Intel�̎�����CPU�ɂ��Č�낤 35
1 �FLGA1366�F
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 34
ttp://pc11.2ch.net/test/read.cgi/jisaku/1209622524/l50
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
ttp://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
Intel�̎�����CPU�ɂ��Č�낤 34
ttp://pc11.2ch.net/test/read.cgi/jisaku/1209622524/l50
���֘A�X��
�yPenryn�z�����ヂ�o�C��CPU�G�k�� 4�yNehalem�z
ttp://pc11.2ch.net/test/read.cgi/notepc/1200200003/
Intel uPs Info 4
ttp://pc11.2ch.net/test/read.cgi/mac/1214461149/
���X����>>950�A�Ղ�i�s�̎���>>850�痧�Ă�錾�����A�o���Ȃ����͈��p���w�������B
��>>950�̓��ݓ������������Ă��܂��B�X�����Ă̈ӎv�̖�������>>950���O�̏������݂͍T���Ă��������B
|
|
|
�@�@ �@ �@ �Q�Q�Q_
�@�@�@�@�^�@�@ �@ �@�_
�@�@ �^�@�@���@ �@ ���_
�@�^ �@�@ �i���j�@�i���j�@�_
�@|�@ �@�@ �@ �i__�l__�j�@ �@ |
�@�_�@�@�@�@ �M �܁L�@�@ �^
,,.....�C.�R�R�A___ �[�[�m�-�.
:�@ �@| �@';�@�______ �m.| �R�@i
�@ �@ |�@�@�_/ށi__)�_,| �@i�@|
�@ �@ ���@�@ �R. �n�@ | �@ |�b
�@�@�@�@�^�@�@ �@ �@�_
�@�@ �^�@�@���@ �@ ���_
�@�^ �@�@ �i���j�@�i���j�@�_
�@|�@ �@�@ �@ �i__�l__�j�@ �@ |
�@�_�@�@�@�@ �M �܁L�@�@ �^
,,.....�C.�R�R�A___ �[�[�m�-�.
:�@ �@| �@';�@�______ �m.| �R�@i
�@ �@ |�@�@�_/ށi__)�_,| �@i�@|
�@ �@ ���@�@ �R. �n�@ | �@ |�b
3 �FLGA1366�F2008/07/24(��) 00:49:12 ID:Gn2fjMCW
���ߋ��X��
34 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
33 ttp://pc11.2ch.net/test/read.cgi/jisaku/1202775674/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
34 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209622524/
33 ttp://pc11.2ch.net/test/read.cgi/jisaku/1202775674/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1193649635/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189626915/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1184713836/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1174309818/
27 ttp://pc9.2ch.net/test/read.cgi/jisaku/1168232324/
26 ttp://pc9.2ch.net/test/read.cgi/jisaku/1157019837/
25 ttp://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
24 ttp://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 ttp://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ttp://pc7.2ch.net/test/read.cgi/jisaku/1139646138/
>>1
�]�v�ȕ���������
�]�v�ȕ���������
���X����980�ŏ\���ł��B
2�ŏ\���ł���
�킩���Ă���������
�u���[�h�����i�[
�T�[�o�[�����������̖���ATP����ANehalem-EP (Gainestown)������DDR3 DIMM�̔��\��
���������B�Ƃ肠����Bloomfield/Gainestown�틤��FB-DIMM���ᖳ�����Ƃ��m��Ƃ���
���ƂŁB�B�B
http://www.atpinc.com/newweb/p5a.php?sn=00000097
�@�@----------------------
�@�@ATP, a leading manufacturer of high performance DRAM and flash
�@�@memory solutions, announces the immediate availability of its
�@�@DDR3 Registered DIMMs and DDR3 ECC DIMMs for the upcoming Intel
�@�@Urbanna, Hanlan Creek, and Bluff Creek servers.
�@�@----------------------
���̔��\���ƁAunbuffered ECC DIMM���T�|�[�g�����͗l���B
���������B�Ƃ肠����Bloomfield/Gainestown�틤��FB-DIMM���ᖳ�����Ƃ��m��Ƃ���
���ƂŁB�B�B
http://www.atpinc.com/newweb/p5a.php?sn=00000097
�@�@----------------------
�@�@ATP, a leading manufacturer of high performance DRAM and flash
�@�@memory solutions, announces the immediate availability of its
�@�@DDR3 Registered DIMMs and DDR3 ECC DIMMs for the upcoming Intel
�@�@Urbanna, Hanlan Creek, and Bluff Creek servers.
�@�@----------------------
���̔��\���ƁAunbuffered ECC DIMM���T�|�[�g�����͗l���B
11 �FMAC�I�^��1 �����F2008/07/24(��) 17:20:40 ID:D02rKv4k
>>1
�@�@---------------------
�@�@���X����>>950
�@�@---------------------
�������猚�Ă�ŕs�s���햳���Ǝv�������ǁB�B�B
�@�@---------------------
�@�@���X����>>950
�@�@---------------------
�������猚�Ă�ŕs�s���햳���Ǝv�������ǁB�B�B
Bloomfield��Mac Pro�ɍ̗p����邾�낤����}�J�[�ɂƂ��Ă͂��ꂵ����ȁB
���C�U�[�J�[�h�g���Ƃ͂���12�{�̃������𓋍ڂ���̂͑�ς�������...
���C�U�[�J�[�h�g���Ƃ͂���12�{�̃������𓋍ڂ���̂͑�ς�������...
ttp://journal.mycom.co.jp/articles/2008/07/24/intel45nm/index.html
>Intel��45nm�v���Z�X�𑼎Ђɐ�삯�Ď��p�����A���Ƀ}�C�N���v���Z�T���i�̔����ȏオ45nm�v���Z�X�Ɉڍs���Ă���B����ɑ��āA���C�o����AMD�́A�����45nm�v���Z�X���g�����i���o�ׂ��n�߂��Ƃ���ł���B
AMD��45nm�v���Z�X���i���ĉ��H
>Intel��45nm�v���Z�X�𑼎Ђɐ�삯�Ď��p�����A���Ƀ}�C�N���v���Z�T���i�̔����ȏオ45nm�v���Z�X�Ɉڍs���Ă���B����ɑ��āA���C�o����AMD�́A�����45nm�v���Z�X���g�����i���o�ׂ��n�߂��Ƃ���ł���B
AMD��45nm�v���Z�X���i���ĉ��H
15 �FMAC�I�^�F2008/07/24(��) 22:53:32 ID:vjLDlZQR
�Ȃ��Bloomfield + x58��9���ɓo��ƌ�����o�Ă������B
�\�[�X��Digitimes�B
http://www.digitimes.com/mobos/a20080724PD205.html
�@�@------------------------------
�@�@Intel brings forward Nehalem launch
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 24 July 2008]
�@�@�@Originally scheduled to launch in November or December this year, Intel's Nehalem-based
�@�@Bloomfield processors will now launch in September along with X58 chipsets, sources at
�@�@motherboard makers have revealed.
�@�@�@However, the sources pointed out that CPUs and motherboards will not officially appear in
�@�@the channel until early October.
�@�@�@Since Bloomfield CPUs are not socket compatible with previous Intel platforms, the
�@�@accelerated launch is not expected to cause competition between the company's own products,
�@�@although the same cannot be said for AMD's scheduled AM3-based CPU launch, noted the
�@�@sources.
�@�@------------------------------
�\�[�X��Digitimes�B
http://www.digitimes.com/mobos/a20080724PD205.html
�@�@------------------------------
�@�@Intel brings forward Nehalem launch
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 24 July 2008]
�@�@�@Originally scheduled to launch in November or December this year, Intel's Nehalem-based
�@�@Bloomfield processors will now launch in September along with X58 chipsets, sources at
�@�@motherboard makers have revealed.
�@�@�@However, the sources pointed out that CPUs and motherboards will not officially appear in
�@�@the channel until early October.
�@�@�@Since Bloomfield CPUs are not socket compatible with previous Intel platforms, the
�@�@accelerated launch is not expected to cause competition between the company's own products,
�@�@although the same cannot be said for AMD's scheduled AM3-based CPU launch, noted the
�@�@sources.
�@�@------------------------------
ES�i��Deneb���e���Ɍ��ؗp�Ƃ��ďo���n�߂Ă�悤�����ǁE�E�E
>>15
�������˂�
QPI�ƃ����R����Xeon�������Xeon�炵���Ȃ�
Gainestown���O�|�����낤��Gainestown���������Ƃ���
FB-DIMM����Ȃ��̂��ǂ�
�������˂�
QPI�ƃ����R����Xeon�������Xeon�炵���Ȃ�
Gainestown���O�|�����낤��Gainestown���������Ƃ���
FB-DIMM����Ȃ��̂��ǂ�
Digitimes���l�^���Ƃ�v�������ǁA�ŋߑ�p�ł���̓Ǝ��\�[�X���ւ�Tom's Hardware��Nehalem��
�����Ȑi���ɂ��ĕĂ��邷�B
http://www.tomshardware.com/news/intel-nehalem-cpu-bloomfield,5968.html
�@�@------------------------
�@�@According to several of our sources, Intel is well on its way with
�@�@silicon yield, and early samples confirm this. With our own sample
�@�@in house, we were able to overclock our samples by nearly 1 GHz.
�@�@What are the performance figures for a quad-core Nehalem system running
�@�@at nearly 4 GHz?
�@�@------------------------
�����Ȑi���ɂ��ĕĂ��邷�B
http://www.tomshardware.com/news/intel-nehalem-cpu-bloomfield,5968.html
�@�@------------------------
�@�@According to several of our sources, Intel is well on its way with
�@�@silicon yield, and early samples confirm this. With our own sample
�@�@in house, we were able to overclock our samples by nearly 1 GHz.
�@�@What are the performance figures for a quad-core Nehalem system running
�@�@at nearly 4 GHz?
�@�@------------------------
Intel��SoC���i�\ - Tolapai����Intel EP80579�̓����\�����l�@����
http://journal.mycom.co.jp/articles/2008/07/24/tolapai/index.html
http://journal.mycom.co.jp/articles/2008/07/24/tolapai/index.html
>>20
90nm�v���Z�X���Ă̂��Ӗ��[���ȁB
�ŐV�v���Z�X��CPU�Ɏg���āA�����v���Z�X���`�b�v�Z�b�g�Ɏg���A�Ƃ����r�W�l�X���f�����A
GPU�����`�b�v�Z�b�g�ɍ����\�������d�͂����߂���l�ɂȂ��������ŁA�j�]����������
�邩��A���̑�֎�i�Ƃ��ēo�ꂵ���A���ĂƂ��납�B
90nm�v���Z�X���Ă̂��Ӗ��[���ȁB
�ŐV�v���Z�X��CPU�Ɏg���āA�����v���Z�X���`�b�v�Z�b�g�Ɏg���A�Ƃ����r�W�l�X���f�����A
GPU�����`�b�v�Z�b�g�ɍ����\�������d�͂����߂���l�ɂȂ��������ŁA�j�]����������
�邩��A���̑�֎�i�Ƃ��ēo�ꂵ���A���ĂƂ��납�B
�Ƃ��������V�����v���Z�X���K���ȓd�͂ɂȂ�A�Ƃ������Ƃ������Ȃ��Ȃ��������̂�����
�������Ȃ���90nm�̓��[�N�d������̗J���ڂɑ������AIntel�ɂƂ��đ厸�s�ȃv���Z�X�Ȗ��B
�匴���̐������ƁA90nm�Ōł߂����炷���ɏo�����Ƃ������Ƃ����ǂˁB
����CPU�R�A��45nm��Bonnell�R�A�x�[�X�ɂȂ�悤������A65nm����āA
��C��45nm�ɂȂ�\���������Ȃ����낤���B
����CPU�R�A��45nm��Bonnell�R�A�x�[�X�ɂȂ�悤������A65nm����āA
��C��45nm�ɂȂ�\���������Ȃ����낤���B
>>18
AMD��45nm��ʎY���鍠�ɂ�INTEL��32nm
AMD��45nm��ʎY���鍠�ɂ�INTEL��32nm
�O�X���Řb�肪�o�Ă�450mm�E�G�n�ڍs�̘b
450mm�Ή����u�J�����蔼���̃��[�J�[���x������\���I�H
http://www.sijapan.com/content/l_news/2008/lo86kc0000004w50.html
450mm�Ή����u�J�����蔼���̃��[�J�[���x������\���I�H
http://www.sijapan.com/content/l_news/2008/lo86kc0000004w50.html
http://www.maido3.com/server/power/
���������撣���Ă��
���������撣���Ă��
�Ȃ��E6320 4GB 2hdd��200W�y�������Ă�́H
������E2180 8GB 2hdd�̓s�[�N��100W�������ǂ����Ȃ̂�
������E2180 8GB 2hdd�̓s�[�N��100W�������ǂ����Ȃ̂�
>>27
�ł���Core2Duo E6300�ɕς���������肩�獡��2ch�x���ˁH
�ł���Core2Duo E6300�ɕς���������肩�獡��2ch�x���ˁH
>>31
����Ȃ��Ƃ��100ms�̓��ĊԒx�����C�ɂ���
C:\>ping www.google.co.jp
Pinging www.l.google.com [66.249.89.104] with 32 bytes of data:
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=7ms TTL=248
Ping statistics for 66.249.89.104:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 6ms, Maximum = 7ms, Average = 6ms
C:\>ping pc11.2ch.net
Pinging pc11.2ch.net [207.29.253.145] with 32 bytes of data:
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=108ms TTL=54
Ping statistics for 207.29.253.145:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 107ms, Maximum = 108ms, Average = 107ms
����Ȃ��Ƃ��100ms�̓��ĊԒx�����C�ɂ���
C:\>ping www.google.co.jp
Pinging www.l.google.com [66.249.89.104] with 32 bytes of data:
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=6ms TTL=248
Reply from 66.249.89.104: bytes=32 time=7ms TTL=248
Ping statistics for 66.249.89.104:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 6ms, Maximum = 7ms, Average = 6ms
C:\>ping pc11.2ch.net
Pinging pc11.2ch.net [207.29.253.145] with 32 bytes of data:
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=107ms TTL=54
Reply from 207.29.253.145: bytes=32 time=108ms TTL=54
Ping statistics for 207.29.253.145:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 107ms, Maximum = 108ms, Average = 107ms
>>33
���߂āApathping �������Ă���B
���߂āApathping �������Ă���B
�S���ʼn��䂠��H
��1��1��Ȃ̂��ȁH
��1��1��Ȃ̂��ȁH
>>35
���A�I���k���Č��炵�Ă�͂������ǁB
���A�I���k���Č��炵�Ă�͂������ǁB
37 �FMAC�I�^��35 �����F2008/08/01(��) 17:24:28 ID:GRi0Viq/
Yorkfield-XE���Ăǂ���H
��p�̃}�U�[�{�[�h�x���_�����Bloomfield�}�U�[�̐i�s��TheINQ��Novakovic�L�҂�
�`���Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/07/31/taipei-update-graphics-sorrows
�@�E�n�C�G���h��SLI�Ή�(nForce200����)�ł�s�]�BnForce 200��Nehalem�킨�납�A�M����
�@�@�]����Tylersburg�`�b�v�������M���傫�����߂Ƃ��B�B�B
�@�E���̂���nForce 200��SLI�F�ؗp�Ɂw�ڂ��Ă��邾���x�Ƃ����g�����ɂȂ肻��
�`���Ă��邷�B
http://www.theinquirer.net/gb/inquirer/news/2008/07/31/taipei-update-graphics-sorrows
�@�E�n�C�G���h��SLI�Ή�(nForce200����)�ł�s�]�BnForce 200��Nehalem�킨�납�A�M����
�@�@�]����Tylersburg�`�b�v�������M���傫�����߂Ƃ��B�B�B
�@�E���̂���nForce 200��SLI�F�ؗp�Ɂw�ڂ��Ă��邾���x�Ƃ����g�����ɂȂ肻��
Nvidia�Ɋւ��Ă�A�`�b�v�Z�b�g�r�W�l�X����P�ނƂ̕��o�Ă��邷�B
�\�[�X��Digitimes�Ȃ�ŁA�S�����p���邷�B
http://www.digitimes.com/mobos/a20080801VL203.html
�@�@---------------------
�@�@Nvidia to quit chipset business
�@�@Ricky Morris, DIGITIMES, Taipei [Friday 1 August 2008]
�@�@�@Nvidia has decided to throw in the towel and quit the chipset business, sources close to the
�@�@situation at one of Taiwan's top motherboard makers have revealed. As the story is told, Nvidia
�@�@called a meeting earlier this week with its motherboard partners to gauge support for it continuing
�@�@to develop chipsets in the future.
�@�@�@The motherboard makers' response? Silence.
�@�@�@It is still early days and not all the facts are known at the time of writing, but it is believed
�@�@Nvidia will transfer the chipset team to working on GPU projects. On the motherboard makers'
�@�@side, some makers have already canceled upcoming high-end motherboard projects based on the
�@�@nForce 7-series chipset.
�@�@---------------------
�@�@[����]
�\�[�X��Digitimes�Ȃ�ŁA�S�����p���邷�B
http://www.digitimes.com/mobos/a20080801VL203.html
�@�@---------------------
�@�@Nvidia to quit chipset business
�@�@Ricky Morris, DIGITIMES, Taipei [Friday 1 August 2008]
�@�@�@Nvidia has decided to throw in the towel and quit the chipset business, sources close to the
�@�@situation at one of Taiwan's top motherboard makers have revealed. As the story is told, Nvidia
�@�@called a meeting earlier this week with its motherboard partners to gauge support for it continuing
�@�@to develop chipsets in the future.
�@�@�@The motherboard makers' response? Silence.
�@�@�@It is still early days and not all the facts are known at the time of writing, but it is believed
�@�@Nvidia will transfer the chipset team to working on GPU projects. On the motherboard makers'
�@�@side, some makers have already canceled upcoming high-end motherboard projects based on the
�@�@nForce 7-series chipset.
�@�@---------------------
�@�@[����]
41 �FMAC�I�^�������F2008/08/02(�y) 00:35:22 ID:wM7rJRQ0
���L���̑������B
�@�@----------------------
�@�@�@The loss of its chipset business is expected to have a significant impact on Nvidia's GPU
�@�@business in the short-term. Reception to the nForce 200 chip (BR04) which will enable SLI
�@�@technology on Intel X58 motherboards has been lukewarm at best, with many makers saying
�@�@they will not bother adding the chip on their boards. This means Nvidia needs to find a way of
�@�@licensing and enabling multi-GPU support on motherboards using Intel and/or AMD chipsets fast.
�@�@Otherwise it will have to cede the top-end of the graphics card market to AMD, which now has
�@�@the benefit of Crossfire.
�@�@�@The news would also debunk any recent speculation that Apple will be adopting Nvidia chipsets
�@�@for its upcoming notebook products. It would be unfortunate if Apple really has poured water on
�@�@the close relationship it has built with Intel over the past few years, only to have its new best
�@�@friend exit the market before products are even announced.
�@�@----------------------
�@�@----------------------
�@�@�@The loss of its chipset business is expected to have a significant impact on Nvidia's GPU
�@�@business in the short-term. Reception to the nForce 200 chip (BR04) which will enable SLI
�@�@technology on Intel X58 motherboards has been lukewarm at best, with many makers saying
�@�@they will not bother adding the chip on their boards. This means Nvidia needs to find a way of
�@�@licensing and enabling multi-GPU support on motherboards using Intel and/or AMD chipsets fast.
�@�@Otherwise it will have to cede the top-end of the graphics card market to AMD, which now has
�@�@the benefit of Crossfire.
�@�@�@The news would also debunk any recent speculation that Apple will be adopting Nvidia chipsets
�@�@for its upcoming notebook products. It would be unfortunate if Apple really has poured water on
�@�@the close relationship it has built with Intel over the past few years, only to have its new best
�@�@friend exit the market before products are even announced.
�@�@----------------------
��̘b�ANvidia���ے�̃R�����g�����Ă����Dailytech���`���Ă��邷�B
http://www.dailytech.com/NVIDIA+Denies+Reports+That+It+Will+Leave+Chipset+Business+/article12563.htm
�@�@----------------------
�@�@NVIDIA recently contacted DailyTech to squash the information regarding it leaving the chipset
�@�@business. NVIDIA's Brian Burke made it clear that NVIDIA's chipset business is stronger than
�@�@ever and touched on these three points:
�@�@�@* Mercury Research has reported that the NVIDIA market share of AMD platforms in Q2 08
�@�@�@�@was 60%. We have been steady in this range for over two years.
�@�@�@* SLI is still the preferred multi-GPU platform thanks to its stellar scaling, game compatibility
�@�@�@�@and driver stability.
�@�@�@* nForce 790i SLI is the recommended choice by editors worldwide due to its compelling
�@�@�@�@combination of memory performance, overclocking, and support for SLI.
�@�@Burke went on to say that "we're looking forward to bringing new and very exciting MCP products
�@�@to the market for both AMD and Intel platforms."
�@�@----------------------
Apple�Ɋւ���ɂ��Ă�m�[�R�����g�Ƃ̂��Ƃ��B
http://www.dailytech.com/NVIDIA+Denies+Reports+That+It+Will+Leave+Chipset+Business+/article12563.htm
�@�@----------------------
�@�@NVIDIA recently contacted DailyTech to squash the information regarding it leaving the chipset
�@�@business. NVIDIA's Brian Burke made it clear that NVIDIA's chipset business is stronger than
�@�@ever and touched on these three points:
�@�@�@* Mercury Research has reported that the NVIDIA market share of AMD platforms in Q2 08
�@�@�@�@was 60%. We have been steady in this range for over two years.
�@�@�@* SLI is still the preferred multi-GPU platform thanks to its stellar scaling, game compatibility
�@�@�@�@and driver stability.
�@�@�@* nForce 790i SLI is the recommended choice by editors worldwide due to its compelling
�@�@�@�@combination of memory performance, overclocking, and support for SLI.
�@�@Burke went on to say that "we're looking forward to bringing new and very exciting MCP products
�@�@to the market for both AMD and Intel platforms."
�@�@----------------------
Apple�Ɋւ���ɂ��Ă�m�[�R�����g�Ƃ̂��Ƃ��B
43 �FSocket774�F2008/08/02(�y) 14:03:05 ID:C1p0NBPR
�������Ⴄ���I
sage���ႤYO!
XtremeSystems�f����Nehalem�X���b�h�ō��܂�JCornell�����|�X�Ƃ���Bloomfield,
Gainstown�̃x���`���ʂƁA��r�p�ɓ��e���ꂽYorkfiled, Barcelona�̌��ʂ��܂Ƃ߂Đ}����
�������m���B
http://www.xtremesystems.org/forums/showpost.php?p=3168831&postcount=816
�g�p����Ă���x���`�}�[�N��A���L�̒ʂ�B
�@- BOINC Manager,
�@- Cinebench 10,
�@- wPrime,
�@- HWiNFO32 benchmark (http://www.hwinfo.com/index.html),
�@- TrueCrypt (http://www.truecrypt.org/screenshots2.php)
Gainstown�̃x���`���ʂƁA��r�p�ɓ��e���ꂽYorkfiled, Barcelona�̌��ʂ��܂Ƃ߂Đ}����
�������m���B
http://www.xtremesystems.org/forums/showpost.php?p=3168831&postcount=816
�g�p����Ă���x���`�}�[�N��A���L�̒ʂ�B
�@- BOINC Manager,
�@- Cinebench 10,
�@- wPrime,
�@- HWiNFO32 benchmark (http://www.hwinfo.com/index.html),
�@- TrueCrypt (http://www.truecrypt.org/screenshots2.php)
�R(´�[`)�m �l�n���� �l�n����
���Ƀx�[����E����Intel��CPU&GPU�n�C�u���b�h�uLarrabee�v
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
�v���O���}�u�����C�g���A�N�Z�����[�^
�������������̘b���ACPU�R�A���������Ă��܂����Ȃ��BCell�Ƃ����������H
���ƃ��[�J���T�u�Z�b�g��L2���ACPU����256KB���Ă��邯�ǁA�S����2.6MB��
�����b�ɂȂ邩��AL2�S�̂��SMB�Ƃ����̂Ƃǂ������W�ɂȂ��Ă�̂��B
�܂���������Əڂ�����o�Ă���̂�҂ĂA������b�Ȃ̂��낤���ǁB
���ƃ��[�J���T�u�Z�b�g��L2���ACPU����256KB���Ă��邯�ǁA�S����2.6MB��
�����b�ɂȂ邩��AL2�S�̂��SMB�Ƃ����̂Ƃǂ������W�ɂȂ��Ă�̂��B
�܂���������Əڂ�����o�Ă���̂�҂ĂA������b�Ȃ̂��낤���ǁB
�]����Core2�Ƃ̔�r�ŁA�_�C�T�C�Y�A�d�͂������悤�Ȃ̂ɂȂ�̂�Larrabee����10�R�A�Ȃ�����
���i��10�R�A���Ă̂́A�㓡���̊��Ⴂ���A�L���̏��������������̂ǂ��炩�B
�܂��R�A���������ɂȂ邩��intel�͖����\�B
���Ȃ݂ɁA�R�A�����ɂ���Đ��\���X�P�[��������ăO���t�ɂ�48�R�A�܂ōڂ��Ă���B
�_�C�T�C�Y���炷���48�R�A����700mm2���炢�ɂȂ肻��������A���i����
�ŏ���32�R�A����ʐ��i�Ƃ��ďo�Ă����Ȃ����낤���B
���i��10�R�A���Ă̂́A�㓡���̊��Ⴂ���A�L���̏��������������̂ǂ��炩�B
�܂��R�A���������ɂȂ邩��intel�͖����\�B
���Ȃ݂ɁA�R�A�����ɂ���Đ��\���X�P�[��������ăO���t�ɂ�48�R�A�܂ōڂ��Ă���B
�_�C�T�C�Y���炷���48�R�A����700mm2���炢�ɂȂ肻��������A���i����
�ŏ���32�R�A����ʐ��i�Ƃ��ďo�Ă����Ȃ����낤���B
Larrabee�Ƃ͉��̊W���Ȃ�80�R�A�̂�������Ⴂ���Ă�l���������Ȃ�
>>49
��CPU�R�A�́AL2�L���b�V���̂����A256KB�̃��[�J���T�u�Z�b�g(Local Subset)�ƒ��ڑ�����Ă���B
�c��̕����̓����R���o�R�̊ԐڃA�N�Z�X�Ȃ�ˁH
��CPU�R�A�́AL2�L���b�V���̂����A256KB�̃��[�J���T�u�Z�b�g(Local Subset)�ƒ��ڑ�����Ă���B
�c��̕����̓����R���o�R�̊ԐڃA�N�Z�X�Ȃ�ˁH
�@���ł�������CUDA������K�v������̂��ǂ��������n�b�L�������Ă���B
���j�[�R�ACPU Larrabee�͊��S�Ȏ��s��
�܂�AVX�����s
Intel�I���^
�܂�AVX�����s
Intel�I���^
Digitimes��Nehalem�x�[�X�̃m�[�g�����v���b�g�t�H�[��"Calpella"�ɂ��ď����Ă��邷�B
http://www.digitimes.com/systems/a20080805PD201.html
�@�@-------------------------
�@�@Intel to launch Calpella notebook platform in 3Q09
�@�@Yen Ting Chen, Taipei; Joseph Tsai, DIGITIMES [Tuesday 5 August 2008]
�@�@�@Intel's next-generation notebook platform (Calpella) is scheduled to launch in the third quarter
�@�@of 2009. As with other Nehalem generation products, Capella will abandon the current northbridge
�@�@and southbridge chipset arrangement and transfer many typical northbridge components to the
�@�@CPU package. A single integrated chipset codenamed Ibex Peak-M will coordinate other features
�@�@on the motherboard, according to sources at notebook makers.
�@�@�@Ibex Peak-M will support Intel's next-generation notebook CPUs (Clarksfield and Auburndale),
�@�@both of which include an on-die DDR3 memory controller. Auburndale will also have a graphics
�@�@core integrated in the CPU package.
�@�@�@The Calpella platform will support Wi-Fi a/b/g/n (Puma Peak) or WiMAX (Kilmer Peak) wireless
�@�@modules.
�@�@�@In additional news, Intel will cease supply of Atom N270 processors at the end of second-quarter
�@�@2009, however the company has so far not released any information regarding the development of
�@�@a next-generation Atom processor.
�@�@-------------------------
http://www.digitimes.com/systems/a20080805PD201.html
�@�@-------------------------
�@�@Intel to launch Calpella notebook platform in 3Q09
�@�@Yen Ting Chen, Taipei; Joseph Tsai, DIGITIMES [Tuesday 5 August 2008]
�@�@�@Intel's next-generation notebook platform (Calpella) is scheduled to launch in the third quarter
�@�@of 2009. As with other Nehalem generation products, Capella will abandon the current northbridge
�@�@and southbridge chipset arrangement and transfer many typical northbridge components to the
�@�@CPU package. A single integrated chipset codenamed Ibex Peak-M will coordinate other features
�@�@on the motherboard, according to sources at notebook makers.
�@�@�@Ibex Peak-M will support Intel's next-generation notebook CPUs (Clarksfield and Auburndale),
�@�@both of which include an on-die DDR3 memory controller. Auburndale will also have a graphics
�@�@core integrated in the CPU package.
�@�@�@The Calpella platform will support Wi-Fi a/b/g/n (Puma Peak) or WiMAX (Kilmer Peak) wireless
�@�@modules.
�@�@�@In additional news, Intel will cease supply of Atom N270 processors at the end of second-quarter
�@�@2009, however the company has so far not released any information regarding the development of
�@�@a next-generation Atom processor.
�@�@-------------------------
Larrabee��x86�A�v��������GPU����B
����IGP�����܂�ɕ������邩��ADX11�Ŏd��Ȃ�������̂��ړI����Ȃ����ȁB
�قƂ�ǎ��v�̖���GPGPU�́A���܂����Ǝv���B
�������ALarrabee1�R�A�����ł�Atom���͋��͂�����A
GPU����CPU�Ƃ��āALarrabee2�R�A�Ƃ������ڂ��ĂȂ�CPU���o�邩������Ȃ��ˁB
����IGP�����܂�ɕ������邩��ADX11�Ŏd��Ȃ�������̂��ړI����Ȃ����ȁB
�قƂ�ǎ��v�̖���GPGPU�́A���܂����Ǝv���B
�������ALarrabee1�R�A�����ł�Atom���͋��͂�����A
GPU����CPU�Ƃ��āALarrabee2�R�A�Ƃ������ڂ��ĂȂ�CPU���o�邩������Ȃ��ˁB
�܂�A�����[�͂���Ȃ��q
>>58
�������H�ނ��냁�j�[�R�A�����o���������Ƒ債�ĕς���Ă��Ȃ��C�����邯�ǁB
http://pc.watch.impress.co.jp/docs/2006/0912/kaigai300.htm
�R�A�⑼�̃��j�b�g�̐ڑ��o�X���s�������ǁA�T�O�}�͂قƂ�Ljꏏ�̂悤�ȁB
http://xtreview.com///images/davis.pdf
2007�N�ɏo�āA������Larrabee�W��������������O��pdf�B
����ɂ͍���Larrabee�ƂقƂ�Ǔ����J�[�h�̐}�܂ōڂ��Ă���B
�������H�ނ��냁�j�[�R�A�����o���������Ƒ債�ĕς���Ă��Ȃ��C�����邯�ǁB
http://pc.watch.impress.co.jp/docs/2006/0912/kaigai300.htm
�R�A�⑼�̃��j�b�g�̐ڑ��o�X���s�������ǁA�T�O�}�͂قƂ�Ljꏏ�̂悤�ȁB
http://xtreview.com///images/davis.pdf
2007�N�ɏo�āA������Larrabee�W��������������O��pdf�B
����ɂ͍���Larrabee�ƂقƂ�Ǔ����J�[�h�̐}�܂ōڂ��Ă���B
����Polaris�̓t�F�C�N���������Ă��Ƃł����H
��������Polaris��Larrabee�Ƃ͑S���W�Ȃ����ǁH
ISSCC�Ńe���X�P�[���R���s���[�e�B���O�̌����p�ɍ�����v���g�^�C�v�����J���ꂽ������
Polaris���̂͂��̂܂��p���������̂ł��Ȃ��B
���j�[�R�A���ăL�[���[�h������Larrabee��Polaris������ɍ�������>>60�݂����Ȕn������t�������Ă����̘b�ł��B
ISSCC�Ńe���X�P�[���R���s���[�e�B���O�̌����p�ɍ�����v���g�^�C�v�����J���ꂽ������
Polaris���̂͂��̂܂��p���������̂ł��Ȃ��B
���j�[�R�A���ăL�[���[�h������Larrabee��Polaris������ɍ�������>>60�݂����Ȕn������t�������Ă����̘b�ł��B
�A����Cell�ɑR���āu�ǂ����E�`�̂͂����Ƒ������v�Ɛ������߂����̃n���{�e��
�����炩�g�����ɂȂ�悤�ɍ�����̂�Larrabee���Ă����̘b����
�����炩�g�����ɂȂ�悤�ɍ�����̂�Larrabee���Ă����̘b����
63 �FSocket774�F2008/08/06(��) 15:14:04 ID:ykHMxqk4
x86�R�A����������ς�ł��Ӗ����Ȃ���
�ߋ��̃V���O���X���b�h�A�v�������̂ɐ��X�N�A�b�h�ʂ���Ώ[��
����ȏ�́A���C�g����G���R�p�̐�p���j�b�g���R�ς�������������
�C���e���͑I�����ԈႦ����
�ߋ��̃V���O���X���b�h�A�v�������̂ɐ��X�N�A�b�h�ʂ���Ώ[��
����ȏ�́A���C�g����G���R�p�̐�p���j�b�g���R�ς�������������
�C���e���͑I�����ԈႦ����
intel��Itanium��x86�݊�����Ȃ��ƂȂ��Ȃ��g���Ă��炦�Ȃ����Čo�������������炶��Ȃ����H
x86�݊����Č����Ă��A�V�݂�VectorUnit�����C�������A���ꂪ�ǂ̒��x���\�o�邩�ŁA
�]�����܂��Ȃ����낤���B
x86�݊����Č����Ă��A�V�݂�VectorUnit�����C�������A���ꂪ�ǂ̒��x���\�o�邩�ŁA
�]�����܂��Ȃ����낤���B
65 �FSocket774�F2008/08/06(��) 17:49:37 ID:ykHMxqk4
�x�N�^���j�b�g������R�ςނׂ�������
�]����x86�R�A�͂����
�]����x86�R�A�͂����
>>63
�����ɂ��Ă͎��ۂɍ���Ă݂�܂ł͕�������A���C����CPU�Ɩ��ڂȋ�����Ƃ��\�ɂȂ�Ǝv����̂�Cell��GPU�Ƃ͂ł��鎖�͈̔͂��ς��Ǝv����B
��������Ƃǂ������ɉe���^���邩�͕s���Ax86�ɂ��Ă��܂������Ƃ̃I�[�o�[�w�b�h�ȉ�������ȏォ�E�E�E
�������m�ɐG���Ă݂����Ƃ���B
�����ɂ��Ă͎��ۂɍ���Ă݂�܂ł͕�������A���C����CPU�Ɩ��ڂȋ�����Ƃ��\�ɂȂ�Ǝv����̂�Cell��GPU�Ƃ͂ł��鎖�͈̔͂��ς��Ǝv����B
��������Ƃǂ������ɉe���^���邩�͕s���Ax86�ɂ��Ă��܂������Ƃ̃I�[�o�[�w�b�h�ȉ�������ȏォ�E�E�E
�������m�ɐG���Ă݂����Ƃ���B
Larrabee�݂����ȃ��m���āA���̕������̉\���͑債�����ɂȂ炸�ɁA
�ꔭ�ڂ̐��i�̏o������őS�Ă����܂��Ă��܂��X�������邩��撣���Ăق�����
�ꔭ�ڂ̐��i�̏o������őS�Ă����܂��Ă��܂��X�������邩��撣���Ăق�����
���X�̉\���Ƃ�炪�傫���قǎ��S�t���O�����Ƃ�
���с[��IGP�Ƃ��ď�����Ƃ��ɂ́A���̃O���t�B�b�N�{�[�h�g�p���ɂ����ʂɂȂ�Ȃ����B
���т���WCG�Ƃ�SETI�ɂ��Ή�����Ɩʔ���������
Core i7
72 �FSocket774�F2008/08/08(��) 17:59:16 ID:VxpF8zOl
http://en.expreview.com/2008/08/08/nehalem-to-become-core-i7-processor/
Nehalem to become Core i7 processor
Nehalem to become Core i7 processor
786���E�E�E�ƁI�H
PentiumPro��6����̎n�܂�ŁA�����Ռ`���Ȃ��Ȃ�قǓO�ꖂ���������̂�CMA���Ƃ���A
����̎���7�ƂȂ邩��A������̒���͍���Ȃ����Ȃ��ȁB
���ꂾ��NetBurst�����j���疕�E����Ă��܂���w
����̎���7�ƂȂ邩��A������̒���͍���Ȃ����Ȃ��ȁB
���ꂾ��NetBurst�����j���疕�E����Ă��܂���w
Windows7�ɕ���Ă�Ƃ��E�E�E
���ꂢ�[��
77 �FSocket774�F2008/08/08(��) 22:58:08 ID:iHoWSS7z
>>74
�ł�Nehalem��CMA���������đ�������E�E�E
Core�̖��O���c��悤�����B
�����j�������������͋C�͓`����Ă��邯�ǂ�
�����7�ɂ͈�a��������ȁB
�ł�Nehalem��CMA���������đ�������E�E�E
Core�̖��O���c��悤�����B
�����j�������������͋C�͓`����Ă��邯�ǂ�
�����7�ɂ͈�a��������ȁB
78 �F,,�E�L��`�E,,�j��-�������F2008/08/08(��) 23:39:50 ID:l8atLJA/
i786�͏���Itanium����B
����i886���Ǝv���Ă��B
����i886���Ǝv���Ă��B
79 �F,,�E�L��`�E,,�j��-�������F2008/08/08(��) 23:57:57 ID:l8atLJA/
�l�b�g����ɓo�^������Larrabee�̘_���ǂ߂��B
Vector�p�C�v��Scaler�p�C�v��2issue�\����Vector���̉��Z�킪512bit��SIMD�B
���̍\�����ƁA128bit SIMD�͂������256bit SIMD�Ńs�[�N���\�������o����
�\���͒Ⴂ�B
AVX�ɗ������R�A�ł͂Ȃ����Ǝ咣���Ă�������͂���ł���B
AVX��肳��ɕ���x�̍���SIMD���߂��B
�x�N�g���v�f���ƂɓƗ��Ƀ��[�h�ł��閽�߂������Ƃ������Ă��鎞�_�ł��ł�
SSE�ł�AVX�ł��Ȃ��B
�V����SIMD���߂ł���B
�t�Ƀ��K�V�[SSE��AVX���T�|�[�g���邩�ǂ�������������B
�I�y�����h�g���ɂ��Ϙa�Z�̓T�|�[�g����悤�Ȃ̂�AVX�ɂ�����VEX�G���R�[�f�B���O
�Ɋ�Â��Ă�\�����c����Ă͂��邪�A�t��MMX/SSE�Ȃǂ̂��T�|�[�g���Ȃ���A
VEX�G���R�[�f�B���O��肳���Opcode��Ԃ̗��p���������シ��B
������MMX/SSE/AVX�ƌ݊��������Ȃ��\�����l����K�v�����邾�낤�B
Intel���������H�ɂ��uGesher���VDP��Larrabee��8-16DP�v���Ď�����
�Ƃ肠�����Y���K�v�����肻�����ȁB
�������܂�����̌������Ƃ���ɂȂ�܂����B
Vector�p�C�v��Scaler�p�C�v��2issue�\����Vector���̉��Z�킪512bit��SIMD�B
���̍\�����ƁA128bit SIMD�͂������256bit SIMD�Ńs�[�N���\�������o����
�\���͒Ⴂ�B
AVX�ɗ������R�A�ł͂Ȃ����Ǝ咣���Ă�������͂���ł���B
AVX��肳��ɕ���x�̍���SIMD���߂��B
�x�N�g���v�f���ƂɓƗ��Ƀ��[�h�ł��閽�߂������Ƃ������Ă��鎞�_�ł��ł�
SSE�ł�AVX�ł��Ȃ��B
�V����SIMD���߂ł���B
�t�Ƀ��K�V�[SSE��AVX���T�|�[�g���邩�ǂ�������������B
�I�y�����h�g���ɂ��Ϙa�Z�̓T�|�[�g����悤�Ȃ̂�AVX�ɂ�����VEX�G���R�[�f�B���O
�Ɋ�Â��Ă�\�����c����Ă͂��邪�A�t��MMX/SSE�Ȃǂ̂��T�|�[�g���Ȃ���A
VEX�G���R�[�f�B���O��肳���Opcode��Ԃ̗��p���������シ��B
������MMX/SSE/AVX�ƌ݊��������Ȃ��\�����l����K�v�����邾�낤�B
Intel���������H�ɂ��uGesher���VDP��Larrabee��8-16DP�v���Ď�����
�Ƃ肠�����Y���K�v�����肻�����ȁB
�������܂�����̌������Ƃ���ɂȂ�܂����B
80 �FSocket774�F2008/08/09(�y) 02:33:48 ID:gR3vLlAi
INTEL��45nm�v���Z�X�̓_�u���p�^�[�j���O�̎��p��1���݂��������A
�Ȃ�ő�����Ȃ��H
ttp://journal.mycom.co.jp/articles/2008/07/24/intel45nm/002.html
�h���C��NA��0.85�ʼnt����1.35�ɉ��ǂ���邩��A32nm�ւ̈ڍs�͊y��
�낤�ȁBHigh-k�����^���Q�[�g���o���ς݂ʼnt�Z�I���@�͎c�蕨�ɂ͕�
������Ŋ����x�̍����̂����������邵�B
�Ȃ�ő�����Ȃ��H
ttp://journal.mycom.co.jp/articles/2008/07/24/intel45nm/002.html
�h���C��NA��0.85�ʼnt����1.35�ɉ��ǂ���邩��A32nm�ւ̈ڍs�͊y��
�낤�ȁBHigh-k�����^���Q�[�g���o���ς݂ʼnt�Z�I���@�͎c�蕨�ɂ͕�
������Ŋ����x�̍����̂����������邵�B
81 �FSocket774�F2008/08/09(�y) 02:37:24 ID:gR3vLlAi
�X���R�P��
�@�@871 ���O�FSocket774 �F2007/10/21(��) 00:17:54 ID:SCAOTIci
�@�@����45nm��ArF�h���C�I���̃_�u���p�^�[�j���O�ł���B
���A���͓����肾�����B
�@�@871 ���O�FSocket774 �F2007/10/21(��) 00:17:54 ID:SCAOTIci
�@�@����45nm��ArF�h���C�I���̃_�u���p�^�[�j���O�ł���B
���A���͓����肾�����B
Well, it could be that�c
386 = i1
486 = i2
P5 = i3
P6 = i4
Netburst = i5
Core = i6
Nehalem = i7
386 = i1
486 = i2
P5 = i3
P6 = i4
Netburst = i5
Core = i6
Nehalem = i7
83 �FSocket774�F2008/08/09(�y) 03:52:39 ID:MeA0AdrL
�l�n�����̎��͂����z���ł��Ȃ�
>>81
���ꏑ�����̉����킗
���ꏑ�����̉����킗
85 �F,,�E�L�́M�E,,�j���F2008/08/09(�y) 08:03:13 ID:PnSTXSwO
�ȑO�o��CPU-Z�X�N�V���͝s���������Ƃ����O���Family=7�̐���
86 �F�R�E�L�́M�E,,�j���������������F2008/08/09(�y) 08:15:35 ID:PnSTXSwO
(��
PowerMac G4
PowerMac G5
MacPro (i6)
MacPro i7
PowerMac G4
PowerMac G5
MacPro (i6)
MacPro i7
>>80
�Ƃ��낪�h�b�R�C�Z�`���l�����ۂ��܂���B
���ɁA65nm����45nm�ŃQ�[�g���͋���35nm�ƃV�������N�ł��Ȃ������B
������32nm�ŃQ�[�g���͊m���ɒZ������K�v������B
(�����炭����EOT��1nm�ňێ����Ă���͂��B)
���Ăǂ��Ȃ�ł��傤�Hfin?
�Ƃ��낪�h�b�R�C�Z�`���l�����ۂ��܂���B
���ɁA65nm����45nm�ŃQ�[�g���͋���35nm�ƃV�������N�ł��Ȃ������B
������32nm�ŃQ�[�g���͊m���ɒZ������K�v������B
(�����炭����EOT��1nm�ňێ����Ă���͂��B)
���Ăǂ��Ȃ�ł��傤�Hfin?
