CPU�A�[�L�e�N�`���ɂ��Č�� 22
�w�l�V�[&�p�^�[�\��
���邢�͉͓��̛�
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 21
http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
�y�ߋ��X���z
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20
http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
���邢�͉͓��̛�
�O�X��
CPU�A�[�L�e�N�`���ɂ��Č�� 21
http://anago.2ch.net/test/read.cgi/jisaku/1324483722/
�y�ߋ��X���z
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
Part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
Part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
Part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
Part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
Part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
Part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
Part16 http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
Part17 http://hibari.2ch.net/test/read.cgi/jisaku/1274809074/
Part18 http://hibari.2ch.net/test/read.cgi/jisaku/1290758715/
Part19 http://hibari.2ch.net/test/read.cgi/jisaku/1305200489/
Part20
http://anago.2ch.net/test/read.cgi/jisaku/1318113870/
|
|
|
2 �FSocket774�F2012/04/11(��) 08:13:17.50 ID:KXV+ghBM
�����ς�
�����ς������ς�
�����ς������ς������ς�
����ς�
��������
�ו�
�ݕ�
����
�n�X�E�F������
�e�X�g
�i�v�E�ցE�j�v���[�I�i�^�E�ցE�j�^�ɂ�[�I
13 �F,,�E�L�́M�E,,�j��-�������F2012/04/15(��) 00:58:53.80 ID:FE/2aiP2
> 998 �FSocket774 [sage] �F2012/04/10(��) 16:01:40.56 ID:DCw9rvKM (2/2)
> >>991
> >>973��restrict�]�X�̂Ƃ��̓G�C���A�V���O�̂��Ƃ������Ă邪
> �O���̓L���X�g�̘b������pointer masquerading�̂��Ƃ���Ȃ���
�܂��܂������Ȃ��P�ꂪ�o�Ă�����
> >>991
> >>973��restrict�]�X�̂Ƃ��̓G�C���A�V���O�̂��Ƃ������Ă邪
> �O���̓L���X�g�̘b������pointer masquerading�̂��Ƃ���Ȃ���
�܂��܂������Ȃ��P�ꂪ�o�Ă�����
���ǁ@IvyBridge�@�̏o�ׂ��x��Ă���̂́A������̂����B����Ƃ�sanday�̍ɂ���������H
�Ȃ�inte��3D�g�����W�X�^�ɋꂵ��ł���悤�����ǂ��̐���v���ȁB
3D�g�����W�X�^��������������AMD��ARM���Ԃ�������ɂȂ����낤���ǁB
�Ȃ�inte��3D�g�����W�X�^�ɋꂵ��ł���悤�����ǂ��̐���v���ȁB
3D�g�����W�X�^��������������AMD��ARM���Ԃ�������ɂȂ����낤���ǁB
90nm�̂Ƃ��Ǝ��Ă���ˁB
����Ŗ{����TDP��95W�A�A�C�h�����̏���d�͑����AOC�ϐ��̒ቺ���{���Ȃ�
�v���X�R�b�g�قǂɂ͂Ȃ��ɂ���h�^�����݂̃g���u���Ɍ���͂Ȃ��Ă������ȁB
����Ŗ{����TDP��95W�A�A�C�h�����̏���d�͑����AOC�ϐ��̒ቺ���{���Ȃ�
�v���X�R�b�g�قǂɂ͂Ȃ��ɂ���h�^�����݂̃g���u���Ɍ���͂Ȃ��Ă������ȁB
�X�e�b�s���O�ύX��҂ׂ�
Tri-gate�������Ȃ��肭�������烊�A����AMD�������Ă��܂���������Ȃ�����
���߂��T���͒��x�ǂ����炢����
intel�I�ɂ�tick-tuck���f�������܂��@�\���Ă���ɂȂ邾�낤��
Tri-gate�������Ȃ��肭�������烊�A����AMD�������Ă��܂���������Ȃ�����
���߂��T���͒��x�ǂ����炢����
intel�I�ɂ�tick-tuck���f�������܂��@�\���Ă���ɂȂ邾�낤��
�v���O���~���O���f���Ɋւ��Ă��ꂭ�炢�w�͂����
Cell������������肭�������̂�������Ȃ�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20120417_526857.html
Cell������������肭�������̂�������Ȃ�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20120417_526857.html
18 �FSocket774�F2012/04/18(��) 16:15:03.49 ID:WDby/O8p
a
The AMD's Cafe
IvyBridge��TDP�ő�95W�ƂȂ邪���ۂ�TDP 77W�ȉ��œ��삷��A6�R�A���f�����o�ꂷ��H
http://blog.livedoor.jp/amd646464/archives/52272471.html
IvyBridge�ŏ�ʃ��f���ƂȂ�Core i7 3770K�̃p�b�P�[�W��TDP 95W�Ə�����Ă��܂������A���ۂ�IvyBridge�̏�ʃ��f����TDP 95W�Ƃ��Ĕ̔������Ƃ̂���
�X�y�b�N���TDP 95W�ł����A���ۂɂ͍ő�TDP 77W�œ��삷��Ƃ̂���
�Ȃ��X�y�b�N��TDP 95W�Ƃ��Ă������ƌ����ƁA�݊����̂��߂Ƀ}�U�[��TDP 95W�ɑΉ������邱�ƂƁA�������i�ŃN���b�N�����コ������6�R�A���f�����o����悤�ɂ��邽�߂̂悤�ł�
���ۂ�6�R�A���v�悳��Ă��邩�͕�����܂��A������҂������Ƃ���ł���
�㔼�̈Ӗ����킩��Ȃ�
IvyBridge��TDP�ő�95W�ƂȂ邪���ۂ�TDP 77W�ȉ��œ��삷��A6�R�A���f�����o�ꂷ��H
http://blog.livedoor.jp/amd646464/archives/52272471.html
IvyBridge�ŏ�ʃ��f���ƂȂ�Core i7 3770K�̃p�b�P�[�W��TDP 95W�Ə�����Ă��܂������A���ۂ�IvyBridge�̏�ʃ��f����TDP 95W�Ƃ��Ĕ̔������Ƃ̂���
�X�y�b�N���TDP 95W�ł����A���ۂɂ͍ő�TDP 77W�œ��삷��Ƃ̂���
�Ȃ��X�y�b�N��TDP 95W�Ƃ��Ă������ƌ����ƁA�݊����̂��߂Ƀ}�U�[��TDP 95W�ɑΉ������邱�ƂƁA�������i�ŃN���b�N�����コ������6�R�A���f�����o����悤�ɂ��邽�߂̂悤�ł�
���ۂ�6�R�A���v�悳��Ă��邩�͕�����܂��A������҂������Ƃ���ł���
�㔼�̈Ӗ����킩��Ȃ�
>>19
1.�u���ۂ͌������������ޏ��95W�v�Ƃ��Ă����A
���[�J�[��Sandy(���邢�͂���ȑO��95W��)�����̔p�M�v���g����
�J����p�E���Ԃ��팸�ł���B
����܂łɂȂ�TDP�т��ݒ肳���ƁA���Ƃ����������ł��������蒼���B
2.GPU��CPU�u���b�N2�ɒu���������V�_�C���ASandy-E����Ivy-E�̃A���R�A��1155�����ɎE�������̂��g����
95W��6�R�A1155���v�悵�Ă���\�����w�E���Ă���H
���ɂ���͍l���ɂ����悤�ȁc
1.�u���ۂ͌������������ޏ��95W�v�Ƃ��Ă����A
���[�J�[��Sandy(���邢�͂���ȑO��95W��)�����̔p�M�v���g����
�J����p�E���Ԃ��팸�ł���B
����܂łɂȂ�TDP�т��ݒ肳���ƁA���Ƃ����������ł��������蒼���B
2.GPU��CPU�u���b�N2�ɒu���������V�_�C���ASandy-E����Ivy-E�̃A���R�A��1155�����ɎE�������̂��g����
95W��6�R�A1155���v�悵�Ă���\�����w�E���Ă���H
���ɂ���͍l���ɂ����悤�ȁc
�P���ɍ��N���b�N�i�𓊓����邽�߂̃}�[�W�����낤�B
�Ȃ���~�X���Ęb���o�Ă�������
23 �FSocket774�F2012/04/21(�y) 22:28:30.06 ID:5Mb3u5w9
E-450���x���ŁA�t�@�����X�\�ȃM���M���̃`�b�v��
sandy���x���ȏ�̍�Ɨp�`�b�v�̃f���A���`�b�v�\���ɂ��ė~������
�t�@�����X�͂���Ϗd�v����
�W���ł������
sandy���x���ȏ�̍�Ɨp�`�b�v�̃f���A���`�b�v�\���ɂ��ė~������
�t�@�����X�͂���Ϗd�v����
�W���ł������
�A�C�h�����͖����ŕ��ׂ����������甚���ł������Ƃ������Ƃ��H
�m�[�g�݂͂�Ȃ���Ȋ������Ǝv����
�m�[�g�݂͂�Ȃ���Ȋ������Ǝv����
25 �F�|���͓��{�̓y�F2012/04/22(��) 20:46:20.13 ID:s3JookxF
Raspberry Pi��Review�͂�����
http://www.bit-tech.net/hardware/pcs/2012/04/16/raspberry-pi-review/1
http://www.bit-tech.net/hardware/pcs/2012/04/16/raspberry-pi-review/1
��Ɨp���ăw�r�[�ȍ�Ɨp��
1.6���s���A�����^
>�n�C�G���h�E���W�b�N�E�p�b�P�[�W�̈��Ƃ��ĕx�m�ʂ���X�[�p�[�R���s���[�^�u���v��
>�S�����ł���CPU�p�b�P�[�W�̏ڍׂ����\���ꂽ�i�u���ԍ�FB1-1�j�B
>45nm�����8�R�A�E���W�b�N�E�`�b�v�́A�`�b�v������1��6000�s����
>�ڑ��[�q���A176��m�Ԋu�Ŕz�u�����͂ڍ��t���b�v�`�b�v�Z�p�ɂ��
>�������Ă���B��U�d���ilow-k�j�����̐≏�w�iinter layer dielectric�FILD�j�ւ�
>�A�Z���u���E�X�g���X���ɘa����ƂƂ��ɁA�����`�����x���������邽�߁A
>19�w�̃K���X�E�Z���~�b�N�X����̗p�����B
ttp://techon.nikkeibp.co.jp/article/NEWS/20120421/214271/
>�n�C�G���h�E���W�b�N�E�p�b�P�[�W�̈��Ƃ��ĕx�m�ʂ���X�[�p�[�R���s���[�^�u���v��
>�S�����ł���CPU�p�b�P�[�W�̏ڍׂ����\���ꂽ�i�u���ԍ�FB1-1�j�B
>45nm�����8�R�A�E���W�b�N�E�`�b�v�́A�`�b�v������1��6000�s����
>�ڑ��[�q���A176��m�Ԋu�Ŕz�u�����͂ڍ��t���b�v�`�b�v�Z�p�ɂ��
>�������Ă���B��U�d���ilow-k�j�����̐≏�w�iinter layer dielectric�FILD�j�ւ�
>�A�Z���u���E�X�g���X���ɘa����ƂƂ��ɁA�����`�����x���������邽�߁A
>19�w�̃K���X�E�Z���~�b�N�X����̗p�����B
ttp://techon.nikkeibp.co.jp/article/NEWS/20120421/214271/
���E��̃X�[�p�[�R���s���[�^�u���v�̍������Z���x����v���Z�b�T���̓W���ɂ���
http://www.pref.mie.lg.jp/TOPICS/2012040229.htm
http://www.pref.mie.lg.jp/TOPICS/2012040229.htm
�x�N�g���^CPU�Ȃ�Ă���Ȃ���
AVX 8�R�A��x86 ��SPARCVIIIfx �Ƒ��x�N�g�����͕ς��Ȃ���
SX-9�̔{��
Cool Chips XV - �u���v��Tofu�C���^�R�l�N�g�̏ڍׂ����炩��
ttp://news.mynavi.jp/articles/2012/04/25/coolchips_xv_tofu/index.html
�C���^�[�R�l�N�g�̒x�����ԂƂ�����̃��[�h�}�b�v�Ƃ��Ȃ��Ȃ������[��
ttp://news.mynavi.jp/articles/2012/04/25/coolchips_xv_tofu/index.html
�C���^�[�R�l�N�g�̒x�����ԂƂ�����̃��[�h�}�b�v�Ƃ��Ȃ��Ȃ������[��
Cool Chips XV - ��u���Ŗ��炩�ƂȂ���IBM��BlueGene/Q
ttp://news.mynavi.jp/photo/articles/2012/04/26/coolchips_xv_bgq/images/015l.jpg
�̏�/�iTFLOPS*���j
�@0.1-1.0�@�@ Cary�@XT3�AXT4
�@2.6-8.0�@�@ x86 cluster
�@0.01-0.03�@BlueGeneL�ABlueGeneP
�����b��ɂȂ��āA�X�p�R���̃X�����e���ɗ����܂����Ă����A
x86 �̃R�X�g�p�t�H�[�}���X���������炻��ȊO�����̂̓o�J�A�݂�����
���Ƃ����������������B���������������f�[�^�������
x86 �̔ėp�I��ėp�l�b�g���[�N�łȂ��������݂����ȃV�X�e����
HPC�p�r�ł̓S�~���Ƃ����̂��悭�킩��B
�ix86 ���g���ĐM�����̍����V�X�e������邱�Ƃ͂ł��邪
��������Ƃ����V�X�e���S�̂̉��i�D�ʂ͋͏��ɂȂ�B
�������D�ʂ͏�����p�������j
ttp://news.mynavi.jp/photo/articles/2012/04/26/coolchips_xv_bgq/images/015l.jpg
{kind=link}
�̏�/�iTFLOPS*���j
�@0.1-1.0�@�@ Cary�@XT3�AXT4
�@2.6-8.0�@�@ x86 cluster
�@0.01-0.03�@BlueGeneL�ABlueGeneP
�����b��ɂȂ��āA�X�p�R���̃X�����e���ɗ����܂����Ă����A
x86 �̃R�X�g�p�t�H�[�}���X���������炻��ȊO�����̂̓o�J�A�݂�����
���Ƃ����������������B���������������f�[�^�������
x86 �̔ėp�I��ėp�l�b�g���[�N�łȂ��������݂����ȃV�X�e����
HPC�p�r�ł̓S�~���Ƃ����̂��悭�킩��B
�ix86 ���g���ĐM�����̍����V�X�e������邱�Ƃ͂ł��邪
��������Ƃ����V�X�e���S�̂̉��i�D�ʂ͋͏��ɂȂ�B
�������D�ʂ͏�����p�������j
>>33���m�b�x�ꂾ�Ƃ�����������
>33�@�����N�悩��
BlueGene/Q
�E1.6GHz �͌��J����Ă������d���������J�@0.8V
�EL2�@��Multi-Versioned Cache
�E4�X���b�h/�R�A�@����͊��m����
�E�C���^�[�R�l�N�g�o���h���͋��ɕ����邪���C�e���V�͋���菭�Ȃ�
BlueGene/Q
�E1.6GHz �͌��J����Ă������d���������J�@0.8V
�EL2�@��Multi-Versioned Cache
�E4�X���b�h/�R�A�@����͊��m����
�E�C���^�[�R�l�N�g�o���h���͋��ɕ����邪���C�e���V�͋���菭�Ȃ�
����top500�̃x���`��������Ƃ��͖��̏��28���Ԋ��������̂���
���Ă݂Ȃ��Ƃ킩��A�Ƃ肠����BG�ɕ����Ă͂��Ȃ�
BW�̑����Cray�炵�����A��̌̏ᗦ��10PF�͌�������
���Ă݂Ȃ��Ƃ킩��A�Ƃ肠����BG�ɕ����Ă͂��Ȃ�
BW�̑����Cray�炵�����A��̌̏ᗦ��10PF�͌�������
x86�͎s�̕i�g���ĂƂ肠���������Œ�����Ƃ��������b�g������̂��ł������ǂ�
�����ȃR���s���[�^�g���Ă�A���炭�d�v�Ȍv�Z����̂ɑf�l�C���͂��肦�Ȃ���
����Ȃ�̋Z�p�҂�p�ӂ��Ă����Ȃ�p�[�c���p�ӂ��Ă�������펯�I��
����Ȃ�̋Z�p�҂�p�ӂ��Ă����Ȃ�p�[�c���p�ӂ��Ă�������펯�I��
>>39
�S�����B�����Œ����郁���b�g���Ƃ��A��̂ǂ��̐��E�̘b�����Ă���B
��������ECC�G���[�ł��܂��͐ݒu�Ǝ҂ɘA������̂����R�����Ă̂�CPU�������Ō������Ȃ��w
�S�����B�����Œ����郁���b�g���Ƃ��A��̂ǂ��̐��E�̘b�����Ă���B
��������ECC�G���[�ł��܂��͐ݒu�Ǝ҂ɘA������̂����R�����Ă̂�CPU�������Ō������Ȃ��w
���ꂩ���PC�p��CPU�̓��o�C���d��
�T�[�o��HPC������CPU�̓R�A��16�A32�Ƒ�����X���ɂ���
Xeon�̒��ł��������̃��C���i�b�v�̂悤��
PC�����̃`�b�v���T�[�o�����ɗ��p������������藧���Ȃ��Ȃ��Ă���낤��
�T�[�o��HPC������CPU�̓R�A��16�A32�Ƒ�����X���ɂ���
Xeon�̒��ł��������̃��C���i�b�v�̂悤��
PC�����̃`�b�v���T�[�o�����ɗ��p������������藧���Ȃ��Ȃ��Ă���낤��
�Ȃ�������HPC�M�҂̊�]�I�ϑ�&�W�҂̐�`�X���ɂȂ���������ȁB
HPC��p�X���̓n�[�h�E�G�A�ɂ���̂ł������ł���Ăق����B
HPC��p�X���̓n�[�h�E�G�A�ɂ���̂ł������ł���Ăق����B
�@���o�C���A�n�C�G���hHCP�F����d�͐��\
�@�f�X�N�g�b�v�F�V���O���X���b�h���\
�ƁA�f�X�N�g�b�v���Ǘ���[�߂Ă����悤�ȋC������
�@�f�X�N�g�b�v�F�V���O���X���b�h���\
�ƁA�f�X�N�g�b�v���Ǘ���[�߂Ă����悤�ȋC������
>42
���ʉ����ȁB���֘A�ŗ����������̃X�����p�\�R����m���Ă����
�R���s���[�^��m���Ă���Ɗ��Ⴂ���Ă���l�Ԃ̃��X�Ŗ��܂��Ă����̂�����
���ʉ����ȁB���֘A�ŗ����������̃X�����p�\�R����m���Ă����
�R���s���[�^��m���Ă���Ɗ��Ⴂ���Ă���l�Ԃ̃��X�Ŗ��܂��Ă����̂�����
>>27
�p�b�P�[�W����o����s����2408�s��������
http://pc.watch.impress.co.jp/img/pcw/docs/396/621/html/252.jpg.html
���̂����M���s����1271�s��������
http://www.ssken.gr.jp/MAINSITE/download/newsletter/2009/20091125-sci-2/lecture-4/ppt.pdf
16,000�s���̑唼�͓d���W�H
�p�b�P�[�W����o����s����2408�s��������
http://pc.watch.impress.co.jp/img/pcw/docs/396/621/html/252.jpg.html
{kind=link}
���̂����M���s����1271�s��������
http://www.ssken.gr.jp/MAINSITE/download/newsletter/2009/20091125-sci-2/lecture-4/ppt.pdf
16,000�s���̑唼�͓d���W�H
>>45
GND
GND
47 �FSocket774�F2012/04/28(�y) 18:21:20.37 ID:V4l297/I
553 ���O:Socket774 :2012/04/28(�y) 16:46:43.98 ID:vz2/P9f4
IvyBridge����/FP���Z�������������Ȃ��Ă��
intel�j��ő�������
http://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-optimization-manual.html
���ƃ��[�u�̏��s��xmm��ymm��������Ȃ��Amov��MOVZX�ł����݂�������
AMD�u����x������������ĂȂ�(ymm�͂���ĂȂ�)����ėp���W�X�^�[��ivy���������
�[���g���ł�������̂��Azeroing idiom�̔��W�ŏ��n�r�b�g�N���A�Ƃ����ł���̂���?
�\�[�X��r16�̏ꍇ�Ɍ��y���Ȃ�����
�\�[�X��r16�̏ꍇ�Ɍ��y���Ȃ�����
>>33
���n�C�G���h�ł̓����b�g���邾�낤���ǂ���ł͏����ɂȂ�Ȃ��̂���肾�ȁB
���ۋ��ł���S�̂��g�����Ƃ͏��Ȃ����B����ȋɁX�ꕔ�̃W���u�Ɍ����Ȃ�����
�Ƃ�����HPC�p�r�Ŕėp�I���S�~���Ƃ������Ƃɂ͂Ȃ�Ȃ��ˁB
���n�C�G���h�ł̓����b�g���邾�낤���ǂ���ł͏����ɂȂ�Ȃ��̂���肾�ȁB
���ۋ��ł���S�̂��g�����Ƃ͏��Ȃ����B����ȋɁX�ꕔ�̃W���u�Ɍ����Ȃ�����
�Ƃ�����HPC�p�r�Ŕėp�I���S�~���Ƃ������Ƃɂ͂Ȃ�Ȃ��ˁB
50 �FSocket774�F2012/04/29(��) 10:12:46.99 ID:tLF1sN56
���掿��r
intel ivy-QSV������������������NVENC��x86�\�t�g�E�F�A�������z�����Ȃ��ǁ�����AMD�{�P�{�P
x86
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/x86.png
gtx680
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/nvenc.png
hd7970
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/amd.png
Intel ivy QSV
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/better.png
intel ivy-QSV������������������NVENC��x86�\�t�g�E�F�A�������z�����Ȃ��ǁ�����AMD�{�P�{�P
x86
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/x86.png
{kind=link}
gtx680
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/nvenc.png
{kind=link}
hd7970
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/amd.png
{kind=link}
Intel ivy QSV
http://images.anandtech.com/reviews/cpu/intel/ivybridge/review/QS/better.png
{kind=link}
����ς�C���ς����
�܂��m����>33�@�͒���K��HPC�ł́`�Ə������ق������������ȁB
�܂��m����>33�@�͒���K��HPC�ł́`�Ə������ق������������ȁB
�����̂�x86�̃����b�g�̓\�t�g�̕��Ȃ낤�ȁc
���������̂̎��s�A����������20�N�̗��j�A�e��ЁE���ˑ�����E�p��
http://www.toyokeizai.net/business/industrial/detail/AC/e6237d9352e5e6259eeeb878b1586b1d/
http://www.toyokeizai.net/business/industrial/detail/AC/e6237d9352e5e6259eeeb878b1586b1d/
����ŃO���[�o�������ɏ��������̂��ĉ�������H
SPARC64 VIIIfx��SPARC64 IXfx�̂悤��CPU�����鍑�͏��Ȃ���ˁH
���߃Z�b�g��SPARC�����ǓƎ��g�����Ă邵���͖��߃Z�b�g�ȏ�Ƀ}�C�N���A�[�L�e�N�`���̕����d�v����
���ꂾ���Z�p�͂͂���Ƃ������Ƃ���
���߃Z�b�g��SPARC�����ǓƎ��g�����Ă邵���͖��߃Z�b�g�ȏ�Ƀ}�C�N���A�[�L�e�N�`���̕����d�v����
���ꂾ���Z�p�͂͂���Ƃ������Ƃ���
���I�푈
�ʏ��Y�ƏȎ���ɂ������B������������
�h�O���[�o���Ȃ�Ƃ��h�ƌĂ��悤�ɂȂ��Ă��Ȃ������Ǝv��
�h�O���[�o���Ȃ�Ƃ��h�ƌĂ��悤�ɂȂ��Ă��Ȃ������Ǝv��
����哱���낤�Ɩ����哱���낤�Ɖ~���ɐi�ތ���ǂ̎Y�Ƃ���͌����Ă�
���{��DRAM���Ȍ��������Ƃ����ˁB
POWER �ł����݂����ȃV�X�e������
>33 �̐����͂��܂�ǂ��Ȃ���������Ȃ�
ttp://cloud.watch.impress.co.jp/img/clw/docs/529/478/html/04.jpg.html
ttp://cloud.watch.impress.co.jp/docs/news/20120426_529478.html
>33 �̐����͂��܂�ǂ��Ȃ���������Ȃ�
ttp://cloud.watch.impress.co.jp/img/clw/docs/529/478/html/04.jpg.html
{kind=link}
ttp://cloud.watch.impress.co.jp/docs/news/20120426_529478.html
���i�������Ă邯�ǁAIBM�͂�����T�|�[�g�����������܂��ȃ\�����[�V���������Ȃ�
���AIBM���ăT�|�[�g������ł���
64 �F�|���͓��{�̓y�F2012/05/02(��) 04:58:58.76 ID:VI+Pqks4
���������̂�ǂ�ł�ƁC1�ʂ��ᖳ����_���ǂ��납�C1�ʂł��܂�����Ȃ��Ǝ�����������
�u�X�p�R���������炷�G���W���v���v
http://www.nationalgeographic.co.jp/news/news_article.php?file_id=20120501002&expand#title
�u�X�p�R���������炷�G���W���v���v
http://www.nationalgeographic.co.jp/news/news_article.php?file_id=20120501002&expand#title
�ߎq���̋L������ܑ債�����Ə����ĂȂ�
���R�V�~�����[�V�����̘b����Ȃ����A��̓V�~�����[�V�����������x��
���悤�ɂȂ��Ă���A�����Ԃ̃f�U�C�����܂�Ȃ��Ȃ����B
�����I�ȕK�R�Ƃ��Ďd�����Ȃ��낤���ǂ�
���悤�ɂȂ��Ă���A�����Ԃ̃f�U�C�����܂�Ȃ��Ȃ����B
�����I�ȕK�R�Ƃ��Ďd�����Ȃ��낤���ǂ�
�P�Ɏ���̕��͋C���끄�����Ԃ̊O�`
��͂Ȃ�čŌ�̍Ō�ɖ��t���Ȃ����x�ɂ�������ł��Ȃ����Ęb����
������Ԃǂꂾ�����邩�Ƃ��A���s�̃f�U�C���ɂ���Ƃ����D��
�����������A������������牡�]��X�s������Ƃ��̖����ȃf�U�C�����������͉����~�߂邾�낤����
��͂Ȃ�čŌ�̍Ō�ɖ��t���Ȃ����x�ɂ�������ł��Ȃ����Ęb����
������Ԃǂꂾ�����邩�Ƃ��A���s�̃f�U�C���ɂ���Ƃ����D��
�����������A������������牡�]��X�s������Ƃ��̖����ȃf�U�C�����������͉����~�߂邾�낤����
�ƂĂ������Ƃ͎v���Ȃ��B�ǂ����Ă��v�����i��ł�
��
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Toyota_Celica_Coupe_A60.jpg
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Isuzu_117_Coupe_005.JPG
��
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:2006-2008_NISSAN_SKYLINE.jpg
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Toyota_Corolla_Axio_0901.jpg
��
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Toyota_Celica_Coupe_A60.jpg
{kind=link}
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Isuzu_117_Coupe_005.JPG
{kind=link}
��
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:2006-2008_NISSAN_SKYLINE.jpg
{kind=link}
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Toyota_Corolla_Axio_0901.jpg
{kind=link}
��͗D��Ȃ�A�݂�ȃv���E�X��C���T�C�g�݂����ɂȂ邾�낗
117�N�[�y�̓C�^���A�̃f�U�C�i�[�ɊO�������ԂŁA���̃Z���J�Ƃ͎�������������Ⴄ��
�ǂ������Ƃ����Ə���Z���J������̂ق�������I�ɋ߂�
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:1970_Toyota_Celica_01.jpg
117�N�[�y�̓C�^���A�̃f�U�C�i�[�ɊO�������ԂŁA���̃Z���J�Ƃ͎�������������Ⴄ��
�ǂ������Ƃ����Ə���Z���J������̂ق�������I�ɋ߂�
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:1970_Toyota_Celica_01.jpg
{kind=link}
�Փˈ��S�̗��݂����邾�낤��
���̕ӂ̔���͒n���ɋ����ă��g���N�^�u�����C�g�͊��S�ɏ��ł��Ă邵
���̕ӂ̔���͒n���ɋ����ă��g���N�^�u�����C�g�͊��S�ɏ��ł��Ă邵
>69�@����Ɠ������A�Ⴆ��
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Datsun_Bluebird_Coupe_%28510%29_001.JPG
http://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:Datsun_Bluebird_Coupe_%28510%29_001.JPG
{kind=link}
>>71
�ŏ����瓯�N��o���Ă��������悗�@10�N�قLjႤ�̂�������A���̍��Y�Ԃł����Ȃ�ς���Ă���Ǝv���扴�͂�
�Ƃ������A���̖�10�N��̃Z���J�Ɣ�ׂ���A����ς莗�Ă�ł���117�N�[�y�Ə���Z���J�ƁA���̃u���[�o�[�h
�ŏ����瓯�N��o���Ă��������悗�@10�N�قLjႤ�̂�������A���̍��Y�Ԃł����Ȃ�ς���Ă���Ǝv���扴�͂�
�Ƃ������A���̖�10�N��̃Z���J�Ɣ�ׂ���A����ς莗�Ă�ł���117�N�[�y�Ə���Z���J�ƁA���̃u���[�o�[�h
������ς莗�Ă�ł���
����
����
����̕��͋C�݂����Ȃ̂킩��Ȃ����Ȃ���
�܁A�X���Ⴂ�̘b��ł����邵�A�N�̌����u�v�����i��ł�v��
��������u����v�ʼn����ďI�����Ă��Ƃɂ��Ƃ�����
�܁A�X���Ⴂ�̘b��ł����邵�A�N�̌����u�v�����i��ł�v��
��������u����v�ʼn����ďI�����Ă��Ƃɂ��Ƃ�����
�ԈႦ�����Ƃ�
NextXbox�̊J���L�b�g�̑���
http://www.computerandvideogames.com/345882/features/microsoft-durango-is-the-next-xbox-more-powerful-than-we-thought/
�ECPU��PowerPC16�R�A
�EGPU��HD7000�V���[�Y
�ǂꂭ�炢�̃T�C�Y�ɂȂ�
http://www.computerandvideogames.com/345882/features/microsoft-durango-is-the-next-xbox-more-powerful-than-we-thought/
�ECPU��PowerPC16�R�A
�EGPU��HD7000�V���[�Y
�ǂꂭ�炢�̃T�C�Y�ɂȂ�
�R�A�����o������̊J����͏o���Ȃ����琔�������₵�܂����I�������������
���ۗ~�����̂�simd���\����������
xbox360,ps3��낵��������in order��
xbox360,ps3��낵��������in order��
Mac�I�^����̐����ǂ���PowerPC A2�Ȃ�Ȃ��H
Bulldozer�̃J�X�^�����Ă̂͂ǂ��ɍs������
�����PS4�̕�
PS4��Bull����Ȃ���K10���ĉ\��
���̒��A�v���O���}�u���V�F�[�_�����ׂĂ���Ȃ��B
�v���O���}�u���V�F�[�_���̗p���Ă��Ȃ��Ƃ���͌��\����B�T�[�o�[�Ȃ�Ă̂������B
������http://www.axell.co.jp/��AG10�Ƃ��A�p�`�X���Ƃ��Ŏg���Ă��邪�A
�v���O���}�u���V�F�[�_�ł͂Ȃ��B
��AVIA�̑g�ݍ��݃v���Z�b�T�[�Ƃ�Matrox��GPU���v���O���}�u���V�F�[�_���g���ĂȂ��B
�v���O���}�u���V�F�[�_���̗p���Ă��Ȃ��Ƃ���͌��\����B�T�[�o�[�Ȃ�Ă̂������B
������http://www.axell.co.jp/��AG10�Ƃ��A�p�`�X���Ƃ��Ŏg���Ă��邪�A
�v���O���}�u���V�F�[�_�ł͂Ȃ��B
��AVIA�̑g�ݍ��݃v���Z�b�T�[�Ƃ�Matrox��GPU���v���O���}�u���V�F�[�_���g���ĂȂ��B
PowerPC A2 �R�A��CPU�͒ʐM�p��PowerEN��BG/Q��CPU���L��������
�Ђ�PBus�A�Ђ�N���X�o�[�Ń`�b�v�Ƃ��Ă͑S�R�Ⴄ���̂��ȁB
A2�R�A���{�����Ƃ��Ă��`�b�v�S�̂͂ǂ���Ƃ����Ă��Ȃ��̂���
�Ђ�PBus�A�Ђ�N���X�o�[�Ń`�b�v�Ƃ��Ă͑S�R�Ⴄ���̂��ȁB
A2�R�A���{�����Ƃ��Ă��`�b�v�S�̂͂ǂ���Ƃ����Ă��Ȃ��̂���
via��igp��dx9�Ή���
matrox��vs��dx9�Ή�
matrox��vs��dx9�Ή�
>>84
���������A�u���̒��������S�Ă���Ȃ��v�̎g�������番�����ĂȂ��r�����Ƃ������Ƃ͂悭���������B
���������A�u���̒��������S�Ă���Ȃ��v�̎g�������番�����ĂȂ��r�����Ƃ������Ƃ͂悭���������B
���{��̖��Ƃ��ׁ̍X�����b�͕ʂɂ��āA�R���V���[�}�Q�[���@�ł�CPU�𒆐S�Ƃ���
�R���s���[�^�A�[�L�e�N�`���ł͖`���͂��Ȃ�����ɂȂ������Ă��Ƃł��傤�ˁB
�w�e���W�j�A�X�R���s���[�e�B���O�����s�邽�߂ɂ̓\�t�g�E�F�A���̃T�|�[�g��
�ǂ��ɂ��Ȃ�Ȃ��Ƃǂ��ɂ��Ȃ�Ȃ����Ă��Ƃł����ˁB
�R���s���[�^�A�[�L�e�N�`���ł͖`���͂��Ȃ�����ɂȂ������Ă��Ƃł��傤�ˁB
�w�e���W�j�A�X�R���s���[�e�B���O�����s�邽�߂ɂ̓\�t�g�E�F�A���̃T�|�[�g��
�ǂ��ɂ��Ȃ�Ȃ��Ƃǂ��ɂ��Ȃ�Ȃ����Ă��Ƃł����ˁB
�Q�[���@���v���O���}�u���V�F�[�_�[���ڂ��Ȃ����Ƃƃw�e���W�j�A�X�͂���܂�W���Ȃ��B
���2�s�ɂ͓��ӁB
���2�s�ɂ͓��ӁB
�@1960�N��@���Ԃ�20�`30um
�@1971�N�@10um�@Intel 4004
�@2008�N�@18um�@�X�p�R��MB
�@2013�N�@30um�@�X�}�[�g�t�H��MB
ttp://news.mynavi.jp/photo/articles/2008/11/25/sx-9/images/017l.jpg
ttp://news.mynavi.jp/news/2012/05/11/105/index.html
�@1971�N�@10um�@Intel 4004
�@2008�N�@18um�@�X�p�R��MB
�@2013�N�@30um�@�X�}�[�g�t�H��MB
ttp://news.mynavi.jp/photo/articles/2008/11/25/sx-9/images/017l.jpg
{kind=link}
ttp://news.mynavi.jp/news/2012/05/11/105/index.html
�G���s�[�_�ɑ����c�u���̊۔����́v�ꋫ�N����
http://headlines.yahoo.co.jp/hl?a=20120522-00000120-mai-bus_all
���l�T�X�I�������
http://headlines.yahoo.co.jp/hl?a=20120522-00000120-mai-bus_all
���l�T�X�I�������
���l�T�X������� orz
93 �FSocket774�F2012/05/23(��) 16:40:03.23 ID:Ispz4Dwa
XBOX360��p�@��PowerPC-AC2�̃J�X�^�����ڗ\��Ƃ̂��Ƃ����A
����CPU16�R�A��1�R�A������̐��\��PPE��(Pentium3�N���X�H�j��
�X���b�h�̃X�P�W���[���[�@�\�������Ă�炵���B
������������ASandy��ivy���݂̐��\������Ƃ��H
����CPU16�R�A��1�R�A������̐��\��PPE��(Pentium3�N���X�H�j��
�X���b�h�̃X�P�W���[���[�@�\�������Ă�炵���B
������������ASandy��ivy���݂̐��\������Ƃ��H
��CPU2�ς�ł邯�ǃo�X�����ň���������Ă��鎞�ɂ͂�������͎~�܂��Ă�Q�[���@���������ȁB
16core�����Ă��o�X�l�b�N�Ŏ���4core���������Ȃ���Ȃ����B
16core�����Ă��o�X�l�b�N�Ŏ���4core���������Ȃ���Ȃ����B
95 �FSocket774�F2012/05/24(��) 09:16:56.87 ID:Q3MCnmpR
�ŋ߂�PowerPC�̓L���b�V�������ڃ������炵������A����͂�����Ƃ������
���ȁB����x86�̃L���b�V���̑ш�ł͑R�ł��Ȃ��B
�����A�L���b�V���̑ш�ł͐��{�ゾ�낤�B
���ȁB����x86�̃L���b�V���̑ш�ł͑R�ł��Ȃ��B
�����A�L���b�V���̑ш�ł͐��{�ゾ�낤�B
���ڃ���������MCM?
�܂��I���_�C�ł��I���_�C�ő�e�ʃL���b�V���ς�x86�ɂ͉����y�Ȃ����Ƃ͊m�����ȁB
�ł����܂�������i3�ʂ̐��\�͏o�邩���B�Q�[���@�Ɏg����l�i�ł���Ȃ炷�����ȁB
�܂��I���_�C�ł��I���_�C�ő�e�ʃL���b�V���ς�x86�ɂ͉����y�Ȃ����Ƃ͊m�����ȁB
�ł����܂�������i3�ʂ̐��\�͏o�邩���B�Q�[���@�Ɏg����l�i�ł���Ȃ炷�����ȁB
���m���łĂȂ���������m�����ȂƂ���
98 �FSocket774�F2012/05/24(��) 10:22:54.32 ID:Q3MCnmpR
�Q�[���@�́A�\�t�g���[�J�[����̃��C�Z���X�ŗ��v�グ�邩��
������x�A�R�X�g�̂�����p�[�c���̗p�ł���BPS2��GPU�̍��ڃ������Ȃ�
���������A���K�͂����ш悪�L�������肷��p�[�c�����邩��
PC�Ƃ̃X�y�b�N��r�̂����ɕ����I�ɗD�ʂɂȂ��Ă��܂��B
������x�A�R�X�g�̂�����p�[�c���̗p�ł���BPS2��GPU�̍��ڃ������Ȃ�
���������A���K�͂����ш悪�L�������肷��p�[�c�����邩��
PC�Ƃ̃X�y�b�N��r�̂����ɕ����I�ɗD�ʂɂȂ��Ă��܂��B
���X����ȌÂ���肩�����Ă��邩�˂�
100 �FSocket774�F2012/05/24(��) 17:47:41.74 ID:Q3MCnmpR
���ڃ������͉��Z�Ŏg�����W�b�NIC�̑f�q�ƃ������[IC�̑f�q������������
�ш���グ������BPower6����Power7��XBOX360��GPU�ɂ��Ă鍬�ڃ�����
�őш�256Gbyte/�b����Ax86CPU�̃L���b�V����DDR��XDR�ɔ�ׂ���
�ш悪���邪100Gbyte/�b�̑ш�܂ł͂Ȃ������͂��B
����ɑ�e�ʂ̃L���b�V���ƌ����Ă�32MB��64MB���̗e�ʂ͂Ȃ��B
�����܂ł��Q�[���@�Ɣ�r���đ��������B�����FPU���\�͑ш�L������
�D�ʂɂȂ�₷���B
Power6 Power7 XBOX360GPU�L���b�V���@256Gbyte/�b
�n�C�G���hGPU 150-200Gbyte/�b
x86CPU�L���b�V�� 50Gbyte/�b�H
�ш���グ������BPower6����Power7��XBOX360��GPU�ɂ��Ă鍬�ڃ�����
�őш�256Gbyte/�b����Ax86CPU�̃L���b�V����DDR��XDR�ɔ�ׂ���
�ш悪���邪100Gbyte/�b�̑ш�܂ł͂Ȃ������͂��B
����ɑ�e�ʂ̃L���b�V���ƌ����Ă�32MB��64MB���̗e�ʂ͂Ȃ��B
�����܂ł��Q�[���@�Ɣ�r���đ��������B�����FPU���\�͑ш�L������
�D�ʂɂȂ�₷���B
Power6 Power7 XBOX360GPU�L���b�V���@256Gbyte/�b
�n�C�G���hGPU 150-200Gbyte/�b
x86CPU�L���b�V�� 50Gbyte/�b�H
XBOX360�̍��ڃ������͕ʃ_�C�A������NEC
������ATI��������GPU�Ƃ̐ڑ�����22�`32GB/s�A����256GB/s
������ATI��������GPU�Ƃ̐ڑ�����22�`32GB/s�A����256GB/s
>>100
�������N�O�Ŏ~�܂��Ă��Ƃ��Ⴄ���B
http://news.mynavi.jp/photo/special/2012/ivybridge/images/graph008l.gif
�������Ă݁B�����Ⴄ����B
�������N�O�Ŏ~�܂��Ă��Ƃ��Ⴄ���B
http://news.mynavi.jp/photo/special/2012/ivybridge/images/graph008l.gif
{kind=link}
�������Ă݁B�����Ⴄ����B
Sandy�EIvy��L3�̍\�����炷��ƁA2MB�ӂ肪���[�J��L3�ւ̃L���b�V���̑ш�ŁA
8MB�ӂ�̓����O�o�X�̑ш�ɂȂ��Ă��Ȃ��́H
8MB�ӂ�̓����O�o�X�̑ш�ɂȂ��Ă��Ȃ��́H
�Q�[���@�̘b�ɂȂ�����₽��L�т��
�Ƃ������t�ɁAx86���ƐL�тȂ����Ă������b���o�s�����Ă邩���
x86�Ȃ�ďI���ƌ����ď\�]�N�A���̊Ԃ�RISC���I�����VLIW�����s�B���߃Z�b�g�̉����g�b�v�R���c��܂����Ƃ��B
Itanium�c
�����u���Q�[���@��PC�̓G�݂����Ȃ�����ȁB
���얯�Ƃ��ẮA�����Q�[���@���Ƃ��̋Z�p�ɕ����͂���Ƃ����C���������邩��ȁB
���얯�Ƃ��ẮA�����Q�[���@���Ƃ��̋Z�p�ɕ����͂���Ƃ����C���������邩��ȁB
RISC���I������Ƃ�������RISC�ACISC�Ƃ����J�e�S���C�Y��
�I�������Ȃ���
�I�������Ȃ���
����VLIW�����͐�ɋ����Ȃ�
111 �FSocket774�F2012/05/25(��) 12:40:57.63 ID:g1G/n7f3
>>110
x86�݂����ɁA�f�R�[�h�ɗ]�v�Ȏ�Ԃ�����̂��̓}�V�B
x86�݂����ɁA�f�R�[�h�ɗ]�v�Ȏ�Ԃ�����̂��̓}�V�B
112 �FSocket774�F2012/05/25(��) 12:48:12.97 ID:aDpEf1ah
Ivy��Sandy�ŃL���b�V���ш�500Gbyte�߂�����̂��A�ւ��ȍ��ڃ�������
GDDR��萫�\����ȁB
GDDR��萫�\����ȁB
113 �FSocket774�F2012/05/25(��) 13:19:07.54 ID:aDpEf1ah
�g�����W�X�^��100�����x�����l�ߍ��߂Ȃ�����ɐ��\�グ��ɂ�RISC�̕���
�ǂ������낤�B
�ǂ������낤�B
>>112
����L���b�V��������I���_�C�Ȃ��B�������DDR3-1600��2ch��25.6GB/S���B
����1core������256KB�̃L���b�V�������邩��4core��1MB�A�����SOC�ł͘b�ɂȂ�Ȃ��B
����L���b�V��������I���_�C�Ȃ��B�������DDR3-1600��2ch��25.6GB/S���B
����1core������256KB�̃L���b�V�������邩��4core��1MB�A�����SOC�ł͘b�ɂȂ�Ȃ��B
MIPS�A�V�v���Z�b�T�R�A�uAptiv�v�t�@�~���[�\
http://pc.watch.impress.co.jp/docs/news/20120525_535532.html
http://pc.watch.impress.co.jp/docs/news/20120525_535532.html
>>112
�ȂF���Ԉ���ĂȂ��H
���\�I(�ш�A���C�e���V)�ɂ́A
�I���_�CSRAM�L���b�V�����I���_�C����DRAM��MCM DRAM���ʃ`�b�vDRAM
�e�ʂ�����܂��ŁA����DRAM��MCM�������ꍇ�����邯�ǁA��{�I���_�CSRAM�L���V�����ő����Ǝv��
�ȂF���Ԉ���ĂȂ��H
���\�I(�ш�A���C�e���V)�ɂ́A
�I���_�CSRAM�L���b�V�����I���_�C����DRAM��MCM DRAM���ʃ`�b�vDRAM
�e�ʂ�����܂��ŁA����DRAM��MCM�������ꍇ�����邯�ǁA��{�I���_�CSRAM�L���V�����ő����Ǝv��
>>115
>CoreMark�̕��������I�Ƃ��āA�����CoreMark�̃X�R�A��O�ʂɑł��o���Ẵv���[���e�[�V�����ƂȂ��Ă���
L1��������}��Ȃ�CoreMark
���S�ɖ��Ӗ��ȃx���`
�܂�ARM��CoreMark�����Ă���
>CoreMark�̕��������I�Ƃ��āA�����CoreMark�̃X�R�A��O�ʂɑł��o���Ẵv���[���e�[�V�����ƂȂ��Ă���
L1��������}��Ȃ�CoreMark
���S�ɖ��Ӗ��ȃx���`
�܂�ARM��CoreMark�����Ă���
�悭�m��Ȃ����A�g�ݍ��n��Dhrystone/CoreMark���W�����Ă��ƂȂ̂���
�g�ݍ��݂Ƃ����Ă��X�}�[�g�t�H���Ɏg����悤�ȏ����ɂȂ��Ă����
SPEC CPU�̂ق������K����Ȃ����Ǝv������
�g�ݍ��݂Ƃ����Ă��X�}�[�g�t�H���Ɏg����悤�ȏ����ɂȂ��Ă����
SPEC CPU�̂ق������K����Ȃ����Ǝv������
Intel��Itanium�̎��̂悤�ɑS���Ⴄ�A�[�L�e�N�`���Ɉڍs����̂ł͂Ȃ���
��{�͈ꏏ�Ŗ��߃t�H�[�}�b�g����
���f�R�[�h�̕��S�̏��Ȃ������I�ȐV�������߃t�H�[�}�b�g��p�ӂ�������̂ł́H
������ARM��ARM���߂�Thumb���߂̂悤�ɐ�ւ������
���X�ɁA���f�R�[�h�̕��S�����Ȃ������I�Ȗ��߃Z�b�g�Ɉڍs�ł�����
�ڍs���Ԃ�10�N���炢����Ί��S�Ɉڍs�ł���ł��傤
��{�͈ꏏ�Ŗ��߃t�H�[�}�b�g����
���f�R�[�h�̕��S�̏��Ȃ������I�ȐV�������߃t�H�[�}�b�g��p�ӂ�������̂ł́H
������ARM��ARM���߂�Thumb���߂̂悤�ɐ�ւ������
���X�ɁA���f�R�[�h�̕��S�����Ȃ������I�Ȗ��߃Z�b�g�Ɉڍs�ł�����
�ڍs���Ԃ�10�N���炢����Ί��S�Ɉڍs�ł���ł��傤
���܂��A��������
>>119
AVX
AVX
122 �FSocket774�F2012/05/26(�y) 11:19:20.08 ID:gU+dIX0q
>>119
�V�˂�����
�V�˂�����
���̃X����Part 1�̍ŏ�����݂Ă��邯�ǁA
>>119�̃A�C�f�A�͑��ɂ݂����Ƃ��Ȃ����A�Ȃ��Ȃ��ʔ����Ƃ������B
>>119�̃A�C�f�A�͑��ɂ݂����Ƃ��Ȃ����A�Ȃ��Ȃ��ʔ����Ƃ������B
�₾ >>119 ���f�G�����ĔG�ꂿ�Ⴄ
>>119�̓C�P�����B
�f�R�[�h���ׂ��ς�邾���Ȃ�
����CPU�ł��������Ȃ��\�t�g��
��郁���b�g���Ȃ����
����CPU�ł��������Ȃ��\�t�g��
��郁���b�g���Ȃ����
���A�ł��A�h���b�V���O���[�h��MMU�̌݊����͕ς����Ȃ�����A
���܂胁���b�g�łȂ�����w
���܂胁���b�g�łȂ�����w
PC�̂悤�ȉߋ�����̃\�t�g���Y����ʂɂ���ꍇ�͂�����������Ȃ���
�����炱��>>119�͈ڍs���Ԃ�10�N���Ă����Ă��ł���
����CPU�̎g�����Ƃ��Ĕėp�@�ł���PC�̊����͂����ƌ����Ă�����Ȃ�����
PC�ɂ�������MAC��68��PPC�̈ڍs�Ƃ��̎�������邵
�����炱��>>119�͈ڍs���Ԃ�10�N���Ă����Ă��ł���
����CPU�̎g�����Ƃ��Ĕėp�@�ł���PC�̊����͂����ƌ����Ă�����Ȃ�����
PC�ɂ�������MAC��68��PPC�̈ڍs�Ƃ��̎�������邵
Intel �F ��
AMD �F ��
NVIDIA �F ��
������F�ق����ȁB
AMD �F ��
NVIDIA �F ��
������F�ق����ȁB
�s���N�͑S�Ǝ�ŒT���Ă��Ȃ��Ȃ��Ȃ���
>>130
LG�Ȃǂ�������
LG�Ȃǂ�������
VLIW�͏����r�b�O�ɂȂ�Ƃ����Ԃ��t���[�^�[�j
133 �FSocket774�F2012/05/26(�y) 18:18:08.63 ID:nnUobCOn
�ł��C�G�[����w�o�Ă�VLIW��
������A�ŋߌ��Ȃ��Ȃ����
>>129
VIA��SIS(RISE����)�������ڂ����Ă��܂��B
VIA��SIS(RISE����)�������ڂ����Ă��܂��B
136 �F�|���͓��{�̓y�F2012/05/31(��) 09:32:54.34 ID:AwRuMDSJ
���Ǎs�������Ƃ���͂����Ȃ�
Supercharging the nervous system with biological, ion-transistor computer chips
http://www.extremetech.com/extreme/130111-supercharging-the-nervous-system-with-biological-ion-transistor-computer-chips
Supercharging the nervous system with biological, ion-transistor computer chips
http://www.extremetech.com/extreme/130111-supercharging-the-nervous-system-with-biological-ion-transistor-computer-chips
���w�E�o�C�I�R���s���[�^�[�͓d�C��������Ȃ��āA���т��H�ׂ����Ȃ��Ɠ����Ȃ�����Ȃ�
����Ȃ�Đl��
�J�����f�o�C�X�Ɛ\�������B
�o�C�I�R���s���[�^�̏o�̓f�o�C�X
ttp://akiba-pc.watch.impress.co.jp/hotline/20120602/image/sfnec2.html
ttp://akiba-pc.watch.impress.co.jp/hotline/20120602/image/sfnec2.html
��͂�]�̃N���b�N�A�b�v��
�}�W���X����Ǝ_���Ŏ��ʋC���B
TurboBoost�Ɠ��������Ŏ��ʑO�ɒZ���Ԃł�߂�B�������
��葱����Ƃ��̂����i�����Ĕ]�̎_�f�Ɠ����̔��~������
��葱����Ƃ��̂����i�����Ĕ]�̎_�f�Ɠ����̔��~������
�i���Q�[���̒��㋉�҂ɂȂ�ƁA�W���͂����߂�u�Ԃ�K�ɐU�蕪����u�ӎ��z���v�Ȃ�ĊT�O�����邭�炢������ȁB
PS4��CPU��power����x86�Ɉڍs����炵�����ǁA�݊������Ȃ��Ȃ邩�炠�܂�ǂ��Ȃ��Ǝv����Ȃ�
power7 4�R�A��PPE 1�R�A+SPE 8�R�A���ڂ���CELLBE�݊��̃w�e���\���ł���Ăق���
�Ƃɂ����݊������Ȃ��͔̂���グ�I�ɂ����
power7 4�R�A��PPE 1�R�A+SPE 8�R�A���ڂ���CELLBE�݊��̃w�e���\���ł���Ăق���
�Ƃɂ����݊������Ȃ��͔̂���グ�I�ɂ����
SPE�Ƃ��S�~�����
��1:SPE���������ăS�~�ƌ����Ȃ��悤�ɂ���
��2:�R�X�g�����䖝����PS3�̃p�[�c�𓋍�
��3:�݊�������vita�̓�̕��ɂȂ�Ȃ����Ƃ�_�ɋF��
��4:�e���r�Q�[�����Ƃ���P��!
