CPUƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‚آ‚¢‚ؤŒê‚ê 24
ƒwƒlƒVپ[&ƒpƒ^پ[ƒ\ƒ“
‚ ‚é‚¢‚ح‰ح“¶‚ج››
پy‘OƒXƒŒپz
CPUƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‚آ‚¢‚ؤŒê‚ê 23
http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
پy‰ك‹ژƒXƒŒپz
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
‚ ‚é‚¢‚ح‰ح“¶‚ج››
پy‘OƒXƒŒپz
CPUƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‚آ‚¢‚ؤŒê‚ê 23
http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
پy‰ك‹ژƒXƒŒپz
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20 http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
Part21 http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
Part22 http://anago.2ch.net/test/read.cgi/jisaku/1334096468/
Part23 http://anago.2ch.net/test/read.cgi/jisaku/1355497868/
|
|
|
پ„http://anago.2ch.net/test/read.cgi/jisaku/1355497868/998
ˆہ‚¢ƒ‹پ[ƒ^‚حپAMIPS‚ئ‚©ARM‚ئ‚©‚جˆہƒ`ƒbƒv‚ھژه—¬‚¶‚ل‚ثپH
چ‚‚¢ƒ‹پ[ƒ^‚ة‚حپAPowerPC‚â‚çx86“™‚جچ‚گ«”\ƒ`ƒbƒv‚ھژg‚ي‚ê‚ھ‚؟
چ‚‚¢ƒ‹پ[ƒ^‚ة‚ب‚é‚ئپAƒvƒچƒOƒ‰ƒ}ƒuƒ‹ASIC‚â‚çFPGA“™‚جPLDپ{چ‚‘¬CPU‚ء‚ؤ‚ج‚ھ
‘½‚¢‚ئ‚¨‚à‚¤‚و
ˆہ‚¢ƒ‹پ[ƒ^‚حپAMIPS‚ئ‚©ARM‚ئ‚©‚جˆہƒ`ƒbƒv‚ھژه—¬‚¶‚ل‚ثپH
چ‚‚¢ƒ‹پ[ƒ^‚ة‚حپAPowerPC‚â‚çx86“™‚جچ‚گ«”\ƒ`ƒbƒv‚ھژg‚ي‚ê‚ھ‚؟
چ‚‚¢ƒ‹پ[ƒ^‚ة‚ب‚é‚ئپAƒvƒچƒOƒ‰ƒ}ƒuƒ‹ASIC‚â‚çFPGA“™‚جPLDپ{چ‚‘¬CPU‚ء‚ؤ‚ج‚ھ
‘½‚¢‚ئ‚¨‚à‚¤‚و
‚ب‚ٌ‚©‚±‚¤پAچ‚‚¢‚ئˆہ‚¢‚جٹ´ٹo‚ةƒYƒŒ‚ھ‚ ‚è‚»‚¤
PowerMac‚ھ•œٹˆ‚µ‚ب‚¢‚±‚ئ‚ة‚ح–ت”’‚ف‚ب‚¢‚ب
>>2
MIPS‚ح‚à‚¤گٹ‘ق‚µ‚ؤ‚邾‚낤پB•د‚ي‚èژي‚إ‚حSH‚à‚ ‚ء‚½‚ھپA‹ئ–±—p‚إ‚حPower‚à‚و‚•·‚پB
MIPS‚ح‚à‚¤گٹ‘ق‚µ‚ؤ‚邾‚낤پB•د‚ي‚èژي‚إ‚حSH‚à‚ ‚ء‚½‚ھپA‹ئ–±—p‚إ‚حPower‚à‚و‚•·‚پB
‚»‚¤‚¢‚âMIPSگVƒRƒA”•\‚ ‚ء‚½‚ب‚±‚ج‘O
LANL‚جRoadrunner‚جŒمŒp‹@‚ج–¼‘O‚ھTrinity‚إŒ»چفŒِ•ه’†پB‹¤“¯‚إ2‘ن‚ـ‚ئ‚ك”ƒ‚¢
‚·‚邤‚؟‚ج1‘ن‚ة‚ب‚éپB13-40ƒyƒ^Flops–ع•W‚ف‚½‚¢‚إ2015/2016”N‰ز“®—\’èپB
http://www.nersc.gov/assets/Trinity--NERSC-8-RFP/Documents/NERSC-8VendorMarketSurveyNov2012.pdf
‚·‚邤‚؟‚ج1‘ن‚ة‚ب‚éپB13-40ƒyƒ^Flops–ع•W‚ف‚½‚¢‚إ2015/2016”N‰ز“®—\’èپB
http://www.nersc.gov/assets/Trinity--NERSC-8-RFP/Documents/NERSC-8VendorMarketSurveyNov2012.pdf
ƒ‹پ[ƒ^پ[‚ةARM‚ب‚ٌ‚ؤژg‚ي‚ê‚ؤ‚½‚ء‚¯پH
MIPS‚âSH‚ج•û‚ھˆہ‚¢‚©‚ç‚و‚ژg‚ي‚ê‚ؤ‚½‚ئژv‚¤پB
MIPS‚âSH‚ج•û‚ھˆہ‚¢‚©‚ç‚و‚ژg‚ي‚ê‚ؤ‚½‚ئژv‚¤پB
>>8
xscaleپEپEپE
xscaleپEپEپE
broadcom‚ئ‚©mips‚¶‚ل‚ë
11 پFSocket774پF2013/09/02(Œژ) 20:22:59.08 ID:VczuL2Vx
‚ ‚°
‚±‚جکb‚ء‚ؤ‚ا‚¤‚ب‚ء‚½
http://pc.watch.impress.co.jp/docs/2004/1117/kaigai135.htm
http://pc.watch.impress.co.jp/docs/2004/1117/kaigai135.htm
PCIe ‚à DMI ‚àƒVƒٹƒAƒ‹‚¶‚ل‚ثپH
14 پFSocket774پF2013/09/03(‰خ) 06:25:15.99 ID:eRWU4W+k
ƒlƒbƒgƒڈپ[ƒN‹@ٹي‚ة‚ح‚»‚ê‚ب‚è‚ةx86ژg‚ي‚ê‚ؤ‚ثپH
چ‚‘¬‰»‚ج‚½‚ك‚ةASIC‚¾‚¯‚إڈˆ—‚إ‚«‚éƒpƒPƒbƒg‚حASIC‚إڈˆ—‚µ‚ؤپA
‚إ‚«‚ب‚¢ƒpƒPƒbƒg‚حCPU‚ة‚à‚ء‚ؤ‚«‚ؤڈˆ—‚ف‚½‚¢‚ب“z
OS‚ة‚حBSDŒn‚جUNIX‚ً‰ü‘¢‚µ‚ؤژg‚ء‚ؤ‚éڈêچ‡‚à‘½‚¢
چ‚‘¬‰»‚ج‚½‚ك‚ةASIC‚¾‚¯‚إڈˆ—‚إ‚«‚éƒpƒPƒbƒg‚حASIC‚إڈˆ—‚µ‚ؤپA
‚إ‚«‚ب‚¢ƒpƒPƒbƒg‚حCPU‚ة‚à‚ء‚ؤ‚«‚ؤڈˆ—‚ف‚½‚¢‚ب“z
OS‚ة‚حBSDŒn‚جUNIX‚ً‰ü‘¢‚µ‚ؤژg‚ء‚ؤ‚éڈêچ‡‚à‘½‚¢
>>14,15
UTM‘•’u‚إ‚ح‚و‚Œ©‚©‚¯‚é‚و‚¤‚ب‹C‚ھ‚·‚éپB
UTM‘•’u‚إ‚ح‚و‚Œ©‚©‚¯‚é‚و‚¤‚ب‹C‚ھ‚·‚éپB
ttp://www.hpc.co.jp/benchmark20130617.html
پ@Xeon E3-1270 v3 FMA3
پ@پ@—ک_گ«”\پ@224GFLOPSپ@HPLƒxƒ“ƒ`پ@174.4GFLOPS
پi“¯ٹi‚ج v2
پ@پ@—ک_گ«”\پ@112GFLOPSپj
‚±‚¤‚¢‚¤ŒvژZ‚ً‚·‚éگl‚ح‚»‚à‚»‚àLGA1150‚ً‘I‚خ‚ب‚¢‚©‚à’m‚ê‚ب‚¢پB
FMA3پ@‚حHaswell-E ‚ھڈo‚ؤ‚©‚ç‚ھ–{”ش‚©
پ@Xeon E3-1270 v3 FMA3
پ@پ@—ک_گ«”\پ@224GFLOPSپ@HPLƒxƒ“ƒ`پ@174.4GFLOPS
پi“¯ٹi‚ج v2
پ@پ@—ک_گ«”\پ@112GFLOPSپj
‚±‚¤‚¢‚¤ŒvژZ‚ً‚·‚éگl‚ح‚»‚à‚»‚àLGA1150‚ً‘I‚خ‚ب‚¢‚©‚à’m‚ê‚ب‚¢پB
FMA3پ@‚حHaswell-E ‚ھڈo‚ؤ‚©‚ç‚ھ–{”ش‚©
ƒ‹ƒlƒTƒXپAƒ‹ƒlƒTƒX ƒ‚ƒoƒCƒ‹‚جژq‰ïژذ‚ئLTEƒ‚ƒfƒ€‹Zڈpژ‘ژY‚ً–ٌ160‰‰~‚إBroadcom‚ة”„‹p
http://news.mynavi.jp/news/2013/09/05/032/
http://news.mynavi.jp/news/2013/09/05/032/
چ‘‚ح‚ـ‚¾“Œژإ‚ھ‚ ‚é‚©‚çƒGƒ‹ƒsپ[ƒ_‚ًŒ©ژج‚ؤ‚½‚ٌ‚¾‚낤‚ب
DRAM‚جژں‚جگ¨‘م‚جƒپƒ‚ƒٹ‚ئ‚µ‚ؤ’چ–ع‚³‚ê‚ؤ‚¢‚éMRAM‚ة‚ح“Œژإ‚àژQ“ü‚·‚é‚ف‚½‚¢‚¾‚µ
DRAM‚جژں‚جگ¨‘م‚جƒپƒ‚ƒٹ‚ئ‚µ‚ؤ’چ–ع‚³‚ê‚ؤ‚¢‚éMRAM‚ة‚ح“Œژإ‚àژQ“ü‚·‚é‚ف‚½‚¢‚¾‚µ
‚ا‚¤‚¹ˆê’ت‚èƒCƒ“ƒTƒCƒ_پ[‚إ³د³د‚µ‚½‚©‚çƒ|ƒC‚³‚ꂽ‚¾‚¯‚¾‚ë
>>19
چ‘‚حپA‚ئŒ¾‚ء‚ؤ‚à–¯ژه“}گŒ ژ‘م‚جژ}–ىŒoژY‘هگb‚ھپAچ‘‚ھ“ْ–{گچô‹âچs‚ً’ت‚¶‚ؤ
‘ف‚µ‚½‹à‚ً–ٌ’è‚ا‚¨‚è•شچد‚¹‚وپA‚ئ‹ˆّ‚ة”—‚ء‚ؤپA‹‡‚µ‚½ƒGƒ‹ƒsپ[ƒ_‚ھپA
‚ب‚çژ‚ء‚ؤ‚¢‚é‹à‘S•”ژ‚ء‚ؤ‚¢‚ء‚ؤ(‚è‚»‚ب‹â‚ض)پA‰ïژذچXگ¶–@گ\گ؟‚µ‚½‚ج‚¾‚وپB
”„چ‘گŒ ‚ھƒGƒ‹ƒs’ׂµ‚ؤٹطچ‘2ژذ‚ً‹‰»‚µ‚و‚¤‚ئ‚µ‚½‚çپA‚»‚¤‚ح‚³‚¹‚¶‚ئ•ؤچ‘
‰ïژذ‚ةگg”„‚è(‹ˆّ‚ةگg”„‚肵‚½‚ج‚إپA•ؤچ‘‚ئ“ْ–{‚إ‘iڈ×چ¹‘؟پBچإچ‚چظ–کچs‚ء‚½)پB
چ‘‚حپA‚ئŒ¾‚ء‚ؤ‚à–¯ژه“}گŒ ژ‘م‚جژ}–ىŒoژY‘هگb‚ھپAچ‘‚ھ“ْ–{گچô‹âچs‚ً’ت‚¶‚ؤ
‘ف‚µ‚½‹à‚ً–ٌ’è‚ا‚¨‚è•شچد‚¹‚وپA‚ئ‹ˆّ‚ة”—‚ء‚ؤپA‹‡‚µ‚½ƒGƒ‹ƒsپ[ƒ_‚ھپA
‚ب‚çژ‚ء‚ؤ‚¢‚é‹à‘S•”ژ‚ء‚ؤ‚¢‚ء‚ؤ(‚è‚»‚ب‹â‚ض)پA‰ïژذچXگ¶–@گ\گ؟‚µ‚½‚ج‚¾‚وپB
”„چ‘گŒ ‚ھƒGƒ‹ƒs’ׂµ‚ؤٹطچ‘2ژذ‚ً‹‰»‚µ‚و‚¤‚ئ‚µ‚½‚çپA‚»‚¤‚ح‚³‚¹‚¶‚ئ•ؤچ‘
‰ïژذ‚ةگg”„‚è(‹ˆّ‚ةگg”„‚肵‚½‚ج‚إپA•ؤچ‘‚ئ“ْ–{‚إ‘iڈ×چ¹‘؟پBچإچ‚چظ–کچs‚ء‚½)پB
ƒGƒ‹ƒs‚حƒپƒCƒ“ƒoƒ“ƒN‚ھŒ©ژج‚ؤ‚½‚©‚çژd•û‚ب‚¢‚¾‚ë
‚ـ‚½ٹج“ü‚إ–_ˆّ‚«‚³‚µ‚ؤگإ‹à“ث‚ءچ‚ق‚ج‚©پH
‚ـ‚½ٹج“ü‚إ–_ˆّ‚«‚³‚µ‚ؤگإ‹à“ث‚ءچ‚ق‚ج‚©پH
>>22
”„چ‘گŒ ‚جˆ«چs‚ح‰B‚¹‚ب‚¢‚وپB
–¯ژه“}گŒ ‚جژ}–ىŒoژY‘هگb‚ج‚à‚ئ‚إپA“ْ–{گچô“ٹژ‘‹âچsپiگ“ٹ‹âپj‚ھگ•{•غڈط
•t‚«‚جŒِ“Iژ‘‹à‚ج–ٌ’è•شچد‚ً‹ˆّ‚ة”—‚ء‚½‚ج‚ھŒ´ˆِپB
پuگ“ٹ‹â‚ھ”j’]‚جˆّ‚«‹à‚ًˆّ‚¢‚½پv‚ئپAژه’£‚·‚é‚ج‚حƒپƒKƒoƒ“ƒN‚جٹضŒWژز‚¾پB
http://sankei.jp.msn.com/economy/news/120317/biz12031718010008-n1.htm
پuچ‘‚جƒGƒ‹ƒsپ[ƒ_ژx‰‡پ@‘S‹â‹¦‰ï’·پw‘±‚¯‚é‚ׂ«‚¾‚ء‚½پxپvپi“ْŒoگV•·‚X–تچ¶‹÷ˆح‚ف‹Lژ–پjپB
http://blog.goo.ne.jp/ozoz0930/e/62204a746c32d52410b3511071ee0341
ˆّ—p‚ھ•د‚بڈٹ‚¾‚ھپA‚à‚ئ‚ج”Œ¾‚ح‚±‚؟‚ç‚إپA‘S‹âکA‚ئ‚µ‚ؤ‚حچ‘‚حژx‰‡Œp‘±‚·‚ׂ«‚¾‚ء‚½‚ئ”Œ¾پB
http://www.zenginkyo.or.jp/news/conference/2012/03/15230000.html
”„چ‘گŒ ‚جˆ«چs‚ح‰B‚¹‚ب‚¢‚وپB
–¯ژه“}گŒ ‚جژ}–ىŒoژY‘هگb‚ج‚à‚ئ‚إپA“ْ–{گچô“ٹژ‘‹âچsپiگ“ٹ‹âپj‚ھگ•{•غڈط
•t‚«‚جŒِ“Iژ‘‹à‚ج–ٌ’è•شچد‚ً‹ˆّ‚ة”—‚ء‚½‚ج‚ھŒ´ˆِپB
پuگ“ٹ‹â‚ھ”j’]‚جˆّ‚«‹à‚ًˆّ‚¢‚½پv‚ئپAژه’£‚·‚é‚ج‚حƒپƒKƒoƒ“ƒN‚جٹضŒWژز‚¾پB
http://sankei.jp.msn.com/economy/news/120317/biz12031718010008-n1.htm
پuچ‘‚جƒGƒ‹ƒsپ[ƒ_ژx‰‡پ@‘S‹â‹¦‰ï’·پw‘±‚¯‚é‚ׂ«‚¾‚ء‚½پxپvپi“ْŒoگV•·‚X–تچ¶‹÷ˆح‚ف‹Lژ–پjپB
http://blog.goo.ne.jp/ozoz0930/e/62204a746c32d52410b3511071ee0341
ˆّ—p‚ھ•د‚بڈٹ‚¾‚ھپA‚à‚ئ‚ج”Œ¾‚ح‚±‚؟‚ç‚إپA‘S‹âکA‚ئ‚µ‚ؤ‚حچ‘‚حژx‰‡Œp‘±‚·‚ׂ«‚¾‚ء‚½‚ئ”Œ¾پB
http://www.zenginkyo.or.jp/news/conference/2012/03/15230000.html
24 پFSocket774پF2013/09/08(“ْ) 10:03:38.43 ID:bipRQ1TP
‘ف‚µڈa‚è‚إ‰ïژذ’ׂµ‚ـ‚‚ء‚ؤژة’ي‚جڈء”ïژز‹à—Zژg‚ء‚ؤ‘½ڈdچآ–±ژزچى‚ء‚ؤژè‚ة“ü‚ꂽ‹à‚إ‚ذ‚½‚·‚çچ‘چآ”ƒ‚ء‚ؤ
•s—اچآŒ ‚ج‚½‚ك‚ةڈم‚ھ‚è‚ً’چ‚¬چ‚ٌ‚إگإ‹à‚ح‚ë‚‚ة•¥‚ي‚ب‚¢‚و‚¤‚ب‹âچs•—ڈî‚ھپuچ‘‚ھڈ•‚¯‚é‚ׂ«‚¾‚ء‚½پIپv
ƒRƒsƒy”]‚ح‚±‚ê‚ھ‚¨‚©‚µ‚¢‚ئژv‚ي‚ٌ‚ج‚©‚ث
•s—اچآŒ ‚ج‚½‚ك‚ةڈم‚ھ‚è‚ً’چ‚¬چ‚ٌ‚إگإ‹à‚ح‚ë‚‚ة•¥‚ي‚ب‚¢‚و‚¤‚ب‹âچs•—ڈî‚ھپuچ‘‚ھڈ•‚¯‚é‚ׂ«‚¾‚ء‚½پIپv
ƒRƒsƒy”]‚ح‚±‚ê‚ھ‚¨‚©‚µ‚¢‚ئژv‚ي‚ٌ‚ج‚©‚ث
‹âچs‚ھ’لƒٹƒXƒN‚ب‰ïژذ‚ة‚µ‚©‘ف‚¹‚ب‚¢‚ج‚ح‹à—ک‚ھˆہ‚¢‚©‚炾‚و
”N—ک‚T‚Oپ“‚ئ‚©ˆل–@‹à—ک‚إ—Zژ‘‚إ‚«‚ê‚خپA‚à‚ء‚ئƒ„ƒoƒC‰ïژذ‚ة‚à—Zژ‘‰آ”\
”N—ک‚T‚Oپ“‚ئ‚©ˆل–@‹à—ک‚إ—Zژ‘‚إ‚«‚ê‚خپA‚à‚ء‚ئƒ„ƒoƒC‰ïژذ‚ة‚à—Zژ‘‰آ”\
•ؤچ‘‚ض‚ج”„چ‘‚حمY—ي‚ب”„چ‘
‘g‚فچ‚فŒü‚¯‚إچ×پX‚ئ‚â‚ء‚ؤ‚ê‚خ—ا‚©‚ء‚½‚ج‚ة‚بپB
ƒTƒ€ƒXƒ“‚ةƒKƒ`‚إŒ–‰ـ”„‚ء‚ؤڈں‚ؤ‚é‚ي‚¯‚ب‚¢پB
ƒTƒ€ƒXƒ“‚ةƒKƒ`‚إŒ–‰ـ”„‚ء‚ؤڈں‚ؤ‚é‚ي‚¯‚ب‚¢پB
•xژm’تƒZƒ~ƒRƒ“ƒ_ƒNƒ^پ[پ@Deeply Depleted Channel(DDC) —تژYپ@55nm
ƒfƒWƒ^ƒ‹ˆêٹلƒJƒپƒ‰پAƒnƒCƒGƒ“ƒhƒRƒ“ƒfƒW—pƒvƒچƒZƒbƒT
ttp://jp.fujitsu.com/group/fsl/release/20130904-1.html
ando ‚³‚ٌ‚جDDCپiSuVolta PowerShrinkپj‰ًگà
ttp://news.mynavi.jp/articles/2011/06/16/powershrink/001.html
ƒfƒWƒ^ƒ‹ˆêٹلƒJƒپƒ‰پAƒnƒCƒGƒ“ƒhƒRƒ“ƒfƒW—pƒvƒچƒZƒbƒT
ttp://jp.fujitsu.com/group/fsl/release/20130904-1.html
ando ‚³‚ٌ‚جDDCپiSuVolta PowerShrinkپj‰ًگà
ttp://news.mynavi.jp/articles/2011/06/16/powershrink/001.html
Apple‚ھ64bit ARMڈo‚µ‚½‚ث
Apple‚جCPU‚ء‚ؤ–{“–‚ة“ئژ©گفŒv‚ب‚ج‚©پH‘پ‚·‚¬‚¾‚ëw
‚±‚ج‘پ‚³‚إڈo‚¹‚é‚ج‚ھ“ئژ©‚بڈط‹’‚¶‚ل‚ب‚¢‚©
”ؤ—p‚¾‚ء‚½‚çƒTƒ€ƒXƒ“‚»‚ج‘¼‚ھگو‚ةڈo‚µ‚ؤ‚邾‚ë
”ؤ—p‚¾‚ء‚½‚çƒTƒ€ƒXƒ“‚»‚ج‘¼‚ھگو‚ةڈo‚µ‚ؤ‚邾‚ë
Apple‚ئŒ¾‚¦‚خ‘¼ژذگ»‚جٹù‘¶•”•i‚ج‘g‚فچ‡‚ي‚¹‚إٹvگV“I‚بƒfƒoƒCƒX‚ًچى‚éٹé‹ئ‚ئ‚¢‚¤ˆَڈغ‚¾‚ء‚½‚ھ
ژ‘م‚ح•د‚ي‚ء‚½‚à‚ٌ‚¾‚ب
ژ‘م‚ح•د‚ي‚ء‚½‚à‚ٌ‚¾‚ب
‚ي‚©‚ء‚؟‚ل‚¢‚é‚ئ‚حژv‚¤‚ھ
apple‚حARM‘n‹ئژ‚جڈoژ‘ژذ‚جˆê‚آ‚إŒ»چف‚à‘هٹ”ژه‚إ‚ ‚è
‘¼ژذ‚ةگو‹ى‚¯‚ؤڈî•ٌ‚ً‹¤—L“üژè‚إ‚«‚é‚ء‚ؤژ–‚ً–Y‚ê‚؟‚ل‘ت–ع‚¾‚¼
‚ئ‚«‚ا‚«ٹ®‘Sژq‰ïژذ‰»‚ج‰\‚ھڈo‚ؤ‚حڈء‚¦‚邯‚ا
apple‚حARM‘n‹ئژ‚جڈoژ‘ژذ‚جˆê‚آ‚إŒ»چف‚à‘هٹ”ژه‚إ‚ ‚è
‘¼ژذ‚ةگو‹ى‚¯‚ؤڈî•ٌ‚ً‹¤—L“üژè‚إ‚«‚é‚ء‚ؤژ–‚ً–Y‚ê‚؟‚ل‘ت–ع‚¾‚¼
‚ئ‚«‚ا‚«ٹ®‘Sژq‰ïژذ‰»‚ج‰\‚ھڈo‚ؤ‚حڈء‚¦‚邯‚ا
‚ٌپHApple‚ئARM‚جٹضŒW‚حˆê’Uژ‚؟ٹ”‚ً‘S•””„‚ء‚ؤٹ®‘S‚ةگط‚ꂽ‚إ‚µ‚ه
http://www.itmedia.co.jp/products/0308/18/ne00_10q.html
‚»‚جŒم‚ـ‚½‘هٹ”ژه‚ة‚ب‚ء‚½‚جپH
‚إA7‚¾‚ھپA10‰ƒgƒ‰ƒ“ƒWƒXƒ^ˆبڈم‚إ102mm2‚ئ‚ج‚±‚ئ‚¾‚©‚çپA28nm‚إ‚ح‚ب‚³‚»‚¤‚ب‚ج‚¾‚ھ‚ح‚ؤ‚³‚ؤ...
http://www.itmedia.co.jp/products/0308/18/ne00_10q.html
‚»‚جŒم‚ـ‚½‘هٹ”ژه‚ة‚ب‚ء‚½‚جپH
‚إA7‚¾‚ھپA10‰ƒgƒ‰ƒ“ƒWƒXƒ^ˆبڈم‚إ102mm2‚ئ‚ج‚±‚ئ‚¾‚©‚çپA28nm‚إ‚ح‚ب‚³‚»‚¤‚ب‚ج‚¾‚ھ‚ح‚ؤ‚³‚ؤ...
>>34
GPUگ¬•ھ‚ھ‘‚¦‚ؤ‚«‚ؤ‚¢‚邵پAAPU‚ئ‚µ‚ؤŒ©‚½‚çپATSMC‚ج28nm‚إ•پ’ت‚ةپA
10‰ƒgƒ‰ƒ“ƒWƒXƒ^ˆبڈم‚إ102mm2‚إ‚ح‚ب‚¢‚جپH
GPUگ¬•ھ‚ھ‘‚¦‚ؤ‚«‚ؤ‚¢‚邵پAAPU‚ئ‚µ‚ؤŒ©‚½‚çپATSMC‚ج28nm‚إ•پ’ت‚ةپA
10‰ƒgƒ‰ƒ“ƒWƒXƒ^ˆبڈم‚إ102mm2‚إ‚ح‚ب‚¢‚جپH
36 پFSocket774پF2013/09/11(گ…) 07:43:02.07 ID:dorLfMdz
A5‚ـ‚إ‚حcortex‚إA6‚ھ“ئژ©
A7‚حv8Œفٹ·‚炵‚¢‚ھA57,53‚ ‚½‚肶‚ل‚ث
A7‚حv8Œفٹ·‚炵‚¢‚ھA57,53‚ ‚½‚肶‚ل‚ث
گک‚¦’u‚«ƒQپ[ƒ€‹@‚ئ”نٹr‚·‚é‚ئ
ƒ‚ƒoƒCƒ‹‚جƒ`ƒbƒv‚ح”¼•ھˆبڈمڈ¬‚³‚¢‚ب
“–‚½‚è‘O‚¾‚ھ
ƒ‚ƒoƒCƒ‹‚جƒ`ƒbƒv‚ح”¼•ھˆبڈمڈ¬‚³‚¢‚ب
“–‚½‚è‘O‚¾‚ھ
Apple“ئژ©‚ء‚ؤ‚¢‚ء‚ؤ‚àپAARM‚ج64bitcore‚ً‚؟‚ه‚ء‚ئƒJƒXƒ^ƒ}ƒCƒY‚µ‚½‚¾‚¯‚إ‚µ‚هپH
A15ˆبچ~‚جARM‚حƒJƒX‚ب‚ج‚ة‚»‚ê‚ًƒxپ[ƒX‚ة‚³‚ê‚ؤ‚à‚ث‚¦
Apple‚ھCPUٹJ”•”‘à‚ً‘‹‚µ‚ؤ‚é‚ء‚ؤ‰\‚ح–{“–‚ب‚ٌ‚¾‚낤‚©
A7‚جARMv8‚ھ–{“–‚ة“ئژ©گفŒvƒRƒA‚¾‚ئ‚·‚ê‚خپAڈ‚ب‚‚ئ‚à2ƒ`پ[ƒ€‚¢‚ب‚¢‚ئ–³—‚ء‚غ‚¢
Swift‚ھ‹ژ”N‚ج“¯ژٹْ‚¾‚©‚çپA‚±‚±2”N‚إگVگفŒvگVƒvƒچƒZƒX‚جƒRƒA‚ً2‚آڈo‚µ‚ؤ‚¢‚邱‚ئ‚ة‚ب‚é
گفŒvٹْٹش‚ھƒIپ[ƒoپ[ƒ‰ƒbƒv‚µ‚ؤ‚¢‚ب‚¢‚ئ–³—‚بŒ|“–
Swift‚ھ‹ژ”N‚ج“¯ژٹْ‚¾‚©‚çپA‚±‚±2”N‚إگVگفŒvگVƒvƒچƒZƒX‚جƒRƒA‚ً2‚آڈo‚µ‚ؤ‚¢‚邱‚ئ‚ة‚ب‚é
گفŒvٹْٹش‚ھƒIپ[ƒoپ[ƒ‰ƒbƒv‚µ‚ؤ‚¢‚ب‚¢‚ئ–³—‚بŒ|“–
PAsemi‚ة2ƒ‰ƒCƒ“‚ ‚ء‚½‚ئ‚حچl‚¦‚ة‚‚¢پB
‚»‚ê‚ةŒg‘ر‚ة2•”‘à‚ح–³‘ت‚ھ‘½‚·‚¬‚éپB
‰آ”\گ«‚ئ‚µ‚ؤ‚حپA
پEƒIپ[ƒoپ[ƒ‰ƒbƒv‚µ‚ؤ‚¢‚é‚و‚¤‚إپAˆسٹO‚ئ‘پ‚ك‚ةٹJ”ٹ®—¹‚µ‚ؤ‚¢‚é
پEARM”إMAC‚ةŒü‚¯‚ؤڈ€”ُ’†
پEMAC‚ھ”„‚ê‚ب‚¢‚ج‚إŒg‘ر‰ïژذ‚ئ‚µ‚ؤ‚â‚ء‚ؤ‚¢‚‚ج‚إپA‘S—ح‚ًŒX‚¯‚ؤ‚¢‚é
ARM”إMAC‚¾‚ء‚½‚ç‚و‚蔄‚ê‚ب‚‚ب‚邾‚낤پB
Bootcamp‚إWindowsRT‚ئ‚©پB
‚»‚ê‚ةŒg‘ر‚ة2•”‘à‚ح–³‘ت‚ھ‘½‚·‚¬‚éپB
‰آ”\گ«‚ئ‚µ‚ؤ‚حپA
پEƒIپ[ƒoپ[ƒ‰ƒbƒv‚µ‚ؤ‚¢‚é‚و‚¤‚إپAˆسٹO‚ئ‘پ‚ك‚ةٹJ”ٹ®—¹‚µ‚ؤ‚¢‚é
پEARM”إMAC‚ةŒü‚¯‚ؤڈ€”ُ’†
پEMAC‚ھ”„‚ê‚ب‚¢‚ج‚إŒg‘ر‰ïژذ‚ئ‚µ‚ؤ‚â‚ء‚ؤ‚¢‚‚ج‚إپA‘S—ح‚ًŒX‚¯‚ؤ‚¢‚é
ARM”إMAC‚¾‚ء‚½‚ç‚و‚蔄‚ê‚ب‚‚ب‚邾‚낤پB
Bootcamp‚إWindowsRT‚ئ‚©پB
‚ـ‚ PASemi‚ج•”‘à‚ح2010”Nڈ‰“ھ‚ة‚حSwift‚جک_—گفŒv‚ًڈI‚¦‚ؤ‚¢‚½‚»‚¤‚ب‚ج‚إ
ARMv8‚جŒِٹJ‚ح2011”NڈH‚¾‚ھپAApple‚ھ‚»‚جˆê”N‚®‚ç‚¢‘O‚©‚çƒAƒNƒZƒX‰آ”\‚إ‚ ‚ء‚½‚ئ‚·‚ê‚خ
ک_—گفŒvژ©‘ج‚حPASemi‚جƒ`پ[ƒ€‚¾‚¯‚إ‚±‚جژٹْ‚ةٹش‚ةچ‡‚ي‚¹‚邱‚ئ‚ح‰آ”\‚¾‚낤
‚½‚¾•¨—گفŒv‚âSoCگفŒv‚حA6‚ئ‚ح•ت‚ج•”‘à‚ھ‚â‚ء‚ؤ‚»‚¤‚ب‹C‚ھ‚·‚邯‚ا‚ب‚
ARMv8‚جŒِٹJ‚ح2011”NڈH‚¾‚ھپAApple‚ھ‚»‚جˆê”N‚®‚ç‚¢‘O‚©‚çƒAƒNƒZƒX‰آ”\‚إ‚ ‚ء‚½‚ئ‚·‚ê‚خ
ک_—گفŒvژ©‘ج‚حPASemi‚جƒ`پ[ƒ€‚¾‚¯‚إ‚±‚جژٹْ‚ةٹش‚ةچ‡‚ي‚¹‚邱‚ئ‚ح‰آ”\‚¾‚낤
‚½‚¾•¨—گفŒv‚âSoCگفŒv‚حA6‚ئ‚ح•ت‚ج•”‘à‚ھ‚â‚ء‚ؤ‚»‚¤‚ب‹C‚ھ‚·‚邯‚ا‚ب‚
44 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/11(گ…) 22:37:35.82 ID:hHBUpY6Y
Cortex-A57‚جIP‚ً‚ظ‚ع‚»‚ج‚ـ‚ـژg‚ء‚ؤژü•س‰ٌکH‚ةژè‚ً“ü‚ꂽ‚ئ‚¢‚¤گà
‚آ‚ـ‚è‚ح”ڑ”Mژd—l‚©
ƒIƒٹƒWƒiƒ‹‚جARMv8‚إ‚àX-Gene‚ًچl‚¦‚ê‚خ‚»‚¤–³—‚إ‚à‚ب‚‚ثپH
ژہ‚حA6‚جژ“_‚إ64bit‚ج‰ٌکH‚ھ“‹چع‚³‚ê‚ؤ‚½‚ھ–³Œّ‰»‚³‚ê‚ؤ‚¢‚½‚ئ‚©
64bit‚¾‚ء‚ؤˆبٹO‚جڈî•ٌ‚ ‚ٌ‚ـ‚è‚ب‚¢‚ب‚
49 پFSocket774پF2013/09/12(–ط) 07:36:13.59 ID:VetpaAnz
28nm‚إA57‚¾‚©‚ç
2core‚ة‚µ‚©‚إ‚«‚ب‚©‚ء‚½
2core‚ة‚µ‚©‚إ‚«‚ب‚©‚ء‚½
50 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/12(–ط) 23:30:24.27 ID:qMB+2yt0
A7چى‚ء‚ؤ‚é‚ج‚ء‚ؤ—ل‚جTSMC 20nm‚إ‚µ‚هپB
چ‚‚¢—ک‰v—¦‚ًŒض‚éApple‚¾‚©‚炱‚»‚إ‚«‚é‹ئ‚¾‚بپB
چ‚‚¢—ک‰v—¦‚ًŒض‚éApple‚¾‚©‚炱‚»‚إ‚«‚é‹ئ‚¾‚بپB
ڈî•ٌ‚¢‚ë‚¢‚ë‚ ‚é‚©‚ç‚ب
“üژ肵‚½گl‚ھڈo‚ؤ‚«‚½‚ç”»–¾‚·‚é‚ٌ‚¾‚낤‚¯‚اٹ¦گ،‚ئ‚©ڈ‘‚¢‚ؤ‚éƒTƒCƒg‚à‚ ‚ء‚½‚¼
“üژ肵‚½گl‚ھڈo‚ؤ‚«‚½‚ç”»–¾‚·‚é‚ٌ‚¾‚낤‚¯‚اٹ¦گ،‚ئ‚©ڈ‘‚¢‚ؤ‚éƒTƒCƒg‚à‚ ‚ء‚½‚¼
Samsung 28nm‚ئ‚¢‚¤گà‚ًˆê”شŒ©‚©‚¯‚é
Gate first‚¾‚©‚ç–§“x‚ھچ‚‚ك‚ئ‚©
Gate first‚¾‚©‚ç–§“x‚ھچ‚‚ك‚ئ‚©
Intel‚ح—\’è’ت‚èپA”N––‚©‚ç—ˆ”N‚ة‚©‚¯‚ؤ14nm‚ةˆعچs‚ف‚½‚¢‚إ‚·‚بپB
20nm gate-last‚ضˆعچs’†‚جTSMC‚ح‚ـ‚¾‚ـ‚µ‚ئ‚µ‚ؤ‚àپA
IBM/GF/Samsung‚حپA‚»‚à‚»‚àgate-last‚ضˆعچs‚إ‚«‚é‚ج‚©پA‚إ‚«‚¸‚ة”s‘ق‚©پH
http://www.geocities.jp/andosprocinfo/wadai13/20130914.htm
20nm gate-last‚ضˆعچs’†‚جTSMC‚ح‚ـ‚¾‚ـ‚µ‚ئ‚µ‚ؤ‚àپA
IBM/GF/Samsung‚حپA‚»‚à‚»‚àgate-last‚ضˆعچs‚إ‚«‚é‚ج‚©پA‚إ‚«‚¸‚ة”s‘ق‚©پH
http://www.geocities.jp/andosprocinfo/wadai13/20130914.htm
‚¦پAFD-SOI‚ھ‚ ‚è‚ـ‚·‚©‚çپI
GFH‚پAFD-SOI‚ب‚çMetal Gate‚ج—L—pگ«‚ھ”–‚‚ب‚é‚炵‚¢
GFH‚پAFD-SOI‚ب‚çMetal Gate‚ج—L—pگ«‚ھ”–‚‚ب‚é‚炵‚¢
FD-SOI‚حڈب“d—ح‚¾‚¯‚ا‘¬“x‚حFinFET‚ة—ٍ‚é‚»‚¤‚¾
ƒpƒ\ƒRƒ“—pCPU‚ئ‚©‚حFinFET‚ھژه—¬‚ة‚ب‚é‚ٌ‚¶‚ل‚ب‚¢پH
GLOBALFOUNDRIES‚ھFDSOI‹Zڈp‚ض‚جŒ©‰ًژ¦‚·پAپuٹî”آƒRƒXƒg‚حƒvƒچƒZƒXپEƒRƒXƒg‚إ‘ٹژE‚إ‚«‚éپv
http://techon.nikkeibp.co.jp/article/NEWS/20130621/289434/
ƒpƒ\ƒRƒ“—pCPU‚ئ‚©‚حFinFET‚ھژه—¬‚ة‚ب‚é‚ٌ‚¶‚ل‚ب‚¢پH
GLOBALFOUNDRIES‚ھFDSOI‹Zڈp‚ض‚جŒ©‰ًژ¦‚·پAپuٹî”آƒRƒXƒg‚حƒvƒچƒZƒXپEƒRƒXƒg‚إ‘ٹژE‚إ‚«‚éپv
http://techon.nikkeibp.co.jp/article/NEWS/20130621/289434/
‚ـپA‚ ‚ٌ‚ـ‚è‰اگè‚ة‚ب‚ء‚ؤ‚à‚آ‚ـ‚ç‚ٌ‚©‚çپAIBM‚»‚ج‘¼‚à‚ھ‚ٌ‚خ‚ê
‚»‚à‚»‚àٹ®‘S‹َ–R‚حFinFET‚إ‚à‚إ‚«‚é‚إ‚µ‚ه
S factor = 60mV/dec‚ء‚ؤIntel‚جtrigate‚إ’Bگ¬‚µ‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
S factor = 60mV/dec‚ء‚ؤIntel‚جtrigate‚إ’Bگ¬‚µ‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
>>53
2گ¢‘مچ·‚حگ¦‚¢‚بپB
2گ¢‘مچ·‚حگ¦‚¢‚بپB
>>57
”‘z‚ھ”½‘خ‚¾پB
trigate‚إ‚ب‚ڈ]—ˆ‚جƒQپ[ƒgچ\‘¢‚إ’Bگ¬‚إ‚«‚邱‚ئ‚ھپA—ا‚¢‚ٌ‚¾پB
ƒ†پ[ƒU‚©‚ç‚حپA’Bگ¬‚·‚ê‚خچ\‘¢‚ح‚ا‚؟‚ç‚إ‚à‚و‚¢‚ھ(‚à‚؟‚ë‚ٌ’l’i‚ھ“¯‚¶‚ب‚ç)
”‘z‚ھ”½‘خ‚¾پB
trigate‚إ‚ب‚ڈ]—ˆ‚جƒQپ[ƒgچ\‘¢‚إ’Bگ¬‚إ‚«‚邱‚ئ‚ھپA—ا‚¢‚ٌ‚¾پB
ƒ†پ[ƒU‚©‚ç‚حپA’Bگ¬‚·‚ê‚خچ\‘¢‚ح‚ا‚؟‚ç‚إ‚à‚و‚¢‚ھ(‚à‚؟‚ë‚ٌ’l’i‚ھ“¯‚¶‚ب‚ç)
SOI‚ة‚µ‚ؤ‚éژ“_‚إƒoƒ‹ƒNƒEƒFƒn‚حژg‚¦‚ب‚¢‚ي‚¯‚إپA’l’i‚ح“¯‚¶‚¶‚ل‚ب‚¢‚ٌ‚¾‚ھ...
‚µ‚©‚àڈب“d—حŒü‚¯‚جƒoƒbƒNƒoƒCƒAƒXگ§Œن‚ب‚ٌ‚©‚à“‚‚ب‚é‚©‚çƒAƒŒ‚¾‚µ
‚µ‚©‚àڈب“d—حŒü‚¯‚جƒoƒbƒNƒoƒCƒAƒXگ§Œن‚ب‚ٌ‚©‚à“‚‚ب‚é‚©‚çƒAƒŒ‚¾‚µ
trigate‚جچH’ِ•ھ‚ھSOI‚ئƒoƒ‹ƒNƒEƒFƒn‚¾‚ئ–â‘è‚ب‚¢‚ٌ‚¾‚ë?
‚إ‚»‚¤‚¢‚¤‚±‚ئ‚ً‚¢‚ء‚ؤ‚¢‚é‚ٌ‚¶‚ل‚ب‚¢‚ج?
ƒoƒbƒNƒoƒCƒAƒXگ§Œن‚ح—ک‚«‚â‚·‚‚ب‚é•ھ臒l‚ً‚¢‚¶‚ê‚é‚©‚ç•à—¯‚ـ‚è‚ًڈم‚°‚邱‚ئ‚à‚إ‚«‚邵پA
ƒRƒXƒg‚ة‘خ‚µ‚ؤ‚حچH•vژں‘و‚¶‚ل‚ب‚¢‚جپB
‚إ‚»‚¤‚¢‚¤‚±‚ئ‚ً‚¢‚ء‚ؤ‚¢‚é‚ٌ‚¶‚ل‚ب‚¢‚ج?
ƒoƒbƒNƒoƒCƒAƒXگ§Œن‚ح—ک‚«‚â‚·‚‚ب‚é•ھ臒l‚ً‚¢‚¶‚ê‚é‚©‚ç•à—¯‚ـ‚è‚ًڈم‚°‚邱‚ئ‚à‚إ‚«‚邵پA
ƒRƒXƒg‚ة‘خ‚µ‚ؤ‚حچH•vژں‘و‚¶‚ل‚ب‚¢‚جپB
Samsung‚حƒnƒbƒ^ƒٹ‚©‚ـ‚·‚¾‚¯‚إپA‹Zڈp‚ح‚³‚ء‚د‚è‚©پH
Can Samsung Deliver As Promised?
http://www.semiwiki.com/forum/content/2162-can-samsung-deliver-promised.html
Samsung 28nm Still Does Not Yield?
http://www.semiwiki.com/forum/content/2180-samsung-28nm-still-does-not-yield.html
Can Samsung Deliver As Promised?
http://www.semiwiki.com/forum/content/2162-can-samsung-deliver-promised.html
Samsung 28nm Still Does Not Yield?
http://www.semiwiki.com/forum/content/2180-samsung-28nm-still-does-not-yield.html
63 پFSocket774پF2013/09/17(‰خ) 07:45:46.38 ID:6vEEP9Lz
http://www.mobile.pro/index.php/benchmark-battle-exynos-5-octa-vs-snapdragon-800-vs-tegra-4/
‚ح‚ء‚½‚è‚إ‚·
‚ح‚ء‚½‚è‚إ‚·
http://www.anandtech.com/show/7335/the-iphone-5s-review/
‚±‚جƒeƒXƒg‚ًŒ©‚éŒہ‚èپAA7‚ح‚©‚ب‚èگ«”\‚ھچ‚‚»‚¤‚¾‚ث
ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\‚إ‚à2GHz’ِ“x‚جCore2ƒNƒ‰ƒX‚ة‚ح“’B‚µ‚ؤ‚¢‚»‚¤‚إپADesktop class‚ئŒ¾‚ء‚ؤ‚¢‚é‚ج‚àèُ‚¯‚é
1.3GHz‚ئ‚¢‚¤‚ج‚ھ–{“–‚ب‚çپAIPC‚ح”ٌڈي‚ةچ‚‚»‚¤
گفŒvƒ`پ[ƒ€‚ح”ٌڈي‚ة‚¢‚¢ژdژ–‚ً‚µ‚ؤ‚¢‚é‚ئŒ¾‚¦‚é
Intel‚حMerrifield‚إ‚±‚ê‚ة‘خچR‚·‚é‚ج‚حŒµ‚µ‚»‚¤ (’¼گع‹£چ‡‚·‚é‚©‚ح”÷–‚¾‚ھ)
‚à‚؟‚ë‚ٌ‘¼‚جARM SoCƒxƒ“ƒ_‚àŒµ‚µ‚¢‚ھ
‚±‚جƒeƒXƒg‚ًŒ©‚éŒہ‚èپAA7‚ح‚©‚ب‚èگ«”\‚ھچ‚‚»‚¤‚¾‚ث
ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\‚إ‚à2GHz’ِ“x‚جCore2ƒNƒ‰ƒX‚ة‚ح“’B‚µ‚ؤ‚¢‚»‚¤‚إپADesktop class‚ئŒ¾‚ء‚ؤ‚¢‚é‚ج‚àèُ‚¯‚é
1.3GHz‚ئ‚¢‚¤‚ج‚ھ–{“–‚ب‚çپAIPC‚ح”ٌڈي‚ةچ‚‚»‚¤
گفŒvƒ`پ[ƒ€‚ح”ٌڈي‚ة‚¢‚¢ژdژ–‚ً‚µ‚ؤ‚¢‚é‚ئŒ¾‚¦‚é
Intel‚حMerrifield‚إ‚±‚ê‚ة‘خچR‚·‚é‚ج‚حŒµ‚µ‚»‚¤ (’¼گع‹£چ‡‚·‚é‚©‚ح”÷–‚¾‚ھ)
‚à‚؟‚ë‚ٌ‘¼‚جARM SoCƒxƒ“ƒ_‚àŒµ‚µ‚¢‚ھ
‹à‚©‚©‚ء‚ؤ‚é‚ٌ‚¾‚낤‚ب‚
”نٹr‘خڈغ‚جandroid‚ء‚ؤƒlƒCƒeƒBƒu‚ب‚ٌپH
‚â‚ح‚èIntel‚جڈم‚ًچs‚¯‚é‚ج‚حDEC‚¾‚¯‚ب‚ج‚©
iphone5s‚جCPU‚ة‚حپAAES‚ئSHA-1‚ًڈˆ—‚·‚éگê—p‚ج–½—ك‚ھ’ا‰ء‚³‚ê‚ؤ‚é‚ج‚©
5s‚ج‚ةپA‚ئ‚¢‚¤‚©ARMv8‚ة’ا‰ء‚³‚ꂽ
32bitARM–½—كƒZƒbƒg‚ھ•³‚¾‚ء‚½‚¾‚¯‚ج—l‚بw
64bitARMپA–½—كƒZƒbƒg‚ھˆê‹C‚ةMIPS•—‚ة‚ب‚ء‚½‚µƒŒƒWƒXƒ^‚à‘‚¦‚½‚µww
64bitARMپA–½—كƒZƒbƒg‚ھˆê‹C‚ةMIPS•—‚ة‚ب‚ء‚½‚µƒŒƒWƒXƒ^‚à‘‚¦‚½‚µww
–Y‚ê‚ؤ‚½‚¯‚اپAVPU‚à‘O’ٌ‚ةڈo—ˆ‚é—l‚ة‚ب‚ء‚½‚µ
‚â‚ء‚دŒفٹ·پAŒفٹ·‚إچs‚‚ئپA‚ا‚¤‚µ‚ؤ‚àŒأ‚¢–½—كƒZƒbƒgژه‘ج‚جƒRپ[ƒh‚ة‚ب‚ء‚؟‚ل‚¤‚©‚ç‚بپc
‚â‚ء‚دŒفٹ·پAŒفٹ·‚إچs‚‚ئپA‚ا‚¤‚µ‚ؤ‚àŒأ‚¢–½—كƒZƒbƒgژه‘ج‚جƒRپ[ƒh‚ة‚ب‚ء‚؟‚ل‚¤‚©‚ç‚بپc
MIPS‚ء‚ؤ’x‰„ƒXƒچƒbƒg‚ئ‚©LO,HIƒŒƒWƒXƒ^‚ھ“ء’¥“I‚¾‚ھ
ARMv8‚ة‚»‚ٌ‚ب‚à‚ج‚ح‚ب‚¢‚¼
ARMv8‚ة‚»‚ٌ‚ب‚à‚ج‚ح‚ب‚¢‚¼
‚©‚ي‚è‚ةڈًŒڈƒRپ[ƒh‚ھ‚ ‚邨
>>72
ٹm‚©‚ة
‚إ‚àپAARM‚جچإ‘ه‚ج“ء’¥‚¾‚ء‚½ڈًŒڈژہچs‚ھمY—يƒTƒbƒpƒٹ‚ئگ®—‚³‚ꂽ
‚±‚ꂾ‚¯‚إ‚ب‚ٌ‚©‚à‚¤پA•پ’تپ`‚ء‚ؤٹ´‚¶‚ة‚ب‚ء‚؟‚ل‚ء‚½‚ج‚إ‚·‚وwwww
pcپAspپAlr‚àگê—p‚ة‚ب‚ء‚½‚©‚çپA‚±‚ꂾ‚¯‚إ‚àڈ]—ˆ‚ة”ن‚ׂؤ”ؤ—p‚ةژg‚¦‚郌ƒWƒXƒ^‚ھ3–{‘‚¦‚ؤ‚é
ٹm‚©‚ة
‚إ‚àپAARM‚جچإ‘ه‚ج“ء’¥‚¾‚ء‚½ڈًŒڈژہچs‚ھمY—يƒTƒbƒpƒٹ‚ئگ®—‚³‚ꂽ
‚±‚ꂾ‚¯‚إ‚ب‚ٌ‚©‚à‚¤پA•پ’تپ`‚ء‚ؤٹ´‚¶‚ة‚ب‚ء‚؟‚ل‚ء‚½‚ج‚إ‚·‚وwwww
pcپAspپAlr‚àگê—p‚ة‚ب‚ء‚½‚©‚çپA‚±‚ꂾ‚¯‚إ‚àڈ]—ˆ‚ة”ن‚ׂؤ”ؤ—p‚ةژg‚¦‚郌ƒWƒXƒ^‚ھ3–{‘‚¦‚ؤ‚é
64bit‚¾‚©‚ç‚ء‚ؤپAThumb‚ب‚µ‚إگي‚¦‚é‚ج‚©‚ث
Intel‚حپAAMD‚ھx64چى‚éچغ‚ةپA‚à‚¤‚·‚±‚µ‚«‚ê‚¢‚ة–½—كƒZƒbƒgچى‚è’¼‚µ‚ؤ‚‚ê‚ؤ‚½‚çپEپEپE‚ء‚ؤژv‚ء‚ؤ‚邾‚낤‚ب
>>76
‚»‚جژv‚¢‚ھAVX‚ةŒ»‚ê‚ؤ‚é‚ٌ‚¾‚وپB
1ƒoƒCƒg–½—ك16Œآ‚à‚آ‚ش‚µ‚ؤŒفٹ·گ«–³‚‚µ‚½ڈم‚ةƒvƒٹƒtƒBƒbƒNƒX‘‚₵‚½‚¾‚¯‚ئ‚©ƒAƒz‚©‚ئپB
‚»‚جژv‚¢‚ھAVX‚ةŒ»‚ê‚ؤ‚é‚ٌ‚¾‚وپB
1ƒoƒCƒg–½—ك16Œآ‚à‚آ‚ش‚µ‚ؤŒفٹ·گ«–³‚‚µ‚½ڈم‚ةƒvƒٹƒtƒBƒbƒNƒX‘‚₵‚½‚¾‚¯‚ئ‚©ƒAƒz‚©‚ئپB
چإ‹كپAƒXƒ}ƒzŒü‚¯‚جCPU‚ًCore 2•ہ‚ئ‚¢‚¤‚â‚آ‚ً‚و‚‚ف‚©‚¯‚é‚ٌ‚¾‚ھپA
‚³‚·‚ھ‚ةCore 2ƒŒƒxƒ‹‚جگ«”\‚ح‚ب‚¢‚¾‚낤‚وپB
‚³‚·‚ھ‚ةCore 2ƒŒƒxƒ‹‚جگ«”\‚ح‚ب‚¢‚¾‚낤‚وپB
Intel‚جٹg’£ƒZƒ“ƒX‚ج–³‚³‚à‘ٹ“–‚¾‚ئژv‚¤پB
>>76
‚ـ‚ intel‚ح’ׂ»‚¤‚ئ‚µ‚ؤ‚½‚ي‚¯‚¾‚µ‚ث‚¦
‚ـ‚ intel‚ح’ׂ»‚¤‚ئ‚µ‚ؤ‚½‚ي‚¯‚¾‚µ‚ث‚¦
>>78
4core‚إcore2duo ULV •ہ‚ة‚ح‚ب‚ء‚ؤ—ˆ‚ؤ‚邼پB
4core‚إcore2duo ULV •ہ‚ة‚ح‚ب‚ء‚ؤ—ˆ‚ؤ‚邼پB
A64‚ح‚à‚¤‚ ‚ـ‚èRISC‚ء‚غ‚‚ب‚¢‚ب‚ں
‚±‚ê‚àژ‘م‚ج—¬‚ê‚ب‚ج‚©‚ثپH
‚؟‚ه‚ء‚ئRISC‚ء‚غ‚¢CISC‚ء‚ؤٹ´‚¶‚¾‚ث
‚ ‚ئپAARM‚â‚çx86‚ھƒZƒLƒ…ƒٹƒeƒBپ[‹@”\‚ً‹‰»‚µ‚ؤ‚«‚½‚ھپA
“ْ–{‚جƒ}ƒCƒRƒ“ƒپپ[ƒJپ[(‚¨‚à‚ةƒ‹ƒlƒTƒX‚ئ‚©)‚ھƒZƒLƒ…ƒٹƒeƒBپ[‹@”\•ْ’u‚µ‚ؤ‚é‚ج‚إپA
‚±‚ٌ‚²‰ئ“d‚âژ©“®ژش‚ھƒlƒbƒgƒڈپ[ƒN‚ة‚آ‚ب‚ھ‚éژ‘م‚ة‘خ‰‚إ‚«‚ب‚‚ؤ
’E—ژ‚·‚é‚©‚à‚µ‚ê‚ب‚¢‚ث
‚±‚ê‚àژ‘م‚ج—¬‚ê‚ب‚ج‚©‚ثپH
‚؟‚ه‚ء‚ئRISC‚ء‚غ‚¢CISC‚ء‚ؤٹ´‚¶‚¾‚ث
‚ ‚ئپAARM‚â‚çx86‚ھƒZƒLƒ…ƒٹƒeƒBپ[‹@”\‚ً‹‰»‚µ‚ؤ‚«‚½‚ھپA
“ْ–{‚جƒ}ƒCƒRƒ“ƒپپ[ƒJپ[(‚¨‚à‚ةƒ‹ƒlƒTƒX‚ئ‚©)‚ھƒZƒLƒ…ƒٹƒeƒBپ[‹@”\•ْ’u‚µ‚ؤ‚é‚ج‚إپA
‚±‚ٌ‚²‰ئ“d‚âژ©“®ژش‚ھƒlƒbƒgƒڈپ[ƒN‚ة‚آ‚ب‚ھ‚éژ‘م‚ة‘خ‰‚إ‚«‚ب‚‚ؤ
’E—ژ‚·‚é‚©‚à‚µ‚ê‚ب‚¢‚ث
‚»‚¤‚¢‚¤”نٹr‚ھˆس–،‚ب‚¢‚ٌ‚¾‚و‚ب‚ پB4ƒRƒA‚إ2ƒRƒA•ہ‚ئ‚©پB
‚±‚±‚ح‰¼‚ة‚àƒAپ[ƒLƒeƒNƒ`ƒƒ‚جƒXƒŒ‚ب‚ٌ‚¾‚ھپACore 2‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ئ
Œ»چفچإگV‚جƒXƒ}ƒz‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًƒuƒچƒbƒNگ}‚ً‚د‚ءŒ©‚½‚¾‚¯‚إپA
‚¨‚و‚»‚جگ«”\‚ھ‘z‘œ‚آ‚©‚ٌ‚â‚آ‚ھƒxƒ“ƒ`‚ف‚ؤ‚à‚ا‚¤“ا‚ف‚ئ‚ء‚ؤ‚¢‚¢‚©‚ي‚©‚ç‚ٌ‚¾‚낤‚وپB
PenMپ¨Core 2‚ ‚½‚è‚©‚ç‚جIPCŒüڈم‚ح‚©‚ب‚è“‚¢‚ٌ‚¾‚ھپAƒRƒAگ”ˆل‚¢”نٹr‚إ“¯“™‚ئ‚©‚¢‚¤‚جƒ}ƒW‚â‚ك‚ؤ‚ظ‚µ‚¢پB
ƒXƒ}ƒz‚ح‚ـ‚¾‚»‚جˆو‚ة‚ح’B‚µ‚ؤ‚¢‚ب‚¢‚وپB
‚±‚±‚ح‰¼‚ة‚àƒAپ[ƒLƒeƒNƒ`ƒƒ‚جƒXƒŒ‚ب‚ٌ‚¾‚ھپACore 2‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ئ
Œ»چفچإگV‚جƒXƒ}ƒz‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًƒuƒچƒbƒNگ}‚ً‚د‚ءŒ©‚½‚¾‚¯‚إپA
‚¨‚و‚»‚جگ«”\‚ھ‘z‘œ‚آ‚©‚ٌ‚â‚آ‚ھƒxƒ“ƒ`‚ف‚ؤ‚à‚ا‚¤“ا‚ف‚ئ‚ء‚ؤ‚¢‚¢‚©‚ي‚©‚ç‚ٌ‚¾‚낤‚وپB
PenMپ¨Core 2‚ ‚½‚è‚©‚ç‚جIPCŒüڈم‚ح‚©‚ب‚è“‚¢‚ٌ‚¾‚ھپAƒRƒAگ”ˆل‚¢”نٹr‚إ“¯“™‚ئ‚©‚¢‚¤‚جƒ}ƒW‚â‚ك‚ؤ‚ظ‚µ‚¢پB
ƒXƒ}ƒz‚ح‚ـ‚¾‚»‚جˆو‚ة‚ح’B‚µ‚ؤ‚¢‚ب‚¢‚وپB
ARM‚ج64bit‚ح32bitŒإ’è’·‚إƒMƒ~ƒbƒNٹO‚µ‚ؤڈƒRISC‰ٌ‹A‚إ‚µ‚ه‚¤‚ھپB
ƒ‚ƒoƒCƒ‹•ھ–ى‚ج’†‚إ‚ج”نٹr‚ب‚ٌ‚¾‚©‚ç–â‘è‚ب‚¢‚¾‚ë
MMX Pentium‚ئ”ن‚ׂب‚¢‚¾‚¯ƒ}ƒV‚¾‚ئژv‚ي‚ب‚¢‚ئ
MMX Pentium‚ئ”ن‚ׂب‚¢‚¾‚¯ƒ}ƒV‚¾‚ئژv‚ي‚ب‚¢‚ئ
‚ب‚ٌ‚إMMX Pentium‚جکb‚ھ‚إ‚ؤ‚‚é‚ٌ‚¾‚©پB
‚ش‚ء‚؟‚ل‚¯پAچ،‚جƒXƒ}ƒz‚جCPU‚جگ«”\‚ھCore 2•ہ‚ئ‚¢‚¦‚éٹ´ٹo‚ج“ف‚¢گl’B‚جٹîڈ€‚إ‚¢‚ء‚½‚çپA
“d—حٹا—‚âƒNƒچƒbƒN‚ھڈم‚ھ‚ء‚½•ھ‚ج‚¼‚¯‚خپA
ڈƒگˆ‚ةƒRƒA‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚جکb‚¾‚¯‚·‚éڈêچ‡پA
PenM‚àCore 2‚àSandy Bridge‚àHaswell‚àپA‚ف‚ٌ‚ب“¯‚¶ˆت‚جIPC‚¾‚وپB
‚»‚ٌ‚‚ç‚¢‚¢‚¢‰ءŒ¸‚بکbپB
‚ش‚ء‚؟‚ل‚¯پAچ،‚جƒXƒ}ƒz‚جCPU‚جگ«”\‚ھCore 2•ہ‚ئ‚¢‚¦‚éٹ´ٹo‚ج“ف‚¢گl’B‚جٹîڈ€‚إ‚¢‚ء‚½‚çپA
“d—حٹا—‚âƒNƒچƒbƒN‚ھڈم‚ھ‚ء‚½•ھ‚ج‚¼‚¯‚خپA
ڈƒگˆ‚ةƒRƒA‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚جکb‚¾‚¯‚·‚éڈêچ‡پA
PenM‚àCore 2‚àSandy Bridge‚àHaswell‚àپA‚ف‚ٌ‚ب“¯‚¶ˆت‚جIPC‚¾‚وپB
‚»‚ٌ‚‚ç‚¢‚¢‚¢‰ءŒ¸‚بکbپB
Pentium M‚©‚çHaswell‚ـ‚إ10”N‚©‚©‚ء‚ؤ‚é‚ٌ‚¾‚¯‚ا‚ثپB
‚±‚ê‚ھ“¯‚¶‚ةŒ©‚¦‚郌ƒxƒ‹‚جکA’†‚جٹ´ٹo‚إ‚حچإگV‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ح‚ئ‚ؤ‚à‚ي‚©‚ç‚ب‚¢‚إ‚هپB
‚±‚ê‚ھ“¯‚¶‚ةŒ©‚¦‚郌ƒxƒ‹‚جکA’†‚جٹ´ٹo‚إ‚حچإگV‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ح‚ئ‚ؤ‚à‚ي‚©‚ç‚ب‚¢‚إ‚هپB
‚¢‚â‚¢‚âSandyˆبچ~‚ ‚ٌ‚ـ‚è•د‚ي‚ç‚ٌ‚ج‚حژ–ژہ‚ئ‚µ‚ؤ‚àPentiumM‚ئƒnƒX‘¾”ن‚ׂ½‚ç‘S‘Rˆل‚¤‚ء‚µ‚هپB
Apple‚ح‘ٹ“–‚ةژè‚ً“ü‚ê‚ؤƒJƒXƒ^ƒ€‚µ‚½‚و‚¤‚إ—]‚ـ‚‚ء‚½ƒgƒ‰ƒ“ƒWƒXƒ^‚إIntel64—p‚جƒnپ[ƒhƒEƒFƒAƒfƒRپ[ƒ_‚ًچى‚èچ‚ٌ‚¾‚ئ‚©
ƒzƒ“ƒg‚©‚و
ƒzƒ“ƒg‚©‚و
گ®گ”گ«”\‚ج‚±‚ئ‚©FP‚جƒXƒ‹پ[ƒvƒbƒg‚©‚إکb‚ح‚©‚ب‚è•د‚ي‚ء‚ؤ‚‚éپi‚ ‚é‚¢‚حƒAƒ“ƒRƒA‚©
>>88
‚¢‚â‚¢‚âPenM 4core‚إCore i3-4010Y•ہ‚ة‚ح‚ب‚é‚ٌ‚¶‚ل‚ب‚¢پH
‚ئ‚¢‚¤”نٹr‚ً‚µ‚ؤ‚àژd•û‚ھ‚ب‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ>>86‚حŒ¾‚¢‚½‚¢‚ج‚إ‚ح
‚¢‚â‚¢‚âPenM 4core‚إCore i3-4010Y•ہ‚ة‚ح‚ب‚é‚ٌ‚¶‚ل‚ب‚¢پH
‚ئ‚¢‚¤”نٹr‚ً‚µ‚ؤ‚àژd•û‚ھ‚ب‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ>>86‚حŒ¾‚¢‚½‚¢‚ج‚إ‚ح
>>91
‚¾‚©‚çIPC‚ھPenM‚ئHas ‚¶‚ل‘S‘Rˆل‚¤‚ٌ‚¾‚ء‚ؤپB
ƒLƒƒƒbƒVƒ…‚ھ‘‚¦‚ؤƒپƒ‚ƒٹ‚ھ‘¬‚‚ب‚ء‚½•ھ‚à‚ ‚邯‚اSSE‚ئ‚©ژg‚ي‚ب‚‚ؤ‚à“¯ˆêƒRƒAگ”“¯ˆêƒNƒچƒbƒN‚إ1.5”{‚©‚ç‰؛ژ肵‚½‚ç2”{ˆل‚¤پB
‚؟‚ب‚ف‚ة2C4T‚ئi3‚ئ1C1T‚جگ«”\‚ج4”{’l‚ً”نٹr‚µ‚ؤ‚àˆس–،‚ح‚ب‚¢‚¼پBPenMƒRƒA‚ً4‚آ•ہ‚ׂؤ‚àگ«”\‚ح2”{‚؟‚ه‚ء‚ئ‚ة‚µ‚©‚ب‚ç‚ب‚¢‚©‚çپB
‚¾‚©‚çIPC‚ھPenM‚ئHas ‚¶‚ل‘S‘Rˆل‚¤‚ٌ‚¾‚ء‚ؤپB
ƒLƒƒƒbƒVƒ…‚ھ‘‚¦‚ؤƒپƒ‚ƒٹ‚ھ‘¬‚‚ب‚ء‚½•ھ‚à‚ ‚邯‚اSSE‚ئ‚©ژg‚ي‚ب‚‚ؤ‚à“¯ˆêƒRƒAگ”“¯ˆêƒNƒچƒbƒN‚إ1.5”{‚©‚ç‰؛ژ肵‚½‚ç2”{ˆل‚¤پB
‚؟‚ب‚ف‚ة2C4T‚ئi3‚ئ1C1T‚جگ«”\‚ج4”{’l‚ً”نٹr‚µ‚ؤ‚àˆس–،‚ح‚ب‚¢‚¼پBPenMƒRƒA‚ً4‚آ•ہ‚ׂؤ‚àگ«”\‚ح2”{‚؟‚ه‚ء‚ئ‚ة‚µ‚©‚ب‚ç‚ب‚¢‚©‚çپB
fpu‚جƒXƒ‹پ[ƒvƒbƒg‚ة‚àIPC‚ء‚ؤ”½‰f‚³‚ê‚é‚جپH
ƒCƒ“ƒeƒ‹—p‚جƒfƒRپ[ƒ_ژdچ‚ق‚‚ç‚¢‚ب‚çپAARM–{—ˆ‚ج‰½‚©‚ةژg‚¤‚¾‚낤‚ئژv‚¤‚ھ‚ب‚
iPhone‚âiPad‚±‚»‚ھچ،‚جApple‚ج–½چj‚ب‚ٌ‚¾‚µ
iPhone‚âiPad‚±‚»‚ھچ،‚جApple‚ج–½چj‚ب‚ٌ‚¾‚µ
ٹب’P‚بƒfƒRپ[ƒ_‚ب‚ç‘g‚فچ‚ك‚邾‚낤‚¯‚اژg‚¢“¹‚ھ‘S‚‚ب‚¢‚و‚بپB
>>64‚جGeekbench‚جٹeچ€–ع‚إIvy, Haswell‚جi3(turboŒّ‰ت‚ًڈœ‚‚½‚ك)‚ئ”ن‚ׂؤ‚ف‚é‚ئ
A7‚جƒRƒA‚حIvy‚ً”²‚¢‚ؤHaswell‚ة•C“G‚·‚é’ِ“x‚جگ®گ”IPC‚ھ‚ ‚è‚»‚¤
‚à‚؟‚ë‚ٌ‚±‚ꂾ‚¯‚إŒ‹ک_‚ًڈo‚·‚ج‚ح‘پŒv‚¾‚ھ
Intel‚حSandyˆبچ~’â‘ط‹C–،‚¾‚ء‚½‚ھپA‚»‚ë‚»‚ë–{‹Cڈo‚³‚ب‚¢‚ئ‚¢‚©‚ٌ
A7‚جƒRƒA‚حIvy‚ً”²‚¢‚ؤHaswell‚ة•C“G‚·‚é’ِ“x‚جگ®گ”IPC‚ھ‚ ‚è‚»‚¤
‚à‚؟‚ë‚ٌ‚±‚ꂾ‚¯‚إŒ‹ک_‚ًڈo‚·‚ج‚ح‘پŒv‚¾‚ھ
Intel‚حSandyˆبچ~’â‘ط‹C–،‚¾‚ء‚½‚ھپA‚»‚ë‚»‚ë–{‹Cڈo‚³‚ب‚¢‚ئ‚¢‚©‚ٌ
‚ پAanand‚جA7‚ح1.3GHz‚إturbo‚ح–³‚¢پA‚ئ‚¢‚¤‚ج‚ًگM‚¶‚ê‚خپA‚جکb‚ث
ƒ^ƒuƒŒƒbƒg—p‚ئ‚µ‚ؤ—D‚ê‚ؤ‚é‚ج‚حژ–ژہ‚ب‚ٌ‚¾‚낤‚¯‚اپAAppleˆبٹO‚ھژg‚¤‚ي‚¯‚إ‚à‚ب‚¢‚µ
iPhone/iPad‚ج‚و‚¤‚ة”نٹr“Iچ‚’l‚إ‚à‘ه—ت‚ة”„‚ê‚éƒfƒoƒCƒX‚¾‚©‚çژg‚¦‚é‚à‚ج‚¾‚낤‚µ
Intel‚ھ‘›‚®‚و‚¤‚ب‚à‚ج‚إ‚à‚ب‚¢‚ٌ‚¶‚ل‚ثپH
iPhone/iPad‚ج‚و‚¤‚ة”نٹr“Iچ‚’l‚إ‚à‘ه—ت‚ة”„‚ê‚éƒfƒoƒCƒX‚¾‚©‚çژg‚¦‚é‚à‚ج‚¾‚낤‚µ
Intel‚ھ‘›‚®‚و‚¤‚ب‚à‚ج‚إ‚à‚ب‚¢‚ٌ‚¶‚ل‚ثپH
AppleˆبٹO‚ح‚±‚ج‚و‚¤‚بچ‚گ«”\’لڈء”ï“d—ح‚بƒRƒA‚ًٹJ”‚إ‚«‚ب‚¢پA‚ئٹyٹد‚إ‚«‚é‚ب‚ç‚¢‚¢‚¯‚ا‚ث
‚±‚جƒŒƒxƒ‹‚جƒRƒA‚ھAndroidژsڈê‚إ’¼گع‹£چ‡‚·‚é‹@ژي‚ة“‹چع‚³‚ê‚é‰آ”\گ«‚ًچl‚¦‚é‚ئ
Silvermont‚إ‚ح‘خچR‚إ‚«‚ب‚¢
A7‚حƒ^ƒuƒŒƒbƒg—p‚¶‚ل‚ب‚‚ؤƒXƒ}ƒz—p‚¾‚و
‚±‚جƒŒƒxƒ‹‚جƒRƒA‚ھAndroidژsڈê‚إ’¼گع‹£چ‡‚·‚é‹@ژي‚ة“‹چع‚³‚ê‚é‰آ”\گ«‚ًچl‚¦‚é‚ئ
Silvermont‚إ‚ح‘خچR‚إ‚«‚ب‚¢
A7‚حƒ^ƒuƒŒƒbƒg—p‚¶‚ل‚ب‚‚ؤƒXƒ}ƒz—p‚¾‚و
‚½‚ش‚ٌ4-way‚إگ®گ”ƒpƒCƒv3–{پAƒچپ[ƒhƒXƒgƒAƒpƒCƒv2–{ژ‚ء‚½ƒRƒA‚¾‚ب
>>99
‚»‚¤‚¢‚â‚»‚¤‚¾‚—
A7Xپi‚ـ‚¾ڈo‚ؤ‚ب‚¢‚¯‚اپj‚ة‚ب‚é‚ٌ‚¾‚낤‚ثƒ^ƒuƒŒƒbƒg—p‚ح
چ،‚ـ‚إ‚ا‚¨‚肾‚ئ‚·‚é‚ئپA‚±‚ê‚ھ‚³‚ç‚ةGPU‚ئƒپƒ‚ƒٹژü‚è‚ھ‹‰»‚³‚ꂽ‚à‚ج‚ة‚ب‚é‚ٌ‚¾‚낤‚ب
‚»‚¤‚¢‚â‚»‚¤‚¾‚—
A7Xپi‚ـ‚¾ڈo‚ؤ‚ب‚¢‚¯‚اپj‚ة‚ب‚é‚ٌ‚¾‚낤‚ثƒ^ƒuƒŒƒbƒg—p‚ح
چ،‚ـ‚إ‚ا‚¨‚肾‚ئ‚·‚é‚ئپA‚±‚ê‚ھ‚³‚ç‚ةGPU‚ئƒپƒ‚ƒٹژü‚è‚ھ‹‰»‚³‚ꂽ‚à‚ج‚ة‚ب‚é‚ٌ‚¾‚낤‚ب
>>96
پ„A7‚جƒRƒA‚حIvy‚ً”²‚¢‚ؤHaswell‚ة•C“G‚·‚é’ِ“x‚جگ®گ”IPC‚ھ‚ ‚è‚»‚¤
‚±‚ٌ‚بŒ‹ک_‚ھڈo‚é‚ ‚½‚è‚©‚çپA‚ق‚µ‚ëGeekbench‚©گ„ک_‰ك’ِ‚ج‚ظ‚¤‚ً‹‚‹^‚¤‚ׂ«‚¾‚ئژv‚¤‚ٌ‚¾‚ھ
پ„A7‚جƒRƒA‚حIvy‚ً”²‚¢‚ؤHaswell‚ة•C“G‚·‚é’ِ“x‚جگ®گ”IPC‚ھ‚ ‚è‚»‚¤
‚±‚ٌ‚بŒ‹ک_‚ھڈo‚é‚ ‚½‚è‚©‚çپA‚ق‚µ‚ëGeekbench‚©گ„ک_‰ك’ِ‚ج‚ظ‚¤‚ً‹‚‹^‚¤‚ׂ«‚¾‚ئژv‚¤‚ٌ‚¾‚ھ
>>102
‘هŒ´‚ف‚½‚¢‚بکA’†‚ھ‘½‚¢‚و‚ث
‘هŒ´‚ف‚½‚¢‚بکA’†‚ھ‘½‚¢‚و‚ث
گ„ک_‚حپA’P‚ةGeekbench‚جMB/s‚ئ‚©MPixels/s‚ئ‚©‚ج’l‚ةژü”gگ””ن‚ًٹ|‚¯‚ؤ”ن‚ׂ½‚¾‚¯‚¾‚و
‚ـ‚ Geekbench‚حژ©•ھ‚à‚ ‚ـ‚èگM—p‚µ‚ؤ‚ب‚¢‚¯‚ا
ƒXƒRƒA‚ح‚±‚±‚ةچع‚ء‚ؤ‚é‚©‚çپAژ©•ھ‚إ”ن‚ׂؤ‚ف‚é‚ئ‚¢‚¢‚و
http://www.anandtech.com/show/7335/the-iphone-5s-review/4
‚ـ‚ Geekbench‚حژ©•ھ‚à‚ ‚ـ‚èگM—p‚µ‚ؤ‚ب‚¢‚¯‚ا
ƒXƒRƒA‚ح‚±‚±‚ةچع‚ء‚ؤ‚é‚©‚çپAژ©•ھ‚إ”ن‚ׂؤ‚ف‚é‚ئ‚¢‚¢‚و
http://www.anandtech.com/show/7335/the-iphone-5s-review/4
گê—p–½—ك‚ًژg‚ء‚ؤ‚¢‚é‚ئژv‚ي‚ê‚éAES‚ئSHA-1‚ج’l‚ح“–‘Rچl—¶‚ة“ü‚ê‚ؤ‚ب‚¢‚و
Haswell‚ة•C“G‚·‚éIPC‚جƒRƒA‚ًPA Semi‚ً”ƒژû‚µ‚ؤ5”N‹‚µ‚©—§‚ء‚ؤ‚¢‚ب‚¢‰ïژذ‚ھپA
‚½‚ء‚½–تگد102sqmm‚جSoC‚إƒzƒCƒzƒC‚ئ‚¾‚¹‚é‚و‚¤‚ب‚à‚ج‚ب‚çپA
Intel‚ب‚ٌ‚ؤ‰ïژذ‚ئ‚ء‚‚ة‚آ‚ش‚ê‚ؤ‚¢‚é‚وپB
‚ب‚ٌ‚©AppleگMژز‚إ‚à•´‚ê‚ؤ‚¢‚é‚ج‚©?ڈ‚µ‚ح—‹ü‚إچl‚¦‚ؤگ”ژڑ‹^‚¦‚وw
‚½‚ء‚½–تگد102sqmm‚جSoC‚إƒzƒCƒzƒC‚ئ‚¾‚¹‚é‚و‚¤‚ب‚à‚ج‚ب‚çپA
Intel‚ب‚ٌ‚ؤ‰ïژذ‚ئ‚ء‚‚ة‚آ‚ش‚ê‚ؤ‚¢‚é‚وپB
‚ب‚ٌ‚©AppleگMژز‚إ‚à•´‚ê‚ؤ‚¢‚é‚ج‚©?ڈ‚µ‚ح—‹ü‚إچl‚¦‚ؤگ”ژڑ‹^‚¦‚وw
PپAPA Semi‚حDEC‚جŒŒ‚ً‚ذ‚¢‚ؤ‚ؤ‹Zڈp—ح‚ ‚邵پI
(ژذˆُ‚ة‚ح“¦‚°‚ç‚ꂽ‚¯‚ا)
(ژذˆُ‚ة‚ح“¦‚°‚ç‚ꂽ‚¯‚ا)
>>103
‘هŒ´‚ج•û‚ھƒfپ[ƒ^‚ئ‹Zڈp“Iچھ‹’‚ً•¹‹L‚·‚é•ھ‚¾‚¯ƒŒƒxƒ‹‚ھچ‚‚¢‚µ‚ـ‚ئ‚à‚¾‚وپB•زڈW‚ھچZگ³‚إ‚«‚ب‚¢‹Lژ–‚ًڈ‘‚‚©‚çٹشˆل‚¢‚ح‘½‚¢‚ھپB
‘هŒ´‚ج•û‚ھƒfپ[ƒ^‚ئ‹Zڈp“Iچھ‹’‚ً•¹‹L‚·‚é•ھ‚¾‚¯ƒŒƒxƒ‹‚ھچ‚‚¢‚µ‚ـ‚ئ‚à‚¾‚وپB•زڈW‚ھچZگ³‚إ‚«‚ب‚¢‹Lژ–‚ًڈ‘‚‚©‚çٹشˆل‚¢‚ح‘½‚¢‚ھپB
>>104
ژ©•ھ‚àچ،Geekbench‚ً”نٹr‚µ‚ؤ‚ف‚½‚¯‚اپAٹm‚©‚ةHaswell/Ivy•ہ‚جIPC‚ة‚ب‚é‚ب‚±‚êw
ژ©•ھ‚àچ،Geekbench‚ً”نٹr‚µ‚ؤ‚ف‚½‚¯‚اپAٹm‚©‚ةHaswell/Ivy•ہ‚جIPC‚ة‚ب‚é‚ب‚±‚êw
>>110
‘هŒ´ژپ‚ج‹Lژ–‚ً‚ـ‚ئ‚à‚ة“ا‚ك‚ؤ‚¢‚éگl‚ئ‚¢‚¤گl‚حپA’m‚ء‚½‚©‚ج‰R‚آ‚«پB‚¾‚ء‚ؤ“ا‚ٌ‚إ—‰ً‚إ‚«‚é‚ي‚¯‚ب‚¢‚à‚ٌ‚ثw
‘هŒ´ژپ‚ج‹Lژ–‚ً‚ا‚ê‚‚ç‚¢گM—p‚µ‚ؤ‚¢‚é‚©پA‘ٹژè‚جƒŒƒxƒ‹‚ھ‚ي‚©‚ء‚ؤ‚µ‚ـ‚¤‚ج‚إپA—‰ً“x”»’èچق—؟‚ئ‚µ‚ؤ‚ح•ض—کw
‘هŒ´ژپ‚ج‹Lژ–‚ً‚ـ‚ئ‚à‚ة“ا‚ك‚ؤ‚¢‚éگl‚ئ‚¢‚¤گl‚حپA’m‚ء‚½‚©‚ج‰R‚آ‚«پB‚¾‚ء‚ؤ“ا‚ٌ‚إ—‰ً‚إ‚«‚é‚ي‚¯‚ب‚¢‚à‚ٌ‚ثw
‘هŒ´ژپ‚ج‹Lژ–‚ً‚ا‚ê‚‚ç‚¢گM—p‚µ‚ؤ‚¢‚é‚©پA‘ٹژè‚جƒŒƒxƒ‹‚ھ‚ي‚©‚ء‚ؤ‚µ‚ـ‚¤‚ج‚إپA—‰ً“x”»’èچق—؟‚ئ‚µ‚ؤ‚ح•ض—کw
Geekbench 3‚جx86ƒvƒ‰ƒbƒgƒtƒHپ[ƒ€‚جƒfپ[ƒ^‚ح‚ظ‚ئ‚ٌ‚ا32bitٹآ‹«‚ج‚µ‚©‚ب‚¢‚©‚ç
‚»‚ج•ھٹ„‚èˆّ‚¢‚ؤچl‚¦‚é‚ׂ«‚¾‚ئ‚حژv‚¤‚¯‚اپA‚»‚ê‚ة‚µ‚ؤ‚àˆظڈي‚ةچ‚‚¢IPC‚¾‚ئژv‚¤‚إ‚µ‚ه
iOS‚¾‚ئJB‚µ‚ؤƒIپ[ƒvƒ“ƒ\پ[ƒX‚جƒcپ[ƒ‹‚ً‰ٌ‚·‚®‚ç‚¢‚µ‚©ٹmژہ‚ةگ«”\‘ھ‚é•û–@‚ھژv‚¢‚آ‚©‚ب‚¢‚ب
‚»‚ج•ھٹ„‚èˆّ‚¢‚ؤچl‚¦‚é‚ׂ«‚¾‚ئ‚حژv‚¤‚¯‚اپA‚»‚ê‚ة‚µ‚ؤ‚àˆظڈي‚ةچ‚‚¢IPC‚¾‚ئژv‚¤‚إ‚µ‚ه
iOS‚¾‚ئJB‚µ‚ؤƒIپ[ƒvƒ“ƒ\پ[ƒX‚جƒcپ[ƒ‹‚ً‰ٌ‚·‚®‚ç‚¢‚µ‚©ٹmژہ‚ةگ«”\‘ھ‚é•û–@‚ھژv‚¢‚آ‚©‚ب‚¢‚ب
‚ـپAGeekBenchگM—p‚إ‚«‚ب‚¢‚ء‚ؤ‚ج‚حگج‚©‚猾‚ي‚ê‚ؤ‚éکb‚¾‚©‚ç’u‚¢‚ئ‚¢‚ؤ
‚»‚ê‚ب‚è‚ة‚ح‘¬‚¢‚ٌ‚¾‚ئژv‚¤‚و
•ت‚جƒxƒ“ƒ`
ttp://www.anandtech.com/show/7335/the-iphone-5s-review/5
‚»‚ê‚ب‚è‚ة‚ح‘¬‚¢‚ٌ‚¾‚ئژv‚¤‚و
•ت‚جƒxƒ“ƒ`
ttp://www.anandtech.com/show/7335/the-iphone-5s-review/5
SPEC CPU2000‚ھژg‚¦‚½‚ç‚¢‚¢‚ٌ‚¾‚ھ
‚½‚ش‚ٌApple‚حƒXƒRƒAڈo‚³‚ب‚¢‚¾‚낤‚µ‚ب‚
Œ»ژہ“I‚بƒڈپ[ƒNƒچپ[ƒh‚ةˆê”ش‹ك‚»‚¤‚ب‚ج‚حJavaScriptŒn‚جƒxƒ“ƒ`‚¾‚ھپA‚¤پ[‚ٌپcپc
>>104
‚¢‚â–½—كگ”‚ھ‚ي‚©‚ç‚ب‚¢‚ٌ‚¶‚لIPC‚حڈo‚¹‚ب‚¢‚إ‚µ‚ه
‚½‚ش‚ٌApple‚حƒXƒRƒAڈo‚³‚ب‚¢‚¾‚낤‚µ‚ب‚
Œ»ژہ“I‚بƒڈپ[ƒNƒچپ[ƒh‚ةˆê”ش‹ك‚»‚¤‚ب‚ج‚حJavaScriptŒn‚جƒxƒ“ƒ`‚¾‚ھپA‚¤پ[‚ٌپcپc
>>104
‚¢‚â–½—كگ”‚ھ‚ي‚©‚ç‚ب‚¢‚ٌ‚¶‚لIPC‚حڈo‚¹‚ب‚¢‚إ‚µ‚ه
Javascript‚حJSƒGƒ“ƒWƒ“‚جگ«”\‚ج‰e‹؟‚ھ‘½•ھ‚ة“ü‚é‚©‚çپAˆل‚¤ƒuƒ‰ƒEƒU‚âƒAپ[ƒLƒeƒNƒ`ƒƒٹش‚إCPUژ©‘ج‚جگ«”\‚ً”ن‚ׂé‚ة‚ح‚ ‚ـ‚èŒü‚¢‚ؤ‚ب‚¢
Œ»‚ةAnand‚ج‹Lژ–‚إ‚àپAٹù‚ةIntel‚ھIE11 on BayTrail‚حSunSpider‚جƒXƒRƒA‚ھ‚à‚ء‚ئ—ا‚¢‚ئ”½ک_‚µ‚ؤ‚¢‚é‚و‚¤‚¾‚—
‚ـ‚ Geekbench‚ب‚ٌ‚©‚و‚è‚حƒٹƒAƒ‹ƒڈپ[ƒ‹ƒh‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚ً”½‰f‚µ‚ؤ‚¢‚éگ”’l‚¾‚ئ‚حژv‚¤‚¯‚ا
IPC‚ئŒ¾‚ء‚½‚ج‚حگ³ٹm‚ب’è‹`‚¶‚ل‚ب‚‚ؤƒNƒچƒbƒNژü”gگ”‚ ‚½‚è‚جگ«”\پA‚ئ‚¢‚¤ˆس–،‚ث
Œ»‚ةAnand‚ج‹Lژ–‚إ‚àپAٹù‚ةIntel‚ھIE11 on BayTrail‚حSunSpider‚جƒXƒRƒA‚ھ‚à‚ء‚ئ—ا‚¢‚ئ”½ک_‚µ‚ؤ‚¢‚é‚و‚¤‚¾‚—
‚ـ‚ Geekbench‚ب‚ٌ‚©‚و‚è‚حƒٹƒAƒ‹ƒڈپ[ƒ‹ƒh‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚ً”½‰f‚µ‚ؤ‚¢‚éگ”’l‚¾‚ئ‚حژv‚¤‚¯‚ا
IPC‚ئŒ¾‚ء‚½‚ج‚حگ³ٹm‚ب’è‹`‚¶‚ل‚ب‚‚ؤƒNƒچƒbƒNژü”gگ”‚ ‚½‚è‚جگ«”\پA‚ئ‚¢‚¤ˆس–،‚ث
IPC‚ح’è‹`‚ا‚¨‚è‚جˆس–،‚إژg‚ي‚ب‚¢‚±‚ئ‚à‚و‚‚ ‚é‚ٌ‚¾‚و‚ثپB‚±‚جگl‚ح‚©‚ب‚è‚ـ‚ئ‚à‚¾‚بپ[پB
‚و‚‚ ‚é‚ پcپc‚ثپ[‚و
‚¢‚âپAک_•¶‚ئ‚©‚إ‚à•پ’ت‚ة‚ ‚é‚وپBIPC‚ء‚ؤ‚ج‚حƒNƒچƒbƒN‚ ‚½‚è‚جگ«”\‚ً‹cک_‚µ‚½‚¢‚ئ‚«‚ة‚و‚ژg‚¤ژw•W‚ب‚ج‚إپA
‹³‰بڈ‘‚ا‚¨‚è‚ة–½—كگ”‚جƒJƒEƒ“ƒg‚ئ‚©‚â‚ء‚ؤ‚à‚µ‚هپ[‚ھ‚ب‚¢‚ئ‚«‚حژg‚ي‚ٌپB
‹³‰بڈ‘‚ا‚¨‚è‚ة–½—كگ”‚جƒJƒEƒ“ƒg‚ئ‚©‚â‚ء‚ؤ‚à‚µ‚هپ[‚ھ‚ب‚¢‚ئ‚«‚حژg‚ي‚ٌپB
‚»‚جک_•¶’ٌژ¦‚µ‚ؤ‚فپH
‚ب‚ٌ‚ع‚إ‚à‚ ‚邾‚낤‚و
‚إ‚à‰½Œج‚©—لژ¦‚حڈo—ˆ‚ب‚¢‚ٌ‚إ‚·‚ثپA‚ي‚©‚è‚ـ‚·
>>82
ژ©“®ژش‚ح•s—ا—¦‚ھژQ“üڈل•ا‚¶‚ل‚ب‚©‚ء‚½‚©‚بپB
ژ©“®ژش‰ïژذ‚ح‚ ‚肦‚ب‚¢’ل•s—ا—¦‚ً—v‹پ‚µ‚ؤ—ˆ‚é‚ھ
‚»‚ê‚إ‚à‘أ‹¦‚µ‚ؤ‚¢‚ؤپA–{“–‚حƒ[ƒچ‚ً—v‹پ‚µ‚½‚¢‚ئ‚©‚ب‚ٌ‚ئ‚©پB
“ْ–{ƒپپ[ƒJپ[‚ة‚و‚é‹ں‹‹‚ح‘±‚‚ھ
ARM‚خ‚©‚è‚ة‚ب‚é‚ئ‚¢‚¤ƒpƒ^پ[ƒ“‚à‚ ‚é‚©‚à
ژ©“®ژش‚ح•s—ا—¦‚ھژQ“üڈل•ا‚¶‚ل‚ب‚©‚ء‚½‚©‚بپB
ژ©“®ژش‰ïژذ‚ح‚ ‚肦‚ب‚¢’ل•s—ا—¦‚ً—v‹پ‚µ‚ؤ—ˆ‚é‚ھ
‚»‚ê‚إ‚à‘أ‹¦‚µ‚ؤ‚¢‚ؤپA–{“–‚حƒ[ƒچ‚ً—v‹پ‚µ‚½‚¢‚ئ‚©‚ب‚ٌ‚ئ‚©پB
“ْ–{ƒپپ[ƒJپ[‚ة‚و‚é‹ں‹‹‚ح‘±‚‚ھ
ARM‚خ‚©‚è‚ة‚ب‚é‚ئ‚¢‚¤ƒpƒ^پ[ƒ“‚à‚ ‚é‚©‚à
ƒGƒ“ƒWƒ“گ§Œن‚ج‘g‚فچ‚ف‚ةARM‰»‚جˆ³—ح‚حژم‚¢‚¾‚낤پB
‚©‚ئ‚¢‚ء‚ؤچ،‚ـ‚إ‚جƒAپ[ƒLƒeƒNƒ`ƒƒ‚ھˆہ‘ׂ©‚ئ‚¢‚¤‚ئ‚»‚¤‚إ‚à‚ب‚¢‚¯‚اپB
‚©‚ئ‚¢‚ء‚ؤچ،‚ـ‚إ‚جƒAپ[ƒLƒeƒNƒ`ƒƒ‚ھˆہ‘ׂ©‚ئ‚¢‚¤‚ئ‚»‚¤‚إ‚à‚ب‚¢‚¯‚اپB
>>76
ƒvƒŒƒtƒBƒbƒNƒXƒoƒCƒg‚ج’ا‰ء‚ئ‚¢‚¤ڈ¬‚³‚ب•دچX‚¾‚ء‚½‚©‚ç•پ‹y‚µ‚½
PC‚إ‚ح7”N‹ك‚32bitCPU‚ئ‚µ‚ؤ‚µ‚©ژg‚ي‚ê‚ب‚©‚ء‚½‚µ‚ب
ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ً‘SچXگV‚µ‚½IA-64‚ح‘هژ¸”s‚µ‚½‚ي‚¯‚¾‚µ
ƒvƒŒƒtƒBƒbƒNƒXƒoƒCƒg‚ج’ا‰ء‚ئ‚¢‚¤ڈ¬‚³‚ب•دچX‚¾‚ء‚½‚©‚ç•پ‹y‚µ‚½
PC‚إ‚ح7”N‹ك‚32bitCPU‚ئ‚µ‚ؤ‚µ‚©ژg‚ي‚ê‚ب‚©‚ء‚½‚µ‚ب
ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ً‘SچXگV‚µ‚½IA-64‚ح‘هژ¸”s‚µ‚½‚ي‚¯‚¾‚µ
ٹù‘¶‚ج–½—كƒZƒbƒg‚ئ‹¤‘¶‚إ‚«‚ب‚¢ƒvƒٹƒtƒBƒbƒNƒX‚إ‚½‚¾‚إ‚³‚¦•،ژG‚بx86 –½—كƒfƒRپ[ƒ_‚ج‚¢‚ء‚»‚¤‚ج•،ژG‰»‚ًڈµ‚‚ب‚çپA‚¢‚ء‚»گV‚½‚ةƒVƒ“ƒvƒ‹‚ب–½—كƒfƒRپ[ƒ_‚ھژہŒ»‚إ‚«‚é–½—كƒZƒbƒg‚ًچى‚ء‚½•û‚ھ‚¢‚¢پB
‚»‚ج•û‚ھگ«”\–ت‚إ‚à‘S‘ج‚ج‰ٌکH‹K–ح‚ج–ت‚إ‚à—ا‚¢Œ‹‰ت‚ھ“¾‚ç‚ê‚éپB
‚½‚ئ‚¦‚خARM‚ج64bit–½—ك‚ح‚»‚¤‚¢‚¤چى‚è‚ة‚ب‚ء‚ؤ‚¢‚éپB
AMD64‚ح64bit‘¦’l‚ھ—ک—p‚إ‚«‚¸8bit‚ـ‚½‚ح32bit‚©‚ç•„چ†ٹg’£‚µ‚ؤژg‚¤ژd—l‚ئ‚·‚邱‚ئ‚إپAƒfƒRپ[ƒ_‚ج•،ژG‰»‚ً‰آ”\‚بŒہ‚è—}‚¦‚½‚ج‚ح•]‰؟‚إ‚«‚é‚ھپAIA32‚جƒAƒhƒŒƒVƒ“ƒOƒ‚پ[ƒh‚ًگ®—‚·‚é—Bˆê‚ج‹@‰ï‚ًˆي‚µ‚½‚ج‚ھ‚ح‚½‚µ‚ؤ—ا‚©‚ء‚½‚ج‚©‘ه‚¢‚ة‹^–â‚ھژc‚éپB
‚»‚ج•û‚ھگ«”\–ت‚إ‚à‘S‘ج‚ج‰ٌکH‹K–ح‚ج–ت‚إ‚à—ا‚¢Œ‹‰ت‚ھ“¾‚ç‚ê‚éپB
‚½‚ئ‚¦‚خARM‚ج64bit–½—ك‚ح‚»‚¤‚¢‚¤چى‚è‚ة‚ب‚ء‚ؤ‚¢‚éپB
AMD64‚ح64bit‘¦’l‚ھ—ک—p‚إ‚«‚¸8bit‚ـ‚½‚ح32bit‚©‚ç•„چ†ٹg’£‚µ‚ؤژg‚¤ژd—l‚ئ‚·‚邱‚ئ‚إپAƒfƒRپ[ƒ_‚ج•،ژG‰»‚ً‰آ”\‚بŒہ‚è—}‚¦‚½‚ج‚ح•]‰؟‚إ‚«‚é‚ھپAIA32‚جƒAƒhƒŒƒVƒ“ƒOƒ‚پ[ƒh‚ًگ®—‚·‚é—Bˆê‚ج‹@‰ï‚ًˆي‚µ‚½‚ج‚ھ‚ح‚½‚µ‚ؤ—ا‚©‚ء‚½‚ج‚©‘ه‚¢‚ة‹^–â‚ھژc‚éپB
IntelŒv‰و‚جڈ‰ٹْYamhille‚ح‚ا‚¤‚¾‚ء‚½‚ج‚¾‚낤‚©پB
ARM‚ج64bit‚حƒfƒRپ[ƒh‚حٹ®‘S‚ة•د‚ي‚ء‚ؤ‚邯‚ا
ƒAƒhƒŒƒbƒVƒ“ƒOƒ‚پ[ƒh‚ب‚ا‚ح‚ ‚ـ‚è•د‚ي‚ء‚ؤ‚ب‚¢‚و
‘S‚•ت‚ج–½—ك‚ة‚ب‚ء‚½‚ي‚¯‚إ‚ح‚ب‚پA
ƒŒƒWƒXƒ^‚ھ‘‚¦‚ؤپAڈًŒڈژہچs‚ھ‚ب‚‚ب‚èپA–½—كƒtƒHپ[ƒ}ƒbƒg‚ھ•د‚ي‚ء‚½ٹ´‚¶
ƒAƒhƒŒƒbƒVƒ“ƒOƒ‚پ[ƒh‚ب‚ا‚ح‚ ‚ـ‚è•د‚ي‚ء‚ؤ‚ب‚¢‚و
‘S‚•ت‚ج–½—ك‚ة‚ب‚ء‚½‚ي‚¯‚إ‚ح‚ب‚پA
ƒŒƒWƒXƒ^‚ھ‘‚¦‚ؤپAڈًŒڈژہچs‚ھ‚ب‚‚ب‚èپA–½—كƒtƒHپ[ƒ}ƒbƒg‚ھ•د‚ي‚ء‚½ٹ´‚¶
32bitŒإ’è’·–½—ك‚ح‚ ‚ـ‚èچإ“K‰ً‚إ‚ح‚ب‚¢پB
x86‚âThumb-2‚إ‚ح32bitŒإ’è’·‚و‚èƒoƒCƒiƒٹƒTƒCƒY‚ھ3ٹ„Œ¸‚é‚ئ‚¢‚¤ŒoŒ±‘¥
ƒoƒCƒiƒٹ‚ھڈ¬‚³‚¢‚ج‚ح–½—كƒLƒƒƒbƒVƒ…‚ھ‘½‚¢پE‘رˆو‚ھ‘¾‚¢‚ج‚ئ“™‰؟‚إ‚ ‚é‚©‚çŒّ‰ت‚ح‘ه‚«‚¢
‚±‚±‚ح‚ذ‚ئ‚آƒŒƒWƒXƒ^5bitپ~3+9=24bitŒإ’è’·‚إ‚ا‚¤‚¾‚낤
ƒoƒCƒiƒٹ‚ھڈ¬‚³‚¢‚ج‚ح–½—كƒLƒƒƒbƒVƒ…‚ھ‘½‚¢پE‘رˆو‚ھ‘¾‚¢‚ج‚ئ“™‰؟‚إ‚ ‚é‚©‚çŒّ‰ت‚ح‘ه‚«‚¢
‚±‚±‚ح‚ذ‚ئ‚آƒŒƒWƒXƒ^5bitپ~3+9=24bitŒإ’è’·‚إ‚ا‚¤‚¾‚낤
24bit‚¶‚لƒAƒhƒŒƒX‚ھ‘«‚è‚ب‚¢‚¾‚ë68K‚ج‚±‚낶‚ل‚ب‚¢‚ٌ‚¾‚µ
–½—ك’·‚ئƒŒƒWƒXƒ^’·پEƒAƒhƒŒƒX’·‚حٹضŒW‚ح‚ب‚¢پB32/64bitƒŒƒWƒXƒ^پE32/64bitƒAƒhƒŒƒbƒVƒ“ƒOپE24bitŒإ’è’·–½—ك‚جƒAپ[ƒLƒeƒNƒ`ƒƒ‚حگ¬—§‚·‚éپB
‚¢‚ë‚ٌ‚بƒپپ[ƒJپ[‚جƒvƒچ‚ھ‚â‚ء‚½Œ‹ک_‚ھŒّ—¦ڈdژ‹‚ب‚ç16/32bit‰آ•د’·پAگ«”\ڈdژ‹‚ب‚ç32bitŒإ’è’·‚ب‚ٌ‚¾پBچ،‚ب‚ç32/64bit‰آ•د’·‚إCISC“I‚بچ‚‹@”\–½—ك‚ة‚µ‚ؤ–½—كگ”‚ًŒ¸‚ç‚·‚ج‚ھˆê”شگ«”\‚ًڈم‚°‚â‚·‚¢‚¾‚낤پB
>>123
ژ©“®ژش‰ïژذ‚حپAƒ‹ƒlƒTƒX‚ج‚±‚جچHڈê‚ج‚±‚جƒvƒچƒZƒX‚ً”F’肵‚ؤ‚»‚جƒvƒچƒZƒX‚إچى‚ç‚ꂽگ»•i‚ً”ƒ‚¤‚ئ‚©‚â‚ء‚ؤ‚é
‚ئ‚±‚ë‚ھپA‚R‚P‚P‚ج‚ئ‚«‚ة‹}篂ׂآ‚جƒvƒچƒZƒX‚إچى‚ء‚ؤ‚à‚ئ‚‚ة–â‘è‚ح‹N‚±‚ء‚ؤ‚ب‚¢
ژ©“®ژش‰ïژذ‚حپAƒ‹ƒlƒTƒX‚ج‚±‚جچHڈê‚ج‚±‚جƒvƒچƒZƒX‚ً”F’肵‚ؤ‚»‚جƒvƒچƒZƒX‚إچى‚ç‚ꂽگ»•i‚ً”ƒ‚¤‚ئ‚©‚â‚ء‚ؤ‚é
‚ئ‚±‚ë‚ھپA‚R‚P‚P‚ج‚ئ‚«‚ة‹}篂ׂآ‚جƒvƒچƒZƒX‚إچى‚ء‚ؤ‚à‚ئ‚‚ة–â‘è‚ح‹N‚±‚ء‚ؤ‚ب‚¢
>>125
‚½‚ئ‚¦x64–½—ك‚ھ‘S–ت“I‚ة•دچX‚³‚ê‚ؤ‚àپA
ٹù‘¶‚جx86–½—ك‚ھ‚؟‚ل‚ٌ‚ئ“®‚¢‚ؤپA
x64‚جOSڈم‚إx64ƒAƒvƒٹ‚ئx86ƒAƒvƒٹ‚ھ“¯ژژہچs‚إ‚«‚é‚و‚¤‚ة‚µ‚ئ‚¯‚خ
Itanium‚ف‚½‚¢‚ة‚ح‚ب‚炸‚ة‚؟‚ل‚ٌ‚ئ•پ‹y‚µ‚½‚ئژv‚¤‚و
‚½‚ئ‚¦x64–½—ك‚ھ‘S–ت“I‚ة•دچX‚³‚ê‚ؤ‚àپA
ٹù‘¶‚جx86–½—ك‚ھ‚؟‚ل‚ٌ‚ئ“®‚¢‚ؤپA
x64‚جOSڈم‚إx64ƒAƒvƒٹ‚ئx86ƒAƒvƒٹ‚ھ“¯ژژہچs‚إ‚«‚é‚و‚¤‚ة‚µ‚ئ‚¯‚خ
Itanium‚ف‚½‚¢‚ة‚ح‚ب‚炸‚ة‚؟‚ل‚ٌ‚ئ•پ‹y‚µ‚½‚ئژv‚¤‚و
ARM‚ھ—¬چs‚èڈo‚µ‚ؤRISC‚ھچؤ‚ر‘ن“ھ‚©‚ئژv‚ي‚ꂽ‚ھپA
CISC‚ج–½—كŒّ—¦‚ج—ا‚³‚ھŒ©’¼‚³‚ê‚邱‚ئ‚ً’cژq‚³‚ٌ‚ھژw“E‚µ‚ؤ‚¢‚½‚بپB
‚³‚·‚ھ‚¾پB
CISC‚ج–½—كŒّ—¦‚ج—ا‚³‚ھŒ©’¼‚³‚ê‚邱‚ئ‚ً’cژq‚³‚ٌ‚ھژw“E‚µ‚ؤ‚¢‚½‚بپB
‚³‚·‚ھ‚¾پB
’cژq‚ح‚ب‚؛چ،“ْ‚جCISC‚جŒّ—¦‚ھ‚¢‚¢‚ج‚©—‰ً‚µ‚ؤ‚¢‚ب‚¢‚¯‚ا‚ث
‚½‚邳‚ٌ‚ً–Y‚ê‚ب‚¢‚إ‚ ‚°‚ؤپI
‚½‚邳‚ٌ‚جپu’n‚ة•ڑ‚µ‚½ڈGچثپv‚ح‚¨‚à‚µ‚ë‚©‚ء‚½‚بپB
ƒtƒٹپ[ƒ‰ƒ“ƒ`‚ھڈI‚ي‚èƒ}ƒ‹ƒ`ƒRƒA‚ھژ‚ؤڑ’‚³‚ê‚ؤ‚à‚ب‚¨پA
‰e‚إƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚جIPCŒüڈم‚ةگSŒŒ‚ً’چ‚¢‚¾Intel‚ج‹Zڈpژز‚½‚؟پB
چ،‚جIntel‚ئAMD‚ًŒ©”ن‚ׂé‚ئٹ´ٹSگ[‚¢‚à‚ج‚ھ‚ ‚éپB
‚½‚邳‚ٌپAƒTƒCƒg•آچ½‚µ‚ؤژc”O‚ئژv‚ء‚ؤ‚½‚ç•œ‹A‚µ‚ؤ‚½‚ج‚ث‚—
ƒtƒٹپ[ƒ‰ƒ“ƒ`‚ھڈI‚ي‚èƒ}ƒ‹ƒ`ƒRƒA‚ھژ‚ؤڑ’‚³‚ê‚ؤ‚à‚ب‚¨پA
‰e‚إƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚جIPCŒüڈم‚ةگSŒŒ‚ً’چ‚¢‚¾Intel‚ج‹Zڈpژز‚½‚؟پB
چ،‚جIntel‚ئAMD‚ًŒ©”ن‚ׂé‚ئٹ´ٹSگ[‚¢‚à‚ج‚ھ‚ ‚éپB
‚½‚邳‚ٌپAƒTƒCƒg•آچ½‚µ‚ؤژc”O‚ئژv‚ء‚ؤ‚½‚ç•œ‹A‚µ‚ؤ‚½‚ج‚ث‚—
”¼‰آ’ت‚جژG•¶‚و‚è‚ح‚é‚©‚ة‚½‚ك‚ة‚ب‚éک_•¶‚ھƒlƒbƒg‚ة‚¢‚‚ç‚إ‚à“]‚ھ‚ء‚ؤ‚¢‚é‚ج‚ة
‚½‚µ‚©‚ةw
ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhŒyژ‹‚µ‚½AMD‚ھ‚ ‚جژSڈَ‚¾‚©‚ç‚ب‚ں
پuiPhone 5sپvƒxƒ“ƒ`ƒ}پ[ƒNŒ‹‰ت„ںGalaxy S4‚âSnapdragon 800پEBayTrail‚ً—½‰ي
http://rbmen.blogspot.jp/2013/09/iphone-5sgalaxy-s4snapdragon-800baytrail.html
http://rbmen.blogspot.jp/2013/09/iphone-5sgalaxy-s4snapdragon-800baytrail.html
‚ي‚´‚ي‚´ˆê“ْ’x‚ê‚إ“ٌژںƒ\پ[ƒX“\‚ç‚ٌ‚إ‚à
—¬‚ê‚ً–³ژ‹‚µ‚ؤپBƒپƒCƒ“ƒtƒŒپ[ƒ€‚حژ€‚ب‚¸
پ„ƒپƒCƒ“ƒtƒŒپ[ƒ€‚حx86ƒxپ[ƒX‚جLinuxƒTپ[ƒo‚ة”ن‚ׂé‚ئ‰½”{‚àچ‚‚¢‚ھپA
پ„–c‘ه‚بƒ\ƒtƒgƒEƒFƒAژ‘ژY‚ًx86 Linux‚ةˆعگA‚µ‚ؤƒeƒXƒg‚·‚éƒRƒXƒg‚ة”ن‚ׂê‚خپA
پ„ƒnپ[ƒhƒEƒFƒA‚جƒRƒXƒg‚ح”÷پX‚½‚é‚à‚ج‚إپAƒپƒCƒ“ƒtƒŒپ[ƒ€‚ًژg‚¢‘±‚¯‚é‚ظ‚¤‚ھˆہڈم‚ھ‚è‚ة‚ب‚éپB
پ„‚ـ‚½پA’·‚¢—ًژj‚إ”|‚ي‚ꂽچ‚گM—ٹگ«‚حپAx86 LinuxƒTپ[ƒo‚ً‚ـ‚¾‚ـ‚¾ٹٌ‚¹•t‚¯‚ب‚¢پB
پ„‚»‚µ‚ؤپAƒNƒŒƒWƒbƒgƒJپ[ƒh‚جŒˆچد‚ج‚و‚¤‚بڈˆ——ت‚حپA”NپX‘‚¦‚ؤ‚¢‚‚ج‚إپA
پ„‚و‚èچ‚گ«”\‚بگV‹@ژي‚جژù—v‚ھگ¶‚ـ‚ê‚é‚ئ‚¢‚¤‚ي‚¯‚إ‚ ‚éپB
IBM‚ھ”•\‚µ‚½zEC12ƒپƒCƒ“ƒtƒŒپ[ƒ€‚جƒvƒچƒZƒTƒTƒuƒVƒXƒeƒ€
ttp://news.mynavi.jp/column/hotchips25/012/index.html
پ„ƒپƒCƒ“ƒtƒŒپ[ƒ€‚حx86ƒxپ[ƒX‚جLinuxƒTپ[ƒo‚ة”ن‚ׂé‚ئ‰½”{‚àچ‚‚¢‚ھپA
پ„–c‘ه‚بƒ\ƒtƒgƒEƒFƒAژ‘ژY‚ًx86 Linux‚ةˆعگA‚µ‚ؤƒeƒXƒg‚·‚éƒRƒXƒg‚ة”ن‚ׂê‚خپA
پ„ƒnپ[ƒhƒEƒFƒA‚جƒRƒXƒg‚ح”÷پX‚½‚é‚à‚ج‚إپAƒپƒCƒ“ƒtƒŒپ[ƒ€‚ًژg‚¢‘±‚¯‚é‚ظ‚¤‚ھˆہڈم‚ھ‚è‚ة‚ب‚éپB
پ„‚ـ‚½پA’·‚¢—ًژj‚إ”|‚ي‚ꂽچ‚گM—ٹگ«‚حپAx86 LinuxƒTپ[ƒo‚ً‚ـ‚¾‚ـ‚¾ٹٌ‚¹•t‚¯‚ب‚¢پB
پ„‚»‚µ‚ؤپAƒNƒŒƒWƒbƒgƒJپ[ƒh‚جŒˆچد‚ج‚و‚¤‚بڈˆ——ت‚حپA”NپX‘‚¦‚ؤ‚¢‚‚ج‚إپA
پ„‚و‚èچ‚گ«”\‚بگV‹@ژي‚جژù—v‚ھگ¶‚ـ‚ê‚é‚ئ‚¢‚¤‚ي‚¯‚إ‚ ‚éپB
IBM‚ھ”•\‚µ‚½zEC12ƒپƒCƒ“ƒtƒŒپ[ƒ€‚جƒvƒچƒZƒTƒTƒuƒVƒXƒeƒ€
ttp://news.mynavi.jp/column/hotchips25/012/index.html