88 �FMAC�I�^���c�q �����F2008/08/09(�y) 10:47:02 ID:I2vHtipF
>>79
�@�@-----------------
�@�@�l�b�g����ɓo�^������Larrabee�̘_���ǂ߂��B
�@�@-----------------
intel�̃T�C�g�ɂ����R�ɓǂ߂�悤�ɒu���Ă��邷�B
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
�@�@-----------------
�@�@�������܂�����̌������Ƃ���ɂȂ�܂����B
�@�@-----------------
(��)
�ł�AVX�Ƃ̊֘A��A�ƊE�̑啨������Ă��邷����c�q����ԈႢ�Ƃ������̘b����
�������B
http://news.cnet.com/8301-13512_3-10006184-23.html
�@�@-----------------
�@�@�l�b�g����ɓo�^������Larrabee�̘_���ǂ߂��B
�@�@-----------------
intel�̃T�C�g�ɂ����R�ɓǂ߂�悤�ɒu���Ă��邷�B
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf
�@�@-----------------
�@�@�������܂�����̌������Ƃ���ɂȂ�܂����B
�@�@-----------------
(��)
�ł�AVX�Ƃ̊֘A��A�ƊE�̑啨������Ă��邷����c�q����ԈႢ�Ƃ������̘b����
�������B
http://news.cnet.com/8301-13512_3-10006184-23.html
89 �F80,81�F2008/08/09(�y) 12:04:34 ID:LOezIAmG
NA=1.35����Ȃ���1.30�̃j�R���@���̗p����݂������B
ttp://www.eetimes.com/news/semi/showArticle.jhtml;jsessionid=1LOD1KMLI5UF4QSNDLOSKH0CJUNN2JVN?articleID=208803035
�i�^�p�R�X�g�������ςނƂ��̂����݂����B�ǂ��܂ŃP�`�Ȃ�!!!�j
>87
45nm�v���Z�X�ł̓��^�����ŒZ������̂Ɠ��l�̌��ʂĂ����A
��2����̃��^�����ł������Ȃ��́H
�h�[�s���O�Ŏd����������Ƃ����ȁB
INTEL�̃v���Z�X�̓Q�[�g���X�g������AMD,IBM�̃Q�[�g�t�@�[�X�g�ƈ����
�����ȑ㏞��NMOS,PMOS�ňႤ���^�����g���闘�_������B
AMD���h�[�v�Ŏd���������邵�������̂ɂ������āA�h�[�v�{���^���̕�
���������`���l�����ł������\�Ɏd���ďグ����A�ł����Ă邩�ȁB
ttp://www.eetimes.com/news/semi/showArticle.jhtml;jsessionid=1LOD1KMLI5UF4QSNDLOSKH0CJUNN2JVN?articleID=208803035
�i�^�p�R�X�g�������ςނƂ��̂����݂����B�ǂ��܂ŃP�`�Ȃ�!!!�j
>87
45nm�v���Z�X�ł̓��^�����ŒZ������̂Ɠ��l�̌��ʂĂ����A
��2����̃��^�����ł������Ȃ��́H
�h�[�s���O�Ŏd����������Ƃ����ȁB
INTEL�̃v���Z�X�̓Q�[�g���X�g������AMD,IBM�̃Q�[�g�t�@�[�X�g�ƈ����
�����ȑ㏞��NMOS,PMOS�ňႤ���^�����g���闘�_������B
AMD���h�[�v�Ŏd���������邵�������̂ɂ������āA�h�[�v�{���^���̕�
���������`���l�����ł������\�Ɏd���ďグ����A�ł����Ă邩�ȁB
�Q�[�g���X�g���L���Ȃ͔̂M��������K�v������
�ޗ��̑I�������L���邩�炶��Ȃ��������ȁB
�ޗ��̑I�������L���邩�炶��Ȃ��������ȁB
�[���Q�[�g����Z���ł��Ȃ��̂̓��[�N���f�J���Ȃ邩����Ęb����Ȃ������́H
>45nm�v���Z�X�ł̓��^�����ŒZ������̂Ɠ��l�̌��ʂĂ����A
>��2����̃��^�����ł������Ȃ��́H
>�h�[�s���O�Ŏd����������Ƃ����ȁB
�Ӗ����킩��Ȃ��B����������낵���B
>INTEL�̃v���Z�X�̓Q�[�g���X�g������AMD,IBM�̃Q�[�g�t�@�[�X�g�ƈ����
>�����ȑ㏞��NMOS,PMOS�ňႤ���^�����g���闘�_������B
�Q�[�g�t�@�[�X�g�ňႤ���^�����g���Ȃ����R���킩��Ȃ��B
INTEL��SEM���������A�Q�[�g�AP�t�@�[�X�g�A �d�Ƀ��X�g�̉\�����̂Ă��Ȃ���H
>AMD���h�[�v�Ŏd���������邵�������̂ɂ������āA�h�[�v�{���^���̕�
>���������`���l�����ł������\�Ɏd���ďグ����A�ł����Ă邩�ȁB
32nm�v���Z�X�ŃQ�[�g��35nm�ŗǂ��̂��H
�ǂ��Ă����̑����ǂꂾ���V�������N����K�v���c�B
�����������̂Ƀ��^�����Ɛ��\����H
>>91
�Q�[�g�œd���𐧌�ł��Ȃ��Ȃ��Ă���B
�h���C���d�����A�V�������N�ɂ��x�z�͂𑝂��Ă����B
�����������邽�߂ɂ�Cox���グ��B
����ɂ�EOT��������A�Q�[�g�ʐς𑝂₷�AFin�\���ł˂�������Ƃ�����i������B
�Ƃ������ƂŋM���̔F���Ǝ��̔F���͓����ł��B
>��2����̃��^�����ł������Ȃ��́H
>�h�[�s���O�Ŏd����������Ƃ����ȁB
�Ӗ����킩��Ȃ��B����������낵���B
>INTEL�̃v���Z�X�̓Q�[�g���X�g������AMD,IBM�̃Q�[�g�t�@�[�X�g�ƈ����
>�����ȑ㏞��NMOS,PMOS�ňႤ���^�����g���闘�_������B
�Q�[�g�t�@�[�X�g�ňႤ���^�����g���Ȃ����R���킩��Ȃ��B
INTEL��SEM���������A�Q�[�g�AP�t�@�[�X�g�A �d�Ƀ��X�g�̉\�����̂Ă��Ȃ���H
>AMD���h�[�v�Ŏd���������邵�������̂ɂ������āA�h�[�v�{���^���̕�
>���������`���l�����ł������\�Ɏd���ďグ����A�ł����Ă邩�ȁB
32nm�v���Z�X�ŃQ�[�g��35nm�ŗǂ��̂��H
�ǂ��Ă����̑����ǂꂾ���V�������N����K�v���c�B
�����������̂Ƀ��^�����Ɛ��\����H
>>91
�Q�[�g�œd���𐧌�ł��Ȃ��Ȃ��Ă���B
�h���C���d�����A�V�������N�ɂ��x�z�͂𑝂��Ă����B
�����������邽�߂ɂ�Cox���グ��B
����ɂ�EOT��������A�Q�[�g�ʐς𑝂₷�AFin�\���ł˂�������Ƃ�����i������B
�Ƃ������ƂŋM���̔F���Ǝ��̔F���͓����ł��B
���̂�����̘b�ł�
> 45nm�ȍ~�̃v���Z�X�Ɍ������V�Z�p���o��
> http://www.ednjapan.com/content/issue/2007/01/pulse/pulse02.html
�v���Z�X���čŏ����H(�\)���@�Ȃ���f�q���ǂ̃T�C�Y�ō�邩�͎��R�B
�L���b�V�������Ƃ��̃��^���̈��������₷���Ȃ�̂��Ӗ������邱�Ƃ��낤���B
> 45nm�ȍ~�̃v���Z�X�Ɍ������V�Z�p���o��
> http://www.ednjapan.com/content/issue/2007/01/pulse/pulse02.html
�v���Z�X���čŏ����H(�\)���@�Ȃ���f�q���ǂ̃T�C�Y�ō�邩�͎��R�B
�L���b�V�������Ƃ��̃��^���̈��������₷���Ȃ�̂��Ӗ������邱�Ƃ��낤���B
�܂��Ƃ肠�����ACPU�Ɠ����傫�����x���̎���RAM�́A�������N�̍����ɂł���
��̂�����A���������������㉺���邾���ŁAIntel�̂��Ƃ����畁�ʂ�32nm�v���Z�X��
���������Ă���Ǝv���B
http://pc.watch.impress.co.jp/docs/2007/0921/hot506.htm
��̂�����A���������������㉺���邾���ŁAIntel�̂��Ƃ����畁�ʂ�32nm�v���Z�X��
���������Ă���Ǝv���B
http://pc.watch.impress.co.jp/docs/2007/0921/hot506.htm
�P�N�O��SRAM���������Ă�Ȃ炻�낻�낾��
IBM������SRAM�Ȃ狎�N����Ă�
"Nehalem"�t�@�~���[�A���e�́uIntel Core i7�v
http://journal.mycom.co.jp/news/2008/08/11/002/index.html
http://journal.mycom.co.jp/news/2008/08/11/002/index.html
i7���Ăǂ������Ӗ��Ȃ��B
Intel�̑�V����CPU���Ă̂��Ⴀ�����ȋC�����邪�B
Intel�̑�V����CPU���Ă̂��Ⴀ�����ȋC�����邪�B
Nehalem�����CPU�u�����h��Core�����ŁAi7�͎��ʎq��Bloomfield�����ɂ������Ȃ�����A
i7�͑�7�����CPU���ĈӖ��Ƃ͈Ⴄ��Ȃ����ȁB
i7�͑�7�����CPU���ĈӖ��Ƃ͈Ⴄ��Ȃ����ȁB
>>96
Intel�Ƃ͎���v���Z�X�̑傫���������ԈႤ�悤������A�傫��CPU���x����
SRAM�����삵�Ă���Intel�̕����A��s���Ă��Ȃ����ȁH
���Ƃ�high-k�̎d�l��IBM�̓Q�[�g�t�@�[�X�g�AIntel�ł̓Q�[�g���X�g��
Intel�̕���>>90���̂����Ă�ʂ�ޗ��̑I���̕����L����̂Ő��\�I�ɂ�
�L���Ȃ�\���������B�M�ɑς����Ȃ��Ƃ��߂炵���̂ŁA�ϋv����
�Q�[�g�t�@�[�X�g�̕�������炵�����B
http://www.itmedia.co.jp/news/articles/0712/11/news017.html
http://journal.mycom.co.jp/articles/2008/07/24/intel45nm/001.html
Intel�Ƃ͎���v���Z�X�̑傫���������ԈႤ�悤������A�傫��CPU���x����
SRAM�����삵�Ă���Intel�̕����A��s���Ă��Ȃ����ȁH
���Ƃ�high-k�̎d�l��IBM�̓Q�[�g�t�@�[�X�g�AIntel�ł̓Q�[�g���X�g��
Intel�̕���>>90���̂����Ă�ʂ�ޗ��̑I���̕����L����̂Ő��\�I�ɂ�
�L���Ȃ�\���������B�M�ɑς����Ȃ��Ƃ��߂炵���̂ŁA�ϋv����
�Q�[�g�t�@�[�X�g�̕�������炵�����B
http://www.itmedia.co.jp/news/articles/0712/11/news017.html
http://journal.mycom.co.jp/articles/2008/07/24/intel45nm/001.html
Cell B.E.�Ǝ��Ĕ�Ȃ�Larrabee�̓����\��
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
http://pc.watch.impress.co.jp/docs/2008/0811/kaigai458.htm
ttp://www.fudzilla.com/index.php?option=com_content&task=view&id=8823&Itemid=1
Larrabee is 2010
So is RV970 and Geforce 11
Larrabee is 2010
So is RV970 and Geforce 11
���̂����ɗ���Hyper-Threading�𓋍ڈӖ��́H
�v���b�V���[������B
�C��
NetBurst�̎��͗]�蕔�����t���Ɏg�����߂�Hyper-Threading�Ńp�t�H�[�}���X�A�b�v����Ȃ����������H
�ł�����Core�}�C�N���A�[�L�e�N�`���Ȃ�1�R�A������̏������A�b�v���ėV��ł镔���Ȃ�Ă���܂�
�Ȃ������Ȃ��Ƒf�l�͎v���܂����B
�ł�����Core�}�C�N���A�[�L�e�N�`���Ȃ�1�R�A������̏������A�b�v���ėV��ł镔���Ȃ�Ă���܂�
�Ȃ������Ȃ��Ƒf�l�͎v���܂����B
Core + Pentium4 = Core + i7 ��������Ȃ̂����v������
Netburst�����������Ƃ����Ă����ΓI�Șb�ŁAOoO��CPU�̓������҂��Ƃ��܂߂�
������������B
������������B
110 �F,,�E�L�́M�E,,�j���F2008/08/11(��) 20:10:44 ID:bXNcKwyG
Core2�͂����܂Ń��o�C���̗��p������B
P6�ȍ~IA�̃��W�X�^���l�[�~���O�����͗\��@�\�iWikipedia�Q�Ɓj�ɕ��ނ����B
PenM��Core2�Ȃǂ̃��o�C���`�[���̍�����A�[�L�͂�����Future File��
�G���g���������Ȃ��i��̓I�ɂ͊eALU�Ɉ���Ԃ牺�����Ă邾���j
FutureFile�͔�r�I����d�͂��傫������A���o�C�����Ƃ��Ă�
���炵���������낤�B
���̂�����1�T�C�N���ɓ����Q�Ƃł��郌�W�X�^���ɐ��������������B
64�r�b�g�ł̐��\���L�тȂ��̂����ꂪ�����B
���Ȃ݂�HT���̂͗L���ȋZ�p�����A2�X���b�h���ɓ���������
�����Q�Ƃł��郌�W�X�^�����������Ƃ��v�������B
���܂ł�Core2�̐v�ł�FutureFile�����Ȃ����đ��g�ɂȂ����킯�B
�m�[�g��2�X���b�h�ŏ\���A64�r�b�g�̐��\�������s�v�ƔF�����Ă��낤�B
�����Ă��������Nehalem�����T�[�o�E�f�X�N�g�b�v�����Ƀ`���[�����ꂽ����CoreMA�Ƃ������ƁB
P6�ȍ~IA�̃��W�X�^���l�[�~���O�����͗\��@�\�iWikipedia�Q�Ɓj�ɕ��ނ����B
PenM��Core2�Ȃǂ̃��o�C���`�[���̍�����A�[�L�͂�����Future File��
�G���g���������Ȃ��i��̓I�ɂ͊eALU�Ɉ���Ԃ牺�����Ă邾���j
FutureFile�͔�r�I����d�͂��傫������A���o�C�����Ƃ��Ă�
���炵���������낤�B
���̂�����1�T�C�N���ɓ����Q�Ƃł��郌�W�X�^���ɐ��������������B
64�r�b�g�ł̐��\���L�тȂ��̂����ꂪ�����B
���Ȃ݂�HT���̂͗L���ȋZ�p�����A2�X���b�h���ɓ���������
�����Q�Ƃł��郌�W�X�^�����������Ƃ��v�������B
���܂ł�Core2�̐v�ł�FutureFile�����Ȃ����đ��g�ɂȂ����킯�B
�m�[�g��2�X���b�h�ŏ\���A64�r�b�g�̐��\�������s�v�ƔF�����Ă��낤�B
�����Ă��������Nehalem�����T�[�o�E�f�X�N�g�b�v�����Ƀ`���[�����ꂽ����CoreMA�Ƃ������ƁB
>>107
HT��CPU�������\�[�X�̗L�����p�����A�������A�N�Z�X�҂��̉B���ׂ̈��傫���̂ł��B
�ܘ_�A�}���`�X���b�h�ʼn^�p����A���Ă̂��O��ł����B
HT��CPU�������\�[�X�̗L�����p�����A�������A�N�Z�X�҂��̉B���ׂ̈��傫���̂ł��B
�ܘ_�A�}���`�X���b�h�ʼn^�p����A���Ă̂��O��ł����B
112 �F,,�E�L�́M�E,,�j����110�F2008/08/11(��) 20:21:15 ID:bXNcKwyG
PenM/Core1�ł�MMX��SSE2���\�t�]���ۂ�������������B
���̍���XMM���W�X�^�̈������㉺�ɕ�����2�G���g���ň����Ă�����B
���̍���XMM���W�X�^�̈������㉺�ɕ�����2�G���g���ň����Ă�����B
>>111
�bLarrabee�̐����ł́A�n�[�h�E�F�A�}���`�X���b�f�B���O�́A�R���p�C�����ɃX�P�W���[�����O�ʼnB���ł��Ȃ�����
�b�X�g�[����L2�L���b�V������̃��[�h���C�e���V���B�����邱�Ƃ���ړI�Ƃ��Ă���Ƃ����B����́A�v���Z�b�T�O��
�b�̊O�t���r�f�I�������ւ̃A�N�Z�X�̃��C�e���V���B�����邱�Ƃ�ړI�Ƃ����AGPU�̃n�[�h�E�F�A�}���`�X���b�f�B���O
�b�Ƃ͈قȂ�B
������ƈႤ�����ł��ˁB
�܂��S�X���b�h�����Ȃ�����A���������C�e���V�̓L���b�V���ʼnB���o����
���Č��ʂ��ł��傤���B
�bLarrabee�̃n�[�h�E�F�A�}���`�X���b�f�B���O��GPU��苷�����R�́A�X�P�W���[�����O��
�b�A�[�L�e�N�`���ɂ���B�R���p�C�����ɗ\���ł��钷�����C�e���V�́ALarrabee�̏ꍇ��
�b�\�t�g�E�F�A�ŃX�P�W���[������B�\�����ł��Ȃ��Z�����C�e���V�A�Ⴆ�AL1�L���b�V��
�b�~�X��L2�L���b�V�����烍�[�h����悤�ȃP�[�X�̓n�[�h�E�F�A�ŃX�C�b�`����BGPU�Ƃ́A
�b�}���`�X���b�f�B���O�̃A�[�L�e�N�`�����قȂ��Ă���BLarrabee��GPU�Ɗr�ׂ�ƁA���
�b�\�t�g�E�F�A����I�ŁA�R���p�C��(�����^�C��)�ɂ��X�P�W���[�����O�ɗ���䗦�������B
�b���ꂾ���R���p�C���Ɏ��M�������Ă��邱�ƂɂȂ�B
������������ƃR���p�C���ɂ��X�P�W���[�����O�ł��A���������C�e���V���B������
���M���L����ۂ��ł����B
�bLarrabee�̐����ł́A�n�[�h�E�F�A�}���`�X���b�f�B���O�́A�R���p�C�����ɃX�P�W���[�����O�ʼnB���ł��Ȃ�����
�b�X�g�[����L2�L���b�V������̃��[�h���C�e���V���B�����邱�Ƃ���ړI�Ƃ��Ă���Ƃ����B����́A�v���Z�b�T�O��
�b�̊O�t���r�f�I�������ւ̃A�N�Z�X�̃��C�e���V���B�����邱�Ƃ�ړI�Ƃ����AGPU�̃n�[�h�E�F�A�}���`�X���b�f�B���O
�b�Ƃ͈قȂ�B
������ƈႤ�����ł��ˁB
�܂��S�X���b�h�����Ȃ�����A���������C�e���V�̓L���b�V���ʼnB���o����
���Č��ʂ��ł��傤���B
�bLarrabee�̃n�[�h�E�F�A�}���`�X���b�f�B���O��GPU��苷�����R�́A�X�P�W���[�����O��
�b�A�[�L�e�N�`���ɂ���B�R���p�C�����ɗ\���ł��钷�����C�e���V�́ALarrabee�̏ꍇ��
�b�\�t�g�E�F�A�ŃX�P�W���[������B�\�����ł��Ȃ��Z�����C�e���V�A�Ⴆ�AL1�L���b�V��
�b�~�X��L2�L���b�V�����烍�[�h����悤�ȃP�[�X�̓n�[�h�E�F�A�ŃX�C�b�`����BGPU�Ƃ́A
�b�}���`�X���b�f�B���O�̃A�[�L�e�N�`�����قȂ��Ă���BLarrabee��GPU�Ɗr�ׂ�ƁA���
�b�\�t�g�E�F�A����I�ŁA�R���p�C��(�����^�C��)�ɂ��X�P�W���[�����O�ɗ���䗦�������B
�b���ꂾ���R���p�C���Ɏ��M�������Ă��邱�ƂɂȂ�B
������������ƃR���p�C���ɂ��X�P�W���[�����O�ł��A���������C�e���V���B������
���M���L����ۂ��ł����B
114 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:21:08 ID:y6R1bzbl
>>113
GPU�Ɣ�ׂăL���b�V���e�ʂ͑��߂�����ˁB
ATI/nVIDIA��GPU�̓_�C�S�̂Ő��\�`���SKB�����Ȃ����ALarrabee�͑S�̂Ő�MB�ɂȂ�B
GPU�Ɣ�ׂăL���b�V���e�ʂ͑��߂�����ˁB
ATI/nVIDIA��GPU�̓_�C�S�̂Ő��\�`���SKB�����Ȃ����ALarrabee�͑S�̂Ő�MB�ɂȂ�B
115 �F80,81�F2008/08/11(��) 21:23:00 ID:uZx+gzIc
PentiumIII�̉��ǂł���PentiumM���S�A
Core���T�ACore2���U�ŁA���̎�������V�Ȃ̂ł́H
Core���T�ACore2���U�ŁA���̎�������V�Ȃ̂ł́H
i7��Bloomfield�̎��ʎq�ŁACPU�̃u�����h��Core���������B
Lynnfield�Ƃ���i7�ȊO�ɂȂ邾�낤����A����͊W�Ȃ����ƁB
Lynnfield�Ƃ���i7�ȊO�ɂȂ邾�낤����A����͊W�Ȃ����ƁB
117 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:34:13 ID:y6R1bzbl
����͗��ɂȂ���B
Pentium M�̓f�X�N�g�b�v�p������Pentium III�Ƃ͈�����v�v�z�őg�܂�Ă���B
�h�h�h�̌�p�͂����܂�4���B�ł��̈����q���������B
Pentium���畕�Ă���x86����\�L�̕������Ƃ��Ă����������Ȃ��B
Family���V����ɂ͂����^�C�~���O����
���Ȃ݂�NetBurst��FamilyID����C��15�ɔ��ł�ْ͈̂[��������B
���̘͐̂b�����A��7�����Itanium�ɂ���x86����̒E�p��}��v�������������B
������Family=7
Pentium M�̓f�X�N�g�b�v�p������Pentium III�Ƃ͈�����v�v�z�őg�܂�Ă���B
�h�h�h�̌�p�͂����܂�4���B�ł��̈����q���������B
Pentium���畕�Ă���x86����\�L�̕������Ƃ��Ă����������Ȃ��B
Family���V����ɂ͂����^�C�~���O����
���Ȃ݂�NetBurst��FamilyID����C��15�ɔ��ł�ْ͈̂[��������B
���̘͐̂b�����A��7�����Itanium�ɂ���x86����̒E�p��}��v�������������B
������Family=7
118 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:34:59 ID:y6R1bzbl
119 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:41:21 ID:y6R1bzbl
����̈Ⴂ��QPI�E�I���_�C�����R���̗L���Ƃ����l�������Ƃ�����ǂ������������Ă��Ƃ����邩���B
>>118
http://www.intel.co.jp/jp/intel/pr/press2008/080811.htm
intel������Core�����Č����Ă���ǁH
Bloomfield��i7�����Ă͉̂��̐��������A���̃��[�h�}�b�v���Ƃ�7�̎��ʎq���t���̂�
Bloomfield�ŊԈႢ�Ȃ����낤�B
http://www.intel.co.jp/jp/intel/pr/press2008/080811.htm
intel������Core�����Č����Ă���ǁH
Bloomfield��i7�����Ă͉̂��̐��������A���̃��[�h�}�b�v���Ƃ�7�̎��ʎq���t���̂�
Bloomfield�ŊԈႢ�Ȃ����낤�B
121 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:46:51 ID:y6R1bzbl
Havendale��Pentium�u�����h�ł����P�����ˁ[���Ǝv�������B
��ԏ�̊K�w�̐���ƍl����Ƃǂ������Ă�7�͂������藈�Ȃ��C������
123 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 21:51:11 ID:y6R1bzbl
�܂��AFamily=7��������i7=786�ňӖ��͊m�肾����
>>119���Ƃ���Ύ�������v�Ő��\�����W�ɍ��킹�ĕʃt�@�~���[�����݂��邱�ƂɂȂ�B
GeForce8��9�݂������Ȃ���B
>>119���Ƃ���Ύ�������v�Ő��\�����W�ɍ��킹�ĕʃt�@�~���[�����݂��邱�ƂɂȂ�B
GeForce8��9�݂������Ȃ���B
���[�͑ʖڂ��ۂ���
125 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 22:08:01 ID:y6R1bzbl
124 ���O�F���ځ`��[���ځ`��] ���e���F���ځ`��
�Ȃ���H
�Ȃ���H
���[��2010�Ƀ~�h����GPU�ŁH
i80786�H
http://www.hkepc.com/?id=1558&fs=c1h
i7�̂Ƃ���ɁA
identifire for new and improved high-end desktop version
�Ƃ��邪�B
i7�̂Ƃ���ɁA
identifire for new and improved high-end desktop version
�Ƃ��邪�B
�Ƃ������AES�łɂȂ邯��Nehalem��CPU-Z��SS���݂��
family��6�ɂȂ��Ă���ȁB
family��6�ɂȂ��Ă���ȁB
130 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 23:19:21 ID:y6R1bzbl
����Ⴭ�[�G���h��Pentium(��ܐ���)���ĕt���郁�[�J�[������
QPI�ڂ̃~�b�h�����W�ȉ��͑掵����̏o�����Ȃ��Ƃł��ʒu�Â���̂ł́H
Family���V�̃^�C�~���O�Ƃ��Ă�Nehalem����Ԃ����Ǝv��
����SandyBridge���ȁB
���Ƃ̉\���́A���Ƃ��uI�v���܂ރt�B�[�`����7���ĈӖ��B
���Ƃ���Improvement, Integrated,...
QPI�ڂ̃~�b�h�����W�ȉ��͑掵����̏o�����Ȃ��Ƃł��ʒu�Â���̂ł́H
Family���V�̃^�C�~���O�Ƃ��Ă�Nehalem����Ԃ����Ǝv��
����SandyBridge���ȁB
���Ƃ̉\���́A���Ƃ��uI�v���܂ރt�B�[�`����7���ĈӖ��B
���Ƃ���Improvement, Integrated,...
131 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 23:20:10 ID:y6R1bzbl
>>131
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=2
http://www.xtremesystems.org/forums/showthread.php?t=190762&page=40
���ꂪ�s���H
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=2
http://www.xtremesystems.org/forums/showthread.php?t=190762&page=40
���ꂪ�s���H
ttp://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3326&p=2
Family��6���ۂ����A�܂��܂��Ȃ�Ƃ�������ȁB
����IDF�҂��ɂȂ�C�����邪�B
Family��6���ۂ����A�܂��܂��Ȃ�Ƃ�������ȁB
����IDF�҂��ɂȂ�C�����邪�B
134 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 23:29:08 ID:y6R1bzbl
>>132
L2��32KB�Ƃ����낢�남�������ȁB
�܂��A���̕ӂ�ES������A�ŕЕt���邱�Ƃ��o���邪�B
Model�l�̂ق�������ES�łƐ��i�łŒl��������̂�Pentium Pro�̂Ƃ��ɂ������悤��
����Banias��Model=12�ɂȂ�\�肾�����̂����i�ł�Timna��9�ɓ���ւ�����B
L2��32KB�Ƃ����낢�남�������ȁB
�܂��A���̕ӂ�ES������A�ŕЕt���邱�Ƃ��o���邪�B
Model�l�̂ق�������ES�łƐ��i�łŒl��������̂�Pentium Pro�̂Ƃ��ɂ������悤��
����Banias��Model=12�ɂȂ�\�肾�����̂����i�ł�Timna��9�ɓ���ւ�����B
�L���b�V���e�ʂ��ςȂ̂͌Â�CPU-Z���g���Ă��邩�炾�낤�B
Anand�͝s���Ȃ��ˁ[��B
CPUID���̂͊ԈႢ�悤�������B���i�łłǂ��Ȃ邩�͒m��ǁB
Anand�͝s���Ȃ��ˁ[��B
CPUID���̂͊ԈႢ�悤�������B���i�łłǂ��Ȃ邩�͒m��ǁB
136 �F,,�E�L��`�E,,�j��-�������F2008/08/11(��) 23:48:55 ID:y6R1bzbl
����������
Intel 22nm Ivy Bridge & Haswell Disclosure
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=92516&threadid=92516&roomid=2
ttp://www.canardplus.com/dossier-35-200-Processeur_de_Nehalem_a_Haswell.html
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=92516&threadid=92516&roomid=2
ttp://www.canardplus.com/dossier-35-200-Processeur_de_Nehalem_a_Haswell.html
22nm Ivy Bridge���C�X���G���`�[���ŁA22nm Haswell���I���S���`�[�����H
�㓡�ɂ���Bridge�V���[�Y��3���㑱���炵���ȁB
SandyBridge�̎�����}�C�N���A�[�L�e�N�`����Haswell�Ƃ��B
SandyBridge�̎�����}�C�N���A�[�L�e�N�`����Haswell�Ƃ��B
�N�����痈�N������PC�������Ǝv���Ă���Core i7���o��悤�Ȃ̂�Core2Q�Ƃǂ����ɂ��悤�������Ă�B
PC�g�ނ̂͏��S�҂Ȃ̂ō��܂ł�CPU�̉��i�����m��Ȃ����狳���ė~�����̂ł����A
�V����CPU���o�āA���̉��i��������n�߂�̂��Ĕ�����ǂ̂��炢�̎����ł����H
��������ɍ����l�i�Ŕ����Đ�����ɑ啝�Ɉ����Ȃ����肷��̂��|���̂ŁE�E�E
�Q�l�ɂ������̂ł�낵�����肢���܂��B
PC�g�ނ̂͏��S�҂Ȃ̂ō��܂ł�CPU�̉��i�����m��Ȃ����狳���ė~�����̂ł����A
�V����CPU���o�āA���̉��i��������n�߂�̂��Ĕ�����ǂ̂��炢�̎����ł����H
��������ɍ����l�i�Ŕ����Đ�����ɑ啝�Ɉ����Ȃ����肷��̂��|���̂ŁE�E�E
�Q�l�ɂ������̂ł�낵�����肢���܂��B
Bloomfield���o�Ă��A����Penryn���l�����肷��Ƃ͎v����ȁB
��炢�Ȃ牿�i���肷�邩������B
��炢�Ȃ牿�i���肷�邩������B
����������Intel���āA����22nm�̃v���Z�X�̎���i���낻�늮�������Ă�낤���H
���[�h�}�b�v�ɂłė���ƌ������Ƃ́A���p���̂߂ǂ͗����Ă�̂��ȁH
���[�h�}�b�v�ɂłė���ƌ������Ƃ́A���p���̂߂ǂ͗����Ă�̂��ȁH
>>144
�������̏o�O�݂����Ȃ�����C�ɂ����畉��
�������̏o�O�݂����Ȃ�����C�ɂ����畉��
>>141
BTO�ɂ��Ƃ�����
BTO�ɂ��Ƃ�����
���쏉�S�ҁA���������i���C�ɂ��Ă���悤�Ȑl�Ԃ�������Core i7��
�I�ԂȂ�āA����Ȃ��Ƃ��ق������Ǖ��s��������܂�Ȃ��Ƃ���
Core i7�͈�Ԉ���Mainstream3��$316��2.66GHz���f����I�Ƃ��Ă��A
������Tylersburg���ڃ}�U�[�����Ȃ����낤����}�U�[���30K���炢�A
����Ɉ����Ȃ����Ƃ͂���DDR2���͒f�R������DDR3��Ȃ���Ȃ��
CPU�̒l�i������������ǂ����悤�A�Ȃ�Ă��Ƃ������ŕ����悤�Ȑl�Ԃ�
�����悤���̂���Ȃ�����A�ǂ��l���Ă�
�I�ԂȂ�āA����Ȃ��Ƃ��ق������Ǖ��s��������܂�Ȃ��Ƃ���
Core i7�͈�Ԉ���Mainstream3��$316��2.66GHz���f����I�Ƃ��Ă��A
������Tylersburg���ڃ}�U�[�����Ȃ����낤����}�U�[���30K���炢�A
����Ɉ����Ȃ����Ƃ͂���DDR2���͒f�R������DDR3��Ȃ���Ȃ��
CPU�̒l�i������������ǂ����悤�A�Ȃ�Ă��Ƃ������ŕ����悤�Ȑl�Ԃ�
�����悤���̂���Ȃ�����A�ǂ��l���Ă�
�Ă�i7���ǂ������|�W�V������CPU�����痝�����ĂȂ��낤�ȁc
i7��PentiumPRO����
$316����Ȃ���$284�ȁB
��������Ȃ�I�ׂ��������
�̂͂Ƃ����������̎���ɏ��S�҂Ə����Ȃ�đ債�ĊW�Ȃ���
��������Ȃ�I�ׂ��������
�̂͂Ƃ����������̎���ɏ��S�҂Ə����Ȃ�đ債�ĊW�Ȃ���
�����̂��W�Ȃ��A�����ōl���Ď����ʼn����ł��Ȃ��z�͎����������Ȃ�����c
EETimes��IDF�v���r���[�L�������ǁANehalem�̏ȓd�͋@�\��P�Ȃ�SpeedStep�̉��nj^
�ł햳���Ɠ`���Ă��邷�B
�@�@-----------------------
�@�@A company spokesman said it is not a direct evolution of the Intel's SpeedStep technology that
�@�@automates frequency scaling based on workloads.
�@�@-----------------------
���̑��AIDF�Ō���鋻���[�����ڂ͂���Ȋ����Ƃ̂��Ƃ��B
�@�ESteve Wozniak�̓o�d
�@�E�V�^SoC���i
�@�ELarrabee�̃\�t�g�E�F�A�헪
�ł햳���Ɠ`���Ă��邷�B
�@�@-----------------------
�@�@A company spokesman said it is not a direct evolution of the Intel's SpeedStep technology that
�@�@automates frequency scaling based on workloads.
�@�@-----------------------
���̑��AIDF�Ō���鋻���[�����ڂ͂���Ȋ����Ƃ̂��Ƃ��B
�@�ESteve Wozniak�̓o�d
�@�E�V�^SoC���i
�@�ELarrabee�̃\�t�g�E�F�A�헪
Larrabee�͒���������
>>154
Steve Wozniak���ĂȂɂ���H���Ă����������ǁAApple][�@�������l���B�������낻�����ˁB
>>155
�O���t�B�b�N�v���Z�b�T�Ƃ��Ă͂����Ȃ邩���ˁB
�T�u�v���Z�b�T�Ƃ��Ă͉�����B
Steve Wozniak���ĂȂɂ���H���Ă����������ǁAApple][�@�������l���B�������낻�����ˁB
>>155
�O���t�B�b�N�v���Z�b�T�Ƃ��Ă͂����Ȃ邩���ˁB
�T�u�v���Z�b�T�Ƃ��Ă͉�����B
http://northwood.blog60.fc2.com/blog-entry-2202.html
Haswell�Ńx�N�^�R�v���Z�b�T�����炵�����ǁA���̎������肩�烁�C����CPU�ł����j�[�R�A�����Ă����̂��낤���H
Haswell�Ńx�N�^�R�v���Z�b�T�����炵�����ǁA���̎������肩�烁�C����CPU�ł����j�[�R�A�����Ă����̂��낤���H
���C���̗p�r�Ŏg�����ɂȂ�Ȃ����͕̂��y�����Ȃ�
159 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 01:38:16 ID:aVFv7Qpb
SSE5(��)�̂��Ƃł��ˁB�킩��܂��B
160 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 02:26:49 ID:aVFv7Qpb
>>157
���ς�炸�N�\������ȁB
3��4�̃R�}���h���Ėꂽ�����͖{���A128�r�b�gSIMD�ɑ���x�N�^���̔{���̂��Ƃ��w���Ă�B
�O�̕��߂�two�ɑ���three��four���B
�ł���������4�{��8�{�Ȃ̂Ō������̂��ԈႢ�B
���ς�炸�N�\������ȁB
3��4�̃R�}���h���Ėꂽ�����͖{���A128�r�b�gSIMD�ɑ���x�N�^���̔{���̂��Ƃ��w���Ă�B
�O�̕��߂�two�ɑ���three��four���B
�ł���������4�{��8�{�Ȃ̂Ō������̂��ԈႢ�B
�����[��������̂͊m��
�Ƃ������Ƃɂ������̂ł��ˁH
2010�ɂǂ̒��x�̃p�t�H�[�}���X�����āH
16�R�A�ŁA16*16*fma=512flops/clock�i�P���x�A���_�l�j
165 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 10:55:21 ID:aVFv7Qpb
16�R�A�Ȃ�2GHz�o���1TF(SP)�B���ł���B
32nm�v���Z�X�ł�48�R�A�܂œW�J�ł���v��炵�����B
32nm�v���Z�X�ł�48�R�A�܂œW�J�ł���v��炵�����B
����͘b�����ŕ����Ƃ����B�{���Ȃ�Pen4������10GHz�����͂��������B
�A�t�B�j�e�B�}�X�N���̊g�����ǂ��Ȃ�̂����B
�A�t�B�j�e�B�}�X�N���̊g�����ǂ��Ȃ�̂����B
�����r�[�̓R�P�邩�ǂ����͂��Ēu���A�g���Ă݂����A�[�L�ł͂��邯��
Nehalem�̕��́A���\�I�ɂ��@�\�I�ɂ��g���܂ł��Ȃ�����������Ă邵�ˁB
Nehalem�̕��́A���\�I�ɂ��@�\�I�ɂ��g���܂ł��Ȃ�����������Ă邵�ˁB
169 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 14:06:28 ID:aVFv7Qpb
>>166
Larrabee�Ŋ�����Win32�A�v���P�[�V�������u���̂܂�܁v�����Ȃ�K�v������
���̂Ƃ��낻������Ȃ��݂��������ȁB
�ǂ����A�v���P�[�V�������Ŗ����I�ɃR�A�𗘗p���郂�f���ɂȂ肻������ˁH
libspe�݂�����IA++�R�A�����z�����郉�C�u���������
�v���O�������ŊǗ��ɂ���̌n�ɂȂ肻���B
Larrabee�Ŋ�����Win32�A�v���P�[�V�������u���̂܂�܁v�����Ȃ�K�v������
���̂Ƃ��낻������Ȃ��݂��������ȁB
�ǂ����A�v���P�[�V�������Ŗ����I�ɃR�A�𗘗p���郂�f���ɂȂ肻������ˁH
libspe�݂�����IA++�R�A�����z�����郉�C�u���������
�v���O�������ŊǗ��ɂ���̌n�ɂȂ肻���B
>>169
Win32���p�[�t�F�N�g�œ������͊��҂��Ă��Ȃ�����ǁA�ċA�Ƃ����Ăяo�����e�ՂɂȂ��
�v���O�����������SPE�̂悤�ȕ��Ƃ͑S���ʕ��ɂȂ�Ǝv����̂ŁA�܂����̂����肪�\���ǂ����A�o���Ȃ��Ƃ��Ă��ȒP�Ȋg���ʼn\�ɂȂ肻�����H�Ƃ��������B
Win32���p�[�t�F�N�g�œ������͊��҂��Ă��Ȃ�����ǁA�ċA�Ƃ����Ăяo�����e�ՂɂȂ��
�v���O�����������SPE�̂悤�ȕ��Ƃ͑S���ʕ��ɂȂ�Ǝv����̂ŁA�܂����̂����肪�\���ǂ����A�o���Ȃ��Ƃ��Ă��ȒP�Ȋg���ʼn\�ɂȂ肻�����H�Ƃ��������B
171 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 15:53:19 ID:aVFv7Qpb
���j�[�R�A�ւ̑Ή��ɂ��Ă�Intel��x2APIC�̋Z�p�������J�����̂��悤�₭���N�B
�Ή��n�[�h�͂ڂ��ڂ��B
���Ƃ�OS���̑Ή����悩�ƁB
������Larrabee�͂ǂ݂̂������̖��߃Z�b�g�ƌ݊����̂Ȃ�
512�r�b�g��SIMD����Ȃ��Ɛ��\�������Ȃ��킯�ŁB
VEX�G���R�[�f�B���O���g���Ȃ�ǂ����̃^�C�~���O��
�ėpIA�R�A�Ƃ̖��߃Z�b�g�̑��݂̌݊������Ƃ��Ă���
�\���͍������Aꡂ��ɐ�̘b�ɂȂ肻���B
�Ή��n�[�h�͂ڂ��ڂ��B
���Ƃ�OS���̑Ή����悩�ƁB
������Larrabee�͂ǂ݂̂������̖��߃Z�b�g�ƌ݊����̂Ȃ�
512�r�b�g��SIMD����Ȃ��Ɛ��\�������Ȃ��킯�ŁB
VEX�G���R�[�f�B���O���g���Ȃ�ǂ����̃^�C�~���O��
�ėpIA�R�A�Ƃ̖��߃Z�b�g�̑��݂̌݊������Ƃ��Ă���
�\���͍������Aꡂ��ɐ�̘b�ɂȂ肻���B
>>169
Larrabee �� Open CL �� DirectX �p�Ȃ�Ȃ����Ǝv���Ă�B
�A�v���P�[�V�������Ŗ����I�ɃR�A�𗘗p����K�v�͂Ȃ��A
Open CL �� DirectX �������́A���̏�ɍڂ���API���g�����ƂŁA
���ӎ��̂����� Larrabee �̃R�A���g�����ă��f���ɂȂ��Ȃ����낤���B
Larrabee �� Open CL �� DirectX �p�Ȃ�Ȃ����Ǝv���Ă�B
�A�v���P�[�V�������Ŗ����I�ɃR�A�𗘗p����K�v�͂Ȃ��A
Open CL �� DirectX �������́A���̏�ɍڂ���API���g�����ƂŁA
���ӎ��̂����� Larrabee �̃R�A���g�����ă��f���ɂȂ��Ȃ����낤���B
173 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 17:58:54 ID:aVFv7Qpb
����ȗp�r�͐��܂�Ȃ�
175 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 18:19:13 ID:aVFv7Qpb
Larrabee�pICC��p�ӂ������PDF�ɏ����Ă�����ǂ�
���A�����������_�����O�T�[�o�p�r�ȂŌ_����t���Ă邺�B
���A�����������_�����O�T�[�o�p�r�ȂŌ_����t���Ă邺�B
����͖��ʂȎ������܂�����
177 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 18:36:38 ID:aVFv7Qpb
�������ˁA�N�̐l���o���Ɛق������͖��ʂ�������
>>171
OS���Ή����邩�ǂ����͂��قǏd�v�ł͂Ȃ��Ǝv����A��ԑ厖�Ȃ̂̓\�t�g�E�F�A�J���Z�@�ɑ��ď�Q�����Ȃ����Ƃ��Ǝv��
�I�u�W�F�N�g�w���I�ɍ��Ȃ��Ƃ��A���������̂���Ԃ܂����AOS���T�|�[�g�����Ƃ��Ă����̂悤��API�ł͎��p�ɂȂ�Ȃ�
�t�ɂ��ꂪ�\�Ȃ�OS���T�|�[�g�����܂����������Ƃ��Ă���������Ǝv�����A������OS�ɑg�ݍ��ނȂ�VM��CLI�ɑg�ݍ��܂�čs���Ǝv���B
������\�ɂ���@�\��������Ă��邩�A������Ă��Ȃ������Ƃ����牽���s�����Ă��邩�A���̕s�����͉����\���Ƃ����_�𑁂����Ă݂����Ƃ���B
OS���Ή����邩�ǂ����͂��قǏd�v�ł͂Ȃ��Ǝv����A��ԑ厖�Ȃ̂̓\�t�g�E�F�A�J���Z�@�ɑ��ď�Q�����Ȃ����Ƃ��Ǝv��
�I�u�W�F�N�g�w���I�ɍ��Ȃ��Ƃ��A���������̂���Ԃ܂����AOS���T�|�[�g�����Ƃ��Ă����̂悤��API�ł͎��p�ɂȂ�Ȃ�
�t�ɂ��ꂪ�\�Ȃ�OS���T�|�[�g�����܂����������Ƃ��Ă���������Ǝv�����A������OS�ɑg�ݍ��ނȂ�VM��CLI�ɑg�ݍ��܂�čs���Ǝv���B
������\�ɂ���@�\��������Ă��邩�A������Ă��Ȃ������Ƃ����牽���s�����Ă��邩�A���̕s�����͉����\���Ƃ����_�𑁂����Ă݂����Ƃ���B
179 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 18:40:09 ID:aVFv7Qpb
�N���Ǝv���u�����[�v�Ƃ��L�V�������̂��Ă�d�g�N��
������i���Ă�SSE5(��)�ɂ��GPU�A�g�����̖ڂ��݂邱�ƂȂ�Ă��蓾�Ȃ��̂ɂ悭�撣���
������i���Ă�SSE5(��)�ɂ��GPU�A�g�����̖ڂ��݂邱�ƂȂ�Ă��蓾�Ȃ��̂ɂ悭�撣���
180 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 18:50:36 ID:aVFv7Qpb
>>178
�uCt�v��Intel�̉�����Ȃ��́H
����OoO�ȃl�C�e�B���R�[�h�f���|�s�����[�Ȍ��ꏈ���n����C++���炢�����A
C++�͌����낤��B
���\�b�h��ϐ��lj����邾���ňˑ������S��
�ăR���p�C�����Ȃ��Ƃ����Ȃ������K�͊J���ɂ͌����Ȃ��B
�p�t�H�[�}���X�������v���O��������ł͐��Y���̖ʂŌ����I��OoO�͗ǂ��������B
�uCt�v��Intel�̉�����Ȃ��́H
����OoO�ȃl�C�e�B���R�[�h�f���|�s�����[�Ȍ��ꏈ���n����C++���炢�����A
C++�͌����낤��B
���\�b�h��ϐ��lj����邾���ňˑ������S��
�ăR���p�C�����Ȃ��Ƃ����Ȃ������K�͊J���ɂ͌����Ȃ��B
�p�t�H�[�}���X�������v���O��������ł͐��Y���̖ʂŌ����I��OoO�͗ǂ��������B
�悭��5%�����y���邩�킩��Ȃ�����GPU�����ɉ����o����āH
182 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 19:05:31 ID:aVFv7Qpb
�܂�Ct���̂͑��X���b�h���x���@�\�荞��C++/OpenMP�̃t�����g�G���h�炵�����ǂȁB
�P���Ct�\�[�X����َ퍬���̃}���`�R�A�ɑΉ������X���b�h�R�[�h������悤�Ȃ̂��I���_����
�P���Ct�\�[�X����َ퍬���̃}���`�R�A�ɑΉ������X���b�h�R�[�h������悤�Ȃ̂��I���_����
183 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 19:07:09 ID:aVFv7Qpb
>>181
AMD��Fusion�̂��Ƃł��ˁB�킩��܂�
AMD��Fusion�̂��Ƃł��ˁB�킩��܂�
�́H
Fusion�Ȃ�ĕʂɊW������ł�����
DX11��Compute Shader���o��̂�
���ŕ��y���錩���݂̖����Ǝ��K�i�Ƀ��U���U�Ή������
Fusion�Ȃ�ĕʂɊW������ł�����
DX11��Compute Shader���o��̂�
���ŕ��y���錩���݂̖����Ǝ��K�i�Ƀ��U���U�Ή������
185 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 19:21:37 ID:aVFv7Qpb
> DX11��Compute Shader���o��̂�
DX11�Ȃ��MS�Ǝ�API�ɂƂ���Ȃ��A�����ƌ�����OS��I�Ȃ�
�X�g���[���v���Z�b�T�Ƃ��Ẵv���O���~���O���f���̘b�����܂��������H
���R�Ȃ���GPU�Ȃ�ĉᒠ�̊O�ł��B
�]�������[(��)�̘b�͂������瑃�ɂ��A�肭�������B
> ���ŕ��y���錩���݂̖����Ǝ��K�i�Ƀ��U���U�Ή������
�܂�AMD�̐V���߂̈�������������
DX11�Ȃ��MS�Ǝ�API�ɂƂ���Ȃ��A�����ƌ�����OS��I�Ȃ�
�X�g���[���v���Z�b�T�Ƃ��Ẵv���O���~���O���f���̘b�����܂��������H
���R�Ȃ���GPU�Ȃ�ĉᒠ�̊O�ł��B
�]�������[(��)�̘b�͂������瑃�ɂ��A�肭�������B
> ���ŕ��y���錩���݂̖����Ǝ��K�i�Ƀ��U���U�Ή������
�܂�AMD�̐V���߂̈�������������
>���R�Ȃ���GPU�Ȃ�ĉᒠ�̊O�ł��B
�����A�ŏ����畁�y��������߂Ă��
�����A�ŏ����畁�y��������߂Ă��
187 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 19:40:34 ID:aVFv7Qpb
�����ˊw�K�\�͖����́H
�����I��PC�s���8���̕��y�������߂�o�����[�X����B
�����̂��ׂĂ̔ėpIA�A�[�L�ɍ��ڂ����x86�x�[�X�̃X�g���[���v���Z�b�T�B
���̒P�̂ł̃v���g�^�C�v��Larrabee�̐^�̎p�B
GPU�Ƃ��Ă̎p�͉����߂ɂ����Ȃ��B
Cell��Tesla�ւ̌������ɂȂ�Έ�Γ��x
�t�ɁuGPU�Ƃ��āvnV��ATi��蔄�ꂿ��������Z����B
�܂�GMA��Intel��GPU�g�b�v�V�F�A�Ȃ��B
�����I��PC�s���8���̕��y�������߂�o�����[�X����B
�����̂��ׂĂ̔ėpIA�A�[�L�ɍ��ڂ����x86�x�[�X�̃X�g���[���v���Z�b�T�B
���̒P�̂ł̃v���g�^�C�v��Larrabee�̐^�̎p�B
GPU�Ƃ��Ă̎p�͉����߂ɂ����Ȃ��B
Cell��Tesla�ւ̌������ɂȂ�Έ�Γ��x
�t�ɁuGPU�Ƃ��āvnV��ATi��蔄�ꂿ��������Z����B
�܂�GMA��Intel��GPU�g�b�v�V�F�A�Ȃ��B
>>182
>�P���Ct�\�[�X����َ퍬���̃}���`�R�A�ɑΉ������X���b�h�R�[�h��
�X�^�b�N�Ƃ��l����ƁA�َ퍬���͓���Ǝv��
�g�ݍ��킹�͉��Ɋ��������Ƃ��Ă��R�[�h�ʂ��������Ă��܂��B
�َ퍬���ɂȂ��Ă��܂�����E�E�E
�����V�������W�͓o�ꂹ��GPU�ŏ\����������̕��j�łƂ������_�ɂȂ��Ă��܂����ƁB
���ꂾ����Larrabee�ɉ����\��������̂ł͂ƌ��Ă����ł����B
>�P���Ct�\�[�X����َ퍬���̃}���`�R�A�ɑΉ������X���b�h�R�[�h��
�X�^�b�N�Ƃ��l����ƁA�َ퍬���͓���Ǝv��
�g�ݍ��킹�͉��Ɋ��������Ƃ��Ă��R�[�h�ʂ��������Ă��܂��B
�َ퍬���ɂȂ��Ă��܂�����E�E�E
�����V�������W�͓o�ꂹ��GPU�ŏ\����������̕��j�łƂ������_�ɂȂ��Ă��܂����ƁB
���ꂾ����Larrabee�ɉ����\��������̂ł͂ƌ��Ă����ł����B
>�����I��PC�s���8���̕��y�������߂�o�����[�X����B
�ϑz�Ȃł���݂�ł���
�ϑz�Ȃł���݂�ł���
Larrabee�n�R�A��intel�̃��C����CPU�ɓ�������āA�S���C���i�b�v�ɍ̗p�����Ƃ��ɁA
CPU�V�F�A��8���ێ��ł��Ă�����A�s��V�F�A8���͌����߂邾�낤�ˁB
����GMA���x�̃V�F�A�ł����Ƃ��Ă��A4���͌����߂邵�B
Haswell�Ńx�N�^�R�v���Z�b�T�����炵������A2012�N�����̎������炢�ŁA
�ʏ탉�C����CPU�ł�Larrabee�Ɩ��ߌ݊��ɂȂ��Ȃ����ȁH
CPU�V�F�A��8���ێ��ł��Ă�����A�s��V�F�A8���͌����߂邾�낤�ˁB
����GMA���x�̃V�F�A�ł����Ƃ��Ă��A4���͌����߂邵�B
Haswell�Ńx�N�^�R�v���Z�b�T�����炵������A2012�N�����̎������炢�ŁA
�ʏ탉�C����CPU�ł�Larrabee�Ɩ��ߌ݊��ɂȂ��Ȃ����ȁH
191 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 20:05:02 ID:aVFv7Qpb
>>188
>�َ퍬���͍���
���̒ʂ�B
���������߃Z�b�g���x���Ō݊��Ȃ����������Ă����݂ɏ�����\�B
�ėpIA��Larrabee��512�r�b�gSIMD���߂��A
�t��Larrabee���K�V�[SSE��128-256�r�b�gAVX��
�T�|�[�g������E�͂Ȃ��Ȃ�B
VEX�G���R�[�f�B���O��512-1024�r�b�gSIMD������ɓ��ꂽ�g���B
Larrabee�̖��߃Z�b�g��VEX�����Ȃ�O������̓N���A�B
>�َ퍬���͍���
���̒ʂ�B
���������߃Z�b�g���x���Ō݊��Ȃ����������Ă����݂ɏ�����\�B
�ėpIA��Larrabee��512�r�b�gSIMD���߂��A
�t��Larrabee���K�V�[SSE��128-256�r�b�gAVX��
�T�|�[�g������E�͂Ȃ��Ȃ�B
VEX�G���R�[�f�B���O��512-1024�r�b�gSIMD������ɓ��ꂽ�g���B
Larrabee�̖��߃Z�b�g��VEX�����Ȃ�O������̓N���A�B
192 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 20:11:31 ID:aVFv7Qpb
�����܂ōs������Intel�������ꂻ�����ˁB
194 �F,,�E�L�́M�E,,�j���F2008/08/15(��) 20:24:45 ID:aVFv7Qpb
�Ƃ�����Larrabee�̊g�����߃Z�b�g��ėpIA�ł��T�|�[�g����Ȃ炷��ŁA
�K�R�I��AMD���T�|�[�g���邱�ƂɂȂ�ł���
�Ȃ�SSSE3��SSE4�����Č��ǃT�|�[�g����݂��������B
���������Ӗ����܂߂�95���B
ISA����x86�̎��Y������ȁB�����`�Ԃ͉������Ă����B
�K�R�I��AMD���T�|�[�g���邱�ƂɂȂ�ł���
�Ȃ�SSSE3��SSE4�����Č��ǃT�|�[�g����݂��������B
���������Ӗ����܂߂�95���B
ISA����x86�̎��Y������ȁB�����`�Ԃ͉������Ă����B
"���с["����"����ς�"�݂����ȃL�������ۂ����O����
�������Ȃ�
755 �FMAC�I�^��u ����F2007/10/14(��) 15:13:36 ID:Nd7fT4Az
>>751
�@�@------------------
�@�@Larrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�@�@------------------
�S�����J����Ă��Ȃ��������ǁA����ϑz���Ă��邷���H
756 �Fu�F2007/10/14(��) 15:14:50 ID:Vcf5EqG/
>>755
����Ax86�x�[�X��SSE��512bit�Ɋg�������Ƃł��ϑz���Ă݂�e�X�g�B
�R���10�����O��x86�x�[�X��512bit��������`�B
�������Ă݂�e�X�c(�\�[�X��������������)�B
�l�b�g�ɋv�X�ɂȂ����̂�Larrabee�̘_���݂�̂͂��ꂩ�炾���A
Tera Tera Tera�̎����͓����Ƃ��Ă͌��ʓI�ɂ͌��\�������Ă�����ƁB
��CIDF�̎����ł�HPC�p�r�������Ă��邵�ALarrabee�͔h���̌v������邩�ƁB
Larrabee��Sandy Bridge�͓���ring bus���̗p���Ă�B
Sandy Bridge��AVX��Larrabee�������IDF�ŏo�����Ƃ���
�s���R�������B�܂��ANehalem�̃A�[�L�̏ڍׂ��������Ƃ��낾�����̂�
����Sandy Bridge��AVX�����̃^�C�~���O��??
Nehalem/Tukwila��CSI�̓����A
Sandy Bridge/Poulson��chip��ring bus�̓���
�Ɨ��āA�[�ǂ݂����Larrabee��512bit SIMD��
����Oregon��Haswell�A�[�L�̖��߂̃e�X�g�ŁA����ring bus������
Larrabee�@+�@Sandy Bridge = Haswell
���Ă����W�J�����肩�Ȃ��ƁB
�ŁAAVX�̕�����Ɍ��J���Ȃ���Haswell��512bit��Larrabee�Ə��Ԃ�
����ւ���Č���肷�邩�炩�Ǝv���Ă݂���B
�ϑz�����ǁB
>>751
�@�@------------------
�@�@Larrabee�͑S���Ⴄ�A�[�L�e�N�`�������B
�@�@------------------
�S�����J����Ă��Ȃ��������ǁA����ϑz���Ă��邷���H
756 �Fu�F2007/10/14(��) 15:14:50 ID:Vcf5EqG/
>>755
����Ax86�x�[�X��SSE��512bit�Ɋg�������Ƃł��ϑz���Ă݂�e�X�g�B
�R���10�����O��x86�x�[�X��512bit��������`�B
�������Ă݂�e�X�c(�\�[�X��������������)�B
�l�b�g�ɋv�X�ɂȂ����̂�Larrabee�̘_���݂�̂͂��ꂩ�炾���A
Tera Tera Tera�̎����͓����Ƃ��Ă͌��ʓI�ɂ͌��\�������Ă�����ƁB
��CIDF�̎����ł�HPC�p�r�������Ă��邵�ALarrabee�͔h���̌v������邩�ƁB
Larrabee��Sandy Bridge�͓���ring bus���̗p���Ă�B
Sandy Bridge��AVX��Larrabee�������IDF�ŏo�����Ƃ���
�s���R�������B�܂��ANehalem�̃A�[�L�̏ڍׂ��������Ƃ��낾�����̂�
����Sandy Bridge��AVX�����̃^�C�~���O��??
Nehalem/Tukwila��CSI�̓����A
Sandy Bridge/Poulson��chip��ring bus�̓���
�Ɨ��āA�[�ǂ݂����Larrabee��512bit SIMD��
����Oregon��Haswell�A�[�L�̖��߂̃e�X�g�ŁA����ring bus������
Larrabee�@+�@Sandy Bridge = Haswell
���Ă����W�J�����肩�Ȃ��ƁB
�ŁAAVX�̕�����Ɍ��J���Ȃ���Haswell��512bit��Larrabee�Ə��Ԃ�
����ւ���Č���肷�邩�炩�Ǝv���Ă݂���B
�ϑz�����ǁB
198 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 00:03:54 ID:KySw3NiX
VDPPD��VEX.256�ł��Ȃ����R���ĂȂ낤��
���l���[�h�̓���d�l�����߂��˂Ă�̂��ȂƎv������B
AES/CLMUL�͊�����AVX�ł�摗�肵���ȂƎv�������B
AVX�͈ӊO�Ƌ}�Ɏd�l�̌��܂������߃Z�b�g�����ˁB���͎�������PDF�̒��g�͓����Ƃ����ԕς���Ă�B
���ɐV���������������߂��������SSE5�ɔ킹�Ă��Ă邠����A�p���m�C�A���Ղ�����Ă�B
���l���[�h�̓���d�l�����߂��˂Ă�̂��ȂƎv������B
AES/CLMUL�͊�����AVX�ł�摗�肵���ȂƎv�������B
AVX�͈ӊO�Ƌ}�Ɏd�l�̌��܂������߃Z�b�g�����ˁB���͎�������PDF�̒��g�͓����Ƃ����ԕς���Ă�B
���ɐV���������������߂��������SSE5�ɔ킹�Ă��Ă邠����A�p���m�C�A���Ղ�����Ă�B
199 �FMAC�I�^��u �����F2008/08/16(�y) 00:13:12 ID:ahwTntRl
>>197
�@�@-------------------
�@�@�R���10�����O��x86�x�[�X��512bit��������`�B
�@�@�������Ă݂�e�X�c(�\�[�X��������������)�B
�@�@-------------------
Tera Tera Tera���\�z�ȏ��Larrabee�̍\���������炳�܂ɏ����Ă����̂펖�������ǁA
���̎��_�ł�F�����ǂ�ŋc�_���Ă����悤�ȁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1189626915/769
�@�@===================
�@�@769 ���O�FMAC�I�^ ���e���F2007/10/14(��) 16:58:25 ID:Nd7fT4Az
�@�@�@�@���ϑO��"Tera Tera Tera"�v���[�����������̂ŏ����Ă������B
�@�@�@�@http://xtreview.com/images/davis.pdf
�@�@===================
�@�@-------------------
�@�@�R���10�����O��x86�x�[�X��512bit��������`�B
�@�@�������Ă݂�e�X�c(�\�[�X��������������)�B
�@�@-------------------
Tera Tera Tera���\�z�ȏ��Larrabee�̍\���������炳�܂ɏ����Ă����̂펖�������ǁA
���̎��_�ł�F�����ǂ�ŋc�_���Ă����悤�ȁB�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1189626915/769
�@�@===================
�@�@769 ���O�FMAC�I�^ ���e���F2007/10/14(��) 16:58:25 ID:Nd7fT4Az
�@�@�@�@���ϑO��"Tera Tera Tera"�v���[�����������̂ŏ����Ă������B
�@�@�@�@http://xtreview.com/images/davis.pdf
�@�@===================
Tera Tera Tera��7DP���Ă̂͂Ƃ肠����AVX�ł�
�Ȃ�Ȃ����A�܂��ύX���낤���ǁc�B
�R��͏�CIDF�̎����ɂ������ʂ�A
Sandy Bridge�ł�Load port��������ƌ��Ă���̂ŁA
AVX�̊g�������킹���core�̋K�͂�
Core 2 �� Nehalem
�̊������������邩�ƌ��Ă���̂����B
Yonah �� Merom
�ɋ߂��C���[�W(���ɔėpALU�͑����Ȃ��Ǝv����)�B
Intel��Tick Tock�����n�߂��̂́A
Merom��Nehalem���V�}�C�N���A�[�L�Ƃ������ƂɊi�グ���ꂽ���ƂȂ�ŁA
�{���̈Ӗ��ł�Tick Tock�H����̐V�J���̃}�C�N���A�[�L��
Sandy Bridge��Haswell�ȍ~�B
Core 2��Nehalem�̃p�^�[���͂�����Ɠ���B
�Ȃ�Ȃ����A�܂��ύX���낤���ǁc�B
�R��͏�CIDF�̎����ɂ������ʂ�A
Sandy Bridge�ł�Load port��������ƌ��Ă���̂ŁA
AVX�̊g�������킹���core�̋K�͂�
Core 2 �� Nehalem
�̊������������邩�ƌ��Ă���̂����B
Yonah �� Merom
�ɋ߂��C���[�W(���ɔėpALU�͑����Ȃ��Ǝv����)�B
Intel��Tick Tock�����n�߂��̂́A
Merom��Nehalem���V�}�C�N���A�[�L�Ƃ������ƂɊi�グ���ꂽ���ƂȂ�ŁA
�{���̈Ӗ��ł�Tick Tock�H����̐V�J���̃}�C�N���A�[�L��
Sandy Bridge��Haswell�ȍ~�B
Core 2��Nehalem�̃p�^�[���͂�����Ɠ���B
1024bit��ް
�l�n�[���[���܂��[
Lynnfield��Havendale�̃\�P�b�g�͌��nj݊��ɂ���̂��ǂ��Ȃ̂��A
����Havendale��CPU-GMCH�Ԃ̃o�X��QuickPath���g���̂��ǂ��Ȃ̂����悭�킩��Ȃ��B
���̕ӂȂ���������H
QuickPath���g���Ƃ����16bit/4.8Gbps���x�ł͏]����FSB�ɑ���A�h�o���e�[�W��
�����Ȃ��l�ȋC�͂��邪�A�������x�ł͏��邩������Ȃ����炢���̂��ǂ����B
����Havendale��CPU-GMCH�Ԃ̃o�X��QuickPath���g���̂��ǂ��Ȃ̂����悭�킩��Ȃ��B
���̕ӂȂ���������H
QuickPath���g���Ƃ����16bit/4.8Gbps���x�ł͏]����FSB�ɑ���A�h�o���e�[�W��
�����Ȃ��l�ȋC�͂��邪�A�������x�ł͏��邩������Ȃ����炢���̂��ǂ����B
204 �FSocket774�F2008/08/16(�y) 11:53:27 ID:sq2CuOyc
�b�o�t�̃L���b�V���̃��C�g�o�b�N����ɂ��ċ����Ă��������B
���C�g�o�b�N���ƁA�ΏۃG���g���ɃE�F�C���ȏ�̃t���[���A�h���X�̃��[�h�E���C�g���������ꍇ��
���C�g�o�b�N�����炵���ł����A
�E�F�C���̈Ӗ����悭�킩��܂���B
���̂ւ�̎d�g�݂���������T�C�g�Ƃ�����܂����H
����͂���Ⴂ�ł����H
���C�g�o�b�N���ƁA�ΏۃG���g���ɃE�F�C���ȏ�̃t���[���A�h���X�̃��[�h�E���C�g���������ꍇ��
���C�g�o�b�N�����炵���ł����A
�E�F�C���̈Ӗ����悭�킩��܂���B
���̂ւ�̎d�g�݂���������T�C�g�Ƃ�����܂����H
����͂���Ⴂ�ł����H
�@�@ �@ �@ �Q�Q�Q_
�@�@�@�@�^�@�@�b�V�@�_
�@�@ �^�@�@���@ �@ ���_
�@�^ �@�@ �i���j�@�i���j�@�_
�@|�@ �@�@ �@ �i__�l__�j�@ �@ |
�@�_�@�@�@�@ �M �܁L�@�@ �^
,,.....�C.�R�R�A___ �[�[�m�-�.
:�@ �@| �@';�@�______ �m.| �R�@i
�@ �@ |�@�@�_/ށi__)�_,| �@i�@|
�@ �@ ���@�@ �R. �n�@ | �@ |�b
�@�@�@�@�^�@�@�b�V�@�_
�@�@ �^�@�@���@ �@ ���_
�@�^ �@�@ �i���j�@�i���j�@�_
�@|�@ �@�@ �@ �i__�l__�j�@ �@ |
�@�_�@�@�@�@ �M �܁L�@�@ �^
,,.....�C.�R�R�A___ �[�[�m�-�.