��2:�R�X�g�����䖝����PS3�̃p�[�c�𓋍�
��3:�݊�������vita�̓�̕��ɂȂ�Ȃ����Ƃ�_�ɋF��
��4:�e���r�Q�[�����Ƃ���P��!
x86�͂Ȃ��ł���B�������{�i�I�ɏI��
�Ƃɂ���PPE�͎̂Ă��낤�Ȃ�
���ƂȂ��Ă�GPU�ł���������肾��
���ƂȂ��Ă�GPU�ł���������肾��
�܂��������ASPE��
��������ɂ��Ă�PPE����Ԃ����
>>147
SPE������������o�X�������ƍ��G�������B�B�B
SPE������������o�X�������ƍ��G�������B�B�B
�Ȃ������d�v�ŃR�A�ȂȂ�ł�������Ȃ��̂��B
Intel�̍ŐV�`�b�v�݂����ȃ��b�`�ȑO�i��ς܂Ȃ��̂Ȃ�
���̓h���O���̔w��ׂ��낤
Intel�̍ŐV�`�b�v�݂����ȃ��b�`�ȑO�i��ς܂Ȃ��̂Ȃ�
���̓h���O���̔w��ׂ��낤
�X���[�v�b�g���K�v�ȃ^�X�N��nVidia��AMD��GPU�ɂ��܂���
CPU��x86�ł�PPC�ł�ARM�ł����ł��ǂ�
����Sony�ɂ����łɂ�EE��VU��Cell��SPE�݂����ȃo�u���[�ȃR�v����V�K�v����̗͂ȂȂ���
�����L�{�[���Ȃ�����ɂȂ�������
CPU��x86�ł�PPC�ł�ARM�ł����ł��ǂ�
����Sony�ɂ����łɂ�EE��VU��Cell��SPE�݂����ȃo�u���[�ȃR�v����V�K�v����̗͂ȂȂ���
�����L�{�[���Ȃ�����ɂȂ�������
>>154
����A�����[������͂��킢��
����A�����[������͂��킢��
ST�AFD-SOI�Z�p��p����28/20nm�f�o�C�X������GF�ƍ���
http://prtimes.jp/main/html/rd/p/000000314.000001337.html
http://prtimes.jp/main/html/rd/p/000000314.000001337.html
intel��FD-SOI�̗̍p���R�X�g�̊ϓ_����a���Ă邯��
���ۂɍ̗p���Ă݂��獡��肳��ɏȓd�͂ɂȂ�̂���?
���ۂɍ̗p���Ă݂��獡��肳��ɏȓd�͂ɂȂ�̂���?
trigate�Ŋ��S��R�ɂł��邩��v���ł���
���łɎ������Ă��
Fin-FET�S�ʂ̓����Ȃ獡�XSOI�Ƃ������Ă݂Ă������Ȋ����Ȃ̂���
Fin-FET�S�ʂ̓����Ȃ獡�XSOI�Ƃ������Ă݂Ă������Ȋ����Ȃ̂���
�A�z��^�ɎȂ������ǂ�
top500 ��150�Ԗڂ�E5 + MIC �̃V�X�e�����ڂ��Ă�B
�_�C���Core��S���͎g���ĂȂ��݂������ȁB�R�A�������[�B
�d�͌�����nv ���ڃV�X�e���Ǝ����悤�Ȓl
�_�C���Core��S���͎g���ĂȂ��݂������ȁB�R�A�������[�B
�d�͌�����nv ���ڃV�X�e���Ǝ����悤�Ȓl
MIC�̔����x86�R�[�h���������Ƃ�
163 �F,,�E�L�́M�E,,�j��-�������F2012/06/19(��) 08:05:32.58 ID:MDLM5KM0
�K�͂��傫���Ȃ�قǃm�[�h�Ԃ̃C���^�[�R�l�N�g�₻��ɂƂ��Ȃ���p�R�X�g�œd�͌����͈������邩��
�����N���X�̃X�p�R���Ɣ�ׂ邪������B
�����N���X�̃X�p�R���Ɣ�ׂ邪������B
164 �F,,�E�L�́M�E,,�j��-�������F2012/06/19(��) 08:17:01.81 ID:MDLM5KM0
>>162
�J���ɖ{����C/C++���g���邱�Ƃ���ˁ[�́H
CUDA��OpenCL�̂悤�Ȃ܂���������Ȃ��ĂˁB
���{�������Ƃ������̂ɕ֗��ȃx�N�g���������߂����邵�g������͂��Ȃ�悳���B
�J���ɖ{����C/C++���g���邱�Ƃ���ˁ[�́H
CUDA��OpenCL�̂悤�Ȃ܂���������Ȃ��ĂˁB
���{�������Ƃ������̂ɕ֗��ȃx�N�g���������߂����邵�g������͂��Ȃ�悳���B
�g���Ղ��Ƃ����ʂł́A�w�e���\�����ӎ����Ȃ��Ɛ��\���o�Ȃ����ē_��
����܂�A�h�o���e�[�W�ɂȂ�Ȃ��B
����܂�A�h�o���e�[�W�ɂȂ�Ȃ��B
MIC�ɍœK������Ȃ�A512bit �x�N�g���ւ̍œK�����K�v���낤�H
����Ȏ��Y�͂Ȃ�����Ȃ���
����Ȏ��Y�͂Ȃ�����Ȃ���
Top500����t�Z�����Knights Corner��
54core
1.11GHz
960GF
����d�͂�Xeon E5-2670 * 2 + Knights Corner * 1��720W
Top500�̏���d�͂͂��������Ȃ��Ƃ����邯�ǂ��ꂪ�{�����Ƃ܂����B
54core
1.11GHz
960GF
����d�͂�Xeon E5-2670 * 2 + Knights Corner * 1��720W
Top500�̏���d�͂͂��������Ȃ��Ƃ����邯�ǂ��ꂪ�{�����Ƃ܂����B
����top500 ��
2xE5 + 2xM2090 766W�Ƃ�4xE5 + 4xM2090 1.56kW �Ƃ����邩���
2xE5 + 2xM2090 766W�Ƃ�4xE5 + 4xM2090 1.56kW �Ƃ����邩���
�~4xE5 + 4xM2090 1.56kW
��2xE5 + 4xM2090 1.56kW
��2xE5 + 4xM2090 1.56kW
DangoCorner�Ɋ��ҁB
171 �FSocket774�F2012/06/19(��) 15:47:48.00 ID:dbbHnxaJ
>>167
�R�X�g���݂ōl���Ă�H
�R�X�g���݂ōl���Ă�H
Intel�̃N���X�^��Infiniband-FDR�g�p�B
HPL��QDR�ǂ��납GbE���x�ł�FLOPS�������͉҂��邩��A�P���Ɋ����Ĕ�r�͂ł��Ȃ��B
�E�E�E�ɂ��Ă�BlueGene/Q�����ȁB���̓d�͌�����3�{�Ƃ��B
HPL��QDR�ǂ��납GbE���x�ł�FLOPS�������͉҂��邩��A�P���Ɋ����Ĕ�r�͂ł��Ȃ��B
�E�E�E�ɂ��Ă�BlueGene/Q�����ȁB���̓d�͌�����3�{�Ƃ��B
�Z�R�C�A��pdf�̒���Cell�̖��O���łĂ��邯�ǁA�ǂ��������Ƃł��H
ttp://graphics.stanford.edu/papers/sequoia/sequoia_sc06.pdf
ttp://graphics.stanford.edu/papers/sequoia/sequoia_sc06.pdf
>>173
�}�W���X�Ȃ̂��l�^�Ȃ̂��킩��Ȃ����ǁA
�ŗL���������Ԃ��Ă��邾������Ȃ��̂���
Sequoia is a programming lanaguage
for writing portable and efficient parallel programs.
http://sequoia.stanford.edu/
�}�W���X�Ȃ̂��l�^�Ȃ̂��킩��Ȃ����ǁA
�ŗL���������Ԃ��Ă��邾������Ȃ��̂���
Sequoia is a programming lanaguage
for writing portable and efficient parallel programs.
http://sequoia.stanford.edu/
��������ڂ����͓ǂ�łȂ�����
�ꉞ�uCell Broadband Engine�v���ďo�Ă邵�ASPE���ǂ��������Ęb�����邩��
���܂��ܓ������O�̕ʂ̂��̂��Ă��Ƃ͂Ȃ���ˁH
�ꉞ�uCell Broadband Engine�v���ďo�Ă邵�ASPE���ǂ��������Ęb�����邩��
���܂��ܓ������O�̕ʂ̂��̂��Ă��Ƃ͂Ȃ���ˁH
Sequoia�͍ŏ�CBE�p������n�߂��݂�����
���U�������V�X�e����Ώۂɂ��Ă���玞�����l����ƑÓ��ȂƂ����낤
���U�������V�X�e����Ώۂɂ��Ă���玞�����l����ƑÓ��ȂƂ����낤
�ǂ��������Ƃ���āA�������Č����Ă�낤��
�x���`�}�[�N�p�̃R�[�h�͌��J����ĂȂ��́H
�x���`�}�[�N�p�̃R�[�h�͌��J����ĂȂ��́H
Sequoia language �Ƃ������t���o�Ă��邩��v���O�����`���݂����Ȃ��̂��ȁB
������g����Cell�œ��ł���SGEMV�Ƃ�HMMER���R�A���ɑ����j�A�ɂȂ�̂��c
������g����Cell�œ��ł���SGEMV�Ƃ�HMMER���R�A���ɑ����j�A�ɂȂ�̂��c
179 �FSocket774�F2012/06/21(��) 18:12:01.53 ID:delJKLyl
�yVLSI 2012���|�[�g�zIntel�AIBM�ASTMicro�̍Ő�[���W�b�N�Z�p
http://pc.watch.impress.co.jp/docs/news/event/20120621_541584.html
http://pc.watch.impress.co.jp/docs/news/event/20120621_541584.html
AMD�̃��j�[�R�A�H�����I���R���Č����Ă邯�ǁA����͂Ȃ�łȂ�H
HW�������o�b�`�R�C�ɂȂ��Ă��A���܂ł�SW���ᐫ�\���g����Ȃ����Ă��ƁH
HW�������o�b�`�R�C�ɂȂ��Ă��A���܂ł�SW���ᐫ�\���g����Ȃ����Ă��ƁH
��]�o�J�����l���Ă��Ӗ��Ȃ�
�G���̏O
�G���̏O
�P�ɃV���O���R�A���\���ق������Ă����ł́H
�R�A�����������悤�ȃ\�t�g�ł͂����Ɛ��\�o�Ă�悤�Ɏv����x���`�}�[�N�Ƃ����Ă��
�R�A�����������悤�ȃ\�t�g�ł͂����Ɛ��\�o�Ă�悤�Ɏv����x���`�}�[�N�Ƃ����Ă��
�Ȃ�قǂ̂��c
�܂��G���̏O���ĈӖ�����GPU�����͒r����������������悤�Ȋ�����
���ǃ\�t�g�����撣����CUDA�Ƃ�OpenCL�݂����Ȃ̂Ń\�t�g����Ă������Ȃ��̂��̂�
�������͂��������𓊂��̂Ă邩
�܂��G���̏O���ĈӖ�����GPU�����͒r����������������悤�Ȋ�����
���ǃ\�t�g�����撣����CUDA�Ƃ�OpenCL�݂����Ȃ̂Ń\�t�g����Ă������Ȃ��̂��̂�
�������͂��������𓊂��̂Ă邩
AMD��M$��������ɋU�f���A���鍐���ꂽ�����
windows�͐����Ă�����Ƀ`���[�j���O����Ă邩�炶�Ⴀ
amd��linux���œK���Ȃ̃r���h����ƃN�A�b�h�R�A�̐��\�o�Ă邯��
GUI�ȃA�v�����}���`�R�A�ŕ��ו��U�݂����Ȃ��Ƃ��ق��������Ȃ��́H
amd��linux���œK���Ȃ̃r���h����ƃN�A�b�h�R�A�̐��\�o�Ă邯��
GUI�ȃA�v�����}���`�R�A�ŕ��ו��U�݂����Ȃ��Ƃ��ق��������Ȃ��́H
���V���i�́ui-PX9800/A100�v�́A�uACOS-4�V���[�Y�v�̑�^�@
���ui-PX9000/A300�v�̌�p���i�B�V�J������NEC���v���Z�b�T
���uNOAH-6�v�𓋍ڂ��ACPU���\�����s�@��ő�3.5�{�Ɍ��サ��
NOAH-6���ĉ��ꂷ���H
���ui-PX9000/A300�v�̌�p���i�B�V�J������NEC���v���Z�b�T
���uNOAH-6�v�𓋍ڂ��ACPU���\�����s�@��ő�3.5�{�Ɍ��サ��
NOAH-6���ĉ��ꂷ���H
>>186
1994�N�Ƀ��C���t���[����CMOS1�`�b�v������NOAH(-1)�A
2001�N��NOAH-5 �܂Ŕ��W�B���̌�Itaniumu�ֈڍs����v������
�J�n�������AItanium�̐悪�s�����ɂȂ�������NOAH-6 ������
�Ƃ��������炵��
1994�N�Ƀ��C���t���[����CMOS1�`�b�v������NOAH(-1)�A
2001�N��NOAH-5 �܂Ŕ��W�B���̌�Itaniumu�ֈڍs����v������
�J�n�������AItanium�̐悪�s�����ɂȂ�������NOAH-6 ������
�Ƃ��������炵��
�܂�NEC�̕a�C���n�܂������[�ƋL�������瑁���˂����܂�Ă����
�����ʖڂ��낱�̉�ЁE�E�E
�����ʖڂ��낱�̉�ЁE�E�E
Itanium�����̗L�l���ች�����肪���邵�A�d���Ȃ�����
���̕����Xeon�Ƃ��g���킯�ɂ������Ȃ�����
���̕����Xeon�Ƃ��g���킯�ɂ������Ȃ�����
�܂��ł��O���ォ��V�������N���ă}���`�R�A����
�N���b�N�A�b�v�����������Ȃ�A����قNJJ����͂������ĂȂ������ˁB
NOAH-6�͕s������NOAH-5 ��150nm �炵��
ttp://www.nec.co.jp/press/ja/0106/1201-02.html
ttp://www.nec.co.jp/press/ja/0106/1201.html
���E�̃��C���t���[���s��͐L�тĂ��邪IBM�̈�l�����B
�������C���t���[���͏k���X���A1142���~�i2010�N�j�A
NEC�̃V�F�A��7%���Ƃ���Ɩ�80���~���B
ttp://ascii.jp/elem/000/000/119/119669/img800.html
ttp://pr.fujitsu.com/jp/ir/library/databook/2011pdf/5.pdf
ttp://pr.fujitsu.com/jp/ir/library/databook/
�N���b�N�A�b�v�����������Ȃ�A����قNJJ����͂������ĂȂ������ˁB
NOAH-6�͕s������NOAH-5 ��150nm �炵��
ttp://www.nec.co.jp/press/ja/0106/1201-02.html
ttp://www.nec.co.jp/press/ja/0106/1201.html
���E�̃��C���t���[���s��͐L�тĂ��邪IBM�̈�l�����B
�������C���t���[���͏k���X���A1142���~�i2010�N�j�A
NEC�̃V�F�A��7%���Ƃ���Ɩ�80���~���B
ttp://ascii.jp/elem/000/000/119/119669/img800.html
ttp://pr.fujitsu.com/jp/ir/library/databook/2011pdf/5.pdf
ttp://pr.fujitsu.com/jp/ir/library/databook/
�Ƃ͂����A��������Ȃ����Ă��낢�딄��邵��
���C���t���[���͐F�X�����Ă��闿���̋�̈�݂����Ȋ����Ȃ̂���
��������A�x�m�ʂ������IBM�݊��@�iPC�݊��@����Ȃ����j�A���d�͓Ǝ��@���Ċ�������Ȃ������������C���t���[��
���ł������Ȃ̂���?
���ł������Ȃ̂���?
�v���O�����n���ꂩ����̂͑�ς�����
�y��ɂȂ銮�S�I���W�i���ȃA�[�L�e�N�`���͂ǂ��Ȃ̂���
�N���X�ȊJ�������̂͂Q�O���I���ɂ���ׂĊy�ɂȂ�������
�y��ɂȂ銮�S�I���W�i���ȃA�[�L�e�N�`���͂ǂ��Ȃ̂���
�N���X�ȊJ�������̂͂Q�O���I���ɂ���ׂĊy�ɂȂ�������
ACOS6�͗R��������Multics�̌n������
�Ǝv������4��
�Ǝv������4��
��������ԍ���9800���ȁB
�Ȃ݂�Ȋ����������Ă����˂�
�v���Z�b�T�̃L���b�V���ɕs���������������g��
http://pc.watch.impress.co.jp/docs/column/semicon/20120703_544296.html
http://pc.watch.impress.co.jp/docs/column/semicon/20120703_544296.html
MRAM�͑g�ݗ��Ă鎞HDD�Ƃ̕s�ӂȐڋ߂Ƃ��S�z�����ǎ��C�V�[���h���Ƃ��ǂ��ɂ��Ȃ邩��
�A�z���c
�M�Ƃ��d�ꎥ��Ƃ��ڂɌ����Ȃ����̘̂b�ɂȂ�ƃA�z�ɂȂ�
���C���t���[���́A�x�m�ʂ�IBM�����S�Ǝ���CPU���ȁB
x86�ł��Ȃ���AARM�ł��Ȃ����APowerPC�ł��Ȃ��B
����Ȕėp����Ȃ�CPU���g�������b�g�͂Ȃ낤��
x86�ł��Ȃ���AARM�ł��Ȃ����APowerPC�ł��Ȃ��B
����Ȕėp����Ȃ�CPU���g�������b�g�͂Ȃ낤��
������u�ėp�@�v��CPU���ėp����Ȃ��Ƃ͂��ꂢ����
�u���C���t���[���I���v�̃E�\
http://ascii.jp/elem/000/000/409/409322/
http://ascii.jp/elem/000/000/425/425923/
>���K�V�[�����C���t���[�����Ǝv�������ԈႢ�ŁA�I�[�v���n�̐��E�ɂ�
>���K�V�[������A������̃��K�V�[���̃X�s�[�h���������A�[�����Ǝ��͎v���܂��ˁB
http://ascii.jp/elem/000/000/409/409322/
http://ascii.jp/elem/000/000/425/425923/
>���K�V�[�����C���t���[�����Ǝv�������ԈႢ�ŁA�I�[�v���n�̐��E�ɂ�
>���K�V�[������A������̃��K�V�[���̃X�s�[�h���������A�[�����Ǝ��͎v���܂��ˁB
�v��Ɓu�I�[�v���n������˂�����ėp�@�ł�����v���Ă��Ƃ�
�Ⴄ�B�K�ޓK���B
cobol����ɂǂ��Ղ�ˑ����Ă�Ƃ�������邩��A���C���t���[�����Ă͖̂S���Ȃ�Ȃ����
�ꎞ�Acobol�}���Z�[����Ă���
�V�K�̃X�p�R���͎g���p�r���Ⴄ�݂�������
�ꎞ�Acobol�}���Z�[����Ă���
�V�K�̃X�p�R���͎g���p�r���Ⴄ�݂�������
COBOL.net�̎��オ������
.net�̐�s���������Ă����悤�ȁH
COBOL++
graph500��BG/Q���Ԃ�������݂��������ǁA���R�͂Ȃ낤�B
�g�����U�N�V�����������^��L2 �Ƃ��W���Ă�̂��ȁB
ttp://www.graph500.org/results_june_2012
Hot Chips 23 BG/Q�`�b�v L2�L���b�V���Ńg�����U�N�V�������������T�|�[�g
ttp://news.mynavi.jp/articles/2011/09/08/hot_chips23_ibm/001.html
BG/Q�ƊW�Ȃ�����
�g�����U�N�V�����������̃T�|�[�g�����炩�ƂȂ���Intel��Haswell
http://news.mynavi.jp/articles/2012/02/16/transaction_memory/index.html
�g�����U�N�V�����������^��L2 �Ƃ��W���Ă�̂��ȁB
ttp://www.graph500.org/results_june_2012
Hot Chips 23 BG/Q�`�b�v L2�L���b�V���Ńg�����U�N�V�������������T�|�[�g
ttp://news.mynavi.jp/articles/2011/09/08/hot_chips23_ibm/001.html
BG/Q�ƊW�Ȃ�����
�g�����U�N�V�����������̃T�|�[�g�����炩�ƂȂ���Intel��Haswell
http://news.mynavi.jp/articles/2012/02/16/transaction_memory/index.html
��ʂ�Green500�͏��K�̓V�X�e���̕����L���Ȃ��ǂ˂�
�C���^�R�l�N�g��������Ă�̂������Ă�̂��H
�C���^�R�l�N�g��������Ă�̂������Ă�̂��H
Intel��ASML�̊�������������
�t�@�E���h���ɂ�锼���̐������u���[�J�[�̈͂����݂��n�܂�̂��H
�t�@�E���h���ɂ�锼���̐������u���[�J�[�̈͂����݂��n�܂�̂��H
���R�o�ς��Ƃǂ����Ă������Ȃ�̂�������Ȃ����A
�ア�Ƃ��낪�͂�t���邱�Ƃ���
�����Ƃ��낪����ɋ����Ȃ邱�Ƃ̕����y�ȃ��[���ɂȂ��Ă���C������
Intel�Ƃ����Ă��Ă܂�Ȃ��ȁB
�t�ɂ��邤�܂����@���ĂȂ��̂��ȁB���W���[���[�O�̐V�l�l��
�i�O�N��������`�[���ɗ��N�D�挠������j�݂�����
�ア�Ƃ��낪�͂�t���邱�Ƃ���
�����Ƃ��낪����ɋ����Ȃ邱�Ƃ̕����y�ȃ��[���ɂȂ��Ă���C������
Intel�Ƃ����Ă��Ă܂�Ȃ��ȁB
�t�ɂ��邤�܂����@���ĂȂ��̂��ȁB���W���[���[�O�̐V�l�l��
�i�O�N��������`�[���ɗ��N�D�挠������j�݂�����
>>214
�j�R���I���̂��m�点�H
�j�R���I���̂��m�点�H
canon��nikon���킹�Ă��͂��Ȃ�����nikon�Ƃ��������{�����Ƃ����̐̂ɃI���R���Ȃ낤
���{�̔����̎Y�ƂȂ�ď��F�����d�@�ƃZ�b�g�Ő��܂ꂽ���a�̖��ʌ������������̐\���q
�g�̒��m�炸�ɗA�o�ʼn҂��ł�Ȃ�Ė@���������������ʂ����̃U�}����
���{�̔����̎Y�ƂȂ�ď��F�����d�@�ƃZ�b�g�Ő��܂ꂽ���a�̖��ʌ������������̐\���q
�g�̒��m�炸�ɗA�o�ʼn҂��ł�Ȃ�Ė@���������������ʂ����̃U�}����
���{�̃G���N�g���j�N�X�Y�Ƃ����������͖̂{������B
�h������h�ĉ���{�C�ɂ����Ă��܂��A�����H����č��̋ꋫ������B
�ĉ��̂����͂����Ɠ����B���ĂȂ��̂Ȃ珟�Ă�
���[���ɕς��Ă��܂��B�Y�ƍ\����O�ꕪ�͂��ĕĉ��������Ȃ�
���[�����u�X�^���_�[�h�v�u�I�[�v���v�ȂǂƏ̂��Č����ł��邩�̂悤��
���������ĉ����t����B
�h������h�ĉ���{�C�ɂ����Ă��܂��A�����H����č��̋ꋫ������B
�ĉ��̂����͂����Ɠ����B���ĂȂ��̂Ȃ珟�Ă�
���[���ɕς��Ă��܂��B�Y�ƍ\����O�ꕪ�͂��ĕĉ��������Ȃ�
���[�����u�X�^���_�[�h�v�u�I�[�v���v�ȂǂƏ̂��Č����ł��邩�̂悤��
���������ĉ����t����B
���{�͂����A�o�J�����Ɋ����̊��K�d����
�헪������p��b���A���Ă�悤�ɂȂ�����
���̃��[�����Ђ�����Ԃ����A�̌J��Ԃ�
�헪������p��b���A���Ă�悤�ɂȂ�����
���̃��[�����Ђ�����Ԃ����A�̌J��Ԃ�
>���[���ɕς��Ă��܂�
�ڐ�̗��v�����l���Ă�
�悪�ǂ��Ȃ邩�͍l���Ă��Ȃ�
�ڐ�̗��v�����l���Ă�
�悪�ǂ��Ȃ邩�͍l���Ă��Ȃ�
���{��������Ή��Ă͋���
�Ă�������Γ����͋���
���B��������Γ��Ă͋���
���ĉ��ōj�������Ă邾������
�Ă�������Γ����͋���
���B��������Γ��Ă͋���
���ĉ��ōj�������Ă邾������
�Ȃ�Ƃ����O���u
���Ⴀ�����͙��z������H���オ�Ⴄ����
�ڂ��ڂ��ł��ˁB
AppliedMicro launches first 64-bit ARM server chip
http://www.bit-tech.net/news/hardware/2012/04/27/advancedmicro-64-bit-arm-chip/1
Linux�A64�r�b�gARM�ɑΉ����邽�߂̃p�b�`�����J
http://headlines.yahoo.co.jp/hl?a=20120711-00000003-mycomj-sci
AppliedMicro launches first 64-bit ARM server chip
http://www.bit-tech.net/news/hardware/2012/04/27/advancedmicro-64-bit-arm-chip/1
Linux�A64�r�b�gARM�ɑΉ����邽�߂̃p�b�`�����J
http://headlines.yahoo.co.jp/hl?a=20120711-00000003-mycomj-sci
���̂�LP64�ɂ����낤
LLP64�Ȃ��MS���炢�����
�Ȃ��Ȃ��i�C�X�ȃ{�P����
Linux�ł�x64��LP64����
ARM��Linux��LP64�ł����Ȃ�
ARM��Linux��LP64�ł����Ȃ�
ARM��64bit�ł�20nm�X�^�[�g�Ȃ̂��ȁc
TSMC��2013�N����20nm�v���Z�X���i�̐��Y�����ʊJ�n����
http://www.xbitlabs.com/news/other/display/20120722131156_TSMC_Confirms_Plans_to_Start_Low_Volume_20nm_Manufacturing_Next_Year.html
ARM��TSMC�C20nm�v���Z�X�Z�p�ȍ~�̋��͑̐��Ɋւ��镡���N�_������
http://www.4gamer.net/games/143/G014356/20120723037/
TSMC��20nm�v���Z�X��1��ށA���ׂ����Đ��i�Ԃ̍�������ꂸ
http://eetimes.jp/ee/articles/1204/23/news044.html
TSMC��2013�N����20nm�v���Z�X���i�̐��Y�����ʊJ�n����
http://www.xbitlabs.com/news/other/display/20120722131156_TSMC_Confirms_Plans_to_Start_Low_Volume_20nm_Manufacturing_Next_Year.html
ARM��TSMC�C20nm�v���Z�X�Z�p�ȍ~�̋��͑̐��Ɋւ��镡���N�_������
http://www.4gamer.net/games/143/G014356/20120723037/
TSMC��20nm�v���Z�X��1��ށA���ׂ����Đ��i�Ԃ̍�������ꂸ
http://eetimes.jp/ee/articles/1204/23/news044.html
���낻����E�������Ă����悤�ȋC��������A�܂����炭�͏�ς݂ł��邵����Ȃ����낤��
�㓡�O��Weekly�C�O�j���[�X��
���o�C��SoC�ɂ�����_�[�N�V���R���̎���
http://pc.watch.impress.co.jp/docs/column/kaigai/20120726_549137.html
���o�C��SoC�ɂ�����_�[�N�V���R���̎���
http://pc.watch.impress.co.jp/docs/column/kaigai/20120726_549137.html
�d���͗��Ƃ��Ȃ��́H
�d�����Ƃ��̂��\�����NjZ�p��x�͌��\������ł���
intel�Ȃ����N��IDC���Ȃ�
�������l�̋ߕӂ܂œd���𗎂Ƃ�����ĐV������H�Z�p��
����I�ō�������Ƃ��d�v�ɂȂ�Z�p�̈�Ƃ����ĐG�ꍞ��ł���
intel�Ȃ����N��IDC���Ȃ�
�������l�̋ߕӂ܂œd���𗎂Ƃ�����ĐV������H�Z�p��
����I�ō�������Ƃ��d�v�ɂȂ�Z�p�̈�Ƃ����ĐG�ꍞ��ł���
�d�����Ƃ��ƕ����܂肪
>�쓮�d��(Vdd)��70%�ւƉ�����
>�g�����W�X�^��1.4�{�̍������삪�\�ɂȂ�B
1/0.7��1.4
Vdd?
>�g�����W�X�^��1.4�{�̍������삪�\�ɂȂ�B
1/0.7��1.4
Vdd?
ARM��64bit��2015�N�Ƃ��}�W�H
�x�����Ęb���ɂȂ���
�x�����Ęb���ɂȂ���
>>236
���ɔ�ׂāH�@236�̎����H
���ɔ�ׂāH�@236�̎����H
> ARMv8�̎��ۂ̐��i��2014�N���炢�ɂȂ邻���ł��B
����̂��Ƃ���ˁH
�x���H
����̂��Ƃ���ˁH
�x���H
Apple�͎��Ђ̃v���Z�T��x86/PPC/M68000�̃f�R�[�_��g�ݍ��ދC�͂Ȃ��ˡ
�g�����W�X�^�]��܂���Ȃ�H
�g�����W�X�^�]��܂���Ȃ�H
���X����ȕ�����Ă����v�Ȃ�����B
Crusoe�����t�̉A����>>239�����߂Ă��܂��B
Transmeta�¶���B
68k�Ȃ�f�R�[�_����Ȃ��Ď����g�ݍ��ق��������Ȃ���
�d�t�u��]�����āi �L�D���R
http://jbpress.ismedia.jp/articles/-/35780
��
��40�N�ȏダ�[�A�̖@�����������Ă��������̂̔������X���[�_�E�����n�߂��B
������5�`10�N�ԂŖ{���Ɏ~�܂邩������Ȃ��B
��
�����̌����́A������̃��\�O���t�BEUV�iExtreme UltraViolet�j�̊J����
����]������Ă��邱�Ƃɂ���B
��
�����\�O���t�B�̗��j�����Ă݂�ƁA��Ɂu�������E���v�u�����͂����~�܂�v
���Ƒ呛�����N�������A���ʓI�ɂ��̕ǂ͓˔j����Ă����B
���������A����Ɍ����Č����A�ǂ����{���ɍ���ȕǂɓ˂��������Ă���B
�����Ȃ��Ƃ��A2013�N�ɗʎY�@�����A2016�N�ɗʎY�K�p�Ƃ����ژ_���͎����s�\�ł���B
http://jbpress.ismedia.jp/articles/-/35780
��
��40�N�ȏダ�[�A�̖@�����������Ă��������̂̔������X���[�_�E�����n�߂��B
������5�`10�N�ԂŖ{���Ɏ~�܂邩������Ȃ��B
��
�����̌����́A������̃��\�O���t�BEUV�iExtreme UltraViolet�j�̊J����
����]������Ă��邱�Ƃɂ���B
��
�����\�O���t�B�̗��j�����Ă݂�ƁA��Ɂu�������E���v�u�����͂����~�܂�v
���Ƒ呛�����N�������A���ʓI�ɂ��̕ǂ͓˔j����Ă����B
���������A����Ɍ����Č����A�ǂ����{���ɍ���ȕǂɓ˂��������Ă���B
�����Ȃ��Ƃ��A2013�N�ɗʎY�@�����A2016�N�ɗʎY�K�p�Ƃ����ژ_���͎����s�\�ł���B
���킟���
TSMC�����\�O���t�B�̊W�ŃR�X�g��������Ȃ��Ȃ�A
20nm�̎���14nm����Ȃ��āA16nm��18nm�����ނ��ċ��N�����āA
���N�ɂȂ��Ă���20nm�̎���16nm���Ęb���o�Ă��Ă邩��ȁ[�B
EUV�͊Ԃɍ���Ȃ��낤�B
x86�Ȃ�č��P���ȃ`�b�v����intel�͉t�Z�ŃS����������̂��ȁB
20nm�̎���14nm����Ȃ��āA16nm��18nm�����ނ��ċ��N�����āA
���N�ɂȂ��Ă���20nm�̎���16nm���Ęb���o�Ă��Ă邩��ȁ[�B
EUV�͊Ԃɍ���Ȃ��낤�B
x86�Ȃ�č��P���ȃ`�b�v����intel�͉t�Z�ŃS����������̂��ȁB
MIPS,PowerPC,AlphaAXP���T�|�[�g����NT4�����肰�Ȃ��f�B�X���Ă��錏�ɂ��āB
NT�J�[�l���͈ڐA���ƌ݊��������˂��ǂ��v����
�܂����̒���PowerPC�œ����Ă邵
�܂����̒���PowerPC�œ����Ă邵
���xARM�ł��o��
����Clipper, SPARC, PA-RISC�ł����݂��邢�͌v�悳���
i860�������̃^�[�Q�b�g�������킯��
����Clipper, SPARC, PA-RISC�ł����݂��邢�͌v�悳���
i860�������̃^�[�Q�b�g�������킯��
IA64�Y���Ƃ������e���[
Yamhill�����t�̉A�Ńn���J�`������ł��܂��B
>>250
�Y��Ă͂Ȃ��������Ȃ̂Ŋ܂߂Ȃ�����
�Y��Ă͂Ȃ��������Ȃ̂Ŋ܂߂Ȃ�����
���낻��ޖ�����
�C���e����NASA�ƈِ��l����Z�p���͂Ă��邩����Ȃ��
�������̐l�ނɂ͎�ɗ]��㕨������o���Ȃ������š
�������̐l�ނɂ͎�ɗ]��㕨������o���Ȃ������š
�Ȃ�قǂȁB
�X���Ⴂ��������Ȃ����ꉞCPU�A�[�L�e�N�`���Ƃ������Ƃł����ɏ������Ă��炤�B
wikipedia��Intel 80386�@ttp://ja.wikipedia.org/wiki/Intel_80386�@��
>x86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p����������}���Ă���B
>80386�̃p�C�v���C����4�i�ō\������Ă���B
�Ƃ���B���ꂪ�ȑO����C�ɂȂ��Ă���B
���̋L�����m���Ȃ�AIntel 80286��386�Ɠ���4�i�̃p�C�v���C���������L��������B
�����łȂ���Intel 80286�@ttp://ja.wikipedia.org/wiki/�@��Intel_80286�̋L�q����
>����AMD�ƃn���X�́A���C�Z���X�����Ȃ�80386�ɑR���邽�߁A16�A20MHz�A�n���X��25MHz�A�Ƃ������A��荂�N���b�N��80286���s��ɓ��������B
>��q����悤��DOS�œ��삳�������A����N���b�N��80386�����������s���x������ꂽ����ł���B
�ƌ��������ƕ����čl�����386�̋L�q����������A80286�̓p�C�v���C�����g�킸��16bit���Z�ł͓���N���b�N��80386�Ɠ�������荂�����\���o�����ƂɂȂ�B
��������intel�ł�����͖����ȋC������B
8086�����߃t�F�b�`�Ǝ��s��2�i�A80286��80386��4�i�̃p�C�v���C���������L��������̂����A�L���Ⴂ�H�H�H
�iwikipedia�̓A���`�������������C���e�����i�̕s���ɒႢ�]���ŏ����Ă���C������j
wikipedia��Intel 80386�@ttp://ja.wikipedia.org/wiki/Intel_80386�@��
>x86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p����������}���Ă���B
>80386�̃p�C�v���C����4�i�ō\������Ă���B
�Ƃ���B���ꂪ�ȑO����C�ɂȂ��Ă���B
���̋L�����m���Ȃ�AIntel 80286��386�Ɠ���4�i�̃p�C�v���C���������L��������B
�����łȂ���Intel 80286�@ttp://ja.wikipedia.org/wiki/�@��Intel_80286�̋L�q����
>����AMD�ƃn���X�́A���C�Z���X�����Ȃ�80386�ɑR���邽�߁A16�A20MHz�A�n���X��25MHz�A�Ƃ������A��荂�N���b�N��80286���s��ɓ��������B
>��q����悤��DOS�œ��삳�������A����N���b�N��80386�����������s���x������ꂽ����ł���B
�ƌ��������ƕ����čl�����386�̋L�q����������A80286�̓p�C�v���C�����g�킸��16bit���Z�ł͓���N���b�N��80386�Ɠ�������荂�����\���o�����ƂɂȂ�B
��������intel�ł�����͖����ȋC������B
8086�����߃t�F�b�`�Ǝ��s��2�i�A80286��80386��4�i�̃p�C�v���C���������L��������̂����A�L���Ⴂ�H�H�H
�iwikipedia�̓A���`�������������C���e�����i�̕s���ɒႢ�]���ŏ����Ă���C������j
80286�ɂ͂S�i�ǂ��납�p�C�v���C�����̂��̂����݂��Ȃ���
8086���t�F�b�`�Ǝ��s�̓�i�Ƃ������Ă鎞�_�ŐM�p�ɒl���Ȃ��B
�����C���e����CPU�͌݊����d���A�V�Z�p�Ƃ�����܂����o���Ȃ����ėނ����������
Wikipedia���ĂȂ����Ǎ��̍ŐV�Z�p�Ă���Ő�[CPU!�݂����Ȃ̂Ɋ���Ă��
�����Ƃ����L�q�������Ƃ��Ă��A���`���������݂����Ȋ��������邾�낤
Wikipedia���ĂȂ����Ǎ��̍ŐV�Z�p�Ă���Ő�[CPU!�݂����Ȃ̂Ɋ���Ă��
�����Ƃ����L�q�������Ƃ��Ă��A���`���������݂����Ȋ��������邾�낤
>>256
�������ɃA���`���ςȕ��͂������Ă���wikipedia�̋L���͓��ɓ��{�̔�r�I�V����CPU�̋L���ł悭�݂����邪�A
���̋L���͕ς��Ă킯�ł��Ȃ��ȁB��������Intel�̃A���`���Đ���I�ɂ��܂�̂̂��ƒm��B
�������ɃA���`���ςȕ��͂������Ă���wikipedia�̋L���͓��ɓ��{�̔�r�I�V����CPU�̋L���ł悭�݂����邪�A
���̋L���͕ς��Ă킯�ł��Ȃ��ȁB��������Intel�̃A���`���Đ���I�ɂ��܂�̂̂��ƒm��B
80286��4�X�e�[�W�p�C�v���C��������
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1457135
8086�͖��߃v���t�F�b�`������̂�2�i�p�C�v���C���ƌ����Ȃ����Ȃ�
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1457135
8086�͖��߃v���t�F�b�`������̂�2�i�p�C�v���C���ƌ����Ȃ����Ȃ�
�A�z����
>>256
CPU�������̏퓅��i �p�C�v���C�������̊�{ �y����1�z
http://ascii.jp/elem/000/000/552/552029/
�������̏퓅��i �p�C�v���C�������̊�{ �y����2�z
http://ascii.jp/elem/000/000/553/553627/
CPU�������̏퓅��i �p�C�v���C�������̊�{ �y����1�z
http://ascii.jp/elem/000/000/552/552029/
�������̏퓅��i �p�C�v���C�������̊�{ �y����2�z
http://ascii.jp/elem/000/000/553/553627/
>>262
�ċx�݂͗L�Ӌ`�ɉ߂������ق���������
8086�̃}�j���A���Ƀv���t�F�b�`�Ǝ�����in a pipelined manner�Ə����Ă�����
�ċx�݂͗L�Ӌ`�ɉ߂������ق���������
8086�̃}�j���A���Ƀv���t�F�b�`�Ǝ�����in a pipelined manner�Ə����Ă�����
>261
�ł���ˁB�@AMD��386�̃Z�J���h�\�[�X�̃��C�Z���X�����炦�Ȃ������Ƃ��A286�͓���N���b�N��386��16bit�R�[�h�Ȃ瓯������荂���Ɛ�`���Ă����B
286���p�C�v���C���Ȃ���4�i�p�C�v���C����386�Ɠ����̐��\���o��͂����Ȃ��B
wikipedia�̋L�q��286��386�Ŗ������Ă���B
>x86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p����������}���Ă���B
�̕������A�p�C�v���C���̗L�������ۂɂ͍������ɖ��ɗ����Ă��Ȃ����ƂɂȂ�
�ł���ˁB�@AMD��386�̃Z�J���h�\�[�X�̃��C�Z���X�����炦�Ȃ������Ƃ��A286�͓���N���b�N��386��16bit�R�[�h�Ȃ瓯������荂���Ɛ�`���Ă����B
286���p�C�v���C���Ȃ���4�i�p�C�v���C����386�Ɠ����̐��\���o��͂����Ȃ��B
wikipedia�̋L�q��286��386�Ŗ������Ă���B
>x86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p����������}���Ă���B
�̕������A�p�C�v���C���̗L�������ۂɂ͍������ɖ��ɗ����Ă��Ȃ����ƂɂȂ�
�}���������Ȃ̂Ŏ��s���č������ł��ĂȂ��Ă������Ƃ����_��
wikipedia�ɏ����Ă邶���
>���N���b�N�A�����\����PC�ŁAMS-DOS�Ȃ�16bit OS�A�܂��v���O�����삳����ꍇ�A�\����32bit�����ꂽ���Ƃ⍂�@�\���̂��߂ɕ��G������80386�����A�\�����V���v���ŃI�[�o�[�w�b�h�Ȃǂ����Ȃ��čς�80286�̕��������炩�����ł������B
>���N���b�N�A�����\����PC�ŁAMS-DOS�Ȃ�16bit OS�A�܂��v���O�����삳����ꍇ�A�\����32bit�����ꂽ���Ƃ⍂�@�\���̂��߂ɕ��G������80386�����A�\�����V���v���ŃI�[�o�[�w�b�h�Ȃǂ����Ȃ��čς�80286�̕��������炩�����ł������B
>>264
�n������
�n������
http://en.wikipedia.org/wiki/Intel_80286
�̕��ɂ͂͂�����
It had 134,000 transistors and consisted of four independent units: address unit, bus unit, instruction unit and execution unit, which formed a pipeline significantly increasing the performance.
�Ə����Ă���
�̕��ɂ͂͂�����
It had 134,000 transistors and consisted of four independent units: address unit, bus unit, instruction unit and execution unit, which formed a pipeline significantly increasing the performance.
�Ə����Ă���
���Ȃ́H
in a pipelined manner
�Ȃ�p�C�v���C���ł��邱�Ƃ������Ă��ˁH
in a pipelined manner
�Ȃ�p�C�v���C���ł��邱�Ƃ������Ă��ˁH
�p�C�v���C���͕�����Ă��邯�Ǖ��ē���ł��Ȃ����Ď��H
��������s�ƃv���t�F�b�`����Ȃ����s��BIU�Ȃ��āB
�|�₷���悤�Ɂi�j��lj����ā@google�|��
It had 134,000 transistors and consisted of four independent units:(address unit, bus unit, instruction unit and execution unit,)
which formed a pipeline significantly increasing the performance.
�����134000�̃g�����W�X�^��L���Ă���A4�Ɨ��������j�b�g���琬���Ă����F�i�A�h���X���j�b�g�A�o�X���j�b�g�A���߃��j�b�g�Ǝ��s���j�b�g�j
����́A�p�t�H�[�}���X���啝�ɑ�������p�C�v���C�����`�������B
����ς�4�i�p�C�v���C������
google�搶���������B
It had 134,000 transistors and consisted of four independent units:(address unit, bus unit, instruction unit and execution unit,)
which formed a pipeline significantly increasing the performance.