–c‘ه‚ب(’N‚à“ا‚ك‚ب‚¢‚ج‚إ‘¼‚جƒvƒ‰ƒbƒgƒtƒHپ[ƒ€‚ض‚جˆعگA‚ھ•s‰آ”\‚ة‚ب‚ء‚ؤ‚µ‚ـ‚ء‚½•‰‚ج)ƒ\ƒtƒgƒEƒFƒAژ‘ژY
ژ‘ژY‰؟’l‚ ‚邾‚¯ƒ}ƒV‚¾‚و
VB‚âPerlCGI‚ب‚ٌ‚ؤٹ®‘SژY”p
.NET(C#)‚âJava‚à‹K–ح‘Oڈo’ِ‚إ‚ح–³‚¢‚©‚à‚µ‚ê‚ٌ‚ھڈ«—ˆٹmژہ‚ةژY”p
VB‚âPerlCGI‚ب‚ٌ‚ؤٹ®‘SژY”p
.NET(C#)‚âJava‚à‹K–ح‘Oڈo’ِ‚إ‚ح–³‚¢‚©‚à‚µ‚ê‚ٌ‚ھڈ«—ˆٹmژہ‚ةژY”p
‚¢‚‚çƒپƒCƒ“ƒtƒŒپ[ƒ€”ل”»‚µ‚و‚¤‚ئ‚àپA‹à—Z‚â–h‰q“™‚¶‚لƒپƒCƒ“ƒtƒŒپ[ƒ€‚حژg‚¢‘±‚¯‚ç‚ê‚ؤ‚¢‚‚و
‚»‚ꌾ‚¢ڈo‚µ‚½‚çپAƒpƒ\ƒRƒ“‚¾‚ء‚ؤPCŒفٹ·‚ئ‚©ٹ®‘S‚ة•‰‚جˆâژY‚¾‚ë
‚ک86‚ب‚ٌ‚©ƒCƒ“ƒeƒ‹‚·‚çژج‚ؤ‚½‚ھ‚ء‚ؤ‚½‚¶‚ل‚ب‚¢‚©چإ‹ك‚ ‚«‚ç‚ك‚½‚ء‚غ‚¢‚¯‚ا('A`)
‚ک86‚ب‚ٌ‚©ƒCƒ“ƒeƒ‹‚·‚çژج‚ؤ‚½‚ھ‚ء‚ؤ‚½‚¶‚ل‚ب‚¢‚©چإ‹ك‚ ‚«‚ç‚ك‚½‚ء‚غ‚¢‚¯‚ا('A`)
Œ‹‹اپA‚إ‚©‚¢ƒLƒƒƒbƒVƒ…چإ‹‚ء‚ؤژ–‚ب‚ٌ‚©پc
Haswell8ƒRƒA‚إ‚ـ‚¾ƒgƒ‰ƒ“ƒWƒXƒ^‚¾‚¾—]‚è‚ب‚ç‚»‚¤‚¾‚ھپAŒ»ژہ‚ح‚»‚¤‚إ‚ب‚¢پB
ˆث‘R‚ئ‚µ‚ؤ•K—vچإڈ¬Œہˆبڈم‚جƒgƒ‰ƒ“ƒWƒXƒ^‚ًSRAM‚ةٹ„‚‚ج‚ح”ٌŒّ—¦پB
ˆث‘R‚ئ‚µ‚ؤ•K—vچإڈ¬Œہˆبڈم‚جƒgƒ‰ƒ“ƒWƒXƒ^‚ًSRAM‚ةٹ„‚‚ج‚ح”ٌŒّ—¦پB
>>150
ƒLƒƒƒbƒVƒ…‚ھ‚¢‚‚ç‚إ‚à‚إ‚©‚‚ؤ‚àƒŒƒCƒeƒ“ƒV‚âƒoƒ“ƒh‚ھƒAƒ“ƒoƒ‰ƒ“ƒX‚¾‚ئˆس–،‚ب‚¢
512KB‚¾‚¯‚ا”¼‘¬128bit‚¾‚ء‚½Katmai‚ئ128KB‚¾‚¯‚اƒtƒ‹ƒXƒsپ[ƒh256bit‚ج‰ح“¶128k‚جƒZƒŒƒچƒ“‚¾‚ئŒمژز‚ج•û‚ھ‘پ‚©‚ء‚½‚è
‹گ‘ه‚إچL‘رˆو‚¾‚¯‚اƒپƒCƒ“ƒپƒ‚ƒٹ‚ئ‘هچ·‚ب‚¢ƒŒƒCƒeƒ“ƒV‚جItanium‚ئ‚©
‚¸‚ء‚±‚¯‚½—ل‚ھ‚¢‚‚ç‚إ‚àپc
ƒLƒƒƒbƒVƒ…‚ھ‚¢‚‚ç‚إ‚à‚إ‚©‚‚ؤ‚àƒŒƒCƒeƒ“ƒV‚âƒoƒ“ƒh‚ھƒAƒ“ƒoƒ‰ƒ“ƒX‚¾‚ئˆس–،‚ب‚¢
512KB‚¾‚¯‚ا”¼‘¬128bit‚¾‚ء‚½Katmai‚ئ128KB‚¾‚¯‚اƒtƒ‹ƒXƒsپ[ƒh256bit‚ج‰ح“¶128k‚جƒZƒŒƒچƒ“‚¾‚ئŒمژز‚ج•û‚ھ‘پ‚©‚ء‚½‚è
‹گ‘ه‚إچL‘رˆو‚¾‚¯‚اƒپƒCƒ“ƒپƒ‚ƒٹ‚ئ‘هچ·‚ب‚¢ƒŒƒCƒeƒ“ƒV‚جItanium‚ئ‚©
‚¸‚ء‚±‚¯‚½—ل‚ھ‚¢‚‚ç‚إ‚àپc
>>152
‚»‚±‚إٹK‘w‰»‚ھڈd—v‚ة‚ب‚ء‚ؤ‚‚éپB
—e—ت‚ھڈ‚ب‚¢‚ھƒŒƒCƒeƒ“ƒVپA‘رˆو‚ئ‚à—اچD‚بL1
ƒŒƒCƒeƒ“ƒVپA‘رˆوپA—e—ت‚ئ‚à’ِپX‚جL2
ƒŒƒCƒeƒ“ƒV‚ھ—ٍ‚é‚ھƒپƒCƒ“ƒپƒ‚ƒٹ‚ً‰î‚³‚¸‚ة•،گ”‚جƒRƒA‚âGPUپA‘¼‚جƒvƒچƒZƒbƒT‚ئ‚جٹش‚ج’تگM‚ةژg‚¦‚鋤—LƒLƒƒƒbƒVƒ…‚جLL
‚»‚ê‚ةx86Œہ’è‚إƒfƒRپ[ƒhŒم‚جuOPS‚ًƒLƒƒƒbƒVƒ…‚·‚éƒgƒŒپ[ƒXƒLƒƒƒbƒVƒ…
Œ»ڈَ‚¾‚ئ‚»‚ٌ‚بچ\گ¬‚ھچإ“K‰ً‚ة‚ب‚éپB
‚؟‚ب‚ف‚ة‘S•”SRAM پBeDRAM‚ًژg‚ء‚½ƒLƒƒƒbƒVƒ…‚حژہژ؟“I‚ة
GPU‚جƒچپ[ƒJƒ‹ƒپƒ‚ƒٹ‚ئ‚µ‚ؤ‹@”\‚·‚é‚ب‚ç—L‚肾‚ھپACPU‚ة‚ح•K—v‚ب‚¢پB
‚»‚±‚إٹK‘w‰»‚ھڈd—v‚ة‚ب‚ء‚ؤ‚‚éپB
—e—ت‚ھڈ‚ب‚¢‚ھƒŒƒCƒeƒ“ƒVپA‘رˆو‚ئ‚à—اچD‚بL1
ƒŒƒCƒeƒ“ƒVپA‘رˆوپA—e—ت‚ئ‚à’ِپX‚جL2
ƒŒƒCƒeƒ“ƒV‚ھ—ٍ‚é‚ھƒپƒCƒ“ƒپƒ‚ƒٹ‚ً‰î‚³‚¸‚ة•،گ”‚جƒRƒA‚âGPUپA‘¼‚جƒvƒچƒZƒbƒT‚ئ‚جٹش‚ج’تگM‚ةژg‚¦‚鋤—LƒLƒƒƒbƒVƒ…‚جLL
‚»‚ê‚ةx86Œہ’è‚إƒfƒRپ[ƒhŒم‚جuOPS‚ًƒLƒƒƒbƒVƒ…‚·‚éƒgƒŒپ[ƒXƒLƒƒƒbƒVƒ…
Œ»ڈَ‚¾‚ئ‚»‚ٌ‚بچ\گ¬‚ھچإ“K‰ً‚ة‚ب‚éپB
‚؟‚ب‚ف‚ة‘S•”SRAM پBeDRAM‚ًژg‚ء‚½ƒLƒƒƒbƒVƒ…‚حژہژ؟“I‚ة
GPU‚جƒچپ[ƒJƒ‹ƒپƒ‚ƒٹ‚ئ‚µ‚ؤ‹@”\‚·‚é‚ب‚ç—L‚肾‚ھپACPU‚ة‚ح•K—v‚ب‚¢پB
—p“r‚ة‚و‚邾‚ë
IBM‚حPOWER‚ةCPU—p‚ئ‚µ‚ؤeDRAMژg‚ء‚ؤ‚é‚ٌ‚¾‚©‚ç
IBM‚حPOWER‚ةCPU—p‚ئ‚µ‚ؤeDRAMژg‚ء‚ؤ‚é‚ٌ‚¾‚©‚ç
‚ق‚â‚ف‚₽‚ç‚ةٹK‘w‘‚₳‚¸‚ةپ«‚ف‚½‚¢‚بٹ´‚¶‚إ‚ـ‚ئ‚ك‚ؤ‚‚ê
ƒتOp Cache 1500ƒتOPS SRAM
L1ƒLƒƒƒbƒVƒ… 128KB SRAM
LLC 128MB eDRAM
RAM 64GB STT-MRAM
ƒتOp Cache 1500ƒتOPS SRAM
L1ƒLƒƒƒbƒVƒ… 128KB SRAM
LLC 128MB eDRAM
RAM 64GB STT-MRAM
>>153
‚»‚¤‚حŒ¾‚ء‚ؤ‚à>>145‹Lژ–‚جzEC12‚ف‚½‚¢‚ب‚ج‚ًŒ©‚é‚ئ‚ب
L1‚ھ64K+96KپAL2‚ھ1M+1MپAL3‚ھ48MB(eDRAMپA6ƒRƒA‚إ‹¤—p)
‚³‚ç‚ةƒgƒhƒپ‚جL4‚ج192M(eDRAMپA2Œآ‚إ1ƒZƒbƒg‚ب‚ج‚إ384MB)‚ئ‚©Œ¾‚ي‚ê‚؟‚ل‚¤‚ئw
‚ـ‚ںL4‚ئŒ¾‚ء‚ؤ‚àپA‚±‚êژ©‘ج‚حFB-DIMM‚جƒoƒbƒtƒ@ƒ`ƒbƒvŒ©‚½‚¢‚بˆµ‚¢‚جƒپƒ‚ƒٹƒTƒuƒVƒXƒeƒ€‘¤‚إ‚؟‚ه‚ء‚ئ‰“‚¢‚©‚ç•t‚¢‚ؤ‚é‚ٌ‚¾‚낤‚µ
36ƒRƒA‚إ‹¤—L‚³‚ê‚éژ–‚ًچl‚¦‚ê‚خچT‚¦‚ك‚بگ”ژڑ‚©‚à’m‚ê‚ب‚¢‚ھ
‚»‚¤‚حŒ¾‚ء‚ؤ‚à>>145‹Lژ–‚جzEC12‚ف‚½‚¢‚ب‚ج‚ًŒ©‚é‚ئ‚ب
L1‚ھ64K+96KپAL2‚ھ1M+1MپAL3‚ھ48MB(eDRAMپA6ƒRƒA‚إ‹¤—p)
‚³‚ç‚ةƒgƒhƒپ‚جL4‚ج192M(eDRAMپA2Œآ‚إ1ƒZƒbƒg‚ب‚ج‚إ384MB)‚ئ‚©Œ¾‚ي‚ê‚؟‚ل‚¤‚ئw
‚ـ‚ںL4‚ئŒ¾‚ء‚ؤ‚àپA‚±‚êژ©‘ج‚حFB-DIMM‚جƒoƒbƒtƒ@ƒ`ƒbƒvŒ©‚½‚¢‚بˆµ‚¢‚جƒپƒ‚ƒٹƒTƒuƒVƒXƒeƒ€‘¤‚إ‚؟‚ه‚ء‚ئ‰“‚¢‚©‚ç•t‚¢‚ؤ‚é‚ٌ‚¾‚낤‚µ
36ƒRƒA‚إ‹¤—L‚³‚ê‚éژ–‚ًچl‚¦‚ê‚خچT‚¦‚ك‚بگ”ژڑ‚©‚à’m‚ê‚ب‚¢‚ھ
157 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 00:18:30.55 ID:mj9eCL89
>>136
ARM–{‰ئ‚ھپuƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ƒvƒچƒZƒbƒTپv‚ة‚à‚©‚©‚ي‚炸
‚¢‚ـ‚ا‚«Dhrystone‚âCoreMark‚ف‚½‚¢‚بپuƒ}ƒCƒRƒ“Œü‚¯پv‚جƒxƒ“ƒ`ƒ}پ[ƒN
ژg‚ء‚ؤ‚é‚ ‚½‚è‚إCortex-AƒVƒٹپ[ƒY‚ج‘fگ«‚ح’m‚ê‚ؤ‚½‚وپB
‚½‚¾پAŒ»ڈَچإگV‚جAtom‚ھARM‚و‚è“d—حŒّ—¦‚ة—D‚ê‚ؤ‚é‚ج‚حپA
ژه—vˆِ‚حIntel‚جگ»‘¢ƒvƒچƒZƒX‚ج—Dˆتگ«‚¾‚ëپB
x86پiCISCپj‚ج—Dˆتگ«‚ئ‚¢‚¤‚ة‚حپA“¯‚¶TSMC‚إچى‚ء‚ؤ‚éAMD BobcatŒnƒvƒچƒZƒbƒT‚ھ
“¯ˆêƒvƒچƒZƒX‚جARM‚ً’´‚¦‚ؤ‚©‚ç‚ة‚µ‚و‚¤‚©پB
>>137
‚ ‚ب‚½‚جپu—‰ًپv‚ً‹³‚¦‚ؤ—~‚µ‚¢پB
>>140
‚»‚جˆ×‚ة‚ب‚éک_•¶‚ً”œ‰ق‚ة‚à‚ي‚©‚é‚و‚¤‚ةٹڑ‚فچس‚¢‚ؤ‹Lژ–‚ة‚·‚é‚ج‚ھ
ƒ‰ƒCƒ^پ[‚جژdژ–‚¶‚ل‚ب‚¢‚©‚ئپB
’M‚³‚ٌ‚حŒم“،‚³‚ٌ‚â‘هŒ´‚³‚ٌ‹Lژ–‚ًƒxپ[ƒX‚ة“ن‚ج“ئژ©چlژ@‚ً‚µ‚ؤ‚邾‚¯‚¾‚©‚ç‚بپB
ARM–{‰ئ‚ھپuƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ƒvƒچƒZƒbƒTپv‚ة‚à‚©‚©‚ي‚炸
‚¢‚ـ‚ا‚«Dhrystone‚âCoreMark‚ف‚½‚¢‚بپuƒ}ƒCƒRƒ“Œü‚¯پv‚جƒxƒ“ƒ`ƒ}پ[ƒN
ژg‚ء‚ؤ‚é‚ ‚½‚è‚إCortex-AƒVƒٹپ[ƒY‚ج‘fگ«‚ح’m‚ê‚ؤ‚½‚وپB
‚½‚¾پAŒ»ڈَچإگV‚جAtom‚ھARM‚و‚è“d—حŒّ—¦‚ة—D‚ê‚ؤ‚é‚ج‚حپA
ژه—vˆِ‚حIntel‚جگ»‘¢ƒvƒچƒZƒX‚ج—Dˆتگ«‚¾‚ëپB
x86پiCISCپj‚ج—Dˆتگ«‚ئ‚¢‚¤‚ة‚حپA“¯‚¶TSMC‚إچى‚ء‚ؤ‚éAMD BobcatŒnƒvƒچƒZƒbƒT‚ھ
“¯ˆêƒvƒچƒZƒX‚جARM‚ً’´‚¦‚ؤ‚©‚ç‚ة‚µ‚و‚¤‚©پB
>>137
‚ ‚ب‚½‚جپu—‰ًپv‚ً‹³‚¦‚ؤ—~‚µ‚¢پB
>>140
‚»‚جˆ×‚ة‚ب‚éک_•¶‚ً”œ‰ق‚ة‚à‚ي‚©‚é‚و‚¤‚ةٹڑ‚فچس‚¢‚ؤ‹Lژ–‚ة‚·‚é‚ج‚ھ
ƒ‰ƒCƒ^پ[‚جژdژ–‚¶‚ل‚ب‚¢‚©‚ئپB
’M‚³‚ٌ‚حŒم“،‚³‚ٌ‚â‘هŒ´‚³‚ٌ‹Lژ–‚ًƒxپ[ƒX‚ة“ن‚ج“ئژ©چlژ@‚ً‚µ‚ؤ‚邾‚¯‚¾‚©‚ç‚بپB
158 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 01:36:17.45 ID:mj9eCL89
> ƒtƒٹپ[ƒ‰ƒ“ƒ`‚ھڈI‚ي‚èƒ}ƒ‹ƒ`ƒRƒA‚ھژ‚ؤڑ’‚³‚ê‚ؤ‚à‚ب‚¨پA
‚»‚à‚»‚àژ‚ؤڑ’‚³‚ê‚ؤ‚ب‚¢
> ‰e‚إƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚جIPCŒüڈم‚ةگSŒŒ‚ً’چ‚¢‚¾Intel‚ج‹Zڈpژز‚½‚؟پB
•ت‚ة— ‚إ‚à‚ب‚ٌ‚إ‚à‚ب‚¢
‚»‚à‚»‚àژ‚ؤڑ’‚³‚ê‚ؤ‚ب‚¢
> ‰e‚إƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚جIPCŒüڈم‚ةگSŒŒ‚ً’چ‚¢‚¾Intel‚ج‹Zڈpژز‚½‚؟پB
•ت‚ة— ‚إ‚à‚ب‚ٌ‚إ‚à‚ب‚¢
spec cpu چ‚‚¢‚ث
ژGژڈ‚âƒjƒ…پ[ƒXƒTƒCƒg‚جƒŒƒrƒ…پ[‚إڈo‚ؤ‚±‚ب‚¢‚ي‚¯‚¾
‹ئٹE’c‘جSPECپCƒnپ[ƒhگ«”\•]‰؟ƒ\ƒtƒg‚جگV”إپuSPEC CPU2006پv‚ً”•\
http://itpro.nikkeibp.co.jp/article/USNEWS/20060825/246397/
SPEC CPU2006‚حپADVDƒپƒfƒBƒA‚جŒ`‘ش‚إ”ج”„‚·‚éپB
‰؟ٹi‚حپAگV‹Kچw“üژ‚ھ800ƒhƒ‹پA
SPEC CPU2000‚©‚ç‚جƒAƒbƒvƒOƒŒپ[ƒhژ‚ھ400ƒhƒ‹پB
ˆê•”‹³ˆç‹@ٹض‚ة‚ح200ƒhƒ‹‚إ’ٌ‹ں‚·‚éپB
ژGژڈ‚âƒjƒ…پ[ƒXƒTƒCƒg‚جƒŒƒrƒ…پ[‚إڈo‚ؤ‚±‚ب‚¢‚ي‚¯‚¾
‹ئٹE’c‘جSPECپCƒnپ[ƒhگ«”\•]‰؟ƒ\ƒtƒg‚جگV”إپuSPEC CPU2006پv‚ً”•\
http://itpro.nikkeibp.co.jp/article/USNEWS/20060825/246397/
SPEC CPU2006‚حپADVDƒپƒfƒBƒA‚جŒ`‘ش‚إ”ج”„‚·‚éپB
‰؟ٹi‚حپAگV‹Kچw“üژ‚ھ800ƒhƒ‹پA
SPEC CPU2000‚©‚ç‚جƒAƒbƒvƒOƒŒپ[ƒhژ‚ھ400ƒhƒ‹پB
ˆê•”‹³ˆç‹@ٹض‚ة‚ح200ƒhƒ‹‚إ’ٌ‹ں‚·‚éپB
‚±‚êƒvƒ‰ƒXƒRƒ“ƒpƒCƒ‰‚ھ•K—v‚¾‚©‚ç‚ب
GCC‚إ‚â‚é‚ب‚çƒRƒ“ƒpƒCƒ‰‘م‚ح–³—؟‚¾‚ھIntel C/C++‚ب‚ا‚ج
ڈ¤—pƒRƒ“ƒpƒCƒ‰ژg‚ء‚ؤ‚½‚炳‚ç‚ة‹à‚ھ‚©‚©‚é
GCC‚إ‚â‚é‚ب‚çƒRƒ“ƒpƒCƒ‰‘م‚ح–³—؟‚¾‚ھIntel C/C++‚ب‚ا‚ج
ڈ¤—pƒRƒ“ƒpƒCƒ‰ژg‚ء‚ؤ‚½‚炳‚ç‚ة‹à‚ھ‚©‚©‚é
‚¨’l’i‚ح‚ئ‚à‚©‚‚ئ‚µ‚ؤپAگ^–ت–ع‚ةSPEC CPU‚إ•]‰؟ژو‚낤‚ئ‚·‚é‚ئ
“®‚©‚·‚ج‚à‘ه•د‚¾‚µڈˆ—Œn‚ئ‚»‚جƒIƒvƒVƒ‡ƒ“‚ئ‚©‚àچl‚¦‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚©‚ç
Œہ‚ç‚ꂽژٹش‚إƒxƒ“ƒ`ƒ}پ[ƒN‰ٌ‚µ‚ؤ‚é‚و‚¤‚بƒ‰ƒCƒ^پ[‚جژè‚ة‚ح—]‚邾‚낤‚ب‚ئ
“®‚©‚·‚ج‚à‘ه•د‚¾‚µڈˆ—Œn‚ئ‚»‚جƒIƒvƒVƒ‡ƒ“‚ئ‚©‚àچl‚¦‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚©‚ç
Œہ‚ç‚ꂽژٹش‚إƒxƒ“ƒ`ƒ}پ[ƒN‰ٌ‚µ‚ؤ‚é‚و‚¤‚بƒ‰ƒCƒ^پ[‚جژè‚ة‚ح—]‚邾‚낤‚ب‚ئ
پ„SPEC‚حپAƒپƒ“ƒoپ[ٹé‹ئ9ژذ‚©‚ç’ٌڈo‚³‚ꂽSPEC CPU2006‚جŒ‹‰ت‚ً
پ„WebƒTƒCƒg‚إŒِٹJ‚µ‚ؤ‚¢‚éپB
Web‚إŒِٹJ‚³‚ê‚ؤ‚¢‚é‚ج‚حSPEC‚جƒپƒ“ƒoپ[ٹé‹ئ‚جŒ‹‰ت‚¾‚¯‚ب‚ج‚©
پ„WebƒTƒCƒg‚إŒِٹJ‚µ‚ؤ‚¢‚éپB
Web‚إŒِٹJ‚³‚ê‚ؤ‚¢‚é‚ج‚حSPEC‚جƒپƒ“ƒoپ[ٹé‹ئ‚جŒ‹‰ت‚¾‚¯‚ب‚ج‚©
ARM‚àSPEC‚جƒپƒ“ƒoپ[ٹé‹ئ‚ب‚ٌ‚¾‚ب
http://www.spec.org/spec/membership.html
http://www.spec.org/spec/membership.html
iPhone 5s‚جپuA7پv‚حSamsungگ»‚ئ”»–¾„ںM3ƒRƒvƒچƒZƒbƒT‚حNXPگ»‚ة
http://rbmen.blogspot.jp/2013/09/iphone-5sa7samsungm3nxp.html
http://rbmen.blogspot.jp/2013/09/iphone-5sa7samsungm3nxp.html
165 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 07:09:12.73 ID:mj9eCL89
’M‚³‚ٌ‚حگ¢ٹشˆê”ت‚ج”Fژ¯‚ً‚و‚’m‚ç‚ب‚¢‚©‚çڈںژè‚بٹ´“®ƒXƒgپ[ƒٹپ[‚ً”]“à‚إ
چى‚èڈم‚°‚ؤ‚é‚و‚¤‚ب‚±‚ئ‚ھ‚ ‚é‚©‚çژn––‚ةچ¢‚é‚ٌ‚¾‚و‚ث
Œ»ژہ‚جƒ\ƒtƒg‹ئٹE‚ج”Fژ¯‚ح‚±‚¤‚¾‚و
WebŒn‚جژ©ڈجITƒxƒ“ƒ`ƒƒپ[‚جژذ’·‚ھ‰´‚ٌ‚ئ‚±‚ةƒپپ[ƒ‹‘—‚ء‚ؤ‚«‚½‚±‚ئ‚ھ‰½“x‚©‚ ‚ء‚ؤ
ƒtƒٹپ[ƒ‰ƒ“ƒ`‚جڈIàپ‚ئƒ}ƒ‹ƒ`ƒRƒA‚جکb‘èگU‚ء‚½‚ç
پu‰½‚»‚ꂨ‚¢‚µ‚¢‚جپHپv‚¾‚ء‚½پB
Œ‹‹اFixstars‚ف‚½‚¢‚بƒ}ƒ‹ƒ`ƒRƒA‚جƒٹپ[ƒfƒBƒ“ƒOƒJƒ“ƒpƒjپ[پiڈخپj‚ئ‚©‚¢‚¤‚ج‚ح
‚ظ‚©‚ة‹£چ‡‘ٹژè‚ھ‚¢‚ب‚¢‚©‚炱‚»ƒ|ƒWƒVƒ‡ƒ“ٹm—§‚إ‚«‚é‚ي‚¯‚إ
‚»‚¤‚¢‚¤“ءژê‚بƒxƒ“ƒ_پ[‚إ‚à‚ب‚¢Œہ‚èژ©•ھ‚ç‚ھ‚â‚낤‚ئ‚¢‚¤‹CٹT‚حژ‚؟چ‡‚ي‚¹‚ؤ‚¢‚ب‚¢‚¾Œ‹‹اپB
‰´ژ©گg‚à‰½“x‚©•ہ—ٌ‰»‹Zڈp‚ج•K—vگ«‚ة‚آ‚¢‚ؤ”„‚èچ‚à‚¤‚ئ‚µ‚½‚¯‚ا
پu‚¤‚؟‚ح‚»‚¤‚¢‚¤‹Zڈp‹پ‚ك‚ؤ‚ب‚¢پv‚ئ‚©ژد‚¦“’ˆù‚ـ‚³‚ꂽ‚肵‚½‚ي‚¯‚وپB
‚»‚à‚»‚àƒ\ƒtƒg‹ئٹE‚ج‘ه”¼‚ح3GHz‚ج4ƒRƒA‚ب‚ٌ‚ؤ–]‚ٌ‚إ‚ب‚¢‚ٌ‚¾‚وپB
”ق‚ç‚ح—~‚ً‚¢‚¦‚خ12GHz‚ج1ƒRƒA‚ھ—~‚µ‚¢پB
Ruby‚ئ‚©‚ـ‚ئ‚à‚ةƒnپ[ƒhƒEƒFƒAƒ}ƒ‹ƒ`ƒXƒŒƒbƒh‘خ‰‚µ‚½‚ج1.9‚©‚炾‚؛پH
چى‚èڈم‚°‚ؤ‚é‚و‚¤‚ب‚±‚ئ‚ھ‚ ‚é‚©‚çژn––‚ةچ¢‚é‚ٌ‚¾‚و‚ث
Œ»ژہ‚جƒ\ƒtƒg‹ئٹE‚ج”Fژ¯‚ح‚±‚¤‚¾‚و
WebŒn‚جژ©ڈجITƒxƒ“ƒ`ƒƒپ[‚جژذ’·‚ھ‰´‚ٌ‚ئ‚±‚ةƒپپ[ƒ‹‘—‚ء‚ؤ‚«‚½‚±‚ئ‚ھ‰½“x‚©‚ ‚ء‚ؤ
ƒtƒٹپ[ƒ‰ƒ“ƒ`‚جڈIàپ‚ئƒ}ƒ‹ƒ`ƒRƒA‚جکb‘èگU‚ء‚½‚ç
پu‰½‚»‚ꂨ‚¢‚µ‚¢‚جپHپv‚¾‚ء‚½پB
Œ‹‹اFixstars‚ف‚½‚¢‚بƒ}ƒ‹ƒ`ƒRƒA‚جƒٹپ[ƒfƒBƒ“ƒOƒJƒ“ƒpƒjپ[پiڈخپj‚ئ‚©‚¢‚¤‚ج‚ح
‚ظ‚©‚ة‹£چ‡‘ٹژè‚ھ‚¢‚ب‚¢‚©‚炱‚»ƒ|ƒWƒVƒ‡ƒ“ٹm—§‚إ‚«‚é‚ي‚¯‚إ
‚»‚¤‚¢‚¤“ءژê‚بƒxƒ“ƒ_پ[‚إ‚à‚ب‚¢Œہ‚èژ©•ھ‚ç‚ھ‚â‚낤‚ئ‚¢‚¤‹CٹT‚حژ‚؟چ‡‚ي‚¹‚ؤ‚¢‚ب‚¢‚¾Œ‹‹اپB
‰´ژ©گg‚à‰½“x‚©•ہ—ٌ‰»‹Zڈp‚ج•K—vگ«‚ة‚آ‚¢‚ؤ”„‚èچ‚à‚¤‚ئ‚µ‚½‚¯‚ا
پu‚¤‚؟‚ح‚»‚¤‚¢‚¤‹Zڈp‹پ‚ك‚ؤ‚ب‚¢پv‚ئ‚©ژد‚¦“’ˆù‚ـ‚³‚ꂽ‚肵‚½‚ي‚¯‚وپB
‚»‚à‚»‚àƒ\ƒtƒg‹ئٹE‚ج‘ه”¼‚ح3GHz‚ج4ƒRƒA‚ب‚ٌ‚ؤ–]‚ٌ‚إ‚ب‚¢‚ٌ‚¾‚وپB
”ق‚ç‚ح—~‚ً‚¢‚¦‚خ12GHz‚ج1ƒRƒA‚ھ—~‚µ‚¢پB
Ruby‚ئ‚©‚ـ‚ئ‚à‚ةƒnپ[ƒhƒEƒFƒAƒ}ƒ‹ƒ`ƒXƒŒƒbƒh‘خ‰‚µ‚½‚ج1.9‚©‚炾‚؛پH
‚¨‘OپA‹U’cژq‚¾‚ëپEپE
‚½‚邳‚ٌ‚ج—iŒى‚ً‚µ‚ئ‚‚ئپAƒAƒ“ƒ` ƒ}ƒ‹ƒ`ƒRƒAپ•ƒVƒ“ƒOƒ‹ژٹچ‚‚ح‚ـ‚³‚ة‚½‚邳‚ٌ‚جژه’£
‚½‚邳‚ٌ‚ج—iŒى‚ً‚µ‚ئ‚‚ئپAƒAƒ“ƒ` ƒ}ƒ‹ƒ`ƒRƒAپ•ƒVƒ“ƒOƒ‹ژٹچ‚‚ح‚ـ‚³‚ة‚½‚邳‚ٌ‚جژه’£
ƒVƒٹƒRƒ“‚¶‚ل‚ب‚‚ؤƒ_ƒCƒ„ƒ‚ƒ“ƒh‚ًژg‚¤‚ئ10GHz‚¢‚¯‚é‚ئ‚¢‚¤Œ¤‹†گ¬‰ت‚ھڈo‚ؤ‚é‚炵‚¢پB
ƒ_ƒCƒ„‚ح“`”Mگ«”\‚ھ‚¢‚¢‚ٌ‚¾('A`)
ƒOƒٹƒXƒoپ[ƒKپ[‚â‚ك‚ؤƒ_ƒCƒ„‚ة‚·‚ê‚خ‚»‚ꂾ‚¯‚إگ«”\ڈم‚ھ‚é‚و('A`)
ƒOƒٹƒXƒoپ[ƒKپ[‚â‚ك‚ؤƒ_ƒCƒ„‚ة‚·‚ê‚خ‚»‚ꂾ‚¯‚إگ«”\ڈم‚ھ‚é‚و('A`)
‚»‚¤‚ب‚ج‚©('A`)
‹âƒOƒٹƒX‚ب‚ç‚تƒ_ƒCƒ„ƒOƒٹƒX‚ئگ\‚µ‚½‚©پB
‚»‚à‚»‚àپA‚س‚آ‚¤‚جƒfƒXƒNƒgƒbƒv—p“r‚إ‚³‚¦چإ’ل‚QƒRƒA‚ب‚¢‚ئƒTƒNƒTƒN“®‚©‚ب‚¢
•ذ•û‚جƒRƒA‚ھ100%•‰‰×‚إˆّ‚ء‚©‚©‚ء‚ؤ‚à‚à‚¤•ذ•û‚جƒRƒA‚إOSپEGUI‚ً“®‚©‚¹‚é‚ج‚إپA
‚QƒRƒA‚ ‚é‚ئ‚PƒRƒAژ‚و‚è‘جٹ´“I‚ة‚©‚ب‚èƒTƒNƒTƒN‚·‚é
•ذ•û‚جƒRƒA‚ھ100%•‰‰×‚إˆّ‚ء‚©‚©‚ء‚ؤ‚à‚à‚¤•ذ•û‚جƒRƒA‚إOSپEGUI‚ً“®‚©‚¹‚é‚ج‚إپA
‚QƒRƒA‚ ‚é‚ئ‚PƒRƒAژ‚و‚è‘جٹ´“I‚ة‚©‚ب‚èƒTƒNƒTƒN‚·‚é
ƒ_ƒCƒ„‚حچdژ؟‚ب‚ج‚إپA
ƒ_ƒCƒ„‚ئƒRƒAٹش‚ج‚·‚«‚ـ‚ً–„‚ك‚邽‚ك‚ةŒ‹‹اƒOƒٹƒX“™‚ھ•K—v‚ة‚ب‚邯‚ا‚ث
ƒ_ƒCƒ„‚ئƒRƒAٹش‚ج‚·‚«‚ـ‚ً–„‚ك‚邽‚ك‚ةŒ‹‹اƒOƒٹƒX“™‚ھ•K—v‚ة‚ب‚邯‚ا‚ث
>>172
ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\ڈم‚°‚邽‚ك‚ةƒXپ[ƒpپ[ƒXƒJƒ‰‚ً“O’ê“I‚ة‹‰»‚·‚é‚ئپAژہژg—pڈَ‘ش‚إ‰‰ژZƒ†ƒjƒbƒg‚ھ—V‚ر‚ـ‚‚é‚©‚çƒ}ƒ‹ƒ`ƒXƒŒƒbƒh‘خ‰‚µ‚ؤپAژہƒRƒA‚à•،گ”‚ ‚ء‚½•û‚ھCPUگè—ج‚إ‚«‚ؤ‚¢‚¢‚و‚ث‚ء‚ؤ‚â‚é‚ئŒ‹‹ا4C16Tˆت‚ة‚ب‚é‹C‚ھ‚·‚邼پB
ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\ڈم‚°‚邽‚ك‚ةƒXپ[ƒpپ[ƒXƒJƒ‰‚ً“O’ê“I‚ة‹‰»‚·‚é‚ئپAژہژg—pڈَ‘ش‚إ‰‰ژZƒ†ƒjƒbƒg‚ھ—V‚ر‚ـ‚‚é‚©‚çƒ}ƒ‹ƒ`ƒXƒŒƒbƒh‘خ‰‚µ‚ؤپAژہƒRƒA‚à•،گ”‚ ‚ء‚½•û‚ھCPUگè—ج‚إ‚«‚ؤ‚¢‚¢‚و‚ث‚ء‚ؤ‚â‚é‚ئŒ‹‹ا4C16Tˆت‚ة‚ب‚é‹C‚ھ‚·‚邼پB
’cژq“ء’肵‚½‚©‚à
176 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 18:23:15.29 ID:Y9m3L35V
>>166
‰´‚ح’P‚ةƒ\ƒtƒgƒEƒFƒA‹ئٹE‚جƒgƒŒƒ“ƒh‚ھƒnپ[ƒhƒEƒFƒA‚ة’ا‚¢‚آ‚¢‚ؤ‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚µ‚©
Œ¾‚ء‚ؤ‚ب‚¢‚¯‚اپH
“–‘RVB6ˆؤŒڈ‚ئ‚©–¢‚¾‚ة“®‚¢‚ؤ‚½‚è‚·‚éچ،‚جŒ»ڈَ‚ھ—ا‚¢‚ئ‚ح‚¢‚ء‚ؤ‚ب‚¢پB
‚ق‚µ‚ë•ہ—ٌ‰»‚جƒjپ[ƒYٹg‘ه‚حƒ\ƒtƒg‹ئٹE‚ھڈپ‚¤ƒ`ƒƒƒ“ƒX‚ب‚ٌ‚¾پB
Œ‹‹اپu‚إ‚«‚éگlچقپv‚ھ‘«‚è‚ؤ‚ب‚¢‚©‚ç“®‚©‚¹‚ب‚¢‚ٌ‚¾‚낤‚ثپB
ٹù‘¶‚جکg‘g‚ف‚¶‚ل‚إ‚«‚ب‚¢‚©‚猳‹C‚ج‚ ‚éٹwگ¶‚ً’†گS‚ةگV‚½‚ة‰ïژذچى‚ء‚ؤژو‚è‘g‚ق
‚‚ç‚¢‚¶‚ل‚ب‚¢‚ئƒ\ƒtƒg‹ئٹE‚جƒpƒ‰ƒ_ƒCƒ€ƒVƒtƒg‚ح‹N‚±‚¹‚ب‚¢‚يپB
‰´‚ح’P‚ةƒ\ƒtƒgƒEƒFƒA‹ئٹE‚جƒgƒŒƒ“ƒh‚ھƒnپ[ƒhƒEƒFƒA‚ة’ا‚¢‚آ‚¢‚ؤ‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚µ‚©
Œ¾‚ء‚ؤ‚ب‚¢‚¯‚اپH
“–‘RVB6ˆؤŒڈ‚ئ‚©–¢‚¾‚ة“®‚¢‚ؤ‚½‚è‚·‚éچ،‚جŒ»ڈَ‚ھ—ا‚¢‚ئ‚ح‚¢‚ء‚ؤ‚ب‚¢پB
‚ق‚µ‚ë•ہ—ٌ‰»‚جƒjپ[ƒYٹg‘ه‚حƒ\ƒtƒg‹ئٹE‚ھڈپ‚¤ƒ`ƒƒƒ“ƒX‚ب‚ٌ‚¾پB
Œ‹‹اپu‚إ‚«‚éگlچقپv‚ھ‘«‚è‚ؤ‚ب‚¢‚©‚ç“®‚©‚¹‚ب‚¢‚ٌ‚¾‚낤‚ثپB
ٹù‘¶‚جکg‘g‚ف‚¶‚ل‚إ‚«‚ب‚¢‚©‚猳‹C‚ج‚ ‚éٹwگ¶‚ً’†گS‚ةگV‚½‚ة‰ïژذچى‚ء‚ؤژو‚è‘g‚ق
‚‚ç‚¢‚¶‚ل‚ب‚¢‚ئƒ\ƒtƒg‹ئٹE‚جƒpƒ‰ƒ_ƒCƒ€ƒVƒtƒg‚ح‹N‚±‚¹‚ب‚¢‚يپB
177 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 18:35:15.98 ID:Y9m3L35V
>>172
چإ‹ك‚جOS‚حƒ}ƒ‹ƒ`ƒRƒA‰»‚ة‚ ‚ي‚¹‚ؤƒ^ƒCƒ€ƒXƒ‰ƒCƒX‚ج—±“x‚ً‘e‚‚µ‚ؤ‚é‚©‚ç
ƒRƒ“ƒeƒNƒXƒgگط‘ض‚ھ’x‚ٹ´‚¶‚ç‚ê‚é‚©‚à‚µ‚ê‚ب‚¢پB
‚à‚؟‚ë‚ٌƒ^ƒCƒ€ƒXƒ‰ƒCƒX—±“x‚ًڈم‚°‚é‚ئ‚©‚·‚ê‚خ‰ü‘P‚·‚é‚ج‚¾‚¯‚اپB
>>174
1ƒXƒŒƒbƒh‚ ‚½‚è‚جƒLƒƒƒbƒVƒ…ƒپƒ‚ƒٹ‚ھŒ¸‚é‚ج‚إ16T‚ح‚ا‚¤‚©‚ح’m‚ç‚ب‚¢‚ھ
ƒTپ[ƒo‚ة‚ح—LŒّ‚©‚à‚µ‚ê‚ب‚¢‚ثپB
Bulldozer‚جگفŒvژv‘z‚ء‚ؤ
پu2ƒRƒA‚ً‚‚ء‚آ‚¯‚½‚à‚جپv‚¶‚ل‚ب‚‚ؤپu2ƒXƒŒƒbƒh“®چىژ‚ةگ«”\’ل‰؛‚µ‚ة‚‚¢SMTپv
‚ً‘_‚ء‚ؤ‚é‚ٌ‚¾‚و‚ثپB
چإ‹ك‚جOS‚حƒ}ƒ‹ƒ`ƒRƒA‰»‚ة‚ ‚ي‚¹‚ؤƒ^ƒCƒ€ƒXƒ‰ƒCƒX‚ج—±“x‚ً‘e‚‚µ‚ؤ‚é‚©‚ç
ƒRƒ“ƒeƒNƒXƒgگط‘ض‚ھ’x‚ٹ´‚¶‚ç‚ê‚é‚©‚à‚µ‚ê‚ب‚¢پB
‚à‚؟‚ë‚ٌƒ^ƒCƒ€ƒXƒ‰ƒCƒX—±“x‚ًڈم‚°‚é‚ئ‚©‚·‚ê‚خ‰ü‘P‚·‚é‚ج‚¾‚¯‚اپB
>>174
1ƒXƒŒƒbƒh‚ ‚½‚è‚جƒLƒƒƒbƒVƒ…ƒپƒ‚ƒٹ‚ھŒ¸‚é‚ج‚إ16T‚ح‚ا‚¤‚©‚ح’m‚ç‚ب‚¢‚ھ
ƒTپ[ƒo‚ة‚ح—LŒّ‚©‚à‚µ‚ê‚ب‚¢‚ثپB
Bulldozer‚جگفŒvژv‘z‚ء‚ؤ
پu2ƒRƒA‚ً‚‚ء‚آ‚¯‚½‚à‚جپv‚¶‚ل‚ب‚‚ؤپu2ƒXƒŒƒbƒh“®چىژ‚ةگ«”\’ل‰؛‚µ‚ة‚‚¢SMTپv
‚ً‘_‚ء‚ؤ‚é‚ٌ‚¾‚و‚ثپB
‚»‚جŒ‹‰ت‚إ‚«‚½‚ج‚ھچإڈ‰‚©‚ç’لگ«”\‚ب‚¾‚¯‚ج‘م•¨‚¾‚ء‚½‚ئ‚ح‹ئ‚جگ[‚¢کb‚¾‚ب
ژv‘z‚©ژہ‘•‚©پA‚ح‚½‚ـ‚½‚»‚ج—¼ژز‚©پA‚¢‚¸‚ê‚ھŒ´ˆِ‚©‚ح’m‚ç‚ٌ‚ھ
ژv‘z‚©ژہ‘•‚©پA‚ح‚½‚ـ‚½‚»‚ج—¼ژز‚©پA‚¢‚¸‚ê‚ھŒ´ˆِ‚©‚ح’m‚ç‚ٌ‚ھ
179 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 19:00:54.10 ID:Y9m3L35V
’x‚ê‚ؤڈo‚ؤ‚«‚½Prescott‚جˆظ•êŒZ’ي‚¾‚©‚ç‚ب
>>178
‹Zڈpژز‚ھSMT‚ئ‚µ‚ؤچى‚ء‚½•¨‚ًڈںژè‚ةژہƒRƒA‚ئ‚µ‚ؤگ…‘‚µ‚µ‚ؤ”„‚ء‚½Œo‰cژز‚ھˆ«‚¢‚ٌ‚¾‚ëپBگ»‘¢ƒ‰ƒCƒ“”„‚ء•¥‚ء‚½Œ‹‰ت‚ھگ»‘¢ƒvƒچƒZƒX‚إ2ژü’x‚ê–ع‘O‚جڈَ‹µ‚àپA‚ـ‚³‚©IBM‚ھ‚±‚±‚ـ‚إ—ژ‚؟‚ش‚ê‚é‚ئ‚حژv‚ي‚ب‚©‚ء‚½‚ة‚¹‚وپAŒo‰c”»’fƒ~ƒX‚¾‚وپB
‹Zڈpژز‚ھSMT‚ئ‚µ‚ؤچى‚ء‚½•¨‚ًڈںژè‚ةژہƒRƒA‚ئ‚µ‚ؤگ…‘‚µ‚µ‚ؤ”„‚ء‚½Œo‰cژز‚ھˆ«‚¢‚ٌ‚¾‚ëپBگ»‘¢ƒ‰ƒCƒ“”„‚ء•¥‚ء‚½Œ‹‰ت‚ھگ»‘¢ƒvƒچƒZƒX‚إ2ژü’x‚ê–ع‘O‚جڈَ‹µ‚àپA‚ـ‚³‚©IBM‚ھ‚±‚±‚ـ‚إ—ژ‚؟‚ش‚ê‚é‚ئ‚حژv‚ي‚ب‚©‚ء‚½‚ة‚¹‚وپAŒo‰c”»’fƒ~ƒX‚¾‚وپB
181 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/21(“y) 19:08:22.16 ID:Y9m3L35V
‚ـ‚ پAƒRƒAگ”گ…‘‚µ‚µ‚ؤ‚àƒRƒA‰غ‹à‚جƒ\ƒtƒgƒ‰ƒCƒZƒ“ƒX‚إ•s—ک‚ب‚¾‚¯‚¾‚©‚ç‚بپB
SMT‚ًپu1ƒRƒA‚ئ‚µ‚ؤˆµ‚ء‚ؤ‚‚êپv‚ئ’Qٹ肵‚ؤ‰ٌ‚ء‚½Intel‚ئپA
SMT‚ج‰„’·‚ب‚ج‚ة2ƒRƒA‚ئ‚µ‚ؤˆµ‚ء‚ؤ‚‚ê‚ئ‚¢‚ء‚½AMD
•ت‚ةƒ}پ[ƒPƒeƒBƒ“ƒOڈم‚جƒRƒAگ”‚ھ”{‘‚µ‚½‚ئ‚±‚ë‚إژہگ«”\ڈمƒپƒٹƒbƒg‚ب‚ٌ‚ؤ‚ب‚¢”¤‚ب‚ج‚ة‚بپB
SMT‚ًپu1ƒRƒA‚ئ‚µ‚ؤˆµ‚ء‚ؤ‚‚êپv‚ئ’Qٹ肵‚ؤ‰ٌ‚ء‚½Intel‚ئپA
SMT‚ج‰„’·‚ب‚ج‚ة2ƒRƒA‚ئ‚µ‚ؤˆµ‚ء‚ؤ‚‚ê‚ئ‚¢‚ء‚½AMD
•ت‚ةƒ}پ[ƒPƒeƒBƒ“ƒOڈم‚جƒRƒAگ”‚ھ”{‘‚µ‚½‚ئ‚±‚ë‚إژہگ«”\ڈمƒپƒٹƒbƒg‚ب‚ٌ‚ؤ‚ب‚¢”¤‚ب‚ج‚ة‚بپB
ژہچغ‚ة‘½‚‚جƒAƒvƒٹ‚حINT’†گS‚ب‚ٌ‚¾‚©‚çپA
SMT‚ئ‚µ‚ؤ”„‚ء‚ؤ‚½‚ç‚©‚ب‚èچ‚گ«”\‚ء‚ؤ•]”»‚ة‚ب‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©
‚ـ‚ ƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒXچl‚¦‚é‚ئ”÷–‚©پc
SMT‚ئ‚µ‚ؤ”„‚ء‚ؤ‚½‚ç‚©‚ب‚èچ‚گ«”\‚ء‚ؤ•]”»‚ة‚ب‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©
‚ـ‚ ƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒXچl‚¦‚é‚ئ”÷–‚©پc
‚¢‚â•ت‚ةSMT‚ئ‚µ‚ؤ”„‚ء‚½‚ئ‚±‚ë‚إگ«”\‚ھ•د‚ي‚é‚ي‚¯‚إ‚à‚ب‚
ƒsپ[ƒNگ«”\‚ح4M‚إIntel‚ج4C8T‚ئ‘هچ·‚ب‚پAƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚إ‚حƒ{ƒچ•‰‚¯پAڈء”ï“d—ح‚ح‚¨کb‚ة‚ب‚ç‚ب‚¢
‚ئ‚¢‚¤ٹî–{ƒXƒyƒbƒN‚ج’ل‚³‚ھ•s•]‚جŒ´ˆِ‚¾‚낤
ƒsپ[ƒNگ«”\‚ح4M‚إIntel‚ج4C8T‚ئ‘هچ·‚ب‚پAƒVƒ“ƒOƒ‹ƒXƒŒƒbƒh‚إ‚حƒ{ƒچ•‰‚¯پAڈء”ï“d—ح‚ح‚¨کb‚ة‚ب‚ç‚ب‚¢
‚ئ‚¢‚¤ٹî–{ƒXƒyƒbƒN‚ج’ل‚³‚ھ•s•]‚جŒ´ˆِ‚¾‚낤
>>116
’xƒŒƒX‚¾‚ھBayTrail‚إIE11‚¾‚ئSunSpider329.6ms‚ب‚ج‚©‚—
ttp://www.youtube.com/watch?v=UXCobb134Vo
Android‚¾‚ئ566.6ms‚¾‚©‚ç1.7”{‚à‘¬‚‚ب‚é‚ئ‚ح
‚ب‚ٌ‚©Android‚ء‚ؤChromeپiNDKپj‚جٹ„‚ةJS‚ئ‚©’x‚¢‚و‚ث
’xƒŒƒX‚¾‚ھBayTrail‚إIE11‚¾‚ئSunSpider329.6ms‚ب‚ج‚©‚—
ttp://www.youtube.com/watch?v=UXCobb134Vo
Android‚¾‚ئ566.6ms‚¾‚©‚ç1.7”{‚à‘¬‚‚ب‚é‚ئ‚ح
‚ب‚ٌ‚©Android‚ء‚ؤChromeپiNDKپj‚جٹ„‚ةJS‚ئ‚©’x‚¢‚و‚ث
”نٹr‘ٹژè‚ھi3‚ة‚ب‚é–َ‚¾‚©‚çƒvƒچƒZƒX‚ج’x‚ê‚جٹ„‚ةٹو’£‚ء‚ؤ‚é‚ئ‚حŒ¾‚ي‚ꂽ‚¾‚낤پBi3‚ج’l’i‚µ‚©ژو‚ê‚ب‚‚ب‚é‚ھژd•û‚ب‚¢پB
Android‚ح‘S‘ج“I‚ة‰½‚à‚©‚à’x‚¢‹C‚ھ‚·‚é‚ھپEپEپE
‘¬“x‚¾‚¯”نٹr‚µ‚ؤ‚à‚µ‚ه‚¤‚ھ‚ب‚¢
ƒپƒ‚ƒٹژg—p—ت‘‚₹‚خ‚¢‚‚ç‚إ‚à(Œ¾‚¢‰ك‚¬)‘¬‚‚ب‚è‚ـ‚·‚؛
ƒپƒ‚ƒٹژg—p—ت‘‚₹‚خ‚¢‚‚ç‚إ‚à(Œ¾‚¢‰ك‚¬)‘¬‚‚ب‚è‚ـ‚·‚؛
‚آ‚ـ‚èBayTrail‚ج‘f‚جگ«”\‚حA7‚و‚èچ‚‚‚ؤAndroid‚ھ‘«‚ًˆّ‚ء’£‚ء‚ؤ‚é‚ج‚©پA
IE11‚ھگ¦‚·‚¬‚é‚ج‚©پA‚»‚ج—¼•û‚©
IE11‚ھگ¦‚·‚¬‚é‚ج‚©پA‚»‚ج—¼•û‚©
iphone5s/5c‚جCPU‚حپAƒTƒ€ƒXƒ“‚ج28nmƒvƒچƒZƒX‚إچى‚ء‚ؤ‚é‚炵‚¢‚و
ƒTƒ€ƒXƒ“‚àTSMC‚ة•ہ‚ٌ‚¾ٹ´‚¶‚¾‚ب
ƒTƒ€ƒXƒ“‚àTSMC‚ة•ہ‚ٌ‚¾ٹ´‚¶‚¾‚ب
>>184
Core i7 377K‚إ‚àSunspider123.7‚ب‚ج‚ة
Baytrail‚جIPC‚حCire i7‚ج”¼•ھ‚‚ç‚¢‚ ‚é‚ج‚©پH
http://hothardware.com/Reviews/Intel-Core-i73770K-Ivy-Bridge-Processor-Review/?page=8
Core i7 377K‚إ‚àSunspider123.7‚ب‚ج‚ة
Baytrail‚جIPC‚حCire i7‚ج”¼•ھ‚‚ç‚¢‚ ‚é‚ج‚©پH
http://hothardware.com/Reviews/Intel-Core-i73770K-Ivy-Bridge-Processor-Review/?page=8
IE11‚ھ‚·‚²‚¢‚ج‚©
IE9‚و‚èSunspider‚جŒ‹‰ت‚ھ1.5”{‚‚ç‚¢‘¬‚¢‚ب
http://pc.watch.impress.co.jp/img/pcw/docs/605/586/html/07.jpg.html
IE9‚و‚èSunspider‚جŒ‹‰ت‚ھ1.5”{‚‚ç‚¢‘¬‚¢‚ب
http://pc.watch.impress.co.jp/img/pcw/docs/605/586/html/07.jpg.html
{kind=link}
‚·‚é‚ئBaytrail‚جIPC‚حCore i7‚ج1/3‚‚ç‚¢‚ ‚é‚ج‚©
1.6GHz‚جƒ‚ƒoƒCƒ‹Core i5‚ئ”ن‚ׂؤ
2.4GHz‚جB}aytrail‚جƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\‚ھ‚؟‚ه‚¤‚ا”¼•ھ‚‚ç‚¢‚ء‚ؤ‚±‚ئپH
2.4GHz‚جB}aytrail‚جƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhگ«”\‚ھ‚؟‚ه‚¤‚ا”¼•ھ‚‚ç‚¢‚ء‚ؤ‚±‚ئپH
http://pc.watch.impress.co.jp/img/pcw/docs/615/175/html/graph2.gif.html
http://pc.watch.impress.co.jp/docs/column/ubiq/20130912_615175.html
{kind=link}
http://pc.watch.impress.co.jp/docs/column/ubiq/20130912_615175.html
>>193
چs“ھ‚ج1.2.‚ھ—ٌ‹“‚ةŒ©‚¦‚؟‚ل‚ء‚½
چs“ھ‚ج1.2.‚ھ—ٌ‹“‚ةŒ©‚¦‚؟‚ل‚ء‚½
ڈء”ï“d—ح‚ً‘ه•‚ةŒ¸‚炵‚آ‚آگ«”\‚ً”{ˆبڈم‚ةˆّ‚«ڈم‚°‚½Apple
‚ا‚ٌ‚بƒ}ƒWƒbƒN‚ًژg‚ء‚½‚ٌ‚¾پH
‚ا‚ٌ‚بƒ}ƒWƒbƒN‚ًژg‚ء‚½‚ٌ‚¾پH
DECƒ}ƒWƒbƒN
ڈء”ï“d—ح‚ھ‘ه•‚ةŒ¸‚ء‚½‚ب‚ٌ‚ؤکb‚ ‚ء‚½‚ء‚¯پH
A7‚ح‰»•¨‚©
128bit FMAx2‚ئ‰ءژZ—p‚ةFADDx2‚àژ‚ء‚ؤ‚é‚ب‚ٌ‚ؤ
128bit FMAx2‚ئ‰ءژZ—p‚ةFADDx2‚àژ‚ء‚ؤ‚é‚ب‚ٌ‚ؤ
200 پFSocket774پF2013/09/23(Œژ) 17:13:56.16 ID:hpyQPzeM
چ،ژ‚»‚ٌ‚ب‚ةFPU‘‚₵‚ؤ‚ا‚¤‚·‚ٌ‚جپH
ƒpƒtƒHپ[ƒ}ƒ“ƒX‚ًڈم‚°ڈب“d—حƒXƒeپ[ƒg‚ً’·‚‚·‚邽‚ك‚¾‚ëپEپEŒ¾‚ي‚¹‚é‚ب‚و’p‚¸‚©‚µ‚¢
ƒ‚ƒoƒCƒ‹‚¾‚©‚炽‚¢‚µ‚ؤ‘ه‚«‚‚ب‚¢ƒ`ƒbƒv‚¾‚ھ
‚»‚ٌ‚ب‚ة–½—ك‚àƒfپ[ƒ^‚à‹ں‹‹‚إ‚«‚é‚ج‚©
‚»‚ٌ‚ب‚ة–½—ك‚àƒfپ[ƒ^‚à‹ں‹‹‚إ‚«‚é‚ج‚©
http://ascii.jp/elem/000/000/827/827471/index-3.html
| ƒXƒ^ƒ“ƒoƒCژ‚جڈء”ï“d—ح‚ئژv‚ي‚ê‚éƒOƒ‰ƒtپBچ¶‚©‚çCloverTrail+پABay Trail-T‚إLPDDR3‚ً2chپA
| DDR3L‚ً2chپALPDDR3‚ً1ch‚ئ‚¢‚¤4‚آ‚جچ\گ¬‚إپAڈcژ²‚حƒnƒbƒLƒٹ‚µ‚ب‚¢پi‘ٹ‘خ’l‚إ‚ح‚ب‚¢‚و‚¤‚¾پj‚ھپA
| mW‚ئژv‚ي‚ê‚é
| ‚â‚ح‚è‚ش‚ء‚؟‚¬‚è‚إDDR3Lپ~2ch‚حچ‚‚‚ب‚ء‚ؤ‚¨‚èپA‚±‚ê‚ھDDR3L‚إ‚ح1ch‚µ‚©ƒTƒ|پ[ƒg‚µ‚ب‚¢——R‚إ‚ ‚낤پB
‘هŒ´گوگ¶‚»‚جƒOƒ‰ƒtپA‘رˆو‚إ‚·پB‰؛‚ة‚؟‚ل‚ٌ‚ئڈ‘‚¢‚ؤ‚ ‚é‚إ‚µ‚ه?
2x64 LPDDR3-1067 17.1GB/s
1x64 LPDDR3-1067 8.53GB/s
‚ش‚ء‚؟‚¬‚è‚إDDR3Lx2ch‚ھچ‚‚¢‚ج‚حگ«”\‚إ‚·پB
| ƒXƒ^ƒ“ƒoƒCژ‚جڈء”ï“d—ح‚ئژv‚ي‚ê‚éƒOƒ‰ƒtپBچ¶‚©‚çCloverTrail+پABay Trail-T‚إLPDDR3‚ً2chپA
| DDR3L‚ً2chپALPDDR3‚ً1ch‚ئ‚¢‚¤4‚آ‚جچ\گ¬‚إپAڈcژ²‚حƒnƒbƒLƒٹ‚µ‚ب‚¢پi‘ٹ‘خ’l‚إ‚ح‚ب‚¢‚و‚¤‚¾پj‚ھپA
| mW‚ئژv‚ي‚ê‚é
| ‚â‚ح‚è‚ش‚ء‚؟‚¬‚è‚إDDR3Lپ~2ch‚حچ‚‚‚ب‚ء‚ؤ‚¨‚èپA‚±‚ê‚ھDDR3L‚إ‚ح1ch‚µ‚©ƒTƒ|پ[ƒg‚µ‚ب‚¢——R‚إ‚ ‚낤پB
‘هŒ´گوگ¶‚»‚جƒOƒ‰ƒtپA‘رˆو‚إ‚·پB‰؛‚ة‚؟‚ل‚ٌ‚ئڈ‘‚¢‚ؤ‚ ‚é‚إ‚µ‚ه?
2x64 LPDDR3-1067 17.1GB/s
1x64 LPDDR3-1067 8.53GB/s
‚ش‚ء‚؟‚¬‚è‚إDDR3Lx2ch‚ھچ‚‚¢‚ج‚حگ«”\‚إ‚·پB
‚¦‚ءپA‚±‚ê‚ح‚³‚·‚ھ‚ةƒMƒƒƒO‚إŒ¾‚ء‚ؤ‚é‚ٌ‚إ‚µ‚هپH
BWپ¨پi‚ب‚؛‚©B‚ھڈء‚¦‚ؤپjWپ¨ڈء”ï“d—ح‚ئ‚©ƒ}ƒW‚إژv‚ء‚ؤ‚ب‚¢‚و‚بپc
BWپ¨پi‚ب‚؛‚©B‚ھڈء‚¦‚ؤپjWپ¨ڈء”ï“d—ح‚ئ‚©ƒ}ƒW‚إژv‚ء‚ؤ‚ب‚¢‚و‚بپc
‚ا‚±‚©‚çڈء”ï“d—ح‚جƒOƒ‰ƒt‚¾‚ب‚ٌ‚ؤ–د‘z‚ھڈo‚ؤ‚«‚½‚ٌ‚¾‚낤...
>>202
‚½‚ش‚ٌFADD‚جƒ|پ[ƒg‚حFMA‚ئ‹¤’ت‚¾‚ئژv‚¤‚و
>>202
‚½‚ش‚ٌFADD‚جƒ|پ[ƒg‚حFMA‚ئ‹¤’ت‚¾‚ئژv‚¤‚و
ARM Mac‚ًڈo‚·‚½‚ك‚ج•zگخ‚¾‚ë
Intel64–½—ك‚ًƒGƒ~ƒ…ƒŒپ[ƒg‚µ‚ؤ“¯ژٹْ‚جژہ‹@‚ةڈں‚ؤ‚é‚ج‚©‚ا‚¤‚©‚ح‹^–₾‚¯‚ا
‚ ‚جگl—قژjڈمچإ‹‚جPowerPC‚إ‚·‚çگ¬‚µ“¾‚ب‚©‚ء‚½‚ج‚ة
Intel64–½—ك‚ًƒGƒ~ƒ…ƒŒپ[ƒg‚µ‚ؤ“¯ژٹْ‚جژہ‹@‚ةڈں‚ؤ‚é‚ج‚©‚ا‚¤‚©‚ح‹^–₾‚¯‚ا
‚ ‚جگl—قژjڈمچإ‹‚جPowerPC‚إ‚·‚çگ¬‚µ“¾‚ب‚©‚ء‚½‚ج‚ة
‚ب‚é‚ظ‚اMac‚جƒGƒ~ƒ…‚ج‚½‚ك‚ة128bitFMACx2“‹چع
‚±‚ê‚ح‘¬‚»‚¤‚¾
‚¤‚ٌ‚¤‚ٌ
‚±‚ê‚ح‘¬‚»‚¤‚¾
‚¤‚ٌ‚¤‚ٌ
>>203
‚»‚ج‹Lژ–‚ج‰؛‚ج•û
پ„2ژںƒLƒƒƒbƒVƒ…‚ج‚ظ‚¤‚ھCPUƒRƒA‚و‚è””M‚ھچ‚‚¢
eSRAM‚ھ2ژںƒLƒƒƒbƒVƒ…‚ئ“¯‚¶6T-SRAMŒ`ژ®‚¾‚ء‚½‚çJaguarƒRƒA‚و‚èچ‚””M‚©پH
‚»‚ج‹Lژ–‚ج‰؛‚ج•û
پ„2ژںƒLƒƒƒbƒVƒ…‚ج‚ظ‚¤‚ھCPUƒRƒA‚و‚è””M‚ھچ‚‚¢
eSRAM‚ھ2ژںƒLƒƒƒbƒVƒ…‚ئ“¯‚¶6T-SRAMŒ`ژ®‚¾‚ء‚½‚çJaguarƒRƒA‚و‚èچ‚””M‚©پH
Œë”ڑ‚إ‚µ‚½
Mac‚إARM‚ًژg‚¤——R‚©پcپB
ƒRƒA‚ًAppleژ©گg‚إƒJƒXƒ^ƒ€‚إ‚«‚é‚ج‚إپA‚»‚ê‚إ‚و‚ظ‚ا‚جچ·•ت‰»‚ھ‚إ‚«‚é‚ج‚ب‚ç‚ ‚é‚¢‚حپB
‚ ‚ئ‚حiOS‚إ“®‚ƒ\ƒtƒgژ‘ژY‚à‚ ‚é‚ئ‚¢‚¦‚خ‚ ‚éپB
Rosetta‚ف‚½‚¢‚ب‚جژg‚¦‚خ‘¬“x‚حڈo‚ب‚¢‚ھƒGƒ~ƒ…ƒŒپ[ƒg‚ح‚إ‚«‚邾‚낤‚µپA
ƒ†ƒjƒoپ[ƒTƒ‹ƒoƒCƒiƒٹ‚ب‚ج‚إ“¯ˆêƒpƒbƒPپ[ƒW‚إx86پAx64پAARM‚·‚ׂؤ‚ة‘خ‰‚ء‚ؤ‚ج‚à‚إ‚«‚ب‚‚ح‚ب‚¢‚ھپcپB
‚إ‚àپA‚ ‚¦‚ؤARM‚ةˆع‚é——R‚à–³‚¢‹C‚ھ‚·‚é‚ٌ‚¾‚و‚ب‚ پB
ƒRƒA‚ًAppleژ©گg‚إƒJƒXƒ^ƒ€‚إ‚«‚é‚ج‚إپA‚»‚ê‚إ‚و‚ظ‚ا‚جچ·•ت‰»‚ھ‚إ‚«‚é‚ج‚ب‚ç‚ ‚é‚¢‚حپB
‚ ‚ئ‚حiOS‚إ“®‚ƒ\ƒtƒgژ‘ژY‚à‚ ‚é‚ئ‚¢‚¦‚خ‚ ‚éپB
Rosetta‚ف‚½‚¢‚ب‚جژg‚¦‚خ‘¬“x‚حڈo‚ب‚¢‚ھƒGƒ~ƒ…ƒŒپ[ƒg‚ح‚إ‚«‚邾‚낤‚µپA
ƒ†ƒjƒoپ[ƒTƒ‹ƒoƒCƒiƒٹ‚ب‚ج‚إ“¯ˆêƒpƒbƒPپ[ƒW‚إx86پAx64پAARM‚·‚ׂؤ‚ة‘خ‰‚ء‚ؤ‚ج‚à‚إ‚«‚ب‚‚ح‚ب‚¢‚ھپcپB
‚إ‚àپA‚ ‚¦‚ؤARM‚ةˆع‚é——R‚à–³‚¢‹C‚ھ‚·‚é‚ٌ‚¾‚و‚ب‚ پB
•”•i‘م‚ھˆہ‚‚ب‚ء‚ؤ—ک‚´‚â‚ھ‰ز‚°‚éƒپƒٹƒbƒg‚ھ—L‚éپB
AppleگMژز‚حگM‹آگS‚ھ‹‚CPUƒAپ[ƒLˆعچs‚ة”؛‚ء‚ؤARM‘خ‰”إƒ\ƒtƒg‚ة‘S‚ؤ”ƒ‚¢’¼‚µ‚ة‚ب‚ء‚ؤ‚à‘¼‚جOS‚ةڈو‚èٹ·‚¦‚ؤڈo‚ؤ‚¢‚ء‚½‚è‚ح‚µ‚ب‚¢‚ج‚إ‰½‚ç–â‘è‚ب‚¢پB‚»‚ê‚ح‰ك‹ژ‚ج—ًژj‚ھڈط–¾‚µ‚ؤ‚¢‚é
AppleگMژز‚حگM‹آگS‚ھ‹‚CPUƒAپ[ƒLˆعچs‚ة”؛‚ء‚ؤARM‘خ‰”إƒ\ƒtƒg‚ة‘S‚ؤ”ƒ‚¢’¼‚µ‚ة‚ب‚ء‚ؤ‚à‘¼‚جOS‚ةڈو‚èٹ·‚¦‚ؤڈo‚ؤ‚¢‚ء‚½‚è‚ح‚µ‚ب‚¢‚ج‚إ‰½‚ç–â‘è‚ب‚¢پB‚»‚ê‚ح‰ك‹ژ‚ج—ًژj‚ھڈط–¾‚µ‚ؤ‚¢‚é
ARM‚ةˆع‚邱‚ئ‚ةƒپƒٹƒbƒg‚ح‚ب‚¢‚ھ
ARM‚ةˆع‚邼‚ئ‹؛‚µ‚ً‚©‚¯‚ç‚ê‚éƒپƒٹƒbƒg‚ح‚ئ‚ؤ‚à‘ه‚«‚¢
ARM‚ةˆع‚邼‚ئ‹؛‚µ‚ً‚©‚¯‚ç‚ê‚éƒپƒٹƒbƒg‚ح‚ئ‚ؤ‚à‘ه‚«‚¢
A7‚جNEON-FPUپAگ^–ت–ع‚ةŒvژZ‚µ‚ؤ‚ف‚é‚ئ
پEFMADD*2ƒ|پ[ƒg, FADD*1ƒ|پ[ƒg
پEFMUL‚حFMADD‚جƒ|پ[ƒg‚إژہچs
پEFADD‚حFMADD‚جƒ|پ[ƒg‚إ‚àژہچs‚إ‚«‚é (Œv3ƒ|پ[ƒg)
latency-throughput‚ح
پEFMADD 8-0.5
پEFMUL 4-0.5
پEFADD (گê—pƒ|پ[ƒg‚إژہچs) 4-1
پEFADD (FMAƒ|پ[ƒg‚إژہچs) 5-0.5
‚ئ‚ب‚ء‚ؤ‚¢‚é‚و‚¤‚ةŒ©‚¦‚é
پEFMADD*2ƒ|پ[ƒg, FADD*1ƒ|پ[ƒg
پEFMUL‚حFMADD‚جƒ|پ[ƒg‚إژہچs
پEFADD‚حFMADD‚جƒ|پ[ƒg‚إ‚àژہچs‚إ‚«‚é (Œv3ƒ|پ[ƒg)
latency-throughput‚ح
پEFMADD 8-0.5
پEFMUL 4-0.5
پEFADD (گê—pƒ|پ[ƒg‚إژہچs) 4-1
پEFADD (FMAƒ|پ[ƒg‚إژہچs) 5-0.5
‚ئ‚ب‚ء‚ؤ‚¢‚é‚و‚¤‚ةŒ©‚¦‚é
>>213
‚ا‚±‚جƒfپ[ƒ^پH
‚ا‚±‚جƒfپ[ƒ^پH
32bit‚ب‚ج‚©ژc”O
‚à‚¤‚؟‚ه‚ء‚ئƒ~ƒbƒNƒX‚جƒpƒ^پ[ƒ“‚ً‚ف‚ؤ‚ف‚ب‚¢‚ئ
‚ب‚ٌ‚ئ‚àŒ¾‚¦‚ب‚¢‚¯‚ا‚ـ‚ ٹT‚ثچ‡‚ء‚ؤ‚»‚¤
‚»‚ê‚ة‚µ‚ؤ‚àVFP‚حٹ®‘S‚ةژج‚ؤ‚ؤ‚é‚بپA‚ـ‚ چ،چX‚¾‚¯‚ا
‚à‚¤‚؟‚ه‚ء‚ئƒ~ƒbƒNƒX‚جƒpƒ^پ[ƒ“‚ً‚ف‚ؤ‚ف‚ب‚¢‚ئ
‚ب‚ٌ‚ئ‚àŒ¾‚¦‚ب‚¢‚¯‚ا‚ـ‚ ٹT‚ثچ‡‚ء‚ؤ‚»‚¤
‚»‚ê‚ة‚µ‚ؤ‚àVFP‚حٹ®‘S‚ةژج‚ؤ‚ؤ‚é‚بپA‚ـ‚ چ،چX‚¾‚¯‚ا
1GHz”¼‚خ‚ج“®چىƒ^پ[ƒQƒbƒg‚إ‚à‚±‚ج’ِ“x‚ج’iگ”‚ئ‚¢‚¤‚±‚ئ‚ح
FPU‚ة‚ح‚ ‚ـ‚葬‚¢ƒgƒ‰ƒ“ƒWƒXƒ^‚حژg‚ء‚ؤ‚ب‚³‚»‚¤‚¾‚ث
’لƒٹپ[ƒN‚جƒgƒ‰ƒ“ƒWƒXƒ^‚إپA’·‚ك‚جƒpƒCƒvƒ‰ƒCƒ“‚ة‚µ‚ؤپAژہچs•‚إگ«”\‚ً‰ز‚®ژv‘z‚ب‚ج‚¾‚낤‚©
FPU‚ة‚ح‚ ‚ـ‚葬‚¢ƒgƒ‰ƒ“ƒWƒXƒ^‚حژg‚ء‚ؤ‚ب‚³‚»‚¤‚¾‚ث
’لƒٹپ[ƒN‚جƒgƒ‰ƒ“ƒWƒXƒ^‚إپA’·‚ك‚جƒpƒCƒvƒ‰ƒCƒ“‚ة‚µ‚ؤپAژہچs•‚إگ«”\‚ً‰ز‚®ژv‘z‚ب‚ج‚¾‚낤‚©
“¯ˆس
’†‚جگl‚إ‚à‚ب‚¢Œہ‚èگ^‘ٹ‚ح•s–¾‚¾‚¯‚ا
ٹO–ى‚ج‰¯‘ھ‚ئ‚µ‚ؤ‚ح‚»‚ê‚ھ‘أ“–‚¶‚ل‚ب‚¢‚©‚ب‚ ‚ئ
’†‚جگl‚إ‚à‚ب‚¢Œہ‚èگ^‘ٹ‚ح•s–¾‚¾‚¯‚ا
ٹO–ى‚ج‰¯‘ھ‚ئ‚µ‚ؤ‚ح‚»‚ê‚ھ‘أ“–‚¶‚ل‚ب‚¢‚©‚ب‚ ‚ئ
چ،‚جMac‚حBootcamp‚إWindows‚ً“ü‚ê‚é‚©
‰¼‘z‰»ƒ\ƒtƒg‚إWindows‚ً‚»‚ج‚ـ‚ـژہچs‚إ‚«‚é“_‚إ
PowerPCژ‘م‚جMac‚و‚蔄‚ê‚ؤ‚¢‚é‚ھ
Windows‚ج‘م‚ي‚è‚ةiOS‚ًژg‚¦‚é‚و‚¤‚ة‚·‚邱‚ئ‚إ
“¯‚¶‚و‚¤‚ةƒ†پ[ƒU‚ً‘‚â‚·Œّ‰ت‚ح‚ ‚é
‰¼‘z‰»ƒ\ƒtƒg‚إWindows‚ً‚»‚ج‚ـ‚ـژہچs‚إ‚«‚é“_‚إ
PowerPCژ‘م‚جMac‚و‚蔄‚ê‚ؤ‚¢‚é‚ھ
Windows‚ج‘م‚ي‚è‚ةiOS‚ًژg‚¦‚é‚و‚¤‚ة‚·‚邱‚ئ‚إ
“¯‚¶‚و‚¤‚ةƒ†پ[ƒU‚ً‘‚â‚·Œّ‰ت‚ح‚ ‚é
>219
‚ب‚ة‚»‚جwindows8
‚ب‚ة‚»‚جwindows8
ڈ«—ˆپAiPad‚ھچ،‚جƒچپ[ƒGƒ“ƒhPC•ہ‚جگ«”\‚ة‚ب‚è
“‹چعƒپƒ‚ƒٹ‚ھ4GB‘OŒم‚ة‘‚¦‚ؤ‚©‚ç‚جکb
Windows 8‚حچ،‚ح‚ـ‚¾ƒ^ƒuƒŒƒbƒg‚ئ‚µ‚ؤ‚حƒIپ[ƒoپ[ƒXƒyƒbƒN‚·‚¬‚é
“‹چعƒپƒ‚ƒٹ‚ھ4GB‘OŒم‚ة‘‚¦‚ؤ‚©‚ç‚جکb
Windows 8‚حچ،‚ح‚ـ‚¾ƒ^ƒuƒŒƒbƒg‚ئ‚µ‚ؤ‚حƒIپ[ƒoپ[ƒXƒyƒbƒN‚·‚¬‚é
چ‚‰؟‚بƒLپ[ƒ{پ[ƒh‚ئƒ}ƒEƒX‚ً•t‚¯‚ب‚‚ؤچد‚ق‚ج‚حƒ†پ[ƒUپ[ƒپƒٹƒbƒg‘ه‚«‚¢‚و‚ب
ƒLپ[ƒ{پ[ƒh‚ئƒ}ƒEƒX‚ھچ‚‰؟‚ء‚ؤپA‰©‹à‚جƒLپ[ƒ{پ[ƒh‚ئ‚©ƒ_ƒCƒ„‚ھ‚؟‚è‚خ‚ك‚ç‚ꂽƒ}ƒEƒX‚إ‚à‚آ‚©‚ء‚ؤ‚ٌ‚ج‚©پH
Mac OS‚ج—p“r‚ًپAiPhone‚âiPad‚جƒ\ƒtƒgƒEƒFƒAٹJ”‚ج“¹‹ï‚ة“ء‰»‚·‚é‚ج‚ب‚çپA
ARM‰»‚ح‚¨‚¨‚¢‚ةƒپƒٹƒbƒg‚ھ—L‚é‚بپB‘¼‚ج—p“r‚ح•ت‚ةMac‚إ‚ب‚‚ؤ‚à‚±‚ب‚¹‚邵
ARM‰»‚ح‚¨‚¨‚¢‚ةƒپƒٹƒbƒg‚ھ—L‚é‚بپB‘¼‚ج—p“r‚ح•ت‚ةMac‚إ‚ب‚‚ؤ‚à‚±‚ب‚¹‚邵
‰و‘œ‚âDTP‚ب‚ٌ‚©‚حWin‚ھ‘‚¦‚ؤ—ˆ‚؟‚ل‚ء‚½‚©‚ç‚ث‚¦
پ@پ@پ@پ@پ@پ@پ@پ@پ@پQپQپQ
پ@پ@پ@پ@پ@پ@پ@پ^ پـپ@پ@پـپ_پ@پ@پ@پ@پ@
پ@پ@پ@پ@پ@ پ^پ@پiپـپjپ@ پiپـپjپ_پ@پ@پ@
پ@پ@پ@پ@پ^ پ@ ///پi__گl__پj///پ_پ@‚Q–œ‰~‚ج‚¨‚¹‚؟—؟—‚ھ”¼ٹz‚¾‚ء‚½‚¨‚—
پ@پ@ پ@ |پ@پ@ u. پ@ `Yپـy'پLپ@پ@پ@ |پ@پ@‚±‚ê‚إ‚¨گ³Œژ‚ح‚خ‚ء‚؟‚肾‚¨ww
پ@ پ@ پ@ پ_ پ@ پ@ پ@ قپ[ پŒپ@پ@,پ^پ@پ@
پ@پ@ پ@ پ^پ@پ@پ@پ@پ@پ@پ@پQپQ|__پQپ@پ@
پ@پ@ پ@| پ@پ@‚Œ..پ@پ@پ@پ^lپ@¸قظ°خكف..`lپ@
پ@پ@ پ@پR پ@ک¤-.,پ^ پ@|پQپ@‚¨‚¹‚؟_|پ@
پ@پ@پ@پ@/`پ[¤پQةپ@پ^پ@پPپPپP پ^پ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ«
پ@پQپQپQپQپQپQپQپQپQپQپQپQپQپQپQپQ
پ@|پ_پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پaپ@پ@پ@پ@پ@پ@ پ^|
پ@|پ@ (پP“÷)پQ/پPVپPپR__پaپQپQپQ__پعپ@ |
پ@|پ@پ@(پP“÷)پ@| ژè| ژè |پ@پaپ@پ@iپ_ء°½ق|پ@ |
پ@|پ@پ@|پMپ[پLپ@پ@| ‰H| ‰H| .پa-پ[¤پ_.پ_ /lپ@ |
پ@|پ@پ@|(پP“÷)پ@| گو| گو| پa تر )پ@ پ_l/lپ@ .|
پ@|پ@پ@| پMپ[پLپ@پ@پSپv^پRة پaپRپQةپ@پ@پ@پ@|_پQ|
پ@|پ_پPپPپPپPپPپPپPپaپPپPپPپPپPپ@پ^|
پ@|پ@„،پ^پـپـپـپـپR.پaپPپPپPپPپPپP|پ@.|پ@پ@پ@پ@پ@پ@پ@
پ@|پ@ (پ@پ@پ@(پ@پ@پ@پSپ@) پaپ@پ@پ@پ@پ@پ@پ@lپـl |پ@|
پ@|پ@ |پ_پ@پ@ژc”ر پ@ /پaپ@پ@پ@پ@پ@/پP|پ@ | |پ@|
پ@|پ@ | پ@پRپ@پ@پ@پ@پj ة پaپ@پ@‚پMپRپAقi.“÷پR )پ@.|پ@
پ@|پ@ |پ@پ@ حپ@پ@ ƒmپ@| پa پ@پ@ .پ_ پ_پTپ@ | |پ@ |پ@ پ@پ@„©پRپ@ -|rپ]¤.پ@عپ@|
پ@|پ@ |پ@پ@پ@ پMپ[^پ['پaپ@پ@پ@پ@پ@پMپRةپP‡Yپ@پ@|پ@پ@.پ@‚„پـ)پ@./|پ@_ةپ@ __ة
پ@پPپPپPپPپPپPپPپPپPپPپPپPپPپPپPپP
پ@پ@پ@پ@پ@پ@پ@پ^ پـپ@پ@پـپ_پ@پ@پ@پ@پ@
پ@پ@پ@پ@پ@ پ^پ@پiپـپjپ@ پiپـپjپ_پ@پ@پ@
پ@پ@پ@پ@پ^ پ@ ///پi__گl__پj///پ_پ@‚Q–œ‰~‚ج‚¨‚¹‚؟—؟—‚ھ”¼ٹz‚¾‚ء‚½‚¨‚—
پ@پ@ پ@ |پ@پ@ u. پ@ `Yپـy'پLپ@پ@پ@ |پ@پ@‚±‚ê‚إ‚¨گ³Œژ‚ح‚خ‚ء‚؟‚肾‚¨ww
پ@ پ@ پ@ پ_ پ@ پ@ پ@ قپ[ پŒپ@پ@,پ^پ@پ@
پ@پ@ پ@ پ^پ@پ@پ@پ@پ@پ@پ@پQپQ|__پQپ@پ@
پ@پ@ پ@| پ@پ@‚Œ..پ@پ@پ@پ^lپ@¸قظ°خكف..`lپ@
پ@پ@ پ@پR پ@ک¤-.,پ^ پ@|پQپ@‚¨‚¹‚؟_|پ@
پ@پ@پ@پ@/`پ[¤پQةپ@پ^پ@پPپPپP پ^پ@
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ«
پ@پQپQپQپQپQپQپQپQپQپQپQپQپQپQپQپQ
پ@|پ_پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پaپ@پ@پ@پ@پ@پ@ پ^|
پ@|پ@ (پP“÷)پQ/پPVپPپR__پaپQپQپQ__پعپ@ |
پ@|پ@پ@(پP“÷)پ@| ژè| ژè |پ@پaپ@پ@iپ_ء°½ق|پ@ |
پ@|پ@پ@|پMپ[پLپ@پ@| ‰H| ‰H| .پa-پ[¤پ_.پ_ /lپ@ |
پ@|پ@پ@|(پP“÷)پ@| گو| گو| پa تر )پ@ پ_l/lپ@ .|
پ@|پ@پ@| پMپ[پLپ@پ@پSپv^پRة پaپRپQةپ@پ@پ@پ@|_پQ|
پ@|پ_پPپPپPپPپPپPپPپaپPپPپPپPپPپ@پ^|
پ@|پ@„،پ^پـپـپـپـپR.پaپPپPپPپPپPپP|پ@.|پ@پ@پ@پ@پ@پ@پ@
پ@|پ@ (پ@پ@پ@(پ@پ@پ@پSپ@) پaپ@پ@پ@پ@پ@پ@پ@lپـl |پ@|
پ@|پ@ |پ_پ@پ@ژc”ر پ@ /پaپ@پ@پ@پ@پ@/پP|پ@ | |پ@|
پ@|پ@ | پ@پRپ@پ@پ@پ@پj ة پaپ@پ@‚پMپRپAقi.“÷پR )پ@.|پ@
پ@|پ@ |پ@پ@ حپ@پ@ ƒmپ@| پa پ@پ@ .پ_ پ_پTپ@ | |پ@ |پ@ پ@پ@„©پRپ@ -|rپ]¤.پ@عپ@|
پ@|پ@ |پ@پ@پ@ پMپ[^پ['پaپ@پ@پ@پ@پ@پMپRةپP‡Yپ@پ@|پ@پ@.پ@‚„پـ)پ@./|پ@_ةپ@ __ة
پ@پPپPپPپPپPپPپPپPپPپPپPپPپPپPپPپP
‚ً‚¢‚ً‚¢Applied Materials‚ئ“Œ‹ƒGƒŒƒNƒgƒچƒ“‚ھچ‡•¹‚µ‚؟‚ـ‚ء‚½‚¼
TEL
“ْ–{ڈI‚ي‚ء‚½‚ب
232 پFSocket774پF2013/09/28(“y) 18:26:58.80 ID:+ZQt32nd
‚à‚ح‚⑬‚¢‚ئ‚¢‚¤‚©پA‚ ‚ꂾ‚¯–‚ًژ‚µ‚½A15‚ح‚ب‚ٌ‚¾‚ء‚½‚ٌ‚¾‚ëپc
‚µ‚©‚µ‚±‚ꂾ‚¯گ«”\‚ھ‚ ‚ê‚خƒNƒچƒbƒNڈم‚°‚ê‚خARM Macڈo—ˆ‚»‚¤‚¾‚ب
‚µ‚©‚µ‚±‚ꂾ‚¯گ«”\‚ھ‚ ‚ê‚خƒNƒچƒbƒNڈم‚°‚ê‚خARM Macڈo—ˆ‚»‚¤‚¾‚ب
233 پFSocket774پF2013/09/28(“y) 18:29:51.14 ID:+ZQt32nd
‚µ‚©‚µIPC‚حA7پài7‚ئ‚©گ¦‚·‚¬‚é
AMD‚ھژ€‚ٌ‚¾‚ئژv‚ء‚½‚çApple‚ھIntel‚جگ^‚جƒ‰ƒCƒoƒ‹‚¾‚ء‚½‚ئ‚ح
AMD‚ھژ€‚ٌ‚¾‚ئژv‚ء‚½‚çApple‚ھIntel‚جگ^‚جƒ‰ƒCƒoƒ‹‚¾‚ء‚½‚ئ‚ح
234 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/28(“y) 18:38:51.80 ID:dh4J+775
1ƒRƒAپEƒNƒچƒbƒN‚ ‚½‚è‚جFLOPSگ”‚إ‚¢‚‚ئBulldozer‚جژ©ڈج‚QƒRƒA‚ً—½‚¢‚إ‚é‚©‚ç‚ب‚ں
ژ©ژذ‚جjaguar‚ة‚à”²‚©‚ê‚ؤ‚ب‚©‚ء‚½پHپƒBulldozer
‚ا‚¤‚¹ژg‚ي‚ê‚é‚ج‚حiPhone‚ئiPad‚¾‚¯پAƒNƒچƒbƒN‚حڈم‚ھ‚ç‚ب‚‚ؤ—ا‚¢‚ئٹ„‚èگط‚ê‚é‚©‚炱‚»
‚±‚ꂾ‚¯IPC‚ھچ‚‚¢گفŒv‚ًڈب“d—ح‚إژہ‘•‚إ‚«‚é‚ج‚©‚à‚µ‚ê‚ب‚¢
‚ـ‚ Bulldozer‚ئ‚ح‘خ‹ة‚جژv‘z‚¾‚—
‚±‚ꂾ‚¯IPC‚ھچ‚‚¢گفŒv‚ًڈب“d—ح‚إژہ‘•‚إ‚«‚é‚ج‚©‚à‚µ‚ê‚ب‚¢
‚ـ‚ Bulldozer‚ئ‚ح‘خ‹ة‚جژv‘z‚¾‚—
‚ ‚ئپA‚ب‚ٌ‚¾‚©‚ٌ‚¾‚¢‚ء‚ؤƒoƒJ”„‚ê‚·‚éƒfƒoƒCƒX‚¾‚ء‚ؤ‚ج‚à‚ ‚é‚و‚ب
‚»‚ꂾ‚¯ٹJ”ƒRƒXƒg‚ً‚©‚¯‚ç‚ê‚é‚ء‚ؤ‚±‚ئ‚إ
‚»‚ꂾ‚¯ٹJ”ƒRƒXƒg‚ً‚©‚¯‚ç‚ê‚é‚ء‚ؤ‚±‚ئ‚إ
ƒNƒچƒbƒNڈم‚°‚é‚و‚è‚àIPCڈم‚°‚é‚ظ‚¤‚ھڈب“d—ح‚¾‚ئAMD‚ح•ھ‚©‚ء‚ؤ‚¢‚½‚ح‚¸‚ب‚ٌ‚¾‚¯‚ا‚ب‚ں
A7‚ء‚ؤŒy—ت‘ه—ت‚جڈˆ—‚ً‚·‚éƒTپ[ƒoپ[‚جٹضŒWژز‚ھ—~‚µ‚ھ‚è‚»‚¤پH
ƒAƒbƒvƒ‹‚حCPUٹضکA‚جٹw‰ï‚ئ‚©‚إ‚ ‚ـ‚蔕\‚µ‚ب‚‚ؤڈعچׂي‚©‚ç‚ٌ‚ج‚ھژc”O
ƒAƒbƒvƒ‹‚حCPUٹضکA‚جٹw‰ï‚ئ‚©‚إ‚ ‚ـ‚蔕\‚µ‚ب‚‚ؤڈعچׂي‚©‚ç‚ٌ‚ج‚ھژc”O
Appleژ©گg‚ھƒTپ[ƒoپ[ƒrƒWƒlƒXژn‚ك‚é‚©‚à‚ب
241 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/28(“y) 21:44:28.98 ID:dh4J+775
XServe“P‘ق‚µ‚ؤ‚ـ‚·‚¯‚ا‚ث
Œ»ڈَ‚إ‚à‚â‚ء‚ؤ‚é‚إ‚µ‚هپB
iCloud‚جƒoƒbƒNƒGƒ“ƒhƒTپ[ƒo‚ء‚ؤ‰½‚ًژg‚ء‚ؤ‚é‚ٌ‚¾‚ëپH
Œ»ڈَ‚إ‚à‚â‚ء‚ؤ‚é‚إ‚µ‚هپB
iCloud‚جƒoƒbƒNƒGƒ“ƒhƒTپ[ƒo‚ء‚ؤ‰½‚ًژg‚ء‚ؤ‚é‚ٌ‚¾‚ëپH
‚¦پA‚»‚ٌ‚ب‚ةƒXƒSƒC‚جپHA7پB
P.A.SemiپAƒXƒQƒF‚ب¥¥¥پB
P.A.SemiپAƒXƒQƒF‚ب¥¥¥پB
G5‚جڈب“d—ح‰»‚â‚ء‚؟‚ل‚ء‚½‚و‚¤‚ب‚ئ‚±‚¾‚©‚ç‚ب
–L•x‚بژ‘‹à‚ھ‚ ‚ê‚خ‚¢‚ë‚¢‚ë‚إ‚«‚邾‚ë
–L•x‚بژ‘‹à‚ھ‚ ‚ê‚خ‚¢‚ë‚¢‚ë‚إ‚«‚邾‚ë
Apple‚جƒTƒCƒg‚إASP.NET‚جƒGƒ‰پ[ƒyپ[ƒW‚ھڈo‚½‚ء‚ؤƒjƒ…پ[ƒX‚ح‚ ‚ء‚½‚ث
ژ©‘O‚جƒTپ[ƒoپ{ٹO•”ƒTپ[ƒo‚ج‘g‚فچ‡‚ي‚¹‚إ‚µ‚هپH
ٹO•”ƒTپ[ƒo‚ة‚آ‚¢‚ؤ‚حپAٹî–{linux‚¶‚ل‚ب‚¢‚جپH
ٹO•”ƒTپ[ƒo‚ة‚آ‚¢‚ؤ‚حپAٹî–{linux‚¶‚ل‚ب‚¢‚جپH
Apple A7 Teardown
ttp://www.ifixit.com/Teardown/Apple+A7+Teardown/17682/1
ttp://www.ifixit.com/Teardown/Apple+A7+Teardown/17682/1
ˆêگl‚جژv‚¢•t‚«‚إگ»•i‚ھ‘إ‚؟گط‚ç‚ê‚é‰ïژذ‚جژI‚ب‚ٌ‚©”ƒ‚¦‚ب‚¢
‚»‚¢‚آژ€‚ٌ‚¾‚¯‚ا‚ب
‚»‚¢‚آژ€‚ٌ‚¾‚¯‚ا‚ب
‚¨‚µ‚ل‚êƒPپ[ƒX‚ج‚¨‚µ‚ل‚ê”ï—p‚ھگ»•i‰؟ٹi‚ةڈمڈو‚¹‚³‚ê‚ؤ‚»‚¤‚إژg‚¤‹C‚ة‚ب‚ç‚ٌپB
250 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/09/29(“ْ) 18:26:28.66 ID:b2l5FK/3
Xeonƒڈپ[ƒNƒXƒeپ[ƒVƒ‡ƒ“‚ئ‚µ‚ؤ‚جMac Pro‚ح‰½Œج‚©HP‚âDell‚ج‚»‚ê‚و‚èٹi’i‚ةˆہ‚¢
چ،”ƒ‚¤‚ئ2گ¢‘م‘O‚جWestmere-EPƒ}ƒVƒ“‚ھ“ح‚‚وپI‚±‚ê‚إ‹ï‘ج“I‚ةچ¢‚é‚ج‚ح‚¢‚ـ‚ا‚«AVX–½—ك‚ھژg‚¦‚ب‚¢“_
چفŒة•ّ‚¦‚·‚¬‚½‚ٌ‚¾‚낤‚©‚ث‚¦
‚©‚آ‚ؤMacProژg‚ء‚ؤ‚½‰f‘œپEˆَچü‹ئٹE‚ئ‚©‚ھ‚ا‚ٌ‚ا‚ٌWindows‚ةˆئ‘ض‚¦‚µ‚ؤپA
ƒrƒWƒlƒX—p“r‚جMac‚ھ‚ا‚ٌ‚ا‚ٌŒ¸‚ء‚ؤ‚é
‹t‚ةƒrƒWƒlƒX—p“r‚إ‚جiPad—ک—p‚ھ‘‚¦‚½
ƒrƒWƒlƒX—p“r‚جMac‚ھ‚ا‚ٌ‚ا‚ٌŒ¸‚ء‚ؤ‚é
‹t‚ةƒrƒWƒlƒX—p“r‚إ‚جiPad—ک—p‚ھ‘‚¦‚½
{kind=link}
ٹï“V—َƒPپ[ƒX‚إٹg’£گ«ٹF–³‚ب‚ج‚à‚â‚خ‚¢‚¯‚ا
‚»‚à‚»‚àXeon‚ج‚‚¹‚ة•ذ”xŒہ’è‚ب‚ج‚ھ’v–½“I
‚»‚à‚»‚àXeon‚ج‚‚¹‚ة•ذ”xŒہ’è‚ب‚ج‚ھ’v–½“I
POWER‚ً‘¢‚ç‚تژز‚ح’nچ–‚ة—ژ‚؟‚é،
PCI-Eژg‚ء‚ؤٹg’£‚إ‚«‚é–{‘ج‚ھچ‚‰؟‚بPro‚µ‚©‚ب‚¢پ¨ٹg’£‹@ٹي‚ھڈo‚ب‚¢پ¨ˆہ‰؟‚ب‹@ژي‚ةٹg’£ƒXƒچƒbƒg‚آ‚¯‚é——R‚ھ‚ب‚¢پ¨پcپc
‚ء‚ؤ‚¢‚¤ˆ«ڈzٹآ‚¾‚ء‚½‚©‚çپAHDD“à‘ ‚إ‚«‚éˆبٹO‚ج‹گ‘ه–{‘ج‚جˆس–،‚ھ‚ب‚‚ب‚ء‚ؤ‚½‚ج‚àژ–ژہ‚¾‚¯‚ا
‰tڈ»•ت‚ج–{‘ج‚إ‚»‚±‚»‚±‚جCPU‚ھ‚آ‚¢‚½‚جڈo‚µ‚ؤ‚‚ê‚ب‚¢‚ئپA”ƒ‚¤‹@ژي‚ھ‚ب‚‚ؤچ¢‚é
‚ ‚é‚¢‚حiMac‚إپA–{‘ج‹N“®‚µ‚ب‚‚ؤ‚àٹO•”PC‚©‚çƒfƒBƒXƒvƒŒƒC‚ئ‚µ‚ؤژg‚¦‚é‹@”\‚ھ‚ ‚ê‚خ‚»‚ê‚إ‚à‚¢‚¢
‚ء‚ؤ‚¢‚¤ˆ«ڈzٹآ‚¾‚ء‚½‚©‚çپAHDD“à‘ ‚إ‚«‚éˆبٹO‚ج‹گ‘ه–{‘ج‚جˆس–،‚ھ‚ب‚‚ب‚ء‚ؤ‚½‚ج‚àژ–ژہ‚¾‚¯‚ا
‰tڈ»•ت‚ج–{‘ج‚إ‚»‚±‚»‚±‚جCPU‚ھ‚آ‚¢‚½‚جڈo‚µ‚ؤ‚‚ê‚ب‚¢‚ئپA”ƒ‚¤‹@ژي‚ھ‚ب‚‚ؤچ¢‚é
‚ ‚é‚¢‚حiMac‚إپA–{‘ج‹N“®‚µ‚ب‚‚ؤ‚àٹO•”PC‚©‚çƒfƒBƒXƒvƒŒƒC‚ئ‚µ‚ؤژg‚¦‚é‹@”\‚ھ‚ ‚ê‚خ‚»‚ê‚إ‚à‚¢‚¢
PCIeƒXƒچƒbƒg‚ھ”pژ~‚³‚ꂽ‚çApogee Symphony64 PCIe‚ھ‚³‚³‚ç‚ب‚‚ب‚ء‚؟‚ل‚¤‚¶‚ل‚ٌ
Apogeeگ»•i‚حMacگê—p‚إPC‚ة‚حژg‚¦‚ب‚¢‚ٌ‚¾‚¯‚اپcپc
Apogeeگ»•i‚حMacگê—p‚إPC‚ة‚حژg‚¦‚ب‚¢‚ٌ‚¾‚¯‚اپcپc
‚»‚è‚لƒrƒWƒlƒXƒ†پ[ƒX‚جƒVƒFƒAŒ¸‚é‚ي‚¯‚¾
—رŒçˆَ‚جƒXƒ^ƒCƒٹƒbƒVƒ…‚بƒ‰ƒbƒNپEƒfƒXƒN‚ھ”ج”„‚³‚ꂽ‚肵‚ؤ،
‰ئ‹ï‚جژں‚ح‰ئ‚جŒڑ‚ؤ”„‚肾‚ب،
‚إپCچإŒم‚ح—رŒçˆَ‚جٹ»‰±‚إچK‚¹‚جˆêگ¶‚ً’÷‚ك‚‚‚éw
‰ئ‹ï‚جژں‚ح‰ئ‚جŒڑ‚ؤ”„‚肾‚ب،
‚إپCچإŒم‚ح—رŒçˆَ‚جٹ»‰±‚إچK‚¹‚جˆêگ¶‚ً’÷‚ك‚‚‚éw
‚»‚ج‚¤‚؟‰ئ‚جƒCƒ“ƒeƒٹƒWƒFƒ“ƒg‰»‚àگi‚ق‚¾‚낤‚©‚çپA‰ئ‚‚ç‚¢‚ـ‚إ‚ح—رŒç‚©‚ا‚¤‚©‚ح‚ئ‚à‚©‚
ƒpƒ\ƒRƒ“ƒپپ[ƒJپ[گ»‚جپi‚ ‚é‚¢‚ح–¼‘O‚ًٹ¥‚µ‚½پj‰ئ‚حڈo‚é‚ٌ‚¶‚ل‚ب‚¢‚©
ƒpƒ\ƒRƒ“ƒپپ[ƒJپ[گ»‚جپi‚ ‚é‚¢‚ح–¼‘O‚ًٹ¥‚µ‚½پj‰ئ‚حڈo‚é‚ٌ‚¶‚ل‚ب‚¢‚©
‚±‚؟‹T‚ج‰½‚©‚牽‚ـ‚إƒRƒ“ƒsƒ…پ[ƒ^گ§Œن‚ج‰ئ‚ًژv‚¢ڈo‚µ‚½پB
>>261
ƒ~ƒTƒڈƒzپ[ƒ€GŒ^ƒnƒEƒX‚جƒRƒ“ƒgƒچپ[ƒ‹ƒ^ƒڈپ[‚ئ‚©
ƒIپ[ƒ‹ƒVƒXƒeƒ€ژذ‚جƒAƒŒ‚ئ‚©
‚»‚è‚ل‚ـ‚ںگج‚©‚çƒzپ[ƒ€ƒRƒ“ƒgƒچپ[ƒ‹‚ء‚ؤ“z‚ح‚ ‚邯‚ا‚³پc
ƒ~ƒTƒڈƒzپ[ƒ€GŒ^ƒnƒEƒX‚جƒRƒ“ƒgƒچپ[ƒ‹ƒ^ƒڈپ[‚ئ‚©
ƒIپ[ƒ‹ƒVƒXƒeƒ€ژذ‚جƒAƒŒ‚ئ‚©
‚»‚è‚ل‚ـ‚ںگج‚©‚çƒzپ[ƒ€ƒRƒ“ƒgƒچپ[ƒ‹‚ء‚ؤ“z‚ح‚ ‚邯‚ا‚³پc
TRON“d”]ڈZ‘î‚©‚—
>>264
ƒ~ƒTƒڈGŒ^‚ئ‚©‚ح‚»‚ê‚و‚è‘O‚جکb‚إ‚ح‚ ‚é
ٹO•”‚©‚ç‚ج‰ئ“dON/OFF‚âƒZƒ“ƒTپ[ژg‚ء‚ؤ‚ج–h”ئ‹@”\‚ب‚ٌ‚ؤ‚ج‚ح
ƒ}ƒCƒRƒ“گ¶‚ـ‚ê‚éˆب‘O‚©‚çچl‚¦‚ç‚ê‚ؤ‚¢‚½کb‚إ‚ح‚ ‚éپc‚ ‚é‚ھپc
‚¾‚ھ‚µ‚©‚µپA‚±‚ٌ‚ب‹@”\‚ء‚ؤ–{“–‚ة•K—v‚ب‚ج?‚ئŒ¾‚¤پAچھ–{“I‚ب‹^–â‚ھw
‚»‚ê‚إ‚àپA21گ¢‹I‚ة“ü‚ê‚خ‚³پA“d“®‰JŒث‚®‚ç‚¢‚ب‚ç•پ‹y‚µ‚ؤ‚é‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚¯‚ا‚بپ`پ`پ`orz
ƒ~ƒTƒڈGŒ^‚ئ‚©‚ح‚»‚ê‚و‚è‘O‚جکb‚إ‚ح‚ ‚é
ٹO•”‚©‚ç‚ج‰ئ“dON/OFF‚âƒZƒ“ƒTپ[ژg‚ء‚ؤ‚ج–h”ئ‹@”\‚ب‚ٌ‚ؤ‚ج‚ح
ƒ}ƒCƒRƒ“گ¶‚ـ‚ê‚éˆب‘O‚©‚çچl‚¦‚ç‚ê‚ؤ‚¢‚½کb‚إ‚ح‚ ‚éپc‚ ‚é‚ھپc
‚¾‚ھ‚µ‚©‚µپA‚±‚ٌ‚ب‹@”\‚ء‚ؤ–{“–‚ة•K—v‚ب‚ج?‚ئŒ¾‚¤پAچھ–{“I‚ب‹^–â‚ھw
‚»‚ê‚إ‚àپA21گ¢‹I‚ة“ü‚ê‚خ‚³پA“d“®‰JŒث‚®‚ç‚¢‚ب‚ç•پ‹y‚µ‚ؤ‚é‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚¯‚ا‚بپ`پ`پ`orz
“d“®‰JŒث‚ً“ü‚ꂽ‚ھپAƒZƒ“ƒTپ[‚âƒٹƒ‚ƒRƒ“‚ھ‚ب‚¢‚ئ•s•ض‚¾‚·
’â“d‚ھ•|‚¢‚—
“d“®‰JŒث‚و‚è21گ¢‹I‚ة‚à‚ب‚ء‚ؤƒ|ƒٹƒJپ[ƒ{ƒlƒCƒg‰JŒث‚ھ•پ‹y‚µ‚ب‚¢‚ج‚ھ•sژv‹c
چ،ژ‚جگV’zڈZ‘î‚إ‚ح‰JŒث‚حƒIƒvƒVƒ‡ƒ“‚إ‚·‚ج‚إپB‚±‚؟‚ç‚©‚ç—ٹ‚ـ‚ب‚¢‚ئگفŒv‚ة“ü‚ء‚ؤ‚ب‚¢پB
ƒTƒbƒV‚ً‹‰»‚·‚ê‚خ‰JŒث‚ح‚à‚¤‚¢‚ç‚ٌ‚ؤٹ´‚¶‚إ‚·‚بپB‰½‚جƒXƒŒ‚¾پB
ƒTƒbƒV‚ً‹‰»‚·‚ê‚خ‰JŒث‚ح‚à‚¤‚¢‚ç‚ٌ‚ؤٹ´‚¶‚إ‚·‚بپB‰½‚جƒXƒŒ‚¾پB
چإ‹ك‚ج‰JŒث‚ء‚ؤ‘‹‚جڈم‘¤‚ةٹھ‚«ژو‚é‚â‚آ‚¶‚ل‚ب‚¢‚جپH
ˆêڈu‰½‚جƒXƒŒ‚©•ھ‚©‚ç‚ب‚ٌ‚¾‚—
—³ٹھ”يٹQ‚ج—\‘zٹ댯‹وˆو‚ةŒڑ•¨‚ھ‚ ‚é‚ج‚ب‚ç
‰JŒث‚ح–½ژç‚é‚ج‚ة”ٌڈي‚ة—LŒّ‚¾‚ب
‰JŒث‚ح–½ژç‚é‚ج‚ة”ٌڈي‚ة—LŒّ‚¾‚ب
‘‹ƒKƒ‰ƒXژ©‘ج‚ًƒ|ƒٹƒJپ[ƒ{ƒlƒCƒg‚ة‚·‚邾‚ëپB
ڈe’e‘إ‚؟چ‚ـ‚ê‚ؤ‚à–â‘è‚ب‚¢‚و‚¤‚بپB
ڈe’e‘إ‚؟چ‚ـ‚ê‚ؤ‚à–â‘è‚ب‚¢‚و‚¤‚بپB
‚¨‚ـ‚¢‚ح‘ه“—ج‚©‰½‚©‚©پH‚—
ƒAƒپƒٹƒJ‰ئ’ë‚إ‚à‚»‚ٌ‚ب‚±‚ئ‚µ‚ثپ[‚و
‚س‚آ‚¤‚ج‰JŒث‚ھ•—‘¬70m/s‚ة‘خ‰‚µ‚ؤ‚é‚ئ‚ح‚¨‚à‚¦‚ٌ
ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ء‚ؤŒڑ’z‚ج‚±‚ئ‚¾‚©‚çٹشˆل‚ء‚ؤ‚ب‚¢‚ب
‚»‚ٌ‚ب‚ة•—‘¬‚ ‚é‚ئژش‚ھ”ٍ‚ٌ‚إ‚‚¼
ڈo—ˆ‚ê‚خگيژشپAچإ’ل‚إ‚à‘•چbژش‚ة‚µ‚ب‚¢‚ئ
ڈo—ˆ‚ê‚خگيژشپAچإ’ل‚إ‚à‘•چbژش‚ة‚µ‚ب‚¢‚ئ
‚»‚à‚»‚à–ط‘¢ڈZ‘î‚جژ“_‚إ‚¢‚‚çڈن•v‚ب‰JŒث‚آ‚¯‚و‚¤‚ھ—³ٹھ‚ة‚ح‘د‚¦‚ç‚ê‚ب‚¢
PCڈZ‘î‚©RCڈZ‘‚ل‚ب‚¢‚ئ
PCڈZ‘î‚©RCڈZ‘‚ل‚ب‚¢‚ئ
ƒfƒ…پ[ƒN“Œ‹½‚؟‚ل‚ٌ
‰JŒث‚و‚ë‚¢Œث–h’eƒKƒ‰ƒX‚إ ƒ`ƒƒƒlƒ‹ƒRƒ“ƒgƒچپ[ƒ‰ ‚ئ DMA ‚ًکA‘z‚µ‚½
پu‚¢‚â‚»‚êDMA controller‚إchannel controller‚ئ‚ح‚؟‚ل‚¤‚إپv
پuٹm‚©‚ةDMA‚ئ‚àŒؤ‚ش‚¯‚ا‚³پEپEپE‚ ‚ج‚ب‚ںپcپv
پuCPU‘پ‚‚ب‚èDMA‚ھ—L‚é‚©‚çchannel controller•s—v‚ئ‚©ƒAƒz‚إ‚·‚©پHگà–¾‚·‚ٌ‚ج–ت“|‚¾‚بپv
پuŒّ—¦ˆل‚¤‚¶‚ل‚ٌ–ˆ‰ٌCPU‚ھDMAژw—كڈo‚·‚ج‚ئˆêکA‚جچى‹ئڈI‚ء‚ؤٹ®—¹’ت’m‚¾‚¯‚ًژَ‚¯ژو‚é‚ج‚ئپv
پu‚ـپAx64‚âARMژg‚ء‚ؤ‚é•ھ‚ة‚ح‚ا‚¤‚إ‚à‚¢‚¢‚¯‚اپv
پu‚¢‚â‚»‚êDMA controller‚إchannel controller‚ئ‚ح‚؟‚ل‚¤‚إپv
پuٹm‚©‚ةDMA‚ئ‚àŒؤ‚ش‚¯‚ا‚³پEپEپE‚ ‚ج‚ب‚ںپcپv
پuCPU‘پ‚‚ب‚èDMA‚ھ—L‚é‚©‚çchannel controller•s—v‚ئ‚©ƒAƒz‚إ‚·‚©پHگà–¾‚·‚ٌ‚ج–ت“|‚¾‚بپv
پuŒّ—¦ˆل‚¤‚¶‚ل‚ٌ–ˆ‰ٌCPU‚ھDMAژw—كڈo‚·‚ج‚ئˆêکA‚جچى‹ئڈI‚ء‚ؤٹ®—¹’ت’m‚¾‚¯‚ًژَ‚¯ژو‚é‚ج‚ئپv
پu‚ـپAx64‚âARMژg‚ء‚ؤ‚é•ھ‚ة‚ح‚ا‚¤‚إ‚à‚¢‚¢‚¯‚اپv
‚¢‚ء‚»ƒWƒIƒtƒچƒ“ƒg‚ةˆعڈZ‚µ‚ë
‚µ‚©‚à‚»‚±‚ة‚حŒ»گ¶گl—قˆبڈم‚ج’m“Iگ¶–½‘ج‚ھ‚¢‚é
‚µ‚©‚à‚»‚±‚ة‚حŒ»گ¶گl—قˆبڈم‚ج’m“Iگ¶–½‘ج‚ھ‚¢‚é
ƒyƒ‹ƒVƒ_پ[‹ضژ~
ƒ^پ[ƒUƒ“‚إ‚¢‚¢‚و‚à‚¤
http://pc.watch.impress.co.jp/docs/news/20131007_618435.html
‚±‚ê‚حGPU‚ئ‚©Phi‚جƒXƒpƒRƒ“‚ة‚ا‚¤‰e‹؟‚·‚é‚ج‚©‚ث
‚±‚ê‚حGPU‚ئ‚©Phi‚جƒXƒpƒRƒ“‚ة‚ا‚¤‰e‹؟‚·‚é‚ج‚©‚ث
‚ب‚؛‚©•ھٹٍ—\‘ھ‚ئ‚©‚جچ€–ع‚ھ“ü‚ء‚ؤ’¼گü”ش’¬‚جGPGPUگ¨‚ھ—ـ–ع‚ة‚ب‚ء‚½‚肵‚ؤ‚ب
>>286
Toward a New Metric for Ranking High Performance Computing Systems
ttp://www.netlib.org/utk/people/JackDongarra/PAPERS/HPCG-Benchmark-utk.pdf
What should replace Linpack for ranking supercomputers?
ttp://www.theregister.co.uk/2013/06/21/hpcg_supercomputing_benchmark_proposal/
–§چs—ٌ‚جƒKƒEƒX‚جڈء‹ژ–@پ¨‘aچs—ٌ‚ج‹¤–ًŒù”z–@پ@پH
Toward a New Metric for Ranking High Performance Computing Systems
ttp://www.netlib.org/utk/people/JackDongarra/PAPERS/HPCG-Benchmark-utk.pdf
What should replace Linpack for ranking supercomputers?