:�@ �@| �@';�@�______ �m.| �R�@i
�@ �@ |�@�@�_/ށi__)�_,| �@i�@|
�@ �@ ���@�@ �R. �n�@ | �@ |�b
206 �FMAC�I�^��204 �����F2008/08/16(�y) 12:09:58 ID:ahwTntRl
>>204
�@�@------------------
�@�@�E�F�C���ȏ�̃t���[���A�h���X�̃��[�h�E���C�g���������ꍇ�Ƀ��C�g�o�b�N�����
�@�@------------------
�w�������ɏ����o�����x�̊ԈႢ���B���C�g�o�b�N��A�L���b�V���ɏ������܂ꂽ���e��K�v�ɔ�����
���A�������ɏ������܂Ȃ����삷�B
�@�@------------------
�@�@�E�F�C���̈Ӗ����悭�킩��܂���B
�@�@���̂ւ�̎d�g�݂���������T�C�g�Ƃ�����܂����H
�@�@------------------
http://journal.mycom.co.jp/column/architecture/006/index.html
http://journal.mycom.co.jp/column/architecture/007/index.html
http://journal.mycom.co.jp/column/architecture/008/index.html
�@�@------------------
�@�@�E�F�C���ȏ�̃t���[���A�h���X�̃��[�h�E���C�g���������ꍇ�Ƀ��C�g�o�b�N�����
�@�@------------------
�w�������ɏ����o�����x�̊ԈႢ���B���C�g�o�b�N��A�L���b�V���ɏ������܂ꂽ���e��K�v�ɔ�����
���A�������ɏ������܂Ȃ����삷�B
�@�@------------------
�@�@�E�F�C���̈Ӗ����悭�킩��܂���B
�@�@���̂ւ�̎d�g�݂���������T�C�g�Ƃ�����܂����H
�@�@------------------
http://journal.mycom.co.jp/column/architecture/006/index.html
http://journal.mycom.co.jp/column/architecture/007/index.html
http://journal.mycom.co.jp/column/architecture/008/index.html
207 �FSocket774�F2008/08/16(�y) 12:27:57 ID:wuVElUXl
�R�[�h�l�[����������P���J����
>>205
cool
cool
>>205
cute
cute
210 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 13:24:47 ID:KySw3NiX
>>204
CQ�o�ŎЂ̃}�C�N���v���Z�b�T�A�[�L�e�N�`������ł���
��������NetBurst����L1�f�[�^�L���b�V���̓��C�g�X���[����������
�X�g���[���v���Z�b�T�Ƃ��Ă͂������̂ق��������Ă��
CQ�o�ŎЂ̃}�C�N���v���Z�b�T�A�[�L�e�N�`������ł���
��������NetBurst����L1�f�[�^�L���b�V���̓��C�g�X���[����������
�X�g���[���v���Z�b�T�Ƃ��Ă͂������̂ق��������Ă��
>>160�Œc�q���w�E���������̕�������
http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
http://www.canardplus.com/img/dossier/divers/idf2008/snb-05b.jpg
����3�I�y�����h�A4�I�y�����h�̂��Ƃ����������������ăI�`����Ȃ����ȁB
���傤�ǘR�ꂽ�X���C�h�̏��Ԃɂ����Ă邵�B
http://www.extremetech.com/slideshow/0,2850,pg%253D0%2526s%253D27771%2526a%253D230963,00.asp
http://www.canardplus.com/img/dossier/divers/idf2008/snb-05b.jpg
{kind=link}
����3�I�y�����h�A4�I�y�����h�̂��Ƃ����������������ăI�`����Ȃ����ȁB
���傤�ǘR�ꂽ�X���C�h�̏��Ԃɂ����Ă邵�B
���T�C�g��URL�R�s�y���s�������B
http://www.canardplus.com/dossier-35-200-Processeur_de_Nehalem_a_Haswell.html
�������������B
http://www.canardplus.com/dossier-35-200-Processeur_de_Nehalem_a_Haswell.html
�������������B
>>210
�N���b�N�������ɏオ���ăL���b�V�����ǂ�ǂ��Ȃ��
�킴�킴���C�g�o�b�N�ɂ���K�v���Ȃ��Ȃ���Ĕ��f��������Ȃ��H
�N���b�N�������ɏオ���ăL���b�V�����ǂ�ǂ��Ȃ��
�킴�킴���C�g�o�b�N�ɂ���K�v���Ȃ��Ȃ���Ĕ��f��������Ȃ��H
214 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 17:58:47 ID:KySw3NiX
>>210
����A����ς������̂ق������R���ȁB
>>213
�t�ɂ��̒�C�e���V�̓��C�g�X���[����Ȃ��Ɩ������ƁB
Larrabee�����C�g�X���[�ł�����ˁH
�ƈ�u�v�������A���L�L���b�V�����ƂԂ牺�����Ă�R�A�S�Ă�
�X�g�A���W�����邩��ш悪�s�������ˁB
����A����ς������̂ق������R���ȁB
>>213
�t�ɂ��̒�C�e���V�̓��C�g�X���[����Ȃ��Ɩ������ƁB
Larrabee�����C�g�X���[�ł�����ˁH
�ƈ�u�v�������A���L�L���b�V�����ƂԂ牺�����Ă�R�A�S�Ă�
�X�g�A���W�����邩��ш悪�s�������ˁB
215 �F,,�E�L�́M�E,,�j���F2008/08/16(�y) 18:25:19 ID:KySw3NiX
Intrinsics Guide for Intel AVX���āAFMA�Ȃ̎d�l��PDF�ƈႤ���ˁH
GNU binutils�̃R�~�b�g���O�������ł́A319433-002�̕��������݂��������B
GNU binutils�̃R�~�b�g���O�������ł́A319433-002�̕��������݂��������B
>>197
512bit���Ă��Ƃ�8ch�������ɂ�����Ă��ƁH����Ƃ������r�[�̏������L���b�V��
�����𗊂�ɂ�����Ă��ƁH�Ⴕ���̓}�U�[�ɃI���{�[�h���߂�VGA�̂悤�Ȍ`���
������Ă��ƁH
512bit���Ă��Ƃ�8ch�������ɂ�����Ă��ƁH����Ƃ������r�[�̏������L���b�V��
�����𗊂�ɂ�����Ă��ƁH�Ⴕ���̓}�U�[�ɃI���{�[�h���߂�VGA�̂悤�Ȍ`���
������Ă��ƁH
217 �F,,�E�L��`�E,,�j��-�������F2008/08/17(��) 12:06:31 ID:s6626r8s
�㓡��XDR�ςނ�������Ȃ��Ƃ������Ă�����
����GDDR5���ĉ\�����B
�������ш�ɂ��Ă͂��̍\�����q���g���ȁH
http://journal.mycom.co.jp/articles/2008/08/13/siggraph02/001.html
����GDDR5���ĉ\�����B
�������ш�ɂ��Ă͂��̍\�����q���g���ȁH
http://journal.mycom.co.jp/articles/2008/08/13/siggraph02/001.html
�����o���l�Ԃ͂��܂��ܒ������ƍ�悳�����
1TB/���������H������XDR�ň�C�ɐ��\�����Ă��ꂽ�������ꂵ����Ȃ��́H
1TB/���������H������XDR�ň�C�ɐ��\�����Ă��ꂽ�������ꂵ����Ȃ��́H
�����I�ɂ�XDR2���Ǝv�����ǁA��悾���̔�r�Ȃ�GDDR5�����\�Ȑ��i������ȁB
������SF�ɍs���B
�����Ă�����Ⴂ
222 �FSocket774�F2008/08/18(��) 02:09:13 ID:vy2LCed0
XDR���Ăo�r�R�Ŏg���Ă��H
���������AXDR2���Ăǂ��Ȃ�����ł��傤�˂��B
�\�肶��2007�N�㔼���琻���J�n?�������悤�ȁE�E�E
�Ȃ���PS4�i�I�H�j������2011�N���炢�܂œ����Ȃ��ł��傤�ˁB
�\�肶��2007�N�㔼���琻���J�n?�������悤�ȁE�E�E
�Ȃ���PS4�i�I�H�j������2011�N���炢�܂œ����Ȃ��ł��傤�ˁB
Core i7���Ȃ�C�ɂȂ��Ă����ł���
�������͂P�O���Ƃ����ϑ��݂����ł����A
���������A�b�o�t���P�̔����H����Ă���
�X���̃��[�J�|�o�b��ʔ̂̂a�s�n�̂o�b�ɓ��ڂ����܂ł̊���
���Ăǂ̂��炢�łȂ낤�HCore 2�̂Ƃ��Ƃ��ǂ��������̂��낤�E�E�B
�������͂P�O���Ƃ����ϑ��݂����ł����A
���������A�b�o�t���P�̔����H����Ă���
�X���̃��[�J�|�o�b��ʔ̂̂a�s�n�̂o�b�ɓ��ڂ����܂ł̊���
���Ăǂ̂��炢�łȂ낤�HCore 2�̂Ƃ��Ƃ��ǂ��������̂��낤�E�E�B
>>224
�����͎������Ȃ��������ȁH
�����͎������Ȃ��������ȁH
�������
�����ł������B�������痈���̂ł悭�킩������B
�ʂ̂Ƃ��T���Č��܂��E�E�B�ǂ����A�����킪�����܂����B
�ʂ̂Ƃ��T���Č��܂��E�E�B�ǂ����A�����킪�����܂����B
Nehalem�̏����ւ��߂��悤�ŁAHexus��Bloomfield/2.93GHz + x58�̃V�X�e�����AQX9770 (Penryn
/3.2GHz), QX6800 (Conroe/2.93GHz), Phenom 9950 (K8L/2.6GHz)�Ɣ�r���Ă��邷�B
http://www.hexus.net/content/item.php?item=15015
�Q�[���x���`�̌��ʂ�Core2��舫���悤�ŁA�܂�GPU���܂ރV�X�e���S�̂Ƃ��Ă��肪�c��
�悤�����ǁAL2�����Ȃ��Ȃ����s���튴���Ȃ����ʂ̗l���B
/3.2GHz), QX6800 (Conroe/2.93GHz), Phenom 9950 (K8L/2.6GHz)�Ɣ�r���Ă��邷�B
http://www.hexus.net/content/item.php?item=15015
�Q�[���x���`�̌��ʂ�Core2��舫���悤�ŁA�܂�GPU���܂ރV�X�e���S�̂Ƃ��Ă��肪�c��
�悤�����ǁAL2�����Ȃ��Ȃ����s���튴���Ȃ����ʂ̗l���B
SMT�̉e�����H
Vantage��RAR�A64bit���ł͒������D�G�����A�Ȃ悭������Ȃ��ȁB
�������̑ш��}�U�[���k�t�H��������Ƃ�P45�g������Ęb�����E�E�E�B
Vantage��RAR�A64bit���ł͒������D�G�����A�Ȃ悭������Ȃ��ȁB
�������̑ш��}�U�[���k�t�H��������Ƃ�P45�g������Ęb�����E�E�E�B
�����[
DDR3-1066 7-7-7-20�̃w�i�`���R�ݒ�ł������܂Ő��\�ł�̂��E�E�E�E�E�E
���{���ɒ�FSB�łǂ��Ȃ邩�Ǝv���Ă����ǁA�e�������̂��E�E�E
FSB�Ƃ͏����Ă͂��邪�A�V�X�e���̃x�[�X�̃N���b�N�Ƃ�������������A���̉e�����Ȃ����낤�B
100MHz���x�[�X�ɂ�����133MHz�ɂ����̂̓������N���b�N�Ƃ̌��ˍ������B
100MHz���x�[�X�ɂ�����133MHz�ɂ����̂̓������N���b�N�Ƃ̌��ˍ������B
��L2�����Ȃ��Ȃ����s���튴���Ȃ����ʂ̗l���B
���������s���ɂȂ����̂��H
���܂ł�L1�����镔���͋��LL2�ő����������Ă��̂�
��pL2�œƐ�I�Ɏg����e�ʑ��������L���Ȃ�H
���������s���ɂȂ����̂��H
���܂ł�L1�����镔���͋��LL2�ő����������Ă��̂�
��pL2�œƐ�I�Ɏg����e�ʑ��������L���Ȃ�H
�`�b�v�Z�b�g��o�X�̕��ɖ�肪����悤�ȁB
�悭�킩��ǃQ�[���ɂ����g��Ȃ����͑҂�����E8600�����Ă�����H
3DMark Vantage CPU Score
Bloomfield 2.93GHz�AYorkfield 3.2GHz
17505�A13448
OC������E�E�Ewktk
Bloomfield 2.93GHz�AYorkfield 3.2GHz
17505�A13448
OC������E�E�Ewktk
core2��DDR3-1600���ڂ��Ă�E�E�E�Ȃ��1066�ɓ��ꂵ�Ȃ�����
�Q�[����Quake�ȊO�͏����ɐL�тĂ���Č��ėǂ���Ȃ���
�Q�[����Quake�ȊO�͏����ɐL�тĂ���Č��ėǂ���Ȃ���
>>238
�����������܂Ő��\�ɉe�����Ȃ����炻��͂Ȃ��B
�����������܂Ő��\�ɉe�����Ȃ����炻��͂Ȃ��B
>>238
CPU Score�������̂ɁAVanatage Score���Ⴂ���牽�����炠��ƍl����ق����������B
CPU Score�������̂ɁAVanatage Score���Ⴂ���牽�����炠��ƍl����ق����������B
>>240
http://journal.mycom.co.jp/special/2008/3dvan/003.html
Vanatage��CPU�e�X�g�͓Ǝ�AI��Test1�ƕ������Z��Test2��
Vantage��Game�e�X�g����Q�[������CPU�̏������e�Ƃ͑S���̕ʕ��B
http://journal.mycom.co.jp/special/2008/3dvan/003.html
Vanatage��CPU�e�X�g�͓Ǝ�AI��Test1�ƕ������Z��Test2��
Vantage��Game�e�X�g����Q�[������CPU�̏������e�Ƃ͑S���̕ʕ��B
CPU�X�R�A��Pen4�ł�HT�������L����3���L�т邩�炻��Ȃ���
>>241
����A��������Ȃ���CPU Score�������̂�Vantage Score���Ⴂ�Ƃ������Ƃ́A
�`�b�v�Z�b�g��PCI-Ex2.0�ɖ�������Ă�\����������Ă��Ƃ��B
����A��������Ȃ���CPU Score�������̂�Vantage Score���Ⴂ�Ƃ������Ƃ́A
�`�b�v�Z�b�g��PCI-Ex2.0�ɖ�������Ă�\����������Ă��Ƃ��B
���ӏ������������E�E�E
�uX48����DDR3-1600�����蓮�삵�Ȃ���������nforce790���g�����B�v�����āB
�uX48����DDR3-1600�����蓮�삵�Ȃ���������nforce790���g�����B�v�����āB
�����VGA�g���ĂāACPU Score�́A4���قǍ����̂�Vantage Score���������Ă�B
����̈Ӗ��������ł��邩�ȁH
����̈Ӗ��������ł��邩�ȁH
Nehalem���x���Ȃ�A�𑜓x���Ⴂ�ق��ō����o��͂��B
QPI���_���ȂȂ�
QPI���_���ȂȂ�
��[�AQPI���_����������Ȃ�A�Ђ���Ƃ���Apple��NVIDIA�`�b�v�Z�b�g�g��
��������rumor�AQPI�Ή���nForce���g�����Ă��Ƃ��ˁH
�܂�HyperTransport�Ōo����ł镪�AIntel���NVIDIA�Ƃ�Broadcom�̕���
(�����) QPI�Ή��`�b�v�Z�b�g�̐��\�悳���������B
���Ȃ��Ƃ��ŏ��̐���́B
��������rumor�AQPI�Ή���nForce���g�����Ă��Ƃ��ˁH
�܂�HyperTransport�Ōo����ł镪�AIntel���NVIDIA�Ƃ�Broadcom�̕���
(�����) QPI�Ή��`�b�v�Z�b�g�̐��\�悳���������B
���Ȃ��Ƃ��ŏ��̐���́B
249 �F,,�E�L�́M�E,,�j���F2008/08/19(��) 22:59:36 ID:wyv3H8Wc
Larrabee��FP�����Z�̓��C�e���V1�T�C�N���̒����\�I
�����Đl�ɎӍ߂��Ȃ�MAC�I�^��搶�̌��t������ԈႢ�Ȃ��B
�����Đl�ɎӍ߂��Ȃ�MAC�I�^��搶�̌��t������ԈႢ�Ȃ��B
����ς�Nehalem��64�r�b�g���\����������Ă��
Core�@2�͂������APhenom���ǂ��l���łĂ�
��64�r�b�g�ł̑�32�r�b�g�Ő��\��(Core 2��QX9770�̌���)
�ECineBench
Core i7:122.9%/Core 2:112.9%/Phenom:119.5%
�EPov-Ray
Core i7: 98.5%/Core 2: 90.9%/Phenom: 96.0%
Core�@2�͂������APhenom���ǂ��l���łĂ�
��64�r�b�g�ł̑�32�r�b�g�Ő��\��(Core 2��QX9770�̌���)
�ECineBench
Core i7:122.9%/Core 2:112.9%/Phenom:119.5%
�EPov-Ray
Core i7: 98.5%/Core 2: 90.9%/Phenom: 96.0%
�����͂���Ă��邪�AAMD64�g������������������64bit���ł̐��\����͑S�̓I�ɂ�͂�Ⴂ�B
���X�����Ă������������Ȃ̂����E�E�E�E�E
���X�����Ă������������Ȃ̂����E�E�E�E�E
�������Đl�ɎӍ߂��Ȃ�MAC�I�^��搶�̌��t������ԈႢ�Ȃ��B
���O�������Ȃ�
���O�������Ȃ�
32��64bit�̐L�т�Phenom���������̂��B
VGA�̕s��i�H�j�������Ăق������̂����B
VGA�̕s��i�H�j�������Ăق������̂����B
Nehalem�X���b�h�ŏЉ��Ă��������ǁAAnandtech��Gelsinger�L�[�m�[�g�E���C�u���|�[�g���B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3377
�@- Dunnington��TPC-C��over 10,000 tpm
�@- �ȓd�͐����v���Z�X (�ŏI�z���w�Ɛړ_�̒��R���A�����[���[�N�g�����W�X�^)
�@- Nehalem��d�͊Ǘ��p�}�C�R��������B�d���E�d���E�d�́E����N���b�N�����j�^
�@�@�����BIOS�ɂăv���O����
�@- PLL��R�A���ƂɓƗ��B�R�A�P�ʂœd��ON/OFF��
�@- Nehalem Turbo Mode: ����R�A�������炵��OC
�@- �T�[�o�[����Nehalem�}�U�[��DDR3 MetaRAM�f��
�@- Havendale�}�U�[��LostPlanet�f���B���N���b�N��Yorkfield���+50%
�@- ���o�C��Nehalem, "Calpella"��2 or 4-core�ŗ��N�o��
�@- GM45�����O���t�B�b�N��NvidiaGPU�̐�ւ��f�� (���b������炵��)
�@- �o�b�e���݂̂�BluRay���[�r�[2���ԍĐ�
�@- WiMAX���ڃm�[�g�퍡�NQ4��7�Ђ�蔭��
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3377
�@- Dunnington��TPC-C��over 10,000 tpm
�@- �ȓd�͐����v���Z�X (�ŏI�z���w�Ɛړ_�̒��R���A�����[���[�N�g�����W�X�^)
�@- Nehalem��d�͊Ǘ��p�}�C�R��������B�d���E�d���E�d�́E����N���b�N�����j�^
�@�@�����BIOS�ɂăv���O����
�@- PLL��R�A���ƂɓƗ��B�R�A�P�ʂœd��ON/OFF��
�@- Nehalem Turbo Mode: ����R�A�������炵��OC
�@- �T�[�o�[����Nehalem�}�U�[��DDR3 MetaRAM�f��
�@- Havendale�}�U�[��LostPlanet�f���B���N���b�N��Yorkfield���+50%
�@- ���o�C��Nehalem, "Calpella"��2 or 4-core�ŗ��N�o��
�@- GM45�����O���t�B�b�N��NvidiaGPU�̐�ւ��f�� (���b������炵��)
�@- �o�b�e���݂̂�BluRay���[�r�[2���ԍĐ�
�@- WiMAX���ڃm�[�g�퍡�NQ4��7�Ђ�蔭��
�@- Dunnington��TPC-C��over 10,000 tpm
100���ł́H
100���ł́H
3DMark Vantage CPU Score
Bloomfield 2.93GHz�F 17500(3.2GHz�̏ꍇ �v�Z��ł� 19100)��Extreme����QPI�̑��x���Ⴄ���߁A�ǂ��Ȃ邩�͕�����Ȃ��B
Yorkfield 3.2GHz�F 13450
Kentsfield 3.2GHz�F 11500
Kentsfield*1.17�{��Yorkfield
Yorkfield*1.42�{��Bloomfield
Kentsfield*1.66�{��Bloomfield
����Ȋ������B
Bloomfield 2.93GHz�F 17500(3.2GHz�̏ꍇ �v�Z��ł� 19100)��Extreme����QPI�̑��x���Ⴄ���߁A�ǂ��Ȃ邩�͕�����Ȃ��B
Yorkfield 3.2GHz�F 13450
Kentsfield 3.2GHz�F 11500
Kentsfield*1.17�{��Yorkfield
Yorkfield*1.42�{��Bloomfield
Kentsfield*1.66�{��Bloomfield
����Ȋ������B
Dunnington�炵�����̂�TPC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108081902
IBM System x3950 M2 X7460 2.66GHz 6*8=48��
�@1,200,632 tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108081901
HP ProLiant DL580G5 X7460 2.67GHz 6*4=24��
�@634,825 tpmC
�Q�l
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108071301
HP ProLiant DL585G5/2.5GHz 4*4=16��
�@471,883 tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108081902
IBM System x3950 M2 X7460 2.66GHz 6*8=48��
�@1,200,632 tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108081901
HP ProLiant DL580G5 X7460 2.67GHz 6*4=24��
�@634,825 tpmC
�Q�l
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=108071301
HP ProLiant DL585G5/2.5GHz 4*4=16��
�@471,883 tpmC
261 �FMAC�I�^��258 �����F2008/08/20(��) 18:42:34 ID:Qtm6YmZc
>>258
�������ӂ��邷�B���ɂ�����ԈႢ�݂������B
�@(��) - ���o�C��Nehalem, "Calpella"��2 or 4-core�ŗ��N�o��
�@(��) - ���o�C��Nehalem "Clarksfield"��"Aubumdale"��Calpella�v���b�g�t�H�[���œo��
�������ӂ��邷�B���ɂ�����ԈႢ�݂������B
�@(��) - ���o�C��Nehalem, "Calpella"��2 or 4-core�ŗ��N�o��
�@(��) - ���o�C��Nehalem "Clarksfield"��"Aubumdale"��Calpella�v���b�g�t�H�[���œo��
IDF�̃T�C�g���痎�Ƃ���ڂڂ����v���[���������B
Nehalem�̊T�v�ƒ����d�͋@�\
http://intel.wingateweb.com/US08/published/sessions/TCHS001/SF08_TCHS001_100t.pdf
��L�����������{�����[���̂���o�[�W����
http://intel.wingateweb.com/US08/published/sessions/NGMS001/SF08_NGMS001_100s.pdf
Atom�ƐV�`�b�v�Z�b�gUS15W
http://intel.wingateweb.com/US08/published/sessions/EMBS003/SF08_EMBS003_100p.pdf
DDR3���[�h�}�b�v
http://intel.wingateweb.com/US08/published/sessions/MASS006/SF08_MASS006_100s.pdf
���o�C�����[�h�}�b�v
http://intel.wingateweb.com/US08/published/sessions/MPTS001/SF08_MPTS001_100r.pdf
PCIe 3.0����
http://intel.wingateweb.com/US08/published/sessions/PCIS002/SF08_PCIS002_100p.pdf
Larrabee
http://intel.wingateweb.com/US08/published/sessions/VCTS001/SF08_VCTS001_100s.pdf
Ct
http://intel.wingateweb.com/US08/published/sessions/VCTS004/SF08_VCTS004_100p.pdf
Nehalem�̊T�v�ƒ����d�͋@�\
http://intel.wingateweb.com/US08/published/sessions/TCHS001/SF08_TCHS001_100t.pdf
��L�����������{�����[���̂���o�[�W����
http://intel.wingateweb.com/US08/published/sessions/NGMS001/SF08_NGMS001_100s.pdf
Atom�ƐV�`�b�v�Z�b�gUS15W
http://intel.wingateweb.com/US08/published/sessions/EMBS003/SF08_EMBS003_100p.pdf
DDR3���[�h�}�b�v
http://intel.wingateweb.com/US08/published/sessions/MASS006/SF08_MASS006_100s.pdf
���o�C�����[�h�}�b�v
http://intel.wingateweb.com/US08/published/sessions/MPTS001/SF08_MPTS001_100r.pdf
PCIe 3.0����
http://intel.wingateweb.com/US08/published/sessions/PCIS002/SF08_PCIS002_100p.pdf
Larrabee
http://intel.wingateweb.com/US08/published/sessions/VCTS001/SF08_VCTS001_100s.pdf
Ct
http://intel.wingateweb.com/US08/published/sessions/VCTS004/SF08_VCTS004_100p.pdf
ttp://www.theinquirer.net/gb/inquirer/news/2008/08/20/nvidia-announce-x86-chip
Nvidia to announce x86 chip next week
Not IDF San Francicsco So say the whispers
�͂Ă���
Nvidia to announce x86 chip next week
Not IDF San Francicsco So say the whispers
�͂Ă���
264 �FMAC�I�^��263 �����F2008/08/20(��) 21:53:02 ID:Qtm6YmZc
>>263
Nvidia�����B�B�B�������C���v���Z�b�T��nano��CELL/B.E.�̓�𓋍ڂ��āAGPU�����L����
�wPS3�݊��p�\�R���x�ł���悷�邵��������Ȃ������ˁB
Nvidia�����B�B�B�������C���v���Z�b�T��nano��CELL/B.E.�̓�𓋍ڂ��āAGPU�����L����
�wPS3�݊��p�\�R���x�ł���悷�邵��������Ȃ������ˁB
Nvidia���C�Z���X�����ł���B
266 �FMAC�I�^��265 �����F2008/08/20(��) 22:01:44 ID:Qtm6YmZc
>>265
�@�@---------------
�@�@Nvidia���C�Z���X�����ł���B
�@�@---------------
�����ɂ풆�������Ŕ̔�����Ƃ��E���g��C���l���Ă���̂����B�B�B
�@�@---------------
�@�@Nvidia���C�Z���X�����ł���B
�@�@---------------
�����ɂ풆�������Ŕ̔�����Ƃ��E���g��C���l���Ă���̂����B�B�B
>>266
�����͗��S�H�Ƃ������݊��i�p�N���j�v���Z�b�T���Ȃ��������H
�����͗��S�H�Ƃ������݊��i�p�N���j�v���Z�b�T���Ȃ��������H
�����ł�����������PS3�݊��p�\�R����������
269 �FMAC�I�^��268 �����F2008/08/21(��) 07:48:25 ID:VXg3bKBV
>>268
PS3�݊��p�\�R���̘b�̕���Ax86���C�Z���X�ƊW�����l�^�Ȃ��ǁB�B�B
PS3�݊��p�\�R���̘b�̕���Ax86���C�Z���X�ƊW�����l�^�Ȃ��ǁB�B�B
>>262�Ɉ��������A�lj����ꂽ�����̂����ʔ������ȃ��m���B
Canmore
http://intel.wingateweb.com/US08/published/sessions/CETS003/SF08_CETS003_100r.pdf
Nehalem�Ή��}�U�[�v
http://intel.wingateweb.com/US08/published/sessions/DPTS001/SF08_DPTS001_100s.pdf
Nehalem�Ή��œK��
http://intel.wingateweb.com/US08/published/sessions/NGMS002/SF08_NGMS002_100r.pdf
AVX���
http://intel.wingateweb.com/US08/published/sessions/NGMS003/SF08_NGMS003_100t.pdf
Tolapi
http://intel.wingateweb.com/US08/published/sessions/QATS001/SF08_QATS001_100p.pdf
Canmore
http://intel.wingateweb.com/US08/published/sessions/CETS003/SF08_CETS003_100r.pdf
Nehalem�Ή��}�U�[�v
http://intel.wingateweb.com/US08/published/sessions/DPTS001/SF08_DPTS001_100s.pdf
Nehalem�Ή��œK��
http://intel.wingateweb.com/US08/published/sessions/NGMS002/SF08_NGMS002_100r.pdf
AVX���
http://intel.wingateweb.com/US08/published/sessions/NGMS003/SF08_NGMS003_100t.pdf
Tolapi
http://intel.wingateweb.com/US08/published/sessions/QATS001/SF08_QATS001_100p.pdf
271 �F,,�E�L�́M�E,,�j���F2008/08/22(��) 03:46:06 ID:6R6YXCRn
http://pc.watch.impress.co.jp/docs/2008/0822/kaigai461.htm
Ct�ɂ��Ă�>>182������ɏ��������Ƃ��h���s�V���B
Larrabee�V���߂͂ǂ����������߂Ƃ�Opcode�H������Ȃ��炵��
�i��512�r�b�g��AVX���̂��̂̐�s�����̉\����j
Larrabee�̈ʒu�Â��Ƃ����A���ǂꂾ���G�X�p�[����
���܂�ɗ\�z�������肷���ĂĂ����������ˁ[
Ct�ɂ��Ă�>>182������ɏ��������Ƃ��h���s�V���B
Larrabee�V���߂͂ǂ����������߂Ƃ�Opcode�H������Ȃ��炵��
�i��512�r�b�g��AVX���̂��̂̐�s�����̉\����j
Larrabee�̈ʒu�Â��Ƃ����A���ǂꂾ���G�X�p�[����
���܂�ɗ\�z�������肷���ĂĂ����������ˁ[
272 �FSocket774�F2008/08/22(��) 05:58:11 ID:EMyXN76K
�܂Ƃ߂ɁA���܂킵�ŃR�P�����ď����Ă��
�Ⴆ��H.264�AVC-1�����Đ�����ꍇ�ɂ�
larrabee�ł͊����CPU(?)���g���A�f�R�[�h�������̓d�͂�����邪
ATI,S3,nVIDIA�ł͍Đ���p�̉�H���g�������d�͂ł��Ȃ��B
�Ⴆ��ATI,S3,nVIDIA�̃e�b�Z���[�^�́A�P���ȌŒ�@�\�ō����ɏ����ł���̂�
larrabee�ł͊����CPU(?)�R�A���g��Ȃ���A�����̃p�t�H�[�}���X�͓����Ȃ��B
larrabee�ł͊����CPU(?)���g���A�f�R�[�h�������̓d�͂�����邪
ATI,S3,nVIDIA�ł͍Đ���p�̉�H���g�������d�͂ł��Ȃ��B
�Ⴆ��ATI,S3,nVIDIA�̃e�b�Z���[�^�́A�P���ȌŒ�@�\�ō����ɏ����ł���̂�
larrabee�ł͊����CPU(?)�R�A���g��Ȃ���A�����̃p�t�H�[�}���X�͓����Ȃ��B
GPU�Ƃ��Ă̓~�h�������W�̐��\�ɓ͂����炢�ł��\�����낤�Ƃ��v���Ă�����
�\�t�g�����̊����������ƃ��[�G���h�̐��\�ɂ���͂��̂��������Ȃ��Ă���ȁB
�\�t�g�����̊����������ƃ��[�G���h�̐��\�ɂ���͂��̂��������Ȃ��Ă���ȁB
�傫�Ȗ��Ƃ��āA���̃~�h�����݂�GPU���ǂ̒��x�̋K�͂Ŏ����\�Ȃ̂�
�Ⴆ��GTX280���݂̋K�͂�9600GT���x�̃p�t�H�[�}���X���Ƃ����甃�����ˁH
�Ⴆ��GTX280���݂̋K�͂�9600GT���x�̃p�t�H�[�}���X���Ƃ����甃�����ˁH
>>273
Cell�Ɠ��������Ă�C������Ȃ��BIntel���ˁB
Cell�Ɠ��������Ă�C������Ȃ��BIntel���ˁB
277 �FSocket774�F2008/08/22(��) 17:06:08 ID:+nf3dF7d
>>275
�l�i���悶��Ȃ����H
2010�N�̃~�h���͒x���Ă�HD4850�N���X��1���~�ʂ��낤����A����Ƃ̔�r�łǂ������ȁB
�������A�⏕�d�������Ńt�@�����X���Œ���������ȁB
�l�i���悶��Ȃ����H
2010�N�̃~�h���͒x���Ă�HD4850�N���X��1���~�ʂ��낤����A����Ƃ̔�r�łǂ������ȁB
�������A�⏕�d�������Ńt�@�����X���Œ���������ȁB
���e��TSMC�Ƀv���Z�X������Ă�̂��ɂ���
�P��GPU�s�v����������Intel�ł�Larabbe�y������ׂɂ�GPU�Ƃ��ē������Ȃ����Ⴂ���Ȃ����Ă̂�����Șb����
�ł�ATi�̂ƈ����nVidia��GPU������剻���Ă邩��AIntel������GPCPU�_����
nVidia�ƂȂ�A���\�R�o����̂ł́H
nVidia�ƂȂ�A���\�R�o����̂ł́H
���āA�t���v���O���}�u����larrabee�̃p�t�H�[�}���X���@���قǂ�
���ɐ��i�ł�larrabee�̃p�t�H�[�}���X��2Tflops�Ƃ��܂��傤��
�����GPU�ɂ�����shader�݂̂Ȃ炸�A�����̌Œ�@�\�Ƃ��Ă�����U�邱�ƂɂȂ�킯����
�܂肱��́APS3�ł悭�l�^�Ɏg����RSX��1.8Tflops�Ɠ��������ɂȂ�킯��
�܂��A�e�N�X�`���֘A��(�ǂ��܂ł��͒m��Ȃ���)�n�[�h�Őςނ悤������
RSX��葽���̓}�V�Ȃ̂��ˁH
���ɐ��i�ł�larrabee�̃p�t�H�[�}���X��2Tflops�Ƃ��܂��傤��
�����GPU�ɂ�����shader�݂̂Ȃ炸�A�����̌Œ�@�\�Ƃ��Ă�����U�邱�ƂɂȂ�킯����
�܂肱��́APS3�ł悭�l�^�Ɏg����RSX��1.8Tflops�Ɠ��������ɂȂ�킯��
�܂��A�e�N�X�`���֘A��(�ǂ��܂ł��͒m��Ȃ���)�n�[�h�Őςނ悤������
RSX��葽���̓}�V�Ȃ̂��ˁH
�R�A16��2GHz����Ƃ��Ă�1TFlops�B
2�N��Ƀg�[�^��1tflops��
�ƂĂ����[�G���h��GPU�ł���
6,000�~�ʂŔ����邩��
�ƂĂ����[�G���h��GPU�ł���
6,000�~�ʂŔ����邩��
�@�@�@�@|���O�@�@�@�@,�, (f�[--���]- ��A
�@�@�@�@|��.�@ �@ ,�/�V�@�@�@�@�@�@�@�@�S= �A
�@�@�@�@|���@�@ N �o�@�@�@�@�@ �@ �@ �@ �@ �@ �_
�@�@�@�@|���@ �.l �R�@�@�@�@�@�@�@�@�@�@�@�@�@�@ l
�@��ׯ.|���@��T���@�@�@�@ �@ �@ ,..����@�@�@�@|
�@�@�@�@|���@ �_`.�A_�@ �@ _,. _�c'��__,.�T�A�@ |�@�@�@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@|���O�@�M�Uf�]����;ʓ�r^���j�� y=ځR �@�@�@���@�@�b�͕������Ă���������I
�@�@�@�@|��.�@�@�@ |fjl�A �M�P�j�O�S) �P�L�@� � @�@�@�@ |�@�@�@�����r�͖ŖS����I
�@�@�@�@|���O�@�@�Sl.`�- �ׂ�,- �M �-�]'�@ ,���@�@�@�@ �@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@|���@�@�@�@�@ l �@ �@ r���]-��@�@�@/:|
�@�@�@�@|���O�@�@�@ �@Ĥ�@�@�M��N�L�@�@,.��@|
�@�@�@�@|���@�@�@�@�@_��::�R�A�@�@�@ .�^�@i�@:Ĥ
�@�@�@�@|���@�@-�]''� F��::�@ `:�[ '�L�@�@,.'�@ � ����
�@�@�@�@|���@�@�@�@Ĥ�S;�..__�@�@�@�@�@, '_,.�^ �^l
�@�@�@�@|��.�@ �@ ,�/�V�@�@�@�@�@�@�@�@�S= �A
�@�@�@�@|���@�@ N �o�@�@�@�@�@ �@ �@ �@ �@ �@ �_
�@�@�@�@|���@ �.l �R�@�@�@�@�@�@�@�@�@�@�@�@�@�@ l
�@��ׯ.|���@��T���@�@�@�@ �@ �@ ,..����@�@�@�@|
�@�@�@�@|���@ �_`.�A_�@ �@ _,. _�c'��__,.�T�A�@ |�@�@�@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�@�@|���O�@�M�Uf�]����;ʓ�r^���j�� y=ځR �@�@�@���@�@�b�͕������Ă���������I
�@�@�@�@|��.�@�@�@ |fjl�A �M�P�j�O�S) �P�L�@� � @�@�@�@ |�@�@�@�����r�͖ŖS����I
�@�@�@�@|���O�@�@�Sl.`�- �ׂ�,- �M �-�]'�@ ,���@�@�@�@ �@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@|���@�@�@�@�@ l �@ �@ r���]-��@�@�@/:|
�@�@�@�@|���O�@�@�@ �@Ĥ�@�@�M��N�L�@�@,.��@|
�@�@�@�@|���@�@�@�@�@_��::�R�A�@�@�@ .�^�@i�@:Ĥ
�@�@�@�@|���@�@-�]''� F��::�@ `:�[ '�L�@�@,.'�@ � ����
�@�@�@�@|���@�@�@�@Ĥ�S;�..__�@�@�@�@�@, '_,.�^ �^l
�R�A���Ƃɓd���I�t�͂������
�C���˂Ȃ��N�A�b�h�ȏ�Ɉڍs�ł���
�C���˂Ȃ��N�A�b�h�ȏ�Ɉڍs�ł���
�h���������������Ŗڎw�������Ƃ���͂킩��C�����邪�A
�������������Ăh���������ɉ��b�������炷�}�����܂蕂���Ȃ��̂��m���B
�ł��A������Intel���ǂꂾ���D�G�ȊJ���\�t�g��ł��邩�ɂ�����āA
�]���������ƕς��C������B
�������������Ăh���������ɉ��b�������炷�}�����܂蕂���Ȃ��̂��m���B
�ł��A������Intel���ǂꂾ���D�G�ȊJ���\�t�g��ł��邩�ɂ�����āA
�]���������ƕς��C������B
>>262, >>270�Ɉ��������A�lj����ꂽ�����̂����ʔ������ȃ��m���B
Nehalem-EP�d�͊Ǘ�
http://intel.wingateweb.com/US08/published/sessions/PWRS005/SF08_PWRS005_100p.pdf
SPECpower
http://intel.wingateweb.com/US08/published/sessions/SFTS004/SF08_SFTS004_100r.pdf
���j�C�R�A�����x���`�}�[�N
http://intel.wingateweb.com/US08/published/sessions/SFTS005/SF08_SFTS005_100p.pdf
Tukwila
http://intel.wingateweb.com/US08/published/sessions/SVRS001/SF08_SVRS001_100r.pdf
QuickPath Interconnect
http://intel.wingateweb.com/US08/published/sessions/SVRS002/SF08_SVRS002_100p.pdf
SSE4.2
http://intel.wingateweb.com/US08/published/sessions/SVRS005/SF08_SVRS005_100p.pdf
Nehalem I/O
http://intel.wingateweb.com/US08/published/sessions/SVRS006/SF08_SVRS006_100r.pdf
Tukwila RAS
http://intel.wingateweb.com/US08/published/sessions/SVRS007/SF08_SVRS007_100r.pdf
�������x�v
http://intel.wingateweb.com/US08/published/sessions/TMTS001/SF08_TMTS001_100r.pdf
CPU�p�b�P�[�W���O��Apple�ł̎�����
http://intel.wingateweb.com/US08/published/sessions/TMTS002/SF08_TMTS002_100r.pdf
USB3.0
http://intel.wingateweb.com/US08/published/sessions/USBS001/SF08_USBS001_100s.pdf
Nehalem-EP�d�͊Ǘ�
http://intel.wingateweb.com/US08/published/sessions/PWRS005/SF08_PWRS005_100p.pdf
SPECpower
http://intel.wingateweb.com/US08/published/sessions/SFTS004/SF08_SFTS004_100r.pdf
���j�C�R�A�����x���`�}�[�N
http://intel.wingateweb.com/US08/published/sessions/SFTS005/SF08_SFTS005_100p.pdf
Tukwila
http://intel.wingateweb.com/US08/published/sessions/SVRS001/SF08_SVRS001_100r.pdf
QuickPath Interconnect
http://intel.wingateweb.com/US08/published/sessions/SVRS002/SF08_SVRS002_100p.pdf
SSE4.2
http://intel.wingateweb.com/US08/published/sessions/SVRS005/SF08_SVRS005_100p.pdf
Nehalem I/O
http://intel.wingateweb.com/US08/published/sessions/SVRS006/SF08_SVRS006_100r.pdf
Tukwila RAS
http://intel.wingateweb.com/US08/published/sessions/SVRS007/SF08_SVRS007_100r.pdf
�������x�v
http://intel.wingateweb.com/US08/published/sessions/TMTS001/SF08_TMTS001_100r.pdf
CPU�p�b�P�[�W���O��Apple�ł̎�����
http://intel.wingateweb.com/US08/published/sessions/TMTS002/SF08_TMTS002_100r.pdf
USB3.0
http://intel.wingateweb.com/US08/published/sessions/USBS001/SF08_USBS001_100s.pdf
AES��3�I�y�����h�ł�AVX�ɒlj����ꂽ
ttp://softwarecommunity.intel.com/isn/downloads/intelavx/Intel-AVX-Programming-Reference-319433003.pdf
ttp://sources.redhat.com/ml/binutils-cvs/2008-08/msg00109.html
#PCLMUL��3�I�y�����h�ɂȂ�Ȃ��̂��H
AES Intrinsic��VC2008SP1�ŃT�|�[�g����Ă���
ttp://msdn.microsoft.com/en-us/library/cc714206.aspx
PCLMUL
ttp://msdn.microsoft.com/en-us/library/cc664767.aspx
ttp://softwarecommunity.intel.com/isn/downloads/intelavx/Intel-AVX-Programming-Reference-319433003.pdf
ttp://sources.redhat.com/ml/binutils-cvs/2008-08/msg00109.html
#PCLMUL��3�I�y�����h�ɂȂ�Ȃ��̂��H
AES Intrinsic��VC2008SP1�ŃT�|�[�g����Ă���
ttp://msdn.microsoft.com/en-us/library/cc714206.aspx
PCLMUL
ttp://msdn.microsoft.com/en-us/library/cc664767.aspx
>>284
���ǂ��E�E�E�A�����ƈ��łĂ����ĉ�����
larrabee�͈ꔭ�ł͐������Ȃ��Ǝv�����A�S���Ă���Ă݂Ăق���
�V����GPU�̌`���ł���Ȃ猩�Ă݂���
���ǂ��E�E�E�A�����ƈ��łĂ����ĉ�����
larrabee�͈ꔭ�ł͐������Ȃ��Ǝv�����A�S���Ă���Ă݂Ăق���
�V����GPU�̌`���ł���Ȃ猩�Ă݂���
GPU�Ƃ��Ă͂��܂���҂��Ȃ����A�X�g���[���v���Z�b�T�Ƃ��Ă͂��Ȃ���҂ł���B
��ʐl�ɂ��܂艶�b���Ȃ��̂ŁA�X�P�[�������b�g���o���ɂ������ł͂���
��ʐl�ɂ��܂艶�b���Ȃ��̂ŁA�X�P�[�������b�g���o���ɂ������ł͂���
291 �F,,�E�L��`�E,,�j��-�������F2008/08/23(�y) 18:13:58 ID:rJ2nlBcm
>>288
Westmere��AES���ĕs�����ȁB
�����[�X���炽����1�N�قǂŏ�ʖ��߂��g����Ƀo�g���^�b�`�Ȃ��B
�Ή�����\�t�g���Ȃ���
Westmere��AES���ĕs�����ȁB
�����[�X���炽����1�N�قǂŏ�ʖ��߂��g����Ƀo�g���^�b�`�Ȃ��B
�Ή�����\�t�g���Ȃ���
292 �F,,�E�L��`�E,,�j��-�������F2008/08/23(�y) 18:39:57 ID:rJ2nlBcm
AVX�܂ł̐V���߂��T�|�[�g����x86/x64�G�~�����[�^�o������
�����ł͘b��ɂȂ��ĂȂ���
http://softwarecommunity.intel.com/articles/eng/3848.htm
�����ł͘b��ɂȂ��ĂȂ���
http://softwarecommunity.intel.com/articles/eng/3848.htm
>>290
�N������Ȃ�
�N������Ȃ�
294 �F,,�E�L��`�E,,�j��-�������F2008/08/23(�y) 19:21:13 ID:rJ2nlBcm
�@�@�@�@�@�@�@�@ �^�P�_
�@�@�@�@�@�@�@�@|�@�@�@ �@|
�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@ �@�^ �P �P�@�_
�@�@�@�@�@�^�@�@�_�@�^�@�@�_
�@�@�@ �^�@�@ �܁@�@�@�� �@�@�_�@�@�@�@�@�@ >>293�悭�����
�@�@�@ |�@�@�@�@�i__�l__�j�@�@ |�@�@�@�@�@�@�J���Ƃ��ă����[�r�����������
�@�@�@ �_�@�@�@ �M �܁L�@�@�@�@�^�@�@�@��
�@�@�@�@/�R�--�[��Q�Q,-�]�L�@�_���^
�@�@ �^�@> �@�@�R������<�_�@�@||��.
�@ / �R��@�@�@�_ i�@|�|�@|/�@ �R�@(�j��M�R.
�@.l�@�@�@�R �@�@�@ l�@|�|�@| ��-�y�@�MƁ@ � �_
�@l�@�@�@�@ |�@�@ �@|�[�� | �P l �@�@�M~�R�Q�m�Q�Q�Q_
�@�@�@�@�^�P�P�P�P�R-'�R--'�@�@�^�@Larrabee�@ �^|
�@�@�@.|�P�P�P�P�P�P|�^|�@�@�@ |�P�P�P�P�P�P|�^| �Q�Q�Q�Q�Q�Q
�^�PLarrabee�^|�@�P|__�v�^_Larrabee�@�@�^|�P|__,�v�Q�Q_�@�@�@�@�^|
|�P�P�P�P�P|�^Larrabee�P�^�P�P�P�P|�^ Larrabee �^|�@�@�^�@.|
|�P�P�P�P�P|�P�P�P�P�P|�^l�P�P�P�P|�P�P�P�P�P|�^|�@�^
|�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P|
�@�@�@�@�@�@�@�@|�@�@�@ �@|
�@�@�@ �@�@�@�@�@�_�Q�^
�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@ �@�^ �P �P�@�_
�@�@�@�@�@�^�@�@�_�@�^�@�@�_
�@�@�@ �^�@�@ �܁@�@�@�� �@�@�_�@�@�@�@�@�@ >>293�悭�����
�@�@�@ |�@�@�@�@�i__�l__�j�@�@ |�@�@�@�@�@�@�J���Ƃ��ă����[�r�����������
�@�@�@ �_�@�@�@ �M �܁L�@�@�@�@�^�@�@�@��
�@�@�@�@/�R�--�[��Q�Q,-�]�L�@�_���^
�@�@ �^�@> �@�@�R������<�_�@�@||��.
�@ / �R��@�@�@�_ i�@|�|�@|/�@ �R�@(�j��M�R.
�@.l�@�@�@�R �@�@�@ l�@|�|�@| ��-�y�@�MƁ@ � �_
�@l�@�@�@�@ |�@�@ �@|�[�� | �P l �@�@�M~�R�Q�m�Q�Q�Q_
�@�@�@�@�^�P�P�P�P�R-'�R--'�@�@�^�@Larrabee�@ �^|
�@�@�@.|�P�P�P�P�P�P|�^|�@�@�@ |�P�P�P�P�P�P|�^| �Q�Q�Q�Q�Q�Q
�^�PLarrabee�^|�@�P|__�v�^_Larrabee�@�@�^|�P|__,�v�Q�Q_�@�@�@�@�^|
|�P�P�P�P�P|�^Larrabee�P�^�P�P�P�P|�^ Larrabee �^|�@�@�^�@.|
|�P�P�P�P�P|�P�P�P�P�P|�^l�P�P�P�P|�P�P�P�P�P|�^|�@�^
|�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P|
>>292
Intel�͂���ς肱�̎�̃\�t�g�E�F�A�J���\�͂������ȁB
AMD��������悢���m�������Ă��A���ǂ�Intel�̎�̏�Ȃ̂́A
�����������J���n�̃\�t�g�E�F�A�J���T�|�[�g��
���Ђł�������o���Ȃ����炾�낤�ȁB
Intel�͂���ς肱�̎�̃\�t�g�E�F�A�J���\�͂������ȁB
AMD��������悢���m�������Ă��A���ǂ�Intel�̎�̏�Ȃ̂́A
�����������J���n�̃\�t�g�E�F�A�J���T�|�[�g��
���Ђł�������o���Ȃ����炾�낤�ȁB
296 �F,,�E�L��`�E,,�j��-�������F2008/08/23(�y) 19:44:15 ID:rJ2nlBcm
AMD������CPU�����p�C�v���C���V�~�����[�^�o���Ă邯�ǂȁB
AMD�v���Z�b�T�łȂ��ƃt���ɓ����Ȃ����ǁB
AMD�v���Z�b�T�łȂ��ƃt���ɓ����Ȃ����ǁB
�܂�x86-64�G�~�����[�^�́A�g�����X���^�ɔC���Ă���ȁB
�uRadeon��GeForce�Ɣ�ׂĂ͂Ȃ�Ȃ��v (8/23)
-----�^�V���b�v�X���k
�@Matrox��VGA�uMatrox M�v�V���[�Y�̍������K�㗝�X��(�W���p���}�e���A��)���T����25�����甭���ƂȂ�B�\���͈ȉ��̒ʂ�B
�EM9120 PCIe x16/J(�^��:M9120/512PEX16) ��\37,000
�EM9120 Plus LP PCIe x16/J(�^��:M9120/512PEX16/LP) ��\46,000
�EM9120 Plus LP PCIe x1/J(�^��:M9120/512PEX1/LP) ��\46,000
�EM9125 PCIe x16 DualLink/J(�^��:M9125/512PEX16) ��\54,200
�EM9140 LP PCIe x16/J(�^��:M9140/512PEX16/LP) ��\82,600
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2�N���larrabee�̎p�������ɂ����
-----�^�V���b�v�X���k
�@Matrox��VGA�uMatrox M�v�V���[�Y�̍������K�㗝�X��(�W���p���}�e���A��)���T����25�����甭���ƂȂ�B�\���͈ȉ��̒ʂ�B
�EM9120 PCIe x16/J(�^��:M9120/512PEX16) ��\37,000
�EM9120 Plus LP PCIe x16/J(�^��:M9120/512PEX16/LP) ��\46,000
�EM9120 Plus LP PCIe x1/J(�^��:M9120/512PEX1/LP) ��\46,000
�EM9125 PCIe x16 DualLink/J(�^��:M9125/512PEX16) ��\54,200
�EM9140 LP PCIe x16/J(�^��:M9140/512PEX16/LP) ��\82,600
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
2�N���larrabee�̎p�������ɂ����
299 �F,,�E�L�́M�E,,�j���F2008/08/24(��) 09:24:28 ID:Q2PjfEOA
x86�}���`�R�A�v���Z�b�T�ƍl�������Ȃ�Ȃ��Ȃ�
RV710������GPU�Ƃ��ĂȂ炠�肦�˂�
M9125���������ɂ���ł́A�����Ȃ��ȁE�E�E
����larrabee�Ȃ�ďo�Ă��Ă�tesla�݂����ɂP�O���~���炢����
����ɔ�����㕨����Ȃ���ł���
����ɔ�����㕨����Ȃ���ł���
�����Ȃ�Ȃ��悤�ɐ����J�����߂�GPU�ɂ�����
�̐S�̃p�t�H�[�}���X�����[�G���h���݂Ȃ̂�
2���~��Radeon HD4450���悤�Ȃ��̂ɂȂ�
�̐S�̃p�t�H�[�}���X�����[�G���h���݂Ȃ̂�
2���~��Radeon HD4450���悤�Ȃ��̂ɂȂ�
�����Đ�������ɂ͐���~�œ�������B
�܂���PhysX�̓�̕��B�����ŃL���b�`�\��B
�܂���PhysX�̓�̕��B�����ŃL���b�`�\��B
��������ƁAi7��
���\3�����炢�A�b�v���邪�A����d�͂�3���A�b�v�����
�Ǝv���Ă��邯�ǁA�����OK�H
���\3�����炢�A�b�v���邪�A����d�͂�3���A�b�v�����
�Ǝv���Ă��邯�ǁA�����OK�H
���ꂩ������Q�N��
http://pc.watch.impress.co.jp/docs/2006/0407/kaigai259.htm
http://www.ne.jp/asahi/comp/tarusan/main144.htm
http://pc.watch.impress.co.jp/docs/2006/0407/kaigai259.htm
http://www.ne.jp/asahi/comp/tarusan/main144.htm
>>305
���\������d�͂���ۂ���UP������x
���\������d�͂���ۂ���UP������x
���낻�딭���������Ă�����i7�ȍ~�̎�����ɂ��Č�낤��
intel�̕��j��ISA�̃t�H�[����VEX�Ɉڂ���
�f�R�[�_�̃V���v���Ő��\�����ڎw���Ƃ������Ƃ͔��\�ς݂Ȃ��A
������ăt�H�[�����ł��������Ԃ�ǂ����ŃI�[�o�[�w�b�h�����������ˁH
intel�͂�����ǂ��ŋz���������ȂH
intel�̕��j��ISA�̃t�H�[����VEX�Ɉڂ���
�f�R�[�_�̃V���v���Ő��\�����ڎw���Ƃ������Ƃ͔��\�ς݂Ȃ��A
������ăt�H�[�����ł��������Ԃ�ǂ����ŃI�[�o�[�w�b�h�����������ˁH
intel�͂�����ǂ��ŋz���������ȂH
����Ԃ��������Ĉ�����
�l�n����
�l�n�[����
�l�n����
�l�w�C����
�ǂꂪ�������ǂݕ��H�H
���{��̓ǂ݂œ����H�Ƃ��o���ĂȂ����玩���̎�����H
�l�n����
�l�n�[����
�l�n����
�l�w�C����
�ǂꂪ�������ǂݕ��H�H
���{��̓ǂ݂œ����H�Ƃ��o���ĂȂ����玩���̎�����H
>>306
PS3���������ʌ����Ă��ꂽ�����orz
PS3���������ʌ����Ă��ꂽ�����orz
312 �FSocket774�F2008/08/26(��) 17:23:00 ID:dMH4laRR
�P�d�q�f�o�C�X��CPU�Ɏg����悤�ɂȂ�̂͂��ɂȂ邱�Ƃ��c
>>311
���F�L���`�N�I���e�B
���F�L���`�N�I���e�B
314 �FSocket774�F2008/08/28(��) 11:03:21 ID:XGqWhlkr
>>313
���O�͂Ȃɂ������Ă��
���O�͂Ȃɂ������Ă��
�؍���Ƃɔ�������āA�������{��ƂƂ͌����Ȃ��Ƃ��������낤
�ǂ��ł��������A�鏤�Ƀ\�j�[�̂������˂��C���_�N�^�������Ă����
http://www.4gamer.net/games/048/G004815/20080820054/
�}���`�R�A�����̃��X�v���œ��N���b�N��QX�Ƃ̐��\���+40���H
�}���`�R�A�����̃��X�v���œ��N���b�N��QX�Ƃ̐��\���+40���H
318 �FSocket774�F2008/08/28(��) 13:52:30 ID:JMhMy6Q4
�����r�[����Windows�����Ȃ����烉���r�[����
Windows�̃Q�[�����u�������́vGeForce��Radeon���݂ɓ�������
����
�u�����r�[�͌����ȁv
���A�����r�[���������B�j���[�^�C�v�͎E����������ł͂Ȃ����āB
DualCore LynnField�ɂ�L3���t���̂��ˁH
324 �F,,�E�L�́M�E,,�F2008/08/28(��) 19:50:15 ID:vX5clrui
>>318
������͓�����B486�ł������݂��������B
�������ǂ�ȃ\�����[�V������p�ӂ���̂����s���B
�����A���sWinAPI�ł�32�r�b�g��32�_��CPU�A64�r�b�g��64�_��CPU�܂ł���
����U��Ȃ��B
Xeon�\�P�b�g�ɑ}����o�[�W�����Ń��C��CPU�Ƃ��Ďg�����ꍇ�A
�n�C�p�[�o�C�U��p�ӂ��ăQ�X�gOS�����点��Ƃ����Ȃ���
�S�R�A�L�����p�ł��Ȃ��Ǝv��
��
���̃X�������Ă���l�͂���ȃX�������Ă��܂��B(ver 0.20)
App Store Part5 ���V�EMac:2ch [�V�Emac]
iPhone 3G �����X�� part 84 [iPhone]
iPhone 3G�̃P�[�X�E�t�B���� 8�P�[�X�� [iPhone]
iPhone 3G �����X�� part 85 [iPhone]
iPhone 3G �����X���@Part85 [iPhone]
������͓�����B486�ł������݂��������B
�������ǂ�ȃ\�����[�V������p�ӂ���̂����s���B
�����A���sWinAPI�ł�32�r�b�g��32�_��CPU�A64�r�b�g��64�_��CPU�܂ł���
����U��Ȃ��B
Xeon�\�P�b�g�ɑ}����o�[�W�����Ń��C��CPU�Ƃ��Ďg�����ꍇ�A
�n�C�p�[�o�C�U��p�ӂ��ăQ�X�gOS�����点��Ƃ����Ȃ���
�S�R�A�L�����p�ł��Ȃ��Ǝv��
��
���̃X�������Ă���l�͂���ȃX�������Ă��܂��B(ver 0.20)
App Store Part5 ���V�EMac:2ch [�V�Emac]
iPhone 3G �����X�� part 84 [iPhone]
iPhone 3G�̃P�[�X�E�t�B���� 8�P�[�X�� [iPhone]
iPhone 3G �����X�� part 85 [iPhone]
iPhone 3G �����X���@Part85 [iPhone]
CPU���ǂ�ȂɊv�V�I�ɐi�����Ă����Ă�OS�����̂܂�܂��Ⴀ��܂萶������Ȃ����
�������낻��Windows���^�Ɋv�V�I�ȃo�[�W�����A�b�v���Ȃ�����
Vista�Ƃ��̊O�ςƂ�����Ȃ���kernel�̂����ƃR�A�ȏ�
�������낻��Windows���^�Ɋv�V�I�ȃo�[�W�����A�b�v���Ȃ�����
Vista�Ƃ��̊O�ςƂ�����Ȃ���kernel�̂����ƃR�A�ȏ�
VISTA�ɂ͂����ȉ��ς��\�肳��Ă������ǁA�قƂ�ǂ�������ɂȂ����Ƃ����̂�����B
����ł�Linux�Ȃ�2.2��2.6�̈Ⴂ���炢�̉��ς�Vista�œ����Ă�
>>325
Windows7�̃~�j�R�A�̂��Ƃł������H
Windows7�̃~�j�R�A�̂��Ƃł������H
Windows7��miniWin���̗p���Ȃ���H
>>327
�Ȃ��Ȃ�
�Ȃ��Ȃ�
>>329
�@�@�@�@�@�@�@�@�@�i �T�@�@�@�i �T�@/�@ �@ �\�Q"�@ �@ �[;=�]�@�@�@�@�@�@�@�@�@|! |!
