AMD�̎�����CPU�ɂ��Č�낤 ��34����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��33����
http://pc11.2ch.net/test/read.cgi/jisaku/1265866982/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��33����
http://pc11.2ch.net/test/read.cgi/jisaku/1265866982/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
|
|
|
���ߋ��X���ꗗ
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1263352294/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1263352294/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
>>1�@��
>>1�@��
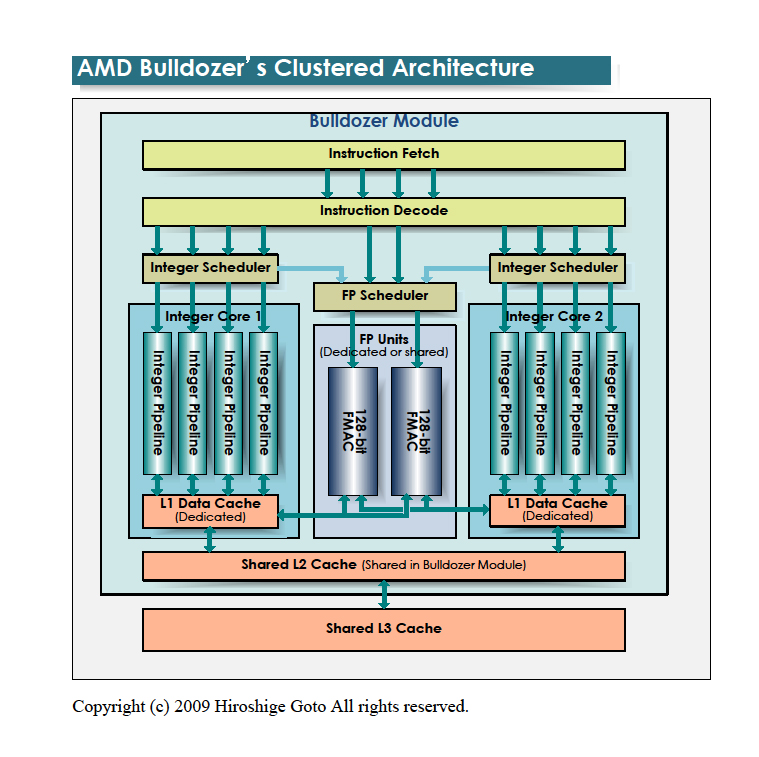
2011�N�@AMD�@�V�A�[�L�e�N�`��
��Bulldozer�@�iZambezi�@4�`8�R�A�j
�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�E3GHz����N���b�N�H
�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�E2ch DDR3-1866�܂őΉ�
�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
http://pc.watch.impress.co.jp/img/pcw/docs/328/392/kaigai6.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/328/384/amd-08.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/328/379/02.jpg
http://pc.watch.impress.co.jp/img/pcw/docs/330/076/kaigai2.jpg
�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�@�]����6�R�A
�@��
�i�E�́E�́E�j�i�E�́E�́E�j�i�E�́E�́E�j�i�E�́E�́E�j�@Bulldozer��8�R�A
2011�N�@AMD�@�V�A�[�L�e�N�`��
��Bulldozer�@�iZambezi�@4�`8�R�A�j
�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�E3GHz����N���b�N�H
�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�E2ch DDR3-1866�܂őΉ�
�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
http://pc.watch.impress.co.jp/img/pcw/docs/328/392/kaigai6.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/328/384/amd-08.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/328/379/02.jpg
{kind=link}
http://pc.watch.impress.co.jp/img/pcw/docs/330/076/kaigai2.jpg
{kind=link}
�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�i�E�́E�j�@�]����6�R�A
�@��
�i�E�́E�́E�j�i�E�́E�́E�j�i�E�́E�́E�j�i�E�́E�́E�j�@Bulldozer��8�R�A
Llano�ɂ���
Llano�̃v���Z�X
�@ �E32nm SOI / High-K + Metal gate�v���Z�X�B
�� 2����̉t�Z�I���Z�p���p������B
Llano�̊T�v
�@ �E4��CPU�R�A
�@ �EDirectX 11�Ή�GPU
�@ �EDDR3�Ή��������R���g���[��
�@ �E�ŏ��̃T���v����2010�N�㔼���\��B
Llano��CPU�R�A
�@ �EL2�L���b�V�����������R�A�̃T�C�Y��9.69mm2
�@ �E1�R�A������̃g�����W�X�^����3500���ȏ�
�@ �E�i1�R�A������H�j2.5�`25W�̏���d��
�@ �E3GHz�ȏ�̎��g��
�@ �E�쓮�d����0.8�`1.3V
Bulldozer�ɂ���
Bulldozer�@�iZambezi�@4�`8�R�A�j
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�@�E3GHz����N���b�N�H
�@�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�@�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�@�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
�@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�@�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�@�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�@�E2ch DDR3-1866�܂őΉ�
�@�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
Llano�̃v���Z�X
�@ �E32nm SOI / High-K + Metal gate�v���Z�X�B
�� 2����̉t�Z�I���Z�p���p������B
Llano�̊T�v
�@ �E4��CPU�R�A
�@ �EDirectX 11�Ή�GPU
�@ �EDDR3�Ή��������R���g���[��
�@ �E�ŏ��̃T���v����2010�N�㔼���\��B
Llano��CPU�R�A
�@ �EL2�L���b�V�����������R�A�̃T�C�Y��9.69mm2
�@ �E1�R�A������̃g�����W�X�^����3500���ȏ�
�@ �E�i1�R�A������H�j2.5�`25W�̏���d��
�@ �E3GHz�ȏ�̎��g��
�@ �E�쓮�d����0.8�`1.3V
Bulldozer�ɂ���
Bulldozer�@�iZambezi�@4�`8�R�A�j
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p
�@�E3GHz����N���b�N�H
�@�E1�̃��W���[����2�R�A������@�R�A���ɓƗ����������X�P�W���[����L1�L���b�V��
�@�E1�̃��W���[���ɋ��LL2�L���b�V���AL3�L���b�V���A�m�[�X�u���b�W�A128-bit��SIMD�Ϙa�Z���j�b�g��2���
�@�E���������_���Z���j�b�g�▽�߃f�R�[�_�Ȃǂ̃��\�[�X��2�̃R�A/�X���b�h�ŋ��L
�@������A�����Ă������������_���Z�̃j�[�Y��GPU�ōs�����Ɓi�w�e���W�j�A�X���j���������Ă���
�@�E�N���X�^�[�h�A�[�L�e�N�`���iHT���}���`�X���b�h���\�������j�@���]�����R�A���𑝂₵�₷���v
�@�EAMD�Ǝ���XOP�AFMA4�ACVT16�ɉ����V���߂�AVX�T�|�[�g
�@�E2ch DDR3-1866�܂őΉ�
�@�E�\�P�b�g�@AM3�i��������AM3r2�j�@�i�`�b�v�Z�b�g890FX, 890GX�ASB850���g�p�\�H�j
Ontario�ɂ���
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p (40nm�Ƃ����b�͂ǂ��Ȃ���?)
�@�EDual-Core CPU��GPU�𓋍ڂ��ADDR3, DDR3L�ɑΉ�
�@�E�p�b�P�[�W��BGA�A�gBrazos�h�v���b�g�t�H�[��
�@�EGPU��DX11�Ή� (Cedar�R�A?)
�@�ECPU�R�A��Bobcat�Ŕ�K10�ABulldozer�Ƃ��Ⴄ (Bulldozer�̃T�u�Z�b�g���ۂ�)
Bobcat�R�A
�@�EInt Pipe*2 + Lord pipe+Store pipe (2way?)
�@�Ex86-64�ASSE1-3�Ή�(SSSE3/4/4.1/4.2�͔�Ή�)
�@�E�R�A�̏���d�͂�1w�ȉ�
Llano�R�A
AMD finally outs the 32nm Llano core
http://www.semiaccurate.com/2010/02/10/amd-finally-outs-32nm-llano-core/
http://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai1_1.jpg.html
AMD��GPU����CPU�uLlano�v��CPU�R�A�̋Z�p�\
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
�@�E32nmSOI�v���Z�X�@High-K/���^���Q�[�g�̗p (40nm�Ƃ����b�͂ǂ��Ȃ���?)
�@�EDual-Core CPU��GPU�𓋍ڂ��ADDR3, DDR3L�ɑΉ�
�@�E�p�b�P�[�W��BGA�A�gBrazos�h�v���b�g�t�H�[��
�@�EGPU��DX11�Ή� (Cedar�R�A?)
�@�ECPU�R�A��Bobcat�Ŕ�K10�ABulldozer�Ƃ��Ⴄ (Bulldozer�̃T�u�Z�b�g���ۂ�)
Bobcat�R�A
�@�EInt Pipe*2 + Lord pipe+Store pipe (2way?)
�@�Ex86-64�ASSE1-3�Ή�(SSSE3/4/4.1/4.2�͔�Ή�)
�@�E�R�A�̏���d�͂�1w�ȉ�
Llano�R�A
AMD finally outs the 32nm Llano core
http://www.semiaccurate.com/2010/02/10/amd-finally-outs-32nm-llano-core/
http://pc.watch.impress.co.jp/img/pcw/docs/328/392/html/kaigai1_1.jpg.html
{kind=link}
AMD��GPU����CPU�uLlano�v��CPU�R�A�̋Z�p�\
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
Ontario���ăo���N����Ȃ��́H
�c�q�͂Ƃ��Ƃ�GPU�̒��\�t�g��萫�\�����̍���
��������ʼn����o���Ăˁ[�����@�_�Z�[
�o����܂ł����ɏ������֎~��
��������ʼn����o���Ăˁ[�����@�_�Z�[
�o����܂ł����ɏ������֎~��
Bulldozer�J���𒆎~���āALLano��K10���R�A�ő�ւ���v������
6������ɔ��\����Ɩϑz
6������ɔ��\����Ɩϑz
�́@�@�@�@1156�i�j�@�@1366�������ŋ��I
���@�@�@�@1156�_(^o^)�^1366
intel�̃\�P�b�g�ύX���b�V�������^
���@�@�@�@1156�_(^o^)�^1366
intel�̃\�P�b�g�ύX���b�V�������^
K10��6�R�A�łő����A�V���O���`�b�v�ł̃R�A���̌��E�ɒB���Ă�
�R�A���̂ɃR�A���̌��E�ȂȂ��B
�g�����W�X�^���Ɠd�́A�C���^�[�R�l�N�g����B
�L���b�V���͎�����K�v���邩�B
�g�����W�X�^���Ɠd�́A�C���^�[�R�l�N�g����B
�L���b�V���͎�����K�v���邩�B
Nehalem-EX��QPI�炵������
8�R�A�̂�����x�ł������O�o�X�̉\�������炢�Ȃ��
�o�X���݂̃A�[�L�ɃR�A�����E�͂���낤
8�R�A�̂�����x�ł������O�o�X�̉\�������炢�Ȃ��
�o�X���݂̃A�[�L�ɃR�A�����E�͂���낤
Intel�̌����p48�R�A�`�b�v�ł�Pentium2��1���W���[���Ƃ��Đv����Ă�
48�̃R�A�S�Ă��o�X�Ɍq�������A�����̃��C�e���V�������Ăł�2��1�̃��W���[����
���ăo�X�ւ̐ڑ��_����24�ӏ��ɂ������������I���Ď����낤
�A�v���[�`��Bulldozer�ɋ߂��Ǝv����
48�̃R�A�S�Ă��o�X�Ɍq�������A�����̃��C�e���V�������Ăł�2��1�̃��W���[����
���ăo�X�ւ̐ڑ��_����24�ӏ��ɂ������������I���Ď����낤
�A�v���[�`��Bulldozer�ɋ߂��Ǝv����
AMD�͌��_�o�����Ƃ��������߂��Ƃ���������Ƃ��낾�ȁE�E�E
�ʂ�bulldozer�A�[�L�e�N�`����AMD�̃}���`�R�A���̌��_����Ȃ����낤
�Ƃ肠����10�R�A���x���n�C�G���h�ɂȂ鍡��5�N���炢��킦�镨�Ƃ��Đ��i�����Ă�����
���̐��SCC�̂悤�ȃ��j�[�R�A�����ɂ͂܂��ʂ̃A�v���[�`�����Ă��邾�낤��
�Ƃ肠����10�R�A���x���n�C�G���h�ɂȂ鍡��5�N���炢��킦�镨�Ƃ��Đ��i�����Ă�����
���̐��SCC�̂悤�ȃ��j�[�R�A�����ɂ͂܂��ʂ̃A�v���[�`�����Ă��邾�낤��
L1D Latency
Bulldozer
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
int 3
fp 5
Sandy Bridge
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
int 5
fp 6
fp256 8
Bulldozer
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
int 3
fp 5
Sandy Bridge
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
int 5
fp 6
fp256 8
>>20
�ǂ��ɏ����Ă���������E�E�E
�������ȑO�o�Ă��\�[�X�i���Ă��N���̉p���R���j�ł͒P�Ƀ��C�e���V5���Ă����������i�̂͂��j������
������3�ێ��Ȃ�N��
way2�{�e��1/4���ǂ��]�Ԃ������
Intel�͟��ςŃ��C�e���V4�������̂ɂ܂�������̂��H
����炩������
�ǂ��ɏ����Ă���������E�E�E
�������ȑO�o�Ă��\�[�X�i���Ă��N���̉p���R���j�ł͒P�Ƀ��C�e���V5���Ă����������i�̂͂��j������
������3�ێ��Ȃ�N��
way2�{�e��1/4���ǂ��]�Ԃ������
Intel�͟��ςŃ��C�e���V4�������̂ɂ܂�������̂��H
����炩������
22 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/06(�y) 22:00:27 ID:LFUwQxdd
>>21
������V�~�����[�^�Ŏ��ۂ̃��C�e���V�E�X���[�v�b�g�����Ă����
�\����H
���Ƃ����mixi�̂�����Ĕ{�����������Ă����Ă邯�Ǔ��I�m���͕ς���ĂȂ��i�ނ��뉺�����Ă����Ă�j�C�������
������V�~�����[�^�Ŏ��ۂ̃��C�e���V�E�X���[�v�b�g�����Ă����
�\����H
���Ƃ����mixi�̂�����Ĕ{�����������Ă����Ă邯�Ǔ��I�m���͕ς���ĂȂ��i�ނ��뉺�����Ă����Ă�j�C�������
24 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/06(�y) 22:36:37 ID:LFUwQxdd
�����o���������
25 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/06(�y) 22:45:07 ID:LFUwQxdd
>>21
LSU-L1�̊Ԃ̃o�b�t�@���[���Ȃ��Ă���ۂ��̂�ˁB
�X�g�A�t�H���[�f�B���O�̋@�\�œ����A�h���X�ɑ���X�g�A�����[�h�̃��C�e���V�̓V�~�����[�^�̒l���
�������Ȃ�Ǝv����̂ŁA���\�ւ̉e���͌y�����ƁB
�X�ɁA���[�h���j�b�g��2�{�ɑ����Ă�Ԃ[�h���s���s�ł��邩��A�R�[�h�V�[�P���X���x���ł݂��
Nehalem���g�[�^�����\�͏オ���Ă��ہB
LSU-L1�̊Ԃ̃o�b�t�@���[���Ȃ��Ă���ۂ��̂�ˁB
�X�g�A�t�H���[�f�B���O�̋@�\�œ����A�h���X�ɑ���X�g�A�����[�h�̃��C�e���V�̓V�~�����[�^�̒l���
�������Ȃ�Ǝv����̂ŁA���\�ւ̉e���͌y�����ƁB
�X�ɁA���[�h���j�b�g��2�{�ɑ����Ă�Ԃ[�h���s���s�ł��邩��A�R�[�h�V�[�P���X���x���ł݂��
Nehalem���g�[�^�����\�͏オ���Ă��ہB
�܂��G�������Ă�̂��B�T�������ȁB
�ŏ�ʂ͂����炭�炢���ȁH�����̉��i����H
����c�q����B������CRZ�������
CRZ�E�E�E�z���_���̃R�s�y���d�g�n�C�u���b�h�H
�����I��AMD Bulldozer�̓����\��
ttp://pc.nikkeibp.co.jp/article/trend/20100217/1022999/
ttp://pc.nikkeibp.co.jp/article/trend/20100217/1022999/
32 �FSocket774�F2010/03/07(��) 11:05:25 ID:6PT1Qt+Z
>>31
���̓\�P�b�g�Ȃ�ڂɂȂ邩�B�B���ȁH
���̓\�P�b�g�Ȃ�ڂɂȂ邩�B�B���ȁH
�Ȃɂ���OOO�W�̃o�b�t�@�ނ̑�����Turbo/PG�̓�����GPU�Ƃ̗Z�����Ă������
K10��Llano�̉��ǂ�Core 2��Nehalem�̉��ǃg�����h�ɋ߂��B
�ނ���AMD����Intel�Ƃ��Čォ��p�ӂ�����Llano�ł���A
Bull�͂�͂�g�����h����〈������̂ŃT�[�o�������낤�B
K10��Llano�̉��ǂ�Core 2��Nehalem�̉��ǃg�����h�ɋ߂��B
�ނ���AMD����Intel�Ƃ��Čォ��p�ӂ�����Llano�ł���A
Bull�͂�͂�g�����h����〈������̂ŃT�[�o�������낤�B
�\�P�b�g�\�P�b�g�����Ă����邯�ǁA
�\�P�b�g��Intel��AMD��������A���ꂩ��́B
���܂ǂ��\�P�b�g�`�����ʼn������ꂵ���̂������ɂ͗����ł��ǁB
�\�P�b�g��Intel��AMD��������A���ꂩ��́B
���܂ǂ��\�P�b�g�`�����ʼn������ꂵ���̂������ɂ͗����ł��ǁB
LGA�͂�߂Ăق�����
AMD��LGA�ɂ����玩���߂郌�x���ł��炢����
AMD��LGA�ɂ����玩���߂郌�x���ł��炢����
36 �FSocket774�F2010/03/07(��) 11:14:01 ID:6PT1Qt+Z
�C�ɂȂ�͈̂�C�Ɉڍs�����邩
���X�Ɉڍs�����邩����
���X�Ɉڍs�����邩����
LGA�͂���܂ł̃\�P�b�g�Ƃ������Ĕ˂݂����ȍ\����CPU�̃s�����͂��ނ̂ł͂Ȃ��āA
CPU�ƃ}�U�[�{�[�h�����ʂŐڐG����悤�ɂȂ��Ă���B
������C���_�N�^���X�̉e���������ɂ����B
�ق�Ƃ���BGA�̂ق����������ABGA�͐ڐG�ʂ����ʂȂ̂Ń\�P�b�g���ł��Ȃ��B
Intel��AMD������er�����Ƀp�b�P�[�W���O��\�P�b�g���l���Ă����Ȃ���ł������炸�B
CPU�ƃ}�U�[�{�[�h�����ʂŐڐG����悤�ɂȂ��Ă���B
������C���_�N�^���X�̉e���������ɂ����B
�ق�Ƃ���BGA�̂ق����������ABGA�͐ڐG�ʂ����ʂȂ̂Ń\�P�b�g���ł��Ȃ��B
Intel��AMD������er�����Ƀp�b�P�[�W���O��\�P�b�g���l���Ă����Ȃ���ł������炸�B
38 �FSocket774�F2010/03/07(��) 11:17:25 ID:6PT1Qt+Z
>>37
�����Ď������ȁH��
�����Ď������ȁH��
����BGA�����ʂŐڐG���Ă�킯����ˁ[�ȁB
BGA�ɂ������������ǖ���������������LGA�̃\�P�b�g�ɂȂ������Ă̂�
�b�ɂ������B
BGA�ɂ������������ǖ���������������LGA�̃\�P�b�g�ɂȂ������Ă̂�
�b�ɂ������B
>>38
����l�ɂ������ȉ��l�ς����邾�낤�B
�����̏ꍇ�͖����ȃs���A�T�C���ƃ\�P�b�g�̍\����
�V��������̓d�C�I�Ȏd�l���������ނƂ����H���͂����łȂ��B
�����\�P�b�g��CPU��������Ȃ�Ă��܂ǂ��܂��������Ȃ����ȁB
�}�U�[�����ꂾ���₷���Ȃ����̂�Win95����̉��l�ς̂�������č����B
����l�ɂ������ȉ��l�ς����邾�낤�B
�����̏ꍇ�͖����ȃs���A�T�C���ƃ\�P�b�g�̍\����
�V��������̓d�C�I�Ȏd�l���������ނƂ����H���͂����łȂ��B
�����\�P�b�g��CPU��������Ȃ�Ă��܂ǂ��܂��������Ȃ����ȁB
�}�U�[�����ꂾ���₷���Ȃ����̂�Win95����̉��l�ς̂�������č����B
41 �FSocket774�F2010/03/07(��) 11:21:41 ID:6PT1Qt+Z
>>41
�C�ɂ���̂͂����Ă����A
�\�P�b�g�~�݂����Ȃ̂�����
�\�P�b�g��������̂̓��[�U�������Ƃ��A
��Q�ϑz�Ő�n�߂�~�[�������łˁB
�܂�����������͕s�����D���̐^���}�]���낤����
���ʂł����삵�Ďg���Ă�������B
�C�ɂ���̂͂����Ă����A
�\�P�b�g�~�݂����Ȃ̂�����
�\�P�b�g��������̂̓��[�U�������Ƃ��A
��Q�ϑz�Ő�n�߂�~�[�������łˁB
�܂�����������͕s�����D���̐^���}�]���낤����
���ʂł����삵�Ďg���Ă�������B
43 �FSocket774�F2010/03/07(��) 11:24:27 ID:6PT1Qt+Z
>>42
���������������Ƃ���
���������������Ƃ���
�f�X�N�g�b�v��934pin��FM1�A
�m�[�g��722pin��FS1���ȁB
GPU�����Ă��邹���ŁA���ꂩ���GPU�̐���ɂ��킹��
�\�P�b�g���ς��A�`���Ȃ��ł��}�C�i�[�`�F���W�Ō݊������Ȃ��Ȃ�
�Ƃ������Ƃ͕��ʂɑ����Ȃ邾�낤�B
�m�[�g��722pin��FS1���ȁB
GPU�����Ă��邹���ŁA���ꂩ���GPU�̐���ɂ��킹��
�\�P�b�g���ς��A�`���Ȃ��ł��}�C�i�[�`�F���W�Ō݊������Ȃ��Ȃ�
�Ƃ������Ƃ͕��ʂɑ����Ȃ邾�낤�B
AMD���I�����̂��LGA�g���Ă���
���[�J�[�̓��[�J�[�̑������肪���邾�낤��
���[�U�[�ɂ����ꂼ�ꂻ��Ȃ̂�����ł���
���[�U�[�ɂ����ꂼ�ꂻ��Ȃ̂�����ł���
>>45
> �f�X�N�g�b�v��934pin��FM1�A
> �m�[�g��722pin��FS1���ȁB
> GPU�����Ă��邹���ŁA���ꂩ���GPU�̐���ɂ��킹��
> �\�P�b�g���ς��A�`���Ȃ��ł��}�C�i�[�`�F���W�Ō݊������Ȃ��Ȃ�
> �Ƃ������Ƃ͕��ʂɑ����Ȃ邾�낤�B
Intel�͂�������AMD�ł���͂Ȃ���
�O���o�X�͍��܂ł�HT�ƃ������o�X�������������ǁA�����GPU�����Ńf�B�X�v���C�o�͂������邾���������
Fusion����Ƃ������Ƃʼnf���o�̓o�X��lj��AHT�o�X����荂�N���b�N�Ή��ȂǁA
���s��葽�������������̂ō���Ă����������K�i�̕ύX���Ȃ�����\�P�b�g�ύX�͕K�v�����Ȃ�
FM1���܂��������ꂶ��Ȃ�����
���炭Bulldozer������z�肵�Ă���͂�������݊����͂��邾�낤
> �f�X�N�g�b�v��934pin��FM1�A
> �m�[�g��722pin��FS1���ȁB
> GPU�����Ă��邹���ŁA���ꂩ���GPU�̐���ɂ��킹��
> �\�P�b�g���ς��A�`���Ȃ��ł��}�C�i�[�`�F���W�Ō݊������Ȃ��Ȃ�
> �Ƃ������Ƃ͕��ʂɑ����Ȃ邾�낤�B
Intel�͂�������AMD�ł���͂Ȃ���
�O���o�X�͍��܂ł�HT�ƃ������o�X�������������ǁA�����GPU�����Ńf�B�X�v���C�o�͂������邾���������
Fusion����Ƃ������Ƃʼnf���o�̓o�X��lj��AHT�o�X����荂�N���b�N�Ή��ȂǁA
���s��葽�������������̂ō���Ă����������K�i�̕ύX���Ȃ�����\�P�b�g�ύX�͕K�v�����Ȃ�
FM1���܂��������ꂶ��Ȃ�����
���炭Bulldozer������z�肵�Ă���͂�������݊����͂��邾�낤
Llano��PCIeBridge�͓������Ȃ��́H
���܂ŏo�Ă���_�C�ʐ^���Ɠ������ĂȂ��悤�����ǁA
�㓡�L���ɂ͓�������̂��{����Llano�݂����Ȃ��Ə����Ă���ǁB
���܂ŏo�Ă���_�C�ʐ^���Ɠ������ĂȂ��悤�����ǁA
�㓡�L���ɂ͓�������̂��{����Llano�݂����Ȃ��Ə����Ă���ǁB
�܂��\�P�b�g���ς��Ȃ��̂��ǂ��ƎG���̓ǂ݂����ŐM������ł����̃Z���X��
�킩���ȁB
����GPU������������Ƃ����ł͂Ȃ��A�����Turbo�̂悤�ȓd�͊Ǘ��Z�p�̐i���ɂƂ��Ȃ���
�d���̗v����������Ă��邵�AGPU�̓d���������邩��M�����������ł��݊�����������̂������̂�
����Ȃ��Ă���B
�킩���ȁB
����GPU������������Ƃ����ł͂Ȃ��A�����Turbo�̂悤�ȓd�͊Ǘ��Z�p�̐i���ɂƂ��Ȃ���
�d���̗v����������Ă��邵�AGPU�̓d���������邩��M�����������ł��݊�����������̂������̂�
����Ȃ��Ă���B
�\�P�b�g�������Ȃ��Ƃ������Ƃ́A�V��������ł͓d����GND�̐����P�`������
�����ȃ��C�A�E�g�ł̈��������e���Ă�킯�ŁA�Ȃ�ł�����ł��Â���������̂܂ܗ��p�ł���̂��������Ă̂͊ԈႢ�B
�Ƃ������}�U�[1���O��̎���Ɏ���CPU�̌������Ă�낱��ł����Ăǂ�����낤�Ȃ��B
�������\�P�b�g�����œd�C�I�Ȏd�l���ς��ꍇ���A�d���Ȃǂ̗v���d�l���V�������̂ɂ��킹�ă��t�@�C������Ă���
�킯�ł����肱������S�Ɗ����邩�A���[�U�����̎d�l�ύX�Ɗ����邩�͈ӌ��̂킩���Ƃ��낾�낤�ȁB
�����ȃ��C�A�E�g�ł̈��������e���Ă�킯�ŁA�Ȃ�ł�����ł��Â���������̂܂ܗ��p�ł���̂��������Ă̂͊ԈႢ�B
�Ƃ������}�U�[1���O��̎���Ɏ���CPU�̌������Ă�낱��ł����Ăǂ�����낤�Ȃ��B
�������\�P�b�g�����œd�C�I�Ȏd�l���ς��ꍇ���A�d���Ȃǂ̗v���d�l���V�������̂ɂ��킹�ă��t�@�C������Ă���
�킯�ł����肱������S�Ɗ����邩�A���[�U�����̎d�l�ύX�Ɗ����邩�͈ӌ��̂킩���Ƃ��낾�낤�ȁB
>>30
�����A�u�����_�͍팸���邯�ǃ��m���̂͗ǂ�����v���Ă�����ƌ������Ƃ���������
�Ϙa�̂��Ƃ������̂�
SSE�݂����uIntel���Ή����邩�炤�����v�u�������Ǝ��ɂ�点�Ă��炤�i�����ϐ���1�����j�v�Ă��Ƃ�
���������C�e���V���啝������������͂�蔲�����낤�Ȃ�
�����A�u�����_�͍팸���邯�ǃ��m���̂͗ǂ�����v���Ă�����ƌ������Ƃ���������
�Ϙa�̂��Ƃ������̂�
SSE�݂����uIntel���Ή����邩�炤�����v�u�������Ǝ��ɂ�点�Ă��炤�i�����ϐ���1�����j�v�Ă��Ƃ�
���������C�e���V���啝������������͂�蔲�����낤�Ȃ�
L1D Latency
Bulldozer
int 3
fp 5
Sandy Bridge
int 5
fp 6
fp256 8
Bulldozer
int 3
fp 5
Sandy Bridge
int 5
fp 6
fp256 8
���C�e���V��ш悾���ł͐��\��}�鎖�͏o���Ȃ��̂�
�����o�Ă��Ă���ł��ǂ�����Ȃ��ł���
�����o�Ă��Ă���ł��ǂ�����Ȃ��ł���
56 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 13:33:37 ID:Y5JV1Fly
��������(��)
Bulldozer
(v)addps 6
(v)mulps 6
Sandy Bridge
(v)addps 3
(v)mulps 4
Bulldozer
(v)addps 6
(v)mulps 6
Sandy Bridge
(v)addps 3
(v)mulps 4
57 �FSocket774�F2010/03/07(��) 13:36:07 ID:hYrPtw3F
>>49
�����ɍl������A���J����Ă���_�C�ʐ^���m�[�g�����Ȃ��
�ꉞ�X�y�b�N�I�ɂ͊O�t��GPU���݂̐��\�������
�命���̃m�[�gPC�ł͕K�v�����Ȃ����Ĕ��f�����̂ł́H
�����ɍl������A���J����Ă���_�C�ʐ^���m�[�g�����Ȃ��
�ꉞ�X�y�b�N�I�ɂ͊O�t��GPU���݂̐��\�������
�命���̃m�[�gPC�ł͕K�v�����Ȃ����Ĕ��f�����̂ł́H
>>56�̂悤�ɒm�I��Q�҂��������ɂ͈���ɍ\��Ȃ��Ƃ��Ă�
Intel�����Ă�����˂��Ă��邾�낤��
GPGPU�������ɂȂ�O����FPU/SSE���蔲��������Ă̂͌��\�Ȗ`������Ȃ�
Intel�����Ă�����˂��Ă��邾�낤��
GPGPU�������ɂȂ�O����FPU/SSE���蔲��������Ă̂͌��\�Ȗ`������Ȃ�
59 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 13:52:52 ID:Y5JV1Fly
�u�蔲���v���Č������Ⴄ���甼�ʂ͍����
���C�e���V����̗����͓K���Ă���
���C�e���V����̗����͓K���Ă���
Bulldozer��2�R�A�Ńf�R�[�_�����L���Ă��邯��
�{����1�R�A���������̂��A�R�A���𑽂����������邽�߂�
�R�A�����W���[���A�������j�b�g���R�A�ƌĂԂ��Ƃɂ����̂��H
�{����1�R�A���������̂��A�R�A���𑽂����������邽�߂�
�R�A�����W���[���A�������j�b�g���R�A�ƌĂԂ��Ƃɂ����̂��H
61 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 14:26:44 ID:Y5JV1Fly
�Ϙa�Z�����Z�킪�P�̂̏�Z��A���Z����[�����Z�p�C�v���C���ɂȂ邱��
�����ăp�C�v���C�����[���Ȃ���̕����߂̃��C�e���V��������͖̂��炩����Ȃ���
����Ȃ��Ƃ����������Ɏ蔲���Ƃ����Ă��܂��̂�AMD�̋Z�p�҂ɑ���`������
�t�Ɍ����ƃ}�C�N���A�[�L�e�N�`�����ς��Ȃ����背�C�e���V�͉��P����Ȃ��ˁB
����������Ȃǔ����ĂȂ�����B
�����ăp�C�v���C�����[���Ȃ���̕����߂̃��C�e���V��������͖̂��炩����Ȃ���
����Ȃ��Ƃ����������Ɏ蔲���Ƃ����Ă��܂��̂�AMD�̋Z�p�҂ɑ���`������
�t�Ɍ����ƃ}�C�N���A�[�L�e�N�`�����ς��Ȃ����背�C�e���V�͉��P����Ȃ��ˁB
����������Ȃǔ����ĂȂ�����B
GPU�����Ȃ̂�x86SIMD�ɓq����Intel
GPGPU�ŏ����_�E�x�N�^��d��������x86SIMD�̕ی����Y��邱�Ƃ��ł��Ȃ�AMD
�����Ă�����Ƃ���ɓd�g����荞�܂��悤�Ƃ���G��
GPGPU�ŏ����_�E�x�N�^��d��������x86SIMD�̕ی����Y��邱�Ƃ��ł��Ȃ�AMD
�����Ă�����Ƃ���ɓd�g����荞�܂��悤�Ƃ���G��
64 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 14:38:46 ID:Y5JV1Fly
GPU�Ȃ�Ďg������܂��܂����C�e���V���傫���Ȃ�܂���������
�N���X�^�\�����Ă���AndyGlew�ɂ��ƁA����Willamette��HTT���x���Ȃ�̂�
���P���邽�߂ɓ�d�������������N���X�^�A�f�R�[�_�Ƃ����L�����܂Ŋ܂߂��S�̂��R�A��
���Ă����炵���B
AndyGlew���炷��ƁA�}�[�P�e�B���O��R�A����{�ɂ��邽�߂ɌĂѕ��ς������ƂɂȂ�炵���B
���P���邽�߂ɓ�d�������������N���X�^�A�f�R�[�_�Ƃ����L�����܂Ŋ܂߂��S�̂��R�A��
���Ă����炵���B
AndyGlew���炷��ƁA�}�[�P�e�B���O��R�A����{�ɂ��邽�߂ɌĂѕ��ς������ƂɂȂ�炵���B
66 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 14:48:41 ID:Y5JV1Fly
Bulldozer�͂�������2009�N���̗\��Ȃ̂�SIMD���j�b�g�̍\����Sandy Bridge�Ɣ�ׂ�
����肵�Ă��v�����Ȃ��ʂ����肻����蔲���ȂǂƂ͌����C�͖ѓ�������
���N���ł�Stream SDK�͖��炩�Ɏ蔲�������
1.0�����������Ȃ��܂�2.0�̃��i�������j�Ƃ��v���̎d������Ȃ�
����肵�Ă��v�����Ȃ��ʂ����肻����蔲���ȂǂƂ͌����C�͖ѓ�������
���N���ł�Stream SDK�͖��炩�Ɏ蔲�������
1.0�����������Ȃ��܂�2.0�̃��i�������j�Ƃ��v���̎d������Ȃ�
�Ƃ�����Bulldozer���_���Ȃ̂�128bitSSE�����L�ɂ����Ƃ��낾�낤�ȁB
�܂��A���L���邵�����������킯�����E�E�E
�܂��A���L���邵�����������킯�����E�E�E
�����C�e���V��ш悾���ł͐��\��}�鎖�͏o���Ȃ��̂�
��
����������(��)
�Ɠ��ӂ������ォ��̎G���̂��̃��C�e���V�ւ̂������悤�͈�̉����낤�H
x86SIMD��L���b�V���̒�e�C�����V�\�������ł��̐搶���c�낤�Ƃ��Ă���Intel�M�҂炵���͂���̂���
���ʁA�p�r�����GPU��100�{���\���������Ă鎖����
AMD���R�A�������FPU�����炵�Ď蔲���Ă��鎖�����S�������Ȃ��Ȃ��Ă���
��
����������(��)
�Ɠ��ӂ������ォ��̎G���̂��̃��C�e���V�ւ̂������悤�͈�̉����낤�H
x86SIMD��L���b�V���̒�e�C�����V�\�������ł��̐搶���c�낤�Ƃ��Ă���Intel�M�҂炵���͂���̂���
���ʁA�p�r�����GPU��100�{���\���������Ă鎖����
AMD���R�A�������FPU�����炵�Ď蔲���Ă��鎖�����S�������Ȃ��Ȃ��Ă���
128bitSSE�A2�p�C�v�̋��L����Ȃ���������
������炷�܂�
������炷�܂�
70 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 14:57:21 ID:Y5JV1Fly
>>67
������R�A������Ȃ��ă��W���[�����Ō���B�ʂɏ��Ȃ��Ȃ�����B
���X��Nehalem/Westmere��4C8T��Bulldozer��4M8C�őΓ��ȏ�ɐ키�\�肾��������
�\���Ó��Ȑ������낤�B
����Sandy Bridge��SIMD���\������������ƁB
������R�A������Ȃ��ă��W���[�����Ō���B�ʂɏ��Ȃ��Ȃ�����B
���X��Nehalem/Westmere��4C8T��Bulldozer��4M8C�őΓ��ȏ�ɐ키�\�肾��������
�\���Ó��Ȑ������낤�B
����Sandy Bridge��SIMD���\������������ƁB
������Intel�̃R�A�����ʂɃf�J���������
�u�������炢�̑傫���ɂȂ肻���ȃ��W���[���P�ʂŔ�ׂ�v���Ă̂��Ȃ�
HT��1�R�A2�X���b�h����
���ʂɕ����ė]�������\�[�X���o�O�ȂNjC�ɂ������߂��g�������Ă����̂��̂���
�u�������炢�̑傫���ɂȂ肻���ȃ��W���[���P�ʂŔ�ׂ�v���Ă̂��Ȃ�
HT��1�R�A2�X���b�h����
���ʂɕ����ė]�������\�[�X���o�O�ȂNjC�ɂ������߂��g�������Ă����̂��̂���
72 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 15:13:26 ID:Y5JV1Fly
�����̃v���v���t�F�t�F�t�F�b�`����� ID:2moEEfAj
73 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 15:33:56 ID:Y5JV1Fly
2�̐����N���X�^�������I�ɓƗ���������Reverse-HT�i�j�������I�ɖ������ƌ����
�u�R�A�v�̐V���Ȓ�`������Ȃ����Ă�̂͏��Ƃ��낾��
���́u�R�A�v������̐���ALU�����������͂ǂ�����Đ��\�d���̂��ȁB
�����ł���SPECint�Ń_�u���X�R�A�ŕ����Ă�̂ɁA�������j�b�g��L1D�L���b�V�������炵�Ă�
�]�T�͂Ȃ��Ǝv�����B
FP�����Ȃ��Ƃ����������Ȃ�A
FP���Z�̃A�h���X�Z�o�ɂ����Đ������j�b�g�g����
1�u�R�A�v������̃f�R�[�_���������j�b�g�������Ă�̂�FPU�𑝂₷�Ȃ�Č����I�ɂ��肦�Ȃ��B
FMA��1���j�b�g������̗��_���\2�{�Ȃ��炻������ꂽ�����f������
�u�R�A�v�̐V���Ȓ�`������Ȃ����Ă�̂͏��Ƃ��낾��
���́u�R�A�v������̐���ALU�����������͂ǂ�����Đ��\�d���̂��ȁB
�����ł���SPECint�Ń_�u���X�R�A�ŕ����Ă�̂ɁA�������j�b�g��L1D�L���b�V�������炵�Ă�
�]�T�͂Ȃ��Ǝv�����B
FP�����Ȃ��Ƃ����������Ȃ�A
FP���Z�̃A�h���X�Z�o�ɂ����Đ������j�b�g�g����
1�u�R�A�v������̃f�R�[�_���������j�b�g�������Ă�̂�FPU�𑝂₷�Ȃ�Č����I�ɂ��肦�Ȃ��B
FMA��1���j�b�g������̗��_���\2�{�Ȃ��炻������ꂽ�����f������
�ꎞ���u2�R�A1�X���͂ǂ������[�I�v�Ɩ������ŎU�X�����Ă����̂͂�͂�G���ł���
����ɂ��Ă̓������
�ł����ۂŃf�R�[�_�Ǝ��s�p�C�v���������̂ɂ��ւ�炸�����X�J�����\���L�тȂ��������Ƃ��
���x���X���ŏo�Ă����̂ɑS���킷��œd�g�Ō�����
��FP���Z�̃A�h���X�Z�o�ɂ����Đ������j�b�g�g����
�G���̃��X��^�Ɏ�̂��A��������
K7�n��AGU3������̂͂��������Ă��̂��߂�
����ɂ��Ă̓������
�ł����ۂŃf�R�[�_�Ǝ��s�p�C�v���������̂ɂ��ւ�炸�����X�J�����\���L�тȂ��������Ƃ��
���x���X���ŏo�Ă����̂ɑS���킷��œd�g�Ō�����
��FP���Z�̃A�h���X�Z�o�ɂ����Đ������j�b�g�g����
�G���̃��X��^�Ɏ�̂��A��������
K7�n��AGU3������̂͂��������Ă��̂��߂�
CPU���璼��GPU�o�͂���̂��ȁH
�C���e���݂�����FDI�݂����ɂ���̂��B
�ǂ����Ȃ낤���B
�C���e���݂�����FDI�݂����ɂ���̂��B
�ǂ����Ȃ낤���B
77 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 16:19:16 ID:Y5JV1Fly
FP�̉��Z���j�b�g�����W���[��������2�����Ȃ����Ƃ��l�b�N���Ƃ���Ȃ��
�]����FMISC/FSTORE����������Ȃ����Ƃ̂ق�������ۂǎ������\���肾��
��������炪�Ϙa���j�b�g�ɑg�ݍ��܂�Ă�Ƃ���A�������s���ł��Ȃ��B
�s��ω��Z�ŕK�v�ȃu���[�h�L���X�g���ł��Ȃ����Ă��ƁB
���̓_��Sandy Bridge��fadd256, fmul256, fperm256��3���j�b�g�\���͗��ɓK���Ă���B
vbroadcastss �� vmulps �� vaddps ��8����̍s��ς�1�C�e���[�V������1�T�C�N���Ŋ������邩��ˁB
���Ȃ݂ɁA�����R�[�h�Ȃ�Bulldozer�͊���v�Z��3�T�C�N��������i�j������
����A�P�ɐ}�ɏ�����ĂȂ�������������Ȃ��̂Œf��͂��Ȃ����ǂ�
�]����FMISC/FSTORE����������Ȃ����Ƃ̂ق�������ۂǎ������\���肾��
��������炪�Ϙa���j�b�g�ɑg�ݍ��܂�Ă�Ƃ���A�������s���ł��Ȃ��B
�s��ω��Z�ŕK�v�ȃu���[�h�L���X�g���ł��Ȃ����Ă��ƁB
���̓_��Sandy Bridge��fadd256, fmul256, fperm256��3���j�b�g�\���͗��ɓK���Ă���B
vbroadcastss �� vmulps �� vaddps ��8����̍s��ς�1�C�e���[�V������1�T�C�N���Ŋ������邩��ˁB
���Ȃ݂ɁA�����R�[�h�Ȃ�Bulldozer�͊���v�Z��3�T�C�N��������i�j������
����A�P�ɐ}�ɏ�����ĂȂ�������������Ȃ��̂Œf��͂��Ȃ����ǂ�
FSTORE�͌^�ϊ��ƃX�g�A(��K10�ł̓��W�X�^�R�s�[)����������
�V���b�t����FADD��FMUL�ɔ��s����
�V���b�t����FADD��FMUL�ɔ��s����
> vbroadcastss �� vmulps �� vaddps ��8����̍s��ς�1�C�e���[�V������1�T�C�N���Ŋ������邩��ˁB
����? ������ă��W�X�^�������Ȃ��ƈӖ��Ȃ���?
Sandy��SSE�n�[�h�E�F�A���W�X�^�������m��Ȃ����ǁA�_��16�{�ő�����?
����? ������ă��W�X�^�������Ȃ��ƈӖ��Ȃ���?
Sandy��SSE�n�[�h�E�F�A���W�X�^�������m��Ȃ����ǁA�_��16�{�ő�����?
IBM��PowerPC�ŁAAltiVec��Apple��Motorola�ƑΗ����Ă���
IBM�́u����d�͂ł�AltiVec�L��300MHz�iCPU�j��AltiVec����500MHz�������A���i�g���ōl����ƌ�҂��ǂ��v�ƌ�������
�����̓}���`���f�B�A�S�����������猋�lj�����ꂽ
����PowerPC MAC��PC�Ɉ���������n�߂Ĕs��
�����̐����Z�p�ł͂܂�128bit��SIMD�ׂ͉��d������
IBM�́u����d�͂ł�AltiVec�L��300MHz�iCPU�j��AltiVec����500MHz�������A���i�g���ōl����ƌ�҂��ǂ��v�ƌ�������
�����̓}���`���f�B�A�S�����������猋�lj�����ꂽ
����PowerPC MAC��PC�Ɉ���������n�߂Ĕs��
�����̐����Z�p�ł͂܂�128bit��SIMD�ׂ͉��d������
81 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 16:55:38 ID:Y5JV1Fly
���̐l�̏�ƃ��W�X�^�R�s�[�̓X�P�W���[�����x���Ō㑱�I�y���[�V�����ƗZ�������悤�Ȃ̂Ő�p���j�b�g�s�v
Store����H�̍œK������Ηv��Ȃ��Ȃ�C������
2�̐Ϙa���j�b�g�ȊO��vpermil2ps���V���O���T�C�N���Ŕ��s�ł��郆�j�b�g������ꍇ
vfmaddps(128b)�~2��vpermil2ps(128b)�~1��16SP/cycle�͈ێ��ł���B
�ܘ_����ɂ�AMD��p�̃R�[�h�������Ă��Ȃ��Ƃ����Ȃ��B
Cell��SPE�Ɠ������]�u�s��ς��g�����@�ɂȂ�̂ŁAIntel�̃f�[�^�̃p�b�L���O���@���̂��̂��ς��B
�i�P����mul+add��fma�ɒu�������������ł͐��\�͏o�Ȃ��j
�������@��2���j�b�g�Ȃ�10.6SP/clk�Abroadcast+FMA����8SP/clk�����o�Ȃ��B
���Ȃ݂ɃR�A���Ŋ���Ƃ��̔����ˁB
Store����H�̍œK������Ηv��Ȃ��Ȃ�C������
2�̐Ϙa���j�b�g�ȊO��vpermil2ps���V���O���T�C�N���Ŕ��s�ł��郆�j�b�g������ꍇ
vfmaddps(128b)�~2��vpermil2ps(128b)�~1��16SP/cycle�͈ێ��ł���B
�ܘ_����ɂ�AMD��p�̃R�[�h�������Ă��Ȃ��Ƃ����Ȃ��B
Cell��SPE�Ɠ������]�u�s��ς��g�����@�ɂȂ�̂ŁAIntel�̃f�[�^�̃p�b�L���O���@���̂��̂��ς��B
�i�P����mul+add��fma�ɒu�������������ł͐��\�͏o�Ȃ��j
�������@��2���j�b�g�Ȃ�10.6SP/clk�Abroadcast+FMA����8SP/clk�����o�Ȃ��B
���Ȃ݂ɃR�A���Ŋ���Ƃ��̔����ˁB
82 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 17:10:49 ID:Y5JV1Fly
>>79
C = A�~B�Ƃ���ƁA8�{��8x8�s����\��C�Ɋ��蓖�Ă�B
�c���8�{�ɂ�A��B���I�ɓǂݍ��܂���B
vbroadcastss�ł̃��[�h��128bit�������g��Ȃ��̂ŁA2�T�C�N����1���vmovaps (256) �����s�o����B
���C�e���V��fmul+fadd�ł�7�Ȃ̂ʼn��Ƃ������B
C = A�~B�Ƃ���ƁA8�{��8x8�s����\��C�Ɋ��蓖�Ă�B
�c���8�{�ɂ�A��B���I�ɓǂݍ��܂���B
vbroadcastss�ł̃��[�h��128bit�������g��Ȃ��̂ŁA2�T�C�N����1���vmovaps (256) �����s�o����B
���C�e���V��fmul+fadd�ł�7�Ȃ̂ʼn��Ƃ������B
���₻��߂�����M���M���ɕ������邪�c�c
�݂�Ȃ̃��W�X�^��c�q�ɂ�����Ƃ������Ă���Ă���B
�݂�Ȃ̃��W�X�^��c�q�ɂ�����Ƃ������Ă���Ă���B
���ꂽ�ꏊ�̃��W�X�^�Ƃ��ق�Ɩ��Ӗ������
85 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 17:33:58 ID:Y5JV1Fly
�Ԃ����Ⴏ���W�X�^���l�[���������broadcastss�p�̃��W�X�^��1�{����Ώ\������B
�c��7�{��B�Ɋ��蓖�ĂāA1�̓X���b�v��������B
�c��7�{��B�Ɋ��蓖�ĂāA1�̓X���b�v��������B
L1D Latency
Bulldozer
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
int 3
fp 5
Sandy Bridge
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
int 5
fp 6
fp256 8
Bulldozer
http://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
int 3
fp 5
Sandy Bridge
http://software.intel.com/en-us/articles/intel-architecture-code-analyzer/
int 5
fp 6
fp256 8
87 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 17:58:07 ID:Y5JV1Fly
�y�\���z
Bulldozer �F 16KB, 4-way set associative
Sandy Bridge �F 32KB, 8-way set associative
�y�ш�z
Bulldozer �F 32 byte?
Sandy Bridge �F 48 byte(32B Load + 16B Store)
Bulldozer �F 16KB, 4-way set associative
Sandy Bridge �F 32KB, 8-way set associative
�y�ш�z
Bulldozer �F 32 byte?
Sandy Bridge �F 48 byte(32B Load + 16B Store)
>>80
IBM��SCEI�ɂ�Cell�̐v�Ɋւ��Ē������Ă���
���[�J���X�g�A�͎g�����肪�������邩��L���b�V���ɂ���ׂ��ƁB
�v��ǖ؎��ƎR�莁�ɂ���Č��lj�����ꂽ����
CPU�̐v�Ɋւ���IBM�͂��������K�ȏ��������Ă��
IBM��SCEI�ɂ�Cell�̐v�Ɋւ��Ē������Ă���
���[�J���X�g�A�͎g�����肪�������邩��L���b�V���ɂ���ׂ��ƁB
�v��ǖ؎��ƎR�莁�ɂ���Č��lj�����ꂽ����
CPU�̐v�Ɋւ���IBM�͂��������K�ȏ��������Ă��
���ς�炸AMD�̘A�z�x�́E�E
������intel�@�������@�͕K��Bulldozer�̐v�v�z���p�N���Ă����
SPE�̃��[�J���X�g�A�̓����͂��Ă����A
> ���[�J���X�g�A�͎g�����肪�������邩��L���b�V���ɂ���ׂ��ƁB
����Ȃ̂́u�J���~�邩��P�����čs���܂��傤�v���x���̖}�f�ȁu�����v����B
> ���[�J���X�g�A�͎g�����肪�������邩��L���b�V���ɂ���ׂ��ƁB
����Ȃ̂́u�J���~�邩��P�����čs���܂��傤�v���x���̖}�f�ȁu�����v����B
93 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 21:10:43 ID:Y5JV1Fly
>>91
���[�U�[������No.1�̌g�уL�����A�̔��蕶�傾����ȁA�����x����
���[�U�[������No.1�̌g�уL�����A�̔��蕶�傾����ȁA�����x����
94 �FMAC�I�^��80 �����F2010/03/07(��) 21:15:30 ID:+7BaEbQg
>>80
�@�@------------------
�@�@�����̓}���`���f�B�A�S�����������猋�lj�����ꂽ
�@�@------------------
������ꂽ�H����IBM��Altivec����������PowerPC��̔����܂���ł����B
�����āA�R�[�h���Y�������Ղ藭�܂�������Ɏ������āA�Q�[���@�⎩�Ђ̃T�[�o�[����
�ő�ׂ����Ă��܂��B
PPC970�ȗ��APOWER6, POWER7, PX (xbox360 CPU), PPE (Cell)�A�S��Altivec�Ƃ���
��p�x�N�g�����߃Z�b�g���������Ă���Ƃ����c
IBM�Ǝ��g�ނ̂́A�����Ǝ������̂ƕς��Ȃ��ł���(��)
�@�@------------------
�@�@�����̓}���`���f�B�A�S�����������猋�lj�����ꂽ
�@�@------------------
������ꂽ�H����IBM��Altivec����������PowerPC��̔����܂���ł����B
�����āA�R�[�h���Y�������Ղ藭�܂�������Ɏ������āA�Q�[���@�⎩�Ђ̃T�[�o�[����
�ő�ׂ����Ă��܂��B
PPC970�ȗ��APOWER6, POWER7, PX (xbox360 CPU), PPE (Cell)�A�S��Altivec�Ƃ���
��p�x�N�g�����߃Z�b�g���������Ă���Ƃ����c
IBM�Ǝ��g�ނ̂́A�����Ǝ������̂ƕς��Ȃ��ł���(��)
95 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 21:22:26 ID:Y5JV1Fly
���N���b�N����������ɂȂ邭�炢��1�X�e�[�W�ɉ��Z���l�ߍ��݂������͎̂����ł���B
����G5��VMX�͖��߂̃��C�e���V��G4��2�{���x�ɐL�тĂ�i���A����ł�x86�̃N���b�N�ɋy�Ȃ������j
����G5��VMX�͖��߂̃��C�e���V��G4��2�{���x�ɐL�тĂ�i���A����ł�x86�̃N���b�N�ɋy�Ȃ������j
������A�����Z�p�ƏW�ϓx���オ�������Ȃ������Ă��Ƃ���B
97 �FMAC�I�^���c�q �����F2010/03/07(��) 21:46:30 ID:+7BaEbQg
>>95
�@�@-----------------
�@�@����ł�x86�̃N���b�N�ɋy�Ȃ�����
�@�@-----------------
������Pentium4�Ɣ�ׂĂ��܂���(��)
�@�@-----------------
�@�@����ł�x86�̃N���b�N�ɋy�Ȃ�����
�@�@-----------------
������Pentium4�Ɣ�ׂĂ��܂���(��)
NG���[�h�����F���C�e���V
�@�@�@���R�F�p�t�H�[�}���X��ǂ���傹���A���̌��t�݂̂��g���l���吙
�@�@�@���R�F�p�t�H�[�}���X��ǂ���傹���A���̌��t�݂̂��g���l���吙
99 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 21:54:19 ID:Y5JV1Fly
Pentium 4�Ɣ�ׂ����肩�H
�܂���Athlon 64�Ɏ������\�ŏ����Ă��Ƃł��H
�܂���Athlon 64�Ɏ������\�ŏ����Ă��Ƃł��H
�L�`�K�C�̗��܂��Ɖ����Ă�ȁB
101 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 22:07:01 ID:Y5JV1Fly
G5(PPC970)��x86�ł���AGU�����̃A�h���X���Z�����ėpALU�ł��Ȃ��Ƃ����Ȃ��̂ɁA
���ꂪ2�{�����Ȃ�����A��ʓI�ȃ��[�N���[�h�ł͓��N���b�N��x86�����������\�͒�߂Ȃ̂ł���B
SIMD�g�����ꍇ�͂��̌��肶��Ȃ����ǁA��������SIMD���j�b�g�̃X���[�v�b�g���x�������ق�
����肪�����Ȃ��̂Łi�ȉ���
���ꂪ2�{�����Ȃ�����A��ʓI�ȃ��[�N���[�h�ł͓��N���b�N��x86�����������\�͒�߂Ȃ̂ł���B
SIMD�g�����ꍇ�͂��̌��肶��Ȃ����ǁA��������SIMD���j�b�g�̃X���[�v�b�g���x�������ق�
����肪�����Ȃ��̂Łi�ȉ���
102 �FMAC�I�^���c�q �����F2010/03/07(��) 22:27:37 ID:+7BaEbQg
>>101
�@�@-----------------
�@�@AGU�����̃A�h���X���Z�����ėpALU�ł��Ȃ��Ƃ����Ȃ�
�@�@-----------------
MMU�Ƃ��A�_��/�����A�h���X�Ƃ��m���Ă��܂����H
�@�@-----------------
�@�@AGU�����̃A�h���X���Z�����ėpALU�ł��Ȃ��Ƃ����Ȃ�
�@�@-----------------
MMU�Ƃ��A�_��/�����A�h���X�Ƃ��m���Ă��܂����H
104 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 22:48:27 ID:Y5JV1Fly
���������Ȃ�
PowerISA�ɊȒP�ȃx�[�X�A�h���X�{�I�t�Z�b�g�i���W�X�^or16�r�b�g�܂ł̑��l�j�݂����ȕn��ȃA�h���b�V���O���[�h�����Ȃ��݂̂͂�Ȓm���Ă邩��
SIB + DISP�݂����Ȏw��͏o���Ȃ�����
PowerISA�ɊȒP�ȃx�[�X�A�h���X�{�I�t�Z�b�g�i���W�X�^or16�r�b�g�܂ł̑��l�j�݂����ȕn��ȃA�h���b�V���O���[�h�����Ȃ��݂̂͂�Ȓm���Ă邩��
SIB + DISP�݂����Ȏw��͏o���Ȃ�����
���ꂪ1���߂ŏo����̂��͂����Ċ������̂��ǂ�����
���������I���Ȃ��b�ɂȂ�Ǝv�����c�c
���������I���Ȃ��b�ɂȂ�Ǝv�����c�c
106 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/07(��) 23:33:52 ID:Y5JV1Fly
�ǂ̐w�c���N���b�N����ɍs���l�܂�I�y���[�V�������x�������グ�邽�߂ɖ��ߊg�����J��Ԃ��Ă�̂��l�����
���p�p�x�̍�������������̖��ߖ��x���ŏ����獂���̂�x86�̋���
�����烌�W�X�^�𑝂₻���Ƃ��R���s���[�^�Ƃ̓�������ǂݏ���������̂������
POWER7�Ȃ�Ĉ��́u����CISC���v�܂ł���Ă邭�炢����
���p�p�x�̍�������������̖��ߖ��x���ŏ����獂���̂�x86�̋���
�����烌�W�X�^�𑝂₻���Ƃ��R���s���[�^�Ƃ̓�������ǂݏ���������̂������
POWER7�Ȃ�Ĉ��́u����CISC���v�܂ł���Ă邭�炢����
�R�e�̊u���X���ł��o���Ȃ����ˁ[
����������ł�
109 �FMAC�I�^���c�q �����F2010/03/08(��) 01:26:24 ID:/G1wwpzL
>>104
�@�@-------------------
�@�@SIB + DISP�݂����Ȏw��͏o���Ȃ�����
�@�@-------------------
RISC�I�ɂ͂ǂ����V���v���������Z���s���Ȃ�A���̕��������Z���j�b�g�𑝂₹�Ηǂ�
�Ƃ������ƂɂȂ�܂��B3�̒P��IU��1�̕��GIU������G4+�́A������������ł��ˁB
�����������_��IBM�̃A�[�L�e�N�`�����ǂ����ǂ����͕ʂ̘b���ƁB
�ނ���>>102�ŏ������������̂́A�������A�N�Z�X�ɓ������Ắu�_���A�h���X�v���v�Z
����ΏI���Ƃ������m�ł͖����Ƃ����b�������̂ł����c
�@�@-------------------
�@�@SIB + DISP�݂����Ȏw��͏o���Ȃ�����
�@�@-------------------
RISC�I�ɂ͂ǂ����V���v���������Z���s���Ȃ�A���̕��������Z���j�b�g�𑝂₹�Ηǂ�
�Ƃ������ƂɂȂ�܂��B3�̒P��IU��1�̕��GIU������G4+�́A������������ł��ˁB
�����������_��IBM�̃A�[�L�e�N�`�����ǂ����ǂ����͕ʂ̘b���ƁB
�ނ���>>102�ŏ������������̂́A�������A�N�Z�X�ɓ������Ắu�_���A�h���X�v���v�Z
����ΏI���Ƃ������m�ł͖����Ƃ����b�������̂ł����c
���R�e�ǂ��A���߂�x86��AVX�ő���
Altivec�Ȃǂ��ł�����
Altivec�Ȃǂ��ł�����
111 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/08(��) 02:19:41 ID:YJZf8+Ym
> RISC�I�ɂ͂ǂ����V���v���������Z���s���Ȃ�A���̕��������Z���j�b�g�𑝂₹�Ηǂ�
> �Ƃ������ƂɂȂ�܂��B3�̒P��IU��1�̕��GIU������G4+�́A������������ł��ˁB
��ŁA����Ȕn�������v�z����E�p�ł��Ȃ�����S�������s�ł��Ȃ�����
���ǃf�R�[�_�̃X���[�v�b�g�ɔ�����x86�ɐ�����������킯�ł���B
32bit�̑��l�����[�h����̂�2���߂�����Ƃ��n���n�������ɂ���������B
���肷��Ɠ��N���b�N��Atom�ȉ��̐��\�ł��ˁB
> �Ƃ������ƂɂȂ�܂��B3�̒P��IU��1�̕��GIU������G4+�́A������������ł��ˁB
��ŁA����Ȕn�������v�z����E�p�ł��Ȃ�����S�������s�ł��Ȃ�����
���ǃf�R�[�_�̃X���[�v�b�g�ɔ�����x86�ɐ�����������킯�ł���B
32bit�̑��l�����[�h����̂�2���߂�����Ƃ��n���n�������ɂ���������B
���肷��Ɠ��N���b�N��Atom�ȉ��̐��\�ł��ˁB
�Ƃ͂����ϒ����߂̃f�R�[�h���܂����ʂ������ăo�J�o�J�������̂�
�������˂��B�����͌������Ȃ���B
�������˂��B�����͌������Ȃ���B
�������߂�64bit���l��1���߂Ń��[�h�ł���VLIW�A�[�L�e�N�`���������
114 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/08(��) 03:46:07 ID:YJZf8+Ym
���₳�A��������G4+����3���߂����f�R�[�h�ł��Ȃ�����ALU�̌����₻�������\������ˁ[�킯�ŁB
�����������N���b�N��Pentium III�̐������Z���\�ɑS�����ĂĂȂ������̂ʼn�����ɂȂ��Ă܂���B
> �ǂ��Ƃ������ƂɂȂ�܂��B
�i�j
�W���u�Y��Photoshop�v���O�C���ł̃x���`1���ڂ�2CPU��g���ď��������̂ƕ�����Ă������
�}�J�[�ɂ͏펯�͒ʂ��Ȃ��̂��ˁB
���������ő�6��OPs�����s�ł���Core MA�ȂƓ����̃N���b�N�����萫�\����������ɂ�
�P���ɍl�����RISC�^��ISA�Ȃ�6���߂�����ȏ���f�R�[�h���Ȃ��Ƃ����Ȃ��킯�ŁA
���Ƀf�R�[�h�o�����Ƃ��āA�ˑ��W���`�F�b�N���ăX�P�W���[�����O����R�X�g�͖��ߐ���2��ɔ�Ⴕ��
�傫���Ȃ邩�猋�ǔj�]����B
��ō�IPC�H���ł͏����ڂ��Ȃ�����IBM��PPC970�̌�p���i�𓀌����ċꂵ����̍��N���b�N�H���ƁB
�����������N���b�N��Pentium III�̐������Z���\�ɑS�����ĂĂȂ������̂ʼn�����ɂȂ��Ă܂���B
> �ǂ��Ƃ������ƂɂȂ�܂��B
�i�j
�W���u�Y��Photoshop�v���O�C���ł̃x���`1���ڂ�2CPU��g���ď��������̂ƕ�����Ă������
�}�J�[�ɂ͏펯�͒ʂ��Ȃ��̂��ˁB
���������ő�6��OPs�����s�ł���Core MA�ȂƓ����̃N���b�N�����萫�\����������ɂ�
�P���ɍl�����RISC�^��ISA�Ȃ�6���߂�����ȏ���f�R�[�h���Ȃ��Ƃ����Ȃ��킯�ŁA
���Ƀf�R�[�h�o�����Ƃ��āA�ˑ��W���`�F�b�N���ăX�P�W���[�����O����R�X�g�͖��ߐ���2��ɔ�Ⴕ��
�傫���Ȃ邩�猋�ǔj�]����B
��ō�IPC�H���ł͏����ڂ��Ȃ�����IBM��PPC970�̌�p���i�𓀌����ċꂵ����̍��N���b�N�H���ƁB
�uAGU��2�{��Core2�͕��v�Ƃ������o���Ă��
116 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/08(��) 06:48:19 ID:YJZf8+Ym
Load/Store���j�b�g�̖{������������Ώ\������
�܂�������킯�Ȃ��Ǝv������
3�{�����Ă�LSU��2����Ȃ�����1�{�͕K���x�ނ悤��
�}�k�P�d�l�Ȃ�R����Ӗ��Ȃ������B
�܂�������킯�Ȃ��Ǝv������
3�{�����Ă�LSU��2����Ȃ�����1�{�͕K���x�ނ悤��
�}�k�P�d�l�Ȃ�R����Ӗ��Ȃ������B
> �܂�������킯�Ȃ��Ǝv������
���̂܂����Ǝv����悤�ȃ}�k�P�d�l������炵���E�E�E
�m���X�P�W���[�����������炱���Ȃ����Ƃ������Ă��Ȃ��E�E�E
�Ƃ��낪�M�҂��̂悤�ɗ������Ă��炸���b�`���Ƒ����ł�炵���E�E�E
���̂܂����Ǝv����悤�ȃ}�k�P�d�l������炵���E�E�E
�m���X�P�W���[�����������炱���Ȃ����Ƃ������Ă��Ȃ��E�E�E
�Ƃ��낪�M�҂��̂悤�ɗ������Ă��炸���b�`���Ƒ����ł�炵���E�E�E
118 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/08(��) 07:41:13 ID:YJZf8+Ym
�܂����A����킯�Ȃ������
�u�f�R�[�h�O�ɃX�P�W���[�����O���Ă邩��X�P�W���[�������́i�د�v���Ƃ��H
������ėv����Ƀ�OP�����x���ł̍ח��x�̃X�P�W���[�����O�͂ł��Ă܂�����Ă��Ƃł����
��ŁA3�{��ALU���Ƀ��U�x�[�V�����X�e�[�V�������Ɨ��Ƃ��H
�����ALU(+AGU)���璷�\���ɂ��Ă��Ȃ��Ɛ��\���ł��Ȃ���Ȃ�����
�\�ɂ͕������ǁA����ȉċx�݂̍H�샌�x���̃|���R�cCPU�Ȃ�Ė{���Ɏ��݂���́H
�s�s�`���̃��x������
�u�f�R�[�h�O�ɃX�P�W���[�����O���Ă邩��X�P�W���[�������́i�د�v���Ƃ��H
������ėv����Ƀ�OP�����x���ł̍ח��x�̃X�P�W���[�����O�͂ł��Ă܂�����Ă��Ƃł����
��ŁA3�{��ALU���Ƀ��U�x�[�V�����X�e�[�V�������Ɨ��Ƃ��H
�����ALU(+AGU)���璷�\���ɂ��Ă��Ȃ��Ɛ��\���ł��Ȃ���Ȃ�����
�\�ɂ͕������ǁA����ȉċx�݂̍H�샌�x���̃|���R�cCPU�Ȃ�Ė{���Ɏ��݂���́H
�s�s�`���̃��x������
>>118
�s�s�`�����Ǝv���̂������̒��ɂ͂����Ȑl�����ĂˁB
����ȋL���������ЂƂ������肷�邩��E�E�E
�Z�J���h�E�I�s�j�I��
184 Core MicroArchitecture������������(8)
http://journal.mycom.co.jp/column/sopinion/184/index.html
> ����K8�ɂ��ẮA��̓��W�ł����������Ƃ���A�ˑ��W�̉�������x���������ɍs���Ă���(Fetch��Pick��Decode 1 / Decode 2��Pack�̒i�K�ŁA
> ��x�ˑ��W�̉������s�������MicroOp�����Ȃ����Ă���)����AALU�̒��O�̃X�P�W���[���̃G���g���������Ȃ��Ă�����قǕs�v�c�ł͂Ȃ��B
> �ނ��낱�������Â����\��������K8�̃p�C�v���C�������Ă��܂��ƁACore Microarchitecture�̃X�P�W���[����ROB���u����ȂɒP���ő��v�Ȃ̂�?�v�Ǝv���Ă��܂��B
�s�s�`�����Ǝv���̂������̒��ɂ͂����Ȑl�����ĂˁB
����ȋL���������ЂƂ������肷�邩��E�E�E
�Z�J���h�E�I�s�j�I��
184 Core MicroArchitecture������������(8)
http://journal.mycom.co.jp/column/sopinion/184/index.html
> ����K8�ɂ��ẮA��̓��W�ł����������Ƃ���A�ˑ��W�̉�������x���������ɍs���Ă���(Fetch��Pick��Decode 1 / Decode 2��Pack�̒i�K�ŁA
> ��x�ˑ��W�̉������s�������MicroOp�����Ȃ����Ă���)����AALU�̒��O�̃X�P�W���[���̃G���g���������Ȃ��Ă�����قǕs�v�c�ł͂Ȃ��B
> �ނ��낱�������Â����\��������K8�̃p�C�v���C�������Ă��܂��ƁACore Microarchitecture�̃X�P�W���[����ROB���u����ȂɒP���ő��v�Ȃ̂�?�v�Ǝv���Ă��܂��B
120 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/08(��) 08:13:52 ID:YJZf8+Ym
�匴������
�n�������ď������˂�������
�n�������ď������˂�������
�u�t�F�b�`���v���t�F�b�`�v�u�f�[�^���^�X�N����v
�Ȃ�ēd�g���l�Z���������Ă�z��
���ʂ̐l�ԂŐF�X�Ə��ɒʂ��Ă�L��
�ǂ�����M���邩�ƌ�������f�R��҂���
�����Ȃ�Ƃ��������Ȃ�܂����������낤��
K8�ł͑����i�K�ňˑ��W�ׂ���Ƃ������Ƃ�
�uK8�̃X�P�W���[���͂낭�Ɉˑ����ׂ��Ƀp�C�v�ɗ����v�Ƃ������͓̂d�g��
���̑���Ɂu�p�C�v���G�ɂƂ��������ʂɎg���v�v���ƂȂ�̂̓L���b�V�����\�̈������Ă��ƂɂȂ�̂���
2way�ł͋Ǐ����̍����I�ł���X���b�V���O����������炵����
�Ȃ�ēd�g���l�Z���������Ă�z��
���ʂ̐l�ԂŐF�X�Ə��ɒʂ��Ă�L��
�ǂ�����M���邩�ƌ�������f�R��҂���
�����Ȃ�Ƃ��������Ȃ�܂����������낤��
K8�ł͑����i�K�ňˑ��W�ׂ���Ƃ������Ƃ�
�uK8�̃X�P�W���[���͂낭�Ɉˑ����ׂ��Ƀp�C�v�ɗ����v�Ƃ������͓̂d�g��
���̑���Ɂu�p�C�v���G�ɂƂ��������ʂɎg���v�v���ƂȂ�̂̓L���b�V�����\�̈������Ă��ƂɂȂ�̂���
2way�ł͋Ǐ����̍����I�ł���X���b�V���O����������炵����
�������ˎl�Z�����v���t�F�b�`�ȌN�̓o�J�����邩��A���Ă�����
960T�ڍׂ܂��`
�匴�N��Sandra�x���`�݂āuPhenom��L3���x���B�R�A�Ԃ̓]�����x���x���i�د�v�Ƃ��������Ⴄ�l������
CPU�A�[�L�ɂ��Ă̓h�f�l
CPU�A�[�L�ɂ��Ă̓h�f�l
��? Phenom��L3�͒x������? �������Intel�Ɣ�r���Ă̘b�����B
�L���b�V���̉e����w�ǎȂ��\�t�g�ł��x����Ȃ��E�E�E
����ς�匴�͔n������?
