����܂�GM107��960SP���Ǝv���Ă����������GPUZ�̊ԈႢ��
5(SMX)*196(SP)=960(SP)�ł͂Ȃ�
5(SMX)*128(SP)=640(SP)�炵��
�����I�ɂ�
786/640=1.2��
�����1.2�{�Ȃ̂�SP������1.44�{�ƂȂ�
�܂�maxwell�����compute capability��4.0���X�L�b�v����5.0�ƂȂ�
GTX750Ti��786SP��650Ti���20%�قǍ���
����܂�GM107��960SP���Ǝv���Ă����������GPUZ�̊ԈႢ��
5(SMX)*196(SP)=960(SP)�ł͂Ȃ�
5(SMX)*128(SP)=640(SP)�炵��
�����I�ɂ�
786/640=1.2��
�����1.2�{�Ȃ̂�SP������1.44�{�ƂȂ�
�܂�maxwell�����compute capability��4.0���X�L�b�v����5.0�ƂȂ�
584 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 08:54:16.75 ID:kt5jcB9L
>>564
���珑�������Ƃ��Ȃ����\�Ȃ̂��ȁ[�Ǝv���܂��āB
�ŐV���߂��g�����߂ɂ��������ꂾ���̃R�[�h�������Ȃ����\�Ȃ̂��ƁB
if (feature.AvxSupported()) {
�@hogehogeAVX();
} else if (feature.SseSupported()) {
�@hogehogeSSE();
} else {
hogehogeGeneral();
}
�܂�������������̂��ς킵���ꍇ�͊��|�C���^���g�����ǂȁB
�N���X�����ă|�����[�t�B�Y���ŕ\�����Ă��悵�B
���珑�������Ƃ��Ȃ����\�Ȃ̂��ȁ[�Ǝv���܂��āB
�ŐV���߂��g�����߂ɂ��������ꂾ���̃R�[�h�������Ȃ����\�Ȃ̂��ƁB
if (feature.AvxSupported()) {
�@hogehogeAVX();
} else if (feature.SseSupported()) {
�@hogehogeSSE();
} else {
hogehogeGeneral();
}
�܂�������������̂��ς킵���ꍇ�͊��|�C���^���g�����ǂȁB
�N���X�����ă|�����[�t�B�Y���ŕ\�����Ă��悵�B
585 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 08:59:46.83 ID:kt5jcB9L
���ƁA�命���őΉ����ĂȂ�API���g���̂��_���ƌ����Ȃ�
AMD���g�b�v�V�F�A���Ƃ�Ȃ�����HSA�͕��y���܂���B
AMD���g�b�v�V�F�A���Ƃ�Ȃ�����HSA�͕��y���܂���B
mantle���Ȃ�
>>577
�����Ŏg����Ƃ�����Ȃ��AARM��AMD���ւ��w��ǂ̊��Ŏg���Ă�������
�܂��A���ɉƓd��H�Ƌ@�B�Ƃ��̑g�ݍ������́ASOC�̐��\���M���M�����낤����g��ꖳ������������
�����Ŏg����Ƃ�����Ȃ��AARM��AMD���ւ��w��ǂ̊��Ŏg���Ă�������
�܂��A���ɉƓd��H�Ƌ@�B�Ƃ��̑g�ݍ������́ASOC�̐��\���M���M�����낤����g��ꖳ������������
Mantle�́APS4�����ɍ�����G���W���𗬗p�ł���炵�����A
AMD���Q�[����Ђɋ���T���Ă�̂ŁA�Ή������Ђ͑�����ł��傤
����T���̂�߂���m���
AMD���Q�[����Ђɋ���T���Ă�̂ŁA�Ή������Ђ͑�����ł��傤
����T���̂�߂���m���
���p�ł��܂���
mantle�悤�ɍ�蒼���ł�
mantle�悤�ɍ�蒼���ł�
�O���t�B�b�N�G���W����Mantle��g�ݍ���ł��邩��
���̃O���t�B�b�N�G���W�����g���Ύ����I�ɑΉ�����
��v�O���t�B�b�N�G���W����5�В�3�Ђ͑Ή�����Ɣ��\���Ă�킯������
���̃O���t�B�b�N�G���W�����g���Ύ����I�ɑΉ�����
��v�O���t�B�b�N�G���W����5�В�3�Ђ͑Ή�����Ɣ��\���Ă�킯������
unity���Ή�������ł������낤��
�����I��ARM�̃Q�[���ւ̓����J����
�����I��ARM�̃Q�[���ւ̓����J����
unity�g���Ă�Q�[���Ȃ�ă��o�C���Q�[�����������c
�f�J�C�^�C�g����unity�g���Ă�g�R�Ȃ�Ă��܂�Ȃ���Ȃ��H
AAA�^�C�g�������Ή����Ȃ��Ƃȁc
�f�J�C�^�C�g����unity�g���Ă�g�R�Ȃ�Ă��܂�Ȃ���Ȃ��H
AAA�^�C�g�������Ή����Ȃ��Ƃȁc
�����I�ɑΉ����銄�ɂ͌��J���������ꂽ��`��o�O���������肷��悤����
���̓o�O���炯���������
����̃h���C�o�ŏ��X�ɉ�������Ă�������
����̃h���C�o�ŏ��X�ɉ�������Ă�������
Intel��k�r���Ⴀ��܂�����Ԏ���AMD�����o���܂���킯��������w
�S�����肪�͂��������x�Ŗw��ǃ{�����e�B�A�ł���Ă����
�S�����肪�͂��������x�Ŗw��ǃ{�����e�B�A�ł���Ă����
����̃h���C�o�ŏ��X�ɉ�������Ă�������
Intel�ɂ͏o���Ȃ����낤����AMD�Ȃ�o���邾�낤��
>>584
���������͍̂ŐV���߂ɕς���Ăǂꂾ���ς��̂����ĕ���
�o����o���Ȃ��̘b�͂ǂ��ł��������Ƃ���A�����܂Ő����Ȃ��̓I�ɃA�v���̗Ⴍ�炢
�����Ȃ��ƂȁB
���������͍̂ŐV���߂ɕς���Ăǂꂾ���ς��̂����ĕ���
�o����o���Ȃ��̘b�͂ǂ��ł��������Ƃ���A�����܂Ő����Ȃ��̓I�ɃA�v���̗Ⴍ�炢
�����Ȃ��ƂȁB
VLIW4�Ƃ�VLIW5���āA�h���C�o�A�b�v�f�[�g���Ă�悤�Ɍ��������āA
�A�b�v�f�[�g���ꂽ�̂̓o�[�W�����ԍ������ŁA���g�͂قƂ�ǃA�b�v�f�[�g����Ă�悤�ɂ͌����Ȃ����E�E�E
�v���I�ȃG���[(����̃Q�[���ŃN���b�V���E�t���[�Y�E�u���[�X�N���[��)���炢�������܂ɏC������銴��
�A�b�v�f�[�g���ꂽ�̂̓o�[�W�����ԍ������ŁA���g�͂قƂ�ǃA�b�v�f�[�g����Ă�悤�ɂ͌����Ȃ����E�E�E
�v���I�ȃG���[(����̃Q�[���ŃN���b�V���E�t���[�Y�E�u���[�X�N���[��)���炢�������܂ɏC������銴��
>>596
�]�T����
DX�̍œK����s��C���͔�1�AMantle��PS4�̃m�E�n�E����̎g���邩���
���́A�o�����ŏ�����Ԏ���Ă邾���ŁA�����ɑΉ����Ė��Ȃ��Ȃ�
�]�T����
DX�̍œK����s��C���͔�1�AMantle��PS4�̃m�E�n�E����̎g���邩���
���́A�o�����ŏ�����Ԏ���Ă邾���ŁA�����ɑΉ����Ė��Ȃ��Ȃ�
Mantle�ł̕s��̓Q�[�����Ɉˑ�����P�[�X�͑����Ȃ邾���
�Q�[������Ă�Ƃ����|���R�c���Ƃǂ����悤���Ȃ�
�T�C�R���Ƃ��_�C�X�Ƃ�DICE�Ƃ���
�Q�[������Ă�Ƃ����|���R�c���Ƃǂ����悤���Ȃ�
�T�C�R���Ƃ��_�C�X�Ƃ�DICE�Ƃ���
���܂ŃQ�t�H�œK���������Ă��Ȃ���������A���f�œK�����悤�Ƃ��Ă��}�ɂ͖�������
���܂ł̌o����m�E�n�E���S���g���Ȃ��āA�[������n�߂Ă����A���肷��̂ɑ����͎��Ԃ�����
�܂��A���Ԃ̖�肾���A�������̎����炢�ł����������P����邾��
���܂ł̌o����m�E�n�E���S���g���Ȃ��āA�[������n�߂Ă����A���肷��̂ɑ����͎��Ԃ�����
�܂��A���Ԃ̖�肾���A�������̎����炢�ł����������P����邾��
�����瑁���Ȃ��Ă��s������ʖڂ��Ȃ����
>>601
�o�O�ׂ����A�v�f�ł��傤
�o�O�ׂ����A�v�f�ł��傤
Mantle�ł̕s��̓Q�[�����������I
��������Ȃ��ƌ����n�߂Ă�̂�
��������Ȃ��ƌ����n�߂Ă�̂�
APU�X���łްё��Ƀo�O��������Č����Ă�̂�
APU�̕\�������R���I�o�O����Ȃ��I�\�[�X�o���I
���đ������Ă���X�������܂���
APU�̕\�������R���I�o�O����Ȃ��I�\�[�X�o���I
���đ������Ă���X�������܂���
�F�����I�ɂ͎��R����ˁH�Ƃ͂��������B
�o�O�Ȃ�C�����ė~�������ǁB
�o�O�Ȃ�C�����ė~�������ǁB
���ꂩ��J�������Q�[���͂Ƃ�����
�����̃Q�[���̓Q�[������Mantle�d�l�ɑΉ������邩�AAMD�����Q�[���ɑΉ������邩
�ǂ������ʓ|�ȏ�����������̂����Y�݂ǂ��낾���
�����̃Q�[���̓Q�[������Mantle�d�l�ɑΉ������邩�AAMD�����Q�[���ɑΉ������邩
�ǂ������ʓ|�ȏ�����������̂����Y�݂ǂ��낾���
AMD��DICE���o�O�Ƃ��ĔF�����ďC�����Ă�ƌ����Ă邩�炻�̂����Ή��p�b�`��h���C�o���o�Ă���
�C���Q�t�H�~�ɂ͐���Ńo�O�ɂ͌����ĂȂ�����
�C���Q�t�H�~�ɂ͐���Ńo�O�ɂ͌����ĂȂ�����
�܂��u���̂����v����
��������肾��
��������肾��
NVIDIA��ARM CPU �uDenver�v�ƁuTegra K1�v�̓W�J
http://pc.watch.impress.co.jp/docs/column/kaigai/20140212_634557.html
�������ߔ��s�x�𑊑ΓI�ɃV���v���ȃn�[�h�E�F�A�Ŏ�������v���Z�b�T�A�[�L�e�N�`���́A�ߋ��ɂ����x�����݂��������B
�����āA����܂ł̋Z�p�̗�����l����A�o�C�i���g�����X���[�V�����ŕ��̍�����������(VLIW�Ȃ�)�ɕϊ����A
�\�t�g�E�F�A�X�P�W���[�����O���L��ȃR�[�h�͈͂ɍs�Ȃ��āA
�R�[�h�̒��̃z�b�g�X�|�b�g�����̖��߂̕��s�x�����߂��@���v�������ׂ���B
����Transmeta��Efficeon�ō̂����悤�Ȏ�@�W�����āA�n�[�h�E�F�A�A�V�X�g�ōs�Ȃ����Ƃ͉\���B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
���������ANVIDIA��GPU�̉�Ђł���AGPU�̓l�C�e�B�u���߂�I�o�������A���A���^�C���R���p�C���ŕϊ�������s�X�^�C�����̂��Ă���B
�g�����X���[�V������GPU�ł͓�����O���B�ł́ADenver�͂ǂ��Ȃ̂��B
�Ⴆ�A�o�C�i���g�����X���[�V������ARM���߂�ϊ����Ď��s����X�^�C���ŁA
�l�C�e�B�u���߂�ʂ����Ƃ��\�ȃA�[�L�e�N�`�����̂��Ă����肷��̂��낤���BHuang���͎��̂悤�ȃq���g���o���B
�u��X�́ADenver��V�����e�N�j�b�N�ɂ���čœK�����Ă��A�����Denver�{�b�N�X�̓����ɗ��߂�̂��ŏ�̃A�v���[�`���ƍl���Ă���B
Denver�̊O�����猩��c�c�A�܂�A�ÓI�R���p�C����OS���猩��A���S�Ƀu���b�N�{�b�N�X�ƂȂ�B
�P�ɁA����IPC(Instruction-per-Clock)�����D�ꂽCPU�̂悤�Ɍ�����ƍl���Ă���B
�\�t�g�E�F�A�̑Ή��͓������悤�ȁACPU�̊O���ɑ���œK���͈�؋��߂Ȃ��v�B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
http://pc.watch.impress.co.jp/docs/column/kaigai/20140212_634557.html
�������ߔ��s�x�𑊑ΓI�ɃV���v���ȃn�[�h�E�F�A�Ŏ�������v���Z�b�T�A�[�L�e�N�`���́A�ߋ��ɂ����x�����݂��������B
�����āA����܂ł̋Z�p�̗�����l����A�o�C�i���g�����X���[�V�����ŕ��̍�����������(VLIW�Ȃ�)�ɕϊ����A
�\�t�g�E�F�A�X�P�W���[�����O���L��ȃR�[�h�͈͂ɍs�Ȃ��āA
�R�[�h�̒��̃z�b�g�X�|�b�g�����̖��߂̕��s�x�����߂��@���v�������ׂ���B
����Transmeta��Efficeon�ō̂����悤�Ȏ�@�W�����āA�n�[�h�E�F�A�A�V�X�g�ōs�Ȃ����Ƃ͉\���B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
���������ANVIDIA��GPU�̉�Ђł���AGPU�̓l�C�e�B�u���߂�I�o�������A���A���^�C���R���p�C���ŕϊ�������s�X�^�C�����̂��Ă���B
�g�����X���[�V������GPU�ł͓�����O���B�ł́ADenver�͂ǂ��Ȃ̂��B
�Ⴆ�A�o�C�i���g�����X���[�V������ARM���߂�ϊ����Ď��s����X�^�C���ŁA
�l�C�e�B�u���߂�ʂ����Ƃ��\�ȃA�[�L�e�N�`�����̂��Ă����肷��̂��낤���BHuang���͎��̂悤�ȃq���g���o���B
�u��X�́ADenver��V�����e�N�j�b�N�ɂ���čœK�����Ă��A�����Denver�{�b�N�X�̓����ɗ��߂�̂��ŏ�̃A�v���[�`���ƍl���Ă���B
Denver�̊O�����猩��c�c�A�܂�A�ÓI�R���p�C����OS���猩��A���S�Ƀu���b�N�{�b�N�X�ƂȂ�B
�P�ɁA����IPC(Instruction-per-Clock)�����D�ꂽCPU�̂悤�Ɍ�����ƍl���Ă���B
�\�t�g�E�F�A�̑Ή��͓������悤�ȁACPU�̊O���ɑ���œK���͈�؋��߂Ȃ��v�B
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
�\�t�g�E�F�A�̑Ή��͓������悤�ȁACPU�̊O���ɑ���œK���͈�؋��߂Ȃ��I(���\���o��Ƃ͌����ĂȂ�)
>>613
>���N�㔼��Denver�x�[�X��Tegra K1���o�ꂷ��B
�{���͍��N�㔼���āAAMD��Mullins���]�T�ŊԂɍ��������ȃX�P�W���[�����Ȃ�
2W��64-bit ARM CPU Tegra K1�ƁA������2W��64-bit x64 CPU Mullins�̑Ό��͖ʔ��������B
>���N�㔼��Denver�x�[�X��Tegra K1���o�ꂷ��B
�{���͍��N�㔼���āAAMD��Mullins���]�T�ŊԂɍ��������ȃX�P�W���[�����Ȃ�
2W��64-bit ARM CPU Tegra K1�ƁA������2W��64-bit x64 CPU Mullins�̑Ό��͖ʔ��������B
Nolan��GCN2.0��HSA�Ή��炵����
ttp://cdn3.wccftech.com/wp-content/uploads/2013/07/AMD-APU-2015.jpg
���s���\�Ƃ��͂���Ȃ����
ttp://cdn3.wccftech.com/wp-content/uploads/2013/07/AMD-APU-2015.jpg
{kind=link}
���s���\�Ƃ��͂���Ȃ����
>>616
HSA�Ɋւ��ẮA>>1�̃��[�h�}�b�v���ɂ͕\�L����Ė�����
ttp://northwood.blog60.fc2.com/blog-entry-6967.html
�������ɂ���Beema�̎��_��HSA�Ή��\��Ƃ���B
ttp://semiaccurate.com/forums/showthread.php?t=7622
ttp://i.imgur.com/7MNoRjM.png
Nolan��Beema�̍X�Ɏ��̐���炵�����ABeema��Nolan�̂ǂ����HSA&SoC&GCN2.0�Ή��ɂȂ��ė���낤�ȁH
HSA�Ɋւ��ẮA>>1�̃��[�h�}�b�v���ɂ͕\�L����Ė�����
ttp://northwood.blog60.fc2.com/blog-entry-6967.html
�������ɂ���Beema�̎��_��HSA�Ή��\��Ƃ���B
ttp://semiaccurate.com/forums/showthread.php?t=7622
ttp://i.imgur.com/7MNoRjM.png
{kind=link}
Nolan��Beema�̍X�Ɏ��̐���炵�����ABeema��Nolan�̂ǂ����HSA&SoC&GCN2.0�Ή��ɂȂ��ė���낤�ȁH
>>607
DICE���o�O�����Ă����Ă邶���
DICE���o�O�����Ă����Ă邶���
>>615
�����Adenver�����|�I�ɍ����\�ɂȂ邾�낤��
�����Adenver�����|�I�ɍ����\�ɂȂ邾�낤��
AMD��ARM�ɖ{������Ăق���
x86�͂����������Ɛ��ނ��Ă�����������
x86�͂����������Ɛ��ނ��Ă�����������
�ނ���T�[�oARM�́A�V�^��ATOM��Xeon�̃��b�p���ǂ�����
�}�ɉ��ɂȂ��������
�}�ɉ��ɂȂ��������
���������ւ����v�����Ȃ��Ȃ肻���ȃX�}�z�Ƃ����o�C���ǂ����낤�ȁ[
�ǂ����Â��\�������Ȃ�����PC��������
win�^�u�����͂悭�킩��Ȃ���
�ǂ����Â��\�������Ȃ�����PC��������
win�^�u�����͂悭�킩��Ȃ���
http://www.youtube.com/watch?v=hjOg0z2XzPE
AMD�ɂ��Ă̓I�T���ȃR���Z�v�gCM
AMD�ɂ��Ă̓I�T���ȃR���Z�v�gCM
624 �FSocket774�F2014/02/12(��) 15:52:10.44 ID:G9XgKaRd
http://www.cpu-world.com/Cores/Beema.html
���ꂩ����|�Ă���
���ꂩ����|�Ă���
>>624
Beema�́A�ȓd�̓f�X�N�g�b�v��o�C���p��x86�݊��R�A�ŁA�ŏI�I�ɂ�Kabini�ɒu�������B
SoC(System on a chip)�œ���ɕK�v�ȃV�X�e���S������̃`�b�v�ɓ��ڂ����B
"Puma" ("Puma+") CPU�A�[�L�e�N�`���ō���AGCN�����ڂ����B
�p�[�c�̓`�b�v�Z�b�g���W�b�N��Z�L�����e�B�v���Z�b�T�[�����A��p��Cortex-A5 ARM chip���g����
2����4��CPU�R�A�ŁATDP��10����25���b�g�ɂȂ�A��Ԃ̓�����CPU��CPU���V�X�e���������[�����L����HSA
���s�@�̂悤�ɁA28nm�Ő����AFT3 BGA�p�b�P�[�W�Ƃ��Đ��Y����A2014�N���Ƀ��[���`����邱�Ƃ��\�z����Ă���
�悭�킩��Ȃ��Ƃ������邯�Ljꉞ��
Beema�́A�ȓd�̓f�X�N�g�b�v��o�C���p��x86�݊��R�A�ŁA�ŏI�I�ɂ�Kabini�ɒu�������B
SoC(System on a chip)�œ���ɕK�v�ȃV�X�e���S������̃`�b�v�ɓ��ڂ����B
"Puma" ("Puma+") CPU�A�[�L�e�N�`���ō���AGCN�����ڂ����B
�p�[�c�̓`�b�v�Z�b�g���W�b�N��Z�L�����e�B�v���Z�b�T�[�����A��p��Cortex-A5 ARM chip���g����
2����4��CPU�R�A�ŁATDP��10����25���b�g�ɂȂ�A��Ԃ̓�����CPU��CPU���V�X�e���������[�����L����HSA
���s�@�̂悤�ɁA28nm�Ő����AFT3 BGA�p�b�P�[�W�Ƃ��Đ��Y����A2014�N���Ƀ��[���`����邱�Ƃ��\�z����Ă���
�悭�킩��Ȃ��Ƃ������邯�Ljꉞ��
<(_ _*)> �ض�ī
Beema��HSA�Ή�������Ă��Ƃ���
Beema��HSA�Ή�������Ă��Ƃ���
AMD at 2014 Mobile World Congress
http://www.youtube.com/watch?v=MFcKHNTJxUs
http://www.youtube.com/watch?v=MFcKHNTJxUs
DICE���Q�[�����̃o�O�����Č����Ă�̂�APU�X������
�o�O�ł͂Ȃ��A�d�l���Amantle�̎��R�Ȕ��F���킩��Ȃ��Ƃ͎��͏�Q��
���Č����o������Ȃ�
�ŋ߂�AMD�X���͋��C�ɖ����Ă����
�o�O�ł͂Ȃ��A�d�l���Amantle�̎��R�Ȕ��F���킩��Ȃ��Ƃ͎��͏�Q��
���Č����o������Ȃ�
�ŋ߂�AMD�X���͋��C�ɖ����Ă����
�o�O�ł��d�l�ł��ǂ����ł�������
�����̐F�������x�̘b�����A����Ńp�t�H�[�}���X���ω����邱�ƂȂ�Ė�������B
�����̐F�������x�̘b�����A����Ńp�t�H�[�}���X���ω����邱�ƂȂ�Ė�������B
Mantle��Radeon���[�U�[�@�����������̎��������ǂȃA��
�ȓd�̓R�A�̕���HSA�ɑΉ����Ȃ��Ƃ���Ă��C�����邪�܂��s�����Ȃ�
AMD�̃^�u���b�g�{�C�ŗ~������
�ł�IntelGPU�Ő���Ƀ����_�����O�o���Ȃ��ƂԂ��@�����
���ƃp�t�H�[�}���X���{���ɕς��Ȃ����ǂ����͏C����҂��Ȃ��Ƃ킩��Ȃ�
���ƃp�t�H�[�}���X���{���ɕς��Ȃ����ǂ����͏C����҂��Ȃ��Ƃ킩��Ȃ�
����҂ł��Ȃ��̂Ɉ̂�����
�ނ��됳��Ƀ����_���Ă�̂�Mantle�̕���������Ȃ��̂�
�ނ��됳��Ƀ����_���Ă�̂�Mantle�̕���������Ȃ��̂�
��������>>628���ADICE���o�O�ł������܂����Č����Ă�̂�
�����������疳�����āh��������Ȃ��h�A�ق�Ƌ����Ă��
�����������疳�����āh��������Ȃ��h�A�ق�Ƌ����Ă��
�ǂ����̃A�z�L�҂�R200�V���[�Y��HD7000�V���[�Y�̃��l�[���i�Ƃ������Ă����ǁAR200�V���[�Y��GCN2.0��HD7000�V���[�Y��GCN1.1����Ȃ��������H
Kaveri��GCN2.0�����A�B�̃��l�[���i���ǂ�����Mantle�������Ă݂��GCN�̃o�[�W�����łǂꂾ���Ⴄ������Ǝv�����A���̕Ӓ��ׂ��L�������o���Ȃ����ȁH
���ꂩ��DICE�̌������o�O�͋����ۂ��̂Ə��̃I�u�W�F�N�g�̔z�u��������Ȃ����������H
Kaveri��GCN2.0�����A�B�̃��l�[���i���ǂ�����Mantle�������Ă݂��GCN�̃o�[�W�����łǂꂾ���Ⴄ������Ǝv�����A���̕Ӓ��ׂ��L�������o���Ȃ����ȁH
���ꂩ��DICE�̌������o�O�͋����ۂ��̂Ə��̃I�u�W�F�N�g�̔z�u��������Ȃ����������H
>>636
�����̑Ή��\��́A�V���[�e�B���O�����W�̐Δz�u�A����Ȃ̂ɓ܂�Ɍ�����o�O���ˁB
����ȊO�ŁA�K���Ƀl�K�R�s�y�Ǝ������Ă�A�����āA�{���ɃQ�[������Ă�̂��^�킵�����x���B
�����̑Ή��\��́A�V���[�e�B���O�����W�̐Δz�u�A����Ȃ̂ɓ܂�Ɍ�����o�O���ˁB
����ȊO�ŁA�K���Ƀl�K�R�s�y�Ǝ������Ă�A�����āA�{���ɃQ�[������Ă�̂��^�킵�����x���B
>>636
�I�u�W�F�N�g�z�u���Ⴄ�b���̃l�K�L�����Ȃ���
���̐l���B������͂����ƕ\������Ă邵
http://screenshotcomparison.com/comparison/61286
�Ƃ����̌�����ɍČ���������悤������A����͂���Ŏ���������
�u��������ւ��i�N���C�A���g�̃��X�^�[�g�j���s��Ȃ������ꍇ�v�Ƃ����A���������t����
�I�u�W�F�N�g�z�u���Ⴄ�b���̃l�K�L�����Ȃ���
���̐l���B������͂����ƕ\������Ă邵
http://screenshotcomparison.com/comparison/61286
�Ƃ����̌�����ɍČ���������悤������A����͂���Ŏ���������
�u��������ւ��i�N���C�A���g�̃��X�^�[�g�j���s��Ȃ������ꍇ�v�Ƃ����A���������t����
�������當�匾���ˁ[�����Ȃ���o��������
��������mantle�Ȃ�Ēx���̃f�J�Camd���ł����K�v�Ƃ���Ă��Ȃ�
��������mantle�Ȃ�Ēx���̃f�J�Camd���ł����K�v�Ƃ���Ă��Ȃ�
����҂��Q�[���Ƀo�O������Ƃ����Ă�
�w�L���v�`���������Ƃɉ��H������x�Ƃ������̂�
AMD���[�U�[�̃N�I���e�B
http://cdn.overclock.net/6/6d/350x700px-LL-6dee5671_dawawda.PNG
�w�L���v�`���������Ƃɉ��H������x�Ƃ������̂�
AMD���[�U�[�̃N�I���e�B
http://cdn.overclock.net/6/6d/350x700px-LL-6dee5671_dawawda.PNG
{kind=link}
"Mantle"�̃p�t�H�[�}���X���m�F���� - �Ή��Q�[���łǂ�قǂ̐��\���オ�݂���̂�?