ttp://www.theregister.co.uk/2013/06/21/hpcg_supercomputing_benchmark_proposal/
–§چs—ٌ‚جƒKƒEƒX‚جڈء‹ژ–@پ¨‘aچs—ٌ‚ج‹¤–ًŒù”z–@پ@پH
‚·‚إ‚ةپAƒvƒچ‚جٹش‚إ‚حپAƒXƒpƒRƒ“‚ج•]‰؟‚حپA
HPC Challenge Benchmarkپ„پ„پ„پ„TOP500(Linpack‚ج‚ف)
‚¾‚©‚ç
‚½‚¾‚µپAƒ}ƒXƒRƒ~“I‚ة‚حپAڈ‡ˆت‚ھ‚آ‚¢‚ؤ‚ي‚©‚è‚â‚·‚¢TOP500‚ج‚ف•ٌ“¹‚µ‚ؤ‚é‚©‚çپA
ˆê”تگl‚حƒ}ƒXƒRƒ~•ٌ“¹‚ة‚و‚èTOP500‚µ‚©’m‚ç‚ب‚¢
HPC Challenge Benchmarkپ„پ„پ„پ„TOP500(Linpack‚ج‚ف)
‚¾‚©‚ç
‚½‚¾‚µپAƒ}ƒXƒRƒ~“I‚ة‚حپAڈ‡ˆت‚ھ‚آ‚¢‚ؤ‚ي‚©‚è‚â‚·‚¢TOP500‚ج‚ف•ٌ“¹‚µ‚ؤ‚é‚©‚çپA
ˆê”تگl‚حƒ}ƒXƒRƒ~•ٌ“¹‚ة‚و‚èTOP500‚µ‚©’m‚ç‚ب‚¢
“à—eژں‘و‚إ‚ح‹‚ھ‚ـ‚½1ˆت‚ً‚ئ‚ê‚é‚©‚à‚µ‚ê‚ب‚¢‚ث
LinpackƒXƒRƒA‚ج‚ف‚جٹîڈ€‚إچl‚¦‚é‚ب‚çXeon Phi‚ح‚¨”ƒ‚¢‘¹‚¾‚ھ
ژہچغ‚ة‚حLinpack‚إŒv‚ê‚ب‚¢گ«”\‚ً‹پ‚ك‚ؤ‚é‚ي‚¯‚إ
LinpackƒXƒRƒA‚ج‚ف‚جٹîڈ€‚إچl‚¦‚é‚ب‚çXeon Phi‚ح‚¨”ƒ‚¢‘¹‚¾‚ھ
ژہچغ‚ة‚حLinpack‚إŒv‚ê‚ب‚¢گ«”\‚ً‹پ‚ك‚ؤ‚é‚ي‚¯‚إ
‚؟‚ه‚¢‚ئژ؟–â‚ب‚ٌ‚¾‚¯‚اپA
پuƒ}ƒ‹ƒ`ƒ^ƒXƒNپv‚ئپuƒ}ƒ‹ƒ`ƒXƒŒƒbƒhپv‚ئپuƒ}ƒ‹ƒ`ƒvƒچƒZƒXپv‚جˆل‚¢‚ھ
—ا‚•ھ‚©‚ç‚ب‚‚ؤ‚²‚ء‚؟‚ل‚ة‚ب‚ء‚ؤ‚¢‚é‚ج‚إپAڈع‚µ‚¢گl‰ًگàƒIƒlƒKƒCƒVƒ}ƒXorz
پuƒ}ƒ‹ƒ`ƒ^ƒXƒNپv‚ئپuƒ}ƒ‹ƒ`ƒXƒŒƒbƒhپv‚ئپuƒ}ƒ‹ƒ`ƒvƒچƒZƒXپv‚جˆل‚¢‚ھ
—ا‚•ھ‚©‚ç‚ب‚‚ؤ‚²‚ء‚؟‚ل‚ة‚ب‚ء‚ؤ‚¢‚é‚ج‚إپAڈع‚µ‚¢گl‰ًگàƒIƒlƒKƒCƒVƒ}ƒXorz
‚¨‚¨‚´‚ء‚د‚ة‚¢‚¤‚ئڈˆ—‚ج‰ٍ‚ج‘ه‚«‚³‚ھ
ƒ^ƒXƒNپ„ƒvƒچƒZƒXپ„ƒXƒŒƒbƒh‚¾‚بپB
ƒuƒ‰ƒEƒU‚ً—ل‚ة‚·‚é‚ئ‚±‚ٌ‚بٹ´‚¶پB
•،گ”‚جƒuƒ‰ƒEƒU‚ھ“¯ژ‚ة“®‚‚ج‚ھƒ}ƒ‹ƒ`ƒ^ƒXƒN
ƒuƒ‰ƒEƒU‚ھ’تگM‚ئ‰و‘œ‚ج•\ژ¦‚ئ‰¹گ؛‚جچؤگ¶‚ً•ہ—ٌ‚µ‚ؤچs‚¤‚ج‚ھƒ}ƒ‹ƒ`ƒvƒچƒZƒX
•،گ”‚ج‰و‘œ‚ً“¯ژ‚ة•\ژ¦‚·‚é‚ج‚ھƒ}ƒ‹ƒ`ƒXƒŒƒbƒh
ƒ^ƒXƒNپ„ƒvƒچƒZƒXپ„ƒXƒŒƒbƒh‚¾‚بپB
ƒuƒ‰ƒEƒU‚ً—ل‚ة‚·‚é‚ئ‚±‚ٌ‚بٹ´‚¶پB
•،گ”‚جƒuƒ‰ƒEƒU‚ھ“¯ژ‚ة“®‚‚ج‚ھƒ}ƒ‹ƒ`ƒ^ƒXƒN
ƒuƒ‰ƒEƒU‚ھ’تگM‚ئ‰و‘œ‚ج•\ژ¦‚ئ‰¹گ؛‚جچؤگ¶‚ً•ہ—ٌ‚µ‚ؤچs‚¤‚ج‚ھƒ}ƒ‹ƒ`ƒvƒچƒZƒX
•،گ”‚ج‰و‘œ‚ً“¯ژ‚ة•\ژ¦‚·‚é‚ج‚ھƒ}ƒ‹ƒ`ƒXƒŒƒbƒh
1995”N‘ن‚©‚çPCژGژڈ“ا‚فژn‚ك‚½‰´‚ج’†‚إ‚ح
ƒ^ƒXƒN=ƒAƒvƒٹ
ƒXƒŒƒbƒh=ƒ^ƒXƒN“à‚جڈˆ—‚ً•ہ—ٌ‚ةچs‚¤‚½‚ك‚ةڈˆ—‚ً•ھ—£‚µ‚½‚à‚ج
ƒvƒچƒZƒX=OSƒŒƒxƒ‹‚إ”گ¶‚·‚éƒ^ƒXƒN‚àٹـ‚ك‚½Œؤ‚ر–¼
‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚¯‚اwiki‚ة‚و‚é‚ئ‘ه‚µ‚½ˆل‚¢‚ح‚ب‚¢‚炵‚¢
http://ja.wikipedia.org/wiki/ƒ}ƒ‹ƒ`ƒ^ƒXƒN
ƒ^ƒXƒN=ƒAƒvƒٹ
ƒXƒŒƒbƒh=ƒ^ƒXƒN“à‚جڈˆ—‚ً•ہ—ٌ‚ةچs‚¤‚½‚ك‚ةڈˆ—‚ً•ھ—£‚µ‚½‚à‚ج
ƒvƒچƒZƒX=OSƒŒƒxƒ‹‚إ”گ¶‚·‚éƒ^ƒXƒN‚àٹـ‚ك‚½Œؤ‚ر–¼
‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚¯‚اwiki‚ة‚و‚é‚ئ‘ه‚µ‚½ˆل‚¢‚ح‚ب‚¢‚炵‚¢
http://ja.wikipedia.org/wiki/ƒ}ƒ‹ƒ`ƒ^ƒXƒN
ƒvƒچƒOƒ‰ƒ€“I‚ة‚حƒپƒ‚ƒٹ‹َٹش‚ھ‹¤—L‚³‚ê‚é‚©•ھ—£‚³‚ê‚é‚©‚إ
ƒvƒچƒZƒX‚ئƒXƒŒƒbƒh‚حگط‚è•ھ‚¯‚ç‚ê‚éپB
ƒvƒچƒZƒX‚ئƒXƒŒƒbƒh‚حگط‚è•ھ‚¯‚ç‚ê‚éپB
>>293
‚»‚¾‚ثپ`
ƒ^ƒXƒN‚ئƒvƒچƒZƒX‚ج—±“x‚ھ“ü‚ê‘ض‚ي‚éڈêچ‡‚ھ‚ ‚邯‚اپA‚ـ‚ںŒ‹‹ا‚حOS‚ة‚و‚é’è‹`‚ج–â‘肾‚©‚ç‚ب
‚»‚¾‚ثپ`
ƒ^ƒXƒN‚ئƒvƒچƒZƒX‚ج—±“x‚ھ“ü‚ê‘ض‚ي‚éڈêچ‡‚ھ‚ ‚邯‚اپA‚ـ‚ںŒ‹‹ا‚حOS‚ة‚و‚é’è‹`‚ج–â‘肾‚©‚ç‚ب
ƒ^ƒXƒN‚ئ‚¢‚¤‚ئƒتITRON‚ًژv‚¢ڈo‚·پBcre_tsk()‚إگV‚µ‚¢ƒ^ƒXƒN‚ًگ¶گ¬‚µپAdel_tsk()‚إƒ^ƒXƒN‚ًڈء‚·پB
CPU‚ة‰¼‘zƒپƒ‚ƒٹ‹@چ\‚ھ•t‚¢‚ؤ‚¨‚炸پAƒپƒ‚ƒٹƒAƒhƒŒƒX‚ح•¨—ƒAƒhƒŒƒX‚ً’¼گعژw‚µ‚ؤ‚¢‚½‚ج‚إ•،گ”‚جƒ^ƒXƒN‚ھƒپƒ‚ƒٹ‹َٹش‚ً‹¤—L‚µ‚ؤ‚¢‚é‚ئŒ¾‚¦‚ب‚‚à‚ب‚¢پB
ƒXƒ^ƒbƒN‚ھƒIپ[ƒoپ[/ƒAƒ“ƒ_پ[ƒtƒچپ[‚·‚é‚ئ—ׂجƒ^ƒXƒN‚جƒڈپ[ƒN—جˆو‚ھ‰َ‚ê‚é
CPU‚ة‰¼‘zƒپƒ‚ƒٹ‹@چ\‚ھ•t‚¢‚ؤ‚¨‚炸پAƒپƒ‚ƒٹƒAƒhƒŒƒX‚ح•¨—ƒAƒhƒŒƒX‚ً’¼گعژw‚µ‚ؤ‚¢‚½‚ج‚إ•،گ”‚جƒ^ƒXƒN‚ھƒپƒ‚ƒٹ‹َٹش‚ً‹¤—L‚µ‚ؤ‚¢‚é‚ئŒ¾‚¦‚ب‚‚à‚ب‚¢پB
ƒXƒ^ƒbƒN‚ھƒIپ[ƒoپ[/ƒAƒ“ƒ_پ[ƒtƒچپ[‚·‚é‚ئ—ׂجƒ^ƒXƒN‚جƒڈپ[ƒN—جˆو‚ھ‰َ‚ê‚é
‰½‚àژ‘—؟‚ً’²‚ׂ¸‚ةڈ‘‚‚ھپAŒأ‚¢UNIXƒVƒXƒeƒ€‚ة‚ح‚à‚ئ‚à‚ئƒvƒچƒZƒX‚µ‚©–³‚پAƒVƒFƒ‹‚إƒvƒچƒZƒX“¯ژm‚ًƒpƒCƒv‚إ‚آ‚ب‚°‚é‚ج‚ھچإچ‚‚ةƒiƒE‚¢‚ئ‚³‚ê‚ؤ‚¢‚½‚ھپA
•،گ”‚جƒRƒ“ƒeƒLƒXƒg‚ھƒپƒ‚ƒٹ‹َٹش‚ً‹¤—L‚·‚éƒXƒŒƒbƒh(ژ…‚ئ‚¢‚¤ˆس–،)‚جٹT”O‚ً1990”N‘م‚ةDEC‚جگl‚ھچى‚ء‚ؤپA‚±‚ê‚ھPOSIXƒXƒŒƒbƒh‚ئ‚µ‚ؤ•Wڈ€‰»‚³‚ꂽ‚ئ‚¢‚¤—¬‚ꂾ‚ء‚½‚ئژv‚¤پB
ƒXƒŒƒbƒh‚ھگâ‘ه‚بŒّ‰ت‚ً”ٹِ‚µ‚½چإڈ‰‚جƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ح1995”N‚²‚ë‚ة“oڈꂵ‚½NetscapeپB‚¾‚ھ2010”N‘م‚ة‚ب‚ء‚ؤWebƒuƒ‰ƒEƒU‚حƒ}ƒ‹ƒ`ƒvƒچƒZƒX‚ة–ك‚ء‚½پB
ƒXƒŒƒbƒh‚و‚è‚à‚³‚ç‚ة‘ه—ت‚ةگ¶گ¬‚·‚邱‚ئ‚ھ‚إ‚«‚éƒtƒ@ƒCƒoپ[‚ئ‚¢‚¤ٹT”O‚ھ‚ ‚é
‚ ‚ئپAGPGPU‚ة‚ح‚¢‚‚آ‚©‚جƒXƒŒƒbƒh‚ً‘©‚ث‚éƒڈپ[ƒv(ڈcژ…‚ئ‚¢‚¤ˆس–،)‚ئ‚¢‚¤ٹT”O‚ھ‚ ‚éپB
•،گ”‚جƒRƒ“ƒeƒLƒXƒg‚ھƒپƒ‚ƒٹ‹َٹش‚ً‹¤—L‚·‚éƒXƒŒƒbƒh(ژ…‚ئ‚¢‚¤ˆس–،)‚جٹT”O‚ً1990”N‘م‚ةDEC‚جگl‚ھچى‚ء‚ؤپA‚±‚ê‚ھPOSIXƒXƒŒƒbƒh‚ئ‚µ‚ؤ•Wڈ€‰»‚³‚ꂽ‚ئ‚¢‚¤—¬‚ꂾ‚ء‚½‚ئژv‚¤پB
ƒXƒŒƒbƒh‚ھگâ‘ه‚بŒّ‰ت‚ً”ٹِ‚µ‚½چإڈ‰‚جƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ح1995”N‚²‚ë‚ة“oڈꂵ‚½NetscapeپB‚¾‚ھ2010”N‘م‚ة‚ب‚ء‚ؤWebƒuƒ‰ƒEƒU‚حƒ}ƒ‹ƒ`ƒvƒچƒZƒX‚ة–ك‚ء‚½پB
ƒXƒŒƒbƒh‚و‚è‚à‚³‚ç‚ة‘ه—ت‚ةگ¶گ¬‚·‚邱‚ئ‚ھ‚إ‚«‚éƒtƒ@ƒCƒoپ[‚ئ‚¢‚¤ٹT”O‚ھ‚ ‚é
‚ ‚ئپAGPGPU‚ة‚ح‚¢‚‚آ‚©‚جƒXƒŒƒbƒh‚ً‘©‚ث‚éƒڈپ[ƒv(ڈcژ…‚ئ‚¢‚¤ˆس–،)‚ئ‚¢‚¤ٹT”O‚ھ‚ ‚éپB
Webƒuƒ‰ƒEƒU‚جƒ}ƒ‹ƒ`ƒvƒچƒZƒX‚حپAƒZƒLƒ…ƒٹƒeƒBپ[‘خچô‚ئپAƒNƒ‰ƒbƒVƒ…‘خچô‚ج‚½‚ك‚ة‚â‚ء‚ؤ‚邾‚¯‚إپA
Webƒuƒ‰ƒEƒUژ©‘ج‚ح‚½‚‚³‚ٌ‚جƒXƒŒƒbƒh‚ًژg‚ء‚ؤ“®‚¢‚ؤ‚é‚و
ƒZƒLƒ…ƒٹƒeƒBپ[پEƒNƒ‰ƒbƒVƒ…‘خچô‚ج‚½‚ك‚ةپAWebƒuƒ‰ƒEƒU‚حپA’ل‚¢Œ Œہ‚جƒvƒچƒZƒX‚إپA‚©‚آƒ^ƒu‚²‚ئ‚ة“ئ—§‚µ‚½ƒvƒچƒZƒX‚إ
“®‚©‚·‚و‚¤‚ة‚ب‚ء‚½
‚±‚¤‚·‚ê‚خپA‚ا‚ê‚©‚جƒ^ƒu‚إ“®‚¢‚ؤ‚éƒvƒچƒZƒX‚ھ‚â‚ç‚ê‚ؤ‚àپAOS–{‘ج‚â•ت‚جƒ^ƒu‚إٹJ‚¢‚ؤ‚éƒyپ[ƒW‚ة
ˆ«‰e‹؟‚ً‹y‚ع‚µ‚ة‚‚‚ب‚ء‚½
‚³‚ç‚ة‚ا‚ê‚©‚P‚آ‚جƒ^ƒu‚ًٹJ‚¢‚ؤ‚éƒvƒچƒZƒX‚ھƒNƒ‰ƒbƒVƒ…‚µ‚ؤ‚àپA‘¼‚جƒ^ƒu‚ة‰e‹؟‚ً‚¨‚و‚ع‚³‚ب‚‚ب‚ء‚½
Webƒuƒ‰ƒEƒUژ©‘ج‚ح‚½‚‚³‚ٌ‚جƒXƒŒƒbƒh‚ًژg‚ء‚ؤ“®‚¢‚ؤ‚é‚و
ƒZƒLƒ…ƒٹƒeƒBپ[پEƒNƒ‰ƒbƒVƒ…‘خچô‚ج‚½‚ك‚ةپAWebƒuƒ‰ƒEƒU‚حپA’ل‚¢Œ Œہ‚جƒvƒچƒZƒX‚إپA‚©‚آƒ^ƒu‚²‚ئ‚ة“ئ—§‚µ‚½ƒvƒچƒZƒX‚إ
“®‚©‚·‚و‚¤‚ة‚ب‚ء‚½
‚±‚¤‚·‚ê‚خپA‚ا‚ê‚©‚جƒ^ƒu‚إ“®‚¢‚ؤ‚éƒvƒچƒZƒX‚ھ‚â‚ç‚ê‚ؤ‚àپAOS–{‘ج‚â•ت‚جƒ^ƒu‚إٹJ‚¢‚ؤ‚éƒyپ[ƒW‚ة
ˆ«‰e‹؟‚ً‹y‚ع‚µ‚ة‚‚‚ب‚ء‚½
‚³‚ç‚ة‚ا‚ê‚©‚P‚آ‚جƒ^ƒu‚ًٹJ‚¢‚ؤ‚éƒvƒچƒZƒX‚ھƒNƒ‰ƒbƒVƒ…‚µ‚ؤ‚àپA‘¼‚جƒ^ƒu‚ة‰e‹؟‚ً‚¨‚و‚ع‚³‚ب‚‚ب‚ء‚½
>>297
’²‚ׂ¸‚ةƒŒƒX‚·‚é‚ھ
DEC‚ھ‚â‚ء‚½‚ج‚حScheduler Activation‚إپAƒAƒhƒŒƒX‹َٹش‚ً‹¤—L‚·‚éƒXƒŒƒbƒh‚ھڈo‚ؤ‚«‚½‚ج‚حV‚©‚à‚ء‚ئ‘O‚¾‚و
V‚حچ،‚إ‚¢‚¤ƒXƒŒƒbƒh‚ج‚±‚ئ‚ًƒvƒچƒZƒX‚ئŒؤ‚ٌ‚إ‚¢‚½‚©‚çپA’²‚ׂà‚ج‚ھ‘ه•د‚¾‚و
’²‚ׂ¸‚ةƒŒƒX‚·‚é‚ھ
DEC‚ھ‚â‚ء‚½‚ج‚حScheduler Activation‚إپAƒAƒhƒŒƒX‹َٹش‚ً‹¤—L‚·‚éƒXƒŒƒbƒh‚ھڈo‚ؤ‚«‚½‚ج‚حV‚©‚à‚ء‚ئ‘O‚¾‚و
V‚حچ،‚إ‚¢‚¤ƒXƒŒƒbƒh‚ج‚±‚ئ‚ًƒvƒچƒZƒX‚ئŒؤ‚ٌ‚إ‚¢‚½‚©‚çپA’²‚ׂà‚ج‚ھ‘ه•د‚¾‚و
MacPro‚إگ…—â‚جPower8+GPU*2‚ھ•Wڈ€چ\گ¬‚ف‚½‚¢‚ب–²‚ج‚ ‚éƒ}ƒVپ[ƒ“‚ح‚à‚¤چى‚ç‚ب‚¢‚ج‚©‚ب
Mac‚ـ‚إintel‚ئ‚©‚؟‚ه‚¤‚آ‚ـ‚ٌ‚ب‚¢‚µپAگMژز‚à”[“¾‚إ‚«‚ب‚¢‚ئژv‚¤‚ٌ‚¾‚ھ‚ا‚¤‚ب‚جپH
Mac‚ـ‚إintel‚ئ‚©‚؟‚ه‚¤‚آ‚ـ‚ٌ‚ب‚¢‚µپAگMژز‚à”[“¾‚إ‚«‚ب‚¢‚ئژv‚¤‚ٌ‚¾‚ھ‚ا‚¤‚ب‚جپH
301 پFSocket774پF2013/10/14(Œژ) 03:21:50.44 ID:79GhMGQK
ƒAƒbƒvƒ‹‚ھ‚·‚邱‚ئ‚ة”[“¾‚إ‚«‚ب‚¢گl‚حپAگMژز‚ئ‚حŒؤ‚ر‚ـ‚¹‚ٌ
چ‚گ«”\ژ©ژذگفŒvCPU‚ھƒfƒXƒNƒgƒbƒv•ہ‚ف‚ة‚ب‚ء‚½‚çڈو‚èٹ·‚¦‚é‚©‚à‚ب
iOS‹@‚ھچ،‚ف‚½‚¢‚ةƒoƒJ”„‚ê‚ء‚ؤڈَ‘ش‚ھ‘±‚¯‚خ‚جکb‚¾‚¯‚ا
Mac‚ةx86‚ء‚ؤ‚ج‚حپAƒKƒ“ƒ_ƒ€‚ةƒVƒƒƒA‚ھڈو‚ء‚ؤ‚é‚ئ‚¢‚¤‚©ƒ„ƒ}ƒgٹح’·‚ھƒfƒXƒ‰پ[‚ئ‚¢‚¤‚©
‚»‚¤‚¢‚¤ڈêˆل‚¢ٹ´‚ح‚ ‚é‚و‚ثپAگ¥”ٌˆب‘O‚ة‚—
iOS‹@‚ھچ،‚ف‚½‚¢‚ةƒoƒJ”„‚ê‚ء‚ؤڈَ‘ش‚ھ‘±‚¯‚خ‚جکb‚¾‚¯‚ا
Mac‚ةx86‚ء‚ؤ‚ج‚حپAƒKƒ“ƒ_ƒ€‚ةƒVƒƒƒA‚ھڈو‚ء‚ؤ‚é‚ئ‚¢‚¤‚©ƒ„ƒ}ƒgٹح’·‚ھƒfƒXƒ‰پ[‚ئ‚¢‚¤‚©
‚»‚¤‚¢‚¤ڈêˆل‚¢ٹ´‚ح‚ ‚é‚و‚ثپAگ¥”ٌˆب‘O‚ة‚—
ƒXƒ^ƒo‚ةPower8‚جگ…—âPCژ‚؟چ‚ٌ‚إƒCƒ“ƒ^پ[ƒl‚ءƒc‚µ‚½‚¢
’†گg‚ق‚«ڈo‚µ‚إگF‚ج‚آ‚¢‚½ƒpƒCƒv‚ئ–ز—َ‚بƒtƒ@ƒ“‚ج‰¹‚إƒ‚ƒe“xƒAƒbƒv
’†گg‚ق‚«ڈo‚µ‚إگF‚ج‚آ‚¢‚½ƒpƒCƒv‚ئ–ز—َ‚بƒtƒ@ƒ“‚ج‰¹‚إƒ‚ƒe“xƒAƒbƒv
>>303
ژüˆح‚جڈ—ژq‚½‚؟‚©‚çث؟ث؟‚³‚ê‚邱‚ئگ؟‚¯چ‡‚¢‚¾‚بپB
ژüˆح‚جڈ—ژq‚½‚؟‚©‚çث؟ث؟‚³‚ê‚邱‚ئگ؟‚¯چ‡‚¢‚¾‚بپB
“ْ‚ة‚و‚ء‚ؤ•‘•‚ئ—â‹p‰tپELEDƒtƒ@ƒ“‚جگF‚ًچ‡‚ي‚¹‚ê‚خ‘¦ƒnƒ{‚â
306 پFSocket774پF2013/10/14(Œژ) 13:27:40.62 ID:TfigyC3o
‚«‚ٌ‚àپ[‚ءپ™
Apple‚حٹو‚ب‚ةژ©ژذSoC‚ًٹO”ج‚µ‚و‚¤‚ئ‚µ‚ب‚¢‚ب،
“–‚½‚è‘O“c‚جƒNƒ‰ƒbƒJپ[
—ˆ”N‚جAMDگ»•i‚ھ28nm‘µ‚¢‚ئ‚¢‚¤‚±‚ئ‚حپAIBM‚ج20nm gate-last‚حژ¸”s‚µ‚½‚ئ‚¢‚¤ژ–‚©پH
http://www.4gamer.net/games/147/G014731/20130910088/
http://www.4gamer.net/games/147/G014731/20130910088/
>>309
IBMگw‰c‚إگi‚ٌ‚إ‚¢‚é‚ج‚حƒTƒ€ƒXƒ“‚¾‚بپBA6پEA7‚ئ‹ں‹‹‚إ‚«‚ؤ‚邵پA20nm—تژY‰»‚àٹْ‘ز‚إ‚«‚é
IBM‚حگh‚¤‚¶‚ؤ32nm‚ًڈ¤•i‰»پAPOWER 8 ‚ئٹO•t‚¯ƒپƒ‚ƒRƒ“‚ح22nm‚إ—ˆ”N””„‚إ‚«‚»‚¤‚بٹ´‚¶‚¾‚¯‚اپAApple‚ة“¦‚°‚ç‚êCELL‚à”ٍ‚خ‚¸پAŒص‚جژq‚ج7پEA2‚àپEپE‚ئƒWƒٹ•n‚ء‚غ‚¢
‚»‚µ‚ؤGF‚ح‰\‚جƒIƒCƒ‹ƒ}ƒlپ[‚ھ‚ ‚é‚ة‚àٹض‚ي‚炸پA–¢‚¾‚ة28nm‚ةˆعچs‚إ‚«‚ؤ‚ب‚¢‚ئ‚±‚ë‚ًŒ©‚é‚ئ‰_چs‚«‚ھپEپEپEƒQپ[ƒ€‹@چج—p‚ً“¦‚µپA‚»‚ج‚¤‚؟AMD‚àژg‚ي‚ب‚‚ب‚é‚ٌ‚¶‚ل‚ب‚¢‚©پH
IBMگw‰c‚إگi‚ٌ‚إ‚¢‚é‚ج‚حƒTƒ€ƒXƒ“‚¾‚بپBA6پEA7‚ئ‹ں‹‹‚إ‚«‚ؤ‚邵پA20nm—تژY‰»‚àٹْ‘ز‚إ‚«‚é
IBM‚حگh‚¤‚¶‚ؤ32nm‚ًڈ¤•i‰»پAPOWER 8 ‚ئٹO•t‚¯ƒپƒ‚ƒRƒ“‚ح22nm‚إ—ˆ”N””„‚إ‚«‚»‚¤‚بٹ´‚¶‚¾‚¯‚اپAApple‚ة“¦‚°‚ç‚êCELL‚à”ٍ‚خ‚¸پAŒص‚جژq‚ج7پEA2‚àپEپE‚ئƒWƒٹ•n‚ء‚غ‚¢
‚»‚µ‚ؤGF‚ح‰\‚جƒIƒCƒ‹ƒ}ƒlپ[‚ھ‚ ‚é‚ة‚àٹض‚ي‚炸پA–¢‚¾‚ة28nm‚ةˆعچs‚إ‚«‚ؤ‚ب‚¢‚ئ‚±‚ë‚ًŒ©‚é‚ئ‰_چs‚«‚ھپEپEپEƒQپ[ƒ€‹@چج—p‚ً“¦‚µپA‚»‚ج‚¤‚؟AMD‚àژg‚ي‚ب‚‚ب‚é‚ٌ‚¶‚ل‚ب‚¢‚©پH
>>310
IBM‚ج’nˆت‚ح‚à‚ء‚ئچ‚‚¢‚¼‚ê
IBM‚ج’nˆت‚ح‚à‚ء‚ئچ‚‚¢‚¼‚ê
ˆê‰2014Q1‚ة‚ح—تژY‘جگ§‚ة“ü‚é‚و‚¤‚¾‚¯‚ا‚ث
‚½‚¾LPDDR“™ˆê•”‚جIP‚ھ2014Q3‚ـ‚إڈم‚ھ‚ء‚ؤ‚±‚ب‚¢‚و‚¤‚¾‚©‚ç
–{ٹi“I‚ة—ت‚ھڈo‚ؤ‚‚é‚ج‚ح‚»‚ج‚ ‚½‚è‚ب‚ج‚©‚à‚µ‚ê‚ب‚¢
http://img.deusm.com/eetimes/2013/10/1319679/20nm-Ready.jpg
‚½‚¾LPDDR“™ˆê•”‚جIP‚ھ2014Q3‚ـ‚إڈم‚ھ‚ء‚ؤ‚±‚ب‚¢‚و‚¤‚¾‚©‚ç
–{ٹi“I‚ة—ت‚ھڈo‚ؤ‚‚é‚ج‚ح‚»‚ج‚ ‚½‚è‚ب‚ج‚©‚à‚µ‚ê‚ب‚¢
http://img.deusm.com/eetimes/2013/10/1319679/20nm-Ready.jpg
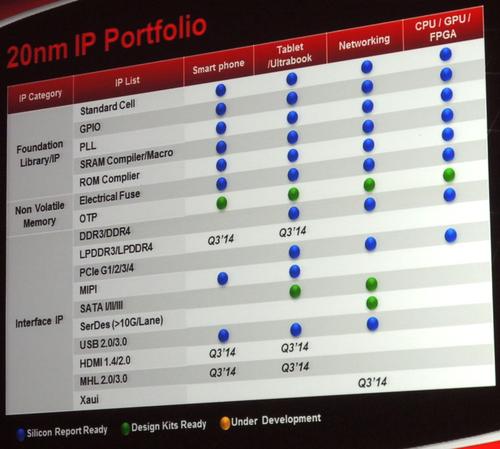{kind=link}
پ@
پ،ƒXƒpƒRƒ“پAٹطچ‘‚ح91ˆتپ@ƒTƒEƒWƒAƒ‰ƒrƒA‚و‚è‚à—ٍ‚é
ٹطچ‘‚جگ¬گر‚حگL‚ر”Y‚ٌ‚¾پB‹Cڈغ’،‚جƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^پ[پuƒwƒIƒ“پvپuƒwƒ_ƒ€پv‚ح‚»‚ꂼ‚ê91ˆتپA
92ˆت‚¾‚ء‚½پB77ˆتپA78ˆت‚¾‚ء‚½چً”N––‚جڈ‡ˆت‚ة”ن‚×14ƒ‰ƒ“ƒNŒم‘ق‚µ‚½پBƒAƒWƒA‚إ‚ح“ْ’†‚¾‚¯‚إ‚ب‚پA
ƒTƒEƒWƒAƒ‰ƒrƒA‚ج2‘نپi52ˆت‚ئ60ˆتپj‚و‚è‚à—ٍ‚ء‚½پB
ٹطچ‘‰بٹw‹Zڈpڈî•ٌŒ¤‹†‰@پiKISITپj‚جپuƒ^ƒLƒIƒ“2پv‚ئƒ\ƒEƒ‹‘ه‚جپuƒ`ƒ‡ƒ“ƒhƒDƒ“پv‚ح‚»‚ꂼ‚ê107ˆتپA
422ˆت‚إ500ˆتŒ—“à‚ة‚ح“ü‚ء‚½‚ھپA‘O‰ٌ•]‰؟‚و‚èڈ‡ˆت‚ھŒم‘ق‚µ‚½پB
پy’©‘N“ْ•ٌپz
http://www.chosunonline.com/site/data/html_dir/2013/06/19/2013061900508.html
پ،ƒXƒpƒRƒ“پAٹطچ‘‚ح91ˆتپ@ƒTƒEƒWƒAƒ‰ƒrƒA‚و‚è‚à—ٍ‚é
ٹطچ‘‚جگ¬گر‚حگL‚ر”Y‚ٌ‚¾پB‹Cڈغ’،‚جƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^پ[پuƒwƒIƒ“پvپuƒwƒ_ƒ€پv‚ح‚»‚ꂼ‚ê91ˆتپA
92ˆت‚¾‚ء‚½پB77ˆتپA78ˆت‚¾‚ء‚½چً”N––‚جڈ‡ˆت‚ة”ن‚×14ƒ‰ƒ“ƒNŒم‘ق‚µ‚½پBƒAƒWƒA‚إ‚ح“ْ’†‚¾‚¯‚إ‚ب‚پA
ƒTƒEƒWƒAƒ‰ƒrƒA‚ج2‘نپi52ˆت‚ئ60ˆتپj‚و‚è‚à—ٍ‚ء‚½پB
ٹطچ‘‰بٹw‹Zڈpڈî•ٌŒ¤‹†‰@پiKISITپj‚جپuƒ^ƒLƒIƒ“2پv‚ئƒ\ƒEƒ‹‘ه‚جپuƒ`ƒ‡ƒ“ƒhƒDƒ“پv‚ح‚»‚ꂼ‚ê107ˆتپA
422ˆت‚إ500ˆتŒ—“à‚ة‚ح“ü‚ء‚½‚ھپA‘O‰ٌ•]‰؟‚و‚èڈ‡ˆت‚ھŒم‘ق‚µ‚½پB
پy’©‘N“ْ•ٌپz
http://www.chosunonline.com/site/data/html_dir/2013/06/19/2013061900508.html
“d‹@ƒپپ[ƒJپ[‚ج‚ب‚©‚إŒم”‚جSamsung‚ح
‘هŒ^ƒRƒ“ƒsƒ…پ[ƒ^چى‚éژ‘م‚ًŒo‚¸‚ة‚¢‚«‚ب‚èPC‚ب‚ٌ‚¾‚بپB
‘هŒ^ƒRƒ“ƒsƒ…پ[ƒ^چى‚éژ‘م‚ًŒo‚¸‚ة‚¢‚«‚ب‚èPC‚ب‚ٌ‚¾‚بپB
‚ ‚ê‚إˆê‰ٌچى‚ء‚ؤ‚ف‚ê‚خ‚و‚©‚ء‚½‚ج‚ةپB
‚ـ‚ چ،‚إ‚ح’آ•…‰»‚µ‚ؤ‚é‚ج‚إ‚à‚¤’x‚¢‚¯‚اپB
‚ـ‚ چ،‚إ‚ح’آ•…‰»‚µ‚ؤ‚é‚ج‚إ‚à‚¤’x‚¢‚¯‚اپB
>>309
‘g‚فچ‚فŒü‚¯‚ء‚ؤ‚±‚ئ‚¾‚©‚çپAچإگVƒvƒچƒZƒX‚و‚è‚حپA‚±‚ب‚ꂽƒvƒچƒZƒX‚ء‚ؤ‚±‚ئ‚à•پ’ت‚¾‚µ
‚»‚ꂾ‚¯‚إگVƒvƒچƒZƒX‚ھ’x‰„‚µ‚ؤ‚é‚ء‚ؤ”»’f‚ح‚إ‚«‚ب‚¢‚ٌ‚¶‚ل‚ب‚¢‚©
‘g‚فچ‚فŒü‚¯‚ء‚ؤ‚±‚ئ‚¾‚©‚çپAچإگVƒvƒچƒZƒX‚و‚è‚حپA‚±‚ب‚ꂽƒvƒچƒZƒX‚ء‚ؤ‚±‚ئ‚à•پ’ت‚¾‚µ
‚»‚ꂾ‚¯‚إگVƒvƒچƒZƒX‚ھ’x‰„‚µ‚ؤ‚é‚ء‚ؤ”»’f‚ح‚إ‚«‚ب‚¢‚ٌ‚¶‚ل‚ب‚¢‚©
21164PCˆê‰چى‚邱‚ئ‚حچى‚ء‚ؤ‚ب‚©‚ء‚½‚©پB
‚ـپ[ƒRƒP‚½‚و‚¤‚¾‚ھپB
‚ـپ[ƒRƒP‚½‚و‚¤‚¾‚ھپB
>>319
ƒpƒ\ƒRƒ“‚½‚؟‚ـ‚؟’[––‹@
ƒpƒ\ƒRƒ“‚½‚؟‚ـ‚؟’[––‹@
http://pc.watch.impress.co.jp/docs/news/20131015_619415.html
ImaginationپAڈ‰‚جMIPS Series 5ƒvƒچƒZƒbƒTپgWarriorپh‚ًگ»•i‰»
پ`چإ‘ه6ƒRƒAپAƒIƒvƒVƒ‡ƒ“‚إ128bit SIMD‚ًƒTƒ|پ[ƒg
ImaginationپAڈ‰‚جMIPS Series 5ƒvƒچƒZƒbƒTپgWarriorپh‚ًگ»•i‰»
پ`چإ‘ه6ƒRƒAپAƒIƒvƒVƒ‡ƒ“‚إ128bit SIMD‚ًƒTƒ|پ[ƒg
MIPSƒTپ[ƒo‚ء‚ؤپA
‚ق‚©‚µEWS4800‚ئ‚©UP4800‚ئ‚©ژg‚ء‚ؤ‚½‹C‚ھ‚·‚é‚؛
‚ق‚©‚µEWS4800‚ئ‚©UP4800‚ئ‚©ژg‚ء‚ؤ‚½‹C‚ھ‚·‚é‚؛
SONY‚©‚ç‘ه—ت‚ج“‹چع‹@‚ھ”„‚ê‚ؤ‚½
‰؛ژè‚ةƒ}ƒCƒiپ[‚بƒRƒAژg‚±‚½‚ç’†گg‚ھ—³گc‚ئ‚â‚炾‚ء‚½‚è—]Œv‚ب”é–§‚ج’تگMƒnپ[ƒhƒEƒFƒA‚ھƒIƒ}ƒP‚إSoC‚³‚ê‚ؤ‚½‚è‚ئ
•|‚¢—\‘z‚¢‚‚ç‚إ‚àڈo—ˆ‚é‚©‚ç
چL”حˆح‚ب”ل•]‚ً–ˆ‰ٌژَ‚¯‚éx64‚©ARM‚إچى‚é‚ة‰z‚µ‚½ژ–‚ح‚ب‚¢‚ث
•|‚¢—\‘z‚¢‚‚ç‚إ‚àڈo—ˆ‚é‚©‚ç
چL”حˆح‚ب”ل•]‚ً–ˆ‰ٌژَ‚¯‚éx64‚©ARM‚إچى‚é‚ة‰z‚µ‚½ژ–‚ح‚ب‚¢‚ث
گجMIPS6”چع‚¹‚½ƒOƒ‰ƒ{‚ھ‚ ‚ء‚½‹L‰¯پB
>>325
چ،‰ٌ‚ج“z‚ح–{‰ئMIPS‚¾‚낤پB‘¶چفˆس‹`‚حŒƒ‚µ‚‹^–₾‚ھپB
چ،‰ٌ‚ج“z‚ح–{‰ئMIPS‚¾‚낤پB‘¶چفˆس‹`‚حŒƒ‚µ‚‹^–₾‚ھپB
>>322
>چ،‰ٌ”•\‚³‚ꂽƒnƒCƒpƒtƒHپ[ƒ}ƒ“ƒX‚جPƒVƒٹپ[ƒY‚ج‚ظ‚©پAƒ~ƒhƒ‹ƒŒƒ“ƒW‚جIƒVƒٹپ[ƒYپAƒGƒ“ƒgƒٹپ[ƒNƒ‰ƒX‚جMƒVƒٹپ[ƒY‚ج3ƒVƒٹپ[ƒY
64bitگ»•i‚حS‚ب‚ج‚©پc
>چ،‰ٌ”•\‚³‚ꂽƒnƒCƒpƒtƒHپ[ƒ}ƒ“ƒX‚جPƒVƒٹپ[ƒY‚ج‚ظ‚©پAƒ~ƒhƒ‹ƒŒƒ“ƒW‚جIƒVƒٹپ[ƒYپAƒGƒ“ƒgƒٹپ[ƒNƒ‰ƒX‚جMƒVƒٹپ[ƒY‚ج3ƒVƒٹپ[ƒY
64bitگ»•i‚حS‚ب‚ج‚©پc
ƒٹƒgƒ‹ƒGƒ“ƒfƒBƒAƒ“‚ب‚ج‚©
http://pc.watch.impress.co.jp/docs/news/20131016_619563.html
BroadcomپA3GHz“®چى‚جƒTپ[ƒoپ[Œü‚¯ARMƒvƒچƒZƒbƒT‚ً”•\
پ`64bit‘خ‰‚جARMv8ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًچج—p
BroadcomپA3GHz“®چى‚جƒTپ[ƒoپ[Œü‚¯ARMƒvƒچƒZƒbƒT‚ً”•\
پ`64bit‘خ‰‚جARMv8ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًچج—p
TSMC‚ج16nmFinFET‚©‚بپB
A7‚جŒّ—¦Œ©‚éŒہ‚èپA‚¢‚«‚ب‚èCore i7’ِ“x‚جگ«”\‚ًٹm•غ‚µ‚»‚¤‚إ–ت”’‚¢پB
A7‚جŒّ—¦Œ©‚éŒہ‚èپA‚¢‚«‚ب‚èCore i7’ِ“x‚جگ«”\‚ًٹm•غ‚µ‚»‚¤‚إ–ت”’‚¢پB
ƒTپ[ƒo—p‚ب‚çپAƒ^ƒuƒŒƒbƒg‚âƒXƒ}پ[ƒgƒzƒ“‚ئˆل‚ء‚ؤ”M‚â“d—ح‚جگ§Œہ‚ن‚é‚¢‚µ
‚»‚ê‚ب‚è‚ةٹْ‘ز‚ح‚إ‚«‚»‚¤‚¾‚و‚ث
‹ة’[‚بکbپAŒ»ڈَ‚ج‚à‚ج‚ة“dˆ³‚©‚¯‚ؤƒIپ[ƒoپ[ƒNƒچƒbƒN‚·‚邾‚¯‚إ‚àگ«”\‚حڈم‚ھ‚邵‚³
‚»‚ê‚ب‚è‚ةٹْ‘ز‚ح‚إ‚«‚»‚¤‚¾‚و‚ث
‹ة’[‚بکbپAŒ»ڈَ‚ج‚à‚ج‚ة“dˆ³‚©‚¯‚ؤƒIپ[ƒoپ[ƒNƒچƒbƒN‚·‚邾‚¯‚إ‚àگ«”\‚حڈم‚ھ‚邵‚³
A7‚جگ«”\‚ھ‚¢‚¢‚ج‚حپAA64‚جگ«”\‚ھ‚¢‚¢‚ج‚©پAApple‚ج–‚‰ü‘¢‚إ—ا‚‚ب‚ء‚½‚ج‚©‚ا‚ء‚؟‚¾‚ëپH
‚½‚ش‚ٌA64‚»‚ج‚à‚ج‚ھچ‚گ«”\‰»‚µ‚½‚ٌ‚¾‚ئ‚¨‚à‚¤
چإڈ‰‚©‚ç28nm‚ًƒ^پ[ƒQƒbƒg‚ةچ‚گ«”\‰»‚·‚é‚و‚¤‚ةگفŒv‚µ‚½‚ٌ‚¶‚ل‚ثپH
‚½‚ش‚ٌA64‚»‚ج‚à‚ج‚ھچ‚گ«”\‰»‚µ‚½‚ٌ‚¾‚ئ‚¨‚à‚¤
چإڈ‰‚©‚ç28nm‚ًƒ^پ[ƒQƒbƒg‚ةچ‚گ«”\‰»‚·‚é‚و‚¤‚ةگفŒv‚µ‚½‚ٌ‚¶‚ل‚ثپH
ƒCƒ“ƒeƒ‹‚جƒuƒ‰ƒCƒAƒ“پEƒNƒ‹ƒUƒjƒbƒ`چإچ‚Œo‰cگس”Cژزپi‚b‚d‚nپj‚ح15“ْ‚ج“dکb‰ï‹c‚إپA14ƒiƒmƒپپ[ƒgƒ‹‚جگ»‘¢‹Zڈp‚ً
ژg‚¤ژںگ¢‘مƒvƒچƒZƒbƒTپ[پuƒuƒچپ[ƒhƒEƒFƒ‹پv‚ة‚آ‚¢‚ؤپA“–ڈ‰Œv‰و‚و‚è‚RƒJŒژ’x‚ê‚ؤ—ˆ”N‚Pپ|‚RŒژپi‘و‚Pژl”¼ٹْپj‚ةگ¶ژY‚ً
ٹJژn‚·‚邱‚ئ‚ً–¾‚ç‚©‚ة‚µ‚½پB
ƒCƒ“ƒeƒ‹‚جٹ”‰؟‚حگ¶ژY‚ج’x‚ê‚ةٹض‚·‚锕\‚ًژَ‚¯پAژٹشٹOژوˆّ‚إˆêژ2.2پ“‰؛—ژ‚µ22.88ƒhƒ‹‚ئ‚ب‚ء‚½پB”„ڈمچ‚Œ©’ت‚µ
”•\Œم‚ة‚حˆêژ24ƒhƒ‹‚ةڈمڈ¸‚·‚éڈê–ت‚à‚ ‚ء‚½پBƒjƒ…پ[ƒˆپ[ƒNژsڈê‚ج’تڈيژوˆّڈI’l‚ح‘O“ْ”ن0.3پ“ˆہ‚ج23.39ƒhƒ‹پB
ژه—ح‚ج‚o‚b—p”¼“±‘ج•”–ه‚ج‚Vپ|‚XŒژپi‘و‚Rژl”¼ٹْپj”„ڈمچ‚‚ح84‰ƒhƒ‹‚إپA‘O”N“¯ٹْ”ن3.5پ“Œ¸پBƒTپ[ƒoپ[—pƒ`ƒbƒv•”–ه‚ج
”„ڈمچ‚‚ح‘O”N“¯ٹْ”ن12پ“‘‚ج29‰ƒhƒ‹پB
‘و‚Rژl”¼ٹْڈƒ—ک‰v‚ح29‰5000–œƒhƒ‹پi‚Pٹ”“–‚½‚è58ƒZƒ“ƒgپj‚ئپA‘O”N“¯ٹْ‚ج29‰7000–œƒhƒ‹پi“¯58ƒZƒ“ƒgپj‚©‚ç
Œ¸ڈ‚µ‚½پB”„ڈمچ‚‚ح‚ظ‚ع‰،‚خ‚¢‚ج135‰ƒhƒ‹پBƒAƒiƒٹƒXƒg—\‘z•½‹د‚إ‚حپA‚Pٹ”—ک‰v‚ح54ƒZƒ“ƒgپA”„ڈمچ‚‚ح135‰ƒhƒ‹‚ئ
Œ©چ‚ـ‚ê‚ؤ‚¢‚½پB‘e—ک‰v—¦‚ح62.4پ“‚إپAƒAƒiƒٹƒXƒg—\‘z•½‹د‚ح61پ“‚¾‚ء‚½پB
http://www.bloomberg.co.jp/bb/newsarchive/MUQ96Z6S974501.html
ژg‚¤ژںگ¢‘مƒvƒچƒZƒbƒTپ[پuƒuƒچپ[ƒhƒEƒFƒ‹پv‚ة‚آ‚¢‚ؤپA“–ڈ‰Œv‰و‚و‚è‚RƒJŒژ’x‚ê‚ؤ—ˆ”N‚Pپ|‚RŒژپi‘و‚Pژl”¼ٹْپj‚ةگ¶ژY‚ً
ٹJژn‚·‚邱‚ئ‚ً–¾‚ç‚©‚ة‚µ‚½پB
ƒCƒ“ƒeƒ‹‚جٹ”‰؟‚حگ¶ژY‚ج’x‚ê‚ةٹض‚·‚锕\‚ًژَ‚¯پAژٹشٹOژوˆّ‚إˆêژ2.2پ“‰؛—ژ‚µ22.88ƒhƒ‹‚ئ‚ب‚ء‚½پB”„ڈمچ‚Œ©’ت‚µ
”•\Œم‚ة‚حˆêژ24ƒhƒ‹‚ةڈمڈ¸‚·‚éڈê–ت‚à‚ ‚ء‚½پBƒjƒ…پ[ƒˆپ[ƒNژsڈê‚ج’تڈيژوˆّڈI’l‚ح‘O“ْ”ن0.3پ“ˆہ‚ج23.39ƒhƒ‹پB
ژه—ح‚ج‚o‚b—p”¼“±‘ج•”–ه‚ج‚Vپ|‚XŒژپi‘و‚Rژl”¼ٹْپj”„ڈمچ‚‚ح84‰ƒhƒ‹‚إپA‘O”N“¯ٹْ”ن3.5پ“Œ¸پBƒTپ[ƒoپ[—pƒ`ƒbƒv•”–ه‚ج
”„ڈمچ‚‚ح‘O”N“¯ٹْ”ن12پ“‘‚ج29‰ƒhƒ‹پB
‘و‚Rژl”¼ٹْڈƒ—ک‰v‚ح29‰5000–œƒhƒ‹پi‚Pٹ”“–‚½‚è58ƒZƒ“ƒgپj‚ئپA‘O”N“¯ٹْ‚ج29‰7000–œƒhƒ‹پi“¯58ƒZƒ“ƒgپj‚©‚ç
Œ¸ڈ‚µ‚½پB”„ڈمچ‚‚ح‚ظ‚ع‰،‚خ‚¢‚ج135‰ƒhƒ‹پBƒAƒiƒٹƒXƒg—\‘z•½‹د‚إ‚حپA‚Pٹ”—ک‰v‚ح54ƒZƒ“ƒgپA”„ڈمچ‚‚ح135‰ƒhƒ‹‚ئ
Œ©چ‚ـ‚ê‚ؤ‚¢‚½پB‘e—ک‰v—¦‚ح62.4پ“‚إپAƒAƒiƒٹƒXƒg—\‘z•½‹د‚ح61پ“‚¾‚ء‚½پB
http://www.bloomberg.co.jp/bb/newsarchive/MUQ96Z6S974501.html
Cortex A15‚ھƒxپ[ƒX‚جA57‚ة
‚»‚ٌ‚بگِچف—ح‚ح‚ب‚¢‚ئژv‚¤‚ٌ‚¾‚ھپB
64bit‚ة‚ب‚ء‚½‚©‚ç‚ئ‚¢‚ء‚ؤ4GB‚ةژû‚ـ‚éƒAƒvƒٹ‚ـ‚إ‘¬‚‚ب‚é—v‘f‚à‚ب‚¢پB
Thumb2‚ھژg‚¦‚ب‚¢‚ج‚ح–½—كƒLƒƒƒbƒVƒ…Œّ—¦“™‚ج–ت‚إ‚ق‚µ‚ë‘«g‚¾‚낤?
‚»‚ٌ‚بگِچف—ح‚ح‚ب‚¢‚ئژv‚¤‚ٌ‚¾‚ھپB
64bit‚ة‚ب‚ء‚½‚©‚ç‚ئ‚¢‚ء‚ؤ4GB‚ةژû‚ـ‚éƒAƒvƒٹ‚ـ‚إ‘¬‚‚ب‚é—v‘f‚à‚ب‚¢پB
Thumb2‚ھژg‚¦‚ب‚¢‚ج‚ح–½—كƒLƒƒƒbƒVƒ…Œّ—¦“™‚ج–ت‚إ‚ق‚µ‚ë‘«g‚¾‚낤?
http://wlog.flatlib.jp/item/1652
A7‚ج32bit,64bit‚إ‚جˆل‚¢‚ح‚ ‚ـ‚è‚ب‚¢‚©‚ç
A7ژ©‘ج‚جچ\‘¢‚ھ—ا‚¢‚ٌ‚¶‚ل‚ب‚¢
A7‚ج32bit,64bit‚إ‚جˆل‚¢‚ح‚ ‚ـ‚è‚ب‚¢‚©‚ç
A7ژ©‘ج‚جچ\‘¢‚ھ—ا‚¢‚ٌ‚¶‚ل‚ب‚¢
A7‚ح“ن‚ھ‘½‚¢پBARM‚ح“ئژ©ƒRƒA‚àٹeژذچى‚ء‚ؤ‚«‚½‚ھˆêژذ‚ھ“ثڈo‚µ‚½‚±‚ئ‚حچ،‚ـ‚إ‚ب‚©‚ء‚½پB
ˆê”ش‰ِ‚µ‚¢‚ج‚حژہژü”gگ”‚©‚ب
‚±‚±‚ـ‚إ‚ة–¾ٹm‚بٹmڈط‚ھ–³‚¢(ˆêژںƒ\پ[ƒX‚حAnand‚ج‚ف)‚إ
‚»‚ê‚àGeekbench 3‚ج•\ژ¦‚ً——R‚ة‚µ‚ؤ‚¢‚é‚—
‚±‚±‚ـ‚إ‚ة–¾ٹm‚بٹmڈط‚ھ–³‚¢(ˆêژںƒ\پ[ƒX‚حAnand‚ج‚ف)‚إ
‚»‚ê‚àGeekbench 3‚ج•\ژ¦‚ً——R‚ة‚µ‚ؤ‚¢‚é‚—
A57‚حA15‚ئ”ن‚ׂؤ‚àƒpƒtƒHپ[ƒ}ƒ“ƒX‚ح‚ ‚ـ‚èڈم‚ھ‚ç‚ب‚¢‚ف‚½‚¢‚و
http://www.itproportal.com/2012/10/31/arm-cortex-a57-and-a53-vs-cortex-a8-a9-a15-and-a7-a-performance-analysis/
http://www.itproportal.com/2012/10/31/arm-cortex-a57-and-a53-vs-cortex-a8-a9-a15-and-a7-a-performance-analysis/
ژہ‚ح”{ƒNƒچƒbƒN? ‚µ‚©‚µ“d—حگ«”\”ن‚جچ‚‚³‚ح•د‚ي‚ç‚ب‚¢پB
Broadcom‚¾‚µپA‚±‚ꂾ‚ثپB3GHz‚ھOK‚©پc
TSMC‚ئARMپA16nm FinFETگ»‘¢‚إڈ‰‚جCortex-A57‚ًƒeپ[ƒvƒAƒEƒg
http://pc.watch.impress.co.jp/docs/news/20130402_594191.html
TSMC‚ئARMپA16nm FinFETگ»‘¢‚إڈ‰‚جCortex-A57‚ًƒeپ[ƒvƒAƒEƒg
http://pc.watch.impress.co.jp/docs/news/20130402_594191.html
ARM‹قگ»‚جCortex‚ھˆê”ش•³‚ئ‚©ڈخ‚¦‚ب‚¢‚ب
A7‚جŒّ—¦‚ج—ا‚³‚ھARMv8‚à‚µ‚‚ح64bit‰»‚ة‚و‚é‚à‚ج‚إ‚ح‚ب‚¢پA
‚ء‚ؤ‚ج‚ح‚ا‚±‚إ‚à‚ظ‚عˆê’v‚µ‚½Œ©‰ً‚ف‚½‚¢‚¾‚بپB
‰¼‚ةƒNƒچƒbƒN‚ھ‰R‚إ‚à‚ء‚ئچ‚‚¢‚ج‚¾‚ئ‚µ‚ؤ‚àپAچ،“x‚ح“d—حŒّ—¦”ن‚ھ”ٌڈي‚ةچ‚‚¢‚±‚ئ‚ة‚ب‚éپB
‚ا‚¤‚â‚ء‚ؤ‚é‚ٌ‚¾‚낤پB
OS‚ئ‚ج‘ٹڈوŒّ‰ت‚ب‚ج‚©پB
‚ء‚ؤ‚ج‚ح‚ا‚±‚إ‚à‚ظ‚عˆê’v‚µ‚½Œ©‰ً‚ف‚½‚¢‚¾‚بپB
‰¼‚ةƒNƒچƒbƒN‚ھ‰R‚إ‚à‚ء‚ئچ‚‚¢‚ج‚¾‚ئ‚µ‚ؤ‚àپAچ،“x‚ح“d—حŒّ—¦”ن‚ھ”ٌڈي‚ةچ‚‚¢‚±‚ئ‚ة‚ب‚éپB
‚ا‚¤‚â‚ء‚ؤ‚é‚ٌ‚¾‚낤پB
OS‚ئ‚ج‘ٹڈوŒّ‰ت‚ب‚ج‚©پB
>>343
CPU‚¾‚¯‚ج“d—ح‘ھ‚ء‚ؤ‚é‹Lژ–‚ ‚ء‚½‚ء‚¯پH
Webƒuƒ‰ƒEƒWƒ“ƒO‚ئ‚©‚ج“d’r‘ھ’肾‚ئ5s‚و‚è5c‚ج•û‚ھژ‚آ‚ف‚½‚¢‚¾‚¯‚ا
CPU‚¾‚¯‚ج“d—ح‘ھ‚ء‚ؤ‚é‹Lژ–‚ ‚ء‚½‚ء‚¯پH
Webƒuƒ‰ƒEƒWƒ“ƒO‚ئ‚©‚ج“d’r‘ھ’肾‚ئ5s‚و‚è5c‚ج•û‚ھژ‚آ‚ف‚½‚¢‚¾‚¯‚ا
ARMپA•Wڈ€IP‚ج‚ف‚إ64bitƒRƒA‚ئ32bitƒRƒA‚ج•د‘¥SMPچ\گ¬‚إ‚«‚é‚ٌ‚¾‚ء‚¯‚©?
ƒoƒXژü‚è‚ةژè‚ً“ü‚ê‚ç‚ê‚郉ƒCƒZƒ“ƒXژ‚؟‚جٹé‹ئ‚ب‚ç
32bitƒRƒA‘¤MMU‚ًٹg’£‚µ‚ؤƒoƒXژü‚èچ‡‚ي‚¹‚ç‚ê‚ê‚خڈo—ˆ‚邾‚낤‚ھپc
ƒoƒXژü‚è‚ةژè‚ً“ü‚ê‚ç‚ê‚郉ƒCƒZƒ“ƒXژ‚؟‚جٹé‹ئ‚ب‚ç
32bitƒRƒA‘¤MMU‚ًٹg’£‚µ‚ؤƒoƒXژü‚èچ‡‚ي‚¹‚ç‚ê‚ê‚خڈo—ˆ‚邾‚낤‚ھپc
‚ق‚µ‚ëA7‚حƒNƒچƒbƒN‚ً1.2GHz‚ئ’ل‚‚·‚邱‚ئ‚إپA
ƒNƒچƒbƒNڈم‚ھ‚ç‚ب‚¢‚¯‚اڈبƒGƒl‚ب‚çƒgƒ‰ƒ“ƒWƒXƒ^‚ًژg‚ء‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚جپH
‚»‚µ‚ؤƒNƒچƒbƒN‰؛‚°‚ؤ‚àگ«”\‚ًڈo‚¹‚é‚و‚¤‚ةIPC‚ًٹو’£‚ء‚ؤچ‚‚ك‚½‚ئ
ƒNƒچƒbƒNڈم‚ھ‚ç‚ب‚¢‚¯‚اڈبƒGƒl‚ب‚çƒgƒ‰ƒ“ƒWƒXƒ^‚ًژg‚ء‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚جپH
‚»‚µ‚ؤƒNƒچƒbƒN‰؛‚°‚ؤ‚àگ«”\‚ًڈo‚¹‚é‚و‚¤‚ةIPC‚ًٹو’£‚ء‚ؤچ‚‚ك‚½‚ئ
ARM‚جƒRƒAژ©‘ج‚ھچ‚گ«”\‰»‚µ‚ؤ‚é‚ج‚©پAApple‚ھ‚ھ‚ٌ‚خ‚ء‚ؤچ‚گ«”\‰»‚µ‚½‚ج‚©
‚ـ‚¾‚ي‚©‚ç‚ب‚¢‚ب
‘¼‚ةARM‚ج64bitƒRƒAژg‚ء‚½ڈ¤•i‚ھ‚¢‚‚آ‚àڈo‚ؤ‚‚ê‚خ‚ا‚ء‚؟‚©”»–¾‚·‚邾‚낤‚¯‚ا
‚ـ‚¾‚ي‚©‚ç‚ب‚¢‚ب
‘¼‚ةARM‚ج64bitƒRƒAژg‚ء‚½ڈ¤•i‚ھ‚¢‚‚آ‚àڈo‚ؤ‚‚ê‚خ‚ا‚ء‚؟‚©”»–¾‚·‚邾‚낤‚¯‚ا
’P‚ب‚éƒxƒ“ƒ`ƒ}پ[ƒNچ¼‹\‚¾‚ء‚½‚肵‚ؤ‚ب
‘¼‚ھ4ƒRƒA‚â‚ء‚ؤ‚é‚ج‚ةApple‚جA7‚ھ2ƒRƒA‚ب‚ج‚حپAƒRƒA‚ھ‚إ‚©‚¢‚ج‚©GPU‚ة‚س‚ء‚ؤ‚邾‚¯‚ب‚ج‚©
ƒXƒ}ƒz—p“r‚¶‚لƒNƒAƒbƒhƒRƒA‚ب‚ٌ‚ؤPCˆبڈم‚ةˆس–،–³‚©‚ء‚½‚ٌ‚¶‚لپEپEپE‚ئ‚¢‚¤‹C‚à‚·‚éپB
ƒRƒA‚ ‚½‚è‚جIPC‚ًچ‚‚ك‚ç‚ê‚é—]’n‚ھ‚ ‚é‚ب‚çپA—]Œv‚ةƒ}ƒ‹ƒ`ƒRƒA‘¤‚ةگU‚ç‚ب‚¢‚ظ‚¤‚ھ‚¢‚¢‚¾‚낤‚µپB
Qualcomm‚ھ64bit‚حƒ}پ[ƒPƒeƒBƒ“ƒOƒڈپ[ƒh‚ف‚½‚¢‚ةŒ¾‚ء‚½‚炵‚¢‚ھپAƒNƒAƒbƒh‚â‚çƒIƒNƒ^ƒRƒA‚â‚ç‚à‚»‚¤‚¾‚ء‚½‚ٌ‚إ‚ح‚ب‚¢‚©‚ئپB
ƒRƒA‚ ‚½‚è‚جIPC‚ًچ‚‚ك‚ç‚ê‚é—]’n‚ھ‚ ‚é‚ب‚çپA—]Œv‚ةƒ}ƒ‹ƒ`ƒRƒA‘¤‚ةگU‚ç‚ب‚¢‚ظ‚¤‚ھ‚¢‚¢‚¾‚낤‚µپB
Qualcomm‚ھ64bit‚حƒ}پ[ƒPƒeƒBƒ“ƒOƒڈپ[ƒh‚ف‚½‚¢‚ةŒ¾‚ء‚½‚炵‚¢‚ھپAƒNƒAƒbƒh‚â‚çƒIƒNƒ^ƒRƒA‚â‚ç‚à‚»‚¤‚¾‚ء‚½‚ٌ‚إ‚ح‚ب‚¢‚©‚ئپB
>>350
‚±‚êژv‚¢ڈo‚·‚ب‚
http://www.chip-architect.com/news/Llano_vs_SandyBridge_vs_Westmere.jpg
Sandy‚ج1ƒRƒA‚ئLlano‚ج2ƒRƒA‚ھ“¯‚¶‚‚ç‚¢‚جƒTƒCƒY
>>351
big.LITTE‚جƒIƒNƒ^‚حٹ®‘S‚ةƒ}پ[ƒPƒbƒeƒBƒ“ƒOƒڈپ[ƒh‚¾‚ي‚ب
‚»‚à‚»‚àSamsungژ©گg‚ھƒXƒiƒhƒ‰800‚ة‚µ‚؟‚ل‚ء‚ؤExynos5‚ح‚ب‚ٌ‚¾‚ء‚½‚ج‚©ڈَ‘ش‚¾‚µ‚—
‚±‚êژv‚¢ڈo‚·‚ب‚
http://www.chip-architect.com/news/Llano_vs_SandyBridge_vs_Westmere.jpg
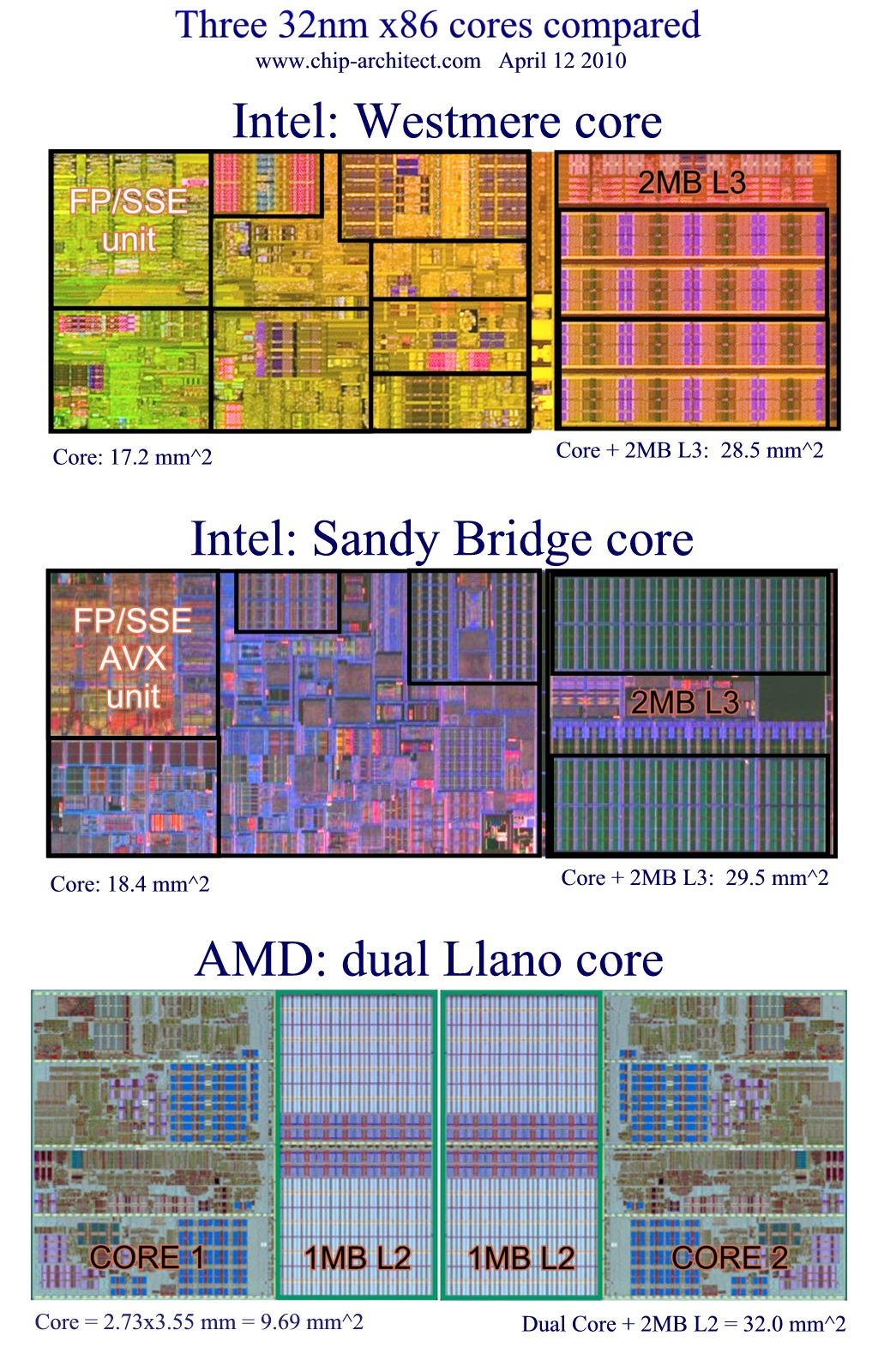{kind=link}
Sandy‚ج1ƒRƒA‚ئLlano‚ج2ƒRƒA‚ھ“¯‚¶‚‚ç‚¢‚جƒTƒCƒY
>>351
big.LITTE‚جƒIƒNƒ^‚حٹ®‘S‚ةƒ}پ[ƒPƒbƒeƒBƒ“ƒOƒڈپ[ƒh‚¾‚ي‚ب
‚»‚à‚»‚àSamsungژ©گg‚ھƒXƒiƒhƒ‰800‚ة‚µ‚؟‚ل‚ء‚ؤExynos5‚ح‚ب‚ٌ‚¾‚ء‚½‚ج‚©ڈَ‘ش‚¾‚µ‚—
ƒuƒ‰ƒEƒU‚ف‚½‚¢‚ةƒXƒŒƒbƒh‚ھ‚ھ‚ٌ‚ھ‚ٌ‹N“®‚·‚éڈêچ‡‚ئ‚©پA‹t‚ة‚ظ‚ئ‚ٌ‚اƒAƒCƒhƒ‹‚بژ‚حڈ¬ƒRƒA‚½‚‚³‚ٌ‚ھ—L—ک‚¾‚¯‚ا‚ث
>>343
CPU‚»‚ج‚à‚ج‚à—ا‚¢‚ئژv‚¤‚¯‚اOS‚ئ‚ج‘ٹڈوŒّ‰ت‚àٹmژہ‚ة‚ ‚邾‚낤‚ثپB
ڈم‚ج•û‚إڈo‚ؤ‚邯‚اBayTrail‚جSunspider‚جƒXƒRƒA‚ھ
Winپ„A7پiiOS7پjپ„Android‚¾‚©‚çOS‚ة‚و‚ء‚ؤ‚¾‚¢‚شگ«”\‚ھ•د‚ي‚ء‚ؤ‚µ‚ـ‚¤پB
>>351
Android‚حƒfƒtƒHƒ‹ƒg‚جƒXƒŒƒbƒhگ§Œن‚ھ”÷–‚إ
ƒ}ƒ‹ƒ`ƒRƒA‚ًڈمژè‚گ¶‚©‚¹‚ؤ‚ب‚¢‚ج‚à‚ ‚é‚ثپB
DVFSپiOndemandپj‚à‚؟‚ه‚ء‚ئ•‰‰×‚ھٹ|‚©‚é‚ئ‚·‚®چإچ‚ƒNƒچƒbƒN‚ة‚ب‚ء‚ؤ
چإ’لƒNƒچƒbƒNپEچإچ‚ƒNƒچƒbƒN‚جژہژ؟2’iٹKپiپ{ƒfƒBپ[ƒvƒXƒٹپ[ƒvپj‚µ‚©‚ب‚¢پB
CPU‚»‚ج‚à‚ج‚à—ا‚¢‚ئژv‚¤‚¯‚اOS‚ئ‚ج‘ٹڈوŒّ‰ت‚àٹmژہ‚ة‚ ‚邾‚낤‚ثپB
ڈم‚ج•û‚إڈo‚ؤ‚邯‚اBayTrail‚جSunspider‚جƒXƒRƒA‚ھ
Winپ„A7پiiOS7پjپ„Android‚¾‚©‚çOS‚ة‚و‚ء‚ؤ‚¾‚¢‚شگ«”\‚ھ•د‚ي‚ء‚ؤ‚µ‚ـ‚¤پB
>>351
Android‚حƒfƒtƒHƒ‹ƒg‚جƒXƒŒƒbƒhگ§Œن‚ھ”÷–‚إ
ƒ}ƒ‹ƒ`ƒRƒA‚ًڈمژè‚گ¶‚©‚¹‚ؤ‚ب‚¢‚ج‚à‚ ‚é‚ثپB
DVFSپiOndemandپj‚à‚؟‚ه‚ء‚ئ•‰‰×‚ھٹ|‚©‚é‚ئ‚·‚®چإچ‚ƒNƒچƒbƒN‚ة‚ب‚ء‚ؤ
چإ’لƒNƒچƒbƒNپEچإچ‚ƒNƒچƒbƒN‚جژہژ؟2’iٹKپiپ{ƒfƒBپ[ƒvƒXƒٹپ[ƒvپj‚µ‚©‚ب‚¢پB
8ƒRƒA‚ء‚ؤچإڈ‰Œ©‚½‚ئ‚«‚ح‚ر‚ر‚ء‚½‚¯‚ا‚ب‚—
‚ ‚ê8ƒRƒA‘S•”“®‚©‚·‚±‚ئ‚إ‚«‚é‚ٌ‚¾‚ء‚¯?پ@’P‚ب‚éڈب“d—ح—pپH
‚ ‚ê8ƒRƒA‘S•”“®‚©‚·‚±‚ئ‚إ‚«‚é‚ٌ‚¾‚ء‚¯?پ@’P‚ب‚éڈب“d—ح—pپH
Apple‚ھگفŒv‚ء‚ؤپA‚ׂآ‚ة0‚©‚çگفŒv‚µ‚ؤ‚é‚ٌ‚¶‚ل‚ب‚پA
ARM‚جƒRƒA‚ًƒxپ[ƒX‚ةƒJƒXƒ^ƒ}ƒCƒY‚µ‚ؤ‚é‚ٌ‚¶‚ل‚ٌ
ARM‚جƒRƒA‚ًƒxپ[ƒX‚ةƒJƒXƒ^ƒ}ƒCƒY‚µ‚ؤ‚é‚ٌ‚¶‚ل‚ٌ
P.A.SemiپAƒ}ƒW‚·‚°‚¥‚بپB
IntelˆبٹO‚إ‘f’¼‚ةٹ´گS‚µ‚½‚ج‚حڈ‰‚ك‚ؤ‚©‚à‚µ‚ٌ‚ب‚¢پB
IntelˆبٹO‚إ‘f’¼‚ةٹ´گS‚µ‚½‚ج‚حڈ‰‚ك‚ؤ‚©‚à‚µ‚ٌ‚ب‚¢پB
p.a.semi‚جکA’†‚حagnilux‚ةچs‚ء‚½‚آ‚ج
jim keller‚حamd‚ةچs‚ء‚½
jim keller‚حamd‚ةچs‚ء‚½
ƒnپ[ƒh‚ج‘g‚فچ‡‚ي‚¹‚ھŒہ‚ç‚ê‚ؤ‚ؤپAOS‚àگê—p‚¾‚©‚炱‚»‚جچ‚Œّ—¦‚¾‚낤
>>355
چ،‚حگط‘ض‚¾‚¯‚اپA‘S•”“®‚©‚·‚ج‚àٹJ”’†
چ،‚حگط‘ض‚¾‚¯‚اپA‘S•”“®‚©‚·‚ج‚àٹJ”’†
>>355
MediaTek‚جگV‚µ‚¢“z‚ئ‚©8ƒRƒA‘S•”“®‚©‚¹‚é“z‚àڈo‚ؤ‚‚é‚و
MediaTek‚جگV‚µ‚¢“z‚ئ‚©8ƒRƒA‘S•”“®‚©‚¹‚é“z‚àڈo‚ؤ‚‚é‚و
363 پFSocket774پF2013/10/17(–ط) 00:20:49.89 ID:Vpf8SigS
http://news.mynavi.jp/articles/2012/03/30/tegra_3/001.html
ƒAƒvƒٹ–ˆ‚ج4ƒRƒA‚»‚ꂼ‚ê‚ج•‰‰×ƒOƒ‰ƒt‚ً‚ف‚é‚ئپA3ƒRƒA–ع4ƒRƒA–ع‚ھ‘S‚–ً‚ة—§‚ء‚ؤ‚¢‚ب‚¢‚ئ‚حŒ¾‚ي‚ب‚¢‚ھپA
‚ئ‚è‚ ‚¦‚¸ƒXƒ}ƒz—p‚ة‚¨‚¢‚ؤ‚ح2ƒRƒA‚ة—¯‚ك‚آ‚آپAƒ^پ[ƒ{‹@”\‚ئ’´’لڈء”ï“d—ح‚ج’ا‹پ‚ةƒٹƒ\پ[ƒX‚ًٹ„‚èگU‚é‚ج‚حگ³‰ً‚¾‚ب
ƒAƒvƒٹ–ˆ‚ج4ƒRƒA‚»‚ꂼ‚ê‚ج•‰‰×ƒOƒ‰ƒt‚ً‚ف‚é‚ئپA3ƒRƒA–ع4ƒRƒA–ع‚ھ‘S‚–ً‚ة—§‚ء‚ؤ‚¢‚ب‚¢‚ئ‚حŒ¾‚ي‚ب‚¢‚ھپA
‚ئ‚è‚ ‚¦‚¸ƒXƒ}ƒz—p‚ة‚¨‚¢‚ؤ‚ح2ƒRƒA‚ة—¯‚ك‚آ‚آپAƒ^پ[ƒ{‹@”\‚ئ’´’لڈء”ï“d—ح‚ج’ا‹پ‚ةƒٹƒ\پ[ƒX‚ًٹ„‚èگU‚é‚ج‚حگ³‰ً‚¾‚ب
>>357
ARM‚جƒRƒA‚ًƒxپ[ƒX‚ةƒJƒXƒ^ƒ}ƒCƒY‚µ‚½‚ç‚ ‚ٌ‚بƒpƒCƒvƒ‰ƒCƒ“‚جچ\گ¬‚ة‚ح‚ب‚ç‚ب‚¢
ARM‚جƒRƒA‚ًƒxپ[ƒX‚ةƒJƒXƒ^ƒ}ƒCƒY‚µ‚½‚ç‚ ‚ٌ‚بƒpƒCƒvƒ‰ƒCƒ“‚جچ\گ¬‚ة‚ح‚ب‚ç‚ب‚¢
ƒAپ[ƒLƒ‰ƒCƒZƒ“ƒXچw“ü‚µ‚ؤ‚ظ‚ئ‚ٌ‚اƒ[ƒچ‚©‚çگفŒv‚µ‚ؤ‚é‚إ‚µ‚ه—رŒç‚جژ‘‹à—ح‚ئƒ}ƒ“ƒpƒڈپ[‚ب‚ç
ƒRƒA‚؟‚ه‚ء‚ئٹو’£‚ء‚ؤ‚¢‚¶‚ء‚ؤ‚ف‚ـ‚µ‚½‚إ‚ا‚¤‚±‚¤‚إ‚«‚éگ«”\‚¶‚ل‚ب‚¢
ƒRƒA‚؟‚ه‚ء‚ئٹو’£‚ء‚ؤ‚¢‚¶‚ء‚ؤ‚ف‚ـ‚µ‚½‚إ‚ا‚¤‚±‚¤‚إ‚«‚éگ«”\‚¶‚ل‚ب‚¢
”ٌŒِٹJ‚جƒJƒXƒ^ƒ€–½—ك‚ئ‚©‚ ‚ء‚½‚肵‚ؤ
’†چ‘گ»PC‚ھ‚ا‚¤‚µ‚½‚ء‚ؤ?
”M“I‚ة‚»‚ج‚ـ‚ـ‚¶‚ل–³—‚¾‚낤‚ث
ƒ^ƒڈپ[Œ^ƒfƒXƒNƒgƒbƒv‚ف‚½‚¢‚ة‚ب‚é‚©پAƒNƒچƒbƒN—ژ‚·‚©
ƒfƒXƒNƒgƒbƒv‹C‚ھ‚»‚ë‚»‚ëڈo‚ؤ‚à‚و‚³‚»‚¤‚ب‹C‚à‚·‚邵‚ب
ƒ^ƒڈپ[Œ^ƒfƒXƒNƒgƒbƒv‚ف‚½‚¢‚ة‚ب‚é‚©پAƒNƒچƒbƒN—ژ‚·‚©
ƒfƒXƒNƒgƒbƒv‹C‚ھ‚»‚ë‚»‚ëڈo‚ؤ‚à‚و‚³‚»‚¤‚ب‹C‚à‚·‚邵‚ب
‚±پA‚±‚ٌ‚بŒأ‚¢•¨‚ً
>>371‚³‚ٌپAژ_‘fŒ‡–Rگ«‚ة‚©‚©‚ء‚ؤپEپEپE
>>371‚³‚ٌپAژ_‘fŒ‡–Rگ«‚ة‚©‚©‚ء‚ؤپEپEپE
‚ب‚é‚ظ‚اپA‘هŒ´‚ج“d”g‚جڈoڈٹ‚حƒfƒ}ژ–ˆؤ‚ج–د‘z‚©
P54C‚ح2ƒpƒCƒv‚جƒXپ[ƒpپ[ƒXƒJƒ‰‚¾‚©‚çƒVƒ…ƒٹƒ“ƒN‚µ‚ؤ‚à
Quark‚ف‚½‚¢‚ب1ƒpƒCƒv‚ة‚ب‚肦‚ب‚¢‚ٌ‚¾‚¯‚ا‚بپB
P54C‚ح2ƒpƒCƒv‚جƒXپ[ƒpپ[ƒXƒJƒ‰‚¾‚©‚çƒVƒ…ƒٹƒ“ƒN‚µ‚ؤ‚à
Quark‚ف‚½‚¢‚ب1ƒpƒCƒv‚ة‚ب‚肦‚ب‚¢‚ٌ‚¾‚¯‚ا‚بپB
ƒCƒ“ƒIپ[ƒ_پ[‚جƒvƒچƒZƒbƒT‚ج‘م•\‚ئ‚µ‚ؤژ‚ء‚ؤ—ˆ‚½‚ٌ‚¾‚ëپB
ƒVƒ“ƒOƒ‹ƒpƒCƒv‚¾‚ئ‚µ‚½‚çi486‚ھ‚¾‚بپcپc
ƒVƒ“ƒOƒ‹ƒpƒCƒv‚¾‚ئ‚µ‚½‚çi486‚ھ‚¾‚بپcپc
>>374‚ج“d”g‚جڈoڈٹ‚ح‚ا‚±‚©‚µ‚ç
‰ٌکH‹K–ح‚ھڈ¬‚³‚¢‚©‚çچ،‚جٹJ”ٹآ‹«‚ب‚ç—]—T‚إگV‹KگفŒv‚إ‚«‚邵ƒxƒ‹پB
377 پFSocket774پF2013/10/23(گ…) 10:54:46.79 ID:dVrDV+5l
‚¢‚ـ‚ا‚«‚ج‘g‚فچ‚فƒvƒچƒZƒbƒT‚حپAڈ]—ˆ‚ئˆل‚ء‚ؤƒlƒbƒgƒڈپ[ƒN‚ةگع‘±‚·‚邱‚ئ‚ھ•Kگ{‚ة‚ب‚ء‚ؤ‚é‚ج‚إپA
‚ق‚©‚µ‚ئˆل‚ء‚ؤƒZƒLƒ…ƒٹƒeƒBپ[‹@”\‚جƒTƒ|پ[ƒg‚ح•Kگ{
گج•—‚جƒvƒچƒZƒbƒT‚¾‚ئپAƒoƒbƒtƒ@ƒIپ[ƒoپ[ƒtƒچپ[“™‚جگئژمگ«‚ھŒ©‚آ‚©‚ê‚خƒnƒbƒJپ[‚ة”Cˆس‚جƒRپ[ƒh‚ً“®‚©‚³‚ê‚ؤ‚µ‚ـ‚¤
Œ»‘م‚جƒvƒچƒZƒbƒT‚ة‚حپA‰¼‚ةOS‚âƒAƒvƒٹ‚جƒoƒO‚ھ‚ ‚ء‚ؤ‚àپAƒnƒbƒJپ[‚ھ”Cˆس‚جƒRپ[ƒh“®‚©‚·‚ج‚ً‘jژ~‚µ‚ب‚¢‚ئ‚¢‚¯‚ب‚¢
“dژqڈگ–¼‚µ‚½ƒRپ[ƒh‚ج‚ف“®چى‚µ‚ؤپA‚»‚êˆبٹO‚جƒRپ[ƒh‚ج“®چى‚ح‹ضژ~‚إ‚«‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚ج‚إپA
‚»‚ê‚ً‰آ”\‚ة‚·‚é‚ׂƒvƒچƒZƒbƒT‘¤‚إƒTƒ|پ[ƒg‚µ‚ب‚¢‚ئ‘ت–ع
pentiumƒRƒA‚ئ‚©‚»‚¤‚¢‚ء‚½‚ج‚ھ‘ه‚«‚Œ‡‚¯‚ؤ‚é
‚ق‚©‚µ‚ئˆل‚ء‚ؤƒZƒLƒ…ƒٹƒeƒBپ[‹@”\‚جƒTƒ|پ[ƒg‚ح•Kگ{
گج•—‚جƒvƒچƒZƒbƒT‚¾‚ئپAƒoƒbƒtƒ@ƒIپ[ƒoپ[ƒtƒچپ[“™‚جگئژمگ«‚ھŒ©‚آ‚©‚ê‚خƒnƒbƒJپ[‚ة”Cˆس‚جƒRپ[ƒh‚ً“®‚©‚³‚ê‚ؤ‚µ‚ـ‚¤
Œ»‘م‚جƒvƒچƒZƒbƒT‚ة‚حپA‰¼‚ةOS‚âƒAƒvƒٹ‚جƒoƒO‚ھ‚ ‚ء‚ؤ‚àپAƒnƒbƒJپ[‚ھ”Cˆس‚جƒRپ[ƒh“®‚©‚·‚ج‚ً‘jژ~‚µ‚ب‚¢‚ئ‚¢‚¯‚ب‚¢
“dژqڈگ–¼‚µ‚½ƒRپ[ƒh‚ج‚ف“®چى‚µ‚ؤپA‚»‚êˆبٹO‚جƒRپ[ƒh‚ج“®چى‚ح‹ضژ~‚إ‚«‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚ج‚إپA
‚»‚ê‚ً‰آ”\‚ة‚·‚é‚ׂƒvƒچƒZƒbƒT‘¤‚إƒTƒ|پ[ƒg‚µ‚ب‚¢‚ئ‘ت–ع
pentiumƒRƒA‚ئ‚©‚»‚¤‚¢‚ء‚½‚ج‚ھ‘ه‚«‚Œ‡‚¯‚ؤ‚é
378 پFSocket774پF2013/10/23(گ…) 11:39:08.12 ID:p3aRbqk5
hUMA‚âhQ‚ح‚±‚جƒXƒŒ“I‚ة‚ح‚ا‚¤‚ب‚ٌ‚¾‚ë
ƒwƒeƒچƒWƒjƒAƒX‚جژd‘g‚ف‚ئ‚µ‚ؤ–ت”’‚»‚¤‚ب‚ٌ‚¾‚¯‚ا
ƒwƒeƒچƒWƒjƒAƒX‚جژd‘g‚ف‚ئ‚µ‚ؤ–ت”’‚»‚¤‚ب‚ٌ‚¾‚¯‚ا
‚ئ‚±‚ë‚إ‚±‚±‚ء‚ؤژ©چىƒpƒ\ƒRƒ“‚ج”آ‚ب‚ٌ‚¾‚و‚ث
>>375
ƒVƒ“ƒOƒ‹ƒCƒVƒ…پ[پA5’iƒpƒCƒvƒ‰ƒCƒ“پAƒfپ[ƒ^/–½—ك‹¤—LL1ƒLƒƒƒbƒVƒ…پA32ƒrƒbƒgƒfپ[ƒ^ƒoƒX
Intel‚ھƒhƒLƒ…ƒپƒ“ƒg‚إŒ¾‚ء‚ؤ‚é“ء’¥‚ح486Œn‚ھƒxپ[ƒX‚إ‚ ‚邱‚ئ‚ًژ¦چ´‚µ‚ؤ‚¢‚é
https://communities.intel.com/servlet/JiveServlet/previewBody/21828-102-2-25120/329676_QuarkDatasheet.pdf
ƒVƒ“ƒOƒ‹ƒCƒVƒ…پ[پA5’iƒpƒCƒvƒ‰ƒCƒ“پAƒfپ[ƒ^/–½—ك‹¤—LL1ƒLƒƒƒbƒVƒ…پA32ƒrƒbƒgƒfپ[ƒ^ƒoƒX
Intel‚ھƒhƒLƒ…ƒپƒ“ƒg‚إŒ¾‚ء‚ؤ‚é“ء’¥‚ح486Œn‚ھƒxپ[ƒX‚إ‚ ‚邱‚ئ‚ًژ¦چ´‚µ‚ؤ‚¢‚é
https://communities.intel.com/servlet/JiveServlet/previewBody/21828-102-2-25120/329676_QuarkDatasheet.pdf
Atom‚ھ486‚ًƒxپ[ƒX‚ةچى‚ء‚ؤ‚½‚ئ‚«‚ةچإڈ‰1issue‚إچى‚낤‚ئ‚µ‚ؤ‚½‚ھ
2issue‚ة‚µ‚و‚¤‚ء‚ؤ‚±‚ئ‚ة‚ب‚ء‚ؤپAƒpƒCƒvƒ‰ƒCƒ“‚ً–„‚ك‚éˆ×‚ة
HyperThreading‚ًƒTƒ|پ[ƒg‚µ‚½‚ئ‚©پB
Quark‚حŒ¾‚¤‚ب‚ê‚خ1issue”إ‚جAtom‚ب‚ٌ‚¶‚ل‚ب‚¢‚جپH
‚ئ‚±‚ë‚إAtom‚ًPentium Pro‚ئ“¯‚¶Family=6‚ة•ھ—ق‚µ‚½‚ج‚ح‰ً‚¹‚ٌ‚يپB
پi‚ا‚¤‚¹ƒ\ƒtƒgƒEƒFƒA‚جŒفٹ·گ«‚ج‚½‚ك‚¾‚낤‚¯‚اپj
‚ ‚ٌ‚ـ‚èکb‘è‚ة‚ب‚ء‚ؤ‚ب‚¢‚¯‚اXeon Phi‚جCPU Family‚حB(11)
‘S‚گV‚µ‚¢CPUƒtƒ@ƒ~ƒٹپ[‚¾
2issue‚ة‚µ‚و‚¤‚ء‚ؤ‚±‚ئ‚ة‚ب‚ء‚ؤپAƒpƒCƒvƒ‰ƒCƒ“‚ً–„‚ك‚éˆ×‚ة
HyperThreading‚ًƒTƒ|پ[ƒg‚µ‚½‚ئ‚©پB
Quark‚حŒ¾‚¤‚ب‚ê‚خ1issue”إ‚جAtom‚ب‚ٌ‚¶‚ل‚ب‚¢‚جپH
‚ئ‚±‚ë‚إAtom‚ًPentium Pro‚ئ“¯‚¶Family=6‚ة•ھ—ق‚µ‚½‚ج‚ح‰ً‚¹‚ٌ‚يپB
پi‚ا‚¤‚¹ƒ\ƒtƒgƒEƒFƒA‚جŒفٹ·گ«‚ج‚½‚ك‚¾‚낤‚¯‚اپj
‚ ‚ٌ‚ـ‚èکb‘è‚ة‚ب‚ء‚ؤ‚ب‚¢‚¯‚اXeon Phi‚جCPU Family‚حB(11)
‘S‚گV‚µ‚¢CPUƒtƒ@ƒ~ƒٹپ[‚¾
Atom‚حƒfپ[ƒ^ƒtƒFƒbƒ`‚ھژهƒpƒCƒvƒ‰ƒCƒ“‚ة‘g‚فچ‚ـ‚ê‚ؤ‚¢‚ؤQuark‚ئ‚حˆل‚¤
5’iƒpƒCƒvƒ‰ƒCƒ“‚ئŒ¾‚ء‚ؤ‚éژ“_‚إAtom‚إ‚ح‚ب‚¢پA‚ـ‚¾Pentium‚ج•û‚ھ‹ك‚¢
>>380‚ج
>ƒfپ[ƒ^/–½—ك‹¤—LL1ƒLƒƒƒbƒVƒ…پA32ƒrƒbƒgƒfپ[ƒ^ƒoƒX
‚ ‚½‚è‚ھPentiumˆبچ~‚جIntelƒvƒچƒZƒbƒT‚ة‚حŒ©‚ç‚ê‚ب‚¢ژd—l‚إ‚ ‚낤
L1‚حƒnپ[ƒoپ[ƒh‚¾‚µپAƒfپ[ƒ^ƒoƒX‚ح64bit‚¾
>>380‚ج
>ƒfپ[ƒ^/–½—ك‹¤—LL1ƒLƒƒƒbƒVƒ…پA32ƒrƒbƒgƒfپ[ƒ^ƒoƒX
‚ ‚½‚è‚ھPentiumˆبچ~‚جIntelƒvƒچƒZƒbƒT‚ة‚حŒ©‚ç‚ê‚ب‚¢ژd—l‚إ‚ ‚낤
L1‚حƒnپ[ƒoپ[ƒh‚¾‚µپAƒfپ[ƒ^ƒoƒX‚ح64bit‚¾
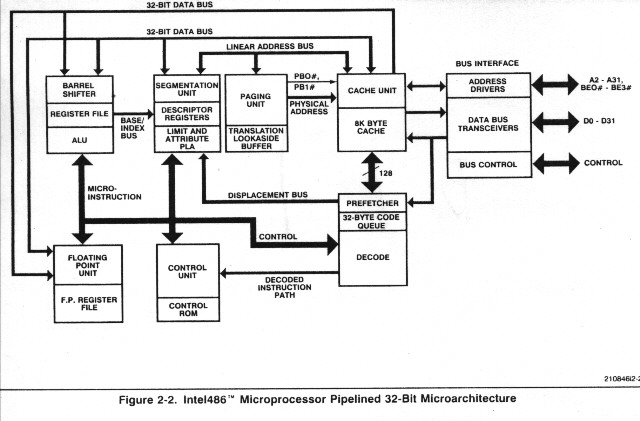{kind=link}
Core Hardware Reference Manual‚ةچع‚ء‚ؤ‚éگ}‚ئٹ®‘S‚ةˆê’v‚µ‚½w
CPU‚ئGPU‚جƒپƒ‚ƒٹ‹َٹش“ˆê‚·‚é‚ج‚ةپA‚¢‚ء‚½‚¢‚ا‚ꂾ‚¯‚جژٹش‚ھ‚©‚©‚ء‚ؤ‚é‚ٌ‚¾پB
‚â‚é‹C‚ ‚ٌ‚ج‚©پH
‚â‚é‹C‚ ‚ٌ‚ج‚©پH
>>381
ƒfƒ}Œ³‚ھP54Cƒxپ[ƒX‚ئ‚¢‚¤گà‚ةژٹ‚ء‚½——R‚ًگ„‘ھ‚µ‚½‚¾‚¯پB
Quark‚ح‰¼‚ة‰ك‹ژ‚جIntelƒvƒچƒZƒbƒT‚ةƒxپ[ƒX‚ھ‚ ‚é‚ة‚¹‚وپA
‚ا‚ê‚ة‚àژ—‚ؤ‚é‚ئ‚حŒ¾‚¢‚ھ‚½‚¢‚ثپB
ƒfƒ}Œ³‚ھP54Cƒxپ[ƒX‚ئ‚¢‚¤گà‚ةژٹ‚ء‚½——R‚ًگ„‘ھ‚µ‚½‚¾‚¯پB
Quark‚ح‰¼‚ة‰ك‹ژ‚جIntelƒvƒچƒZƒbƒT‚ةƒxپ[ƒX‚ھ‚ ‚é‚ة‚¹‚وپA
‚ا‚ê‚ة‚àژ—‚ؤ‚é‚ئ‚حŒ¾‚¢‚ھ‚½‚¢‚ثپB
390 پFSocket774پF2013/10/23(گ…) 22:47:28.21 ID:1JueLR0s
>>387
‚»‚à‚»‚àCPU‚ئGPU‚جƒپƒ‚ƒٹ‹َٹش“ˆê‚µ‚ؤ‚ب‚ٌ‚©ƒپƒٹƒbƒg‚ ‚é‚جپH‚ء‚ؤٹ´‚¶
‚ـ‚ ‚²‚‚²‚ˆê•”‚ج—ک—p–@‚إ‚حƒپƒٹƒbƒg‚ ‚邾‚낤‚¯‚اپA‚»‚ج‘¼‚ظ‚ئ‚ٌ‚ا‚ج—ک—p–@‚إ‚حƒپƒٹƒbƒg–³‚¢‚إ‚µ‚ه‚¤
‚»‚ج‚²‚‚²‚ˆê•”‚ج—ک—p–@‚ًژ‚؟ڈم‚°‚ؤپAƒپƒ‚ƒٹ‹َٹش“ˆê‚·‚ê‚خٹv–½‚إ‚à‹N‚±‚é“I‚بژه’£‚ً
ˆê•”‚جگl‚ھ‚µ‚ؤ‚邾‚¯
‚»‚à‚»‚àCPU‚ئGPU‚جƒپƒ‚ƒٹ‹َٹش“ˆê‚µ‚ؤ‚ب‚ٌ‚©ƒپƒٹƒbƒg‚ ‚é‚جپH‚ء‚ؤٹ´‚¶
‚ـ‚ ‚²‚‚²‚ˆê•”‚ج—ک—p–@‚إ‚حƒپƒٹƒbƒg‚ ‚邾‚낤‚¯‚اپA‚»‚ج‘¼‚ظ‚ئ‚ٌ‚ا‚ج—ک—p–@‚إ‚حƒپƒٹƒbƒg–³‚¢‚إ‚µ‚ه‚¤
‚»‚ج‚²‚‚²‚ˆê•”‚ج—ک—p–@‚ًژ‚؟ڈم‚°‚ؤپAƒپƒ‚ƒٹ‹َٹش“ˆê‚·‚ê‚خٹv–½‚إ‚à‹N‚±‚é“I‚بژه’£‚ً
ˆê•”‚جگl‚ھ‚µ‚ؤ‚邾‚¯
پiHPCˆبٹO‚جپj•پ’ت‚جƒAƒvƒٹ‚إ‚àGPGPU‚ئ‚©ƒwƒeƒچƒWƒjƒAƒX‚ئ‚©Œ¾‚ي‚ê‚ؤ‚½‚¯‚ا‘S‘R•پ‹y‚µ‚ؤ‚ب‚¢‚à‚ٌ‚ب
>>390
CPUپجGPU‚جƒfپ[ƒ^“]‘—‚جƒIپ[ƒoپ[ƒwƒbƒh‚ھ‚ب‚‚ب‚é‚ج‚حƒfƒJ‚¢‚وپB
چ،‚âƒ{ƒgƒ‹ƒlƒbƒN‚ح‰‰ژZ‚إ‚ح‚ب‚پAƒfپ[ƒ^—A‘—‚¾‚©‚ç‚ثپB
CPUپجGPU‚جƒfپ[ƒ^“]‘—‚جƒIپ[ƒoپ[ƒwƒbƒh‚ھ‚ب‚‚ب‚é‚ج‚حƒfƒJ‚¢‚وپB
چ،‚âƒ{ƒgƒ‹ƒlƒbƒN‚ح‰‰ژZ‚إ‚ح‚ب‚پAƒfپ[ƒ^—A‘—‚¾‚©‚ç‚ثپB
ƒfپ[ƒ^—A‘—‚ھƒ{ƒgƒ‹ƒlƒbƒN‚ء‚ؤپAGPU-ƒپƒ‚ƒٹٹش‚جکb‚إ‚µ‚ه
GPU‚ًٹˆ‚©‚¹‚é‚و‚¤‚ب—p“r‚إ‚حCPU-GPUٹش‚ب‚ٌ‚ؤ‚ا‚¤‚إ‚à‚¢‚¢‚ئژv‚¤‚ھ‚ث
ƒvƒچƒOƒ‰ƒ~ƒ“ƒOƒ‚ƒfƒ‹“I‚ةƒپƒ‚ƒٹ‹َٹش“چ‡‚µ‚½‚ظ‚¤‚ھ‚¢‚¢پA‚ئ‚¢‚¤کb‚ح•ھ‚©‚é‚و
‚إ‚à‚»‚ê‚ھ‘¬“xŒüڈم‚ةŒq‚ھ‚é‚©‚ئ‚¢‚¤‚ئ‚½‚ش‚ٌƒmپ[‚¾
GPU‚ًٹˆ‚©‚¹‚é‚و‚¤‚ب—p“r‚إ‚حCPU-GPUٹش‚ب‚ٌ‚ؤ‚ا‚¤‚إ‚à‚¢‚¢‚ئژv‚¤‚ھ‚ث
ƒvƒچƒOƒ‰ƒ~ƒ“ƒOƒ‚ƒfƒ‹“I‚ةƒپƒ‚ƒٹ‹َٹش“چ‡‚µ‚½‚ظ‚¤‚ھ‚¢‚¢پA‚ئ‚¢‚¤کb‚ح•ھ‚©‚é‚و
‚إ‚à‚»‚ê‚ھ‘¬“xŒüڈم‚ةŒq‚ھ‚é‚©‚ئ‚¢‚¤‚ئ‚½‚ش‚ٌƒmپ[‚¾
IGP‚جGPGPUگ«”\‚ب‚ٌ‚ؤٹْ‘ز‚·‚ٌ‚ب‚وپB
‚¢‚‚牉ژZƒ†ƒjƒbƒg”nژگد‚ف‚µ‚½‚ئ‚±‚ë‚إپA”ؤ—p‰‰ژZ‚إ‚ح
ƒپƒ‚ƒٹ‘رˆوˆبڈم‚ج‚±‚ئ‚ح‚إ‚«‚ب‚¢‚ٌ‚¾‚©‚炳
Haswell‚إ‚·‚إ‚ةFlops/Bytes(ƒپƒ‚ƒٹ‘رˆو‚ ‚½‚è‚ج•‚“®ڈ¬گ”“_‰‰ژZگ«”\)“I‚ة‚ح
Kepler‚ً’´‚¦‚ؤ–Oکaڈَ‘ش‚ة‚ ‚éپB
Intel‚حDDR4ƒTƒ|پ[ƒg‚جŒم‚ة‚±‚جڈم‚³‚ç‚ة512ƒrƒbƒg‰»‚ً‚â‚낤‚ئ‚µ‚ؤ‚éپB
ƒfپ[ƒ^‚جƒپƒ‚ƒٹ“n‚µ‚ب‚ٌ‚ؤ‚ك‚ٌ‚ا‚‚³‚¢‚±‚ئ‚â‚ç‚ب‚‚ئ‚àCPUƒRƒA“à‚جƒfپ[ƒ^‚ً
ƒŒƒWƒXƒ^‚إƒfپ[ƒ^‚ً’¼گع“n‚¹‚é“à‘ ‚جSSE/AVX‚جƒ†ƒjƒbƒg‚ً
‹‰»‚·‚é‚ظ‚¤‚ھƒAƒvƒچپ[ƒ`‚ئ‚µ‚ؤ—‚ة‚©‚ب‚ء‚ؤ‚邾‚ëپB
‚¢‚‚牉ژZƒ†ƒjƒbƒg”nژگد‚ف‚µ‚½‚ئ‚±‚ë‚إپA”ؤ—p‰‰ژZ‚إ‚ح
ƒپƒ‚ƒٹ‘رˆوˆبڈم‚ج‚±‚ئ‚ح‚إ‚«‚ب‚¢‚ٌ‚¾‚©‚炳
Haswell‚إ‚·‚إ‚ةFlops/Bytes(ƒپƒ‚ƒٹ‘رˆو‚ ‚½‚è‚ج•‚“®ڈ¬گ”“_‰‰ژZگ«”\)“I‚ة‚ح
Kepler‚ً’´‚¦‚ؤ–Oکaڈَ‘ش‚ة‚ ‚éپB
Intel‚حDDR4ƒTƒ|پ[ƒg‚جŒم‚ة‚±‚جڈم‚³‚ç‚ة512ƒrƒbƒg‰»‚ً‚â‚낤‚ئ‚µ‚ؤ‚éپB
ƒfپ[ƒ^‚جƒپƒ‚ƒٹ“n‚µ‚ب‚ٌ‚ؤ‚ك‚ٌ‚ا‚‚³‚¢‚±‚ئ‚â‚ç‚ب‚‚ئ‚àCPUƒRƒA“à‚جƒfپ[ƒ^‚ً
ƒŒƒWƒXƒ^‚إƒfپ[ƒ^‚ً’¼گع“n‚¹‚é“à‘ ‚جSSE/AVX‚جƒ†ƒjƒbƒg‚ً
‹‰»‚·‚é‚ظ‚¤‚ھƒAƒvƒچپ[ƒ`‚ئ‚µ‚ؤ—‚ة‚©‚ب‚ء‚ؤ‚邾‚ëپB
>>392
‚»‚¤ژv‚¤‚ب‚ç“à‘ GPU‚ةƒ^ƒXƒN“ٹ‚°‚é‚ب‚ٌ‚ؤ”nژ‚ب‚±‚ئ‚ً‚â‚ك‚ؤCPU‚ج
SIMDٹg’£‚ً‹}‚¢‚إIntel‚ة’ا‚¢‚آ‚¢‚ؤ‚‚ê‚ئ‚µ‚©پB
Steamroller‚إ‚·‚ç256bit‰»‚³‚ê‚ب‚¢‚»‚¤‚¾‚بپB
‚»‚¤ژv‚¤‚ب‚ç“à‘ GPU‚ةƒ^ƒXƒN“ٹ‚°‚é‚ب‚ٌ‚ؤ”nژ‚ب‚±‚ئ‚ً‚â‚ك‚ؤCPU‚ج
SIMDٹg’£‚ً‹}‚¢‚إIntel‚ة’ا‚¢‚آ‚¢‚ؤ‚‚ê‚ئ‚µ‚©پB
Steamroller‚إ‚·‚ç256bit‰»‚³‚ê‚ب‚¢‚»‚¤‚¾‚بپB
CPU1ƒRƒA‚ ‚½‚è‚جƒپƒ‚ƒٹ‘رˆو‚حDDR400ƒfƒ…ƒAƒ‹‚جچ ‚©‚ç•د‚ي‚ء‚ؤ‚ب‚¢‚ٌ‚¾‚و‚ب‚ں
‚à‚¤10”Nگi•à‚ھ‚ب‚¢‚±‚ئ‚ة‚ب‚é
‚à‚¤10”Nگi•à‚ھ‚ب‚¢‚±‚ئ‚ة‚ب‚é
ƒVپ[ƒPƒ“ƒVƒƒƒ‹‚إ‚·‚ç‚»‚¤‚¢‚¤‘ج‚½‚ç‚‚إƒ‰ƒ“ƒ_ƒ€‚ح—ض‚ً‚©‚¯‚ؤچ“‚¢پB
RandomAccessMemory ‚ج–¼‚ھ‹ƒ‚¢‚ؤ‚¢‚é
RandomAccessMemory ‚ج–¼‚ھ‹ƒ‚¢‚ؤ‚¢‚é
398 پFSocket774پF2013/10/24(–ط) 01:01:53.46 ID:qNBSOQ4A
>>395
SR‚ح“¯‚¶ژd—l‚ً‰½”N‚à‚©‚¯‚ؤچى‚ء‚ؤ‚éچ،ژ’؟‚µ‚¢
‚ج‚ٌ‚«ژزCPU
“–‘Rگج‚¾‚ئٹvگV“I‚¾‚ء‚½‚ٌ‚¾‚낤‚ھ—ˆ”Nڈo‚ؤ‚«‚ؤ‚à‚à‚¤’x‚¢
Intel‚ةگو‰z‚³‚ê‚ؤ‚ـ‚¤‚ي
SR‚ح“¯‚¶ژd—l‚ً‰½”N‚à‚©‚¯‚ؤچى‚ء‚ؤ‚éچ،ژ’؟‚µ‚¢
‚ج‚ٌ‚«ژزCPU
“–‘Rگج‚¾‚ئٹvگV“I‚¾‚ء‚½‚ٌ‚¾‚낤‚ھ—ˆ”Nڈo‚ؤ‚«‚ؤ‚à‚à‚¤’x‚¢
Intel‚ةگو‰z‚³‚ê‚ؤ‚ـ‚¤‚ي
>>396
ƒ}ƒ‹ƒ`ƒRƒA‚¾‚ئRAM‚âƒXƒgƒŒپ[ƒW‚ھƒ{ƒgƒ‹ƒlƒbƒN‚ة‚ب‚é
ƒ}ƒ‹ƒ`PC‚¾‚ئPCٹش’تگM‚ھƒ{ƒgƒ‹ƒlƒbƒN‚ة‚ب‚é
>>397
“à•”‚جƒپƒ‚ƒٹƒNƒچƒbƒN‚ھڈم‚ھ‚ç‚ب‚¢ˆبڈم‚ا‚¤‚µ‚و‚¤‚à‚ب‚¢‚ث
ژںگ¢‘مƒپƒ‚ƒٹ‚ح‚ـ‚¾‚©
ƒ}ƒ‹ƒ`ƒRƒA‚¾‚ئRAM‚âƒXƒgƒŒپ[ƒW‚ھƒ{ƒgƒ‹ƒlƒbƒN‚ة‚ب‚é
ƒ}ƒ‹ƒ`PC‚¾‚ئPCٹش’تگM‚ھƒ{ƒgƒ‹ƒlƒbƒN‚ة‚ب‚é
>>397
“à•”‚جƒپƒ‚ƒٹƒNƒچƒbƒN‚ھڈم‚ھ‚ç‚ب‚¢ˆبڈم‚ا‚¤‚µ‚و‚¤‚à‚ب‚¢‚ث
ژںگ¢‘مƒپƒ‚ƒٹ‚ح‚ـ‚¾‚©
CPU‚ئiGPU‚جٹش‚ج’تگM‚ھ‘½ڈ‘¬‚‚ب‚ء‚½‚ئ‚±‚ë‚إCPUƒRƒA‚ة“à‘ ‚³‚ꂽSIMDƒ†ƒjƒbƒg‚ئ‚ئ‚ح‘S‚”نٹr‚ة‚ب‚ç‚ب‚¢Œ…ˆل‚¢‚ج’x‚³‚إ‚ ‚èپAiGPU‚ح—±“x‚جڈ¬‚³‚¢ƒ^ƒXƒN‚ً‘–‚点‚é‚ج‚ة‚حŒü‚©‚ب‚¢پB
—±“x‚ج‘ه‚«‚¢ƒ^ƒXƒN‚ب‚çdGPU‚ج‚و‚¤‚ة‚ق‚µ‚ëCPU‚ئ“ئ—§‚µ‚½ƒپƒ‚ƒٹƒoƒX‚ً—L‚µ‚ؤ‚¢‚½•û‚ھ—L—ک‚إ‚ ‚éپB
CPU‚ئƒپƒ‚ƒٹ‘رˆو‚ًƒVƒFƒA‚·‚éiGPU‚ة‚¨‚¢‚ؤCPU‚ئiGPU‚جٹش‚ج’تگM‚ًƒپƒCƒ“ƒپƒ‚ƒٹ‚ً‰î‚·‚邱‚ئ‚ب‚ژہچs‚إ‚«‚ê‚خگ«”\–ت‚إƒپƒٹƒbƒg‚ھ‚ ‚éپB
CPUپAGPU‚ئ‚à‚ة‘ه—ت‚جƒپƒ‚ƒٹ‚ً•K—v‚ئ‚·‚邽‚كiGPUگê—p‚جڈ¬—e—ت‚جƒچپ[ƒJƒ‹ƒپƒ‚ƒٹ‚ً”z’u‚µ‚ؤ‚àˆس–،‚ھ‚ب‚¢پB
‚ ‚é’ِ“x‚ج—e—ت‚جCPU/iGPU‹¤—L‚جƒLƒƒƒbƒVƒƒ‚ً“à‘ ‚·‚é‚ج‚ھ•Kگ{‚إ‚ ‚éپB
CPU‚ئiGPU‚جƒپƒ‚ƒٹ‹َٹش‚ً“چ‡‚·‚ê‚خƒfپ[ƒ^“]‘—‚ھ•s—v‚ئ‚ب‚èگ«”\–ت‚إ–]‚ـ‚µ‚¢‚ھOS‚âƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ج‘خ‰‚ھ•K—v‚إ‚ ‚邽‚كƒQپ[ƒ€ƒRƒ“ƒ\پ[ƒ‹‚ب‚ç‚ئ‚à‚©‚PC‚إ‚حژہ—pگ«‚ھ’ل‚¢پB
—±“x‚ج‘ه‚«‚¢ƒ^ƒXƒN‚ب‚çdGPU‚ج‚و‚¤‚ة‚ق‚µ‚ëCPU‚ئ“ئ—§‚µ‚½ƒپƒ‚ƒٹƒoƒX‚ً—L‚µ‚ؤ‚¢‚½•û‚ھ—L—ک‚إ‚ ‚éپB
CPU‚ئƒپƒ‚ƒٹ‘رˆو‚ًƒVƒFƒA‚·‚éiGPU‚ة‚¨‚¢‚ؤCPU‚ئiGPU‚جٹش‚ج’تگM‚ًƒپƒCƒ“ƒپƒ‚ƒٹ‚ً‰î‚·‚邱‚ئ‚ب‚ژہچs‚إ‚«‚ê‚خگ«”\–ت‚إƒپƒٹƒbƒg‚ھ‚ ‚éپB
CPUپAGPU‚ئ‚à‚ة‘ه—ت‚جƒپƒ‚ƒٹ‚ً•K—v‚ئ‚·‚邽‚كiGPUگê—p‚جڈ¬—e—ت‚جƒچپ[ƒJƒ‹ƒپƒ‚ƒٹ‚ً”z’u‚µ‚ؤ‚àˆس–،‚ھ‚ب‚¢پB
‚ ‚é’ِ“x‚ج—e—ت‚جCPU/iGPU‹¤—L‚جƒLƒƒƒbƒVƒƒ‚ً“à‘ ‚·‚é‚ج‚ھ•Kگ{‚إ‚ ‚éپB
CPU‚ئiGPU‚جƒپƒ‚ƒٹ‹َٹش‚ً“چ‡‚·‚ê‚خƒfپ[ƒ^“]‘—‚ھ•s—v‚ئ‚ب‚èگ«”\–ت‚إ–]‚ـ‚µ‚¢‚ھOS‚âƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ج‘خ‰‚ھ•K—v‚إ‚ ‚邽‚كƒQپ[ƒ€ƒRƒ“ƒ\پ[ƒ‹‚ب‚ç‚ئ‚à‚©‚PC‚إ‚حژہ—pگ«‚ھ’ل‚¢پB
‚¾‚©‚炱‚ê‚©‚çOS‚âƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ً‘خ‰‚³‚¹‚é‚ء‚ؤکb‚¾‚ëپB
پuŒ»ژ“_‚إ‚حپvژہ—pگ«‚ھ’ل‚¢(‚ئ‚¢‚¤‚©ٹF–³)‚ب‚ج‚حٹm‚©‚¾‚ھپB
پuŒ»ژ“_‚إ‚حپvژہ—pگ«‚ھ’ل‚¢(‚ئ‚¢‚¤‚©ٹF–³)‚ب‚ج‚حٹm‚©‚¾‚ھپB
‚¾‚¢‚ش‘O‚©‚ç‚»‚¤Œ¾‚ء‚ؤ‚é‚ٌ‚¾‚¯‚اˆêŒü‚ة‘خ‰‚µ‚ب‚¢‚ث
ƒzƒ“ƒg‚ة‘خ‰‚µ‚ؤ‚½‚çAMD‚à‚à‚¤ڈ‚µ—¬چs‚ء‚ؤ‚½‚©‚à‚ب
ƒzƒ“ƒg‚ة‘خ‰‚µ‚ؤ‚½‚çAMD‚à‚à‚¤ڈ‚µ—¬چs‚ء‚ؤ‚½‚©‚à‚ب
پھ‚»‚ê’N‚ھ“¾‚·‚é‚جپH
AMD”ة‰hپiڈخپj‚ج‚½‚ك‚ةMS‚⑼‚جٹé‹ئ‚ھ‹¦—ح‚µ‚ؤ‚‚ê‚é‚ئ‚إ‚àپH
MS‚حhSA‚ةژQ‰ء‚µ‚ؤ‚ب‚¢‚وپH
APU‚ح‘fگ°‚炵‚¢‚à‚ج‚¾‚ئژ©Œبگô”]‚·‚邽‚ك‚ةٹè–]‚ًڈq‚ׂé‚ج‚ح‚¢‚¢‰ءŒ¸‚â‚ك‚و‚¤‚و
ڈ‚ب‚‚ئ‚àPC‚ة‚¨‚¢‚ؤiGP“چ‡‚جچإ‘ه‚ج——R‚حƒmپ[ƒgPCŒü‚¯‚جƒRƒXƒgƒ_ƒEƒ“‚ج‚½‚ك‚إ
ƒfƒXƒNƒgƒbƒv—p“r‚إ‚ح‚½‚©‚¾‚©GPU‚ًƒAƒbƒvƒOƒŒپ[ƒh‚·‚邽‚ك‚ةƒ}ƒUƒ{‚²‚ئŒًٹ·‚ھ
•K—v‚¾‚ء‚½‚è”ٌچ‡—“I‚ب‚à‚ج‚إ‚µ‚©‚ب‚¢پB
–{‰¹‚ً‰B‚·‚½‚ك‚جŒڑ‘O‚ة‘ه‚«‚بˆس–،‚ً‹پ‚ك‚½‚ئ‚±‚ë‚إ–ى•é‚¾‚و
ƒپƒCƒ“ƒپƒ‚ƒٹ‘رˆو‚إ–Oکa‚·‚é‚ب‚çCPU‚جSIMDƒ†ƒjƒbƒg‚ًƒVƒFپ[ƒ_‚ئ‚µ‚ؤژg‚ء‚ؤ‚à“¯‚¶‚¾‚و‚بپH
Larrabee‚جƒVƒFپ[ƒ_–½—كƒZƒbƒg‚©‚ç”hگ¶‚µ‚½AVX-512‚ً”ؤ—pƒRƒA‚إ‚àƒTƒ|پ[ƒg‚·‚邱‚ئ‚إ
Intel‚ح“چ‡GPU‚ًڈء–إ‚³‚¹‚éڈ€”ُ‚ً’…پX‚ئگi‚ك‚ؤ‚¢‚éپB
‚±‚ء‚؟‚ة‚حMS‚à‹¦—ح“I‚¾پB
AMD”ة‰hپiڈخپj‚ج‚½‚ك‚ةMS‚⑼‚جٹé‹ئ‚ھ‹¦—ح‚µ‚ؤ‚‚ê‚é‚ئ‚إ‚àپH
MS‚حhSA‚ةژQ‰ء‚µ‚ؤ‚ب‚¢‚وپH
APU‚ح‘fگ°‚炵‚¢‚à‚ج‚¾‚ئژ©Œبگô”]‚·‚邽‚ك‚ةٹè–]‚ًڈq‚ׂé‚ج‚ح‚¢‚¢‰ءŒ¸‚â‚ك‚و‚¤‚و
ڈ‚ب‚‚ئ‚àPC‚ة‚¨‚¢‚ؤiGP“چ‡‚جچإ‘ه‚ج——R‚حƒmپ[ƒgPCŒü‚¯‚جƒRƒXƒgƒ_ƒEƒ“‚ج‚½‚ك‚إ
ƒfƒXƒNƒgƒbƒv—p“r‚إ‚ح‚½‚©‚¾‚©GPU‚ًƒAƒbƒvƒOƒŒپ[ƒh‚·‚邽‚ك‚ةƒ}ƒUƒ{‚²‚ئŒًٹ·‚ھ
•K—v‚¾‚ء‚½‚è”ٌچ‡—“I‚ب‚à‚ج‚إ‚µ‚©‚ب‚¢پB
–{‰¹‚ً‰B‚·‚½‚ك‚جŒڑ‘O‚ة‘ه‚«‚بˆس–،‚ً‹پ‚ك‚½‚ئ‚±‚ë‚إ–ى•é‚¾‚و
ƒپƒCƒ“ƒپƒ‚ƒٹ‘رˆو‚إ–Oکa‚·‚é‚ب‚çCPU‚جSIMDƒ†ƒjƒbƒg‚ًƒVƒFپ[ƒ_‚ئ‚µ‚ؤژg‚ء‚ؤ‚à“¯‚¶‚¾‚و‚بپH
Larrabee‚جƒVƒFپ[ƒ_–½—كƒZƒbƒg‚©‚ç”hگ¶‚µ‚½AVX-512‚ً”ؤ—pƒRƒA‚إ‚àƒTƒ|پ[ƒg‚·‚邱‚ئ‚إ
Intel‚ح“چ‡GPU‚ًڈء–إ‚³‚¹‚éڈ€”ُ‚ً’…پX‚ئگi‚ك‚ؤ‚¢‚éپB
‚±‚ء‚؟‚ة‚حMS‚à‹¦—ح“I‚¾پB
Œ»ژ“_‚إ‚حAPU‚جگi‚ق“¹‚و‚èAVX‚جGPU‰»‚جگi‚ق“¹‚ج•û‚ھŒ¯‚µ‚»‚¤‚¾پB
‚ـ‚ پAIntel‚ھگ^Œ•‚ةژو‚è‘g‚ٌ‚¾‚ç‚ا‚¤‚ب‚é‚©‚ي‚©‚ç‚ب‚¢‚ھپB
‚ـ‚ پAIntel‚ھگ^Œ•‚ةژو‚è‘g‚ٌ‚¾‚ç‚ا‚¤‚ب‚é‚©‚ي‚©‚ç‚ب‚¢‚ھپB
‚و‚‚ي‚©‚ç‚ٌ‚ھپA•ت‚ةAPU(HSA)‚âAMD‚ة“ء’iژv‚¢“ü‚ê‚ھ‚ ‚é‚ي‚¯‚إ‚à‚ب‚¢‚ج‚¾‚ھپEپEپEپB
‚½‚¾پA‚ا‚¤ژہ‘•‚·‚é‚ج‚©‚جڈعچׂà‚ي‚©‚ç‚ٌ’iٹK‚إپA
OS‚âƒ\ƒtƒg‚ھ‘خ‰‚µ‚ؤ‚ب‚¢‚©‚çˆس–،‚ھ–³‚¢‚ئ‚©’f’肵‚؟‚ل‚¤‚ج‚حژٹْڈ®‘پ‚·‚¬‚邾‚ëپA‚ء‚ؤ‚¾‚¯‚جکbپB
ˆê‘ج‚ب‚ة‚ئگي‚ء‚ؤ‚é‚ٌ‚¾پH
‚½‚¾پA‚ا‚¤ژہ‘•‚·‚é‚ج‚©‚جڈعچׂà‚ي‚©‚ç‚ٌ’iٹK‚إپA
OS‚âƒ\ƒtƒg‚ھ‘خ‰‚µ‚ؤ‚ب‚¢‚©‚çˆس–،‚ھ–³‚¢‚ئ‚©’f’肵‚؟‚ل‚¤‚ج‚حژٹْڈ®‘پ‚·‚¬‚邾‚ëپA‚ء‚ؤ‚¾‚¯‚جکbپB
ˆê‘ج‚ب‚ة‚ئگي‚ء‚ؤ‚é‚ٌ‚¾پH
406 پFSocket774پF2013/10/24(–ط) 07:15:14.66 ID:btZumgky
AVX-512‚حXeonˆبٹO‚ة‚حچع‚ç‚ب‚¢‚ف‚½‚¢‚¾‚¼
‚آپ[‚©‚»‚ج‘O‚ةCeleron‚إ‚àAVX“®‚‚و‚¤‚ة‚µ‚ë
‚آپ[‚©‚»‚ج‘O‚ةCeleron‚إ‚àAVX“®‚‚و‚¤‚ة‚µ‚ë
>>406
‚»‚ê‚ح“ا‚فٹشˆل‚¢‚¾‚بپA‚ا‚±‚ة‚à‚»‚ٌ‚ب‚±‚ئ‚حڈ‘‚¢‚ؤ‚ب‚¢
Xeon‚إژg‚¦‚é‚ج‚ئXeon‚إ‚µ‚©ژg‚¦‚ب‚¢‚ج‚حˆل‚¤‚¼
Core*‚ئ“¯‚¶ƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒگفŒv‚ة‚·‚邱‚ئ‚إƒRƒXƒgƒ_ƒEƒ“‚µ‚ؤ‚é‚ج‚إ‚ ‚ء‚ؤ
Core*‚ةژہ‘•‚³‚ê‚ب‚¢‹@”\‚ًXeon‚إژہ‘•‚·‚é‚ج‚ح
‚ـ‚ء‚½‚•ت‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًچى‚é‚ج‚ئ“¯‚¶‚±‚ئ‚ة‚ب‚éپB
‚ن‚‚ن‚‚حIntel‚ج‘SƒvƒچƒZƒbƒT‚إژg‚¦‚é‚و‚¤‚ة‚ب‚é‚إ‚µ‚ه
پiAVX-512‚ً“‹چع‚µ‚½Atom‚ء‚ؤژںٹْXeon Phi‚جƒRƒA‚»‚ج‚à‚ج‚¾‚ëپHپj
‚ـ‚ پA‰ئ’ë—pPC‚ة‚¨‚¢‚ؤDDR4ˆبچ~‚جDRAM‘رˆو–â‘è‚ةŒ»ژہ“I‚ب‘إٹJچô‚ھ‚ب‚¢‚±‚ئ‚ً‹tژè‚ة‚ئ‚ê‚خ
SIMDگê—p‚جƒvƒچƒZƒbƒT‚ً‘½گ”“à‘ ‚·‚邱‚ئ‚ح–³ˆس–،‚ة‚ب‚éپB
‚»‚ê‚ح“ا‚فٹشˆل‚¢‚¾‚بپA‚ا‚±‚ة‚à‚»‚ٌ‚ب‚±‚ئ‚حڈ‘‚¢‚ؤ‚ب‚¢
Xeon‚إژg‚¦‚é‚ج‚ئXeon‚إ‚µ‚©ژg‚¦‚ب‚¢‚ج‚حˆل‚¤‚¼
Core*‚ئ“¯‚¶ƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒگفŒv‚ة‚·‚邱‚ئ‚إƒRƒXƒgƒ_ƒEƒ“‚µ‚ؤ‚é‚ج‚إ‚ ‚ء‚ؤ
Core*‚ةژہ‘•‚³‚ê‚ب‚¢‹@”\‚ًXeon‚إژہ‘•‚·‚é‚ج‚ح
‚ـ‚ء‚½‚•ت‚جƒ}ƒCƒNƒچƒAپ[ƒLƒeƒNƒ`ƒƒ‚ًچى‚é‚ج‚ئ“¯‚¶‚±‚ئ‚ة‚ب‚éپB
‚ن‚‚ن‚‚حIntel‚ج‘SƒvƒچƒZƒbƒT‚إژg‚¦‚é‚و‚¤‚ة‚ب‚é‚إ‚µ‚ه
پiAVX-512‚ً“‹چع‚µ‚½Atom‚ء‚ؤژںٹْXeon Phi‚جƒRƒA‚»‚ج‚à‚ج‚¾‚ëپHپj
‚ـ‚ پA‰ئ’ë—pPC‚ة‚¨‚¢‚ؤDDR4ˆبچ~‚جDRAM‘رˆو–â‘è‚ةŒ»ژہ“I‚ب‘إٹJچô‚ھ‚ب‚¢‚±‚ئ‚ً‹tژè‚ة‚ئ‚ê‚خ
SIMDگê—p‚جƒvƒچƒZƒbƒT‚ً‘½گ”“à‘ ‚·‚邱‚ئ‚ح–³ˆس–،‚ة‚ب‚éپB
Skylake‚إ‚حCPUƒRƒA‚ةGPUŒü‚¯‚جŒإ’胆ƒjƒbƒg‚ھˆê•”گVگف‚³‚ê‚é‚©‚à‚ب‚ٌ‚ؤگ„‘ھ‚à‚ ‚é‚ھپAIntel‚ة‚ـ‚ئ‚à‚بƒhƒ‰ƒCƒo‚ً—pˆس‚إ‚«‚é‚©Œƒ‚µ‚•sˆہ
BayTrail‚إ‚حAtom‚ًPentium,Celeron‚ة“ا‚ف‘ض‚¦‚ؤ‚é‚©‚ç‚ب
‚»‚ج‚¤‚؟CoreŒn‚جPentium,Celeron‚ح”pژ~‚³‚ê‚é‚ٌ‚¶‚ل‚ثپH
‚»‚ج‚¤‚؟CoreŒn‚جPentium,Celeron‚ح”pژ~‚³‚ê‚é‚ٌ‚¶‚ل‚ثپH
گ«”\‚ء‚ؤˆس–،‚إ‚حٹmژہ‚ةڈمڈ¸‚·‚邾‚ë
GPU‚ةژdژ–•ھ’S‚³‚¹‚ç‚ê‚ê‚خ‚»‚ج‚ش‚ٌCPU‚ھ‹َ‚‚ي‚¯‚إ
‚»‚جٹشCPU‚ةژdژ–‚³‚¹‚ê‚خگ«”\‚حڈم‚ھ‚é
GPU‚ةژdژ–•ھ’S‚³‚¹‚ç‚ê‚ê‚خ‚»‚ج‚ش‚ٌCPU‚ھ‹َ‚‚ي‚¯‚إ
‚»‚جٹشCPU‚ةژdژ–‚³‚¹‚ê‚خگ«”\‚حڈم‚ھ‚é
پھƒپƒ‚ƒٹ‚ھ•ھ‚©‚ê‚ؤ‚éƒfƒBƒXƒNƒٹپ[ƒgGPU‚ب‚çˆê—‚ ‚é‚ھ
APU‚¾‚ئGPU‚ھRAM‘رˆوژو‚ء‚؟‚ل‚ء‚ؤCPU‚جƒ^ƒXƒN‚ھ’â‘ط‚·‚é‚©‚à‚ث
APU‚¾‚ئGPU‚ھRAM‘رˆوژو‚ء‚؟‚ل‚ء‚ؤCPU‚جƒ^ƒXƒN‚ھ’â‘ط‚·‚é‚©‚à‚ث
ƒپƒ‚ƒٹ‚ھگآ“Vˆن‚ب‚çCPUپ{GPU‚ج’Pڈƒ‚ب‘«‚µژZ‚إ‚¢‚¯‚é‚ھ
Œ»ژہ‚ة‚حڈمŒہ‚ھŒˆ‚ـ‚ء‚ؤ‚ؤ‚ا‚ء‚؟‚©‚ھƒپƒ‚ƒٹ‘رˆو‚ً‚ئ‚ê‚خ‚à‚¤•ذ•û‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ
’ل‰؛‚·‚éپuˆّ‚«ژZپv‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
CPU‚ج‘م‚ي‚è‚ً‚³‚¹‚é‚ج‚ھ–ع“I‚ب‚çCPUƒRƒA‚»‚ج‚à‚ج‚ً‘‚₵‚½•û‚ھ
‚و‚èٹmژہ‚ة”ؤ—pƒRƒ“ƒsƒ…پ[ƒeƒBƒ“ƒOگ«”\ƒ}ƒV‚بƒAƒvƒچپ[ƒ`‚و‚وپH
Œ»ژہ‚ة‚ح‘رˆو•s‘«‚إƒRƒA‘‚₵‚ؤ‚àˆس–،‚ھ‚ب‚¢‚µGPU‚ة“ٹ‚°‚ؤ‚àڈ®چX‚ب‚ٌ‚¾
ƒRƒXƒgƒ_ƒEƒ“‚ج‚½‚ك‚ةGPU‚ً“چ‡‚·‚é‚ج‚ةپy‘OŒü‚«‚炵‚¢پz——R‚ً‚آ‚¯‚½‚¢
‚¾‚¯‚ب‚ٌ‚¾‚©‚çٹْ‘ز‚ب‚ٌ‚إ‚·‚ٌ‚ب‚و
Œ»ژہ‚ة‚حڈمŒہ‚ھŒˆ‚ـ‚ء‚ؤ‚ؤ‚ا‚ء‚؟‚©‚ھƒپƒ‚ƒٹ‘رˆو‚ً‚ئ‚ê‚خ‚à‚¤•ذ•û‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ
’ل‰؛‚·‚éپuˆّ‚«ژZپv‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
CPU‚ج‘م‚ي‚è‚ً‚³‚¹‚é‚ج‚ھ–ع“I‚ب‚çCPUƒRƒA‚»‚ج‚à‚ج‚ً‘‚₵‚½•û‚ھ
‚و‚èٹmژہ‚ة”ؤ—pƒRƒ“ƒsƒ…پ[ƒeƒBƒ“ƒOگ«”\ƒ}ƒV‚بƒAƒvƒچپ[ƒ`‚و‚وپH
Œ»ژہ‚ة‚ح‘رˆو•s‘«‚إƒRƒA‘‚₵‚ؤ‚àˆس–،‚ھ‚ب‚¢‚µGPU‚ة“ٹ‚°‚ؤ‚àڈ®چX‚ب‚ٌ‚¾
ƒRƒXƒgƒ_ƒEƒ“‚ج‚½‚ك‚ةGPU‚ً“چ‡‚·‚é‚ج‚ةپy‘OŒü‚«‚炵‚¢پz——R‚ً‚آ‚¯‚½‚¢
‚¾‚¯‚ب‚ٌ‚¾‚©‚çٹْ‘ز‚ب‚ٌ‚إ‚·‚ٌ‚ب‚و
‚»‚è‚ل“–‘Rڈ«—ˆ“I‚ة‚حƒپƒ‚ƒٹ‚ـ‚ي‚è‚ج‹‰»‚à‚·‚邾‚ë
Œ»ڈَ‚إ‚جکb‚إ‚¢‚¤‚ب‚çپAگV‹Zڈp‚ب‚ٌ‚ؤ‚½‚¢‚ؤ‚¢ژ‚؟•…‚ꂾ‚و
Œ»ڈَ‚إ‚جکb‚إ‚¢‚¤‚ب‚çپAگV‹Zڈp‚ب‚ٌ‚ؤ‚½‚¢‚ؤ‚¢ژ‚؟•…‚ꂾ‚و
‚ـ‚¸‚ح‘«Œ³‚ًŒإ‚ك‚éڈٹ‚©‚çژn‚ك‚½•û‚ھ‚¢‚¢‚ئژv‚¤‚¼پB
Œم3پ`4”NŒم‚ة‚حTSVƒپƒ‚ƒٹ‚ب‚ٌ‚©‚à”ؤ—pPCŒü‚¯‚ةچ~‚è‚ؤ‚‚邾‚낤‚©‚ç"چ،"‚جڈَ‹µ‚إ‚ پ[‚¾پA‚±پ[‚½Œ¾‚ء‚ؤ‚àژd•û‚ب‚¢
ٹeژذپAژ©•ھ‚جژèژ‚؟‚جƒJپ[ƒh‚إگi‚à‚¤‚ئ‚µ‚ؤ‚é‚ٌ‚¾‚©‚çپAŒ¨‚ج—ح‚ً”²‚¢‚ؤگ„ˆع‚ًŒ©ژç‚낤‚؛
ٹeژذپAژ©•ھ‚جژèژ‚؟‚جƒJپ[ƒh‚إگi‚à‚¤‚ئ‚µ‚ؤ‚é‚ٌ‚¾‚©‚çپAŒ¨‚ج—ح‚ً”²‚¢‚ؤگ„ˆع‚ًŒ©ژç‚낤‚؛
ƒŒƒCƒeƒ“ƒV‰B‚µ‚â‚·‚¢‚ٌ‚¾‚©‚çSIMDƒپƒ‚ƒٹگê—p‚جƒVƒٹƒAƒ‹ƒoƒX‚ھ‘•”ُ‚³‚ê‚é‚و‚¤‚ةگ¬‚é‚ٌ‚¶‚ل‚ب‚¢‚©‚ب
hUMA‚ئ‚©Œ¾‚¤ƒ„ƒc‚ئ‚ح‚؛‚ٌ‚؛‚ٌ‹t•ûŒü‚¾‚¯‚ا
hUMA‚ئ‚©Œ¾‚¤ƒ„ƒc‚ئ‚ح‚؛‚ٌ‚؛‚ٌ‹t•ûŒü‚¾‚¯‚ا
417 پFSocket774پF2013/10/24(–ط) 10:35:52.80 ID:nkC8a0ov
‚»‚ê‚ح’P‚ة‘رˆو‚ًƒtƒ‹‚ةژg‚¤‚و‚¤‚بƒ\ƒtƒgƒEƒFƒA‚ً“®‚©‚µ‚ؤ‚ب‚¢‚©‚炾‚ë
ƒVƒٹƒRƒ“ƒOƒ‰ƒtƒBƒbƒNƒX‚ھڈo‚µ‚ؤ‚½WS‚ب‚ٌ‚©‚¾‚ئ
“–ژ‚ة‚µ‚ؤ‚حچ‚‘¬‚بƒپƒ‚ƒٹژg‚ء‚ؤپACPU‚ئƒOƒ‰ƒtƒBƒbƒN—¼•ûƒtƒ‹‚ةژg‚ء‚ؤ‚à•½‹C‚ب‚و‚¤‚ة‚µ‚ؤ‚½‚ب
‚à‚ء‚ئ‚à‘گفƒپƒ‚ƒٹ‚ھ‚¢‚â‚ة‚ب‚é‚ظ‚اچ‚‰؟‚¾‚ء‚½‚炵‚¢‚¯‚اپi‚½‚µ‚©ƒJƒ^ƒچƒO‚ةˆہ‚”ƒ‚¤‘م‘ض•i‚جکb‚ھچع‚ء‚ؤ‚½‚—پj
“–ژ‚ة‚µ‚ؤ‚حچ‚‘¬‚بƒپƒ‚ƒٹژg‚ء‚ؤپACPU‚ئƒOƒ‰ƒtƒBƒbƒN—¼•ûƒtƒ‹‚ةژg‚ء‚ؤ‚à•½‹C‚ب‚و‚¤‚ة‚µ‚ؤ‚½‚ب
‚à‚ء‚ئ‚à‘گفƒپƒ‚ƒٹ‚ھ‚¢‚â‚ة‚ب‚é‚ظ‚اچ‚‰؟‚¾‚ء‚½‚炵‚¢‚¯‚اپi‚½‚µ‚©ƒJƒ^ƒچƒO‚ةˆہ‚”ƒ‚¤‘م‘ض•i‚جکb‚ھچع‚ء‚ؤ‚½‚—پj
PCƒپپ[ƒJپ[‚جƒRƒXƒgƒ_ƒEƒ“‚ھژه–ع“I‚ج“چ‡‚ب‚ج‚ة’P‘جCPU‚ئ’P‘جGPU‚ج‘g‚فچ‡‚ي‚¹‚و‚èچ‚ƒRƒXƒg‚ب‚猳‚àژq‚à‚ب‚¢‚ب
Iris‚ج‚ ‚ê‚حL4ƒLƒƒƒbƒVƒ…‚ئ‚µ‚ؤ‚àژg‚¦‚邵Phi‚جƒ\ƒPƒbƒg”إ‚ب‚ٌ‚©‚ة‚àژg‚¦‚é—LŒّ‚ب‹Zڈp‚¾‚©‚ç‚¢‚¢‚ئ‚µ‚ؤ‚à
Iris‚ج‚ ‚ê‚حL4ƒLƒƒƒbƒVƒ…‚ئ‚µ‚ؤ‚àژg‚¦‚邵Phi‚جƒ\ƒPƒbƒg”إ‚ب‚ٌ‚©‚ة‚àژg‚¦‚é—LŒّ‚ب‹Zڈp‚¾‚©‚ç‚¢‚¢‚ئ‚µ‚ؤ‚à
421 پFSocket774پF2013/10/24(–ط) 13:32:45.88 ID:qB6kooBm
ƒVƒٹƒRƒ“ƒOƒ‰ƒtƒBƒbƒNƒX‚جWS‚حپAWindowsNT4.0Workstationپ{OpenGL‘خ‰GPU‚ًگد‚ٌ‚¾
ƒOƒ‰ƒtƒBƒbƒN—pPC‚ةٹ®‘S‚ة‚â‚ç‚ê‚ؤڈء‚¦‚ؤ‚ب‚‚ب‚ء‚½‚ب‚ں
ƒOƒ‰ƒtƒBƒbƒN—pPC‚ةٹ®‘S‚ة‚â‚ç‚ê‚ؤڈء‚¦‚ؤ‚ب‚‚ب‚ء‚½‚ب‚ں
SGI‚ء‚ؤ–¼‘O‚حƒJƒ‹ƒg‚ة”„‚ء‚½‚ٌ‚¾‚ء‚¯
ƒVƒٹƒRƒ“ƒOƒ‰ƒtƒBƒbƒNƒX‚ج‹Zڈpژز‚جˆê•”‚ھArtXŒo—R‚إAMD‚ة–ل‚ي‚ê‚ؤ‚¢‚ء‚½‚ٌ‚¾‚ء‚¯‚©
‹ŒArtX‚ةŒہ‚炸‹ŒATIپANVپA‹Œ3Dfx ‚ظ‚ئ‚ٌ‚اSGI—£’E‘g‚ھ‚©‚©‚ي‚ء‚ؤ‚é
‚½‚¾ژٹْ‚ئŒoˆـ‚ھڈ‚µˆل‚¤‚¾‚¯پA–رگF‚ھˆل‚¤‚ج‚حPVR‚ئ‹ŒBitBoys‚‚ç‚¢
‚½‚¾ژٹْ‚ئŒoˆـ‚ھڈ‚µˆل‚¤‚¾‚¯پA–رگF‚ھˆل‚¤‚ج‚حPVR‚ئ‹ŒBitBoys‚‚ç‚¢
425 پFSocket774پF2013/10/24(–ط) 15:06:29.03 ID:nkC8a0ov
GPUٹE‚جDEC‚ف‚½‚¢‚ب‚à‚ج‚©
Compaq‚ھ‚ئ‚ؤ‚à‘‚©‚ء‚½‰´پB
AMD‚ح’P‚ة“à•”ƒoƒX‚ھچׂ¢‚¾‚¯‚¾‚ë
•پ’ت‚ةچl‚¦‚ê‚خ’²’â–³‚µ‚¾‚ئƒ‰ƒCƒuorƒfƒbƒhƒچƒbƒN‚ض
ˆê’¼گü‚ب‚ي‚¯‚إ–³‘خچô‚ئ‚¢‚¤‚ج‚ح‚؟‚ه‚ء‚ئچl‚¦‚ç‚ê‚ب‚¢‚و‚ث
Œ«‚³‚ح‚ئ‚à‚©‚چإ’لŒہ‚جƒAپ[ƒrƒ^‚ح—L‚邾‚낤
ˆê’¼گü‚ب‚ي‚¯‚إ–³‘خچô‚ئ‚¢‚¤‚ج‚ح‚؟‚ه‚ء‚ئچl‚¦‚ç‚ê‚ب‚¢‚و‚ث
Œ«‚³‚ح‚ئ‚à‚©‚چإ’لŒہ‚جƒAپ[ƒrƒ^‚ح—L‚邾‚낤
431 پFSocket774پF2013/10/24(–ط) 21:09:25.75 ID:yNIbFTM/
ٹî–{“I‚ةCPU‚ج‚ظ‚¤‚ھ‘رˆوگH‚ي‚ب‚¢‚©‚çپA
CPU—Dگو‚إ‚¢‚¢‚و
CPU—Dگو‚إ‚¢‚¢‚و
‘رˆوگH‚ي‚ب‚¢•û‚ً—Dگو‚µ‚½‚ç‘S‘رˆو‚ئ‚µ‚ؤ‚ح—]‚ء‚ؤ‚é‚ج‚ة
GPU‘رˆو‘«‚è‚ب‚‚ب‚ء‚½‚肹‚ٌ‚©پB
GPU‘رˆو‘«‚è‚ب‚‚ب‚ء‚½‚肹‚ٌ‚©پB
‚»‚ٌ‚ب‚à‚ٌGDDR5ژg‚¦‚خ‘¦‰ًŒˆ
–{“–‚ةPS4‚حŒ„‚ج‚ب‚¢—‘z‚جƒnپ[ƒh‚¾‚ب
PC‚ح‰½”N‚©‚¯‚ê‚خ’ا‚¢‚آ‚¯‚é‚ٌ‚¾‚낤
–{“–‚ةPS4‚حŒ„‚ج‚ب‚¢—‘z‚جƒnپ[ƒh‚¾‚ب
PC‚ح‰½”N‚©‚¯‚ê‚خ’ا‚¢‚آ‚¯‚é‚ٌ‚¾‚낤
PS3‚حLinuxڈo‚ؤ‚½‚¯‚اپAPS4‚ح‰½‚©”ؤ—pOSچع‚é‚ج‚©‚ب
435 پFSocket774پF2013/10/25(‹à) 11:57:20.31 ID:YSrb9SfI
‹tƒUƒ„‚إ”„‚ء‚ؤ‚éƒnپ[ƒh‚إ”ؤ—pOS“®‚¢‚ؤ‚à
SCE‚ح‚P‘K‚ج“¾‚à‚µ‚ب‚¢‚¾‚ë
‚ـ‚½ƒZƒLƒ…ƒٹƒeƒBپ[ƒzپ[ƒ‹‚ف‚آ‚¯‚ç‚ê‚ؤƒnƒbƒJپ[‚ةƒtƒ@پ[ƒ€ƒEƒFƒA‰ًگح‚³‚ê‚é‚©‚à‚µ‚ê‚ب‚¢‚µ
SCE‚ح‚P‘K‚ج“¾‚à‚µ‚ب‚¢‚¾‚ë
‚ـ‚½ƒZƒLƒ…ƒٹƒeƒBپ[ƒzپ[ƒ‹‚ف‚آ‚¯‚ç‚ê‚ؤƒnƒbƒJپ[‚ةƒtƒ@پ[ƒ€ƒEƒFƒA‰ًگح‚³‚ê‚é‚©‚à‚µ‚ê‚ب‚¢‚µ
Œ¾‚ء‚ؤ‚é“à—e‚ة‚ح‚ظ‚ع“¯ˆس‚¾‚¯‚اپAڈo‚ؤ‚‚ꂽ‚ç–ت”’‚¢‚¾‚ë
”ؤ—pOS“®‚©‚·‚ئƒKƒbƒJƒٹ‚·‚éگ«”\
438 پFSocket774پF2013/10/25(‹à) 12:49:56.10 ID:qRyDPOhb
”ؤ—pOSچع‚¹‚ؤ‰½‚ً‚·‚é‚ٌ‚¾?