����ς�匴�͔n������?
�G���̏K�����炷���>>127�@1�s�ڂ̎��́uL3�L���b�V���v
>125
L3�x���͎̂�������
L3�x���͎̂�������
�x���Ƃ������Ƃ��ǂ��ł�������
�����Œ��ӂ���_�́u�G���v
�����Œ��ӂ���_�́u�G���v
�G���Ƃ�AMD�ɕs���Ȏ��������l��j�[�g�Ɍ��������l�̂���
�����̐l����l���Ǝv�����肷��a�C�������A�Ă��錾�t
�����̐l����l���Ǝv�����肷��a�C�������A�Ă��錾�t
�G����
>>131
���H�@�}�W�Ō����Ă���́H
���H�@�}�W�Ō����Ă���́H
>>135
PPU��PowerPC 970�݊��������̂͊o���Ă邪�A
970��POWER4�x�[�X��
���Ƃ��ƁAPOWER4�̓f���A���R�A����������
����POWER���f���A���R�A�����āA10�N�o�̂��`
PPU��PowerPC 970�݊��������̂͊o���Ă邪�A
970��POWER4�x�[�X��
���Ƃ��ƁAPOWER4�̓f���A���R�A����������
����POWER���f���A���R�A�����āA10�N�o�̂��`
POWER4->PowerPC 970->��[���p�pin-order�Ɋȑf�����č��N���b�N�������Ⴄ���[->PPE
�Ȃ̂ŁA�uPOWER4���J�b�g�A�E�g�����v�Ƃ͌����C�����邪�A
���������㓡�������ŏ������L���������B
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
Cell�������5�N����������������
�Ȃ̂ŁA�uPOWER4���J�b�g�A�E�g�����v�Ƃ͌����C�����邪�A
���������㓡�������ŏ������L���������B
http://pc.watch.impress.co.jp/docs/2005/0209/kaigai154.htm
Cell�������5�N����������������
>>122
�ł��f�R�[�h�i�K�ňˑ��W�ׂ���Ƃ͎v���Ȃ����
K8�̃��U�x�[�V�����X�e�[�V�����ɂ�Core�ƈ���ĕ���O�̃�ops�������Ă�
�ő��Core��3�{�̃�ops��1�G���g���ɋl�ߍ��܂�Ă���\��������
������K8��8�G���g����32�G���g����Core��蒘�������Ȃ��Ƃ͌����Ȃ��Ǝv��
���ۂ�K8�̃_�C�ɐ�߂�3�{�̃X�P�W���[���̖ʐς͑傫��
�ł��f�R�[�h�i�K�ňˑ��W�ׂ���Ƃ͎v���Ȃ����
K8�̃��U�x�[�V�����X�e�[�V�����ɂ�Core�ƈ���ĕ���O�̃�ops�������Ă�
�ő��Core��3�{�̃�ops��1�G���g���ɋl�ߍ��܂�Ă���\��������
������K8��8�G���g����32�G���g����Core��蒘�������Ȃ��Ƃ͌����Ȃ��Ǝv��
���ۂ�K8�̃_�C�ɐ�߂�3�{�̃X�P�W���[���̖ʐς͑傫��
����ōl���邾���Ȃ�ǂꂾ���ł��ǂ��̂��l������
�ł����i�Ƃ��ďo���ɂ͐F��Ȑ�����킯��
������ӂ��l�����Ɏ��ۂ̐��i����Ă��~��v�l�ł����Ȃ�
�܂��Ă�ォ��Ȃ牽�Ƃł������邩���
�c�q����
�ł����i�Ƃ��ďo���ɂ͐F��Ȑ�����킯��
������ӂ��l�����Ɏ��ۂ̐��i����Ă��~��v�l�ł����Ȃ�
�܂��Ă�ォ��Ȃ牽�Ƃł������邩���
�c�q����
�����I�ȕ��̌��������Ă��
�����Ɍ����u���Ƃł�������v�Ƃ����̂͗L�蓾�Ȃ�
�{���Ɂu���Ƃł��v�����Ă�͎̂G������
�����ď�ɏ���
�����Ɍ����u���Ƃł�������v�Ƃ����̂͗L�蓾�Ȃ�
�{���Ɂu���Ƃł��v�����Ă�͎̂G������
�����ď�ɏ���
>>138
Core�̃��U�x�[�V�����X�e�[�V����������O�̃�ops�������Ă�͂�����B
http://download.intel.com/jp/developer/jpdoc/vol7iss2_art03_j.pdf
Page 8
> ���̗Z�������}�C�N��
> Op �ɑ��ăA���P�[�V�����ƃ��l�[�����s���A1�G
> ���g���Ƃ��ă��I�[�_�E�o�b�t�@�ƃ��U�x�[�V�����E
> �X�e�[�V�����ɑ����܂��B�Z�����ꂽ�}�C�N�� Op
> ��������悤�ɂ��邽�߁A���U�x�[�V�����E�X�e�[
> �V�����̊e�G���g���͍ő�3�̃\�[�X�E�I�y�����h
> �ɑΉ��ł���悤�ɂȂ��Ă��܂��B
Core�̃��U�x�[�V�����X�e�[�V����������O�̃�ops�������Ă�͂�����B
http://download.intel.com/jp/developer/jpdoc/vol7iss2_art03_j.pdf
Page 8
> ���̗Z�������}�C�N��
> Op �ɑ��ăA���P�[�V�����ƃ��l�[�����s���A1�G
> ���g���Ƃ��ă��I�[�_�E�o�b�t�@�ƃ��U�x�[�V�����E
> �X�e�[�V�����ɑ����܂��B�Z�����ꂽ�}�C�N�� Op
> ��������悤�ɂ��邽�߁A���U�x�[�V�����E�X�e�[
> �V�����̊e�G���g���͍ő�3�̃\�[�X�E�I�y�����h
> �ɑΉ��ł���悤�ɂȂ��Ă��܂��B
http://www.pcmag.com/article2/0,2817,2361273,00.asp
> OTOY, AMD To Ship Remote-Gaming Servers in Q2
Radeon���ׂă����_�����O�T�[�o�͂킩�邪�A�Q�[���͂Ȃ����낤�Ǝv�����B
���C�e���V�ǂ�������Ă����B
> OTOY, AMD To Ship Remote-Gaming Servers in Q2
Radeon���ׂă����_�����O�T�[�o�͂킩�邪�A�Q�[���͂Ȃ����낤�Ǝv�����B
���C�e���V�ǂ�������Ă����B
>>143
�c���C�e���V�H�@���������Ă���̂��H
�c���C�e���V�H�@���������Ă���̂��H
> to allow games to be remotely played via PCs, without
> the need for enthusiasts to constantly reinvest in new hardware.
�ŐV��GPU�������Ȃ�PC�Ń����[�g�v���C
> the need for enthusiasts to constantly reinvest in new hardware.
�ŐV��GPU�������Ȃ�PC�Ń����[�g�v���C
�������͉����ɂł�����ق����}�V���낤
�m�[�g��l�b�g�u�b�N���p�ґw�����[�U�[�ɉ�������Ȃ���������d�g�݂ɂȂ��
�PGb/s�Őڑ����Ă�PCIe�̑��x��40���̂P�����ȁB
USB3.0��U��X�s�[�h�Őڑ����Ă�8����1�B
����p�G���hGPU������Q�t�H���x�̐��\�ɉ�������Ă��Ƃ��ȁB
������ĒN��
USB3.0��U��X�s�[�h�Őڑ����Ă�8����1�B
����p�G���hGPU������Q�t�H���x�̐��\�ɉ�������Ă��Ƃ��ȁB
������ĒN��
NVIDIA��"Optimus"�Ɠ�������������B
>>148
�ȒP�����B�u1Gb/s�v�Ȃ�Ēᑬ�Őڑ����Ȃ�������B
�O�t��PCIe�K�i�����邵�A�Ȃ�ł���Ȓᑬ��O��Ƃ���̂����R���킩���B
�ȒP�����B�u1Gb/s�v�Ȃ�Ēᑬ�Őڑ����Ȃ�������B
�O�t��PCIe�K�i�����邵�A�Ȃ�ł���Ȓᑬ��O��Ƃ���̂����R���킩���B
��?
���̃X�����v��?
���̃X�����v��?
�ŐV�̓��戳�k�Z�p���g�p���Ă��邽�߁A
�ŐV��GPU�Ńf�R�[�h���Ă���͂��B
�ŐV��GPU�Ńf�R�[�h���Ă���͂��B
���������đ��v�Ȃ킯���Ȃ�
���B>>143�̋L����ǂ�ł݂Ă킩������
�I�����S�������Ⴂ�̂��ƌ����Ă�Ȃ�
�I�����S�������Ⴂ�̂��ƌ����Ă�Ȃ�
�������A���ԕ����Ɉ��k���Ă���͂��Ȃ̂�
�v���C���[�̓��͂Ń��A���^�C���ɐ��������f����
�ǂ�����Ēx���Ȃ��ŃG���R�[�h���Ĕz�M�ł���낤�ȁB
���̋Z�p�����^�₾�B
�v���C���[�̓��͂Ń��A���^�C���ɐ��������f����
�ǂ�����Ēx���Ȃ��ŃG���R�[�h���Ĕz�M�ł���낤�ȁB
���̋Z�p�����^�₾�B
>>150
�قƂ�ǖ����ɋ߂��悤�ȊO���ڑ�PCIe���Ⴡ���b�g���Ȃ��Ȃ邾��
��������ŏ���������ł����킯�ł́H
���������A������Ă���悭��GPU�\�͂���������V�F�A�ł�����ĖړI�Ȃ�H
�܂��]�����x�̃{�g���l�b�N���傫�����ă����[�gGPU������ɂ͉ۑ肪����������Ęb�B
�قƂ�ǖ����ɋ߂��悤�ȊO���ڑ�PCIe���Ⴡ���b�g���Ȃ��Ȃ邾��
��������ŏ���������ł����킯�ł́H
���������A������Ă���悭��GPU�\�͂���������V�F�A�ł�����ĖړI�Ȃ�H
�܂��]�����x�̃{�g���l�b�N���傫�����ă����[�gGPU������ɂ͉ۑ肪����������Ęb�B
�ނ��딄��͎��ۂ̃T�[�r�X�Ǝ҂̃T�C�g�Ő�`����Ă���悤�ɁA
�v���b�g�t�H�[���Ɉˑ����Ȃ����Ƃ��낤�ˁB
���Ƃ���PC�ƌg�ѓd�b�œ����Q�[�����ł��Ă����������Ȃ��B
�g�ё��͉𑜓x��������������B
�v���b�g�t�H�[���Ɉˑ����Ȃ����Ƃ��낤�ˁB
���Ƃ���PC�ƌg�ѓd�b�œ����Q�[�����ł��Ă����������Ȃ��B
�g�ё��͉𑜓x��������������B
>>156
�L����ǂތ���A�uGPU����������V�F�A�v�ł͂Ȃ��āA
�Q�[���N���C�A���g�≽���͑S�������ɂ����āA
���̌��ʂ������A���Ă��銴������B
�Ԃ����Ⴏ���b�ŁA�����I�ɂ�PC�ł͂Ȃ�TV�ł����Ă��A
�l�b�g�ɐڑ��ł�����̂܂܃Q�[�����ł���悤�ȋZ�p����B
���ׂ̈̃T�[�o�[����ˁH�@�ǂ݊ԈႦ�ĂȂ���B
�L����ǂތ���A�uGPU����������V�F�A�v�ł͂Ȃ��āA
�Q�[���N���C�A���g�≽���͑S�������ɂ����āA
���̌��ʂ������A���Ă��銴������B
�Ԃ����Ⴏ���b�ŁA�����I�ɂ�PC�ł͂Ȃ�TV�ł����Ă��A
�l�b�g�ɐڑ��ł�����̂܂܃Q�[�����ł���悤�ȋZ�p����B
���ׂ̈̃T�[�o�[����ˁH�@�ǂ݊ԈႦ�ĂȂ���B
>>157
����͗��z�ł����āA���ۂ͑��쐫��
�l���Ȃ��Ⴂ���Ȃ�����ł��Ȃ����낤>PC�ƌg�тœ����Q�[��
���Ƃ��APSP�́uPS�̃Q�[�������̂܂܈ڐA�ł���I=�\�t�g���Y���L�x�v�Ȃ̂�
���肾�������ALR�{�^��������Ȃ��������APlaystation archieve�̃\�t�g��
���͂�����Ƃ����������Ȃ��B
PS2�̃Q�[�������ẮALR�����ł͂Ȃ��āA�X�e�B�b�N�̐�������Ȃ�����A
���������ڐA����o�Ȃ����Ƃ������BFF10�Ƃ��A�o�C�I4�������
�o�Ă����������Ȃ��͂��Ȃ̂ɁB
�Q�[���@�ł��ꂾ����A�g�ѓd�b��PC�œ����Q�[���Ȃ�Ė����ꂾ�낤(�������A���̂ɂ�邾�낤����)
����͗��z�ł����āA���ۂ͑��쐫��
�l���Ȃ��Ⴂ���Ȃ�����ł��Ȃ����낤>PC�ƌg�тœ����Q�[��
���Ƃ��APSP�́uPS�̃Q�[�������̂܂܈ڐA�ł���I=�\�t�g���Y���L�x�v�Ȃ̂�
���肾�������ALR�{�^��������Ȃ��������APlaystation archieve�̃\�t�g��
���͂�����Ƃ����������Ȃ��B
PS2�̃Q�[�������ẮALR�����ł͂Ȃ��āA�X�e�B�b�N�̐�������Ȃ�����A
���������ڐA����o�Ȃ����Ƃ������BFF10�Ƃ��A�o�C�I4�������
�o�Ă����������Ȃ��͂��Ȃ̂ɁB
�Q�[���@�ł��ꂾ����A�g�ѓd�b��PC�œ����Q�[���Ȃ�Ė����ꂾ�낤(�������A���̂ɂ�邾�낤����)
�N���C�A���g���̓v���C���[�̓��͂��T�[�o�ɓ`����̂ƁA
�T�[�o����X�g���[���ł��铮��f�[�^���f�R�[�h���ĕ\������
���Ă����B������T�[�o���ł��肱�݂��������肵�Ă���A
�N���C�A���g���̊��ɂ͂قƂ�Ljˑ����Ȃ��B
Web�J�����ŃQ�[����ʔz�M���āA�R���g���[������̓��͂�
�C���^�[�l�b�g�ɂ̂������Ă��邾�����ăC���[�W�B
�T�[�o����X�g���[���ł��铮��f�[�^���f�R�[�h���ĕ\������
���Ă����B������T�[�o���ł��肱�݂��������肵�Ă���A
�N���C�A���g���̊��ɂ͂قƂ�Ljˑ����Ȃ��B
Web�J�����ŃQ�[����ʔz�M���āA�R���g���[������̓��͂�
�C���^�[�l�b�g�ɂ̂������Ă��邾�����ăC���[�W�B
>>159
���C�g�ȃQ�[���Ȃ�\����B
�Ȃɂ��n�[�h��FPS���g�т�PC�őΐ킵�悤�ȂǂƂ͂����ĂȂ��B
�N���C�A���g���̃\�t�g�̊J����͊i�i�ɂ�������ꂽ�����ŁA
���p�҂��ӂ₷���Ƃ��ł���B
���C�g�ȃQ�[���Ȃ�\����B
�Ȃɂ��n�[�h��FPS���g�т�PC�őΐ킵�悤�ȂǂƂ͂����ĂȂ��B
�N���C�A���g���̃\�t�g�̊J����͊i�i�ɂ�������ꂽ�����ŁA
���p�҂��ӂ₷���Ƃ��ł���B
�����Ȃ̂�(�L�E�ցE�M)
Java�ȏ�ɕ��y�ɍ�����ɂ߂����Șb������
Java�ȏ�ɕ��y�ɍ�����ɂ߂����Șb������
�܂��ł��G���R��ʐM�x���̖�肪���邩��A���̋Z�p�ɂ͌��E�����邾�낤�ȁB
�w�r�[���[�U�̊Ԃł͂�͂�͂��Ȃ����?
�w�r�[���[�U�̊Ԃł͂�͂�͂��Ȃ����?
���B���m�O���邦�邪����̂��B����ɂ��Ċy�����̂��H�@>>159�H
������錾���������ɁA�����Ă��Ȃ��̂ͷ��̓T�^�Ⴞ���B
>>162
�m���ɂ���͂���ȁB�܂��B�ł��l�b�g���[�N�����W����A
���قǍ���ł��Ȃ������ȋC�����邪�c�B
���邢�́A�C���^�[�l�b�g����ł͂Ȃ��āA
�l�b�g�J�t�F���ōl����Ȃ�A
���[�ɗǂ��N���X��PC��Ȃ��Ă������Ƃ��Ȃ�
������錾���������ɁA�����Ă��Ȃ��̂ͷ��̓T�^�Ⴞ���B
>>162
�m���ɂ���͂���ȁB�܂��B�ł��l�b�g���[�N�����W����A
���قǍ���ł��Ȃ������ȋC�����邪�c�B
���邢�́A�C���^�[�l�b�g����ł͂Ȃ��āA
�l�b�g�J�t�F���ōl����Ȃ�A
���[�ɗǂ��N���X��PC��Ȃ��Ă������Ƃ��Ȃ�
���炭������Ƃ����������ʼni���ɂ�����Ȃ�Ă����ĂȂ����A
��]�����B�N�̃I�c���ł͗����ł��Ȃ����疳���ɂ��̌��ɂ��ċc�_���Ȃ���OK�B
��]�����B�N�̃I�c���ł͗����ł��Ȃ����疳���ɂ��̌��ɂ��ċc�_���Ȃ���OK�B
�l�b�g���[�N��ʂ��ꍇ�A�ш�͂܂����₹�邯�ǁA���C�e���V�����炷�͍̂���Ȃ�ł���B
>>166
�u���C�e���V�v���u���̃��C�e���V�v���w���Ă��邩�킩��c�B
�A�����H�@�l�g�Q��"�x��"��"���O"�݂����Ȃ��̂������Ă���̂��H
����̓l�b�g���[�N��"��"�̖��ł́H
�u���C�e���V�v���u���̃��C�e���V�v���w���Ă��邩�킩��c�B
�A�����H�@�l�g�Q��"�x��"��"���O"�݂����Ȃ��̂������Ă���̂��H
����̓l�b�g���[�N��"��"�̖��ł́H
>>166
���������B�����I�ȋ����̕ǂ��ǂ����Ă�
���߂��Ȃ���ˁB
>>167
�Ⴆ�A��x�ɒx���f�[�^��
1Mbit����100Mbit�ɂ���̂͊ȒP�����ǁA
�v���������܂ł̎��Ԃ�100ms����10ms�ɂ���̂�
���ɍ���B�Ȃ��Ȃ畨���I�ɋ�����
����Ă邩��B�N���E�h����ɂȂ��Ă���A
���ɏd�v������Ă�B
���������B�����I�ȋ����̕ǂ��ǂ����Ă�
���߂��Ȃ���ˁB
>>167
�Ⴆ�A��x�ɒx���f�[�^��
1Mbit����100Mbit�ɂ���̂͊ȒP�����ǁA
�v���������܂ł̎��Ԃ�100ms����10ms�ɂ���̂�
���ɍ���B�Ȃ��Ȃ畨���I�ɋ�����
����Ă邩��B�N���E�h����ɂȂ��Ă���A
���ɏd�v������Ă�B
>>168
����Ȃ��"OTOY"�݂����ȃQ�[���T�[�o�[���A
�n�悲�Ƃɕ����䌚�Ă邵�������@���Ȃ��̂ł́H
�ł��A���܂̃l�g�Q�����āA�I�����{�����ɕ�����B
�n�悲�Ƃɂ���Ƃ͕����Ȃ�������v����Ȃ��H
����Ȃ��"OTOY"�݂����ȃQ�[���T�[�o�[���A
�n�悲�Ƃɕ����䌚�Ă邵�������@���Ȃ��̂ł́H
�ł��A���܂̃l�g�Q�����āA�I�����{�����ɕ�����B
�n�悲�Ƃɂ���Ƃ͕����Ȃ�������v����Ȃ��H
���C�e���V�Ƃ����Ă�
�d�C�M�������p���ē`�B���邱�Ƃɂ�����̒x��
���[�^�[�Ȃ�n�u�Ȃ�̉�H��t�@�[��������ʉ߂���ʐM��H��̒x��
�T�[�o��ł̃\�t�g����
��3��ނ��炢����̍������Ă����Ă�̂����B
����̕����̏ꍇ�́A�X�g���[���Œ���邩��ш悪������(���C�e���V�͒��ڊW�Ȃ�)���Ă̂ƁA
�������k���ŃG���R�[�h�����邽�߂ɂ͉��t���[�����f�[�^�����߂�
�K�v������̂ł����ŃG���R�[�h�̒x��������B
�C���^�[�l�b�g��̃��C�e���V�̋��傳���l����A
�N���E�h(��)�Ȃ�Ă����̂̓R���s���[�^������̎��ԃR�X�g�����ɕ������ō팸���Ă������j��
�܂���������ے肷��悤�Ȉ�ߐ��̓d�g�v�z�ɂ����Ȃ��̂ŁA���Ăɂ��Ă͂����Ȃ��Ƃ������Ƃ��B
�d�C�M�������p���ē`�B���邱�Ƃɂ�����̒x��
���[�^�[�Ȃ�n�u�Ȃ�̉�H��t�@�[��������ʉ߂���ʐM��H��̒x��
�T�[�o��ł̃\�t�g����
��3��ނ��炢����̍������Ă����Ă�̂����B
����̕����̏ꍇ�́A�X�g���[���Œ���邩��ш悪������(���C�e���V�͒��ڊW�Ȃ�)���Ă̂ƁA
�������k���ŃG���R�[�h�����邽�߂ɂ͉��t���[�����f�[�^�����߂�
�K�v������̂ł����ŃG���R�[�h�̒x��������B
�C���^�[�l�b�g��̃��C�e���V�̋��傳���l����A
�N���E�h(��)�Ȃ�Ă����̂̓R���s���[�^������̎��ԃR�X�g�����ɕ������ō팸���Ă������j��
�܂���������ے肷��悤�Ȉ�ߐ��̓d�g�v�z�ɂ����Ȃ��̂ŁA���Ăɂ��Ă͂����Ȃ��Ƃ������Ƃ��B
�b���̒E���ɔ��Ԃ������Ă��܂�������Ō����̂��A��������
���낻��E����߂Ȃ����H
���낻��E����߂Ȃ����H
�W���̌n���l����ƃN���E�h�Ɍ������͕̂K�R���낤
���[�͂��͂��A�܂芄��̍���̑������Ă��Ƃ�
That'sON����
�����Ȃ�e�����ɃQ�[���T�[�o�[�����Ƃ����������Ȃ�����
���邢�͖��ʂɃn�C�G���h��GPU�������Ă�l���L���Ń}�V���p���[�����Ƃ�
���邢�͖��ʂɃn�C�G���h��GPU�������Ă�l���L���Ń}�V���p���[�����Ƃ�
���Ǔ����Ƒ�゠����ɃT�[�o�u���Ă����܂�
�Ȃ��iPhone��Crysis���I�H�Q�[���X�g���[�~���O�T�[�r�X��AMD���́uOTOY�v���Q��
http://beeep.jp/2009/092580.html
���N���Ƀf�����Ă邵
http://beeep.jp/2009/092580.html
���N���Ƀf�����Ă邵
1�R�A�ӂ̐��\��r����Ȃ�
SpecInt�̒l����̂����������H
4CPU�Ƃ����v����Ȃ��āA1CPU�̐��\�l
���������ǂǂ����ɖ������Ȃ�
SpecInt�̒l����̂����������H
4CPU�Ƃ����v����Ȃ��āA1CPU�̐��\�l
���������ǂǂ����ɖ������Ȃ�
>>177
�������E�E�E���\���ۂ��ł��E�E�E
�������E�E�E���\���ۂ��ł��E�E�E
AMD��OTOY�̑��ɂ��Q�[���X�g���[�~���O�T�[�r�X�͉��Ђ����n�߂�\�肾��
�����̓Q�[���\�t�g���̂��T�[�o�[���ɂ��邩��A�������łȂ��ƃ\�t�g�̃_�E�����[�h���疳����
�z�[���y�[�W�J���ă{�^��1�N���b�N�ł����Ȃ�Q�[�����n�߂���炵��
�����ł͔F�\�t�g���炢�͗v�邩������ǂ�
�����̓Q�[���\�t�g���̂��T�[�o�[���ɂ��邩��A�������łȂ��ƃ\�t�g�̃_�E�����[�h���疳����
�z�[���y�[�W�J���ă{�^��1�N���b�N�ł����Ȃ�Q�[�����n�߂���炵��
�����ł͔F�\�t�g���炢�͗v�邩������ǂ�
OnLive�������ǁA��͂背�C�e���V�ɂ��Ă͉������y���ĂȂ��ˁB
�T�[�r�X�C���̉������J��Ԃ����A�����͂��ȃ��[�U���Ŋ������������A
�Ō�̓g���Y�����܂���100void�B
���C�e���V�����e�����SLG�Ƃ�RPG�Ƃ��Ȃ�AUI�̓��[�J���Ŏ��s���āA
�����_�����O�����I�t���[�h�Ȃ�Ă̂����肤�邯�ǁA�A�N�V�����S��
�X�g���[�~���O���͖����B
�T�[�r�X�C���̉������J��Ԃ����A�����͂��ȃ��[�U���Ŋ������������A
�Ō�̓g���Y�����܂���100void�B
���C�e���V�����e�����SLG�Ƃ�RPG�Ƃ��Ȃ�AUI�̓��[�J���Ŏ��s���āA
�����_�����O�����I�t���[�h�Ȃ�Ă̂����肤�邯�ǁA�A�N�V�����S��
�X�g���[�~���O���͖����B
���C�e���V�]�X������A�z��
�l�b�g��FPS�̑ΐ�o���Ȃ����Č����Ă�̂Ɠ������ɂȂ���Ȃ�
�l�b�g��FPS�̑ΐ�o���Ȃ����Č����Ă�̂Ɠ������ɂȂ���Ȃ�
�ΐ�Q�[���́A�p�P�b�g�������ɓ͂��Ȃ��Ă������ڕs���R�ɂȂ�Ȃ��悤�ɁA
���C�e���V��W�b�^���B������d�g�݂��Q�[���V�X�e���̒��ɍ�肱��ł���̂ł���B
�ł��R���g���[�����쁨��ʕ\���͉B���̂��悤���Ȃ��B
���C�e���V��W�b�^���B������d�g�݂��Q�[���V�X�e���̒��ɍ�肱��ł���̂ł���B
�ł��R���g���[�����쁨��ʕ\���͉B���̂��悤���Ȃ��B
>>178
�C�}�h�L�̃R���p�C���͎������ŏ���Ƀ}���`�X���b�h�R�[�h��f�����肷�邩��A
SPECInt���V���O���X���b�h���\��\���Ƃ͌���Ȃ���
�C�}�h�L�̃R���p�C���͎������ŏ���Ƀ}���`�X���b�h�R�[�h��f�����肷�邩��A
SPECInt���V���O���X���b�h���\��\���Ƃ͌���Ȃ���
>>183
�͂��͂��B�u���C�e���V�v���Č��t���g���������Ă���̂͗��������B
�����̔�������Ɖ��Ŕے肵�����ĉ����y�����̂��H
�͂��͂��B�u���C�e���V�v���Č��t���g���������Ă���̂͗��������B
�����̔�������Ɖ��Ŕے肵�����ĉ����y�����̂��H
����͂����Ɓu��ʕ\���͉B�����Ȃ��v�Ƃ������Ԕ���
���������Ȃ��>>182�̔��������������������ȁB
����ID:mcQhq8zA�����������̂�
�u���C�e���V�̓v���O�����ʼnB���o���邪��ʕ\���͉B�����Ȃ�
�@������A�N�V�����i�S�ʁj�́~�����i�ΐ�j�A�N�V�����́����v
���Ă��Ƃ���
���ꂪ�G���Ă���
�u���C�e���V�̓v���O�����ʼnB���o���邪��ʕ\���͉B�����Ȃ�
�@������A�N�V�����i�S�ʁj�́~�����i�ΐ�j�A�N�V�����́����v
���Ă��Ƃ���
���ꂪ�G���Ă���
����ɒx����������̂͊m�����낤��
�����炱���Q�[���X�g���[�~���O�T�[�r�X�n�̉�Ђ͂ǂ������_��S���W�J���Ă�
�ł��A�x�������锽�ʁA�ΐ�Ȃǂł́w�悯���͂��Ȃ̂ɍU�����������H�H�H�x�Ƃ������͐����Ȃ��Ȃ邩��ǂ��_������
���͂Ƃ�����APC��ƒ�p�Q�[���@�Ȃǃl�b�g�[�����[�U�[�S�Ăɔ̔��@�������͔̂�������
�l�b�g�֘A��Ƃ�T�[�o�[���[�J�[�����������ɃT�[�r�X���_�����Ă�������邩������Ȃ�
�s��K�͂�5.5���~�ŋ���ȎY�ƂȖ���
�����炱���Q�[���X�g���[�~���O�T�[�r�X�n�̉�Ђ͂ǂ������_��S���W�J���Ă�
�ł��A�x�������锽�ʁA�ΐ�Ȃǂł́w�悯���͂��Ȃ̂ɍU�����������H�H�H�x�Ƃ������͐����Ȃ��Ȃ邩��ǂ��_������
���͂Ƃ�����APC��ƒ�p�Q�[���@�Ȃǃl�b�g�[�����[�U�[�S�Ăɔ̔��@�������͔̂�������
�l�b�g�֘A��Ƃ�T�[�o�[���[�J�[�����������ɃT�[�r�X���_�����Ă�������邩������Ȃ�
�s��K�͂�5.5���~�ŋ���ȎY�ƂȖ���
����DX11���x���̂̃O���t�B�b�N�������ł���n�[�h�͎���HD5000�V���[�Y�����Ȃ�����ȁA
�����ǂ��]��ł�AMD�̓ƒd��ɂȂ��Ȃ�����
�����ǂ��]��ł�AMD�̓ƒd��ɂȂ��Ȃ�����
GTX4�n�̔��\�܂ł܂���T�Ԉȏ゠�邵��
>>183
�����������ƁH
�E�G�����N���C�A���g�ōs��
�ʐM�Ƀ��O�������Ă��A�ߋ��Ɏ�������Ǝ��L�����ɑ��鑀������
��ɉR�̕\���𑱂��邱�Ƃ��ł���B
�G�⑼�v���C���[�̓��������O�邱�Ƃ������Ă����L�����̓��O��Ȃ��B
�E�G�����T�[�o�ōs��
���L�����ɑ��鑀����N���C�A���g���ő������f�����邱�Ƃ��ł��Ȃ��̂�
���L�����܂Ń��O��B
�����������ƁH
�E�G�����N���C�A���g�ōs��
�ʐM�Ƀ��O�������Ă��A�ߋ��Ɏ�������Ǝ��L�����ɑ��鑀������
��ɉR�̕\���𑱂��邱�Ƃ��ł���B
�G�⑼�v���C���[�̓��������O�邱�Ƃ������Ă����L�����̓��O��Ȃ��B
�E�G�����T�[�o�ōs��
���L�����ɑ��鑀����N���C�A���g���ő������f�����邱�Ƃ��ł��Ȃ��̂�
���L�����܂Ń��O��B
>>193
�����炾���ǁA����ō����Ă��Ȃ����ȁB
���̃��O�̓x�������T�[�o�ŊG��聨�G���R���z�M������A����荓���Ȃ�Ǝv���B
������N���C�A���g�Ńf�R�[�h���ꂽ���m�ɑ��Ă�����A�������������Ȃ��Ȃ����ȁB
�T�[�o�����ނƃ��O���Ȃ邾������Ȃ��āA���ŋ����o�b�t�@�����O���c�Ƃ��ɂȂ�\�����B
�T�[�o�������ʂ̃X�g���[�~���O�ƈ���Ċe���[�U���ɑS�ĈقȂ�G�𑗂�K�v�����邩��
�t�����ƃo�b�N�G���h�̑ш���������ɂȂ邵�A�T�[�o�̏���d�͂ƃ��b�N�X�y�[�X��
�]���̃^�C�v�ɔ�ׂċ��낵�����ɂȂ肻���B����܂łƓ����l�i�ł͖������ƁB
�����炾���ǁA����ō����Ă��Ȃ����ȁB
���̃��O�̓x�������T�[�o�ŊG��聨�G���R���z�M������A����荓���Ȃ�Ǝv���B
������N���C�A���g�Ńf�R�[�h���ꂽ���m�ɑ��Ă�����A�������������Ȃ��Ȃ����ȁB
�T�[�o�����ނƃ��O���Ȃ邾������Ȃ��āA���ŋ����o�b�t�@�����O���c�Ƃ��ɂȂ�\�����B
�T�[�o�������ʂ̃X�g���[�~���O�ƈ���Ċe���[�U���ɑS�ĈقȂ�G�𑗂�K�v�����邩��
�t�����ƃo�b�N�G���h�̑ш���������ɂȂ邵�A�T�[�o�̏���d�͂ƃ��b�N�X�y�[�X��
�]���̃^�C�v�ɔ�ׂċ��낵�����ɂȂ肻���B����܂łƓ����l�i�ł͖������ƁB
�����Ƃ��ԎD�Ȃ���Ȃ��i�������j
>>193
�`��@�\�̏ꏊ�ł̋�ʂ̌��Ȃ��>183�ɏ����ĂȂ�����
�`��@�\�̏ꏊ�ł̋�ʂ̌��Ȃ��>183�ɏ����ĂȂ�����
30fps��{�ŁA�ш�ɂ���ĉ𑜓x���l�l�ŕς���Ă����Ȃ����ȁB
�Q�[���J�n���Ɋ������ʼn�����x�����āA�v���C�\�ȉ𑜓x��FPS��ݒ肵�Ă���J�n�Ƃ���
�w�ǂ̃��[�U�[��VGA(640*480)��30fps�̐ݒ�ɂȂ��Ȃ�����
�������戳�k�Z�p���i�����Ă�����荂�ݒ�ɏo������������
�Q�[���J�n���Ɋ������ʼn�����x�����āA�v���C�\�ȉ𑜓x��FPS��ݒ肵�Ă���J�n�Ƃ���
�w�ǂ̃��[�U�[��VGA(640*480)��30fps�̐ݒ�ɂȂ��Ȃ�����
�������戳�k�Z�p���i�����Ă�����荂�ݒ�ɏo������������
���k���̂͐e�@���̃n�[�h�E�F�A�ł�������������
199 �Fsage�F2010/03/15(��) 12:51:06 ID:0+CQ7iuY
>197
���XVGA�ŋq�͌ĂׂȂ���c�c
�g�тłȂ�Ƃ������B�g�ѐ�p�ɂ��Ă��������ǁA���ꂶ�Ⴙ�������̃v���b�g�t�H�[����ˑ��̃E�����̂Ă邱�ƂɂȂ�B
���Ƃ����Ċ��ɗ]�T�̂���l�͍��𑜓x�������肷��ƁA����I�Ɏ��邩��Q�[���o�����X������B
���̂��߂ɉ𑜓x�⎋�E���������肷��ƁA���Q�m��
���XVGA�ŋq�͌ĂׂȂ���c�c
�g�тłȂ�Ƃ������B�g�ѐ�p�ɂ��Ă��������ǁA���ꂶ�Ⴙ�������̃v���b�g�t�H�[����ˑ��̃E�����̂Ă邱�ƂɂȂ�B
���Ƃ����Ċ��ɗ]�T�̂���l�͍��𑜓x�������肷��ƁA����I�Ɏ��邩��Q�[���o�����X������B
���̂��߂ɉ𑜓x�⎋�E���������肷��ƁA���Q�m��
���ݒ�o����ƃQ�[���o�����X����E�E�E
�ш�Ɍ��������I�u�W�F�N�g�𑗂��Ă�������������Ȃ�����
�W�I���g�����������Č�͔C���Ă��܂��Ƃ��ł�������
�T�[�o�[�Ń��[�U�[���֗^�ł��Ȃ��͈͂̕������Z���ς܂��Ă��܂��Ƃ����ʔ���
�W�I���g�����������Č�͔C���Ă��܂��Ƃ��ł�������
�T�[�o�[�Ń��[�U�[���֗^�ł��Ȃ��͈͂̕������Z���ς܂��Ă��܂��Ƃ����ʔ���
�v���b�g�z�[���t���[���`��������
���������[�gGPU�̘b�Ȃ̂�
�T�[�o�[�T�C�h�����^�����O�Ɗ��Ⴂ����
�S�����Y�����
�T�[�o�[�T�C�h�����^�����O�Ɗ��Ⴂ����
�S�����Y�����
�����_�����O�T�[�o�[�Ƃ����̐̂ɕ��y��������Ďs����o���オ���Ă邶���B
>>199
> ���XVGA�ŋq�͌ĂׂȂ���c�c
�ʂ�VGA�I�����[�Ƃ��ō���VGA�Ƃ�����Ȃ�����
�S��������HD�]�T�Ƃ��Ȃ킯����Ȃ��A�T�[�o�[���̃��\�[�X���ʓI�ȉ�����x���l����Ƃ��Ă�����
> �g�тłȂ�Ƃ������B�g�ѐ�p�ɂ��Ă��������ǁA���ꂶ�Ⴙ�������̃v���b�g�t�H�[����ˑ��̃E�����̂Ă邱�ƂɂȂ�B
������ˑ��ȂH
�v���b�g�t�H�[���̈Ⴂ�ȂA�𑜓x�ƃf�R�[�h�\�͂̍������Ȃ�
> ���Ƃ����Ċ��ɗ]�T�̂���l�͍��𑜓x�������肷��ƁA����I�Ɏ��邩��Q�[���o�����X������B
�Ӗ��s������
���𑜓x�ɂȂ��Ă��f�e�[�����ڍׂɂȂ邾���ŃI�u�W�F�N�g�̐���ʒu�W���ς��킯����Ȃ���
���Ȃ��Ƃ��Q�[�����ɉe���͑S���Ȃ�
> ���̂��߂ɉ𑜓x�⎋�E���������肷��ƁA���Q�m��
���̒����Q�������݂��Ȃ��̂�
> ���XVGA�ŋq�͌ĂׂȂ���c�c
�ʂ�VGA�I�����[�Ƃ��ō���VGA�Ƃ�����Ȃ�����
�S��������HD�]�T�Ƃ��Ȃ킯����Ȃ��A�T�[�o�[���̃��\�[�X���ʓI�ȉ�����x���l����Ƃ��Ă�����
> �g�тłȂ�Ƃ������B�g�ѐ�p�ɂ��Ă��������ǁA���ꂶ�Ⴙ�������̃v���b�g�t�H�[����ˑ��̃E�����̂Ă邱�ƂɂȂ�B
������ˑ��ȂH
�v���b�g�t�H�[���̈Ⴂ�ȂA�𑜓x�ƃf�R�[�h�\�͂̍������Ȃ�
> ���Ƃ����Ċ��ɗ]�T�̂���l�͍��𑜓x�������肷��ƁA����I�Ɏ��邩��Q�[���o�����X������B
�Ӗ��s������
���𑜓x�ɂȂ��Ă��f�e�[�����ڍׂɂȂ邾���ŃI�u�W�F�N�g�̐���ʒu�W���ς��킯����Ȃ���
���Ȃ��Ƃ��Q�[�����ɉe���͑S���Ȃ�
> ���̂��߂ɉ𑜓x�⎋�E���������肷��ƁA���Q�m��
���̒����Q�������݂��Ȃ��̂�
ID:IjRghQpW���Q�[���ɑ��錩�������Ƃ��悭�킩����
�����^�B�܂����̃l�^�̋c�_����Ă�̂��B
���Ԃ�Z�̎d��
>>196
����B
> �ł��R���g���[�����쁨��ʕ\���͉B���̂��悤���Ȃ��B
�����̂����肩��Ȃ�ƂȂ��ǂݎ�����B
��������̂ł��G����Ă�ˁB
ttp://www.geocities.jp/andosprocinfo/wadai10/20100313.htm
����B
> �ł��R���g���[�����쁨��ʕ\���͉B���̂��悤���Ȃ��B
�����̂����肩��Ȃ�ƂȂ��ǂݎ�����B
��������̂ł��G����Ă�ˁB
ttp://www.geocities.jp/andosprocinfo/wadai10/20100313.htm
���܂̂Ƃ���̓A�N�V�������̍����Q�[���ł͂�͂�x�����ł������ăQ�[���ɂȂ�Ȃ��炵���ȁB
���C�g�ȃQ�[���͂���Ȃ�ɗV�ׂ�悤���B
�Q�[�~���O�N���E�h�T�[�r�X�uOnLive�v�A�x�[�^�e�X�g�̗l�q�͂ǂ����H
http://beeep.jp/2010/017738.html
OnLive�Ƃ͂������Ⴄ�B�ݗ��҂ł���f�r�b�h�E�y���[�������CGaikai�����C�e���V�����̕��@
http://www.4gamer.net/games/000/G000000/20090714033/
OnLive Game Service Preview - Is this the future of PC gaming?
http://www.pcper.com/article.php?aid=859&type=expert&pid=6
���C�g�ȃQ�[���͂���Ȃ�ɗV�ׂ�悤���B
�Q�[�~���O�N���E�h�T�[�r�X�uOnLive�v�A�x�[�^�e�X�g�̗l�q�͂ǂ����H
http://beeep.jp/2010/017738.html
OnLive�Ƃ͂������Ⴄ�B�ݗ��҂ł���f�r�b�h�E�y���[�������CGaikai�����C�e���V�����̕��@
http://www.4gamer.net/games/000/G000000/20090714033/
OnLive Game Service Preview - Is this the future of PC gaming?
http://www.pcper.com/article.php?aid=859&type=expert&pid=6
�u�������ɂ���v6�R�A AMD Opteron(TM)�v���Z�b�T�v���b�g�t�H�[��
http://ad.impress.co.jp/special/amd1003/enterprise/
http://ad.impress.co.jp/special/amd1003/enterprise/
AMD����̋Z�p�͂͐��E����ۂ�
�Ȃ��iPhone��Crysis���I�H�Q�[���X�g���[�~���O�T�[�r�X��AMD���́uOTOY�v���Q��
ttp://beeep.jp/2009/092580.html
�EiPhone��Crysis���X�g���[�~���O�����ē���
�EBioshock��Grand Theft Auto IV�AWorld of Warcraft�������łɓ��삵�Ă���A
�EOTOY��1080p��60fps�ŃX�g���[�~���O���s���Ă���A
���K�ȃv���C���y���߂�l�b�g���[�N�ш敝�Ƃ���20M�r�b�g�O�オ臒l�ɂȂ�
�ۋ��V�X�e�����\�z�ł���Ή^�p�o�������ȃ��x���Ɏd�オ���Ă�݂�����w
�Ȃ��iPhone��Crysis���I�H�Q�[���X�g���[�~���O�T�[�r�X��AMD���́uOTOY�v���Q��
ttp://beeep.jp/2009/092580.html
�EiPhone��Crysis���X�g���[�~���O�����ē���
�EBioshock��Grand Theft Auto IV�AWorld of Warcraft�������łɓ��삵�Ă���A
�EOTOY��1080p��60fps�ŃX�g���[�~���O���s���Ă���A
���K�ȃv���C���y���߂�l�b�g���[�N�ш敝�Ƃ���20M�r�b�g�O�オ臒l�ɂȂ�
�ۋ��V�X�e�����\�z�ł���Ή^�p�o�������ȃ��x���Ɏd�オ���Ă�݂�����w
���E���ɋ��_�����̂Ȃ�A���x���̓X�g���[�~���O�T�[�r�X�������
���͏����\�͂̉���������ƂɃ����^��������Ƃ����ʔ���������
���͏����\�͂̉���������ƂɃ����^��������Ƃ����ʔ���������
�\���c�����X��
Fusion��Ȃ��ď������܂��
Fusion��Ȃ��ď������܂��
�G�͂��܂ŃO�_�O�_������˂��l�^���������ĂE�U�C���������N�Y
�����̃Q�[���ƊE�̃n�[�h�E�F�A��AMD(OTOY)���x�z����������
�l�b�g���[�N�����_�����O�̃T�[�o�[��RADEON+Opteron��OTOY
�R���V���[�}�@��GPU��Radeon�̔h��(DX11��OGL4����)
�g�ы@�̒��g��Snapdragon(Radeon�̃T�u�Z�b�g)
PC�̃f�B�X�N���[�g��Radeon
DX11�����AMD�哱�A�����^����OGL4��AMD����s
DX11�Q�[���J���̂قڑS�Ăɋ@�ޑݗ^�ȂǂŊ֗^
XBX360��Wii��Radeon�̃T�u�Z�b�g
�T�[�o�[�p��Opteron��ATI Stream�̑����v���b�g�t�H�[������
�l�b�g���[�N�����_�����O�̃T�[�o�[��RADEON+Opteron��OTOY
�R���V���[�}�@��GPU��Radeon�̔h��(DX11��OGL4����)
�g�ы@�̒��g��Snapdragon(Radeon�̃T�u�Z�b�g)
PC�̃f�B�X�N���[�g��Radeon
DX11�����AMD�哱�A�����^����OGL4��AMD����s
DX11�Q�[���J���̂قڑS�Ăɋ@�ޑݗ^�ȂǂŊ֗^
XBX360��Wii��Radeon�̃T�u�Z�b�g
�T�[�o�[�p��Opteron��ATI Stream�̑����v���b�g�t�H�[������
����オ���Ă܂���܂����I�I�I
�Ȃɂ��ɁA�J���ŕ��U�����_�͏d�v����ȁB
Super Micro to launch AMD render cloud
ttp://www.theregister.co.uk/2010/03/11/supermicro_otoy_render_cloud/
�X�[�p�[�}�C�N����OTOY�Ƌ����J���Ń����[�X�\��ł��B
�X�y�b�N�� 2way 12core Opteron 2.2G 125set �y�� HD5970 ��500���ŁA�{���x����500TFlops�B
���������ł�250TFlops�A�P���x�Ȃ�2.3P�ʁB
ttp://www.theregister.co.uk/2010/03/11/supermicro_otoy_render_cloud/
�X�[�p�[�}�C�N����OTOY�Ƌ����J���Ń����[�X�\��ł��B
�X�y�b�N�� 2way 12core Opteron 2.2G 125set �y�� HD5970 ��500���ŁA�{���x����500TFlops�B
���������ł�250TFlops�A�P���x�Ȃ�2.3P�ʁB
�f���A��12�R�AOpteron��5970��4���ڂ����T�[�o��125�䃉�b�N�ɔ[�߂āA
���l�i$2M������A�T�[�o��䂠�����144���~�B����Ȃ��˂��B
���l�i$2M������A�T�[�o��䂠�����144���~�B����Ȃ��˂��B
�ٕ��삩�痘�v��D���B(�����\��������d�͂ցB)
http://www.ne.jp/asahi/comp/tarusan/main223.htm
http://www.ne.jp/asahi/comp/tarusan/main223.htm
>>221
�킴�킴�K���O�̋��Ԕ������肷��l�ɂ́A�ʔ����Ȃ������\�z���Ȃ��E�E�E
���̎Ԃɖ��͂������Ȃ��悤�ɁA�o�b�ɂ����͊����Ȃ��Ȃ��Ă����낤�ȁE�E�E
�킴�킴�K���O�̋��Ԕ������肷��l�ɂ́A�ʔ����Ȃ������\�z���Ȃ��E�E�E
���̎Ԃɖ��͂������Ȃ��悤�ɁA�o�b�ɂ����͊����Ȃ��Ȃ��Ă����낤�ȁE�E�E
���邳��͓K���Ȃ��Ƃ�s���̂������������Ȃ����킹��
�����Ƃ��炵��(�����)�����ŏ��������Ă邾���ł���B
�����Ƃ��炵��(�����)�����ŏ��������Ă邾���ł���B
�Ƃ肠�����N���܂Ƃ߂�
������H�L���Ȑl�Ȃ́H
�����̃T�C�g�Ő��ꗬ���Ă镪�ɂ͏��肾���A
�f���ɏ��������̂Ȃ�t���{�b�R�K���Ȏߏ�̖ϑz�B
�j���[�X��C�h�V���[�̃R�����e�[�^�[(w��f�i�Ƃ�����B
��m���Ō������Ă�̂��]�v�ɒɁX�����B
�����̃T�C�g�Ő��ꗬ���Ă镪�ɂ͏��肾���A
�f���ɏ��������̂Ȃ�t���{�b�R�K���Ȏߏ�̖ϑz�B
�j���[�X��C�h�V���[�̃R�����e�[�^�[(w��f�i�Ƃ�����B
��m���Ō������Ă�̂��]�v�ɒɁX�����B
Ballmer���̓q���|�N���E�h�ɑS�ʃV�t�g����Microsoft
http://enterprise.watch.impress.co.jp/docs/series/infostand/20100315_354806.html
�c�q�����������Ƃ��v���o���ēǂނƂ�肢�������y���߂܂�
http://enterprise.watch.impress.co.jp/docs/series/infostand/20100315_354806.html
�c�q�����������Ƃ��v���o���ēǂނƂ�肢�������y���߂܂�
�E���R�̔����Ȃ�Ďv���o�������ő���Ȑl���̘Q��
����ȃf�����b�g���B����قlj��l���锭���Ȃ̂��H
����ȃf�����b�g���B����قlj��l���锭���Ȃ̂��H
229 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/16(��) 12:45:57 ID:jkEkPe8f
>>138-139
RS�̃G���g���u���v�͑債����肶��Ȃ��Ǝv�����ǂˁB
�ނ���K7�����p�C�v���C���̎�_�́A�f�B�X�p�b�`���ꂽ��OP�����[���ύX�ł��Ȃ����ƁB
�Ɨ������Ԑ�3�i���U�^RS�j�ƁA����ɉ����ĎԐ��ύX�ł���4�Ԑ��i�W���^RS�j�ƁA
�ǂ������a���₷�����͖��炩���ˁB
�t��������ƁA�ԂƂ͈���Ė��߂̗���ɂ̓N���e�B�J���p�X�����邩��A�ˑ��W�ɂ���ĘA���I�ɃX�g�[������B
����������1�Ƃ��Ă����C�e���V�͕s��Ȃ̂Ƀf�R�[�h�O�i�K�ŏ[�U�����߂�X�P�W���[�����O���ł���킯���Ȃ������B
�܂��A��������L1D��2-Way Set Associative��������A�X���[�v�b�g���オ��Ȃ����R�͕������肻�������ǂˁB
Bulldozer���\����傫���ς��Ă����̂͂��̂ւ�̔��ȓ_���f���邯�ǂȁB
>>226
���[�ƁA�������������H
XMLHttpRequest�̊��p���@����V�Q��Google�ɕ����Ă�悤���Ⴓ�������N�Ԏ������MSN����B
����ł������ȁH
RS�̃G���g���u���v�͑債����肶��Ȃ��Ǝv�����ǂˁB
�ނ���K7�����p�C�v���C���̎�_�́A�f�B�X�p�b�`���ꂽ��OP�����[���ύX�ł��Ȃ����ƁB
�Ɨ������Ԑ�3�i���U�^RS�j�ƁA����ɉ����ĎԐ��ύX�ł���4�Ԑ��i�W���^RS�j�ƁA
�ǂ������a���₷�����͖��炩���ˁB
�t��������ƁA�ԂƂ͈���Ė��߂̗���ɂ̓N���e�B�J���p�X�����邩��A�ˑ��W�ɂ���ĘA���I�ɃX�g�[������B
����������1�Ƃ��Ă����C�e���V�͕s��Ȃ̂Ƀf�R�[�h�O�i�K�ŏ[�U�����߂�X�P�W���[�����O���ł���킯���Ȃ������B
�܂��A��������L1D��2-Way Set Associative��������A�X���[�v�b�g���オ��Ȃ����R�͕������肻�������ǂˁB
Bulldozer���\����傫���ς��Ă����̂͂��̂ւ�̔��ȓ_���f���邯�ǂȁB
>>226
���[�ƁA�������������H
XMLHttpRequest�̊��p���@����V�Q��Google�ɕ����Ă�悤���Ⴓ�������N�Ԏ������MSN����B
����ł������ȁH
�������Ԓ��L�^��������(�K�́K)���������b!!