ttp://news.mynavi.jp/articles/2014/02/12/mantle/index.html
�匴�搶�Ȃ�HD7970�H
ttp://news.mynavi.jp/articles/2014/02/12/mantle/index.html
�匴�搶�Ȃ�HD7970�H
���͂��̃o�O�Ń}���g���ł͂��̒��x�̊m�F���炵�Ă��Ȃ��̂�
�y�������Ă���Ȃ��Ďv������
�y�������Ă���Ȃ��Ďv������
>>641
�I�����C���L������A����ς�}�C�i�r�̉������Ԗʔ����ȁB
�I�����C���L������A����ς�}�C�i�r�̉������Ԗʔ����ȁB
�s����̑�����D�悵�����ʂȂ̂������ꂸ
�}������Ă��̂ŗD��x�̒Ⴂ�o�O�͌�ɂ��܂����A�Ƃ�
�}������Ă��̂ŗD��x�̒Ⴂ�o�O�͌�ɂ��܂����A�Ƃ�
ID:G3+3C20s
���ɋA���(�L�E�ցE`)
���ɋA���(�L�E�ցE`)
�����Ȃ̂ɖ��蒋�̏������݂��������Ă����������
648 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 23:14:57.11 ID:kt5jcB9L
>>599
���̃��x���ł�SSE2�ōœK���������[�`���̍ő�2�{�A�X�J��������20�{�o�Ă邪�H
http://pastie.org/pastes/8674992/text
�����ƍ��x�ȃ}���`�p�^�[���}�b�`���O�Ȃł͍��͌����ɏo�邾�낤�B
GNU��OS�Ƃ�MacOS�Ȃ͕W���������ʂ�AVX2�ɑΉ����Ă���B
�ŋ߂ł�LLVM���̂�AVX-512�Ή���i�߂Ă���B
����ɂ����LLVM���o�b�N�G���h�Ƃ��Ďg�����ꏈ���n�S�āA���Ƃ���
Clang�ȂŎ����I�ɉ��b������B
Windows����WIX���g�����A�v���A��̓I�ɂ̓X�g�A�A�v���̂قڑS�Ă�
AVX2�Ή��ł��ˁB
���̃��x���ł�SSE2�ōœK���������[�`���̍ő�2�{�A�X�J��������20�{�o�Ă邪�H
http://pastie.org/pastes/8674992/text
�����ƍ��x�ȃ}���`�p�^�[���}�b�`���O�Ȃł͍��͌����ɏo�邾�낤�B
GNU��OS�Ƃ�MacOS�Ȃ͕W���������ʂ�AVX2�ɑΉ����Ă���B
�ŋ߂ł�LLVM���̂�AVX-512�Ή���i�߂Ă���B
����ɂ����LLVM���o�b�N�G���h�Ƃ��Ďg�����ꏈ���n�S�āA���Ƃ���
Clang�ȂŎ����I�ɉ��b������B
Windows����WIX���g�����A�v���A��̓I�ɂ̓X�g�A�A�v���̂قڑS�Ă�
AVX2�Ή��ł��ˁB
>>648
�c�q�̓v���O����������̂��A�Ȃ������ȁB
AMD���[�U�[���X�ɐ��\�̂ł�HSA�܂���openCL���g�����̂��o����,orz�ɂȂ��
�c�q�̓v���O����������̂��A�Ȃ������ȁB
AMD���[�U�[���X�ɐ��\�̂ł�HSA�܂���openCL���g�����̂��o����,orz�ɂȂ��
650 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 23:28:05.70 ID:kt5jcB9L
OpenCL��HSA�̃����^�C����1��Ăяo���܂ł̊Ԃ�CPU�����͕�����I�[��
���\����͌����Ă�ł��傤�ȁB
���������������ł́A�ߏ��̏��X�X�ɗ[�т̔������s���Ƃ��Ƀ��[���[�X�P�[�g��
�X�P�{�[���邢�͎��]�Ԃ��g�����o�Ŏg�������̂ł���B
���������u�_���v�J�[�v���`���[�^�[����K�v�͂Ȃ��̂ł��B
CPU������SIMD���j�b�g�𑬂����Ă���A����ȊO�͗v��Ȃ��B
���\����͌����Ă�ł��傤�ȁB
���������������ł́A�ߏ��̏��X�X�ɗ[�т̔������s���Ƃ��Ƀ��[���[�X�P�[�g��
�X�P�{�[���邢�͎��]�Ԃ��g�����o�Ŏg�������̂ł���B
���������u�_���v�J�[�v���`���[�^�[����K�v�͂Ȃ��̂ł��B
CPU������SIMD���j�b�g�𑬂����Ă���A����ȊO�͗v��Ȃ��B
>>650
�c�q�A���O�̂Ƃ���
>���X�X�ɗ[�т̔������s���Ƃ��Ƀ��[���[�X�P�[�g��X�P�{�[
����Ȏ�w���ʂɂ���̂��H�@�Ȃ�������w�ŏ���
�c�q�A���O�̂Ƃ���
>���X�X�ɗ[�т̔������s���Ƃ��Ƀ��[���[�X�P�[�g��X�P�{�[
����Ȏ�w���ʂɂ���̂��H�@�Ȃ�������w�ŏ���
�ʂɎ�w�ł���K�v�͂Ȃ���
�l�ԂȂ���[�т͐H�ׂ��
�l�ԂȂ���[�т͐H�ׂ��
>>642
���ǃQ�[���G���W�����Ή������炠�Ƃ͂��傱���ƒ���������
�Ή��ł����Ƃ��Ă��e�X�g�Ȃ�Ă̂͂܂���ƕ��ׂɂȂ��Ă�����
�ŁA���C����DirectX�ł�GPU���Ƃɕ\����������肷�邩��
���ꂾ���ő�ςȂ̂ɂ���ɒlj��Ŋm�F�Ȃ��Mantle���ʂł�قǔ�������
�ڏ��ł��Ȃ����\�[�X�����Ȃ����
�ƂȂ�ƃe�X�g���[�܂���͎̂g���邩�ǂ����킩���
Mantle�ɂȂ���Ă��Ƃ���
�Ƃ肠���������Ȃ��m�F�������ĕ\���͕s�������Ή�����Ⴂ���Ƃ���
�X�^���X���낤��
���̂���Mantle�͑Ή��͂��܂����A�ł�����ۏ͂��܂���Ƃ��ɂȂ鈫��
���ǃQ�[���G���W�����Ή������炠�Ƃ͂��傱���ƒ���������
�Ή��ł����Ƃ��Ă��e�X�g�Ȃ�Ă̂͂܂���ƕ��ׂɂȂ��Ă�����
�ŁA���C����DirectX�ł�GPU���Ƃɕ\����������肷�邩��
���ꂾ���ő�ςȂ̂ɂ���ɒlj��Ŋm�F�Ȃ��Mantle���ʂł�قǔ�������
�ڏ��ł��Ȃ����\�[�X�����Ȃ����
�ƂȂ�ƃe�X�g���[�܂���͎̂g���邩�ǂ����킩���
Mantle�ɂȂ���Ă��Ƃ���
�Ƃ肠���������Ȃ��m�F�������ĕ\���͕s�������Ή�����Ⴂ���Ƃ���
�X�^���X���낤��
���̂���Mantle�͑Ή��͂��܂����A�ł�����ۏ͂��܂���Ƃ��ɂȂ鈫��
654 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 23:43:46.34 ID:kt5jcB9L
>>651
�ʂɂ����ɓ˂����ޕK�v�Ȃ��̂����ǁB
�킴�킴�\������ă`���[�^�[���Ȃ��ƌĂׂȂ��u�_���v�J�[�v�̗����ʒu
strlen�݂����Ȋ���GHz�I�[�_�[��CPU�ł͕��Ϗ������Ԃ�1�`2��nsec���x���̖��B
GPU�ł�낤�Ƃ����烉�����C�����o�R���ĊO���v���Z�b�T�ɓ����鎞�_��usec�`msec
�I�[�_�[�̎��Ԃ��K�v�ɂȂ�B
�����Ƒ傫�ȏ����ɂ����K�p�ł��Ȃ����Ă��Ƃ�B
���ꂪCPU��SIMD��GPGPU�̌���I�ȍ��B
�ʂɂ����ɓ˂����ޕK�v�Ȃ��̂����ǁB
�킴�킴�\������ă`���[�^�[���Ȃ��ƌĂׂȂ��u�_���v�J�[�v�̗����ʒu
strlen�݂����Ȋ���GHz�I�[�_�[��CPU�ł͕��Ϗ������Ԃ�1�`2��nsec���x���̖��B
GPU�ł�낤�Ƃ����烉�����C�����o�R���ĊO���v���Z�b�T�ɓ����鎞�_��usec�`msec
�I�[�_�[�̎��Ԃ��K�v�ɂȂ�B
�����Ƒ傫�ȏ����ɂ����K�p�ł��Ȃ����Ă��Ƃ�B
���ꂪCPU��SIMD��GPGPU�̌���I�ȍ��B
>>654
�\�t�g�̂��Ƃ͕�����ǁA
����GPGPU�̓I�[�o�[�w�b�h�ł������ă_���v�J�[�����ǁA
Kaveri��HSA�̓I�[�o�[�w�b�h���Ȃ����āA����芴�o�Ŏg����悤�ɂȂ��Ă����Ȃ��̂��B
���̃X���ɂ�HSA����HSA�v���O��������Ă���z���邾�낤����AHSA�͂���芴�o�Ŏg����
�c�q��i5(AVX2)���Kaveri�͂���Ȃɐ��\���ǂ��Ȃ���Ď����Ă�����Ȃ����B
�\�t�g�̂��Ƃ͕�����ǁA
����GPGPU�̓I�[�o�[�w�b�h�ł������ă_���v�J�[�����ǁA
Kaveri��HSA�̓I�[�o�[�w�b�h���Ȃ����āA����芴�o�Ŏg����悤�ɂȂ��Ă����Ȃ��̂��B
���̃X���ɂ�HSA����HSA�v���O��������Ă���z���邾�낤����AHSA�͂���芴�o�Ŏg����
�c�q��i5(AVX2)���Kaveri�͂���Ȃɐ��\���ǂ��Ȃ���Ď����Ă�����Ȃ����B
656 �F,,�E�L�́M�E,,�j��-�������F2014/02/12(��) 23:59:44.42 ID:kt5jcB9L
> Kaveri��HSA�̓I�[�o�[�w�b�h���Ȃ����āA����芴�o�Ŏg����悤�ɂȂ��Ă����Ȃ��̂��B
������`
PCIe�o�R���I���_�C��GPU���Ȃ�đS���c�_�Ώۂ���Ȃ��̂�B
CPU�R�[�h����_�C���N�g�ɏ����ł��邩�ǂ���
CPU�T�C�N����1�`2���N���b�N����������Ȃ����Č����Ă邶���
����������������邽�߂ɕ���������d���������^�C���R�[����
���͖̂{���]�|�Ȃ̂�B
������`
PCIe�o�R���I���_�C��GPU���Ȃ�đS���c�_�Ώۂ���Ȃ��̂�B
CPU�R�[�h����_�C���N�g�ɏ����ł��邩�ǂ���
CPU�T�C�N����1�`2���N���b�N����������Ȃ����Č����Ă邶���
����������������邽�߂ɕ���������d���������^�C���R�[����
���͖̂{���]�|�Ȃ̂�B
>�c�q��i5(AVX2)���Kaveri�͂���Ȃɐ��\���ǂ��Ȃ���Ď����Ă�����Ȃ����B
AMD�X���ɂ���ȃ\�t�g������̂��E�E�E�H
AMD�X���ɂ���ȃ\�t�g������̂��E�E�E�H
>>657
�����Ŏ��ۂɎ��������Ƃ���Ȃ���HSA/openCL���g����AMD�͂��������Č����z����ł͂Ȃ�����B
openCL��HSA��M������Ă���z�̒��ɂ́A������HSA/openCL�ł���z�����Ȃ����B
�c�q���R�[�h�����Ē��킵�Ă��Ă���̂ɁA����HSA/openCL�����ς�ł��Ȃ��悶��ȁB
�����Ŏ��ۂɎ��������Ƃ���Ȃ���HSA/openCL���g����AMD�͂��������Č����z����ł͂Ȃ�����B
openCL��HSA��M������Ă���z�̒��ɂ́A������HSA/openCL�ł���z�����Ȃ����B
�c�q���R�[�h�����Ē��킵�Ă��Ă���̂ɁA����HSA/openCL�����ς�ł��Ȃ��悶��ȁB
659 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 00:11:26.83 ID:7mxiCmZT
GPU�ŏo���邱�Ƃ̌��E���m���Ă�̂��D�ꂽ�v���O���}�ł��ȁB
660 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 00:16:01.56 ID:7mxiCmZT
�uGPU�ɍ��킹��API����蒼���I�v
���ꂶ��݊������ۂĂȂ��B
�{����SSE��AVX�ɍ��킹�Ď��R��API���Ē�`���Ă����Ƃ����Ȃ�
�����ƌ����̂���API����邱�Ƃ��o����B
�����܂Ń��K�V�[��API�̎d�l�͈͓���AVX2��K�p���č������ł���
�Ƃ�����������Ă���B
�\�t�g�J�����Ċ�{�I�ɕێ�I�ł���B
���ꂶ��݊������ۂĂȂ��B
�{����SSE��AVX�ɍ��킹�Ď��R��API���Ē�`���Ă����Ƃ����Ȃ�
�����ƌ����̂���API����邱�Ƃ��o����B
�����܂Ń��K�V�[��API�̎d�l�͈͓���AVX2��K�p���č������ł���
�Ƃ�����������Ă���B
�\�t�g�J�����Ċ�{�I�ɕێ�I�ł���B
opencl��������̐l��������A����Șb�͏o���
�����ƕ������v���O���}�͓��X�Z������ł�
��ʃA�v���́A�R�s�y�ł����Ă�����
���̕��A�C�f�A�����ł�����ł���
�����̐l���v���O���}�[�Ƃ͌���Ȃ��C�����邯��
���̑��吨�������ł��y�ł��Đ��̂��L�����
����ŗǂ���ł���
�����ƕ������v���O���}�͓��X�Z������ł�
��ʃA�v���́A�R�s�y�ł����Ă�����
���̕��A�C�f�A�����ł�����ł���
�����̐l���v���O���}�[�Ƃ͌���Ȃ��C�����邯��
���̑��吨�������ł��y�ł��Đ��̂��L�����
����ŗǂ���ł���
>>658
�����O�A��Ƃ̔ᔻ�͓�����Ƃ���������s���Ȃ��h�Ȃ́H
���[�U�[���_�ł��ꂼ��̃v���O���}��������v���O�������Q�l�ɔ�]����Ηǂ���������H
�Ⴆ�A2ch�̃g���b�v��T�����邱�̃\�t�g��AVX2�ɂ�OpenCL�ɂ��Ή����Ă��āAi7-4770K���A10-4850K�̕����������ĕ��o�Ă��邼�H
�y�g���b�v�����zMERIKEN's Tripcode Finder ����6
ttp://anago.2ch.net/test/read.cgi/software/1387954016/
�y���U�g���b�v�����zMeriken's Tripcode Yggdrasil
ttp://toro.2ch.net/test/read.cgi/esite/1379214816/
�����O�A��Ƃ̔ᔻ�͓�����Ƃ���������s���Ȃ��h�Ȃ́H
���[�U�[���_�ł��ꂼ��̃v���O���}��������v���O�������Q�l�ɔ�]����Ηǂ���������H
�Ⴆ�A2ch�̃g���b�v��T�����邱�̃\�t�g��AVX2�ɂ�OpenCL�ɂ��Ή����Ă��āAi7-4770K���A10-4850K�̕����������ĕ��o�Ă��邼�H
�y�g���b�v�����zMERIKEN's Tripcode Finder ����6
ttp://anago.2ch.net/test/read.cgi/software/1387954016/
�y���U�g���b�v�����zMeriken's Tripcode Yggdrasil
ttp://toro.2ch.net/test/read.cgi/esite/1379214816/
663 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 00:43:22.75 ID:7mxiCmZT
�Ȃ�uHSA on Rails�v�I�ȊȒP�ɐ��`������̂ł�����Ă���������
�R�s�y�ōς܂���ނ̃v���O���}��C����ł���ς킵������
����y�������s���x�̒x���X�N���v�g������D��Ŏg���Ă܂���
OpenCL����C���y���ɖʓ|�ł���B
���̎��_�ŊԈ���Ă܂���B
�R�s�y�ōς܂���ނ̃v���O���}��C����ł���ς킵������
����y�������s���x�̒x���X�N���v�g������D��Ŏg���Ă܂���
OpenCL����C���y���ɖʓ|�ł���B
���̎��_�ŊԈ���Ă܂���B
664 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 00:44:42.07 ID:7mxiCmZT
�uTripcode�v�͂��₳��̑���ł�
�ɒ[�Ȑl������
GPU���g���ƃ��C�e���V�傫���̂͊m�������ǁC
���������GPU������Ȃ��ƌ��߂���͎̂��삪�����Ȃ�
���������GPU������Ȃ��ƌ��߂���͎̂��삪�����Ȃ�
���������g���b�v���̂���̌��E����˂�
������������x86�p�ʼn��b��悤�ȃt���[�\�t�g�Ȃ�Đ�łɋ߂��C�͂��邯�ǂ�
������������x86�p�ʼn��b��悤�ȃt���[�\�t�g�Ȃ�Đ�łɋ߂��C�͂��邯�ǂ�
668 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 00:57:28.48 ID:7mxiCmZT
DES�ɂ���SHA-1�ɂ���������p���̂Ȃ��Í��Ȃ��
�������C�܂���Ƃ������Đ��ō̗p���Ă邾���ł����Ȃ�
�g���b�v�V�тȂ�Ċy�����ł����H
�������C�܂���Ƃ������Đ��ō̗p���Ă邾���ł����Ȃ�
�g���b�v�V�тȂ�Ċy�����ł����H
>>662
����̓_���v�J�[�ł�����ق����ǂ���Ƃ��Ă��Ƃ͂Ȃ��̂��H
�����A����������ƂȂ瓖�RGPGPU�̕����ǂ�����ȁB
�ŁA�c�q�������Ă���̂́A����芴�o�ŋC�y��(��y��)�g���č����\�����ł���̂���Ƃ�������
�����āA�c�q�̃R�[�h��avx2������芴�o�Ŏg���Ă�����Ȑ��\�ł܂���Ⴞ�Ǝv���B
��y�ł������\�����ł���Ȃ�F�X�Ȃ��ƂɎg���Ă��ꂻ������ȁB
>>663
�ŁA�c�q��openCL���g�����Ƃ����������łɎ�y�ł͂Ȃ��Ƃ������Ƃ��B
����̓_���v�J�[�ł�����ق����ǂ���Ƃ��Ă��Ƃ͂Ȃ��̂��H
�����A����������ƂȂ瓖�RGPGPU�̕����ǂ�����ȁB
�ŁA�c�q�������Ă���̂́A����芴�o�ŋC�y��(��y��)�g���č����\�����ł���̂���Ƃ�������
�����āA�c�q�̃R�[�h��avx2������芴�o�Ŏg���Ă�����Ȑ��\�ł܂���Ⴞ�Ǝv���B
��y�ł������\�����ł���Ȃ�F�X�Ȃ��ƂɎg���Ă��ꂻ������ȁB
>>663
�ŁA�c�q��openCL���g�����Ƃ����������łɎ�y�ł͂Ȃ��Ƃ������Ƃ��B
>>656
�Ȃc�q�̌����Ă�̂͂P�b�����鏈����0.9�b�ɂ���悤�ȏ����̘b
���茾���Ă�C�����ĂȂ�Ȃ����ǁA10�b�������Ď��p���ł��Ȃ�����
���ǂP�b���炢�ɂȂ��Ď��p���o���܂��I�Șb�����������킯�ŁB
AMD����86�̋��������Ȃ��Ƃ����Ă�킯�ł��Ȃ��̂�AVX2��512�̎���1024�ł�
�����H�C���e���́i�j
�Ȃc�q�̌����Ă�̂͂P�b�����鏈����0.9�b�ɂ���悤�ȏ����̘b
���茾���Ă�C�����ĂȂ�Ȃ����ǁA10�b�������Ď��p���ł��Ȃ�����
���ǂP�b���炢�ɂȂ��Ď��p���o���܂��I�Șb�����������킯�ŁB
AMD����86�̋��������Ȃ��Ƃ����Ă�킯�ł��Ȃ��̂�AVX2��512�̎���1024�ł�
�����H�C���e���́i�j
�ŋ߂�1�b�����鏈����100������1.3�b�ŏ����ł��Ă���ɏȓd�͂ł��݂����Ȃ̂����Ȃ̂�
�@�艟���Ԃɂ��_���v�J�[�ɂ��œK�ȗp�r������Ȃ�A�y�g���ɂ����čœK��
�p�r�͂���ł���B�g���������������Ȃ��B
�p�r�͂���ł���B�g���������������Ȃ��B
673 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 01:17:21.47 ID:7mxiCmZT
> �Ȃc�q�̌����Ă�̂͂P�b�����鏈����0.9�b�ɂ���悤�ȏ����̘b
�����\����������Ӗ����Ȃ��Ƃł��H
HTML,XML,CSS,JavaScript,JSON�E�E�E�ƃe�L�X�g���ʂɈ����T�[�o�ł�
�e�L�X�g�����̍��������Ă������d�v�ȃe�[�}�ł���B
1�b�̏�����0.9�b�ōς瓯���ڑ����[�U�[����10%���₷���Ƃ��ł��邶��Ȃ��́B
�������o�ϓI�����b�g�����邺�H
�Ƃ������d���������̓T�[�o���Ŋ撣�邩��N���C�A���g�̓��C�e���V�œK�����Ă���
���Ċ����ł��ȁB
PC������Ȃ��Ȃ��ă^�u���b�g�̏o�ׂ��g�債�Ă�̂͗v����ɂ����������Ƃ���H
�����\����������Ӗ����Ȃ��Ƃł��H
HTML,XML,CSS,JavaScript,JSON�E�E�E�ƃe�L�X�g���ʂɈ����T�[�o�ł�
�e�L�X�g�����̍��������Ă������d�v�ȃe�[�}�ł���B
1�b�̏�����0.9�b�ōς瓯���ڑ����[�U�[����10%���₷���Ƃ��ł��邶��Ȃ��́B
�������o�ϓI�����b�g�����邺�H
�Ƃ������d���������̓T�[�o���Ŋ撣�邩��N���C�A���g�̓��C�e���V�œK�����Ă���
���Ċ����ł��ȁB
PC������Ȃ��Ȃ��ă^�u���b�g�̏o�ׂ��g�債�Ă�̂͗v����ɂ����������Ƃ���H
>>673
�^�u������Ă�̂͐Q���]�����ăl�b�g���ł��鎖��r���A�[�p�Ƃ��Čy���ăo�b�e���[�������������炾��B
�C�`����҂̓N���C�A���g��C�e���V�Ȃ�ċC�ɂ��Ȃ���B
�^�u������Ă�̂͐Q���]�����ăl�b�g���ł��鎖��r���A�[�p�Ƃ��Čy���ăo�b�e���[�������������炾��B
�C�`����҂̓N���C�A���g��C�e���V�Ȃ�ċC�ɂ��Ȃ���B
676 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 01:25:13.78 ID:7mxiCmZT
����ŃT�[�o���̃L���p���������Ȃ��Č��ʓI��Xeon������܂����Ă�킯�ł�����
677 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 01:29:07.42 ID:7mxiCmZT
���C�e���V�͑厖����
������LTE�I�t�ɂ��ăX�}�z�Q�[����Ă݁H
�A���e�i5�{�ł��X�g���X���}�b�n�ł���B
������LTE�I�t�ɂ��ăX�}�z�Q�[����Ă݁H
�A���e�i5�{�ł��X�g���X���}�b�n�ł���B
�A�X�y�c�q
>>673
�ꊄ�̐��\�A�b�v�œ�����p�A�������p��͂܂��Ȃ��Ȃ�����H
���[�X�Œ��x�X�V�����Ȃ�b�͂킩�邯�ǁB
�܂��Ǝ�ƋK�͂ɂ��̂��ȁB
�ꊄ�̐��\�A�b�v�œ�����p�A�������p��͂܂��Ȃ��Ȃ�����H
���[�X�Œ��x�X�V�����Ȃ�b�͂킩�邯�ǁB
�܂��Ǝ�ƋK�͂ɂ��̂��ȁB
�������N����2ch�d���I����ďA�Q�܂�2ch��ςȂ��d���ł���(�E�́E)
http://hissi.org/read.php/jisaku/20140212/a3Q1amNCOUw.html
http://hissi.org/read.php/jisaku/20140213/N214aUNtWlQ.html
http://hissi.org/read.php/jisaku/20140212/a3Q1amNCOUw.html
http://hissi.org/read.php/jisaku/20140213/N214aUNtWlQ.html
681 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 01:40:29.68 ID:7mxiCmZT
> �ꊄ�̐��\�A�b�v�œ�����p�A�������p��͂܂��Ȃ��Ȃ�����H
����B
������������悤�Ƃ�Sandy Bridge���d�͌����̈������sOpteron�ւ̃��v���[�X��
�L�蓾�Ȃ����Ƃ͂킩���ˁH
GNU�͍ŏ�����AVX2�Ȃǂ̍ŐV���߂ɍœK�����ꂽC���C�u��������R���p�C����
���p�ł��邩�炱�����g�����唼�̃c�[���Q�͒lj��R�X�g�Ȃ��ōŐVCPU�ɂ��
���\������ʂ邱�Ƃ��ł���B
���Ƃ͊e���p�\�t�g�ɂ�����\�t�g�E�F�A�̍œK���͓������ʂ��R�X�g�Ɍ������̗p
�ĂȊ����ł���B
APU��Opteron�����ǂ�GPU�����͌���͑唼�̃T�[�o�A�v���Ńf�b�h�u���b�N
�ł����Ȃ����炱�����͂�ϋɓI�ɓ�������Ӗ����Ȃ��B
�f�b�h�u���b�N�łȂ����p���悤�Ƃ����炻�ꂱ����p�Ό��ʂ�x�O������
�V�K�\�t�g�J�����K�v�ɂȂ�B
�����܂�APU�Ɍ����ꂵ������I�ǂ������������Ȃ���B
����B
������������悤�Ƃ�Sandy Bridge���d�͌����̈������sOpteron�ւ̃��v���[�X��
�L�蓾�Ȃ����Ƃ͂킩���ˁH
GNU�͍ŏ�����AVX2�Ȃǂ̍ŐV���߂ɍœK�����ꂽC���C�u��������R���p�C����
���p�ł��邩�炱�����g�����唼�̃c�[���Q�͒lj��R�X�g�Ȃ��ōŐVCPU�ɂ��
���\������ʂ邱�Ƃ��ł���B
���Ƃ͊e���p�\�t�g�ɂ�����\�t�g�E�F�A�̍œK���͓������ʂ��R�X�g�Ɍ������̗p
�ĂȊ����ł���B
APU��Opteron�����ǂ�GPU�����͌���͑唼�̃T�[�o�A�v���Ńf�b�h�u���b�N
�ł����Ȃ����炱�����͂�ϋɓI�ɓ�������Ӗ����Ȃ��B
�f�b�h�u���b�N�łȂ����p���悤�Ƃ����炻�ꂱ����p�Ό��ʂ�x�O������
�V�K�\�t�g�J�����K�v�ɂȂ�B
�����܂�APU�Ɍ����ꂵ������I�ǂ������������Ȃ���B
���̌������Ƃ͂��̂Ƃ��肾���A
OpenCL��HSA���g���Ӗ����Ȃ��p�r�ł���炪�Ӗ����Ȃ��ƌ����Ă���
����Ⴛ������A�Ƃ���
OpenCL��HSA���g���Ӗ����Ȃ��p�r�ł���炪�Ӗ����Ȃ��ƌ����Ă���
����Ⴛ������A�Ƃ���
683 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 01:48:12.59 ID:7mxiCmZT
> OpenCL��HSA���g���Ӗ����Ȃ��p�r
�Ӗ�������p�r�̂ق�������ۂǏ��Ȃ��Ă��s�������������
�g���b�v�N���b�N�Ŕт��H����Ȃ炸���Ƒ����Ă�悗
�Ӗ�������p�r�̂ق�������ۂǏ��Ȃ��Ă��s�������������
�g���b�v�N���b�N�Ŕт��H����Ȃ炸���Ƒ����Ă�悗
Xeon�T�[�o������Ă�Ƃ�����DELL�Ƃ������������T�[�o�������j���[�ɗp�ӂ��ĂȂ������
�c�O�Ȃ�����苟������Ă��Ȃ��ƁA�Ɩ��Ŏg���̂͌�����
�܂�AMD�������ƕ������Ă���R���X�^���g�ɍ���Ă����낤����
�ɕ��������Ȃ����낤����Kaveri�݂����ɓr��r��̋����ɂȂ����Ⴄ�̂���
Kaveri�̒��g��2�{�ɂ���4ch�������ɂ����T�[�o�pAPU�����ĐQ��
�c�O�Ȃ�����苟������Ă��Ȃ��ƁA�Ɩ��Ŏg���̂͌�����
�܂�AMD�������ƕ������Ă���R���X�^���g�ɍ���Ă����낤����
�ɕ��������Ȃ����낤����Kaveri�݂����ɓr��r��̋����ɂȂ����Ⴄ�̂���
Kaveri�̒��g��2�{�ɂ���4ch�������ɂ����T�[�o�pAPU�����ĐQ��
685 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 02:07:01.16 ID:7mxiCmZT
�̂̉��l�Ȃ瑬���ق������[�U�[�ɍD�܂��Ǝv����MFC��������WinAPI���@���Ƃ�
WTL�Ƃ��g���ăK���K�������Ă����ǂ���͂���Ő��Y�����E�E�E�ˁB
�����ŋ߂�WinForms��WPF�������g���ăA�v�������Ă��B
�Ƃ������ق��̃����o�[���ێ�ł��Ȃ����牴������ɍ��킹�Ă邾�������ǁB
�uGPGPU�g�������I�v�Ƃ����̂͂ނ��냊�A���E��̉�����Ă��Ă闧�ꂾ�����肷��B
i3�ȏ�ł����g���Ȃ�AVX2�Ɣ�ׂăS�V������ׂ��Ƃ�ł�OpenCL�͎g���邩��ȁB
�����ɂ͂����܂Ő��\�s�����Ă�p�r���Ȃ��Ƃ������A�ۑ�ƂȂ��Ă��肪
�c�O�Ȃ���GPU�̐��\�����ɂ��Ƃ��Ƃ��}�b�`���ĂȂ���B
�\�t�g�������H�������A�\�t�g�ɍ��킹���Ȃ��n�[�h�������B
WTL�Ƃ��g���ăK���K�������Ă����ǂ���͂���Ő��Y�����E�E�E�ˁB
�����ŋ߂�WinForms��WPF�������g���ăA�v�������Ă��B
�Ƃ������ق��̃����o�[���ێ�ł��Ȃ����牴������ɍ��킹�Ă邾�������ǁB
�uGPGPU�g�������I�v�Ƃ����̂͂ނ��냊�A���E��̉�����Ă��Ă闧�ꂾ�����肷��B
i3�ȏ�ł����g���Ȃ�AVX2�Ɣ�ׂăS�V������ׂ��Ƃ�ł�OpenCL�͎g���邩��ȁB
�����ɂ͂����܂Ő��\�s�����Ă�p�r���Ȃ��Ƃ������A�ۑ�ƂȂ��Ă��肪
�c�O�Ȃ���GPU�̐��\�����ɂ��Ƃ��Ƃ��}�b�`���ĂȂ���B
�\�t�g�������H�������A�\�t�g�ɍ��킹���Ȃ��n�[�h�������B
����d�͓I�ɂ͂ǂ��Ȃ�?