�@�@�@�@�@�@�@�@�@�@c�g�@�@�@�@c�g�@/�O�_Ɂ@ | �.__�@�@ �i.__ �@ �P�P�P�P �@ �E �E
�~�:::;,!�@�@�@�@�@�@u�@�@�@�@�@�@�@�M�"~�L�@�@�@�S�c::l�^VvVw�A ,yv�SN�R�@�@�U�S�@ ,.�@,.�@,.�@�A��S�T�Rr���S
�::::;/�@�@�P�`�-.��@�@�@�@�@u�@�@;,,;�@�@�@j�@�@ �Sk'!�@' l�@/ '� ^�Ŕ_�@�@ ,rށU�-"��m /�@l!�@!�R ���@|
�~/�@�@�@�@J�@�@�@�`���@�@�@"�@;, ;;;�@,;;�@ށ@�@u �Si�@�@�@ ,,./�@,�@,��S�S�@�@ | '-- �..,,�R�@ j�@ !�@| N�S|
'"�@�@�@�@�@�@�@_,,.. -���T.��@�@�@;, "�@;;�@�@�@_,,..._�U�__�^/�V i.! il�S�U�R�@ | ��@ .r�D�@�S-�;;�,.:-��'"i
�@�@j�@�@�@�@�^�@�@ ,.- ��@ �S�R�A�@;; ;;�@_,-���@�@/�^_,,�_' "' !|�@:l �i !_,,�R.l�@`�[��--�@ ��' (�D 7 /
�@�@�@�@�@�@:�@�@�@�@' �E���@�@�P������L,-��@�R /��L r�D�@`�[-'� ,.-�L��@�@i�@�@�@�@ u�@�@�S�M`�[' �
�@�@�@�@�@�@ �__�@�@�@ _,,......::�@�@�@�L�i��@`�N�@/�@i�@�R.__,,... '�@ u �l�L.i�j.�q,��l�@ �^ �M`-�..-�@�m�@:u l
�@�@�@u�@�@�@�@�@�P�P�@�@�c"�@�@�@�A�S�P�M`�::.l�@�@u�@�@�@j�@�@i��M�['�@.i /�@/�._�@�@�@�@�M'y�@�@ /
�@�@�@�@�@�@�@�@�@�@�@�@�@�@u�@�@�@�@�@�@�M�R�@�@�:l�@�@ ,.::- �,,�@,.�@�m�@� u�@!�@/_�@�@�P�@�[/�@u�@/
�@�@�@�@�@�@�@�@�@�@�@_,,..,,_�@�@�@�@,.���@ �^�@�@�@|�@ /__�@�@ �M`- �_�@�@�@ l�@l�@ �M`�t�_�@/�@�@�^
�@�@ށ@�@�@u�@�@,.�^�L�@"�@ �M`- �_�i�@r'�L�@ u�@���@.l,...�@�M�[��''/�@�@�@�m�@ � �,,_____�@�/�@�^
�@�@�@�@�@�@�@ ./�Q_�@�@�@�@�@�@�@�@��V�@�@�@�@/�A�@l�@�@ 'ށ@�R/�@ ,. '"�@�@�_�M�--- ",.::���
�@�@�@�@�@�@�@/;;;''"�@�P�P ������/�@�@ށ@ ,::'�@ �_�S�==��'"�^ �M- ��@�@�@ށ[�� '�L�@/�@�_..,,__
�A�@�@�@�@�@ .i:��`��-�_,....�@�@�@�@l�@�@�@�^�@�@�@�@ �M�[����'�@�@�@�@�@ �R�@�@�@ :l�@ �^�@ , '�@�M�\�R
�S�R�@�@�@�@ l�@�@�@�@�@ `�@ �M�R�A l�@ .�^�@�@�R�@�@�@�@�@ l�@�@�@�@�@�@�@�@�@�j�@�@,; �^�@�@�@,'�@�@�@�@'^i
�@�@�@�@�@�@�@�@�@�i �T�@�@�@�i �T�@/�@ �@ �\�Q"�@ �@ �[;=�]�@�@�@�@�@�@�@�@�@|! |!
�@�@�@�@�@�@�@�@�@�@c�g�@�@�@�@c�g�@/�O�_Ɂ@ | �.__�@�@ �i.__ �@ �P�P�P�P �@ �E �E
�~�:::;,!�@�@�@�@�@�@u�@�@�@�@�@�@�@�M�"~�L�@�@�@�S�c::l�^VvVw�A ,yv�SN�R�@�@�U�S�@ ,.�@,.�@,.�@�A��S�T�Rr���S
�::::;/�@�@�P�`�-.��@�@�@�@�@u�@�@;,,;�@�@�@j�@�@ �Sk'!�@' l�@/ '� ^�Ŕ_�@�@ ,rށU�-"��m /�@l!�@!�R ���@|
�~/�@�@�@�@J�@�@�@�`���@�@�@"�@;, ;;;�@,;;�@ށ@�@u �Si�@�@�@ ,,./�@,�@,��S�S�@�@ | '-- �..,,�R�@ j�@ !�@| N�S|
'"�@�@�@�@�@�@�@_,,.. -���T.��@�@�@;, "�@;;�@�@�@_,,..._�U�__�^/�V i.! il�S�U�R�@ | ��@ .r�D�@�S-�;;�,.:-��'"i
�@�@j�@�@�@�@�^�@�@ ,.- ��@ �S�R�A�@;; ;;�@_,-���@�@/�^_,,�_' "' !|�@:l �i !_,,�R.l�@`�[��--�@ ��' (�D 7 /
�@�@�@�@�@�@:�@�@�@�@' �E���@�@�P������L,-��@�R /��L r�D�@`�[-'� ,.-�L��@�@i�@�@�@�@ u�@�@�S�M`�[' �
�@�@�@�@�@�@ �__�@�@�@ _,,......::�@�@�@�L�i��@`�N�@/�@i�@�R.__,,... '�@ u �l�L.i�j.�q,��l�@ �^ �M`-�..-�@�m�@:u l
�@�@�@u�@�@�@�@�@�P�P�@�@�c"�@�@�@�A�S�P�M`�::.l�@�@u�@�@�@j�@�@i��M�['�@.i /�@/�._�@�@�@�@�M'y�@�@ /
�@�@�@�@�@�@�@�@�@�@�@�@�@�@u�@�@�@�@�@�@�M�R�@�@�:l�@�@ ,.::- �,,�@,.�@�m�@� u�@!�@/_�@�@�P�@�[/�@u�@/
�@�@�@�@�@�@�@�@�@�@�@_,,..,,_�@�@�@�@,.���@ �^�@�@�@|�@ /__�@�@ �M`- �_�@�@�@ l�@l�@ �M`�t�_�@/�@�@�^
�@�@ށ@�@�@u�@�@,.�^�L�@"�@ �M`- �_�i�@r'�L�@ u�@���@.l,...�@�M�[��''/�@�@�@�m�@ � �,,_____�@�/�@�^
�@�@�@�@�@�@�@ ./�Q_�@�@�@�@�@�@�@�@��V�@�@�@�@/�A�@l�@�@ 'ށ@�R/�@ ,. '"�@�@�_�M�--- ",.::���
�@�@�@�@�@�@�@/;;;''"�@�P�P ������/�@�@ށ@ ,::'�@ �_�S�==��'"�^ �M- ��@�@�@ށ[�� '�L�@/�@�_..,,__
�A�@�@�@�@�@ .i:��`��-�_,....�@�@�@�@l�@�@�@�^�@�@�@�@ �M�[����'�@�@�@�@�@ �R�@�@�@ :l�@ �^�@ , '�@�M�\�R
�S�R�@�@�@�@ l�@�@�@�@�@ `�@ �M�R�A l�@ .�^�@�@�R�@�@�@�@�@ l�@�@�@�@�@�@�@�@�@�j�@�@,; �^�@�@�@,'�@�@�@�@'^i
332 �F,,�E�L��`�E,,�j��-�������F2008/08/29(��) 01:43:15 ID:XA+DpWi/
���X��CE7��Win7�ŃJ�[�l���̃x�[�X��������\�肾������ȁB
MacOS��Mac�p��iPod�p�œ����J�[�l���̕ʃr���h�ł���悤�ɁB
���Ȃ݂Ɏ����I�ɂ͎��o�[�W������Windows 6.1
Windows Vista Second Edition�Ƃł������ׂ���
MacOS��Mac�p��iPod�p�œ����J�[�l���̕ʃr���h�ł���悤�ɁB
���Ȃ݂Ɏ����I�ɂ͎��o�[�W������Windows 6.1
Windows Vista Second Edition�Ƃł������ׂ���
Vista�����ăJ�[�l���h�����h�Ȃ炻��Ȃɑ傫���Ȃ����낤�B
��ő����Ă�T�[�r�X���A���Ȃ����ŁE�E�E
��ő����Ă�T�[�r�X���A���Ȃ����ŁE�E�E
334 �F,,�E�L��`�E,,�j��-�������F2008/08/29(��) 01:53:40 ID:XA+DpWi/
�[���X�[�p�[�t�F�b�`�͋C������������B
2000��XP�܂Ń��������[�N�ŋ������ǂ�ǂ��Ă���
�ċN��������Ȃ��Ȃ邱�Ƃ�������������g���E�}�Ȃ낤��
���ۂ͋N���𑁂����邽�߂��Ă͉̂����Ă���ǂ�
2000��XP�܂Ń��������[�N�ŋ������ǂ�ǂ��Ă���
�ċN��������Ȃ��Ȃ邱�Ƃ�������������g���E�}�Ȃ낤��
���ۂ͋N���𑁂����邽�߂��Ă͉̂����Ă���ǂ�
>>330
2.2->2.6�͌����߂������A2.4->2.6���炢�ɂ͕ω����Ă邾��B
����2k->XP���XP->Vista�̂ق����ω����傫���B��ʃ��[�U�[�ɂ͕�������ŁB
2.2->2.6�͌����߂������A2.4->2.6���炢�ɂ͕ω����Ă邾��B
����2k->XP���XP->Vista�̂ق����ω����傫���B��ʃ��[�U�[�ɂ͕�������ŁB
�������ɒ��N�������Ă�
2k��XP����XP��Vista�̕����ω����������Ȃ�Ďv���Ă����Ȃ�����B
XP�ȍ~�Ɏ���n�߂���Ƃ�2k�S�����������ƂȂ��Ȃ�ʂ����B
XP�͏��X�Ɋ����x�������Ă�����������2k�̏Ă������ŁB
2k��Home�ł�DirectX�̌݊����Ƃ��ŗ\���肨���ꂽ����A
�d���Ȃ����Ƃ��炾������A���Ƃ��Ƃ́B
2k��XP����XP��Vista�̕����ω����������Ȃ�Ďv���Ă����Ȃ�����B
XP�ȍ~�Ɏ���n�߂���Ƃ�2k�S�����������ƂȂ��Ȃ�ʂ����B
XP�͏��X�Ɋ����x�������Ă�����������2k�̏Ă������ŁB
2k��Home�ł�DirectX�̌݊����Ƃ��ŗ\���肨���ꂽ����A
�d���Ȃ����Ƃ��炾������A���Ƃ��Ƃ́B
�g���Ă��邩�Ȃ����͊W������łȂ��H
�g�������Ȃ��Ă������Ɍ��𗦂�����2���̎���S���m��Ȃ����ēz�͂��Ȃ����낤��
�g�������Ȃ��Ă������Ɍ��𗦂�����2���̎���S���m��Ȃ����ēz�͂��Ȃ����낤��
������Me�̈����͂����܂ł�
339 �FSocket774�F2008/08/30(�y) 01:47:54 ID:aypMmmQK
���v�����ǁAwindows��home edition�Ƃ�����Ȃ��Ȃ��H
�ǂ����Ă��A�g���ɂ������Čڋq�������߂Ă���悤�ɂ��������Ȃ��B
�ǂ����Ă��A�g���ɂ������Čڋq�������߂Ă���悤�ɂ��������Ȃ��B
���̒��ɂ̓l�b�g�T�[�t�B����Q�[����������l�������
Pro ���������邽�߂ɂ��� Home
�������C�Z���X���p�ӂ��Ă����Ȃ��ƁA�����������C�Z���X�����Ȃ�������
�{���ɐ��Windows�łȂ���Ȃ�Ȃ����H���Č������^����
�n�߂��Ă��܂��A�ʂɐ�ł͂Ȃ����Ƃ���Ă��܂�
�{���ɐ��Windows�łȂ���Ȃ�Ȃ����H���Č������^����
�n�߂��Ă��܂��A�ʂɐ�ł͂Ȃ����Ƃ���Ă��܂�
Nvidia��QPI�̃��C�Z���X�Ă��邱�Ƃ�A�m�F���ꂽ�͗l���B
http://www.bit-tech.net/news/2008/08/29/nvidia-has-a-qpi-license/1
�@�@------------------
�@�@Following a discussion with Tom Petersen, Director of Technical Marketing for Nvidia�fs chipset
�@�@business, it became apparent that Nvidia does indeed have a QPI license to make chipsets for
�@�@Intel�fs Bloomfield processors.
�@�@Petersen was adamant that Nvidia�fs cross-licensing agreement with Intel includes a Quick Path
�@�@Interface licence, enabling the company to develop chipsets for Intel�fs latest processors.
�@�@------------------
Intel������Ȃ�ɃI�[�v���ł���؋��ł�����AQPI�ڑ���GPU��GPGPU���o�ꂷ��\������������
���m�ł�����B�B�B
http://www.bit-tech.net/news/2008/08/29/nvidia-has-a-qpi-license/1
�@�@------------------
�@�@Following a discussion with Tom Petersen, Director of Technical Marketing for Nvidia�fs chipset
�@�@business, it became apparent that Nvidia does indeed have a QPI license to make chipsets for
�@�@Intel�fs Bloomfield processors.
�@�@Petersen was adamant that Nvidia�fs cross-licensing agreement with Intel includes a Quick Path
�@�@Interface licence, enabling the company to develop chipsets for Intel�fs latest processors.
�@�@------------------
Intel������Ȃ�ɃI�[�v���ł���؋��ł�����AQPI�ڑ���GPU��GPGPU���o�ꂷ��\������������
���m�ł�����B�B�B
���X�����ǁAi7����ł̓��������C���^�[���[�u�ő�������@�\���Ĕp�~���ꂽ�́H
345 �F,,�E�L�́M�E,,�F2008/08/30(�y) 11:02:01 ID:DThLhIVJ
�Ȃ�����Ȃ��Ƃ��H
�܂��`���l���P�ʂł̃C���^�[���[�u�Ȃ�`���l������2�ׂ̂���łȂ��Ɩ������낤����
DDR3���́A����N���b�N������̃X���[�v�b�g��DDR2�̔{������A�C�ɂ��Ȃ��Ă������ƁB
����ɁA�������C���^�[���[�u�̓V���O���R�A�ł̋Ǐ��I�ȃA�N�Z�X�ɂ͗L���ȋZ�p������
�}���`�R�A�ł̓C���^�[���[�u���Ȃ��Ă��A�N�Z�X�����ǂ����U����邩��債�ĈӖ��͂Ȃ��B
�܂��`���l���P�ʂł̃C���^�[���[�u�Ȃ�`���l������2�ׂ̂���łȂ��Ɩ������낤����
DDR3���́A����N���b�N������̃X���[�v�b�g��DDR2�̔{������A�C�ɂ��Ȃ��Ă������ƁB
����ɁA�������C���^�[���[�u�̓V���O���R�A�ł̋Ǐ��I�ȃA�N�Z�X�ɂ͗L���ȋZ�p������
�}���`�R�A�ł̓C���^�[���[�u���Ȃ��Ă��A�N�Z�X�����ǂ����U����邩��債�ĈӖ��͂Ȃ��B
346 �F,,�E�L�́M�E,,�F2008/08/30(�y) 11:18:19 ID:DThLhIVJ
�� Intel������Ȃ�ɃI�[�v���ł���؋��ł�����AQPI�ڑ���GPU��GPGPU���o�ꂷ��\������������
�� ���m�ł�����B�B�B
����̂͒P�Ȃ鑊�݃��C�Z���X����B
Intel���̌��ޗ��́A���Ѓ}�U�[�{�[�h��SLI�̃��C�Z���X��
�i���܂��̓^�_�Ŏ�Ƃ����̂ւ�ˁH�B
�N���X���C�Z���X���u�I�[�v���v�Ƃ͌���Ȃ��B
����̊�ƂɋZ�p���J����̂��I�[�v���ƌ�������Windows����I�[�v���\�[�X���B
�܁ALarrabee�����nVIDIA�̃r�f�I�J�[�h�������}���鍂���}�U�[���������ׂ����
���f�����\���͂���ȁB
�� ���m�ł�����B�B�B
����̂͒P�Ȃ鑊�݃��C�Z���X����B
Intel���̌��ޗ��́A���Ѓ}�U�[�{�[�h��SLI�̃��C�Z���X��
�i���܂��̓^�_�Ŏ�Ƃ����̂ւ�ˁH�B
�N���X���C�Z���X���u�I�[�v���v�Ƃ͌���Ȃ��B
����̊�ƂɋZ�p���J����̂��I�[�v���ƌ�������Windows����I�[�v���\�[�X���B
�܁ALarrabee�����nVIDIA�̃r�f�I�J�[�h�������}���鍂���}�U�[���������ׂ����
���f�����\���͂���ȁB
�C���e�������`�b�v�Z�b�g����k�r��������SLI��AMD�v���b�g�z�[�������I�����[�Ȃ�ĂȂ������ς�����ȁB
���̏��AMD���N���X�t�@�C�A�����Ѓv���b�g�z�[����p�Ȃ�Ă�����Q�[�}�[�����s�ꂲ�����莝���Ă����B
���̏��AMD���N���X�t�@�C�A�����Ѓv���b�g�z�[����p�Ȃ�Ă�����Q�[�}�[�����s�ꂲ�����莝���Ă����B
111 �F,,�E�L�́M�E,, [��] �F2008/08/29(��) 19:06:12 ID:XA+DpWi/
Intel's Larrabee GPU Will Support Linux
http://www.phoronix.com/scan.php?page=news_item&px=NjYzOA
�ʔ������ƂɂȂ�����
112 �FSocket774 [��] �F2008/08/29(��) 19:24:32 ID:0dK6Hl59
�H
X�̘b����Ȃ���
Intel's Larrabee GPU Will Support Linux
http://www.phoronix.com/scan.php?page=news_item&px=NjYzOA
�ʔ������ƂɂȂ�����
112 �FSocket774 [��] �F2008/08/29(��) 19:24:32 ID:0dK6Hl59
�H
X�̘b����Ȃ���
�Ȃ�قǁADDR3�����1�������������c
350 �FSocket774�F2008/08/30(�y) 13:01:15 ID:ymqQsV2+
1366�̌��R
�����������B�g�܂Ȃ��ŏ����Ƃ������B
�����������B�g�܂Ȃ��ŏ����Ƃ������B
351 �FMAC�I�^���c�q �����F2008/08/30(�y) 14:15:11 ID:rRKT6K+V
>>346
�@�@----------------
�@�@����̊�ƂɋZ�p���J����̂��I�[�v���ƌ�������Windows����I�[�v���\�[�X���B
�@�@----------------
�^�_�ŖႦ��Ƃ��A����ɉ��ςł���B�B�B�����B��H�̒�`����(��)
�n�[�h�E�F�A�̐��E�Łw�I�[�v���x�Ƃ����̂�A������ƃj���A���X������āA���ЂƑ��݉^�p������Ƃ��A
�s��Ŏ��R�ɍw���ł���Ƃ����Ӗ����B
���肵���A�������̍����̍X�V�ł�����ȋL�����B
http://www.geocities.jp/andosprocinfo/wadai08/20080830.htm
�@�@--------------------
�@�@�܂��C�����HT�ŁCAMD��CPU�ɂ����g���܂��C���Ђ�Intel��QPI�̃��C�Z���X�����Ă���C
�@�@Intel CPU�p�̐��i���J������\��ł��B
�@�@--------------------
�V����Ƃł������̑㉿�Ŏ�ɓ��郉�C�Z���X�̗l�����ǁB�B�B
�@�@----------------
�@�@����̊�ƂɋZ�p���J����̂��I�[�v���ƌ�������Windows����I�[�v���\�[�X���B
�@�@----------------
�^�_�ŖႦ��Ƃ��A����ɉ��ςł���B�B�B�����B��H�̒�`����(��)
�n�[�h�E�F�A�̐��E�Łw�I�[�v���x�Ƃ����̂�A������ƃj���A���X������āA���ЂƑ��݉^�p������Ƃ��A
�s��Ŏ��R�ɍw���ł���Ƃ����Ӗ����B
���肵���A�������̍����̍X�V�ł�����ȋL�����B
http://www.geocities.jp/andosprocinfo/wadai08/20080830.htm
�@�@--------------------
�@�@�܂��C�����HT�ŁCAMD��CPU�ɂ����g���܂��C���Ђ�Intel��QPI�̃��C�Z���X�����Ă���C
�@�@Intel CPU�p�̐��i���J������\��ł��B
�@�@--------------------
�V����Ƃł������̑㉿�Ŏ�ɓ��郉�C�Z���X�̗l�����ǁB�B�B
�\�t�g�E�F�A�̃I�[�v���\�[�X�ƃn�[�h�E�F�A�̃I�[�v���A�[�L���Ă͓̂����I�[�v���ł�
�܂������Ӗ���������Ⴄ�킯�����E�E�E
�����QPI�𑼎ЂɃ��C�Z���X����̂�����
�`�b�v�Z�b�g�̋����s�������������Ă�C���e����M�p������Ȃ�
OEM���[�J�[�������v�]����������Ă̂��{���̂Ƃ��낾�낤��
�܂������Ӗ���������Ⴄ�킯�����E�E�E
�����QPI�𑼎ЂɃ��C�Z���X����̂�����
�`�b�v�Z�b�g�̋����s�������������Ă�C���e����M�p������Ȃ�
OEM���[�J�[�������v�]����������Ă̂��{���̂Ƃ��낾�낤��
11���ɂȂ��ĊePC�n�T�C�g�ɕ��Ԃł��낤Bloomfield�x���`���ʂ̒���
SLI�̍����Ȃ��̂�Intel�ɂƂ��Ă���낵���Ȃ�����
SLI�̍����Ȃ��̂�Intel�ɂƂ��Ă���낵���Ȃ�����
354 �FSocket774�F2008/08/30(�y) 15:18:42 ID:wtzg0s1F
�X���^�C�͊m��Intel�̎�����CPU�ɂ��Č�낤�������͂��E�E�E
>Intel�ɂƂ��Ă���낵���Ȃ�����
Intel�̓O���t�B�b�N�J�[�h�͗v��Ȃ��h������ʂɂ�����ˁB
G45�̔��\�̂Ƃ��ȂA�u����Ȃł����J�[�h�͂���Ȃ����I�v���āAGeForce���Ȃ��Ă�����
Intel�̓O���t�B�b�N�J�[�h�͗v��Ȃ��h������ʂɂ�����ˁB
G45�̔��\�̂Ƃ��ȂA�u����Ȃł����J�[�h�͂���Ȃ����I�v���āAGeForce���Ȃ��Ă�����
�����O���t�B�N�X�̂Ȃ�Core i7�{X58�̓G���X�[�����n�C�G���h�v���b�g�t�H�[��
G45�ӂ�Ƃ̓A�s�[������Ώۂ��Ⴄ
G45�ӂ�Ƃ̓A�s�[������Ώۂ��Ⴄ
��Ɨp�̓I���{�[�h�O���t�B�b�N������Ɣ��Ɋy���ȁB
�[���A������ЂŎg���p�\�R���Ƀr�f�I�J�[�h�Ȃ���Ă��ˁ[�B
�[���A������ЂŎg���p�\�R���Ƀr�f�I�J�[�h�Ȃ���Ă��ˁ[�B
��ƌ�����i810�̎����炻���Ȃ��Ă�
>>355
�C���e���̃O���{���č��x�͊��|��H
�O��"�����v���Z�X�̏������ŏȓd�͂��������邺�I"�݂����Ȃ��ƌ����ĂȂ������H
�C���e���̃O���{���č��x�͊��|��H
�O��"�����v���Z�X�̏������ŏȓd�͂��������邺�I"�݂����Ȃ��ƌ����ĂȂ������H
360 �F,,�E�L�́M�E,,�F2008/08/30(�y) 23:48:26 ID:DThLhIVJ
>>351
�����Ή����[�J�[���������������b�g���邩���
�����Ή����[�J�[���������������b�g���邩���
361 �F,,�E�L�́M�E,,�F2008/08/30(�y) 23:51:23 ID:DThLhIVJ
>>351
���Ȃ݂�ATI��CrossFire�͐V�̈Ӗ��ŃI�[�v���ȋK�i
���Ȃ݂�ATI��CrossFire�͐V�̈Ӗ��ŃI�[�v���ȋK�i
362 �F,,�E�L�́M�E,,�F2008/08/30(�y) 23:59:52 ID:DThLhIVJ
�^�́A��
�I�[�v�����Ă̂�USB�Ƃ�SCSI�݂����ȒN�ł��g������Ă��Ƃł���B
�I�[�v�����Ă̂�USB�Ƃ�SCSI�݂����ȒN�ł��g������Ă��Ƃł���B
�N��300���̉���SCSI�Ȃ�Ďg���܂���
�N�S���炢PC�ɂ܂킹��B
��Q�ҔN���̔N��100���̉��Ɏӂ�
���߂�
367 �FSocket774�F2008/09/02(��) 01:55:29 ID:0YakD0dA
�������������l�����s��������悤�Ȃ��̂ɂȂ��
PC�Q�[���͐V�삪�N�X�o�Ȃ��Ȃ��Ă邵�ȁA8�N�A���̎s��k��������
����xbox360��PS3���v���b�g�z�[���ɊJ�����āA�����PC�ɈڐA���邩���Ȃ������ė���ł���
�͖̂ʔ������ŃO���t�B�b�N���������V�삪�o�邩�獂���\VGA���~�������Ċ���x�X���������Ǎ���͂ǂ��Ȃ���
Larrabee���o�邱��ɂ͐F�X�Ȃ��Ƃ����Ƃ͈���Ă�͂�
����xbox360��PS3���v���b�g�z�[���ɊJ�����āA�����PC�ɈڐA���邩���Ȃ������ė���ł���
�͖̂ʔ������ŃO���t�B�b�N���������V�삪�o�邩�獂���\VGA���~�������Ċ���x�X���������Ǎ���͂ǂ��Ȃ���
Larrabee���o�邱��ɂ͐F�X�Ȃ��Ƃ����Ƃ͈���Ă�͂�
larrabee�������邱�Ƃɂ͂����͂Ȃ���
�N���C�A���g�����n�C�p�t�H�[�}���X�ł���K�v����
�@��ʂɃ\�t�g����肩����K�v���߂����������Ȃ邩����
ttp://jp.techcrunch.com/archives/20080709otoy-developing-server-side-3d-rendering-technology/
OTOY�̃T�[�o�T�C�h�E�����_�����O�Z�p
�N���C�A���g�����n�C�p�t�H�[�}���X�ł���K�v����
�@��ʂɃ\�t�g����肩����K�v���߂����������Ȃ邩����
ttp://jp.techcrunch.com/archives/20080709otoy-developing-server-side-3d-rendering-technology/
OTOY�̃T�[�o�T�C�h�E�����_�����O�Z�p
Hot chips �I��������Ǔ��{��̋L������܂�o�Ă��Ȃ���
>>370
Net�Q�[���̓l�b�g�̃��C�e���V�����o�I�ɉB�����邽�߂�
�F�X�ȍH�v�����Ă��邪�A�T�[�o�T�C�h�����_���ƂقƂ��
�B���ł��Ȃ��Ȃ�悤�ȋC������B�C���C��������
Net�Q�[���̓l�b�g�̃��C�e���V�����o�I�ɉB�����邽�߂�
�F�X�ȍH�v�����Ă��邪�A�T�[�o�T�C�h�����_���ƂقƂ��
�B���ł��Ȃ��Ȃ�悤�ȋC������B�C���C��������
�i���Љ�ŁA�݂�Ȃ����������B
375 �FSocket774�F2008/09/03(��) 20:40:25 ID:e217tWWs
Q8200 E5200 �̔����ŁA2008�N8���̉��i����^�V�������o��������B
�������������ǁA���͂����ȁB
�������������ǁA���͂����ȁB
>>343
QPI��CPU��GPU�Ԃ̐ڑ��Ɏg����̂�GPU����CPU�̃P�[�X��������
QPI��CPU�O���Ƃ̐ڑ��Ɏg����ꍇ�A���̑���̓`�b�v�Z�b�g
������CPU��QPI��Geforce�Ɍq���鎖�͖���
NVIDIA��QPI�̃��C�Z���X���g���P�[�X��X58��T�[�o�����`�b�v�Z�b�g���J������ꍇ�̂�
QPI��CPU��GPU�Ԃ̐ڑ��Ɏg����̂�GPU����CPU�̃P�[�X��������
QPI��CPU�O���Ƃ̐ڑ��Ɏg����ꍇ�A���̑���̓`�b�v�Z�b�g
������CPU��QPI��Geforce�Ɍq���鎖�͖���
NVIDIA��QPI�̃��C�Z���X���g���P�[�X��X58��T�[�o�����`�b�v�Z�b�g���J������ꍇ�̂�
QPI�ڑ���GPU�͍��邾�낤���A�q���鑊�肪��Bloomfield��Xeon�����ŁA
�������ڑ��̎d�����ǂ��ł���A�Ǝ��ɂȂ邾�낤����A�G���h���[�U�ɂ͂���܊W�Ȃ��悤�ȁB
Lynnfield�AHavendale��PCIe2.0x16���V�X�e���o�X�Ɍ����Ă��`�b�v�Z�b�g�̕���
�܂����肦�����ȋC���B
�������ڑ��̎d�����ǂ��ł���A�Ǝ��ɂȂ邾�낤����A�G���h���[�U�ɂ͂���܊W�Ȃ��悤�ȁB
Lynnfield�AHavendale��PCIe2.0x16���V�X�e���o�X�Ɍ����Ă��`�b�v�Z�b�g�̕���
�܂����肦�����ȋC���B
CPU�ƊO��GPU��QPI�Œ��������ꍇ�A����GPU�Ƀ`�b�v�Z�b�g�̖����������Ȃ���Ȃ���
CPU�Ɠ���GPU��QPI�Ō��ԏꍇ�́AGPU�Ƀ`�b�v�Z�b�g�̋@�\�����������
CPU�Ɠ���GPU��QPI�Ō��ԏꍇ�́AGPU�Ƀ`�b�v�Z�b�g�̋@�\�����������
�́H
QPI�̃C���^�[�t�F�C�X�����������������
QPI�̃C���^�[�t�F�C�X�����������������
>>380
��ʌ���Nehalem��QPI�͈�{����������
�����X58������ɏ�����`�b�v�Z�b�g�Ɍq���Ȃ��Ȃ�ANehalem�͂ǂ������PCIe��SATA���̑���MB�̋@�\�փA�N�Z����O�O�G
��ʌ���Nehalem��QPI�͈�{����������
�����X58������ɏ�����`�b�v�Z�b�g�Ɍq���Ȃ��Ȃ�ANehalem�͂ǂ������PCIe��SATA���̑���MB�̋@�\�փA�N�Z����O�O�G
�ȂA����Ȓ��x�̘b��
�������l����ƁA�n�[�t��QPI��2�{�ɂ킯��B
QPI�����[�����m�[�X�����̃`�b�v�����B
GPGPU�ł�PCIe2.0���QPI�̕��������������Ő��\����قnj��シ��Ȃ�A���肦�Ȃ��͂Ȃ����낤���ǁA
�o�Ă���Ƃ��Ă������Ɛ�̘b�ȋC������B
QPI�����[�����m�[�X�����̃`�b�v�����B
GPGPU�ł�PCIe2.0���QPI�̕��������������Ő��\����قnj��シ��Ȃ�A���肦�Ȃ��͂Ȃ����낤���ǁA
�o�Ă���Ƃ��Ă������Ɛ�̘b�ȋC������B
>>383
2Way����Nehalem�Ȃ�Q�{�iCPU�Ԑڑ��p��1�A�`�b�v�Z�b�g�ڑ��p��1�j
4Way�����Ȃ�S�{�iCPU�Ԑڑ��p��3�A�`�b�v�Z�b�g�ڑ��p��1�j
��QPI������
�������g���O���t�B�b�N��p�o�X�͗p�ӂł��邾�낤����
���i�̐܂荇���͕t���Ȃ�������
�Ƃ�������ʌ���Nehalem�ł�QPI���g����̂̓n�C�G���h�݂̂�
���̉���QPI�̕ς��ɁACPU����`�b�v�Z�b�g�ڑ��p�o�X��DMI��PCI-Ex16���o��
�}���`GPU�����ɕύX����Ȃ�QPI����Ȃ��āACPU����o��PCI-E�̐��𑝂₷��������Ȃ���
�ł���������̂�Larrabee���������Ă���̋C�����邗
2Way����Nehalem�Ȃ�Q�{�iCPU�Ԑڑ��p��1�A�`�b�v�Z�b�g�ڑ��p��1�j
4Way�����Ȃ�S�{�iCPU�Ԑڑ��p��3�A�`�b�v�Z�b�g�ڑ��p��1�j
��QPI������
�������g���O���t�B�b�N��p�o�X�͗p�ӂł��邾�낤����
���i�̐܂荇���͕t���Ȃ�������
�Ƃ�������ʌ���Nehalem�ł�QPI���g����̂̓n�C�G���h�݂̂�
���̉���QPI�̕ς��ɁACPU����`�b�v�Z�b�g�ڑ��p�o�X��DMI��PCI-Ex16���o��
�}���`GPU�����ɕύX����Ȃ�QPI����Ȃ��āACPU����o��PCI-E�̐��𑝂₷��������Ȃ���
�ł���������̂�Larrabee���������Ă���̋C�����邗
32nm����Ȃ�PCI-E��32���[���ɂ���̂́A�������ɗe�Ղ��낤�ȁB
�ł�������_�C�T�C�Y�I�ɗ]�T�����낤���A�w�ǎg���Ȃ��\��
�̂���@�\���C���v�������g����̂͌o�c���f�I�ɁE�E�E
�ł�������_�C�T�C�Y�I�ɗ]�T�����낤���A�w�ǎg���Ȃ��\��
�̂���@�\���C���v�������g����̂͌o�c���f�I�ɁE�E�E
Lynnfield��Havendale���Ă��̊Ԃ�DDR3-1066�Ɍ�ނ���������́H
DDR3-1333�Ή��������͂��Ȃ̂�
DDR3-1333�Ή��������͂��Ȃ̂�
�Ƃ�����Bloomfield��DDR3-1066�܂łɂȂ���
>>387
��������AG45��P45��DDR3-1333�Ή��������͂���
���ۂ�DDR3-1066�܂ł����Ή����ĂȂ���
DDR3-1333���ĉ�����肠���H
�ꉞJEDEC�Ő����ɋK�i������Ă���
��������AG45��P45��DDR3-1333�Ή��������͂���
���ۂ�DDR3-1066�܂ł����Ή����ĂȂ���
DDR3-1333���ĉ�����肠���H
�ꉞJEDEC�Ő����ɋK�i������Ă���
>>388
Bloomfield��DRAM�d���ƃR�A�d�����A������\���Ȃ̂ŁA�������ɂ��킹��1.65V������������
�R�A���������@�������ȁB
ELPIDA���o����1.5V�쓮�i�̓o���f�[�V�������Ԃɍ����ĂȂ���Ȃ����ȁB
Bloomfield��DRAM�d���ƃR�A�d�����A������\���Ȃ̂ŁA�������ɂ��킹��1.65V������������
�R�A���������@�������ȁB
ELPIDA���o����1.5V�쓮�i�̓o���f�[�V�������Ԃɍ����ĂȂ���Ȃ����ȁB
�ق�ƂɘA������̂��ˁH
>>391
���̒ʂ�ŁAAMD������Ă邱�Ƃ�Intel�����Ȃ��킯�͂Ȃ��Ǝv�����ǂȁB
�����ă����R�����R�A�d���ƘA��������AEIST��C�X�e�[�g�̑J�ڂ̂Ƃ��͂ǂ��Ȃ�̂��Č����^�₪�B
���̒ʂ�ŁAAMD������Ă邱�Ƃ�Intel�����Ȃ��킯�͂Ȃ��Ǝv�����ǂȁB
�����ă����R�����R�A�d���ƘA��������AEIST��C�X�e�[�g�̑J�ڂ̂Ƃ��͂ǂ��Ȃ�̂��Č����^�₪�B
�P�D��������Y���
�Q�D�������R���g���[������1���ڂȂ�ŁA�����͑�ڂ�
�R�D�ȓd�͋@�\�͕ʐ��i�E�ʉ��i�ł��������܂��B
�Q�D�������R���g���[������1���ڂȂ�ŁA�����͑�ڂ�
�R�D�ȓd�͋@�\�͕ʐ��i�E�ʉ��i�ł��������܂��B
�R�A���̃p���[�Q�[�e�B���O�������ď����Ă��������B
����ł��ĘA��������Ăǂ̃R�A�ƘA������̂�
����ł��ĘA��������Ăǂ̃R�A�ƘA������̂�
���낻�냁���R�����}���`�ɂ��悤��
���������������̖��������Ƃ����Ԃɉ�����
���������������̖��������Ƃ����Ԃɉ�����
���ڃ������ʂ��}���`�ɂȂ��ă��[�U�ɕ��ׂ��s���̂ł��ˁB�킩��܂��B
397 �FSocket774�F2008/09/05(��) 14:54:16 ID:AQ8eQ3HW
>>395
AMD��6�R�A���j�R�C�`����12�R�A�Ń����R��2���g����l�ɂ���炵��
AMD��6�R�A���j�R�C�`����12�R�A�Ń����R��2���g����l�ɂ���炵��
>>395
OS��NUMA�T�|�[�g���Ȃ��Ɛ��\�łȂ���Ȃ��B
Windows��2003server����T�|�[�g����Ă邪�A
�l������Vista�ł͖����ɂȂ��Ă邾��B
OS��NUMA�T�|�[�g���Ȃ��Ɛ��\�łȂ���Ȃ��B
Windows��2003server����T�|�[�g����Ă邪�A
�l������Vista�ł͖����ɂȂ��Ă邾��B
������ƒ��ׂ���64bit�ł�XP�ł�NUMA�T�|�[�g����Ă��E�E
http://itpro.nikkeibp.co.jp/free/NT/WinInterview/20050525/1/
http://itpro.nikkeibp.co.jp/free/NT/WinInterview/20050525/1/
�����R����CPU���番������Ζ�������
�R�A��������Α�����قǃ{�g���l�b�N�ɂȂ�B
cc-NUMA��Win�ł�Linux�ł����łɃT�|�[�g����ĂȂ���������?
�����R���̃}���`�͕����I�ɕ����̂����Ę_���w�ł͂P�Ƃ��ē��삷��悤�ɂ����OK����
�����intel�͍���ACPU���Ƀ������`���l��������čs���Ƃ������Ă�����
CPU������̃`���l���͂���炸���x���܂������Ȃ�Ȃ���?
�}���`�ɂ����Ԃ��d�͂���
�����R���̃}���`�͕����I�ɕ����̂����Ę_���w�ł͂P�Ƃ��ē��삷��悤�ɂ����OK����
�����intel�͍���ACPU���Ƀ������`���l��������čs���Ƃ������Ă�����
CPU������̃`���l���͂���炸���x���܂������Ȃ�Ȃ���?
�}���`�ɂ����Ԃ��d�͂���
�h�C�c��PC Games Hardware�ɂ��ƁA�ʎY�ł�Core i7�̐��\��l�b�g��ɏo����Ă���x���`
���ʂ��ǂ��Ȃ�Ƃ̂��Ƃ��B
http://www.pcgameshardware.de/aid,658911/News/Intel_Bisherige_Core_i7-/Nehalem-Tests_im_Internet_nicht_aussagekraeftig/
�ʎY�ł̃X�e�b�s���O��B1�ȍ~�ŁAB0�X�e�b�s���O�ł̃x���`���ʂ�u���Ӗ��v�Ƃ��B
������������NAMD���畷�����悤�ȋC�����邷���ǁA���ʂ��������ǂ����팻���҂����B
���ʂ��ǂ��Ȃ�Ƃ̂��Ƃ��B
http://www.pcgameshardware.de/aid,658911/News/Intel_Bisherige_Core_i7-/Nehalem-Tests_im_Internet_nicht_aussagekraeftig/
�ʎY�ł̃X�e�b�s���O��B1�ȍ~�ŁAB0�X�e�b�s���O�ł̃x���`���ʂ�u���Ӗ��v�Ƃ��B
������������NAMD���畷�����悤�ȋC�����邷���ǁA���ʂ��������ǂ����팻���҂����B
�u��v�͂�߂�u��v��
407 �FMAC�I�^��406 �����F2008/09/06(�y) 22:07:06 ID:izCBmakR
>>406
�@�@-------------------
�@�@�����o�Ȃ��Ɣ���Ȃ��͍̂����̂��ꏏ
�@�@-------------------
������������������Ȃ���M�҂̊��҂���������܂������^�Ђ�����������(��)
http://www.dailytech.com/Stumbling+in+the+Aisles+Barcelona+Thoughts/article8804.htm
�@�@===================
�@�@One AMD developer, who wished to remain anonymous for non-disclosure purposes, stated,
�@�@"B1 versus BA should be at least a 5%, if not more, gain in stream, integer and FPU performance."
�@�@An AMD engineer, when confronted with the claim, stated that 5% gains when moving from B1
�@�@to BA processors "seem conservative."
�@�@===================
�@�@-------------------
�@�@�����o�Ȃ��Ɣ���Ȃ��͍̂����̂��ꏏ
�@�@-------------------
������������������Ȃ���M�҂̊��҂���������܂������^�Ђ�����������(��)
http://www.dailytech.com/Stumbling+in+the+Aisles+Barcelona+Thoughts/article8804.htm
�@�@===================
�@�@One AMD developer, who wished to remain anonymous for non-disclosure purposes, stated,
�@�@"B1 versus BA should be at least a 5%, if not more, gain in stream, integer and FPU performance."
�@�@An AMD engineer, when confronted with the claim, stated that 5% gains when moving from B1
�@�@to BA processors "seem conservative."
�@�@===================
>>407
��H�ŋ߂���E5200�����\����ɓ��Ă͂܂���H
�[���A�܂������Ԃ�Â��Ƃ��납����������Ă��Ă��
����Ȃɂ��C�ɓ���̋L���Ȃ̂����H
��H�ŋ߂���E5200�����\����ɓ��Ă͂܂���H
�[���A�܂������Ԃ�Â��Ƃ��납����������Ă��Ă��
����Ȃɂ��C�ɓ���̋L���Ȃ̂����H
409 �FMAC�I�^��408 �����F2008/09/06(�y) 22:47:08 ID:izCBmakR
>>408
�@�@------------------
�@�@�܂������Ԃ�Â��Ƃ��납����������Ă��Ă��
�@�@------------------
�ق��1�N�O�̋L���Ȃ��ǁB�B�B�ȒP�Ƀ��m��Y�ꂿ�Ⴄ����(��)
�@�@------------------
�@�@�܂������Ԃ�Â��Ƃ��납����������Ă��Ă��
�@�@------------------
�ق��1�N�O�̋L���Ȃ��ǁB�B�B�ȒP�Ƀ��m��Y�ꂿ�Ⴄ����(��)
intel��2007�N��IDF�ŁA2013�N���ڎw���Č�CPU����܂����Ă����Ă��Ǝv�����ǁA
���̌�̑�����ĂȂ���?
�̂�10GHz�ڎw���܂����Ă�����̔��\��������?
���̌�̑�����ĂȂ���?
�̂�10GHz�ڎw���܂����Ă�����̔��\��������?
B0����B1�̃X�e�b�s���O�A�b�v�ł���Ȃɐ��\���ς��Ƃ͎v���Ȃ����ǁc
�o�O���L��Ό��I�ɐ��\�͕ς邾��B
�w�m�����o�O�L���B2�Ńo�O�Ώ��Œx���Ȃ��Ă��̂��AB3�ŃA�b�v�����݂����ɁB
�w�m�����o�O�L���B2�Ńo�O�Ώ��Œx���Ȃ��Ă��̂��AB3�ŃA�b�v�����݂����ɁB
414 �FSocket774�F2008/09/08(��) 16:04:55 ID:JbA+kkvZ
Nehalem����ɂȂ�ƃf���A����GPU�����ł����o���Ȃ��́H
�����\��Intel GPU�ʼn䖝���邩�A�N�A�b�h�����ĊO�t��GPU�g�����Ă��ƁH
E8500+GeForce8600�݂����Ȏ��v�͂ǂ��Ȃ�́H
�����\��Intel GPU�ʼn䖝���邩�A�N�A�b�h�����ĊO�t��GPU�g�����Ă��ƁH
E8500+GeForce8600�݂����Ȏ��v�͂ǂ��Ȃ�́H
��������GPU�̋@�\�g�킸�A�O�t��GPU�g�����Ă��ƂɂȂ�Ⴀ�H
PCI-Express2.0x16��1�{���邵�B
����GPU���������C���ɂȂ邯�ǁA�`�b�v�������Ɗ���G45��P45��1000���b�g�̉��i�͈ꏏ�������肷��B
Havendale��GPU�@�\�E�������f�����o���Ƃ��Ă��A���܂艿�i���͂Ȃ��Ǝv���B
PCI-Express2.0x16��1�{���邵�B
����GPU���������C���ɂȂ邯�ǁA�`�b�v�������Ɗ���G45��P45��1000���b�g�̉��i�͈ꏏ�������肷��B
Havendale��GPU�@�\�E�������f�����o���Ƃ��Ă��A���܂艿�i���͂Ȃ��Ǝv���B
�Ƃ������A��{�I�ɓ����`�b�v�ŃO���t�B�b�N���E���Ă邾���������悤��>P45,P35
��ʂ̔z�����q���邩��AI/O�����̖ʐς��m�ۂ��邽�߂Ɉ��K�͂̃`�b�v�̑傫���͕K�v
�X�J�X�J�̃`�b�v���Ă̂����������Ȃ�����O���t�B�N�X�@�\�ł��ڂ��Ă݂����
�E�E�E���Ă̂������^�`�b�v�̎n�܂肾�Ƃ�
�X�J�X�J�̃`�b�v���Ă̂����������Ȃ�����O���t�B�N�X�@�\�ł��ڂ��Ă݂����
�E�E�E���Ă̂������^�`�b�v�̎n�܂肾�Ƃ�
���Ƃ����C���X�g���[���N���X�̃f���A���R�A��
P45 P43 G45 G43��E7200 E7300 E8400 E8500 E8600��
�g�ݍ��킹���l���������ł�20�ʂ�B
�W�T�J�[�I�ɂ�OEM�I�ɂ��ANehalem����őI���������܂�Ƃ�����₵���Ȃ��B
P45 P43 G45 G43��E7200 E7300 E8400 E8500 E8600��
�g�ݍ��킹���l���������ł�20�ʂ�B
�W�T�J�[�I�ɂ�OEM�I�ɂ��ANehalem����őI���������܂�Ƃ�����₵���Ȃ��B
>>418
�V�\�P�͂������������Ǝv������
�V�\�P�͂������������Ǝv������
����Core2�̓L���b�V��,FSB�̑召��������
�E�f���A���R�A
�E���̃N�A�b�h�R�A
��2�^�C�v�����Ȃ����ǁANehalem��
�EGPU�t���̃R�X�g�팸��2�R�A
�EDual Channel��MC,PCIE�����̕��y�ŃN�A�b�h�R�A
�ETriple Channel��MC,QPI�����̔p�G���h/�T�[�o�[�p
�E�G���^�[�v���C�Y�p�̒��W����8�R�A
����Ȋ�����CPU���̂��̂̓o���G�e�B�������Ėʔ�����ˁB
�E�f���A���R�A
�E���̃N�A�b�h�R�A
��2�^�C�v�����Ȃ����ǁANehalem��
�EGPU�t���̃R�X�g�팸��2�R�A
�EDual Channel��MC,PCIE�����̕��y�ŃN�A�b�h�R�A
�ETriple Channel��MC,QPI�����̔p�G���h/�T�[�o�[�p
�E�G���^�[�v���C�Y�p�̒��W����8�R�A
����Ȋ�����CPU���̂��̂̓o���G�e�B�������Ėʔ�����ˁB
�p�\�R���o�ׂ̔����͊�ƌ����N���C�A���gPC
Q963/Q965/Q33/Q35�ɑ������郉�C���i�b�v�͏o���
Q963/Q965/Q33/Q35�ɑ������郉�C���i�b�v�͏o���
422 �FSocket774�F2008/09/08(��) 22:27:13 ID:myVKJACW
���J�L�R�ł��B
CORE 2 DUO E6600�i�l�̍��̃p�\�b�o�t�j��100�Ƃ���ƁACore 2 Quad Q9550 BOX�͂ǂꂮ�炢�̔\�͂�����܂����H
CORE 2 DUO E6600�i�l�̍��̃p�\�b�o�t�j��100�Ƃ���ƁACore 2 Quad Q9550 BOX�͂ǂꂮ�炢�̔\�͂�����܂����H
����GPU��2��ނ���Ƃ����b�����邯�ǁA��ƌ����ɂ���ɂ��Ęb�͍��̂Ƃ���Ȃ��ˁB
PCH�̕��ɊǗ��p�̋@�\�g�ݍ��ނ��`�b�v���邩���āA�v���b�g�t�H�[���ŋ�ʂ���̂����B
PCH�̕��ɊǗ��p�̋@�\�g�ݍ��ނ��`�b�v���邩���āA�v���b�g�t�H�[���ŋ�ʂ���̂����B
424 �F,,�E�L�́M�E,,�j��-�������F2008/09/08(��) 22:34:01 ID:0V3+5JgQ
>>420
���o�C���pULV�ł�����Core 2 Solo�͂���B
���o�C���pULV�ł�����Core 2 Solo�͂���B
�Ȃ������ȁACore Solo�B
���ƂȂ��Ă͂���Ӗ��M�d���B
���ƂȂ��Ă͂���Ӗ��M�d���B
426 �F,,�E�L�́M�E,,�j��-�������F2008/09/08(��) 23:10:31 ID:0V3+5JgQ
��������B
http://www.intel.co.jp/jp/products/processor/core2solo/index.htm
Core 2 Solo��VAIO type U�����ڂ��Ă��͂��B
�ł����낻�낱�̃����W��Atom�ɒu�������ȋC������B
http://www.intel.co.jp/jp/products/processor/core2solo/index.htm
Core 2 Solo��VAIO type U�����ڂ��Ă��͂��B
�ł����낻�낱�̃����W��Atom�ɒu�������ȋC������B
Atom�n�̓V���O���X���b�h���\�̌���͂��܂���ҏo���Ȃ�����ȁB
�����R������&DDR3��5%���x�������Ċ������B���Ƃ͂܂����̃^�[�{
���[�h���ڂ̗\�������邪�E�E�E
�����R������&DDR3��5%���x�������Ċ������B���Ƃ͂܂����̃^�[�{
���[�h���ڂ̗\�������邪�E�E�E
428 �FSocket774�F2008/09/09(��) 14:35:58 ID:z5T0ui29
Solo����Duo�̕s�Ǖi����Ȃ������̂�
���݂܂���ǂȂ���422�̓������肢���܂�m(_ _)m
431 �FSocket774�F2008/09/09(��) 17:23:24 ID:tbC6uehd
ULV��Solo�͂ނ��뒴�I�ʕi���ȁB
�`���C������ULV Celeron
���̉��������炭�ʏ�d����LV�̃��o�C��Celelon
�`���C������ULV Celeron
���̉��������炭�ʏ�d����LV�̃��o�C��Celelon
>>427
�����܂Ń��o�C��������B
ULV Core2�̓N���b�N�}��������Ă镪���\�͑債�Ă悭�Ȃ��B
Atom��1.6GHz�ł�4W�ȉ�������A���ʓI�ɂ�UMPC�p�Ƃ��Ă̐��\�͂���Ȃ肾��B
�ނ���o�b�e���[�̎������d�v�BCore2�̓��o�C���p�Ƃ��Ă͐H�炢�������B
�����܂Ń��o�C��������B
ULV Core2�̓N���b�N�}��������Ă镪���\�͑債�Ă悭�Ȃ��B
Atom��1.6GHz�ł�4W�ȉ�������A���ʓI�ɂ�UMPC�p�Ƃ��Ă̐��\�͂���Ȃ肾��B
�ނ���o�b�e���[�̎������d�v�BCore2�̓��o�C���p�Ƃ��Ă͐H�炢�������B
Dual Core Atom 330�̎ʐ^�ƃx���`�}�[�N���o�Ă��邷�B
http://en.expreview.com/2008/09/08/dual-core-atom-330-leak-pics-and-bench-numbers/
�@�� Samdra 2009
�@�@�EProcessor Arithmetric Test
�@�@�@Intel Atom N270 1.6GHz -- 8291 kpixels/s
�@�@�@Intel Atom 330 1.6GHz Dual Core -- 16920 kpixels/s
�@�@�@Intel Core 2 Duo U7700 1.3GHz -- 24742 kpixels/s
�@�@�EMemory Bandwidth Test
�@�@�@Intel Atom N270 1.6GHz -- 3.54 GB/s
�@�@�@Intel Atom 330 1.6GHz Dual Core -- 7.18 GB/s
�@�@�@Intel Core 2 Duo U7700 1.3GHz -- 9.53 GB/s
http://en.expreview.com/2008/09/08/dual-core-atom-330-leak-pics-and-bench-numbers/
�@�� Samdra 2009
�@�@�EProcessor Arithmetric Test
�@�@�@Intel Atom N270 1.6GHz -- 8291 kpixels/s
�@�@�@Intel Atom 330 1.6GHz Dual Core -- 16920 kpixels/s
�@�@�@Intel Core 2 Duo U7700 1.3GHz -- 24742 kpixels/s
�@�@�EMemory Bandwidth Test
�@�@�@Intel Atom N270 1.6GHz -- 3.54 GB/s
�@�@�@Intel Atom 330 1.6GHz Dual Core -- 7.18 GB/s
�@�@�@Intel Core 2 Duo U7700 1.3GHz -- 9.53 GB/s
435 �FMAC�I�^���⑫�F2008/09/10(��) 00:53:02 ID:whUJSKU4
�������x���`�̌��ʂ��P����2�{�ɂȂ��Ă���̂��������������B
400MHz FSB�Ƃ��āA�������ш��
�@400 [MHz] x 8 [byte] = 3200 [MB/s]
���������͂��ŁA�f���A���R�A�ɂȂ��Ă������锤���������B
400MHz FSB�Ƃ��āA�������ш��
�@400 [MHz] x 8 [byte] = 3200 [MB/s]
���������͂��ŁA�f���A���R�A�ɂȂ��Ă������锤���������B
�f���A���R�A���ăI���_�C����Ȃ������̂�
�܂��A����Ⴛ����
�܂��A����Ⴛ����
Sandra����1�X���b�h�v���~���s�\�X���b�h��
�̃A�z�x���`����Ȃ��������H
�̃A�z�x���`����Ȃ��������H
>>434-435
sandra2009�ɓo�^����Ă錋�ʂ��̂܂܂��
Arithmetric Test��multi media int�̂��̂ʼn��̂�float�͂Ȃ�
����nano��multi media float�͌��\�D�G�Ȃ悤��
>738 �FSocket774 [��] �F2008/09/09(��) 22:29:17 ID:zCTJYcG5
>Multi media float��OS�̈Ⴂ�i32bit,64bit)�Ŗ�2���قǑ����Ȃ�悤��
>�iInt�͑����Ȃ��j
>1.8GHz��9410Pixel/s��11520Pixel/s�ƂȂ�
>�i���Ȃ݂�celeron440 32bit��10427Kpixel/s�ƂȂ�j
>�iint��Celeron440�̔������x�ƂȂ邯�ǂˁj
>�inano 1.8GHz 32bit 9824kPixel/s�j
>�icele 2.0GHz 32bit 18561kPixel/s�j
>�܂��A64bit�ł�Dhrystone��7%,Whetstone��5%�����Ȃ�
>�i���Ȃ݂�nano 1.8GHz�Fcele2.0GHz�Łj
>�iDhrystone 5229:7801 MIPS�j
>�iWhetstone 4514:7305 MFLOPS�j
>Multi media float���Ȃُ�ɑ�������
Cryptography�̃e�X�g���lj������padlock�������W��
C7,nano�͂��炢���ƂɂȂ��Ă�
sandra2009�ɓo�^����Ă錋�ʂ��̂܂܂��
Arithmetric Test��multi media int�̂��̂ʼn��̂�float�͂Ȃ�
����nano��multi media float�͌��\�D�G�Ȃ悤��
>738 �FSocket774 [��] �F2008/09/09(��) 22:29:17 ID:zCTJYcG5
>Multi media float��OS�̈Ⴂ�i32bit,64bit)�Ŗ�2���قǑ����Ȃ�悤��
>�iInt�͑����Ȃ��j
>1.8GHz��9410Pixel/s��11520Pixel/s�ƂȂ�
>�i���Ȃ݂�celeron440 32bit��10427Kpixel/s�ƂȂ�j
>�iint��Celeron440�̔������x�ƂȂ邯�ǂˁj
>�inano 1.8GHz 32bit 9824kPixel/s�j
>�icele 2.0GHz 32bit 18561kPixel/s�j
>�܂��A64bit�ł�Dhrystone��7%,Whetstone��5%�����Ȃ�
>�i���Ȃ݂�nano 1.8GHz�Fcele2.0GHz�Łj
>�iDhrystone 5229:7801 MIPS�j
>�iWhetstone 4514:7305 MFLOPS�j
>Multi media float���Ȃُ�ɑ�������
Cryptography�̃e�X�g���lj������padlock�������W��
C7,nano�͂��炢���ƂɂȂ��Ă�
ARM�AIntel�ɂ��Atom�D�ʂ̎咣�ɋ������_
ttp://pc.watch.impress.co.jp/docs/2008/0910/arm.htm
�L�҂������Ă邪�O�O�����AARM�������_�Ɏv����B
Intel �͑�l����ATOM�̗D�ʂ� x86 �̃\�t�g�E�F�A���Y���Ƃ����咣��
���߂Ă��������̂ɁA�����\�ɐG��Ă�Ԃւт��Ċ���
ttp://pc.watch.impress.co.jp/docs/2008/0910/arm.htm
�L�҂������Ă邪�O�O�����AARM�������_�Ɏv����B
Intel �͑�l����ATOM�̗D�ʂ� x86 �̃\�t�g�E�F�A���Y���Ƃ����咣��
���߂Ă��������̂ɁA�����\�ɐG��Ă�Ԃւт��Ċ���
���̂ւ�̈������[�^�Ȃ�ARM���Ă�������E���R�����ǁAATOM�͂�����E���R�Ȃ̂��c�B
ARM��Atom���Z�ޏꏊ���Ⴄ�ׂ�
�����ARM���Ă����Ă��ŏ�ʂƍʼn��ʂł͈ꌅ�ȏ㐫�\�Ⴄ�͂�
�[��ARM����IP�ł̒���?