PS3‚إ‚حBOINC‚إٹàژ،—أ‚ةچvŒ£‚µ‚½‚؛پB
‘¼‚ة‚آ‚¢‚ؤ‚حژ@‚µ‚ëپB
‘¼‚ة‚آ‚¢‚ؤ‚حژ@‚µ‚ëپB
ƒAƒZƒ“ƒuƒ‰‚إˆب‰؛‚ج–â‘è‚ي‚©‚é•û‚¨ٹè‚¢‚µ‚ـ‚·پB
(1)ƒŒƒWƒXƒ^‚ج‰؛ˆت8bit‚ًƒ[ƒچٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(2)ƒŒƒWƒXƒ^‚ج‰؛ˆت8bit‚ً•„چ†ٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(3)ƒŒƒWƒXƒ^‚ج‰؛ˆت16bit‚ًƒ[ƒچٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(4)ƒŒƒWƒXƒ^‚ج‰؛ˆت16bit‚ً•„چ†ٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(5)32bitƒŒƒWƒXƒ^‚ً•„چ†ٹg’£‚µ‚ؤƒŒƒWƒXƒ^2–{‚إ64bit‚ة‚¹‚و
‚½‚¾‚µپA
ڈًŒڈ•ھٹٍ–½—ك‚ً—p‚¢‚ؤ‚ح‚¢‚¯‚ب‚¢
ƒپƒ‚ƒٹ‚ة‚حƒAƒNƒZƒX‚¹‚¸ƒŒƒWƒXƒ^‚¾‚¯‚إڈˆ—‚·‚邱‚ئ
–½—كگ”‚جڈ‚ب‚¢‰ً“ڑ‚ًچإ“K‚ب‰ً“ڑ‚ئ‚·‚é
‚إ‚«‚ê‚خچ،ڈT––‚ـ‚إ‚ة‚¨ٹè‚¢‚µ‚ـ‚·پB
(1)ƒŒƒWƒXƒ^‚ج‰؛ˆت8bit‚ًƒ[ƒچٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(2)ƒŒƒWƒXƒ^‚ج‰؛ˆت8bit‚ً•„چ†ٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(3)ƒŒƒWƒXƒ^‚ج‰؛ˆت16bit‚ًƒ[ƒچٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(4)ƒŒƒWƒXƒ^‚ج‰؛ˆت16bit‚ً•„چ†ٹg’£‚µ‚ؤ32bit‚ة‚¹‚و
(5)32bitƒŒƒWƒXƒ^‚ً•„چ†ٹg’£‚µ‚ؤƒŒƒWƒXƒ^2–{‚إ64bit‚ة‚¹‚و
‚½‚¾‚µپA
ڈًŒڈ•ھٹٍ–½—ك‚ً—p‚¢‚ؤ‚ح‚¢‚¯‚ب‚¢
ƒپƒ‚ƒٹ‚ة‚حƒAƒNƒZƒX‚¹‚¸ƒŒƒWƒXƒ^‚¾‚¯‚إڈˆ—‚·‚邱‚ئ
–½—كگ”‚جڈ‚ب‚¢‰ً“ڑ‚ًچإ“K‚ب‰ً“ڑ‚ئ‚·‚é
‚إ‚«‚ê‚خچ،ڈT––‚ـ‚إ‚ة‚¨ٹè‚¢‚µ‚ـ‚·پB
‚ پ[‚±‚ê1ƒ–Œژ‚©‚©‚é‚و
>>440
ŒN‚ب‚çژ©—ح‚إ•K‚¸‚إ‚«‚éپIƒKƒ“ƒoپI
ŒN‚ب‚çژ©—ح‚إ•K‚¸‚إ‚«‚éپIƒKƒ“ƒoپI
443 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/25(‹à) 17:51:57.14 ID:I/5+qs8y
‚ب‚ٌ‚جCPU‚¾‚و
eax‚ةچع‚ء‚ؤ‚é‚ئ‰¼’肵‚ؤ
(1) movzx eax, al
(2) movsx eax, al
(3) movzx eax, ax
(4) movsx eax, ax
(5)
mov edx, eax
shr edx, 31
eax‚ةچع‚ء‚ؤ‚é‚ئ‰¼’肵‚ؤ
(1) movzx eax, al
(2) movsx eax, al
(3) movzx eax, ax
(4) movsx eax, ax
(5)
mov edx, eax
shr edx, 31
444 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/25(‹à) 17:55:12.88 ID:I/5+qs8y
shr‚حک_—ƒVƒtƒg‚¾‚ء‚½
mov edx, eax
sar edx, 31
mov edx, eax
sar edx, 31
>>443
(5)‚حcdq‚¾‚ب
(5)‚حcdq‚¾‚ب
446 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/25(‹à) 20:37:13.05 ID:I/5+qs8y
‚ ‚ پA‚ ‚ء‚½‚ث‚»‚ٌ‚ب–½—كپB“ھ‚©‚ç‚·‚ء‚©‚蔲‚¯—ژ‚؟‚ؤ‚½پB
‚±‚ê‚جREX”إپiCQOپj‚ب‚ٌ‚ؤ‚ ‚邯‚اگâ‘خژg‚ي‚ث‚¦‚—‚—‚—
‚ب‚ٌ‚ةژg‚¤‚ٌ‚¾128ƒrƒbƒgگ®گ”‚ب‚ٌ‚ؤ‚—‚—‚—
x86‚¾‚ئ•ھٹٍژg‚ء‚ؤڈ‘‚±‚¤‚ئ‚µ‚½‚ظ‚¤‚ھ‚©‚¦‚ء‚ؤ“‚¢‚ٌ‚¾‚ھ
‚½‚ش‚ٌMIPS‚ئ‚©‚ب‚ٌ‚¶‚ل‚ب‚¢‚جپH
‚±‚ê‚جREX”إپiCQOپj‚ب‚ٌ‚ؤ‚ ‚邯‚اگâ‘خژg‚ي‚ث‚¦‚—‚—‚—
‚ب‚ٌ‚ةژg‚¤‚ٌ‚¾128ƒrƒbƒgگ®گ”‚ب‚ٌ‚ؤ‚—‚—‚—
x86‚¾‚ئ•ھٹٍژg‚ء‚ؤڈ‘‚±‚¤‚ئ‚µ‚½‚ظ‚¤‚ھ‚©‚¦‚ء‚ؤ“‚¢‚ٌ‚¾‚ھ
‚½‚ش‚ٌMIPS‚ئ‚©‚ب‚ٌ‚¶‚ل‚ب‚¢‚جپH
447 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/25(‹à) 21:02:04.03 ID:I/5+qs8y
‚ پARSAˆأچ†‚ئ‚©‚إ‘½”{’·ژg‚¤‚©
‚à‚ج‚ً’m‚ç‚ب‚¢‚¾‚¯‚ب‚ج‚إ‹–‚µ‚ؤ‚â‚ء‚ؤ
450 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/25(‹à) 21:32:18.39 ID:I/5+qs8y
‚ـ‚ •„چ†ٹg’£گê—p–½—كژ‚½‚ب‚¢CPU‚إ‚à‘ه’ï‚حچ¶ƒVƒtƒgپ{‰EژZڈpƒVƒtƒg‚إ
•„چ†ٹg’£‚إ‚«‚ـ‚·‚¯‚ا‚ثپB
‚ؤ‚©•ھٹٍ•K—v‚ب32bitƒvƒچƒZƒbƒT‚ء‚ؤ‚ ‚é‚جپH
i = ((signed int)i) << 24 >> 24;
•„چ†ٹg’£‚إ‚«‚ـ‚·‚¯‚ا‚ثپB
‚ؤ‚©•ھٹٍ•K—v‚ب32bitƒvƒچƒZƒbƒT‚ء‚ؤ‚ ‚é‚جپH
i = ((signed int)i) << 24 >> 24;
’cژq‚³‚ٌ‚ج“¾ˆس‚بکb‘肾‚ثپB
گê–هٹwچZ‚ج‰غ‘背ƒxƒ‹‚ھ“¾ˆس‚بکb‘è‚ء‚ؤ‚³‚è‚°‚ب‚dis‚ء‚ؤ‚ـ‚·‚ث
453 پFSocket774پF2013/10/26(“y) 01:09:47.08 ID:ldPLoI9Z
’cژq‚ھٹأ‚â‚©‚µ‚½‚¨‚©‚°‚إپA
‚±‚ê‚إ‚ـ‚½ˆêگl‚ن‚ئ‚èٹwگ¶‚ج‚إ‚«‚ ‚ھ‚è‚©
‹¹”M‚¾‚ب
‚±‚ê‚إ‚ـ‚½ˆêگl‚ن‚ئ‚èٹwگ¶‚ج‚إ‚«‚ ‚ھ‚è‚©
‹¹”M‚¾‚ب
‚±‚ٌ‚ب‚ئ‚±‚ë‚ةڈ‘‚«چ‚ٌ‚إ‚éژ“_‚إ‘fژ؟‚ھ–³‚¢‚©‚ç‘پ‚‚ ‚«‚ç‚ك‚½•û‚ھ—ا‚¢‚©‚ئپB
چ،ژx86‚جƒgƒٹƒrƒA‚ف‚½‚¢‚ب‚ج‚â‚ء‚ؤ‚éژ“_‚إژ‘م’x‚ê‚ب‚ٌ‚¾‚µپB
چ،ژx86‚جƒgƒٹƒrƒA‚ف‚½‚¢‚ب‚ج‚â‚ء‚ؤ‚éژ“_‚إژ‘م’x‚ê‚ب‚ٌ‚¾‚µپB
455 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/26(“y) 06:56:16.77 ID:gzXA7lNB
Mac Pro‚ھچ‚گ«”\‚·‚¬‚ؤ–@—كڈم‚حƒXƒpƒRƒ“‚ةپBگ•{‚إ”ƒ‚¤ڈêچ‡‚ح“üژDپAگRچ¸پA•ٌچگ‚ھ•K—v
http://hayabusa3.2ch.net/test/read.cgi/news/1382709937/
http://hayabusa3.2ch.net/test/read.cgi/news/1382709937/
پu4ƒRƒA‚جPC—pHaswell‚ح224ƒMƒKƒtƒچƒbƒvƒX‚ب‚ج‚إپATitan‚ئ‘g‚فچ‡‚ي‚¹‚é‚ئ
”{گ¸“x1.5ƒeƒ‰ƒtƒچƒbƒvƒX’´‚¦–@—كڈم‚حƒXƒpƒRƒ“‚ة‚ب‚èپAگ•{‹@ٹض‹y‚ر
“ئ—§چsگ–@گl‚ج1.5”Nˆبڈم‚©‚©‚éƒXƒpƒRƒ“’²’B‚ج‘خڈغ‚ة‚ب‚è‚ـ‚·پv
‰½Œج‚±‚جƒcƒCپ[ƒg‚©‚çMac Pro‚جکb‚ة‚ب‚éپH
Mac Pro‚ح12ƒRƒA‚جIvy Bridge‚ةRadeon‚إ‚µ‚ه
”{گ¸“x1.5ƒeƒ‰ƒtƒچƒbƒvƒX’´‚¦–@—كڈم‚حƒXƒpƒRƒ“‚ة‚ب‚èپAگ•{‹@ٹض‹y‚ر
“ئ—§چsگ–@گl‚ج1.5”Nˆبڈم‚©‚©‚éƒXƒpƒRƒ“’²’B‚ج‘خڈغ‚ة‚ب‚è‚ـ‚·پv
‰½Œج‚±‚جƒcƒCپ[ƒg‚©‚çMac Pro‚جکb‚ة‚ب‚éپH
Mac Pro‚ح12ƒRƒA‚جIvy Bridge‚ةRadeon‚إ‚µ‚ه
NVIDIA Geforce 860 ”{گ¸“x2150 GFLOPS‚ئ‚©‚ح•ھ—قڈمƒXƒpƒRƒ“‚ة‚ب‚é‚ج‚©پB
‚ئ‚±‚ë‚إNVIDIA‚حDirectX 11.1‚ة‘خ‰‚·‚é‹C‚ح‚ب‚¢‚ج‚إ‚µ‚ه‚¤‚©
‚ئ‚±‚ë‚إNVIDIA‚حDirectX 11.1‚ة‘خ‰‚·‚é‹C‚ح‚ب‚¢‚ج‚إ‚µ‚ه‚¤‚©
>>459
ڈ‡ڈک‚ھ‹t‚إپAپuگVMac Pro‚ھ”•\‚³‚ê‚邯‚اپA‚±‚êƒXƒpƒRƒ“ˆµ‚¢‚ب‚ٌ‚¾‚و‚ثپv‚ئ‚¢‚¤گ™–{گوگ¶‚جƒcƒCپ[ƒg
پihttps://twitter.com/tsgmt/status/392671944748699648پj‚ھکb‚ج”’[‚إپA‚»‚±‚©‚ç‚ب‚ٌ‚إ‚»‚ٌ‚ب‚±‚ئ
‚ة‚ب‚é‚ج‚©‚ئ‚¢‚¤•ûŒü‚ة—¬‚ê‚ؤ‚¢‚ء‚ؤپA‚»‚جپu4ƒRƒA‚جPC—pHaswell‚ھپ`پv‚ئ‚¢‚¤ƒcƒCپ[ƒg‚ھڈo‚ؤ‚«‚½
‚¾‚©‚çچإڈ‰‚©‚çMac Pro‚ ‚è‚«‚ب‚ٌ‚¾‚و
ڈ‡ڈک‚ھ‹t‚إپAپuگVMac Pro‚ھ”•\‚³‚ê‚邯‚اپA‚±‚êƒXƒpƒRƒ“ˆµ‚¢‚ب‚ٌ‚¾‚و‚ثپv‚ئ‚¢‚¤گ™–{گوگ¶‚جƒcƒCپ[ƒg
پihttps://twitter.com/tsgmt/status/392671944748699648پj‚ھکb‚ج”’[‚إپA‚»‚±‚©‚ç‚ب‚ٌ‚إ‚»‚ٌ‚ب‚±‚ئ
‚ة‚ب‚é‚ج‚©‚ئ‚¢‚¤•ûŒü‚ة—¬‚ê‚ؤ‚¢‚ء‚ؤپA‚»‚جپu4ƒRƒA‚جPC—pHaswell‚ھپ`پv‚ئ‚¢‚¤ƒcƒCپ[ƒg‚ھڈo‚ؤ‚«‚½
‚¾‚©‚çچإڈ‰‚©‚çMac Pro‚ ‚è‚«‚ب‚ٌ‚¾‚و
‚ئ‚¢‚¤‚©پA‚»‚ë‚»‚ë’è‹`‚ج‚ظ‚¤ƒAƒbƒvƒfپ[ƒg‚µ‚ë‚و‚ئ‚—
‚»‚ج‚¤‚؟iPad‚إ‚·‚çƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^‚ة‚ب‚ء‚؟‚ل‚¤‚¼‚—
‚»‚ج‚¤‚؟iPad‚إ‚·‚çƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^‚ة‚ب‚ء‚؟‚ل‚¤‚¼‚—
GeForceFX‚ھRADEON8500“ئژ©‚ج‚جƒsƒNƒZƒ‹ƒVƒFپ[ƒ_پ[1.4‚ج–½—ك‚ً‰ًژك‚إ‚«‚é‚و‚¤‚ة
MS‚ھDirectX12‚ً”•\‚·‚ê‚خŒ™‚إ‚à‘خ‰‚µ‚ؤ‚‚é‚©‚ئ
MS‚ھDirectX12‚ً”•\‚·‚ê‚خŒ™‚إ‚à‘خ‰‚µ‚ؤ‚‚é‚©‚ئ
Œ»چsƒ‚ƒfƒ‹‚حDirectX11.1‚ة‘خ‰‚µ‚ؤ‚邾‚ëپB
>>462
”÷چ׉»‚جچs‚«‹l‚ـ‚è‚ًچl‚¦‚é‚ئ–³—‚¶‚ل‚ثپH
”÷چ׉»‚جچs‚«‹l‚ـ‚è‚ًچl‚¦‚é‚ئ–³—‚¶‚ل‚ثپH
14nm‚ـ‚إچs‚¯‚خپAGPUƒRƒ~‚إ1.5ƒeƒ‰ƒtƒچƒbƒvƒX‚حٹyڈں
intel‚حAVX-512–½—ك‚ة‰ء‚¦چ،‚ج40EUˆبڈم‚جGPU‚ً’ا‰ء‚·‚é‚إ‚ ‚낤
Skylakeگ¢‘م‚ ‚½‚è‚إ1.5TFLOPS‚حچs‚«‚»‚¤‚ب—\ٹ´
‚ئ‚¢‚¤‚©چ،‚جژ“_‚إIrisPro5200‚جGPU‚¾‚¯‚إ832GFLOPS‚¾‚©‚ç
CPUچ‚ف‚ب‚ç‚PTFLOPS‚ً’´‚¦‚ؤ‚é‚ح‚¸
Skylakeگ¢‘م‚ ‚½‚è‚إ1.5TFLOPS‚حچs‚«‚»‚¤‚ب—\ٹ´
‚ئ‚¢‚¤‚©چ،‚جژ“_‚إIrisPro5200‚جGPU‚¾‚¯‚إ832GFLOPS‚¾‚©‚ç
CPUچ‚ف‚ب‚ç‚PTFLOPS‚ً’´‚¦‚ؤ‚é‚ح‚¸
ƒgƒ‰ƒ“ƒWƒXƒ^’P‰؟‚ھˆہ‚‚ب‚ç‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚ح
گ«”\ڈم‚ھ‚é‚ھ‰؟ٹi‚à“ٌ”{‚ئ‚¢‚¤‚±‚ئپBژsڈê‚ح‹}‘¬‚ةŒ¸ڈ‚·‚éپB‚±‚±‚ھ”÷چ׉»‚جŒہٹEپB
گ«”\ڈم‚ھ‚é‚ھ‰؟ٹi‚à“ٌ”{‚ئ‚¢‚¤‚±‚ئپBژsڈê‚ح‹}‘¬‚ةŒ¸ڈ‚·‚éپB‚±‚±‚ھ”÷چ׉»‚جŒہٹEپB
Intel‚ئ‚©‚ح‚»‚ê‚ً‚ي‚©‚ء‚ؤ‚ؤƒ_ƒCƒTƒCƒY‚ًڈkڈ¬‚³‚¹‚ب‚ھ‚çƒgƒ‰ƒ“ƒWƒXƒ^‹K–ح‚ًڈ‚µ‚¸‚آ‘ه‚«‚‚µ‚ؤ‚é‚©‚ç‚ب
AMD‚جKaveri‚ئ‚©‚ح32nmپ¨28nm‚ئ‚¢‚¤ڈ¬‚³‚ب‰ü—ا‚إCPU‚ئGPU‚ج‰ü—ا‚ً‚â‚ء‚ؤ‚µ‚ـ‚ء‚½‚¹‚¢‚إ‘S‘Rڈ¬‚³‚‚ب‚ç‚ب‚¢‚¯‚ا
AMD‚جKaveri‚ئ‚©‚ح32nmپ¨28nm‚ئ‚¢‚¤ڈ¬‚³‚ب‰ü—ا‚إCPU‚ئGPU‚ج‰ü—ا‚ً‚â‚ء‚ؤ‚µ‚ـ‚ء‚½‚¹‚¢‚إ‘S‘Rڈ¬‚³‚‚ب‚ç‚ب‚¢‚¯‚ا
5200‚ج832‚ح’Pگ¸“xپB”{گ¸“x1T‚ح‚ـ‚¾‰“‚¢
471 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/27(“ْ) 00:02:45.01 ID:gzXA7lNB
AMD‚ح8ƒRپc‚¢‚âپA‚ب‚ٌ‚إ‚à‚ب‚¢پc
‚ ‚êڈ¬گ”“_‰‰ژZٹي”¼•ھƒPƒ`‚ء‚ؤ‚é‚©‚ç4‚آ•ھ‚µ‚©–³‚¢‚وپB
AMD‚ح‚ ‚ê‚إٹ®‘S‚ةƒXƒx‚ء‚½‚و‚ب¥¥¥
AMD‚ج8ƒRƒA‚حپA‚½‚ئ‚¦ƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ‘½ڈ—ژ‚؟‚ؤ‚àپA
ƒgپ[ƒ^ƒ‹ƒpƒtƒHپ[ƒ}ƒ“ƒXپAƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھIntel‚ًڈم‰ٌ‚ء‚ؤ‚ê‚خ‚ـ‚¾‚ـ‚µ‚¾‚ء‚½‚©‚à‚µ‚ê‚ٌ‚ھپA
ژہچغ‚حپAƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ‘ه‚«‚—ٍ‰»پA
ƒgپ[ƒ^ƒ‹ƒpƒtƒHپ[ƒ}ƒ“ƒX‚àƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚àIntel‚و‚舫‚‚ب‚ء‚½‚©‚ç
ƒgپ[ƒ^ƒ‹ƒpƒtƒHپ[ƒ}ƒ“ƒXپAƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھIntel‚ًڈم‰ٌ‚ء‚ؤ‚ê‚خ‚ـ‚¾‚ـ‚µ‚¾‚ء‚½‚©‚à‚µ‚ê‚ٌ‚ھپA
ژہچغ‚حپAƒVƒ“ƒOƒ‹ƒXƒŒƒbƒhƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ‘ه‚«‚—ٍ‰»پA
ƒgپ[ƒ^ƒ‹ƒpƒtƒHپ[ƒ}ƒ“ƒX‚àƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚àIntel‚و‚舫‚‚ب‚ء‚½‚©‚ç
‚ـپAƒvƒچƒZƒX‚ج‚ظ‚¤‚إ‘هچ·‚آ‚¢‚ؤ‚é‚©‚ç‚ب‚
>>466
”{گ¸“x‚ح’Pگ¸“x‚ج4”{‚‚ç‚¢–تگد‚ھ—v‚éپB
Intel‚ھ14nm‚إGPU‚ةٹ„‚è“–‚ؤ‚é–تگد‚ھIris5200‚ئ“¯‚¶‚‚ç‚¢‚¾‚ئ‚µ‚½‚ç
‚à‚µ‚àdouble ‚ًƒTƒ|پ[ƒg‚µ‚½‚ئ‚µ‚ؤ‚à500پ`600GFLOPS‚‚ç‚¢پB
GPU“à‘ ƒ^ƒCƒv‚جƒRƒAگ”‚ھ4‚و‚è‚à‘‚¦‚é‚ئ‚حچl‚¦‚ة‚‚¢پB
512bit‰»‚µ‚½‚ئ‚µ‚ؤ‚àHaswellپ@224GFLOPS‚ج”{‚ً‚â‚â’´‚¦‚é’ِ“x
1TFLOPS‚ة“ح‚‚©‚à‚µ‚ê‚ب‚¢‚ھ1.5‚حپhچى‚ç‚ب‚¢پh‚¾‚낤پB
GPU‚ج‚ب‚¢Xeon‚ب‚ç512bit‰»‚ئƒRƒAگ”‘‰ء‚ً‚â‚ê‚خ1.5TFLOPS‚ة“ح‚‚©‚àپB
”{گ¸“x‚ح’Pگ¸“x‚ج4”{‚‚ç‚¢–تگد‚ھ—v‚éپB
Intel‚ھ14nm‚إGPU‚ةٹ„‚è“–‚ؤ‚é–تگد‚ھIris5200‚ئ“¯‚¶‚‚ç‚¢‚¾‚ئ‚µ‚½‚ç
‚à‚µ‚àdouble ‚ًƒTƒ|پ[ƒg‚µ‚½‚ئ‚µ‚ؤ‚à500پ`600GFLOPS‚‚ç‚¢پB
GPU“à‘ ƒ^ƒCƒv‚جƒRƒAگ”‚ھ4‚و‚è‚à‘‚¦‚é‚ئ‚حچl‚¦‚ة‚‚¢پB
512bit‰»‚µ‚½‚ئ‚µ‚ؤ‚àHaswellپ@224GFLOPS‚ج”{‚ً‚â‚â’´‚¦‚é’ِ“x
1TFLOPS‚ة“ح‚‚©‚à‚µ‚ê‚ب‚¢‚ھ1.5‚حپhچى‚ç‚ب‚¢پh‚¾‚낤پB
GPU‚ج‚ب‚¢Xeon‚ب‚ç512bit‰»‚ئƒRƒAگ”‘‰ء‚ً‚â‚ê‚خ1.5TFLOPS‚ة“ح‚‚©‚àپB
478 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/27(“ْ) 12:39:43.98 ID:eYTY8GYY
ƒNƒچƒbƒN‚ ‚½‚èگ«”\‚¾‚ئ–{“–‚ةBayTrail‚ئ‚ا‚ٌ‚®‚è‚ج”w”ن‚ׂة‚ب‚è‚»‚¤‚¾
پ@پ@پ@پ@پ@پ@پ@Opteron 3380 پ@پ@پ@Atom C2750
Coreپ@پ@پ@پ@پ@پ@پ@8(4 module) پ@پ@پ@پ@پ@پ@پ@8
Freqپ@پ@پ@پ@پ@پ@پ@2.6GHz پ@پ@پ@پ@پ@پ@پ@2.4GHz
TDPپ@پ@پ@پ@پ@پ@پ@65Wپ@پ@پ@پ@پ@پ@پ@پ@پ@پ@20W
Cinebench پ@پ@پ@پ@4.60پ@پ@پ@پ@پ@پ@پ@پ@پ@3.77
7-zip(MIPS)پ@پ@پ@14333پ@پ@پ@پ@پ@پ@پ@پ@13509پ@پ@پ@پ@پ@پ@
TrueCrypt(AES)پ@ 2.2GB/sپ@پ@پ@پ@پ@2.0 GB/s
http://www.servethehome.com/Server-detail/amd-opteron-3380-review-benchmarks-review/
http://forums.servethehome.com/processors-motherboards/2444-intel-avoton-c2750-benchmarks-supermicro-a1sai-2750f.html
پ@پ@پ@پ@پ@پ@پ@Opteron 3380 پ@پ@پ@Atom C2750
Coreپ@پ@پ@پ@پ@پ@پ@8(4 module) پ@پ@پ@پ@پ@پ@پ@8
Freqپ@پ@پ@پ@پ@پ@پ@2.6GHz پ@پ@پ@پ@پ@پ@پ@2.4GHz
TDPپ@پ@پ@پ@پ@پ@پ@65Wپ@پ@پ@پ@پ@پ@پ@پ@پ@پ@20W
Cinebench پ@پ@پ@پ@4.60پ@پ@پ@پ@پ@پ@پ@پ@پ@3.77
7-zip(MIPS)پ@پ@پ@14333پ@پ@پ@پ@پ@پ@پ@پ@13509پ@پ@پ@پ@پ@پ@
TrueCrypt(AES)پ@ 2.2GB/sپ@پ@پ@پ@پ@2.0 GB/s
http://www.servethehome.com/Server-detail/amd-opteron-3380-review-benchmarks-review/
http://forums.servethehome.com/processors-motherboards/2444-intel-avoton-c2750-benchmarks-supermicro-a1sai-2750f.html
ˆê‚آ‘O‚جOpteron 3280پ@2.4GH‚ڑ‚¾‚ئ‹t“]‚³‚ê‚ؤ‚à‚¨‚©‚µ‚‚ب‚¢‚ب
>>476
’Pڈƒ‚ةƒvƒچƒZƒX‚¾‚¯‚ج–â‘肶‚ل‚ب‚¢‚إ‚µ‚ه‚¤
‚¢‚ـ‚¾‚ة32nm‚جSandyBridge‚جگ«”\پEƒڈƒbƒp‚ة
AMD‚ج32/28nm‚جƒvƒچƒZƒbƒT‚ھ’ا‚¢‚آ‚¢‚ؤ‚ب‚¢‚ٌ‚¾‚©‚ç
’Pڈƒ‚ةƒvƒچƒZƒX‚¾‚¯‚ج–â‘肶‚ل‚ب‚¢‚إ‚µ‚ه‚¤
‚¢‚ـ‚¾‚ة32nm‚جSandyBridge‚جگ«”\پEƒڈƒbƒp‚ة
AMD‚ج32/28nm‚جƒvƒچƒZƒbƒT‚ھ’ا‚¢‚آ‚¢‚ؤ‚ب‚¢‚ٌ‚¾‚©‚ç
>>480
Bull‚ح–{—ˆ45nmگ¢‘م‚ج‚à‚ج‚¾‚µپEپE
Bull‚ح–{—ˆ45nmگ¢‘م‚ج‚à‚ج‚¾‚µپEپE
482 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/27(“ْ) 16:45:08.83 ID:eYTY8GYY
45nm‚إڈo‚¹‚ب‚©‚ء‚½‚©‚çPhenom II X6‚ب‚ٌ‚¾‚낤
AMD‚ج28nmگ¢‘م‚حCPU‚جƒfƒRپ[ƒ_‚ئƒLƒƒƒbƒVƒ…‚ج‹‰»‚ئGPU‚جGCN‰»پ{SP‚ج‘‰ء‚ھچT‚¦‚ؤ‚é‚©‚ç
32nmگ¢‘م‚جƒ_ƒC‚و‚è”ى‘ه‰»‚·‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
32nmگ¢‘م‚جƒ_ƒC‚و‚è”ى‘ه‰»‚·‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
>>464
Comparison of Nvidia graphics processing units‚ًŒ©‚é‚ئپAچإگVƒ‚ƒfƒ‹‚àDirectX 11.0‚ئڈ‘‚¢‚ؤ‚ ‚é‚وپB
ƒOƒO‚é‚ئNvidia‚جKepler‚حDirectX 11.1‚ًƒTƒ|پ[ƒg‚µ‚ب‚¢‚ئ‚¢‚¤‹Lژ–‚ھڈo‚ؤ‚‚éپB
Comparison of Nvidia graphics processing units‚ًŒ©‚é‚ئپAچإگVƒ‚ƒfƒ‹‚àDirectX 11.0‚ئڈ‘‚¢‚ؤ‚ ‚é‚وپB
ƒOƒO‚é‚ئNvidia‚جKepler‚حDirectX 11.1‚ًƒTƒ|پ[ƒg‚µ‚ب‚¢‚ئ‚¢‚¤‹Lژ–‚ھڈo‚ؤ‚‚éپB
>>481
ƒtƒ‰ƒ“ƒX‚ةŒأ‚‚©‚ç‚ ‚éƒRƒ“ƒsƒ…پ[ƒ^پ[گ»‘¢‰ïژذ‚جBull‚ج‚±‚ئ‚©‚ئژv‚ء‚½‚çAMD‚جBulldozer‚ج‚±‚ئ‚©پA•د‚ب—ھ‚µ•û‚µ‚ب‚¢‚إ—~‚µ‚¢‚ب
ƒtƒ‰ƒ“ƒX‚ةŒأ‚‚©‚ç‚ ‚éƒRƒ“ƒsƒ…پ[ƒ^پ[گ»‘¢‰ïژذ‚جBull‚ج‚±‚ئ‚©‚ئژv‚ء‚½‚çAMD‚جBulldozer‚ج‚±‚ئ‚©پA•د‚ب—ھ‚µ•û‚µ‚ب‚¢‚إ—~‚µ‚¢‚ب
486 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/27(“ْ) 21:31:41.34 ID:eYTY8GYY
‚؟‚ه‚ء‚ئگ®گ”‚جabs(n)‚جچإ“K‰»ƒAƒZƒ“ƒuƒٹƒRپ[ƒhŒ©‚ؤ‚½‚çcdq‚ھڈo‚ؤ‚«‚½
ٹm‚©‚ة•„چ†“WٹJ‚µ‚½”r‘¼“Iک_—کa‚ئ‚ê‚خگâ‘خ’l‚ئ‚ê‚é‚و‚ب
ٹm‚©‚ة•„چ†“WٹJ‚µ‚½”r‘¼“Iک_—کa‚ئ‚ê‚خگâ‘خ’l‚ئ‚ê‚é‚و‚ب
‚ب‚ٌ‚ؤƒCƒPƒپƒ“‚بabs‚ب‚ٌ‚¾¥¥¥
گ”’l‰‰ژZŒn‚جچإ“K‰»ƒRپ[ƒh‚حپAگl‚ھڈ‘‚‚و‚èپAƒRƒ“ƒpƒCƒ‰‚ةچإگVƒvƒچƒZƒbƒT‚جƒRƒ“ƒpƒCƒ‰ƒIƒvƒVƒ‡ƒ“‚آ‚¯‚ؤ
“f‚«ڈo‚³‚¹‚½ƒRپ[ƒhŒ©‚½‚ظ‚¤‚ھŒّ—¦‚ھ‚¢‚¢ƒRپ[ƒh‚ة‚ب‚ء‚ؤ‚½‚è‚·‚é
“f‚«ڈo‚³‚¹‚½ƒRپ[ƒhŒ©‚½‚ظ‚¤‚ھŒّ—¦‚ھ‚¢‚¢ƒRپ[ƒh‚ة‚ب‚ء‚ؤ‚½‚è‚·‚é
489 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/28(Œژ) 00:37:20.87 ID:wFrpwgbW
cdq‚حeax‚ئedx‚ًŒإ’è‚إژg‚¤‚ج‚إ‘ق”ً‚جƒRƒXƒgچl‚¦‚é‚ئڈي‚ةچإ‘¬‚ج•û–@‚ئ‚حŒہ‚ç‚ب‚¢پB
‚±‚ê‚àIvy Bridgeˆبچ~‚¾‚ئ‚ ‚ـ‚è‹C‚ة‚µ‚ب‚‚ؤ‚¢‚¢‚ج‚¾‚낤‚¯‚اپB
‚±‚ê‚àIvy Bridgeˆبچ~‚¾‚ئ‚ ‚ـ‚è‹C‚ة‚µ‚ب‚‚ؤ‚¢‚¢‚ج‚¾‚낤‚¯‚اپB
‘ق”ً‚جƒRƒXƒgچl‚¦‚ب‚¢‚ب‚ç‚»‚à‚»‚àmov+sar‚إ‚و‚‚ث
491 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/10/28(Œژ) 21:41:46.81 ID:wFrpwgbW
Pen4‚³‚¦Œ©ژج‚ؤ‚ؤ‚¢‚¢‚ب‚ç‚ثپi‚à‚¤‚¢‚¢‚¾‚ë
http://news.bbcimg.co.uk/media/images/70755000/jpg/_70755176_iron.jpg
ژE’ژچـ‚ھچ¬“ü‚µ‚ؤ‚¢‚½—â“€éLژq‚ب‚اپA
’†چ‘‚©‚ç—A“ü‚³‚ꂽگH•i‚ةٹ댯‚ب–ٍ•¨‚ھچ¬“ü‚µ‚ؤ‚¢‚邱‚ئ‚ھ‚ ‚è‚ـ‚·‚ھپA
ٹ댯‚بƒ‚ƒm‚ھچ¬“ü‚µ‚ؤ‚¢‚é‚ج‚حگH•i‚¾‚¯‚ةŒہ‚ç‚ب‚¢‚و‚¤‚إپA
ƒچƒVƒA‚إ‚ح—A“ü‚³‚ꂽ’†چ‘گ»‚ج“d‰»گ»•i‚ة•sگ³‚بƒ`ƒbƒv‚ھچ¬“ü‚µ‚ؤ‚¢‚é‚ئ‚¢‚¤ژ–—ل‚ھ”گ¶‚µ‚ـ‚µ‚½پB
چ‘‚©‚ç—A“ü‚³‚ꂽ“d‹Cژ®ƒAƒCƒچƒ“‚ة‰B‚³‚ê‚ؤ‚¢‚½‚ج‚حڈ¬‚³‚بƒ`ƒbƒvپB
‚±‚جƒ`ƒbƒv‚ح”¼Œa200mˆب“à‚إˆأچ†ƒLپ[‚ب‚µ‚إگع‘±‚إ‚«‚éWi-Fi‚ً—ک—p‚µ‚ؤ‚¢‚éPC‚ةگN“ü‚µپA
ƒEƒCƒ‹ƒX‚ً‚ـ‚«ژU‚ç‚·‚و‚¤‚ةگفŒv‚³‚ê‚ؤ‚¢‚½‚ئ‚ج‚±‚ئپB
ژ—‚½‚و‚¤‚بƒ`ƒbƒv‚ھ’†چ‘گ»‚جŒg‘ر“dکb‚âژ©“®ژشپAƒJƒپƒ‰‚©‚ç‚à”Œ©‚³‚ê‚ؤ‚¨‚èپA
گê–ه‰ئ‚حپu“d‰»گ»•i‚âژ©“®ژش‚ة‰B‚³‚ê‚ؤ‚¢‚½ƒ`ƒbƒv‚حپA
پ@‰ïژذ‚جƒlƒbƒgƒڈپ[ƒN‚ةگN“ü‚µƒXƒpƒ€ƒپپ[ƒ‹‚ً‘—گM‚·‚邱‚ئ‚ةژg—p‚³‚ê‚ؤ‚¢‚½‚à‚ج‚إ‚µ‚ه‚¤پv‚ئکb‚µ‚ؤ‚¢‚ـ‚·پB
ƒچƒVƒA‚ج’تگMژذRosbalt‚ة‚و‚é‚ئپu’¼‹ك‚ج”z’B‚حگH‚¢ژ~‚ك‚ç‚ꂽ‚à‚ج‚جپA
پ@•sگ³‚بƒ`ƒbƒv‚ھٹـ‚ـ‚ꂽ30Œآˆبڈم‚ج“d‰»گ»•i‚ھ
پ@ƒTƒ“ƒNƒgƒyƒeƒ‹ƒuƒ‹ƒN‚جڈ¬”„“X‚ة”z’B‚³‚ê‚ؤ‚µ‚ـ‚ء‚½پv‚ئ‚ج‚±‚ئ‚إ‚·پB
http://gigazine.net/news/20131029-spam-chips-hidden-in-iron/
{kind=link}
ژE’ژچـ‚ھچ¬“ü‚µ‚ؤ‚¢‚½—â“€éLژq‚ب‚اپA
’†چ‘‚©‚ç—A“ü‚³‚ꂽگH•i‚ةٹ댯‚ب–ٍ•¨‚ھچ¬“ü‚µ‚ؤ‚¢‚邱‚ئ‚ھ‚ ‚è‚ـ‚·‚ھپA
ٹ댯‚بƒ‚ƒm‚ھچ¬“ü‚µ‚ؤ‚¢‚é‚ج‚حگH•i‚¾‚¯‚ةŒہ‚ç‚ب‚¢‚و‚¤‚إپA
ƒچƒVƒA‚إ‚ح—A“ü‚³‚ꂽ’†چ‘گ»‚ج“d‰»گ»•i‚ة•sگ³‚بƒ`ƒbƒv‚ھچ¬“ü‚µ‚ؤ‚¢‚é‚ئ‚¢‚¤ژ–—ل‚ھ”گ¶‚µ‚ـ‚µ‚½پB
چ‘‚©‚ç—A“ü‚³‚ꂽ“d‹Cژ®ƒAƒCƒچƒ“‚ة‰B‚³‚ê‚ؤ‚¢‚½‚ج‚حڈ¬‚³‚بƒ`ƒbƒvپB
‚±‚جƒ`ƒbƒv‚ح”¼Œa200mˆب“à‚إˆأچ†ƒLپ[‚ب‚µ‚إگع‘±‚إ‚«‚éWi-Fi‚ً—ک—p‚µ‚ؤ‚¢‚éPC‚ةگN“ü‚µپA
ƒEƒCƒ‹ƒX‚ً‚ـ‚«ژU‚ç‚·‚و‚¤‚ةگفŒv‚³‚ê‚ؤ‚¢‚½‚ئ‚ج‚±‚ئپB
ژ—‚½‚و‚¤‚بƒ`ƒbƒv‚ھ’†چ‘گ»‚جŒg‘ر“dکb‚âژ©“®ژشپAƒJƒپƒ‰‚©‚ç‚à”Œ©‚³‚ê‚ؤ‚¨‚èپA
گê–ه‰ئ‚حپu“d‰»گ»•i‚âژ©“®ژش‚ة‰B‚³‚ê‚ؤ‚¢‚½ƒ`ƒbƒv‚حپA
پ@‰ïژذ‚جƒlƒbƒgƒڈپ[ƒN‚ةگN“ü‚µƒXƒpƒ€ƒپپ[ƒ‹‚ً‘—گM‚·‚邱‚ئ‚ةژg—p‚³‚ê‚ؤ‚¢‚½‚à‚ج‚إ‚µ‚ه‚¤پv‚ئکb‚µ‚ؤ‚¢‚ـ‚·پB
ƒچƒVƒA‚ج’تگMژذRosbalt‚ة‚و‚é‚ئپu’¼‹ك‚ج”z’B‚حگH‚¢ژ~‚ك‚ç‚ꂽ‚à‚ج‚جپA
پ@•sگ³‚بƒ`ƒbƒv‚ھٹـ‚ـ‚ꂽ30Œآˆبڈم‚ج“d‰»گ»•i‚ھ
پ@ƒTƒ“ƒNƒgƒyƒeƒ‹ƒuƒ‹ƒN‚جڈ¬”„“X‚ة”z’B‚³‚ê‚ؤ‚µ‚ـ‚ء‚½پv‚ئ‚ج‚±‚ئ‚إ‚·پB
http://gigazine.net/news/20131029-spam-chips-hidden-in-iron/
—گگ”گ¶گ¬ٹي‚ةNSA‚جƒoƒbƒNƒhƒA‚ھ‚ ‚é‚ئ‚¢‚¤‰\‚ح‚ظ‚ٌ‚ئ‚¤‚ب‚ج‚©‚ب‚ں
494 پFSocket774پF2013/10/29(‰خ) 23:29:56.23 ID:2Ap7vcvR
>>492
گ¢‚à––‚¾‚ب
گ¢‚à––‚¾‚ب
’†چ‘گ»‚جژ©“®ژش—A“ü‚µ‚ؤ‚éژ“_‚إ
‚ا‚¤‚©‚µ‚ؤ‚é‚و
‚ا‚¤‚©‚µ‚ؤ‚é‚و
‚±‚جƒTƒCƒY‚إƒlƒbƒgŒq‚¢‚إƒپپ[ƒ‹‚خ‚ç‚ـ‚¯‚é‚ج‚©
ƒ‚ƒoƒCƒ‹—pGPUƒRƒA‚جژsڈêƒVƒFƒAپAImagination‚ھ‘¼ژذ‚ًˆ³“|
http://eetimes.jp/ee/articles/1203/26/news071.html
http://eetimes.jp/ee/articles/1203/26/news071.html
A7‚جCyclone‚ح6-way‚جƒoƒPƒ‚ƒmƒXƒyƒbƒN?
http://anandtech.com/show/7460/apple-ipad-air-review/2
>As far as I can tell, peak issue width of Cyclone is 6 instructions.
>That's at least 2x the width of Swift and Krait, and at best more than
>3x the width depending on instruction mix. Limitations on co-issuing
>FP and integer math have also been lifted as you can run up to four
>integer adds and two FP adds in parallel. You can also perform up to
>two loads or stores per clock.
http://anandtech.com/show/7460/apple-ipad-air-review/2
>As far as I can tell, peak issue width of Cyclone is 6 instructions.
>That's at least 2x the width of Swift and Krait, and at best more than
>3x the width depending on instruction mix. Limitations on co-issuing
>FP and integer math have also been lifted as you can run up to four
>integer adds and two FP adds in parallel. You can also perform up to
>two loads or stores per clock.
ƒXƒ}ƒtƒH‚ج“d—ح‚ةژû‚ـ‚é‚ج‚ھ“ن‚¾‚بپB
ARM‚جISA‚إ‚»‚ê‚ھ‰آ”\‚ب‚çپAARMژ©گg‚ھٹù‚ة‚â‚ء‚ؤ‚¢‚»‚¤‚ب‚à‚ج‚¾‚ھپB
ARM‚جISA‚إ‚»‚ê‚ھ‰آ”\‚ب‚çپAARMژ©گg‚ھٹù‚ة‚â‚ء‚ؤ‚¢‚»‚¤‚ب‚à‚ج‚¾‚ھپB
A15‚إٹو’£‚ء‚ؤٹg’£‚µ‚½‚çڈء”ï“d—ح‚à‚¾‚¢‚شڈم‚ھ‚ء‚½‚µ‚ث
A15‚و‚èچX‚ةٹg’£‚µ‚ؤڈبƒGƒl‚ئ‚©–³—ƒQپ[
A15‚و‚èچX‚ةٹg’£‚µ‚ؤڈبƒGƒl‚ئ‚©–³—ƒQپ[
‚»‚¤‚¢‚₱‚±‚µ‚خ‚ç‚iPad‚ج‚ح‚‰‚o‚ˆ‚ڈ‚ژ‚…—p‚ج‚à‚ج‚و‚èGPU‹‰»‚³‚ꂽ‚à‚ج‚ء‚ؤƒpƒ^پ[ƒ“‚¾‚ء‚½‚ج‚ة
چ،‚ج‚ئ‚±‚ë‚جڈî•ٌ‚¾‚ئiPad‚àA7‚»‚ج‚ـ‚ٌ‚ـ‚ء‚ؤکb‚¾‚µپAگ«”\‚ة—]—T‚ھ‚ ‚é‚ئŒ©‚½‚ٌ‚¾‚낤‚ب
چ،‚ج‚ئ‚±‚ë‚جڈî•ٌ‚¾‚ئiPad‚àA7‚»‚ج‚ـ‚ٌ‚ـ‚ء‚ؤکb‚¾‚µپAگ«”\‚ة—]—T‚ھ‚ ‚é‚ئŒ©‚½‚ٌ‚¾‚낤‚ب
>>499
2ƒRƒA1.3GHz‚¾‚µپA4ƒRƒA2GHz‘OŒم‚جKrait‚âA15‚ئ”ن‚ׂè‚لƒRƒA‚ ‚½‚è‚جگ«”\‚ًڈم‚°‚ç‚ê‚é‚ج‚ح“¹—
2ƒRƒA1.3GHz‚¾‚µپA4ƒRƒA2GHz‘OŒم‚جKrait‚âA15‚ئ”ن‚ׂè‚لƒRƒA‚ ‚½‚è‚جگ«”\‚ًڈم‚°‚ç‚ê‚é‚ج‚ح“¹—
‚»‚ê‚إ‚àƒZƒچƒٹƒ“‚ة‰“‚‹y‚خ‚ب‚¢‚ج‚©
ƒfƒXƒNƒgƒbƒvŒü‚¯‚ف‚½‚¢‚بƒXƒyƒbƒN‚¾‚ب‚ں
ESRAMچع‚¹‚½ƒ}ƒ‹ƒ`SoC‚بMOVEƒGƒ“ƒWƒ“
گد‘wƒپƒ‚ƒٹپ{HSA
direct blue
kinect2.0
49800‰~
گد‘wƒپƒ‚ƒٹپ{HSA
direct blue
kinect2.0
49800‰~
[’ل””M]پy’لگ«”\پzMac‚جCPU‚ًARM‚ةپI2 [ڈب“d—ح]
http://anago.2ch.net/test/read.cgi/mac/1355508479/
http://anago.2ch.net/test/read.cgi/mac/1355508479/
پhƒvƒچƒOƒ‰ƒ€‚ھڈ¬‚³‚‚ؤƒfپ[ƒ^‚ھ‘ه‚«‚¢‚ج‚ب‚ç
ƒvƒچƒOƒ‰ƒ€‚ھƒfپ[ƒ^‚ج‚ ‚éƒRƒA‚ضچs‚ء‚ؤژdژ–‚ً‚µ‚ؤ—ˆ‚¢پh
MIT‚ج110ƒRƒAƒvƒچƒZƒT‚ً—p‚¢‚½ƒXƒŒƒbƒhƒ}ƒCƒOƒŒپ[ƒVƒ‡ƒ“
ttp://news.mynavi.jp/column/hotchips25/026/index.html
ttp://news.mynavi.jp/column/hotchips25/027/index.html
ƒvƒچƒOƒ‰ƒ€‚ھƒfپ[ƒ^‚ج‚ ‚éƒRƒA‚ضچs‚ء‚ؤژdژ–‚ً‚µ‚ؤ—ˆ‚¢پh
MIT‚ج110ƒRƒAƒvƒچƒZƒT‚ً—p‚¢‚½ƒXƒŒƒbƒhƒ}ƒCƒOƒŒپ[ƒVƒ‡ƒ“
ttp://news.mynavi.jp/column/hotchips25/026/index.html
ttp://news.mynavi.jp/column/hotchips25/027/index.html
ƒfپ[ƒ^‹ى“®ƒ}ƒVƒ“‚حƒ‚ƒm‚ة‚ح‚ب‚ç‚ٌ‚و‚ب
—ًژj‚حŒJ‚è•ش‚·پAƒfپ[ƒ^ƒtƒچپ[ƒ}ƒVƒ“چؤ‚ر
‚»‚êŒn‚ج”hگ¶‹Zڈp‚إ—Bˆê‚ة‚µ‚ؤچإ‘ه‚ج‹àژڑ“ƒ‚حOoO
‘S–ت“I‚ة“K—p‚µ‚½‚ئ‚±‚ë‚إŒّ—¦‚حˆ«‰»‚·‚é‚ئŒ¾‚¤‚ج‚ھ
‰ك‹ژ‚ج’mŒ©‚¾‚ء‚½‚ج‚إ‚حپH
‚»‚ê‚ئ‚à‰½‚©‘O’ٌڈًŒڈ‚إ‚à•د‚ي‚ء‚½‚ج‚¾‚낤‚©
پcپc‚ؤ‚¢‚¤‚©MIT‚جTRIPS‚ح‰½ڈˆ‚ضچs‚ء‚½پH
‚»‚êŒn‚ج”hگ¶‹Zڈp‚إ—Bˆê‚ة‚µ‚ؤچإ‘ه‚ج‹àژڑ“ƒ‚حOoO
‘S–ت“I‚ة“K—p‚µ‚½‚ئ‚±‚ë‚إŒّ—¦‚حˆ«‰»‚·‚é‚ئŒ¾‚¤‚ج‚ھ
‰ك‹ژ‚ج’mŒ©‚¾‚ء‚½‚ج‚إ‚حپH
‚»‚ê‚ئ‚à‰½‚©‘O’ٌڈًŒڈ‚إ‚à•د‚ي‚ء‚½‚ج‚¾‚낤‚©
پcپc‚ؤ‚¢‚¤‚©MIT‚جTRIPS‚ح‰½ڈˆ‚ضچs‚ء‚½پH
TRIPS‚حƒeƒLƒTƒX‘هƒIپ[ƒXƒ`ƒ“
!!!!!
‘f‚إ‹L‰¯ˆل‚¢‚ً‚µ‚ؤ‚¢‚½پI
‚»‚¤‚¢‚âMIT‚حRawTile‚¾‚ء‚½‚©پcپc
‚¢‚¸‚ê‚ة‚µ‚ؤ‚à‚ ‚جژè‚جŒ¤‹†‚ح‚ا‚¤‚ب‚ء‚½‚ج‚¾پH
‘f‚إ‹L‰¯ˆل‚¢‚ً‚µ‚ؤ‚¢‚½پI
‚»‚¤‚¢‚âMIT‚حRawTile‚¾‚ء‚½‚©پcپc
‚¢‚¸‚ê‚ة‚µ‚ؤ‚à‚ ‚جژè‚جŒ¤‹†‚ح‚ا‚¤‚ب‚ء‚½‚ج‚¾پH
Tilera‚إ
ƒXƒ^ƒeƒBƒbƒNƒfپ[ƒ^ƒtƒچپ[‚ح—¬چs‚ٌ‚ب‚¢‚ث
ƒXƒ^ƒeƒBƒbƒNƒfپ[ƒ^ƒtƒچپ[‚ح—¬چs‚ٌ‚ب‚¢‚ث
گج‚جDOS/Vƒ}ƒKƒWƒ“‚ةƒRƒvƒچ‚ئ‚µ‚ؤƒپƒ‚ƒٹ‚ةڈ¬گ”‰‰ژZٹيچع‚¹‚½‘م•¨‚جکb‚ھ‚ ‚ء‚½‚ج‚ًژv‚¢ڈo‚µ‚½‰´پB
‚»‚ٌ‚ب‚ج‚ ‚ء‚½‚ج‚©پAژتگ^‚إ‚¢‚¢‚©‚猩‚ؤ‚ف‚½‚¢
‚·‚°‚¦‚بپA‚ظ‚ٌ‚ئ‚ة‚ ‚ء‚½‚ج‚©
‚ئ‚ح‚¢‚¦‚»‚جDIMMˆبٹO‚ج‚ئ‚±‚ةƒfپ[ƒ^‚ھ‚ ‚ء‚½‚ç‚ا‚¤‚ب‚é‚ٌ‚¾‚낤‚ئ‚¢‚¤‹^–â‚à‚ي‚‚ب‚
‚ئ‚ح‚¢‚¦‚»‚جDIMMˆبٹO‚ج‚ئ‚±‚ةƒfپ[ƒ^‚ھ‚ ‚ء‚½‚ç‚ا‚¤‚ب‚é‚ٌ‚¾‚낤‚ئ‚¢‚¤‹^–â‚à‚ي‚‚ب‚
ƒnپ[ƒhƒEƒFƒAژx‰‡‚ء‚ؤ‚·‚®’آ•…‰»‚·‚é‚©‚ç‚ب‚ں
ƒnپ[ƒhƒEƒFƒAƒAƒVƒXƒg‚حپACPU‚ج20”{ˆبڈم‚جگ«”\Œüڈم‚ھ“¾‚ç‚ê‚é‚ئ”„‚ê‚é‚ئŒ¾‚ي‚ê‚ؤ‚¢‚éپB
20”{‚ً‰؛‰ٌ‚é‚ئCPU‚جگ«”\Œüڈم‚ة‚و‚ء‚ؤ‚ ‚ء‚ئ‚¢‚¤ٹش‚ةƒSƒ~‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
‚»‚جˆس–،‚إ‚±‚جڈ¤•i‚ح“–ژ‚جCPU‚ج4”{‚µ‚©ڈo‚ؤ‚¢‚ب‚¢‚ج‚إDOA‚¾پB
20”{‚ً‰؛‰ٌ‚é‚ئCPU‚جگ«”\Œüڈم‚ة‚و‚ء‚ؤ‚ ‚ء‚ئ‚¢‚¤ٹش‚ةƒSƒ~‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
‚»‚جˆس–،‚إ‚±‚جڈ¤•i‚ح“–ژ‚جCPU‚ج4”{‚µ‚©ڈo‚ؤ‚¢‚ب‚¢‚ج‚إDOA‚¾پB
519 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/02(“y) 16:54:27.45 ID:KLXw0XtZ
GPU‚à‚à‚¤ˆêŒ…”{‚‚ç‚¢‚ة‚ب‚ء‚ؤ‚µ‚ـ‚ء‚½‚¯‚ا‚ا‚¤‚¾‚낤‚ث
گê—pƒnپ[ƒhƒEƒFƒA‚ً“¯’ِ“x‚ج‰ٌکH‹K–ح‚جCPU‚إƒGƒ~ƒ…ƒŒپ[ƒg‚·‚é‚ئ100”{’x‚‚ب‚éپBƒnپ[ƒhƒEƒFƒA‚حژ©—R“x‚ھ‘S‚–³‚¢‘م‚ي‚è‚ة100”{‘¬‚‚ب‚é‚ئ‚¢‚¤‚±‚ئپB‚ ‚é’ِ“xژ©—R“x‚ًژ‚½‚¹‚½DSP‚¾‚ئ10”{‘¬‚‚ب‚éپB
GPU‚حROP‚حگê—pƒnپ[ƒhƒEƒFƒAپAƒVƒFپ[ƒ_‚حDSP‚ف‚½‚¢‚ب‚à‚ج‚¾‚©‚çƒOƒ‰ƒtƒBƒbƒNڈˆ—‚¾‚ئگ”ڈ\”{‚جگ«”\‚ھڈo‚é‚ھپAGPGPU‚ة‚ب‚é‚ئ10”{ˆب‰؛‚جگ«”\‚µ‚©ڈo‚ب‚¢‚ج‚ح—‚ة“K‚ء‚ؤ‚¢‚éپB
GPU‚حROP‚حگê—pƒnپ[ƒhƒEƒFƒAپAƒVƒFپ[ƒ_‚حDSP‚ف‚½‚¢‚ب‚à‚ج‚¾‚©‚çƒOƒ‰ƒtƒBƒbƒNڈˆ—‚¾‚ئگ”ڈ\”{‚جگ«”\‚ھڈo‚é‚ھپAGPGPU‚ة‚ب‚é‚ئ10”{ˆب‰؛‚جگ«”\‚µ‚©ڈo‚ب‚¢‚ج‚ح—‚ة“K‚ء‚ؤ‚¢‚éپB
521 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/02(“y) 18:06:53.32 ID:KLXw0XtZ
‹t‚ةŒ¾‚¤‚ئ‚»‚جŒإ’è‹@”\‚إ‚à‚ء‚½‚ظ‚¤‚ھ‚¢‚¢ƒ†ƒjƒbƒg‚ًCPU‚ة“à‘ ‚·‚ê‚خ
GPU‚ھ•s—v‚ة‚ب‚é‚ج‚ح‚»‚¤‰“‚‚ب‚¢کb‚ئ‚¢‚¤‚±‚ئ‚¾‚ث
http://microboy.seesaa.net/article/358592842.html
ژہچغ‚±‚ٌ‚بƒlƒ^‚à‚ ‚邯‚اپAIntel‚ح“ء‹–‚»‚ج‚à‚ج‚ئ‚ح’¼گعٹضŒW‚ب‚¢•”•ھ‚ة‚آ‚¢‚ؤ
ƒ~ƒXƒٹپ[ƒh‚·‚é‚و‚¤‚بگ}‚ً“ü‚ê‚é‚ج‚ح‚و‚‚ ‚éکb‚إ‚ح‚ ‚é‚ٌ‚¾‚¯‚ا
KNCni‚¨‚و‚رAVX-512‚حLarrabee‚جƒOƒ‰ƒtƒBƒbƒN—p‚ج–½—كƒZƒbƒgٹg’£‚ً‚ظ‚ع‚»‚ج‚ـ‚ـ
ژَ‚¯Œp‚¢‚إ‚é‚©‚çپA‚ا‚±‚©‚جƒ^ƒCƒ~ƒ“ƒO‚إپEپEپE‚ح‚ ‚肤‚éکb‚¾پB
GPU‚ھ•s—v‚ة‚ب‚é‚ج‚ح‚»‚¤‰“‚‚ب‚¢کb‚ئ‚¢‚¤‚±‚ئ‚¾‚ث
http://microboy.seesaa.net/article/358592842.html
ژہچغ‚±‚ٌ‚بƒlƒ^‚à‚ ‚邯‚اپAIntel‚ح“ء‹–‚»‚ج‚à‚ج‚ئ‚ح’¼گعٹضŒW‚ب‚¢•”•ھ‚ة‚آ‚¢‚ؤ
ƒ~ƒXƒٹپ[ƒh‚·‚é‚و‚¤‚بگ}‚ً“ü‚ê‚é‚ج‚ح‚و‚‚ ‚éکb‚إ‚ح‚ ‚é‚ٌ‚¾‚¯‚ا
KNCni‚¨‚و‚رAVX-512‚حLarrabee‚جƒOƒ‰ƒtƒBƒbƒN—p‚ج–½—كƒZƒbƒgٹg’£‚ً‚ظ‚ع‚»‚ج‚ـ‚ـ
ژَ‚¯Œp‚¢‚إ‚é‚©‚çپA‚ا‚±‚©‚جƒ^ƒCƒ~ƒ“ƒO‚إپEپEپE‚ح‚ ‚肤‚éکb‚¾پB
“®‰وچؤگ¶ژx‰‡‚àGPU“à•”‚ة“®‰وگê—p‰ٌکH‚ً“ü‚ê‚ؤ‚é‚©‚çپA
گV‚µ‚¢ƒtƒHپ[ƒ}ƒbƒg‚ھڈo‚ؤ‚‚é‚ئŒأ‚¢ƒnƒCƒGƒ“ƒh‚ح–¢‘خ‰‚إپA
گV‚µ‚¢ƒ~ƒhƒ‹پEƒچپ[‚ح‘خ‰‚ب‚ٌ‚ؤژ–‚ھ–ˆ“x‹N‚±‚é‚ث
Œأ‚¢ƒnƒCƒGƒ“ƒh‚ح‚¹‚ء‚©‚چ‚گ«”\GPU‚ھ‚ ‚é‚ٌ‚¾‚©‚çپA
GPGPUژg‚ء‚ؤ‘خ‰‚µ‚ؤ‚‚ê‚ê‚خ‚ء‚ؤژv‚¤‚ھŒّ—¦ˆ«‚·‚¬‚é‚ج‚©‚ب
گV‚µ‚¢ƒtƒHپ[ƒ}ƒbƒg‚ھڈo‚ؤ‚‚é‚ئŒأ‚¢ƒnƒCƒGƒ“ƒh‚ح–¢‘خ‰‚إپA
گV‚µ‚¢ƒ~ƒhƒ‹پEƒچپ[‚ح‘خ‰‚ب‚ٌ‚ؤژ–‚ھ–ˆ“x‹N‚±‚é‚ث
Œأ‚¢ƒnƒCƒGƒ“ƒh‚ح‚¹‚ء‚©‚چ‚گ«”\GPU‚ھ‚ ‚é‚ٌ‚¾‚©‚çپA
GPGPUژg‚ء‚ؤ‘خ‰‚µ‚ؤ‚‚ê‚ê‚خ‚ء‚ؤژv‚¤‚ھŒّ—¦ˆ«‚·‚¬‚é‚ج‚©‚ب
ƒVƒFپ[ƒ_‚ًCPU‚جƒpƒCƒvƒ‰ƒCƒ“‚إڈˆ—‚·‚é‚ج‚ح‰‰ژZٹي‚و‚è‚àƒXƒPƒWƒ…پ[ƒ‰‚ة–³‘ت‚ھ‘½‚¢‚©‚çƒVƒFپ[ƒ_‚ھ‚³‚ç‚ةچ‚‹@”\‰»‚µ‚ؤƒwƒeƒچƒWƒjƒAƒXƒ}ƒ‹ƒ`ƒRƒA‰»‚·‚邱‚ئ‚ح‚ ‚ء‚ؤ‚à–³‚‚ب‚邱‚ئ‚ح–³‚¢‚¾‚낤پB
LLC‚ً‹¤—L‚·‚é•تƒ†ƒjƒbƒg‚ئ‚¢‚¤چ\گ¬‚ح•د‚ي‚ç‚ب‚¢‚ثپB
LLC‚ً‹¤—L‚·‚é•تƒ†ƒjƒbƒg‚ئ‚¢‚¤چ\گ¬‚ح•د‚ي‚ç‚ب‚¢‚ثپB
”¼“±‘ج‹Zڈp‚جگi•à‚ھچs‚‚ئ‚±‚ë‚ـ‚إچs‚ء‚ؤپA
گi•à‚جگi‚ف•û‚ھ“ف‰»‚µ‚½‚ç
گê—pƒnپ[ƒhƒEƒFƒA‚جژ‘م‚ح—ˆ‚é‚ٌ‚¶‚ل‚ب‚¢‚جپH
گi•à‚جگi‚ف•û‚ھ“ف‰»‚µ‚½‚ç
گê—pƒnپ[ƒhƒEƒFƒA‚جژ‘م‚ح—ˆ‚é‚ٌ‚¶‚ل‚ب‚¢‚جپH
ژں‚حƒXƒsƒ“ƒgƒچƒjƒNƒX‚ئ‚©—تژqƒfƒoƒCƒX‚جژ‘م‚إ‚·‚و
>>524
IBM‚ح‚»‚ج•ûŒü‚إŒں“¢‚µ‚ؤ‚é‚ف‚½‚¢‚¾‚ث
IBM‚ح‚»‚ج•ûŒü‚إŒں“¢‚µ‚ؤ‚é‚ف‚½‚¢‚¾‚ث
ƒXƒsƒ“ƒgƒچƒjƒNƒX‚إŒ€“I‚ة“d—ح‚ھ‰؛‚ھ‚è
”MپX‚¾‚©‚çگد‚ك‚ب‚¢‚ئ‚¢‚¤”›‚ھ‰ً‚©‚ê‚ؤ
ƒAƒz‚ف‚½‚¢‚ةگد‘w‚إ‚«‚é‚و‚¤‚ة‚ب‚éپBپ@‚ئ‚¢‚¤ٹè–]
”MپX‚¾‚©‚çگد‚ك‚ب‚¢‚ئ‚¢‚¤”›‚ھ‰ً‚©‚ê‚ؤ
ƒAƒz‚ف‚½‚¢‚ةگد‘w‚إ‚«‚é‚و‚¤‚ة‚ب‚éپBپ@‚ئ‚¢‚¤ٹè–]
گد‚ق•ûŒü‚حپAڈWگد“x‚حڈم‚ھ‚ء‚ؤ‚àˆہ‚‚ح‚ب‚ç‚ب‚¢ˆ«ٹ¦
چإ‹ك‚حƒgƒ‰ƒ“ƒWƒXƒ^‚ ‚½‚è‚ج‰؟ٹi‚ح”÷چ׉»‚µ‚ؤ‰؛‚ھ‚ç‚ب‚¢‚ئ‚¢‚ي‚ê‚ؤ‚¢‚éپB
‚¨‚»‚ç‚گد‘w‚à‰؛‚ھ‚ء‚ؤ‚‚ê‚ب‚¢‚¾‚낤‚ثپB
‚إ‚àGDDR5‚ً‘ه—ت‚ةٹO•t‚¯‚·‚é‚و‚èDDR3‚©DDR4‚ج
2048ƒrƒbƒg•‚جƒپƒ‚ƒٹ‚ًگد‘w‚µ‚½•û‚ھˆہ‚¢پA‚ئ‚©‚ح‚ ‚è‚»‚¤پB
‚¨‚»‚ç‚گد‘w‚à‰؛‚ھ‚ء‚ؤ‚‚ê‚ب‚¢‚¾‚낤‚ثپB
‚إ‚àGDDR5‚ً‘ه—ت‚ةٹO•t‚¯‚·‚é‚و‚èDDR3‚©DDR4‚ج
2048ƒrƒbƒg•‚جƒپƒ‚ƒٹ‚ًگد‘w‚µ‚½•û‚ھˆہ‚¢پA‚ئ‚©‚ح‚ ‚è‚»‚¤پB
’·‚¢ƒXƒpƒ“‚إŒ©‚½‚çˆہ‚‚ب‚é‚إ‚µ‚ه
گف”ُ“ٹژ‘‚ح‚¢‚¸‚êڈ‹p‚³‚ê‚邵
Œأ‚¢‹Zڈp‚ح•K‚¸’آ•…‰»‚·‚邵
گف”ُ“ٹژ‘‚ح‚¢‚¸‚êڈ‹p‚³‚ê‚邵
Œأ‚¢‹Zڈp‚ح•K‚¸’آ•…‰»‚·‚邵
ڈژ–¯‚ھ”ƒ‚¦‚é‚©”ƒ‚¦‚ب‚¢‚©‚جکb‚إ—ٹ‚ق
ƒپƒ‚ƒٹپ[‚جƒRƒqپ[ƒŒƒ“ƒVژü‚è‚جƒJƒXƒ^ƒ}ƒCƒY‚ئ‚©
DSP‚ًƒJƒXƒ^ƒ}ƒCƒY‚µ‚½ƒIپ[ƒfƒBƒIƒvƒچƒZƒbƒT‚âپAeSRAM‚ج“چ‡
DSP‚ًƒJƒXƒ^ƒ}ƒCƒY‚µ‚½ƒIپ[ƒfƒBƒIƒvƒچƒZƒbƒT‚âپAeSRAM‚ج“چ‡
>>527
‚»‚¤‚ب‚è‚لƒAƒz‚ف‚½‚¢‚ةژü”gگ”‚ ‚°‚ê‚خ‚¢‚¢‚¶‚ل‚ٌ
‚»‚¤‚ب‚è‚لƒAƒz‚ف‚½‚¢‚ةژü”gگ”‚ ‚°‚ê‚خ‚¢‚¢‚¶‚ل‚ٌ
534 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/04(Œژ) 12:00:38.52 ID:tynDA+J+
‚ك‚à‚èپ™‚·‚½پ@‚¢‚آ‚إ‚·‚©پH
ƒXƒsƒ“ƒgƒچƒjƒNƒX‚ء‚ؤŒ‹‹ا‚ـ‚ئ‚à‚ةگ»•i‚ھژg‚ي‚ê‚ؤ‚ٌ‚جHDD‚جƒwƒbƒh‚‚ç‚¢‚©‚ث
MRAM‚àƒXƒsƒ“ƒgƒچƒjƒNƒX‚ج•ھ–ى‚¾‚ء‚¯‚©
MRAM‚àƒXƒsƒ“ƒgƒچƒjƒNƒX‚ج•ھ–ى‚¾‚ء‚¯‚©
>>520
ƒOƒ‰ƒtƒBƒbƒN‚جƒtƒچƒ“ƒgƒGƒ“ƒh‚ًCell‚إ‚â‚ء‚ؤپAƒoƒbƒNƒGƒ“ƒh‚ًگê—p‰ٌکH‚إ‚â‚éCell GPUچ\‘z‚ح
Œ‹‹اژ¸”s‚µ‚½‚¯‚اپA‚ـ‚½ژ—‚½‚و‚¤‚ب‚ج‚ھ•œٹˆ‚·‚é‚ج‚©‚بپH
‚½‚ش‚ٌSCE/“Œژإ‚حپAROP‚ة‚ ‚½‚é•”•ھ‚ًگê—pASICپAƒVƒFپ[ƒ_‚ة“–‚½‚é•”•ھ‚ًCell‚إ
ژہŒ»‚µ‚و‚¤‚ئچ\‘z‚µ‚ؤ‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚بپH
ƒOƒ‰ƒtƒBƒbƒN‚جƒtƒچƒ“ƒgƒGƒ“ƒh‚ًCell‚إ‚â‚ء‚ؤپAƒoƒbƒNƒGƒ“ƒh‚ًگê—p‰ٌکH‚إ‚â‚éCell GPUچ\‘z‚ح
Œ‹‹اژ¸”s‚µ‚½‚¯‚اپA‚ـ‚½ژ—‚½‚و‚¤‚ب‚ج‚ھ•œٹˆ‚·‚é‚ج‚©‚بپH
‚½‚ش‚ٌSCE/“Œژإ‚حپAROP‚ة‚ ‚½‚é•”•ھ‚ًگê—pASICپAƒVƒFپ[ƒ_‚ة“–‚½‚é•”•ھ‚ًCell‚إ
ژہŒ»‚µ‚و‚¤‚ئچ\‘z‚µ‚ؤ‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚بپH
CPU‚ئƒپƒ‚ƒٹٹش‚ًƒVƒٹƒAƒ‹ƒoƒX‚ة‚·‚ê‚خ
eDRAM‚ف‚½‚¢‚بڈ¬چ×چH‚ح‚¢‚ç‚ٌ‚ج‚إ‚·
eDRAM‚ف‚½‚¢‚بڈ¬چ×چH‚ح‚¢‚ç‚ٌ‚ج‚إ‚·
FB-DIMM‚جڈo”ش‚©
>>536
‚ئ‚¢‚¤‚©‚»‚ê‚ھCell‚جVU on EE + GS‚»‚ج‚à‚ج‚ب‚ٌ‚إ‚·‚ھ‚ث
‚ئ‚¢‚¤‚©‚»‚ê‚ھCell‚جVU on EE + GS‚»‚ج‚à‚ج‚ب‚ٌ‚إ‚·‚ھ‚ث
Cell‚ج‚ء‚ؤ‚ب‚ٌ‚¾پAPS2‚جپA‚¾
>>478
ƒrƒWƒlƒXپEƒTپ[ƒoŒnƒxƒ“ƒ`‚àژو‚ء‚ؤ‚ظ‚µ‚¢‚ب
ƒrƒWƒlƒXپEƒTپ[ƒoŒnƒxƒ“ƒ`‚àژو‚ء‚ؤ‚ظ‚µ‚¢‚ب
542 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/04(Œژ) 22:28:11.91 ID:tynDA+J+
–{“–‚حSPECint‚ئ‚©‚ھ‚¢‚¢‚ٌ‚¾‚¯‚اپA‚±‚±‚ةUNIXŒn‚جƒxƒ“ƒ`Œ‹‰ت‚ھچع‚ء‚ؤ‚é
Œآگl‚إ‚àژ©‘îƒTپ[ƒo‚ئ‚©‚â‚ء‚ؤ‚éگl‚ة‚حڈ\•ھ“±“ü‚ًŒں“¢‚·‚é‰؟’l‚ ‚èپH
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
پi‚µ‚©‚µMulti‚جOpteron 3380‚جƒXƒRƒAپASystem Call Overhead‚ھ‚PŒ…ٹشˆل‚ء‚ؤ‚é‹C‚ھ‚·‚é‚ٌ‚¾‚ھپj
Œآگl‚إ‚àژ©‘îƒTپ[ƒo‚ئ‚©‚â‚ء‚ؤ‚éگl‚ة‚حڈ\•ھ“±“ü‚ًŒں“¢‚·‚é‰؟’l‚ ‚èپH
http://www.servethehome.com/Server-detail/intel-atom-c2750-8-core-avoton-rangeley-benchmarks-fast-power/
پi‚µ‚©‚µMulti‚جOpteron 3380‚جƒXƒRƒAپASystem Call Overhead‚ھ‚PŒ…ٹشˆل‚ء‚ؤ‚é‹C‚ھ‚·‚é‚ٌ‚¾‚ھپj
ƒRƒXƒp‚ھ‚©‚¦‚ء‚ؤˆ«‚¢‚ئ‚¢‚¤ƒŒƒxƒ‹پB
‚إ‚àڈء”ï“d—حچl‚¦‚ê‚خŒ³‚ئ‚ê‚؟‚ل‚¤‚ج‚©‚بپB
‚إ‚àڈء”ï“d—حچl‚¦‚ê‚خŒ³‚ئ‚ê‚؟‚ل‚¤‚ج‚©‚بپB
544 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/04(Œژ) 23:58:15.31 ID:tynDA+J+
پuڈب“d—ح‚¾‚©‚ç”ٌ—ح‚إ‚àژd•û‚ب‚¢‚ثپv‚ئ‚¢‚¤Œ©•û‚ً‚µ‚ب‚‚ؤ‚à‚¢‚¢’ِ“x‚ة‚ح
گâ‘خگ«”\‚إ‚à‘i‹پ—ح‚ھ‚ ‚邶‚ل‚ٌپB
‚±‚êOpteron‚ئ‚¢‚¤‚©پAXeon E3‚جڈب“d—ح”إ‚·‚狤گH‚¢‚³‚ê‚é‚و‚¤‚بƒŒƒxƒ‹‚إ‚·‚µپB
ƒGƒ“ƒvƒ‰Œü‚¯‚¾‚©‚çچ‚‚¢‚ج‚حژd•û‚ب‚¢‚ھپA‚»‚ê‚إ‚àŒآگl‚إ‚à‚ب‚ـ‚¶ژè‚ھ“ح‚ƒŒƒxƒ‹
‚ء‚ؤ‚ج‚ح‚¢‚¢ژ‘م‚¶‚ل‚ب‚¢‚جپB
Atom‚¶‚ل‚ب‚‚ؤPentiumƒuƒ‰ƒ“ƒh‚ة‚ح‚ب‚é‚ھپA‚»‚ج‚¤‚؟4ƒRƒA‚إGPU‚آ‚«‚ج
Mini-ITXƒ}ƒUپ[‚ھڈo‚邾‚낤‚©‚çŒآگlŒü‚¯‚ة‚ح‚»‚ء‚؟‚ً‘ز‚ء‚½‚ظ‚¤‚ھ‚¢‚¢‚©‚à‚µ‚ê‚ٌ‚ث
‚ ‚‚ـ‚إŒآگlŒü‚¯گ»•i‚ب‚ج‚إ‘«‰ٌ‚è‚ح‘½ڈ”ٌ—ح‚ة‚ب‚邾‚낤‚ھپB
گâ‘خگ«”\‚إ‚à‘i‹پ—ح‚ھ‚ ‚邶‚ل‚ٌپB
‚±‚êOpteron‚ئ‚¢‚¤‚©پAXeon E3‚جڈب“d—ح”إ‚·‚狤گH‚¢‚³‚ê‚é‚و‚¤‚بƒŒƒxƒ‹‚إ‚·‚µپB
ƒGƒ“ƒvƒ‰Œü‚¯‚¾‚©‚çچ‚‚¢‚ج‚حژd•û‚ب‚¢‚ھپA‚»‚ê‚إ‚àŒآگl‚إ‚à‚ب‚ـ‚¶ژè‚ھ“ح‚ƒŒƒxƒ‹
‚ء‚ؤ‚ج‚ح‚¢‚¢ژ‘م‚¶‚ل‚ب‚¢‚جپB
Atom‚¶‚ل‚ب‚‚ؤPentiumƒuƒ‰ƒ“ƒh‚ة‚ح‚ب‚é‚ھپA‚»‚ج‚¤‚؟4ƒRƒA‚إGPU‚آ‚«‚ج
Mini-ITXƒ}ƒUپ[‚ھڈo‚邾‚낤‚©‚çŒآگlŒü‚¯‚ة‚ح‚»‚ء‚؟‚ً‘ز‚ء‚½‚ظ‚¤‚ھ‚¢‚¢‚©‚à‚µ‚ê‚ٌ‚ث
‚ ‚‚ـ‚إŒآگlŒü‚¯گ»•i‚ب‚ج‚إ‘«‰ٌ‚è‚ح‘½ڈ”ٌ—ح‚ة‚ب‚邾‚낤‚ھپB
545 پFSocket774پF2013/11/05(‰خ) 19:46:35.08 ID:iuvewL3X
‚ب‚؛iPhone 5s‚ئiPad Air‚ح3DMark•¨—ƒeƒXƒg‚جŒ‹‰ت‚ھˆ«‚¢‚ج‚©
پ`Futuremark‚ھŒںڈط‚ًژہژ{ - PC Watch
http://pc.watch.impress.co.jp/docs/news/20131105_622195.html
A7‚حƒXƒ}پ[ƒgƒtƒHƒ“Œü‚¯SoC‚إڈ‰‚ك‚ؤ64bit‚ة‘خ‰
پuA6پv‚ة‘خ‚µ‚ؤپACPU/GPU‚ئ‚àچإ‘ه‚إ2”{چ‚گ«”\
ٹm‚©‚ةGPUگ«”\‚ح5,191‘خ17,961(iPhone 5‘خiPhone 5s)‚إپAiPhone 5‚ج3”{ˆبڈم‘¬‚¢
‚µ‚©‚µپACPUگ«”\‚ح‚ئ‚¢‚¤‚ئپA8,197‘خ7,783(“¯)‚إپAiPhone 5‚ًژلٹ±‰؛‰ٌ‚錋‰ت
A6‚ئA7‚ح‚¢‚¸‚ê‚àƒfƒ…ƒAƒ‹ƒRƒA‚إ1.3GHz‹ى“®
گ«”\چ·‚ھڈo‚é‚ئ‚·‚é‚ئپA‚»‚ê‚حƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‹Nˆِ
Futuremark‚إ‚ح64bit”إ‚ج3DMark‚ًچىگ¬‚µŒںڈط‚µ‚½‚ئ‚±‚ëپAگ«”\‚حŒüڈم‚µ‚½‚ھپA
‚»‚جٹ„چ‡‚ح7%‚ة—¯‚ـ‚èپA64bit‰»‚ھ•¨—ƒeƒXƒg‚جŒ‹‰ت‚ة‚ح‘ه‚«‚ب‰e‹؟‚ً—^‚¦‚ب‚¢
A6‚حپAƒCƒ“ƒIپ[ƒ_پ[ڈˆ—(گو‚جƒeƒXƒgƒRپ[ƒh‚ھٹY“–)‚إ‚àپAƒAƒEƒgƒIƒuƒIپ[ƒ_پ[ڈˆ—(Bullet)‚إ‚àپA
گ«”\‚ة•د‰»‚ح‚ب‚¢‚ج‚¾‚ھپAA7‚حƒAƒEƒgƒIƒuƒIپ[ƒ_پ[‚¾‚ئگ«”\‚ھ‰؛‚ھ‚é
‚ـ‚½پAƒfپ[ƒ^ˆث‘¶گ«‚àA7‚جگ«”\‚ة‘ه‚«‚‰e‹؟‚·‚é
ƒfپ[ƒ^‚جƒپƒ‚ƒٹ‚ض‚ج‹Lک^•û–@‚ًگ®—ٌ‰»‚³‚¹پAƒfپ[ƒ^ˆث‘¶گ«‚ًŒ¸‚炵‚½ڈCگ³”إ‚جBullet‚ًژژچى
A7‚جŒ‹‰ت‚حŒüڈم‚µ‚½‚ج‚¾‚ھپA“xچ‡‚¢‚ح17%‚ة—¯‚ـ‚ء‚½
‚±‚جƒXƒRƒA‚حSnapdragon 800‚و‚è‚àˆث‘R’ل‚¢
A7‚حپAƒAپ[ƒLƒeƒNƒ`ƒƒ“I‚ة•¨—‰‰ژZ‚ج‚و‚¤‚بڈˆ—‚ھ‹êژè
“¯ژذ‚ح‚±‚ê‚ç‚جŒ‹‰ت‚âƒRپ[ƒh‚ًApple‚ة‚à’ٌ‹ں‚µ‚ؤ‚¨‚èپAApple‚إ‚à“ئژ©‚جƒeƒXƒg‚إپA‚»‚جڈاڈَ‚ًٹm”F
پ`Futuremark‚ھŒںڈط‚ًژہژ{ - PC Watch
http://pc.watch.impress.co.jp/docs/news/20131105_622195.html
A7‚حƒXƒ}پ[ƒgƒtƒHƒ“Œü‚¯SoC‚إڈ‰‚ك‚ؤ64bit‚ة‘خ‰
پuA6پv‚ة‘خ‚µ‚ؤپACPU/GPU‚ئ‚àچإ‘ه‚إ2”{چ‚گ«”\
ٹm‚©‚ةGPUگ«”\‚ح5,191‘خ17,961(iPhone 5‘خiPhone 5s)‚إپAiPhone 5‚ج3”{ˆبڈم‘¬‚¢
‚µ‚©‚µپACPUگ«”\‚ح‚ئ‚¢‚¤‚ئپA8,197‘خ7,783(“¯)‚إپAiPhone 5‚ًژلٹ±‰؛‰ٌ‚錋‰ت
A6‚ئA7‚ح‚¢‚¸‚ê‚àƒfƒ…ƒAƒ‹ƒRƒA‚إ1.3GHz‹ى“®
گ«”\چ·‚ھڈo‚é‚ئ‚·‚é‚ئپA‚»‚ê‚حƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‹Nˆِ
Futuremark‚إ‚ح64bit”إ‚ج3DMark‚ًچىگ¬‚µŒںڈط‚µ‚½‚ئ‚±‚ëپAگ«”\‚حŒüڈم‚µ‚½‚ھپA
‚»‚جٹ„چ‡‚ح7%‚ة—¯‚ـ‚èپA64bit‰»‚ھ•¨—ƒeƒXƒg‚جŒ‹‰ت‚ة‚ح‘ه‚«‚ب‰e‹؟‚ً—^‚¦‚ب‚¢
A6‚حپAƒCƒ“ƒIپ[ƒ_پ[ڈˆ—(گو‚جƒeƒXƒgƒRپ[ƒh‚ھٹY“–)‚إ‚àپAƒAƒEƒgƒIƒuƒIپ[ƒ_پ[ڈˆ—(Bullet)‚إ‚àپA
گ«”\‚ة•د‰»‚ح‚ب‚¢‚ج‚¾‚ھپAA7‚حƒAƒEƒgƒIƒuƒIپ[ƒ_پ[‚¾‚ئگ«”\‚ھ‰؛‚ھ‚é
‚ـ‚½پAƒfپ[ƒ^ˆث‘¶گ«‚àA7‚جگ«”\‚ة‘ه‚«‚‰e‹؟‚·‚é
ƒfپ[ƒ^‚جƒپƒ‚ƒٹ‚ض‚ج‹Lک^•û–@‚ًگ®—ٌ‰»‚³‚¹پAƒfپ[ƒ^ˆث‘¶گ«‚ًŒ¸‚炵‚½ڈCگ³”إ‚جBullet‚ًژژچى
A7‚جŒ‹‰ت‚حŒüڈم‚µ‚½‚ج‚¾‚ھپA“xچ‡‚¢‚ح17%‚ة—¯‚ـ‚ء‚½
‚±‚جƒXƒRƒA‚حSnapdragon 800‚و‚è‚àˆث‘R’ل‚¢
A7‚حپAƒAپ[ƒLƒeƒNƒ`ƒƒ“I‚ة•¨—‰‰ژZ‚ج‚و‚¤‚بڈˆ—‚ھ‹êژè
“¯ژذ‚ح‚±‚ê‚ç‚جŒ‹‰ت‚âƒRپ[ƒh‚ًApple‚ة‚à’ٌ‹ں‚µ‚ؤ‚¨‚èپAApple‚إ‚à“ئژ©‚جƒeƒXƒg‚إپA‚»‚جڈاڈَ‚ًٹm”F
ƒLƒƒƒbƒVƒ…‚ھƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚ةژم‚¢‚ج‚©پH
x86چإ‹‚ء‚ؤ‚±‚ء‚½پB
’Pڈƒڈˆ—‚جƒxƒ“ƒ`‚¾‚ئڈم‚إڈo‚ؤ‚é‚و‚¤‚ة‘¬‚¦‚¦‚ء‚ؤ‚ب‚é‚ھپA
ژہچغ‚جƒAƒvƒٹ‚ج•،ژG‚بڈˆ—‚¾‚ئ‘ه‚µ‚½‚±‚ئ‚ب‚¢‚ء‚ؤژ–پH
ژہچغ‚جƒAƒvƒٹ‚ج•،ژG‚بڈˆ—‚¾‚ئ‘ه‚µ‚½‚±‚ئ‚ب‚¢‚ء‚ؤژ–پH
ƒLƒƒƒbƒVƒ…‚ئ‚©‚ھژم‚¢‚ء‚ؤ‚ب‚ٌ‚©AMD‚ف‚½‚¢‚¾‚ث
’†‚جگl‚ج”Œ¾
http://community.futuremark.com/forum/showthread.php?177840-Why-iphone5-and-iphone5S-share-same-physics-score&p=1788929&viewfull=1#post1788929
‚â‚ء‚دƒVپ[ƒPƒ“ƒVƒƒƒ‹ƒAƒNƒZƒX‚¾‚ئƒLƒƒƒbƒVƒ…ƒqƒbƒg‚µ‚ؤ‘¬‚¢
ƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚¾‚ئƒvƒٹƒtƒFƒbƒ`‚ھŒّ‚©‚¸’x‚¢
‚ئ‚¢‚¤‚±‚ئ‚ج‚و‚¤‚¾‚ث
L2‚ھ1MB‚µ‚©‚ب‚¢‚©‚çپA2MB‚ ‚éƒVƒXƒeƒ€(Snapdragon, Exynos, Tegra)‚ئ”ن‚ׂé‚ئ•s—ک‚ب–ت‚ح‚ ‚é‚©‚à
‚ـ‚ ‚¢‚¸‚ê‚ة‚¹‚وƒRƒAگ«”\‚ئƒپƒ‚ƒٹƒVƒXƒeƒ€گ«”\‚ھƒAƒ“ƒoƒ‰ƒ“ƒX‚¾‚ئƒ}ƒCƒNƒچƒxƒ“ƒ`ƒ}پ[ƒN”ش’·‚ة‚ب‚é‚ث
http://community.futuremark.com/forum/showthread.php?177840-Why-iphone5-and-iphone5S-share-same-physics-score&p=1788929&viewfull=1#post1788929
‚â‚ء‚دƒVپ[ƒPƒ“ƒVƒƒƒ‹ƒAƒNƒZƒX‚¾‚ئƒLƒƒƒbƒVƒ…ƒqƒbƒg‚µ‚ؤ‘¬‚¢
ƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚¾‚ئƒvƒٹƒtƒFƒbƒ`‚ھŒّ‚©‚¸’x‚¢
‚ئ‚¢‚¤‚±‚ئ‚ج‚و‚¤‚¾‚ث
L2‚ھ1MB‚µ‚©‚ب‚¢‚©‚çپA2MB‚ ‚éƒVƒXƒeƒ€(Snapdragon, Exynos, Tegra)‚ئ”ن‚ׂé‚ئ•s—ک‚ب–ت‚ح‚ ‚é‚©‚à
‚ـ‚ ‚¢‚¸‚ê‚ة‚¹‚وƒRƒAگ«”\‚ئƒپƒ‚ƒٹƒVƒXƒeƒ€گ«”\‚ھƒAƒ“ƒoƒ‰ƒ“ƒX‚¾‚ئƒ}ƒCƒNƒچƒxƒ“ƒ`ƒ}پ[ƒN”ش’·‚ة‚ب‚é‚ث
‚»‚¤‚©پAƒnپ[ƒhƒEƒFƒAƒvƒٹƒtƒFƒbƒ`‚ب‚¢‚ج‚ثپB
‚»‚è‚لIntel‚ھ‹‚¥‚يپB
‚»‚è‚لIntel‚ھ‹‚¥‚يپB
‚¢‚âCyclone‚ة‚àƒvƒٹƒtƒFƒbƒ`‚ح‚ ‚é‚و
‚½‚¾ƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚¾‚ئŒّ‚«‚و‚¤‚ھ‚ب‚¢‚إ‚µ‚ه
‚½‚¾ƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚¾‚ئŒّ‚«‚و‚¤‚ھ‚ب‚¢‚إ‚µ‚ه
‚»‚¤‚ب‚ج‚©پB
x86‚جƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚ج‹‚³‚حˆê‘ج‰½‚ة‚و‚é‚à‚ج‚ب‚ٌ‚¾¥¥¥
x86‚جƒ‰ƒ“ƒ_ƒ€ƒAƒNƒZƒX‚ج‹‚³‚حˆê‘ج‰½‚ة‚و‚é‚à‚ج‚ب‚ٌ‚¾¥¥¥
‚»‚ج‚¤‚؟پAARM‚àƒnƒCƒpƒtƒHپ[ƒ}ƒ“ƒX”إ‚حپAƒfƒXƒNƒgƒbƒvCPU‚ف‚½‚¢‚ةپA
ƒRƒA‚²‚ئ‚ةL2پA‹¤—L‚جL3‚ـ‚إ‚à‚آ‚و‚¤‚ة‚ب‚é‚ٌ‚¶‚ل‚ثپH
ƒRƒA‚²‚ئ‚ةL2پA‹¤—L‚جL3‚ـ‚إ‚à‚آ‚و‚¤‚ة‚ب‚é‚ٌ‚¶‚ل‚ثپH
Physics‚جƒXƒRƒA‚ًƒRƒA‚ ‚½‚è‚إŒ©‚é‚ئ
Silvermont > Cyclone > Krait 400, Cortex-A15 > Krait 300
‚ج‚و‚¤‚بٹ´‚¶‚©
‚ـ‚ CPU‚ج‘چچ‡گ«”\‚ئ‚µ‚ؤ‚حڈ‡“–‚¶‚ل‚ث
http://pc.watch.impress.co.jp/img/pcw/docs/615/175/graph9.gif
http://images.anandtech.com/graphs/graph7335/58200.png
http://images.anandtech.com/graphs/graph7460/59409.png
Silvermont > Cyclone > Krait 400, Cortex-A15 > Krait 300
‚ج‚و‚¤‚بٹ´‚¶‚©
‚ـ‚ CPU‚ج‘چچ‡گ«”\‚ئ‚µ‚ؤ‚حڈ‡“–‚¶‚ل‚ث
http://pc.watch.impress.co.jp/img/pcw/docs/615/175/graph9.gif
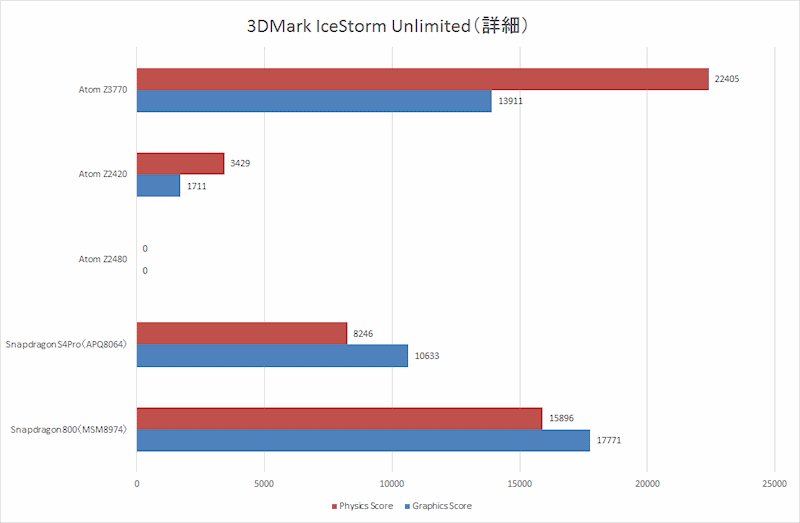{kind=link}
http://images.anandtech.com/graphs/graph7335/58200.png
{kind=link}
http://images.anandtech.com/graphs/graph7460/59409.png
{kind=link}
>>554
Wide I/O‚ئ‚©‚إƒoƒ“ƒh•—pˆس‚إ‚«‚éARM‘g‚فچ‚ف‚حL3‚ح‚¢‚ç‚ٌ‚¾‚낤پB
L2‚حگ·‚ء‚ؤ‚‚é‚©‚à‚µ‚ê‚ب‚¢‚¯‚اپB
ژI—p‚ح‚ا‚¤‚ب‚é‚©’m‚ç‚ب‚¢پB
Wide I/O‚ئ‚©‚إƒoƒ“ƒh•—pˆس‚إ‚«‚éARM‘g‚فچ‚ف‚حL3‚ح‚¢‚ç‚ٌ‚¾‚낤پB
L2‚حگ·‚ء‚ؤ‚‚é‚©‚à‚µ‚ê‚ب‚¢‚¯‚اپB
ژI—p‚ح‚ا‚¤‚ب‚é‚©’m‚ç‚ب‚¢پB
ƒLƒƒƒbƒVƒ…‚ئƒپƒ‚ƒٹƒoƒ“ƒh‚ھ•nژم‚بٹ„‚ةA7‚حگ«”\‚ھچ‚‚¢–َ‚¾‚µڈء”ï“d—ح‚àچl‚¦‚é‚ئ—ا‚‚إ‚«‚½CPU‚¾‚ئژv‚¤‚وپB
‚½‚¾ƒxƒ“ƒ`ƒ}پ[ƒN‘خچô‚µ‚ؤ‚½‚ج‚ھƒoƒŒ‚؟‚ل‚ء‚½‚ء‚ؤ‚±‚ئ‚©‚بپB
‚½‚¾ƒxƒ“ƒ`ƒ}پ[ƒN‘خچô‚µ‚ؤ‚½‚ج‚ھƒoƒŒ‚؟‚ل‚ء‚½‚ء‚ؤ‚±‚ئ‚©‚بپB
ƒRƒAگ«”\‚ة‘خ‚µ‚ؤپAƒپƒ‚ƒٹƒoƒ“ƒh•‚âƒLƒƒƒbƒVƒ…گ«”\‚ھˆ«‚¢‚¾‚¯‚إ
ƒxƒ“ƒ`‘خچô‚µ‚ؤ‚é‚ي‚¯‚¶‚ل‚ب‚¢‚إ‚µ‚ه‚¤
ƒRƒAگ«”\‚ھچ‚‚¢‚±‚ئ‚ح•د‚ي‚ç‚ب‚¢
ƒxƒ“ƒ`‘خچô‚µ‚ؤ‚é‚ي‚¯‚¶‚ل‚ب‚¢‚إ‚µ‚ه‚¤
ƒRƒAگ«”\‚ھچ‚‚¢‚±‚ئ‚ح•د‚ي‚ç‚ب‚¢
‚»‚à‚»‚àiPhone/iPad‚ة‚µ‚©“‹چع‚³‚ê‚ب‚¢‚ي‚¯‚¾‚µ‚بپcپc
>>555
3D Mark Unlimited Physics‚جŒ‹‰ت‚ح
Atom3770‚حSnapdragon800‚جMSM8974‚ج1.4”{
NVIDIA Shield(Tegra 4)‚ج1.31”{
iPhone 5s‚ج2.83”{‚©
NVIDIA Shield(Tegra 4)‚حiPhone 5s‚ج2.15”{
3D Mark Unlimited Physics‚جŒ‹‰ت‚ح
Atom3770‚حSnapdragon800‚جMSM8974‚ج1.4”{
NVIDIA Shield(Tegra 4)‚ج1.31”{
iPhone 5s‚ج2.83”{‚©
NVIDIA Shield(Tegra 4)‚حiPhone 5s‚ج2.15”{
Atom 3770پAMSM8974پATegra 4‚حƒNƒAƒbƒhƒRƒA
iPhone 5s‚جA7‚حƒfƒ…ƒAƒ‹ƒRƒA
‚±‚ê‚ً‚¨–Y‚ê‚ب‚
iPhone 5s‚جA7‚حƒfƒ…ƒAƒ‹ƒRƒA
‚±‚ê‚ً‚¨–Y‚ê‚ب‚
BayTrailگ«”\(پEپحپE)²²إ!!