6�R�A�����͂��H
4�������[���`��5���������\��
>>226
�N���E�h�~�͗L�Q�ł��B
�N���E�h�~�͗L�Q�ł��B
RS��OOO�̃X�P�W���[�����O�̂��߂ɂ���̐S�̑僊�\�[�X�Ȃ̂�
�f�R�[�h�̒i�K�ňˑ������Ȃ��O���d�g�ɂ̓����^�B
�f�R�[�h�̒i�K�ňˑ������Ȃ��O���d�g�ɂ̓����^�B
>>235
�悤�A��������
�悤�A��������
���܂��܃p�[�c�ς���̂��D���Ȃ̂ŁA�\�P�b�g�݊��͂��肪�����B
>>236
�܂��m���Ɍ͂�Ă邯�ǂȁB����Atom���炢���������Ȃ����B
�܂��m���Ɍ͂�Ă邯�ǂȁB����Atom���炢���������Ȃ����B
>>229
���f�R�[�h�O�i�K�ŏ[�U�����߂�X�P�W���[�����O���ł���킯���Ȃ�
K8�̃p�b�N�o�b�t�@�ł͈ˑ��������ł���킯���Ȃ�����A�Ă郌�[�����l�߂ď[�U�������߂Ă邾������˂��Ęb�ł�
���f�R�[�h�O�i�K�ŏ[�U�����߂�X�P�W���[�����O���ł���킯���Ȃ�
K8�̃p�b�N�o�b�t�@�ł͈ˑ��������ł���킯���Ȃ�����A�Ă郌�[�����l�߂ď[�U�������߂Ă邾������˂��Ęb�ł�
240 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/17(��) 03:06:06 ID:WLpABbW8
Pentium 4����������ŖY�ꂪ�������ǁAAthlon�̐������Z���\����
�R�A�̃T�C�Y�����ȉ���Pentium III�iALU 2�{�j�Ƃǂ�������������B
���̓�������3Way�̕��U�^RS��ALU+AGU���Ԃ牺����\����������B
FP�N���X�^����36�G���g���̏W���^�X�P�W���[���ōēx�X�P�W���[�����O���Ă�B
�i���N���b�N��Intel�v���Z�b�T����FP�ix87�j���\�ŗD��Ă������R�͂����ɂ���Ǝv����j
������ɂ��惌�C�e���V�E�X���[�v�b�g�ς̖��߂��������ŋ����Z���j�b�g��
�Ջ@���ςɃ�OP��U�蕪����ɂ͏W���^RS�̕����s���������ł��B
�R�A�̃T�C�Y�����ȉ���Pentium III�iALU 2�{�j�Ƃǂ�������������B
���̓�������3Way�̕��U�^RS��ALU+AGU���Ԃ牺����\����������B
FP�N���X�^����36�G���g���̏W���^�X�P�W���[���ōēx�X�P�W���[�����O���Ă�B
�i���N���b�N��Intel�v���Z�b�T����FP�ix87�j���\�ŗD��Ă������R�͂����ɂ���Ǝv����j
������ɂ��惌�C�e���V�E�X���[�v�b�g�ς̖��߂��������ŋ����Z���j�b�g��
�Ջ@���ςɃ�OP��U�蕪����ɂ͏W���^RS�̕����s���������ł��B
�p�b�h���́��T�[�o�[�������߂�(�O���t�B�b�N�Ԃ�)���A16ms�̃��[�J�����ƁA
���ꂪ10�{�ő���邩������Ȃ��������x�̃l�b�g���[�N�����_�����O�ł́A
�V�ׂ�Q�[���W�������Ɋu���肪�����ˁ[�B
�V���[�e�B���O�Ƃ��A�N�V�����͖����ł��傤�B
���ꂪ10�{�ő���邩������Ȃ��������x�̃l�b�g���[�N�����_�����O�ł́A
�V�ׂ�Q�[���W�������Ɋu���肪�����ˁ[�B
�V���[�e�B���O�Ƃ��A�N�V�����͖����ł��傤�B
�l�b�g���[�N�����_�����O�̘b�͏o�Ă��ĂȂ���
�f���A���R�APOWER4��Athlon64 X2���N���j�_
>>234,240,243
�G���ɓ����I�ȓ˔��I�d�g
�G���ɓ����I�ȓ˔��I�d�g
�Ƃ肠������蒬��IX�i�C���^�[�l�b�g�G�N�X�`�F���W�j�ߕӂɏZ�������I
C:\>ping pc11.2ch.net �i�J���t�H���j�A�B�T���t�����V�X�R�j
Pinging pc11.2ch.net [207.29.253.145] with 32 bytes of data:
Reply from 207.29.253.145: bytes=32 time=129ms TTL=51
Reply from 207.29.253.145: bytes=32 time=108ms TTL=51
Reply from 207.29.253.145: bytes=32 time=132ms TTL=51
Reply from 207.29.253.145: bytes=32 time=108ms TTL=51
Ping statistics for 207.29.253.145:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 108ms, Maximum = 132ms, Average = 119ms
C:\>ping clock.nc.fukuoka-u.ac.jp �i�����������s�j
Pinging clock.nc.fukuoka-u.ac.jp [133.100.9.2] with 32 bytes of data:
Reply from 133.100.9.2: bytes=32 time=32ms TTL=49
Reply from 133.100.9.2: bytes=32 time=31ms TTL=49
Reply from 133.100.9.2: bytes=32 time=31ms TTL=49
Reply from 133.100.9.2: bytes=32 time=30ms TTL=49
Ping statistics for 133.100.9.2:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 30ms, Maximum = 32ms, Average = 31ms
C:\>ping www.jpix.ad.jp �i�����s���c��j
Pinging www1.jpix.ad.jp [202.90.10.90] with 32 bytes of data:
Reply from 202.90.10.90: bytes=32 time=6ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Ping statistics for 202.90.10.90:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 5ms, Maximum = 6ms, Average = 5ms
C:\>ping pc11.2ch.net �i�J���t�H���j�A�B�T���t�����V�X�R�j
Pinging pc11.2ch.net [207.29.253.145] with 32 bytes of data:
Reply from 207.29.253.145: bytes=32 time=129ms TTL=51
Reply from 207.29.253.145: bytes=32 time=108ms TTL=51
Reply from 207.29.253.145: bytes=32 time=132ms TTL=51
Reply from 207.29.253.145: bytes=32 time=108ms TTL=51
Ping statistics for 207.29.253.145:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 108ms, Maximum = 132ms, Average = 119ms
C:\>ping clock.nc.fukuoka-u.ac.jp �i�����������s�j
Pinging clock.nc.fukuoka-u.ac.jp [133.100.9.2] with 32 bytes of data:
Reply from 133.100.9.2: bytes=32 time=32ms TTL=49
Reply from 133.100.9.2: bytes=32 time=31ms TTL=49
Reply from 133.100.9.2: bytes=32 time=31ms TTL=49
Reply from 133.100.9.2: bytes=32 time=30ms TTL=49
Ping statistics for 133.100.9.2:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 30ms, Maximum = 32ms, Average = 31ms
C:\>ping www.jpix.ad.jp �i�����s���c��j
Pinging www1.jpix.ad.jp [202.90.10.90] with 32 bytes of data:
Reply from 202.90.10.90: bytes=32 time=6ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Reply from 202.90.10.90: bytes=32 time=5ms TTL=56
Ping statistics for 202.90.10.90:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 5ms, Maximum = 6ms, Average = 5ms
���̃X���̎G�����b�e���~ == ����
���������Ȃ������ɂ���������G���X���ɂ�������ł�w
���������Ȃ������ɂ���������G���X���ɂ�������ł�w
247 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/17(��) 23:38:19 ID:WLpABbW8
���܂�Pentium 4�ɂ�L1D�������Ƃ��v���t�F�b�`�Ƃ���������������Ȃ��ł���
>>240
��������ɂ��惌�C�e���V�E�X���[�v�b�g�ς̖��߂��������ŋ����Z���j�b�g��
���Ջ@���ςɃ�OP��U�蕪����ɂ͏W���^RS�̕����s���������ł��B
���Z���j�b�g�̓p�C�v���C��������Ă���A�l�܂�͉̂��Z���j�b�g�łȂ�RS�̂ق�����
��K�͋��LRS������s�\��3�`4��ops��1�T�C�N���őI�яo���Ȃ�Č|���͂ǂꂾ���̎����������낤
��������ɂ��惌�C�e���V�E�X���[�v�b�g�ς̖��߂��������ŋ����Z���j�b�g��
���Ջ@���ςɃ�OP��U�蕪����ɂ͏W���^RS�̕����s���������ł��B
���Z���j�b�g�̓p�C�v���C��������Ă���A�l�܂�͉̂��Z���j�b�g�łȂ�RS�̂ق�����
��K�͋��LRS������s�\��3�`4��ops��1�T�C�N���őI�яo���Ȃ�Č|���͂ǂꂾ���̎����������낤
�n���̑��肷��Ȃ�
250 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 01:59:30 ID:+1oFHTk6
LSU�̓f�[�^�n�U�[�h�ŋl�܂邵����ɔ����Č㑱�̖��ߔ��s����B
��ŁA���ΓI�ɔėpALU�ɋ��ł��邩��A�ˑ��W�̂Ȃ����߂�T���Ă���
���s���邱�ƂŗՋ@���ςɃp�C�v���C���𗧂Ē������Ƃ��o����B
��ʓI�ɏW���^RS�̑�K�͉��͍���Ƃ����Ă邯��
����3��ALU�ɓ������s��4 issue�̎�����Core MA������Ă�킯������
3-Way�̕��U�^��������G���킯���Ȃ��B
����͑O��Ƃ��āABulldozer��2�`3issue�i�H�j�̏W���^RS�𐮐��N���X�^���Ɏ��\����
�Ȃ��Ă�悤�Ɏv������B
���FP�N���X�^�̂ق��́A����ȁi�d�g�ȁj���܂ŗ���Ă邯��
http://aceshardware.freeforums.org/server-cpus-in-2010-and-2011-an-overview-t934-30.html
��ŁA���ΓI�ɔėpALU�ɋ��ł��邩��A�ˑ��W�̂Ȃ����߂�T���Ă���
���s���邱�ƂŗՋ@���ςɃp�C�v���C���𗧂Ē������Ƃ��o����B
��ʓI�ɏW���^RS�̑�K�͉��͍���Ƃ����Ă邯��
����3��ALU�ɓ������s��4 issue�̎�����Core MA������Ă�킯������
3-Way�̕��U�^��������G���킯���Ȃ��B
����͑O��Ƃ��āABulldozer��2�`3issue�i�H�j�̏W���^RS�𐮐��N���X�^���Ɏ��\����
�Ȃ��Ă�悤�Ɏv������B
���FP�N���X�^�̂ق��́A����ȁi�d�g�ȁj���܂ŗ���Ă邯��
http://aceshardware.freeforums.org/server-cpus-in-2010-and-2011-an-overview-t934-30.html
251 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 02:12:24 ID:+1oFHTk6
�ǂ���猳�l�^�͂���炵��
Bridged Floating-Point Fused Multiply-Add Design
http://users.ece.utexas.edu/~quinnell/Research/Bridged%20Floating-Point%20Fused%20Multiply-Add%20Design.pdf
FMUL�~2, FADD�~4�Ƃ��Ă��g����
SSE���\��Sandy Bridge
Bridged Floating-Point Fused Multiply-Add Design
http://users.ece.utexas.edu/~quinnell/Research/Bridged%20Floating-Point%20Fused%20Multiply-Add%20Design.pdf
FMUL�~2, FADD�~4�Ƃ��Ă��g����
SSE���\��Sandy Bridge
252 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 02:15:38 ID:+1oFHTk6
����A�r���œ��e���Ă��܂���
���ꂪBulldozer�Ɏ���������FMUL�~2, FADD�~2��4���j�b�g�Ƃ��Ă��g����\��������B
���ʁA���K�V�[SSE���\��8�R�A��Sandy Bridge��6�R�A���z������E�E�E��������Ȃ��B
���ꂪBulldozer�Ɏ���������FMUL�~2, FADD�~2��4���j�b�g�Ƃ��Ă��g����\��������B
���ʁA���K�V�[SSE���\��8�R�A��Sandy Bridge��6�R�A���z������E�E�E��������Ȃ��B
�������ځ[���ۂɂȂ����Ȃ��B
�R�e��NG�o�^����ŏ�����\�����Ȃ��Ȃ�����H
�R�e��NG�o�^����ŏ�����\�����Ȃ��Ȃ�����H
�����A��������
�d�g�n�̃R�e�͂��ځ`��
�d�g�n�̃R�e�͂��ځ`��
>>251
>Bridged Floating-Point Fused Multiply-Add Design
�ʏ��FMA���Z���(�Ɨ��������Z��Ɣ�ׂ�)���Z���Z�̐��\���ቺ���邪
BFMA���Z��͉��Z��Ə�Z����u���b�W����̂�
���Z�Ə�Z�̐��\�͗����Ȃ�(FMA�̐��\�͗�����?)
�Ƃ����̂���ȓ��e�ł͂Ȃ��̂��낤��?
>Bridged Floating-Point Fused Multiply-Add Design
�ʏ��FMA���Z���(�Ɨ��������Z��Ɣ�ׂ�)���Z���Z�̐��\���ቺ���邪
BFMA���Z��͉��Z��Ə�Z����u���b�W����̂�
���Z�Ə�Z�̐��\�͗����Ȃ�(FMA�̐��\�͗�����?)
�Ƃ����̂���ȓ��e�ł͂Ȃ��̂��낤��?
257 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 06:16:36 ID:+1oFHTk6
����A�]��FMA�Ɠ����̐��\�͏o��̂ł�
�ނ���FMA�{FAdd�ł����C�����Ă��
�ނ���FMA�{FAdd�ł����C�����Ă��
258 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 06:27:35 ID:+1oFHTk6
>>255
����������v���t�F�b�`�t�F�`
����������v���t�F�b�`�t�F�`
Pentium 4��L1D��v���t�F�b�`�̘b�莩�̂�����Ƃ���̃X���ŏo�Ȃ������͂�������
������Ɖ�ǂ̂��悤���Ȃ�
�܂��ɓˑR�d�g
������Ɖ�ǂ̂��悤���Ȃ�
�܂��ɓˑR�d�g
260 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/18(��) 08:53:34 ID:+1oFHTk6
�v���t�F�b�`����͂Ƃڂ���̂����܂��˃����X
����ϒc�q��CR-Z���Ė{�c���ɂ����Ă�́H�A���`���Ȃ́H
bulldozer���Ăǂ̂��炢�̐��\�ɂȂ�̂��Ȃ��c�B
�_CPU�ɂȂ�Ɗ��҂��Ă���ǁA100GFlops���ɂȂ邩�ȁB
�_CPU�ɂȂ�Ɗ��҂��Ă���ǁA100GFlops���ɂȂ邩�ȁB
�����_��CPU�Ɍv�Z����������Ȃ点�߂�K10�ɂ��Ƃ�
Bulldozer�͐������]���ɂ��ăR�A���𑝂₷�B128bit�O��ōl����R�A�������
Float���Z��͕ς��Ȃ�����A�R�A�����������������������_���Z���\�͏オ��A
�Ƃ����ژ_���A��](���邢�͖ϑz)�B
Float���Z��͕ς��Ȃ�����A�R�A�����������������������_���Z���\�͏オ��A
�Ƃ����ژ_���A��](���邢�͖ϑz)�B
���ʂ��Ȃ��Đ������\���グ��̂�Bull
�ׂ������Ƃ͒m��NJ��o�̐}�Ȃ��������128bitSSE��2�1��
���C�e���V��FP�ӂ�͑啝�ɑ�����
�ׂ������Ƃ͒m��NJ��o�̐}�Ȃ��������128bitSSE��2�1��
���C�e���V��FP�ӂ�͑啝�ɑ�����
SSE��1���W���[����2���˂��́H
1�X���b�h������̐��\���Ƃ��Ȃ�
���W���[�����Ɂ{����HT�������炢���Ȃ��Ɛ키�O���畉���ĂˁH
���W���[�����Ɂ{����HT�������炢���Ȃ��Ɛ키�O���畉���ĂˁH
>>268
�u1�X���b�h������̐��\���Ƃ��v�Ƃ����Ă��A�u���_�l�v�𗎂Ƃ������������Ȃ��B
���N���b�N�Ŕ�r�����ꍇ�ACPU�̋@�\���t���Ŏg����悤�ȁA
�u���z�I�ȃv���O�����v�������ꍇ�͊m����K10�̕����D��Ă��邪�A
�����ɂ͂���ȁu���z�E�ϑz�v�v���O���������v���鎞�Ȃ�āA
�قƂ�NJF���ɓ���������A�����D����Ƃ����̂͂���������B
���ƁA"�키�O"����"���ɕ����Ă��邩"���^��B
�u1�X���b�h������̐��\���Ƃ��v�Ƃ����Ă��A�u���_�l�v�𗎂Ƃ������������Ȃ��B
���N���b�N�Ŕ�r�����ꍇ�ACPU�̋@�\���t���Ŏg����悤�ȁA
�u���z�I�ȃv���O�����v�������ꍇ�͊m����K10�̕����D��Ă��邪�A
�����ɂ͂���ȁu���z�E�ϑz�v�v���O���������v���鎞�Ȃ�āA
�قƂ�NJF���ɓ���������A�����D����Ƃ����̂͂���������B
���ƁA"�키�O"����"���ɕ����Ă��邩"���^��B
Bulldozer��1���W���[��������128bitSSE�~2��
�Е��̃R�A��SSE���j�b�g���g�p���Ă��Ȃ��Ƃ���2��Ƃ���p�ł��邵�A256bitSSE�Ƃ��Ă��g����
�Е��̃R�A��SSE���j�b�g���g�p���Ă��Ȃ��Ƃ���2��Ƃ���p�ł��邵�A256bitSSE�Ƃ��Ă��g����
Bulldozer�͕����I�ɂ́A�Ⴆ��4���W���[��8�R�A�Ȃ�128bitSSE�~8��
�ł��g�p�ɂ���ĐU�镑���͈قȂ�
�@4���W���[��8�R�A��128bitSSE���t�����[�h�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�128bitSSE�~8��
�@�@���R�A������128bitSSE�~1��
�@4���W���[��8�R�A��256bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~4��
�@�@���R�A������256bitSSE�~0.5��
�B4���W���[��8�R�A��128bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�128bitSSE�~16��
�@�@���R�A������256bitSSE�~2��
�C4���W���[��8�R�A��256bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~8��
�@�@���R�A������256bitSSE�~1��
�D�e���W���[����1�R�A�����g��Ȃ��ꍇ
��4���W���[��8�R�A�Ȃ�128bitSSE�~16��
�@�@���R�A������256bitSSE�~2��
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~8��
�@�@���R�A������256bitSSE�~1��
����SSE�̏[�U���ɋ�����B�E�C�̂悤�ȃP�[�X�ł͋��낵�������\�͂ɂȂ�
�ł��g�p�ɂ���ĐU�镑���͈قȂ�
�@4���W���[��8�R�A��128bitSSE���t�����[�h�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�128bitSSE�~8��
�@�@���R�A������128bitSSE�~1��
�@4���W���[��8�R�A��256bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~4��
�@�@���R�A������256bitSSE�~0.5��
�B4���W���[��8�R�A��128bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�128bitSSE�~16��
�@�@���R�A������256bitSSE�~2��
�C4���W���[��8�R�A��256bitSSE���j�b�g���p�x�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~8��
�@�@���R�A������256bitSSE�~1��
�D�e���W���[����1�R�A�����g��Ȃ��ꍇ
��4���W���[��8�R�A�Ȃ�128bitSSE�~16��
�@�@���R�A������256bitSSE�~2��
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~8��
�@�@���R�A������256bitSSE�~1��
����SSE�̏[�U���ɋ�����B�E�C�̂悤�ȃP�[�X�ł͋��낵�������\�͂ɂȂ�
��������
�����̏�������~�X���E�E�E
�@��2�x�o�Ă��邪�A2�x�ڂ̇@�͐������́�
�A4���W���[��8�R�A��256bitSSE���j�b�g���t�����[�h�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~4��
�@�@���R�A������256bitSSE�~0.5��
���Ɠ��R�Ȃ���A�B��C�͕����I�ȃR�A�̐��z����1�N���b�N������̏����\�͂��{�ɂȂ�Ƃ����Ӗ��ł͂Ȃ�
�����̏�������~�X���E�E�E
�@��2�x�o�Ă��邪�A2�x�ڂ̇@�͐������́�
�A4���W���[��8�R�A��256bitSSE���j�b�g���t�����[�h�Ŏg���ꍇ
�@��4���W���[��8�R�A�Ȃ�256bitSSE�~4��
�@�@���R�A������256bitSSE�~0.5��
���Ɠ��R�Ȃ���A�B��C�͕����I�ȃR�A�̐��z����1�N���b�N������̏����\�͂��{�ɂȂ�Ƃ����Ӗ��ł͂Ȃ�
�ǂ����Ȃ�4���W���[��8�R�A���Č���������߂�
���ʂ�4�R�A8�X���b�h���Č����Ƃ������̂ɂ�
���ʂ�4�R�A8�X���b�h���Č����Ƃ������̂ɂ�
�}�[�P�e�B���O�̖��ł���H�@���Ƃ͐��\���������ǂ����B
>Pentium 4����������ŖY�ꂪ�������ǁAAthlon�̐������Z���\����
>�R�A�̃T�C�Y�����ȉ���Pentium III�iALU 2�{�j�Ƃǂ�������������B
����A�ނ��R�A�̐��\��Athlon�̂ق����ゾ���A
�L���b�V���̐��\���Ō݊p���x���܂łȂ�Ƃ������������Ă����̂�PenIII����B
���A�v���S�̂�Intel�n�ɍœK������Ă���Ƃ��������l���ɂ����ƁA
�ǂ��l���Ă�Pentium III���͊i��ł��B
>�R�A�̃T�C�Y�����ȉ���Pentium III�iALU 2�{�j�Ƃǂ�������������B
����A�ނ��R�A�̐��\��Athlon�̂ق����ゾ���A
�L���b�V���̐��\���Ō݊p���x���܂łȂ�Ƃ������������Ă����̂�PenIII����B
���A�v���S�̂�Intel�n�ɍœK������Ă���Ƃ��������l���ɂ����ƁA
�ǂ��l���Ă�Pentium III���͊i��ł��B
>>273
ttp://pc.watch.impress.co.jp/docs/column/tawada/20100311_353995.html
> �����APassMark�̕��������_���Z�e�X�g�̂悤�ɉ��Z���j�b�g��
> �t���Ɏg���Ă��邱�Ƃ������ƌ�����HT�L��/�����̍����Ȃ����ʂ�A
> ������ PassMark��Find Prime Numbers�̂悤��
> �I�[�o�[�w�b�h�������ƌ�����HT�������̂ق���
> �ǍD�ȃX�R�A���o�����ʂ������邱�Ƃ��C�ɗ��߂Ă��������B
ttp://www.4gamer.net/games/084/G008477/20100310068/
> �Q�[���ɂ����ẮCHTT���������ق���������ʂ������Ό�����
�����ƗL���ő卷�Ȃ�Hyper-Threading���g����Intel��N�R�A2N�X���b�h��
���Ƀf�R�[�_�����2�X���b�h�ŋ��L����x�^�ȍ\�����Ƃ��Ă�
1�X���b�h���Ƃɂ�����K6-III������iK6�n�̓v���t�F�b�`�Ȃǂ��Ȃ����A����\���Ȃǂ��`�[�v�j
�ł��낤Bull��N�R�A2N�X���b�h��ɕ��ׂĔ���ق�AMD��CPU����ɗ]�T�͂Ȃ��ł���
�i����Ӗ��A�ႢIPC��NetBurst�̍��N���b�N�Ƀ��f���i���o�[���Ԃ����̂Ɠ����j
�]�T������A����ɂ������
�uIntel��N�R�A2N�X���b�h��N�R�AN�X���b�h�Ƒ卷�Ȃ��v
�Ƃ����l�K�L������ł��Đ키������邯��
ttp://pc.watch.impress.co.jp/docs/column/tawada/20100311_353995.html
> �����APassMark�̕��������_���Z�e�X�g�̂悤�ɉ��Z���j�b�g��
> �t���Ɏg���Ă��邱�Ƃ������ƌ�����HT�L��/�����̍����Ȃ����ʂ�A
> ������ PassMark��Find Prime Numbers�̂悤��
> �I�[�o�[�w�b�h�������ƌ�����HT�������̂ق���
> �ǍD�ȃX�R�A���o�����ʂ������邱�Ƃ��C�ɗ��߂Ă��������B
ttp://www.4gamer.net/games/084/G008477/20100310068/
> �Q�[���ɂ����ẮCHTT���������ق���������ʂ������Ό�����
�����ƗL���ő卷�Ȃ�Hyper-Threading���g����Intel��N�R�A2N�X���b�h��
���Ƀf�R�[�_�����2�X���b�h�ŋ��L����x�^�ȍ\�����Ƃ��Ă�
1�X���b�h���Ƃɂ�����K6-III������iK6�n�̓v���t�F�b�`�Ȃǂ��Ȃ����A����\���Ȃǂ��`�[�v�j
�ł��낤Bull��N�R�A2N�X���b�h��ɕ��ׂĔ���ق�AMD��CPU����ɗ]�T�͂Ȃ��ł���
�i����Ӗ��A�ႢIPC��NetBurst�̍��N���b�N�Ƀ��f���i���o�[���Ԃ����̂Ɠ����j
�]�T������A����ɂ������
�uIntel��N�R�A2N�X���b�h��N�R�AN�X���b�h�Ƒ卷�Ȃ��v
�Ƃ����l�K�L������ł��Đ키������邯��
����A�ނ��R�A�̐��\��Athlon64�̂ق����ゾ���A
�L���b�V���̐��\���Ō݊p�ȏヌ�x���łȂ�Ƃ������������Ă����̂�Core2����B
���A�v���S�̂�Intel�n�ɍœK������Ă���Ƃ��������l���ɂ����ƁA
�ǂ��l���Ă�Core2���͊i��ł��B
�L���b�V���̐��\���Ō݊p�ȏヌ�x���łȂ�Ƃ������������Ă����̂�Core2����B
���A�v���S�̂�Intel�n�ɍœK������Ă���Ƃ��������l���ɂ����ƁA
�ǂ��l���Ă�Core2���͊i��ł��B
>>277
�Ȃɂ����������̂��悭��炩��ȁB
Core 2�͂����������Ă��Ȃ��āAAthlon64�ɗ]�T�ł����Ă�����ȁB
Intel�ɃL���b�V�����ӂ̐��\���ł܂����Ƃ����Ă������ȏ�͐�������B
�Ȃɂ����������̂��悭��炩��ȁB
Core 2�͂����������Ă��Ȃ��āAAthlon64�ɗ]�T�ł����Ă�����ȁB
Intel�ɃL���b�V�����ӂ̐��\���ł܂����Ƃ����Ă������ȏ�͐�������B
AMD�s�k�̗��j�́A
�EIntel�ɐ����v���Z�X�Œx����Ƃ��Ă���
�E��Ɗ֘A���Ă��邪Intel�̍���/��e�ʂ̃L���b�V���ɂ܂��Ă���
�E���̂����A�[�L�e�N�`���I�Ƀ������I�[�_�����O���ア�܂�
���啔���̌������߂Ă���ȁB
���Ƃ́A���A�v���ɂ�Intel�����ɍœK������Ă��̂������Ƃ����̂��I�}�P�Ƃ��Ă���B
�EIntel�ɐ����v���Z�X�Œx����Ƃ��Ă���
�E��Ɗ֘A���Ă��邪Intel�̍���/��e�ʂ̃L���b�V���ɂ܂��Ă���
�E���̂����A�[�L�e�N�`���I�Ƀ������I�[�_�����O���ア�܂�
���啔���̌������߂Ă���ȁB
���Ƃ́A���A�v���ɂ�Intel�����ɍœK������Ă��̂������Ƃ����̂��I�}�P�Ƃ��Ă���B
�Ƃ����̂͌y���E�\���B
Athlon��ALU��3������̂ɁA
Pentium III��2�����Ȃ��B
�R�A�̃g�����W�X�^���ł݂Ă�Athlon�̕������������͂��B
�܂�R�A��Athlon�̕����C���������Ă���B
Athlon��ALU��3������̂ɁA
Pentium III��2�����Ȃ��B
�R�A�̃g�����W�X�^���ł݂Ă�Athlon�̕������������͂��B
�܂�R�A��Athlon�̕����C���������Ă���B
��]�߂�������낽
���邦��̃��X���ł݂Ă����邦��̕������������͂��B
�܂背�X���e�͂��邦��̕����C���������Ă���B
�܂背�X���e�͂��邦��̕����C���������Ă���B
Athlon vs Katmai
http://www.tomshardware.com/reviews/athlon-processor,121-21.html
Thunderbird vs Coppermine
http://www.tomshardware.com/reviews/amd,198-5.html
L1/L2�L���b�V���p�t�H�[�}���X��r
http://kiti.main.jp/Paso/L1L2/linkp0251.htm
����d��
http://www.geocities.co.jp/SiliconValley-Bay/8521/k7.htm#thunderbird
http://www.geocities.co.jp/SiliconValley-Bay/8521/p6.htm#coppermine
http://www.tomshardware.com/reviews/athlon-processor,121-21.html
Thunderbird vs Coppermine
http://www.tomshardware.com/reviews/amd,198-5.html
L1/L2�L���b�V���p�t�H�[�}���X��r
http://kiti.main.jp/Paso/L1L2/linkp0251.htm
����d��
http://www.geocities.co.jp/SiliconValley-Bay/8521/k7.htm#thunderbird
http://www.geocities.co.jp/SiliconValley-Bay/8521/p6.htm#coppermine
�Ȃ�قǂ��̂Ƃ��肾�ȁB
�䂦��Ahtlon�̂ق����C���������Ă���B
���M���Ȃ��̂�
�����Ƌ�̓I�ɑ̌n�I�ɐ������Ăق����ˁB
�䂦��Ahtlon�̂ق����C���������Ă���B
���M���Ȃ��̂�
�����Ƌ�̓I�ɑ̌n�I�ɐ������Ăق����ˁB
Katmai vs Athlon�̂Ƃ���Athlon�������Ă�����
Thunderbird�ł͌݊p�B
Thunderbird��L2��64bit/clock�̑ш悾���A
Coppermine��L2�͓�������256bit/clock��������ł��B
�܂�cache�̍���Coppermine�������������Ă���Ƃ����B
Thunderbird�ł͌݊p�B
Thunderbird��L2��64bit/clock�̑ш悾���A
Coppermine��L2�͓�������256bit/clock��������ł��B
�܂�cache�̍���Coppermine�������������Ă���Ƃ����B
�ǂ����ăR�e�������͂������A���Ȃ�
�e�w���Ȃ���
128bit�i�͂܂��ꂽ���珝�S���s�ł��s���ė���Ŏ��̂���
128bit�i�͂܂��ꂽ���珝�S���s�ł��s���ė���Ŏ��̂���
289 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 01:19:14 ID:ltH+oqt5
Pentium III�̓��W�X�^-�������ԃI�y���[�V������Complex Decoder�ł����J���Ȃ���������x�������B
��OPs Fusion����������Pentium M�ł͓��N���b�N��K7, K8�ƌ݊p�ȏ�ɂ�荇���Ă�B
�v�����ALU�̐��ł͂Ȃ��Ƃ������Ƃ�
��OPs Fusion����������Pentium M�ł͓��N���b�N��K7, K8�ƌ݊p�ȏ�ɂ�荇���Ă�B
�v�����ALU�̐��ł͂Ȃ��Ƃ������Ƃ�
http://pc.watch.impress.co.jp/docs/2009/0318/kaigai495.htm
�������炭�A�����AAMD��CPU�͂������炪IBM�̗�������ރA�[�L�e�N�`�����Ǝw�E�ł���悤�ɂȂ邾�낤�B
Bulldozer���Ăǂ̂ւ�IBM���ۂ��́H
�������炭�A�����AAMD��CPU�͂������炪IBM�̗�������ރA�[�L�e�N�`�����Ǝw�E�ł���悤�ɂȂ邾�낤�B
Bulldozer���Ăǂ̂ւ�IBM���ۂ��́H
291 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 01:32:36 ID:ltH+oqt5
����SSSE3���g����pmaddubsw��pmaddwd��pshufb�����łł���ȁB
pmaddubsw�̑�2����
__m128i vGSMultipler1 = _mm_set_epi8(
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0
);
pmaddwd�̑�2����
__m128i vGSMultipler2 = _mm_set_epi16(1, 1, 1, 1, 1, 1, 1, 1);
pshufb�̑�2����
__m128i vSplat = _mm_set_epi8(
0xff, 15, 15, 15,
0xff, 11, 11, 11,
0xff, 7, 7, 7,
0xff, 3, 3, 3);
pmaddubsw�̑�2����
__m128i vGSMultipler1 = _mm_set_epi8(
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0,
ScaleR, ScaleG, ScaleB, 0
);
pmaddwd�̑�2����
__m128i vGSMultipler2 = _mm_set_epi16(1, 1, 1, 1, 1, 1, 1, 1);
pshufb�̑�2����
__m128i vSplat = _mm_set_epi8(
0xff, 15, 15, 15,
0xff, 11, 11, 11,
0xff, 7, 7, 7,
0xff, 3, 3, 3);
292 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 01:36:48 ID:ltH+oqt5
�딚����
>>290
SSE5(��XOP)�̎d�l�����Ƃ����̂�����Altivec�ۂ����Ďv�������E�E�E
������MAC���^�i�j�������ɂ�Altivec/VMX�iXOP�ł���vpperm�jvperm��
AIM�A���������̓����������Ă邾�Ƃ��]�X
>>290
SSE5(��XOP)�̎d�l�����Ƃ����̂�����Altivec�ۂ����Ďv�������E�E�E
������MAC���^�i�j�������ɂ�Altivec/VMX�iXOP�ł���vpperm�jvperm��
AIM�A���������̓����������Ă邾�Ƃ��]�X
����K6��K7�̔�r���U�X����Ă����̂�
�m�I��Q�҂����Ӗ���Pen3�����o�����̐}
�m�I��Q�҂����Ӗ���Pen3�����o�����̐}
294 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 07:33:05 ID:ltH+oqt5
�ƁA�킯�̂킩��Ȃ����Ƃ���߂����炷�v���t�F�b�`�ł�����
�m�I��Q�҂�>293�𗝉��o���Ȃ��̂�
K6�������p�C�v2�{�Ȍ����U�X�����Ă����Ƃ��u���ɂ��ĖY�ꂳ���Ă��邩�炩
����Ƃ���͂�m�\���ŏd�x�̏�Q���Ă��邽�߂�
K6�������p�C�v2�{�Ȍ����U�X�����Ă����Ƃ��u���ɂ��ĖY�ꂳ���Ă��邩�炩
����Ƃ���͂�m�\���ŏd�x�̏�Q���Ă��邽�߂�
296 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 08:09:54 ID:ltH+oqt5
���������Ă��v���t�F�b�`�̓v���t�F�b�`
���͗ǂ��Ȃ�܂����
���͗ǂ��Ȃ�܂����
�ŋ߂̔n���̓X�[�p�[�p�C�v���C���������̂��B
K6��P6/K7�ȍ~�̃X�[�p�[�p�C�v���C��x86�Ƃ͐v�v�z����������Ă��邩���r�ɂȂ���B
K6��P6/K7�ȍ~�̃X�[�p�[�p�C�v���C��x86�Ƃ͐v�v�z����������Ă��邩���r�ɂȂ���B
�ߋ���Y��Ă��܂����㓡��Bob��Bull��K6�����Ă���ȂǂƂ������d�g���Ƃ��Ă��邪�A
Bob/Bull�̓X�[�p�[�p�C�v���C�����낤�ˁB
Bob/Bull�̓X�[�p�[�p�C�v���C�����낤�ˁB
�R�s�y�����\��������
24���Ԍ����ŐV�����P�ꂪ������Ɠr�[�ɂ���𐒂ߕ���Ă��܂��낤����
ttp://www.daw-pc.info/hard/cpu/cpu2.htm
���ʂȋZ�p�Ƃ��łȂ��i���̑�����
����E�X�[�p�[�E�n�C�p�[�ƌ��������Ă�̂��������E
�ܘ_������̂��Ԕ��̂��Ƃ͑����グ�܂���
24���Ԍ����ŐV�����P�ꂪ������Ɠr�[�ɂ���𐒂ߕ���Ă��܂��낤����
ttp://www.daw-pc.info/hard/cpu/cpu2.htm
���ʂȋZ�p�Ƃ��łȂ��i���̑�����
����E�X�[�p�[�E�n�C�p�[�ƌ��������Ă�̂��������E
�ܘ_������̂��Ԕ��̂��Ƃ͑����グ�܂���
300 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/19(��) 20:12:58 ID:ltH+oqt5
�L�����v���t�F�b�`
�����R�N���炢�ɂȂ�̂��H���̕��R�e���萶���Ă���
�����̓d�g�����i�悤����Ƀt�F�b�`���v���t�F�b�`�j�ł�3�N���O�����炳��ɑO����R�e�o���Ă�Ȃ�4�N�͂�����Ȃ��́H
116 ���O�F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/12(��) 22:49:24 ID:QMJBB7zy
�f�[�^���[�h�̓��@���s�̂��Ƃ�����v���t�F�b�`�ȊO���肦���A�r���̕����ɂ��݉�
116 ���O�F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/12(��) 22:49:24 ID:QMJBB7zy
�f�[�^���[�h�̓��@���s�̂��Ƃ�����v���t�F�b�`�ȊO���肦���A�r���̕����ɂ��݉�
>>299
�p�C�v���C���ƃX�[�p�[�p�C�v���C���o�ꂵ�������ƈӐ}���قȂ�̂����A
����Ȃ̂������ł��Ȃ�����������ȁB
�n�C�p�[��Intel�p��̈���łĂ��Ȃ�����܂��ʂ����B
�p�C�v���C���ƃX�[�p�[�p�C�v���C���o�ꂵ�������ƈӐ}���قȂ�̂����A
����Ȃ̂������ł��Ȃ�����������ȁB
�n�C�p�[��Intel�p��̈���łĂ��Ȃ�����܂��ʂ����B
���߂̃��C�e���V���炵��Bulldozer�͍��N���b�N�w�����\�z�����킯�ł���
�����i�����������p�C�v���C���ɂȂ肻���Ȃ�����
�����i�����������p�C�v���C���ɂȂ肻���Ȃ�����
����ANetBurst, POWER6, Cell
�̂悤�ȃN���b�N�Ő��\���҂��Ƃ����A�v���[�`�͎��Ȃ��Ǝv����B
�������A�㓡�̂悤��Bull/Bob�̃R�A��K6�Ǝ��Ă���Ƃ����̂͂��܂�ɂ��i���Z���X���ȁB
�p�C�v���C���������Ă����̂�CPU���̃��\�[�X�����ԕ����ɃI�[�o�[���b�v���Ď��s����Ƃ����l��
(�X���[�v�b�g��1����1�T�C�N���ɋ߂Â���)�Ƃ������z�����A
�X�[�p�[�p�C�v���C�����Ă����͉̂�H�v�I�Ȑ��i���͂�����
���N���b�N�ړI�Ńp�C�v���C���s�b�`������ɓ����A�œK���A���X�e�[�W����������Ƃ�����B
����͍��ł͓�����O�̍œK���ł����āALRB�̂悤�ȗ�O���̂������܂���ėpCPU��
6�X�e�[�W�Ƃ����肦�Ȃ��ˁB
�̂悤�ȃN���b�N�Ő��\���҂��Ƃ����A�v���[�`�͎��Ȃ��Ǝv����B
�������A�㓡�̂悤��Bull/Bob�̃R�A��K6�Ǝ��Ă���Ƃ����̂͂��܂�ɂ��i���Z���X���ȁB
�p�C�v���C���������Ă����̂�CPU���̃��\�[�X�����ԕ����ɃI�[�o�[���b�v���Ď��s����Ƃ����l��
(�X���[�v�b�g��1����1�T�C�N���ɋ߂Â���)�Ƃ������z�����A
�X�[�p�[�p�C�v���C�����Ă����͉̂�H�v�I�Ȑ��i���͂�����
���N���b�N�ړI�Ńp�C�v���C���s�b�`������ɓ����A�œK���A���X�e�[�W����������Ƃ�����B
����͍��ł͓�����O�̍œK���ł����āALRB�̂悤�ȗ�O���̂������܂���ėpCPU��
6�X�e�[�W�Ƃ����肦�Ȃ��ˁB
>>304
Power6��5�ƃp�C�v���C���i���ꏏ�ŃN���b�N�啝��
���̗��R�̓C���I�[�_���̂��߂Ƃ�����ꂽ��
�Z�p�҂̓��b�g�p�t�H�[�}���X�̂��߂̃C���I�[�_���ƌ����Ă���i�N���b�N�Ɍ��y���ĂȂ����Ă��Ƃ͏�L�͖����Ɓj
�^���͈ł�����
���x��299�����N��̍Ō�ɃX�[�p�[�X�J���ƃN���b�N�̊W���ڂ��Ă���
�R�A�S�̂̃N���b�N�Ȃ�Ăǂ����{�g���l�b�N�ɂȂ��Ă��オ��Ȃ����낤�Ǝv������
�p�C�v���C���{�����炵��������ĕK���N���b�N�オ�����Ȃ����낤����
���������ʂ��Ȃ����v�͍��N���b�N�̂��߂��낤��
�u�V���O���X���b�h���\�őË����Ȃ��v���Ă͖̂����ɏd�v����
Power6��5�ƃp�C�v���C���i���ꏏ�ŃN���b�N�啝��
���̗��R�̓C���I�[�_���̂��߂Ƃ�����ꂽ��
�Z�p�҂̓��b�g�p�t�H�[�}���X�̂��߂̃C���I�[�_���ƌ����Ă���i�N���b�N�Ɍ��y���ĂȂ����Ă��Ƃ͏�L�͖����Ɓj
�^���͈ł�����
���x��299�����N��̍Ō�ɃX�[�p�[�X�J���ƃN���b�N�̊W���ڂ��Ă���
�R�A�S�̂̃N���b�N�Ȃ�Ăǂ����{�g���l�b�N�ɂȂ��Ă��オ��Ȃ����낤�Ǝv������
�p�C�v���C���{�����炵��������ĕK���N���b�N�オ�����Ȃ����낤����
���������ʂ��Ȃ����v�͍��N���b�N�̂��߂��낤��
�u�V���O���X���b�h���\�őË����Ȃ��v���Ă͖̂����ɏd�v����
>Power6��5�ƃp�C�v���C���i���ꏏ�ŃN���b�N�啝��
IBM�M�҂�?
Power6�̓p�C�v���C���X�e�[�W���͂قƂ�Ǖς���ĂȂ��̂ɓ���ȋZ�p�ō����������Ƃ���
�傰���Ȃӂꂱ�݂����������ۂɂ͑����Ă����̂ƁAOOO��IO�̕ύX�ŕ��ʂ͓����x���ł��X�e�[�W�����邩��
�g�[�^���Ƃ��Ă͂��Ȃ�ו�������Ă������Ă����������͂����B
Power6��5�ƃp�C�v���C���i���ꏏ�ŃN���b�N�啝��
http://home.dei.polimi.it/silvano/FilePDF/ARC-MULTIMEDIA/Presentation_IBM_Power6.pdf
�܂������̃p�C�v���C���̐}�݂ăv���R�[�h���琔���Ă����Ȃ��Ƃ�������������
�����[�Z���X���Ǝv���B
IBM�M�҂�?
Power6�̓p�C�v���C���X�e�[�W���͂قƂ�Ǖς���ĂȂ��̂ɓ���ȋZ�p�ō����������Ƃ���
�傰���Ȃӂꂱ�݂����������ۂɂ͑����Ă����̂ƁAOOO��IO�̕ύX�ŕ��ʂ͓����x���ł��X�e�[�W�����邩��
�g�[�^���Ƃ��Ă͂��Ȃ�ו�������Ă������Ă����������͂����B
Power6��5�ƃp�C�v���C���i���ꏏ�ŃN���b�N�啝��
http://home.dei.polimi.it/silvano/FilePDF/ARC-MULTIMEDIA/Presentation_IBM_Power6.pdf
�܂������̃p�C�v���C���̐}�݂ăv���R�[�h���琔���Ă����Ȃ��Ƃ�������������
�����[�Z���X���Ǝv���B
POWER6�͒����d�͂Ƃ������������ABull�̎v�z�ɂ͂����ĂȂ��B
POWER7�̂ق���OOO�ł���Ȃ��瑽���}���`�R�A�����ɂȂ����Ƃ�����B
POWER7�̂ق���OOO�ł���Ȃ��瑽���}���`�R�A�����ɂȂ����Ƃ�����B
Bulldozer�ɂ��^�[�{�u�[�X�g���悹�Ă���Ǝv����
CPU�����̃N���b�N�̋��͂ǂ̃��x���Ő݂��Ă���낤��
CPU�����̃N���b�N�̋��͂ǂ̃��x���Ő݂��Ă���낤��
�܂�POWER7�̓d�͂��ł������Ƃ͂ł������B
>>306
�܂������Ԃ����킷�悤�ȃ}�W���X�͍T���Ă������ǁA
�{���ɃV���O���X���b�h�ł������\�Ȃ�A�͂�����
�u�V���O���X���b�h�ł��]����CPU���������\���v
�Ƃ����Ă���͂��Ȃ�B�������Ƃ����ق����}�[�P�e�B���O�������炳�B
���̂�����́A�ނ��낱�ꂩ���GPU�����邩��ǂ��݂̂����Ȃ�������������ł��܂�����Ă���B
�܂������Ԃ����킷�悤�ȃ}�W���X�͍T���Ă������ǁA
�{���ɃV���O���X���b�h�ł������\�Ȃ�A�͂�����
�u�V���O���X���b�h�ł��]����CPU���������\���v
�Ƃ����Ă���͂��Ȃ�B�������Ƃ����ق����}�[�P�e�B���O�������炳�B
���̂�����́A�ނ��낱�ꂩ���GPU�����邩��ǂ��݂̂����Ȃ�������������ł��܂�����Ă���B
L1D�̃T�C�Y���������Ȃ����̂́A
�v�`�[�������Z�b�g����Ĕr���L���b�V���̓`������߂��ƍl�����
�����ȏ�͐����ł����Ȃ���?
���C�e���V�Ɋւ��Ă͂��̕����₷���Ȃ����Ǝv���B
�v�`�[�������Z�b�g����Ĕr���L���b�V���̓`������߂��ƍl�����
�����ȏ�͐����ł����Ȃ���?
���C�e���V�Ɋւ��Ă͂��̕����₷���Ȃ����Ǝv���B
�g���[�X�L���b�V�����ǂ���2�R�A�ŋ��p�ɂȂ�̂���
����Ƃ��R�A���ƂɎ��̂���
����Ƃ��R�A���ƂɎ��̂���
���Ƃ�����R�A�����낤�ȁB
�E�u�p�C�v���C���ƃX�[�p�[�p�C�v���C�����Ă̂͂����������{�I�ɈႤ��ł�
�@��̓I�ɂǂ��Ⴄ�����ā[�ƒi�����Ⴄ�v�i���_���Ă�悤�œ��ӂ��Ă���j
�E�u�p�C�v���C���͑����Ă���I�vPower6�̐}�����o���Ȃ�
�ق�ƃR�s�y�����\������
�@��̓I�ɂǂ��Ⴄ�����ā[�ƒi�����Ⴄ�v�i���_���Ă�悤�œ��ӂ��Ă���j
�E�u�p�C�v���C���͑����Ă���I�vPower6�̐}�����o���Ȃ�
�ق�ƃR�s�y�����\������
�R�e�̂Ƃ���25%�܂ł����͂������Ă͂����Ȃ��̂�
���邦�郋�[���Ȃ�ł��B
���邦�郋�[���Ȃ�ł��B
�܂��R�e�������ɗ]�O���Ȃ��A�����A
�R�e�̃X�����̒��Ő��ɂ͂܂����甲���o���Ȃ��̂́A
��x�Ȃ̂������B
�R�e�̃X�����̒��Ő��ɂ͂܂����甲���o���Ȃ��̂́A
��x�Ȃ̂������B
( �L�t)˿(�L�t�M)˿(�t�M )˿
>>306
POWER5,6�̃p�C�v���C���̐}���炢�l�b�g�ł��傢�ƌ���������̂悤�ɂ����݂������
�������͊m�F���Ă��珑���Ƃ����Ӑ}�ł����\���ĂȂ��B
���҂����ł��Ȃ��Ƃ��Ȃ�Ƃ������Ă邯�ǁA�����؋������߂����ɂ��炾�玩���̖ϑz�������Ă���ق���
�ǂ�ł��鑤���炷��ƕs���Ȃ�B�܂��A�����̏ꍇ�͂킴�ƒ����ĂȂ����ǂˁB
>���������ʂ��Ȃ����v�͍��N���b�N�̂��߂��낤��
Bull�̓R�A�����R���p�N�g�ɂ��ēd�͐��\��ƃX���[�v�b�g���҂�
�Ƃ����l���łӂ��ɗ����\�B���ʂ��Ȃ����̂͂��̂��߁B
�d�͂�����������N���b�N�͂������邪�A
NetBurst, POWER6, Cell�ȂǂƂ̓N���b�N�̒Nj��ɑ���X�^���X�͈قȂ邾�낤���Ęb�B
POWER5,6�̃p�C�v���C���̐}���炢�l�b�g�ł��傢�ƌ���������̂悤�ɂ����݂������
�������͊m�F���Ă��珑���Ƃ����Ӑ}�ł����\���ĂȂ��B
���҂����ł��Ȃ��Ƃ��Ȃ�Ƃ������Ă邯�ǁA�����؋������߂����ɂ��炾�玩���̖ϑz�������Ă���ق���
�ǂ�ł��鑤���炷��ƕs���Ȃ�B�܂��A�����̏ꍇ�͂킴�ƒ����ĂȂ����ǂˁB
>���������ʂ��Ȃ����v�͍��N���b�N�̂��߂��낤��
Bull�̓R�A�����R���p�N�g�ɂ��ēd�͐��\��ƃX���[�v�b�g���҂�
�Ƃ����l���łӂ��ɗ����\�B���ʂ��Ȃ����̂͂��̂��߁B
�d�͂�����������N���b�N�͂������邪�A
NetBurst, POWER6, Cell�ȂǂƂ̓N���b�N�̒Nj��ɑ���X�^���X�͈قȂ邾�낤���Ęb�B
Bulldozer�̃R���Z�v�g�̓R�A������̐��\�𗎂Ƃ��Ȃ��Ōy�ʉ�����
�����K6�Ɏ��Ă���Ă����ŁAK6���̂��̂��Ă킯����Ȃ�����
K10����3way��2way�̂悤�ɉߏ胆�j�b�g��������āA�X�[�p�[�X�J����OOO�Ƃ��̕����I�Ȃ��͉̂��ǂ��āA
�g�[�^���Ő��\�ێ��A�_�C�T�C�Y���^����ڎw���Ă���Ǝv��
���̌���K10.5�̌y�ʔŁA���邢��K6�̌��㕗���j���[�A���ł݂����Ȃ���ɂȂ��Ă����Ȃ�����
���̌����K6���ĈӖ������Ō����Ă邾�����낤
���Ȃ݂ɁABobcat��Bulldozer�̐��\����(-10%���x)�Ń_�C�̏��^��
Bulldozer�Ƃ�K10��K8�݂����ȊW����
�����K6�Ɏ��Ă���Ă����ŁAK6���̂��̂��Ă킯����Ȃ�����
K10����3way��2way�̂悤�ɉߏ胆�j�b�g��������āA�X�[�p�[�X�J����OOO�Ƃ��̕����I�Ȃ��͉̂��ǂ��āA
�g�[�^���Ő��\�ێ��A�_�C�T�C�Y���^����ڎw���Ă���Ǝv��
���̌���K10.5�̌y�ʔŁA���邢��K6�̌��㕗���j���[�A���ł݂����Ȃ���ɂȂ��Ă����Ȃ�����
���̌����K6���ĈӖ������Ō����Ă邾�����낤
���Ȃ݂ɁABobcat��Bulldozer�̐��\����(-10%���x)�Ń_�C�̏��^��
Bulldozer�Ƃ�K10��K8�݂����ȊW����
K10�R�A�iL2�܂Ŋ܂ށj�̒��Ő������Z�킪��߂�ʐς���2�`3���ŁA��������p�C�v���C����1�{���炵�Ă�1�����邩�ǂ���
�X�P�W���[���̕����ʐώ�����ł���B
323 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 01:59:00 ID:lZIalqH7
K6-2�̃u���b�N�_�C�A�O����
http://www.pctechguide.com/images/25K6-2.gif
����ނ���Pentium II�Ɏ��Ă邯�ǂȃI�C
Bulldozer��Athlon�̓����ł���Int.��FP/SIMD�ŃN���X�^���ʂꂽ�\���P���Ă�
������uK6�v�����Č����Ă�z�͔��ʈȊO�̂Ȃ�ł��Ȃ��B
http://www.pctechguide.com/images/25K6-2.gif
{kind=link}
����ނ���Pentium II�Ɏ��Ă邯�ǂȃI�C
Bulldozer��Athlon�̓����ł���Int.��FP/SIMD�ŃN���X�^���ʂꂽ�\���P���Ă�
������uK6�v�����Č����Ă�z�͔��ʈȊO�̂Ȃ�ł��Ȃ��B
���̘b�̗���́A�~���ʂŐ�����
�u�^�~������A�Ǝ��Ă�v
�u�ȉ~����B�ł���v
�u����l�p������C����v
�ƌ��������Ă�悤�ɂ����v����
�u�^�~������A�Ǝ��Ă�v
�u�ȉ~����B�ł���v
�u����l�p������C����v
�ƌ��������Ă�悤�ɂ����v����
������Ⴄ�B
�uK6-2��Pen2�͂������肾����
Pen2��Pen3�͑�Ⴂ
������Athlon�Ɣ�ׂ�Ȃ�K6����Ȃ�Pen3�IPen3�ɐ�����[�����������I�I�v
�Ȃǂ�SIMMSIMM�����Ă�z���Ƃ苏��킯���ˁ�
�uK6-2��Pen2�͂������肾����
Pen2��Pen3�͑�Ⴂ
������Athlon�Ɣ�ׂ�Ȃ�K6����Ȃ�Pen3�IPen3�ɐ�����[�����������I�I�v
�Ȃǂ�SIMMSIMM�����Ă�z���Ƃ苏��킯���ˁ�
326 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 09:43:11 ID:lZIalqH7
>>324
���⌋�ǐ���ALU�̖{������������K6���ゾ���Č����Ă�A�t�H�����邩��b���X���킯�ŁB
K6�A�[�L�e�N�`���̓����������
�ESIMD���Z���j�b�g�ƔėpALU������|�[�g�ɂԂ牺�����Ă���
�E24�G���g���̏W���^���U�x�[�V�����X�e�[�V����
��ŁA�x�[�X�ɂȂ��Ă�Nx586�ł�FPU�͊O���R�v���Z�b�T�������̂�K6�ł����̖��c��
x87���j�b�g�͓Ɨ��|�[�g�ɂȂ��Ă���ƁB
���K7�ȍ~��FP�����SIMD���j�b�g�͕ʂ̃N���X�^�ɕ����Ĕėp�����Ƃ͕ʌɃX�P�W���[�����O����Ă���B
http://www.thg.ru/cpu/19990809/images/k7-architecture.jpg
���̕ӂ�AlphaAXP�R���̐v�v�z�ł����āABulldozer�ɂ������p����Ă���v�f�B
�����N���X�^�̍\�����ς���������ŁA��{�v�̓f�B�X�N���[�g�p�C�v���C��������Ƃ���
K7�̌n���͈����p���ł���B
�i���ėp���W�X�^-XMM���W�X�^�Ԃ̃f�[�^�ړ��̓{�g���l�b�N�ł��葱����Ƃ������Ɓj
���⌋�ǐ���ALU�̖{������������K6���ゾ���Č����Ă�A�t�H�����邩��b���X���킯�ŁB
K6�A�[�L�e�N�`���̓����������
�ESIMD���Z���j�b�g�ƔėpALU������|�[�g�ɂԂ牺�����Ă���
�E24�G���g���̏W���^���U�x�[�V�����X�e�[�V����
��ŁA�x�[�X�ɂȂ��Ă�Nx586�ł�FPU�͊O���R�v���Z�b�T�������̂�K6�ł����̖��c��
x87���j�b�g�͓Ɨ��|�[�g�ɂȂ��Ă���ƁB
���K7�ȍ~��FP�����SIMD���j�b�g�͕ʂ̃N���X�^�ɕ����Ĕėp�����Ƃ͕ʌɃX�P�W���[�����O����Ă���B
http://www.thg.ru/cpu/19990809/images/k7-architecture.jpg
{kind=link}
���̕ӂ�AlphaAXP�R���̐v�v�z�ł����āABulldozer�ɂ������p����Ă���v�f�B
�����N���X�^�̍\�����ς���������ŁA��{�v�̓f�B�X�N���[�g�p�C�v���C��������Ƃ���
K7�̌n���͈����p���ł���B
�i���ėp���W�X�^-XMM���W�X�^�Ԃ̃f�[�^�ړ��̓{�g���l�b�N�ł��葱����Ƃ������Ɓj
327 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 10:18:32 ID:lZIalqH7
Bridge-FMA��Bulldozer�ɍ̗p�����Ƃ���Α������͂���B
�t�ɂ��̃^�C�~���O�����Ȃ��Ǝv����B
��v�A�v����AVX(����256bit�f�[�^����)�Ɉڍs�����ゾ�Ǝ|�����Ȃ��Z�p�����B
�t�ɂ��̃^�C�~���O�����Ȃ��Ǝv����B
��v�A�v����AVX(����256bit�f�[�^����)�Ɉڍs�����ゾ�Ǝ|�����Ȃ��Z�p�����B
ALU 2��3�@�̔�r���Ł���ۂł��U�X�o���̂�
�uPen2�Ƃ͈Ⴄ�̂���Pen2�Ƃ́v�Ƃ܂Ŏ咣���K����Pen3�𐄂��m�I��Q��
�uPem3�IPen3�ɐ�����[���I
�[��������E���R�ł��\���܂���I�v�v
�uPen2�Ƃ͈Ⴄ�̂���Pen2�Ƃ́v�Ƃ܂Ŏ咣���K����Pen3�𐄂��m�I��Q��
�uPem3�IPen3�ɐ�����[���I
�[��������E���R�ł��\���܂���I�v�v
329 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 10:40:13 ID:lZIalqH7
�v���t�F�b�`��Pentium III
��Q�ϑz����܂��
��Q�ϑz����܂��
����������܂Ő��������̏o�Ȃ�����
�������ꂪ�������ƌ�������ɍ����Ԃ��Ă�A�z�E��
���̃A�z�E�ɔS�����Ă�L�`�K�C�ƂŃX���������Ă�ˁH
�������ꂪ�������ƌ�������ɍ����Ԃ��Ă�A�z�E��
���̃A�z�E�ɔS�����Ă�L�`�K�C�ƂŃX���������Ă�ˁH
331 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:10:42 ID:lZIalqH7
���̎w�E�͓I�m������
332 �FMAC�I�^��330 �����F2010/03/20(�y) 11:14:23 ID:2FaaqQLO
>>330
�@�@-------------------
�@�@����������܂Ő��������̏o�Ȃ���
�@�@-------------------
�{�C�ł���ȋY����M���Ă���Ȃ�A���̃X���b�h�ɗ��Ă����ꃋ�[�}�[���x����邾����
���v�ł���B��ʌ����ɔ̔������悤�Ȑ��i�́A����"Rocket Science"�Ƃ͖Ⴄ��
�ł��B
�@�@-------------------
�@�@����������܂Ő��������̏o�Ȃ���
�@�@-------------------
�{�C�ł���ȋY����M���Ă���Ȃ�A���̃X���b�h�ɗ��Ă����ꃋ�[�}�[���x����邾����
���v�ł���B��ʌ����ɔ̔������悤�Ȑ��i�́A����"Rocket Science"�Ƃ͖Ⴄ��
�ł��B
333 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:18:49 ID:lZIalqH7
Reverse-HT�Ȃ�ĉe���`���Ȃ������M�����Ă������Ԕ��X���b�h�������
>>331,332
���C�Ȃ������̍��ŁA���̃A�z�E�̒��ł��_�D�̍����L�邱�Ƃ�����ȁB
���^���}�W�Ŏ����̖��T����M���Ă�^���Ƃ�����������B
���C�Ȃ������̍��ŁA���̃A�z�E�̒��ł��_�D�̍����L�邱�Ƃ�����ȁB
���^���}�W�Ŏ����̖��T����M���Ă�^���Ƃ�����������B
335 �FMAC�I�^���c�q �����F2010/03/20(�y) 11:24:07 ID:2FaaqQLO
>>333
���̂̃q�g�B�͒N������������Ȃ��ė��_�����o��������܂����A
�����̃��O�ł��T���܂��傤���H
�c�q��������낻��Ⴍ�Ȃ��̂ł�����A�v�����݂ō����̖����b���菑��
�Ă���ƃ_���ł���BLarrabee�Ƃ�AVX 128-bit���Ƃ��A���Â����Ƃ������ł��傤�ɁB
���̂̃q�g�B�͒N������������Ȃ��ė��_�����o��������܂����A
�����̃��O�ł��T���܂��傤���H
�c�q��������낻��Ⴍ�Ȃ��̂ł�����A�v�����݂ō����̖����b���菑��
�Ă���ƃ_���ł���BLarrabee�Ƃ�AVX 128-bit���Ƃ��A���Â����Ƃ������ł��傤�ɁB
���ɂ͂��̓�l�̂����̕Е��͎G�Ȃ낤�Ȃ��炢�̔��f�͂ł�����
337 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:29:49 ID:lZIalqH7
��AVX 128-bit��
Sandy Bridge����O�Ȃ�128�r�b�g����
�㉺�ŕʁX�̃��j�b�g������
��ʂƉ��ʂ������|�[�g�ɂԂ牺�����Ă邾����
Sandy Bridge����O�Ȃ�128�r�b�g����
�㉺�ŕʁX�̃��j�b�g������
��ʂƉ��ʂ������|�[�g�ɂԂ牺�����Ă邾����
338 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:34:20 ID:lZIalqH7
�uSuper Shuffle Engine��Intel��Apple�̃N���X���C�Z���X���v�Ə������l�����܂�����
���҂̂ǂ����ł����������ĂȂ��A�X���[�X�L�����Ă������̂����ɂ��Ă͂ǂ����ˁH
����suicide�X�L���𐄂���
�u���l�ɋ���ɏ�����͎������m�ł���肢���ݍ����ď�𗬂��v
���Ă��Ƃœ���l������
MAD�I�^�̓\�[�X�\��t������œd�g����i�����̍l���������j���Ǝ��̏��Ȃ���
4 ���O�FMAC�I�^[] ���e���F2008/01/03(��) 15:36:18 ID:0OGEg5J1
���̈�A�̃X���b�h�̏����ɂ�uAMD�Ɏ�����Ȃ�Ė����v�Ə������������m�����ǁA�i��Ђ̐�s��
�̕s��������ʂɂ����)AMD�̎�����̕�����������Ɩ��炩�ɂȂ��Ă������B
�N���ɓ������Ă��傤�Ǘǂ��@��Ȃ̂ŁA�ȒP�ɂ܂Ƃ߂Ă������B
��Stars�R�A(Barcelona/Phenom/K10/K8L)�ɂ���
���܂��猾���܂ł�����K8L��P�Ȃ�K8�̉������BK8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
������Aerrata���C������悤���A�����v���Z�X�̉��P�����낤������傫������N���b�N�����シ��
���Ƃ��������A�L���b�V���̑��ʈȊO��IPC����̗v�����������B
�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[
��K8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
K8��90nm��3.2G�AK10��65nm��2.6G�i�������H�j
�Ƃ�����ƍl���������ŗL�蓾�Ȃ����ƂC�Ō���
���ɂ�
������傫������N���b�N�����シ�邱�Ƃ�����
K10�͌���3.4G
���L���b�V���̑��ʈȊO��IPC����̗v��������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
�i��32nm�łł̃A�[�L�e�N�`����̊g���j
�����ĎO�A�E���R�͌��Ă̒ʂ�MAD�ɗւ������č���
���Ă��Ƃœ���l������
MAD�I�^�̓\�[�X�\��t������œd�g����i�����̍l���������j���Ǝ��̏��Ȃ���
4 ���O�FMAC�I�^[] ���e���F2008/01/03(��) 15:36:18 ID:0OGEg5J1
���̈�A�̃X���b�h�̏����ɂ�uAMD�Ɏ�����Ȃ�Ė����v�Ə������������m�����ǁA�i��Ђ̐�s��
�̕s��������ʂɂ����)AMD�̎�����̕�����������Ɩ��炩�ɂȂ��Ă������B
�N���ɓ������Ă��傤�Ǘǂ��@��Ȃ̂ŁA�ȒP�ɂ܂Ƃ߂Ă������B
��Stars�R�A(Barcelona/Phenom/K10/K8L)�ɂ���
���܂��猾���܂ł�����K8L��P�Ȃ�K8�̉������BK8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
������Aerrata���C������悤���A�����v���Z�X�̉��P�����낤������傫������N���b�N�����シ��
���Ƃ��������A�L���b�V���̑��ʈȊO��IPC����̗v�����������B
�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[
��K8�p�C�v���C���̌��E��A���̂܂�K8L�̌��E
K8��90nm��3.2G�AK10��65nm��2.6G�i�������H�j
�Ƃ�����ƍl���������ŗL�蓾�Ȃ����ƂC�Ō���
���ɂ�
������傫������N���b�N�����シ�邱�Ƃ�����
K10�͌���3.4G
���L���b�V���̑��ʈȊO��IPC����̗v��������
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
�i��32nm�łł̃A�[�L�e�N�`����̊g���j
�����ĎO�A�E���R�͌��Ă̒ʂ�MAD�ɗւ������č���
�䖝���o���Ȃ��c�t�Ȑ��i�Ȃ���X���[�Ȃ�đ�l�̑Ή��͖�������
�R�s�y�Ŏ��ȏЉ��z�͂��߂Ă݂��킗
���ׂȒ��������ǁA�G���b�^�C���O��2.4G���������E�E�E
345 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:45:25 ID:lZIalqH7
�v���t�F�b�`�t�F�`�̍ςށu�������̐��E�v�ɂ�Pen4��L1I���Ȃ������
Pen4��L1I�̑���Ƀg���[�X�L���b�V�����ڂ��Ă���
���܂�ɋ@�\���Ⴄ���߂ɂ����L1I���ƔF�߂ĂȂ��l��
�l�b�g�Ō�������Α����o�ė��邱�Ƃ��킩��
����͌������E�̘b
>247�œˑR�o�ė����uPentium 4�ɂ�L1D�������v��
���Ɍ������E�̏펯�ł͍l�����Ȃ��Ǝv���
���܂�ɋ@�\���Ⴄ���߂ɂ����L1I���ƔF�߂ĂȂ��l��
�l�b�g�Ō�������Α����o�ė��邱�Ƃ��킩��
����͌������E�̘b
>247�œˑR�o�ė����uPentium 4�ɂ�L1D�������v��
���Ɍ������E�̏펯�ł͍l�����Ȃ��Ǝv���
347 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 11:56:19 ID:lZIalqH7
���̗����ł�����K7���v���f�R�[�h�L���b�V��������L1I����Ȃ���
348 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:04:04 ID:lZIalqH7
���������{��ɓY�킵�܂�
Pen4��L1I�͎��O�ɖ��߂��f�R�[�h����OPs�ɕϊ�������ԂŋL������g���[�X�L���b�V���ō\������Ă���
�@�\�͏]����L1I���̂��̂Ȃ̂ɂ����L1I���ƔF�߂ĂȂ���1�ő̂�AMD�̎�����CPU�ɑ��H���Ă���
�l�b�g�Ō���������̒�����������������
Pen4��L1I�͎��O�ɖ��߂��f�R�[�h����OPs�ɕϊ�������ԂŋL������g���[�X�L���b�V���ō\������Ă���
�@�\�͏]����L1I���̂��̂Ȃ̂ɂ����L1I���ƔF�߂ĂȂ���1�ő̂�AMD�̎�����CPU�ɑ��H���Ă���
�l�b�g�Ō���������̒�����������������
349 �FMAC�I�^���c�q �����F2010/03/20(�y) 12:08:18 ID:2FaaqQLO
>>338
�{����Vector Permute��AIM�̓����Ȃ�ł����ẮB
http://www.patentstorm.us/patents/5996057/claims.html
Intel�����̕���ł̊�{�����Ƃ��ĔF�߂Ă��邱�Ƃ́AIntel���g�̓����ň��p���Ă���
���Ƃ�������邩�ƁB
http://www.patentstorm.us/patents/7047393/fulltext.html
http://www.patentstorm.us/patents/7120781/fulltext.html
�ŁA�����ƃ\�[�X�̂��锽�_��(��)
�{����Vector Permute��AIM�̓����Ȃ�ł����ẮB
http://www.patentstorm.us/patents/5996057/claims.html
Intel�����̕���ł̊�{�����Ƃ��ĔF�߂Ă��邱�Ƃ́AIntel���g�̓����ň��p���Ă���
���Ƃ�������邩�ƁB
http://www.patentstorm.us/patents/7047393/fulltext.html
http://www.patentstorm.us/patents/7120781/fulltext.html
�ŁA�����ƃ\�[�X�̂��锽�_��(��)
ttp://www.ne.jp/asahi/comp/tarusan/main89.htm
���킩��₷�������ƁA�u���������߂̋��ڂł���B�v�� ���炩���߃~�V���ڂ����Ă����悤�Ȃ����ł���B
������ɂ��A�P�ڂ̖��߃f�R�[�h������҂����ɁA���s���ĂQ�ځA�R�ڂ̃f�R�[�h���s����킯���B
���̗����ł�����
�E�E�E���Ă������Ƃ�����>348�Ɂu�g���[�X�L���b�V����L1I���̂��́v
��OPs�L���b�V����x86�L���b�V���Ƃ������Ă���
���ς�炸��ׂ�
���킩��₷�������ƁA�u���������߂̋��ڂł���B�v�� ���炩���߃~�V���ڂ����Ă����悤�Ȃ����ł���B
������ɂ��A�P�ڂ̖��߃f�R�[�h������҂����ɁA���s���ĂQ�ځA�R�ڂ̃f�R�[�h���s����킯���B
���̗����ł�����
�E�E�E���Ă������Ƃ�����>348�Ɂu�g���[�X�L���b�V����L1I���̂��́v
��OPs�L���b�V����x86�L���b�V���Ƃ������Ă���
���ς�炸��ׂ�
351 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:15:22 ID:lZIalqH7
���₻�̓����͒m���Ă���Ă���
���ĉ��x�ڂ��Ȃ���
pshufb��SSSE3�����������Ă���Ȃ�Penryn����̎�����Apple�i�j�ƌ����Ȃ���Ȃ�Ȃ��́H
��������pshufb�̃\�[�X�I�y�����h��2�ł����ē����̂���Ƃ͈قȂ�ˁB
AMD XOP��vpperm���������Ă�̂͋C�ɂȂ邵�AIntel��AVX�̎d�l����vpermil2ps���폜�����̂������[���ł��B
���ĉ��x�ڂ��Ȃ���
pshufb��SSSE3�����������Ă���Ȃ�Penryn����̎�����Apple�i�j�ƌ����Ȃ���Ȃ�Ȃ��́H
��������pshufb�̃\�[�X�I�y�����h��2�ł����ē����̂���Ƃ͈قȂ�ˁB
AMD XOP��vpperm���������Ă�̂͋C�ɂȂ邵�AIntel��AVX�̎d�l����vpermil2ps���폜�����̂������[���ł��B
352 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:19:32 ID:lZIalqH7
���邳��i�j���Ă��̑O�����_�j���ċL���C������������Ȃ���
> Execution Trace Cache:
> Advanced L1 instruction cache removes decoder pipeline latency, and
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> caches "decoded" instructions, thus improving efficiency and hit rate to
> cached instructions. The 12 K��op portion of the L1 cache supplies decoded
> instructions into the processor pipeline. There is also an 8 KB data portion of
> L1 cache.
http://www.intel.com/support/processors/pentium4/sb/CS-007988.htm
�@�@�@�@�@�@�@~~~~~~
> Execution Trace Cache:
> Advanced L1 instruction cache removes decoder pipeline latency, and
�@~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> caches "decoded" instructions, thus improving efficiency and hit rate to
> cached instructions. The 12 K��op portion of the L1 cache supplies decoded
> instructions into the processor pipeline. There is also an 8 KB data portion of
> L1 cache.
http://www.intel.com/support/processors/pentium4/sb/CS-007988.htm
�@�@�@�@�@�@�@~~~~~~
Intel���g���[�X�L���b�V����L1I�Ă�肵�Ă邩�����
�u��OPs�L���b�V����x86�L���b�V���v���ؖ����ꂽ�Ƃ������Ă�
�������E�ł͂܂��ʗp���Ȃ�
����Ƀf�[�^���^�X�N����Ƃ������d�g�ŕ��ʂ̐l�Ԃ�_�j�o����̂��H�L�蓾�Ȃ�
�u��OPs�L���b�V����x86�L���b�V���v���ؖ����ꂽ�Ƃ������Ă�
�������E�ł͂܂��ʗp���Ȃ�
����Ƀf�[�^���^�X�N����Ƃ������d�g�ŕ��ʂ̐l�Ԃ�_�j�o����̂��H�L�蓾�Ȃ�
354 �FMAC�I�^���c�q �����F2010/03/20(�y) 12:29:53 ID:2FaaqQLO
>>351
�@�@-----------------
�@�@pshufb��SSSE3�����������Ă���Ȃ�Penryn����̎�����Apple�i�j��
�@�@�����Ȃ���Ȃ�Ȃ��́H
�@�@-----------------
���g�ŏ����Ă���悤��pshufb��Altivec��vperm�Ƃ͈Ⴂ�܂���B
�@�@-----------------
�@�@��������pshufb�̃\�[�X�I�y�����h��2�ł����ē����̂���Ƃ͈قȂ�ˁB
�@�@-----------------
���̘b��́A�폜�����O��AVX��vperm���߂̘b�B�폜��ɏ������悤�ɘb������ւ�
���Ă�����̂ł����c
�@�@-----------------
�@�@pshufb��SSSE3�����������Ă���Ȃ�Penryn����̎�����Apple�i�j��
�@�@�����Ȃ���Ȃ�Ȃ��́H
�@�@-----------------
���g�ŏ����Ă���悤��pshufb��Altivec��vperm�Ƃ͈Ⴂ�܂���B
�@�@-----------------
�@�@��������pshufb�̃\�[�X�I�y�����h��2�ł����ē����̂���Ƃ͈قȂ�ˁB
�@�@-----------------
���̘b��́A�폜�����O��AVX��vperm���߂̘b�B�폜��ɏ������悤�ɘb������ւ�
���Ă�����̂ł����c
355 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:33:11 ID:lZIalqH7
���O��Intel��Penryn��Super Shuffle Engine�����������^�C�~���O�ł��̘b��������o�������炾��
���RPenryn�ɂ�AVX�͓��ڂ���Ă��Ȃ�
���RPenryn�ɂ�AVX�͓��ڂ���Ă��Ȃ�
356 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:35:08 ID:lZIalqH7
357 �FMAC�I�^�������F2010/03/20(�y) 12:36:56 ID:2FaaqQLO
>>354�͂�����ƕʂ̋L���ƍ������Ă܂����B�c�q����>>338�Ŏw�E�����̂�
Super Shuffle�����̍��̘b��̕��ł��ˁc
������Ɠ����̃��O�������ė��܂��B
Super Shuffle�����̍��̘b��̕��ł��ˁc
������Ɠ����̃��O�������ė��܂��B
358 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:38:59 ID:lZIalqH7
����̘b���AltiVec����(�Q)�̒���VPERM��������������������ǁA��ʂɒm�I���L���� ��{������c��Ȏ��ӓ����Ōł߂Ă��郂�m������AApple������AltiVec�Ɋւ��錠�����ǂ� �悤�Ȃ��̂ł��邩��m��Ȃ�����A�S�Ă퉯���ɉ߂��Ȃ����B ...