�ʎY��Bloomfield�̃X�e�b�s���O�̘b�肷���ǁA���Ȃ��Ă����s�̃T���v����>>228��
Hexus�̃x���`�}�[�N�̍����X�e�b�s���O�ԍ���2��i��ł���炵�����B
�@�EHexus�x���`��CPU-Z
�@�@http://channel.hexus.net/content/item.php?item=15115&page=1&search=bloomfield
�@�EXtremeSystems�f���ɓ��e���ꂽ�V�����ڂ�SS
�@�@http://www.xtremesystems.org/forums/showpost.php?p=3269328&postcount=1235
���Ă̒ʂ�stepping��2->4�ɂȂ��Ă��邷�B
Hexus�̃x���`�}�[�N�̍����X�e�b�s���O�ԍ���2��i��ł���炵�����B
�@�EHexus�x���`��CPU-Z
�@�@http://channel.hexus.net/content/item.php?item=15115&page=1&search=bloomfield
�@�EXtremeSystems�f���ɓ��e���ꂽ�V�����ڂ�SS
�@�@http://www.xtremesystems.org/forums/showpost.php?p=3269328&postcount=1235
���Ă̒ʂ�stepping��2->4�ɂȂ��Ă��邷�B
�u��v�Ƃ��u�`���v�͂�߂悤���H
�|���ɂ�����ł��ȁc
���̔ɂ���Ȃ��Č����Ă��悗
���̔ɂ���Ȃ��Č����Ă��悗
>>445
���l�ɑ��Ă̓l�K�e�B�u�Ȍ��ʂ����Ȃ����Ƃ��A�C�̖�����
�����������l�q�ł��Ȃ����X�ƌp�����Ă���̂�����
���������l���Ƃ������ƂȂ̂��낤�B
���l�ɑ��Ă̓l�K�e�B�u�Ȍ��ʂ����Ȃ����Ƃ��A�C�̖�����
�����������l�q�ł��Ȃ����X�ƌp�����Ă���̂�����
���������l���Ƃ������ƂȂ̂��낤�B
444�̌��ʂ�����ƁAIDF���O��Hexus���o�������̂Ɣ�ׂ�3DMark Vantage��
�p�t�H�[�}���X���啪�ǂ��Ȃ��Ă�ˁB
���N���b�N��Yorkfield�ƕ��ʂɌ�����ׂ��鐔�l�ɂȂ����悤�ȁB
ttp://en.hardspell.com/doc/showcont.asp?news_id=3866
��Yorkfield 4.0GHz + RADEON HD4870X2 CF�̌���
����4870X2��Core750/Mem3600(900)�ɐݒ肳��Ă�̂ɑ��āA444�̃����N���
HD4870X2��Core800/Mem3800��OC����Ă邩�炿����ƒP���ɂ͔�r�ł��Ȃ����ǁA
OC����K���ɂ����҂��Ă�Yorkfiled�ɗ��悤�Ȑ��l�ɂ͂Ȃ�Ȃ������B
�X�e�b�s���O���ς����QPI�܂��ł��������ă{�g���l�b�N�����P�����ˁH
Hexus�̃x���`�̌��ʂł�QuakeWars���ȂŒ�𑜓x�ŗǂ��č��𑜓x�ň�C��
���������̂�����������AQPI�܂�肪���Ȃ�������������������B
�p�t�H�[�}���X���啪�ǂ��Ȃ��Ă�ˁB
���N���b�N��Yorkfield�ƕ��ʂɌ�����ׂ��鐔�l�ɂȂ����悤�ȁB
ttp://en.hardspell.com/doc/showcont.asp?news_id=3866
��Yorkfield 4.0GHz + RADEON HD4870X2 CF�̌���
����4870X2��Core750/Mem3600(900)�ɐݒ肳��Ă�̂ɑ��āA444�̃����N���
HD4870X2��Core800/Mem3800��OC����Ă邩�炿����ƒP���ɂ͔�r�ł��Ȃ����ǁA
OC����K���ɂ����҂��Ă�Yorkfiled�ɗ��悤�Ȑ��l�ɂ͂Ȃ�Ȃ������B
�X�e�b�s���O���ς����QPI�܂��ł��������ă{�g���l�b�N�����P�����ˁH
Hexus�̃x���`�̌��ʂł�QuakeWars���ȂŒ�𑜓x�ŗǂ��č��𑜓x�ň�C��
���������̂�����������AQPI�܂�肪���Ȃ�������������������B
449 �F,,�E�L�́M�E,,�j���F2008/09/11(��) 12:06:31 ID:mB6U7ole
�p�t�H�[�}���X�����W��ARM��Intel�����č���Ă���ˁB
����ς�XScale�͌��삾�B
���x�̃T���X���̌g�тɂ����ڂ����悤�����B
����ς�XScale�͌��삾�B
���x�̃T���X���̌g�тɂ����ڂ����悤�����B
450 �F,,�E�L�́M�E,,�j���F2008/09/11(��) 12:21:51 ID:mB6U7ole
ARM�K�i��CPU�͔N�Ԗ�30���o�ׂ���ĂāA�����x86�̖�10�{�ɑ�������B
���������i��100�{�Ⴄ�B
Atom�ɂ��Ă��ŏ�ʃ��f���̉��i�͍ň���Celeron�Ȃ݂ɂ͂���B
Atom�̓d�͖ʂł̎�_�̓`�b�t�Z�b�g���炢����
���������i��100�{�Ⴄ�B
Atom�ɂ��Ă��ŏ�ʃ��f���̉��i�͍ň���Celeron�Ȃ݂ɂ͂���B
Atom�̓d�͖ʂł̎�_�̓`�b�t�Z�b�g���炢����
451 �FSocket774�F2008/09/11(��) 16:11:23 ID:mB6U7ole
�v����߂���������Ăǂ�ȊԈႢ���扴
AcesHardware�f����Charlie "Groo" Demerjian����Nehalem�̃����[�X�����̏ɂ���
�����Ă��邷�B
http://aceshardware.freeforums.org/nehalem-launch-schedule-t618.html#7870
�@�@---------------------
�@�@DP has been long scheduled after SP. SP is Q4 some time, DP looks to be Q1. There have
�@�@been several leaks from the voltage regulator folks saying that it will be in Q1 some time.
�@�@---------------------
��͂�V�d�͊Ǘ��@�\��A�}�U�[�{�[�h�̓d���v������͗l���B�܂�Bloomfiled���o��
Gainestown���x��C���Ƃ���������A������Bloomfield�ɔ�т��̂�����Ɋ댯��������Ȃ����B
�����Ă��邷�B
http://aceshardware.freeforums.org/nehalem-launch-schedule-t618.html#7870
�@�@---------------------
�@�@DP has been long scheduled after SP. SP is Q4 some time, DP looks to be Q1. There have
�@�@been several leaks from the voltage regulator folks saying that it will be in Q1 some time.
�@�@---------------------
��͂�V�d�͊Ǘ��@�\��A�}�U�[�{�[�h�̓d���v������͗l���B�܂�Bloomfiled���o��
Gainestown���x��C���Ƃ���������A������Bloomfield�ɔ�т��̂�����Ɋ댯��������Ȃ����B
�V�d�͊Ǘ��@�\������Ȃ���Ζ��Ȃ�����
NordicHardware��Bloomfield/Gainestown�̃������T�|�[�g��B
http://www.vr-zone.com/articles/AMD_Desktop_CPU_Roadmap/6046.html
�����������T�|�[�g�̏�Q��d���d���݂̂�1.7V����Ɗ댯�B2.0V���Ɖ��鋰�ꂪ����Ƃ��B
1.7V�ȉ����Ɠ���m�F���i�݂���Ƃ̂��Ƃ��B
�@�@-----------------------
�@�@Already, tests with Corsair's DDR3-1333 memory that handles 1600MHz at 1.64V and
�@�@1800MHz at 1.7V have been performed so we should still see some decent memory
�@�@frequencies on the Nehalem platform, but it will certainly be a more delicate process of
�@�@reaching there than it has been before.
�@�@-----------------------
http://www.vr-zone.com/articles/AMD_Desktop_CPU_Roadmap/6046.html
�����������T�|�[�g�̏�Q��d���d���݂̂�1.7V����Ɗ댯�B2.0V���Ɖ��鋰�ꂪ����Ƃ��B
1.7V�ȉ����Ɠ���m�F���i�݂���Ƃ̂��Ƃ��B
�@�@-----------------------
�@�@Already, tests with Corsair's DDR3-1333 memory that handles 1600MHz at 1.64V and
�@�@1800MHz at 1.7V have been performed so we should still see some decent memory
�@�@frequencies on the Nehalem platform, but it will certainly be a more delicate process of
�@�@reaching there than it has been before.
�@�@-----------------------
�ȂႤ�̒����Ă邼
456 �FMAC�I�^�������F2008/09/12(��) 22:01:21 ID:pcGcDMcc
���r�W�����オ������o���f�[�V�����Ƃ����̂��o�Ă��邩��
atom���ē��N���b�N��Pen4���݂̐��\����́H
�Ȃ�����
ttp://nueda.main.jp/blog/archives/003621.html
�A�v������B�V���O���X���b�h���\�Ȃ�Pen4�̕�����̏ꍇ�����B
�A�v������B�V���O���X���b�h���\�Ȃ�Pen4�̕�����̏ꍇ�����B
2���L���b�V���e�ʂɂ�����A���������ȋC������Ȃ��B
464 �F,,�E�L�́M�E,,�j���F2008/09/15(��) 12:48:09 ID:hwsUS/ft
�m���ɘmүċ�����Ȃ��E�E�E
��Intel�A�uMatchbox�v�̉pOpenedHand��
http://sourceforge.jp/magazine/08/09/01/047226
>Intel�͓��Ђ��擾���邱�ƂŁA���Ѓ��o�C��Linux�̎��g�݂ł���uMoblin�v����������_���B
http://sourceforge.jp/magazine/08/09/01/047226
>Intel�͓��Ђ��擾���邱�ƂŁA���Ѓ��o�C��Linux�̎��g�݂ł���uMoblin�v����������_���B
���u�����H
���炭�������O���ȁB
���炭�������O���ȁB
467 �F,,�E�L�́M�E,,�j���F2008/09/15(��) 22:27:29 ID:hwsUS/ft
�t���Z�b�g��Linux����������ɓ��ꂽ�̂Ƀ��o�C�������̈Ӗ��͂�����
>>466
�S�R���������E�E�E
http://www.google.co.jp/search?hl=ja&q=%E3%83%A2%E3%83%96%E3%83%AA%E3%83%B3&lr=&aq=f&oq=
�S�R���������E�E�E
http://www.google.co.jp/search?hl=ja&q=%E3%83%A2%E3%83%96%E3%83%AA%E3%83%B3&lr=&aq=f&oq=
�m���ɉ����Ȃ���
470 �F,,�E�L�́M�E,,�j���F2008/09/16(��) 10:32:34 ID:0EuaHeCT
�Q�C�cOS�ɂ͌Â�����edlin.exe�Ƃ������O�̃��C���G�f�B�^������
�����IVista�ɂ������Ă���
dos3.3d�Ƃ��̎���ɏ��߂ĐG�����G�f�B�^����B
Dunnington materializes as six-core Xeon 7400
http://techreport.com/discussions.x/15514
Processor Cores �@Speed�@L3 cache TDP
Xeon X7460�@ 6 �@2.66GHz �@16MB�@ 130W
Xeon E7450�@ 6 �@2.40GHz �@12MB �@90W
Xeon E7440�@ 4 �@2.40GHz �@16MB �@90W
Xeon E7430�@ 4 �@2.13GHz �@12MB �@90W
Xeon E7420�@ 4 �@2.13GHz �@8MB�@�@90W
Xeon L7455�@ 6 �@2.13GHz �@12MB �@65W
Xeon L7445�@ 4 �@2.13GHz �@12MB �@50W
http://techreport.com/discussions.x/15514
Processor Cores �@Speed�@L3 cache TDP
Xeon X7460�@ 6 �@2.66GHz �@16MB�@ 130W
Xeon E7450�@ 6 �@2.40GHz �@12MB �@90W
Xeon E7440�@ 4 �@2.40GHz �@16MB �@90W
Xeon E7430�@ 4 �@2.13GHz �@12MB �@90W
Xeon E7420�@ 4 �@2.13GHz �@8MB�@�@90W
Xeon L7455�@ 6 �@2.13GHz �@12MB �@65W
Xeon L7445�@ 4 �@2.13GHz �@12MB �@50W
Moblin�A���А�SoC�ɍڂ���Ƃ����Ƃ����Ęb����Ȃ��̂�?
���Ƃ��Όg�т̃V�X�e���p�ɂƂ��B
�����烂�o�C���@��CPU�P�̂��`�b�v�ŋ������Ă͖̂������݂�߂���B
���Ƃ��Όg�т̃V�X�e���p�ɂƂ��B
�����烂�o�C���@��CPU�P�̂��`�b�v�ŋ������Ă͖̂������݂�߂���B
Intel�����y��Nehalem�̗ʎY��2010�NQ1�ɉ���
http://pc.watch.impress.co.jp/docs/2008/0918/ubiq227.htm
�ȂC�O�̉\�ňȑO�����C�����邪�A�ǂ����{���̂悤���B
http://pc.watch.impress.co.jp/docs/2008/0918/ubiq227.htm
�ȂC�O�̉\�ňȑO�����C�����邪�A�ǂ����{���̂悤���B
476 �FSocket774�F2008/09/18(��) 12:35:49 ID:x5Qn/5ci
Auburndale���Core 2+GPU�̕����������낫����
nehalem�͂₭�o�Ȃ����ȁ`
�o�Ă���Ȃ��ƈ����Ȃ�\���Core2duo�������Ȃ�����Ȃ���
�͂₭PentiumD�������������
�o�Ă���Ȃ��ƈ����Ȃ�\���Core2duo�������Ȃ�����Ȃ���
�͂₭PentiumD�������������
nehalem�o�Ă�Core2Duo�͈����Ȃ�Ȃ��ł���
>>475
Quad�҂��ɂ͊W�Ȃ��ȁB
Quad�҂��ɂ͊W�Ȃ��ȁB
Intel�͈������炴��Ȃ��Ȃ�O��
���ߑ��߂ɍ��̂�߂Ă��܂������
���ߑ��߂ɍ��̂�߂Ă��܂������
481 �FSocket774�F2008/09/19(��) 20:05:46 ID:9gYIR1p8
775�����Ƃ���QX9870��E8800���ڂ�
�Ȃ������Ă�Celeron(R)���ō����ȁO�O
AMD��6000�~�܂ň����Ȃ邩�炢����B
�t�ɍ����Ƃ������Ȃ��B
���[�G���h��2MB��X2�����ނ�����̂͑����������ǂˁB
����̓R�X�g�������������ĂȂ�������
�Ԃ�Ă��������ˁB
�t�ɍ����Ƃ������Ȃ��B
���[�G���h��2MB��X2�����ނ�����̂͑����������ǂˁB
����̓R�X�g�������������ĂȂ�������
�Ԃ�Ă��������ˁB
>>482
�����B���܂��̃��C���o�b�������
�����B���܂��̃��C���o�b�������
>>483
�ł��A���h��6000�~�̂�Ȃ�ăZ�������ɖт����������x�̐��\����H
�ł��A���h��6000�~�̂�Ȃ�ăZ�������ɖт����������x�̐��\����H
X2�Z�������ȉ�
ttp://pc.watch.impress.co.jp/docs/2008/0922/kaigai468.htm
>�Ƃ��낪�A����Nehalem�n�}�C�N���A�[�L�e�N�`���́A�ŏ��̐��i����������Ă���o�����[�f�X�N�g�b�vPC�ƃ��C���X�g���[�����o�C��PC�ɂ܂ŐZ�����n�߂�̂ɁA
>�����Ă�1�N1�l����������B���̂��߁A�{�����[���]�[���̃f�X�N�g�b�vCPU�������2�N������3�N�A���o�C���̃��C���X�g���[���ł�3�N�����A�[�L�e�N�`���̍X�V�T�C�N�����Ă��܂��B
>���̈���ŁA����Sandy Bridge��2010�N�㔼����2011�N�ɂ͓o�ꂷ�錩���݂��B���̂��߁A�{�����[���]�[���ł�Nehalem�A�[�L�e�N�`���̎����́A
>2�N�ۂ��Ȃ��ŁASandy Bridge�n�ɍ��V�����Ɨ\�z�����B�܂��A2009�N�̃r�W�l�X�ł́AUS�ő傫�ȃV�[�Y���ł���u�o�b�N�c�[�X�N�[���v�������łȂ��A
>�z���f�[�V�[�Y���N��������������ƂɂȂ�ANehalem�̑��݊��͂܂��܂����炮���낤�B
>�Ƃ��낪�A����Nehalem�n�}�C�N���A�[�L�e�N�`���́A�ŏ��̐��i����������Ă���o�����[�f�X�N�g�b�vPC�ƃ��C���X�g���[�����o�C��PC�ɂ܂ŐZ�����n�߂�̂ɁA
>�����Ă�1�N1�l����������B���̂��߁A�{�����[���]�[���̃f�X�N�g�b�vCPU�������2�N������3�N�A���o�C���̃��C���X�g���[���ł�3�N�����A�[�L�e�N�`���̍X�V�T�C�N�����Ă��܂��B
>���̈���ŁA����Sandy Bridge��2010�N�㔼����2011�N�ɂ͓o�ꂷ�錩���݂��B���̂��߁A�{�����[���]�[���ł�Nehalem�A�[�L�e�N�`���̎����́A
>2�N�ۂ��Ȃ��ŁASandy Bridge�n�ɍ��V�����Ɨ\�z�����B�܂��A2009�N�̃r�W�l�X�ł́AUS�ő傫�ȃV�[�Y���ł���u�o�b�N�c�[�X�N�[���v�������łȂ��A
>�z���f�[�V�[�Y���N��������������ƂɂȂ�ANehalem�̑��݊��͂܂��܂����炮���낤�B
sandybridge�͒x��Ȃ��Ƃ����O���������B
AMD���Ⴀ��܂����A�\��͒x�����̂��Ȃ�Ă��ƂȂ���
�I���S���`�[���̓z���g�_������
���W�����[�v
���W�����[�v
���@�̃��W�����[�v�E�E�E�E
203 �FSocket774 [sage] �F2007/04/02(��) 12:35:29 ID:+UutI8ZY
>>198
Intel�͓����ɃC���^�[�R�l�N�g�Ƃ����ėp�A�^�b�`�����g����������
�R�A���̂͏]���H���̊g���Ȃ��ǂȁB
�����܂ŗv���ɉ����č��ډ\
275 �F+++ [sage] �F2007/04/14(�y) 03:05:38 ID:CcRvQrVT
�f�B�X�N���[�gGPU����̉����B�Ȃ��Ȃ��ʔ����B
Nehalem�ɓ����̂�����̏k���ł���Ȃ����ȁB
�i�������ق��������Ɍ��܂��Ă邩��j
�ŁANehalem�Ɠ������Ƀf�B�X�N���[�gGPU�������Ƒz���B
430 �FSocket774 [sage] �F2007/10/02(��) 20:51:34 ID:vZgUesa6
>>429
>�v�͈�u�ŏI����Ă��o���f�[�V������10�`12����
�V�v�R�A����Ȃ������̔h���Ȃ炻��Ȋ|������B
431 �FSocket774 [sage] �F2007/10/02(��) 20:52:11 ID:UhTZl2Zy
���W�����[������Ό��̊��Ԃ��Z���čς�
Linux Kernel�Ɠ�����
448 �FSocket774 [sage] �F2007/10/03(��) 00:55:34 ID:E9cBDwux
>�T�[�o��n�C�G���h�f�X�N�g�b�v�ł͂������A
>���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
>�X�P�[���r���e�B�����܂萶�����Ȃ��B
Intel�̌����X�P�[���r���e�B�̈Ӗ������Ⴆ�Ă�ȁB
�T�[�o�[���烂�o�C���܂ŏ_��ɍ\����ς��Đ����ł���_���X�P�[���u���Ƃ����Ă���̂ł����āB
472 �FSocket774 [sage] �F2007/10/03(��) 12:43:56 ID:ZIH4SEyM
���W�����[�[�Ă������R�A�D�L���b�V���DCSI�D�����R���̕��т��������B
1�R�A����4�R�A�܂œ���R�A�v�ŕ�����ނ̃}�X�N�����܂���ƁB
488 �FSocket774 [sage] �F2007/10/04(��) 20:59:02 ID:kq1gzQ1S
Nehalem�Ń��W�����[���ɑ������̂́u����̓R�P�܂����v�錾�B
���W�����[�v
���@�̃��W�����[�v�E�E�E�E
203 �FSocket774 [sage] �F2007/04/02(��) 12:35:29 ID:+UutI8ZY
>>198
Intel�͓����ɃC���^�[�R�l�N�g�Ƃ����ėp�A�^�b�`�����g����������
�R�A���̂͏]���H���̊g���Ȃ��ǂȁB
�����܂ŗv���ɉ����č��ډ\
275 �F+++ [sage] �F2007/04/14(�y) 03:05:38 ID:CcRvQrVT
�f�B�X�N���[�gGPU����̉����B�Ȃ��Ȃ��ʔ����B
Nehalem�ɓ����̂�����̏k���ł���Ȃ����ȁB
�i�������ق��������Ɍ��܂��Ă邩��j
�ŁANehalem�Ɠ������Ƀf�B�X�N���[�gGPU�������Ƒz���B
430 �FSocket774 [sage] �F2007/10/02(��) 20:51:34 ID:vZgUesa6
>>429
>�v�͈�u�ŏI����Ă��o���f�[�V������10�`12����
�V�v�R�A����Ȃ������̔h���Ȃ炻��Ȋ|������B
431 �FSocket774 [sage] �F2007/10/02(��) 20:52:11 ID:UhTZl2Zy
���W�����[������Ό��̊��Ԃ��Z���čς�
Linux Kernel�Ɠ�����
448 �FSocket774 [sage] �F2007/10/03(��) 00:55:34 ID:E9cBDwux
>�T�[�o��n�C�G���h�f�X�N�g�b�v�ł͂������A
>���[�G���h��o�C���̂悤�ȍ\���̍ŏ��P�ʂɋ߂��̈�ł�
>�X�P�[���r���e�B�����܂萶�����Ȃ��B
Intel�̌����X�P�[���r���e�B�̈Ӗ������Ⴆ�Ă�ȁB
�T�[�o�[���烂�o�C���܂ŏ_��ɍ\����ς��Đ����ł���_���X�P�[���u���Ƃ����Ă���̂ł����āB
472 �FSocket774 [sage] �F2007/10/03(��) 12:43:56 ID:ZIH4SEyM
���W�����[�[�Ă������R�A�D�L���b�V���DCSI�D�����R���̕��т��������B
1�R�A����4�R�A�܂œ���R�A�v�ŕ�����ނ̃}�X�N�����܂���ƁB
488 �FSocket774 [sage] �F2007/10/04(��) 20:59:02 ID:kq1gzQ1S
Nehalem�Ń��W�����[���ɑ������̂́u����̓R�P�܂����v�錾�B
SandyBridge���X�P�W���[���ʂ�o��ۏ��Ȃ��̂����������A������͂������
�ŏ����烁�C���X�g���[�����o�����킯�ł��Ȃ��ˁH
�ŏ����烁�C���X�g���[�����o�����킯�ł��Ȃ��ˁH
��������Core2�̂قڑS���i���C�����������グ�����Ⴞ����������
Nehalem�̃X�P�W���[�������ʂȂ��
Nehalem�̃X�P�W���[�������ʂȂ��
���������A�I���S���̎��s���J�o�[���邽�߂̃`�N�^�N�헪�������̂ɁA
���̃I���S�����^�[����(�X�P�W���[����)�R�P�Ă��܂����̂͂�����ƃA�������ǂȁB
Sandybridge�̏ڍׂ͒m��Ȃ����A�}�CoreMA�𗧂��グ���C�X���G����
2�N�ŐV�A�[�L��SSKU�Ő��Y���C���ɏ悹��悤�Ȍ|�����ł��邩�͋^��B
��������ł�����I���S���́c�B
���̃I���S�����^�[����(�X�P�W���[����)�R�P�Ă��܂����̂͂�����ƃA�������ǂȁB
Sandybridge�̏ڍׂ͒m��Ȃ����A�}�CoreMA�𗧂��グ���C�X���G����
2�N�ŐV�A�[�L��SSKU�Ő��Y���C���ɏ悹��悤�Ȍ|�����ł��邩�͋^��B
��������ł�����I���S���́c�B
495 �F,,�E�L�́M�E,,�j���F2008/09/26(��) 00:57:05 ID:THuHfulP
CoreMA���̂��̂͂��Ƃ��Ƃ̓��o�C����p�ɗp�ӂ��ꂽ�A�[�L����
�f�X�N�g�b�v�ւ̒u�����������ċ}篂ł��Ȃ�ł��Ȃ��B
Prescott���o���ď�w�������o���ƔF�����āA�Ȃ�2�N�]���NetBurst�Ōq���ł�B
PenD�Ȃ�č��ɂ���������Dothan�̍��N���b�N��MCM�łł��p�ӂ���悩�����Ǝv�����ȁB
�f�X�N�g�b�v�ւ̒u�����������ċ}篂ł��Ȃ�ł��Ȃ��B
Prescott���o���ď�w�������o���ƔF�����āA�Ȃ�2�N�]���NetBurst�Ōq���ł�B
PenD�Ȃ�č��ɂ���������Dothan�̍��N���b�N��MCM�łł��p�ӂ���悩�����Ǝv�����ȁB
Dothan����MCM�ł���́H
yonah���f�X�N�g�b�v�Ɏ����Ă���悩�����̂ɂˁB
yonah���f�X�N�g�b�v�Ɏ����Ă���悩�����̂ɂˁB
>>495
PenD�͌o�c���̔��f�ŁACoreMA�܂ł̌q���Ƃ��ďo������������Ȃ����������H
���ۂh���������̋Z�p�҂����s��ƌ����Ă邭�炢����
��������������ɁE�E�E
PenD�͌o�c���̔��f�ŁACoreMA�܂ł̌q���Ƃ��ďo������������Ȃ����������H
���ۂh���������̋Z�p�҂����s��ƌ����Ă邭�炢����
��������������ɁE�E�E
�v���X�R�������O���甚�M�ƌ����܂����ĉ�������z����������
D�͂������ɂȂ�����
D�͂������ɂȂ�����
>>497
���[�J�[�����炷��Όq���Ƃ��Ă͑听�����낤�B
�J������Ȃ��Z���ōς�MCM�Őݔ�������p���Œ���ɗ}����ꂽ�B
AMD�����l�ɐݒ肵�Ă��ꂽ�̂Ŋ������������܂łȂ��A
Intel�u�����h�̗͂����肻��Ȃ�̐��͏o�Ă���B
���[�U�[�����炷��Έ����f���A���R�A�ȊO�̈Ӌ`�͂���܂�Ȃ��ȁB
(����Phenom�I�|�W�V��������)
���[�J�[�����炷��Όq���Ƃ��Ă͑听�����낤�B
�J������Ȃ��Z���ōς�MCM�Őݔ�������p���Œ���ɗ}����ꂽ�B
AMD�����l�ɐݒ肵�Ă��ꂽ�̂Ŋ������������܂łȂ��A
Intel�u�����h�̗͂����肻��Ȃ�̐��͏o�Ă���B
���[�U�[�����炷��Έ����f���A���R�A�ȊO�̈Ӌ`�͂���܂�Ȃ��ȁB
(����Phenom�I�|�W�V��������)
Phenom�̖��_��PenD�ƈ����
�債�ăR�X�g�������Ȃ��Ƃ������Ƃ���
�債�ăR�X�g�������Ȃ��Ƃ������Ƃ���
���ɂȂ��Ă݂��MCM�̗ǂ����K�ɂȂ����Ƃ����������B
�^��MCM�Ƃ�����������͂ǂ���w
�^��MCM�Ƃ�����������͂ǂ���w
90nm��PenD��MCM����Ȃ��ĂQ��Pen4�_�C��藣�����ɂ��̂܂��߯���މ����Ă�
MCM��65nmPenD�ɂȂ��Ă���
MCM��65nmPenD�ɂȂ��Ă���
>>502
�悭�������Smithfield��MCM�̈�`�Ԃ���Ȃ��̂��H
ttp://ja.wikipedia.org/wiki/%E3%83%91%E3%83%83%E3%82%B1%E3%83%BC%E3%82%B8_(%E9%9B%BB%E5%AD%90%E9%83%A8%E5%93%81)
>MCM (Multi Chip Module)
>�����̃x�A�`�b�v��1�̃p�b�P�[�W���ɕ������A�����Ŕz����ڑ��������́B
>MCP�̈��ł��邪�A��Ƀx�A�`�b�v��2�����I�ɔz�u���{���f�B���O���C���[�Ń`�b�v���m��z���������̂��w���B
ttp://journal.mycom.co.jp/special/2005/dualcore/001.html
>�ł�Smithfield�����̏ꍇ�ǂ��Ȃ邩? �Ƃ����ƁA�E�F�n�[�����Ƃ���܂ł͑S�������ł���B
>�������_�C�V���O�̍ہA2�̃R�A����ׂ��`�Ő�悤�ɂ��A���Ń{���f�B���O��2�̃_�C�ɑ��Ĕz�����s���A
>���Ƃ̓p�b�P�[�W���O���ďI���ł���B
ttp://pc.watch.impress.co.jp/docs/2005/0303/kaigai161.htm
>�Ⴆ��Ȃ�A�ʏ�̃f���A���R�ACPU���L�b�`���◁�������L����2���яZ��Ȃ̂ɑ��āA
>Smithfield�͌��ւ���n�܂�S�Ă��������ꂽ�A�����������Ă��邾����2���яZ��B
ttp://techon.nikkeibp.co.jp/article/NEWS/20080811/156302/?ST=mcu_PRINT
>Pentium 4��MCM�i�ł���Smithfield���ŏ��̐��i
�悭�������Smithfield��MCM�̈�`�Ԃ���Ȃ��̂��H
ttp://ja.wikipedia.org/wiki/%E3%83%91%E3%83%83%E3%82%B1%E3%83%BC%E3%82%B8_(%E9%9B%BB%E5%AD%90%E9%83%A8%E5%93%81)
>MCM (Multi Chip Module)
>�����̃x�A�`�b�v��1�̃p�b�P�[�W���ɕ������A�����Ŕz����ڑ��������́B
>MCP�̈��ł��邪�A��Ƀx�A�`�b�v��2�����I�ɔz�u���{���f�B���O���C���[�Ń`�b�v���m��z���������̂��w���B
ttp://journal.mycom.co.jp/special/2005/dualcore/001.html
>�ł�Smithfield�����̏ꍇ�ǂ��Ȃ邩? �Ƃ����ƁA�E�F�n�[�����Ƃ���܂ł͑S�������ł���B
>�������_�C�V���O�̍ہA2�̃R�A����ׂ��`�Ő�悤�ɂ��A���Ń{���f�B���O��2�̃_�C�ɑ��Ĕz�����s���A
>���Ƃ̓p�b�P�[�W���O���ďI���ł���B
ttp://pc.watch.impress.co.jp/docs/2005/0303/kaigai161.htm
>�Ⴆ��Ȃ�A�ʏ�̃f���A���R�ACPU���L�b�`���◁�������L����2���яZ��Ȃ̂ɑ��āA
>Smithfield�͌��ւ���n�܂�S�Ă��������ꂽ�A�����������Ă��邾����2���яZ��B
ttp://techon.nikkeibp.co.jp/article/NEWS/20080811/156302/?ST=mcu_PRINT
>Pentium 4��MCM�i�ł���Smithfield���ŏ��̐��i
��4�N�Ԃ�Ɏ���ɗ����̂���
�����̓v���X�R(��)�C���e��(��)�������̂�����C���e���}���Z�[�ŃJ���`���[�V���b�N����
�����̓v���X�R(��)�C���e��(��)�������̂�����C���e���}���Z�[�ŃJ���`���[�V���b�N����
���\�őI�����郆�[�U�w��939�����AMD�}���Z�[���āA����INTEL�}���Z�[
���Ă��邾��������ˁB
���̎�����������ł���������Ȃ�����Ă��������ς���Ă���Ǝv����B
���Ă��邾��������ˁB
���̎�����������ł���������Ȃ�����Ă��������ς���Ă���Ǝv����B
�ł��ꎞ���̃C���e���̂b�l�͂悩������
�p�\�R���m��Ȃ��l�E���߂Ĕ����ɗ���l�ł��C���e���͂����Ă܂����H���ĕ����Ă��邮�炢����������Ȃ�
PC����ƂɈ��ɂȂ��Ă�������CM���厖�ȂȂƎv������
������Ƃ��Z�p�Ƃ��������ꂽ�b�����ǂˁE�E�E
�p�\�R���m��Ȃ��l�E���߂Ĕ����ɗ���l�ł��C���e���͂����Ă܂����H���ĕ����Ă��邮�炢����������Ȃ�
PC����ƂɈ��ɂȂ��Ă�������CM���厖�ȂȂƎv������
������Ƃ��Z�p�Ƃ��������ꂽ�b�����ǂˁE�E�E
>>503
���̌��Intel CPU�ł�MCM�̏K��ɂȂ����̂͊m�������A�����ɂ�MCM���̂��̂ł͂Ȃ��B�}���`�`�b�v����Ȃ�����ˁB
MCM�̗��_�̈�͂��ꂼ��̃R�A���e�X�g���Ă���p�b�P�[�W���O�ł���̂�
�����ʐς̃V���O���`�b�v�������܂肪���シ�邱�Ƃ����i������MCM�����̂��̂͑����s�Ǘ���������j�A
SmithField�̏ꍇ�͊J�����y�ő����Ƃ������_���������ĂȂ��B
���̌��Intel CPU�ł�MCM�̏K��ɂȂ����̂͊m�������A�����ɂ�MCM���̂��̂ł͂Ȃ��B�}���`�`�b�v����Ȃ�����ˁB
MCM�̗��_�̈�͂��ꂼ��̃R�A���e�X�g���Ă���p�b�P�[�W���O�ł���̂�
�����ʐς̃V���O���`�b�v�������܂肪���シ�邱�Ƃ����i������MCM�����̂��̂͑����s�Ǘ���������j�A
SmithField�̏ꍇ�͊J�����y�ő����Ƃ������_���������ĂȂ��B
>>507
�Ó�
���ɏ����Smithfield��MCM�ƌĂԂ̂��ꕾ�������ȁB
MCM�̃����b�g�ł���A�s�ǃ`�b�v�����O���ăR�X�g�_�E������A���Ă̂�
�����āA�Q�R�A�P�_�C�Ȑ^��DualCore�Ɠ��������B
������MCM�ł̃f�����b�g�ł���A�����̃`�b�v���p�b�P�[�W�ɓ����
�Ƃ�������Ŗʓ|�ȋZ�p���s�v�����B�i�{���f�B���O�̎�Ԃ͎�����邪�B�j
�Ó�
���ɏ����Smithfield��MCM�ƌĂԂ̂��ꕾ�������ȁB
MCM�̃����b�g�ł���A�s�ǃ`�b�v�����O���ăR�X�g�_�E������A���Ă̂�
�����āA�Q�R�A�P�_�C�Ȑ^��DualCore�Ɠ��������B
������MCM�ł̃f�����b�g�ł���A�����̃`�b�v���p�b�P�[�W�ɓ����
�Ƃ�������Ŗʓ|�ȋZ�p���s�v�����B�i�{���f�B���O�̎�Ԃ͎�����邪�B�j
���̌��KentsField��YorkField�ŋ������Ђ����|���Ă��邱�Ƃ��l����ƁA
MCM�Z�p�̓����͐����������̂��낤�ˁB
MCM�Z�p�̓����͐����������̂��낤�ˁB
MCM�Z�p�̓������]�X�ȑO��AMD���������Ă邾�����Ǝv��
> MCM�Z�p�̓������]�X�ȑO��AMD���������Ă邾�����Ǝv��
�����Ȃ�Ă��ĂȂ�����AAMD�͐���t����Ă�B
PenD�̂悤�ȑ傫�ȃ~�X�������킯�ł��Ȃ��B
�P�ɋZ�ʂ����肸�A�̗͂��Ȃ�����Intel�ɑS�����������Ȃ������B
�����Ȃ�Ă��ĂȂ�����AAMD�͐���t����Ă�B
PenD�̂悤�ȑ傫�ȃ~�X�������킯�ł��Ȃ��B
�P�ɋZ�ʂ����肸�A�̗͂��Ȃ�����Intel�ɑS�����������Ȃ������B
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
�������A���͂��̃T�C�N���͊��S�ɕς���Ă���B
���݂�K8�n�A�[�L�e�N�`��(Athlon 64/Opteron)�̌�p�ƂȂ�͂��������uK9�v�̓L�����Z���A���̎��́uK10�v���A���������Ȃ��B
K9���L�����Z�����ꂽ���獡��K10 Phenom�i�j������킯�����E�E�E�B
�������A���͂��̃T�C�N���͊��S�ɕς���Ă���B
���݂�K8�n�A�[�L�e�N�`��(Athlon 64/Opteron)�̌�p�ƂȂ�͂��������uK9�v�̓L�����Z���A���̎��́uK10�v���A���������Ȃ��B
K9���L�����Z�����ꂽ���獡��K10 Phenom�i�j������킯�����E�E�E�B
>>507
PenD920�̕���PenD820��肩�Ȃ�f�B�X�R��������������
������ĒP��65nm�v���Z�X�̋����Ȃ���������H
�R�X�g�I�ɐ^��MCM(�R�A�����I�ʕi������)���L���Ȃ炻�����c���͂�����ˁB
PenD920�̕���PenD820��肩�Ȃ�f�B�X�R��������������
������ĒP��65nm�v���Z�X�̋����Ȃ���������H
�R�X�g�I�ɐ^��MCM(�R�A�����I�ʕi������)���L���Ȃ炻�����c���͂�����ˁB
���̕ӂ����y���Ă���ƃ�����������ς���Ă���̂��ˁH
�y�����́z�o�b�t�@���[�ƃG���s�[�_�A�����̃������Ő��E�ő����������@2400MHz�m08/09/30�n
http://gimpo.2ch.net/test/read.cgi/bizplus/1222732402/
�O���d�q�A�T�O�i�m�Q�M�K�c�q�`�l�����̗ʎY��
http://japanese.joins.com/article/article.php?aid=105401&servcode=300§code=330
�y�����́z�o�b�t�@���[�ƃG���s�[�_�A�����̃������Ő��E�ő����������@2400MHz�m08/09/30�n
http://gimpo.2ch.net/test/read.cgi/bizplus/1222732402/
�O���d�q�A�T�O�i�m�Q�M�K�c�q�`�l�����̗ʎY��
http://japanese.joins.com/article/article.php?aid=105401&servcode=300§code=330
K9 �� NetBurst�I�ȍ��N���b�N�u���̃A�[�L�e�N�`���������̂��ȁH
>>513
D820�������������̂́A��R�X�g�f���A���R�A�Ƃ��Ċe��x���_�[������������������������炾�낤�ˁB
���i�т͂�����ƈႤ���AQ6600���₽��Ƒ��������̂Ɨ��R�͂��������ꏏ�B
D820�������������̂́A��R�X�g�f���A���R�A�Ƃ��Ċe��x���_�[������������������������炾�낤�ˁB
���i�т͂�����ƈႤ���AQ6600���₽��Ƒ��������̂Ɨ��R�͂��������ꏏ�B
>>516
Q6600�����l�ɋ^��Ɏv���Ă܂��B
��R�X�g�Ȃ�V�v���Z�X�̕����{���L���������C�ɑS���͖����ł������u��������
���̂����V�v���Z�XCPU����ɂȂ���̂��ƁB
�������Ȃ��Ȃ����P�o���Ȃ��Ƃ��A���v���Z�X�̐ݔ���Ɩ��ʂ������Ƃ��A
���u�����n���p�Ȃ��Ƃ�����̂��ȁB
���[�U�[�Ƃ��Ă͒l�i�����̕����Ƃ��Ă����Ƃ������ǂˁB
Q6600�����l�ɋ^��Ɏv���Ă܂��B
��R�X�g�Ȃ�V�v���Z�X�̕����{���L���������C�ɑS���͖����ł������u��������
���̂����V�v���Z�XCPU����ɂȂ���̂��ƁB
�������Ȃ��Ȃ����P�o���Ȃ��Ƃ��A���v���Z�X�̐ݔ���Ɩ��ʂ������Ƃ��A
���u�����n���p�Ȃ��Ƃ�����̂��ȁB
���[�U�[�Ƃ��Ă͒l�i�����̕����Ƃ��Ă����Ƃ������ǂˁB
>515
K9��Tejas�̑R�Ƃ��č��N���b�N�d�l�Ƃ������܂�����B
���܂̂��s�V�̗ǂ��i����d�͓I�ɁjCore2�n�Ɋ���Ă��܂���
Tejas�̔��M�E���Ȕ��M�ׂ̈ɃN���b�N���グ���Ȃ����v���X�RCPU��
�g���Ă݂����C�������E�E�|������������w
K9��Tejas�̑R�Ƃ��č��N���b�N�d�l�Ƃ������܂�����B
���܂̂��s�V�̗ǂ��i����d�͓I�ɁjCore2�n�Ɋ���Ă��܂���
Tejas�̔��M�E���Ȕ��M�ׂ̈ɃN���b�N���グ���Ȃ����v���X�RCPU��
�g���Ă݂����C�������E�E�|������������w
���M�ł�E8500���炢�̂�AMD���~������
K9�̓l�g�o�̃A�[�L�e�N�g��AMD�Ɉڂ��č�낤�Ƃ������́B
���N���b�N�AHT�A�}���`�X���b�h�����^�̃l�g�o2�݂����Ȃ̂�����B
���ǂ�AMD������������K9�͓ڍ��B
�A�[�L�e�N�g�̓C���e���ɖ߂��ăI���S���Ńl�n�����̊�b��������B
�{�l�̃u���O���ǂ����ɂ�������ȁB
AMD��K8��P6�R�s�[�������Ƃ��A����Ȋ����́B
���N���b�N�AHT�A�}���`�X���b�h�����^�̃l�g�o2�݂����Ȃ̂�����B
���ǂ�AMD������������K9�͓ڍ��B
�A�[�L�e�N�g�̓C���e���ɖ߂��ăI���S���Ńl�n�����̊�b��������B
�{�l�̃u���O���ǂ����ɂ�������ȁB
AMD��K8��P6�R�s�[�������Ƃ��A����Ȋ����́B
521 �FMAC�I�^��520 �����F2008/10/02(��) 08:52:42 ID:T4sHq+4p
>>520
�@�@------------------
�@�@K9�̓l�g�o�̃A�[�L�e�N�g��AMD�Ɉڂ��č�낤�Ƃ������́B
�@�@------------------
Andy Glew��P6�̃A�[�L�e�N�g���B
http://www.geocities.com/andrew_f_glew/glew-resume-1-page.html
�ނ�NetBurst�Ɋւ���ӌ���A������B
http://groups.google.com/group/comp.lang.misc/msg/c28c003a7285e7a2
�@�@=======================
�@�@Pentium 4 is fragile, just like Itanium.
�@�@=======================
AMD��ٌ삷�邽�߂Ȃ�AP6�A�[�L�e�N�`���̊J���҂�K7/K8���^���Ă���Andy Glew�܂�
�@���Ƃ�B�B�B�������A�����Ƃ����ׂ�����(��)
�@�@------------------
�@�@K9�̓l�g�o�̃A�[�L�e�N�g��AMD�Ɉڂ��č�낤�Ƃ������́B
�@�@------------------
Andy Glew��P6�̃A�[�L�e�N�g���B
http://www.geocities.com/andrew_f_glew/glew-resume-1-page.html
�ނ�NetBurst�Ɋւ���ӌ���A������B
http://groups.google.com/group/comp.lang.misc/msg/c28c003a7285e7a2
�@�@=======================
�@�@Pentium 4 is fragile, just like Itanium.
�@�@=======================
AMD��ٌ삷�邽�߂Ȃ�AP6�A�[�L�e�N�`���̊J���҂�K7/K8���^���Ă���Andy Glew�܂�
�@���Ƃ�B�B�B�������A�����Ƃ����ׂ�����(��)
�A�����J�̐l�ނ̗������͂ق�Ɩʔ�����
�����o����Z�p�������Ƃ��Ă�Ή��\��]�E���Ă����_�ɂȂ�Ȃ��Љ����ȁB
���{�͂���炪�C�}�C�`�Ȃ�30�Β����Ă̓]�E�͓���A
����炪�����Ă�3�炢�܂ł͂�������5��͉������Ȃ�B
���{�͂���炪�C�}�C�`�Ȃ�30�Β����Ă̓]�E�͓���A
����炪�����Ă�3�炢�܂ł͂�������5��͉������Ȃ�B
CEATEC JAPAN 2008�F�uMID��OS��Linux���œK�v�����`�����h���V�[�J���AAtom��MID����� - ITmedia +D PC USER
http://plusd.itmedia.co.jp/pcuser/articles/0810/02/news059.html
http://plusd.itmedia.co.jp/pcuser/articles/0810/02/news059.html
525 �F,,�E�L�́M�E,,�j���F2008/10/03(��) 01:43:32 ID:TENa2zGJ
Intel�̐����R�X�g���f���́A���̉�ЂƂ͈Ⴄ����B
�V�����v���Z�b�T�ɂ͍ŐVFab�̌������p�����悹����̂ō����Ȃ�B
�Ȃ��Ȃ�A�Ő�[�v���Z�X�̐��i�͗D�ʐ������邤���ɂł��邾��
���l�Ŕ������ق������v���傫������B
�t�Ɍ͂ꂽ�v���Z�X�����߂���`�b�v�Z�b�g�ł́A
���p�����悹���Ȃ��Ă�������傫�߂̃_�C�ł��ቿ�i�Œł���B
Q6600�����C���i�b�v�Ɏc���Ă�̂��������R�BCeleron������65nm�B
65nm�v���Z�X�͌������p���i��ŕ����܂���オ���Ă邩��
�K���������R�X�g�ł͂Ȃ��Ƃ������ƁB�t�ɁA�������p���ς܂����v���Z�X���[���ŏ\�������͂̍������i������̂͋��݂��B
�ނ�����������͂��܂łȂɂ����琶�Y���C�������Ă��������B
�V�����v���Z�b�T�ɂ͍ŐVFab�̌������p�����悹����̂ō����Ȃ�B
�Ȃ��Ȃ�A�Ő�[�v���Z�X�̐��i�͗D�ʐ������邤���ɂł��邾��
���l�Ŕ������ق������v���傫������B
�t�Ɍ͂ꂽ�v���Z�X�����߂���`�b�v�Z�b�g�ł́A
���p�����悹���Ȃ��Ă�������傫�߂̃_�C�ł��ቿ�i�Œł���B
Q6600�����C���i�b�v�Ɏc���Ă�̂��������R�BCeleron������65nm�B
65nm�v���Z�X�͌������p���i��ŕ����܂���オ���Ă邩��
�K���������R�X�g�ł͂Ȃ��Ƃ������ƁB�t�ɁA�������p���ς܂����v���Z�X���[���ŏ\�������͂̍������i������̂͋��݂��B
�ނ�����������͂��܂łȂɂ����琶�Y���C�������Ă��������B
�딚�����
527 �F,,�E�L�́M�E,,�j���F2008/10/03(��) 09:06:02 ID:TENa2zGJ
��������>>517�����Ȃ��ǂȁB
���Ȃ݂�Atom���P�����������z���g�Ȃ�͂ꂽ90nm�`65nm���炢�ō�肽���͂�����
����d�͂����萫�\��ARM�ɑ���A�h�o���e�[�W�������Ȃ�Ƃ��~�����i���邢�͗߂����j����d���Ȃ��B
�܂��_�C�������������n�ʂ͑����̂Ō����ė����͒Ⴍ�͂Ȃ��͂�����
�����I�ɂ͂��������Ȃ�
���Ȃ݂�Atom���P�����������z���g�Ȃ�͂ꂽ90nm�`65nm���炢�ō�肽���͂�����
����d�͂����萫�\��ARM�ɑ���A�h�o���e�[�W�������Ȃ�Ƃ��~�����i���邢�͗߂����j����d���Ȃ��B
�܂��_�C�������������n�ʂ͑����̂Ō����ė����͒Ⴍ�͂Ȃ��͂�����
�����I�ɂ͂��������Ȃ�
>>527
�������߂�A�����A�t�H��������
�������߂�A�����A�t�H��������
ttp://www.theinquirer.net/gb/inquirer/news/2008/10/03/performance-ram-damage-nehalem
Performance RAM will damage your Nehalem
Performance RAM will damage your Nehalem
530 �FMAC�I�^��520 �����F2008/10/04(�y) 09:51:45 ID:YIMBdh96
>>529
>>454�Ɠ����e�̘b�肷�B�Ȃ��A���Y�L���̑���ɂ���Asus�ł�1.7V���퓮��m�F���Ă���Ƃ�
�R�����g������ꂽ�Ƃ̂��Ƃ��B
�@�@-----------------------
�@�@ They are currently running a 1.7V kit in their UK office, but beyond that, you're on your own.
�@�@-----------------------
>>454�Ɠ����e�̘b�肷�B�Ȃ��A���Y�L���̑���ɂ���Asus�ł�1.7V���퓮��m�F���Ă���Ƃ�
�R�����g������ꂽ�Ƃ̂��Ƃ��B
�@�@-----------------------
�@�@ They are currently running a 1.7V kit in their UK office, but beyond that, you're on your own.
�@�@-----------------------
CPU�����I�ɃI�[�o�[�N���b�N����@�\�ŏ\���B
���₷���Ƃ����̂͂ނ��남�o�J�ȃI�[�o�[�N���b�J�[�̈��@�����̋��т�����������wktk
���₷���Ƃ����̂͂ނ��남�o�J�ȃI�[�o�[�N���b�J�[�̈��@�����̋��т�����������wktk
�I�[�o�[�N���b�J�[�ɑ��ĉ��₷���d�l�ɂ��Ƃ����̕�����������w
Intel��x58�}�U�[��BIOS�ݒ��ʂƂ̂��Ƃ��BTurbo mode�̐ݒ�Ƃ������[�����B
http://forum.coolaler.com/showthread.php?t=191367&page=4
http://forum.coolaler.com/showthread.php?t=191367&page=4
�ł�Turbo mode����extreme�����Ȃ��
extreme����ł͂Ȃ��炵�����H
���ɍʼn��ʂ܂őΉ�����Ƃ͎v���
���ɍʼn��ʂ܂őΉ�����Ƃ͎v���
�C���e���̒��̐l�������ŃN���b�N�Ⴂ���f���̕���
�^�[�{���[�h�̉��b��ƌ����Ă�����Ȃ����I
�Ď��͉��ʃ��f���ɂ��^�[�{���邾��B
�^�[�{���[�h�̉��b��ƌ����Ă�����Ȃ����I
�Ď��͉��ʃ��f���ɂ��^�[�{���邾��B
>>537
����ቺ�ʃN���b�N�i�̕������b�͑傫����B
�ł�Enable�ɂȂ邩�ǂ����͉c�Ə�̖�肾��B
�����܂ŕt�����l���Ȃ��Ă�����邾�낤���B
����ቺ�ʃN���b�N�i�̕������b�͑傫����B
�ł�Enable�ɂȂ邩�ǂ����͉c�Ə�̖�肾��B
�����܂ŕt�����l���Ȃ��Ă�����邾�낤���B
�ŐV�̏��Ȃ��͕̂������Ă��邯�ǁA
�������Ă�x���`�̐��\�ł͔���邩�H�Ƌ^����������ɂ͂����Ȃ��B
�������Ă�x���`�̐��\�ł͔���邩�H�Ƌ^����������ɂ͂����Ȃ��B
shanghai���悶��?
intel��penryn�n�R�A�̔h����Nehalem�o��͍i�邾�낤���A
Core2�ȉ��ɂȂ�Ƃ���͂���ȂɌ����Ȃ����B
intel��penryn�n�R�A�̔h����Nehalem�o��͍i�邾�낤���A
Core2�ȉ��ɂȂ�Ƃ���͂���ȂɌ����Ȃ����B
����Ŋ����̍����Q�[���ʼn�����Ă邶���B
�����o�Ă��画�f�����B
�X���̈Ӌ`���悭�킩��Ȃ��Ȃ邪�B
�X���̈Ӌ`���悭�킩��Ȃ��Ȃ邪�B
�V���O���X���b�h��10%���A�b�v���ĂȂ�Penryn������邮�炢��������v���B
�n�R�l�͎���o���Ȃ����낤���B
�n�R�l�͎���o���Ȃ����낤���B
5-second Linux boots on low-powered hardware
http://www.linuxdevices.com/news/NS7654890804.html
>The system was developed by two Intel developers
http://www.linuxdevices.com/news/NS7654890804.html
>The system was developed by two Intel developers
ttp://www.anandtech.com/memory/showdoc.aspx?i=3426
Core i7 - Is High VDimm really a Problem?
Core i7 - Is High VDimm really a Problem?
