CPU�A�[�L�e�N�`���ɂ��Č�� 25
�w�l�V�[&�p�^�[�\��
���邢�͉͓��̛�
�y�O�X���z
CPU�A�[�L�e�N�`���ɂ��Č�� 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
�y�ߋ��X���z
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
Part24 http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
���邢�͉͓��̛�
�y�O�X���z
CPU�A�[�L�e�N�`���ɂ��Č�� 24
http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
�y�ߋ��X���z
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
Part24 http://anago.2ch.net/test/read.cgi/jisaku/1377863763/
|
|
|
���Ō�������OS����Ȃ��g���n�̕������|�I����ˁH
3 �FSocket774�F2013/12/08(��) 08:19:17.99 ID:hCH+ZcFO
���������A�g�ݍ��ݗp��4bit8bit���x���̃}�C�R���̑����́A
OS�ڂ����قǃX�y�b�N�����Ȃ������
OS�ڂ����قǃX�y�b�N�����Ȃ������
�����Ȃ�Ƃ������I�ɓ����@��Ȃ�A�������K�͂ȑg�ݍ��݂ł�OS�Ƃ��������j�^�I�Ȃ��̂͂ǂ����Ă��K�v�ɂȂ�
RAM��2KB�Ƃ�����OS�͏��Ȃ��ˁBmain����C�ŏ����āA�A�Z���u���ŏ������u�[�g�X�g���b�v����Ă肷��B
C�W�����C�u�������Ăяo����DATA��BSS���傫���ē���Ȃ��Ȃ����肷��
C�W�����C�u�������Ăяo����DATA��BSS���傫���ē���Ȃ��Ȃ����肷��
RAM1KB�����ł�"OS"�͓����ȁA���ꂪ�B
http://www.tjsys.co.jp/page.jsp?id=746
IoT�ɕK�v��TCP/IP�v���g�R���X�^�b�N���A�Ƃ����킯�ɂ͂����Ȃ����ǂˁB
http://www.tjsys.co.jp/page.jsp?id=746
IoT�ɕK�v��TCP/IP�v���g�R���X�^�b�N���A�Ƃ����킯�ɂ͂����Ȃ����ǂˁB
OS���ڂ���̂��ړI�ł͂Ȃ��BOS���ڂ��ĉ�������̂������B�����܂�RAM�����Ȃ��Ȃ��OS���ڂ��Ă��M�d�ȃ��\�[�X�����ʂɂȂ邾���B�K�v�ȋ@�\�������ŏ�����낵���B
�X�N���b�`������������Ƃ���ŁA�ǂ����݂����A���^�C��OS������悤�ȋ@�\�͉�������K�v�ɂȂ邾�낤?
�\�[�X�R�[�h�̃|�[�^�r���e�B���f�G�Ȃ��̂�����̂����H
�\�[�X�R�[�h�̃|�[�^�r���e�B���f�G�Ȃ��̂�����̂����H
���̎��_���J����ƁA���z���������u�g����v(�����ڂ��Ă��邾���ł͂Ȃ��āA�g����Ƃ����̂��̗v�B)
�}�C�R����OS���ڂ��Ă��ǂ��BOS���Ǘ�����ׂ����̂����邩��ˁB
�}�C�R����OS���ڂ��Ă��ǂ��BOS���Ǘ�����ׂ����̂����邩��ˁB
���z�������T�|�[�g�ƈ���ɂ����Ă��g�ݍ��݂ł͂��������������邪�A�ǂ�̂��Ƃ������Ă���̂��B
RAM1KB�̃}�C�R���v���O�����������Ă�l�Ƀ|�[�^�r���e�B�ƌ����Ă����ďI���ł��B
���A���^�C��OS�H�^�C�}���荞�݂ɏ��������������B
���A���^�C��OS�H�^�C�}���荞�݂ɏ��������������B
����ł̓����e�i���X����R�[�h�ɂȂ�B
>>11
���A���^�C���n�̊��ł́A���z��������Ή��i���z�������ɃX���b�v�A�E�g���Ă��܂��Ɖ������Ԃ�ۏł��Ȃ��Ȃ���j��OS�Ƃ�������O�ɂ��邯�ǁB
���A���^�C���n�̊��ł́A���z��������Ή��i���z�������ɃX���b�v�A�E�g���Ă��܂��Ɖ������Ԃ�ۏł��Ȃ��Ȃ���j��OS�Ƃ�������O�ɂ��邯�ǁB
���i�r�[�̑��A
��������Ɠd����10�N���炢�O����32bit�ɂȂ��Ă邯�ǁA
���낻��64bit���o�Ă��Ă�̂���
���낻��64bit���o�Ă��Ă�̂���
�J���K���[����Ȃ���
>>18
2004�N���\��NEC��DTV�`�b�v������64bit�R�AVR5500
NEC/���l�T�X�̃n�C�r�W�������R�pSOC��EMMA2RH��EMMA3�V���[�Y�������Ƃ��̃R�A
�p�i�Ⓦ�ł͎���32bitCPU�R�A���������ǐ��N�O��Cortex-A9�f���A���ɐؑ�
64bit�͂܂����ۂ����ǁAVR5500�͌Â����N���b�N���Ⴂ��ł������̂ق�������
2004�N���\��NEC��DTV�`�b�v������64bit�R�AVR5500
NEC/���l�T�X�̃n�C�r�W�������R�pSOC��EMMA2RH��EMMA3�V���[�Y�������Ƃ��̃R�A
�p�i�Ⓦ�ł͎���32bitCPU�R�A���������ǐ��N�O��Cortex-A9�f���A���ɐؑ�
64bit�͂܂����ۂ����ǁAVR5500�͌Â����N���b�N���Ⴂ��ł������̂ق�������
>>8
TCP/IP�������ɂ͎���32bit�}�C�R�����K�{����
TCP/IP�������ɂ͎���32bit�}�C�R�����K�{����
�h�����h���ǂ������Ӗ����킩��Ȃ��ȁB
"TCP/IP"��MS-DOS�ł��g����
"TCP/IP"��MS-DOS�ł��g����
Cell���e���r�ɓ����ĂȂ����������H
>>23
�Z�����O�U�̓o�O���炯�d�C�H���߂��ŁA��CEVO(Cortex-A9�f���A��)�ɑ�ւ��
�Z�����O�U�̓o�O���炯�d�C�H���߂��ŁA��CEVO(Cortex-A9�f���A��)�ɑ�ւ��
10BASE-T�Ȃ�AZ80�n�R�A��TCP/IP�����`�b�v���������肷��
H8+ethernet�̃}�C�R���{�[�h���H��������ŕ��ʂɔ����܂�����
PIC��H8�����[�J�[���W��TCP/IP�X�^�b�N�����J����
H8��16�r�b�g�����I
http://www.anandtech.com/show/7573/qualcomm-announces-snapdragon-410-based-on-64bit-arm-cortex-a53-and-adreno-306-gpu
Qualcomm Announces Snapdragon 410 Based on 64-bit ARM Cortex A53
�Ǝ��J��������߂��H
Qualcomm Announces Snapdragon 410 Based on 64-bit ARM Cortex A53
�Ǝ��J��������߂��H
���ʃ��f���ƕ�����Ƃ�
�܂�Krait�����ʉ��ɂȂ��Ă��悤�ɂ͌����Ȃ�����
��߂Ă��s�v�c�͂Ȃ������
�܂�Krait�����ʉ��ɂȂ��Ă��悤�ɂ͌����Ȃ�����
��߂Ă��s�v�c�͂Ȃ������
�N�A���R���̗��_�́A4G/LTE�̃`�b�v�E�\�t�g��A�e�L�����A�Ή��\�t�g�E�F�A�A
Android�̎��Ѓ`�b�v�Ή��J�X�^���i�܂Ń����X�g�b�v�Œo���邱�Ƃɂ���̂ŁA
�ނ���CPU�R�A�Ȃ��ARM��IP����傫���������K�v�Ȃ���Ȃ����H
Android�̎��Ѓ`�b�v�Ή��J�X�^���i�܂Ń����X�g�b�v�Œo���邱�Ƃɂ���̂ŁA
�ނ���CPU�R�A�Ȃ��ARM��IP����傫���������K�v�Ȃ���Ȃ����H
�Ƃ��낪�`���I��CPUGPU�Ƃ����O�Ȃ�ˁBQualcomm �̐��Y�ʂȂ炻�̕�������?
A53�͒ቿ�i�����d�̓R�A���낤�B
�ቿ�i�i�͎���̂��ˁB
�ቿ�i�i�͎���̂��ˁB
���20nm��A57�����
2013�N��DRAM�����A���E�����̔���グ5.2%�� - �K�[�g�i�[����
���E�����̃��[�J�[ ����グ�g�b�v10
http://news.mynavi.jp/news/2013/12/10/241/images/001l.jpg
���E�����̃��[�J�[ ����グ�g�b�v10
http://news.mynavi.jp/news/2013/12/10/241/images/001l.jpg
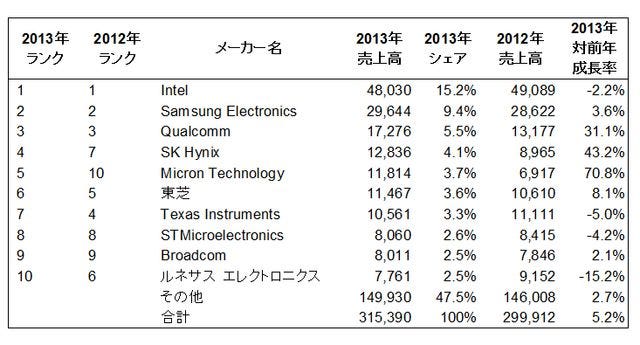{kind=link}
�����������50%���ł�����2/3�ɂȂ��Ă�Ƃ������Ƃ��B
����Snapdragon���ă��f����RF�܂Ń����`�b�v�ȂȁB
���Ђ̓o���f�[�V��������ς��B
���Ђ̓o���f�[�V��������ς��B
HSA�@HSAIL
ttp://news.mynavi.jp/column/hotchips25/index.html�@�i�ڎ��j
CUDA6�@cudaMallocManaged
ttp://news.mynavi.jp/column/sc13/004/index.html
ttp://news.mynavi.jp/column/sc13/005/index.html
Knight�fs Landing
ttp://www.geocities.jp/andosprocinfo/wadai13/20131207.htm
ttp://www.hpcwire.com/2013/12/06/intel-sheds-light-corner-landing-leap/
ttp://news.mynavi.jp/column/hotchips25/index.html�@�i�ڎ��j
CUDA6�@cudaMallocManaged
ttp://news.mynavi.jp/column/sc13/004/index.html
ttp://news.mynavi.jp/column/sc13/005/index.html
Knight�fs Landing
ttp://www.geocities.jp/andosprocinfo/wadai13/20131207.htm
ttp://www.hpcwire.com/2013/12/06/intel-sheds-light-corner-landing-leap/
�܂��A�ŏI�I�ɂ͉�H�ޑS������ă����`�b�v�ɂ��������낤����
"�ŏI�I"�ɂ͉���l�Ԃ���荞��Ń����`�b�v�ɂ��Ȃ��Ƃ������
�Ƃ肠����H.265�G���R�[�_�����Ă���B
TI�̃T�C�g�����Ă���DSP���v���Ԃ�Ɍ��������B
���ǂ�x86��CPU��SIMD�Ƃ�AVX�Ƃ�����̂ɁADSP�̖��ǂ���͂���̂��ȁH
DSP�̕������|�I�ɑ����A�݂����Ȏc���Ă鎖�����̂����H
���ǂ�x86��CPU��SIMD�Ƃ�AVX�Ƃ�����̂ɁADSP�̖��ǂ���͂���̂��ȁH
DSP�̕������|�I�ɑ����A�݂����Ȏc���Ă鎖�����̂����H
AV�Ɠd�Ƃ�����DSP�̓V������Ȃ��̂��H
�킴�킴�ėpCPU��GPU�ɂ�点��͔̂n���炵����
�킴�킴�ėpCPU��GPU�ɂ�点��͔̂n���炵����
ARM��SIMD(NEON)�Ȃ炻��Ȃɍ����͂Ȃ�����
DSP�̂ق����d�̓R�X�g���_�C�R�X�g���ėp���Z�������
���ꂾ��GPGPU�����Ă�̂Ɂi�ŋ߂͔����H�j�A
GPU�̓���Đ���H��GPGPU����Ȃ��Đ�p��H�ɂȂ��Ă邵��
GPU�̓���Đ���H��GPGPU����Ȃ��Đ�p��H�ɂȂ��Ă邵��
DSP�œ��������ق�������d�͂����|�I�ɏ�����������ACPU�̐��\��2�����N�����Ă��悭�Ȃ�����A��p��H�����瑼�̎d�������荞��ł��Ȃ�����R�}��тƂ��N����������萫������������A
�s����`�b�v�����Ǝ҂̐ӔC�ɂȂ����肷��̂ł�
�s����`�b�v�����Ǝ҂̐ӔC�ɂȂ����肷��̂ł�
���ǂ��̃^�u���b�g/�X�}�[�g�t�H������SoC ��2��
�`Qualcomm�ASamsung�̋����͂ǂ��ɂ���̂�
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131212_627187.html
��������ꂸ�Ɍ����ASamsung�ɂ͎��Ђ�CPU��GPU��v����\�͂��Ȃ��B
�`Qualcomm�ASamsung�̋����͂ǂ��ɂ���̂�
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131212_627187.html
��������ꂸ�Ɍ����ASamsung�ɂ͎��Ђ�CPU��GPU��v����\�͂��Ȃ��B
�ł������\�͂͋ƊE�g�b�v���x������Ȃ���
Samsung�Ƃ�����Common Platform��Intel/TSMC�Ɏ��������Ԃ�
�d�̓R�X�g��ꂪ���o�C���̍ŗD�掖���Ȃ�ŁA
�������Ђ�����Ԃ�Ȃ�����A�Œ�@�\�̎����́A��p��H�ł��ė���͑����͂��B
���܂��ɁA�v���Z�X�̔����̂��A�ŁA�����Ȑ�p��H��
�������镪�ɂ́A�̂قǃV�r�A�ł͂Ȃ����B
GPU�N�����ď������������ɁADSP������d�͉�����Ȃ�AGPU�ł��Ęb�ɂ�
�Ȃ邩������Ȃ����A�ėp���W�b�N���Ⴀ�A��p���W�b�N�ɂ́A��Ώ��Ăˁ[���ȁE�E�E�B
�������Ђ�����Ԃ�Ȃ�����A�Œ�@�\�̎����́A��p��H�ł��ė���͑����͂��B
���܂��ɁA�v���Z�X�̔����̂��A�ŁA�����Ȑ�p��H��
�������镪�ɂ́A�̂قǃV�r�A�ł͂Ȃ����B
GPU�N�����ď������������ɁADSP������d�͉�����Ȃ�AGPU�ł��Ęb�ɂ�
�Ȃ邩������Ȃ����A�ėp���W�b�N���Ⴀ�A��p���W�b�N�ɂ́A��Ώ��Ăˁ[���ȁE�E�E�B
�����ɁC�o�b�e���[�����ɕs�������l�͑�������킯�š
�����`�C��������I
�����o�b�e���[��ɂ͔Y�܂Ȃ�...�X�����ʕW�����\�[���[�p�l���̏[�d�X�e�[�V�����Ɂi����j : �M�Y���[�h�E�W���p��
http://www.gizmodo.jp/2013/06/post_12568.html
��Ԃł����d�\�Ȃ悤�ɁC
�g360���������Ƃ炦��h�c�n�C�u���b�h���͔��d�@�uF.W.P.S.�v�b�t�^�L�̎��́F����Љ�b�t�^�L�S�H
http://www.futakitekkou.com/case/case_05.html
������ЃV�O�i�X�F���͔��d�@���I�[�_�[���C�h�ō�郁�[�J�[������ЃV�O�i�X
http://www.cygnus.sc/order/
��d�͐ݔ��̏u���Ƀf���͒��߂��悤�����C
�z���C�g�y�[�p�[�F���`�E���C�I���d�r�ƃX�[�p�[�L���p�V�^�̃e�N�m���W�[��r - �e�b�N�Z���^�[ - �z���C�g�y�[�p�[�^�Z�p���� - �e�b�N�Z���^�[ - Dell �R�~���j�e�B
http://ja.community.dell.com/techcenter/m/mediagallery/1895.aspx
�����d�͂Ɩ��d�ɁA���`�E���C�I���L���p�V�^���Z���Ԓ�d�⏞���u���J�� | ���X�|���X
http://response.jp/article/2012/01/20/168696.html
�����d�́b���`�E���C�I���L���p�V�^���Z���Ԓ�d�⏞���u�̊J���ɂ��ā`���`�E���C�I���L���p�V�^�̗̍p�ɂ��A�⏞���Ԃ��ԉ��` - �v���X�����[�X�i2012�N�j
http://www.chuden.co.jp/corporate/publicity/pub_release/press/3175577_6926.html
�G�l���M�[�Z�p ��e�ʃL���p�V�^�F��1�� �����A�Ȃ��L���p�V�^�Ȃ̂� (1/4) - EE Times Japan
http://eetimes.jp/ee/articles/0907/06/news080.html
�����`�C��������I
�����o�b�e���[��ɂ͔Y�܂Ȃ�...�X�����ʕW�����\�[���[�p�l���̏[�d�X�e�[�V�����Ɂi����j : �M�Y���[�h�E�W���p��
http://www.gizmodo.jp/2013/06/post_12568.html
��Ԃł����d�\�Ȃ悤�ɁC
�g360���������Ƃ炦��h�c�n�C�u���b�h���͔��d�@�uF.W.P.S.�v�b�t�^�L�̎��́F����Љ�b�t�^�L�S�H
http://www.futakitekkou.com/case/case_05.html
������ЃV�O�i�X�F���͔��d�@���I�[�_�[���C�h�ō�郁�[�J�[������ЃV�O�i�X
http://www.cygnus.sc/order/
��d�͐ݔ��̏u���Ƀf���͒��߂��悤�����C
�z���C�g�y�[�p�[�F���`�E���C�I���d�r�ƃX�[�p�[�L���p�V�^�̃e�N�m���W�[��r - �e�b�N�Z���^�[ - �z���C�g�y�[�p�[�^�Z�p���� - �e�b�N�Z���^�[ - Dell �R�~���j�e�B
http://ja.community.dell.com/techcenter/m/mediagallery/1895.aspx
�����d�͂Ɩ��d�ɁA���`�E���C�I���L���p�V�^���Z���Ԓ�d�⏞���u���J�� | ���X�|���X
http://response.jp/article/2012/01/20/168696.html
�����d�́b���`�E���C�I���L���p�V�^���Z���Ԓ�d�⏞���u�̊J���ɂ��ā`���`�E���C�I���L���p�V�^�̗̍p�ɂ��A�⏞���Ԃ��ԉ��` - �v���X�����[�X�i2012�N�j
http://www.chuden.co.jp/corporate/publicity/pub_release/press/3175577_6926.html
�G�l���M�[�Z�p ��e�ʃL���p�V�^�F��1�� �����A�Ȃ��L���p�V�^�Ȃ̂� (1/4) - EE Times Japan
http://eetimes.jp/ee/articles/0907/06/news080.html
Google��ARM�x�[�X�̓Ǝ��v���Z�b�T�̊J������������Bloomberg��
http://rbmen.blogspot.jp/2013/12/googlearmbloomberg.html?m=1
Google��ARM�x�[�X�̓Ǝ��v���Z�b�T�̊J����
�������Ă��邱�Ƃ�����������
�����̘b�Ƃ���Bloomberg���܂����B
���Ђ̃f�[�^�Z���^�[�̉^�p��
�K�v�ȃT�[�o�[�����̗p�r�ɂȂ�Ƃ̂��ƁB
ARM�A�[�L�e�N�`�������p���āA
�T�[�o�[�̃v���Z�b�T�ڐv���鎖��O����
������i�߂Ă���͗l�B
Google���`�b�v�ڐv�����ꍇ�A
�n�[�h�E�F�A-�\�t�g�E�F�A�Ԃ̑��ݍ�p�̔��������҂���܂��B
�܂�Google�͐��E�̃T�[�o�E�v���Z�b�T�s��ł͋���ȍw���͂�����A
Intel�ɂƂ���5�Ԗڂɑ傫�Ȍڋq�ł���A
Google���Ǝ��v���Z�b�T�̊J���ɏ��o�����ꍇ�A
Intel�ɂ͑傫�ȑŌ��ɂȂ�Ɠ`�����Ă��܂��B
http://rbmen.blogspot.jp/2013/12/googlearmbloomberg.html?m=1
Google��ARM�x�[�X�̓Ǝ��v���Z�b�T�̊J����
�������Ă��邱�Ƃ�����������
�����̘b�Ƃ���Bloomberg���܂����B
���Ђ̃f�[�^�Z���^�[�̉^�p��
�K�v�ȃT�[�o�[�����̗p�r�ɂȂ�Ƃ̂��ƁB
ARM�A�[�L�e�N�`�������p���āA
�T�[�o�[�̃v���Z�b�T�ڐv���鎖��O����
������i�߂Ă���͗l�B
Google���`�b�v�ڐv�����ꍇ�A
�n�[�h�E�F�A-�\�t�g�E�F�A�Ԃ̑��ݍ�p�̔��������҂���܂��B
�܂�Google�͐��E�̃T�[�o�E�v���Z�b�T�s��ł͋���ȍw���͂�����A
Intel�ɂƂ���5�Ԗڂɑ傫�Ȍڋq�ł���A
Google���Ǝ��v���Z�b�T�̊J���ɏ��o�����ꍇ�A
Intel�ɂ͑傫�ȑŌ��ɂȂ�Ɠ`�����Ă��܂��B
54 �FSocket774�F2013/12/14(�y) 04:14:13.36 ID:L6iShlUS
Intel�I���b�e���ɂȂ��Ă��܂��̂��I�H
Google��ARM��Intel���Y���������B
ARM��Intel�����Y��������Ȃ���������Ȃ����A
Google���͐V�K�Ɏn�߂�Ȃ�v�c�[����Intel�ɍ��킹��������B
ARM��Intel�����Y��������Ȃ���������Ȃ����A
Google���͐V�K�Ɏn�߂�Ȃ�v�c�[����Intel�ɍ��킹��������B
ARM������o���Ƃ�Google���ߑ��Ȃ���!
���{�̓y�ǘA���̓Ǝ��A�v���ɂ��Ă�������ƍl���Ăق�������
���{�̓y�ǘA���̓Ǝ��A�v���ɂ��Ă�������ƍl���Ăق�������
�Ȃ�ƂȂ�������nv��arm soc�g�������ȋC������
�X�e�B�[�u�E�X�R�b�g���݂�
�X�e�B�[�u�E�X�R�b�g���݂�
���������Ă�Ȃ�5�N��Ƃ����������b����
����5�N��Ƃ��āA�C���e���Ƒ��t�@�u�Ƃ̋Z�p���͖��܂��Ă邾�낤���A�J���Ă����Ă邾�낤��
Apple�ɂȂ肽��Google�搶
Google�搶��Oracle�ł݂����ȃR�A���C�Z���X�Ƃ�DB��CAL�Ƃ�������
���ʂ����Ȃ���20n�ȍ~�̏���l�����x86�ɂ���������
ARM�g���ăN���C�A���g�ƊJ�����ꂷ��Ƃ��AIntel�Ɉˑ��������
�����ŃR���g���[������ق����܂��Ȃ낤�Ƃ������f�����邾�낤�ˁB
�u���t�̉\�������邯�ǁB
���ʂ����Ȃ���20n�ȍ~�̏���l�����x86�ɂ���������
ARM�g���ăN���C�A���g�ƊJ�����ꂷ��Ƃ��AIntel�Ɉˑ��������
�����ŃR���g���[������ق����܂��Ȃ낤�Ƃ������f�����邾�낤�ˁB
�u���t�̉\�������邯�ǁB
10�N��ɂ�Samsung��Intel����Ɨ\������I
�����A�v���o�����BGoogle�搶�͍��O�����{�Ɂu���v���d���܂��̂����Ȃ낤�ȁB
�������A�C������ASIC�d����ł���̂��ꂽ���A�Ɏd�|������ƌ��o������B
���Ƃ���Ȃ琫�\�W�Ȃ��ɐ����I�Z�p�I���R��ARM�Ɉڍs���邾�낤�B
Fab�������悤�ȗ��R�Œ����l������TSMC�ł͂Ȃ�GF���g����������Ȃ����A
L7SW�⏫���I�ɂ̓��[�g�F�؋ǂ܂Ŏ��O�ʼn^�p���邱�ƂɂȂ邾�낤�ȁB
�������A�C������ASIC�d����ł���̂��ꂽ���A�Ɏd�|������ƌ��o������B
���Ƃ���Ȃ琫�\�W�Ȃ��ɐ����I�Z�p�I���R��ARM�Ɉڍs���邾�낤�B
Fab�������悤�ȗ��R�Œ����l������TSMC�ł͂Ȃ�GF���g����������Ȃ����A
L7SW�⏫���I�ɂ̓��[�g�F�؋ǂ܂Ŏ��O�ʼn^�p���邱�ƂɂȂ邾�낤�ȁB
�d�q�@����g��Ȃ���Ό��Ȃ�Ďd���܂�邱�Ƃ͂Ȃ�
���E���M�E�����E�v�Z�ڂł�����
���E���M�E�����E�v�Z�ڂł�����
���͂̐l�Ԃ����@��̃J������}�C�N�������Ă��Ĉȉ���
�@�����̗��o�������ɂȂ��ĂȂ�����A
���}�̂ł̕ۊǂ������������炵���ˁB
���}�̂ł̕ۊǂ������������炵���ˁB
�����݂łĂ���Andoroid��iOS�̈�ԃn�C�X�y�b�N�ȃX�}�z�@��͂���PS3�̐��\���Ă��邾�낤�B
CPU��������AARM�n����Snapdragon�ƁA64bit��A7���낤���ǁA�����ȉ��Z���\�ŁAPS3���Ă��邾�낤�B
�������[��2G�����B
PS4�ɑ��Ă��A�X�}�z�̍ō��@��͒ǂ��������������x�̐��\��̂�5�N��������Ȃ���ˁH
�ƂȂ�����A����PC��PC�Q�[����X�}�z�ɋ쒀����関�����\�z�����B
CPU��������AARM�n����Snapdragon�ƁA64bit��A7���낤���ǁA�����ȉ��Z���\�ŁAPS3���Ă��邾�낤�B
�������[��2G�����B
PS4�ɑ��Ă��A�X�}�z�̍ō��@��͒ǂ��������������x�̐��\��̂�5�N��������Ȃ���ˁH
�ƂȂ�����A����PC��PC�Q�[����X�}�z�ɋ쒀����関�����\�z�����B
���܂łƓ����y�[�X�Ő��\����o�������J���Ȃ����
ARM�͌��X���\�������ďȃG�l�������̂��A
���\���グ�ēd�͐H���悤�ɂ��Ă����̂����邵
ARM�͌��X���\�������ďȃG�l�������̂��A
���\���グ�ēd�͐H���悤�ɂ��Ă����̂����邵
���Z���\�Ō�������A8�R�A�Ԃ�܂킹��PS3�Ƀ��o�C���p�ȁi�d�͂ɐ����̂���jARM�ŏ��Ă�̂��H
�����I�ɂ͂Ƃ������A���͂܂��Ȃ�Ȃ��́H
�����I�ɂ͂Ƃ������A���͂܂��Ȃ�Ȃ��́H
��������3GB��������O����
32bit�Ƃ������g���O�ꂽ���C��4GB�����Ă������낤��
https://www.nttdocomo.co.jp/product/smart_phone/sc02f/topics_01.html?to_feature=top_h3_1#t_01
32bit�Ƃ������g���O�ꂽ���C��4GB�����Ă������낤��
https://www.nttdocomo.co.jp/product/smart_phone/sc02f/topics_01.html?to_feature=top_h3_1#t_01
�f���A���`���l����2GB�Ȃ�킩�邯��
3GB�͂ǂ������ڑ��Ȃ낤��
3GB�͂ǂ������ڑ��Ȃ낤��
LPDDR3 6Gbit�`�b�v��4���ڂ��Ă�
�\�t�g�E�F�A�̓V�ˏW�c���v���Z�T�̐v����|������C�Ŏv���o����
Bitboys
http://www2.nsknet.or.jp/~azuma/b/b0084.htm
�ySIGGRAPH����z�t�B�������hBitboys�C�O���t�B�b�N�X�����p�v���Z�T��IP�R�A��NEC�G���N�g���j�N�X�Ƀ��C�Z���X������ - �Ɠd�EPC - Tech-On�I
http://techon.nikkeibp.co.jp/members/NEWS/20040816/104941/
Bitboys�A2�N�̒��ق�j�� "XBA"���ڃr�f�I�`�b�v�uAXE�v�\ | �}�C�i�r�j���[�X
http://news.mynavi.jp/news/2002/09/06/20.html
Bitboys�AOpenGL ES�ɑΉ��������o�C���@������O���t�B�b�N�R�A�\ | �}�C�i�r�j���[�X
http://news.mynavi.jp/news/2003/07/29/22.html
BitBoys�Ƃ� - goo Wikipedia (�E�B�L�y�f�B�A)
http://wpedia.goo.ne.jp/enwiki/Bitboys
Bitboys
http://www2.nsknet.or.jp/~azuma/b/b0084.htm
�ySIGGRAPH����z�t�B�������hBitboys�C�O���t�B�b�N�X�����p�v���Z�T��IP�R�A��NEC�G���N�g���j�N�X�Ƀ��C�Z���X������ - �Ɠd�EPC - Tech-On�I
http://techon.nikkeibp.co.jp/members/NEWS/20040816/104941/
Bitboys�A2�N�̒��ق�j�� "XBA"���ڃr�f�I�`�b�v�uAXE�v�\ | �}�C�i�r�j���[�X
http://news.mynavi.jp/news/2002/09/06/20.html
Bitboys�AOpenGL ES�ɑΉ��������o�C���@������O���t�B�b�N�R�A�\ | �}�C�i�r�j���[�X
http://news.mynavi.jp/news/2003/07/29/22.html
BitBoys�Ƃ� - goo Wikipedia (�E�B�L�y�f�B�A)
http://wpedia.goo.ne.jp/enwiki/Bitboys
6Gbit�i! ������!
>>63
��Čn�t�@�u���|���A���Ă�Ȃ珮�X�C���e���������ˁ[��
��Čn�t�@�u���|���A���Ă�Ȃ珮�X�C���e���������ˁ[��
x86��ARM���������g������Đ��\���オ���Ă������ǁA
����10�f�R�[�_�A20���s���j�b�g�Ƃ�������������ɂ͂ǂ�ȃ��������K�v�Ȃ̂��c
����10�f�R�[�_�A20���s���j�b�g�Ƃ�������������ɂ͂ǂ�ȃ��������K�v�Ȃ̂��c
>PS3�̃R�A��DSP�����Ă�
���킵����������
���킵����������
���� ���l�T�X���`2013�N�������`
http://eetimes.jp/ee/articles/1312/18/news016.html
���[�A�̖@�����I������}��������b�g�ɂȂ�\�\�u���[�h�R��CTO�C���^�r���[
http://eetimes.jp/ee/articles/1312/18/news062.html
�u�G���h���[�U�[�������i�̃C�m�x�[�V�������x�́A����݉�
���Ă������낤�B����Ȃ鏬�^����ቿ�i���A����������������
�͂͊m���ɐ����A����15�N�ȓ��ɂ͍s���l�܂�Ƃ݂���v
�u1mm2������̃_�C�R�X�g���}���ɑ������Ă��邱�Ƃ���A
����Ȃ������i�߂邱�Ƃɑ��Ė��͂��������v
�u����ɏd�v�Ȃ̂��A28nm�ȍ~�̃v���Z�X�Z�p�ł́A���\������
�̃R�X�g���������Ă����Ƃ����_���B������v���Z�X�Z�p�ւ�
�ڍs�Ɋւ��ẮA�n�l����K�v������Ƃ�����v�i�����j�B
http://eetimes.jp/ee/articles/1312/18/news016.html
���[�A�̖@�����I������}��������b�g�ɂȂ�\�\�u���[�h�R��CTO�C���^�r���[
http://eetimes.jp/ee/articles/1312/18/news062.html
�u�G���h���[�U�[�������i�̃C�m�x�[�V�������x�́A����݉�
���Ă������낤�B����Ȃ鏬�^����ቿ�i���A����������������
�͂͊m���ɐ����A����15�N�ȓ��ɂ͍s���l�܂�Ƃ݂���v
�u1mm2������̃_�C�R�X�g���}���ɑ������Ă��邱�Ƃ���A
����Ȃ������i�߂邱�Ƃɑ��Ė��͂��������v
�u����ɏd�v�Ȃ̂��A28nm�ȍ~�̃v���Z�X�Z�p�ł́A���\������
�̃R�X�g���������Ă����Ƃ����_���B������v���Z�X�Z�p�ւ�
�ڍs�Ɋւ��ẮA�n�l����K�v������Ƃ�����v�i�����j�B
��肽����肽���Ȃ��ȑO�̖��Ƃ��āA���������̂łǂ����悤���Ȃ�
�����A�����|���邩�牽���J������ȂƂ��������������������ŁA
���̘b�����Ƃ��ɂ͓����
�����A�����|���邩�牽���J������ȂƂ��������������������ŁA
���̘b�����Ƃ��ɂ͓����
�����������e�N�m���W�[�n��Ƃł́A
�Ȃɂ����Ȃ����X�N�̂ق����Ȃɂ���郊�X�N���傫��
�Ȃɂ����Ȃ��Ƃ����Ɏ���
�o�c�҂��n���Ȃ�
�Ȃɂ����Ȃ����X�N�̂ق����Ȃɂ���郊�X�N���傫��
�Ȃɂ����Ȃ��Ƃ����Ɏ���
�o�c�҂��n���Ȃ�
�Ȃɂ����Ȃ����X�N�Ȃ�ĂȂ�����
IEDM 2013�F�u�����̋ƊE�̋��ʂ̉ۑ�͔����v
http://eetimes.jp/ee/articles/1312/19/news054.html
�u7nm�v���Z�X�Z�p�J���ɂ����āA����܂ł̂悤�Ȑ����Ŕ�����i�߂邱�Ƃ͕s�\���v�Əq�ׂ�B
�����͂Ƃ�킯�AEUV���\�O���t�B�Z�p�Ȃǂ̏d�v�ȃc�[���̊J�����x��Ă���_�����������B
���̂���Samsung�́AEUV�Ɉˑ�������7nm�v���Z�X�J����i�߂Ă����\�肾�Ƃ����B
http://eetimes.jp/ee/articles/1312/19/news054.html
�u7nm�v���Z�X�Z�p�J���ɂ����āA����܂ł̂悤�Ȑ����Ŕ�����i�߂邱�Ƃ͕s�\���v�Əq�ׂ�B
�����͂Ƃ�킯�AEUV���\�O���t�B�Z�p�Ȃǂ̏d�v�ȃc�[���̊J�����x��Ă���_�����������B
���̂���Samsung�́AEUV�Ɉˑ�������7nm�v���Z�X�J����i�߂Ă����\�肾�Ƃ����B
���\�̌��E�Ȃ���d�����Ȃ��B�����͂������߂悤���B
�W-�X���ޗ��Ƃ����C���^�R�l�N�g�Ƃ����P����Ƃ��͂܂����邼�I�I
Substance Engine Increases PS4 & Xbox One Texture Generation Speed To 14 MB/s & 12 MB/s Respectively
Read more at http://gamingbolt.com/substance-engine-increases-ps4-xbox-one-texture-generation-speed-to-14-mbs-12-mbs-respectively#c5JXUW2XFv3QQwPA.99
Tegra 4��3.5MB/s
Tegra 5�͂ǂꂭ�炢�ɂȂ邩�ǂ����͒m��Ȃ����ATegra7�`8�ɂȂ邱�Ƃɂ́APS4��Xbox One�͔�����Ă��ˁB
Read more at http://gamingbolt.com/substance-engine-increases-ps4-xbox-one-texture-generation-speed-to-14-mbs-12-mbs-respectively#c5JXUW2XFv3QQwPA.99
Tegra 4��3.5MB/s
Tegra 5�͂ǂꂭ�炢�ɂȂ邩�ǂ����͒m��Ȃ����ATegra7�`8�ɂȂ邱�Ƃɂ́APS4��Xbox One�͔�����Ă��ˁB
�x�l�t�B�b�g��^�[���Ƃ������t��m��Ȃ�>>84
�f�[�^�E�Z���^�[���̐���Z�p�Ⓖ�����d�Z�p�̕W�����Ɍ��������ȉ������ - �G�l���M�[ - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130605/285887/
�O�H�d�@�A�f�[�^�Z���^�[�̏ȃG�l���������鍂�d���������d�V�X�e���� - �v���X�����[�X - Tech-On�I
http://techon.nikkeibp.co.jp/article/RELEASE/20130730/295128/
�O�H�d�@�A�f�[�^�Z���^�[����380V�̒������d�V�X�e���uMELUPS DECO�v�� - �G�l���M�[ - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130730/295193/
���d�ɂ�Li�C�I���E�L���p�V�^���̗p�CEDLC�ȏ�̎s������� - ���o�G���N�g���j�N�X - Tech-On�I
http://techon.nikkeibp.co.jp/article/HONSHI/20090804/173848/?ref=RL3
������C���^�[�l�b�g��NTT�f�[�^��[�Z�p�A�������d���̗p�̃f�[�^�Z���^�[��{�i�ғ� - �G�l���M�[ - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130321/272315/
��e�ʃL���p�V�^�s��A2013�N�x�͑O�N��72.3������80��4500���~��---���o�ς��\�� - �Y�Ƌ@��E���� - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130703/290893/?ref=RL3
�y��1���F���_�zEthernet��USB��100W�@�I�t�B�X��ƒ�ŗ��p�g��F���o�G���N�g���j�N�XDigital
http://techon.nikkeibp.co.jp/article/NED/20121023/247144/
�uUPS�Ȃ��ł�OK�v�ANEC��2���d�r�����̃��b�N�E�}�E���g�^�T�[�o�[�� - �Y�Ƌ@��E���� - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20121219/257333/
��������CHPC��f�[�^�Z���^�[���x����C���t���n�̘b���ĒN�����グ�ĂȂ���
http://techon.nikkeibp.co.jp/article/NEWS/20130605/285887/
�O�H�d�@�A�f�[�^�Z���^�[�̏ȃG�l���������鍂�d���������d�V�X�e���� - �v���X�����[�X - Tech-On�I
http://techon.nikkeibp.co.jp/article/RELEASE/20130730/295128/
�O�H�d�@�A�f�[�^�Z���^�[����380V�̒������d�V�X�e���uMELUPS DECO�v�� - �G�l���M�[ - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130730/295193/
���d�ɂ�Li�C�I���E�L���p�V�^���̗p�CEDLC�ȏ�̎s������� - ���o�G���N�g���j�N�X - Tech-On�I
http://techon.nikkeibp.co.jp/article/HONSHI/20090804/173848/?ref=RL3
������C���^�[�l�b�g��NTT�f�[�^��[�Z�p�A�������d���̗p�̃f�[�^�Z���^�[��{�i�ғ� - �G�l���M�[ - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130321/272315/
��e�ʃL���p�V�^�s��A2013�N�x�͑O�N��72.3������80��4500���~��---���o�ς��\�� - �Y�Ƌ@��E���� - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20130703/290893/?ref=RL3
�y��1���F���_�zEthernet��USB��100W�@�I�t�B�X��ƒ�ŗ��p�g��F���o�G���N�g���j�N�XDigital
http://techon.nikkeibp.co.jp/article/NED/20121023/247144/
�uUPS�Ȃ��ł�OK�v�ANEC��2���d�r�����̃��b�N�E�}�E���g�^�T�[�o�[�� - �Y�Ƌ@��E���� - Tech-On�I
http://techon.nikkeibp.co.jp/article/NEWS/20121219/257333/
��������CHPC��f�[�^�Z���^�[���x����C���t���n�̘b���ĒN�����グ�ĂȂ���
���\�A�s�[���n��ARM SoC���B��Snapdragon�����Tegra�Ƃ��s��ł܂���������ɂ���Ė��������
>>89
�����������́H���l�ł���
�����������́H���l�ł���
Snapdragonn�Ȃ�ACPU��������Ȃ��A�����֘A�`�b�v�A�J���x���T�[�r�X�ASnapdragon�pAndroid��\�t�g�E�F�A�A
���t�@�����X�����܂Ń����X�g�b�v�Œ����
�X�}�z��Z���ԂŊJ������ɂ́ASnapdragon��I�Ԃ̂�������y
���t�@�����X�����܂Ń����X�g�b�v�Œ����
�X�}�z��Z���ԂŊJ������ɂ́ASnapdragon��I�Ԃ̂�������y
>>48�̋L�����ƁAQ�ЈȊO�̓I���R��
�����ۂ��锼���̃x���_�[�́u�������Z�p�I��LTE���f������邱�Ƃ͉\�����A
���L�����A�F�ɗv�����ԂƃR�X�g���l����ƁA�㔭�g�̓r�W�l�X�Ƃ��Ă��łɐ������Ȃ��v�ƌ���Ă����B
�����ۂ��锼���̃x���_�[�́u�������Z�p�I��LTE���f������邱�Ƃ͉\�����A
���L�����A�F�ɗv�����ԂƃR�X�g���l����ƁA�㔭�g�̓r�W�l�X�Ƃ��Ă��łɐ������Ȃ��v�ƌ���Ă����B
�W���K�[(��)����8�R�A�ł�Snapdragon800��Tegra4��萫�\�Ⴂ�ł���
�������ɂ����܂Ő��\�Ⴉ������ARM�ɂ��Ă��Ȃ����A����SONY�Ƃ�Vita�����邵
CPU�͓����x���A���̓������̗e�ʂ���
ARM��64�r�b�g�������Ƃ�������������Ή\���͂�����
ARM��64�r�b�g�������Ƃ�������������Ή\���͂�����
>>95
CPU�X���ɋ��Ċw���ʂ����ꂩ�E�E�E
CPU�X���ɋ��Ċw���ʂ����ꂩ�E�E�E
�X�}�z��SoC�͈�����
�G���g���[���x��5�h����������500�~�ȉ����Ă��Ƃł���H
��ʔ������O��Ƃ͂����A�~�h�������W�ł�500�~����1500�~����
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131219_628127.html
> ���āA�O��Љ��Qualcomm�Ƃ�Samsung��SoC�́A
> �}3�ł����~�h�������W����v���~�A�������Ƃ����ʒu�t���ɂȂ�B
> �}2�ł͂��ꂼ���SoC�̃`�b�v���i���A
>
> �G���g���[���x��:5�h������
> �~�h�������W:5�`15�h��
> �v���~�A��:15�`20�h��
>
> �Ɛ��肵�Ă���B�������A����͂����܂�2017�N�ɂ����鉿�i�ł����āA
> ����͂��������l�i�������A
>
> �G���g���[���x��:10�h������
> �~�h�������W:10�`20�h��
> �v���~�A��:20�h���ȏ�
>
> �Ƃ������Ƃ���B�����Ƃ��A
> SoC�̒l�i�ɒ艿�Ƃ������̂͑��݂��Ȃ��B
> �Ƃ����͓̂��R�������ʂɉ����Ēl�i���ς��
> ���Ύ���x�[�X������ł��邪�A
> ����ł��Ⴆ�n�C�G���h������SoC�ł�40�h���ȏ�
> �Ƃ��������������Ƃ�����B�����܂��Ɍ����A
> ���i�̍ŏI���i��5%�O��Ƃ����̂�SoC�̒l�i�̑���ł��邩��A
> �X�}�[�g�t�H���̒l�i����A
> �t�Z��������悻��SoC���i�͑z���ł��邾�낤�B
�G���g���[���x��5�h����������500�~�ȉ����Ă��Ƃł���H
��ʔ������O��Ƃ͂����A�~�h�������W�ł�500�~����1500�~����
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131219_628127.html
> ���āA�O��Љ��Qualcomm�Ƃ�Samsung��SoC�́A
> �}3�ł����~�h�������W����v���~�A�������Ƃ����ʒu�t���ɂȂ�B
> �}2�ł͂��ꂼ���SoC�̃`�b�v���i���A
>
> �G���g���[���x��:5�h������
> �~�h�������W:5�`15�h��
> �v���~�A��:15�`20�h��
>
> �Ɛ��肵�Ă���B�������A����͂����܂�2017�N�ɂ����鉿�i�ł����āA
> ����͂��������l�i�������A
>
> �G���g���[���x��:10�h������
> �~�h�������W:10�`20�h��
> �v���~�A��:20�h���ȏ�
>
> �Ƃ������Ƃ���B�����Ƃ��A
> SoC�̒l�i�ɒ艿�Ƃ������̂͑��݂��Ȃ��B
> �Ƃ����͓̂��R�������ʂɉ����Ēl�i���ς��
> ���Ύ���x�[�X������ł��邪�A
> ����ł��Ⴆ�n�C�G���h������SoC�ł�40�h���ȏ�
> �Ƃ��������������Ƃ�����B�����܂��Ɍ����A
> ���i�̍ŏI���i��5%�O��Ƃ����̂�SoC�̒l�i�̑���ł��邩��A
> �X�}�[�g�t�H���̒l�i����A
> �t�Z��������悻��SoC���i�͑z���ł��邾�낤�B
�펯�ł���
�����G���g���[���x����Cortex-A5�̃I���`��������ȁB
�G���g���[���x���̃��o�C������SoC���āANokia�Ƃ����V����������16�h���Ƃ��Ŕ����Ă�g�ѓd�b�p��SoC�Ȃ�Ȃ���
��L�v�Z���@�ɂ���SoC��80�Z���g���炢����
��L�v�Z���@�ɂ���SoC��80�Z���g���炢����
�v���Z�X���[�����āA����ȏ�������Ă��Ӗ��≶�b���Ă���̂��ˁH
(���ɃV���R���E�F�n+�����f�ޔz���̏ꍇ)
�Ⴆ�A65nm��45 or 40nm�A45nm��32nm or 28nm�A����
�����ɂ�鍂�N���b�N���A�����d��etc�̉��b���\���ɓ���ꂽ����ǁA
32nm��28nm��A28nm��22nm�͗v�������Z�p�͂̊��ɁA
�����b�g���������悤�Ɏv�����ˁB�����̏��ǂ��Ȃ낤�H
��A�����݂�����x�͂�Ĉ��肵�Ă���v���Z�X���[���̒���
��Ԕ������Ă���̂��āA45 or 40nm�ł����̂��ȁH
(���ɃV���R���E�F�n+�����f�ޔz���̏ꍇ)
�Ⴆ�A65nm��45 or 40nm�A45nm��32nm or 28nm�A����
�����ɂ�鍂�N���b�N���A�����d��etc�̉��b���\���ɓ���ꂽ����ǁA
32nm��28nm��A28nm��22nm�͗v�������Z�p�͂̊��ɁA
�����b�g���������悤�Ɏv�����ˁB�����̏��ǂ��Ȃ낤�H
��A�����݂�����x�͂�Ĉ��肵�Ă���v���Z�X���[���̒���
��Ԕ������Ă���̂��āA45 or 40nm�ł����̂��ȁH
���͂����邯�lj��b�͂���Ȃ�ɂ��邾��
���܂ł݂����ɊȒP�Ɉ����ɂ͂Ȃ�Ȃ����낤����
���܂ł݂����ɊȒP�Ɉ����ɂ͂Ȃ�Ȃ����낤����
>>104
�ȓd�͂����\�����߂�g�����h�͏I����ĂȂ�
���܂ōH�����邨����1�N�ʼn���ł�������
���ꂪ2�N�ɂȂ�����3�N�ɂȂ����肷�邾��
�ȓd�͂����\�����߂�g�����h�͏I����ĂȂ�
���܂ōH�����邨����1�N�ʼn���ł�������
���ꂪ2�N�ɂȂ�����3�N�ɂȂ����肷�邾��
>>104
�g�����W�X�^�𑽂��ς߂�B���ꂾ���ł��\�����l������B
�����Ƃ��lj��g�����W�X�^�Ɛ��\����́A�ǂ����œV���ɂ����Ȃ���_�����낯��
�����炱�����j�A�ɐ��\�̏オ��i&�����I�ɕK�v�Ƃ���Ă���jFP�ɏœ_�����킹��
�e��GPGPU�������胁�j�B�[�R�A��������SIMD�̉��Z���̊g���𐄂��i�߂Ă��ł���B
�����炱���g�����W�X�^�𑽂��ς߂邱�Ǝ��̂��d�v�B�i���ɑO�����萫�\�𗎂Ƃ��Ȃ�����j
�g�����W�X�^�𑽂��ς߂�B���ꂾ���ł��\�����l������B
�����Ƃ��lj��g�����W�X�^�Ɛ��\����́A�ǂ����œV���ɂ����Ȃ���_�����낯��
�����炱�����j�A�ɐ��\�̏オ��i&�����I�ɕK�v�Ƃ���Ă���jFP�ɏœ_�����킹��
�e��GPGPU�������胁�j�B�[�R�A��������SIMD�̉��Z���̊g���𐄂��i�߂Ă��ł���B
�����炱���g�����W�X�^�𑽂��ς߂邱�Ǝ��̂��d�v�B�i���ɑO�����萫�\�𗎂Ƃ��Ȃ�����j
20nm�ȍ~�̓R�X�g����������R�X�g�Ɍ�����Ȃ�
�ƁA�����Ă��瑼�̉�������1xnm�����n�߂Ď���Ɏ��c�����B����ȋƊE�B
�����_�ł̓R�X�g�Ɍ�����Ȃ��Ƃ����l�������A�����Ǝv�����ǁB
�ƁA�����Ă��瑼�̉�������1xnm�����n�߂Ď���Ɏ��c�����B����ȋƊE�B
�����_�ł̓R�X�g�Ɍ�����Ȃ��Ƃ����l�������A�����Ǝv�����ǁB
>>106
���\�Ɋւ��Ă�PC�A�g�ђ[���ł͏I������ˁB
���\�Ɋւ��Ă�PC�A�g�ђ[���ł͏I������ˁB
�g�ђ[���ł͌��퉻���Ă�Ƃ����낗
64bit���Ƃ�8�R�A�Ƃ��A�ǂ�ǂ�ߌ������Ă�Ƃ����
PC�͂��Ƃ܂킵�ɂ���Ă銴�͂���ˁB
���̂����^�u���b�g�Ƃ��ɐH��ꂿ�Ⴄ������
64bit���Ƃ�8�R�A�Ƃ��A�ǂ�ǂ�ߌ������Ă�Ƃ����
PC�͂��Ƃ܂킵�ɂ���Ă銴�͂���ˁB
���̂����^�u���b�g�Ƃ��ɐH��ꂿ�Ⴄ������
111 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 04:30:31.15 ID:XxGJcBDs
> 64bit���Ƃ�8�R�A�Ƃ��A�ǂ�ǂ�ߌ������Ă�Ƃ����
���\���グ���Ȃ�����떂�����Ă邾���ł́H
���E�ň�Ԕ���Ă�^�u���b�g��8�R�A�ǂ��납2�R�A�ł���
���\���グ���Ȃ�����떂�����Ă邾���ł́H
���E�ň�Ԕ���Ă�^�u���b�g��8�R�A�ǂ��납2�R�A�ł���
���\���グ�Â炭�Ȃ��Ă���ĂƂ��܂ł͊��S�ɓ��ӂ�����
�����炱�����ɍ���������Ȃ牽�ł���邾��
���Ȃ݂�64bit�ɍŏ��Ɏ���o�����̂͂��̈�Ԕ���Ă鐻�i�ł����
�����炱�����ɍ���������Ȃ牽�ł���邾��
���Ȃ݂�64bit�ɍŏ��Ɏ���o�����̂͂��̈�Ԕ���Ă鐻�i�ł����
�^�u���b�g����Ȃ炱�����̕��������ˁH
http://www.mouse-jp.co.jp/luvpad/wn1100/
http://www.mouse-jp.co.jp/luvpad/wn1100/
114 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 08:49:52.61 ID:XxGJcBDs
�J���҂Ɋ��ꂳ���Ă������߂ɂ�������64�r�b�g���͕K�v�ł��傤
115 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 08:53:40.65 ID:XxGJcBDs
>>113
�d�r�������Ȃ����t�@����]�����邳�����
�d�r�������Ȃ����t�@����]�����邳�����
>>104
28nm�v���Z�X�̒�������O��ɓ������ꂽARM�̐VCPU�R�A�uCortex-A12�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20130711_607295.html
�E�F�n���AFab�ł���܂ł�葽���̃v���Z�X�H�����o��悤�ɂȂ�ƁA
���̕��A���H�Ɏ��Ԃ�������悤�ɂȂ�A�����R�X�g���オ���Ă��܂��B
�@���̂��߁A���ʂ́A��X�̃R�A���A28nm�v���Z�X����20nm�Ɉڂ��Ă��A
�R�X�g�팸�̌��ʂ͂��܂���҂ł��Ȃ��B
20nm��FinFET�v���Z�X�ŁA�m����(�_�C�ʐς�)�������Ȃ邪�A
�E�F�n�R�X�g���オ���Ă��܂��̂ŁA���ʂƂ��ăR�X�g��������Ȃ����낤�B
�@����͂ǂ��������ω��������炷�̂��B
�����͊ȒP�ŁA�ꕔ�̐��i�ł�(���ׂȃv���Z�X�ւ�
�ڍs����Ӗ��������Ȃ�)�A���݂̃v���Z�X�ɗ��܂낤�Ƃ���B
�Ⴆ�A�G���g���[���x���X�}�[�g�t�H���ł́A
���݂�TSMC��28HPM�v���Z�X���A
���ɒ������Ԏg���邱�ƂɂȂ邾�낤�B
���̂��߁A��X��Cortex-A12��Cortex-A7���A
�����I��28HPM�̂����R�A�ɂȂ邾�낤�ƍl���Ă���B
28nm�͔��ɒ��������m�[�h�ɂȂ邾�낤�B
�������A����̓~�b�h�����W�ȉ��̃X�}�[�g�t�H���ɂ��Ăł�����
�A�n�C�G���h�X�}�[�g�t�H���ł͈قȂ�X�g�[���[���B
�n�C�G���h�ƃ~�b�h�����W�̍��{�I�ȈႢ�́A
�n�C�G���h�ł̓R�X�g������قǏd�����Ȃ��_���B
���̑���A��ɓ���ō��̋Z�p���g����������ƍl����B
������A��i�̃v���Z�X�ւƈڍs����B
�~�b�h�^�C�A�ł́A���R�X�g�Ƃ̃o�����X����邽�߁A
�o�ϓI�ȃv���Z�X�ɗ��܂�B
28nm�v���Z�X�̒�������O��ɓ������ꂽARM�̐VCPU�R�A�uCortex-A12�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20130711_607295.html
�E�F�n���AFab�ł���܂ł�葽���̃v���Z�X�H�����o��悤�ɂȂ�ƁA
���̕��A���H�Ɏ��Ԃ�������悤�ɂȂ�A�����R�X�g���オ���Ă��܂��B
�@���̂��߁A���ʂ́A��X�̃R�A���A28nm�v���Z�X����20nm�Ɉڂ��Ă��A
�R�X�g�팸�̌��ʂ͂��܂���҂ł��Ȃ��B
20nm��FinFET�v���Z�X�ŁA�m����(�_�C�ʐς�)�������Ȃ邪�A
�E�F�n�R�X�g���オ���Ă��܂��̂ŁA���ʂƂ��ăR�X�g��������Ȃ����낤�B
�@����͂ǂ��������ω��������炷�̂��B
�����͊ȒP�ŁA�ꕔ�̐��i�ł�(���ׂȃv���Z�X�ւ�
�ڍs����Ӗ��������Ȃ�)�A���݂̃v���Z�X�ɗ��܂낤�Ƃ���B
�Ⴆ�A�G���g���[���x���X�}�[�g�t�H���ł́A
���݂�TSMC��28HPM�v���Z�X���A
���ɒ������Ԏg���邱�ƂɂȂ邾�낤�B
���̂��߁A��X��Cortex-A12��Cortex-A7���A
�����I��28HPM�̂����R�A�ɂȂ邾�낤�ƍl���Ă���B
28nm�͔��ɒ��������m�[�h�ɂȂ邾�낤�B
�������A����̓~�b�h�����W�ȉ��̃X�}�[�g�t�H���ɂ��Ăł�����
�A�n�C�G���h�X�}�[�g�t�H���ł͈قȂ�X�g�[���[���B
�n�C�G���h�ƃ~�b�h�����W�̍��{�I�ȈႢ�́A
�n�C�G���h�ł̓R�X�g������قǏd�����Ȃ��_���B
���̑���A��ɓ���ō��̋Z�p���g����������ƍl����B
������A��i�̃v���Z�X�ւƈڍs����B
�~�b�h�^�C�A�ł́A���R�X�g�Ƃ̃o�����X����邽�߁A
�o�ϓI�ȃv���Z�X�ɗ��܂�B
>>114
UNIX�nOS�S�ʂɌ����邱�Ƃ�����
���s��32bit��UNIX�nOS�̂قƂ�ǂ�2038�N��������Ă�
Linux�AFreeBSD�AAndroid�AiOS����O�ł͂Ȃ�
�����炢�����64bit�Ɉڍs���Ȃ��Ƃ����Ȃ�
Linux��64bit�ł�2038�N���ɑΉ��ς�
�����炭iOS��64bit����2038�N���ɑΉ����Ă邾�낤
UNIX�nOS�S�ʂɌ����邱�Ƃ�����
���s��32bit��UNIX�nOS�̂قƂ�ǂ�2038�N��������Ă�
Linux�AFreeBSD�AAndroid�AiOS����O�ł͂Ȃ�
�����炢�����64bit�Ɉڍs���Ȃ��Ƃ����Ȃ�
Linux��64bit�ł�2038�N���ɑΉ��ς�
�����炭iOS��64bit����2038�N���ɑΉ����Ă邾�낤
118 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 09:55:56.53 ID:XxGJcBDs
�����f�[�^��64�r�b�g�ɂ���̂�CPU��64�r�b�g���͂܂������̕ʖ��
���������āACPU��32�r�b�g����64�r�b�g�����^��unix time�������Ȃ��Ɗ��Ⴂ���Ă���̂��ȁB
���ɁA�v���O������1�x�����������Ƃ��Ȃ��l��UNIX���g������ɂȂ����̂�!