�X�}�z����2D��GPU�`�悪�J���҃I�v�V�����ŗp�ӂ���Ă��肷�邯��
�X�}�z����2D��GPU�`�悪�J���҃I�v�V�����ŗp�ӂ���Ă��肷�邯��
�gSeattle�h is an SoC, so there are no chipsets and the 10GbE is integrated into the processor.
���Ƃ��A�P�O�O�����̌��f�[�^��p�ӂ��āA����ɑ��ĕ����Z�������Ȃ���
���ʂ��܂Ƃ߂ĂP�O�O�����m�肽�����Ă����ꍇ�́AHSA�Ȃ������GPGPU�ł��̂������Ȃ�ł��傤
�ł��A���ۂ́A���̌��f�[�^�ɂ������ĕ����Z���s���Ă����Ɍ��ʂ��m�肽���A
�݂����Ȃ̂��قƂ�ǂȂ̂ŁA����Ȍv�Z��HSA/GPGPU�Ȃł������x�����Ďg�����ɂȂ�Ȃ�
���ʂ��܂Ƃ߂ĂP�O�O�����m�肽�����Ă����ꍇ�́AHSA�Ȃ������GPGPU�ł��̂������Ȃ�ł��傤
�ł��A���ۂ́A���̌��f�[�^�ɂ������ĕ����Z���s���Ă����Ɍ��ʂ��m�肽���A
�݂����Ȃ̂��قƂ�ǂȂ̂ŁA����Ȍv�Z��HSA/GPGPU�Ȃł������x�����Ďg�����ɂȂ�Ȃ�
�����������Ȃ��v�Z�Ȃ牽�g���Ă��u�x������v���Ă��Ƃɂ͂Ȃ�낤�B
�̊��o����悤�ȍ��ɂ͂Ȃ�낤����ˁB
�̊��o����悤�ȍ��ɂ͂Ȃ�낤����ˁB
���A�P�O�O�������ď��������ǁA�P�O�O�����Ȃ�CPU�̂ق���������
�P�����Ȃ炳������GPU�̂ق����������H
�P�����Ȃ炳������GPU�̂ق����������H
������̓������o�X�l�b�N�ŃL���b�V������������P��������Ă�CPU�̕������������B
���܂��͎O�����ȏ�̌`�ɍL�����ʂ̃f�[�^�ɑ��ē��ꉉ�Z���J��Ԃ��p�r�łȂ�����GPGPU�̏o�Ԃ͂Ȃ��B
�t�ɂ��������f�[�^�ɑ��Ă͔��ɗL���Ȃ̂ŃQ�[���̕����V�~�����[�V������A�L�l�N�g�̔F���̓L���[�R���e���c�ɂȂ肤��B
���܂��͎O�����ȏ�̌`�ɍL�����ʂ̃f�[�^�ɑ��ē��ꉉ�Z���J��Ԃ��p�r�łȂ�����GPGPU�̏o�Ԃ͂Ȃ��B
�t�ɂ��������f�[�^�ɑ��Ă͔��ɗL���Ȃ̂ŃQ�[���̕����V�~�����[�V������A�L�l�N�g�̔F���̓L���[�R���e���c�ɂȂ肤��B
BF4 TEST RANGE 1080p �ō��ݒ�
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
�@�@�@�@�Q�Q�Q
�@�@�@�^�@ �_::/�_�@�@�@�l��APU�t�@��������ABF4������
�@�@�^�@�(��)::(��)��@�@����ȃK�`��r�Œǂ��l�߂����Ȃ���������
�@ �b::�@�@��(_�l_)߁b�@RADEON�F�̉�X���ŕςȂ̂�����ŗ�������
�@�@�_ �@߁@`�܁L�^߁@�@������Ⴂ�܂����A�A�A
�@�@�^ �܁R�P�P�Rߡ
�@ / _�Q�_ �_/�_ �_�@�@�I������A�A�AAPU�����S�ɏI������A�A�A
�@�ƁQ�Q)_�R_�� �R_��
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
�@�@�@�@�Q�Q�Q
�@�@�@�^�@ �_::/�_�@�@�@�l��APU�t�@��������ABF4������
�@�@�^�@�(��)::(��)��@�@����ȃK�`��r�Œǂ��l�߂����Ȃ���������
�@ �b::�@�@��(_�l_)߁b�@RADEON�F�̉�X���ŕςȂ̂�����ŗ�������
�@�@�_ �@߁@`�܁L�^߁@�@������Ⴂ�܂����A�A�A
�@�@�^ �܁R�P�P�Rߡ
�@ / _�Q�_ �_/�_ �_�@�@�I������A�A�AAPU�����S�ɏI������A�A�A
�@�ƁQ�Q)_�R_�� �R_��
�@ /�_�Q�Q_�^�_
�^�@�^�@�@ �@�_ ::: �_�@�@�@�G�ABF4�v���C���[
|�@�i���j,�@�A�i���j�A�@|�@�@�@�G�A7850K�g��
|�@�@,,�m(�A_, )�R�A,, �@ |�@�@�@�G�Amantle�g��
|�@�@�@,;�]���]�R �@ .:::::|�@�@�@�G�ADG�g��
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_�@�@�@�@���X���f��
�@ �@�@�@�@ .��:n�@�@�@ �����@�@�@NO THANK YOU
�@ �@ �@�@nf|�b| �@�@�@| | |^!n�@GET OFF
�@ �@ �@�@��|.| | ���@�@��|..| |.|
�@ �@ �@�@|: ::�@ ! }�@�@{�I ::: :|
�@ �@�@�@ �R�@�@,� �@�@�R�@ :�
�^�@�^�@�@ �@�_ ::: �_�@�@�@�G�ABF4�v���C���[
|�@�i���j,�@�A�i���j�A�@|�@�@�@�G�A7850K�g��
|�@�@,,�m(�A_, )�R�A,, �@ |�@�@�@�G�Amantle�g��
|�@�@�@,;�]���]�R �@ .:::::|�@�@�@�G�ADG�g��
�_�@�@�M�j�j�L�@ .:::�^
�^�M�[�]--�]�]�\�L�L�_�@�@�@�@���X���f��
�@ �@�@�@�@ .��:n�@�@�@ �����@�@�@NO THANK YOU
�@ �@ �@�@nf|�b| �@�@�@| | |^!n�@GET OFF
�@ �@ �@�@��|.| | ���@�@��|..| |.|
�@ �@ �@�@|: ::�@ ! }�@�@{�I ::: :|
�@ �@�@�@ �R�@�@,� �@�@�R�@ :�
694 �FSocket774�F2014/02/13(��) 07:05:35.93 ID:4aAG88sH
intel�̐�`�}�������鏊����Ȃ�
695 �FSocket774�F2014/02/13(��) 07:46:16.36 ID:8by6YlnZ
GM107 has a TDP of 60W
http://videocardz.com/49557/exclusive-nvidia-maxwell-gm107-architecture-unveiled
The facts about Maxwell
NVIDIA Maxwell GM107 specifications
Full GM107 has 5 SMs with 128 CUDAs each, which gives 640 in total.
This means that GTX 750 Ti has 640 CUDAs (5 SMX) and GTX 750 has 512 (4 SMX).
http://videocardz.com/images/2014/02/Maxwell-GM107.png
Larger L2 cache.
This is the main difference between Kepler and Maxwell. Larger L2 cache will limit the queries to the GPU.
GM107 L2 cache has 2MB. GK107��s cache has 256KB.
Workload balancing and complier-based scheduling has been improved.
The number of instructions per clock cycle has been increased.
SM has been redesigned into four processing blocks (as explained above).
Maxwell introduces even faster H.264 encoding and decoding with improved NVENC (which is used, for instance, in ShadowPlay).
New GC5 power state (low sleep state).
http://videocardz.com/49557/exclusive-nvidia-maxwell-gm107-architecture-unveiled
The facts about Maxwell
NVIDIA Maxwell GM107 specifications
Full GM107 has 5 SMs with 128 CUDAs each, which gives 640 in total.
This means that GTX 750 Ti has 640 CUDAs (5 SMX) and GTX 750 has 512 (4 SMX).
http://videocardz.com/images/2014/02/Maxwell-GM107.png
{kind=link}
Larger L2 cache.
This is the main difference between Kepler and Maxwell. Larger L2 cache will limit the queries to the GPU.
GM107 L2 cache has 2MB. GK107��s cache has 256KB.
Workload balancing and complier-based scheduling has been improved.
The number of instructions per clock cycle has been increased.
SM has been redesigned into four processing blocks (as explained above).
Maxwell introduces even faster H.264 encoding and decoding with improved NVENC (which is used, for instance, in ShadowPlay).
New GC5 power state (low sleep state).
696 �FSocket774�F2014/02/13(��) 07:56:09.16 ID:4aAG88sH
NVIDIA��Intel�̐�`�}�����X���Ⴂ
AMD Mantle Interview with Oxide Games' Dan Baker
http://www.maximumpc.com/AMD_Mantle_Interview_2014
http://www.maximumpc.com/AMD_Mantle_Interview_2014
698 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 09:04:51.36 ID:IQBskJFc
�S�������Ƃ��̃p�^�[���}�b�`�Ȃ�Ђ���Ƃ�����GPU�g���邩��
�ł��C���f�b�N�X�o�^����̂͂��Ԃ�CPU�̂ق���������
�ł��C���f�b�N�X�o�^����̂͂��Ԃ�CPU�̂ق���������
dis�邾���̃��c�͋����B
����S�̂���l�͕����Ă�B�ŋ߂̕���͂����ς�HSA�̘b��B��N���̉��AMD�̐l���u�t�ɗ����Ă����ˁB
����S�̂���l�͕����Ă�B�ŋ߂̕���͂����ς�HSA�̘b��B��N���̉��AMD�̐l���u�t�ɗ����Ă����ˁB
>Radeon R9 280X��Radeon HD 7970�̃��u�����h�ł������悤�ɁARadeon R9 280����{�I�ɂ�Radeon R9 280�̃��u�����h�ł���B
���{��ŗ���
���{��ŗ���
����DDR3��16GB���o���
Review: Sapphire Radeon R7 250, Dual Graphics and Mantle
ttp://hexus.net/tech/reviews/graphics/65977-sapphire-radeon-r7-250-dual-graphics-mantle/
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/3D.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Bio.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/GRID.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Rome.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/BF4.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Power1.png
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Power2.png
ttp://hexus.net/tech/reviews/graphics/65977-sapphire-radeon-r7-250-dual-graphics-mantle/
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/3D.png
{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Bio.png
{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/GRID.png
{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Rome.png
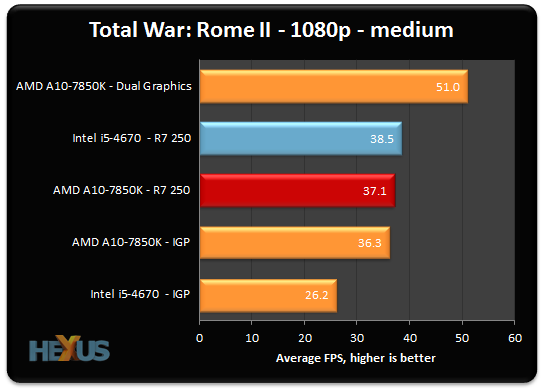{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/BF4.png
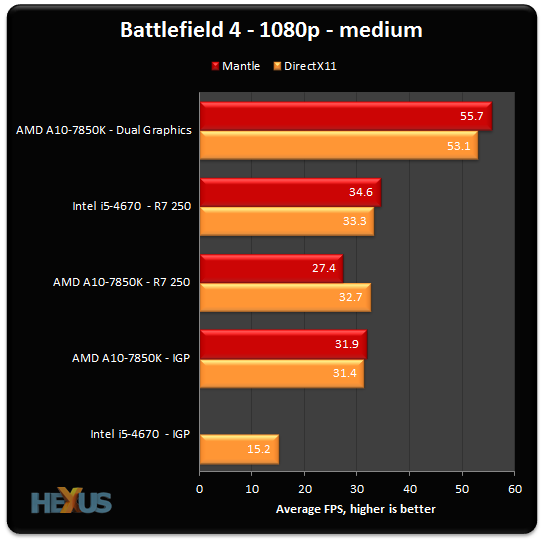{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Power1.png
{kind=link}
ttp://img.hexus.net/v2/graphics_cards/amd/R7250/Power2.png
{kind=link}
Amazon.co.jp��2��12���A�ԕi�|���V�[�̕ύX�����m�����B
����܂ŋq�̓s���ɂ��g�p�ς݁E�J���ςݏ��i�̕ԕi�ł��ꕔ�������S�z�ԋ����Ă������A����͕ԋ��z�����z�ɂȂ�B
�܂�����C�ł́u�g�p�ς݁v�Ɣ��f���ꂽ�ꍇ�A�ԕi�͕s�ɂȂ�B
3��10���ȍ~��Amazon�ԕi�W�ɓ��������ԕi���i����K�p����B
http://www.itmedia.co.jp/news/articles/1402/12/news158.html
����܂ŋq�̓s���ɂ��g�p�ς݁E�J���ςݏ��i�̕ԕi�ł��ꕔ�������S�z�ԋ����Ă������A����͕ԋ��z�����z�ɂȂ�B
�܂�����C�ł́u�g�p�ς݁v�Ɣ��f���ꂽ�ꍇ�A�ԕi�͕s�ɂȂ�B
3��10���ȍ~��Amazon�ԕi�W�ɓ��������ԕi���i����K�p����B
http://www.itmedia.co.jp/news/articles/1402/12/news158.html
DG�X�Q�[�������
����ܕς���̂�
�c��_���� �u�䂪���͊؍��ɑ��A�o�ϊW�̒f��ł���邵���Ȃ��v�@�����̓s�m���ɂ��Ȃ������c
http://hayabusa3.2ch.net/test/read.cgi/news/1392253426/
�c��_�r�Y @toshio_tamogami
�؍����Ԉ��w�̓��𐧒肷�邻���ł��B
�܂��Q�O�P�V�N�܂łɃ��l�X�R�̐��E�L����Y�ւ̓o�^��ڎw����Ƃɓ��邻���ł��B
���̍��͉R���̖��l�ł����A��̂ǂ��܂ł��C�����ނ̂��A
�䂪���͊؍��ɑ��o�ϊW�̒f��ł���邵���Ȃ��̂ł��傤���B
���{���Ȃ���Ί؍��͓|�Y���܂��B
https://twitter.com/toshio_tamogami/status/433729029653295105
�y�������Ă����؍��ɓ��{���������Ă��������z�z
1965�N 60���~�����̃C���t����������n
1965�N 800���~�{�������� ���؊�{���
1983�N ���ʌo�ϋ��� 4000���~�x��
1997�N �؍��ʉ݊�@ 1���~�x��
2006�N �E�H�����~�ώx�� 2���~�x��
�i�؍������́u���{�̉����͖��f�������v�ƕs������\���j
2008�N ���[�}���V���b�N��@ 3���~�x��
�i�؍������́A�u���{�͏o���ɂ��݂��Ă���v�ƕs������\���j
�����{��k�Ђ̋`�����ł́A��p���S�O�O���~���̋`�����œ��{�������Ă��ꂽ���A
���A���F�肷��ŕn���́A
30�J������̌v��6���~�����؍��͒�z
�������A�؍��͑S���E�̒��ŗB��h�`�����ɑ��錩�Ԃ�h��v��
����Ɂw�����{��k�Ђ����j�����܂��x�ȂǂƖ���ȏj�ӂ�\������B
���̑��A2002����W�t�X�^�W�A�����ݔ�Z��300���~���ԍ�
���{��IMF����8400���~�Ƃ��̑O��1��4000���~�A
�X�Ɉȍ~��1��2000���~��ODA�̗L���q���̗��q
�v��1070���h���A��13���~�̕��ɑ���
�؍��͖���1�~���ԍς��Ă��Ȃ��B
70���~�߂��������������ĉ������āA����ɕʌ���13���~���݂��Ă����āA���ꂾ���z�����Ă����A�ł́u���ȁi�����j������Ȃ��v�Ɣ��A
�\�E���̐��j�f���i�����f���j��
���T���{�����ƓV�c�É��̏ё����R�₵������؍��l�B
http://hayabusa3.2ch.net/test/read.cgi/news/1392253426/
�c��_�r�Y @toshio_tamogami
�؍����Ԉ��w�̓��𐧒肷�邻���ł��B
�܂��Q�O�P�V�N�܂łɃ��l�X�R�̐��E�L����Y�ւ̓o�^��ڎw����Ƃɓ��邻���ł��B
���̍��͉R���̖��l�ł����A��̂ǂ��܂ł��C�����ނ̂��A
�䂪���͊؍��ɑ��o�ϊW�̒f��ł���邵���Ȃ��̂ł��傤���B
���{���Ȃ���Ί؍��͓|�Y���܂��B
https://twitter.com/toshio_tamogami/status/433729029653295105
�y�������Ă����؍��ɓ��{���������Ă��������z�z
1965�N 60���~�����̃C���t����������n
1965�N 800���~�{�������� ���؊�{���
1983�N ���ʌo�ϋ��� 4000���~�x��
1997�N �؍��ʉ݊�@ 1���~�x��
2006�N �E�H�����~�ώx�� 2���~�x��
�i�؍������́u���{�̉����͖��f�������v�ƕs������\���j
2008�N ���[�}���V���b�N��@ 3���~�x��
�i�؍������́A�u���{�͏o���ɂ��݂��Ă���v�ƕs������\���j
�����{��k�Ђ̋`�����ł́A��p���S�O�O���~���̋`�����œ��{�������Ă��ꂽ���A
���A���F�肷��ŕn���́A
30�J������̌v��6���~�����؍��͒�z
�������A�؍��͑S���E�̒��ŗB��h�`�����ɑ��錩�Ԃ�h��v��
����Ɂw�����{��k�Ђ����j�����܂��x�ȂǂƖ���ȏj�ӂ�\������B
���̑��A2002����W�t�X�^�W�A�����ݔ�Z��300���~���ԍ�
���{��IMF����8400���~�Ƃ��̑O��1��4000���~�A
�X�Ɉȍ~��1��2000���~��ODA�̗L���q���̗��q
�v��1070���h���A��13���~�̕��ɑ���
�؍��͖���1�~���ԍς��Ă��Ȃ��B
70���~�߂��������������ĉ������āA����ɕʌ���13���~���݂��Ă����āA���ꂾ���z�����Ă����A�ł́u���ȁi�����j������Ȃ��v�Ɣ��A
�\�E���̐��j�f���i�����f���j��
���T���{�����ƓV�c�É��̏ё����R�₵������؍��l�B
707 �FSocket774�F2014/02/13(��) 10:28:08.11 ID:bfBQLMPg
>>695
�Ƃ肠�����S�~�ȉ�����
�Ƃ肠�����S�~�ȉ�����
>>702������茋��HD7750���D�G�Ȃ����ŃZ���������D�G�Ȃ킯����Ȃ����
�������i�тȂ�A4�Ƃ�A6�V���[�Y�Ɣ�ׂ��炢��������
APU������P�̂��Ⴛ�ꂱ���Z�������Ȃ��b���ɂȂ��
�������i�тȂ�A4�Ƃ�A6�V���[�Y�Ɣ�ׂ��炢��������
APU������P�̂��Ⴛ�ꂱ���Z�������Ȃ��b���ɂȂ��
>>695
�X�y�b�N���S�~�����ASM����SP���������SM�̐��𑝂₵TPC���グ�Ȃ��Ⴂ���Ȃ������̂����ǂ���B
���sKepler�͎��s�����Č����Ă�l�Ȃ����
�X�y�b�N���S�~�����ASM����SP���������SM�̐��𑝂₵TPC���グ�Ȃ��Ⴂ���Ȃ������̂����ǂ���B
���sKepler�͎��s�����Č����Ă�l�Ȃ����
AMD�͂��܂Ń��l�[���Ղ葱����́H
711 �FSocket774�F2014/02/13(��) 12:27:52.71 ID:8by6YlnZ
texture unit��SMM������8��kepler��SMX�ł�16
�s��
GTX750Ti�ł�40TMU�ƂȂ�
GTX650Ti�ł�64TMU�ƂȂ�
SP����SMM������128,SMX������192
GTX750Ti�ł�640SP�ƂȂ�
GTX650Ti�ł�768SP�ƂȂ�
�J�^���O�X�y�b�N�͗����Ă邪���s���\�͏オ���Ă�
�s��
GTX750Ti�ł�40TMU�ƂȂ�
GTX650Ti�ł�64TMU�ƂȂ�
SP����SMM������128,SMX������192
GTX750Ti�ł�640SP�ƂȂ�
GTX650Ti�ł�768SP�ƂȂ�
�J�^���O�X�y�b�N�͗����Ă邪���s���\�͏オ���Ă�
����͂������Ȃ��B�d�͂����萫�\���{����2�{�ɂȂ肻���Ȃ̂�
Llano(VLIW5)��Trinity(VLIW4)��Richland(VLIW4)��Kaveri(GCN)
������Ɖ������Ă邩������Ȃ��ł��˂�
������Ɖ������Ă邩������Ȃ��ł��˂�
GPU�̓d�͓�����̐��\����Ȃ��ACPU�̓d�͓�����̐��\�������Ƃ�����AMD
Intel�Ɋ��s����ˁ[��
Intel�Ɋ��s����ˁ[��
Kepler����Fermi���ɖ߂������AFermi��Kepler��Fepler�݂�����
28nm��60W GTX480���炢���}�W�Ȃ琦���˂��A�܂��������i�Ȃ̂�
20nm��CPU���������^Maxwell�͂ǂ��Ȃ���
�Ƃ肠�������̂܂܂��ƃ��o�C��dGPU�ł̃��f�҉�͖�������
28nm��60W GTX480���炢���}�W�Ȃ琦���˂��A�܂��������i�Ȃ̂�
20nm��CPU���������^Maxwell�͂ǂ��Ȃ���
�Ƃ肠�������̂܂܂��ƃ��o�C��dGPU�ł̃��f�҉�͖�������
>>710
���l�[������Ȃ�GCN1.1����GCN2.0�ւ̃o�[�W�����A�b�v�i�B
���XGCN2.0��Kaveri�Ƒg�ݍ��킹��Mantle����ɂ͂��̃o�[�W�����̈Ⴂ�Ő��\�����o��B
���l�[������Ȃ�GCN1.1����GCN2.0�ւ̃o�[�W�����A�b�v�i�B
���XGCN2.0��Kaveri�Ƒg�ݍ��킹��Mantle����ɂ͂��̃o�[�W�����̈Ⴂ�Ő��\�����o��B
http://cdn4.wccftech.com/wp-content/uploads/2014/01/GeForce-GTX-750-Ti-Maxwell-Performance.jpg
performance
GTX650Ti:34.0
GTX750Ti:41.2
TDP
GTX650Ti:110
GTX750Ti:75�i�H�j
(41.2/34.0)*(110/75)=1.777
60w�Ȃ�2.222�{
(41.2/34.0)*(110/60)=2.222
TMU
(8*5)/(16*4)=0.625
SP
(128*5)/(192*4)=0.833
{kind=link}
performance
GTX650Ti:34.0
GTX750Ti:41.2
TDP
GTX650Ti:110
GTX750Ti:75�i�H�j
(41.2/34.0)*(110/75)=1.777
60w�Ȃ�2.222�{
(41.2/34.0)*(110/60)=2.222
TMU
(8*5)/(16*4)=0.625
SP
(128*5)/(192*4)=0.833
>>717
�t�@�����X��HD7750,HD7850,R7-250,R9-270���i�����ɂ���̂ɉ����̒��r���[�Ŕ��������鐫�\
�t�@�����X��HD7750,HD7850,R7-250,R9-270���i�����ɂ���̂ɉ����̒��r���[�Ŕ��������鐫�\
Radeon�͌Â��Q�[���ŕs��N��������
���ꂪ���ŃT�u�ƃ��C����Radeon��Geforce�����g���킯�Ă��
���̕p�ɂȃA�b�v�f�[�g���ĂقƂ�Ǎŋ߂̃Q�[�������̏C���������
���ꂪ���ŃT�u�ƃ��C����Radeon��Geforce�����g���킯�Ă��
���̕p�ɂȃA�b�v�f�[�g���ĂقƂ�Ǎŋ߂̃Q�[�������̏C���������
Pre-order prices of "Kabini" socket AM1 APUs
http://www.cpu-world.com/news_2014/2014021202_Pre-order_prices_of_Kabini_socket_AM1_APUs.html
http://www.cpu-world.com/news_2014/2014021202_Pre-order_prices_of_Kabini_socket_AM1_APUs.html
(41.2/34.0)*((192*4)/(128*5))=1.454
SP������1.45�{�̐��\�A�b�v����
TMU�������������m�g���V�i�C��
SP������1.45�{�̐��\�A�b�v����
TMU�������������m�g���V�i�C��
�s���]���Ă���������FM2�ŏo�������̂�
DG�Ȃ��Ȃ����������̐L�т���
������ӂ͂܂��`���[�j���O�̗]�n�����邾�낤��
�|�X�g�G�t�F�N�g����APU���ōs�����Ă̂������낢��
������ӂ͂܂��`���[�j���O�̗]�n�����邾�낤��
�|�X�g�G�t�F�N�g����APU���ōs�����Ă̂������낢��
Kabini���ƃT�E�X���������Ă邩��\�P�b�g������̂͂��傤��������Ȃ�����
�����̂��ɂ���ɂ��Ă�PCIe��4���[�������Ȃ��͂�����
�����̂��ɂ���ɂ��Ă�PCIe��4���[�������Ȃ��͂�����
>>697
��Believe it or not, Mantle is actually easier to support than OpenGL.