�m���ɕ��傪�������ɁAFSB1033����̃}�U�[�ł͓����Ȃ�Penryn���o�J���ꂵ�Ă��ȁB
Nehalem�Ƀl�K�L��������Ӗ������܂ЂƂ킩���B
�ܔM��E6600�Ɨp�r�ɂ���Ă͕ς��Ȃ����\��Q6600���o�J���ꂵ�����B
Nehalem�Ƀl�K�L��������Ӗ������܂ЂƂ킩���B
�ܔM��E6600�Ɨp�r�ɂ���Ă͕ς��Ȃ����\��Q6600���o�J���ꂵ�����B
>>546
�킴�킴�C���e���W�̃X���Ńl�K�L��������z�̍l���邱�ƂȂ�Ĉ�����Ȃ����낤�B
���܂���A���M�������̊��ɂ͑����Ȃ�Ȃ�����VDimm��OC���������g����������
��ɔ����Ȃ�I���������Ȃ��Ȃ邩��ȁI
�킴�킴�C���e���W�̃X���Ńl�K�L��������z�̍l���邱�ƂȂ�Ĉ�����Ȃ����낤�B
���܂���A���M�������̊��ɂ͑����Ȃ�Ȃ�����VDimm��OC���������g����������
��ɔ����Ȃ�I���������Ȃ��Ȃ邩��ȁI
���������l�n��HPC�s������ŁA�f�X�N�g�b�v�͂��ł���H
�f�X�N�g�b�v�ő啝�ɍ����ɂȂ鎖�͖����͓̂�����O
���̂����AHPC�s��ł�Opteron��Ђ��[����ǂ��o���ɂ͂Ȃ邪
�f�X�N�g�b�v�ő啝�ɍ����ɂȂ鎖�͖����͓̂�����O
���̂����AHPC�s��ł�Opteron��Ђ��[����ǂ��o���ɂ͂Ȃ邪
�Ȃ����N���b�N���オ�肻���Ō��Ȃ�ȁB
�l�q�����������Ȃ�B
�l�q�����������Ȃ�B
550 �F,,�E�L�́M�E,,�j���F2008/10/10(��) 18:17:41 ID:pckzxKRn
Atom N�V���[�Y��64�r�b�g�E����Ă�ƒm���đS�͂ňނ���
�܂��v��Ȃ�������v��Ȃ���
�܂��v��Ȃ�������v��Ȃ���
itx�ɏ���Ă��͎g���邶���H
552 �FSocket774�F2008/10/10(��) 18:40:20 ID:ZQcoNNhz
554 �FSocket774�F2008/10/11(�y) 02:14:41 ID:IAtR7vEV
Lynfield�܂ŐQ�Ă��B
555 �FSocket774�F2008/10/11(�y) 10:51:55 ID:++kvhOY9
>>549
PenD�v�����`�[��������̒S���炵������ǂ����Ă��F�ዾ�ł݂Ă��܂���B
>>550
�R����ŋߒm�����B
�e�������肻�����Ƃ�����A�����Č�����PC-linux���炢�H
�܂��v��Ȃ�������v��Ȃ���Ȃ�
PenD�v�����`�[��������̒S���炵������ǂ����Ă��F�ዾ�ł݂Ă��܂���B
>>550
�R����ŋߒm�����B
�e�������肻�����Ƃ�����A�����Č�����PC-linux���炢�H
�܂��v��Ȃ�������v��Ȃ���Ȃ�
>>550
�����Atom��Intel64�Ή����A�Ȃ��搂��Ă��A�قڍ��\�݂����Ȃ���Ȃ��B
�������A�����܂�64�Ή��@�\�͕����܂肪�������Ď��Ȃ�ł��傤���ˁH
�܂������o�ׂ���ׂɎ����H�����Ȃ��Ă邾���A�Ȃ̂�������ǁB
���Ƃ͔��M���ǂ����Ă������邩��A64���삾�ƌ��̂SW��TDP��w�ǎ��Ȃ����������B
�����Atom��Intel64�Ή����A�Ȃ��搂��Ă��A�قڍ��\�݂����Ȃ���Ȃ��B
�������A�����܂�64�Ή��@�\�͕����܂肪�������Ď��Ȃ�ł��傤���ˁH
�܂������o�ׂ���ׂɎ����H�����Ȃ��Ă邾���A�Ȃ̂�������ǁB
���Ƃ͔��M���ǂ����Ă������邩��A64���삾�ƌ��̂SW��TDP��w�ǎ��Ȃ����������B
�ق��̃{�[�h��l�b�g�u�b�N�͒m��AD945GCLF��GCLF2��x64�������B
�x���_�[���@�\��L���ɂ��邩���Ȃ����Ƃ��������̖�肶��Ȃ��̂��ˁB
�x���_�[���@�\��L���ɂ��邩���Ȃ����Ƃ��������̖�肶��Ȃ��̂��ˁB
N�V���[�Y���ăl�b�g�u�b�N�����̕������ǁB
�l�b�g�g�b�v������230�A330��64bit�Ή��B
Z��64bit��Ή��Ȃ̂ŁA����Atom�ɓ��ڂ���Ă���@�\��S�Ďg����v���Z�b�T��
���i������Ă��Ȃ������肷�邗
�l�b�g�g�b�v������230�A330��64bit�Ή��B
Z��64bit��Ή��Ȃ̂ŁA����Atom�ɓ��ڂ���Ă���@�\��S�Ďg����v���Z�b�T��
���i������Ă��Ȃ������肷�邗
��PC�������Ǝv���Ă�z�A���͔�����!����������89
http://pc11.2ch.net/test/read.cgi/pc/1223378014/
http://pc11.2ch.net/test/read.cgi/pc/1223378014/
�����Ӑ�̗ь炩�疾�m��IntelGPU�� NO �Ƌ��ۂ��ꂽ�킯�����E�E�E
�A�b�v���AMacBook�V���[�Y�����f���`�F���W
ttp://pc.watch.impress.co.jp/docs/2008/1015/apple1.htm
���ꂪHavendale�̉����ɉe�����Ă�̂��A�ǂ������Ȃ̂�
�A�b�v���AMacBook�V���[�Y�����f���`�F���W
ttp://pc.watch.impress.co.jp/docs/2008/1015/apple1.htm
���ꂪHavendale�̉����ɉe�����Ă�̂��A�ǂ������Ȃ̂�
1160�����C���X�g���[������ˁH
>>563
nVidia�̃`�b�v�Z�b�g��1�`�b�v�̔�������ALAN��nVidia���ł́H
nVidia�̃`�b�v�Z�b�g��1�`�b�v�̔�������ALAN��nVidia���ł́H
NVIDIA��NIC�͂�����ۂ������Ȃ��B
>>561
����Apple�Ƀf�X�N�g�b�v������Core2���g���Ă�@��͖�������AHavendale�͊W�Ȃ�����
����Apple�Ƀf�X�N�g�b�v������Core2���g���Ă�@��͖�������AHavendale�͊W�Ȃ�����
�m�[�g�p��Auburndale�����ʐv�����瓯�l�ɒx���̂ŁA�e���͂���Ǝv���B
���������\�Ȃ�����P��GPU�d���Ȃ͎̂b���O����̌X���Ȃ̂ŁAApple�̃_���o���Œx��Ă��ł͂Ȃ��Ǝv�����ǂˁB
������GPU�������s�A�[�L�e�N�`���̂܂܂����猀�I�ȕ`�搫�\������L�蓾�Ȃ��̂��ŏ����画���Ă��b�����B
���������\�Ȃ�����P��GPU�d���Ȃ͎̂b���O����̌X���Ȃ̂ŁAApple�̃_���o���Œx��Ă��ł͂Ȃ��Ǝv�����ǂˁB
������GPU�������s�A�[�L�e�N�`���̂܂܂����猀�I�ȕ`�搫�\������L�蓾�Ȃ��̂��ŏ����画���Ă��b�����B
2010�N�ȍ~��Intel CPU�������Ă���Larrabee�V����
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
http://pc.watch.impress.co.jp/docs/2008/1017/kaigai472.htm
nVidia�̌��ז��̃X�N�[�v�̌�A�L�����M���T�{���Ă���Charlie "Groo" Demerjean��
RealWorldTech�f��������ɂɗǂ��������݂����Ă��邷�B
�ŁA�ނɂ��Nehalem Xeon�̃����[�X���B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=93852&threadid=93850&roomid=2
�@�@--------------------------
�@�@1S is next month (17th?), 2S was always Q1 in low volumes, later in Q1/early Q2 in real volume.
�@�@--------------------------
RealWorldTech�f��������ɂɗǂ��������݂����Ă��邷�B
�ŁA�ނɂ��Nehalem Xeon�̃����[�X���B
http://www.realworldtech.com/forums/index.cfm?action=detail&id=93852&threadid=93850&roomid=2
�@�@--------------------------
�@�@1S is next month (17th?), 2S was always Q1 in low volumes, later in Q1/early Q2 in real volume.
�@�@--------------------------
LGA1160�̎���Larrabee�H
>>571
�Ⴄ�BLarrabee��x86�����ǎ��CPU�p����Ȃ��B
����Pentium����{�ɐV�^SIMD���j�b�g����+���j�[�R�A�ɂ����\���ŁA
���Ƃ��Č����Ȃ�uGPU��CPU�v�B
---��������`���V�̗�---
�㓡���̈ӌ���
�u�x�[�X������Pentium�Ȃ̂́A�ŏ��̐��i���O���t�B�b�N�X�p�r�Ȃ̂Łw�}���`�X���b�h>>>�V���O���X���b�h�x������B
�ڋʂ̐V�^SIMD���j�b�g���̂͑��p�r�ɂ��]�p�\�Ȃ͂��B
���̏ꍇ�͏]���^�̃R�A��Larrabee�R�A�����ڂ��邩�A�]���R�A��SIMD����u�������邾�낤�v
����^�Ɏ����̃A�z�\�z��
�u���ݔ������Ă�Intel�̃��[�h�}�b�v��
�wNehalem(���V�A�����R�������A4�R�A)��Westmere(���ǁA32nm�A6�R�A)
��Sandy Bridge(���V�AAVX���ߓ��ځAGPU���ڐ��L��A8�R�A)��Ivy Bridge(���ǁA22nm)
��??? Bridge(���ǁA�ڍוs���AIvy��Haswell�̃o�b�N�A�b�v�v����?)��Haswell(���V�A�ڂ������e�͕s��)�x
�cHaswell������ō��ڂ�����?�v
---�`���V�̗������܂�---
�Ⴄ�BLarrabee��x86�����ǎ��CPU�p����Ȃ��B
����Pentium����{�ɐV�^SIMD���j�b�g����+���j�[�R�A�ɂ����\���ŁA
���Ƃ��Č����Ȃ�uGPU��CPU�v�B
---��������`���V�̗�---
�㓡���̈ӌ���
�u�x�[�X������Pentium�Ȃ̂́A�ŏ��̐��i���O���t�B�b�N�X�p�r�Ȃ̂Łw�}���`�X���b�h>>>�V���O���X���b�h�x������B
�ڋʂ̐V�^SIMD���j�b�g���̂͑��p�r�ɂ��]�p�\�Ȃ͂��B
���̏ꍇ�͏]���^�̃R�A��Larrabee�R�A�����ڂ��邩�A�]���R�A��SIMD����u�������邾�낤�v
����^�Ɏ����̃A�z�\�z��
�u���ݔ������Ă�Intel�̃��[�h�}�b�v��
�wNehalem(���V�A�����R�������A4�R�A)��Westmere(���ǁA32nm�A6�R�A)
��Sandy Bridge(���V�AAVX���ߓ��ځAGPU���ڐ��L��A8�R�A)��Ivy Bridge(���ǁA22nm)
��??? Bridge(���ǁA�ڍוs���AIvy��Haswell�̃o�b�N�A�b�v�v����?)��Haswell(���V�A�ڂ������e�͕s��)�x
�cHaswell������ō��ڂ�����?�v
---�`���V�̗������܂�---
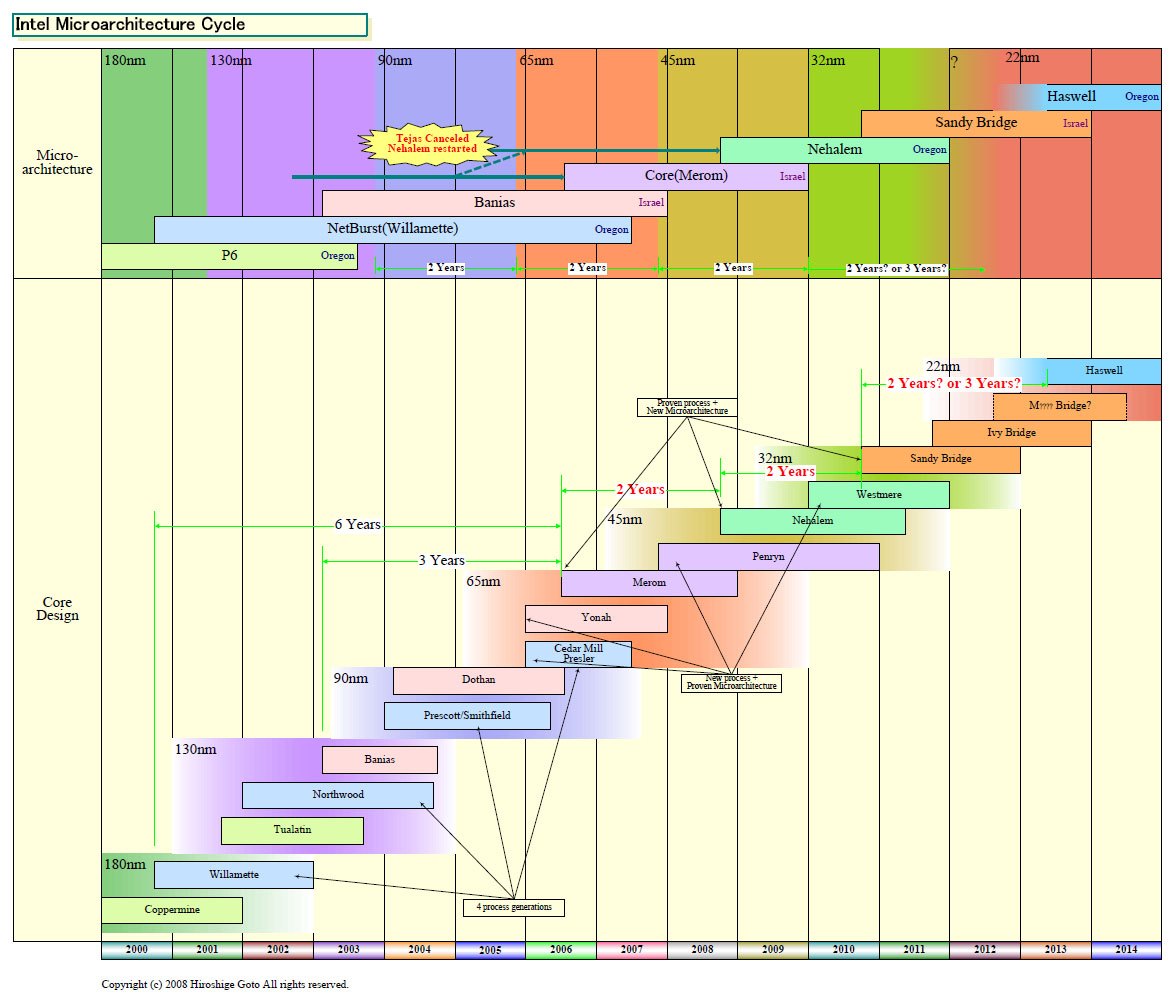{kind=link}
574 �F,,�E�L�́M�E,,�j��-�������F2008/10/20(��) 23:28:23 ID:JOKQA1OF
�����炵�Ă����܂���
�ySandy Bridge�̃��j�b�g�\���z
�E�eALU/LSU��256-bit�ł͂Ȃ�128-bit
�ELoad��128-bit 2�{�B����1�{��Store(�~1)�Ɣr���H
�EALU�|�[�g�͈�������3 Way�B����1��̂�3����1�o�̖͂��߂��_�C���N�g�Ɏ��s�\�B
�ESIMD������3�I�y�����h�g���ȊO�AWestmere������ɑ傫�Ȋg���Ȃ�
�E���������͊eALU�|�[�g�� FMAC, FADD, FMUL ���Ԃ牺�����ĂĂ������128�r�b�g��
�EFMAC��FP��Z�E�V���b�t���EFP�����Z���p�C�v���C�����������j�b�g�B
�@SIMD��Z����ѐ��������Z���܂�SIMD�����Z�̂����ꂩ�����s�ł���ł���ق��A
�@�{���x�̓���(v)dppd��1�N���b�N�ł��Ȃ���B
�@�{��4DP/8SP����FMA���߃Z�b�g���T�|�[�g����ĂȂ��̂Ŏ����s�[�N3DP�B
�ETera Tera Tera�ɏo�Ă�7DP�̓�����������A (v)addpd [2] + (v)mulpd [2] + (v)dppd [3]
�Evdpps�͎���1�������߂ł͂ł��Ȃ��H�i�������Z��2�i�K�K�v�̂��߁j
�ySandy Bridge�̃��j�b�g�\���z
�E�eALU/LSU��256-bit�ł͂Ȃ�128-bit
�ELoad��128-bit 2�{�B����1�{��Store(�~1)�Ɣr���H
�EALU�|�[�g�͈�������3 Way�B����1��̂�3����1�o�̖͂��߂��_�C���N�g�Ɏ��s�\�B
�ESIMD������3�I�y�����h�g���ȊO�AWestmere������ɑ傫�Ȋg���Ȃ�
�E���������͊eALU�|�[�g�� FMAC, FADD, FMUL ���Ԃ牺�����ĂĂ������128�r�b�g��
�EFMAC��FP��Z�E�V���b�t���EFP�����Z���p�C�v���C�����������j�b�g�B
�@SIMD��Z����ѐ��������Z���܂�SIMD�����Z�̂����ꂩ�����s�ł���ł���ق��A
�@�{���x�̓���(v)dppd��1�N���b�N�ł��Ȃ���B
�@�{��4DP/8SP����FMA���߃Z�b�g���T�|�[�g����ĂȂ��̂Ŏ����s�[�N3DP�B
�ETera Tera Tera�ɏo�Ă�7DP�̓�����������A (v)addpd [2] + (v)mulpd [2] + (v)dppd [3]
�Evdpps�͎���1�������߂ł͂ł��Ȃ��H�i�������Z��2�i�K�K�v�̂��߁j
575 �F,,�E�L�́M�E,,�j��-�������F2008/10/20(��) 23:30:38 ID:JOKQA1OF
�E256bit SIMD��2�̃|�[�g�ɕ�����̂ł͂Ȃ��A�������j�b�g��2����s�H�i�X�P�W���[�����O�̓s���j
CNET�u���O��IDF Taipei���|�[�g���B
http://news.cnet.com/8301-13924_3-10070319-64.html
�f�ڂ���Ă���Core i7�̃X���C�h�ɉ��C�� "Overspeed Protection Removed"�Ƃ������Ă��邷�B
http://news.cnet.com/8301-13924_3-10070319-64.html
�f�ڂ���Ă���Core i7�̃X���C�h�ɉ��C�� "Overspeed Protection Removed"�Ƃ������Ă��邷�B
IDF Taipei�̍u���������B
https://intel.wingateweb.com/taiwan08/scheduler/controller/catalog
https://intel.wingateweb.com/taiwan08/scheduler/controller/catalog
�����������Z��1�N���b�N(��)
�����ł܂����̔{�����j�b�g�Ƃ��L�{��
580 �F,,�E�L�́M�E,,�j����FP���Z���C�e���V1CLK�I�^�����F2008/10/22(��) 00:23:20 ID:yn2f9k6s
Nehalem-Westmere�̐������Z����͓{���̐i�����Ǝv������
���Ƃ���ŁAPOWER7��VSX���Ă悤�̓x�N�^�ƃX�J�����ׂ����߂��Ȃ������̂����X�lj�������������H
��SSE�ɂ悤�₭�ǂ����������ɂ��������Ȃ����B�ǂ����̒N���͕�����Ă��Ȃ��̂Ɉ�l��`�ɕK�������B
���Ƃ���ŁAPOWER7��VSX���Ă悤�̓x�N�^�ƃX�J�����ׂ����߂��Ȃ������̂����X�lj�������������H
��SSE�ɂ悤�₭�ǂ����������ɂ��������Ȃ����B�ǂ����̒N���͕�����Ă��Ȃ��̂Ɉ�l��`�ɕK�������B
���ɂȂ�����SpMT�����������́H
�d�͌����㏸�̌��E�����Ă���������C�������B
583 �F,,�E�L�́M�E,,�j��-�������F2008/10/23(��) 01:47:21 ID:le5WL46E
�}���`�X���b�h�ɂ��čs���Ȃ��������\�t�g�J���҂������ă\�t�g�E�F�A�̐��Y�����Ɏx��𗈂��悤�ɂȂ��
�K�R�I�ɂ����Ȃ�
�K�R�I�ɂ����Ȃ�
�C���e�����uiPhone�v�����]�A�A�b�v���Ƃ̖����͏I����
ttp://japan.cnet.com/mobile/story/0,3800078151,20382453,00.htm
����iPhone�ɂ����ݕt������
ttp://japan.cnet.com/mobile/story/0,3800078151,20382453,00.htm
����iPhone�ɂ����ݕt������
>>584
�������
�u�T�[�r�X���i�ʼn����Ă���Ă��̂�NVIDIA�`�b�v�Z�b�g�̗p���₪����
�@�d�艿�i�グ����(�K�D�K)��٧�v
DELL��HP�݂����C���˂���K�v�������̂Ō�����������
�������
�u�T�[�r�X���i�ʼn����Ă���Ă��̂�NVIDIA�`�b�v�Z�b�g�̗p���₪����
�@�d�艿�i�グ����(�K�D�K)��٧�v
DELL��HP�݂����C���˂���K�v�������̂Ō�����������
Phenom���ڂ���Mac���o������߂��̂��H
>>584
MacBook�Ƀ`�b�v�Z�b�g�ς�ł��炦�Ȃ������̂��A��قlj����������Ȃ�
Intel��GPU�����܂Ōo���Ă�����ڂ����炻���Ȃ��������Ȃ̂ɂ�
MacBook�Ƀ`�b�v�Z�b�g�ς�ł��炦�Ȃ������̂��A��قlj����������Ȃ�
Intel��GPU�����܂Ōo���Ă�����ڂ����炻���Ȃ��������Ȃ̂ɂ�
���낻��SkyFire���o����̌�������l���Ă���������������
589 �F,,�E�L�́M�E,,�j��-�������F2008/10/24(��) 01:24:32 ID:JJ0keCsa
�ĊOMac mini���ׂꂽ�̂�Intel�Ƃ̖����I���̂���������
������m�[�g�̐v���g���܂킵�ăf�B�X�v���C�E�L�[�{�[�h�E�o�b�e����������Ĉ�������
���Ĕ��z���̂����͂⎞�����Ȃ̂�������B
������m�[�g�̐v���g���܂킵�ăf�B�X�v���C�E�L�[�{�[�h�E�o�b�e����������Ĉ�������
���Ĕ��z���̂����͂⎞�����Ȃ̂�������B
����gLarrabee�h��48�R�A
http://northwood.blog60.fc2.com/blog-entry-2380.html
http://northwood.blog60.fc2.com/blog-entry-2380.html
591 �F,,�E�L�́M�E,,�j��-�������F2008/10/24(��) 01:34:30 ID:JJ0keCsa
�����Ȃ�48����
nVIDIA�̌����ɏo����I�C
nVIDIA�̌����ɏo����I�C
592 �F,,�E�L�́M�E,,�j��-�������F2008/10/24(��) 01:49:55 ID:JJ0keCsa
����������L�҂����قȊ��Ⴂ���ĂĈނ���
���80�R�A�͂܂������̕ʕ��ł��̂ŁB
���80�R�A�͂܂������̕ʕ��ł��̂ŁB
�����܂ő��₳�Ȃ��Ǝg�����ɂȂ�Ȃ���ł���
������܂�
������܂�
�Ă��A��������larrabee����16����10�R�A�̏��^�R�A�ςꍇquad core�Ɠ��K�͂��Ęb����������
48�R�A�Ȃ�24�����x�Ƀi�b�`���E��
48�R�A�Ȃ�24�����x�Ƀi�b�`���E��
��LSI�Ȃ�ʁA��CORE�B
300���g�����W�X�^�łȂ��A300���R�A����������鎞��ցB
300���g�����W�X�^�łȂ��A300���R�A����������鎞��ցB
Intel�AiPhone�Ɋւ���u�s�K�v�Ȕ��������
ttp://www.itmedia.co.jp/news/articles/0810/24/news036.html
�܂��A�uiPhone�͐V�����G�L�T�C�e�B���O�Ȏs��@����\�ɂ�����Ɋv�V�I�Ȑ��i�ł���A
��p�ł̔����͕s�K�������BIntel�̑�\����̓I�Ȍڋq�̐v�ɃR�����g����ׂ��ł͂Ȃ������v�Ƃ��q�ׂĂ���B
����������������������������������������������
ttp://www.itmedia.co.jp/news/articles/0810/24/news036.html
�܂��A�uiPhone�͐V�����G�L�T�C�e�B���O�Ȏs��@����\�ɂ�����Ɋv�V�I�Ȑ��i�ł���A
��p�ł̔����͕s�K�������BIntel�̑�\����̓I�Ȍڋq�̐v�ɃR�����g����ׂ��ł͂Ȃ������v�Ƃ��q�ׂĂ���B
����������������������������������������������
iPhone���[�U�[�Ƃ��Ă�Moorestown���ڂ�ɖ]�ށB
>>594
�S�W�R�A�ł�nVidia�̍ŐVGPU�Ɣ�r������A�����傫���͂Ȃ��̂ł́H
�S�W�R�A�ł�nVidia�̍ŐVGPU�Ɣ�r������A�����傫���͂Ȃ��̂ł́H
��̓I�Ȑ����͂Ȃ����ǁAMerom��10�R�A��Larrabee���������炢�̃_�C�T�C�Y�A����d�͂炵���B
���̔�r�����������v���Z�X�Ȃ�A45nm��48�R�A�Ȃ�500mm2���炢���낤���B
���̔�r�����������v���Z�X�Ȃ�A45nm��48�R�A�Ȃ�500mm2���炢���낤���B
>Merom��10�R�A��Larrabee���������炢�̃_�C�T�C�Y
16�R�A�������悤�ȁH
16�R�A�������悤�ȁH
601 �FMAC�I�^��600 �����F2008/10/24(��) 23:13:51 ID:UfGzgUTG
>>600
�@�@-----------------
�@�@16�R�A�������悤�ȁH
�@�@-----------------
10�R�A�Ő��������BLarrabee�_��Table 1�̒��߂��
�@�@=================
�@�@Table 1: Out-of-order vs. in-order CPU comparison: designing the processor for increased
�@�@throughput can result in . the peak single-stream performance, but 20x the peak vector
�@�@throughput with roughly the same area and power.
�@�@=================
�ꉞ�A"These in-order cores are not Larrabee, but are similar."�Ƃ������߂���Ă��邷�B
�@�@-----------------
�@�@16�R�A�������悤�ȁH
�@�@-----------------
10�R�A�Ő��������BLarrabee�_��Table 1�̒��߂��
�@�@=================
�@�@Table 1: Out-of-order vs. in-order CPU comparison: designing the processor for increased
�@�@throughput can result in . the peak single-stream performance, but 20x the peak vector
�@�@throughput with roughly the same area and power.
�@�@=================
�ꉞ�A"These in-order cores are not Larrabee, but are similar."�Ƃ������߂���Ă��邷�B
602 �F,,�E�L�́M�E,,�j��-�������F2008/10/25(�y) 00:58:43 ID:ixbtkhbG
Mac��Intel�X����u��10�R�A�����i�Ƃ��ẴR�A�����Ɗ��Ⴂ���Ă���
603 �F,,�E�L�́M�E,,�j��-�������F2008/10/25(�y) 11:30:53 ID:ixbtkhbG
�T���X���Ƃ���
>>599
Itanium�����Ȃ�����
8�R�A�P�ʂ�1�̃����O�o�X���ď����ǂ����ɂ������ȁB
8�R�A�Ȃ���16�R�A�P�ʂŐ�������MCM�Ō�������Ȃ�����܂�͂ǂ��ɂł��Ȃ肻�������B
Larrabee���o�闈�N���ɂ̓n�C�G���h�`�A�b�p�[�~�h�������W���i��32nm�Ɉڍs����
45nm�̓o�����[�����W���i���S�ɒu�������B
Intel�ɂƂ��Ă�Celeron�Ɠ��������Ύ������Ă��Ƃ��B
�ƍl����ƁA�g�[�^���_�C�T�C�Y���傫���Ȃ�̂͂���Ȃɖ��Ȃ��̂ł́H
�ȑO�ǂ����ŏE�������
45nm 16�R�A/32�R�A
32nm 24�R�A/48�R�A
�������ȁB�ǂ������Ƃ����Ɖ��͂��������x�����Ă�B
1.5�{���Ĕ䗦�́APenryn/Nehalem���ő�4�R�A, Westmere/SandyBridge���ő�6�R�A
�V�������N�ɂ��k�������Ƃ�����Ɛ����͂̂��鐔����
>>599
Itanium�����Ȃ�����
8�R�A�P�ʂ�1�̃����O�o�X���ď����ǂ����ɂ������ȁB
8�R�A�Ȃ���16�R�A�P�ʂŐ�������MCM�Ō�������Ȃ�����܂�͂ǂ��ɂł��Ȃ肻�������B
Larrabee���o�闈�N���ɂ̓n�C�G���h�`�A�b�p�[�~�h�������W���i��32nm�Ɉڍs����
45nm�̓o�����[�����W���i���S�ɒu�������B
Intel�ɂƂ��Ă�Celeron�Ɠ��������Ύ������Ă��Ƃ��B
�ƍl����ƁA�g�[�^���_�C�T�C�Y���傫���Ȃ�̂͂���Ȃɖ��Ȃ��̂ł́H
�ȑO�ǂ����ŏE�������
45nm 16�R�A/32�R�A
32nm 24�R�A/48�R�A
�������ȁB�ǂ������Ƃ����Ɖ��͂��������x�����Ă�B
1.5�{���Ĕ䗦�́APenryn/Nehalem���ő�4�R�A, Westmere/SandyBridge���ő�6�R�A
�V�������N�ɂ��k�������Ƃ�����Ɛ����͂̂��鐔����
���܂����Ă���B
���܂��̓_���S���I���Ȃ̂��H
���܂��̓_���S���I���Ȃ̂��H
>>603
SIGGRAPH�ł̘_������1�����O��16�R�A�܂ł��ď����Ă����B
1�`�b�v����Ȃ���MCM�ŏo���Ȃ�A�R�A���̌��E�͏���d�͂Ō��܂�낤�ȁB
SIGGRAPH�ł̘_������1�����O��16�R�A�܂ł��ď����Ă����B
1�`�b�v����Ȃ���MCM�ŏo���Ȃ�A�R�A���̌��E�͏���d�͂Ō��܂�낤�ȁB
�Ƃ���Ə����ł�1�����O���낤����A
16�R�A�ȉ����Ă̂͊m�肾�Ǝv���B
16�R�A�ȉ����Ă̂͊m�肾�Ǝv���B
607 �F,,�E�L�́M�E,,�j��-�������F2008/10/25(�y) 14:49:10 ID:ixbtkhbG
608 �F,,�E�L�́M�E,,�j��-�������F2008/10/25(�y) 14:52:35 ID:ixbtkhbG
���������������̂ق���24�R�A���o����Ęb���o�Ă�����8�R�A��1�����O���Đ����������Ǝv���Ă��B
32�R�A��8�R�A�����ł̐����l�������ǁA�ǂ������܂舫������Ă����B
32�R�A��8�R�A�����ł̐����l�������ǁA�ǂ������܂舫������Ă����B
> ���L�R�e����B�N�ł��������B
����A�n���ɂ͖��������E�E�E
����A�n���ɂ͖��������E�E�E
611 �F,,�E�L�́M�E,,�j��-�������F2008/10/25(�y) 15:12:22 ID:ixbtkhbG
���C�h�Ȃ��₳��
612 �F,,�E �� �E,,�j��-�������F2008/10/25(�y) 18:01:54 ID:L+S6Bhz8
Larrabee�͎��s��ł���!!
�܂��o���オ���Ă����Ȃ��̂Ɏ��s�����( ^��^�G)
614 �FSocket774�F2008/10/25(�y) 23:41:15 ID:vXmhH6Ps
�c�q�~�̕�����]�B
��=AMD�~=503�ł��A�Ƃ����F���Ȃ��A�����Ă�H
��=AMD�~=503�ł��A�Ƃ����F���Ȃ��A�����Ă�H
�c�q�~��,,�E�L�́M�E,,�j��-���������_���S���I��
�e�w���^���E�G����1201���ƌĂꂽ�l����
�A���~(�E�L��`�E)
503���@��
����4�l�͕ʐl�ł�
�e�w���^���E�G����1201���ƌĂꂽ�l����
�A���~(�E�L��`�E)
503���@��
����4�l�͕ʐl�ł�
617 �F(�E�L��`�E)��[503�ł�]�F2008/10/26(��) 18:58:18 ID:kW/tArnr
���b�N�I������
�˂炢����
�˂炢����
618 �FFAQ�I�^�G����517�����F2008/10/26(��) 19:02:51 ID:kW/tArnr
���Ȃ���N�����H
�A�n�Q�����B(�E�L��`�E)
�A�n�Q�����B(�E�L��`�E)
619 �F,,�@�@�@�E�L�@�@�́@�@�@�M�E�@�@�@,,�@�j�����������������F2008/10/26(��) 19:08:39 ID:kW/tArnr
>>617-618
����������
����������
620 �F,,�L�@_�T�@`,,�j��-�������F2008/10/26(��) 19:53:53 ID:1sNmbZgv
.
�Q�n�~�͑�����i���ɏo�Ă��Ȃ��ŗ~����
622 �F,,�E�L�́M�E,,�j��-�������F2008/10/27(��) 17:45:03 ID:f8wUFYf4
�@
�_���S���I�������B
624 �F,,�E �� �E,,�j��-�������F2008/10/27(��) 20:53:06 ID:Awv+woA0
>>613
�ł��������Ă��Ȃ����̂��A
����܂ł̏�画�f���Ď��s�Ƃ����Ă���̂��B
���݂̂悤�Ȓ�\����̗\�z�Ƃ��Ȃ�������Ō��Ȃ��ŗ~�����B
����͒c�q�����B
�ł��������Ă��Ȃ����̂��A
����܂ł̏�画�f���Ď��s�Ƃ����Ă���̂��B
���݂̂悤�Ȓ�\����̗\�z�Ƃ��Ȃ�������Ō��Ȃ��ŗ~�����B
����͒c�q�����B
625 �F,,�E�L�́M�E,,�j��[���₳��]�F2008/10/27(��) 23:29:23 ID:npNHSIHg
�悭������B�J���Ƀ����[�r����������낤(AAry
626 �F,,�E�L�́M�E,,�j��-�������F2008/10/28(��) 01:02:39 ID:lHYR19XG
�܂��߂ɂ����I
627 �F,,�E�L�́M�E,,�j��-�������F2008/10/28(��) 01:13:04 ID:lHYR19XG
628 �F,,�E �� �E,,�j��-�������F2008/10/28(��) 19:46:40 ID:dtulCC5A
Lincroft�͕��ʂ̐l�������ˁB
����̉�Ђł͂��ł�Eee PC with Atom��U��Ď咣���Ă��������܂�Ƃ���B
�����������A�^��Intel�ʂ�Larrabee���āA10�N���
����ȋ����i��U�̊g���J�[�h������������!!
�Ǝ�������̂��B
�����Larrabee���ˁB
����̉�Ђł͂��ł�Eee PC with Atom��U��Ď咣���Ă��������܂�Ƃ���B
�����������A�^��Intel�ʂ�Larrabee���āA10�N���
����ȋ����i��U�̊g���J�[�h������������!!
�Ǝ�������̂��B
�����Larrabee���ˁB
629 �F,,�E �� �E,,�j��-�������F2008/10/28(��) 19:47:11 ID:dtulCC5A
�咣����Ȃ��ďo������
630 �F,,�E�L�́M�E,,�j��-�������F2008/10/28(��) 23:48:02 ID:lHYR19XG
�i���������̘b�j
nVIDIA�̓��{�@�l�H�̐l���烁�[�����E�E�E
�uCUDA�Ή����Ă��ꂽ�炤���̉�Ђ̃T�C�g�ł��Ȃ��̃\�t�g���Љ�Ă����܂���v
����͈����̗U�����H
nVIDIA�̓��{�@�l�H�̐l���烁�[�����E�E�E
�uCUDA�Ή����Ă��ꂽ�炤���̉�Ђ̃T�C�g�ł��Ȃ��̃\�t�g���Љ�Ă����܂���v
����͈����̗U�����H
�K���Ȃ�ł�
632 �F,,�E�L�́M�E,,�j��-�������F2008/10/28(��) 23:54:53 ID:lHYR19XG
���낤�ȁBRadeon HD 4xxx�o�Ă���ATi�ɕ������ςȂ������B
�u����Larrabee�{���ł�����v���ăT�C�g�ɏ����Ă�T���炠�̃��[���͂ˁ[��Ǝv�����B
�����܂ŕK���Ȃ��A�Ȃ����������o�����@������B
���܂����̐l���Ȃ��߂���ΊJ���@���ڂ�Core 2 Extreme�{GTX280���炢��
���炦�邩�������B
�����������ē����ɂ��������̂����Ȃ�B
�u����Larrabee�{���ł�����v���ăT�C�g�ɏ����Ă�T���炠�̃��[���͂ˁ[��Ǝv�����B
�����܂ŕK���Ȃ��A�Ȃ����������o�����@������B
���܂����̐l���Ȃ��߂���ΊJ���@���ڂ�Core 2 Extreme�{GTX280���炢��
���炦�邩�������B
�����������ē����ɂ��������̂����Ȃ�B
�Ȃɒ��q����Ă��?
634 �F,,�E�L�́M�E,,�j��-�������F2008/10/29(��) 01:28:00 ID:PL3EJ2gj
,,�E�L�́M�E,,�j��-������������Ăˁ[��
�@���q
����Ƀ����b�g�����������ɂ��������b�g����������Ȃ瑊�肪
���ނ킯�Ȃ����낤�B�����Ƀ����b�g������������l����
�����Ȃ��̂Ȃ���߂�B
���ނ킯�Ȃ����낤�B�����Ƀ����b�g������������l����
�����Ȃ��̂Ȃ���߂�B
�܂�Larrabee�o�ĂȂ����A�����CUDA������낤�A�c�q����B
���Џ����Ȃ����Ă�����������
�Ƃ����Photoshop��CUDA�Ή������܂����������A
Larrabee�����ӂ�intel���͂Ŕ����O�ɂǂ�ǂ�Ή��������
�j�b�`�ȑw���炶�킶��ƕ��y���Ă����\���B
�X��apple�Ƀf���点���(���_�����SOS�̋@�\�Ƃ���)����ꕔ�Ƃ���Ɋ�������₷���A�����ނ��B
���Џ����Ȃ����Ă�����������
�Ƃ����Photoshop��CUDA�Ή������܂����������A
Larrabee�����ӂ�intel���͂Ŕ����O�ɂǂ�ǂ�Ή��������
�j�b�`�ȑw���炶�킶��ƕ��y���Ă����\���B
�X��apple�Ƀf���点���(���_�����SOS�̋@�\�Ƃ���)����ꕔ�Ƃ���Ɋ�������₷���A�����ނ��B
>�Ƃ����Photoshop��CUDA�Ή������܂����������A
����CUDA�Ȃ�Ďg���Ă܂���ł����Ƃ��Ό���������Ȃ�
����CUDA�Ȃ�Ďg���Ă܂���ł����Ƃ��Ό���������Ȃ�
adobe reader8��GPU�x���̂Ƃ�������������
nv�����\����O����ATI����g������
nv�����\����O����ATI����g������
639 �F,,�E�L�́M�E,,�j��-�������F2008/10/29(��) 08:00:59 ID:PL3EJ2gj
>>635
�u8400GS�̃��[�v�����������Ă܂����BGTX200�V���[�Y�ł̓���E�p�t�H�[�}���X�ۏȂ�Ăł��܂����v
�܂��O���͉R�Ȃ�ł����ǂˁB
����A9800GT���炢�܂łȂ玩�����Ă��������ȂƎv���Ă��邪
���߂ăp�t�H�[�}���X���ؗp�Ƀe�X�g�}�V���𐔑������Ă����Ȃ���
�����[�g�f�X�N�g�b�v�ŁB
���{�@�l����Ȃ��ăT���^�N�����̂ق����������B
���߂�ˁA����AVX�܂ł͊��ɑΉ��o���Ă��
Larrabee�͂����512�r�b�g�Ɉ������������ł�����Ǝv����
�u8400GS�̃��[�v�����������Ă܂����BGTX200�V���[�Y�ł̓���E�p�t�H�[�}���X�ۏȂ�Ăł��܂����v
�܂��O���͉R�Ȃ�ł����ǂˁB
����A9800GT���炢�܂łȂ玩�����Ă��������ȂƎv���Ă��邪
���߂ăp�t�H�[�}���X���ؗp�Ƀe�X�g�}�V���𐔑������Ă����Ȃ���
�����[�g�f�X�N�g�b�v�ŁB
���{�@�l����Ȃ��ăT���^�N�����̂ق����������B
���߂�ˁA����AVX�܂ł͊��ɑΉ��o���Ă��
Larrabee�͂����512�r�b�g�Ɉ������������ł�����Ǝv����
�R�[�h�̏����₷���͖{���Ƀ����r�[�̃A�h�o���e�[�W�Ƃ��Ĉ��|�I����ȁB
���Ƃ͐��\���ǂꂾ���o�邩�����ǃG���R�[�_���������Ή����Ă����B
���Ƃ͐��\���ǂꂾ���o�邩�����ǃG���R�[�_���������Ή����Ă����B
�u�����r�[�͌����ȁv
643 �F,,�E�L�́M�E,,�j��[�������~]�F2008/10/29(��) 12:33:30 ID:8jseBovK
���_�F
��������nVIDIA�~���܂�
�Ƃ肠���������Ȃ������͈����o����
���ƁA�J���Ҍ����ɂ͂��������Ȃ������ɘN����܂��inVIDIA�Г��̋@�������������ł��j�B
���Ȃ݂ɁA���͌Œ�@�\������Ȃ����AGPGPU�Ƃ��Ă�Larrabee�̂ق����d�͌����I�ɗD�ʂ���Ȃ����Ǝv���Ă���B�t�ɂˁB
��������nVIDIA�~���܂�
�Ƃ肠���������Ȃ������͈����o����
���ƁA�J���Ҍ����ɂ͂��������Ȃ������ɘN����܂��inVIDIA�Г��̋@�������������ł��j�B
���Ȃ݂ɁA���͌Œ�@�\������Ȃ����AGPGPU�Ƃ��Ă�Larrabee�̂ق����d�͌����I�ɗD�ʂ���Ȃ����Ǝv���Ă���B�t�ɂˁB
����S3����
http://logs.ubuntu-eu.org/freenode/2008/10/28/%23ubuntu-jp.html
>The early documentation from Intel about Atom said many things that made lpia different. As there are more Atom processors released, some of these things are no longer true.
>Some moblin gcc patches are in Ubuntu gcc for lpia. No significant improvements. The primary gain seems to be compiling for i686 vs. i586.
���[��…���o�C�����ʃ\�t�g�E�F�A�ʂŖ�����?
>The early documentation from Intel about Atom said many things that made lpia different. As there are more Atom processors released, some of these things are no longer true.
>Some moblin gcc patches are in Ubuntu gcc for lpia. No significant improvements. The primary gain seems to be compiling for i686 vs. i586.
���[��…���o�C�����ʃ\�t�g�E�F�A�ʂŖ�����?
CPU���^������OS���^�����ăA�v���P�[�V�������^��������
Symbian��WM��Ajax/Flash�������u���E�U��������������Ɗy�����
Symbian��WM��Ajax/Flash�������u���E�U��������������Ɗy�����
>>643
���x��Cell�~���o�Ă��邩�ȁH
���[�h�e�b�N�A���ŁuSpursEngine�v���ڃJ�[�h�̔�����������
http://pc.watch.impress.co.jp/docs/2008/1029/leadtek.htm
���x��Cell�~���o�Ă��邩�ȁH
���[�h�e�b�N�A���ŁuSpursEngine�v���ڃJ�[�h�̔�����������
http://pc.watch.impress.co.jp/docs/2008/1029/leadtek.htm
Intel��IGP����Ɍ��������Microsoft
ttp://code.msdn.microsoft.com/Win7DeveloperGuide/Release/ProjectReleases.aspx?ReleaseId=1702
The Windows Advanced Rasterization Platform (WARP) implements fast, multi-core scalable CPU rendering for Direct3D 10,
enabling full-featured graphics rendering on systems without graphics hardware.
The addition of new �gFeature Levels,�h specifically called Direct3D 10 Level 9,�@allow the Direct3D 10 and Direct3D 11 APIs to drive Direct3D 9-class hardware,
expanding the number of configurations a Direct3D 10 or Direct3D 11 application can target to nearly every computer system on the market.
�Ӗ�
CPU�ŕ`�悵�����������̂ł����ł���悤�ɂ��܂���
DirectX 10�h���C�o�̏o���������̂ł������ŗp�ӂ��܂���
�����̌���
ttp://pc.watch.impress.co.jp/docs/2008/1029/mobile429.htm
���m�{��ThinkPad X300��Core 2 Duo L7100(1.2GHz)���f���ł���A��������4GB���ڂ��Ă���(32bit�ł̂���3GB�̂ݔF��)�Ƃ͂����A
Intel GM965�̓����O���t�B�b�N�X�ŁA�����܂őf�����������̂͗\�z�O�������B
�܂�CPU�����ɐ�O�ł��Č��\�Ȃ��ƁH
ttp://code.msdn.microsoft.com/Win7DeveloperGuide/Release/ProjectReleases.aspx?ReleaseId=1702
The Windows Advanced Rasterization Platform (WARP) implements fast, multi-core scalable CPU rendering for Direct3D 10,
enabling full-featured graphics rendering on systems without graphics hardware.
The addition of new �gFeature Levels,�h specifically called Direct3D 10 Level 9,�@allow the Direct3D 10 and Direct3D 11 APIs to drive Direct3D 9-class hardware,
expanding the number of configurations a Direct3D 10 or Direct3D 11 application can target to nearly every computer system on the market.
�Ӗ�
CPU�ŕ`�悵�����������̂ł����ł���悤�ɂ��܂���
DirectX 10�h���C�o�̏o���������̂ł������ŗp�ӂ��܂���
�����̌���
ttp://pc.watch.impress.co.jp/docs/2008/1029/mobile429.htm
���m�{��ThinkPad X300��Core 2 Duo L7100(1.2GHz)���f���ł���A��������4GB���ڂ��Ă���(32bit�ł̂���3GB�̂ݔF��)�Ƃ͂����A
Intel GM965�̓����O���t�B�b�N�X�ŁA�����܂őf�����������̂͗\�z�O�������B
�܂�CPU�����ɐ�O�ł��Č��\�Ȃ��ƁH
�`�b�v�Z�b�g��CPU�Ɏ�荞��ǂ�����ĉߋ��̑��u�̌������p�����B
650 �F,,�E�L�́M�E,,�j���F2008/10/29(��) 22:43:48 ID:8jseBovK
�����Ő�[�ł��邤���ɍ��t�����l�Ȃ��̂��Č������p�������߂邩����Ȃ��ł���
�ŋ߂͑��u���I�[�N�V�����Ŕ���ɏo���Ă�
�ŋ߂͑��u���I�[�N�V�����Ŕ���ɏo���Ă�
�܂��T�E�X���c���Ă邵�A
�g�ݍ��ݗp�̗����ȃv���Z�b�T�Ȃ�
���낢�날�邾��
�g�ݍ��ݗp�̗����ȃv���Z�b�T�Ȃ�
���낢�날�邾��
Intel��NIC����ʐ��Y����āA���\�����u���ʼn��i������1/10�Ŕ�����悤�ɂȂ�
����Ȗ����������
����Ȗ����������
>>644
���Ђ̍\����
��---��---��--->
�ł���̂ɑ�
��---
�@�@�@�b--->
��---
����
nv��ati�̂悤�ȋ���Shader���Ȃ�����
���Ђ̍\����
��---��---��--->
�ł���̂ɑ�
��---
�@�@�@�b--->
��---
����
nv��ati�̂悤�ȋ���Shader���Ȃ�����
654 �F,,�E�L�́M�E,,�j��[NVIDIA�Ɩ�����]�F2008/10/29(��) 23:13:18 ID:8jseBovK
>>647
SpursEngine��MPEG2/H.264�̃G���R�E�f�R�[�h�p�̌Œ�@�\���j�b�g�������Ă�B
4��SPE�̓t�B���^�p�B
�܂�����ɓ��������G���W������ˁH
SpursEngine��MPEG2/H.264�̃G���R�E�f�R�[�h�p�̌Œ�@�\���j�b�g�������Ă�B
4��SPE�̓t�B���^�p�B
�܂�����ɓ��������G���W������ˁH
>>647
���������\�t�g���f�o�C�X�ɑ��āA�J�̉����ɓ���ȊO�̗p�r���L��̂��B
���������\�t�g���f�o�C�X�ɑ��āA�J�̉����ɓ���ȊO�̗p�r���L��̂��B
����
>>656
����p�Ƃ��ďo���Ă�̂ɂ��̓˂����݂̓A�z�Ƃ����v���B
����p�Ƃ��ďo���Ă�̂ɂ��̓˂����݂̓A�z�Ƃ����v���B
http://pc.watch.impress.co.jp/docs/2008/1031/kaigai474.htm
���㓡�O��Weekly�C�O�j���[�X��
SSE�Ƃ͍��{�I�ɈقȂ�Larrabee�̃x�N�^�v���Z�b�T
���㓡�O��Weekly�C�O�j���[�X��
SSE�Ƃ͍��{�I�ɈقȂ�Larrabee�̃x�N�^�v���Z�b�T
660 �F,,�E�L�́M�E,,�j��-�������F2008/10/31(��) 01:33:45 ID:4XY8bTKQ
�}�X�N���W�X�^���Ă���ȏ�����������
16�r�b�g�̃}�X�N���K�v�Ȃ��Ƃ͂������8���̎����ǂ琄���ł�������
ecx���W�X�^�ł��g���܂킷�̂��Ǝv���Ă��B
16�r�b�g�̃}�X�N���K�v�Ȃ��Ƃ͂������8���̎����ǂ琄���ł�������
ecx���W�X�^�ł��g���܂킷�̂��Ǝv���Ă��B
��Larrabee�^�A�[�L�e�N�`���̏ꍇ�̗��_�́A�A�v���P�[�V�����ɂ���Đ���I�ɕς��邱�Ƃ��ł���_���B�_��ɁA�u���b�N�̃t�H�[���[�V��������ύX�ł���B
���@�̏_����A�z�ɂł��킩��悤�ɐ������Ă�����������
���@�̏_����A�z�ɂł��킩��悤�ɐ������Ă�����������
662 �F,,�E�L�́M�E,,�j��-�������F2008/10/31(��) 08:39:28 ID:4XY8bTKQ
NVIDIA��SIMT���Ă��邶���B
�������߂��̃X�J���v���Z�b�T�œ������s������Ă�B
Larrabee��SIMD���j�b�g�̓X�J���~16Way SIMT�Ƃ݂Ȃ����Ƃ��A���邢��
2Way SIMD�~8Way SIMT�A4Way SIMD�~4Way SIMT�E�E�E�Ƃ��Ă݂邱�Ƃ��ł���Ǝv���B
�������16Way SIMD���̂܂�g���Ă����܂�Ȃ�
nVIDIA�̏ꍇ�͍��̎����ł̓f�[�^���x����w, x, y, z�Ƃ�������ŕ���łĂ�1��1�̗v�f�ɕ�����
���s���邶���B
���ƁA����SP�Ŏg���Ă�f�[�^�����o���̂͊���Ǝ��Ԃ�����B
Larrabee��4������Ă�f�[�^��4���܂�܁A4�g�̃f�[�^�ɑ��ē�������������邱�Ƃ��ł���E�E�E�Ǝv���B
4WaySIMD�~4Way SIMT�����Ȃ��̂��\�Ȃ킯���B
�����Ă����炭�͑g���܂������f�[�^�V���b�t�����_��ɍs����B
�������߂��̃X�J���v���Z�b�T�œ������s������Ă�B
Larrabee��SIMD���j�b�g�̓X�J���~16Way SIMT�Ƃ݂Ȃ����Ƃ��A���邢��
2Way SIMD�~8Way SIMT�A4Way SIMD�~4Way SIMT�E�E�E�Ƃ��Ă݂邱�Ƃ��ł���Ǝv���B
�������16Way SIMD���̂܂�g���Ă����܂�Ȃ�
nVIDIA�̏ꍇ�͍��̎����ł̓f�[�^���x����w, x, y, z�Ƃ�������ŕ���łĂ�1��1�̗v�f�ɕ�����
���s���邶���B
���ƁA����SP�Ŏg���Ă�f�[�^�����o���̂͊���Ǝ��Ԃ�����B
Larrabee��4������Ă�f�[�^��4���܂�܁A4�g�̃f�[�^�ɑ��ē�������������邱�Ƃ��ł���E�E�E�Ǝv���B
4WaySIMD�~4Way SIMT�����Ȃ��̂��\�Ȃ킯���B
�����Ă����炭�͑g���܂������f�[�^�V���b�t�����_��ɍs����B
�����̐l�B�ڂ����������炨�q�˂������B
�ʂ̃��C���X�g���[����������
4Core�̂�PCIex16x1or8x2�2Core+GPU�̂�1x1���d�l���ۂ�����
16x2�Ƃ�3�͎d�l�㖳���Ȃ̂��̂��c
�ʂ̃��C���X�g���[����������
4Core�̂�PCIex16x1or8x2�2Core+GPU�̂�1x1���d�l���ۂ�����
16x2�Ƃ�3�͎d�l�㖳���Ȃ̂��̂��c
665 �F,,�E�L�́M�E,,�j��-�������F2008/11/01(�y) 15:53:04 ID:sHed6bxe
NVIDIA�Ɂu�n�C�G���h��4�R�A���~�b�h�����W��2�R�A�{GPGPU�̂ق��������ł���v���Ĕ���������ꂽ�獢�邩��܂��h�q��
�ECPU����L�т�PCI Express Gen2��PCI Express�X�C�b�`�ŎāA���[���𑝂₷�B
�E���А��T�E�X�u���b�W�Ɋ��҂���B
�ǂ������㗬�����{�g���l�b�N�ɂȂ肦��\�������A�킴�킴����Ȗʓ|�ȍ\����
�������郁�[�J�[������̂����Ė��͂��邪�B
�Ă��APCI Express�������~�����̂Ȃ�ABloomfield�x�[�X�̍\������Ԃ��B
Tylersburg-24D��2�悹���V�X�e���Ȃ�PCI Express Gen2�����v48���[���B36D�~2�Ȃ�72���[���B
NVIDIA�Ȃ�48���[����1�`�b�v�ɏW�ς���Bloomfield�����`�b�v�Z�b�g�Ƃ�����Ă��邾�낤���B
�E���А��T�E�X�u���b�W�Ɋ��҂���B
�ǂ������㗬�����{�g���l�b�N�ɂȂ肦��\�������A�킴�킴����Ȗʓ|�ȍ\����
�������郁�[�J�[������̂����Ė��͂��邪�B
�Ă��APCI Express�������~�����̂Ȃ�ABloomfield�x�[�X�̍\������Ԃ��B
Tylersburg-24D��2�悹���V�X�e���Ȃ�PCI Express Gen2�����v48���[���B36D�~2�Ȃ�72���[���B
NVIDIA�Ȃ�48���[����1�`�b�v�ɏW�ς���Bloomfield�����`�b�v�Z�b�g�Ƃ�����Ă��邾�낤���B
���y��2�A3���ł����Ȃ��}���`GPU�ׂ̈�
�v���b�g�t�H�[���S�̂̃R�X�g�A�b�v�Ȃ�Ď������킯�Ȃ����B
�v���b�g�t�H�[���S�̂̃R�X�g�A�b�v�Ȃ�Ď������킯�Ȃ����B
�F���肪��
>>666
�����܂ŃS�[�W���X�Ȃ̂͂�����w
�d���Ȃ�i7�|�`�邩�̂��c
���������v�������Ƃ͌����A���炩�ɑމ��̗���͗҂����̂�
>>666
�����܂ŃS�[�W���X�Ȃ̂͂�����w
�d���Ȃ�i7�|�`�邩�̂��c
���������v�������Ƃ͌����A���炩�ɑމ��̗���͗҂����̂�
670 �F,,�E �� �E,,�j��-�������F2008/11/01(�y) 23:15:48 ID:d7iGSxnD
>>668
���O�����ɓ��ʋ����Ă��B
Nehalem��Bloomfield�ȊO�͂��܂̂Ƃ���n���v�f���ڂ��B
Bloomfield��f���ɂ����Ă��������������B
���O�����ɓ��ʋ����Ă��B
Nehalem��Bloomfield�ȊO�͂��܂̂Ƃ���n���v�f���ڂ��B
Bloomfield��f���ɂ����Ă��������������B
���܂�A668����Ȃ����Ǐڂ����I
672 �F,,�E �� �E,,�j��-�������F2008/11/01(�y) 23:18:42 ID:d7iGSxnD
Bloomfled�����Ȃ�2010�N�ȍ~�܂ň��肷��̂��܂����Ȃ��˂��B
673 �F,,�E �� �E,,�j��-�������F2008/11/01(�y) 23:23:12 ID:d7iGSxnD
>>671
����͂����Ȃ̂ł����Ɛ������Ȃ����ǁA
Havendale���x��Ă�̂��炷�łɉ����������Ȃ���?
Lynnfield�͍��̂Ƃ���X�P�W���[���ɏ���Ă��邪�A
�Ⴆ�A���N��ɂł�Havendale��Lynnfield�̃}�U�[�{�[�h��
�\�P�b�g�͋��ʂ����A�݊������ʂ����Ă��邾�낤��?
Bloomfield��IMC���QuickPath��炪����Ȃ��炩�Ȃ肤�܂����������B
����͂����Ȃ̂ł����Ɛ������Ȃ����ǁA
Havendale���x��Ă�̂��炷�łɉ����������Ȃ���?
Lynnfield�͍��̂Ƃ���X�P�W���[���ɏ���Ă��邪�A
�Ⴆ�A���N��ɂł�Havendale��Lynnfield�̃}�U�[�{�[�h��
�\�P�b�g�͋��ʂ����A�݊������ʂ����Ă��邾�낤��?