�Ȃ�Œc�q����MAC�I�^�̌����ɂȂ��Ă�́H
360 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 12:53:09 ID:lZIalqH7
���X���̂܂�܈��p����
IntelCPU�̘b�͂������̃X���ł��{���N����
������AMD CPU�X�����}�k�P��
������AMD CPU�X�����}�k�P��
�mGDC 2010�nLarrabee�v��̉������e�𗎂Ƃ��CIntel�́g�O���t�B�b�N�X�œK���h�Z�b�V����
http://www.4gamer.net/games/107/G010710/20100317030/
���@�������W���J���Ă݂�C���̓��e�́u�f���A���R�ACore i7�Ei5�Ei3�v���Z�b�T�ɓ��ڂ��ꂽ
���wIntel HD Graphics�x�ƁC���O���t�B�b�N�X�@�\�Ɍ������œK���̘b��̂݁v�Ƃ����C���������e�B
�������ł����ՎU�Ƃ����Z�b�V���������C���X�ɗ�������Q���҂��ڗ����C���u�҂͕M�҂��܂߂Đ�������x�������B
http://www.4gamer.net/games/107/G010710/20100317030/
���@�������W���J���Ă݂�C���̓��e�́u�f���A���R�ACore i7�Ei5�Ei3�v���Z�b�T�ɓ��ڂ��ꂽ
���wIntel HD Graphics�x�ƁC���O���t�B�b�N�X�@�\�Ɍ������œK���̘b��̂݁v�Ƃ����C���������e�B
�������ł����ՎU�Ƃ����Z�b�V���������C���X�ɗ�������Q���҂��ڗ����C���u�҂͕M�҂��܂߂Đ�������x�������B
�@�@�R�.�O �Ƥ�Q �Q�Q�Q _,. �]'�L�^/-��==����=-��S �@ �@ �@ �^�R
�@�@�@�@�@�@�@ ,.�]'�L�@`''�]- �._�R �@ /.i�@��,. -��;==:- ��T�];----//�@�S.�
�@�@�@�@�@�@�@[�@|�!�@ /'�Pr'b�T}��. {`�L '�L�Q_ �i_Y_�j,. |.r-'�]���]l l�܁@| }
�@�@�@�@�@�@�@ �l |�M}�@..:�R--ށ]�LP�Rd��@''''�@ �P�P�@ |l�@�@�@!�! !�� //
.�@�@�@�@�@�@ �@ i.! l .:::::�@�@ �@ �;;:..�@ �R�._�@�@�@�@�@_,�m'�@�@�@�@�@�U�j�m./
�@�@�@�@�@�@�@�@ �M ���=--�]'�L(__,. �@ ..�A�@�P�P�P�@�@�@�@�@�@i�^�]'�^
�@�@�@�@�@�@�@�@�@ i�@�@�@�@ �@ .:::Ĥ �P �L�@�@�@�@�@�@�@�@�@�@�@ l�_�^::|
�@�@�@�@�@�@�@�@�@�@!�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ |:�@ �@ |
�@�@�@�@ �@ �@ �@ �@ �R�@�@�@�@�@��]==:��Ɓ��@�@�@�@�@ �@ �@ !::�@�@�@�g�
���ꂽ���͂Ƃ�ł��Ȃ��v���Ⴂ�����Ă����悤���B��������Ă݂�B
991 ���O�F�R�E�L�́M�E,,�j����������������[sage] ���e���F2008/02/25(��) 21:53:07 ID:YxY/EGHv
>>983
���������
pre = ���O
�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[
����ɂ���āu�v���t�F�b�`�����O�Ƀt�F�b�`���Ă����v
�u�v���f�R�[�h�����łɃf�R�[�h�͍ς܂����v
�ƂȂ�u�t�F�b�`���v���t�F�b�`�v�u�f�R�[�h���v���f�R�[�h�v�u��OPs�L���b�V������86�L���b�V���v����������
�������n���̎����������ė~����
pre-[ pr-, pri- ]�@�u�c�ȑO�́v�u�c�̑O���ɂ���v
�Ƃ���u�t�F�b�`�̑O�ɍs�����Ɓv�u�f�R�[�h�̑O�ɍs�����Ɓv�Ɩ̂����{�ꂾ�낤
�iyahoo�����ɂ́u���炩���߁v�̈Ӗ����o�Ă��邪
�������ɓ��Ă͂߂Ă݂�Ƃ��������̂Ŋ�������
pre-quake�@���炩���ߗh���H
pre-birth�@���炩���ߐ��܂��H�j
�v���f�R�[�h�Ƃ���������ς܂������̂�AMD��K5����L1I�ɓ���Ă��炵����
Intel�̂ق��͂悭�����Core2���v���f�R�[�h�ς݂�x86���߂����[�v��p�L���b�V����
i7�Ńf�R�[�h�ς݂̃�OPs�����[�v��p�g���[�X�L���b�V���ɓ����悤�ɂ������Ƃ͔����Ă���
�@�@�@�@�@�@�@ ,.�]'�L�@`''�]- �._�R �@ /.i�@��,. -��;==:- ��T�];----//�@�S.�
�@�@�@�@�@�@�@[�@|�!�@ /'�Pr'b�T}��. {`�L '�L�Q_ �i_Y_�j,. |.r-'�]���]l l�܁@| }
�@�@�@�@�@�@�@ �l |�M}�@..:�R--ށ]�LP�Rd��@''''�@ �P�P�@ |l�@�@�@!�! !�� //
.�@�@�@�@�@�@ �@ i.! l .:::::�@�@ �@ �;;:..�@ �R�._�@�@�@�@�@_,�m'�@�@�@�@�@�U�j�m./
�@�@�@�@�@�@�@�@ �M ���=--�]'�L(__,. �@ ..�A�@�P�P�P�@�@�@�@�@�@i�^�]'�^
�@�@�@�@�@�@�@�@�@ i�@�@�@�@ �@ .:::Ĥ �P �L�@�@�@�@�@�@�@�@�@�@�@ l�_�^::|
�@�@�@�@�@�@�@�@�@�@!�@�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ �@ �@ �@ |:�@ �@ |
�@�@�@�@ �@ �@ �@ �@ �R�@�@�@�@�@��]==:��Ɓ��@�@�@�@�@ �@ �@ !::�@�@�@�g�
���ꂽ���͂Ƃ�ł��Ȃ��v���Ⴂ�����Ă����悤���B��������Ă݂�B
991 ���O�F�R�E�L�́M�E,,�j����������������[sage] ���e���F2008/02/25(��) 21:53:07 ID:YxY/EGHv
>>983
���������
pre = ���O
�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[�[
����ɂ���āu�v���t�F�b�`�����O�Ƀt�F�b�`���Ă����v
�u�v���f�R�[�h�����łɃf�R�[�h�͍ς܂����v
�ƂȂ�u�t�F�b�`���v���t�F�b�`�v�u�f�R�[�h���v���f�R�[�h�v�u��OPs�L���b�V������86�L���b�V���v����������
�������n���̎����������ė~����
pre-[ pr-, pri- ]�@�u�c�ȑO�́v�u�c�̑O���ɂ���v
�Ƃ���u�t�F�b�`�̑O�ɍs�����Ɓv�u�f�R�[�h�̑O�ɍs�����Ɓv�Ɩ̂����{�ꂾ�낤
�iyahoo�����ɂ́u���炩���߁v�̈Ӗ����o�Ă��邪
�������ɓ��Ă͂߂Ă݂�Ƃ��������̂Ŋ�������
pre-quake�@���炩���ߗh���H
pre-birth�@���炩���ߐ��܂��H�j
�v���f�R�[�h�Ƃ���������ς܂������̂�AMD��K5����L1I�ɓ���Ă��炵����
Intel�̂ق��͂悭�����Core2���v���f�R�[�h�ς݂�x86���߂����[�v��p�L���b�V����
i7�Ńf�R�[�h�ς݂̃�OPs�����[�v��p�g���[�X�L���b�V���ɓ����悤�ɂ������Ƃ͔����Ă���
364 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 13:34:16 ID:lZIalqH7
�������v���v��
365 �FSocket774�F2010/03/20(�y) 13:37:06 ID:1DV8azMB
�f�R�[�h�O��x86���߂��L���b�V������̂����ʂ�L1���߃L���b�V��
x86���f�R�[�h��̃�op�̏�ԂŃL���b�V������̂��g���[�X�L���b�V��
(�q�b�g�����Ƃ��́A�f�R�[�_�[���X�L�b�v)
�f�R�[�_�[�̑O���ォ(x86���߂���������)�̈Ⴂ������
�@�\�I�ɂ͂܂����������Ȃ�Ȃ��́H
x86���f�R�[�h��̃�op�̏�ԂŃL���b�V������̂��g���[�X�L���b�V��
(�q�b�g�����Ƃ��́A�f�R�[�_�[���X�L�b�v)
�f�R�[�_�[�̑O���ォ(x86���߂���������)�̈Ⴂ������
�@�\�I�ɂ͂܂����������Ȃ�Ȃ��́H
366 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 13:41:37 ID:lZIalqH7
���t�K�ɂ₽�玷�����鎩�ǂ̕��ɂ͈Ⴄ���Ɍ�����炵���ł���
�ӂ���̓v���t�F�b�`
>>365
��ȑ�G�c�ɕ�������RAM�S���ꏏ���Č����Ă����������Ȃ��Ȃ�
���߃L���b�V���ɂǂ�����ăR�[�h���l�ߍ��ނ�������������ōl�����
���ʂ�L1��way���ɕ����ĉ�ōڂ�����
L2�ȉ��̃L���b�V��������̃��C�e���V�Ƒш悪�l�b�N
�g���[�X�L���b�V���̓f�R�[�h���Ȃ��ƍڂ�Ȃ�����f�R�[�_�̐��ʼno���A�l�b�N�ɂ��Ȃ�
L2�ȉ�����f�R�[�_�ɖ��߃t�F�b�`���邽�тɃ��C�e���V�|����Ƃ����炩�Ȃ荓�����ƂɂȂ肻��
��ȑ�G�c�ɕ�������RAM�S���ꏏ���Č����Ă����������Ȃ��Ȃ�
���߃L���b�V���ɂǂ�����ăR�[�h���l�ߍ��ނ�������������ōl�����
���ʂ�L1��way���ɕ����ĉ�ōڂ�����
L2�ȉ��̃L���b�V��������̃��C�e���V�Ƒш悪�l�b�N
�g���[�X�L���b�V���̓f�R�[�h���Ȃ��ƍڂ�Ȃ�����f�R�[�_�̐��ʼno���A�l�b�N�ɂ��Ȃ�
L2�ȉ�����f�R�[�_�ɖ��߃t�F�b�`���邽�тɃ��C�e���V�|����Ƃ����炩�Ȃ荓�����ƂɂȂ肻��
369 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 14:27:14 ID:lZIalqH7
���g���[�X�L���b�V���̓f�R�[�h���Ȃ��ƍڂ�Ȃ�����f�R�[�_�̐��ʼno���A�l�b�N�ɂ��Ȃ�
��L2�ȉ�����f�R�[�_�ɖ��߃t�F�b�`���邽�тɃ��C�e���V�|����Ƃ����炩�Ȃ荓�����ƂɂȂ肻��
�A�z�����ĕ����Ă���������������
������Ăǂ��̉�Ђ�CPU�̂��Ƃ��낤�ˁH
> �v���f�R�[�h�E�r�b�g
> x86���߂̃f�R�[�f�B���O�͓��ɓ�����A���̗��R�͖��߂��ϒ��ł���A1
> �o�C�g����15�o�C�g�܂ł̖��ߒ����Ƃ蓾�邩��ł���B�v���f�R�[�h�E���W�b�N
> �͊e���߃o�C�g�ɑΉ�����v���f�R�[�h�E�r�b�g����������B�v���f�R�[�h�E�r�b�g
> �͎���x86���߂̊J�n�_�܂ł̃o�C�g����\������B�v���f�R�[�h�E�r�b�g�́A�}
> 2�Ɏ����ʂ�A�ex86���߃o�C�g�̖T��̊g�����߃L���b�V�����Ɋi�[�����B�v
> ���f�R�[�h�E�r�b�g�͖��߃o�C�g�Ƌ��ɁA����炪����x86���߃f�R�[�f�B���O��
> �A�V�X�g����f�R�[�_�Ɉ����n�����B
http://www17.tok2.com/home/taro/j20695h.pdf
��L2�ȉ�����f�R�[�_�ɖ��߃t�F�b�`���邽�тɃ��C�e���V�|����Ƃ����炩�Ȃ荓�����ƂɂȂ肻��
�A�z�����ĕ����Ă���������������
������Ăǂ��̉�Ђ�CPU�̂��Ƃ��낤�ˁH
> �v���f�R�[�h�E�r�b�g
> x86���߂̃f�R�[�f�B���O�͓��ɓ�����A���̗��R�͖��߂��ϒ��ł���A1
> �o�C�g����15�o�C�g�܂ł̖��ߒ����Ƃ蓾�邩��ł���B�v���f�R�[�h�E���W�b�N
> �͊e���߃o�C�g�ɑΉ�����v���f�R�[�h�E�r�b�g����������B�v���f�R�[�h�E�r�b�g
> �͎���x86���߂̊J�n�_�܂ł̃o�C�g����\������B�v���f�R�[�h�E�r�b�g�́A�}
> 2�Ɏ����ʂ�A�ex86���߃o�C�g�̖T��̊g�����߃L���b�V�����Ɋi�[�����B�v
> ���f�R�[�h�E�r�b�g�͖��߃o�C�g�Ƌ��ɁA����炪����x86���߃f�R�[�f�B���O��
> �A�V�X�g����f�R�[�_�Ɉ����n�����B
http://www17.tok2.com/home/taro/j20695h.pdf
�������Z�Z�Z�Ђ�CPU�ł���
����i�[����̂Ƀp���e�B�r�b�g�𗘗p���Ă܂��B
����i�[����̂Ƀp���e�B�r�b�g�𗘗p���Ă܂��B
�_���S�w�Z�x�݂Ȃ�H
>>369
�u�f�R�[�h���v���f�R�[�h������AMD�̂��f�R�[�h�ς܂��Ȃ���L1I�ɍڂ����Ȃ��v
���Č������������Ȃ������������
�u�f�R�[�h���v���f�R�[�h������AMD�̂��f�R�[�h�ς܂��Ȃ���L1I�ɍڂ����Ȃ��v
���Č������������Ȃ������������
373 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 17:13:03 ID:lZIalqH7
�ާ��͕��͂��ǂ߂Ȃ���
���ߒ����o��x86�̃f�R�[�h�ɂ�����ł��R�X�g�̍���������
���ߒ����o��x86�̃f�R�[�h�ɂ�����ł��R�X�g�̍���������
�����ŌŒ蒷���߂����悗
375 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 17:24:46 ID:lZIalqH7
���Ȃ݂�K7�ȍ~�́uInt��FP/SIMD�ǂ���̃N���X�^�ɐU�蕪���邩�v�̏����i�[���Ă���
�܂薽�߂̎�ނ܂Ŕ��肵�Ă���B
�I�y�����h�ȊO�̂قڑS�Ă̏���L1I�Ƀt�F�b�`����i�K�Ŏ��O�f�R�[�h���Ă邱�ƂɂȂ�B
�v���t�F�b�`����̌����悤�Ɂu�v���f�R�[�h���f�R�[�h�v�͔��������B�����˂�������
�����Ƃ��A�v���f�R�[�h�^�O�ɕێ����Ă�̂͒������ƃN���X�^�̋�ʂ��炢������A�f�R�[�_��ʂ��Ƃ���
�ēx�v���t�B�N�X�o�C�g��ǂݒ������ƂɂȂ邯�ǂˁB
�܂薽�߂̎�ނ܂Ŕ��肵�Ă���B
�I�y�����h�ȊO�̂قڑS�Ă̏���L1I�Ƀt�F�b�`����i�K�Ŏ��O�f�R�[�h���Ă邱�ƂɂȂ�B
�v���t�F�b�`����̌����悤�Ɂu�v���f�R�[�h���f�R�[�h�v�͔��������B�����˂�������
�����Ƃ��A�v���f�R�[�h�^�O�ɕێ����Ă�̂͒������ƃN���X�^�̋�ʂ��炢������A�f�R�[�_��ʂ��Ƃ���
�ēx�v���t�B�N�X�o�C�g��ǂݒ������ƂɂȂ邯�ǂˁB
�����Ȃ݂�K7�ȍ~�́uInt��FP/SIMD�ǂ���̃N���X�^�ɐU�蕪���邩�v�̏����i�[���Ă���
int��float���ϐ��i�I�y�����h�j�̌^�������Ă���
��
���܂薽�߂̎�ނ܂Ŕ��肵�Ă���B
���I�y�����h�ȊO�̂قڑS�Ă̏���L1I�Ƀt�F�b�`����i�K�Ŏ��O�f�R�[�h���Ă邱�ƂɂȂ�B
�I�y�����h������
��
�I�y�����h�ȊO������
�Ӗ��s��
�ڂ����l�������
int��float���ϐ��i�I�y�����h�j�̌^�������Ă���
��
���܂薽�߂̎�ނ܂Ŕ��肵�Ă���B
���I�y�����h�ȊO�̂قڑS�Ă̏���L1I�Ƀt�F�b�`����i�K�Ŏ��O�f�R�[�h���Ă邱�ƂɂȂ�B
�I�y�����h������
��
�I�y�����h�ȊO������
�Ӗ��s��
�ڂ����l�������
377 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 17:54:35 ID:lZIalqH7
�{���Ƀh�����f�l����
��int��float���ϐ��i�I�y�����h�j�̌^�������Ă���
Operand�Ȃ�Ă̂͂����̐��������B
���Ƃ���ModRM.reg�t�B�[���h��0�������Ă����Ƃ��āA���ꂪXMM0��ST(0)�Ȃ̂�AX�Ȃ̂���
������O��opcode�ɂ���Č��܂�B
�������ߒ����o�̒i�K�ł͕K�v�̂Ȃ���B
��������̂�ModRM�̓X�L�������邪SIB, DISP�̗L���i�����j��������o����
��̏��͓ǂݎ̂ĂĂ���B
�قڊ��S��decode�i��ǁj�͍s���Ă��邪�A��OPs�����Ȃ������
��int��float���ϐ��i�I�y�����h�j�̌^�������Ă���
Operand�Ȃ�Ă̂͂����̐��������B
���Ƃ���ModRM.reg�t�B�[���h��0�������Ă����Ƃ��āA���ꂪXMM0��ST(0)�Ȃ̂�AX�Ȃ̂���
������O��opcode�ɂ���Č��܂�B
�������ߒ����o�̒i�K�ł͕K�v�̂Ȃ���B
��������̂�ModRM�̓X�L�������邪SIB, DISP�̗L���i�����j��������o����
��̏��͓ǂݎ̂ĂĂ���B
�قڊ��S��decode�i��ǁj�͍s���Ă��邪�A��OPs�����Ȃ������
378 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 17:58:49 ID:lZIalqH7
(�����j
�{�f�R�[�h�ŕ���ɏ������₷���悤�Ƀ^�O��f���o���Ċi�[���Ă���B
L1I�~�X�q�b�g���̃y�i���e�B�Ȃ�NetBurst�Ƒ卷�ˁ[��B
x86�͗e�ʌ�������������A64KB����������ő��Ƀ~�X�q�b�g���Ȃ����ǂȁB
�{�f�R�[�h�ŕ���ɏ������₷���悤�Ƀ^�O��f���o���Ċi�[���Ă���B
L1I�~�X�q�b�g���̃y�i���e�B�Ȃ�NetBurst�Ƒ卷�ˁ[��B
x86�͗e�ʌ�������������A64KB����������ő��Ƀ~�X�q�b�g���Ȃ����ǂȁB
�ڂ����l���Ă̂͒m���������Ɨ������Ă�l�̂��Ƃ�
�Q�t�H��CPU�݂����ɃX�[�p�[�X�J�������iSMT���A�E�g�I�u�I�[�_�j���Ă�\�[�X�����ė���
�u������S�Ă�SIMD�ŃX�J���Ȃ�Ė����v�Ƃ������Ă��ׂ��z�̂��Ƃ���Ȃ���
202 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/07/22(��) 06:59:49 ID:3rqpGJeJ
�����ł��ǂ�ł�����
http://www.4gamer.net/games/050/G005004/20080614003/
�uSIMT�v��CUDA�̃v���O���~���O���f�����r�����}�[�L�e�N�`���ł����Ȃ�
1�̊��̒��g�������Ƃ��̓x�N�g������Ȃ��āA�e�v�f�ɑ��鉉�Z���`���邾���B
GeForce�̃n�[�h�I�ɂ�
�E1�̖��߃��j�b�g�i�f�R�[�_�j�ɑ��āA8�̘A�����ē�������/�P���x���s���j�b�g�����遨����SIMD�ȊO�̂Ȃ�ł��Ȃ��ł�
�E�X�L���^�E�M���U�[���T�|�[�g���郍�[�h�E�X�g�A���j�b�g�@��Larrabee��LSU�͍X�ɍ��@�\
�E�v���f�B�P�[�g���W�X�^�ɂ����s�E�s���s�̑I�����ł��遨Larrabee�̓}�X�N�l���m�̃r�b�g�_�����Z���T�|�[�g
NVIDIA���}�[�P�e�B���O�p�ꂻ�낻��ς��Ă��鍠���Ǝv���̂����ǁE�E�E
�Q�t�H��CPU�݂����ɃX�[�p�[�X�J�������iSMT���A�E�g�I�u�I�[�_�j���Ă�\�[�X�����ė���
�u������S�Ă�SIMD�ŃX�J���Ȃ�Ė����v�Ƃ������Ă��ׂ��z�̂��Ƃ���Ȃ���
202 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/07/22(��) 06:59:49 ID:3rqpGJeJ
�����ł��ǂ�ł�����
http://www.4gamer.net/games/050/G005004/20080614003/
�uSIMT�v��CUDA�̃v���O���~���O���f�����r�����}�[�L�e�N�`���ł����Ȃ�
1�̊��̒��g�������Ƃ��̓x�N�g������Ȃ��āA�e�v�f�ɑ��鉉�Z���`���邾���B
GeForce�̃n�[�h�I�ɂ�
�E1�̖��߃��j�b�g�i�f�R�[�_�j�ɑ��āA8�̘A�����ē�������/�P���x���s���j�b�g�����遨����SIMD�ȊO�̂Ȃ�ł��Ȃ��ł�
�E�X�L���^�E�M���U�[���T�|�[�g���郍�[�h�E�X�g�A���j�b�g�@��Larrabee��LSU�͍X�ɍ��@�\
�E�v���f�B�P�[�g���W�X�^�ɂ����s�E�s���s�̑I�����ł��遨Larrabee�̓}�X�N�l���m�̃r�b�g�_�����Z���T�|�[�g
NVIDIA���}�[�P�e�B���O�p�ꂻ�낻��ς��Ă��鍠���Ǝv���̂����ǁE�E�E
�A�E�g�I�u�I�[�_�͈Ⴄ��
�����R��2�������X���b�g2�{�ɂ��Ă����
382 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 19:41:54 ID:lZIalqH7
�A�E�g�I�u�I�[�_��������
�p����������g���Ȃ��z�ɏ��̐^��̔��f��C����قǖ��ʂȂ��Ƃ͂Ȃ�
�p����������g���Ȃ��z�ɏ��̐^��̔��f��C����قǖ��ʂȂ��Ƃ͂Ȃ�
�\�[�X������ꍇ�͗��܂ꂸ�Ƃ�����ɏo����
�o���Ȃ�����2ch���\�[�X�Ȃ����ɃR�s�y���ςœ��e�O�`���O�`��
����ɂ���āu�t�F�b�`���v���t�F�b�`�v�u�f�[�^���^�X�N����v�u��OPs�L���b�V����x86�L���b�V���v
�Ƃ����f���炵���@���̐��X�����܂��
�Ă̂��p�^�[�������ǂ˂�
�o���Ȃ�����2ch���\�[�X�Ȃ����ɃR�s�y���ςœ��e�O�`���O�`��
����ɂ���āu�t�F�b�`���v���t�F�b�`�v�u�f�[�^���^�X�N����v�u��OPs�L���b�V����x86�L���b�V���v
�Ƃ����f���炵���@���̐��X�����܂��
�Ă̂��p�^�[�������ǂ˂�
385 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 20:45:18 ID:lZIalqH7
>>383
�듚���匴�����肪�����̊T�v���Љ�Ă��C���������Y�ꂽ�B
K7-K8�̎����ł�1���߂�����5�r�b�g�ł��邱�Ƃ��m���Ă�B
���ߒ���4�r�b�g�ix86��1���ߒ��͋K�i��1�`15�o�C�g�j�A�X��1�r�b�g��INT�p�C�v��FP�p�C�v���̏����i�[�����
5�r�b�g�ł��ނˁB
x87���߂̏ꍇ�ŏ���1�o�C�g�������FP���߂��Ƃ킩�邪�A0F�Ŏn�܂�2�o�C�g���߂�
�X�J�����߂�SIMD���߂��}�b�s���O����Ă邩�猋�ǍŌ��Opcode�܂ł݂Ĕ��肵�Ȃ��Ƃ����Ȃ��B
���Ȃ݂ɂ��̃^�O�AK10����y1�o�C�g������3�r�b�g�z�ɂȂ��Ă�炵�����Ǐڍׂ͕s���B
��Ŏ����̏ڍׂ�
http://www.patentstorm.us/patents/5819059/claims.html
Intel���f�R�[�h�i�����R�X�g�ƒm���Core MA�Œ����f�R�[�h�̕������̂��Ă�̂�
AMD�����̓��������Ă邩��Ǝv���Ă邪�B
�듚���匴�����肪�����̊T�v���Љ�Ă��C���������Y�ꂽ�B
K7-K8�̎����ł�1���߂�����5�r�b�g�ł��邱�Ƃ��m���Ă�B
���ߒ���4�r�b�g�ix86��1���ߒ��͋K�i��1�`15�o�C�g�j�A�X��1�r�b�g��INT�p�C�v��FP�p�C�v���̏����i�[�����
5�r�b�g�ł��ނˁB
x87���߂̏ꍇ�ŏ���1�o�C�g�������FP���߂��Ƃ킩�邪�A0F�Ŏn�܂�2�o�C�g���߂�
�X�J�����߂�SIMD���߂��}�b�s���O����Ă邩�猋�ǍŌ��Opcode�܂ł݂Ĕ��肵�Ȃ��Ƃ����Ȃ��B
���Ȃ݂ɂ��̃^�O�AK10����y1�o�C�g������3�r�b�g�z�ɂȂ��Ă�炵�����Ǐڍׂ͕s���B
��Ŏ����̏ڍׂ�
http://www.patentstorm.us/patents/5819059/claims.html
Intel���f�R�[�h�i�����R�X�g�ƒm���Core MA�Œ����f�R�[�h�̕������̂��Ă�̂�
AMD�����̓��������Ă邩��Ǝv���Ă邪�B
�b�������ꒃ�߂��ĕt���Ă����Ȃ��B
387 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 21:10:06 ID:lZIalqH7
�A�E�g�I�u�I�[�_�N��NGID�o�^����Α����܂Ƃ��ȋZ�p�_�ɂȂ邩����
>>385
�L���b�V���̒[�����ɓ�����́AK7����1�o�C�g������3�r�b�g�ɂȂ��Ă�炵��
���ʓI�ɂ�INT�p�C�v��FP�p�C�v����������邩������Ȃ����A>>385���ǂނ�
ttp://www.freepatentsonline.com/6460132.pdf
�v���t�B�N�X�o�C�g���ۂ��AModRM�̏ꏊ��SIB�o�C�g�̗L���A���炢������������
�L���b�V���̒[�����ɓ�����́AK7����1�o�C�g������3�r�b�g�ɂȂ��Ă�炵��
���ʓI�ɂ�INT�p�C�v��FP�p�C�v����������邩������Ȃ����A>>385���ǂނ�
ttp://www.freepatentsonline.com/6460132.pdf
�v���t�B�N�X�o�C�g���ۂ��AModRM�̏ꏊ��SIB�o�C�g�̗L���A���炢������������
�ʖڂ��R�C�c
>>385
�u5�r�b�g�̃^�O�v�Ƃ����̂��ǂ��̒i�K�̉����w���Ă���̂�������Ȃ�orz
�u5�r�b�g�̃^�O�v�Ƃ����̂��ǂ��̒i�K�̉����w���Ă���̂�������Ȃ�orz
391 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 21:41:34 ID:lZIalqH7
>>388
�ŏ���3�r�b�g�̂���1�r�b�g���u1�o�C�g���߂��A���o�C�g���߂��v�̃t���O�Ɋ��蓖�Ă�
�c���2�o�C�g�ڈȍ~�����Ɏg���Ƃ����Α����ˁB
�듚�������ɂ͏������߂��ʏ햽�߂��̃t���O�r�b�g�����݂���炵����
�ߋ��L��������̂������h�C
�ŏ���3�r�b�g�̂���1�r�b�g���u1�o�C�g���߂��A���o�C�g���߂��v�̃t���O�Ɋ��蓖�Ă�
�c���2�o�C�g�ڈȍ~�����Ɏg���Ƃ����Α����ˁB
�듚�������ɂ͏������߂��ʏ햽�߂��̃t���O�r�b�g�����݂���炵����
�ߋ��L��������̂������h�C
392 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/20(�y) 21:44:54 ID:lZIalqH7
����̃v���f�R�[�h�^�O�̃f�[�^�\���͐����킩���
K10�A�[�L��256bit-���߃X�g���[���{160-bit�̃v���f�R�[�h���Ȃ�ĉ���������������
�i�܂�1�o�C�g������5�r�b�g�j
K10�A�[�L��256bit-���߃X�g���[���{160-bit�̃v���f�R�[�h���Ȃ�ĉ���������������
�i�܂�1�o�C�g������5�r�b�g�j
L1�L���b�V���ɗ]�v�ȃr�b�g������A
x86�̃o�C�i�������̗ǂ����E������Ȃ��́B
x86�̃o�C�i�������̗ǂ����E������Ȃ��́B
394 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 07:56:55 ID:NRePceAu
����ǂ��납���ߐ�p�L���b�V���͓Ǎ���p������p�[�W���Ƀ��C�g�o�b�N���䂪�K�v���Ȃ��Ƃ��������b�g�܂�
�r���L���b�V���@�\�ɂ���ĎE���Ă���
�r���L���b�V���@�\�ɂ���ĎE���Ă���
�܂�����
L1���߃L���b�V���܂Ŕr���c�c���Ɓc�c?
���̔��z�͂Ȃ������B�{��? AMD�͂�ς˂��ȁB
���̔��z�͂Ȃ������B�{��? AMD�͂�ς˂��ȁB
397 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 08:33:48 ID:NRePceAu
����Duron�F
L1I 64KB
L1D 64KB
L2 64KB
�r�������邵���Ȃ��ł���B
L1I 64KB
L1D 64KB
L2 64KB
�r�������邵���Ȃ��ł���B
�t�ɁA����Ȃ�����҂肵���Ȃ��Ȃ�A
L2�̓f�[�^��p���Ċ���������ăy�i���e�B�͂����͂������B
�L���b�V���Ɏ��܂�R�[�h�ʂ�64KB��64KB+���ɂȂ邩�����̈Ⴂ�ł���?
���̕������f�[�^�L���b�V����������疳�ʂ���Ȃ����B
L2�̓f�[�^��p���Ċ���������ăy�i���e�B�͂����͂������B
�L���b�V���Ɏ��܂�R�[�h�ʂ�64KB��64KB+���ɂȂ邩�����̈Ⴂ�ł���?
���̕������f�[�^�L���b�V����������疳�ʂ���Ȃ����B
��܃L���b�V����L2�͉��ʂ���
K7�̍���AMD�r���̓T�u�E�\������
ttp://www.killernotebooks.com/core_duo_specs.aspx
K8�̃f�[�^������L2@1MB��16way
1way�ӂ�̃T�C�Y��L1�̔{���x�H
�����L1��L2�Ńf�[�^����ւ���̂ɓs�����ǂ��̂ł͂Ȃ���
�̂���L���b�V���̖ʐϓI�ɕs������������
���f�[�^��p���Ċ���������ā@���Ă������
�\���Ŋ�����Ă��̂�AMD���낤��
K7�̍���AMD�r���̓T�u�E�\������
ttp://www.killernotebooks.com/core_duo_specs.aspx
K8�̃f�[�^������L2@1MB��16way
1way�ӂ�̃T�C�Y��L1�̔{���x�H
�����L1��L2�Ńf�[�^����ւ���̂ɓs�����ǂ��̂ł͂Ȃ���
�̂���L���b�V���̖ʐϓI�ɕs������������
���f�[�^��p���Ċ���������ā@���Ă������
�\���Ŋ�����Ă��̂�AMD���낤��
400 �FMAC�I�^���c�q �����F2010/03/21(��) 11:42:04 ID:tQ2m2qMB
>>358
�x���Ȃ��Ď��炵�܂����B�����̘_�_���Ăނ��낻�̑O�ɍs�����c�_�̃R���ł́H
http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/475
�@�@-----------------------
�@�@475 ���O�FMAC�I�^���c�q ���� ���e���F2007/04/07(�y) 10:48:04 ID:BW1UDr9K
�@�@�@�@>>470
�@�@�@�@-----------------
�@�@�@�@�V���b�t���P�ʂ�128�r�b�g�ɂȂ������ƂŁA�P��OPs�ŏ����ł���悤�ɂȂ������Ƃ�
�@�@�@�@-----------------
�@�@�N���X�o�[�X�C�b�`���Ēm���Ă邷���HAltiVec�����ł̐����͈͂�A�����Ȃ��Ă��邷�B
�@�@http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=1&p=1&f=G&l=50&d=PTXT&S1=5,996,057.PN.&OS=PN/5,996,057&RS=PN/5,996,057
�@�@�@�@=================
�@�@�@�@8. The apparatus of claim 7 wherein the vector elements of said first and second vector
�@�@�@�@registers comprise a set of 2.sup.n input vector elements, and wherein, in response to each
�@�@�@�@of said vector elements of said control vector, the combination network selects one of said
�@�@�@�@2.sup.n input vector elements.
�@�@�@�@=================
�@�@-----------------------
�x���Ȃ��Ď��炵�܂����B�����̘_�_���Ăނ��낻�̑O�ɍs�����c�_�̃R���ł́H
http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/475
�@�@-----------------------
�@�@475 ���O�FMAC�I�^���c�q ���� ���e���F2007/04/07(�y) 10:48:04 ID:BW1UDr9K
�@�@�@�@>>470
�@�@�@�@-----------------
�@�@�@�@�V���b�t���P�ʂ�128�r�b�g�ɂȂ������ƂŁA�P��OPs�ŏ����ł���悤�ɂȂ������Ƃ�
�@�@�@�@-----------------
�@�@�N���X�o�[�X�C�b�`���Ēm���Ă邷���HAltiVec�����ł̐����͈͂�A�����Ȃ��Ă��邷�B
�@�@http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=1&p=1&f=G&l=50&d=PTXT&S1=5,996,057.PN.&OS=PN/5,996,057&RS=PN/5,996,057
�@�@�@�@=================
�@�@�@�@8. The apparatus of claim 7 wherein the vector elements of said first and second vector
�@�@�@�@registers comprise a set of 2.sup.n input vector elements, and wherein, in response to each
�@�@�@�@of said vector elements of said control vector, the combination network selects one of said
�@�@�@�@2.sup.n input vector elements.
�@�@�@�@=================
�@�@-----------------------
401 �FMAC�I�^�������F2010/03/21(��) 11:47:28 ID:tQ2m2qMB
�ŁA���܂���Ȃ�������̐���������ǂݒ����Ă݂܂�������ǁA�����p���Ƃ��Ă�
vector permute �p�N���X�o�[�X�C�b�`���̂ɓ������͖����悤�ŁA�ނ���>>351�ɂ���
�悤��3����(����2 + �ʒu�w��)�ł��邱�Ƃ������Ă��܂��B
Super Shuffle Engine ���̂ɂ͓���VPERM������N�Q���郂�m�ł͖��������ł����B
vector permute �p�N���X�o�[�X�C�b�`���̂ɓ������͖����悤�ŁA�ނ���>>351�ɂ���
�悤��3����(����2 + �ʒu�w��)�ł��邱�Ƃ������Ă��܂��B
Super Shuffle Engine ���̂ɂ͓���VPERM������N�Q���郂�m�ł͖��������ł����B
���Ă͍H��͑S�����{�ɂ����āA�J���҂͑S�����Ј��ŁA�N������ŋ������ǂ�ǂ�����
�@�l�ł������S�R�������ċK�������Č������āA��Ƃ͊��̎�����������Ă���
�Љ�}�⋤�Y�}�������č��������肾�����̂�
�����������ē��{�̓A�����J�Ɏ����i���o�[�Q�̒n�ʂɂ�����
�Ƃ��낪�A�R�X�g���팸���čH����ǂ�ǂ�C�O�Ɉړ]�����Đ��Ј�����Ĕh���ɂ��܂�����
�@�l�Ō��ł��܂����ċK���ɘa���܂����Ċ�Ƃ̎��������������p���܂�����
�Љ�}�⋤�Y�}�͏��ł��������Ăăl�b�g�E������ɂȂ����̂�
���o���ς͖\�����Đ�i���̒n�ʂ���]��
�ςɂ܂܂ꂽ�悤�Șb�����
�@�l�ł������S�R�������ċK�������Č������āA��Ƃ͊��̎�����������Ă���
�Љ�}�⋤�Y�}�������č��������肾�����̂�
�����������ē��{�̓A�����J�Ɏ����i���o�[�Q�̒n�ʂɂ�����
�Ƃ��낪�A�R�X�g���팸���čH����ǂ�ǂ�C�O�Ɉړ]�����Đ��Ј�����Ĕh���ɂ��܂�����
�@�l�Ō��ł��܂����ċK���ɘa���܂����Ċ�Ƃ̎��������������p���܂�����
�Љ�}�⋤�Y�}�͏��ł��������Ăăl�b�g�E������ɂȂ����̂�
���o���ς͖\�����Đ�i���̒n�ʂ���]��
�ςɂ܂܂ꂽ�悤�Șb�����
403 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 12:02:01 ID:NRePceAu
>>401
��ŁAXOP��VPPERM�́H
�ʔ������ƂɈ����t�H�[�}�b�g���̂܂��AltiVec/VMX��VPPERM�݊�����B
�i�G���f�B�A���̈Ⴂ�͂��邯�ǁj
���ꂱ���܂���IBM�̃N���X���C�Z���X�̐��ʂ���Ȃ��́H
��ŁAXOP��VPPERM�́H
�ʔ������ƂɈ����t�H�[�}�b�g���̂܂��AltiVec/VMX��VPPERM�݊�����B
�i�G���f�B�A���̈Ⴂ�͂��邯�ǁj
���ꂱ���܂���IBM�̃N���X���C�Z���X�̐��ʂ���Ȃ��́H
404 �FMAC�I�^���c�q �����F2010/03/21(��) 12:04:39 ID:tQ2m2qMB
>>403
�@�@-----------------
�@�@���ꂱ���܂���IBM�̃N���X���C�Z���X�̐��ʂ���Ȃ��́H
�@�@-----------------
�����v���Z�X�ȊO�ł���ȃj���[�X�͕��������Ƃ��Ȃ��̂ł����H
�@�@-----------------
�@�@���ꂱ���܂���IBM�̃N���X���C�Z���X�̐��ʂ���Ȃ��́H
�@�@-----------------
�����v���Z�X�ȊO�ł���ȃj���[�X�͕��������Ƃ��Ȃ��̂ł����H
���o���ςȂ��2004�N���̐����ɖ߂��Ă邪
406 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 12:12:50 ID:NRePceAu
�EVPERM�ƈ����݊���VPPERM
�EVSEL���̂��̂�VPCMOV
�E�v�f���ɕϗʉς̃r�b�g�V�t�g����
�E���A�r�b�g���[�e�[�g����
����SSE�ɂ͂Ȃ���AltiVec�ɂ���v�f���肾��
�����̓d�g���Ă͂߂�Ȃ炱���Ȃ�̂���
Apple��AMD��AltiVec�̊֘A���������C�Z���X����
�EVSEL���̂��̂�VPCMOV
�E�v�f���ɕϗʉς̃r�b�g�V�t�g����
�E���A�r�b�g���[�e�[�g����
����SSE�ɂ͂Ȃ���AltiVec�ɂ���v�f���肾��
�����̓d�g���Ă͂߂�Ȃ炱���Ȃ�̂���
Apple��AMD��AltiVec�̊֘A���������C�Z���X����
407 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 12:17:29 ID:NRePceAu
Super Shuffle Engine���o�Ă����Ƃ���Intel��Apple�̌q����i�j��������Ǝv������
AMD��AltiVec�ɍ����������ߊg���������疳�������
�ǂ��c��Apple������
AMD��AltiVec�ɍ����������ߊg���������疳�������
�ǂ��c��Apple������
408 �FMAC�I�^���c�q �����F2010/03/21(��) 12:22:24 ID:tQ2m2qMB
>>406-407
�@�@------------------
�@�@�ǂ��c��Apple������
�@�@------------------
Altivec������AIM�O�ЂɌ���������܂�����A Apple�̖��ł͂���܂����B
�@�@------------------
�@�@�ǂ��c��Apple������
�@�@------------------
Altivec������AIM�O�ЂɌ���������܂�����A Apple�̖��ł͂���܂����B
>>405
�N��150���ȉ��̐l������������Ȃ��������H
�N��150���ȉ��̐l������������Ȃ��������H
410 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 13:28:23 ID:NRePceAu
>>408
��ŁAAMD XOP��AltiVec�����̊֘A���͂ǂ��Ȃ́H
����ς��悤���H
����AMD��IBM��̃��C�Z���X����VPERM���̂��̂ȃV���b�t�����j�b�g�y�і��߂�����������
�������ɂȂ��ȁH
����͂܂�ǂ��������Ƃ����킩���ȁH
��ŁAAMD XOP��AltiVec�����̊֘A���͂ǂ��Ȃ́H
����ς��悤���H
����AMD��IBM��̃��C�Z���X����VPERM���̂��̂ȃV���b�t�����j�b�g�y�і��߂�����������
�������ɂȂ��ȁH
����͂܂�ǂ��������Ƃ����킩���ȁH
������CPU�X���ƂȂ�̊W������́H
XOP�̃��[�c��b���Ă�݂��������炢����Ȃ��H
413 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 14:07:47 ID:NRePceAu
Bulldozer�̘b��ł��B
�EBulldozer��Altivec�̈����݊��̖���(XOP)��lj�
�EPOWER7��SSE���C�N�Ȗ���(VSX)��lj�
�����̌��ʂƂ��āABulldozer��POWER7�ƂŁASIMD Intrinsics���x���ŋL�q���ꂽ�R�[�h��
���݈ڐA����r�I�e�ՂɂȂ��ˁB
�܂��APOWER7�ɂ��ĕ�����Ă��Ȃ��̂Ɋ��X�ƌ���Ă�MAC�I�^�Ƃ��Ă�
�v�l��~������Ȃ�㩁B
�uApple��Intel��Super Shuffle Engine�����C�Z���X�����v�Ȃ�ăg���f���_�͏o�Ă��Ă��A
�����MAC�I�^�͓��������Ă邯��
�F�߂�̂�������ɂ炵���ȁB
�EBulldozer��Altivec�̈����݊��̖���(XOP)��lj�
�EPOWER7��SSE���C�N�Ȗ���(VSX)��lj�
�����̌��ʂƂ��āABulldozer��POWER7�ƂŁASIMD Intrinsics���x���ŋL�q���ꂽ�R�[�h��
���݈ڐA����r�I�e�ՂɂȂ��ˁB
�܂��APOWER7�ɂ��ĕ�����Ă��Ȃ��̂Ɋ��X�ƌ���Ă�MAC�I�^�Ƃ��Ă�
�v�l��~������Ȃ�㩁B
�uApple��Intel��Super Shuffle Engine�����C�Z���X�����v�Ȃ�ăg���f���_�͏o�Ă��Ă��A
�����MAC�I�^�͓��������Ă邯��
�F�߂�̂�������ɂ炵���ȁB
414 �FMAC�I�^���c�q �����F2010/03/21(��) 14:53:46 ID:tQ2m2qMB
>>410
�@�@---------------------
�@�@����AMD��IBM��̃��C�Z���X����VPERM���̂��̂ȃV���b�t��
�@�@���j�b�g�y�і��߂�����������������ɂȂ��ȁH
�@�@---------------------
�Ȃ�܂��B
�������A����ȑO�Ƀv���Z�b�T�����E�̔����Ƃ�IBM�̓������ЂƂ��g��Ȃ��ŏ�����
�o�����͖����̂ł���(��)
����Ȓm���ȑO�̂��Ƃ��苭�ق��邩��q�ǂ�����������ł���B
�@�@---------------------
�@�@����AMD��IBM��̃��C�Z���X����VPERM���̂��̂ȃV���b�t��
�@�@���j�b�g�y�і��߂�����������������ɂȂ��ȁH
�@�@---------------------
�Ȃ�܂��B
�������A����ȑO�Ƀv���Z�b�T�����E�̔����Ƃ�IBM�̓������ЂƂ��g��Ȃ��ŏ�����
�o�����͖����̂ł���(��)
����Ȓm���ȑO�̂��Ƃ��苭�ق��邩��q�ǂ�����������ł���B
415 �FMAC�I�^���⑫�F2010/03/21(��) 14:55:34 ID:tQ2m2qMB
POWER7��VSX����SSE���C�N�Ȃ�?