���ɁA�v���O������1�x�����������Ƃ��Ȃ��l��UNIX���g������ɂȂ����̂�!
8bit�̃t�@�~�R���ł���65535(�ȏ�)������̂ɂ�
>>118�A119
���݂�Linux�ł�time_t�^��long�^�ɂȂ��Ă�
Linux��64bit�ł�LP64���̗p����Ă��邩��
32bit�ł�long�^��32bit����64bit�ł�long�^�ł�64bit�ɂȂ�
���ۂ�32bit Linux�ł�2038�N�ȍ~�̔N���ݒ�ł��Ȃ�
C����͂��Ƃ���UNIX���L�q����ׂɍ��ꂽ���ꂾ����
C�����time_t�^�̈����ɂ͖��ڂȊW������
�܂��AAndroid��iOS��32bit�ł����l��2038�N�ȍ~�̔N���ݒ�ł��Ȃ�
���݂�Linux�ł�time_t�^��long�^�ɂȂ��Ă�
Linux��64bit�ł�LP64���̗p����Ă��邩��
32bit�ł�long�^��32bit����64bit�ł�long�^�ł�64bit�ɂȂ�
���ۂ�32bit Linux�ł�2038�N�ȍ~�̔N���ݒ�ł��Ȃ�
C����͂��Ƃ���UNIX���L�q����ׂɍ��ꂽ���ꂾ����
C�����time_t�^�̈����ɂ͖��ڂȊW������
�܂��AAndroid��iOS��32bit�ł����l��2038�N�ȍ~�̔N���ݒ�ł��Ȃ�
���Ȃ݂�Windows�ł͂������������͂Ȃ�
32bit Windows�ł�2038�N���ɂ͑Ή��ς�
32bit Windows�ł�2038�N���ɂ͑Ή��ς�
���ۂ�32bit��Linux���ǂꂩ�C���X�g�[�����Ă݂�킩��
2038�N�ȍ~�̔N�̐ݒ肪�ł��Ȃ�����
64bit Linux�ł͂����������Ƃ͂Ȃ�
2038�N�ȍ~�̔N�̐ݒ肪�ł��Ȃ�����
64bit Linux�ł͂����������Ƃ͂Ȃ�
32bit �ł�64-bit time_t ���g����UNIX�nOS�͂���A
linux �����܂��܂����ł͂Ȃ����ɓ����Ă��邾������
�[���Ȃ�Ăǂ��Ƃł��Ȃ�B����̂͑g�ݍ��݂Ƃ����[�^�[�Ƃ�
�u����2038�N���v�Ńg���u���������@2004/04/01
ttp://itpro.nikkeibp.co.jp/members/NC/ITARTICLE/20040325/1/
ttp://en.wikipedia.org/wiki/Year_2038_problem
linux �����܂��܂����ł͂Ȃ����ɓ����Ă��邾������
�[���Ȃ�Ăǂ��Ƃł��Ȃ�B����̂͑g�ݍ��݂Ƃ����[�^�[�Ƃ�
�u����2038�N���v�Ńg���u���������@2004/04/01
ttp://itpro.nikkeibp.co.jp/members/NC/ITARTICLE/20040325/1/
ttp://en.wikipedia.org/wiki/Year_2038_problem
32bit 64bit��ubuntu�Ŋm�F�����������Ƃ�time_t�^��long�^�Œ�`����Ă���
FreeBSD�ł�64bit�ł�__int64_t�^�A32bit�ł�__int32_t�^�Œ�`����Ă���
FreeBSD�ł�64bit�ł�__int64_t�^�A32bit�ł�__int32_t�^�Œ�`����Ă���
>>126
���݂�Linux�̎����������Ȃ��Ă���炵�傤���Ȃ�
Android������Linux�J�[�l���g���Ă邵iOS������2038�N���ɑΉ����ĂȂ�
�����珬���������ύX����������64bit���������������I
���݂�Linux�̎����������Ȃ��Ă���炵�傤���Ȃ�
Android������Linux�J�[�l���g���Ă邵iOS������2038�N���ɑΉ����ĂȂ�
�����珬���������ύX����������64bit���������������I
����̂Ȃ��悤��
iOS��Linux����Ȃ�����ǂ��Ȃ��Ă邩����Ȃ���
�����炭�A64bit�łɂ�2038�N���ɑΉ����Ă邾�낤��
iOS��Linux����Ȃ�����ǂ��Ȃ��Ă邩����Ȃ���
�����炭�A64bit�łɂ�2038�N���ɑΉ����Ă邾�낤��
25�N�O�Ȃ�Z80�g���Ă��B
25�N��Ȃ炨�ꎀ��ł邩����Ȃ��B
25�N��Ȃ炨�ꎀ��ł邩����Ȃ��B
��������łĂ��~�N����͎���łȂ����炻����������
32bitUNIX�nOS�ł�time_t��64bit����
�ߋ��̃\�t�g�Ƃ̌݊����̖��Ƃ����낢�날��悤����
http://ja.wikipedia.org/wiki/UNIX
���̖��ɑΏ����Ă���o�[�W����������B
�Ⴆ�ASolaris��Linux��64�r�b�g�łł́Atime_t ��64�r�b�g�ƂȂ��Ă���A
OS���g��64�r�b�g�̃A�v���P�[�V�����Q��
��2920���N�Ԑ��������삷��B
64�r�b�g��Solaris�Ŋ�����32�r�b�g�A�v���P�[�V������
���삳���邱�Ƃ��ł��邪�A���̏ꍇ�͖�肪�c�����܂܂ł���B
�ꕔ�x���_�[�͕W���� time_t �͂��̂܂܂ɂ��āA
64�r�b�g�̑�փf�[�^�^�Ƃ�����g�p����API��ʓr�p�ӂ��Ă���B
NetBSD�ł́A���̃��W���[�o�[�W�����ł��� 6.x ��
32�r�b�g�łł� time_t ��64�r�b�g�Ɋg�����邱�Ƃ����肵���B
�]����32�r�b�g�� time_t ���g�p���Ă���A�v���P�[�V�����́A
�o�C�i���݊������C���[������đΉ�����B
�ߋ��̃\�t�g�Ƃ̌݊����̖��Ƃ����낢�날��悤����
http://ja.wikipedia.org/wiki/UNIX
���̖��ɑΏ����Ă���o�[�W����������B
�Ⴆ�ASolaris��Linux��64�r�b�g�łł́Atime_t ��64�r�b�g�ƂȂ��Ă���A
OS���g��64�r�b�g�̃A�v���P�[�V�����Q��
��2920���N�Ԑ��������삷��B
64�r�b�g��Solaris�Ŋ�����32�r�b�g�A�v���P�[�V������
���삳���邱�Ƃ��ł��邪�A���̏ꍇ�͖�肪�c�����܂܂ł���B
�ꕔ�x���_�[�͕W���� time_t �͂��̂܂܂ɂ��āA
64�r�b�g�̑�փf�[�^�^�Ƃ�����g�p����API��ʓr�p�ӂ��Ă���B
NetBSD�ł́A���̃��W���[�o�[�W�����ł��� 6.x ��
32�r�b�g�łł� time_t ��64�r�b�g�Ɋg�����邱�Ƃ����肵���B
�]����32�r�b�g�� time_t ���g�p���Ă���A�v���P�[�V�����́A
�o�C�i���݊������C���[������đΉ�����B
133 �F,,�E�L�́M�E,,�j��-�������F2013/12/22(��) 12:15:17.24 ID:XxGJcBDs
�����v��2037�N�ȍ~�ɐݒ肷��ƃN���b�V�������ȁB
NTP���Ȃ�Ƃ����Ă���B
NTP���Ȃ�Ƃ����Ă���B
�����64bit�z���𐳂����n���h�����O���ĂȂ�NTP�N���C�A���g�̎����̖�肾�낤
NTP�̖���2036�N���Ƃ��ėL��
http://www.wdic.org/w/TECH/2036%E5%B9%B4%E5%95%8F%E9%A1%8C
http://www.wdic.org/w/TECH/2036%E5%B9%B4%E5%95%8F%E9%A1%8C
����ANTP�̓v���g�R���I�ɂ̓N���A���Ă��Ȃ��́H
CPU��ł�unsigned��signed�̈����̍��݂����Ȏ�@�ł�
CPU��ł�unsigned��signed�̈����̍��݂����Ȏ�@�ł�
137 �F,,�E�L�́M�E,,�j��-�������F2013/12/23(��) 07:15:34.62 ID:RkfXxEXv
NTP�̖�肾��time_t�̖�肾���m��Ȃ���Yahoo!�K�W�F�b�g��2038�N�ȍ~��
�ݒ肵����N���b�V�������Ȃ��B�܂�������ĂȂ����ǁB
�ݒ肵����N���b�V�������Ȃ��B�܂�������ĂȂ����ǁB
�����d�l�ɖ�肪����ꍇ�ƁA�����ɖ��͂Ȃ���
�d�l��ԗ����Ȃ����������z���Ă���ꍇ�A���f�B�A�ł�
�ǂ�����܂Ƃ߂ĉ��Ƃ����ƌĂ�邾�낤��
�d�l��ԗ����Ȃ����������z���Ă���ꍇ�A���f�B�A�ł�
�ǂ�����܂Ƃ߂ĉ��Ƃ����ƌĂ�邾�낤��
2038�N�ȍ~���g�ݍ��ݗp�r���ᓖ����O��32bit�ȉ���CPU���g���������邾�낤���A
32bit�ȉ���OS/C����ł��A64bit�Ŏ��Ԃ������V��/API/���C�u������p�ӂ��ׂ�
�Ǝ��g������Ȃ��A�W�������đS���K�p��
32bit�ȉ���OS/C����ł��A64bit�Ŏ��Ԃ������V��/API/���C�u������p�ӂ��ׂ�
�Ǝ��g������Ȃ��A�W�������đS���K�p��
Android������64bitARM��SoC��Cortex-A53���g����
�~�h�������W�A���[�G���h����SoC����ɂł�������
Cortex-A53�Ȃ�TSMC��28nm�̂܂܂ŏ\������
����Qualcomm��Snapdragon 410�\����
�uSnapdragon�v�Œቿ�iLTE�X�}�z�������\�ɁA4G�`�b�v�s��͋���������
http://eetimes.jp/ee/articles/1312/20/news067.html
�~�h�������W�A���[�G���h����SoC����ɂł�������
Cortex-A53�Ȃ�TSMC��28nm�̂܂܂ŏ\������
����Qualcomm��Snapdragon 410�\����
�uSnapdragon�v�Œቿ�iLTE�X�}�z�������\�ɁA4G�`�b�v�s��͋���������
http://eetimes.jp/ee/articles/1312/20/news067.html
>�ቿ�iLTE�X�}�z
���{����o���Ȃ���
�ς��Ɍ^�����n�C�G���h����ɓ��邾��
���{����o���Ȃ���
�ς��Ɍ^�����n�C�G���h����ɓ��邾��
http://www.geocities.jp/andosprocinfo/wadai13/20131221.htm
�P�DARM�T�[�o�`�b�v�̃p�C�I�j�A��Calxeda���Ɩ����~
Calxeda��2014�N�̏I���܂łɂ�64bit�ł��o���v��\���Ă��܂����C����܂Ŏ������������C
���Y��ی삷�邽�߁C�Ɩ����~���CIP�̔��p�Ȃǂ�S�����鏭���̏]�ƈ����c���āC
�啔���̏]�ƈ������ق���Ƃ̂��Ƃł��B
�P�DARM�T�[�o�`�b�v�̃p�C�I�j�A��Calxeda���Ɩ����~
Calxeda��2014�N�̏I���܂łɂ�64bit�ł��o���v��\���Ă��܂����C����܂Ŏ������������C
���Y��ی삷�邽�߁C�Ɩ����~���CIP�̔��p�Ȃǂ�S�����鏭���̏]�ƈ����c���āC
�啔���̏]�ƈ������ق���Ƃ̂��Ƃł��B
ARM�I�Ȃ�ĕ��y����킯�Ȃ��Ǝv���Ă����ǁA
�����̂͂₷��w
�����̂͂₷��w
�܂��Ax86�Ɋ�����Ȃ���ȁc���Ďv���Ă��܂�܂����B
�����Intel��Xeon�ǂ��납�AAMD�̃G���g���[�����ɂ���G���āc
�����Intel��Xeon�ǂ��납�AAMD�̃G���g���[�����ɂ���G���āc
���̌��Ɋւ��Ă�64bit���̎������Ȃ������������Ă��Ƃ���
�����������͂Ȋ�Ƃ��Q�����Ă������Ȃ̂Ŏ㏬����������ǂ��Ă����Ȃ������Ƃ���
�����������͂Ȋ�Ƃ��Q�����Ă������Ȃ̂Ŏ㏬����������ǂ��Ă����Ȃ������Ƃ���
�N���A�C���g�͂��납�T�[�o����ł����قƂ�ǂ̗p�r��32bit�ŏ\���B
ARM�T�[�o�͉��z���x���@�\�̃X�y�b�N���ł܂��Ă���
PC�݂����Ƀn�[�h���K�i������ĂȂ��ƌ�������Ȃ��́B
ARM�����낻��1�Ɍ��߂Ăق����ˁBPC�݂����Ƀ��[�U�[���D����OS��������悤�ɂȂ�ƐF�X�ƒ���
ARM v8�R�AOpteron�\�gSeattle�h�̓����������I�ɖ��炩��
http://northwood.blog60.fc2.com/blog-entry-7272.html
http://northwood.blog60.fc2.com/blog-entry-7272.html
���o�C���n�͐��\�グ����Ђ�������d�͂������Ă����
TSMC 16nm FinFET�v���Z�X�̃��X�N���Y���J�n
http://northwood.blog60.fc2.com/blog-entry-7278.html
http://northwood.blog60.fc2.com/blog-entry-7278.html
�y���r���[�zAtom C2750�}�U�[�uSupermicro A1SAi-2750F�v���r���[ �`8�R�AAtom�ŏ�ʂ̐��\�ƃT�[�o�[�{�[�h�̎g����������� - PC Watch
http://pc.watch.impress.co.jp/docs/topic/review/20131221_628428.html
Atom�̐��\�͓��N���b�N��Bulldozer���݂�
2.4GHz����ł�Silvermont�APiledriver�AHaswell�̔�r�������[��
http://pc.watch.impress.co.jp/docs/topic/review/20131221_628428.html
Atom�̐��\�͓��N���b�N��Bulldozer���݂�
2.4GHz����ł�Silvermont�APiledriver�AHaswell�̔�r�������[��
�g�ݍ��݂Ȃ炻��ł������낤���ǁA
�I�ł��������Ⴂ����B
�I�ł��������Ⴂ����B
�T�[�o�Ȃ�UEFI�g����Ȃ��́H
http://community.arm.com/groups/processors/blog/2013/09/26/uefi-a-new-opportunity-for-preboot-firmware-on-arm-based-systems
http://community.arm.com/groups/processors/blog/2013/09/26/uefi-a-new-opportunity-for-preboot-firmware-on-arm-based-systems
���ł�ARM�x�[�X�̃}�U�[�{�[�h�Ƃ������Ă��邵�A
UEFI�x�[�X�ɂȂ��Ȃ��́H
UEFI�x�[�X�ɂȂ��Ȃ��́H
http://pc.watch.impress.co.jp/docs/topic/feature/20131228_629501.html
�y�i��z�����ق�64bit�̘b���o�܂������A�����_�ł��̉��b�͂���܂�?
�㓡�O�Ύ�
�y�㓡�z�݂�Ȃ�����������Ă��āAARM��64bit��
�ق���CPU��64bit�ƈႤ���Ď���S�R�l���ĂȂ��B
ARM�͂Ƃ�����32bit�̏o�����Ђǂ��B
�����Ђǂ���? RISC�Ȃ̂ɔėp���W�X�^��16�{�����Ȃ��A
���̓���3�{�̓v���O�����֘A�Ŏg�����Ⴄ�̂ŁA
�ėp�Ɏg����̂͂�����13�{�B
����ŁA���[�h/�X�g�A�A�[�L�e�N�`����
�n���h�����O�����Ȃ���Ȃ�Ȃ��B
��������ƃR���p�C���������I�ȃR�[�h��f���Ȃ��B
�̂ŁA�R�[�h�X�e�b�v�����ɒ����Ȃ�B
���64bit�ɂȂ�Ɣėp���W�X�^��31�{�A
SIMD���f�B�A���W�X�^��32�{������A
�R���p�C�������̂����������I�ȃR�[�h��f����悤�ɂȂ�
�B
�y�R�c�z�܂荡��ARM��32bit�͂Ђǂ��ƁB
�y�㓡�z�Ђǂ��B�����āA�l�̒m�荇����
�l�C�e�B�uARM 32bit�ɐG�ꂽ�l�͊F
�u�ϑԖ��߃Z�b�g�v���Č����Ă邵(��)�B
�y�R�c�z����A�Ȃ�ł����܂ł͂�����낤?
�y�㓡�z���傤���Ȃ�����(��)�B
���������Ђǂ����Ƃ��Ȃ��Ȃ�̂�64bit��ARMv8�B
������A�R�[�f�B���O���œK�����y�ɂȂ邵�A
�R���p�C���������Ȃ邵�A�S�̓I�ɍ������ł���B
�y�i��z�����ق�64bit�̘b���o�܂������A�����_�ł��̉��b�͂���܂�?
�㓡�O�Ύ�
�y�㓡�z�݂�Ȃ�����������Ă��āAARM��64bit��
�ق���CPU��64bit�ƈႤ���Ď���S�R�l���ĂȂ��B
ARM�͂Ƃ�����32bit�̏o�����Ђǂ��B
�����Ђǂ���? RISC�Ȃ̂ɔėp���W�X�^��16�{�����Ȃ��A
���̓���3�{�̓v���O�����֘A�Ŏg�����Ⴄ�̂ŁA
�ėp�Ɏg����̂͂�����13�{�B
����ŁA���[�h/�X�g�A�A�[�L�e�N�`����
�n���h�����O�����Ȃ���Ȃ�Ȃ��B
��������ƃR���p�C���������I�ȃR�[�h��f���Ȃ��B
�̂ŁA�R�[�h�X�e�b�v�����ɒ����Ȃ�B
���64bit�ɂȂ�Ɣėp���W�X�^��31�{�A
SIMD���f�B�A���W�X�^��32�{������A
�R���p�C�������̂����������I�ȃR�[�h��f����悤�ɂȂ�
�B
�y�R�c�z�܂荡��ARM��32bit�͂Ђǂ��ƁB
�y�㓡�z�Ђǂ��B�����āA�l�̒m�荇����
�l�C�e�B�uARM 32bit�ɐG�ꂽ�l�͊F
�u�ϑԖ��߃Z�b�g�v���Č����Ă邵(��)�B
�y�R�c�z����A�Ȃ�ł����܂ł͂�����낤?
�y�㓡�z���傤���Ȃ�����(��)�B
���������Ђǂ����Ƃ��Ȃ��Ȃ�̂�64bit��ARMv8�B
������A�R�[�f�B���O���œK�����y�ɂȂ邵�A
�R���p�C���������Ȃ邵�A�S�̓I�ɍ������ł���B
�y�R�c�z�ŁA���܂ł̃m�E�n�E�͊��������?
�y�㓡�z�����A�f�R�[�_���Ⴄ�B
�y�R�c�z�����̓R���p�C�����ʓ|�����ł���?
�y�㓡�z�����B�����ǁA�J���҂��œK���̂��߂�
��J���Ȃ��ėǂ��Ȃ�B
�Ⴆ��ARM 32bit�̏ꍇ�́A�V�t�g�E���Z�ƕ��ׂ��
�����Ȃ�Ƃ��A�ςȍœK���������ς�����B
��͊���Z���ߎg������_�����Ƃ��B
������Cortex-A9�܂ł͊���Z���Z�킪�Ȃ���������B
������!? ��̂���CPU? ���Ċ����ł���?(��)�B
�@���ꂩ��(64bit�̉��b��)�Z�L�����e�B���f���B
ARM�̃Z�L�����e�B�����K�w�́A�������ρB
���ʂ�Ring0�A1�A2�A3�A�Z�L���A�o�C�U�[�A
�n�C�p�[�o�C�U�[�AOS�A�A�v���Ƃł��邯�ǁA
ARM�̏ꍇ�A���ꂪ�ł��Ȃ��B
���ARMv8�����4�K�w�ŁA���ʂɃZ�L���A��
�n�C�p�[�o�C�U�[�ߍ��߂�B
�����炭iPhone 5s�͂�����g���ĂāA
�w��f�[�^�������ɓ���Ă�B�w��f�[�^���������ɓW�J���鎞�A
�Z�L���A��������ԂɈڂ��ɂ́A���������d�g�݂��K�v�ɂȂ�B
�@������(�悭������)�A�h���X���(�̃����b�g)��3�ԖڂȂ�ł���B
�y�}���zARMv8R�������d�l����Ȃ��ł���?
�y�㓡�zv8R�͋C�ɂ��Ȃ��ėǂ���(��)�B
�y�}���z�l�͂�������āA�ȂႻ���Ǝv���܂�����(��)�B
�y�㓡�z�����A�f�R�[�_���Ⴄ�B
�y�R�c�z�����̓R���p�C�����ʓ|�����ł���?
�y�㓡�z�����B�����ǁA�J���҂��œK���̂��߂�
��J���Ȃ��ėǂ��Ȃ�B
�Ⴆ��ARM 32bit�̏ꍇ�́A�V�t�g�E���Z�ƕ��ׂ��
�����Ȃ�Ƃ��A�ςȍœK���������ς�����B
��͊���Z���ߎg������_�����Ƃ��B
������Cortex-A9�܂ł͊���Z���Z�킪�Ȃ���������B
������!? ��̂���CPU? ���Ċ����ł���?(��)�B
�@���ꂩ��(64bit�̉��b��)�Z�L�����e�B���f���B
ARM�̃Z�L�����e�B�����K�w�́A�������ρB
���ʂ�Ring0�A1�A2�A3�A�Z�L���A�o�C�U�[�A
�n�C�p�[�o�C�U�[�AOS�A�A�v���Ƃł��邯�ǁA
ARM�̏ꍇ�A���ꂪ�ł��Ȃ��B
���ARMv8�����4�K�w�ŁA���ʂɃZ�L���A��
�n�C�p�[�o�C�U�[�ߍ��߂�B
�����炭iPhone 5s�͂�����g���ĂāA
�w��f�[�^�������ɓ���Ă�B�w��f�[�^���������ɓW�J���鎞�A
�Z�L���A��������ԂɈڂ��ɂ́A���������d�g�݂��K�v�ɂȂ�B
�@������(�悭������)�A�h���X���(�̃����b�g)��3�ԖڂȂ�ł���B
�y�}���zARMv8R�������d�l����Ȃ��ł���?
�y�㓡�zv8R�͋C�ɂ��Ȃ��ėǂ���(��)�B
�y�}���z�l�͂�������āA�ȂႻ���Ǝv���܂�����(��)�B
���������A���Ȃ�RISC CPU�ł��A
Power�ASPARC�AAlpha�AMIPS�APA-RISC�́A�{�i�I��32bit�}���`�^�X�NOS�����삷��T�[�o�E���[�N�X�e�[�V�����p��
�n�C�p�t�H�[�}���XCPU�Ƃ��č��ꂽ���A
ARM�́A�g�ݍ������̒�R�X�gCPU�Ƃ��č��ꂽ
ARM��32bit������32bit RISC CPU��肵��ڂ��͓̂��R�Ƃ�����
ARM��64bit�����ɑ���RISC CPU���݂ɂ܂Ƃ���CPU�ɂȂ�̂́A
���[�A�̖@���ɂ���āA�i��CPU�ł���ʂ̃g�����W�X�^���g����悤�ɂȂ�������
Power�ASPARC�AAlpha�AMIPS�APA-RISC�́A�{�i�I��32bit�}���`�^�X�NOS�����삷��T�[�o�E���[�N�X�e�[�V�����p��
�n�C�p�t�H�[�}���XCPU�Ƃ��č��ꂽ���A
ARM�́A�g�ݍ������̒�R�X�gCPU�Ƃ��č��ꂽ
ARM��32bit������32bit RISC CPU��肵��ڂ��͓̂��R�Ƃ�����
ARM��64bit�����ɑ���RISC CPU���݂ɂ܂Ƃ���CPU�ɂȂ�̂́A
���[�A�̖@���ɂ���āA�i��CPU�ł���ʂ̃g�����W�X�^���g����悤�ɂȂ�������
64�r�b�gARM�̃C���X�g���N�V�����A�[�L�e�N�`�����܂Ƃ��Ȃ̂́A32�r�b�gARM�Ƃ̘A������f�����đS���ʂ̃A�[�L�����������ł�
�S���b�����ݍ����ĂȂ�ww
���y����v���Z�b�T��
�͂��߃��[�R�X�g�Ń��[�G���h�ŕ��y����
���X�Ƀn�C�G���h�ɐH������ł�����������
���[�R�X�g��8bit���h�L��16bitCPU��8088��IBM-PC�ɍ̗p���ꂽ�̂�
�g�ѓd�b��ARM���̗p���ꂽ�̂���������
�͂��߃��[�R�X�g�Ń��[�G���h�ŕ��y����
���X�Ƀn�C�G���h�ɐH������ł�����������
���[�R�X�g��8bit���h�L��16bitCPU��8088��IBM-PC�ɍ̗p���ꂽ�̂�
�g�ѓd�b��ARM���̗p���ꂽ�̂���������
���������AARM�����[�ȁA�Ǝv���Ă��疽�߃Z�b�g�������������Ă��ʂ�����̂���B
64bit�ɂȂ��Ăǂ��Ȃ邩�����̂��ȁB
64bit�ɂȂ��Ăǂ��Ȃ邩�����̂��ȁB
CISC CPU�̓��W�X�^���m�̑��Ƀ��W�X�^-�������Ԃł̉��Z���ł��邪
RISC CPU�̓��W�X�^���m�ł������Z���ł��Ȃ�����
13�̃��W�X�^�ł͏��Ȃ�������
�ꉞR0����R15�܂ł��邪
�ėp�Ɏg���郌�W�X�^��R0����R12��
R13�̓X�^�b�N�|�C���^�AR14�̓����N���W�X�^�AR15�̓v���O�����J�E���^����
RISC CPU�̓��W�X�^���m�ł������Z���ł��Ȃ�����
13�̃��W�X�^�ł͏��Ȃ�������
�ꉞR0����R15�܂ł��邪
�ėp�Ɏg���郌�W�X�^��R0����R12��
R13�̓X�^�b�N�|�C���^�AR14�̓����N���W�X�^�AR15�̓v���O�����J�E���^����
>>163
�@���������o���Ƃ����瓖�����Ă���ʂ����邪�A
ARM�o��܂�32bit�g�ݍ��݂�MIPS�͌��\�o�Ă������A
���l�T�X�̃��[�R�X�g�͌����݊O��Ă���B
Intel��ARM�����[�R�X�g����n�C�G���h�֔��W�������S�����������A
DEC��HP�͑g�ݍ��݂���郂�`�x�[�V�����͂Ȃ������B
���l�T�X�͔������̑g�ݍ��݂�������Ă����������B
�܂�͊J�����̂��C�̖��ł͂Ȃ����B
�@���������o���Ƃ����瓖�����Ă���ʂ����邪�A
ARM�o��܂�32bit�g�ݍ��݂�MIPS�͌��\�o�Ă������A
���l�T�X�̃��[�R�X�g�͌����݊O��Ă���B
Intel��ARM�����[�R�X�g����n�C�G���h�֔��W�������S�����������A
DEC��HP�͑g�ݍ��݂���郂�`�x�[�V�����͂Ȃ������B
���l�T�X�͔������̑g�ݍ��݂�������Ă����������B
�܂�͊J�����̂��C�̖��ł͂Ȃ����B
�����݊O��Ă�����ĂȂ�ł���
�������\���Ȃ̂Ńl�b�g��̂��̐l�̏������݂����ł������ł���
�������\���Ȃ̂Ńl�b�g��̂��̐l�̏������݂����ł������ł���
>>167
���{������n�߂ĉ��N�ł����H
>>168
���̃��x���y�ƌ����Ă��܂�����>>163�̐����̂��������Ȃ��B
������SuperH�������������ȁB
���{������n�߂ĉ��N�ł����H
>>168
���̃��x���y�ƌ����Ă��܂�����>>163�̐����̂��������Ȃ��B
������SuperH�������������ȁB
>�����̑g�ݍ���PA-RISC
�R����m���Ă����͜W���̃}�j�A���W�҂���
��������Ȃ��̂��L��������Y�ꂩ���Ă���
�R����m���Ă����͜W���̃}�j�A���W�҂���
��������Ȃ��̂��L��������Y�ꂩ���Ă���
>>164
�O�X���Ŋ��o�̓z����A15��A57��10%���x�̐��\����
�O�X���Ŋ��o�̓z����A15��A57��10%���x�̐��\����
>>167
�����s��̂�Ƃ肳��ł����H
�����s��̂�Ƃ肳��ł����H
>>160
>ARM�́A�g�ݍ������̒�R�X�gCPU�Ƃ��č��ꂽ
ttp://en.wikipedia.org/wiki/ARM_architecture
>The British computer manufacturer Acorn Computers first developed
> ARM in the 1980s to use in its personal computers.
�H
>ARM�́A�g�ݍ������̒�R�X�gCPU�Ƃ��č��ꂽ
ttp://en.wikipedia.org/wiki/ARM_architecture
>The British computer manufacturer Acorn Computers first developed
> ARM in the 1980s to use in its personal computers.
�H
32bitARM�������������͂��̖��߃Z�b�g����������ȁB
�R�[�h�����i�o�C�i���T�C�Y�j�͂����������\�͂͒Ⴂ�B
x86�̓R�[�h��������������d�͂����������\�͍����B
�Ƃ͂����Ă�ARM�̎s���x86�ŐH�����ނ̂͌݊�����
�ϓ_���������ǁB
�R�[�h�����i�o�C�i���T�C�Y�j�͂����������\�͂͒Ⴂ�B
x86�̓R�[�h��������������d�͂����������\�͍����B
�Ƃ͂����Ă�ARM�̎s���x86�ŐH�����ނ̂͌݊�����
�ϓ_���������ǁB
>>166�͘_���I�Ȏv�l���ł��Ȃ��悤���ȁB
���y����v���Z�b�T�̓��[�G���h���畁�y����ƌ����Ă��邾���ŁA
�S�Ẵ��[�G���h�v���Z�b�T�͕��y������Ęb����Ȃ�����B
���y����v���Z�b�T�̓��[�G���h���畁�y����ƌ����Ă��邾���ŁA
�S�Ẵ��[�G���h�v���Z�b�T�͕��y������Ęb����Ȃ�����B
�ԈႢ���w�E���Ă݂Ă���A�������B
>>177
�ԈႢ�Ƃ�������{�I�ɖ��߃Z�b�g�́A���̖��߃Z�b�g���g���Ă��鐻�i���q�b�g����
���y���邩�ǂ����ɏ��Ȃ��Ƃ��x�z�I�ȉe����^���Ȃ���B
���ۂ͋t�ŁA�q�b�g���鐻�i�ɁA���̂Ƃ��v���d�l��v���P�������܂��܍��v���āA���܂��܍̗p���ꂽ
�v���Z�b�T���A�q�b�g�������������y����B
�e�̐��i���V�F�A30%�̃q�b�g�Ȃ�A����ɏ]������30%���A���̖��߃Z�b�g�����y���邵�A
�f�t�@�N�g�X�^���_�[�h�ɂȂ�悤�Ȓ��q�b�g��������A���̖��߃Z�b�g���f�t�@�N�g�X�^���_�[�h�ɂȂ�B
��{�I�ɖ��߃Z�b�g���g�ړI�Ȍ����Ƃ������߃Z�b�g�̈ڍs�Ƃ������ۂ͂����Ȃ���B
�ԈႢ�Ƃ�������{�I�ɖ��߃Z�b�g�́A���̖��߃Z�b�g���g���Ă��鐻�i���q�b�g����
���y���邩�ǂ����ɏ��Ȃ��Ƃ��x�z�I�ȉe����^���Ȃ���B
���ۂ͋t�ŁA�q�b�g���鐻�i�ɁA���̂Ƃ��v���d�l��v���P�������܂��܍��v���āA���܂��܍̗p���ꂽ
�v���Z�b�T���A�q�b�g�������������y����B
�e�̐��i���V�F�A30%�̃q�b�g�Ȃ�A����ɏ]������30%���A���̖��߃Z�b�g�����y���邵�A
�f�t�@�N�g�X�^���_�[�h�ɂȂ�悤�Ȓ��q�b�g��������A���̖��߃Z�b�g���f�t�@�N�g�X�^���_�[�h�ɂȂ�B
��{�I�ɖ��߃Z�b�g���g�ړI�Ȍ����Ƃ������߃Z�b�g�̈ڍs�Ƃ������ۂ͂����Ȃ���B
���C���t���[�����~�j�R���A�~�j�R����WS�AWS��PC�̎s��ω��ɂ����
���߃Z�b�g���]���I�Ɉڍs����(�悤�ɂ݂���)���ۂ͋N���邯�ǁA
����͂��̂Ƃ���͂��������i�ɂ��܂��܍̗p����Ă������߃Z�b�g��
�]���I�ɕ��y�������Ă����ŁA���߃Z�b�g���g�͈ڍs�̌����⌴���͂ł͂Ȃ��̂ˁB
���߃Z�b�g���]���I�Ɉڍs����(�悤�ɂ݂���)���ۂ͋N���邯�ǁA
����͂��̂Ƃ���͂��������i�ɂ��܂��܍̗p����Ă������߃Z�b�g��
�]���I�ɕ��y�������Ă����ŁA���߃Z�b�g���g�͈ڍs�̌����⌴���͂ł͂Ȃ��̂ˁB
MIPS��ARM�Ȃ�ǂ���������Ă��邩���x�̍������Ȃ���
CISC����RISC�ւ̈ڍs�͖��߃Z�b�g�ɂ����̂��傫���̂���
�ނ�ړI�ȗv���Ƃ��Ă�RISC�̃p���[��R�X�g�p�t�H�[�}���X�����ߎ肾��
CISC����RISC�ւ̈ڍs�͖��߃Z�b�g�ɂ����̂��傫���̂���
�ނ�ړI�ȗv���Ƃ��Ă�RISC�̃p���[��R�X�g�p�t�H�[�}���X�����ߎ肾��
>>181
CISC����RISC�̈ڍs�́A�f�B�X�N���[�gCPU����}�C�N���v���Z�b�T�ւ̎s��ω��ƁA
���C���t���[������~�j�R���ւ̎s��ω��ɏ]�����āARISC WS�����ꂽ���������y���������B
������WS��菭�����̃Z�O�����g�ł���PC�A�[�L�e�N�`�����䓪�����̂ŁA
RISC��CISC���ɊW�Ȃ��A���܂���CISC������PC�ɂ����CISC�Ɉڍs�����B
CISC����RISC�̈ڍs�́A�f�B�X�N���[�gCPU����}�C�N���v���Z�b�T�ւ̎s��ω��ƁA
���C���t���[������~�j�R���ւ̎s��ω��ɏ]�����āARISC WS�����ꂽ���������y���������B
������WS��菭�����̃Z�O�����g�ł���PC�A�[�L�e�N�`�����䓪�����̂ŁA
RISC��CISC���ɊW�Ȃ��A���܂���CISC������PC�ɂ����CISC�Ɉڍs�����B
���C���t���[��/�~�j�R������WS�ւ̎s��ω�
�̊ԈႢ��
�̊ԈႢ��
185 �FSocket774�F2013/12/29(��) 22:53:13.86 ID:lKtue8tO
>>158
x86�͌Â��A�i32bit�jARM���V�����Č����I���Ƃ������Ă��l�͂ǂ��ɍs�����̂�
x86�͌Â��A�i32bit�jARM���V�����Č����I���Ƃ������Ă��l�͂ǂ��ɍs�����̂�
>>179
����A166��MIPS�����y����������163�̖@������ʂł����������Ȃ��Ǝw�E�����̂ɁA
����166�̎w�E���_���I�łȂ���175�͎咣�����킯����B
�܂�AMIPS�����y���Ă��Ȃ����AMIPS�̓��[�G���h���甭�W�����Əؖ����邵��
�Ȃ��Ǝv���̂����B
�܂���2�s�ȏ�̕��͂�ǂ߂Ȃ��l�Ƃ�����Ȃ���ȁB
����A166��MIPS�����y����������163�̖@������ʂł����������Ȃ��Ǝw�E�����̂ɁA
����166�̎w�E���_���I�łȂ���175�͎咣�����킯����B
�܂�AMIPS�����y���Ă��Ȃ����AMIPS�̓��[�G���h���甭�W�����Əؖ����邵��
�Ȃ��Ǝv���̂����B
�܂���2�s�ȏ�̕��͂�ǂ߂Ȃ��l�Ƃ�����Ȃ���ȁB
�܂��AMIPS�͌��ǂ�ARM�ɕ����ĕ��y���Ȃ������킯��������Ȃ��ˁB
�܂��v���Z�b�T�̗��j�Ƃ��m���l�Ȃ̂��낤�ȁB
189 �FSocket774�F2013/12/29(��) 23:30:45.76 ID:MJ7ZcLJM
>>163�̘b(�������̂͂��ꂶ��Ȃ�����)�̏œ_�́A
���y�����v���Z�b�T�͉ߋ��ɂ̓��[�G���h�������A�Ȃ̂����c�B
���ꂶ�Ⴀ�v���Z�b�T�̗��j�Ɏ��̏ڂ���>>188����ɁA
MIPS���g�ݍ��݂��炩��n�C�G���h�ւƕ��y���Ă������o�܂�
����Ă��炨������?
���y�����v���Z�b�T�͉ߋ��ɂ̓��[�G���h�������A�Ȃ̂����c�B
���ꂶ�Ⴀ�v���Z�b�T�̗��j�Ɏ��̏ڂ���>>188����ɁA
MIPS���g�ݍ��݂��炩��n�C�G���h�ւƕ��y���Ă������o�܂�
����Ă��炨������?
>>166��WS����g�ݍ��݂ɕ��y����MIPS��>>163�̔���Ƃ��ċ��������A
>>175������͘_���I�ł͂Ȃ��Ƃ����B
175�̌����ʂ肾�Ƃ�����MIPS���g�ݍ��݂���WS�ɔ��W�������ƂɂȂ邪�A
���x��175�Ɠ���ID��190��MIPS�͑g�ݍ��݂���n�C�G���h�֕��y���������ؖ�����Ƃ����B
���O�����o�J�B
>>175������͘_���I�ł͂Ȃ��Ƃ����B
175�̌����ʂ肾�Ƃ�����MIPS���g�ݍ��݂���WS�ɔ��W�������ƂɂȂ邪�A
���x��175�Ɠ���ID��190��MIPS�͑g�ݍ��݂���n�C�G���h�֕��y���������ؖ�����Ƃ����B
���O�����o�J�B
MIPS�̗��j�͖���See MIPS Run�̍ŏ��̕��̏͂ɏ����Ă����B
�~�j�R����UNIX���[�N�X�e�[�V�����p�r�̍����\�}�C�N���v���Z�b�T�B
���̌��64�r�b�g��������������B�}���`�v���Z�b�T�\���ɂ������̃L���b�V���R�q�[�����V�̈ێ���������_�ƌ����Ă���
�~�j�R����UNIX���[�N�X�e�[�V�����p�r�̍����\�}�C�N���v���Z�b�T�B
���̌��64�r�b�g��������������B�}���`�v���Z�b�T�\���ɂ������̃L���b�V���R�q�[�����V�̈ێ���������_�ƌ����Ă���
>>189
�����Ȃ��ȁA�R����ww
������PIC32�ɂ����MIPS�̋t�P���n�܂�c���Ď��͖����c
�Ǝv�����ǁA�g�ݍ��ݕ���ł�microchip�V�F�A�����Ă邩��Ȃ�
�����Ȃ��ȁA�R����ww
������PIC32�ɂ����MIPS�̋t�P���n�܂�c���Ď��͖����c
�Ǝv�����ǁA�g�ݍ��ݕ���ł�microchip�V�F�A�����Ă邩��Ȃ�
>>191
>>175�ŁA�_���I�ł͂Ȃ��Ƃ������̂́A>>166��
���l�T�X�̃��[�R�X�g�͌����݊O��Ă���
�Ƃ��̉��肾��B>>166�̓��[�G���h�Ȃ�Ε��y����A�݂����ȓ��e�ł���B
�܈ӂƓ��l�̋�ʂ����ĂȂ����ĈӖ��ŁA�_���I����Ȃ����Č����Ă�����A
�܂��A�����̏��������Ƃ�s���悭�����I�ɖY�����x�̐l�݂��������A������̌����Ă��邱�Ƃ�
��������͖̂����Ȃ낤�c�B
>>175�ŁA�_���I�ł͂Ȃ��Ƃ������̂́A>>166��
���l�T�X�̃��[�R�X�g�͌����݊O��Ă���
�Ƃ��̉��肾��B>>166�̓��[�G���h�Ȃ�Ε��y����A�݂����ȓ��e�ł���B
�܈ӂƓ��l�̋�ʂ����ĂȂ����ĈӖ��ŁA�_���I����Ȃ����Č����Ă�����A
�܂��A�����̏��������Ƃ�s���悭�����I�ɖY�����x�̐l�݂��������A������̌����Ă��邱�Ƃ�
��������͖̂����Ȃ낤�c�B
>>194
�����������͂̍s�Ԃ�ǂݍ��ޕ����_���I�ł͂Ȃ��B
������͔����������Ă���킯�ŁB
190�݂����Ȃ��n���ȕ��͏���������Ă����Ȃ��Ă����p�������ȁB
�����������͂̍s�Ԃ�ǂݍ��ޕ����_���I�ł͂Ȃ��B
������͔����������Ă���킯�ŁB
190�݂����Ȃ��n���ȕ��͏���������Ă����Ȃ��Ă����p�������ȁB
���_�AMIPS��g�ݍ��������Ǝv���Ă�킯�Ȃ����ȁB
WS�ɂ��g�ݍ��݂ɂ��Ɨ��ɂ�����x���ꂽ���ǁA���ǁA�ŏI�I�ɕ��y���Ȃ���������
���̋c�_�̔���ɂ͎c�O�Ȃ���Ȃ�Ȃ��B
WS�ɂ��g�ݍ��݂ɂ��Ɨ��ɂ�����x���ꂽ���ǁA���ǁA�ŏI�I�ɕ��y���Ȃ���������
���̋c�_�̔���ɂ͎c�O�Ȃ���Ȃ�Ȃ��B
���̘b���āA����MIPS�����y�������A���Ȃ��������̂Ƃ���̔c���ɐH���Ⴂ�������Ȃ����B
MIPS�͍L���g���e���r��STB�̒��ɓ����Ă���̂ł����MIPS�͕��y�����Ǝv���B
MIPS�͍L���g���e���r��STB�̒��ɓ����Ă���̂ł����MIPS�͕��y�����Ǝv���B
����ARM�ɂ͕����Ă邪MIPS�͑g�ݍ��݂ł܂����݊����邯�ǁB
�������Ɠd���[�J�[�͓��������Ĉꎞ���S��MIPS�Ɏ���o���Ă����A
���ł��g���Ă鏊�͑����B
���̊ԍ��Y�̉F���pMPU�̋L����������MIPS�������ˁB���O���o�Ă��Ȃ����B
�������Ɠd���[�J�[�͓��������Ĉꎞ���S��MIPS�Ɏ���o���Ă����A
���ł��g���Ă鏊�͑����B
���̊ԍ��Y�̉F���pMPU�̋L����������MIPS�������ˁB���O���o�Ă��Ȃ����B
MIPS�����y�������ǂ����ł͂Ȃ��āA
���[�G���h�ɕ��y���āA����𑫂�����Ƀn�C�G���h�ɓW�J�����p�^�[���ɂ͂Ȃ�Ȃ������̂ŁA
���̔��Ⴉ��͊O�����Ă��ƁB
���[�G���h�ɕ��y���āA����𑫂�����Ƀn�C�G���h�ɓW�J�����p�^�[���ɂ͂Ȃ�Ȃ������̂ŁA
���̔��Ⴉ��͊O�����Ă��ƁB
MIPS���g�ݍ��݂Ō��\�����Ă���B�ߋ���WS������Ă����A
���Ƃ͂��̃X���̏Z�l�Ȃ�펯�ł���A����Ȑ����̋c�_���ĂȂ���B
���Ƃ͂��̃X���̏Z�l�Ȃ�펯�ł���A����Ȑ����̋c�_���ĂȂ���B
>>199
���̗�������������̂Ȃ���l�T�X�̃��[�R�X�g������ɂ͂Ȃ�Ȃ��_�@�ƍ��킹�āA
�ǂ̂悤�ȕ��y�o�܂ł����Ă�>>163�̔���ɂ͂Ȃ�Ȃ��ƌ����������ȁB
���̗�������������̂Ȃ���l�T�X�̃��[�R�X�g������ɂ͂Ȃ�Ȃ��_�@�ƍ��킹�āA
�ǂ̂悤�ȕ��y�o�܂ł����Ă�>>163�̔���ɂ͂Ȃ�Ȃ��ƌ����������ȁB
�Ƃ������A��������163�̎咣�ɂ͖���������A�S�������͂������ł��ˁB
���ǂ̂Ƃ���A163�͋c�_����ɒl���Ȃ������炯�̎咣�ŁA�ꌾ�Ō����Ύ����ł͂���܂���B�Ƃ������Ƃł��̘b�͏I���ł��傤�B
���`��A�����>>163, >>175�͐������Ǝv�����ǁB
�������Ƃ������A�ߋ�20�N���炢�̋c�_�ŁA����ȏ㐳�����Ǝv����F����m��Ȃ��B
�ܘ_�A���R�̖@���̋c�_���Ă��킯����Ȃ��̂ŁA99%�ȏ��O�͂Ȃ��Ƃ͌����Ȃ����A
����̔F���Ƃ��Đ������ƔF�߂���Ȃ��B
����ł��̃X���̏Z�l�̑唼������ł��Ȃ��Ƃ���A�f���ɕ�����F�߂���Ȃ��c�B
�Ƃ����킯�ŁA����̋c�_�͏I���B
�������Ƃ������A�ߋ�20�N���炢�̋c�_�ŁA����ȏ㐳�����Ǝv����F����m��Ȃ��B
�ܘ_�A���R�̖@���̋c�_���Ă��킯����Ȃ��̂ŁA99%�ȏ��O�͂Ȃ��Ƃ͌����Ȃ����A
����̔F���Ƃ��Đ������ƔF�߂���Ȃ��B
����ł��̃X���̏Z�l�̑唼������ł��Ȃ��Ƃ���A�f���ɕ�����F�߂���Ȃ��c�B
�Ƃ����킯�ŁA����̋c�_�͏I���B
>>204
����166�����ǁA��̏����p�^�[���Ƃ��Ă̓A���Ȃ�B
������u�������Ă���ʂ�����v�Ə������B
�ł��_���I�v�l����ʂ������Ȃ�N���̃��c�����̃X���ɋ����B
�����璷�X�c�_���Ă���킯�����A�z���g�Ȃ�170������ŏI����ĂĂ����͂��B
����166�����ǁA��̏����p�^�[���Ƃ��Ă̓A���Ȃ�B
������u�������Ă���ʂ�����v�Ə������B
�ł��_���I�v�l����ʂ������Ȃ�N���̃��c�����̃X���ɋ����B
�����璷�X�c�_���Ă���킯�����A�z���g�Ȃ�170������ŏI����ĂĂ����͂��B
��H�@���̂�ID�����݂ɕς���Ă�B
205=201=198���B
205=201=198���B
����AID�ǂ��킩�邪�A�_���I�v�l����ʂ�s�����̂͂���Ȃ���w
�܂��A���̋c�_�͏I���ł�����B
�܂��A���̋c�_�͏I���ł�����B
�������A����ɉ����āAMIPS�̂悤�Ƀn�C�G���h���珉�߂āA�v���Z�X���[���̃V�������N�ɂ���ĕ��y���i�тɍ~��Ă���Ƃ��������p�^�[�����F�߂Ă��܂����Ȃ�A
���͂�163�̂悤�ȕ����咣�͂ł��Ȃ��̂ł́B
���͂�163�̂悤�ȕ����咣�͂ł��Ȃ��̂ł́B
����163�ɏ�����Ă�����e�ɂ��āA�_���I�v�l���o�Ă���܂ł��Ȃ��P���ɊԈ���Ă��āA�����ł͂Ȃ��Ǝv���܂��B
���̒��ɂ͑�R�̃v���Z�b�T�����y���Ă���̂ɁA���E�̒���x86��ARM���������Ă��Ȃ����싷���ԂȂ̂ł́B
���̒��ɂ͑�R�̃v���Z�b�T�����y���Ă���̂ɁA���E�̒���x86��ARM���������Ă��Ȃ����싷���ԂȂ̂ł́B
�v�̓E�H�[�^�[�t�H�[���������̂��A���̋t�������̂��A�ł���B
������L���s�����x�̘b�ł����Ȃ��B
������L���s�����x�̘b�ł����Ȃ��B
���ɂ�����Ȃ��c�_�ł����ˁB���Ԃ̖��ʂł����B
CPU�̐��\���オ��Ȃ�����X�g���X�ŃC���C�����Ă��
>>176
�ǂ��ɂǂ�ȗ]�n������̂��킩��Ȃ�
�ǂ��ɂǂ�ȗ]�n������̂��킩��Ȃ�
���̒�POWER���������ĂȂ��q�g��������w
MAC�I�^�ǂ�������w
MAC�I�^�ǂ�������w
�������悤�����A
MIPS�́AWS�Ƒg�ݍ��݂̗����ł��ꂼ����̃V�F�A�͎�������ǁA
WS����A���邢�͑g�ݍ��݂���A�n�C�G���h�Ɍ����ēW�J���邱�ƂŐ����c���邱�Ƃ��Ȃ������A
���Ȃ킿���������Z�O�����g���ő��̋����v���Z�b�T�ɕ������p�^�[���B
�����>>163�̔��ɂ��ؖ��ɂ��Ȃ�Ȃ���B
MIPS�́AWS�Ƒg�ݍ��݂̗����ł��ꂼ����̃V�F�A�͎�������ǁA
WS����A���邢�͑g�ݍ��݂���A�n�C�G���h�Ɍ����ēW�J���邱�ƂŐ����c���邱�Ƃ��Ȃ������A
���Ȃ킿���������Z�O�����g���ő��̋����v���Z�b�T�ɕ������p�^�[���B
�����>>163�̔��ɂ��ؖ��ɂ��Ȃ�Ȃ���B
215����́A�uMIPS�͕��y���Ȃ������v�Ƃ����A�����ɂ���N�Ƃ��قȂ��������������Ă���̂ł��ˁB
����A���̃V�F�A����������ď����Ă��邯��w
���{��ǂ߂܂�?
���{��ǂ߂܂�?
�����������A���^�C�����ゾ���A90�N�����32-bit�ȏ�͑g�ݍ��݂̒��ł̓n�C�G���h�������B
���̑g�ݍ��ݓ��ł̃n�C�G���h�ł͈ꎞ���͊m���ɔ��ꂽ���ǁA���ǁA��������W�J���Ȃ��āA
MIPS������ARM�ɂ���������H���邱�ƂɂȂ����킯�����B
������MIPS���ꂽ���ꂽ�����ł���������m�b��MIPS�m���������ŁA�����̏ǂ��Ă��̂���?
���̑g�ݍ��ݓ��ł̃n�C�G���h�ł͈ꎞ���͊m���ɔ��ꂽ���ǁA���ǁA��������W�J���Ȃ��āA
MIPS������ARM�ɂ���������H���邱�ƂɂȂ����킯�����B
������MIPS���ꂽ���ꂽ�����ł���������m�b��MIPS�m���������ŁA�����̏ǂ��Ă��̂���?
���ꂾ����R�̋@��ɍڂ��āA�L���g���Ă�����̂��A���y���Ȃ������Ƃ����B
�i�C�[���Ƃ��������悤���Ȃ��ł��ˁB
�i�C�[���Ƃ��������悤���Ȃ��ł��ˁB
����ܗǂ��������Ȃ������B
http://gse.ufsc.br/~bezerra/disciplinas/Extensao/semana_academica/2003/painel/material_suporte/Embedded%20Processors,%20Part%20Three%20of%20Three.htm
�����ɃO���t���邯�ǁAMIPS�͑g�ݍ���RISC�̒���96-97�N�Ɉꎞ������Ă��邯�ǁA��������ARM�ɉ�����Ă���ˁB
MIPS���߂��Ⴍ���ᔄ��Ă��݂����Ȏ咣���Ă���ЂƂ́A���܂������̒m���Ă���@���MIPS���������Ă����ł�?
�����̈�ۂł͑g�ݍ��ݎs��͑S�̂ŁARISC�ȊO���܂߂Ă����Ȗ��߃Z�b�g��MPU������Ă�����B
http://gse.ufsc.br/~bezerra/disciplinas/Extensao/semana_academica/2003/painel/material_suporte/Embedded%20Processors,%20Part%20Three%20of%20Three.htm
�����ɃO���t���邯�ǁAMIPS�͑g�ݍ���RISC�̒���96-97�N�Ɉꎞ������Ă��邯�ǁA��������ARM�ɉ�����Ă���ˁB
MIPS���߂��Ⴍ���ᔄ��Ă��݂����Ȏ咣���Ă���ЂƂ́A���܂������̒m���Ă���@���MIPS���������Ă����ł�?