�����134000�̃g�����W�X�^��L���Ă���A4�Ɨ��������j�b�g���琬���Ă����F�i�A�h���X���j�b�g�A�o�X���j�b�g�A���߃��j�b�g�Ǝ��s���j�b�g�j
����́A�p�t�H�[�}���X���啝�ɑ�������p�C�v���C�����`�������B
����ς�4�i�p�C�v���C������
google�搶���������B
google �|��
in a pipelined manner �@->�p�C�v���C�������ꂽ���@��
>268�A>270�@�͏����̉p����ǂ߂Ȃ��n��
�@ .��i 7�@�@�@ �@ �^�m�@�@�@�R�_ �@�@�o�[�J�������@�o�[�J������
l^l | | �� ,/) �@ �^ �^߁R�@ �^߁S�_�@�@�@�@�@ .��
', U ! �' / �^�@�@�@�܁@�@�@�܁@�@�_�@�@ l^l.| | /�j
/�@�@�@ �q�@|�@�@�i�Q�Q__�l�Q�Q�j�@�@| �@ | U �'/�^)
�@�@�@�@�@�R�_�@�@�@�@|lr��-l|�@�@�@�^�@�@Ɂ@�@�@ �^
�@�^�L�P�P�m�@�@�@�@�=�j��"�@�@�@�_���j �@�@�@�@|
in a pipelined manner �@->�p�C�v���C�������ꂽ���@��
>268�A>270�@�͏����̉p����ǂ߂Ȃ��n��
�@ .��i 7�@�@�@ �@ �^�m�@�@�@�R�_ �@�@�o�[�J�������@�o�[�J������
l^l | | �� ,/) �@ �^ �^߁R�@ �^߁S�_�@�@�@�@�@ .��
', U ! �' / �^�@�@�@�܁@�@�@�܁@�@�_�@�@ l^l.| | /�j
/�@�@�@ �q�@|�@�@�i�Q�Q__�l�Q�Q�j�@�@| �@ | U �'/�^)
�@�@�@�@�@�R�_�@�@�@�@|lr��-l|�@�@�@�^�@�@Ɂ@�@�@ �^
�@�^�L�P�P�m�@�@�@�@�=�j��"�@�@�@�_���j �@�@�@�@|
http://download.intel.com/jp/developer/jpdoc/IA32_Arh_Dev_Man_Vol1_Online_i.pdf
�ɂ��ƁA386�ŕ���X�e�[�W�̃T�|�[�g���ď����Ă��邩��A
286�܂ł́A���j�b�g�͓Ɨ����Ă��邯�ǁA�p�C�v���C���͏������ĂȂ��������Ă��Ƃ��낤���B
�ɂ��ƁA386�ŕ���X�e�[�W�̃T�|�[�g���ď����Ă��邩��A
286�܂ł́A���j�b�g�͓Ɨ����Ă��邯�ǁA�p�C�v���C���͏������ĂȂ��������Ă��Ƃ��낤���B
�X�e�[�W�ƃp�C�v���C���͕ʕ��B���ꂪ�������Ă���Ǝv���B
1999�ł̃C���e���E�A�[�L�e�N�`���E�\�t�g�E�F�A�E�f�B�x���b�p�[�Y�E�}�j���A���㊪�F��{�A�[�L�e�N�`���i�����ԍ�243190J�j
�ł�>276�����ڂ���������Ă���̂ň��p����B
�C���e���E�A�[�L�e�N�`���ł́A���Ђ̌ڋq�̖c��ȃ\�t�g�E�F�A���Y��ی삷�邽�߁A�I�u�W�F�N�g�E�R�[�h�E���x���ɂ����鉺�ʌ݊����̈ێ��ɑS�͂�������Ă����B
�����ɁA�A�[�L�e�N�`���̊e����ɂ����čő��A�ŋ��̃v���Z�b�T�����邽�߁A��ɍŐV���ō������̃}�C�N���v���Z�b�T�E�A�[�L�e�N�`���ƃV���R�������Z�p�̓������}���Ă����B
�C���e���͉�����ɂ��킽��A���C���t���[���E�A�[�L�e�N�`�������������ꂽ�Z�@���}�C�N���v���Z�b�T�E�A�[�L�e�N�`���ɓ������邱�Ƃɓw�͂��X���Ă����B
�����̋Z�@�̂Ȃ��Ő��\�̌���ɍł���^�����̂��A�����p�̊e�탆�j�b�g�ł���B
Intel386?�v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B
����X�e�[�W�Ɋ܂܂��̂́A�o�X�E�C���^�[�t�F�[�X�E���j�b�g�i���̃��j�b�g�̃�������I/O �ɃA�N�Z�X����j�A
�R�[�h�E�v���t�F�b�`�E���j�b�g�i�o�X�E���j�b�g����I�u�W�F�N�g�E�R�[�h�����A�����16 �r�b�g�E�L���[�ɓn���j�A
���߃f�R�[�h�E���j�b�g�i�v���t�F�b�`�E���j�b�g���������I�u�W�F�N�g�E�R�[�h���}�C�N���R�[�h�Ƀf�R�[�h����j�A
���s���j�b�g�i�}�C�N���R�[�h���߂����s����j�A
�Z�O�����g�E���j�b�g�i�_���A�h���X�����j�A�E�A�h���X�ɕϊ�����ƂƂ��ɁA�ی�`�F�b�N�����s����j�A
����уy�[�W���O�E���j�b�g�i���j�A�E�A�h���X���A�h���X�ɕϊ����A�y�[�W�E�x�[�X�̕ی�`�F�b�N�����s���A
�ŋ߃A�N�Z�X���ꂽ�ő�32 �̃y�[�W�Ɋւ���������L���b�V�����i�[����j�ł���B
�����B
1999�ł̃C���e���E�A�[�L�e�N�`���E�\�t�g�E�F�A�E�f�B�x���b�p�[�Y�E�}�j���A���㊪�F��{�A�[�L�e�N�`���i�����ԍ�243190J�j
�ł�>276�����ڂ���������Ă���̂ň��p����B
�C���e���E�A�[�L�e�N�`���ł́A���Ђ̌ڋq�̖c��ȃ\�t�g�E�F�A���Y��ی삷�邽�߁A�I�u�W�F�N�g�E�R�[�h�E���x���ɂ����鉺�ʌ݊����̈ێ��ɑS�͂�������Ă����B
�����ɁA�A�[�L�e�N�`���̊e����ɂ����čő��A�ŋ��̃v���Z�b�T�����邽�߁A��ɍŐV���ō������̃}�C�N���v���Z�b�T�E�A�[�L�e�N�`���ƃV���R�������Z�p�̓������}���Ă����B
�C���e���͉�����ɂ��킽��A���C���t���[���E�A�[�L�e�N�`�������������ꂽ�Z�@���}�C�N���v���Z�b�T�E�A�[�L�e�N�`���ɓ������邱�Ƃɓw�͂��X���Ă����B
�����̋Z�@�̂Ȃ��Ő��\�̌���ɍł���^�����̂��A�����p�̊e�탆�j�b�g�ł���B
Intel386?�v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B
����X�e�[�W�Ɋ܂܂��̂́A�o�X�E�C���^�[�t�F�[�X�E���j�b�g�i���̃��j�b�g�̃�������I/O �ɃA�N�Z�X����j�A
�R�[�h�E�v���t�F�b�`�E���j�b�g�i�o�X�E���j�b�g����I�u�W�F�N�g�E�R�[�h�����A�����16 �r�b�g�E�L���[�ɓn���j�A
���߃f�R�[�h�E���j�b�g�i�v���t�F�b�`�E���j�b�g���������I�u�W�F�N�g�E�R�[�h���}�C�N���R�[�h�Ƀf�R�[�h����j�A
���s���j�b�g�i�}�C�N���R�[�h���߂����s����j�A
�Z�O�����g�E���j�b�g�i�_���A�h���X�����j�A�E�A�h���X�ɕϊ�����ƂƂ��ɁA�ی�`�F�b�N�����s����j�A
����уy�[�W���O�E���j�b�g�i���j�A�E�A�h���X���A�h���X�ɕϊ����A�y�[�W�E�x�[�X�̕ی�`�F�b�N�����s���A
�ŋ߃A�N�Z�X���ꂽ�ő�32 �̃y�[�W�Ɋւ���������L���b�V�����i�[����j�ł���B
�����B
>277�̑���
Intel486 �v���Z�b�T�́A��{�I�ɂ�Intel386?�v���Z�b�T�̖��߃f�R�[�h�E���j�b�g�Ǝ��s���j�b�g���p�C�v���C�������ꂽ5 �X�e�[�W�Ƃ��邱�ƂŁA����ɕ�����s�����@�\�����P�������̂ł���B
�e�X�e�[�W�͕K�v�ɉ����āA�قȂ���s�X�e�[�W�ɂ���ő�5 �̖��߂𑼂̃X�e�[�W�ƕ���ɏ�������B
�e�X�e�[�W�́A�N���b�N������1 ���߂������ł��邽�߁A���ʂƂ���Intel486? �ł�CPU �N���b�N������1 ���߂��������鑬�x�œ��삷��B
�܂��A8K �o�C�g��L1 �L���b�V�����I���`�b�v�Ńv���Z�b�T�ɒlj��������ƂŁA�N���b�N������̃X�J���E���[�g�Ŏ��s�\�Ȗ��߂̊������啝�ɑ��債���i�I�y�����h��L1 �L���b�V���ɂ���ꍇ�́A�������E�A�N�Z�X���߂��܂܂��j�B
Intel486 �v���Z�b�T�͂܂��A���������_���j�b�g��CPU �Ɠ���`�b�v��ɓ������邱�Ƃł��A�C���e�����̃v���Z�b�T�ƂȂ����i���̌��2.3. �߁u�C���e���E�A�[�L�e�N�`���̕��������_���j�b�g�̕ϑJ�v���Q�Ɓj�B
����ɁA�s���A�r�b�g�A����і��߂�V���ɒlj��������Ƃɂ��AL2 �L���b�V����}���`�v���Z�b�T�Ȃǂ̂�蕡�G�ŋ��͂ȃV�X�e�����T�|�[�g�ł���悤�ɂȂ����B
�悭�ǂ�ł��炤�ƃp�C�v���C���ƃX�e�[�W���قȂ�̂��킩��Ǝv���B
286�Ƀp�C�v���C�����Ȃ��ƌ����Ă���l�́A�p�C�v���C���ƃX�e�[�W���������Ă���B
��L�ɏ]���A
��Intel386? �v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B
������4�i�p�C�v���C���B
Intel486 �v���Z�b�T�́A��{�I�ɂ�Intel386?�v���Z�b�T�̖��߃f�R�[�h�E���j�b�g�Ǝ��s���j�b�g���p�C�v���C�������ꂽ5 �X�e�[�W�Ƃ��邱�ƂŁA����ɕ�����s�����@�\�����P�������̂ł���B
�e�X�e�[�W�͕K�v�ɉ����āA�قȂ���s�X�e�[�W�ɂ���ő�5 �̖��߂𑼂̃X�e�[�W�ƕ���ɏ�������B
�e�X�e�[�W�́A�N���b�N������1 ���߂������ł��邽�߁A���ʂƂ���Intel486? �ł�CPU �N���b�N������1 ���߂��������鑬�x�œ��삷��B
�܂��A8K �o�C�g��L1 �L���b�V�����I���`�b�v�Ńv���Z�b�T�ɒlj��������ƂŁA�N���b�N������̃X�J���E���[�g�Ŏ��s�\�Ȗ��߂̊������啝�ɑ��債���i�I�y�����h��L1 �L���b�V���ɂ���ꍇ�́A�������E�A�N�Z�X���߂��܂܂��j�B
Intel486 �v���Z�b�T�͂܂��A���������_���j�b�g��CPU �Ɠ���`�b�v��ɓ������邱�Ƃł��A�C���e�����̃v���Z�b�T�ƂȂ����i���̌��2.3. �߁u�C���e���E�A�[�L�e�N�`���̕��������_���j�b�g�̕ϑJ�v���Q�Ɓj�B
����ɁA�s���A�r�b�g�A����і��߂�V���ɒlj��������Ƃɂ��AL2 �L���b�V����}���`�v���Z�b�T�Ȃǂ̂�蕡�G�ŋ��͂ȃV�X�e�����T�|�[�g�ł���悤�ɂȂ����B
�悭�ǂ�ł��炤�ƃp�C�v���C���ƃX�e�[�W���قȂ�̂��킩��Ǝv���B
286�Ƀp�C�v���C�����Ȃ��ƌ����Ă���l�́A�p�C�v���C���ƃX�e�[�W���������Ă���B
��L�ɏ]���A
��Intel386? �v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B
������4�i�p�C�v���C���B
>>278
�p�C�v���C���̒i���Ƃ��Đ�����Ƃ��́A���߃f�R�[�h�̃X�e�[�W���琔���Ă邩�炶��Ȃ��́H
486��386�ɂ���o�X�E�C���^�[�t�F�C�X�E���j�b�g�Ƃ��܂߂ĂȂ�����Ȃ��B
286���p�C�v���C��������Ă���̂��A����ĂȂ��̂��́A���ɂ͂悭�킩��ǁB
���������A�e�X�e�[�W�������ł��Ȃ��ƁA�p�C�v���C�������Ă���Ƃ͌����Ȃ��Ǝv�����B
�p�C�v���C���̒i���Ƃ��Đ�����Ƃ��́A���߃f�R�[�h�̃X�e�[�W���琔���Ă邩�炶��Ȃ��́H
486��386�ɂ���o�X�E�C���^�[�t�F�C�X�E���j�b�g�Ƃ��܂߂ĂȂ�����Ȃ��B
286���p�C�v���C��������Ă���̂��A����ĂȂ��̂��́A���ɂ͂悭�킩��ǁB
���������A�e�X�e�[�W�������ł��Ȃ��ƁA�p�C�v���C�������Ă���Ƃ͌����Ȃ��Ǝv�����B
�����286�]�X�ɓ˂����݂����Ă͂��Ȃ����Ȃ�
���������p��Ȃǂ��ł�������
�{���A�n��������
���������p��Ȃǂ��ł�������
�{���A�n��������
>280�́@8086�͖��߃v���t�F�b�`�Ǝ��s�@�ł͂Ȃ��o�X�C���^�[�t�F�[�X���j�b�g(BIU)�Ǝ��s���j�b�g�̂Q���ƌ��������́H
�o�X�C���^�[�t�F�[�X���j�b�g(BIU)���A���ݎ��s���̖��߂̎��̖��߂�ǂݍ��߂���͖��߃v���t�F�b�`���Ǝv�����ǁB
ttp://ascii.jp/elem/000/000/552/552029/index-3.html�̐}�T���p�C�v���C��������Ă��Ȃ��\���������A
writeback�̑O��fetch������
���Â�CPU�ł́ADecode��Data Fetch���ꏏ�ɂȂ���4�X�e�[�W�Ƃ��A
��Execute��Writeback���ꏏ�ɂ���3�X�e�[�W�Ƃ��A
��Fetch��Decode���ꏏ�ɂ���2�X�e�[�W�Ƃ��A������ł��ȒP�ɂ͂ł���̂����A
���@�\�ŕ�����������ނ˂���5�X�e�[�W�ƂȂ�B
��2�X�e�[�W�̃p�C�v���C���ŁA8086�������Ȃ�B
>280��8086��BIU�Ǝ��s���j�b�g�͕��삵�Ȃ��ƌ��������́H
����Ƃ����̂�������������o�J�ƌ��������́B
�o�X�C���^�[�t�F�[�X���j�b�g(BIU)���A���ݎ��s���̖��߂̎��̖��߂�ǂݍ��߂���͖��߃v���t�F�b�`���Ǝv�����ǁB
ttp://ascii.jp/elem/000/000/552/552029/index-3.html�̐}�T���p�C�v���C��������Ă��Ȃ��\���������A
writeback�̑O��fetch������
���Â�CPU�ł́ADecode��Data Fetch���ꏏ�ɂȂ���4�X�e�[�W�Ƃ��A
��Execute��Writeback���ꏏ�ɂ���3�X�e�[�W�Ƃ��A
��Fetch��Decode���ꏏ�ɂ���2�X�e�[�W�Ƃ��A������ł��ȒP�ɂ͂ł���̂����A
���@�\�ŕ�����������ނ˂���5�X�e�[�W�ƂȂ�B
��2�X�e�[�W�̃p�C�v���C���ŁA8086�������Ȃ�B
>280��8086��BIU�Ǝ��s���j�b�g�͕��삵�Ȃ��ƌ��������́H
����Ƃ����̂�������������o�J�ƌ��������́B
�p�C�v���C�����ĉ��ł����H�@���x���̔n���͋~���Ȃ��ȁB
>>279
386�̃f�[�^�V�[�g����������Ȃ��̂ŁAIntel386? EX EMBEDDED MICROPROCESSOR USER�fS MANUAL
���甲������B
3.2 Intel386 CX PROCESSOR INTERNAL ARCHITECTURE�@
Figure 3-1. Instruction Pipelining�i�}���Č��ł���������j
BusUnit�@�@ �@�FFetch1| Fecth2 �bFetch3�@ �bFecth4 | StoreResult1| Fecth5 |
DecodeUnit �F�@ �@ | Decode1 �bDecode2 �bDecode3 | Decode4 |
ExectionUnit �F �b Execute1 �bExecute2| Execute3|
MMU �F �@�@ �@ | Adrr&MMU | �@�@ �@ |
�̂悤�Ɂ@Fetch1�̖��߂��p�C�v���C����Execute1�ɐi��AExecute1���s����Adrr&MMU��������s�����B
���ꂪ�u�e�X�e�[�W�������v�̈Ӗ��̂͂��B
Execute1�� Adrr&MMU ������Ɏ��s�ł��Ȃ��Ă��p�C�v���C���͐��藧�B
�������Ȃ��̂Ő��������ǁ@DOS�̃v���O�����Ȃ�A Execute1�̎��s��Adrr&MMU�����s���Ă�,MMU���W���Ȃ����A���x���ቺ���Ȃ��̂ł́B
80386�̌�A���s�Ɏ��s�ł��郆�j�b�g����������悤�ȃA�[�L�e�N�`������������A
�u�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B�v
�ƋL�ڂ���Ă���̂��Ǝv���B
�X�e�[�W�ƌ����̂�����킵�����ǁA���j�b�g���ƃp�C�v���C���i���͓��R�قȂ邵�A
�����p�C�v���C���i���ł�������s�\�ȃ��j�b�g�͓��R�قȂ�i�X�[�p�[�X�J���j�B
386�̃f�[�^�V�[�g����������Ȃ��̂ŁAIntel386? EX EMBEDDED MICROPROCESSOR USER�fS MANUAL
���甲������B
3.2 Intel386 CX PROCESSOR INTERNAL ARCHITECTURE�@
Figure 3-1. Instruction Pipelining�i�}���Č��ł���������j
BusUnit�@�@ �@�FFetch1| Fecth2 �bFetch3�@ �bFecth4 | StoreResult1| Fecth5 |
DecodeUnit �F�@ �@ | Decode1 �bDecode2 �bDecode3 | Decode4 |
ExectionUnit �F �b Execute1 �bExecute2| Execute3|
MMU �F �@�@ �@ | Adrr&MMU | �@�@ �@ |
�̂悤�Ɂ@Fetch1�̖��߂��p�C�v���C����Execute1�ɐi��AExecute1���s����Adrr&MMU��������s�����B
���ꂪ�u�e�X�e�[�W�������v�̈Ӗ��̂͂��B
Execute1�� Adrr&MMU ������Ɏ��s�ł��Ȃ��Ă��p�C�v���C���͐��藧�B
�������Ȃ��̂Ő��������ǁ@DOS�̃v���O�����Ȃ�A Execute1�̎��s��Adrr&MMU�����s���Ă�,MMU���W���Ȃ����A���x���ቺ���Ȃ��̂ł́B
80386�̌�A���s�Ɏ��s�ł��郆�j�b�g����������悤�ȃA�[�L�e�N�`������������A
�u�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B�v
�ƋL�ڂ���Ă���̂��Ǝv���B
�X�e�[�W�ƌ����̂�����킵�����ǁA���j�b�g���ƃp�C�v���C���i���͓��R�قȂ邵�A
�����p�C�v���C���i���ł�������s�\�ȃ��j�b�g�͓��R�قȂ�i�X�[�p�[�X�J���j�B
��283
�}���S�R�_���ł����@orz
�}���S�R�_���ł����@orz
����Ō����ł��傤���H
ttp://iup.2ch-library.com/i/i0720365-1345297964.png
ttp://iup.2ch-library.com/i/i0720365-1345297964.png
{kind=link}
80486����̓L���b�V�����������ꂽ�̂�
�v���t�F�b�`��MMU�Ȃǂ̓p�C�v���C���ɐ����Ȃ��Ȃ����̂�
�ȒP�Ȗ��߂�1�N���b�N�Ŏ��s�ł���悤�ɂȂ����̂�
RISC�I�ȁA1�X�e�[�W1�T�C�N���̃p�C�v���C���ɂȂ���
�v���t�F�b�`��MMU�Ȃǂ̓p�C�v���C���ɐ����Ȃ��Ȃ����̂�
�ȒP�Ȗ��߂�1�N���b�N�Ŏ��s�ł���悤�ɂȂ����̂�
RISC�I�ȁA1�X�e�[�W1�T�C�N���̃p�C�v���C���ɂȂ���
IA-32 �C���e��R �A�[�L�e�N�`���\�t�g�E�F�A�E�f�x���b�p�[�Y�E�}�j���A����Intel386�Ɋւ���L�q�́A
�EIntel386?�v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����B�E�E�E�E�E�E�E
����
��ő�4G �o�C�g�̕������������T�|�[�g����32 �r�b�g�E�A�h���X�E�o�X
��Z�O�����g�E�������E���f������сu�t���b�g�v1 ���������f��
�4K �o�C�g�̌Œ�y�[�W�T�C�Y�ɂ���ĉ��z�������Ǘ�����������y�[�W���O
�����X�e�[�W�̃T�|�[�g
�Ɋȗ������ꂽ�B
��277,278�Ɠ��l�̋L�q������pdf(�p��,1997�N�j
ttp://download.intel.com/design/intarch/manuals/24319001.PDF
�Ƃ���ŁA��277�ɋL�q����Ă���Z�O�����g�E���j�b�g�ƃy�[�W���O�E���j�b�g�͒ʏ��MMU�ƌĂ�邩��A
�uIntel386?�v���Z�b�T�́A�����̕���X�e�[�W�@�]�X�v�̕����́A�uintel386�ɂ�CPU��MMU���܂܂�ACPU��MMU�͕���\�B�v���炢�̈Ӗ��ɂȂ�B
���l��
8086,286��CPU
80386��CPU+MMU
80486��CPU+MMU+FPU+�L���b�V���R���g���[���{�L���b�V��������
�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E
core i7��CPU+MMU+FPU+�L���b�V���R���g���[���{�L���b�V��������+???+�������R���g���[��+GPU
�Ƃ������ꂩ�炷��Ɗm���ɁA�h�����̕���h�X�e�[�W�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ɂȂ�B
�ux86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p���v��u80286�ɂ͂S�i�ǂ��납�p�C�v���C�����̂��̂����݂��Ȃ��� �v�Ƃ����̂�
�uIntel386?�v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����v
�́h�����̕���X�e�[�W�h�̕������h�p�C�v���C���h�Ɖ��߂����������B
�i���̕�������ǂނƂ����������̂������͂Ȃ����ǁj
RISCvsCISC�ƕ����Ĕ��ł��܂�����
�c�q����H���ACISC�̃R�[�h���x�̍����͑傫�ȗ��_�B
�����v���B
�����v���B
236 ���O�F�s���ȃf�o�C�X����[sage] ���e���F2012/08/18(�y) 11:29:58.87 ID:60SXhEqU
GRAPE-DR�x�[�X�̐V�`�b�v���삪�قڌ��肵�����ۂ�
http://zaimuhp2.sec.tsukuba.ac.jp/public/data/1344408659924310.pdf
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/028/shiryo/__icsFiles/afieldfile/2012/08/14/1324574_3_1.pdf
GRAPE-DR�x�[�X�̐V�`�b�v���삪�قڌ��肵�����ۂ�
http://zaimuhp2.sec.tsukuba.ac.jp/public/data/1344408659924310.pdf
http://www.mext.go.jp/b_menu/shingi/chousa/shinkou/028/shiryo/__icsFiles/afieldfile/2012/08/14/1324574_3_1.pdf
>>289
V850��ARM��thumb2�̂悤��2�o�C�g���߂�4�o�C�g����2��ނ��邾���ł��Ȃ荂�x���x�͍����Ȃ�
MIPS�ɂ�microMIPS�����邵�A�g�ݍ������Ŏg����CPU�ł͓�����O�ɂȂ�����
V850��ARM��thumb2�̂悤��2�o�C�g���߂�4�o�C�g����2��ނ��邾���ł��Ȃ荂�x���x�͍����Ȃ�
MIPS�ɂ�microMIPS�����邵�A�g�ݍ������Ŏg����CPU�ł͓�����O�ɂȂ�����
>>291
x86�̑��݈Ӌ`�����܂�˂�
x86�̑��݈Ӌ`�����܂�˂�
293 �F,,�E�L�́M�E,,�j��-�������F2012/08/22(��) 23:01:57.47 ID:wjf2WpES
�܂������ړI���Ⴄ���ǂ�
����͒P��RAM�e�ʂ̏��Ȃ��}�C�R�������ɕ��σR�[�h�T�C�Y�����������邽�߂ł�����
���\���҂����߂ł͂Ȃ��B
x86��1���߂�����̉��Z���x�Ƀt�H�[�J�X���Ă���B
SPARC64 VIIIfx��HPC-ACE�ł́A����1���߂�����6�o�C�g�Ɋg�����Ă��邵
POWER��8�o�C�g���߂�p�ӂ��Ă���B
�I�y�����h��Ԃ��g�����邽�߂ɖ��ߒ������邱�Ƃ͈��ł͂Ȃ��B
1���߂�����ŏo���鉉�Z�����@�\����A���ʓI�ɃR�[�h���x���������Ȃ�B
����͒P��RAM�e�ʂ̏��Ȃ��}�C�R�������ɕ��σR�[�h�T�C�Y�����������邽�߂ł�����
���\���҂����߂ł͂Ȃ��B
x86��1���߂�����̉��Z���x�Ƀt�H�[�J�X���Ă���B
SPARC64 VIIIfx��HPC-ACE�ł́A����1���߂�����6�o�C�g�Ɋg�����Ă��邵
POWER��8�o�C�g���߂�p�ӂ��Ă���B
�I�y�����h��Ԃ��g�����邽�߂ɖ��ߒ������邱�Ƃ͈��ł͂Ȃ��B
1���߂�����ŏo���鉉�Z�����@�\����A���ʓI�ɃR�[�h���x���������Ȃ�B
294 �F,,�E�L�́M�E,,�j��-�������F2012/08/22(��) 23:05:12.22 ID:wjf2WpES
���R�[�h���x���������Ȃ�B
�R�[�h���x�������Ȃ�^�R�[�h���R���p�N�g�ɂȂ�
�R�[�h���x�������Ȃ�^�R�[�h���R���p�N�g�ɂȂ�
��x86��1���߂�����̉��Z���x�Ƀt�H�[�J�X���Ă���B
16bit�̍�����̌݊����������p���ł邾�������
����16bit�̖��߂�8bit��8080������̌݊����������p���ł���
�@�B�I�ȕϊ���8080�̖��߂���8086�̖��߂֕ϊ��ł���
16bit�̍�����̌݊����������p���ł邾�������
����16bit�̖��߂�8bit��8080������̌݊����������p���ł���
�@�B�I�ȕϊ���8080�̖��߂���8086�̖��߂֕ϊ��ł���
���ȁB�����̐K����������Ă��_�����悗
CISC vs RISC���Ď����̘b����˂��̂���
298 �F,,�E�L�́M�E,,�j��-�������F2012/08/23(��) 11:22:04.87 ID:6xJW9hE1
> ����16bit�̖��߂�8bit��8080������̌݊����������p���ł���
> �@�B�I�ȕϊ���8080�̖��߂���8086�̖��߂֕ϊ��ł���
������A�Z���u���j�[���j�b�N�̌݊����ł����ăR�[�h�̌n�ł͂Ȃ��͂������E�E�E
> �@�B�I�ȕϊ���8080�̖��߂���8086�̖��߂֕ϊ��ł���
������A�Z���u���j�[���j�b�N�̌݊����ł����ăR�[�h�̌n�ł͂Ȃ��͂������E�E�E
299 �F,,�E�L�́M�E,,�j��-�������F2012/08/23(��) 11:43:35.25 ID:6xJW9hE1
> CISC vs RISC���Ď����̘b����˂��̂���
�T�[�o��C���X�g���[��PC�����̍����\CPU�i���[�W�R�A�j�ɂ́A���G�ȉ��Z���j�b�g������
�e���Z�p�r�ɓ����������߂�lj����Ă���CISC�I�A�v���[�`�̂ق����L����
�i���߂�P�������ăN���b�N������̂����邢�̓p�C�v���C������IPC������̂����Ɍ��E�j
�g�ݍ������̃X���[���R�A�ɂ�2�o�C�g���[�h�̃R�[�h�̌n�������Ƃ��������ł́H
�ł�x86�̃p�t�H�[�}���X�̗v���ăA�h���b�V���O���[�h�Ȃ�ˁB
�ǂ������Ƃ����ƃp�t�H�[�}���X�̗v�ɂȂ��Ă�̂�ModRM (+ SIB + DISP) �ɂ��A�h���b�V���O
���Ǝv���Ă���ǂȁBRISC�̃R�[�h�̌n�ł͂قڕs�\�����B
���Z�l�̓��W�X�^�ɒu���H�A�z���ƁB
�������ȁH
8086�@�@�@�@�@�@ModR/M�ɂ�郌�W�X�^�^�������A�h���b�V���O���[�h
80386�@�@�@ �@�@SIB�̒lj�
Opteron�@�@�@�@REX�̒lj�
Sandy Bridge�@VEX�ɂ��Œ蒷�v���t�B�b�N�X�����3���W�X�^�I�y�����h��
�T�[�o��C���X�g���[��PC�����̍����\CPU�i���[�W�R�A�j�ɂ́A���G�ȉ��Z���j�b�g������
�e���Z�p�r�ɓ����������߂�lj����Ă���CISC�I�A�v���[�`�̂ق����L����
�i���߂�P�������ăN���b�N������̂����邢�̓p�C�v���C������IPC������̂����Ɍ��E�j
�g�ݍ������̃X���[���R�A�ɂ�2�o�C�g���[�h�̃R�[�h�̌n�������Ƃ��������ł́H
�ł�x86�̃p�t�H�[�}���X�̗v���ăA�h���b�V���O���[�h�Ȃ�ˁB
�ǂ������Ƃ����ƃp�t�H�[�}���X�̗v�ɂȂ��Ă�̂�ModRM (+ SIB + DISP) �ɂ��A�h���b�V���O
���Ǝv���Ă���ǂȁBRISC�̃R�[�h�̌n�ł͂قڕs�\�����B
���Z�l�̓��W�X�^�ɒu���H�A�z���ƁB
�������ȁH
8086�@�@�@�@�@�@ModR/M�ɂ�郌�W�X�^�^�������A�h���b�V���O���[�h
80386�@�@�@ �@�@SIB�̒lj�
Opteron�@�@�@�@REX�̒lj�
Sandy Bridge�@VEX�ɂ��Œ蒷�v���t�B�b�N�X�����3���W�X�^�I�y�����h��
>>299
���͂悭������ǁA��4�s�͕�������
���͂悭������ǁA��4�s�͕�������
���ǂ������Ƃ����ƃp�t�H�[�}���X�̗v�ɂȂ��Ă�̂�ModRM (+ SIB + DISP) �ɂ��A�h���b�V���O
x86�̗��_�̓��[�h���߂Ɖ��Z���߂������̓X�g�A���߂Ɖ��Z���߂�1���߂Ŏ��s�ł��邱��
RISC�ɂ͂���͂ł��Ȃ�����R�[�h�T�C�Y���傫���Ȃ�
ARM��PowerPC�̃������A�h���b�V���O���[�h�͂���قǕn�ザ��Ȃ�
PowerPC�̃��[�h���߁A�X�g�A���߂ł�16bitDISP+�x�[�X���W�X�^�̃A�h���X�w��
�܂��̓x�[�X���W�X�^+�C���f�b�N�X���W�X�^�̃A�h���X�w�肪�ł�
�x�[�X���W�X�^�{�C���f�b�N�X���W�X�^�̃A�h���X�Ń��������烍�[�h��
�x�[�X���W�X�^�{�C���f�b�N�X���W�X�^�̒l���x�[�X���W�X�^�ɑ�����郂�[�h������
ARM�͂����ƕ��G��12bitDISP(���[�e�[�g�\)+�x�[�X���W�X�^
�܂��̓x�[�X���W�X�^+�C���f�b�N�X���W�X�^(5bit�܂ō��V�t�g�\)�ŃA�h���X�w�肪�ł�
PowerPC�Ɠ��l�Ƀ��[�h��Ƀx�[�X���W�X�^�ƃC���f�b�N�X���W�X�^�𑫂����l��
�x�[�X���W�X�^���X�V���邱�Ƃ��\
�܂��A�x�[�X���W�X�^���A�h���X�Ƃ��ă��[�h�������
�x�[�X���W�X�^�ƃC���f�b�N�X���W�X�^�𑫂����l��
�x�[�X���W�X�^���X�V����A�h���b�V���O���[�h������
�t��RISC�̌��_�̓��[�h���߁A�X�g�A���߂��g��Ȃ��ƃ������ɃA�N�Z�X�ł���
���Z���߂̓��W�X�^���m�̉��Z�����ł��Ȃ����ƂŃR�[�h�T�C�Y���傫���Ȃ邱��
x86�̌��_�͏ꍇ��DISP��8bit��32bit�����w��ł���
��Ԏg�p�p�x����������16bitDISP���g����
8bit�͈̔͂Ɏ��܂�Ȃ��ꍇ�ɃR�[�h�T�C�Y���傫���Ȃ�
x86�̗��_�̓��[�h���߂Ɖ��Z���߂������̓X�g�A���߂Ɖ��Z���߂�1���߂Ŏ��s�ł��邱��
RISC�ɂ͂���͂ł��Ȃ�����R�[�h�T�C�Y���傫���Ȃ�
ARM��PowerPC�̃������A�h���b�V���O���[�h�͂���قǕn�ザ��Ȃ�
PowerPC�̃��[�h���߁A�X�g�A���߂ł�16bitDISP+�x�[�X���W�X�^�̃A�h���X�w��
�܂��̓x�[�X���W�X�^+�C���f�b�N�X���W�X�^�̃A�h���X�w�肪�ł�
�x�[�X���W�X�^�{�C���f�b�N�X���W�X�^�̃A�h���X�Ń��������烍�[�h��
�x�[�X���W�X�^�{�C���f�b�N�X���W�X�^�̒l���x�[�X���W�X�^�ɑ�����郂�[�h������
ARM�͂����ƕ��G��12bitDISP(���[�e�[�g�\)+�x�[�X���W�X�^
�܂��̓x�[�X���W�X�^+�C���f�b�N�X���W�X�^(5bit�܂ō��V�t�g�\)�ŃA�h���X�w�肪�ł�
PowerPC�Ɠ��l�Ƀ��[�h��Ƀx�[�X���W�X�^�ƃC���f�b�N�X���W�X�^�𑫂����l��
�x�[�X���W�X�^���X�V���邱�Ƃ��\
�܂��A�x�[�X���W�X�^���A�h���X�Ƃ��ă��[�h�������
�x�[�X���W�X�^�ƃC���f�b�N�X���W�X�^�𑫂����l��
�x�[�X���W�X�^���X�V����A�h���b�V���O���[�h������
�t��RISC�̌��_�̓��[�h���߁A�X�g�A���߂��g��Ȃ��ƃ������ɃA�N�Z�X�ł���
���Z���߂̓��W�X�^���m�̉��Z�����ł��Ȃ����ƂŃR�[�h�T�C�Y���傫���Ȃ邱��
x86�̌��_�͏ꍇ��DISP��8bit��32bit�����w��ł���
��Ԏg�p�p�x����������16bitDISP���g����
8bit�͈̔͂Ɏ��܂�Ȃ��ꍇ�ɃR�[�h�T�C�Y���傫���Ȃ�
SIB�܂ł��Ɩ��߂����r���[�ɂł����Ȃ邵��
���[�h�����l�͈���g���P�[�X�������̂Ń��W�X�^�������ԉ��Z���߂͌��ʂ͑傫��
����䂦x86�̃��W�X�^�̏��Ȃ��͌��������̓}�V��
���R�̎Y�����Ƃ͎v�����A68�~���@���ق�x86�͈����Ȃ��A��68���ゾ��
�܂�������Ɩ��߃Z�b�g�͐����������������Ǝv��
���[�h�����l�͈���g���P�[�X�������̂Ń��W�X�^�������ԉ��Z���߂͌��ʂ͑傫��
����䂦x86�̃��W�X�^�̏��Ȃ��͌��������̓}�V��
���R�̎Y�����Ƃ͎v�����A68�~���@���ق�x86�͈����Ȃ��A��68���ゾ��
�܂�������Ɩ��߃Z�b�g�͐����������������Ǝv��
>>304
x64�̊����x�͂��Ȃ荂���̂ł������Ă������͂Ȃ�Ȃ��Ǝv��
�v���t�B�b�N�X�̎R�����͂ǂ��ɂ������ق��������Ƃ͎v�����ǂ�
x64�̊����x�͂��Ȃ荂���̂ł������Ă������͂Ȃ�Ȃ��Ǝv��
�v���t�B�b�N�X�̎R�����͂ǂ��ɂ������ق��������Ƃ͎v�����ǂ�
306 �F,,�E�L�́M�E,,�j��-�������F2012/08/24(��) 03:28:54.92 ID:m6Ip1J2e
1�o�C�gOpcode�̋�Ԃ������������ʂ��Ȃ��Ǝv���B
���Ƃ���add eax, ecx��1�o�C�g�ōςނ��ǁAdest��eax�̂Ƃ������R�[�h�T�C�Y���������Ȃ���
�ǂꂾ�������b�g������̂��H
�債�Ė�����ˁB
1�o�C�gOpcode��p���āA�S�Ă̖��߂�ModRM�����悤�ɂ����ق����A������
�f�R�[�_�̓V���v���ɂł��������ˁB
���ƁA�V�t�g�̕ϗʂ�*CX����Ȃ��ĔC�ӂ̃��W�X�^���w��ł���悤�ɂ��ė~�����Ƃ�
�A�Z���u�����x���ŃR�[�f�B���O���Ă�ƃ������Ƃ��邱�Ƃ͑����ˁB
���Ƃ���add eax, ecx��1�o�C�g�ōςނ��ǁAdest��eax�̂Ƃ������R�[�h�T�C�Y���������Ȃ���
�ǂꂾ�������b�g������̂��H
�債�Ė�����ˁB
1�o�C�gOpcode��p���āA�S�Ă̖��߂�ModRM�����悤�ɂ����ق����A������
�f�R�[�_�̓V���v���ɂł��������ˁB
���ƁA�V�t�g�̕ϗʂ�*CX����Ȃ��ĔC�ӂ̃��W�X�^���w��ł���悤�ɂ��ė~�����Ƃ�
�A�Z���u�����x���ŃR�[�f�B���O���Ă�ƃ������Ƃ��邱�Ƃ͑����ˁB
�K�v���Ȃ��̂ɁA���Ŋ��������Ƃɐ��o���Ă��
POWER7+ ��L3��80MB �i10MB/core�j ������
�_�C�ʐ^�ɂ͂���ȑ傫�ȃ������̈斳������AeDRAM��Wide I/O�݂����Ȃ̂�
�ڑ������̂��ȁH
http://www.theregister.co.uk/2012/08/20/ibm_power7_plus_processor_preview/
�ڑ������̂��ȁH
http://www.theregister.co.uk/2012/08/20/ibm_power7_plus_processor_preview/
���N�͐VCPU���\�̓���N�Ȃ̂ˁB
�v���Z�T�̔��\���z�b�g��Hot Chips 24 - 8��27���`29���ɊJ��
http://news.mynavi.jp/articles/2012/06/05/hotchips24_preview/index.html
�v���Z�T�̔��\���z�b�g��Hot Chips 24 - 8��27���`29���ɊJ��
http://news.mynavi.jp/articles/2012/06/05/hotchips24_preview/index.html
IBM��TSV�̌�������Ă邪�A������肻��炵���p�b�h�͂Ȃ���Power6�iL3�O�t�j��Power7�iL3�`�b�v���ɓ����j�Ƃ����o�܂����邩��7+���������낤�B45nm��32nm�Ɣ��������邩��ȁB
���܂胁�����ʐς��Ȃ��悤�Ɍ����āAeDRAM��SRAM�Ɣ�ׂă`�b�v�ʐςɑ��傫�ȗe�ʂ����B���������낵���قǎ�Ԃ������邩���҂�s�����郁�C���t���[�������ƌ������Ƃ��낾�B
���܂胁�����ʐς��Ȃ��悤�Ɍ����āAeDRAM��SRAM�Ɣ�ׂă`�b�v�ʐςɑ��傫�ȗe�ʂ����B���������낵���قǎ�Ԃ������邩���҂�s�����郁�C���t���[�������ƌ������Ƃ��낾�B
�匴����̋L�����Č㓡�����̋L�����炢�ɐM�p�ł��郌�x���H
�C�ۏ��ƒn�k�\�m���炢����
�b�̂܂Ƃ܂�Ȃ��Ō�������匴����̉E�ɏo��l�͂��Ȃ�
���ꂾ�������p�ӂ���͈̂̂��Ǝv������
�Ō�̃y�[�W�����b�����œǂ�ł����Ηǂ��A�Ƃ����c
���ꂾ�������p�ӂ���͈̂̂��Ǝv������
�Ō�̃y�[�W�����b�����œǂ�ł����Ηǂ��A�Ƃ����c
�匴����A�v�����݂ŏ����Ċm�F�����ɊԈႦ�邱�Ƃ��ڂɂ�
���̋L���̊ԈႢ�̌����͉��Ȃ낤
http://ascii.jp/elem/000/000/718/718826/
Yonah��SIMD���Z�킪128bit�����ꂽ�Ɗ��Ⴂ���āA������Merom�Ɠ������Ǝv�����̂��낤��
http://ascii.jp/elem/000/000/718/718826/
Yonah��SIMD���Z�킪128bit�����ꂽ�Ɗ��Ⴂ���āA������Merom�Ɠ������Ǝv�����̂��낤��
�Q�l�ɂȂ����B�d�B
�Ƃ肠�����A�����j�V���[�Y�͂������낢�̂œǂނ�
�Ƃ肠�����A�����j�V���[�Y�͂������낢�̂œǂނ�
PS Vita��Wide I/O���̗p���Ă����͗l
Wide I/O�̗p�@�̗ʎY�͂��ꂪ�j�㏉���H
TSV�ł͖���CPU�_�C��DRAM�_�C�̔z���w��Ζʂ������`�̂��̂�����
http://www.chipworks.com/en/technical-competitive-analysis/resources/technology-blog/2012/07/sony%E2%80%99s-ps-vita-uses-chip-on-chip-sip-%E2%80%93-3d-but-not-3d/
Wide I/O�̗p�@�̗ʎY�͂��ꂪ�j�㏉���H
TSV�ł͖���CPU�_�C��DRAM�_�C�̔z���w��Ζʂ������`�̂��̂�����
http://www.chipworks.com/en/technical-competitive-analysis/resources/technology-blog/2012/07/sony%E2%80%99s-ps-vita-uses-chip-on-chip-sip-%E2%80%93-3d-but-not-3d/
http://news.mynavi.jp/articles/2012/08/28/hot_chips24_tutorial/
29���̌ߌ�ɁA�f�[�^�Z���^�[�`�b�v�̃Z�b�V�����A
����ɑ����Ō�̃Z�b�V�������r�b�O�A�C�A���Ƒ肷��Z�b�V�����ł���B
����2�̃Z�b�V�����̓T�[�o�p�̃v���Z�T�̃Z�b�V�����ŁA
IBM��POWER 7+�A
Intel��Xeon E5 2600�A
AMC��64bit ARM�v���Z�TX-Gene�A
�x�m�ʂ�16�R�A��SPARC64 X�AOracle��16�R�ASPARC T5�A
IBM�̎����チ�C���t���[���v���Z�T��zNext�Ɛ����R�̔��\���s��ꂱ�ƂɂȂ��Ă���B
29���̌ߌ�ɁA�f�[�^�Z���^�[�`�b�v�̃Z�b�V�����A
����ɑ����Ō�̃Z�b�V�������r�b�O�A�C�A���Ƒ肷��Z�b�V�����ł���B
����2�̃Z�b�V�����̓T�[�o�p�̃v���Z�T�̃Z�b�V�����ŁA
IBM��POWER 7+�A
Intel��Xeon E5 2600�A
AMC��64bit ARM�v���Z�TX-Gene�A
�x�m�ʂ�16�R�A��SPARC64 X�AOracle��16�R�ASPARC T5�A
IBM�̎����チ�C���t���[���v���Z�T��zNext�Ɛ����R�̔��\���s��ꂱ�ƂɂȂ��Ă���B
PSP�ł���180nm�̃J�X�^��DRAM��ϑw������
21GB/s���o���Ă��炵����
���x�̂͂ǂꂭ�炢�̑ш�ɂȂ�낤���H
http://www.sony.net/Products/SC-HP/cx_news/vol50/featuring1_3.html
21GB/s���o���Ă��炵����
���x�̂͂ǂꂭ�炢�̑ш�ɂȂ�낤���H
http://www.sony.net/Products/SC-HP/cx_news/vol50/featuring1_3.html
PSP�������̗\��ǂ���8MB��EDRAM�݂̂�������
���I�̃N�\�n�[�h�ɂȂ��Ă��낤��
���I�̃N�\�n�[�h�ɂȂ��Ă��낤��
x86 CPU�̎�_����������ɂȂ���Nehalem�}�C�N���A�[�L�e�N�`��
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
���Ⴆ�A�I�y�����h��A�h���X�̃T�C�Y��ω������閽�߃v���t�B�b�N�X�uLCP(Length-Changing Prefixes)�v��
������ƁA�v���f�R�[�h���ɂ߂Ēx���Ȃ��_�B
��Core MA�́A�ʏ�Ȃ�ő�6���߂�1�T�C�N���Ń}�[�L���O�ł��邪�ALCP�����ƌ����������Ă��܂��B
�Ȃ�ł���ȃA�z�Ȗ��ߍ�����́H
�����Ȃ݂ɁA�v���f�R�[�h�S�ʂɂ��Č���ƁA
��Intel�̎��̖��ߊg���uIntel Advanced Vector Extensions (Intel AVX)�v�́uVEX(Vector Extension)�v
���G���R�[�h�t�H�[�}�b�g���A�L���ɂȂ邩������Ȃ��BVEX�ł͍ŏ���1byte�ŁA
�����߃I�y�R�[�h�̈ʒu���킩�邽�߁A���߃}�[�L���O�����e�ՂɂȂ�\�������邩�炾�B
�͂��߂��炱�����Ƃ��C�C�̂ɁA
Intel�̃A�[�L�e�N�g���ăA�z�Ȃ�H
http://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
���Ⴆ�A�I�y�����h��A�h���X�̃T�C�Y��ω������閽�߃v���t�B�b�N�X�uLCP(Length-Changing Prefixes)�v��
������ƁA�v���f�R�[�h���ɂ߂Ēx���Ȃ��_�B
��Core MA�́A�ʏ�Ȃ�ő�6���߂�1�T�C�N���Ń}�[�L���O�ł��邪�ALCP�����ƌ����������Ă��܂��B
�Ȃ�ł���ȃA�z�Ȗ��ߍ�����́H
�����Ȃ݂ɁA�v���f�R�[�h�S�ʂɂ��Č���ƁA
��Intel�̎��̖��ߊg���uIntel Advanced Vector Extensions (Intel AVX)�v�́uVEX(Vector Extension)�v
���G���R�[�h�t�H�[�}�b�g���A�L���ɂȂ邩������Ȃ��BVEX�ł͍ŏ���1byte�ŁA
�����߃I�y�R�[�h�̈ʒu���킩�邽�߁A���߃}�[�L���O�����e�ՂɂȂ�\�������邩�炾�B
�͂��߂��炱�����Ƃ��C�C�̂ɁA
Intel�̃A�[�L�e�N�g���ăA�z�Ȃ�H
�����REX prefix���l�^��AMD��@�����ꂩ
LCP��32�r�b�g�Z�O�����g����16�r�b�g�Z�O�����g�̃f�[�^����y�ɃA�N�Z�X���邽�߂̂��̂Ȃ̂�
win95����͂Ƃ������������Ȃ�̃����b�g���Ȃ�
win95����͂Ƃ������������Ȃ�̃����b�g���Ȃ�
>>327
���Ȃ����Ȃ���
16bit���Z���s����LCP�v���t�B�b�N�X�����߂ɕt��
CWDE�Ƃ���AX���W�X�^���g���������ʂ�EAX���W�X�^�Ɋi�[���閽��
MOVSX�Ƃ���8bit��16bit�ɕ����g��������16bit��32bit�ɕ����g�����閽��
MOVZX�Ƃ���8bit��16bit�Ƀ[���g��������16bit��32bit�Ƀ[���g�����閽��
�����̖��߂����邩��16bit������32bit�����ɕ����g����[���g������
32bit�����Ƃ��ĉ��Z���邱�Ƃ�LCP�v���t�B�b�N�X�̎g�p�p�x�͂��Ȃ茸�点��
�����A16bit�������������ɕۑ�����Ƃ���LCP�v���t�B�b�N�X���K�v
LCP���g��Ȃ�16bit���W�X�^��16bit�������̖��߂���������悩�����̂�
���Ȃ����Ȃ���
16bit���Z���s����LCP�v���t�B�b�N�X�����߂ɕt��
CWDE�Ƃ���AX���W�X�^���g���������ʂ�EAX���W�X�^�Ɋi�[���閽��
MOVSX�Ƃ���8bit��16bit�ɕ����g��������16bit��32bit�ɕ����g�����閽��
MOVZX�Ƃ���8bit��16bit�Ƀ[���g��������16bit��32bit�Ƀ[���g�����閽��
�����̖��߂����邩��16bit������32bit�����ɕ����g����[���g������
32bit�����Ƃ��ĉ��Z���邱�Ƃ�LCP�v���t�B�b�N�X�̎g�p�p�x�͂��Ȃ茸�点��
�����A16bit�������������ɕۑ�����Ƃ���LCP�v���t�B�b�N�X���K�v
LCP���g��Ȃ�16bit���W�X�^��16bit�������̖��߂���������悩�����̂�
x86�Ɍ��炸�ARISC CPU�ł�
16bit������32bit�����ɕ����g����[���g������
32bit�����Ƃ��ĉ��Z����
16bit������32bit�����ɕ����g����[���g������
32bit�����Ƃ��ĉ��Z����
4�N�ȏ�O�̋L�����X�����Ă���Ƃ���ɔ��X������������
>>330
���������ł���H
���������ł���H
332 �F,,�E�L�́M�E,,�j��-�������F2012/09/01(�y) 03:39:41.96 ID:kAQ/Rvz6
��OPs cache������̂ŗ��p�p�x�̍����R�[�h�ł�LCP�X�g�[���͖ő��ɋN���܂���
Agner��Sandy�ł�LCP�X�g�[���̔����͊m�F�ł��Ȃ��Ə����Ă��
�܂�LCP�X�g�[�����L�낤�Ɩ����낤�Ƃǂ݂̂�partial register access�������߂�movsx/movzx���g�����ق�������
�܂�LCP�X�g�[�����L�낤�Ɩ����낤�Ƃǂ݂̂�partial register access�������߂�movsx/movzx���g�����ق�������
��OPs cache���Ȃ�Atom�́H
Atom�͌�����Intel CPU�ŗB��LCP�X�g�[�����������Ȃ�
336 �F,,�E�L�́M�E,,�j��-�������F2012/09/02(��) 04:56:59.30 ID:2DlnZNLD
2����f�R�[�h�����疽�߂̓��o���͂���Ȃɕ��G����Ȃ�����ˁB
LCP�X�g�[���͉�H���P�`���ăf�R�[�_�̕���x�������邽�߂̃g���[�h�I�t�ł���
LCP�X�g�[���͉�H���P�`���ăf�R�[�_�̕���x�������邽�߂̃g���[�h�I�t�ł���
��OPs cache
�̒��g�������Ƃ����
�̒��g�������Ƃ����
Ivy Bridge�̍ג����`�b�v�̎ʐ^�����Ă���ƁA�Ȃ������������̓L���b�V����s��ndy��1.5�{�ɂ��Ȃ������̂��낤�Ǝv���B
22n�̕����肪�����̂��Ƃ��v�������A�����ł��Ȃ��炵�����B
�L���b�V����1�R�A�R�l�a�i�S�R�A�P�Q�l�a�j�ɂ���A���\�͂��������サ�A���M���y�ɂȂ����Ǝv���B
�f�o�t�ɂ����������ʐς����蓖�ĂĐ��\����ł����Ǝv���B
22n�̕����肪�����̂��Ƃ��v�������A�����ł��Ȃ��炵�����B
�L���b�V����1�R�A�R�l�a�i�S�R�A�P�Q�l�a�j�ɂ���A���\�͂��������サ�A���M���y�ɂȂ����Ǝv���B
�f�o�t�ɂ����������ʐς����蓖�ĂĐ��\����ł����Ǝv���B
Tick����
CPU��Atom�݂����ȃV���v���ȃR�A�ɂ��āA
���Ƃ͂f�o�t�����Ƀg�����W�X�^���蓖�Ă�����������Ȃ����B
���Ƃ͂f�o�t�����Ƀg�����W�X�^���蓖�Ă�����������Ȃ����B
���ꂶ�ጋ��Atom�ł�����CPU�Ƃ��Ă����̑��
�C���e������鎖����Ȃ������̉��l�͂Ȃ���
�����I�ɂ̓r�b�O�R�A���X�{�V���v���R�A��MIC��
GPU��������������ăV���v��IA�R�A�̏o�Ԃ��Ē����v�悶���
�C���e������鎖����Ȃ������̉��l�͂Ȃ���
�����I�ɂ̓r�b�O�R�A���X�{�V���v���R�A��MIC��
GPU��������������ăV���v��IA�R�A�̏o�Ԃ��Ē����v�悶���
�ϑ����Y�ł����C�Z���X�K�v�Ȃ̂��B�iGF�̎��ЊJ���͂Ȃ���ˁB�j
ARM Adds Globalfoundries to 64-bit SoC Manufacturers
http://www.tomshardware.com/news/arm-globalfoundries-soc-fab-chips,16871.html
ARM Adds Globalfoundries to 64-bit SoC Manufacturers
http://www.tomshardware.com/news/arm-globalfoundries-soc-fab-chips,16871.html
������ƈႤ
�ǂ��Ȃ��Ă您����
���Ѓt�@�u�ɍœK�����ꂽ�R�A��p�ӂ��Ă�����
ASIC �f�U�C����Ђɔ��荞�ނ�ˁH
ASIC �f�U�C����Ђɔ��荞�ނ�ˁH
ARM�ƃt�@�E���_���͋��͂��āA�e�t�@�E���_�����Ƃɍ��킹���̂�����āA
������t�@�E���_�����S�ŁA�v��Ђ̓��C�Z���X���t���[�Ŏg������ă��C�Z���X�`�Ԃ����邩��A
64bit��ARM�ł������悤�Ȃ��Ƃ���Ȃ��́H
������t�@�E���_�����S�ŁA�v��Ђ̓��C�Z���X���t���[�Ŏg������ă��C�Z���X�`�Ԃ����邩��A
64bit��ARM�ł������悤�Ȃ��Ƃ���Ȃ��́H
�匴��Nehalem�̋L�������X���������ς�炸�ϑz�S�J����
LSD���o�b�t�@�̖��O���Ȃ��Ɗ��Ⴂ���Ă邵
��������LSD��Core2�ɂ�������Ă�
������macro fusion�\�ȑg�ݍ��킹�����������Ƃ�
movups/movdqu�����P�������Ƃɂ͑S���G��Ȃ��Ƃ���
�R�C�c��Intel�̃}�j���A������ǂދC���Ȃ��̂��H
LSD���o�b�t�@�̖��O���Ȃ��Ɗ��Ⴂ���Ă邵
��������LSD��Core2�ɂ�������Ă�
������macro fusion�\�ȑg�ݍ��킹�����������Ƃ�
movups/movdqu�����P�������Ƃɂ͑S���G��Ȃ��Ƃ���
�R�C�c��Intel�̃}�j���A������ǂދC���Ȃ��̂��H
�ǂ܂��ɏ����Ă��d�����Ȃ��Ȃ�Ȃ�����
�ʂɎd�l���̎��������Ȃ�����G��Ȃ��Ƃ����낪�����Ă������Ǝv����
LSD��Intel���o�b�t�@�ƌ����Ă�����炻��d���Ă����������Ȃ�
LSD��Intel���o�b�t�@�ƌ����Ă�����炻��d���Ă����������Ȃ�
�}�j���A���ǂޓz�̓S�~�ȂQ�Ƃ��Ȃ������薳��
������������Ȃ�
352 �FSocket774�F2012/09/11(��) 23:47:43.82 ID:OGrwqlRe
�f�[�^�V�[�g��}�j���A����ǂ�ł��A�uIntel386?�v���Z�b�T�́A�����̕���X�e�[�W�iIntel386 �ł�6 �X�e�[�W�j�����ŏ��̃C���e���E�A�[�L�e�N�`���E�v���Z�b�T�ƂȂ����v��
�ux86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p���v�Ȃǂƌ������o�J��A�z���吨���邩��A�킩��₷������͕K�v�B
�匴����̋L�����u�킩��₷������v���ǂ����͕ʂɂ��āB
�ux86�A�[�L�e�N�`��CPU�Ƃ��Ă͏��߂ăp�C�v���C�����̗p���v�Ȃǂƌ������o�J��A�z���吨���邩��A�킩��₷������͕K�v�B
�匴����̋L�����u�킩��₷������v���ǂ����͕ʂɂ��āB
�匴�̓o�X�̐��Ƃł͂��邪���W�b�N�̑f�l�ł��藝���̃��x���͓ǎ҂Ƒ傫�����Ȃ��B���̏�ł₽��Ɛ����ŋL���������B�����̍����͎v�����݂ƃx���`�}�[�N���ʂ��B
�����炢�낢��Ԉ�������Ƃ������Ă͒������J��Ԃ����ƂɂȂ�B
�����炢�낢��Ԉ�������Ƃ������Ă͒������J��Ԃ����ƂɂȂ�B
�v���g�^�C�v�����T�[�o�̌`�ɂ��ĔN���ɂ͏o��݂����B
Early ARM 64-bit prototype servers could come by year's end
http://www.pcworld.com/article/262122/early_arm_64bit_prototype_servers_could_come_by_years_end.html
Early ARM 64-bit prototype servers could come by year's end
http://www.pcworld.com/article/262122/early_arm_64bit_prototype_servers_could_come_by_years_end.html
MRAM�̎g�����͂��������������c
�ƊE����MRAM����SSD�A�o�b�t�@���[���Y�ƌ����ɐ��i��
http://eetimes.jp/ee/articles/1205/08/news057.html
�ƊE����MRAM����SSD�A�o�b�t�@���[���Y�ƌ����ɐ��i��
http://eetimes.jp/ee/articles/1205/08/news057.html
HDD�Ƒg�ݍ��킹�Ă����_�ɂȂ肻��������MRAM���Ď��C�Ɏア������
wikipedia�ɂ͂�����ア�Ə����Ă����
358 �F,,�E�L�́M�E,,�j��-�������F2012/09/16(��) 23:30:19.22 ID:HY713TAZ
���{�b�g��������
>>358
�Ȃɂ��H�ǂ̂ւH
�Ȃɂ��H�ǂ̂ւH
��_������ق����q�[���[�̘b�͍��₷����I
����WiiU����PowerG7�H
>>361
�J�X�^�� 45nm power7 chip ����SOI�f�U�C��
https://twitter.com/Xbicio/status/247078734027431937
https://twitter.com/IBMWatson/status/247460688283463680
�J�X�^�� 45nm power7 chip ����SOI�f�U�C��
https://twitter.com/Xbicio/status/247078734027431937
https://twitter.com/IBMWatson/status/247460688283463680
363 �FSocket774�F2012/09/17(��) 15:35:18.60 ID:L8JcM27n
iPhone 5��Greekbench�CA6�`�b�v�̓f���A���R�A1GHz
iPhone 5�ɂ��Ăł�
�EiPhone 5 Benchmarks Appear in Geekbench Showing a Dual Core, 1GHz A6 CPU�@�@by�@MacRumors
iPhone 5��Greekbench���ʂ��f�ڂ���Ă��܂��X�y�b�N���o�Ă���C
ARMv7�x�[�X��2�R�A@1GHz�Ɣ������܂���
�����������ʂ�1GB�ƂȂ��Ă��܂���
�X�R�A��1601�Əo�Ă���C
�V�^iPad(A5X�`�b�v�C2�R�A1GHz)�̂��傤��2�{���x�C
iPhone 4S(A5�`�b�v�C800MHz)��2.5�{���x�ƂȂ��Ă��܂�
Android�Ɣ�r�����4�R�A1.3GHz��Google Nexus 7�Ƃقړ����ƂȂ��Ă���ǂ������ł���
Cortex A9�Ɣ�r�����IPC�����Ȃ荂�����ŁC�ǂ̂悤�ȃR�A���g���Ă���̂��C�ɂȂ�Ƃ���ł�
iPhone 5�ɂ��Ăł�
�EiPhone 5 Benchmarks Appear in Geekbench Showing a Dual Core, 1GHz A6 CPU�@�@by�@MacRumors
iPhone 5��Greekbench���ʂ��f�ڂ���Ă��܂��X�y�b�N���o�Ă���C
ARMv7�x�[�X��2�R�A@1GHz�Ɣ������܂���
�����������ʂ�1GB�ƂȂ��Ă��܂���
�X�R�A��1601�Əo�Ă���C
�V�^iPad(A5X�`�b�v�C2�R�A1GHz)�̂��傤��2�{���x�C
iPhone 4S(A5�`�b�v�C800MHz)��2.5�{���x�ƂȂ��Ă��܂�
Android�Ɣ�r�����4�R�A1.3GHz��Google Nexus 7�Ƃقړ����ƂȂ��Ă���ǂ������ł���
Cortex A9�Ɣ�r�����IPC�����Ȃ荂�����ŁC�ǂ̂悤�ȃR�A���g���Ă���̂��C�ɂȂ�Ƃ���ł�
>>363
iPhone5�͐��E��Cortex-A15�̃f���A���R�ACPU���ڂł��邱�Ƃ�����
http://ggsoku.com/2012/09/iphone5-cortex-a15/
ARM�̊J���X�P�W���[���̊W�ŁA���N�̑O������Cortex-A9�̃N���b�h�R�ACPU
���ŋ��ŁA���N�̌㔼����Cortex-A15�����p�\�œ��ڃ������ʂ�4G�����\�B
����2014�N��ARM 64bit�ŁA���ꖘ�͂��܂�i���������B
�S�������T���\�����Ȃ̂ŋ��3S�ɂ̓n�[�h�X�y�b�N��iPhone�͏��ĂȂ��B
iOS�̗D�ʂ����ꂽ�炠���Ƃ����ԂɁc
iPhone5�͐��E��Cortex-A15�̃f���A���R�ACPU���ڂł��邱�Ƃ�����
http://ggsoku.com/2012/09/iphone5-cortex-a15/
ARM�̊J���X�P�W���[���̊W�ŁA���N�̑O������Cortex-A9�̃N���b�h�R�ACPU
���ŋ��ŁA���N�̌㔼����Cortex-A15�����p�\�œ��ڃ������ʂ�4G�����\�B
����2014�N��ARM 64bit�ŁA���ꖘ�͂��܂�i���������B
�S�������T���\�����Ȃ̂ŋ��3S�ɂ̓n�[�h�X�y�b�N��iPhone�͏��ĂȂ��B
iOS�̗D�ʂ����ꂽ�炠���Ƃ����ԂɁc
Cortex-A15���ƌ������̂�Anandtech�ŁA���A15�ł͂Ȃ��Ǝ��̃R�A��������Ȃ��ƒ������Ă���
�Ǝ��̃R�A���Ƃ��Ă��AARMv7�x�[�X�͖Y��Ȃ��łˁB
Cortex-A15�͓d�C�H���Ō����Ă��āACortex-A9�����ǂ���Cortex-A15�̋@�\
���J�o�[���悤�Ƃ��郁�[�J�[������݂��������ACortex-A9�̃R�A�͔�͂���
��2�R�A�̂܂܂Ŕ{���Ȃ�Cortex-A15�x�[�X���Ǝv���B
Cortex-A15�͓d�C�H���Ō����Ă��āACortex-A9�����ǂ���Cortex-A15�̋@�\
���J�o�[���悤�Ƃ��郁�[�J�[������݂��������ACortex-A9�̃R�A�͔�͂���
��2�R�A�̂܂܂Ŕ{���Ȃ�Cortex-A15�x�[�X���Ǝv���B
Apple��A4���o�����̂�2�N�O�����炻�̍�����Ǝ��R�A�̊J�������Ă����\�����ے�ł��Ȃ�
Qualcomm��Krait�Ɠ����悤�Ɋ��S�ȓƎ��R�A��������Ȃ���
Qualcomm��Krait�Ɠ����悤�Ɋ��S�ȓƎ��R�A��������Ȃ���
����Ȃ�̎��͂̂���Ƃ��딃�����Ă���A�����]���Ă邵�A�Ǝ��R�A�ɍs���Ă��s�v�c�͂Ȃ���Ȋm����
ID: joK0Ycmn
�]�����y
�]�����y
>>362
Thank you so much!