417 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 15:22:33 ID:NRePceAu
�������ɔF�߂����B�ǂ��q�ǂ��q
�Ƃ������A>>401�Ŏ����Ō����Ă邩�瓦������Ȃ���ˁB
���ł�
> Altivec������AIM�O�ЂɌ���������܂�����A Apple�̖��ł͂���܂����B
AIM�A���Ȃ�Ă̂͂Ƃ��̐́iIntel�ڍs�i�K�j�ɉ������Ă�킯�Ȃ�
Apple�������Ɏ����Ă錠�����Ĉ�̂Ȃ�
�Ƃ������A>>401�Ŏ����Ō����Ă邩�瓦������Ȃ���ˁB
���ł�
> Altivec������AIM�O�ЂɌ���������܂�����A Apple�̖��ł͂���܂����B
AIM�A���Ȃ�Ă̂͂Ƃ��̐́iIntel�ڍs�i�K�j�ɉ������Ă�킯�Ȃ�
Apple�������Ɏ����Ă錠�����Ĉ�̂Ȃ�
418 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/21(��) 15:28:36 ID:NRePceAu
>>416
AltiVec�̓V���b�t���Ȃǂ̃p�^�[���w��ɑ��l�I�y�����h�����悤�Ȗ��߂��Ȃ������B
���Ȃ킿�V���b�t���p�^�[�����\�[�X���W�X�^�Ƀ��[�h���Ă��Ȃ��Ƃ����Ȃ������B
���VSX�ł�SSE�̂悤�ɑ��l�t�B�[���h�Ńp�^�[���w��o���閽�߂��lj����ꂽ�B
���Ƃ̓X�J��-�x�N�^�Ԃ̃f�[�^���_�C���N�g�Ɍ������閽�߂Ƃ�
AltiVec�̓V���b�t���Ȃǂ̃p�^�[���w��ɑ��l�I�y�����h�����悤�Ȗ��߂��Ȃ������B
���Ȃ킿�V���b�t���p�^�[�����\�[�X���W�X�^�Ƀ��[�h���Ă��Ȃ��Ƃ����Ȃ������B
���VSX�ł�SSE�̂悤�ɑ��l�t�B�[���h�Ńp�^�[���w��o���閽�߂��lj����ꂽ�B
���Ƃ̓X�J��-�x�N�^�Ԃ̃f�[�^���_�C���N�g�Ɍ������閽�߂Ƃ�
419 �FMAC�I�^���c�q �����F2010/03/21(��) 16:48:16 ID:tQ2m2qMB
>>417
�@�@-----------------
�@�@AIM�A���Ȃ�Ă̂͂Ƃ��̐́iIntel�ڍs�i�K�j�ɉ������Ă�킯�Ȃ�
�@�@-----------------
AIM�A���Ƃ�����Ɩ��͖����̂ł����c
Apple, IBM, Motorola�̎O�Ђ����ɏ��L���Ă���Ƃ����Ӗ��������ł��Ȃ����Ă̂́w���������邪�܂܂ɂ��������ł��Ȃ��x�Ƃ����]�̍\���̖��Ȃ�ł��傤���H
>>349�Ń����N����������"Asignee"�̍��ڂ�Apple��IBM�̖��O������܂���B
>>418
�@�@-----------------
�@�@AltiVec�̓V���b�t���Ȃǂ̃p�^�[���w��ɑ��l�I�y�����h�����悤�Ȗ��߂��Ȃ������B
�@�@-----------------
����͈Ⴂ�܂��ˁBVSX�ŔėpPermute���߂��~�߂āA���̂悤�Ȃ����ɂ����̂̓��W�X�^����16�ɂ���ƁA�p�^�[���w��p���W�X�^��p����4�����̖��߃t�H�[�}�b�g���s�\�ɂȂ�Ƃ��������̘b���ł��B
�@�@-----------------
�@�@AIM�A���Ȃ�Ă̂͂Ƃ��̐́iIntel�ڍs�i�K�j�ɉ������Ă�킯�Ȃ�
�@�@-----------------
AIM�A���Ƃ�����Ɩ��͖����̂ł����c
Apple, IBM, Motorola�̎O�Ђ����ɏ��L���Ă���Ƃ����Ӗ��������ł��Ȃ����Ă̂́w���������邪�܂܂ɂ��������ł��Ȃ��x�Ƃ����]�̍\���̖��Ȃ�ł��傤���H
>>349�Ń����N����������"Asignee"�̍��ڂ�Apple��IBM�̖��O������܂���B
>>418
�@�@-----------------
�@�@AltiVec�̓V���b�t���Ȃǂ̃p�^�[���w��ɑ��l�I�y�����h�����悤�Ȗ��߂��Ȃ������B
�@�@-----------------
����͈Ⴂ�܂��ˁBVSX�ŔėpPermute���߂��~�߂āA���̂悤�Ȃ����ɂ����̂̓��W�X�^����16�ɂ���ƁA�p�^�[���w��p���W�X�^��p����4�����̖��߃t�H�[�}�b�g���s�\�ɂȂ�Ƃ��������̘b���ł��B
>���W�X�^����16�ɂ����
�����̃R�e�n���̐l�̓g���b�v���Ȃ��|���V�[�ł�����낤���B
�܂��A3�҂̊Ԃł͘b�̓��e�����ő���̋�ʂ����̂�������Ȃ��B
�G���ƌĂ�Ă��l�����邦��@�ł����Ă�H
�܂��A3�҂̊Ԃł͘b�̓��e�����ő���̋�ʂ����̂�������Ȃ��B
�G���ƌĂ�Ă��l�����邦��@�ł����Ă�H
�I�^�Ƃ��͂�����10�N���炢���邾��B�@�r���ŕʂ̐l�ɕς���Ă�\�������邪�B
�ÎQ���m�̓g���b�v���Ȃ��Ă����݂����F���ł����ˁH
�ÎQ���m�̓g���b�v���Ȃ��Ă����݂����F���ł����ˁH
�F���ł���Ȃ��A�g���b�v�t���ĐӔC���������Ȃ���
424 �FMAC�I�^��420 �����F2010/03/21(��) 18:19:36 ID:tQ2m2qMB
>>420
���w�E���ӂ��܂��B64�̊ԈႢ�ł��ˁB
���w�E���ӂ��܂��B64�̊ԈႢ�ł��ˁB
425 �FMAC�I�^��423 �����F2010/03/21(��) 18:22:15 ID:tQ2m2qMB
>>423
�����Super Shuffle Engine�̌��ł�����l�ɁA�̂̃J�L�R�~�ɂ��ӔC�͎����܂���B
���̂��߂ɌŒ�n���h����10�N����������ł����ł��B
�����Super Shuffle Engine�̌��ł�����l�ɁA�̂̃J�L�R�~�ɂ��ӔC�͎����܂���B
���̂��߂ɌŒ�n���h����10�N����������ł����ł��B
>>425
�Ȃ�g���b�v���t�������������ł���
�Ȃ�g���b�v���t�������������ł���
2�����˂�͖�������������Ǝv�����ǁA
CPU�_�����ɂ͑S���Ƀ��x�����\���Ă������ق������₷����ȁB
�ǂ����ɂ��傤�ǂ����f���͂͂Ȃ��̂��̂��B
�������͎��͂��Ȃɂ��Ȃ��̂ɂ��炻�[�Ȃ����̔n����9���肾����ȁB
CPU�_�����ɂ͑S���Ƀ��x�����\���Ă������ق������₷����ȁB
�ǂ����ɂ��傤�ǂ����f���͂͂Ȃ��̂��̂��B
�������͎��͂��Ȃɂ��Ȃ��̂ɂ��炻�[�Ȃ����̔n����9���肾����ȁB
���́H��
�ł�MAC�I�^�̋U�ҏo�����ƃi�N�l�H
ID������Ő�ւ���̂��ˁB�������D�������Ă��ɂ����B
���x���̓f�t�H���g�ŌX�Ɋ��蓖�ĂĂق����ȁB
�Ȃ����\��}���ȒP�ɓ\��āA�������̍����f�����x�X�g�B
����������Ɉڍs���Ă��B
���x���̓f�t�H���g�ŌX�Ɋ��蓖�ĂĂق����ȁB
�Ȃ����\��}���ȒP�ɓ\��āA�������̍����f�����x�X�g�B
����������Ɉڍs���Ă��B
�����҂ɂȂ�
�g���t������������
��������Ă��u���ɖ����������Ƃɂ��ĕ��R�Ɩ\���s���ɂ͒N���G��Ȃ�
�܂��R�e�ɖ\��Ă�ꂢ�邾���ՌÒ����͂܂����낤�B
�㓡�}���Z�[�X���Ȃ����b��Řb�������Ȃ��Ȃ������B
�㓡�}���Z�[�X���Ȃ����b��Řb�������Ȃ��Ȃ������B
>>425
> �����Super Shuffle Engine�̌��ł�����l�ɁA�̂̃J�L�R�~�ɂ��ӔC�͎����܂���B
���[���̓��B���ŐQ���������Ă��C�����邪�A�A���͒��������̂��ˁB
> ���̂��߂ɌŒ�n���h����10�N����������ł����ł��B
Apple�͈����Ă��ꂽ�����H
> �����Super Shuffle Engine�̌��ł�����l�ɁA�̂̃J�L�R�~�ɂ��ӔC�͎����܂���B
���[���̓��B���ŐQ���������Ă��C�����邪�A�A���͒��������̂��ˁB
> ���̂��߂ɌŒ�n���h����10�N����������ł����ł��B
Apple�͈����Ă��ꂽ�����H
apple������apple
�܂�PC8001��MZ80B�̃��[�U�[�őΗ����Ă����Aapple�U���[�U�[�͍����̌�����Ԃ������B
CPU��6502�ŐF��4�F���������ǃh�b�g�ׂ͍����������A�\�t�g���F�X�o�Ă��B
���̌ジ���Ɗւ�鎖�͖����������ǁA
�����ŋ߂ɂȂ���iphone�Ȃ���̂��g���Ă���B�����Ǝg��������������A���������B
�܂�PC8001��MZ80B�̃��[�U�[�őΗ����Ă����Aapple�U���[�U�[�͍����̌�����Ԃ������B
CPU��6502�ŐF��4�F���������ǃh�b�g�ׂ͍����������A�\�t�g���F�X�o�Ă��B
���̌ジ���Ɗւ�鎖�͖����������ǁA
�����ŋ߂ɂȂ���iphone�Ȃ���̂��g���Ă���B�����Ǝg��������������A���������B
2�����˂�̌Œ�n���h���̋@�\��
�g�����ؖ�������A���������ƍ��ł���悤�Ȃ��̂ł͂Ȃ��āA
�P�Ȃ郉�x���@�\�ɂ��������Ȃ��̂��B
�����炢���������L�ɂȂ�悤�Ȃ��Ƃł͂Ȃ��B
�R�e�͓���l�����p�����ď������݂���ꍇ�̖ڈ���x�̈Ӗ������ł����Ȃ��̂ɁA
2�����˂�ł͖��������f�H�t���g�ݒ�łӂ��̓R�e�͖����Ȃ��Ƃ��������Ȃ��߂ɁA
�R�e�Ƃ������x���@�\���g���������ňُ�l���ƔF�߂��邱�ƂɂȂ�(�����ȏ�͐�������w)�B
�������A�����l�^��Ώۂɂ��Čp���I�ɕ�����A�������ɂ킽���ď������݂��s���ꍇ�ɂ́A
���x�����Ȃ��Ƒ�������玩�����p�����ď����Ă���Ƃ������Ƃ��`���Ȃ����߁A
���ۂ̂Ƃ���s�ւȂ��Ƃ������̂������B
�Ƃ����킯�ŕ������ɂ킽���ē��l�^�𑱂��邽�߂ɂ͍r�炵�ɓs���������f�����b�g���������
�f�t�H���g���������Ƃ����ݒ�͕s�ւ����t���܂Ƃ������ŁA2�����˂�̖��������S��`�̕�����
�s�ւ��ɑ���M�Ƃ������邾�낤�B
�����I�Ƀ��x��������U��(�p�����邩�ǂ����͊e�l�̎��R)�A���O���Ƀn���h��������̂��ӂ�
�Ƃ��������ł���c�_�͂�قǂ��₷���̂Ɏc�O�Ȃ��Ƃ��B
�g�����ؖ�������A���������ƍ��ł���悤�Ȃ��̂ł͂Ȃ��āA
�P�Ȃ郉�x���@�\�ɂ��������Ȃ��̂��B
�����炢���������L�ɂȂ�悤�Ȃ��Ƃł͂Ȃ��B
�R�e�͓���l�����p�����ď������݂���ꍇ�̖ڈ���x�̈Ӗ������ł����Ȃ��̂ɁA
2�����˂�ł͖��������f�H�t���g�ݒ�łӂ��̓R�e�͖����Ȃ��Ƃ��������Ȃ��߂ɁA
�R�e�Ƃ������x���@�\���g���������ňُ�l���ƔF�߂��邱�ƂɂȂ�(�����ȏ�͐�������w)�B
�������A�����l�^��Ώۂɂ��Čp���I�ɕ�����A�������ɂ킽���ď������݂��s���ꍇ�ɂ́A
���x�����Ȃ��Ƒ�������玩�����p�����ď����Ă���Ƃ������Ƃ��`���Ȃ����߁A
���ۂ̂Ƃ���s�ւȂ��Ƃ������̂������B
�Ƃ����킯�ŕ������ɂ킽���ē��l�^�𑱂��邽�߂ɂ͍r�炵�ɓs���������f�����b�g���������
�f�t�H���g���������Ƃ����ݒ�͕s�ւ����t���܂Ƃ������ŁA2�����˂�̖��������S��`�̕�����
�s�ւ��ɑ���M�Ƃ������邾�낤�B
�����I�Ƀ��x��������U��(�p�����邩�ǂ����͊e�l�̎��R)�A���O���Ƀn���h��������̂��ӂ�
�Ƃ��������ł���c�_�͂�قǂ��₷���̂Ɏc�O�Ȃ��Ƃ��B
438 �FMAC�I�^��435 �����F2010/03/21(��) 20:27:14 ID:hb18Li8q
MAC�I�^��c�q�A�ߍ��Y�܂ꂽ�V��̂��邦��ӂ�́A
���̃X���œd�g����Ă܂����Ă���݂��������A
���̎��o������̂��R�e��t���Ă��鎖�͕]���ł���B
�܂��B�g���t���悤�ƕt���܂��ƁA�d�g�̋����ɏ㉺�͂��Ȃ����A
�ז��ɂȂ�E�Ȃ�Ȃ��Ƃ����ϓ_���炷��Ǝז��ɂɂȂ�Ȃ��ł��Ă����B
>>436
�Ӳ�B
���̃X���œd�g����Ă܂����Ă���݂��������A
���̎��o������̂��R�e��t���Ă��鎖�͕]���ł���B
�܂��B�g���t���悤�ƕt���܂��ƁA�d�g�̋����ɏ㉺�͂��Ȃ����A
�ז��ɂȂ�E�Ȃ�Ȃ��Ƃ����ϓ_���炷��Ǝז��ɂɂȂ�Ȃ��ł��Ă����B
>>436
�Ӳ�B
>>439
�����ς܂����B
�����ς܂����B
������ʂ�
�Ă��}�V�ȃ��X�Ȃق�
�Ă��}�V�ȃ��X�Ȃق�
�������゠�����CPU�ɓ��������̂��ȁH
���낢��|���V�[�͂���̂�������Ȃ����ǁA
�{���ƋU���̋�ʂ����Ȃ�����g���b�v�����Ăق����B
������2ch�̃��O�Ƀg���b�v���Ȃ��͎̂d�����Ȃ����ǁB
�{���ƋU���̋�ʂ����Ȃ�����g���b�v�����Ăق����B
������2ch�̃��O�Ƀg���b�v���Ȃ��͎̂d�����Ȃ����ǁB
MAC�I�^���̂��炱���ɂ���Ǝ��̂��Ă邯�ǁA
�r���ŕʂ̐l�ɕς���Ă邩������Ȃ����ȁB
�܂��A�������e���炵�āA�����Ɠ����l���낤���ǂ�
�r���ŕʂ̐l�ɕς���Ă邩������Ȃ����ȁB
�܂��A�������e���炵�āA�����Ɠ����l���낤���ǂ�
445 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/22(��) 03:45:59 ID:oQigsKs+
>>419
����Ȃ��ƒm���Ă邪
Apple��IBM�Ƃ̒�g�W�����������̂�Yahoo�ɂ��ڂ����j���[�X�ł����邪
��ŁA�N�̑�D����Apple�������ɓ�������ێ����Ă�Ƃ��āA
IBM�����łȂ�Apple��AMD��AltiVec�����̎g�p��F�߂����ƂɂȂ�킯�Ȃ����̓_�ǂ��ł����H
�i�Ă�AltiVec�Ƃ̊֘A���]�X�Ɋւ��ẮuSSE5�v�̎d�l�̂Ƃ�����w�E���Ă��j
����Ȃ��ƒm���Ă邪
Apple��IBM�Ƃ̒�g�W�����������̂�Yahoo�ɂ��ڂ����j���[�X�ł����邪
��ŁA�N�̑�D����Apple�������ɓ�������ێ����Ă�Ƃ��āA
IBM�����łȂ�Apple��AMD��AltiVec�����̎g�p��F�߂����ƂɂȂ�킯�Ȃ����̓_�ǂ��ł����H
�i�Ă�AltiVec�Ƃ̊֘A���]�X�Ɋւ��ẮuSSE5�v�̎d�l�̂Ƃ�����w�E���Ă��j
446 �F,,�E�L�́M�E,,�j��-��������CR-Z�F2010/03/22(��) 05:35:07 ID:oQigsKs+
�g���b�v�t����Ɩ������Ɍ�����Ƃ͂�����Ȃ�
447 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/22(��) 06:01:26 ID:oQigsKs+
#CR-Z
448 �F���͌��c�� ��OhjIkO1O8o �F2010/03/22(��) 06:03:12 ID:miHSbTxS
#CR-Z
�������s�������g�Ńt�H���[���Ă�̌���̂͂����ƃL����
�����Ȃ���Ȃ��ȁB2ch���n�߂Ă�����������O���S���Ȃ��B
����������ɏ����閼�����g�����l�ȊO�ł�
�Y�����Ȃ��l���������Ƃ��Ȃ�
����������ɏ����閼�����g�����l�ȊO�ł�
�Y�����Ȃ��l���������Ƃ��Ȃ�
451 �FSocket774�F2010/03/22(��) 08:28:05 ID:aRPuqwyd
452 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/22(��) 09:03:52 ID:oQigsKs+
��������ORE ORE���\
�������Ȃ�ł̖͂ό����ȁB
���Ԃ��ŃR�e�_��W�J���Ă��閼�������R�e�𖼏������
�����ɉ��サ�Ď��g�ُ̈킳�����炯�o�����ʂɂȂ邾�낤�ˁB
2�����˂�̃R�e�͏��F���x���@�\�B
���ł��������ɖ߂邱�Ƃ��ł�����ՂȎ��Ȑ\���̃V�X�e�������B
�U�Ҕ�Q�ŃR�e���g�������Ă���Ȃ�b�͕ʂ����A
���̐l������l���ł��邩�ǂ����ɓǂݎ葤���ُ펷������̂́A
�������͈���œ���l���ł��邩���ʂł��Ȃ��Ȃ邪�����e�F���Ă���A
���R�e�����ł��������ł܂��������݂ł���A
�Ƃ���2�����˂�̎d�g�݂��炢���Ė��Ӗ��Ȃ�B
�������ʼn��X�r�炵�H�삵�Ă���l�Ԃ̕��������ɂ��������Ŏ��ۂ̂Ƃ��됔����������B
���Ԃ��ŃR�e�_��W�J���Ă��閼�������R�e�𖼏������
�����ɉ��サ�Ď��g�ُ̈킳�����炯�o�����ʂɂȂ邾�낤�ˁB
2�����˂�̃R�e�͏��F���x���@�\�B
���ł��������ɖ߂邱�Ƃ��ł�����ՂȎ��Ȑ\���̃V�X�e�������B
�U�Ҕ�Q�ŃR�e���g�������Ă���Ȃ�b�͕ʂ����A
���̐l������l���ł��邩�ǂ����ɓǂݎ葤���ُ펷������̂́A
�������͈���œ���l���ł��邩���ʂł��Ȃ��Ȃ邪�����e�F���Ă���A
���R�e�����ł��������ł܂��������݂ł���A
�Ƃ���2�����˂�̎d�g�݂��炢���Ė��Ӗ��Ȃ�B
�������ʼn��X�r�炵�H�삵�Ă���l�Ԃ̕��������ɂ��������Ŏ��ۂ̂Ƃ��됔����������B
�}�f�Ȃ̂�MAC�I�^�ƒc�q�̃L���b�L���E�t�t�ɍ����낤�ƕK���Ȋ��Ⴂ����C����ȁB
���ȁB
�P�c�����Ԃł���I�^�ƒc�q�ɍ����낤�Ȃ�3�N������B
�P�c�����Ԃł���I�^�ƒc�q�ɍ����낤�Ȃ�3�N������B
���N�������������Ȃ�
MAC�I�^��-�������́A
���Ƃ���mac�⃀���ǂ�������L�ѐ���̎���PC�ւ킴�킴�咣���Ă���
���̌�Z�ݒ������ږ��Ȃ킯�Ő̂��炸���ƈ����ɂ����Ȃ���B
���g�̔�CPU�̘b����m���ł��Ȃ��������玩��PC�ɂ���Ă������B
�嗬�h�̗͂𗝉����Ė�����������\�������R�e�̃E�H�b�`�Ȃ�Ă��ĂȂ��ŁA
�����Ƃ܂Ƃ��ȏ������݂ł���悤�ɂȂ�܂��傤�ˁB
���Ƃ���mac�⃀���ǂ�������L�ѐ���̎���PC�ւ킴�킴�咣���Ă���
���̌�Z�ݒ������ږ��Ȃ킯�Ő̂��炸���ƈ����ɂ����Ȃ���B
���g�̔�CPU�̘b����m���ł��Ȃ��������玩��PC�ɂ���Ă������B
�嗬�h�̗͂𗝉����Ė�����������\�������R�e�̃E�H�b�`�Ȃ�Ă��ĂȂ��ŁA
�����Ƃ܂Ƃ��ȏ������݂ł���悤�ɂȂ�܂��傤�ˁB
458 �FMAC�I�^���c�q �����F2010/03/22(��) 13:47:03 ID:nu4n+fPH
>>445
�@�@--------------------
�@�@Apple��IBM�Ƃ̒�g�W�����������̂�Yahoo�ɂ��ڂ����j���[�X�ł����邪
�@�@--------------------
�@�I�����ƃj���[�X�L����ɕ��ׂāA�m�I���L���̏��݂ɂ��Ēm�������U�邩��q�ǂ����������Ǝv���̂ł����c
�@�@--------------------
�@�@IBM�����łȂ�Apple��AMD��AltiVec�����̎g�p��F�߂����ƂɂȂ�킯�Ȃ�
�@�@���̓_�ǂ��ł����H
�@�@--------------------
�������܂ފJ�����ʂɊւ��ĎQ����Ƃ����ꂼ��ǂ̂悤�Ȍ������s�g�ł��邩�́A�_���Ɏ��ׂ��ɋL����Ă��܂��B
�_�̓��e���r�߂Ă�����ƁA�ꍇ�ɂ���Ă͎Q���Ƃ̋�������ɔ����Ă��܂����Ƃ��炠��܂��BSCEI�Ј���STI�f�U�C���Z���^�[�ōs����PPE�J���̐��ʂ��AMS�ɔ����Ă��܂����̂͂��̈��ł͂Ȃ��ł��傤���H
�@�@--------------------
�@�@Apple��IBM�Ƃ̒�g�W�����������̂�Yahoo�ɂ��ڂ����j���[�X�ł����邪
�@�@--------------------
�@�I�����ƃj���[�X�L����ɕ��ׂāA�m�I���L���̏��݂ɂ��Ēm�������U�邩��q�ǂ����������Ǝv���̂ł����c
�@�@--------------------
�@�@IBM�����łȂ�Apple��AMD��AltiVec�����̎g�p��F�߂����ƂɂȂ�킯�Ȃ�
�@�@���̓_�ǂ��ł����H
�@�@--------------------
�������܂ފJ�����ʂɊւ��ĎQ����Ƃ����ꂼ��ǂ̂悤�Ȍ������s�g�ł��邩�́A�_���Ɏ��ׂ��ɋL����Ă��܂��B
�_�̓��e���r�߂Ă�����ƁA�ꍇ�ɂ���Ă͎Q���Ƃ̋�������ɔ����Ă��܂����Ƃ��炠��܂��BSCEI�Ј���STI�f�U�C���Z���^�[�ōs����PPE�J���̐��ʂ��AMS�ɔ����Ă��܂����̂͂��̈��ł͂Ȃ��ł��傤���H
�Ђ炪�Ȏl�����̐l�͐^���̃A�����ۂ���
460 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/22(��) 14:44:57 ID:oQigsKs+
�Ȃ��Ȃ����܂���ɓ�������
����͓���������A����C�e���V���������
����͓���������A����C�e���V���������
��T���Ђ͗�_�v�҂��Ă��B
GLOBALFOUNDRIES�A2010�N����25���ăh����ݔ������ɔ�₷�v��
http://www.eetimes.jp/news/3784
�Ȃ�Ƃ����I�C���}�l�[�̗�
��������������
AMD�͉����������Ă�ATI�����AGF�����Ɛ��������f�������Ă�C������
http://www.eetimes.jp/news/3784
�Ȃ�Ƃ����I�C���}�l�[�̗�
��������������
AMD�͉����������Ă�ATI�����AGF�����Ɛ��������f�������Ă�C������
����
�肱
�������IBM�̌�ǂ��ł����H
�́H�����v�H>>465
ttp://alienbabeltech.com/main/?p=16214
>Phenom II X6 Six Core
>1090T Black Edition: 125(W), AM3 Socket, 9MB Cache, 3.2 GHz Freq @ 295 USD
>1055T: 125(W), AM3 Socket, 9MB Cache, 2.8 GHz Freq @ 199 USD
D�X�e�b�s���O����E�X�e�b�s���O�����m��nj��\�撣�����������Ȃ�
>Phenom II X6 Six Core
>1090T Black Edition: 125(W), AM3 Socket, 9MB Cache, 3.2 GHz Freq @ 295 USD
>1055T: 125(W), AM3 Socket, 9MB Cache, 2.8 GHz Freq @ 199 USD
D�X�e�b�s���O����E�X�e�b�s���O�����m��nj��\�撣�����������Ȃ�
X6 3.2GHz��125W�ł�����Ȃ�AX4 ��3.0GHz�����95W�ɉ��������̂������Ă���
X6��i5�ǂ����ɂ��ׂ���
X6 1090T��$300�Ă��Ƃ́A���C���i�b�v��n���݂����ɑ��₳�Ȃ��Ɨ��v�ɂȂ�Ȃ����Ă��Ƃ�����A
100MHz�Ԋu��X5��X4���ׂ����o�Ă���낤�ȁB
100MHz�Ԋu��X5��X4���ׂ����o�Ă���낤�ȁB
�n���ł�
�o�J�݂����Ƀ��C���i�b�v��������O�Ƀo�J���������B
95w95w���Ă悭���邪�A�ǂ����Γ�������������������������
����Ƃ���̫�̺�Ђ̂悤�ȏȓd�͋@�\����D���Ȃ̂��H
����Ƃ���̫�̺�Ђ̂悤�ȏȓd�͋@�\����D���Ȃ̂��H
�n���ł�
>>473
�l�I�ɂ�125W�ł�95W�ł��ǂ���"K10stat"�ӂ���g�����A
"K10stat"�̂悤�ȃ\�t�g���i���Ɏg����Ƃ͌���Ȃ����A
"Thuban"�ł͎g���Ȃ���������Ȃ��B
����Ȃ킯�ŁA�����ł������Ă��邩�ǂ������C�ɂ���l�͑����B
����ɂ��Ă͗����ł��邵�A����������C�ɂ��Ȃ�Ȃ��B
�ނ���C�ɂ��Ȃ��z�̕��������ł��Ȃ��B
����Ȃɂ܂Łu�\�t�g�E�F�A�̖��\���v�����҂ł��邨�Ԕ��ɁB
�l�I�ɂ�125W�ł�95W�ł��ǂ���"K10stat"�ӂ���g�����A
"K10stat"�̂悤�ȃ\�t�g���i���Ɏg����Ƃ͌���Ȃ����A
"Thuban"�ł͎g���Ȃ���������Ȃ��B
����Ȃ킯�ŁA�����ł������Ă��邩�ǂ������C�ɂ���l�͑����B
����ɂ��Ă͗����ł��邵�A����������C�ɂ��Ȃ�Ȃ��B
�ނ���C�ɂ��Ȃ��z�̕��������ł��Ȃ��B
����Ȃɂ܂Łu�\�t�g�E�F�A�̖��\���v�����҂ł��邨�Ԕ��ɁB
��]�I�ϑ������ł��Ȃ��l���𑗂��Ă镉���g�ɁB
�����A��̐�]�I�m�\�̋��g�����E�E�E
X5���܂Ƃ܂��ďo����قǐ��Y����̂���
X6�Ɏg���Ȃ��_�C�͑S��X4�ɉ���Ȃ��̂�
�^���ǂ���A�����b�N����X5��X6�Ŏg���邩��������
X6�Ɏg���Ȃ��_�C�͑S��X4�ɉ���Ȃ��̂�
�^���ǂ���A�����b�N����X5��X6�Ŏg���邩��������
479 �F���͌��c�� ��OhjIkO1O8o �F2010/03/23(��) 19:23:12 ID:Og4Bl1OF
>>478
> X6�Ɏg���Ȃ��_�C�͑S��X4�ɉ���Ȃ��̂�
������_���Ȃ�X2�ɉ�邩���m��Ȃ�
�^���ǂ���A�����b�N����X5��X6�Ŏg���邩��������
�ł����͗v��Ȃ�w
> X6�Ɏg���Ȃ��_�C�͑S��X4�ɉ���Ȃ��̂�
������_���Ȃ�X2�ɉ�邩���m��Ȃ�
�^���ǂ���A�����b�N����X5��X6�Ŏg���邩��������
�ł����͗v��Ȃ�w
�G���͎����̃X���ɋA��
481 �F���͌��c�� ��OhjIkO1O8o �F2010/03/23(��) 19:39:57 ID:Og4Bl1OF
�����ƃg���b�v�t���Ă邨
>>480
����ȉ��z�Ȃ��ƌ����Ȃ�E�E�E�o�ɂł��҂��Ă�������ł�������
����ȉ��z�Ȃ��ƌ����Ȃ�E�E�E�o�ɂł��҂��Ă�������ł�������
SOI���s�v�ɁA��Innovative Silicon�Ђ��L���p�V�^�E���XDRAM�Z�p������
http://eetimes.jp/news/3790
http://eetimes.jp/news/3790
>>475�͌��\���_���Ǝv�����c�B
�Ƃ�����K10stat��6�R�A�Ή����Ă邵
���L�������Ȃ�AOD�ł�BIOS�ł��g���邩���
���L�������Ȃ�AOD�ł�BIOS�ł��g���邩���
�d�C��ō��z���̌�������l�i�Ȃ�~�����ȁB
�t���^���[�P�[�X�Ȃ̂ŔM�͂��܂�C�ɂ��Ȃ��B
�t���^���[�P�[�X�Ȃ̂ŔM�͂��܂�C�ɂ��Ȃ��B
�P��95W�܂ł����T�|�[�g���Ȃ�MB��
�g���܂킵���������Ȃ��ǂˁB
�N������K10stat�Ȃǂ̐��䉺�ɂȂ�܂łɒ����Ȃ���Ζ���
�Ȃ��͂������A���_�q�����낵���Ȃ�
�g���܂킵���������Ȃ��ǂˁB
�N������K10stat�Ȃǂ̐��䉺�ɂȂ�܂łɒ����Ȃ���Ζ���
�Ȃ��͂������A���_�q�����낵���Ȃ�
PhenomII XVI
MAC�I�^�̓g���b�v���Ăق����Ǝv��(��������)���ǁA���̐l�͂ǂ��ł������ȁB
>>489
X68K�v���o��������ˁ[���B
X68K�v���o��������ˁ[���B
68000 XVI������w
24Mhz�ɂ��ėV�Ȃ��E�E�E�B
24Mhz�ɂ��ėV�Ȃ��E�E�E�B
�@�@�@�@�@�@�@�Q�@�Q�Q_�Q�@�@�@�@�@�@�@ А���������c
�@�@�@�@ �^;;;;;;;;�Q,;;;;;;;;;,;;;;;;;__;;�R�@�@�@ �~
�@�@�@ /;;;;;�^�@ __ �_�P �^__�_;;�j�@ �O �Ɓ[�����Ƃ��[�����
�@�@�@ |;;;;;'�U_�^__�R�� �U��_�R�/�@�@ �O �I�������̖��`�Ŏ؋�����
�@�@ ,�ۤ;;|�@ ���n�@�r�@ �q.�O }�@{�@�@�@ �O �p�`���R�ɍs���Ă邾���E�E
�@ /�@�@ �U�@�@ �P�@�@�@ �P�@ �@�܁R �O ���ꂪ�q���蓖�āE�E�I�H
�@ |�@�@�@ U �@ �@�@ �@�@�@/���R�@} �O
�@ �___�@�@�@�@�@ �@�@�@�@|'��'��V�@/.�@�c����������~
�@�@ �@ �P�R�Q�Q�@�@ �@ �T �ƃm�^
�y�����̖��`�ŐŎ��ȏ�̎؋����đ�ʃo���}�L�ցz
"�V�K���A�ߋ��ő�̂S�S���~" �Q�O�P�O�N�x�\�Z�������B���z�ߋ��ő�X�Q���~
http://tsushima.2ch.net/test/read.cgi/newsplus/1269420683/l50
�@�@�@�@ �^;;;;;;;;�Q,;;;;;;;;;,;;;;;;;__;;�R�@�@�@ �~
�@�@�@ /;;;;;�^�@ __ �_�P �^__�_;;�j�@ �O �Ɓ[�����Ƃ��[�����
�@�@�@ |;;;;;'�U_�^__�R�� �U��_�R�/�@�@ �O �I�������̖��`�Ŏ؋�����
�@�@ ,�ۤ;;|�@ ���n�@�r�@ �q.�O }�@{�@�@�@ �O �p�`���R�ɍs���Ă邾���E�E
�@ /�@�@ �U�@�@ �P�@�@�@ �P�@ �@�܁R �O ���ꂪ�q���蓖�āE�E�I�H
�@ |�@�@�@ U �@ �@�@ �@�@�@/���R�@} �O
�@ �___�@�@�@�@�@ �@�@�@�@|'��'��V�@/.�@�c����������~
�@�@ �@ �P�R�Q�Q�@�@ �@ �T �ƃm�^
�y�����̖��`�ŐŎ��ȏ�̎؋����đ�ʃo���}�L�ցz
"�V�K���A�ߋ��ő�̂S�S���~" �Q�O�P�O�N�x�\�Z�������B���z�ߋ��ő�X�Q���~
http://tsushima.2ch.net/test/read.cgi/newsplus/1269420683/l50
>Phenom I�̂Ƃ��́A�ڂ����������炩�����ł��B�u����ʼn���b�����Ă�v���āi�j�B
>�������炩�����ł��B�u����ʼn���b�����Ă�v���āi�j�B
>�u����ʼn���b�����Ă�v
http://plusd.itmedia.co.jp/pcuser/articles/1002/12/news034_2.html
>�������炩�����ł��B�u����ʼn���b�����Ă�v���āi�j�B
>�u����ʼn���b�����Ă�v
http://plusd.itmedia.co.jp/pcuser/articles/1002/12/news034_2.html
�y���@�����ł��ˁB���Ƃ����ԈႢ�܂��BPhenom I�̂Ƃ��́A�ڂ����������炩�����ł��B�u����ʼn���b�����Ă�v���āi�j�B
�ł���������Phenom II��������Ă���āB
�ł���������Phenom II��������Ă���āB
����ł�core2�ɒǂ����܂���ł�������
>497
���܂�Phenom II�g���ĂȂ����낤�H
�G�����r���[�ɗx�炳��Ă���N�`����
i7 > Phenom II > core2�@����Ȋ����ł���
���܂�Phenom II�g���ĂȂ����낤�H
�G�����r���[�ɗx�炳��Ă���N�`����
i7 > Phenom II > core2�@����Ȋ����ł���
PhenomIIvsCore2��Athlon64X2vsPenD�̍Č�
�ց[�i�j
>500
������ww
�����ґ���ɂ��Ă��d���Ȃ��낤�A�܂Ƃ��Ȑe�Ɉ�Ă��Ȃ������z������ނ��炢��
�]�T�����Ƃ����B�����Ƒ������Ă݂̂���M���Ă����w
������ww
�����ґ���ɂ��Ă��d���Ȃ��낤�A�܂Ƃ��Ȑe�Ɉ�Ă��Ȃ������z������ނ��炢��
�]�T�����Ƃ����B�����Ƒ������Ă݂̂���M���Ă����w
503 �F���͌��c�� ��OhjIkO1O8o �F2010/03/25(��) 15:29:20 ID:HeNjiRoS
2-Way Set Associative��L1�L���b�V���ŃX���b�V���O�㓙��Phenom�U�Ń��X�|���X�������Ă��Ȃ��E�E�E
i7���l�ÂĂ̘b������ł͂��Ȃ胄�o�C�݂�������
���e�[���N�[���[�̂܂܂��ƃQ�[���������x��CPU���ׂ�������W�O�x������
����ɍċN���ɂȂ�Ƃ��B
����̃C���e���֘A�X���b�h�ł�i7�ʼn��x�R�O�x�i�j�Ƃ����C�ŏ�������ł郌�X�������ς����邯�ǁA
������Ė��炩�Ƀ��e�[���N�[���[�g���ĂȂ��̂ɉ����g���Ă邩�͕����Ă��ˁB
�����������炻������i7���̂��̂��g���ĂȂ��āA�K���ɏ����Ă邾����������Ȃ��Ǝא����Ă��܂��B
���e�[���N�[���[�̂܂܂��ƃQ�[���������x��CPU���ׂ�������W�O�x������
����ɍċN���ɂȂ�Ƃ��B
����̃C���e���֘A�X���b�h�ł�i7�ʼn��x�R�O�x�i�j�Ƃ����C�ŏ�������ł郌�X�������ς����邯�ǁA
������Ė��炩�Ƀ��e�[���N�[���[�g���ĂȂ��̂ɉ����g���Ă邩�͕����Ă��ˁB
�����������炻������i7���̂��̂��g���ĂȂ��āA�K���ɏ����Ă邾����������Ȃ��Ǝא����Ă��܂��B
�EnVidia rename technology
�EIntel Socket change technolog
�EIntel Socket change technolog
Intel�̓��N�U
Nvidia�͍��\�t
Nvidia�͍��\�t
�e�w�G�����������ɃK�Z�L������������ł���Č������Ƃ�
�t�F���~�̔ߎS����X6�̗L�]�����������Ď�����
�t�F���~�̔ߎS����X6�̗L�]�����������Ď�����
AMD�M�҂̃j�[�g�]��120%�͖ϑz�łł��Ă��܂�
�����~�̋L���y���݂���
NV�������ɒ��C�^�[��I��ŏ�������炵����
NV�������ɒ��C�^�[��I��ŏ�������炵����
���₵���̂������������e�w�G���₵���̂�������������
Fermi�X�����Ă�ƃ��b�g�p�t�H�[�}���X�̏d�v�����ˁE�E�E
Bulldozer�ɂ�����Ƀ��b�g�p�t�H�[�}���X�����P���Ă��鎖�����҂��Ƃ�
Bulldozer�ɂ�����Ƀ��b�g�p�t�H�[�}���X�����P���Ă��鎖�����҂��Ƃ�
32nm SOI��HKMG�̗p�ł܂������͖������낤
Fermi�c�����|����
NV��Fermi�̉��ǂŁAAMD��HD6xxx�͐V�A�[�L�e�N�`��
�܂������t�̗�������蓾�邩��A�D���Ȃ����ɉ҂��ł����������
�܂������t�̗�������蓾�邩��A�D���Ȃ����ɉ҂��ł����������
ATI��2900HT�ős��ɔ����������HD3870�Ŕ����̘T���������������
遂�͋֕�����
遂�͋֕�����
�ߋ��ɂ�ATI�����x���V����������������邯�ǁA�����O���V������������˂��B
����͓V�����������ĕs���ɂȂ邗
����͓V�����������ĕs���ɂȂ邗
ATi�̓V�����Ă����Z����Ȃ�
�u�����h��AMD�ɂȂ��Ď����������H
�����Ɛ̂��狣���ɒE�������ɐ����c���Ă����̂͐����Ǝv���B
���̃��[�J�[�͓]�����ɂǂ�ǂ�E�����Ă�̂ɁB
�u�����h��AMD�ɂȂ��Ď����������H
�����Ɛ̂��狣���ɒE�������ɐ����c���Ă����̂͐����Ǝv���B
���̃��[�J�[�͓]�����ɂǂ�ǂ�E�����Ă�̂ɁB
Intel�ɑR�ł���̂�AMD�������Ȃ������
intel�̓ƍق������ł��}���邽�߂ɁA����Ɍ����Ȃ��Ƃ���ŐF��Ȋ�Ƃ�@�ւ̏����������Ă���낤
intel�̓ƍق������ł��}���邽�߂ɁA����Ɍ����Ȃ��Ƃ���ŐF��Ȋ�Ƃ�@�ւ̏����������Ă���낤
�������
Intel�ƍق�}���邽�߂����ɉ������Ă������肪�A
�����ڂ��Ă��܂��A���̂܂ɂ�AMD�ۛ��ɁB
�����ڂ��Ă��܂��A���̂܂ɂ�AMD�ۛ��ɁB
AMD�̍ő�̖��͍͂��ɂ����������Ȃ̂ɂ��Ȃ��Ɋ撣���Ă�Ƃ��낾
������ƌÂ����A2005�N�iIntel-Core�n���o��O�j�̎������z��Intel��18�ʁAAMD��900�ԑ�
�z�ɂ����1/20�ȉ�
������ƌÂ����A2005�N�iIntel-Core�n���o��O�j�̎������z��Intel��18�ʁAAMD��900�ԑ�
�z�ɂ����1/20�ȉ�
>>519
���������ϑz���ł���A�~�͑f���炵���Ǝv����
���������ϑz���ł���A�~�͑f���炵���Ǝv����
524 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/28(��) 11:03:45 ID:nvnx7jQ0
AMD���Ď���IBM��x86���傾��
�����~�͐��o��̂��ˁH
�����X��������
�����҉�
���_�ԏ�
���_�ԏ�
>>524
�Ȃ�ł����v���̂��ȁH
�Ȃ�ł����v���̂��ȁH
530 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/28(��) 12:48:53 ID:nvnx7jQ0
�����{�����������_�ŏ͑����ς���Ă���̂�
�E�v���Z�X�J����IBM�哱
�E������IBM�o�g������
�ESSE5�i��XOP�j�́i�ȉ���
�E�v���Z�X�J����IBM�哱
�E������IBM�o�g������
�ESSE5�i��XOP�j�́i�ȉ���
�E���܂�Pentium 4�ɂ�L1D�������i���������j
AMD�̐l���Ăǂꂾ������̂���
��̘A�����Ă݂�ȑ������痈����炾��
��̘A�����Ă݂�ȑ������痈����炾��
533 �FMAC�I�^���c�q �����F2010/03/28(��) 14:42:35 ID:Xy1m3rTn
>>530
�@�@----------------
�@�@�E������IBM�o�g������
�@�@----------------
�\�[�X�͂�����ł�����̂ł�����A�����ƒ��ׂ������c
http://www.amd.com/us/aboutamd/corporate-information/executives/Pages/amd-executives.aspx
Dirk Meyer: DEC -> AMD (1995)
Chekib Akrout: IBM -> Freescale -> AMD (2008)
Rick Bergman: IBM(���Ј�) -> TI -> Exponetial -> S3 -> ATI (2001) -> AMD
Nigel Dessau: IBM -> StorageTek -> Sun -> AMD (2008)
Emilio Ghilardi: HP -> AMD (2008)
Ahmed Mahmoud: Kodak -> Dell -> AMD (2008)
Thomas M. McCoy: �@�������� -> AMD (1995)
Robert J. Rivet: Motorola SPS -> AMD (2000)
Thomas Seifert: Siemens -> Infineon/Quimonda -> AMD (2009)
Marty Seyer: NCR -> Penguin Computing -> AMD (2002)
Allen Sockwell: IBM(���Ј�) -> Compaq -> Crossroads Systems -> AMD(2002)
IBM�ł����Ƃ����L�����A��ς�ł���̂́AAkrout���� Dessau�����炢���Ɓc
�@�@----------------
�@�@�E������IBM�o�g������
�@�@----------------
�\�[�X�͂�����ł�����̂ł�����A�����ƒ��ׂ������c
http://www.amd.com/us/aboutamd/corporate-information/executives/Pages/amd-executives.aspx
Dirk Meyer: DEC -> AMD (1995)
Chekib Akrout: IBM -> Freescale -> AMD (2008)
Rick Bergman: IBM(���Ј�) -> TI -> Exponetial -> S3 -> ATI (2001) -> AMD
Nigel Dessau: IBM -> StorageTek -> Sun -> AMD (2008)
Emilio Ghilardi: HP -> AMD (2008)
Ahmed Mahmoud: Kodak -> Dell -> AMD (2008)
Thomas M. McCoy: �@�������� -> AMD (1995)
Robert J. Rivet: Motorola SPS -> AMD (2000)
Thomas Seifert: Siemens -> Infineon/Quimonda -> AMD (2009)
Marty Seyer: NCR -> Penguin Computing -> AMD (2002)
Allen Sockwell: IBM(���Ј�) -> Compaq -> Crossroads Systems -> AMD(2002)
IBM�ł����Ƃ����L�����A��ς�ł���̂́AAkrout���� Dessau�����炢���Ɓc
534 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/28(��) 14:56:58 ID:nvnx7jQ0
����������������Ȃ����x���ł͂����Ƒ�����Ȃ��H
���ƕ���̏c���莩�̂��A�ޔC�O��Hester�iIBM��23�N�Ζ��j�̍��グ���̐������B
���ƕ���̏c���莩�̂��A�ޔC�O��Hester�iIBM��23�N�Ζ��j�̍��グ���̐������B
535 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/28(��) 15:18:41 ID:nvnx7jQ0
FAC�I�^�N��Hester��AMD�ɘA��Ă�����POWER�̃A�[�L�e�N�g���ǂ�Ȗ�E�ɏA���Ă��邩
���ׂĂ݂�Ɨǂ���
���ׂĂ݂�Ɨǂ���
�����l�ޓI��IBM���ł����Ă����{�I��IBM���ł͂Ȃ����낗
�c�q���߂Ō�����INTEL�͂܂������t�F�A�`���C���h���Ă��Ƃɂ��Ȃ邺��
>>529
�����v�����܂Ȃ��ƁA���_�̈��肪�ۂĂȂ��B
�����v�����܂Ȃ��ƁA���_�̈��肪�ۂĂȂ��B
�����̒N��������J������Ă��邩�͂ǂ��ł�����
Intel��Nvidia�ȊO�̌����I�ȑI�����Ƃ��đ��݂��邱�Ƃ��d�v
Intel��Nvidia�ȊO�̌����I�ȑI�����Ƃ��đ��݂��邱�Ƃ��d�v
�Ԃ����Ⴏ�������ȁBIBM�̎�悾�낤���A��Alpha�̎c�}���낤���Ȃ낤���A
�R���͂����đ��݂��Ă��邱�Ƃ̕����A����҂ɂƂ��Ă�ꡂ��ɏd�v�B
�R���͂����đ��݂��Ă��邱�Ƃ̕����A����҂ɂƂ��Ă�ꡂ��ɏd�v�B
541 �FMAC�I�^���c�q �����F2010/03/28(��) 16:18:32 ID:Xy1m3rTn
>>535
�@�@--------------
�@�@Hester��AMD�ɘA��Ă�����POWER�̃A�[�L�e�N�g
�@�@--------------
�܂��\�[�X���o���Ȃ��K���Șb��(��)
��������POWER�̃A�[�L�e�N�g�����������ė��闧��Ƃ����Ȃ�A����Akrout���ᖳ����ł����H
�@�@--------------
�@�@Hester��AMD�ɘA��Ă�����POWER�̃A�[�L�e�N�g
�@�@--------------
�܂��\�[�X���o���Ȃ��K���Șb��(��)
��������POWER�̃A�[�L�e�N�g�����������ė��闧��Ƃ����Ȃ�A����Akrout���ᖳ����ł����H
542 �FMAC�I�^���⑫�F2010/03/28(��) 16:23:16 ID:Xy1m3rTn
Chkib Akrout���̒��x�ǂ��Љ�͂��̋L���Ƃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20060426/116637/?ST=edaonline
�@�@----------------
�@�@IBM����ɂ�Cell��Xbox 360�p�v���Z�T�ȂǁCPowerPC�x�[�X��SoC�J���ȂǂɌg������B
�@�@----------------
http://techon.nikkeibp.co.jp/article/NEWS/20060426/116637/?ST=edaonline
�@�@----------------
�@�@IBM����ɂ�Cell��Xbox 360�p�v���Z�T�ȂǁCPowerPC�x�[�X��SoC�J���ȂǂɌg������B
�@�@----------------
���{�̓A�u�_�r�Ől�͊W�߂�����
��Ɖ���X���Ȃ̂��b�o�t�̃A�[�L�e�N�g�����X���Ȃ̂���臂��Œ��ꒃ�ɂȂ��Ă��
�A�[�L�e�N�g�Ȃ炠���Ă�W����
�]���X���Œ��ꒃ�ȃR�e�̒�ȃX���Ƃ����̂�����
�]�݂������Ԕ��ȃR�e�Ɠd�g�A�~�����X������H
���̍��Ԃ�D���Ď�����CPU�b�����Ă��銴���B
���̍��Ԃ�D���Ď�����CPU�b�����Ă��銴���B
548 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/28(��) 17:43:03 ID:nvnx7jQ0
>>541
���O�uFAC�I�^�v�������̂��I�Ռ��̎����I
���O�uFAC�I�^�v�������̂��I�Ռ��̎����I
IBM���W�[����Ȃ�
�����AAMD�͒������{�̉�ЂɂȂ�\���������������������イ���������
�����AAMD�͒������{�̉�ЂɂȂ�\���������������������イ���������
�A�u�_�r����
�Y�����͖��͊���̋��ׂ���i��T���Ă���
������H�ꂾ���������킯
�Y�����͖��͊���̋��ׂ���i��T���Ă���
������H�ꂾ���������킯
�A�u�_�r�̓����Ƃ���������������H
�H��̉^�c���Ɠ����������፬���ɂ���l���āE�E�E
�H��̉^�c���Ɠ����������፬���ɂ���l���āE�E�E
�����Ƃ���Ȃ��Đ��{�n������Ђ����ǂ�
�����Ƃ�
�����Ƃ�
ATIC�͕ʂ����܂��
AMD(Advanced Mubadala Development)
�Ƃ������Ă���
AMD(Advanced Mubadala Development)
�Ƃ������Ă���
Abu dhabi Mubadala Development����������
�܁BAMD�{�̂̓A�����J�����p�����o���Ȃ����낤�ȁB
AMD�Ń^�[�{�u�[�X�g�̎d�l���o�Ă����悤�ł��B
http://lkml.org/lkml/2010/3/22/336
�@�@-------------------
�@�@Starting with F10h, revE, AMD processors add support for a dynamic
�@�@core boosting feature called Core Performance Boost. When a specific
�@�@condition is present, a subset of the cores on a system are boosted
�@�@beyond their P0 operating frequency to speed up the performance of
�@�@single-threaded applications.
�@�@-------------------
�ڍׂ̓����N��ɏ����Ă��� powernow-k8 �̃p�b�`���ǂ����B
http://lkml.org/lkml/2010/3/22/336
�@�@-------------------
�@�@Starting with F10h, revE, AMD processors add support for a dynamic
�@�@core boosting feature called Core Performance Boost. When a specific
�@�@condition is present, a subset of the cores on a system are boosted
�@�@beyond their P0 operating frequency to speed up the performance of
�@�@single-threaded applications.
�@�@-------------------
�ڍׂ̓����N��ɏ����Ă��� powernow-k8 �̃p�b�`���ǂ����B
����CPB�L�����ʂƗL���������ւ��t���O�Ɋւ���p�b�`
�\�[�X�݂Ă�CPB�̓���͑S���킩����
���ۂ̓����US20100058078�Ɋ�Ǝv�����ǂ�
�\�[�X�݂Ă�CPB�̓���͑S���킩����
���ۂ̓����US20100058078�Ɋ�Ǝv�����ǂ�
>>536
K8�ȍ~�͐��i���́A�Z�p��@�\��IBM�����Ă܂����c
K8�ȍ~�͐��i���́A�Z�p��@�\��IBM�����Ă܂����c
559 �FMAC�I�^��558 �����F2010/03/28(��) 23:50:48 ID:Xy1m3rTn
>>558
�@�@------------------
�@�@K8�ȍ~�͐��i���́A�Z�p��@�\��IBM�����Ă܂����c
�@�@------------------
��̓I�ɂǂ̕ӂł��傤���H
�@�@------------------
�@�@K8�ȍ~�͐��i���́A�Z�p��@�\��IBM�����Ă܂����c
�@�@------------------
��̓I�ɂǂ̕ӂł��傤���H
>>548
SEX�ˑ��ǂ݂����Ȃ��H
SEX�ˑ��ǂ݂����Ȃ��H
>>558
�ŁH�@����̉��������H
�ŁH�@����̉��������H
AMD�A�ő�12�R�A���������Magny-Cours����Opteron 6100�V���[�Y
http://pc.watch.impress.co.jp/docs/news/20100329_357660.html
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
http://pc.watch.impress.co.jp/docs/news/20100329_357660.html
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
�����\�͂����Ƃ��Ă��x���`�ł����Ă�́H
�X���C�h������\�z�ʂ�V���{���Ă�낽
�܁[����������̌J��Ԃ����n�܂�̂���
566 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 17:24:07 ID:lLYIWZPL
>>563
> �����\�͂����Ƃ��Ă��x���`�ł����Ă�́H
�ǂ��Ȃ낤�ˁA����܂ł͓��R�A���̑Ό��Ń_�u���X�R�A�ŕ����Ă���AMD
���������Ԃ�����12�R�A�ƃR�A����{�ɂ���������4�`���l�����E���\�P�b�g�ւ�1�z�b�v�ڑ��ɋ���
�����ē��ӂ�ACP�\�L��105W�A����N���b�N��2.3GHz�Ƒ啝�ɗ}�������lj��i��$1,386�ƈ��������̐ݒ�B
���āAIntel�͑R�i���o���ė��܂�����?
���̑z�����Ɩ������ďl�X��Sandy Bridge�ւ̃����[�X��i�߂Ă����̂��Ǝv���܂��B
> �����\�͂����Ƃ��Ă��x���`�ł����Ă�́H
�ǂ��Ȃ낤�ˁA����܂ł͓��R�A���̑Ό��Ń_�u���X�R�A�ŕ����Ă���AMD
���������Ԃ�����12�R�A�ƃR�A����{�ɂ���������4�`���l�����E���\�P�b�g�ւ�1�z�b�v�ڑ��ɋ���
�����ē��ӂ�ACP�\�L��105W�A����N���b�N��2.3GHz�Ƒ啝�ɗ}�������lj��i��$1,386�ƈ��������̐ݒ�B
���āAIntel�͑R�i���o���ė��܂�����?
���̑z�����Ɩ������ďl�X��Sandy Bridge�ւ̃����[�X��i�߂Ă����̂��Ǝv���܂��B
�ŏ���sandy�܂ʼn���������Ǝv���Ă�A�z��
Sandy Bridge�҂��Ȃ��Ă�Nehalem-EX�ɒǂ������ꂻ���ȗ\��������
SPECfp_rate�͔�����Ȃ������m��Ȃ�����
SPECfp_rate�͔�����Ȃ������m��Ȃ�����
569 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/29(��) 17:39:30 ID:DmuxX2gp
Westmere 6�R�A��1.4�{���̋���_�C�ŁA�X�ɃN���b�N�E�d���}����MCM���������̂�
�o�����i�Ŕ���܂����Ęb������ȁB
����ł����^�ɗD�ʂ�������Ƃ��āAWestmere�ł��S���������Ƃ��\����H
�i�ނ���MCM�����Ɋւ��Ă�Intel�̂ق������їL��j
���R�̂��ƂȂ���N���b�N���Ƃ����������V���O���X���b�h���\�͗����邵
����Nehalem�őg�V�X�e����Westmere�ւ̈ڍs�R�X�g�����܂肩����Ȃ�
�̂ɉ��i�E���\���Ɍ̂ɑ債�����Ђɂ͂Ȃ炸�AIntel������o���\���͒Ⴂ㩁B
�t�Ɍ����ƁAIntel�ɂƂ��č̎Z�������n���n�������Ă��Ȃ����Ƃ��A
AMD�������Ă�邱�ƂŌ��Ԃ̎��v��_�������̘b�ł����ȁB
�ƁA������O�̂��Ƃ������Ă݂�
�o�����i�Ŕ���܂����Ęb������ȁB
����ł����^�ɗD�ʂ�������Ƃ��āAWestmere�ł��S���������Ƃ��\����H
�i�ނ���MCM�����Ɋւ��Ă�Intel�̂ق������їL��j
���R�̂��ƂȂ���N���b�N���Ƃ����������V���O���X���b�h���\�͗����邵
����Nehalem�őg�V�X�e����Westmere�ւ̈ڍs�R�X�g�����܂肩����Ȃ�
�̂ɉ��i�E���\���Ɍ̂ɑ債�����Ђɂ͂Ȃ炸�AIntel������o���\���͒Ⴂ㩁B
�t�Ɍ����ƁAIntel�ɂƂ��č̎Z�������n���n�������Ă��Ȃ����Ƃ��A
AMD�������Ă�邱�ƂŌ��Ԃ̎��v��_�������̘b�ł����ȁB
�ƁA������O�̂��Ƃ������Ă݂�
���₨��
�ǂ�����GPU�݂����ł���
�ǂ�����GPU�݂����ł���
��������u���܂�Pentium 4�ɂ�L1D�������v���������
Nehalem-EX�̓��������肨�������
���������I�����Ȃ�fp���int����
�����R���������ĂȂ�����ł�Woodcrest�ȍ~�͂܂��H���r�炳��Ă����̂ɂ܂��킩���ĂȂ��̂���
���������I�����Ȃ�fp���int����
�����R���������ĂȂ�����ł�Woodcrest�ȍ~�͂܂��H���r�炳��Ă����̂ɂ܂��킩���ĂȂ��̂���
Magny-Cours�̉��i�͏Ռ��I�����AIntel�͏œy���Ɉ������܂ꂽ���͖������낤��
���u�����Ȃ��H
���u�����Ȃ��H
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
>Opteron 6100��Intel�����\���������Westmere�R�A��Xeon�ɔ�ׂ�
���\�������ȏ�ŁA����d�͂��Ⴍ�A�����i�������Ƃ������Ƃ����������B
575 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 18:22:49 ID:lLYIWZPL
>>574
Westmere�R�A��Xeon�͍ŏ�ʂ��ƁE�E
X5680 6�R�A 3.33GHz 130W 6.4GT�^�b 1663�h��
�ƂȂ�킯�ŁA�m���ɉ��i��12�R�A��6176SE�̕�������($1,386)
�Ƃ���ACP vs TDP�Ƃ����c�Ȃ���105W(ACP) vs 130W(TDP)�Ό��ł�6176SE�̕����������l�ł͂���B
���́u���\�������ȏ�v�Ƃ������Ƃ��낤�ˁB
�V���O���X���b�h���\��X5680�̈����Ȃ̂͌����܂ł��Ȃ����}���`�X���b�h���\���Ƃǂ��Ȃ낤?
���I�ɂ͔����Ȋ���������B
�����I��6176SE��X5680������x���`�͑��݂���Ǝv���̂����E�E�E
�S�̓I�ɔ�ׂ�Ƃǂ��Ȃ낤?
Westmere�R�A��Xeon�͍ŏ�ʂ��ƁE�E
X5680 6�R�A 3.33GHz 130W 6.4GT�^�b 1663�h��
�ƂȂ�킯�ŁA�m���ɉ��i��12�R�A��6176SE�̕�������($1,386)
�Ƃ���ACP vs TDP�Ƃ����c�Ȃ���105W(ACP) vs 130W(TDP)�Ό��ł�6176SE�̕����������l�ł͂���B
���́u���\�������ȏ�v�Ƃ������Ƃ��낤�ˁB
�V���O���X���b�h���\��X5680�̈����Ȃ̂͌����܂ł��Ȃ����}���`�X���b�h���\���Ƃǂ��Ȃ낤?
���I�ɂ͔����Ȋ���������B
�����I��6176SE��X5680������x���`�͑��݂���Ǝv���̂����E�E�E
�S�̓I�ɔ�ׂ�Ƃǂ��Ȃ낤?
576 �FSocket774�F2010/03/29(��) 18:58:39 ID:WtVmhbws
�V���O���R�A���\����C�ɗ����鎞��̓������B
����Anandtech��Johan de Gelas����� Magny Cours�̃��r���[���B
http://it.anandtech.com/IT/showdoc.aspx?i=3784
2�{�̕��ʂ𓊓�����Westmere-EP�ɏ�����Ȃ��Ƃ������Ƃ̂悤�Łc
http://it.anandtech.com/IT/showdoc.aspx?i=3784
2�{�̕��ʂ𓊓�����Westmere-EP�ɏ�����Ȃ��Ƃ������Ƃ̂悤�Łc
578 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 19:26:24 ID:lLYIWZPL
>>577
Cinebench 11.5��X5670�ɕ����Ă�̂͐����Ȃ��Ƃ�����
http://it.anandtech.com/IT/showdoc.aspx?i=3784&p=6
Cinebench 11.5��X5670�ɕ����Ă�̂͐����Ȃ��Ƃ�����
http://it.anandtech.com/IT/showdoc.aspx?i=3784&p=6
�ȂA�P�p�b�P�[�W������
>12 cores, 692 mm2 die, 19.6MB of cache on-die
MCM�����瓖�R���B
>12 cores, 692 mm2 die, 19.6MB of cache on-die
MCM�����瓖�R���B
146 ���O�FSocket774[sage] ���e���F2007/09/23(��) 02:16:45 ID:uqQtZWII
�G����������炸�������o���Ă�ȁ[�B
148 ���O�F���͌��c��[sage] ���e���F2007/09/23(��) 02:41:12 ID:/aojbA/5
>>146
> �G����������炸�������o���Ă�ȁ[�B
�܂��ȁA�o�J�͒����ɒᑭ�ւƓ����đ������瑊��ɂ������˂����ǂ܂���ɂ͗ǂ�����w
�G����������炸�������o���Ă�ȁ[�B
148 ���O�F���͌��c��[sage] ���e���F2007/09/23(��) 02:41:12 ID:/aojbA/5
>>146
> �G����������炸�������o���Ă�ȁ[�B
�܂��ȁA�o�J�͒����ɒᑭ�ւƓ����đ������瑊��ɂ������˂����ǂ܂���ɂ͗ǂ�����w
�Ԃ����ႯMagny-Cours�͉��z�����p���낤
���z�����ł͘_���R�A��HT���g���Ȃ�����A�����R�A�������ɂȂ邪
���̕���ł�Magny-Cours�͍ŋ����낤
4�\�P�b�g�ł̉��i��Xeon���i�Ⴂ�Ɉ�������A���̎�̃T�[�o�[�̃n�[�h�ʂ̃R�X�g������Ɉ�����������E�E�E����
���z�����ł͘_���R�A��HT���g���Ȃ�����A�����R�A�������ɂȂ邪
���̕���ł�Magny-Cours�͍ŋ����낤
4�\�P�b�g�ł̉��i��Xeon���i�Ⴂ�Ɉ�������A���̎�̃T�[�o�[�̃n�[�h�ʂ̃R�X�g������Ɉ�����������E�E�E����
�G���b�^30���AMDCPU�͎I���p
�G���b�^3����IntelCPU�̓x���`�i&�Ëa�j�p
�G���b�^3����IntelCPU�̓x���`�i&�Ëa�j�p
583 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/29(��) 20:34:37 ID:DmuxX2gp
> ���z�����ł͘_���R�A��HT���g���Ȃ�����A�����R�A�������ɂȂ邪
�@��@�́@�ǁ@���@�́@���@�z�@���@�\�@�t�@�g�@�́@�b�@�Ł@���@���@�H
�@��@�́@�ǁ@���@�́@���@�z�@���@�\�@�t�@�g�@�́@�b�@�Ł@���@���@�H
584 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 20:36:58 ID:lLYIWZPL
>>583
������������AMD�А��̔���J�\�t�g�Ȃ̂���w
������������AMD�А��̔���J�\�t�g�Ȃ̂���w
>>577
http://images.anandtech.com/graphs/amd12core_032610044429/22224.png
AES-NI �����^
������256����B
http://images.anandtech.com/graphs/amd12core_032610044429/22224.png
{kind=link}
AES-NI �����^
������256����B
586 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/29(��) 20:38:59 ID:DmuxX2gp
X5570�@�Ȃ�Hyper-V�ŕ��ʂ�16�_��CPU�g���Ă܂���B
XP���[�ǃg�J�W���l
http://it.anandtech.com/printarticle.aspx?i=3784
��Âɂ݂�ƁAMagny-Coour�������̂ƁAIstanbul�������̂ƁAIntel�������̂�
���\����Ă�ȁB�T�[�o���K�ޓK���Ƃ������Ƃ��B
��Âɂ݂�ƁAMagny-Coour�������̂ƁAIstanbul�������̂ƁAIntel�������̂�
���\����Ă�ȁB�T�[�o���K�ޓK���Ƃ������Ƃ��B
����܂ł��啪�킦�郂�m�o���Ă�����
bulldozer���y���݂���
bulldozer���y���݂���
�܂����������A�[�L�e�N�`�����ʗp����̂́A
�����܂ł��T�[�o�̘b�Ńf�X�N�g�b�v�ł͖��_�ւ�ւ�Ȃ킯�����B
�����܂ł��T�[�o�̘b�Ńf�X�N�g�b�v�ł͖��_�ւ�ւ�Ȃ킯�����B
�ŋ߂̓G���R�p�r�ł��N�A�b�h�R�A�ŊԂɍ������Ⴄ���Ȃ�
2.2GHz�悷����낽
����d�͂̂��Ăˁ`
�H�H
12core��24core??
12core��24core??
595 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 21:28:08 ID:lLYIWZPL
>>588
> ��Âɂ݂�ƁAMagny-Coour�������̂ƁAIstanbul�������̂ƁAIntel�������̂�
> ���\����Ă�ȁB�T�[�o���K�ޓK���Ƃ������Ƃ��B
�ǂ����Ȃ��A����24�R�A vs 12�R�A�Ό��ł��̏�Ԃ�����������Ă܂��B
> ��Âɂ݂�ƁAMagny-Coour�������̂ƁAIstanbul�������̂ƁAIntel�������̂�
> ���\����Ă�ȁB�T�[�o���K�ޓK���Ƃ������Ƃ��B
�ǂ����Ȃ��A����24�R�A vs 12�R�A�Ό��ł��̏�Ԃ�����������Ă܂��B
�P�R�A�����ŋ�����āA�̂���P�P�R�A���`�[�v�ɂ���Ηǂ������̂ɁB
Intel Xeon W5680 6 130W 3.3GHz $1663 vs AMD Opteron 6176 SE 12 105/137W 2.3 GHz $1386
Intel Xeon X5670 6 95W 2.93GHz $1440
Magny-Cours�̍ŏ�ʂł���Opteron 6176SE�̈ʒu�Â����A
W5680�̑R�n������ȁB�R�A���͖��ł͂Ȃ��BAMD�͐g������Ĉ���������j������Ȃ��B
Intel��X5670��AMD�I�ɂ͊i���̈ʒu�Â��ł��邪�A�����\�͂��Ă����AOpteron 6176SE�̂ق��������悤���ˁB
Intel Xeon X5670 6 95W 2.93GHz $1440
Magny-Cours�̍ŏ�ʂł���Opteron 6176SE�̈ʒu�Â����A
W5680�̑R�n������ȁB�R�A���͖��ł͂Ȃ��BAMD�͐g������Ĉ���������j������Ȃ��B
Intel��X5670��AMD�I�ɂ͊i���̈ʒu�Â��ł��邪�A�����\�͂��Ă����AOpteron 6176SE�̂ق��������悤���ˁB
>>596
���ꂾ
2core�����b�`�ɂ��đ����V���v���ɂ����
�V���O�����}���`����������ɂ�
����Intel�̖ژ_������˂������
���ꂾ
2core�����b�`�ɂ��đ����V���v���ɂ����
�V���O�����}���`����������ɂ�
����Intel�̖ژ_������˂������
Anand�̃x���`�Ń��r���[����Ă���̂͊i����6174�����炳��Ɉ����ˁB
���i�I�ɂ͊��S�Ɋi��Ƃ̔�r�ɂȂ��Ă�ȁB
���i�I�ɂ͊��S�Ɋi��Ƃ̔�r�ɂȂ��Ă�ȁB
600 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 21:39:00 ID:lLYIWZPL
>>596
> �P�R�A�����ŋ�����āA�̂���P�P�R�A���`�[�v�ɂ���Ηǂ������̂ɁB
����OS�̓V���O���X���b�h���쎞�ɂ��̍ŋ��ȃR�A���g�p���Ă����ł��傤��w
> �P�R�A�����ŋ�����āA�̂���P�P�R�A���`�[�v�ɂ���Ηǂ������̂ɁB
����OS�̓V���O���X���b�h���쎞�ɂ��̍ŋ��ȃR�A���g�p���Ă����ł��傤��w
�V�X�e���P�ʂŐ��\�E���i�E����d�͂��ǂ������ŗǂ�
����d�͂͂������ł���
603 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 21:44:04 ID:lLYIWZPL
>>599
> Anand�̃x���`�Ń��r���[����Ă���̂͊i����6174��
X5670���i�������璚�x�悢�̂ł�?
> ���i�I�ɂ͊��S�Ɋi��Ƃ̔�r�ɂȂ��Ă�ȁB
�l�i��AMD�����ˁB�������̉��i�łȂ��Ŕ���Ȃ��ƌ��z���������ł̒l�t���ȂƎv���܂��B
> Anand�̃x���`�Ń��r���[����Ă���̂͊i����6174��
X5670���i�������璚�x�悢�̂ł�?
> ���i�I�ɂ͊��S�Ɋi��Ƃ̔�r�ɂȂ��Ă�ȁB
�l�i��AMD�����ˁB�������̉��i�łȂ��Ŕ���Ȃ��ƌ��z���������ł̒l�t���ȂƎv���܂��B
�ʏ�Ŏg�����ɂ�Opteron 6164HE�ƃV���O���\�P�b�g��H8SGL-F�Ƃ̑g�ݍ��킹���R�X�g�p�t�H�[�}���X�I�ɂ͂悳������
Nehalem-EX�Ƃ̔�r�͂Ȃ��̂��H
����
�����̒m�I��Q�҂̏W�����J�I�ȋ��g��������
�����̒m�I��Q�҂̏W�����J�I�ȋ��g��������
��Do remember that this is a completely synthetic benchmark. A 100% encryption performance advantage might translate in a very small performance advantage in a real world application
���`
���`
608 �F���͌��c�� ��OhjIkO1O8o �F2010/03/29(��) 22:38:19 ID:lLYIWZPL
>>604
1.7GHz���Ƃ�����Ƃ܂����肵�Ă邯��12�R�A�Ƃ������ƂŃT�[�o�[�Ƃ��Ă͗ǂ��I�����Ȃ̂����m��܂���ȁB
�g�������炷��A�}���ȑ��x�ቺ�͌��������ǍŐV�̃T�[�o�[�Ȃ̂ɂȂ܂����肵�Ă��Ȃ��`���Ċ�����?
1.7GHz���Ƃ�����Ƃ܂����肵�Ă邯��12�R�A�Ƃ������ƂŃT�[�o�[�Ƃ��Ă͗ǂ��I�����Ȃ̂����m��܂���ȁB
�g�������炷��A�}���ȑ��x�ቺ�͌��������ǍŐV�̃T�[�o�[�Ȃ̂ɂȂ܂����肵�Ă��Ȃ��`���Ċ�����?
609 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/30(��) 02:34:13 ID:SOh+hHxU
�{���N�����g���Ȃ琫�\�I�ɂ����i�I�ɂ�Westmere-DP���悳�����ȁB
24�X���b�h���낤�������R�A��12�ŃJ�E���g����邩��R�A�W��0.5��������6CPU���B
Magny-Cours�͓��ɌW�����������Ȃ���Ⴊ�Ȃ����12CPU���̃��C�Z���X����������B
24�X���b�h���낤�������R�A��12�ŃJ�E���g����邩��R�A�W��0.5��������6CPU���B
Magny-Cours�͓��ɌW�����������Ȃ���Ⴊ�Ȃ����12CPU���̃��C�Z���X����������B
�}�j�N�[���̑��݈Ӌ`��Westmere�ɏ����Ƃ���Ȃ��A
�V�F�A�̒ቺ��}���邽�߂ɁA�R�X�g��TDP�����Ő��\�����ł��H�炢��������ȁB
���N�㔼��Bulldozer16�R�A�܂łȂ�Ƃ��킦��Ό�̎�
�c�Ƃ��ABulldozer�ւ̃A�b�v�O���[�h���Ń}�[�P�e�B���O���s���Ă��邾�낤�B
�܂��A���\�������Ă���悤�ŁA����Ȃ�1�N���炢�͂Ȃ�Ƃ��Ȃ��ˁH
������Windows���s��Linux�����͏���w
ttp://it.anandtech.com/IT/showdoc.aspx?i=3784&p=7
�@�@�@�@�@�@�@�@�@�@�@win�@�@Lin
Op 6174(2.2G)�@�@32s��18s
Op 2435(2.6G)�@�@41s��27s
Xeon 5670(2.9G) 26s��32s
Xeon 5570(2.9G) 35s��33s
�V�F�A�̒ቺ��}���邽�߂ɁA�R�X�g��TDP�����Ő��\�����ł��H�炢��������ȁB
���N�㔼��Bulldozer16�R�A�܂łȂ�Ƃ��킦��Ό�̎�
�c�Ƃ��ABulldozer�ւ̃A�b�v�O���[�h���Ń}�[�P�e�B���O���s���Ă��邾�낤�B
�܂��A���\�������Ă���悤�ŁA����Ȃ�1�N���炢�͂Ȃ�Ƃ��Ȃ��ˁH
������Windows���s��Linux�����͏���w
ttp://it.anandtech.com/IT/showdoc.aspx?i=3784&p=7
�@�@�@�@�@�@�@�@�@�@�@win�@�@Lin
Op 6174(2.2G)�@�@32s��18s
Op 2435(2.6G)�@�@41s��27s
Xeon 5670(2.9G) 26s��32s
Xeon 5570(2.9G) 35s��33s
HD5870vsGTX480�������ザ��]�Tw
TDP�����d�͕͂��ʂ̃n�C�G���h�A�����܂������Ȃ�A���C�o���Ɠ�����
�_�C�T�C�Y��3�{�����ǁA����ȊO���펯�͈̔͂Ɏ��܂��Ă��邩�畁�ʂɔ���邾�낤�B
TDP�����d�͕͂��ʂ̃n�C�G���h�A�����܂������Ȃ�A���C�o���Ɠ�����
�_�C�T�C�Y��3�{�����ǁA����ȊO���펯�͈̔͂Ɏ��܂��Ă��邩�畁�ʂɔ���邾�낤�B
>HD5870vsGTX480
�]�T�ł܂��Ă��
�]�T�ł܂��Ă��
>>612
GTX480�������グ�I���f�g�Ew
����͂ǂ����Ă�GTx480�̎S�s����w
DX11��5�����炢��������+130W���Ĕn�������邾��w
GTX480�������グ�I���f�g�Ew
����͂ǂ����Ă�GTx480�̎S�s����w
DX11��5�����炢��������+130W���Ĕn�������邾��w
>HD5870vsGTX480
�~�h���ƃn�C�G���h���ׂ��
�~�h���ƃn�C�G���h���ׂ��
RADEON�̒l�����Ȃ��悤����Fermi�ɋ����͖͂����낤�Ȃ�
�ނ���HD58xx�AHD5970�����������Ŕ���n�߂Ă�ȁB
Fermi�҂����Ă��l���������߂�RADEON�ɑ�������
Fermi�҂����Ă��l���������߂�RADEON�ɑ�������
�����o���邾���̕��ʂ��S�����������
���⌎�Ԑ��\���o�ׂ��Ă��ď��i�s����HD5870�ɑ��A
�o�א�����GTX4xx���ች�̈��͂ɂ��Ȃ�Ȃ��B
���⌎�Ԑ��\���o�ׂ��Ă��ď��i�s����HD5870�ɑ��A
�o�א�����GTX4xx���ች�̈��͂ɂ��Ȃ�Ȃ��B
�A�[�L�e�N�`����ʂɂ��ă_�C�T�C�Y�����Řb���Ƃ��Ă�
������x��剻������j�R�C�`�ɂ���̂�������
500~600m�u�ł��܂������`�b�v�ɍS��Ƃ��������_�C�Ȃ̂Ƀj�R�C�`�ɂ���Ƃ�
�܂��؋����މ�ₔ��o�ł������̂��H���Ă��炢�Ӗ��s��
������x��剻������j�R�C�`�ɂ���̂�������
500~600m�u�ł��܂������`�b�v�ɍS��Ƃ��������_�C�Ȃ̂Ƀj�R�C�`�ɂ���Ƃ�
�܂��؋����މ�ₔ��o�ł������̂��H���Ă��炢�Ӗ��s��
PC�̏o�ב䐔�͔N��3���`��
�T�[�o�[�͔N��1�疜�`��
PC�p�̃`�b�v�𗬗p���ăT�[�o�[��p�`�b�v�J���̃R�X�g�������邱�Ƃ������b�g�Ȃ낤��
���ƁAMCM�Ȃ獂�i���i�͍��i���i�ƁA��i���i�͒�i���i�ƃy�A�ɂ��邱�Ƃ��o���邩��A�Ǖi�����₷���̂���
�T�[�o�[�͔N��1�疜�`��
PC�p�̃`�b�v�𗬗p���ăT�[�o�[��p�`�b�v�J���̃R�X�g�������邱�Ƃ������b�g�Ȃ낤��
���ƁAMCM�Ȃ獂�i���i�͍��i���i�ƁA��i���i�͒�i���i�ƃy�A�ɂ��邱�Ƃ��o���邩��A�Ǖi�����₷���̂���
���̂�6�R�ACPU�����ł����킯���B
��ʌ����ɂ�PhenomII X6�Ƃ��Ĕ�����
�I�����ɂ�Opteron6�R�A���A2��MCM����12�R�A�Ŕ���B
2�R�A���ׂ���������PhenomII X4��
Opeteron4�R�A��2��MCM����8�R�A�Ŕ���
����������Opteron�͑S���C���i�b�v�ŋ@�\�̍��ق��Ȃ����Ƃ�����ɂ��Ă��ȁB
��������Y���C��1�{���̒m�b���B
��ʌ����ɂ�PhenomII X6�Ƃ��Ĕ�����
�I�����ɂ�Opteron6�R�A���A2��MCM����12�R�A�Ŕ���B
2�R�A���ׂ���������PhenomII X4��
Opeteron4�R�A��2��MCM����8�R�A�Ŕ���
����������Opteron�͑S���C���i�b�v�ŋ@�\�̍��ق��Ȃ����Ƃ�����ɂ��Ă��ȁB
��������Y���C��1�{���̒m�b���B
MCM�̃R�X�g���������ǂ�
622 �F622��621 �����F2010/03/30(��) 10:08:24 ID:ZCQx/oQw
>>621
�܂��\�[�X���o���Ȃ��K���Șb��(��)
�܂��\�[�X���o���Ȃ��K���Șb��(��)
12�R�A��1�_�C���o���オ��R�X�g���͈�����ł���
����MAC�I�^�H
�V�R�e�a���̏u��
�N������u������������Ő����Y������ǂ��������Ȃ낤
�������Ǝv����
628 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/30(��) 12:23:36 ID:SOh+hHxU
>>623
Westmere-EX(Beckton)�̂��Ƃ��낤����
XeonMP�͋���_�C�ɑǂ���Ĉȍ~�A�����܂����̂��߂ɑS�R�A�����͍̂ŏ�ʂ����ɗ��߂Ă���B
�o�חʂ������̂͑�T2�R�A�E���ł���B
����łȂ��Ƃ������Z�p�����Ȃ�Ă����邩��傫���_�C�ł�������x���������܂肪�ۂĂ�B
�P�����̂��������ˁB
����Nehalem-EX�Ɋւ��Ă�HPC�����ɓ��������̂͂����܂�6�R�A��
Westmere-EX(Beckton)�̂��Ƃ��낤����
XeonMP�͋���_�C�ɑǂ���Ĉȍ~�A�����܂����̂��߂ɑS�R�A�����͍̂ŏ�ʂ����ɗ��߂Ă���B
�o�חʂ������̂͑�T2�R�A�E���ł���B
����łȂ��Ƃ������Z�p�����Ȃ�Ă����邩��傫���_�C�ł�������x���������܂肪�ۂĂ�B
�P�����̂��������ˁB
����Nehalem-EX�Ɋւ��Ă�HPC�����ɓ��������̂͂����܂�6�R�A��
���Ⴀ�����̂ǂ����悤���Ȃ��]���X�͂ǂ�����
Beckton����Nehalem-EX�̂��Ƃ���Ȃ������������H
632 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/30(��) 14:55:10 ID:SOh+hHxU
����
�܂����̕�����MP�T�[�o�����͂��炭Nehalem-Westmere�����G��Ԃ��낤��
DP�T�[�o�����Ɍ������Ȃ���ł�
�@�@�@�@�@�@Opteron-DP�@�@�@�@�@�@�@�@�@�@Xeon-DP
2010Q1�@Magny-Cours 12C(MCM)�@Westmere 6C
2010Q2�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2010Q3�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2010Q4�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Sandy Bridge 6C
2011Q1�@Bulldozer 8C �@�@�@�@�@�@�@�@�b
2011Q2�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2011Q3�@Bulldozer 16C(MCM)�@�@�@�@�b
2011Q4�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Ivy Bridge 8C�@�@�@�@�@�@�@�@�@�@��DDR4���[���`�H
2012Q1�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2012Q2�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2012Q3�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Haswell 8C + Larrabee3 ?