�����̈�ۂł͑g�ݍ��ݎs��͑S�̂ŁARISC�ȊO���܂߂Ă����Ȗ��߃Z�b�g��MPU������Ă�����B
�ǂ�Ȏ����������Ă����Ƃ��Ă��uMIPS�͕��y���Ȃ������v�Ƃ������Ƃɂ͂Ȃ�܂���B
����Ƃ��A���݃V�F�A1�ʂ��Ƃ��Ă���v���Z�b�T�ȊO�̃v���Z�b�T�͑S�����y���Ȃ������A�Ƃ������Ƃɂ������A�Ƃ����咣�ł��傤���B
����Ƃ��A���݃V�F�A1�ʂ��Ƃ��Ă���v���Z�b�T�ȊO�̃v���Z�b�T�͑S�����y���Ȃ������A�Ƃ������Ƃɂ������A�Ƃ����咣�ł��傤���B
>>215
�܂艺�����Ɍ������̂��N�̒�`���镁�y�ł�����
�ォ�牺������MIPS�͕��y�Ƃ͌���Ȃ����甽�ɂ͂Ȃ�Ȃ��ƌ��������킯����H
�N�̒�`���猾���Ε��y�͑���>>163�̎咣�̎�������g�[�g���W�[�Ƃ������c����B
��ʓI�ɕ��y�ƌ�������ʓI���邢�͓��ڗ��I�Ȓ�`���낤�B
���ꂪ���݂�ARM��艺�����畁�y���ĂȂ��Ƃ����̂Ȃ�c�_�̗]�n�͂��邪�A
215�̎咣�͘_���I���ǂ����ȑO�Ɋ�n�O�̂��ꂾ�B
�܂艺�����Ɍ������̂��N�̒�`���镁�y�ł�����
�ォ�牺������MIPS�͕��y�Ƃ͌���Ȃ����甽�ɂ͂Ȃ�Ȃ��ƌ��������킯����H
�N�̒�`���猾���Ε��y�͑���>>163�̎咣�̎�������g�[�g���W�[�Ƃ������c����B
��ʓI�ɕ��y�ƌ�������ʓI���邢�͓��ڗ��I�Ȓ�`���낤�B
���ꂪ���݂�ARM��艺�����畁�y���ĂȂ��Ƃ����̂Ȃ�c�_�̗]�n�͂��邪�A
215�̎咣�͘_���I���ǂ����ȑO�Ɋ�n�O�̂��ꂾ�B
>>222
���y�̒�`�̘b�Ȃ��ĂȂ����B���y�Ƃ������t�Ɏ������Ă���̂� ID:hmB0QuYc �ł����āA���ł͂Ȃ��B
�������������̂́A>>163�̍ŏ���3�s�̈Ӗ������܂�����߂ĂȂ��ł�����Ă����B
���[�G���h�ŕ��y���ăn�C�G���h�ɂȂ���ď����Ă��邪�A
MIPS�͓��������Z�O�����g�ŏI�������̂ŁA���[�G���h�~�܂�ŏI����������B
�����>>163�̃P�[�X�̔��ɂ͂Ȃ�Ȃ��́B���[�G���h���K�����y������Ęb�����Ă���킯����Ȃ�����ˁB
���y�̒�`�̘b�Ȃ��ĂȂ����B���y�Ƃ������t�Ɏ������Ă���̂� ID:hmB0QuYc �ł����āA���ł͂Ȃ��B
�������������̂́A>>163�̍ŏ���3�s�̈Ӗ������܂�����߂ĂȂ��ł�����Ă����B
���[�G���h�ŕ��y���ăn�C�G���h�ɂȂ���ď����Ă��邪�A
MIPS�͓��������Z�O�����g�ŏI�������̂ŁA���[�G���h�~�܂�ŏI����������B
�����>>163�̃P�[�X�̔��ɂ͂Ȃ�Ȃ��́B���[�G���h���K�����y������Ęb�����Ă���킯����Ȃ�����ˁB
�������B
�ǂ��̃p���������[���h���낤���B
�ǂ��̃p���������[���h���낤���B
�܂�A222����̐����������A���y�Ƃ������t�̈Ӗ����Ɠ��̂��̂ŁA��ʂ̐l�X�����y�Ƃ������t����z�N������̂Ƃ͈قȂ��`�������Ƃ������Ƃł��ˁB
>>225
���t�̒�`�]�X�̘b�͂��ĂȂ���B>>163�̍ŏ���3�s�̈Ӗ���f���ɂ��̂܂ܓǂ߂Η����ł���b�ł��B
���̃V�F�A���Ƃ��Ă��A���ꂪ�n�C�G���h�ɂȂ���Ȃ�������A���̃Z�O�����g�~�܂�Ȃ̂�����A
>>163�̔��̃P�[�X�ɂ͊Y�����Ȃ��ł���B>>163�̍ŏ���3�s�͂����Ɠǂ�ŁA�Ӗ����l���ĂˁB
���t�̒�`�]�X�̘b�͂��ĂȂ���B>>163�̍ŏ���3�s�̈Ӗ���f���ɂ��̂܂ܓǂ߂Η����ł���b�ł��B
���̃V�F�A���Ƃ��Ă��A���ꂪ�n�C�G���h�ɂȂ���Ȃ�������A���̃Z�O�����g�~�܂�Ȃ̂�����A
>>163�̔��̃P�[�X�ɂ͊Y�����Ȃ��ł���B>>163�̍ŏ���3�s�͂����Ɠǂ�ŁA�Ӗ����l���ĂˁB
�����B���͍��₠�Ȃ��̎咣�����S�ɗ������܂����B
�u���y����v���Z�b�T�Ƃ́A�͂��߃��[�R�X�g�Ń��[�G���h�ŕ��y���ď��X�Ƀn�C�G���h�ɐH������ł��������̃v���Z�b�T�̂��Ƃł���B�v�Ƃ������Ƃł���ˁB
�u���y����v���Z�b�T�Ƃ́A�͂��߃��[�R�X�g�Ń��[�G���h�ŕ��y���ď��X�Ƀn�C�G���h�ɐH������ł��������̃v���Z�b�T�̂��Ƃł���B�v�Ƃ������Ƃł���ˁB
>>227
�܂�>>163���������͎̂��ł͂Ȃ����ǁA�����������Ƃ��ˁB
���́A�n�C�G���h�ő������Ă���v���Z�b�T��~
���炢���Ó��������낤���A�Ӗ��͂킩��B
�܂�>>163���������͎̂��ł͂Ȃ����ǁA�����������Ƃ��ˁB
���́A�n�C�G���h�ő������Ă���v���Z�b�T��~
���炢���Ó��������낤���A�Ӗ��͂킩��B
32�r�b�g�}�C�R���̃O���t�����邯�ǂ��̐Ԃ�NonARM�͉��Ȃ̂����Ęb���ȁB
�Ԃ��������̊����Ő�߂Ă���Ε��y�ƌ����č����x���Ȃ����낤
ttp://monoist.atmarkit.co.jp/mn/articles/1212/21/news108.html
�Ԃ��������̊����Ő�߂Ă���Ε��y�ƌ����č����x���Ȃ����낤
ttp://monoist.atmarkit.co.jp/mn/articles/1212/21/news108.html
>>229
�܂��A���l��RX�Ƃ��t���[�X�P�[����ColdFire�Ȃ��CISC
���[��~�h�����甄��ăn�C�G���h�ɏオ���Ă����p�^�[���ƁA
�t�Ƀn�C�G���h�Ŕ���ă��[�ɍ~��Ă����p�^�[���̗���������͎̂�������
���̌������O�҂��ŏI�������Ă���悤��
�Ȃ̂�>>163�͂���ȂɈ�a���͂Ȃ�
�����Ƃ��Ⴊx86��ARM�����Ȃ��Ȃ킯����
�܂��A���l��RX�Ƃ��t���[�X�P�[����ColdFire�Ȃ��CISC
���[��~�h�����甄��ăn�C�G���h�ɏオ���Ă����p�^�[���ƁA
�t�Ƀn�C�G���h�Ŕ���ă��[�ɍ~��Ă����p�^�[���̗���������͎̂�������
���̌������O�҂��ŏI�������Ă���悤��
�Ȃ̂�>>163�͂���ȂɈ�a���͂Ȃ�
�����Ƃ��Ⴊx86��ARM�����Ȃ��Ȃ킯����
ARM�@79�����C�Z���X�@�@�@�@�@�@ �@1��
ARC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@10%�@2��
MIPS�@6��5600�����C�Z���X�@6%�@3��
2011�N
ttp://eetimes.jp/ee/articles/1205/16/news007.html
ARC�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@10%�@2��
MIPS�@6��5600�����C�Z���X�@6%�@3��
2011�N
ttp://eetimes.jp/ee/articles/1205/16/news007.html
>>230
�n�C�G���h���烍�[�ɍ~��Ă����p�^�[�����ĉ�������?
MIPS��VAX�ɒׂ��ꂽ�킯����Ȃ���x86�ɉ�����Ђ�����Ԃ��ꂽ���A
�g�ݍ��݂�ARM�ɉ�����Ђ�����Ԃ��ꂽ�̂ŁA
��ɕ��y����O�ɉ�����@���ꂽ�̂ŊԂɍ���Ȃ��������߂Ŗ��Ȃ��ł���B
����ȊO�ɁA�n�C���烍�[�̃p�^�[�����m�肽���B
�n�C�G���h���烍�[�ɍ~��Ă����p�^�[�����ĉ�������?
MIPS��VAX�ɒׂ��ꂽ�킯����Ȃ���x86�ɉ�����Ђ�����Ԃ��ꂽ���A
�g�ݍ��݂�ARM�ɉ�����Ђ�����Ԃ��ꂽ�̂ŁA
��ɕ��y����O�ɉ�����@���ꂽ�̂ŊԂɍ���Ȃ��������߂Ŗ��Ȃ��ł���B
����ȊO�ɁA�n�C���烍�[�̃p�^�[�����m�肽���B
�\�t�g�I�ɂ͂���������̂��̂����ɍ~��Ă���
��������Ă��悤�ƃV�F�A1�ʈȊO�͕��y���Ă��Ȃ��ƂƂ炦��悤��
�v�l��H�ɂ͂Ȃ肽���Ȃ���
�v�l��H�ɂ͂Ȃ肽���Ȃ���
������A���y���Č��t����������������Ă���悤������ǁA
>>163���R�ɓǂ߂ΈӖ��킩�邶���B���͂̐������l�������ȊO�ɉ��߂̂��悤�Ȃ����B
�Ȃ�ł���Ȃ̂��Ƃ������ł���l��3�l������̂��낤�c�B
>>163���R�ɓǂ߂ΈӖ��킩�邶���B���͂̐������l�������ȊO�ɉ��߂̂��悤�Ȃ����B
�Ȃ�ł���Ȃ̂��Ƃ������ł���l��3�l������̂��낤�c�B
���ẴX�}�z��MIPS�����������̂ɁA�Ȃ�ň�C��ARM�ɂȂ����낤�ˁH
4�l�ڂł�
���낻�뎩���̂ق����Ԉ���Ă���ƋC�t���Ă��������ł���
�ꉞ�������Ă�����
MIPS: �n�C�G���hWS�p�Ƃ��ēo�ꂵ�A�������ᐫ�\�ȑg�ݍ��݂ɍ~��Ă���
ARM: �����̓p�\�R���p�ł͂�����������Ȃ������̂�PDA�ōďo�����A���悤�₭��荂�������\�ȃT�[�o�[�p���o�Ă���
���낻�뎩���̂ق����Ԉ���Ă���ƋC�t���Ă��������ł���
�ꉞ�������Ă�����
MIPS: �n�C�G���hWS�p�Ƃ��ēo�ꂵ�A�������ᐫ�\�ȑg�ݍ��݂ɍ~��Ă���
ARM: �����̓p�\�R���p�ł͂�����������Ȃ������̂�PDA�ōďo�����A���悤�₭��荂�������\�ȃT�[�o�[�p���o�Ă���
>>237
�Ō��2�s�����ǂ���͖ܘ_�c�����Ă����B
�n�C�G���hWS�p�Ƃ��ăX�^�[�g����x86�ɉ�����Ђ�����Ԃ��ꂽ�A
�g�ݍ��݂�WS�Ƃ͓Ɨ��ɂ��������ARM�ɉ�����Ђ�����Ԃ��ꂽ��
���Ȃ��BMIPS�̃n�C�G���h�Ƒg�ݍ��݂͏��X�ɉ��ɕ��y���Ă������킯����Ȃ�����A�A�������Ȃ��B
�����ARM�������BARM�̓������͂��������p�\�R����艺���Ă����Ɠd��Ƃ����炢�����Ȃ����ȁB
x86�݂����Ƀp�\�R�����珙�X�Ƀ^�u���b�g�A�X�}�z�ɗ��Ƃ��Ă���̂ƈႤ�B
�Ō��2�s�����ǂ���͖ܘ_�c�����Ă����B
�n�C�G���hWS�p�Ƃ��ăX�^�[�g����x86�ɉ�����Ђ�����Ԃ��ꂽ�A
�g�ݍ��݂�WS�Ƃ͓Ɨ��ɂ��������ARM�ɉ�����Ђ�����Ԃ��ꂽ��
���Ȃ��BMIPS�̃n�C�G���h�Ƒg�ݍ��݂͏��X�ɉ��ɕ��y���Ă������킯����Ȃ�����A�A�������Ȃ��B
�����ARM�������BARM�̓������͂��������p�\�R����艺���Ă����Ɠd��Ƃ����炢�����Ȃ����ȁB
x86�݂����Ƀp�\�R�����珙�X�Ƀ^�u���b�g�A�X�}�z�ɗ��Ƃ��Ă���̂ƈႤ�B
�����킩����
����A�[�L�̃��C���i�b�v�ƁACPU�s��S�̂̃V�F�A�̋�ʂ������Ȃ��l��������
����A�[�L�̃��C���i�b�v�ƁACPU�s��S�̂̃V�F�A�̋�ʂ������Ȃ��l��������
MIPS��R3000, R4000, R5000�ƌ��XWS�����̂��̂ɂ�����Ǝ�����đg�ݍ������ɂ��Ă���
WS�ƓƗ��ɂ�������Ȃ�ĂƂ�ł��Ȃ�
�A���L���f�X�͓�����386�}�V����3�{���炢�����������\�@���������A����Ȃ������̂Ō�p�`�b�v������܂�Ȃ���
���傤���Ȃ�����A�b�v���Ǝ��g���PDA��������ďo��������
�����ŃA�[�L�����Ȃ�������ꂽ
���̌��StrongARM��XScale�Ȃǂ�MIPS�̂悤�ɉ����̗��p�ł͂Ȃ��A��ʂ̃��C���i�b�v�Ƃ��ĐV�K�J�������킯�ł���
WS�ƓƗ��ɂ�������Ȃ�ĂƂ�ł��Ȃ�
�A���L���f�X�͓�����386�}�V����3�{���炢�����������\�@���������A����Ȃ������̂Ō�p�`�b�v������܂�Ȃ���
���傤���Ȃ�����A�b�v���Ǝ��g���PDA��������ďo��������
�����ŃA�[�L�����Ȃ�������ꂽ
���̌��StrongARM��XScale�Ȃǂ�MIPS�̂悤�ɉ����̗��p�ł͂Ȃ��A��ʂ̃��C���i�b�v�Ƃ��ĐV�K�J�������킯�ł���
>MIPS��R3000, R4000, R5000�ƌ��XWS�����̂��̂ɂ�����Ǝ�����đg�ݍ������ɂ��Ă���
>WS�ƓƗ��ɂ�������Ȃ�ĂƂ�ł��Ȃ�
������m���Ă����B�R�A�̃}�C�N���A�[�L�e�N�`����WS�̗��p�B�[���ARISC WS�n�̑g�ݍ��݂͖w�ǂ����B
����Ǝs��Z�O�����g���A�����Ă���̂͊W���Ȃ��BMIPS�̏ꍇ�́AWS�Ŕ���Ȃ��đg�ݍ��݂ŏo�Ȃ�������Ȃ��āA
WS��������x����Ă��鎞�ɁAPC�Ƃ���������đg�ݍ��݂�Ɨ��ɂ��������������AMIPS�́B
�ŁAWS�Ƒg�ݍ��݂����ꂼ��ʂ�x86��ARM�ɂЂ�����Ԃ���Ă���̂Ŗ��Ȃ����Ď咣�B
>WS�ƓƗ��ɂ�������Ȃ�ĂƂ�ł��Ȃ�
������m���Ă����B�R�A�̃}�C�N���A�[�L�e�N�`����WS�̗��p�B�[���ARISC WS�n�̑g�ݍ��݂͖w�ǂ����B
����Ǝs��Z�O�����g���A�����Ă���̂͊W���Ȃ��BMIPS�̏ꍇ�́AWS�Ŕ���Ȃ��đg�ݍ��݂ŏo�Ȃ�������Ȃ��āA
WS��������x����Ă��鎞�ɁAPC�Ƃ���������đg�ݍ��݂�Ɨ��ɂ��������������AMIPS�́B
�ŁAWS�Ƒg�ݍ��݂����ꂼ��ʂ�x86��ARM�ɂЂ�����Ԃ���Ă���̂Ŗ��Ȃ����Ď咣�B
�Ƃ����킯�ŁA��x��Ŏ��s���ďo�Ȃ������Ƃ��A���s���ĂȂ����ǃn�C�G���h�ƃ��[�G���h��2���������p�^�[����
�ʂƂ��āA�n�C�G���h�s�ꂩ�珙�X�Ƀ��[�ɍ~���p�^�[���ł͈�ʂɂ��܂������Ȃ���FA����?
�ʂƂ��āA�n�C�G���h�s�ꂩ�珙�X�Ƀ��[�ɍ~���p�^�[���ł͈�ʂɂ��܂������Ȃ���FA����?
�������̂�x86��ARM�����Ȃ��ň�ʘ_�ƌ����Ă��Ȃ�
Cortex-M��Quark���S�ʔs�k���Ă����������Ă���
Cortex-M��Quark���S�ʔs�k���Ă����������Ă���
�ł��A���؍ޗ������̂Ƃ���Ȃ����A���ꂩ���x86vsARM����ł�����茟��������ł���B
���Ȃ݂ɁA������Cortex-M���o�����Ӑ}�͂���AQuark�͂�������s�k����Ǝv��w
���Ȃ݂ɁA������Cortex-M���o�����Ӑ}�͂���AQuark�͂�������s�k����Ǝv��w
��������R��������Ƃ���A
WS�̂�������CPU�͏���肪����܂肫���Ȃ���
ARM�͂悭�m���SH���炢�̂قǂقǂ̂��g���₷���������������(SH�̏オPA-RISC��������)
�������x���_�[�ׂ͖���n�C�G���h�肽����
���S�A�_���A���
WS�̂�������CPU�͏���肪����܂肫���Ȃ���
ARM�͂悭�m���SH���炢�̂قǂقǂ̂��g���₷���������������(SH�̏オPA-RISC��������)
�������x���_�[�ׂ͖���n�C�G���h�肽����
���S�A�_���A���
MIPS�͑g�ݍ��݂̒��ł����\�d���̐��i�Ɏg��ꂽ�����
�g�ѓd�b��g�уQ�[���@�ł͎g���Ȃ�����
ARM�͒ᐫ�\�����������[�R�X�g�A�����d�͂��������炱��
�g�ѓd�b�ł悭�g���
�X�}�z�Ƃ����o�חʂ����P�ʂŁA
������x���\���v������鐻�i�Ɏg����悤�ɂȂ��������
�g�ѓd�b��g�уQ�[���@�ł͎g���Ȃ�����
ARM�͒ᐫ�\�����������[�R�X�g�A�����d�͂��������炱��
�g�ѓd�b�ł悭�g���
�X�}�z�Ƃ����o�חʂ����P�ʂŁA
������x���\���v������鐻�i�Ɏg����悤�ɂȂ��������
���A����������PSP��MIPS��������
>���܂������̒m���Ă���@���MIPS���������Ă����ł�?
�N��6�����A3�N�����Ȃ�ݐ�20���A��i���Ɠr�㍑�ł�
���x�ɊJ�������邩���i���Ȃ炻�ꂱ�������炶�イ�ɃS���S�����Ă���
�����ɁA�N�����Ƃ�3�ʂƂ��̋K�͂��Ƃ͒m��Ȃ������ƌ��������̂�
�N��6�����A3�N�����Ȃ�ݐ�20���A��i���Ɠr�㍑�ł�
���x�ɊJ�������邩���i���Ȃ炻�ꂱ�������炶�イ�ɃS���S�����Ă���
�����ɁA�N�����Ƃ�3�ʂƂ��̋K�͂��Ƃ͒m��Ȃ������ƌ��������̂�
MIPS�͓��������Z�O�����g�ŏI�������p���������[���h�̐l��
���܂ł��b���Ăĕ����ʂ蕽�s�����낤�B
���܂ł��b���Ăĕ����ʂ蕽�s�����낤�B
ARM��ϑ�ISA�ƌ����l�������ł���̂���Ȃ�
�������s�ȊO�ɒ������Ƃ���͎v�����Ȃ���(���������Nova������)
�ϑԂƂ����Ȃ�x������̂ق�������ۂ�
MIPS�̓t���O���Ȃ��̂ő��{�����Z��I�[�o�[�t���[�̃n���h���ɋ�J���邵
SPARC�̃��W�X�^�E�B���h�E�͌��킸������
Alpha�͂Ƃ��ɕςȂƂ���͂Ȃ�����
POWER�͕���Ƃ��Ɠ������
�������s�ȊO�ɒ������Ƃ���͎v�����Ȃ���(���������Nova������)
�ϑԂƂ����Ȃ�x������̂ق�������ۂ�
MIPS�̓t���O���Ȃ��̂ő��{�����Z��I�[�o�[�t���[�̃n���h���ɋ�J���邵
SPARC�̃��W�X�^�E�B���h�E�͌��킸������
Alpha�͂Ƃ��ɕςȂƂ���͂Ȃ�����
POWER�͕���Ƃ��Ɠ������
>>239
227��ǂ�A237��ǂ�ł݂Ă��������B��������āA�ǂꂾ���L���g���悤�Ƃ�227�̕��y�̒�`�ɂ͓��Ă͂܂�Ȃ��̂ł��B
���̐l�ƌ��t���ʂ����A�܂Ƃ��ɋc�_���ł��Ȃ��͓̂��R�ł��B
227��ǂ�A237��ǂ�ł݂Ă��������B��������āA�ǂꂾ���L���g���悤�Ƃ�227�̕��y�̒�`�ɂ͓��Ă͂܂�Ȃ��̂ł��B
���̐l�ƌ��t���ʂ����A�܂Ƃ��ɋc�_���ł��Ȃ��͓̂��R�ł��B
ARM��SH�͔ėp���W�X�^�̏��Ȃ�RISC�Ƃ����̂��ϑԁB
C����̎g�p��O��Ƃ��Ă���g�ݍ��݂ł͎g���ɂ����B
�����̂ő�ʂɔ������̂ł���ΊJ����̌������邪�ł���Ύg�������Ȃ��B
���MIPS��68K�ƕ��Ԕ������v���Z�b�T�Ńv���O���}�ɂ͐l�C�������B������68K��荂���\�ȑg�ݍ���CPU���K�v�ɂȂ������Ɏg��ꂽ�B
�x���X���b�g�Ȃ�NOP�����Ƃ��������p�C�v���C���X�g�[�����������s�T�C�N�����ǂ߂镪�D�ꂽ�d�l�������B�X�[�p�[�p�C�v���C���Ƃ��X�[�p�[�X�J���Ƃ��o�Ă���܂ł́B
C����̎g�p��O��Ƃ��Ă���g�ݍ��݂ł͎g���ɂ����B
�����̂ő�ʂɔ������̂ł���ΊJ����̌������邪�ł���Ύg�������Ȃ��B
���MIPS��68K�ƕ��Ԕ������v���Z�b�T�Ńv���O���}�ɂ͐l�C�������B������68K��荂���\�ȑg�ݍ���CPU���K�v�ɂȂ������Ɏg��ꂽ�B
�x���X���b�g�Ȃ�NOP�����Ƃ��������p�C�v���C���X�g�[�����������s�T�C�N�����ǂ߂镪�D�ꂽ�d�l�������B�X�[�p�[�p�C�v���C���Ƃ��X�[�p�[�X�J���Ƃ��o�Ă���܂ł́B
254 �FSocket774�F2013/12/30(��) 15:15:26.31 ID:SjE+mmAK
>251
�b���Ԃ��������Ĉ�������
����������Alpha���č��͊��S�ɃI���R���Ȃ́H
Alpha���}���`�R�A������SIMD���������Ă������獡�ł��\���ɒʗp����H
���A���^�C���ł�Alpha��m��Ȃ�����ł�
�b���Ԃ��������Ĉ�������
����������Alpha���č��͊��S�ɃI���R���Ȃ́H
Alpha���}���`�R�A������SIMD���������Ă������獡�ł��\���ɒʗp����H
���A���^�C���ł�Alpha��m��Ȃ�����ł�
�A�Z���u�����菑�����Ă���悤�ȑ��x���v������镔���Œx������X���b�g��NOP��������Ė������Ă�Ǝv���B
�x������X���b�g�ɏ����ꂽ���߂͕��������ꍇ�����Ȃ��ꍇ���K�����s�����̂ōŌ�Ɏ��s���閽�߂�x������X���b�g�ɏ�����������������NOP�����闝�R�͉����Ȃ��B
���ꂷ�炵�Ȃ��悤�Ȃ��C�̂Ȃ��l���A�Z���u�����菑�����邭�炢�Ȃ�C�ŏ����čœK���ɔC�����ق����x������X���b�g���L���Ɏg���Č����̂悢�R�[�h���o�����Ȃ����B
�x������X���b�g�ɏ����ꂽ���߂͕��������ꍇ�����Ȃ��ꍇ���K�����s�����̂ōŌ�Ɏ��s���閽�߂�x������X���b�g�ɏ�����������������NOP�����闝�R�͉����Ȃ��B
���ꂷ�炵�Ȃ��悤�Ȃ��C�̂Ȃ��l���A�Z���u�����菑�����邭�炢�Ȃ�C�ŏ����čœK���ɔC�����ق����x������X���b�g���L���Ɏg���Č����̂悢�R�[�h���o�����Ȃ����B
>>254
�����Ƃ����t�c�[�̃v���Z�b�T
�o�ꎞ�͐�s�A�[�L�̌��_�𒍈Ӑ[����菜���āA�������C�����������Ă����̂łԂ�������ɑ�����������
�����Ƃ����t�c�[�̃v���Z�b�T
�o�ꎞ�͐�s�A�[�L�̌��_�𒍈Ӑ[����菜���āA�������C�����������Ă����̂łԂ�������ɑ�����������
>254
Alpha�͂��̓����̐����v���Z�X�ł��̍��N���b�N���������Ƃ��v�ŁA
���ꂪ�ł����̂͐E�l�|�̂��������ƕ������B�\�[�X��2ch
�N���b�N�Ɍ������悤�ɓ����Ƃ��Ă͏���ȃL���b�V����C���������o���h����
�^�����Ă�������A�x���`�}�[�N�Ԓ��ł͂Ȃ������Ƒ�������
����������Ă�v���Z�b�T�J���̂���ShenWei��
"inspired by DEC Alpha" �ƌ����Ă���ȁB
FeiTeng ��SPARC�ALoongson�iGodson�j��MIPS�̉e��������
Alpha�͂��̓����̐����v���Z�X�ł��̍��N���b�N���������Ƃ��v�ŁA
���ꂪ�ł����̂͐E�l�|�̂��������ƕ������B�\�[�X��2ch
�N���b�N�Ɍ������悤�ɓ����Ƃ��Ă͏���ȃL���b�V����C���������o���h����
�^�����Ă�������A�x���`�}�[�N�Ԓ��ł͂Ȃ������Ƒ�������
����������Ă�v���Z�b�T�J���̂���ShenWei��
"inspired by DEC Alpha" �ƌ����Ă���ȁB
FeiTeng ��SPARC�ALoongson�iGodson�j��MIPS�̉e��������
68k�́A�̂��킢���Ǝv���Ă����A�C�h���̎ʐ^�����݂�ƃ_�T��������̂Ɠ����C������
x86�̓Ɠ��̃^�C�g�Ȑv�͍��ł��ʗp���邪
x86�̓Ɠ��̃^�C�g�Ȑv�͍��ł��ʗp���邪
�������AAMD64�̌v�҂�
Alpha�J���`�[���ɂ����l���ւ���Ă��͂�
Alpha�J���`�[���ɂ����l���ւ���Ă��͂�
����̂���ڂ����l�v�Z�v���O��������������
Alpha�͓�����Intel��5�{���炢�����ċ������o��������Ȃ�
gcc����S�R�����Ȃ��ď����̃R���p�C���g��Ȃ��Ƒʖڂ���������
Alpha�͓�����Intel��5�{���炢�����ċ������o��������Ȃ�
gcc����S�R�����Ȃ��ď����̃R���p�C���g��Ȃ��Ƒʖڂ���������
Wikipedia���
http://ja.wikipedia.org/wiki/X64
AMD64���߃Z�b�g�ɂ́A
�C���e����IA-32�A�[�L�e�N�`���Ɏw�E�����A���o�����X�œ��قȕ������A
���ꂢ�Ŏg���₷�����̂ɂ���Ƃ����ژ_�����������B
�܂��A�����ɐ�s���Ă��� 64�r�b�gRISC���Ɏ�����
�A�[�L�e�N�`���ɂ��悤�ƍl���Đv���ꂽ�B
DEC Alpha �̐v�҂̈�l �_�[�N�E���C���[ ��
AMD64�d�l�̍쐬�Ɋւ��A
�ނ��͂��߂Ƃ���DEC�o�g�҂̌o�������̃v���W�F�N�g�Ɋ������ꂽ�B
http://ja.wikipedia.org/wiki/X64
AMD64���߃Z�b�g�ɂ́A
�C���e����IA-32�A�[�L�e�N�`���Ɏw�E�����A���o�����X�œ��قȕ������A
���ꂢ�Ŏg���₷�����̂ɂ���Ƃ����ژ_�����������B
�܂��A�����ɐ�s���Ă��� 64�r�b�gRISC���Ɏ�����
�A�[�L�e�N�`���ɂ��悤�ƍl���Đv���ꂽ�B
DEC Alpha �̐v�҂̈�l �_�[�N�E���C���[ ��
AMD64�d�l�̍쐬�Ɋւ��A
�ނ��͂��߂Ƃ���DEC�o�g�҂̌o�������̃v���W�F�N�g�Ɋ������ꂽ�B
>>255
���O�g�ݍ��݂�������Ɩ�������
���O�g�ݍ��݂�������Ɩ�������
>>262
���̐��ʂ���ʂ̃v���t�B�N�X�ł���B
���̐��ʂ���ʂ̃v���t�B�N�X�ł���B
���͑g�ݍ��݂�����Ă��܂�������������Ă��܂����A���x�̒Ⴂ�g�ݍ��݂͂�������ƂȂ��ł��B
����MIPS�Ȃ�ă��W�X�^��8+2�����Ȃ��̂ł���͎��̂����Ȃ肳��ł�
����x86��VC�̃R���p�C���ŃC�C�����B
>>228
�n�C�G���h�̒�`���킩��Ȃ��ȁBXeon E7�͑��̃A�[�L�e�N�`����
�����������Ȃ��قǔ���Ă邾�낤���H�@E5�Ȃ爳�|�I�Ȑ�����
E5������悤�Ȓ�`�ł����̂��A�n�C�G���h����
�n�C�G���h�̒�`���킩��Ȃ��ȁBXeon E7�͑��̃A�[�L�e�N�`����
�����������Ȃ��قǔ���Ă邾�낤���H�@E5�Ȃ爳�|�I�Ȑ�����
E5������悤�Ȓ�`�ł����̂��A�n�C�G���h����
1������̃��C�����e�B��MIPS�̕�����������
MIPS��ARM��荂���\�����p�r�������낤��
http://eetimes.jp/ee/articles/1205/16/news007.html
ARM��2011�N�ɁA79���̃`�b�v�̃��C�����e�B����ɂ����B
2011�N�̃`�b�v1������̃��C�����e�B�͕���4.6�ăZ���g�ŁA
ARM�̃��C�����e�B������2007�N����2011�N�ɂ�����
�N����19���̃y�[�X�ő������Ă���B
����ɑ��A�����Ԃ̔����̋ƊE�S�̂̔��㍂�̑�������
4���ɂƂǂ܂��Ă���B
�@����AMIPS Technologies��2011�N�Ƀ��C�����e�B�������`�b�v��
6��5600���ŁA�`�b�v1������̃��C�����e�B��7�ăZ���g���Ƃ����B
CPU�R�A�s��ł́ASynopsys��CPU�R�A�uARC�v��10���̃V�F�A���l�����Ă���BMIPS�̓V�F�A6���ŁASynopsys�Ɏ����s���3�ʂɈʒu����B
MIPS��ARM��荂���\�����p�r�������낤��
http://eetimes.jp/ee/articles/1205/16/news007.html
ARM��2011�N�ɁA79���̃`�b�v�̃��C�����e�B����ɂ����B
2011�N�̃`�b�v1������̃��C�����e�B�͕���4.6�ăZ���g�ŁA
ARM�̃��C�����e�B������2007�N����2011�N�ɂ�����
�N����19���̃y�[�X�ő������Ă���B
����ɑ��A�����Ԃ̔����̋ƊE�S�̂̔��㍂�̑�������
4���ɂƂǂ܂��Ă���B
�@����AMIPS Technologies��2011�N�Ƀ��C�����e�B�������`�b�v��
6��5600���ŁA�`�b�v1������̃��C�����e�B��7�ăZ���g���Ƃ����B
CPU�R�A�s��ł́ASynopsys��CPU�R�A�uARC�v��10���̃V�F�A���l�����Ă���BMIPS�̓V�F�A6���ŁASynopsys�Ɏ����s���3�ʂɈʒu����B
�ŁA��������������o�Ă��Ă�
Broadcom��ARM�x�[�X��64�r�b�gSoC�����ցAMIPS����V�t�g
http://eetimes.jp/ee/articles/1310/22/news018.html
MIPS���̂Ă��A�Ƃ����킯�ł͂Ȃ��v Broadcom�A
ARM�x�[�X��64�r�b�gSoC�����
http://eetimes.jp/ee/articles/1312/06/news059.html
Broadcom��ARM�x�[�X��64�r�b�gSoC�����ցAMIPS����V�t�g
http://eetimes.jp/ee/articles/1310/22/news018.html
MIPS���̂Ă��A�Ƃ����킯�ł͂Ȃ��v Broadcom�A
ARM�x�[�X��64�r�b�gSoC�����
http://eetimes.jp/ee/articles/1312/06/news059.html
>>269��
��1������̃��C�����e�B��MIPS�̕�����������
��MIPS��ARM��荂���\�����p�r�������낤��
MIPS�͍����\�����p�r����������
1�����胍�C�����e�B��ARM��荂���낤��
�Ƃ����Ӗ��ŏ���������
��1������̃��C�����e�B��MIPS�̕�����������
��MIPS��ARM��荂���\�����p�r�������낤��
MIPS�͍����\�����p�r����������
1�����胍�C�����e�B��ARM��荂���낤��
�Ƃ����Ӗ��ŏ���������
�uMIPS���̂Ă��A�Ƃ����킯�ł͂Ȃ��v
�P�ނ���Ƃ��́A�݂�Ȃ���������ȁB
�P�ނ���Ƃ��́A�݂�Ȃ���������ȁB
273 �F,,�E�L�́M�E,,�j��-�������F2013/12/30(��) 17:32:05.34 ID:sRzLDleo
���܂ǂ��_�����W�X�^���Ȃ�Đ��\�ʂł���������肶��Ȃ��̂����ǂ�
�������瑝�����Ńf�����b�g��������
�������瑝�����Ńf�����b�g��������
>>251
ARM�́A�v���Z�b�T�Ƃ��Ăׂ͂ɕϑ�ISA�ł͂Ȃ����ǁA
RISC�v���Z�b�T�Ƃ��Ă͕ϑ�ISA����
RISC�v���Z�b�T�Ƃ��Ă͂��Ȃ肨�����ȕ���������
ARM�́A�v���Z�b�T�Ƃ��Ăׂ͂ɕϑ�ISA�ł͂Ȃ����ǁA
RISC�v���Z�b�T�Ƃ��Ă͕ϑ�ISA����
RISC�v���Z�b�T�Ƃ��Ă͂��Ȃ肨�����ȕ���������
�P�ނ��Ȃ��Ƃ����P�ނ���Ƃ����A�����悤�ɓP�ނ��Ȃ��Ƃ���
�i�o����O�́u����Ȃ��̂̓N�Y�v���Ă̂����
�w�l�p�^�M�҂��č��ł�����ˁB
MIPS�Ȃ�ă`�b�v������g����3�`4GHz�ɒ���t���Ă��鍡�A
���₷�������Ő��\�o��A�[�L�e�N�`������Ȃ��̂ɁB
MIPS�Ȃ�ă`�b�v������g����3�`4GHz�ɒ���t���Ă��鍡�A
���₷�������Ő��\�o��A�[�L�e�N�`������Ȃ��̂ɁB
����512bit�~32���W�X�^�Ńu�C�u�C���킹������
AMD64���ėp���W�X�^16�{�����Ȃ���ȁB
32�r�b�gARM������ŕϑԂ��Ă̂͂悭�킩���B
32�r�b�gARM������ŕϑԂ��Ă̂͂悭�킩���B
x64���������ϑԂȂ����ł�����IA64��������64bitCPU�B
281 �F,,�E�L�́M�E,,�j��-�������F2013/12/30(��) 18:54:53.20 ID:sRzLDleo
AVX2�́A����128bit�̎����̂��Ƃ��l�����Ă����128�r�b�g�E����128�r�b�g��
�܂������V�t�g�Ƃ��V���b�t�����g���ɂ����Ȃ��Ă�̂��炢�ł��ˁB
512�r�b�g�ɍs���O��AVX2.1��p�ӂ��ė~�����Ƃ����̂������ȂƂ���
AVX-512�́A1�o�C�g�~64��2�o�C�g�~32���o���Ȃ�����l�I�ɂ�
�u���Ă��ꂽ��������܂��B
�iOpenCL�̃R�[�h�����̂܂ܓ������̂ɂ͂�����������Ȃ����ǂˁj
�܂������V�t�g�Ƃ��V���b�t�����g���ɂ����Ȃ��Ă�̂��炢�ł��ˁB
512�r�b�g�ɍs���O��AVX2.1��p�ӂ��ė~�����Ƃ����̂������ȂƂ���
AVX-512�́A1�o�C�g�~64��2�o�C�g�~32���o���Ȃ�����l�I�ɂ�
�u���Ă��ꂽ��������܂��B
�iOpenCL�̃R�[�h�����̂܂ܓ������̂ɂ͂�����������Ȃ����ǂˁj
282 �F,,�E�L�́M�E,,�j��-�������F2013/12/30(��) 19:01:52.34 ID:sRzLDleo
>>279
x86�̓��W�X�^-�������Ԃ̉��Z���o�����
base + index*scale + displacement
�݂����ȉ��Z��g�ݍ��߂邩��RISC���y���Ƀ��W�X�^���v��Ȃ���
�Y��ł��邱�ƂƎ��p�I�ł��邱�Ƃ͑S���̕ʖ��Ȃ̂��B
Cortex-A9�ȍ~��OoO�{����\��������s���A�v���f�B�P�[�g���g�����ق���
�������Đ��\��������X��������ꂽ�B
�����32�r�b�g�Œ蒷�̂����A4�r�b�g�Ɏ����Ӗ��������Ȃ����悤�Ȃ��́B
x86�̓��W�X�^-�������Ԃ̉��Z���o�����
base + index*scale + displacement
�݂����ȉ��Z��g�ݍ��߂邩��RISC���y���Ƀ��W�X�^���v��Ȃ���
�Y��ł��邱�ƂƎ��p�I�ł��邱�Ƃ͑S���̕ʖ��Ȃ̂��B
Cortex-A9�ȍ~��OoO�{����\��������s���A�v���f�B�P�[�g���g�����ق���
�������Đ��\��������X��������ꂽ�B
�����32�r�b�g�Œ蒷�̂����A4�r�b�g�Ɏ����Ӗ��������Ȃ����悤�Ȃ��́B
�F�A�e���
���ŏ��̋L���̌㓡�̔����Ŋ��o�Ȃ̂�
����ŗ����ł��Ȃ��l������̂�
������ŁA���[�h/�X�g�A�A�[�L�e�N�`���̃n���h�����O�����Ȃ���Ȃ�Ȃ��B
���ŏ��̋L���̌㓡�̔����Ŋ��o�Ȃ̂�
����ŗ����ł��Ȃ��l������̂�
������ŁA���[�h/�X�g�A�A�[�L�e�N�`���̃n���h�����O�����Ȃ���Ȃ�Ȃ��B
op [base+index*n+ofs32 ],imm32
����Ɠ������Ƃ�RISC�ł���7���߁A���[�N���W�X�^2���K�v�B
����������Ȃ̂��������g��Ȃ����炠�܂�Ӗ��͂Ȃ��B
����Ɠ������Ƃ�RISC�ł���7���߁A���[�N���W�X�^2���K�v�B
����������Ȃ̂��������g��Ȃ����炠�܂�Ӗ��͂Ȃ��B
286 �F,,�E�L�́M�E,,�j��-�������F2013/12/30(��) 20:15:25.73 ID:sRzLDleo
load + ops + store ��x86�ł��x������g���Ȃ��ĕ��j�ł���
MMX�ȍ~�̒lj����߂��������ԉ��Z�͂قƂ��load+ops���������B
MMX�ȍ~�̒lj����߂��������ԉ��Z�͂قƂ��load+ops���������B
read-modify-write�Ŋ��荞�֎~�ɂ��Ȃ��Ă����Ƃ��������₩�ȃ����b�g�͂��邪
�A�h���b�V���O�̒��𐫂Ƃ��̂��߂ɗp�ӂ���̂͂������Ӗ�����
�A�h���b�V���O�̒��𐫂Ƃ��̂��߂ɗp�ӂ���̂͂������Ӗ�����
288 �F,,�E�L�́M�E,,�j��-�������F2013/12/31(��) 09:54:32.49 ID:6TycY0I/
�uBroadcom��ARMv8�̗p�ő叟���I�v�Ƃ��ߑ��̖������Ƃ����y������킯�ł���
�l�b�g���[�N�R���g���[���Ȃ�Intel����10�N�ȏ�O��ARM�̗p���Ă�����
�iXScale�x�[�X�ˁj
��ŁA�T�[�o�Ő�s����MIPS���ǂꂾ���e���͂������Ă����l����ƁE�E�E�ˁB
�l�b�g���[�N�R���g���[���Ȃ�Intel����10�N�ȏ�O��ARM�̗p���Ă�����
�iXScale�x�[�X�ˁj
��ŁA�T�[�o�Ő�s����MIPS���ǂꂾ���e���͂������Ă����l����ƁE�E�E�ˁB
�l�b�g���[�N�R���g���[���Ƃ��O��SATA�R���g���[����SAS�R���g���[���Ȃ�
�A�[�L�I�Ɏ嗬�Ȃ̂�ARM�Ȃ̂��ˁH����Ƃ�MIPS�H
�A�[�L�I�Ɏ嗬�Ȃ̂�ARM�Ȃ̂��ˁH����Ƃ�MIPS�H
>>289
�l�b�g���[�N�n���Ă��s���L�����ȁB
�ƒ�p�̃u���[�^�[�ӂ肾�ƍŋ߂�ARM����ԑ����ȁB��̑O��MIPS�����\�������Ǝv�������ǁB
10���O��̋Ɩ����_�������ƁANEC��Freescale��Power�AYAMAHA��
�F�X�g�����ǁAMIPS�����ACISCO�͂ǂ��������H1812j�ӂ��NEC�Ɠ�����QICC�g���Ă��Ǝv��������A
890�V���[�Y�������Ȃ�Power�n���ȁB
�X�C�b�`������n��ARM/MIPS/Power�ƗL�邯�ǁA�ŋ߂̂��ƁAARM or Power���ۂ��C������B
RAID�R���g���[���[�͂Ԃ����Ⴏ�A�P�̂Ŕ����Ă镨�͂قƂ��LSI�Ɛ��ԁB
��ŁA������Power�������͂��B
Marvell��Intel���甃����Xscale�g���Ă�͂�������AARM���ȁB
���̑����ЊJ���́A�������B���ǁAARM��Power����ŁAMIPS�͂����ˁ[��Ȃ����ȁB
�l�b�g���[�N�n���Ă��s���L�����ȁB
�ƒ�p�̃u���[�^�[�ӂ肾�ƍŋ߂�ARM����ԑ����ȁB��̑O��MIPS�����\�������Ǝv�������ǁB
10���O��̋Ɩ����_�������ƁANEC��Freescale��Power�AYAMAHA��
�F�X�g�����ǁAMIPS�����ACISCO�͂ǂ��������H1812j�ӂ��NEC�Ɠ�����QICC�g���Ă��Ǝv��������A
890�V���[�Y�������Ȃ�Power�n���ȁB
�X�C�b�`������n��ARM/MIPS/Power�ƗL�邯�ǁA�ŋ߂̂��ƁAARM or Power���ۂ��C������B
RAID�R���g���[���[�͂Ԃ����Ⴏ�A�P�̂Ŕ����Ă镨�͂قƂ��LSI�Ɛ��ԁB
��ŁA������Power�������͂��B
Marvell��Intel���甃����Xscale�g���Ă�͂�������AARM���ȁB
���̑����ЊJ���́A�������B���ǁAARM��Power����ŁAMIPS�͂����ˁ[��Ȃ����ȁB
291 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 11:29:52.65 ID:hlV9Oqd6
�u�����h�I�ȈӖ��ł�XScale�̌n���͓r�₦�Ă�B
WileressMMX������ARMADA�V���[�Y�͂Ƃ������Ƃ���
Cortex-A�V���[�Y�����̂܂g���Ă�PXA9xx, 10xx�V���[�Y��
XScale�̌�p�ƌĂ�ł������́E�E�E
WileressMMX������ARMADA�V���[�Y�͂Ƃ������Ƃ���
Cortex-A�V���[�Y�����̂܂g���Ă�PXA9xx, 10xx�V���[�Y��
XScale�̌�p�ƌĂ�ł������́E�E�E
>>290
�ƒ�p���[�^�[�n���āACPU��IP�̒l�i����߂銄���͂��Ȃ菬�������A
CPU��ʌn���̂ɑւ���ƃ\�t�g�E�F�A�I�ɑ�ςŊJ���������̂ŁA
����MIPS���g���đ����[�J�[�͈�������MIPS�A����ARM���g���đ����[�J�[�͂Ђ��Â�ARM�Ƃ��A
�ނ����g���Ă�CPU�����̂܂g���Ă��ۂ���
�ƒ�p���[�^�[�n���āACPU��IP�̒l�i����߂銄���͂��Ȃ菬�������A
CPU��ʌn���̂ɑւ���ƃ\�t�g�E�F�A�I�ɑ�ςŊJ���������̂ŁA
����MIPS���g���đ����[�J�[�͈�������MIPS�A����ARM���g���đ����[�J�[�͂Ђ��Â�ARM�Ƃ��A
�ނ����g���Ă�CPU�����̂܂g���Ă��ۂ���
��wifi���[�^�ɓ����Ă�realtek��SoC��MIPS(Lexra)����
�ǂ�����������������B
���̋@��XP�c
�y�����^�z�@������^���̋@acure���t���[�Y�@���@WindowsXP���C���X�g�[������Ă邱�Ƃ��o����
ttp://hayabusa3.2ch.net/test/read.cgi/news/1388543401/
�y�����^�z�@������^���̋@acure���t���[�Y�@���@WindowsXP���C���X�g�[������Ă邱�Ƃ��o����
ttp://hayabusa3.2ch.net/test/read.cgi/news/1388543401/
���W�ɂ�ATM�ɂ������@�ɂ��S��Windows�����ׂɂ��������Ȃ������
�L�����ĂȂ�����悭�킩��A�������XP�ł����̂��Ƃ����^��͂킭��
WindowsXP Embedded�͌��\�L���g���Ă��B���݉���
�����^�u���b�g�Ȃɂ������Ă���̂�����B
���������g�ݍ��n�[���̓E�H�b�`�h�b�O�^�C�}�[��������
�\�t�g�E�F�A�������I�Ƀ��W�X�^���N���A���Ȃ��Ǝ����I��
�ċN����������V�X�e���ɂȂ��Ă��B
�����^�u���b�g�Ȃɂ������Ă���̂�����B
���������g�ݍ��n�[���̓E�H�b�`�h�b�O�^�C�}�[��������
�\�t�g�E�F�A�������I�Ƀ��W�X�^���N���A���Ȃ��Ǝ����I��
�ċN����������V�X�e���ɂȂ��Ă��B
���Ȃ��������A�[�P�[�h�Q�[���@��win7 Embedded�������ȁB
�m���ɂ�����Embedded�Ƃ͌����A���XXP?�Ƃ͎v���B
�m���ɂ�����Embedded�Ƃ͌����A���XXP?�Ƃ͎v���B
�Q�[���̏ꍇ�ADirectX�̃o�[�W������GPU�h���C�o�������邩��A
XP����ʖڂ�������ł��傤
WindowsXP Embedded��2019�N�܂ʼn����T�|�[�g������邵�A
�����ɐVOS�����K�v������
XP����ʖڂ�������ł��傤
WindowsXP Embedded��2019�N�܂ʼn����T�|�[�g������邵�A
�����ɐVOS�����K�v������
�u������v���}�W�Ȃ�5�N���������Ȃ�OS����܂����Ȃ����H
����ȂɂЂ�ς�ɓ���ւ�������̂Ƃ��v���Ȃ���
����ȂɂЂ�ς�ɓ���ւ�������̂Ƃ��v���Ȃ���
������Ƃ����Ă����N�O����ғ����Ă�͂�����
��̓I�ɂ��Ƃ͎v���o���Ȃ��������ԑO�ɂ��ꌩ�čŋ߂̎��̋@�͌��\�������ȂƎv�����L��������
��̓I�ɂ��Ƃ͎v���o���Ȃ��������ԑO�ɂ��ꌩ�čŋ߂̎��̋@�͌��\�������ȂƎv�����L��������
���Ȃ��Ƃ��A�����̈����̎��̋@��Windows�ڂ��Ăł������t���ςޕK�v�͂Ȃ�
����Ȏ��̋@�Ɉꕔ�̓���p�r�Ɏg���邾���ŁA
�R�X�g�E�����e�i���X���̂��߂ɊX�̈����̎��̋@�Ɏg���邱�Ƃ͖���
����Ȏ��̋@�Ɉꕔ�̓���p�r�Ɏg���邾���ŁA
�R�X�g�E�����e�i���X���̂��߂ɊX�̈����̎��̋@�Ɏg���邱�Ƃ͖���
��p�@�o��܂Ŏ�����@������I
���̎�����^���̋@�ăX�^���h�A�����Ȃ̂�H
307 �F,,�E�L�́M�E,,�j��-�������F2014/01/01(��) 23:33:10.03 ID:hlV9Oqd6
Atom 330 + XP Embedded������Ȃ�A������u���̐l�v����Ă����Ƃ�����B
���ʐ��Y�V�X�e���̐���ɂ͋�����ˁB�R�X�g�I�Ȗ��ŁB
���ʐ��Y�V�X�e���̐���ɂ͋�����ˁB�R�X�g�I�Ȗ��ŁB
309 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 00:02:22.03 ID:hlV9Oqd6
�R�J�R�[���̂�Ȃ�WiMAX�Ƃ�ATM�ԂɑΉ����Ă�
���̎����̔��@��OS�͑f��XP���ۂ�
Embedded�Ȃ�N����ʂ�Xindows XP Embedded���ĕ\������邩��
http://alfalfalfa.com/archives/7024663.html
http://2.bp.blogspot.com/_oRNbPfIiGnE/TApzfy0ausI/AAAAAAAAA18/BouiHUD7mo0/s400/windows+xp+embedded.jpg
Embedded�Ȃ�N����ʂ�Xindows XP Embedded���ĕ\������邩��
http://alfalfalfa.com/archives/7024663.html
http://2.bp.blogspot.com/_oRNbPfIiGnE/TApzfy0ausI/AAAAAAAAA18/BouiHUD7mo0/s400/windows+xp+embedded.jpg
{kind=link}
��p�d����p�ӂł��鏊�Ȃ�Ȃɓ������Ă�����܂����Ȃ����
HDD�ς܂Ȃ��Ⴂ���Ȃ�d�����Ă����邱�ƂȂ����ȁB
GUI��l�b�g����Windows�̊J���R�X�g�����|�I�Ɉ�������ȁB
GUI��l�b�g����Windows�̊J���R�X�g�����|�I�Ɉ�������ȁB
�܂Ƃ��ɍ�荞�����Ƃ���ƃR�X�g���ˏオ��܂�����
����v���O�����A�ڑ��悪����ADNS�g�킸���g�p�|�[�g�Ȃ���Ȃ����
315 �FSocket774�F2014/01/02(��) 08:06:57.78 ID:WAxpZYLv
Vista���]��������Linux�̎��オ���邩�Ǝv�������ǁA
�W���J���Ă݂��XP���g�������đ҂�������7�Ɉڍs���A
�g�ݍ��݂܂�Windows�������Ă�Ƃ́c
�W���J���Ă݂��XP���g�������đ҂�������7�Ɉڍs���A
�g�ݍ��݂܂�Windows�������Ă�Ƃ́c
GUI�J����Qt�͂ǂ��Ȃ́H
������OS��œ��삷�邯��
���܂��畷���Ȃ� GUI�J���t���[�����[�N�uQt�v���p
�`�g�ݍ��@��J���őI��闝�R�`
http://monoist.atmarkit.co.jp/mn/articles/1308/21/news002.html
������OS��œ��삷�邯��
���܂��畷���Ȃ� GUI�J���t���[�����[�N�uQt�v���p
�`�g�ݍ��@��J���őI��闝�R�`
http://monoist.atmarkit.co.jp/mn/articles/1308/21/news002.html
317 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 10:20:56.41 ID:pSce6GE7
Qt�ӊO�Ǝg���Ă���
http://ja.wikipedia.org/wiki/Qt#Qt.E3.82.92.E4.BD.BF.E7.94.A8.E3.81.97.E3.81.A6.E3.81.84.E3.82.8B.E4.B8.BB.E3.81.AA.E3.82.BD.E3.83.95.E3.83.88.E3.82.A6.E3.82.A7.E3.82.A2
Windows���g���Ă�̂͋Z�p�҂��m�ۂ��₷��������Ă̂���Ԃł����Ǝv���B
PC�A�[�L�e�N�`�������̂܂ܗ��p���Ă��镪�ێ�����₷���Ƃ���x86�G�R�V�X�e��
�Ȃ�ł͂̃����b�g���B
�N�Ԑ��S���䔄���@��ɑg�ݍ��ޏꍇ�͂܂��ʂ̗������������ǁB
http://ja.wikipedia.org/wiki/Qt#Qt.E3.82.92.E4.BD.BF.E7.94.A8.E3.81.97.E3.81.A6.E3.81.84.E3.82.8B.E4.B8.BB.E3.81.AA.E3.82.BD.E3.83.95.E3.83.88.E3.82.A6.E3.82.A7.E3.82.A2
Windows���g���Ă�̂͋Z�p�҂��m�ۂ��₷��������Ă̂���Ԃł����Ǝv���B
PC�A�[�L�e�N�`�������̂܂ܗ��p���Ă��镪�ێ�����₷���Ƃ���x86�G�R�V�X�e��
�Ȃ�ł͂̃����b�g���B
�N�Ԑ��S���䔄���@��ɑg�ݍ��ޏꍇ�͂܂��ʂ̗������������ǁB
GUI OS�́A�{�����e�B�A�x�[�X�̃t���[�̂͂Ȃ������s��Ȃ�
����ς�A������ĉ�Ђ���w���ē����l�����Ȃ��ƁA
���ꂼ��l����肽�����Ƃ�������Ă��A
�������肽���Ȃ��������܂Ƃ܂�Ȃ��낤��
����ς�A������ĉ�Ђ���w���ē����l�����Ȃ��ƁA
���ꂼ��l����肽�����Ƃ�������Ă��A
�������肽���Ȃ��������܂Ƃ܂�Ȃ��낤��
�}�j�A�Ȃ�Ƃ������A�f�l�Ɏg�킹�悤�Ƃ�����A���ꂩ����������܂Ƃ߂ĂȂ��Ƌꂵ�����낤��
��������Ă��o���オ��̂�Win8
���Ⴀ�A�����܂���������ĂȂ�OS�������Ă��炨����
322 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 17:56:04.77 ID:pSce6GE7
Windows8�̐^�����Ȃ��Ă������̂ɐ^�����č�����̂�Ubuntu��Unity�f�X�N�g�b�v
�ŏ��[���̊J�������番���炸�������L��������>Unity
����Ȓ����I����Ȃ�UI�N���v��������Ă���
Windows8�̐^���Ȃ̂��HWin8���͑����O����Ȃ��H
����Ȓ����I����Ȃ�UI�N���v��������Ă���
Windows8�̐^���Ȃ̂��HWin8���͑����O����Ȃ��H
324 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 19:34:28.18 ID:pSce6GE7
���m�Ɍ�����MS-Office 2010����̗p���ꂽ�X�^�[�g�X�N���[�����ȁB
325 �F,,�E�L�́M�E,,�j��-�������F2014/01/02(��) 19:35:06.05 ID:pSce6GE7
���̓ƑP�I��UI�̂����Ń��[�U�[������N�����Ă�̂�Windows 8�Ɠ���
���҂Ɉ��ʒc�q�̘V�Q�Ԃ�
327 �FSocket774�F2014/01/02(��) 22:08:00.50 ID:Vh6uhXx3
�Ȃ��ǂ̉�Ђ��������s���̂�
���܂łƕς�����Ƃ��������ʼn����������
���邽�߂ɕύX�̂��߂̕ύX������Ă��܂�����B
���[�U��UI�ɓ������Ă�
�ύX�����Ƃ�������������������Ă킩���Ăĕς��Ă��ł�����
�ύX�����Ƃ�������������������Ă킩���Ăĕς��Ă��ł�����
Windows8�́A�]���ʂ�L�[�{�[�h�ƃ}�E�X�ő��삷��f�X�N�g�b�v���[�U�[�ɂ͏]���Ɠ������̂���������ŁA
�^�b�`�p�l������UI�����悩�����̂ɁA
�]���^���[�U�[�ɂ��ւ��UI�����������̂���������
OS�́AWindows7���y�������ɂȂ����̂ɁAUI�̂����ŕ]���K�^����
�^�b�`�p�l������UI�����悩�����̂ɁA
�]���^���[�U�[�ɂ��ւ��UI�����������̂���������
OS�́AWindows7���y�������ɂȂ����̂ɁAUI�̂����ŕ]���K�^����
332 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 00:17:13.10 ID:R5ACY5z8
����͂ǂ��l���Ă��@�\�I�łȂ��B
�f�X�N�g�b�v���B���Ă��܂����߂ɁA�I�����C���w���v���m�F���Ȃ��瑀��A
�݂����Ȃ̂��ł��Ȃ��Ȃ��Ă��܂����B
�f�X�N�g�b�v���B���Ă��܂����߂ɁA�I�����C���w���v���m�F���Ȃ��瑀��A
�݂����Ȃ̂��ł��Ȃ��Ȃ��Ă��܂����B
UI�ς���̂͂������ǂ��낢���������
�f����Android�̃M�~�b�N�p�N��悩�����̂�
�f����Android�̃M�~�b�N�p�N��悩�����̂�
>>332
�f�X�N�g�b�v��ʂƃ��g����ʂ̕����͈ꉞ�ł��邼
�f�X�N�g�b�v��ʂƃ��g����ʂ̕����͈ꉞ�ł��邼
OSX��iOS�����N�U��������MS�̂���Ă邱�Ƃ͊ԈႢ����Ȃ�
����Apple���S�Ăɂ����Đ��`�ƌ����邩�ǂ����͒m��Ȃ���
����Apple���S�Ăɂ����Đ��`�ƌ����邩�ǂ����͒m��Ȃ���
�����`���[����}���`�^�X�N�Ǘ��̑��삪�ǂ��Ȃ�
���g���A�v���͊�{�I�ɑS��ʕ\���Ȃ̂ɂ��̉�ʓ���G�点�邱�ƂɂȂ�
�}���`�^�X�N�Ǘ��̐��������Ƃ�ĂȂ�
�Ⴆ�f�X�N�g�b�v��ʂŃX�i�b�v�r���[�g���ă��g���A�v���𒆎~���邱�Ƃ͂ł��邯��
���g����ʂŃX�i�b�v�r���[�g���ăf�X�N�g�b�v�A�v���𒆎~�ł��Ȃ�
�ł��Ȃ������Ȃ�܂��������ǃf�X�N�g�b�v��ʂ܂邲�ƒ��~�݂����ȑ���ɂȂ�
����Ă��X�i�b�v�r���[����ꎞ�I�ɏ����邾���ʼn����N���Ȃ�
�����o�O�̗̈�
���g���A�v���͊�{�I�ɑS��ʕ\���Ȃ̂ɂ��̉�ʓ���G�点�邱�ƂɂȂ�
�}���`�^�X�N�Ǘ��̐��������Ƃ�ĂȂ�
�Ⴆ�f�X�N�g�b�v��ʂŃX�i�b�v�r���[�g���ă��g���A�v���𒆎~���邱�Ƃ͂ł��邯��
���g����ʂŃX�i�b�v�r���[�g���ăf�X�N�g�b�v�A�v���𒆎~�ł��Ȃ�
�ł��Ȃ������Ȃ�܂��������ǃf�X�N�g�b�v��ʂ܂邲�ƒ��~�݂����ȑ���ɂȂ�
����Ă��X�i�b�v�r���[����ꎞ�I�ɏ����邾���ʼn����N���Ȃ�
�����o�O�̗̈�
Lindows! Lindows!