Bloomfield��IMC���QuickPath��炪����Ȃ��炩�Ȃ肤�܂����������B
674 �F,,�E�L�́M�E,,�j��-�������F2008/11/02(��) 00:53:27 ID:VSq7429Y
���тȂ�����߂�����������
675 �F,,�E �� �E,,�j��-�������F2008/11/02(��) 00:57:17 ID:0RmjN6mi
���܂��̊�̂��L�����B
������������͔��т������̂���B
�ǂ������ڂ����킩���u�T�ʂłˁB
������������͔��т������̂���B
�ǂ������ڂ����킩���u�T�ʂłˁB
676 �F,,�E�L�́M�E,,�j��-�������F2008/11/02(��) 01:05:42 ID:VSq7429Y BE:334497683-PLT(12021)
�܁A���������{���ؖ������i�͂�����ǂ�
�������c
678 �F,,�L�E�@�́@�E�M,,�j��-�������F2008/11/02(��) 10:15:24 ID:VSq7429Y BE:55750122-PLT(12021)
�R�A���Ԃ��
���Ȃ炱������
���Ȃ炱������
�M�@��
�E�@�ق��̐Ԃ���
���Ǝv���Ă��E�E�E
�E�@�ق��̐Ԃ���
���Ǝv���Ă��E�E�E
�ǂ��ł�����
681 �F���L�́M���j��-�������F2008/11/02(��) 11:36:12 ID:VSq7429Y BE:668995968-PLT(12021)
>>679
����ł������H
����ł������H
�r�[�ɋC���������Ȃ����E�E�E
683 �F�L���́��M�j��-�������F2008/11/02(��) 14:58:04 ID:sztnUjIK
�ނ��낱������
684 �F´��∀���M�j��-�������F2008/11/02(��) 15:19:07 ID:5ybCyzH/
�݂�ȁANehalem�����Ă���邩�ȁ[�H
�ނ���NVIDIA�̑����T�E�X�ƃO���t�B�b�N��
Intel�̑����m�[�X������CPU�͊������g�ݍ��킹
Intel�̑����m�[�X������CPU�͊������g�ݍ��킹
NVIDIA Havendale�Ɋ���
���T��WinHEC��Apple�ɑ�����MS�����Havendale�I���̂��m�点���鍐���ꂻ����
���ꂪ�����ʼn��������Ƃ��l�����邯��
���ꂪ�����ʼn��������Ƃ��l�����邯��
�J���R�[�h�l�[��"�J�I�X�t�B�[���h"��ާ-? �i��ͥ �j��/���܁�����
689 �F,,�E�L�́M�E,,�j��-�������F2008/11/03(��) 22:10:56 ID:5gt90vqJ
AbsoluteTerrorField�Ƃǂ������悩�ˁH
SandyBridge�܂��[�H
691 �FSocket774�F2008/11/04(��) 19:58:59 ID:Fr/YOjq1
�C���e���́u�R�Ai7�v�A�����̕]���͏�X�yWSJ�z
http://it.nikkei.co.jp/business/news/index.aspx?n=RSCLY8215%2004112008
�u�G�N�X�g���[���e�N�v�u���W�g���r���[�Y�v�u�A�i���h�e�b�N�v�Ȃǂ̃E�F�u�T�C�g�����\�����e�X�g
���ʂɂ��ƁA�u�C���e���E�R�Ai7�v�ƌĂ�锼���̃V���[�Y�i�J���R�[�h���u�l�n�����v�j�𗘗p����
���̃f�X�N�g�b�v�p�\�R���ł́A�ގ��̓��А������̂��g�p�����ꍇ�ɔ�ׂĈꕔ�̉��Z�^�X�N�̏������x
��30-40�����サ���B�����̃E�F�u�T�C�g�̔�]�Ƃ́A����t�@�C���쐬��O�����i3D�j�摜�̃����_�����O
�Ƃ������^�X�N�œ��ɒ��������\���オ�݂�ꂽ�A�Ƃ��Ă���B
�@�����A�R�Ai7�Ɋ�Â��@��́A�ꕔ�̃Q�[���₻�̑��̕W���I�\�t�g�E�G�A�̎��s�ł͏������x������ق�
���サ�Ȃ������Ƃ����B����ɁA�C���e���̊��������̂ɔ�ׂď���d�͂��傫�����Ƃ���A���ヂ�f����
�g�їp�R���s���[�^�[�ɂ͌����Ȃ����悤�B
http://it.nikkei.co.jp/business/news/index.aspx?n=RSCLY8215%2004112008
�u�G�N�X�g���[���e�N�v�u���W�g���r���[�Y�v�u�A�i���h�e�b�N�v�Ȃǂ̃E�F�u�T�C�g�����\�����e�X�g
���ʂɂ��ƁA�u�C���e���E�R�Ai7�v�ƌĂ�锼���̃V���[�Y�i�J���R�[�h���u�l�n�����v�j�𗘗p����
���̃f�X�N�g�b�v�p�\�R���ł́A�ގ��̓��А������̂��g�p�����ꍇ�ɔ�ׂĈꕔ�̉��Z�^�X�N�̏������x
��30-40�����サ���B�����̃E�F�u�T�C�g�̔�]�Ƃ́A����t�@�C���쐬��O�����i3D�j�摜�̃����_�����O
�Ƃ������^�X�N�œ��ɒ��������\���オ�݂�ꂽ�A�Ƃ��Ă���B
�@�����A�R�Ai7�Ɋ�Â��@��́A�ꕔ�̃Q�[���₻�̑��̕W���I�\�t�g�E�G�A�̎��s�ł͏������x������ق�
���サ�Ȃ������Ƃ����B����ɁA�C���e���̊��������̂ɔ�ׂď���d�͂��傫�����Ƃ���A���ヂ�f����
�g�їp�R���s���[�^�[�ɂ͌����Ȃ����悤�B
�l�n�͂��܂Ŏ����㈵���ȂH
693 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 01:07:34 ID:fcNayTJ9
�����ʒu�I�ɑ���Willamette������Ȃ�
Westmere��L3 12MB�ɂȂ��Đ��n�����ƁB
�Ă��A�Ԃ����Ⴏ�C�X���G���̐V��܂ł̌q��
Westmere��L3 12MB�ɂȂ��Đ��n�����ƁB
�Ă��A�Ԃ����Ⴏ�C�X���G���̐V��܂ł̌q��
����B�n����L1�L���b�V���A�N�Z�X���x���Ȃ��Ă�̂͂Ȃ��H
695 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 01:33:31 ID:fcNayTJ9
HT�T�|�[�g��64bit�̐��\���P�̂��߂ɃA�N�e�B�u���W�X�^�t�@�C���̃G���g�����₵��
�M���x������d�͂��オ����������������ɂǂ������琫�\���K�v���o�Ă���
�Ƃ�����
�M���x������d�͂��オ����������������ɂǂ������琫�\���K�v���o�Ă���
�Ƃ�����
>�Ă��A�Ԃ����Ⴏ�C�X���G���̐V��܂ł̌q��
PentiumD����Core2�̂悤�Ȍ��I�Ȑ��\���P���Ă��͂△���ł�?
������C�X���G���ł��B
����Nehalem���ォ���ׂĐ��\�A�b�v�͔�����
�I���S���̐V��҂��Ƃ����������B
PentiumD����Core2�̂悤�Ȍ��I�Ȑ��\���P���Ă��͂△���ł�?
������C�X���G���ł��B
����Nehalem���ォ���ׂĐ��\�A�b�v�͔�����
�I���S���̐V��҂��Ƃ����������B
�C�X���G���̐V������O���炷��Ƃ���q������ȁc
>>696
��AVX
��AVX
�͂𒍂��ׂ���
1�Ƀv���Z�X�J���A2�Ƀv���Z�X�J���A3�Ƀv���Z�X�i��
�Ȏ���ɂȂ�����Ă邩��˂�
1�Ƀv���Z�X�J���A2�Ƀv���Z�X�J���A3�Ƀv���Z�X�i��
�Ȏ���ɂȂ�����Ă邩��˂�
�C�X���G���V��̃R�[�h�ɂ��颋����
��q�������Ȃ��(�V����)�����o�X�����
��q�������Ȃ��(�V����)�����o�X�����
Core i7�͍ʼn��ʃ��f���ł�Core 2�̍ŏ�ʂ����̂�
http://pc.nikkeibp.co.jp/article/news/20081103/1009419/
��Core i7�́A�R�A���̂��̂̉��ǂɂ�蓯�����g����Core 2�V���[�Y�����������Z�\�͂������Ă���B
��Hyper-Threading���A�p�r�ɂ���Ă���͂��邪�AIntel�̎咣����悤��2�`3���قǐ��\�����シ��P�[�X������B
��Hyper-Threading�ƃ^�[�{���L���ɂȂ����W����Ԃł́ACore 2�V���[�Y�����i�i�ɍ������\�������Ă���ƌ�����B
�uCore i7�v��b�e�X�g���|�[�g�BCore 2�Ƃ͉����Ⴄ�̂����˂��˂��ƌ�����
http://www.4gamer.net/games/043/G004345/20081102002/
��������ɂ��Ă��CCore 2���o�ꂵ���Ƃ��̂悤�ɁC
��������Łu�����v�Ɛ�^�ł���CPU�Ƃ͌�����Ȃ��B
�����ꂪ�CCore i7�ɑ���M�҂̌����_�ɂ����錩���ł���B
���ꂽ��
http://pc.nikkeibp.co.jp/article/news/20081103/1009419/
��Core i7�́A�R�A���̂��̂̉��ǂɂ�蓯�����g����Core 2�V���[�Y�����������Z�\�͂������Ă���B
��Hyper-Threading���A�p�r�ɂ���Ă���͂��邪�AIntel�̎咣����悤��2�`3���قǐ��\�����シ��P�[�X������B
��Hyper-Threading�ƃ^�[�{���L���ɂȂ����W����Ԃł́ACore 2�V���[�Y�����i�i�ɍ������\�������Ă���ƌ�����B
�uCore i7�v��b�e�X�g���|�[�g�BCore 2�Ƃ͉����Ⴄ�̂����˂��˂��ƌ�����
http://www.4gamer.net/games/043/G004345/20081102002/
��������ɂ��Ă��CCore 2���o�ꂵ���Ƃ��̂悤�ɁC
��������Łu�����v�Ɛ�^�ł���CPU�Ƃ͌�����Ȃ��B
�����ꂪ�CCore i7�ɑ���M�҂̌����_�ɂ����錩���ł���B
���ꂽ��
���������ŋ�����ɗ��_�͂��邯�ǁA���\����̃����b�g�̕����ł�������B
���ɕ������͂�I�p�r�ł́B
8�\�P�ł̔�r�Ƃ�����Ă݂Ăق����ȁB
���ɕ������͂�I�p�r�ł́B
8�\�P�ł̔�r�Ƃ�����Ă݂Ăق����ȁB
703 �FSocket774�F2008/11/05(��) 07:37:03 ID:EpSxDziB
�C�X���G�����J������Ƃ܂��������肪�������������ȁB
���o�̓X�|���T�[�ɂ͈������Ə����Ȃ�����Ђ������
�������Ə����Ă��܂������̂ɁE�E�E
�������Ə����Ă��܂������̂ɁE�E�E
���o���āA�ǔ��n�������H
�E���n���c�B
�E���n���c�B
�ǂ�����˂����߂悢���̂��c
��납�炶��Ȃ���
�l�n��CPU�\�P�b�g���������p�ӂ���悤�Ȋ����Ɓi�v��XEON�����j�A
�������\�����ł邾�낤�ȁB
OS��64bit�ɂ������ɏ]����荷�������낤�B
�{���ɎI�Ƃ��G���v�������ȂȂ��B
�������\�����ł邾�낤�ȁB
OS��64bit�ɂ������ɏ]����荷�������낤�B
�{���ɎI�Ƃ��G���v�������ȂȂ��B
>>702
Phenom�Ɠ����ŎI�Ƃ��̃G���^�[�v���C�Y�p�r�ł̐��\�E�v�����C�������Ď����낤�ˁB
>>709
������f�X�N�g�b�v�p�ɂ́A���o������p�R�A���J�������p�������W�����l�B
Phenom�Ɠ����ŎI�Ƃ��̃G���^�[�v���C�Y�p�r�ł̐��\�E�v�����C�������Ď����낤�ˁB
>>709
������f�X�N�g�b�v�p�ɂ́A���o������p�R�A���J�������p�������W�����l�B
>>710
���o�C��������p�R�A��Nehalem�AWestmere����ł͂Ȃ���B
�v���b�g�t�H�[�������o�C���ƃf�X�N�g�b�v�����ʂɂȂ��Ă��邾���B
Intel�I�ɂ͏���d�͂̑���MCH��45nm��CPU�ɓ������āAFSB���Ȃ�������A
�V�X�e���S�̂̏���d�͂͏]���Ȃ݂��Č����낤���ǁACPU��TDP�オ�邩��A
�m�[�gPC�x���_�[�͑�ς��낤�ˁB
���o�C��������p�R�A��Nehalem�AWestmere����ł͂Ȃ���B
�v���b�g�t�H�[�������o�C���ƃf�X�N�g�b�v�����ʂɂȂ��Ă��邾���B
Intel�I�ɂ͏���d�͂̑���MCH��45nm��CPU�ɓ������āAFSB���Ȃ�������A
�V�X�e���S�̂̏���d�͂͏]���Ȃ݂��Č����낤���ǁACPU��TDP�オ�邩��A
�m�[�gPC�x���_�[�͑�ς��낤�ˁB
712 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 18:35:27 ID:9Sl/DSog
�ā[���A�f�X�N�g�b�v�̃x���`�����݂�Nehalem�����s��Ƃ��q��
�Ƃ��v���Ă��͑f�l����B
Sandy Bridge���傪����ȕϊv������QPI���IMC�͈����p�����킯�ŁB
�C�X���G�����������������|�W�V�����ɂ���Ƃ������B
Larrabee�͎��s�삾���ǁB
�Ƃ��v���Ă��͑f�l����B
Sandy Bridge���傪����ȕϊv������QPI���IMC�͈����p�����킯�ŁB
�C�X���G�����������������|�W�V�����ɂ���Ƃ������B
Larrabee�͎��s�삾���ǁB
713 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 18:38:24 ID:9Sl/DSog
>>711
�t�B�m�[�gPC�����ɊJ�����ꂽ�R�A���f�X�N�g�b�v�Ɏg�����B
�t�B�m�[�gPC�����ɊJ�����ꂽ�R�A���f�X�N�g�b�v�Ɏg�����B
CUDA�Ɏ���o���Ă����̂Ђ��ς����悤��
Larrabee�̕]����ς���ӂ�A��������Ȃ����B
Larrabee�̕]����ς���ӂ�A��������Ȃ����B
������Ȃ������
���������l��������orz
717 �F,,�E�L�́M�E,,�j��[�k�r�f������]�F2008/11/05(��) 21:07:01 ID:G/2E0Q9S
�܁APenryn,GM45��DDR3��������킹�������̂��̂��uCentrino2�v�Ɩ����������_��
Intel�̑��ӎu�Ƃ��ă��o�C���ɂ�����Nehalem�̗����ʒu�͔����Ȃ킯����
Intel�̑��ӎu�Ƃ��ă��o�C���ɂ�����Nehalem�̗����ʒu�͔����Ȃ킯����
718 �F,,�E�L�́M�E,,�j���F2008/11/05(��) 21:25:06 ID:G/2E0Q9S
�p�t�H�[�}���X�v�Ƃ��Č��s��CUDA�͂���Ӗ��ł�Cell��libspe���N�\�Ȃ��ǂ�
���ʂ��A���Ă���܂ŃX���b�h���u���b�N������H
���R�[���̌`�ł���GPU���g���Ȃ��B
SPE�̎������[�h�݂����Ȃ̂��~����
�m���u���b�L���O�ŕ��삵�A���b�Z�[�W�L���[�Ńf�[�^���Ƃ�݂����ȁB
���ʂ��A���Ă���܂ŃX���b�h���u���b�N������H
���R�[���̌`�ł���GPU���g���Ȃ��B
SPE�̎������[�h�݂����Ȃ̂��~����
�m���u���b�L���O�ŕ��삵�A���b�Z�[�W�L���[�Ńf�[�^���Ƃ�݂����ȁB
719 �F,,�E�L�́M�E,,�j���F2008/11/05(��) 22:01:54 ID:G/2E0Q9S
Larrabee���N�\���Č����Ă�z��GPU�ł̔ėp�X�g���[���R���s���[�e�B���O
�ɂǂꂾ�������������邩�m��Ȃ��n����������u����B
����������I�ɂ́A�Q�[����p��Vertex/Pixel�����V�F�[�_�Ƃ��Ă͖����
�ÓI�ȃX�P�W���[�����O�̂��ɂ������Z�ł͐��\�{���{����
ATi�݂����Ȃ̂��ō��Ȃ�H
����L���b�V���e�ʂ����Ȃ�����낭�ȃv���O���������Ȃ��̂�B
���I��CPU��SIMD���Z�̑�ւƂ��Ă�Larrabee�ȊO�ɑI����������ԁB
�ނ��CUDA���ق�Ƃ͌���������B���(��)������Ȃ��ɂ��惍�[�J�����������Ȃ����B
����ł�������闝�R�́A���ƃR�l�̂��߁B���Ƃ͉ɂԂ��B
�ɂǂꂾ�������������邩�m��Ȃ��n����������u����B
����������I�ɂ́A�Q�[����p��Vertex/Pixel�����V�F�[�_�Ƃ��Ă͖����
�ÓI�ȃX�P�W���[�����O�̂��ɂ������Z�ł͐��\�{���{����
ATi�݂����Ȃ̂��ō��Ȃ�H
����L���b�V���e�ʂ����Ȃ�����낭�ȃv���O���������Ȃ��̂�B
���I��CPU��SIMD���Z�̑�ւƂ��Ă�Larrabee�ȊO�ɑI����������ԁB
�ނ��CUDA���ق�Ƃ͌���������B���(��)������Ȃ��ɂ��惍�[�J�����������Ȃ����B
����ł�������闝�R�́A���ƃR�l�̂��߁B���Ƃ͉ɂԂ��B
GPU�ɉߓx�̔ėp���ȂǕs�v
�v���D��Ă�����̂��s��𐧔e����킯����Ȃ�����B
�N��GPU�Ƃ��Ċ��҂��ĂȂ�Larrabee�͂��ꂪ�S�z���B
NVIDIA������Geforce�ł�CUDA�̐���������������
Tesla�荞�߂�킯�ŁB
�N��GPU�Ƃ��Ċ��҂��ĂȂ�Larrabee�͂��ꂪ�S�z���B
NVIDIA������Geforce�ł�CUDA�̐���������������
Tesla�荞�߂�킯�ŁB
722 �F,,�E�L�́M�E,,�j���F2008/11/05(��) 22:27:05 ID:G/2E0Q9S
>>721
�X�g���[���v���Z�b�T�Ƃ��Ĕ��荞�܂Ȃ���Ȃ�炢�܂ŃI���{�[�hGPU�ɃV�F�A�D��ꂽ
�f�B�X�N���[�gGPU�̏�����GPU�Ƃ��Ẵj�[�Y�̂ق����]�����҂ł����
�X�g���[���v���Z�b�T�Ƃ��Ĕ��荞�܂Ȃ���Ȃ�炢�܂ŃI���{�[�hGPU�ɃV�F�A�D��ꂽ
�f�B�X�N���[�gGPU�̏�����GPU�Ƃ��Ẵj�[�Y�̂ق����]�����҂ł����
723 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 22:28:04 ID:9Sl/DSog
�قق�
Larrabee�}���Z�[��Nehalem�ے�̓d�g�������͎嗬�Ȃ̂��B
����l�͒P����Larrabee�����s�삾�Ƃ����Ă��邾���Ȃ̂ɂȂɂ��
���ђc�q����͂�������炸�s�傾�ȁB
Penryn�ł��m�[�g��4�R�A�ł�45W��TDP�����A�ŏ�ʂ�������Ȃ��Ă��B
���ŏo�Ă�TDP�X�y�b�N�Ȃ�AMCH�������������Ă����Ȃ��Ă�Penryn�Ƃ���ȕς��Ȃ����B
�S�z�Ȃ̂̓X�P�W���[���̕����ȁB���M�Ƃ����ނ���Larrabee�̕����s�m��v�f��B
Larrabee�}���Z�[��Nehalem�ے�̓d�g�������͎嗬�Ȃ̂��B
����l�͒P����Larrabee�����s�삾�Ƃ����Ă��邾���Ȃ̂ɂȂɂ��
���ђc�q����͂�������炸�s�傾�ȁB
Penryn�ł��m�[�g��4�R�A�ł�45W��TDP�����A�ŏ�ʂ�������Ȃ��Ă��B
���ŏo�Ă�TDP�X�y�b�N�Ȃ�AMCH�������������Ă����Ȃ��Ă�Penryn�Ƃ���ȕς��Ȃ����B
�S�z�Ȃ̂̓X�P�W���[���̕����ȁB���M�Ƃ����ނ���Larrabee�̕����s�m��v�f��B
724 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 22:31:06 ID:9Sl/DSog
���������A����Larrabee�̕]���{�[�h�ł����?
10�R�A�����̃V���{�J�[�h�̓��������v���v�������B
�I���`���Ƃ��Ă͂��傤�ǂ������ǁB
10�R�A�����̃V���{�J�[�h�̓��������v���v�������B
�I���`���Ƃ��Ă͂��傤�ǂ������ǁB
725 �F,,�E�L�́M�E,,�j���F2008/11/05(��) 22:34:37 ID:G/2E0Q9S
Nehalem�̃��o�C���ł̓C�X���G���`�[���Ɋ��ɑʖڂ�������Ă�㕨������Ȃ��B
����GPU�ƃj�R�C�`�̂ق��B
�R�A�v���T�[�o�����ɂ͗ǂ���������Ȃ����A���o�C���ɂ̓V�������N�ƃ`���[�j���O���K�v����
����GPU�ƃj�R�C�`�̂ق��B
�R�A�v���T�[�o�����ɂ͗ǂ���������Ȃ����A���o�C���ɂ̓V�������N�ƃ`���[�j���O���K�v����
726 �F,,�E�L�́M�E,,�j���F2008/11/05(��) 22:36:37 ID:G/2E0Q9S
16�̔{���R�A��1�����O�Ȃ̂�10�R�A���Ă���������
�������Ȃ�
�������Ȃ�
727 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 22:37:54 ID:9Sl/DSog
�������������O�Ȃ̂�16�R�A�̔{������Ȃ��Ⴂ���Ȃ��Ȃ��
���������
���������
>>722
�f�B�X�N���[�gGPU���I���{�[��GPU�ɃV�F�A��D���Ă�_�͑S�������ē���
����Larrabee��Tesla�̂悤�ɉf���o�͂ł��Ȃ�
�����ȃX�g���[���v���Z�b�T�Ƃ��Ă����荞�߂�̂ɁA
���̗����ڂ̃f�B�X�N���[�gGPU�̋@�\�����Ă�����H
���\�I�ɂ����҂���ĂȂ��̂ɁB
�f�B�X�N���[�gGPU���I���{�[��GPU�ɃV�F�A��D���Ă�_�͑S�������ē���
����Larrabee��Tesla�̂悤�ɉf���o�͂ł��Ȃ�
�����ȃX�g���[���v���Z�b�T�Ƃ��Ă����荞�߂�̂ɁA
���̗����ڂ̃f�B�X�N���[�gGPU�̋@�\�����Ă�����H
���\�I�ɂ����҂���ĂȂ��̂ɁB
16�R�A��6�R�A�E���Ȃ�ĕ����܂�ǂ���������Ă���
���ӂ�MCM
���ӂ�MCM
730 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 22:53:50 ID:9Sl/DSog
�܂�f�B�X�N���[�gGPU��Larrabee������[�ї��s���ƁB
�悭����ȓd�̓C�[�^�[�ɉ������������ȁB
����VRAM�J�[�h�Ƃ��Ẳ��l��8�������Ă̂ɁB
�悭����ȓd�̓C�[�^�[�ɉ������������ȁB
����VRAM�J�[�h�Ƃ��Ẳ��l��8�������Ă̂ɁB
731 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 23:20:32 ID:fcNayTJ9
32nm��Westmere�̃��[���`�Ɠ�������45nm�œo�ꂷ��
���̈Ӗ����킩��H
�͂�Ă��Ɍ������p�قƂ�ǏI����Ă�45nm�Ń��[���`�B
����͂܂�Celeron��ʎY���Ă����̂Ɠ����ʂ̒�X�N�Ő��Y���邱�Ƃ��ł���B
45nm High-K&���^���Q�[�g�ł��B
����d�͐v�ʂł��~�X�̃��X�N�����Ȃ��BCore 2�Ŋ��Ɏ��т����邩��ˁB
���ASIGGRAPH�̘_���ŏo�Ă��u10�R�A�v���Ă����͓̂��N���b�N��Core 2 Quad��Larrabee��
�R�A10�����قړ���_�C�T�C�Y�E�������d�͂Ɏ��܂���ĈӖ�������
���i��10�R�A���ĈӖ��ł͂Ȃ��BMac��u�݂����ȊԈႢ�͂���Ȃ�B
���̔䗦��16�R�A�Ȃ�Nehalem�N�A�b�h�R�A��AMD�̃L�[�z���_�[�̃_�C�T�C�Y�Ƃ�������������B
16�R�A�ł�32�R�A�ł����邱�Ƃ����Ă邪�A16�R�A��1�_�C�ƍl�����ق��������Ǝv�����ȁB
���Ƃ�MCM�ŁA�ꕔ�ʼn\�ɂȂ��Ă�Ƃ���48�R�A�i3�_�C�H�j�����邩������Ȃ��B
�ŁA16�R�A�������o��Ƃ��āA�܂�1���炢�s�ǂ��o�邱�Ƃ��l������15�R�A���H
16�R�A��6�R�A���ʂȂ�Ă��ꂱ����ՓI�ȕ����܂�̈������ȁB
���̈Ӗ����킩��H
�͂�Ă��Ɍ������p�قƂ�ǏI����Ă�45nm�Ń��[���`�B
����͂܂�Celeron��ʎY���Ă����̂Ɠ����ʂ̒�X�N�Ő��Y���邱�Ƃ��ł���B
45nm High-K&���^���Q�[�g�ł��B
����d�͐v�ʂł��~�X�̃��X�N�����Ȃ��BCore 2�Ŋ��Ɏ��т����邩��ˁB
���ASIGGRAPH�̘_���ŏo�Ă��u10�R�A�v���Ă����͓̂��N���b�N��Core 2 Quad��Larrabee��
�R�A10�����قړ���_�C�T�C�Y�E�������d�͂Ɏ��܂���ĈӖ�������
���i��10�R�A���ĈӖ��ł͂Ȃ��BMac��u�݂����ȊԈႢ�͂���Ȃ�B
���̔䗦��16�R�A�Ȃ�Nehalem�N�A�b�h�R�A��AMD�̃L�[�z���_�[�̃_�C�T�C�Y�Ƃ�������������B
16�R�A�ł�32�R�A�ł����邱�Ƃ����Ă邪�A16�R�A��1�_�C�ƍl�����ق��������Ǝv�����ȁB
���Ƃ�MCM�ŁA�ꕔ�ʼn\�ɂȂ��Ă�Ƃ���48�R�A�i3�_�C�H�j�����邩������Ȃ��B
�ŁA16�R�A�������o��Ƃ��āA�܂�1���炢�s�ǂ��o�邱�Ƃ��l������15�R�A���H
16�R�A��6�R�A���ʂȂ�Ă��ꂱ����ՓI�ȕ����܂�̈������ȁB
732 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 23:24:49 ID:fcNayTJ9
>>728
��������������L�ш��PCIe x16�X���b�g���g������
��
GPU���h���Ȃ��Ȃ�
��
�Ȃ�GPU�@�\���G�~�����[�V����������������
��������������L�ш��PCIe x16�X���b�g���g������
��
GPU���h���Ȃ��Ȃ�
��
�Ȃ�GPU�@�\���G�~�����[�V����������������
733 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 23:25:41 ID:9Sl/DSog
���ђc�q����Larrabee�����Ȃ̂͂킩�����B
�����A����I�ɂ̓l�^CPU�Ƃ��Ċ��҂͑傫�����A
�܂��߂Ȋ��҂͂��Ă��Ȃ��B�������ꂾ���̂������B
�����A����I�ɂ̓l�^CPU�Ƃ��Ċ��҂͑傫�����A
�܂��߂Ȋ��҂͂��Ă��Ȃ��B�������ꂾ���̂������B
734 �F,,�E �� �E,,�j��-�������F2008/11/05(��) 23:28:06 ID:9Sl/DSog
�ā[���A�悭�����܂Ŋ��҂ł����ȁB
SIGGRAPH�̘_�����ł����_�ŁA
�u���A���ꂾ�߂��ˁv
���Ă̂�Larrabee�ǂ������Ă������̂̐����Ȋ��z���낤�B
���̌�����҂ł���b��͂Ȃ��ȁB
�����̓����b�͕ʂƂ��āB
SIGGRAPH�̘_�����ł����_�ŁA
�u���A���ꂾ�߂��ˁv
���Ă̂�Larrabee�ǂ������Ă������̂̐����Ȋ��z���낤�B
���̌�����҂ł���b��͂Ȃ��ȁB
�����̓����b�͕ʂƂ��āB
>>732
�܂Ă܂Ă�
�f�B�X�N���[�g�����ژ_�ƁuGPU���h���Ȃ��Ȃ�v���Ƃ��莋���闧����ꗂ��邾��
��ꂻ��Ȏ���ĕt����GPU�@�\�Ȃ�A�I���{�[�hGPU�ŏ\���ɂȂ�Ȃ����H
�܂Ă܂Ă�
�f�B�X�N���[�g�����ژ_�ƁuGPU���h���Ȃ��Ȃ�v���Ƃ��莋���闧����ꗂ��邾��
��ꂻ��Ȏ���ĕt����GPU�@�\�Ȃ�A�I���{�[�hGPU�ŏ\���ɂȂ�Ȃ����H
736 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 23:41:17 ID:fcNayTJ9
>>735
��H�n�C�G���hGPU�̓J�[���[�X�Ɠ�������H
F1�J�[�̔R�����ɂ��Ȃ��̂Ɠ����悤�ɁA�J���[���ł���K�v�͖����B
�j�b�`�}�[�P�b�g�ł��邱�Ƃ͖��Ȃ��B
�����炱��Intel���^����Celeron�i�\��j�Ɠ��������v���Z�X�ō�낤�Ƃ��Ă�킯��
��H�n�C�G���hGPU�̓J�[���[�X�Ɠ�������H
F1�J�[�̔R�����ɂ��Ȃ��̂Ɠ����悤�ɁA�J���[���ł���K�v�͖����B
�j�b�`�}�[�P�b�g�ł��邱�Ƃ͖��Ȃ��B
�����炱��Intel���^����Celeron�i�\��j�Ɠ��������v���Z�X�ō�낤�Ƃ��Ă�킯��
737 �F,,�E�L�́M�E,,�j��-�������F2008/11/05(��) 23:47:09 ID:fcNayTJ9
CPU�ւ�Larrabee�̃_�C����
�������ʂ�GMA��Larrabee�u������
�������ʂ�GMA��Larrabee�u������
Larrabee�́A�N�����҂��Ă��Ȃ�GPU�@�\��
�����ɂȂ邩����Ȃ������I��CPU�ւ̓������`���Ȃ��Ɣ���Ȃ����Ď�����B
Intel���g����Ԃ킩���Ă�B
�����ɂȂ邩����Ȃ������I��CPU�ւ̓������`���Ȃ��Ɣ���Ȃ����Ď�����B
Intel���g����Ԃ킩���Ă�B
739 �F,,�E�L�́M�E,,�j��-�������F2008/11/06(��) 00:34:26 ID:wmoi9z9s
����̓\�t�g�J���҂��H�������ǂ����̎����̘b�ł�����
�G���h���[�U�[���S������̂͂����܂ł����L���Ɋ�������\�t�g�����邩�ǂ������Ă���
�Q�[���������Q�[��������B
���A�ł��\�t�g�J���ғI�ɂ͕ςȉ���C����Ȃ��đf��C/C++���g����Ȃ�Ă̂��d�v�ȃ|�C���g����
�G���h���[�U�[���S������̂͂����܂ł����L���Ɋ�������\�t�g�����邩�ǂ������Ă���
�Q�[���������Q�[��������B
���A�ł��\�t�g�J���ғI�ɂ͕ςȉ���C����Ȃ��đf��C/C++���g����Ȃ�Ă̂��d�v�ȃ|�C���g����
��h���[�U�[����ԃ\�t�g���ĉ���
���q���x���܂ŕ������Z���Ă����G���Q
����ł�ӻ��ȏ�Ɍ��Â炢���낤�Ɂc
�l�g�o�̓�̕����B
Core i7�͍ʼn��ʃ��f���ł�Core 2�̍ŏ�ʂ𗽂�
�V�X�e���̏���d�͂͑啝�ɑ���
http://itpro.nikkeibp.co.jp/article/NEWS/20081104/318416/
Core i7�͍ʼn��ʃ��f���ł�Core 2�̍ŏ�ʂ𗽂�
�V�X�e���̏���d�͂͑啝�ɑ���
http://itpro.nikkeibp.co.jp/article/NEWS/20081104/318416/
����ʂɁB
>>743���\�������HT��TB��������ƁAi7 965��QX9770�̍��̓s�[�N�ł�10W���炢�Ɏ��܂�B
�ŁA�����ƃx���`�̕������Ă݂���AHT��TB���ł�����i7 965�������Ă���B
�ǂ����urboBoost�ɂ��N���b�N�A�b�v��HTT�I�����d�͑����̎�v���ŁA
CPU�R�A���̂̏���d�͂�����̃p�t�H�[�}���X��Core2�Ɣ�r����
�������Ă�����Ă킯����Ȃ����ۂ��B
�ŁA�����ƃx���`�̕������Ă݂���AHT��TB���ł�����i7 965�������Ă���B
�ǂ����urboBoost�ɂ��N���b�N�A�b�v��HTT�I�����d�͑����̎�v���ŁA
CPU�R�A���̂̏���d�͂�����̃p�t�H�[�}���X��Core2�Ɣ�r����
�������Ă�����Ă킯����Ȃ����ۂ��B
747 �FSocket774�F2008/11/07(��) 00:34:22 ID:OFB+Loo1
�ʏ��PC�I�`4CPU16�R�A����HPC�����̐��낤�H
�f�X�N�g�b�v�Ŏg�����Ǝ��̊Ԉ���Ă�Ǝv�����E�E�E
�f�X�N�g�b�v�Ŏg�����Ǝ��̊Ԉ���Ă�Ǝv�����E�E�E
��Opteron�I�ȏ����Ōf�ڂ���Ȃ��Ăق��Ƃ��Ă�z����������A����w
749 �F,,�E�L�́M�E,,�j��[SandyBridge���o��܂�Wolfdale����]�F2008/11/07(��) 02:30:01 ID:lyain5tu
�����ȈӖ��ł�
750 �F,,�E�L�́M�E,,�j��-�������F2008/11/07(��) 03:55:29 ID:dB60gONV
���Ă������A���o�C���m�[�g�̂Ƃ���Yonah��Merom�̗���ɋ߂������ˁB
SSE���\�͊i�i�ɏオ�������Ǔd�r�̂����������Ȃ�������
���炭��Yonah�̂ق����d�ꂽ�B
����d�͂̑����Ȃ�Ď��Ԃ���������B
�[���AKentsfield����̏�芷���Ȃ�\���A�����Ǝv����B
Yorkfield���炾�Ɣ����Ȃ����ŁB
SSE���\�͊i�i�ɏオ�������Ǔd�r�̂����������Ȃ�������
���炭��Yonah�̂ق����d�ꂽ�B
����d�͂̑����Ȃ�Ď��Ԃ���������B
�[���AKentsfield����̏�芷���Ȃ�\���A�����Ǝv����B
Yorkfield���炾�Ɣ����Ȃ����ŁB
sossaman��DP�I�����Ƃ���悩�����B���ł��~�����A�C�e���B
http://www.tomshardware.com/reviews/core-i7-gaming,2061-5.html
�Q�[���ł�GTX280��SLIx3�������܂ň����o������ݔ\��
�Q�[���ł�GTX280��SLIx3�������܂ň����o������ݔ\��
Windows7�̃��S�v���O���������J���ꂽ�킯�����E�E�E
�����ł����h���C�o�J���x���̂Ɋe�F10bit�o�̓T�|�[�g���Ȃ����Ⴂ���Ȃ��Ƃ��������낱��
Havendale�ǂ��Ȃ��
ttp://www.microsoft.com/whdc/device/display/GraphicsGuide_Win7.mspx
�����ł����h���C�o�J���x���̂Ɋe�F10bit�o�̓T�|�[�g���Ȃ����Ⴂ���Ȃ��Ƃ��������낱��
Havendale�ǂ��Ȃ��
ttp://www.microsoft.com/whdc/device/display/GraphicsGuide_Win7.mspx
�ނ��덡���ɂȂ���ROP�t����GDI�I�y���[�V�����̃A�N�Z�����[�g��v������ق����c
�e�F10bit�̃��[�h��DirectX�̃����_�����O�T�[�t�F�X�̑I�����ɂ��łɂ����B
10-10-10-2��32bpp�Ƃ�
10-10-10-2��32bpp�Ƃ�
>�e�F10bit�o��
����Ɨ������B
�t�������̃N���X�����ʂɔ�����悤�ɂȂ�Ƃ����ȁB
����Ɨ������B
�t�������̃N���X�����ʂɔ�����悤�ɂȂ�Ƃ����ȁB
>>750
Kentsfield�����}�U�[�Ȃ�Yorkfield��CPU�ڂ��ւ��ł������Ⴄ��Ȃ��H
Kentsfield�����}�U�[�Ȃ�Yorkfield��CPU�ڂ��ւ��ł������Ⴄ��Ȃ��H
High Color �� Display Calibration Wizard �� High-DPI
�����C�ɃO���t�B�b�N�X�̐����オ�肻������
�����C�ɃO���t�B�b�N�X�̐����オ�肻������
759 �F,,�E�L�́M�E,,�j��-�������F2008/11/08(�y) 14:48:57 ID:sUAKIs8V
��������Nehalem�̒��ł�Havendale������CPU�_�C��GMCH�_�C��������Ă���
����������̐��\��Lynnfield�ɔ�ׂĈ��������肷��낤��
����������̐��\��Lynnfield�ɔ�ׂĈ��������肷��낤��
���������AYork��Wolf��DDR3�͈Ӗ����������̂��H
762 �F,,�E�L�́M�E,,�j��-�������F2008/11/08(�y) 18:38:18 ID:sUAKIs8V
�Ȃ��B�ш�̎�������B
763 �F,,�E�L�́M�E,,�j��-�������F2008/11/08(�y) 18:53:55 ID:sUAKIs8V
Centrino 2�ł�DDR3���̗p�v���Ƃ��Ă邪
DDR2���N���b�N������̓]�����[�g���{�ƂȂ�A���ʓI�ɐ��\������̃N���b�N�i����d�͂ɒ����j�������邩��B
�܂��ACentrino 2�̂�������DDR3�̃R�X�g�������������Ȃ艿�i���\�������Ă���邱�낪�������������B
DDR2���N���b�N������̓]�����[�g���{�ƂȂ�A���ʓI�ɐ��\������̃N���b�N�i����d�͂ɒ����j�������邩��B
�܂��ACentrino 2�̂�������DDR3�̃R�X�g�������������Ȃ艿�i���\�������Ă���邱�낪�������������B
>>758
�p�l���ƃ��j�^���̊K�����䂪�t���Ă����ȁB
�p�l���ƃ��j�^���̊K�����䂪�t���Ă����ȁB
765 �F,,�E�L�́M�E,,�j��-�������F2008/11/09(��) 13:09:15 ID:Q0DrVeIN
��×p�t���p�l�����ĂقƂ��VA�炵���ˁB����p�����K�����\�d���ŁB
Sandy Bridge��Core2�Ɠ��l�Ƀg�b�v�c�[�{�g���œW�J�o����Ȃ�ALynnfield��Havendale�̉����ɂ���āA
���C���X�g���[����Westmere�n��32nm����CPU�����܂��ڍs����Ȃ�Ėϑz���Ă݂��B
���C���X�g���[����Westmere�n��32nm����CPU�����܂��ڍs����Ȃ�Ėϑz���Ă݂��B
Core 2 Quad Q9650��Core 2 Duo E8600���Ăǂ����̕������\�����́H
>>767
���O�̌����Ƃ���́u���\�v�̎w�W�𖾂炩�ɂ���
���O�̌����Ƃ���́u���\�v�̎w�W�𖾂炩�ɂ���
769 �F,,�E�L�́M�E,,�j��-�������F2008/11/13(��) 11:28:32 ID:HSq3drXB
11���قǃN���b�N���傫�����x���̓R�A��2�{�̂ق����Ȃ�ƂȂ������Ȋ����͂��邯�ǂȁB
���́A�j�R�C�`�Ȃ̂ɒP��2�{�ȏ�ɍ�������
���́A�j�R�C�`�Ȃ̂ɒP��2�{�ȏ�ɍ�������
>>768
3D�̃Q�[�������Ƃ��Ƃ�������G���R����Ƃ��̏������x���ẮH
3D�̃Q�[�������Ƃ��Ƃ�������G���R����Ƃ��̏������x���ẮH
>>770
�Q�[���̃^�C�g���ƃG���R�A�v�����m�ɂ���Ί�������
�Q�[���̃^�C�g���ƃG���R�A�v�����m�ɂ���Ί�������
core i�V���c2���̕��������x������Ȃ��̂��B�P���ɁB
��͂�]�������̐i����c2�������肪�\���Ƃ��čs�������Ƃ��܂ł�������Ȃ����˂��B
��͂�]�������̐i����c2�������肪�\���Ƃ��čs�������Ƃ��܂ł�������Ȃ����˂��B
�������Ƃ̗Z���𖧂ɉʂ������A�[�L�e�N�`���A���s��͖]��ł����B
�Ƃ���ŃC�X���G���͂��������Ȃɂ�����ĂH
�Ƃ���ŃC�X���G���͂��������Ȃɂ�����ĂH
774 �F,,�E�L�́M�E,,�j��-�������F2008/11/14(��) 13:39:41 ID:dkxKaXUE
�����͐��S�h�����ȁB
���{���Ɖ~���Ҍ����ĂȂ����獂�����ǁA�l�b�g�u�b�N��ʂ�mini�̒l�i���ăh���Ō�����
����Ȃɕς��Ȃ��B1.83GHz��599�h���B
����͎������mini���u�錾���B
���ہA1000�h���ȏ��PC�̔���グ�̏�ʂ�Apple������B
�ǂ���PC���[�J�[���A�ቿ�i���i�̃��C���i�b�v�𑝂₵�Ă����̕����������i���i��
����Ȃ��Ȃ�Ƃ����f�����b�g������B
���������Ă邩��Intel��Atom�ɂ͋@�\�������ۂ��Ă���B
>>410
�~����у`�F�b�N�Ƃ�������H�܂��O���f�[�V���������ł���O�ꂾ�ȁB
���{���Ɖ~���Ҍ����ĂȂ����獂�����ǁA�l�b�g�u�b�N��ʂ�mini�̒l�i���ăh���Ō�����
����Ȃɕς��Ȃ��B1.83GHz��599�h���B
����͎������mini���u�錾���B
���ہA1000�h���ȏ��PC�̔���グ�̏�ʂ�Apple������B
�ǂ���PC���[�J�[���A�ቿ�i���i�̃��C���i�b�v�𑝂₵�Ă����̕����������i���i��
����Ȃ��Ȃ�Ƃ����f�����b�g������B
���������Ă邩��Intel��Atom�ɂ͋@�\�������ۂ��Ă���B
>>410
�~����у`�F�b�N�Ƃ�������H�܂��O���f�[�V���������ł���O�ꂾ�ȁB
775 �F,,�E�L�́M�E,,�j��-�������F2008/11/14(��) 13:41:33 ID:dkxKaXUE
�딚
�@
>>772-773
�f�X�N�g�b�v�Ƃ��Ă�Core2�͊������ꂽ�`��1���ƌ�����Ǝv���ˁB
�P��(�P���ł��Ȃ�����)�ȃR�A�ŃL���b�V���𑝂₵�Đ��\���グ�����
�����l�������ˁB���ꂩ��GPGPU���\����R�v���I�ȕ��𑽗l����}�V��
�������Ă���Α����ǂ�CPU�������l�ȕ����Ɍ�������Ȃ����ȁH
�����A�o�X����������ˁB���܂ł͂���ŗǂ�������������Ȃ�����
���ꂩ��͐��\�グ��͓̂���Ȃ��Ă���Ǝv���B���̓_��₤�̂�i7
�����Ǝv����B
AMD��Phenom�͋t�Ɍ��\���b�`�ȃR�A��n��������4�Z�߂Đς�ł�̂�
�����Ǝv���B����Ƃ������ʂŐ��\�̗������݂��ɂ߂ď��Ȃ����A�o�X
����������ł͂��肷����ʂ��邵�B���̕�����d�͂��オ�������ǁA����
�v���Z�X�̕ύX�ŏ���d�͂������ăN���b�N���グ�鎖���o�����炩�Ȃ�
���͂�CPU�ɂȂ�Ǝv���B�����X�p�R���œ����^�C�v��CPU�����̂܂܃f�X�N
�g�b�v�ɂ������݂����ȃ���������ˁB
�f�X�N�g�b�v�Ƃ��Ă�Core2�͊������ꂽ�`��1���ƌ�����Ǝv���ˁB
�P��(�P���ł��Ȃ�����)�ȃR�A�ŃL���b�V���𑝂₵�Đ��\���グ�����
�����l�������ˁB���ꂩ��GPGPU���\����R�v���I�ȕ��𑽗l����}�V��
�������Ă���Α����ǂ�CPU�������l�ȕ����Ɍ�������Ȃ����ȁH
�����A�o�X����������ˁB���܂ł͂���ŗǂ�������������Ȃ�����
���ꂩ��͐��\�グ��͓̂���Ȃ��Ă���Ǝv���B���̓_��₤�̂�i7
�����Ǝv����B
AMD��Phenom�͋t�Ɍ��\���b�`�ȃR�A��n��������4�Z�߂Đς�ł�̂�
�����Ǝv���B����Ƃ������ʂŐ��\�̗������݂��ɂ߂ď��Ȃ����A�o�X
����������ł͂��肷����ʂ��邵�B���̕�����d�͂��オ�������ǁA����
�v���Z�X�̕ύX�ŏ���d�͂������ăN���b�N���グ�鎖���o�����炩�Ȃ�
���͂�CPU�ɂȂ�Ǝv���B�����X�p�R���œ����^�C�v��CPU�����̂܂܃f�X�N
�g�b�v�ɂ������݂����ȃ���������ˁB
778 �F,,�E�L�́M�E,,�j��-�������F2008/11/15(�y) 11:47:03 ID:0EXHNI7+
�P���ł��Ȃ���B�ǂ��������b�`�ŕ��G�B
AMD��Intel��1������s�����Ƃ���3�����̘J�͂��₵�Ă邩�犊���Ă邾���B
AMD��Intel��1������s�����Ƃ���3�����̘J�͂��₵�Ă邩�犊���Ă邾���B
�o�X���Ɋւ��Ă�Intel��AMD�������ɑ���Ȃ��Ȃ�
���ɁAHT�ł���SSD��RAID0x6�Ƃ��g�ނƃo�X��������Ȃ����ˁB
HPC�ł͂���ɐ[���ŁAOpteron��HT�ł���CPU���V��ł��܂��������Ȃ��Ȃ��B
(�������QPI�����l�̂��Ƃ��\�z�����)
Intel�̓R�A�ŗ]�T���������AQPI������ɐi�������鎖�ɒ��͂��Ăق�����
���ɁAHT�ł���SSD��RAID0x6�Ƃ��g�ނƃo�X��������Ȃ����ˁB
HPC�ł͂���ɐ[���ŁAOpteron��HT�ł���CPU���V��ł��܂��������Ȃ��Ȃ��B
(�������QPI�����l�̂��Ƃ��\�z�����)
Intel�̓R�A�ŗ]�T���������AQPI������ɐi�������鎖�ɒ��͂��Ăق�����
��䖜��̃N���X�^�\���̓m�[�h�ԃC���^�[�R�l�N�g���d�v
781 �F,,�E�L�́M�E,,�j��-�������F2008/11/15(�y) 13:16:51 ID:0EXHNI7+
��HPC�ł͂���ɐ[���ŁAOpteron��HT�ł���CPU���V��ł��܂��������Ȃ��Ȃ��B
�L���b�V������ĂȂ�����ł́H�Ǝv�������͑f�l��
Intel�͖��ʂɊO���o�X�ш摝�₷�悤�Ȃ��Ƃ͂��Ȃ����āB������������L�����p���đш�����}����B
Larrabee�ɂ��Ă��]��GPU�̃V�F�[�_�R�A�Ɣ�ׂĂ��L���b�V���͑��߂��B
�L���b�V������ĂȂ�����ł́H�Ǝv�������͑f�l��
Intel�͖��ʂɊO���o�X�ш摝�₷�悤�Ȃ��Ƃ͂��Ȃ����āB������������L�����p���đш�����}����B
Larrabee�ɂ��Ă��]��GPU�̃V�F�[�_�R�A�Ɣ�ׂĂ��L���b�V���͑��߂��B
>>777
�挎�o���ӂ����゠�t���̃}�X�R�b�g�Q�[���ƁAC2D��3.0G�ł��d���Ďd���Ȃ����ǂˁc
�挎�o���ӂ����゠�t���̃}�X�R�b�g�Q�[���ƁAC2D��3.0G�ł��d���Ďd���Ȃ����ǂˁc
783 �FSocket774�F2008/11/16(��) 16:53:37 ID:60/DPR96
>>781
Nvidia��GPU��������A���X����ŁAShared Memory�̑����͍l���Ă��邾�낤�B
��������Cell�������ɂȂ����Ⴄ���ǂȁB
Nvidia��GPU��������A���X����ŁAShared Memory�̑����͍l���Ă��邾�낤�B
��������Cell�������ɂȂ����Ⴄ���ǂȁB
HPC�p�A�v���ɂ̓f�[�^�̋Ǐ������قƂ�ǂȂ�����
HPC�pCPU�ɃL���b�V�����ʂ��Ă�����
HPC�pCPU�ɃL���b�V�����ʂ��Ă�����
785 �FMAC�I�^��784 �����F2008/11/16(��) 19:37:23 ID:pou63Jfp
>>784
�@�@----------------
�@�@HPC�p�A�v���ɂ̓f�[�^�̋Ǐ������قƂ�ǂȂ�
�@�@----------------
���q���͊w�Ƃ����q�@�Ƃ����������Ƃ햳�������H
�@�@----------------
�@�@HPC�p�A�v���ɂ̓f�[�^�̋Ǐ������قƂ�ǂȂ�
�@�@----------------
���q���͊w�Ƃ����q�@�Ƃ����������Ƃ햳�������H
�� gemm���ɂ�����cell�}���Z�[�̂���
FSB�AHT�̑ш���ĕs�����Ă���́H
���Ȃ��Ƃ��l�p�r�ł͗L��]���Ă����Ȃ����ȁB
Phenom�͇U�Ŋo�������
���Ȃ��Ƃ��l�p�r�ł͗L��]���Ă����Ȃ����ȁB
Phenom�͇U�Ŋo�������
����Ȃ�����L���b�V���ӂ₵�Ă�ˁH�@�悭�m���
�ŏ�����uAM3���łĂ���{�̔����v���Č����Ă邵��
�\�h�����Ă�Ƃ���������
�\�h�����Ă�Ƃ���������
����������ȏ�ipc���グ��w�͂͋ꂵ���ȁB�̊����x�ɂ̓������A�d�������ɂ͕���R���s���[�e�B���O�Ɛ��ݕ������n�b�L�����Ă��Ă�B
�}�W�łǂ����낱�ꂩ��B
�}�W�łǂ����낱�ꂩ��B
���Ƃ����ăN���b�N���g�������ʂ��悭�Ȃ����������Aatom�Ȃ�ăR�A�����Ɏs��Ɏ�����Ă��錻����ӂ݂�ɂ��낻��Z�p����̓]�����Ȃ�Ȃ����ˁB
�����core i7�Ŕ���ɂ����܂��܂Ƃ����Z�p�̕NJ�����������ɂȂ����Ǝv����B
���ׂĂł��邱�Ƃ͑S�����܂����A�݂����Ȋ���������ȁ�i7
Atom�̑䓪�́A�l���z�[���T�[�o�Ȃǂŕ����䎝������f�������̂ł����āA
Atom���Z�p�̌������������Ƃ͖����̂ł́H����Ƃ���Ώ���d�͂��炢�B
�����I�ɂ̓m�C�}���^����̒E�p��A���Ɍ`�͒��������j���[���R���s���[�^���c
Atom���Z�p�̌������������Ƃ͖����̂ł́H����Ƃ���Ώ���d�͂��炢�B
�����I�ɂ̓m�C�}���^����̒E�p��A���Ɍ`�͒��������j���[���R���s���[�^���c
>>789
AM3�ŕς�邱�Ƃ�DDR3�ɂȂ邱�ƂƁAHT3.1�ɂȂ邱�Ƃ����ǁA
�I�����ł�HT�̕����傫���Ȃ�̂͂������Ƃ��낤���ǁA
��ʌ����ɂ͂���قǑ傫�ȍ����o��Ƃ͎v���Ȃ����c�B
����CPU�͖{���ɎI�������B��ʌ����ɔ���������������C������B
AM3�ŕς�邱�Ƃ�DDR3�ɂȂ邱�ƂƁAHT3.1�ɂȂ邱�Ƃ����ǁA
�I�����ł�HT�̕����傫���Ȃ�̂͂������Ƃ��낤���ǁA
��ʌ����ɂ͂���قǑ傫�ȍ����o��Ƃ͎v���Ȃ����c�B
����CPU�͖{���ɎI�������B��ʌ����ɔ���������������C������B
>>793
���낻��f�[�R�[�_�����̑��p�̎������ˁB�܂��ǂ����ł���������Ă�̂���
���낻��f�[�R�[�_�����̑��p�̎������ˁB�܂��ǂ����ł���������Ă�̂���
>>796
AVX���܂��ɂ��ꂶ���B���ꂩ��̖��ߊg��������ɓ��ꂽ�f�R�[�h���₷���t�H�[�}�b�g�B
AVX���܂��ɂ��ꂶ���B���ꂩ��̖��ߊg��������ɓ��ꂽ�f�R�[�h���₷���t�H�[�}�b�g�B
i�V�̓z���Ƃɋꂵ���i�������Ă���B�̊����x�issd�j�ɂ͊�^�����A�d�͌����ɏG�ł邱�Ƃ��Ȃ��Aweb�{�����̓���I�ȏ����ɂ͗]�͂����Ă��܂��iatom)�A���Ƃ����ďd�������͐����͂̂������
���ʂ����ʂ܂�(gpgpu)�B
���������L�[�p�[�c�𑼂ł��Ȃ�intel���g���}�������Ă��鎖���ӂ݂�ɁAx86�����i���͂���i7�ŏI�����}����\���������B
atom�ȂǏo���T�[�o�[����ȊO�Ŏ��g�̎���i�߂邱�ƂɂȂ鎖�͉������薾�炩�������Ǝv�����A����ł�intel���g�ݍ��ݗp�ɓ��ݍ��̂́A���̌����ɍR�����͍���Ɖ����Ă�������B
�����@�ōł������Ŕj�ł���C���p�N�g�������Ă���̂�gpu�Ƃ̗Z�����낤�B
gpu�Ƃ̗Z���ɂ͉��^�I�Ȉӌ����U�����ꂽ�Ǝv�����A���悢��I���Ȃ��Ƃ͌����Ă��Ȃ��Ȃ��Ă����B
���ʂ����ʂ܂�(gpgpu)�B
���������L�[�p�[�c�𑼂ł��Ȃ�intel���g���}�������Ă��鎖���ӂ݂�ɁAx86�����i���͂���i7�ŏI�����}����\���������B
atom�ȂǏo���T�[�o�[����ȊO�Ŏ��g�̎���i�߂邱�ƂɂȂ鎖�͉������薾�炩�������Ǝv�����A����ł�intel���g�ݍ��ݗp�ɓ��ݍ��̂́A���̌����ɍR�����͍���Ɖ����Ă�������B
�����@�ōł������Ŕj�ł���C���p�N�g�������Ă���̂�gpu�Ƃ̗Z�����낤�B
gpu�Ƃ̗Z���ɂ͉��^�I�Ȉӌ����U�����ꂽ�Ǝv�����A���悢��I���Ȃ��Ƃ͌����Ă��Ȃ��Ȃ��Ă����B
�܂�PARROT���T���Ă邩���
���ꂾ��penryn���_CPU�ł���Ǝv���������
�����Ƃ�Bloomfield�͎�����cpu�ł͂Ȃ��BYorkfield�̃��������苭�����������ƌ������Ă��ߌ��ł͂Ȃ����낤�B
�������K���̃��C�e���V�B�����������Đ��\����Ɋ�^���Ȃ����Ƃ��n�b�L�������m�F�p��cpu���ȁB
�������K���̃��C�e���V�B�����������Đ��\����Ɋ�^���Ȃ����Ƃ��n�b�L�������m�F�p��cpu���ȁB
����ǂ��납�A�����R�����ڂɂ��N���b�N�݉����މ�����cpu
�P���~�̎������s���Hw
�d���������G���R�[�h�݂̂�����
�ł��܂����̌����Ă邱�Ƃ͊T�ˍ����Ă���ǂˁB
������N�O���炱���Ō����Ă��ǂ݂�ȏ��n���ɂ��Ď�荇��Ȃ���ˁB
�ł��ˁA�ԈႢ�Ȃ����̌������Ƃ���ɂȂ��B
������N�O���炱���Ō����Ă��ǂ݂�ȏ��n���ɂ��Ď�荇��Ȃ���ˁB
�ł��ˁA�ԈႢ�Ȃ����̌������Ƃ���ɂȂ��B
64bit�ł̐��\�����Windows�g���ܖ�wwwLinux�g������www
807 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 19:49:51 ID:78Oru3Pq
����̂��܂��A���ɐ��]����Ȃ��悤�ɂ�
�R�s�y����
>���̓_�ŁAPenryn��Nehalem�̓����R���lj����Ă��債�Đ��\�オ���ĂȂ��B
Nehalem��QPI�ɂ��Ă��̎�̊��Ⴂ����������B
Nehalem�Ńf�X�N�g�b�v�x���`�̐��т݂āA
������FSB�ł���������������Ă����邺���A�Ɣ]���v�Z�ŗǍD�Ȍ��ʂ�����ꂽ�炵���ȁB
���N���O����킩���Ă������z���Ȃ�������Ȃ��ǂ��悤�₭���z�����B
���̑��p�̉��l���킩���ĂȂ��V�₳��B��Nehalem����鎑�i�͂Ȃ�㩁B
�Ƃ����낤��AMD�̃X���ł���Ȉӌ������X�ł�Ƃ͂ˁB
Opteron�ɂƂ��Ă�Core 2���ꡂ��ɋ��G�ɂȂ������B
�R�s�y����
>���̓_�ŁAPenryn��Nehalem�̓����R���lj����Ă��債�Đ��\�オ���ĂȂ��B
Nehalem��QPI�ɂ��Ă��̎�̊��Ⴂ����������B
Nehalem�Ńf�X�N�g�b�v�x���`�̐��т݂āA
������FSB�ł���������������Ă����邺���A�Ɣ]���v�Z�ŗǍD�Ȍ��ʂ�����ꂽ�炵���ȁB
���N���O����킩���Ă������z���Ȃ�������Ȃ��ǂ��悤�₭���z�����B
���̑��p�̉��l���킩���ĂȂ��V�₳��B��Nehalem����鎑�i�͂Ȃ�㩁B
�Ƃ����낤��AMD�̃X���ł���Ȉӌ������X�ł�Ƃ͂ˁB
Opteron�ɂƂ��Ă�Core 2���ꡂ��ɋ��G�ɂȂ������B
>>807
�Ō�̈�s�������āA���������Ă�̂������ς蕪����Ȃ�
> Opteron�ɂƂ��Ă�Core 2���ꡂ��ɋ��G�ɂȂ�����
����͓�����O�ANUMA�\���ŃX�P�[���r���e�B�����サ�Ă��邩�炾�B
�Ƃ�����Nehalem�ɑR�ł���Opteron�͖������낤(Shanghai�܂߂�)
�Ō�̈�s�������āA���������Ă�̂������ς蕪����Ȃ�
> Opteron�ɂƂ��Ă�Core 2���ꡂ��ɋ��G�ɂȂ�����
����͓�����O�ANUMA�\���ŃX�P�[���r���e�B�����サ�Ă��邩�炾�B
�Ƃ�����Nehalem�ɑR�ł���Opteron�͖������낤(Shanghai�܂߂�)
���₢�₻���������Ƃ������Ă��Ȃ���c�q�����B
���A���������݂đS�̑����܂�Ō����ĂȂ���B
�������������̂̓G���h���[�U�[���~���镨������̂���������߂�w�W�ɂȂ�Ƃ������ƁB
intel��ipc����݉��̕NJ��𒆓r���[�ȃ}���`�R�A�ɂ������ăf�x���b�p�ɐӔC�]�ł��Ă������A�����݂�ȂɃo���o���Ȃ�B
�s�ꂪ�~���Ă���͕̂K�v�A�s�K�v�ł�����蕪����������Ƃ킩��₷��cpu�̎g������̏�ɐ��藧������B
���͒f������B�������intel�̎�����cpu�łЂƂ̑傫�ȗ�������̂�gpu��cpu�̂����̃V���v���Ȍ����ł���ƁB
���A���������݂đS�̑����܂�Ō����ĂȂ���B
�������������̂̓G���h���[�U�[���~���镨������̂���������߂�w�W�ɂȂ�Ƃ������ƁB
intel��ipc����݉��̕NJ��𒆓r���[�ȃ}���`�R�A�ɂ������ăf�x���b�p�ɐӔC�]�ł��Ă������A�����݂�ȂɃo���o���Ȃ�B
�s�ꂪ�~���Ă���͕̂K�v�A�s�K�v�ł�����蕪����������Ƃ킩��₷��cpu�̎g������̏�ɐ��藧������B
���͒f������B�������intel�̎�����cpu�łЂƂ̑傫�ȗ�������̂�gpu��cpu�̂����̃V���v���Ȍ����ł���ƁB
>>809
Intel��Larrabee�J��������?