��OpenGL has many unobvious pitfalls and traps, whereas Mantle really doesn't.
�f���炵��
��Believe it or not, Mantle is actually easier to support than OpenGL.
��OpenGL has many unobvious pitfalls and traps, whereas Mantle really doesn't.
�f���炵��
ARM�C�~�b�h�����W�����̐VCPU�R�A�uCortex-A17�v�ƐVGPU�R�A�uMali-T720�v�\�B
�̗p���i��2015�N�ȍ~�ɓo��̗\��
http://www.4gamer.net/games/143/G014356/20140212012/
Mali-T720��HSA�ɑΉ����Ă���
�̗p���i��2015�N�ȍ~�ɓo��̗\��
http://www.4gamer.net/games/143/G014356/20140212012/
Mali-T720��HSA�ɑΉ����Ă���
������ǂތ���Ή����ĂȂ�
http://pc.watch.impress.co.jp/docs/news/event/20131207_626735.html
http://pc.watch.impress.co.jp/docs/news/event/20131207_626735.html
Mali��T604��Opencl��HEVC��VP9���Đ��ł�����Ęb�͕�����
N�̂ق�����͑S�����������̂Ȃ���ˁ[
N�̂ق�����͑S�����������̂Ȃ���ˁ[
>>683
OpenCL��HSA��ɂ��Ă邯��
HSA��OpenCL�̂悤�Ɍ���ꂽ�p�r�ŃX�^���_�[�h�ɂȂ�Ǝv���H
���������Ȃ�\�����Ǝv����
OpenCL��HSA��ɂ��Ă邯��
HSA��OpenCL�̂悤�Ɍ���ꂽ�p�r�ŃX�^���_�[�h�ɂȂ�Ǝv���H
���������Ȃ�\�����Ǝv����
>>727
���N��GPU�ł��Ή����Ă��Ȃ����āAARM�͂���܂�HSA�ɋC������ĂȂ��̂�
����ARM�͂܂�����HSA�ŁA���AMD�͕K����HSA�AHSA���Ă��銴���Ȃ�
CPU���ǂ����悤���Ȃ���Ԃ�����A�����Ȃ炴�链�Ȃ��낤��
>>729
PC�̌���ꂽ�p�r��"�X�^���_�[�h"�ł͂Ȃ��āA�Ɍ���ꂽ�p�r�ł����g���Ȃ����Ċ������낤
���N��GPU�ł��Ή����Ă��Ȃ����āAARM�͂���܂�HSA�ɋC������ĂȂ��̂�
����ARM�͂܂�����HSA�ŁA���AMD�͕K����HSA�AHSA���Ă��銴���Ȃ�
CPU���ǂ����悤���Ȃ���Ԃ�����A�����Ȃ炴�链�Ȃ��낤��
>>729
PC�̌���ꂽ�p�r��"�X�^���_�[�h"�ł͂Ȃ��āA�Ɍ���ꂽ�p�r�ł����g���Ȃ����Ċ������낤
>>727
���܂�A�ԈႦ���B�Ή����Ă�̂�Mali-T760�̕�������
���܂�A�ԈႦ���B�Ή����Ă�̂�Mali-T760�̕�������
732 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 19:15:05.97 ID:IQBskJFc
>>699
��̓I�Ȑ��ʂ��o���Ȃ������Ɂu����S�v�����z�̓o�J��
�ق��̌���̕���ł�GitHub��SlideShare�ɋ�̓I�Ȑ��ʕ���
������̂��ʗႾ��HSA�ł���Ȃ��̂͌������Ƃ����������Ƃ��Ȃ��B
�����邾������ĉ������ɗ����ĂȂ��؋��B
��̓I�Ȑ��ʂ��o���Ȃ������Ɂu����S�v�����z�̓o�J��
�ق��̌���̕���ł�GitHub��SlideShare�ɋ�̓I�Ȑ��ʕ���
������̂��ʗႾ��HSA�ł���Ȃ��̂͌������Ƃ����������Ƃ��Ȃ��B
�����邾������ĉ������ɗ����ĂȂ��؋��B
���O�������������ĂȂ���������Ȃ���
>>729
HSA�ڐG��Ƃ��������Ȃ�l���ɂ����̂ŁA
����܂�Ӗ����Ȃ��c�_���Ǝv��
���ꎩ�̂��v���O���~���O���������OpenCL�Ƃ͕������悤���Ȃ�
HSA�ڐG��Ƃ��������Ȃ�l���ɂ����̂ŁA
����܂�Ӗ����Ȃ��c�_���Ǝv��
���ꎩ�̂��v���O���~���O���������OpenCL�Ƃ͕������悤���Ȃ�
735 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 19:19:55.10 ID:IQBskJFc
x86����͖����o�g�Ƃ����𗝌������҂Ƃ������������c�������̂�
GPGPU�E�G�͎c�O�Ȑl�������Ȃ����
GPGPU�E�G�͎c�O�Ȑl�������Ȃ����
���l�v�Z�W��CUDA����Ă�l�͌��\����Ǝv��
OpenCL�͏Љ��邱�Ƃ͂��邯�ǂ܂�Ő���オ���Ă銴�������Ȃ�
HSA�͂����������m���Ȃ��̂Ŗ��O����
OpenCL�͏Љ��邱�Ƃ͂��邯�ǂ܂�Ő���オ���Ă銴�������Ȃ�
HSA�͂����������m���Ȃ��̂Ŗ��O����
737 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 19:23:51.56 ID:5W3MT0Nh
gpgpu�͉摜���ʂƂ��F�،n�̃A�v���Ƃ��ȂȁH
�C�y�ɂł���A�v���ł͂����ɂ��������ȁB
�C�y�ɂł���A�v���ł͂����ɂ��������ȁB
739 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 19:38:52.42 ID:5W3MT0Nh
������ɂ��Ă�HSA�ŕ������͋�������B
Haswell��256�r�b�gAVX���j�b�g��3����Ă�̂�1�o�C�g������̏�����
1�R�A������96ops/clk
GPU�ł�1�o�C�g�P�ʂ�SIMD���Z�̓T�|�[�g���ĂȂ��̂�512SP��GCN��
��������512ops/clk�B
����ɍX�ɃN���b�N�E�R�A������������E�E�E
���_�s�[�N���\�̎��_��Core i3�ɕ����Ă�B
Haswell��256�r�b�gAVX���j�b�g��3����Ă�̂�1�o�C�g������̏�����
1�R�A������96ops/clk
GPU�ł�1�o�C�g�P�ʂ�SIMD���Z�̓T�|�[�g���ĂȂ��̂�512SP��GCN��
��������512ops/clk�B
����ɍX�ɃN���b�N�E�R�A������������E�E�E
���_�s�[�N���\�̎��_��Core i3�ɕ����Ă�B
MT6595��Cortex-A17��Cortex-A7��4���big.LITTLE�\���ŏW�ς��C
H.265/HEVC�x�[�X��4K�r�f�I���G���R�[�h���f�R�[�h�ł���n�[�h�E�F�A����������Ƃ̂��Ƃ�
x86���s�ł���w
H.265/HEVC�x�[�X��4K�r�f�I���G���R�[�h���f�R�[�h�ł���n�[�h�E�F�A����������Ƃ̂��Ƃ�
x86���s�ł���w
741 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 19:43:44.25 ID:5W3MT0Nh
���o��̂͗��N���{
A17���Ă̂����ɖ�������
HEVC�R�[�f�b�N�̃n�[�h�����Ȃ��IP�����Ă���Ȃ�ɂł������ł��������
�ʂɌւ����ł��Ȃ��B
�ނ��듮���z�M����T�[�o��CPU�͈ˑRx86�Ȃ�
A17���Ă̂����ɖ�������
HEVC�R�[�f�b�N�̃n�[�h�����Ȃ��IP�����Ă���Ȃ�ɂł������ł��������
�ʂɌւ����ł��Ȃ��B
�ނ��듮���z�M����T�[�o��CPU�͈ˑRx86�Ȃ�
HSA�M�҂�HSA����̓I�ɉ��łǂ�����Ďg���̂������Ă����B�^�ʖڂɒm�肽���̂����B
>>741
����Intel��AMD��HEVC��IP�Ƃ�����Ȃ����낤�B
AMD�͏ꍇ�ɂ���āA�����������甃����������Ȃ����A
Intel��QSV�Ɏ��O�ŋ@�\�lj����đΉ����邾�낤�B
ARM�̃j���[�X�͗��N�ɂ�HEVC�����p�I�ȑ��x�Ŏg�p�ł���Ƃ����Ӗ�������B
�掿��H.264���悯��A�܂�����ŁB
����Intel��AMD��HEVC��IP�Ƃ�����Ȃ����낤�B
AMD�͏ꍇ�ɂ���āA�����������甃����������Ȃ����A
Intel��QSV�Ɏ��O�ŋ@�\�lj����đΉ����邾�낤�B
ARM�̃j���[�X�͗��N�ɂ�HEVC�����p�I�ȑ��x�Ŏg�p�ł���Ƃ����Ӗ�������B
�掿��H.264���悯��A�܂�����ŁB
Phenom�U�ɎU�X������������A4�̏o�����ǂ��ăA�z�݂�����������
�������Z�ŏ����\�͂��K�v�ȕ���ł͂قڑS��HSA���g���邾��
746 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 21:17:15.12 ID:5W3MT0Nh
���Ⴀ���̉�͂��肢���܂�
���ǂ̃A�v���Ŏg���邩
�������́A���ǂ̃A�v�����g����悤�ɂȂ�̂�����H
�������́A���ǂ̃A�v�����g����悤�ɂȂ�̂�����H
748 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 21:27:52.82 ID:5W3MT0Nh
�R�[�h�����������Ȃ���قǐ����ł���������PS3�̂Ƃ���Cell�Ƃ������肾��
Cell�Ȃ�C�̕W�����C�u�������g������x�ɂ͔ėp��������������
����Ȃ�ɂ͎g������GPGPU�͂�����y���ɕs���R�������
Cell�Ȃ�C�̕W�����C�u�������g������x�ɂ͔ėp��������������
����Ȃ�ɂ͎g������GPGPU�͂�����y���ɕs���R�������
�p�[�e�B�N����������GPU�̓��ӕ��삶���
750 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 21:45:05.46 ID:5W3MT0Nh
�����o���h�����������瑽ch��GDDR5�ς�GPU�L������
�ł�DDR3����CPU�ƕς����B
�ł�DDR3����CPU�ƕς����B
A17�������Ȃ�SoFIA�͉��ɂȂ�c�s�����H
�m���AHSA�̃��f������
���C�u������HSA�����^�C���˃t�@�C�i���C�U�˃n�[�h
���������B���̌���ł́A�c�q�������Ƃ���́u�v�\��_���v�J�[�v�ɂȂ���Ă��Ƃ��ˁB
���C�u������HSA�����^�C���˃t�@�C�i���C�U�˃n�[�h
���������B���̌���ł́A�c�q�������Ƃ���́u�v�\��_���v�J�[�v�ɂȂ���Ă��Ƃ��ˁB
753 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 22:25:07.60 ID:5W3MT0Nh
XMM7260�͖�����TSMC������
��R�X�g���̂��߂Ƀ����`�b�v������ɂ͑���Fab�̂ق����s���������ꍇ�����Ă��邾�낤
�t�ɍl�����TSMC�ł��̂܂ܐ����ł���ق�Atom��IP�͏_����������Ƃ�
�ؖ����邱�ƂɂȂ邾�낤
��R�X�g���̂��߂Ƀ����`�b�v������ɂ͑���Fab�̂ق����s���������ꍇ�����Ă��邾�낤
�t�ɍl�����TSMC�ł��̂܂ܐ����ł���ق�Atom��IP�͏_����������Ƃ�
�ؖ����邱�ƂɂȂ邾�낤
754 �FSocket774�F2014/02/13(��) 22:26:48.37 ID:KMQ6CETE
�V���㓞���I �w�e���W�j�A�X�E�R���s���[�e�B���O�ŐV�����y�O�ҁz (1/4)
2014�N1��14���A�w�e���W�j�A�X�E�R���s���[�e�B���O�Ɍ������t���[�����[�N�uHSA�v�iHeterogeneous System Architecture�j��
�n�[�h�E�F�A���x���ŏ��߂ăT�|�[�g����AMD A�V���[�Y�v���Z�b�T�gKaveri�h�������ɔ��\���ꂽ�B
HSA�Ή��A�v���P�[�V�����̊J���v���b�g�t�H�[���Ƃ��Ă����҂��W�߂Ă���Kaveri�𒆐S�ɁAHSA�̌���ƍ����T��B
http://eetimes.jp/ee/articles/1402/06/news074.html
2014�N1��14���A�w�e���W�j�A�X�E�R���s���[�e�B���O�Ɍ������t���[�����[�N�uHSA�v�iHeterogeneous System Architecture�j��
�n�[�h�E�F�A���x���ŏ��߂ăT�|�[�g����AMD A�V���[�Y�v���Z�b�T�gKaveri�h�������ɔ��\���ꂽ�B
HSA�Ή��A�v���P�[�V�����̊J���v���b�g�t�H�[���Ƃ��Ă����҂��W�߂Ă���Kaveri�𒆐S�ɁAHSA�̌���ƍ����T��B
http://eetimes.jp/ee/articles/1402/06/news074.html
HSA
�@Kaveri�ő�̓����ƂȂ�̂́A��͂�HSA�̃T�|�[�g���B
?�����v���O�������ACPU��GPU���ӎ����邱�ƂȂ�����ł���悤�ɂ���v���O���~���O���f���̐���
?�V�X�e����A�[�L�e�N�`���̈Ⴂ���z�����钆�Ԍ������^�C���̐���
?CPU��GPU�̃������A�h���X���L�ƁACPU�[GPU�Ԃ̃������R�q�[�����V�i�������j�̎���
�@Kaveri�ő�̓����ƂȂ�̂́A��͂�HSA�̃T�|�[�g���B
?�����v���O�������ACPU��GPU���ӎ����邱�ƂȂ�����ł���悤�ɂ���v���O���~���O���f���̐���
?�V�X�e����A�[�L�e�N�`���̈Ⴂ���z�����钆�Ԍ������^�C���̐���
?CPU��GPU�̃������A�h���X���L�ƁACPU�[GPU�Ԃ̃������R�q�[�����V�i�������j�̎���
HSA�ł́A�����̂��ƂȂǂ�W��������Ax86�ł�ARM�v���b�g�t�H�[���ł��A�����āA�����Ȃ�GPU�A�[�L�e�N�`���ł��A�v���O������傫���ύX���邱�ƂȂ�����ł���悤�ɂ��悤�Ƃ��Ă���B
���̊�{�I�Ȏd�g�݂́AHSAIL�iHSA Intermediate Language�j�ƌĂ�钆�Ԍ���ɂ����GPU�i�܂���CPU���܂ށj�̖��߃Z�b�g�̈Ⴂ���z�����A
JIT�iJust In Time�j�R���p�C���܂��̓����^�C���i�e�n�[�h�E�F�A�x���_�[���p�ӂ���t�@�C�i���C�U�j��GPU�i�܂���CPU�j�̃l�C�e�B�u���߃Z�b�g�ɕϊ�����Ƃ������́B
�����AHSAIL�����ۉ�����̂́A���GPU�����ӂƂ���������߂ł���ACPU�ŏ����������������I�ȉ��Z������AGPU�{���̖����ł���O���t�B�b�N�X�����͊܂܂Ȃ��B
HSA�t�@�E���f�[�V�����ł́A1�̃v���O�����R�[�h�ŁA�S�Ẵv���b�g�t�H�[�����T�|�[�g�ł���悤�ɂ��邱�Ƃ��ŏI�I�ȃS�[���Ƃ��Ă���A
���t�@�E���f�[�V�����̃����o�[��CPU�A�[�L�e�N�`���A���Ȃ킿x86�AARM�A������MIPS�i2012�N����Imagenation Technologies�������j�̊ԂŁA
�ϋɓI�Ƀo�C�i���ϊ����ł�����𐮂������悤����������\�����c����Ă���B
���̊�{�I�Ȏd�g�݂́AHSAIL�iHSA Intermediate Language�j�ƌĂ�钆�Ԍ���ɂ����GPU�i�܂���CPU���܂ށj�̖��߃Z�b�g�̈Ⴂ���z�����A
JIT�iJust In Time�j�R���p�C���܂��̓����^�C���i�e�n�[�h�E�F�A�x���_�[���p�ӂ���t�@�C�i���C�U�j��GPU�i�܂���CPU�j�̃l�C�e�B�u���߃Z�b�g�ɕϊ�����Ƃ������́B
�����AHSAIL�����ۉ�����̂́A���GPU�����ӂƂ���������߂ł���ACPU�ŏ����������������I�ȉ��Z������AGPU�{���̖����ł���O���t�B�b�N�X�����͊܂܂Ȃ��B
HSA�t�@�E���f�[�V�����ł́A1�̃v���O�����R�[�h�ŁA�S�Ẵv���b�g�t�H�[�����T�|�[�g�ł���悤�ɂ��邱�Ƃ��ŏI�I�ȃS�[���Ƃ��Ă���A
���t�@�E���f�[�V�����̃����o�[��CPU�A�[�L�e�N�`���A���Ȃ킿x86�AARM�A������MIPS�i2012�N����Imagenation Technologies�������j�̊ԂŁA
�ϋɓI�Ƀo�C�i���ϊ����ł�����𐮂������悤����������\�����c����Ă���B
�@HSA�ł́AHSAIL�̐�����C++AMP�Ȃǂ̍����x���R���p�C���ɂ��v���O���~���O�̑��AOpen CL�ŏ����ꂽ�v���O�����́A
Clang��EDG�iEdison Design Group�j�̃t�����g�G���h��Open CL��SPIR�iStandard Portable Intermediate Representation�j�ɕϊ����ꂽ��A
LLVM�iLow Level Virtual Machine�j��HSAIL�ɍœK�������B
�܂��AJava�̕���v���O���~���O�Ɋւ��ẮAOracle��AMD�������J������Open CL�A�N�Z�����[�V����API��APARAPI�iA PARallel API�j�𗘗p���邱�ƂŁA
HSA�ł��ėp���Z������GPU�Ɋ��蓖�Ă邱�Ƃ��ł���悤�ɂȂ�B
�������āAHSAIL�̃o�C�i���R�[�h�����邱�ƂŁA�e�n�[�h�E�F�A�̖��߃Z�b�g�A�[�L�e�N�`���ɋ߂����x���ŃA�v���P�[�V���������s�ł��邽�߁A
�������I�����p�t�H�[�}���X��������Ƃ����̂��AHSA�w�c�̎咣���B
Clang��EDG�iEdison Design Group�j�̃t�����g�G���h��Open CL��SPIR�iStandard Portable Intermediate Representation�j�ɕϊ����ꂽ��A
LLVM�iLow Level Virtual Machine�j��HSAIL�ɍœK�������B
�܂��AJava�̕���v���O���~���O�Ɋւ��ẮAOracle��AMD�������J������Open CL�A�N�Z�����[�V����API��APARAPI�iA PARallel API�j�𗘗p���邱�ƂŁA
HSA�ł��ėp���Z������GPU�Ɋ��蓖�Ă邱�Ƃ��ł���悤�ɂȂ�B
�������āAHSAIL�̃o�C�i���R�[�h�����邱�ƂŁA�e�n�[�h�E�F�A�̖��߃Z�b�g�A�[�L�e�N�`���ɋ߂����x���ŃA�v���P�[�V���������s�ł��邽�߁A
�������I�����p�t�H�[�}���X��������Ƃ����̂��AHSA�w�c�̎咣���B
hQ�́AOS������Ƀ��[�U�[���[�h��GPU�̃L���[�i�҂��s��j�ɉ��Z�����̃p�P�b�g�s�ł���悤�ɂ���
���݁A�A�v���P�[�V������GPU�𗘗p���悤�Ƃ���ƁAOS��API��ʂ��ăO���t�B�b�N�X�h���C�o�o�R��GPU�ɃA�N�Z�X���邱�ƂɂȂ�A���G���I�[�o�[�w�b�h���傫���Ȃ�Ƃ������_������B
hQ�ł́AHSA�����^�C������ċ��L�������A�h���X��Ԃ�HSA�L���[�����AOS����邱�ƂȂ����[�U�[���[�h��GPU�Ŏ��s����p�P�b�g�s���邱�Ƃ��ł���悤�ɂȂ�
hQ�̃T�|�[�g�ɂ���āA�A�v���P�[�V������CPU�𗘗p����Ƃ��Ɠ����悤�ɁA�_�C���N�g��GPU�𗘗p�ł���悤�ɂȂ�
���݁A�A�v���P�[�V������GPU�𗘗p���悤�Ƃ���ƁAOS��API��ʂ��ăO���t�B�b�N�X�h���C�o�o�R��GPU�ɃA�N�Z�X���邱�ƂɂȂ�A���G���I�[�o�[�w�b�h���傫���Ȃ�Ƃ������_������B
hQ�ł́AHSA�����^�C������ċ��L�������A�h���X��Ԃ�HSA�L���[�����AOS����邱�ƂȂ����[�U�[���[�h��GPU�Ŏ��s����p�P�b�g�s���邱�Ƃ��ł���悤�ɂȂ�
hQ�̃T�|�[�g�ɂ���āA�A�v���P�[�V������CPU�𗘗p����Ƃ��Ɠ����悤�ɁA�_�C���N�g��GPU�𗘗p�ł���悤�ɂȂ�
���݂̈�ʓI�ȃA�v���P�[�V������GPU���p�ł́AGPU�ŏ���������f�[�^���V�X�e������������GPU���̃������ɃR�s�[����ȂǁA�ώG�ȏ������K�v�ƂȂ�B
CPU��GPU��1�̃`�b�v�Ɏ��߂�APU��SoC�ł��A���݂�CPU��GPU�����ꂼ��ʂɉ��z��������ԂƎ���������Ԃ������Ȃ���Ȃ炸�A
CPU��GPU��A�W�����邽�߂ɂ́A�����̃�������ԂŃf�[�^�R�s�[������̃`�F�b�N�Ȃǂ��K�v�ƂȂ�
AMD�ɂƂ���Kaveri�́A2006�N����X�^�[�g����CPU��GPU������gFusion�h�̍ŏ��̃S�[���ł���AAPU��1�̊����`�ƈʒu�t������Ă���
AMD�ŏ��̎��APU�gLlano�h�́A������CPU�R�A��GPU�R�A���V���R�����������ɉ߂��Ȃ������B
��2����APU�́gTrinity�h�Ƃ��̋����łƂȂ����gRichland�h�ł́AIOMMU x2���lj����ꉼ�z�������A�h���X��Ԃ��T�|�[�g�ł���悤�ɂȂ������ACPU�[GPU�Ԃ̃f�[�^�ш���g�傳�ꂽ
����HSA�Ή�APU�ƂȂ����gKaveri�h�ł́A�n�[�h�E�F�A��CPU��GPU�̃������R�q�[�����V������悤�ɂȂ�ȂǁAHSA�̋@�\�����荞�܂�ACPU��GPU����薧�ɘA�W�ł���悤�ɂȂ����B
Kaveri�ɂ�����HSA�̃T�|�[�g�BCPU��GPU���������A�h���X��Ԃ����L����hUMA�ȂǂɑΉ�����
CPU��GPU��1�̃`�b�v�Ɏ��߂�APU��SoC�ł��A���݂�CPU��GPU�����ꂼ��ʂɉ��z��������ԂƎ���������Ԃ������Ȃ���Ȃ炸�A
CPU��GPU��A�W�����邽�߂ɂ́A�����̃�������ԂŃf�[�^�R�s�[������̃`�F�b�N�Ȃǂ��K�v�ƂȂ�
AMD�ɂƂ���Kaveri�́A2006�N����X�^�[�g����CPU��GPU������gFusion�h�̍ŏ��̃S�[���ł���AAPU��1�̊����`�ƈʒu�t������Ă���
AMD�ŏ��̎��APU�gLlano�h�́A������CPU�R�A��GPU�R�A���V���R�����������ɉ߂��Ȃ������B
��2����APU�́gTrinity�h�Ƃ��̋����łƂȂ����gRichland�h�ł́AIOMMU x2���lj����ꉼ�z�������A�h���X��Ԃ��T�|�[�g�ł���悤�ɂȂ������ACPU�[GPU�Ԃ̃f�[�^�ш���g�傳�ꂽ
����HSA�Ή�APU�ƂȂ����gKaveri�h�ł́A�n�[�h�E�F�A��CPU��GPU�̃������R�q�[�����V������悤�ɂȂ�ȂǁAHSA�̋@�\�����荞�܂�ACPU��GPU����薧�ɘA�W�ł���悤�ɂȂ����B
Kaveri�ɂ�����HSA�̃T�|�[�g�BCPU��GPU���������A�h���X��Ԃ����L����hUMA�ȂǂɑΉ�����
>>759
�����ł͗��x�̂��Ƃ������Ă���̂ł͂Ȃ��AGPU���R�[������̂ɂ��[���Ԃ�������_�������Ă��܂��B
�u�v�\��v���Ă����̂͂��������Ӗ����Ɨ������Ă��܂��B
�����ł͗��x�̂��Ƃ������Ă���̂ł͂Ȃ��AGPU���R�[������̂ɂ��[���Ԃ�������_�������Ă��܂��B
�u�v�\��v���Ă����̂͂��������Ӗ����Ɨ������Ă��܂��B
762 �FSocket774�F2014/02/13(��) 22:56:27.84 ID:0lqmyzcl
149�h���́gR9 270 LE�h���g���N���b�N��HD 7850�h�́C���ꏊ���m�ۂł��邩
Radeon R7 265
http://www.4gamer.net/games/234/G023456/20140211001/
3DMark Fire Strike
http://www.4gamer.net/games/234/G023456/20140211001/SS/017.gif
BF4
http://www.4gamer.net/games/234/G023456/20140211001/SS/019.gif
Crysis 3
http://www.4gamer.net/games/234/G023456/20140211001/SS/020.gif
Bioshock Infinite
http://www.4gamer.net/games/234/G023456/20140211001/SS/022.gif
Skyrim