563 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/06(گ…) 11:57:24.71 ID:2otxOPKB
>>561
A7‚حƒfƒ…ƒAƒ‹ƒRƒA‚إ‚à‘¼‚جARM‚ج4ƒRƒA•ھˆبڈم‚جƒgƒ‰ƒ“ƒWƒXƒ^گ”‚ًٹ„‚¢‚ؤ‚é‚ي‚¯‚إ
•ت‚ة•sŒِ•½‚ب”نٹr‚إ‚ح‚ب‚¢پB
A7‚حƒfƒ…ƒAƒ‹ƒRƒA‚إ‚à‘¼‚جARM‚ج4ƒRƒA•ھˆبڈم‚جƒgƒ‰ƒ“ƒWƒXƒ^گ”‚ًٹ„‚¢‚ؤ‚é‚ي‚¯‚إ
•ت‚ة•sŒِ•½‚ب”نٹr‚إ‚ح‚ب‚¢پB
”nژ‚©پBƒRƒA‚ج”نٹr‚¾‚©‚çˆس–،‚ ‚é‚ٌ‚¾‚ëپB
565 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/06(گ…) 12:27:57.68 ID:2otxOPKB
iPhone 5s‚جƒXƒRƒA‚ً’Pڈƒ2”{‚ة‚µ‚ؤ‚àZ3770‚ح1.4”{‘¬‚¢‚؛
BayTrail‚جƒgƒ‰ƒ“ƒWƒXƒ^گ”‚ح?
567 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/06(گ…) 12:57:59.60 ID:2otxOPKB
’m‚ç‚ٌپBApple‚àŒِٹJ‚µ‚ؤ‚ب‚¢‚¾‚ëپB
ƒvƒچƒZƒXƒ‹پ[ƒ‹“I‚ة‚ح”¼ƒmپ[ƒh•ھ‘ٹ“–ˆل‚¤‚ھپA‚ا‚ء‚؟‚à100mm^2‹‚¾‚µپA
CPUƒRƒA‚ج–تگد‚©‚炨ژ@‚µ‚‚¾‚³‚¢پB
http://pc.watch.impress.co.jp/docs/column/kaigai/20130912_615261.html
http://iphone-mania.jp/news-6492/
ƒvƒچƒZƒXƒ‹پ[ƒ‹“I‚ة‚ح”¼ƒmپ[ƒh•ھ‘ٹ“–ˆل‚¤‚ھپA‚ا‚ء‚؟‚à100mm^2‹‚¾‚µپA
CPUƒRƒA‚ج–تگد‚©‚炨ژ@‚µ‚‚¾‚³‚¢پB
http://pc.watch.impress.co.jp/docs/column/kaigai/20130912_615261.html
http://iphone-mania.jp/news-6492/
>>555‚جƒOƒ‰ƒt‚ج3‚آ–ع‚جNVIDIA Shield‚جƒNƒچƒbƒN‚ح‚ا‚ج‚‚ç‚¢پH
‰pŒê”إ‚جWikipedia‚إ‚ح1.9GHz‚ئ‚ب‚ء‚ؤ‚邯‚ا
‚¾‚ئ‚·‚é‚ئƒNƒچƒbƒN“–‚½‚è‚جگ«”\‚©‚ب‚èچ‚‚‚ب‚¢‚©پH
Atom 3770‚ح2.4GHz‚إNVIDIA Shield‚ج1.31”{
2.4GHz پ€ 1.9GHz = 1.26”{‚¾‚µ
3D Mark‚إ‚حBaytrail‚ئƒNƒچƒbƒN“–‚½‚è‚جگ«”\‚ ‚ـ‚è•د‚ي‚ç‚ب‚¢‚ء‚ؤ‚±‚ئپH
‰pŒê”إ‚جWikipedia‚إ‚ح1.9GHz‚ئ‚ب‚ء‚ؤ‚邯‚ا
‚¾‚ئ‚·‚é‚ئƒNƒچƒbƒN“–‚½‚è‚جگ«”\‚©‚ب‚èچ‚‚‚ب‚¢‚©پH
Atom 3770‚ح2.4GHz‚إNVIDIA Shield‚ج1.31”{
2.4GHz پ€ 1.9GHz = 1.26”{‚¾‚µ
3D Mark‚إ‚حBaytrail‚ئƒNƒچƒbƒN“–‚½‚è‚جگ«”\‚ ‚ـ‚è•د‚ي‚ç‚ب‚¢‚ء‚ؤ‚±‚ئپH
569 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/06(گ…) 16:02:59.68 ID:2otxOPKB
2.4‚حTBژ‚جƒNƒچƒbƒN
‚»‚à‚»‚àچ‚ƒNƒچƒbƒN‚ة‚ب‚é‚ةڈ]‚ء‚ؤƒpƒCƒvƒ‰ƒCƒ“‚ھچ×گط‚ê‚ة‚ب‚è
ƒtƒ‰ƒbƒVƒ…‚جƒyƒiƒ‹ƒeƒB‚ھ‘‚¦‚é‚ٌ‚¾‚©‚çپAƒNƒچƒbƒN“–‚½‚è‚ج
گ«”\‚¾‚¯‚ًگط‚èڈo‚µ‚ؤŒê‚邱‚ئ‚ة‚ب‚ٌ‚جˆس–،‚à‚ب‚¢‚و‚¤‚ب
ƒtƒ‰ƒbƒVƒ…‚جƒyƒiƒ‹ƒeƒB‚ھ‘‚¦‚é‚ٌ‚¾‚©‚çپAƒNƒچƒbƒN“–‚½‚è‚ج
گ«”\‚¾‚¯‚ًگط‚èڈo‚µ‚ؤŒê‚邱‚ئ‚ة‚ب‚ٌ‚جˆس–،‚à‚ب‚¢‚و‚¤‚ب
‹t‘ٹ‚àژg‚¤چى‚è‚ة‚·‚ê‚خژہژ؟‚جƒNƒچƒbƒN‚حŒ©‚©‚¯ڈم‚جƒNƒچƒbƒN‚ج2”{‚ة‚ب‚éپBˆظ‚ب‚éƒAپ[ƒLƒeƒNƒ`ƒƒپ[‚إƒNƒچƒbƒN‚ً”ن‚ׂ邱‚ئژ©‘ج‚ھˆس–،‚ج‚ب‚¢‚±‚ئ‚¾‚وپB
>>537
SERDES‚جƒŒƒCƒeƒ“ƒVپ[‚ھƒoƒJ‚ة‚ب‚ç‚ب‚¢‚©‚çƒپƒ‚ƒٹ‚حƒpƒ‰ƒŒƒ‹‚ج•û‚ھƒXƒW‚ھ—ا‚¢پB‚¾‚©‚çWideIO‚ئ‚©‚â‚ء‚ؤ‚ٌ‚¶‚ل‚ٌپB
SERDES‚جƒŒƒCƒeƒ“ƒVپ[‚ھƒoƒJ‚ة‚ب‚ç‚ب‚¢‚©‚çƒپƒ‚ƒٹ‚حƒpƒ‰ƒŒƒ‹‚ج•û‚ھƒXƒW‚ھ—ا‚¢پB‚¾‚©‚çWideIO‚ئ‚©‚â‚ء‚ؤ‚ٌ‚¶‚ل‚ٌپB
574 پFSocket774پF2013/11/06(گ…) 22:18:32.13 ID:FpsflWWM
>>573
ƒpƒ‰ƒŒƒ‹‚ج•û‚ھ‹ط‚ھ—ا‚¢‚ء‚ؤ‚¢‚¤‚©پA’P‚ةSerial‚ة‚µ‚ؤ‚àپAڈء”ï“d—حپE””M‚جٹضŒW‚إƒNƒچƒbƒNڈم‚°‚ç‚ê‚ب‚¢‚©‚çپA
’لڈ””ï“d—ح‚إ‘¬“x‰ز‚°‚éWideIO‚ة‘–‚ء‚½‚ٌ‚¾‚ئژv‚ء‚½‚ھپB
ƒIƒ“ƒ_ƒC‚âپAƒIƒ“ƒ`ƒbƒv‚إڈو‚¹‚é‚ب‚çپAWideBUS‚جگ§Œہ‚ھٹةکaڈo—ˆ‚é‚©‚çپB
ƒpƒ‰ƒŒƒ‹‚ج•û‚ھ‹ط‚ھ—ا‚¢‚ء‚ؤ‚¢‚¤‚©پA’P‚ةSerial‚ة‚µ‚ؤ‚àپAڈء”ï“d—حپE””M‚جٹضŒW‚إƒNƒچƒbƒNڈم‚°‚ç‚ê‚ب‚¢‚©‚çپA
’لڈ””ï“d—ح‚إ‘¬“x‰ز‚°‚éWideIO‚ة‘–‚ء‚½‚ٌ‚¾‚ئژv‚ء‚½‚ھپB
ƒIƒ“ƒ_ƒC‚âپAƒIƒ“ƒ`ƒbƒv‚إڈو‚¹‚é‚ب‚çپAWideBUS‚جگ§Œہ‚ھٹةکaڈo—ˆ‚é‚©‚çپB
>>568
‚ئ‚¢‚¤‚©A15‚حHKMGژg‚ء‚ؤ‚é‚ج‚ةExynos5‚ج1.6GHz‚ئ‚©Tegra4‚ج1.9GHzپu‚µ‚©پvڈم‚°‚ç‚ê‚ب‚¢‚ٌ‚¾‚و
IPCڈم‚°‚½‚çڈء”ï“d—ح‚àڈم‚ھ‚ء‚ؤ‚µ‚ـ‚ء‚½‚ج‚إƒNƒچƒbƒN‚ً—}‚¦‚´‚é‚ً“¾‚ب‚¢
‚ئ‚¢‚¤‚©A15‚حHKMGژg‚ء‚ؤ‚é‚ج‚ةExynos5‚ج1.6GHz‚ئ‚©Tegra4‚ج1.9GHzپu‚µ‚©پvڈم‚°‚ç‚ê‚ب‚¢‚ٌ‚¾‚و
IPCڈم‚°‚½‚çڈء”ï“d—ح‚àڈم‚ھ‚ء‚ؤ‚µ‚ـ‚ء‚½‚ج‚إƒNƒچƒbƒN‚ً—}‚¦‚´‚é‚ً“¾‚ب‚¢
Tegra4‚إ‚àSheild‚ج‚â‚آ‚حƒAƒNƒeƒBƒuƒNپ[ƒٹƒ“ƒO‘O’ٌ‚¾‚©‚ç‚ب
577 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 00:13:14.64 ID:gGw5biDh
ŒآپX‚جSoC‚ًˆّ‚«چ‡‚¢‚ةڈo‚·‚ج‚حCPU‚¾‚¯“d—حŒّ—¦‚ج”نٹr‚ة‚ح“K‚³‚ب‚¢‚و‚ب
‚¢‚‚çCPU‚ھڈب“d—ح‚إ‚àGPU‚ھ”M‚¢‚ئƒAƒNƒeƒBƒu—â‹p•Kگ{‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤‚µپB
‚¢‚‚çCPU‚ھڈب“d—ح‚إ‚àGPU‚ھ”M‚¢‚ئƒAƒNƒeƒBƒu—â‹p•Kگ{‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤‚µپB
ڈ‰ٹْ‚جATOM‚ًژv‚¢ڈo‚µ‚½‰´پB
579 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 20:39:17.66 ID:+ZOtL3UI
Cortex A15‚âA57‚جƒTپ[ƒo”إ‚جگ«”\Œ©‚ؤ‚ف‚½‚¢‚و‚ب
ڈء”ï“d—ح‚جگ§–ٌ‚ب‚µ‚إƒNƒچƒbƒN‚ ‚°‚ç‚ê‚é‚ٌ‚¾‚ë
‚ـ‚ ‚³‚·‚ھ‚ةAtom C2750‚جگ«”\‚ھ‚و‚·‚¬‚ؤ‘¾“پ‘إ‚؟‚إ‚«‚ب‚¢‚©پEپEپE
ڈء”ï“d—ح‚جگ§–ٌ‚ب‚µ‚إƒNƒچƒbƒN‚ ‚°‚ç‚ê‚é‚ٌ‚¾‚ë
‚ـ‚ ‚³‚·‚ھ‚ةAtom C2750‚جگ«”\‚ھ‚و‚·‚¬‚ؤ‘¾“پ‘إ‚؟‚إ‚«‚ب‚¢‚©پEپEپE
گ«”\ˆê–{‚إ‚ ‚ê‚خC2750‚¾‚ء‚ؤ‘I‚ش——R‚ھ‚ب‚¢پB
‚»‚¤‚ب‚é‚ئƒRƒAƒTƒCƒY‚جڈ¬‚³‚³‚إA57‚ً‘I‚ش‰آ”\گ«‚à‚ ‚éپB
‹t‚ةŒ¾‚¦‚خگ«”\’ا‹پ‚µ‚ب‚¢‚ء‚ؤژ–‚حگ«”\‚إ‘I‚خ‚ê‚é‰آ”\گ«‚ًژج‚ؤ‚ؤ‚é‚ي‚¯‚إپA
ƒ}ƒ‹ƒ`ƒRƒAکHگü‚ئ‚¢‚¤‚ج‚àŒ«‚¢کHگü‚إ‚ح‚ب‚¢‚ي‚¯‚¾پB
‚»‚¤‚ب‚é‚ئƒRƒAƒTƒCƒY‚جڈ¬‚³‚³‚إA57‚ً‘I‚ش‰آ”\گ«‚à‚ ‚éپB
‹t‚ةŒ¾‚¦‚خگ«”\’ا‹پ‚µ‚ب‚¢‚ء‚ؤژ–‚حگ«”\‚إ‘I‚خ‚ê‚é‰آ”\گ«‚ًژج‚ؤ‚ؤ‚é‚ي‚¯‚إپA
ƒ}ƒ‹ƒ`ƒRƒAکHگü‚ئ‚¢‚¤‚ج‚àŒ«‚¢کHگü‚إ‚ح‚ب‚¢‚ي‚¯‚¾پB
581 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 22:44:53.73 ID:+ZOtL3UI
ARMƒTپ[ƒo‚ئ‚¢‚¦‚خ‚±‚ꂾ‚ثپB
Cortex A57‚ً‚»‚ج‚ـ‚ـژg‚¤‚ئ‚¢‚ي‚ê‚ؤ‚é‚ھ
http://www.engadget.com/2013/06/18/amd-seattle-arm-server-chip/
“à‘ GPU‚ھ–ً‚ة—§‚½‚ب‚¢ˆê”تƒTپ[ƒo—p“r‚ًٹ®‘S‚ةژج‚ؤ‚ؤ‚«‚½‚ج‚حˆَڈغ“I‚¾‚بپB
ƒQپ[ƒ~ƒ“ƒOƒNƒ‰ƒEƒh‚ف‚½‚¢‚بژsڈê‚إگ¬Œ÷‚·‚é‘إژZ‚ھ‚ ‚é‚ج‚©‚ئ‚¢‚¤‚ئژہ‚ح‚»‚¤‚¶‚ل‚ب‚‚ؤ
ƒmپ[ƒgپEƒfƒXƒNƒgƒbƒvŒü‚¯‚جKaveri‚ئ“¯ˆêƒ}ƒXƒN‚¾‚©‚çƒTپ[ƒo‚إ”„‚ê‚ب‚‚ؤ‚à
‘ه‚µ‚ؤ–â‘è‚ة‚ب‚ç‚ب‚¢‚¾‚¯‚¾‚ء‚½‚èپB
A57‚ء‚ؤ‚»‚ج‚ـ‚ـA15‚ج64ƒrƒbƒgٹg’£”إ‚ف‚½‚¢‚بŒXŒü‚炵‚¢‚©‚ç
ƒ^ƒuƒŒƒbƒg‚جگ«”\Œ©‚éŒہ‚肾‚ئ‚ ‚ٌ‚ـ‚èٹْ‘ز‚إ‚«‚ب‚¢‚ج‚ثپB
Cortex A57‚ً‚»‚ج‚ـ‚ـژg‚¤‚ئ‚¢‚ي‚ê‚ؤ‚é‚ھ
http://www.engadget.com/2013/06/18/amd-seattle-arm-server-chip/
“à‘ GPU‚ھ–ً‚ة—§‚½‚ب‚¢ˆê”تƒTپ[ƒo—p“r‚ًٹ®‘S‚ةژج‚ؤ‚ؤ‚«‚½‚ج‚حˆَڈغ“I‚¾‚بپB
ƒQپ[ƒ~ƒ“ƒOƒNƒ‰ƒEƒh‚ف‚½‚¢‚بژsڈê‚إگ¬Œ÷‚·‚é‘إژZ‚ھ‚ ‚é‚ج‚©‚ئ‚¢‚¤‚ئژہ‚ح‚»‚¤‚¶‚ل‚ب‚‚ؤ
ƒmپ[ƒgپEƒfƒXƒNƒgƒbƒvŒü‚¯‚جKaveri‚ئ“¯ˆêƒ}ƒXƒN‚¾‚©‚çƒTپ[ƒo‚إ”„‚ê‚ب‚‚ؤ‚à
‘ه‚µ‚ؤ–â‘è‚ة‚ب‚ç‚ب‚¢‚¾‚¯‚¾‚ء‚½‚èپB
A57‚ء‚ؤ‚»‚ج‚ـ‚ـA15‚ج64ƒrƒbƒgٹg’£”إ‚ف‚½‚¢‚بŒXŒü‚炵‚¢‚©‚ç
ƒ^ƒuƒŒƒbƒg‚جگ«”\Œ©‚éŒہ‚肾‚ئ‚ ‚ٌ‚ـ‚èٹْ‘ز‚إ‚«‚ب‚¢‚ج‚ثپB
582 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 23:25:31.28 ID:+ZOtL3UI
‚؟‚ب‚ف‚ةAtom C‚حƒTپ[ƒo‚ة‚¨‚¯‚éڈء”ï“d—ح‚ ‚½‚è‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚جچإ‘ه‰»‚ً‘_‚ء‚ؤ‚é‚ج‚إ‚µ‚هپB
ARM‚ھگiڈo‚ً‘_‚ء‚ؤ‚éWebƒTپ[ƒo‚جƒtƒچƒ“ƒgƒGƒ“ƒh‚ف‚½‚¢‚ب•¨—تڈں•‰‚جژsڈê‚ةƒ^پ[ƒQƒbƒg‚ًچi‚ء‚ؤ‚éپB
â‘ج‚ھڈ¬‚³‚•ْ”M‚ھڈ‚ب‚¯‚ê‚خژہ‘•–§“x‚ًڈم‚°‚邱‚ئ‚ھ‚إ‚«‚ؤپAƒfپ[ƒ^ƒZƒ“ƒ^پ[‚ج
ƒXƒyپ[ƒX‚ج‘‰ء‚ًچs‚ي‚ب‚‚ؤ‚àڈˆ—”\—ح‚ح‚ ‚°‚ç‚ê‚é‚ئ‚¢‚¤‚ي‚¯پB
A15‚âA57‚ء‚ؤ•ت‚ةAtom‚و‚èڈ¬‚³‚‚à–³‚¢‚إ‚µ‚ه
ARM‚ھگiڈo‚ً‘_‚ء‚ؤ‚éWebƒTپ[ƒo‚جƒtƒچƒ“ƒgƒGƒ“ƒh‚ف‚½‚¢‚ب•¨—تڈں•‰‚جژsڈê‚ةƒ^پ[ƒQƒbƒg‚ًچi‚ء‚ؤ‚éپB
â‘ج‚ھڈ¬‚³‚•ْ”M‚ھڈ‚ب‚¯‚ê‚خژہ‘•–§“x‚ًڈم‚°‚邱‚ئ‚ھ‚إ‚«‚ؤپAƒfپ[ƒ^ƒZƒ“ƒ^پ[‚ج
ƒXƒyپ[ƒX‚ج‘‰ء‚ًچs‚ي‚ب‚‚ؤ‚àڈˆ—”\—ح‚ح‚ ‚°‚ç‚ê‚é‚ئ‚¢‚¤‚ي‚¯پB
A15‚âA57‚ء‚ؤ•ت‚ةAtom‚و‚èڈ¬‚³‚‚à–³‚¢‚إ‚µ‚ه
583 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 23:39:19.54 ID:+ZOtL3UI
Jaguar 1GH‚ڑ‚ئExynos 1.7GH‚ڑ
http://d.hatena.ne.jp/w_o/20130714
ARM‚ھAMD‚ة‹à‚ًڈo‚·‚ئ‚©‚إ–³‚¢Œہ‚èARM”إOpteron‚ح“¾چô‚ةژv‚¦‚ب‚¢پB
http://d.hatena.ne.jp/w_o/20130714
ARM‚ھAMD‚ة‹à‚ًڈo‚·‚ئ‚©‚إ–³‚¢Œہ‚èARM”إOpteron‚ح“¾چô‚ةژv‚¦‚ب‚¢پB
‚±‚جژè‚جڈب“d—حچ‚–§“xƒTپ[ƒo‚ھ–{“–‚ة•K—v‚ئ‚³‚ê‚ؤ‚¢‚é‚ب‚ç
Niagara‚ئ‚©‚¾‚ء‚ؤ‚à‚ء‚ئ”„‚ê‚ؤ‚¢‚锤پB”¤پB
Niagara‚ئ‚©‚¾‚ء‚ؤ‚à‚ء‚ئ”„‚ê‚ؤ‚¢‚锤پB”¤پB
585 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/07(–ط) 23:51:24.67 ID:+ZOtL3UI
Œ‹‹اƒIپ[ƒvƒ“ƒ\پ[ƒX‚âˆہ‰؟‚بƒ\ƒtƒgژ‘ژY‚ھ–L•x‚ة‚ ‚éIAƒTپ[ƒo‚¾‚©‚炱‚»
ƒ†پ[ƒUپ[‚ة‘I‚خ‚ê‚ؤ‚é‚ج‚إ‚حپH
ƒTپ[ƒo•ھ–ى‚إƒAƒEƒFƒC‚بARM‚إƒTپ[ƒoچى‚é‚ء‚ؤ‚ج‚à‚ـ‚ء‚½‚”ü–،‚µ‚‚ب‚¢کbپB
ƒ†پ[ƒUپ[‚ة‘I‚خ‚ê‚ؤ‚é‚ج‚إ‚حپH
ƒTپ[ƒo•ھ–ى‚إƒAƒEƒFƒC‚بARM‚إƒTپ[ƒoچى‚é‚ء‚ؤ‚ج‚à‚ـ‚ء‚½‚”ü–،‚µ‚‚ب‚¢کbپB
ƒIپ[ƒvƒ“ƒ\پ[ƒX‚ء‚ؤ‚ب‚ç‚»‚ꂱ‚»SunŒü‚¯‚ة‚حƒTپ[ƒoŒü‚¯‚بƒIپ[ƒvƒ“ƒ\پ[ƒX‚جƒ\ƒtƒg‚ھ‚½‚‚³‚ٌ‚ ‚é–َ‚¾‚µ
webƒtƒچƒ“ƒgƒGƒ“ƒh‚ء‚ؤ‚ب‚ç‚»‚ꂱ‚»Sun‚جJava‚ئ‚©oracle‚جƒfپ[ƒ^ƒyپ[ƒX‚ھ(ry
‚إ‚àNiagaraŒn‚ح‚³پ`
Œ‹‹اپA’l’i‚ب‚ٌ‚¶‚ل‚ث‚¥‚ج‚©‚ئ
’l’iڈں•‰‚إ‚«‚é‚ب‚çARM‚ة‚¾‚ء‚ؤڈں‚؟–ع‚ھ(ry
webƒtƒچƒ“ƒgƒGƒ“ƒh‚ء‚ؤ‚ب‚ç‚»‚ꂱ‚»Sun‚جJava‚ئ‚©oracle‚جƒfپ[ƒ^ƒyپ[ƒX‚ھ(ry
‚إ‚àNiagaraŒn‚ح‚³پ`
Œ‹‹اپA’l’i‚ب‚ٌ‚¶‚ل‚ث‚¥‚ج‚©‚ئ
’l’iڈں•‰‚إ‚«‚é‚ب‚çARM‚ة‚¾‚ء‚ؤڈں‚؟–ع‚ھ(ry
•K—v‚ئ‚·‚éٹé‹ئ‚جگ”‚حڈ‚ب‚ˆêƒ–ڈٹ‚ج‹K–ح‚ھ‘ه‚«‚¢ژsڈꂾ‚»‚¤‚¾
588 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/08(‹à) 08:32:43.77 ID:OWVsQfeM
SPARC‚ھ“d—حŒّ—¦‚¢‚¢‚ب‚ç‚ب‚ٌ‚إ‚±‚±‚ةƒXƒRƒA“oک^‚³‚ê‚ؤ‚ب‚¢‚ٌ‚¾‚낤‚ثپH
http://www.spec.org/power_ssj2008/results/power_ssj2008.html
SPARC‚جچإگV‚جƒ`ƒbƒv‚ح‰½nmƒvƒچƒZƒX‚إگ»‘¢‚³‚ê‚ؤ‚éپH
ژv‚¤‚ةٹù‚ة‰ك‹ژ‚جƒRپ[ƒhژ‘ژY‚ج‚ف‚ة—ٹ‚éڈَ‹µ‚ب‚ج‚إ‚حپH
‚؟‚ه‚ء‚ئ‚ر‚ء‚‚肵‚½‚ٌ‚¾‚ھپAXeon‚ج“d—حŒّ—¦‚ء‚ؤ‚à‚¤‚±‚ٌ‚ب—جˆو‚ة’B‚µ‚ؤ‚é‚ٌ‚¾‚ث
PowerEdge R720 (Intel Xeon E5-2660 v2, 2.20 GHz) 8,458
http://www.spec.org/power_ssj2008/results/res2013q4/power_ssj2008-20131001-00642.txt
PRIMERGY TX140 S2 (Intel Xeon E3-1265Lv3) 6,797
http://www.spec.org/power_ssj2008/results/res2013q4/power_ssj2008-20130906-00627.txt
Atom C‚جƒXƒRƒA‚ھ“oک^‚³‚ê‚ê‚خ5Œ…‘ن“ث“ü‚©‚بپH
پiچج—pƒxƒ“ƒ_پ[ژں‘و‚ب‹C‚ھ‚·‚é‚ھپj
http://www.spec.org/power_ssj2008/results/power_ssj2008.html
SPARC‚جچإگV‚جƒ`ƒbƒv‚ح‰½nmƒvƒچƒZƒX‚إگ»‘¢‚³‚ê‚ؤ‚éپH
ژv‚¤‚ةٹù‚ة‰ك‹ژ‚جƒRپ[ƒhژ‘ژY‚ج‚ف‚ة—ٹ‚éڈَ‹µ‚ب‚ج‚إ‚حپH
‚؟‚ه‚ء‚ئ‚ر‚ء‚‚肵‚½‚ٌ‚¾‚ھپAXeon‚ج“d—حŒّ—¦‚ء‚ؤ‚à‚¤‚±‚ٌ‚ب—جˆو‚ة’B‚µ‚ؤ‚é‚ٌ‚¾‚ث
PowerEdge R720 (Intel Xeon E5-2660 v2, 2.20 GHz) 8,458
http://www.spec.org/power_ssj2008/results/res2013q4/power_ssj2008-20131001-00642.txt
PRIMERGY TX140 S2 (Intel Xeon E3-1265Lv3) 6,797
http://www.spec.org/power_ssj2008/results/res2013q4/power_ssj2008-20130906-00627.txt
Atom C‚جƒXƒRƒA‚ھ“oک^‚³‚ê‚ê‚خ5Œ…‘ن“ث“ü‚©‚بپH
پiچج—pƒxƒ“ƒ_پ[ژں‘و‚ب‹C‚ھ‚·‚é‚ھپj
ƒhƒJƒ“‚ئ‘ه‚«‚بƒ^ƒXƒNڈˆ—‚µ‚½‚¢ڈêچ‡‚ئپAگ”‘½‚‚جƒgƒ‰ƒ“ƒUƒNƒVƒ‡ƒ“‚ًˆµ‚¢‚½‚¢ڈêچ‡‚ئ‚ ‚é‚©‚çپAƒTپ[ƒoپ[‰®‚³‚ٌ‚à—p“r‚ة‰‚¶‚½ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ً—pˆس‚µ‚ب‚¯‚è‚ل‚ب‚ç‚ب‚‚ؤ‘ه•د‚¾‚ثپB
Œمژز‚ج—v‹پ‚©‚çƒ}ƒCƒNƒچƒTپ[ƒoپ[‚جژù—v‚ح‚±‚ê‚©‚çگL‚ر‚ؤ‚‚ف‚½‚¢پBƒfپ[ƒ^ƒZƒ“ƒ^پ[‚àچׂ©‚گط‚蔄‚è‚إ‚«‚éڈ¤”„‚ح–£—ح“I‚¾‚낤‚µپB
Œمژز‚ج—v‹پ‚©‚çƒ}ƒCƒNƒچƒTپ[ƒoپ[‚جژù—v‚ح‚±‚ê‚©‚çگL‚ر‚ؤ‚‚ف‚½‚¢پBƒfپ[ƒ^ƒZƒ“ƒ^پ[‚àچׂ©‚گط‚蔄‚è‚إ‚«‚éڈ¤”„‚ح–£—ح“I‚¾‚낤‚µپB
i5-4200UپAٹî–{‚ج“®چىژü”gگ”‚ھ1.6GHz‚µ‚©‚ب‚¢‚ھ
ƒxƒ“ƒ`ƒ}پ[ƒN‚ح‚»‚ê‚ب‚è
haswell‚ة‚ب‚ء‚ؤ–½—ك”چsƒ|پ[ƒg‚ھ8‚ة‚ب‚ء‚½‚©‚çپH
–½—كƒZƒbƒg‚ھ64bit‚ةٹg’£–½—ك‚ھ‚آ‚¢‚ؤ‚¢‚邹‚¢پH
1ƒNƒچƒbƒN‚ ‚½‚è‚جڈˆ—”\—ح‚ھچ‚‚¢پH
‚ا‚¤‚àڈب“d—حcpu‚ة‚حŒسژUڈL‚³‚ًٹ´‚¶‚éپcپc
ƒxƒ“ƒ`ƒ}پ[ƒN‚ح‚»‚ê‚ب‚è
haswell‚ة‚ب‚ء‚ؤ–½—ك”چsƒ|پ[ƒg‚ھ8‚ة‚ب‚ء‚½‚©‚çپH
–½—كƒZƒbƒg‚ھ64bit‚ةٹg’£–½—ك‚ھ‚آ‚¢‚ؤ‚¢‚邹‚¢پH
1ƒNƒچƒbƒN‚ ‚½‚è‚جڈˆ—”\—ح‚ھچ‚‚¢پH
‚ا‚¤‚àڈب“d—حcpu‚ة‚حŒسژUڈL‚³‚ًٹ´‚¶‚éپcپc
‰½‚ئ”ن‚ׂؤ‘¬‚¢‚ئŒ¾‚ء‚ؤ‚é‚جپH
”MگفŒv”حˆح“à‚ب‚çTurboBoost‚à‚«‚‚©‚ç‚ث
ƒxƒ“ƒ`ƒ}پ[ƒNŒv‘ھژ‚ةƒNƒچƒbƒNژü”gگ”‚âCPU‰·“x‚ًƒ‚ƒjƒ^ƒٹƒ“ƒO‚إ‚«‚éƒ\ƒtƒg‚ھ‚ ‚é‚ب‚ç
‘ھ‚ء‚ؤ‚ف‚é‚ج‚àژè‚©‚à
”MگفŒv”حˆح“à‚ب‚çTurboBoost‚à‚«‚‚©‚ç‚ث
ƒxƒ“ƒ`ƒ}پ[ƒNŒv‘ھژ‚ةƒNƒچƒbƒNژü”gگ”‚âCPU‰·“x‚ًƒ‚ƒjƒ^ƒٹƒ“ƒO‚إ‚«‚éƒ\ƒtƒg‚ھ‚ ‚é‚ب‚ç
‘ھ‚ء‚ؤ‚ف‚é‚ج‚àژè‚©‚à
چإ‹ك‚جCPU‚ح“~‚ة‚ب‚é‚ئ‘¬‚‚ب‚é‚ج‚©پBƒfƒu‚ب‚ٌ‚¾‚بپB
http://pc.watch.impress.co.jp/docs/biz/20131115_623795.html
CPU‚ئ‚¢‚¤‚ي‚¯‚إ‚ح‚ب‚¢‚ھپB
CPU‚ئ‚¢‚¤‚ي‚¯‚إ‚ح‚ب‚¢‚ھپB
ƒyƒC‚·‚é‚®‚ç‚¢‚جˆّ‚«چ‡‚¢‚ ‚é‚ج‚©‚ب
595 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/15(‹à) 18:17:52.99 ID:z+3DgPNl
Intel‚ئ‚ج’ٌŒg‚ً‘إ‚؟گط‚ء‚ؤ“ئژ©ٹJ”‚·‚é‚‚ç‚¢‚¾‚µ‹q‚ح‚¢‚é‚ٌ‚¶‚ل‚ب‚¢‚جپB
FLOPS‚ ‚½‚è‘رˆو‚ھ•K—v‚ب—p“r‚إپB
> 4ƒRƒA‚ً“à‘ ‚·‚邽‚كپA‰‰ژZگ«”\‚ح256GFLOPSپAƒپƒ‚ƒٹ‘رˆو‚ح256GB/sec‚ئ‚ب‚éپB
ƒپƒ‚ƒٹ—e—ت‚ح‚ا‚ٌ‚ب‚à‚ٌ‚ب‚ج‚©‚µ‚ç‚ثپH
Xeon Phi 5110PƒJپ[ƒh1–‡‚ ‚½‚è‚ج‰‰ژZگ«”\‚ح1010.88 GFLOPS(DP)
ƒپƒ‚ƒٹ‚حGDDR5‚ج8GB‚إ320GB/s
‚ٌ‚إپA‚±‚ê‚ً8ٹîچع‚¹‚½2UƒTپ[ƒoپ~8ƒmپ[ƒh‚إ5000–œپ`‚‚ç‚¢پH
FLOPS‚ ‚½‚è‘رˆو‚ھ•K—v‚ب—p“r‚إپB
> 4ƒRƒA‚ً“à‘ ‚·‚邽‚كپA‰‰ژZگ«”\‚ح256GFLOPSپAƒپƒ‚ƒٹ‘رˆو‚ح256GB/sec‚ئ‚ب‚éپB
ƒپƒ‚ƒٹ—e—ت‚ح‚ا‚ٌ‚ب‚à‚ٌ‚ب‚ج‚©‚µ‚ç‚ثپH
Xeon Phi 5110PƒJپ[ƒh1–‡‚ ‚½‚è‚ج‰‰ژZگ«”\‚ح1010.88 GFLOPS(DP)
ƒپƒ‚ƒٹ‚حGDDR5‚ج8GB‚إ320GB/s
‚ٌ‚إپA‚±‚ê‚ً8ٹîچع‚¹‚½2UƒTپ[ƒoپ~8ƒmپ[ƒh‚إ5000–œپ`‚‚ç‚¢پH
‚¢‚é‚©‚¢‚ب‚¢‚©‚إŒ¾‚¦‚خ‚¢‚é‚ج‚ح’m‚ء‚ؤ‚é‚ھپAچجژZ‚ئ‚ê‚ب‚¢‚©‚çnV‚ئ‚©Larrabee ‚ئ‚©GPU‹¤—p‚ة‚µ‚ؤ‹êکJ‚µ‚ؤ‚é‚ي‚¯‚إپB
ڈ¬ƒچƒbƒg‚إچ‚گ«”\‚ب”¼“±‘ج‚ً‚»‚±‚»‚±‚جƒRƒXƒg‚إچى‚é‹Zڈp‚إ‚à‚ ‚ê‚خ–ت”’‚¢‚ج‚¾‚ھپA‚»‚ٌ‚ب‚à‚ج‚à‚ب‚¢‚µپB
ڈ¬ƒچƒbƒg‚إچ‚گ«”\‚ب”¼“±‘ج‚ً‚»‚±‚»‚±‚جƒRƒXƒg‚إچى‚é‹Zڈp‚إ‚à‚ ‚ê‚خ–ت”’‚¢‚ج‚¾‚ھپA‚»‚ٌ‚ب‚à‚ج‚à‚ب‚¢‚µپB
597 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/15(‹à) 18:22:35.80 ID:z+3DgPNl
چع‚ء‚ؤ‚½پB1ƒmپ[ƒhپi4ƒRƒAپj‚ ‚½‚è64GB’ِ“x‚¾پB
Xeon Phi‚ج8GB‚ج8”{‚ح‚ ‚邯‚اپA‚±‚ꂾ‚¯‚¾‚ئ•êٹح‚ًDDR3“ءگ·‚ة‚µ‚ئ‚¯‚خ
‚¢‚¢‚ٌ‚¶‚ل‚ثپH‚ئ‚©ژv‚ء‚½‚èپB
Xeon Phi‚ج8GB‚ج8”{‚ح‚ ‚邯‚اپA‚±‚ꂾ‚¯‚¾‚ئ•êٹح‚ًDDR3“ءگ·‚ة‚µ‚ئ‚¯‚خ
‚¢‚¢‚ٌ‚¶‚ل‚ثپH‚ئ‚©ژv‚ء‚½‚èپB
>>595
Intel‚ئ‚ج’ٌŒg‘إ‚؟گط‚ء‚½‚ء‚¯پH
Intel‚ئ‚ج’ٌŒg‘O‚©‚çNEC‚جƒXƒpƒRƒ“•”–ه‚ھگ\‚µ–َ’ِ“x‚ة‚â‚ء‚ؤ‚½
ƒXƒJƒ‰•”–ه‚ج‹‰»‚ھIntel‚ئ‚ج’ٌŒg‚ج–ع“I‚إ‚µ‚هپB
SX‚حژn‚ك‚©‚çIntel‚ئ‚حٹضŒW‚ب‚¢پB
Intel‚ئ‚ج’ٌŒg‘إ‚؟گط‚ء‚½‚ء‚¯پH
Intel‚ئ‚ج’ٌŒg‘O‚©‚çNEC‚جƒXƒpƒRƒ“•”–ه‚ھگ\‚µ–َ’ِ“x‚ة‚â‚ء‚ؤ‚½
ƒXƒJƒ‰•”–ه‚ج‹‰»‚ھIntel‚ئ‚ج’ٌŒg‚ج–ع“I‚إ‚µ‚هپB
SX‚حژn‚ك‚©‚çIntel‚ئ‚حٹضŒW‚ب‚¢پB
599 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/15(‹à) 20:12:49.16 ID:z+3DgPNl
‚»‚¤‚¾‚ء‚½‚ء‚¯پH
SX‚جƒ‰ƒCƒ“‚à‚â‚ك‚ؤLarrabee‚ةچ‡—¬‚·‚é‚à‚ج‚¾‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚ھ
پi‚؟‚ه‚¤‚اƒxƒNƒgƒ‹•‚ھ”{گ¸“xپ~8‚¾‚µپj
SX‚جƒ‰ƒCƒ“‚à‚â‚ك‚ؤLarrabee‚ةچ‡—¬‚·‚é‚à‚ج‚¾‚ئژv‚ء‚ؤ‚½‚ٌ‚¾‚ھ
پi‚؟‚ه‚¤‚اƒxƒNƒgƒ‹•‚ھ”{گ¸“xپ~8‚¾‚µپj
‚»‚ٌ‚ب”•\‚ح‚ب‚©‚ء‚½‚بپBڈ‚ب‚‚ئ‚à‰´‚ج’m‚éŒہ‚èپB
‘fگl‚ج’P‚ب‚éƒEƒHƒbƒ`ƒƒپ[ƒŒƒxƒ‹‚¾‚¯‚ا‚³پB
ƒxƒNƒgƒ‹پEƒXƒJƒ‰‚ة‚±‚¾‚ي‚é•K—v‚ح‚ب‚¢‚ھپAٹù‘¶SXƒ†پ[ƒUپ[‚ًچl‚¦‚é‚ئپA
‚â‚ح‚èƒxƒNƒgƒ‹Œp‘±‚إپA‚ئ‚¢‚¤‚ج‚ھ‚ ‚é‚ٌ‚¶‚ل‚ب‚¢‚©پB
ˆê‚آچl‚¦‚ç‚ê‚é‚ج‚ح’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^پ[2‚جچXگVژٹْ‚ھ‹ك‚¢ژ–پB
‘fگl‚ج’P‚ب‚éƒEƒHƒbƒ`ƒƒپ[ƒŒƒxƒ‹‚¾‚¯‚ا‚³پB
ƒxƒNƒgƒ‹پEƒXƒJƒ‰‚ة‚±‚¾‚ي‚é•K—v‚ح‚ب‚¢‚ھپAٹù‘¶SXƒ†پ[ƒUپ[‚ًچl‚¦‚é‚ئپA
‚â‚ح‚èƒxƒNƒgƒ‹Œp‘±‚إپA‚ئ‚¢‚¤‚ج‚ھ‚ ‚é‚ٌ‚¶‚ل‚ب‚¢‚©پB
ˆê‚آچl‚¦‚ç‚ê‚é‚ج‚ح’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^پ[2‚جچXگVژٹْ‚ھ‹ك‚¢ژ–پB
چ،‚ج’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚ھSX-9/Eƒxپ[ƒX‚إ131TFLOPS‚ئ‚ج‚±‚ئ‚إپA“d—ح‚ ‚½‚èگ«”\10”{‚¾‚ئچXگV‚µ‚ؤ‚à2PFLOPS‚ة“ح‚©‚¸پA‹ê‚µ‚¢‹C‚ھ‚µ‚ـ‚·پB
>>601
ƒXƒJƒ‰ƒXƒpƒRƒ“‚ئ“¯‚¶‚و‚¤‚ةچl‚¦‚؟‚ل‚¾‚ك‚¾‚ثپB
گ«”\’ل‰؛‚ھڈ‚ب‚¢ژ–‚ھƒxƒNƒgƒ‹‚ج”„‚è‚ب‚ٌ‚¾‚©‚çپB
‚à‚ء‚ئ‚àƒXƒJƒ‰‚جƒtƒBپ[ƒ`ƒƒپ[‚ًژو‚è“ü‚ꂽ‚ج‚ھچ،‰ٌ‚جSX-ACE‚ب‚ج‚إ
ƒXƒJƒ‰‚ئ“¯—l‚ةگ«”\’ل‰؛‚·‚é‰آ”\گ«‚ھ‚ ‚éپB
‚ا‚ج‚و‚¤‚ة‚ـ‚ئ‚كڈم‚°‚½‚ج‚©‘±•ٌ‚ھ‹C‚ة‚ب‚é‚ئ‚±‚ëپB
ƒXƒJƒ‰ƒXƒpƒRƒ“‚ئ“¯‚¶‚و‚¤‚ةچl‚¦‚؟‚ل‚¾‚ك‚¾‚ثپB
گ«”\’ل‰؛‚ھڈ‚ب‚¢ژ–‚ھƒxƒNƒgƒ‹‚ج”„‚è‚ب‚ٌ‚¾‚©‚çپB
‚à‚ء‚ئ‚àƒXƒJƒ‰‚جƒtƒBپ[ƒ`ƒƒپ[‚ًژو‚è“ü‚ꂽ‚ج‚ھچ،‰ٌ‚جSX-ACE‚ب‚ج‚إ
ƒXƒJƒ‰‚ئ“¯—l‚ةگ«”\’ل‰؛‚·‚é‰آ”\گ«‚ھ‚ ‚éپB
‚ا‚ج‚و‚¤‚ة‚ـ‚ئ‚كڈم‚°‚½‚ج‚©‘±•ٌ‚ھ‹C‚ة‚ب‚é‚ئ‚±‚ëپB
چ،‚·‚إ‚ة‚ ‚é‹‚âTitan ‚ة”ن‚ׂؤ‚à“d—حŒّ—¦‚ھ2پ`5”{ˆ«‚¢‚ٌ‚¶‚ل‚ب‚¢‚إ‚µ‚ه‚¤‚©پBژہŒّŒّ—¦‚جچ‚‚³‚إ‚ح–„‚ـ‚ç‚ب‚¢‹C‚ھ‚µ‚ـ‚·‚وپB
چ،‚إ‚ب‚‚ئ‚àƒxƒNƒgƒ‹Œ^‚ھڈ«—ˆٹھ‚«•ش‚·“W–]‚ئ“¹‹ط‚ھ‚ ‚é‚ئ–ت”’‚¢‚ٌ‚إ‚·‚¯‚ا‚ثپB
چ،‚إ‚ب‚‚ئ‚àƒxƒNƒgƒ‹Œ^‚ھڈ«—ˆٹھ‚«•ش‚·“W–]‚ئ“¹‹ط‚ھ‚ ‚é‚ئ–ت”’‚¢‚ٌ‚إ‚·‚¯‚ا‚ثپB
604 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/15(‹à) 21:42:20.14 ID:z+3DgPNl
پu‚ب‚ٌ‚ج“d—حŒّ—¦پv‚©‚ح’m‚ç‚ب‚¢‚¯‚اLinpack‚ج‚ف‚إ—ا‚µˆ«‚µ‚ًŒˆ‚ك‚é•—’ھ‚ح•]‰؟‚إ‚«‚ب‚¢پB
ژه‚½‚é–ع“I‚جڈˆ—‚ة‘خ‚·‚éŒّ—¦‚إ”»’f‚·‚ׂµپB
‚à‚؟‚ë‚ٌ–{‹ئ‚½‚é—¬‘ج‰‰ژZ‚إ‚ج“d—حŒّ—¦‚ھˆہ‰؟‚بPCƒTپ[ƒoپEGPGPUƒTپ[ƒo‚ئ
”ن‚ׂؤˆ«‚¢‚ئ‚¢‚¤‚±‚ئ‚إ‚ ‚ê‚خپA‹à‚ج–³‘ت‚إ‚·‚ھپB
ژه‚½‚é–ع“I‚جڈˆ—‚ة‘خ‚·‚éŒّ—¦‚إ”»’f‚·‚ׂµپB
‚à‚؟‚ë‚ٌ–{‹ئ‚½‚é—¬‘ج‰‰ژZ‚إ‚ج“d—حŒّ—¦‚ھˆہ‰؟‚بPCƒTپ[ƒoپEGPGPUƒTپ[ƒo‚ئ
”ن‚ׂؤˆ«‚¢‚ئ‚¢‚¤‚±‚ئ‚إ‚ ‚ê‚خپA‹à‚ج–³‘ت‚إ‚·‚ھپB
>>603
“d—حŒّ—¦‚جژ–‚خ‚©‚茾‚ء‚ؤ‚é‚و‚¤‚¾‚ھپA
ڈˆ—Œّ—¦1ƒpپ[ƒZƒ“ƒg‘OŒم‚جƒXƒJƒ‰ƒXƒpƒRƒ“‚إ‰½ڈ\”{‚àژٹش‚©‚¯‚ؤ—¬‘ج‚â‚é‚ج‚ح
“d—حŒّ—¦‚ھ‚ق‚µ‚눫‚¢پB
—¬‘جˆبٹO‚إ‚àƒxƒNƒgƒ‹‚ح‚»‚ê‚ب‚è‚ةگ«”\”ٹِ‚إ‚«‚é‚ھپA
‚ـ‚ ƒXƒJƒ‰‚ئ‘هچ·‚آ‚¢‚½Œ»ڈَ‚إ‚ح‚ظ‚ع—¬‘جگê—p‚©‚à‚µ‚ê‚ٌ‚ثپB
“d—حŒّ—¦‚جژ–‚خ‚©‚茾‚ء‚ؤ‚é‚و‚¤‚¾‚ھپA
ڈˆ—Œّ—¦1ƒpپ[ƒZƒ“ƒg‘OŒم‚جƒXƒJƒ‰ƒXƒpƒRƒ“‚إ‰½ڈ\”{‚àژٹش‚©‚¯‚ؤ—¬‘ج‚â‚é‚ج‚ح
“d—حŒّ—¦‚ھ‚ق‚µ‚눫‚¢پB
—¬‘جˆبٹO‚إ‚àƒxƒNƒgƒ‹‚ح‚»‚ê‚ب‚è‚ةگ«”\”ٹِ‚إ‚«‚é‚ھپA
‚ـ‚ ƒXƒJƒ‰‚ئ‘هچ·‚آ‚¢‚½Œ»ڈَ‚إ‚ح‚ظ‚ع—¬‘جگê—p‚©‚à‚µ‚ê‚ٌ‚ثپB
606 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/16(“y) 00:09:14.05 ID:6Aw4VNLi
—¬‘ج‰‰ژZ‚ء‚ؤ‚¢‚‚çƒLƒƒƒbƒVƒ…گد‚ٌ‚إ‚àDRAM‘رˆو‚ھپ`‚ء‚ؤ‚و‚Œ¾‚ي‚ê‚ؤ‚邯‚ا
GT3e‚ج128MB‚àگد‚ك‚خ‚ ‚é’ِ“xƒپƒ‚ƒٹƒgƒ‰ƒtƒBƒbƒNٹةکa‚إ‚«‚é‚ٌ‚¾‚ب‚ء‚ؤژv‚¢‚ـ‚µ‚½
‚à‚؟‚ë‚ٌ‹K–ح‚ة‚à‚و‚é‚ج‚¾‚낤‚¯‚ا
‚ب‚ٌ‚¾‚©‚ٌ‚¾‚إƒپƒ‚ƒٹٹK‘w‚ًچl—¶‚µ‚½چإ“K‰»‚ح•K—v‚ة‚ب‚é‚ئژv‚¢‚ـ‚·‚و
GT3e‚ج128MB‚àگد‚ك‚خ‚ ‚é’ِ“xƒپƒ‚ƒٹƒgƒ‰ƒtƒBƒbƒNٹةکa‚إ‚«‚é‚ٌ‚¾‚ب‚ء‚ؤژv‚¢‚ـ‚µ‚½
‚à‚؟‚ë‚ٌ‹K–ح‚ة‚à‚و‚é‚ج‚¾‚낤‚¯‚ا
‚ب‚ٌ‚¾‚©‚ٌ‚¾‚إƒپƒ‚ƒٹٹK‘w‚ًچl—¶‚µ‚½چإ“K‰»‚ح•K—v‚ة‚ب‚é‚ئژv‚¢‚ـ‚·‚و
Green500‚ئ‚©‚حtop500‚ئ“¯—l‚ةHPL‚إFLOPS/“d—حŒ©‚ؤ‚邾‚¯‚¾‚©‚ç‚بپB
‚¹‚ك‚ؤHPCC‚جٹeچ€–ع‚ج“d—ح‚‚ç‚¢‚ف‚ب‚¢‚ئ
‚¹‚ك‚ؤHPCC‚جٹeچ€–ع‚ج“d—ح‚‚ç‚¢‚ف‚ب‚¢‚ئ
ƒCƒ“ƒeƒ‹‚ئNECپAڈ«—ˆ‚ةŒü‚¯‚½ƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^پ[‹Zڈp‚ج‹¤“¯ٹJ”‚ةچ‡ˆسپ@2009”N11Œژ17“ْ
ttp://www.nec.co.jp/press/ja/0911/1701.html
‚إ‚½‚ç‚كڈ‘‚«چ‚ٌ‚إ‚éگl‚ح•œڈK‚µ‚ë
ttp://www.nec.co.jp/press/ja/0911/1701.html
‚إ‚½‚ç‚كڈ‘‚«چ‚ٌ‚إ‚éگl‚ح•œڈK‚µ‚ë
ژںگ¢‘مƒxƒNƒgƒ‹Œ^ƒXپ[ƒpƒRƒ“ƒsƒ…پ[ƒ^‚جگ»•i‰»‚ة‚آ‚¢‚ؤ
ttp://www.nec.co.jp/press/ja/1111/0702.html
ttp://www.nec.co.jp/press/ja/1111/0702.html
ƒxƒNƒgƒ‹‘€چى‚ء‚ؤƒAƒNƒZƒ‰ƒŒپ[ƒ^‚بٹ´‚¶‚¾‚ب
611 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/16(“y) 09:32:36.43 ID:6Aw4VNLi
>>608
‚»‚جچ ‚ةپuNEC‚حLarrabee‚ًŒ©ژج‚ؤ‚½پv‚ئڈ‘‚©‚ê‚ؤ‚½‚ج‚à‚±‚جƒXƒŒ‚¾‚ء‚½‚ئژv‚¤‚وپB
گ^‚ةژَ‚¯‚½‚ج‚à‰´‚¾‚ھپB
‚»‚جچ ‚ةپuNEC‚حLarrabee‚ًŒ©ژج‚ؤ‚½پv‚ئڈ‘‚©‚ê‚ؤ‚½‚ج‚à‚±‚جƒXƒŒ‚¾‚ء‚½‚ئژv‚¤‚وپB
گ^‚ةژَ‚¯‚½‚ج‚à‰´‚¾‚ھپB
Cool Chips 16 - •ھژUƒپƒ‚ƒٹ‚ئ‚ب‚éNEC‚جژںگ¢‘مƒxƒNƒgƒ‹ƒXƒpƒRƒ“
http://news.mynavi.jp/articles/2013/04/24/coolchips16_ngv_01/index.html
1ƒ`ƒbƒv‚ةƒپƒ‚ƒٹ‚ًDDR3‚ب‚ھ‚ç16ƒ`ƒƒƒlƒ‹256GB/sec‚إŒq‚¢‚إپA1GHz‚ج’لƒNƒچƒbƒN‚إ‹ى“®‚·‚é‚ج‚ھPCƒNƒ‰ƒXƒ^‚ة‘خ‚·‚éچ·•ت‰»—v‘f?
http://news.mynavi.jp/articles/2013/04/24/coolchips16_ngv_01/index.html
1ƒ`ƒbƒv‚ةƒپƒ‚ƒٹ‚ًDDR3‚ب‚ھ‚ç16ƒ`ƒƒƒlƒ‹256GB/sec‚إŒq‚¢‚إپA1GHz‚ج’لƒNƒچƒbƒN‚إ‹ى“®‚·‚é‚ج‚ھPCƒNƒ‰ƒXƒ^‚ة‘خ‚·‚éچ·•ت‰»—v‘f?
613 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/16(“y) 10:55:26.82 ID:6Aw4VNLi
Knights Landing‚إ‚ح‚±‚¤‚¢‚¤چ\گ¬‚ھ‚إ‚«‚é‚و‚¤‚ة‚ب‚é‚©‚ç
SX‚جژç”ُ”حˆح‚à‚»‚ê‚ب‚è‚ةگNگH‚·‚é‚ج‚إ‚ح
DDR4پپPhiپ|PhiپپDDR4
پ@پ@پ@پ@پ@پbپ@پ@پb
DDR4پپPhiپ|PhiپپDDR4
SX‚جژç”ُ”حˆح‚à‚»‚ê‚ب‚è‚ةگNگH‚·‚é‚ج‚إ‚ح
DDR4پپPhiپ|PhiپپDDR4
پ@پ@پ@پ@پ@پbپ@پ@پb
DDR4پپPhiپ|PhiپپDDR4
Core-iƒVƒٹپ[ƒY‚ة512bitSIMD‘پ‚وپB
615 پFSocket774پF2013/11/16(“y) 17:10:38.49 ID:pWnDik9f
“d—حŒّ—¦‚حچs‚¤‰‰ژZ‚ة‚و‚ء‚ؤˆظ‚ب‚é
TOP500‚âGREEN500‚حپALinpack‰‰ژZ‚جگ«”\پE“d—حŒّ—¦‚ج‚ف‚إ•]‰؟‚·‚éژwگ”‚ب‚ج‚إپA
‘¼‚جژي—ق‚ج‰‰ژZ‚ة‚ ‚ؤ‚ح‚ـ‚é‚ي‚¯‚¶‚ل‚ب‚¢
HPCC‚ج“d—حŒّ—¦”إ‚ھ‚ ‚ê‚خ‚¢‚¢‚ج‚ة
4ژي—ق‚ج‰‰ژZ‚إ‚»‚ꂼ‚ê“d—حŒّ—¦‚ًڈo‚·“z
TOP500‚âGREEN500‚حپALinpack‰‰ژZ‚جگ«”\پE“d—حŒّ—¦‚ج‚ف‚إ•]‰؟‚·‚éژwگ”‚ب‚ج‚إپA
‘¼‚جژي—ق‚ج‰‰ژZ‚ة‚ ‚ؤ‚ح‚ـ‚é‚ي‚¯‚¶‚ل‚ب‚¢
HPCC‚ج“d—حŒّ—¦”إ‚ھ‚ ‚ê‚خ‚¢‚¢‚ج‚ة
4ژي—ق‚ج‰‰ژZ‚إ‚»‚ꂼ‚ê“d—حŒّ—¦‚ًڈo‚·“z
617 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/16(“y) 20:20:57.33 ID:6Aw4VNLi
•ت‚ةNECƒXƒpƒRƒ“‚ًگ¢ٹE1ˆت‚ة‚³‚¹‚邽‚ك‚جژw•W‚ھ•K—v‚©پH
‚ء‚ؤ‚¢‚¤‚ئ‚»‚¤‚حژv‚ي‚ب‚¢پB
—¬‘ج‰‰ژZ‚إ‚ح‚½‚µ‚©‚ةFLOPS”ش’·‚ح–³ˆس–،‚¾‚ھ
FLOPS”ش’·‚إ‚à’ت‚¶‚ؤ‚µ‚ـ‚¤•ھ–ى‚à‘½گ”‘¶چف‚·‚é‚ي‚¯‚¾‚©‚ç
ٹwژ¯ژز‚ح•K—v‚ب—p“r‚إ‚ح–ظ‚ء‚ؤ‚ؤ‚àژg‚¤‚ٌ‚¾‚©‚çپA‚»‚ꂼ‚ê‚ج
کHگü•à‚ٌ‚¾‚©‚炦‚¦پB
‚ء‚ؤ‚¢‚¤‚ئ‚»‚¤‚حژv‚ي‚ب‚¢پB
—¬‘ج‰‰ژZ‚إ‚ح‚½‚µ‚©‚ةFLOPS”ش’·‚ح–³ˆس–،‚¾‚ھ
FLOPS”ش’·‚إ‚à’ت‚¶‚ؤ‚µ‚ـ‚¤•ھ–ى‚à‘½گ”‘¶چف‚·‚é‚ي‚¯‚¾‚©‚ç
ٹwژ¯ژز‚ح•K—v‚ب—p“r‚إ‚ح–ظ‚ء‚ؤ‚ؤ‚àژg‚¤‚ٌ‚¾‚©‚çپA‚»‚ꂼ‚ê‚ج
کHگü•à‚ٌ‚¾‚©‚炦‚¦پB
ٹwژ¯ژز‚حژg‚¢‚½‚¢‚ج‚ًژg‚¦‚خ‚¢‚¢‚ء‚ؤ‚¢‚¤‚ج‚حŒڑ‘O‚إپA
‚â‚ء‚د‚èTOP500‚جLinpack‚ف‚½‚¢‚بژw•W‚حƒ}ƒXƒRƒ~‚âگژ،‰ئژَ‚¯‚ھ‚و‚پA—\ژZ‚à‚آ‚«‚â‚·‚¢
TOP500‚جگ”ژڑ‚ة—x‚炳‚ê‚ب‚¢‚ج‚حپA•¶•”‰بٹwڈب‚ج–ًگl‚ئ‚©پA‚ ‚ئ‚حŒ»ژہ‚ةHPCژg‚ء‚ؤ‚郆پ[ƒUپ[‚ئ‚©‚¶‚ل‚ب‚¢‚جپH
‚â‚ء‚د‚èTOP500‚جLinpack‚ف‚½‚¢‚بژw•W‚حƒ}ƒXƒRƒ~‚âگژ،‰ئژَ‚¯‚ھ‚و‚پA—\ژZ‚à‚آ‚«‚â‚·‚¢
TOP500‚جگ”ژڑ‚ة—x‚炳‚ê‚ب‚¢‚ج‚حپA•¶•”‰بٹwڈب‚ج–ًگl‚ئ‚©پA‚ ‚ئ‚حŒ»ژہ‚ةHPCژg‚ء‚ؤ‚郆پ[ƒUپ[‚ئ‚©‚¶‚ل‚ب‚¢‚جپH
G-FFT‚إFLOPS/W ‘ھ‚ء‚½‚çGreen500ڈمˆت‚حPower775‚ةژS”s‚¾‚낤‚بپB
POWER7ژ©‘ج‚حŒّ—¦‚و‚‚ب‚¢‚¯‚اƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚جٹi‚ھˆل‚¤پB
ٹi‚ھˆل‚¤•ھ“‚‚ؤBlueWater‚ج—\ژZ‚ً‚ح‚فڈo‚µ‚ؤ‚µ‚ـ‚ء‚½‚ھ
POWER7ژ©‘ج‚حŒّ—¦‚و‚‚ب‚¢‚¯‚اƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚جٹi‚ھˆل‚¤پB
ٹi‚ھˆل‚¤•ھ“‚‚ؤBlueWater‚ج—\ژZ‚ً‚ح‚فڈo‚µ‚ؤ‚µ‚ـ‚ء‚½‚ھ
620 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/16(“y) 20:39:45.75 ID:6Aw4VNLi
•ت‚ة‚»‚ê‚ھˆ«‚¢‚ئ‚حŒ¾‚ي‚ب‚¢‚µ”ل”»‚·‚é‹C‚ح–³‚¢‚ج‚¾‚¯‚ا
‹‚ًژg‚ء‚ؤNBODY‚ج–â‘è‰ً‚«‚ـ‚µ‚½‚ب‚ٌ‚ؤ‚ج‚ھƒSپ[ƒhƒ“ƒxƒ‹ڈـ
ژَڈـ‚µ‚ؤ‚ـ‚µ‚½‚ثپB
پu‚»‚ê‹‚ً‚ي‚´‚ي‚´ژg‚¤‚و‚¤‚ب–â‘è‚©پHپv‚ئ‚¢‚¤‚ج‚حژv‚ء‚½‚ي‚¯‚إپB
پiŒ»ڈَNBODY‚ھچ‘“à‚إˆê”ش‘¬‚¢ƒXƒpƒRƒ“‚ب‚ج‚حٹشˆل‚¢‚ب‚¢‚¯‚اپj
Œآگl“I‚ة‚ح‚ ‚ٌ‚ـ‚èپu”ؤ—pپv‚ة‚±‚¾‚ي‚è‚·‚¬‚ؤ”ؤ—p“I‚¶‚ل‚ب‚¢‚à‚ج‚ً
ژg‚¤‚ئ‚¢‚¤‚ج‚حٹضگS‚µ‚ب‚¢پB
‹‚ًژg‚ء‚ؤNBODY‚ج–â‘è‰ً‚«‚ـ‚µ‚½‚ب‚ٌ‚ؤ‚ج‚ھƒSپ[ƒhƒ“ƒxƒ‹ڈـ
ژَڈـ‚µ‚ؤ‚ـ‚µ‚½‚ثپB
پu‚»‚ê‹‚ً‚ي‚´‚ي‚´ژg‚¤‚و‚¤‚ب–â‘è‚©پHپv‚ئ‚¢‚¤‚ج‚حژv‚ء‚½‚ي‚¯‚إپB
پiŒ»ڈَNBODY‚ھچ‘“à‚إˆê”ش‘¬‚¢ƒXƒpƒRƒ“‚ب‚ج‚حٹشˆل‚¢‚ب‚¢‚¯‚اپj
Œآگl“I‚ة‚ح‚ ‚ٌ‚ـ‚èپu”ؤ—pپv‚ة‚±‚¾‚ي‚è‚·‚¬‚ؤ”ؤ—p“I‚¶‚ل‚ب‚¢‚à‚ج‚ً
ژg‚¤‚ئ‚¢‚¤‚ج‚حٹضگS‚µ‚ب‚¢پB
ژg‚¢‚½‚¢‚ئ‚«‚ةژg‚¦‚ب‚¢ƒXƒpƒRƒ“‚ب‚ٌ‚ؤ–ً‚ة—§‚؟‚ـ‚¹‚ٌپB
—\–ٌگ§پHپ@‘e‘هƒSƒ~‚إ‚·پB
—\–ٌگ§پHپ@‘e‘هƒSƒ~‚إ‚·پB
>>615
“ء•ت‚بڈî•ٌŒ¹‚ًژ‚ء‚ؤ‚¢‚é‚ي‚¯‚¶‚ل‚ب‚¢‚©‚çŒِ•\‚³‚ê‚ؤ‚¢‚邱‚ئ‚µ‚©’m‚ç‚ب‚¢‚وپB
“ء•ت‚بڈî•ٌŒ¹‚ًژ‚ء‚ؤ‚¢‚é‚ي‚¯‚¶‚ل‚ب‚¢‚©‚çŒِ•\‚³‚ê‚ؤ‚¢‚邱‚ئ‚µ‚©’m‚ç‚ب‚¢‚وپB
’cژq‚جŒ¾‚¢•ھ‚ح•ھ‚©‚邵ژ^“¯‚إ‚«‚é•”•ھ‚à‚ ‚é‚ھپA
ژہچغگ¢‚ج’†‚»‚ٌ‚ب•—‚ة‚ح‰ô‚ء‚ؤ‚ب‚¢‚©‚ç‚ب‚
‚ح‚ں-
ژہچغگ¢‚ج’†‚»‚ٌ‚ب•—‚ة‚ح‰ô‚ء‚ؤ‚ب‚¢‚©‚ç‚ب‚
‚ح‚ں-
—¬‘جŒvژZ‚¾‚ئ–¢‚¾‚ة’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚ھƒgƒbƒvƒ‰ƒ“ƒN‚ة‚¢‚é‚ٌ‚¾‚©‚ç•ت‚ة‚¢‚¢‚ٌ‚¶‚ل‚ث‚©
ƒAƒvƒٹƒPپ[ƒVƒ‡ƒ““ء‰»Œ^‚¾‚¯‚ة
“¾ˆس‚جŒvژZ‚إˆêˆت‚ئ‚ê‚ب‚¢‚ئ–ع‚à“–‚ؤ‚ç‚ê‚ب‚¢‚ب
“¾ˆس‚جŒvژZ‚إˆêˆت‚ئ‚ê‚ب‚¢‚ئ–ع‚à“–‚ؤ‚ç‚ê‚ب‚¢‚ب
’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚ً—L‚è“ï‚ھ‚ء‚ؤ‚é‚ج‚حƒlƒgƒEƒˆ‚¾‚¯‚¾‚ئژv‚ء‚ؤ‚½‚وپB
627 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 09:11:59.05 ID:NgNK3ZSO
Œ»چف4ˆت‚ج‹‚ھپu1ˆت‚¾‚ء‚½‚±‚ئپv‚ء‚ؤ‚»‚ٌ‚ب‚ةڈd—v‚¾‚ء‚½‚ٌ‚¾‚낤‚©پH
‚ـ‚ پAژ¯ژز‚إƒ}ƒ“ƒZپ[‚µ‚ؤ‚¢‚éگl‚حژ©•ھ‚جŒ©‚½Œہ‚è‚إ‚ح‚ظ‚ئ‚ٌ‚ا‰½‚ç‚©‚جٹضکAٹé‹ئپEŒ¤‹†‹@ٹض‚ج—کٹQٹضŒWژز‚¾‚ء‚½‚ثپB
“ء’è‚ج–ع“I‚ب‚µ‚ةƒXƒpƒRƒ“چى‚ء‚ؤ‚àژd•û‚ب‚¢پB—\ژZ‘خŒّ‰ت‚ًŒ©‹ة‚ك‚ç‚ê‚ب‚¢ژ“_‚إچ‘‰ئƒvƒچƒWƒFƒNƒg‚ئ‚µ‚ؤ•³پB
“ء’è‚ج–ع“I‚ب‚µ‚ةƒXƒpƒRƒ“چى‚ء‚ؤ‚àژd•û‚ب‚¢پB—\ژZ‘خŒّ‰ت‚ًŒ©‹ة‚ك‚ç‚ê‚ب‚¢ژ“_‚إچ‘‰ئƒvƒچƒWƒFƒNƒg‚ئ‚µ‚ؤ•³پB
629 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 09:31:34.62 ID:NgNK3ZSO
—Œ¤‚ب‚ç‚ت—کŒ
’N‚¤‚ـ
>>628
ƒTƒ€ƒXƒ“‚ھ64bit‚جARM SoC—p‚ج“ئژ©ƒRƒA‚جٹJ”‚ً•\–¾‚µ‚ؤ‚é
‰½‚à‚µ‚ب‚¢‚ئ10”NŒم‚ةٹطچ‘‚ة•‰‚¯‚邱‚ئ‚ة‚ب‚é‚©‚à‚و
ƒTƒ€ƒXƒ“‚ھ64bit‚جARM SoC—p‚ج“ئژ©ƒRƒA‚جٹJ”‚ً•\–¾‚µ‚ؤ‚é
‰½‚à‚µ‚ب‚¢‚ئ10”NŒم‚ةٹطچ‘‚ة•‰‚¯‚邱‚ئ‚ة‚ب‚é‚©‚à‚و
>>627,629
‘ه‹K–ح•ہ—ٌƒXƒpƒRƒ“‚ًچى‚é‚ج‚ح‘Sƒmپ[ƒhژg—p‚جƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً‚â‚é‚ج‚ح
ƒپƒ‚ƒٹ—ت‚ج“sچ‡‚إ‚ظ‚©‚جƒXƒpƒRƒ“‚إ‚ح–³—‚¾‚©‚çپA‚ئ‚¢‚¤کb‚à‚ ‚éپB
‚»‚êˆبٹO‚جŒvژZپEƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ةٹض‚µ‚ؤ‚حƒmپ[ƒhگ”‚ًƒWƒ‡ƒu‚ة‰‚¶‚ؤٹ„‚è“–‚ؤ‚é‚ج‚إ
گ¢ٹEˆê‚جƒXƒsپ[ƒh‚ئ‚©‘S‚ˆس–،‚ح‚ب‚¢پB
‚ة‚à‚©‚©‚ي‚炸پAڈم‚ج——R‚إگ¢ٹEˆê‚ھچى‚ç‚ê‚؟‚ل‚¤‚ي‚¯‚¾پB
‘ه‹K–ح•ہ—ٌƒXƒpƒRƒ“‚ًچى‚é‚ج‚ح‘Sƒmپ[ƒhژg—p‚جƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً‚â‚é‚ج‚ح
ƒپƒ‚ƒٹ—ت‚ج“sچ‡‚إ‚ظ‚©‚جƒXƒpƒRƒ“‚إ‚ح–³—‚¾‚©‚çپA‚ئ‚¢‚¤کb‚à‚ ‚éپB
‚»‚êˆبٹO‚جŒvژZپEƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ةٹض‚µ‚ؤ‚حƒmپ[ƒhگ”‚ًƒWƒ‡ƒu‚ة‰‚¶‚ؤٹ„‚è“–‚ؤ‚é‚ج‚إ
گ¢ٹEˆê‚جƒXƒsپ[ƒh‚ئ‚©‘S‚ˆس–،‚ح‚ب‚¢پB
‚ة‚à‚©‚©‚ي‚炸پAڈم‚ج——R‚إگ¢ٹEˆê‚ھچى‚ç‚ê‚؟‚ل‚¤‚ي‚¯‚¾پB
>>631
‚ب‚ٌ‚إ‘¼چ‘ٹé‹ئ‚جARMƒ`ƒbƒv‚ض‚ج‘خچRچى‚ھپAچ‘چôƒXƒpƒRƒ“‚ب‚ج?w
‚«‚ف‚ح‰½‚إ‚à‘خٹطچ‘‚ةŒ‹‚ر‚آ‚¯‚ê‚خپAƒlƒbƒg‚إ‚ح‹–‚³‚ê‚é‚ئژv‚ء‚ؤ‚¢‚é‚ج‚©‚¢?
ژ–‹ئژd•ھ‚¯ˆب‘O‚ةپA‹‚ح‹Zڈp“I‚ب“à—e‚âƒvƒچƒWƒFƒNƒg‚جگi‚ك•û‚إپAگê–ه‰ئ‚©‚ç‚¢‚ë‚¢‚ë–â‘è‚ة‚³‚ê‚ـ‚‚ء‚ؤ‚½‚ٌ‚¾‚وپB
ژ–‹ئژd•ھ‚¯ˆبچ~‚ةپAˆê”تƒپƒfƒBƒA‚إ‘›‚ھ‚ê‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚©‚çپA
پu2ˆت‚¶‚ل‚¾‚ك‚ب‚ٌ‚إ‚·‚©پv‚إک@نuک@نu‚³‚ي‚¬‚ـ‚‚ء‚ؤ‚邾‚¯‚ج”nژ‚ا‚à‚ھپA
‰بٹw‚â‹Zڈp‚ة—‰ً‚ج‚ب‚¢”nژ‚بکA’†‚ھپA–عگو‚جگچô‚إƒXƒpƒRƒ“ƒvƒچƒWƒFƒNƒg‚ً‚½‚¾’ׂ»‚¤‚ئ‚µ‚ؤ‚¢‚é‚ف‚½‚¢‚ة
ˆê”ت‚ة‚ح‘¨‚¦‚ç‚ê‚؟‚ل‚ء‚ؤ‚¢‚邯‚ا‚ثپB
‚ب‚ٌ‚إ‘¼چ‘ٹé‹ئ‚جARMƒ`ƒbƒv‚ض‚ج‘خچRچى‚ھپAچ‘چôƒXƒpƒRƒ“‚ب‚ج?w
‚«‚ف‚ح‰½‚إ‚à‘خٹطچ‘‚ةŒ‹‚ر‚آ‚¯‚ê‚خپAƒlƒbƒg‚إ‚ح‹–‚³‚ê‚é‚ئژv‚ء‚ؤ‚¢‚é‚ج‚©‚¢?