2012Q4�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
���Ȃ݂�AMD�̎�������@�����Bulldozer 16�R�A�͐���3GHz�O�ゾ���A�ƁB
�܂����̕�����MP�T�[�o�����͂��炭Nehalem-Westmere�����G��Ԃ��낤��
DP�T�[�o�����Ɍ������Ȃ���ł�
�@�@�@�@�@�@Opteron-DP�@�@�@�@�@�@�@�@�@�@Xeon-DP
2010Q1�@Magny-Cours 12C(MCM)�@Westmere 6C
2010Q2�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2010Q3�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2010Q4�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Sandy Bridge 6C
2011Q1�@Bulldozer 8C �@�@�@�@�@�@�@�@�b
2011Q2�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2011Q3�@Bulldozer 16C(MCM)�@�@�@�@�b
2011Q4�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Ivy Bridge 8C�@�@�@�@�@�@�@�@�@�@��DDR4���[���`�H
2012Q1�@�b�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2012Q2�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
2012Q3�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@Haswell 8C + Larrabee3 ?
2012Q4�@�H�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�b
���Ȃ݂�AMD�̎�������@�����Bulldozer 16�R�A�͐���3GHz�O�ゾ���A�ƁB
����ł���
�R�A������̃p�t�H�[�}���X�ŋ����Ă��E�E�E�Ȃ��
���ŏ������Ă���
�T�[�o�[�͂���ł��ǂ��낤����
�N���C�A���g�͂ǂ�����̂���
����
�R�A������̃p�t�H�[�}���X�ŋ����Ă��E�E�E�Ȃ��
���ŏ������Ă���
�T�[�o�[�͂���ł��ǂ��낤����
�N���C�A���g�͂ǂ�����̂���
����
634 �F634��632 �����F2010/03/30(��) 15:11:25 ID:ZCQx/oQw
>>632
�܂��\�[�X���o���Ȃ��K���Șb��(��)
�܂��\�[�X���o���Ȃ��K���Șb��(��)
>>632
SandyBridge6C/8C�͑����Ă�2011Q2�ȍ~����A����2010Q4�͂Ȃ��B
���ꂶ��Westmere�̎������Z�����Ĕ����Ȃ��Č����Ă�悤�Ȃ���
����ɁA�}�j�N�[���̂悤�ɍ���̃T�[�o�[�����̓V���O����MCM�������[�X�ɂȂ邾�낤����
Bulldozer 8C/16C�͓���������B
2012�ȍ~�͐����\�z�s�\����
AMD��Bull+HD6xxx��Fusion
Intel��Haswell+Larrabee
�ǂ�������Ђ̋Z�p�͂��l�����Ă�����ł͓����ƌ��Ă��������
�o�ꎞ�����݂��̗l�q���Ŏ��������ǂ��킹�Ă���Ǝv��
SandyBridge6C/8C�͑����Ă�2011Q2�ȍ~����A����2010Q4�͂Ȃ��B
���ꂶ��Westmere�̎������Z�����Ĕ����Ȃ��Č����Ă�悤�Ȃ���
����ɁA�}�j�N�[���̂悤�ɍ���̃T�[�o�[�����̓V���O����MCM�������[�X�ɂȂ邾�낤����
Bulldozer 8C/16C�͓���������B
2012�ȍ~�͐����\�z�s�\����
AMD��Bull+HD6xxx��Fusion
Intel��Haswell+Larrabee
�ǂ�������Ђ̋Z�p�͂��l�����Ă�����ł͓����ƌ��Ă��������
�o�ꎞ�����݂��̗l�q���Ŏ��������ǂ��킹�Ă���Ǝv��
>>635
Dempsey�u���O�̗D�����ɑS�����������v
Dempsey�u���O�̗D�����ɑS�����������v
Intel��8�R�A���ቼ�z���I��Bulldozer 16C(MCM)�ɑR�ł���
Intel��MCM����Ă���낤
Intel��MCM����Ă���낤
>>637
�L������߂�Ȃ炻���Ȃ��Ăق���
�L������߂�Ȃ炻���Ȃ��Ăق���
Bull�͑O����v���Z�XK10�̃N���b�N+1GH�����炢���ˁH
>�}�j�N�[���̑��݈Ӌ`��Westmere�ɏ����Ƃ���Ȃ��A
>�V�F�A�̒ቺ��}���邽�߂ɁA�R�X�g��TDP�����Ő��\�����ł��H�炢��������ȁB
Bulldozer��Sandy Bridge�ɑ���|�W�V�����������I�ɂ͓����l�Ȋ����ɂȂ肻������ȁB
Mangy-Cours��Istanbul��Bulldozer�̂Ȃ��Ƃ������݂ł́A
�X���[�v�b�g���ɂȂ����킯�ł܂����܂��Ƃ���Ɏ��܂��Ă�ȁB
>>609
AMD�̃}�[�P�e�B���O����̓A�t�H�Ȃ��ƂɁA
1���W���[��1�R�A�Ƃ��ăA�s�[�����Ă���A�{���N�����͂��߂Ƃ��郉�C�Z���X���������ς�ŁA
�g�����Ȃ��Ă�����������Ȃ��̂ɁA�����v������16�R�A-!!!�Ƃ������Ă邩��Ȃ��B
�����l���Ė������B
>�V�F�A�̒ቺ��}���邽�߂ɁA�R�X�g��TDP�����Ő��\�����ł��H�炢��������ȁB
Bulldozer��Sandy Bridge�ɑ���|�W�V�����������I�ɂ͓����l�Ȋ����ɂȂ肻������ȁB
Mangy-Cours��Istanbul��Bulldozer�̂Ȃ��Ƃ������݂ł́A
�X���[�v�b�g���ɂȂ����킯�ł܂����܂��Ƃ���Ɏ��܂��Ă�ȁB
>>609
AMD�̃}�[�P�e�B���O����̓A�t�H�Ȃ��ƂɁA
1���W���[��1�R�A�Ƃ��ăA�s�[�����Ă���A�{���N�����͂��߂Ƃ��郉�C�Z���X���������ς�ŁA
�g�����Ȃ��Ă�����������Ȃ��̂ɁA�����v������16�R�A-!!!�Ƃ������Ă邩��Ȃ��B
�����l���Ė������B
����T�[�o�͖{�̉��i�����d�C��̂ق��������Ƃ������炢�̈������嗬���Ƃ����̂ɁA
����̓R�A�̐�������=�ǂ�����
�̂悤�ȃ}�[�P�e�B���O�̓T�[�o�pCPU�Ƃ��Ă̓��C�Z���X�̂��Ƃ��l����Ύ��E�s�ׂȂ̂Ŕp��Ă��������m���ȁB
����̓R�A�̐�������=�ǂ�����
�̂悤�ȃ}�[�P�e�B���O�̓T�[�o�pCPU�Ƃ��Ă̓��C�Z���X�̂��Ƃ��l����Ύ��E�s�ׂȂ̂Ŕp��Ă��������m���ȁB
�Ƃ����͉̂R�B
���̓\�P�b�g���̃��C�Z���X�ɂȂ��Ă����̂������B
���̓\�P�b�g���̃��C�Z���X�ɂȂ��Ă����̂������B
�}���`�R�A�v���Z�b�T���p���̕K�v���C�Z���X��
http://www.oracle.com/lang/jp/corporate/pricing/mcpu.html
http://www.oracle.com/lang/jp/corporate/pricing/mcpu.html
�Ȃ���B��ѐ��Ȃ������B
�{���N�������ȁB
�{���N�������ȁB
���z���I�g���Ƃ��ɁA���z�R�A���������R�A������ƃV�X�e���S�̂̐��\��������
�����畨���R�A���̑����͑傫�ȃA�h�o���e�[�W
���ƃ��C�Z���X�͍��͂ǂ��Ȃ́H
�����畨���R�A���̑����͑傫�ȃA�h�o���e�[�W
���ƃ��C�Z���X�͍��͂ǂ��Ȃ́H
647 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/30(��) 19:14:22 ID:SOh+hHxU
�\�P�b�g�P�ʉۋ��Ȃ̂�Standard Edition��Standard Edition One����B
��ԏ��Enterprise Edition��Processor���C�Z���X�͑��ς�炸�����R�A���~�R�A�W������B
http://www.oracle.com/lang/jp/corporate/pricing/dbee.html
EE��1CPU���C�Z���X�ix86�̏ꍇ2�R�A�����j������500��������n���ɂȂ��
��ԏ��Enterprise Edition��Processor���C�Z���X�͑��ς�炸�����R�A���~�R�A�W������B
http://www.oracle.com/lang/jp/corporate/pricing/dbee.html
EE��1CPU���C�Z���X�ix86�̏ꍇ2�R�A�����j������500��������n���ɂȂ��
MCM�����Ǝv���Ă�������悤�����A
Intel��Smithfield��Pen D����킴�킴Presler�����Ȃ����Ă���Xeon�����Ƃ��ɂ́A
�킴�킴MCM�̐ݔ��ɓ������Ă܂ŁAMCM�ɂ��Ă������BClarkdale�݂Ă��₷���̂킩�邾��B
�����R�X�g�̓_�C�T�C�Y�ɑ��Ďw�����I�ɑ�����Ƃ�����{���o���Ă���̂Ȃ�A
���S����mm�������番�����ق����f�R�������đz�������낤�ȁB
Intel��Smithfield��Pen D����킴�킴Presler�����Ȃ����Ă���Xeon�����Ƃ��ɂ́A
�킴�킴MCM�̐ݔ��ɓ������Ă܂ŁAMCM�ɂ��Ă������BClarkdale�݂Ă��₷���̂킩�邾��B
�����R�X�g�̓_�C�T�C�Y�ɑ��Ďw�����I�ɑ�����Ƃ�����{���o���Ă���̂Ȃ�A
���S����mm�������番�����ق����f�R�������đz�������낤�ȁB
AMD�̓T�[�o�p�\�t�g�x���_�[��Bull�̃��C�Z���X��
�L���ɓ�������悤�����͂������킯���c�B
�l�I�ɂ̓f�R�[�_���L���Ă���̂ɁA�����R�A2�Ƃ����v���͌ӎU�L���Ǝv�����B
�L���ɓ�������悤�����͂������킯���c�B
�l�I�ɂ̓f�R�[�_���L���Ă���̂ɁA�����R�A2�Ƃ����v���͌ӎU�L���Ǝv�����B
����������
>>385
���܂���Ȃ���A
Pentium II�`III���炢�̎����K6�n������Ȃ�ɃN���b�N�������Đ킦���Ă̂���
���v�����Ȃ�P�킾�ȁB
K6��OOO�t��6�X�e�[�W�����Ȃ��̂�10���X�e�[�W����P6�ɂ��炢���Ă����̂́A
�v���f�R�[�h�`�f�R�[�h�̎d�g�݂����Ȃ�v�����Ă�̂����ȁB
FPU���c�O�v����������A�܂����ǂ͏��ĂȂ������킯�����B
���܂���Ȃ���A
Pentium II�`III���炢�̎����K6�n������Ȃ�ɃN���b�N�������Đ킦���Ă̂���
���v�����Ȃ�P�킾�ȁB
K6��OOO�t��6�X�e�[�W�����Ȃ��̂�10���X�e�[�W����P6�ɂ��炢���Ă����̂́A
�v���f�R�[�h�`�f�R�[�h�̎d�g�݂����Ȃ�v�����Ă�̂����ȁB
FPU���c�O�v����������A�܂����ǂ͏��ĂȂ������킯�����B
652 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/30(��) 20:31:02 ID:SOh+hHxU
�������R�X�g�̓_�C�T�C�Y�ɑ��Ďw�����I�ɑ�����Ƃ�����{���o���Ă���̂Ȃ�A
�_�C�T�C�Y���{�ȏ�ɂȂ��Ă��璷�����ĕs�ǃu���b�N���E�����Ƃ������Ȃ�ނ�������܂�͌���\�B
���l�̂��Ƃ�Cell�����ۂ���Ă邵�ˁB
��ŁA�������̂̃R�X�g�����ǂ��B�B�B
�����������m���V�b�N�_�C�Ȃ���������ł��ނ��̂��O���ڑ��C���^�[�t�F�C�X���g���Č������Ȃ��Ƃ����Ȃ��킯�ŁB
L3�Ԃ̒���ɂ���A�_�C���ׂ��ۂɓd�C�M�����p����������V���A���i���ۂɂ͋����p�������j�ɕϊ����Ȃ��Ƃ����Ȃ����ˁB
�P���L3�L���b�V���ɂԂ牺�����ăR�q�[�����V��ۂ��Ă郂�m���V�b�N�_�C�Ɣ�ׂĂ����|�I�ɒ���R�X�g�͑傫�����B
HT�ɂ���AIstanbul�ɂ̓_�C���Ƃɍ��v4�E�F�C���邪�A2�E�F�C�����_�C�Ԍ����Ɏg���Ă�̂�
�O�������Ɏg����̂͌��ǃp�b�P�[�W������4�E�F�C�B
�_�C�T�C�Y���{�ȏ�ɂȂ��Ă��璷�����ĕs�ǃu���b�N���E�����Ƃ������Ȃ�ނ�������܂�͌���\�B
���l�̂��Ƃ�Cell�����ۂ���Ă邵�ˁB
��ŁA�������̂̃R�X�g�����ǂ��B�B�B
�����������m���V�b�N�_�C�Ȃ���������ł��ނ��̂��O���ڑ��C���^�[�t�F�C�X���g���Č������Ȃ��Ƃ����Ȃ��킯�ŁB
L3�Ԃ̒���ɂ���A�_�C���ׂ��ۂɓd�C�M�����p����������V���A���i���ۂɂ͋����p�������j�ɕϊ����Ȃ��Ƃ����Ȃ����ˁB
�P���L3�L���b�V���ɂԂ牺�����ăR�q�[�����V��ۂ��Ă郂�m���V�b�N�_�C�Ɣ�ׂĂ����|�I�ɒ���R�X�g�͑傫�����B
HT�ɂ���AIstanbul�ɂ̓_�C���Ƃɍ��v4�E�F�C���邪�A2�E�F�C�����_�C�Ԍ����Ɏg���Ă�̂�
�O�������Ɏg����̂͌��ǃp�b�P�[�W������4�E�F�C�B
�璷�����Ă����Ă����邯�ǁA
�ނ���T�[�o�p��MCM����e�Ղɂł���悤��I/F��v�ɂ��āA
MCM�ŃR�A�������ʉ������ق����J������l�����炢�������ȁB
�Ԃ����Ⴏ���ʃx�[�X�ł݂�����炩��PC���������Ȃ��̂ɁA
�ʂɃ_�C��p�ӂ���̂������Ă����B
�ނ���T�[�o�p��MCM����e�Ղɂł���悤��I/F��v�ɂ��āA
MCM�ŃR�A�������ʉ������ق����J������l�����炢�������ȁB
�Ԃ����Ⴏ���ʃx�[�X�ł݂�����炩��PC���������Ȃ��̂ɁA
�ʂɃ_�C��p�ӂ���̂������Ă����B
�ʂɐ�p�_�C��p�ӂ��Ă���̂�Intel�ɂ����ł��Ȃ��悤��
����I�͋Z�Ȃ�ł��ꂪ������O���Ȃ�Ďv��Ȃ��łˁB
IBM, AMD�N���X��MCM�������I�B
����I�͋Z�Ȃ�ł��ꂪ������O���Ȃ�Ďv��Ȃ��łˁB
IBM, AMD�N���X��MCM�������I�B
�����܂�ƌ������Ǖi������Ȃ�����
�P�Ȃ����̌v�Z�����E�E�E
�Ⴆ��10���g�����W�X�^�̃`�b�v��Ⴆ�N���b�N��A�AB�AC...J�܂�10�����N�ɋ敪����
���������Z�p��20���g�����W�X�^��1�`�b�v������
A�����N�F1/100�AB�����N�F3/100�AC�����N�F5/100....J�����N�F19/100�ƂȂ�
�ł�10���̃`�b�v2��MCM�Ȃ�
A�����N�F10/100�AB�����N�F10/100�AC�����N�F10/100...J�����N�F10/100�ƂȂ�
�P�Ȃ����̌v�Z�����E�E�E
�Ⴆ��10���g�����W�X�^�̃`�b�v��Ⴆ�N���b�N��A�AB�AC...J�܂�10�����N�ɋ敪����
���������Z�p��20���g�����W�X�^��1�`�b�v������
A�����N�F1/100�AB�����N�F3/100�AC�����N�F5/100....J�����N�F19/100�ƂȂ�
�ł�10���̃`�b�v2��MCM�Ȃ�
A�����N�F10/100�AB�����N�F10/100�AC�����N�F10/100...J�����N�F10/100�ƂȂ�
�܂��f�J�_�C������ȂɃR�X�g�����b�g������̂Ȃ�A
Bulldozer���ŏ�����16�R�A�ł����Ă��ȁB
���Ԃ�Cell�̂悤�Ƀ����O����Ȃ����낤���A�璷�R�A�����e�Ղł͂Ȃ��̂�������Ȃ��B
MCM�͊�{�I�ɂ͊��IC���̂���������Z�p�̉���������A
��x���C�����ł��Ă��܂��@�B����邳���傤��11�̂��邩�����̂��邩�̍��Ȃ̂ŁA
�����܂ō����Ȃ��͂�����B�ŏ��̎������u�̐ݔ������������ȁB
Bulldozer���ŏ�����16�R�A�ł����Ă��ȁB
���Ԃ�Cell�̂悤�Ƀ����O����Ȃ����낤���A�璷�R�A�����e�Ղł͂Ȃ��̂�������Ȃ��B
MCM�͊�{�I�ɂ͊��IC���̂���������Z�p�̉���������A
��x���C�����ł��Ă��܂��@�B����邳���傤��11�̂��邩�����̂��邩�̍��Ȃ̂ŁA
�����܂ō����Ȃ��͂�����B�ŏ��̎������u�̐ݔ������������ȁB
�����O����Ȃ��̂Ə璷���ɉ��̊W��
AMD�A�T�[�o����12�R�A�v���Z�b�T�uAMD Opteron 6100�V���[�Y�v�\
http://journal.mycom.co.jp/news/2010/03/29/035/index.html
���z������|2�`4�\�P�b�g�T�[�o�[�Ŏg����ቿ�i�E12�R�A�́uOpteron 6100�v
http://enterprise.watch.impress.co.jp/docs/series/virtual/20100330_357638.html
http://journal.mycom.co.jp/news/2010/03/29/035/index.html
���z������|2�`4�\�P�b�g�T�[�o�[�Ŏg����ቿ�i�E12�R�A�́uOpteron 6100�v
http://enterprise.watch.impress.co.jp/docs/series/virtual/20100330_357638.html
���u�o�ς�������钆�A�G���h���[�U�[�̓T�[�o�̉��l�����ɂ߁A�Ⴂ������
���ő���̌��ʂ��o�������ƍl���Ă���B�������邱�Ƃɂ�蕂�����R�X�g���A
�����D�G�Ȑl�ނ̈��~�߂�g�[�Ȃǂ։��Ƃ��\�ƂȂ邩�炾�B
����X�́A�����������Ƃ��^�ɉ\�ƂȂ�悤�ɁA2�\�P�b�g����CPU��4�\�P�b�g
������CPU�����i�ɂ��A��荂�����\���R�X�g�Ŏ����ł���悤�ɂ����v
���ƁA4�\�P�b�g����CPU�̂�������̂��̂������������Ƃ���������B
���܂��A4�\�P�b�g�T�[�o�̎s��V�F�A��10�N�O�ɂ�10%�����������݂�
��4%�Ɍ����A���̂܂܍s���Ώ����Ă��܂��\��������Ƃ̌��������邪�A
���u���������{�I�Ɍ������K�v���������B���ʂƂ��āA2�\�P�b�g
�������Ɠ����R�X�g��4�\�P�b�g�������o����A�s���4�\�P�b�g������
���p�t�H�[�}���X�������Ǝv���������o�Ă���͂��ƍl�����v
�E�E�E�E�A�v���
MP�������_���s���O���i�Œ��Ȃ���Xeon DP�Ɛ킦�܂���i�����j
���Ă��ƂȂ�ˁH
���ő���̌��ʂ��o�������ƍl���Ă���B�������邱�Ƃɂ�蕂�����R�X�g���A
�����D�G�Ȑl�ނ̈��~�߂�g�[�Ȃǂ։��Ƃ��\�ƂȂ邩�炾�B
����X�́A�����������Ƃ��^�ɉ\�ƂȂ�悤�ɁA2�\�P�b�g����CPU��4�\�P�b�g
������CPU�����i�ɂ��A��荂�����\���R�X�g�Ŏ����ł���悤�ɂ����v
���ƁA4�\�P�b�g����CPU�̂�������̂��̂������������Ƃ���������B
���܂��A4�\�P�b�g�T�[�o�̎s��V�F�A��10�N�O�ɂ�10%�����������݂�
��4%�Ɍ����A���̂܂܍s���Ώ����Ă��܂��\��������Ƃ̌��������邪�A
���u���������{�I�Ɍ������K�v���������B���ʂƂ��āA2�\�P�b�g
�������Ɠ����R�X�g��4�\�P�b�g�������o����A�s���4�\�P�b�g������
���p�t�H�[�}���X�������Ǝv���������o�Ă���͂��ƍl�����v
�E�E�E�E�A�v���
MP�������_���s���O���i�Œ��Ȃ���Xeon DP�Ɛ킦�܂���i�����j
���Ă��ƂȂ�ˁH
Phenom��X3�̖����R�A�́A�e�X�g���Ă�̂����������Ȃ����ȁB
MP������CPU�͍������āA4�\�P�b�g�őg�ނ��炢�Ȃ�u���[�h�T�[�o�[�Ő��𑩂˂���������I������
AMD�̓��[�}���E�u���U�[�Y���Ă���Magny-Cours�J���͂��߂��������c�B
�܂����܂�C�ɂ���قǓx���������͂����ǁB
�܂����܂�C�ɂ���قǓx���������͂����ǁB
���̒��̓N���E�h�����Ă�悤�����A
���Ԃ̓T�[�oCPU�����\�������肷���āA4S�ȉ��̃��[�G���h�T�[�o��
�قƂ�ǂ̃j�[�Y�܂��Ȃ���悤�ɂȂ��Ă��܂��āA�ꕔ�̃j�b�`�l�^�ȊO�́A
���͂�l������d�C����̃����j���O�R�X�g�ł������ʉ��ł���l�^���Ȃ��Ȃ��Ă��܂������Ă̂�
�{���̂Ƃ���Ȃ낤�Ȃ��B
�N���E�h�͂��̕ӂ̎�������܂��B�����Ă���閂�@�̌��t�B
�{���͈����T�[�o�����ɂȂ��ł���ǂꂽ�炩������邢����A
�ڋq�̓T�[�o�̎�ނ⒆�g�Ȃ�čl���Ȃ��Ă������炾�܂��Ĉϑ�����݂����ȁB
���Ԃ̓T�[�oCPU�����\�������肷���āA4S�ȉ��̃��[�G���h�T�[�o��
�قƂ�ǂ̃j�[�Y�܂��Ȃ���悤�ɂȂ��Ă��܂��āA�ꕔ�̃j�b�`�l�^�ȊO�́A
���͂�l������d�C����̃����j���O�R�X�g�ł������ʉ��ł���l�^���Ȃ��Ȃ��Ă��܂������Ă̂�
�{���̂Ƃ���Ȃ낤�Ȃ��B
�N���E�h�͂��̕ӂ̎�������܂��B�����Ă���閂�@�̌��t�B
�{���͈����T�[�o�����ɂȂ��ł���ǂꂽ�炩������邢����A
�ڋq�̓T�[�o�̎�ނ⒆�g�Ȃ�čl���Ȃ��Ă������炾�܂��Ĉϑ�����݂����ȁB
�[���A4S���̃~�h���ȏ�̃T�[�o���ǂ�ǂ���v�Ȃ��Ȃ��Ă�̂����������Ă̂ɁA
�N���E�h�Œ����W������������킯�ˁ[�����B�N���E�h�~�����B
Google�Ƃ��̃X�[�p�[�j�b�`�Ȃ�ĎQ�l�ɂȂ�˂����ȁB
�������̂Ȃ��ꂾ���ăT�[�o�̐��\���������āA1�ɂ܂Ƃ߂��ق���
�ێ���₷���Ȃ�̂��킩�������Ă�������B�ނ���ǂ��l���Ă��T�[�o�͐��ނɂނ����Ă�ȁB
�N���E�h�Œ����W������������킯�ˁ[�����B�N���E�h�~�����B
Google�Ƃ��̃X�[�p�[�j�b�`�Ȃ�ĎQ�l�ɂȂ�˂����ȁB
�������̂Ȃ��ꂾ���ăT�[�o�̐��\���������āA1�ɂ܂Ƃ߂��ق���
�ێ���₷���Ȃ�̂��킩�������Ă�������B�ނ���ǂ��l���Ă��T�[�o�͐��ނɂނ����Ă�ȁB
���v�͏o��낤���A�V�F�A�̊g��Ɍq���邩�ǂ����͌���������������
>>659
���̕��ŗv����Ƃ��B���ނ�����{��w�Z�����Ă���B
���̕��ŗv����Ƃ��B���ނ�����{��w�Z�����Ă���B
Opteron 4100�V���[�Y�̃��C���i�b�v�Ɖ��i
ttp://northwood.blog60.fc2.com/blog-entry-3687.html
2P�ȉ��ŏ\���Ƃ����Ȃ�Ȃ����牿�i���d�v�ł��Ȃ�
ttp://northwood.blog60.fc2.com/blog-entry-3687.html
2P�ȉ��ŏ\���Ƃ����Ȃ�Ȃ����牿�i���d�v�ł��Ȃ�
>>659
MP�̃v���~�A�����Ȃ��������i�ݒ�͎�����T�[�o�[���ɑ���⏕��
MP�̃v���~�A�����Ȃ��������i�ݒ�͎�����T�[�o�[���ɑ���⏕��
����ɂ��Ă����̂Ƃ���AMD�̎���J��o���y�[�X�����܂�����
�[���I���v���Ă܂�����́H
���Z�I�̓A�������ACG�p�H
���Z�I�̓A�������ACG�p�H
Nehalem-EX�o��
ttp://www.theregister.co.uk/2010/03/30/intel_nehalem_ex_launch/page2.html
ttp://regmedia.co.uk/2010/03/30/intel_nehalem_ex_table.gif
���ɒZ���V����������
ttp://www.theregister.co.uk/2010/03/30/intel_nehalem_ex_launch/page2.html
ttp://regmedia.co.uk/2010/03/30/intel_nehalem_ex_table.gif
{kind=link}
���ɒZ���V����������
>>672
���Ƃ̓x���`�}�[�N����
���Ƃ̓x���`�}�[�N����
�Ƃ�����Nehalem-EX��Westmere���ēo�ꎞ���������炢�Ȃ̂�
intel�͂ǂ������C���Ŕ��肽���H
intel�͂ǂ������C���Ŕ��肽���H
SemiAccurate :: ATI's next generation plans outed
http://www.semiaccurate.com/2010/03/30/atis-next-generation-outed/
�����A�e�͂Ȃ���
http://www.semiaccurate.com/2010/03/30/atis-next-generation-outed/
�����A�e�͂Ȃ���
>>674
Westmere-EP��2�\�P�b�g�܂ŗp��Nehalem-EX��4�\�P�b�g�ȏ�p����Ȃ�����
Nehalem-EX��>>672���������Westmere-EP���啪�N���b�N���Ⴂ����A2�\�P�b�g�܂łȂ牉�Z�\�͂ł�Westmere-EP�ɂ͋y�Ȃ���
Westmere-EP��2�\�P�b�g�܂ŗp��Nehalem-EX��4�\�P�b�g�ȏ�p����Ȃ�����
Nehalem-EX��>>672���������Westmere-EP���啪�N���b�N���Ⴂ����A2�\�P�b�g�܂łȂ牉�Z�\�͂ł�Westmere-EP�ɂ͋y�Ȃ���
���Ƃ͂Ȃɂ�艿�i����ˁH
�s�[�N�p�t�H�[�}���X�ł͂ǂ��݂Ă��킦�Ȃ�����
CPU�̃R�X�g�p�t�H�[�}���X�Ō����
���炩��AMD�ɕ�������
�s�[�N�p�t�H�[�}���X�ł͂ǂ��݂Ă��킦�Ȃ�����
CPU�̃R�X�g�p�t�H�[�}���X�Ō����
���炩��AMD�ɕ�������
678 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 14:09:47 ID:swjCQpSQ
CPU�̒P�������i�̒P����傫�����E����̂́u�p�\�R���v�܂ŁB
�~�b�h�����W�ȏ�̃T�[�o�[��CPU�ȏ�ɍ������i�Ȃ�ăU���ɂ��邵
�\�t�g�E�F�A�̃��C�Z���X��T�|�[�g�A���̑��l����ݍ��݂ōl�����
CPU�����̉��i���Ȃ�Ė{������Ȃ��Ȃ�B
�~�b�h�����W�ȏ�̃T�[�o�[��CPU�ȏ�ɍ������i�Ȃ�ăU���ɂ��邵
�\�t�g�E�F�A�̃��C�Z���X��T�|�[�g�A���̑��l����ݍ��݂ōl�����
CPU�����̉��i���Ȃ�Ė{������Ȃ��Ȃ�B
AMD�̃����b�g�́A�v���b�g�t�H�[���̑��̒������Ǝv���B
�ƁA�����̃\�PF�I���\���Ă���܂���
�ƁA�����̃\�PF�I���\���Ă���܂���
>>678
���������ɂ���m�I��Q��
���������ɂ���m�I��Q��
681 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 14:39:34 ID:swjCQpSQ
���Ƃ���Magny-Cours��DDR3 4ch������
3ch�ɗ��߂Ă�Westmere-EP���}�U�{�̒P�������ςނł��傤���H
���̂ւ�͏펯�ōl���Ă�
3ch�ɗ��߂Ă�Westmere-EP���}�U�{�̒P�������ςނł��傤���H
���̂ւ�͏펯�ōl���Ă�
�܂�Westmere-EP�͕n�R��Ƒ���ɔ����Ƃ������Ƃ����
�m�I��Q�҂̔����͂���܂ł̗���Ɩ��W�Ȃ��̂������Ă��邤����
��CPU�ȏ�ɍ������i�Ȃ�ăU���ɂ���
��
CPU�������}�U�{�̘b
�Ƃ����̒������ł����ꂪ����������
�R�s�y���猻���ƈႦ��悤�ɂ����Ες��Ă�����Ƃǂ����悤���Ȃ�
��CPU�ȏ�ɍ������i�Ȃ�ăU���ɂ���
��
CPU�������}�U�{�̘b
�Ƃ����̒������ł����ꂪ����������
�R�s�y���猻���ƈႦ��悤�ɂ����Ες��Ă�����Ƃǂ����悤���Ȃ�
684 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 14:56:19 ID:swjCQpSQ
Westmere��DDR3 1600MHz�܂Ō����Ή����Ă邩��\���ł��傤�B
Magny-Cours�͂Ȃ���1066/1333�̂ݑΉ��ɂ��Ă邯�ǁi������ɂ�1600��������Ƃ��j
���Ȃ݂ɍő僁�������ڗ�
Nehalem/Westmere-EP: 384GB
Magny-Cours: 128GB
Magny-Cours�͂Ȃ���1066/1333�̂ݑΉ��ɂ��Ă邯�ǁi������ɂ�1600��������Ƃ��j
���Ȃ݂ɍő僁�������ڗ�
Nehalem/Westmere-EP: 384GB
Magny-Cours: 128GB
http://pc.watch.impress.co.jp/docs/news/20100331_357926.html
���Ή���������DDR3-1066/978/800
http://ad.impress.co.jp/special/amd1003/pc2/
��2P�\���Ȃ�192GB�A4P�\���Ȃ��384GB
���Ή���������DDR3-1066/978/800
http://ad.impress.co.jp/special/amd1003/pc2/
��2P�\���Ȃ�192GB�A4P�\���Ȃ��384GB
>681 ���O�F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o [sage] ���e���F2010/03/31(��) 14:39:34 ID:swjCQpSQ [2/3]
>���Ƃ���Magny-Cours��DDR3 4ch������
>3ch�ɗ��߂Ă�Westmere-EP���}�U�{�̒P�������ςނł��傤���H
>
>���̂ւ�͏펯�ōl���Ă�
����Ȃ��ƌ���������ɁANehalem/Westmere-EP�̍ő僁�������ڗʂ������B
���R�������您�O�́B
>���Ƃ���Magny-Cours��DDR3 4ch������
>3ch�ɗ��߂Ă�Westmere-EP���}�U�{�̒P�������ςނł��傤���H
>
>���̂ւ�͏펯�ōl���Ă�
����Ȃ��ƌ���������ɁANehalem/Westmere-EP�̍ő僁�������ڗʂ������B
���R�������您�O�́B
687 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 15:15:09 ID:swjCQpSQ
>>685
> http://pc.watch.impress.co.jp/docs/news/20100331_357926.html
> ���Ή���������DDR3-1066/978/800
����̂ǂ���Westmere�Ȃ�ł����H
> http://ad.impress.co.jp/special/amd1003/pc2/
> ��2P�\���Ȃ�192GB�A4P�\���Ȃ��384GB
���i���x���̘b����B
http://pc.watch.impress.co.jp/docs/news/20100330_357892.html
> �@���Ƃ��āAH8SGL-F��H8SGL�́A�V���O���\�P�b�g��ATX�t�H�[���t�@�N�^���̗p����̂������B
> ��������DDR3-1333/1066 /800�ɑΉ����ARegistered ECC�ł͍ő�128GB�AUnbuffered ECC/non-ECC�ł͍ő�32GB�܂ł��T�|�[�g����B
Nehalem EP�Ŋ���384GB�܂�
https://www.cisco.com/web/JP/product/hs/ucs/ucs_b/prodlit/pdf/at_a_glance_c45-531022.pdf
> Cisco UCS B-250 M1 �ɂ́A�V�X�R���������擾�����g��������
> �e�N�m���W�[���̗p����Ă��܂��B���̃e�N�m���W�[�͏]����
> 2 �\�P�b�g �T�[�o�� 2 �{�ȏ�̗e�ʂ̋ƊE�W���������i384 GB�j
> ����A���z�}�V�����R���e����ꍇ��A��e�ʃf�[�^ �Z�b
> �g�������V�X�e���ɍœK�ł��B���邢�́A����قǑ����������̗e
> �ʂ�K�v�Ƃ��Ȃ��ꍇ�ɂ��A�������𑽂��ݒu�ł��邱�Ƃ𗘗p��
> �ăR�X�g���ʂ̍��������� �\�����[�V�����Ƃ��Ă��g���܂��B
> http://pc.watch.impress.co.jp/docs/news/20100331_357926.html
> ���Ή���������DDR3-1066/978/800
����̂ǂ���Westmere�Ȃ�ł����H
> http://ad.impress.co.jp/special/amd1003/pc2/
> ��2P�\���Ȃ�192GB�A4P�\���Ȃ��384GB
���i���x���̘b����B
http://pc.watch.impress.co.jp/docs/news/20100330_357892.html
> �@���Ƃ��āAH8SGL-F��H8SGL�́A�V���O���\�P�b�g��ATX�t�H�[���t�@�N�^���̗p����̂������B
> ��������DDR3-1333/1066 /800�ɑΉ����ARegistered ECC�ł͍ő�128GB�AUnbuffered ECC/non-ECC�ł͍ő�32GB�܂ł��T�|�[�g����B
Nehalem EP�Ŋ���384GB�܂�
https://www.cisco.com/web/JP/product/hs/ucs/ucs_b/prodlit/pdf/at_a_glance_c45-531022.pdf
> Cisco UCS B-250 M1 �ɂ́A�V�X�R���������擾�����g��������
> �e�N�m���W�[���̗p����Ă��܂��B���̃e�N�m���W�[�͏]����
> 2 �\�P�b�g �T�[�o�� 2 �{�ȏ�̗e�ʂ̋ƊE�W���������i384 GB�j
> ����A���z�}�V�����R���e����ꍇ��A��e�ʃf�[�^ �Z�b
> �g�������V�X�e���ɍœK�ł��B���邢�́A����قǑ����������̗e
> �ʂ�K�v�Ƃ��Ȃ��ꍇ�ɂ��A�������𑽂��ݒu�ł��邱�Ƃ𗘗p��
> �ăR�X�g���ʂ̍��������� �\�����[�V�����Ƃ��Ă��g���܂��B
688 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 15:18:55 ID:swjCQpSQ
>>686
CPU�̈����ɑË����Ă͍ő���̃p�t�H�[�}���X�͓����Ȃ����Ă��Ƃł���
CPU�̈����ɑË����Ă͍ő���̃p�t�H�[�}���X�͓����Ȃ����Ă��Ƃł���
689 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 15:25:22 ID:swjCQpSQ
���z���ɋ����i�د
http://www.anandtech.com/show/2978/amd-s-12-core-magny-cours-opteron-6174-vs-intel-s-6-core-xeon/11
http://www.anandtech.com/show/2978/amd-s-12-core-magny-cours-opteron-6174-vs-intel-s-6-core-xeon/11
�I�p��Westmere����DDR3 1600MHz�܂őΉ����Ă�����H�@
691 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 15:51:33 ID:swjCQpSQ
ECC�t����1600MHz���W���[���͂܂��܂������ʏ��Ȃ����A���̖��ł���
AMD��Intel�������R���̓��C�Z���X�̊W��Rumbus���^�̓����R���g���[���[���W���[����ς�ł�������
�������͈��������ǂ��Ɍ��܂��Ă�
�Ƃ����Nehalem-EX��8�R�A��2.26GHz�Ȃ��Ƃ��l�����
12�R�A��2.3GHz��Magny-Cours�����\�������C������
�܂��g�����W�X�^����5���قLjႤ����
�Ƃ����Nehalem-EX��8�R�A��2.26GHz�Ȃ��Ƃ��l�����
12�R�A��2.3GHz��Magny-Cours�����\�������C������
�܂��g�����W�X�^����5���قLjႤ����
�Ȃ��X�Ԕ��ł邯�NjC�����N���Ă�H
Nehalem-EX��600mm2���炵������N���b�N�グ��̂͑�ς���������
696 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 19:07:55 ID:swjCQpSQ
>>693
�ǂ��撣���Ă�̂�kwsk
�ǂ��撣���Ă�̂�kwsk
6core��240mm2�Ȃ̂�
8core��600mm2�Ȃ̂������
45nm����
8core��600mm2�Ȃ̂������
45nm����
698 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 19:16:07 ID:swjCQpSQ
�����Nehalem-EX��45nm��������
Xeon MP��1�N�x��Ȃ̂͐̂��炾�낤
Xeon MP��1�N�x��Ȃ̂͐̂��炾�낤
����A�P�ɈӊO������������
700 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 19:23:49 ID:swjCQpSQ
Magny-Cours�͉ߔM����Ǝ����N���b�N�_�E������@�\��t���邱�Ƃ�2.3GHz�̃N���b�N����������B
�v����ɋtTurbo-Boost����
���Ȃ݂�Nehalem-EX�ŏ�ʂ�X7560��TB��2.66GHz�܂Ńu�[�X�g���邪
������u2.66GHz�v�Ƃ��Ă͔���Ȃ��B
�p���̈Ⴂ���o�ĂĖʔ�����
�v����ɋtTurbo-Boost����
���Ȃ݂�Nehalem-EX�ŏ�ʂ�X7560��TB��2.66GHz�܂Ńu�[�X�g���邪
������u2.66GHz�v�Ƃ��Ă͔���Ȃ��B
�p���̈Ⴂ���o�ĂĖʔ�����
�܁AVIA������nano U2250�͎����N���b�N�A�b�v��1.6GHz�ŏ펞�ғ����Ă邯��1.3+GHz���Ă��Ă�
TDP���őS�R�A�t�����[�h�o�����i�N���b�N��
2.26G��2.3G�̍���
�����̒m�I��Q�ł������������邢���̒m�I��Q��
2.26G��2.3G�̍���
�����̒m�I��Q�ł������������邢���̒m�I��Q��
703 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 20:34:54 ID:swjCQpSQ
�s��ς݂����ȑS���Z���j�b�g�t���o�[���ȃv���O�������������Ƃ�
�N���b�N�_�E������\���������B
�N���b�N�_�E������\���������B
�܂�Magny-Cours��2S�������ŁA
��RISC�T�[�o�F�̋���Nehalem-EX�Ƃ͎��ۂ̂Ƃ���_�����Ⴄ���i�Ȃ̂ŁA
����Ȃɋ������Ȃ��킯�ł��邪�B
��RISC�T�[�o�F�̋���Nehalem-EX�Ƃ͎��ۂ̂Ƃ���_�����Ⴄ���i�Ȃ̂ŁA
����Ȃɋ������Ȃ��킯�ł��邪�B
���܂�L1D������Pentium 4�̘b�͗v��Ȃ��ł�
�������E�ł�TDP�Ɨ�p�\�͕͂ʖ��
ttp://pc.watch.impress.co.jp/docs/news/20100329_357660.html
�q�[�g�V���N���O�ꂽ��t�@������ꂽ��G�A�t���[���l�܂�����ȂǂŔ��M�����E������
���܂ł͏đ��h�~�ŋ�����~�ɂł��Ȃ��Ă��̂��ȁH
���ꂪ�N���b�N���Ƃ������ōςނ悤�ɂȂ��Ȃ炢�����Ƃ�
�������E�ł�TDP�Ɨ�p�\�͕͂ʖ��
ttp://pc.watch.impress.co.jp/docs/news/20100329_357660.html
�q�[�g�V���N���O�ꂽ��t�@������ꂽ��G�A�t���[���l�܂�����ȂǂŔ��M�����E������
���܂ł͏đ��h�~�ŋ�����~�ɂł��Ȃ��Ă��̂��ȁH
���ꂪ�N���b�N���Ƃ������ōςނ悤�ɂȂ��Ȃ炢�����Ƃ�
>>705
Intel��TDP�̒l���I�ǂ݂����ĂāA���̂܂܃o�J�����ɍ�����I�͕��ׂ��������
�T�[�}���X���b�g�����O��T�[�}���V���b�g�_�E��������CPU�������B
�������A�L�`���ƃ��b�L���O����DC�ɒu���ĂĂ����Ȃ�B
�Ζ���ɂ��̃��f�����c���Ă邗
Intel��TDP�̒l���I�ǂ݂����ĂāA���̂܂܃o�J�����ɍ�����I�͕��ׂ��������
�T�[�}���X���b�g�����O��T�[�}���V���b�g�_�E��������CPU�������B
�������A�L�`���ƃ��b�L���O����DC�ɒu���ĂĂ����Ȃ�B
�Ζ���ɂ��̃��f�����c���Ă邗
707 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 21:57:18 ID:swjCQpSQ
���\������ǂތ���TDP�ʂ�ɑg�ނ�Magny-Cours�ł������Ȃ邼
��PentiumD������ł������悤�Șb���ȁB
>>700
Magny-Cours���Ė{����AMD�ł�Smithfield����Ȃ���
Smithfield�����C�o��(Athlon64X2)�ɒu���Ă���Ȃ����߂�MCM������
Clovertown�݂����ȃ��C�o����˂��������߂�MCM�ł͂Ȃ�
Magny-Cours���Ė{����AMD�ł�Smithfield����Ȃ���
Smithfield�����C�o��(Athlon64X2)�ɒu���Ă���Ȃ����߂�MCM������
Clovertown�݂����ȃ��C�o����˂��������߂�MCM�ł͂Ȃ�
711 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/03/31(��) 23:43:53 ID:swjCQpSQ
http://pc.watch.impress.co.jp/docs/news/20100329_357660.html
> �uAMD Cool Speed Technology�v�ƌĂ��ȓd�͋@�\����������Ă���A
> ���x�Z���T�[�ʼn��x�����E���}�����Ɣ��f�����Ƃ��A�v���Z�b�T��P�X�e�[�g�����
> �Ⴂ�i�K�ւƋ����I�Ɉڍs������@�\���B
> �����̋@�\�ɂ��A�v���Z�b�T�̓d�͌�����O����ɔ�ׂč��߂Ă���B
�܂��ڍׂ�PDF�ł��ǂ߂����Ƃ���
�����ʂ�̔M�v���ƁA�������ׂ������邽�тɁuAMD Cool Speed Technology�v�i�j�����������ȁB
> �uAMD Cool Speed Technology�v�ƌĂ��ȓd�͋@�\����������Ă���A
> ���x�Z���T�[�ʼn��x�����E���}�����Ɣ��f�����Ƃ��A�v���Z�b�T��P�X�e�[�g�����
> �Ⴂ�i�K�ւƋ����I�Ɉڍs������@�\���B
> �����̋@�\�ɂ��A�v���Z�b�T�̓d�͌�����O����ɔ�ׂč��߂Ă���B
�܂��ڍׂ�PDF�ł��ǂ߂����Ƃ���
�����ʂ�̔M�v���ƁA�������ׂ������邽�тɁuAMD Cool Speed Technology�v�i�j�����������ȁB
>>710
�͂��͂�
�͂��͂�
>712
�͂��͂��@����Ȃ��āB
�Y�ƈꏏ�ɂ��ꂿ��Magny-Cours�����킢�������B
������͂����Ɛ�������Ă���ł���B
�͂��͂��@����Ȃ��āB
�Y�ƈꏏ�ɂ��ꂿ��Magny-Cours�����킢�������B
������͂����Ɛ�������Ă���ł���B
>>700
������ĒP�Ƀt�@������ꂽ��A������P�[�X���̉��x�������Ȃ��ė�p�\�͂����ꍇ�ɁA
�N���b�N��}���Ĕj�����~��h�~������Ă�������B
�������肵���ł̒�i����ł��ُ픭�M�����肪����݂����ȈӖ����Ⴀ�Ȃ��B
�܂��AMagni-Cours���o�J�ɂ����Ȃ߂����悤�����ǁA
�����琫�\�̐^���������ŏ��Ă�Ƃ͒N���v���ĂȂ�����Ӗ���������B
6�R�A��������W���n������A��������12�R�A����芸��������Ă݂܂������Ă����B
������ĒP�Ƀt�@������ꂽ��A������P�[�X���̉��x�������Ȃ��ė�p�\�͂����ꍇ�ɁA
�N���b�N��}���Ĕj�����~��h�~������Ă�������B
�������肵���ł̒�i����ł��ُ픭�M�����肪����݂����ȈӖ����Ⴀ�Ȃ��B
�܂��AMagni-Cours���o�J�ɂ����Ȃ߂����悤�����ǁA
�����琫�\�̐^���������ŏ��Ă�Ƃ͒N���v���ĂȂ�����Ӗ���������B
6�R�A��������W���n������A��������12�R�A����芸��������Ă݂܂������Ă����B
��芸�����AWestmere6c�̃X�y�b�N�͕����������A����32nm��Sandybridge8C�̃X�y�b�N����̗\�z�o����ȁB
���炭8C/16T 2.8G�`3G��130W���낤�B(2�R�A�����ăN���b�N�ꊄ��)
����AMD�́ABulldozer���S���s��������32nm Llano 4C 3G=60W�����ɓK���ɗ\�z���Ă݂悤�B
��芸�����P�R�A���\��k10=Bull�ATDP��K10 2C=bull 3C���Ɖ��肷��B
K10 4�R�A��40W�Ƃ����2�R�A 20W������A
Bull 3�R�A 20W��16�R�A 110W�ɂȂ�B
�L���b�V������20W�Ƃ���Bull 16�R�A 3G 130W�ł����������ˁB
�܂�8�R�A 3G��65W�ɂȂ�̂�w
�����I�ɂ�Bull 16C 3G vs Sandy 8C/16T 3G�����ڂԂ���ˁB
���N�㔼��AMDvsIntel�ŃK�`�̖h�䖳���̉��荇���ɂȂ���ɖʔ�������w
���炭8C/16T 2.8G�`3G��130W���낤�B(2�R�A�����ăN���b�N�ꊄ��)
����AMD�́ABulldozer���S���s��������32nm Llano 4C 3G=60W�����ɓK���ɗ\�z���Ă݂悤�B
��芸�����P�R�A���\��k10=Bull�ATDP��K10 2C=bull 3C���Ɖ��肷��B
K10 4�R�A��40W�Ƃ����2�R�A 20W������A
Bull 3�R�A 20W��16�R�A 110W�ɂȂ�B
�L���b�V������20W�Ƃ���Bull 16�R�A 3G 130W�ł����������ˁB
�܂�8�R�A 3G��65W�ɂȂ�̂�w
�����I�ɂ�Bull 16C 3G vs Sandy 8C/16T 3G�����ڂԂ���ˁB
���N�㔼��AMDvsIntel�ŃK�`�̖h�䖳���̉��荇���ɂȂ���ɖʔ�������w
Smithfield��2�̃_�C�̊ԂɑS���ʐM�H���Ȃ��A
�`�b�v�Z�b�g���o�R���Ȃ��Ƃ����Ȃ��A�{���̃j�R�C�`�B
Magny-Cours�͓�̃_�C��HT�����N��ł����ƌq�����Ă�
�`�b�v�Z�b�g���o�R���Ȃ��Ƃ����Ȃ��A�{���̃j�R�C�`�B
Magny-Cours�͓�̃_�C��HT�����N��ł����ƌq�����Ă�
350mm2��MCM��500MM2�̐����R�X�g�͂ǂ����������낤�ȁB
�T�C�Y�䂪HD5970 vs GTX480���ۂ����ǁB
�K���Ɍv�Z���Ă݂��B
�����܂��350mm2��60%�A500mm2��40%�ʂ��ˁB
���ꂼ��E�F�n����150�A100�̃R�A���̂��Ƃ��Čv�Z����ƁA
150*0.6��90�A100*0.3��30�̂�邱�ƂɂȂ�ȁB
MCM�����甼����45���ɂȂ�Ƃ���ƁA
1�E�F�n����}�j�N�[����45�AX7000��30�Ƃ������Ƃ��B
SOI�̕��R�X�g���オ���Ă��������������x�̃R�X�g���ȁB
�R�X�g�ꏏ�ő����̂��ꍇ�̃����b�g�͂Ȃ낤�B
�T�C�Y�䂪HD5970 vs GTX480���ۂ����ǁB
�K���Ɍv�Z���Ă݂��B
�����܂��350mm2��60%�A500mm2��40%�ʂ��ˁB
���ꂼ��E�F�n����150�A100�̃R�A���̂��Ƃ��Čv�Z����ƁA
150*0.6��90�A100*0.3��30�̂�邱�ƂɂȂ�ȁB
MCM�����甼����45���ɂȂ�Ƃ���ƁA
1�E�F�n����}�j�N�[����45�AX7000��30�Ƃ������Ƃ��B
SOI�̕��R�X�g���オ���Ă��������������x�̃R�X�g���ȁB
�R�X�g�ꏏ�ő����̂��ꍇ�̃����b�g�͂Ȃ낤�B
>>716
�ɂ킩��
�ɂ킩��
>>718
�ϴ��Ű�B
�ϴ��Ű�B
�������A�Ȃ�ł����ň��Ƃ��ƕK���ɏ����Ă�̂��ȁ[�H��
��p�X�����邾��H�������ł���B
��p�X�����邾��H�������ł���B
Magny-Cours�͓����Ȃ���Ǝv�������o�Ă�����������Ƃ���Ȃ�ɂ���
722 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 03:13:33 ID:SFrIv+ox
>>714
�Ⴂ�܂��BTDP�g�Ɏ��߂邽�߂́u�ȓd�͋Z�p�v�Ƃ��Ďg���Ă܂��B
�Ⴂ�܂��BTDP�g�Ɏ��߂邽�߂́u�ȓd�͋Z�p�v�Ƃ��Ďg���Ă܂��B
723 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 03:49:11 ID:SFrIv+ox
������AMD�̒��̐l������d�͂�}����Z�p�����Đ������Ă邩��F�߂悤��
> Some of the AMD-P 2.0 power savings features include AMD CoolSpeed Technology,
> which reduces p-states when a temperature limit is reached, and C1E, a sleep state
> invoked when all processor cores in a system are idle. These have significant end-user
> benefits, discussed in the next section.
http://developer.amd.com/documentation/articles/pages/Magny-Cours-Direct-Connect-Architecture-2.0.aspx
> Some of the AMD-P 2.0 power savings features include AMD CoolSpeed Technology,
> which reduces p-states when a temperature limit is reached, and C1E, a sleep state
> invoked when all processor cores in a system are idle. These have significant end-user
> benefits, discussed in the next section.
http://developer.amd.com/documentation/articles/pages/Magny-Cours-Direct-Connect-Architecture-2.0.aspx
>>720
Windows�Ńp�\�R���ǂꂪ�����Ȃ�Ęb�������Ă����
������芄�荞��ł���Mac�E�߂Ă���S����C��ǂ߂Ȃ��}�J�[�ƈꏏ�Ȃ�ˁH
Mac��Win�ɁA�}�J�[���h�U�[�ɂ��Ă�������
Windows�Ńp�\�R���ǂꂪ�����Ȃ�Ęb�������Ă����
������芄�荞��ł���Mac�E�߂Ă���S����C��ǂ߂Ȃ��}�J�[�ƈꏏ�Ȃ�ˁH
Mac��Win�ɁA�}�J�[���h�U�[�ɂ��Ă�������
>>722
�Ӗ��s������
��i���ō�2.3GHz�A�ُ퉷�x���̃N���b�N�����@�\�t��
�܂Ƃ���➑̂��p�@�\�A�����Ȃ�N���肦�Ȃ���펖�Ԃɔ������@�\����B
��intel��Pen4�Ŏ��������A�q�[�g�V���N���O���Ă��N���b�N��d����啝�ɉ����ē�����������ēz�B
�����AMD�ł��Ă����B
�܂�����i��2.3GHz����M�\���������Ƃł����������̂��Hw
�Ӗ��s������
��i���ō�2.3GHz�A�ُ퉷�x���̃N���b�N�����@�\�t��
�܂Ƃ���➑̂��p�@�\�A�����Ȃ�N���肦�Ȃ���펖�Ԃɔ������@�\����B
��intel��Pen4�Ŏ��������A�q�[�g�V���N���O���Ă��N���b�N��d����啝�ɉ����ē�����������ēz�B
�����AMD�ł��Ă����B
�܂�����i��2.3GHz����M�\���������Ƃł����������̂��Hw
C1E������d�͂�}����Z�p�Ƃ͌����Ă邯��CoolSpeed�͉��x�Ɋւ��Ă̌��y����������
�]���Ȃ牷�x����ɒB����Ɠ�����~���Ă��̂��A�N���b�N�Ɠd���𗎂Ƃ��ē�����p������悤�ɂȂ���
���ʂƂ��Đ��\/�d�͂̌������オ���Ă���
���������Ӗ��ŏȓd�͋@�\(AMD-P 2.0)�Ƃ��Ĉꊇ��ɂ���Ă�Ǝv������
�]���Ȃ牷�x����ɒB����Ɠ�����~���Ă��̂��A�N���b�N�Ɠd���𗎂Ƃ��ē�����p������悤�ɂȂ���
���ʂƂ��Đ��\/�d�͂̌������オ���Ă���
���������Ӗ��ŏȓd�͋@�\(AMD-P 2.0)�Ƃ��Ĉꊇ��ɂ���Ă�Ǝv������
727 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 04:25:01 ID:SFrIv+ox
>>725
�����N����ł�
http://blogs.amd.com/developer/2010/03/29/you-down-with-amd-p/
> AMD CoolSpeed technology is a capability that enables the processor(s) to automatically drop into a
> lower power mode if the processor thermal specifications are exceeded. Once the processor thermals
> return within specification the processor can automatically return to full performance.
�v��F���x�����������玩���I�Ɍ��̓d���E�N���b�N�ɖ߂��ăt���p�t�H�[�}���X�����ł���悤�ɂȂ�܂���
> �܂Ƃ���➑̂��p�@�\�A�����Ȃ�N���肦�Ȃ���펖�Ԃɔ������@�\
�Ƃ����̂͂ǂ��l���Ă��ϑz�̈���o�܂���ł����Ƃ�
�����N����ł�
http://blogs.amd.com/developer/2010/03/29/you-down-with-amd-p/
> AMD CoolSpeed technology is a capability that enables the processor(s) to automatically drop into a
> lower power mode if the processor thermal specifications are exceeded. Once the processor thermals
> return within specification the processor can automatically return to full performance.