http://www.4gamer.net/games/234/G023456/20140211001/SS/024.gif
FF14
http://www.4gamer.net/games/234/G023456/20140211001/SS/027.gif
GRID 2
http://www.4gamer.net/games/234/G023456/20140211001/SS/028.gif
�V�X�e���S�̂̏���d��
http://www.4gamer.net/games/234/G023456/20140211001/TN/030.gif
GPU�̉��x
http://www.4gamer.net/games/234/G023456/20140211001/TN/031.gif
GTX650Ti BOOST���S�Ɏ��S
�@�@�@�@�@�@,,,
(�@߄t�)��
Radeon R7 265
http://www.4gamer.net/games/234/G023456/20140211001/
3DMark Fire Strike
http://www.4gamer.net/games/234/G023456/20140211001/SS/017.gif
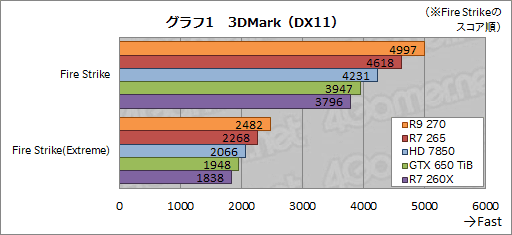{kind=link}
BF4
http://www.4gamer.net/games/234/G023456/20140211001/SS/019.gif
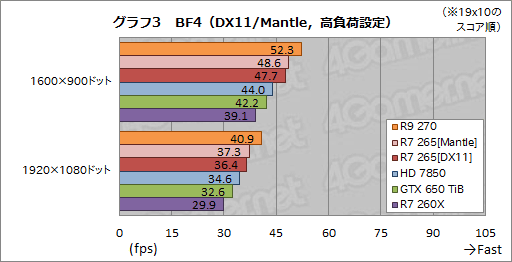{kind=link}
Crysis 3
http://www.4gamer.net/games/234/G023456/20140211001/SS/020.gif
{kind=link}
Bioshock Infinite
http://www.4gamer.net/games/234/G023456/20140211001/SS/022.gif
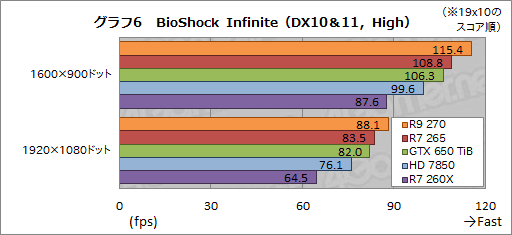{kind=link}
Skyrim
http://www.4gamer.net/games/234/G023456/20140211001/SS/024.gif
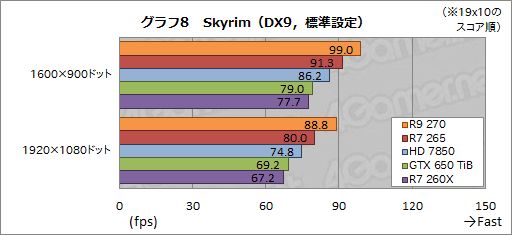{kind=link}
FF14
http://www.4gamer.net/games/234/G023456/20140211001/SS/027.gif
{kind=link}
GRID 2
http://www.4gamer.net/games/234/G023456/20140211001/SS/028.gif
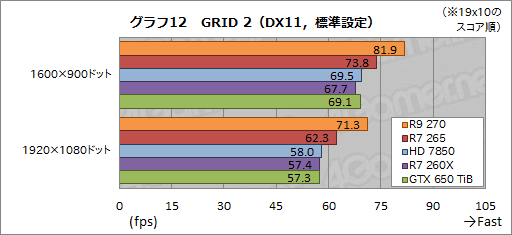{kind=link}
�V�X�e���S�̂̏���d��
http://www.4gamer.net/games/234/G023456/20140211001/TN/030.gif
{kind=link}
GPU�̉��x
http://www.4gamer.net/games/234/G023456/20140211001/TN/031.gif
{kind=link}
GTX650Ti BOOST���S�Ɏ��S
�@�@�@�@�@�@,,,
(�@߄t�)��
����Carrizo APU���{���ł���
����GPU�͓����Ƀ^�X�N�������艽��D�悳���邩�Ƃ����������������ア����
GPGPU�A�v���P�[�V���������Ɖ�ʕ`��̏������I���ɒx���Ȃ�Ƃ�������ԂɂȂ邯�ǂ��ꂪ���P�����
http://pc.watch.impress.co.jp/img/pcw/docs/598/132/html/04.png.html
����GPU�͓����Ƀ^�X�N�������艽��D�悳���邩�Ƃ����������������ア����
GPGPU�A�v���P�[�V���������Ɖ�ʕ`��̏������I���ɒx���Ȃ�Ƃ�������ԂɂȂ邯�ǂ��ꂪ���P�����
http://pc.watch.impress.co.jp/img/pcw/docs/598/132/html/04.png.html
{kind=link}
���낤���낤���낤�c�܂���������B
�Ƃ�����TSMC��Atom��������Ƃ��O���炠������ˁB�N�����Ă��Ȃ��ĂȂ��Ȃ������ǁB
�ł��̂Ƃ��͋C�Â��Ȃ��������AIntel���g�����Ƃ����I�������������̂ɂ������Ȃ������B
���̂܂܂�����Intel��Fab�ō�葱���āA���ʂ͌����ł��c�ō��B�������������CEO���悻�ɏo���Ƃ����̂��B
���_�Ȃ�ĂЂƂ���ˁB�uIntel��Fab����ǂ�����Ă��������܂���ł����v�B
�Ƃ�����TSMC��Atom��������Ƃ��O���炠������ˁB�N�����Ă��Ȃ��ĂȂ��Ȃ������ǁB
�ł��̂Ƃ��͋C�Â��Ȃ��������AIntel���g�����Ƃ����I�������������̂ɂ������Ȃ������B
���̂܂܂�����Intel��Fab�ō�葱���āA���ʂ͌����ł��c�ō��B�������������CEO���悻�ɏo���Ƃ����̂��B
���_�Ȃ�ĂЂƂ���ˁB�uIntel��Fab����ǂ�����Ă��������܂���ł����v�B
766 �FSocket774�F2014/02/13(��) 23:13:14.37 ID:ZPPwnuEU
>>765
4�T�̏���d�͂͌����Ƃ͋t�ł���̂�AMD���[�U�[�̏펯
���r���[�ŏ���d�͂������������ۂɂ͒Ⴂ�ƌ���̂��Ó��ł���
���R�̓��[�J�[�������������āA���肽�������`���邽�߂炵���A
���̏ꍇ��265�肽��AMD�������������Ă�킯���ȁA�J�[�h��AMD���炾��
�^��������A�^����
4�T�̏���d�͂͌����Ƃ͋t�ł���̂�AMD���[�U�[�̏펯
���r���[�ŏ���d�͂������������ۂɂ͒Ⴂ�ƌ���̂��Ó��ł���
���R�̓��[�J�[�������������āA���肽�������`���邽�߂炵���A
���̏ꍇ��265�肽��AMD�������������Ă�킯���ȁA�J�[�h��AMD���炾��
�^��������A�^����
>>766
�Ȃ�FX9590���ŋ��ł����H
�Ȃ�FX9590���ŋ��ł����H
�����A���X�S�CHSA�����ڂ���Ă���A10-7850���ŋ��ł��B
�����������ꂵ�čɂ��Ȃ����Ă����������Ƃ��ɍŋ��ł��B
�����������ꂵ�čɂ��Ȃ����Ă����������Ƃ��ɍŋ��ł��B
>>761
�c�q�̂��Ƃ��ɏ������̂Ȃ��ʐl���_���v��\�Ă܂Ŏg���p�r�������Ă���
���ĈӖ��Ń_���v�Ȃ����B�\�Ă܂Ń_���u���g���p�r���Ȃ��Ȃ�g��Ȃ������̘b��
�K�v�ȂƂ��Ɏg������=��86�R�A���x�����Č������������B
�g�o�b��I�n�͂`�l�c�͔����錾���Ă�̂Ɍ@��Ԃ��Đ����Ƃ��Ă��ƂˁB
GPGPU�ňЗ͂��������ȔF�،n�͊e���[�J�[���Ɛ肵�����Z�p���Ǝv���邵��ʉ�
���邱�Ƃ͂��Ȃ��ɂȂ肻���H�W�F�X�`���[�n��PC���ĂłĂ�͂��Ȃ̂ɂǂ��ɂ��邩����
������Ȃ����B���ʂ��Ă�̂��ȁH
�c�q�̂��Ƃ��ɏ������̂Ȃ��ʐl���_���v��\�Ă܂Ŏg���p�r�������Ă���
���ĈӖ��Ń_���v�Ȃ����B�\�Ă܂Ń_���u���g���p�r���Ȃ��Ȃ�g��Ȃ������̘b��
�K�v�ȂƂ��Ɏg������=��86�R�A���x�����Č������������B
�g�o�b��I�n�͂`�l�c�͔����錾���Ă�̂Ɍ@��Ԃ��Đ����Ƃ��Ă��ƂˁB
GPGPU�ňЗ͂��������ȔF�،n�͊e���[�J�[���Ɛ肵�����Z�p���Ǝv���邵��ʉ�
���邱�Ƃ͂��Ȃ��ɂȂ肻���H�W�F�X�`���[�n��PC���ĂłĂ�͂��Ȃ̂ɂǂ��ɂ��邩����
������Ȃ����B���ʂ��Ă�̂��ȁH
�Q�t�H�~�{��̃l�K�L����
>762
�����i�т�GTX660�Ɣ�ׂ�ׂ����낤��
�����i�т�GTX660�Ɣ�ׂ�ׂ����낤��
�G�v�\����temash�^�u�Ŋ�F�؎g������Ă�B
�W�F�X�`���[�̕��͎g�����킩���A���������A���ƁB
�W�F�X�`���[�̕��͎g�����킩���A���������A���ƁB
��F��
��
��
>>772
���̊�F�̃��x�����Ǝʐ^�ł��F�����Ă��܂����炢�̕��ʔF���ۂ����ȁB
�L�l�N�g���炢�̔F���͂���Ƃ��ꂵ�����ǁB�������̂���APU����PC��
�L�l�N�g�t����MS�����ˁ[���ȁB�Ɗ��҂��Ă�B
���̊�F�̃��x�����Ǝʐ^�ł��F�����Ă��܂����炢�̕��ʔF���ۂ����ȁB
�L�l�N�g���炢�̔F���͂���Ƃ��ꂵ�����ǁB�������̂���APU����PC��
�L�l�N�g�t����MS�����ˁ[���ȁB�Ɗ��҂��Ă�B
777 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 23:47:22.70 ID:5W3MT0Nh
>>764
������SoFIA�̓��f�������̃����`�b�v�����Ă�
����͖����`�b�v��TSMC�ł������Ȃ�
22nm�̃��W�I�`�b�v���{�i�I�Ɏg����悤�ɂȂ�������Ɉڍs���邾��
������SoFIA�̓��f�������̃����`�b�v�����Ă�
����͖����`�b�v��TSMC�ł������Ȃ�
22nm�̃��W�I�`�b�v���{�i�I�Ɏg����悤�ɂȂ�������Ɉڍs���邾��
778 �F,,�E�L�́M�E,,�j��-�������F2014/02/13(��) 23:54:26.88 ID:5W3MT0Nh
http://pc.watch.impress.co.jp/docs/column/ubiq/20131123_624814.html
> ���ł����ڂ̓��f���AWi-Fi�ABluetooth�AGPS�ȂǃX�}�[�g�t�H���ɕK�v��
> �@�\�����ׂē�������SoC�ƂȂ�uSoFIA�v(�\�t�B�A�A�J���R�[�h�l�[��)���B
����SoC�Ɏg���Ă��炤�ׂ�TSMC�ł������ł���悤�ɐv���Ă���Atom�Ƃ�
�����3G��LTE�̃`�b�v�͂����ŋߑ������甃���ė������̂�����
�܂�Intel�̃v���Z�X�ɍœK���ł��ĂȂ��킯��B
����ȓ�����O�̗����Ȃ̂ɂǂ��Ƀz���z������v�f�������
> ���ł����ڂ̓��f���AWi-Fi�ABluetooth�AGPS�ȂǃX�}�[�g�t�H���ɕK�v��
> �@�\�����ׂē�������SoC�ƂȂ�uSoFIA�v(�\�t�B�A�A�J���R�[�h�l�[��)���B
����SoC�Ɏg���Ă��炤�ׂ�TSMC�ł������ł���悤�ɐv���Ă���Atom�Ƃ�
�����3G��LTE�̃`�b�v�͂����ŋߑ������甃���ė������̂�����
�܂�Intel�̃v���Z�X�ɍœK���ł��ĂȂ��킯��B
����ȓ�����O�̗����Ȃ̂ɂǂ��Ƀz���z������v�f�������
>>778
�z���z���ɂ킽�����B���N�l�Ɠ����v�l������ł���
�z���z���ɂ킽�����B���N�l�Ɠ����v�l������ł���
780 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 00:23:52.98 ID:Qa9qBTLp
>>776
��F����AMD�̂ق����㔭��H
���Ȃ݂ɑ傫�ȉw�Ƃ��ł��܂Ɍ���X�}�[�g���̋@�ɂ�
Intel�ސ��̊�F���V�X�e���������Ă��
http://japan.zdnet.com/release/30015044/
��F����AMD�̂ق����㔭��H
���Ȃ݂ɑ傫�ȉw�Ƃ��ł��܂Ɍ���X�}�[�g���̋@�ɂ�
Intel�ސ��̊�F���V�X�e���������Ă��
http://japan.zdnet.com/release/30015044/
HSA�̈�ʌ��J��2014Q2�̗\��
����܂ŊO�̐l�͎����㗘�p�s�\
�g���Ȃ����̂ɑ��ĕ���������Ȃ����낤���Ƃ͗e�Ղɐ����\
�Ƃ������A���O�番�����ĂČ����Ă邾�낗
����܂ŊO�̐l�͎����㗘�p�s�\
�g���Ȃ����̂ɑ��ĕ���������Ȃ����낤���Ƃ͗e�Ղɐ����\
�Ƃ������A���O�番�����ĂČ����Ă邾�낗
782 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 00:30:17.33 ID:Qa9qBTLp
����ȑO�Ƀ��t�@�����X�I�Ȃ��̂{�����ė~������
���ɐG��Ȃ��l�ł��{��������Ε��ł����
����ȕ��ɂ�
http://www.7netshopping.jp/books/detail/-/accd/1106365731/subno/1
���ɐG��Ȃ��l�ł��{��������Ε��ł����
����ȕ��ɂ�
http://www.7netshopping.jp/books/detail/-/accd/1106365731/subno/1
�����������ȁc����infinion����̔�����3�N�ȏ�O�����B4�N��������3G���瓝���ǂ��납�����ł��Ȃ����Ăǂ��˂����߂����́H
�ŁA����Atom���炸����TSMC�œ����`�b�v����邱�Ƃ͂ł��āA���Ȃ��������ʂ����̃X�}�z�̃V�F�A�i�j�Ȃ�ł���B
���������MediaTek���AQualcomm��64bit ARM�`�b�v��4G-LTE������2014�N�o�ׂ����ǁA2015�N�Ă����Ԃ�ƗI���Ȃ��ƂŁB
�ŁA����Atom���炸����TSMC�œ����`�b�v����邱�Ƃ͂ł��āA���Ȃ��������ʂ����̃X�}�z�̃V�F�A�i�j�Ȃ�ł���B
���������MediaTek���AQualcomm��64bit ARM�`�b�v��4G-LTE������2014�N�o�ׂ����ǁA2015�N�Ă����Ԃ�ƗI���Ȃ��ƂŁB
>>781
��Liblle Office 4.2(���̃o�[�W�������HSA�Ή�)
�@http://ja.libreoffice.org/download/
���ł�HSA�Ή��\�t�g���o�Ă���̂ɁA��ʌ��J��2014Q2����AMD�͉������Ă����
��Liblle Office 4.2(���̃o�[�W�������HSA�Ή�)
�@http://ja.libreoffice.org/download/
���ł�HSA�Ή��\�t�g���o�Ă���̂ɁA��ʌ��J��2014Q2����AMD�͉������Ă����
785 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 00:41:53.73 ID:Qa9qBTLp
����32nm��Rosepoint�����삵�Ă邪�����܂ŊJ���p�������������
2012�N���_�Łu���i����5�N�ȓ��v�ƌ����Ă邩��܂������Ă��ė��N���炢�����
TSMC��28nm�v���Z�X�ł�Atom�̎��͂��@���Ȃ����������Ȃ�
ARM�̗���͖����Ȃ������͂���Ŗʔ������ǂ�
�@��ʂŃX�}�z�E�^�u���b�g���E���iPhone, iPad�ł������͕ʃ`�b�v����
���t�����l�̋@��ł̓`�b�v����������̂͂���قǖ��ɂȂ��̂ł���B
����BayTrail�͍����\�E�����u���B
2012�N���_�Łu���i����5�N�ȓ��v�ƌ����Ă邩��܂������Ă��ė��N���炢�����
TSMC��28nm�v���Z�X�ł�Atom�̎��͂��@���Ȃ����������Ȃ�
ARM�̗���͖����Ȃ������͂���Ŗʔ������ǂ�
�@��ʂŃX�}�z�E�^�u���b�g���E���iPhone, iPad�ł������͕ʃ`�b�v����
���t�����l�̋@��ł̓`�b�v����������̂͂���قǖ��ɂȂ��̂ł���B
����BayTrail�͍����\�E�����u���B
786 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 00:45:05.99 ID:Qa9qBTLp
http://akiba-pc.watch.impress.co.jp/docs/news/news/20140207_634277.html
���Q����3�l�����������炵���ȁBAMD�������l�C���ȁi�_�j
���Q����3�l�����������炵���ȁBAMD�������l�C���ȁi�_�j
��Ⴞ���������E�E�E
�ł�����u�K��ł͂��܂�l�W�܂�Ȃ������Ǝv����
�ł�����u�K��ł͂��܂�l�W�܂�Ȃ������Ǝv����
ps4���x��GCN�R�A����GCN�R�A������̃������o���h���̃n�[�h������A
���\��т��Ƃ��둽���Ǝv�����ǂȁB
computeshader�̗L�p���͗��N�������GDC�Ƃ��ʼn���I�Ȑ��ʏo�Ă���Ǝv���B
���\��т��Ƃ��둽���Ǝv�����ǂȁB
computeshader�̗L�p���͗��N�������GDC�Ƃ��ʼn���I�Ȑ��ʏo�Ă���Ǝv���B
>>784
�������HSA Ready�ł����āAHSA�œ����Ă���킯�ł͖����Ǝv��
�܂�Mantle�Ή�BF4���o�Ă邯�ǁAMantle�Ή��h���C�o���o�Ă��Ȃ��̂Ɠ������
HSA�V�~�����[�^��
ttp://code.google.com/p/aparapi/wiki/HSAEnablementOfLambdaBranch
���Q�l�ɂ��Ă�
�������HSA Ready�ł����āAHSA�œ����Ă���킯�ł͖����Ǝv��
�܂�Mantle�Ή�BF4���o�Ă邯�ǁAMantle�Ή��h���C�o���o�Ă��Ȃ��̂Ɠ������
HSA�V�~�����[�^��
ttp://code.google.com/p/aparapi/wiki/HSAEnablementOfLambdaBranch
���Q�l�ɂ��Ă�
791 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 00:55:24.24 ID:Qa9qBTLp
Threading Building Blocks�̍X�ɏ�ɁA�g���ɂ������b�p�[�N���X�����Ԃ���Ƃ���
�v�Z���X�̂�������Ȃ�Bolt�i�j�Ȃ炷���g���܂���B
�N���g��������Ȃ����ǂȁB
�����Ă��A���p���p���悤�Ƃ�����Intel�ɏ��p���C�Z���X���w�����Ȃ��Ƃ����Ȃ���
AMD�̃��C�u�����Ȃ̂ɂȂ���Intel�̏����ɍv������Ӗ��s���ȃ��C�u����
�v�Z���X�̂�������Ȃ�Bolt�i�j�Ȃ炷���g���܂���B
�N���g��������Ȃ����ǂȁB
�����Ă��A���p���p���悤�Ƃ�����Intel�ɏ��p���C�Z���X���w�����Ȃ��Ƃ����Ȃ���
AMD�̃��C�u�����Ȃ̂ɂȂ���Intel�̏����ɍv������Ӗ��s���ȃ��C�u����
>>790
HSAIL���������Ă������킩��c
HSAIL�Ȃ��SPIR�ŏ\����p�\�����A�ނ���W���f�����Ƃ����Ӗ��ŊQ���ł����Ȃ�����B
HSAIL���������Ă������킩��c
HSAIL�Ȃ��SPIR�ŏ\����p�\�����A�ނ���W���f�����Ƃ����Ӗ��ŊQ���ł����Ȃ�����B
OpenACC����C++ AMP����GPU���������@�͑����Ă邪
�㔭�̋K�i�قǑS�R�g���Ă����ۂ�����
�㔭�̋K�i�قǑS�R�g���Ă����ۂ�����
http://pc.watch.impress.co.jp/img/pcw/docs/612/591/html/07.jpg.html
���f���Ă�킯����Ȃ��Ǝv����
LLVM�̃C���t�����g�����j�ɂ������Ă��Ƃł���
{kind=link}
���f���Ă�킯����Ȃ��Ǝv����
LLVM�̃C���t�����g�����j�ɂ������Ă��Ƃł���
>>790
AMD���Ή��\�t�g�ɂ��킹�ăh���C�o���J�ł��Ȃ����Ă̂���
AMD���Ή��\�t�g�ɂ��킹�ăh���C�o���J�ł��Ȃ����Ă̂���
796 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 01:08:58.36 ID:Qa9qBTLp
��������HSAIL��Khronos�W���ł͂Ȃ���
CUDA�ł���PTX�ɑ���������̂������ō���Ă邾���ł���
SPIR�̋Z�p�d�l�����ł݁H
NVIDIA��Intel������Z�p�҂����O��A�˂Ă邩��B
CUDA�ł���PTX�ɑ���������̂������ō���Ă邾���ł���
SPIR�̋Z�p�d�l�����ł݁H
NVIDIA��Intel������Z�p�҂����O��A�˂Ă邩��B
�Ƃ�����kaveri�̔�������ꃖ�����o�����̂ɖ�����Kaveri�̐����Ή��̃h���C�o���o���ĂȂ��L�l������ȁE�E�E
�P��GPU�Ɋւ��Ă�R7 250X��R7 265���x�[�^�Ńh���C�o�����ĕ��C�Ŕ̔��ɓ��ݐ��Ă邵
�P��GPU�Ɋւ��Ă�R7 250X��R7 265���x�[�^�Ńh���C�o�����ĕ��C�Ŕ̔��ɓ��ݐ��Ă邵
���Ƃ���Windows7�ȍ~�̑Ή����Ȃ�W���Ŏg����GPGPU���̂͂���
DirectCompute���Q�[���ȊO�̃\�t�g�E�F�A�łǂꂾ���g��ꂽ�̂��Ƃ����ƁE�E�E
DirectCompute���Q�[���ȊO�̃\�t�g�E�F�A�łǂꂾ���g��ꂽ�̂��Ƃ����ƁE�E�E
>>797
����̃}���g���̓x�[�^�AHSA��2Q
����ȏ���PC���[�J�[��Kaveri����PC���o�����S�O������
�Ƃ������ƂŁA�x�[�^��Ή��h���C�ȏo�Ȃ����Ă����에�����鎩���s�ɂ����̂���
����̃}���g���̓x�[�^�AHSA��2Q
����ȏ���PC���[�J�[��Kaveri����PC���o�����S�O������
�Ƃ������ƂŁA�x�[�^��Ή��h���C�ȏo�Ȃ����Ă����에�����鎩���s�ɂ����̂���
>>794
����ASPIR��LLVM IR������A�킴�킴HSAIL���͂��ރ����b�g�������Ǝv�����B
�c�[����SPIR�o���āA��������l�C�e�B�uISA�ɕϊ����Ă��ł��邱�Ƃ͂���Ȃɕς��Ȃ��B
����ASPIR��LLVM IR������A�킴�킴HSAIL���͂��ރ����b�g�������Ǝv�����B
�c�[����SPIR�o���āA��������l�C�e�B�uISA�ɕϊ����Ă��ł��邱�Ƃ͂���Ȃɕς��Ȃ��B
�f�X�N�g�b�v�����̔̔����s�������ɑ��PC���[�J����Ή����i���o�Ȃ��͖̂��炩��AMD���̖�肾����Ȃ��E�E�E
cTDP������Ƃ͂������PC���[�J�[(�Ⴆ��HP)���g��APU��65W�łȂ̂�95W���i�͖��ʂ�������
�����炩�Ɍ���͑�ʂɔ���C�������Ƃ����v���Ȃ�
cTDP������Ƃ͂������PC���[�J�[(�Ⴆ��HP)���g��APU��65W�łȂ̂�95W���i�͖��ʂ�������
�����炩�Ɍ���͑�ʂɔ���C�������Ƃ����v���Ȃ�
>>786
�c�q���Ăǂ��̓c�ɂ��悗
���̓��̊֓����ǂ��Ȃ��Ă����m��Ȃ��̂��H
http://ascii.jp/elem/000/000/864/864839/
�[���A�����������쏉�S�Ҍ����C�x���g�Ȃ��Intel���낤���債�Đl�W�܂�ˁ[��
������ˁ[���ƂŐ����Ă�ˁ[���N�Y
�c�q���Ăǂ��̓c�ɂ��悗
���̓��̊֓����ǂ��Ȃ��Ă����m��Ȃ��̂��H
http://ascii.jp/elem/000/000/864/864839/
�[���A�����������쏉�S�Ҍ����C�x���g�Ȃ��Intel���낤���債�Đl�W�܂�ˁ[��
������ˁ[���ƂŐ����Ă�ˁ[���N�Y
�������� 4.2�̃R�[�h�� HSA ��grep�����������A
>> In AMD(HSA/NHSA) GPU compiler not support expressions like -double/double,
�Ƃ����̂����邾���������B
NHSA���ĉ��H
>> In AMD(HSA/NHSA) GPU compiler not support expressions like -double/double,
�Ƃ����̂����邾���������B
NHSA���ĉ��H
�����������Ɩ����l�����C�x���g�ł���Ȃ��ƌ����Ă��ł���
�Ă�HSA���ĒP���x��p�Ȃ̂�?
�������̂ق�����������
�������̂ق�����������
���₲�߂�S���́��ŁA�ȂR���p�C���̃o�O�̘b���ۂ��B
>Fix compilation problems on AMD OCL of finaancial functions
>
>In AMD(HSA/NHSA) GPU compiler not support expressions like -double/double,
>must generate as -1*(double/double). Changed functions: COUPDAYS,
>COUPDAYBS, YIELD.
>Fix compilation problems on AMD OCL of finaancial functions
>
>In AMD(HSA/NHSA) GPU compiler not support expressions like -double/double,
>must generate as -1*(double/double). Changed functions: COUPDAYS,
>COUPDAYBS, YIELD.