Thank you so much!
371 �F,,�E�L�́M�E,,�j��-�������F2012/09/17(��) 21:00:32.44 ID:lVNEtUEj
>>359
���C�������̃A�[���̐���
���C�������̃A�[���̐���
IBM once again explains Wii U's connection to Watson
http://www.gonintendo.com/?mode=viewstory&id=185647
http://www.gonintendo.com/?mode=viewstory&id=185647
373 �F,,�E�L�́M�E,,�j��-�������F2012/09/22(�y) 17:37:12.54 ID:IMmXM5Df
���l�T�X�̓��������͂�����
��Д������͕i�����炵�ă��C�u�������������������ǂ���W���}�C�J�B
DDR4��1600MHz����X�^�[�g���Ă���Ȃ�����
3000MHz���炢�o����悤�ɂȂ��Ă��珤�i�������Ǝv����
3000MHz���炢�o����悤�ɂȂ��Ă��珤�i�������Ǝv����
JEDEC���A�����f�X�N�g�b�v�͂��łŃ��o�C���ɂ���M�S�Ȋ���
Fused Multiply Add���ĉ������ꂵ���́H�H
�Ϙa�Z�Ȃ�dpps�����邶���H
�Ϙa�Z�Ȃ�dpps�����邶���H
�܂�����ł����Ƃ�����
ttp://news.mynavi.jp/articles/2012/09/18/idf03/images/002l.jpg
ttp://news.mynavi.jp/articles/2012/09/18/idf03/images/010l.jpg
��������dpps/dppd�̉��Z�̓G�������g�̑��a������Haswell�Œlj������Ϙa���߂Ƃ͕ʂ���
�X���[�v�b�g���ǂ��Ȃ邩��������
ttp://news.mynavi.jp/articles/2012/09/18/idf03/images/002l.jpg
{kind=link}
ttp://news.mynavi.jp/articles/2012/09/18/idf03/images/010l.jpg
{kind=link}
��������dpps/dppd�̉��Z�̓G�������g�̑��a������Haswell�Œlj������Ϙa���߂Ƃ͕ʂ���
�X���[�v�b�g���ǂ��Ȃ邩��������
>>378
�Ȃ�قǁB
��������dpps�Ƃ͈Ⴄ�ˁB
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai_05b.gif
�������A���̐}�̂悤�ɁAAVX�ɕC�G����悤�ȃ��x���̃g�s�b�N�ł͂Ȃ��悤�ȋC�����饥�
�Ȃ�قǁB
��������dpps�Ƃ͈Ⴄ�ˁB
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai_05b.gif
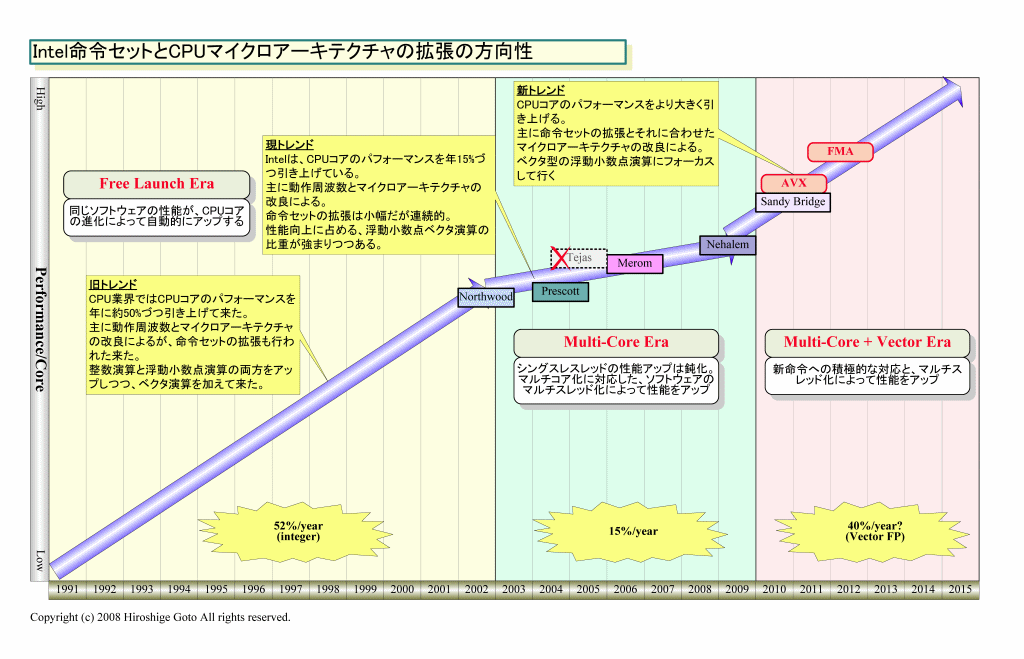{kind=link}
�������A���̐}�̂悤�ɁAAVX�ɕC�G����悤�ȃ��x���̃g�s�b�N�ł͂Ȃ��悤�ȋC�����饥�
�s�[�NFLOPS��{�ɂ���Ƃ����Ӗ��ł�AVX�Ɠ����C���p�N�g�B
�X�J�����Z�ɂ������Ƃ����Ӗ��ł�AVX���L�p��������Ȃ��B
�X�J�����Z�ɂ������Ƃ����Ӗ��ł�AVX���L�p��������Ȃ��B
>>380
���A�X�J���ł������̂��B
Intel�̎�������CPU�uHaswell�v�����ɖ��炩��
http://pc.watch.impress.co.jp/docs/column/kaigai/20120912_559065.html
�������Ƀs�[�NFLOPS���啝�ɏオ��ˁB
�iAVX��Z���ł���|�[�g��2�ɂȂ������Ƃ��f�J���������ǁj
���[�A����GPU�ƃ�������ԋ��L���āA
�v���O���~���O�����Ղ�������Ă���ˁ[���Ȃ����
���A�X�J���ł������̂��B
Intel�̎�������CPU�uHaswell�v�����ɖ��炩��
http://pc.watch.impress.co.jp/docs/column/kaigai/20120912_559065.html
�������Ƀs�[�NFLOPS���啝�ɏオ��ˁB
�iAVX��Z���ł���|�[�g��2�ɂȂ������Ƃ��f�J���������ǁj
���[�A����GPU�ƃ�������ԋ��L���āA
�v���O���~���O�����Ղ�������Ă���ˁ[���Ȃ����
Bulldozer��Sandy���ǂ��Ȃ�ȃx���`�ŗǂ�C-Ray���������邯��
����̓\�[�X���X�J���̕��������_���Z�݂̂ŏ�����Ă�
�R���p�C�����X�J����FMA4���߂�����Ƒ����Ȃ�A�Ƃ������炭��
Haswell�ł͋t�]���邾�낤��
����̓\�[�X���X�J���̕��������_���Z�݂̂ŏ�����Ă�
�R���p�C�����X�J����FMA4���߂�����Ƒ����Ȃ�A�Ƃ������炭��
Haswell�ł͋t�]���邾�낤��
�X�J��FP����Ȃ��āASIMD���Ƃǂ��Ȃ�́H
������������̃A�v���P�[�V�������ăx�N�g���������ɗL��������
�C���[�W�������
������������̃A�v���P�[�V�������ăx�N�g���������ɗL��������
�C���[�W�������
SIMD�g����Bulldozer��Sandy�̃s�[�NFLOPS/clk���͓̂���������
�蓮�ōœK������߂��X�R�A�ɂȂ��Ȃ�
C-Ray�ɃR���p�C���̎����x�N�g�������������ǂ����͒m���
�Ƃ������A�Z���u���R�[�h����ؓ����Ă��Ȃ��͎̂���
�蓮�ōœK������߂��X�R�A�ɂȂ��Ȃ�
C-Ray�ɃR���p�C���̎����x�N�g�������������ǂ����͒m���
�Ƃ������A�Z���u���R�[�h����ؓ����Ă��Ȃ��͎̂���
�匴��NetBurst�̋L���ł܂��A�z�Ȃ��Ƃ�...
>���̔{��ALU�́A��x�Ƀf�[�^�����ł��镝��16bit�������Ȃ��B
>���̂���32bit���߂���������ƁA������ALU�Ɠ����������\�ɂ����Ȃ�Ȃ��B
�R�C�c��32bit���낤��0.5�T�C�N�����ɓ��͂ł��邲�Ƃ𗝉��ł���̂�?
���Z�펩�̂�0.5�T�C�N���̃��C�e���V�A2���4����/clk�̃X���[�v�b�g��
�܂����ۂ̓g���[�X�L���b�V���ƃ��^�C���̑ш悪3uop/clk������4uop/cycle�͈ێ��ł���
>���̔{��ALU�́A��x�Ƀf�[�^�����ł��镝��16bit�������Ȃ��B
>���̂���32bit���߂���������ƁA������ALU�Ɠ����������\�ɂ����Ȃ�Ȃ��B
�R�C�c��32bit���낤��0.5�T�C�N�����ɓ��͂ł��邲�Ƃ𗝉��ł���̂�?
���Z�펩�̂�0.5�T�C�N���̃��C�e���V�A2���4����/clk�̃X���[�v�b�g��
�܂����ۂ̓g���[�X�L���b�V���ƃ��^�C���̑ш悪3uop/clk������4uop/cycle�͈ێ��ł���
�匴����̋L�����ĉR�����Ȃ̂��B
�����܂Ō�����ƐM�p�ł��Ȃ��Ȃ�˥��
�����A�c�q���L��������B
�����܂Ō�����ƐM�p�ł��Ȃ��Ȃ�˥��
�����A�c�q���L��������B
��xbitlabs���������ǂ����ɍڂ��Ă��l�g�o��replay�Ɋւ�����{�����܂��[�H
�c�q��
Oracle�ƕx�m�ʂ��^�b�O�ADB�����A�V�X�g�@�\��CPU�ɑg�ݍ��ގ�����T�[�o�uAthena�v�J��
http://www.itmedia.co.jp/enterprise/articles/1210/01/news079.html
http://www.itmedia.co.jp/enterprise/articles/1210/01/news079.html
>>388
����Ȃ̌������ɂ�B
http://ja.wikipedia.org/wiki/%E3%83%AA%E3%83%97%E3%83%AC%E3%82%A4%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0
http://applause.elfmimi.jp/diary/m200506.shtml
����Ȃ̌������ɂ�B
http://ja.wikipedia.org/wiki/%E3%83%AA%E3%83%97%E3%83%AC%E3%82%A4%E3%82%B7%E3%82%B9%E3%83%86%E3%83%A0
http://applause.elfmimi.jp/diary/m200506.shtml
392 �FSocket774�F2012/10/05(��) 21:09:52.07 ID:HF+JjCbu
>>130
��������Ă����ɁuGPU�����̏����v�Ɏ�������ŏ����ւ邵���Ȃ��Ȃ����̂��B
�Ȃ��CPU�Ȃ̂�CPUvsCPU�ŕ]�����Ȃ��H
100�������Ă��܂����炾��H
�A�����̓u�[�������ɂȂ邱�Ƃ��������Ȃ��r��
�u�u�u�u�u�u�u�uCPU���\�͂����\���Ƃ��`���P�Ȍ�����ő����S�v�v�v�v�v�v�v�v�v�v�v�v
3770��2600�����悤�ȓz�炪�P��GPU�����ĂȂ��Ƃł��v���Ă�́H��
�n�R�l������2600���甃���܂�����Đ����Ɍ��������̂ɂ�����������������������������
�u���y�����Ȃ������R�g�ɂ��Ă�ˁ[�搶�S�~��Y��������������������
�܂���ӂ̃J�X�ɂ͂��������������z�{���Ă����������AMD�����m������������������������
��������Ă����ɁuGPU�����̏����v�Ɏ�������ŏ����ւ邵���Ȃ��Ȃ����̂��B
�Ȃ��CPU�Ȃ̂�CPUvsCPU�ŕ]�����Ȃ��H
100�������Ă��܂����炾��H
�A�����̓u�[�������ɂȂ邱�Ƃ��������Ȃ��r��
�u�u�u�u�u�u�u�uCPU���\�͂����\���Ƃ��`���P�Ȍ�����ő����S�v�v�v�v�v�v�v�v�v�v�v�v
3770��2600�����悤�ȓz�炪�P��GPU�����ĂȂ��Ƃł��v���Ă�́H��
�n�R�l������2600���甃���܂�����Đ����Ɍ��������̂ɂ�����������������������������
�u���y�����Ȃ������R�g�ɂ��Ă�ˁ[�搶�S�~��Y��������������������
�܂���ӂ̃J�X�ɂ͂��������������z�{���Ă����������AMD�����m������������������������
>>391
���̋L�����o�����܂��ɂ�����Intel�X���ł��̉�����̂܂�܂̏������݂������C������
���̋L�����o�����܂��ɂ�����Intel�X���ł��̉�����̂܂�܂̏������݂������C������
394 �F,,�E�L�́M�E,,�j��-�������F2012/10/06(�y) 00:11:22.72 ID:D3oqgAgc
NetBurst��L2�L���b�V���̎������C�e���V���p�C�v���C���i���ƈ�v���Ă邱�Ƃɂ���
�������_�q�ׂ����Ƃ���������
�܂��A������L1D�͎����v���t�F�b�`�����͂ȂƁA���邳����������Ă��C��
�������_�q�ׂ����Ƃ���������
�܂��A������L1D�͎����v���t�F�b�`�����͂ȂƁA���邳����������Ă��C��
>>394
���̘b��������
���̘b��������
�ǂ�ǂ��\�ɂȂ��Ă�����Ȃ��E�E�E
�ł��A�ǂ����̋L���Ō��������A�Ȋw�Z�p���Z�n�̋����̌��t����ۓI�������B
���̃p�\�R�����āACPU�͂������ǁA�\�t�g�E���䂪�_���B
�����铪�͂������ǁA���̓��̎g�������ǂ����Ă��Ȃ����Č����Ă��B
��łɂȂ�������Ă�̂��ȁA���̃R���s���[�^���āB
�ł��A�ǂ����̋L���Ō��������A�Ȋw�Z�p���Z�n�̋����̌��t����ۓI�������B
���̃p�\�R�����āACPU�͂������ǁA�\�t�g�E���䂪�_���B
�����铪�͂������ǁA���̓��̎g�������ǂ����Ă��Ȃ����Č����Ă��B
��łɂȂ�������Ă�̂��ȁA���̃R���s���[�^���āB
�n�[�h�Ƃ��Č���Ȃ�A�����Ȃ��Ă����ł�����ˁH
�������Ȃ���ǂ����悤���Ȃ�������Ă̂͂���킯�����A�����Ȃ�Α����Ȃ�قǎg���镪��������Ă���
�܂��������Ă̂͊Ԉ���ĂȂ��Ǝv���ˁB
�������Ȃ���ǂ����悤���Ȃ�������Ă̂͂���킯�����A�����Ȃ�Α����Ȃ�قǎg���镪��������Ă���
�܂��������Ă̂͊Ԉ���ĂȂ��Ǝv���ˁB
���̘b�͊ԈႢ�ł͂Ȃ���
������50�N�O����̉ۑ�ł�
������50�N�O����̉ۑ�ł�
399 �F,,�E�L�́M�E,,�j��-�������F2012/10/07(��) 00:07:04.77 ID:YwnVQghP
�ȒP�ɂ����ƁANetBurst�̃X�P�W���[���́A�f�[�^��L1�L���b�V���i���C�e���V2�j��
�q�b�g����Ƃ����O��őg�܂�Ăă�OPs�̎��s��������Ō��߂Ă�B
�ŁA�L���b�V���~�X�͕���\���ƃ~�X�����~�X�Ɠ����̃y�i���e�B���������
��OPs�ł͂Ȃ��u���s�g���[�X�v���L���b�V������NetBurst�Ȃ�ł̖͂�肾�ˁB
���̂ւ�͂��邳��̃y�[�W�̉ߋ����O�ɂ��������Ǝv���B
�q�b�g����Ƃ����O��őg�܂�Ăă�OPs�̎��s��������Ō��߂Ă�B
�ŁA�L���b�V���~�X�͕���\���ƃ~�X�����~�X�Ɠ����̃y�i���e�B���������
��OPs�ł͂Ȃ��u���s�g���[�X�v���L���b�V������NetBurst�Ȃ�ł̖͂�肾�ˁB
���̂ւ�͂��邳��̃y�[�W�̉ߋ����O�ɂ��������Ǝv���B
>>399
���肪��
���肪��
>>398
�̂���̉ۑ肾���ǁA�[�֊����◘�p���i���Ȃ��Ȃ��i��ł��Ȃ����Ă̂����Ƃ��c
�������Ƀ}�X�`�^�X�NOS���͕̂��y�������́A�����ɃV���O���X���b�h�����g�܂Ȃ��l�����C���c
���Ƃ����X���b�h�Ƃ��ď����Ղ�����Ƃ�����ʖڂŁA���������I�ɃX���b�h���������Ⴄ�R���p�C���Ƃ������y���Ȃ��ƑʖڂȂ̂����ȁc
�̂���̉ۑ肾���ǁA�[�֊����◘�p���i���Ȃ��Ȃ��i��ł��Ȃ����Ă̂����Ƃ��c
�������Ƀ}�X�`�^�X�NOS���͕̂��y�������́A�����ɃV���O���X���b�h�����g�܂Ȃ��l�����C���c
���Ƃ����X���b�h�Ƃ��ď����Ղ�����Ƃ�����ʖڂŁA���������I�ɃX���b�h���������Ⴄ�R���p�C���Ƃ������y���Ȃ��ƑʖڂȂ̂����ȁc
�p�t�H�[�}���X�グ�悤�ƃ}���`�X���b�h�Ń��[�v�����������̃I�[�o�[�w�b�h�ŋt�ɒx���Ȃ�B
���ȃ^�X�N����̂ɂ͌��ʓI�����ǁA�^�X�N�Ԃł̃f�[�^�̎n���̃R�[�h�L�q���ώG�ʼnǐ��������������B
���̓_�ɂ��Ă̓g�����U�N�V���i���������ʼn��������H�H
���ȃ^�X�N����̂ɂ͌��ʓI�����ǁA�^�X�N�Ԃł̃f�[�^�̎n���̃R�[�h�L�q���ώG�ʼnǐ��������������B
���̓_�ɂ��Ă̓g�����U�N�V���i���������ʼn��������H�H
�C���e���R���p�C���͎����Ń}���`�X���b�h������@�\���邯�ǃC�}�C�`
�������Ēx���Ȃ����肷�邩�玩���őg�ނق����ǂ�
�ł������}���`�X���b�h�v���O���~���O�͓�Փx�����̂�
�����炶�イ�ɂ���v���O���}�[�ɂ�点�悤�Ƃ��Ă�����
���ʃX���b�h���͂Ȃ��Ȃ��i�܂Ȃ�
�������Ēx���Ȃ����肷�邩�玩���őg�ނق����ǂ�
�ł������}���`�X���b�h�v���O���~���O�͓�Փx�����̂�
�����炶�イ�ɂ���v���O���}�[�ɂ�点�悤�Ƃ��Ă�����
���ʃX���b�h���͂Ȃ��Ȃ��i�܂Ȃ�
���������ӁB
�}���`�X���b�h�����i�܂Ȃ��̂́A�l�Ԃ̖{�����痈����̂���Ȃ�����
�d�����`�[���ł����A��l�ł�����ق����y������
�l�Ԃ̎Љ�i���ԁj���A�S�ۂ݂����Ɂu�S�ɂ��ČA�ɂ��đS�v�������玩���ƃ}���`�X���b�h�̃X�^�C���ɂȂ�Ǝv��
�����̂Ȃ��z�������ǁA���[�_�[�I�C���̐l�̓}���`�X���b�h�����ӂ����ȋC������
�d���̑S�̂𑨂��A�v�f�ɕ������āA�X�̃����o�[�Ɏd��������U��̂����ӂȐl��
�d�����`�[���ł����A��l�ł�����ق����y������
�l�Ԃ̎Љ�i���ԁj���A�S�ۂ݂����Ɂu�S�ɂ��ČA�ɂ��đS�v�������玩���ƃ}���`�X���b�h�̃X�^�C���ɂȂ�Ǝv��
�����̂Ȃ��z�������ǁA���[�_�[�I�C���̐l�̓}���`�X���b�h�����ӂ����ȋC������
�d���̑S�̂𑨂��A�v�f�ɕ������āA�X�̃����o�[�Ɏd��������U��̂����ӂȐl��
�Ȃ�قǂˁB
�V���O���X���b�h���\���ǂ�ǂ���サ�Ă�������͈�l�̗D�G�Ȑl�Ԃ��ǂ�ǂ�d�������Ȃ��Ă����C���[�W�B
�������A�d���̋K�͂��傫���ȂĂ���ƁA��l�ł͂ǂ����Ă������������Ȃ邽�߁A�`�[����g�ނ��ƂɂȂ�B
ILP��d�͂̌��E�ɒB���ă}���`�R�A�H���ɓ]�������̂����̏B
�d���̍ו����͂ǂ�ǂ�i��ł����AGPU�R�A�I�Ȍ���ꂽ��啪��̎d���������悭���Ȃ���������
������Ƃ����A���Ƃ̗l����悷��悤�ɂȂ��Ă���B
���_�A�������܂Ƃ߂�A�[�L�e�N�g�I���݂��ł��d�v�B
�V���O���X���b�h���\���ǂ�ǂ���サ�Ă�������͈�l�̗D�G�Ȑl�Ԃ��ǂ�ǂ�d�������Ȃ��Ă����C���[�W�B
�������A�d���̋K�͂��傫���ȂĂ���ƁA��l�ł͂ǂ����Ă������������Ȃ邽�߁A�`�[����g�ނ��ƂɂȂ�B
ILP��d�͂̌��E�ɒB���ă}���`�R�A�H���ɓ]�������̂����̏B
�d���̍ו����͂ǂ�ǂ�i��ł����AGPU�R�A�I�Ȍ���ꂽ��啪��̎d���������悭���Ȃ���������
������Ƃ����A���Ƃ̗l����悷��悤�ɂȂ��Ă���B
���_�A�������܂Ƃ߂�A�[�L�e�N�g�I���݂��ł��d�v�B
���V�A��Elbrus��ARM�p��x86�G�~�����[�^���J��
http://www.geocities.jp/andosprocinfo/wadai12/20121006.htm
http://www.eetimes.com/electronics-news/4397620/Russian-software-runs-x86-code-on-ARM
http://www.geocities.jp/andosprocinfo/wadai12/20121006.htm
http://www.eetimes.com/electronics-news/4397620/Russian-software-runs-x86-code-on-ARM
>>402�`406
�����O�_�O�_�����Ă邩�瓱�����i�܂Ȃ��̂��c
�����X���b�h�����f�t�H���g�ɂ��āA�x���Ȃ镔���������ɂȂ�̂��Ɋ���Đ�������
�}���`�X���b�h���͑����i�ޔ�!!!
�ƌ������ƂŁA�����X���b�h���R���p�C�����������ƕ��y���Ă��܂��Ηǂ��ƌ�������www
�����O�_�O�_�����Ă邩�瓱�����i�܂Ȃ��̂��c
�����X���b�h�����f�t�H���g�ɂ��āA�x���Ȃ镔���������ɂȂ�̂��Ɋ���Đ�������
�}���`�X���b�h���͑����i�ޔ�!!!
�ƌ������ƂŁA�����X���b�h���R���p�C�����������ƕ��y���Ă��܂��Ηǂ��ƌ�������www
409 �FSocket774�F2012/10/08(��) 06:38:04.94 ID:a8WhMOtx
Elbrus����99�N����ɁAIA-64��荂���\�ȓƎ��A�[�L�̃T�[�oCPU
E2K���J�������ƌ����Ă��Ƃ�����ȁB
������āA�d�l���ǂ���ɍ������IA-64�����Ă����̂��ȁH
E2K���J�������ƌ����Ă��Ƃ�����ȁB
������āA�d�l���ǂ���ɍ������IA-64�����Ă����̂��ȁH
�G�~�����[�^�̗��������܂����������ĂȂ��̂����A
x86��CISC��CPU�͕������߃Z�b�g�œ������A�������̂��߂ɍ��ł͒��g��
�k�����߃Z�b�g�Ōv�Z����RISC�`�b�v�ɂȂ��Ă���B
x86�`�b�v�͕������߃Z�b�g�̕ϊ��@�\���n�[�h�Ŏ�������OP�Ƃ����k������
�Z�b�g�ɕϊ�����RISC���Z��H�Ōv�Z����B
x86��CISC�̕������߃Z�b�g��ARM��RISC�̏k�����߃Z�b�g�ɕϊ�����\�t�g��
���G�~�����[�^���ł���B���́A�}���`�R�A���ゾ����x��ł���R�A��
�ϊ��̎d��������U��Ό��\������B�@�c�Ƃ������ŗǂ��̂��ȁH
x86��CISC��CPU�͕������߃Z�b�g�œ������A�������̂��߂ɍ��ł͒��g��
�k�����߃Z�b�g�Ōv�Z����RISC�`�b�v�ɂȂ��Ă���B
x86�`�b�v�͕������߃Z�b�g�̕ϊ��@�\���n�[�h�Ŏ�������OP�Ƃ����k������
�Z�b�g�ɕϊ�����RISC���Z��H�Ōv�Z����B
x86��CISC�̕������߃Z�b�g��ARM��RISC�̏k�����߃Z�b�g�ɕϊ�����\�t�g��
���G�~�����[�^���ł���B���́A�}���`�R�A���ゾ����x��ł���R�A��
�ϊ��̎d��������U��Ό��\������B�@�c�Ƃ������ŗǂ��̂��ȁH
�ǂ���HotSpot VM����
0.5�N���b�N
�������œ�����H�����̐��ɂ����
�F���l�H
�����l�H
�������œ�����H�����̐��ɂ����
�F���l�H
�����l�H
x86�G�~�����[�^��ARM�łł������̑����Ȃ������̌����Ă��˂�
�uPC-AT�݊��@�G�~�����[�^�v�������Ȃ���Ӗ�������
�uPC-AT�݊��@�G�~�����[�^�v�������Ȃ���Ӗ�������
�}���`�X���b�h�̓R���e�L�X�g�X�C�b�`�̃I�[�o�[�w�b�h���ł��������Ă��C������
���������������܂��B�����ăv���O���~���O���邱�Ƃ��K�v�Ȃ���
��ʃv���O���}�ɂ͂ł��Ȃ��Ȃ���ȁA���ꂪ
���������̂́A�ނ���v���O���~���O����i�Ƃ��Ďg�p����Z�p�Ҍ����҂̕�����肭�v���O���~���O�ł����Ⴄ��
��ʃv���O���}�ɂ͂ł��Ȃ��Ȃ���ȁA���ꂪ
���������̂́A�ނ���v���O���~���O����i�Ƃ��Ďg�p����Z�p�Ҍ����҂̕�����肭�v���O���~���O�ł����Ⴄ��
�B�������Ă��Ȃ��A�R�A���Ƃ�CMT�Ƃ�HT�Ƃ��AOS�J�[�l���̌������������Ƃ��A
���������O���t�@�N�^�[�Ŏ��s���x�����܂�ɂ��ω������}���`�X���b�h�v���O������
CPU�R�A�̃V���O���X���b�h���\�́A�R�A�A�[�L�A�N���b�N�AL2�e�ʁADRAM�e�ʁE���x�ł�����x�ǂ߂邵�A�ω��ʂ�����������
���������O���t�@�N�^�[�Ŏ��s���x�����܂�ɂ��ω������}���`�X���b�h�v���O������
CPU�R�A�̃V���O���X���b�h���\�́A�R�A�A�[�L�A�N���b�N�AL2�e�ʁADRAM�e�ʁE���x�ł�����x�ǂ߂邵�A�ω��ʂ�����������
�A�v�����x���̃R���e�L�X�g�X�C�b�`�̃I�[�o�[�w�b�h���āA�Ȃ�̂��Ƃ��H
GPU�݂����Ƀn�[�h�E�F�A�X���b�h����ŐؑփR�X�g0�ɂ��Ăق������A
���ꂪ�ł��Ȃ��Ȃ�AOS�������Ƃ��Ăق����B
�����ł����A���_�[���̖@���ɐ��ꂿ�Ⴄ�̂ɁA
���_�𑝂₵�Ăǁ[����̂�B
���ꂪ�ł��Ȃ��Ȃ�AOS�������Ƃ��Ăق����B
�����ł����A���_�[���̖@���ɐ��ꂿ�Ⴄ�̂ɁA
���_�𑝂₵�Ăǁ[����̂�B
���T�̑匴�͖`����>>385�̌���������Ă���悤�Ɍ����邪
���̌�����Œ��ꒃ�ł��͂�ǂނɑς��Ȃ�
���̌�����Œ��ꒃ�ł��͂�ǂނɑς��Ȃ�
> ���������̔{��ALU�́A��x�Ƀf�[�^�����ł��镝��16bit�������Ȃ��B���̂���32bit���߂���������ƁA������ALU�Ɠ����������\�ɂ����Ȃ�Ȃ��B
16bit���߂Ȃ�t���ɔ{�����o��Ƃ����ǂ߂Ȃ����
�ŁA���T��
> ������₷���_�ł��邪�A���̎d�g�݂ł�16bit���Z�̃X���[�v�b�g�͕ς��Ȃ��킯���B
������Ƃ���Ȃ��Ƃ������Ă���킯��
16bit���߂Ȃ�t���ɔ{�����o��Ƃ����ǂ߂Ȃ����
�ŁA���T��
> ������₷���_�ł��邪�A���̎d�g�݂ł�16bit���Z�̃X���[�v�b�g�͕ς��Ȃ��킯���B
������Ƃ���Ȃ��Ƃ������Ă���킯��
�匴�F���
http://ascii.jp/elem/000/000/733/733015/
�܂Ƃ��Ȃ��Ƃ������Ă�悤�Ɏv����
�܂Ƃ��Ȃ��Ƃ������Ă�悤�Ɏv����
����
Willamette/Northwood��fast ALU1�́A2�̔{��16bit �T�uALU�ō\������Ă���B
1���߂����s����ۂ́A�ŏ���0.5�T�C�N���ʼn���16bit���A����0.5�T�C�N���ŏ��16bit���v�Z����B
���R�p�C�v���C��������Ă���A���16bit���v�Z���Ă���Ԃɉ��ʗp�̃T�uALU�ł�
���̖��߂̉���16bit���v�Z�ł���̂ŁA0.5�T�C�N�������ɖ��߂s�ł���B
���ʓI��fast ALU�ɔ��s�ł��閽�ߊԂ̃��C�e���V��0.5�T�C�N��
�X���[�v�b�g��0.5�T�C�N���Ƃ����̂�Willamette/Northwood�̎����Ȃ킯���B
(Prescott�ł̓t�H���[�f�B���O�p�X���ꕔ�ȗ����ꂽ�̂����C�e���V��1�T�C�N��)
32bit�̓���ALU1�ł͂��ꂼ��1�T�C�N���ɂ����Ȃ�Ȃ��B
1���߂����s����ۂ́A�ŏ���0.5�T�C�N���ʼn���16bit���A����0.5�T�C�N���ŏ��16bit���v�Z����B
���R�p�C�v���C��������Ă���A���16bit���v�Z���Ă���Ԃɉ��ʗp�̃T�uALU�ł�
���̖��߂̉���16bit���v�Z�ł���̂ŁA0.5�T�C�N�������ɖ��߂s�ł���B
���ʓI��fast ALU�ɔ��s�ł��閽�ߊԂ̃��C�e���V��0.5�T�C�N��
�X���[�v�b�g��0.5�T�C�N���Ƃ����̂�Willamette/Northwood�̎����Ȃ킯���B
(Prescott�ł̓t�H���[�f�B���O�p�X���ꕔ�ȗ����ꂽ�̂����C�e���V��1�T�C�N��)
32bit�̓���ALU1�ł͂��ꂼ��1�T�C�N���ɂ����Ȃ�Ȃ��B
�h�~�m��H����c���B
�d�݂͋����ŁA������߂�������˥���B
�d�݂͋����ŁA������߂�������˥���B
> NetBurst Architecture��ALU�̍\���B�}�ł͉��Ə�A2��ALU���z����Ă���悤�Ɍ����邪�A���ۂ͂ЂƂ�16bit ALU��2�{���œ����Ă���B���16bit����ALU�͓��͂̎�O�Ƀ��b�`���p�ӂ���A����16bit����ALU�����삵�Ă���Ԃ́A���16bit���̃f�[�^��ێ����Ă���
>�����{���Ŗ��߂s���悤�Ƃ���Ƃ���Fast ALU�݂̂Ȃ炸�AScheduler��Register File�Ȃǂ��{���œ����Ȃ��ƊԂɍ���Ȃ��Ȃ�
���������ϑz�������B���R�{���Ŕ��s���邽�߂ɂ������{��������Ă���B
�����Ƙ_�����o���Ă�̂ɂ˂�
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=1705373
���������ϑz�������B���R�{���Ŕ��s���邽�߂ɂ������{��������Ă���B
�����Ƙ_�����o���Ă�̂ɂ˂�
http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=1705373
>>426
���������O�炵�ĊԈ�������������Ă邩�炠��ȃA�z�ȓ��e�ɂȂ�낤�Ȃ�
�����̊m�F��莩���̖ϑz�������ɐ��������邩�ŕ��͂������Ă�Ƃ����v���Ȃ�
���������O�炵�ĊԈ�������������Ă邩�炠��ȃA�z�ȓ��e�ɂȂ�낤�Ȃ�
�����̊m�F��莩���̖ϑz�������ɐ��������邩�ŕ��͂������Ă�Ƃ����v���Ȃ�
>>428
�v�����݂������������ɃA�z�ŃZ���X���Ȃ�����A�T�uALU�̃t�B�[�h�o�b�N�����Ă����Ƃ��v��Ȃ��낤��w
�v�����݂������������ɃA�z�ŃZ���X���Ȃ�����A�T�uALU�̃t�B�[�h�o�b�N�����Ă����Ƃ��v��Ȃ��낤��w
�����搶�A����܂��B
ARM Announces On-Chip Interconnect Technology, Memory Controller for Many-Core, Heterogeneous Chips.
ARM Introduces 1Tb/s On-Chip Interconnect for Many-Core, Heterogeneous Microprocessors
http://www.xbitlabs.com/news/cpu/display/20121010230349_ARM_Announces_On_Chip_Interconnect_Technology_Memory_Controller_for_Many_Core_Heterogeneous_Chips.html
ARM Introduces 1Tb/s On-Chip Interconnect for Many-Core, Heterogeneous Microprocessors
http://www.xbitlabs.com/news/cpu/display/20121010230349_ARM_Announces_On_Chip_Interconnect_Technology_Memory_Controller_for_Many_Core_Heterogeneous_Chips.html
AMD�̓����^�`�b�v��CUP�ʐς�Atom��菬�����̂��ˁB
nm�͈Ⴄ���AL2�L���b�V���ʐς���͂�����V�������N�i��łȂ����A
���\�͂ǂ��Ȃ̂��낤�c
http://i.imgur.com/ygXKz.jpg
nm�͈Ⴄ���AL2�L���b�V���ʐς���͂�����V�������N�i��łȂ����A
���\�͂ǂ��Ȃ̂��낤�c
http://i.imgur.com/ygXKz.jpg
{kind=link}
Silverthone�̎����CPU�iL2�܂ށj�P�̂Ńo�X�̕����m�ۂ��Ȃ��Ƃ����Ȃ�������
���Ƃ̃m�[�X������Atom�͂���Silverthone�̃}�X�N�v�����̂܂g���܂킵��
�����`�b�v�����Ă邩�瓖�R�ł���B
���������̍��ɂ͂������C���X�g���[��CPU�ł�32nm�̗ʎY���n�܂��Ă�
45nm��Fab���\�[�X�͕���قǂ������B
�R�A�����������闝�R�����������킯���B
�ŏ�����GPU�����O��ŋɗ͏������Ȃ�悤�ɑg�܂�Ă�Bobcat�Ɣ�ׂ�Ζʐς�
�����o�Ă����������Ȃ��ł���B
����łȂ��Ƃ�TSMC�ɐ��Y�ϑ����č���Ă邩��1���̃E�G�n����
�����������悤�ɂ���K�v�͂������B
���Ƃ̃m�[�X������Atom�͂���Silverthone�̃}�X�N�v�����̂܂g���܂킵��
�����`�b�v�����Ă邩�瓖�R�ł���B
���������̍��ɂ͂������C���X�g���[��CPU�ł�32nm�̗ʎY���n�܂��Ă�
45nm��Fab���\�[�X�͕���قǂ������B
�R�A�����������闝�R�����������킯���B
�ŏ�����GPU�����O��ŋɗ͏������Ȃ�悤�ɑg�܂�Ă�Bobcat�Ɣ�ׂ�Ζʐς�
�����o�Ă����������Ȃ��ł���B
����łȂ��Ƃ�TSMC�ɐ��Y�ϑ����č���Ă邩��1���̃E�G�n����
�����������悤�ɂ���K�v�͂������B
�Ex86������
Google�AARM���ڂ̐V�^ �uChromebook�v�𓊓�
http://itpro.nikkeibp.co.jp/article/NEWS/20121019/431022/
http://japanese.engadget.com/2012/10/18/google-11-249-chromebook-cortex-a15-exynos-5/
�]���� Chromebook ��������� Atom �ȂǃC���e���x�[�X�������̂ɑ��āA
�V Chromebook ��ARM�x�[�X�� Exynos 5 Dual�v���Z�b�T���̗p���܂��B
Google�AARM���ڂ̐V�^ �uChromebook�v�𓊓�
http://itpro.nikkeibp.co.jp/article/NEWS/20121019/431022/
http://japanese.engadget.com/2012/10/18/google-11-249-chromebook-cortex-a15-exynos-5/
�]���� Chromebook ��������� Atom �ȂǃC���e���x�[�X�������̂ɑ��āA
�V Chromebook ��ARM�x�[�X�� Exynos 5 Dual�v���Z�b�T���̗p���܂��B
�����x86�̂��ƍD���ɂȂ����̂ɥ��
Chrome����PC�݂����Ȃ��낤���ǁA�ȑO�����Ă�����Ĕ��ꂽ�C�����Ȃ����E�E�E�B
���x������������̂��˂��E�E�E�B
���x������������̂��˂��E�E�E�B
���������X���Ŕ����Ă�Ƃ�����������Ƃ��Ȃ�
���̃I�����[�Ƃ��������낤��
�ł����������̂��āA�s�s���Ƃ��K���p�S�X�Ƃ��A�܂Ƃ��ɔ��ꂸ��
�P�ނ���j�]�����Ă̂������܂�̃p�^�[��������Ȃ�
���̃I�����[�Ƃ��������낤��
�ł����������̂��āA�s�s���Ƃ��K���p�S�X�Ƃ��A�܂Ƃ��ɔ��ꂸ��
�P�ނ���j�]�����Ă̂������܂�̃p�^�[��������Ȃ�
438 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/19(��) 20:59:07.44 ID:+YmB7zMK
�K���p�S�X���������Ȃ�
NetWalker���v���o��������
NetWalker���v���o��������
�����ƃ����[�E�G���N�\��������ł͎��s����V���N���C�A���g���f�B�X��̂͂����܂ł�
CE�n�Ƃ�Linux�n�Ƃ��Aweb�������Ƃ��������ȓz�́A�܂��o���Ă͏����āA����ȁc
web�u���E�U�����ŗǂ����ĂȂ�^�u���b�g�ł��䖝�ł�����
�L�[�{�[�h���~�������Ď��́A���͎d���c
�܂�͕����쐬�܂߂��A���炩��office�n�X�C�[�g���g���������ė~������������c
>>439
wwwwwwwwwwwwwwww
web�u���E�U�����ŗǂ����ĂȂ�^�u���b�g�ł��䖝�ł�����
�L�[�{�[�h���~�������Ď��́A���͎d���c
�܂�͕����쐬�܂߂��A���炩��office�n�X�C�[�g���g���������ė~������������c
>>439
wwwwwwwwwwwwwwww
>>439
���z���f�X�N�g�b�v�Ȃ璅���ɕ��y���Ă܂�
�f�X�N�g�b�v���z����I�����郆�[�U�[�������A2016�N�܂ł�30����������
http://japan.zdnet.com/virtualization/analysis/35019995/
���z���f�X�N�g�b�v�Ȃ璅���ɕ��y���Ă܂�
�f�X�N�g�b�v���z����I�����郆�[�U�[�������A2016�N�܂ł�30����������
http://japan.zdnet.com/virtualization/analysis/35019995/
�Ƃ������A���́u�^�u���b�g�v�ɃL�[�{�[�h�����z���Ă��Ƃ��낱��BARM�ŏo���Ă������Ă��Ƃ͂��悢��{�i�I�ɂ��B
Android�ŏ[������B
>>442
����AZ�Ƃ�NEC lifetouch Android�͔����������ǂȁB
�u���傢�p�\�v�Ȃ�A�܂������Ă͂��邪
�����͍��{�I��CPU�p���[�s��������c
AllwinerA10�ςo�[�W����������ɂ͂��邪�B
����AZ�Ƃ�NEC lifetouch Android�͔����������ǂȁB
�u���傢�p�\�v�Ȃ�A�܂������Ă͂��邪
�����͍��{�I��CPU�p���[�s��������c
AllwinerA10�ςo�[�W����������ɂ͂��邪�B
�p���[�Ƃ�����A6�͂ǂ̂��炢�����
�R�A��������A5�̔{�����Ă��Ƃ́A���������Ȃ���Ȃ�������
�R�A��������A5�̔{�����Ă��Ƃ́A���������Ȃ���Ȃ�������
A6�Ƃ��܂���킵���ł�
�x���`�ł͂��Ȃ葁��
http://kettya.com/2012/log100310006.htm
http://kettya.com/2012/log100310006.htm
�U���@�Ȃ̂���̃s���ԍ��Ȃ̂�
��ڂł͋�ʂ��Ȃ������[
��ڂł͋�ʂ��Ȃ������[
449 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/24(��) 18:41:12.19 ID:6yOxAW3x
Cortex�����邵�������"Apple A7"���ĕ\�L���Ȃ���
�ǂ�����A7������Ă��ƂɂȂ肩�˂Ȃ����
�ǂ�����A7������Ă��ƂɂȂ肩�˂Ȃ����
������������A6��A��Apple�̈Ӗ��Ȃ̂��A
���������������瓪�ɂ��ɂ���ԂɂȂ�̂��Ƃ��l�����肷��
���������������瓪�ɂ��ɂ���ԂɂȂ�̂��Ƃ��l�����肷��
������Ƃō쎌�Ƃ�A6�コ��̂��Ƃ�������Ȃ�����Ȃ��ł����₾�[
��₱�������������Ă��܂�@AppleA6���Ă��Ƃ�
����������Atom�ɕC�G��������ĂƂ��܂ŗ��Ă�̂��B
�o�b�e���쓮������߂ăN���b�N�グ����A���낻��f�X�N�g�b�v���������Ȃ������ċC�͂����
����������Atom�ɕC�G��������ĂƂ��܂ŗ��Ă�̂��B
�o�b�e���쓮������߂ăN���b�N�グ����A���낻��f�X�N�g�b�v���������Ȃ������ċC�͂����
Allwinner A10
454 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/24(��) 19:21:57.34 ID:6yOxAW3x
���[����AMD�̂��������ȁB��C������Y��Ă����B
�c�q�����Intel�M�҂�����˂�
456 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/24(��) 22:38:58.14 ID:6yOxAW3x
����A��������Jaguar(28nm)�̓��o�C�Ǝv���i���͓I�ȈӖ��Łj
AMD�̃��C���i�b�v�̒��ň�Ԕ����C�N����̂�E�V���[�Y������ˁB
���s�̂�SSE��Atom���x���P�[�X�����邩��w�����������Ă邪
��_��ׂ��ꂽ�甃��Ȃ����R���Ȃ��Ȃ�B
AMD�̃��C���i�b�v�̒��ň�Ԕ����C�N����̂�E�V���[�Y������ˁB
���s�̂�SSE��Atom���x���P�[�X�����邩��w�����������Ă邪
��_��ׂ��ꂽ�甃��Ȃ����R���Ȃ��Ȃ�B
�����c�q��NG���ĂȂ��z������̂���
bobcat������X�ɑg�ݍ��ݗp�ɓ��������jaguar�����SSE128bit���Ȃ�Ė��p�̒���
�g�ݍ���]�p�r�͊��S�ɐ�̂Ăł�
>>458
Cortex-A15��Apple A6���킴�킴NEON��128bit�����Ă����̂ɂ���͂Ȃ�
Cortex-A15��Apple A6���킴�킴NEON��128bit�����Ă����̂ɂ���͂Ȃ�
�c�q����̃��X�͂��߂ɂȂ��B
�匴�͂��̂܂܂���������̂悤����
�匴����̋L���������Ȃ�
>�ȒP�ȉ��Z���߁u�����v�Ȃ��1�T�C�N��������2���߂ƂȂ邪�A
>��ʓI�ȁu���[�h�{���Z�v���߂��ƁA1�T�C�N��������1���߂������I�ȃX���[�v�b�g�ł���B
>�������O�q�̂Ƃ���A�ꉞ2���ߓ������s�̎��s���j�b�g�������Ă���Ƃ͌����A
>������1����/�T�C�N���̏��������ł��Ȃ������B3���ߓ������s��Pentium M�Ɣ�r�����3����1�ŁA
>4���ߓ������s��Core 2�ȍ~�Ɣ�ׂ����ɐ��\�͗��B
�˂����݂ǂ����
�E�u���[�h�{���Z�v���߂���ʓI���͂܂��u���Ă����Ƃ���
Sandy���O�̐���������̖��߂�1����/�T�C�N�������o�Ȃ�
�E��������Atom��P6�n�Ƃ͈قȂ�u���[�h�{���Z�v���߂�uop�ɕ��������Ɏ��s����̂�
�u���[�h�{���Z�v���߂�port0�݂̂��g���Aport1�ł��̑��̖��߂����s�\
���Ȃ킿�u���[�h�{���Z�v���߂Ɖ��Z���߂̑g�ݍ��킹�ł�������2����/clk���o����
�����PenM�܂łƓ����̃X���[�v�b�g�Auop fusion�̖���Pen3�܂łƔ�ׂ�ƃf�R�[�_�̐��Ȃ����L��
Atom���s�[�N2IPC+�C���I�[�_�Ŏ���IPC�����Ȃ�Ⴂ�ƌ����_�͒N�����F�߂�Ƃ��낾�Ǝv������
���̘_����S�������Ⴂ�̗��R�ŕЕt����̂������ɂ��匴�炵��
����Ȃ̂�����ƃR�[�h�����ĉĂ݂�Ε�����̂ɂ�
>�ȒP�ȉ��Z���߁u�����v�Ȃ��1�T�C�N��������2���߂ƂȂ邪�A
>��ʓI�ȁu���[�h�{���Z�v���߂��ƁA1�T�C�N��������1���߂������I�ȃX���[�v�b�g�ł���B
>�������O�q�̂Ƃ���A�ꉞ2���ߓ������s�̎��s���j�b�g�������Ă���Ƃ͌����A
>������1����/�T�C�N���̏��������ł��Ȃ������B3���ߓ������s��Pentium M�Ɣ�r�����3����1�ŁA
>4���ߓ������s��Core 2�ȍ~�Ɣ�ׂ����ɐ��\�͗��B
�˂����݂ǂ����
�E�u���[�h�{���Z�v���߂���ʓI���͂܂��u���Ă����Ƃ���
Sandy���O�̐���������̖��߂�1����/�T�C�N�������o�Ȃ�
�E��������Atom��P6�n�Ƃ͈قȂ�u���[�h�{���Z�v���߂�uop�ɕ��������Ɏ��s����̂�
�u���[�h�{���Z�v���߂�port0�݂̂��g���Aport1�ł��̑��̖��߂����s�\
���Ȃ킿�u���[�h�{���Z�v���߂Ɖ��Z���߂̑g�ݍ��킹�ł�������2����/clk���o����
�����PenM�܂łƓ����̃X���[�v�b�g�Auop fusion�̖���Pen3�܂łƔ�ׂ�ƃf�R�[�_�̐��Ȃ����L��
Atom���s�[�N2IPC+�C���I�[�_�Ŏ���IPC�����Ȃ�Ⴂ�ƌ����_�͒N�����F�߂�Ƃ��낾�Ǝv������
���̘_����S�������Ⴂ�̗��R�ŕЕt����̂������ɂ��匴�炵��
����Ȃ̂�����ƃR�[�h�����ĉĂ݂�Ε�����̂ɂ�
�S�����͂���Ȃ��A�}���Ȃ����āA���̕⑫�͂ɂ��Ă����Ƃ��肪����
>>463
������
> ���Ȃ݂ɃC���e���ɂ��A��ʓI�ȃv���O�������s���̓���������Ă݂�ƁA���ς�96���̖��߂��A�ЂƂ̃�Op�ɂ��̂܂ܕϊ��ł���Ƃ����B
�Ə����Ă邭���ɂ˂�
���W�X�^�Ə����ׂ��Ƃ���܂�Register File�Ə����Ă邵�A���������Ӗ��s���ȋL�q������
������
> ���Ȃ݂ɃC���e���ɂ��A��ʓI�ȃv���O�������s���̓���������Ă݂�ƁA���ς�96���̖��߂��A�ЂƂ̃�Op�ɂ��̂܂ܕϊ��ł���Ƃ����B
�Ə����Ă邭���ɂ˂�
���W�X�^�Ə����ׂ��Ƃ���܂�Register File�Ə����Ă邵�A���������Ӗ��s���ȋL�q������
466 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/26(��) 19:39:44.26 ID:c8Gvi8BP
�u�����������v�̂��납��V�Q�����Ă��悤��
Core MA�̓�����3IPC���Ƃ������K���Ɏ咣���Ă��ȁB
> �����uRegister File�v�́A���ۂɖ��߂���������ɂ������āA�ǂ�Register File���g�������蓖�Ă镔�����B
>�@�uAG�v�uDC1�v�uDC2�v�Ƒ����̂��A�f�[�^�L���b�V������̃f�[�^��荞�݂ł���B�uAddress Generator�v�ɂ���Ď�荞�ރA�h���X���m�肵�A����ɑ�������f�[�^��2�T�C�N��������DC1/DC2�̃X�e�[�W�Ŏ�荞�݁A���IRF�Ŋm�肵��Register File�Ɋi�[����B
�匴��AIRF�X�e�[�W�Ń��W�X�^��ǂ܂��ɂǂ�����ăA�h���X��������肾
�r���̃X�e�[�W�Ń��W�X�^�ɏ�������łǂ������
�匴��AGU��������Ȃ��Ǝv������ł���悤����(�|�[�g���Ƃɂ���)
http://origin.arstechnica.com/news.media/sv-diagram.gif
�����
> Issue�ł́A�ǂ���̖��߃|�[�g�Ŏ��s���邩�����肳���(��q)�B�p�C�v���C���}�ł͂����������2�{�o�Ă���悤�Ɍ����邪�A���ۂ́u�ǂ���̖��߃|�[�g�ŏ������邩�v������1bit�̃^�O����Op�ɕt������邾���ŁA�����I�ɂ͂܂���{������Ă���B
����Ȗϑz���y���Ă���̂�
>�@�uAG�v�uDC1�v�uDC2�v�Ƒ����̂��A�f�[�^�L���b�V������̃f�[�^��荞�݂ł���B�uAddress Generator�v�ɂ���Ď�荞�ރA�h���X���m�肵�A����ɑ�������f�[�^��2�T�C�N��������DC1/DC2�̃X�e�[�W�Ŏ�荞�݁A���IRF�Ŋm�肵��Register File�Ɋi�[����B
�匴��AIRF�X�e�[�W�Ń��W�X�^��ǂ܂��ɂǂ�����ăA�h���X��������肾
�r���̃X�e�[�W�Ń��W�X�^�ɏ�������łǂ������
�匴��AGU��������Ȃ��Ǝv������ł���悤����(�|�[�g���Ƃɂ���)
http://origin.arstechnica.com/news.media/sv-diagram.gif
{kind=link}
�����
> Issue�ł́A�ǂ���̖��߃|�[�g�Ŏ��s���邩�����肳���(��q)�B�p�C�v���C���}�ł͂����������2�{�o�Ă���悤�Ɍ����邪�A���ۂ́u�ǂ���̖��߃|�[�g�ŏ������邩�v������1bit�̃^�O����Op�ɕt������邾���ŁA�����I�ɂ͂܂���{������Ă���B
����Ȗϑz���y���Ă���̂�
�c�q��������
���O���匴�Ƒ卷�Ȃ�
���O���匴�Ƒ卷�Ȃ�
470 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/28(��) 10:42:51.22 ID:l25aju+u
>>468�͉�����Ȃ�����
472 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/28(��) 14:04:44.20 ID:l25aju+u
��Ȃ����O���h����Ő������Ȃ��Ă������Ɛ��m�Ȏ�������킢��
Atom��4�N�͎g���Ă邵��
Atom��4�N�͎g���Ă邵��
473 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/10/28(��) 14:07:04.68 ID:l25aju+u
�܂��C�t���ĂȂ��̂���
���̓˂����݂ɂ͏d��Ȍ�肪�������
���̓˂����݂ɂ͏d��Ȍ�肪�������
�c�q����A�������������
�G�ꂿ�Ⴄ���
�c�q�͂����h���炾��
477 �F�|���͓��{�̓y�F2012/10/29(��) 23:13:53.96 ID:Pk6lCYbJ
IBM creates first high-density, self-assembled carbon nanotube computer chip
http://www.extremetech.com/computing/138995-ibm-creates-first-mass-producible-self-assembled-carbon-nanotube-computer-chip
http://www.extremetech.com/computing/138995-ibm-creates-first-mass-producible-self-assembled-carbon-nanotube-computer-chip
AMD�A�uARM�x�[�X��Opteron�v�J����\��
http://www.itmedia.co.jp/pcuser/articles/1210/30/news051.html
�J�����̐��i
64bitARM
Steamroller
Jaguar
�����炿��������Ђ������A�[�L�e�N�`�����s������ȂƏ��ꎞ��
http://www.itmedia.co.jp/pcuser/articles/1210/30/news051.html
�J�����̐��i
64bitARM
Steamroller
Jaguar
�����炿��������Ђ������A�[�L�e�N�`�����s������ȂƏ��ꎞ��
�������鍠�ɂ�ARM�������
���ɂȂ��Ă����ȋC�����Ă���
���ɂȂ��Ă����ȋC�����Ă���
ARM�Q���Ŋ������ǂ��Ȃ��Ă邩�m�F�������^�n���P�[���̉e����NYSE�͂��x�݂ł���
�m�x�r�d��31���̓d�q����Ή��������A����t���A�ɑ��Q�Ȃ�
http://jp.reuters.com/article/jpnewEnv/idJPTYE89T04F20121030
�m�x�r�d��31���̓d�q����Ή��������A����t���A�ɑ��Q�Ȃ�
http://jp.reuters.com/article/jpnewEnv/idJPTYE89T04F20121030
opteron�Ď���arm�T�[�o�[���z�菤�i�H
��
v8�͍Ō�̃��W���[ISA�ɂȂ邩������Ȃ��̂ɁA�S���ʔ����Ɍ�����
v8�͍Ō�̃��W���[ISA�ɂȂ邩������Ȃ��̂ɁA�S���ʔ����Ɍ�����
64bit ARM�̏�o�Ă�����
http://www.anandtech.com/show/6420/arms-cortex-a57-and-cortex-a53-the-first-64bit-armv8-cpu-cores
http://www.anandtech.com/show/6420/arms-cortex-a57-and-cortex-a53-the-first-64bit-armv8-cpu-cores
http://images.anandtech.com/doci/6420/Screen%20Shot%202012-10-30%20at%2012.22.04%20PM%20copy.png
�����A���������ɍ����߂��p�X������̂������[����
���@���s�p����
A15�ɂ���Ȃ�������
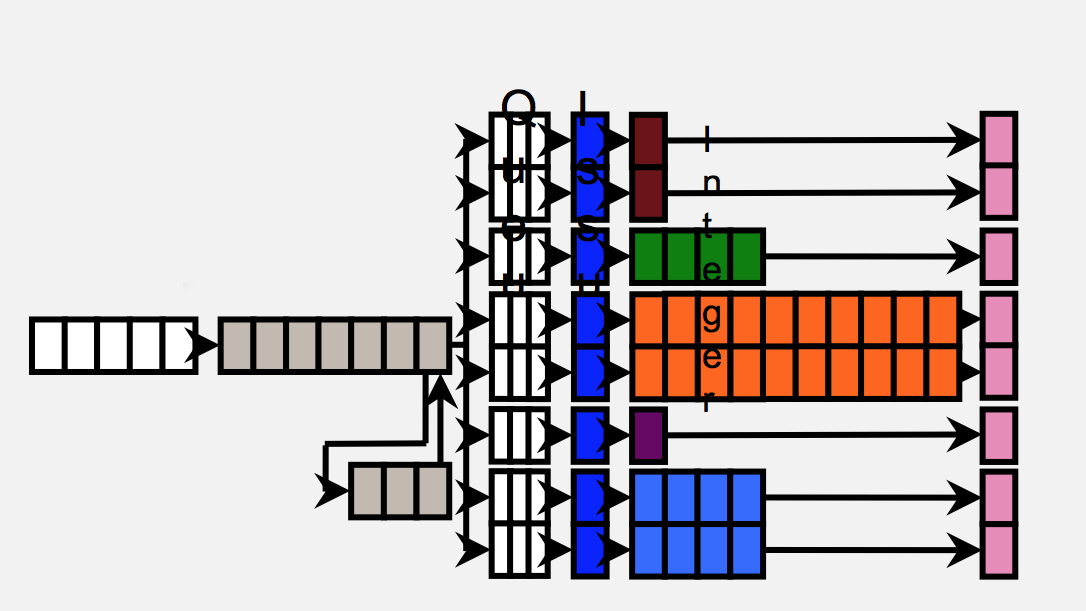{kind=link}
�����A���������ɍ����߂��p�X������̂������[����
���@���s�p����
A15�ɂ���Ȃ�������
loop buffer�ł���
http://pc.watch.impress.co.jp/img/pcw/docs/554/303/html/9.jpg.html
http://pc.watch.impress.co.jp/img/pcw/docs/554/303/html/9.jpg.html
{kind=link}
http://www.eetimes.com/electronics-news/4400351/ARM-A57-core-detailed-in-technical-session
Cortex-A57��SPECint2000�̃X�R�A��[email protected]
�N���b�N������Ō�����Banias/Dothan�Ɠ������炢
http://www.arm.com/images/performance.jpg
���̐}�ɂ���A15�͂�����20%�x���Ƃ������ƂŁA�C�}�C�`����
Cortex-A57��SPECint2000�̃X�R�A��[email protected]
�N���b�N������Ō�����Banias/Dothan�Ɠ������炢
http://www.arm.com/images/performance.jpg
{kind=link}
���̐}�ɂ���A15�͂�����20%�x���Ƃ������ƂŁA�C�}�C�`����
�X�R�A�������Ă���X���C�h�͂���http://eetimes.com/ContentEETimes/Images/ARM7.jpg
{kind=link}
int2000�Ƃ������傢�Â߂̃x���`�Ȃ̂��A�܂������ɂ�ARM���Ȃ�
���R�A2006���g��Ȃ��̂͂Ȃ��H�Ƃ����b�ɂȂ����Ⴄ���
490 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/03(�y) 11:03:29.47 ID:W+oNa/Z6
2006��2000��胁������H�����炶��Ȃ��́H
Cortex A5x��4GB�ȏ�̃��������T�|�[�g���邯�ǎ��ۂ�4GB�ȏ�̃�������ς��ł�
�d�͌����̃X�C�[�g�X�|�b�g���O���Ă��܂��Ƃ��������ȃv���Z�b�T���Ǝv���Ă�
Cortex A5x��4GB�ȏ�̃��������T�|�[�g���邯�ǎ��ۂ�4GB�ȏ�̃�������ς��ł�
�d�͌����̃X�C�[�g�X�|�b�g���O���Ă��܂��Ƃ��������ȃv���Z�b�T���Ǝv���Ă�
3�N���8Gbit��DRAM��4�q������d�͌����̃X�C�[�g�X�|�b�g���O��? ����ȃo�i�i
492 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/03(�y) 15:58:27.81 ID:W+oNa/Z6
3�N�ォ���B20nm���Ă���Ȑ�̘b�ȂȁB
Microsoft�I��64�r�b�gARM�͂��܂�D���ł͂Ȃ��悤�����ǁB
Microsoft�I��64�r�b�gARM�͂��܂�D���ł͂Ȃ��悤�����ǁB
�����AMS�̎��Y��x86�ɑ啔������Ă邩��
�ʂ̃A�[�L�e�N�`�����䓪������MS�̉��l�͂��̕��������邱�ƂɂȂ�B
���Ƃ�����64bitARM��Windows Server�o�����Ƃ���Ŏs�ꐫ�͂Ȃ�����A
������܂˂��Č��Ă��邵���Ȃ��B
�ʔ����͂��͂Ȃ��ȁB
�ʂ̃A�[�L�e�N�`�����䓪������MS�̉��l�͂��̕��������邱�ƂɂȂ�B
���Ƃ�����64bitARM��Windows Server�o�����Ƃ���Ŏs�ꐫ�͂Ȃ�����A
������܂˂��Č��Ă��邵���Ȃ��B
�ʔ����͂��͂Ȃ��ȁB
arm�̓^�u���b�g��b�d�@����Ő��ݕ����ł������
�����ƁANT4���f�B�X��̂͂����܂ł��B
496 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/03(�y) 18:26:02.22 ID:W+oNa/Z6
NT5�J�[�l����Xbox360�ɂ��ڐA����Ă邯�ǂ�
�㓡������Cortex-A57�̏ڕ��Ă�B
2014�N�̃n�C�G���h�X�}�[�g�t�H��&�^�u���b�g��CPU�R�A�uCortex-A57�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20121102_570458.html
���\���\���ǂ����������A�R�A�P�i�̐��\��AMD�̃R�A�Ō����Ƃǂ̈ʂ��낤���H
Atom���͂��Ȃ�ǂ�����ABobcat�R�A����ŁAPiledriver�R�A�ɋ߂��H
2014�N�̃n�C�G���h�X�}�[�g�t�H��&�^�u���b�g��CPU�R�A�uCortex-A57�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20121102_570458.html
���\���\���ǂ����������A�R�A�P�i�̐��\��AMD�̃R�A�Ō����Ƃǂ̈ʂ��낤���H
Atom���͂��Ȃ�ǂ�����ABobcat�R�A����ŁAPiledriver�R�A�ɋ߂��H
Atom��Bobcat�̒��x���Ԃ�����
>>498
Atom��Bobcat����CPU�R�A�P�i�̐��\�͂���Ȃɕς�����
>>497�����A57�͓��N���b�N�̃V���O���X���b�h�Ŕ{���炢�o�Ăˁ[�H
Pentium M�Ƃ�Athlon II�ɋ߂��R�A���\�Ȃ�H
Atom��Bobcat����CPU�R�A�P�i�̐��\�͂���Ȃɕς�����
>>497�����A57�͓��N���b�N�̃V���O���X���b�h�Ŕ{���炢�o�Ăˁ[�H
Pentium M�Ƃ�Athlon II�ɋ߂��R�A���\�Ȃ�H
�܂�IPC�������ׂ����̂��^�[�Q�b�g���g�����܂߂������I�Ȑ��\�̘b���������̂����͂����肵�Ȃ���
IPC�͍���������750mW��2.5GHz���Čv��ʂ�ɍs���Ȃ猋�\���\������
�m�肽���͎̂��g�������킹���Ƃ���IPC�ł��B
ARM�̃R�A�͔��M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ����̂ŁB
ARM�̃R�A�͔��M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ����̂ŁB
>���M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ����
����������
����������
>>503
Cortex-A15�̗Ⴕ���Ȃ����ǁB�ubig.LITTLE�̓d�͂Ɛ��\�v�Q�ƁB
http://pc.watch.impress.co.jp/docs/column/kaigai/20120214_511793.html
Cortex-A15�̗Ⴕ���Ȃ����ǁB�ubig.LITTLE�̓d�͂Ɛ��\�v�Q�ƁB
http://pc.watch.impress.co.jp/docs/column/kaigai/20120214_511793.html
>>504
���̐}�͓d���グ�Ď��g�����グ��ΐ��\�͌��シ��Ƃ���
�萫�I�ȃA�^���}�G�̘b��������Ă��邾���B
�����͂���ǂǂ�ȃv���Z�b�T�����Ă����ł��傤��A
��ʓI�ȃO���t�ł͂Ȃ��̂ŊT�O�}�ȏ�̈Ӗ��͖����ˁB
���̐}�͓d���グ�Ď��g�����グ��ΐ��\�͌��シ��Ƃ���
�萫�I�ȃA�^���}�G�̘b��������Ă��邾���B
�����͂���ǂǂ�ȃv���Z�b�T�����Ă����ł��傤��A
��ʓI�ȃO���t�ł͂Ȃ��̂ŊT�O�}�ȏ�̈Ӗ��͖����ˁB
���̃O���t���ǂ��ǂނƁu���M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ���� �v�ɂȂ��
�����Ƃ��Ԃ���
�N���l���Ă���悤�ȈӖ��ł͂Ȃ�
�ł��d���グ���3GHz���Ƃ��o�Ă邩��
���\���g�����グ����A���Č�������
�����ԈႢ�ł��Ȃ��悤�ȁH
���\���g�����グ����A���Č�������
�����ԈႢ�ł��Ȃ��悤�ȁH
>504�̐}�͊T�O�}�������̂ˁB
Cortex-A15��2�R�A��4GHz�܂ŏオ���TI�͌����Ă���悤�ȋC������̂����c
http://www.tij.co.jp/lsds/ti_ja/arm/overview.page
Cortex-A15��2�R�A��4GHz�܂ŏオ���TI�͌����Ă���悤�ȋC������̂����c
http://www.tij.co.jp/lsds/ti_ja/arm/overview.page
�Ȃ��Ⴂ���Ă���悤����
ARM�̓��C�Z���X�`�Ԃɂ���邪��{�V���Z�T�C�U�u��IP������
���C�Z���V���Ńp�C�v���C�����蒼���Ύ��g���Ȃ�
������ł��ς�����B���ǂ̓o�����X�̘b�Ȃ̂ł����
�Ӗ������邩�ǂ����̔��f�͕ʁB
ttp://www.arm.com/ja/products/processors/cortex-a/cortex-a15.php
ARM���z�肵�Ă���̂�2.5GHz�Ńn�[�h�}�N���͂������^�[�Q�b�g��
���Ă��鎖�͎f����B
TI��4GHz�ƌ���������ƌ����đS�Ă�A15��4GHz�œ����킯�ł͂Ȃ��B
ARM�̓��C�Z���X�`�Ԃɂ���邪��{�V���Z�T�C�U�u��IP������
���C�Z���V���Ńp�C�v���C�����蒼���Ύ��g���Ȃ�
������ł��ς�����B���ǂ̓o�����X�̘b�Ȃ̂ł����
�Ӗ������邩�ǂ����̔��f�͕ʁB
ttp://www.arm.com/ja/products/processors/cortex-a/cortex-a15.php
ARM���z�肵�Ă���̂�2.5GHz�Ńn�[�h�}�N���͂������^�[�Q�b�g��
���Ă��鎖�͎f����B
TI��4GHz�ƌ���������ƌ����đS�Ă�A15��4GHz�œ����킯�ł͂Ȃ��B
�ŁA���ɂȂ�����ARM�ł���y����ł���悤�ɂȂ�́H
����łЂ�����ARM�̘b���U�葱���邭��������
����łЂ�����ARM�̘b���U�葱���邭��������
ARM�ȂǁA��ΐ��\�ł�x86�̑����ɂ��y��B
�ꐡ�O�ɂ���Șb�����������ǁB
http://news.mynavi.jp/news/2011/08/23/079/index.html
http://news.mynavi.jp/news/2011/08/23/079/index.html
�܂������Ă��܂�A15���̂̐��i�o�ׂ���ĂȂ�����Ȃ��B
�ǂ�����\�ǂ܂�B
�ǂ�����\�ǂ܂�B
>>511
�ł�TI�������ʼn_��4GHz�Ƃ������Ă��Ȃ����낤��
���\�N���b�N�ϐ����肻���Ȋ��������邯�ǂ�
TSMC��28nm��2.9GHz��3W������ƂƂ����ď����Ă邵
�ł�TI�������ʼn_��4GHz�Ƃ������Ă��Ȃ����낤��
���\�N���b�N�ϐ����肻���Ȋ��������邯�ǂ�
TSMC��28nm��2.9GHz��3W������ƂƂ����ď����Ă邵
>>515
����10����nexus10�����邺
����10����nexus10�����邺
>>515
Chromebook�͔�������
Chromebook�͔�������
519 �FSocket774�F2012/11/04(��) 00:09:45.35 ID:nsPRnlbk
>>516
�����ʼn_�Ȃ̂��Ӗ��s���B
�S�R�������Ă��Ȃ��悤�Ȃ̂ŁA��������ꂸ�����Ȃ�����TI��A15��
ARM��A15�͏����v�}������Ȃ����̕ʃ��m���ƌ����Ă���B
�����ʼn_�Ȃ̂��Ӗ��s���B
�S�R�������Ă��Ȃ��悤�Ȃ̂ŁA��������ꂸ�����Ȃ�����TI��A15��
ARM��A15�͏����v�}������Ȃ����̕ʃ��m���ƌ����Ă���B
�����郉�{�ł̘b���낤�ˁ�4GHz
>>519
�ǂ��ʃ��m�Ȃ̂��m���TI�������v���œK�����ĂĂ�
������܂߂�ARM�A�[�L�̍����g�����������
A15������X�e�[�W����15+���Ă͕̂ς���
���Ȃ荂�N���b�N�u���ȃR�A�Ɏd�オ���Ă�ƌ����č����x������
�p�r���}�C�N���T�[�o�[�Ƃ��Ȃ�3GHz�������ʂɏo�Ă�����
�ǂ��ʃ��m�Ȃ̂��m���TI�������v���œK�����ĂĂ�
������܂߂�ARM�A�[�L�̍����g�����������
A15������X�e�[�W����15+���Ă͕̂ς���
���Ȃ荂�N���b�N�u���ȃR�A�Ɏd�オ���Ă�ƌ����č����x������
�p�r���}�C�N���T�[�o�[�Ƃ��Ȃ�3GHz�������ʂɏo�Ă�����
>>521
>������܂߂�ARM�A�[�L�̍����g������
4GHz��TI��A15��ARM���t�@�����X�̓d�͓����͓���ł͂Ȃ����낤�B
�X�s�[�h�r���̈Ⴂ������2.5�|4.0�̂���͂��蓾�Ȃ��B
����āA�������ЂƂ�����Ɍ�邱�Ƃ��K�����Ƃ͎v���Ȃ��B
���ہA�I�����ւ����A9�̓��[�p���[�ɐU�����ׁAX00MHz�����o�Ȃ����A
������ƌ�����2.5GHz��A9�Ɠ���Ɉ������炨�����Șb�ɂȂ邾�낤�H
>������܂߂�ARM�A�[�L�̍����g������
4GHz��TI��A15��ARM���t�@�����X�̓d�͓����͓���ł͂Ȃ����낤�B
�X�s�[�h�r���̈Ⴂ������2.5�|4.0�̂���͂��蓾�Ȃ��B
����āA�������ЂƂ�����Ɍ�邱�Ƃ��K�����Ƃ͎v���Ȃ��B
���ہA�I�����ւ����A9�̓��[�p���[�ɐU�����ׁAX00MHz�����o�Ȃ����A
������ƌ�����2.5GHz��A9�Ɠ���Ɉ������炨�����Șb�ɂȂ邾�낤�H
�܂��A�������i���ǂ��܂ŃI���W�i�������ċC�͂����
�ނ����T���X����ARM�����1GHz�z���œ��������Ƃ��̂��Ƃ��v���o��
�ނ����T���X����ARM�����1GHz�z���œ��������Ƃ��̂��Ƃ��v���o��
>>522
�����v��t�@�u���Ⴆ�Γd�͓���������Ȃ�Ă��肦��
����Șb���A�[�L�e�N�`���I�ɂ̓p�C�v���C���i����15�`������
P6��10�ANetBurst��20�APrescott��31�ACore MA��14��
�����g���Ƃ̐e�a���͊T��Core MA�N���X
���Ƃ̓v���Z�X�Ƃ������v������čl����Ⴂ����ˁ[�́H
���ۃ��t�@�����X��A15��TSMC20nm�Ȃ�2W�ȉ���3GHz���Ă��Ȃ肶���
�����v��t�@�u���Ⴆ�Γd�͓���������Ȃ�Ă��肦��
����Șb���A�[�L�e�N�`���I�ɂ̓p�C�v���C���i����15�`������
P6��10�ANetBurst��20�APrescott��31�ACore MA��14��
�����g���Ƃ̐e�a���͊T��Core MA�N���X
���Ƃ̓v���Z�X�Ƃ������v������čl����Ⴂ����ˁ[�́H
���ۃ��t�@�����X��A15��TSMC20nm�Ȃ�2W�ȉ���3GHz���Ă��Ȃ肶���
>>511
�킩�����Ⴂ��Ƃ͎v�����A�����\�ȃ\�t�g�}�N��IP�̃��C�Z���X�ƌ����Ă�
�p�C�v���C����Ȃ�������ɒ��g�����郉�C�Z���X�ƁA�����ꂿ��ʖڂ��ă��C�Z���X�����邩��ȁB
TI�͖��߃Z�b�g�܂߂Ē��g�Ɏ�������郉�C�Z���X�����ǁA���g�Ɏ����ꂽ�R�A�Ȃ�
�N�A���R����SNAPDRAGON�݂����ɕʂ̖��O�ŌĂԂ̂��ʗႾ���A
Cortex-A15�ƌ����Ă�ȏ�͒��g�ɂ͑傫����������Ă��Ȃ��ƍl����ׂ��B
�킩�����Ⴂ��Ƃ͎v�����A�����\�ȃ\�t�g�}�N��IP�̃��C�Z���X�ƌ����Ă�
�p�C�v���C����Ȃ�������ɒ��g�����郉�C�Z���X�ƁA�����ꂿ��ʖڂ��ă��C�Z���X�����邩��ȁB
TI�͖��߃Z�b�g�܂߂Ē��g�Ɏ�������郉�C�Z���X�����ǁA���g�Ɏ����ꂽ�R�A�Ȃ�
�N�A���R����SNAPDRAGON�݂����ɕʂ̖��O�ŌĂԂ̂��ʗႾ���A
Cortex-A15�ƌ����Ă�ȏ�͒��g�ɂ͑傫����������Ă��Ȃ��ƍl����ׂ��B
527 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/04(��) 11:16:00.07 ID:hX3rLMq2
���s��A9���J�^���O�X�y�b�N��ł�40nm��upto 2GHz������
>>524
>���t�@�����X��A15��TSMC20nm�Ȃ�2W�ȉ���3GHz
��������TI��4GHz�ƌ����Ă��邩��A�ꗥA15�͍����g������
�Ȃ�̂͂��������ƌ����Ă���
��{�̘b�̗���>���M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ����
�Ƃ����b�ɂ͂ǂ��]��ł��Ȃ�Ȃ�
���Ȃ݂�ARM�̏o������d�͂̓L���b�V�������̒l�������
>���t�@�����X��A15��TSMC20nm�Ȃ�2W�ȉ���3GHz
��������TI��4GHz�ƌ����Ă��邩��A�ꗥA15�͍����g������
�Ȃ�̂͂��������ƌ����Ă���
��{�̘b�̗���>���M���C�ɂ��Ȃ��Ȃ猋�\���g�����グ����
�Ƃ����b�ɂ͂ǂ��]��ł��Ȃ�Ȃ�
���Ȃ݂�ARM�̏o������d�͂̓L���b�V�������̒l�������
���̊ϓ_�ł́A���͂�SoC�̎���Ȃ̂ŃL���b�V�������Ƃ��킸���ӑS���݂̓d�͂Ŕ�r���Ȃ��ƈӖ��͂Ȃ������ˁB
>>528
�����\�\�t�g�R�A�́A�L���b�V���ʂ����[�U�[�ݒ肾����ȁ`
>>529
ARM���̂�IP��������ASoC�P�ʂɂȂ�Ƃ˂��B
�p�r�Ⴂ��SoC��ׂĂ����ĂȂ����Ⴄ����c
�����\�\�t�g�R�A�́A�L���b�V���ʂ����[�U�[�ݒ肾����ȁ`
>>529
ARM���̂�IP��������ASoC�P�ʂɂȂ�Ƃ˂��B
�p�r�Ⴂ��SoC��ׂĂ����ĂȂ����Ⴄ����c
>>527
TSMC40nmA9�N�A�b�h��Tegra3�������肾��
�J�X�^���J�[�l���̃I�[�o�[�N���b�N��2GHz�������Ⴄ�炵����
�s�����1.8GHz�ɗ}���������������Č����Ă邯��
http://androidcommunity.com/nexus-7-quad-core-overclocked-to-2-0-ghz-shatters-benchmarks-20120825/
TSMC40nmA9�N�A�b�h��Tegra3�������肾��
�J�X�^���J�[�l���̃I�[�o�[�N���b�N��2GHz�������Ⴄ�炵����
�s�����1.8GHz�ɗ}���������������Č����Ă邯��
http://androidcommunity.com/nexus-7-quad-core-overclocked-to-2-0-ghz-shatters-benchmarks-20120825/
>>528
�܂�������������ł��N���b�N�C�[���h�݂����Șb�Ńo�����͏o�邾��
�ꗥ�Ƃ�����Șb�͂��ĂȂ�����Ȃ��H
�d����TDP���グ����p�r�Ȃ���g���������オ�邾��H�H
�悭����Ȃ����ǂ����ے肵�Ă�́H�H
�܂�������������ł��N���b�N�C�[���h�݂����Șb�Ńo�����͏o�邾��
�ꗥ�Ƃ�����Șb�͂��ĂȂ�����Ȃ��H
�d����TDP���グ����p�r�Ȃ���g���������オ�邾��H�H
�悭����Ȃ����ǂ����ے肵�Ă�́H�H
����ɏo����(�����肪������)���x���Ŗ����A�������Č����Ă�낗
>>532
>�N���b�N�C�[���h�݂����Șb�Ńo����
�X�s�[�h�r���̘b�͊��ɂ����B���̚g�͕s�K��
>�悭����Ȃ����ǂ����ے肵�Ă�́H�H
�Ƃ������A���f���邾���̏��͂܂��o�Ă��Ă��Ȃ��B
�����v����TDP��d�������Ƃ͌���Ȃ�
�����ăp�C�v�i���݂̂��琄���ʂ�镨�ł��Ȃ��B
Ivy�o��O�Ƀp�C�v���C����Sandy��������p����22nm��
�g�����W�X�^�����������Ă��邩��AIvy�̓N���b�N�A�b�v
�����肾��IYH�A�ƌ����Ă����y�Ɖ����ς��Ȃ��B
�����x�ɋ����Șb���B
>�N���b�N�C�[���h�݂����Șb�Ńo����
�X�s�[�h�r���̘b�͊��ɂ����B���̚g�͕s�K��
>�悭����Ȃ����ǂ����ے肵�Ă�́H�H
�Ƃ������A���f���邾���̏��͂܂��o�Ă��Ă��Ȃ��B
�����v����TDP��d�������Ƃ͌���Ȃ�
�����ăp�C�v�i���݂̂��琄���ʂ�镨�ł��Ȃ��B
Ivy�o��O�Ƀp�C�v���C����Sandy��������p����22nm��
�g�����W�X�^�����������Ă��邩��AIvy�̓N���b�N�A�b�v
�����肾��IYH�A�ƌ����Ă����y�Ɖ����ς��Ȃ��B
�����x�ɋ����Șb���B
�d���グ��Ȃ琔�����炢�̃N���b�N�̐L�т���͂���ɂ��܂��Ă낗
���̃X���ł����̂�������ǂ��邳���
���炟����B
�y�����ǂ܂��Ă�����Ă܂����B
�����l�ł����B
�y�����ǂ܂��Ă�����Ă܂����B
�����l�ł����B
�ˑR�������̂Ńr�r����
�₵���Ȃ�ȁE�E�E
�₵���Ȃ�ȁE�E�E
�ߋ��̋L���܂ŏ������ƂȂ��낤�ɁE�E�E
�ߋ��̋L���܂ŏ����Ȃ��Ă��悢�ȁc
�uA53�̐��\���炷��ƁAA9�v���Z�b�T�̌�p�Ƃ��Ă̎��i�͏\�����邾�낤�B�v�Ƃ��B
ARM TechCon 2012�@/�@Cortex-A53��
http://news.mynavi.jp/articles/2012/11/01/arm01/001.html
�uA53�̐��\���炷��ƁAA9�v���Z�b�T�̌�p�Ƃ��Ă̎��i�͏\�����邾�낤�B�v�Ƃ��B
ARM TechCon 2012�@/�@Cortex-A53��
http://news.mynavi.jp/articles/2012/11/01/arm01/001.html
541 �FSocket774�F2012/11/06(��) 10:10:25.97 ID:cc30NzJr
����[�܂���
����͎c�O���Ȃ�
�܂������ꕜ�����Ă���邱�Ƃ�M���Ă��
����͎c�O���Ȃ�
�܂������ꕜ�����Ă���邱�Ƃ�M���Ă��
ARM TechCon 2012�@/�@Cortex-A57��
http://news.mynavi.jp/articles/2012/11/05/arm02/index.html
http://news.mynavi.jp/articles/2012/11/05/arm02/index.html
�A�b�v���̋Z�p�҂�͎��Ѓ��o�C���[���Ɏg�p���Ă��锼���̃f�U�C���ł�
�f�X�N�g�b�v��b�v�g�b�v�^�̃p�\�R���p�Ƃ��ď\���ȃp���[������Ƃ̊m�M
�����߂���ƁA����ɏڂ����R�l�̊W�҂��A�v�悪�閧�����ł��邱�Ƃ�
���R�ɓ����Ō�����B
�ăA�b�v���A�l�����p�����̂̃C���e������̐�ւ�������
http://www.bloomberg.co.jp/news/123-MD199C6S972D01.html
�f�X�N�g�b�v��b�v�g�b�v�^�̃p�\�R���p�Ƃ��ď\���ȃp���[������Ƃ̊m�M
�����߂���ƁA����ɏڂ����R�l�̊W�҂��A�v�悪�閧�����ł��邱�Ƃ�
���R�ɓ����Ō�����B
�ăA�b�v���A�l�����p�����̂̃C���e������̐�ւ�������
http://www.bloomberg.co.jp/news/123-MD199C6S972D01.html
>>536
����Ȏ�O���X�S�J�̖ϑz���͂����܂܂Ŋy�����ǂ߂Ă��Ȃ�āc�c�����Ȃ�
����Ȏ�O���X�S�J�̖ϑz���͂����܂܂Ŋy�����ǂ߂Ă��Ȃ�āc�c�����Ȃ�
>>543
�܂��c
����68k����PowerPC�Ɉڂ������̈�����
����PowerPC����Intel�Ɉڂ������̈�����
�J��Ԃ��̂��c
����Ȃ��˂�w
�܂��c
����68k����PowerPC�Ɉڂ������̈�����
����PowerPC����Intel�Ɉڂ������̈�����
�J��Ԃ��̂��c
����Ȃ��˂�w
Jobs�����Ȃ����̌o�c�w����
���������ɂ͈ڍs�̌��f�͂ł��Ȃ�����
���������ɂ͈ڍs�̌��f�͂ł��Ȃ�����
�M�S�̌���������A������r�b�O�E�F�[�u
�O��͖ق��ĐM�҂̂�������s���Ɋ��҂��Ă邾���ł����ȒP�ȃC�x���g�ł������܂�
�O��͖ق��ĐM�҂̂�������s���Ɋ��҂��Ă邾���ł����ȒP�ȃC�x���g�ł������܂�
��_�̂���W���u�Y�����Ȃ��Ȃ����킯������ȁB
�ڍs�������琶���c��Ă���Ƃ����킯�B
�����b�g�������Ă̈ڍs�Ȃ番����Ȃ��b�ł͂Ȃ���
�������Ă���h��̐������Ȃ��Ȃ����Ƃ��ɂ�
��������o�čs���Ȃ��Ă͂Ȃ�Ȃ��̂ŁA���̂Ƃ��̑�͑ł��Ă������Ċ����B
��������o�čs���Ȃ��Ă͂Ȃ�Ȃ��̂ŁA���̂Ƃ��̑�͑ł��Ă������Ċ����B
552 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/06(��) 22:02:48.78 ID:rA1mXodc
�W���u�Y��Apple�̑n�ݎ҂ɂ��Čo�c��𗧂Ē��������т����邩�炱������Ă�킯��
���������l�����ĊF�������
�N�b�N�͗D�G�ł͂��邾�낤���NjZ�p����m��Ȃ������
���������l�����ĊF�������
�N�b�N�͗D�G�ł͂��邾�낤���NjZ�p����m��Ȃ������
>>544
�G����l�b�g�̋L����������m���Ă܂������Ċ������������
�G����l�b�g�̋L����������m���Ă܂������Ċ������������
�����ł��Ȃ�
X-Gene��4���ߓ������sOoO3GHz��ARMv8�R�A���đf�G����
2012�N���܂łɐ��i�����ē��ʂ͍ō����\��ARM�`�b�v�ɂȂ肻�������
2012�N���܂łɐ��i�����ē��ʂ͍ō����\��ARM�`�b�v�ɂȂ肻�������
16�R�A�A������4ch�A�`�b�v�S�̂�50W���炢�HRAS�܂ł��Ă���������͂Ȃ���ȁB
MIPS�AAST�ɑ唼�̏��L�����p - IMG�ɂ�锃���ɍ���
http://news.nicovideo.jp/watch/nw422256
http://news.nicovideo.jp/watch/nw422256
559 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/07(��) 21:26:28.07 ID:iPnw+suZ
�������ϑw����22nm��Penwell����B
CloverTrail+���܂��������̒i�K�ō̗p�@�킪�������o�Ă邱�Ɠ_�A��Ƃ͍̗p�ɑO�������ȁB
CloverTrail+���܂��������̒i�K�ō̗p�@�킪�������o�Ă邱�Ɠ_�A��Ƃ͍̗p�ɑO�������ȁB
�������ϑw����SoC�ŁA�������W���i���Ă�
�X�}�z��鑤���炵����A�̗p���ɂ������i����B
Android2.3����Android4�݂����ɁA�Ƃ肠��������̂܂܂�
�������������₹�Ȃ�Ƃ��������Ă̂����Ƃ��ASoC���Ɣ���������!���ĂȘb��
�Ԃ����ႯSoC����Ĕ��鑤�ɂƂ��ėL���ɂȂ邾�������?
�X�}�z��鑤���炵����A�̗p���ɂ������i����B
Android2.3����Android4�݂����ɁA�Ƃ肠��������̂܂܂�
�������������₹�Ȃ�Ƃ��������Ă̂����Ƃ��ASoC���Ɣ���������!���ĂȘb��
�Ԃ����ႯSoC����Ĕ��鑤�ɂƂ��ėL���ɂȂ邾�������?
���\���オ���ď��^�����ł���
�R�X�g���Ó��Ȃ�ϑw���Ȃ����R�͋@�탁�[�J�[�ɂ͂Ȃ�
�R�X�g���Ó��Ȃ�ϑw���Ȃ����R�͋@�탁�[�J�[�ɂ͂Ȃ�
PoP��DRAM�ϑw�Ȃ�ĕ��ʂɍ̗p���Ă���
Apple��A4,A5,A6�ƑS��PoP�g���Ă�
Apple��A4,A5,A6�ƑS��PoP�g���Ă�
Core i7 3970X��6-core��HyperThreading technology�ɂ��12-thread�쓮�ɑΉ�����B
L3�L���b�V���e�ʂ�15MB �A�������R���g���[����Quad-channel DDR3�ɑΉ�����B
���g���͒�i3.50GHz / Turbo��4.00GHz�ƂȂ�B
�Ή�Socket�͍��܂ł́gSandyBridge-E�h���lLGA2011�ł��邪�A
TDP��150W�ƂȂ�A���܂ł̃��f���Ɣ�r�����20W�����ݒ肳��Ă���B
ttp://northwood.blog60.fc2.com/
L3�L���b�V���e�ʂ�15MB �A�������R���g���[����Quad-channel DDR3�ɑΉ�����B
���g���͒�i3.50GHz / Turbo��4.00GHz�ƂȂ�B
�Ή�Socket�͍��܂ł́gSandyBridge-E�h���lLGA2011�ł��邪�A
TDP��150W�ƂȂ�A���܂ł̃��f���Ɣ�r�����20W�����ݒ肳��Ă���B
ttp://northwood.blog60.fc2.com/
Win���v��Ȃ��Ȃ�H
Microsoft will allow iOS users to purchase an Office 365 subscription within the app, or let organizations distribute codes to enable Office Mobile editing for users.
The apps will allow for basic editing, but we're told this won't go very far in attempting to replace regular full use of a desktop Office version.
Exclusive: Microsoft Office for iPhone, iPad, and Android revealed
http://www.theverge.com/2012/11/7/3612422/microsoft-office-mobile-ipad-iphone-android-screenshots?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+WinRumors+%28WinRumors%29&utm_content=Google+Reader
Microsoft will allow iOS users to purchase an Office 365 subscription within the app, or let organizations distribute codes to enable Office Mobile editing for users.
The apps will allow for basic editing, but we're told this won't go very far in attempting to replace regular full use of a desktop Office version.
Exclusive: Microsoft Office for iPhone, iPad, and Android revealed
http://www.theverge.com/2012/11/7/3612422/microsoft-office-mobile-ipad-iphone-android-screenshots?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+WinRumors+%28WinRumors%29&utm_content=Google+Reader
�K���s�K���AARM�ł͂܂Ƃ��ɓ������
�����ARM�v��Ȃ��Ƃ����l������A
�����Office�v��Ȃ��Ƃ����l�����邾�낤
�����ARM�v��Ȃ��Ƃ����l������A
�����Office�v��Ȃ��Ƃ����l�����邾�낤
�ւ��A����ȂɃ}�C�N���\�t�g�̋Z�p�͒ቺ���Ă�̂�
�n�Ǝ҂ő傫���Ȃ�����Ђ́A�n�Ǝ҂���j�����ĂȂ��ƁA
�q�̒N���]��ł��Ȃ��A�d���̂��߂̎d�������n�߂Ă��܂��̂���B
�X�^�[�g�{�^����菜���Ă݂���A���n�߂���B
�q�̒N���]��ł��Ȃ��A�d���̂��߂̎d�������n�߂Ă��܂��̂���B
�X�^�[�g�{�^����菜���Ă݂���A���n�߂���B
�ԕ��̃}�b�L���g�b�V���Ɛ\�������B
����͑n�Ǝ҂̎d��
>>564
��{�N���b�N��0.2GHz�L�т�TB��N���b�N��0.1GHz�����L�тȂ�
���̏�TDP��20W���オ����150w�ƂȂ�Ƒi���͂�����Ȃ��C������
OC�ϐ��������ς��Ȃ�������
������
��{�N���b�N��0.2GHz�L�т�TB��N���b�N��0.1GHz�����L�тȂ�
���̏�TDP��20W���オ����150w�ƂȂ�Ƒi���͂�����Ȃ��C������
OC�ϐ��������ς��Ȃ�������
������
http://pc.watch.impress.co.jp/docs/news/20121109_571911.html
IA-64����p�@������Ɠo�ꂷ��݂�������
IA-64��PC�ɏ����͉i�v�ɂ���Ă�������������
IA-64����p�@������Ɠo�ꂷ��݂�������
IA-64��PC�ɏ����͉i�v�ɂ���Ă�������������
�Vitanium�͓�����g������C�ɏオ������
���̐��i�������10�N�̊Ԃ܂������N���b�N���オ���ĂȂ��������
���̐��i�������10�N�̊Ԃ܂������N���b�N���オ���ĂȂ��������
�f�p�ȋ^��B
Out-of-Oder�łȂ��AIn-Oder�ł��A
�R���p�C���̎��_�ŕ���Ɏ��s�ł��閽�߂��߂����Ă����A
�������\�܂Ŏ����čs����̂ł́H
���G�ȃX�P�W���[���𓋍ڂ��Ȃ��ăC�C���A
�_�C�R�X�g�I�ɂ�����d�͓I�ɂ��E�n�E�n�����B
Out-of-Oder�łȂ��AIn-Oder�ł��A
�R���p�C���̎��_�ŕ���Ɏ��s�ł��閽�߂��߂����Ă����A
�������\�܂Ŏ����čs����̂ł́H
���G�ȃX�P�W���[���𓋍ڂ��Ȃ��ăC�C���A
�_�C�R�X�g�I�ɂ�����d�͓I�ɂ��E�n�E�n�����B
�ʃA�[�L�e�N�`�����ƂɃA�v�����œK������C��
OoO�̓L���b�V���~�X�����ꍇ�ł��㑱�̖��߂����s�ł��A���ꂪ�v���t�F�b�`�I�ɓ����̂ŋ���
>>575
���A�������B
OoO����̂�uOps�����
���႟�A����Ȃ̂͂ǂ����낤�H
uOps�̖��ߗo�C�i���ɂȂ������s�t�@�C���i�Ȍ�uOpsExe�j�����s����Ƃ��āA
�ŏ�����uOps�ɑΉ�����������CPU��������A���̂܂܃o�C�i���𗬂��Ă��C�C���A
������x86�o�C�i������f�R�[�h����^�C�v��CPU��������A
�����^�C����h���C�o�ň�URISC->x86�ɃR���o�[�h����B
���A�������B
OoO����̂�uOps�����
���႟�A����Ȃ̂͂ǂ����낤�H
uOps�̖��ߗo�C�i���ɂȂ������s�t�@�C���i�Ȍ�uOpsExe�j�����s����Ƃ��āA
�ŏ�����uOps�ɑΉ�����������CPU��������A���̂܂܃o�C�i���𗬂��Ă��C�C���A
������x86�o�C�i������f�R�[�h����^�C�v��CPU��������A
�����^�C����h���C�o�ň�URISC->x86�ɃR���o�[�h����B
�I�[�o�[�w�b�h�̓f�J�����A�����Ȃ����Ƃ͂Ȃ��Č݊����͈ێ��ł��邵�A
�V�����u�ŏ�����uOpsCPU�v�ɔ����ւ���ƂĂ����K�ɂȂ�܂���I(߁��)
���Ăȋ�ōw���ӗ~�������B
�V�����u�ŏ�����uOpsCPU�v�ɔ����ւ���ƂĂ����K�ɂȂ�܂���I(߁��)
���Ăȋ�ōw���ӗ~�������B
>>576
����̓L���b�V���~�X�ɂ�郁�����A�N�Z�X�𑼂̖��ߎ��s�ʼnB��������Ă��Ƃ���ˁH
�C���I�[�_�[�ł����߃E�B���h�E�𑊓��L�����Ă��Α��v����Ȃ��̂��Ȃ��H
����ɍ��̓n�[�h�E�F�A�v���t�F�b�`������ł��邵�A���������L���b�V���T�C�Y���c�傾�B
����̓L���b�V���~�X�ɂ�郁�����A�N�Z�X�𑼂̖��ߎ��s�ʼnB��������Ă��Ƃ���ˁH
�C���I�[�_�[�ł����߃E�B���h�E�𑊓��L�����Ă��Α��v����Ȃ��̂��Ȃ��H
����ɍ��̓n�[�h�E�F�A�v���t�F�b�`������ł��邵�A���������L���b�V���T�C�Y���c�傾�B
�C���I�[�_�[��CPU���V���v���ɕۂ��A�R���p�C���ŐF�X�撣���ĕ���������Ƃ����̂�ڎw����CPU�Ƃ����̂�
���̂��̂����Itanium�Ȃ킯�ł����E�E�E
���̂��̂����Itanium�Ȃ킯�ł����E�E�E
��ops�͖��ߒ��������R�[�h���x���Ⴂ�̂ŃR�A�̊O�ɏo���ƃt�F�b�`�������ւ�
�C���I�[�_�[�Ŗ��߃E�B���h�E�Ƃ����Ƃ��납�炵�ė������Ԉ���Ă���
>>580
Itanium�͉��Ŕe�����Ƃ������H�H
>>581
�Ȃ�قǥ��
x86�̓f�R�[�h����ς����ǁA�R�[�h���x�͍����B
RISC�I���߂̓f�R�[�h�͊ȒP�����ǁA�R�[�h���x�͒Ⴂ�B
�ǂ������ǂ�����B
>>582
����܂���A�悭�������ĂȂ���
Itanium�͉��Ŕe�����Ƃ������H�H
>>581
�Ȃ�قǥ��
x86�̓f�R�[�h����ς����ǁA�R�[�h���x�͍����B
RISC�I���߂̓f�R�[�h�͊ȒP�����ǁA�R�[�h���x�͒Ⴂ�B
�ǂ������ǂ�����B
>>582
����܂���A�悭�������ĂȂ���
>>583
���̔��z���Ԉ���Ă��̂Ŕe�����Ƃ�Ȃ�����
���̔��z���Ԉ���Ă��̂Ŕe�����Ƃ�Ȃ�����
���߂ė\��ʂ�o�Ă�܂��ڂ����������̂�
���Ƃ��̕��݂�����x86�R�A�������č��݂����ȃ\�t�g�G�~�����[�V�������[�h�ŏ����玝�Ƃ�
�܂�����ɂ������ă��W�X�^�����߂��ă_�C�R�X�g�����[�Ȃ������������p�C�v���C�����S�R���܂�Ȃ�����
�߂s��������VLIW/EPIC�̎�_�����܂ł������ł��Ȃ��Ƃ��J�����x��ɒx��ăp�t�H�[�}���X���S�R�オ��Ȃ����
�����[�U�[���J�������������AOracle�����MS�����������̂͗\�z�O����������
���Ƃ��̕��݂�����x86�R�A�������č��݂����ȃ\�t�g�G�~�����[�V�������[�h�ŏ����玝�Ƃ�
�܂�����ɂ������ă��W�X�^�����߂��ă_�C�R�X�g�����[�Ȃ������������p�C�v���C�����S�R���܂�Ȃ�����
�߂s��������VLIW/EPIC�̎�_�����܂ł������ł��Ȃ��Ƃ��J�����x��ɒx��ăp�t�H�[�}���X���S�R�オ��Ȃ����
�����[�U�[���J�������������AOracle�����MS�����������̂͗\�z�O����������
�̂���݊����̍����ق��������Ă�������Ȃ�
x86�Ƃقړ�����AMD64���o���Ƃ����IA64�̖��^�͐s����
�݊����ɑR�ł��鐔���Ȃ������̏����u�����v�Ȃ�Ă̂����邯�ǁAIA64�͂ނ��덂����������
x86�Ƃقړ�����AMD64���o���Ƃ����IA64�̖��^�͐s����
�݊����ɑR�ł��鐔���Ȃ������̏����u�����v�Ȃ�Ă̂����邯�ǁAIA64�͂ނ��덂����������
����ς�C���I�[�_�[�̓_���������
�����A�w�e���W�j�A�X�R�A�ł���邵���ˁ[�ȁB
�����A�w�e���W�j�A�X�R�A�ł���邵���ˁ[�ȁB
�R���p�C���̖��Ƃ��āA������������X�P�W���[�����O�����ɂ��ɂ����Ƃ����̂������
���ǃw�e���R�A���v���O���~���O���f���ς��Ȃ��Ƃ����Ȃ��������R�[�h�Ńp�t�H�[�}���X���オ��킯�ł��Ȃ�
AES-NI��VT�݂����ɃA�N�Z�����[�^���t�����ꂽ���b�`�ȃR�A��4�`16�R�A���ԏ�����������ł˂����Ȃ�
GPGPU��HPC�ł������y���Ȃ��̂��v�́u���ʂ̃v���O���}�v�������Ȃ����炾��
������Flops���~������������ĂȂ�Knights�ɕ��蓊������肠�������̂܂ܓ����킯������
AES-NI��VT�݂����ɃA�N�Z�����[�^���t�����ꂽ���b�`�ȃR�A��4�`16�R�A���ԏ�����������ł˂����Ȃ�
GPGPU��HPC�ł������y���Ȃ��̂��v�́u���ʂ̃v���O���}�v�������Ȃ����炾��
������Flops���~������������ĂȂ�Knights�ɕ��蓊������肠�������̂܂ܓ����킯������
��{�u���b�N�����X�P�W���[�����O��
�ł��邾�����ق��Ă����������Ă�������
�ł��邾�����ق��Ă����������Ă�������
�n�C�p�[�u���b�N�ϊ��������v(^^)v
VLIW��OoO�̓��ނ̃R�A��p�ӂ��Ă����āA
�ǂ���Ŏ��s���邩�A�R�[�h�����̓����ɉ����Đ�ւ���Ƃ�����
�_����ǂC������
�ǂ���Ŏ��s���邩�A�R�[�h�����̓����ɉ����Đ�ւ���Ƃ�����
�_����ǂC������
�Ӗ����킩���
VLIW�̖��߂�����OoO�Ŏ��s����̂��H
����Ƃ�VLIW�p��OoO�p�ɕʂ̃o�C�i����p�ӂ���̂��H
VLIW�̖��߂�����OoO�Ŏ��s����̂��H
����Ƃ�VLIW�p��OoO�p�ɕʂ̃o�C�i����p�ӂ���̂��H
Thumb�݂����ɕ��ʂɃ��[�h��ւ��ł�����Ȃ�
�����b�g�͔����Ǝv������
�����b�g�͔����Ǝv������
VLIW�̖��ߏ[�U���̒Ⴓ�₢�����Ȃ�Itanium�݂����Ƀn�[�h�E�F�A�}���`�X���b�h����Ƃ�
���@���s�X���b�h�ŕ�����s�����Ă����������̗p�Ƃ���������˂�
���@���s�X���b�h�ŕ�����s�����Ă����������̗p�Ƃ���������˂�
>>593
����o�������ǁA�m�����z�}�V�������܂��Ă�����
�ʏ��OoO�R�A���g���A�v���t�@�C�����ʂ�����
�R�[�h�Ђ�VLIW�֕ϊ�������ĕ��@
����o�������ǁA�m�����z�}�V�������܂��Ă�����
�ʏ��OoO�R�A���g���A�v���t�@�C�����ʂ�����
�R�[�h�Ђ�VLIW�֕ϊ�������ĕ��@
intel��PARROT�݂����Ȃ���
Transmeta�����݂Ȃ����⥥�
�����H
���ۖ��Ƃ��āA����OoO�R�A�͌������������A����\�����悾��IPC�����E�ɋ߂�
�����g���[�X�I�ɍœK������A�v���[�`���d�͓I�ɂ��J�������ĉv���Ȃ���
���ʂ̓}���`�R�A���j�[�R�A�ȊO�ɂ͂Ȃ�����
�R�A�Ԃ̓����ƒʐM���n��Ȃ͍̂���҂����A���̂����Ȃ�Ƃ��Ȃ邾�낤
�����g���[�X�I�ɍœK������A�v���[�`���d�͓I�ɂ��J�������ĉv���Ȃ���
���ʂ̓}���`�R�A���j�[�R�A�ȊO�ɂ͂Ȃ�����
�R�A�Ԃ̓����ƒʐM���n��Ȃ͍̂���҂����A���̂����Ȃ�Ƃ��Ȃ邾�낤
�����v���O���}�ɕ��S�����Ă���������A
���������ǂ��ăI�[�o�[�w�b�h���������v���Z�b�T����Ă����B
������ăv���O�������邩��B
�т̃^�l�ɂ��Ȃ邵�˂�
���������ǂ��ăI�[�o�[�w�b�h���������v���Z�b�T����Ă����B
������ăv���O�������邩��B
�т̃^�l�ɂ��Ȃ邵�˂�
���p�ɂ���邪FPGA�ł�����Ă���
FPGA�x���楥��i�܁j
125MHz���炢�Ŕߖ����₪�邗
����x�ʼn҂����Ƃ�����A
����RAM��DSP�͂����g���ʂ����Ă��܂��B
��͂�ASIC�ŃM���E�M���E�ɋl�ߍ��܂ꂽCPU��GPU����Ԃ��B
125MHz���炢�Ŕߖ����₪�邗
����x�ʼn҂����Ƃ�����A
����RAM��DSP�͂����g���ʂ����Ă��܂��B
��͂�ASIC�ŃM���E�M���E�ɋl�ߍ��܂ꂽCPU��GPU����Ԃ��B
���Ⴀ�A���R���t�B�M�����u�����ς��Ƃ��Ȃ���
Tilera�Ƃ�
Tilera�Ƃ�
>>601
Cell��SPE����
Cell��SPE����
>>603
����͂����ԋ��������FPGA�g���Ă��
Virtex-5(�X�s�[�h�O���[�h-1)�ł�250-300MHz���炢�͑_����
�ŐV����Ȃ�500MHz�O��͍s������
����͂����ԋ��������FPGA�g���Ă��
Virtex-5(�X�s�[�h�O���[�h-1)�ł�250-300MHz���炢�͑_����
�ŐV����Ȃ�500MHz�O��͍s������
���AXilinx�̏ꍇ��Spartan���������B
����Cyclon��100MHz���炢�����E�������ȁB
>>601
���ł�SpursEngine���ˁB
���ł�SpursEngine���ˁB
611 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/11(��) 10:45:05.13 ID:LP/Es3mT
> ���������ǂ��ăI�[�o�[�w�b�h���������v���Z�b�T����Ă����B
����Cell���Ɩ������Ă��ˁH
���Ƃ���8�r�b�g�l�̃��[�h�E�X�g�A�̃R�[�h�����Ă݂�킩�邯�lj����߂��������Č����Č����͂悭�Ȃ���
�����Ă鉉�Z������I�B
�v���O���}�ɕ��S��������Ȃ��̂ƍ������͗���������Ǝv���Ă���B
���N���b�N�̓��[�N�d���������ă_���A��IPC��4������x�Ŏ��p��̌��E�B
�����đ�O�ǂ́u���I�y���[�V�������x�v�B
�悭�g�����Z�ɓ����������̉��Z���j�b�g������ĕ����I�y���[�V������1�ɓZ�ߏグ�邱�Ƃ�
���\�������グ��B
���ߐ����������邪���x�ȃr�b�g���Z��1�T�C�N���̃X���[�v�b�g�ʼn\�ɂȂ�B
�ŋ߂�FPGA���P���ȃr�b�g�_����������Ȃ��ĉ��Z�팩�����Ȃ悭�g���̂�
���炩���ߗp�ӂ��Ă邵�B
����Cell���Ɩ������Ă��ˁH
���Ƃ���8�r�b�g�l�̃��[�h�E�X�g�A�̃R�[�h�����Ă݂�킩�邯�lj����߂��������Č����Č����͂悭�Ȃ���
�����Ă鉉�Z������I�B
�v���O���}�ɕ��S��������Ȃ��̂ƍ������͗���������Ǝv���Ă���B
���N���b�N�̓��[�N�d���������ă_���A��IPC��4������x�Ŏ��p��̌��E�B
�����đ�O�ǂ́u���I�y���[�V�������x�v�B
�悭�g�����Z�ɓ����������̉��Z���j�b�g������ĕ����I�y���[�V������1�ɓZ�ߏグ�邱�Ƃ�
���\�������グ��B
���ߐ����������邪���x�ȃr�b�g���Z��1�T�C�N���̃X���[�v�b�g�ʼn\�ɂȂ�B
�ŋ߂�FPGA���P���ȃr�b�g�_����������Ȃ��ĉ��Z�팩�����Ȃ悭�g���̂�
���炩���ߗp�ӂ��Ă邵�B
CISC�̉������ˁB���̓}�C�N���R�[�h�ɂ������ɂ͂Ȃ�Ȃ��Ǝv�����B
�ȓd�͖ړI�Ȃ�google��Androd �̕p�o�R�[�h�̃n�[�h�����������Ă����悤�ȁB
�ȓd�͖ړI�Ȃ�google��Androd �̕p�o�R�[�h�̃n�[�h�����������Ă����悤�ȁB
>>611
������ۂ��������݂��Ă邯�ǁA���̕ӂɂ悭����`���s�����x�Ȃ�
������ۂ��������݂��Ă邯�ǁA���̕ӂɂ悭����`���s�����x�Ȃ�
�c�q�͌��ʂ��肫�����玝���o���Ⴊ�����ɒ[�Ȃ�
�c�q�͑匴�Ƃ�������Ŋ�]��ϑz�ɂ��킹�Ď������˂��Ȃ���^�C�v����
616 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/11(��) 17:43:10.26 ID:xz3gPmow
���ǂ�����ARM�~�ƈꏏ�ŒP��ID�Ŏ�����P���Ȃ���^�C�v����
�c�q������P��ID����Ȃ��ł����`���@�₾�`��
top500 ��Xeon Phi �̃V�X�e����7�ʂ��܂߂�
7�قǓ����Ă�ˁBLINPACK�Ȃ痝�_�l��70%���炢��
7�قǓ����Ă�ˁBLINPACK�Ȃ痝�_�l��70%���炢��
�J��C�ɂȂ����̂�opteron�ƃP�v���[�ň�ʂɂȂ����@��
���i����Ԉ���������Ȃ����H
���i����Ԉ���������Ȃ����H
DOE�������ȁ[
�W���u�Y�����������PPC���ډԕ�iPad�ŒǓ���������
60�R�A��Xeon Phi��62�R�A�����A2�璷�R�A�̂悤����
http://pc.watch.impress.co.jp/img/pcw/docs/572/526/html/00.jpg.html
top500 �Ƀ����N�C�������V�X�e����61x������60x�����̓�ʂ肠��
http://pc.watch.impress.co.jp/img/pcw/docs/572/526/html/00.jpg.html
{kind=link}
top500 �Ƀ����N�C�������V�X�e����61x������60x�����̓�ʂ肠��
���A�v���Ŏ��s�����ǂ炢�o�����
DGEMM����Cypress��90%�ATesla�iG200�j70�㔼���炢���ċL�������邪
DGEMM����Cypress��90%�ATesla�iG200�j70�㔼���炢���ċL�������邪
IBM �����V�A�ōs����POWER7+���\�̃v���[����POWER8�̊J���̋L�ڂ�����܂��B
www.ibm.com/ru/events/presentations/astana2012/boyko.pdf (P.8)
�@�EMore Cores
�@�ELarger Cache
�@�E4th Gen SMT
�@�EReliability ++
�@�EAccelerator ++
�@�E22nm
�@�EHigh Level design complete and in implementation phase
www.ibm.com/ru/events/presentations/astana2012/boyko.pdf (P.8)
�@�EMore Cores
�@�ELarger Cache
�@�E4th Gen SMT
�@�EReliability ++
�@�EAccelerator ++
�@�E22nm
�@�EHigh Level design complete and in implementation phase
������� POWER8 �̘b�B���̃v���[���A��� IBM �ސ� HPC �����V�X�e�����l�^�ɂ��ăn�[�h�E�F�A�̎����̂����Ńv���O���}����J����c�Ƃ����b��Ȃ̂ł����AP17�� POWER8 �ɂ����� VSX ISA �̉��ǂ���������Ă��܂��B
xsci.pnnl.gov/PPME/pdf/Almas_pres.pdf
�@�@--------------------
�@�@��No instructions to communicate between VSX vector registers and fixed-point registers
�@�@�@- Units designed by two different committees
�@�@��Solutions: bounce through altivec registers; bounce through cache
�@�@��Power8 will fix this
�@�@--------------------
xsci.pnnl.gov/PPME/pdf/Almas_pres.pdf
�@�@--------------------
�@�@��No instructions to communicate between VSX vector registers and fixed-point registers
�@�@�@- Units designed by two different committees
�@�@��Solutions: bounce through altivec registers; bounce through cache
�@�@��Power8 will fix this
�@�@--------------------
�܂�������GPR-VR�Ԃ̓]�����߂������Ă�Bulldozer�݂�����round-trip��20�T�C�N�����炢������悤�ȃ^�R�������።���ł����ǂ�
������AltiVec�͑��l�ŃV���b�t��/�V�t�g/���[�e�[�g���ł��Ȃ��̂������[�g���ɂ��������L�������邯��
���̂�����͉��P���ꂽ�̂���
���̂�����͉��P���ꂽ�̂���
���B�܂�5bit��imm��S���[����broadcast���閽�߂͂���������
�V�t�g/���[�e�[�g�͂܂��}�V���������ǂ�
�V���b�t���Ɋւ��Ă�1�o�C�g�P�ʂ�permute���閽�߂���������������
��������imm�ł͕s�Ȃ��A4�o�C�g�P�ʂŕ��בւ���������
�킴�킴���������permute vector��p�ӂ��ɂ�Ȃ��̂Ŗʓ|�Ȏ����̏�Ȃ�����
���ׂĂ݂��VSX�ł͔{���x�̂�imm�ŃV���b�t���ł���悤�ɂȂ����݂�����
�V�t�g/���[�e�[�g�͂܂��}�V���������ǂ�
�V���b�t���Ɋւ��Ă�1�o�C�g�P�ʂ�permute���閽�߂���������������
��������imm�ł͕s�Ȃ��A4�o�C�g�P�ʂŕ��בւ���������
�킴�킴���������permute vector��p�ӂ��ɂ�Ȃ��̂Ŗʓ|�Ȏ����̏�Ȃ�����
���ׂĂ݂��VSX�ł͔{���x�̂�imm�ŃV���b�t���ł���悤�ɂȂ����݂�����
����Ȃ��ƂŖʓ|���������Ă�����SH�Ȃ�āc�u�c�u�c
�߂�ǂ������v���O���~���O�͈����B
>>632
ARM�̃A�Z���u���͂߂�ǂ������ł���c
ARM�̃A�Z���u���͂߂�ǂ������ł���c
x86���u���āc�c���܂�
�A�Z���u���Ɋւ��Ă�x86-64�͂��ȁ[��V�����Ǝv��
windows����calling convention�����傢���Ȋ���������
ARM�͂܂����₷���BPPC�͍ŏ��X�^�b�N�t���[������킩������B
windows����calling convention�����傢���Ȋ���������
ARM�͂܂����₷���BPPC�͍ŏ��X�^�b�N�t���[������킩������B
�P�Ɋ��ꂶ��Ȃ���('A`)
x86�Ɋ���Ă�l������������A�����x86����Ԋy����('A`)
x86�Ɋ���Ă�l������������A�����x86����Ԋy����('A`)
RISC�͏����Ƃ��͂������ǂނƂ��͐h����
>>637
ABI�Ƃ����Ă�calling convention�ȊO�͓��Ɉӎ�����K�v�͂Ȃ��ł���B
x86-64�̃X�^�b�N�t���[���̐���̓X�^�b�N�g�b�v��alignment��������x�B
�����������W�X�^�������A���������̐��̈��������W�X�^�n���ł���
�X�^�b�N�t���[���̍\�z���y�ŁAIP���A�h���b�V���O���o����̂�PIC�ȃR�[�h�̋L�q���y�B
�萔�̈������y�����A�����̖��߂Ń������I�y�����h���g����B
����ȊO�̗��R��x86-64�����Ɣ�ׂēV�����Ǝv���͈̂ȏ�̓_�B
ABI�Ƃ����Ă�calling convention�ȊO�͓��Ɉӎ�����K�v�͂Ȃ��ł���B
x86-64�̃X�^�b�N�t���[���̐���̓X�^�b�N�g�b�v��alignment��������x�B
�����������W�X�^�������A���������̐��̈��������W�X�^�n���ł���
�X�^�b�N�t���[���̍\�z���y�ŁAIP���A�h���b�V���O���o����̂�PIC�ȃR�[�h�̋L�q���y�B
�萔�̈������y�����A�����̖��߂Ń������I�y�����h���g����B
����ȊO�̗��R��x86-64�����Ɣ�ׂēV�����Ǝv���͈̂ȏ�̓_�B
>>640
g++-4�̓r���Ŏd�l���ς����c++�̃V���{����namespace������̕��G���͕ʊi�Ƃ��āA
���낢��Ȍ^�̈����������͂ǂꂪ�ǂ̃��W�X�^�łǂꂪ�X�^�b�N�ɓn���Ă��邩�A
�\���̂̓n������Ԃ����A������calling convention�A
�����ł����\�グ�邽�ߌ����悭���邱�Ƃ��ړI�Ȃ낤����ǁA���\�߂�ǂ������������ȁ[�B
�܂��Z���u���ŏ����ʂ��猩���A�[�L�e�N�`���Ƃ��ẮA�����₷�������Ǝv��������ǁB
g++-4�̓r���Ŏd�l���ς����c++�̃V���{����namespace������̕��G���͕ʊi�Ƃ��āA
���낢��Ȍ^�̈����������͂ǂꂪ�ǂ̃��W�X�^�łǂꂪ�X�^�b�N�ɓn���Ă��邩�A
�\���̂̓n������Ԃ����A������calling convention�A
�����ł����\�グ�邽�ߌ����悭���邱�Ƃ��ړI�Ȃ낤����ǁA���\�߂�ǂ������������ȁ[�B
�܂��Z���u���ŏ����ʂ��猩���A�[�L�e�N�`���Ƃ��ẮA�����₷�������Ǝv��������ǁB
TI�̓A�v���P�[�V�����v���Z�b�T�s�ꂩ��P��
http://japan.cnet.com/news/business/35024468/
�g�ы@�����ARM SoC��Qualcomm vs Samsung vs NV��3����
�������������~�̐��i��������PC�p��CPU�ƈ���Ă����܂ŕt�����l���߂Ă͔���Ȃ�����
SoC���̂��厲�Ƃ��Đ키�͓̂���̂���
���ǖׂ���̂̓��C�����e�B���m���ɓ���ARM�����Ƃ����I�`��
http://japan.cnet.com/news/business/35024468/
�g�ы@�����ARM SoC��Qualcomm vs Samsung vs NV��3����
�������������~�̐��i��������PC�p��CPU�ƈ���Ă����܂ŕt�����l���߂Ă͔���Ȃ�����
SoC���̂��厲�Ƃ��Đ키�͓̂���̂���
���ǖׂ���̂̓��C�����e�B���m���ɓ���ARM�����Ƃ����I�`��
���AOMAP�Ȃ��Ȃ�̂���
Apple�͑��Ќ����ɂ͍���ĂȂ��̂ŏ��O���Ƃ���
�������̏ꍇ����i�f�o�C�X�Ƃ��������t�����l���i�ɓ��邩��C�y����
�������̏ꍇ����i�f�o�C�X�Ƃ��������t�����l���i�ɓ��邩��C�y����
Samsung ���ĊO�̂��Ă�����
���S�ɌX���O�ɓP�ނ��锻�f�̑����͌��K������
>>647
�f�U�C���E�B���I�ȈӖ���
�f�U�C���E�B���I�ȈӖ���
>>642
Tegra�������f�B�X��Ȃ�
Tegra�������f�B�X��Ȃ�
>>642
�A�}�]����TI�̃��o�C���`�b�v���唃�����邩�����ĕ��o�Ă����ǁA�֘A����̂���?