339 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 06:20:01.57 ID:OosgDtQq
>>334
��肽���̂́u�����v����Ȃ��ăf�X�N�g�b�v��ɃA�v�����E�B���h�E�\���Ȃ��
8.1��������X�^�[�g�{�^�����R���W���i�C�����Y����B
�܂��R�}���h���s�ƃV���b�g�_�E�������ł��ł��邩��g���Ȃ��͖������B
Vista��7�̃X�^�[�g���j���[���ăT�C�Y���Œ�ł���ȏ�f�X�N�g�b�v��
�����B���Ȃ�����D�ꂽ�f�U�C���Ȃ�ˁB
�Ȃ��D�ꂽ���̂܂Ŕے肷��̂��B
>>335
Marvericks�̂ǂ���iOS���C�N�Ȃ�H
OSX�͂����Ӗ��ł��ێ�I�����B
��肽���̂́u�����v����Ȃ��ăf�X�N�g�b�v��ɃA�v�����E�B���h�E�\���Ȃ��
8.1��������X�^�[�g�{�^�����R���W���i�C�����Y����B
�܂��R�}���h���s�ƃV���b�g�_�E�������ł��ł��邩��g���Ȃ��͖������B
Vista��7�̃X�^�[�g���j���[���ăT�C�Y���Œ�ł���ȏ�f�X�N�g�b�v��
�����B���Ȃ�����D�ꂽ�f�U�C���Ȃ�ˁB
�Ȃ��D�ꂽ���̂܂Ŕے肷��̂��B
>>335
Marvericks�̂ǂ���iOS���C�N�Ȃ�H
OSX�͂����Ӗ��ł��ێ�I�����B
Vista�S�ے�~���肾�Ǝv���Ă��������ł��Ȃ������ȁB
341 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 08:03:26.11 ID:OosgDtQq
����Vista�o���Ƃ�����x64�Ŏg���Ă���
>>341
����Vista��x64�͂���OS��������ˁB�����������ς��ς߂ΐς������K�ɂȂ邵�B
����Vista��x64�͂���OS��������ˁB�����������ς��ς߂ΐς������K�ɂȂ邵�B
Vista�́A���[�J�[PC��������512MB���������̂�Vista�ςނƂ��A���Ȃ荓����������Ȃ�
C2D�ȍ~��CPU�{2GB�ȏ�̃������K�{�݂�����OS�Ȃ̂ɁA
���X�y�b�NPC�ɂ܂Őς܂ꂽ����
C2D�ȍ~��CPU�{2GB�ȏ�̃������K�{�݂�����OS�Ȃ̂ɁA
���X�y�b�NPC�ɂ܂Őς܂ꂽ����
�܂��PC���[�J�[�������݂�����
OS�̍\���ς���āA�o�O�A�݊�����肪���o�������Nj͗ǂ�����
���̃g���u�������ƃ{�g���l�b�N����������pOS�Ƃ����̂�
2000(��ʃ��[�U�[�ɂ͕��y�����A�r�W�l�X�����ƃ}�j�A�嗬)��XP
Vista��7�͎��Ă�Ǝv��
Vista�S�����̓`�b�v�Z�b�g�ƃ������̐���ō��������̂�
7�o�ꎞ�́ADDR3�������Ɖ~���ADRAM���[�J�[�_���s���O���d�Ȃ��Ă���
�v���C���X�g�[��OS��32/64bit�I���̉ߓx�����o�āA64bit�f�t�H�ɑ����ɐ�ւ����
���Ȃ�AVista/7�X���[�ł�Xp��8.1(�f�X�N�g�b�v�Œ�)�ւ̔����ւ������������Ǝv��
Aero�̔����ߕ\����m���Ă�ƃV���{�������邵
���̃g���u�������ƃ{�g���l�b�N����������pOS�Ƃ����̂�
2000(��ʃ��[�U�[�ɂ͕��y�����A�r�W�l�X�����ƃ}�j�A�嗬)��XP
Vista��7�͎��Ă�Ǝv��
Vista�S�����̓`�b�v�Z�b�g�ƃ������̐���ō��������̂�
7�o�ꎞ�́ADDR3�������Ɖ~���ADRAM���[�J�[�_���s���O���d�Ȃ��Ă���
�v���C���X�g�[��OS��32/64bit�I���̉ߓx�����o�āA64bit�f�t�H�ɑ����ɐ�ւ����
���Ȃ�AVista/7�X���[�ł�Xp��8.1(�f�X�N�g�b�v�Œ�)�ւ̔����ւ������������Ǝv��
Aero�̔����ߕ\����m���Ă�ƃV���{�������邵
>>339
�X�^�[�g���j���[�ƃ��g���A�v����Ɍ��̂͂��������ˁH
�X�^�[�g���j���[�ƃ��g���A�v����Ɍ��̂͂��������ˁH
347 �F,,�E�L�́M�E,,�j��-�������F2014/01/03(��) 13:44:05.92 ID:OosgDtQq
8�̃X�^�[�g�X�N���[����Metro�A�v���݂����Ȃ���ł���
�킴�킴�L���f�X�N�g�b�v��ʂ����ׂĕ����B���K�v�͂ǂ��ɂ��Ȃ��B
�B���ꂽ���Ȃ��Ȃ�}���`�f�B�X�v���C�g�����Ă����Ȃ�܂��d���Ȃ����B
�킴�킴�L���f�X�N�g�b�v��ʂ����ׂĕ����B���K�v�͂ǂ��ɂ��Ȃ��B
�B���ꂽ���Ȃ��Ȃ�}���`�f�B�X�v���C�g�����Ă����Ȃ�܂��d���Ȃ����B
348 �FSocket774�F2014/01/03(��) 13:47:48.75 ID:vTNy4knm
�b���Ԃ��������Đ\����Ȃ��ł���
Apple(��P.A.semi)��ARM32bit�݊���r�������S��ARM64bit��MPU��v������
��DEC�̃��Ɣ�ׂĂ����\�̂���MPU(�f���̗ǂ��Ƃ����Ӗ�)���ł�����̂��ȁH�ǂ�����
Apple(��P.A.semi)��ARM32bit�݊���r�������S��ARM64bit��MPU��v������
��DEC�̃��Ɣ�ׂĂ����\�̂���MPU(�f���̗ǂ��Ƃ����Ӗ�)���ł�����̂��ȁH�ǂ�����
��
�܂�ARMv8�̂ǂ̂ւf���������̂������Ă����Ȃ���
351 �FSocket774�F2014/01/03(��) 13:59:23.75 ID:wnSbJcM8
352 �FSocket774�F2014/01/03(��) 14:01:40.88 ID:vRQXV4cw
�����Q�[������
http://webblogsakusei.main.jp/game-video-free-pc-niconico-osusume-soft-obs-maiku.html
http://webblogsakusei.main.jp/game-video-free-pc-niconico-osusume-soft-obs-maiku.html
alpha�̓n�C�G���h�͂Ƃ��������[�G���h�̐��\�͌����Ăق߂�ꂽ���̂���Ȃ��킯��[
�Ȃ̂ʼn��������̂�����킩���̂�
�Ȃ̂ʼn��������̂�����킩���̂�
�������Ńf�^�����Ȗϑz�ł��A�Ƃɂ����A�b�v���ŋ������� ���Č���������������
PC��CPU��100MHz��������������ALPHA200MHz��
���͂��������ǂˁB������͂����܂ł������B
���͂��������ǂˁB������͂����܂ł������B
���Ȃ��Ƃ�����{�ȏ����������悤��CPU�A�[�L�e�N�`���͂�������('A`)
�l��PC�ɓ����Ă���CPU�����ɔ{�ȏ����������Ă��܂�
Alpha������CPU��荂�N���b�N�������̂̓A�[�L�e�N�`������Ȃ��ėD�ꂽ����
�i�����v�j�̎�����������
�i�����v�j�̎�����������
�A�[�L�e�N�`���ɂ����N���b�N�ނ��̍H�v�͂��������ǂ�
8KB�y�[�W�T�C�Y�Ƃ�
8KB�y�[�W�T�C�Y�Ƃ�
360 �FSocket774�F2014/01/03(��) 23:34:11.04 ID:vTNy4knm
ARMv8�ƍŋ߂̈�ԐV����Atom���ƂP�R�A������̐��\��
�ǂ������悳�����Ȃ̂��ȁH
�ǂ������悳�����Ȃ̂��ȁH
���Ƃ͂Ȃ����AFPU�̒x����O������
ARMv8���Č����Ă��F�X���邪A57�Ƃ��Ă��N���b�N���悾��
IPC��A57�̕����ǂ���������28nm����N���b�N���グ���Ȃ�
�O�X����3DMark�̌��ʂ���Z3770��A15-1.9GHz��1.3�{���炢����
Z3770��2.4GHz�Ȃ�Z3770��A15��IPC���������炢�ɂȂ邪�A
Z3770��3DMark���̃N���b�N���悭������Ȃ��i1.4GHz�`TB���ő�2.4GHz�j
A57��A15���10%�ȏ㑬���炵���������s���ł悭������Ȃ�
IPC��A57�̕����ǂ���������28nm����N���b�N���グ���Ȃ�
�O�X����3DMark�̌��ʂ���Z3770��A15-1.9GHz��1.3�{���炢����
Z3770��2.4GHz�Ȃ�Z3770��A15��IPC���������炢�ɂȂ邪�A
Z3770��3DMark���̃N���b�N���悭������Ȃ��i1.4GHz�`TB���ő�2.4GHz�j
A57��A15���10%�ȏ㑬���炵���������s���ł悭������Ȃ�
363 �F,,�E�L�́M�E,,�j��-�������F2014/01/04(�y) 00:02:37.42 ID:OosgDtQq
�ʂ����āA���W�X�^���������邩�琫�\���L�т�Ƃ��������͐������̂��H
Cortex-A9����Load/Store�|�[�g��NEON���Ԃ牺����\���������肵������
�Q�Ƃ���f�[�^�����W�X�^����R�[�h���Ɛ��\�ቺ�������������B
�������ɘ_�����W�X�^���𑝂₹�Α����͂悭�Ȃ邯�ǁA��ԑ傫���̂�
�A�[�L�e�N�`���̎����̖��ł��傤�H
A57��A15��64�r�b�g�łƂ��������ŁAAthlonXP��Athlon64�ɂȂ����قǂ̐L�ѕ�
����Ȃ��Ǝv���Ă�B
Cortex-A9����Load/Store�|�[�g��NEON���Ԃ牺����\���������肵������
�Q�Ƃ���f�[�^�����W�X�^����R�[�h���Ɛ��\�ቺ�������������B
�������ɘ_�����W�X�^���𑝂₹�Α����͂悭�Ȃ邯�ǁA��ԑ傫���̂�
�A�[�L�e�N�`���̎����̖��ł��傤�H
A57��A15��64�r�b�g�łƂ��������ŁAAthlonXP��Athlon64�ɂȂ����قǂ̐L�ѕ�
����Ȃ��Ǝv���Ă�B
�܂�����������X��������������\��10%���x�Ȃ̂ł����Ȃ�ł��傤��
���W�X�^��������ƃX�s��������A�������͂��A�����[���ł���
���ꂾ��
���ꂾ��
A57�̂ق����L���b�V���������Ă邵
�A�E�g�I�u�I�[�_�[�Ƃ�����������Ă�炵��
�A�E�g�I�u�I�[�_�[�Ƃ�����������Ă�炵��
���Ȃ��̂ő����悤�ɍ���Ă��\�t�g�́A���Ƃ��Ƃ���ȍ��������Ȃ�����
ARM 64bit�ł͖{�Ƃ�Apple�J�X�^���̂ǂ��炪��ɂȂ�̂��낤��
��������
��������
���������P���ȋ^��Ȃ���
apple�̃A����
A64�R�[�h���������������H
A32��thumb2���F���������H
apple�̃A����
A64�R�[�h���������������H
A32��thumb2���F���������H
���ʂɍl������AApple�̂́uiOS�ł悭�g���v������������ˁH�@��bit�Ƃ�����Ȃ�
>>368
�{�Ƃ��"�ǂ����m"�����郁�[�J�[������낤�Ƃ͂��Ȃ��C���E�E
�{�Ƃ��"�ǂ����m"�����郁�[�J�[������낤�Ƃ͂��Ȃ��C���E�E
>>370
�������̓x���`�}�[�N����������B
�������̓x���`�}�[�N����������B
�x���`�}�[�N�Ƃ������}�C�N���x���`�}�[�N�Ԓ��݂�����
�Ȃ�iPhone 5s��iPad Air��3DMark�����e�X�g�̌��ʂ������̂� �`Futuremark���������{ - PC Watch
http://pc.watch.impress.co.jp/docs/news/20131105_622195.html
�Ȃ�iPhone 5s��iPad Air��3DMark�����e�X�g�̌��ʂ������̂� �`Futuremark���������{ - PC Watch
http://pc.watch.impress.co.jp/docs/news/20131105_622195.html
���\���������ڂȂ̂�apple���v�������ǂ��Ɏ̂Ă邩�Ȃ�ˁH
�Ȃ��̂Ă�Ǝv���̂���
>>373
>�������ACPU���\�͂Ƃ����ƁA8,197��7,783(��)�ŁAiPhone 5�������錋�ʂ��o�Ă���̂�
�c32bit���ƑʖڂȂ̂�
>Futuremark�ł�64bit�ł�3DMark���쐬���������Ƃ���A���\�͌��サ�����A���̊�����7%�ɗ��܂�
>64bit���������e�X�g�̌��ʂɂ͑傫�ȉe����^���Ȃ����Ƃ���������
�c
>�������ACPU���\�͂Ƃ����ƁA8,197��7,783(��)�ŁAiPhone 5�������錋�ʂ��o�Ă���̂�
�c32bit���ƑʖڂȂ̂�
>Futuremark�ł�64bit�ł�3DMark���쐬���������Ƃ���A���\�͌��サ�����A���̊�����7%�ɗ��܂�
>64bit���������e�X�g�̌��ʂɂ͑傫�ȉe����^���Ȃ����Ƃ���������
�c
�Ƃ������A���̃x���`�ɑ�������悤�Ȏg������iOS���Ⴀ��܂���Ȃ��낤�B
���̋L���̃O���t�������Ă��������Z�ȊO�͏����ɏオ���Ă���A��̑I���Ƃ��Ă͑Ó��ł�
���̋L���̃O���t�������Ă��������Z�ȊO�͏����ɏオ���Ă���A��̑I���Ƃ��Ă͑Ó��ł�
28nm�Ŗ������64bit�ɂ�����
���܂ǂ�������1GB�����Ȃ���
���낢�낢�тȂ��
iPad�ł�1GB�Ƃ��т����肵����
���܂ǂ�������1GB�����Ȃ���
���낢�낢�тȂ��
iPad�ł�1GB�Ƃ��т����肵����
�ʂ�64bit���͖�������Ȃ��B
R4000��20�N�ȏ�O��
R4000��20�N�ȏ�O��
ARM�ɂ���A57��16nm����
�����28nm�ł����疳��������
���܂ǂ��f���A���R�A����
�����28nm�ł����疳��������
���܂ǂ��f���A���R�A����
�m�����̔ł̓V���O���̐��\���܂����ŃR�A���d���̂ǂ�����
CPU�͂ڂ낭���ɂ��Ȃ���ĂȂ�������
CPU�͂ڂ낭���ɂ��Ȃ���ĂȂ�������
�����Ȃ��Ƃ��AARM�̏ꍇ�A64bit���ō����̂܂Ƃ���RISC�v���Z�b�T�ɂȂ����̂ŁA
ARM�̏ꍇ�A32bit�p�v���O�������ăR���p�C������64bit�����邾����
���\���オ���҂ł���
ARM�̏ꍇ�A32bit�p�v���O�������ăR���p�C������64bit�����邾����
���\���オ���҂ł���
>>382
���\�����10%���x�炵������A
�R���p�C��������������10%�Ǝv�����A
OS�Ƃ��F�X�Ή������Ă�10%�Ǝv�����ň���Ă��邩��
���\�����10%���x�炵������A
�R���p�C��������������10%�Ǝv�����A
OS�Ƃ��F�X�Ή������Ă�10%�Ǝv�����ň���Ă��邩��
denver���ł�����
7way superscalar
http://www.4gamer.net/games/244/G024410/20140106001/
�W�ς����GPU�R�A��192��B�g�ݍ��킳���CPU�R�A�́C�uCortex-A15�v�~4�\�\�����ꂽ�C���[�W�摜���������C
CPU�R�A�́CTegra 4�܂ł�4-PLUS-1�ł͂Ȃ��CARM��big.LITTLE�ɋ߂��g4��̃r�b�O�`�b�v��1��̃X���[���`�b�v�h�Ɍ�����\�\
��������64bit��CPU�R�A�uDenver�v�~2�ƂȂ�C�����Tegra K1��2���C���i�b�v�W�J�ƂȂ�B
http://www.4gamer.net/games/244/G024410/20140106001/TN/004.jpg
7way superscalar
http://www.4gamer.net/games/244/G024410/20140106001/
�W�ς����GPU�R�A��192��B�g�ݍ��킳���CPU�R�A�́C�uCortex-A15�v�~4�\�\�����ꂽ�C���[�W�摜���������C
CPU�R�A�́CTegra 4�܂ł�4-PLUS-1�ł͂Ȃ��CARM��big.LITTLE�ɋ߂��g4��̃r�b�O�`�b�v��1��̃X���[���`�b�v�h�Ɍ�����\�\
��������64bit��CPU�R�A�uDenver�v�~2�ƂȂ�C�����Tegra K1��2���C���i�b�v�W�J�ƂȂ�B
http://www.4gamer.net/games/244/G024410/20140106001/TN/004.jpg
{kind=link}
7-way���ăf�R�[�h�ƃ��^�C���̑ш悪7���߂��Ă���?
����Ȏ������o�C�������ł��蓾��̂�����
����Ȏ������o�C�������ł��蓾��̂�����
3way��4�R�A��7way��2�R�A�����炻��Ȃ���Ȃ���
SMT�Ƃ��H
http://www.nvidia.com/object/tegra-k1-processor.html
http://game.watch.impress.co.jp/docs/news/20140106_629664.html
Tegra K1��32�r�b�g��64�r�b�g��2�̃o�[�W����������A32�r�b�g���i�̓��ڋ@�킪2014�N�㔼���A
64�r�b�g���i�̓��ڋ@�킪2014�N�������ɔ��������\��B
http://game.watch.impress.co.jp/docs/news/20140106_629664.html
Tegra K1��32�r�b�g��64�r�b�g��2�̃o�[�W����������A32�r�b�g���i�̓��ڋ@�킪2014�N�㔼���A
64�r�b�g���i�̓��ڋ@�킪2014�N�������ɔ��������\��B
7way���Ɩ��߃t�F�b�`������28B/clk�H�����
�d����������POWER7��6-way�APOWER8��8-way�Ƃ����̂͂��邪
�����̓��o�C����������Ȃ����387�̌����悤�Ƀ}���`�X���b�f�B���O�Ŗ��߂�O��̐��������
�d����������POWER7��6-way�APOWER8��8-way�Ƃ����̂͂��邪
�����̓��o�C����������Ȃ����387�̌����悤�Ƀ}���`�X���b�f�B���O�Ŗ��߂�O��̐��������
A15�ł�28nm�Ȍ�
391 �FSocket774�F2014/01/06(��) 16:27:24.60 ID:9vajQsoN
�А��̂����������Ă��̂Ɍ���28nm�~�܂肩�c
20nm�Ȃ�384SP�ς�ł������Ȃ�
denver�ł�20nm�ł��肢���������̂�
denver�ł�20nm�ł��肢���������̂�
���f�����s���Ȉȏ�A�n�C�G���h��Qualcomm�Ƃ͐킢�ɂ���
���̕���MediaTek�Ɛ키�Ȃ�28nm���낤
���̕���MediaTek�Ɛ키�Ȃ�28nm���낤
AnandTech��Denver�ł�28nm�ł͂Ȃ����ƌ����Ă�
http://www.anandtech.com/show/7621/nvidia-reveals-first-details-about-project-denver-cpu-core
http://www.anandtech.com/show/7621/nvidia-reveals-first-details-about-project-denver-cpu-core
TSMC��20nm�v���Z�X���g���Ȃ����R�͉�����H
���p�R�X�g���������邩��A����Ƃ��v���Z�X�Z�p��
�����n�ŕ����܂肪�オ��Ȃ��Ƃ�
�����ɂȂ�v�f���F�X�����Ă悭������Ȃ�
���p�R�X�g���������邩��A����Ƃ��v���Z�X�Z�p��
�����n�ŕ����܂肪�オ��Ȃ��Ƃ�
�����ɂȂ�v�f���F�X�����Ă悭������Ȃ�
20nm���C���͊m�ۂł��������S��Tesla/Quadro/GeForce�ɓ˂��������ׂ��邩��B
���������ɏo��́H
Tegra K1��32�r�b�g��64�r�b�g��2�̃o�[�W����������A32�r�b�g���i�̓��ڋ@�킪2014�N�㔼���A
64�r�b�g���i�̓��ڋ@�킪2014�N�������ɔ��������\��B
64�r�b�g���i�̓��ڋ@�킪2014�N�������ɔ��������\��B
���o�C���p�r��64bit�͖��ʈȊO�̂Ȃɂ��̂ł��Ȃ��B
LPDDR3�͍��N����8Gbit���o���
�n�C�G���h�X�}�z�̃������e�ʂ�4GB�ɒB���邾�낤
���N�ȍ~�̃^�u���b�g���Ȃ��Ɗm����4GB�ȏア��
�n�C�G���h�X�}�z�̃������e�ʂ�4GB�ɒB���邾�낤
���N�ȍ~�̃^�u���b�g���Ȃ��Ɗm����4GB�ȏア��
iPad<�c�c
nvidia�́A20nm�͂܂��̓n�C�G���hGPU���炾��
�n�C�G���hGPU�p�_�C���܂���20nm�Ő��Y���āA
�����ɐ��Y�o���Ă���R�X�g���̖ړr�����ĂA
���o�C���`�b�v�ɂ����p�����ˁH
�n�C�G���hGPU�p�_�C���܂���20nm�Ő��Y���āA
�����ɐ��Y�o���Ă���R�X�g���̖ړr�����ĂA
���o�C���`�b�v�ɂ����p�����ˁH
�}�X�z��4GB���ς疳�ʂɏ���d�͂������Ă���Ɏg�p���ԒZ���Ȃ邾���B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140107_629706.html
ARM���g��64-bit CPU�R�A�uCortex-A57�v��3-way�X�[�p�[�X�J���ɉ߂����A
Denver��ARMv8�nCPU�̒��ł͍ō��̖��߃��x������x�ƂȂ�B
�܂�A���ꂾ���V���O���X���b�h���\�������B
Intel��Core i�nCPU��CISC(Complex Instruction Set Computer)��4-way(Macro-Fusion���܂߂��5-way)�Ȃ̂ŁA
RISC��7-way��Denver�͓����x��������ȏ�̕���x�ƂȂ�B
64-bit�ł�Tegra K1�͍��N(2014�N)�㔼�ɓo��\�肾�B
ARM���g��64-bit CPU�R�A�uCortex-A57�v��3-way�X�[�p�[�X�J���ɉ߂����A
Denver��ARMv8�nCPU�̒��ł͍ō��̖��߃��x������x�ƂȂ�B
�܂�A���ꂾ���V���O���X���b�h���\�������B
Intel��Core i�nCPU��CISC(Complex Instruction Set Computer)��4-way(Macro-Fusion���܂߂��5-way)�Ȃ̂ŁA
RISC��7-way��Denver�͓����x��������ȏ�̕���x�ƂȂ�B
64-bit�ł�Tegra K1�͍��N(2014�N)�㔼�ɓo��\�肾�B
7���ߓ������s�A�Ƃ͂܂��Ⴄ�̂���?
SMT�K�{�ȋC�����邪�A��Ȃ̂��Ȃ��B
SMT�K�{�ȋC�����邪�A��Ȃ̂��Ȃ��B
406 �F,,�E�L�́M�E,,�j��-�������F2014/01/07(��) 08:21:40.42 ID:PZOPEiR3
ARM�͑��l�t�B�[���h��12�r�b�g�����Ȃ�������
�������A�h���b�V���O��x86�ɔ�ׂĕn��Ȃ̂�
�����I�y���[�V��������x86������Ƃ͌���Ȃ��Ƃ���͒��ӂˁB
����x�����̂܂ܐ��\�ɒu���������Ƃ���ňӖ��͖����B
3Way Superscalar��Cortex A15��2Way��Atom���݂�����ȉ���
���\�����o���ĂȂ����Ƃ�������炩�����B
�܂������Apple A7�ł��������Ƃ������邯�ǁB
�������A�h���b�V���O��x86�ɔ�ׂĕn��Ȃ̂�
�����I�y���[�V��������x86������Ƃ͌���Ȃ��Ƃ���͒��ӂˁB
����x�����̂܂ܐ��\�ɒu���������Ƃ���ňӖ��͖����B
3Way Superscalar��Cortex A15��2Way��Atom���݂�����ȉ���
���\�����o���ĂȂ����Ƃ�������炩�����B
�܂������Apple A7�ł��������Ƃ������邯�ǁB
��������denver��VLIW�����ăZ�~�̃`���[���[�������Ă���
���̏ꍇ���ƃp�t�H�[�}���X�͂��܂���҂ł��Ȃ������Ȃ�
�����R�[�h���[�t�B���O���ʔ������ł͂���
GPU���݂ł�
���̏ꍇ���ƃp�t�H�[�}���X�͂��܂���҂ł��Ȃ������Ȃ�
�����R�[�h���[�t�B���O���ʔ������ł͂���
GPU���݂ł�
1�X���b�h�łǂ̂��炢�̓������s�ڕW�Ȃ̂��͂킩��Ȃ����ǁA
���\�V���O���X���b�h���\�ǂ������Ŗʔ���
�p�C�v���C���̏ڍׂ͂�
���\�V���O���X���b�h���\�ǂ������Ŗʔ���
�p�C�v���C���̏ڍׂ͂�
�܂�4�R�AA15��2�R�ADenver������A
Denver��A15��2�{���炢�̃V���O���X���b�h�����Ƃ�
Denver��A15��2�{���炢�̃V���O���X���b�h�����Ƃ�
http://www.anandtech.com/show/7622/nvidia-tegra-k1/2
anand�̋L���ł�code morphing����Ȃ������Ă����Ƃ��
anand�̋L���ł�code morphing����Ȃ������Ă����Ƃ��
�����A�R�[�h���[�t�Ƃ������t�ɂ͗ǂ���ۂ�����
�g�����X���^�قǃ��b�T���Ƃ������t����������CPU�͖�������
�g�����X���^�قǃ��b�T���Ƃ������t����������CPU�͖�������
ARM��VLIW�ɕϊ�? �Ȃ��Ǝv�����ǂȂ��B
�킴�킴���ʂ�RISC�Ŏ��肭�ǂ����Ƃ����闝�R����������
ARMv8�̎d�l���ł܂�O�ɍ��n�߂�����Ƃ����낤��
ARMv8�̎d�l���ł܂�O�ɍ��n�߂�����Ƃ����낤��
nvidia��transmeta�̋Z�p�҂��ق��Ă�Ƃ�
effecion�Ɩ��ߕ���x��L���b�V���T�C�Y����v����Ƃ�
�ςȏ؋��͑����Ă���悤��
effecion�Ɩ��ߕ���x��L���b�V���T�C�Y����v����Ƃ�
�ςȏ؋��͑����Ă���悤��
���Ⴀ����x86�������Ƃ�
�ꎞ��NV��transmeta�̋Z�p���g����x86�݊�CPU�����Ƃ��\���ꂽ���Ƃ�����������
���ꂪ���菄����ARM�ɂȂ����̂���
http://www.theregister.co.uk/2009/11/04/nvidia_transmeta_x86/
http://www.xbitlabs.com/news/mobile/display/20100816162024_Nvidia_Uses_Transmeta_Technology_to_Create_New_Chip_for_Tablets_Rumours.html
���ꂪ���菄����ARM�ɂȂ����̂���
http://www.theregister.co.uk/2009/11/04/nvidia_transmeta_x86/
http://www.xbitlabs.com/news/mobile/display/20100816162024_Nvidia_Uses_Transmeta_Technology_to_Create_New_Chip_for_Tablets_Rumours.html
�D�ɗ����Ȃ��_�͂�����������̂�
���̃l�^���{���̂��̂Ƃ��Ă����ė��R�������ɒT����
VLIW�Ȃ�n�[�h�̐v���i�i�Ɋy���낤�Ƃ����̂͑z���ɓ�Ȃ�
���̃l�^���{���̂��̂Ƃ��Ă����ė��R�������ɒT����
VLIW�Ȃ�n�[�h�̐v���i�i�Ɋy���낤�Ƃ����̂͑z���ɓ�Ȃ�
�{�f�R�[�h�O�Ƀq���g����t�����ĕ������ߗ��VLIW�I�Ɉ����A�Ƃ��o���Ȃ����ȁB
���A������ăo���h�����B
���A������ăo���h�����B
420 �F,,�E�L�́M�E,,�j��-�������F2014/01/07(��) 19:20:00.46 ID:PZOPEiR3
��������Transmeta���Ȃ��R�[�h���[�t�B���O����Ă����Ƃ�����
�uModRM+SIB+DISP���_�C���N�g�ɉ�͂��Ď��s���邽�߂̃n�[�h��
�����Ƃ����N���e�B�J���ȕ�����Intel�������擾���ĂāA�������������
�����������邽�߂ɕʂ̐���ł̍œK�����K�v����������B
�{���ɓ���VLIW���Ƃ���Ȃ�A���Ƃ��ƌŒ蒷�t�H�[�}�b�g������
x86�̃f�R�[�h���ϊ��قǂɂ̓R�X�g������Ȃ��C������B
�uModRM+SIB+DISP���_�C���N�g�ɉ�͂��Ď��s���邽�߂̃n�[�h��
�����Ƃ����N���e�B�J���ȕ�����Intel�������擾���ĂāA�������������
�����������邽�߂ɕʂ̐���ł̍œK�����K�v����������B
�{���ɓ���VLIW���Ƃ���Ȃ�A���Ƃ��ƌŒ蒷�t�H�[�}�b�g������
x86�̃f�R�[�h���ϊ��قǂɂ̓R�X�g������Ȃ��C������B
���܂�ڂ����m��Ȃ����AVLIW���Ċ����o�C�i����
���ɂ��Ȃ����̂���������
���ɂ��Ȃ����̂���������
DK���o�C�i���g�����X���[�V��������Ă���Č����Ă��̂�
https://twitter.com/TheKanter/status/420283744847548416
https://twitter.com/TheKanter/status/420283744847548416
�����v�X�Ɍ㓡�����т����ȃv���Z�b�T���Ȃ�
424 �FSocket774�F2014/01/08(��) 00:20:41.14 ID:zZwiBkwN
CPU�́A�Í����Ƃ��n�b�V���Ƃ��̐�p���߂���������č����ɏ����ł���悤�ɂȂ����肵�Ă邪�A
�Ȃ��DCT(���U�R�T�C���ϊ�)�Ƃ��Agzip/deflate�̐�p���߂���������Ȃ��́H
���ꂪ���������Ό��\���x�A�b�v����C�������
�Ȃ��DCT(���U�R�T�C���ϊ�)�Ƃ��Agzip/deflate�̐�p���߂���������Ȃ��́H
���ꂪ���������Ό��\���x�A�b�v����C�������
�ׂ����
>�Ȃ�Ł`��������Ȃ��́H
DCT�Ƃ��͂��܂܂ł�SIMD�ŏ\���ɉ��b�����邩��
���A�����Ă�SIMD�͂��̂��߂ɓ�������Ă��܂�
>���x�A�b�v����C�������
�C�̂����ł��B
����ȏ㓥�ݍ���ł��p�C�v���C����
���G�����ċt�ɒx���Ȃ邾������
DCT�Ƃ��͂��܂܂ł�SIMD�ŏ\���ɉ��b�����邩��
���A�����Ă�SIMD�͂��̂��߂ɓ�������Ă��܂�
>���x�A�b�v����C�������
�C�̂����ł��B
����ȏ㓥�ݍ���ł��p�C�v���C����
���G�����ċt�ɒx���Ȃ邾������
�܁A���ꂶ�ᑫ���Ƃ��������ɂ�
GPU�Ȃ�XEON-Phi�Ȃ�ŕ�����̂���������
��̂ɂ�DCT��ASIC���ƌ������b�������܂�����
�ŋ߂͂��܂蕷���Ȃ��悤��
GPU�Ȃ�XEON-Phi�Ȃ�ŕ�����̂���������
��̂ɂ�DCT��ASIC���ƌ������b�������܂�����
�ŋ߂͂��܂蕷���Ȃ��悤��
https://twitter.com/ProfMatsuoka
���̂ЂƂ�VLIW�\�z
���̂ЂƂ�VLIW�\�z
CES2014��20nm��16/14nmFinFET���S���o�ė��Ȃ����c
�X�}�z�W��SoC�Ƃ���2����MWC������
Transmeta�̖S���I�I
CPU���炱�������ƃV�[�����X��GPU�g����悤�ɂȂ��̂��B
����CPU�̑��R�A�ł���V�[�����X�Ƃ����킯�ɂ͂����Ȃ�����˂��B�R�v���Z�b�T�ɂ܂Ŏd���Ă�Ȃ�Ƃ��Ȃ邪���s���삵�Ȃ���p�t�H�[�}���X�̃����b�g�͔����B
�قƂ�ǘb��ɂȂ�Ȃ��g�ѓd�b(�K���P�[)�Ɏg���Ă���v���Z�T�
���̐��\���ĈӊO�ɍ�����PenM 2GHz��������炵���H
���̐��\���ĈӊO�ɍ�����PenM 2GHz��������炵���H
�ǂ����ɂ������āAGPU�ɋ�킹�閽�߃Z�b�g�͕ʂɊo���Ȃ��Ⴂ���Ȃ����˂�
�ʓ|�ł��鎖�ɕς��͖�����ȁc
�ʓ|�ł��鎖�ɕς��͖�����ȁc
GPGPU����ʌ�������S�R����オ��Ȃ�����
SIMD�����Ŏ��t�����
SIMD�����Ŏ��t�����
>>434
�K���P�[�p��3�N���炢�O��ARM1GHz�f���A��������łɐi���~�܂��Ă܂����Ȃɂ�
�K���P�[�p��3�N���炢�O��ARM1GHz�f���A��������łɐi���~�܂��Ă܂����Ȃɂ�
>>432
SSE/AVX�ł��������
SSE/AVX�ł��������
�K���P�[�́ALinux�x�[�X�ɂȂ��Ă���������肵�Ăǂ����C�ɓ��������
�ŁA�K���P�[�����܂ł���������������Ȃ��̂ɁAiPhone3GS�ł�������������āA
iPhone3GS�o�����_�ł����K���P�[��������Ȃ��Ċ�����
�ŁA�K���P�[�����܂ł���������������Ȃ��̂ɁAiPhone3GS�ł�������������āA
iPhone3GS�o�����_�ł����K���P�[��������Ȃ��Ċ�����
>>439
����ς�GPU�̂悤��SIMT�Ɣ�ׂ�Ɛ������������˥��
����ς�GPU�̂悤��SIMT�Ɣ�ׂ�Ɛ������������˥��
442 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 07:37:02.88 ID:qDYMkzqH
>>441
CPU�I�����[��OpenCL�����^�C�����邯�ǁH
OpenCL 1.2�����̃R�[�h�������邶���
�ǂ���GPU��萧��������́H
�ySSE/AVX���@�����Ƃł���CUDA��OpenCL�ɂł��Ȃ����Ɓz
�E�X�J���ɗ��Ƃ�����ŏ_��ȕ��s����
�E1�o�C�g/2�o�C�g�P�ʂ̃I�y���[�V�����̏[��
�EAoS�\���̂܂܂ł��f�[�^�𑀍�ł���
�ESIMD���W�X�^��ł̏����P�ʂ̃V�[�����X�ȕϊ��i��F2byte�~8��4byte�~4�j
�E���W�X�^��̗v�f�̃V���b�t��
�@��SIMT�ł����ߖT�́u�X���b�h�v�Ԃ̃f�[�^�����ɂ킴�킴�����������K�v������
GPU��萧��������Ƃ��ǂ̖ʂ��Č����Ă�̂������ς�킩���ȁB
CPU�I�����[��OpenCL�����^�C�����邯�ǁH
OpenCL 1.2�����̃R�[�h�������邶���
�ǂ���GPU��萧��������́H
�ySSE/AVX���@�����Ƃł���CUDA��OpenCL�ɂł��Ȃ����Ɓz
�E�X�J���ɗ��Ƃ�����ŏ_��ȕ��s����
�E1�o�C�g/2�o�C�g�P�ʂ̃I�y���[�V�����̏[��
�EAoS�\���̂܂܂ł��f�[�^�𑀍�ł���
�ESIMD���W�X�^��ł̏����P�ʂ̃V�[�����X�ȕϊ��i��F2byte�~8��4byte�~4�j
�E���W�X�^��̗v�f�̃V���b�t��
�@��SIMT�ł����ߖT�́u�X���b�h�v�Ԃ̃f�[�^�����ɂ킴�킴�����������K�v������
GPU��萧��������Ƃ��ǂ̖ʂ��Č����Ă�̂������ς�킩���ȁB
CPU����GPU�ւ̃I�t���[�h���Č������ǎ���GPU�����Ȃ̂́A�C���[�W�v���Z�b�V���O�ȊO�ɂȂ�
NV����ɏo�����̂�UI�Ɉ��k�Ƃ��ŁACPU�ł��ėp���Z�]�X�ł͂Ȃ����
�����AK1�̓J�����@�\�ɑ��Ă͈ӗ~�I���Ǝv����tegra4�ł�chimera���Ă���HDR�@�\����ɂ��Ă���
GPU�̋��݂�����������̂ł�����
K1�ł�ISP��dual�ɂ��čX�ɋ������Ă��Ă邵�ԍڂł�ADAS�Ȃł��L�����낤
PC�p�r�ƈ���ă^�u���b�g��X�}�z�̓J�����t���ʼn摜����������p�x�͑�������
�itegra note�ŏ펞HDR�B�e�͉��K�ł��B����ł�HDR�B�e�ł��܂��B�j
http://www.tomshardware.com/reviews/tegra-k1-kepler-project-denver,3718-5.html
http://www.nvidia.co.jp/content/PDF/tegra_white_papers/Tegra_K1_whitepaper_v1.0.pdf
http://www.nvidia.co.jp/object/advanced-driver-assistance-systems-jp.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20140109_630091.html
NVIDIA�̍ŋ����o�C��SoC�uTegra K1�v�̏ȓd�͋Z�p�̔閧
CPU����̃I�t���[�h�ł́A�ėp�����������݂�GPU�R�A�͔��ɏd�v���B
�����̏�����GPU�R�A�Ɉڂ����Ƃ��ł���B
GPU�̕���CPU���A�d�͌�����7�`10�{���������߁AGPU�ɃI�t���[�h�����������|�I�ɗL���ƂȂ�B
���̂��߁A��������ڍs���n�܂�A���o�C���@��̕���PC����GPU�R���s���[�e�B���O�ւ̓K�p���}���ɐi�މ\��������B
NVIDIA���AKepler�R�A��Tegra�ɂ����炵�AGPU�R���s���[�e�B���O�̐Z����ڎw���w�i�ɂ́A���������������B
NV����ɏo�����̂�UI�Ɉ��k�Ƃ��ŁACPU�ł��ėp���Z�]�X�ł͂Ȃ����
�����AK1�̓J�����@�\�ɑ��Ă͈ӗ~�I���Ǝv����tegra4�ł�chimera���Ă���HDR�@�\����ɂ��Ă���
GPU�̋��݂�����������̂ł�����
K1�ł�ISP��dual�ɂ��čX�ɋ������Ă��Ă邵�ԍڂł�ADAS�Ȃł��L�����낤
PC�p�r�ƈ���ă^�u���b�g��X�}�z�̓J�����t���ʼn摜����������p�x�͑�������
�itegra note�ŏ펞HDR�B�e�͉��K�ł��B����ł�HDR�B�e�ł��܂��B�j
http://www.tomshardware.com/reviews/tegra-k1-kepler-project-denver,3718-5.html
http://www.nvidia.co.jp/content/PDF/tegra_white_papers/Tegra_K1_whitepaper_v1.0.pdf
http://www.nvidia.co.jp/object/advanced-driver-assistance-systems-jp.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20140109_630091.html
NVIDIA�̍ŋ����o�C��SoC�uTegra K1�v�̏ȓd�͋Z�p�̔閧
CPU����̃I�t���[�h�ł́A�ėp�����������݂�GPU�R�A�͔��ɏd�v���B
�����̏�����GPU�R�A�Ɉڂ����Ƃ��ł���B
GPU�̕���CPU���A�d�͌�����7�`10�{���������߁AGPU�ɃI�t���[�h�����������|�I�ɗL���ƂȂ�B
���̂��߁A��������ڍs���n�܂�A���o�C���@��̕���PC����GPU�R���s���[�e�B���O�ւ̓K�p���}���ɐi�މ\��������B
NVIDIA���AKepler�R�A��Tegra�ɂ����炵�AGPU�R���s���[�e�B���O�̐Z����ڎw���w�i�ɂ́A���������������B
�J�����̉摜�����n�͑���SoC�ɐ�p��H�������Ă�̂ł́H
BayTrail-T�ɂ������Ă邵
GPU�ɂ�点�Ă��d�͌����͏オ��낤
BayTrail-T�ɂ������Ă邵
GPU�ɂ�点�Ă��d�͌����͏オ��낤
445 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 21:50:07.90 ID:P13k86Ye
Intel�ƊeFPGA�x���_�[���ĒP��Fab�݂���������Ȃ���
�uGPGPU���ˁv�ŗ��Q�W����v���Ă邩���
�uGPGPU���ˁv�ŗ��Q�W����v���Ă邩���
>>442
OpenCL/CUDA�̂ق������������͓̂��ӂ����c
> �E1�o�C�g/2�o�C�g�P�ʂ̃I�y���[�V�����̏[��
�[�����Ă�Ƃ͌����Ȃ����LjꉞCUDA�ɂ͂��邾��(vadd2�Ƃ�)
> �E���W�X�^��̗v�f�̃V���b�t��
�����CUDA�ɂ͂���
����Ɛ����ł͂Ȃ�����
> �EAoS�\���̂܂܂ł��f�[�^�𑀍�ł���
�܂Ƃ��ȃM���U�[�����Ă�GPU�̂ق����ȒP�ȏꍇ������
> �E�X�J���ɗ��Ƃ�����ŏ_��ȕ��s����
SIMD�ƕ��������SIMT�����̂ق����ȒP�ȏꍇ������
OpenCL/CUDA�̂ق������������͓̂��ӂ����c
> �E1�o�C�g/2�o�C�g�P�ʂ̃I�y���[�V�����̏[��
�[�����Ă�Ƃ͌����Ȃ����LjꉞCUDA�ɂ͂��邾��(vadd2�Ƃ�)
> �E���W�X�^��̗v�f�̃V���b�t��
�����CUDA�ɂ͂���
����Ɛ����ł͂Ȃ�����
> �EAoS�\���̂܂܂ł��f�[�^�𑀍�ł���
�܂Ƃ��ȃM���U�[�����Ă�GPU�̂ق����ȒP�ȏꍇ������
> �E�X�J���ɗ��Ƃ�����ŏ_��ȕ��s����
SIMD�ƕ��������SIMT�����̂ق����ȒP�ȏꍇ������
447 �F,,�E�L�́M�E,,�j��-�������F2014/01/09(��) 23:40:17.25 ID:P13k86Ye
> �EAoS�\���̂܂܂ł��f�[�^�𑀍�ł���
> SIMD�ƕ��������SIMT�����̂ق����ȒP�ȏꍇ������
�����Ȃ��A���V���[�g�J�b�g���ł��Ȃ����Z�ł�����GPU��
�L���ȃP�[�X�����邾�낤�ˁB
�������A�u�}���v���邾���ʼn��Z�ʂ�1�`2���ς���Ă���悤�ȉ��Z��
���X������Ă��Ƃ�B
���������ꍇ�̓X�J���ɗ��Ƃ�����ʼn��Z���l�ߒ����K�v������B
����u�X���b�h�v�Ƃ����T�O�ɔ�����GPGPU�̃v���O���~���O���f���ł�
�}�����G���K���g�Ɉ������Ƃ��ł��Ȃ��B
> SIMD�ƕ��������SIMT�����̂ق����ȒP�ȏꍇ������
�����Ȃ��A���V���[�g�J�b�g���ł��Ȃ����Z�ł�����GPU��
�L���ȃP�[�X�����邾�낤�ˁB
�������A�u�}���v���邾���ʼn��Z�ʂ�1�`2���ς���Ă���悤�ȉ��Z��
���X������Ă��Ƃ�B
���������ꍇ�̓X�J���ɗ��Ƃ�����ʼn��Z���l�ߒ����K�v������B
����u�X���b�h�v�Ƃ����T�O�ɔ�����GPGPU�̃v���O���~���O���f���ł�
�}�����G���K���g�Ɉ������Ƃ��ł��Ȃ��B
�܁[���c�q�̋ɒ[�ȃP�[�X�̈�ʉ����͂��܂���
�c�q��CUDA�̂��Ƃ��悭�m�炸�ɘb���Ă�Ƃ����̂͂킩����
450 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 00:18:19.90 ID:Qjsbm7RH
�}���Ȃ�ăr�b�O�f�[�^���͂ł͓�����O�ɂ�邼�H
����GPGPU�ł̕��̃{�g���l�b�N�ɂȂ��Ă�̂��}��菈����
�R�X�g�̖��ŁACPU�{�f�B�X�N���[�gGPU���ƁA���������ꂷ���Ă�
CPU�ɏ����߂��ď�������̂�GPU�ł�点��̂ɂ��x���B
AMD��CPU��GPU�̋������߂����炱���������Z�ɏ_��ɑΉ��ł���
�Ƃ������Ă邪�A���Ɍ��킹��œK�Ȃ̂�AVX-512�B
����GPGPU�ł̕��̃{�g���l�b�N�ɂȂ��Ă�̂��}��菈����
�R�X�g�̖��ŁACPU�{�f�B�X�N���[�gGPU���ƁA���������ꂷ���Ă�
CPU�ɏ����߂��ď�������̂�GPU�ł�点��̂ɂ��x���B
AMD��CPU��GPU�̋������߂����炱���������Z�ɏ_��ɑΉ��ł���
�Ƃ������Ă邪�A���Ɍ��킹��œK�Ȃ̂�AVX-512�B
�ŋ��k�`�͑����ł���Ă���
GPGPU���g���ɂ������炱���AXeon Phi�������킯��
�J�^���O�X�y�b�N�����Ŕ���Ă�킯����Ȃ���
�J�^���O�X�y�b�N�����Ŕ���Ă�킯����Ȃ���
AVX-512���ă��C���������̑ш摫���̂��ȁH
Xeon Phi�݂�����GDDR5���ڂ��Ă�킯�ł��Ȃ���
Xeon Phi�݂�����GDDR5���ڂ��Ă�킯�ł��Ȃ���
454 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 00:32:57.73 ID:Qjsbm7RH
>>449
�m���Ă��炠��Ȃ��̂�LINPACK��N-Body�ȊO�ł܂Ƃ��Ɏg�����̂ɂȂ�Ȃ����Ƃ킩�邾��B
>>488
�J�^���O�X�y�b�N��FLOPS�������Ńg�[�^�����\�����܂�悤�ȋɒ[�ȃP�[�X�̘b��
���͂��ĂȂ����B�����Ǝ��p�I�ȃA�v���P�[�V�����œ�����O�ɒ��ʂ���{�g���l�b�N�̖�肾�B
SIMT�Ȃ�Ă��̂�SIMD+�v���f�B�P�[�g�ɋ[���X���b�h�Ƃ������킹�����̈ȏ�̂Ȃ�ł��Ȃ��B
����Ȃ��̂͊Q���B
�m���Ă��炠��Ȃ��̂�LINPACK��N-Body�ȊO�ł܂Ƃ��Ɏg�����̂ɂȂ�Ȃ����Ƃ킩�邾��B
>>488
�J�^���O�X�y�b�N��FLOPS�������Ńg�[�^�����\�����܂�悤�ȋɒ[�ȃP�[�X�̘b��
���͂��ĂȂ����B�����Ǝ��p�I�ȃA�v���P�[�V�����œ�����O�ɒ��ʂ���{�g���l�b�N�̖�肾�B
SIMT�Ȃ�Ă��̂�SIMD+�v���f�B�P�[�g�ɋ[���X���b�h�Ƃ������킹�����̈ȏ�̂Ȃ�ł��Ȃ��B
����Ȃ��̂͊Q���B
456 �FSocket774�F2014/01/10(��) 00:44:19.85 ID:ESmbJ23m
HPC�͊��S��GPGPU��F�ɂȂ���CPU�͘e���ɒǂ����ꂽ����˂�
HPC���Ă����Z�p�r�ɂ��BGPU�͂ǂ��܂ł����Ă�
�X�g���[�~���O�v���Z�b�T�ȏ�ɂ͂Ȃ�Ȃ��̂ŁA��������
�p�r�i�����t�H�[�}�b�g�̃f�[�^�Ƀo�b�`�����I�Ɏg���j
�ɂ͌����Ă邯�ǁA�_����܂�łȂ��B
�X�g���[�~���O�v���Z�b�T�ȏ�ɂ͂Ȃ�Ȃ��̂ŁA��������
�p�r�i�����t�H�[�}�b�g�̃f�[�^�Ƀo�b�`�����I�Ɏg���j
�ɂ͌����Ă邯�ǁA�_����܂�łȂ��B
458 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 01:02:49.66 ID:Qjsbm7RH
>>442�͂Ȃɂ��Ԉ���ĂȂ�����
���Ƃ���SSE4.2 string search�ɑ������閽�߂Ƃ������������H
Warp����shuffle�͊m����Kepler�Łu�悤�₭�v�������ꂽ���ǁA
�������ȑO�̎����ł̓n�[�h�I�ɃT�|�[�g����ĂȂ��B
�����������_�N�V�������L�q����̂Ȃ�x�N�g�����B�����Ȃ��ق���
�͂邩�ɉǐ��͍����킯�ŁB
ArBB�Ƃ�Cilk++�̃G���K���g���ɔ�ׂ��CUDA�Ƃ�OpenCL�̂����
����v�����{�I�ɊԈ���Ă�Ƃ��������悤���Ȃ��B
���Ƃ���SSE4.2 string search�ɑ������閽�߂Ƃ������������H
Warp����shuffle�͊m����Kepler�Łu�悤�₭�v�������ꂽ���ǁA
�������ȑO�̎����ł̓n�[�h�I�ɃT�|�[�g����ĂȂ��B
�����������_�N�V�������L�q����̂Ȃ�x�N�g�����B�����Ȃ��ق���
�͂邩�ɉǐ��͍����킯�ŁB
ArBB�Ƃ�Cilk++�̃G���K���g���ɔ�ׂ��CUDA�Ƃ�OpenCL�̂����
����v�����{�I�ɊԈ���Ă�Ƃ��������悤���Ȃ��B
>>456
>GPGPU��F
�ǂ����H
���������̂��A�͂��܂��ڂ����������̂��A���邢�͗�����
http://www.top500.org/list/2013/11/
>GPGPU��F
�ǂ����H
���������̂��A�͂��܂��ڂ����������̂��A���邢�͗�����
http://www.top500.org/list/2013/11/
460 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 01:09:21.01 ID:Qjsbm7RH
����I�ɓ\��Ȃ��Ƃ�������>>456�݂����ȃo�J��������
http://www.top500.org/lists/
�@�@�@�@�@�@�@�@�@12Jun�@12Nov 13Jun 13Nov
Intel Xeon Phi �@�@1�@�@�@�@7�@�@�@12�@�@14
NVIDIA Tesla �@�@53�@�@�@50�@�@�@40�@�@ 39
AMD FirePro�@�@�@ 2�@�@�@ 3�@�@�@ 3�@�@�@2
�����ڂ̏ꍇ�͏d���J�E���g
�c�O������GPU���ڃX�p�R���͌����ɓ]���Ă܂��B
http://www.top500.org/lists/
�@�@�@�@�@�@�@�@�@12Jun�@12Nov 13Jun 13Nov
Intel Xeon Phi �@�@1�@�@�@�@7�@�@�@12�@�@14
NVIDIA Tesla �@�@53�@�@�@50�@�@�@40�@�@ 39
AMD FirePro�@�@�@ 2�@�@�@ 3�@�@�@ 3�@�@�@2
�����ڂ̏ꍇ�͏d���J�E���g
�c�O������GPU���ڃX�p�R���͌����ɓ]���Ă܂��B
TOP500�Ŏg����Linpack�́A���͂��ʂ̏������x�̎w�W����Ȃ��A
����̓���ȏ������x�̎w�W������Ȃ�
Linpack���x�ƁA���A�v���̌v�Z���x�������N���Ȃ��ꍇ�������Ȃ��Ă���
����̓���ȏ������x�̎w�W������Ȃ�
Linpack���x�ƁA���A�v���̌v�Z���x�������N���Ȃ��ꍇ�������Ȃ��Ă���
Xeon-Phi��GPU���ڂɂ̓J�E���g���Ȃ��̂��ȁB
�ƂȂ�ƁA�z���W�j�A�X���w�e���W�j�A�X���Ƃ����_���_�_�Ȃ킯���낤���B
�ƂȂ�ƁA�z���W�j�A�X���w�e���W�j�A�X���Ƃ����_���_�_�Ȃ킯���낤���B
���̂���Intel��CPU��SIMD�g����Xeon-Phi�������m���̉����āA
NVIDIA��GPU��ARM��CPU�ڂ��ĒP�Ƃœ����悤�ɂ��āA
���̗��҂ő������オ����̂��Ȃ�
AMD�͏��ł��c
NVIDIA��GPU��ARM��CPU�ڂ��ĒP�Ƃœ����悤�ɂ��āA
���̗��҂ő������オ����̂��Ȃ�
AMD�͏��ł��c
464 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 01:36:18.76 ID:Qjsbm7RH
Phi�̓R�v���Z�b�T���邢�̓A�N�Z�����[�^�ł͂����Ă��uGPU�v����Ȃ��ł���B
�uLinux�������ėp��x86�}�V���v�ł����ăv���O���~���O�X�^�C����CPU���̂��́B
��������GPU��Phi�̃R�A�̂悤�ȁu�x�N�g�����j�b�g��������ėp�X�J���v���Z�b�T�v
�ł���A�����܂ŕs���R�ȃv���O���~���O�X�^�C�����������ꂸ�ɂ��킯�ŁB
�܁A���ꂾ��GPU�{���̗p�r�ɂ͕s�����ɂȂ�낤����d���Ȃ��ˁB
�uLinux�������ėp��x86�}�V���v�ł����ăv���O���~���O�X�^�C����CPU���̂��́B
��������GPU��Phi�̃R�A�̂悤�ȁu�x�N�g�����j�b�g��������ėp�X�J���v���Z�b�T�v
�ł���A�����܂ŕs���R�ȃv���O���~���O�X�^�C�����������ꂸ�ɂ��킯�ŁB
�܁A���ꂾ��GPU�{���̗p�r�ɂ͕s�����ɂȂ�낤����d���Ȃ��ˁB
xeon phi��gpgpu�̈ꕔ�ɐN�H�������ǁA���S�ɒu�������邱�Ƃ͂Ȃ����
�ꕔ�̃��[�N���[�h�������Ă͂߂�gpu��unko�Ƃ������͂Ȃ���
AMD��ARM���j�[�R�A�����āA�����������烏���`�������邩������Ȃ���
�ꕔ�̃��[�N���[�h�������Ă͂߂�gpu��unko�Ƃ������͂Ȃ���
AMD��ARM���j�[�R�A�����āA�����������烏���`�������邩������Ȃ���
���C����������GDDR5�ɂ��āA���C���������ш��300GB/sec�N���X�ɏグ�āA
Xeon Phi�̃R�A��CPU�_�C�ɏ悹�邩�A
������CPU�R�A�ɂ���AVX���A300GB/sec�̑ш�����邭�炢���������������
���ꂩ���C����������8ch DDR4�ɂ��āA�n�C�G���hGPU���݂̃������ш�m�ۂ��邩
Xeon Phi�̃R�A��CPU�_�C�ɏ悹�邩�A
������CPU�R�A�ɂ���AVX���A300GB/sec�̑ш�����邭�炢���������������
���ꂩ���C����������8ch DDR4�ɂ��āA�n�C�G���hGPU���݂̃������ш�m�ۂ��邩
467 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 01:55:48.72 ID:Qjsbm7RH
��������Knights Landing����̃\�P�b�g��Phi�ł��������
Hadoop�݂����ȕ��U�����t���[�����[�N�������ɂ�
�ш�Ɍ����������̉��Z���j�b�g���ɂƂǂ߂Ă�����
���ʂ͂Ȃ��Ă��ނ�B
MapReduce��CUDA�p�����͐��N���u����Ă邯��
���������̂̓f�B�X�N���[�gGPU�Ɍ����Ȃ���Ȃ낤�ȁB
AMD�uCPU�ƕ����������߂����珟��I�v
Hadoop�݂����ȕ��U�����t���[�����[�N�������ɂ�
�ш�Ɍ����������̉��Z���j�b�g���ɂƂǂ߂Ă�����
���ʂ͂Ȃ��Ă��ނ�B
MapReduce��CUDA�p�����͐��N���u����Ă邯��
���������̂̓f�B�X�N���[�gGPU�Ɍ����Ȃ���Ȃ낤�ȁB
AMD�uCPU�ƕ����������߂����珟��I�v
AMD�́AHSA�ɂ��CPU��GPU�̃[���R�s�[���ǂ��L���������f�����o���Ăق����Ȃ��B
PC�p��APU�̓��������ˁc
�Q�[���@�p�̂��ǂꂭ�炢������̂������[��
�Q�[���@�p�̂��ǂꂭ�炢������̂������[��
�����A���������L�c��������B
Stacked Memory Cube���������p�����Ăق����Ȃ��B
�����łȂ��Ƃ��A�L���b�V���Ɏ��܂邭�炢�̏��f�[�^�Ȃ甚�������Ȃ����ȁH
�����Ƀ[���R�s�[�̌��ʂ����Ă݂����B
Stacked Memory Cube���������p�����Ăق����Ȃ��B
�����łȂ��Ƃ��A�L���b�V���Ɏ��܂邭�炢�̏��f�[�^�Ȃ甚�������Ȃ����ȁH
�����Ƀ[���R�s�[�̌��ʂ����Ă݂����B
>>444
���ʂ̃J���������̓Z���T�[��ISP�ŏI���
���Rtegra4�y�ё���SoC�ł�ISP�͕t���Ă���
���Ȃ̂�HDR�B�e���s���ꍇ��
���ʂ͎ʐ^��I�o�̍������̂ƒႢ���̂��B�e���������čŏI�C���[�W�����
�ʐ^�Ƃ��Ƃ�����t�H�g�V���b�v�ł��炵�����A
�X�}�z���̃J�����A�v���ł�CPU���g�����\�t�g�������s�����ߎ��Ԃ�������
�������B�e���邽�߃\�t�g�ɂ���Ă͓����̂�����̂��B�e����Ƒ����Ԃꂽ���̂ɂȂ��Ďg�����̂ɂȂ�Ȃ�
�i�ꖇ�ڂ̎B�e���g�p����̎B�e�ŘI�o���C�����郂�m����3���B�e���邯�ǂˁj
tegra4��chimera�ł͂����OpenGL ES���g����GPU��CPU�̑g�ݍ��킹�ō����ɏ������邱�Ƃ��\�Ƃ�
�펞HDR�B�e���\�ƂȂ��Ă���
�g���Ă݂�킩�邯�ǁA��ʓI��HDR�A�v����2-5�b�����邯�ǁi�j�R����S800c���Ă���android�J������CPU���V���{�C�̂ł͂����Ƃ�����j
chimera�g���ƈ�u�Ȃ̂Ńg�[�^���œd�͂͌����Ă���
�iGPU��2W���Ă��Ƃ�CPU 3W��2�b��6W�ACPU+GPU��5W��0.1�b�Ƃ���0.5W���ĂȊ�����)
tegranote�̃J�����A�v���ŎB�e
http://i.imgur.com/cD7cAOs.jpg
http://i.imgur.com/icNWa7x.jpg
http://i.imgur.com/4emSmro.jpg
http://i.imgur.com/nMOmjML.jpg
���ʂ̃J���������̓Z���T�[��ISP�ŏI���
���Rtegra4�y�ё���SoC�ł�ISP�͕t���Ă���
���Ȃ̂�HDR�B�e���s���ꍇ��
���ʂ͎ʐ^��I�o�̍������̂ƒႢ���̂��B�e���������čŏI�C���[�W�����
�ʐ^�Ƃ��Ƃ�����t�H�g�V���b�v�ł��炵�����A
�X�}�z���̃J�����A�v���ł�CPU���g�����\�t�g�������s�����ߎ��Ԃ�������
�������B�e���邽�߃\�t�g�ɂ���Ă͓����̂�����̂��B�e����Ƒ����Ԃꂽ���̂ɂȂ��Ďg�����̂ɂȂ�Ȃ�
�i�ꖇ�ڂ̎B�e���g�p����̎B�e�ŘI�o���C�����郂�m����3���B�e���邯�ǂˁj
tegra4��chimera�ł͂����OpenGL ES���g����GPU��CPU�̑g�ݍ��킹�ō����ɏ������邱�Ƃ��\�Ƃ�
�펞HDR�B�e���\�ƂȂ��Ă���
�g���Ă݂�킩�邯�ǁA��ʓI��HDR�A�v����2-5�b�����邯�ǁi�j�R����S800c���Ă���android�J������CPU���V���{�C�̂ł͂����Ƃ�����j
chimera�g���ƈ�u�Ȃ̂Ńg�[�^���œd�͂͌����Ă���
�iGPU��2W���Ă��Ƃ�CPU 3W��2�b��6W�ACPU+GPU��5W��0.1�b�Ƃ���0.5W���ĂȊ�����)
tegranote�̃J�����A�v���ŎB�e
http://i.imgur.com/cD7cAOs.jpg
{kind=link}
http://i.imgur.com/icNWa7x.jpg
{kind=link}
http://i.imgur.com/4emSmro.jpg
{kind=link}
http://i.imgur.com/nMOmjML.jpg
{kind=link}
�\�P�b�g����CPU�ł̓s���s���Ń������ш�Ɍ��E������
CPU�����������}�U�[�{�[�h�ɒ��t����GDDR5�������g�����A
���ꂩCPU�̓}�U�[�{�[�h�ɒ��t���A��������DIMM�X���b�g�ō�������
8ch DDR4�Ƃ��ɂ��Ȃ���
CPU�����������}�U�[�{�[�h�ɒ��t����GDDR5�������g�����A
���ꂩCPU�̓}�U�[�{�[�h�ɒ��t���A��������DIMM�X���b�g�ō�������
8ch DDR4�Ƃ��ɂ��Ȃ���
����xeon phi�̓\�P�b�g���ɂȂ邪�A�\�P�b�g���̑ш�s����₤���߂ɍL�ш惁������MCM�œ��ڂ���Ƃ����b
300GB/s�̂�16GB�炵����
�L���b�V���K�w���ɗ��_���E�͂Ȃ��̂���?