�܂��A����������Ԃ������ʌ��J�o���Ȃ��낤�ˁB
AMD�M�҂̐M�S�̓��u���C�o�[�ȉ��A�ƁB
811 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 07:38:51.44 ID:Qa9qBTLp
�㓡����}�Ԉ���Ă邼
Steamroller��SIMD�N���X�^�̎��s�p�C�v��4�{����Ȃ���3�{
Steamroller��SIMD�N���X�^�̎��s�p�C�v��4�{����Ȃ���3�{
�a�ݏオ�肾�����邵��
813 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 09:03:53.16 ID:Qa9qBTLp
>>803
���̒��x�̐ϐ�Ȃ炱�����Ȃ��ł���
���̒��x�̐ϐ�Ȃ炱�����Ȃ��ł���
814 �FSocket774�F2014/02/14(��) 11:41:59.38 ID:G0zqx8ps
>>771
Radeon R7 265 149�h��
GeForece GTX660 189�h��
Metro: Last Light
http://images.anandtech.com/graphs/graph7754/61092.png
Company of Heroes 2
http://images.anandtech.com/graphs/graph7754/61093.png
Crysis: Warhead
http://images.anandtech.com/graphs/graph7754/61108.png
Hitman: Absolution
http://images.anandtech.com/graphs/graph7754/61112.png
GRID 2
http://images.anandtech.com/graphs/graph7754/61116.png
BF4
http://images.anandtech.com/graphs/graph7754/61102.png
LuxMark 2.0
http://images.anandtech.com/graphs/graph7754/61119.png
Sony Vegas is a benchmark
http://images.anandtech.com/graphs/graph7754/61120.png
CLBenchmark�fs
http://images.anandtech.com/graphs/graph7754/61121.png
http://images.anandtech.com/graphs/graph7754/61122.png
Folding @ Home performance
http://images.anandtech.com/graphs/graph7754/61123.png
SystemCompute
http://images.anandtech.com/graphs/graph7754/61125.png
���C��GTX660�܂ŎE����Ă�̂�
�@�@�@�@�@�@,,,
(�@߄t�)��
Radeon R7 265 149�h��
GeForece GTX660 189�h��
Metro: Last Light
http://images.anandtech.com/graphs/graph7754/61092.png
{kind=link}
Company of Heroes 2
http://images.anandtech.com/graphs/graph7754/61093.png
{kind=link}
Crysis: Warhead
http://images.anandtech.com/graphs/graph7754/61108.png
{kind=link}
Hitman: Absolution
http://images.anandtech.com/graphs/graph7754/61112.png
{kind=link}
GRID 2
http://images.anandtech.com/graphs/graph7754/61116.png
{kind=link}
BF4
http://images.anandtech.com/graphs/graph7754/61102.png
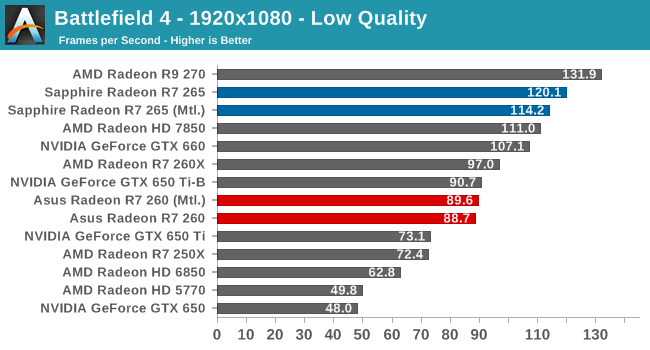{kind=link}
LuxMark 2.0
http://images.anandtech.com/graphs/graph7754/61119.png
{kind=link}
Sony Vegas is a benchmark
http://images.anandtech.com/graphs/graph7754/61120.png
{kind=link}
CLBenchmark�fs
http://images.anandtech.com/graphs/graph7754/61121.png
{kind=link}
http://images.anandtech.com/graphs/graph7754/61122.png
{kind=link}
Folding @ Home performance
http://images.anandtech.com/graphs/graph7754/61123.png
{kind=link}
SystemCompute
http://images.anandtech.com/graphs/graph7754/61125.png
{kind=link}
���C��GTX660�܂ŎE����Ă�̂�
�@�@�@�@�@�@,,,
(�@߄t�)��
>>813
�A�X�y���ۂ����X�ǂ���
�N�̃h�c�ɂł͕��ʂ����m��ǁA���������ᐔ�\�N�Ԃ�̑��Ȃ�ł����`
���R��ʏ�Q�o�Đl�ʂ�͌��邵�A�߂�X�����o����킯
��������H
�A�X�y���ۂ����X�ǂ���
�N�̃h�c�ɂł͕��ʂ����m��ǁA���������ᐔ�\�N�Ԃ�̑��Ȃ�ł����`
���R��ʏ�Q�o�Đl�ʂ�͌��邵�A�߂�X�����o����킯
��������H
>>809
�Z�K�M�҂Ȃ̂ɔC�V����D������AMD�M�҂Ȃ̂�Intel���g�����ǁA
���{�͔��S���̐_�̍������炢������I
�N���X�}�X�݂����Ȃ��B
���Ƃ��̃X�����Ƃ₽��Windows�M�҂��ČĂ�邯�ǁA�ǂ��炩�Ƃ����ƃ}�J�[�ł��B
�Z�K�M�҂Ȃ̂ɔC�V����D������AMD�M�҂Ȃ̂�Intel���g�����ǁA
���{�͔��S���̐_�̍������炢������I
�N���X�}�X�݂����Ȃ��B
���Ƃ��̃X�����Ƃ₽��Windows�M�҂��ČĂ�邯�ǁA�ǂ��炩�Ƃ����ƃ}�J�[�ł��B
�P���Ɍ�A���Ǝv�����ǂ�
820 �FSocket774�F2014/02/14(��) 15:28:57.69 ID:5z6QM5Zx
Tizen�̃p�[�g�i�[�v���O�����A�\�t�g�o���N���Q��
�i2014/2/13 21:01�j
�@Tizen Association��12���i�č����ԁj�A�V����15�̊�Ƃ��p�[�g�i�[�v���O�����ɎQ�悷��Ɣ��\�����B�V���ȃp�[�g�i�[�̈��ɂ́A�\�t�g�o���N���o�C��������A�˂Ă���B
�@Tizen�̃p�[�g�i�[�v���O�����́B�J������p��������ɉ���������ׂ��A��N11���ɓ����B�܂���ACCESS�A�Z���V�X�A�G�C�`�A�C�A�R�i�~�A�}�J�t�B�[�A�V���[�v�Ȃǂ��Q�������B
�����č���A15�̊�Ƃ��Q�����A���̒��ɂ̓\�t�g�o���N���o�C���A�X�v�����g�AZTE�AAccuWeather�A���b�h�x���h�\�t�g�E�F�A�Ȃǂ��܂܂�Ă���B
�@�p�[�g�i�[�v���O�����ւ̉����ɂ��āA�\�t�g�o���N�ł́A�u�v���b�g�t�H�[���̋Z�p�����̈�Ƃ��ĉ��������B��̓I�ȃA�N�V�����ɂ��ė\��͑S���Ȃ��v�ƃR�����g���Ă���B
�@�Ȃ��AOS�Ƃ���Tizen�𓋍ڂ���X�}�[�g�t�H���́ANTT�h�R�����甭���������j�����炩�ɂ���Ă������̂́A�h�R����1���A2013�N�x���̔�����������Ɣ��\�B��s���͕s�����ƂȂ��Ă���B
http://k-tai.impress.co.jp/docs/news/20140213_635161.html
�i2014/2/13 21:01�j
�@Tizen Association��12���i�č����ԁj�A�V����15�̊�Ƃ��p�[�g�i�[�v���O�����ɎQ�悷��Ɣ��\�����B�V���ȃp�[�g�i�[�̈��ɂ́A�\�t�g�o���N���o�C��������A�˂Ă���B
�@Tizen�̃p�[�g�i�[�v���O�����́B�J������p��������ɉ���������ׂ��A��N11���ɓ����B�܂���ACCESS�A�Z���V�X�A�G�C�`�A�C�A�R�i�~�A�}�J�t�B�[�A�V���[�v�Ȃǂ��Q�������B
�����č���A15�̊�Ƃ��Q�����A���̒��ɂ̓\�t�g�o���N���o�C���A�X�v�����g�AZTE�AAccuWeather�A���b�h�x���h�\�t�g�E�F�A�Ȃǂ��܂܂�Ă���B
�@�p�[�g�i�[�v���O�����ւ̉����ɂ��āA�\�t�g�o���N�ł́A�u�v���b�g�t�H�[���̋Z�p�����̈�Ƃ��ĉ��������B��̓I�ȃA�N�V�����ɂ��ė\��͑S���Ȃ��v�ƃR�����g���Ă���B
�@�Ȃ��AOS�Ƃ���Tizen�𓋍ڂ���X�}�[�g�t�H���́ANTT�h�R�����甭���������j�����炩�ɂ���Ă������̂́A�h�R����1���A2013�N�x���̔�����������Ɣ��\�B��s���͕s�����ƂȂ��Ă���B
http://k-tai.impress.co.jp/docs/news/20140213_635161.html
�k�X���� - Intel �gBroadwell�h�̃X�P�W���[���������\�s��ɏo���̂�'14Q4��
ttp://northwood.blog60.fc2.com/blog-entry-7385.html
Has����ĂȂ��Ƃ�
ttp://northwood.blog60.fc2.com/blog-entry-7385.html
Has����ĂȂ��Ƃ�
�f����14nm�̃X�P�W���[�����\��ʂ�i�����ĂȂ����Č��������̂ɂ�
���������ł�Kabini�̋L�����邯�ǁA�\��$38�`65�����Ă�
���{���Ⴂ����ɂȂ邩�m��ACeleron�APentium�܂ŐH�����܂�����
���{���Ⴂ����ɂȂ邩�m��ACeleron�APentium�܂ŐH�����܂�����
>821
����Ă��Ȃ��Ƃ������A�}���K�v���Ȃ��Ȃ������Ăق��ł́c�c�B
AMD�����̏�Ԃ����炳�B
�N������AMD�̗l�q�������������낤�B
APU�̐V��o��������ǁA�O�]�������悩�������A
���ۂɃx���`���������ߎS�����A���i�������Ȃ�����������B
����Ă��Ȃ��Ƃ������A�}���K�v���Ȃ��Ȃ������Ăق��ł́c�c�B
AMD�����̏�Ԃ����炳�B
�N������AMD�̗l�q�������������낤�B
APU�̐V��o��������ǁA�O�]�������悩�������A
���ۂɃx���`���������ߎS�����A���i�������Ȃ�����������B
AMD���]�X�̑O�ɐV���i�ɔ��������Ă��ǂ��Ǝv���鐫�\���Ȃ������̘b�B
���ɒL���ɋC�Â��n�߂����Ă����B
���ɒL���ɋC�Â��n�߂����Ă����B
AMD�W�˂�����
�܂��ɂ��O�������ȏ��w
tizen�Ƃ��X�}�z����Ŏg�����Ƃ͉������ꂽ���獡�̂Ƃ���Ȃ��Ƃ����b���������肾�Ƃ����̂�
tizen�Ƃ��X�}�z����Ŏg�����Ƃ͉������ꂽ���獡�̂Ƃ���Ȃ��Ƃ����b���������肾�Ƃ����̂�
EUV�̉������n���Ɍ����Ă�̂�������Ȃ���
intel���{���Ȃ�t�Z�I���Ȃ�Ď̂ĂĂ�͂��������̂�
�����g�����ƂɂȂ肻��
�������t�Z�{�}���`�p�^�[�j���O�̓R�X�g���������Č���
14nm���i��ʂɍ���Ĕ����Ă�22nm��藘�v���o�Ȃ��\����������
�݂Ă��Ȃ����낤��
�L���m�����i�m�C���v�����g�ɗ͂�����݂�������
���̂܂܂���EUV�Z�p���̂����������Ă��܂�����
�����Z�p�̑�s���`��������Ȃ���
���ꂩ��͐��i�̃T�C�N�����啝�ɐL�тĂ������ƂɂȂ肻��
AMD�͋Z�p�ŗ��TSMC��GF���݂����炳��ɉ���������
intel���{���Ȃ�t�Z�I���Ȃ�Ď̂ĂĂ�͂��������̂�
�����g�����ƂɂȂ肻��
�������t�Z�{�}���`�p�^�[�j���O�̓R�X�g���������Č���
14nm���i��ʂɍ���Ĕ����Ă�22nm��藘�v���o�Ȃ��\����������
�݂Ă��Ȃ����낤��
�L���m�����i�m�C���v�����g�ɗ͂�����݂�������
���̂܂܂���EUV�Z�p���̂����������Ă��܂�����
�����Z�p�̑�s���`��������Ȃ���
���ꂩ��͐��i�̃T�C�N�����啝�ɐL�тĂ������ƂɂȂ肻��
AMD�͋Z�p�ŗ��TSMC��GF���݂����炳��ɉ���������
>>824
Haswell Refresh�͑O�|������݂��������ǁH
http://www.digitimes.com/news/a20140214PD204.html
�ߎS�Ȃ̂�Haswell�̍ɂ�14nm�̕����܂���Ęb
Haswell Refresh�͑O�|������݂��������ǁH
http://www.digitimes.com/news/a20140214PD204.html
�ߎS�Ȃ̂�Haswell�̍ɂ�14nm�̕����܂���Ęb
Intel���i�̃��C�o����AMD�ł͂Ȃ��A���Ђ̑O����
>>746
��ʂɃ������[�������FEM��BEM�͑������C�}�C�`�����AFDTD�̂悤�ȃ��[�v�̏����������͑哾�ӂ����B
��ʂɃ������[�������FEM��BEM�͑������C�}�C�`�����AFDTD�̂悤�ȃ��[�v�̏����������͑哾�ӂ����B
���t���b�V���Ƃ������Ă����ňꉞ�債�ĕς�Ȃ����ǎ�����
�Ȃ������̍ɏ����i�J�����@����
�Ȃ������̍ɏ����i�J�����@����
�ȁ[���̃X���̂��O��͒c�q�ɉ�������ςȂ����ȁB
��҂Ƀl�b�g�̒m���ŗ����������N���[�}�[���҂ɗǂ����Ƃ�B
��҂Ƀl�b�g�̒m���ŗ����������N���[�}�[���҂ɗǂ����Ƃ�B
���X�ܔ̔��f�[�^�A���̎��������L���O
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
AMD���ς�炸���ł��Ă܂��_(^o^)�^
http://bcnranking.jp/category/subcategory_0026_month.html
http://bcnranking.jp/category/subcategory_0026.html
AMD���ς�炸���ł��Ă܂��_(^o^)�^
836 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 19:14:01.33 ID:EZiyO7zP
>>815
AMD���s�l�C�Ȃ̂��̂����ɂł��Ă悩������
AMD���s�l�C�Ȃ̂��̂����ɂł��Ă悩������
APU�̓S�~���ăo�������������Ȃ�
���z��G1820 + HD7750�̕������\�������ăo������������Ȃ�
BF4 TEST RANGE 1080p �ō��ݒ�
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
���z��G1820 + HD7750�̕������\�������ăo������������Ȃ�
BF4 TEST RANGE 1080p �ō��ݒ�
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
��F�����āA��b�Ԃɉ���l���ƍ�����p�r����m��A
��ʐl�����O�C�����Ɋ�F���邭�炢����ׂ�GPGPU�Ƃ��s�v����
�{���ɏ������x���K�v�Ȋ�F�́A
���Ƃ���`�̓����R���ŁA�u���b�N���X�g����l���Ɗ炪���v���邩���ׂ���A
�����������ꍇ����
��ʐl�����O�C�����Ɋ�F���邭�炢����ׂ�GPGPU�Ƃ��s�v����
�{���ɏ������x���K�v�Ȋ�F�́A
���Ƃ���`�̓����R���ŁA�u���b�N���X�g����l���Ɗ炪���v���邩���ׂ���A
�����������ꍇ����
�J�r�ƍ�����2GH���ȉ��̃N���b�N����H
Kaveri��3.7GHz�ł��̐��\���Ď��̓f�X�N�g�b�v�ł�Celeron��Pentium�ɂ͓͂��Ȃ���Ȃ��́H
Kaveri��3.7GHz�ł��̐��\���Ď��̓f�X�N�g�b�v�ł�Celeron��Pentium�ɂ͓͂��Ȃ���Ȃ��́H
A��B�̊Ԃɂ͖����̓_������
������̂ɂƂ��Ă�A�̂悱��B������
�����W���[�ȃv���O���~���O����́A�������邾�낤
ruby���s�v���ƌ����Ă��g���l������
������g���l�ɂ͗��R�����ꂼ�ꂠ��
�ے�͎g��Ȃ����߂̗��R�ł���
�g�����R�̑啔���́A���͒P�Ɍ��ꂪ�ʔ������ł���
������̂ɂƂ��Ă�A�̂悱��B������
�����W���[�ȃv���O���~���O����́A�������邾�낤
ruby���s�v���ƌ����Ă��g���l������
������g���l�ɂ͗��R�����ꂼ�ꂠ��
�ے�͎g��Ȃ����߂̗��R�ł���
�g�����R�̑啔���́A���͒P�Ɍ��ꂪ�ʔ������ł���
AM1�̓T�E�X����Ȃ��̂Ɠd������ɂ��R�X�g�����Ȃ��Ă��ނ���}�U�[�������ė~������
�~�jITX��3000�~�Ȃǂŏo�Ȃ����̂�����
�~�jITX��3000�~�Ȃǂŏo�Ȃ����̂�����
842 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 19:26:37.41 ID:EZiyO7zP
�܂�APU�̃v���O���~���O���Ėʔ����Ȃ���Ȃ��́H
���̃X���̒N��l�Ƃ��ăv���O���~���O���悤�Ƃ��ĂȂ������
���̃X���̒N��l�Ƃ��ăv���O���~���O���悤�Ƃ��ĂȂ������
CPU�I���{�[�h�ŁA�N�[���[���t���ւ�����̂��~�����ȁB�����N�[���[��8cm�t�@���Ƃ�����Ȃ��A�T�~���G���Ƃ��Ńt�@�����X��������
kabini��25W��4�R�A�ȂƂ��낪�����Ǝv��
���̃N���X��CPU�����l�̓G���R�Ƃ����Ȃ����낤���A���X�x���Ă�������������ꂽ���o���Ȃ̂ł�
���̃N���X��CPU�����l�̓G���R�Ƃ����Ȃ����낤���A���X�x���Ă�������������ꂽ���o���Ȃ̂ł�
>>842
���̃X�����Č�����2ch�̎���er���ăQ�[�}�[�A�A�j�I�^�Ńv���O�����Ȃ�Ă��Ȃ�����B
�ł�2ch����er�Z�l�łȂ��z�ɂ�FX�Ń}���`�R�A�v���O�����AAPU��GPGPU�v���O�������Ă���͔̂��ɑ�������
���̃X�����Č�����2ch�̎���er���ăQ�[�}�[�A�A�j�I�^�Ńv���O�����Ȃ�Ă��Ȃ�����B
�ł�2ch����er�Z�l�łȂ��z�ɂ�FX�Ń}���`�R�A�v���O�����AAPU��GPGPU�v���O�������Ă���͔̂��ɑ�������
�R�R�͎���ł�����
�v���O���}�͕ʂɂ���܂����(�L�_�`)
�v���O���}�͕ʂɂ���܂����(�L�_�`)
847 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 19:58:10.32 ID:EZiyO7zP
�����܂�v���O���~���O�������Ȃ����
�u��������ԓ����Ńv���O���~���O���ȒP�ɂȂ�v�i�j
�݂����Ȓm�b�x��ۏo��������A�Ă��Ă�̂�
�u��������ԓ����Ńv���O���~���O���ȒP�ɂȂ�v�i�j
�݂����Ȓm�b�x��ۏo��������A�Ă��Ă�̂�
�Ȃɂ����܂���B
���錾���@���l���v���O���~���O�̗��ꂻ�̂܂܂�����
���������̂̓v���O���~���O�ł��������
���������̂̓v���O���~���O�ł��������
Beema�͂܂��̓m�[�g�Ȃnj����Ŕ��N���炢������AM1�p���o��̂���
����Puma�̋Z�p���\���Ȃ�����
����Puma�̋Z�p���\���Ȃ�����
Kabini��TDP25W�ł����ۂ̓E���ƒႢ
�t���f�B�X�v���C�̋P�x50���ŃA�C�h������7W�Ƃ�����3D Mark Fire Strike��21W��
Radeon 8670M���ڂ�HP�ł̘b��
�t���f�B�X�v���C�̋P�x50���ŃA�C�h������7W�Ƃ�����3D Mark Fire Strike��21W��
Radeon 8670M���ڂ�HP�ł̘b��
Kabini��cTDP�������Ă͂���ˁ[
>>847
��������B
opencl�͎g�������ƂȂ�(�����ς蕪�����)�̂�opencl�g����APU�����ɂȂ�Ƃ�
HSA�͎g�������ƂȂ��̂ɂ���ł�F�̐��\��������B
���F�l�b�g�j���[�X�Ȃǂœ������ł��[�����[���ł��������낾��
��������B
opencl�͎g�������ƂȂ�(�����ς蕪�����)�̂�opencl�g����APU�����ɂȂ�Ƃ�
HSA�͎g�������ƂȂ��̂ɂ���ł�F�̐��\��������B
���F�l�b�g�j���[�X�Ȃǂœ������ł��[�����[���ł��������낾��
855 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 20:27:06.27 ID:EZiyO7zP
�v���O�����ł�HSA�̘b��Ȃ�ĂقƂ�nj��Ȃ���B
�����َ͈����߂���
�����َ͈����߂���
����Ⴛ����
���̓R�[�h���낢�돑���Ă��
���̓R�[�h���낢�돑���Ă��
>>844
�G���R���Q�[�������Ȃ��Ȃ�Q�R�A�ŏ\������
�G���R���Q�[�������Ȃ��Ȃ�Q�R�A�ŏ\������
858 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 20:45:02.34 ID:EZiyO7zP
����鑤�ō�鑤�̋�J�Ȃ�đS���m��Ȃ�����
�D�����肢����킯��
�������E�ɂ�GPGPU���g��������Ȃ�ĂقƂ�ǂ��Ȃ�
�D�����肢����킯��
�������E�ɂ�GPGPU���g��������Ȃ�ĂقƂ�ǂ��Ȃ�
>>851
C2D����Q2D�ɕς����Ƃ��A���s��Ƃ���Ƃ���
�̓I�ȂЂ������肪�Z���Ȃ��Ă��Ȃ���K�ɂȂ�������
������x�\�t�g�𗧂��グ�ĂȂ���l�Ȃ�4�R�A�͎��R�Ǝg���Ǝv����
��ʃ��[�X���ƃu���E�U���������グ��݂����Ȃ̂���������2�R�A�ŏ[����������Ȃ�����
C2D����Q2D�ɕς����Ƃ��A���s��Ƃ���Ƃ���
�̓I�ȂЂ������肪�Z���Ȃ��Ă��Ȃ���K�ɂȂ�������
������x�\�t�g�𗧂��グ�ĂȂ���l�Ȃ�4�R�A�͎��R�Ǝg���Ǝv����
��ʃ��[�X���ƃu���E�U���������グ��݂����Ȃ̂���������2�R�A�ŏ[����������Ȃ�����
���Ȃ��Ƃ��AOpenCL�Ɋւ��ẮAIntel�ł�nvidia�ł�AMD�ł��g����悤�ɂȂ������A
�s�̃A�v����OpenCL�Ή��͑������
�����{�ȏ㔄���悤�ȃ\�t�g�Ɋւ��Ă�OpenCL�ō��̂������I
�������A����̃V�X�e����p�ɊJ������悤�ȁA�P�O�R�s�[�ȉ������g���Ȃ��悤�ȃ\�t�g�Ɋւ��ẮA
OpenCL�݂����ȊJ�����ɂ��������A�J�����₷������ŊJ�����āA�K�v�ȃX�y�b�N�̃n�[�h��p�ӂ�����Ă����A
�n�[�h���\�t�g�ɍ��킹��ق��������ł��傤
����Adobe�Ƃ������ȃ\�t�g��OpenCL�Ή������Ă邩���
�s�̃A�v����OpenCL�Ή��͑������
�����{�ȏ㔄���悤�ȃ\�t�g�Ɋւ��Ă�OpenCL�ō��̂������I
�������A����̃V�X�e����p�ɊJ������悤�ȁA�P�O�R�s�[�ȉ������g���Ȃ��悤�ȃ\�t�g�Ɋւ��ẮA
OpenCL�݂����ȊJ�����ɂ��������A�J�����₷������ŊJ�����āA�K�v�ȃX�y�b�N�̃n�[�h��p�ӂ�����Ă����A
�n�[�h���\�t�g�ɍ��킹��ق��������ł��傤
����Adobe�Ƃ������ȃ\�t�g��OpenCL�Ή������Ă邩���
�����̐l�̋C������
����̓����◝�O�̏@���푈�ɂ܂�
�������܂ꂿ�Ⴝ�܂�Ȃ�
����
����̓����◝�O�̏@���푈�ɂ܂�
�������܂ꂿ�Ⴝ�܂�Ȃ�
����
GPU�̃R�A��x86��������?