ژ–‹ئژd•ھ‚¯ˆب‘O‚ةپA‹‚ح‹Zڈp“I‚ب“à—e‚âƒvƒچƒWƒFƒNƒg‚جگi‚ك•û‚إپAگê–ه‰ئ‚©‚ç‚¢‚ë‚¢‚ë–â‘è‚ة‚³‚ê‚ـ‚‚ء‚ؤ‚½‚ٌ‚¾‚وپB
ژ–‹ئژd•ھ‚¯ˆبچ~‚ةپAˆê”تƒپƒfƒBƒA‚إ‘›‚ھ‚ê‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚©‚çپA
پu2ˆت‚¶‚ل‚¾‚ك‚ب‚ٌ‚إ‚·‚©پv‚إک@نuک@نu‚³‚ي‚¬‚ـ‚‚ء‚ؤ‚邾‚¯‚ج”nژ‚ا‚à‚ھپA
‰بٹw‚â‹Zڈp‚ة—‰ً‚ج‚ب‚¢”nژ‚بکA’†‚ھپA–عگو‚جگچô‚إƒXƒpƒRƒ“ƒvƒچƒWƒFƒNƒg‚ً‚½‚¾’ׂ»‚¤‚ئ‚µ‚ؤ‚¢‚é‚ف‚½‚¢‚ة
ˆê”ت‚ة‚ح‘¨‚¦‚ç‚ê‚؟‚ل‚ء‚ؤ‚¢‚邯‚ا‚ثپB
“ْ–{Œê‚إڈ‘‚¯‚و >>‚¨‚ê
635 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 11:08:03.24 ID:NgNK3ZSO
گ¢ٹEˆê‚ًژو‚ء‚½ˆذگM‚ة‚و‚ء‚ؤ‹Zڈp‚ًگ¢ٹE‚ة—Aڈo‚إ‚«‚é‚ئ‚©‰]پX‚ث
‚»‚ٌ‚ب‚ج‚إ—Aڈo‚إ‚«‚é‚ب‚çپA‹t‚ة4ˆت‚ـ‚إ—ژ‚؟‚½چ،‚ح‘ٹژè‚ة‚³‚ê‚ب‚¢‚ء‚ؤکb‚ة‚ب‚邶‚ل‚ٌپB
ƒXƒpƒRƒ“‚ھ•s—v‚¾‚ئ‚¢‚ء‚ؤ‚é“z‚ح‚½‚¾‚جƒoƒJ‚¾‚وپB
ٹwڈpپEژY‹ئٹE‚ح‚à‚ء‚ئ‰‰ژZگ«”\‚ً•K—v‚ئ‚µ‚ؤ‚éپB
1000‰ژg‚ء‚ؤ‚½‚ء‚½1‘ن‚µ‚©10PFLOPS‹‰‚ج”ؤ—pƒXƒpƒRƒ“چى‚ê‚ب‚¢
ƒRƒXƒp‚جˆ«‚³‚ھ–â‘è‚ب‚ي‚¯‚إپB
‚»‚ٌ‚ب‚ج‚إ—Aڈo‚إ‚«‚é‚ب‚çپA‹t‚ة4ˆت‚ـ‚إ—ژ‚؟‚½چ،‚ح‘ٹژè‚ة‚³‚ê‚ب‚¢‚ء‚ؤکb‚ة‚ب‚邶‚ل‚ٌپB
ƒXƒpƒRƒ“‚ھ•s—v‚¾‚ئ‚¢‚ء‚ؤ‚é“z‚ح‚½‚¾‚جƒoƒJ‚¾‚وپB
ٹwڈpپEژY‹ئٹE‚ح‚à‚ء‚ئ‰‰ژZگ«”\‚ً•K—v‚ئ‚µ‚ؤ‚éپB
1000‰ژg‚ء‚ؤ‚½‚ء‚½1‘ن‚µ‚©10PFLOPS‹‰‚ج”ؤ—pƒXƒpƒRƒ“چى‚ê‚ب‚¢
ƒRƒXƒp‚جˆ«‚³‚ھ–â‘è‚ب‚ي‚¯‚إپB
>>633
‹‚ح•xژm’ت‚ھچى‚ء‚ؤ‚éCPU‚جSPARC64‚ھٹî–{‚ة‚ب‚ء‚ؤ‚é‚©‚ç‚ب
•xژm’ت‚ح‚¸‚ء‚ئSPARC‚ًچى‚葱‚¯‚½‚©‚çچ،‚ج•xژm’ت‚ھ‚ ‚é
ƒTƒ€ƒXƒ“‚حƒXƒ}ƒz‚إ30%ˆبڈم‚جƒVƒFƒA‚ًژ‚ء‚ؤ‚邵
ژ©ژذ‚جSoC‚ًƒپƒCƒ“‚إژg‚¤‚±‚ئ‚à‰آ”\‚¾‚©‚ç
‚±‚ê‚©‚ç‹Zڈp—ح‚ً‚آ‚¯‚ؤ‚‚é‚©‚à‚µ‚ê‚ب‚¢
‹‚ح•xژm’ت‚ھچى‚ء‚ؤ‚éCPU‚جSPARC64‚ھٹî–{‚ة‚ب‚ء‚ؤ‚é‚©‚ç‚ب
•xژm’ت‚ح‚¸‚ء‚ئSPARC‚ًچى‚葱‚¯‚½‚©‚çچ،‚ج•xژm’ت‚ھ‚ ‚é
ƒTƒ€ƒXƒ“‚حƒXƒ}ƒz‚إ30%ˆبڈم‚جƒVƒFƒA‚ًژ‚ء‚ؤ‚邵
ژ©ژذ‚جSoC‚ًƒپƒCƒ“‚إژg‚¤‚±‚ئ‚à‰آ”\‚¾‚©‚ç
‚±‚ê‚©‚ç‹Zڈp—ح‚ً‚آ‚¯‚ؤ‚‚é‚©‚à‚µ‚ê‚ب‚¢
‹‚ح1000‰‰~‹K–ح‚ج‹à‚©‚©‚©‚ء‚ؤ‚é‚©‚à‚µ‚ê‚ب‚¢‚ھ
”Nٹش‚ة‚·‚ê‚خ100‰‚ئ‚©200‰‰~’ِ“x
–ˆ”N‹‚ً‚آ‚‚é‚ي‚¯‚¶‚ل‚ب‚¢‚ٌ‚¾‚و
‚»‚±‚ً‰½‚©ٹ¨ˆل‚¢‚µ‚ؤ‚é
”Nٹش‚ة‚·‚ê‚خ100‰‚ئ‚©200‰‰~’ِ“x
–ˆ”N‹‚ً‚آ‚‚é‚ي‚¯‚¶‚ل‚ب‚¢‚ٌ‚¾‚و
‚»‚±‚ً‰½‚©ٹ¨ˆل‚¢‚µ‚ؤ‚é
638 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 11:19:15.38 ID:NgNK3ZSO
> ”Nٹش‚ة‚·‚ê‚خ100‰‚ئ‚©200‰‰~’ِ“x
–ˆ”NچإگVƒXƒyƒbƒN‚ج•”•i‚إƒXƒpƒRƒ“‚ًچى‚ء‚½‚ظ‚¤‚ھ‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚ج‚©
–ˆ”NچإگVƒXƒyƒbƒN‚ج•”•i‚إƒXƒpƒRƒ“‚ًچى‚ء‚½‚ظ‚¤‚ھ‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚ج‚©
>>636
‚»‚ê‚ح‰ًژك‚جڈ‡”ش‚ھ‹t‚ب‚ٌ‚¾‚و‚بپB
Samsung‚حپAƒXƒ}ƒz/ƒ^ƒuƒŒƒbƒg”„‚肽‚¢‚µپAژہچغ”„‚ê‚ؤ‚¢‚é‚©‚çپA
ARMv8‚ج“ئژ©ƒRƒAٹJ”‚ة‚ـ‚إ“¥‚فگط‚é’iٹK‚ة‚«‚½‚ج‚إ‚ ‚ء‚ؤپA
ARMv8‚ً”„‚肽‚¢‚©‚çپAARMv8‚ج“ئژ©ƒRƒA‚ًٹJ”‚·‚é‚©‚ç‹؛ˆذ‚ب‚ٌ‚¶‚ل‚ب‚¢‚¾‚낤پB
‹t‚ة”„‚é‚à‚ج‚ھٹù‚ة‚ ‚ء‚ؤپAˆê’ِ“xˆبڈم”„‚ê‚邱‚ئ‚ھ‚ ‚ê‚خپA‹Zڈp‚ء‚ؤ‚ج‚حٹO‚©‚甃‚¦‚éپB
ژہچغپASamsung‚جARMv8ٹJ”‚ء‚ؤپAŒ³AMD‚جBobcat/Jaguarƒ`پ[ƒ€‚جˆّ‚«”²‚«‚¾‚µپB
“ْ–{‚à•ت‚ة‹Zڈp—ح‚إ‘خچR‚إ‚«‚ؤ‚ب‚¢‚ٌ‚¶‚ل‚ب‚‚ؤپA‚ا‚¤‚¢‚¤ڈ¤•i‚ًچى‚ê‚خ”„‚ê‚é‚ج‚©?‚ء‚ؤ‚¢‚ئ‚±‚ë‚ج
Œ©گط‚è‚إ•‰‚¯‚ؤ‚¢‚é‚ٌ‚إ‚µ‚هپB
ƒXƒpƒRƒ“‚à“¯‚¶‚إپA—‘z‚ًŒ¾‚¦‚خپAŒRژ–‚ة‚µ‚ë‰بٹw‹ZڈpŒvژZ‚ة‚µ‚ëƒ\ƒtƒg‚جŒ¤‹†‚ة‚µ‚ëپA
ƒXƒpƒRƒ“‚ج•K—v‚ئ‚·‚鑤‚جژY‹ئ‚ھ‚¤‚ـ‚‚ي‚½‚ء‚ؤ‚¢‚ؤپA‚©‚آ—ک—pژز‚جƒٹƒeƒ‰ƒV‚ھچL‚چs‚«“n‚ء‚ؤ‚¢‚ê‚خپA
–³—‚ة–ع“I‚ھB–†‚ج‚ـ‚ـ1ˆت‘_‚¢‚إƒ}ƒVƒ“چى‚ç‚ب‚‚ؤ‚àپA–{—ˆڈںژè‚ةTOP500‚ةƒ‰ƒ“ƒN‚³‚ê‚éƒ}ƒVƒ“‚ح‘‚¦‚éپB
‚»‚ê‚ح‰ًژك‚جڈ‡”ش‚ھ‹t‚ب‚ٌ‚¾‚و‚بپB
Samsung‚حپAƒXƒ}ƒz/ƒ^ƒuƒŒƒbƒg”„‚肽‚¢‚µپAژہچغ”„‚ê‚ؤ‚¢‚é‚©‚çپA
ARMv8‚ج“ئژ©ƒRƒAٹJ”‚ة‚ـ‚إ“¥‚فگط‚é’iٹK‚ة‚«‚½‚ج‚إ‚ ‚ء‚ؤپA
ARMv8‚ً”„‚肽‚¢‚©‚çپAARMv8‚ج“ئژ©ƒRƒA‚ًٹJ”‚·‚é‚©‚ç‹؛ˆذ‚ب‚ٌ‚¶‚ل‚ب‚¢‚¾‚낤پB
‹t‚ة”„‚é‚à‚ج‚ھٹù‚ة‚ ‚ء‚ؤپAˆê’ِ“xˆبڈم”„‚ê‚邱‚ئ‚ھ‚ ‚ê‚خپA‹Zڈp‚ء‚ؤ‚ج‚حٹO‚©‚甃‚¦‚éپB
ژہچغپASamsung‚جARMv8ٹJ”‚ء‚ؤپAŒ³AMD‚جBobcat/Jaguarƒ`پ[ƒ€‚جˆّ‚«”²‚«‚¾‚µپB
“ْ–{‚à•ت‚ة‹Zڈp—ح‚إ‘خچR‚إ‚«‚ؤ‚ب‚¢‚ٌ‚¶‚ل‚ب‚‚ؤپA‚ا‚¤‚¢‚¤ڈ¤•i‚ًچى‚ê‚خ”„‚ê‚é‚ج‚©?‚ء‚ؤ‚¢‚ئ‚±‚ë‚ج
Œ©گط‚è‚إ•‰‚¯‚ؤ‚¢‚é‚ٌ‚إ‚µ‚هپB
ƒXƒpƒRƒ“‚à“¯‚¶‚إپA—‘z‚ًŒ¾‚¦‚خپAŒRژ–‚ة‚µ‚ë‰بٹw‹ZڈpŒvژZ‚ة‚µ‚ëƒ\ƒtƒg‚جŒ¤‹†‚ة‚µ‚ëپA
ƒXƒpƒRƒ“‚ج•K—v‚ئ‚·‚鑤‚جژY‹ئ‚ھ‚¤‚ـ‚‚ي‚½‚ء‚ؤ‚¢‚ؤپA‚©‚آ—ک—pژز‚جƒٹƒeƒ‰ƒV‚ھچL‚چs‚«“n‚ء‚ؤ‚¢‚ê‚خپA
–³—‚ة–ع“I‚ھB–†‚ج‚ـ‚ـ1ˆت‘_‚¢‚إƒ}ƒVƒ“چى‚ç‚ب‚‚ؤ‚àپA–{—ˆڈںژè‚ةTOP500‚ةƒ‰ƒ“ƒN‚³‚ê‚éƒ}ƒVƒ“‚ح‘‚¦‚éپB
100‰پA200‰’ِ“x‚إ‚حگVƒvƒچƒZƒbƒT‚ـ‚إچى‚ê‚ب‚¢‚¾‚ëپH
ٹOچ‘گ»‚جCPU‚ًژg‚ء‚ؤچى‚ء‚½ƒXƒpƒRƒ“‚ًچ‘ژY‚ئŒؤ‚ش‚ج‚حٹٹŒm‚¾
ٹOچ‘گ»‚جCPU‚ًژg‚ء‚ؤچى‚ء‚½ƒXƒpƒRƒ“‚ًچ‘ژY‚ئŒؤ‚ش‚ج‚حٹٹŒm‚¾
ŒvژZ—ت‚ً•K—v‚ئ‚µ‚ؤ‚éگl‚ھ‹‚ًژ©—R‚ةژg‚¦‚ب‚¢‚ٌ‚¾‚©‚ç‘e‘هƒSƒ~‚ئ•د‚ي‚ç‚ٌپB
گ«”\‚ھ‚¢‚‚ç—ٍ‚낤‚ئپAٹeŒ¤‹†ڈٹپAŒ¤‹†ژ؛‚ةƒXƒpƒRƒ“‚ھ‚ب‚¢‚ئ–ً‚ة—§‚½‚ب‚¢پB
گ«”\‚ھ‚¢‚‚ç—ٍ‚낤‚ئپAٹeŒ¤‹†ڈٹپAŒ¤‹†ژ؛‚ةƒXƒpƒRƒ“‚ھ‚ب‚¢‚ئ–ً‚ة—§‚½‚ب‚¢پB
>>639
•xژm’ت‚¾‚ء‚ؤSPARC64‚ًچى‚ء‚ؤƒTپ[ƒo”„‚ء‚ؤ‚邾‚ëپH
چ،‚â–{‰ئƒIƒ‰ƒNƒ‹‚ة•C“G‚·‚é‚‚ç‚¢‚جƒVƒFƒA‚ ‚邼
•xژm’ت‚ھژ©ژذƒTپ[ƒoŒü‚¯‚ةSPARC64‚ًچى‚葱‚¯‚½‚©‚çچ،‚ھ‚ ‚邵
‹‚إ”|‚ء‚½‹Zڈp‚حƒnƒCƒGƒ“ƒhƒTپ[ƒoŒü‚¯‚جSPARC64 X‚ب‚ا‚ة‰—p‚³‚ê‚ؤ‚¢‚é
•xژm’ت‚¾‚ء‚ؤSPARC64‚ًچى‚ء‚ؤƒTپ[ƒo”„‚ء‚ؤ‚邾‚ëپH
چ،‚â–{‰ئƒIƒ‰ƒNƒ‹‚ة•C“G‚·‚é‚‚ç‚¢‚جƒVƒFƒA‚ ‚邼
•xژm’ت‚ھژ©ژذƒTپ[ƒoŒü‚¯‚ةSPARC64‚ًچى‚葱‚¯‚½‚©‚çچ،‚ھ‚ ‚邵
‹‚إ”|‚ء‚½‹Zڈp‚حƒnƒCƒGƒ“ƒhƒTپ[ƒoŒü‚¯‚جSPARC64 X‚ب‚ا‚ة‰—p‚³‚ê‚ؤ‚¢‚é
643 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 11:29:46.51 ID:NgNK3ZSO
پuچ‘ژY‚¶‚ل‚ب‚¢‚ئ‚¾‚ك‚ب‚ٌ‚إ‚·‚©پHپv‚ئپB
Œ¤‹†ٹJ”‚جŒ»ڈê‚حچ‘ژY‚¾‚낤‚ھ‚ب‚©‚낤‚ھچ،ژg‚¦‚鑬‚¢‚à‚ج‚ً
‹پ‚ك‚ؤ‚é‚ي‚¯‚إپATesla‚إ‚àXeon Phi‚إ‚à‚©‚ـ‚ي‚ب‚¢‚وپB
VenusƒAپ[ƒLƒeƒNƒ`ƒƒ‚حگ¢ٹE‚إ‹£‘ˆ—ح‚ًژ‚ء‚ؤ‚¢‚é‚©پH
”غپB
Œ¤‹†ٹJ”‚جŒ»ڈê‚حچ‘ژY‚¾‚낤‚ھ‚ب‚©‚낤‚ھچ،ژg‚¦‚鑬‚¢‚à‚ج‚ً
‹پ‚ك‚ؤ‚é‚ي‚¯‚إپATesla‚إ‚àXeon Phi‚إ‚à‚©‚ـ‚ي‚ب‚¢‚وپB
VenusƒAپ[ƒLƒeƒNƒ`ƒƒ‚حگ¢ٹE‚إ‹£‘ˆ—ح‚ًژ‚ء‚ؤ‚¢‚é‚©پH
”غپB
IntelگMژز‚ج‘½‚¢‚±‚جƒXƒŒ‚إ‚»‚¤‚¢‚¤کb‚حچr‚ê‚é‚©‚ç‚â‚ك‚ؤ‚¨‚
>>642
‚¾‚©‚çپA—v‚·‚é‚ةƒXƒpƒRƒ“’P“ئƒlƒ^‚إٹو’£‚ء‚ؤ‹ZڈpٹJ”‚µ‚ؤ‚à‘ت–ع‚ء‚ؤ‚±‚ئ‚إ‚µ‚هپB
‘¼‚جژY‹ئ‚ھ‚¤‚ـ‚‰ٌ‚ء‚ؤ‚ب‚¢‚ئ‹ZڈpٹJ”‚ةژ‘±—ح‚ب‚¢‚©‚çˆس–،‚ب‚¢پB
ƒXƒpƒRƒ“‚جچ‘‰ئƒvƒچƒWƒFƒNƒg‚حژ–ژہڈمپAƒnپ[ƒh‚جگ»•iٹJ”‚ة‚ب‚ء‚؟‚ل‚ء‚ؤ‚é‚ج‚ھ‚و‚‚ب‚¢پB
ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚¾‚¯‚ب‚çپAPC‚إ‚à‚إ‚«‚é‚ٌ‚¾‚©‚çپA‚ـ‚¸‚ح—Œn‚ب‚çٹwگ¶‚ج‚ئ‚«‚©‚çƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‹Zڈp‚جƒٹƒeƒ‰ƒV‚ً‚آ‚¯‚ؤپA
ƒpƒ\ƒRƒ“‚إ‚¢‚¢‚©‚瑽‚‚جگl‚ھƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“ƒvƒچƒOƒ‰ƒ€‚ًڈ‘‚¢‚½‚èپA—ک—p‚µ‚½‚肵‚ؤ‚ب‚¢‚ئپB
‘ه‹K–ح‚بŒvژZ‚ھ–{“–‚ة•K—v‚ب‚ئ‚«‚ة‚¾‚¯ƒXƒpƒRƒ“ژg‚¦‚خ‚¢‚¢‚ٌ‚¾‚وپB
ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚جƒٹƒeƒ‰ƒV‚ًژ‚ء‚ؤ‚¢‚éگlچق‚ھ‘‚¦‚ê‚خپA‘ه‹K–ح‚بŒvژZ‚·‚é‚ج‚ةƒXƒpƒRƒ“ژg‚¨‚¤‚©?‚ء‚ؤگl‚àڈ«—ˆ“I‚ة‘‚¦‚éپB
‚¾‚©‚çپA—v‚·‚é‚ةƒXƒpƒRƒ“’P“ئƒlƒ^‚إٹو’£‚ء‚ؤ‹ZڈpٹJ”‚µ‚ؤ‚à‘ت–ع‚ء‚ؤ‚±‚ئ‚إ‚µ‚هپB
‘¼‚جژY‹ئ‚ھ‚¤‚ـ‚‰ٌ‚ء‚ؤ‚ب‚¢‚ئ‹ZڈpٹJ”‚ةژ‘±—ح‚ب‚¢‚©‚çˆس–،‚ب‚¢پB
ƒXƒpƒRƒ“‚جچ‘‰ئƒvƒچƒWƒFƒNƒg‚حژ–ژہڈمپAƒnپ[ƒh‚جگ»•iٹJ”‚ة‚ب‚ء‚؟‚ل‚ء‚ؤ‚é‚ج‚ھ‚و‚‚ب‚¢پB
ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚¾‚¯‚ب‚çپAPC‚إ‚à‚إ‚«‚é‚ٌ‚¾‚©‚çپA‚ـ‚¸‚ح—Œn‚ب‚çٹwگ¶‚ج‚ئ‚«‚©‚çƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‹Zڈp‚جƒٹƒeƒ‰ƒV‚ً‚آ‚¯‚ؤپA
ƒpƒ\ƒRƒ“‚إ‚¢‚¢‚©‚瑽‚‚جگl‚ھƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“ƒvƒچƒOƒ‰ƒ€‚ًڈ‘‚¢‚½‚èپA—ک—p‚µ‚½‚肵‚ؤ‚ب‚¢‚ئپB
‘ه‹K–ح‚بŒvژZ‚ھ–{“–‚ة•K—v‚ب‚ئ‚«‚ة‚¾‚¯ƒXƒpƒRƒ“ژg‚¦‚خ‚¢‚¢‚ٌ‚¾‚وپB
ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚جƒٹƒeƒ‰ƒV‚ًژ‚ء‚ؤ‚¢‚éگlچق‚ھ‘‚¦‚ê‚خپA‘ه‹K–ح‚بŒvژZ‚·‚é‚ج‚ةƒXƒpƒRƒ“ژg‚¨‚¤‚©?‚ء‚ؤگl‚àڈ«—ˆ“I‚ة‘‚¦‚éپB
>>645
‚ ‚ئ10”N‚‚ç‚¢‚إƒVƒٹƒRƒ“‚ًژg‚ء‚½”¼“±‘ج‚ھ
”÷چ׉»‚جŒہٹE‚ًŒ}‚¦‚é‚ٌ‚¾‚©‚ç‚ ‚ئ‚à‚¤ڈ‚µ‚¾‚ë
‚»‚êˆبŒم‚جƒRƒ“ƒsƒ…پ[ƒ^‚جگ«”\Œüڈم‚ح“ف‰»‚µ‚ؤ‚¢‚
چ،پAƒٹƒ^ƒCƒ„‚µ‚½‚ç‚à‚ء‚½‚¢‚ب‚¢
‚ ‚ئ10”N‚‚ç‚¢‚إƒVƒٹƒRƒ“‚ًژg‚ء‚½”¼“±‘ج‚ھ
”÷چ׉»‚جŒہٹE‚ًŒ}‚¦‚é‚ٌ‚¾‚©‚ç‚ ‚ئ‚à‚¤ڈ‚µ‚¾‚ë
‚»‚êˆبŒم‚جƒRƒ“ƒsƒ…پ[ƒ^‚جگ«”\Œüڈم‚ح“ف‰»‚µ‚ؤ‚¢‚
چ،پAƒٹƒ^ƒCƒ„‚µ‚½‚ç‚à‚ء‚½‚¢‚ب‚¢
>>646
‚»‚ê‚ھ‚ب‚ٌ‚إپAƒXƒpƒRƒ“‚ئ‚¢‚¤ƒRƒ“ƒsƒ…پ[ƒ^‚ج“ء’è‚جˆêƒWƒƒƒ“ƒ‹‚ةŒ‹‚ر‚آ‚¢‚ؤ‚¢‚‚ج‚©ˆس–،•s–¾‚¾‚بپB
1100‰‰~‚ج—\ژZ‚ھ‚ ‚é‚ب‚çپAƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً—ک—p‚إ‚«‚éگlچقپAƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‹Zڈp‚ًٹJ”‚إ‚«‚éگlچق‚ج
ˆçگ¬•û–@‚ً“ھ”P‚ء‚ؤپA‚¤‚ـ‚چl‚¦‚ؤپA‚»‚±‚ة‚¨‹à“ٹ“ü‚µ‚½‚ظ‚¤‚ھ—ا‚¢‚وپBگ³’¼پA1100‰‚à‚¢‚ç‚ٌ‚ئژv‚¤‚ھپB
‚»‚ê‚إڈ«—ˆ“I‚بژù—v‚ًٹ«‹N‚إ‚«‚é‚ٌ‚ب‚çپAƒXƒpƒRƒ“ƒپپ[ƒJپ[‚ة‚ئ‚ء‚ؤ‚à–عگوچ‚گ«”\‚بƒRƒ“ƒsƒ…پ[ƒ^‚جٹJ”‚ًˆب—ˆ‚³‚ê‚邱‚ئ‚و‚è‚àپA
‚و‚ء‚غ‚اڈ¤”„ڈم‚جڈ•‚¯‚ة‚ب‚éپB
‚»‚ê‚ھ‚ب‚ٌ‚إپAƒXƒpƒRƒ“‚ئ‚¢‚¤ƒRƒ“ƒsƒ…پ[ƒ^‚ج“ء’è‚جˆêƒWƒƒƒ“ƒ‹‚ةŒ‹‚ر‚آ‚¢‚ؤ‚¢‚‚ج‚©ˆس–،•s–¾‚¾‚بپB
1100‰‰~‚ج—\ژZ‚ھ‚ ‚é‚ب‚çپAƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً—ک—p‚إ‚«‚éگlچقپAƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‹Zڈp‚ًٹJ”‚إ‚«‚éگlچق‚ج
ˆçگ¬•û–@‚ً“ھ”P‚ء‚ؤپA‚¤‚ـ‚چl‚¦‚ؤپA‚»‚±‚ة‚¨‹à“ٹ“ü‚µ‚½‚ظ‚¤‚ھ—ا‚¢‚وپBگ³’¼پA1100‰‚à‚¢‚ç‚ٌ‚ئژv‚¤‚ھپB
‚»‚ê‚إڈ«—ˆ“I‚بژù—v‚ًٹ«‹N‚إ‚«‚é‚ٌ‚ب‚çپAƒXƒpƒRƒ“ƒپپ[ƒJپ[‚ة‚ئ‚ء‚ؤ‚à–عگوچ‚گ«”\‚بƒRƒ“ƒsƒ…پ[ƒ^‚جٹJ”‚ًˆب—ˆ‚³‚ê‚邱‚ئ‚و‚è‚àپA
‚و‚ء‚غ‚اڈ¤”„ڈم‚جڈ•‚¯‚ة‚ب‚éپB
>>647
‚»‚ج1000‰‚ج—\ژZ‚ج’†‚ةƒ\ƒtƒgƒEƒFƒAٹJ”‚ج”ï—p‚àٹـ‚ـ‚ê‚ؤ‚é‚و
‚»‚ج1000‰‚ج—\ژZ‚ج’†‚ةƒ\ƒtƒgƒEƒFƒAٹJ”‚ج”ï—p‚àٹـ‚ـ‚ê‚ؤ‚é‚و
>>648
‚»‚è‚لپAگV‹Kƒnپ[ƒh‚ًٹJ”‚µ‚ؤپAƒ\ƒtƒg‚جگV‹KٹJ”‚ھ‘S‚‚ب‚¢‚ب‚ٌ‚ؤ‚ ‚蓾‚ب‚¢‚©‚ç‚بپB
wikipediaƒ\پ[ƒX‚إ‚ح‚ ‚é‚ھپA‹‚جٹJ””ï‚ج‘ه•”•ھ‚ح•xژm’ت‚جƒnپ[ƒh‚ةژg‚ي‚ê‚ؤ‚¢‚éپB
>‹‚جٹJ””ï‚ح‘چٹz1120‰‰~‚إپA‚¤‚؟665‰‰~‚ھ•xژm’ت‚ة‚و‚鉉ژZ‘•’u‚جٹJ”‚ة“ٹ“ü‚³‚êپA•xژm’ت‚ح‰‰ژZ‘•’u‚جٹj‚ئ‚ب‚锼“±‘جƒ`ƒbƒvٹJ”—p‚ةژOڈdچHڈê‚ةگ»‘¢گف”ُ‚ًگVگف‚µ‚½
‚»‚è‚لپAگV‹Kƒnپ[ƒh‚ًٹJ”‚µ‚ؤپAƒ\ƒtƒg‚جگV‹KٹJ”‚ھ‘S‚‚ب‚¢‚ب‚ٌ‚ؤ‚ ‚蓾‚ب‚¢‚©‚ç‚بپB
wikipediaƒ\پ[ƒX‚إ‚ح‚ ‚é‚ھپA‹‚جٹJ””ï‚ج‘ه•”•ھ‚ح•xژm’ت‚جƒnپ[ƒh‚ةژg‚ي‚ê‚ؤ‚¢‚éپB
>‹‚جٹJ””ï‚ح‘چٹz1120‰‰~‚إپA‚¤‚؟665‰‰~‚ھ•xژm’ت‚ة‚و‚鉉ژZ‘•’u‚جٹJ”‚ة“ٹ“ü‚³‚êپA•xژm’ت‚ح‰‰ژZ‘•’u‚جٹj‚ئ‚ب‚锼“±‘جƒ`ƒbƒvٹJ”—p‚ةژOڈdچHڈê‚ةگ»‘¢گف”ُ‚ًگVگف‚µ‚½
ID:n1FCpugv
ƒAƒz‚·‚¬
ƒAƒz‚·‚¬
ƒnƒCƒGƒ“ƒhƒTپ[ƒoŒü‚¯‚جCPU‚ًچى‚ء‚ؤ‚é‚ج‚ح
IBM‚ئIntel‚ئƒIƒ‰ƒNƒ‹‚ئ•xژm’ت
•xژm’تˆبٹO‚ح‚·‚ׂؤƒAƒپƒٹƒJ‚ج‰ïژذ
“ْ–{‚حژ©‹s“I‚ة‚ب‚ç‚ب‚‚ؤ‚à‚¢‚¢‚ج‚ة
IBM‚ئIntel‚ئƒIƒ‰ƒNƒ‹‚ئ•xژm’ت
•xژm’تˆبٹO‚ح‚·‚ׂؤƒAƒپƒٹƒJ‚ج‰ïژذ
“ْ–{‚حژ©‹s“I‚ة‚ب‚ç‚ب‚‚ؤ‚à‚¢‚¢‚ج‚ة
1000‰‚‚ç‚¢‚ج–³‘تŒ‚¢‚ح‘¼‚ة‚½‚‚³‚ٌ‚ ‚é‚ج‚ة
ƒXƒpƒRƒ“‚âƒچƒPƒbƒgٹJ”‚ة‚ح”ٌ“ï‚ھڈW’†‚·‚é
‚ا‚ٌ‚بگl‚½‚؟‚ھ”ٌ“‚ؤ‚é‚©‚ي‚·‚®‚ة‚ي‚©‚é
ƒXƒpƒRƒ“‚âƒچƒPƒbƒgٹJ”‚ة‚ح”ٌ“ï‚ھڈW’†‚·‚é
‚ا‚ٌ‚بگl‚½‚؟‚ھ”ٌ“‚ؤ‚é‚©‚ي‚·‚®‚ة‚ي‚©‚é
ƒCƒ“ƒh‚إ‚·‚ç‰خگ¯’Tچ¸‰qگ¯‚ًژ©—ح‚إ‘إ‚؟ڈم‚°‚éژ‘م‚¾‚¼پH
654 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 12:24:22.33 ID:NgNK3ZSO
ƒnپ[ƒh‚جگV‹KٹJ”‚ةژg‚¤‹à‚ھ‚ ‚é‚ب‚çٹù‘¶‚ج‚ ‚è‚à‚ج‚ج
ƒnپ[ƒh‚ً”ƒ‚¤‚½‚ك‚ةژg‚ء‚ؤ‚ ‚°‚ؤ‚‚¾‚³‚¢پB
ƒAƒپƒٹƒJ‚حPS3‚ًƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚ؤƒXƒpƒRƒ“‚ًژg‚¤‚‚ç‚¢‚ة‚½‚‚ـ‚µ‚¢‚¼
ƒnپ[ƒh‚ً”ƒ‚¤‚½‚ك‚ةژg‚ء‚ؤ‚ ‚°‚ؤ‚‚¾‚³‚¢پB
ƒAƒپƒٹƒJ‚حPS3‚ًƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚ؤƒXƒpƒRƒ“‚ًژg‚¤‚‚ç‚¢‚ة‚½‚‚ـ‚µ‚¢‚¼
PS3ژg‚ء‚½‚ج‚حچإگو’[‚ج‚ًچى‚낤‚ء‚ؤƒvƒچƒWƒFƒNƒg‚¶‚ل‚ب‚¢‚¾‚ë‚—
پuچى‚肽‚¢‚â‚آ‚ھچى‚肽‚¢‚à‚ج‚ًچى‚éپv‚¾‚ëپB
گ¢ٹEˆê‚جƒXƒpƒRƒ“‚ھچى‚肽‚¢“z‚ھڈW‚ـ‚ء‚ؤ‹‚ًچى‚ء‚½پBٹب’P‚ب‚±‚ئ‚¾پB
’cژq‚ھ‚ ‚è‚à‚جƒnپ[ƒh‚إƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚½‚¢‚ب‚ç‚â‚ê‚خ‚¢‚¢پB‚µ‚©‚é‚ׂ«گlٹشگà“¾‚µ‚ؤ—\ژZ’ت‚¹‚خچى‚ê‚éپB
گ¢ٹEˆê‚جƒXƒpƒRƒ“‚ھچى‚肽‚¢“z‚ھڈW‚ـ‚ء‚ؤ‹‚ًچى‚ء‚½پBٹب’P‚ب‚±‚ئ‚¾پB
’cژq‚ھ‚ ‚è‚à‚جƒnپ[ƒh‚إƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚½‚¢‚ب‚ç‚â‚ê‚خ‚¢‚¢پB‚µ‚©‚é‚ׂ«گlٹشگà“¾‚µ‚ؤ—\ژZ’ت‚¹‚خچى‚ê‚éپB
پu’cژqƒVƒ~ƒ…ƒŒپ[ƒ^پv‚ج’aگ¶‚إ‚ ‚éپB
658 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 12:57:30.78 ID:NgNK3ZSO
>>655
ƒXƒpƒRƒ“‚ًژg‚ء‚ؤƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚µ‚ؤگVژY‹ئ‚ة‚ا‚¤–ً—§‚ؤ‚é‚ھƒXƒpƒRƒ“‚ج
ژg–½‚إ‚ ‚ء‚ؤپAپuچإگو’[‚ًچى‚邱‚ئپv‚ً–ع“I‚ة‚µ‚ب‚¢‚إ‚ظ‚µ‚¢‚ج‚¾‚ھ
ƒXƒpƒRƒ“‚ًژg‚ء‚ؤƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚µ‚ؤگVژY‹ئ‚ة‚ا‚¤–ً—§‚ؤ‚é‚ھƒXƒpƒRƒ“‚ج
ژg–½‚إ‚ ‚ء‚ؤپAپuچإگو’[‚ًچى‚邱‚ئپv‚ً–ع“I‚ة‚µ‚ب‚¢‚إ‚ظ‚µ‚¢‚ج‚¾‚ھ
659 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 12:58:48.11 ID:NgNK3ZSO
>>656
ƒAƒپƒٹƒJ‚ح‚»‚ê‚إ‚¢‚ë‚ٌ‚ب“ء‰»Œ^ƒXƒpƒRƒ“‚ًچى‚ء‚ؤ‚é‚©‚爳“|“I‚ة‹‚¢‚ٌ‚¾‚وپB
ƒAƒپƒٹƒJ‚ح‚»‚ê‚إ‚¢‚ë‚ٌ‚ب“ء‰»Œ^ƒXƒpƒRƒ“‚ًچى‚ء‚ؤ‚é‚©‚爳“|“I‚ة‹‚¢‚ٌ‚¾‚وپB
’cژq‚à‚»‚ë‚»‚ëپu‚¨‘O‚ç‚»‚ٌ‚ب‚ج‚â‚é‚بپv‚¶‚ل‚ب‚‚ؤپu‰´‚ھ‚â‚邱‚ê‚ًŒ©‚ëپv‚¶‚ل‚ب‚¢‚ئŒê‚ê‚ب‚‚ب‚é”N—‚낤پB
>>658
‚»‚ê‚ح’P‚ةŒآگl‚جچl‚¦•û‚¾‚بپB‚»‚¤‚¢‚¤چl‚¦‚à‚ ‚肾‚낤‚¯‚اپAگâ‘خ“I‚بگ³‹`‚إ‚à‚ب‚¢
‚»‚ê‚ح’P‚ةŒآگl‚جچl‚¦•û‚¾‚بپB‚»‚¤‚¢‚¤چl‚¦‚à‚ ‚肾‚낤‚¯‚اپAگâ‘خ“I‚بگ³‹`‚إ‚à‚ب‚¢
662 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 13:09:41.39 ID:NgNK3ZSO
1000‰ژg‚¤‚±‚ئ‚ھ–â‘è‚ب‚ٌ‚¶‚ل‚ب‚‚ؤ
ژ©‘OٹJ”‚ة‚±‚¾‚ي‚ء‚½Œ‹‰ت‚ئ‚µ‚ؤ”ï—p‘خŒّ‰ت‚ھڈ‚ب‚¢‚±‚ئ‚ھ
Venus‚حٹCٹO‚إ‚ح‘S‚”„‚ê‚ؤ‚ب‚¢‚µ
‚ب‚¯‚ب‚µ‚جچ‘“àژù—v‚à
پu‹‚إ“®‚©‚·ƒRپ[ƒh‚جƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ةڈ¬‹K–ح‚ب‚à‚ج‚ً“±“üپv
‚ئپA‹‚ ‚è‚«‚ة‚ب‚ء‚ؤ‚µ‚ـ‚ء‚ؤ‚éپB
‘S‚چL‚ھ‚è‚ھ–³‚¢پB
SPARC64ژ©‘ج‚àXeon‚و‚è‹£‘ˆ—ح‚ً“¾‚½‚©‚ئ‚¢‚¤‚ئ
‚ـ‚ء‚½‚‚»‚ٌ‚ب‚±‚ئ‚ح‚ب‚¢‚ي‚¯‚إ
ژ©‘OٹJ”‚ة‚±‚¾‚ي‚ء‚½Œ‹‰ت‚ئ‚µ‚ؤ”ï—p‘خŒّ‰ت‚ھڈ‚ب‚¢‚±‚ئ‚ھ
Venus‚حٹCٹO‚إ‚ح‘S‚”„‚ê‚ؤ‚ب‚¢‚µ
‚ب‚¯‚ب‚µ‚جچ‘“àژù—v‚à
پu‹‚إ“®‚©‚·ƒRپ[ƒh‚جƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ةڈ¬‹K–ح‚ب‚à‚ج‚ً“±“üپv
‚ئپA‹‚ ‚è‚«‚ة‚ب‚ء‚ؤ‚µ‚ـ‚ء‚ؤ‚éپB
‘S‚چL‚ھ‚è‚ھ–³‚¢پB
SPARC64ژ©‘ج‚àXeon‚و‚è‹£‘ˆ—ح‚ً“¾‚½‚©‚ئ‚¢‚¤‚ئ
‚ـ‚ء‚½‚‚»‚ٌ‚ب‚±‚ئ‚ح‚ب‚¢‚ي‚¯‚إ
گ¬Œ÷‚µ‚½ژز‚ً”±‚·‚é‚بپB
گ¬Œ÷ژز‚إ‚à–â‘è‚ح‚ظ‚¶‚ê‚خ‚¢‚‚ç‚إ‚àڈo‚ؤ‚‚éپBگ¢ٹEˆêˆت‚ً‚ئ‚ء‚ؤ‚àپA‚â‚ê‹à‚ً‚©‚¯‚·‚¬‚¾‚ئ‚©پB
ژ¸”s‚إ‚ ‚ء‚ؤ‚à”±‚·‚é‚ج‚حگTڈd‚إ‚ ‚é‚ׂ«‚إپA‚ـ‚µ‚ؤ‚âگ¬Œ÷‚µ‚½ژز‚ً”±‚µ‚ؤ‚¢‚½‚çپA‚¾‚ê‚à’§گي‚µ‚ب‚‚ب‚éپB
گ¬Œ÷ژز‚إ‚à–â‘è‚ح‚ظ‚¶‚ê‚خ‚¢‚‚ç‚إ‚àڈo‚ؤ‚‚éپBگ¢ٹEˆêˆت‚ً‚ئ‚ء‚ؤ‚àپA‚â‚ê‹à‚ً‚©‚¯‚·‚¬‚¾‚ئ‚©پB
ژ¸”s‚إ‚ ‚ء‚ؤ‚à”±‚·‚é‚ج‚حگTڈd‚إ‚ ‚é‚ׂ«‚إپA‚ـ‚µ‚ؤ‚âگ¬Œ÷‚µ‚½ژز‚ً”±‚µ‚ؤ‚¢‚½‚çپA‚¾‚ê‚à’§گي‚µ‚ب‚‚ب‚éپB
چ،”„‚ê‚ؤ‚ب‚¢‚©‚ç‚ء‚ؤŒ¤‹†ژج‚ؤ‚ؤ‚ ‚è‚à‚ج‚إچد‚ـ‚¹‚ؤƒWƒٹ•n‚ء‚ؤ‚ج‚à‚و‚‚ ‚éکb‚¾‚µ‚ب‚—
665 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 13:28:33.13 ID:NgNK3ZSO
>>663
100‰‰~‹K–ح‚جƒXƒpƒRƒ“‚ة1پ`2”N‚إ”²‚©‚ê‚é‚ج‚ًگ¬Œ÷‚µ‚½‚ئ‚©
‚ا‚ٌ‚¾‚¯ƒnپ[ƒhƒ‹’ل‚¢‚ج
‹‚ج‚à‚ئ‚à‚ئ‚جŒv‰و‚ة‚ح‹‚ج‹Zڈp‚ج—Aڈo‚à“ü‚ء‚ؤ‚½‚ھ”ƒ‚¢ژè‚ح‚آ‚©‚¸
’Bگ¬‚إ‚«‚ؤ‚¢‚ب‚¢پB
100‰‰~‹K–ح‚جƒXƒpƒRƒ“‚ة1پ`2”N‚إ”²‚©‚ê‚é‚ج‚ًگ¬Œ÷‚µ‚½‚ئ‚©
‚ا‚ٌ‚¾‚¯ƒnپ[ƒhƒ‹’ل‚¢‚ج
‹‚ج‚à‚ئ‚à‚ئ‚جŒv‰و‚ة‚ح‹‚ج‹Zڈp‚ج—Aڈo‚à“ü‚ء‚ؤ‚½‚ھ”ƒ‚¢ژè‚ح‚آ‚©‚¸
’Bگ¬‚إ‚«‚ؤ‚¢‚ب‚¢پB
چ،‚ح‚¨‹à‚ھ‚ ‚ê‚خŒآگl‚إ‚àƒXƒpƒRƒ“‚ًچى‚낤‚ئژv‚¦‚خڈo—ˆ‚ب‚‚ح‚ب‚¢‚©‚ç‚¢‚¢ژ‘م‚ة‚ب‚ء‚½‚à‚ٌ‚¾‚ب
ƒfƒXƒNƒgƒbƒvƒpƒ\ƒRƒ“‚ةƒ^ƒCƒ^ƒ“‚ً2–‡‘}‚·‚¾‚¯‚إŒo—ڈمƒXƒpƒRƒ“ˆµ‚¢‚ة‚ب‚éƒXƒpƒRƒ“‚ًچى‚ê‚é
668 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/17(“ْ) 14:32:40.91 ID:NgNK3ZSO
پu1.5TFLOPSˆبڈم‚إƒXƒpƒRƒ“پv‚ء‚ؤ‚¢‚¤ٹîڈ€‚جکb‚ً‚µ‚ؤ‚é‚ب‚ç
‹t‚ةŒآگl‚إ‚ب‚¢‚ئ‚«‚آ‚‚ثپH
Teslaڈمˆت‚âXeon Phi‚حƒJپ[ƒh1–‡‚إ1TFLOPS‚ً’´‚¦‚ؤ‚é‚©‚ç
2–‡ˆبڈمگد‚ٌ‚¾ژ“_‚إŒِ”ï‚إچw“ü‚·‚é‚ج‚ھ–ت“|‚ة‚ب‚éپB
‘هٹw‚ة‚¨‚낵‚ؤ‚éHPCƒxƒ“ƒ_پ[‚إ‚àXeon Phi“‹چعƒTپ[ƒo‚ح
ƒJپ[ƒh1–‡چ·‚µ‚ج‚ًŒ©‚邾‚¯‚إپA2–‡‘}‚µˆبڈم‚جƒ‰ƒCƒ“ƒiƒbƒv‚ً
‚ب‚©‚ب‚©Œ©‚©‚¯‚ب‚¢‚ج‚ح‚»‚¤‚¢‚¤‚±‚ئ‚إ‚·‚µپB
‚ـ‚ پAژ„—§‘هٹw‚ھ–ôگi‚·‚éƒ`ƒƒƒ“ƒX‚إ‚à‚ ‚é‚ئ‚ح‚¢‚¦‚é‚©پEپEپE
‹t‚ةŒآگl‚إ‚ب‚¢‚ئ‚«‚آ‚‚ثپH
Teslaڈمˆت‚âXeon Phi‚حƒJپ[ƒh1–‡‚إ1TFLOPS‚ً’´‚¦‚ؤ‚é‚©‚ç
2–‡ˆبڈمگد‚ٌ‚¾ژ“_‚إŒِ”ï‚إچw“ü‚·‚é‚ج‚ھ–ت“|‚ة‚ب‚éپB
‘هٹw‚ة‚¨‚낵‚ؤ‚éHPCƒxƒ“ƒ_پ[‚إ‚àXeon Phi“‹چعƒTپ[ƒo‚ح
ƒJپ[ƒh1–‡چ·‚µ‚ج‚ًŒ©‚邾‚¯‚إپA2–‡‘}‚µˆبڈم‚جƒ‰ƒCƒ“ƒiƒbƒv‚ً
‚ب‚©‚ب‚©Œ©‚©‚¯‚ب‚¢‚ج‚ح‚»‚¤‚¢‚¤‚±‚ئ‚إ‚·‚µپB
‚ـ‚ پAژ„—§‘هٹw‚ھ–ôگi‚·‚éƒ`ƒƒƒ“ƒX‚إ‚à‚ ‚é‚ئ‚ح‚¢‚¦‚é‚©پEپEپE
ٹwگ¶‚ة‚»‚ꂼ‚êƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^ˆê‘ن‚¸‚آ‘ف—^‚ئ‚©‚â‚ء‚½‚çپA‘fگl‚¾‚ـ‚·‚ج‚ة‚¢‚¢‚©‚à
GPGPU‚إ‚·‚ç‘S‘Rژg‚ء‚ؤ‚à‚炦‚ب‚¢‚ج‚ةٹwگ¶1TFLOPS•K—v‚ب‚¢‚¾‚ëپB
BASIC‚إƒoƒuƒ‹ƒ\پ[ƒg‚إ‚àڈ‘‚¢‚ؤ‚ëپB
BASIC‚إƒoƒuƒ‹ƒ\پ[ƒg‚إ‚àڈ‘‚¢‚ؤ‚ëپB
ٹwگ¶ˆêگl‚ذ‚ئ‚è‚ة‚ح•K—v‚ب‚¢‚ثپBƒXƒpƒRƒ“‚حڈيژ100پ“‰ز“‚³‚¹‘±‚¯‚ؤڈ‰‚ك‚ؤگ¶‚«‚ؤ‚‚éپBˆêگl‚ذ‚ئ‚è‚ة—^‚¦‚ؤ‚à‰ز“—¦‚ھ’ل‚‚ب‚ء‚ؤ–³‘ت‚¾
چ،‚ح–S‚«Orion‚جDS-96‚ھژv‚¢•‚‚©‚ٌ‚¾‰´پB
ƒAƒ‹ƒSƒٹƒYƒ€‚ًچى‚ء‚ؤ‚àچؤ”–¾‚خ‚ء‚©‚肾‚ء‚½‚¯‚ا–ت”’‚©‚ء‚½پB
‘¼گl‚جچl‚¦‚½‚à‚ج‚ً•×‹‚µ‚ؤ‚邾‚¯‚إ‚ح‘S‚‚آ‚ـ‚ç‚ٌپB
ژdژ–‚ب‚ç•×‹‚·‚ׂ«‚¾‚ھٹwگ¶‚جچ ‚¾‚©‚ç‚ـ‚ ‹–‚³‚ê‚邾‚낤پB
‘¼گl‚جچl‚¦‚½‚à‚ج‚ً•×‹‚µ‚ؤ‚邾‚¯‚إ‚ح‘S‚‚آ‚ـ‚ç‚ٌپB
ژdژ–‚ب‚ç•×‹‚·‚ׂ«‚¾‚ھٹwگ¶‚جچ ‚¾‚©‚ç‚ـ‚ ‹–‚³‚ê‚邾‚낤پB
ƒXƒpƒRƒ“’@‚¢‚ؤ‚é“z‚حپA’P‚ةƒJƒ^ƒچƒOƒXƒyƒbƒN‚جFLOPSگ”‚ئ‚©پALinpack‚µ‚©Œ©‚ؤ‚ب‚¢‚ٌ‚¾‚ëپH
ƒJƒ^ƒچƒOƒXƒyƒbƒN‚جFLOPSگ”‚âپALinpackƒxƒ“ƒ`‚ج‚ف‚ب‚çپAGPGPUƒNƒ‰ƒXƒ^‚â‚çپAXeon PhiƒNƒ‰ƒXƒ^‚ھ
‚¢‚؟‚خ‚ٌƒRƒXƒgƒpƒtƒHپ[ƒ}ƒ“ƒXپEƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ‚¢‚¢‚ھپAگ¢‚ج’†‚»‚¤“sچ‡‚ھ‚¢‚¢‰‰ژZ‚¾‚¯‚¶‚ل‚ب‚¢‚©‚ç‚ب
‚ ‚ئپAƒXƒpƒRƒ“‚ج”ï—p‚ء‚ؤ‚¢‚¤‚ج‚حپAچ‘چغ“I‚بٹîڈ€‚ھ‚ ‚é‚ي‚¯‚¶‚ل‚ب‚پA
‹‚حپAٹJ””ïپE“y’nŒڑ•¨‘مپEگlŒڈ”ïپEƒnپ[ƒh‘مپEƒ\ƒtƒg‘مپE‰^—p”ï“™پA•،گ””N“x—\ژZ‘S•”“ü‚ء‚½”ï—p‚¾‚©‚ç‚ب
ƒvƒچƒWƒFƒNƒg‘S‘ج”ï—p‚إŒvژZ‚µ‚ؤ‚é‚à‚ج‚ة‘خ‚µ‚ؤپAƒnپ[ƒh‘م‚ج‚ف‚إŒvژZ‚µ‚½ٹOچ‘‚جƒXƒpƒRƒ“‚ئ”نٹr‚³‚ê‚ê‚خ
ˆ³“|“I‚ةچ‚—\ژZ‚ةٹ´‚¶‚é
ƒJƒ^ƒچƒOƒXƒyƒbƒN‚جFLOPSگ”‚âپALinpackƒxƒ“ƒ`‚ج‚ف‚ب‚çپAGPGPUƒNƒ‰ƒXƒ^‚â‚çپAXeon PhiƒNƒ‰ƒXƒ^‚ھ
‚¢‚؟‚خ‚ٌƒRƒXƒgƒpƒtƒHپ[ƒ}ƒ“ƒXپEƒڈƒbƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚ھ‚¢‚¢‚ھپAگ¢‚ج’†‚»‚¤“sچ‡‚ھ‚¢‚¢‰‰ژZ‚¾‚¯‚¶‚ل‚ب‚¢‚©‚ç‚ب
‚ ‚ئپAƒXƒpƒRƒ“‚ج”ï—p‚ء‚ؤ‚¢‚¤‚ج‚حپAچ‘چغ“I‚بٹîڈ€‚ھ‚ ‚é‚ي‚¯‚¶‚ل‚ب‚پA
‹‚حپAٹJ””ïپE“y’nŒڑ•¨‘مپEگlŒڈ”ïپEƒnپ[ƒh‘مپEƒ\ƒtƒg‘مپE‰^—p”ï“™پA•،گ””N“x—\ژZ‘S•”“ü‚ء‚½”ï—p‚¾‚©‚ç‚ب
ƒvƒچƒWƒFƒNƒg‘S‘ج”ï—p‚إŒvژZ‚µ‚ؤ‚é‚à‚ج‚ة‘خ‚µ‚ؤپAƒnپ[ƒh‘م‚ج‚ف‚إŒvژZ‚µ‚½ٹOچ‘‚جƒXƒpƒRƒ“‚ئ”نٹr‚³‚ê‚ê‚خ
ˆ³“|“I‚ةچ‚—\ژZ‚ةٹ´‚¶‚é
675 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 00:05:03.64 ID:UR5NJH36
> “y’nŒڑ•¨‘م
ƒ|پ[ƒgƒAƒCƒ‰ƒ“ƒh2ٹْ‚ح“y’n‚ھ‚ظ‚عƒ^ƒ_‚ف‚½‚¢‚ب‚à‚ٌ‚¾‚ء‚½‚»‚¤‚إ‚·‚ھپB
‹ك‚‚ة–^ژ„—§‘هٹw‚ج‚إ‚©‚¢ƒLƒƒƒ“ƒpƒXˆع“]‚µ‚ؤ‚«‚½‚إ‚µ‚هپB
‚»‚ج’ِ“x‚ج’n‰؟پB
ƒ|پ[ƒgƒAƒCƒ‰ƒ“ƒh2ٹْ‚ح“y’n‚ھ‚ظ‚عƒ^ƒ_‚ف‚½‚¢‚ب‚à‚ٌ‚¾‚ء‚½‚»‚¤‚إ‚·‚ھپB
‹ك‚‚ة–^ژ„—§‘هٹw‚ج‚إ‚©‚¢ƒLƒƒƒ“ƒpƒXˆع“]‚µ‚ؤ‚«‚½‚إ‚µ‚هپB
‚»‚ج’ِ“x‚ج’n‰؟پB
676 پFSocket774پF2013/11/19(‰خ) 08:50:58.08 ID:xPm7OE+D
‚ـ‚½ƒ†ƒ_Œِ‚ھ–\‚ê‚ؤ‚ٌ‚ج‚©
“ْ–{گl‚ب‚çBlueWaters‚ً’@‚±‚¤‚؛
“ْ–{گl‚ب‚çBlueWaters‚ً’@‚±‚¤‚؛
‚ش‚ء‚؟‚ل‚¯”ï—p‘خŒّ‰ت‚ئ‚©‚ا‚¤‚إ‚à‚¢‚¢
ƒ‚ƒm‚ئ‚µ‚ؤ–ت”’‚¯‚ê‚خ‚»‚ê‚إ‚¢‚¢
ƒ‚ƒm‚ئ‚µ‚ؤ–ت”’‚¯‚ê‚خ‚»‚ê‚إ‚¢‚¢
FٹضŒWژز•Kژ€‚¾‚بپB
F‚ج—ک‰v = چ‘‚ج—ک‰v
‚¶‚ل‚ب‚¢‚إ‚µ‚هپB
F‚ج—ک‰v = چ‘‚ج—ک‰v
‚¶‚ل‚ب‚¢‚إ‚µ‚هپB
>>674
‚؟‚ل‚ٌ‚ئƒXƒŒ‚ج“à—e‚ف‚ؤ‚é?
’N‚àƒXƒpƒRƒ“‚»‚ج‚à‚ج‚ً’@‚¢‚ؤ‚¢‚é‚ي‚¯‚¶‚ل‚ب‚¢‚µپA‹‚ج—\ژZ‚ج‘ه•”•ھ‚حƒnپ[ƒh‚ةژg‚ي‚ê‚ؤ‚¢‚é‚ٌ‚¾‚ھپB
‚±‚جƒXƒŒ‚إLinpack‚µ‚©‚µ‚ç‚ٌ‚ب‚ٌ‚ؤ‚¢‚¤ڈ‰گSژز‚ح‚ئ‚ء‚‚ة‚¢‚ب‚¢‚µپA
ˆê”تƒjƒ…پ[ƒX‚ج’mژ¯‚إ’@‚©‚ê‚ؤ‚à‚بپB
‚؟‚ل‚ٌ‚ئƒXƒŒ‚ج“à—e‚ف‚ؤ‚é?
’N‚àƒXƒpƒRƒ“‚»‚ج‚à‚ج‚ً’@‚¢‚ؤ‚¢‚é‚ي‚¯‚¶‚ل‚ب‚¢‚µپA‹‚ج—\ژZ‚ج‘ه•”•ھ‚حƒnپ[ƒh‚ةژg‚ي‚ê‚ؤ‚¢‚é‚ٌ‚¾‚ھپB
‚±‚جƒXƒŒ‚إLinpack‚µ‚©‚µ‚ç‚ٌ‚ب‚ٌ‚ؤ‚¢‚¤ڈ‰گSژز‚ح‚ئ‚ء‚‚ة‚¢‚ب‚¢‚µپA
ˆê”تƒjƒ…پ[ƒX‚ج’mژ¯‚إ’@‚©‚ê‚ؤ‚à‚بپB
‘½‚ك‚ة‚ف‚ؤ‚àTofu Interconnect‚¾‚¯چى‚ê‚خ‚و‚‚ؤ
CPU‚ً1‚©‚çچى‚邱‚ئ‚ةŒإژ·‚µ‚ب‚¯‚ê‚خ‚à‚ء‚ئˆہ‚چد‚ٌ‚¾‚ح‚¸‚إ
“¯‚¶1000‰‚إ‹‚ئ“¯“™گ«”\‚جƒXƒpƒRƒ“‚ً‚Q‚آ‚©‚R‚آ‚حچى‚ꂽ‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ
‚»‚µ‚ؤ‚»‚ء‚؟‚ج‚ظ‚¤‚ھ“ْ–{‚جژY‹ئ‚ج”“W‚ة–ً—§‚ء‚ؤ‚½‚ج‚إ‚حپA‚ئ
ƒXƒpƒRƒ“‚ھژg‚¢‚½‚‚ؤ‚àژg‚¦‚ب‚¢‚ئ‚¢‚¤‘هٹw‚âٹé‹ئ‚ح‘½گ”‚ ‚é‚ي‚¯‚إ
چ‘ژYCPU‚إگ¢ٹEˆê‚ة‚·‚邱‚ئ‚ھ“ْ–{‚جژY‹ئ‚ة–ً—§‚آ‚ٌ‚¶‚ل‚ب‚‚ؤ
“ْ–{‚جژY‹ئ‚ة–ً—§‚آƒXƒpƒRƒ“‚ًپA—\ژZکg“à‚إچإ‘هŒہ‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚إ
چى‚é‚ׂ«‚ب‚ٌ‚¾‚وپB
ƒXƒpƒRƒ“‚ة1000‰‚©‚¯‚½‚±‚ئ‚ً”ٌ“ï‚·‚éگl‚حڈ‚ب‚¢پB
‚ق‚µ‚ë‰بٹw‹Zڈp—\ژZ‚ح‘‚â‚·‚ׂ«‚¾پB
‚½‚¾‚µ‚±‚ٌ‚بƒRƒXƒp‚جˆ«‚¢‚â‚è•û‚ح‚â‚ك‚ë‚ئ‚¢‚¤‚±‚ئپB
ژ¸”s‚ب‚ج‚ح’N‚ھŒ©‚ؤ‚à–¾‚ç‚©‚إ‚µ‚هپB
CPU‚ً1‚©‚çچى‚邱‚ئ‚ةŒإژ·‚µ‚ب‚¯‚ê‚خ‚à‚ء‚ئˆہ‚چد‚ٌ‚¾‚ح‚¸‚إ
“¯‚¶1000‰‚إ‹‚ئ“¯“™گ«”\‚جƒXƒpƒRƒ“‚ً‚Q‚آ‚©‚R‚آ‚حچى‚ꂽ‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ
‚»‚µ‚ؤ‚»‚ء‚؟‚ج‚ظ‚¤‚ھ“ْ–{‚جژY‹ئ‚ج”“W‚ة–ً—§‚ء‚ؤ‚½‚ج‚إ‚حپA‚ئ
ƒXƒpƒRƒ“‚ھژg‚¢‚½‚‚ؤ‚àژg‚¦‚ب‚¢‚ئ‚¢‚¤‘هٹw‚âٹé‹ئ‚ح‘½گ”‚ ‚é‚ي‚¯‚إ
چ‘ژYCPU‚إگ¢ٹEˆê‚ة‚·‚邱‚ئ‚ھ“ْ–{‚جژY‹ئ‚ة–ً—§‚آ‚ٌ‚¶‚ل‚ب‚‚ؤ
“ْ–{‚جژY‹ئ‚ة–ً—§‚آƒXƒpƒRƒ“‚ًپA—\ژZکg“à‚إچإ‘هŒہ‚جƒpƒtƒHپ[ƒ}ƒ“ƒX‚إ
چى‚é‚ׂ«‚ب‚ٌ‚¾‚وپB
ƒXƒpƒRƒ“‚ة1000‰‚©‚¯‚½‚±‚ئ‚ً”ٌ“ï‚·‚éگl‚حڈ‚ب‚¢پB
‚ق‚µ‚ë‰بٹw‹Zڈp—\ژZ‚ح‘‚â‚·‚ׂ«‚¾پB
‚½‚¾‚µ‚±‚ٌ‚بƒRƒXƒp‚جˆ«‚¢‚â‚è•û‚ح‚â‚ك‚ë‚ئ‚¢‚¤‚±‚ئپB
ژ¸”s‚ب‚ج‚ح’N‚ھŒ©‚ؤ‚à–¾‚ç‚©‚إ‚µ‚هپB
–¢’m‚ج‹Zڈp(–ع•W)‚ب‚ٌ‚ؤچإڈI–ع•W‚¾‚¯‚ف‚½‚瓾‚ؤ‚µ‚ؤƒRƒXƒgƒpƒtƒHپ[ƒ}ƒ“ƒX‚حچإˆ«‚¾‚ë
’·ٹْ“W–]‚â•›ژY•¨‚ً‚àٹـ‚ك‚ؤ•پ’ت‚حچl‚¦‚é
’·ٹْ“W–]‚â•›ژY•¨‚ً‚àٹـ‚ك‚ؤ•پ’ت‚حچl‚¦‚é
–q–ىگوگ¶‚ئ‚©ڈ¼‰ھگوگ¶‚ئ‚©پA‚ ‚ج•س‚جگl‚جTwitter‚إ‚ج”½‰‚ًŒ©‚ؤ‚é‚ئپA
‚½‚ش‚ٌƒAƒNƒZƒ‰ƒŒپ[ƒ^Œ^‚ًگ„‚µ‚ؤ‚¢‚½گl’B‚¾‚ئ‚¢‚¤‚±‚ئ‚ًٹ„‚èˆّ‚¢‚ؤ‚à
‹‚ح”÷–‚ب•]‰؟‚ء‚ؤ‚¢‚¤ƒjƒ…ƒAƒ“ƒX‚ھگ@‚¦‚ب‚¢
‚½‚ش‚ٌƒAƒNƒZƒ‰ƒŒپ[ƒ^Œ^‚ًگ„‚µ‚ؤ‚¢‚½گl’B‚¾‚ئ‚¢‚¤‚±‚ئ‚ًٹ„‚èˆّ‚¢‚ؤ‚à
‹‚ح”÷–‚ب•]‰؟‚ء‚ؤ‚¢‚¤ƒjƒ…ƒAƒ“ƒX‚ھگ@‚¦‚ب‚¢
‚»‚à‚»‚àچ‘‰ئƒvƒچƒWƒFƒNƒg‚إٹé‹ئ“àƒvƒچƒWƒFƒNƒg‚ف‚½‚¢‚ب‚±‚ئ‚â‚é‚ب‚و‚ب‚ٌ‚¾‚ھپA‚»‚ê‚ًچ·‚µ’u‚¢‚ؤ‚à
’P‚ةچ‚‘¬‚بƒXƒpƒRƒ“‚ً’²’B‚µ‚½‚¢‚ٌ‚¾‚ء‚½‚çپAٹùگ¬‚ج‚à‚ج‚ًٹCٹO‚©‚ç‚إ‚à‚و‚¢‚©‚ç’²’B‚·‚ê‚خ‚¢‚¢‚µپA
’P‚ة‘S‚گV‚µ‚¢ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة’§گي‚µ‚½‚¢‚ٌ‚¾‚ء‚½‚çپAڈ¬‹K–ح‚بƒXƒpƒRƒ“‚إ‚àژaگV‚ب‚à‚ج‚ًگFپX‚بƒ`پ[ƒ€‚ةچى‚点‚ê‚خ‚¢‚¢‚ج‚ةپA
‚±‚ج•س‚ج‹cک_‚ھ‚²‚ء‚؟‚ل‚إپAˆê“x‚ةˆê‚آ‚ج—\ژZ‚إ‚â‚낤‚ئ‚µ‚ؤ‚¢‚é‚©‚炨‚©‚µ‚‚ب‚é‚ٌ‚¾‚و‚بپB
‚إپATOP500‚إ‚ـ‚½1ˆت‘_‚¨‚¤‚ئ‚µ‚ؤ‚¢‚é‚©‚çپA‹‚جŒمŒp‹@‚حژں‚ح2020”N‚ب‚ٌ‚¾‚و‚ث
‹à’™‚ك‚ؤ‚ـ‚إ1ˆت‘_‚ي‚ب‚‚ؤ‚¢‚¢‚©‚çپA2020”N‚ـ‚إ‚ة100‰‚جƒXƒpƒRƒ“10‘ن’²’B‚µ‚½‚ظ‚¤‚ھ
‚و‚ء‚غ‚ا—ا‚¢پB‹‚ج‹cک_‚ج‚¹‚¢‚إ‚ـ‚·‚ـ‚·1ˆت‚ةچS‚ç‚ب‚«‚ل‚¢‚¯‚ب‚‚ب‚ء‚ؤ‚µ‚ـ‚ء‚½•¾ٹQپB
’P‚ةچ‚‘¬‚بƒXƒpƒRƒ“‚ً’²’B‚µ‚½‚¢‚ٌ‚¾‚ء‚½‚çپAٹùگ¬‚ج‚à‚ج‚ًٹCٹO‚©‚ç‚إ‚à‚و‚¢‚©‚ç’²’B‚·‚ê‚خ‚¢‚¢‚µپA
’P‚ة‘S‚گV‚µ‚¢ƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة’§گي‚µ‚½‚¢‚ٌ‚¾‚ء‚½‚çپAڈ¬‹K–ح‚بƒXƒpƒRƒ“‚إ‚àژaگV‚ب‚à‚ج‚ًگFپX‚بƒ`پ[ƒ€‚ةچى‚点‚ê‚خ‚¢‚¢‚ج‚ةپA
‚±‚ج•س‚ج‹cک_‚ھ‚²‚ء‚؟‚ل‚إپAˆê“x‚ةˆê‚آ‚ج—\ژZ‚إ‚â‚낤‚ئ‚µ‚ؤ‚¢‚é‚©‚炨‚©‚µ‚‚ب‚é‚ٌ‚¾‚و‚بپB
‚إپATOP500‚إ‚ـ‚½1ˆت‘_‚¨‚¤‚ئ‚µ‚ؤ‚¢‚é‚©‚çپA‹‚جŒمŒp‹@‚حژں‚ح2020”N‚ب‚ٌ‚¾‚و‚ث
‹à’™‚ك‚ؤ‚ـ‚إ1ˆت‘_‚ي‚ب‚‚ؤ‚¢‚¢‚©‚çپA2020”N‚ـ‚إ‚ة100‰‚جƒXƒpƒRƒ“10‘ن’²’B‚µ‚½‚ظ‚¤‚ھ
‚و‚ء‚غ‚ا—ا‚¢پB‹‚ج‹cک_‚ج‚¹‚¢‚إ‚ـ‚·‚ـ‚·1ˆت‚ةچS‚ç‚ب‚«‚ل‚¢‚¯‚ب‚‚ب‚ء‚ؤ‚µ‚ـ‚ء‚½•¾ٹQپB
‚إپAگ”•S‰“ٹ‚¶‚ؤچى‚ء‚½SPARC64‚ھ‚ا‚ٌ‚ب–ً‚ة—§‚؟‚ـ‚µ‚½‚©پH
22nm‚جXeon‚ئ”ن‚ׂؤ‚ا‚ꂾ‚¯‚ج—Dˆتگ«‚ھ‚ ‚è‚ـ‚·‚©پH
•ؤچ‘‚ح–ˆ”Nچى‚é50پ`100‰‰~‹K–ح‚جƒXƒpƒRƒ“‚ًچى‚é‚©‚ç‹‚¢‚ج‚إ‚ ‚ء‚ؤ
5”N‚©‚¯‚ؤ1000‰‚ف‚½‚¢‚بˆê“_چ‹‰طژه‹`‚حŒّ—¦‚جˆ«‚¢ژg‚¢•û‚إ‚µ‚ه‚¤‚و‚ئپB
‚½‚ئ‚¦’Zٹْٹش‚إچى‚ء‚½’†“r”¼’[‚بƒXƒyƒbƒN‚ب‚à‚ج‚إ‚ ‚ء‚ؤ‚àژg‚¢‚½‚¢گl‚ح‘½‚¢‚ي‚¯‚إپB
22nm‚جXeon‚ئ”ن‚ׂؤ‚ا‚ꂾ‚¯‚ج—Dˆتگ«‚ھ‚ ‚è‚ـ‚·‚©پH
•ؤچ‘‚ح–ˆ”Nچى‚é50پ`100‰‰~‹K–ح‚جƒXƒpƒRƒ“‚ًچى‚é‚©‚ç‹‚¢‚ج‚إ‚ ‚ء‚ؤ
5”N‚©‚¯‚ؤ1000‰‚ف‚½‚¢‚بˆê“_چ‹‰طژه‹`‚حŒّ—¦‚جˆ«‚¢ژg‚¢•û‚إ‚µ‚ه‚¤‚و‚ئپB
‚½‚ئ‚¦’Zٹْٹش‚إچى‚ء‚½’†“r”¼’[‚بƒXƒyƒbƒN‚ب‚à‚ج‚إ‚ ‚ء‚ؤ‚àژg‚¢‚½‚¢گl‚ح‘½‚¢‚ي‚¯‚إپB
CPU‚àچى‚é‚ج‚ھ–ع“I‚¾‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚ج
چإ’ل‚إ‚à‹Zڈp‚جڈK“¾‚âˆغژ‚ة‚ح–ً—§‚ء‚ؤ‚邾‚ë
ˆہ‚¢‚ج‚إ‚و‚¯‚ê‚خ“ْ–{‚إ‚àچى‚ç‚ê‚ؤ‚é‚ي‚¯‚إ
•ت‚ة‹‚µ‚©چى‚ç‚ê‚ؤ‚ب‚¢‚ي‚¯‚إ‚ح‚ب‚¢
چإ’ل‚إ‚à‹Zڈp‚جڈK“¾‚âˆغژ‚ة‚ح–ً—§‚ء‚ؤ‚邾‚ë
ˆہ‚¢‚ج‚إ‚و‚¯‚ê‚خ“ْ–{‚إ‚àچى‚ç‚ê‚ؤ‚é‚ي‚¯‚إ
•ت‚ة‹‚µ‚©چى‚ç‚ê‚ؤ‚ب‚¢‚ي‚¯‚إ‚ح‚ب‚¢
‚ـ‚¶‚ê‚·‚·‚é‚ئCPU‚جگفŒvژ©‘ج‚حژہ‚ح‚»‚ٌ‚بڈd—v‚ب‹Zڈp‚¶‚ل‚ب‚¢پB
ٹجگS‚ب‚ج‚ح”¼“±‘جگ»‘¢‹Zڈp‚ج•ûپB
’†چ‘‚ھچ‘ژY‚إچ‚گ«”\CPUچى‚ê‚ب‚¢‚ج‚ح”¼“±‘جژY‹ئ‚ھ”’B‚µ‚ؤ‚ب‚‚ؤپA
گ»‘¢‹Zڈp‚ھ‚ب‚¢‚©‚çپBگفŒv‹Zڈp‚حگlچق‚ة‹à‚¾‚¹‚خ”ƒ‚¦‚éپB
گ»‘¢‹ZڈpپEƒmƒEƒnƒE‚حچHڈꔃ‚¦‚خ‚©‚¦‚邯‚اپA‘¼چ‘‚©‚ç‚ح”ƒ‚¦‚ب‚¢‚©‚ç‚ثپB
ٹجگS‚ب‚ج‚ح”¼“±‘جگ»‘¢‹Zڈp‚ج•ûپB
’†چ‘‚ھچ‘ژY‚إچ‚گ«”\CPUچى‚ê‚ب‚¢‚ج‚ح”¼“±‘جژY‹ئ‚ھ”’B‚µ‚ؤ‚ب‚‚ؤپA
گ»‘¢‹Zڈp‚ھ‚ب‚¢‚©‚çپBگفŒv‹Zڈp‚حگlچق‚ة‹à‚¾‚¹‚خ”ƒ‚¦‚éپB
گ»‘¢‹ZڈpپEƒmƒEƒnƒE‚حچHڈꔃ‚¦‚خ‚©‚¦‚邯‚اپA‘¼چ‘‚©‚ç‚ح”ƒ‚¦‚ب‚¢‚©‚ç‚ثپB
‚إپA“–‚جFژذ‚àCPUٹـ‚ك‚ؤTSMC‚ةˆعچs‚µ‚؟‚ل‚ء‚½‚¯‚اپB
ŒRژ––ع“I‚إپAچ‘“à‚ج‹Zڈp‚جڈK“¾‚âˆغژ‚جڈd—vگ«‚ً‚ ‚°‚éگl‚ھ‘½‚¢‚¯‚اپA
گي‘ˆ‚ئ‚©‚إ‚à‚µچق—؟‚ھ’²’B‚إ‚«‚ب‚‚ب‚ء‚½‚çپA‚¢‚‚çگفŒv‹Zڈp‚ ‚ء‚ؤ‚àچHڈê‰ٌ‚ç‚ب‚¢‚©‚çˆس–،‚ب‚¢‚ج‚وپB
‹t‚ةCPU“™‚جٹ®گ¬•i‚ً‘¼چ‘‚©‚ç’²’B‚إ‚«‚郋پ[ƒg‚ًٹm•غپEˆغژ‚إ‚«‚ê‚خپAƒVƒXƒeƒ€‚ح‚ب‚ٌ‚ئ‚©چى‚ê‚éپB
ŒRژ––ع“I‚إ‹Zڈp‚جˆغژ‚ھ‘هژ–‚ء‚ؤ‚¢‚ء‚ؤ‚é‚â‚آ‚ح“ھ‚ھ‘¾•½—mگي‘ˆ‚جچ ‚©‚çگi•à‚µ‚ؤ‚ب‚¢‚©‚çپA
ƒRƒ“ƒsƒ…پ[ƒ^‚جگفŒv‚ھ–¢‚¾‚ةچإگو’[‹Zڈp‚¾‚ئژv‚¢‚±‚ٌ‚إ‚¢‚邾‚¯پB
ژہچغ‚حƒRƒ“ƒsƒ…پ[ƒ^‚ب‚ٌ‚ؤچ،‚جژ‘م‚ح‚½‚¾‚ج•¨ژ‘‚¾‚وپB
ڈ¬ٹwگ¶‚إ‚·‚çGflopsƒIپ[ƒ_پ[‚جŒg‘رژ‚ء‚ؤ‚¢‚éژ‘م‚¾‚©‚ç‚ثپB
—Lژ–‚ة‚ح•¨ژ‘‚ج’²’Bƒ‹پ[ƒg‚جٹm•غپEˆغژ‚ھ‘هژ–‚إپAچ‘ژY‚إگفŒv—ح‚¾‚¯‚ ‚ء‚ؤ‚à‚µ‚ه‚¤‚ھ‚ب‚¢پB
ŒRژ––ع“I‚إپAچ‘“à‚ج‹Zڈp‚جڈK“¾‚âˆغژ‚جڈd—vگ«‚ً‚ ‚°‚éگl‚ھ‘½‚¢‚¯‚اپA
گي‘ˆ‚ئ‚©‚إ‚à‚µچق—؟‚ھ’²’B‚إ‚«‚ب‚‚ب‚ء‚½‚çپA‚¢‚‚çگفŒv‹Zڈp‚ ‚ء‚ؤ‚àچHڈê‰ٌ‚ç‚ب‚¢‚©‚çˆس–،‚ب‚¢‚ج‚وپB
‹t‚ةCPU“™‚جٹ®گ¬•i‚ً‘¼چ‘‚©‚ç’²’B‚إ‚«‚郋پ[ƒg‚ًٹm•غپEˆغژ‚إ‚«‚ê‚خپAƒVƒXƒeƒ€‚ح‚ب‚ٌ‚ئ‚©چى‚ê‚éپB
ŒRژ––ع“I‚إ‹Zڈp‚جˆغژ‚ھ‘هژ–‚ء‚ؤ‚¢‚ء‚ؤ‚é‚â‚آ‚ح“ھ‚ھ‘¾•½—mگي‘ˆ‚جچ ‚©‚çگi•à‚µ‚ؤ‚ب‚¢‚©‚çپA
ƒRƒ“ƒsƒ…پ[ƒ^‚جگفŒv‚ھ–¢‚¾‚ةچإگو’[‹Zڈp‚¾‚ئژv‚¢‚±‚ٌ‚إ‚¢‚邾‚¯پB
ژہچغ‚حƒRƒ“ƒsƒ…پ[ƒ^‚ب‚ٌ‚ؤچ،‚جژ‘م‚ح‚½‚¾‚ج•¨ژ‘‚¾‚وپB
ڈ¬ٹwگ¶‚إ‚·‚çGflopsƒIپ[ƒ_پ[‚جŒg‘رژ‚ء‚ؤ‚¢‚éژ‘م‚¾‚©‚ç‚ثپB
—Lژ–‚ة‚ح•¨ژ‘‚ج’²’Bƒ‹پ[ƒg‚جٹm•غپEˆغژ‚ھ‘هژ–‚إپAچ‘ژY‚إگفŒv—ح‚¾‚¯‚ ‚ء‚ؤ‚à‚µ‚ه‚¤‚ھ‚ب‚¢پB
‘¼‚ة‚¢‚‚ç‚إ‚à–³‘تŒ‚¢‚µ‚ؤ‚¢‚é‚ج‚¾‚©‚ç
10”N‚ة1‰ٌ1000‰‰~‚©‚¯‚ؤƒXƒpƒRƒ“چى‚ء‚½‚ء‚ؤ‚¢‚¢‚¶‚ل‚ب‚¢‚©
ڈ¬Œ^‚جƒXƒpƒRƒ“‚ھ•K—v‚ب‚ç
‚»‚ê‚ح•ت‚ة—\ژZ‚ً‚ئ‚ء‚ؤ‚‚ê‚خ‚¢‚¢‚¾‚¯‚جکb
–‚ة‚±‚جکb‘è‚ةŒإژ·‚µ‚ؤ‚é‚â‚آ‚ھ‚¢‚é‚ھ
“ْ–{‚جگإ‹à‚إIntel‚جCPU”ƒ‚ء‚ؤ‚‚¾‚³‚¢‚ئ‚¢‚¤‚±‚ئ‚©پH
10”N‚ة1‰ٌ1000‰‰~‚©‚¯‚ؤƒXƒpƒRƒ“چى‚ء‚½‚ء‚ؤ‚¢‚¢‚¶‚ل‚ب‚¢‚©
ڈ¬Œ^‚جƒXƒpƒRƒ“‚ھ•K—v‚ب‚ç
‚»‚ê‚ح•ت‚ة—\ژZ‚ً‚ئ‚ء‚ؤ‚‚ê‚خ‚¢‚¢‚¾‚¯‚جکb
–‚ة‚±‚جکb‘è‚ةŒإژ·‚µ‚ؤ‚é‚â‚آ‚ھ‚¢‚é‚ھ
“ْ–{‚جگإ‹à‚إIntel‚جCPU”ƒ‚ء‚ؤ‚‚¾‚³‚¢‚ئ‚¢‚¤‚±‚ئ‚©پH
‚ ‚ئپA‚±‚ج‹cک_‚·‚é‚ئپA‘¼•ھ–ى‚إ–³‘تŒ‚¢‚µ‚ؤ‚¢‚é‚©‚ç‚‚ٌ‚ھ•K‚¸ڈo‚ؤ‚‚é‚ٌ‚¾‚ھپA
‚±‚±‚حƒRƒ“ƒsƒ…پ[ƒ^ƒAپ[ƒLƒeƒNƒ`ƒƒ‚جƒXƒŒ‚ب‚ٌ‚¾‚©‚çپA
ƒRƒ“ƒsƒ…پ[ƒ^‚ج•ھ–ى‚ج—\ژZ‚جکb‚ةڈW’†‚·‚é‚ج‚ح“–‚½‚è‘OپB
‘¼•ھ–ى‚إ‚جگإ‹à‚ج–³‘تŒ‚¢‚جکb‚µ‚½‚¢‚ب‚çپA‘¼‚جگê–ه”آ‚جƒXƒŒ‚إŒآ•ت‚ة‚â‚ء‚ؤ‚‚ê‚وپB
چ‚‘¬“¹کH‚ئ‚©‚جƒKƒ`ƒIƒ^گ¨‚ھ“¯‚¶‚و‚¤‚ة‘ٹژ肵‚ؤ‚‚ê‚é‚ٌ‚¶‚ل‚ب‚¢‚©?w
‚±‚±‚حƒRƒ“ƒsƒ…پ[ƒ^ƒAپ[ƒLƒeƒNƒ`ƒƒ‚جƒXƒŒ‚ب‚ٌ‚¾‚©‚çپA
ƒRƒ“ƒsƒ…پ[ƒ^‚ج•ھ–ى‚ج—\ژZ‚جکb‚ةڈW’†‚·‚é‚ج‚ح“–‚½‚è‘OپB
‘¼•ھ–ى‚إ‚جگإ‹à‚ج–³‘تŒ‚¢‚جکb‚µ‚½‚¢‚ب‚çپA‘¼‚جگê–ه”آ‚جƒXƒŒ‚إŒآ•ت‚ة‚â‚ء‚ؤ‚‚ê‚وپB
چ‚‘¬“¹کH‚ئ‚©‚جƒKƒ`ƒIƒ^گ¨‚ھ“¯‚¶‚و‚¤‚ة‘ٹژ肵‚ؤ‚‚ê‚é‚ٌ‚¶‚ل‚ب‚¢‚©?w
>>688
‚ع‚‚ھ‚©‚ٌ‚ھ‚¦‚½ƒRƒXƒp‚³‚¢‚«‚ه‚¤‚جƒXƒpƒRƒ“‚ً‚ف‚ٌ‚ب‚إ‚آ‚‚ء‚ؤپA‚ئŒ¾‚ء‚ؤ‚¢‚é
‚ع‚‚ھ‚©‚ٌ‚ھ‚¦‚½ƒRƒXƒp‚³‚¢‚«‚ه‚¤‚جƒXƒpƒRƒ“‚ً‚ف‚ٌ‚ب‚إ‚آ‚‚ء‚ؤپA‚ئŒ¾‚ء‚ؤ‚¢‚é
> 10”N‚ة1‰ٌ1000‰‰~‚©‚¯‚ؤƒXƒpƒRƒ“چى‚ء‚½‚ء‚ؤ‚¢‚¢‚¶‚ل‚ب‚¢‚©
1000‰‚©‚¯‚邱‚ئ‚ة’N‚à”½‘خ‚ح‚µ‚ب‚¢‚ھƒKƒ‰ƒpƒSƒX‰»‚·‚é‚و‚¤‚ب‚à‚ج‚ح‚â‚ك‚ؤ
‚à‚ء‚ئˆہ‚’²’B‚إ‚«‚é‚à‚ج‚ًژg‚ء‚ؤ”ï—p‘خŒّ‰ت‚ًڈم‚°‚ë‚ء‚ؤ‚±‚ئ‚¾‚و
> “ْ–{‚جگإ‹à‚إIntel‚جCPU”ƒ‚ء‚ؤ‚‚¾‚³‚¢‚ئ‚¢‚¤‚±‚ئ‚©پH
•xژm’ت‚ة’چ‚¬چ‚ٌ‚إIntel‚ةƒRƒXƒg‚إ‚àگ«”\‚إ‚àڈں‚ؤ‚ب‚¢‚ب‚ç“–‘R‚»‚¤‚ب‚éپB
ٹˆ—p‚µ‚ؤ‚±‚»‚جƒXƒpƒRƒ“پB
چى‚邱‚ئ‚¾‚¯‚ةڈI‚ي‚ء‚ؤ‚¢‚ؤ‚ح‰بٹw‹Zڈp‚ج”“W‚ح‚ب‚¢پB
‹‚ًژg‚ء‚ؤƒSپ[ƒhƒ“ƒxƒ‹ڈـژَڈـ‚µ‚ؤ‚½ژ—’¹‚³‚ٌ‚ب‚ٌ‚©‚ھ
x86چإ“K‰»•×‹‰ï‚ة‚½‚ر‚½‚رژQ‰ء‚µ‚ؤ‚é‚ج‚ًŒ©‚ê‚خ
ƒXƒpƒRƒ“‚ج–¢—ˆ‚ح‚»‚ء‚؟‚ج•ûŒü‚ةŒü‚©‚ء‚ؤ‚é‚ئ‚µ‚©
1000‰‚©‚¯‚邱‚ئ‚ة’N‚à”½‘خ‚ح‚µ‚ب‚¢‚ھƒKƒ‰ƒpƒSƒX‰»‚·‚é‚و‚¤‚ب‚à‚ج‚ح‚â‚ك‚ؤ
‚à‚ء‚ئˆہ‚’²’B‚إ‚«‚é‚à‚ج‚ًژg‚ء‚ؤ”ï—p‘خŒّ‰ت‚ًڈم‚°‚ë‚ء‚ؤ‚±‚ئ‚¾‚و
> “ْ–{‚جگإ‹à‚إIntel‚جCPU”ƒ‚ء‚ؤ‚‚¾‚³‚¢‚ئ‚¢‚¤‚±‚ئ‚©پH
•xژm’ت‚ة’چ‚¬چ‚ٌ‚إIntel‚ةƒRƒXƒg‚إ‚àگ«”\‚إ‚àڈں‚ؤ‚ب‚¢‚ب‚ç“–‘R‚»‚¤‚ب‚éپB
ٹˆ—p‚µ‚ؤ‚±‚»‚جƒXƒpƒRƒ“پB
چى‚邱‚ئ‚¾‚¯‚ةڈI‚ي‚ء‚ؤ‚¢‚ؤ‚ح‰بٹw‹Zڈp‚ج”“W‚ح‚ب‚¢پB
‹‚ًژg‚ء‚ؤƒSپ[ƒhƒ“ƒxƒ‹ڈـژَڈـ‚µ‚ؤ‚½ژ—’¹‚³‚ٌ‚ب‚ٌ‚©‚ھ
x86چإ“K‰»•×‹‰ï‚ة‚½‚ر‚½‚رژQ‰ء‚µ‚ؤ‚é‚ج‚ًŒ©‚ê‚خ
ƒXƒpƒRƒ“‚ج–¢—ˆ‚ح‚»‚ء‚؟‚ج•ûŒü‚ةŒü‚©‚ء‚ؤ‚é‚ئ‚µ‚©
‚»‚ج‰ًژك‚ح‚ب‚¢‚بپB’P‚ة‚ ‚é‚ج“®‚©‚µ‚ؤ‚é‚ء‚ؤ‚¾‚¯‚إ‚µ‚هپB
‚½‚ر‚½‚ر‚¶‚ل‚ب‚‚ؤپA1‰ٌ‚µ‚©ژQ‰ء‚µ‚ؤ‚ب‚¢‚µپB‚»‚à‚»‚à“à—e‚ھPhiƒfƒBƒX‚肾‚µ‚بپB
‚½‚ر‚½‚ر‚¶‚ل‚ب‚‚ؤپA1‰ٌ‚µ‚©ژQ‰ء‚µ‚ؤ‚ب‚¢‚µپB‚»‚à‚»‚à“à—e‚ھPhiƒfƒBƒX‚肾‚µ‚بپB
—\ژZ‚ح–³گs‘ ‚ة•¦‚¢‚ؤ‚‚é‚ي‚¯‚¶‚ل‚ب‚©‚ç‚ب‚ں
گ§Œہ‚ب‚¯‚ê‚خ•ت‚ةچD‚«ڈںژè‚ة–³گ§Œہ‚ة‚â‚ء‚ؤ‚à
•ت‚ة‚ا‚¤‚ئŒ¾‚¤‚±‚ئ‚à‚ب‚¢‚ھŒ»ژہ‚ح‚»‚¤‚¶‚ل‚ب‚¢پA
ڈ‚ب‚¢—\ژZ‚إ•Kژ€‚ة‚â‚肂肵‚ؤ‚¢‚éگl‚½‚؟‚©‚ç
—§ڈê‚ةŒسچ؟‚ً‚©‚¢‚ؤƒeƒLƒgپ[‚ة—\ژZ‚ًژg‚¢’ׂµ‚ؤ‚¢‚é
”\–³‚µ’B‚ة(twitter‚إڈ‘‚©‚ê‚ؤ‚é‚و‚¤‚ب)‰…ڑl‚جگ؛‚ھ
ڈم‚ھ‚é‚ج‚ح“–‘R‚ج‚±‚ئ‚©‚ئ
گ§Œہ‚ب‚¯‚ê‚خ•ت‚ةچD‚«ڈںژè‚ة–³گ§Œہ‚ة‚â‚ء‚ؤ‚à
•ت‚ة‚ا‚¤‚ئŒ¾‚¤‚±‚ئ‚à‚ب‚¢‚ھŒ»ژہ‚ح‚»‚¤‚¶‚ل‚ب‚¢پA
ڈ‚ب‚¢—\ژZ‚إ•Kژ€‚ة‚â‚肂肵‚ؤ‚¢‚éگl‚½‚؟‚©‚ç
—§ڈê‚ةŒسچ؟‚ً‚©‚¢‚ؤƒeƒLƒgپ[‚ة—\ژZ‚ًژg‚¢’ׂµ‚ؤ‚¢‚é
”\–³‚µ’B‚ة(twitter‚إڈ‘‚©‚ê‚ؤ‚é‚و‚¤‚ب)‰…ڑl‚جگ؛‚ھ
ڈم‚ھ‚é‚ج‚ح“–‘R‚ج‚±‚ئ‚©‚ئ
694 پFSocket774پF2013/11/19(‰خ) 13:31:22.94 ID:2N28PR4X
>>687
گي‘ˆ‚µ‚½‚çٹOچ‘‚©‚甃‚¦‚ب‚‚ب‚邾‚ëw
“àگ»ڈo—ˆ‚ب‚¢‚ب‚çگي‘ˆ‚µ‚؟‚ل‚¾‚ك
گي‘ˆ‘O’ٌ‚ب‚ç“àگ»‰»‚µ‚ب‚¢‚ئƒAƒEƒg
گي‘ˆ‚µ‚½‚çٹOچ‘‚©‚甃‚¦‚ب‚‚ب‚邾‚ëw
“àگ»ڈo—ˆ‚ب‚¢‚ب‚çگي‘ˆ‚µ‚؟‚ل‚¾‚ك
گي‘ˆ‘O’ٌ‚ب‚ç“àگ»‰»‚µ‚ب‚¢‚ئƒAƒEƒg
IBM and NVIDIA Announce Data Analytics & Supercomputer Partnership
http://www.anandtech.com/show/7522/ibm-and-nvidia-announce-data-analytics-supercomputer-partnership
http://www.anandtech.com/show/7522/ibm-and-nvidia-announce-data-analytics-supercomputer-partnership
ƒRƒA‚ج’†گg‚ةŒûڈo‚¹‚ب‚¢ˆبڈمپAx86‚إ‚حپu‘¼ڈٹ‚إ‚àچى‚ê‚é‚à‚جپv‚µ‚©چى‚ê‚ٌ‚ج‚¾‚وپB—â‹p‚ئ‚©ƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ح‚ـ‚ ٹو’£‚ê‚邯‚اپA‚»‚±‚ح‘¼ڈٹ‚àٹو’£‚ء‚ؤ‚¢‚éپB
ƒLƒƒƒbƒ`ƒAƒbƒv‚ة—¯‚ـ‚炸پA‚¢‚آ‚©“ئژ©ƒRƒA‚ةx86‚ً‚ش‚ء‚؟‚¬‚é“ئژ©‚جژd‘g‚ف‚ًگ·‚èچ‚ك‚é‚©‚à‚µ‚ê‚تپB–²‚¾‚ھپA–²‚ھ‚ب‚¢‚ج‚ھٹm’肵‚ؤ‚é–¢—ˆ‚ب‚ٌ‚ؤگ¶‚«‚ؤ‚ؤ‚آ‚ـ‚ç‚ٌ‚¼پB
‚³‚ç‚ةŒ¾‚¤‚ئپA‹£چ‡‚·‚é‘م‘ض“ئژ©‹Zڈp‚ھ‚ ‚é‚©‚çx86‚ح’lˆّ‚«‚³‚ê‚é‚ج‚إ‚ ‚ء‚ؤپA“ئژ©‹Zڈp‚ب‚©‚ء‚½‚çx86‚à‚س‚ء‚©‚¯‚ç‚ê‚é‚ج‚وپB
ƒLƒƒƒbƒ`ƒAƒbƒv‚ة—¯‚ـ‚炸پA‚¢‚آ‚©“ئژ©ƒRƒA‚ةx86‚ً‚ش‚ء‚؟‚¬‚é“ئژ©‚جژd‘g‚ف‚ًگ·‚èچ‚ك‚é‚©‚à‚µ‚ê‚تپB–²‚¾‚ھپA–²‚ھ‚ب‚¢‚ج‚ھٹm’肵‚ؤ‚é–¢—ˆ‚ب‚ٌ‚ؤگ¶‚«‚ؤ‚ؤ‚آ‚ـ‚ç‚ٌ‚¼پB
‚³‚ç‚ةŒ¾‚¤‚ئپA‹£چ‡‚·‚é‘م‘ض“ئژ©‹Zڈp‚ھ‚ ‚é‚©‚çx86‚ح’lˆّ‚«‚³‚ê‚é‚ج‚إ‚ ‚ء‚ؤپA“ئژ©‹Zڈp‚ب‚©‚ء‚½‚çx86‚à‚س‚ء‚©‚¯‚ç‚ê‚é‚ج‚وپB
ID:2N28PR4X
‚ب‚ٌ‚¾AMDƒXƒŒ‚إ–\‚ê‚ؤ‚éDQN‚©
‚ب‚ٌ‚¾AMDƒXƒŒ‚إ–\‚ê‚ؤ‚éDQN‚©
>>692
•ت‚ةƒfƒBƒX‚ء‚ؤ‚ب‚‚ثپH
Phantom GRAPE‚ب‚ٌ‚©‚à‚ ‚جگl‚¾‚µ‚¾‚¢‚ش‘O‚©‚çx86‚ًژg‚ء‚½چإ“K‰»‹Zڈp‚ً
ژ‚ء‚½گl‚¾‚و
‚à‚؟‚ë‚ٌ’·چè‘هٹw‚ج—ل‚ج’ل—\ژZGPGPUƒXƒpƒRƒ“‚ة‚à‚©‚©‚ي‚ء‚ؤ‚é‚©‚ç“ء‚ة
ƒAپ[ƒL‚ض‚ج‚±‚¾‚ي‚è‚ح‚ب‚¢‚و‚¤‚¾‚ھپB
>>696
‚»‚ê‚إڈo—ˆڈم‚ھ‚ء‚½SPARC64‚ھIntel‚ة‘خ‚·‚é’lˆّ‚«چق—؟‚ة‚ب‚ء‚ؤ‚é‚©‚ئ‚¢‚¤‚ئ
‚ـ‚ء‚½‚کb‚ة‚ب‚ء‚ؤ‚ب‚¢‚ي‚¯‚إپB
Intel‚جXeon‚ھ‹‚¢‚ج‚حƒpƒ\ƒRƒ“—p‚جCPUƒRƒAگفŒv‚ً‚»‚ج‚ـ‚ـƒTپ[ƒo‚ة
ژ‚؟چ‚ك‚é‚ئ‚¢‚¤ˆ³“|“I‚بƒXƒPپ[ƒ‹ƒپƒٹƒbƒgپB
‚»‚¤‚¢‚¤‚ج‚ھ–³‚¢ˆبڈم‚ا‚¤‚ ‚ھ‚¢‚ؤ‚àڈں‚ؤ‚ٌپB
چ‘“à‚إSPARC64چL‚ژg‚ء‚ؤ‚à‚炤‚½‚ك‚ةx86ƒvƒچƒZƒbƒT—A“ü‹ضژ~‚ة‚µ‚ـ‚·‚©پH
‚»‚ء‚؟‚ج‚ظ‚¤‚ھ‚و‚ء‚غ‚اچ‘“àژY‹ئگٹ‘ق‚µ‚ـ‚·‚وپB
•ت‚ةƒfƒBƒX‚ء‚ؤ‚ب‚‚ثپH
Phantom GRAPE‚ب‚ٌ‚©‚à‚ ‚جگl‚¾‚µ‚¾‚¢‚ش‘O‚©‚çx86‚ًژg‚ء‚½چإ“K‰»‹Zڈp‚ً
ژ‚ء‚½گl‚¾‚و
‚à‚؟‚ë‚ٌ’·چè‘هٹw‚ج—ل‚ج’ل—\ژZGPGPUƒXƒpƒRƒ“‚ة‚à‚©‚©‚ي‚ء‚ؤ‚é‚©‚ç“ء‚ة
ƒAپ[ƒL‚ض‚ج‚±‚¾‚ي‚è‚ح‚ب‚¢‚و‚¤‚¾‚ھپB
>>696
‚»‚ê‚إڈo—ˆڈم‚ھ‚ء‚½SPARC64‚ھIntel‚ة‘خ‚·‚é’lˆّ‚«چق—؟‚ة‚ب‚ء‚ؤ‚é‚©‚ئ‚¢‚¤‚ئ
‚ـ‚ء‚½‚کb‚ة‚ب‚ء‚ؤ‚ب‚¢‚ي‚¯‚إپB
Intel‚جXeon‚ھ‹‚¢‚ج‚حƒpƒ\ƒRƒ“—p‚جCPUƒRƒAگفŒv‚ً‚»‚ج‚ـ‚ـƒTپ[ƒo‚ة
ژ‚؟چ‚ك‚é‚ئ‚¢‚¤ˆ³“|“I‚بƒXƒPپ[ƒ‹ƒپƒٹƒbƒgپB
‚»‚¤‚¢‚¤‚ج‚ھ–³‚¢ˆبڈم‚ا‚¤‚ ‚ھ‚¢‚ؤ‚àڈں‚ؤ‚ٌپB
چ‘“à‚إSPARC64چL‚ژg‚ء‚ؤ‚à‚炤‚½‚ك‚ةx86ƒvƒچƒZƒbƒT—A“ü‹ضژ~‚ة‚µ‚ـ‚·‚©پH
‚»‚ء‚؟‚ج‚ظ‚¤‚ھ‚و‚ء‚غ‚اچ‘“àژY‹ئگٹ‘ق‚µ‚ـ‚·‚وپB
ƒmپ[ƒhٹش’تگM‚ج‘رˆوپE’ل’x‰„‚ھ‚ ‚ـ‚è•K—v‚ب‚¢ƒXƒpƒRƒ“‚حپAGPUƒNƒ‰ƒXƒ^‚©PhiƒNƒ‰ƒXƒ^‚إ‚¢‚¢‚ھپA
ƒmپ[ƒhٹش‚إچ‚‘رˆوپE’ل’x‰„’تگM‚ھ•K—v‚بƒXƒpƒRƒ“‚حپA‚¢‚ـ‚¾‚ةگê—pگفŒv‚¶‚ل‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚ب
ڈ«—ˆ‚ح’m‚ç‚ٌ‚ھ
ƒmپ[ƒhٹش‚إچ‚‘رˆوپE’ل’x‰„’تگM‚ھ•K—v‚بƒXƒpƒRƒ“‚حپA‚¢‚ـ‚¾‚ةگê—pگفŒv‚¶‚ل‚ب‚¢‚ئ‚¢‚¯‚ب‚¢‚ب
ڈ«—ˆ‚ح’m‚ç‚ٌ‚ھ
چ‘ژYگي“¬‹@ٹJ”‚ف‚½‚¢‚ب‚à‚ٌ‚¾‚ب
Œ»ڈَ‚¶‚ل—Aڈo—p‚جƒ‚ƒ“ƒLپ[ƒ‚ƒfƒ‹‚ة‚·‚ç‹y‚خ‚ب‚¢
Œ»ڈَ‚¶‚ل—Aڈo—p‚جƒ‚ƒ“ƒLپ[ƒ‚ƒfƒ‹‚ة‚·‚ç‹y‚خ‚ب‚¢
ƒXƒpƒRƒ“—p“ئژ©ƒRƒA‚ب‚ٌ‚¼’†چ‘‚إ‚àچى‚ê‚éپB•غŒ¯‚¾‚©‚ç–³‘ت‚ة‚ف‚¦‚ؤ‚àچى‚ء‚ئ‚¯پB
چى‚ê‚é“z‚ھ‚¢‚邤‚؟‚حپA‚بپB
چى‚ê‚é“z‚ھ‚¢‚邤‚؟‚حپA‚بپB
702 پFSocket774پF2013/11/19(‰خ) 14:21:31.43 ID:2N28PR4X
>>697
–\‚ê‚ؤ‚¢‚é‚ج‚ح‚¨‘O‚ف‚½‚¢‚بDQNˆْگ~‚¾‚ب
–\‚ê‚ؤ‚¢‚é‚ج‚ح‚¨‘O‚ف‚½‚¢‚بDQNˆْگ~‚¾‚ب
703 پFSocket774پF2013/11/19(‰خ) 14:25:09.37 ID:2N28PR4X
گê—pƒRƒA‚ئگê—pOS‚âژه—vƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“پA‚آ‚¢‚إ‚ةX86ƒGƒ~ƒ…‚ھ‚ ‚é‚ئ‚¢‚¢‚ب
“ْ–{ٹو’£‚ê
“ْ–{ٹو’£‚ê
>>700
‚¢‚؟‚¨‚¤“ْ–{‚جƒپپ[ƒJپ[‚àƒ{پ[ƒCƒ“ƒO‚جژه—v‚ب•”•iگ¶ژY‚·‚é‚‚ç‚¢—ح‚ح‚ ‚é‚ٌ‚¾‚¯‚ا‚بپB
چ‘‰ئ—\ژZژg‚ي‚¸‚ة–¯ٹش‚إ‰½‚ئ‚©‚µ‚ë‚ئŒ¾‚¢‚½‚¢‚¯‚ا‚بپB
“ْ–{‚جŒِ‹¤ژ–‹ئ‚ة“ء‰»‚µ‚½CPU‚ً‚¢‚‚çچى‚ء‚½‚ئ‚±‚ë‚إ–¯ٹش‚إ‚ج‹£‘ˆ—ح‚حˆç‚½‚ٌپB
“ء‰»Œ^‚ح•K—v‚¾‚ھپA–¯ٹش‚ة‚ـ‚©‚¹‚ؤ‚¨‚¯‚خ‚¢‚¢”ؤ—pƒvƒچƒZƒbƒT‚ًچ‘‚ج‹à‚إ
چؤ”–¾‚µ‚½‚ئ‚±‚ë‚إ–³‘ت‚ة‚µ‚©‚ب‚ç‚ٌپB
‚¢‚؟‚¨‚¤“ْ–{‚جƒپپ[ƒJپ[‚àƒ{پ[ƒCƒ“ƒO‚جژه—v‚ب•”•iگ¶ژY‚·‚é‚‚ç‚¢—ح‚ح‚ ‚é‚ٌ‚¾‚¯‚ا‚بپB
چ‘‰ئ—\ژZژg‚ي‚¸‚ة–¯ٹش‚إ‰½‚ئ‚©‚µ‚ë‚ئŒ¾‚¢‚½‚¢‚¯‚ا‚بپB
“ْ–{‚جŒِ‹¤ژ–‹ئ‚ة“ء‰»‚µ‚½CPU‚ً‚¢‚‚çچى‚ء‚½‚ئ‚±‚ë‚إ–¯ٹش‚إ‚ج‹£‘ˆ—ح‚حˆç‚½‚ٌپB
“ء‰»Œ^‚ح•K—v‚¾‚ھپA–¯ٹش‚ة‚ـ‚©‚¹‚ؤ‚¨‚¯‚خ‚¢‚¢”ؤ—pƒvƒچƒZƒbƒT‚ًچ‘‚ج‹à‚إ
چؤ”–¾‚µ‚½‚ئ‚±‚ë‚إ–³‘ت‚ة‚µ‚©‚ب‚ç‚ٌپB
‚ء‚ؤ‚¢‚¤‚©پAƒ{پ[ƒCƒ“ƒOˆب‘O‚ة•ؤچ‘‚جگي“¬‹@‚à•”•iƒŒƒxƒ‹‚إ‚ح“ْ–{‚جژg‚ء‚ؤ‚½‚è‚·‚é‚ٌ‚¾‚ھپB
ŒR”ُ‚ح‚·‚ׂؤ“àگ»‰»‚µ‚ؤ‚ب‚«‚ل‚¾‚ك‚ئ‚©‚¢‚ء‚ؤ‚éگl‚حŒ»ژہٹ´ٹo‚جŒ‡—ژ‚µ‚½—‘zژه‹`ژز‚¾‚©‚ç‚بپB
ŒR”ُ‚ح‚·‚ׂؤ“àگ»‰»‚µ‚ؤ‚ب‚«‚ل‚¾‚ك‚ئ‚©‚¢‚ء‚ؤ‚éگl‚حŒ»ژہٹ´ٹo‚جŒ‡—ژ‚µ‚½—‘zژه‹`ژز‚¾‚©‚ç‚بپB
706 پFSocket774پF2013/11/19(‰خ) 15:30:21.80 ID:2N28PR4X
707 پFSocket774پF2013/11/19(‰خ) 15:32:44.12 ID:2N28PR4X
“ْ–{‚ح“‡چ‘‚¾‚©‚çٹCڈم••چ½‚³‚ꂽ‚çژ€‚ت‚و
’Zٹْٹش‚ب‚ç‚ب‚ٌ‚ئ‚©‚ب‚é‚ھ’·ٹْ‰»‚µ‚½‚牽‚àچى‚ê‚ب‚¢‚و
’Zٹْٹش‚ب‚ç‚ب‚ٌ‚ئ‚©‚ب‚é‚ھ’·ٹْ‰»‚µ‚½‚牽‚àچى‚ê‚ب‚¢‚و
ARM‚ء‚ؤڈ«—ˆ“I‚ةx86‹ى’€‚·‚é‚جپH
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
http://hayabusa3.2ch.net/test/read.cgi/morningcoffee/1384202732/
“ْ–{‚ھ’†چ‘‚ئگي‘ˆ‚µ‚½‚çƒpƒ\ƒRƒ“‚ج‹ں‹‹‚ھ‚ظ‚ئ‚ٌ‚ا’âژ~‚·‚é‚بپcپc
710 پFSocket774پF2013/11/19(‰خ) 15:51:25.67 ID:2N28PR4X
711 پFSocket774پF2013/11/19(‰خ) 16:36:29.58 ID:2N28PR4X
’†چ‘‚ئگي‘ˆ‚µ‚½‚çƒAƒپƒٹƒJ‚ئ‚©‚ھژx‰‡‚µ‚ؤ‚‚ê‚é
ƒAƒپƒٹƒJ‚ئگي‘ˆ‚µ‚½‚ç’nگ}ڈم‚©‚ç–S‚‚ب‚é
‘¼‚ئ‚ب‚ç—]—T
“ْ–{‚ج‚½‚؟ˆت’u‚حƒRƒ“ƒiƒ‚ƒ“‚¾‚©‚çپAژ©چ‘‚¾‚¯‚إٹ®گ¬‚إ‚«‚éƒVƒXƒeƒ€‚ح‚ ‚ء‚½•û‚ھ‚¢‚¢
ƒAƒپƒٹƒJ‚ئگي‘ˆ‚µ‚½‚ç’nگ}ڈم‚©‚ç–S‚‚ب‚é
‘¼‚ئ‚ب‚ç—]—T
“ْ–{‚ج‚½‚؟ˆت’u‚حƒRƒ“ƒiƒ‚ƒ“‚¾‚©‚çپAژ©چ‘‚¾‚¯‚إٹ®گ¬‚إ‚«‚éƒVƒXƒeƒ€‚ح‚ ‚ء‚½•û‚ھ‚¢‚¢
ˆہ‘S•غڈل‚ھ‘هژ–‚ب‚çƒ\ƒtƒg‚ًچى‚ê‚ب‚‚·‚é’کچىŒ •غŒى–@‚ً‰½‚ئ‚©‚µ‚ئ‚¯پB
چ‘“à‚ةژI‚à’u‚¯‚ب‚¢‚ئ‚©ڈخ‚ي‚¹‚ؤ‚‚ê‚éپB
چ‘“à‚ةژI‚à’u‚¯‚ب‚¢‚ئ‚©ڈخ‚ي‚¹‚ؤ‚‚ê‚éپB
‹‚جگفŒvژ‚ة‚حx86‚âGPU‚ح‚ـ‚¾”M‚â‘دŒجڈلگ«‚âژg‚¢ڈںژè‚ب‚ا‚à‚ج‚ة‚ب‚ء‚ؤ‚¢‚ب‚©‚ء‚½‚ج‚ھژ–ژہ
‘I‘ً‚ج—]’n‚ح‚ب‚¢
‘I‘ً‚ج—]’n‚ح‚ب‚¢
714 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 17:06:11.37 ID:QIkrjRpz
–¼‘ه‚à‹م‘ه‚àXeon Phi“‹چعƒVƒXƒeƒ€‚إƒgƒbƒv500“ü‚肵‚ؤ‚ـ‚·‚µ
KEK‚حBlueGeneژg‚ء‚ؤ‚ـ‚·‚وپB
“ْ–{‚ج‘هٹwپEŒ¤‹†ڈٹ‚ة‚·‚çگد‹ةچج—p‚³‚ê‚ب‚¢‹‚ج‘¶چفˆس‹`‚ء‚ؤ‚ب‚ٌ‚ب‚ج‚و
“Œ‘ه‚ئ‚©‚جSPARC64 IXfxƒVƒXƒeƒ€‚ج“±“ü–ع“I‚·‚ç
پu‹‚إ“®‚©‚·ƒRپ[ƒh‚جژ–‘OƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚كپv‚ئ‚©‚إ‚·‚µپB
‚¢‚ë‚ٌ‚بˆس–،‚إ“ْ–{‚ج‰بٹw‹Zڈpگچô‚حڈI‚ي‚ء‚ؤ‚é‚ثپB
‚ ‚ئ‚±‚ê‚à“\‚ء‚ؤ‚¨‚‚ثپB
ٹeگMژز‚³‚ـ‚ح‘¶•ھ‚ة”‹¶‚¨ٹè‚¢‚µ‚ـ‚·پB
پyTop500ƒXƒpƒRƒ“‚ة‚¨‚¯‚éژه—v‚بƒAƒNƒZƒ‰ƒŒپ[ƒ^چج—pƒVƒXƒeƒ€گ”‚جگ„ˆعپz
http://www.top500.org/lists/
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@12Junپ@12Nov 13Jun 13Nov
Intel Xeon Phi پ@پ@پ@پ@پ@1پ@پ@پ@پ@7پ@پ@پ@12پ@پ@14
NVIDIA Tesla پ@پ@پ@پ@پ@53پ@پ@پ@50پ@پ@پ@40پ@پ@ 39
AMD FirePro/Streamپ@2پ@پ@پ@پ@3پ@پ@پ@ 3پ@پ@پ@2
پ¦چ¬چع‚جڈêچ‡‚حڈd•،ƒJƒEƒ“ƒg
KEK‚حBlueGeneژg‚ء‚ؤ‚ـ‚·‚وپB
“ْ–{‚ج‘هٹwپEŒ¤‹†ڈٹ‚ة‚·‚çگد‹ةچج—p‚³‚ê‚ب‚¢‹‚ج‘¶چفˆس‹`‚ء‚ؤ‚ب‚ٌ‚ب‚ج‚و
“Œ‘ه‚ئ‚©‚جSPARC64 IXfxƒVƒXƒeƒ€‚ج“±“ü–ع“I‚·‚ç
پu‹‚إ“®‚©‚·ƒRپ[ƒh‚جژ–‘OƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚كپv‚ئ‚©‚إ‚·‚µپB
‚¢‚ë‚ٌ‚بˆس–،‚إ“ْ–{‚ج‰بٹw‹Zڈpگچô‚حڈI‚ي‚ء‚ؤ‚é‚ثپB
‚ ‚ئ‚±‚ê‚à“\‚ء‚ؤ‚¨‚‚ثپB
ٹeگMژز‚³‚ـ‚ح‘¶•ھ‚ة”‹¶‚¨ٹè‚¢‚µ‚ـ‚·پB
پyTop500ƒXƒpƒRƒ“‚ة‚¨‚¯‚éژه—v‚بƒAƒNƒZƒ‰ƒŒپ[ƒ^چج—pƒVƒXƒeƒ€گ”‚جگ„ˆعپz
http://www.top500.org/lists/
پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@پ@12Junپ@12Nov 13Jun 13Nov
Intel Xeon Phi پ@پ@پ@پ@پ@1پ@پ@پ@پ@7پ@پ@پ@12پ@پ@14
NVIDIA Tesla پ@پ@پ@پ@پ@53پ@پ@پ@50پ@پ@پ@40پ@پ@ 39
AMD FirePro/Streamپ@2پ@پ@پ@پ@3پ@پ@پ@ 3پ@پ@پ@2
پ¦چ¬چع‚جڈêچ‡‚حڈd•،ƒJƒEƒ“ƒg
>>713
‰½‚ًŒ¾‚¨‚¤‚ئŒم”‚ة’ا‚¢”²‚©‚ꂽ‚çڈI‚ي‚è
‰½‚ًŒ¾‚¨‚¤‚ئŒم”‚ة’ا‚¢”²‚©‚ꂽ‚çڈI‚ي‚è
چ¬چف‚à‚ ‚é‚ٌ‚â
1000‰‚إˆê‘نچى‚é‚ب‚ç10‰‚إ100‘نچى‚é‚ظ‚¤‚ھ‚ا‚ٌ‚¾‚¯‚ ‚ç‚ن‚é•ھ–ى‚إ–ً‚ة—§‚آ‚±‚ئ‚©پB
‚ئ‚ة‚©‚پA‘و“ٌژںگ¢ٹE‘هگي‚ة“ْ–{‚ھƒWƒFƒbƒgگي“¬‹@‚ئŒ´ژq—ح‹َ•ê‚ًژg‚¦‚خڈں‚ؤ‚½‚ف‚½‚¢‚بکb‚حژ~‚ك‚ؤ‚‚ê
719 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 17:25:08.24 ID:QIkrjRpz
‚³‚µ‚¸‚ك‹‚حگيٹح‘هکa‚إ‚·‚©پH
‹‚ج’²’Bژٹْ‚ةپiƒVƒXƒeƒ€‚ج‹K–ح‚ًڈœ‚پjژd—l‚ج‚ا‚±‚ًŒ©‚ؤ‚à
‹‚ة—ٍ‚é‰سڈٹ‚ھ‚ب‚¢ƒXƒpƒRƒ“‚ب‚ٌ‚ؤ”„‚ء‚ؤ‚½‚©پH‚ا‚±‚©‚ç‚ب‚甃‚¦‚½‚ٌ‚¾
x86 ‚حƒپƒ‚ƒRƒ“ژd—l‚ھIntel‚جŒ¾‚¢‚ب‚è‚ئ‚¢‚¤‚ج‚ھƒXƒpƒRƒ“–عژw‚·‚ة‚ح’ة‚·‚¬‚éپB
x86 ‚ح‚ا‚±‚ـ‚إچs‚ء‚ؤ‚à”ؤ—pپB“¯‚¶‹Zڈpگ…ڈ€‚ب‚ç“ء‰»‚ة‚حڈں‚ؤ‚ب‚¢پB
ڈں‚ؤ‚ب‚¢‚ح‚¸‚ج‚ئ‚±‚ë‚ًڈں‚آ‚½‚ك‚ةIntel‚ح
“¯‚¶‚¶‚ل‚ب‚¢گ»‘¢ƒvƒچƒZƒX‚ً•Kژ€‚إˆغژ‚µ‚ؤ‚¢‚é‚ي‚¯‚¾‚ب
‹‚ة—ٍ‚é‰سڈٹ‚ھ‚ب‚¢ƒXƒpƒRƒ“‚ب‚ٌ‚ؤ”„‚ء‚ؤ‚½‚©پH‚ا‚±‚©‚ç‚ب‚甃‚¦‚½‚ٌ‚¾
x86 ‚حƒپƒ‚ƒRƒ“ژd—l‚ھIntel‚جŒ¾‚¢‚ب‚è‚ئ‚¢‚¤‚ج‚ھƒXƒpƒRƒ“–عژw‚·‚ة‚ح’ة‚·‚¬‚éپB
x86 ‚ح‚ا‚±‚ـ‚إچs‚ء‚ؤ‚à”ؤ—pپB“¯‚¶‹Zڈpگ…ڈ€‚ب‚ç“ء‰»‚ة‚حڈں‚ؤ‚ب‚¢پB
ڈں‚ؤ‚ب‚¢‚ح‚¸‚ج‚ئ‚±‚ë‚ًڈں‚آ‚½‚ك‚ةIntel‚ح
“¯‚¶‚¶‚ل‚ب‚¢گ»‘¢ƒvƒچƒZƒX‚ً•Kژ€‚إˆغژ‚µ‚ؤ‚¢‚é‚ي‚¯‚¾‚ب
721 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 17:35:02.39 ID:QIkrjRpz
‘رˆو‚¹‚ـ‚‚ؤ’x‚¢‚¾‚¯‚ب‚çپA’x‚¢•ھ‚¾‚¯‰‰ژZژٹش‚©‚¯‚ê‚خ‚¢‚¢‚¶‚ل‚ب‚¢پB
‚»‚ج•ھˆہ‚چد‚ـ‚¹‚ؤگ”‚ًچى‚ê‚خ‚¢‚¢پB
’P‹@‚إ10PFLOPS‚ح—§”h‚¾‚ھپA—\–ٌ‚ھ–„‚ـ‚ء‚ؤ‚ؤژg‚¦‚ب‚¢‚و‚¤‚بƒXƒpƒRƒ“‚ة‰؟’l‚ح–³‚¢پB
‚»‚ج•ھˆہ‚چد‚ـ‚¹‚ؤگ”‚ًچى‚ê‚خ‚¢‚¢پB
’P‹@‚إ10PFLOPS‚ح—§”h‚¾‚ھپA—\–ٌ‚ھ–„‚ـ‚ء‚ؤ‚ؤژg‚¦‚ب‚¢‚و‚¤‚بƒXƒpƒRƒ“‚ة‰؟’l‚ح–³‚¢پB
—\–ٌ‚إ–„‚ـ‚é‘هگ¬Œ÷‚ش‚è‚ةژ¹“i
Intel‚ة‚µ‚ؤ‘رˆو”¼•ھپE‘¬“x”¼•ھ‚إپA‚ء‚ؤ‚¢‚¤‚ج‚حŒ»ژہ“I‚ة‰آ”\‚¾‚ء‚½‚¾‚낤‚ھپA
‘ه‹K–حƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً‚â‚éڈم‚إ‘¬“x’x‚¢‚ج‚ح’v–½“I‚بڈêچ‡‚à‚ ‚邾‚ëپB
چ،‰ٌ”»’f‚ج‚µ‚ا‚±‚ë‚ھˆل‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ‚حژv‚¤پB
‹‚ج100”{‚ج‚â‚آ‚ح‚ا‚¤‚·‚é‚آ‚à‚è‚ب‚ج‚©پB
‘ه‹K–حƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً‚â‚éڈم‚إ‘¬“x’x‚¢‚ج‚ح’v–½“I‚بڈêچ‡‚à‚ ‚邾‚ëپB
چ،‰ٌ”»’f‚ج‚µ‚ا‚±‚ë‚ھˆل‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚ئ‚حژv‚¤پB
‹‚ج100”{‚ج‚â‚آ‚ح‚ا‚¤‚·‚é‚آ‚à‚è‚ب‚ج‚©پB
‚·‚إ‚ةڈ‘‚©‚ê‚ؤ‚邯‚اپA‹‚جٹJ”ٹJژnژٹْ‚ة‚¨‚¢‚ؤIntelƒ`ƒbƒv‚ھŒ»ژہ“I‚¾‚ء‚½‚ئ‚حژv‚¦‚ب‚¢پB
Phi‚ةژٹ‚ء‚ؤ‚ح‘¶چف‚·‚炵‚ؤ‚¢‚ب‚¢پB
Œم•t‚إ‚جچl‚¦‚¾‚ëپB
Phi‚ةژٹ‚ء‚ؤ‚ح‘¶چف‚·‚炵‚ؤ‚¢‚ب‚¢پB
Œم•t‚إ‚جچl‚¦‚¾‚ëپB
725 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 17:56:00.31 ID:QIkrjRpz
> ‘ه‹K–حƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ً‚â‚éڈم‚إ‘¬“x’x‚¢‚ج‚ح’v–½“I‚بڈêچ‡‚à‚ ‚邾‚ëپB
‚ب‚ٌ‚إپH
60fps‚جƒQپ[ƒ€‚إ‚à‚â‚é‚جپH
‚ب‚ٌ‚إپH
60fps‚جƒQپ[ƒ€‚إ‚à‚â‚é‚جپH
‹‚جƒxƒ“ƒ`Œِ•\‚ھ2011”N6ŒژپB‚±‚جژٹْ‚ةٹش‚ةچ‡‚ي‚¹‚é‚ة‚ح