�K�w�������ƂɃT�C�Y�͑傫���Ȃ��đ��x�͒x���Ȃ����A��p�Ό��ʂ͉����x�I�Ɉ����Ȃ��Ă������������ǁB
�K�w�������ƂɃT�C�Y�͑傫���Ȃ��đ��x�͒x���Ȃ����A��p�Ό��ʂ͉����x�I�Ɉ����Ȃ��Ă������������ǁB
476 �FSocket774�F2014/01/10(��) 13:04:15.96 ID:VFjl42cf
>>470
�A�h�r�̃t�H�g�V���b�v�Ȃ�Cpu OpenGL Gpgpu�̘A�g������������������HSA�Ή�������ʔ���������
���łɃ}���g���Ή�������F�X�����Ȃ��
�A�h�r�̃t�H�g�V���b�v�Ȃ�Cpu OpenGL Gpgpu�̘A�g������������������HSA�Ή�������ʔ���������
���łɃ}���g���Ή�������F�X�����Ȃ��
8x15=120�R�A���\��Ivy Bridge-EX�̓R�X�g����������Ƃ��Ă��A
Ivy Bridge-EP�ł�4x12=48�R�A�܂Ńm�[�h�ԒʐM�����Ȃ��Ă����B
�\�P�b�g������̃R�A��������������AXeon Phi 61�R�A�̂悤��
�v���Z�b�T�Ƒ傫���Ⴄ�킯�ł͂Ȃ��Ȃ��Ă���B
Intel�ő�̓G��Intel�Ƃ����p�^�[���ƌ����Ȃ����Ȃ�
Ivy Bridge-EP�ł�4x12=48�R�A�܂Ńm�[�h�ԒʐM�����Ȃ��Ă����B
�\�P�b�g������̃R�A��������������AXeon Phi 61�R�A�̂悤��
�v���Z�b�T�Ƒ傫���Ⴄ�킯�ł͂Ȃ��Ȃ��Ă���B
Intel�ő�̓G��Intel�Ƃ����p�^�[���ƌ����Ȃ����Ȃ�
478 �F,,�E�L�́M�E,,�j��-�������F2014/01/10(��) 18:55:00.89 ID:Qjsbm7RH
�����̓��C�e���V�œK���^�ƃX���[�v�b�g�œK���ōœK�ȃ`�b�v��I�ׂ����B
Xeon E3��Atom C2000(Avoton)���ȓd�̓T�[�o�s��ŋ������Ă邵
�����Ӗ��ł����ΑI�����������Ă���B
Xeon E3��Atom C2000(Avoton)���ȓd�̓T�[�o�s��ŋ������Ă邵
�����Ӗ��ł����ΑI�����������Ă���B
>>463
ARM��SIMD�H������
ARM��SIMD�H������
���낻�냁������������邩�Ȃ�
����������������������o������
���{���������ƃ������ĎQ��������ẮB
>>483
�t�@�u�̂Ă��A�̂Ă������Ă�x���_�ɂ������Ȃ�ł������ȑ��k��w
�t�@�u�̂Ă��A�̂Ă������Ă�x���_�ɂ������Ȃ�ł������ȑ��k��w
�����Ƌ��Z�ɘa����1�h��200�~�ɂ�������̂��B
>>476
HSA��Mantle�ɥ��AMD�̓C�C�^�}�����Ă�B
������Ăق������B
>>480
����AHSA�ȊO��GPU��CPU�̃�������Ԃ�ʂŊǗ����Ă�B
HSA��GPU��CPU�������f�[�^�ɓ����|�C���^�ŃA�N�Z�X�ł���B
GPU�p�ACPU�p�̋�ʂȂ����B
HSA��Mantle�ɥ��AMD�̓C�C�^�}�����Ă�B
������Ăق������B
>>480
����AHSA�ȊO��GPU��CPU�̃�������Ԃ�ʂŊǗ����Ă�B
HSA��GPU��CPU�������f�[�^�ɓ����|�C���^�ŃA�N�Z�X�ł���B
GPU�p�ACPU�p�̋�ʂȂ����B
HSA��Mantle���n�[�h���グ��������B
>>486
�Ƃ肠�������������������[���R�s�[�Ȃ�Ȃ���
HSA�ɑΉ����Ȃ��Ɠ����������̒���CPU�pGPU�p2�f�[�^���K�v���Ă��ƁH
���������Ȃ烁���������̃����b�g���āu�����I�ɋ߂��v�����Ȃ̂���
�Ƃ肠�������������������[���R�s�[�Ȃ�Ȃ���
HSA�ɑΉ����Ȃ��Ɠ����������̒���CPU�pGPU�p2�f�[�^���K�v���Ă��ƁH
���������Ȃ烁���������̃����b�g���āu�����I�ɋ߂��v�����Ȃ̂���
>>488
�����ȂB
���̂Ƃ���A
�EPCIe�̐�ł͂Ȃ�CPU�_�C�̃C���^�[�R�l�N�g�Ɍq�����Ă���
�EGPU�p��DRAM�`�b�v���ʂł͂Ȃ��������̂����L���Ă���
���炢�����ŁA�킴�킴GPU�̗̈��CPU�̗̈���R�s�[���Ȃ��狤�L���Ă���Ƃ��������͕ς��Ȃ��B
��C�ɂ��ׂĂ�ς���̂̓��N�X���������A�J�����\�[�X������Ȃ����ŁA
�������ς��Ă����Ă�悤���ˁB
�����ȂB
���̂Ƃ���A
�EPCIe�̐�ł͂Ȃ�CPU�_�C�̃C���^�[�R�l�N�g�Ɍq�����Ă���
�EGPU�p��DRAM�`�b�v���ʂł͂Ȃ��������̂����L���Ă���
���炢�����ŁA�킴�킴GPU�̗̈��CPU�̗̈���R�s�[���Ȃ��狤�L���Ă���Ƃ��������͕ς��Ȃ��B
��C�ɂ��ׂĂ�ς���̂̓��N�X���������A�J�����\�[�X������Ȃ����ŁA
�������ς��Ă����Ă�悤���ˁB
PS4��XBOX One���Q�[���@�̃��C���ɂȂ��
VRAM���v�������e�ʂ��傫���Ȃ邩��
VRAM�ƃ��C�������������Ȃ���
�Q�[������Ƃ�����VRAM�Ɋ��蓖�Ă郁�����𑽂�����K�v���o�Ă��邵
32bit�̃Q�[�����ƃ��C���������e�ʂ��������邩��
APU��VRAM�ƃ��C���������̓����͕K�{�����ɂȂ��Ă�����
Battlefield 4�Ȃ�Đ�����VRAM�e�ʂ�3GB�������
VRAM���v�������e�ʂ��傫���Ȃ邩��
VRAM�ƃ��C�������������Ȃ���
�Q�[������Ƃ�����VRAM�Ɋ��蓖�Ă郁�����𑽂�����K�v���o�Ă��邵
32bit�̃Q�[�����ƃ��C���������e�ʂ��������邩��
APU��VRAM�ƃ��C���������̓����͕K�{�����ɂȂ��Ă�����
Battlefield 4�Ȃ�Đ�����VRAM�e�ʂ�3GB�������
�������e�ʁE�ш�������Ă܂���Battlefield
APU��Battlefield? �Ȃ��Ȃ��B
BF2�̍ō��掿�̊ԈႢ����H
�}���g����45%������Ęb����
�b�����Ƃ��Ă�����c�c�@�M���M���V�ׂ邩�ǂ������ďꍇ�ɂ͂�������������������
�܂�Ń_���ȏꍇ�Ƃ��A�ꉞ�V�ׂ邯�nj��コ�������Ƃ����ƈӖ��Ȃ���������
�b�����Ƃ��Ă�����c�c�@�M���M���V�ׂ邩�ǂ������ďꍇ�ɂ͂�������������������
�܂�Ń_���ȏꍇ�Ƃ��A�ꉞ�V�ׂ邯�nj��コ�������Ƃ����ƈӖ��Ȃ���������
�n�C�G���hGPU�̃v���Z�X���A�[�L�e�N�`�������ʂ��Ă��܂��ȏ�A
���̑���2���ȏ�̍���t������Ƃ����̂͋��ٓI���B
���̑���2���ȏ�̍���t������Ƃ����̂͋��ٓI���B
���̐}�������
PowerPC�ł�64bit���ő����x���Ȃ��Ă邪
x86�ł�64bit���ő��������Ȃ��Ă�
PowerPC�̔�r�Ɏg���Ă邱�̍���Mac��
�J�[�l����32bit���Ƃ����낢�날�邪
����ς�x64�Ń��W�X�^�����������Ƃ̌��ʂ͂���̂���
http://blog-imgs-22-origin.fc2.com/d/o/u/doubleko/64_32bench100206.gif
http://doubleko.blog18.fc2.com/blog-entry-2957.html
PowerPC�ł�64bit���ő����x���Ȃ��Ă邪
x86�ł�64bit���ő��������Ȃ��Ă�
PowerPC�̔�r�Ɏg���Ă邱�̍���Mac��
�J�[�l����32bit���Ƃ����낢�날�邪
����ς�x64�Ń��W�X�^�����������Ƃ̌��ʂ͂���̂���
http://blog-imgs-22-origin.fc2.com/d/o/u/doubleko/64_32bench100206.gif
{kind=link}
http://doubleko.blog18.fc2.com/blog-entry-2957.html
PPC 64bit�͖{���ɔėp���W�X�^���̊g������������
�ʏ�p�r�ł͑����Ȃ�v�f���Ȃ�
�ʏ�p�r�ł͑����Ȃ�v�f���Ȃ�
����Ⴀx86��8�Ƃ����ɒ[�ɏ��Ȃ�����������16�ɑ�������R�[�h���Z���Ȃ邾�낤
PPC��32�r�b�g�̎�����32���������APPC��64�r�b�g�o�C�i���͎��ۓ��삪�x���Ȃ����B
RISC�̓L���b�V�������[�h�C�x���g�����炷�̂��������̒�����A�������A�h���X��4�o�C�g����8�o�C�g�ɑ������炻�ꂾ���ŃL���b�V���̃v���b�V���[���オ���Đ��\��������
PPC��32�r�b�g�̎�����32���������APPC��64�r�b�g�o�C�i���͎��ۓ��삪�x���Ȃ����B
RISC�̓L���b�V�������[�h�C�x���g�����炷�̂��������̒�����A�������A�h���X��4�o�C�g����8�o�C�g�ɑ������炻�ꂾ���ŃL���b�V���̃v���b�V���[���オ���Đ��\��������
>>489
�f�^����������
HSA�łȂ��Ă��[���R�s�[�͏o����A
�Ƃ�����HSA�͂����܂ł��t���[�����[�N�̈��ł�����
����ȊO�͏o���Ă͂Ȃ�Ȃ��Ƃ������R�Ȃǖ���
http://pc.watch.impress.co.jp/docs/column/kaigai/20131028_621178.html
�f�^����������
HSA�łȂ��Ă��[���R�s�[�͏o����A
�Ƃ�����HSA�͂����܂ł��t���[�����[�N�̈��ł�����
����ȊO�͏o���Ă͂Ȃ�Ȃ��Ƃ������R�Ȃǖ���
http://pc.watch.impress.co.jp/docs/column/kaigai/20131028_621178.html
HSA�Ȃ�Ă܂��n�܂��Ă���Ȃ���
CPU��GPU�œ���̃�������ԁA�����f�[�^�ɓ����|�C���^�ŃA�N�Z�X�Ƃ������́A
CPU�̗v�������C�e���V�ƁAGPU�̗v�����鍂�]�����x�̗�����
���˔�����������(HMC��)���o�Ă���A�t�Ɂu���S��CPU�̃R�A�̈ꕔ�v
�Ƃ���dGPU�N���X�̃��j�b�g�������CPU�`�b�v���o�Ă���Ƃ������͖����̂��ȁH
(TDP��200W�Ƃ��̃`�b�v�ɂȂ��Ă��܂����ˁH)
CPU�̗v�������C�e���V�ƁAGPU�̗v�����鍂�]�����x�̗�����
���˔�����������(HMC��)���o�Ă���A�t�Ɂu���S��CPU�̃R�A�̈ꕔ�v
�Ƃ���dGPU�N���X�̃��j�b�g�������CPU�`�b�v���o�Ă���Ƃ������͖����̂��ȁH
(TDP��200W�Ƃ��̃`�b�v�ɂȂ��Ă��܂����ˁH)
��������ԋ��L������Ă��Ƃ̓R�q�[�����V�ǂ�����낤�ˁB
����Ȃ�GPU����CPU�R�A�������ق����悳�����ȋC������
CPU�̃p�C�v���C����GPU�݂����ȃ��j�b�g����荞�ނƂ����̂�Intel�̘_���������ŏo�Ă��Ǝv��
ARM��64bit���͌����I��6�{���x�ɑ����Ȃ�͂��Ȃ�
��������������
��������������
����͂Ȃ�Ƃ��������ł����H
x86�F32bit
AVX�F256bit
��8�{��
AVX�F256bit
��8�{��
���(���܂�)���_
ARM�~�̓��͉��������������B
x86��SP���X�^�b�N�|�C���^�Ȃ̂Ŏ���7�{�̃��W�X�^
ARM��R13���X�^�b�N�|�C���^�AR14�������N���W�X�^
R15���v���O�����J�E���^�Ȃ̂Ŏ���R0����R12��13�{
���ꂪ64bit����31�{�ɂȂ�
128bit�̃��f�B�A���W�X�^��16�{��32�{�ɂȂ�
ARM��x86�̂悤��64bit�ő����Ȃ�̂��ȁH
ARM��R13���X�^�b�N�|�C���^�AR14�������N���W�X�^
R15���v���O�����J�E���^�Ȃ̂Ŏ���R0����R12��13�{
���ꂪ64bit����31�{�ɂȂ�
128bit�̃��f�B�A���W�X�^��16�{��32�{�ɂȂ�
ARM��x86�̂悤��64bit�ő����Ȃ�̂��ȁH
�{����x86��8�{�����ǁAPentiumPro�̎��_�œ������W�X�^��40�{�ɂȂ��ĂāA
���W�X�^���l�[�~���O�@�\�Ŏ����Ĕz�u�������ĕ��������ǁH
���W�X�^���l�[�~���O�@�\�Ŏ����Ĕz�u�������ĕ��������ǁH
�����͂��ꂱ���D���ɕύX�ł����Ȃ��́H
PentiumPro����킴�킴��������K�v�Ȃ��悤�ȋC�������
PentiumPro����킴�킴��������K�v�Ȃ��悤�ȋC�������
�����̏��āAFuturemark�ł�64bit�ł�
��3DMark���쐬���������Ƃ���A���\�͌��サ�����A
�����̊�����7%�ɗ��܂�A
��64bit���������e�X�g�̌��ʂɂ�
���傫�ȉe����^���Ȃ����Ƃ����������B
x86�Ɠ����悤�ɐ��p�[�Z���g�����Ȃ��
��3DMark���쐬���������Ƃ���A���\�͌��サ�����A
�����̊�����7%�ɗ��܂�A
��64bit���������e�X�g�̌��ʂɂ�
���傫�ȉe����^���Ȃ����Ƃ����������B
x86�Ɠ����悤�ɐ��p�[�Z���g�����Ȃ��
���ł�4�����L�A�u�؍��n�C�j�b�N�X�ƐV�^�����̃������[�ʎY�v
http://kabutan.jp/news/marketnews/?b=n201401060092
http://kabutan.jp/news/marketnews/?b=n201401060092
��������ԋ��L��XEON��Knights Landing�̂Q�\�P��
���������x���̂��Y�݂ǂ���
���������x���̂��Y�݂ǂ���
�v���O���}���猩����v���O���~���O���f���I�ɂ�
�Ex86�@EAX/EBX/ECX/EDX/ESI/EDI/ESP/EBP/XMM0�`7
�Ex64�@RAX�`RBP�{R8�`R15/XMM0�`15
���W�X�^���l�[����PentiumM����������Ă����悤�ȋC������B
x86�͊�{�v���Â����āA�R���p�C���쐬�҂��y�ł���悤��
���W�X�^���Ƃɗp�r�����߂��Ă����E�E�E�E���ǁA����Ȃ���
����Ă��獂���ɂȂ�Ȃ��̂ŋߑ�̃R���p�C���͂�����x����
���[����������B
�Ex86�@EAX/EBX/ECX/EDX/ESI/EDI/ESP/EBP/XMM0�`7
�Ex64�@RAX�`RBP�{R8�`R15/XMM0�`15
���W�X�^���l�[����PentiumM����������Ă����悤�ȋC������B
x86�͊�{�v���Â����āA�R���p�C���쐬�҂��y�ł���悤��
���W�X�^���Ƃɗp�r�����߂��Ă����E�E�E�E���ǁA����Ȃ���
����Ă��獂���ɂȂ�Ȃ��̂ŋߑ�̃R���p�C���͂�����x����
���[����������B
���W�X�^�����p�r���ƂɈ���Ă�ƃA�Z���u���ŃR�[�h�������ɂ킩��₷��
���Ƃ��A�ėp���W�X�^��16����A�[�L�e�N�`�����������Ƃ��āA
16�̃��W�X�^�̖��O�ɘA�Ԃ��U���Ă��邾�����ƁA
�R�[�h���p�b�ƌ��Ă����̃��W�X�^���킩�炸�ɉ�͂��ʓ|�ɂȂ�
�Ƃ��낪�A16�̔ėp���W�X�^���������Ƃ��āA
�ŏ���8�ɂ́A�p�r���ƂɈႤ���O�����āA���Ƃ�8�̖��O��A�ԂŐU��悤�ɂ���ƁA
�A�Z���u���Ō������ɁA������x���W�X�^�̗p�r���킩���ė������₷��
���Ƃ��A�ėp���W�X�^��16����A�[�L�e�N�`�����������Ƃ��āA
16�̃��W�X�^�̖��O�ɘA�Ԃ��U���Ă��邾�����ƁA
�R�[�h���p�b�ƌ��Ă����̃��W�X�^���킩�炸�ɉ�͂��ʓ|�ɂȂ�
�Ƃ��낪�A16�̔ėp���W�X�^���������Ƃ��āA
�ŏ���8�ɂ́A�p�r���ƂɈႤ���O�����āA���Ƃ�8�̖��O��A�ԂŐU��悤�ɂ���ƁA
�A�Z���u���Ō������ɁA������x���W�X�^�̗p�r���킩���ė������₷��
SP��PC��FLAG�ɘA�Ԃӂ��Ă��Ȃ��B�N����˂�B
RISC�ł��[�����W�X�^�ɘA�ԐU�����肷�邩��A�ƊE���K�ł��傤�B
522 �F,,�E�L�́M�E,,�j��-�������F2014/01/12(��) 19:18:11.79 ID:A/1sVEii
>>517
�����Ńp�b�P�[�W���ڂł���
���ʂ����傫���Ȃ�KNL��16GB��Near Memory�ʂ�Xeon�ɂ�
�ڂ��Ă��܂���������ˁH
QPI��4�\�P�b�g��������64GB�B
�f�[�^�x�[�X�̋���e�[�u���̑���Ƃ������[�𗧂������B
�����Ńp�b�P�[�W���ڂł���
���ʂ����傫���Ȃ�KNL��16GB��Near Memory�ʂ�Xeon�ɂ�
�ڂ��Ă��܂���������ˁH
QPI��4�\�P�b�g��������64GB�B
�f�[�^�x�[�X�̋���e�[�u���̑���Ƃ������[�𗧂������B
523 �F,,�E�L�́M�E,,�j��-�������F2014/01/12(��) 19:22:27.67 ID:A/1sVEii
�{���̔ėp���W�X�^�����A�Ԃ�U���Ă��܂��Ɨp�r�ʂ̃��W�X�^����ɕʂ�
Opcode������U��Ȃ��Ƃ����Ȃ��Ȃ�B
x86��*BP�����W�X�^�I�y�����h�Ɋ���U��v�͐����������Ǝv����B
Opcode������U��Ȃ��Ƃ����Ȃ��Ȃ�B
x86��*BP�����W�X�^�I�y�����h�Ɋ���U��v�͐����������Ǝv����B
���W�X�^���▽�ߖ��Ȃ�ăj�[���j�b�N�����̘b����Ȃ��̂��B
OP�R�[�h��1��1�ɑΉ�����K�v����Ȃ��B
OP�R�[�h��1��1�ɑΉ�����K�v����Ȃ��B
x86�ɂ�opcode�Ŏg�����W�X�^���Œ肳��閽�߂����������邩��...�Ƃ����b�łȂ���
LOOP�Ƃ�REP MOVS�Ȃ�ECX���J�E���^�ŌŒ�B
���s�[�g�n���߂͒x����ŁA������CPU���Ɠ������߂�
�ϊ�����ƒ�ō����ȕʃI�y���[�V�����ɕϊ�������
�v�����ǂˁB
���s�[�g�n���߂͒x����ŁA������CPU���Ɠ������߂�
�ϊ�����ƒ�ō����ȕʃI�y���[�V�����ɕϊ�������
�v�����ǂˁB
����MRAM�����p������A
DRAM���͂₢SRAM�ɋ߂�������������
DRAM��荂���r�b�g���x�ŋl�ߍ��߂���
DRAM���͂₢SRAM�ɋ߂�������������
DRAM��荂���r�b�g���x�ŋl�ߍ��߂���
�������⒴�����R���s���[�^������Ƃ�����ꂽ�W���Z�t�\���f�q���č�������Ă��
�R�p���[�_�[�̒����[�m�C�YADC�ȂǓ���p�r�Ɏg���Ă���
�W���Z�t�\����-200�x���炢�܂ŗ�₷�Ƃ����̂��l�b�N�łȁB
�y�C�x���g���|�[�g�zIntel��SD�J�[�h�^�R���s���[�^�uEdison�v�̏ڍׂ����� �`512KB�������A2GB�X�g���[�W�A�����@�\�Ȃǂ��l�ߍ��� - PC Watch
http://pc.watch.impress.co.jp/docs/news/event/20140111_630478.html
�ƂȂ�ƁC����͂�͂�t���A�Z���u���őg�ނ̂��������C�Ƃ������ƂɂȂ�̂��
http://pc.watch.impress.co.jp/docs/news/event/20140111_630478.html
�ƂȂ�ƁC����͂�͂�t���A�Z���u���őg�ނ̂��������C�Ƃ������ƂɂȂ�̂��
>>531
>�t���A�Z���u���őg�ނ̂��������C�Ƃ������ƂɂȂ�
�ǂ����ǂ����߂����炻��ȃg���`�L�Ȍ��_���o�Ă���̂���������
>�t���A�Z���u���őg�ނ̂��������C�Ƃ������ƂɂȂ�
�ǂ����ǂ����߂����炻��ȃg���`�L�Ȍ��_���o�Ă���̂���������
512KB�����DOS�����Ȃ��炢����ł�C/C++�ŏ����܂���B���C�u�����ɐ���͐����邯��ǂ��B�f�[�^�\���̃������œK�����{�����Ƃ��l����A�t���A�Z���u���͂ނ��������ׂ��ł��傤�B
512KB��LPDDR2�`�b�v�Ȃ�Ă���̂�
����ȏ��e�ʂȂ�I���`�b�vSRAM�ɂ�������̂�
����ȏ��e�ʂȂ�I���`�b�vSRAM�ɂ�������̂�
11���Ɉ�ʔ̔����J�n���ꂽGalileo��512KB��SRAM���`�b�v�ɓ�������Ă�悤�ł���
���߃Z�b�g��Pentium�݊��Ƃ̂��Ƃł��������\�͔@�����̂��̂Ȃ�ł����H
���߃Z�b�g��Pentium�݊��Ƃ̂��Ƃł��������\�͔@�����̂��̂Ȃ�ł����H
��itron�Ƃ����̂Ă̑g�ݍ���OS�p�Ȃ瓮���ł���
�Ă�x86������Ƃ����č��XDOS�����̂̓A�z�߂���
�܂������܂Ń��[�N�����������Ȃ���TCP/IP����̎������邾���Ŕߖ��グ��������
�Ă�x86������Ƃ����č��XDOS�����̂̓A�z�߂���
�܂������܂Ń��[�N�����������Ȃ���TCP/IP����̎������邾���Ŕߖ��グ��������
�W���Z�t�\������
http://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A7%E3%82%BB%E3%83%95%E3%82%BD%E3%83%B3%E5%8A%B9%E6%9E%9C
�����̎��g���͓d��1�~���{���g������483.5979 GHz�ł���B
�W���Z�t�\���f�q�����[�I�I
SF�̐��E�݂����Ȃ��Ƃ������ɋN����̂ȥ���B
���ꔭ�������l�Ƀm�[�x���܂��������A�Ǝv�������������Ă���
��͉��x��������B
�N���퉷�Œ��`���ł���悤�ɂ��āB
http://ja.wikipedia.org/wiki/%E3%82%B8%E3%83%A7%E3%82%BB%E3%83%95%E3%82%BD%E3%83%B3%E5%8A%B9%E6%9E%9C
�����̎��g���͓d��1�~���{���g������483.5979 GHz�ł���B
�W���Z�t�\���f�q�����[�I�I
SF�̐��E�݂����Ȃ��Ƃ������ɋN����̂ȥ���B
���ꔭ�������l�Ƀm�[�x���܂��������A�Ǝv�������������Ă���
��͉��x��������B
�N���퉷�Œ��`���ł���悤�ɂ��āB
�K���E����f�����̂Ȃ������ゾ�̉����̂Ƃ����R���s���[�^�ɂ��Ȃ����
�V���R�������E�ɂԂ��������Ă��炩�ȁH
�V���R�������E�ɂԂ��������Ă��炩�ȁH
������Ə퉷���`���\���Ă��邗
>>536
���[�N���������̂͊O�t����DRAM����
����SRAM 512KB��(4K x128�y�[�W or 512K x1�y�[�W)����������Ԃ̓���̃y�[�W�Ɋ���U���Ƃ�������
���[�N���������̂͊O�t����DRAM����
����SRAM 512KB��(4K x128�y�[�W or 512K x1�y�[�W)����������Ԃ̓���̃y�[�W�Ɋ���U���Ƃ�������
�K���E���q�f���ĉ���������Ȃ��B
�����܂Ŕ������i�ނƁA���������ĕs������Ȃ��́H
�����܂Ŕ������i�ނƁA���������ĕs������Ȃ��́H
�K���E���q�f�͍����g�p�����̂Ƃ��Ɏg���Ă邪�A
�ʏ�̃��W�b�N�̔ėp�i�ɂ͎g���ĂȂ���
�ʏ�̃��W�b�N�̔ėp�i�ɂ͎g���ĂȂ���
�����S�z
GaAs��RF��H�Ɏg�����̂Ń��W�b�N��H�ɂ͎g���Ȃ���B
538�̌�����������Ă̂�III-V���`���l���̂��ƂłȂ���
BS�A���e�i�Ƃ��A12GHz�Ƃ��̓d�g�����Ă邩��A
�V���R������Ȃ������̂��g���Ă��
12GHz�Ŏ��d�g��BS�A���e�i��1-2GHz�ɕϊ����Ă�
�V���R������Ȃ������̂��g���Ă��
12GHz�Ŏ��d�g��BS�A���e�i��1-2GHz�ɕϊ����Ă�
�K����f�������o���l���܂�����Ƃ͋���
��̂Ɏ�����̖{���Ƃ������̖ڂ����Ȃ������̂�
n�^�̈ړ��x��Si��6.5�{�قǂ�����̂́Ap�^��0.85�{�����Ȃ�����
Si-CMOS���S���ɂȂ��Ă����ɏ��Ȃ��Ȃ����̂�
���̃A���o�����X�́A�|�X�gSi�̌Ăѐ������������̂�Si��
�Ѓ`���l���̓��삾��������ŁACMOS�S���̍��A����III-V����
GaAs�𐄂��l�͂��Ȃ�
��̂Ɏ�����̖{���Ƃ������̖ڂ����Ȃ������̂�
n�^�̈ړ��x��Si��6.5�{�قǂ�����̂́Ap�^��0.85�{�����Ȃ�����
Si-CMOS���S���ɂȂ��Ă����ɏ��Ȃ��Ȃ����̂�
���̃A���o�����X�́A�|�X�gSi�̌Ăѐ������������̂�Si��
�Ѓ`���l���̓��삾��������ŁACMOS�S���̍��A����III-V����
GaAs�𐄂��l�͂��Ȃ�
GaAs�͍����g�p�r�ł�GaN�ɐZ�H����Ă��Ă��
GaN�͍����g��d�͔����̂Ɍ����Ă�
��d�͕s�v�Ȃ�GaN�̕K�v�͂Ȃ���
��d�͕s�v�Ȃ�GaN�̕K�v�͂Ȃ���
90�N���2�N��top500��1�ʂ���������NAL�i��JAXA�j�̐��l�����i�x�m�ʁj��
GaAs���g���Ă����B�x�N�g���}�V���ŁA�ŋ߂�LINPACK�Ԓ��Ƃ�
�قȂ�FFT�Ȃǂł������Ƒ���������
ttp://news.mynavi.jp/articles/2011/09/20/miyoshi_sympo/
ttp://museum.ipsj.or.jp/computer/super/0020.html
GaAs���g���Ă����B�x�N�g���}�V���ŁA�ŋ߂�LINPACK�Ԓ��Ƃ�
�قȂ�FFT�Ȃǂł������Ƒ���������
ttp://news.mynavi.jp/articles/2011/09/20/miyoshi_sympo/
ttp://museum.ipsj.or.jp/computer/super/0020.html
�Ȃ�LED�Ȃ��܂߂Đ�����Ɋ������܂ꂻ��������>Ga�n
���[���b�p�͂Ȃɂ��������̂��悭�킩����
���X�N���قƂ�ǖ������̂�����͑ʖڂ���͑ʖڂƂ��K�����āA
�����X�N�Ȃ��̂������ɂ����肵�Ă邵
�܂���X�N�ł��}�X�R�~����������K�����č����X�N�ł��}�X�R�~�������Ȃ���K�����Ȃ�
���{�݂����ȍ������邯�ǂ�
���X�N���قƂ�ǖ������̂�����͑ʖڂ���͑ʖڂƂ��K�����āA
�����X�N�Ȃ��̂������ɂ����肵�Ă邵
�܂���X�N�ł��}�X�R�~����������K�����č����X�N�ł��}�X�R�~�������Ȃ���K�����Ȃ�
���{�݂����ȍ������邯�ǂ�
���{���E�@�n�[�u������ɂ��đ喃�K�������肵�Ă邵
���������̂͂��肪��
���������̂͂��肪��
�E�@�n�[�u���ǂ�ǂ�K�����Ă����Ă邼�Ԃɍ����ĂȂ�������
�����������݂��m���ĂȂ����̂��K������킯�ɂ������Ȃ��̂ŁA�ŋ߂͐����Ƃ��ŋK�����悤�Ƃ������b���������悤��
�����������݂��m���ĂȂ����̂��K������킯�ɂ������Ȃ��̂ŁA�ŋ߂͐����Ƃ��ŋK�����悤�Ƃ������b���������悤��
����͍H�Ɛ��i�K�����Ă��ΒY�̔��d��������ł͈Ӗ��Ȃ��Ƃ���
�b������悤���ȁB���d�������邶��Ȃ��͈̂ꕔ�̐�i������
�b������悤���ȁB���d�������邶��Ȃ��͈̂ꕔ�̐�i������
�ΎR�����ŏ���ɏo�Ă����肷�邵��
�_�j���[�����
>>555
�C�ꂩ��̕��o�����l����Ƃ���ɈӖ��͂Ȃ��Ȃ�ȁB
�܂�����͂Ƃ�����
���̗������^�[�r���^�������Η͂ŕ��̉��H���ɐ���₻�̑������������̂��L��
�C�ꂩ��̕��o�����l����Ƃ���ɈӖ��͂Ȃ��Ȃ�ȁB
�܂�����͂Ƃ�����
���̗������^�[�r���^�������Η͂ŕ��̉��H���ɐ���₻�̑������������̂��L��
�ƒ�p�ΒY�X�g�[�u�����ɐΒY�̌����x���Ƃ�����Ă鍑�Ƃ������łȁc
���{�̉Η͔��d���͏d���������O���ɏo�Ȃ��悤�ɂȂ��Ă��
�r�C����PC�ENOx�ESOx�����ߒ��ł��łɎ���Ă��܂�����
�r�C����PC�ENOx�ESOx�����ߒ��ł��łɎ���Ă��܂�����
���ꂩ�|��
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
Method and system for separate compilation of device code embedded in host code
https://www.google.com/patents/US20130305233
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
Method and system for separate compilation of device code embedded in host code
https://www.google.com/patents/US20130305233
���悢��Google�Z���Z�ސ��v���Z�T���o�ꂷ��̂�
�Ƃ��Ƃ�Apple�ƒ��荇�����肾��
�Ƃ��Ƃ�Apple�ƒ��荇�����肾��
Google�̓���������NVIDIA���o�肵���̏E���Ă�����������
564 �FSocket774�F2014/01/16(��) 20:23:43.50 ID:xMxOBXP0
>>562
�W���p�[���I
�W���p�[���I
�O�X���ɓX�܂�POS���W��Windows�œ����Ă���Ƃ����b�����������ǁA
�č��̉Ɠd�ʔ̓XTarget�X����Windows POS���W����N���W�b�g�J�[�h�̎��C���ƈÏؔԍ������疜�������o�������Ăŗ��ꂪ�ς�邩��
�č��̉Ɠd�ʔ̓XTarget�X����Windows POS���W����N���W�b�g�J�[�h�̎��C���ƈÏؔԍ������疜�������o�������Ăŗ��ꂪ�ς�邩��
> Method and system for ...
��
on-demand.gputechconf.com/gtc-express/2012/presentations/gpu-object-linking.pdf
�Ɠ������e�Ɍ����邪�c�����Ă�l�����������B
�|��Ɓcobj���ɖ��܂��Ă�f�o�C�X�R�[�h�������N����A�݂����Șb�B�܂�����CPU�A�[�L�e�N�`���Ƃ͊W�Ȃ��B
��
on-demand.gputechconf.com/gtc-express/2012/presentations/gpu-object-linking.pdf
�Ɠ������e�Ɍ����邪�c�����Ă�l�����������B
�|��Ɓcobj���ɖ��܂��Ă�f�o�C�X�R�[�h�������N����A�݂����Șb�B�܂�����CPU�A�[�L�e�N�`���Ƃ͊W�Ȃ��B
Instruction-optimizing processor with branch-count table in hardware
CPU�܂���GPU�e�Ƀg�����X���[�^���Ă�
��l�C�e�B�u��������HW decoder������ăg�����X���[�^�ɂ܂킷
��l�C�e�B�u���߂ɑΉ�����œK�����ꂽ�l�C�e�B�u���߂́A
�܂��g�����߂ɖ��߃L���b�V���Ɋi�[�����
�g�����X���[�^������s���j�b�g�ɂ܂킷
CPU�܂���GPU�e�Ƀg�����X���[�^���Ă�
��l�C�e�B�u��������HW decoder������ăg�����X���[�^�ɂ܂킷
��l�C�e�B�u���߂ɑΉ�����œK�����ꂽ�l�C�e�B�u���߂́A
�܂��g�����߂ɖ��߃L���b�V���Ɋi�[�����
�g�����X���[�^������s���j�b�g�ɂ܂킷
Intel�A���o�C���ƃf�[�^�Z���^�[�������D����2�N�Ԃ�̑��v
http://www.itmedia.co.jp/news/articles/1401/17/news042.html
http://www.itmedia.co.jp/news/articles/1401/17/news042.html
Sony creates custom PS3 hardware for PlayStation Now
http://www.eurogamer.net/articles/digitalfoundry-2014-sony-creates-custom-ps3-for-playstation-now
http://www.eurogamer.net/articles/digitalfoundry-2014-sony-creates-custom-ps3-for-playstation-now
���_���n�[�h�ŕ����N���C�A���g�T�|�[�g�ł��Ȃ��Q�[���z�M�ɉ��̎|���������Ȃ�
�����̃y�[�X������
�@�撣���ăJ�X�^�����W�b�N������Ă������ɔėpCPU�ɔ�����邩��
�@�����T������Z�Ȃǂ̖Œ��ꒃ�������镪��ł����y�C���Ȃ�
�����̃y�[�X���x���Ȃ�
�@�J�X�^�����W�b�N�̎��������т�̂Ńy�C���镪�삪��������
��������~
�@�ėpCPU�A���r���[��GPU�̗L�����삪�h�J�X�^�������Ȃ��ق�
�@�����Ȏs��h�����ɏk�����čs��
�������n��X�p�R���@����ς�����͐��\�A�u���v��100�{
�@ttp://www.nikkei.com/article/DGXNZO65257670U4A110C1TJM000/
������MD��p�@ MDGRAPE-4 �J���ƍ���̓W�J
�@ttp://www.bscrc.jp/freePresen_131018/131018MDGRAPE4s.pdf
�@ttp://www.bscrc.jp/event.html
�@�撣���ăJ�X�^�����W�b�N������Ă������ɔėpCPU�ɔ�����邩��
�@�����T������Z�Ȃǂ̖Œ��ꒃ�������镪��ł����y�C���Ȃ�
�����̃y�[�X���x���Ȃ�
�@�J�X�^�����W�b�N�̎��������т�̂Ńy�C���镪�삪��������
��������~
�@�ėpCPU�A���r���[��GPU�̗L�����삪�h�J�X�^�������Ȃ��ق�
�@�����Ȏs��h�����ɏk�����čs��
�������n��X�p�R���@����ς�����͐��\�A�u���v��100�{
�@ttp://www.nikkei.com/article/DGXNZO65257670U4A110C1TJM000/
������MD��p�@ MDGRAPE-4 �J���ƍ���̓W�J
�@ttp://www.bscrc.jp/freePresen_131018/131018MDGRAPE4s.pdf
�@ttp://www.bscrc.jp/event.html
�����Z�p�ō�������p��H�̂ق������\���������
�ėpCPU �ɐ�p�A�N�Z�����[�^���q����悤�ɂ���\�z�Ȃ�Ăǂ�����?
�܂��ATorrenza���Ă������ǂˁB
�܂��ATorrenza���Ă������ǂˁB
�̂�opteron�̃\�P�b�g�ɂ�����FPGA���������ǂ�
AMD��������������������torrenza
AMD��������������������torrenza
CPU+FPGA�̓C���e�����n�߂������
>561
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
�̓����W�҂̑O��
Ben Hertzberg - intel
Madhu Swarna - intel
Ross Segelken - intel
Rupert Brauch - ?Hewlett-Packard
David Dunn - transmeta
denver��translation���ʔ�������
JITC���n�[�h�Ŏ�荞�悤�ȁE�E�H
�l�C�e�B�u�͉��Ȃ�devner
Instruction-optimizing processor with branch-count table in hardware
https://www.google.com/patents/US20130311752
�̓����W�҂̑O��
Ben Hertzberg - intel
Madhu Swarna - intel
Ross Segelken - intel
Rupert Brauch - ?Hewlett-Packard
David Dunn - transmeta
denver��translation���ʔ�������
JITC���n�[�h�Ŏ�荞�悤�ȁE�E�H
�l�C�e�B�u�͉��Ȃ�devner
577 �F,,�E�L�́M�E,,�j��-�������F2014/01/18(�y) 16:03:22.75 ID:4Tn7Dzg2
�u����CISC�v����������
���������Ă͂�܂���
�v�X�ɒ��ʔ��A�[�L������ˁH
�ʔ����A�C�f�A���܂������ɂ̂邱�Ƃ͂Ȃ�
�C���e���I�������
GPU���̕����v�V�I��CPU����Ƃ͂��������Ȃ�
GPU���̕����v�V�I��CPU����Ƃ͂��������Ȃ�
>>581
age
age
�R�[�h���[�t�B���O�Ȃ̂�SMT�Ȃ̂������ŗǂ�������𗊂�
�\�t�g�E�F�A������̕��݊��͕K�{��������Ȃ�
���ꂱ���l�ނ̌���̌n��CPU�����ڗ����\�Ȃ��̂ɕς���ׂ���������
���ꂱ���l�ނ̌���̌n��CPU�����ڗ����\�Ȃ��̂ɕς���ׂ���������
�����{�P���������[
�����ƃJ�E���g�̌��o���n�[�h�ł�铮�I�o�C�i���ϊ�����
�ڍׂ������ɂȂ��������ŁA���܂肨�����낢�b�ł͂Ȃ�
�ڍׂ������ɂȂ��������ŁA���܂肨�����낢�b�ł͂Ȃ�
TSMC��20nm�v���Z�X���i�̑�ʐ��Y��2014�N2���ɊJ�n����
http://northwood.blog60.fc2.com/blog-entry-7001.html
http://northwood.blog60.fc2.com/blog-entry-7001.html
�匴�̍��T�̋L�����Ĕ�����
���ł�������MOSFET�̊T���}�͂�
http://ascii.jp/elem/000/000/858/858849/g3_553x193.jpg
���ł�������MOSFET�̊T���}�͂�
http://ascii.jp/elem/000/000/858/858849/g3_553x193.jpg
{kind=link}
��ɂ��� �C���o�[�^�[(NOP��H) ���Ȃ��Ȃ�
�Ƃ���������NMOS�C���o�[�^�̓��͂ɕt���Ă�v���_�E����R�͉��Ȃ�
����Ȃ���t�����炽���ł���ratioed logic�Ȃ̂Ƀt���X�C���O����X�ɉ����Ȃ�킗
����Ȃ���t�����炽���ł���ratioed logic�Ȃ̂Ƀt���X�C���O����X�ɉ����Ȃ�킗
���
�����ƁA���ꂾ�I
�ҏW�̍Ō�Ń��C�A�E�g�����ꂽ��I
�ƁA�������i�삵�Ă݂�c�c�Ȃ���
�����ƁA���ꂾ�I
�ҏW�̍Ō�Ń��C�A�E�g�����ꂽ��I
�ƁA�������i�삵�Ă݂�c�c�Ȃ���
�������R���̓R���Ŗ������邩�������
Body�Ƀh���C���d���������Ƃ��A�a�V����ˁH
Body�Ƀh���C���d���������Ƃ��A�a�V����ˁH
���n�L�҂Ȃ�Ă���Ȃ��̂ł���B
�L���̖`����
>��[�v���Z�X�̘b����X�o�Ă��邪�A���̑O�ɏ�����{�I�Ȃ��Ƃ̂����炢�����Ă��������B
�Ƃ������Ă��邯�ǁAMOSFET�̍\�����番�����ĂȂ��l���ǂ�����Đ�[�v���Z�X�̘b�������...
�}�C�N���A�[�L�e�N�`���W�̋L�����ڒ����Ȃ��̂��肾�����̐l���X������Ă��̂Ǝv���o�������Ă݂���
�\�t�g�E�F�A�����������ۂ��H
>��[�v���Z�X�̘b����X�o�Ă��邪�A���̑O�ɏ�����{�I�Ȃ��Ƃ̂����炢�����Ă��������B
�Ƃ������Ă��邯�ǁAMOSFET�̍\�����番�����ĂȂ��l���ǂ�����Đ�[�v���Z�X�̘b�������...
�}�C�N���A�[�L�e�N�`���W�̋L�����ڒ����Ȃ��̂��肾�����̐l���X������Ă��̂Ǝv���o�������Ă݂���
�\�t�g�E�F�A�����������ۂ��H
���ϓI�Ȏ���̏Z�l���̓R���s���[�^���̌o�����Ǝv��
���ǐ̎d���ꂽ�܂ܐF�����Ă���o���ɂȂ����m�����m�F�����������Ⴄ�^�C�v
���ǐ̎d���ꂽ�܂ܐF�����Ă���o���ɂȂ����m�����m�F�����������Ⴄ�^�C�v
>>589
�o�C�|�[���Ƃ�BiCMOS�̐������ȂႱ���I�ȁc
�o�C�|�[���Ƃ�BiCMOS�̐������ȂႱ���I�ȁc
�匴���̓C���^�t�F�[�X�W�̐l�������悤��
PCI-E�Ƃ�USB�̋L�����������C������
PCI-E�Ƃ�USB�̋L�����������C������
�L���̌X�����炷��Ƃ��������z���������������A�n�[�h���������`�Ղ͂Ȃ���
http://www.yusuke-ohara.com/profile.htm
http://www.yusuke-ohara.com/profile.htm
��������Ȃ��Ǝv�����A���x�J��Ԃ��Ă����e�˗����Ȃ��Ȃ�Ȃ��ȁB
�ǂ������d�g�݂ɂȂ��Ă���̂��낤��
�ǂ������d�g�݂ɂȂ��Ă���̂��낤��
�R�l�N�V����
�����Ă��O��̂����Ȃ��ƌ����ĂĂ����e�͏����Ȃ������c�c
MOSFET�̐}�͏����邩������Ȃ���(���ꂷ�������?)
MOSFET�̐}�͏����邩������Ȃ���(���ꂷ�������?)