>>860
�㔼�͊J���҂Ȃ�Ƃ������A����er�������Ă����Ċ���������
�㔼�͊J���҂Ȃ�Ƃ������A����er�������Ă����Ċ���������
AMD�C�x���g�Q���҂�3�l�������̂͋��J�ł͂Ȃ��I��J���I
����Larra�c����Ȃ�ł��Ȃ��B
866 �F,,�E�L�́M�E,,�j��-�������F2014/02/14(��) 21:19:48.69 ID:EZiyO7zP
> ����Adobe�Ƃ������ȃ\�t�g��OpenCL�Ή������Ă邩���
���G�����\�t�g�ł��G�����p�n�[�h�E�F�A�����p���邱�ƂɂȂ�̋^����Ȃ���
�Ȃɂ��_�̐��������ł���B
����HGPGPU��1�`2�����ڂ�GP����Graphic Processing�����������H
������
���G�����\�t�g�ł��G�����p�n�[�h�E�F�A�����p���邱�ƂɂȂ�̋^����Ȃ���
�Ȃɂ��_�̐��������ł���B
����HGPGPU��1�`2�����ڂ�GP����Graphic Processing�����������H
������
>>859
����ȁ@�G���R�͂��Ȃ��Ă�2ch�ƃX���Q�[�ƃG�����挩�Ȃ���V�R��
���̕��������Ȃ��ł���̂�4�R�A�̂��������낤�ɁB2�R�A�ŏ\���Ƃ�
�����J���Ă���Ƃ͕ʂɃA�j������Ƃ�������ꔭ�ňႢ������
����ȁ@�G���R�͂��Ȃ��Ă�2ch�ƃX���Q�[�ƃG�����挩�Ȃ���V�R��
���̕��������Ȃ��ł���̂�4�R�A�̂��������낤�ɁB2�R�A�ŏ\���Ƃ�
�����J���Ă���Ƃ͕ʂɃA�j������Ƃ�������ꔭ�ňႢ������
868 �FSocket774�F2014/02/14(��) 21:38:54.60 ID:uLs5uGkp
2�R�A�ŏ\�������ǁA8�R�A���~����
>>830
�ǂ����ŕ������Z���t
�ǂ����ŕ������Z���t
�������E�ɂ�GPGPU���g��������Ȃ�ĂقƂ�ǂ��Ȃ�
�����ł��Ȃ���Ƃ͐��ނ��邾�������ǂȁB
�����ł��Ȃ���Ƃ͐��ނ��邾�������ǂȁB
>>866�@��ʐl�̃n�C�X�y�p�r�Ȃ�ĉ摜�A����A�RD���唼����ˁH
�������E�ɂ̓f���A���R�A���g��������Ȃ�ĂقƂ�ǂ��Ȃ�
���炢�̖�������870��
���炢�̖�������870��
>>859
>>867
���̒��x�ŃJ�N���̂�AMD��APU�́E�E�E
2�R�A��PenG�g���Ă邪���̒��x�̏����͂܂��������Ȃ���
AMD��CPU�������ア���ĕ����Ă����Ǎ��������
>>867
���̒��x�ŃJ�N���̂�AMD��APU�́E�E�E
2�R�A��PenG�g���Ă邪���̒��x�̏����͂܂��������Ȃ���
AMD��CPU�������ア���ĕ����Ă����Ǎ��������
>>873
C2D�����Ƃ邾�냁�N�������O�͂�����������������
���Ȃ݂ɓ���Đ��ł����ƃf�[�^���悶��sandy�ȍ~��i7�ł�50%�Ƃ����C�Ŏg����
C2D�����Ƃ邾�냁�N�������O�͂�����������������
���Ȃ݂ɓ���Đ��ł����ƃf�[�^���悶��sandy�ȍ~��i7�ł�50%�Ƃ����C�Ŏg����
>>874
PenG�Ƃ����Ă�G6950������C2D E8400�Ƒ債�ĕς���A���O�������N�����H
>���Ȃ݂ɓ���Đ��ł����ƃf�[�^���悶��sandy�ȍ~��i7�ł�50%�Ƃ����C�Ŏg����
�A�z�ł����H���ƃf�[�^����Ȃ�ē�����O�����A�����u���Ȃ݂Ɂv��������
���̊��ʼn��̊��z���q�ׂ��܂ł���
PenG�Ƃ����Ă�G6950������C2D E8400�Ƒ債�ĕς���A���O�������N�����H
>���Ȃ݂ɓ���Đ��ł����ƃf�[�^���悶��sandy�ȍ~��i7�ł�50%�Ƃ����C�Ŏg����
�A�z�ł����H���ƃf�[�^����Ȃ�ē�����O�����A�����u���Ȃ݂Ɂv��������
���̊��ʼn��̊��z���q�ׂ��܂ł���
>>867�͒m���>>859��Intel�̂Q�R�A���S�R�A�̘b���Ă�̂ɂȂ��AMD��CPU�ア���Ęb�ɂȂ�悗������������
�u�E�`�̊�����Q�R�A���S�R�A�Ō��ʂ�������`�v���u�E�`�̊��Ȃ�Q�R�A�ŏ\���AAMD�ア�������v
�Ӗ����킩��܂�������������������������������
�u�E�`�̊�����Q�R�A���S�R�A�Ō��ʂ�������`�v���u�E�`�̊��Ȃ�Q�R�A�ŏ\���AAMD�ア�������v
�Ӗ����킩��܂�������������������������������
>>876�@2600���ApowerDVD�ŕ��ʂɃt��HDMP4�̃A�j�����\�t�g�E�F�A�f�R�[�h�ŕ�����܂�������o�[�`�����T���E���h���ꂽ�肵�Ă���Ȋ���
�u�ԓI��50%�߂��A���ς�25%���炢������Q�R�A�ł��ł��ˁ[���Ƃ͂Ȃ���������ꉞi5�ȏ㐄���̃\�t�g�����炩�n���ɏd��
���Ƃ�air�@video�@sever�Ń��A���^�C���G���R�z�M���鎞���n���ɏd�����ǂ��ꂭ�炢���ȁH
�����r�Ȃ�kaveri�̕�@�\�ǂ�Ȋ����������Ă݂������ǁA�܂��g���Ȃ������H
�u�ԓI��50%�߂��A���ς�25%���炢������Q�R�A�ł��ł��ˁ[���Ƃ͂Ȃ���������ꉞi5�ȏ㐄���̃\�t�g�����炩�n���ɏd��
���Ƃ�air�@video�@sever�Ń��A���^�C���G���R�z�M���鎞���n���ɏd�����ǂ��ꂭ�炢���ȁH
�����r�Ȃ�kaveri�̕�@�\�ǂ�Ȋ����������Ă݂������ǁA�܂��g���Ȃ������H
>>878
�T���v������́H
�T���v������́H
>>879�@����ǂ��ɂ���H
���ȂʂɃv���O���������Ă���킯�ł��Ȃ����A���삵�Ă�킯�ł��Ȃ����ǁA�����ɋZ�p�I�ȋ��������邩�珑������ł���肵�Ă��邾���B
�ʂɑ����Ă��������Ȃ����A�c�q���̘b�����āu�Ȃ�قǁ[�v���Ďv�����炢�B
��肠�����A�܂��܂��w�͂���ƁAAMD���������Ă͕̂��������B
�ʂɑ����Ă��������Ȃ����A�c�q���̘b�����āu�Ȃ�قǁ[�v���Ďv�����炢�B
��肠�����A�܂��܂��w�͂���ƁAAMD���������Ă͕̂��������B
�c�q�̘b�͉��X�ƃv���O���}�[�̓s����b���Ă邾���A�G���h���[�U�[�ɂ͂���܊W�Ȃ��b���������ǂ�
�������Ƃ��ĂT�`�P�O�����x�̐��\���ザ���ʑw�̔����ւ��Ȃ�ċN����Ȃ��A����ō�������N���E�h�I�N���E�h�[�[�[�[�I������
�������͎s��̂����ɂ��邩���Ȃ�������j�b�`�Ȏs��Ȃ̂ɂ�����
���ʂ�2�{3�{�̐��\��������Ƃ��Ȃ������@�\������Ƃ��ŏ��߂Ĕ����ւ����������郌�x��
HSA��OpenCL2.0���������@�\�ɂȂ�邩�͂܂��킩��ǁAGPU����ʂ����Ԑ��\�҂��₷���̂���������
�������Ƃ��ĂT�`�P�O�����x�̐��\���ザ���ʑw�̔����ւ��Ȃ�ċN����Ȃ��A����ō�������N���E�h�I�N���E�h�[�[�[�[�I������
�������͎s��̂����ɂ��邩���Ȃ�������j�b�`�Ȏs��Ȃ̂ɂ�����
���ʂ�2�{3�{�̐��\��������Ƃ��Ȃ������@�\������Ƃ��ŏ��߂Ĕ����ւ����������郌�x��
HSA��OpenCL2.0���������@�\�ɂȂ�邩�͂܂��킩��ǁAGPU����ʂ����Ԑ��\�҂��₷���̂���������
�c�q�̓g���f�B�V���i����IT�y���������Ńu���Ȃ������
�����ɐV�������Ƃ������Ɋy�����Ĕт�H���邩�Ƃ����̂��厖����
�܂����̒��̑����̓��Ƃ͂������낤
�����ɐV�������Ƃ������Ɋy�����Ĕт�H���邩�Ƃ����̂��厖����
�܂����̒��̑����̓��Ƃ͂������낤
884 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 09:21:44.64 ID:JenHeghE
> �c�q�̘b�͉��X�ƃv���O���}�[�̓s����b���Ă邾���A
�G���h���[�U�[�������GPGPU�A�v�������ŏ����Ďg�����ɂ͐��b�Ȃ���
�������̂������o���ď���Ȗϑz��W�J����Ȃ��ċՓc
�G���h���[�U�[�������GPGPU�A�v�������ŏ����Ďg�����ɂ͐��b�Ȃ���
�������̂������o���ď���Ȗϑz��W�J����Ȃ��ċՓc
885 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 09:33:57.89 ID:JenHeghE
> �������Ƃ��ĂT�`�P�O�����x�̐��\���ザ���ʑw�̔����ւ��Ȃ�ċN����Ȃ�
CPU�R�[�h�ł�10�{20�{�̍������͕��C�łł��邯�ǁH
�A���S���Y���̉��ǂ�SIMD���Ƃ��ˁB
���̃v���O�����̃{�g���l�b�N�͒P���x���Z���j�b�g�̐������ł͂Ȃ��̂���B
�[��B2B���S�̐��E�ɂ͂Ȃ�̂����ǁA���J���Í��Ŏg��
RSA��ElGamal�Í��̏����Ȃ����\CPU�����g�����ǂ�
���ʌ��̂���肷��ɂ��܂����J�����g������
�g��Ȃ��H
�C���^�[�l�b�g�ɐ��p�P�b�g���ꗬ���Ă��C�ɂ��Ȃ����@�J�͂���ł��������Ȃ�
GPU�̊��p�͕��ł���������ׂ����Ă�邾���ł���
���̑唼�́u������Ȗ��v���܂�GPU�ɓ����悤�Ƃ������z�ɂ͎���Ȃ��B
SHA-3�ɂ��ẮA����炵��������Ȃ���GPU�ł������n�b�V���̕�����
�\���\�Ƃ������_�ɂ͎������B���������g���G���f�B�A�����œK�B
�������{�I�Ȗ��Ƃ��ĕ����̃n�b�V�������Z���ĉ������������낤���B
�G���h���[�U�[�Ɏ��v�����܂��Ƃ����
�����̃I�b�T����2ch�g���b�v��SHA-3�ɂ��邭�炢����
CPU�R�[�h�ł�10�{20�{�̍������͕��C�łł��邯�ǁH
�A���S���Y���̉��ǂ�SIMD���Ƃ��ˁB
���̃v���O�����̃{�g���l�b�N�͒P���x���Z���j�b�g�̐������ł͂Ȃ��̂���B
�[��B2B���S�̐��E�ɂ͂Ȃ�̂����ǁA���J���Í��Ŏg��
RSA��ElGamal�Í��̏����Ȃ����\CPU�����g�����ǂ�
���ʌ��̂���肷��ɂ��܂����J�����g������
�g��Ȃ��H
�C���^�[�l�b�g�ɐ��p�P�b�g���ꗬ���Ă��C�ɂ��Ȃ����@�J�͂���ł��������Ȃ�
GPU�̊��p�͕��ł���������ׂ����Ă�邾���ł���
���̑唼�́u������Ȗ��v���܂�GPU�ɓ����悤�Ƃ������z�ɂ͎���Ȃ��B
SHA-3�ɂ��ẮA����炵��������Ȃ���GPU�ł������n�b�V���̕�����
�\���\�Ƃ������_�ɂ͎������B���������g���G���f�B�A�����œK�B
�������{�I�Ȗ��Ƃ��ĕ����̃n�b�V�������Z���ĉ������������낤���B
�G���h���[�U�[�Ɏ��v�����܂��Ƃ����
�����̃I�b�T����2ch�g���b�v��SHA-3�ɂ��邭�炢����
887 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 09:46:20.63 ID:JenHeghE
IPA�����̈Í��ɉ����Ă�SHA-1�̕��������ӂȂ�Č����Ă�
2ch�̃N�\�R�e�̃g���b�v�Ɏg�����炢�������p���Ȃ�����ȁ[
2ch�̃N�\�R�e�̃g���b�v�Ɏg�����炢�������p���Ȃ�����ȁ[
>>831
FEM BEM FDTD�̈Ӗ��������Ă�������
FEM BEM FDTD�̈Ӗ��������Ă�������
>>834
����Ō����Ă�̂��܂��Ȃ̂��悭�킩���
����Ō����Ă�̂��܂��Ȃ̂��悭�킩���
Maxwell����ȁA���v���Z�X�ł���Ȏ��ł���̂���
�}�W��GCN�I���^���������
�}�W��GCN�I���^���������
891 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:09:31.25 ID:JenHeghE
>>888
http://ja.wikipedia.org/wiki/%E9%9B%BB%E7%A3%81%E5%A0%B4%E8%A7%A3%E6%9E%90
���[���⍡�̐E��ɓd���C�w�̔��m�����������邪���ɂ����������͖�����
http://ja.wikipedia.org/wiki/%E9%9B%BB%E7%A3%81%E5%A0%B4%E8%A7%A3%E6%9E%90
���[���⍡�̐E��ɓd���C�w�̔��m�����������邪���ɂ����������͖�����
�d���C�w�̔��m���Ȃ�Ă���̂��c
���������{�g���l�b�N�ɂȂ闬�̉�͂́A��{�I��GPU��8GB���炢�̃��������ōςތv�Z�Ɋւ��Ă�
GPGPU�������ł���
�������������Ƒ�ʂɕK�v�Ƃ���ꍇ�́APC�̃��C���������ł��ƒx�߂����A
PC�N���X�^��Gbit�C�[�T���Ƃ���ɒx��
GPGPU�������ł���
�������������Ƒ�ʂɕK�v�Ƃ���ꍇ�́APC�̃��C���������ł��ƒx�߂����A
PC�N���X�^��Gbit�C�[�T���Ƃ���ɒx��
894 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:15:54.01 ID:JenHeghE
���m�ɂ͔��m�i���w�j�Ř_�����܂��ɓd������
�Г���CUDA����ł��������ȁE�E�E
�Г���CUDA����ł��������ȁE�E�E
895 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:17:28.18 ID:JenHeghE
>>893
�ł́APC�̃��C�������������g���Ȃ�����GPU�͂ǂ��g���E�E�E
�ł́APC�̃��C�������������g���Ȃ�����GPU�͂ǂ��g���E�E�E
>>891
����Q�[���Ƃ��Ɏg���Ă�Z�p�H
���̉�͗��̉�͂��ăQ�[�����̗��̂������b���Ǝv���Ă�����
���������ĉȊw�I�Ȍ�������̂��Ƃ������̂���
����Q�[���Ƃ��Ɏg���Ă�Z�p�H
���̉�͗��̉�͂��ăQ�[�����̗��̂������b���Ǝv���Ă�����
���������ĉȊw�I�Ȍ�������̂��Ƃ������̂���
�c�q��������O�`�O�`��������OpenCL�g���\�t�g�͂����������y���Ă邵�AHSA���Ή��\��\�t�g������킯������
�ʂ�gpu�g���Ȃ�����Ŏg���Ƃ͌�����A�����g����Ȃ�g�����Ă���
���OpenCL2.0�̉��z���������L��kaveri�ȍ~�̂�UMA�łȂł��邱�Ƒ�����̂��ȁ`���Ęb�ɑ��Ă܂�
�Ђ�����V�X�e�����̋�s��������Ă��m��Ȃ�
���Ƃł��邱�ƕς��Ȃ��̂Ȃ獡�����Ă�f�o�C�X����܂Ŏg������
�ʂ�gpu�g���Ȃ�����Ŏg���Ƃ͌�����A�����g����Ȃ�g�����Ă���
���OpenCL2.0�̉��z���������L��kaveri�ȍ~�̂�UMA�łȂł��邱�Ƒ�����̂��ȁ`���Ęb�ɑ��Ă܂�
�Ђ�����V�X�e�����̋�s��������Ă��m��Ȃ�
���Ƃł��邱�ƕς��Ȃ��̂Ȃ獡�����Ă�f�o�C�X����܂Ŏg������
�l�I�ɂ͏d���Q�[���������ƈ������K�ɂȂ����
�������ꂾ��
�������ꂾ��
�C�O���ƃQ�[���̕\���Ɏg�������A
���{����MMD�̕������Z�����b�`�ɂȂ�����Ƃ��~�N����̃X�J�[�g�����A���ɂƂ��A���������g��������낤���B
���{����MMD�̕������Z�����b�`�ɂȂ�����Ƃ��~�N����̃X�J�[�g�����A���ɂƂ��A���������g��������낤���B
>>896
���ʂ͐v�̃V�~�����[�V�����Ƃ��Ȋw�Z�p�v�Z�̘b
������ۂ�������ړI�Ō����Ɍv�Z����K�v���Ȃ��Q�[���ł�
���Ԃ��悤�ɂ͂��Ȃ��Ǝv�����c�d����
���ʂ͐v�̃V�~�����[�V�����Ƃ��Ȋw�Z�p�v�Z�̘b
������ۂ�������ړI�Ō����Ɍv�Z����K�v���Ȃ��Q�[���ł�
���Ԃ��悤�ɂ͂��Ȃ��Ǝv�����c�d����
901 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:31:47.28 ID:JenHeghE
>>896
�Q�[���������Ă����Ɗȗ����������̂ł���
�Q�[���������Ă����Ɗȗ����������̂ł���
>>900
���肪�Ƃ�
���肪�Ƃ�
�j���e���h�[�_�C���N�g��GPGPU���Č��t���o�ė������́AWiiU�łق�Ƃɏo����́H���Ďv�����B
���p���Ă�Q�[���͂���낤��
���p���Ă�Q�[���͂���낤��
WiiU��GPU����irisPro���炢�H
906 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:39:24.55 ID:JenHeghE
>>897
�c�O�����NJG�`���₳��ƃQ�[�}�[�����ɂ����{���ɔ���Ȃ��Ȃ�����
PC�ƊE���̏I��肾��B
���ۂ̃R���s���[�^�̃j�[�Y�Ƃ����̂͂����܂ŋ����͖���
���������r�W�l�X�V�[���ł��r�b�O�f�[�^��́i�j�Ƃ��������ȃX�C�[�c��
�ڂ̑O�ɓ]�����Ă�킯�ŁA������R���s���[�^�ł����ɏ������邩�Ƃ���
��肪����킯��B
������T�����ăo�C�I�P�~�J������ł����p���Ă��
�����Ƃ�������Ŋi�[���Ă邩��ˁB
�c�O�����NJG�`���₳��ƃQ�[�}�[�����ɂ����{���ɔ���Ȃ��Ȃ�����
PC�ƊE���̏I��肾��B
���ۂ̃R���s���[�^�̃j�[�Y�Ƃ����̂͂����܂ŋ����͖���
���������r�W�l�X�V�[���ł��r�b�O�f�[�^��́i�j�Ƃ��������ȃX�C�[�c��
�ڂ̑O�ɓ]�����Ă�킯�ŁA������R���s���[�^�ł����ɏ������邩�Ƃ���
��肪����킯��B
������T�����ăo�C�I�P�~�J������ł����p���Ă��
�����Ƃ�������Ŋi�[���Ă邩��ˁB
907 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:40:15.60 ID:JenHeghE
>>905
����VLIW5�ɉ������҂��Ă�̂�
����VLIW5�ɉ������҂��Ă�̂�
>>907
iGPU�ȉ��Ȃ́H��낽
������>>903�̓������m�肽��
�Q�[���G���W���Ƃ��̓����ł�FEM BEM FDTD�݂����Ȃ��̂��g���Ă�̂�
iGPU�ȉ��Ȃ́H��낽
������>>903�̓������m�肽��
�Q�[���G���W���Ƃ��̓����ł�FEM BEM FDTD�݂����Ȃ��̂��g���Ă�̂�
�\��͖���
�����݂łǂ��Ή����Ă�̂�
�����݂łǂ��Ή����Ă�̂�
910 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:46:14.13 ID:JenHeghE
���A���^�C�����������ł͂Ȃ��Ǝv����
>>908
ttp://d.hatena.ne.jp/henschel/20080504/p1
����݂���ꉞ��b�̊T�O�Ƃ���FEM�Ƃ��͎g���Ă�݂���
�������p�����[�^���v�������茸�炵�Ă�̂ŃV�~�����[�V�����Ƃ��Ă͔���
�Ƃ������Ƃ͌����������{�����ۂ��Ȃ�Ȃ��̂ŏ����I�ȕ������Ƃ��Ă͋^��
���x��ǂ�����ɂ͌v�Z�Ɏg�������l���������Ȃ��Ƃ����Ȃ���
�����{���Ɏg���ƌv�Z�ʂ����I�Ǝv��
ttp://d.hatena.ne.jp/henschel/20080504/p1
����݂���ꉞ��b�̊T�O�Ƃ���FEM�Ƃ��͎g���Ă�݂���
�������p�����[�^���v�������茸�炵�Ă�̂ŃV�~�����[�V�����Ƃ��Ă͔���
�Ƃ������Ƃ͌����������{�����ۂ��Ȃ�Ȃ��̂ŏ����I�ȕ������Ƃ��Ă͋^��
���x��ǂ�����ɂ͌v�Z�Ɏg�������l���������Ȃ��Ƃ����Ȃ���
�����{���Ɏg���ƌv�Z�ʂ����I�Ǝv��
913 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 10:57:48.38 ID:JenHeghE
�����������̗����G�t�F�N�g�Ƃ��ɊȈՓI�Ȃ��̂��g�����炢����
�Q�[���ŋ��߂��郊�A�����͖{���̃��A������Ȃ��āA������ۂ������郊�A��������ˁB
915 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 11:01:35.61 ID:JenHeghE
�Q�[���Ŋ���鑋�K���X��ق��āA���炩���ߔj�Ђ��`���Ă�����
��юU����������A���^�C�����Z���Ă�ł���
��юU����������A���^�C�����Z���Ă�ł���
�����ς������悾����ɍ���Ă���������
>>905
A10-7850K 0.72GHz
11.5GPixels/s 23GTexels/s 737.2GFlops DDR3-2133 34.1GB/s
Iris Pro 5200 1.15GHz
9.2GPixels/s 18.4GTexels/s 736GFlops DDR3-1600 25.6GB/s eDRAM 128MB
Wii U 0.55GHz
2.2GPixels/s 4.4GTexels/s 176GFlops DDR3-1600 12.8GB/s eDRAM 32MB
A10-7850K 0.72GHz
11.5GPixels/s 23GTexels/s 737.2GFlops DDR3-2133 34.1GB/s
Iris Pro 5200 1.15GHz
9.2GPixels/s 18.4GTexels/s 736GFlops DDR3-1600 25.6GB/s eDRAM 128MB
Wii U 0.55GHz
2.2GPixels/s 4.4GTexels/s 176GFlops DDR3-1600 12.8GB/s eDRAM 32MB
Wii U��750�n�Ȃ����H
�X�}�z�A�^�u�A�m�[�g�A�Q�[�~���O�m�[�g
�f�X�N�g�b�v�A�Q�[�~���OPC�A���I
���zPC�p�I�A�N���E�h�p�I�\��
PC�͂��̎��v�ɂ���Ă�����ł�����
�����̐l�́A�X�}�z�ƃf�X�N�g�b�v�ȊO���݂��Ȃ��悤��
1��0�����A�K�v�Ȑl�ɂ͂������
���v���@��N�������A���̂Ȃ�Z�p�́A
�d�������s������
�Q�����Ȃ����R�́A������ł�����
�Q�����闝�R�́A�Ȍ��ł��̐l�ɂ���
�f�X�N�g�b�v�A�Q�[�~���OPC�A���I
���zPC�p�I�A�N���E�h�p�I�\��
PC�͂��̎��v�ɂ���Ă�����ł�����
�����̐l�́A�X�}�z�ƃf�X�N�g�b�v�ȊO���݂��Ȃ��悤��
1��0�����A�K�v�Ȑl�ɂ͂������
���v���@��N�������A���̂Ȃ�Z�p�́A
�d�������s������
�Q�����Ȃ����R�́A������ł�����
�Q�����闝�R�́A�Ȍ��ł��̐l�ɂ���
CS�@�p�`�b�v�ɊJ�����\�[�X�g���������ŐVGPU�̓��l�[���Ղ��AMD��
���o�C�����������ēd�͌����ŗD��ŐVGPU������Ă�NV
���o�C�����������ēd�͌����ŗD��ŐVGPU������Ă�NV
���O��X���^�C�ǂ߂Ȃ��́H
���˂ɗN���Ă���nvidia�}���Z�[�N�͂��͂�P�Ⴞ��
�ǂ��������Č����ƃ��l�[���̐��҂͂���N�Ђ���Ȃ��ł����ˁH
926 �FSocket774�F2014/02/15(�y) 12:25:32.02 ID:Ayr+h1qu
�ʔ����̂�CPU��GPU�����ĂȂ�nvidia�̕���
CPU�����܂��g����GPU�̐��\���グ�Ă邱�Ƃ���
CPU�����܂��g����GPU�̐��\���グ�Ă邱�Ƃ���
���l�[�����c��ATI����A������Mawell�̓����ꏊ�͂���炵��
���S��77�����n��E���ɗ��Ă�ATDP110W+�̐��\��55-60W�ŏo���Ƃ��}�W�L�`
���S��77�����n��E���ɗ��Ă�ATDP110W+�̐��\��55-60W�ŏo���Ƃ��}�W�L�`
>>906�@�����܂ň�ʌ����̘b�Ȃ��ǂ���������H����
��ʂŏd���������ĉ摜�A����ҏW�A�RD����A�Q�[��etc��GPU�g���鏈���������킯��
�����������X�ƋƊE�i�j�̘b����Ă��������Ⴂ�������Aintel�Ɍ����Ă���ʌ����͂S�R�A�����C���X�g���[���A�n�C�G���h�łU�R�A
����ɑ���WS����HPC���̂�XEON�͂P�U�R�A��������}���`CPU��������Phi���������x86�ł��艟�����
������ꏏ�����Ɍ���Ă��m��ȂƂ����A����Ȋ���O��ɂ�����ʃA�v���Ȃo��킯�ˁ[���炳��
��ʂŏd���������ĉ摜�A����ҏW�A�RD����A�Q�[��etc��GPU�g���鏈���������킯��
�����������X�ƋƊE�i�j�̘b����Ă��������Ⴂ�������Aintel�Ɍ����Ă���ʌ����͂S�R�A�����C���X�g���[���A�n�C�G���h�łU�R�A
����ɑ���WS����HPC���̂�XEON�͂P�U�R�A��������}���`CPU��������Phi���������x86�ł��艟�����
������ꏏ�����Ɍ���Ă��m��ȂƂ����A����Ȋ���O��ɂ�����ʃA�v���Ȃo��킯�ˁ[���炳��
>>927
�������܂��������ˁH
���\��hd7770�A����d�͂�hd7790�Ƃ���
�N��GPU�ɂȂ�Ȃ���������E�E�E
�R�A����20%�����Ă邪�A���g����20�`25%�����Ă邵�E�E�E
�������܂��������ˁH
���\��hd7770�A����d�͂�hd7790�Ƃ���
�N��GPU�ɂȂ�Ȃ���������E�E�E
�R�A����20%�����Ă邪�A���g����20�`25%�����Ă邵�E�E�E
Intel��iGPU�������ăX�}�z�ł���GPU�Ώd�Ȃ̂ɂȂ�CPU���艟�����厖���Ǝv���̂�
>>929
�R�A�����������R�A�����萫�\��+35%�AP/W��2�{
Kepler���Z����750Ti��864SP 1.0�`1.1GHz 128bit������TDP60W
750��691SP������TDP55W�A�⏕�d���������ǂ��납6Pin�~1����
���ʃ��x��
�R�A�����������R�A�����萫�\��+35%�AP/W��2�{
Kepler���Z����750Ti��864SP 1.0�`1.1GHz 128bit������TDP60W
750��691SP������TDP55W�A�⏕�d���������ǂ��납6Pin�~1����
���ʃ��x��
>>931
�\�[�X�͂ǂ��H
�\�[�X�͂ǂ��H
ttp://videocardz.com/49557/exclusive-nvidia-maxwell-gm107-architecture-unveiled
ttp://videocardz.com/49632/nvidia-geforce-gtx-750-ti-gtx-750-final-specifications
ttp://videocardz.com/49632/nvidia-geforce-gtx-750-ti-gtx-750-final-specifications
�P���Ɍv�Z�ł���
http://cdn4.wccftech.com/wp-content/uploads/2014/01/GeForce-GTX-750-Ti-Maxwell-Performance.jpg
performance
GTX650Ti:34.0
GTX750Ti:41.2
TDP
GTX650Ti:110
GTX750Ti:75�i?�j
(41.2/34.0)*(110/75)=1.777�{
60w�Ȃ�2.222�{
(41.2/34.0)*(110/60)=2.222�{
TMU
(8*5)/(16*4)=0.625�{
SP
(128*5)/(192*4)=0.833�{
(41.2/34.0)*((192*4)/(128*5))=1.454�{
SP������1.45�{�̐��\�A�b�v
http://cdn4.wccftech.com/wp-content/uploads/2014/01/GeForce-GTX-750-Ti-Maxwell-Performance.jpg
performance
GTX650Ti:34.0
GTX750Ti:41.2
TDP
GTX650Ti:110
GTX750Ti:75�i?�j
(41.2/34.0)*(110/75)=1.777�{
60w�Ȃ�2.222�{
(41.2/34.0)*(110/60)=2.222�{
TMU
(8*5)/(16*4)=0.625�{
SP
(128*5)/(192*4)=0.833�{
(41.2/34.0)*((192*4)/(128*5))=1.454�{
SP������1.45�{�̐��\�A�b�v
935 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 14:46:08.03 ID:JenHeghE
>>928
����������Ȃ炨�O��́uGPU�S�������v�͍�����
GPU�ŃS�������ł��Ȃ�����͐��O���X���Ⴂ���Ɗ����U�炷
> XEON�͂P�U�R�A��������
Haswell�ł���ŏ�ʂ�14�R�A�Ȃ̂ɂ���16�R�A�Ȃ�ďo���
�ꉞB2C�������肪���Ă��ǂ�
��ʃR���V���[�}�����̃p�\�R���œ����g�߂ȃr�b�O�f�[�^�����Ƃ���
�E�B���X�`�F�b�N������̂����A���������ʂ�GPGPU���p�͂ǂ��Ȃ��Ă�̂��ˁH
NVIDIA���\�����������Ă��班�Ȃ��Ƃ���ʐ��i�����ł͋�̓I�ȓ���������
��Intel�̔�������McAfee�͕ʂɋƊE�g�b�v�ł��Ȃ�ł��Ȃ���
����������Ȃ炨�O��́uGPU�S�������v�͍�����
GPU�ŃS�������ł��Ȃ�����͐��O���X���Ⴂ���Ɗ����U�炷
> XEON�͂P�U�R�A��������
Haswell�ł���ŏ�ʂ�14�R�A�Ȃ̂ɂ���16�R�A�Ȃ�ďo���
�ꉞB2C�������肪���Ă��ǂ�
��ʃR���V���[�}�����̃p�\�R���œ����g�߂ȃr�b�O�f�[�^�����Ƃ���
�E�B���X�`�F�b�N������̂����A���������ʂ�GPGPU���p�͂ǂ��Ȃ��Ă�̂��ˁH
NVIDIA���\�����������Ă��班�Ȃ��Ƃ���ʐ��i�����ł͋�̓I�ȓ���������
��Intel�̔�������McAfee�͕ʂɋƊE�g�b�v�ł��Ȃ�ł��Ȃ���
�c�q�͎�����AMD�X����AMD�|�Y�F�肾�����Ă������ˁH
wktk����X������˂��̂���A�����B���{�ے肵���]�����Ăˁ[����˃F���B
wktk����X������˂��̂���A�����B���{�ے肵���]�����Ăˁ[����˃F���B
>>937
2�{�̃p�t�H�[�}���X�ł͂Ȃ�2�{�̃p�t�H�[�}���X�p�[���b�g
2�{�̃p�t�H�[�}���X�ł͂Ȃ�2�{�̃p�t�H�[�}���X�p�[���b�g
939 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 15:00:07.83 ID:JenHeghE
�f�B�X�N���[�gGPU�łł��邱�Ƃ�����Ăł��ĂȂ������
�Ƃ肠����
�P�DCPU��SIMD��艓���AdGPU���x�����������ш拷������GPU��
�@����ł����ł��Ȃ����ƂȂ�Ĉ�̉�������̂��B
�Q�D����Carrizo�ʼn����u�����v����낤���B
���̂Ƃ���CPU���̖��߃Z�b�g��Intel�̕��j�Ɉ��������܂����Ă邯��
�����ʔ����V����SSE5�ł�Fusion���܂����H
�Ƃ肠����
�P�DCPU��SIMD��艓���AdGPU���x�����������ш拷������GPU��
�@����ł����ł��Ȃ����ƂȂ�Ĉ�̉�������̂��B
�Q�D����Carrizo�ʼn����u�����v����낤���B
���̂Ƃ���CPU���̖��߃Z�b�g��Intel�̕��j�Ɉ��������܂����Ă邯��
�����ʔ����V����SSE5�ł�Fusion���܂����H
940 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 15:04:11.32 ID:JenHeghE
�R�DNVIDIA��CUDA6���f�B�X�N���[�gGPU���S�ɓW�J���邱�Ƃ�
�@�@Intel CPU�v���b�g�t�H�[���ł��g����悤�ɂ���B
�@�@AMD��HSA���O�t����Radeon�ł��g����悤�ɂ��Ȃ��̂��B
�Z�p�I�ɂł��邱�Ƃ����Ȃ��̂͂����̎���CPU�S�������ł����Ȃ����
�@�@Intel CPU�v���b�g�t�H�[���ł��g����悤�ɂ���B
�@�@AMD��HSA���O�t����Radeon�ł��g����悤�ɂ��Ȃ��̂��B
�Z�p�I�ɂł��邱�Ƃ����Ȃ��̂͂����̎���CPU�S�������ł����Ȃ����
���[��������
GTX 750��GTX 650Ti BOOST�AGTX 750Ti��GTX 660�̐��\���o��̂��B
�����������̏���d�͂ŁB
���悻50%��SP���߂邱�Ƃ��o���邩�����̂��ȁB
GTX 750��GTX 650Ti BOOST�AGTX 750Ti��GTX 660�̐��\���o��̂��B
�����������̏���d�͂ŁB
���悻50%��SP���߂邱�Ƃ��o���邩�����̂��ȁB
>>941
660Ti����150W�Ȃ��A�N�̐��E�ł�60��2�{����150�Ȃ́H
660Ti����150W�Ȃ��A�N�̐��E�ł�60��2�{����150�Ȃ́H
945 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 15:15:31.36 ID:JenHeghE
60W�N���X��GPU�Ȃ�SFF�ł��\�����܂邩��S�V��������叟������
>944
2nd��CPU(denver)�����������炵��
1st�ł�compute capability��5.0�Ȃ�悤��3.7���Ă̂�����������CUDA6.0RC��cuda_occupancy.h�����GK210��3.7�炵��(�o��H)
�Ƃ肠����1st��Register file cache�Atwo-level warp scheduler�͂���Ă�������
��{�\���͉���P10�ɋ߂��Ǝv��
http://www.cs.utexas.edu/~mgebhart/papers/ISCA_Slides.pdf
http://www.cs.utexas.edu/~mgebhart/papers/ISCA_Slides.pptx
2nd��CPU(denver)�����������炵��
1st�ł�compute capability��5.0�Ȃ�悤��3.7���Ă̂�����������CUDA6.0RC��cuda_occupancy.h�����GK210��3.7�炵��(�o��H)
�Ƃ肠����1st��Register file cache�Atwo-level warp scheduler�͂���Ă�������
��{�\���͉���P10�ɋ߂��Ǝv��
http://www.cs.utexas.edu/~mgebhart/papers/ISCA_Slides.pdf
http://www.cs.utexas.edu/~mgebhart/papers/ISCA_Slides.pptx
>>940
�͂����݂͓Ƌ֖@�Ƃ��ɂ͂Ђ�������Ȃ��̂��̂�
�͂����݂͓Ƌ֖@�Ƃ��ɂ͂Ђ�������Ȃ��̂��̂�
750Ti��A10-7850K(DDR3-2400)+R7 250 GDDR5�̑g�ݍ��킹�ɂ͏��ĂȂ���ł���ǂ���
����DG�������Ȃ��^�C�g���������Ďg���Ȃ��Ƃ����������˂����݂Ȗ�����
950 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 15:38:14.31 ID:JenHeghE
����AMD�̓V�F�A�I�Ɋe���̃h�~�i���g�K���̑ΏۊO�ł́B
{kind=link}
952 �FSocket774�F2014/02/15(�y) 15:44:21.36 ID:essq9LVi
>>925
Radeon�͏��ォ�猇�������ƂȂ��A���l�[�����i������
���܂ꂽ�����烊�l�[���̗��j������
�������ă��l�[�����ĂȂ�NVIDIA�ȂǁA���l�[���ƊE�̃g�b�vAMD�̓G�ł͂Ȃ�
Radeon�͏��ォ�猇�������ƂȂ��A���l�[�����i������
���܂ꂽ�����烊�l�[���̗��j������
�������ă��l�[�����ĂȂ�NVIDIA�ȂǁA���l�[���ƊE�̃g�b�vAMD�̓G�ł͂Ȃ�
Denver������Tegrak1��Kepler����������������CC3.5�ǂ܂�Ȃ�
954 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 15:48:09.58 ID:JenHeghE
ARM�R�A��CUDA Core�ƓƗ����đ��݂���ȏ�CC�Ƃ͊W�Ȃ�����
�Ȃ�ƂȂ��uARM��Larrabee�v�I�Ȃ��̂ɋ߂Â��Ă�C�͂��邪�B
�Ȃ�ƂȂ��uARM��Larrabee�v�I�Ȃ��̂ɋ߂Â��Ă�C�͂��邪�B
���l�[�����@�Ɋ֘A���錟���L�[���[�h
nvidia���l�[�����@
���ꂪ���̒��Ȃ��ǁH
nvidia���l�[�����@
���ꂪ���̒��Ȃ��ǁH
>>951
����TDP����Ȃ��ł���AGTX660Ti��TDP��150W
��������16ROP 128bit��24ROP 192bit��ׂĂ����傤���Ȃ���
���\�ւ̉e���傫�����瓯��16ROP 128bit���m�łǂ��������Ȃ���
�v��Ȃ�
����TDP����Ȃ��ł���AGTX660Ti��TDP��150W
��������16ROP 128bit��24ROP 192bit��ׂĂ����傤���Ȃ���
���\�ւ̉e���傫�����瓯��16ROP 128bit���m�łǂ��������Ȃ���
�v��Ȃ�
tegra K1��GK20A�炵���̂�
����͂��ꂪGK210���������
����͂��ꂪGK210���������
960 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 16:02:45.09 ID:JenHeghE
Denver����CUDA6�̃z�X�gCPU�Ƃ��Ă�������ȁB
��͂œ����v���Z�X����GPU���ARM�R�A�Ƀ^�X�N���f�B�X�p�b�`����d�g�݂�
���R����͂��ŁA���̂����肪�ǂ��Ȃ��Ă�̂���R�������o�Ă����B
��͂œ����v���Z�X����GPU���ARM�R�A�Ƀ^�X�N���f�B�X�p�b�`����d�g�݂�
���R����͂��ŁA���̂����肪�ǂ��Ȃ��Ă�̂���R�������o�Ă����B
>>957
����������Ȃ烏�b�g�p�t�H�[�}���X��TDP�̘b����Ȃ����ǂ�
����������Ȃ烏�b�g�p�t�H�[�}���X��TDP�̘b����Ȃ����ǂ�
�yBF4 1080p �ō��z
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
�yFF14 1080p �f�X�N�W���z
7850K �� 3,741
G1820 + HD7750 �� 7,604
http://youtu.be/-xJnZ4zD6o4
�yMHF 1080p�z
7850K �� 2,689
G1820 + HD7750 �� 4,762
http://youtu.be/BItdDQndzc0
�yDQX 1080p �W���z
7850K �� 6,351
G1820 + HD7750 �� 12,657
http://youtu.be/jr3RLVkqEwE
�yPSO2 1080p �ݒ�5�z
7850K �� 1,337
G1820 + HD7750 �� 4,712
http://youtu.be/DN7fzaKRKwA
�ySF4 1080p �f�t�H���g�z
7850K �� 5,686
G1820 + HD7750 �� 17,615
http://youtu.be/bYrhaWecwRo
<(�Oo�O)>�@7850K�́[
�@�@�i�@�j
�@�^�^
<(�Oo�O)>�@�@���͂��̂܂��Ł[
�i�@�j
�@�_�_
..�O�@�@�@�@<(�Oo�O)>�@�Ȃ��Ȃ��ł��������[��
�@�O�@�@�@�@�i�@�j
�O�@�@�@�@�^�^
7850K �� 16fps
G1820 + HD7750 �� 31fps
http://youtu.be/B16tV5xgidE
�yFF14 1080p �f�X�N�W���z
7850K �� 3,741
G1820 + HD7750 �� 7,604
http://youtu.be/-xJnZ4zD6o4
�yMHF 1080p�z
7850K �� 2,689
G1820 + HD7750 �� 4,762
http://youtu.be/BItdDQndzc0
�yDQX 1080p �W���z
7850K �� 6,351
G1820 + HD7750 �� 12,657
http://youtu.be/jr3RLVkqEwE
�yPSO2 1080p �ݒ�5�z
7850K �� 1,337
G1820 + HD7750 �� 4,712
http://youtu.be/DN7fzaKRKwA
�ySF4 1080p �f�t�H���g�z
7850K �� 5,686
G1820 + HD7750 �� 17,615
http://youtu.be/bYrhaWecwRo
<(�Oo�O)>�@7850K�́[
�@�@�i�@�j
�@�^�^
<(�Oo�O)>�@�@���͂��̂܂��Ł[
�i�@�j
�@�_�_
..�O�@�@�@�@<(�Oo�O)>�@�Ȃ��Ȃ��ł��������[��
�@�O�@�@�@�@�i�@�j
�O�@�@�@�@�^�^
�����܂�NV�̃X�e�}
>>961
��{�c�w�W��TDP����������TDP�Ō��邵���Ȃ��Ǝv����
��{�c�w�W��TDP����������TDP�Ō��邵���Ȃ��Ǝv����
�c�N���p�\�R���{�X�C�x���g�uGIGABYTE&AMD�Q�[���C�x���g�v
http://www.ustream.tv/recorded/43829757
http://www.ustream.tv/recorded/43829757
966 �FSocket774�F2014/02/15(�y) 16:43:47.06 ID:cYY3sqps
�C���e���ƃk�r�A���̍Ō�̂���������
�P�̂��ᑊ��ɂȂ�Ȃ����A�ʂɐi��AMD�̈�l�����ɂ����Ȃ��
�Q�z�����̃C���e����A�e�X�������̃[�I���Ƃ��S�~�ȉ��ɂȂ邩���
�P�̂��ᑊ��ɂȂ�Ȃ����A�ʂɐi��AMD�̈�l�����ɂ����Ȃ��
�Q�z�����̃C���e����A�e�X�������̃[�I���Ƃ��S�~�ȉ��ɂȂ邩���
AMD introduces the first 64-bit ARM-based server CPU
http://www.youtube.com/watch?v=Zsv2bkJGDlk
http://www.youtube.com/watch?v=Zsv2bkJGDlk
Dell��ARM�I�͎n�߂�悤�����܂��ǂ��Ȃ���킩����
>>940�@�܂����������ł͂Ȃ��낤���AOpenCL2.0�̉��z���������L���Ă�GPU�ł��g���邵APU�̂�UMA�������悤�ȁH
�܂����R2.0�ɑΉ����Ă��Intel��iGPU�ł��g����낤���Akaveri��2.0�ɑΉ����Ă邩�͉������������ǂ�
�������HSAIL����Bolt���̕ςȂ̎g��Ȃ��ł��̘b�A��GPU�ɂ�UMA�ς܂Ȃ��̂͂ȂZ�p�̖�肶��ˁ[�́H
APU�ł����ł��Ȃ����Ƃ��Ă͓̂��ɂȂ��ł���A2.0�Ɍ��炸JAVA��HSA�Ή��ɂ������Ă��̑O�ɓ����@�\������GPU�����ɏo����邵
HSA�Ή�搂��Ă�Ƃ��͂قڂ���Ȋ���
�Ƃ肠�������A�v���o�Ă���A����s���茩�Ă݂Ȃ��Ɠ��ł������ț��������˂����ĂĂ����̈Ӗ����Ȃ��ˁH
�܂����R2.0�ɑΉ����Ă��Intel��iGPU�ł��g����낤���Akaveri��2.0�ɑΉ����Ă邩�͉������������ǂ�
�������HSAIL����Bolt���̕ςȂ̎g��Ȃ��ł��̘b�A��GPU�ɂ�UMA�ς܂Ȃ��̂͂ȂZ�p�̖�肶��ˁ[�́H
APU�ł����ł��Ȃ����Ƃ��Ă͓̂��ɂȂ��ł���A2.0�Ɍ��炸JAVA��HSA�Ή��ɂ������Ă��̑O�ɓ����@�\������GPU�����ɏo����邵
HSA�Ή�搂��Ă�Ƃ��͂قڂ���Ȋ���
�Ƃ肠�������A�v���o�Ă���A����s���茩�Ă݂Ȃ��Ɠ��ł������ț��������˂����ĂĂ����̈Ӗ����Ȃ��ˁH
����1�T�Ԍ��PS4�����������
���܂萷��オ���ĂȂ��ˁB
���܂��Ƀ��h�o�V�Ƃ��ŗ\��ł���ȁB
���܂��Ƀ��h�o�V�Ƃ��ŗ\��ł���ȁB
>>969
�@Kaveri��OpenCL�̉��z���������L�ɁA���ۂ̃��������L�ɒu��������
�`�őΉ����Ă����B���RAPU�̕��������ɏ����ł���B
�@Kaveri��OpenCL�̉��z���������L�ɁA���ۂ̃��������L�ɒu��������
�`�őΉ����Ă����B���RAPU�̕��������ɏ����ł���B
PS4�͓��ɂ�肽���Q�[���������APS3�Ŏ����肻�������炵�炭�҂�
>>967
PCI-E�^�C�v���o���̂�
PCI-E�^�C�v���o���̂�
�́H
>>973
������APU���A�X�V�����x�ɔ��������������������w
������APU���A�X�V�����x�ɔ��������������������w
dGPU��OpenCL2.0���L���ɂȂ����Ƃ���PCIE�Ńf�[�^���Ƃ肵�Ă�����胁�����̃A�N�Z�X�X�s�[�h���i�Ⴂ�B
APU��PCIE�̔��肪�Ȃ��B
���������Ⴂ���Ȃ����ǁA��������ΓI�ɈႤ�Ƃ���B
������ӂ�maxwell�������B
dGPU�ł������CPU�Ƃ̃f�[�^���L�ɂǂ����Ă��������o��B
����ȃ������g���A�v������̂��Ɩ₤��������Ȃ���
�Z�p�҂͎g������͎̂g���Ă��邩��܂��҂��Ă���Ƃ����B
APU��PCIE�̔��肪�Ȃ��B
���������Ⴂ���Ȃ����ǁA��������ΓI�ɈႤ�Ƃ���B
������ӂ�maxwell�������B
dGPU�ł������CPU�Ƃ̃f�[�^���L�ɂǂ����Ă��������o��B
����ȃ������g���A�v������̂��Ɩ₤��������Ȃ���
�Z�p�҂͎g������͎̂g���Ă��邩��܂��҂��Ă���Ƃ����B
http://www.tomshardware.com/reviews/a10-7850k-a8-7600-kaveri,3725-8.html
Dual Graphics�����܂������Ă��
�����������L����Skyrim�����J�N���Č����邪
Dual Graphics�����܂������Ă��
�����������L����Skyrim�����J�N���Č����邪
>>978
����Ȃ��7850K�ł���ĂȂ��H
>>977
����Ńv���O���}��HSA�ł͂Ȃ��ăf�[�^�R�s�[�O���dGPU�ɂ��킹���v���O�����\���ɂ����������
����Ȃ��7850K�ł���ĂȂ��H
>>977
����Ńv���O���}��HSA�ł͂Ȃ��ăf�[�^�R�s�[�O���dGPU�ɂ��킹���v���O�����\���ɂ����������
PCIe����GDDR5�Ƃ��Ɗr�ׂĒx���́H
981 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 21:27:49.50 ID:JenHeghE
�͂��A�u�f�[�^�R�s�[�K�[�v���������܂���
PCIe Gen3 x16�̑ш��32GB/s�ł��BGPU���Ɋ��蓖�Ă�ꂽ
���C���������ш���l����I���U�t���C�ł��S�R�����
���ɕ�͑�����3GB���x�̃f�[�^��GPU���̃������ɑS�R�s�[����
�X�ɏ����߂��Ƃ��Ă��g�[�^���Ł{0.3�b�����邩�ǂ������ˁB
���̎��ԓ��łǂ��̏���������GPU�łł�����ẮH
����ȏ������킴�킴GPU�ł�邱�Ǝ��̂����������Ԉ���Ă��ˁH
����Ȃ�CPU��SIMD�ōς܂���B
PCIe Gen3 x16�̑ш��32GB/s�ł��BGPU���Ɋ��蓖�Ă�ꂽ
���C���������ш���l����I���U�t���C�ł��S�R�����
���ɕ�͑�����3GB���x�̃f�[�^��GPU���̃������ɑS�R�s�[����
�X�ɏ����߂��Ƃ��Ă��g�[�^���Ł{0.3�b�����邩�ǂ������ˁB
���̎��ԓ��łǂ��̏���������GPU�łł�����ẮH
����ȏ������킴�킴GPU�ł�邱�Ǝ��̂����������Ԉ���Ă��ˁH
����Ȃ�CPU��SIMD�ōς܂���B
>>888
FEM�iFinite Element Method�j���L���v�f�@�ő�\�I�ȃ\���o�Ƃ��Ă�nastran�Aansys�Als-dyna�Aabaqus�Ȃǂ�����B
GPGPU�Ɍ������v�Z���Ǝv������A�F�X��Q������݂����Ō��ʂ͔��Ɍ���I�Ȗ͗l�B
hUMA�ł��Ȃ�{�g���l�b�N�����������Ǝv�����ǂˁB
FEM�iFinite Element Method�j���L���v�f�@�ő�\�I�ȃ\���o�Ƃ��Ă�nastran�Aansys�Als-dyna�Aabaqus�Ȃǂ�����B
GPGPU�Ɍ������v�Z���Ǝv������A�F�X��Q������݂����Ō��ʂ͔��Ɍ���I�Ȗ͗l�B
hUMA�ł��Ȃ�{�g���l�b�N�����������Ǝv�����ǂˁB
>>977
CPU�ł̓��X�g���x���L���b�V���ɍ��������x�̉��Z�ł̂������ő剻����킯����
VRAM��LLC�̂悤�ɗ��������dGPU�ł�GPGPU�Ɋ���U��ׂ��������������Ă���̂ł́H
CPU�ł̓��X�g���x���L���b�V���ɍ��������x�̉��Z�ł̂������ő剻����킯����
VRAM��LLC�̂悤�ɗ��������dGPU�ł�GPGPU�Ɋ���U��ׂ��������������Ă���̂ł́H
AMD���M��OpenCL���p�͕s�����Ǝv���Ă邩�炱��
HSA�𗧂��グ���̂�OpenCL�������グ��͔̂�AMDer
HSA�𗧂��グ���̂�OpenCL�������グ��͔̂�AMDer
985 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 21:52:36.43 ID:JenHeghE
>>984
��������HSA�Ƃ������ꏈ���n������킯����Ȃ���
OpenCL�̏����n�̓Ǝ������Ƃ���HSA������Ƃ����������Ǝv����
�J���҂����ڐG�錾���OpenCL���̂��̂���
��������HSA�Ƃ������ꏈ���n������킯����Ȃ���
OpenCL�̏����n�̓Ǝ������Ƃ���HSA������Ƃ����������Ǝv����
�J���҂����ڐG�錾���OpenCL���̂��̂���
��
>>981
�X�y�b�N�ʂ�̃p�t�H�[�}���X�͏o�Ȃ��̂ƁA32GB/s�Ȃ̂͑o�����ł̂��ƂŕЕ�������16GB/s�ˁB
���Ƃ��̃X�s�[�h�̓o���N�]�������炱���o����X�s�[�h�B
�����_���A�N�Z�X�ł͂���ȑш�łȂ��B
�t�Ɉ�C��GPU�Ƀf�[�^�𑗂��ď������悤���čl�����ɂȂ�̂�
PCIE�o�R�̃����_���A�N�Z�X���ƂĂ��Ȃ��x�������
������ӂ��������悤�Ƃ��Ă���̂�APU�B
�X�y�b�N�ʂ�̃p�t�H�[�}���X�͏o�Ȃ��̂ƁA32GB/s�Ȃ̂͑o�����ł̂��ƂŕЕ�������16GB/s�ˁB
���Ƃ��̃X�s�[�h�̓o���N�]�������炱���o����X�s�[�h�B
�����_���A�N�Z�X�ł͂���ȑш�łȂ��B
�t�Ɉ�C��GPU�Ƀf�[�^�𑗂��ď������悤���čl�����ɂȂ�̂�
PCIE�o�R�̃����_���A�N�Z�X���ƂĂ��Ȃ��x�������
������ӂ��������悤�Ƃ��Ă���̂�APU�B
988 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 22:13:00.22 ID:JenHeghE
DDR3���̂������_���A�N�Z�X���x�����ǂȂ�
GDDR5���y���ɋ���DDR3�̃��[�N�������ł�肭��ł��鉉�Z�ƂȂ��
�K�R�I�ɋ��������L���b�V�����邢�̓��W�X�^��̃f�[�^�̃��[�J���e�B��
�����ˑ��������Z�݂̂Ɍ��肳���B
�Ȃ����AdGPU�̓]�����l�b�N�ɂȂ���āH
����ȏ��K�͂ȉ��Z�Ȃ�������낤���O�����낤��
�yGPU���̂��g���Ӗ����̂��Ȃ��z���Č����Ă邶���B
GPU�̃����^�C�����C�u�����N�����鎞�Ԃ̖��ʂ�����AVX�g���悗
GPU���ŏ������Ă�Ԃ�CPU���̃��\�[�X�͂�����x���ł����
GPU�����Ɏg���f�[�^�����O��CPU�z�X�g�ŃM���U�����O���Ă������Ƃ��ł���B
�܂��A����Ȃ킯��CUDA6�̂ق���HSA���y���ɕ��y���邾�낤�B
GDDR5���y���ɋ���DDR3�̃��[�N�������ł�肭��ł��鉉�Z�ƂȂ��
�K�R�I�ɋ��������L���b�V�����邢�̓��W�X�^��̃f�[�^�̃��[�J���e�B��
�����ˑ��������Z�݂̂Ɍ��肳���B
�Ȃ����AdGPU�̓]�����l�b�N�ɂȂ���āH
����ȏ��K�͂ȉ��Z�Ȃ�������낤���O�����낤��
�yGPU���̂��g���Ӗ����̂��Ȃ��z���Č����Ă邶���B
GPU�̃����^�C�����C�u�����N�����鎞�Ԃ̖��ʂ�����AVX�g���悗
GPU���ŏ������Ă�Ԃ�CPU���̃��\�[�X�͂�����x���ł����
GPU�����Ɏg���f�[�^�����O��CPU�z�X�g�ŃM���U�����O���Ă������Ƃ��ł���B
�܂��A����Ȃ킯��CUDA6�̂ق���HSA���y���ɕ��y���邾�낤�B
�R���\�[����ARM�{NVIDIA���ڂ��Ă�Ό��������̂ɂ�
x86�{AMD�ɂȂ��������ŋ����͂̎������L�т������
x86�{AMD�ɂȂ��������ŋ����͂̎������L�т������
3�N4�N����Ă����y���Ȃ��������X�ǂ��ɂ��Ȃ��Ȃ�����@wCUAD
991 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 23:04:55.20 ID:JenHeghE
F�����N��
����Ⓦ�H��Ȃ̊w���͕��ʂɕ��ł���Ă邩��
�C���^�[���ł��Ȃ��Ȃ��킩�肪�悭�Ďg����Ȃ��Ǝv������
����Ⓦ�H��Ȃ̊w���͕��ʂɕ��ł���Ă邩��
�C���^�[���ł��Ȃ��Ȃ��킩�肪�悭�Ďg����Ȃ��Ǝv������
�����Ⴄ���Ƃ��m��Ȃ��ŕK���Ɏ�܂����Ă�G�������܂�����_�����낗
993 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 23:11:03.32 ID:JenHeghE
��������AMD�̍L��̉R���R�ƌ������邾���̊w���Ȃ���̏W�܂肾��
���ɂ��ǂ��Ƃ���
>>984
�@OpenCL�u�����v�ł͕~�����������ĕ��y���i�܂Ȃ��Ƃ����b�ł����āA
HSA�Ή�APU�ł��S�͂������o�����߂ɂ�OpenCL�̕����L���Ȃ̂�
AMD���F�߂Ă��邵�A�EOpenCL�Ȃ�ĂЂƂ��Ƃ������Ă��Ȃ��B
�@OpenCL�u�����v�ł͕~�����������ĕ��y���i�܂Ȃ��Ƃ����b�ł����āA
HSA�Ή�APU�ł��S�͂������o�����߂ɂ�OpenCL�̕����L���Ȃ̂�
AMD���F�߂Ă��邵�A�EOpenCL�Ȃ�ĂЂƂ��Ƃ������Ă��Ȃ��B
996 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 23:13:32.59 ID:JenHeghE
�ƁA�R���x����Ă������z���K���ł�
��Amd���i�t���[�����[�g���̋^�f
NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CHD 7970 GE��CrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
GTX 680 SLI�̏ꍇ�CFraps�̃X�R�A��57.15fps�CNative FPS��57.05�ŁC�Ⴂ��0.2�����Ȃ��̂����CHD 7970 GE��CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���CNative FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCHD 7970 GE��CrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
NVIDIA�̌f�����^�`
�uRadeon���ڊ��C�Ƃ���CrossFire�\���̊��ł́CFraps�̃X�R�A�������ۂɂ͒Ⴂ�t���[�����[�g���������Ȃ��\��������v
�uRadeon��CrossFire���ł́C�t���[���\���Ɉُ킪����̂ł͂Ȃ����v
NVIDIA���w�E����\���ُ�Ƃ����̂́C4Gamer�ł���Ɍf�ڂ����e�X�g�L���Ŋm�F�ł��Ă���
www.4gamer.net/games/032/G003251/20130528026/
www.4gamer.net/games/022/G002212/20130802001/
www.4gamer.net/games/022/G002212/20130807092/
������ɂ��Ă��CHD 7970 GE��CrossFire�\�����ƁCFraps�œ����镽�σt���[�����[�g��Native FPS�̈Ⴂ���ɂ߂đ傫���B
GTX 680 SLI�̏ꍇ�CFraps�̃X�R�A��57.15fps�CNative FPS��57.05�ŁC�Ⴂ��0.2�����Ȃ��̂����CHD 7970 GE��CrossFire����Fraps�̃X�R�A��93.32fps�̂Ƃ���CNative FPS�͂Ȃ��45.05fps�B
��48.3�������o�Ă��Ȃ��̂ł���B
���ہCHD 7970 GE��CrossFire�ł͋ɒ[�ɍ����t���[�����[�g���v�������ȂǁC�o���c�L�����ɑ傫���B
����ɋ^��[������������Ȃ�CAMD�̃O���t�B�b�N�X�h���C�o�������I�ɃV�[���̕`���[�܂��Ă���Ƃ������Ƃ����蓾�Ȃ��͂Ȃ��B
���uAMD������̉𑜓x�ɑ��ċ����ȍœK�����s���Ă���v�ƒf���ł���
���u�𑜓x��ς���Ƃ����Ȃ��肪�Ȃ��Ȃ�v�Ƃ����̂��s���R
�����R�Ȃ̂����炵��ˁ[���ǎז��Ȃ���
999 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 23:14:44.67 ID:JenHeghE
1000 �F,,�E�L�́M�E,,�j��-�������F2014/02/15(�y) 23:15:18.35 ID:JenHeghE
1000�Ȃ�HSA���S
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/