�v��F���x�����������玩���I�Ɍ��̓d���E�N���b�N�ɖ߂��ăt���p�t�H�[�}���X�����ł���悤�ɂȂ�܂���
> �܂Ƃ���➑̂��p�@�\�A�����Ȃ�N���肦�Ȃ���펖�Ԃɔ������@�\
�Ƃ����̂͂ǂ��l���Ă��ϑz�̈���o�܂���ł����Ƃ�
728 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 04:27:39 ID:SFrIv+ox
���x������������́u�tTurboBoost�v��
729 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 04:32:38 ID:SFrIv+ox
�܂���TDP�ʂ�ɑg�܂�Ă�ǂ�ȕ��ׂ����Ă�2.3GHz�őS�R�A��������������Ƃł��v�����̂��H
��Ƃ�͎�����ǂޗ͂��Ȃ���
��Ƃ�͎�����ǂޗ͂��Ȃ���
730 �FSocket774�F2010/04/01(��) 04:57:05 ID:KhjlrTns
�܂�ŎԂ̃u���[�L�͒�Ԃ��邽�߂ɂ���̂��������邽�߂ɂ���̂��Ƌc�_���Ă�悤�Ŋ��m���ȁB
���̈����R�e�ɘb�����킹��Ɣn�������邼�B
���̈����R�e�ɘb�����킹��Ɣn�������邼�B
731 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 05:04:53 ID:SFrIv+ox
�u�ǂ�ȕ��ׂ����Ă��S�R�A��������������N���b�N�v���i�ɂ�����2GHz�~�܂�̐��i�����o���Ȃ��Ǝv���B
�ᕉ�ׂɌ�����2.3GH���œ����Z�p�ƍl����Ίm����
�iCPU���ُ픭�M����ی삷��Z�p�ł͂Ȃ��j�d�͌��������P����Z�p�ƃJ�e�S���C�Y����Ă�
��a���͂Ȃ�����
�ᕉ�ׂɌ�����2.3GH���œ����Z�p�ƍl����Ίm����
�iCPU���ُ픭�M����ی삷��Z�p�ł͂Ȃ��j�d�͌��������P����Z�p�ƃJ�e�S���C�Y����Ă�
��a���͂Ȃ�����
�����t�@�����~�܂�����A�����P�[�X��������A�������T�n���������ɔM���������i�������Ȃ����낤���B
��i���Ă̂͂ǂ�ȕ��ׂ�^���Ă��A�K���ȗ�p������Ă�Ζ��Ȃ��������Ă��Ƃ���B
�c�q�̓Z�������p�̕n��ȃN�[���[�����ăt���h���C�u�݂����ȃA�z�ȏł��z�肵�Ă���̂��Hw
�ُ픭�M�Ȃ�ēV�Ђ��l�Ђł����N����Ȃ����낤���A�T�[�o�[�̊Ǘ��҈ȊO�͋C�ɂ��邱�Ƃł��Ȃ����낤�B
��i���Ă̂͂ǂ�ȕ��ׂ�^���Ă��A�K���ȗ�p������Ă�Ζ��Ȃ��������Ă��Ƃ���B
�c�q�̓Z�������p�̕n��ȃN�[���[�����ăt���h���C�u�݂����ȃA�z�ȏł��z�肵�Ă���̂��Hw
�ُ픭�M�Ȃ�ēV�Ђ��l�Ђł����N����Ȃ����낤���A�T�[�o�[�̊Ǘ��҈ȊO�͋C�ɂ��邱�Ƃł��Ȃ����낤�B
733 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 05:19:42 ID:SFrIv+ox
�����盛�����́uCoolSpeed�v�i�j�̖{���𐳂����������Ă���ɂ��Ă���
AMD�̃C�x���g�Œ��̐l�Ɏ��₵�Ă��������B
���Ɠ������������Ԃ��Ă��Ȃ�����
AMD�̃C�x���g�Œ��̐l�Ɏ��₵�Ă��������B
���Ɠ������������Ԃ��Ă��Ȃ�����
Intel���uTDP���Ɏ��߂邽�߂ɏȓd�͋Z�p���g���Ă���v����Ƃ�����
AMD������ɓ��Ă͂܂�Ƃ͌���Ȃ�
TDP�𐳂����������Ă���Ƃ���͂��́u�ő���M�ʁv�Ƃ����Ӗ��ʂ�ɒ�i����
�ȓd�͋Z�p�͒ʏ�^�p�ł̓d�͂��Ȃ����߂ɗp����
�����ĎO�A�E���R�̒m�\�͑��ς�炸��������
AMD������ɓ��Ă͂܂�Ƃ͌���Ȃ�
TDP�𐳂����������Ă���Ƃ���͂��́u�ő���M�ʁv�Ƃ����Ӗ��ʂ�ɒ�i����
�ȓd�͋Z�p�͒ʏ�^�p�ł̓d�͂��Ȃ����߂ɗp����
�����ĎO�A�E���R�̒m�\�͑��ς�炸��������
735 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 06:04:32 ID:SFrIv+ox
�܂��E������܂���
736 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 06:18:10 ID:SFrIv+ox
����A��������Shanghai��3�{�̃R�A���ς�łȂ�2GH����œ������ƂɂȂ�̋^��������Ȃ������̂��ƁB
�����ׂ��������CoolSpeed�i�j�œd���E�N���b�N���������TDP�i�M�v����d�́��ő����d�́j�Ɏ��܂��ł���i�j
�ƁA�~�X���[�h�͂��̂ւ�ɂ��Ă�����
�܂��AAMD��f�B�A���u�ȓd�͋@�\�v�Ƃ����Ă�̂ɂ́A��������������肩�Ȃ�����Ƃ��炵�����R��������B
�q���g�F�ᕉ�ׂ̂Ƃ��ł�CoolSpeed�͔�������P�[�X������i�ނ���ᕉ�ׂ����炱���j
�����ׂ��������CoolSpeed�i�j�œd���E�N���b�N���������TDP�i�M�v����d�́��ő����d�́j�Ɏ��܂��ł���i�j
�ƁA�~�X���[�h�͂��̂ւ�ɂ��Ă�����
�܂��AAMD��f�B�A���u�ȓd�͋@�\�v�Ƃ����Ă�̂ɂ́A��������������肩�Ȃ�����Ƃ��炵�����R��������B
�q���g�F�ᕉ�ׂ̂Ƃ��ł�CoolSpeed�͔�������P�[�X������i�ނ���ᕉ�ׂ����炱���j
�c�q������TDP�Ɨ��߂����邩��������Ȃ���Ȃ�
��������Intel������Thermal Monitor 2�Ƃ������l�̋@�\������ł���
���������ᕉ���̂ݒ�i�œ����@�\�ƌ�������킯����
��������Intel������Thermal Monitor 2�Ƃ������l�̋@�\������ł���
���������ᕉ���̂ݒ�i�œ����@�\�ƌ�������킯����
738 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 06:30:15 ID:SFrIv+ox
�^����AMD�̃T�C�g�ɂ��ڂ��Ă�Ƃ��肾��B
���������i�E�L�́M�E�j�ݽ݂������̂Ŋ����ďꏊ�͎����Ȃ��B
���������i�E�L�́M�E�j�ݽ݂������̂Ŋ����ďꏊ�͎����Ȃ��B
�u���܂�Pentium 4�ɂ�L1D�������v�Ƃ�����Ȗ��ʂō����ȋZ�p
�����璴������Intel�ł��L�蓾��킯������
�����璴������Intel�ł��L�蓾��킯������
�c�q�H�ׂ���
�̂͐���\�[�X�o���Ă������c�q���Ӓn���ɂȂ��Ă����Ȃ�
742 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 06:52:13 ID:SFrIv+ox
>>740
�͂炱�킷���H
>>737
�����̓��^�k�L�̓������ǃ}�W���X�Ńq���g
��������Intel��TM�Ɠ��l�ɔM�_�C�I�[�h���g���ăR�A���x���v��������臒l���z����ƃN���b�N�_�E������B
���̊�ՋZ�p�ɂ͕ς��͂Ȃ����ǁA��ړI���Ⴄ�B
�i���ۖ��Intel��TM���u�ȓd�͋@�\�v�Ƃ����������Ƃ͈�x���Ȃ��j
�͂炱�킷���H
>>737
�����̓��^�k�L�̓������ǃ}�W���X�Ńq���g
��������Intel��TM�Ɠ��l�ɔM�_�C�I�[�h���g���ăR�A���x���v��������臒l���z����ƃN���b�N�_�E������B
���̊�ՋZ�p�ɂ͕ς��͂Ȃ����ǁA��ړI���Ⴄ�B
�i���ۖ��Intel��TM���u�ȓd�͋@�\�v�Ƃ����������Ƃ͈�x���Ȃ��j
AthlonII X4 605e��4�R�A2.3GH����TDP45W
�P����3�{�����12�R�A2.3GH����TDP135W
PhenomII X4 910e��4�R�A2.6GH��L3@6MB��TDP65W
�P����3�{�����12�R�A2.6GH��L3@18MB��TDP195W
������A��������Shanghai��3�{�̃R�A���ς�łȂ�2GH����œ������ƂɂȂ�̋^��������Ȃ������̂��ƁB
�����ʂ�œ�����O�̂��Ƃ���枖ς�������
�P����3�{�����12�R�A2.3GH����TDP135W
PhenomII X4 910e��4�R�A2.6GH��L3@6MB��TDP65W
�P����3�{�����12�R�A2.6GH��L3@18MB��TDP195W
������A��������Shanghai��3�{�̃R�A���ς�łȂ�2GH����œ������ƂɂȂ�̋^��������Ȃ������̂��ƁB
�����ʂ�œ�����O�̂��Ƃ���枖ς�������
�Ȃɂ��̎Z��
�݂�ȍ�����4/1��
���܂܂Œc�q���C�`���������Ă����Ǎ�����4/1��
���Ƃ͂킩����
���܂܂Œc�q���C�`���������Ă����Ǎ�����4/1��
���Ƃ͂킩����
746 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 07:35:58 ID:SFrIv+ox
>>745
�قق��A����{���ɋ߂Â��Ă��������ˁ�
�y�ő�̃q���g�z
�q�[�g�V���N���O�ꂽ��t�@�����̏Ⴕ���ꍇ�m����CPU�̉��x��������K�v���邯�ǂ��B
����Ȃ��Ƃ��������̂ɁA�Ȃ�ł킴�킴�u��߂��玩���I�Ƀt���X�s�[�h�œ����v�Ȃ��
�����K�v�����H
�܂�A�V�X�e���̏�Q�ł͂Ȃ����퓮�쎞�ł���臒l���z���Ă��܂��P�[�X��z�肵�����̂�
���ꂪ�ӂɂ�ӂɂ�ȗ��R�Ō��ʓI�ɓd�͌��������コ���邱�ƂɂȂ�킯�B
�܂���i�����d���E�N���b�N����������̕���������d�͌���̂͊m��I�ɖ��炩����
TB�̂悤�ɖZ�����R�A�̃N���b�N��������Ȃ�Ƃ������A�N���b�N���Ƃ����Ƃœd�͌��������P����Ƃ�
�Ƃ��Ă��l���ɂ�����ˁB�N���b�N���Ƃ��Ώ������ԐL�т���炳�B
�܂�A�t�ɍl����ƁB
�Ȃ�ł킴�킴�u��߂��玩���I�Ƀt���X�s�[�h�œ����v�Ə����Ă������̂��B
�قق��A����{���ɋ߂Â��Ă��������ˁ�
�y�ő�̃q���g�z
�q�[�g�V���N���O�ꂽ��t�@�����̏Ⴕ���ꍇ�m����CPU�̉��x��������K�v���邯�ǂ��B
����Ȃ��Ƃ��������̂ɁA�Ȃ�ł킴�킴�u��߂��玩���I�Ƀt���X�s�[�h�œ����v�Ȃ��
�����K�v�����H
�܂�A�V�X�e���̏�Q�ł͂Ȃ����퓮�쎞�ł���臒l���z���Ă��܂��P�[�X��z�肵�����̂�
���ꂪ�ӂɂ�ӂɂ�ȗ��R�Ō��ʓI�ɓd�͌��������コ���邱�ƂɂȂ�킯�B
�܂���i�����d���E�N���b�N����������̕���������d�͌���̂͊m��I�ɖ��炩����
TB�̂悤�ɖZ�����R�A�̃N���b�N��������Ȃ�Ƃ������A�N���b�N���Ƃ����Ƃœd�͌��������P����Ƃ�
�Ƃ��Ă��l���ɂ�����ˁB�N���b�N���Ƃ��Ώ������ԐL�т���炳�B
�܂�A�t�ɍl����ƁB
�Ȃ�ł킴�킴�u��߂��玩���I�Ƀt���X�s�[�h�œ����v�Ə����Ă������̂��B
�������E��4/1��1�N�̂���1��������
�N���G�C�v�����t�[�����Ȃ�Ă��̏d�x�m�I��Q�҈ȊO�N�����Ȃ�
�N���G�C�v�����t�[�����Ȃ�Ă��̏d�x�m�I��Q�҈ȊO�N�����Ȃ�
�܂�,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o���s�������̂�
749 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 08:04:04 ID:SFrIv+ox
http://akiba.kakaku.com/pc/1003/31/235500.php
> �ȓd�͋@�\�uAMD CoolSpeed technology�v�̓��ځA
�ǂ����>>748�ɂ��Ƃ���͉��̝s���L���炵����
> �ȓd�͋@�\�uAMD CoolSpeed technology�v�̓��ځA
�ǂ����>>748�ɂ��Ƃ���͉��̝s���L���炵����
750 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 08:05:34 ID:SFrIv+ox
���̃X���ɉp�ꂪ�ǂ߂�z�����Ȃ����Ƃ͂킩����
����A��p�����������肵�Ă���������̘b����
752 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 08:12:41 ID:SFrIv+ox
����
�L���͐��������F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o�͝s��
��p�ʂ��������ď�����x�ɒB���₷���̂ƁA
CoolSpeed�̌��\�͕����čl���������ǂ��Ǝv�����ǂ�
CoolSpeed�̗L���Ɨ�p���\�s���ŏ�����x�ɒB���₷�����ǂ����͊W���������
�c�q��AMD�̃}�[�P�e�B���O�ɗx�炳��Ă�C������
���͉��ł��ȓd�͂��Đ����ɋ��ׂΗǂ����ゾ��
CoolSpeed�̌��\�͕����čl���������ǂ��Ǝv�����ǂ�
CoolSpeed�̗L���Ɨ�p���\�s���ŏ�����x�ɒB���₷�����ǂ����͊W���������
�c�q��AMD�̃}�[�P�e�B���O�ɗx�炳��Ă�C������
���͉��ł��ȓd�͂��Đ����ɋ��ׂΗǂ����ゾ��
C32�}�U�[�̏��Ȃ��H
���͂���g�݂������B
���͂���g�݂������B
�A���������Ȃ�����
��AMD CoolSpeed technology
���{AMD�ɖ₢���킹��͂����肷���ˁ[��
�[���A���̂���2.3GHz���������l���o�Ă��邾�낤����
�����ԃt�����[�h�ŃN���b�N���ō��̂܂܈ێ�����邩�����Ă��炤�̂��A���B�B�B
���{AMD�ɖ₢���킹��͂����肷���ˁ[��
�[���A���̂���2.3GHz���������l���o�Ă��邾�낤����
�����ԃt�����[�h�ŃN���b�N���ō��̂܂܈ێ�����邩�����Ă��炤�̂��A���B�B�B
�E2.3GH����ACP105W�A2.2GH����ACP80W��TDP���\�ɂȂ邩�ǂ���
�E����̗�p���u��ACP105W���₵��邩�ǂ���
���ꂾ���l����Ή��ł��Ȃ�
�_�C�T�C�Y�ł����Ȃ�Γ�TDP�EACP�ł��X�ɗ�p�͊y�ɂȂ邵
�E����̗�p���u��ACP105W���₵��邩�ǂ���
���ꂾ���l����Ή��ł��Ȃ�
�_�C�T�C�Y�ł����Ȃ�Γ�TDP�EACP�ł��X�ɗ�p�͊y�ɂȂ邵
{kind=link}
>>759
�I�H
�I�H
���{�͂�����^�ʖڂɂ���Ă�����Ȃ�
�ǂ��ł�����Ă邾��
���{�́A�Ƃ��L���`�L������
���{�́A�Ƃ��L���`�L������
����������
>>717
12Core��8Core�̃��C���i�b�v�i�_�C�T�C�Y�E�g�����W�X�^������j
���Ă���ӂ�MCM&���ɃR�A�̕����R�X�g�_�E���͏o����ł���
>�����܂��350mm2��60%�A500mm2��40%�ʂ��ˁB
�S�Ẵg�����W�X�^�G���[��0�ƌ������Ƃ͂Ȃ�
��ł�����
(���Ȃꂽ45nm�v���Z�X������70%�͖����Ǝv�����ǂ�)
0.6�O9=4.6%�i6Core�S�������j
0.6^5+0.1*6=68%�i5Core�j
0.6^4+0.1*6=73%(4Core)
0.6^3+0.1*6=82%(3Core)
2Core�Ȃ�100%�i���_�l�j
12Core�����̃��C���i�b�v�Ȃ�����܂��5%�ɖ����Ȃ�����
8Core���܂߂�ƕ����܂��70%����
12Core��8Core�̃��C���i�b�v�i�_�C�T�C�Y�E�g�����W�X�^������j
���Ă���ӂ�MCM&���ɃR�A�̕����R�X�g�_�E���͏o����ł���
>�����܂��350mm2��60%�A500mm2��40%�ʂ��ˁB
�S�Ẵg�����W�X�^�G���[��0�ƌ������Ƃ͂Ȃ�
��ł�����
(���Ȃꂽ45nm�v���Z�X������70%�͖����Ǝv�����ǂ�)
0.6�O9=4.6%�i6Core�S�������j
0.6^5+0.1*6=68%�i5Core�j
0.6^4+0.1*6=73%(4Core)
0.6^3+0.1*6=82%(3Core)
2Core�Ȃ�100%�i���_�l�j
12Core�����̃��C���i�b�v�Ȃ�����܂��5%�ɖ����Ȃ�����
8Core���܂߂�ƕ����܂��70%����
�y�����z
0.6�O6=4.6%�i6Core�S�������j
0.6�O6=4.6%�i6Core�S�������j
Magny-Cours��Westmere�̏���d�͔�r
http://www.bit-tech.net/hardware/cpus/2010/03/31/amd-opteron-6174-vs-intel-xeon-x5650-review/10
6174�i12�R�A/2.2GHz�j��X5650�i6�R�A/2.66GHz�j�ƌ݊p
���ꂩ��2380�i4�R�A/2.6GHz�j�Ɠ����x���Ă̂��Ռ����킗
http://www.bit-tech.net/hardware/cpus/2010/03/31/amd-opteron-6174-vs-intel-xeon-x5650-review/10
6174�i12�R�A/2.2GHz�j��X5650�i6�R�A/2.66GHz�j�ƌ݊p
���ꂩ��2380�i4�R�A/2.6GHz�j�Ɠ����x���Ă̂��Ռ����킗
32nm�Ɣ�ׂ�Ȃ�āE�E�E
AMD�͂ł��邱�Ƃ������Ă���Ă�����
45nm��������Ƃ����ǂ��Ă����Ă�낤��
45nm��������Ƃ����ǂ��Ă����Ă�낤��
>>768
intel���`�b�N�^�b�N����Ă�݂�����
�����L���p���Ȃ����T�d�ɂ���Ă��
�m���ȃv���Z�X�ŐV��H�v���邵
�V���ȃv���Z�X�ł͂��Ȃꂽ��H�Ő��i�������Ă邩���
intel���`�b�N�^�b�N����Ă�݂�����
�����L���p���Ȃ����T�d�ɂ���Ă��
�m���ȃv���Z�X�ŐV��H�v���邵
�V���ȃv���Z�X�ł͂��Ȃꂽ��H�Ő��i�������Ă邩���
>>766
�Ƃ͂����O�̃y�[�W��6174��X5650�ɃR�e���p���ɂ���Ă�Ƃ��������ƁA
����d�͂������x����S�R���͓I�Ɍ�����B���i��6174�̂ق����������B
�܂��g�����x���`�}�[�N�����܂�X�P�[������낵���Ȃ��\�t�g���Ă̂�����낤���ǂˁB
�Ƃ͂����O�̃y�[�W��6174��X5650�ɃR�e���p���ɂ���Ă�Ƃ��������ƁA
����d�͂������x����S�R���͓I�Ɍ�����B���i��6174�̂ق����������B
�܂��g�����x���`�}�[�N�����܂�X�P�[������낵���Ȃ��\�t�g���Ă̂�����낤���ǂˁB
>>766
�����������ʂ������
HTT�ɂ��_���R�A���u����v�Ȃ�ȁB
�����I��12�R�A�p�ӂ���̂�
����d�͓I�ɕ�����������B
�����������ʂ������
HTT�ɂ��_���R�A���u����v�Ȃ�ȁB
�����I��12�R�A�p�ӂ���̂�
����d�͓I�ɕ�����������B
LightWave�Ƃ��܂������R�A������������ĂȂ���
�����ƃ}�V�ȃx���`��p�ӂł��Ȃ������̂���
�����ƃ}�V�ȃx���`��p�ӂł��Ȃ������̂���
>>771
������ӂ��œK�����邽�߂�Bulldozer�Ȃ�Ȃ�
������ӂ��œK�����邽�߂�Bulldozer�Ȃ�Ȃ�
���ɂ���\�t�g���}���`�X���b�h�ւ̍œK�����i������ł͂Ȃ��ȏ�d���Ȃ������B
Lightwave�̓��W���[�ȃ^�C�g�������B
Lightwave�̓��W���[�ȃ^�C�g�������B
�u���h�[�U�[�̓V���O���X���b�h���\�𗎂Ƃ�����ɁA
����ȏ�Ƀ_�C�T�C�Y���팸���邱�ƂŁA���b�g�p�t�H�[�}���X�ƃ_�C�T�C�Y�p�t�H�[�}���X��
�Nj���������B
�y���݂��Ȃ�
����ȏ�Ƀ_�C�T�C�Y���팸���邱�ƂŁA���b�g�p�t�H�[�}���X�ƃ_�C�T�C�Y�p�t�H�[�}���X��
�Nj���������B
�y���݂��Ȃ�
CoolSpeed�������̂��O�ƃx���`�̌��ʂ������Ƃ����������
AthlonII X4 605e�� 2.3G 4�R�A��45W
3�{��12�R�A��135W�B
�R�A�̉��ǂƂ��l����Ȃ�Ƃ��Ȃ肻������
L3�L���b�V���̍��H
AthlonIIX2 250(3GHz) 65W��PhenomII X4 945(3GHz) 95W�̂悤�ɁA
L3+�R�A�{���ł��債�����������Ȃ����Ƃ��l����Ƃǂ��ł��悳���B
3�{��12�R�A��135W�B
�R�A�̉��ǂƂ��l����Ȃ�Ƃ��Ȃ肻������
L3�L���b�V���̍��H
AthlonIIX2 250(3GHz) 65W��PhenomII X4 945(3GHz) 95W�̂悤�ɁA
L3+�R�A�{���ł��債�����������Ȃ����Ƃ��l����Ƃǂ��ł��悳���B
>>735
�K���Ɍ�������12�R�A 2.3G �͑S�͂ł��Ȃ�Ƃ��Ȃ肻���ł�
�K���Ɍ�������12�R�A 2.3G �͑S�͂ł��Ȃ�Ƃ��Ȃ肻���ł�
>>775
> �u���h�[�U�[�̓V���O���X���b�h���\�𗎂Ƃ�����ɁA
> ����ȏ�Ƀ_�C�T�C�Y���팸���邱�ƂŁA���b�g�p�t�H�[�}���X�ƃ_�C�T�C�Y�p�t�H�[�}���X��
> �Nj���������B
>
> �y���݂��Ȃ�
������ƈႤ
�V���O���X���b�h���\�����サ�Ȃ�����Ƀ_�C�T�C�Y�팸���ēd�͐��\��T�C�Y���\��Nj��B
�������\�ōœK�����ď��^���ƌ����������������ȁB
> �u���h�[�U�[�̓V���O���X���b�h���\�𗎂Ƃ�����ɁA
> ����ȏ�Ƀ_�C�T�C�Y���팸���邱�ƂŁA���b�g�p�t�H�[�}���X�ƃ_�C�T�C�Y�p�t�H�[�}���X��
> �Nj���������B
>
> �y���݂��Ȃ�
������ƈႤ
�V���O���X���b�h���\�����サ�Ȃ�����Ƀ_�C�T�C�Y�팸���ēd�͐��\��T�C�Y���\��Nj��B
�������\�ōœK�����ď��^���ƌ����������������ȁB
�c�q�̂������Ƃ��������ꍇ
2.3G���쁨�M�\�����N���b�N�ቺ����p��2.3G���쁨�M�\�����̖������[�v
���ʂɂ��肦�Ȃ����삾�Ǝv����
�����ׂŕp�ɂɃN���b�N���㉺���Đ��\�̕ϓ����������ł��Ƃ��A
���PC�Ƃ��Ă���肢�����Ȃ̂ɍ����ד�����O�ȃT�[�o�[��HPC�ł���Ȃ̂��x���_�[���F�߂��Ȃ��B
����ɓ����N���b�N�ō���ċ�������ƌ����邾���B
2.3G���쁨�M�\�����N���b�N�ቺ����p��2.3G���쁨�M�\�����̖������[�v
���ʂɂ��肦�Ȃ����삾�Ǝv����
�����ׂŕp�ɂɃN���b�N���㉺���Đ��\�̕ϓ����������ł��Ƃ��A
���PC�Ƃ��Ă���肢�����Ȃ̂ɍ����ד�����O�ȃT�[�o�[��HPC�ł���Ȃ̂��x���_�[���F�߂��Ȃ��B
����ɓ����N���b�N�ō���ċ�������ƌ����邾���B
>>779
�㓡�^���̋L�������ǂ�łȂ����ǁA
�������s�\���ߐ���2/3�ɍ팸���邩��A����IPC��2/3���͂������낤
���NJm���ɉ������ł́B
���̂����2�R�A��1���W���[���ɗZ�������ăg�����W�X�^�����Ɠd�͌���������B
���W���[�������ڂ��ă}���`�X���b�h���\����B
�_�C�T�C�Y50�����Ńp�t�H�[�}���X80�����Ƃ����̂͂��̂�������w���Ă��ł͂Ȃ����ƁB
�������V���O���X���b�h���\��X6�œ��������悤�ȃ^�[�{�u�[�X�g�ňꕔ���W���[��
�̃N���b�N�����邱�ƂőΉ������Ȃ��̂��ȁB
�㓡�^���̋L�������ǂ�łȂ����ǁA
�������s�\���ߐ���2/3�ɍ팸���邩��A����IPC��2/3���͂������낤
���NJm���ɉ������ł́B
���̂����2�R�A��1���W���[���ɗZ�������ăg�����W�X�^�����Ɠd�͌���������B
���W���[�������ڂ��ă}���`�X���b�h���\����B
�_�C�T�C�Y50�����Ńp�t�H�[�}���X80�����Ƃ����̂͂��̂�������w���Ă��ł͂Ȃ����ƁB
�������V���O���X���b�h���\��X6�œ��������悤�ȃ^�[�{�u�[�X�g�ňꕔ���W���[��
�̃N���b�N�����邱�ƂőΉ������Ȃ��̂��ȁB
�E���R�̂������Ƃ��������ꍇ
���܂�Pentium 4�ɂ�L1D�����������܂�Pentium 4�ɂ�L1D���L�遨���܂�Pentium 4�ɂ�L1D���������̖������[�v
�V���O���X���b�h���\�Ȃ�Đ����X�J���͂Ƃ��̐̂ɐ��l�܂��
�����_�Ƃ������x�N�^�ŐL���Ă邾���Ƃ����̂�����̌���
�E���R����Bulldozer 16�R�A�͐���3GHz�O��@�Ƃ������Ă���
���ꂪ����������{�����Ƃ����Bull�͕���x�����������ɃN���b�N���グ��
�V���O���X���b�h�i�����X�J���j���\���グ��ژ_�����낤
�������}���`�X���b�h�x�N�^���\�͌���������������
���܂�Pentium 4�ɂ�L1D�����������܂�Pentium 4�ɂ�L1D���L�遨���܂�Pentium 4�ɂ�L1D���������̖������[�v
�V���O���X���b�h���\�Ȃ�Đ����X�J���͂Ƃ��̐̂ɐ��l�܂��
�����_�Ƃ������x�N�^�ŐL���Ă邾���Ƃ����̂�����̌���
�E���R����Bulldozer 16�R�A�͐���3GHz�O��@�Ƃ������Ă���
���ꂪ����������{�����Ƃ����Bull�͕���x�����������ɃN���b�N���グ��
�V���O���X���b�h�i�����X�J���j���\���グ��ژ_�����낤
�������}���`�X���b�h�x�N�^���\�͌���������������
>>742
�������l���v��������������̘b����B
�������l���v��������������̘b����B
���肦�Ȃ��Ǝv�����Ƃ����肦�Ȃ�
785 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 15:51:49 ID:SFrIv+ox
�y���₳��p������z
�����܂Łi�E�L�́M�E�j�ݽ݂���
--------------------------------------------
�����܂Łi�E�L�́M�E�j�ݽ݂���
--------------------------------------------
�c�q�ɂȂ�?
>>781
> >>779
> �㓡�^���̋L�������ǂ�łȂ����ǁA
> �������s�\���ߐ���2/3�ɍ팸���邩��A����IPC��2/3���͂������낤
> ���NJm���ɉ������ł́B
�قƂ�ǂ̏�����2way�ŏ\���A�ɋH��3way�ȂƂ���������x
����Ȏ���2clk�g���ď���������������B���邢��2�R�A�g���ď�������Ƃ��B
������A������ꍇ�����܂ɂ��邩���˂��Ē��x����
> ���̂����2�R�A��1���W���[���ɗZ�������ăg�����W�X�^�����Ɠd�͌���������B
> ���W���[�������ڂ��ă}���`�X���b�h���\����B
> �_�C�T�C�Y50�����Ńp�t�H�[�}���X80�����Ƃ����̂͂��̂�������w���Ă��ł͂Ȃ����ƁB
���̒��ɂ�HTT�Ő��\�ቺ����v���O�����ƌ����̂����Ȃ��炸����B
����͘_���R�A�����R�A�����ᐫ�\�ȂƂ��납�痈�Ă���B
�������畨���R�A�����ł��������Ƃ����̂�Bulldozer�̃R���Z�v�g�B
���Ȃ݂�k10�R�A��k8����p�������Ŋg�����܂����Č����������B
������V�v�����ē����\�ŏ��^�������ƍl�����ق��������B
> >>779
> �㓡�^���̋L�������ǂ�łȂ����ǁA
> �������s�\���ߐ���2/3�ɍ팸���邩��A����IPC��2/3���͂������낤
> ���NJm���ɉ������ł́B
�قƂ�ǂ̏�����2way�ŏ\���A�ɋH��3way�ȂƂ���������x
����Ȏ���2clk�g���ď���������������B���邢��2�R�A�g���ď�������Ƃ��B
������A������ꍇ�����܂ɂ��邩���˂��Ē��x����
> ���̂����2�R�A��1���W���[���ɗZ�������ăg�����W�X�^�����Ɠd�͌���������B
> ���W���[�������ڂ��ă}���`�X���b�h���\����B
> �_�C�T�C�Y50�����Ńp�t�H�[�}���X80�����Ƃ����̂͂��̂�������w���Ă��ł͂Ȃ����ƁB
���̒��ɂ�HTT�Ő��\�ቺ����v���O�����ƌ����̂����Ȃ��炸����B
����͘_���R�A�����R�A�����ᐫ�\�ȂƂ��납�痈�Ă���B
�������畨���R�A�����ł��������Ƃ����̂�Bulldozer�̃R���Z�v�g�B
���Ȃ݂�k10�R�A��k8����p�������Ŋg�����܂����Č����������B
������V�v�����ē����\�ŏ��^�������ƍl�����ق��������B
AMD�̃X���C�h�̐��\�\��̓R�A������̐��\���オ���ĂȂ��ƒB���ł��Ȃ�����
�V���O���X���b�h���\���オ����Ď���
�V���O���X���b�h���\���オ����Ď���
>>787
>���Ȃ݂�k10�R�A��k8����p�������Ŋg�����܂����Č����������B
>������V�v�����ē����\�ŏ��^�������ƍl�����ق��������B
���ۂ�K7���疬�X�����g���������
���XK7 DEC�Z�p�҂���̎v�z���炷��ƑS�R�ԋt�ɂȂ��Ă邵��
>>788
���̕ӂ́A�u��H���V���v���ɂ��镪�N���b�N�グ�₷���Ȃ�v
���Ď����낤�Ǝv���܂���
>���Ȃ݂�k10�R�A��k8����p�������Ŋg�����܂����Č����������B
>������V�v�����ē����\�ŏ��^�������ƍl�����ق��������B
���ۂ�K7���疬�X�����g���������
���XK7 DEC�Z�p�҂���̎v�z���炷��ƑS�R�ԋt�ɂȂ��Ă邵��
>>788
���̕ӂ́A�u��H���V���v���ɂ��镪�N���b�N�グ�₷���Ȃ�v
���Ď����낤�Ǝv���܂���
�P���Ɍv�Z���Ă��A�u���͍��Ɠ���45nm�v���Z�X�ł�20%���炢�_�C�T�C�Y
�������o������
�X��32nm�ō�����瑊���������Ȃ肻�����B
�������o������
�X��32nm�ō�����瑊���������Ȃ肻�����B
791 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 17:14:41 ID:SFrIv+ox
���_�����ƁA�܁[���N�������ĂȂ�
���퓮�쎞���N���b�N�_�E����������Ă̂͒��̐l���F�߂Ă铮��ɂȂ邯��
�N���b�N�_�E�����̂��̂��ȓd�͋@�\����Ȃ�����ˁ�
�i>>751-752�����肪���͍ő�̃q���g�����j
��Bulldozer�i�j�����ǁE�E�E
�������Z���\��2/3�ɂȂ�Ȃ�Ă̂�ALU��3�����ɉғ��ł���ꍇ�Ɍ������b�ŁA
�����ɂ́A�P���Ƀ|���b�N�̋t�@����K�p����ƁA�N���b�N�����蕽�ϐ������Z���\��
��(2/3)��81%���x���Ă��ƂɂȂ�
������R�[�h�V�[�P���X�����ALU�ɍ�p���閽�߂���Ƃ����O���ǂˁB
��������K7�`K10��ALU�ғ������ߑ�]���������Ȃ�
���ɁASPECint��Nehalem�Ƀ_�u���X�R�A�ŕ����錻�Ȃ��Ƃ��������g����ĂȂ�
���Ƃ͖��炩���낤�B
Load/Store�P�Ɩ��߂��͂���ALU���g��Ȃ����߂̔䗦���l����AALU�̗��p���Ȃ��
�x�X�g�P�[�X�ł�7���������Ȃ��B�ɒ[�Șb�A���Ƃ���
�@mov eax, [esi]
�@mov [edi], edx
�@sub ecx, 2
�݂����ȃV�[�P���X���ƁA�iL1�Ƀq�b�g����O��Łj3���ߓ������s�ł��邪ALU��1�����ғ����Ȃ���
������łȂ��Ƃ����U�^RS�͓��I�ȃ��\�[�X�A���P�[�V�����Ɏア�B
RS���W���^�ɂȂ�Ȃ�ނ���ALU�̎����ғ����͉��P���邾�낤�B
�ĂȂ킯�Ō����ɂ͐����R�A������̃N���b�N�����萮�����Z���\�́AK10��Ńg���g���`
�����Ƃ�1���������x�Ɨ\�z�B
�ǂ������Ƃ����ƃL���b�V���e�ʐS�z����������������
> ���̒��ɂ�HTT�Ő��\�ቺ����v���O�����ƌ����̂����Ȃ��炸����B
> ����͘_���R�A�����R�A�����ᐫ�\�ȂƂ��납�痈�Ă���B
�܂��\�[�X���o���Ȃ��e�L�g�[�Ȃ��Ƃ���������
VTune�Ńp�t�H�[�}���X���͂��Ă݂�Η��R�͂킩���B
��T�AHT����������L1�L���b�V���~�X���������Ă邱�Ƃ��킩��B
1�X���b�h������̃L���b�V���e�ʂ����Ȃ��Ȃ邩�瓖�R����
���퓮�쎞���N���b�N�_�E����������Ă̂͒��̐l���F�߂Ă铮��ɂȂ邯��
�N���b�N�_�E�����̂��̂��ȓd�͋@�\����Ȃ�����ˁ�
�i>>751-752�����肪���͍ő�̃q���g�����j
��Bulldozer�i�j�����ǁE�E�E
�������Z���\��2/3�ɂȂ�Ȃ�Ă̂�ALU��3�����ɉғ��ł���ꍇ�Ɍ������b�ŁA
�����ɂ́A�P���Ƀ|���b�N�̋t�@����K�p����ƁA�N���b�N�����蕽�ϐ������Z���\��
��(2/3)��81%���x���Ă��ƂɂȂ�
������R�[�h�V�[�P���X�����ALU�ɍ�p���閽�߂���Ƃ����O���ǂˁB
��������K7�`K10��ALU�ғ������ߑ�]���������Ȃ�
���ɁASPECint��Nehalem�Ƀ_�u���X�R�A�ŕ����錻�Ȃ��Ƃ��������g����ĂȂ�
���Ƃ͖��炩���낤�B
Load/Store�P�Ɩ��߂��͂���ALU���g��Ȃ����߂̔䗦���l����AALU�̗��p���Ȃ��
�x�X�g�P�[�X�ł�7���������Ȃ��B�ɒ[�Șb�A���Ƃ���
�@mov eax, [esi]
�@mov [edi], edx
�@sub ecx, 2
�݂����ȃV�[�P���X���ƁA�iL1�Ƀq�b�g����O��Łj3���ߓ������s�ł��邪ALU��1�����ғ����Ȃ���
������łȂ��Ƃ����U�^RS�͓��I�ȃ��\�[�X�A���P�[�V�����Ɏア�B
RS���W���^�ɂȂ�Ȃ�ނ���ALU�̎����ғ����͉��P���邾�낤�B
�ĂȂ킯�Ō����ɂ͐����R�A������̃N���b�N�����萮�����Z���\�́AK10��Ńg���g���`
�����Ƃ�1���������x�Ɨ\�z�B
�ǂ������Ƃ����ƃL���b�V���e�ʐS�z����������������
> ���̒��ɂ�HTT�Ő��\�ቺ����v���O�����ƌ����̂����Ȃ��炸����B
> ����͘_���R�A�����R�A�����ᐫ�\�ȂƂ��납�痈�Ă���B
�܂��\�[�X���o���Ȃ��e�L�g�[�Ȃ��Ƃ���������
VTune�Ńp�t�H�[�}���X���͂��Ă݂�Η��R�͂킩���B
��T�AHT����������L1�L���b�V���~�X���������Ă邱�Ƃ��킩��B
1�X���b�h������̃L���b�V���e�ʂ����Ȃ��Ȃ邩�瓖�R����
>>643
�p����������w
�p����������w
�������A�T�[�o�p��CPU�ł���ȂɃR�����g���t���Ƃ́A�������ڂ���Ă�ȁB
2010/04/01(��) 11:40 | URL | LGA774 #-[ �ҏW]
�{���͎���Ƃ͊W�Ȃ��J�e�S���[�����班���R�����g���t�����炢�ȂǁA����o�������Ȃ��炢�������狻�����o���l�������낤�B
2way�}�U�[��5�����炢�Ȃ�A4180(2.6G 6�R�A $188)2�Ƒg������10���~�Ŕ�������H
2.6G 12�R�A���ꎮ10���~�Ƃ��{�C�o����������w
97�R�����g��
2010/04/01(��) 11:40 | URL | LGA774 #-[ �ҏW]
�{���͎���Ƃ͊W�Ȃ��J�e�S���[�����班���R�����g���t�����炢�ȂǁA����o�������Ȃ��炢�������狻�����o���l�������낤�B
2way�}�U�[��5�����炢�Ȃ�A4180(2.6G 6�R�A $188)2�Ƒg������10���~�Ŕ�������H
2.6G 12�R�A���ꎮ10���~�Ƃ��{�C�o����������w
97�R�����g��
���|���b�N�̖@���i�ۂ�����̂ق������j�Ƃ́A�w�v���Z�b�T�̐��\�͂��̃_�C�T�C�Y�̕������ɔ�Ⴗ��x�Ƃ����o�����i�E�B�L�y�j
ALU���j�b�g�����_�C�T�C�Y
�����ʂ�̓��Z�d�g��
ALU���j�b�g�����_�C�T�C�Y
�����ʂ�̓��Z�d�g��
http://www.amdzone.com/joomla/index.php?option=com_content&view=article&id=12578:amd-bulldozer-exclusive&catid=60&Itemid=92
Bulldozer Benchmark Review
Bulldozer Benchmark Review
797 �FMAC�I�^��796 �����F2010/04/01(��) 17:50:08 ID:Xb5zlDzT
>>796
��ɏ�����Ă��܂��܂������c�`���Q�[���̓^�����y���݂Ƃ������ƂŁi��)
��ɏ�����Ă��܂��܂������c�`���Q�[���̓^�����y���݂Ƃ������ƂŁi��)
>>759
�I
�I
�e�[�v�A�E�g�����́H
>>796
����́E�E�E�E�E�E�ǂ̂��炢�{�C�ɂ��Ă����́H
����́E�E�E�E�E�E�ǂ̂��炢�{�C�ɂ��Ă����́H
�Ƃ肠�������������̃T���v���`�b�v���炢�͎d�オ���Ă��Ȃ�
�g�тȂ̂ł݂��
>>759���̋L�����ł邱�Ƃ��肤��
>>759���̋L�����ł邱�Ƃ��肤��
�R�[�h�l�[�������̔�r������A�R�A�������Ă���Ȃ��ƂȁE�E�E��
���ꂾ���O�t�����������ǂ����ɏ����Ă���Ǝv������
������interlagos�͌Â����[�h�}�b�v�ɂ��ΎI�p�l�[����8�R�A�Ƃ��̃j�R�C�`
zambezi��DT�p8�R�A
���R�A����Intel��AMD�Ŕ{�Ⴄ���ǃR�A�T�C�Y���{���炢�Ⴂ����������ȉ���
������interlagos�͌Â����[�h�}�b�v�ɂ��ΎI�p�l�[����8�R�A�Ƃ��̃j�R�C�`
zambezi��DT�p8�R�A
���R�A����Intel��AMD�Ŕ{�Ⴄ���ǃR�A�T�C�Y���{���炢�Ⴂ����������ȉ���
805 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 18:08:33 ID:SFrIv+ox
http://www.amdzone.com/joomla/images/cpus/bulldozeraf/BulldozerArchitectureUpdatev03.png
���āA4�~�iALU�{AGU�j�̐}���o�Ă܂���܂���
{kind=link}
���āA4�~�iALU�{AGU�j�̐}���o�Ă܂���܂���
Interlagos��16�R�A��Zambezi��8�R�A�����
Interlagos��Power Consumption������
Interlagos��Power Consumption������
807 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 18:11:42 ID:SFrIv+ox
4KB�g���[�X�L���b�V���E�E�E
���ꂪ����R�A���ł���Ȃ�}���`�X���b�h���V���O���X���b�h��Nehalem���邱�ƂɂȂ�ȁB
�������o���h���������L�����Ă邯�ǁA�Ȃo���h���L����ύX���Ă����������H
�l�g�E���u������̂����Ŏ���ꂽ�P�O�N���Q�O�N�ɂȂ�v
����
���{���A���P���������V�I���ߋ�10�N�ōō�
�����\��
����
���{���A���P���������V�I���ߋ�10�N�ōō�
�����\��
Bull�����[�ȁB�����\�z�O�B
2ALU�̃V���{�ł͂Ȃ��������B
2ALU�̃V���{�ł͂Ȃ��������B
�O�l�Q�����ƗX�����x�z�����グ�̎��_�Ŋ��ɃN�\
�~���X�ɓ����z�͒�]�F��
�~���X�ɓ����z�͒�]�F��
���ǂ̂Ƃ���A���̒��Ɂw����ҁx�Ƃ��w��ҁx�Ƃ������̂����݂���킯�ł͖����A�����ɓs���̗ǂ��A���܂��b�ɔ�т����Ⴄ�q�g���Ă̂����邾���Ȃ�ł��ˁc
�@
�@
�\�z�O�����ĐM�����܂����
815 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 18:37:10 ID:SFrIv+ox
FP�̃p�t�H�[�}���X��Nehalem�ƍ������ĂȂ��Ƃ���������
Bridge-FMA�i2 FADD + 2 FMUL�Ƃ��Ă��g����j�͌�����ꂽ�̂��ȁB
��ł�����SSE�����̐��\�����I�ɋ������Ă闝�R�͂��ꂩ�B
> The integer execution units - arithmetic logic units (ALUs) and address generation units (AGUs)
> - are organized in four pairs - one per instruction pipeline. They can execute both x86 integer code,
> memory ops (also for FP/SIMD ops) and, which is the biggest change, can be combined to execute
> SSE or AVX integer code. This increases throughput significantly and frees the FP units somewhat.
> The general purpose register file (GPRF) has been widened to 128 bit to allow for such a feature.
> The registers will be copied between GPRF and the floating point register file (FPRF) if an architectural
> SIMD register (the registers specified by the ISA) is used for integer first and floating point later or vice versa.
> Since this doesn't happen often, it has practically no impact on performance. Instead the option to use the
> integer units for integer SIMD code (SSE, XOP and AVX) the overall throughput of SIMD code increases dramatically.
�܂����ꂾ��SIMD�������Z���ߎg�p��ɓ������W�X�^��FP���Z���߂s����ꍇ�ɐ��\�ቺ����Ǝv�����ǂ�
Bridge-FMA�i2 FADD + 2 FMUL�Ƃ��Ă��g����j�͌�����ꂽ�̂��ȁB
��ł�����SSE�����̐��\�����I�ɋ������Ă闝�R�͂��ꂩ�B
> The integer execution units - arithmetic logic units (ALUs) and address generation units (AGUs)
> - are organized in four pairs - one per instruction pipeline. They can execute both x86 integer code,
> memory ops (also for FP/SIMD ops) and, which is the biggest change, can be combined to execute
> SSE or AVX integer code. This increases throughput significantly and frees the FP units somewhat.
> The general purpose register file (GPRF) has been widened to 128 bit to allow for such a feature.
> The registers will be copied between GPRF and the floating point register file (FPRF) if an architectural
> SIMD register (the registers specified by the ISA) is used for integer first and floating point later or vice versa.
> Since this doesn't happen often, it has practically no impact on performance. Instead the option to use the
> integer units for integer SIMD code (SSE, XOP and AVX) the overall throughput of SIMD code increases dramatically.
�܂����ꂾ��SIMD�������Z���ߎg�p��ɓ������W�X�^��FP���Z���߂s����ꍇ�ɐ��\�ቺ����Ǝv�����ǂ�
�G�C�v�����t�[���l�^�ł���H
�ȉ����[�v
�G�C�v�����t�[���̊��ł������x���������y����
���y�����}�z�͊��S�Ȕ������}�ł���B
�������}�u�ږ�1000���l����v�̎�����
http://www.nikkeibp.co.jp/news/biz08q2/575417/
�������}�͒���Ɍ��łP���S�C�O�O�O���~�𓊓��B
�@�@http://q.hatena.ne.jp/1062123112
���ݓ��ɂ���z���t���x��
�@�@http://news.livedoor.com/article/detail/3994761/
�������l�A�؍��l���w���ɔN�ԂT�O�O���~���^�_�ł����Ă��鎩���}�B
�@�@http://bbs.jpcanada.com/log/6/2504.html
���؍��l�ւ̃r�U�Ə����P�v�����������}
�@�@http://www.nikkansports.com/ns/general/f-so-tp0-060206-0020.html
�������}���w���R�O���l�v��
�@�@http://www.relay.co.jp/news/718/
���l���i��@�Ă̐�����ڎw�������}
�@�@http://ja.wikipedia.org/wiki/%E4%BA%BA%E6%A8%A9%E6%93%81%E8%AD%B7%E6%B3%95%E6%A1%88
���O���l�̋�`�w��̎�A�ݓ���Ə����������}(2007�N11��30���j
�@�@http://news18.2ch.net/test/read.cgi/news2/1148755375/1-100
�����ʉi�Z�ғ��̍��Ў擾����@�� �����}�A��o�Ɉӗ~�i�͂��o�����ō����Q�����j
�@�@http://cotodama-6000.iza.ne.jp/blog/entry/502594/
�������}�̕��c�����N���A�n��Ƃ����@�������o�I
�@�@http://society6.2ch.net/test/read.cgi/soc/1192439698/l50
���������Y�����ꋦ������g���l��������̌ږ��
�@�@http://www.asyura2.com/07/senkyo29/msg/846.html
�����ꋳ��֘A�c�̂Ɉ��{���[�������u�j�d�v
�@�@http://www.news.janjan.jp/government/0606/0606206368/1.php
���X��N���k���N�������L�ɐe��
�@�@http://www.toyo-keizai.co.jp/news/digest/2000/post_3447.php
�������}�u�ږ�1000���l����v�̎�����
http://www.nikkeibp.co.jp/news/biz08q2/575417/
�������}�͒���Ɍ��łP���S�C�O�O�O���~�𓊓��B
�@�@http://q.hatena.ne.jp/1062123112
���ݓ��ɂ���z���t���x��
�@�@http://news.livedoor.com/article/detail/3994761/
�������l�A�؍��l���w���ɔN�ԂT�O�O���~���^�_�ł����Ă��鎩���}�B
�@�@http://bbs.jpcanada.com/log/6/2504.html
���؍��l�ւ̃r�U�Ə����P�v�����������}
�@�@http://www.nikkansports.com/ns/general/f-so-tp0-060206-0020.html
�������}���w���R�O���l�v��
�@�@http://www.relay.co.jp/news/718/
���l���i��@�Ă̐�����ڎw�������}
�@�@http://ja.wikipedia.org/wiki/%E4%BA%BA%E6%A8%A9%E6%93%81%E8%AD%B7%E6%B3%95%E6%A1%88
���O���l�̋�`�w��̎�A�ݓ���Ə����������}(2007�N11��30���j
�@�@http://news18.2ch.net/test/read.cgi/news2/1148755375/1-100
�����ʉi�Z�ғ��̍��Ў擾����@�� �����}�A��o�Ɉӗ~�i�͂��o�����ō����Q�����j
�@�@http://cotodama-6000.iza.ne.jp/blog/entry/502594/
�������}�̕��c�����N���A�n��Ƃ����@�������o�I
�@�@http://society6.2ch.net/test/read.cgi/soc/1192439698/l50
���������Y�����ꋦ������g���l��������̌ږ��
�@�@http://www.asyura2.com/07/senkyo29/msg/846.html
�����ꋳ��֘A�c�̂Ɉ��{���[�������u�j�d�v
�@�@http://www.news.janjan.jp/government/0606/0606206368/1.php
���X��N���k���N�������L�ɐe��
�@�@http://www.toyo-keizai.co.jp/news/digest/2000/post_3447.php
������4/1
Bulldozer�̋L�����^���Ă��������ق��C���y������
Bulldozer�̋L�����^���Ă��������ق��C���y������
>>817
����
����
�ł����W���[�����̃R�A���ɃN���b�N�ύX������Ƃ����̂�
�ق�Ƃ��Ƃ�����܂���2�R�A�Ƌ��𐰂�閲�̂���b����Ȃ�
�ق�Ƃ��Ƃ�����܂���2�R�A�Ƌ��𐰂�閲�̂���b����Ȃ�
ttp://www.amdzone.com/joomla/images/cpus/bulldozeraf/buldozeraflogo2.png
���ꂪ�A������Ȃ�
BulldozerX8�Ƃ��ɂ���̂���
{kind=link}
���ꂪ�A������Ȃ�
BulldozerX8�Ƃ��ɂ���̂���
>>820
�͂��͂��O���l��{�@�����X�����X��
�͂��͂��O���l��{�@�����X�����X��
�������̂�5���Ԃ��炢�͂₢�您�O��B
�m���������B
�m���������B
�͂��͂�
�킽�ʂ�
�킽�ʂ�
�킽�ʂ�
�킽�ʂ�
Barcelona�̎���������1.5�{���������̏��ɒނ�ꂽ�̂��v���o�����B
�A�����J�ɂ��G�C�v���[���t�[�����Ă���̂��H
�����ꂷ�ɂ����Ȃ��Ǝv���Ă���?
�G�C�v���[�����삡��
�G�C�v���[�����삡��
831 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 19:45:54 ID:SFrIv+ox
�ނ���A�����J�̕�������萷��
�C���^�[�l�b�g�̐��E���ƃW���[�NRFC�����������肷��̂�����
���Ȃ�O�̂��ƁA�`�������g�����ʐM�v���g�R���Ƃ��Ȃ�����
�C���^�[�l�b�g�̐��E���ƃW���[�NRFC�����������肷��̂�����
���Ȃ�O�̂��ƁA�`�������g�����ʐM�v���g�R���Ƃ��Ȃ�����
> Thursday, 01 April 2010 01:01
����͍���
����͍���
833 �FSocket774�F2010/04/01(��) 20:30:18 ID:qyUfcwWe
BulldozerX6(2GHz)��3���~���炢���Ǝv���B
�l�^���ۂ���
835 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 20:37:05 ID:SFrIv+ox
836 �FMAC�I�^���c�q �����F2010/04/01(��) 20:41:17 ID:Xb5zlDzT
>>835
���܂�����U���Ă��c��(��)
���܂�����U���Ă��c��(��)
837 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 20:43:01 ID:SFrIv+ox
�l�^�Ƃ��Ă͊����x�����Ǝv��
������낽
>>837
���E������A�N�Z�X����邱�Ƃ��l����A�b��W�߂�A�N�Z�X���҂���
�K���ȏ��p�j���[�X�T�C�g�Ȃ�A���ꂮ�炢�̎�̂��l�^������Ă�
���������͂Ȃ���
���E������A�N�Z�X����邱�Ƃ��l����A�b��W�߂�A�N�Z�X���҂���
�K���ȏ��p�j���[�X�T�C�g�Ȃ�A���ꂮ�炢�̎�̂��l�^������Ă�
���������͂Ȃ���
MAC�I�^����Ԃ݂Ȃ̉��Z�ɂ��܂��ꂽ�Ƃ������ƂŏI���ł��ˁB
�܂�Intel�����������Ƃ�܂����Ă���Trace Cache��
AMD���܂�ܓ������O�Ǝ����Ŏg���Ă���킯�����̂����A
�u���b�N�}�����_���ȁB
AMD���܂�ܓ������O�Ǝ����Ŏg���Ă���킯�����̂����A
�u���b�N�}�����_���ȁB
Nice ApriI
�܁B4/1�����B
Bull�����[�ȁB�����\�z�O�B
2ALU�̃V���{�ł͂Ȃ��������B
2ALU�̃V���{�ł͂Ȃ��������B
�s�{�ӂɂ��G���̋C�����������ĔF�����Ă��܂���
>>794
�S�������ꉴ�̃R�����g�Ȃ�
�S�������ꉴ�̃R�����g�Ȃ�
�ǂ��܂ł��z���g�łǂ����炪�l�^�Ȃ낤��
�O���t�̓l�^�ł��A�c�q���x����Ĕ[������قǃ��A���ȉR�������̂͋��Q�����
�l�^���Ɨ����������ł����ۂ����̂��炢�Ȃ�Ȃ����ƌ���x�Ɏv��w
SSE��Q�[���Ȃ����̐��\�A�b�v�Ń��A�������A
�R�A�����{�ɂȂ�}���`�X���b�h�ł��R�A���ʂ̍��ɂȂ��Ă�B
����d�͂�45nm SOI��32nm SOI HKMG������8�R�A�ł��啪�Ⴍ�Ȃ�B
�O���t�̓l�^�ł��A�c�q���x����Ĕ[������قǃ��A���ȉR�������̂͋��Q�����
�l�^���Ɨ����������ł����ۂ����̂��炢�Ȃ�Ȃ����ƌ���x�Ɏv��w
SSE��Q�[���Ȃ����̐��\�A�b�v�Ń��A�������A
�R�A�����{�ɂȂ�}���`�X���b�h�ł��R�A���ʂ̍��ɂȂ��Ă�B
����d�͂�45nm SOI��32nm SOI HKMG������8�R�A�ł��啪�Ⴍ�Ȃ�B
848 �F�t�@�����X���F2010/04/01(��) 21:38:45 ID:jQuibCAl
�^���e�[�v�ƃe�w�͓����l���Ȃ�?
(��)�����̉����܂����̂ŁA�Q�l�܂łɁB
http://www.xtremesystems.org/forums/showpost.php?p=4318190&postcount=40
���āA���ꂩ��y�����͍̂����̕��ꃋ�[�}�[�T�C�g���ǂ������|���邩�Ȃ̂ł����c
http://www.xtremesystems.org/forums/showpost.php?p=4318190&postcount=40
���āA���ꂩ��y�����͍̂����̕��ꃋ�[�}�[�T�C�g���ǂ������|���邩�Ȃ̂ł����c
851 �F�t�@�����X���F2010/04/01(��) 21:45:24 ID:jQuibCAl
�I�^�̊��҂Ƃ͗�����
���i����C�O�L�����łăG�C�v�����t�[���l�^�y����ł�
�A�������܂����킯�˂Ȃ����B
���i����C�O�L�����łăG�C�v�����t�[���l�^�y����ł�
�A�������܂����킯�˂Ȃ����B
���Ăǂ����Ō������Ƃ���G����
��Inteli�APentiam 8�������\
�`MetBurst�ȗ�5�N�Ԃ�̐V�A�[�L�e�N�`��
ttp://pc.watch.impress.co.jp/docs/2005/0401/uocchi/inteli.htm
ttp://pc.watch.impress.co.jp/docs/2005/0401/uocchi/inteli01.gif
��Inteli�APentiam 8�������\
�`MetBurst�ȗ�5�N�Ԃ�̐V�A�[�L�e�N�`��
ttp://pc.watch.impress.co.jp/docs/2005/0401/uocchi/inteli.htm
ttp://pc.watch.impress.co.jp/docs/2005/0401/uocchi/inteli01.gif
{kind=link}
>>796
���ꂪ�{����������Pentium4��CoreMA�̏Ռ��Ȃ�ď��b�ɂ����Ȃ��c
���ꂪ�{����������Pentium4��CoreMA�̏Ռ��Ȃ�ď��b�ɂ����Ȃ��c
���̓x���`�͖{���ŁA�G�C�v�����t�[������[��Ƃ�����R�B
856 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/01(��) 23:06:02 ID:SFrIv+ox
Sandra�ɂ�鉉�Z���j�b�g�̃X���[�v�b�g�̐����������Ǝ��Ă邩��ʔ�����ȁB
���̋L�҂����҂���ˁ[��B���炩�Ƀv���̔ƍs������B
���Ȃ݂�Interagos��3.2GHz���Ă̂͂�����̃X�y�b�N�\�z�l�Ƒ�̓������Ă�B
�iAMD���\�����̐���X���[�v�b�g����t�Z�j
�t��Integer�̃X���[�v�b�g����������������ł���͂Ȃ��ƋC�Â����B
�����������XSIMD������Integer�p�C�v�ł̎��s�ɖ߂��킯���Ȃ���B
3�\�[�X�I�y�����h�ɑΉ��������߃X�P�W���[����FMA�����Ɏg���ܑ͖̂̂Ȃ��̂�
IMAC��PCMOV, PPERM�Ȃǂ̃I�y���[�V���������s���Ď�������Ӗ������܂��B
�B����������Ƃ��ė�́u�u���b�WFMA�v����ˁH
Bulldozer�Ŏ������Ă���̂Ȃ�FP�N���X�^�͐��ݓI�ɃN���b�N����2�\�[�X�I�y�����h��
4�I�y���[�V���������s�\���Ă��ƂɂȂ�B
���̋L�҂����҂���ˁ[��B���炩�Ƀv���̔ƍs������B
���Ȃ݂�Interagos��3.2GHz���Ă̂͂�����̃X�y�b�N�\�z�l�Ƒ�̓������Ă�B
�iAMD���\�����̐���X���[�v�b�g����t�Z�j
�t��Integer�̃X���[�v�b�g����������������ł���͂Ȃ��ƋC�Â����B
�����������XSIMD������Integer�p�C�v�ł̎��s�ɖ߂��킯���Ȃ���B
3�\�[�X�I�y�����h�ɑΉ��������߃X�P�W���[����FMA�����Ɏg���ܑ͖̂̂Ȃ��̂�
IMAC��PCMOV, PPERM�Ȃǂ̃I�y���[�V���������s���Ď�������Ӗ������܂��B
�B����������Ƃ��ė�́u�u���b�WFMA�v����ˁH
Bulldozer�Ŏ������Ă���̂Ȃ�FP�N���X�^�͐��ݓI�ɃN���b�N����2�\�[�X�I�y�����h��
4�I�y���[�V���������s�\���Ă��ƂɂȂ�B
>>853
����I�Ɏ���"K9"��"K10"���L�����Z������Ă���̂ŁA���蓾�Ȃ��b�ł͂Ȃ��B
�����ǂȂ��B�܂��B�G�C�v���[���t�[������c�������ɁB
����I�Ɏ���"K9"��"K10"���L�����Z������Ă���̂ŁA���蓾�Ȃ��b�ł͂Ȃ��B
�����ǂȂ��B�܂��B�G�C�v���[���t�[������c�������ɁB
K10��Phenom����
>>858
���ʓI�ɂ����Ȃ���"����"�����ǂȁB
���ʓI�ɂ����Ȃ���"����"�����ǂȁB
�͂₭X6�̃x���`���ʏo�Ȃ����ȁ[
�\�̂悤��4�����������Ȃ�A�����x���`�o�Ă��Ă������͂��Ȃ�
�\�̂悤��4�����������Ȃ�A�����x���`�o�Ă��Ă������͂��Ȃ�
���o�̓��e�����ꉞ�����Ă����B
���\�̌�����Nj�����Bulldozer�̃A�[�L�e�N�`���[
http://pc.nikkeibp.co.jp/article/trend/20100323/1023810/
���\�̌�����Nj�����Bulldozer�̃A�[�L�e�N�`���[
http://pc.nikkeibp.co.jp/article/trend/20100323/1023810/
�����Bulldozer�̃y�[�W���f���[�g����Ă����
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/264
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/272
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/281
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/310
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/379
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/387
>>735
������܂�����
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/272
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/281
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/310
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/379
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/387
>>735
������܂�����
864 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/02(��) 04:26:06 ID:VnW/HhAl
�E�����Č�����̋C�ɂ��Ă���
�R���v���b�N�X�h�������������
�R���v���b�N�X�h�������������
�yNOD32�z�G�����{��Part43�y�A�X�x���z
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
http://mamono.2ch.net/test/read.cgi/tubo/1253431254/
ID:SFrIv+ox
3�A�E���R��24�A�d�g
�u�P���Ƀ|���b�N�̋t�@���v�ŋt�Z�����1�E���R�ɂ�8�d�g
zambezi�ɑR���Ă�悤�ŋC��������
3�A�E���R��24�A�d�g
�u�P���Ƀ|���b�N�̋t�@���v�ŋt�Z�����1�E���R�ɂ�8�d�g
zambezi�ɑR���Ă�悤�ŋC��������
http://www.fabtech.org/news/_a/intel_only_losing_small_market_share_to_amd/?utm_source=feedburner&utm_medium=feed&utm_campaign=Fabtech+-+News&utm_content=livedoor
http://techreport.com/discussions.x/18702
http://techreport.com/discussions.x/18702
������Windows���s��Linux�����͏���w
ttp://it.anandtech.com/IT/showdoc.aspx?i=3784&p=7
�@�@�@�@�@�@�@�@�@�@�@win�@�@Lin
Op 6174(2.2G)�@�@32s��18s
Op 2435(2.6G)�@�@41s��27s
Xeon 5670(2.9G) 26s��32s
Xeon 5570(2.9G) 35s��33s
ttp://it.anandtech.com/IT/showdoc.aspx?i=3784&p=7
�@�@�@�@�@�@�@�@�@�@�@win�@�@Lin
Op 6174(2.2G)�@�@32s��18s
Op 2435(2.6G)�@�@41s��27s
Xeon 5670(2.9G) 26s��32s
Xeon 5570(2.9G) 35s��33s
869 �FSocket774�F2010/04/02(��) 10:31:35 ID:Tcp8tAIQ
�Ɨ��x�������Ɖ��Ńo�O�v���Z�b�T�̓S�~���݉�����́H
���{��ł���
>>869
Linux������Ő����ł���̂͏�̓�����ł́H
Linux������Ő����ł���̂͏�̓�����ł́H
>>872
�Ȃ�ق�
�Ȃ�ق�
874 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/02(��) 14:13:38 ID:VnW/HhAl
�R���p�C�����Ⴄ����
Win64�ł�Visual Studio 2008��Linux�ł�GCC
Win64�ł�Visual Studio 2008��Linux�ł�GCC
875 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/02(��) 14:15:16 ID:VnW/HhAl
���łɌ�����GCC x86-64�̃f�t�H���g�œK���I�v�V������-march=opteron����Ȃ���������
-march=core2�Ƃ�-march=nocona������ōăr���h���Ă݂�Ɩʔ������ƂɂȂ�Ǝv��
-march=core2�Ƃ�-march=nocona������ōăr���h���Ă݂�Ɩʔ������ƂɂȂ�Ǝv��
876 �F���͌��c�� ��OhjIkO1O8o �F2010/04/02(��) 21:16:57 ID:yJA1Gm6U
�c�q���w�E����܂ł��Ȃ��A>868�̌��ʂ�Win��Linux�Ő��\���傫�����Ă���Xeon�̌��ʂ��ُ�ł��邱�Ƃ͖����ł���
���낻��AMD�n�̗L��(?)�ȃR�e�łĂ��Ȃ����Ȃ��B
�퓬�\��
�c�q 20
MAC�I�^ 20
AMD������CPU�X���Z�l���� 5
�A���~ 1
���炢��FA?
�c�q 20
MAC�I�^ 20
AMD������CPU�X���Z�l���� 5
�A���~ 1
���炢��FA?