�A�}�]����TI�̃��o�C���`�b�v���唃�����邩�����ĕ��o�Ă����ǁA�֘A����̂���?
>>653
�������B���i�������Ȃ玖�Ƃ͔����ɂ����B
�������B���i�������Ȃ玖�Ƃ͔����ɂ����B
�������Amazon��TI�̑����OMAP�肽���̂ł͂Ȃ��AKindle�ƃf�[�^�Z���^��ARM SoC���œK����������ǂ�ȉ��l�����܂�邩���l���Ă���B
CPU�R�A�͂��Ĕ����̂̒��S���������A���܂�S�͂��̎��ӂɉ����ǂ��g�ݍ��킹�邩�Ɉڂ����B
CPU�R�A�͂��Ĕ����̂̒��S���������A���܂�S�͂��̎��ӂɉ����ǂ��g�ݍ��킹�邩�Ɉڂ����B
�߂������ɒ���SoC�ɂ݂�Ȃ��Ă��ꂽ�肵��
>>655
intel�͔���Ȏs�����������
It�̃��[�f�B���O�J���p�j�[�̈��amazon����������Α������}�l���邾�낤��amazon�͎��э���đ�K�̓V�X�e��������C������
intel�͔���Ȏs�����������
It�̃��[�f�B���O�J���p�j�[�̈��amazon����������Α������}�l���邾�낤��amazon�͎��э���đ�K�̓V�X�e��������C������
658 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/16(��) 23:11:35.71 ID:/mHHxkpq
Amazon�͐�^�Ԏ��v�㒆�ł���
�N���E�h�s���VMware����Q��
����CEO����Intel�̃Q���W���K�[���Ă̂��ʔ����ȁB
�N���E�h�s���VMware����Q��
����CEO����Intel�̃Q���W���K�[���Ă̂��ʔ����ȁB
amazon���đn�ƈȗ��Ԏ������������͂������A�����ɂȂ������Ԃ������
����ɂ��Ă�Phi�͂��炵����
����ɂ��Ă�Phi�͂��炵����
�c�Ɨ��v862 Million US$ �i2011�N12�����j[4]
�����v631 Million US$ �i2011�N12�����j[5]
�����Y25,278 Million US$ �i2011�N12��31�����_�j[6]
�����v631 Million US$ �i2011�N12�����j[5]
�����Y25,278 Million US$ �i2011�N12��31�����_�j[6]
�ׂ�x86���ARM�}�V����VM��ʂɑ��点��Ƃ��ł��������
��Ȃ��Ƃ��邮�炢�Ȃ�l�C�e�B�u���s�ł���x86���z���̂ق���������������
��Ȃ��Ƃ��邮�炢�Ȃ�l�C�e�B�u���s�ł���x86���z���̂ق���������������
���c��x86�G�~����
Atom��AVX�����������̂͂����ɂȂ��ł����ˁE�E�E
amazon�ɑR���āAKobo�����i.MX�����W�J�Ɋ���
�܂������O��CPU���炢�����ĂȂ���IT��ƂƂ��đf�l�Ƃ������オ����Ƃ͂�
667 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/17(�y) 10:44:01.78 ID:Oq279gwn
�c�q��FFT�g�p���邱�Ƃ���̂��H
����Ȃ̂��Ȃ����p�r�ł����g���Ǝv�����E�E�E
�m�����x���߂�Ƃ����̂���
����Ȃ̂��Ȃ����p�r�ł����g���Ǝv�����E�E�E
�m�����x���߂�Ƃ����̂���
�M�������ł悭�g����B
>>668
��K�͂ȐU����͂Ƃ����l�B���邩��
��K�͂ȐU����͂Ƃ����l�B���邩��
>>670
�c�q�͂���Ȃ��Ƃ���ĂȂ��͂�������
�c�q�͂���Ȃ��Ƃ���ĂȂ��͂�������
672 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/17(�y) 14:25:03.11 ID:Oq279gwn
�܁[�m���ɉ��l�ň�Ԏg���̂͒P���x��4x4�s��ς��ʂɁE�E�E�Ƃ��H��
Phi���Ɗ�{����ŗǂ�����y�Ȃ��ǂ��i�C���^�[���[�u����K�v�����邪�j
vloadps zmm0, zmmword ptr [A]
vloadps zmm1, zmmword ptr [B]
vmulps zmm2, zmm0, zmm1{aaaa}
vmadd231ps zmm2, zmm0, zmm1{bbbb}
vmadd231ps zmm2, zmm0, zmm1{cccc}
vmadd231ps zmm2, zmm0, zmm1{dddd}
vstoreps zmmword ptr [C], zmm2
Haswell����FMA2�ɑ���shuffle���j�b�g����Ȃ��Ȃ����ȂƎv���Ă�
LRBni�݂�����Swizzle��FMA��������W�X�^���P�`�����ǁB
Phi���Ɗ�{����ŗǂ�����y�Ȃ��ǂ��i�C���^�[���[�u����K�v�����邪�j
vloadps zmm0, zmmword ptr [A]
vloadps zmm1, zmmword ptr [B]
vmulps zmm2, zmm0, zmm1{aaaa}
vmadd231ps zmm2, zmm0, zmm1{bbbb}
vmadd231ps zmm2, zmm0, zmm1{cccc}
vmadd231ps zmm2, zmm0, zmm1{dddd}
vstoreps zmmword ptr [C], zmm2
Haswell����FMA2�ɑ���shuffle���j�b�g����Ȃ��Ȃ����ȂƎv���Ă�
LRBni�݂�����Swizzle��FMA��������W�X�^���P�`�����ǁB
673 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/17(�y) 15:09:56.43 ID:Oq279gwn
�V���W����Ă�l�̃c�C�[�g�ʔ����Ȃ�
https://twitter.com/k_nitadori
https://twitter.com/k_nitadori
�c�q�́A���̒c�q�A�C�R���̎��A�J�ȊO��twitter�A�J�͎����ĂȂ���?
�ŋ߂�GPU����CPU�̏ꍇ�A�f�B�X�N���[�gGPU�ɔ�ׂ�PCIExpress���o�R���Ȃ��ōςޕ��A
CPU->GPU�̓]���������Ȃ̂��ȁH
�܂���������Ԃ܂ł͓�������ĂȂ�����A�`����ACPU�����U�AGPU�Ɋ��蓖�Ă�ꂽ�������̈��
�R�s�[�����낤���ǁALastLevel�L���b�V���ɏ���Ă�A�Z���C�e���V�ŃR�s�[�\�ŁA
�f�B�X�N���[�gGPU�ւ̃R�s�[���x������̂ł́H
CPU->GPU�̓]���������Ȃ̂��ȁH
�܂���������Ԃ܂ł͓�������ĂȂ�����A�`����ACPU�����U�AGPU�Ɋ��蓖�Ă�ꂽ�������̈��
�R�s�[�����낤���ǁALastLevel�L���b�V���ɏ���Ă�A�Z���C�e���V�ŃR�s�[�\�ŁA
�f�B�X�N���[�gGPU�ւ̃R�s�[���x������̂ł́H
CPU��GPU�̊ԂŃf�[�^���s��������P�[�X�͏��Ȃ��̂ŁA���܂育���v�͂Ȃ�
677 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/18(��) 00:49:44.49 ID:ltoLbOqO
SSE�Ɠ������o�Ŏg�����Ă͖̂������ˁB
�ėp���W�X�^-*MM���W�X�^�Ԃ̓]����1�T�C�N���łł���̂͂������֗��Ȃ���
�ėp���W�X�^-*MM���W�X�^�Ԃ̓]����1�T�C�N���łł���̂͂������֗��Ȃ���
��������GPU�Ŏ��s����Α����Ȃ�悤�Ȃ��͕̂���x�̕������ш��H���킯��
���C�e���V��������������
���C�e���V��������������
�ʂ̂��̂�����ʂ̊��o�Ŏg�����Ă��Ƃ���Ȏg���ɂ��Ă�
���C�e���V�����\�ɉe������͉̂B��������Ȃ��������Ȃ킯��
GPU�̂悤�ɗ��x�̔��ɍr���v�Z�����ł��Ȃ��ꍇ�ɂ͒�C�e���V�ł����܂�W���Ȃ�
Phi�Ȃ炤�ꂵ������
GPU�̂悤�ɗ��x�̔��ɍr���v�Z�����ł��Ȃ��ꍇ�ɂ͒�C�e���V�ł����܂�W���Ȃ�
Phi�Ȃ炤�ꂵ������
>>676
GPGPU�ł͈�ʓI����Ȃ��H
>>677
SSE�Ɠ������o�Ŏg������ō��Ȃ��ǂȂ��B
>>678
>>680
SSE�ł��ɂ͏d�����ŁA
dGPU�ł��ɂ͌y�����āA�J�[�l���N���Ɏ��Ԃ�������߂�����A
�X���b�h���\���ɗ����オ�炸�A�������A�N�Z�X�X�g�[�����B���ł��Ȃ��B
�������������Ȉʒu�t���̉��Z�Ƃ����̂�����B
�Ƃ������A���ʂ��Ă���i���j
GPGPU�ł͈�ʓI����Ȃ��H
>>677
SSE�Ɠ������o�Ŏg������ō��Ȃ��ǂȂ��B
>>678
>>680
SSE�ł��ɂ͏d�����ŁA
dGPU�ł��ɂ͌y�����āA�J�[�l���N���Ɏ��Ԃ�������߂�����A
�X���b�h���\���ɗ����オ�炸�A�������A�N�Z�X�X�g�[�����B���ł��Ȃ��B
�������������Ȉʒu�t���̉��Z�Ƃ����̂�����B
�Ƃ������A���ʂ��Ă���i���j
682 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/18(��) 23:21:15.23 ID:ltoLbOqO
���̐����Xeon Phi��P5�x�[�X��x86�R�A����Atom�R�A�ɒu�������Ƃ����Ă邯��
���̃����b�g���ĉ����Ǝv���H
���Ƃ��A��荂�N���b�N�œ��삷��B
����14nm�̐VAtom�R�A��2.5GHz���x�ł����삷��Ǝv����
����x�N�g�����j�b�g�̓N���b�N�̔�����1.25GHz����ɂƂǂ߂�B
�x�N�g�����j�b�g�����猩�ăx�N�g�����Z���߂̋������ő�2�{�ɑ����A�������\�䂪�オ��B
Core*�ɂ͋y�Ȃ��܂ł�����Ȃ�̃X�J�����\������B
��������ƁACPU��Phi���Ŗ����ɘA�g���Ȃ��Ă��A�܂�܂�Phi���ɓ���������Ă��������ƂɂȂ��ˁB
���������Ȃ��>>681���̃j�[�Y�͂�����x�͖������邩������Ȃ��B
���̃����b�g���ĉ����Ǝv���H
���Ƃ��A��荂�N���b�N�œ��삷��B
����14nm�̐VAtom�R�A��2.5GHz���x�ł����삷��Ǝv����
����x�N�g�����j�b�g�̓N���b�N�̔�����1.25GHz����ɂƂǂ߂�B
�x�N�g�����j�b�g�����猩�ăx�N�g�����Z���߂̋������ő�2�{�ɑ����A�������\�䂪�オ��B
Core*�ɂ͋y�Ȃ��܂ł�����Ȃ�̃X�J�����\������B
��������ƁACPU��Phi���Ŗ����ɘA�g���Ȃ��Ă��A�܂�܂�Phi���ɓ���������Ă��������ƂɂȂ��ˁB
���������Ȃ��>>681���̃j�[�Y�͂�����x�͖������邩������Ȃ��B
�t�����g�G���h�Ɖ��Z��Ŏ��g���̃h���C���܂ŕς����Ⴄ�Ƃ��낢����ȋC������
>>682
����������ƁACPU��Phi���Ŗ����ɘA�g���Ȃ��Ă��A�܂�܂�Phi���ɓ���������Ă��������ƂɂȂ��ˁB
���炵���B
�������ɃX�J�����Z�\�͂����������������A�ۓ����������B
Intel�͍���Phi��CPU�R�A�ɓ�������v�����������Ă���낤���H
�����`�b�v�ł��������̒l�i�Ŏ�ɓ���悤�ɂȂ�����҂��������B
����������ƁACPU��Phi���Ŗ����ɘA�g���Ȃ��Ă��A�܂�܂�Phi���ɓ���������Ă��������ƂɂȂ��ˁB
���炵���B
�������ɃX�J�����Z�\�͂����������������A�ۓ����������B
Intel�͍���Phi��CPU�R�A�ɓ�������v�����������Ă���낤���H
�����`�b�v�ł��������̒l�i�Ŏ�ɓ���悤�ɂȂ�����҂��������B
685 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/18(��) 23:54:59.58 ID:ltoLbOqO
Phi�̃R�A�͂ǂ��܂�x64�Ȃ̂��悭�킩����
�C���e���ȊO�̃c�[���x���_�[���Q�����₷���Ȃ�Ȃ�劽�}
�C���e���ȊO�̃c�[���x���_�[���Q�����₷���Ȃ�Ȃ�劽�}
687 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/19(��) 00:51:55.68 ID:6ml5ec7c
ABI�ɂ��Ă�GNU binutils��K1OM�̖��O�ŃR�~�b�g����Ă�B
���̂���GCC�Ƃ��̊J���c�[�����g����悤�ɂȂ�ł��傤�B
Phi���Linux�������ƌ������Ƃ͎�����I�[�v���\�[�XOS�͉��ł������Ƃ������ƁB
Cell�̂Ƃ���SPU�̓��C�u�������o�R���Ď��O�ŐG�邵���Ȃ���������
Phi�p�̃I�[�v���\�[�X�̊J���c�[���͉����T���Ă�B
���߃Z�b�g���P��������킴�킴���O��YASM�������Ă�Œ������ǂ�����
���A�����܂Ŏ�ˁB
Fixstars�����肪1��P�ʂŔ�����J�[�h�o���Ă����Ȃ�l�ōw�����Ă݂悤������
�Ȃɂ�����ׂ��̓���������B
���̂���GCC�Ƃ��̊J���c�[�����g����悤�ɂȂ�ł��傤�B
Phi���Linux�������ƌ������Ƃ͎�����I�[�v���\�[�XOS�͉��ł������Ƃ������ƁB
Cell�̂Ƃ���SPU�̓��C�u�������o�R���Ď��O�ŐG�邵���Ȃ���������
Phi�p�̃I�[�v���\�[�X�̊J���c�[���͉����T���Ă�B
���߃Z�b�g���P��������킴�킴���O��YASM�������Ă�Œ������ǂ�����
���A�����܂Ŏ�ˁB
Fixstars�����肪1��P�ʂŔ�����J�[�h�o���Ă����Ȃ�l�ōw�����Ă݂悤������
�Ȃɂ�����ׂ��̓���������B
�l�X�ȃv���Z�b�T�ł̎��p�I�x���`�}�[�N�Ƃ��āA7-zip �̈��k/�𓀑��x���r�����T�C�g�����J����Ă��܂����B
���ʂ�MIPS�l��Core2/2GHz�� 2000 �Ƃ��ċK�i�����Ă���Ƃ̂��ƁBFPU, SSE, �}���`�X���b�h�Ή��͖����ŃR���p�C������Ă���Ƃ̂��ƁB
//www.7-cpu.com/
�V���O���R�A�̌��ʂ����������o���Ă݂�Ƃ���Ȋ����B
�@�@�@CPU�@�@�@�@�@�@�@�@�@�@�@���k[MIPS]�@�@�@��[MIPS]
�@Cortex A9/1.2GHz�@�@�@�@�@�@790�@�@�@�@�@�@�@1080
�@Cortex A15/1.7GHz�@�@�@�@�@1850�@�@�@�@�@�@�@1830
�@���c3A/900MHz�@�@�@�@�@�@�@476�@�@�@�@�@�@�@�@650
�@POWER7/3.55GHz�@�@�@�@�@�@2700�@�@�@�@�@�@�@3350
�@AMD K8/2GHz�@�@�@�@�@�@�@�@1800�@�@�@�@�@�@�@2080
�@Intel Atom/1.6GHz�@�@�@�@�@�@700�@�@�@�@�@�@�@�@900
�@Intel SandyBridge/3.1GHz�@3830�@�@�@�@�@�@�@3430 (Turbo disabled)
�\�[�X��o�C�i�������J����Ă��܂��̂ŁA�����Ŏ����Ă݂邱�Ƃ��\�ł��B
���ʂ�MIPS�l��Core2/2GHz�� 2000 �Ƃ��ċK�i�����Ă���Ƃ̂��ƁBFPU, SSE, �}���`�X���b�h�Ή��͖����ŃR���p�C������Ă���Ƃ̂��ƁB
//www.7-cpu.com/
�V���O���R�A�̌��ʂ����������o���Ă݂�Ƃ���Ȋ����B
�@�@�@CPU�@�@�@�@�@�@�@�@�@�@�@���k[MIPS]�@�@�@��[MIPS]
�@Cortex A9/1.2GHz�@�@�@�@�@�@790�@�@�@�@�@�@�@1080
�@Cortex A15/1.7GHz�@�@�@�@�@1850�@�@�@�@�@�@�@1830
�@���c3A/900MHz�@�@�@�@�@�@�@476�@�@�@�@�@�@�@�@650
�@POWER7/3.55GHz�@�@�@�@�@�@2700�@�@�@�@�@�@�@3350
�@AMD K8/2GHz�@�@�@�@�@�@�@�@1800�@�@�@�@�@�@�@2080
�@Intel Atom/1.6GHz�@�@�@�@�@�@700�@�@�@�@�@�@�@�@900
�@Intel SandyBridge/3.1GHz�@3830�@�@�@�@�@�@�@3430 (Turbo disabled)
�\�[�X��o�C�i�������J����Ă��܂��̂ŁA�����Ŏ����Ă݂邱�Ƃ��\�ł��B
689 �FMAC�I�^���c�q �����F2012/11/19(��) 06:39:57.05 ID:RjfJdDqk
>>687
Xeon Phi �̊J���c�[���Ȃ�A���J����Ă���MPSS�Ɋ܂܂�Ă��܂���B
//software.intel.com/en-us/articles/intel-many-integrated-core-architecture-intel-mic-architecture-platform-software-stack
���Y�T�[�r�X���J�n����ƁA�ǂ�����PC�N���X�^�pOS�̂悤�� MIC �J�[�h����OS��z�z���ău�[�g���Ă����Ƃ̂��ƁB
�N����� ssh ��t���̃c�[���ŒʐM�ł���悤�ł��B
Xeon Phi �̊J���c�[���Ȃ�A���J����Ă���MPSS�Ɋ܂܂�Ă��܂���B
//software.intel.com/en-us/articles/intel-many-integrated-core-architecture-intel-mic-architecture-platform-software-stack
���Y�T�[�r�X���J�n����ƁA�ǂ�����PC�N���X�^�pOS�̂悤�� MIC �J�[�h����OS��z�z���ău�[�g���Ă����Ƃ̂��ƁB
�N����� ssh ��t���̃c�[���ŒʐM�ł���悤�ł��B
�X�g���[�WOS��p�Ŏg����悤��DSP��DMA�R���g���[���������ASIC�Ƃ��ˁ[�̂��ȁH
SandyBridge�͂�����
���k�������̂̓�����������\����
���k�������̂̓�����������\����
AES-NI����Ȃ���?
�d�͂������g�����W�X�^������Ŋ���Ɩʔ���
A15��Core2����IPC�Ȃ̂�
������Atom�F�c
������Atom�F�c
���̃e�X�g�ł�SSE�s�g�p�Ȃ̂ł܂��ϐg���c���Ă���ȁB
���k��RAM�̑��x�ˑ�(���k������32MB�ŃL���b�V���Ɏ��܂�Ȃ�)�A�W�J�͐������Z�ˑ����������B
���o�C���͋}���Ƀo�X���g�債�Ă���̂ŁA�f�X�N�g�b�vCPU�̔�r�D�ʂ͍���h�炮��������Ȃ��B
���k��RAM�̑��x�ˑ�(���k������32MB�ŃL���b�V���Ɏ��܂�Ȃ�)�A�W�J�͐������Z�ˑ����������B
���o�C���͋}���Ƀo�X���g�債�Ă���̂ŁA�f�X�N�g�b�vCPU�̔�r�D�ʂ͍���h�炮��������Ȃ��B
���߃Z�b�g���o���o���Ȃ̂�
MIPS���Ăǂ��������ƁH
MIPS���Ăǂ��������ƁH
Drystone MIPS ����n�܂��āACPU�̑��ΐ��\�l��MIPS�ƌĂ�銵�K������B
���̏ꍇ��Instruction�́A�����Č�����Core 2 2GHz��1�N���b�N��1���ߏ�������Ƃ݂Ȃ����Ƃ��̉��z�I�Ȗ��߂̂��Ƃ��B
���̏ꍇ��Instruction�́A�����Č�����Core 2 2GHz��1�N���b�N��1���ߏ�������Ƃ݂Ȃ����Ƃ��̉��z�I�Ȗ��߂̂��Ƃ��B
���������̊̐S��Cortex-A15�̐��l���ʂ��Ԉ���Ă邵...
compression��1850����Ȃ���1350��
compression��1850����Ȃ���1350��
�����͑S����32MB��������Ȃ����ǎ������̌��̃q�b�g����
���Ă��ȁH
���Ă��ȁH
Cortex-A15�̎����͂��܂蒷�������������ȁB
�{����Cortex-A57�����B
Atom�̐������~�߂邽�߂ɒ��p���ŏo�Ă��������B
�{����Cortex-A57�����B
Atom�̐������~�߂邽�߂ɒ��p���ŏo�Ă��������B
>>699
Samsung Exynos 5250 (Cortex-A15) (2 cores)11700 1350 1830
2 2270 3560
4 2450 3540
�S�X���b�h��i7 3960x��1/10�O�ォ
���i�����d�͂�1/10�ȉ�������ǂ�
Samsung Exynos 5250 (Cortex-A15) (2 cores)11700 1350 1830
2 2270 3560
4 2450 3540
�S�X���b�h��i7 3960x��1/10�O�ォ
���i�����d�͂�1/10�ȉ�������ǂ�
Imagination�CPowerVR Series6�̎����f�������J�B
MIPS������C���̈��́H
ttp://www.4gamer.net/games/144/G014402/20121118001/SS/013.jpg
ttp://www.4gamer.net/games/144/G014402/20121118001/
MIPS������C���̈��́H
ttp://www.4gamer.net/games/144/G014402/20121118001/SS/013.jpg
{kind=link}
ttp://www.4gamer.net/games/144/G014402/20121118001/
http://www.phoronix.com/scan.php?page=article&item=samsung_chrome_a15
A15�̃x���`�����Afp�͑��������������̓p�b�Ƃ���ȁBAtom 2C4T�ɏ������蕉������
fp�����̂�FMA�̃��C�e���V�����P�����̂���
A15�̃x���`�����Afp�͑��������������̓p�b�Ƃ���ȁBAtom 2C4T�ɏ������蕉������
fp�����̂�FMA�̃��C�e���V�����P�����̂���
�Ƃ��Ă����@���ȂȂ߂���I
707 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/21(��) 19:21:48.30 ID:EMzRlJFJ
���s��Atom���FP��������FP���\�\�����Ƃ��v��Ȃ����ǂ�
SSE*��SIMD�̘_�����W�X�^���Ȃ�����A�Ƃ��Ƀ��C�e���V�̑傫��FP���Z��
���W�X�^���l�[�~���O���Ȃ��Ƃ낭�ɐ��\�o�Ȃ����Ă̂͂킩�肫�������Ƃ�����
SSE*��SIMD�̘_�����W�X�^���Ȃ�����A�Ƃ��Ƀ��C�e���V�̑傫��FP���Z��
���W�X�^���l�[�~���O���Ȃ��Ƃ낭�ɐ��\�o�Ȃ����Ă̂͂킩�肫�������Ƃ�����
�E�����A�E�p�Јˑ��I
�������[�J�[�A���A�A�N�Z�X�l�b�g���[�N�e�N�m���W����I�I
�h�R���A���̃X�}�z�����̍��ْ��~�@�Z�p���o���O
http://www.logsoku.com/r/newsplus/1333377457/
> �x�m�ʂȂǍ������[�J�[�͔����̋Z�p���C�O�ɗ��o����̂����O�B
> �Z�p�𑊌݂ɃI�[�v���ɂ������T���X�����̏������̂߂��A�����s���l�܂���
��
�x�m�ʃ^�u���b�g�uARROWS Tab�v�ɍڂ�A�g���Y�h�ʐM�����v���Z�b�T�uCOSMOS�v�Ƃ�
http://www.itmedia.co.jp/pcuser/articles/1211/20/news092.html
> ���YCP�i�ʐM����v���Z�b�T�j�ŏ��߂�LTE���T�|�[�g�����]���`�b�v�A
> �J���R�[�h���FSAKURA�{UBB4�̎�����łƂ��ēW�J���A
> GSM�i2G�j�{W-DCMA�i3G�j�{LTE�i3.9G�@FDD�ATDD�Ƃ��ɑΉ��j��
> �}���`�Z�p��1�`�b�v�ŃT�|�[�g�A100Mbps���̃f�[�^�ʐM�ɑΉ�
> �uQualcomm�̌����㓯�����\��CP�Ɣ�ׁA����d�͂�2���قǒႢ�v�i�������j
> �uANT�̓A�v���P�[�V�����v���Z�b�T�x���_�[�iNVIDIA�Ȃǁj�Ƃ�
> �����E�A�g���Ȃ���i�߂Ă����B�v�iANT�̍�c�В��j
�������[�J�[�A���A�A�N�Z�X�l�b�g���[�N�e�N�m���W����I�I
�h�R���A���̃X�}�z�����̍��ْ��~�@�Z�p���o���O
http://www.logsoku.com/r/newsplus/1333377457/
> �x�m�ʂȂǍ������[�J�[�͔����̋Z�p���C�O�ɗ��o����̂����O�B
> �Z�p�𑊌݂ɃI�[�v���ɂ������T���X�����̏������̂߂��A�����s���l�܂���
��
�x�m�ʃ^�u���b�g�uARROWS Tab�v�ɍڂ�A�g���Y�h�ʐM�����v���Z�b�T�uCOSMOS�v�Ƃ�
http://www.itmedia.co.jp/pcuser/articles/1211/20/news092.html
> ���YCP�i�ʐM����v���Z�b�T�j�ŏ��߂�LTE���T�|�[�g�����]���`�b�v�A
> �J���R�[�h���FSAKURA�{UBB4�̎�����łƂ��ēW�J���A
> GSM�i2G�j�{W-DCMA�i3G�j�{LTE�i3.9G�@FDD�ATDD�Ƃ��ɑΉ��j��
> �}���`�Z�p��1�`�b�v�ŃT�|�[�g�A100Mbps���̃f�[�^�ʐM�ɑΉ�
> �uQualcomm�̌����㓯�����\��CP�Ɣ�ׁA����d�͂�2���قǒႢ�v�i�������j
> �uANT�̓A�v���P�[�V�����v���Z�b�T�x���_�[�iNVIDIA�Ȃǁj�Ƃ�
> �����E�A�g���Ȃ���i�߂Ă����B�v�iANT�̍�c�В��j
http://pc.watch.impress.co.jp/docs/column/kaigai/20121121_574241.html
�EAMD�i�̗��p����t�@�u�j��28nm�v���Z�X�̗����グ�ɓ�q���Ă�B
�E���������Ď�����Q�[���@���Ő�[�v���Z�X�ŃX�^�[�g�ł��Ȃ����낤�B
�EIBM�̃t�@�u�͐V�v���Z�X�̗����グ���̃`�F�b�N��Cell���g���Ă������A32nm�ȍ~Cell���Ȃ��Ȃ����̂ŁA�����グ�ɓ�q���Ă���B
�E����ł�Intel�̂�28nm�v���Z�X�̗����グ�ɐ������Ă���B
�EAMD�i�̗��p����t�@�u�j�͐V�v���Z�X�̗����グ����FinFET�ڍs�������ɍs���A��C�ɒǂ������Ƃ��Ă���B
�EAMD�i�̗��p����t�@�u�j��28nm�v���Z�X�̗����グ�ɓ�q���Ă�B
�E���������Ď�����Q�[���@���Ő�[�v���Z�X�ŃX�^�[�g�ł��Ȃ����낤�B
�EIBM�̃t�@�u�͐V�v���Z�X�̗����グ���̃`�F�b�N��Cell���g���Ă������A32nm�ȍ~Cell���Ȃ��Ȃ����̂ŁA�����グ�ɓ�q���Ă���B
�E����ł�Intel�̂�28nm�v���Z�X�̗����グ�ɐ������Ă���B
�EAMD�i�̗��p����t�@�u�j�͐V�v���Z�X�̗����グ����FinFET�ڍs�������ɍs���A��C�ɒǂ������Ƃ��Ă���B
�����Intel�Ƒ����ȁB
���Ƀv���Z�X�����ŒN���t���Ă����Ȃ��Ȃ������
���Ƀv���Z�X�����ŒN���t���Ă����Ȃ��Ȃ������
�܂�������Intel��28nm�͂��߂��̂���
���V���g�����|�[�g�̂܂Ƃ߂ɂȂ��ĂȂ��܂Ƃ߂��e���G
���V���g�����|�[�g�̂܂Ƃ߂ɂȂ��ĂȂ��܂Ƃ߂��e���G
Intel�A14nm���܂������グ����̂��Ȃ����
�m����Intel����s���Ă邩�����14nm�ł܂Â��Ȃ��ۏ͉����Ȃ���Ȃ�
14nm�v���Z�X�ɍs���O�ɁA21nm�v���Z�X�Ƃ��̒i�K�����邾�낤�B
28nm�v���Z�X�Ő�s���Ă���ȏ�A14nm�v���Z�X�ɍs���O�̂ЂƂЂƂ̃v���Z�X�̉ۑ��
�N���A���Ă����A�T�����Ƃ͂Ȃ��B
28nm�v���Z�X�Ő�s���Ă���ȏ�A14nm�v���Z�X�ɍs���O�̂ЂƂЂƂ̃v���Z�X�̉ۑ��
�N���A���Ă����A�T�����Ƃ͂Ȃ��B
�N���A�ł�����������ǁA�ł���Ƃ͌���Ȃ�
�ǂ����ǂ����Ō��E�ɂԂ���킯�����A��s���Ă镪�A��Ɍ��E�ɂԂ���\���͍���
�ǂ����ǂ����Ō��E�ɂԂ���킯�����A��s���Ă镪�A��Ɍ��E�ɂԂ���\���͍���
���Ɏn�߂Ă鑼�Ђ���������CPU�ȊO�̏ȓd�͉������ꂶ��Ȃ���
�K�i�݂����ɂȂ����Ⴆ��intel�ȊO��CPU�ɏ�芷�����Ȃ��Ȃ邵
�K�i�݂����ɂȂ����Ⴆ��intel�ȊO��CPU�ɏ�芷�����Ȃ��Ȃ邵
���AIntel��22nm����Ȃ��̂��H
>>716
pc�ŎU�X��`���r�߂Ă邾�� intel�����ׂ����đ��͂ǂ����ׂ���Ȃ����ĘH��
������g�b�v�V�F�A��hp�ł���pc���Ƃ肽�����Ă���
�X�}�z�A�^�u�œ������ƌJ��Ԃ������Ȃ��� ���ɖׂ��肻���ȓ����ꂪ�Ȃ��̂� �����Ƃ��ׂ����Ă�̂�apple samsung���炢�炵����
��������OMAP��15�h���ATegra3 82mm2��20�h�������C���Ȃ̂�intel�������ɎQ�����ė��v���o����̂�
���������u���Ă����炻�ꂱ��������čŏI�I�Ɏ��ʂ��낤
�ꉞ����������~�߂悤�Ƃ͂��Ă���݂��������ǁA���܂������ĂȂ��݂�������
pc�ŎU�X��`���r�߂Ă邾�� intel�����ׂ����đ��͂ǂ����ׂ���Ȃ����ĘH��
������g�b�v�V�F�A��hp�ł���pc���Ƃ肽�����Ă���
�X�}�z�A�^�u�œ������ƌJ��Ԃ������Ȃ��� ���ɖׂ��肻���ȓ����ꂪ�Ȃ��̂� �����Ƃ��ׂ����Ă�̂�apple samsung���炢�炵����
��������OMAP��15�h���ATegra3 82mm2��20�h�������C���Ȃ̂�intel�������ɎQ�����ė��v���o����̂�
���������u���Ă����炻�ꂱ��������čŏI�I�Ɏ��ʂ��낤
�ꉞ����������~�߂悤�Ƃ͂��Ă���݂��������ǁA���܂������ĂȂ��݂�������
�ăq���[���b�g�E�p�b�J�[�h�i�g�o�j�ƕăf���̂Q��p�\�R�����[�J�[����킵�Ă���B
�ăA�b�v���́u���o�����v�ɑ�\�����^�u���b�g�[���̐����ɉ�����A��͏��i�̌l�����p�\�R���Ȃǂ�����Ȃ��Ȃ��Ă��邩�炾�B
�g�o�E�f���A����@�^�u���b�g�l�C�A�o�b���ꂸ
http://www.asahi.com/digital/pc/TKY201211210787.html
�ăA�b�v���́u���o�����v�ɑ�\�����^�u���b�g�[���̐����ɉ�����A��͏��i�̌l�����p�\�R���Ȃǂ�����Ȃ��Ȃ��Ă��邩�炾�B
�g�o�E�f���A����@�^�u���b�g�l�C�A�o�b���ꂸ
http://www.asahi.com/digital/pc/TKY201211210787.html
130�A90�A65�A45�A32�A22�A14�A10�A7�A5�A3���Ċ��S��70���ɂȂ��ĂȂ��ˁB
����22�̎���16����Ȃ��H
����22�̎���16����Ȃ��H
>>721
�C���e���ȊO�ł�16nm�ł�郁�[�J�[������݂�����
�C���e���ȊO�ł�16nm�ł�郁�[�J�[������݂�����
723 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/22(��) 21:47:31.92 ID:VmXNCnHP
16���������Q�[�g�s�b�`���k���ł�������ł́H
���ǃp�\�R���s��́A���А��i�̍��ʉ����ł��Ȃ��s��ɂȂ�������Ă邩���
Apple�͗�O�Ƃ��āA���Ƃ͎��Ђʼn����H�v���Ă��AWindows�W���ƈ���Ă���s�ւ����猙����
�W���̋@�\������������A�f�l���g��ł����\���Ȑ��\�Ƒϋv��������
�ŁA���i�Ɣ[���ȊO�Ń��[�J�[���H�v����]�n���قƂ�ǂȂ��Ȃ��Ă��܂���
Apple�͗�O�Ƃ��āA���Ƃ͎��Ђʼn����H�v���Ă��AWindows�W���ƈ���Ă���s�ւ����猙����
�W���̋@�\������������A�f�l���g��ł����\���Ȑ��\�Ƒϋv��������
�ŁA���i�Ɣ[���ȊO�Ń��[�J�[���H�v����]�n���قƂ�ǂȂ��Ȃ��Ă��܂���
>>721
>�u15nm�Ȃ���16nm��14nm�ɂȂ����͖̂��O�����̘b�ł͂Ȃ��A
>�{���ɕς����(Real Change)�Ƃ������Ƃ����͌�����B
>�X�P�[�����O�����猾���A22nm����14nm�Ƃ����̂͂��������̂����A
>��������14nm�ɂȂ�Ƃ������Ƃ͊ԈႢ�Ȃ��v
>�Ƃ����A���Ɋ܂݂̑����Ԏ����Ԃ��Ă����B
http://news.mynavi.jp/articles/2011/05/09/intel/index.html
�Ƃ����킯�ŁA�������N�����炵��
�܂��V�����L�[�e�N�m���W�����������̂���
>�u15nm�Ȃ���16nm��14nm�ɂȂ����͖̂��O�����̘b�ł͂Ȃ��A
>�{���ɕς����(Real Change)�Ƃ������Ƃ����͌�����B
>�X�P�[�����O�����猾���A22nm����14nm�Ƃ����̂͂��������̂����A
>��������14nm�ɂȂ�Ƃ������Ƃ͊ԈႢ�Ȃ��v
>�Ƃ����A���Ɋ܂݂̑����Ԏ����Ԃ��Ă����B
http://news.mynavi.jp/articles/2011/05/09/intel/index.html
�Ƃ����킯�ŁA�������N�����炵��
�܂��V�����L�[�e�N�m���W�����������̂���
EUV�Ƃ͈Ⴄ�������I�H
�x�m�ʁ������p�̏ؖ�
�h�R���^au�ŁuOptimus G�v���r����i��ҁj�\�\�ʐM���x��o�b�e���[�̎����͂ǂ��H
http://www.itmedia.co.jp/mobile/articles/1211/22/news064_2.html
> ���؎��Ɍ��炸�AL-01E�ł͖{��LTE�G���A�ł���͂��̏ꏊ�ŁA
> �X���[�v������A�����`���\���̊ԁALTE�ŒʐM�ł��Ȃ����ۂ��悭
> ����ꂽ�B���̏ꍇ���AF-05D�̕��͂�͂�LTE�ŒʐM�ł��Ă����B
>
> ����͕M�҂����܂Ō����Ă���Xi�[���ł̋����ʂł�
> �o�����̘b�ɂȂ��Ă��܂��̂����AL-01E���܂߂�
> Qualcomm����LTE�ʐM�`�b�v�𓋍ڂ��Ă���Xi�X�}�[�g�t�H���ł́A
> ���x�̍���������A���̂悤�Ȍ��ۂ��悭������B
>
> ����A���А��̃`�b�v�𓋍ڂ��Ă���[���iF-05D��
> �uARROWS X F-10D�v�j�ł́A���̂悤�Ȍ��ۂ́u��d�E�v��
> ������d�g�̎ア��ԂłȂ�����N����Ȃ��B
>
> �h�R����Xi�[���̑�����Qualcomm���`�b�v�ł��邱�Ƃ��ӂ݂�ƁA
> ���̌��ۂ͊ʼn߂ł��Ȃ��͂��Ȃ̂����c�c�B
�h�R���^au�ŁuOptimus G�v���r����i��ҁj�\�\�ʐM���x��o�b�e���[�̎����͂ǂ��H
http://www.itmedia.co.jp/mobile/articles/1211/22/news064_2.html
> ���؎��Ɍ��炸�AL-01E�ł͖{��LTE�G���A�ł���͂��̏ꏊ�ŁA
> �X���[�v������A�����`���\���̊ԁALTE�ŒʐM�ł��Ȃ����ۂ��悭
> ����ꂽ�B���̏ꍇ���AF-05D�̕��͂�͂�LTE�ŒʐM�ł��Ă����B
>
> ����͕M�҂����܂Ō����Ă���Xi�[���ł̋����ʂł�
> �o�����̘b�ɂȂ��Ă��܂��̂����AL-01E���܂߂�
> Qualcomm����LTE�ʐM�`�b�v�𓋍ڂ��Ă���Xi�X�}�[�g�t�H���ł́A
> ���x�̍���������A���̂悤�Ȍ��ۂ��悭������B
>
> ����A���А��̃`�b�v�𓋍ڂ��Ă���[���iF-05D��
> �uARROWS X F-10D�v�j�ł́A���̂悤�Ȍ��ۂ́u��d�E�v��
> ������d�g�̎ア��ԂłȂ�����N����Ȃ��B
>
> �h�R����Xi�[���̑�����Qualcomm���`�b�v�ł��邱�Ƃ��ӂ݂�ƁA
> ���̌��ۂ͊ʼn߂ł��Ȃ��͂��Ȃ̂����c�c�B
����ς�i���Ȃ���{���ȁB
450mm�V���R���E�G�n�[��EUV���\�O���t�B�[�̓����ł����炭3.5nm��2.5nm�܂ł͊����낤�B
�ł�������X�ɔ�������Ȃ�J�[�{���i�m�`���[�u&�O���t�F�������p�����ăV���R���ƌ���
���邵���Ȃ��ˁB���ꂪ����������1nm�ȉ����\�ɂȂ�B
����10�N�ȓ��Ɏ������錩���݂͂قږ����B20�N���675mm�E�G�n�[��EUV���\�O���t�B�[�̌�p��
�g�ݍ��킹��1nm�ȉ��ɂȂ邾�낤
�ł�������X�ɔ�������Ȃ�J�[�{���i�m�`���[�u&�O���t�F�������p�����ăV���R���ƌ���
���邵���Ȃ��ˁB���ꂪ����������1nm�ȉ����\�ɂȂ�B
����10�N�ȓ��Ɏ������錩���݂͂قږ����B20�N���675mm�E�G�n�[��EUV���\�O���t�B�[�̌�p��
�g�ݍ��킹��1nm�ȉ��ɂȂ邾�낤
730 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/23(��) 10:43:15.82 ID:wBb8EgZt
���TSMC��14nm����16nm�Ɍ�ނ����B
28nm ARM vs 32nm Atom�łقڐ��\�݊p�Ƃ���Ȃ�A16nm ARM��14nm Atom�Ȃ�
������͎���1���㕪Atom�̂ق��������������ƂɂȂ�B
28nm ARM vs 32nm Atom�łقڐ��\�݊p�Ƃ���Ȃ�A16nm ARM��14nm Atom�Ȃ�
������͎���1���㕪Atom�̂ق��������������ƂɂȂ�B
�K���Z�p���邱�̗����AMD���ۂ���
���ƁA32nm��Atom�����ܐ���Ă鑊����āA40nm��Tegra3����Ȃ��H
�����āA16nm TSMC��14nm Intel�ł�������v��������������A
�����v��Ƃ��������Ă���Intel�̕����ł��傤�B
���������AWindows8�������̗L��l�Ȃ̂ɁAWindows �^�u���b�g�͎s�ꂠ���ł��傤��?