�����炯�̌��e�ł����Ȃ珑�����͑������낤�B
���n�[�h�E�F�A�J���҂̃e�N�j�J�����C�^�[�Ƃ����ƈ�����Ύ��������
���`�E���C�I���d�r�̉��i�������ł���ˁB���݂̑���́A1kWh�����肨�悻5���~�
�匴�͖��ʂɃx���`�}�[�N�e�X�g�̃O���t����ׂăy�[�W�����҂��̂��~�߂�B
���g�̖������Ƃ��̏㖳���B
���g�̖������Ƃ��̏㖳���B
RMMA�Ƃ��͑��̃��C�^�[�͎g��Ȃ�����A
�M�d�ȃf�[�^�ȋC�����邯��
�M�d�ȃf�[�^�ȋC�����邯��
�@��
>>604
�����搶�̋L���͑��Ǝ������Ⴄ�B
�����搶�̋L���͑��Ǝ������Ⴄ�B
�匴����̌��t�����u�_�̏�̐l�v�������
�z���g�̐��Ƃ���
�z���g�̐��Ƃ���
SPARC�̊J���ɏ]�����Ă��炵�����A�A�[�L�e�N�g���������낤���H
���Ƃ�����A�ǂ��炢���C�^�[����
���Ƃ�����A�ǂ��炢���C�^�[����
�Z�t������
SPARC64 V��JSSC�_���Ńt�@�[�X�g�I�[�T�[����
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.108.3165
ISSCC�ł����\���Ă�ˑ���
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=1234286
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.108.3165
ISSCC�ł����\���Ă�ˑ���
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=1234286
�N�r�ɂȂ肻���ȃ��x���Ƃ��v���Ȃ����A��N�ސE�Ń��C�^�[�Ƃ����ȁH
dos/v����₻��ȑO����PC�n���C�^�[���Ă�A���݂͂ȘV�l�ɂȂ��Ă������B
�ނ�̌���p���悤�ȎႢ�l�͊F�������ǁA����������PC�ƊE�̓g�����h���[�_�[�ł����ł��Ȃ�������Ȃ����B
�ނ�̌���p���悤�ȎႢ�l�͊F�������ǁA����������PC�ƊE�̓g�����h���[�_�[�ł����ł��Ȃ�������Ȃ����B
���̃X�����̂������L���������ǂ�
��������͔N�������҂���
���m�{�A�h�a�l�̂o�b�T�[�o�[���Ɣ����@2400���~��
http://www.nikkei.com/article/DGXNASGM2305H_T20C14A1FF2000/
http://www.nikkei.com/article/DGXNASGM2305H_T20C14A1FF2000/
PC�T�[�o���ׂ���Ȃ�����ɂȂ����Ƃ������Ƃ�
PC���T�[�o���A��p�[�c�{�ėp�p�[�c�{���i����{�g��
���ĂȂ��Ă邩���
��p�[�c����Ă��ЁiCPU�EGPU�E�������EHDD�EOS�j�ȊO�́A
���������i�����ɂ��炳��āA��i���̃��[�J�[�ł͍̎Z������Ȃ��Ȃ��Ă���
���ĂȂ��Ă邩���
��p�[�c����Ă��ЁiCPU�EGPU�E�������EHDD�EOS�j�ȊO�́A
���������i�����ɂ��炳��āA��i���̃��[�J�[�ł͍̎Z������Ȃ��Ȃ��Ă���
�����ɂ��z���z��
�ŁA���x�͉��������ɂ��Ĕ����?>IBM
2013.08.20
�߉��H����ŔC�V����Y
Wii U�̖����ɍĂшÉ_
http://diamond.jp/articles/-/40403?display=b
�o�c�Č����̔����̑��A���l�T�X�G���N�g���j�N�X���߉��H��i�R�`���j�̕������߂����ƂŁA
�C�V������������Ă���B�C�V���̍ŐV�Q�[���@�uWii U�v�̎��ƌv�悪�����ꂩ�˂Ȃ����߂��B
2013.12.09
���l�T�X�ɐL�т�g�N���̎��h
�\�j�[���߉��H��o��������
http://diamond.jp/articles/-/45626?display=b
�߉��H�ꂪ�C�V�����͂��߂Ƃ��鑽���̌ڋq�ɕ]������Ă������R�̈�́A�Z�p�͂̍����ɂ���B
�Ƃ�킯�A�����܂��������i���̗v�ł���A�����v���Z�X���œK������m�E�n�E�́A
�ƊE�ł���ڒu����Ă����B���̏W�听�̈���AWii U�ɂ��̗p���ꂽ���������
�u����DRAM�v�ƌĂ�锼���̗̂ʎY�ŁA���E�ł�����ꂽ�H��ł����������Ă��Ȃ��B
2013�N12��06��
���l�T�X�߉��H�ꤢ�Ɨ��\�z��̑S�e
�\�j�[�̏o�����e�R�ɍH��̑�����ڎw��
http://toyokeizai.net/articles/-/25732?display=b
�\�����v��i�߂郋�l�T�X�́A�V�K�̐ݔ��������܂܂Ȃ�Ȃ���ԁB�߉��H�ꂩ��
�߉ύH��֑��u���ڐ݂��邱�Ƃɂ��A���Ƃ��Ăł������͂������������̂��{�����B
�\�j�[���́u�������u���ʂɎ����Ă����ꂽ�甃������������Ӗ����Ȃ��v�ƍl���Ă���A
�ǂ��܂荇����t���邩�������������E���邱�ƂɂȂ肻�����B
2014�N01��28�� 18:50
�\�j�[�A���l�T�X�̒߉��H���70��80���~�Ŕ�����
http://jp.reuters.com/article/topNews/idJPTYEA0R07B20140128
�X�}�[�g�t�H����f�W�^���J�����ɓ��ڂ��锼���̐��i�̂b�l�n�r�C���[�W�Z���T�̐��Y�H��ɓ]�p����B
�߉��H����ŔC�V����Y
Wii U�̖����ɍĂшÉ_
http://diamond.jp/articles/-/40403?display=b
�o�c�Č����̔����̑��A���l�T�X�G���N�g���j�N�X���߉��H��i�R�`���j�̕������߂����ƂŁA
�C�V������������Ă���B�C�V���̍ŐV�Q�[���@�uWii U�v�̎��ƌv�悪�����ꂩ�˂Ȃ����߂��B
2013.12.09
���l�T�X�ɐL�т�g�N���̎��h
�\�j�[���߉��H��o��������
http://diamond.jp/articles/-/45626?display=b
�߉��H�ꂪ�C�V�����͂��߂Ƃ��鑽���̌ڋq�ɕ]������Ă������R�̈�́A�Z�p�͂̍����ɂ���B
�Ƃ�킯�A�����܂��������i���̗v�ł���A�����v���Z�X���œK������m�E�n�E�́A
�ƊE�ł���ڒu����Ă����B���̏W�听�̈���AWii U�ɂ��̗p���ꂽ���������
�u����DRAM�v�ƌĂ�锼���̗̂ʎY�ŁA���E�ł�����ꂽ�H��ł����������Ă��Ȃ��B
2013�N12��06��
���l�T�X�߉��H�ꤢ�Ɨ��\�z��̑S�e
�\�j�[�̏o�����e�R�ɍH��̑�����ڎw��
http://toyokeizai.net/articles/-/25732?display=b
�\�����v��i�߂郋�l�T�X�́A�V�K�̐ݔ��������܂܂Ȃ�Ȃ���ԁB�߉��H�ꂩ��
�߉ύH��֑��u���ڐ݂��邱�Ƃɂ��A���Ƃ��Ăł������͂������������̂��{�����B
�\�j�[���́u�������u���ʂɎ����Ă����ꂽ�甃������������Ӗ����Ȃ��v�ƍl���Ă���A
�ǂ��܂荇����t���邩�������������E���邱�ƂɂȂ肻�����B
2014�N01��28�� 18:50
�\�j�[�A���l�T�X�̒߉��H���70��80���~�Ŕ�����
http://jp.reuters.com/article/topNews/idJPTYEA0R07B20140128
�X�}�[�g�t�H����f�W�^���J�����ɓ��ڂ��锼���̐��i�̂b�l�n�r�C���[�W�Z���T�̐��Y�H��ɓ]�p����B
>>623
>IBM will invest more than $1 billion into the Watson Group,
> focusing on development and research and bringing cloud-delivered
> cognitive applications and services to market.
ttp://www-03.ibm.com/press/us/en/pressrelease/42867.wss
>IBM will invest more than $1 billion into the Watson Group,
> focusing on development and research and bringing cloud-delivered
> cognitive applications and services to market.
ttp://www-03.ibm.com/press/us/en/pressrelease/42867.wss
AMD�A���Џ���ARM�A�[�L�e�N�`���v���Z�b�T�uOpteron A1100�v
http://pc.watch.impress.co.jp/docs/news/20140129_632853.html
It Begins: AMD Announces Its First ARM Based Server SoC, 64-bit/8-core Opteron A1100
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
http://pc.watch.impress.co.jp/docs/news/20140129_632853.html
It Begins: AMD Announces Its First ARM Based Server SoC, 64-bit/8-core Opteron A1100
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
627 �FSocket774�F2014/01/29(��) 14:06:42.76 ID:v1JlR/Le
�Ƃ肠����ARM��Linux����āA�ŐVATOM�̗p�̎����悤�ȋ@���
�x���`�}�[�N����Ăق�����
�x���`�}�[�N����Ăق�����
>>626
Freedom Fabric���Ăǂ������Z�p�Ȃ낤�B����SeaMicro��
�C���^�[�R�l�N�g�Z�p�ő��x��x���̊��ɃR�X�g��������Ȃ��݂�������
Freedom Fabric���Ăǂ������Z�p�Ȃ낤�B����SeaMicro��
�C���^�[�R�l�N�g�Z�p�ő��x��x���̊��ɃR�X�g��������Ȃ��݂�������
�~���f�t���ƎY�Ƃ̋��͍ݓ��̐헪�������H�@�P�^�Q
http://www.youtube.com/watch?v=nl7snBp2KUA
�~���f�t���ƎY�Ƃ̋��͍ݓ��̐헪�������H�Q�^�Q
http://www.youtube.com/watch?v=euneMIC5k4s
http://www.youtube.com/watch?v=nl7snBp2KUA
�~���f�t���ƎY�Ƃ̋��͍ݓ��̐헪�������H�Q�^�Q
http://www.youtube.com/watch?v=euneMIC5k4s
630 �F,,�E�L�́M�E,,�j��-�������F2014/01/29(��) 20:28:14.57 ID:/fCaZ8RH
�@�@�@�@�@�@�@�@Opteron A11xx�@�@�@�@Atom C2750
Cores�@�@�@�@�@�@�@�@8�@�@�@�@�@�@�@�@�@�@�@�@�@8
Freq(GHz)�@�@�@�@ 2.0�@�@�@�@�@�@�@�@�@�@�@�@�@2.4
L2 Cache�@�@�@�@�@4MB�@�@�@�@�@�@�@�@�@�@�@4MB
L3 Cache�@�@�@�@�@8MB�@�@�@�@�@�@�@�@�@�@�@�@-
PCIe�@�@�@�@�@�@�@3.0 x8�@�@�@�@�@�@�@�@�@�@�@2.0 x16
SATA�@�@�@�@�@�@SATA3 x8�@�@�@�@�@�@�@�@6Gb x2, 3Gb x4
Ethernet�@�@�@�@10GbE x2�@�@�@�@�@�@�@�@�@GbE x4
TDP�@�@�@�@�@�@�@�@25W�@�@�@�@�@�@�@�@�@�@�@ 20W
Cores�@�@�@�@�@�@�@�@8�@�@�@�@�@�@�@�@�@�@�@�@�@8
Freq(GHz)�@�@�@�@ 2.0�@�@�@�@�@�@�@�@�@�@�@�@�@2.4
L2 Cache�@�@�@�@�@4MB�@�@�@�@�@�@�@�@�@�@�@4MB
L3 Cache�@�@�@�@�@8MB�@�@�@�@�@�@�@�@�@�@�@�@-
PCIe�@�@�@�@�@�@�@3.0 x8�@�@�@�@�@�@�@�@�@�@�@2.0 x16
SATA�@�@�@�@�@�@SATA3 x8�@�@�@�@�@�@�@�@6Gb x2, 3Gb x4
Ethernet�@�@�@�@10GbE x2�@�@�@�@�@�@�@�@�@GbE x4
TDP�@�@�@�@�@�@�@�@25W�@�@�@�@�@�@�@�@�@�@�@ 20W
Wii U���S�I�H
���l�T�X�ƃ\�j�[�A���l�T�X�߉��H��Ɛ����ݔ��̃\�j�[�ւ̏��n�ō���
http://news.mynavi.jp/news/2014/01/29/290/
�����l�T�X�����ݒ߉��H��ɂĐ��Y���s���Ă���V�X�e��LSI�ȂǂɊւ��ẮA
��SCK���ۗL����������Ђ����ӂ��������ԁA���Y�ϑ��Ƃ����`�Ő��Y���p�����邪�A
�����̌�A���l�T�X�̓߉ύH��ւ̐��i�ڊǂ܂��͐��Y�I���ƂȂ�\�肾�Ƃ����B
���l�T�X�ƃ\�j�[�A���l�T�X�߉��H��Ɛ����ݔ��̃\�j�[�ւ̏��n�ō���
http://news.mynavi.jp/news/2014/01/29/290/
�����l�T�X�����ݒ߉��H��ɂĐ��Y���s���Ă���V�X�e��LSI�ȂǂɊւ��ẮA
��SCK���ۗL����������Ђ����ӂ��������ԁA���Y�ϑ��Ƃ����`�Ő��Y���p�����邪�A
�����̌�A���l�T�X�̓߉ύH��ւ̐��i�ڊǂ܂��͐��Y�I���ƂȂ�\�肾�Ƃ����B
632 �F,,�E�L�́M�E,,�j��-�������F2014/01/29(��) 20:45:55.49 ID:/fCaZ8RH
�����͓߉ς����炵����̂̕�����
633 �FSocket774�F2014/01/29(��) 20:48:05.24 ID:v1JlR/Le
��ݶ�ݶ��
2-4-11
636 �F,,�E�L�́M�E,,�j��-�������F2014/01/30(��) 00:25:22.64 ID:E2ycePfS
�������������v�����H
Avoton/Rangeley�̃_�C�T�C�Y��100mm^2���x�ɉ߂��܂��B
���ꂱ���X�P�[���r���e�B�ŋ����Ȃ�Silvermont�x�[�X�̃R�A��72�R�A���ڂ���
Knights Landing���T���Ă�킯�ł����B
�iARMv8A������1�m�[�h�ő�16�R�A�܂ł����T�|�[�g�ł��Ȃ�ARM�ɂ͂��������s�\�ȍ\���j
���[����Supermicro��6U��112�m�[�h�̃T�[�o�o���Ă��ˁB
���̎��_��SM15000��3�{�ȏ�̃R�A�W�ϓx�B
http://www.supermicro.com/newsroom/pressreleases/2013/press130904_avoton.cfm
TDP25W�g�ł����4�R�A8�X���b�h�EL3 8MB��Xeon E3-1230Lv3�������
���̂ɂ���Ă͂������̂ق���Avoton���d�͌������D��Ă�A�v���P�[�V������
����悤�����B
Avoton/Rangeley�̃_�C�T�C�Y��100mm^2���x�ɉ߂��܂��B
���ꂱ���X�P�[���r���e�B�ŋ����Ȃ�Silvermont�x�[�X�̃R�A��72�R�A���ڂ���
Knights Landing���T���Ă�킯�ł����B
�iARMv8A������1�m�[�h�ő�16�R�A�܂ł����T�|�[�g�ł��Ȃ�ARM�ɂ͂��������s�\�ȍ\���j
���[����Supermicro��6U��112�m�[�h�̃T�[�o�o���Ă��ˁB
���̎��_��SM15000��3�{�ȏ�̃R�A�W�ϓx�B
http://www.supermicro.com/newsroom/pressreleases/2013/press130904_avoton.cfm
TDP25W�g�ł����4�R�A8�X���b�h�EL3 8MB��Xeon E3-1230Lv3�������
���̂ɂ���Ă͂������̂ق���Avoton���d�͌������D��Ă�A�v���P�[�V������
����悤�����B
feedam fabric�͂ǂ��Ȃ����B
�܂��v������葁�������ȁBddr4�Ή��͂悭�撣�����ق�����Ȃ����B
�܂��v������葁�������ȁBddr4�Ή��͂悭�撣�����ق�����Ȃ����B
��������128GB�܂ŃT�|�[�g���Ă�̂͗p�r�I�ɗǂ����������ˁ�Seattle
��͂�R�A�̐��\�ɔ�ׂ�Ƒ���肪��������
��͂�R�A�̐��\�ɔ�ׂ�Ƒ���肪��������
Intel����Sandy��PCH�𖢂��Ɏg���Ă�̂�
���낻��S�ʃ��j���[�A����������̂�
Intel�̃`�b�v�Z�b�g���ĉ������珉���s�NjN�����Ă�C���[�W
�R�A�Ɣ�ׂ�ƃV���{�C
���낻��S�ʃ��j���[�A����������̂�
Intel�̃`�b�v�Z�b�g���ĉ������珉���s�NjN�����Ă�C���[�W
�R�A�Ɣ�ׂ�ƃV���{�C
Sandy��PCH��USB3.0�Ή��ASATA3.0x6�|�[�g�A32nm�����̂��̂�����Ȃ狓���Ă݂�
641 �F,,�E�L�́M�E,,�j��-�������F2014/01/30(��) 07:04:56.63 ID:E2ycePfS
>>637
�Ȃ����ǁA10GbE/40GbE�Ȃ�Intel FM5224�őΉ����Ă�悤����
�u���\�v�Ƃ͂����Ă���̓I�ȕi�Ԃ��܂߂��X�y�b�N���܂�
�o�Ă��ĂȂ����A���\�Ɠ����Ɋe�Ђ���̗p���i�����\���ꂽ
Avoton�Ɣ�ׂ�Ƃ܂������肪���ĂȂ�����������B
�R�A�P�̂̐��\��Silvermont�ɋy�Ȃ���Ȃ�������
2.4-2.6GHz�����C2760�ɑ���Seattle�͍ő�2GHz
�Ȃ����ǁA10GbE/40GbE�Ȃ�Intel FM5224�őΉ����Ă�悤����
�u���\�v�Ƃ͂����Ă���̓I�ȕi�Ԃ��܂߂��X�y�b�N���܂�
�o�Ă��ĂȂ����A���\�Ɠ����Ɋe�Ђ���̗p���i�����\���ꂽ
Avoton�Ɣ�ׂ�Ƃ܂������肪���ĂȂ�����������B
�R�A�P�̂̐��\��Silvermont�ɋy�Ȃ���Ȃ�������
2.4-2.6GHz�����C2760�ɑ���Seattle�͍ő�2GHz
ARM�T�[�o����C�ɉ��ɂȂ����̂́A�ŐVATOM�̐��\�i���b�p�E��ΐ��\�j���ǂ������̂ƁA
Intel���̂�����CPU�R�A�g����SoC�����ɏ��C�Ȃ̂������ł��傤
�{�C��ARM�T�[�o�������Ă���Ƃ��A���܂�Intel�ƍD�����Ŏ�����邽�߂�
ARM�����o���Ă��Ȃ������ċC�������
Intel���̂�����CPU�R�A�g����SoC�����ɏ��C�Ȃ̂������ł��傤
�{�C��ARM�T�[�o�������Ă���Ƃ��A���܂�Intel�ƍD�����Ŏ�����邽�߂�
ARM�����o���Ă��Ȃ������ċC�������
�R�A���\�������`���I�Ȑ킢�łȂ��A���[�U�[��Ƒ��ɓs���悭�`�b�v(�̃A���R�A��)���J�X�^���ł��邩�Ƃ����킢�Ɉڂ��Ă�Ǝv�����ǁB
Anand�͐��i�o���Q4�Ƃ������Ă邵��Intel�Ō���Ȃ�Avoton���Denverton���o�Ă�����
Avoton���VIA�̏I�����Ƀg�h������
Bobcat���L�������ꂽ���_�ŏI���Ă�����
Bobcat���L�������ꂽ���_�ŏI���Ă�����
646 �F,,�E�L�́M�E,,�j��-�������F2014/01/30(��) 19:58:02.88 ID:TVBVzvml
>>645
VIA�͕ʂɃ}�C�N���T�[�o�s��ő��݊������������ƂȂ�ĂȂ���
��͂̎Y�Ɨp�g�ݍ��ݗp�Ƃ����Ӗ��ł�45nm Atom���o�����_�ŏI����Ă��B
Opteron A1100��SeaMicro��Freedom Fabric�ɓ�������SoC�ł͂���ˁB
Avoton�ł�10GbE���T�|�[�g����̂ɃR���p�j�I���`�b�v���K�v������B
VIA�͕ʂɃ}�C�N���T�[�o�s��ő��݊������������ƂȂ�ĂȂ���
��͂̎Y�Ɨp�g�ݍ��ݗp�Ƃ����Ӗ��ł�45nm Atom���o�����_�ŏI����Ă��B
Opteron A1100��SeaMicro��Freedom Fabric�ɓ�������SoC�ł͂���ˁB
Avoton�ł�10GbE���T�|�[�g����̂ɃR���p�j�I���`�b�v���K�v������B
���ł���ȂɃS�^�S�^���Ă�c�c
���܂�딚
>>641
SPECint_rate2006�̔�r�ł�
Opteron A1100��80@>=2GHz
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
Avoton��[email protected]
http://www.intel.com/content/www/us/en/benchmarks/atom/atom-microserver-specint-rate-base-2006.html
SPECint_rate2006�̔�r�ł�
Opteron A1100��80@>=2GHz
http://www.anandtech.com/show/7724/it-begins-amd-announces-its-first-arm-based-server-soc-64bit8core-opteron-a1100
Avoton��[email protected]
http://www.intel.com/content/www/us/en/benchmarks/atom/atom-microserver-specint-rate-base-2006.html
�v���[����A57�ł��ꂭ�炢�̐��\�o��Ȃ�
���˂���Ă�Denver�Ƃ����Ă�����Ɩʔ���������
���˂���Ă�Denver�Ƃ����Ă�����Ɩʔ���������
651 �F,,�E�L�́M�E,,�j��-�������F2014/02/03(��) 00:21:30.49 ID:OoowO0jf
��������Avoton��SPECint_rate2006�ŋ��Ƃ����킯�ł��Ȃ��̂����ǂ�
Intel�̃X���C�h�ł�Xeon E3 1230L(TDP25W)��1P�T�[�o�����ł����Ƃ��d�͌�����
�����Ƃ������ƂɂȂ��Ă���
http://www.spec.org/cpu2006/results/res2013q4/cpu2006-20130917-26307.html
�ĊOAvoton��L3�L���b�V���t�����瓯�N���b�N��Xeon E3�ɔ����̂�������Ȃ����ǁB
���܂�L���b�V�����������A���s�[�N���\�����܂苁�߂��Ȃ�����Ɍ����Ă�̂��낤��
Intel�̃X���C�h�ł�Xeon E3 1230L(TDP25W)��1P�T�[�o�����ł����Ƃ��d�͌�����
�����Ƃ������ƂɂȂ��Ă���
http://www.spec.org/cpu2006/results/res2013q4/cpu2006-20130917-26307.html
�ĊOAvoton��L3�L���b�V���t�����瓯�N���b�N��Xeon E3�ɔ����̂�������Ȃ����ǁB
���܂�L���b�V�����������A���s�[�N���\�����܂苁�߂��Ȃ�����Ɍ����Ă�̂��낤��
��B��̌����J�������V�X�p�R�����ғ��A�������\��1PFLOPS�ɂ�
http://cloud.watch.impress.co.jp/docs/news/20140203_633396.html
http://cloud.watch.impress.co.jp/docs/news/20140203_633396.html
�s�RFlops�Ǝv������y�^���B
�s�R�Ȃ�s�R�ŋ����[�����ǂȂ�
�����������̂��߂ɂǂ�����Ď������Ă�̂����Ă�
�����������̂��߂ɂǂ�����Ď������Ă�̂����Ă�
655 �F,,�E�L�́M�E,,�j��-�������F2014/02/03(��) 22:31:16.25 ID:TJGfoumU
�����Z����̂ɂȂ��܂�˂���܂���
�̂̋@�B���v�Z�@���ĉ�Flops�Ȃ̂��Ȃ������
����͐������Z�@����B
�@�B���v�Z�@���ĕ��������_���Z�o����́H
�P�R�[��
��H���������_�����ǂ͐������Z�̑g�ݍ��킹�łł��Ă��Ȃ��́H�H
�ǂ��܂ł��@�B���Ƃ����̂��m��A��v�Z�@���Ə����_�͎����œ������ĂȂ�������
������R���s���[�^�̋@�B���̂͒m���B
������R���s���[�^�̋@�B���̂͒m���B
�͎̂��Ԏ��v�Z�@�Ń~�T�C������Ă����B
�M�����邩�H��
�M�����邩�H��
��ԂƂ��ɍڂ��Ă�e���v�Z�@��70�N�ギ�炢�܂ŃA�i���O�������悤��
>>663
�����AV2�͎��Ԃ���B
http://www.benedict.co.jp/Smalltalk/talk-43.htm
������A���I�ȃZ���T�[��R���s���[�^���Ȃ�����ɁA����Ȑ��k�Ȑ�����ǂ�����Ď��������̂��H
�����P�b�g�̎p������́A�W���C���ŋ@�̂̌X�������o���A��߂��i�H�Ƃ̃Y�����r���A
�����ˑǂƕ����ǂŎp�����C�������B
���܂��A�����x����͑O�q�����U��q�W���C���Ǝ��Ԍv�Z�@�ōs��ꂽ�B
���d�q������R���s���[�^���Ȃ�����ɁA�@�B�����䂾����300km����s�����̂ł���B
�����Ղȓd�q����Ɋ��ꂽ����̋Z�p�҂���݂���قł���B
�����AV2�͎��Ԃ���B
http://www.benedict.co.jp/Smalltalk/talk-43.htm
������A���I�ȃZ���T�[��R���s���[�^���Ȃ�����ɁA����Ȑ��k�Ȑ�����ǂ�����Ď��������̂��H
�����P�b�g�̎p������́A�W���C���ŋ@�̂̌X�������o���A��߂��i�H�Ƃ̃Y�����r���A
�����ˑǂƕ����ǂŎp�����C�������B
���܂��A�����x����͑O�q�����U��q�W���C���Ǝ��Ԍv�Z�@�ōs��ꂽ�B
���d�q������R���s���[�^���Ȃ�����ɁA�@�B�����䂾����300km����s�����̂ł���B
�����Ղȓd�q����Ɋ��ꂽ����̋Z�p�҂���݂���قł���B
�A�i���O�R���s���[�^�Ƌ@�B���v�Z�@�͕ʕ��������
>>665
V2�̓��P�b�g�����A�~�T�C������Ȃ���
���P�b�g�~�T�C���͌����ɋ�ʂ�����킯����Ȃ����A
�ʏ탍�P�b�g�͂����̉���ɂ���悤�ɒe����s���镨��
����~�T�C���͏��q�~�T�C���̂悤�Ɉ��̍��x���ё�������A
��~�T�C���̂悤�ɑ���Ɍ������Ĕ��A�e����s���Ȃ�����
V2�̓��P�b�g�����A�~�T�C������Ȃ���
���P�b�g�~�T�C���͌����ɋ�ʂ�����킯����Ȃ����A
�ʏ탍�P�b�g�͂����̉���ɂ���悤�ɒe����s���镨��
����~�T�C���͏��q�~�T�C���̂悤�Ɉ��̍��x���ё�������A
��~�T�C���̂悤�ɑ���Ɍ������Ĕ��A�e����s���Ȃ�����
���x�����ĂɂȂ�Ȃ����甭�ˊp�Ȃ�ēK����OK��
��������ɂ�����v���͂��B
��������ɂ�����v���͂��B
>667�݂����Ȓ�`�͏��������K���Ȏ������ĂȂ���?
���P�b�g�̓G���W���̂��Ƃ�
�~�T�C���͗U�����đ̂̂��Ƃ��Ǝv���Ă�
�~�T�C���͗U�����đ̂̂��Ƃ��Ǝv���Ă�
��������U���i�������I�Ɍ�����ς���j��i�����邩�ǂ����ŋ�ʂ���邱�Ƃ��������A���ɞB���Ȍ��t�ł�����
�����������{��Łu���P�b�g�v�ƌ����Ƃ��A���P�b�g�e�̂��Ƃ��w�����Ƃ������
�q���̑ł��グ�Ɏg�����P�b�g���w�����Ƃ�����
���P�b�g���[�^�[�Ƃ������t������悤�ɁA�V�X�e���S�̂ł͂Ȃ��Đ��i��i���w�����Ƃ�����
���Ƃ����ă��P�b�g�e�ł���Ζ��U�����Ƃ����ƁA
�ŋ߂̕���̓��P�b�g�e��U�������������Ȃ��̂��ǂ�ǂ�o�Ă��Č��i�ȕ��ނƂ͌����Ȃ�
�����Ⴄ�Ƃ����ƂЂǂ��āA���V�A�ꂾ�Ƌ�ʂ��Ȃ��炵��
���V�A�헪���P�b�g�R�͓`���I�Ƀ��P�b�g�Ɩ�邪��舵���̂͒e���~�T�C����
�p��ł�rocket��missile����������
�����������{��Łu���P�b�g�v�ƌ����Ƃ��A���P�b�g�e�̂��Ƃ��w�����Ƃ������
�q���̑ł��グ�Ɏg�����P�b�g���w�����Ƃ�����
���P�b�g���[�^�[�Ƃ������t������悤�ɁA�V�X�e���S�̂ł͂Ȃ��Đ��i��i���w�����Ƃ�����
���Ƃ����ă��P�b�g�e�ł���Ζ��U�����Ƃ����ƁA
�ŋ߂̕���̓��P�b�g�e��U�������������Ȃ��̂��ǂ�ǂ�o�Ă��Č��i�ȕ��ނƂ͌����Ȃ�
�����Ⴄ�Ƃ����ƂЂǂ��āA���V�A�ꂾ�Ƌ�ʂ��Ȃ��炵��
���V�A�헪���P�b�g�R�͓`���I�Ƀ��P�b�g�Ɩ�邪��舵���̂͒e���~�T�C����
�p��ł�rocket��missile����������
���P�b�g�ƃ~�T�C����ʂ��������̂̓A�����J�炵���̂ŁA
���V�A�͋�ʖ����낤�˂�
���V�A�͋�ʖ����낤�˂�
������ɓ�����̂����œ������삵�Ă������̂��Č�����A
����l�̎�ɕ����Ȃ����̂͑������邾�낤�ȁB
�V�����v�Ȃ���Փx����
����l�̎�ɕ����Ȃ����̂͑������邾�낤�ȁB
�V�����v�Ȃ���Փx����
���{�ꂾ�ƗU���e�̓~�T�C���A����ȊO�̓��P�b�g�A������V2�����͗�O�Ń��P�b�g�B
����>>667�݂����Șb�͌������Ƃ����������Ƃ��Ȃ���
�嗤�Ԓe���e�A������ICBM��M���ă~�T�C����M������
ICBM�Ƃ�����TRON���ǂ��Ȃ��ĂH
�嗤�Ԓe���e�A������ICBM��M���ă~�T�C����M������
ICBM�Ƃ�����TRON���ǂ��Ȃ��ĂH
�~�T�C�������đ�
���P�b�g���K�X�̔������g�����i����
�����Ƃ����Ɏ���͈͂̍L���P��ł�
���P�b�g���K�X�̔������g�����i����
�����Ƃ����Ɏ���͈͂̍L���P��ł�
>>673�������Ă�悤�ɗU��������ƃ~�T�C���A�����ƃ��P�b�g�̗Ⴊ������
����ICBM�͓V���U���Ƃ��t���Ă邵
V2���P�b�g�͊����U���݂̂����烍�P�b�g�����Ȃ̂���
����ICBM�͓V���U���Ƃ��t���Ă邵
V2���P�b�g�͊����U���݂̂����烍�P�b�g�����Ȃ̂���
�@�ڍׂ͌����Ȃ����A�S�Ă̋Z�p�����������A�P��FLOPS/Linpack����ƌ��������a�I���g���b�N����E�炵���A
�@IDC�^�r�b�O�f�[�^�ɂ��v�V�I�Ȑi���������炷�A�^�̈Ӗ��ł́u���E��v�̃X�p�R���ƂȂ�ł��낤
tubame3.0�ɂ��ď��������������Ă邯��
2.5�܂ł�GPU�Ƃ͂�����ƈႤ���Ă��Ƃ���
IDC�^�r�b�O�f�[�^�ɂ����Ă��Ƃ�many core�H
phi��KNL�Ȃ�many core�������������nvidia�I�V������Ȃ�
maxwell����ő傫�ȕω�������̂���
�@IDC�^�r�b�O�f�[�^�ɂ��v�V�I�Ȑi���������炷�A�^�̈Ӗ��ł́u���E��v�̃X�p�R���ƂȂ�ł��낤
tubame3.0�ɂ��ď��������������Ă邯��
2.5�܂ł�GPU�Ƃ͂�����ƈႤ���Ă��Ƃ���
IDC�^�r�b�O�f�[�^�ɂ����Ă��Ƃ�many core�H
phi��KNL�Ȃ�many core�������������nvidia�I�V������Ȃ�
maxwell����ő傫�ȕω�������̂���
>680
���̋L��?�Ǝv���Ă���������twitter���B
�����낻�̊T�v�����J�����̂���? �y���݁B
���̋L��?�Ǝv���Ă���������twitter���B
�����낻�̊T�v�����J�����̂���? �y���݁B
���Ԃ��Č�����Linpack�͋����Ă��Ƃ���
�܂��A�Ⴄ�g��������Ȃ�ʂɋ��ł����܂�Ȃ���
�܂��A�Ⴄ�g��������Ȃ�ʂɋ��ł����܂�Ȃ���
LINPACK���͂ނ��땽���ŁA���a�̓o���h����C�e���V����
�x�N�g���X�p�R���̎�������Ȃ��낤���B
20�N�Ԃ��܂�̗��top500�M����
���l�����ƒn���V�~�����[�^�ȊO�݂͂�ȑO�҂���
�x�N�g���X�p�R���̎�������Ȃ��낤���B
20�N�Ԃ��܂�̗��top500�M����
���l�����ƒn���V�~�����[�^�ȊO�݂͂�ȑO�҂���
ARM�A�[�L�e�N�`����64�r�b�g�T�[�o�[�����̎d�l�uSBSA�v�̌��J���n�܂�
http://techon.nikkeibp.co.jp/article/NEWS/20140203/331705/
ARM�CARMv8-A�x�[�X�T�[�o�[�����W���d�lARM
SBSA(Server Base System Architecture)
http://blog.livedoor.jp/amd646464/archives/52398031.html
http://techon.nikkeibp.co.jp/article/NEWS/20140203/331705/
ARM�CARMv8-A�x�[�X�T�[�o�[�����W���d�lARM
SBSA(Server Base System Architecture)
http://blog.livedoor.jp/amd646464/archives/52398031.html
686 �F,,�E�L�́M�E,,�j��-�������F2014/02/05(��) 19:34:47.79 ID:GyGmSJkn
�V�����Ƃ��Â��Ƃ������Ȃ��̂ł�
�R���f�B�e�B�ȃv���Z�b�T��1�`�b�v��8MB�₻��ȏ�̗e�ʂ�
�����L���b�V���ςނ��ƂȂ�ď��a���ɂ͂��肦�Ȃ������b�ŁB
�L���b�V���ɂ����ۂ���܂镔���s�傫���Ȃ������ƂŁA������
�������ш��m�[�h�ԒʐM�̃{�g���l�b�N�����ΓI�ɏ������Ȃ����B
���̂��Ƃ�LINPACK�����ӂȃV�X�e���Ƃ���ȊO�̂��Ƃ���
���̉��Z�����ӂȃV�X�e���̍��ق��傫���Ȃ����̂ł́B
�R���f�B�e�B�ȃv���Z�b�T��1�`�b�v��8MB�₻��ȏ�̗e�ʂ�
�����L���b�V���ςނ��ƂȂ�ď��a���ɂ͂��肦�Ȃ������b�ŁB
�L���b�V���ɂ����ۂ���܂镔���s�傫���Ȃ������ƂŁA������
�������ш��m�[�h�ԒʐM�̃{�g���l�b�N�����ΓI�ɏ������Ȃ����B
���̂��Ƃ�LINPACK�����ӂȃV�X�e���Ƃ���ȊO�̂��Ƃ���
���̉��Z�����ӂȃV�X�e���̍��ق��傫���Ȃ����̂ł́B
IBM��x86�T�[�o���Ɣ��p�������炷�g��
x86�T�[�o�s�ꂪ���ł���\����
http://www.itmedia.co.jp/enterprise/articles/1402/06/news025.html
x86�T�[�o�s�ꂪ���ł���\����
http://www.itmedia.co.jp/enterprise/articles/1402/06/news025.html
���_����ĂĂ悭�킩���
x86�Ƃ����ǂ��T�[�o�̓R���f�B�e�B�Ƃ͌����Ȃ����i�����Ă���
x86�Ƃ����ǂ��T�[�o�̓R���f�B�e�B�Ƃ͌����Ȃ����i�����Ă���
�Ƃ͂����A�ׂ����Ă�Ȃ������Ȃ����낤���A����܂肨�������Ȃ��낤���̒l�i��
IBM�̏ꍇ�����i�I��Power�����邩��x86�͈��I�����Ȃ낤�B
Power���瑶���낤���BSOI�g���̓���Ȑv�̃`�b�v������Fab�������Ȃ��Ăł���̂��낤���c
�Ăh�a�l�A�����̎��Ɣ��p�������@���ă��f�B�A��
http://www.nikkei.com/article/DGXNASGN07025_X00C14A2000000/
�Ăh�a�l�A�����̎��Ɣ��p�������@���ă��f�B�A��
http://www.nikkei.com/article/DGXNASGN07025_X00C14A2000000/
���p���GF���T���X���̓���ł���
GF/�T���X��/IBM�ō��ٍ��Ǝv�������A����ł̓R�����v���b�g�t�H�[��
�Ɠ����ŁA���ꂪ���s���Ă��邩�炱��Ȏ��ɂȂ��Ă���̂��낤���c
�Ɠ����ŁA���ꂪ���s���Ă��邩�炱��Ȏ��ɂȂ��Ă���̂��낤���c
�����̂悤��HP������������ˁH
RAS�Ȃǃt���T�|�[�g����POWER�T�[�o�[�Ɣ�r�����
x86�T�[�o�[�͈�����������Ȃ����A����ł�IBM��x86�T�[�o�[������
top500 ��1/4����V�F�A���l���Ă�悤�Ȏ��Ƃ��BCray�ł���35/500�B
���������{�̓d�@���[�J�[�Ȃ��������Ƃ͂܂��Ȃ����낤��
x86�T�[�o�[�͈�����������Ȃ����A����ł�IBM��x86�T�[�o�[������
top500 ��1/4����V�F�A���l���Ă�悤�Ȏ��Ƃ��BCray�ł���35/500�B
���������{�̓d�@���[�J�[�Ȃ��������Ƃ͂܂��Ȃ����낤��
���͑��v�ł����N��ɂ͊m���Ɏ��ʂƗ\�z���Ă���̂��낤
HDD��PC���T�[�o�[�������̂��A���v�o�Ĕ���邤���Ɍ�����Ă̂�
������IBM�Ƃ͎v�����ǁA���������Ƀl�^�ǂ��c���Ă�낤��
������IBM�Ƃ͎v�����ǁA���������Ƀl�^�ǂ��c���Ă�낤��
���̂Ƃ��뉽���c���Ă�낤��
power��IP?
power��IP?
�Ĕ��_�@����
�X���Ă���Ȃ��Ĕ����Ă��^�C�v��
�Ŏ��Ӕ_�Ƃ̔������Ă����Ď��{�͂��o�b�N�Ɏ��Ƃ̐V������ŐV���ɐ�߂�͍�
�X���Ă���Ȃ��Ĕ����Ă��^�C�v��
�Ŏ��Ӕ_�Ƃ̔������Ă����Ď��{�͂��o�b�N�Ɏ��Ƃ̐V������ŐV���ɐ�߂�͍�
PC�T�[�o�߂��Ⴍ��������đ�������ȁB
�n�[�h�ׂ͖����V�X�e���J�������ɒ��͂���낤�B
�n�[�h�ׂ͖����V�X�e���J�������ɒ��͂���낤�B
>>697
�ǂ����̓��{�d�C�ƈꏏ�ɂ��Ȃ���!
�ǂ����̓��{�d�C�ƈꏏ�ɂ��Ȃ���!
702 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 19:33:53.82 ID:j8lUve94
�\�j�[��VAIO���Ƃ������ɂ���Ƃ����Ⴂ�܂�����
33 ���O�FSocket774[sage] ���e���F2014/02/07(��) 14:26:08.47 ID:+ysyAdDN
LINPACK�͉ߋ��̂��̂�
�V���ȃx���`�}�[�NHPCG
http://news.mynavi.jp/column/sc13/010/
�܂�ALINPACK�������Ă�����ƌ����̖��Ƃ͐������قȂ�ALINPACK���\���������Ƃ����A�v���̎��s���\��
�������Ƃɂ��܂�q����Ȃ��Ȃ��Ă��܂��Ă���B
�����Ȃ�ƁA����LINPACK���\��B������Top500��1�ʂ���낤�Ƃ����w�͂́A���p�I�ɂ͈Ӗ��̖����w�͂ŁA
Top500�̑��݂̓X�p�R���̔��W�Ƀv���X�ɂȂ�ǂ��납�A�Ԉ���������ɃX�p�R���̊J�������������Ă��܂�
�}�C�i�X�v���ɂȂ��Ă��܂��B
���̂悤�Ȍ��O����A�e�l�V�[���Jack Dongarra�������HPCG(High Performance Conjugate Gradient)�Ƃ���
�x���`�}�[�N�v���O�������J��������B
�Ȃ��AJack Dongarra�����́ATop500�̎�Î҂�1�l�ŁAHPL���J�����l���ł���B
http://news.mynavi.jp/photo/column/sc13/010/images/008l.jpg
���̐}�Ɏ����悤�ɁA32�m�[�h�̃V�X�e���̃s�[�N���Z���\��5000GFlops��ŁAHPL�ł�4000GFlops���ƃs�[�N��
80%�ȏ�̐��\���o�Ă��邪�AHPCG�̏ꍇ�́A0.5%���x�̐��\�����o�Ă��Ȃ��B�܂�AHPCG�ł͉��Z���Ԃ����A
��є�т̃������A�N�Z�X��m�[�h�Ԃ�MPI�ʐM�̎��Ԃ����\�ɑ傫���e�����Ă���B
���̂��߁AHPL�Ő��\�������V�X�e����HPCG�ł����\�������Ƃ͌���Ȃ��B
�܂��AHPCG�ō����\���o�����߂̋Z�p�̊J�����K�v�ƂȂ�B
LINPACK�͉ߋ��̂��̂�
�V���ȃx���`�}�[�NHPCG
http://news.mynavi.jp/column/sc13/010/
�܂�ALINPACK�������Ă�����ƌ����̖��Ƃ͐������قȂ�ALINPACK���\���������Ƃ����A�v���̎��s���\��
�������Ƃɂ��܂�q����Ȃ��Ȃ��Ă��܂��Ă���B
�����Ȃ�ƁA����LINPACK���\��B������Top500��1�ʂ���낤�Ƃ����w�͂́A���p�I�ɂ͈Ӗ��̖����w�͂ŁA
Top500�̑��݂̓X�p�R���̔��W�Ƀv���X�ɂȂ�ǂ��납�A�Ԉ���������ɃX�p�R���̊J�������������Ă��܂�
�}�C�i�X�v���ɂȂ��Ă��܂��B
���̂悤�Ȍ��O����A�e�l�V�[���Jack Dongarra�������HPCG(High Performance Conjugate Gradient)�Ƃ���
�x���`�}�[�N�v���O�������J��������B
�Ȃ��AJack Dongarra�����́ATop500�̎�Î҂�1�l�ŁAHPL���J�����l���ł���B
http://news.mynavi.jp/photo/column/sc13/010/images/008l.jpg
{kind=link}
���̐}�Ɏ����悤�ɁA32�m�[�h�̃V�X�e���̃s�[�N���Z���\��5000GFlops��ŁAHPL�ł�4000GFlops���ƃs�[�N��
80%�ȏ�̐��\���o�Ă��邪�AHPCG�̏ꍇ�́A0.5%���x�̐��\�����o�Ă��Ȃ��B�܂�AHPCG�ł͉��Z���Ԃ����A
��є�т̃������A�N�Z�X��m�[�h�Ԃ�MPI�ʐM�̎��Ԃ����\�ɑ傫���e�����Ă���B
���̂��߁AHPL�Ő��\�������V�X�e����HPCG�ł����\�������Ƃ͌���Ȃ��B
�܂��AHPCG�ō����\���o�����߂̋Z�p�̊J�����K�v�ƂȂ�B
704 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 19:48:19.54 ID:j8lUve94
>>688
Intel���͂�t����O��RISC�T�[�o�����S���������l���Ă݂ẮH
���N��Hisa Ando����HPCG�ɂ��Č��y���Ă�
http://www.geocities.jp/andosprocinfo/wadai13/20130629.htm
Intel���͂�t����O��RISC�T�[�o�����S���������l���Ă݂ẮH
���N��Hisa Ando����HPCG�ɂ��Č��y���Ă�
http://www.geocities.jp/andosprocinfo/wadai13/20130629.htm
>>703
80�N��̃X�p�R���A���l�����A�n���V�~�����[�^�Ȃǂ�
�a�ȃf�[�^�̋������z�@�������Ƃ��Ă͑��������B
�ʂɐV�����킯�ł͂Ȃ���A����
80�N��̃X�p�R���A���l�����A�n���V�~�����[�^�Ȃǂ�
�a�ȃf�[�^�̋������z�@�������Ƃ��Ă͑��������B
�ʂɐV�����킯�ł͂Ȃ���A����
706 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 21:01:16.80 ID:j8lUve94
�x���`�}�[�N�̕��@���ς����������ĉȊw�ҁE�Z�p�҂����߂Ă�R���s���[�^��
���\���ς��킯����Ȃ���ł����ǂ�
����肪�����R���s���[�^�������L���O��ʂɂȂ邱�ƂŁA���������R���s���[�^��
���߂Ă镪��ŗ\�Z���Ƃ���₷���Ȃ�Ƃ��������ŁB
���\���ς��킯����Ȃ���ł����ǂ�
����肪�����R���s���[�^�������L���O��ʂɂȂ邱�ƂŁA���������R���s���[�^��
���߂Ă镪��ŗ\�Z���Ƃ���₷���Ȃ�Ƃ��������ŁB
>>706
���̎���̉\�ȍő���ƁA�����ł��܂����\���o����Ȋw�v�Z�Ƃ����͕̂ς��䂭���̂ŁA���������Ӗ��ł͋��߂�v�Z�͕ς���Ă���B
�܂��A�ς��Ƃ������A���܂����Ă͂܂�v�Z���A���̎��ゲ�ƂɂőI��Ă����Ă���Ă��Ƃ��B���������ɋ߂��B
���̎���̉\�ȍő���ƁA�����ł��܂����\���o����Ȋw�v�Z�Ƃ����͕̂ς��䂭���̂ŁA���������Ӗ��ł͋��߂�v�Z�͕ς���Ă���B
�܂��A�ς��Ƃ������A���܂����Ă͂܂�v�Z���A���̎��ゲ�ƂɂőI��Ă����Ă���Ă��Ƃ��B���������ɋ߂��B
708 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 21:53:50.26 ID:j8lUve94
�������]���͓d�͌�������p�Ό��ʂ������̂������Ȃ킯��
���̈Ӗ��ł��܂́uLinpack�Ԓ��v�݂����ȍ\�����Ԉ���Ă�킯�ł��Ȃ����
�����m�[�h�̉��Z���ʂ��킴�킴�Ƃ��Ă����莩���̂Ƃ���̃m�[�h��
�v�Z�����ق��������Ȃ�ăP�[�X�͂悭����b�ŁB
���̈Ӗ��ł��܂́uLinpack�Ԓ��v�݂����ȍ\�����Ԉ���Ă�킯�ł��Ȃ����
�����m�[�h�̉��Z���ʂ��킴�킴�Ƃ��Ă����莩���̂Ƃ���̃m�[�h��
�v�Z�����ق��������Ȃ�ăP�[�X�͂悭����b�ŁB
709 �FSocket774�F2014/02/07(��) 22:18:04.61 ID:5UzTzY1x
���������A�P�̃x���`�}�[�N�ŃX�p�R���̐��\���������Ă̂��A
�X�p�R���p�ҁE���O�̐l�E�}�X�R�~�ɂ킩��₷�������ŁA
�X�p�R���̌���ɂ���l�Ȃ�AHPCC�݂����ȕ�����ނ̃x���`�}�[�N�������Ă�����āA
�����͂��̌v�Z���d�����邩�炱�̃x���`�������z�A�����͕ʂ̌v�Z�d��������ʂ̃x���`�������z�A
�݂����Ȃ̂�������
�X�p�R���p�ҁE���O�̐l�E�}�X�R�~�ɂ킩��₷�������ŁA
�X�p�R���̌���ɂ���l�Ȃ�AHPCC�݂����ȕ�����ނ̃x���`�}�[�N�������Ă�����āA
�����͂��̌v�Z���d�����邩�炱�̃x���`�������z�A�����͕ʂ̌v�Z�d��������ʂ̃x���`�������z�A
�݂����Ȃ̂�������
�S�m�[�h��L����悤�ȃx���`���点��͕̂����I�ɓ������˂�
�ӂ��̓X�p�R�����ē�������O�Ɍv�Z�ړI�͂͂����肵�Ă邩��ȁB
���{�̌������ƃX�p�R���ȊO��w
���{�̌������ƃX�p�R���ȊO��w
712 �FSocket774�F2014/02/07(��) 22:31:20.16 ID:5UzTzY1x
���{�ȊO�ł�TOP500�ɂ̂��Ă�X�p�R���͑S���������Ƃ����
��Ƃ��X�p�R���������Ă��肷�邯�ǁA�O���Ƀx���`�͏o���Ȃ�
�d�d�E�d�H�E�����ԁE�q��F���̑��Ƃ��A�S�����ЃX�p�R�������Ă�ł���H
��Ƃ��X�p�R���������Ă��肷�邯�ǁA�O���Ƀx���`�͏o���Ȃ�
�d�d�E�d�H�E�����ԁE�q��F���̑��Ƃ��A�S�����ЃX�p�R�������Ă�ł���H
>TOP500�ɂ̂��Ă�X�p�R���͑S���������Ƃ����
�L�~�̌��͋Ȃ����Ă�̂ł͂Ȃ����B
�L�~�̌��͋Ȃ����Ă�̂ł͂Ȃ����B
714 �F,,�E�L�́M�E,,�j��-�������F2014/02/07(��) 22:38:53.07 ID:j8lUve94
��Ƃ̕��ʂ̃f�[�^�Z���^�[��PC�T�[�o���牺�ʂɓ����Ă�
����݂����ȑ�����w�̑S�w�i+�S���������p�j���T�[�r�X�ΏۂƂ���
��������ꍇ�͂ЂƂ̗p�r�ɂ����鐫�\���Ђ�������킯�ɂ͍s����
�I���ɋꗶ���Ă����ȁB
���̌��ʁA�\�Z�S�������ނ̂ł͂Ȃ��Ⴄ�X���̃V�X�e����
�������ĕ����ғ�������X���ɂȂ�A�����̃V�X�e���̓���������
��K�̓V�X�e���̓����͌����Ă��܂���
��������ꍇ�͂ЂƂ̗p�r�ɂ����鐫�\���Ђ�������킯�ɂ͍s����
�I���ɋꗶ���Ă����ȁB
���̌��ʁA�\�Z�S�������ނ̂ł͂Ȃ��Ⴄ�X���̃V�X�e����
�������ĕ����ғ�������X���ɂȂ�A�����̃V�X�e���̓���������
��K�̓V�X�e���̓����͌����Ă��܂���
�ӂ��̈ȏ�H�@�O�͎�v��w�̎�V�X�e����
�傫�Ȍv�Z���ł��鍑���Ŏ�v�ȃV�X�e������������
���݂����ȃZ���^�[�͕K�v�Ȃ������B
�����悩�{���悩�킩��A��v��w�̃V�X�e�������̂悤��
�������ƁA�L�������킳�ʋK�͂̃Z���^�[���Ȃ��ƍ���C�͂����
�傫�Ȍv�Z���ł��鍑���Ŏ�v�ȃV�X�e������������
���݂����ȃZ���^�[�͕K�v�Ȃ������B
�����悩�{���悩�킩��A��v��w�̃V�X�e�������̂悤��
�������ƁA�L�������킳�ʋK�͂̃Z���^�[���Ȃ��ƍ���C�͂����
����v��w�̃V�X�e�������̂悤�ɏ���
��v��w�������ݖ@�l�����ċ����a�Ɋׂ��Ă��邩��ˁB
�݂̂����ɕK�v���𗝉����Ă��炦���瓱���ł��鎞��ł͂Ȃ�����B
��v��w�������ݖ@�l�����ċ����a�Ɋׂ��Ă��邩��ˁB
�݂̂����ɕK�v���𗝉����Ă��炦���瓱���ł��鎞��ł͂Ȃ�����B
���������_���Z���āA���Z���鏇�Ԃ��ς��ƁA���w�I�ɂ͓����͂��ł��A�R���s���[�^�ł͕ς���Ă��邶��Ȃ��B
�ł��A�������̏��Ԃ��C�ɂ��Ȃ��Ă��C�C�悤�ȃA�v���P�[�V�����̏ꍇ�A
������v���O���}���w�肵�Ă��ACPU�͂��̐���ɔ���ꂸ��OoO�̕����L�����A
���ʁA���Z��̉ғ������グ����ł͂Ȃ��낤���H
�ł��A�������̏��Ԃ��C�ɂ��Ȃ��Ă��C�C�悤�ȃA�v���P�[�V�����̏ꍇ�A
������v���O���}���w�肵�Ă��ACPU�͂��̐���ɔ���ꂸ��OoO�̕����L�����A
���ʁA���Z��̉ғ������グ����ł͂Ȃ��낤���H
719 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 13:42:03.61 ID:4IK07MtE
�������I�V�ˁI
�ł�����SIMD���Ă�����
�ł�����SIMD���Ă�����
��Hgcc��-ffast-math�̂悤�Șb����Ȃ��āH
721 �FSocket774�F2014/02/08(�y) 14:31:53.84 ID:fAEPs0Hp
float��double�ŁA����1�`2bit�̌v�Z���ʂ��ς�낤��
�قƂ�ǂ̏ꍇ�ʂɖ��Ȃ����낤��
�قƂ�ǂ̏ꍇ�ʂɖ��Ȃ����낤��
1+1e100-1e100�݂����Ȃ̂���B
������1
�O����v�Z�����0
�ォ��v�Z�����1
������1
�O����v�Z�����0
�ォ��v�Z�����1
��@�A���S���Y�����l����l�Ԃ��������ɔz������̂͏������Ǝv���B
�܂Ƃ��ȕ��������_�����C�u�����͌������̌��ʂ��܂ޓ���ۏ�
���͔͈͂��o�͂̌덷�ƂƂ��ɖ��L�����B
�܂Ƃ��ȕ��������_�����C�u�����͌������̌��ʂ��܂ޓ���ۏ�
���͔͈͂��o�͂̌덷�ƂƂ��ɖ��L�����B
�����t�q�̂悤�ɂ͂����Ȃ��킯����
�@2014�N2��7����EE Times���CFinancial Times�̋L���������āCIBM�������̕���̔��p���T�����߂ɁCGoldman Sachs���ق��Ă���ƕĂ��܂��B
IBM�́C���̌��Ɋւ��Ă͉������\���Ă��炸�C���̃\�[�X�́C�����̎���ɏڂ����W�҂Ƃ̂��Ƃł��B
http://www.eetimes.com/document.asp?doc_id=1320914
IBM�́C���̌��Ɋւ��Ă͉������\���Ă��炸�C���̃\�[�X�́C�����̎���ɏڂ����W�҂Ƃ̂��Ƃł��B
http://www.eetimes.com/document.asp?doc_id=1320914
�A�[�L�e�N�`���H
�T���`�������p�N��悗
�T���`�������p�N��悗
�A�����J�Ƃ��ẮA�C���e�������邩�炢���Ƃ������ƂɂȂ�낤���B�U�X����𒍂�����ł������ǁA�s��̗���ɂ͂����炦�Ȃ��A���傤���Ȃ����Ă��Ƃ��B
���C�o���I�ȕx�m�ʂ̗��ꂪ�ǂ��Ȃ��Ă��������A�v���ڂ��ȁB�܂����Ƃ͎v�����ǁA�x�m�ʂ��z���A����Ȃ��ȁB
���C�o���I�ȕx�m�ʂ̗��ꂪ�ǂ��Ȃ��Ă��������A�v���ڂ��ȁB�܂����Ƃ͎v�����ǁA�x�m�ʂ��z���A����Ȃ��ȁB
729 �F,,�E�L�́M�E,,�j��-�������F2014/02/08(�y) 23:02:49.34 ID:4IK07MtE
�C�V���ǂ������H
>>729
�\�j�[�Ƀ��l�T�X������́A���肯�����肾�ȁB
IBM�̔����̔��p�͑��ɂ����낢��e�������肻���ŋC�ɂȂ�B�����̂Ƌ������Ă���������Ȃ́A�����������炢�����ȁBNVIDIA��GPU�ƂȂ��b���ǂ��Ȃ邩�ȁBNVIDIA��������������Ƃ��v���Ȃ����B
�\�j�[�Ƀ��l�T�X������́A���肯�����肾�ȁB
IBM�̔����̔��p�͑��ɂ����낢��e�������肻���ŋC�ɂȂ�B�����̂Ƌ������Ă���������Ȃ́A�����������炢�����ȁBNVIDIA��GPU�ƂȂ��b���ǂ��Ȃ邩�ȁBNVIDIA��������������Ƃ��v���Ȃ����B
���ʂɒ����n����������
734 �FSocket774�F2014/02/09(��) 08:20:32.12 ID:rfvYGTKP
�C�V���́A���ʂ͂��܂܂Œʂ胋�l�T�X�EIBM�ɔ������āA
��������\�j�[�Ȃ�GF�ɐ����ϑ����Ĕ[�i���邾���ł���H
��������\�j�[�Ȃ�GF�ɐ����ϑ����Ĕ[�i���邾���ł���H
���̎d�l��LSI������i�����Ă����j�̂�
���l�T�X�����Ȃ��Ƃ����̂����Ȃ̂ł́H
���l�T�X�����Ȃ��Ƃ����̂����Ȃ̂ł́H
736 �FSocket774�F2014/02/09(��) 10:32:35.59 ID:rfvYGTKP
�C�V����GPU��eDRAM���A20nm�v���Z�X���炢�ɂȂ�A
eDRAM����eSRAM�����āATSMC������Ő������������ˁH
�݊����̂��߂ɁAeSRAM�̃^�C�~���O��eDRAM�Ɗ��S�Ɉ�v����悤�ɂ���Ƃ��̑������
eDRAM����eSRAM�����āATSMC������Ő������������ˁH
�݊����̂��߂ɁAeSRAM�̃^�C�~���O��eDRAM�Ɗ��S�Ɉ�v����悤�ɂ���Ƃ��̑������
�Ƃ������A���Ƃ��ƔC�V���͐ɃR�X�g�����Ȃ��Ƃ�����
��ɓ���ɂ����Ȃ�����ʂ̉����ōς܂����Ȃ��́AARM������ł�
��ɓ���ɂ����Ȃ�����ʂ̉����ōς܂����Ȃ��́AARM������ł�
�����ő���͓̂��������
���R�Ȃ��琻���͓���A���̃m�E�n�E�́u���m�d�b�̍Ő�[�̋Z�p���l�܂����g��`�̃^���h�̂悤�Ȃ��́v�i�ƊE�W�ҁj�B
���郋�l�T�X�����́u�ʎY�ł���H��͐��E�ł��߉������B�悻�ō��̂Ȃ�A��̔����̂��g���ȂǁA�v���̂��̂���蒼���K�v������̂ł́v
�O�o�̋ƊE�W�҂́u��̌����Ȃ�Wii U�̂��߂ɁA�C�V���̂킪�܂܂��Ă���锼���̐�����Ђ�����̂��v�Ǝ茵�����B
���R�Ȃ��琻���͓���A���̃m�E�n�E�́u���m�d�b�̍Ő�[�̋Z�p���l�܂����g��`�̃^���h�̂悤�Ȃ��́v�i�ƊE�W�ҁj�B
���郋�l�T�X�����́u�ʎY�ł���H��͐��E�ł��߉������B�悻�ō��̂Ȃ�A��̔����̂��g���ȂǁA�v���̂��̂���蒼���K�v������̂ł́v
�O�o�̋ƊE�W�҂́u��̌����Ȃ�Wii U�̂��߂ɁA�C�V���̂킪�܂܂��Ă���锼���̐�����Ђ�����̂��v�Ǝ茵�����B
740 �FSocket774�F2014/02/09(��) 12:16:02.17 ID:rfvYGTKP
>>738
���HeSRAM�Ȃ�ׂ�TSMC�ł��ǂ��ł������ł��邶���
���HeSRAM�Ȃ�ׂ�TSMC�ł��ǂ��ł������ł��邶���
GF�������Ă邵�ȁ�eDRAM
�H����ڂ��ȏ�v�ύX�͕K�v�����ǁA�����eDRAM�̗L���Ɋւ�炸�N���邱�Ƃ�����
�����Ƃ����N��ɂ킴�킴WiiU�̐v�ύX���s�����͓䂾��
�H����ڂ��ȏ�v�ύX�͕K�v�����ǁA�����eDRAM�̗L���Ɋւ�炸�N���邱�Ƃ�����
�����Ƃ����N��ɂ킴�킴WiiU�̐v�ύX���s�����͓䂾��
>>740
�����ł�����Ď��ƁA�K�v�������ł��郉�C�����m�ۏo������Ď��́A�ʖ����Ď�
�����ł�����Ď��ƁA�K�v�������ł��郉�C�����m�ۏo������Ď��́A�ʖ����Ď�
���Ă̘A�g��[�߂�Ƃ������ƂŁA���ł�IBM�������������ˁB�閧�ی�@�ʼn��n���o���Ă邵�A�ČR��Ȃ���̋@�����̘R�k������閼�ڂɂȂ��Ă邾�낤�B�U�W���p���t�@�u�ɂ��Ă�������Ȃ����H
����ŁA�\�j�[�ƈꏏ�ɃQ�[���p�̂Ȃ��܂����������w
����ŁA�\�j�[�ƈꏏ�ɃQ�[���p�̂Ȃ��܂����������w
744 �F,,�E�L�́M�E,,�j��-�������F2014/02/09(��) 13:23:04.38 ID:ZfCA/xE3
IBM�͔����̐��������͔��蕥���Ă��v�����͔���Ȃ��Ǝv����
����A�����̂̔����̐i�ݕ����݉������
�����v�̃v���Z�b�T�������Ԏg����悤�ɂȂ邩��
���̏o�Ȃ��v���Z�b�T�ł��v�ɂ�������������悤�ɂȂ邩���
IBM�̂悤�ȑ�^�̃R���s���[�^�������Ƃ���ɂƂ��Ă͗L���ɂȂ��Ă���
����A�����̂̔����̐i�ݕ����݉������
�����v�̃v���Z�b�T�������Ԏg����悤�ɂȂ邩��
���̏o�Ȃ��v���Z�b�T�ł��v�ɂ�������������悤�ɂȂ邩���
IBM�̂悤�ȑ�^�̃R���s���[�^�������Ƃ���ɂƂ��Ă͗L���ɂȂ��Ă���
�T���`�������p�N��悗
�~������x�����Ǝ������p�ӂł�������������̂͒����n�t�@�E���h��
����Ȃ茈�܂邩��
����Ȃ茈�܂邩��
�Ő�[�����O�ɏo�����A�Ƃ����̂����邯�ǁA���[���t���[���Ƃ��ǂ�����̂��ˁB
�A�����J�ł͂���Ȃɏd�v������Ă��Ȃ��̂��ȁB
�A�����J�ł͂���Ȃɏd�v������Ă��Ȃ��̂��ȁB
IBM�̔��p�悪�C���e���݂������Ƃ��i�l�^�͉p���j�B
TSMC�͔����ے肵���݂����BIBM���C���e���ɍs���Ă��܂���GF�ܖڂ��Ƃ�w
http://blog.livedoor.jp/amd646464/archives/52398841.html
TSMC�͔����ے肵���݂����BIBM���C���e���ɍs���Ă��܂���GF�ܖڂ��Ƃ�w
http://blog.livedoor.jp/amd646464/archives/52398841.html
�Ȃɂ���APOWER�V���[�Y���C���e���ňϑ����Y������Ă��ƁH
�u���[���v�t���[���Ƃ��V������BMain�̂��Ƃ����[���Ȃ�ď����̂�
���̂�m��Ȃ�����������B
���̂�m��Ȃ�����������B
�m���Ƀ��[���͂��܂肫���Ȃ���
�v�����X�Ń��[���C�x���g�Ƃ������̂����炢��
�ł��A�������w����������A�܂���t���[���Ƃ��ǂႢ���������ǂ�
�v�����X�Ń��[���C�x���g�Ƃ������̂����炢��
�ł��A�������w����������A�܂���t���[���Ƃ��ǂႢ���������ǂ�
��s�@�̋@�̂�G���W����v����̂ɑ�^�̃R���s���[�^���K�v������
PFLOPS���x�ł͍œK������̂ɐ��\�����肸�AZFLOPS�������y����2030�N�܂ő҂��Ȃ��Ƃ����Ȃ��ƒm���Đ�]
�����N�O�܂ł̓y�^���o��ł�����ƊE���ς��`�݂����Ș_���������̂�w
PFLOPS���x�ł͍œK������̂ɐ��\�����肸�AZFLOPS�������y����2030�N�܂ő҂��Ȃ��Ƃ����Ȃ��ƒm���Đ�]
�����N�O�܂ł̓y�^���o��ł�����ƊE���ς��`�݂����Ș_���������̂�w
�K�͂�ڍׂ̍��A���邢�̓u���t
sp�ꂪ�{���Ȃ獡���ł�@�̂͂ǂ��Ȃ̂�
sp�ꂪ�{���Ȃ獡���ł�@�̂͂ǂ��Ȃ̂�
�p�����[�^�Z�o��������x�[�܂��Čo���l�⏠�̊��ŃV�����Ă�Ɍ��܂��Ă��
>>750
�����܂Ŕ����̐�������
POWER�Ƃ���킯����Ȃ�
IBM�A�����̐������Ƃ̔��p������
http://jp.wsj.com/article/SB10001424052702303996604579368101327392252.html?dsk=y
�����܂Ŕ����̐�������
POWER�Ƃ���킯����Ȃ�
IBM�A�����̐������Ƃ̔��p������
http://jp.wsj.com/article/SB10001424052702303996604579368101327392252.html?dsk=y
>>754
���Ԃ������炾����[Philippe RICOUX.pdf - Symphos 2013]���ăO�O���Ă݁A
5�y�[�W�ڂɕ�����₷�������Ă���
70m�~70m�~20m�̓S�̉�Ԏ��A���ɓ����闱�q���̗�����S�Čv�Z����ɂ�
cray��IBM�̃X�p�R����������Ă������̂�
���Ԃ������炾����[Philippe RICOUX.pdf - Symphos 2013]���ăO�O���Ă݁A
5�y�[�W�ڂɕ�����₷�������Ă���
70m�~70m�~20m�̓S�̉�Ԏ��A���ɓ����闱�q���̗�����S�Čv�Z����ɂ�
cray��IBM�̃X�p�R����������Ă������̂�
>>751
�p��̃J�^�J�i�\�L�ɂ������̂��o�J�o�J�����̂ŐV���\�L�ɑ������������B
�l���Ă݂��NOAH-6�������͈ϑ���������Ȃ����B
�p��̃J�^�J�i�\�L�ɂ������̂��o�J�o�J�����̂ŐV���\�L�ɑ������������B
�l���Ă݂��NOAH-6�������͈ϑ���������Ȃ����B
�L���p�V�e�B�����ЂŖ��߂��Ȃ��Ȃ��č����Ă�Intel���������������Ɍ��������?