2011”N2Œژ‚ج 32nm Xeon‚ح‚¨‚»‚ç‚–³—پB
45nm Xeon‚µ‚©ژg‚¦‚ب‚¢پB45nm Xeon‚جFLOPS/W‚âByte/FLOPS‚إ
5پ`10Peta‚جƒXƒpƒRƒ“پB‚»‚ê‚ھ—ا‚©‚ء‚½‚ئ‚ح“’êژv‚¦‚ب‚¢پB
2011”N2Œژ‚ج 32nm Xeon‚ح‚¨‚»‚ç‚–³—پB
45nm Xeon‚µ‚©ژg‚¦‚ب‚¢پB45nm Xeon‚جFLOPS/W‚âByte/FLOPS‚إ
5پ`10Peta‚جƒXƒpƒRƒ“پB‚»‚ê‚ھ—ا‚©‚ء‚½‚ئ‚ح“’êژv‚¦‚ب‚¢پB
‘هکa‚ح—LŒّ‚ةژg‚¦‚ب‚©‚ء‚½‚ھ•ؤŒR‚جگيٹح‚حگيŒم‚à”C–±‚ةڈA‚¢‚ؤ‚¢‚½‚ٌ‚¾‚ھپB
‹‚à“¯‚¶‚ئ‚¢‚¤‚ب‚çˆê”ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ة‚ ‚ج‘ه‹K–ح‚ھ—LŒّ‚¾‚ء‚½‚ئ‚¢‚¤
ژه’£‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
‹‚à“¯‚¶‚ئ‚¢‚¤‚ب‚çˆê”ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ة‚ ‚ج‘ه‹K–ح‚ھ—LŒّ‚¾‚ء‚½‚ئ‚¢‚¤
ژه’£‚ة‚ب‚ء‚ؤ‚µ‚ـ‚¤پB
>>727
5پ`10Peta‚جƒXƒpƒRƒ“پ@پ¨پ@5پ`10Peta•ھ‚جƒXƒpƒRƒ“
5پ`10Peta‚جƒXƒpƒRƒ“پ@پ¨پ@5پ`10Peta•ھ‚جƒXƒpƒRƒ“
>>727پ@‚ ‚è‚لپ@32nmXeonDP ‚ح2010”N3Œژ‚©پBپ@ٹشˆل‚¦‚½پAژg‚¦‚é
گ¢‚ج’†‚ة‚حپA‹‚â‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚¶‚ل‚ب‚¢‚ئŒvژZ‚إ‚«‚ب‚¢ŒvژZ‚ھ‚½‚‚³‚ٌ‚ ‚é‚©‚炱‚»پA
‚»‚¤‚¢‚ء‚½ƒXƒpƒRƒ“‚ج—ک—p‚ھ—\–ٌ‚إ‚ز‚ء‚½‚è–„‚ـ‚ء‚ؤ‚é‚ٌ‚¾‚و
‚؟‚ب‚ف‚ةپA‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚جƒRƒXƒp‚ح‚©‚ب‚è‚¢‚¢‚ئ‚¨‚à‚¤‚¼
“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚¾‚©‚ç’ل—\ژZ‚إچد‚ٌ‚إ‚é
‚»‚¤‚¢‚ء‚½ƒXƒpƒRƒ“‚ج—ک—p‚ھ—\–ٌ‚إ‚ز‚ء‚½‚è–„‚ـ‚ء‚ؤ‚é‚ٌ‚¾‚و
‚؟‚ب‚ف‚ةپA‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚جƒRƒXƒp‚ح‚©‚ب‚è‚¢‚¢‚ئ‚¨‚à‚¤‚¼
“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚¾‚©‚ç’ل—\ژZ‚إچد‚ٌ‚إ‚é
‹‚à‚¨‚»‚ç‚‚T”N–ع‚‚ç‚¢‚ةƒnپ[ƒhƒEƒFƒAچXگV‚ھ‚ ‚邾‚낤‚¯‚اپA
‚»‚جژ‚ح“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚إ‚¢‚¢‚ج‚إپA‚©‚ب‚è’لƒRƒXƒg‚ة‚ب‚é‚ئ‚¨‚à‚¤‚و
‚»‚جژ‚ح“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚إ‚¢‚¢‚ج‚إپA‚©‚ب‚è’لƒRƒXƒg‚ة‚ب‚é‚ئ‚¨‚à‚¤‚و
ژZگ”‚إ‚«‚ب‚¢”nژ‚©‚وپB
734 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 18:54:01.85 ID:QIkrjRpz
Sandy Bridge‚¶‚ل‚ب‚‚ؤWestmere‚ة‚ب‚邯‚ا‚ثپB
‚ ‚ئGPGPUپiFermiپj‚حٹù‚ة‚ ‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚بپB
‚à‚ئ‚à‚ئƒnƒCƒuƒٹƒbƒh‚ة‚·‚é—\’肾‚ء‚½‚‚ç‚¢‚¾‚µپA
ƒmپ[ƒh‚ح•”•ھ“I‚ة‚إ‚àچXگV‚µ‚ؤ‚à‚¢‚¢‚ي‚¯‚إ‚µ‚هپH
ˆêˆت‚ًˆغژ‚إ‚«‚ب‚¢ˆêˆت‚ةˆس–،‚ھ‚ ‚é‚ج‚©‚ئ‚¢‚¤‚ئپA‚à‚ج‚·‚²‚¢‰ِ‚µ‚¢‚إ‚·پB
> ‘هکa‚ح—LŒّ‚ةژg‚¦‚ب‚©‚ء‚½‚ھ•ؤŒR‚جگيٹح‚حگيŒم‚à”C–±‚ةڈA‚¢‚ؤ‚¢‚½‚ٌ‚¾‚ھپB
“ْ–{‚حگي‘ˆ‚ً‚â‚ك‚½‚ھƒAƒپƒٹƒJ‚ح•د‚ي‚炸ŒRژ–چ‘‰ئ‚¾‚ء‚½پB‚»‚ꂾ‚¯‚©‚ئپB
46cm–C‚ب‚ٌ‚ؤگد‚ٌ‚إ‚½‚ج‚ح‘هکaŒ^‚‚ç‚¢‚إ‚·‚µپB
گيٹح1گا‚جƒAƒEƒgƒŒƒ“ƒW–CŒ‚‚إ100گا‚جٹح‘à‚ً’¾‚ك‚é‚ئ‚¢‚¤–³–d‚بژژ‚ف‚إ‚·‚ثپB
‚»‚ê‚ـ‚³‚ة‹‚ب‚ي‚¯‚إ‚·‚ھپB
‚ׂآ‚ةگيٹح‹‰‚جƒXƒpƒRƒ“‚ح‚ ‚ء‚ؤ‚à‚¢‚¢‚¯‚اپuگ”‚ھ—~‚µ‚¢پv‚ھ
ƒzƒ“ƒg‚ج‚ئ‚±‚ë‚إ‚ح‚ب‚¢‚إ‚·‚©پB
‚ ‚ئGPGPUپiFermiپj‚حٹù‚ة‚ ‚ء‚½‚ٌ‚¶‚ل‚ب‚¢‚©‚بپB
‚à‚ئ‚à‚ئƒnƒCƒuƒٹƒbƒh‚ة‚·‚é—\’肾‚ء‚½‚‚ç‚¢‚¾‚µپA
ƒmپ[ƒh‚ح•”•ھ“I‚ة‚إ‚àچXگV‚µ‚ؤ‚à‚¢‚¢‚ي‚¯‚إ‚µ‚هپH
ˆêˆت‚ًˆغژ‚إ‚«‚ب‚¢ˆêˆت‚ةˆس–،‚ھ‚ ‚é‚ج‚©‚ئ‚¢‚¤‚ئپA‚à‚ج‚·‚²‚¢‰ِ‚µ‚¢‚إ‚·پB
> ‘هکa‚ح—LŒّ‚ةژg‚¦‚ب‚©‚ء‚½‚ھ•ؤŒR‚جگيٹح‚حگيŒم‚à”C–±‚ةڈA‚¢‚ؤ‚¢‚½‚ٌ‚¾‚ھپB
“ْ–{‚حگي‘ˆ‚ً‚â‚ك‚½‚ھƒAƒپƒٹƒJ‚ح•د‚ي‚炸ŒRژ–چ‘‰ئ‚¾‚ء‚½پB‚»‚ꂾ‚¯‚©‚ئپB
46cm–C‚ب‚ٌ‚ؤگد‚ٌ‚إ‚½‚ج‚ح‘هکaŒ^‚‚ç‚¢‚إ‚·‚µپB
گيٹح1گا‚جƒAƒEƒgƒŒƒ“ƒW–CŒ‚‚إ100گا‚جٹح‘à‚ً’¾‚ك‚é‚ئ‚¢‚¤–³–d‚بژژ‚ف‚إ‚·‚ثپB
‚»‚ê‚ـ‚³‚ة‹‚ب‚ي‚¯‚إ‚·‚ھپB
‚ׂآ‚ةگيٹح‹‰‚جƒXƒpƒRƒ“‚ح‚ ‚ء‚ؤ‚à‚¢‚¢‚¯‚اپuگ”‚ھ—~‚µ‚¢پv‚ھ
ƒzƒ“ƒg‚ج‚ئ‚±‚ë‚إ‚ح‚ب‚¢‚إ‚·‚©پB
‚¤‚ٌپAگ”چى‚ê‚خ‚و‚‚ث? ‚»‚¤‚¢‚¤ƒvƒچƒWƒFƒNƒg‚à‚ ‚ء‚ؤ‚¢‚¢پB
پcپc‹‚ج—\ژZ‚ً‰،ژو‚肵‚½‚¢? ‚»‚è‚لپA–³—‚¾پB
پcپc‹‚ج—\ژZ‚ً‰،ژو‚肵‚½‚¢? ‚»‚è‚لپA–³—‚¾پB
736 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 19:00:09.63 ID:QIkrjRpz
پu—¼•û—~‚µ‚¢پv‚ھƒzƒ“ƒg‚ج‚ئ‚±‚ë‚ب‚ج‚إ‚حپB
ٹّٹح‚ح•K—v‚¾‚¯‚اپA‹ى’€ٹح‚ ‚ء‚ؤ‚جٹح‘à‚إ‚·‚µپB
ٹّٹح‚ح•K—v‚¾‚¯‚اپA‹ى’€ٹح‚ ‚ء‚ؤ‚جٹح‘à‚إ‚·‚µپB
ƒAƒz‚ف‚½‚¢‚بŒR”ُ‚إ‚ج—ل‚¦‚ح‚à‚¤‚â‚ك‚ëپA‚±‚ج•ھ–ى‚إ‹پ‚ك‚ç‚ê‚ؤ‚é‚ج‚حژه‚ةژٹش‚ج’Zڈk‚¾‚ë
ŒvژZ—ت‚ً•K—v‚ئ‚·‚錤‹†ژز‚ج‘½‚‚ھ‹‚ح‚¢‚ç‚ب‚¢‚ئ‚¢‚ء‚ؤ‚é‚ٌ‚¾‚©‚ç‚»‚¤‚¢‚¤‚±‚ئ‚¾‚وپB
‚ا‚±‚àŒ¤‹†ژ؛‚ةƒXƒpƒRƒ“‚ھ‚ظ‚µ‚¢‚ٌ‚¾‚وپB1/100‚ج’x‚³‚إ‚à‚بپB
‚ا‚±‚àŒ¤‹†ژ؛‚ةƒXƒpƒRƒ“‚ھ‚ظ‚µ‚¢‚ٌ‚¾‚وپB1/100‚ج’x‚³‚إ‚à‚بپB
”ٍچs‹@‚ح‚¢‚ç‚ب‚¢پAچ‚‘¬ƒoƒX‚ً‘‚₹‚ئŒ¾‚ء‚ؤ‚é‚و‚¤‚ب‚à‚ٌ‚¾‚ب
740 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 20:16:39.02 ID:QIkrjRpz
‚¾‚©‚ç‘ه‚«‚¢ƒXƒpƒRƒ“‚àڈ¬‚³‚بƒXƒpƒRƒ“‚à‚½‚ئ‚¦‚é‚ب‚ç‘D‚¾‚ء‚ؤ‚جپB
چ‚‘¬ƒoƒX‚ح•K—v‚¾‚ëپi•ت‚جˆس–،‚إپj
چ‚‘¬ƒoƒX‚ح•K—v‚¾‚ëپi•ت‚جˆس–،‚إپj
چ‚‘¬ƒoƒX‚¶‚ل‚ب‚‚ؤƒcƒAپ[ƒoƒX‚ھ—~‚µ‚¢‚ٌ‚¾‚ë
ڈ¬‹K–حƒXƒpƒRƒ“‚ج•K—vگ«‚ً”F‚ك‚ب‚¢‹ژxژژز‚ح‚¢‚ب‚¢
ژ©•ھ‚½‚؟‚ھژg‚ي‚ب‚¢‚©‚ç•s—v‚¾‚ئŒ¾‚ء‚ؤ‚¢‚锽‘خ”h‚جƒoƒJ‚ھ‚¢‚邾‚¯
ژ©•ھ‚½‚؟‚ھژg‚ي‚ب‚¢‚©‚ç•s—v‚¾‚ئŒ¾‚ء‚ؤ‚¢‚锽‘خ”h‚جƒoƒJ‚ھ‚¢‚邾‚¯
>>ID:0pNHI3sZ
ڈ«—ˆ‚جژلژز‚ة”œ‘ه‚بژط‹à‰ں‚µ•t‚¯‚ؤ‚ـ‚إچى‚é‚ظ‚¤‚ھ”nژپB
‚»‚ٌ‚ب‚ة‘ه‹K–حƒXƒpƒRƒ“‚ظ‚µ‚©‚ء‚½‚çژg‚¤“z‚ھژ©•ھ‚ج‹àڈo‚µ‚ؤچى‚êپB
ڈ«—ˆ‚جژلژز‚ة”œ‘ه‚بژط‹à‰ں‚µ•t‚¯‚ؤ‚ـ‚إچى‚é‚ظ‚¤‚ھ”nژپB
‚»‚ٌ‚ب‚ة‘ه‹K–حƒXƒpƒRƒ“‚ظ‚µ‚©‚ء‚½‚çژg‚¤“z‚ھژ©•ھ‚ج‹àڈo‚µ‚ؤچى‚êپB
>>743 ‚جŒ¾‚¢•ھ‚حپA”_‰ئ‚ة‹à‚ھ‚à‚ء‚½‚¢‚ب‚¢‚©‚ç”ى—؟”ƒ‚¤‚ب‚ء‚ؤ‚¢‚¤‚‚ç‚¢”nژ‚بژه’£
•s–ر‚¾‚©‚çپA‚»‚ë‚»‚ë‹Zڈp“I‚بٹد“_‚ة–ك‚ء‚ؤ‚«‚ؤ‚‚ê
ٹeŒ¤‹†ژ؛‚ة“±“ü‰آ”\‚ب1/100ƒXƒpƒRƒ“پA‚¢‚¢‚¶‚ل‚ب‚¢پBچى‚낤‚وپB
‚»‚ê‹‚ئ–³ٹضŒW‚ةڈo—ˆ‚邱‚ئ‚¾‚©‚çپA‚ا‚ٌ‚ا‚ٌ‚â‚낤پB
‚»‚ê‹‚ئ–³ٹضŒW‚ةڈo—ˆ‚邱‚ئ‚¾‚©‚çپA‚ا‚ٌ‚ا‚ٌ‚â‚낤پB
>>744
”_‰ئ‚ح‚¨‚ـ‚¦‚ئˆل‚ء‚ؤچجژZگ«چl‚¦‚ؤ“ٹژ‘‚·‚邾‚وپAژZگ”‚إ‚«‚ب‚¢‚¨”nژ‚³‚ٌپB
ƒLƒ~‚ة‚ح“d‘ى‚إ‚·‚çژg‚¢‚±‚ب‚¹‚ب‚¢پB
”_‰ئ‚ح‚¨‚ـ‚¦‚ئˆل‚ء‚ؤچجژZگ«چl‚¦‚ؤ“ٹژ‘‚·‚邾‚وپAژZگ”‚إ‚«‚ب‚¢‚¨”nژ‚³‚ٌپB
ƒLƒ~‚ة‚ح“d‘ى‚إ‚·‚çژg‚¢‚±‚ب‚¹‚ب‚¢پB
748 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/19(‰خ) 23:25:15.87 ID:QIkrjRpz
‹‚ھ’Zٹْٹش‚ج‚¤‚؟‚ة4ˆت‚ـ‚إ—ژ‚؟‚½‚±‚ئ‚إ
ƒXƒpƒRƒ“‚»‚ج‚à‚ج‚ھپuگإ‹à‚ج–³‘تپv‚ئ‚¢‚¤گ¢ک_‚ھچ‚‚ـ‚ء‚ؤ‚é‚ي‚¯‚إ‚µ‚ؤ
ٹwڈpپEژY‹ئٹE‚ة‚ئ‚ء‚ؤ”ٌڈي‚ةƒ}ƒCƒiƒX‚¾‚ئژv‚¤‚ي‚¯‚إ‚·‚¯‚ا
‰ك‚¬‚½‚±‚ئ‚حژd•û‚ب‚¢پB
‚¶‚ل‚ چ،Œم‚ا‚¤‚·‚éپH
ڈ‚ب‚‚ئ‚àپuچ‘ژYCPUپi·ط¯پv‚ب‚ٌ‚ؤ‚à‚ج‚إچى‚ê‚ح‚µ‚ب‚‚ب‚é‚ي‚¯‚إ‚·‚µپB
ƒXƒpƒRƒ“‚»‚ج‚à‚ج‚ھپuگإ‹à‚ج–³‘تپv‚ئ‚¢‚¤گ¢ک_‚ھچ‚‚ـ‚ء‚ؤ‚é‚ي‚¯‚إ‚µ‚ؤ
ٹwڈpپEژY‹ئٹE‚ة‚ئ‚ء‚ؤ”ٌڈي‚ةƒ}ƒCƒiƒX‚¾‚ئژv‚¤‚ي‚¯‚إ‚·‚¯‚ا
‰ك‚¬‚½‚±‚ئ‚حژd•û‚ب‚¢پB
‚¶‚ل‚ چ،Œم‚ا‚¤‚·‚éپH
ڈ‚ب‚‚ئ‚àپuچ‘ژYCPUپi·ط¯پv‚ب‚ٌ‚ؤ‚à‚ج‚إچى‚ê‚ح‚µ‚ب‚‚ب‚é‚ي‚¯‚إ‚·‚µپB
749 پFSocket774پF2013/11/19(‰خ) 23:30:11.52 ID:xPm7OE+D
ƒXƒpƒRƒ“‚جگ¢ٹE‚إ‚حڈ¬پ~•،گ”‘ن‚ح‘ه‚ًŒ“‚ث‚é‚جپHپH
‚»‚جگ¢ک_‚حڈ‰ژ¨
751 پFSocket774پF2013/11/19(‰خ) 23:44:03.14 ID:xPm7OE+D
ˆہ“،ژپ‚ة‚و‚é‚ئپu‹پv‚جƒVƒXƒeƒ€گ»چى”ï‚ح458‰‰~‚炵‚¢‚ھپAƒvƒچƒZƒbƒTٹJ””ïچ‚ف‚ة‚µ‚ؤ‚ح‚¦‚炈ہ‚¢
پEپEپEپE‚ء‚ؤپAƒtƒچƒ€ƒXƒNƒ‰ƒbƒ`‚¶‚ل‚ب‚¢SPARC 64 VII‘‰ü’z”إ‚¾‚©‚çƒvƒچƒZƒbƒTٹJ””ï‚جٹ„چ‡‚ح’ل‚¢‚ج‚©‚ب
http://l2.upup.be/f/r/kSEcvsegpk.png
پEپEپEپE‚ء‚ؤپAƒtƒچƒ€ƒXƒNƒ‰ƒbƒ`‚¶‚ل‚ب‚¢SPARC 64 VII‘‰ü’z”إ‚¾‚©‚çƒvƒچƒZƒbƒTٹJ””ï‚جٹ„چ‡‚ح’ل‚¢‚ج‚©‚ب
http://l2.upup.be/f/r/kSEcvsegpk.png
{kind=link}
752 پFSocket774پF2013/11/19(‰خ) 23:51:22.09 ID:xPm7OE+D
ژ‚؟ڈo‚µ‚إƒOƒO‚ء‚ؤ‚ف‚½‚ç‚â‚ء‚د‚è458‰‰~‚¾‚¯‚¶‚ل–³—‚¾‚ي‚ب
ژ©ژذƒ}ƒlپ[“ث‚ءچ‚ٌ‚¾•xژm’ت‚³‚ٌ‰³پANEC‚³‚ٌ‚à•ت‚جˆس–،‚إ‰³‚—
پ„08”N“x‚حژںگ¢‘مƒXƒpƒRƒ“‚جڈعچ×گفŒv‚جژٹْ‚إپAچ‘‰ئ—\ژZ65‰‰~‚ھ”ï‚₳‚ꂽپB
پ„”¼ٹz‚ھNEC•ھ‚¾‚ء‚½‚ئ‚µ‚ؤ‚àپAپu‚»‚جگ””{‚حژ‚؟ڈo‚µ‚½پvپiNECٹ²•”پjپB
پ„‚±‚ج‚ـ‚ـ‚إ‚حپANEC‚ج•‰’Sٹz‚ح–ٌ500‰‰~‚ة‚ب‚é‚ئ‚ف‚ç‚ê‚ؤ‚¢‚½پB
پ„•xژm’تٹ²•”‚àپu‘Sٹْٹش‚إ–ٌ500‰‰~‚جژ‚؟ڈo‚µپv‚ئ‚µ‚ؤ‚¨‚èپAŒ»چف‚جŒoچدڈîگ¨‰؛‚إ‚ح’ة‚¢ڈo”ïپB
پ„چ~”آ‚ةˆê’è‚ج—‰ً‚ح“¾‚ç‚ê‚»‚¤‚¾پB
ژ©ژذƒ}ƒlپ[“ث‚ءچ‚ٌ‚¾•xژm’ت‚³‚ٌ‰³پANEC‚³‚ٌ‚à•ت‚جˆس–،‚إ‰³‚—
پ„08”N“x‚حژںگ¢‘مƒXƒpƒRƒ“‚جڈعچ×گفŒv‚جژٹْ‚إپAچ‘‰ئ—\ژZ65‰‰~‚ھ”ï‚₳‚ꂽپB
پ„”¼ٹz‚ھNEC•ھ‚¾‚ء‚½‚ئ‚µ‚ؤ‚àپAپu‚»‚جگ””{‚حژ‚؟ڈo‚µ‚½پvپiNECٹ²•”پjپB
پ„‚±‚ج‚ـ‚ـ‚إ‚حپANEC‚ج•‰’Sٹz‚ح–ٌ500‰‰~‚ة‚ب‚é‚ئ‚ف‚ç‚ê‚ؤ‚¢‚½پB
پ„•xژm’تٹ²•”‚àپu‘Sٹْٹش‚إ–ٌ500‰‰~‚جژ‚؟ڈo‚µپv‚ئ‚µ‚ؤ‚¨‚èپAŒ»چف‚جŒoچدڈîگ¨‰؛‚إ‚ح’ة‚¢ڈo”ïپB
پ„چ~”آ‚ةˆê’è‚ج—‰ً‚ح“¾‚ç‚ê‚»‚¤‚¾پB
TOP500ƒ‰ƒ“ƒLƒ“ƒO‚ً—ˆ”N‚©‚çLinpack‚¶‚ل‚ب‚G-FFT‚ة•د‚¦‚ê‚خ‚¢‚¢‚ج‚ة
‚»‚¤‚·‚è‚ل‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚àڈمˆت‚ة•œٹˆ‚µ‚ؤ‹‚àƒ‰ƒ“ƒLƒ“ƒO‚ ‚ھ‚é‚ج‚ة
‚»‚¤‚·‚è‚ل‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚àڈمˆت‚ة•œٹˆ‚µ‚ؤ‹‚àƒ‰ƒ“ƒLƒ“ƒO‚ ‚ھ‚é‚ج‚ة
‚¾‚©‚猾‚ء‚ؤ‚邾‚ëپB‹à‚ب‚ٌ‚©‚ا‚¤‚ئ‚إ‚à“sچ‡‚آ‚‚ٌ‚¾‚©‚çپA
پu‚â‚肽‚¢پv‚ء‚ؤŒ¾‚ء‚ؤ‚¢‚é‚â‚آ‚ھ‚¢‚邤‚؟پAچى‚ê‚é“z‚ھ‚¢‚邤‚؟‚ح‚â‚낤‚ء‚ؤپB
‚»‚ج‚¤‚؟‚±‚جچ‘‚©‚ç‚»‚ٌ‚ب“z‚à‚¢‚ب‚‚ب‚ء‚؟‚ل‚¤(‚©‚à‚µ‚ê‚ب‚¢)‚ٌ‚¾‚©‚çپB
پu‚â‚肽‚¢پv‚ء‚ؤŒ¾‚ء‚ؤ‚¢‚é‚â‚آ‚ھ‚¢‚邤‚؟پAچى‚ê‚é“z‚ھ‚¢‚邤‚؟‚ح‚â‚낤‚ء‚ؤپB
‚»‚ج‚¤‚؟‚±‚جچ‘‚©‚ç‚»‚ٌ‚ب“z‚à‚¢‚ب‚‚ب‚ء‚؟‚ل‚¤(‚©‚à‚µ‚ê‚ب‚¢)‚ٌ‚¾‚©‚çپB
‚ا‚¤‚¹‚±‚±‚جڈZگl‚ء‚ؤ’P‚ةژ©•ھ‚ة‚ھچD‚«‚إ–ت”’‚¢‚©‚ç‚â‚ء‚ؤ‚ظ‚µ‚¢‚ء‚ؤ‚¾‚¯‚ب‚ٌ‚إ‚µ‚ه?پ@>‹
>>751
SPARC-V9 ‚ة‰½‚ً’ا‰ء‚µ‚½‚ج‚©
ttp://jp.fujitsu.com/about/magazine/backnumber/vol63-3.html#b4
SPARC‚âƒپƒCƒ“ƒtƒŒپ[ƒ€پAگج‚جƒxƒNƒgƒ‹‹@‚ج’~گد‚ھ‚ب‚©‚ء‚½‚çپA”ï—p‚âژٹش‚ح
‚à‚ء‚ئ‚©‚©‚ء‚½‚¾‚낤پB‚ئ‚¢‚¤‚©پA‚à‚µ‚àˆâژY‚ھ‚ب‚¯‚ê‚خژہ—ح“I‚ة‚إ‚«‚ب‚©‚ء‚½‚ئژv‚ي‚êپB
SPARC-V9 ‚ة‰½‚ً’ا‰ء‚µ‚½‚ج‚©
ttp://jp.fujitsu.com/about/magazine/backnumber/vol63-3.html#b4
SPARC‚âƒپƒCƒ“ƒtƒŒپ[ƒ€پAگج‚جƒxƒNƒgƒ‹‹@‚ج’~گد‚ھ‚ب‚©‚ء‚½‚çپA”ï—p‚âژٹش‚ح
‚à‚ء‚ئ‚©‚©‚ء‚½‚¾‚낤پB‚ئ‚¢‚¤‚©پA‚à‚µ‚àˆâژY‚ھ‚ب‚¯‚ê‚خژہ—ح“I‚ة‚إ‚«‚ب‚©‚ء‚½‚ئژv‚ي‚êپB
–ت”’‚¢‚©‚ا‚¤‚©‚إ‚¢‚¤‚ئ‹‚ح–ت”’‚‚ب‚¢‚ظ‚¤
758 پFSocket774پF2013/11/20(گ…) 10:17:41.68 ID:3HK3jhie
500‰‰~‚ح5‰ƒhƒ‹
–ˆ”N100‰ƒhƒ‹‚‚ç‚¢‰ز‚¢‚إ‚éƒCƒ“ƒeƒ‹‚ب‚ç—]—T‚إٹJ”‚ة”ï‚₵‚ؤ‚¢‚»‚¤‚¾‚ب
–ˆ”N100‰ƒhƒ‹‚‚ç‚¢‰ز‚¢‚إ‚éƒCƒ“ƒeƒ‹‚ب‚ç—]—T‚إٹJ”‚ة”ï‚₵‚ؤ‚¢‚»‚¤‚¾‚ب
پyITپz’†چ‘‚جƒXƒpƒRƒ“پu“V‰ح‚Qچ†پvپAگ¢ٹEˆê‚ًژç‚é
http://anago.2ch.net/test/read.cgi/scienceplus/1384823948/
http://anago.2ch.net/test/read.cgi/scienceplus/1384823948/
MicronپADDR3ƒپƒ‚ƒٹŒ`ڈَ‚ج•ہ—ٌڈˆ—Œü‚¯ƒvƒچƒZƒbƒT
http://pc.watch.impress.co.jp/docs/news/20131120_624325.html
PEMM‚ئˆل‚ء‚ؤƒپƒ‚ƒٹ‚ئŒفٹ·گ«‚ھ‚ ‚é‚ي‚¯‚إ‚ح‚ب‚¢‚ئ‚ج‚±‚ئ
http://pc.watch.impress.co.jp/docs/news/20131120_624325.html
PEMM‚ئˆل‚ء‚ؤƒپƒ‚ƒٹ‚ئŒفٹ·گ«‚ھ‚ ‚é‚ي‚¯‚إ‚ح‚ب‚¢‚ئ‚ج‚±‚ئ
762 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/20(گ…) 19:47:12.24 ID:sqTkcBVi
2010”N‚ج100‹ƒXƒpƒRƒ“—p‚جCPUچى‚ê‚»‚¤‚ب‚ج‚ھIntel‚‚ç‚¢‚µ‚©‚¢‚ب‚¢پB
ƒAƒNƒZƒ‰ƒŒپ[ƒ^چ¬گ¬‚ب‚çTesla‚âFirePro‚à‚ ‚èپH
ٹe‘هٹw‚ھ‚ب‚¯‚ب‚µ‚ج—\ژZ‚إ‘g‚ٌ‚إ‚éٹw“àƒXƒpƒRƒ“‚ًƒXƒPپ[ƒ‹ƒAƒbƒv‚³‚¹‚½‚و‚¤‚ب‚à‚ج‚ھ
ˆê”ش–³‘ت‚ھ–³‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ئپB
ƒAƒNƒZƒ‰ƒŒپ[ƒ^چ¬گ¬‚ب‚çTesla‚âFirePro‚à‚ ‚èپH
ٹe‘هٹw‚ھ‚ب‚¯‚ب‚µ‚ج—\ژZ‚إ‘g‚ٌ‚إ‚éٹw“àƒXƒpƒRƒ“‚ًƒXƒPپ[ƒ‹ƒAƒbƒv‚³‚¹‚½‚و‚¤‚ب‚à‚ج‚ھ
ˆê”ش–³‘ت‚ھ–³‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ئپB
ڈٹ‘Fگ¢ٹش‚ب‚ٌ‚ؤ•³‚ج–ً‚ة‚à—§‚½‚ٌƒxƒ“ƒ`ƒ}پ[ƒN‚جƒ‰ƒ“ƒLƒ“ƒO‚µ‚©•]‰؟‚µ‚ب‚¢‚ي‚¯‚إ
‘ه‚¢‚ب‚é•sچK‚¾‚ي‚ب
‘ه‚¢‚ب‚é•sچK‚¾‚ي‚ب
764 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/20(گ…) 22:08:43.96 ID:sqTkcBVi
‚ب‚ة‚©‚µ‚çˆê”ش‚ب‚ç•]‰؟‚³‚ê‚éپB
“ٌ”ش‚ح•]‰؟‚³‚ê‚ب‚¢پB
“ْ–{‚إ“ٌ”ش–ع‚ةچ‚‚¢ژR‚ء‚ؤ’m‚ء‚ؤ‚éپH
گ¢ٹE‚إ‚حپH
ژv‚¢•‚‚©‚خ‚ب‚¢‚¾‚ëپH‚»‚¤‚¢‚¤‚±‚ئ‚¾پB
“ٌ”ش‚ح•]‰؟‚³‚ê‚ب‚¢پB
“ْ–{‚إ“ٌ”ش–ع‚ةچ‚‚¢ژR‚ء‚ؤ’m‚ء‚ؤ‚éپH
گ¢ٹE‚إ‚حپH
ژv‚¢•‚‚©‚خ‚ب‚¢‚¾‚ëپH‚»‚¤‚¢‚¤‚±‚ئ‚¾پB
1ˆت‚ة‚ب‚邽‚ك‚ة‚¶‚ل‚ب‚‚ؤژذ‰ï‚ة–ً‚ة—§‚آ‚½‚ك‚ةچى‚ê‚و
ژذ‰ï‚ة–ً‚ة—§‚آ‚½‚ك‚ة‚ھ‚ٌ‚خ‚葱‚¯‚ؤ‚Pˆت‚ة‚ب‚éپEپEپE‚±‚ê‚ھ—‘z‚ئ‚¢‚¤‚±‚ئ‚¾‚ث‚ء
FLOPSگ”‚إƒgƒbƒv‚ً–عژw‚·‚ب‚çپAGPGPUƒNƒ‰ƒXƒ^‚©PhiƒNƒ‰ƒXƒ^‚ً”ؤ—p‚جƒCپ[ƒTپ[ƒlƒbƒg‚إ
گع‘±‚·‚é‚ج‚ھ‚ھ‚¢‚؟‚خ‚ٌŒّ—¦‚ھ‚¢‚¢‚¾‚낤‚¯‚اپA
’P‚ةƒxƒ“ƒ`‚ھ–ع“I‚¶‚ل‚ب‚¢‚ٌ‚¾‚µپA‚ׂآ‚ة‚»‚ٌ‚ب‚ج‚ًچى‚é•K—v‚ح–³‚¢‚إ‚µ‚هپH
‚؟‚ب‚ف‚ةپA‹‚à5”N‚¨‚«‚‚ç‚¢‚ةƒnپ[ƒh‚ھچXگV‚³‚ê‚邾‚낤‚µپA
‚Q‘م–ع‹‚حپA“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚ب‚ج‚إپA‚©‚ب‚è’لƒRƒXƒg‚إچد‚ق‚ئژv‚¤‚و
‚¾‚ê‚ة‚à’چ–ع‚³‚ê‚ب‚¢‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚حŒ‹چ\ٹˆ–ô‚µ‚ؤ‚é‚ٌ‚¾‚؛
‚Q‘م–ع‹‚à‚¨‚»‚ç‚‚¾‚ê‚ة‚à’چ–ع‚³‚ê‚ب‚¢‚¾‚낤‚ھپA‚©‚ب‚èٹˆ–ô‚·‚é‚ئژv‚¤
گع‘±‚·‚é‚ج‚ھ‚ھ‚¢‚؟‚خ‚ٌŒّ—¦‚ھ‚¢‚¢‚¾‚낤‚¯‚اپA
’P‚ةƒxƒ“ƒ`‚ھ–ع“I‚¶‚ل‚ب‚¢‚ٌ‚¾‚µپA‚ׂآ‚ة‚»‚ٌ‚ب‚ج‚ًچى‚é•K—v‚ح–³‚¢‚إ‚µ‚هپH
‚؟‚ب‚ف‚ةپA‹‚à5”N‚¨‚«‚‚ç‚¢‚ةƒnپ[ƒh‚ھچXگV‚³‚ê‚邾‚낤‚µپA
‚Q‘م–ع‹‚حپA“y’nŒڑ•¨‚حژg‚¢‰ٌ‚µ‚ب‚ج‚إپA‚©‚ب‚è’لƒRƒXƒg‚إچد‚ق‚ئژv‚¤‚و
‚¾‚ê‚ة‚à’چ–ع‚³‚ê‚ب‚¢‚Q‘م–ع’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚حŒ‹چ\ٹˆ–ô‚µ‚ؤ‚é‚ٌ‚¾‚؛
‚Q‘م–ع‹‚à‚¨‚»‚ç‚‚¾‚ê‚ة‚à’چ–ع‚³‚ê‚ب‚¢‚¾‚낤‚ھپA‚©‚ب‚èٹˆ–ô‚·‚é‚ئژv‚¤
>>767
پ„”ؤ—p‚جƒCپ[ƒTپ[ƒlƒbƒg‚إ
پ„گع‘±‚·‚é‚ج‚ھ‚ھ‚¢‚؟‚خ‚ٌŒّ—¦‚ھ‚¢‚¢
—¬گخ‚ة‚»‚ê‚ح–³‚¢
ژہچغپAtop500‚جڈمˆت50‚إƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ة
ƒCپ[ƒTƒlƒbƒg‚ًچج—p‚µ‚½ƒAƒz‚بƒVƒXƒeƒ€‚ح‚ب‚¢
ƒJƒXƒ^ƒ€پAInfinibandپAGeminiپAAries‚ج‚¢‚¸‚ê‚©
پ„”ؤ—p‚جƒCپ[ƒTپ[ƒlƒbƒg‚إ
پ„گع‘±‚·‚é‚ج‚ھ‚ھ‚¢‚؟‚خ‚ٌŒّ—¦‚ھ‚¢‚¢
—¬گخ‚ة‚»‚ê‚ح–³‚¢
ژہچغپAtop500‚جڈمˆت50‚إƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ة
ƒCپ[ƒTƒlƒbƒg‚ًچج—p‚µ‚½ƒAƒz‚بƒVƒXƒeƒ€‚ح‚ب‚¢
ƒJƒXƒ^ƒ€پAInfinibandپAGeminiپAAries‚ج‚¢‚¸‚ê‚©
“ْ–{‚ح” ‚ة‹à‚ًٹ|‚¯‚ؤ‚¨‚©‚ب‚¢‚ئپA
—h‚ê‚ؤ•ِ‚ꂽ‚èٹCگ…‚ة—¬‚³‚ꂽ‚è
‚·‚邶‚ل‚ب‚¢‚إ‚·‚©پ[‚—
—h‚ê‚ؤ•ِ‚ꂽ‚èٹCگ…‚ة—¬‚³‚ꂽ‚è
‚·‚邶‚ل‚ب‚¢‚إ‚·‚©پ[‚—
>>768
ˆہڈم‚ھ‚肨ژèŒy‚إ‚¢‚¤‚ب‚çƒCپ[ƒTƒlƒbƒgپA‚»‚ê‚ا‚±‚ë‚©ƒCƒ“ƒ^پ[ƒlƒbƒgژg‚ء‚ؤBOINC‚ج‚ظ‚¤‚ھˆہڈم‚ھ‚肾
–â‘è‚حپAˆہڈم‚ھ‚è‚ب‚آ‚ب‚°•û‚¾‚ئŒہٹE‚ھ’ل‚پA‚¹‚ء‚©‚‚ج‰‰ژZگ«”\‚ھژہ’n‚إگ¶‚©‚µ‚أ‚ç‚¢‚ئ‚¢‚¤‚¾‚¯‚جکb
ˆہڈم‚ھ‚è‚إ–¼–عڈم‚جگ«”\‚¾‚¯‰ز‚¢‚إ‚àˆس–،‚ب‚¢‚ٌ‚¶‚ل‚ثپH‚ء‚ؤکb‚¶‚ل‚ث‚¦‚جپA>>767‚ء‚ؤ‚³
ˆہڈم‚ھ‚肨ژèŒy‚إ‚¢‚¤‚ب‚çƒCپ[ƒTƒlƒbƒgپA‚»‚ê‚ا‚±‚ë‚©ƒCƒ“ƒ^پ[ƒlƒbƒgژg‚ء‚ؤBOINC‚ج‚ظ‚¤‚ھˆہڈم‚ھ‚肾
–â‘è‚حپAˆہڈم‚ھ‚è‚ب‚آ‚ب‚°•û‚¾‚ئŒہٹE‚ھ’ل‚پA‚¹‚ء‚©‚‚ج‰‰ژZگ«”\‚ھژہ’n‚إگ¶‚©‚µ‚أ‚ç‚¢‚ئ‚¢‚¤‚¾‚¯‚جکb
ˆہڈم‚ھ‚è‚إ–¼–عڈم‚جگ«”\‚¾‚¯‰ز‚¢‚إ‚àˆس–،‚ب‚¢‚ٌ‚¶‚ل‚ثپH‚ء‚ؤکb‚¶‚ل‚ث‚¦‚جپA>>767‚ء‚ؤ‚³
>>770
Linpack‚إ‚·‚ç‘ھ‚邱‚ئ‚جڈo—ˆ‚ب‚¢‘f‚جFLOPSگ”‚جکbپH
‹K’è–³‚µ‚جˆêژR‚¢‚‚ç‚ج‰‰ژZ”\—ح‚إ‚¢‚¢‚ب‚ç
‹ة’[‚بکb‚µپA‚»‚ꂱ‚»ƒlƒbƒgƒڈپ[ƒN‚·‚ç‚¢‚ç‚ب‚¢
‚»‚à‚»‚àBOINC‚ًپuƒXƒpƒRƒ“•ہ‚ف‚جپv‚ئ•\Œ»‚·‚éŒü‚«‚ح‘½‚¢‚ھ
پuƒXƒpƒRƒ“‚¾پv‚ئ‹•ظ‚·‚é‚ج‚حƒAƒz‚µ‚©‚¢‚ب‚¢
Linpack‚إ‚·‚ç‘ھ‚邱‚ئ‚جڈo—ˆ‚ب‚¢‘f‚جFLOPSگ”‚جکbپH
‹K’è–³‚µ‚جˆêژR‚¢‚‚ç‚ج‰‰ژZ”\—ح‚إ‚¢‚¢‚ب‚ç
‹ة’[‚بکb‚µپA‚»‚ꂱ‚»ƒlƒbƒgƒڈپ[ƒN‚·‚ç‚¢‚ç‚ب‚¢
‚»‚à‚»‚àBOINC‚ًپuƒXƒpƒRƒ“•ہ‚ف‚جپv‚ئ•\Œ»‚·‚éŒü‚«‚ح‘½‚¢‚ھ
پuƒXƒpƒRƒ“‚¾پv‚ئ‹•ظ‚·‚é‚ج‚حƒAƒz‚µ‚©‚¢‚ب‚¢
>>771
’P‚ة”l“|‚µ‚½‚¢‚¾‚¯‚ء‚ؤ‚ج‚ح‚و‚‚ي‚©‚ء‚½‚—
پu–¼–عڈم‚جگ”ژڑ‚¶‚لˆس–،‚ث‚¦پv‚ء‚ؤکb‚ة•s–‚ب‚çپAپu–¼–عڈم‚جگ”ژڑچإچ‚پIپv‚ف‚½‚¢‚ب‚ج‚ً‚ش‚آ‚¯‚ؤ‚‚é‚ׂ«‚¾‚و‚—
’P‚ة”l“|‚µ‚½‚¢‚¾‚¯‚ء‚ؤ‚ج‚ح‚و‚‚ي‚©‚ء‚½‚—
پu–¼–عڈم‚جگ”ژڑ‚¶‚لˆس–،‚ث‚¦پv‚ء‚ؤکb‚ة•s–‚ب‚çپAپu–¼–عڈم‚جگ”ژڑچإچ‚پIپv‚ف‚½‚¢‚ب‚ج‚ً‚ش‚آ‚¯‚ؤ‚‚é‚ׂ«‚¾‚و‚—
–â‘è‚حچ‘ƒvƒچ‚¶‚لƒپپ[ƒJپ[‚ح–ׂ©‚ç‚ب‚¢‚ء‚ؤڈˆ‚¾‚و‚ثپBFژذ‚à‹‚ج–¼‘Oژg‚ء‚ؤگé“`”ï‚ئ‚µ‚ؤ‰ٌژû‚·‚é‚ج‚ة•Kژ€پB
‚¢‚âƒCپ[ƒTپ[ƒlƒbƒg‚إ‚ح–¼–عڈم‚جگ”ژڑ‚·‚çڈo‚ب‚¢‚ء‚ؤکb‚إ‚µ‚هپB
•ت‚ة‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚جپBƒCپ[ƒTپ[ƒlƒbƒg‚ج‚و‚¤‚ب’لƒRƒXƒg‚بپA
‚ء‚ؤ‚¢‚¤‚آ‚à‚è‚ب‚ٌ‚¾‚낤‚µپBŒ¾—t‚¶‚è‚ةژْ‚ي‚ê‚é‚ج‚±‚»–³ˆس–،پB
•ت‚ة‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚جپBƒCپ[ƒTپ[ƒlƒbƒg‚ج‚و‚¤‚ب’لƒRƒXƒg‚بپA
‚ء‚ؤ‚¢‚¤‚آ‚à‚è‚ب‚ٌ‚¾‚낤‚µپBŒ¾—t‚¶‚è‚ةژْ‚ي‚ê‚é‚ج‚±‚»–³ˆس–،پB
’·چè‘ه‚جƒSپ[ƒhƒ“ƒxƒ‹ڈـ‚ئ‚ء‚½GPUƒNƒ‰ƒXƒ^‚àƒMƒKƒrƒbƒgƒCپ[ƒT‚©‚çInfiniband‚ة•د‚¦‚½‚çژہŒّگ«”\‚ھƒ_ƒ“ƒ`‚¾‚ء‚½‚ف‚½‚¢‚¾‚µƒCپ[ƒTƒlƒbƒg‚حƒŒƒCƒeƒ“ƒV‚ھ‚إ‚©‚·‚¬‚ؤˆہ‚¢ˆبڈم‚جˆس–،‚ح‚ب‚¢‚ب
‚¹‚¢‚؛‚¢ٹwگ¶ژہŒ±‚إƒNƒ‰ƒXƒ^‘g‚ق‚®‚ç‚¢‚¾‚ë
‚¹‚¢‚؛‚¢ٹwگ¶ژہŒ±‚إƒNƒ‰ƒXƒ^‘g‚ق‚®‚ç‚¢‚¾‚ë
‹‘¬‚â’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚حپAƒvƒچƒZƒbƒT‚جƒJƒ^ƒچƒOƒXƒyƒbƒN‚و‚è‚àƒmپ[ƒhٹش‚جƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚جƒXƒ‹پ[ƒvƒbƒgڈdژ‹‚إپA
ƒmپ[ƒhگ”‘©‚ث‚½‚¾‚¯‚جƒJƒ^ƒچƒOƒXƒyƒbƒN‚إ‚ح‚»‚¤‚»‚¤‚ة1ˆت‚©‚ç“]—ژ‚µ‚½‚¯‚اپAژہŒّگ«”\‚إ‚ح–¢‚¾‚ةƒgƒbƒvƒNƒ‰ƒX‚ئ‚¢‚¤پB
•n–Rچ‘‚â•n–Rچ‘‘هٹw‚إ‚حپAژs”ج‚جPC‚ًژs”ج‚جƒXƒCƒbƒ`ƒnƒu‚إŒq‚¢‚إHPC‘g‚ٌ‚إ‚邯‚اپA
‚±‚¤‚¢‚¤‚ج‚حگ«”\‚ھGbE‚ج‘رˆو‚âƒXƒCƒbƒ`ƒnƒu‚جƒNƒچƒXƒoپ[‚جگ«”\‚إ—¥‘¬‚³‚ê‚ؤ‚µ‚ـ‚¤‚©‚çپA
ژs”ج‚جˆہPC‚ةژs”ج‚جƒQپ[ƒ€—pGPUژw‚µ‚ؤLAN‚إŒq‚¢‚¾‚¾‚¯‚إگ«”\’n‹…ƒVƒ€’´‚¦www—\ژZ‰½–œ•ھ‚جˆêwwwتقغ½www
پc‚ف‚½‚¢‚ج‚ح‰½‚à‚ي‚©‚ء‚؟‚ل‚¢‚ب‚¢
‚إ‚àژs”ج•i‚ً”ƒ‚ء‚ؤ‚‚邾‚¯‚إ–k’©‘N‚ف‚½‚¢‚بڈٹ‚إ‚à‚»‚¤‚¢‚¤‚ج‚ھ‘g‚ك‚ؤ‚µ‚ـ‚¤‚ج‚ح•s–،‚¢‚و‚ب
ƒmپ[ƒhگ”‘©‚ث‚½‚¾‚¯‚جƒJƒ^ƒچƒOƒXƒyƒbƒN‚إ‚ح‚»‚¤‚»‚¤‚ة1ˆت‚©‚ç“]—ژ‚µ‚½‚¯‚اپAژہŒّگ«”\‚إ‚ح–¢‚¾‚ةƒgƒbƒvƒNƒ‰ƒX‚ئ‚¢‚¤پB
•n–Rچ‘‚â•n–Rچ‘‘هٹw‚إ‚حپAژs”ج‚جPC‚ًژs”ج‚جƒXƒCƒbƒ`ƒnƒu‚إŒq‚¢‚إHPC‘g‚ٌ‚إ‚邯‚اپA
‚±‚¤‚¢‚¤‚ج‚حگ«”\‚ھGbE‚ج‘رˆو‚âƒXƒCƒbƒ`ƒnƒu‚جƒNƒچƒXƒoپ[‚جگ«”\‚إ—¥‘¬‚³‚ê‚ؤ‚µ‚ـ‚¤‚©‚çپA
ژs”ج‚جˆہPC‚ةژs”ج‚جƒQپ[ƒ€—pGPUژw‚µ‚ؤLAN‚إŒq‚¢‚¾‚¾‚¯‚إگ«”\’n‹…ƒVƒ€’´‚¦www—\ژZ‰½–œ•ھ‚جˆêwwwتقغ½www
پc‚ف‚½‚¢‚ج‚ح‰½‚à‚ي‚©‚ء‚؟‚ل‚¢‚ب‚¢
‚إ‚àژs”ج•i‚ً”ƒ‚ء‚ؤ‚‚邾‚¯‚إ–k’©‘N‚ف‚½‚¢‚بڈٹ‚إ‚à‚»‚¤‚¢‚¤‚ج‚ھ‘g‚ك‚ؤ‚µ‚ـ‚¤‚ج‚ح•s–،‚¢‚و‚ب
778 پFSocket774پF2013/11/21(–ط) 14:50:33.45 ID:WVJ8APzA
ƒXƒpƒRƒ“‚ةSPARC V9–½—كƒZƒbƒg‚ح•s—v‚¾‚ئژv‚¤‚¯‚اپA“ْ–{گlگفŒv‚جƒvƒچƒZƒbƒT‚ھ‚ب‚‚ب‚é‚ئ‚µ‚½‚çژ₵‚¢‚ب‚
پiSPARC64 VIIIfx‚ح100zپ““ْ–{گlگفŒvپj
‚ـ‚ ‚ئ‚ة‚©‚—â‹pپAڈWگدپAƒCƒ“ƒ^ƒRƒlƒNƒgپAƒXƒgƒŒپ[ƒWژü‚èپA‚ئٹJ”‚جژè‚ًٹة‚ك‚é‚ي‚¯‚ة‚ح‚¢‚©‚ٌ‚µ—\ژZ‚ح‚à‚ء‚ئ‚à‚ء‚ئ•K—v‚¾
پiSPARC64 VIIIfx‚ح100zپ““ْ–{گlگفŒvپj
‚ـ‚ ‚ئ‚ة‚©‚—â‹pپAڈWگدپAƒCƒ“ƒ^ƒRƒlƒNƒgپAƒXƒgƒŒپ[ƒWژü‚èپA‚ئٹJ”‚جژè‚ًٹة‚ك‚é‚ي‚¯‚ة‚ح‚¢‚©‚ٌ‚µ—\ژZ‚ح‚à‚ء‚ئ‚à‚ء‚ئ•K—v‚¾
779 پFSocket774پF2013/11/21(–ط) 14:52:09.20 ID:WVJ8APzA
پu‹پvŒمŒp‹@‚إگ¢ٹEƒgƒbƒv‹‰‚جƒXƒpƒRƒ“•K—vپپ—Œ¤پEˆنڈمژپپ@2013”N6Œژ
http://jp.reuters.com/article/topNews/idJPTYE95G05Z20130617
„ں„ں‹‚جٹJ”‚إ‚حپAژ–‹ئژd•ھ‚¯‚إ–¯ژه“}‚جک@نuژQ‹c‰@‹cˆُ‚ة‚و‚é
پu‚Qˆت‚¶‚ل‚¾‚ك‚ب‚ج‚©پv‚ئ‚¢‚¤–â‚¢‚©‚¯‚ھ—L–¼‚ة‚ب‚ء‚½پB
‚ا‚ꂾ‚¯’لƒRƒXƒg‚إچى‚é‚ج‚©‚ئ‚¢‚¤‚ج‚àگ«”\‚جˆê‚آ‚إ‚حپB
ˆنڈمژپپu‹‚جٹJ””ï‚حپA2006”N‚©‚ç12”N6Œژ‚ـ‚إ‚ج‘«ٹ|‚¯7”N‚إ1111‰‰~پB
’èڈي“I‚ب—\ژZپi–M‰ف‚إ”Nٹش1500‰‰~’ِ“xپj‚ًŒvڈم‚·‚éƒAƒپƒٹƒJ‚ة”ن‚×پA
‚P”Nٹش‚ة‚ب‚ç‚·‚ئ“ْ–{‚ج“ٹژ‘ٹz‚حڈ¬‚³‚¢پBƒAƒپƒٹƒJ‚ة‚¨‚¯‚é
Œp‘±“I‚بژو‚è‘g‚ف‚ة”ن‚ׂé‚ئپAپi“ْ–{‚حپj‚ا‚¤‚µ‚ؤ‚àژم‚³‚ھڈo‚éپv
http://jp.reuters.com/article/topNews/idJPTYE95G05Z20130617
„ں„ں‹‚جٹJ”‚إ‚حپAژ–‹ئژd•ھ‚¯‚إ–¯ژه“}‚جک@نuژQ‹c‰@‹cˆُ‚ة‚و‚é
پu‚Qˆت‚¶‚ل‚¾‚ك‚ب‚ج‚©پv‚ئ‚¢‚¤–â‚¢‚©‚¯‚ھ—L–¼‚ة‚ب‚ء‚½پB
‚ا‚ꂾ‚¯’لƒRƒXƒg‚إچى‚é‚ج‚©‚ئ‚¢‚¤‚ج‚àگ«”\‚جˆê‚آ‚إ‚حپB
ˆنڈمژپپu‹‚جٹJ””ï‚حپA2006”N‚©‚ç12”N6Œژ‚ـ‚إ‚ج‘«ٹ|‚¯7”N‚إ1111‰‰~پB
’èڈي“I‚ب—\ژZپi–M‰ف‚إ”Nٹش1500‰‰~’ِ“xپj‚ًŒvڈم‚·‚éƒAƒپƒٹƒJ‚ة”ن‚×پA
‚P”Nٹش‚ة‚ب‚ç‚·‚ئ“ْ–{‚ج“ٹژ‘ٹz‚حڈ¬‚³‚¢پBƒAƒپƒٹƒJ‚ة‚¨‚¯‚é
Œp‘±“I‚بژو‚è‘g‚ف‚ة”ن‚ׂé‚ئپAپi“ْ–{‚حپj‚ا‚¤‚µ‚ؤ‚àژم‚³‚ھڈo‚éپv
780 پFSocket774پF2013/11/21(–ط) 14:56:17.75 ID:WVJ8APzA
TOP500‚ة‚ف‚éگ¢ٹE‚جƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^‚جڈَ‹µپ@2011”N10Œژ
http://www.nistep.go.jp/achiev/ftx/jpn/stfc/stt125j/report2.pdf
گ}•\5‚ةپA‚»‚ج7ƒ–چ‘‚ج‰ك‹ژ10”N‚جLINPACKگ«”\‚جچ‡Œv‚جگ„ˆع‚ًژ¦‚·پB
2011”N6Œژژ“_‚إ‚حپA“ْ–{پE’†چ‘پEƒtƒ‰ƒ“ƒXپEƒhƒCƒcپE‰pچ‘پEƒچƒVƒA‚جڈ‡‚إ‚ ‚éپB
ڈمˆت7ƒ–چ‘‚حپA•ؤچ‘ˆبٹO‚إ‚ح‰¢ڈB‚ئƒAƒWƒA2چ‘‚ة•ھ‚¯‚ç‚ê‚éپB
‚±‚ê‚ç‚جچ‘پX‚ً2ˆتƒOƒ‹پ[ƒv‚ئ‘¨‚¦‚é‚ئپAچإ‹ك‚ج“ء’¥‚ئ‚µ‚ؤپA
‚±‚ج2ˆتƒOƒ‹پ[ƒv‚جگL‚ر‚ھ‹}ڈs‚إ‚ ‚邱‚ئ‚ھ•ھ‚©‚éپB
http://www.nistep.go.jp/achiev/ftx/jpn/stfc/stt125j/report2.pdf
گ}•\5‚ةپA‚»‚ج7ƒ–چ‘‚ج‰ك‹ژ10”N‚جLINPACKگ«”\‚جچ‡Œv‚جگ„ˆع‚ًژ¦‚·پB
2011”N6Œژژ“_‚إ‚حپA“ْ–{پE’†چ‘پEƒtƒ‰ƒ“ƒXپEƒhƒCƒcپE‰pچ‘پEƒچƒVƒA‚جڈ‡‚إ‚ ‚éپB
ڈمˆت7ƒ–چ‘‚حپA•ؤچ‘ˆبٹO‚إ‚ح‰¢ڈB‚ئƒAƒWƒA2چ‘‚ة•ھ‚¯‚ç‚ê‚éپB
‚±‚ê‚ç‚جچ‘پX‚ً2ˆتƒOƒ‹پ[ƒv‚ئ‘¨‚¦‚é‚ئپAچإ‹ك‚ج“ء’¥‚ئ‚µ‚ؤپA
‚±‚ج2ˆتƒOƒ‹پ[ƒv‚جگL‚ر‚ھ‹}ڈs‚إ‚ ‚邱‚ئ‚ھ•ھ‚©‚éپB
781 پFSocket774پF2013/11/21(–ط) 14:58:25.26 ID:WVJ8APzA
پu–¯ژه“}‚جڈيژ¯پپگ¢ٹE‚ج”ٌڈيژ¯پvپu‰بٹwڈkڈ¬پc“ْ–{‚جچ‘—ح’ل‰؛‚إٹى‚شژü•سچ‘پv
ٹطچ‘پw“ْ–{پA“ن‚جژ©ژEچsˆ×پxپ@ƒWƒƒپ[ƒiƒٹƒXƒg“،‘؛ٹ²—Yپ@2009”N11Œژ
http://www.asyura.com/09/senkyo75/msg/349.html
گ•{‚جچsگچüگV‰ï‹c‚ة‚و‚éپuژ–‹ئژd•ھ‚¯پv‚إپA‰بٹw‹ZڈpŒo”ï‚ھ‘±پXڈkڈ¬
‚³‚ê‚ؤ‚¢‚邱‚ئ‚ًپA•ؤ’†کI‚âٹطچ‘‚ب‚اژü•سڈ”چ‘‚حپuٹ½Œ}پv‚µ‚ؤ‚¢‚éپB
“ْ–{‚جŒض‚é‰بٹw‹Zڈp—ح‚ھچ،Œم’ل‰؛‚µپA‹£‘ˆ—ح‚ھژم‚ـ‚é‰آ”\گ«‚ھ‹‚¢‚©‚炾پB
‚ ‚éٹطچ‘‚جٹOŒًٹ¯‚حپu“ْ–{‚ھ‰½‚إ‚±‚ج‚و‚¤‚بژ©ژEچsˆ×‚ً‚·‚é‚ج‚©‚و‚
•ھ‚©‚ç‚ب‚¢پv‚ئƒRƒپƒ“ƒg‚µ‚½پBƒچƒVƒA‚جٹOŒًٹ¯‚àپuگ¢ٹE‚ج—¬‚ê‚ئ‹tچs
‚µ‚ؤ‚¢‚éپv‚ئکb‚µ‚½پBƒچƒVƒA‚إ‚حپAƒvپ[ƒ`ƒ“گŒ ‰؛‚إ‰بٹw‹Zڈp—\ژZ‚ح
چإ‚àچ‚‚¢گL‚ر‚ًژ¦‚µپAچً”N—ˆ‚ج‹à—Zٹë‹@Œم‚àچي‚ç‚ê‚ؤ‚¢‚ب‚¢‚ئ‚¢‚¤پB
ٹطچ‘پw“ْ–{پA“ن‚جژ©ژEچsˆ×پxپ@ƒWƒƒپ[ƒiƒٹƒXƒg“،‘؛ٹ²—Yپ@2009”N11Œژ
http://www.asyura.com/09/senkyo75/msg/349.html
گ•{‚جچsگچüگV‰ï‹c‚ة‚و‚éپuژ–‹ئژd•ھ‚¯پv‚إپA‰بٹw‹ZڈpŒo”ï‚ھ‘±پXڈkڈ¬
‚³‚ê‚ؤ‚¢‚邱‚ئ‚ًپA•ؤ’†کI‚âٹطچ‘‚ب‚اژü•سڈ”چ‘‚حپuٹ½Œ}پv‚µ‚ؤ‚¢‚éپB
“ْ–{‚جŒض‚é‰بٹw‹Zڈp—ح‚ھچ،Œم’ل‰؛‚µپA‹£‘ˆ—ح‚ھژم‚ـ‚é‰آ”\گ«‚ھ‹‚¢‚©‚炾پB
‚ ‚éٹطچ‘‚جٹOŒًٹ¯‚حپu“ْ–{‚ھ‰½‚إ‚±‚ج‚و‚¤‚بژ©ژEچsˆ×‚ً‚·‚é‚ج‚©‚و‚
•ھ‚©‚ç‚ب‚¢پv‚ئƒRƒپƒ“ƒg‚µ‚½پBƒچƒVƒA‚جٹOŒًٹ¯‚àپuگ¢ٹE‚ج—¬‚ê‚ئ‹tچs
‚µ‚ؤ‚¢‚éپv‚ئکb‚µ‚½پBƒچƒVƒA‚إ‚حپAƒvپ[ƒ`ƒ“گŒ ‰؛‚إ‰بٹw‹Zڈp—\ژZ‚ح
چإ‚àچ‚‚¢گL‚ر‚ًژ¦‚µپAچً”N—ˆ‚ج‹à—Zٹë‹@Œم‚àچي‚ç‚ê‚ؤ‚¢‚ب‚¢‚ئ‚¢‚¤پB
ƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ھƒCپ[ƒTƒlƒbƒg‚جژ—”ٌƒXƒpƒRƒ“‚ح
top500ڈمˆت‚ة‚ح‘S‘R“ü‚ء‚ؤ‚ب‚¢‚ھپA‰؛ˆت‚إ‚ح‚ـ‚¾ˆê‘هگ¨—ح‚¾‚بپB
‚؟‚ه‚ء‚ئ‘O‚حƒCپ[ƒTƒlƒbƒg‚¾‚炯‚إ500‚ج”¼گ”‚ھ1G‚¾‚ء‚½پB
پ@پ@پ@پ@10G Etherپ@پ@پ@پ@پ@پ@1G EtherپiچإڈمˆتپA500’†پA100’†پj
پ@ 56 77/500 5/100پ@پ@62 135/500 6/100پ@پ@2013/11
پ@ 49 75/500 4/100پ@پ@56 141/500 1/100پ@پ@2013/06
پ@ 48 30/500 2/100پ@پ@44 159/500 2/100پ@پ@2012/11
پ@ 72 12/500 1/100پ@پ@61 195/500 1/100پ@پ@2012/06
پ@ 42 14/500 1/100پ@پ@67 210/500 1/100پ@پ@2011/11
پ@124 11/500 0/100پ@پ@45 222/500 1/100پ@پ@2011/06
پ@126 07/500 0/100پ@پ@39 221/500 1/100پ@پ@2010/11
پ@102 02/500 0/100پ@پ@28 240/500 1/100پ@پ@2010/06
پ@486 01/500 0/100پ@پ@22 258/500 2/100پ@پ@2009/11
ƒJƒXƒ^ƒ€‚ح”÷‘‚إEther‚ج‘م‚ي‚è‚ةInfiniband‚ھ‘‰ءپB
ƒCپ[ƒTƒlƒbƒg‚ئInfiniband‚إ‚حŒّ—¦پiƒxƒ“ƒ`/—ک_’lپj‚ھ–¾‚ç‚©‚ةˆل‚¤
top500ڈمˆت‚ة‚ح‘S‘R“ü‚ء‚ؤ‚ب‚¢‚ھپA‰؛ˆت‚إ‚ح‚ـ‚¾ˆê‘هگ¨—ح‚¾‚بپB
‚؟‚ه‚ء‚ئ‘O‚حƒCپ[ƒTƒlƒbƒg‚¾‚炯‚إ500‚ج”¼گ”‚ھ1G‚¾‚ء‚½پB
پ@پ@پ@پ@10G Etherپ@پ@پ@پ@پ@پ@1G EtherپiچإڈمˆتپA500’†پA100’†پj
پ@ 56 77/500 5/100پ@پ@62 135/500 6/100پ@پ@2013/11
پ@ 49 75/500 4/100پ@پ@56 141/500 1/100پ@پ@2013/06
پ@ 48 30/500 2/100پ@پ@44 159/500 2/100پ@پ@2012/11
پ@ 72 12/500 1/100پ@پ@61 195/500 1/100پ@پ@2012/06
پ@ 42 14/500 1/100پ@پ@67 210/500 1/100پ@پ@2011/11
پ@124 11/500 0/100پ@پ@45 222/500 1/100پ@پ@2011/06
پ@126 07/500 0/100پ@پ@39 221/500 1/100پ@پ@2010/11
پ@102 02/500 0/100پ@پ@28 240/500 1/100پ@پ@2010/06
پ@486 01/500 0/100پ@پ@22 258/500 2/100پ@پ@2009/11
ƒJƒXƒ^ƒ€‚ح”÷‘‚إEther‚ج‘م‚ي‚è‚ةInfiniband‚ھ‘‰ءپB
ƒCپ[ƒTƒlƒbƒg‚ئInfiniband‚إ‚حŒّ—¦پiƒxƒ“ƒ`/—ک_’lپj‚ھ–¾‚ç‚©‚ةˆل‚¤
>>782
Infiniband‚ھEther‚ً‹ٍ‚ء‚ؤ‚é‚ئ‚¢‚¤ژ–‚حپAInfiniband‚حˆہ‚¢‚ج‚©‚ثپH
‚ـ‚ 10GbE‚ة”ن‚ׂè‚لچ‚‚»‚¤‚¾‚µپA“ئژ©‚ة”ن‚ׂè‚لˆہ‚¢‚¾‚낤‚ھپB
Infiniband‚ھEther‚ً‹ٍ‚ء‚ؤ‚é‚ئ‚¢‚¤ژ–‚حپAInfiniband‚حˆہ‚¢‚ج‚©‚ثپH
‚ـ‚ 10GbE‚ة”ن‚ׂè‚لچ‚‚»‚¤‚¾‚µپA“ئژ©‚ة”ن‚ׂè‚لˆہ‚¢‚¾‚낤‚ھپB
‚±‚ê‚©‚ç‚حƒXƒpƒRƒ“‚ً–¼ڈو‚éˆبڈم
ƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ةƒCپ[ƒTƒlƒbƒg‚ب‚ٌ‚ؤژg‚¤‚ׂ«‚¶‚ل‚ب‚¢
ڈمˆت‚ح‚»‚¤‚ب‚ء‚ؤ‚«‚ؤ‚¢‚邯‚ا
‚ـ‚¾‚ـ‚¾‚µ‚ش‚ئ‚¢‚ب
ƒCپ[ƒTƒlƒbƒgژg‚¤‚ب‚炽‚¾‚جPCƒNƒ‰ƒXƒ^
ƒXƒpƒRƒ“‚©‚炳‚ء‚³‚ئڈء‚¦‚é‚ׂ«
ƒCƒ“ƒ^پ[ƒRƒlƒNƒg‚ةƒCپ[ƒTƒlƒbƒg‚ب‚ٌ‚ؤژg‚¤‚ׂ«‚¶‚ل‚ب‚¢
ڈمˆت‚ح‚»‚¤‚ب‚ء‚ؤ‚«‚ؤ‚¢‚邯‚ا
‚ـ‚¾‚ـ‚¾‚µ‚ش‚ئ‚¢‚ب
ƒCپ[ƒTƒlƒbƒgژg‚¤‚ب‚炽‚¾‚جPCƒNƒ‰ƒXƒ^
ƒXƒpƒRƒ“‚©‚炳‚ء‚³‚ئڈء‚¦‚é‚ׂ«
nttxstore.jp/_NGXM_01_16_24?FREE_WORD=INFINIBAND&MKRCD
nttxstore.jp/_NGXM_01_10_01?FREE_WORD=10G
Infiniband‚ھˆہ‚¢‚ئŒ¾‚¤‚و‚è‚حپA10GbE‚ھچ‚‚·‚¬‚ب‚و‚¤‚ب‹C‚ھ......
nttxstore.jp/_NGXM_01_10_01?FREE_WORD=10G
Infiniband‚ھˆہ‚¢‚ئŒ¾‚¤‚و‚è‚حپA10GbE‚ھچ‚‚·‚¬‚ب‚و‚¤‚ب‹C‚ھ......
‚»‚¤‚ح‚¢‚¤‚¯‚اپAƒpƒ\ƒRƒ“ˆê‘ن‚إƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^‚بژ‘م‚¾‚¼‚—
787 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/21(–ط) 17:15:13.12 ID:SpiNeNhW
GRAPE‚ف‚½‚¢‚ب‚ج‚حGPGPU‚ئ”نٹr‚µ‚ؤٹ„‚ةچ‡‚¤Œہ‚è‚ح‘±‚¯‚ؤ—~‚µ‚¢‚¯‚ا‚ث
>>786
‚»‚¤‚¢‚¤‚ج‚إƒlƒ^‚ة‚³‚ꂽ‚ج‚ح1998”N‚جPowerMac G4‚ھچإڈ‰‚©‚ثپB
“–ژ‚إ‚³‚¦‚‚¾‚ç‚ث‚¦کb‚¾‚ء‚½‚ھپA‚»‚ê‚©‚ç15”NŒo‚ء‚ؤڈ®چX‚‚¾‚ç‚ث‚¦کb‚ة‚ب‚ء‚½پB
‚»‚¤‚¢‚¤‚ج‚إƒlƒ^‚ة‚³‚ꂽ‚ج‚ح1998”N‚جPowerMac G4‚ھچإڈ‰‚©‚ثپB
“–ژ‚إ‚³‚¦‚‚¾‚ç‚ث‚¦کb‚¾‚ء‚½‚ھپA‚»‚ê‚©‚ç15”NŒo‚ء‚ؤڈ®چX‚‚¾‚ç‚ث‚¦کb‚ة‚ب‚ء‚½پB
InfiniBand+IPoIB‚إTCP/IP‚ج‚ـ‚ـƒCپ[ƒTƒlƒbƒg‚©‚çInfiniBand‚ةˆعچs‚µ‚ؤ‚¢‚é‚ج‚©پAƒlƒCƒeƒBƒuInfiniBandگع‘±‚ب‚ج‚©‚ھ‹C‚ة‚ب‚é‚ب‚ںپB
790 پFSocket774پF2013/11/21(–ط) 18:51:54.66 ID:WVJ8APzA
“ŒچH‘هƒXƒpƒRƒ“پuTSUBAME-KFCپv‚ھڈبƒGƒlگ«”\ƒ‰ƒ“ƒLƒ“ƒO‚إ2ٹ¥پI
http://cloud.watch.impress.co.jp/docs/news/20131121_624581.html
http://cloud.watch.impress.co.jp/docs/news/20131121_624581.html
‚±‚±‚إ‚àڈ‘‚©‚ê‚ؤ‚½Intelƒtƒ@ƒuگ»‘¢‚إARM-A53‚ًگد‚ٌ‚¾FPGA‚ء‚ؤ‚ج‚ھڈo‚ؤ‚«‚½‚¯‚ا
Stratix 10 FPGA: ‘z‘œ‚ً’´‚¦‚éگ«”\‚ًژہŒ»
ttp://www.altera.co.jp/devices/fpga/stratix-fpgas/stratix10/stx10-index.jsp
’Pگ¸“x‚ئ‚حŒ¾‚¦پA10TFLOPS ‚ء‚·‚©
DSPƒuƒچƒbƒN‚جچ‡Œv’l‚ب‚ي‚¯‚إژہ‰ٌکHƒtƒBƒbƒeƒBƒ“ƒO‚µ‚½ژ‚ة‚ا‚¤‚ب‚é‚ج‚©‚ح’m‚ç‚ب‚¢‚¯‚ا
‚·‚°‚¦‚ب
Stratix 10 FPGA: ‘z‘œ‚ً’´‚¦‚éگ«”\‚ًژہŒ»
ttp://www.altera.co.jp/devices/fpga/stratix-fpgas/stratix10/stx10-index.jsp
’Pگ¸“x‚ئ‚حŒ¾‚¦پA10TFLOPS ‚ء‚·‚©
DSPƒuƒچƒbƒN‚جچ‡Œv’l‚ب‚ي‚¯‚إژہ‰ٌکHƒtƒBƒbƒeƒBƒ“ƒO‚µ‚½ژ‚ة‚ا‚¤‚ب‚é‚ج‚©‚ح’m‚ç‚ب‚¢‚¯‚ا
‚·‚°‚¦‚ب
‚¨چ‚‚¢‚ٌ‚إ‚µ‚ه‚¤?
793 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/21(–ط) 21:35:25.98 ID:SpiNeNhW
‚±‚ê‚إGRAPE‚ًچى‚ê‚خ1–‡‚إGRAPE9‚ً‚µ‚ج‚¬‚»‚¤‚¾‚ثپB
http://www.kfcr.jp/grape9.html
http://www.kfcr.jp/grape9.html
”ؤ—pƒCپ[ƒTپ[ƒlƒbƒg‚إ‚àڈ\•ھƒXƒsپ[ƒh‚ھڈo‚éŒvژZ‚©‚çپA
‚à‚ء‚ئچ‚‘¬’ل’x‰„ƒlƒbƒgƒڈپ[ƒN‚إŒ‹‚خ‚ب‚¢‚ئƒXƒsپ[ƒh‚ھڈo‚ب‚¢ŒvژZ‚ـ‚إ‚ ‚é
‚â‚鉉ژZ‚ة‚و‚ء‚ؤ‚ح”ؤ—pƒCپ[ƒTپ[ƒlƒbƒg‚إڈ\•ھ
‚ـ‚ پA”ؤ—pƒCپ[ƒTƒlƒbƒg‚¾‚ئپA‘¬“x‚ًڈo‚¹‚éŒvژZ‚جژي—ق‚ھڈ‚ب‚¢‚©‚çپA
‚س‚آ‚¤‚حHPC—pƒlƒbƒgƒڈپ[ƒNژg‚¤‚¯‚ا‚ث
‚à‚ء‚ئچ‚‘¬’ل’x‰„ƒlƒbƒgƒڈپ[ƒN‚إŒ‹‚خ‚ب‚¢‚ئƒXƒsپ[ƒh‚ھڈo‚ب‚¢ŒvژZ‚ـ‚إ‚ ‚é
‚â‚鉉ژZ‚ة‚و‚ء‚ؤ‚ح”ؤ—pƒCپ[ƒTپ[ƒlƒbƒg‚إڈ\•ھ
‚ـ‚ پA”ؤ—pƒCپ[ƒTƒlƒbƒg‚¾‚ئپA‘¬“x‚ًڈo‚¹‚éŒvژZ‚جژي—ق‚ھڈ‚ب‚¢‚©‚çپA
‚س‚آ‚¤‚حHPC—pƒlƒbƒgƒڈپ[ƒNژg‚¤‚¯‚ا‚ث
Linpack‚·‚çƒXƒsپ[ƒh‚إ‚ب‚¢‚ئژv‚¤پB
•ؤ‹َŒR‚حPS3ƒNƒ‰ƒXƒ^پ[‚ً‘g‚ٌ‚إ‚½‚»‚¤‚¾‚ھپA
•ؤ‹َŒR‚جŒ¤‹†‚ح‚©‚ب‚è“ءژê‚ب‚à‚ج‚¾‚µپA•ت‚ة•پ’ت‚جƒXƒpƒRƒ“ژ‚ء‚ؤ‚邵‚بپB
•ؤ‹َŒR‚حPS3ƒNƒ‰ƒXƒ^پ[‚ً‘g‚ٌ‚إ‚½‚»‚¤‚¾‚ھپA
•ؤ‹َŒR‚جŒ¤‹†‚ح‚©‚ب‚è“ءژê‚ب‚à‚ج‚¾‚µپA•ت‚ة•پ’ت‚جƒXƒpƒRƒ“ژ‚ء‚ؤ‚邵‚بپB
BOINC‚ف‚½‚¢‚ب–â‘è‚ً‰ً‚©‚¹‚é‚ب‚çGbE‚إ‚à‘S‘Rچ\‚ي‚ٌ‚¾‚낤‚ث
>>785
eBay ‚ة‚ؤInfiniband PCIe‚إŒںچُ‚·‚é‚ئگV•i‚إ‚à‚»‚ٌ‚ب‚ةچ‚‚‚ب‚¢پB
چ‘“à‚جچ‚‘¬ƒfƒoƒCƒX‚حƒ{ƒbƒ^ƒNƒٹ‚¾‚ئژv‚¤‚ھپA‚ا‚¤‚µ‚ؤ‚©‚ب
eBay ‚ة‚ؤInfiniband PCIe‚إŒںچُ‚·‚é‚ئگV•i‚إ‚à‚»‚ٌ‚ب‚ةچ‚‚‚ب‚¢پB
چ‘“à‚جچ‚‘¬ƒfƒoƒCƒX‚حƒ{ƒbƒ^ƒNƒٹ‚¾‚ئژv‚¤‚ھپA‚ا‚¤‚µ‚ؤ‚©‚ب
>>784
پ„ڈمˆت‚ح‚»‚¤‚ب‚ء‚ؤ‚«‚ؤ‚¢‚邯‚ا
ڈمˆت‚حگج‚àچ،‚àƒCپ[ƒTƒlƒbƒg‚ح‚¨Œؤ‚ر‚¶‚ل‚ب‚¢پB
ƒCپ[ƒTƒlƒbƒg‚ح100M‚جچ ‚ح–³ژ‹‚³‚ê‚ؤ‚¢‚ؤپA1G‚ھˆہ‚‚ب‚ء‚½چ ‚ة
ƒCپ[ƒTƒlƒbƒg‚إ‚à‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ںپHپ@‚ئ‚ب‚ء‚ؤ’†ˆت‰؛ˆت‚ة‘گB‚µ‚½پB
Myrinet‚ھ1GƒCپ[ƒT‚ئ‹£‚ء‚ؤ‚¢‚½‚ھƒmپ[ƒhگ”‚ھ‘‚¦‚é‚ةڈ]‚¢
ƒCپ[ƒT‚ة‰ں‚³‚ê‚ؤŒ¸‚ء‚ؤچs‚ء‚½پB
چإ‹كInfiniband‚ھ—Dگ¨‚ب‚ج‚حپAƒCپ[ƒT‚ھ10G‚إ‘«“¥‚ف‚µ‚ؤ‚¢‚éٹش‚ة
Infiniband‚ھ20GپA40G‚ًƒٹپ[ƒYƒiƒuƒ‹‚بƒRƒXƒg‚إژg‚¦‚é‚و‚¤‚ة
‚ب‚ء‚½‚©‚ç‚©‚à‚µ‚ê‚ب‚¢پB
پ„ڈمˆت‚ح‚»‚¤‚ب‚ء‚ؤ‚«‚ؤ‚¢‚邯‚ا
ڈمˆت‚حگج‚àچ،‚àƒCپ[ƒTƒlƒbƒg‚ح‚¨Œؤ‚ر‚¶‚ل‚ب‚¢پB
ƒCپ[ƒTƒlƒbƒg‚ح100M‚جچ ‚ح–³ژ‹‚³‚ê‚ؤ‚¢‚ؤپA1G‚ھˆہ‚‚ب‚ء‚½چ ‚ة
ƒCپ[ƒTƒlƒbƒg‚إ‚à‚¢‚¢‚ٌ‚¶‚ل‚ب‚¢‚©‚ںپHپ@‚ئ‚ب‚ء‚ؤ’†ˆت‰؛ˆت‚ة‘گB‚µ‚½پB
Myrinet‚ھ1GƒCپ[ƒT‚ئ‹£‚ء‚ؤ‚¢‚½‚ھƒmپ[ƒhگ”‚ھ‘‚¦‚é‚ةڈ]‚¢
ƒCپ[ƒT‚ة‰ں‚³‚ê‚ؤŒ¸‚ء‚ؤچs‚ء‚½پB
چإ‹كInfiniband‚ھ—Dگ¨‚ب‚ج‚حپAƒCپ[ƒT‚ھ10G‚إ‘«“¥‚ف‚µ‚ؤ‚¢‚éٹش‚ة
Infiniband‚ھ20GپA40G‚ًƒٹپ[ƒYƒiƒuƒ‹‚بƒRƒXƒg‚إژg‚¦‚é‚و‚¤‚ة
‚ب‚ء‚½‚©‚ç‚©‚à‚µ‚ê‚ب‚¢پB
>>797
چ‘“à‚إ‚à‚à‚¤ڈ\•ھ‚ة10GbE‚ئ‘»گF–³‚ˆہ‚¢‚ج‚ة‰½Œ¾‚ء‚ؤ‚é‚ٌ‚¾پH
‚ئژv‚ء‚ؤeBay‚ً‚ف‚½‚çپcپcƒIƒN‚ئ‚ح‚¢‚¦‚à‚ء‚ئˆہ‚¢‚ج‚بپB
‚ذ‚ه‚ء‚ئ‚µ‚ؤ10GbE‚ء‚ؤپAگج—\‘ھ‚³‚ê‚ؤ‚¢‚½’ِ‚ة‚ح•پ‹y‚µ‚ؤ‚¢‚ب‚¢‚ج‚©پH
Infiniband‚ھ‹ى’€‚³‚ê‚é‚ئ‚¢‚¤—\‘ھ‚·‚ç‚ ‚ء‚½‚و‚¤‚ب‹C‚ھ‚·‚é‚ج‚¾‚ھپB
چ‘“à‚إ‚à‚à‚¤ڈ\•ھ‚ة10GbE‚ئ‘»گF–³‚ˆہ‚¢‚ج‚ة‰½Œ¾‚ء‚ؤ‚é‚ٌ‚¾پH
‚ئژv‚ء‚ؤeBay‚ً‚ف‚½‚çپcپcƒIƒN‚ئ‚ح‚¢‚¦‚à‚ء‚ئˆہ‚¢‚ج‚بپB
‚ذ‚ه‚ء‚ئ‚µ‚ؤ10GbE‚ء‚ؤپAگج—\‘ھ‚³‚ê‚ؤ‚¢‚½’ِ‚ة‚ح•پ‹y‚µ‚ؤ‚¢‚ب‚¢‚ج‚©پH
Infiniband‚ھ‹ى’€‚³‚ê‚é‚ئ‚¢‚¤—\‘ھ‚·‚ç‚ ‚ء‚½‚و‚¤‚ب‹C‚ھ‚·‚é‚ج‚¾‚ھپB
intel‚حinfiniband‚â‚ك‚½‚ج‚ة–ك‚ء‚ؤ‚«‚½‚µ
http://www.green500.org/lists/green201311
1-10‚ـ‚إnvidia‚©
1-10‚ـ‚إnvidia‚©
>>801
"green"‚¾‚©‚炶‚ل‚ثپH
"green"‚¾‚©‚炶‚ل‚ثپH
803 پFSocket774پF2013/11/22(‹à) 09:38:05.12 ID:tEfyPDj0
GREEN500‚حپAMFLOPS/W‚¶‚ل‚ٌ
‚ا‚ٌ‚ب‚ةژہŒّ‘¬“x‚ھ’x‚‚ؤ‚àپAƒJƒ^ƒچƒOƒXƒyƒbƒN‚ ‚½‚è‚جFLOPSگ”ڈں•‰‚ة‚ب‚ء‚ؤ‚é
‚¹‚ك‚ؤپALinpack/W‚â‚çپAG-FFT/W‚ئ‚©‚إ‚â‚ê‚خ‚¢‚¢‚ج‚ة
‚ا‚ٌ‚ب‚ةژہŒّ‘¬“x‚ھ’x‚‚ؤ‚àپAƒJƒ^ƒچƒOƒXƒyƒbƒN‚ ‚½‚è‚جFLOPSگ”ڈں•‰‚ة‚ب‚ء‚ؤ‚é
‚¹‚ك‚ؤپALinpack/W‚â‚çپAG-FFT/W‚ئ‚©‚إ‚â‚ê‚خ‚¢‚¢‚ج‚ة
http://news.mynavi.jp/articles/2011/01/12/sc10_hpc_challenge/001.html
گ«”\/“d—ح‚ً•]‰؟‚·‚éGreen500
Œ»چف‚جGreen500‚حپATop500‚ةƒ‰ƒ“ƒLƒ“ƒO‚³‚ꂽƒVƒXƒeƒ€‚ًپALINPACKگ«”\/ڈء”ï“d—ح‚ج’l‚إƒ‰ƒ“ƒLƒ“ƒO‚µ’¼‚µ‚ؤ‚¢‚éپB
Top500‚ة‚àڈء”ï“d—ح—“‚ھ‚ ‚é‚ھپAGreen500‚إ‚حƒVƒXƒeƒ€‚ة‚حٹـ‚ـ‚ê‚ؤ‚¢‚ؤ‚àLINPACK’l‚ج‘ھ’è‚ة‚حژg—p‚³‚ê‚ؤ‚¢‚ب‚¢
ƒRƒ“ƒ|پ[ƒlƒ“ƒg‚جڈء”ï“d—ح‚حڈœ‚¢‚ؤ‚و‚¢‚ئ‚¢‚¤ƒ‹پ[ƒ‹‚إ‚ ‚èپATop500‚جڈء”ï“d—ح‚ئ‚حˆظ‚ب‚éڈêچ‡‚ة‚حپA
Green500‚ة•ت“rƒGƒ“ƒgƒٹ‚µ‚ؤƒfپ[ƒ^‚ً‘—‚é•K—v‚ھ‚ ‚éپB
گ«”\/“d—ح‚ً•]‰؟‚·‚éGreen500
Œ»چف‚جGreen500‚حپATop500‚ةƒ‰ƒ“ƒLƒ“ƒO‚³‚ꂽƒVƒXƒeƒ€‚ًپALINPACKگ«”\/ڈء”ï“d—ح‚ج’l‚إƒ‰ƒ“ƒLƒ“ƒO‚µ’¼‚µ‚ؤ‚¢‚éپB
Top500‚ة‚àڈء”ï“d—ح—“‚ھ‚ ‚é‚ھپAGreen500‚إ‚حƒVƒXƒeƒ€‚ة‚حٹـ‚ـ‚ê‚ؤ‚¢‚ؤ‚àLINPACK’l‚ج‘ھ’è‚ة‚حژg—p‚³‚ê‚ؤ‚¢‚ب‚¢
ƒRƒ“ƒ|پ[ƒlƒ“ƒg‚جڈء”ï“d—ح‚حڈœ‚¢‚ؤ‚و‚¢‚ئ‚¢‚¤ƒ‹پ[ƒ‹‚إ‚ ‚èپATop500‚جڈء”ï“d—ح‚ئ‚حˆظ‚ب‚éڈêچ‡‚ة‚حپA
Green500‚ة•ت“rƒGƒ“ƒgƒٹ‚µ‚ؤƒfپ[ƒ^‚ً‘—‚é•K—v‚ھ‚ ‚éپB
>>803
Run Rulesپ@پ@ttp://www.green500.org/faq
>The HPL runs should comply with all the run rules of the Top500 List.
Run Rulesپ@پ@ttp://www.green500.org/faq
>The HPL runs should comply with all the run rules of the Top500 List.
806 پFSocket774پF2013/11/22(‹à) 14:25:18.33 ID:QD0oHr2m
FirePro 10000‚ج‚ھ4ˆت‚ئ‚©‚¶‚ل‚ب‚©‚ء‚½‚©‚ب
چ،‰ٌ‚ح12ˆت‚ة‚ ‚ء‚½‚و‚¤‚ب‚«‚ھ‚µ‚½
GPGPU‚جگ·‚è‰؛‚ھ‚è‚ف‚ؤ‚àپA–{“–‚ح‚à‚¤•ہ—ٌŒvژZ—ت‚ب‚ٌ‚ؤ‚¢‚ç‚ب‚¢‚ٌ‚¾‚وپB
‚ئ‚ء‚‚ةPC‚حA‹‰ƒvƒچٹûژm‚ةڈں‚ؤ‚邵پA“V‹C—\•ٌ‚à‚و‚“–‚½‚ء‚ؤ‚邵پA
DNA‰ًگح‚µ‚ؤ‚àƒnƒQ‚جˆâ“`‚حڈء‚¹‚ب‚¢پBŒvژZ—ت‚ھ1000”{‚ة‚ب‚ء‚½‚ئ‚±‚ë‚إژg‚¢“¹‚ھ‚ب‚¢پB
‚ئ‚ء‚‚ةPC‚حA‹‰ƒvƒچٹûژm‚ةڈں‚ؤ‚邵پA“V‹C—\•ٌ‚à‚و‚“–‚½‚ء‚ؤ‚邵پA
DNA‰ًگح‚µ‚ؤ‚àƒnƒQ‚جˆâ“`‚حڈء‚¹‚ب‚¢پBŒvژZ—ت‚ھ1000”{‚ة‚ب‚ء‚½‚ئ‚±‚ë‚إژg‚¢“¹‚ھ‚ب‚¢پB
>>808
‹Cڈغ—\‘ھ‚حگو‚ة‚ب‚é‚ظ‚ا“‚“–‚½‚ç‚ب‚‚ب‚éپBگl‚ح—~گ[‚¢‚©‚çپA
چ،“–‚½‚é’ِ“x‚ج–¢—ˆ‚¾‚¯‚إ‚ح–‘«‚إ‚«‚¸‚ةچ،‚ح“–‚½‚ç‚ب‚¢‚‚ç‚¢گو‚ج
“ْ‚ج—\•ٌ‚à—~‚µ‚‚ب‚éپBگl‚ھ‹ئ‚ًژج‚ؤ‚ب‚¢Œہ‚è
ƒRƒ“ƒsƒ…پ[ƒ^‚ة‘خ‚·‚鑬“x—v‹پ‚ةڈI‚ي‚è‚ح—ˆ‚ب‚¢پB
ttp://japan.cnet.com/news/society/35018492/6/
>Œ»چفپi2011”Nپj‚ج5“ْٹش—\•ٌ‚جگ¸“x‚ھ1988”N“–ژ‚ج3“ْٹش—\•ٌ‚ئ
>“¯“™‚إ‚ ‚邱‚ئ‚ھ‚±‚جƒfپ[ƒ^‚©‚ç“ا‚فژو‚ê‚éپB
‹Cڈغ—\‘ھ‚حگو‚ة‚ب‚é‚ظ‚ا“‚“–‚½‚ç‚ب‚‚ب‚éپBگl‚ح—~گ[‚¢‚©‚çپA
چ،“–‚½‚é’ِ“x‚ج–¢—ˆ‚¾‚¯‚إ‚ح–‘«‚إ‚«‚¸‚ةچ،‚ح“–‚½‚ç‚ب‚¢‚‚ç‚¢گو‚ج
“ْ‚ج—\•ٌ‚à—~‚µ‚‚ب‚éپBگl‚ھ‹ئ‚ًژج‚ؤ‚ب‚¢Œہ‚è
ƒRƒ“ƒsƒ…پ[ƒ^‚ة‘خ‚·‚鑬“x—v‹پ‚ةڈI‚ي‚è‚ح—ˆ‚ب‚¢پB
ttp://japan.cnet.com/news/society/35018492/6/
>Œ»چفپi2011”Nپj‚ج5“ْٹش—\•ٌ‚جگ¸“x‚ھ1988”N“–ژ‚ج3“ْٹش—\•ٌ‚ئ
>“¯“™‚إ‚ ‚邱‚ئ‚ھ‚±‚جƒfپ[ƒ^‚©‚ç“ا‚فژو‚ê‚éپB
ƒnƒQˆâ“`ژq‚ھ‚¢‚‚آ‚©“ء’肳‚ê‚ؤƒnƒQژ،—أ–ٍ‚ح‚à‚¤ڈo‚ؤ‚邼
‚¾‚©‚ç‚ ‚«‚ç‚ك‚ٌ‚ب‚وƒnƒQ
〷‚إ‚«‚ب‚¢‚©‚ç–³‘ت‚ب‚ٌ‚ؤ•s–ر‚بکb‚ح‚â‚ك‚ë‚وƒnƒQ
‚¾‚©‚ç‚ ‚«‚ç‚ك‚ٌ‚ب‚وƒnƒQ
〷‚إ‚«‚ب‚¢‚©‚ç–³‘ت‚ب‚ٌ‚ؤ•s–ر‚بکb‚ح‚â‚ك‚ë‚وƒnƒQ
811 پFSocket774پF2013/11/22(‹à) 15:41:43.55 ID:QD0oHr2m
PC‚حƒEƒBƒ“ƒhƒEƒY‚ج‹N“®‚ھ1•bˆب‰؛‚ة‚ب‚é‚‚ç‚¢‚ة‚حگi‰»‚µ‚ب‚¢‚ئƒ_ƒپ‚¾‚ë
ƒXƒٹپ[ƒv‚âƒTƒXƒyƒ“ƒh‚ج—ق‚إ‘م—p‚·‚é‚و‚¤‚ة‚ب‚é‚ٌ‚¶‚ل‚ب‚¢‚©PC‚جƒIƒ“ƒIƒt‚ح
Windows‚ح’m‚ç‚ٌ‚ھMac‚إ‚ح‚»‚¤گ„ڈ§‚µ‚ؤ‚邵پAƒXƒ}پ[ƒgƒzƒ“‚âƒ^ƒuƒŒƒbƒg—ق‚à‚»‚¤‚¾‚µپAڈKٹµ‚ئ‚µ‚ؤ‚»‚ء‚؟‚ة•د‚ي‚ء‚ؤ‚¢‚‚¾‚ë
Windows‚ح’m‚ç‚ٌ‚ھMac‚إ‚ح‚»‚¤گ„ڈ§‚µ‚ؤ‚邵پAƒXƒ}پ[ƒgƒzƒ“‚âƒ^ƒuƒŒƒbƒg—ق‚à‚»‚¤‚¾‚µپAڈKٹµ‚ئ‚µ‚ؤ‚»‚ء‚؟‚ة•د‚ي‚ء‚ؤ‚¢‚‚¾‚ë
‘هگج‚جWindowsCE“‹چعPDA‚ف‚½‚ˆêڈu‚إON/OF(ژہ‘ش‚حچ،‚جƒXƒ}ƒz‚ئ“¯‚¶‚ƒXƒٹپ[ƒv)
‚ئ‚©‚ة‚ب‚é‚ة‚ح•âڈ•‹L‰¯‘•’u‚ھHDD‚إ‚ ‚éŒہ‚è–³—‚¾‚낤‚ب
‚ئ‚©‚ة‚ب‚é‚ة‚ح•âڈ•‹L‰¯‘•’u‚ھHDD‚إ‚ ‚éŒہ‚è–³—‚¾‚낤‚ب
>>808
Tsubame2.0‚إگ«”\‚ھ‘«‚è‚ؤ‚ب‚¢‚©‚ç
2.5‚ةupdate‚µ‚ؤ‚é‚ج‚ة‰½‚¢‚ء‚ؤ‚ٌ‚¾‚©‚—
چ،‰ٌ‚جKFC‚ح3.0‚ضupdate‚·‚邽‚ك‚ج
—v‘f‹ZڈpٹJ”‚إ‚à‚ ‚é‚ي‚¯‚¾‚ë
چ،‚¾‚ء‚ؤ‰‰ژZ‚ٌ”\—ح‚ھ‘S‘R‚½‚è‚ب‚‚ؤƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚إ‚«‚ب‚¢
•ھ–ى‚ھژR‚ظ‚ا‚ ‚é‚ج‚ة•K—v‚ب‚¢‚ئ‚©–³’m‚ح•|‚¢‚ي
Tsubame2.0‚إگ«”\‚ھ‘«‚è‚ؤ‚ب‚¢‚©‚ç
2.5‚ةupdate‚µ‚ؤ‚é‚ج‚ة‰½‚¢‚ء‚ؤ‚ٌ‚¾‚©‚—
چ،‰ٌ‚جKFC‚ح3.0‚ضupdate‚·‚邽‚ك‚ج
—v‘f‹ZڈpٹJ”‚إ‚à‚ ‚é‚ي‚¯‚¾‚ë
چ،‚¾‚ء‚ؤ‰‰ژZ‚ٌ”\—ح‚ھ‘S‘R‚½‚è‚ب‚‚ؤƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚إ‚«‚ب‚¢
•ھ–ى‚ھژR‚ظ‚ا‚ ‚é‚ج‚ة•K—v‚ب‚¢‚ئ‚©–³’m‚ح•|‚¢‚ي
x گ«”\‚ھ‘«‚è‚ب‚¢
o ژdژ–‚‚ê‚ب‚¢‚ئگH‚ء‚ؤ‚¢‚¯‚ب‚¢
>ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚إ‚«‚ب‚¢
NPچ¢“ï‚ج‚à‚ج‚حگ«”\‚ھ1–œ”{‚ب‚ء‚ؤ‚àNPچ¢“ï‚ج‚ـ‚ـ‚ب‚ج‚إپA
ژdژ–‚‚ê‚‚ê——R‚ئ‚µ‚ؤ‚ح‰i‰“‚ةژg‚¦‚éپB–hچذŒِ‹¤ژ–‹ئ‚ئ“¯‚¶پB
–³’m‚حéx‚¹‚ؤ‚àژ©چىPC”آ‚إ‚ح’ت—p‚µ‚ب‚¢پB
o ژdژ–‚‚ê‚ب‚¢‚ئگH‚ء‚ؤ‚¢‚¯‚ب‚¢
>ƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚إ‚«‚ب‚¢
NPچ¢“ï‚ج‚à‚ج‚حگ«”\‚ھ1–œ”{‚ب‚ء‚ؤ‚àNPچ¢“ï‚ج‚ـ‚ـ‚ب‚ج‚إپA
ژdژ–‚‚ê‚‚ê——R‚ئ‚µ‚ؤ‚ح‰i‰“‚ةژg‚¦‚éپB–hچذŒِ‹¤ژ–‹ئ‚ئ“¯‚¶پB
–³’m‚حéx‚¹‚ؤ‚àژ©چىPC”آ‚إ‚ح’ت—p‚µ‚ب‚¢پB
ژ©چىPC”حˆح‚إ‚µ‚©چl‚¦‚ç‚ê‚ب‚¢‚¾‚¯
گhç…‚ئ‚¢‚¤‚©ƒ~ƒ‚ƒtƒ^ƒ‚ƒiƒC‚ب‚—‚—‚—
O(LogN)ƒNƒ‰ƒX‚إƒMƒٹƒMƒٹژè‚ھ“ح‚©‚ب‚¢گط‰H‹l‚ء‚½
–â‘è‚ھ‚ ‚ê‚خ‰؟’l‚ً‘i‹پ‚إ‚«‚é‚ج‚©‚à‚µ‚ê‚ٌ‚ثپB
‚ـ‚ پA‘«‚ًگô‚ء‚ؤ‹v‚µ‚¢‚ج‚إ‚»‚ٌ‚ب“sچ‡‚ج—ا‚¢کb‚ھ
—L‚é‚ج‚©‚ا‚¤‚©‚ح’m‚ç‚ٌ‚¯‚اپB
O(LogN)ƒNƒ‰ƒX‚إƒMƒٹƒMƒٹژè‚ھ“ح‚©‚ب‚¢گط‰H‹l‚ء‚½
–â‘è‚ھ‚ ‚ê‚خ‰؟’l‚ً‘i‹پ‚إ‚«‚é‚ج‚©‚à‚µ‚ê‚ٌ‚ثپB
‚ـ‚ پA‘«‚ًگô‚ء‚ؤ‹v‚µ‚¢‚ج‚إ‚»‚ٌ‚ب“sچ‡‚ج—ا‚¢کb‚ھ
—L‚é‚ج‚©‚ا‚¤‚©‚ح’m‚ç‚ٌ‚¯‚اپB
>>808-809
چ،‚ح5kmƒپƒbƒVƒ…‚جڈعچ×—\•ٌ‚ھ33ژٹش‚¾‚©‚çژتگ^‚ھژï–،‚¾‚ئ—ٹ‚è‚ب‚¢
>>811-812
Win‚إ‚àVista‚©‚çƒfƒtƒHƒ‹ƒg‚ھƒnƒCƒuƒٹƒbƒhƒXƒٹپ[ƒv
چ،ژ‚ي‚´‚ي‚´ƒVƒƒƒbƒgƒ_ƒEƒ“‚µ‚ؤ‚é“z‚ح‹ڈ‚ب‚¢‚إ‚µ‚ه
چ،‚ح5kmƒپƒbƒVƒ…‚جڈعچ×—\•ٌ‚ھ33ژٹش‚¾‚©‚çژتگ^‚ھژï–،‚¾‚ئ—ٹ‚è‚ب‚¢
>>811-812
Win‚إ‚àVista‚©‚çƒfƒtƒHƒ‹ƒg‚ھƒnƒCƒuƒٹƒbƒhƒXƒٹپ[ƒv
چ،ژ‚ي‚´‚ي‚´ƒVƒƒƒbƒgƒ_ƒEƒ“‚µ‚ؤ‚é“z‚ح‹ڈ‚ب‚¢‚إ‚µ‚ه
‘½چ€ژ®‚ًŒ©‚‚ر‚ء‚ؤ‚ب‚¢‚©پB‚ׂ«ڈو‚ج‘‰ء‚ً•ژ‚é‚ج‚ح‚¢‚©‚ھ‚ب‚à‚ج‚©
>Œ»چفپi2011”Nپj‚ج5“ْٹش—\•ٌ‚جگ¸“x‚ھ1988”N“–ژ‚ج3“ْٹش—\•ٌ‚ئ
>“¯“™‚إ‚ ‚邱‚ئ‚ھ‚±‚جƒfپ[ƒ^‚©‚ç“ا‚فژو‚ê‚éپB
23”N‚إ2“ْگL‚ر‚ؤ‚àپA‚¶‚ل‚ چ،‚©‚ç20”NŒم‚ح‚ا‚¤‚©‚ئ‚¢‚¤‚ئ1“ْ‚àگL‚ر‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚¾‚بپB
>“¯“™‚إ‚ ‚邱‚ئ‚ھ‚±‚جƒfپ[ƒ^‚©‚ç“ا‚فژو‚ê‚éپB
23”N‚إ2“ْگL‚ر‚ؤ‚àپA‚¶‚ل‚ چ،‚©‚ç20”NŒم‚ح‚ا‚¤‚©‚ئ‚¢‚¤‚ئ1“ْ‚àگL‚ر‚ب‚¢‚ئ‚¢‚¤‚±‚ئ‚¾‚بپB
‹Cڈغ—\•ٌ‚حŒvژZ‘¬“x‚ھڈم‚ھ‚ê‚خ‚¢‚¢‚ء‚ؤ•¨‚إ‚à‚ب‚¢‚©‚ç‚ث
“ü—ح‚·‚éƒpƒ‰ƒپپ[ƒ^‚جŒëچ·پA—\‘ھ‚·‚éƒAƒ‹ƒSƒٹƒYƒ€‚جŒëچ·پA
’n‹…‚ج‹Cڈغژ©‘ج‚ج•د‰»پA‚»‚¤‚¢‚¤‚ج‚ھگد‚فڈd‚ب‚é‚©‚ç’·ٹْ—\•ٌ‚ح‚ا‚¤‚µ‚ؤ‚àŒëچ·‚ھڈo‚é
‚ب‚ج‚إچإ‹ك‚ح’Zٹْ—\•ٌ‚ًچ‚•p“x‰»پAچ‚–§“x‰»‚µ‚ؤ‚¢‚•û‚ة”نڈd‚ھˆع‚ء‚ؤ‚é‚ئ‚©پiƒQƒٹƒ‰چ‹‰J‚ئ‚©پj
“ü—ح‚·‚éƒpƒ‰ƒپپ[ƒ^‚جŒëچ·پA—\‘ھ‚·‚éƒAƒ‹ƒSƒٹƒYƒ€‚جŒëچ·پA
’n‹…‚ج‹Cڈغژ©‘ج‚ج•د‰»پA‚»‚¤‚¢‚¤‚ج‚ھگد‚فڈd‚ب‚é‚©‚ç’·ٹْ—\•ٌ‚ح‚ا‚¤‚µ‚ؤ‚àŒëچ·‚ھڈo‚é
‚ب‚ج‚إچإ‹ك‚ح’Zٹْ—\•ٌ‚ًچ‚•p“x‰»پAچ‚–§“x‰»‚µ‚ؤ‚¢‚•û‚ة”نڈd‚ھˆع‚ء‚ؤ‚é‚ئ‚©پiƒQƒٹƒ‰چ‹‰J‚ئ‚©پj
ƒپƒbƒVƒ…‚ھ‚إ‚©‚¢‚©‚çŒëچ·‚à‚إ‚©‚¢‚ٌ‚¾‚ë
‘¬“x‚ھڈم‚ھ‚ê‚خƒپƒbƒVƒ…‚ًچׂ©‚‚·‚éژ–‚ھ‰آ”\‚¾‚©‚瑬“x‚ھڈم‚ھ‚ê‚خ‚¢‚¢‚ء‚ؤ•¨‚¾‚و
‘¬“x‚ھڈم‚ھ‚ê‚خƒپƒbƒVƒ…‚ًچׂ©‚‚·‚éژ–‚ھ‰آ”\‚¾‚©‚瑬“x‚ھڈم‚ھ‚ê‚خ‚¢‚¢‚ء‚ؤ•¨‚¾‚و
3ژںŒ³ƒپƒbƒVƒ…‚¾‚ئ“r•û‚à‚ب‚¢‚¯‚ا‚ب
‚»‚è‚لژOژںŒ³‚¾‚ë
Œ©‚¦‚é‚ج‚ح2ژںŒ³‚¾‚¯‚اŒvژZ‚ح“–‘R3ژںŒ³
826 پFSocket774پF2013/11/23(“y) 18:55:30.58 ID:tNfwiDhX
ƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^پu‹پv‚إHPCƒ`ƒƒƒŒƒ“ƒWڈـƒNƒ‰ƒX1پA2پiڈ‰پj‚ًژَڈـ
http://www.riken.jp/pr/topics/2013/20131122_1/
http://www.riken.jp/pr/topics/2013/20131122_1/
BG/Qگ¨‚حHPCC‚ةƒGƒ“ƒgƒٹپ[‚µ‚ب‚¢‚ٌ‚¾‚بپB‚µ‚ب‚¢——R‚ح‚ب‚ٌ‚¾‚낤
چ،‚ج‚ـ‚ـƒGƒ“ƒgƒٹپ[‚µ‚ؤ‚àڈں‚ؤ‚ب‚¢‚µTOP500‚ئ”ن‚ׂé‚ئƒ}ƒCƒiپ[‚¾‚©‚ç‘خچô”ï—p‚ًٹ|‚¯‚é‰؟’l‚ھ–³‚¢‚ئژv‚ء‚ؤ‚é‚ٌ‚¶‚ل‚ثپH
Œ©‚ؤ‚éگl‚ح‚؟‚ل‚ٌ‚ئŒ©‚ؤ‚éپB‚¾‚©‚ç‹‚ح”„‚ê‚ب‚¢پB
830 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/24(“ْ) 18:32:04.49 ID:hSzzZi69
BG/Q‚ة‚ئ‚ء‚ؤLINPACK‚ھˆê”ش—LŒّ‚بHPCŒü‚¯”ؤ—pƒxƒ“ƒ`ƒ}پ[ƒN‚¾‚©‚ç‚إ‚µ‚هپB
‚ي‚´‚ي‚´ڈ‡ˆت‚ً‰؛‚°‚邽‚ك‚ة“oک^‚·‚é‚و‚¤‚ب‚±‚ئ‚ح‚·‚é•K—v‚ھ–³‚¢پB
‚ـ‚ پA“ْ–{‚جچ‘—§‘هٹw‚âچ‘Œ¤‚ھBG/Q‚âXeon Phi‚ًچج—p‚µ‚ؤ‚é‚ٌ‚¾‚©‚çگ¢کb–³‚¢‚يپB
‹‚جƒ~ƒjƒ}ƒ€”إ‚ح‹‚جƒvƒچƒOƒ‰ƒ€‚جژ–‘OƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ة‚µ‚©
”„‚ê‚ؤ‚¢‚ب‚¢پB
‚ي‚´‚ي‚´ڈ‡ˆت‚ً‰؛‚°‚邽‚ك‚ة“oک^‚·‚é‚و‚¤‚ب‚±‚ئ‚ح‚·‚é•K—v‚ھ–³‚¢پB
‚ـ‚ پA“ْ–{‚جچ‘—§‘هٹw‚âچ‘Œ¤‚ھBG/Q‚âXeon Phi‚ًچج—p‚µ‚ؤ‚é‚ٌ‚¾‚©‚çگ¢کb–³‚¢‚يپB
‹‚جƒ~ƒjƒ}ƒ€”إ‚ح‹‚جƒvƒچƒOƒ‰ƒ€‚جژ–‘OƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚ج‚½‚ك‚ة‚µ‚©
”„‚ê‚ؤ‚¢‚ب‚¢پB
‹‚جƒ~ƒjƒ}ƒ€”إ‚ح’Pڈƒ‚ة‰؟ٹi‹£‘ˆ—ح‚ھ‚ب‚¢‚µپA‚»‚ꂱ‚»‹‚إ“®‚©‚·ƒvƒچƒOƒ‰ƒ€‚جڈ€”ُ‚ئ‚©‚و‚ء‚غ‚ا‚ج”ƒ‚¤——R‚ھ‚ب‚¢‚ئ‘I‘ًژˆ‚ة“ü‚ç‚ب‚¢‚إ‚µ‚ه‚¤پB
‚¶‚لپ[‚¨‘O‚ç‚ب‚ٌ‚©چl‚¦‚ë‚و‚à‚ء‚ئˆہ‚‚·‚é•û–@
CPU‚ةٹض‚µ‚ؤ‚حƒRƒ“ƒVƒ…پ[ƒ}Œü‚¯‚©‚çHPCŒü‚¯‚ـ‚إ
“¯‚¶ƒRƒA‚ًƒXƒPپ[ƒ‹ƒAƒbƒv‚إ‘خ‰‚إ‚«‚é‚و‚¤‚ة‚¹‚ٌ‚ئ
Intel‚âNV‚ئ‰؟ٹi–ت‚إ“¯‚¶“y•U‚ة‚ح—§‚ؤ‚ٌ‚إ‚µ‚ه
چ،‚©‚ç“ْ–{ٹé‹ئ‚ھ‚â‚é‚ب‚çARM‚®‚ç‚¢‚µ‚©‚ب‚¢‚©
“¯‚¶ƒRƒA‚ًƒXƒPپ[ƒ‹ƒAƒbƒv‚إ‘خ‰‚إ‚«‚é‚و‚¤‚ة‚¹‚ٌ‚ئ
Intel‚âNV‚ئ‰؟ٹi–ت‚إ“¯‚¶“y•U‚ة‚ح—§‚ؤ‚ٌ‚إ‚µ‚ه
چ،‚©‚ç“ْ–{ٹé‹ئ‚ھ‚â‚é‚ب‚çARM‚®‚ç‚¢‚µ‚©‚ب‚¢‚©
834 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/24(“ْ) 20:43:11.81 ID:hSzzZi69
”C“V“°‚â‚çƒ\ƒjپ[‚â‚ç‚جƒQپ[ƒ€ƒnپ[ƒhƒپپ[ƒJپ[‚ھ“ْ–{‚ة‚ ‚é‚ج‚ة
‚»‚ء‚؟‚ج‹ئٹE‚ئ‚جŒ‹‚ر‚آ‚«‚ھژم‚¢‚ٌ‚¾‚و‚ثپB
PS3‚ج‚ئ‚«‚ةCell“‹چعƒXƒpƒRƒ“‚ھ•ؤچ‘‚إ‚¢‚‚çچج—p‚³‚ꂽ‚©چl‚¦‚é‚ئپEپEپE
‚»‚ء‚؟‚ج‹ئٹE‚ئ‚جŒ‹‚ر‚آ‚«‚ھژم‚¢‚ٌ‚¾‚و‚ثپB
PS3‚ج‚ئ‚«‚ةCell“‹چعƒXƒpƒRƒ“‚ھ•ؤچ‘‚إ‚¢‚‚çچج—p‚³‚ꂽ‚©چl‚¦‚é‚ئپEپEپE
’Pگ¸“x”nژ‚جƒQپ[ƒ€‹@‚ب‚ٌ‚ؤ‚¢‚è‚ـ‚¹‚ٌ‚©‚ç
”{گ¸“x‚بcell‚ب‚©‚ء‚½‚ء‚¯پH
838 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/24(“ْ) 23:54:28.17 ID:EY24foET
2008Junپ`2009Jun‚ـ‚إ‚ج3ٹْ‚ة‚ي‚½‚ء‚ؤ1ˆت‚ًژç‚ء‚½RoadRunner‚ة
ژg‚ي‚ꂽ‚ج‚ھ”{گ¸“xٹg’£”إ‚جPowerXCell 8i
ƒQپ[ƒ€‹@‚ء‚ؤ”nژ‚ة‚µ‚ؤ‚邯‚اSPARC‚و‚è—DڈG‚¶‚ل‚ٌ
ژg‚ي‚ꂽ‚ج‚ھ”{گ¸“xٹg’£”إ‚جPowerXCell 8i
ƒQپ[ƒ€‹@‚ء‚ؤ”nژ‚ة‚µ‚ؤ‚邯‚اSPARC‚و‚è—DڈG‚¶‚ل‚ٌ
Cell‚حƒLƒƒƒ“ƒZƒ‹‚³‚ê‚ـ‚µ‚½
‚¨ژ@‚µ
‚¨ژ@‚µ
>>836
PowerXCell 8i‚ث
IBM‚جŒv‰و‚إ‚ح‚»‚جŒم”{گ¸“x1TFlops–عژw‚µ‚½PowerXCell 32iv‚â8iv‚ھŒں“¢‚³‚ê‚ؤ‚½‚ف‚½‚¢‚¾‚¯‚ا
PowerXCell 8i‚ث
IBM‚جŒv‰و‚إ‚ح‚»‚جŒم”{گ¸“x1TFlops–عژw‚µ‚½PowerXCell 32iv‚â8iv‚ھŒں“¢‚³‚ê‚ؤ‚½‚ف‚½‚¢‚¾‚¯‚ا
841 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/25(Œژ) 00:43:35.60 ID:t1qN1P83
‹‚¾‚ء‚ؤژہژ؟1گ¢‘مŒہ‚肶‚ل‚ٌ
•xژm’ت‚ھŒمŒp‚ً100PFLOPS–عژw‚µ‚ؤچى‚ء‚ئ‚é‚»‚¤‚¾‚و
ƒپƒ‚ƒٹ‚حHMC‚ء‚ؤ‚ج‚ھ‚و‚‚ي‚©‚ç‚ٌ‚¯‚ا
ƒپƒ‚ƒٹ‚حHMC‚ء‚ؤ‚ج‚ھ‚و‚‚ي‚©‚ç‚ٌ‚¯‚ا
TSV‚إگد‘w‚·‚éHybrid Memory Cube‚¾‚ء‚¯
JEDEC‚إ‚ب‚پA‚µ‚©‚à‚ـ‚¾ƒuƒŒƒCƒN‚ھŒ©‚¦‚ب‚¢TSV‘O’ٌ
‰ت‚½‚µ‚ؤƒ‚ƒm‚ة‚ب‚é‚ج‚©‚ا‚¤‚©?
‰ت‚½‚µ‚ؤƒ‚ƒm‚ة‚ب‚é‚ج‚©‚ا‚¤‚©?