�����āA16nm TSMC��14nm Intel�ł�������v��������������A
�����v��Ƃ��������Ă���Intel�̕����ł��傤�B
���������AWindows8�������̗L��l�Ȃ̂ɁAWindows �^�u���b�g�͎s�ꂠ���ł��傤��?
�����28nm�̎��v���N�����Ăď\���ɋ����ł��Ȃ����炾��H
������28nm������łȂ����̊Ԃ�
Intel�͂����ƃA�Q�A�Q�ł����Ȃ��Ƃ������Ȃ������B
����ς���v�Ȃ���ł���Ax86�X�}�t�H�BARM Windows �Ɠ������炢�B
�o�C�i���͂����݂̋��͂��́A�܂���x86�̗��j�������ʂ�ł���B
Intel�͂����ƃA�Q�A�Q�ł����Ȃ��Ƃ������Ȃ������B
����ς���v�Ȃ���ł���Ax86�X�}�t�H�BARM Windows �Ɠ������炢�B
�o�C�i���͂����݂̋��͂��́A�܂���x86�̗��j�������ʂ�ł���B
EUV�͎�������
�挎ASML��Cymer�������Ă����A�܂����C���ۂ����ǂ�
737 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/23(��) 15:01:44.89 ID:wBb8EgZt
TI�̓X�}�z��������P�ނ��ĎԍځE�}�C�N���T�[�o�����̃n�C�G���h�ɓ�������悤������
���������ʂȂ�Atom�����Z�����Ȃ�������H
28nm��SoC1�`�b�v50�h�����x�����B
���������ʂȂ�Atom�����Z�����Ȃ�������H
28nm��SoC1�`�b�v50�h�����x�����B
EUV�����Ď��͒x����Ƃ��Ă���{���ɂ����@������
���Ȃ��E�E�E�����ˁ[���낤��
���Ȃ��E�E�E�����ˁ[���낤��
EUV��ASML�̈�l����
���{��Ƃ��J�����ĊJ���Č�ǂ����悤�ɂ������̃��[�J�[��
�t�@�u���X���Ŕ[����̊�Ƃ͌���A�c���Ă��Ƃ�ASML��
���т����[���Ȃ��Ă�Ƃ������
���{��Ƃ��J�����ĊJ���Č�ǂ����悤�ɂ������̃��[�J�[��
�t�@�u���X���Ŕ[����̊�Ƃ͌���A�c���Ă��Ƃ�ASML��
���т����[���Ȃ��Ă�Ƃ������
����������h�u�Ɏ̂ĂĂ邾������
�j�R����L���m����EUV�̌�����肪�ǂ��ɂ��Ȃ�Ȃ����Ƃ��悭�킩���Ă�
�j�R����L���m����EUV�̌�����肪�ǂ��ɂ��Ȃ�Ȃ����Ƃ��悭�킩���Ă�
��ւȂ��ł���������Ă��F�����悤��
�l�ނ͍��A�i���̊�H�ɗ�������Ă���̂�
EUV�͎��p���o���Ȃ�����
�C���e���̈�l�����ɂȂ����Ⴄ�낤��
�C���e���̈�l�����ɂȂ����Ⴄ�낤��
EB���`�̎��オ
���Ɛ��\�N��ɂ�pm���オ����̂��ȁH
>>744
�X���[�v�b�g����
�X���[�v�b�g����
�p��������
�I���ɕC�G�������x���҂����Ǝv������A���E����Fab�Ŗ��ߐs�����Ȃ��Ƃ����Ȃ�����
�X�e���V���g���ăX�^�Z���x�[�X�̐v�������ɒ��`����Z�p�Ȃ���������Ă���
EB�ő����`�����Ƃ��ł���̂��I�H
�����T�u1nm��������Ȃ��ȥ��
���{���x���Ƃ��ł͂������������ׂȃv���Z�b�T�Ƃ����삵�Ă�낤���H
���Ă݂���������ޭ��
�����T�u1nm��������Ȃ��ȥ��
���{���x���Ƃ��ł͂������������ׂȃv���Z�b�T�Ƃ����삵�Ă�낤���H
���Ă݂���������ޭ��
Intel���X�}�z�Q������̂�ARM�Ɠ����i�т�SoC��Ȃ��Ƌ����ł��Ȃ���
ARM�̍����\���ɂ�肻��Ƌ�������Atom�������\�����Ȃ��Ƌ����ł��Ȃ�
���̒ቿ�i�A�����\������Atom��PC���[�U��������
��荂���i�Ŕ���Ă���CPU������Ȃ��Ȃ�
�����Ȃ��Intel�̗��v�͌������Ă��܂�
ARM�̍����\���ɂ�肻��Ƌ�������Atom�������\�����Ȃ��Ƌ����ł��Ȃ�
���̒ቿ�i�A�����\������Atom��PC���[�U��������
��荂���i�Ŕ���Ă���CPU������Ȃ��Ȃ�
�����Ȃ��Intel�̗��v�͌������Ă��܂�
ARM��64bit�����A�X�}�z��4GB�܂��͂���ȏ�̃����������ڂ����悤�ɂȂ��
�����郁�����e�ʂ𐧌�����Ƃ����������ł��Ȃ��Ȃ�
�����郁�����e�ʂ𐧌�����Ƃ����������ł��Ȃ��Ȃ�
>>752
�������ɗ��N�̃��f����3GB��4GB�̃X�}�z�삵�Ă��郁�[�J�[������悤���B
4GB�̕��͊��S�Ɏ��샂�f���ŗ��N�͏��i������邱�Ƃ͖������낤���B
�������ɗ��N�̃��f����3GB��4GB�̃X�}�z�삵�Ă��郁�[�J�[������悤���B
4GB�̕��͊��S�Ɏ��샂�f���ŗ��N�͏��i������邱�Ƃ͖������낤���B
�X�}�t�H�͂���ȏ��e�ʉ�������
�s�������������������Ƃ��낾�낤��
�s�������������������Ƃ��낾�낤��
>>754
���p����64bitARM����ɂȂ肻��������
���p����64bitARM����ɂȂ肻��������
�t�Z���\�O���t�B�̎���EUV���\�O���t�B�[�ɍs���O�Ƀ_�u���p�^�[�j���O�𒆌p����
�����ق��������ȁB�ꕔ�̓��{��Ƃ̓_�u���p�^�[�j���O�ł��炭���̂��݂�������
�����ق��������ȁB�ꕔ�̓��{��Ƃ̓_�u���p�^�[�j���O�ł��炭���̂��݂�������
�S���E�ł����ł���
http://pc.watch.impress.co.jp/img/pcw/docs/394/622/08_s.gif
1�T�C�N��������A128bit�̃��[�h�����ł��Ȃ��Ƃ������Ƃ́A
AVX���g����256bit�̓��Z�̃X���[�v�b�g��2�ɂȂ����Ⴄ��ˁH
�܂����ǂ̗]�n����H�H
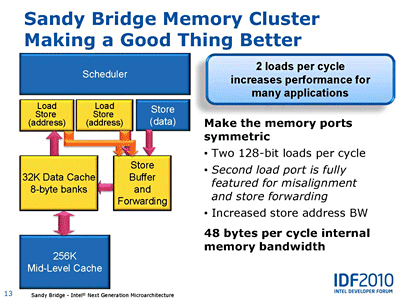{kind=link}
1�T�C�N��������A128bit�̃��[�h�����ł��Ȃ��Ƃ������Ƃ́A
AVX���g����256bit�̓��Z�̃X���[�v�b�g��2�ɂȂ����Ⴄ��ˁH
�܂����ǂ̗]�n����H�H
�����߂�A�u1�T�C�N��������256bit�̃��[�h�����ł��Ȃ��v�ɒ����B
����Ⴭ�[�h�Ɖ��Z�̔䗦���悾�ȁB
���[�h�̔䗦�������R�[�h�ł�Sandy����256bit�����Ă��債�����ʂ͏o�Ȃ����낤��
>AVX���g����256bit�̓��Z�̃X���[�v�b�g��2�ɂȂ����Ⴄ���
�����S�Ă̓��̓I�y�����h�������烍�[�h���Ȃ��Ⴂ���Ȃ��Ȃ�
�����I�ȃX���[�v�b�g�͂����Ȃ邪��
Haswell�ł�256bit���[�h2��256bit�X�g�A1�������s�ł��邩��
���[�h�̃X���[�v�b�g�ɑ��鐧���͊ɘa���Ă���B
���[�h�̔䗦�������R�[�h�ł�Sandy����256bit�����Ă��債�����ʂ͏o�Ȃ����낤��
>AVX���g����256bit�̓��Z�̃X���[�v�b�g��2�ɂȂ����Ⴄ���
�����S�Ă̓��̓I�y�����h�������烍�[�h���Ȃ��Ⴂ���Ȃ��Ȃ�
�����I�ȃX���[�v�b�g�͂����Ȃ邪��
Haswell�ł�256bit���[�h2��256bit�X�g�A1�������s�ł��邩��
���[�h�̃X���[�v�b�g�ɑ��鐧���͊ɘa���Ă���B
http://pc.watch.impress.co.jp/img/pcw/docs/394/622/12.jpg
Sandy�ƃl�g�o�̈Ⴂ��������Ȃ����
�l�g�o�̓g���[�X�L���b�V��������d�͂傳����v���������ƕ����������
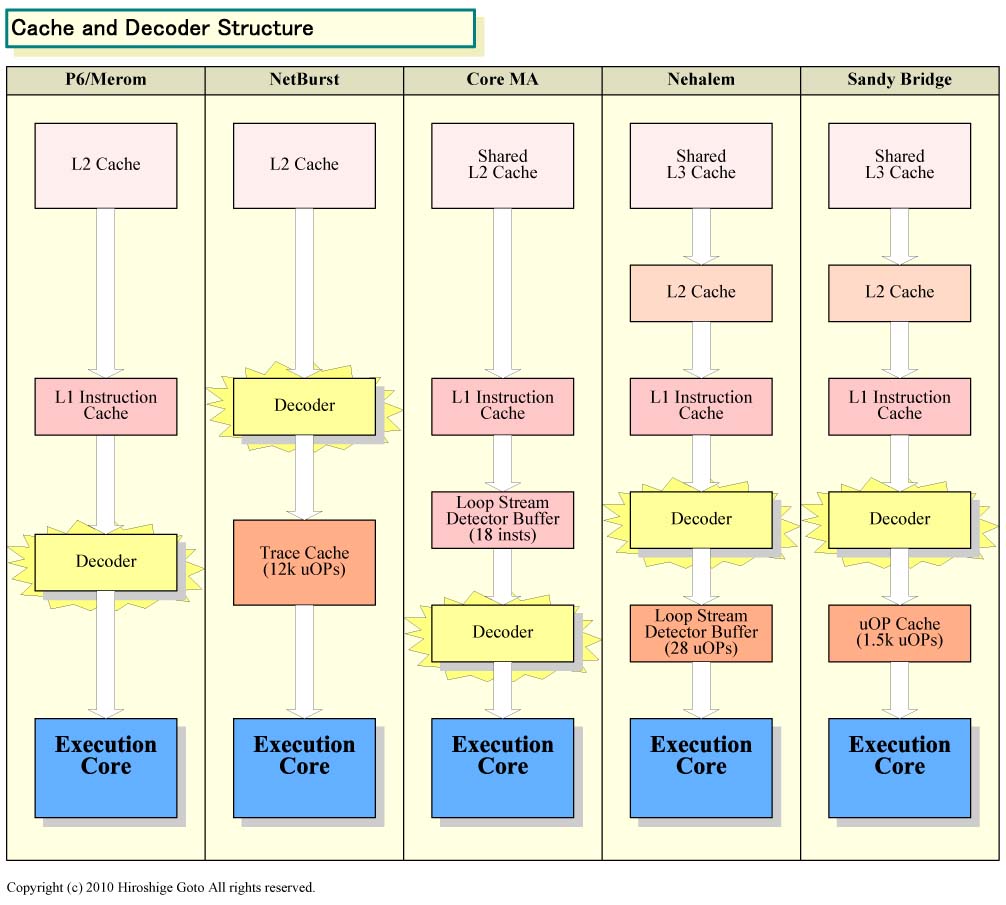{kind=link}
Sandy�ƃl�g�o�̈Ⴂ��������Ȃ����
�l�g�o�̓g���[�X�L���b�V��������d�͂傳����v���������ƕ����������
����݂ĉ���Ȃ��Ƃ�����ꂽ��ǂ����悤���Ȃ�
Pentium4����L1���߃L���b�V���Ȃ������H�����܂Ő���Ă����ȁB
�[��Sandy�̃f�R�[�_��uop cache���c���ڑ������Ă邻�̐}�͂���������
�����uop queue+LSD�̍\����Sandy�ȍ~�ɂ����邵��
�����uop queue+LSD�̍\����Sandy�ȍ~�ɂ����邵��
http://pc.watch.impress.co.jp/img/pcw/docs/394/622/06.jpg
Intel�̃X���C�h�B
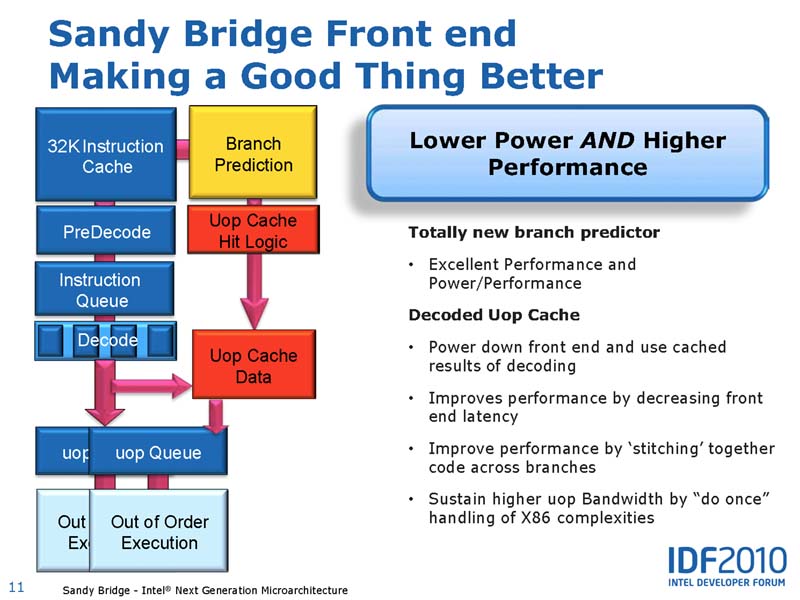{kind=link}
Intel�̃X���C�h�B
SB�̂̓g���[�X�L���b�V������Ȃ��悤��
http://www.realworldtech.com/sandy-bridge/4/
http://www.realworldtech.com/sandy-bridge/4/
768 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/25(��) 21:44:19.83 ID:byzWFWOT
Nehalem�܂ł�128�r�b�gLoad���j�b�g�~1�ł�肭�肵�Ă��̂�
256�r�b�g���[�h�ł�32/64/128�r�b�g�l�̃u���[�h�L���X�g�̓��[�h1�ōςނ̂�
�s��ςȂł͂���ق�Load���j�b�g�̃X���[�v�b�g�̓l�b�N�ɂȂ�Ȃ��B
256�r�b�g���[�h�ł�32/64/128�r�b�g�l�̃u���[�h�L���X�g�̓��[�h1�ōςނ̂�
�s��ςȂł͂���ق�Load���j�b�g�̃X���[�v�b�g�̓l�b�N�ɂȂ�Ȃ��B
�������Z�p�t�H�[�}���X���]���ɂ��Č��������AMD�́uBulldozer�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
���S�ȃ}���`�R�A��SMT�̒��Ԃ�������u���B
�ǂ����Ă����܂ŐU���Ȃ�������H�H
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
���S�ȃ}���`�R�A��SMT�̒��Ԃ�������u���B
�ǂ����Ă����܂ŐU���Ȃ�������H�H
�d�͐��\���g�����W�X�^�����萫�\���}�f�������͗���������B
���
�u���̃A�[�L�e�N�g�̓N�r���˥��^^�G
�u���̃A�[�L�e�N�g�̓N�r���˥��^^�G
CMT�ƃu���̐��\�͑S���W�Ȃ�
Atom����i7�܂Ő��\�S�R�Ⴄ�̂ɑS��SMT������ƈꊇ��ɂ���悤�Ȃ���
Atom����i7�܂Ő��\�S�R�Ⴄ�̂ɑS��SMT������ƈꊇ��ɂ���悤�Ȃ���
�u�����ł��Ȃ��q�Ȃ̂̓c�[�������������Ƃ����b��
�c�[���̑I���̎��_�ŏ����͂Ƃ����Ɏn�܂��Ă܂�����
775 �FAMD������X������o�����j���J ��RjPzts7DLUKR �F2012/11/25(��) 23:04:39.32 ID:n8UgAaqK
��낤�Ƃ��Ă��邱�Ƃ͈����Ƃ͎v��Ȃ���
����Ӗ��������Ă���Ƃ������邯��
�s�[�N���\�Ō���ׂ�Ǝc�O�����
����Ӗ��������Ă���Ƃ������邯��
�s�[�N���\�Ō���ׂ�Ǝc�O�����
�n�܂�����ł͂Ȃ����܂����Ƃ����Ӗ�����
�������v���ꕔ�����������������H
������������������������������
����GPU���\�������Ȃ������瑧�̍����~�߂��Ă��ˁB
������������������������������
����GPU���\�������Ȃ������瑧�̍����~�߂��Ă��ˁB
�����v��S���g��Ȃ����ƂȂ�Ă���̂���
GPU����Ƃ̃N���X�G���W�j�A�����O���ǂ��̂����̂������Ă������
GPU�̐v�Ƌ��L�ł���u���b�N�͂Ȃ�ׂ����L���{�������ɂ��Ă�낤
CPU�̊J���̒x���GPU�Ƃ��ɂ��e������\���͍���
GPU�̐v�Ƌ��L�ł���u���b�N�͂Ȃ�ׂ����L���{�������ɂ��Ă�낤
CPU�̊J���̒x���GPU�Ƃ��ɂ��e������\���͍���
��������1�R�A������̃g�����W�X�^���炵�Đ��\�ƐH���d�C�}���āA
����ɃR�A�����₵�ď�������Ƃ�����Ȃ������������B
����ɃR�A�����₵�ď�������Ƃ�����Ȃ������������B
GPU���ꏊ���Ƃ邩��CPU���R���p�N�g�ɂ��Ă����̂��ŏ��̒��z�H�Ȃ��
����Bull�̊J�����x�ꂽ����A����APU�Ƃ���k8�������n�C�G���h�����c���ĂȂ�����R�A�{���ɓ�����
����Bull�̊J�����x�ꂽ����A����APU�Ƃ���k8�������n�C�G���h�����c���ĂȂ�����R�A�{���ɓ�����
�V���v���Ȃق������\���ꎩ�̂͏グ�ɂ������nj����͏オ�邩��
��������̃V���v���ȃR�A�����Ă̂́A���̓����悭�����Ă������
cell�Ȃ����̗��ꂩ��
��������̃V���v���ȃR�A�����Ă̂́A���̓����悭�����Ă������
cell�Ȃ����̗��ꂩ��
�V���v���ȕ������Ă���ᓖ�����[��荡���̂�����
GPU��MIC�Ȃ͂��̋ɒn�̃V���v���R�A
ARM��big.LITTLE�Ȃ͂������������܂������\�ƌ����̃o�����X���
���͔ėp�������Ƒ�T�A���_�[���̖@���ŕ��o���Ȃ������Ɉ�����������Ă��
���̕����̍��������ǂ����邩�Ƃ������ňَ�R�A�����v���Z�b�T�[�����[����ɂȂ���
������APU��GPU���̍�����R�A�Ə������S������W�]�������Ȃ�
���[�ɃV���v���R�A��TLP�̍����r�b�O�_�C���̗p���ăX���[�v�b�g�_�����̂͂�����ƈӖ��s��
GPU��MIC�Ȃ͂��̋ɒn�̃V���v���R�A
ARM��big.LITTLE�Ȃ͂������������܂������\�ƌ����̃o�����X���
���͔ėp�������Ƒ�T�A���_�[���̖@���ŕ��o���Ȃ������Ɉ�����������Ă��
���̕����̍��������ǂ����邩�Ƃ������ňَ�R�A�����v���Z�b�T�[�����[����ɂȂ���
������APU��GPU���̍�����R�A�Ə������S������W�]�������Ȃ�
���[�ɃV���v���R�A��TLP�̍����r�b�O�_�C���̗p���ăX���[�v�b�g�_�����̂͂�����ƈӖ��s��
����AMD�ɂ�brainiac�͖����Ȃ̂�
>>783
Bulldozer���V���v���R�A�H�H
������CPU��GPU�̖������S���厖���Ƃ����Ă��A���G�ō�IPC�ȃV���O���R�A�{GPU��APU�Ȃ�ėp��������
Bulldozer���V���v���R�A�H�H
������CPU��GPU�̖������S���厖���Ƃ����Ă��A���G�ō�IPC�ȃV���O���R�A�{GPU��APU�Ȃ�ėp��������
�Ȃ���ĂQ�R�A���������邽�߂ɁABulldozer �͂ނ��땡�G�ɂȂ���
���܂��Ă���Ǝv����
���܂��Ă���Ǝv����
��IPC�Ȑ����R�A2���fp�R�A1����P�̕������W���[���Ƃ����w���e�RCPU
�C���e����2�R�A�̏�ʂ�4�R�A�A
�C���e����3.xGHz�̏�ʂ�4GHz�A
���Ăȋ�ŋ������}�[�P�e�B���O�I�Ș_�������ł�����悤�Ƃ�����Ȃ����ˁH
�C���e����2�R�A�̏�ʂ�4�R�A�A
�C���e����3.xGHz�̏�ʂ�4GHz�A
���Ăȋ�ŋ������}�[�P�e�B���O�I�Ș_�������ł�����悤�Ƃ�����Ȃ����ˁH
>>785
�Ƃ肠����Core MA�Ƃ̎���IPC�i���߂Ȃ���APU���̗m���ȏ���
�Ƃ肠����Core MA�Ƃ̎���IPC�i���߂Ȃ���APU���̗m���ȏ���
����Bull��1���W���[����Sandy��1�R�A(SMT)���y���ɑ傫������d�͂��H���̂�
�}���`�X���b�h���\���������������x�ł����Ȃ����ƁB
���R�V���O���X���b�h(�����R�A�̔������V��)���Ƃ��b�ɂȂ�Ȃ��B
�X���[�v�b�g�u���Ȃ�V���O���X���b�h�ŕ�����͎̂d���Ȃ��Ă�
�}���`�X���b�h�ŕ���2-3�����x�͏���Ȃ��Ɗ��ɍ���Ȃ��B
�}���`�X���b�h���\���������������x�ł����Ȃ����ƁB
���R�V���O���X���b�h(�����R�A�̔������V��)���Ƃ��b�ɂȂ�Ȃ��B
�X���[�v�b�g�u���Ȃ�V���O���X���b�h�ŕ�����͎̂d���Ȃ��Ă�
�}���`�X���b�h�ŕ���2-3�����x�͏���Ȃ��Ɗ��ɍ���Ȃ��B
�u2�R�A�t���[�W����������_������������߂��ˁB�Ăւ�v�܂Ŋ܂߂ăM���O�������̂�
�r���ŏ�����đޏꂳ����ꂽ�̂�AMD
�r���ŏ�����đޏꂳ����ꂽ�̂�AMD
http://www.anandtech.com/show/6422/samsung-chromebook-xe303-review-testing-arms-cortex-a15/7
Cortex-A15�̓f���A���R�A�ł����Ȃ�d�C�H�����ۂ���
5W���炢�͂��肻��
Cortex-A15�̓f���A���R�A�ł����Ȃ�d�C�H�����ۂ���
5W���炢�͂��肻��
792 �F,,�@�E�L�@�́@�M�E�@,,�j��-�������F2012/11/27(��) 18:38:16.50 ID:xz5kVEa4
Apple A6��PWRficient���������P.A.semi�̐v�`�[�����O��I�ɓd�͊Ǘ�����Ă邩��
����d�͂�}�����Ă��ł����āA���@�ł��Ȃ��Ɩ������Ă��Ƃł���B
20nm�̎���20nm+FinFET�ɉ߂��Ȃ�����16nm�B
�ǂ���疂�@�͂Ȃ������ł��ˁB
����d�͂�}�����Ă��ł����āA���@�ł��Ȃ��Ɩ������Ă��Ƃł���B
20nm�̎���20nm+FinFET�ɉ߂��Ȃ�����16nm�B
�ǂ���疂�@�͂Ȃ������ł��ˁB
CPU�������Ǝ��v�A�����̐�ƃ��[�J�[���݂ɂȂ����A�b�v��
http://business.nikkeibp.co.jp/article/report/20121121/239698/?rt=nocnt
�V�^iPad�p�v���Z�b�T�uA6X�v�̏ڍׂ������A4�R�AGPU�Ő��\��
http://eetimes.jp/ee/articles/1211/21/news049.html
Samsung�AGalaxy S IV�ɓ��ڂ���Exynos�v���Z�b�T��big.LITTLE�����Z�p���̗p
http://juggly.cn/archives/75603.html
Samsung�ACortex-A15�N�A�b�h�R�A�uExynos 5440�v���J�����I
http://rbmen.blogspot.jp/2012/11/samsungcortex-a15exynos-5440.html
Samsung�AISSCC2013�ŐV�^�N�A�b�h�R�ASoC�\�ցIExynos 5 Quad�̉\����
http://rbmen.blogspot.jp/2012/11/samsungieee2013socexynos-5-quad.html
MediaTek�̃N�A�b�h�R�A�v���Z�b�T�uMT6589�v�𓋍ڂ������Lenovo�[���̏ڍ���o
http://juggly.cn/archives/75361.html
ZTE�A8�R�ACPU���ڃX�}�z�uApache�v�̊J�����v��H
http://rbmen.blogspot.jp/2012/11/zte8cpuapache.html
Google��Apple�A�����푈�Řa���̒����BSamsung�͌Ǘ��H
http://rbmen.blogspot.jp/2012/11/googleapplesamsung.html
�A�[�����v���Z�b�T��64�r�b�g��
Web�A�v���������_���A�O�[�O���̗v����
http://itpro.nikkeibp.co.jp/article/COLUMN/20121116/437984/
http://business.nikkeibp.co.jp/article/report/20121121/239698/?rt=nocnt
�V�^iPad�p�v���Z�b�T�uA6X�v�̏ڍׂ������A4�R�AGPU�Ő��\��
http://eetimes.jp/ee/articles/1211/21/news049.html
Samsung�AGalaxy S IV�ɓ��ڂ���Exynos�v���Z�b�T��big.LITTLE�����Z�p���̗p
http://juggly.cn/archives/75603.html
Samsung�ACortex-A15�N�A�b�h�R�A�uExynos 5440�v���J�����I
http://rbmen.blogspot.jp/2012/11/samsungcortex-a15exynos-5440.html
Samsung�AISSCC2013�ŐV�^�N�A�b�h�R�ASoC�\�ցIExynos 5 Quad�̉\����
http://rbmen.blogspot.jp/2012/11/samsungieee2013socexynos-5-quad.html
MediaTek�̃N�A�b�h�R�A�v���Z�b�T�uMT6589�v�𓋍ڂ������Lenovo�[���̏ڍ���o
http://juggly.cn/archives/75361.html
ZTE�A8�R�ACPU���ڃX�}�z�uApache�v�̊J�����v��H
http://rbmen.blogspot.jp/2012/11/zte8cpuapache.html
Google��Apple�A�����푈�Řa���̒����BSamsung�͌Ǘ��H
http://rbmen.blogspot.jp/2012/11/googleapplesamsung.html
�A�[�����v���Z�b�T��64�r�b�g��
Web�A�v���������_���A�O�[�O���̗v����
http://itpro.nikkeibp.co.jp/article/COLUMN/20121116/437984/
EUV���\�O���t�B�[�ɂ����Ȃ�s���Ȃ��Ń_�u���p�^�[�j���O�𒆌p���Ƃ��č̗p���悤�ƌ���
���[�J�[�̕��������C������ȁB�C���e���Ȃ�ă_�u���p�^�[�j���O���̗p���Ȃ���
�����Ȃ�EUV�ɍs�����Ƃ��Ă��邵
���[�J�[�̕��������C������ȁB�C���e���Ȃ�ă_�u���p�^�[�j���O���̗p���Ȃ���
�����Ȃ�EUV�ɍs�����Ƃ��Ă��邵
���܂�������EUV�̂ق����������Ă��Ƃ͂ˁ[�́H
Intel��45nm����_�u���p�^�[�j���O���̗p���Ă܂���
>>794
Intel�͐��IDF�ŁAEUV�͓������p���x���ɒB���Ȃ�����
�̗p���Ȃ��ƌ����Ă����肶��Ȃ��H
> Bohr said extreme ultraviolet lithography is
> "not quite ready for manufacturing or meeting cost goals".
> He also said Intel is "not betting on extreme ultraviolet for 10nm",
> which is expected to tip up around the 2016 timeframe.
IDF: Intel isn't betting on 450mm wafers or extreme ultraviolet for 10nm
http://www.theinquirer.net/inquirer/news/2205142/idf-intel-isnt-betting-on-450mm-wafers-or-extreme-ultraviolet-for-10nm
Intel�͐��IDF�ŁAEUV�͓������p���x���ɒB���Ȃ�����
�̗p���Ȃ��ƌ����Ă����肶��Ȃ��H
> Bohr said extreme ultraviolet lithography is
> "not quite ready for manufacturing or meeting cost goals".
> He also said Intel is "not betting on extreme ultraviolet for 10nm",
> which is expected to tip up around the 2016 timeframe.
IDF: Intel isn't betting on 450mm wafers or extreme ultraviolet for 10nm
http://www.theinquirer.net/inquirer/news/2205142/idf-intel-isnt-betting-on-450mm-wafers-or-extreme-ultraviolet-for-10nm
EUV��450mm�V���R���E�G�n�[��10nm���炩�ȁH
2016�N�Ƃ������Ă���݂���������2018�N���炢�ɂȂ肻���ȋC������B
�C���e���ł��ꂾ����TSMC��GF�Ȃ�2020�N���炢�ɂȂ��Ȃ��H
���{���[�J�[�͍X�Ɍ�ɂȂ肻��
2016�N�Ƃ������Ă���݂���������2018�N���炢�ɂȂ肻���ȋC������B
�C���e���ł��ꂾ����TSMC��GF�Ȃ�2020�N���炢�ɂȂ��Ȃ��H
���{���[�J�[�͍X�Ɍ�ɂȂ肻��
�x�m�ʒE���A���l�T�X�E���A�G���s�[�_�����ł��E�����O��
���{���͒N��10nm�܂Ŏc��Ȃ��悤�ȁB
���{���͒N��10nm�܂Ŏc��Ȃ��悤�ȁB
�C���e�����X�L�b�v����̂͊��ɍ̗p���Ă���_�u���p�^�[�j���O�ł͂Ȃ�
�g���v���p�^�[�j���O�B�_�u���p�^�[�j���O��EUV�ƌ����̂����N�O����̌v��B
>>799
�~���������������Ȃ�Ƃ��Ȃ�Ǝv����B���̌���ُ͈�ȉ~�������������B
�g���v���p�^�[�j���O�B�_�u���p�^�[�j���O��EUV�ƌ����̂����N�O����̌v��B
>>799
�~���������������Ȃ�Ƃ��Ȃ�Ǝv����B���̌���ُ͈�ȉ~�������������B
�~�����v���̈�����A�C�O���ɃL���b�`�A�b�v�ł��Ȃ��傫�Ȗ��͕ʂɂ���B���Ƀ��l�T�X�B
802 �FSocket774�F2012/11/29(��) 17:16:09.22 ID:C9L6D4Vm
�ȃG�l�A�ߓd�ō�������������Ȃ��Ƃ������Ă鐭���Ƃ����邵�Ȃ�
�����ł���K�v�͂Ƃ������d�C�̈��苟���������Ȃ��
���ȏ�ɓ��{�ɍH��u���K�v�������Ȃ�
�����ł���K�v�͂Ƃ������d�C�̈��苟���������Ȃ��
���ȏ�ɓ��{�ɍH��u���K�v�������Ȃ�
>>801
���l�T�X�́A���������ԍڂɓ������Ă���ȊO�͂��C�i�N�l�c
���l�T�X�́A���������ԍڂɓ������Ă���ȊO�͂��C�i�N�l�c
>>803
�E�}�C�R���A�A�i���O�E�p���[�͗͂�����
�ESoC�̃z�[���}���`���f�B�A�����͎������
�E�Љ�C���t������SoC�͗͂�����
http://eetimes.jp/ee/articles/1208/30/news045.html
http://eetimes.jp/ee/articles/1209/05/news041.html
�z�[���}���`���f�B�A�͎�������炵������
WiiU�̂悤�ȑ�^�Č��͗�O�Ȃ̂���
�E�}�C�R���A�A�i���O�E�p���[�͗͂�����
�ESoC�̃z�[���}���`���f�B�A�����͎������
�E�Љ�C���t������SoC�͗͂�����
http://eetimes.jp/ee/articles/1208/30/news045.html
http://eetimes.jp/ee/articles/1209/05/news041.html
�z�[���}���`���f�B�A�͎�������炵������
WiiU�̂悤�ȑ�^�Č��͗�O�Ȃ̂���
805 �F,,�E�L�́M�E,,�j��-�������F2012/11/29(��) 19:23:24.59 ID:MUp4U8MX
���ɐ��������_���������킯�Ȃ��ł���
�V�K���Ȃ�������
�V�K���Ȃ�������
>>800
http://pc.watch.impress.co.jp/docs/news/event/20120914_559826.html
14nm��ArF�t�Z�Ȃ̂Ńg���v���p�^�[�j���O�̉\���A��
http://pc.watch.impress.co.jp/docs/news/event/20120914_559826.html
14nm��ArF�t�Z�Ȃ̂Ńg���v���p�^�[�j���O�̉\���A��
���⋻��������͍̂��ゾ��B�@�uWiiU�̂悤�ȈČ��v���uWiiU�̈Č��v
808 �F,,�E�L�́M�E,,�j��-�������F2012/11/29(��) 23:05:01.29 ID:MUp4U8MX
����Đ��疜���WiiU�������������ǂ����킩��Ȃ����ǂ�
�Ɠd�ɂ��ڂ��ăQ�[���@�ɂ��A�Ȃ�����������ǁA�Q�[���@��p����H���Ȃ��ł���
�Ɠd�ɂ��ڂ��ăQ�[���@�ɂ��A�Ȃ�����������ǁA�Q�[���@��p����H���Ȃ��ł���
>>808
���̎���ɐ����Ă�H
���̎���ɐ����Ă�H
810 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 04:35:20.75 ID:0LpsBb20
�t�ɕ����������ǃ��l�T�X����WiiU�ɗ����Ƃ��悤��IP���Ă������H
WiiU����Wii�ƌ݊���邽�߂��m���G3�x�[�X��1.2GHz�Ȃ��āH
�ߔN��Ɍ���厸�s�ɂȂ肻��
�g�ы@������ڂ��������܂��}�V�ȃ��x������
�ߔN��Ɍ���厸�s�ɂȂ肻��
�g�ы@������ڂ��������܂��}�V�ȃ��x������
>>811
�܂����m����Ȃ�H
�܂����m����Ȃ�H
�O���ł��������ĂȂ������������B
���[�����ς萮�����ς��Ƃ��Ȃ���
http://www.phoronix.com/scan.php?page=article&item=samsung_exynos5_dual
�[��4�R�A�ł������Cortex-A9���Ăǂ��x����
http://www.phoronix.com/scan.php?page=article&item=samsung_exynos5_dual
�[��4�R�A�ł������Cortex-A9���Ăǂ��x����
ARM��Cortex-A15����ł��傤�ˁBCortex-A9�̓C���e���Ɛ키�ɂ͕͗s���B
A15�ɂȂ��Ă����ۂɃ��������q�����Ă�ш敝��32bit�̂܂܂��ᓯ���Ȃ�ĂƂĂ���������ˁc
Apple�̂̓������������ۂ�Ƃ��Ă��Ȃ�������
818 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 20:11:46.45 ID:TMl+Z+7m
Apple�͂�����PC�Ɠ���64bit�f�[�^�o�X���ˁB
ARM��A9 MPcore�\�����Ƃ���Atom��葬�����Đ������Ă��̂ɂȁ[
���W�X�^��Ńf�[�^�����ˉ̂����͓��ӂ����ǃ������̓ǂݏ����͋��ł����Ƃ���
�z��ǂ���̃I�`�������킯�ŁB
CPU�R�A�̐��\���̂�4�N�O��45nm��N270�����肩��قƂ�Ǖς���ĂȂ��̂�
�}�ɍ����\�ɂȂ����ɂȂ������̂悤�ȍ��o���o���鍡�����̍��B
Atom���̂͂����[�x�����I
ARM��A9 MPcore�\�����Ƃ���Atom��葬�����Đ������Ă��̂ɂȁ[
���W�X�^��Ńf�[�^�����ˉ̂����͓��ӂ����ǃ������̓ǂݏ����͋��ł����Ƃ���
�z��ǂ���̃I�`�������킯�ŁB
CPU�R�A�̐��\���̂�4�N�O��45nm��N270�����肩��قƂ�Ǖς���ĂȂ��̂�
�}�ɍ����\�ɂȂ����ɂȂ������̂悤�ȍ��o���o���鍡�����̍��B
Atom���̂͂����[�x�����I
CoreMark(��)�ŏ����錾���Ă���
820 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 20:20:37.91 ID:TMl+Z+7m
A15��Dhrystone��CoreMark�����̓N���b�N�����萫�\Phenom X4�Ȃ݂ł�����
http://www.phoronix.com/scan.php?page=article&item=samsung_exynos5_dual
Exynos 5 Dual also easily beat out all of the tested Intel Atom processors.
Exynos 5 Dual also easily beat out all of the tested Intel Atom processors.
�܂��Ȃ�������Snapdragon�o��F
�����d�͂ƍ��p�t�H�[�}���X�̗����@�uSnapdragon�v�̊J���v�z
http://www.itmedia.co.jp/mobile/articles/1211/30/news032.html
������̖`���ł́A2012�N3���܂�
Intel�̃V�j�A�o�C�X�v���W�f���g��
�E���g�����r���e�B����̃W�F�l�����}�l�W���[�߁A
8����Qualcomm�̃V�j�A�o�C�X�v���W�f���g��CMO��
�A�C��������̃A�i���h�E�`�����h���V�[�J����
Qualcomm�̎��Ƃ̊T�v�⒍�͕������������B
������Intel��Centrino��Atom�Ƃ������A���o�C��������
�v���b�g�t�H�[���𗧂��グ�Ă����o�������A
PC�ƊE�ł͂��Ȃ薼�̒m�ꂽ�l���B
IT�ƊE�̎����̕ω���@���Ɋ���������ꖋ�������B
�����d�͂ƍ��p�t�H�[�}���X�̗����@�uSnapdragon�v�̊J���v�z
http://www.itmedia.co.jp/mobile/articles/1211/30/news032.html
������̖`���ł́A2012�N3���܂�
Intel�̃V�j�A�o�C�X�v���W�f���g��
�E���g�����r���e�B����̃W�F�l�����}�l�W���[�߁A
8����Qualcomm�̃V�j�A�o�C�X�v���W�f���g��CMO��
�A�C��������̃A�i���h�E�`�����h���V�[�J����
Qualcomm�̎��Ƃ̊T�v�⒍�͕������������B
������Intel��Centrino��Atom�Ƃ������A���o�C��������
�v���b�g�t�H�[���𗧂��グ�Ă����o�������A
PC�ƊE�ł͂��Ȃ薼�̒m�ꂽ�l���B
IT�ƊE�̎����̕ω���@���Ɋ���������ꖋ�������B
�u�悭�g���Ƃ����������v���Ă͈̂����Ȃ��I�����Ǝv�����ǂ�
�����Ɓu�悭�g���Ƃ��v�ɂȂ��Ă邩�ǂ����́A�^�u���b�g�Ƃ��̃\�t�g��������ƂȂ��̂Œm���
�����Ɓu�悭�g���Ƃ��v�ɂȂ��Ă邩�ǂ����́A�^�u���b�g�Ƃ��̃\�t�g��������ƂȂ��̂Œm���
825 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 22:11:43.13 ID:TMl+Z+7m
����AA9�o���Ƃ��Ɋ���Atom�����Ă���ł����BARM�̑�{�c���\�ł͂ˁB
�Ƃ肠����A15��20nm�ɂȂ�Ȃ��ƃX�}�z�ɂ͎g�����ɂȂ�Ȃ���
Atom�����Ă��܂ł������ꂵ�Ȃ��킯�ł͂Ȃ��B
�Ƃ肠����A15��20nm�ɂȂ�Ȃ��ƃX�}�z�ɂ͎g�����ɂȂ�Ȃ���
Atom�����Ă��܂ł������ꂵ�Ȃ��킯�ł͂Ȃ��B
826 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 22:15:03.66 ID:TMl+Z+7m
>>824
CoreMark���������Ď��A�v�����{���{�����Ă̂͂ǂ�����������Ă�낤�ȂƎv�����ǂ�
����d�͑����邩�烁�����ш�T���߁A�P���������Ȃ�����L���b�V���e�ʍT����
���̂����肪��{�c�x���`�قǂɂ�ARM�̎������\���U���Ȃ��v���B
�t�ɃX�}�z�p�Ƃ������g���Ƃ��Ă��Ƃ��������L�т����ȋC�͂���B
CoreMark���������Ď��A�v�����{���{�����Ă̂͂ǂ�����������Ă�낤�ȂƎv�����ǂ�
����d�͑����邩�烁�����ш�T���߁A�P���������Ȃ�����L���b�V���e�ʍT����
���̂����肪��{�c�x���`�قǂɂ�ARM�̎������\���U���Ȃ��v���B
�t�ɃX�}�z�p�Ƃ������g���Ƃ��Ă��Ƃ��������L�т����ȋC�͂���B
>>825
28nm��A15�̃X�}�z�͗��N��ʂɏo�Ă���Ǝv����
�o�b�e���[��big.LITTLE�ŏ�肭�̍ق𐮂��邾�낤
�v�̓t�@�u�̃X���[�v�b�g�̖��Ń{�����[�����m�ۂł����
�^�u���b�g�ƃX�}�z�Ń`�b�v�I�ʁA�U�蕪�����s���₷���Ȃ�
���N�̓n�C�G���h�X�}�z����CPU�̐����オ�i��
28nm��A15�̃X�}�z�͗��N��ʂɏo�Ă���Ǝv����
�o�b�e���[��big.LITTLE�ŏ�肭�̍ق𐮂��邾�낤
�v�̓t�@�u�̃X���[�v�b�g�̖��Ń{�����[�����m�ۂł����
�^�u���b�g�ƃX�}�z�Ń`�b�v�I�ʁA�U�蕪�����s���₷���Ȃ�
���N�̓n�C�G���h�X�}�z����CPU�̐����オ�i��
828 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 22:34:21.59 ID:TMl+Z+7m
����28nm�Ő�������Ă�̂���Apple A6���炢���ȁH
A6��32nm����Ȃ��̂�
A6��32nm��>>821��Exynos5�Ɠ����v���Z�X
�܂��Ȃ�28nm������Exynos5450�Ɉڍs����炵��
�܂��Ȃ�28nm������Exynos5450�Ɉڍs����炵��
Krait��TSMC��28nm����
Cortex-A15��Atom�Ɛ��ʂ���킦�鐫�\�ɂ悤�₭�Ȃ�B
�����āA��{����Cortex-A57�Ɍq����킯���B
Cortex-A9�͎c�O�Ȃ���͕s���͔ے�ł��Ȃ��BWindowsRT��MS���S�R���C�������̂�
Cortex-A9���ᐫ�\�����炾�낤�BCortex-A15�Ŗ{�C���o���āACortex-A57�Ő��n�ƌ����̂�
�_�����낤
�����āA��{����Cortex-A57�Ɍq����킯���B
Cortex-A9�͎c�O�Ȃ���͕s���͔ے�ł��Ȃ��BWindowsRT��MS���S�R���C�������̂�
Cortex-A9���ᐫ�\�����炾�낤�BCortex-A15�Ŗ{�C���o���āACortex-A57�Ő��n�ƌ����̂�
�_�����낤
833 �F,,�E�L�́M�E,,�j��-�������F2012/11/30(��) 22:56:24.94 ID:TMl+Z+7m
�ǂ̐����Atom�Ƃ�H
����Atom�Ȃ�45nm����S���i�����Ă��Ȃ��B
22nm�͍̂ő��ʕ��B
����Atom�Ȃ�45nm����S���i�����Ă��Ȃ��B
22nm�͍̂ő��ʕ��B
�X�}�z�Ƃ���SoC�͂ȁ`
���Ƀf�o�C�X���ȁ`
���ɒ��،n�Ƃ��́c���Ă��A���̎�łԂ����Ⴏ�����ėp�o�X�Ƃ��Ďg����z����USB���炢������ȁB
����LAN�Ƃ��̒ʐM�W��USB�ڑ��ŕʃ��W���[���ɂ�����A���ꂱ�����g�p���\���ǂ��Ȃ邩�����Ă邾�낤��ww
�A���e�i���݂ŋ��F����Ă�ʃ��W���[���g��������Ԃ��������Ă͉̂�����c
���낤����SD�Ƃ��t���b�V���������̓C���^�[�R�l�N�g��SoC����IP�Ɍq�����Ă郂�m����������
�Ԃ����Ⴏ����SD��t���b�V���������̑��x����ȁB
�������Ƃ��āA���̓z�̐헪���i(Apple�Ƃ�Samsung�Ƃ�)�pSoC�ł���������A����܂���҂��Ȃ������ǂ����c
���Ƀf�o�C�X���ȁ`
���ɒ��،n�Ƃ��́c���Ă��A���̎�łԂ����Ⴏ�����ėp�o�X�Ƃ��Ďg����z����USB���炢������ȁB
����LAN�Ƃ��̒ʐM�W��USB�ڑ��ŕʃ��W���[���ɂ�����A���ꂱ�����g�p���\���ǂ��Ȃ邩�����Ă邾�낤��ww
�A���e�i���݂ŋ��F����Ă�ʃ��W���[���g��������Ԃ��������Ă͉̂�����c
���낤����SD�Ƃ��t���b�V���������̓C���^�[�R�l�N�g��SoC����IP�Ɍq�����Ă郂�m����������
�Ԃ����Ⴏ����SD��t���b�V���������̑��x����ȁB
�������Ƃ��āA���̓z�̐헪���i(Apple�Ƃ�Samsung�Ƃ�)�pSoC�ł���������A����܂���҂��Ȃ������ǂ����c
Itanium���߂���s���Ɗ���
http://cloud.watch.impress.co.jp/docs/column/virtual/20121130_576132.html
http://cloud.watch.impress.co.jp/docs/column/virtual/20121130_576132.html
��r�Ώۂ��Â��ȁBAtom��Clovertrail����{�C�o��������B22nm���炾����?
>>837
���̊�arm���i�������
���̊�arm���i�������
�A�g�~�b�N�ȏ��������₷���悤�ɃR�A�����ɋ��L��������...
�����̂ق��œ\���Ă�x86�AA9�AA15�̃x���`�݂�Ɛ������x���Ƃ͂��������A�v���x���`����FP�ł�
��]�I�Ȋi���t�����ĂăL���b�V���ƃ������o���h������ڂ����[���傷�����_������ɏo�Ă�̂��Ȃ�
WideIO�Ƃ������チ���������ă��������L�ш��e�ʂɂȂ�������͉��P�����̂��˂�
��]�I�Ȋi���t�����ĂăL���b�V���ƃ������o���h������ڂ����[���傷�����_������ɏo�Ă�̂��Ȃ�
WideIO�Ƃ������チ���������ă��������L�ш��e�ʂɂȂ�������͉��P�����̂��˂�
841 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 08:58:02.31 ID:nVYXn2Ur
Apple�݂����ɍ�������鐻�i�����Ă�Ȃ�L���b�V�����傫�����悤�����邵
�N���b�N�Q�[�e�B���O�Ȃǂ̓d�͊Ǘ��@�\�Ƀg�����W�X�^�����Ă��̕��������ш���傫�����悤�����邪
��R�X�g������ɂȂ��Ă�Ƃǂ����Ă�����Ȃ��
�N���b�N�Q�[�e�B���O�Ȃǂ̓d�͊Ǘ��@�\�Ƀg�����W�X�^�����Ă��̕��������ш���傫�����悤�����邪
��R�X�g������ɂȂ��Ă�Ƃǂ����Ă�����Ȃ��
������i7�Ŗׂ������v���X�}�t�H�ɒ��������
����ĂȂ��̂ɍ����\�`�b�v���_���s���O�ł���Atom�ł���!
���Ă��Ƃł���?
����ĂȂ��̂ɍ����\�`�b�v���_���s���O�ł���Atom�ł���!
���Ă��Ƃł���?