�c�q 20
MAC�I�^ 20
�e�w 10
AMD������CPU�X���Z�l���� 5
�A���~ 1
MAC�I�^ 20
�e�w 10
AMD������CPU�X���Z�l���� 5
�A���~ 1
881 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 00:29:49 ID:uQbVaWoM
GCC����AMD�ۛ��Ƃ������Ax86-64�Ő�ڂ�����AMD�ɗ�������̂͑O���猾���Ă�����
���A�\�[�X������肾�Ƒf��C/C++������A�R���p�C���̍�������ɏo��B
����source/kernel/gen_system/GEN_Matrix4x4.cpp������Ƃ��ASSE Intrinsics�g������
�����炩���\���P�ł��������ȁB
���A�\�[�X������肾�Ƒf��C/C++������A�R���p�C���̍�������ɏo��B
����source/kernel/gen_system/GEN_Matrix4x4.cpp������Ƃ��ASSE Intrinsics�g������
�����炩���\���P�ł��������ȁB
�܂�Intel��AMD64�Ő�������ꂽ�Ƃ��̂��̌��EM64T�̊����x�̌o�߂��݂邩����A
���߃Z�b�g�ő��Ђɂ������������Ƃ����̂͂��Ȃ�̑Ō��̂悤���ˁB
�����������Œ��N�����̂����Ă���AMD�̎��͂̓V�F�A2����̃��[�J�[�Ƃ��Ă͊�Ղɋ߂��ȁB
���߃Z�b�g�ő��Ђɂ������������Ƃ����̂͂��Ȃ�̑Ō��̂悤���ˁB
�����������Œ��N�����̂����Ă���AMD�̎��͂̓V�F�A2����̃��[�J�[�Ƃ��Ă͊�Ղɋ߂��ȁB
Magny-Cours�ł̒�N���b�N������݂Ă��킩��Ƃ���A
Bulldozer�̏��R�A���̗R���͓d�͂����������Œ�N���b�N�ɂ��Ȃ����߂̕���
�Ƃ����̂��ЂƂ����ꂽ�Ƃ����Ă�������������Ȃ��B
Bulldozer�̏��R�A���̗R���͓d�͂����������Œ�N���b�N�ɂ��Ȃ����߂̕���
�Ƃ����̂��ЂƂ����ꂽ�Ƃ����Ă�������������Ȃ��B
�c�q�����������A�����Ăď���
>>880
> >>876
> Intel�̎肪���܂�y��ł��Ȃ�Linux�̗̈�ł�
����ȗ̈�x86�̗p���ĂȂ����삭�炢��������
�g�ѓd�b�Ƃ��g���݂Ƃ�
> >>876
> Intel�̎肪���܂�y��ł��Ȃ�Linux�̗̈�ł�
����ȗ̈�x86�̗p���ĂȂ����삭�炢��������
�g�ѓd�b�Ƃ��g���݂Ƃ�
Xeon 5570/5670����AMD64�ɍœK�������R�A����Intel�������Ă���
�}�N�����Ƃ���64bit�ɑΉ����Č��I�ɐ��\�A�b�v�I�I���Čւ炵���ɂˁB
GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āAXeon�̂��̗��Ղ�́A
�A�[�L�e�N�`����v���c�ŁA�J���J���ɍœK�����Ȃ��ƃ��N�ł��Ȃ����Ď��������Ă��Ȃ����ȁB
�R�A�A�L���V���A�o�X�̂ǂ���Ƃ��Ă�Opteron���D��Ă���Xeon�̃_�����Ղ������Ƃ����v���B
�}�N�����Ƃ���64bit�ɑΉ����Č��I�ɐ��\�A�b�v�I�I���Čւ炵���ɂˁB
GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āAXeon�̂��̗��Ղ�́A
�A�[�L�e�N�`����v���c�ŁA�J���J���ɍœK�����Ȃ��ƃ��N�ł��Ȃ����Ď��������Ă��Ȃ����ȁB
�R�A�A�L���V���A�o�X�̂ǂ���Ƃ��Ă�Opteron���D��Ă���Xeon�̃_�����Ղ������Ƃ����v���B
�c�q 20
MAC�I�^ 20
AMD������CPU�X���Z�l���� 5
�A���~ 1 (�E�L�ցM�E)
�e�w 0�i�s���H����̈��l�����j
MAC�I�^ 20
AMD������CPU�X���Z�l���� 5
�A���~ 1 (�E�L�ցM�E)
�e�w 0�i�s���H����̈��l�����j
889 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 02:28:56 ID:uQbVaWoM
���ႠOpenMP���C�u�����̍����H
890 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 02:32:11 ID:uQbVaWoM
>>883
����A���ۓf���o���R�[�h�V�[�P���X�ɍ����o�����d���Ȃ��B
����A���ۓf���o���R�[�h�V�[�P���X�ɍ����o�����d���Ȃ��B
891 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 02:33:05 ID:uQbVaWoM
>>887
> GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āA
���O�̎v�����݂Ȃ�ĎQ�l�ɂ��鉿�l�͔��o���Ȃ�
��������12�R�A��6�R�A�ɕ����邱�Ƃ��p�����������B
> GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āA
���O�̎v�����݂Ȃ�ĎQ�l�ɂ��鉿�l�͔��o���Ȃ�
��������12�R�A��6�R�A�ɕ����邱�Ƃ��p�����������B
���N���b�N�f���A���iCore2�j��
��N���b�N�N�A�b�h�iPhenom�j���ǂ������������b���v���o����
�l�i��2�R�A��4�R�A���������炢
�d�́H�G�����Ⴂ����
��N���b�N�N�A�b�h�iPhenom�j���ǂ������������b���v���o����
�l�i��2�R�A��4�R�A���������炢
�d�́H�G�����Ⴂ����
���C�u������AMD��Intel�ɏ��Ă��Ȃ�����w
�Ƃ������A���A�T�|�[�g�A�\�t�g�E�F�A�̂ǂ���Ƃ��Ă�Intel��ꡂ���������Ă�
���̕ӂ����炩�Ɏア���炳��@����Ă���̂�AMD�Ȃ�
�Ƃ������A���A�T�|�[�g�A�\�t�g�E�F�A�̂ǂ���Ƃ��Ă�Intel��ꡂ���������Ă�
���̕ӂ����炩�Ɏア���炳��@����Ă���̂�AMD�Ȃ�
>>891
> >>887
> > GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āA
> ���O�̎v�����݂Ȃ�ĎQ�l�ɂ��鉿�l�͔��o���Ȃ�
>
> ��������12�R�A��6�R�A�ɕ����邱�Ƃ��p�����������B
Opteron�ɕ�����ȑO�ɁA4�R�A��6�R�A�Ő��\����1�b�����Ȃ��͖̂��炩�ɂ�����������
����ɁA�R�A�̐��\���ƃN���b�N�����啪���邩��A
�_���R�A���������Ȃ�HTT�̌����̈��������������Ă�Opteron�Ƃ͌݊p�ȏ�ɂ͂Ȃ�͂��B
> >>887
> > GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C�����ăC���[�W�������āA
> ���O�̎v�����݂Ȃ�ĎQ�l�ɂ��鉿�l�͔��o���Ȃ�
>
> ��������12�R�A��6�R�A�ɕ����邱�Ƃ��p�����������B
Opteron�ɕ�����ȑO�ɁA4�R�A��6�R�A�Ő��\����1�b�����Ȃ��͖̂��炩�ɂ�����������
����ɁA�R�A�̐��\���ƃN���b�N�����啪���邩��A
�_���R�A���������Ȃ�HTT�̌����̈��������������Ă�Opteron�Ƃ͌݊p�ȏ�ɂ͂Ȃ�͂��B
895 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 02:59:12 ID:uQbVaWoM
�����邦��
���Ƃ���͗]�k����
���Ƃ����A�œK�������������HT�̌��ʂɂ����킯�����ǁA�t��
HT�����ōœK�������߂ɂ��邱�ƂŁA�ɂ��œK����肩�����Đ��\��������
�P�[�X�i-O3��-O1��-O2���x���Ȃ�Ƃ��j�������B
���Ƃ��A1�X���b�h������1�R�A�̃��\�[�X���L����ꍇ�A3���ALU���������邽�߂ɁA
3���߂����鑀���5���߂��炢�ɓW�J�����肷��悤�ȍœK�����悭�s����B
�������AHT�����ł�2�X���b�h�ʼn��Z���\�[�X���V�F�A����̂ŁA�����ڂ̖��߂�
���C�e���V�E�X���[�v�b�g�͖��ɂȂ�B
��ŁA�ނ��떽�ߐ��̑�����œK���͂������ċt���ʂɂȂ�B
��ŁAIntel�R���p�C���ɂ́uHT�p�̍œK���v�̃X�C�b�`�����݂���B
���̃R���p�C���Ȃ�A�ȈՓI�ɂ́A�R�[�h�T�C�Y��������œK����}�~����
-Os �I�v�V�������L����������Ȃ��ˁB
���Ƃ���͗]�k����
���Ƃ����A�œK�������������HT�̌��ʂɂ����킯�����ǁA�t��
HT�����ōœK�������߂ɂ��邱�ƂŁA�ɂ��œK����肩�����Đ��\��������
�P�[�X�i-O3��-O1��-O2���x���Ȃ�Ƃ��j�������B
���Ƃ��A1�X���b�h������1�R�A�̃��\�[�X���L����ꍇ�A3���ALU���������邽�߂ɁA
3���߂����鑀���5���߂��炢�ɓW�J�����肷��悤�ȍœK�����悭�s����B
�������AHT�����ł�2�X���b�h�ʼn��Z���\�[�X���V�F�A����̂ŁA�����ڂ̖��߂�
���C�e���V�E�X���[�v�b�g�͖��ɂȂ�B
��ŁA�ނ��떽�ߐ��̑�����œK���͂������ċt���ʂɂȂ�B
��ŁAIntel�R���p�C���ɂ́uHT�p�̍œK���v�̃X�C�b�`�����݂���B
���̃R���p�C���Ȃ�A�ȈՓI�ɂ́A�R�[�h�T�C�Y��������œK����}�~����
-Os �I�v�V�������L����������Ȃ��ˁB
896 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 03:30:53 ID:uQbVaWoM
>>883
������ۂ��f�[�^���邼�BHarpertown�̍��̃x���`����
http://www.univ2000.com/intel/index.html
���̃O���t��Intel�R���p�C������ɐ��K�����Ă݂�Ɩʔ�����BXeon�ł�
Intel C++��Visual C++��GCC��Apple��GCC
�ɂȂ��Ă邩�炗��
�����A����Mac�Ŋm�F�������Ƃ��邯��Apple�r���h��GCC���ĉ��̂����O�Ńr���h�����{��GCC��萫�\�����B
�܂�Linux��GCC��AMD�L�����Ă͎̂�����Ȃ���d���Ȃ��B
�Г��Ɩ��Ńp�b�`�����Ă邭�炢�����B
���̐l���`�̃R�~�b�g�����Ă݁BAMD�����|�I�ɑ�������B
�������Intel�ɂ��œK���m�E�n�E��GNU�ɒ��錠���͂��邪�A
���А��R���p�C���̎s������Ȃ��Ƃ����Ȃ��B
�v���v���C�G�^���_�ł���MS�ɂ�VC�ɍœK��������Ă�
�I�[�v���\�[�X�ł���GCC�ɂ͍Œ���x�̏���o���Ȃ���ˁH
���ۖ��Intel�w�c�i�H�j�ł܂Ƃ��ɃR�~�b�g�������Ă�̂���H.J.Lu���炢����
������ۂ��f�[�^���邼�BHarpertown�̍��̃x���`����
http://www.univ2000.com/intel/index.html
���̃O���t��Intel�R���p�C������ɐ��K�����Ă݂�Ɩʔ�����BXeon�ł�
Intel C++��Visual C++��GCC��Apple��GCC
�ɂȂ��Ă邩�炗��
�����A����Mac�Ŋm�F�������Ƃ��邯��Apple�r���h��GCC���ĉ��̂����O�Ńr���h�����{��GCC��萫�\�����B
�܂�Linux��GCC��AMD�L�����Ă͎̂�����Ȃ���d���Ȃ��B
�Г��Ɩ��Ńp�b�`�����Ă邭�炢�����B
���̐l���`�̃R�~�b�g�����Ă݁BAMD�����|�I�ɑ�������B
�������Intel�ɂ��œK���m�E�n�E��GNU�ɒ��錠���͂��邪�A
���А��R���p�C���̎s������Ȃ��Ƃ����Ȃ��B
�v���v���C�G�^���_�ł���MS�ɂ�VC�ɍœK��������Ă�
�I�[�v���\�[�X�ł���GCC�ɂ͍Œ���x�̏���o���Ȃ���ˁH
���ۖ��Intel�w�c�i�H�j�ł܂Ƃ��ɃR�~�b�g�������Ă�̂���H.J.Lu���炢����
897 �F���͌��c�� ��OhjIkO1O8o �F2010/04/03(�y) 05:16:30 ID:brVGgCBl
>>887
> GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C��
����Ő��\���傫�����Ă���̂Ȃ畳�R���p�C���ł��������킯����w
�펯�I�ɍl���đ��݉��l�͂قƂ�ǖ����B
> GCC�͕ςȍœK���Ƃ����Ȃ��f���ȃR���p�C��
����Ő��\���傫�����Ă���̂Ȃ畳�R���p�C���ł��������킯����w
�펯�I�ɍl���đ��݉��l�͂قƂ�ǖ����B
�݂��ɐ��\�������o��������g���Ηǂ��Ƃ��������̘b
Opteron 6174 18s(Linux)
Xeon 5670 �@ 26s(windows)
Opteron 6174 18s(Linux)
Xeon 5670 �@ 26s(windows)
GCC�����ł̑��݈Ӌ`�������Ƃ�ww
�M�~�b�N�g�������ꉉ�Z�����̂ŁA����𑽗p���Ȃ��Ƌ����������ł��Ȃ��̂��˂��B
�T�[�o�p�r�Ƃ������́A�Q�[���}�V���ŃJ���R���ƍœK�����Ă���C���[�W�ɋ߂��̂����B
�T�[�o�p�r�Ƃ������́A�Q�[���}�V���ŃJ���R���ƍœK�����Ă���C���[�W�ɋ߂��̂����B
901 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 06:59:17 ID:uQbVaWoM
qn24b�����A�ꉞ�R���p�C���I�v�V�����̕ύX�ł��̒��x�͐��\�ς��
�y-march=opteron�z
$ ./qn24b_openmp 16
qn24b OpenMP version 1.0.0 2004-04-21
There are 9844 tasks
=============================================
qn24b OpenMP version 1.0.0 2004-04-21
problem size n : 16
total solutions : 14772512
correct solutions : 14772512
million solutions/sec : 4.627
elapsed time (sec) : 3.193
=============================================
�y-march=core2�z
$ ./qn24b_openmp 16
qn24b OpenMP version 1.0.0 2004-04-21
There are 9844 tasks
=============================================
qn24b OpenMP version 1.0.0 2004-04-21
problem size n : 16
total solutions : 14772512
correct solutions : 14772512
million solutions/sec : 4.801
elapsed time (sec) : 3.077
=============================================
�y-march=opteron�z
$ ./qn24b_openmp 16
qn24b OpenMP version 1.0.0 2004-04-21
There are 9844 tasks
=============================================
qn24b OpenMP version 1.0.0 2004-04-21
problem size n : 16
total solutions : 14772512
correct solutions : 14772512
million solutions/sec : 4.627
elapsed time (sec) : 3.193
=============================================
�y-march=core2�z
$ ./qn24b_openmp 16
qn24b OpenMP version 1.0.0 2004-04-21
There are 9844 tasks
=============================================
qn24b OpenMP version 1.0.0 2004-04-21
problem size n : 16
total solutions : 14772512
correct solutions : 14772512
million solutions/sec : 4.801
elapsed time (sec) : 3.077
=============================================
902 �F���͌��c�� ��OhjIkO1O8o �F2010/04/03(�y) 08:26:29 ID:brVGgCBl
>>900
> GCC�����ł̑��݈Ӌ`�������Ƃ�
�قƂ�ǖ����Ǝv�����B
���s���x���ɒ[�ɒቺ����悤�ȃo�C�i���[������R���p�C���͕��ƌĂԂɂӂ��킵���̂ł͂Ȃ����ȁH
���\��CPU�͍��Ȃ��̂�����ł���A���ׂ̈ɐF�X�Ɛ��ۂ����Ă���̂�����B
���̐���ɏ]���A�o���邾�������ɏ�����������s�R�[�h������̂��R���p�C���̖����ł�����
���\���ɒ[�ɒቺ����悤�Ȏ��s�R�[�h������R���p�C���̓S�~�ł����Ȃ��A�Q������w
> GCC�����ł̑��݈Ӌ`�������Ƃ�
�قƂ�ǖ����Ǝv�����B
���s���x���ɒ[�ɒቺ����悤�ȃo�C�i���[������R���p�C���͕��ƌĂԂɂӂ��킵���̂ł͂Ȃ����ȁH
���\��CPU�͍��Ȃ��̂�����ł���A���ׂ̈ɐF�X�Ɛ��ۂ����Ă���̂�����B
���̐���ɏ]���A�o���邾�������ɏ�����������s�R�[�h������̂��R���p�C���̖����ł�����
���\���ɒ[�ɒቺ����悤�Ȏ��s�R�[�h������R���p�C���̓S�~�ł����Ȃ��A�Q������w
�R���p�C���̖�ڂ͍�������ŋL�q�����\�[�X���瓮���o�C�i�������邱�Ƃł���B
���x�͗D�揇��2�ԖځB
���x�͗D�揇��2�ԖځB
�D�揇�ʍ����Ȃ�
�܂��ǂ���z���̔��e���o�Ă��Ȃ��ӌ����ȁB
����Anand�̐����ł́A
Intel�n�ł̓x���`�̌㔼��CPU���ׂ������܂ł����������ǁA
Opteron�ł�100%�������������ď����Ă���ȁB
��������Alpha�ł����A�܂Ƃ��ɓ����Ă��邩�ǂ�������悭�킩���Ƃ����I�`�B
����Anand�̐����ł́A
Intel�n�ł̓x���`�̌㔼��CPU���ׂ������܂ł����������ǁA
Opteron�ł�100%�������������ď����Ă���ȁB
��������Alpha�ł����A�܂Ƃ��ɓ����Ă��邩�ǂ�������悭�킩���Ƃ����I�`�B
���ƁAWin�ł͂���Linux�̂ق����������ʂ��łĂ���̂ɁA
�����GCC����邢�Ƃ���������AMS C�͂��������Ȃ�Ȃ�ƁB
�����GCC����邢�Ƃ���������AMS C�͂��������Ȃ�Ȃ�ƁB
>906
�R���鑊��̃p�t�H�[�}���X��������̂ɕK���ŁA
�����̂Ƃ��̂����X�������Ă��d���Ȃ��Ƃ����I�`�������肵�āB��
�R���鑊��̃p�t�H�[�}���X��������̂ɕK���ŁA
�����̂Ƃ��̂����X�������Ă��d���Ȃ��Ƃ����I�`�������肵�āB��
6�R�A���Č����Ă�12�X���b�h�����ł���킯����
�c�q���ꂿ����Ƌꂵ���Ȃ���
�c�q���ꂿ����Ƌꂵ���Ȃ���
����Ȃ��b�͎�����R���p�C���X���ł����ĂĂ���Ă���
�݂�ȃA�Z���u���ō������̂�
GCC��linux�ň�ԗL���Ń��[�U�[�������R���p�C������H
����g���Đ��\�o�Ȃ��悤�ȕ�CPU��������肾�낤w
����g���Đ��\�o�Ȃ��悤�ȕ�CPU��������肾�낤w
ICC��Linux�ł͖��������猋�\���p�҂��邾��
913 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 17:19:38 ID:uQbVaWoM
>>908
SMT�̐��\���㗦�Ȃ�Ă�������2�`3������Ό�̎��ł����H
SMT�̐��\���㗦�Ȃ�Ă�������2�`3������Ό�̎��ł����H
914 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 17:47:19 ID:uQbVaWoM
>>907
�Ȃ��Microsoft��AMD�ƑR����K�v������H������
Intel�Ɗ��Ⴂ���Ă�悤��������SPECint�̃X�R�A�݂Ă�ICC��AMD�ɂƂ��Ă��ő��̃R���p�C���Ȃ��炢����
�v�����AMD��MS�̘A�g�s���Ȃ�ˁH��
�܂��A�R�A�K�͓͂��������A
Opteron�F�@2.3[GHz] * 12[core] = 27.6
Xeon�F�@�@�@3.2[GHz] * 6[core] * 1.3[HT] = 24.6
�g�����W�X�^���{��������ŁA�ނ��돟�Ă�ق������R�Ȃ��B
�Ȃ��Microsoft��AMD�ƑR����K�v������H������
Intel�Ɗ��Ⴂ���Ă�悤��������SPECint�̃X�R�A�݂Ă�ICC��AMD�ɂƂ��Ă��ő��̃R���p�C���Ȃ��炢����
�v�����AMD��MS�̘A�g�s���Ȃ�ˁH��
�܂��A�R�A�K�͓͂��������A
Opteron�F�@2.3[GHz] * 12[core] = 27.6
Xeon�F�@�@�@3.2[GHz] * 6[core] * 1.3[HT] = 24.6
�g�����W�X�^���{��������ŁA�ނ��돟�Ă�ق������R�Ȃ��B
915 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 17:54:38 ID:uQbVaWoM
���߂�X5680��3.33GHz��������
3.33 * 6 * 1.3 = 25.974
3.33 * 6 * 1.3 = 25.974
Sandy����1�R�A�ӂ�30mm2�ʂ�����A8�R�A��240mm2�A�A���R�A�܂߂�300mm2�ʂ��ȁH
45nm��K10��L3�t��6�R�A�Ŗ�300mm2�A�V�������N������6������180mm2�B
K10 6�R�A�� Bull 8�R�A���������炢�Ȃ�ABull 8�R�A��180mm2�A��������200mm2�B
Sandy 8C/16T �� 3GHz��130W���낤�ȁB
Bull 8C��3Ghz��65W���x�ŁABull 16C��130W���ȁB
Bull 3G��1�A�R�A�̐��\��1.3�{�AHTT����1.3�Ƃ���130W���̐��\��K���ɔ�r(
Sandy 8C/16T 3G =1.3*8*1.3=13.52
Bull 16C 3G = 16
Sandy 8C 300mm2��Bull 16C 200*2=400mm2
300mm2��200mm2 2�Ȃ�R�X�g�͓������炢���낤�B
�c�q�̌����Ƃ���Ȃ�AAVX�g��Ȃ����艿�i�тł��Ԃ�Bulldozer�ɂ͐������x���ŕ����邱�ƂɂȂ�ȁB
45nm��K10��L3�t��6�R�A�Ŗ�300mm2�A�V�������N������6������180mm2�B
K10 6�R�A�� Bull 8�R�A���������炢�Ȃ�ABull 8�R�A��180mm2�A��������200mm2�B
Sandy 8C/16T �� 3GHz��130W���낤�ȁB
Bull 8C��3Ghz��65W���x�ŁABull 16C��130W���ȁB
Bull 3G��1�A�R�A�̐��\��1.3�{�AHTT����1.3�Ƃ���130W���̐��\��K���ɔ�r(
Sandy 8C/16T 3G =1.3*8*1.3=13.52
Bull 16C 3G = 16
Sandy 8C 300mm2��Bull 16C 200*2=400mm2
300mm2��200mm2 2�Ȃ�R�X�g�͓������炢���낤�B
�c�q�̌����Ƃ���Ȃ�AAVX�g��Ȃ����艿�i�тł��Ԃ�Bulldozer�ɂ͐������x���ŕ����邱�ƂɂȂ�ȁB
917 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 18:15:22 ID:uQbVaWoM
L1�L���b�V�����������Ȃ������ƂŐ��\�ቺ����A�v�����l���ɓ���Ȃ�������Ȃ邩����
919 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 18:22:13 ID:uQbVaWoM
�����Ă��̐�������ɏo��IvyBridge 8�R�A�Ɍ����ł��ˁB�킩��܂��B
�ŁABulldozer+HD7xxx��ry
>>914
X5680��32nm����A45nm���Z��450�`500mm2�����ɂȂ�B
Op 6174 ��700mm2������A���Ƃ��Ă͂�������5�����x���낤�B
�V�������N�ɂ���d�͉�����������A
�}�j�N�[����Westmere-EP�ɐ����I�ȍ��͖����ɓ�������B
�}�j�N�[����32nm�ɃV�������N�����350mm2/3GHz�ʂɂȂ邾�낤���ˁB
X5680��32nm����A45nm���Z��450�`500mm2�����ɂȂ�B
Op 6174 ��700mm2������A���Ƃ��Ă͂�������5�����x���낤�B
�V�������N�ɂ���d�͉�����������A
�}�j�N�[����Westmere-EP�ɐ����I�ȍ��͖����ɓ�������B
�}�j�N�[����32nm�ɃV�������N�����350mm2/3GHz�ʂɂȂ邾�낤���ˁB
922 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 18:43:36 ID:uQbVaWoM
923 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 18:48:07 ID:uQbVaWoM
> �}�j�N�[����32nm�ɃV�������N�����350mm2/3GHz�ʂɂȂ邾�낤���ˁB
�Ղ͂�����
1�m�[�h�̃V�������N�Ń_�C�T�C�Y�����ɂȂ��Ă��̂��Ĉ�̂��̎���̘b���悗������
���N���b�N�v���Z�X�őf���ɔ����ɏk���ł���͔̂M���x�̏�����SRAM�ق�
�A���R�A���̃A�N�Z�X�p�x�̏������u���b�N���炢�ł���
�_�C�T�C�Y�̑唼��SRAM�^�A���R�A�ō\�������Intel�v���Z�b�T�Ȃ�e���p
Magny-Cours�͂��Ƃ���SRAM�ʐϔ䏬��������K�b�J�����܂���B
�Ă��N�͐����̗\�z�͂��Ȃ��ق���������B
�Ղ͂�����
1�m�[�h�̃V�������N�Ń_�C�T�C�Y�����ɂȂ��Ă��̂��Ĉ�̂��̎���̘b���悗������
���N���b�N�v���Z�X�őf���ɔ����ɏk���ł���͔̂M���x�̏�����SRAM�ق�
�A���R�A���̃A�N�Z�X�p�x�̏������u���b�N���炢�ł���
�_�C�T�C�Y�̑唼��SRAM�^�A���R�A�ō\�������Intel�v���Z�b�T�Ȃ�e���p
Magny-Cours�͂��Ƃ���SRAM�ʐϔ䏬��������K�b�J�����܂���B
�Ă��N�͐����̗\�z�͂��Ȃ��ق���������B
>>919
���̐��J�����Bull 8C + HD6750�Ɍ������A�Z�����U�������ˁB
AMD�̃n�C�G���h���[�h�}�b�v�͂���Ȃ��H
CPU
2011/�� 32nm Bull 8C(200mm2)/16C
2012/�� 32nm Bull 8C + HD6xxx (300mm2)
2012/�� 22nm Bull 16C(200mm2)/32C
2013/�� 22nm Bull 16C + HD7xxx (300mm2)
2013/�� 22nm �z������ww
Intel�͂���Ȃ���
2011/�� 32nm Sandy 8C (300mm2)
2012/�� 22nm Ivy �~�h���ȉ�
2012/�� 22nm Ivy 16C�@(300mm2)
2013/�� 22nm Has 8C + Larra (300mm2)
2013/�� 22nm Has 16C (300mm2)
�Ȃ�Ƃ������A����GPGPU����ɓ��ꂽ���v���Z�X����̍��͈Ӗ����Ȃ��Ȃ������ۂ�
���̐��J�����Bull 8C + HD6750�Ɍ������A�Z�����U�������ˁB
AMD�̃n�C�G���h���[�h�}�b�v�͂���Ȃ��H
CPU
2011/�� 32nm Bull 8C(200mm2)/16C
2012/�� 32nm Bull 8C + HD6xxx (300mm2)
2012/�� 22nm Bull 16C(200mm2)/32C
2013/�� 22nm Bull 16C + HD7xxx (300mm2)
2013/�� 22nm �z������ww
Intel�͂���Ȃ���
2011/�� 32nm Sandy 8C (300mm2)
2012/�� 22nm Ivy �~�h���ȉ�
2012/�� 22nm Ivy 16C�@(300mm2)
2013/�� 22nm Has 8C + Larra (300mm2)
2013/�� 22nm Has 16C (300mm2)
�Ȃ�Ƃ������A����GPGPU����ɓ��ꂽ���v���Z�X����̍��͈Ӗ����Ȃ��Ȃ������ۂ�
>>923
������ۂ��W���g�����K���ȗ\�z������C�ɂ����w
Larrabee�Ő���Ɏ����������O�Ɍ���ꂽ���Ȃ���w
����Ƀ}�j�N�[����Lisbon 350mm2��MCM�Ŗ�700mm2�����ǁA
���͖�300mm2��Thuban�����邩��A����g����32nm 12�R�A 350mm2�͉\���낤�B
������ۂ��W���g�����K���ȗ\�z������C�ɂ����w
Larrabee�Ő���Ɏ����������O�Ɍ���ꂽ���Ȃ���w
����Ƀ}�j�N�[����Lisbon 350mm2��MCM�Ŗ�700mm2�����ǁA
���͖�300mm2��Thuban�����邩��A����g����32nm 12�R�A 350mm2�͉\���낤�B
>>922
�������ɓ��{�ꂪ�����ς���w
�ו��܂ŗ������Ă��鎩���ō�����n�[�h�̃\�t�g�������ō��̂ƁA
�悭����l��������n�[�h�̃\�t�g���������Ȃ�����̂���A
�ŏI�I�ȃ\�t�g�̐��\�ɍ����ł���͓̂��R���낤���Ă������B
�������ɓ��{�ꂪ�����ς���w
�ו��܂ŗ������Ă��鎩���ō�����n�[�h�̃\�t�g�������ō��̂ƁA
�悭����l��������n�[�h�̃\�t�g���������Ȃ�����̂���A
�ŏI�I�ȃ\�t�g�̐��\�ɍ����ł���͓̂��R���낤���Ă������B
�b�d�k�k��������̃v���Z�X�������Ă���Ƃ����b�����邪�A�V�������N���̃Q�[�g��������D�荞���
������d�͂̃Q�[�g������d�͂̃Q�[�g�ɒu����������A������d�͂̃Q�[�g����1/3����1/4�ɂȂ���
�`�b�v�T�C�Y�A����d�͋��ɗ\��ȏ�ɏ������Ȃ����Ƃ����Ă����ȁB
�܂��A����N���b�N�������ł�������̐��E�Ƃ����������邪�c�B
������d�͂̃Q�[�g������d�͂̃Q�[�g�ɒu����������A������d�͂̃Q�[�g����1/3����1/4�ɂȂ���
�`�b�v�T�C�Y�A����d�͋��ɗ\��ȏ�ɏ������Ȃ����Ƃ����Ă����ȁB
�܂��A����N���b�N�������ł�������̐��E�Ƃ����������邪�c�B
928 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 20:07:06 ID:uQbVaWoM
��������2-issue�̃V���v��RISC�����ȁB
�v���Z�b�T�̓�����E�͏���d�͂����M���x�Ɏx�z�����
�v���Z�b�T�̓�����E�͏���d�͂����M���x�Ɏx�z�����
929 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 20:11:16 ID:uQbVaWoM
>>926
�ق��AGCC���������AMD�����R���p�C���̃|�W�V���������˂Ă鎖���܂��ĕ����Ɩʔ����ӌ���
�i�O�Ȃ�PathScale������������NVIDIA�w�c�ɍs�������j
�ق��AGCC���������AMD�����R���p�C���̃|�W�V���������˂Ă鎖���܂��ĕ����Ɩʔ����ӌ���
�i�O�Ȃ�PathScale������������NVIDIA�w�c�ɍs�������j
GC2�ɂ͂܂�ATI�̃V�[�����\����̂�
�Ƃ肠�����K���ɍ���Ă����\������Ȃ�ɏo��̂�Opteron�A
�C������ăJ���J���Ƀ`���[�j���O���Ȃ��Ƃ낭�ɐ��\���łȂ�Xeon
�C������ăJ���J���Ƀ`���[�j���O���Ȃ��Ƃ낭�ɐ��\���łȂ�Xeon
932 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 20:50:41 ID:uQbVaWoM
�����>>905��
933 �FSocket774�F2010/04/03(�y) 21:45:10 ID:vSggtOuV
>>905
>Intel�n�ł̓x���`�̌㔼��CPU���ׂ������܂ł����������ǁA
>Opteron�ł�100%�������������ď����Ă���ȁB
���̓ǂ݊ԈႢ���ȁD
"Intel�n"�ł͂Ȃ���Opteron 6174��Windows�Ŏg�����ꍇ
�Ə����Ă���Ǝv�����ǁD
>Intel�n�ł̓x���`�̌㔼��CPU���ׂ������܂ł����������ǁA
>Opteron�ł�100%�������������ď����Ă���ȁB
���̓ǂ݊ԈႢ���ȁD
"Intel�n"�ł͂Ȃ���Opteron 6174��Windows�Ŏg�����ꍇ
�Ə����Ă���Ǝv�����ǁD
934 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 22:10:30 ID:uQbVaWoM
935 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 22:28:02 ID:uQbVaWoM
Anand�̕��͂ǂ���Ȃ�A�P����VC��OMPLIB���^�X�N�����̗��x�e���������������
Xeon�̓X���b�h�������Ȃ��ꍇ�ɉ��Z���\�[�X��1�X���b�h�Ő�L�ł��邵
Turbo Boost�ňꕔ�̃R�A�̃N���b�N���u�[�X�g�ł���B
���������āA���[�J�[�X���b�h���������Ă����\���ቺ���ɂ����B
Magny-Cours��24�X���b�h�ϓ��ɏ��������Ă��Ȃ��ƃt���ɐ��\���ł��Ȃ��B
Xeon�̓X���b�h�������Ȃ��ꍇ�ɉ��Z���\�[�X��1�X���b�h�Ő�L�ł��邵
Turbo Boost�ňꕔ�̃R�A�̃N���b�N���u�[�X�g�ł���B
���������āA���[�J�[�X���b�h���������Ă����\���ቺ���ɂ����B
Magny-Cours��24�X���b�h�ϓ��ɏ��������Ă��Ȃ��ƃt���ɐ��\���ł��Ȃ��B
936 �F���͌��c�� ��OhjIkO1O8o �F2010/04/03(�y) 22:58:11 ID:brVGgCBl
> Magny-Cours��24�X���b�h�ϓ��ɏ��������Ă��Ȃ��ƃt���ɐ��\���ł��Ȃ�
���ɑ傫�Ȏ�_���ȁB�p�r�ɂ���Ă̓S�~�ɂȂ�B
���ɑ傫�Ȏ�_���ȁB�p�r�ɂ���Ă̓S�~�ɂȂ�B
INTEL���R�A���������Ȃ������ł́H
>>936->>937
�c�q�̐����͂킩��ɂ������ȒP�Șb�B�悤�����AMD�̓R�A�������̂ŁA
���Ƃ���12�X���b�h�����X�d�������������āA�ق���12�X���b�h�̎d���������̂��܂��Ă�悤�ȏ���������B
�����Blender�̃x���`�}�[�N�ł�Win/Linux�ԂŃx���`�̌㔼�Ō����ɈႢ�Ƃ��ďo�Ă����Ƃ��������B
�R���p�C���Ƃ����C�u�����Ƃ��̏����n��������Ȃ���Blender�ʼn��������_�����O���Ă邩�ł��ς�肻������B
����̓X���[�v�b�g�u��/�����R�A�u���̐v�ŋ��ʂ̖�肾����ȁB
�R�A�������Ȃ��ق����S�R�A���x�ݖ��������A���\�����₷���Ƃ����͓̂�����O�B
�c�q�̐����͂킩��ɂ������ȒP�Șb�B�悤�����AMD�̓R�A�������̂ŁA
���Ƃ���12�X���b�h�����X�d�������������āA�ق���12�X���b�h�̎d���������̂��܂��Ă�悤�ȏ���������B
�����Blender�̃x���`�}�[�N�ł�Win/Linux�ԂŃx���`�̌㔼�Ō����ɈႢ�Ƃ��ďo�Ă����Ƃ��������B
�R���p�C���Ƃ����C�u�����Ƃ��̏����n��������Ȃ���Blender�ʼn��������_�����O���Ă邩�ł��ς�肻������B
����̓X���[�v�b�g�u��/�����R�A�u���̐v�ŋ��ʂ̖�肾����ȁB
�R�A�������Ȃ��ق����S�R�A���x�ݖ��������A���\�����₷���Ƃ����͓̂�����O�B
���ƔM���x(��)�͕����p�ꕗ�듚��Ȃ̂ł��܂�����̂͂������߂��Ȃ���B
Power Density�ŏ\���B
796+1 �F���邦�� [��] �F2009/06/20(�y) 19:15:15 ID:KQ8pkTrR (9/17)
Quad�̘b�͂����܂ł�Lynnfield�Ƃ̔�r�Ō����Ă邾�������B
���ƁA�M���x�Ȃ�Č㓡only�p��𖢂��ɂ����Ă��������邪�A
���̌㓡�L����ǂ߂A
http://www.watch.impress.co.jp/pc/docs/article/20010206/kaigai01.htm
http://www.watch.impress.co.jp/pc/docs/article/20010206/kaigai01.jpg
�M���x(��)��Core 2�ȍ~�A�w�Ǐオ���Ă��Ȃ����Ƃ������ł��邾�낤�B
798+1 �F[Fn]�{[����������] [��] �F2009/06/20(�y) 19:18:27 ID:xt/N5PGQ (7/10)
>>796
�M���x��Core2�ȍ~�オ���ĂȂ��Ƃ����̂ł͂Ȃ��A
�M���x�����E�ɂȂ��ăN���b�N���}�����Ă��܂��Ă�
���Ă̂��{���̂Ƃ���
799+1 �F���邦�� [��] �F2009/06/20(�y) 19:19:58 ID:KQ8pkTrR (10/17)
>>797
>BloomField��Lynnfield�̃��[�N��Ă����A�p�t�H�[�}���X���b�g�i���ɃA�C�h���j���F�����Ȃ��̂���肾�Ƃ����Ă�
Gainestown vs Harpertown
Core 2 Quad vs Lynnfield
�o���̌v���ɂ����āA���[�h���͓����A�A�C�h�����́ANehalem�n�������Ă����B
Bloomfield�͂���́AXeon�Ȃ�A�v���b�g�t�H�[���̐v���B
���̌o�܂�����Ȃ����Nehalem�͓��ʓd�͏���傫���Ɗ��Ⴂ���Đ��m�ł͂Ȃ����𖠉������Ă����̂��B
802 �F���邦�� [��] �F2009/06/20(�y) 19:22:52 ID:KQ8pkTrR (12/17)
>>798
�����Ɛl�̃��X�ƁA�����N��̌㓡�L�����?
�㓡������ɔM���x(��)�ƌĂ�ł���̂�Power Density�ł����āA
�d�͒l���_�C�ʐςŊ��������m����B
�M���x(��)���{���ɑ傫���Ȃ��Ă��邩�ǂ����́A
Nehalem�̏���d�͂��_�C�T�C�Y�Ŋ����āAPentium 4��Core 2�Ɣ�r���Ă݂�����B
804 �F���邦�� [��] �F2009/06/20(�y) 19:25:15 ID:KQ8pkTrR (13/17)
>>801
���߂Č�������ƃg�b�v�̕��Ɍ㓡�L��������ȁB
�悢�q�͔M���x�Ȃ�Ă��������p��͎g��Ȃ��悤�ɒ��ӂ��܂��傤�B
���M���x?
Power Density�ŏ\���B
796+1 �F���邦�� [��] �F2009/06/20(�y) 19:15:15 ID:KQ8pkTrR (9/17)
Quad�̘b�͂����܂ł�Lynnfield�Ƃ̔�r�Ō����Ă邾�������B
���ƁA�M���x�Ȃ�Č㓡only�p��𖢂��ɂ����Ă��������邪�A
���̌㓡�L����ǂ߂A
http://www.watch.impress.co.jp/pc/docs/article/20010206/kaigai01.htm
http://www.watch.impress.co.jp/pc/docs/article/20010206/kaigai01.jpg
{kind=link}
�M���x(��)��Core 2�ȍ~�A�w�Ǐオ���Ă��Ȃ����Ƃ������ł��邾�낤�B
798+1 �F[Fn]�{[����������] [��] �F2009/06/20(�y) 19:18:27 ID:xt/N5PGQ (7/10)
>>796
�M���x��Core2�ȍ~�オ���ĂȂ��Ƃ����̂ł͂Ȃ��A
�M���x�����E�ɂȂ��ăN���b�N���}�����Ă��܂��Ă�
���Ă̂��{���̂Ƃ���
799+1 �F���邦�� [��] �F2009/06/20(�y) 19:19:58 ID:KQ8pkTrR (10/17)
>>797
>BloomField��Lynnfield�̃��[�N��Ă����A�p�t�H�[�}���X���b�g�i���ɃA�C�h���j���F�����Ȃ��̂���肾�Ƃ����Ă�
Gainestown vs Harpertown
Core 2 Quad vs Lynnfield
�o���̌v���ɂ����āA���[�h���͓����A�A�C�h�����́ANehalem�n�������Ă����B
Bloomfield�͂���́AXeon�Ȃ�A�v���b�g�t�H�[���̐v���B
���̌o�܂�����Ȃ����Nehalem�͓��ʓd�͏���傫���Ɗ��Ⴂ���Đ��m�ł͂Ȃ����𖠉������Ă����̂��B
802 �F���邦�� [��] �F2009/06/20(�y) 19:22:52 ID:KQ8pkTrR (12/17)
>>798
�����Ɛl�̃��X�ƁA�����N��̌㓡�L�����?
�㓡������ɔM���x(��)�ƌĂ�ł���̂�Power Density�ł����āA
�d�͒l���_�C�ʐςŊ��������m����B
�M���x(��)���{���ɑ傫���Ȃ��Ă��邩�ǂ����́A
Nehalem�̏���d�͂��_�C�T�C�Y�Ŋ����āAPentium 4��Core 2�Ɣ�r���Ă݂�����B
804 �F���邦�� [��] �F2009/06/20(�y) 19:25:15 ID:KQ8pkTrR (13/17)
>>801
���߂Č�������ƃg�b�v�̕��Ɍ㓡�L��������ȁB
�悢�q�͔M���x�Ȃ�Ă��������p��͎g��Ȃ��悤�ɒ��ӂ��܂��傤�B
���M���x?
940 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/03(�y) 23:34:48 ID:uQbVaWoM
>>939
�����H�Ȃ��āH
http://www.patentjp.com/13/R/R100049/DA10058.html
http://www.aec.go.jp/jicst/NC/senmon/kakuyugo2/siryo/kaihatsu20/siryo12.pdf
�����H�Ȃ��āH
http://www.patentjp.com/13/R/R100049/DA10058.html
http://www.aec.go.jp/jicst/NC/senmon/kakuyugo2/siryo/kaihatsu20/siryo12.pdf
>>940
����͂��܂��g���Ă��܂������x�����ˁB�M���x�Ȃ�Ă������t�͈�ʂɂ͂Ȃ��B
Power Density�Ȃ炮���������ł��łĂ��邪�ˁB
����͂��܂��g���Ă��܂������x�����ˁB�M���x�Ȃ�Ă������t�͈�ʂɂ͂Ȃ��B
Power Density�Ȃ炮���������ł��łĂ��邪�ˁB
http://ja.wikipedia.org/wiki/%E9%9B%BB%E5%8A%9B%E5%AF%86%E5%BA%A6
���o�͂̔����̂ɂ����đ̐ς�����̎��o����d�͂�\���B
���o�����P�ʎ��Ԃ�����̔M�ʂ��������Ƃ�����B�P�ʂ̓��b�g�������Z���`���[�g�� (W/cm3)�B
���o�͂̔����̂ɂ����đ̐ς�����̎��o����d�͂�\���B
���o�����P�ʎ��Ԃ�����̔M�ʂ��������Ƃ�����B�P�ʂ̓��b�g�������Z���`���[�g�� (W/cm3)�B
>>935>>936>>938
CnQ�iOpteron��PowerNow�������H)�m��Ȃ��́H
���ׂ��Ⴂ�R�A�̓N���b�N���Ƃ��ďȃG�l�ɂȂ��H
����Ƀ^�[�{���ď��X���b�h���ɐ��SMhz�A�b�v���邾�������A
2���ȉ��������\�͏オ����A����C�x�߂��Ă���w
����������Way���g���Đ��\�X���b�h���������C����Xeon��Opteron�ŁA
�V���O���⏭�X���b�h���\�����Ă��d���Ȃ�����w
>�R�A�������Ȃ��ق����S�R�A���x�ݖ��������A���\�����₷���Ƃ����͓̂�����O�B
���̌���Blender�ł͐��\���Ⴂ�ł�����Ӗ����Ȃ�w
CnQ�iOpteron��PowerNow�������H)�m��Ȃ��́H
���ׂ��Ⴂ�R�A�̓N���b�N���Ƃ��ďȃG�l�ɂȂ��H
����Ƀ^�[�{���ď��X���b�h���ɐ��SMhz�A�b�v���邾�������A
2���ȉ��������\�͏オ����A����C�x�߂��Ă���w
����������Way���g���Đ��\�X���b�h���������C����Xeon��Opteron�ŁA
�V���O���⏭�X���b�h���\�����Ă��d���Ȃ�����w
>�R�A�������Ȃ��ق����S�R�A���x�ݖ��������A���\�����₷���Ƃ����͓̂�����O�B
���̌���Blender�ł͐��\���Ⴂ�ł�����Ӗ����Ȃ�w
944 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 00:21:47 ID:w2IUsqCK
Windows��CoolSpeed Technology�i�j�@�������������
945 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 00:23:22 ID:7XU6kjpZ
>>943
> ����������Way���g���Đ��\�X���b�h���������C����Xeon��Opteron�ŁA
> �V���O���⏭�X���b�h���\�����Ă��d���Ȃ�����w
����V���O���X���b�h���\���d�v����B
�Ј�A�uAMD�̍ŐVCPU���ڃT�[�o�[�ɕς���Ă���Ă��鎞�ԑтł��������肷��悤�ɂȂ����ˁA�Ȃ������������݂���v
�Ј�B�u�������ˁA�����ǂ��s�[�N�̎��ԑтł̌��d�͉������ꂽ���E�E�E�v
�Ј�A�u����s�[�N���ԑт͎g��Ȃ����疳�W�v
�E�E�E
> ����������Way���g���Đ��\�X���b�h���������C����Xeon��Opteron�ŁA
> �V���O���⏭�X���b�h���\�����Ă��d���Ȃ�����w
����V���O���X���b�h���\���d�v����B
�Ј�A�uAMD�̍ŐVCPU���ڃT�[�o�[�ɕς���Ă���Ă��鎞�ԑтł��������肷��悤�ɂȂ����ˁA�Ȃ������������݂���v
�Ј�B�u�������ˁA�����ǂ��s�[�N�̎��ԑтł̌��d�͉������ꂽ���E�E�E�v
�Ј�A�u����s�[�N���ԑт͎g��Ȃ����疳�W�v
�E�E�E
946 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 00:26:22 ID:w2IUsqCK
��ʃG���v���p�r�ɂ���HPC����Ȃ������ɖZ�����킯����Ȃ���
�ނ���^�X�N�͎��ʂƂ��ɂ��
���Ȃ��X���b�h�������ɎJ����\�����[�V�������K�v����B
����Sun�Ȃ�Č�����������Ȃ�
�ނ���^�X�N�͎��ʂƂ��ɂ��
���Ȃ��X���b�h�������ɎJ����\�����[�V�������K�v����B
����Sun�Ȃ�Č�����������Ȃ�
�T�[�o�ŃV���O���X���b�h���\���K�v�Ȃ����Ă̂�CPU���̂����킯����ȁB
�T�[�o���R�A�����������Ȃ��Ȃ�����T�[�o�ɂ͂Ȃ�̖�����������B
�Ђ���������Ȃ��āA����ł��䐔����Ȃ��Ȃ��Ă����^���B
�V���O���X���b�h���\���Ȃ��Ƃ����炵�����Ƃ��ĂقƂ�ǂł��Ȃ�����Ȃ��B
�T�[�o���R�A�����������Ȃ��Ȃ�����T�[�o�ɂ͂Ȃ�̖�����������B
�Ђ���������Ȃ��āA����ł��䐔����Ȃ��Ȃ��Ă����^���B
�V���O���X���b�h���\���Ȃ��Ƃ����炵�����Ƃ��ĂقƂ�ǂł��Ȃ�����Ȃ��B
TB���đ唼�̃R�A���A�C�h���@���ɂ��ď����̃R�A���������OC����@�\����H
12�R�A��10�R�A�Ƃ����A�C�h���ȉ��ɂȂ�Ƃ����ʂ��肦�Ȃ�
�o�������Ă����Ă��A�}���`�X���b�h����{�Ȃ���S���ɂ���Ȃ�̕��ׂ͂�����
�����������X���b�h�̐��\���~�������4�R�A��6�R�A�̍��N���b�N�i���g�������B
�����TB�̌��㗦�͂�������2���ȉ��Ȃ���A�債�č����ɂ͎J���Ȃ���B
12�R�A��10�R�A�Ƃ����A�C�h���ȉ��ɂȂ�Ƃ����ʂ��肦�Ȃ�
�o�������Ă����Ă��A�}���`�X���b�h����{�Ȃ���S���ɂ���Ȃ�̕��ׂ͂�����
�����������X���b�h�̐��\���~�������4�R�A��6�R�A�̍��N���b�N�i���g�������B
�����TB�̌��㗦�͂�������2���ȉ��Ȃ���A�債�č����ɂ͎J���Ȃ���B
949 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 00:45:41 ID:w2IUsqCK
�o�J�W���l�[�m�H
2GHz�����3GH����̂ق����m���ɑ�������
2GHz�����3GH����̂ق����m���ɑ�������
950 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 00:47:51 ID:7XU6kjpZ
>>948
����V���O���X���b�h���\���̂��̂��傫����������A�_�t���X�R�A�ŕ����Ă���̂͊ʼn߂ł��Ȃ�w
����V���O���X���b�h���\���̂��̂��傫����������A�_�t���X�R�A�ŕ����Ă���̂͊ʼn߂ł��Ȃ�w
�܂����̃��[�h�}�b�v��̎�����炢����
AMD�������߂ɂ͂Ȃɂ��̔��q��eDRAM��Intel�����ꑫ��ɓ������Ă��܂��Ƃ�
�˔�Ȃ��Ƃ������Ȃ�������͓���ȁB
��͂茋�ǁALlano�̌�p���ǂ��Ȃ邩��������C�ɂȂ�Ƃ���ł���B
AMD�������߂ɂ͂Ȃɂ��̔��q��eDRAM��Intel�����ꑫ��ɓ������Ă��܂��Ƃ�
�˔�Ȃ��Ƃ������Ȃ�������͓���ȁB
��͂茋�ǁALlano�̌�p���ǂ��Ȃ邩��������C�ɂȂ�Ƃ���ł���B
952 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:03:07 ID:w2IUsqCK
�܂��I�Ԃ̂͏���҂������
Turbo Boost VS CoolSpeed(��)
Turbo Boost VS CoolSpeed(��)
953 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 01:14:43 ID:7XU6kjpZ
�܂��AAMD�̍��̋Z�p�͂��Ɛ��ʑΌ�����Intel�ɏ��Ă�v�f�͖w�ǖ������猄�Ԃ����ł��D�ʂɂ��Ă������Ƃ����
�V���O���X���b�h���\���̂Ăđ��R�A���ɐi�ނ͔̂J�뎩�R����B
�V���O���X���b�h���\���̂Ăđ��R�A���ɐi�ނ͔̂J�뎩�R����B
954 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:20:40 ID:w2IUsqCK
�����{���ɑS�R�A��ɖZ�����Ȃ�
ACP�i�j�Ȃ�Ă�������d�͂̓�d�̖ڈ��Ȃ�ĕK�v�Ȃ���
CoolSpeed�i�j���K�v�Ȃ��i���ꑊ���̔M�v�E�N���b�N���ɍŏ�������܂��Ă�Ζ{���I�ɕs�v�ȋ@�\�j
ACP�i�j�Ȃ�Ă�������d�͂̓�d�̖ڈ��Ȃ�ĕK�v�Ȃ���
CoolSpeed�i�j���K�v�Ȃ��i���ꑊ���̔M�v�E�N���b�N���ɍŏ�������܂��Ă�Ζ{���I�ɕs�v�ȋ@�\�j
955 �FSocket774�F2010/04/04(��) 01:23:58 ID:oems6CJn
>>952
CoolSpeed����OS�̑Ή����K�v�Ȃ̂��D
�������Ƃ��Ă��Ή��͂܂��Ȃ̂ł́D
Turbo Boost�̔���������������Ă���Ƃ�����Ă���H
����Ȃɕq���ɂ͕ω����Ȃ��Ǝv�����ǁD
CoolSpeed����OS�̑Ή����K�v�Ȃ̂��D
�������Ƃ��Ă��Ή��͂܂��Ȃ̂ł́D
Turbo Boost�̔���������������Ă���Ƃ�����Ă���H
����Ȃɕq���ɂ͕ω����Ȃ��Ǝv�����ǁD
956 �FSocket774�F2010/04/04(��) 01:28:46 ID:NS+SUC9k
ID:w2IUsqCK
�悭�킩��A�K����������
�悭�킩��A�K����������
����ᑬ�����ǂ��A�^�[�{��1GHz�Ƃ��{�Ɍ���Ƃ�����킯����Ȃ�����H
6�R�A�ŏ�� X5680 ��i 3.3G/Max Turbo 3.6G ����1�����300MHz
6�R�A�ʼn��� X5650 ��i 2.6G/Max Turbo 3G ���͂P������400MHz
1/2�R�A�݂̂ő��R�A���A�C�h���ɂ���Max���ł��炱�̒��x�A�ǂ��݂Ă��C�x�߂ł����Ȃ��c
���������̔��[��Blender�͑S�R�A�g���^�C�v�̃\�t�g����H
�Ȃ�ŃV���O���⏭�X���b�h�̐��\��������Əオ�邾����Turbo�ɂ���ȂɎ����グ��̂�
�V���O���X���b�h����N���b�N���������Ⴂ�����ăn�i���瑊��ɂȂ�Ȃ��̂͂킩���Ă��w
�}���`�X���b�h�Ő��\�o�Ȃ��̂���������������Č����Ă�̂�A��������
6�R�A�ŏ�� X5680 ��i 3.3G/Max Turbo 3.6G ����1�����300MHz
6�R�A�ʼn��� X5650 ��i 2.6G/Max Turbo 3G ���͂P������400MHz
1/2�R�A�݂̂ő��R�A���A�C�h���ɂ���Max���ł��炱�̒��x�A�ǂ��݂Ă��C�x�߂ł����Ȃ��c
���������̔��[��Blender�͑S�R�A�g���^�C�v�̃\�t�g����H
�Ȃ�ŃV���O���⏭�X���b�h�̐��\��������Əオ�邾����Turbo�ɂ���ȂɎ����グ��̂�
�V���O���X���b�h����N���b�N���������Ⴂ�����ăn�i���瑊��ɂȂ�Ȃ��̂͂킩���Ă��w
�}���`�X���b�h�Ő��\�o�Ȃ��̂���������������Č����Ă�̂�A��������
958 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 01:33:13 ID:7XU6kjpZ
���e�[���N�[���[�������ƒc�q��Tripcode Explorer�𑖂点����CoolSpeed Technology�ɂ���ăN���b�N�_�E������\���傾�ȁc
�Ƃ������O����c�q�͕K���Ȃ�
�Ƃ������O����c�q�͕K���Ȃ�
959 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:33:47 ID:w2IUsqCK
>>955
�����Ŕ��������
�����Ŕ��������
960 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:35:49 ID:w2IUsqCK
961 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:40:55 ID:w2IUsqCK
�Ƃ�����Budweizer�Ƃ��̓X���b�h���Ȃ��Ƃ��ɃV���O���X���b�h���\�������
962 �FSocket774�F2010/04/04(��) 01:48:28 ID:oems6CJn
Opteron 6100�V���[�Y��MCM�̕Е����x�܂��Ă����Е����u�[�X�g�Ƃ������x�ł�������
Turbo�@�\����ė~���������ȁD
>>961
Budweizer ?
Turbo�@�\����ė~���������ȁD
>>961
Budweizer ?
963 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 01:52:19 ID:w2IUsqCK
���傤��F1�݂Ă����炿�傢�{�P�Ă݂�
http://pc.watch.impress.co.jp/img/pcw/docs/348/705/html/1.jpg.html
Llano���XAPM Boost�����Ă��邩�炠���邾�낤�ȁB
���Ȃ��Ƃ����̌v���ł́B
{kind=link}
Llano���XAPM Boost�����Ă��邩�炠���邾�낤�ȁB
���Ȃ��Ƃ����̌v���ł́B
���펞�Ƀ��e�[���N�[���[�g���Đ��\������Ƃ�AMD�����ł�IBM��HP��������w
AMD��L1I��D��32B���Ȃ̂�
Intel�͂��܂���16B���������̂��B
Blender�͂����������Ƃ��˂��B
Intel�͂��܂���16B���������̂��B
Blender�͂����������Ƃ��˂��B
>>967
Xeon���m�ł�����N���b�N��4�R�A��6�R�A�̐��\����1�b���������̂́A����Ȃ���������Ȃ�����
Xeon���m�ł�����N���b�N��4�R�A��6�R�A�̐��\����1�b���������̂́A����Ȃ���������Ȃ�����
�܂�Thuban��APM�Ȃ�����_��͂Ȃ����������APower Gating���Ȃ����낤����A
�{�i�I�ɂ�Llano�ȍ~�����Ȃ��B
�{�i�I�ɂ�Llano�ȍ~�����Ȃ��B
�{�i�I����Ȃ�����400�`500MHz���シ����B
�{�i�I�ɂȂ�����ǂꂾ�����シ����B
�{�i�I�ɂȂ�����ǂꂾ�����シ����B
�E���ĂƂ����\���͌�����ꂻ�����ȁB
���������O�̂Ƃ���Idle(C-state)�ŃN���b�N�A�b�v���ȁB
���������O�̂Ƃ���Idle(C-state)�ŃN���b�N�A�b�v���ȁB
�Ȃ��1�l�R������Ă�́H
>>971
�N���b�N�̕���������Ȃ��āA
�R�A���̍��݂Ƃ��A�ω�����N���b�N�̍��݁A���ԓI���x(�������x)�A���ߐ�
�Ȃǂ̊����x������̂ŁBIntel������IDA�̂Ƃ��͂قƂ�ǂ͂��炩�Ȃ��ĕ��������낤�B
�N���b�N�̕���������Ȃ��āA
�R�A���̍��݂Ƃ��A�ω�����N���b�N�̍��݁A���ԓI���x(�������x)�A���ߐ�
�Ȃǂ̊����x������̂ŁBIntel������IDA�̂Ƃ��͂قƂ�ǂ͂��炩�Ȃ��ĕ��������낤�B
975 �F ��////////HQ �F2010/04/04(��) 02:41:54 ID:6z9Y4H3d
�Ȃ��c�q��Tripcode Explorer��GPGPU�ō���́H
HD5870CF��������GPU�ɂ�点���300Mtrips/s�Ɣn�����Ȃ�
���ꂩ��͎g�������Ȃ��Ƃ������
HD5870CF��������GPU�ɂ�点���300Mtrips/s�Ɣn�����Ȃ�
���ꂩ��͎g�������Ȃ��Ƃ������
>>974
�f���A���R�A�����g��Ȃ��悤�ȃQ�[���Ƃ����ƗL�����낤
Intel�̃^�[�{�͒m��AAMD�̂�3�R�A�P�ʂ����猋�\�g���ǂ���͑������낤�B
�N���b�N�̍��݂�500MHz�A�b�v���邩���Ȃ����̓�������B
������3�R�A�ȏ�Idle�A3�R�A�ȉ������ׁB
�f���A���R�A�����g��Ȃ��悤�ȃQ�[���Ƃ����ƗL�����낤
Intel�̃^�[�{�͒m��AAMD�̂�3�R�A�P�ʂ����猋�\�g���ǂ���͑������낤�B
�N���b�N�̍��݂�500MHz�A�b�v���邩���Ȃ����̓�������B
������3�R�A�ȏ�Idle�A3�R�A�ȉ������ׁB
977 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 03:12:16 ID:7XU6kjpZ
978 �F ��////////HQ �F2010/04/04(��) 03:22:38 ID:6z9Y4H3d
http://sourceforge.jp/projects/naniya/releases/36697/note
AMDCALRT.DLL, AMDCALCL.DLL���Ȃ���CPU����ɂȂ��Ă��܂���
���݂�ATI*****.DLL�ɖ��O���ς���Ă���̂�AMD*****.DLL�Ƀ��l�[�����Ďg��
���s�t�@�C���Ɠ����f�B���N�g���ɃR�s�[���ĕ��荞��ł���OK
AMDCALRT.DLL, AMDCALCL.DLL���Ȃ���CPU����ɂȂ��Ă��܂���
���݂�ATI*****.DLL�ɖ��O���ς���Ă���̂�AMD*****.DLL�Ƀ��l�[�����Ďg��
���s�t�@�C���Ɠ����f�B���N�g���ɃR�s�[���ĕ��荞��ł���OK
979 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 03:41:29 ID:w2IUsqCK
��l3�������B�b�͂��ꂩ�炾�B
��H�͗v���B
��H�͗v���B
980 �F ��////////HQ �F2010/04/04(��) 03:48:11 ID:6z9Y4H3d
����������̖S�҂�
�̂����ɂ��Ă邪���O�̂�x�������
�O�q�̃\�t�g�ɂ��܂��ŕt���Ă���CPU����ɂ����ǂ��t���Ȃ���
�̂����ɂ��Ă邪���O�̂�x�������
�O�q�̃\�t�g�ɂ��܂��ŕt���Ă���CPU����ɂ����ǂ��t���Ȃ���
981 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 03:51:04 ID:w2IUsqCK
���ꂪ�ǂ����������H
982 �F���͌��c�� ��OhjIkO1O8o �F2010/04/04(��) 03:52:53 ID:7XU6kjpZ
>>979
�[�����A>978������Ȃ�s�v�����?
�[�����A>978������Ȃ�s�v�����?
983 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 03:54:16 ID:w2IUsqCK
�Ă���������Ȃ��ƂɎ��Ԏg�����Ǝ��̂��s�v
984 �F ��////////HQ �F2010/04/04(��) 03:59:42 ID:6z9Y4H3d
>>981
�c�O�Ȃ���g���b�v�̌����̊W�Ŋ��S���삵�Ȃ��̂���
�w��ł���̂�8���܂�14���g���b�v�Ȃ�Ă̂ɂ��Ή����Ȃ�
�Ƃ肠��������Ă݂܂������x�̂��̂炵��
�c�O�Ȃ���g���b�v�̌����̊W�Ŋ��S���삵�Ȃ��̂���
�w��ł���̂�8���܂�14���g���b�v�Ȃ�Ă̂ɂ��Ή����Ȃ�
�Ƃ肠��������Ă݂܂������x�̂��̂炵��
985 �F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o �F2010/04/04(��) 04:01:52 ID:w2IUsqCK
������14���g���b�v�Ȃ�Ăł����H
�����Ȃ�����m��Ȃ������B
�����Ȃ�����m��Ȃ������B
986 �F ��////////HQ �F2010/04/04(��) 04:03:11 ID:6z9Y4H3d
��14���g���b�v�Ȃ�Ă̂ɂ��Ή����Ȃ�
���̕����폜
���̕����폜
987 �F ��////////HQ �F2010/04/04(��) 04:03:48 ID:6z9Y4H3d
>>985
���܂�A���Ⴂ��
���܂�A���Ⴂ��
988 �F,,�E�L�́M�E,,�j��-���������F2010/04/04(��) 04:18:09 ID:w2IUsqCK
Be�t������������
�g���b�v�K�v�Ȃ��ˁH
�g���b�v�K�v�Ȃ��ˁH
989 �F ��////////HQ �F2010/04/04(��) 04:30:17 ID:6z9Y4H3d BE:4214743698-PLT(65754)
Be�����邯�ǃg���b�v�̕��������ڂ���낵���̂�
990 �F,,�E�L�́M�E,,�j��-�������F2010/04/04(��) 04:31:37 ID:w2IUsqCK
�v����
991 �F ��////////HQ �F2010/04/04(��) 04:35:27 ID:6z9Y4H3d
���̃\�t�g��8���܂ł��������o���Ȃ��̂�
�уo����h�����߂Ȃ̂�������Ȃ���
10�����x�Ȃ炻��قǎ��Ԃ������Ȃ��Ă������o������������
�уo����h�����߂Ȃ̂�������Ȃ���
10�����x�Ȃ炻��قǎ��Ԃ������Ȃ��Ă������o������������
992 �F,,�E�L�́M�E,,�j��-�������F2010/04/04(��) 04:46:49 ID:w2IUsqCK
���Ƃ��ƃg���b�v�Ȃ�Ė����l����
993 �F ��////////HQ �F2010/04/04(��) 04:52:39 ID:6z9Y4H3d
�����f���œ��ꐫ���m�F�ł��铹��
���͂Ŋm�F�����Ă��܂��l�����邪�g�����ɂ��
���͂Ŋm�F�����Ă��܂��l�����邪�g�����ɂ��
994 �F,,�E�L�́M�E,,�j��-�������F2010/04/04(��) 04:55:59 ID:w2IUsqCK
���ꂱ��Be�ŏ\������ˁ[��
�R�e�����x�����Ȃ��z���g���b�v�Ƃ��G�����܂�����
�R�e�����x�����Ȃ��z���g���b�v�Ƃ��G�����܂�����
995 �F ��////////HQ �F2010/04/04(��) 05:07:08 ID:6z9Y4H3d
�܂����͏펞�R�e�n���ł��Ȃ��ł����A�������ݐ����������ł��Ȃ��ł����ǂ�
��l�p�L���b�v���g���b�v
GPGPU���݂Ȃ炻��قǃX���`����Ȃ��Ǝv���Ęb���U���Ă݂������ł���
��l�p�L���b�v���g���b�v
GPGPU���݂Ȃ炻��قǃX���`����Ȃ��Ǝv���Ęb���U���Ă݂������ł���
test
hoge
998
999
1000�Ȃ�AMD�|�Y
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/