760 �FSocket774�F2014/02/11(��) 10:59:18.32 ID:is2ZNr0H
���{�̏ꍇ�A�����ɕ��������ʃ��[�J�[�����ɋZ�p����
�����{�̏����g���[�J�[�����̍U���Ń_�E�����ĕ����g�ɂȂ�
���Ă̂�����������Ȃ�
�����Ă鑤�������Ɣ����Ȃ肵�Ă���A����Ȏ��Ԃɂ͂Ȃ�Ȃ�����
�����Ă�ق��������Ă鑤�����Ă����̂́A�Z�p�E�l�ނ����C�o�����[�J�[�ɗ��o����̂�h�����Ƃɂ��Ȃ�
�����{�̏����g���[�J�[�����̍U���Ń_�E�����ĕ����g�ɂȂ�
���Ă̂�����������Ȃ�
�����Ă鑤�������Ɣ����Ȃ肵�Ă���A����Ȏ��Ԃɂ͂Ȃ�Ȃ�����
�����Ă�ق��������Ă鑤�����Ă����̂́A�Z�p�E�l�ނ����C�o�����[�J�[�ɗ��o����̂�h�����Ƃɂ��Ȃ�
�䂪�h�C�c�R�̋Z�p�͂͐��E��B�B�B�B�B�B�B�B�b�I
�������ق����������Ē��x�ɂ�肯�肾��B
�����ɍl���ĕ������ق�=����Ă��킯�ŁA����Ă����܂ŕ������ނ̂̓��_����
�ނ���D�G�Ȑl�����E���H�����Ƃ̂ł��Ȃ��l�����x�̂ق������
�����ɍl���ĕ������ق�=����Ă��킯�ŁA����Ă����܂ŕ������ނ̂̓��_����
�ނ���D�G�Ȑl�����E���H�����Ƃ̂ł��Ȃ��l�����x�̂ق������
>>760
����@�ۋƊE�Ŏ��؍ς݁B�y�ώ�`�Őݔ��������s�������Y�k�����o�c����
���ꂵ����ɐݔ����i�����ÂƂ��ĊC�O�ɔ̔����C�O�ɕ����遨�s�������Y�k�����c
IBM�̍H����Z�p���ƃC���e���������AIBM�̊J�������Z�p���������R
(�R����P�̉��͕����Ă�����)�œ��肵�Ă���GF�E�����̋Z�p�J�����X�g�b�v
���āA������V�X�e��LSI�����̓C���e��/TSMC��2�Ђ����ɂȂ肻�����ȁc
����@�ۋƊE�Ŏ��؍ς݁B�y�ώ�`�Őݔ��������s�������Y�k�����o�c����
���ꂵ����ɐݔ����i�����ÂƂ��ĊC�O�ɔ̔����C�O�ɕ����遨�s�������Y�k�����c
IBM�̍H����Z�p���ƃC���e���������AIBM�̊J�������Z�p���������R
(�R����P�̉��͕����Ă�����)�œ��肵�Ă���GF�E�����̋Z�p�J�����X�g�b�v
���āA������V�X�e��LSI�����̓C���e��/TSMC��2�Ђ����ɂȂ肻�����ȁc
>>763
�Z�p�I�ɗ���ĕ�����p�^�[���ƁA
�Z�p�͗���ĂȂ������̗v���ŕ�����p�^�[���������āA
���{�̃n�C�e�N�Y�Ƃ͌�҂���������
��҂̍����Z�p����������O�����[�J�[�ɗ���āA
�����g���[�J�[�܂ŕ����g�]������̂͂悭���邱�Ƃ���
�Z�p�I�ɗ���ĕ�����p�^�[���ƁA
�Z�p�͗���ĂȂ������̗v���ŕ�����p�^�[���������āA
���{�̃n�C�e�N�Y�Ƃ͌�҂���������
��҂̍����Z�p����������O�����[�J�[�ɗ���āA
�����g���[�J�[�܂ŕ����g�]������̂͂悭���邱�Ƃ���
���Ȃ݂ɃV���[�v�����ʋ@���Ƃ��T���X���ɔ����Ă�A
�L���m���E���R�[�E�x�m�[���b�N�X�̓T���X���̑�U���ɂ����
�����������ɑ�Ԏ��ɂȂ��Ă��Ƃ�������
�L���m���E���R�[�E�x�m�[���b�N�X�̓T���X���̑�U���ɂ����
�����������ɑ�Ԏ��ɂȂ��Ă��Ƃ�������
IBM���t�@�u�����������IBM�p�̃`�b�v�͂ǂ��ō��́H
TSMC
����������ɍ�点�邾��
�Ȃ������āA����m����Fab����
�Ȃ������āA����m����Fab����
�t�@�u����Ƃ��ɁA������N�Ԃ�IBM�̃`�b�v���Ȃ��Ƃ����Ȃ����Ă����������Ĕ��邾��
771 �F,,�E�L�́M�E,,�j��-�������F2014/02/11(��) 20:58:59.98 ID:qr9HLeI3
���RPOWER��z�V���[�Y�����ł���
��eDRAM�ƌ�����intel��IBM������
�Ȃʔ������W���邩�ˁH
�Ȃʔ������W���邩�ˁH
�㓡�����̐����ł�Intel��eDRAM�͉ߓx�I�Ȏ�i�AIBM�͐������唄�p�A�{����Sony�E���ŘA���͓P�ލ�
Google��ARM�̂悤�ȓV�ˏW�c�ɏ[�d�r�̊J������������
�E�������i1����ȏ�̋}���[���d�j
�E�����x�i�]����2���d�r�̔{�ȏ�j
�E���M���قƂ�ǂȂ����S
�E�t�̂��g��Ȃ��̂ʼnt�R�ꖳ���B
�E���A�A�[�X���g��Ȃ��̂ň���
�ȕ����������邩����
�E�������i1����ȏ�̋}���[���d�j
�E�����x�i�]����2���d�r�̔{�ȏ�j
�E���M���قƂ�ǂȂ����S
�E�t�̂��g��Ȃ��̂ʼnt�R�ꖳ���B
�E���A�A�[�X���g��Ȃ��̂ň���
�ȕ����������邩����
���l�T���X�̎��ザ�Ⴀ��܂���
���\�̋S�˂ɂȂ��قnj���Ȋw�͊Â��Ȃ�
���\�̋S�˂ɂȂ��قnj���Ȋw�͊Â��Ȃ�
�Ƃ������d�r�̓V�˂��d�r���[�J�[�Ƃ��ō��J���Ȃ����Ă邩��}�l�͑҂��Ă�
�d�r�̓V�˂��u���ǁv�͂���Ă邯�ǁA
���ǂɂƂǂ܂�Ȃ��v���I�Ȑi���͑����삩��o�Ă��邱�Ƃ�����
���ǂɂƂǂ܂�Ȃ��v���I�Ȑi���͑����삩��o�Ă��邱�Ƃ�����
�{����google��ARM���V�ˏW�c�Ȃ玩�Ђ̃T�[�r�X�������Ɨǂ��Ȃ��Ă邾�낗
IBM���Y����w
�h�a�l�A�����̂̍��ٖ͍��@���p��q�Ńp�[�g�i�[�T���ɏd�_
http://www.sankeibiz.jp/macro/news/140211/mcb1402110503015-n1.htm
�h�a�l�A�����̂̍��ٖ͍��@���p��q�Ńp�[�g�i�[�T���ɏd�_
http://www.sankeibiz.jp/macro/news/140211/mcb1402110503015-n1.htm
IBM�͍��z�Ȑ�[�t�@�u�������s�v�ɂȂ�m�����A�Ƃ����d�g�����̔]���Q���}�j�E���ɔ�э���ł���
�O������ėp�v���Z�X���ƈ��l�����ɎN�����
�킪�����s�������v���Z�X�͔����ǂ��ăR�P��Ɩ{�̂��R�P�邭�炢�̊J���������K�v
�����c�[���Ŕėp�Ɛv�݊������邭�炢�̕t�����l�v���Z�X�Ȃ�Ă��������v������
�̂Ă邩�H�I
�ƂȂ���
�킪�����s�������v���Z�X�͔����ǂ��ăR�P��Ɩ{�̂��R�P�邭�炢�̊J���������K�v
�����c�[���Ŕėp�Ɛv�݊������邭�炢�̕t�����l�v���Z�X�Ȃ�Ă��������v������
�̂Ă邩�H�I
�ƂȂ���
��[�v���Z�X�ُ͈킾�����B
�Z�p�̈�Ԑ擪�͌��������Ȃ̂�������O�ł���B
�����Ȃ��̂̓{�����[���]�[���̃s�[�N�ɂ͂Ȃꂸ���v�������
���v���͏グ���Ă����v�̐�Ηʂ͑��₹�Ȃ��B
LSI�����Y�Ƃ͂��������@������O�ꂽ��O�������B
��O�ɐ��蓾���̂�LSI���g�����W�X�^�̒P���������葱��������B
���̉���������݉�����Ƃ������Ƃ́A��O�ł͂Ȃ��Ȃ菇����
�@���ɓ��Ă͂܂�Y�Ƃւ��Ɉڍs���n�߂��Ƃ������Ƃ��B
�Z�p�̈�Ԑ擪�͌��������Ȃ̂�������O�ł���B
�����Ȃ��̂̓{�����[���]�[���̃s�[�N�ɂ͂Ȃꂸ���v�������
���v���͏グ���Ă����v�̐�Ηʂ͑��₹�Ȃ��B
LSI�����Y�Ƃ͂��������@������O�ꂽ��O�������B
��O�ɐ��蓾���̂�LSI���g�����W�X�^�̒P���������葱��������B
���̉���������݉�����Ƃ������Ƃ́A��O�ł͂Ȃ��Ȃ菇����
�@���ɓ��Ă͂܂�Y�Ƃւ��Ɉڍs���n�߂��Ƃ������Ƃ��B
>>782
����Ȃ��Ƃ͂Ȃ��B���̐�[�Z�p�ɑ��đ�O����̎��v������A�����R�X�g���Ⴂ�ꍇ�A�J�����c��Ȏs�ꂩ�瓾����R���f�B�e�B�s��͍Ő�[�Z�p������������B���łɃ��o�C���������̂��Ђ��ς��Ă�͖̂��炩�B�Q�[�������āA�f�悾���āA���̍ł����B
����Ȃ��Ƃ͂Ȃ��B���̐�[�Z�p�ɑ��đ�O����̎��v������A�����R�X�g���Ⴂ�ꍇ�A�J�����c��Ȏs�ꂩ�瓾����R���f�B�e�B�s��͍Ő�[�Z�p������������B���łɃ��o�C���������̂��Ђ��ς��Ă�͖̂��炩�B�Q�[�������āA�f�悾���āA���̍ł����B
���{�����Ő�[�v���Z�X����P�ނ�����A���ē��{����ǂ������闧�ꂾ����Intel��TSMC���Ő�[�ɗ����āA
TSMC�Ȃ�ĒI���牲�O�݂Ŕ���Ȏ��v���グ��悤�ɂȂ���
TSMC�Ȃ�ĒI���牲�O�݂Ŕ���Ȏ��v���グ��悤�ɂȂ���
785 �FSocket774�F2014/02/15(�y) 15:30:38.47 ID:KlZ+c6fw
>>783
���o�C�������Ă���ȏ�̊J��������z���ł��Ȃ��Ȃ��Ă邩��
�g��&�X�}�z����SoC�V�K�J������P�ނ����Ƃ�������Łc
���o�C�������Ă���ȏ�̊J��������z���ł��Ȃ��Ȃ��Ă邩��
�g��&�X�}�z����SoC�V�K�J������P�ނ����Ƃ�������Łc
>>782,783
�g�����W�X�^�T�C�Y�������ɂȂ邩���[�Z�p�̃R�X�g���B�����Ă��܂��Ă����킯���B
���݂ł͉B��������Ȃ��قǍ��R�X�g�ȍŐ�[�v���Z�X�ƁA
��[�v���Z�X�ɂ�鉶�b�̌����Ƃ������ԂɂȂ��Ă���B
TSMC��T���X���͕��ƂŃX�p�R���p�������ǂ����ˁB
���P���ō��_�C�T�C�Y�A��[�v���Z�X�̉��b�͎���B
�܂��A���܂��܂Ȗ�肪�����ĊȒP�ɂ͂����Ȃ����낤���ǁB
>>784
������Ƃ����Ⴄ����BTSMC���䓪���Đ�[�ɗ���������
���{�����Ԏ��Ő��Y�܂Ŏ�|����Ӗ����Ȃ��Ȃ�P�ނ����B
�g�����W�X�^�T�C�Y�������ɂȂ邩���[�Z�p�̃R�X�g���B�����Ă��܂��Ă����킯���B
���݂ł͉B��������Ȃ��قǍ��R�X�g�ȍŐ�[�v���Z�X�ƁA
��[�v���Z�X�ɂ�鉶�b�̌����Ƃ������ԂɂȂ��Ă���B
TSMC��T���X���͕��ƂŃX�p�R���p�������ǂ����ˁB
���P���ō��_�C�T�C�Y�A��[�v���Z�X�̉��b�͎���B
�܂��A���܂��܂Ȗ�肪�����ĊȒP�ɂ͂����Ȃ����낤���ǁB
>>784
������Ƃ����Ⴄ����BTSMC���䓪���Đ�[�ɗ���������
���{�����Ԏ��Ő��Y�܂Ŏ�|����Ӗ����Ȃ��Ȃ�P�ނ����B
ST�A�f�W�^���z�[������64�r�b�gSoC�A�[�L�e�N�`���uSTi8K�v�\
ttp://news.mynavi.jp/news/2014/01/31/397/index.html
�挎�̋L�������AFD-SIO�̗ʎY�`�b�v�͏��߂Ă��ȁB
�܂���ʂɔ����Ƃ͌���Ȃ����B
ttp://news.mynavi.jp/news/2014/01/31/397/index.html
�挎�̋L�������AFD-SIO�̗ʎY�`�b�v�͏��߂Ă��ȁB
�܂���ʂɔ����Ƃ͌���Ȃ����B
���͐̉��d�C��FD-SOI��LSI������Ă�
>>786
TSMC�͕x�m�ʂ̋��Ŏg���Ă�SPARC�̐�������Ă��ł���
TSMC�͕x�m�ʂ̋��Ŏg���Ă�SPARC�̐�������Ă��ł���
ttp://news.mynavi.jp/news/2011/11/08/020/
>�u���v�ŗp����ꂽ�v���Z�b�T�uSPARC64 VIIIfx�v�ō̗p���Ă�������45nm�v���Z�X����A
>SPARC64 IXfx��TSMC(Taiwan Semiconductor Manufacturing)��40nm�v���Z�X�ւƕύX����A
����VIIIfx �x�m�ʐ����AFX10��IXfx TSMC
>�u���v�ŗp����ꂽ�v���Z�b�T�uSPARC64 VIIIfx�v�ō̗p���Ă�������45nm�v���Z�X����A
>SPARC64 IXfx��TSMC(Taiwan Semiconductor Manufacturing)��40nm�v���Z�X�ւƕύX����A
����VIIIfx �x�m�ʐ����AFX10��IXfx TSMC
>>619�@>687�@>695
���m�{�AIBM�̃X�p�R���r�W�l�X�̔����ے�
Lenovo denies buying part of IBM's supercomputer business
ttp://wraltechwire.com/lenovo-denies-buying-part-of-ibm-s-supercomputer-business/13407789/
���m�{�AIBM�̃X�p�R���r�W�l�X�̔����ے�
Lenovo denies buying part of IBM's supercomputer business
ttp://wraltechwire.com/lenovo-denies-buying-part-of-ibm-s-supercomputer-business/13407789/
VIA�Cx86 CPU�J���𒆍����{�n������ЂƂ̍��ى�ЂɈڂ��H
http://blog.livedoor.jp/amd646464/archives/52400403.html
�T���X���A64bit�Ή��Ǝv����V�^���o�C���v���Z�b�T�uExynos Infinity�v�� MWC 2014 �Ő������\�\��
http://gpad.tv/develop/samsung-exynos-infinity-64bit/
http://blog.livedoor.jp/amd646464/archives/52400403.html
�T���X���A64bit�Ή��Ǝv����V�^���o�C���v���Z�b�T�uExynos Infinity�v�� MWC 2014 �Ő������\�\��
http://gpad.tv/develop/samsung-exynos-infinity-64bit/
�����̃x���`���[��Ƃ͏����Ă����̂��H ISSCC�œ��_
http://eetimes.jp/ee/articles/1402/21/news074.html
�ߔN�A�����̋ƊE�̐V����Ƃ͂Ђǂ�������ƂȂ��Ă���B
2011�N�ȍ~�A�������{��100���߂��܂ʼn���ł����P�[�X�͂߂����ɂȂ��B
�������A���Ȃ��������̊�Ƃɓ���������A�������{�̂���60���������\����50��������B
�x���`���[�L���s�^�����t�@�u�ւ̓��������������Ă���͎̂��������A
����͓��R�̐���s�����B���E�́A�V�����t�@�u�����݂�������A
Google��LinkedIn�̂悤�ȃl�b�g���[�L���O�T�[�r�X��Ƃ����߂Ă���B
http://eetimes.jp/ee/articles/1402/21/news074.html
�ߔN�A�����̋ƊE�̐V����Ƃ͂Ђǂ�������ƂȂ��Ă���B
2011�N�ȍ~�A�������{��100���߂��܂ʼn���ł����P�[�X�͂߂����ɂȂ��B
�������A���Ȃ��������̊�Ƃɓ���������A�������{�̂���60���������\����50��������B
�x���`���[�L���s�^�����t�@�u�ւ̓��������������Ă���͎̂��������A
����͓��R�̐���s�����B���E�́A�V�����t�@�u�����݂�������A
Google��LinkedIn�̂悤�ȃl�b�g���[�L���O�T�[�r�X��Ƃ����߂Ă���B
794 �FSocket774�F2014/02/22(�y) 03:20:06.87 ID:5aU1274G
>>753
�^�ƃZ���X�Ŏ��삵�낗
�^�ƃZ���X�Ŏ��삵�낗
795 �F,,�E�L�́M�E,,�j��-�������F2014/02/22(�y) 10:32:15.78 ID:QzOfo4PQ
NP����Ȗ��̐��\�v���ɏI���Ȃ�ĂȂ�
��X�̐��w���n���ł���Ƃ������[�g�������?
797 �FSocket774�F2014/02/22(�y) 15:07:29.96 ID:uxrbSgSr
Skylake�ł͏]���̃r�b�O�R�A�S�ȊO��
���炩�̃X���[���R�A���lj������̂��낤��
���炩�̃X���[���R�A���lj������̂��낤��
798 �F,,�E�L�́M�E,,�j��-�������F2014/02/22(�y) 15:41:17.16 ID:UA8D8qBT
�����Ȃ�Ɨ\�z���鍪����������
NP���S���̓R���s���[�^�[�̐��\���ł͎������Ȃ��B
�����NP���S�̂��߂ɍ��������邱�ƂɈӖ����Ȃ��B
�����NP���S�̂��߂ɍ��������邱�ƂɈӖ����Ȃ��B
���ɂ��Ƃ����B�g�ݍ��킹�������N�����悤�Ȗ�肾�ƁA
���ۏ�̓q���[���X�e�B�b�N�ȃA���S���Y�����g���킯������
�v�Z���\�[�X�������߂Ή������P����Ƃ��͂���b�Ȃ̂�
NP���S�Ō����Ȃ�A������������SAT���ɗ��Ƃ��Ă���
SAT�\���o�ɉ�������A�v���[�`�����邯�ǁA�悭������������Ă���
���ۏ�̓q���[���X�e�B�b�N�ȃA���S���Y�����g���킯������
�v�Z���\�[�X�������߂Ή������P����Ƃ��͂���b�Ȃ̂�
NP���S�Ō����Ȃ�A������������SAT���ɗ��Ƃ��Ă���
SAT�\���o�ɉ�������A�v���[�`�����邯�ǁA�悭������������Ă���
>>800
����̓R���s���[�^�[�̍������ł͂Ȃ��B
�ʂ̉���̓K�p���B
���łɂ����ƃq���[���X�e�B�b�N�Ƃ��A�����ȁB
�o�J���Ɛ�`���Ă���悤�ȕ����B
����̓R���s���[�^�[�̍������ł͂Ȃ��B
�ʂ̉���̓K�p���B
���łɂ����ƃq���[���X�e�B�b�N�Ƃ��A�����ȁB
�o�J���Ɛ�`���Ă���悤�ȕ����B
>>801
�N�����̂܂܉����Ȃ�Č����n�߂���ł��H
�N�����̂܂܉����Ȃ�Č����n�߂���ł��H
�N�Ȃ̂�����
�삯�����Ă䂭�@���̃������A��
�삯�����Ă䂭�@���̃������A��
�����Ȃ��Ƃ����I����
���u�Ƃ����I����
�摗��Ƃ����I����
�̂̃G�����l�B�͊F�������Ă���
���u�Ƃ����I����
�摗��Ƃ����I����
�̂̃G�����l�B�͊F�������Ă���
���������ǎ����̃m�[�g�ɏ����Ă��������̐l��������?
���������ǁA������������ɂ͎��������Ȃ�����Ə������l��������H
Agner�}�j���A����Steamroller��fp���Z2�p�C�v�����Ă�1�X���b�h�ł�1�{���������Ȃ��Ƃ�����͌��ʂ�...
fp�n�̃x���`�Ŗ��ɐ��\�����Ă�̂������̂͂��̂�����
fp�n�̃x���`�Ŗ��ɐ��\�����Ă�̂������̂͂��̂�����
���낢��r��肾��ˁux86���� Bulldozer����v
int.main.jp/txt/bulldozer/
int.main.jp/txt/bulldozer/
>>804
���������Ȃ����A���{�����Ȃ�����
������Ղ��������l����肴�����ăA�s�[�����A���ʂ��Ǝ咣���ˁB
���͂قƂ�Ǎ����Ȃ��̂ɁA�ړI���͂��Ⴆ�B
����Ȋw�Z�p�̈�̃_�[�N�T�C�h���ȁB
���������Ȃ����A���{�����Ȃ�����
������Ղ��������l����肴�����ăA�s�[�����A���ʂ��Ǝ咣���ˁB
���͂قƂ�Ǎ����Ȃ��̂ɁA�ړI���͂��Ⴆ�B
����Ȋw�Z�p�̈�̃_�[�N�T�C�h���ȁB
�������Ƃ̃S�~�ǂ���NP����𗘗p���邩��ق�ƃ^�`�������B
AMD��CPU���r��肶��Ȃ��������Ȃ��
813 �F,,�E�L�́M�E,,�j��-�������F2014/02/26(��) 08:09:37.56 ID:IpRviJDh
���̂ւ��Athlon���ォ��̓`�������ǁA
movd xmm, reg + movd reg, xmm�̃��C�e���V��18�T�C�N���Ƃ���k�݂����ɒx����
�i��9�T�C�N���H�j
movd xmm, reg + movd reg, xmm�̃��C�e���V��18�T�C�N���Ƃ���k�݂����ɒx����
�i��9�T�C�N���H�j
>>813
�X�g�A�o�b�t�@���̂��ˁB�����͂����ł��Ȃ�����A�Ƃ�����菬�����̂����m��Ȃ����B
�X�g�A�o�b�t�@���̂��ˁB�����͂����ł��Ȃ�����A�Ƃ�����菬�����̂����m��Ȃ����B
�������o�R����Ȃ��ă��W�X�^���m�̌���������X�g�A�o�b�t�@�Ƃ��W�Ȃ���
�G�N�T���ς�����( ߄t�)ν��c
���b�P�O�O����v�Z�ł���G�N�T���p�\�R���U�v��
�_�ˎs����ÎY�Ɠs�s�ɊJ�����_����
http://sankei.jp.msn.com/west/west_economy/news/140225/wec14022513390000-n1.htm
�_�˂̃X�p�R���u���v��p�@�@�G�N�T���J����
http://www.kobe-np.co.jp/news/shakai/201402/0006736154.shtml
���b�P�O�O����v�Z�ł���G�N�T���p�\�R���U�v��
�_�ˎs����ÎY�Ɠs�s�ɊJ�����_����
http://sankei.jp.msn.com/west/west_economy/news/140225/wec14022513390000-n1.htm
�_�˂̃X�p�R���u���v��p�@�@�G�N�T���J����
http://www.kobe-np.co.jp/news/shakai/201402/0006736154.shtml
�n���V�~�����[�^�[��6�N�̍X�V�����}��3��ڂɂȂ�炵���B�ڍׂ͂܂��s���B
�iSX-ACE�͒ʏ�ő�8���b�N�̂Ƃ���16���b�N�ȏ�̍\���ɂȂ��Ȃ����Ǝv���j
�ŁA4��ڂ�����Ƃ���ƃG�N�T�X�P�[���Ɠ���2020�N���Ȃ̂�
�ƊE�͑������C�Â���Ȃ����B
�iSX-ACE�͒ʏ�ő�8���b�N�̂Ƃ���16���b�N�ȏ�̍\���ɂȂ��Ȃ����Ǝv���j
�ŁA4��ڂ�����Ƃ���ƃG�N�T�X�P�[���Ɠ���2020�N���Ȃ̂�
�ƊE�͑������C�Â���Ȃ����B
���C�t���Ȃ���������NEC���x�m�ʂ�fab�藣�����낤��
�A�z�炵
�A�z�炵
HPC�p�`�b�v�Ȃ�Đ����ۏ��Ȃ����ăt�@�u�̉ғ������グ�邱�Ƃ͖���
HPC�����C�Â��̂ƃt�@�u�r�W�l�X�ɂ͂قƂ�NJW�Ȃ�
HPC�����C�Â��̂ƃt�@�u�r�W�l�X�ɂ͂قƂ�NJW�Ȃ�
�v����ɂ��ɂȂ��Ă��q�����Ȃ����ɃP�c�@���Ă��炤������
���d���Ȃ��C�t�����͉i�v�ɖ������Ď�
���d���Ȃ��C�t�����͉i�v�ɖ������Ď�
�ǂ����ŏI�I�ɂ͌R���p�Ȃ���V��ŗ\�Z���Ԃ����߂�������
���ꂪ1000���h���Ƃ�200���h���ł����Ȃ�
���ꂪ1000���h���Ƃ�200���h���ł����Ȃ�
�R�p��������đ�ʂ̗\�Z���������ꂽ�̂͑�̘̂b��
���ɂ���10�N���炢��COTS�Ƃ������Ė����i���ɗ͗��p���闬��
���ɂ���10�N���炢��COTS�Ƃ������Ė����i���ɗ͗��p���闬��
�ł��A���ۂǂ��Ȃ낤�ˁB���Y�A�R�Y�X�p�R���n�̗\�Z��S�����āA�S�������i�ɂ����炩�����Ă��܂����悤�ɂȂ邩�ȁH�����Ȋ_�����Ƃ�Ă����C�����邯�ǁA�R���n�̃n�b�N�͕|���Ȃ��B
������Lenovo��IBM�̃X�p�R�����Ƃ��ȁA�߯�����Ă���
IBM�̃X�p�R�����Ƃ͒����v���Ƃ����甄��Ȃ���w
�������̂́A������̖��Ԃ̉�ЂŎg���i����x86�T�[�o�[����B
�������̂́A������̖��Ԃ̉�ЂŎg���i����x86�T�[�o�[����B
�@�т̐e�ʂ݂����Ȃ��
�@�т̂ق������̒l�i�������x�����������
�@�т̂ق������̒l�i�������x�����������
827 �F,,�E�L�́M�E,,�j��-�������F2014/02/27(��) 23:54:18.18 ID:GdSkwkzE
����A�X�p�R���p���܂߂��Sx86�T�[�o�����B
POWER��z�V���[�Y�������c�����B
POWER��z�V���[�Y�������c�����B
���������̂����E�s��Ŗׂ���Ȃ�����͒l���t�������ɑ�_�ɔ��肳�����IBM�́B
�挩�̖��͊m���ɂ���B
�������͔������ŁA���������̂����Ȃ�ׂ���Z�i�������Ă���B
�������̒ʂ�ЂƂ蕉���Ȃ̂͌��d�q�������{�B
�ŋ������̎Q����ǁE�d�d����ȊO�A����Ɏ��ŁA��ŃX�p�C���������~�܂炸�B
�uNP����Ȗ��̐��\�v���ɏI���Ȃ�ĂȂ��v�Ƃ������Ă���r���Ɍ����Ă��n�܂�Ȃ����c
�挩�̖��͊m���ɂ���B
�������͔������ŁA���������̂����Ȃ�ׂ���Z�i�������Ă���B
�������̒ʂ�ЂƂ蕉���Ȃ̂͌��d�q�������{�B
�ŋ������̎Q����ǁE�d�d����ȊO�A����Ɏ��ŁA��ŃX�p�C���������~�܂炸�B
�uNP����Ȗ��̐��\�v���ɏI���Ȃ�ĂȂ��v�Ƃ������Ă���r���Ɍ����Ă��n�܂�Ȃ����c
>>825
�X�p�R����肻�̕ӂɓ]�����Ă���
���O���o�J�ɂ����悤�ȏ���������x86�T�[�o�[�̕���
�����ēK�p�͈͂��L���A���ɗ����A�����I�Ȍo�ϓI�����ɗL�v����Ȃ��H
�Ӗ�������Ȃ�����X�͖��p�B
�X�p�R����肻�̕ӂɓ]�����Ă���
���O���o�J�ɂ����悤�ȏ���������x86�T�[�o�[�̕���
�����ēK�p�͈͂��L���A���ɗ����A�����I�Ȍo�ϓI�����ɗL�v����Ȃ��H
�Ӗ�������Ȃ�����X�͖��p�B
>>828�@��̓I�ɒN�H
>>831
�����ǃg�b�v�ɗ��Ă�Ƃ��v���Ȃ��B�G�N�T�X�P�[���͂悻���v�悵�Ă���B
���͈ꉞ�����L���O2�炢�g�b�v�������C�����邪�B
�����ǃg�b�v�ɗ��Ă�Ƃ��v���Ȃ��B�G�N�T�X�P�[���͂悻���v�悵�Ă���B
���͈ꉞ�����L���O2�炢�g�b�v�������C�����邪�B
�X�p�R�����Č����Ă��Alinpack�Ԓ��Ȃ̂Ƃ����łȂ��̂����邩��Ȃ�
TOP500�Ƃ�����Linpack�Ԓ����L���ȃ����L���O���AHPCC�̂ق������ɗ���
TOP500�Ƃ�����Linpack�Ԓ����L���ȃ����L���O���AHPCC�̂ق������ɗ���
�L�҂��悭�킩���ĂȂ��̂��A�ǂ�ł�����܂�s���Ɨ��Ȃ���
�Ƃ肠�����������ɖ𗧂��������Ęb���ۂ���
ttp://www.nikkei.com/article/DGXNZO67335170U4A220C1TJM000/
�Ƃ肠�����������ɖ𗧂��������Ęb���ۂ���
ttp://www.nikkei.com/article/DGXNZO67335170U4A220C1TJM000/
���̋Z�p�g���X�p�R�������^PC���݂ɂȂ���Ă̂͊ԈႢ
���̎�����A�X�p�R���͈��PC�̐����{�̏������x�����R���s���[�^�������
���̎�����A�X�p�R���͈��PC�̐����{�̏������x�����R���s���[�^�������
�X�p�R�����p�X�R����ɂ�
���̃n�C�G���h�ɋ߂��O���t�B�b�N�X�{�[�h�̓X�p�R�����Č����Ă�����
838 �F,,�E�L�́M�E,,�j��-�������F2014/02/28(��) 19:22:04.67 ID:F3r/YyZa
�{���x��1.5TF�������
Linpack��pASIC�����TOP500���r���܂��낤��
840 �F,,�E�L�́M�E,,�j��-�������F2014/02/28(��) 23:18:18.26 ID:F3r/YyZa
ClearSpeed�E�E�E����Ȃ�ł��Ȃ�
>>839
��҂͂����ƗL�Ӌ`�Ȃ��Ƃɓ��ƘJ�͂Ǝ��Ԃ��g���ĸ�ցf
��҂͂����ƗL�Ӌ`�Ȃ��Ƃɓ��ƘJ�͂Ǝ��Ԃ��g���ĸ�ցf
�����Ƃͼ�ɔC�����B
�Ϙa��ج�ǂ��낤�A�����ׂƁB
��ł��ꂪ���fHz�Ő��S������ɂ�������ǂ���B
���ς���z��̓��e�A���l�͕s��A�Ӗ��E�Ӌ`�s��B
�ذ�߯Ĕz�����āA����z�番�U���ē��͂��X�J���[�ɑ����݂Ⴈ���܂��B
����Ȃ���A�R���s���[�^�[����Ȃ��B
���߂Ă�������Ȃ��B
��ł��ꂪ���fHz�Ő��S������ɂ�������ǂ���B
���ς���z��̓��e�A���l�͕s��A�Ӗ��E�Ӌ`�s��B
�ذ�߯Ĕz�����āA����z�番�U���ē��͂��X�J���[�ɑ����݂Ⴈ���܂��B
����Ȃ���A�R���s���[�^�[����Ȃ��B
���߂Ă�������Ȃ��B
�����Ƃ͒r���̃_���S�ƁA�Љ�ɂł��т�đ�w�ŃO�_�O�_�����閾���Ȃ�ưĂɂ܂������B
�c�o���ł��������Ă����_���ʎY���Ă���ĂA�ǂ�ł����Ȃ�����B
���Ȃ݂Ɋ��זE�̉摜���H�͂����ƍI���ɂ���Â��ǂ��B
�c�o���ł��������Ă����_���ʎY���Ă���ĂA�ǂ�ł����Ȃ�����B
���Ȃ݂Ɋ��זE�̉摜���H�͂����ƍI���ɂ���Â��ǂ��B
>>838
�{���x�̃\�[�X�~����
�{���x�̃\�[�X�~����
846 �F,,�E�L�́M�E,,�j��-�������F2014/03/01(�y) 08:37:34.10 ID:rOMt9Y3v
����ȏ�͉�������Ȃ�����
https://twitter.com/ProfMatsuoka/status/350961284285599745
https://twitter.com/ProfMatsuoka/status/350961284285599745
�Ƃ������A�܂����̊�Ȃ̂�YO
�����p�\�R�������Ȃ����
�����p�\�R�������Ȃ����
848 �F,,�E�L�́M�E,,�j��-�������F2014/03/01(�y) 10:18:27.24 ID:rOMt9Y3v
Xeon Phi��Tesla��2���ŃA�E�g�ł���
�N�A���R�����В��u���o�C���v���Z�b�T�ɂ�����CPU�͏d�v�ł͂Ȃ��v
http://rbmen.blogspot.jp/2014/03/cpu.html
�����́u���݂̃��o�C��SoC�̖ʐς�CPU����߂銄����
�͂�15���قǂ����Ȃ��v�Ƃ�
�uCPU����GPU�E�x�[�X�o���h�`�b�v�E�}���`���f�B�A���\���d�v���B
�܂�CPU�͏d�v�ł͂Ȃ��v�Ɩ��炩�ɂ��܂����B
http://rbmen.blogspot.jp/2014/03/cpu.html
�����́u���݂̃��o�C��SoC�̖ʐς�CPU����߂銄����
�͂�15���قǂ����Ȃ��v�Ƃ�
�uCPU����GPU�E�x�[�X�o���h�`�b�v�E�}���`���f�B�A���\���d�v���B
�܂�CPU�͏d�v�ł͂Ȃ��v�Ɩ��炩�ɂ��܂����B
�딚
Denver�͂���ȂɌx������Ă���̂�w
CPU�d�v����Ȃ��Ȃ�64bit 8core�Ƃ�����Ȃ�����Ȃ��ł���
A53���Ă��Ƃ�����A�����Ǝ��ō��͂��������Đ錾�Ƃ����E�E
A53���Ă��Ƃ�����A�����Ǝ��ō��͂��������Đ錾�Ƃ����E�E
CPU�͏d�v�ł͂Ȃ����A�o�C�i���݊��͈��������d�v���ȁB����Qualcomm��IP�ƕ������킹�ɂ����Ƃ��Ă��AMIPS��Ǝ��A�[�L�e�N�`���������甄��Ȃ����낤�B
>>849
CPU�͏d�v�ł͂Ȃ����Ă������ACPU�͏d�v������CPU���ᑼ�Ђƍ��ʉ����ɂ������Ċ�������H
�N�A���R�����听�������̂́A�����E�����n�\�t�g�E�F�A�E�J���x���T�[�r�X���́A
��CPU�����ō��ʉ��ł�������
CPU�͏d�v�ł͂Ȃ����Ă������ACPU�͏d�v������CPU���ᑼ�Ђƍ��ʉ����ɂ������Ċ�������H
�N�A���R�����听�������̂́A�����E�����n�\�t�g�E�F�A�E�J���x���T�[�r�X���́A
��CPU�����ō��ʉ��ł�������
855 �F,,�E�L�́M�E,,�j��-�������F2014/03/01(�y) 11:33:45.20 ID:rOMt9Y3v
�`�����h���V�[�J����A���̔����ŐӔC��炳��Ă�����
http://iphone-mania.jp/news-7005/
�N�A���R���̃}�[�P�e�B���O�S��������Anand Chandrasekher�����u64�r�b�g�v���Z�b�T�[��A7
�`�b�v�̗p�Ƃ������\�̓A�b�v���̂����̍L����@�ŁA���[�U�[��A7�`�b�v���瓾�郁���b�g�͂Ȃ��v
http://www.teach-me.biz/iphone/iphone5/s/131218.html
A7 �̃����[�X���A�N�A���R����CMO�i�ō��}�[�P�e�B���O�ӔC�ҁj�������A�i���h�E�`�����h��
�V�[�J���́A�A�b�v����64�r�b�g�̃X�}�z�`�b�v�̓W�]��@�ŏ��悤�Ȕ��������܂����B
�u����͉c���ړI�̃}�[�P�e�B���O�̎d�|���ɉ߂��Ȃ��B����҂����b����v�f�̓[�����v�ƁA�����B
��
���������ꂩ��1�T�Ԃ��o�߂��Ȃ������ɁA�N�A���R���͓����̔������u�s���m���v�Ƃ��A��������C���܂����B
��
�g���v��SIM�Ή���64�r�b�g�����A�s�[������N�A���R��
http://m.k-tai.watch.impress.co.jp/docs/event/mwc2014/20140225_636837.html
http://ascii.jp/elem/000/000/870/870322/
�u�X�P�W���[���̊W�ł��܂��܃~�h�������W�ȉ�����̑Ή��ƂȂ������ASnapdragon 800�V���[�Y
�ł̑Ή����i�߂Ă���B����64bit���嗬�ɂȂ�͖̂����Ȃ̂ŁA�K�ȃ^�C�~���O�œ�������\��v
http://iphone-mania.jp/news-7005/
�N�A���R���̃}�[�P�e�B���O�S��������Anand Chandrasekher�����u64�r�b�g�v���Z�b�T�[��A7
�`�b�v�̗p�Ƃ������\�̓A�b�v���̂����̍L����@�ŁA���[�U�[��A7�`�b�v���瓾�郁���b�g�͂Ȃ��v
http://www.teach-me.biz/iphone/iphone5/s/131218.html
A7 �̃����[�X���A�N�A���R����CMO�i�ō��}�[�P�e�B���O�ӔC�ҁj�������A�i���h�E�`�����h��
�V�[�J���́A�A�b�v����64�r�b�g�̃X�}�z�`�b�v�̓W�]��@�ŏ��悤�Ȕ��������܂����B
�u����͉c���ړI�̃}�[�P�e�B���O�̎d�|���ɉ߂��Ȃ��B����҂����b����v�f�̓[�����v�ƁA�����B
��
���������ꂩ��1�T�Ԃ��o�߂��Ȃ������ɁA�N�A���R���͓����̔������u�s���m���v�Ƃ��A��������C���܂����B
��
�g���v��SIM�Ή���64�r�b�g�����A�s�[������N�A���R��
http://m.k-tai.watch.impress.co.jp/docs/event/mwc2014/20140225_636837.html
http://ascii.jp/elem/000/000/870/870322/
�u�X�P�W���[���̊W�ł��܂��܃~�h�������W�ȉ�����̑Ή��ƂȂ������ASnapdragon 800�V���[�Y
�ł̑Ή����i�߂Ă���B����64bit���嗬�ɂȂ�͖̂����Ȃ̂ŁA�K�ȃ^�C�~���O�œ�������\��v
857 �F,,�E�L�́M�E,,�j��-�������F2014/03/01(�y) 12:21:32.57 ID:rOMt9Y3v
Apple�������`�b�v�Z�b�g���Ă����厖�ȋq�������
�X�}�z�Ŏ��삪�o���邼
http://japanese.engadget.com/2014/02/28/google-project-ara-2015-50/
http://japanese.engadget.com/2014/02/28/google-project-ara-2015-50/
>>859
���i1000����1�ŗe��10000�{�̕�����������B���������Ȃ�^�_�Ȃ���B
���i1000����1�ŗe��10000�{�̕�����������B���������Ȃ�^�_�Ȃ���B
�e��1���{�ɂ���ƁA�G�l���M�[���x���K�\������100�{�Ƃ��ɂȂ��āA���ԂȂ������ɂȂ肻��
�d�r�̗e�ʂɕ������킹�ăf�o�C�X���Q�V�Q�V�d�C�g���悤�ɂȂ�����
�����Ƃ��̑e���i���[�J�[���E�l���F�݂����Ȑ��i��܂������ł₾
�����Ƃ��̑e���i���[�J�[���E�l���F�݂����Ȑ��i��܂������ł₾
863 �F,,�E�L�́M�E,,�j��-�������F2014/03/02(��) 13:32:52.37 ID:BSRNtgcQ
�M�ŗ��Ȃ��d�r����]����
���s�̃��`�E���C�I���͍���
���s�̃��`�E���C�I���͍���
�G�l���M�[�̐ϖ��x���グ��ƁA�M���x�������Ă��܂��B
➑̂̕��M���\�����̂܂܂��ƁA���x�̋ύt�_���オ��B
�M�ɂ��d�r�̗��ޗ��ɂ���ĉ��P�����Ƃ��Ă��A�g�p�҂Ɋ댯��������B
�������{�I�ɉ�������ɂ́A���o���d�������炷�ׂ��B
�d�r�̑̐ρA�\�ʐς����܂菬�������Ȃ����������B
➑̂̕��M���\�����̂܂܂��ƁA���x�̋ύt�_���オ��B
�M�ɂ��d�r�̗��ޗ��ɂ���ĉ��P�����Ƃ��Ă��A�g�p�҂Ɋ댯��������B
�������{�I�ɉ�������ɂ́A���o���d�������炷�ׂ��B
�d�r�̑̐ρA�\�ʐς����܂菬�������Ȃ����������B
�����ł͂����܂ō������Ȃ��Ƃ͎v�����A���̋Z�p�͋C�ɂȂ�
�uGalaxy S5�v�̌��Ⴂ�̃o�b�e���[������PowerXtend�Z�p���̗p�������߁H
http://rbmen.blogspot.jp/2014/03/galaxy-s5powerxtend.html
��PowerXtend Suite�̓\�t�g�E�F�A�A���S���Y���ɂ��A�o�b�e���[�������ő��50�����g�����邱�Ƃ��ł��܂��B
�uGalaxy S5�v�̌��Ⴂ�̃o�b�e���[������PowerXtend�Z�p���̗p�������߁H
http://rbmen.blogspot.jp/2014/03/galaxy-s5powerxtend.html
��PowerXtend Suite�̓\�t�g�E�F�A�A���S���Y���ɂ��A�o�b�e���[�������ő��50�����g�����邱�Ƃ��ł��܂��B
����͋C�ɂȂ�ȁB
�C�I�����X���Ō�������A���w�d�r�ޗ��̒P�̌��f�Ƃ��Ă̓��`�E���ȏ�̃��m���č��̃g�R�l�����Ȃ���
�z��&�A�ɍޗ��̗]�n�͂܂�����낤����
���̃��`�E���d�r�ɑ��鎎�s������āA�ǂꂾ����R�̃��`�E�����l�ߍ��ނ����Ęb���قƂ�ǂ���
���ʁA����I�ɗe�ʉ��P�ł���d�r���Ă̂͏o�Ă��Ȃ��̂ł́c
�z��&�A�ɍޗ��̗]�n�͂܂�����낤����
���̃��`�E���d�r�ɑ��鎎�s������āA�ǂꂾ����R�̃��`�E�����l�ߍ��ނ����Ęb���قƂ�ǂ���
���ʁA����I�ɗe�ʉ��P�ł���d�r���Ă̂͏o�Ă��Ȃ��̂ł́c
�R���d�r�����Ęb�͈ꎞ�����������Ǖ����Ȃ��Ȃ�����
�G�l���M�[���x���ꌅ�グ��ɂ͔R���d�r�����Ȃ����A
��d�͂��o���Ȃ�����Ԃ┭�d�@�ɂ͎g�����A���^���ł��Ȃ����烂�o�C���ɂ͎g�����A���d�͂Ȃ瑾�z�d�r�����⋋�Ŏg����B
���ߎ�ƂȂ�p�r������������p�����x��ɒx��Ă���B
��d�͂��o���Ȃ�����Ԃ┭�d�@�ɂ͎g�����A���^���ł��Ȃ����烂�o�C���ɂ͎g�����A���d�͂Ȃ瑾�z�d�r�����⋋�Ŏg����B
���ߎ�ƂȂ�p�r������������p�����x��ɒx��Ă���B
���ꂢ�Ȑ����o������c
>>869
�@������C�d�r
�@������C�d�r
>>871
��������p���̖ڏ��������ĂȂ�����B
��������p���̖ڏ��������ĂȂ�����B
�� ���ʑ̔M�d�r
���ʑ̂̔M�d�r���āA�ؐ���艓���ɍs���悤�Ȃ̂ɂ����g���ĂȂ�����
���͐S���y�[�X���[�J�[�ɂ��g���Ă��B�V�K�ɐ����͂���Ă��Ȃ����A���ł��ғ����̂��̂͑��݂���B
TI���ޏꂵ�ANV���قڑޏ��ԂƂȂ����A�X�}�[�g�t�H���J�e�S�������v���Z�b�T�E�G��
���n���Ă����̂��Ǝv������A��T��MWC 2014���Ԓ��������\���ꂽ�B�܂��܂��M����
Qualcomm�@Snapdragon 610(64bit 4�R�A)�ASnapdragon 615(64bit 8�R�A)
Samsung�@Exynos 5260(6�R�A)�AExynos 5422(8�R�A)
MediaTek�@MT6732(64bit 4�R�A)�AMT6591(6�R�A)�AMT6752(64bit 6�R�A)
Hisilicon(Huawei)�@kirin 910(4�R�A)
��ׂ����Ȃ����A���̊�����VIA AMD Cyrix IDT�Ɠ��藐��Ă�������PC�Ő������v���N������
���n���Ă����̂��Ǝv������A��T��MWC 2014���Ԓ��������\���ꂽ�B�܂��܂��M����
Qualcomm�@Snapdragon 610(64bit 4�R�A)�ASnapdragon 615(64bit 8�R�A)
Samsung�@Exynos 5260(6�R�A)�AExynos 5422(8�R�A)
MediaTek�@MT6732(64bit 4�R�A)�AMT6591(6�R�A)�AMT6752(64bit 6�R�A)
Hisilicon(Huawei)�@kirin 910(4�R�A)
��ׂ����Ȃ����A���̊�����VIA AMD Cyrix IDT�Ɠ��藐��Ă�������PC�Ő������v���N������
a53����قƂ��
��i�������n�C�G���h�@�� Qualcomm
����ȊO�@Samsung�EMediaTek�EHisilicon�ŐH������
���낤��
����ȊO�@Samsung�EMediaTek�EHisilicon�ŐH������
���낤��
MediaTek���Ă悭������
�ǂꂾ���`�b�v�J�����Ă�낤
�ǂꂾ���`�b�v�J�����Ă�낤
Qualcomm �𓌋��h�[���Ƃ����
MediaTek�͑�����O���E���h���炢
MediaTek�͑�����O���E���h���炢
MediaTek�̓f�W�^���Ɠd�����`�b�v�Z�b�g��肾���
���{���[�J�[�̃V�F�A�͂������������Ă��ꂽ
���{���[�J�[�̃V�F�A�͂������������Ă��ꂽ
�匴���[��A20nm��Q�Ђ��T���v���o�ׂ��Ă܂���[
http://ascii.jp/elem/000/000/871/871695/index-2.html
TSMC��20nm���̂��̂͏����ł��邪�A����͂܂����X�N�v���_�N�V����
�i�댯��`���Ăł��ʎY���}�����Ɓj���܂��Ȃ��I���Ƃ��������ŁA
���ł�Xilinx���͂��߂Ƃ��鉽�Ђ����V���R������肵�Ă�����̂́A
�܂��Г����̒i�K��OEM�����ɃG���W�j�A�����O�T���v�����o����ł͂Ȃ��B
http://ascii.jp/elem/000/000/870/870322/index-2.html
�uGobi 9x30�v��20nm�v���Z�X�Ő�������ALTE Advanced Category 6�ɑΉ�����A��4�����LTE���f���ƂȂ�B
http://news.mynavi.jp/news/2014/02/24/475/
�Ȃ��AGobi 9x30�͂��łɃT���v���o�ׂ��J�n���Ă���B
http://ascii.jp/elem/000/000/871/871695/index-2.html
TSMC��20nm���̂��̂͏����ł��邪�A����͂܂����X�N�v���_�N�V����
�i�댯��`���Ăł��ʎY���}�����Ɓj���܂��Ȃ��I���Ƃ��������ŁA
���ł�Xilinx���͂��߂Ƃ��鉽�Ђ����V���R������肵�Ă�����̂́A
�܂��Г����̒i�K��OEM�����ɃG���W�j�A�����O�T���v�����o����ł͂Ȃ��B
http://ascii.jp/elem/000/000/870/870322/index-2.html
�uGobi 9x30�v��20nm�v���Z�X�Ő�������ALTE Advanced Category 6�ɑΉ�����A��4�����LTE���f���ƂȂ�B
http://news.mynavi.jp/news/2014/02/24/475/
�Ȃ��AGobi 9x30�͂��łɃT���v���o�ׂ��J�n���Ă���B
883 �F,,�E�L�́M�E,,�j��-�������F2014/03/04(��) 08:51:35.50 ID:SAO0EY89
�A�X�L�[�̋L����Web�Ɍ��J�����̂��Ď��ʂ̈ꌎ�x�ꂭ�炢����Ȃ���������
�ɂ��Ă��������ׂĂȂ��ȁ[
�ɂ��Ă��������ׂĂȂ��ȁ[
���邢�͏����Ă�̂��f�ڂ̂��Ȃ�O�Ȃ̂�
���{�̃e�N�m���W�[���C�^�[�́A
���e���ǎ������ǁA������ɂ����E�ǂ݂ɂ����L���������l�ƁA
���ɓ��e���Ꮏ�����ǁA�킩��₷���ǂ݂₷���L���������l�������
�Ƃ��Ɍ�҂͓K�x�ɐ�������ꂽ�L���������̂ŁA���ڂ���₷��
���e���ǎ������ǁA������ɂ����E�ǂ݂ɂ����L���������l�ƁA
���ɓ��e���Ꮏ�����ǁA�킩��₷���ǂ݂₷���L���������l�������
�Ƃ��Ɍ�҂͓K�x�ɐ�������ꂽ�L���������̂ŁA���ڂ���₷��
�X�}�z��^�u���b�g�̗e�ς�95%���o�b�e���[�Ȃ��
���ꂪ���Ǎ��̐l�ނ̓��B�_
���ꂪ���Ǎ��̐l�ނ̓��B�_
�o�b�e���[������ɖ������d�����W����
��������O���o�b�e���[�ցA�O���o�b�e���[���狋�d�X�|�b�g������
�Ȃ�ė�����L�肤���
��������O���o�b�e���[�ցA�O���o�b�e���[���狋�d�X�|�b�g������
�Ȃ�ė�����L�肤���
>�X�}�z��^�u���b�g�̗e�ς�95%���o�b�e���[
�Ȃ����̂悤�ȏo�L�ڂɂ���������x�����̂��낤��
ttp://www.ifixit.com/Teardown/iPhone+5s+Teardown/17383
ttp://www.ifixit.com/Teardown/iPad+Air+Teardown/18907
�Ȃ����̂悤�ȏo�L�ڂɂ���������x�����̂��낤��
ttp://www.ifixit.com/Teardown/iPhone+5s+Teardown/17383
ttp://www.ifixit.com/Teardown/iPad+Air+Teardown/18907
�o�b�e���[�o�b�N�ł���o�b�e���[��95���Ȃ�Ă͖̂����̂ɁB
�������痈���̂�������Ȃ�
891 �FSocket774�F2014/03/06(��) 12:56:19.60 ID:FFiBzitv
�}����P�̃��r�L�^�X����
�o��������X�}�[�g�t�H������64bit SoC
�`Android�[���ł̓�����2014�N�㔼������
http://pc.watch.impress.co.jp/docs/column/ubiq/20140306_638324.html
�o��������X�}�[�g�t�H������64bit SoC
�`Android�[���ł̓�����2014�N�㔼������
http://pc.watch.impress.co.jp/docs/column/ubiq/20140306_638324.html
�[���̒Z�ӂ�95%��d�r�Ő�߂邱�Ƃ�������B
�܂��Ă�e�ϔ��95%�����̍ޗ��Ŗ������̂͂ƂĂ��Ȃ�����B
�Ȃ��95%���d�r���Ǝv���Ă��܂����̂��B
�d�r�����p�̂ӂ����J�������Ƃ��Ȃ��̂��H
�܂��Ă�e�ϔ��95%�����̍ޗ��Ŗ������̂͂ƂĂ��Ȃ�����B
�Ȃ��95%���d�r���Ǝv���Ă��܂����̂��B
�d�r�����p�̂ӂ����J�������Ƃ��Ȃ��̂��H
893 �FSocket774�F2014/03/10(��) 18:28:31.50 ID:pjVAq9DH
�y�㓡�O��Weekly�C�O�j���[�X�zHaswell�̍����\�O���t�B�b�N�X�̃J�M�uIntel����eDRAM�v�̏ڍ� - PC Watch
http://pc.watch.impress.co.jp/docs/column/kaigai/20140310_638791.html
Intel��eDRAM�`�b�v�œ��ɖڗ��̂́A1�̃`�b�v��102.4GB/sec�N���X�̃������ш���������Ă���_���B
��r����ƁAGDDR5���ō���7.2Gtps���ɃV���O���`�b�v(x32��)��28.8GB/sec�Ȃ̂ŁAIntel��eDRAM��GDDR5�`�b�v��4�{�߂��ш�ƂȂ�B
JEDEC�̎���DRAM�uHBM(High Bandwidth Memory)�v��4�_�C���X�^�b�N�������̑ш�͍L����
1�`�b�v������̑ш��Intel��eDRAM�̔������x�܂łƂȂ�BHaswell��eDRAM�́A�_�C������̑ш�ł͔��Q�̋Z�p�ƂȂ�B
����1�ڗ��̂̓������A�N�Z�X�̃G�l���M�[���B
OPIO�̃r�b�g������̃G�l���M�[�����1.22pj/b(picoJoule/bit:�s�R�W���[��/�r�b�g)�Ƃ����B
�R���s���[�^�ƊE���ڕW�Ƃ��Ă���1pj/b�ȉ��̑��ɂ��ƈ���̂Ƃ���܂ŋ߂Â����B
http://pc.watch.impress.co.jp/docs/column/kaigai/20140310_638791.html
Intel��eDRAM�`�b�v�œ��ɖڗ��̂́A1�̃`�b�v��102.4GB/sec�N���X�̃������ш���������Ă���_���B
��r����ƁAGDDR5���ō���7.2Gtps���ɃV���O���`�b�v(x32��)��28.8GB/sec�Ȃ̂ŁAIntel��eDRAM��GDDR5�`�b�v��4�{�߂��ш�ƂȂ�B
JEDEC�̎���DRAM�uHBM(High Bandwidth Memory)�v��4�_�C���X�^�b�N�������̑ш�͍L����
1�`�b�v������̑ш��Intel��eDRAM�̔������x�܂łƂȂ�BHaswell��eDRAM�́A�_�C������̑ш�ł͔��Q�̋Z�p�ƂȂ�B
����1�ڗ��̂̓������A�N�Z�X�̃G�l���M�[���B
OPIO�̃r�b�g������̃G�l���M�[�����1.22pj/b(picoJoule/bit:�s�R�W���[��/�r�b�g)�Ƃ����B
�R���s���[�^�ƊE���ڕW�Ƃ��Ă���1pj/b�ȉ��̑��ɂ��ƈ���̂Ƃ���܂ŋ߂Â����B
DRAM�̏���d�͂�32mW����1W�ւ�30�{���������A�r�b�g������̃G�l���M�[��1pJ/b����1.22pJ/b�ւ�2���������āA�ڕW���牓�������Ă���悤�Ɍ����邯��
32mW���ĉ��̘b?