Micron‚ھ’†گS‚ب‚ٌ‚¾‚낤‚¯‚اƒRƒ“ƒ\پ[ƒVƒAƒ€‚ھ‚إ‚«‚ؤ‚ؤپA
ٹ„‚ئژہ—p‰»‚ج—\’èژٹْ‚ح‹ك‚©‚ء‚½‚و‚¤‚ب
‚»‚à‚»‚àگ””N‘O‚جIDF‚إژژچى•i‚ھڈo‚ؤ‚½‚®‚ç‚¢‚¾‚©‚ç
ٹ„‚ئژہ—p‰»‚ج—\’èژٹْ‚ح‹ك‚©‚ء‚½‚و‚¤‚ب
‚»‚à‚»‚àگ””N‘O‚جIDF‚إژژچى•i‚ھڈo‚ؤ‚½‚®‚ç‚¢‚¾‚©‚ç
Wide-I/O‚à‚»‚¤‚¾‚ھTSV‘O’ٌ‚ج‹Kٹi‚حTSV‚ج’ل‰؟ٹi‰»‚ج’x‰„‚ةٹھ‚«چ‚ـ‚ê‚ؤ‚¢‚éپB
ڈ‚ب‚‚ئ‚à2.5DپA‚آ‚ـ‚èJEDEC‚جHBM‚جگ»•i‚ھڈo‚½Œم‚¾‚و‚ثپB
‹£‘ˆ—ح‚ ‚é‚©‚ا‚¤‚©‚ي‚©‚ç‚ٌ‚بپA‚ئپB
ڈ‚ب‚‚ئ‚à2.5DپA‚آ‚ـ‚èJEDEC‚جHBM‚جگ»•i‚ھڈo‚½Œم‚¾‚و‚ثپB
‹£‘ˆ—ح‚ ‚é‚©‚ا‚¤‚©‚ي‚©‚ç‚ٌ‚بپA‚ئپB
“ى•ؤ‚جƒ‚ƒoƒCƒ‹OSƒVƒFƒA1ˆت‚حAndroidپ@2ˆت‚حWindows Phoneپ@3ˆت‚جiOS‚ح‚ا‚ٌ‚ا‚ٌ—£‚³‚ê‚ؤ‚¢‚é–ح—l
http://kohada.2ch.net/test/read.cgi/pcnews/1385336469/
http://kohada.2ch.net/test/read.cgi/pcnews/1385336469/
‚ب‚ٌ‚إژlژںƒ\پ[ƒX“\‚é‚ٌ‚¾‚وپBˆêژں‚ح‚ب‚¢‚¯‚ا“ٌژں‚ح‚ ‚邾‚낤
Windows Phone remains second mobile platform in Latin America
http://finchannel.com/Main_News/Tech/129051_Windows_Phone_remains_second_mobile_platform_in_Latin_America/
http://finchannel.com/Main_News/Tech/129051_Windows_Phone_remains_second_mobile_platform_in_Latin_America/
iPhone‚ة‚ح—ُ‰؟”إ‚ھ‚ب‚¢‚©‚ç‚ب‚ پcپc5c‚إگوگiچ‘‚ب‚ç—ُ‰؟”إ‚ب‚ٌ‚¾‚ھپA”¼ٹz‚‚ç‚¢‚ج‚ھ“rڈمچ‘ƒVƒFƒAٹJ‘ٌ‚ة‚ح‚ظ‚µ‚¢‚ئ‚±‚ë
‚ ‚é‚¢‚حژ©“®ژش‚إŒ¾‚¤چ‚‹‰ژشƒ|ƒWƒVƒ‡ƒ“‚ً‘_‚ء‚ؤ‚¢‚é‚ج‚©
‚ ‚é‚¢‚حژ©“®ژش‚إŒ¾‚¤چ‚‹‰ژشƒ|ƒWƒVƒ‡ƒ“‚ً‘_‚ء‚ؤ‚¢‚é‚ج‚©
”„‚èڈم‚°‘نگ”ƒxپ[ƒX‚إ‚حiPhoneˆبٹO‚ھگL‚ر‚ؤ‚àپAƒپپ[ƒJپ[‚ج—ک‰vƒxپ[ƒX‚إ‚ح
‚¢‚ـ‚ج‚ئ‚±‚ëiPhone‚ھˆ³ڈں
‚½‚¾‚µپA“d‹@‹ئٹE‚ح‚¸‚ء‚ئپAƒ{ƒٹƒ…پ[ƒ€ƒ]پ[ƒ“‚ًگ§‚µ‚½ٹé‹ئ‚ھŒ‹‹اچ‚‹‰•iژsڈê‚à‚©‚ء‚³‚ç‚ء‚ؤپA
چ‚‹‰•i‚ة“¦‚°‚½ƒپپ[ƒJپ[‚ھ“P‘ق‚ء‚ؤ‚¢‚¤‚ج‚ًŒJ‚è•ش‚µ‚ؤ‚½‚©‚çپA
‚¢‚ـ‚ـ‚إ‚ج“d‹@‹ئٹE‚ج—ًژj‚إ‚¢‚‚ئApple‚ح‚â‚خ‚¢
‚½‚¾‚µپAApple‚ة‚¢‚ـ‚ـ‚إ‚ج“d‹@‹ئٹE‚ج—ًژj‚ھ’ت—p‚·‚é‚©‚ا‚¤‚©‚ح’m‚ç‚ٌ
‚¢‚ـ‚ج‚ئ‚±‚ëiPhone‚ھˆ³ڈں
‚½‚¾‚µپA“d‹@‹ئٹE‚ح‚¸‚ء‚ئپAƒ{ƒٹƒ…پ[ƒ€ƒ]پ[ƒ“‚ًگ§‚µ‚½ٹé‹ئ‚ھŒ‹‹اچ‚‹‰•iژsڈê‚à‚©‚ء‚³‚ç‚ء‚ؤپA
چ‚‹‰•i‚ة“¦‚°‚½ƒپپ[ƒJپ[‚ھ“P‘ق‚ء‚ؤ‚¢‚¤‚ج‚ًŒJ‚è•ش‚µ‚ؤ‚½‚©‚çپA
‚¢‚ـ‚ـ‚إ‚ج“d‹@‹ئٹE‚ج—ًژj‚إ‚¢‚‚ئApple‚ح‚â‚خ‚¢
‚½‚¾‚µپAApple‚ة‚¢‚ـ‚ـ‚إ‚ج“d‹@‹ئٹE‚ج—ًژj‚ھ’ت—p‚·‚é‚©‚ا‚¤‚©‚ح’m‚ç‚ٌ
>>850
Apple‚حƒnƒi‚ء‚©‚çچ‚‹‰ژشƒ|ƒWƒVƒ‡ƒ“‚µ‚©‘_‚ء‚ؤ‚ب‚¢‚¾‚ë
‚²–{‘¸‚ھ‚¢‚ب‚¢ˆêژٹْ‚ةˆہ”„‚肵‚و‚¤‚ئ‚µ‚½ژ–‚ھ‚ ‚ء‚½‚¾‚¯‚¾‚©‚ç‚بپc
Apple‚حƒnƒi‚ء‚©‚çچ‚‹‰ژشƒ|ƒWƒVƒ‡ƒ“‚µ‚©‘_‚ء‚ؤ‚ب‚¢‚¾‚ë
‚²–{‘¸‚ھ‚¢‚ب‚¢ˆêژٹْ‚ةˆہ”„‚肵‚و‚¤‚ئ‚µ‚½ژ–‚ھ‚ ‚ء‚½‚¾‚¯‚¾‚©‚ç‚بپc
853 پFSocket774پF2013/11/25(Œژ) 19:07:04.66 ID:NDC7riJ/
گ»‘¢ƒRƒXƒg‚ج4پ`5”{‚ج—ک‰v‚ًڈمڈو‚¹‚µ‚½’´ƒ{ƒbƒ^’l5c‚ح‚ ‚ـ‚è‚ج•sگl‹C‚ء‚ص‚è‚ةگ¶ژY’âژ~‚ب‚¤
ƒWƒ‡ƒuƒY•œ‹A‘وˆêچى‚جiMac‚ھچ‚‹‰ژش‚ئ‚ح•n–Rگl‚ة‚à’ِ‚ھ‚ ‚é
‚ح‚¢‚ح‚¢پAچ‚‹‰ژش‚¶‚ل‚ب‚‚ؤچK‰^‚ًŒؤ‚ش’ظ‚إ‚·‚ثپB
>>790
K20X‚جƒNƒچƒbƒN‚حŒ³پXTitan‚و‚è‚à’ل‚¢‚ھپA
Green500 ƒGƒ“ƒgƒٹپ[‚ج‘ھ’èژ‚ح‚à‚ء‚ئ‰؛‚°‚½‚ٌ‚¾‚بپB
پ@GTX780Ti 875MHzپ@پ@Titan 837MH‚ڑپ@پ@K20X 732MHz
پ@KFC 614MH‚ڑپiGreen500“oک^پjپA732MH‚ڑپitop500“oک^پj
ttp://pc.watch.impress.co.jp/img/pcw/docs/625/044/html/24.jpg.html
ttp://pc.watch.impress.co.jp/img/pcw/docs/625/044/html/23.jpg.html
ttp://pc.watch.impress.co.jp/docs/news/20131125_625044.html
K20X‚جƒNƒچƒbƒN‚حŒ³پXTitan‚و‚è‚à’ل‚¢‚ھپA
Green500 ƒGƒ“ƒgƒٹپ[‚ج‘ھ’èژ‚ح‚à‚ء‚ئ‰؛‚°‚½‚ٌ‚¾‚بپB
پ@GTX780Ti 875MHzپ@پ@Titan 837MH‚ڑپ@پ@K20X 732MHz
پ@KFC 614MH‚ڑپiGreen500“oک^پjپA732MH‚ڑپitop500“oک^پj
ttp://pc.watch.impress.co.jp/img/pcw/docs/625/044/html/24.jpg.html
{kind=link}
ttp://pc.watch.impress.co.jp/img/pcw/docs/625/044/html/23.jpg.html
{kind=link}
ttp://pc.watch.impress.co.jp/docs/news/20131125_625044.html
Apple‚جƒCƒپپ[ƒW پF ‚¨ں—ژ‚ب‚¨ŒZ‚³‚ٌ
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF چى‹ئ•’…‚½‚¨‚ء‚³‚ٌ
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF چى‹ئ•’…‚½‚¨‚ء‚³‚ٌ
Apple‚جƒCƒپپ[ƒW پF ƒXپ[ƒc’…‚½“أگe•ƒ
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF چى‹ئ•’…‚½‚¨‚ء‚³‚ٌ
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF چى‹ئ•’…‚½‚¨‚ء‚³‚ٌ
Apple‚جƒCƒپپ[ƒW پF •K—v‚ب‹@”\‚ًچi‚èپA–³‘ت‚ًڈب‚¢‚½ƒVƒ“ƒvƒ‹ƒXƒ^ƒCƒ‹
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF •K—v‚ب‹@”\‚ًژج‚ؤپA–³‘ت‹@”\‚¾‚¯‚ًڈW‚ك‚½ƒKƒ‰ƒpƒSƒX
“ْ–{‚ج“d‹@ƒپپ[ƒJپ[‚جƒCƒپپ[ƒW پF •K—v‚ب‹@”\‚ًژج‚ؤپA–³‘ت‹@”\‚¾‚¯‚ًڈW‚ك‚½ƒKƒ‰ƒpƒSƒX
‚آ‚ء‚ؤ‚àژٌ“sŒ—‚إFeliCa‚ج‚ب‚¢iPhone‚إ‚حگ¶‚«‚ؤ‚¢‚¯‚ٌ‚µ‚بپcپcƒKƒ‰ƒpƒSƒX‚ة‚حƒKƒ‰ƒpƒSƒX‚جگ¶‘¶—vŒڈ‚ھ‚ ‚ء‚ؤ‚ ‚ ‚ب‚ء‚ؤ‚¢‚é‚ج‚¾پB
861 پFSocket774پF2013/11/26(‰خ) 20:40:26.78 ID:5RNDNEIg
ژٌ“sŒ—‚ئ‚¢‚¤ٹ‡‚è‚إ‚اپ[‚ب‚ج‚©‚ح’m‚ç‚ٌ‚ھپA“sگS•”‹y‚ر‚»‚ج‹ك•س‚ج
JR‚âƒپƒgƒچ‚âژ„“S‚إŒ©‚©‚¯‚éiPhone—¦‚ح‘Sچ‘•½‹د‚و‚è—y‚©‚ةچ‚‚¢‚و‚¤‚ةٹ´‚¶‚é‚ج‚¾‚ھ
JR‚âƒپƒgƒچ‚âژ„“S‚إŒ©‚©‚¯‚éiPhone—¦‚ح‘Sچ‘•½‹د‚و‚è—y‚©‚ةچ‚‚¢‚و‚¤‚ةٹ´‚¶‚é‚ج‚¾‚ھ
862 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/26(‰خ) 21:08:47.48 ID:VKbBpJQU
•پ’ت‚ة3گl‚ةˆêگl‚حiPhone
‹t‚ةژٌ“sŒ—‚حƒIپ[ƒgƒ`ƒƒپ[ƒWSuica‚ھ‚ ‚ê‚خOK‚¾‚µ
AppleگMژز‚حژ©•ھ‚ھ•s•ض‚¾‚ئ‚¢‚¤‚±‚ئ‚ة‚حگâ‘خ‚ة‹C‚أ‚©‚ب‚¢‚µپA
‹³‚¦‚ؤ‚àژَ‚¯“ü‚ê‚ب‚¢‚©‚çٹضŒW‚ھ‚ب‚¢پB
‹³‚¦‚ؤ‚àژَ‚¯“ü‚ê‚ب‚¢‚©‚çٹضŒW‚ھ‚ب‚¢پB
865 پFSocket774پF2013/11/26(‰خ) 21:40:03.77 ID:5RNDNEIg
ƒXƒ}پ[ƒgƒtƒHƒ“ڈٹ—L—¦‚ھژٌ“sŒ—ڈœ‚‘Sچ‘•½‹د12.7پ“پAژٌ“sŒ—33.9پ“‚ئ‚¢‚¤
ƒXƒ}ƒz•پ‹yڈ‰ٹْ‚ج’²چ¸‚µ‚©ˆّ‚ء‚©‚©‚ç‚ب‚©‚ء‚½‚ھپAژٌ“sŒ—vs‚»‚ج‘¼’nˆو‚ئ‚¢‚¤ژ‹“_‚إ‚ح
پ„ژٌ“sŒ—‚إ‚حiPhone‚ًƒپƒCƒ“‚إ—ک—p‚·‚郆پ[ƒUپ[‚ح14.5پ“پAژٌ“sŒ—‚ًڈœ‚‘Sچ‘‚إ‚ح3.4پ“‚ئ‚ب‚ء‚ؤ‚¢‚éپB
ƒXƒ}ƒz•پ‹yڈ‰ٹْ‚ج’²چ¸‚µ‚©ˆّ‚ء‚©‚©‚ç‚ب‚©‚ء‚½‚ھپAژٌ“sŒ—vs‚»‚ج‘¼’nˆو‚ئ‚¢‚¤ژ‹“_‚إ‚ح
پ„ژٌ“sŒ—‚إ‚حiPhone‚ًƒپƒCƒ“‚إ—ک—p‚·‚郆پ[ƒUپ[‚ح14.5پ“پAژٌ“sŒ—‚ًڈœ‚‘Sچ‘‚إ‚ح3.4پ“‚ئ‚ب‚ء‚ؤ‚¢‚éپB
چ،‚حژلژز‚ح9ٹ„‚‚ç‚¢ƒXƒ}ƒz
867 پFSocket774پF2013/11/26(‰خ) 21:46:38.75 ID:FL5u0abf
ƒKƒ‰ƒPپ[‚إ‚ب‚ٌ‚©‚·‚ف‚ـ‚¹‚ٌ
چ‚—îژز‚ب‚çƒKƒ‰ƒPپ[‚ھ•پ’ت‚¾‚©‚çژس‚é•K—v‚ح‚ب‚¢
ژلژز‚¾‚ء‚½‚çپc
ژلژز‚¾‚ء‚½‚çپc
869 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/26(‰خ) 22:01:21.81 ID:VKbBpJQU
Wi-Fi WIN‘خ‰auƒKƒ‰ƒPپ[پ{WiMAXƒ‹پ[ƒ^‚ھٹ„‚ئŒ«‚¢ƒ†پ[ƒUپ[‚ج‘I‘ً‚¾‚ء‚½
‚à‚¤ڈI—¹‚µ‚½‚¯‚ا‚ث
‚à‚¤ڈI—¹‚µ‚½‚¯‚ا‚ث
IBM ‚ ‚½‚è ”{گ¸“xƒ‚ƒ“ƒXƒ^پ[‚بƒvƒچƒZƒT‚ئ‚©‹Y‚ê‚ةچى‚è‚»‚¤‚ب‚à‚ج‚¾‚ھ‚ب
‚»‚ج‹Y‚ê‚ة‰½گl‚جگlٹش‚ً’£‚è•t‚¯‚ب‚«‚ل‚¢‚¯‚ب‚¢‚©‚ًچl‚¦‚é‚ئ
‚ب‚©‚ب‚©IBM‚إ‚à“‚¢‚ج‚¾‚낤
‚ب‚©‚ب‚©IBM‚إ‚à“‚¢‚ج‚¾‚낤
IBM‚à•xژm’ت‚àNEC‚àƒپƒCƒ“ƒtƒŒپ[ƒ€گê—pƒ‚ƒ“ƒXƒ^پ[ƒvƒچƒZƒbƒT‚آ‚‚ء‚ؤ‚邯‚ا‚ب
ژه‹ئ‚©‚çٹO‚ꂽ‘هٹ|‚©‚è‚بژہŒ±ƒvƒچƒWƒFƒNƒgگi‚ك‚é‚ة‚حcellƒ\ƒjپ[‚ف‚½‚¢‚ب‚¨ƒoƒJ‚بƒpƒgƒچƒ“‚ًŒ©‚آ‚¯‚ب‚«‚ل‚ث
NEC‚حIntel‚ئ•t‚«چ‡‚¢‚ ‚é‚ٌ‚¾‚©‚ç
NOAH-6پASX-ACE‚â‚»‚ê‚ç‚جŒمŒp‚جگ»‘¢‚ًˆث—ٹ‚µ‚ؤ‚à‚¢‚¢‚©‚à‚ب
NOAH-6پASX-ACE‚â‚»‚ê‚ç‚جŒمŒp‚جگ»‘¢‚ًˆث—ٹ‚µ‚ؤ‚à‚¢‚¢‚©‚à‚ب
>>872
‚ ‚ê‚ح‹Y‚ê‚إ‚ب‚ƒ}ƒW–ׂ©‚é‚©‚ç
‚ ‚ê‚ح‹Y‚ê‚إ‚ب‚ƒ}ƒW–ׂ©‚é‚©‚ç
ƒ‚ƒ“ƒXƒ^پ[ƒvƒچƒZƒbƒT‚ء‚ؤ‚ا‚جˆتƒ‚ƒ“ƒXƒ^پ[‚ب‚ج‚وپH
>>876
ƒ_ƒCƒTƒCƒY‚ھ‚±‚ج‚‚ç‚¢
http://web.canon.jp/technology/approach/special/images/cmos_ph001.jpg
http://dc.watch.impress.co.jp/img/dcw/docs/477/641/002.jpg
http://www.pronews.jp/photo/canon_0195.jpg
ƒ_ƒCƒTƒCƒY‚ھ‚±‚ج‚‚ç‚¢
http://web.canon.jp/technology/approach/special/images/cmos_ph001.jpg
{kind=link}
http://dc.watch.impress.co.jp/img/dcw/docs/477/641/002.jpg
{kind=link}
http://www.pronews.jp/photo/canon_0195.jpg
{kind=link}
>>877
‰½‚ةژg‚¤‚جپH
‰½‚ةژg‚¤‚جپH
‰tڈ»‚ب‚ٌ‚©‚àƒ}ƒUپ[ƒKƒ‰ƒX‚©‚ç1–‡ژو‚è‚ب‚ٌ‚ؤچ‹‰ُ‚ب‚ج‚à‚ ‚ء‚½‚¯‚اپA
CPU‚¾‚ئ1–‡ژو‚肵‚ؤCPU1000ƒRƒAپEƒپƒ‚ƒٹ666chپETDP20kW‚ئ‚©‚ب‚ء‚ؤ‚àژg‚¢‚±‚ب‚¹‚ب‚¢‚ب‚—
‚ء‚ؤ‚©”zگü“I‚ةƒpƒ‰ƒŒƒ‹I/F‚ح–³—‚إFB-DIMM‚¾‚جژg‚¤‚µ‚©‚ب‚³‚°
CPU‚¾‚ئ1–‡ژو‚肵‚ؤCPU1000ƒRƒAپEƒپƒ‚ƒٹ666chپETDP20kW‚ئ‚©‚ب‚ء‚ؤ‚àژg‚¢‚±‚ب‚¹‚ب‚¢‚ب‚—
‚ء‚ؤ‚©”zگü“I‚ةƒpƒ‰ƒŒƒ‹I/F‚ح–³—‚إFB-DIMM‚¾‚جژg‚¤‚µ‚©‚ب‚³‚°
>>878
ˆّ‚«چ‡‚¢‚ھ‚ ‚é‚ئ‚µ‚½‚ç“V•¶ٹد‘ھ—p‚¶‚ل‚ب‚¢‚©‚بپB
8x10ƒCƒ“ƒ`‚ج‘ه”»ƒtƒBƒ‹ƒ€‚ج‘م‘ضپA‚ف‚½‚¢‚بژg‚¢‚©‚½‚ھ‚إ‚«‚½‚ç‚¢‚¢‚بپ[پB
‚¢‚âپA60x45mm2‚ج’†”»ƒJƒپƒ‰‚إ‚à‚¢‚¢‚©‚çگ»•i‰»‚µ‚â‚ھ‚ê‚‚¾‚³‚¢پB
ˆّ‚«چ‡‚¢‚ھ‚ ‚é‚ئ‚µ‚½‚ç“V•¶ٹد‘ھ—p‚¶‚ل‚ب‚¢‚©‚بپB
8x10ƒCƒ“ƒ`‚ج‘ه”»ƒtƒBƒ‹ƒ€‚ج‘م‘ضپA‚ف‚½‚¢‚بژg‚¢‚©‚½‚ھ‚إ‚«‚½‚ç‚¢‚¢‚بپ[پB
‚¢‚âپA60x45mm2‚ج’†”»ƒJƒپƒ‰‚إ‚à‚¢‚¢‚©‚çگ»•i‰»‚µ‚â‚ھ‚ê‚‚¾‚³‚¢پB
‚±‚±‚ـ‚إ‚¢‚‚ئپA‚ب‚ة‚à‚©‚à“چ‡‚إ‚«‚»‚¤
ƒIƒ“ƒ_ƒCSSD‚ئ‚©
ƒIƒ“ƒ_ƒCSSD‚ئ‚©
•اژ†—p‚جƒJƒپƒ‰‚ئ‚©‚ء‚ؤ•”‰®‚‚ç‚¢‚جƒTƒCƒY‚إژB‚ء‚ؤ‚é‚ٌ‚¾‚و‚ب
‚ ‚ê‚حCCDƒZƒ“ƒT‚ة’u‚«ٹ·‚¦‚é‚ج‘ه•د‚»‚¤‚¾
‚ ‚ê‚حCCDƒZƒ“ƒT‚ة’u‚«ٹ·‚¦‚é‚ج‘ه•د‚»‚¤‚¾
چ،‚جCPU‚ب‚çƒپƒCƒ“ƒپƒ‚ƒٹ–³‚µ‚إWindowsXP“®‚©‚¹‚éپH
http://anago.2ch.net/test/read.cgi/jisaku/1385561348/
http://anago.2ch.net/test/read.cgi/jisaku/1385561348/
ŒvژZ‹@‚جچ\‘¢‚ھƒپƒCƒ“ƒپƒ‚ƒٹ–³‚µ‚إ“®‚‚و‚¤‚ة‚ح‚إ‚«‚ؤ‚¢‚ب‚¢‚ج‚إ–³—‚إ‚·پB
ƒKƒ“ƒ_ƒ€‚ب‚çƒپƒCƒ“ƒJƒپƒ‰‚â‚ç‚ê‚ؤ‚àگي‚¦‚é‚ج‚ةپB
DRAM‚ً‚آ‚ب‚°‚¸‚ةپADRAMŒفٹ·ƒCƒ“ƒ^پ[ƒtƒFƒCƒX‚ًژ‚آ‰½‚©پA‚ً
CPU‚ة‚آ‚ب‚°‚ؤ‚â‚ê‚خ“®‚‚ب
CPU‚ة‚آ‚ب‚°‚ؤ‚â‚ê‚خ“®‚‚ب
>>878
‚·‚خ‚é–]‰“‹¾‚ئ‚©Œُٹw–]‰“‹¾‚¾‚بپB
‚±‚ê‚ً‰t‘ج’‚‘f‚إ‚ھ‚ٌ‚ھ‚ٌ—â‚â‚·‚جپB
‚à‚؟‚ë‚ٌƒEƒGƒnŒ‡‘¹‚ئ‚©‚ ‚é‚©‚ç•K—v—ت‚جگ””{‚حچى‚éپB
‚·‚خ‚é–]‰“‹¾‚ئ‚©Œُٹw–]‰“‹¾‚¾‚بپB
‚±‚ê‚ً‰t‘ج’‚‘f‚إ‚ھ‚ٌ‚ھ‚ٌ—â‚â‚·‚جپB
‚à‚؟‚ë‚ٌƒEƒGƒnŒ‡‘¹‚ئ‚©‚ ‚é‚©‚ç•K—v—ت‚جگ””{‚حچى‚éپB
“ْ–{‚جڈdچHپEڈd“dٹضکA‚ج‹£‘ˆ—ح‚ھڈم‚ھ‚ء‚ؤ‚«‚½‚ج‚حپA
—¬‘جƒVƒ~ƒ…“™‚إ‚àچ‚‘¬‚ةŒvژZ‚إ‚«‚éƒXƒpƒRƒ“‚ھ‚ ‚ء‚½‚ج‚ھ‘ه‚«‚¢‚ئژv‚¤‚و
Linpack”ش’·‚¶‚ل‚ب‚¢‚â‚آ‚ث
‚ا‚ء‚©‚ج’cژq‚ف‚½‚¢‚ةپAGPUƒNƒ‰ƒXƒ^‚âPhiƒNƒ‰ƒXƒ^‚إڈ\•ھŒ©‚½‚¢‚بƒAƒz‚ب‚±‚ئ‚ً‚·‚é‚ئپA
ڈd“dپEڈdچH•ھ–ى‚ج‹£‘ˆ—ح‚ھڈم‚ھ‚ç‚ب‚©‚ء‚½‚ئژv‚¤‚و
—¬‘جƒVƒ~ƒ…“™‚إ‚àچ‚‘¬‚ةŒvژZ‚إ‚«‚éƒXƒpƒRƒ“‚ھ‚ ‚ء‚½‚ج‚ھ‘ه‚«‚¢‚ئژv‚¤‚و
Linpack”ش’·‚¶‚ل‚ب‚¢‚â‚آ‚ث
‚ا‚ء‚©‚ج’cژq‚ف‚½‚¢‚ةپAGPUƒNƒ‰ƒXƒ^‚âPhiƒNƒ‰ƒXƒ^‚إڈ\•ھŒ©‚½‚¢‚بƒAƒz‚ب‚±‚ئ‚ً‚·‚é‚ئپA
ڈd“dپEڈdچH•ھ–ى‚ج‹£‘ˆ—ح‚ھڈم‚ھ‚ç‚ب‚©‚ء‚½‚ئژv‚¤‚و
889 پFSocket774پF2013/11/29(‹à) 18:37:54.93 ID:cBgfgAP0
ƒpƒiƒ\ƒjƒbƒNپA•sگU‚ج”¼“±‘جژ–‹ئڈkڈ¬‚ضپ@’أ‰êژذ’·پuˆêچڈ‚à‘پ‚پgژ~ŒŒپh‚·‚éپv
http://www.itmedia.co.jp/news/articles/1311/29/news048.html
•ھژذ‰»‚·‚é‚ج‚ح•xژRŒ§‹›’أپA“v”g‚ج—¼ژs‚ئگVٹƒŒ§–چ‚ژs‚ة‚ ‚é3چHڈê‚إپA
‚¢‚¸‚ê‚à”¼“±‘ج‚جٹîٹ²•”•i‚جگ¶ژY‚ًژè‚ھ‚¯‚ؤ‚¢‚éپBٹ”ژ®‚ج‰ك”¼‚ًƒCƒXƒ‰ƒGƒ‹
‚ج”¼“±‘جژَ‘ُگ¶ژY‘هژèپAƒ^ƒڈپ[ƒWƒƒƒY‚ة”„‹p‚·‚é•ûŒü‚إ’²گ®‚µ‚ؤ‚¢‚éپB
’†چ‘‚âƒCƒ“ƒhƒlƒVƒA‚ب‚ا‚جٹCٹOچHڈê‚ة‚آ‚¢‚ؤ‚àپAƒVƒ“ƒKƒ|پ[ƒ‹ٹé‹ئ‚ئ”„‹p‚â
ڈoژ‘ژَ‚¯“ü‚ê‚جŒًڈآ‚ة“ü‚ء‚ؤ‚¢‚éپB‚±‚ê‚ة‚و‚èپAگ”گçگl‹K–ح‚جگlˆُچيŒ¸‚ة‚آ‚ب‚°‚éپB
ƒVƒXƒeƒ€LSI‚ة‚آ‚¢‚ؤ‚حپA•xژm’ت‚ئگفŒvپEٹJ”•”–ه‚ً“چ‡‚µپAگV‰ïژذ‚ًگف—§‚·‚éپB
http://www.itmedia.co.jp/news/articles/1311/29/news048.html
•ھژذ‰»‚·‚é‚ج‚ح•xژRŒ§‹›’أپA“v”g‚ج—¼ژs‚ئگVٹƒŒ§–چ‚ژs‚ة‚ ‚é3چHڈê‚إپA
‚¢‚¸‚ê‚à”¼“±‘ج‚جٹîٹ²•”•i‚جگ¶ژY‚ًژè‚ھ‚¯‚ؤ‚¢‚éپBٹ”ژ®‚ج‰ك”¼‚ًƒCƒXƒ‰ƒGƒ‹
‚ج”¼“±‘جژَ‘ُگ¶ژY‘هژèپAƒ^ƒڈپ[ƒWƒƒƒY‚ة”„‹p‚·‚é•ûŒü‚إ’²گ®‚µ‚ؤ‚¢‚éپB
’†چ‘‚âƒCƒ“ƒhƒlƒVƒA‚ب‚ا‚جٹCٹOچHڈê‚ة‚آ‚¢‚ؤ‚àپAƒVƒ“ƒKƒ|پ[ƒ‹ٹé‹ئ‚ئ”„‹p‚â
ڈoژ‘ژَ‚¯“ü‚ê‚جŒًڈآ‚ة“ü‚ء‚ؤ‚¢‚éپB‚±‚ê‚ة‚و‚èپAگ”گçگl‹K–ح‚جگlˆُچيŒ¸‚ة‚آ‚ب‚°‚éپB
ƒVƒXƒeƒ€LSI‚ة‚آ‚¢‚ؤ‚حپA•xژm’ت‚ئگفŒvپEٹJ”•”–ه‚ً“چ‡‚µپAگV‰ïژذ‚ًگف—§‚·‚éپB
ƒpƒi‚ء‚ؤ“ْ–{گ¨‚إ—Bˆê32nmƒچƒWƒbƒN‚ًگ¶ژY‚µ‚ؤ‚½‚ٌ‚¾‚ء‚¯پH
‚±‚ê‚إپA“ْ–{گ¨‚حژ©‘O‚إ‚ح40nm‚ـ‚إ‚µ‚©گ¶ژY‚إ‚«‚ب‚‚ب‚é
‚â‚ء‚د‚±‚±‚ح“Œژإ‚ھƒچƒWƒbƒN‚àچؤژQ“ü‚·‚邵‚©‚ب‚¢‚ب
‚±‚ê‚إپA“ْ–{گ¨‚حژ©‘O‚إ‚ح40nm‚ـ‚إ‚µ‚©گ¶ژY‚إ‚«‚ب‚‚ب‚é
‚â‚ء‚د‚±‚±‚ح“Œژإ‚ھƒچƒWƒbƒN‚àچؤژQ“ü‚·‚邵‚©‚ب‚¢‚ب
ƒjƒRƒ“‚ ‚½‚è‚ھƒuƒŒƒCƒNƒXƒ‹پ[‚µ‚ؤ‚‚ê‚ٌ‚©‚بپB
892 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/11/29(‹à) 19:33:23.39 ID:/ksKY9Zk
>>888
’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚جکb‚ب‚ç•ت‚ة”غ’肵‚ؤ‚ثپ[‚و
SX-ACE‚ح‚»‚ê‚ب‚è‚ةˆّ‚«چ‡‚¢‚ھ‚ ‚é‚ج‚ح’m‚ء‚ؤ‚éپB
‚إ‚à‹‚جƒ~ƒjƒ}ƒ€”إ‚ح’N‚à•K—v‚ئ‚µ‚ؤ‚ب‚¢پB
’n‹…ƒVƒ~ƒ…ƒŒپ[ƒ^‚جکb‚ب‚ç•ت‚ة”غ’肵‚ؤ‚ثپ[‚و
SX-ACE‚ح‚»‚ê‚ب‚è‚ةˆّ‚«چ‡‚¢‚ھ‚ ‚é‚ج‚ح’m‚ء‚ؤ‚éپB
‚إ‚à‹‚جƒ~ƒjƒ}ƒ€”إ‚ح’N‚à•K—v‚ئ‚µ‚ؤ‚ب‚¢پB
ٹJ”‹@”\‚ًژ‚ء‚ؤ‚½“ك‰د‚جچHڈê‚ح‚ا‚¤‚ب‚ء‚ؤ‚é‚ج‚©‚ب
ƒAƒxƒmƒ~ƒNƒX‚إ”¼“±‘جژ–‹ئ‚حٹ®‘S‰َ–إ‚¾‚بپB
“Œژإ‚ء‚ؤNAND‚ً‘I‘ًپAڈW’†“ٹژ‘‚ً“O’ê‚·‚éژ–‚إچ‘“à‚ة”¼“±‘جچHڈêژc‚·‚±‚ئ‚ةگ¬Œ÷‚µ‚½‚ٌ‚إ‚µ‚ه
‰½‚جچô‚à–³‚ژ¸”s‚µ‚½ژ–‹ئ‚ـ‚½‚â‚ء‚½‚ء‚ؤŒ‹‰ت‚ح’m‚ê‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
‰½‚جچô‚à–³‚ژ¸”s‚µ‚½ژ–‹ئ‚ـ‚½‚â‚ء‚½‚ء‚ؤŒ‹‰ت‚ح’m‚ê‚ؤ‚é‚ٌ‚¶‚ل‚ب‚¢‚ج
>>890
IBMکAچ‡‚إ‚¢‚؟‘پ‚32nm & High-Kƒپƒ^ƒ‹
IBMکAچ‡‚إ‚¢‚؟‘پ‚32nm & High-Kƒپƒ^ƒ‹
>>894
Œ³گ»‘¢‘•’u‚جگفŒv‰®‚¾‚¯‚ا”¼“±‘جƒپپ[ƒJپ[‚ب‚ٌ‚ؤƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‘O‚ة“Œژإ‚جƒtƒ‰ƒbƒVƒ…ˆبٹO‚ئ‚ء‚‚ةژ€‚ٌ‚إ‚½‚و
‚»‚ë‚»‚ë‘•’uƒپپ[ƒJپ[‚à‹¦—ح‰ïژذ‚ح“‘‘؟‚ھگi‚ق‚¾‚낤‚وپiژه‚ةƒGƒŒƒNƒgƒچƒ“•û–تپj
Œ³گ»‘¢‘•’u‚جگفŒv‰®‚¾‚¯‚ا”¼“±‘جƒپپ[ƒJپ[‚ب‚ٌ‚ؤƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‘O‚ة“Œژإ‚جƒtƒ‰ƒbƒVƒ…ˆبٹO‚ئ‚ء‚‚ةژ€‚ٌ‚إ‚½‚و
‚»‚ë‚»‚ë‘•’uƒپپ[ƒJپ[‚à‹¦—ح‰ïژذ‚ح“‘‘؟‚ھگi‚ق‚¾‚낤‚وپiژه‚ةƒGƒŒƒNƒgƒچƒ“•û–تپj
‹t‚ة‚ب‚ٌ‚إ‚à‚â‚ء‚ؤ‚é‚ئپAژs‹µ‚ة‰‚¶‚ؤگف”ُ‚ً“]—p‚³‚¹‚â‚·‚¢‚ٌ‚¾‚و
‚½‚ئ‚¦‚خپADRAMپ•Flash—¼•ûچى‚ء‚ؤ‚éƒپپ[ƒJپ[‚حپA
ژs‹µ‚ة‰‚¶‚ؤDRAM‚ئFlash‚»‚ꂼ‚ꃉƒCƒ““]ٹ·‚µ‚ؤپA
‚ا‚؟‚ç‚©‚ھژs‹µˆ«‰»‚·‚ê‚خپA‘¼•û‚ةƒ‰ƒCƒ““]ٹ·‚µ‚ؤ‚ب‚ٌ‚ئ‚©‚إ‚«‚é
‹t‚ةƒGƒ‹ƒsپ[ƒ_‚حDRAMƒIƒ“ƒٹپ[‚إFlash‚â‚ء‚ؤ‚ب‚©‚ء‚½‚ج‚إپA
DRAMژs‹µ‚ھ‹ة’[‚ةˆ«‰»‚µ‚½ژ‚ةپAƒTƒ€ƒXƒ“‚âƒnƒCƒjƒNƒXپAƒ}ƒCƒNƒچƒ“‚ف‚½‚¢‚ة
Flash‚إ‰ز‚®‚±‚ئ‚ھ‚إ‚«‚ب‚©‚ء‚½
‹t‚ةDRAMژs‹µˆ«‰»‚ًFlash“]ٹ·‚إگ¶‚«‰„‚ر‚½‰ïژذ‚حپA‚¢‚ـ‚جDRAMچ‚“«‚إDRAM‚إ‘ه–ׂ¯‚إ‚«‚é‚و‚¤‚ة‚ب‚ء‚½
‚½‚ئ‚¦‚خپADRAMپ•Flash—¼•ûچى‚ء‚ؤ‚éƒپپ[ƒJپ[‚حپA
ژs‹µ‚ة‰‚¶‚ؤDRAM‚ئFlash‚»‚ꂼ‚ꃉƒCƒ““]ٹ·‚µ‚ؤپA
‚ا‚؟‚ç‚©‚ھژs‹µˆ«‰»‚·‚ê‚خپA‘¼•û‚ةƒ‰ƒCƒ““]ٹ·‚µ‚ؤ‚ب‚ٌ‚ئ‚©‚إ‚«‚é
‹t‚ةƒGƒ‹ƒsپ[ƒ_‚حDRAMƒIƒ“ƒٹپ[‚إFlash‚â‚ء‚ؤ‚ب‚©‚ء‚½‚ج‚إپA
DRAMژs‹µ‚ھ‹ة’[‚ةˆ«‰»‚µ‚½ژ‚ةپAƒTƒ€ƒXƒ“‚âƒnƒCƒjƒNƒXپAƒ}ƒCƒNƒچƒ“‚ف‚½‚¢‚ة
Flash‚إ‰ز‚®‚±‚ئ‚ھ‚إ‚«‚ب‚©‚ء‚½
‹t‚ةDRAMژs‹µˆ«‰»‚ًFlash“]ٹ·‚إگ¶‚«‰„‚ر‚½‰ïژذ‚حپA‚¢‚ـ‚جDRAMچ‚“«‚إDRAM‚إ‘ه–ׂ¯‚إ‚«‚é‚و‚¤‚ة‚ب‚ء‚½
‚ا‚ء‚؟‚à—ا‚µˆ«‚µ‚¾‚ب‚—
گ¶‚«‰„‚ر‚½‚çگ³‹`‚ء‚ؤٹ´‚¶‚©
گ¶‚«‰„‚ر‚½‚çگ³‹`‚ء‚ؤٹ´‚¶‚©
‰~چ‚—U“±‚³‚ê‚ؤپAƒfƒtƒŒگچô‚³‚ê‚ؤپAژù—vگوگH‚¢گچô‚³‚ꂽ‚çپA‚ب‚ة‚â‚ء‚ؤ‚à–³—‹طپB
“Œژإ‚حFlashگê‹ئ‚إگ¶‚«ژc‚ء‚½‚ھپA
‰¼‚ةFlash‚ھ‹ں‹‹‰كڈè‚إFlashژs‹µ‚ھ‚©‚آ‚ؤ‚جDRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‚çپA
‹t‚ة“Œژإ‚ھ‹ê‹«‚ةٹׂء‚ؤ‚½
‚½‚ـ‚½‚ـFlash‚ھژs‹µˆ«‰»‚·‚éژٹْ‚ھڈ‚µ‚µ‚©–³‚©‚ء‚½‚ج‚إ‚و‚©‚ء‚½‚à‚ج‚جپA
‰؛ژè‚·‚é‚ئDRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‰آ”\گ«‚ح‚ ‚é
‚â‚ح‚èچ‚‰؟‚بگف”ُ‚إFlash‚µ‚©چى‚ç‚ب‚¢‚ء‚ؤ‚¢‚¤‚ج‚حپAƒٹƒXƒN‚ھŒ‹چ\‘½‚¢‚ئژv‚¤‚¼
Flash‚ئDRAM‚ً’Zٹْٹش‚إ“]ٹ·‚إ‚«‚郉ƒCƒ“‚ة‚µ‚ؤپAژs‹µ‚ة‰‚¶‚ؤچإ“K‚ب‚ظ‚¤‚ًچى‚é‚ظ‚¤‚ھ’لƒٹƒXƒN‚ب‚ٌ‚¶‚لپH
‰¼‚ةFlash‚ھ‹ں‹‹‰كڈè‚إFlashژs‹µ‚ھ‚©‚آ‚ؤ‚جDRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‚çپA
‹t‚ة“Œژإ‚ھ‹ê‹«‚ةٹׂء‚ؤ‚½
‚½‚ـ‚½‚ـFlash‚ھژs‹µˆ«‰»‚·‚éژٹْ‚ھڈ‚µ‚µ‚©–³‚©‚ء‚½‚ج‚إ‚و‚©‚ء‚½‚à‚ج‚جپA
‰؛ژè‚·‚é‚ئDRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‰آ”\گ«‚ح‚ ‚é
‚â‚ح‚èچ‚‰؟‚بگف”ُ‚إFlash‚µ‚©چى‚ç‚ب‚¢‚ء‚ؤ‚¢‚¤‚ج‚حپAƒٹƒXƒN‚ھŒ‹چ\‘½‚¢‚ئژv‚¤‚¼
Flash‚ئDRAM‚ً’Zٹْٹش‚إ“]ٹ·‚إ‚«‚郉ƒCƒ“‚ة‚µ‚ؤپAژs‹µ‚ة‰‚¶‚ؤچإ“K‚ب‚ظ‚¤‚ًچى‚é‚ظ‚¤‚ھ’لƒٹƒXƒN‚ب‚ٌ‚¶‚لپH
گج‚ح“Œژإچڈˆَ‚جSDRAM‚à‚ ‚ء‚½‚ٌ‚¾‚µٹو’£‚ء‚ؤ‚ظ‚µ‚¢‚ئ‚±‚ë
>>902
“Œژإ‚حٹm‚©‘¼ژذ‚ھSLCƒپƒCƒ“‚جچ ‚©‚烉ƒCƒ“‚ً‚ظ‚ئ‚ٌ‚اMLC‚ة‚µ‚ؤƒRƒXƒgچيŒ¸ٹو’£‚ء‚ؤ‚½‚ج‚à‚ ‚é
“Œژإ‚حٹm‚©‘¼ژذ‚ھSLCƒپƒCƒ“‚جچ ‚©‚烉ƒCƒ“‚ً‚ظ‚ئ‚ٌ‚اMLC‚ة‚µ‚ؤƒRƒXƒgچيŒ¸ٹو’£‚ء‚ؤ‚½‚ج‚à‚ ‚é
ƒٹپ[ƒ}ƒ“پEƒVƒ‡ƒbƒN‚إ‘ج—ح‚ج‚ ‚é“Œژإ‚ح“¥‚ف‚ئ‚ا‚ـ‚è
—]—T‚ج‚ب‚©‚ء‚½ƒVƒƒپ[ƒv‚ح‚ ‚جƒUƒ}پA‚ء‚ؤƒCƒپپ[ƒW‚ھ‚ ‚é
”¼“±‘ج‚â‰tڈ»‚حگف”ُژY‹ئ‚¾‚©‚ç‘ج—ح‚ب‚¢‚ئ–³—‚¾‚ي‚ب
—]—T‚ج‚ب‚©‚ء‚½ƒVƒƒپ[ƒv‚ح‚ ‚جƒUƒ}پA‚ء‚ؤƒCƒپپ[ƒW‚ھ‚ ‚é
”¼“±‘ج‚â‰tڈ»‚حگف”ُژY‹ئ‚¾‚©‚ç‘ج—ح‚ب‚¢‚ئ–³—‚¾‚ي‚ب
>>905
‘ج—ح‚ھڈ‚ب‚¢‰ئ“dƒپƒCƒ“‚جٹé‹ئ‚ھŒX‚¢‚ؤ‚é‚ث
‘ج—ح‚ھ‚ ‚éڈd“dژ‚ء‚ؤ‚éٹé‹ئ‚ح“¥‚ف‚ئ‚ا‚ـ‚ء‚ؤ‚邵پA
•sچجژZ‰ئ“d‚©‚ç‚ج“P‘قŒˆ’f‚à‘f‘پ‚¢
‘ج—ح‚ھڈ‚ب‚¢‰ئ“dƒپƒCƒ“‚جٹé‹ئ‚ھŒX‚¢‚ؤ‚é‚ث
‘ج—ح‚ھ‚ ‚éڈd“dژ‚ء‚ؤ‚éٹé‹ئ‚ح“¥‚ف‚ئ‚ا‚ـ‚ء‚ؤ‚邵پA
•sچجژZ‰ئ“d‚©‚ç‚ج“P‘قŒˆ’f‚à‘f‘پ‚¢
>>905
ƒVƒƒپ[ƒv‚ح‘I‘ً‚ئڈW’†‚إƒeƒŒƒr—p‰tڈ»ƒpƒlƒ‹‚ة‘ه‹K–ح“ٹژ‘‚µ‚ؤ‘هژ¸”s‚µ‚½‚ٌ‚¾‚و‚ب
ƒpƒi‚جƒvƒ‰ƒYƒ}پAƒGƒ‹ƒsپ[ƒ_‚جDRAM‚ا‚ê‚à‚¢‚ء‚µ‚ه
“Œژإ‚جFlash‚ض‚ج‘I‘ً‚ئڈW’†‚ھگ¬Œ÷‚µ‚½‚ج‚إپA‘I‘ً‚ئڈW’†‚µ‚½‰ïژذ‚ًژ‚؟ڈم‚°‚ؤ‚é‚ھپA
‚ق‚µ‚ëƒVƒƒپ[ƒvپEƒpƒiپEƒGƒ‹ƒsپ[ƒ_‚ح‘I‘ً‚ئڈW’†‚إ‘هژ¸”s‚µ‚ؤ‚é
‘I‘ً‚ئڈW’†‚·‚ê‚خ‚¢‚¢‚ئ‚©پA–{”„‚ء‚ؤ‚é•]ک_‰ئ‚ھ‚¢‚ء‚ؤ‚邾‚¯‚إپA
ژہچغ‚ة‚حژ¸”s—ل‚ھ‚©‚ب‚葽‚¢
ƒVƒƒپ[ƒv‚ح‘I‘ً‚ئڈW’†‚إƒeƒŒƒr—p‰tڈ»ƒpƒlƒ‹‚ة‘ه‹K–ح“ٹژ‘‚µ‚ؤ‘هژ¸”s‚µ‚½‚ٌ‚¾‚و‚ب
ƒpƒi‚جƒvƒ‰ƒYƒ}پAƒGƒ‹ƒsپ[ƒ_‚جDRAM‚ا‚ê‚à‚¢‚ء‚µ‚ه
“Œژإ‚جFlash‚ض‚ج‘I‘ً‚ئڈW’†‚ھگ¬Œ÷‚µ‚½‚ج‚إپA‘I‘ً‚ئڈW’†‚µ‚½‰ïژذ‚ًژ‚؟ڈم‚°‚ؤ‚é‚ھپA
‚ق‚µ‚ëƒVƒƒپ[ƒvپEƒpƒiپEƒGƒ‹ƒsپ[ƒ_‚ح‘I‘ً‚ئڈW’†‚إ‘هژ¸”s‚µ‚ؤ‚é
‘I‘ً‚ئڈW’†‚·‚ê‚خ‚¢‚¢‚ئ‚©پA–{”„‚ء‚ؤ‚é•]ک_‰ئ‚ھ‚¢‚ء‚ؤ‚邾‚¯‚إپA
ژہچغ‚ة‚حژ¸”s—ل‚ھ‚©‚ب‚葽‚¢
>>904
‚¢‚ـ‚حƒTƒ€ƒXƒ“‚ھTLC‚إٹو’£‚ء‚ؤپA“Œژإ‚ح’x‚ê‚ؤ‚éٹ´‚¶‚ھ‚·‚é‚ي
‚¢‚ـ‚حƒTƒ€ƒXƒ“‚ھTLC‚إٹو’£‚ء‚ؤپA“Œژإ‚ح’x‚ê‚ؤ‚éٹ´‚¶‚ھ‚·‚é‚ي
ژم“dپEƒRƒ“ƒVƒ…پ[ƒ}‚ح‚ا‚ê‚à‚±‚ê‚àگ…•½•ھ‹ئ‰»‚ً‘jژ~‚µ‚ب‚©‚ء‚½‚©‚ç
گ‚’¼‘O’ٌ‘جگ§‚ج“ْ–{ٹé‹ئ‚ح—ک‰v/ٹJ””ï‚ھ–\—ژپB
ژں‚ة‘_‚ي‚ê‚é‚ج‚حژم“dپE‹ئ–±—pپA‚»‚جژں‚ھڈd“d
گ‚’¼‘O’ٌ‘جگ§‚ج“ْ–{ٹé‹ئ‚ح—ک‰v/ٹJ””ï‚ھ–\—ژپB
ژں‚ة‘_‚ي‚ê‚é‚ج‚حژم“dپE‹ئ–±—pپA‚»‚جژں‚ھڈd“d
TLC‚حƒ_ƒC–تگد‚ھ‚»‚ê‚ظ‚اŒ¸‚ç‚ب‚¢ٹ„‚ةƒZƒ‹‚جژُ–½‚ھŒ€“I‚ة’Z‚‚ب‚ء‚ؤ‚»‚ê‚ظ‚ا‚·‚²‚¢‚à‚ٌ‚¶‚ل‚ث‚¦‚و
‘½’l‰»‚ب‚ç3bit‚à4bit‚à“Œژإ‚ھگوچs‚µ‚ؤٹJ”‚µ‚½‚¯‚اƒgƒŒپ[ƒhƒIƒt‚ھ’ق‚èچ‡‚ي‚ب‚¢‚©‚çچج—p‚µ‚ؤ‚ب‚¢‚µ
‘½’l‰»‚ب‚ç3bit‚à4bit‚à“Œژإ‚ھگوچs‚µ‚ؤٹJ”‚µ‚½‚¯‚اƒgƒŒپ[ƒhƒIƒt‚ھ’ق‚èچ‡‚ي‚ب‚¢‚©‚çچج—p‚µ‚ؤ‚ب‚¢‚µ
‘اژو‚è‚ھ70's‚جƒLƒ`ƒKƒCگ¢‘م‚إ
“ھ”]‚ھƒoƒuƒ‹80's‚إ
ژہ–±‚ھƒٹƒZƒbƒgگ~90's
چ،‚ج“ْ–{‚ح‘د‚¦‚éژٹْ
“ھ”]‚ھƒoƒuƒ‹80's‚إ
ژہ–±‚ھƒٹƒZƒbƒgگ~90's
چ،‚ج“ْ–{‚ح‘د‚¦‚éژٹْ
‚ن‚ئ‚èپA‚³‚ئ‚èپA•X‰حٹْ‚و‚è‚حڈ\•ھ‚¢‚¢‚¾‚ë
>>907
ˆêژ‚جƒTƒ€ƒXƒ“‚حگ¶ژY”\—ح‚ھ‰كڈè‚·‚¬‚ؤپAچى‚ء‚½‚à‚جچى‚ء‚½‚à‚ج‚ھ’l•ِ‚ꂵپiDRAM‚ئflash‚ج‚±‚ئپj
‘¼ژذ‚حƒTƒ€ƒXƒ“‚جچى‚ء‚ؤ‚¢‚ب‚¢‚ظ‚¤‚إˆہ“g‚·‚é‚ئ‚¢‚¤”ç“÷‚ب‚±‚ئ‚ة‚ب‚ء‚½‚±‚ئ‚ھ‚ ‚éپB
‚â‚ء‚دژù—v‚ئ‹ں‹‹‚جƒoƒ‰ƒ“ƒX‚ء‚ؤ‘هژ–‚¾‚و‚ثپB
ˆêژ‚جƒTƒ€ƒXƒ“‚حگ¶ژY”\—ح‚ھ‰كڈè‚·‚¬‚ؤپAچى‚ء‚½‚à‚جچى‚ء‚½‚à‚ج‚ھ’l•ِ‚ꂵپiDRAM‚ئflash‚ج‚±‚ئپj
‘¼ژذ‚حƒTƒ€ƒXƒ“‚جچى‚ء‚ؤ‚¢‚ب‚¢‚ظ‚¤‚إˆہ“g‚·‚é‚ئ‚¢‚¤”ç“÷‚ب‚±‚ئ‚ة‚ب‚ء‚½‚±‚ئ‚ھ‚ ‚éپB
‚â‚ء‚دژù—v‚ئ‹ں‹‹‚جƒoƒ‰ƒ“ƒX‚ء‚ؤ‘هژ–‚¾‚و‚ثپB
“Œژإ‚ھFlash‚ةڈW’†‚µ‚½‚©‚炤‚ـ‚‚¢‚ء‚½‚ء‚ؤ‚ج‚حŒ‹‰تک_‚إپA
‰؛ژè‚·‚è‚لFlash‚ھƒXƒ}ƒzپEƒ^ƒuƒŒƒbƒg‚إژù—vŒƒ‘‚µ‚ب‚¯‚è‚لپADRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‰آ”\گ«‚à‚ ‚é
‚â‚ء‚د‚èپADRAMڈW’†‚àFlashڈW’†‚àگي—ھ“I‚ةژ¸”s‚إپA
چإ“K‚ب‘I‘ً‚حپADRAMپEFlash—¼•û‚â‚ء‚ؤژs‹µ‚ة‰‚¶‚ؤƒ‰ƒCƒ““]—p‚µ‚ؤ‘خڈˆ‚ء‚ؤ‚¢‚¤‚ج‚ھ
گ³‰ً‚¾‚ء‚½‚ئژv‚¤‚و
‰؛ژè‚·‚è‚لFlash‚ھƒXƒ}ƒzپEƒ^ƒuƒŒƒbƒg‚إژù—vŒƒ‘‚µ‚ب‚¯‚è‚لپADRAM‚ف‚½‚¢‚ة‚ب‚ء‚ؤ‚½‰آ”\گ«‚à‚ ‚é
‚â‚ء‚د‚èپADRAMڈW’†‚àFlashڈW’†‚àگي—ھ“I‚ةژ¸”s‚إپA
چإ“K‚ب‘I‘ً‚حپADRAMپEFlash—¼•û‚â‚ء‚ؤژs‹µ‚ة‰‚¶‚ؤƒ‰ƒCƒ““]—p‚µ‚ؤ‘خڈˆ‚ء‚ؤ‚¢‚¤‚ج‚ھ
گ³‰ً‚¾‚ء‚½‚ئژv‚¤‚و
>>913
‚ق‚µ‚ë‹£چ‡‘¼ژذژE‚µ‚ج‚½‚ك‚ة‚â‚ء‚ؤ‚ٌ‚¶‚ل‚ب‚¢‚©‚ئژv‚ء‚½‰´پB
‚ق‚µ‚ë‹£چ‡‘¼ژذژE‚µ‚ج‚½‚ك‚ة‚â‚ء‚ؤ‚ٌ‚¶‚ل‚ب‚¢‚©‚ئژv‚ء‚½‰´پB
‹£چ‡ژE‚µ‚¾‚낤‚ب
ƒ_ƒ“ƒsƒ“ƒO‚إ‹£چ‡ژE‚µ‚حƒ„ƒc‚ç‚جڈي“…ژè’i‚¾‚ë
ƒJƒ‹ƒeƒ‹ژه“±‚µ‚ئ‚¢‚ؤ–§چگ‚µ‚ؤ–ئگس‚ئ‚ـ‚³‚ةٹO“¹
ƒJƒ‹ƒeƒ‹ژه“±‚µ‚ئ‚¢‚ؤ–§چگ‚µ‚ؤ–ئگس‚ئ‚ـ‚³‚ةٹO“¹
DRAM‚à‰؛‚ھ‚è‚ـ‚‚ء‚ؤ‘¼ژذ‚ھ“P‘ق‚µ‚½ŒمپA
‹}Œƒ‚ة’lڈم‚ھ‚è‚ئ‚©‰½“x‚à‚ ‚ء‚½‚©‚ç‚ب
‹}Œƒ‚ة’lڈم‚ھ‚è‚ئ‚©‰½“x‚à‚ ‚ء‚½‚©‚ç‚ب
>>907
>ƒVƒƒپ[ƒv‚ح‘I‘ً‚ئڈW’†‚إƒeƒŒƒr—p‰tڈ»ƒpƒlƒ‹‚ة‘ه‹K–ح“ٹژ‘‚µ‚ؤ‘هژ¸”s‚µ‚½‚ٌ‚¾‚و‚ب
“–ژ‚جƒ}ƒXƒRƒ~‚ح‘I‘ً‚ئڈW’†‚ھ‘fگ°‚炵‚¢‚ئژUپXژ‚ؤڑ’‚µ‚½‚µٹ”‰؟‚àˆêژٹْگ¦‚©‚ء‚½–َ‚¾‚¯‚ا
‚ـ‚ںڈW’†‚·‚é‚ء‚ؤژ–‚حپAŒ‹‹ا‚جƒgƒRپA‚»‚êˆبٹO‚ج‰آ”\گ«‚ًژج‚ؤ‚é‚ء‚ؤکb‚¾‚µ‚بپc
>ƒVƒƒپ[ƒv‚ح‘I‘ً‚ئڈW’†‚إƒeƒŒƒr—p‰tڈ»ƒpƒlƒ‹‚ة‘ه‹K–ح“ٹژ‘‚µ‚ؤ‘هژ¸”s‚µ‚½‚ٌ‚¾‚و‚ب
“–ژ‚جƒ}ƒXƒRƒ~‚ح‘I‘ً‚ئڈW’†‚ھ‘fگ°‚炵‚¢‚ئژUپXژ‚ؤڑ’‚µ‚½‚µٹ”‰؟‚àˆêژٹْگ¦‚©‚ء‚½–َ‚¾‚¯‚ا
‚ـ‚ںڈW’†‚·‚é‚ء‚ؤژ–‚حپAŒ‹‹ا‚جƒgƒRپA‚»‚êˆبٹO‚ج‰آ”\گ«‚ًژج‚ؤ‚é‚ء‚ؤکb‚¾‚µ‚بپc
گ¬Œ÷‚µ‚½‚ç–J‚ك‚»‚₳‚ê‚邵پAژ¸”s‚µ‚½‚ç’@‚©‚ê‚é
‚½‚¾‚»‚ꂾ‚¯‚ج‚±‚ئ‚ةژv‚¦‚é‚ي
‚½‚¾‚»‚ꂾ‚¯‚ج‚±‚ئ‚ةژv‚¦‚é‚ي
‚¢‚â‚¢‚âپAگ¬Œ÷‚µ‚ؤ‚àچr‚ً’T‚µ‚ؤ’@‚©‚ê‚ـ‚·پB
پu‹‚«‚ً‚‚¶‚«ژم‚«‚ً‚¯‚ب‚·پB‚±‚ê‚ھ“ْ–{گl‚ج‰ُٹ´Œ´‘¥‚ةˆê”شچ‡‚¤‚ٌ‚¾پBپv
“àٹC‰غ’·@ƒpƒgƒŒƒCƒoپ[
“àٹC‰غ’·@ƒpƒgƒŒƒCƒoپ[
>ƒVƒƒپ[ƒv‚ح‘I‘ً‚ئڈW’†‚إƒeƒŒƒr—p‰tڈ»ƒpƒlƒ‹‚ة‘ه‹K–ح“ٹژ‘‚µ‚ؤ‘هژ¸”s‚µ‚½‚ٌ‚¾‚و‚ب
‚ ‚êپAƒVƒƒپ[ƒv‚ج‰tڈ»ƒpƒlƒ‹‚ة‚آ‚¢‚ؤ‚ح‘¼ژذ‚ض‹ں‹‹‚ً‚·‚é–ٌ‘©‚ً‚µ‚½‚¯‚ا‚»‚ê‚ً”½Œج‚ة‚µ‚½‚ھˆ×‚ة
‚ا‚±‚©‚ç‚àژوˆّ‚³‚ê‚ب‚‚ب‚ء‚ؤڈI—¹‚µ‚½‚ئ‚¢‚¤کb‚ً•·‚¢‚½‚¯‚اˆل‚¤‚جپH
‚ ‚êپAƒVƒƒپ[ƒv‚ج‰tڈ»ƒpƒlƒ‹‚ة‚آ‚¢‚ؤ‚ح‘¼ژذ‚ض‹ں‹‹‚ً‚·‚é–ٌ‘©‚ً‚µ‚½‚¯‚ا‚»‚ê‚ً”½Œج‚ة‚µ‚½‚ھˆ×‚ة
‚ا‚±‚©‚ç‚àژوˆّ‚³‚ê‚ب‚‚ب‚ء‚ؤڈI—¹‚µ‚½‚ئ‚¢‚¤کb‚ً•·‚¢‚½‚¯‚اˆل‚¤‚جپH
‚ـ‚³‚©ˆہ”{گŒ ‚©‚ç–ƒگ¶گŒ ‚ـ‚إ‚ةƒhƒ‹‰~‚ھ120‰~‘ن‚©‚ç80‰~‘ن‚ـ‚إ
‰~چ‚گi‚ٌ‚¾‚ç‚»‚è‚لژوˆّ‚ح”½Œج‚ة‚ب‚邾‚ëپB
ژ©–¯‚جƒLƒ`ƒKƒC‰~چ‚گچô‚ًƒVƒƒپ[ƒv‚جŒo‰cگس”C‚ة‚³‚ꂽ‚ç‚©‚ي‚¢‚»‚¤پB
“ْ–{‚ج‚½‚ك‚ة“ْ–{‚ةچHڈê‚ًچى‚ء‚½ƒVƒƒپ[ƒv‚ً’ׂ·گچô‚·‚é‚ب‚ٌ‚ؤچ“‚·‚¬‚éپB
‰~چ‚گi‚ٌ‚¾‚ç‚»‚è‚لژوˆّ‚ح”½Œج‚ة‚ب‚邾‚ëپB
ژ©–¯‚جƒLƒ`ƒKƒC‰~چ‚گچô‚ًƒVƒƒپ[ƒv‚جŒo‰cگس”C‚ة‚³‚ꂽ‚ç‚©‚ي‚¢‚»‚¤پB
“ْ–{‚ج‚½‚ك‚ة“ْ–{‚ةچHڈê‚ًچى‚ء‚½ƒVƒƒپ[ƒv‚ً’ׂ·گچô‚·‚é‚ب‚ٌ‚ؤچ“‚·‚¬‚éپB
–c‘ه‚بƒrƒbƒOƒfپ[ƒ^‚ًƒٹƒAƒ‹ƒ^ƒCƒ€ڈˆ—پANEC‚ھگV‹Zڈp‚ًٹJ”
http://cloud.watch.impress.co.jp/docs/news/20131203_626070.html
پ›“ئژ©‚جƒپƒjپ[ƒRƒAƒTپ[ƒoپ[Œü‚¯•ہ—ٌ‰»‹Zڈp
‹ï‘ج“I‚ةپi1پj‚إ‚حپANEC‚ھƒxƒNƒgƒ‹Œ^ƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^ٹJ”‚إ”|‚ء‚½
ƒvƒچƒOƒ‰ƒ€‚ج•ہ—ٌ‰»‹Zڈp‚ً‰—p‚µپA•ہ—ٌ‰»‚³‚ê‚ؤ‚¢‚ب‚¢ƒvƒچƒOƒ‰ƒ€‚ً
•ہ—ٌڈˆ—‚ة“K‚µ‚½ƒvƒچƒOƒ‰ƒ€‚ةٹب’P‚ة•دٹ·‚إ‚«‚é‹Zڈp‚ًٹJ”پB
پ›ƒTپ[ƒoپ[‚جگ«”\‚ًچإ‘هŒہ‚ـ‚إˆّ‚«ڈo‚·•‰‰×•ھژU‹Zڈp
پi2پj‚إ‚حپA•ہ—ٌڈˆ—‚إ”گ¶‚·‚éƒvƒچƒZƒbƒTƒRƒAٹش‚جڈˆ—•‰‰×‚جچ·ˆظ‚ً
ڈuژ‚ة‹دˆê‰»‚·‚é‹Zڈp‚ًٹJ”پB•‰‰×‚ھ‘ه‚«‚¢ƒvƒچƒZƒbƒTƒRƒA‚©‚ç
ڈ¬‚³‚¢ƒvƒچƒZƒbƒTƒRƒA‚ضپAژ©“®“I‚ةڈˆ—‚ًˆع‚·ٹK‘w“I•‰‰×گ§Œن‚ً
ژہŒ»‚·‚邱‚ئ‚إپA”ؤ—pƒپƒjپ[ƒRƒAƒTپ[ƒoپ[‚جگ«”\‚ًچإ‘هŒہ‚ةˆّ‚«ڈo‚¹‚éپB
پ›ڈˆ—‘¬“x‚ً100”{ˆبڈم‚ةچ‚‚ك‚ç‚ê‚邱‚ئ‚ًٹm”F
گ”•Sگl‚ھ‰f‚ء‚ؤ‚¢‚é‰f‘œ‚ج’†‚©‚ç1–¼‚ً“ء’è‚·‚éڈˆ—‚ة“¯‹Zڈp‚ً“K—p‚µپA
•SŒآˆبڈم‚جƒvƒچƒZƒbƒTƒRƒA‚ً“‹چع‚µ‚½ƒپƒjپ[ƒRƒAƒTپ[ƒoپ[‚إژہچs‚µ‚½پB
‚»‚جŒ‹‰تپAڈ]—ˆ‚حگ”•ھ‚ً—v‚µ‚ؤ‚¢‚½ڈˆ—‚ً1•bˆب“à‚ة’Zڈk‚إ‚«پA
پuڈˆ—‘¬“x‚ً100”{ˆبڈم‚ةچ‚‚ك‚ç‚ê‚邱‚ئ‚ًٹm”F‚µ‚½پv‚ئ‚µ‚ؤ‚¢‚éپB
http://cloud.watch.impress.co.jp/docs/news/20131203_626070.html
پ›“ئژ©‚جƒپƒjپ[ƒRƒAƒTپ[ƒoپ[Œü‚¯•ہ—ٌ‰»‹Zڈp
‹ï‘ج“I‚ةپi1پj‚إ‚حپANEC‚ھƒxƒNƒgƒ‹Œ^ƒXپ[ƒpپ[ƒRƒ“ƒsƒ…پ[ƒ^ٹJ”‚إ”|‚ء‚½
ƒvƒچƒOƒ‰ƒ€‚ج•ہ—ٌ‰»‹Zڈp‚ً‰—p‚µپA•ہ—ٌ‰»‚³‚ê‚ؤ‚¢‚ب‚¢ƒvƒچƒOƒ‰ƒ€‚ً
•ہ—ٌڈˆ—‚ة“K‚µ‚½ƒvƒچƒOƒ‰ƒ€‚ةٹب’P‚ة•دٹ·‚إ‚«‚é‹Zڈp‚ًٹJ”پB
پ›ƒTپ[ƒoپ[‚جگ«”\‚ًچإ‘هŒہ‚ـ‚إˆّ‚«ڈo‚·•‰‰×•ھژU‹Zڈp
پi2پj‚إ‚حپA•ہ—ٌڈˆ—‚إ”گ¶‚·‚éƒvƒچƒZƒbƒTƒRƒAٹش‚جڈˆ—•‰‰×‚جچ·ˆظ‚ً
ڈuژ‚ة‹دˆê‰»‚·‚é‹Zڈp‚ًٹJ”پB•‰‰×‚ھ‘ه‚«‚¢ƒvƒچƒZƒbƒTƒRƒA‚©‚ç
ڈ¬‚³‚¢ƒvƒچƒZƒbƒTƒRƒA‚ضپAژ©“®“I‚ةڈˆ—‚ًˆع‚·ٹK‘w“I•‰‰×گ§Œن‚ً
ژہŒ»‚·‚邱‚ئ‚إپA”ؤ—pƒپƒjپ[ƒRƒAƒTپ[ƒoپ[‚جگ«”\‚ًچإ‘هŒہ‚ةˆّ‚«ڈo‚¹‚éپB
پ›ڈˆ—‘¬“x‚ً100”{ˆبڈم‚ةچ‚‚ك‚ç‚ê‚邱‚ئ‚ًٹm”F
گ”•Sگl‚ھ‰f‚ء‚ؤ‚¢‚é‰f‘œ‚ج’†‚©‚ç1–¼‚ً“ء’è‚·‚éڈˆ—‚ة“¯‹Zڈp‚ً“K—p‚µپA
•SŒآˆبڈم‚جƒvƒچƒZƒbƒTƒRƒA‚ً“‹چع‚µ‚½ƒپƒjپ[ƒRƒAƒTپ[ƒoپ[‚إژہچs‚µ‚½پB
‚»‚جŒ‹‰تپAڈ]—ˆ‚حگ”•ھ‚ً—v‚µ‚ؤ‚¢‚½ڈˆ—‚ً1•bˆب“à‚ة’Zڈk‚إ‚«پA
پuڈˆ—‘¬“x‚ً100”{ˆبڈم‚ةچ‚‚ك‚ç‚ê‚邱‚ئ‚ًٹm”F‚µ‚½پv‚ئ‚µ‚ؤ‚¢‚éپB
927 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/03(‰خ) 21:34:41.08 ID:KcV2EvDs
ƒvƒŒƒXƒٹƒٹپ[ƒXŒ©‚ê‚خ‚ي‚©‚邯‚اSX-ACE‚إ‚â‚è‚ـ‚µ‚½‚ء‚ؤکb‚¶‚ل‚ب‚‚ؤ
Xeon + Xeon Phiژg‚ء‚ؤ‚é‚ٌ‚¾‚؛
Xeon + Xeon Phiژg‚ء‚ؤ‚é‚ٌ‚¾‚؛
ƒVƒƒپ[ƒv‚ئ‚¢‚¦‚خƒ}ƒCƒNƒچƒ\ƒtƒg‚جƒXƒ}پ[ƒgƒzƒ“‚ً‘هپX“I‚ةچى‚éŒ_–ٌ‚ً‚µ‚ؤ
”•\’¼Œم‚©‚»‚ج‚‚ç‚¢‚جƒ^ƒCƒ~ƒ“ƒO‚إƒLƒƒƒ“ƒZƒ‹‚³‚ê‚ؤ‚½‚ب
‚ ‚ê‚à‘ٹ“–’ة‚©‚ء‚½‚و‚¤‚ب‹C‚ھ‚·‚é
”•\’¼Œم‚©‚»‚ج‚‚ç‚¢‚جƒ^ƒCƒ~ƒ“ƒO‚إƒLƒƒƒ“ƒZƒ‹‚³‚ê‚ؤ‚½‚ب
‚ ‚ê‚à‘ٹ“–’ة‚©‚ء‚½‚و‚¤‚ب‹C‚ھ‚·‚é
‚»‚¤‚¢‚¦‚خ’cژq‰®‚³‚ٌ‚ح
پuNEC‚حLarrabee‚ًŒ©ژج‚ؤ‚½پv
پuNEC‚حIntel‚ئ‚ج’ٌŒg‚ً‘إ‚؟گط‚ء‚½پv
‚ئ‚©Œ¾‚ء‚ؤ‚ب‚©‚ء‚½‚ء‚¯پH
پuNEC‚حLarrabee‚ًŒ©ژج‚ؤ‚½پv
پuNEC‚حIntel‚ئ‚ج’ٌŒg‚ً‘إ‚؟گط‚ء‚½پv
‚ئ‚©Œ¾‚ء‚ؤ‚ب‚©‚ء‚½‚ء‚¯پH
>>923
ƒ\ƒjپ[‚ھچنچHڈê‚ض‚جڈoژ‘پA“Œژإ‚ھ‹ں‹‹Œ_–ٌŒ‹‚ٌ‚إپAƒVƒƒپ[ƒv‚ح“Œژإگ»SOC‘S–تچج—p‚µ‚½‚¯‚ا
Œ‹‹اپAƒ\ƒjپ[‚حڈoژ‘ژو‰؛‚°پA“Œژإ‚à‚½‚¢‚µ‚ؤژg‚ي‚¸IPSƒپƒCƒ“‚ة‘–‚ء‚½‚ي‚ب
ƒ\ƒjپ[‚ھچنچHڈê‚ض‚جڈoژ‘پA“Œژإ‚ھ‹ں‹‹Œ_–ٌŒ‹‚ٌ‚إپAƒVƒƒپ[ƒv‚ح“Œژإگ»SOC‘S–تچج—p‚µ‚½‚¯‚ا
Œ‹‹اپAƒ\ƒjپ[‚حڈoژ‘ژو‰؛‚°پA“Œژإ‚à‚½‚¢‚µ‚ؤژg‚ي‚¸IPSƒپƒCƒ“‚ة‘–‚ء‚½‚ي‚ب
>>924
‚»‚ج•س‚حƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‚à‚ ‚ء‚ؤ•s‰آچR—ح‚إ‚ح‚ ‚ء‚½‚낤
–â‘è‚ح–¯ژه“}گŒ پAƒAƒŒ‚إ“ْ–{‚ج“dژqژY‹ئ‚حƒgƒhƒپژh‚³‚ꂽ
‚»‚ج•س‚حƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‚à‚ ‚ء‚ؤ•s‰آچR—ح‚إ‚ح‚ ‚ء‚½‚낤
–â‘è‚ح–¯ژه“}گŒ پAƒAƒŒ‚إ“ْ–{‚ج“dژqژY‹ئ‚حƒgƒhƒپژh‚³‚ꂽ
گlژ–”¨پE‹à—Z”¨‚جŒo‰cگw‚إڈم‘w•”‚ًŒإ‚ك‚½‚çƒAƒJƒ“‚إ‚µ‚ه
–¯ژه‚¾‚낤‚ھژ©–¯‚¾‚낤‚ھ“¯‚¶Œ‹‰ت‚ة‚ب‚ء‚ؤ‚½‚ي
پu“؟گى‚جژô”›پv’f‚؟گط‚é‚ׂµپI
–¯ژه‚¾‚낤‚ھژ©–¯‚¾‚낤‚ھ“¯‚¶Œ‹‰ت‚ة‚ب‚ء‚ؤ‚½‚ي
پu“؟گى‚جژô”›پv’f‚؟گط‚é‚ׂµپI
933 پFSocket774پF2013/12/04(گ…) 01:57:48.57 ID:NwIoQgfa
>>931
ƒlƒgƒEƒˆ‚ء‚ؤ‚ا‚ٌ‚¾‚¯ƒAƒz‚ب‚جپH
ƒlƒgƒEƒˆ‚ء‚ؤ‚ا‚ٌ‚¾‚¯ƒAƒz‚ب‚جپH
>>928
KIN‚ح‚؟‚ل‚ٌ‚ئ””„‚³‚ꂽ‚¼پB3‚©Œژ‚إگ»‘¢’†ژ~‚ة‚ب‚ء‚½‚ھSHARP‚ج‚¹‚¢‚¶‚ل‚ب‚¢‚µپB
KIN‚ح‚؟‚ل‚ٌ‚ئ””„‚³‚ꂽ‚¼پB3‚©Œژ‚إگ»‘¢’†ژ~‚ة‚ب‚ء‚½‚ھSHARP‚ج‚¹‚¢‚¶‚ل‚ب‚¢‚µپB
>>931
’´‰~چ‚‚حگkچذ‚إ“ْ–{ٹé‹ئ‚ھ“ْ–{‚ة‹à–ك‚»‚¤‚ئ‚·‚é‚ج‚ًŒ©‰z‚µ‚ؤ
ٹCٹOƒtƒ@ƒ“ƒh‚ھ‰~”ƒ‚¢‚µ‚ـ‚‚ء‚½‚©‚炾‚ëپB
ƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‚إ“ْ–{‚ھˆê”شƒ}ƒV‚بژ‘‹à“¦”ًگو‚ئ‚¢‚¤‚ج‚à‚ ‚ء‚½‚ھپB
’´‰~چ‚‚حگkچذ‚إ“ْ–{ٹé‹ئ‚ھ“ْ–{‚ة‹à–ك‚»‚¤‚ئ‚·‚é‚ج‚ًŒ©‰z‚µ‚ؤ
ٹCٹOƒtƒ@ƒ“ƒh‚ھ‰~”ƒ‚¢‚µ‚ـ‚‚ء‚½‚©‚炾‚ëپB
ƒٹپ[ƒ}ƒ“ƒVƒ‡ƒbƒN‚إ“ْ–{‚ھˆê”شƒ}ƒV‚بژ‘‹à“¦”ًگو‚ئ‚¢‚¤‚ج‚à‚ ‚ء‚½‚ھپB
936 پFSocket774پF2013/12/04(گ…) 09:52:25.61 ID:y709v9RB
“ء‚ة”¼“±‘ج‚ح‚ظ‚ع100پ“‚ج”„‚èڈم‚°‚ھˆ×‘ض‚ةچ¶‰E‚³‚ê‚é
ˆ×‘ض‚ًچ¶‰E‚·‚é‚ج‚ح’†‰›‹âچs‚ھ‚ا‚ꂾ‚¯’ت‰ف‚ً‹ں‹‹‚·‚é‚©‚ًپhŒ©’ت‚¹‚é‚©پh
Œ»چفˆہ”{‹~چ‘‘چ—‚ھ“ْ–{=“ْ‹â‚ًژو‚è–ك‚µ‚½‚ç‹}‘¬‚ةŒi‹C‰ٌ•œ‚µ‚ؤ‚«‚½ژ–‚ًŒ©‚ê‚خ
“ْ‹âپE‹à—ZٹةکaپEƒCƒ“ƒtƒŒƒ^پ[ƒQƒbƒg‚جچ‘‰ئچإچ‚ƒŒƒxƒ‹‚جڈd—vگ«‚ھ‚و‚‚ي‚©‚邾‚낤
ˆ×‘ض‚ًچ¶‰E‚·‚é‚ج‚ح’†‰›‹âچs‚ھ‚ا‚ꂾ‚¯’ت‰ف‚ً‹ں‹‹‚·‚é‚©‚ًپhŒ©’ت‚¹‚é‚©پh
Œ»چفˆہ”{‹~چ‘‘چ—‚ھ“ْ–{=“ْ‹â‚ًژو‚è–ك‚µ‚½‚ç‹}‘¬‚ةŒi‹C‰ٌ•œ‚µ‚ؤ‚«‚½ژ–‚ًŒ©‚ê‚خ
“ْ‹âپE‹à—ZٹةکaپEƒCƒ“ƒtƒŒƒ^پ[ƒQƒbƒg‚جچ‘‰ئچإچ‚ƒŒƒxƒ‹‚جڈd—vگ«‚ھ‚و‚‚ي‚©‚邾‚낤
Dell‚àHP‚à—ح‚ً‚آ‚¯‚؟‚ل‚ء‚ؤپAIntel‚جژہŒ±‘ن‚ة‚ب‚ء‚ؤ‚‚ê‚éƒTپ[ƒoپ[‰®‚³‚ٌ‚حNEC‚µ‚©‚¢‚ب‚‚ب‚ء‚½‚ج‚إ‚·‚ثپB
CPU–O‚«‚ؤ‚«‚½پ[
‚¨‚©‚µ‚¢‚بپOپOپGپG‰ïگS‚جƒMƒƒƒO‚ب‚ٌ‚¾‚¯‚ا‚بپOپOپGپGپG
942 پFSocket774پF2013/12/05(–ط) 13:02:47.80 ID:JiY9m1/G
چ،‚ا‚«‚جƒ^ƒuƒŒƒbƒg/ƒXƒ}پ[ƒgƒtƒHƒ“Œü‚¯SoCپ`‘و1‰ٌ
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131205_626007.html
http://pc.watch.impress.co.jp/docs/column/1month-kouza/20131205_626007.html
ascii‚ج‚ئƒlƒ^‚©‚ش‚è
ˆب‘O‚ةژںگ¢‘مƒCƒ“ƒ^پ[ƒtƒFƒCƒX‚àƒ}ƒCƒRƒ~کAچع‚ئƒlƒ^‚©‚ش‚è‚إڈ‘‚©‚¹‚ؤ‚½‚ب
ˆب‘O‚ةژںگ¢‘مƒCƒ“ƒ^پ[ƒtƒFƒCƒX‚àƒ}ƒCƒRƒ~کAچع‚ئƒlƒ^‚©‚ش‚è‚إڈ‘‚©‚¹‚ؤ‚½‚ب
944 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/05(–ط) 19:17:35.03 ID:KCcda2fQ
>>942
>ARM v6‚ئARM11ƒRƒA‚حچL‚ژg‚ي‚ꂽ‚ھ
پc
ARM v6‚جARM9ŒnپA“ء‚ةARM926EJ(-S)‚جƒqƒbƒg“x‚ئ”ن‚ׂؤARM11Œn‚ھƒpƒb‚ئ‚µ‚ب‚©‚ء‚½‚©‚ç
ARM v7A‚ھ“oڈꂵ‚½‚ئ‹L‰¯‚µ‚ؤ‚¢‚éww
>ARM v6‚ئARM11ƒRƒA‚حچL‚ژg‚ي‚ꂽ‚ھ
پc
ARM v6‚جARM9ŒnپA“ء‚ةARM926EJ(-S)‚جƒqƒbƒg“x‚ئ”ن‚ׂؤARM11Œn‚ھƒpƒb‚ئ‚µ‚ب‚©‚ء‚½‚©‚ç
ARM v7A‚ھ“oڈꂵ‚½‚ئ‹L‰¯‚µ‚ؤ‚¢‚éww
Œg‘ر“dکb‚جOS‚حTRON(·ط¯ پc‚¶‚ل‚ب‚©‚ء‚½‚ٌ‚إ‚·‚©پ[
>>945
پ~ARM v6‚جARM9Œn
پ›ARM v5TEJ‚جARM9Œn
iPhone‚جƒqƒbƒg‚ھ–³‚¯‚ê‚خچ،‚جƒXƒ}ƒz‘Sگ·‚à–³‚
ARMƒRƒA‚جگ«”\Œüڈم‚àٹة‚â‚©‚¾‚ء‚½‚ٌ‚¾‚낤‚©پc
پ~ARM v6‚جARM9Œn
پ›ARM v5TEJ‚جARM9Œn
iPhone‚جƒqƒbƒg‚ھ–³‚¯‚ê‚خچ،‚جƒXƒ}ƒz‘Sگ·‚à–³‚
ARMƒRƒA‚جگ«”\Œüڈم‚àٹة‚â‚©‚¾‚ء‚½‚ٌ‚¾‚낤‚©پc
–¢‚¾ƒKƒ‰ƒPپ[‚ھ‰ك”¼گ”’´‚¦‚ؤ‚é‚ج‚ة‘Sگ·‚ح‚ب‚¢‚¾‚ëپB
‚ئ‚ح‚¢‚¦PC‚ًگ”‚إ‚ح’´‚¦‚ؤ‚«‚ؤ‚é‚ٌ‚¾‚و‚ث
>>944
‚¾‚©‚炱‚»Intel‚جŒ¾‚¢‚ب‚è‚إژہ‘•‚µ‚ؤ‚½‚¶‚ل‚ب‚¢‚©پBICM‚ئ‚©‚³پBƒTپ[ƒhƒpپ[ƒeƒB‚àˆç‚ء‚ؤ‚«‚½‚©‚çIntelˆبٹO‚جژہ‘•‘I‚ش‚و‚¤‚ة‚ب‚ء‚½‚و‚ثپB
‚¾‚©‚炱‚»Intel‚جŒ¾‚¢‚ب‚è‚إژہ‘•‚µ‚ؤ‚½‚¶‚ل‚ب‚¢‚©پBICM‚ئ‚©‚³پBƒTپ[ƒhƒpپ[ƒeƒB‚àˆç‚ء‚ؤ‚«‚½‚©‚çIntelˆبٹO‚جژہ‘•‘I‚ش‚و‚¤‚ة‚ب‚ء‚½‚و‚ثپB
>>946
Linuxƒxپ[ƒX‚جOS‚ًچج—p‚µژn‚ك‚ؤ‚©‚ç‚àƒxپ[ƒXƒoƒ“ƒhOS‚ئ‚µ‚ؤژg‚¤—ل‚ھ‚ ‚ء‚½‚و‚¤‚¾‚ھپA
ƒxپ[ƒXƒoƒ“ƒhپEƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‹¤‚ةچ،‚ح‚à‚¤گâ–³پB
‚»‚جٹش‚ةTOPPERS‚ھچL‚ھ‚ء‚ؤ‚«‚ؤژ©“®ژش‚ة“ü‚肱‚ٌ‚إ‚邯‚اپA
ژ©“®ژش‚à‹Zڈp‹¤’ت‰»‚ج•û‚ضگi‚ف‚»‚¤‚إژں‰½‚â‚é‚ٌ‚¾‚وپB
Linuxƒxپ[ƒX‚جOS‚ًچج—p‚µژn‚ك‚ؤ‚©‚ç‚àƒxپ[ƒXƒoƒ“ƒhOS‚ئ‚µ‚ؤژg‚¤—ل‚ھ‚ ‚ء‚½‚و‚¤‚¾‚ھپA
ƒxپ[ƒXƒoƒ“ƒhپEƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‹¤‚ةچ،‚ح‚à‚¤گâ–³پB
‚»‚جٹش‚ةTOPPERS‚ھچL‚ھ‚ء‚ؤ‚«‚ؤژ©“®ژش‚ة“ü‚肱‚ٌ‚إ‚邯‚اپA
ژ©“®ژش‚à‹Zڈp‹¤’ت‰»‚ج•û‚ضگi‚ف‚»‚¤‚إژں‰½‚â‚é‚ٌ‚¾‚وپB
‚»‚¤‚¢‚¦‚خTRONShow2013‚جˆؤ“à‚ًŒ©‚½‚ج‚¾‚ھپAچ،TRON‚ء‚ؤ‚ا‚¤‚¢‚¤CPU‚جڈم‚إ“®‚¢‚ؤ‚é‚جپHFreescale‚ئ‚©‚ةچع‚ء‚ؤ‚郓‚¾‚ء‚¯پH
ƒتITRON‚ج‚±‚ئ‚ب‚çگج‚àچ،‚à‚½‚¢‚ؤ‚¢‚ج‘g‚فچ‚ف—pCPU‚إ“®‚¢‚ؤ‚éپB
>>953
ARM? MIPS? Power? x86‚إ‚à‚ا‚ê‚إ‚à“®‚‚و‚¤‚ةڈ‘‚©‚ê‚ؤ‚邯‚اپAژہچغژg‚ي‚ê‚ؤ‚é‚ج‚ح‰½‚ب‚ٌ‚¾‚낤پB
ARM? MIPS? Power? x86‚إ‚à‚ا‚ê‚إ‚à“®‚‚و‚¤‚ةڈ‘‚©‚ê‚ؤ‚邯‚اپAژہچغژg‚ي‚ê‚ؤ‚é‚ج‚ح‰½‚ب‚ٌ‚¾‚낤پB
‘g‚فچ‚ف‚¾‚ئ–¢‚¾MIPS‚ئ‚©Z8‚ئ‚©H8‚ئ‚©‚ھˆê‘هگ¨—ح‚¾‚©‚ç‚ب
”ؤ—pOS‚©‚ç”hگ¶‚µ‚½‚ج‚ھچع‚é‚و‚¤‚ب‚â‚آ‚¾‚ئ‚ا‚±‚à‚©‚µ‚±‚àWindow‚¾‚炯‚¾
”ؤ—pOS‚©‚ç”hگ¶‚µ‚½‚ج‚ھچع‚é‚و‚¤‚ب‚â‚آ‚¾‚ئ‚ا‚±‚à‚©‚µ‚±‚àWindow‚¾‚炯‚¾
Windows‚حƒ‰ƒCƒZƒ“ƒX—؟‚ًچl‚¦‚é‚ئچ‚‰؟ٹiڈ¤•i‚ة‚µ‚©چع‚¹‚ç‚ê‚ب‚¢‚©‚ç‘g‚فچ‚ف‚ج’†‚إ‚ح“K—p‚إ‚«‚é•ھ–ى‚ھ‘ٹ“–‹·‚¢ٹ´‚¶‚ھ‚·‚邯‚اپBڈ‚ب‚‚ئ‚àWindows‚¾‚炯‚ئ‚¢‚¤•—‚ة‚ح‘S‘Rٹ´‚¶‚ç‚ê‚ب‚¢
•ھ–ى‚ھ‹·‚¢‚ء‚ؤپEپE‰½‚ً‘g‚فچ‚ف‚ئŒ©‚é‚©‚جˆل‚¢پB‚½‚ئ‚¦‚خگ†”رٹي‚ة‚ح‚ـ‚¾OS—v‚ç‚ب‚¢‚¾‚ë
‘g‚فچ‚ف‚ج’†‚إپuWindows‚¾‚炯پv‚ج•ھ–ى‚ئ‚¢‚¤‚ج‚ح‚ا‚ٌ‚ب•ھ–ى‚ب‚ج‚إ‚µ‚ه‚¤‚©پB
چ،—¬چs‚جگک’uŒ^ƒlƒbƒgƒڈپ[ƒNƒIپ[ƒfƒBƒIƒvƒŒپ[ƒ„پ[‚ج’†‚ةپA‚¢‚‚آ‚©Windows‚ھ“ü‚ء‚ؤ‚¢‚é‹@ژي‚ھ‚ ‚é‚ئ•·‚¢‚½‚±‚ئ‚ھ‚ ‚è‚ـ‚·پB
‰´‚ھ’m‚ء‚ؤ‚¢‚é‚ج‚حپA‚ ‚ئ‚حƒAƒLƒ…ƒtƒFپ[ƒYDG48‚ئDG58‚‚ç‚¢‚إ‚·‚ث
چ،—¬چs‚جگک’uŒ^ƒlƒbƒgƒڈپ[ƒNƒIپ[ƒfƒBƒIƒvƒŒپ[ƒ„پ[‚ج’†‚ةپA‚¢‚‚آ‚©Windows‚ھ“ü‚ء‚ؤ‚¢‚é‹@ژي‚ھ‚ ‚é‚ئ•·‚¢‚½‚±‚ئ‚ھ‚ ‚è‚ـ‚·پB
‰´‚ھ’m‚ء‚ؤ‚¢‚é‚ج‚حپA‚ ‚ئ‚حƒAƒLƒ…ƒtƒFپ[ƒYDG48‚ئDG58‚‚ç‚¢‚إ‚·‚ث
ƒŒƒW‚ب‚ٌ‚©‚ح‘ه’ïWindows‚ھ“ü‚ء‚ؤ‚é‚ب
‚ض‚¥پ`پB
JR‰w‚ج“Vˆن‚©‚ç’ف‚è‰؛‚ھ‚ء‚ؤ‚¢‚é“dژش‚ج”ژشژچڈ•\ژ¦‚ج40Œ^‚‚ç‚¢‚ج‘ه‚«‚³‚جLCDƒfƒBƒXƒvƒŒƒC‚حپAƒ}پ[ƒLپ[‚جƒXƒNƒچپ[ƒ‹‚ھGDI‚إ•`‰و‚µ‚½‚و‚¤‚بƒMƒNƒVƒƒƒNٹ´‚ھ‚ ‚é‚ئ‚±‚ë‚©‚çWindows‚إ‚ ‚é‚ئگ„‘ھ‚µ‚ؤ‚¢‚ـ‚·پB
JR‰w‚ج“Vˆن‚©‚ç’ف‚è‰؛‚ھ‚ء‚ؤ‚¢‚é“dژش‚ج”ژشژچڈ•\ژ¦‚ج40Œ^‚‚ç‚¢‚ج‘ه‚«‚³‚جLCDƒfƒBƒXƒvƒŒƒC‚حپAƒ}پ[ƒLپ[‚جƒXƒNƒچپ[ƒ‹‚ھGDI‚إ•`‰و‚µ‚½‚و‚¤‚بƒMƒNƒVƒƒƒNٹ´‚ھ‚ ‚é‚ئ‚±‚ë‚©‚çWindows‚إ‚ ‚é‚ئگ„‘ھ‚µ‚ؤ‚¢‚ـ‚·پB
ƒŒƒW‚ب‚ٌ‚©‰´‚ف‚½‚¢‚ب‘fگl‚ة‚حLinux‚âپAڈêچ‡‚ة‚و‚ء‚ؤ‚ح“ئژ©OS‚إ
چ¢‚ç‚ب‚¢‚و‚¤‚بپi‚µ‚©‚àˆہ‚‚آ‚پj‹C‚ھ‚·‚é‚ٌ‚¾‚ھ
‚ب‚ٌ‚إ‚ ‚ٌ‚ب‚ةWindows‚ج‚ً‚و‚Œ©‚©‚¯‚é‚ٌ‚¾‚낤‚ب
چ¢‚ç‚ب‚¢‚و‚¤‚بپi‚µ‚©‚àˆہ‚‚آ‚پj‹C‚ھ‚·‚é‚ٌ‚¾‚ھ
‚ب‚ٌ‚إ‚ ‚ٌ‚ب‚ةWindows‚ج‚ً‚و‚Œ©‚©‚¯‚é‚ٌ‚¾‚낤‚ب
>>960
“dŒُŒfژ¦”آ‚ح–ت”’‚¢‚ث‚—
http://up.gc-img.net/post_img/2013/09/mw6pinV1f4mR1TY_CIYqE_40.jpeg
http://livedoor.blogimg.jp/suponuke122/imgs/5/7/57f56afd.jpg
http://livedoor.blogimg.jp/yoshio_ch/imgs/c/7/c753c923.jpg
http://farm4.staticflickr.com/3684/8975470795_80b8450125_z.jpg
“dŒُŒfژ¦”آ‚ح–ت”’‚¢‚ث‚—
http://up.gc-img.net/post_img/2013/09/mw6pinV1f4mR1TY_CIYqE_40.jpeg
{kind=link}
http://livedoor.blogimg.jp/suponuke122/imgs/5/7/57f56afd.jpg
{kind=link}
http://livedoor.blogimg.jp/yoshio_ch/imgs/c/7/c753c923.jpg
{kind=link}
http://farm4.staticflickr.com/3684/8975470795_80b8450125_z.jpg
{kind=link}
963 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/06(‹à) 20:56:31.42 ID:dHAn+Uxu
‚ ‚ٌ‚ـ‚èگ”‚ھڈo‚ب‚¢ƒVƒXƒeƒ€‚حٹJ”ƒRƒXƒg•‚‚©‚¹‚邽‚ك‚ة
x86+WindowsƒGƒRƒVƒXƒeƒ€‚ً—¬—p‚·‚邱‚ئ‚ھ‘½‚¢
x86+WindowsƒGƒRƒVƒXƒeƒ€‚ً—¬—p‚·‚邱‚ئ‚ھ‘½‚¢
>>961
ƒlƒbƒgƒڈپ[ƒN•Kگ{‚¾‚µپAATM‚⃌ƒW‚حŒ‹چ\‘O‚©‚çWindows
Linix‚âƒtƒٹپ[ƒEƒFƒAژg‚¤‚ئڈêچ‡‚ة‚و‚ء‚ؤ‚حƒ\پ[ƒXŒِٹJ‚¹‚ة‚ل‚ب‚ç‚ٌ
‰ئ“dƒŒƒR‚ب‚ٌ‚©‚ح‚¯‚ء‚±‚¤Linux‚آ‚©‚ء‚ؤ‚é‚ي‚ب
ƒlƒbƒgƒڈپ[ƒN•Kگ{‚¾‚µپAATM‚⃌ƒW‚حŒ‹چ\‘O‚©‚çWindows
Linix‚âƒtƒٹپ[ƒEƒFƒAژg‚¤‚ئڈêچ‡‚ة‚و‚ء‚ؤ‚حƒ\پ[ƒXŒِٹJ‚¹‚ة‚ل‚ب‚ç‚ٌ
‰ئ“dƒŒƒR‚ب‚ٌ‚©‚ح‚¯‚ء‚±‚¤Linux‚آ‚©‚ء‚ؤ‚é‚ي‚ب
>>962
• •ّ‚¦‚ؤـغہ‚—
• •ّ‚¦‚ؤـغہ‚—
Windowsژg‚ء‚ؤ‚éATM‚ھچؤ‹N“®ŒJ‚è•ش‚µ‚ؤ‚é‚ج‚حŒ©‚½‚±‚ئ‚ ‚é‚بپB
êt–¾ٹْ‚جPOSƒŒƒW‚ب‚ٌ‚©‚à‚و‚گآ‰و–ت‚إ•ْ’u‚³‚ê‚ؤ‚½
ٹدŒُ—p‚جڈî•ٌ’[––‚ئ‚©‚¢‚ي‚ن‚éˆê•i•¨‚ح‚ظ‚عWindows‚¾‚بپB
چإ‹ك‚جƒAپ[ƒPپ[ƒhƒQپ[ƒ€‹@‚àWindows‚ھ‘½‚¢‚بپB
ƒOƒ‰ƒtƒBƒbƒN‚ً‘½—p‚·‚éƒTƒCƒlپ[ƒWŒn‚âTCP/IP’‚éPOS‚ب‚ٌ‚©‚ح‘½‚¢‚ثپB
–³گü’‚点‚é‚ئ‚³‚ç‚ة‘ه•د‚ة‚ب‚é‚ج‚إپA‚±‚¤‚¢‚¤‚ج‚حWindowsپA
ƒOƒ‰ƒtƒBƒbƒN‚ة‚±‚¾‚ي‚ç‚ب‚¢‚ٌ‚ب‚çBSDŒn‚ھ‘½‚¢پB
‚±‚ـ‚¢ƒfƒoƒCƒX‚ح’m‚ç‚ٌپB
چإ‹ك‚حiPAD‚ةCAT‚آ‚¯‚ؤƒJپ[ƒhŒˆچد‚إ‚«‚é‚و‚¤‚ة‚µ‚½ƒŒƒW‚ھ
ˆùگH“XŒü‚¯‚ة‘‚¦‚ؤ‚¢‚éپB
–³گü’‚点‚é‚ئ‚³‚ç‚ة‘ه•د‚ة‚ب‚é‚ج‚إپA‚±‚¤‚¢‚¤‚ج‚حWindowsپA
ƒOƒ‰ƒtƒBƒbƒN‚ة‚±‚¾‚ي‚ç‚ب‚¢‚ٌ‚ب‚çBSDŒn‚ھ‘½‚¢پB
‚±‚ـ‚¢ƒfƒoƒCƒX‚ح’m‚ç‚ٌپB
چإ‹ك‚حiPAD‚ةCAT‚آ‚¯‚ؤƒJپ[ƒhŒˆچد‚إ‚«‚é‚و‚¤‚ة‚µ‚½ƒŒƒW‚ھ
ˆùگH“XŒü‚¯‚ة‘‚¦‚ؤ‚¢‚éپB
ƒTƒCƒlپ[ƒW’[––‚إ‚àپAچ،‚حƒlƒbƒgƒڈپ[ƒN‚ةŒq‚ھ‚ء‚ؤ‚é‚ج‚ھˆê”ت“I‚ة‚ب‚ء‚½‚©‚ç
ƒuƒ‹ƒXƒN•ْ’u‚حڈ‚ب‚‚ب‚ء‚ؤ‚«‚½‚ثپc
ƒuƒ‹ƒXƒN•ْ’u‚حڈ‚ب‚‚ب‚ء‚ؤ‚«‚½‚ثپc
‚ ‚é“ْ’N‚©‚ھٹXٹp‚ج‰f‘œ•\ژ¦‚ً‘S‚ؤڈو‚ءژو‚ء‚ؤپA‚ئ‚¢‚¤‚ج‚ھ
Œ´—“I‚ة‚ح‰آ”\‚ة‚ب‚è‚آ‚آ‚ ‚é‚ج‚©
Œ´—“I‚ة‚ح‰آ”\‚ة‚ب‚è‚آ‚آ‚ ‚é‚ج‚©
‘ه•¨ƒnƒٹƒEƒbƒhƒXƒ^پ[‚ھ•پ’ت‚ة“أ‚°‚ؤ‚é‚ج‚ًŒ©‚é‚ئپA
ˆç–رچـ‚ء‚ؤŒّ‰ت‚ ‚é‚ج‚©‹^–â‚ةژv‚¦‚ؤ‚‚é
ˆç–رچـ‚ء‚ؤŒّ‰ت‚ ‚é‚ج‚©‹^–â‚ةژv‚¦‚ؤ‚‚é
Œë”ڑƒXƒ}ƒ\
Linux‚ة‚حGPLv3–â‘è‚ھ‚ ‚é‚ٌ‚¾‚و‚ب
GPLv3‚حپAٹé‹ئ‚ة“G‘خ‚·‚é‚و‚¤‚بƒ‰ƒCƒZƒ“ƒX‚ة‚ب‚ء‚ؤپA
‚»‚جƒRپ[ƒh‚ًڈ¤—pگ»•i‚ةژg‚¤‚ج‚ح”ٌڈي‚ة“‚‚ب‚ء‚ؤ‚«‚½
ƒRƒA•”•ھ‚ةGPLv3‚ًٹـ‚ـ‚ب‚¢Linux‚ًژg‚¤‚©پA‚ق‚µ‚‚حFreeBSDŒn‚ة“¦‚°‚é‚©‚ً‘I‘ً‚µ‚ب‚¢‚ئ‚¢‚¯‚ب‚‚ب‚ء‚ؤ‚«‚½
چK‚¢پALinus‚ھGPLv3‚ة”غ’è“I‚إپAƒJپ[ƒlƒ‹•”•ھ‚ة‚حGPLv3‚¶‚ل‚ب‚¢‚ج‚إپA
‚¢‚ـ‚ج‚ئ‚±‚ë‚ح‰ٌ”ً‰آ”\‚¾‚¯‚اپA‰ٌ”ً‚·‚邽‚ك‚ةژèٹش‚ھ‚©‚©‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚«‚½
GPLv3‚حپAٹé‹ئ‚ة“G‘خ‚·‚é‚و‚¤‚بƒ‰ƒCƒZƒ“ƒX‚ة‚ب‚ء‚ؤپA
‚»‚جƒRپ[ƒh‚ًڈ¤—pگ»•i‚ةژg‚¤‚ج‚ح”ٌڈي‚ة“‚‚ب‚ء‚ؤ‚«‚½
ƒRƒA•”•ھ‚ةGPLv3‚ًٹـ‚ـ‚ب‚¢Linux‚ًژg‚¤‚©پA‚ق‚µ‚‚حFreeBSDŒn‚ة“¦‚°‚é‚©‚ً‘I‘ً‚µ‚ب‚¢‚ئ‚¢‚¯‚ب‚‚ب‚ء‚ؤ‚«‚½
چK‚¢پALinus‚ھGPLv3‚ة”غ’è“I‚إپAƒJپ[ƒlƒ‹•”•ھ‚ة‚حGPLv3‚¶‚ل‚ب‚¢‚ج‚إپA
‚¢‚ـ‚ج‚ئ‚±‚ë‚ح‰ٌ”ً‰آ”\‚¾‚¯‚اپA‰ٌ”ً‚·‚邽‚ك‚ةژèٹش‚ھ‚©‚©‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚«‚½
android‚ھ‚ا‚¤‚µ‚½‚ء‚ؤپH
Linux‚حپAƒJپ[ƒlƒ‹‚âlibc‚ح‚ـ‚¾GPLv3‚¶‚ل‚ب‚¢
‚¾‚©‚çپAGPLv3‚جƒRپ[ƒh‚ًژg‚ي‚ب‚¢‚و‚¤‚ة‚·‚ê‚خ‚ـ‚¾“¦‚°‚ç‚ê‚é
Google‚ف‚½‚¢‚بٹJ”—ح‚ج‚ ‚é‰ïژذ‚¶‚ل‚ـ‚¾GPLv3‚©‚ç‚ح“¦‚°‚ç‚ê‚é
‚¾‚©‚çپAGPLv3‚جƒRپ[ƒh‚ًژg‚ي‚ب‚¢‚و‚¤‚ة‚·‚ê‚خ‚ـ‚¾“¦‚°‚ç‚ê‚é
Google‚ف‚½‚¢‚بٹJ”—ح‚ج‚ ‚é‰ïژذ‚¶‚ل‚ـ‚¾GPLv3‚©‚ç‚ح“¦‚°‚ç‚ê‚é
’T‚¹‚خ’n•û‹âچs‚إ‚ـ‚¾‰ز“‚µ‚ؤ‚éNT4.0‚جATM‚ئ‚©‚ ‚é‚ح‚¸
‰ٌگü‚ھƒAƒiƒچƒO‚©ISDN‚إPONپiŒُ‰ٌگü‚إ‚àGPONپj‚آ‚©‚ء‚½ATMپi’تگM•ûژ®‚ج•ûپjƒlƒbƒgƒڈپ[ƒN‚¾‚©‚ç‚»‚ê‚إ‚àچ¢‚ç‚ب‚¢‚ھ‚ن‚¦‚ةپc
‰ٌگü‚ھƒAƒiƒچƒO‚©ISDN‚إPONپiŒُ‰ٌگü‚إ‚àGPONپj‚آ‚©‚ء‚½ATMپi’تگM•ûژ®‚ج•ûپjƒlƒbƒgƒڈپ[ƒN‚¾‚©‚ç‚»‚ê‚إ‚àچ¢‚ç‚ب‚¢‚ھ‚ن‚¦‚ةپc
‘ه•¨“أƒEƒbƒhƒXƒ^پ[‚ج“ھ‚ةƒXƒ}پ[ƒgƒEƒBƒbƒO‚ًچع‚¹‚邨ژdژ–
http://www.nikkan.co.jp/news/nkx0320131202bjag.html
http://www.nikkan.co.jp/news/nkx0320131202bjag.html
980 پFSocket774پF2013/12/07(“y) 12:55:49.98 ID:OjEEgfQF
•ں“cŒ‹ڈ»‹ZڈpŒ¤پA’¼Œa‚P‚OƒCƒ“ƒ`‚جƒTƒtƒ@ƒCƒA’PŒ‹ڈ»چىگ»‚ةگ¬Œ÷پ|‚b‚y–@‚إگ¢ٹEڈ‰
http://www.nikkan.co.jp/news/nkx0820131206aaac.html
ƒVƒٹƒRƒ“ƒEƒFƒnپ[•ہ‚ف‚ج‘هŒ^ƒTƒtƒ@ƒCƒ„ƒEƒFƒnپ[گ»‘¢‚ةگ¬Œ÷
http://www.nikkan.co.jp/news/nkx0820131206aaac.html
ƒVƒٹƒRƒ“ƒEƒFƒnپ[•ہ‚ف‚ج‘هŒ^ƒTƒtƒ@ƒCƒ„ƒEƒFƒnپ[گ»‘¢‚ةگ¬Œ÷
OSX‚àGPLv3‘خچô‚إŒ‹چ\‘O‚©‚ç‚¢‚ë‚¢‚ë“ئژ©ژہ‘•‚ةگط‚è‘ض‚¦‚ؤ‚é
‚ظ
>>961
ƒlƒbƒgƒڈپ[ƒN•Kگ{‚¾‚µƒlƒbƒgƒڈپ[ƒNڈم‚جƒTپ[ƒrƒX‚ً—ک—p‚·‚郂ƒWƒ…پ[ƒ‹‚àPC‚ئ‹¤—p‚إ‚«‚邵پA“®‰و‚âƒxƒNƒgƒ‹ƒOƒ‰ƒtƒBƒbƒN‚àPC‚ج‚à‚ج‚ھ‚»‚ج‚ـ‚ـژg‚¦‚é‚©‚çWindowsƒxپ[ƒX‚ج•û‚ھƒ‰ƒNپA‚ء‚ؤٹ´‚¶‚ةپB
ƒ‚ƒoƒCƒ‹Œn‚إ‚حadobe‚ھ‚ب‚؛‚©ژ©ژذ‚ً•s—ک‚ة‚µ‚ؤ‚ـ‚إƒWƒ‡ƒuƒY‚ج–دŒ¾‚ةڈ]‚ء‚ؤ“WٹJژ©ڈl‚µ‚ؤ‚µ‚ـ‚ء‚½‚¯‚اپAPCƒxپ[ƒX‚جPOSƒŒƒW‚âƒTƒCƒlپ[ƒW‚إ‚ح‚»‚ꂱ‚»Flash‚»‚ج‚à‚ج‚ھ“ü‚ء‚ؤ“®‚¢‚ؤ‚é‚à‚ج‚ھ“–‚½‚è‘O‚ة‚ ‚éپB
‚à‚؟‚ë‚ٌ‚»‚±‚إچؤگ¶‚³‚ê‚éƒRƒ“ƒeƒ“ƒc‚àFlashپBژ©ڈlژ©–إ‚·‚éFlash‚ج‘م‘ض‚ئŒ¾‚ي‚ꂽSilver‚ب‚ٌ‚؟‚ل‚ç‚حپAŒ‹‹ا•پ‹y‚µ‚ب‚¢‚ـ‚ـڈI‘§‚©
ƒlƒbƒgƒڈپ[ƒN•Kگ{‚¾‚µƒlƒbƒgƒڈپ[ƒNڈم‚جƒTپ[ƒrƒX‚ً—ک—p‚·‚郂ƒWƒ…پ[ƒ‹‚àPC‚ئ‹¤—p‚إ‚«‚邵پA“®‰و‚âƒxƒNƒgƒ‹ƒOƒ‰ƒtƒBƒbƒN‚àPC‚ج‚à‚ج‚ھ‚»‚ج‚ـ‚ـژg‚¦‚é‚©‚çWindowsƒxپ[ƒX‚ج•û‚ھƒ‰ƒNپA‚ء‚ؤٹ´‚¶‚ةپB
ƒ‚ƒoƒCƒ‹Œn‚إ‚حadobe‚ھ‚ب‚؛‚©ژ©ژذ‚ً•s—ک‚ة‚µ‚ؤ‚ـ‚إƒWƒ‡ƒuƒY‚ج–دŒ¾‚ةڈ]‚ء‚ؤ“WٹJژ©ڈl‚µ‚ؤ‚µ‚ـ‚ء‚½‚¯‚اپAPCƒxپ[ƒX‚جPOSƒŒƒW‚âƒTƒCƒlپ[ƒW‚إ‚ح‚»‚ꂱ‚»Flash‚»‚ج‚à‚ج‚ھ“ü‚ء‚ؤ“®‚¢‚ؤ‚é‚à‚ج‚ھ“–‚½‚è‘O‚ة‚ ‚éپB
‚à‚؟‚ë‚ٌ‚»‚±‚إچؤگ¶‚³‚ê‚éƒRƒ“ƒeƒ“ƒc‚àFlashپBژ©ڈlژ©–إ‚·‚éFlash‚ج‘م‘ض‚ئŒ¾‚ي‚ꂽSilver‚ب‚ٌ‚؟‚ل‚ç‚حپAŒ‹‹ا•پ‹y‚µ‚ب‚¢‚ـ‚ـڈI‘§‚©
>>970
BSDŒn‚ب‚ٌ‚ؤژg‚ء‚ؤ‚éڈٹ‚ثپ[‚وˆ«–‚‹³“k‚ح‚±‚¤‚¢‚¤ڈٹ‚إ•½‹C‚إ‰Rگ‚‚ê‚é
LinuxŒn‚ھ‚ ‚ـ‚è•پ‹y‚µ‚ؤ‚ب‚¢‚ج‚àFlash‚â“®‰و‚جƒ‰ƒ“ƒ^ƒCƒ€‚ج–â‘è‚âپAƒ‰ƒ“ƒ^ƒCƒ€ژ©‘ج‚ح‹ں‹‹‚ھ‚ ‚ء‚ؤ‚àƒpƒtƒHپ[ƒ}ƒ“ƒX‚ة–â‘è‚ھ‚ ‚è‚·‚¬‚½‚è‚·‚é‚ء‚ؤژ–ڈî‚ھ‘ه‚«‚¢پB
GPL‰کگُ‚حŒ¾‚ي‚ê‚é’ِ–â‘è‚إ‚à‚ب‚¢‚ء‚ؤ‚¢‚¤‚©پAGPLƒ‰ƒCƒZƒ“ƒX‚جƒ‰ƒCƒuƒ‰ƒٹ‚ًƒnپ[ƒhƒٹƒ“ƒN‚·‚é‚و‚¤‚ب‹ً‚©‚بگ^ژ—‚إ‚à‚µ‚ب‚¢Œہ‚èƒ\پ[ƒX‚ـ‚إŒِٹJ‚³‚¹‚ç‚ê‚éژ–‚ح–³‚¢‚µپA
ژہچغ‚ة‰ئ“d‚جBDƒŒƒRپ[ƒ_پ[‚ب‚ٌ‚©’†‚إLinux‚ھ“®‚¢‚ؤ‚邯‚اپAٹجگS‚جƒGƒ“ƒRپ[ƒhƒfƒRپ[ƒhژü‚è‚â‰f‘œڈˆ—‚ج•”•ھ‚ح“ئژ©ƒRپ[ƒh‚¾‚µپA
GPLƒxپ[ƒX‚àƒ‰ƒCƒuƒ‰ƒٹ‚ًƒٹƒ“ƒN‚µ‚ؤ‚ب‚¢‚©‚çƒ\پ[ƒX‚جŒِٹJ‹`–±‚à‚ب‚¢پBژہچغ‚ةŒِٹJ‚à‚³‚ê‚ؤ‚ب‚¢
GPL‚ةٹض‚µ‚ؤ‚ح‚±‚¤‚â‚ء‚ؤ‚¹‚ء‚¹‚ئFUD‚ًگ‚‚ê—¬‚·ˆ«–‚‹³“k‚ھ‚¢‚é‚©‚çپAŒ©‚آ‚¯ژں‘وژE‚¹پBGPL‚àWindows‚àپAƒfƒ^ƒ‰ƒپ‚ب’@‚«•û‚µ‚ؤ‚é‚ج‚ح9ٹ„•û‚±‚¢‚آ‚炾پB
ژ©•ھ‚إ”»’f‚إ‚«‚ب‚¢ƒSƒCƒ€‘ٹژè‚ب‚çپA‰R‚إ‚à‰½‚إ‚àگپ‚«چ‚ٌ‚إéx‚µ‚ؤ‚à‚»‚ê‚ھگ³‹`‚¾‚ئژv‚ء‚ؤ‚â‚ھ‚éپB
گ¢ٹE‚©‚ç”rڈœ‚³‚ê‚é‚ׂ«‚حWindows‚إ‚àGPL‚إ‚à‚ب‚پABSD‚جلإ‘°‚¾‚يپB‚±‚¢‚آ‚ç‚ھ‹ڈ‚ب‚‚ب‚ê‚خپAوy‚¢‚ج9ٹ„‚ھڈء‚¦‚邾‚낤
BSDŒn‚ب‚ٌ‚ؤژg‚ء‚ؤ‚éڈٹ‚ثپ[‚وˆ«–‚‹³“k‚ح‚±‚¤‚¢‚¤ڈٹ‚إ•½‹C‚إ‰Rگ‚‚ê‚é
LinuxŒn‚ھ‚ ‚ـ‚è•پ‹y‚µ‚ؤ‚ب‚¢‚ج‚àFlash‚â“®‰و‚جƒ‰ƒ“ƒ^ƒCƒ€‚ج–â‘è‚âپAƒ‰ƒ“ƒ^ƒCƒ€ژ©‘ج‚ح‹ں‹‹‚ھ‚ ‚ء‚ؤ‚àƒpƒtƒHپ[ƒ}ƒ“ƒX‚ة–â‘è‚ھ‚ ‚è‚·‚¬‚½‚è‚·‚é‚ء‚ؤژ–ڈî‚ھ‘ه‚«‚¢پB
GPL‰کگُ‚حŒ¾‚ي‚ê‚é’ِ–â‘è‚إ‚à‚ب‚¢‚ء‚ؤ‚¢‚¤‚©پAGPLƒ‰ƒCƒZƒ“ƒX‚جƒ‰ƒCƒuƒ‰ƒٹ‚ًƒnپ[ƒhƒٹƒ“ƒN‚·‚é‚و‚¤‚ب‹ً‚©‚بگ^ژ—‚إ‚à‚µ‚ب‚¢Œہ‚èƒ\پ[ƒX‚ـ‚إŒِٹJ‚³‚¹‚ç‚ê‚éژ–‚ح–³‚¢‚µپA
ژہچغ‚ة‰ئ“d‚جBDƒŒƒRپ[ƒ_پ[‚ب‚ٌ‚©’†‚إLinux‚ھ“®‚¢‚ؤ‚邯‚اپAٹجگS‚جƒGƒ“ƒRپ[ƒhƒfƒRپ[ƒhژü‚è‚â‰f‘œڈˆ—‚ج•”•ھ‚ح“ئژ©ƒRپ[ƒh‚¾‚µپA
GPLƒxپ[ƒX‚àƒ‰ƒCƒuƒ‰ƒٹ‚ًƒٹƒ“ƒN‚µ‚ؤ‚ب‚¢‚©‚çƒ\پ[ƒX‚جŒِٹJ‹`–±‚à‚ب‚¢پBژہچغ‚ةŒِٹJ‚à‚³‚ê‚ؤ‚ب‚¢
GPL‚ةٹض‚µ‚ؤ‚ح‚±‚¤‚â‚ء‚ؤ‚¹‚ء‚¹‚ئFUD‚ًگ‚‚ê—¬‚·ˆ«–‚‹³“k‚ھ‚¢‚é‚©‚çپAŒ©‚آ‚¯ژں‘وژE‚¹پBGPL‚àWindows‚àپAƒfƒ^ƒ‰ƒپ‚ب’@‚«•û‚µ‚ؤ‚é‚ج‚ح9ٹ„•û‚±‚¢‚آ‚炾پB
ژ©•ھ‚إ”»’f‚إ‚«‚ب‚¢ƒSƒCƒ€‘ٹژè‚ب‚çپA‰R‚إ‚à‰½‚إ‚àگپ‚«چ‚ٌ‚إéx‚µ‚ؤ‚à‚»‚ê‚ھگ³‹`‚¾‚ئژv‚ء‚ؤ‚â‚ھ‚éپB
گ¢ٹE‚©‚ç”rڈœ‚³‚ê‚é‚ׂ«‚حWindows‚إ‚àGPL‚إ‚à‚ب‚پABSD‚جلإ‘°‚¾‚يپB‚±‚¢‚آ‚ç‚ھ‹ڈ‚ب‚‚ب‚ê‚خپAوy‚¢‚ج9ٹ„‚ھڈء‚¦‚邾‚낤
985 پFSocket774پF2013/12/07(“y) 19:04:45.74 ID:ToK5X86C
>>984
‰R‚حŒ¾‚ء‚ؤ‚ب‚¢‚ئژv‚¤‚¼پH
‘g‚فچ‚ف‚ب‚ٌ‚إپA’†گg•ھ‚©‚ç‚ب‚¢‚¾‚¯‚إپA‘î”z‚جژَ‚¯ژو‚èBOX‚©‚çپA
ƒvƒٹƒ“ƒ^پ[‚ـ‚إپAژg‚ء‚ؤ‚éƒپپ[ƒJپ[‚ح‚ ‚éپB
ƒٹƒRپ[‚حNetBSDژg‚ء‚ؤ‚½‚بپB
ƒpƒi‚جƒXƒ}پ[ƒgVIERA‚ةپAƒ\ƒjƒŒƒR‚àBSDƒxپ[ƒX‚ج‚à‚ٌ—L‚ء‚½‚¾‚ëٹm‚©پB
ڈںژè‚ة‰R‚ئŒˆ‚ك‚آ‚¯‚éپA‚¨‚ـ‚¦‚±‚»”rڈœ‚³‚ê‚é‚ׂ«‚¶‚ل‚ثپH
‰R‚حŒ¾‚ء‚ؤ‚ب‚¢‚ئژv‚¤‚¼پH
‘g‚فچ‚ف‚ب‚ٌ‚إپA’†گg•ھ‚©‚ç‚ب‚¢‚¾‚¯‚إپA‘î”z‚جژَ‚¯ژو‚èBOX‚©‚çپA
ƒvƒٹƒ“ƒ^پ[‚ـ‚إپAژg‚ء‚ؤ‚éƒپپ[ƒJپ[‚ح‚ ‚éپB
ƒٹƒRپ[‚حNetBSDژg‚ء‚ؤ‚½‚بپB
ƒpƒi‚جƒXƒ}پ[ƒgVIERA‚ةپAƒ\ƒjƒŒƒR‚àBSDƒxپ[ƒX‚ج‚à‚ٌ—L‚ء‚½‚¾‚ëٹm‚©پB
ڈںژè‚ة‰R‚ئŒˆ‚ك‚آ‚¯‚éپA‚¨‚ـ‚¦‚±‚»”rڈœ‚³‚ê‚é‚ׂ«‚¶‚ل‚ثپH
986 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/07(“y) 19:12:11.68 ID:T/f6Ixp4
‚¾‚©‚çWindows‚ھژxژ‚³‚ê‚ؤ‚é—vˆِ‚ح
ƒ‚ƒbƒNƒAƒbƒvƒAƒvƒٹ‚ج’iٹK‚©‚çWindowsٹJ”‚إچى‚肱‚ٌ‚إ
ˆعگA‚جژèٹش‚ھ‚©‚©‚ç‚ب‚¢گ¶ژYگ«‚جچ‚‚³‚¾‚ء‚ؤپB
ƒ‚ƒbƒNƒAƒbƒvƒAƒvƒٹ‚ج’iٹK‚©‚çWindowsٹJ”‚إچى‚肱‚ٌ‚إ
ˆعگA‚جژèٹش‚ھ‚©‚©‚ç‚ب‚¢گ¶ژYگ«‚جچ‚‚³‚¾‚ء‚ؤپB
‚ظ
‚»‚¤‚¢‚âPS4‚ھFreeBSDƒxپ[ƒX‚¾‚ء‚¯
AMD‚حƒhƒ‰ƒCƒo‚ج‘خ‰‚ئ‚©Œ©‚éŒہ‚è
Win‚ئLinux‚ة‚µ‚©‹»–،‚ھ‚ب‚¢‚ئژv‚ء‚ؤ‚½‚©‚çˆسٹO‚¾‚ء‚½
AMD‚حƒhƒ‰ƒCƒo‚ج‘خ‰‚ئ‚©Œ©‚éŒہ‚è
Win‚ئLinux‚ة‚µ‚©‹»–،‚ھ‚ب‚¢‚ئژv‚ء‚ؤ‚½‚©‚çˆسٹO‚¾‚ء‚½
—ًژj“Iژ–ڈî‚ة‚و‚èlinux‚ح“à•”چ\‘¢‚ھbsd‚و‚育‚؟‚ل‚²‚؟‚ل‚µ‚ؤ‚é‚©‚ç‚ثپ[
GPLˆبٹO‚ة‚à
GPLˆبٹO‚ة‚à
990 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/07(“y) 20:08:06.02 ID:T/f6Ixp4
Linux‚حX Server‚جŒمŒp‚à–¢‚¾‚ة“ˆê‚³‚ê‚ؤ‚ب‚¢‚©‚ç‚ثپ[
‚ ‚ئƒfƒXƒNƒgƒbƒvٹآ‹«‚à‚à‚¤Qt‚àƒ‰ƒCƒZƒ“ƒX–â‘è‰ًŒˆ‚µ‚½‚ٌ‚¾‚µKDE‚إ‚¢‚¢‚¶‚ل‚ٌپB
GNOMEŒ™‚¢پB
‚ ‚ئƒfƒXƒNƒgƒbƒvٹآ‹«‚à‚à‚¤Qt‚àƒ‰ƒCƒZƒ“ƒX–â‘è‰ًŒˆ‚µ‚½‚ٌ‚¾‚µKDE‚إ‚¢‚¢‚¶‚ل‚ٌپB
GNOMEŒ™‚¢پB
UNIX”آ‚©‚ç’ا‚¢ڈo‚³‚ꂽ’cژq‚³‚ٌ‚¾
992 پF,,پEپLپحپMپE,,پj‚ء-پ›پ›پ›پF2013/12/07(“y) 20:33:53.36 ID:T/f6Ixp4
‚»‚ٌ‚ب”آ’m‚ç‚ٌ
>>985
گ”ڈ‚ب‚¢—لٹO‚ًژ‚ء‚ؤ‚«‚ؤƒzƒ‰‚±‚ٌ‚ب‚ة‚ ‚邼‚ئچِٹo‚³‚¹‚و‚¤‚ئ‚·‚鈫–‚‹³“k‚حژ€‚ت‚ׂ«پB
گ”ڈ‚ب‚¢—لٹO‚ًژ‚ء‚ؤ‚«‚ؤƒzƒ‰‚±‚ٌ‚ب‚ة‚ ‚邼‚ئچِٹo‚³‚¹‚و‚¤‚ئ‚·‚鈫–‚‹³“k‚حژ€‚ت‚ׂ«پB
گجRD-A1‚ئ‚¢‚¤Intel “‹چع‚جچإ‹¥HDDƒŒƒRپ[ƒ_پ[‚ھ‚ ‚ء‚ؤ‚بپcپc
>>990
•¶–¬‚©‚çX Window System‚ئ‚¢‚¤‚ج‚ھگ³‚µ‚¢
>>993
ƒXƒyƒNƒgƒ‰ƒ€‚ھچL‚¢‘g‚فچ‚ف‚ًڈ\”cˆê—چ‚°‚ة‚µ‚ؤپA‚ـ‚é‚إ‘g‚فچ‚ف‹ئٹE‘S‘ج‚إWindows‚ھ‘½‚ژg‚ي‚ê‚ؤ‚¢‚é‚©‚ج‚و‚¤‚ب‚±‚ئ‚ًŒ¾‚ء‚ؤ‚¢‚éکA’†‚à“¯چك
•¶–¬‚©‚çX Window System‚ئ‚¢‚¤‚ج‚ھگ³‚µ‚¢
>>993
ƒXƒyƒNƒgƒ‰ƒ€‚ھچL‚¢‘g‚فچ‚ف‚ًڈ\”cˆê—چ‚°‚ة‚µ‚ؤپA‚ـ‚é‚إ‘g‚فچ‚ف‹ئٹE‘S‘ج‚إWindows‚ھ‘½‚ژg‚ي‚ê‚ؤ‚¢‚é‚©‚ج‚و‚¤‚ب‚±‚ئ‚ًŒ¾‚ء‚ؤ‚¢‚éکA’†‚à“¯چك
چ‚’P‰؟‚إڈگ”‚ج‘g‚فچ‚فŒn‚ة‚حWindows‚ھ‚©‚ب‚è‚و‚ژg‚ي‚ê‚ؤ‚é‚و
997 پFSocket774پF2013/12/07(“y) 23:01:33.77 ID:sGyMlZtV
CPUƒAپ[ƒLƒeƒNƒ`ƒƒ‚ة‚آ‚¢‚ؤŒê‚ê 25
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
http://anago.2ch.net/test/read.cgi/jisaku/1386424858/
>>994
ƒAƒŒ‚حHDDVD—pSOCپiEMMA3پj‚ھ‚إ‚«‚é‘O‚إ
ƒfƒWƒ^ƒ‹•ْ‘—‘خ‰DVDƒŒƒR—pSOCپiEMMA2RHپj‚إ•s‘«•ھ‚ً
HDiپiHDDVD—pƒXƒNƒٹƒvƒgŒ¾Œêپj‚ئUIڈˆ——p‚ة‚جCeleron“ü‚ء‚ؤ‚½‚ٌ‚¾‚ء‚¯‚©
ƒAƒŒ‚حHDDVD—pSOCپiEMMA3پj‚ھ‚إ‚«‚é‘O‚إ
ƒfƒWƒ^ƒ‹•ْ‘—‘خ‰DVDƒŒƒR—pSOCپiEMMA2RHپj‚إ•s‘«•ھ‚ً
HDiپiHDDVD—pƒXƒNƒٹƒvƒgŒ¾Œêپj‚ئUIڈˆ——p‚ة‚جCeleron“ü‚ء‚ؤ‚½‚ٌ‚¾‚ء‚¯‚©
ƒٹƒAƒ‹ƒ^ƒCƒ€گ§Œن‚ھ•K—v‚ب•”•ھ‚¾‚¯ƒVپ[ƒPƒ“ƒTپ[‚إ‘g‚ٌ‚إپAUIپADBپAƒlƒbƒgƒڈپ[ƒN‚ب‚ٌ‚©‚حWindows‚إچى‚é‚ج‚ھ•پ’ت‚¾‚وپB
1001 پF‚P‚O‚O‚PپF
1‘ن‚جƒ}ƒVƒ“‚ھ‘g‚فڈم‚ھ‚è‚ـ‚µ‚½پBپBپB
گV‚µ‚¢â‘ج‚ً—pˆس‚µ‚ؤ‚‚¾‚³‚¢‚إ‚·پBپBپBپB
پ@پ@پ@پ@پ@پ@پ@پ@پ@ژ©چىPC”آپ—2ch http://anago.2ch.net/jisaku/
گV‚µ‚¢â‘ج‚ً—pˆس‚µ‚ؤ‚‚¾‚³‚¢‚إ‚·پBپBپBپB
پ@پ@پ@پ@پ@پ@پ@پ@پ@ژ©چىPC”آپ—2ch http://anago.2ch.net/jisaku/