�o�b�e���̎�����������ƈ����Ă������\�Ȃ甄�����ĈӐ}������낤����Atom�����`�ȂƎv�����ǁB
�O���������ш敝�̓R�X�g�ɂ�����d�͂ɂ���������v�f������c
��ɂ������|����A�ƌ������w�^��SoC���Ɗ�̕�������������ww
�O���������ш敝�̓R�X�g�ɂ�����d�͂ɂ���������v�f������c
��ɂ������|����A�ƌ������w�^��SoC���Ɗ�̕�������������ww
844 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 12:24:24.48 ID:nVYXn2Ur
>>842
���v������܂ł͂����Ȃ�ˁB
���ꂢ������I�����C���T�[�r�X�Ȃ�Ă݂�Ȃ���Ȃ����B
��{�����ŐԎ����ꗬ���Ă�����x���[�U�[�����Ă�����ۋ��R���e���c�ʼn������B
Atom��Celeron���������������̂Ő������o���Η��v�ɂȂ�B
32nm���ӊO�Ƃ��܂��������̂�22nm�����͌��ɂ��ꂱ�悤����
>>843
����A15�ł͂Ȃ��āH
���v������܂ł͂����Ȃ�ˁB
���ꂢ������I�����C���T�[�r�X�Ȃ�Ă݂�Ȃ���Ȃ����B
��{�����ŐԎ����ꗬ���Ă�����x���[�U�[�����Ă�����ۋ��R���e���c�ʼn������B
Atom��Celeron���������������̂Ő������o���Η��v�ɂȂ�B
32nm���ӊO�Ƃ��܂��������̂�22nm�����͌��ɂ��ꂱ�悤����
>>843
����A15�ł͂Ȃ��āH
Celeron��T���ق������ǑS�R�����ĂȂ���
Pentium�Ȃ�T���ɏ����Ă̂Ɂc
Pentium�Ȃ�T���ɏ����Ă̂Ɂc
Clovertrail�͂��܂��ł��͂�������
���܂�����Ă銴���͑S�R���Ȃ���B
���܂�����Ă銴���͑S�R���Ȃ���B
847 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 12:34:30.62 ID:nVYXn2Ur
�X�}�z�͂Ƃ�����Win8�^�u���b�g�͂����������]���Ă�Ǝv������
���Ǝԍڃi�r�Ƃ��ł������͂���悤����
���Ǝԍڃi�r�Ƃ��ł������͂���悤����
�N���g�̉��Ŕ����܂����H�~�����Ȃ��Ęb��ɂȂ�܂����H
Netbook��iPad�͂������������o�ŁA��������Ă�Ȃ��Ċ��������ǁB
Windows 8�͂����_������(��ΐ��͈ˑR�Ƃ��Ĕ��傾���ǁA�����I�ȈӖ���)�A�����ɑ������ˑ����Ă���Intel��
���Ђ̐��i�̏o���Ɩ��W�ɉ̕�����͖̂Ƃ�Ȃ����ƁB
Netbook��iPad�͂������������o�ŁA��������Ă�Ȃ��Ċ��������ǁB
Windows 8�͂����_������(��ΐ��͈ˑR�Ƃ��Ĕ��傾���ǁA�����I�ȈӖ���)�A�����ɑ������ˑ����Ă���Intel��
���Ђ̐��i�̏o���Ɩ��W�ɉ̕�����͖̂Ƃ�Ȃ����ƁB
Surface Pro�͔��ɖ��͓I����
����邩�ǂ����͂Ƃ������Ƃ���
����邩�ǂ����͂Ƃ������Ƃ���
�l���Ă݂�A�T�^�I�ɂ�MIPS��Alpha�ł����ACPU�͂��ꎩ�̂̏o���s�o�������A������̗p�������i�̎s�ꂩ��̉e����
�����Ă��܂����j�ł����ˁB
�����Ă��܂����j�ł����ˁB
>>835
���̓���Itanium��Xeon�����S�ɓ����iItanium��Xeon�̖��߂��S�ď����
�G�~���ł͂Ȃ����S�Ȃ�݊��������j����āA�T�[�o�[�p�̋@�\�����Ƃ����PC�ɂ����ڂ���鎖���肤�B
���̓���Itanium��Xeon�����S�ɓ����iItanium��Xeon�̖��߂��S�ď����
�G�~���ł͂Ȃ����S�Ȃ�݊��������j����āA�T�[�o�[�p�̋@�\�����Ƃ����PC�ɂ����ڂ���鎖���肤�B
IA-64�C���l
853 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 13:24:39.06 ID:nVYXn2Ur
>>848
����A�܂��������ᔄ���Ă�Ƃ����Ȃ��ł���B
�R���V���[�}�������i�ł͂Ȃ��Ƃ���Ŏg���Ă�Ƃ��ł͒n���Ɏg���Ă��B
�i�Ԃ����Ⴏ�ꎞ�����������ʂ́u���̐l�v����Ă����j
�v�����VIA�̗̕����H���Ă�킯���B
���̂��ď���d�͂������I�ɗ������ɂ����ΐ��\��4�N�O�ɑ�q�b�g�ɂȂ���EeePC 901X��
�債�ĕς���ĂȂ��킯�ŁA�l�I�ɂ�22nm���悩�Ȃ��Ǝv���B
����A�܂��������ᔄ���Ă�Ƃ����Ȃ��ł���B
�R���V���[�}�������i�ł͂Ȃ��Ƃ���Ŏg���Ă�Ƃ��ł͒n���Ɏg���Ă��B
�i�Ԃ����Ⴏ�ꎞ�����������ʂ́u���̐l�v����Ă����j
�v�����VIA�̗̕����H���Ă�킯���B
���̂��ď���d�͂������I�ɗ������ɂ����ΐ��\��4�N�O�ɑ�q�b�g�ɂȂ���EeePC 901X��
�債�ĕς���ĂȂ��킯�ŁA�l�I�ɂ�22nm���悩�Ȃ��Ǝv���B
���肪���낢��Ƃ������o�C����atom������čs���邾�낤���H
Krait�Ȃ��28nm�ł�HKMG�g���Ė����Ƃ����b����
���z��intel�v���Z�b�T���Ƌꂵ���C������
Krait�Ȃ��28nm�ł�HKMG�g���Ė����Ƃ����b����
���z��intel�v���Z�b�T���Ƌꂵ���C������
�܂��o����ƌ����Ă���悤�����炠�Ƃ͂�i���o���
�s�ꂪ���f������
�s�ꂪ���f������
WiiU��CPU��GPU�ɂ��Ă͂ǂ��H
GPU�܂ŁAPS3��360�������\�����Ƃ����킯�ł͂Ȃ����
GPU�܂ŁAPS3��360�������\�����Ƃ����킯�ł͂Ȃ����
��������̏��Œm��������intel�̍���Tri-gate���ď���d�͓I�Ƀ��o�C���ł͎g���Ȃ��炵��
FinFET���R�X�g��̗��R�Ń��o�C���Ŏg���͓̂���Ƃ̈ӌ������邻����
�Ƃ�����Aatom�����̐�ǂ��Ȃ邩�����[�������Ƃ��悤
FinFET���R�X�g��̗��R�Ń��o�C���Ŏg���͓̂���Ƃ̈ӌ������邻����
�Ƃ�����Aatom�����̐�ǂ��Ȃ邩�����[�������Ƃ��悤
>>847
arm�Ŋ�Ր����Ă�̂ɂ킴�킴atom�̗p�������Ȗ{���ɉ�Ђ�����̂��� �R�X�g���������낤��
arm�Ŋ�Ր����Ă�̂ɂ킴�킴atom�̗p�������Ȗ{���ɉ�Ђ�����̂��� �R�X�g���������낤��
>>851
itanium�ɖ����Ǒf�l��
itanium�ɖ����Ǒf�l��
�X�}�t�H�̓d�̓o�W�F�b�g�̂܂�ARM����{������̗p����邩���ł��ȁB���������ǁB
861 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 17:34:01.61 ID:nVYXn2Ur
Atom�Ȃ�Windows Embedded for x86�������B
VC++�œ���Windows�A�v���P�[�V���������̂܂܂����Ă��ē�������́B
�J���I�Ղ܂Łu���@�v��p�ӂ���K�v���Ȃ��̂ŒZ���ԁE��R�X�g�ŊJ�����\�B
�Y�ƌ����g�ݍ��ݕ��ʂ́APC�x�[�X�̋@��𗬗p���Ă���̂�������B
�W���J���Ă݂���Intel�ސ���D525�̃}�U�[�{�[�h�����̂܂ܓ����Ă�Ȃ�Ă��Ƃ��悭����b�B
���ʐ��Y�i�͂킴�킴�P��������s�̕i���g�����ق����������B
����FPGA�{�[�h�Ȃ̃R���g���[���ł��̗p���i���������B
���������ʂ�PowerPC�Ȃ��g���Ă����삾�ˁB
VC++�œ���Windows�A�v���P�[�V���������̂܂܂����Ă��ē�������́B
�J���I�Ղ܂Łu���@�v��p�ӂ���K�v���Ȃ��̂ŒZ���ԁE��R�X�g�ŊJ�����\�B
�Y�ƌ����g�ݍ��ݕ��ʂ́APC�x�[�X�̋@��𗬗p���Ă���̂�������B
�W���J���Ă݂���Intel�ސ���D525�̃}�U�[�{�[�h�����̂܂ܓ����Ă�Ȃ�Ă��Ƃ��悭����b�B
���ʐ��Y�i�͂킴�킴�P��������s�̕i���g�����ق����������B
����FPGA�{�[�h�Ȃ̃R���g���[���ł��̗p���i���������B
���������ʂ�PowerPC�Ȃ��g���Ă����삾�ˁB
�����ĂċC�t���Ă�Ǝv�����ǁA����u���ʐ��Y�i�v������
VIA�ɂ͂�������Intel�ɂ͐h���Ȃ�?
VIA�ɂ͂�������Intel�ɂ͐h���Ȃ�?
�����ĂċC�t���Ă�Ǝv�����ǁA�u���ʐ��Y�i�v���u�l�X�Ȋ�Ƃ��瑽��ށv�̔�����Ă��邩��
���v���Ƃ��������̐��ɂȂ��B
���v���Ƃ��������̐��ɂȂ��B
864 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 18:09:01.23 ID:nVYXn2Ur
> VIA�ɂ͂�������
���ʐ��Y�Ȃ�̉��i���ӂ������Ă邩�炢����ł���B
Atom���o�Ă������炤�܂������Ȃ��Ȃ����B
VIA���ō��o����Ă�̂�Atom���o�Ă���ȑO�ɃI�[�_�[�m�肵�����̂��唼����B
�g�ݍ��݂�10�N�͒��Ȃ��Ƃ����Ȃ�����ˁB
> Intel�ɂ͐h���Ȃ�?
���������ʂ�Intel�͎��샆�[�U�[�������v�����˂�mini-ITX�{�[�h���Ă邾����
�g�ݍ��������ɓ��ʉ����R�X�g�������Ă���Ă�킯�ł͂Ȃ��B
PCI/PCIe/USB�ȂLj�ʂ�̊g�����͂��邩���͂��D���ɁA�ł���B
�܂��A��������ɔ���Ȃ��Ȃ����甄��Ȃ��Ȃ����ʼn��i���ӂ������邱�Ƃ��ł���B
�X�}�z�E�^�u���b�g�͂܂��ʖ��B
�ł��^�u���b�g�͂����ނː�������Ȃ����ȁB
���Ƃ͂��̃^�u���b�g���g���Ăǂ��Ɩ��Ɋ��p���邩�B���̂ւ�̓A�v�������悾�B
Windows 8�^�u���b�g�����̃A�v����iPad�̂悤��Objective-C�ł͂Ȃ��AVB��C#�ŊJ���ł��邵
�����ȃG�~�����[�^�ȂǗv��Ȃ��B
���ʐ��Y�Ȃ�̉��i���ӂ������Ă邩�炢����ł���B
Atom���o�Ă������炤�܂������Ȃ��Ȃ����B
VIA���ō��o����Ă�̂�Atom���o�Ă���ȑO�ɃI�[�_�[�m�肵�����̂��唼����B
�g�ݍ��݂�10�N�͒��Ȃ��Ƃ����Ȃ�����ˁB
> Intel�ɂ͐h���Ȃ�?
���������ʂ�Intel�͎��샆�[�U�[�������v�����˂�mini-ITX�{�[�h���Ă邾����
�g�ݍ��������ɓ��ʉ����R�X�g�������Ă���Ă�킯�ł͂Ȃ��B
PCI/PCIe/USB�ȂLj�ʂ�̊g�����͂��邩���͂��D���ɁA�ł���B
�܂��A��������ɔ���Ȃ��Ȃ����甄��Ȃ��Ȃ����ʼn��i���ӂ������邱�Ƃ��ł���B
�X�}�z�E�^�u���b�g�͂܂��ʖ��B
�ł��^�u���b�g�͂����ނː�������Ȃ����ȁB
���Ƃ͂��̃^�u���b�g���g���Ăǂ��Ɩ��Ɋ��p���邩�B���̂ւ�̓A�v�������悾�B
Windows 8�^�u���b�g�����̃A�v����iPad�̂悤��Objective-C�ł͂Ȃ��AVB��C#�ŊJ���ł��邵
�����ȃG�~�����[�^�ȂǗv��Ȃ��B
���l�T�X���q�̗v�]�ŏ��ʐ��Y�i�𑽐������Ă��������Ə����Ă�������
866 �F,,�E�L�́M�E,,�j��-�������F2012/12/01(�y) 20:30:27.93 ID:nVYXn2Ur
�ėp���͂������Ă邩��ʎY�i�����ʃj�[�Y�ɖ𗧂ĂĂ���Ƃ����̂�
Atom�̑g�ݍ��ݎs��̐헪�ł���B
Intel��Cortex-A�Ȃ݂̃n�C�G���h�g�ݍ��݂�����ȏ�̒P���Ŕ����s��ɂ����i�o���邾���Ȃ̂�
����Ȃɕ��L��������͂Ȃ�
�X�̎Y�ƕʂ�SoC�����낤���Ă킯����Ȃ����A���ꂱ���e�p�r�ɉ�����
�R���p�j�I���`�b�v���悹���ق����������Ē�R�X�g�ɂȂ�ł��傤�B
���l�T�X�͂��ꂱ���P��100�~�ȉ��̃����`�b�v�}�C�R�����܂߂Ă����ʐ��Y��������
�������Ă����i���C�������܂������ł��Ȃ������̂��j�]�̌������ƁB
�~���̉e��������ɂ����Ă邵�ˁB
Atom�̑g�ݍ��ݎs��̐헪�ł���B
Intel��Cortex-A�Ȃ݂̃n�C�G���h�g�ݍ��݂�����ȏ�̒P���Ŕ����s��ɂ����i�o���邾���Ȃ̂�
����Ȃɕ��L��������͂Ȃ�
�X�̎Y�ƕʂ�SoC�����낤���Ă킯����Ȃ����A���ꂱ���e�p�r�ɉ�����
�R���p�j�I���`�b�v���悹���ق����������Ē�R�X�g�ɂȂ�ł��傤�B
���l�T�X�͂��ꂱ���P��100�~�ȉ��̃����`�b�v�}�C�R�����܂߂Ă����ʐ��Y��������
�������Ă����i���C�������܂������ł��Ȃ������̂��j�]�̌������ƁB
�~���̉e��������ɂ����Ă邵�ˁB
�܂��������̕i�퓝�������X��肭�����Ȃ��āA�����O�ɔ�ׂăV�F�A�𗎂Ƃ��Ă��邩��ȁc
��Бg�D�����ɔ����Ă̕i�퓝�p����z�肵�����[�U�[�����S��ɑ���͓̂��R�Ȃ̂�
�V�F�A���ꎞ�I�ɗ��Ƃ������̂͑z�肳��Ă������̔������ǁA����ɂ��Ă��c
�܂��k�Ў��̐��Y�x����Ă̂����̋ꋫ�̒��ړI�������낤���ǁB
��Бg�D�����ɔ����Ă̕i�퓝�p����z�肵�����[�U�[�����S��ɑ���͓̂��R�Ȃ̂�
�V�F�A���ꎞ�I�ɗ��Ƃ������̂͑z�肳��Ă������̔������ǁA����ɂ��Ă��c
�܂��k�Ў��̐��Y�x����Ă̂����̋ꋫ�̒��ړI�������낤���ǁB
�C���e���͏����I�ɂ�SoC���X�ɐi�߂āA�����pLSI�܂ł���̉�����悤���B
���̎��̓I�[�f�B�I�A���v�����S�Ƀf�W�^�������Ĉ�̉����Ă��܂������������[
�ȊO�͑S��1�`�b�v���ł���ȁi�������[���̂�TSV�Z�p�̓����ł��Ȃ�̕�����1�`�b�v���ł��邩��
�ȑO�قǂɂ͊O�t���̃������[�͏d�v����Ȃ��Ȃ�j
���̎��̓I�[�f�B�I�A���v�����S�Ƀf�W�^�������Ĉ�̉����Ă��܂������������[
�ȊO�͑S��1�`�b�v���ł���ȁi�������[���̂�TSV�Z�p�̓����ł��Ȃ�̕�����1�`�b�v���ł��邩��
�ȑO�قǂɂ͊O�t���̃������[�͏d�v����Ȃ��Ȃ�j
���l�T�X�ُ͈�Ȃ܂ł̉~���̉e��������ɔ�����`���ȁB
�G���s�[�_��������ǂ��B
�l�I�ɂ̓��o�C��SH-G5��������64bitCPU�ɂ��ĎQ�����ė~�������E�E�E�E
�G���s�[�_��������ǂ��B
�l�I�ɂ̓��o�C��SH-G5��������64bitCPU�ɂ��ĎQ�����ė~�������E�E�E�E
����̃h���~120�~�ɖ߂���l�T�X�͉���ɂ�݂�����܂���
����Ɍ�������CPU��������������̂ɂǂ�Ȑl�ނ��ǂꂭ�炢�v��̂��ȁB
�˔\����Ⴂ�l���猩�āA���{���ł���܂ő����Ă���
��������CPU�Ɍg��邱�Ƃ͖��͓I���낤��
�˔\����Ⴂ�l���猩�āA���{���ł���܂ő����Ă���
��������CPU�Ɍg��邱�Ƃ͖��͓I���낤��
�����
��N�����H
��N�����H
ando ����̂Ƃ����
adapteva��Epiphany �̏o�����W�߂邱�Ƃɐ��������L�������グ�Ă��
ttp://www.adapteva.com/support/docs/e3-reference-manual/
adapteva��Epiphany �̏o�����W�߂邱�Ƃɐ��������L�������グ�Ă��
ttp://www.adapteva.com/support/docs/e3-reference-manual/
>>873
���ꂾ�������B
ttp://gigazine.net/news/20121007-supercomputer-parallella/
10���I���ɂ͖ڕW���z���W�܂������Ęb���o�Ă��ˁB
���ꂾ�������B
ttp://gigazine.net/news/20121007-supercomputer-parallella/
10���I���ɂ͖ڕW���z���W�܂������Ęb���o�Ă��ˁB
�N�A���R���uSnapdragon�v�̏�����
�����`�b�v�Z�b�g�ň�l�����𑱂���Q�Ђ̎��̈��
http://sp.ch.nicovideo.jp/article/ar20333
�����`�b�v�Z�b�g�ň�l�����𑱂���Q�Ђ̎��̈��
http://sp.ch.nicovideo.jp/article/ar20333
�Ȃ�ł��A�L���L���̐�`��YO
VIA�u�c�c�c�c�B�v
IBM�AMIPS�A�T���}�C�N���u�E�E�E�E�E�E�v
VIA��x86��ARM�����
���l�T�X�u�c�c�c�v
ARM�̎������z��107���|���h
1�|���h130�~�Ƃ���
1��3900���~
ARM�͊ȒP�ɔ����ł��Ȃ��K�͂̊�ƂɂȂ��Ă�����
1�|���h130�~�Ƃ���
1��3900���~
ARM�͊ȒP�ɔ����ł��Ȃ��K�͂̊�ƂɂȂ��Ă�����
�t��ARM���ł���悤�Ȋ�Ƃ͓Ƌ֖@�̐�������悤�Ȋ�Ƃ̂�
���[���b�p��Ƃ�����]�v��ARM���ȒP�ɔ����ł���IT��Ƃ͂Ȃ�
���[���b�p��Ƃ�����]�v��ARM���ȒP�ɔ����ł���IT��Ƃ͂Ȃ�
��������ARM�̉��l�̓��C�Z���V�[�ɃA�[�L�e�N�`�������J����Ă��邱�ƂȂ̂�
�������铮�@���Ă���?
�������铮�@���Ă���?
arm�̎��Y���l�̓��C�Z���V�[�̑����ȊO������������B
���C�Z���V�[���������R����[�v���Z�X�t�@�u�̌��ݔ���ɂ�蔼���̐��Y���������ƂɈȍ~�����g�ɂ��܂���ꂽ�����ŁA���\�Ƃ��ׂ͖����ĊJ������|������悤�ɂȂ������ŋ߂܂ŃS�~���x�����������B
���C�Z���V�[���������R����[�v���Z�X�t�@�u�̌��ݔ���ɂ�蔼���̐��Y���������ƂɈȍ~�����g�ɂ��܂���ꂽ�����ŁA���\�Ƃ��ׂ͖����ĊJ������|������悤�ɂȂ������ŋ߂܂ŃS�~���x�����������B
50���~(�ő�100���~)��IGZO��Qualcomm�Ƀv���[���g
�E�E�E���ăA�z����A�����肵����
���C�Ƃ̌������X�ƈ����L���Ă������ʂ����ꂩ�悗
�V���[�v���ăN�A���R���Ǝ�����p�l���J���ցA�o�������
http://headlines.yahoo.co.jp/hl?a=20121204-00000029-reut-bus_all
�f���炵���o����SH-02E�A�_�@���肩�H
http://suzunonejh.blog15.fc2.com/blog-entry-3144.html
�y������z�V���[�v�V�@��uAQUOS PHONE ZETA SH-02E�v���_�@������Ƙb���
http://kizitora.doorblog.jp/lite/archives/20852517.html
�E�E�E���ăA�z����A�����肵����
���C�Ƃ̌������X�ƈ����L���Ă������ʂ����ꂩ�悗
�V���[�v���ăN�A���R���Ǝ�����p�l���J���ցA�o�������
http://headlines.yahoo.co.jp/hl?a=20121204-00000029-reut-bus_all
�f���炵���o����SH-02E�A�_�@���肩�H
http://suzunonejh.blog15.fc2.com/blog-entry-3144.html
�y������z�V���[�v�V�@��uAQUOS PHONE ZETA SH-02E�v���_�@������Ƙb���
http://kizitora.doorblog.jp/lite/archives/20852517.html
StrongARM�������Ƃ��Ă͐��\����������Ă���
���C�o����SH3��MIPS R4x00
���C�o����SH3��MIPS R4x00
>>887
SH-G5�̕����ƍĊJ���ꂽ�VMIPS64���R���Ă���Ȃ�����
SH-G5�̕����ƍĊJ���ꂽ�VMIPS64���R���Ă���Ȃ�����
>>887
StrongARM���o�Ă������ɂ�SH4����������c
�����{�̂���o��SH4���ڃR���V���[�}����CE�@��HPW-600�n��Handheld PC Pro3.0�@�����ŏI��������ǂ��B
���߂�Handheld PC 2000�ō���ė~���������c
StrongARM���o�Ă������ɂ�SH4����������c
�����{�̂���o��SH4���ڃR���V���[�}����CE�@��HPW-600�n��Handheld PC Pro3.0�@�����ŏI��������ǂ��B
���߂�Handheld PC 2000�ō���ė~���������c
SH4��Dreamcast�ɍڂ��ĂȂ������������B
SA110���o�ׂ��ꂽ�̂�1996�N����
SH4��1998�N12��
SH4�͂�����ƃn�C�G���h�����Ē��ڂ̃��C�o���ɂ͂Ȃ�Ȃ�
SH4��1998�N12��
SH4�͂�����ƃn�C�G���h�����Ē��ڂ̃��C�o���ɂ͂Ȃ�Ȃ�
NEC V�V���[�Y��Wikipedia
���e�푽�l�ȃI�y���[�V�����ɐl�m�ꂸ��ʍ̗p����Ă���B
���
���e�푽�l�ȃI�y���[�V�����ɐl�m�ꂸ��ʍ̗p����Ă���B
���
�Ƃ肠�����AStrongARM���Ȃ�������ǂ��Ȃ��Ă������͂킩����
StrongARM�������ɉ���I�ɑ�����������Newton���[�U�[���،����Ă����ł��傤
StrongARM�������ɉ���I�ɑ�����������Newton���[�U�[���،����Ă����ł��傤
�Ƃ肠����14nm����Ō����CPU�{GPU�{�m�[�X�u���b�W�ɉ����ăT�E�X�u���b�W��
���������킯���BSoC�����S�ɂ���ɂ͎��̓������[��������邱�ƂɂȂ邾�낤�B
���������킯���BSoC�����S�ɂ���ɂ͎��̓������[��������邱�ƂɂȂ邾�낤�B
DRAM�楥����͂��܂������
MRAM���������i���������������Ȃ��Ă����DRAM�����ނł����Ȃ���
DRAM�u�䂪���U�Ɉ�Ђ̉����Ȃ��I�I�v
SRAM�͂��Ƀ��C���������ɂ͂Ȃ蓾�Ȃ��̂��B
��SoC�����S�ɂ���ɂ͎��̓������[��������邱�ƂɂȂ邾�낤�B
eDRAM�Ƃǂ��Ⴄ�́H
eDRAM�Ƃǂ��Ⴄ�́H
eDRAM = CPU�_�C�̈ꕔ��DRAM���B
SoC�����S�ɂ���ɂ͎��̓������[����� = TSV�ɂ��DRAM�̓���
SoC�����S�ɂ���ɂ͎��̓������[����� = TSV�ɂ��DRAM�̓���
eDRAM��CPU�_�C�ɓ��������ǁATSV�͏ォ��\��t���銴�����ȁH
eDRAM�͉���TSV�͏�ƌ����C���[�W�Ȃ��B
�������͐�����eDRAM�Ő�����TSV��
eDRAM�͉���TSV�͏�ƌ����C���[�W�Ȃ��B
�������͐�����eDRAM�Ő�����TSV��
���o�C���ƃT�[�o��2���ʍ���W�J����ARM��64bit�R�A�uCortex-A50�v
http://news.mynavi.jp/articles/2012/12/06/arm_cortex-a50/
http://news.mynavi.jp/articles/2012/12/06/arm_cortex-a50/
�C���e����CPU�̓T�E�X�u���b�W������������DMI��QPI��FDI���v��Ȃ��Ȃ邩��
�X�Ƀ_�C�T�C�Y�͏������Ȃ��ė]�T���o����Ǝv��
�X�Ƀ_�C�T�C�Y�͏������Ȃ��ė]�T���o����Ǝv��
���x�̓s�������������
���ł�����ł�1�`�b�v�ɂ܂Ƃ߂�ƃs��������Ȃ����o���f�[�V�����R�X�g�オ�邵�����ō��Â炢���_�C�T�C�Y�オ���ăG���[�����オ�邵
IO�̍��d���Ƃ������Ă���̂Ńg�����W�X�^�̎�ޕς��ɂ�Ȃ�ł��܂肢�����Ɩ�����
IO�̍��d���Ƃ������Ă���̂Ńg�����W�X�^�̎�ޕς��ɂ�Ȃ�ł��܂肢�����Ɩ�����
>>905
����Ȃ����H
����Ȃ����H
�����镪�����Ƃ���PCH����o�Ă����s����
���镪��DMI�̃s�����APCH�p�d���֘A�s��
�����镪�̂ق���������ˁH
���镪��DMI�̃s�����APCH�p�d���֘A�s��
�����镪�̂ق���������ˁH
�Ƃ肠����Hasswell�̃��o�C������SKU�ɂ��Ă�MCM������o���f�[�V�����Ƃ��_�C�T�C�Y�͋C�ɂ��Ȃ��Ă���
>>898
����CPU���ăL���b�V���~�X����������ɒ[�ɒx�����A
�����L���b�V�������C���������Ƃ��ē��삵�Ă�悤�Ȃ��̂���Ȃ����B
�����A�s�����̈Ⴂ�͂��邯�ǁA�L���b�V����DRAM�̊W��
����ꂽDRAM��HDD���z�L���������Ă����̂Ɩ{���I�ɓ������낤
����CPU���ăL���b�V���~�X����������ɒ[�ɒx�����A
�����L���b�V�������C���������Ƃ��ē��삵�Ă�悤�Ȃ��̂���Ȃ����B
�����A�s�����̈Ⴂ�͂��邯�ǁA�L���b�V����DRAM�̊W��
����ꂽDRAM��HDD���z�L���������Ă����̂Ɩ{���I�ɓ������낤
�A�h���b�V���O���Ⴄ
>>909
�ړI�����Ȃ���
�ړI�����Ȃ���
��G�c�ɂ����A�ǂ�����A�N�Z�X���Ԃ��]���ɂ��ċ�Ԃ̍L���Ă���B�{���I�ɓ����ƌ����ėǂ����낤�B
>>912�͔�����������
�L���b�V���͂ӂ������A�h���X�����AHDD�͈Ⴄ
�P��A�h���X���OS�����邯�ǁA����܂��ʓI����Ȃ����
�L���b�V���͂ӂ������A�h���X�����AHDD�͈Ⴄ
�P��A�h���X���OS�����邯�ǁA����܂��ʓI����Ȃ����
>>913
�_���A�h���X�L���b�V�������Ă��邵�A�Ⴂ����������~�X�q�b�g�̏����E�Ǘ���̂��牽���牽�܂ňႤ�B
�����́u�{���v�̘b����Ȃ��B
�_���A�h���X�L���b�V�������Ă��邵�A�Ⴂ����������~�X�q�b�g�̏����E�Ǘ���̂��牽���牽�܂ňႤ�B
�����́u�{���v�̘b����Ȃ��B
�L���b�V���Ɖ��z�L�����������Ă͂�����ȁB
���Ă�̂͊K�w�\���ɂȂ��Ă鏊���������B
�L���b�V�����n�[�h�E�F�A�����䁁����SRAM���ᑬSRAM��DRAM/ROM
���z�L����OS�����䁁DRAM(��L��)��SSD��HDD�����C�e�[�vor���f�B�X�Nwith�I�[�g�`�F���W���[
���Ă�̂͊K�w�\���ɂȂ��Ă鏊���������B
�L���b�V�����n�[�h�E�F�A�����䁁����SRAM���ᑬSRAM��DRAM/ROM
���z�L����OS�����䁁DRAM(��L��)��SSD��HDD�����C�e�[�vor���f�B�X�Nwith�I�[�g�`�F���W���[
�n�[�h�E�F�A����̉��z�L�����ߋ��ɂ͂���������
�p�\�R���ł͌������Ȃ����
�p�\�R���ł͌������Ȃ����
�ŁA>>914�̍D���Ș_���A�h���X�L���b�V����OS�����䂵�Ȃ��Ǝg�����ɂȂ�Ȃ��킯����
�܂��ɊK�w�\���������R���s���[�^�̃������̖{���A�u��ԂƎ��Ԃ̃g���[�h�I�t�v��\���Ă���̂���B
�t�̎�������Ă݂悤�B909�̂����L���b�V����DRAM�̊W�Ɓu�{���I�ɓ����v���̗̂�Ƃ��āA���ɉ���������?
�t�̎�������Ă݂悤�B909�̂����L���b�V����DRAM�̊W�Ɓu�{���I�ɓ����v���̗̂�Ƃ��āA���ɉ���������?
CPU�̐��\�w�W���قڃL���b�V���Ɉˑ����Ă���B
�قڃm�[�q�b�g�̃P�[�X�ł͎w�W���S����R�ɂȂ�B
����ȏ�Ԃ�DRAM���h���C���h�������ƌĂ�ł����������������
�قڃm�[�q�b�g�̃P�[�X�ł͎w�W���S����R�ɂȂ�B
����ȏ�Ԃ�DRAM���h���C���h�������ƌĂ�ł����������������
��L���̑`��͊O���L���A�L���b�V����DRAM��BIOS ROM��CPU���璼�ڃA�N�Z�X�ł�����̂͑S����L�����B
�匳�̔��z���Ǐ����𗘗p���č�������}�邽�߂̃L���b�V����
���x���]���ɂ��ăA�v���P�[�V��������̎g������Ƒ�e�ʂ�ڎw�������z�L���͖ړI���Ⴄ����B
�L���b�V���Ȃ烁�����Ɍ��炸�l�b�g�W�ł�����ł������Ⴊ���邩�玩���Œ��ׂ�B
�匳�̔��z���Ǐ����𗘗p���č�������}�邽�߂̃L���b�V����
���x���]���ɂ��ăA�v���P�[�V��������̎g������Ƒ�e�ʂ�ڎw�������z�L���͖ړI���Ⴄ����B
�L���b�V���Ȃ烁�����Ɍ��炸�l�b�g�W�ł�����ł������Ⴊ���邩�玩���Œ��ׂ�B
�N���T�O�Ǝ����̋�ʂ����ĂȂ���������
�L���b�V���Ɖ��z�L���͕ʂ̎������瓯���T�O�ɓ��B���������̂���
�L���b�V���Ɖ��z�L���͕ʂ̎������瓯���T�O�ɓ��B���������̂���
�Ȃ�������A�Ԉ���Ă͂��Ȃ����ǁA�����������������Ċ�����
�ړI�̘b�Ńl�b�g�������o���͓̂K�Ȃ̂��ȁB
�l�b�g�̃L���b�V���̖ړI�̓g���t�B�b�N�̌y�������
���C�e���V�̒Z�k�͂��܂����낤�B
CPU�L���b�V���̓��C�e���V�̕�����B
�ǂ����o���h���͊O���`�b�v�Ƃ̃o���h���Ő�������Ă��܂�
�l�b�g�̃L���b�V���̖ړI�̓g���t�B�b�N�̌y�������
���C�e���V�̒Z�k�͂��܂����낤�B
CPU�L���b�V���̓��C�e���V�̕�����B
�ǂ����o���h���͊O���`�b�v�Ƃ̃o���h���Ő�������Ă��܂�
>>924
>�ǂ����o���h���͊O���`�b�v�Ƃ̃o���h���Ő�������Ă��܂�
�܂������Ȃ��ǁA�L���b�V���̃��C���t�B�����삪�僁�����̃o�[�X�g�]���@�\�𗘗p���鎖�ɂ����
�僁�����̃o���h����L���ɗ��p���Ă���Ƃ������ʂ����邩��c
>�ǂ����o���h���͊O���`�b�v�Ƃ̃o���h���Ő�������Ă��܂�
�܂������Ȃ��ǁA�L���b�V���̃��C���t�B�����삪�僁�����̃o�[�X�g�]���@�\�𗘗p���鎖�ɂ����
�僁�����̃o���h����L���ɗ��p���Ă���Ƃ������ʂ����邩��c
>>924
�������ĂHCPU�L���b�V���̑ш悪�ǂꂾ���L�����m��Ȃ��̂��B
�ꎟ�L���b�V���͖��߂ƕ����̃f�[�^�A�N�Z�X���ɍs���āA�L���b�V����CPU�R�A�Ɠ���N���b�N�œ��삷��B�O���������Ƃ͌����Ⴄ�B
�������A�N�Z�X���L���b�V�����Ŋ������ĊO�ɏo���Ȃ����炻�ꂾ���L���ш悪�L�����p�ł����ŁA�l�b�g�Ɩ{���͓��������B
�������ĂHCPU�L���b�V���̑ш悪�ǂꂾ���L�����m��Ȃ��̂��B
�ꎟ�L���b�V���͖��߂ƕ����̃f�[�^�A�N�Z�X���ɍs���āA�L���b�V����CPU�R�A�Ɠ���N���b�N�œ��삷��B�O���������Ƃ͌����Ⴄ�B
�������A�N�Z�X���L���b�V�����Ŋ������ĊO�ɏo���Ȃ����炻�ꂾ���L���ш悪�L�����p�ł����ŁA�l�b�g�Ɩ{���͓��������B
927 �FSocket774�F2012/12/08(�y) 03:45:42.81 ID:T8QChHh/
�̘b�������1990�N��̃X�[�p�R���s���[�^�͂r�q�`�l�����C���������B
SX2�Ƃ�VP�Ƃ��B
�A�N�Z�X���x10-15nsec���炢�̔��r�q�`�l�������Ǝv���B
SX2�Ƃ�VP�Ƃ��B
�A�N�Z�X���x10-15nsec���炢�̔��r�q�`�l�������Ǝv���B
���c���ɂ��ז��������̓��C����������DRAM���Ƃ���������Ă����̂�S820���Ǝv��
VPP��DRAM�ł�
VPP��DRAM�ł�
���Ⴀ�����ƃL���b�V����������ς߂�����ˁi���
��������ςނɂ̓L���b�V��������Ȃ��i�\�Z
�L���b�V����ς߂L���b�V����ς�ł�����ł��ˁH
�x�N�g���X�p�R���̎�L���̓o���N�C���^�[���[�u���Ă���̂�
���X�x��DRAM�ł����܂�Ȃ��̂ł�
���X�x��DRAM�ł����܂�Ȃ��̂ł�
�L���b�V���e�ʂłɑ��₵�Ă����C�e���V�������Č��ʂ��Ȃ�����ȁB�e�ʂ��ꌅ�Ⴄ�����̊K�w�ɕ����āA����ɃX�R�[�v��������̂��������ǂ��B
L0�F��KB�F�f�R�[�h�ώ��s������
L1�F���\KB�F���߁A�f�[�^�Ɨ�
L2�F���SKB�F�R�A�Ɨ�
L3�F��MB�F�����R�A�AGPU���L
coreMA���ƃR�A�����������L3�̗e�ʂ�������ƂƂ��ɋߐڃR�A����̃��C�e���V���������A���u�R�A����̃��C�e���V���傫���Ȃ��āA�����I��L4�����˂铮���ɂȂ�悤�l�����Ă���B
���Ȃ��Ƃ��L���b�V���Ɋւ��Ă�coreMA�͍Ő�[���s���Ă���B
L0�F��KB�F�f�R�[�h�ώ��s������
L1�F���\KB�F���߁A�f�[�^�Ɨ�
L2�F���SKB�F�R�A�Ɨ�
L3�F��MB�F�����R�A�AGPU���L
coreMA���ƃR�A�����������L3�̗e�ʂ�������ƂƂ��ɋߐڃR�A����̃��C�e���V���������A���u�R�A����̃��C�e���V���傫���Ȃ��āA�����I��L4�����˂铮���ɂȂ�悤�l�����Ă���B
���Ȃ��Ƃ��L���b�V���Ɋւ��Ă�coreMA�͍Ő�[���s���Ă���B
L4�L���b�V����eDRAM
L5�L���b�V����TSV
�����zL1�`L3�܂ł�SRAM
L5�L���b�V����TSV
�����zL1�`L3�܂ł�SRAM
eDRAM��SRAM���2�{���x�̗e�ʂ����Ȃ�
�����������݉��l���w��ǖ�������Z�����Ă��Ȃ�
���Ȃ�Power�̂悤��L3�����ւ���Ƃ��ł�����
�e�ʂ��卷�Ȃ��̂�L3��L4�̕��݂Ȃǔn���炵������
���ł�3D��2.5D�ő�e�ʍL�ш悪����Ɖv�X���݉��l���Ȃ��Ȃ�
>>934�ȂNJ��S�Ȗ���
�����������݉��l���w��ǖ�������Z�����Ă��Ȃ�
���Ȃ�Power�̂悤��L3�����ւ���Ƃ��ł�����
�e�ʂ��卷�Ȃ��̂�L3��L4�̕��݂Ȃǔn���炵������
���ł�3D��2.5D�ő�e�ʍL�ш悪����Ɖv�X���݉��l���Ȃ��Ȃ�
>>934�ȂNJ��S�Ȗ���
BG/Q��L2��32MB��eDRAM����
���ɂ��惏�[�N�Z�b�g���l�������ɊK�w�������₵�Ă��L�Q���v
�L���b�V���̃I�[�o�[�w�b�h�͏������Ȃ�
���ɂ��惏�[�N�Z�b�g���l�������ɊK�w�������₵�Ă��L�Q���v
�L���b�V���̃I�[�o�[�w�b�h�͏������Ȃ�
�����f�[�^�ɂ���čœK�Ȑv�͈قȂ邯�ǁA�����_��CPU�O���ɃL���b�V����݂���̂�NG����Ȃ����B�I���_�C�ŃL���b�V����������x�ڂ��Ă��܂��Ό�̓��C�e���V�A�X���[�v�b�g�Ƃ����r���[�ȊO���L���b�V�������X���[�v�b�g�̍��������������������������B�@�@
�L���b�V���p��SRAM�q���ʂȂ�DRAM�̃o�X���L���������������Ă��ƁB
�L���b�V���p��SRAM�q���ʂȂ�DRAM�̃o�X���L���������������Ă��ƁB
Alpha21064����21164�����̓��C�e���V�}���邽�߂�L1��4KB�ɗ}���Ă��L���B
I/D�Ƃ���8KB�����ǁH
�y�[�W�T�C�Y������ɂ��킹��8K�ɂȂ��Ă���
�y�[�W�T�C�Y������ɂ��킹��8K�ɂȂ��Ă���
�L���Ⴂ���B���܂�B
�����Ƃ��A��ʓI��4KB�y�[�W�ł͂Ȃ��̂�
�_�C���N�g�}�b�v�ɂ������������炩�������
�_�C���N�g�}�b�v�ɂ������������炩�������
>>935
GPGPU�Ƃ��čl����Ȃ�eDRAM������Ȃ�ł́HCPU�������Ă��炻��Ȃ̗v��Ȃ�����
����GPU�ׂ̈�L4�L���b�V���Ƃ���eDRAM�𓋍ڂ���͂�����Ȃ��H
CPU�͂���܂łǂ���L1�`L3��SRAM���g�p�����炢�������B
�ꉞ��eDRAM��SRAM�̔{���x�̗e�ʂ͓��ڂ���邵GPU�ɂ͗L������
GPGPU�Ƃ��čl����Ȃ�eDRAM������Ȃ�ł́HCPU�������Ă��炻��Ȃ̗v��Ȃ�����
����GPU�ׂ̈�L4�L���b�V���Ƃ���eDRAM�𓋍ڂ���͂�����Ȃ��H
CPU�͂���܂łǂ���L1�`L3��SRAM���g�p�����炢�������B
�ꉞ��eDRAM��SRAM�̔{���x�̗e�ʂ͓��ڂ���邵GPU�ɂ͗L������
>>942
���ς�炸�n�����Ȃ�
2�{���x�������Ȃ����Ă̂�
SRAM20M�ς߂鏊��SRAM10M+eDRAM20M�ɂȂ��
���x��2�{����2�{����l�߂Ȃ���
����Ȃ�ŊK�w���₷�Ӗ��Ȃ���
���߂�1���Ⴄ�ʂ���Ȃ��Ƒ��݈Ӗ�������
eDRAM���S�R�L�܂�Ȃ��͈̂Ӗ����Ȃ��Ƃ��O�ȊO�݂�ȉ����Ă邩��
���ς�炸�n�����Ȃ�
2�{���x�������Ȃ����Ă̂�
SRAM20M�ς߂鏊��SRAM10M+eDRAM20M�ɂȂ��
���x��2�{����2�{����l�߂Ȃ���
����Ȃ�ŊK�w���₷�Ӗ��Ȃ���
���߂�1���Ⴄ�ʂ���Ȃ��Ƒ��݈Ӗ�������
eDRAM���S�R�L�܂�Ȃ��͈̂Ӗ����Ȃ��Ƃ��O�ȊO�݂�ȉ����Ă邩��
>>943
�C���N���[�V�u�L���b�V�����Ɨe�ʕς���w
�C���N���[�V�u�L���b�V�����Ɨe�ʕς���w
>>944
�͂�����x���Ȃ邾���ƌ����Ă���B
�͂�����x���Ȃ邾���ƌ����Ă���B
POWER7�̋L���ɂ���
ttp://news.mynavi.jp/news/2010/02/09/051/index.html
ttp://www-06.ibm.com/systems/jp/power/info/pdf/power_guru_seminar01.pdf
��CPU�ɑg�ݍ��܂ꂽeDRAM�ɂ��A
��L3�L���b�V���ւ̃A�N�Z�X���x�i���C�e���V�j��
���iPOWER6��MCM eDRAM L3��j6�{�ɂ܂Ō���i�o���h����x2�j�B
��SRAM�ɔ�ׂāA�X�y�[�X��3����1�A
���ҋ@����d�͂͏]���iSRAM�j��5����1�A
���\�t�g�G���[�������́iSRAM�́j250����1�ɗ}�����Ă���B
ttp://news.mynavi.jp/news/2010/02/09/051/index.html
ttp://www-06.ibm.com/systems/jp/power/info/pdf/power_guru_seminar01.pdf
��CPU�ɑg�ݍ��܂ꂽeDRAM�ɂ��A
��L3�L���b�V���ւ̃A�N�Z�X���x�i���C�e���V�j��
���iPOWER6��MCM eDRAM L3��j6�{�ɂ܂Ō���i�o���h����x2�j�B
��SRAM�ɔ�ׂāA�X�y�[�X��3����1�A
���ҋ@����d�͂͏]���iSRAM�j��5����1�A
���\�t�g�G���[�������́iSRAM�́j250����1�ɗ}�����Ă���B
ttp://news.mynavi.jp/articles/2009/09/16/hot_chips21_power7/index.html
��eDRAM�e�N�m���W���g����3���L���b�V����CPU�`�b�v��
�������������Ƃɂ��A3���L���b�V���̃A�N�Z�X�������ƂȂ�A���A
���o���h�����傫�����邱�Ƃ��\�ɂȂ����B���̂��߁A�e�R�A��������
��2���L���b�V����256KB�ƁiPOWER6��4MB����j�T�C�Y�̏k�����\�ƂȂ�A
��eDRAM�e�N�m���W���g����3���L���b�V����CPU�`�b�v��
�������������Ƃɂ��A3���L���b�V���̃A�N�Z�X�������ƂȂ�A���A
���o���h�����傫�����邱�Ƃ��\�ɂȂ����B���̂��߁A�e�R�A��������
��2���L���b�V����256KB�ƁiPOWER6��4MB����j�T�C�Y�̏k�����\�ƂȂ�A
��eDRAM���S�R�L�܂�Ȃ��͈̂Ӗ����Ȃ��Ƃ��O�ȊO�݂�ȉ����Ă邩��
ttp://toyokeizai.net/articles/-/9575?page=2
���߉����������d�͂̍��ڂc�q�`�l�Z�p�́A
�����E�ł����l�T�X�Ƃh�a�l���������Ȃ��B
ttp://toyokeizai.net/articles/-/9575?page=2
���߉����������d�͂̍��ڂc�q�`�l�Z�p�́A
�����E�ł����l�T�X�Ƃh�a�l���������Ȃ��B
eDRAM������Ȃɂ������̂Ȃ�A�������l�̓E�n�E�n����
�悭�V����CPU����������锼�N���炢�O����A�A�[�L�e�N�`���̏ڍׂ\�����肷�邯�ǁA
������āA���Ђɒm���đ��ɂȂ�Ȃ��̂��ȁH
��������Ȃ���}�l����邱�Ƃ��Ȃ����낤�ɁB
������āA���Ђɒm���đ��ɂȂ�Ȃ��̂��ȁH
��������Ȃ���}�l����邱�Ƃ��Ȃ����낤�ɁB
���\�������ĊT�v�����Őv����̃m�E�n�E�����J���Ă��Ȃ���
�}�l����Ă���������܂ʼn��N���|�����Ċ�����������ɂ͎���x��ɂȂ��Ă�
�}�l����Ă���������܂ʼn��N���|�����Ċ�����������ɂ͎���x��ɂȂ��Ă�
Intel�̍ŐVCPU��^���ĉ��N�������č�������ςȂ��ƂɂȂ���AMD�ł��˂킩��܂�
�Ȃ�قǁB
�J���Ăт�����ʎ蔠�A�ނ��닣������Ɏ��������̗D�ʂ��������邭�炢�ȂˁB
������ǂ��������Ȃ�ǂ����Ă݂��A���Ă��B
�܂��A�t�̗���ɂȂ�\�������邯�ǥ���B
�u�����h����Ŕ��\���Ă��l�̐S���͔@���قǂ������������
�J���Ăт�����ʎ蔠�A�ނ��닣������Ɏ��������̗D�ʂ��������邭�炢�ȂˁB
������ǂ��������Ȃ�ǂ����Ă݂��A���Ă��B
�܂��A�t�̗���ɂȂ�\�������邯�ǥ���B
�u�����h����Ŕ��\���Ă��l�̐S���͔@���قǂ������������
eDRAM���L�܂�Ȃ��̂͐����R�X�g�������邩�炾�낤
>>952
AMD��AMD64���}�l���畳�x������C2D�AAMD�̃����R���������}�l���烁�����̑������o�܂�����Nehalem�Ȃ�m���Ă邪�A
���̋t�͒m���Ȃ��B
AMD��AMD64���}�l���畳�x������C2D�AAMD�̃����R���������}�l���烁�����̑������o�܂�����Nehalem�Ȃ�m���Ă邪�A
���̋t�͒m���Ȃ��B
�O���X�o�[�K�[�ł�5�N�ȏ��s���Ă�AMD�̐����Z�p�͐��E�ꂡ�`
>AMD�̃����R���������}�l����
����Ȃ��ƌ�������M�҈���������
����Ȃ��ƌ�������M�҈���������
Intel�����X�Ƀm�[�X�ƃ����R�����������������ǁA
Rambus��CSI�֘A�̓����ŃS�l�Č�����ɂȂ�����ˁB
Rambus��CSI�֘A�̓����ŃS�l�Č�����ɂȂ�����ˁB
���\�������x�̃l�^�Ȃ甭�\�҂��Ȃ��Ă��m���Ă邾��
���ۂɍ����ȑO�ɗ��_�Ƃ��\�z�͏o�����
���i�ł����Ȃ����I�Ȃ��̂��o�Ă�����Ȃ�āA�����Ă��킸�����낤
�������u�������Ђ����i�ɓ˂�����ł���v���Ă̂͋M�d�ȏ�낤����
���ۂɍ����ȑO�ɗ��_�Ƃ��\�z�͏o�����
���i�ł����Ȃ����I�Ȃ��̂��o�Ă�����Ȃ�āA�����Ă��킸�����낤
�������u�������Ђ����i�ɓ˂�����ł���v���Ă̂͋M�d�ȏ�낤����
�C���e����CPU�Ɠ���GPU�̋��n���ׂ̈�L4�L���b�V���𓋍ڂ��鎖���������Ă���悤����
�܂�SRAM�Ȃ̂��ȁHeDRAM�������Ƃ�����
�܂�SRAM�Ȃ̂��ȁHeDRAM�������Ƃ�����
��������Ȃ�TSV�����
>>959
���_�Ƃ��č\�z����Ă���̂��قƂ�ǂ��낤���ǁA
����i�Ƃ��ē����������ǂ�����m����̂��ǂ����Ǝv�����ǁB
���x��Haswell�����āA�����p�C�v�𑝂₵�����Č���������Ă邯�ǁA
�閧�̃x�[���ɕ��ł����A
�������i���o�Ă����Ƃ��ɂ߂��Ⴍ���ᑬ���ƂȂ�A
�Ȃ��Ȃ낤�A�Ƌ������Ђ������ӂ����邶���B
�p�C�v���₵�����Ēm���Ă���A
�u�悵�A���႟�A��������p�C�v���₻���v���ĊȒP�Ƀ}�l���ꂿ�Ⴄ�����B
���_�Ƃ��č\�z����Ă���̂��قƂ�ǂ��낤���ǁA
����i�Ƃ��ē����������ǂ�����m����̂��ǂ����Ǝv�����ǁB
���x��Haswell�����āA�����p�C�v�𑝂₵�����Č���������Ă邯�ǁA
�閧�̃x�[���ɕ��ł����A
�������i���o�Ă����Ƃ��ɂ߂��Ⴍ���ᑬ���ƂȂ�A
�Ȃ��Ȃ낤�A�Ƌ������Ђ������ӂ����邶���B
�p�C�v���₵�����Ēm���Ă���A
�u�悵�A���႟�A��������p�C�v���₻���v���ĊȒP�Ƀ}�l���ꂿ�Ⴄ�����B
�������Ђ��s�b��Ȃ�����
AMD�͑������̂��̂����o����������˥��
APU��HSA�̎u�͂��炵���̂ɁA�ǂ����Ă����Ȃ������
APU��HSA�̎u�͂��炵���̂ɁA�ǂ����Ă����Ȃ������
>>962
�p�C�v���C���𑝂₷���Ă͕̂ς�������z����Ȃ�����Ȃ�
�p�C�v���C���𑝂₷���Ă͕̂ς�������z����Ȃ�����Ȃ�
AMD����Ȃ��܂̍ő�v���̓L���b�V������@�\�̃V�p�[�C�ł���
>>968
Duron�̎��̓L���b�V���@�\�ɋ~��ꂽ�̂ɂ˂��c
Duron�̎��̓L���b�V���@�\�ɋ~��ꂽ�̂ɂ˂��c
�L���b�V������Ƃ�����Ƃ̈�l�ɉ߂��Ȃ�
AMD�͊O�l�������������݈Č���������d���ł��Ȃ��̎������߂Ȃ�����_�����낤�BK7����K8�͊撣�������ǂ܂Ƃ߂ĒP��}�C�N���A�[�L�e�N�`���[�Ŋ����Ă������A����Ȍ�͌�@�������������B
�Z�p�͂��Z�p�҂̐ӔC�ɂ��Ă����̂͐��i�̗ǂ������܂�
��Ђ��X���̂�100%���\�Ȍo�c�w�̂���
��Ђ��X���̂�100%���\�Ȍo�c�w�̂���
>>961
TSV�͂܂������Ȃ�Ȃ��H
TSV�͂܂������Ȃ�Ȃ��H
������eDRAM���J��������͊m���ɑ���
atom�����̊F�����
�ă��g���[���A�g�ђ[���̐��Y�P�ށ@Google�u�����z����ꂽ����A�H��C���l���������������v
http://hayabusa3.2ch.net/test/read.cgi/news/1355290383/
�ă��g���[���A�g�ђ[���̐��Y�P�ށ@Google�u�����z����ꂽ����A�H��C���l���������������v
http://hayabusa3.2ch.net/test/read.cgi/news/1355290383/
>>974
L4�L���b�V�������ʂ�SRAM�ł�������
L4�L���b�V�������ʂ�SRAM�ł�������
��L�_�C�ʐς��傫�����Ɍ��ʂ������A�Ƃ����]���ɂȂ�ł��낤
�e�ʑ��₵������Ƃ���ǂ̓��C�e���V�オ���ăL���b�V���̈Ӗ��Ȃ��Ȃ邵�c
����ŁA�߉����������d�͂̍��ڂc�q�`�l�Z�p�́A���E�ł����l�T�X�Ƃh�a�l���������Ȃ��B
���݂͔C�V���������唼�����A���o�C���Ȃǒ����d�͂ւ̎��v���Ő��E�L���̂h�s��Ƃ���
�̈����������}���ɑ����Ă���B
�������eDRAM�����̖ڂ�����Ƃ���������Ă��Ƃ�
���݂͔C�V���������唼�����A���o�C���Ȃǒ����d�͂ւ̎��v���Ő��E�L���̂h�s��Ƃ���
�̈����������}���ɑ����Ă���B
�������eDRAM�����̖ڂ�����Ƃ���������Ă��Ƃ�
L4�L���b�V���͓���GPU��CPU�Ƃ̋��n���łǂ����Ă��K�v�ɂȂ��Ă���B
TSV�͂����ɂ͖��������AeDRAM�̓_�����Ƃ�����SRAM�������͖���
�C���e���͂ǂ����邩�ȁHeDRAM�̗p�����烋�l�T�X���~�����ɂȂ邪
eDRAM�͋Z�p�I�ɈӖ����������炵�����疳���̂��ȁH
TSV�͂����ɂ͖��������AeDRAM�̓_�����Ƃ�����SRAM�������͖���
�C���e���͂ǂ����邩�ȁHeDRAM�̗p�����烋�l�T�X���~�����ɂȂ邪
eDRAM�͋Z�p�I�ɈӖ����������炵�����疳���̂��ȁH
��
��
��
eDRAM���āw���ǂ�ށx�H
��
�]��RAM
�����h�����H
���X���́H
>>984
EDO-DRAM���ǂ������B
EDO-DRAM���ǂ������B
��
����
>>990
RIMM�͍����\���Ƃ��Ă��L����Ȃ���Γ��������ƌ��������𖣂����Ă��ꂽ��
RIMM�͍����\���Ƃ��Ă��L����Ȃ���Γ��������ƌ��������𖣂����Ă��ꂽ��
RIMM�͑S�R�����\����Ȃ���������
������ɏo��DDR�ɕ����Ă������i��10�{
�����킯�˂�
������ɏo��DDR�ɕ����Ă������i��10�{
�����킯�˂�
RIMM�͐��\�����X���b�g�ɂ��M���G���}���邽�߂Ƀ_�~�[�J�[�h�����Ȃ���Ȃ�����̂���Ԃ̖�肾������
���܂��ƃ{�[�h��̃^�[�~�l�[�^�ōςނ��Ǔ����͂܂��܂��������������ł��Ȃ���������˂�
���܂��ƃ{�[�h��̃^�[�~�l�[�^�ōςނ��Ǔ����͂܂��܂��������������ł��Ȃ���������˂�
���\���o�Ă��C-RIMM���炢�͕���o�Ȃ������悤�ȋC������
.
.
1000 �F���q�D�q ��YUKOH0W58Q �F2012/12/15(�y) 07:53:20.33 ID:Fhezr51i
�@�@��,,,�ȁ@
�@( �@�E�́E)�@1000�Ȃ�W���[�X�ł����ނ�
�@ (�@�@ �@)�@
�@�@����J�@
�@( �@�E�́E)�@1000�Ȃ�W���[�X�ł����ނ�
�@ (�@�@ �@)�@
�@�@����J�@
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://anago.2ch.net/jisaku/