896 �F,,�E�L�́M�E,,�j��-�������F2014/03/10(��) 23:11:55.19 ID:GOxtATTJ
�o�b�e���[95%�̐l�Ɠ����l����Ȃ��́H
�u�I���p�b�P�[�W�ł̓����v�̉摜�̃r�b�g������G�l���M�[����̔�r�}�B�ǂ����Ă��ςȐ}�Ȃ���
���������āA������eDRAM�̓������Z���̏���d�͂����݂̐��l�������Ă����āA�E����PCH�̏���d�͂̓������Z���̏���d�͂��܂�łȂ��̂��ȁH
���ꂶ�Ⴀ���̔�r�ɂ��Ȃ��ĂȂ������Ǝv�����B
���������āA������eDRAM�̓������Z���̏���d�͂����݂̐��l�������Ă����āA�E����PCH�̏���d�͂̓������Z���̏���d�͂��܂�łȂ��̂��ȁH
���ꂶ�Ⴀ���̔�r�ɂ��Ȃ��ĂȂ������Ǝv�����B
���܂Ŏ����ōl�������Ƃ͑S�ĖY��āA�܂�����ȓ��ł�����x�L�����ŏ�����Ō�܂Œʂ��ēǂݒ����Ă݂āB�����ĂȂ����Ƃ�����ɕ⊮�Ƃ������ɁB
899 �F,,�E�L�́M�E,,�j��-�������F2014/03/10(��) 23:35:36.07 ID:GOxtATTJ
��r�H�ǂ�����r�Ȃ�
������������ˁ[�́H
�E�̃_�C��LV/ULV��Haswell�̃_�C���B������E���g���u�b�N�p�B
�ʂ�eDRAM�̂ق����d�͌������D��Ă�Ȃ�Ă��Ƃ͌����ĂȂ��B
������������ˁ[�́H
�E�̃_�C��LV/ULV��Haswell�̃_�C���B������E���g���u�b�N�p�B
�ʂ�eDRAM�̂ق����d�͌������D��Ă�Ȃ�Ă��Ƃ͌����ĂȂ��B
�����A�Ȃ�قǁAeDRAM�͓d�͌����͗D��Ă��Ȃ���ł��ˁB
�G�l���M�[�������ڋʂ݂����ȏ�����������Ă���悤�Ɍ������̂ŁA�ǂ��̂��Ɗ��Ⴂ���Ă��܂��܂����B
�G�l���M�[�������ڋʂ݂����ȏ�����������Ă���悤�Ɍ������̂ŁA�ǂ��̂��Ɗ��Ⴂ���Ă��܂��܂����B
901 �F,,�E�L�́M�E,,�j��-�������F2014/03/11(��) 00:01:19.66 ID:GOxtATTJ
�ʏ�d����eDRAM���ڂƏȓd�͔Ń_�C��r���Ăǂ������D��Ă邩�Ȃ��
�s�тȋc�_���B
���������}�����Ĕ�r���Ǝv���ق����o�J����B
�ǂ��ɔ�r�Ȃ�ď����Ă���B
�s�тȋc�_���B
���������}�����Ĕ�r���Ǝv���ق����o�J����B
�ǂ��ɔ�r�Ȃ�ď����Ă���B
902 �F,,�E�L�́M�E,,�j��-�������F2014/03/11(��) 00:04:54.36 ID:+m1Gtyjx
> �����A�Ȃ�قǁAeDRAM�͓d�͌����͗D��Ă��Ȃ���ł��ˁB
��������Ⴂ���ȁB
�����������O����r���Ɗ��Ⴂ����Crystal Well��Haswell-UL�̐}��
�y��r�p�ɕ��ׂĂ���킯�ł͂Ȃ��z
��������Ⴂ���ȁB
�����������O����r���Ɗ��Ⴂ����Crystal Well��Haswell-UL�̐}��
�y��r�p�ɕ��ׂĂ���킯�ł͂Ȃ��z
�Ȃ�قǁA���̐}�́A����CPU�͏���d�͂��傫��������CPU�ŁA�E��CPU�͏���d�͂��������ᑬ��CPU�Ƃ������Ƃł���
�㓡�搶�̐��蕶�ɖڂ�����܂���āA������CPU�͍����ł������ȓd�͂Ȃ̂��Ǝv���}�����āA����A�ς��Ȃ��Ǝv���Ă��܂��܂���
���蕶�ւ̑ϐ����Ⴗ���Ĕ��f�����܂����B
�㓡�搶�̐��蕶�ɖڂ�����܂���āA������CPU�͍����ł������ȓd�͂Ȃ̂��Ǝv���}�����āA����A�ς��Ȃ��Ǝv���Ă��܂��܂���
���蕶�ւ̑ϐ����Ⴗ���Ĕ��f�����܂����B
�E��ʓI�ɂ͍�����IF�قǃG�l���M�[����(pJ/bit)�͈����Ȃ�
�EeDRAM-CPU�Ԃ�IF�͓����I���p�b�P�[�W��IF�ł���PCH-CPU�Ԃ�IF�Ɣ�ׂ�
�@�]�����x��25�{���x���������G�l���M�[�����͓����ɋ߂����x��(1.22pJ/bit vs 1pJ/bit)�ɗ}����
�Ă��Ƃł���H�������ɏ����������̒��x�̃��e���V�[�͊��҂��Ă���Ǝv���̂���
�EeDRAM-CPU�Ԃ�IF�͓����I���p�b�P�[�W��IF�ł���PCH-CPU�Ԃ�IF�Ɣ�ׂ�
�@�]�����x��25�{���x���������G�l���M�[�����͓����ɋ߂����x��(1.22pJ/bit vs 1pJ/bit)�ɗ}����
�Ă��Ƃł���H�������ɏ����������̒��x�̃��e���V�[�͊��҂��Ă���Ǝv���̂���
25�{��6.4vs2
�F����̂��A�ō��₷�����藝�����܂����BeDRAM��IF�͏]����DRAM��IF�����d�C�𑽂��H�����A�����Ƃ������Ƃł��ˁB
�����āA�R���s���[�^�[�ƊE���ڕW�Ƃ��Ă���1pJ/b�ȉ��Ƃ����ڕW�Ɂu���ƈ���̂Ƃ���܂ŋ߂Â����v�ǂ��납�A�t�ɂނ����≓���������̂ł��ˁB
�����āA�R���s���[�^�[�ƊE���ڕW�Ƃ��Ă���1pJ/b�ȉ��Ƃ����ڕW�Ɂu���ƈ���̂Ƃ���܂ŋ߂Â����v�ǂ��납�A�t�ɂނ����≓���������̂ł��ˁB
�����`���l��������̓�����g��(3.2GHz vs 1GHz)��
�]�����x��102.4GB/s vs 4GB/s�ł���
�]�����x��102.4GB/s vs 4GB/s�ł���
�r����
>���ꂾ���̍��ш�C���^�[�t�F�C�X�ŁA����d�͂͂킸��1W���ɗ}�����Ă���B
�Ə����Ă���牽�̘b���Ă邩���炢�킩�邾��A����
>���ꂾ���̍��ш�C���^�[�t�F�C�X�ŁA����d�͂͂킸��1W���ɗ}�����Ă���B
�Ə����Ă���牽�̘b���Ă邩���炢�킩�邾��A����
�u�������p�̍���IF�Ƃ��āv�ڕW�Ƃ��Ă���Ƃ܂ŏ�����ƕ�����H
�[��PCH-CPU�Ԃ�IF�����]����DRAM�pIF�ɂȂ�����
�[��PCH-CPU�Ԃ�IF�����]����DRAM�pIF�ɂȂ�����
���Ԃ���
�����Ɋ��ɖڕW�B���ς݂�IF�����݂���̂ɁA��������������̂��o���Ă��āA�ڕW�ɋ߂Â����Ƃ����̂͑S���[���o���Ȃ��ł���
912 �F,,�E�L�́M�E,,�j��-�������F2014/03/11(��) 00:29:19.57 ID:+m1Gtyjx
eDRAM�Ȃ���PCH���ڕW�B���i�j���Ă�Ƃ�
�����A�t�H����
�����A�t�H����
���s��DDR3-1600 1���W���[���ł���12.8GB/s����̂ɁA4GB/s�̂ǂ����ڕW�B���ς݂Ȃ́H
�ш�Ə���d�͂̓�̗v���������ā`�Ƃ����b�����Ă�Ƃ����̂�
�N���N���p�[�͌���F�߂Ȃ����獢��
�N���N���p�[�͌���F�߂Ȃ����獢��
���H���̐}�̏���d�͂́AeDRAM���̂̏���d�͂��܂߂Ă̂��̂Ȃ̂ł����H���Ƃ����獶��eDRAM�͑ш�A�d�͌����̗��ʂň������Ă��邱�ƂɂȂ�̂ł́B
916 �FSocket774�F2014/03/11(��) 00:34:55.90 ID:eTId+kJ3
�Ȃ��PCH��DRAM��I/F�ɂȂ��wwww
PCH���Ă̂̓T�E�X�u���b�W����
CPU��PCH�i�T�E�X�u���b�W�j�����ԒᑬI/F��DMI��
DRAM��I/F��CPU���������A
�̂̓m�[�X�u���b�W�ɂ�����FSB��QPI�Ō���Ă�����
PCH�Ƃ͑S���֘A�����Ȃ�
PCH���Ă̂̓T�E�X�u���b�W����
CPU��PCH�i�T�E�X�u���b�W�j�����ԒᑬI/F��DMI��
DRAM��I/F��CPU���������A
�̂̓m�[�X�u���b�W�ɂ�����FSB��QPI�Ō���Ă�����
PCH�Ƃ͑S���֘A�����Ȃ�
���������ł������B�Ӗ����肰��PCH�Ə����Ă���̂�PCH����DRAM���Ȃ���̂��Ǝv���Ă��܂��܂���
������x�ǂ݂Ȃ����Ă݂āA�V��������������܂����B����́A�܂�����eDRAM�̘b�ł�DRAM�̘b�ł��Ȃ��āA�ڑ�IO�̏���d�̘͂b�������̂ł��ˁB
ISSCC�l�^���Ƃނ���FIVR�W�̂ق����ʔ��������̂���
�㓡�L���ɂȂ�̂��ȁH
����Ȑ}�Ƃ��o�Ă� http://i.imgur.com/72jEE3r.jpg
�㓡�L���ɂȂ�̂��ȁH
����Ȑ}�Ƃ��o�Ă� http://i.imgur.com/72jEE3r.jpg
{kind=link}
>>919
Haswell�ȓd�͋@�\�̃J�M�uFIVR�v�Ƃ��̍��� - PC Watch
http://pc.watch.impress.co.jp/docs/column/kaigai/20140226_636847.html
Haswell�ȓd�͋@�\�̃J�M�uFIVR�v�Ƃ��̍��� - PC Watch
http://pc.watch.impress.co.jp/docs/column/kaigai/20140226_636847.html
���[���łɋL���ɂȂ��Ă��̂ˁA����
AArch64�ŗV��ł݂����NJ���Apple�̃A�Z���u����GNU as�ō\���Ɉꕔ�݊��������ă����^
�f�B�X�v���C�d�l�̗��s�֍œK�������GPU�̃A�[�L�e�N�`���B
�Ƃ������Ƃ́A�܂��ꉩ���̋@�\���\�ɍ��E����Ă���B
�v���Z�b�T�����傹��͐l�Ԃ������ړI�������ꂽ����ł����Ȃ��A
���Ղ̘_�����u��ڎw������̂ł͂Ȃ��̂��Ƃ��炽�߂Ďv���o������b
ttp://pc.watch.impress.co.jp/img/pcw/docs/640/315/html/10.png.html
�Ƃ������Ƃ́A�܂��ꉩ���̋@�\���\�ɍ��E����Ă���B
�v���Z�b�T�����傹��͐l�Ԃ������ړI�������ꂽ����ł����Ȃ��A
���Ղ̘_�����u��ڎw������̂ł͂Ȃ��̂��Ƃ��炽�߂Ďv���o������b
ttp://pc.watch.impress.co.jp/img/pcw/docs/640/315/html/10.png.html
{kind=link}
�g�����W�X�^�Ɠd�͂͌����Ă�̂�
�f�o�C�X�����Ɛl�Ԃ̊��o�ɂ��킹�čœK�������ł���B
�f�o�C�X�����Ɛl�Ԃ̊��o�ɂ��킹�čœK�������ł���B
���������œK���͍ő命���̐l�ԂɍœK�������̂ŁA�����̐l������H���B
�s�̃f�B�X�v���C��3���F������3�F�^�F�o�̐l�ɍœK������Ă邽��4�F�^�F�o�������Ă鏭���h�͐F�Č����ɕs�����o�邯�ǖ��������Ƃ������
�s�̃f�B�X�v���C��3���F������3�F�^�F�o�̐l�ɍœK������Ă邽��4�F�^�F�o�������Ă鏭���h�͐F�Č����ɕs�����o�邯�ǖ��������Ƃ������
��������4�F�ȉt������Ă�Ƃ���������
�F�Ƃ��ǂ��Ȃ�A��x�������Ă݂���
�F�Ƃ��ǂ��Ȃ�A��x�������Ă݂���
�N�A�g�����͉Ɠd�X�Ō����邶���
�N�A�g�����̌��\�́A�F�Č��̍�������Ȃ��ċP�x��p���傾���c
�����̂͐F�ϊ����ςƂ������N�Z������������
�ŋ߂̂�3�F�ƕ��ׂĔ�r�Ő��Y�킾����
�ŋ߂̂�3�F�ƕ��ׂĔ�r�Ő��Y�킾����
�u���b�N���C�g������ƈÂ��̂�ῂ������������邯�ǁA
���������Ď��O�������Ă�́H
���������Ď��O�������Ă�́H
���O���Ŗڂ��Ă��Ă邾�������
�����ԊO�����זE���~������
���[�A�̖@���A28nm���g�Ō�̃m�[�h�h�ƂȂ�\����
http://eetimes.jp/ee/articles/1403/24/news059.html
http://eetimes.jp/ee/articles/1403/24/news059.html
�����Ō�̃m�[�h�ɂȂ�����獑�����͂���������ƔS��悩�����ȁB
�܂��A28�͂��ꂾ����������낤���ǁB
�܂��A28�͂��ꂾ����������낤���ǁB
936 �FSocket774�F2014/03/25(��) 21:32:11.01 ID:8DaIQS93
�A���e�������Intel 14nm���^���Ă邯�ǁA�R�X�g�ɂ��Ă͐G��ĂȂ��B
����ς�`���[�������̂�����H
http://members2.jcom.home.ne.jp/t.hattori/columns/EJSV1305.pdf
Intel��I��゙���R��2����B�܂�゙�͍ł���z�����Z�p�͂Ƃ����ϓ_���炽゙�B
������̐��i�J�����s�����߂ɂ�゙�̊�Ƃ�゙�ł��L�]�ȋZ�p�������Ă��邩�A���Ԃ������Ē��������B
�t�@���g゙���[��゙���邩�ۂ��͍l������゙�A�S�Ă̔����̊�Ƃ��Ώۂɂ����B
���̌��ʁA����d�́A���\�A������3�_�����̂�Intel��゙����゙�Ƃ������Ƃ�゙�킩�����B
����ς�`���[�������̂�����H
http://members2.jcom.home.ne.jp/t.hattori/columns/EJSV1305.pdf
Intel��I��゙���R��2����B�܂�゙�͍ł���z�����Z�p�͂Ƃ����ϓ_���炽゙�B
������̐��i�J�����s�����߂ɂ�゙�̊�Ƃ�゙�ł��L�]�ȋZ�p�������Ă��邩�A���Ԃ������Ē��������B
�t�@���g゙���[��゙���邩�ۂ��͍l������゙�A�S�Ă̔����̊�Ƃ��Ώۂɂ����B
���̌��ʁA����d�́A���\�A������3�_�����̂�Intel��゙����゙�Ƃ������Ƃ�゙�킩�����B
FPGA���[�J�[���猩��Ɣz�����܂߂����S��14nm�̓����b�g�傫�����
���Ђ�16/14nm�͔z����20nm�̂܂܂���
���Ђ�16/14nm�͔z����20nm�̂܂܂���
���͂�菬����nm�����݂��邩�ǂ����ł͂Ȃ��A
���z�V�F�A�ő�̍���������nm�֏����邩�ǂ������낤�B
���Y�ʍő�̐����v���Z�X��32/28nm�ł���Ȃ��B
���z�V�F�A�ő�̍���������nm�֏����邩�ǂ������낤�B
���Y�ʍő�̐����v���Z�X��32/28nm�ł���Ȃ��B
TSMC��16nmFinFET��2016�N�ɂ��ꍞ�ނ炵��
http://www.anandtech.com/show/7894/nvidia-gtc-2014-keynote-live-blog
2014 Maxwell 20nm
2016 Pascal 16nmFinFET
http://www.anandtech.com/show/7894/nvidia-gtc-2014-keynote-live-blog
2014 Maxwell 20nm
2016 Pascal 16nmFinFET
940 �FSocket774�F2014/03/26(��) 08:59:48.89 ID:7WcvGKNs
���S��Intel���D�ʂɂ����Ă��
[Intel]
22nm 2012�N
[TSMC]
20nm 2014�N
[Intel]
14nmFinFET 2014�N
[TSMC]
16nmFinFET 2016�N
[Intel]
22nm 2012�N
[TSMC]
20nm 2014�N
[Intel]
14nmFinFET 2014�N
[TSMC]
16nmFinFET 2016�N
�������Ȃ����Ă̂���낵���Ȃ������
�͂₢�Ƃ������C���e���ɒǂ����āA�ǂ��z�����炢�ɂȂ��Ă����Ȃ���
�͂₢�Ƃ������C���e���ɒǂ����āA�ǂ��z�����炢�ɂȂ��Ă����Ȃ���
942 �FSocket774�F2014/03/26(��) 10:10:31.48 ID:VCp6NC1a
���̒�Cpu��������Gpu���p�ɃV�t�g���Ă邩��AGpu�N�\��InteI�͔����ŗL���ł������͂͑債�č����Ȃ���
Pascal���o��܂ő҂�������X��
http://anago.2ch.net/test/read.cgi/jisaku/1395805397/
http://anago.2ch.net/test/read.cgi/jisaku/1395805397/
http://jbpress.ismedia.jp/ud/pressrelease/53313b0f6a8d1e11e5000001
�A���e���A������f�[�^�Z���^�[�̊J���Ɍ����āAIBM OpenPOWER Foundation�ɎQ��
power�ɂȂ���̂�
�A���e���A������f�[�^�Z���^�[�̊J���Ɍ����āAIBM OpenPOWER Foundation�ɎQ��
power�ɂȂ���̂�
945 �FSocket774�F2014/03/26(��) 15:10:53.23 ID:+fuL+bSj
�mGTC 2014�nNVIDIA�̎�����GPU��2016�N�́uPascal�v�B3�����������Z�p�őш敝��1TB/s��
http://www.4gamer.net/games/251/G025177/20140326001/
�� PCI Express 3.0���5�`12�{�̑ш敝�������C
�� CPU��GPU�ԁC���邢��GPU��GPU�Ԃ��Ȃ��uNVLink�v
nvidia�̏�����GPU�ɓ��ڂ����NVLink���āA���ꂪ���p�������ƁA
���܂̃X�[�p�[�R���s���[�^�����S��GPGPU�ɂƂ��Ă������\��������Z�p�Ȃ��
�]���^�X�p�R����PC�N���X�^��GPU�N���X�^�́A
�R�A���\�͂��ł�PC�N���X�^����ŁA�R�A-�������Ԃ̐��\��GPU����ɂȂ��Ă���
�]���^�X�p�R���̍ő�̗��_�͈��|�I�ȃm�[�h�ԒʐM���x�݂̂ɂȂ���
NVLink���i�����Ă��������N���X�^�ɂ��K�p�ł���悤�ɂȂ�ƁA
�]���^�X�p�R���ɔ�ׂĈ��|�I�ɒ�R�X�g�Ȕėp�i�x�[�X�ō����GPU�N���X�^���A
��K�̓T�C�g�̃m�[�h�ԒʐM�ɂ����Ă����|�I�Ƀ��[�h����\��������
http://www.4gamer.net/games/251/G025177/20140326001/
�� PCI Express 3.0���5�`12�{�̑ш敝�������C
�� CPU��GPU�ԁC���邢��GPU��GPU�Ԃ��Ȃ��uNVLink�v
nvidia�̏�����GPU�ɓ��ڂ����NVLink���āA���ꂪ���p�������ƁA
���܂̃X�[�p�[�R���s���[�^�����S��GPGPU�ɂƂ��Ă������\��������Z�p�Ȃ��
�]���^�X�p�R����PC�N���X�^��GPU�N���X�^�́A
�R�A���\�͂��ł�PC�N���X�^����ŁA�R�A-�������Ԃ̐��\��GPU����ɂȂ��Ă���
�]���^�X�p�R���̍ő�̗��_�͈��|�I�ȃm�[�h�ԒʐM���x�݂̂ɂȂ���
NVLink���i�����Ă��������N���X�^�ɂ��K�p�ł���悤�ɂȂ�ƁA
�]���^�X�p�R���ɔ�ׂĈ��|�I�ɒ�R�X�g�Ȕėp�i�x�[�X�ō����GPU�N���X�^���A
��K�̓T�C�g�̃m�[�h�ԒʐM�ɂ����Ă����|�I�Ƀ��[�h����\��������
nvlink��intel��KNL��QPI�ڑ��o����̂ɑΌ����邽�߂Ǝv����
AMD��PS4��kaveri�łƂ����ɓ��ڂ��Ă�hUMA���ǂ�����
2�N�x���HPC����œ��ڂ�
2�N�x���HPC����œ��ڂ�
�S�R�Ⴂ�܂�
���ɂ���A���h�̏ꍇ�������o�Ă��Ă݂Ȃ����Ƃɂ͑S���M�p���Ȃ�����ȁB
�}���g���Q�[�������ăZ�������{�Q�t�H��DX11�̕������������肷���B
�}���g���Q�[�������ăZ�������{�Q�t�H��DX11�̕������������肷���B
APU�Ȃ�Ė�������Ƃ����CPU��GPU�����r���[�̕����g�ݘA���������
�O���o�X���܂߂����̂�
�v��hUMA+Freedom Fabric�Ǝ����悤�Ȃ���
��������Intel Xeon�̃I�}�P�����甄��Ă��̂ɓG���Ăǂ�����w
����Ƃ�QPI�݊��ɂł�����Ƃ��H
�ǂ݂̂�Phi�ƃZ�b�g�Ŕ���o����邩��A���ꏊ�Ȃ��Ȃ邾�낤��
�܂���Nvidia�P�̂ł����Ă�Ƃ����Ⴂ����������H
�v��hUMA+Freedom Fabric�Ǝ����悤�Ȃ���
��������Intel Xeon�̃I�}�P�����甄��Ă��̂ɓG���Ăǂ�����w
����Ƃ�QPI�݊��ɂł�����Ƃ��H
�ǂ݂̂�Phi�ƃZ�b�g�Ŕ���o����邩��A���ꏊ�Ȃ��Ȃ邾�낤��
�܂���Nvidia�P�̂ł����Ă�Ƃ����Ⴂ����������H
titan��opteron�͖{���ɂ��܂����������ǂ�
�����荂���\��FirePro���邩��ʂɂ���ǂ�
CUDA���肪�������炻���Ȃ��Ă邾���ŁAOpenCL�����y���Ă��鍡�Ȃ�ʂɖ����Ă������
AMD��x86�AARM�A�����O���o�X�A�R�q�[�����g�o�X�AdGPU�AiGPU�S�������Ă邩��AIntel��Nvidia���Ȃ��Ă��S��������
CUDA���肪�������炻���Ȃ��Ă邾���ŁAOpenCL�����y���Ă��鍡�Ȃ�ʂɖ����Ă������
AMD��x86�AARM�A�����O���o�X�A�R�q�[�����g�o�X�AdGPU�AiGPU�S�������Ă邩��AIntel��Nvidia���Ȃ��Ă��S��������
amd�͑S���e���`���Ȃ���
955 �FSocket774�F2014/03/26(��) 17:56:53.94 ID:+fuL+bSj
�����AInfiniBand�AQPI�AHyperTransport�ANVLink�A�݂����Ȃ̂����W���āA
��K�̓X�p�R���ɂ����p�\�ɂȂ�A���̎��͏]���^�X�p�R���I���̎��ł��傤
�t�ɂ���܂ł́A�]���^�X�p�R��������Ă�����
��K�̓X�p�R���ɂ����p�\�ɂȂ�A���̎��͏]���^�X�p�R���I���̎��ł��傤
�t�ɂ���܂ł́A�]���^�X�p�R��������Ă�����
�ǂ������̂��]���^�Ǝv���Ă���낤
�����̉�Ђ̖��O���K�i�̖��O�ɂ����Ⴄ�̂͂ǂ����ȂƎv��
���y������C���������Ȃ�
���y������C���������Ȃ�
�x�N�g���^�ƃX�J���[�^�̎������������̂�������Ȃ��B
���A
���̃��x���ʼn����\�������C�ɂȂ��Ă��A���́A�`�Œ����B
���A
���̃��x���ʼn����\�������C�ɂȂ��Ă��A���́A�`�Œ����B
>>958
�����Ԃ������(�L�E�ցE`)
�����Ԃ������(�L�E�ցE`)
>>957
���y������C�͂ˁ[�ׂ�
���y������C�͂ˁ[�ׂ�
962 �FSocket774�F2014/03/26(��) 18:25:23.85 ID:L7RAKlPu
��́@�ėpCPU���A�X�p�R����CPU�̂ق������|�I�ɍ����\��Alpha21264���Pentium3�Œǂ������
�́@�ėp���������A�X�p�R���p�������̂ق������|�I�ɍ����\��GDDR5�ς�GPGPU�Œǂ������
���@�ėp�̃m�[�h�ԒʐM(InfiniBand��Ethernet)���X�p�R���p�̐�p�m�[�h�ԒʐM�̂ق������|�I�ɍ����\
�Ō�̑�K�̓X�p�R���̍����m�[�h�ԒʐM������ɔėp�i�łł���悤�ɂȂ�A
�]���^�X�p�R���̗��_���Ȃ��Ȃ�A���̎��ɏ]���^�X�p�R������ł���
�́@�ėp���������A�X�p�R���p�������̂ق������|�I�ɍ����\��GDDR5�ς�GPGPU�Œǂ������
���@�ėp�̃m�[�h�ԒʐM(InfiniBand��Ethernet)���X�p�R���p�̐�p�m�[�h�ԒʐM�̂ق������|�I�ɍ����\
�Ō�̑�K�̓X�p�R���̍����m�[�h�ԒʐM������ɔėp�i�łł���悤�ɂȂ�A
�]���^�X�p�R���̗��_���Ȃ��Ȃ�A���̎��ɏ]���^�X�p�R������ł���
963 �FSocket774�F2014/03/26(��) 18:27:43.03 ID:L7RAKlPu
>>959
���̋敪�Ō����Ă�킯����Ȃ�
�����_�ŁA�]���^�X�p�R���͍�����x���ȃm�[�h�ԒʐM���炢�������_���Ȃ��Ȃ���
�̂ŁA������x���m�[�h�ԒʐM���K�v�ȃA�v���P�[�V�����ł͈��|�I�ȃp�t�H�[�}���X���o�����A
�����łȂ��v�Z�Ɋւ��ẮAPC�N���X�^��GPU�N���X�^�ŏ\��
���̋敪�Ō����Ă�킯����Ȃ�
�����_�ŁA�]���^�X�p�R���͍�����x���ȃm�[�h�ԒʐM���炢�������_���Ȃ��Ȃ���
�̂ŁA������x���m�[�h�ԒʐM���K�v�ȃA�v���P�[�V�����ł͈��|�I�ȃp�t�H�[�}���X���o�����A
�����łȂ��v�Z�Ɋւ��ẮAPC�N���X�^��GPU�N���X�^�ŏ\��
>>963
�C���^�[�R�l�N�g���̂��Ęb���������悤��
��
���̒��x�̔F���ł�GbE�̕��y�œr�㍑�������ȃN���X�^�^HPC���������Ă��܂�
�ȂǂƊ뜜����Ă���15�N���炢�O���v���o���āA�`���B
�C���^�[�R�l�N�g���̂��Ęb���������悤��
��
���̒��x�̔F���ł�GbE�̕��y�œr�㍑�������ȃN���X�^�^HPC���������Ă��܂�
�ȂǂƊ뜜����Ă���15�N���炢�O���v���o���āA�`���B
���������������ł��������ł���
�����C�_�����������āI
���ꂪ�T�^�j�Y�����_�I�I
�����C�_�����������āI
���ꂪ�T�^�j�Y�����_�I�I
>>962
��������f�[�^�Z���^�[�����̒������d�V�X�e������ʌ����ˌ��ďZ��ł��g�p�ł���悤�ɂ��ė~������
�I���f�}���h�ő�d�͂������\�ɂȂ����������K�v�ȃV�X�e�����
��������f�[�^�Z���^�[�����̒������d�V�X�e������ʌ����ˌ��ďZ��ł��g�p�ł���悤�ɂ��ė~������
�I���f�}���h�ő�d�͂������\�ɂȂ����������K�v�ȃV�X�e�����
�����p�̔ėp�K�i�����y���Ă��A��p�@�͂���ȏ�����߂āA����ɏ�̊K��֏����Ă�������������Ȃ��B
�R�X�g�����悤����ɂ͂Ȃ邯�ǁA�g�b�v�������x�z����v�f�łȂȂ���
����Ȃ��Ƃ��킩��Ȃ��\���җl�̗x����ދ��ŁA�����̃��b�p���v�[
�R�X�g�����悤����ɂ͂Ȃ邯�ǁA�g�b�v�������x�z����v�f�łȂȂ���
����Ȃ��Ƃ��킩��Ȃ��\���җl�̗x����ދ��ŁA�����̃��b�p���v�[
>955 >962
InfiniBand�ł̃m�[�h�Ԑڑ��͊��ƈȑO����X�p�R���ōL���g���Ă���̂ɁA
���X���������Ă����? �ߔN���Ə�ʂ̃X�p�R���̖��Ŏg���Ă�B
>964�̂����ʂ�A�F����15�N�ȏ�Â��B
���Ƃ��̘b��͂����炩�ɁuCPU�A�[�L�e�N�`���v�̘b�ł͂Ȃ�����B
�X���Ⴂ�������X���ł��B
InfiniBand�ł̃m�[�h�Ԑڑ��͊��ƈȑO����X�p�R���ōL���g���Ă���̂ɁA
���X���������Ă����? �ߔN���Ə�ʂ̃X�p�R���̖��Ŏg���Ă�B
>964�̂����ʂ�A�F����15�N�ȏ�Â��B
���Ƃ��̘b��͂����炩�ɁuCPU�A�[�L�e�N�`���v�̘b�ł͂Ȃ�����B
�X���Ⴂ�������X���ł��B
��������DENVER��GPU�����Ƃ����b�͂ǂ��Ȃ����낤��
����͍L�`��CPU�A�[�L�e�N�`�����Ǝv����
����͍L�`��CPU�A�[�L�e�N�`�����Ǝv����
��������100V�̂��肶��Ȃ���ȁB�����d�͂œd������������
�d�������邩��z����AC�����������Ȃ��Ƒ����A���M�������Ă��܂��B
�R���Z���g�ɏ��I�o��ԂɂȂ�̂́A���d����d������
��d�����d���̕�����Ȃ��B�f�[�^�Z���^�[�͑f�l��
����Ȃ����炢�����ǁB
�d�������邩��z����AC�����������Ȃ��Ƒ����A���M�������Ă��܂��B
�R���Z���g�ɏ��I�o��ԂɂȂ�̂́A���d����d������
��d�����d���̕�����Ȃ��B�f�[�^�Z���^�[�͑f�l��
����Ȃ����炢�����ǁB
>>962
��Pentium3��
������Ȃ�ł��T�o�ǂ݂���
x86
�@1994 P5 100MHz 0.1GFLOPS
�@1999 PIII 800MHz 1.2GFLOPS
�@2000 PIII 1133MHz 1.7GFLOPS
�@2001 PIII 1.4GHz 2.1GFLOPS
SX
�@1994 SX-4 2GFLOPS�@���ꃁ�������64GFLOPS
�@1998 SX-5 8GFLOPS�@���ꃁ�������128GFLOPS
�@2001 SX-6 8GFLOPS�@���ꃁ�������64GFLOPS
���ꃁ�������
�@x86 �̃}���`�R�A��DP�AMP�̂悤�Ȃ���
��Pentium3��
������Ȃ�ł��T�o�ǂ݂���
x86
�@1994 P5 100MHz 0.1GFLOPS
�@1999 PIII 800MHz 1.2GFLOPS
�@2000 PIII 1133MHz 1.7GFLOPS
�@2001 PIII 1.4GHz 2.1GFLOPS
SX
�@1994 SX-4 2GFLOPS�@���ꃁ�������64GFLOPS
�@1998 SX-5 8GFLOPS�@���ꃁ�������128GFLOPS
�@2001 SX-6 8GFLOPS�@���ꃁ�������64GFLOPS
���ꃁ�������
�@x86 �̃}���`�R�A��DP�AMP�̂悤�Ȃ���
Super�̃w���v�ɁA1993�N�̃X�p�R��HITAC S-3800/480��100�����̌v�Z��5�b�łł���Ə����Ă���܂��ˁB
Core i7 3770K��7.1GH���ɃI�[�o�[�N���b�N����PC��5�b07�Ƃ����L�^������̂ŁA�f�X�N�g�b�v�p�\�R���̐��\��1993�N�̃X�p�R���ɒǂ�������Ƃ����ł��傤�B
Core i7 3770K��7.1GH���ɃI�[�o�[�N���b�N����PC��5�b07�Ƃ����L�^������̂ŁA�f�X�N�g�b�v�p�\�R���̐��\��1993�N�̃X�p�R���ɒǂ�������Ƃ����ł��傤�B
974 �FSocket774�F2014/03/26(��) 20:39:21.68 ID:AJrjdnNj
�u�����ɂ��R�X�g�_�E���͍s���l�܂�v�\�\�V�m�v�V�X�
http://eetimes.jp/ee/spv/1403/26/news050.html
�V�m�v�V�X�̔����̐v�c�[���Őv���ꂽ�`�b�v�̂����A28nm�v���Z�X��p�������̂͂킸��5���������Ƃ����B
180nm�v���Z�X���ł������A�S�̂�30�����߂Ă��āA�����65nm��250nm���������B
http://eetimes.jp/ee/spv/1403/26/news050.html
�V�m�v�V�X�̔����̐v�c�[���Őv���ꂽ�`�b�v�̂����A28nm�v���Z�X��p�������̂͂킸��5���������Ƃ����B
180nm�v���Z�X���ł������A�S�̂�30�����߂Ă��āA�����65nm��250nm���������B
975 �FSocket774�F2014/03/26(��) 21:55:15.07 ID:5GQ0eqCc
>>974
�V�m�v�V�X���g���Ă�ڋq���A�������K�v�Ȃ������̂�v���Ă郁�[�J�[�Ȃ�
�V�m�v�V�X���g���Ă�ڋq���A�������K�v�Ȃ������̂�v���Ă郁�[�J�[�Ȃ�
976 �F,,�E�L�́M�E,,�j��-�������F2014/03/26(��) 22:38:08.32 ID:NYLn+9+7
>>973
����x�N�g�������݂ł���B
SuperPI���o����������x86�ɂ�MMX��SSE���Ȃ��������A�܂���
�{�i�I��SMP�T�|�[�g���Ȃ������B
�����݂ŏ����������v���O�����Ȃ�ACore 2 Duo���_��
�Ƃ�����3�b���Ă�B
����x�N�g�������݂ł���B
SuperPI���o����������x86�ɂ�MMX��SSE���Ȃ��������A�܂���
�{�i�I��SMP�T�|�[�g���Ȃ������B
�����݂ŏ����������v���O�����Ȃ�ACore 2 Duo���_��
�Ƃ�����3�b���Ă�B
>>974
���Ă��Ő�[�̍����i�v���Z�X�i���o�J�X�J����������
����Ȃɔ����̃x���_�P�ޑ����Ȃ��������@��x���_�����ĔS�邾��ww
���Ă��Ő�[�̍����i�v���Z�X�i���o�J�X�J����������
����Ȃɔ����̃x���_�P�ޑ����Ȃ��������@��x���_�����ĔS�邾��ww
65nm���ď�����Core2���炢���������ȁc�c���̋L�����������Ƃ���ƁA���ł������Ă�����ŊԂɍ����C������
180����Pentium2�����肩�A�}���łȂ��p���Ȃ�Ȃ�Ƃ��Ȃ��Ȃ���
180����Pentium2�����肩�A�}���łȂ��p���Ȃ�Ȃ�Ƃ��Ȃ��Ȃ���
>>158
http://developers.slashdot.jp/comments.pl?sid=627062&cid=2568375
> �Ƃ������A���ƋC���̔��ʂ�����������Ȃ��Ƃ������Ă�L���ŁAARM 32-bit�̉ӏ��Ƃ��A
> �ǂ�łĂ��������C�p���������Ȃ��Ă��܂��ˁB
http://developers.slashdot.jp/comments.pl?sid=627062&cid=2568375
> �Ƃ������A���ƋC���̔��ʂ�����������Ȃ��Ƃ������Ă�L���ŁAARM 32-bit�̉ӏ��Ƃ��A
> �ǂ�łĂ��������C�p���������Ȃ��Ă��܂��ˁB
ARMv8�͖��߂���V����ĕʎ����Ȃ�Ęb�������������ǁA
ARM������10%���x���Č����Ă����A�x���`�ł����̂��炢�����A
����x86��32bit��64bit�̌��㗦�Ƒ卷�Ȃ�������
ARM������10%���x���Č����Ă����A�x���`�ł����̂��炢�����A
����x86��32bit��64bit�̌��㗦�Ƒ卷�Ȃ�������
981 �FSocket774�F2014/03/26(��) 23:05:42.41 ID:5GQ0eqCc
���ׂȕ���������Ă邩������A
ARM 32bit�̖��߂��������Ƃɂ͕ς��Ȃ�
ARM 32bit�̖��߂��������Ƃɂ͕ς��Ȃ�
982 �F,,�E�L�́M�E,,�j��-�������F2014/03/26(��) 23:35:42.57 ID:NYLn+9+7
OoO�E����\�������悤�ɂȂ���32bit���̖��߂̂���4�r�b�g���߂�
�v���f�B�P�[�g�������㎀�Ƀr�b�g��������Ƃ��A���ƃ��[�h�E�X�g�A���߂�
�A�h���b�V���O�Ȃǂɗp���鑦�l�t�B�[���h��12�r�b�g�����Ȃ�������Ƃ��B
�v���f�B�P�[�g�������㎀�Ƀr�b�g��������Ƃ��A���ƃ��[�h�E�X�g�A���߂�
�A�h���b�V���O�Ȃǂɗp���鑦�l�t�B�[���h��12�r�b�g�����Ȃ�������Ƃ��B
�J���҂ɂƂ��Ă͑���64�r�b�g�Ɉڍs���Ă��炢�������낤��
PC�ƈ���Ĕ����ւ��T�C�N�����������܂���������
PC�ƈ���Ĕ����ւ��T�C�N�����������܂���������
>>973
������ă��O�̏����o�����Ԃ����݂ł̎��ԂȂ̂��낤����20�N�O����̋^�₾��
������ă��O�̏����o�����Ԃ����݂ł̎��ԂȂ̂��낤����20�N�O����̋^�₾��
>>981
���k��ł�ARM�̃��W�X�^��16�{�����Ȃ��̂ō����ƌ����Ă邯�ǁAARM�Ɋւ��ẮA���W
�X�^�̐��͎��ۂ���قǍ����d�l�ł͂Ȃ��Ǝv���B
�R���p�C���̓f�����R�[�h�����Ă����W�X�^�̐��͑���Ă�ꍇ�͑������A����Ȃ��ꍇ�ł��A���W
�X�^�̐������炸�������Ɋ��蓖�Ă���f�[�^�͎g�p�p�x�̒Ⴂ���̂��D�悳�ꂽ�肷��̂�
���ʂȂ̂ŁA���قǖ��Ƃ͎v��Ȃ��B
�l�I�ɂ�1��32bit�̒��Ɏ��s�������3�I�y�����h���ł��܂�L�����p����ĂȂ�bit����������
����̂ŃR�[�h���x���Ⴂ�Ƃ���͂��������Ȃ��Ȃ��Ƃ͎v�����A�����Ƃ������ł͂Ȃ��B
���k��ł�ARM�̃��W�X�^��16�{�����Ȃ��̂ō����ƌ����Ă邯�ǁAARM�Ɋւ��ẮA���W
�X�^�̐��͎��ۂ���قǍ����d�l�ł͂Ȃ��Ǝv���B
�R���p�C���̓f�����R�[�h�����Ă����W�X�^�̐��͑���Ă�ꍇ�͑������A����Ȃ��ꍇ�ł��A���W
�X�^�̐������炸�������Ɋ��蓖�Ă���f�[�^�͎g�p�p�x�̒Ⴂ���̂��D�悳�ꂽ�肷��̂�
���ʂȂ̂ŁA���قǖ��Ƃ͎v��Ȃ��B
�l�I�ɂ�1��32bit�̒��Ɏ��s�������3�I�y�����h���ł��܂�L�����p����ĂȂ�bit����������
����̂ŃR�[�h���x���Ⴂ�Ƃ���͂��������Ȃ��Ȃ��Ƃ͎v�����A�����Ƃ������ł͂Ȃ��B
�ڂ������Ȑl�o�ꂵ�����玿�₵�Ă݂�
>>985
x86�Apower�Aarm�ȂǁA�ǂ̖��߃Z�b�g����ԗD��Ă�Ǝv���܂����H
�ǂꂪ���y����̂��J���҂ɂƂ��Ĉ�ԗǂ��Ǝv���܂���
>>985
x86�Apower�Aarm�ȂǁA�ǂ̖��߃Z�b�g����ԗD��Ă�Ǝv���܂����H
�ǂꂪ���y����̂��J���҂ɂƂ��Ĉ�ԗǂ��Ǝv���܂���
�u��������̂Ɂv�D��Ă��邩���Ă��Ȃ��Ƃ�
�}�C�N���v���Z�b�T�̗p�r�Ȃ�āA�d�C������X�[�p�[�R���s���[�^�܂ł���킯��
��������ǂ�ɂނ��Ă��œK�Ƃ��Ȃ����땁��
�}�C�N���v���Z�b�T�̗p�r�Ȃ�āA�d�C������X�[�p�[�R���s���[�^�܂ł���킯��
��������ǂ�ɂނ��Ă��œK�Ƃ��Ȃ����땁��
���̃X���I�ɂ́A�n�C�X�y�b�N�ȃX�}�z�E�^�u���b�g�EPC�E�T�[�o�EHPC�p��CPU�ł�������
�X�}�z����HPC�܂ł��či��C�Ȃ������
x86����Ԃ��ȁB
���j���ؖ����Ă�B
���j���ؖ����Ă�B
���j���Č����Ă��g�����ߑ����܂����Ă邯�ǂ�
992 �F,,�E�L�́M�E,,�j��-�������F2014/03/27(��) 01:38:47.54 ID:iUrdW09J
���₹��̂������b�g����B
����剻���ăC���^�[�l�b�g�ɗ�������c��ȃf�[�^���������邽�߂ɁA
�����Z�\�͂�����ɍ��߂Ă����K�v������Ɛ�������
ttp://pc.watch.impress.co.jp/img/pcw/docs/641/416/html/359.jpg.html
�����f�[�^���剻�����Ă���ӔC�̔������炢�͏�������\�͂�
���܂������Ƃł���A����䂦�ނ��눫������̂ł͂Ƌ��l������
�����Z�\�͂�����ɍ��߂Ă����K�v������Ɛ�������
ttp://pc.watch.impress.co.jp/img/pcw/docs/641/416/html/359.jpg.html
{kind=link}
�����f�[�^���剻�����Ă���ӔC�̔������炢�͏�������\�͂�
���܂������Ƃł���A����䂦�ނ��눫������̂ł͂Ƌ��l������
994 �F,,�E�L�́M�E,,�j��-�������F2014/03/27(��) 01:50:00.47 ID:iUrdW09J
�����̔ے肾��
�y�\���zBTO�w�����k���y���ς�z��11
http://toro.2ch.net/test/read.cgi/hard/1395327997/
http://toro.2ch.net/test/read.cgi/hard/1395327997/
�f�[�^�̔�剻�⏟���\�͂̌���͖��Ȃ�
�����C����ɂ�����d�͂����傷�邱�Ƃ�������肾
�����C����ɂ�����d�͂����傷�邱�Ƃ�������肾
���̃X���̐l�A�m�I�ł�������������B
999 �F �E�@���yLv=12,xxxPT�z(1+0�F5) �F2014/03/27(��) 05:55:49.23 ID:Sm1dzjCU
�~
CPU�A�[�L�e�N�`���ɂ��Č�� 26
http://anago.2ch.net/test/read.cgi/jisaku/1395873247/
http://anago.2ch.net/test/read.cgi/jisaku/1395873247/
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/