�������_��ȕ����ɍœK�ȍ\����Larrabee����
�����CPU���������邱�ƂŎ���ɑ�����CPU�ƂȂ�
ATi��nVIDIA�̕����͐����������_��Ɍ����邩�甭�W�͖]�߂Ȃ�
��͂�GPU��GPU�Ƃ��ē������������Ői�����ׂ�����
CPU�ƌ�������Ȃ��p��GPU��萫�\������Ă��_��ɕx��Larrabee���悢�Ǝv����
Intel��Larrabee�J��������?
�������_��ȕ����ɍœK�ȍ\����Larrabee����
�����CPU���������邱�ƂŎ���ɑ�����CPU�ƂȂ�
ATi��nVIDIA�̕����͐����������_��Ɍ����邩�甭�W�͖]�߂Ȃ�
��͂�GPU��GPU�Ƃ��ē������������Ői�����ׂ�����
CPU�ƌ�������Ȃ��p��GPU��萫�\������Ă��_��ɕx��Larrabee���悢�Ǝv����
���A���Ȃ݂ɉ��̓_���S����Ȃ��S���_��w
>>809
�n�C�n�C�ǁ[��
http://pc.watch.impress.co.jp/docs/article/970221/mediagx.jpg
http://pc.watch.impress.co.jp/docs/article/20000825/kgi3_6.jpg
http://pc.watch.impress.co.jp/docs/2008/1027/kaigai_4.jpg
�n�C�n�C�ǁ[��
http://pc.watch.impress.co.jp/docs/article/970221/mediagx.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/article/20000825/kgi3_6.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2008/1027/kaigai_4.jpg
{kind=link}
���̏�Ƀ��X�����l�Ɍ�������B�R�e���c�q����B
���̐l�ׂ����Z�p�_�ɖ�����߂��đ傫�ȗ�����������Ă��B
���̐l�ׂ����Z�p�_�ɖ�����߂��đ傫�ȗ�����������Ă��B
814 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 20:56:33 ID:78Oru3Pq
>���͒f������B�������intel�̎�����cpu�łЂƂ̑傫�ȗ�������̂�gpu��cpu�̂����̃V���v���Ȍ����ł���ƁB
�������낢�ȁB
QPI��PCU�Ƃ������n���]�������ɁA
�����������ꂩ��̖��邢CPU+GPU�̐��E���Ă���B
�����������Ɍ����ĂȂ��̂�ɁA�����͌�����킯�Ȃ������B
�������낢�ȁB
QPI��PCU�Ƃ������n���]�������ɁA
�����������ꂩ��̖��邢CPU+GPU�̐��E���Ă���B
�����������Ɍ����ĂȂ��̂�ɁA�����͌�����킯�Ȃ������B
816 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 20:57:46 ID:78Oru3Pq
Nehalem�Ő�J�����C���t�����g�p���Ȃ�Larrabee�B
��������ςĂ݂�����A�S���B
��������ςĂ݂�����A�S���B
���₵���R�A����L���Ɋ��p�ł��Ȃ���������ATurboBoost�ŃN���b�N�グ�āA
�}���`�X���b�h�ɑΉ����Ă���N���b�N����Ȃ�őS�R�A���p�Ƃ������j�Ȃ�Ȃ��́H
�}���`�X���b�h�ɑΉ����Ă���N���b�N����Ȃ�őS�R�A���p�Ƃ������j�Ȃ�Ȃ��́H
�����������܂�������ł��܂����B
�}���`�X���b�h�ɑΉ����Ă���A�v���Ȃ�A�N���b�N�͂���Ȃ��
�ɒ����B
�}���`�X���b�h�ɑΉ����Ă���A�v���Ȃ�A�N���b�N�͂���Ȃ��
�ɒ����B
>>815
Intel��Havendale�i2Q�X���b�v����2010�N�\��j�����X�ɔ�������
AMD��FUSION/APU�i���݂̌v��ł�������2�N�x��j���听������
�t�@���^�W�[�������E�������Ă�����ł����H
Intel��Havendale�i2Q�X���b�v����2010�N�\��j�����X�ɔ�������
AMD��FUSION/APU�i���݂̌v��ł�������2�N�x��j���听������
�t�@���^�W�[�������E�������Ă�����ł����H
����������B����̌��ʂ����߂邱�Ƃ��B���܂��炵������o���Ƃ��Ƃ�B�c�q���ȁB
larrabee(�j
2�N�O�AFUSION�IGPU�����I�ƘA�Ă��Ă�AMD fanboy�ł���ŋ߂�
���ƂȂ�������𒍎����Ă����Ԃ̒��A�Ȃ��Ȃ����C�������Ă�낵����
���ƂȂ�������𒍎����Ă����Ԃ̒��A�Ȃ��Ȃ����C�������Ă�낵����
���ǂ̂Ƃ���GPU�����̍ő�̌����͂�PC�̎~�܂�Ȃ��ቿ�i�ł���B
�����812��3��Lincroft�͎���̓k�ԁi�j����Ȃ���
2009�N�\��̃v���Z�b�T�i�t�@�[�X�g�V���R������f�����J�ς݁j
�Ȃ���A�����Ɗ��҂��đ҂��Ă����Ȃ�����B
2009�N�\��̃v���Z�b�T�i�t�@�[�X�g�V���R������f�����J�ς݁j
�Ȃ���A�����Ɗ��҂��đ҂��Ă����Ȃ�����B
825 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 21:33:10 ID:78Oru3Pq
�uGPU�����v
���Č��t�Ɋv�V�I�ȃC���[�W�������A�l�^���ؓI�ȃC���[�W���������Ă����ꂽ��
���͌�҂��ȁBLarrabee�̓�����GPU�̓����Ƃ͎v���ĂȂ����B
���Č��t�Ɋv�V�I�ȃC���[�W�������A�l�^���ؓI�ȃC���[�W���������Ă����ꂽ��
���͌�҂��ȁBLarrabee�̓�����GPU�̓����Ƃ͎v���ĂȂ����B
826 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 22:09:30 ID:78Oru3Pq
�����A���ђc�q�Ɗ��Ⴂ���Ă�ƒm���Ă��Ȃ��疳�ʂɃ��X���Ă��܂�����B
����͐V�������Ƃ��̓I�Ȃ��Ƃ͑S�������Ȃ����肾���A
�ׂ����Z�p�_��ϑz�_�����ӂȂ̂́A���ђc�q�̕������B
����͐V�������Ƃ��̓I�Ȃ��Ƃ͑S�������Ȃ����肾���A
�ׂ����Z�p�_��ϑz�_�����ӂȂ̂́A���ђc�q�̕������B
828 �F,,�E �� �E,,�j��-�������F2008/11/17(��) 22:28:44 ID:78Oru3Pq
>>670, >>673�Ō������Ƃ��肾�ȁB
���R�Ƃ͂����A����������l���B
Nehalem�m��h�ł�Lynnfield��Havendale�ɂ͊��҂ł��Ȃ��^�C�v�Ȃ̂�B
���R�Ƃ͂����A����������l���B
Nehalem�m��h�ł�Lynnfield��Havendale�ɂ͊��҂ł��Ȃ��^�C�v�Ȃ̂�B
�a���҂�����
�N�A�b�h�ō��I
>>809
>�������������̂̓G���h���[�U�[���~���镨
����PC�ɏڂ����Ȃ��A�����B�V�F�A�ɐ�߂邻�������A���̊����͂ł����B
�ł��������A���͌��dVISTA�Ɍ��d�Z�L�����e�B�\�t�g������̂�CPU�͂�����ł������ȕ����ǂ��B
GPU��NB��CPU�ɓ�������Ƃ�����@���R�X�g�_�E���ɗL�����i�B
>�������������̂̓G���h���[�U�[���~���镨
����PC�ɏڂ����Ȃ��A�����B�V�F�A�ɐ�߂邻�������A���̊����͂ł����B
�ł��������A���͌��dVISTA�Ɍ��d�Z�L�����e�B�\�t�g������̂�CPU�͂�����ł������ȕ����ǂ��B
GPU��NB��CPU�ɓ�������Ƃ�����@���R�X�g�_�E���ɗL�����i�B
>>825
����GPU�𖧂ɓ�������K�v�Ȃ�������Ȃ��B
GPU�����`�b�v�Z�b�g�Ƒg�ݍ��킹��A���̗p���͍ςႤ���B
�������JavaScript�Ƃ��̍����������Ƃ����ė~�����Ƃ��낾���A����Ȃ�
GPU�ɂ��������@�\���ڂ���ς݂��������B
����GPU�𖧂ɓ�������K�v�Ȃ�������Ȃ��B
GPU�����`�b�v�Z�b�g�Ƒg�ݍ��킹��A���̗p���͍ςႤ���B
�������JavaScript�Ƃ��̍����������Ƃ����ė~�����Ƃ��낾���A����Ȃ�
GPU�ɂ��������@�\���ڂ���ς݂��������B
Lincroft�ŏ\���ł��ˁA�킩��܂��B
�A�h�r�ALinux�Ή�64�r�b�g�uFlash Player�v�̃A���t�@�ł������[�X
http://japan.cnet.com/news/media/story/0,2000056023,20383771,00.htm?ref=rss
http://japan.cnet.com/news/media/story/0,2000056023,20383771,00.htm?ref=rss
835 �F,,�E�L�́M�E,,�j��-�������F2008/11/18(��) 17:25:49 ID:U8Mj5UiB
PPC Linux��Flash�܂��ł����[
836 �F,,�E�L�́M�E,,�j��-�������F2008/11/18(��) 17:38:16 ID:U8Mj5UiB
Larrabee�͗Ⴆ��Ȃ灛��������������W���[�ɏo�Ă���d��Ԃ��ȂB
���̂��ċ��働�{�b�g�̋r�����ƂȂ�B
�͂Ȃ����p�v�̏d��ԁiGPU�j�Ƃ�肠���C�͖����B
�ł����邩��Q������B�I���������˂ĂˁB
>>832
JavaScript�̎��s����̂͂����܂Ń\�t�g�E�F�A�����H
Google��v8��SSE�R�[�h���ɑΉ�����������͂����܂ŃX�J�����߂ɂ��邾���B
�x�N�g�����Ƃ��p���������Ƃ��͑S�R��̘b�B
GPU�����Ė��@�̔�����Ȃ��B�\�t�g�E�F�A�������̂͊J���ҁB
������ɂ͐�p�̃v���~�e�B�u�ߍ���A��p�̌�����g�����肵�ċL�q���Ȃ��Ƃ������Ȃ��B
�ƂȂ�AJavaScript����Ȃ���ActiveX�ɂ���������Ęb�ɂȂ����Ⴄ���āB
���̂��ċ��働�{�b�g�̋r�����ƂȂ�B
�͂Ȃ����p�v�̏d��ԁiGPU�j�Ƃ�肠���C�͖����B
�ł����邩��Q������B�I���������˂ĂˁB
>>832
JavaScript�̎��s����̂͂����܂Ń\�t�g�E�F�A�����H
Google��v8��SSE�R�[�h���ɑΉ�����������͂����܂ŃX�J�����߂ɂ��邾���B
�x�N�g�����Ƃ��p���������Ƃ��͑S�R��̘b�B
GPU�����Ė��@�̔�����Ȃ��B�\�t�g�E�F�A�������̂͊J���ҁB
������ɂ͐�p�̃v���~�e�B�u�ߍ���A��p�̌�����g�����肵�ċL�q���Ȃ��Ƃ������Ȃ��B
�ƂȂ�AJavaScript����Ȃ���ActiveX�ɂ���������Ęb�ɂȂ����Ⴄ���āB
�������ɂ�点��ꂻ���Ȏd�����ăx�N�g�����Z�ȊO�Ȃ���H
�ˑ��W�������Ă͑ʖڂȂ�ˁH
�ˑ��W�������Ă͑ʖڂȂ�ˁH
>>837
���ł��l�ꔪ�ꂵ�Ă�̂Ɋ��҂���ق����n�������?
���߂�Larrabee���炢�̔ėp����L���Ă�Ί�]���傫��������͓��ꂾ
Ait�ɂ��Ă�nVidia�ɂ��Ă����ҏo����͈͔͂��ɋ����̂���������
���ł��l�ꔪ�ꂵ�Ă�̂Ɋ��҂���ق����n�������?
���߂�Larrabee���炢�̔ėp����L���Ă�Ί�]���傫��������͓��ꂾ
Ait�ɂ��Ă�nVidia�ɂ��Ă����ҏo����͈͔͂��ɋ����̂���������
Core i7�̐������\�ɍ��킹�āASPEC2006�̐��т����J����Ă��邷�B
�ڍׂ�A�����炷���Lj��|�I�Ȑ��т��B����SMT�̈З͂�SPECint_rate2006��Shanghai/2.7GHz
����Ƃ����B�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/484-488
�ڍׂ�A�����炷���Lj��|�I�Ȑ��т��B����SMT�̈З͂�SPECint_rate2006��Shanghai/2.7GHz
����Ƃ����B�B�B
http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/484-488
>>832
Nehalem�ȍ~�A�`�b�v�Z�b�g����GPU���������ɃA�N�Z�X����ɂ�CPU���o�R���Ȃ��Ⴂ���Ȃ�
���ꂾ�Ɛ��\�ł��R�X�g�ł��d�͌����ł����������Ȃ�
��ʌ����ɂ�CPU��GPU��g�ݍ��ނ̂��x�X�g
Nehalem�ȍ~�A�`�b�v�Z�b�g����GPU���������ɃA�N�Z�X����ɂ�CPU���o�R���Ȃ��Ⴂ���Ȃ�
���ꂾ�Ɛ��\�ł��R�X�g�ł��d�͌����ł����������Ȃ�
��ʌ����ɂ�CPU��GPU��g�ݍ��ނ̂��x�X�g
Side Port Memory����ʖڂł��������ł���
���ʂ̑�֎�i�Ƃ��Ă͗ǂ����������I�ɂ͑ʖڂ���
>>840
���uLFB�v
���uLFB�v
>>843
LFB��Side Port Memory
LFB��Side Port Memory
>>845
���\����Ȃ��ăR�X�g�Ŋ��ɍ���Ȃ��ł���
LFB�̒l�i�͂������A�m�[�g�⏬�^�v���b�g�t�H�[���ł͎����ʐς̃R�X�g���傫��
�������LFB�ς�ł�����ƃp�t�H�[�}���X���ɂ��o����璷�����L�����ɉz�������͖�������
��{�͂�͂�R�X�g�p�t�H�[�}���X�ǐ^�ŃV�X�e�����l���Ȃ��Ƃ�
���\����Ȃ��ăR�X�g�Ŋ��ɍ���Ȃ��ł���
LFB�̒l�i�͂������A�m�[�g�⏬�^�v���b�g�t�H�[���ł͎����ʐς̃R�X�g���傫��
�������LFB�ς�ł�����ƃp�t�H�[�}���X���ɂ��o����璷�����L�����ɉz�������͖�������
��{�͂�͂�R�X�g�p�t�H�[�}���X�ǐ^�ŃV�X�e�����l���Ȃ��Ƃ�
�C���e���̃T�[�o�����`�b�v�Z�b�g�̃��[�h�}�b�v���Ăǂ����ɖ������ȁH
�f�X�N�g�b�vCPU�Ȃ͂��������ɂ�����E�E�E�E�B
���ɍ���̃G���g���[�T�[�o�����`�b�v�������ς�킩���B
�f�X�N�g�b�vCPU�Ȃ͂��������ɂ�����E�E�E�E�B
���ɍ���̃G���g���[�T�[�o�����`�b�v�������ς�킩���B
849 �FMAC�I�^��848 �����F2008/11/19(��) 19:06:34 ID:5QkxaR/H
>>848
�@�@----------------------
�@�@���ɍ���̃G���g���[�T�[�o�����`�b�v�������ς�킩���B
�@�@----------------------
�f���A���\�P�b�g���܂߂�x58(Tylersburg)�����̂܂g�����B
ftp://download.intel.com/pressroom/kits/events/idffall_2008/SSmith_briefing_roadmap.pdf
�@�@----------------------
�@�@���ɍ���̃G���g���[�T�[�o�����`�b�v�������ς�킩���B
�@�@----------------------
�f���A���\�P�b�g���܂߂�x58(Tylersburg)�����̂܂g�����B
ftp://download.intel.com/pressroom/kits/events/idffall_2008/SSmith_briefing_roadmap.pdf
Intel3200��3210�̌�p��X58�H
�V���O���\�P�b�g�������Ԃ������ȁc�B
�ǂ������I�̓��[�J�[������������낤���ǁB
�V���O���\�P�b�g�������Ԃ������ȁc�B
�ǂ������I�̓��[�J�[������������낤���ǁB
851 �FMAC�I�^��850 �����F2008/11/19(��) 20:10:21 ID:5QkxaR/H
>>850
�V���O���\�P�b�g��Nehalem Xeon�Ɋւ��Ă�A����Supermicro���Ή��}�U�[�\���Ă��邷�B
http://www.supermicro.com/products/motherboard/Xeon3000/#1366
�V���O���\�P�b�g��Nehalem Xeon�Ɋւ��Ă�A����Supermicro���Ή��}�U�[�\���Ă��邷�B
http://www.supermicro.com/products/motherboard/Xeon3000/#1366
Supermicro����ECC�Ή��ȂȁB
>>851
�܂����B
����̓��[�J�[�̃G���g���[���f���̎I�ł���4�R�A���f�t�H���g�ɂȂ�̂��H
�V���O���\�P�b�g��AMD�I�̂����|�I�Ɉ����Ȃ��āA���x�[�X�ŃV�F�A�L���������ȁB
�܂����B
����̓��[�J�[�̃G���g���[���f���̎I�ł���4�R�A���f�t�H���g�ɂȂ�̂��H
�V���O���\�P�b�g��AMD�I�̂����|�I�Ɉ����Ȃ��āA���x�[�X�ŃV�F�A�L���������ȁB
854 �FMAC�I�^��852 �����F2008/11/19(��) 20:39:06 ID:5QkxaR/H
>>852
�����}�j���A�����_�E�����[�h�ł���悤�ɂȂ��Ă��邷���ǁA��������ECC�Ή��Ɋւ��Ă�A
�v���Z�b�T�ɂ�肯��B�B�B�Ƃ��������ȕ\���ɂȂ��Ă��邷�B
Supermicro�̃T�|�[�g�ɐq�˂��Ƃ�����ArsTechnica�f���ɂ��邷���ǁACore i7
�u�����h�Ŕ̔�����Ă���`�b�v��ECC�Ή���������悤�ŁB�B�B
http://episteme.arstechnica.com/eve/forums/a/tpc/f/77909774/m/730002845931?r=418009265931#418009265931
�@�@--------------------------
�@�@Based on Intel's product roadmap, Core i7 is a desktop processor and will not support
�@�@ECC memory. The upcoming Nehalem-WS processors, Xeon 3500 series and Xeon 5500
�@�@series will work in X58 boards and will support ECC.
�@�@--------------------------
�������Xeon 3500��Core i7�̒��g�퓯�����m������T�|�[�g�̗L���̖��Ƃ�v�����B������
�ň��̏ꍇXeon 3500��X�e�b�s���O���グ�ēo�ꂷ�邩������Ȃ����B
�����}�j���A�����_�E�����[�h�ł���悤�ɂȂ��Ă��邷���ǁA��������ECC�Ή��Ɋւ��Ă�A
�v���Z�b�T�ɂ�肯��B�B�B�Ƃ��������ȕ\���ɂȂ��Ă��邷�B
Supermicro�̃T�|�[�g�ɐq�˂��Ƃ�����ArsTechnica�f���ɂ��邷���ǁACore i7
�u�����h�Ŕ̔�����Ă���`�b�v��ECC�Ή���������悤�ŁB�B�B
http://episteme.arstechnica.com/eve/forums/a/tpc/f/77909774/m/730002845931?r=418009265931#418009265931
�@�@--------------------------
�@�@Based on Intel's product roadmap, Core i7 is a desktop processor and will not support
�@�@ECC memory. The upcoming Nehalem-WS processors, Xeon 3500 series and Xeon 5500
�@�@series will work in X58 boards and will support ECC.
�@�@--------------------------
�������Xeon 3500��Core i7�̒��g�퓯�����m������T�|�[�g�̗L���̖��Ƃ�v�����B������
�ň��̏ꍇXeon 3500��X�e�b�s���O���グ�ēo�ꂷ�邩������Ȃ����B
�}�j���A���܂ł͂����ƌ��ĂȂ������B
UP��Nehalem Xeon��i7�ƒl�i�ꏏ�̂悤������AECC�K�v�Ȃ�f����Xeon��I�ق����ǂ����Ă��Ƃ��B
UP��Nehalem Xeon��i7�ƒl�i�ꏏ�̂悤������AECC�K�v�Ȃ�f����Xeon��I�ق����ǂ����Ă��Ƃ��B
>>853
2�R�A���̂������B
������Ə��Â����������AXeon 5500�V���[�Y(Nehalem-EP�܂���Gainstown)�̃��C���i�b�v�͂���Ȋ����B
4�R�A/8�X���b�h/PQI 6.4GT/�^�[�{�u�[�X�g�t��
�EXeon W5580/3.20GHz/L2 512KB*4/L3 8MB/TDP130W/$1,600
�EXeon X5570/2.93GHz/L2 512KB*4/L3 8MB/TDP130W/$1,386
�EXeon X5560/2.80GHz/L2 512KB*4/L3 8MB/TDP95W/$1,172
�EXeon X5550/2.66GHz/L2 512KB*4/L3 8MB/TDP95W/$958
4�R�A/8�X���b�h/PQI 5.86GT/�^�[�{�u�[�X�g�t��
�EXeon E5540/2.53GHz/L2 512KB*4/L3 8MB/TDP80W/$744
�EXeon E5530/2.40GHz/L2 512KB*4/L3 8MB/TDP80W/$530
�EXeon E5520/2.26GHz/L2 512KB*4/L3 8MB/TDP80W/$373
�EXeon L5220/2.26GHz/L2 512KB*4/L3 8MB/TDP60W/$530
4�R�A/4�X���b�h/PQI 4.8GT
�EXeon E5506/2.13GHz/L2 512KB*4/L3 4MB/TDP80W/$266
�EXeon E5504/2.00GHz/L2 512KB*4/L3 4MB/TDP80W/$224
�EXeon L5506/2.13GHz/L2 512KB*4/L3 4MB/TDP60W/$423
2�R�A/2�X���b�h/PQI 4.8GT
�EXeon E5502/1.86GHz/L2 512KB*2/L3 4MB/TDP80W/$188
2�R�A���̂������B
������Ə��Â����������AXeon 5500�V���[�Y(Nehalem-EP�܂���Gainstown)�̃��C���i�b�v�͂���Ȋ����B
4�R�A/8�X���b�h/PQI 6.4GT/�^�[�{�u�[�X�g�t��
�EXeon W5580/3.20GHz/L2 512KB*4/L3 8MB/TDP130W/$1,600
�EXeon X5570/2.93GHz/L2 512KB*4/L3 8MB/TDP130W/$1,386
�EXeon X5560/2.80GHz/L2 512KB*4/L3 8MB/TDP95W/$1,172
�EXeon X5550/2.66GHz/L2 512KB*4/L3 8MB/TDP95W/$958
4�R�A/8�X���b�h/PQI 5.86GT/�^�[�{�u�[�X�g�t��
�EXeon E5540/2.53GHz/L2 512KB*4/L3 8MB/TDP80W/$744
�EXeon E5530/2.40GHz/L2 512KB*4/L3 8MB/TDP80W/$530
�EXeon E5520/2.26GHz/L2 512KB*4/L3 8MB/TDP80W/$373
�EXeon L5220/2.26GHz/L2 512KB*4/L3 8MB/TDP60W/$530
4�R�A/4�X���b�h/PQI 4.8GT
�EXeon E5506/2.13GHz/L2 512KB*4/L3 4MB/TDP80W/$266
�EXeon E5504/2.00GHz/L2 512KB*4/L3 4MB/TDP80W/$224
�EXeon L5506/2.13GHz/L2 512KB*4/L3 4MB/TDP60W/$423
2�R�A/2�X���b�h/PQI 4.8GT
�EXeon E5502/1.86GHz/L2 512KB*2/L3 4MB/TDP80W/$188
>>856
����ɂ͂���B�@������E5504�Ɣ�ׂ��E5502�̑��݈Ӌ`���c
����ɂ͂���B�@������E5504�Ɣ�ׂ��E5502�̑��݈Ӌ`���c
���ቿ�i�T�[�o�̉��i�т�������A�͂�$40���炸�̈Ⴂ�����ƂȂ���Ⴂ�Ȋ����Ɍ�����㩁B
������������������J�o�[���AIntel�Ƃ��Ă͈ꕔ�R�A�������Ȃ��_�C�i�Ɣ����A�Ƃ������i���C���̋C������B
������������������J�o�[���AIntel�Ƃ��Ă͈ꕔ�R�A�������Ȃ��_�C�i�Ɣ����A�Ƃ������i���C���̋C������B
��[�܂��������ȁB
���Ƃ́A5502�Ŏ䂫���Ă����āA5504 5506 �֗U�����鋙�Ζ����B
$40�ŃR�A�{�{�N���b�N�A�b�v�������
���Ƃ́A5502�Ŏ䂫���Ă����āA5504 5506 �֗U�����鋙�Ζ����B
$40�ŃR�A�{�{�N���b�N�A�b�v�������
���[�J�[�I�ł�CPU�A�b�v�O���[�h�̍��z��40�h���ȏ�ɂȂ邾�낤���ȁB
AMD�A����Ȋ�Ɣ閧���C���e�����瓐���Ј����̗p--�u�m��ʁA�����ʁv�ɃC���e���͌��{
http://news.livedoor.com/article/detail/3908514/
http://news.livedoor.com/article/detail/3908514/
�Ȃ�Ő�i��AMD��intel�̊�Ɣ閧���Ƃ��𓐂܂ɂႢ����̂�B���ق��B
Anand��Nehalem����L���̎�ނ�Gelsinger����Nehlem�̃��[�h�A�[�L�e�N�g�ARonak Sinhal��
����d���ꂽ���ڂ�b���܂Ƃ߂Ă��邷�B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3461
�@�EL2�T�C�Y (256KB)�̑I���ɂ���
�@�@- 4-core���i��L2+L3��9MB�Ƃ����l���̂�A45-nm�v���Z�X����Ƃ��Ă핁�ʂ̑I��
�@�@- Intel�퍡��̐i���̕�������}���`�R�A�ɂ���ƌ��Ă���A�V���O���R�A�̐��\���ߏ��
�@�@�@�Nj�����I���͂��Ȃ�����
�@�@- Nehalem���̂�4-8�R�A�ōœK�Ȑ��\������悤�ɐv����Ă���
�@�@- ���̂��ߒ�C�e���V�ŏ��e�ʂ�L2�Ƒ�e��L3�Ƃ����H�����I�����ꂽ
�@�@- L2�̃T�C�Y��A��Ƃ��ă��C�e���V�ɂ�萧��A512KB�ɂ����ꍇ��X��20%�����������낤
�@�@- �����ɂ����Ă�L2�T�C�Y�ɑ��郌�C�e���V�̐����ς��Ȃ����߁A�������e�ʂɂȂ�
�@�@�@�����݂����Ȃ�
�@�@- Intel�Ƃ��Ă�A�ނ���L3�A�N�Z�X�̒�C�e���V���ɒ��͂��Ă���A���s��41-cycle����30-cycle
�@�@�@���x�܂ł�Z�k�ł��錩���݂�����B
�@�@- L3�Ɋւ��Ă�A�X�Ȃ��e�ʉ����\�肳��Ă���͗l
����d���ꂽ���ڂ�b���܂Ƃ߂Ă��邷�B
http://www.anandtech.com/cpuchipsets/intel/showdoc.aspx?i=3461
�@�EL2�T�C�Y (256KB)�̑I���ɂ���
�@�@- 4-core���i��L2+L3��9MB�Ƃ����l���̂�A45-nm�v���Z�X����Ƃ��Ă핁�ʂ̑I��
�@�@- Intel�퍡��̐i���̕�������}���`�R�A�ɂ���ƌ��Ă���A�V���O���R�A�̐��\���ߏ��
�@�@�@�Nj�����I���͂��Ȃ�����
�@�@- Nehalem���̂�4-8�R�A�ōœK�Ȑ��\������悤�ɐv����Ă���
�@�@- ���̂��ߒ�C�e���V�ŏ��e�ʂ�L2�Ƒ�e��L3�Ƃ����H�����I�����ꂽ
�@�@- L2�̃T�C�Y��A��Ƃ��ă��C�e���V�ɂ�萧��A512KB�ɂ����ꍇ��X��20%�����������낤
�@�@- �����ɂ����Ă�L2�T�C�Y�ɑ��郌�C�e���V�̐����ς��Ȃ����߁A�������e�ʂɂȂ�
�@�@�@�����݂����Ȃ�
�@�@- Intel�Ƃ��Ă�A�ނ���L3�A�N�Z�X�̒�C�e���V���ɒ��͂��Ă���A���s��41-cycle����30-cycle
�@�@�@���x�܂ł�Z�k�ł��錩���݂�����B
�@�@- L3�Ɋւ��Ă�A�X�Ȃ��e�ʉ����\�肳��Ă���͗l
864 �FMAC�I�^�������F2008/11/20(��) 22:35:57 ID:AzjAMs+l
�@�ELynnfield��Havendale�ɂ���
�@�@- LGA1366��LGA1156�틤�ɒ����I�T�|�[�g���\�肳��Ă���
�@�@- LGA1156���i�ɂ��Ă�OC������݂��Ȃ�
�@�@- �������Ȃ���OC�̊ϓ_�ł�LGA1366���i�̕����D��Ă���B
�@�E������32-nm�v���Z�X����̐��i�ɂ���
�@�@- Westmere�ɂ��Ă�A�����̓���N���b�N�̌���ƃL���b�V���̑��ʂ�����̂�
�@�@- Sandy Bridge�̃|�C���g��AVX�̃T�|�[�g
�@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
�@�@- LGA1366��LGA1156�틤�ɒ����I�T�|�[�g���\�肳��Ă���
�@�@- LGA1156���i�ɂ��Ă�OC������݂��Ȃ�
�@�@- �������Ȃ���OC�̊ϓ_�ł�LGA1366���i�̕����D��Ă���B
�@�E������32-nm�v���Z�X����̐��i�ɂ���
�@�@- Westmere�ɂ��Ă�A�����̓���N���b�N�̌���ƃL���b�V���̑��ʂ�����̂�
�@�@- Sandy Bridge�̃|�C���g��AVX�̃T�|�[�g
�@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
865 �FMAC�I�^�������܂��F2008/11/20(��) 22:39:06 ID:AzjAMs+l
�ŋ߂�Anand��A�ǂ��������̌㓡�G�̋L����f�i�Ƃ����邷�B
�ǂ��\�[�X�ɃR�l�������A�f���ȋ^��𓊂�������C���^�r���[���A���ɗǂ��������B
�ǂ��\�[�X�ɃR�l�������A�f���ȋ^��𓊂�������C���^�r���[���A���ɗǂ��������B
�Ƃ����Anand��A>>864�ɂ���悤�ɒc�q�����������Ă���wx86 -> AVX -> LRB�x
�Ƃ���SIMD���̑����ɒ��ڂ����i���̕������ł햳���A�ʏ��CPU��GPU������Larrabee��
��������ISA�Ƃ���AVX�𑨂��Ă��邷�B
������l�^�Ƃ��Ă�AIntel��LRB��AVX�̊W���ǂ̂悤�ɍl���Ă��邩�̋c�_��2�N��܂�
�����������B
�Ƃ���SIMD���̑����ɒ��ڂ����i���̕������ł햳���A�ʏ��CPU��GPU������Larrabee��
��������ISA�Ƃ���AVX�𑨂��Ă��邷�B
������l�^�Ƃ��Ă�AIntel��LRB��AVX�̊W���ǂ̂悤�ɍl���Ă��邩�̋c�_��2�N��܂�
�����������B
�Ƃ����SandyBridge�̃\�P�b�g���ĉ��ɂȂ��
868 �F,,�E�L�́M�E,,�j��-�������F2008/11/21(��) 01:36:03 ID:IoVgtMoH
AVX�Ɋւ��ẮA����512-bit/��������1024-bit�܂ł̊g���v��ł��o���Ă邩��
�܂���512-bit/1024-bit��Larrabee�̂���Ȃ�Ȃ��́H
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/287
�ɂ����傱���Ə��������ǁA
NVIDIA�̓��j�b�g�\���I�ɂ�32bit�~8��SIM'T'�ŊeSP��2issue���s����
4�N���b�N�ŃC���^�[���[�u����32�X���b�h���T�|�[�g����B
����͎���1024bit SIMD����Ă�̂Ɠ������Ƃ��B�f�R�[�_�͔����œ����Ă�B
2���ߔ��s�~8�f�[�^�����1�N���b�N���ɂ��ƁA�����f�R�[�_��2��K�v�ɂȂ�B
���j�b�g�̓��ڐ���4�{�Ɉ����������ƂŔ����~1�ōς܂��Ă�B
���āALarrabee��2issue�̃p�C�v���C���ŁA�Е��̃f�R�[�_���n���
���G�f�R�[�_�������@�\���Ȃ����Ƃ������Ƃ�����
����ł�Intel�H���u�f�R�[�h�͏\���Ԃɍ����v
�����ōl�������A���������Ɍ�����1024�r�b�g��SIMD���T�|�[�g����
���Ă��Ƃ͂Ȃ���ȁH
�����������Z�̃��C�e���V�B���Ɩ��߃t�F�b�`�ш�̐ߖ�̈Ӗ����������߂ĂˁB
���Ȃ݂�CUDA�̃h�L���\�����g�ǂނɁA���[�h�E�X�g�A�ɂ����鐧���
Larrabee��CUDA�̂�����債�ĕς���B
NVIDIA�̔���ł���SP���ׂ���������Ă邩��SIMD��藱�x���ׂ����������o������Ă̂͑�R�B
�������Larrabee�̂悤�ȁu�_��̍���SIMD�v�ł��������Ƃ͂ł��܂��B
�܂���512-bit/1024-bit��Larrabee�̂���Ȃ�Ȃ��́H
http://pc11.2ch.net/test/read.cgi/jisaku/1217915128/287
�ɂ����傱���Ə��������ǁA
NVIDIA�̓��j�b�g�\���I�ɂ�32bit�~8��SIM'T'�ŊeSP��2issue���s����
4�N���b�N�ŃC���^�[���[�u����32�X���b�h���T�|�[�g����B
����͎���1024bit SIMD����Ă�̂Ɠ������Ƃ��B�f�R�[�_�͔����œ����Ă�B
2���ߔ��s�~8�f�[�^�����1�N���b�N���ɂ��ƁA�����f�R�[�_��2��K�v�ɂȂ�B
���j�b�g�̓��ڐ���4�{�Ɉ����������ƂŔ����~1�ōς܂��Ă�B
���āALarrabee��2issue�̃p�C�v���C���ŁA�Е��̃f�R�[�_���n���
���G�f�R�[�_�������@�\���Ȃ����Ƃ������Ƃ�����
����ł�Intel�H���u�f�R�[�h�͏\���Ԃɍ����v
�����ōl�������A���������Ɍ�����1024�r�b�g��SIMD���T�|�[�g����
���Ă��Ƃ͂Ȃ���ȁH
�����������Z�̃��C�e���V�B���Ɩ��߃t�F�b�`�ш�̐ߖ�̈Ӗ����������߂ĂˁB
���Ȃ݂�CUDA�̃h�L���\�����g�ǂނɁA���[�h�E�X�g�A�ɂ����鐧���
Larrabee��CUDA�̂�����債�ĕς���B
NVIDIA�̔���ł���SP���ׂ���������Ă邩��SIMD��藱�x���ׂ����������o������Ă̂͑�R�B
�������Larrabee�̂悤�ȁu�_��̍���SIMD�v�ł��������Ƃ͂ł��܂��B
Intel��SIMD���Z���512�`1024bit�̒��Ɋ֘A�̖����f�[�^�ł���1�Z�b�g�ɏo������Ă��ƁH
870 �F,,�E�L�́M�E,,�j��-�������F2008/11/21(��) 19:05:33 ID:IoVgtMoH
�X���[�v�b�g�����C�ɂ��Ȃ��������SSE�ł�insert/extract/shuffle���߂Ŏ��R�ɑg�ݑւ��ł��邯�ǂˁB
NVIDIA�̓����V�F�[�_�ł���Ă邱�Ƃ̓A���C�������g���ꂽ64�o�C�g�P�ʂł̃��[�h�E�X�g�A�{�V���b�t��
Larrabee�������B
�����64�o�C�g�A�h���X�u���b�N�ɏ������f�[�^�Ȃ瓯���Ƀ��[�h�E�X�g�A�\�����A
�ʁX�Ȃ炻�̃u���b�N�����̃N���b�N����������B
NVIDIA�̓����V�F�[�_�ł���Ă邱�Ƃ̓A���C�������g���ꂽ64�o�C�g�P�ʂł̃��[�h�E�X�g�A�{�V���b�t��
Larrabee�������B
�����64�o�C�g�A�h���X�u���b�N�ɏ������f�[�^�Ȃ瓯���Ƀ��[�h�E�X�g�A�\�����A
�ʁX�Ȃ炻�̃u���b�N�����̃N���b�N����������B
���
�ƌ�������CUDA�ł��w�ʁX�Ȃ炻�̃u���b�N�����̃N���b�N����������B�x���Ď����ȁH
�ƌ�������CUDA�ł��w�ʁX�Ȃ炻�̃u���b�N�����̃N���b�N����������B�x���Ď����ȁH
872 �F,,�E �� �E,,�j��-�������F2008/11/21(��) 22:57:33 ID:TgO1VzeM
�c�O�Ȃ������Anand�͂��̌�A�����������Ă��邷�B
�@�E������32-nm�v���Z�X����̐��i�ɂ���
�@�@- Larrabee��512-bit���Ƃ������Ƃ����炩�ɂȂ����̂ŁAAVX�œ����Ƃ����l�I�ȍl���͑������ے肳�ꂽ
�@�@- AVX��SSE�̑f���Ȋg���łł���ALarrabee�̂悤�ȃx�N�g���v���Z�b�T�u���ł͂Ȃ�
�@�E������32-nm�v���Z�X����̐��i�ɂ���
�@�@- Larrabee��512-bit���Ƃ������Ƃ����炩�ɂȂ����̂ŁAAVX�œ����Ƃ����l�I�ȍl���͑������ے肳�ꂽ
�@�@- AVX��SSE�̑f���Ȋg���łł���ALarrabee�̂悤�ȃx�N�g���v���Z�b�T�u���ł͂Ȃ�
873 �FMAC�I�^��872 �����F2008/11/21(��) 23:23:25 ID:KjSGo7TB
>>872
�@�@------------------
�@�@AVX�œ����Ƃ����l�I�ȍl���͑������ے肳�ꂽ
�@�@------------------
�ǂ���ǂ�ŁA���������Ă���Ǝv��������������H
�@�@------------------
�@�@AVX�œ����Ƃ����l�I�ȍl���͑������ے肳�ꂽ
�@�@------------------
�ǂ���ǂ�ŁA���������Ă���Ǝv��������������H
�{���̒c�q�͂ǂ��H>>873
>>872
MAC�I�^�̋C�����������X���R�s�y���Ă�˂��B���ˁB
MAC�I�^�̋C�����������X���R�s�y���Ă�˂��B���ˁB
876 �F,,�E �� �E,,�j��-�������F2008/11/21(��) 23:32:56 ID:TgO1VzeM
>>873
�@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
�����̈��p���̋߂��ɏ����Ă��邷���ǁB
�F������m�F���������߂��邷�B
�@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
�����̈��p���̋߂��ɏ����Ă��邷���ǁB
�F������m�F���������߂��邷�B
877 �FMAC�I�^��876 �����F2008/11/21(��) 23:49:50 ID:KjSGo7TB
>>876
�p�ꂪ�ǂ߂Ȃ��̂��o����̂ŁA���͂����p�ł��Ȃ�����(��)
�p�ꂪ�ǂ߂Ȃ��̂��o����̂ŁA���͂����p�ł��Ȃ�����(��)
878 �F,,�E �� �E,,�j��-�������F2008/11/22(�y) 00:00:11 ID:jEkA2Xry
>>872��ǂ��ƂɁA���Y���p�ӏ������x���ǂݕԂ��Ă݂�悢�B
���̂��Ƃǂ��ɏ����Ă��邩�킩��͂����B
���̂��Ƃǂ��ɏ����Ă��邩�킩��͂����B
879 �F,,�E�L�́M�E,,�j��-�������F2008/11/22(�y) 00:40:25 ID:yJs+x2OE
Anand�̒��̐l�Ȃ�ď��F�l�̎q����
�Ȃ�ň�c����Ƃ̑����̋@�������͂�o�c�헪�������������Ƃ��ł����
�Ȃ�ň�c����Ƃ̑����̋@�������͂�o�c�헪�������������Ƃ��ł����
Nehalem�ȍ~��CPU��Larrabee�̓X�J�������ƃx�N�^�[���������ꂼ��u���b�N������Ă���
�g�ݍ��킹�̓���ւ��Ȃǂ��e�Ղɐv����Ă�
�g�ݍ��킹�̓���ւ��Ȃǂ��e�Ղɐv����Ă�
881 �FMAC�I�^���c�q �����F2008/11/22(�y) 01:02:14 ID:TaEFwxau
>>879
Anand��AAnandTech�̃I�[�i�[�Ȃ��ǁB
�T�C�g���L���ɂȂ������퍂�Z�������������ǁA�����ƃj�[�g�������ɑ�w�����Ƃ����Ƃ̂��Ƃ��B
http://en.wikipedia.org/wiki/Anand_Lal_Shimpi
Anand��AAnandTech�̃I�[�i�[�Ȃ��ǁB
�T�C�g���L���ɂȂ������퍂�Z�������������ǁA�����ƃj�[�g�������ɑ�w�����Ƃ����Ƃ̂��Ƃ��B
http://en.wikipedia.org/wiki/Anand_Lal_Shimpi
>AVX is merely the first step in that direction.
�܂䂰�̂Ȃ��c�q���w�E���Ă�̂��Ă��̕��́H
���́A��̒i����AVX��CPU��GPU�̋��n���ɂȂ�Ƃ������Ă��邩��A
SandyBridge�œ��ڂ����AVX��Larrabee�n�̖��߂Ɠ������邽�߂̑����ɉ߂��Ȃ����Ă����ŁA�A
���AVX�̊g���œ������Ȃ��Ƃ܂ł͐������ĂȂ��悤�Ɏv�����B
�܂䂰�̂Ȃ��c�q���w�E���Ă�̂��Ă��̕��́H
���́A��̒i����AVX��CPU��GPU�̋��n���ɂȂ�Ƃ������Ă��邩��A
SandyBridge�œ��ڂ����AVX��Larrabee�n�̖��߂Ɠ������邽�߂̑����ɉ߂��Ȃ����Ă����ŁA�A
���AVX�̊g���œ������Ȃ��Ƃ܂ł͐������ĂȂ��悤�Ɏv�����B
techrader.com��Nahalem-EP��2.8GHz�T���v����SPEC CPU2006�𑖂点�Ă݂��Ƃ̂��Ƃ��B
http://www.techradar.com/news/computing-components/processors/world-exclusive-intel-s-dual-socket-nehalem-ep-platform-benchmarked-487131
�@�@--------------------
�@�@The big number many will be waiting for is the SPECfp base rate. So here it is: 160.
�@�@--------------------
��r�p�̃f�[�^���B
�@Dual Shanghai/2.7GHz: 105 (base) / 118 (peak)
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05684.html
�@Dual Penryn/3.4GHz: 87.2 / 95.6
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20080915-05364.html
�@Single Nehalem/3.2GHz: 82.9 / 86.1
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05710.html
�@Single Nehalem/2.66GHz: 76.0 / 78.9
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05718.html
http://www.techradar.com/news/computing-components/processors/world-exclusive-intel-s-dual-socket-nehalem-ep-platform-benchmarked-487131
�@�@--------------------
�@�@The big number many will be waiting for is the SPECfp base rate. So here it is: 160.
�@�@--------------------
��r�p�̃f�[�^���B
�@Dual Shanghai/2.7GHz: 105 (base) / 118 (peak)
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05684.html
�@Dual Penryn/3.4GHz: 87.2 / 95.6
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20080915-05364.html
�@Single Nehalem/3.2GHz: 82.9 / 86.1
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05710.html
�@Single Nehalem/2.66GHz: 76.0 / 78.9
�@http://www.spec.org/cpu2006/results/res2008q4/cpu2006-20081024-05718.html
>>883
����A�}�W�����@�Ȃ��l�^�݂����ȑ������Ȃ�
����A�}�W�����@�Ȃ��l�^�݂����ȑ������Ȃ�
Penryn�̕����H
L5520�ˌ��m��
887 �FSocket774�F2008/11/22(�y) 07:19:58 ID:BMfeR7ng
�O�ɏo�Ă���NehalemEP��SPECfp�X�R�A��171��������
�N���b�N�͔���Ȃ���������
�N���b�N�͔���Ȃ���������
>>887
���ꂾ��H�قƂ�Ǎ����Ă鏊���|���ȁB
�Ȃ�ŃC���e�����Q����Shanghai�̐��\�m���Ă�̂����䂾����
http://blogs.zdnet.com/Ou/images/nehalem-estimate.png
���ꂾ��H�قƂ�Ǎ����Ă鏊���|���ȁB
�Ȃ�ŃC���e�����Q����Shanghai�̐��\�m���Ă�̂����䂾����
http://blogs.zdnet.com/Ou/images/nehalem-estimate.png
{kind=link}
Nehalem�̂ق���Dual�͂Ȃ��̂��H
��łłĂ�̂�dual��
SPEC����3.2GHz��Nehalem-EP��2P�Ȃ�A2.7GHz��Shanghai��4P�ɔ��邭�炢�̐����o���������ȁB
892 �F,,�E�L�́M�E,,�j��-�������F2008/11/22(�y) 11:13:42 ID:yJs+x2OE
L3�L���b�V��������������������B����ˁH
�����L���b�V���̌��ʂ��Ċ���V�~�����[�V�����ł���i�K�ɂȂ��Ă��Ȃ��́H
�����L���b�V���̌��ʂ��Ċ���V�~�����[�V�����ł���i�K�ɂȂ��Ă��Ȃ��́H
893 �F,,�E�L�́M�E,,�j��-�������F2008/11/22(�y) 11:49:02 ID:yJs+x2OE
>>881
�����ĂȂ����B
Anand���ǂ��v��������Ȃ��[�́B�Ӗ��s���Ȃ��Ƃ��������₪��ˁB
> �@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
>�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
����Ȃ��Ɩ{���Ɍ������̂������T���̂��߂�ǂ�����������Ȃ�����
�{���Ɍ������Ȃ猩���ɓI�O��ȗ\�z�������ˁB
�����m�̂Ƃ���iSandy Bridge�₻�̎��̖��߃Z�b�g�g���̔��e�Łj
AVX�ɂ�512bit��VPU���������߂͑��݂��Ȃ��B
���Ȃ݂�Intel�͈��N���炢�܂�Larrabee��SIMD���߂��uSSE�v���Č����Ă�����ˁB
�����ĂȂ����B
Anand���ǂ��v��������Ȃ��[�́B�Ӗ��s���Ȃ��Ƃ��������₪��ˁB
> �@�@- Anand�̌l�I�����Ƃ��āAAVX�팻�s��x86 ISA��GPU�������ӎ������k����������������
>�@�@�@LRB ISA���������m�ɂȂ�ƍl���Ă���B
����Ȃ��Ɩ{���Ɍ������̂������T���̂��߂�ǂ�����������Ȃ�����
�{���Ɍ������Ȃ猩���ɓI�O��ȗ\�z�������ˁB
�����m�̂Ƃ���iSandy Bridge�₻�̎��̖��߃Z�b�g�g���̔��e�Łj
AVX�ɂ�512bit��VPU���������߂͑��݂��Ȃ��B
���Ȃ݂�Intel�͈��N���炢�܂�Larrabee��SIMD���߂��uSSE�v���Č����Ă�����ˁB
>>893
�uAnand�̒��̐l�Ȃ�ď��F�l�̎q�v�ɔ���
��
�܂�Anand�͐l�̎q�ł͂Ȃ����_
��
���̗��R�́u�iAnand�́j�j�[�g�������ɑ�w�����Ɓv
��������
�uAnand�̒��̐l�Ȃ�ď��F�l�̎q�v�ɔ���
��
�܂�Anand�͐l�̎q�ł͂Ȃ����_
��
���̗��R�́u�iAnand�́j�j�[�g�������ɑ�w�����Ɓv
��������
895 �F,,�E �� �E,,�j��-�������F2008/11/22(�y) 15:47:07 ID:POEkl9Fn
����l�̃G�X�p�[�p���[�Ńf���A��Nehalem-EP�����Ă݂��Ƃ���A
rate�̐��т��悢�̂́A1��SMT�A2��4�R�A�̃l�C�e�B�u���A3��QPI���ʂƂł����B
QPI��4�\�P�b�g�ȏ�ōX�Ɍ��ʂ�����炵���B
���R�̌��ʂɋ����}�l�������Ƃ������Ƃ��납�B��C��SMT����Ȃ����ȁB
rate�̐��т��悢�̂́A1��SMT�A2��4�R�A�̃l�C�e�B�u���A3��QPI���ʂƂł����B
QPI��4�\�P�b�g�ȏ�ōX�Ɍ��ʂ�����炵���B
���R�̌��ʂɋ����}�l�������Ƃ������Ƃ��납�B��C��SMT����Ȃ����ȁB
896 �F,,�E �� �E,,�j��-�������F2008/11/22(�y) 15:58:00 ID:POEkl9Fn
>>893
>�{���Ɍ������Ȃ猩���ɓI�O��ȗ\�z�������ˁB
���E�̂ǂ����̊��Ⴂ���A�����̖ϑz�ƍ��������Ƃ����o�܂��l�����邷�B
Anand�ɂ��ẮA�~�X�̃��x�����Ⴗ���₵�Ȃ���?
>�{���Ɍ������Ȃ猩���ɓI�O��ȗ\�z�������ˁB
���E�̂ǂ����̊��Ⴂ���A�����̖ϑz�ƍ��������Ƃ����o�܂��l�����邷�B
Anand�ɂ��ẮA�~�X�̃��x�����Ⴗ���₵�Ȃ���?
����HDD�ƃ������͊Ԃ�CPU-�T�E�X-�m�[�X���͂����Ăċ������͂Ȃ�Ă��邯��
���낻��HDD�ƃ�������point-to-point�Ō��ԃA�[�L��intel���o���ė����Ȃ����Ɨ\�z
�ǂ���QPI�ш���S�R����ĂȂ����s�����D����Ȃ���?
�܂��ASATA3�̎���ɂȂ��Ă���̘b������
���낻��HDD�ƃ�������point-to-point�Ō��ԃA�[�L��intel���o���ė����Ȃ����Ɨ\�z
�ǂ���QPI�ш���S�R����ĂȂ����s�����D����Ȃ���?
�܂��ASATA3�̎���ɂȂ��Ă���̘b������
Intel Turbo Memory���₵�����ɂ����������Ă��܂��B
���Ԃɂ��Ă����܂����H
�@�͂�
�@������
�������瓊���̂Ă�
�@�͂�
�@������
�������瓊���̂Ă�
�Ȃ�ő���f�[�^�x�[�X��32bit�I�����[������ł���
����������[�A�ŋ߃������[�̗e�ʂ�����Ȃ�
���������ŐV��CPU�ł��������Ȃ̂Ɂc�c
�͂�݂��64�r�b�g�Ή������R���`�N�V���[
#SMT�Ή����Ă݂��A�\�z�ʂ�R�[�h�̏������ɐ���R�ł����
#�����I�ȃR�[�f�B���O�ɂ͌����ċ��Ȃ��̂͂�͂�ɂ�
#�p���[�͏�o���A�ł��Ȃ}�V���s����A������������
����������[�A�ŋ߃������[�̗e�ʂ�����Ȃ�
���������ŐV��CPU�ł��������Ȃ̂Ɂc�c
�͂�݂��64�r�b�g�Ή������R���`�N�V���[
#SMT�Ή����Ă݂��A�\�z�ʂ�R�[�h�̏������ɐ���R�ł����
#�����I�ȃR�[�f�B���O�ɂ͌����ċ��Ȃ��̂͂�͂�ɂ�
#�p���[�͏�o���A�ł��Ȃ}�V���s����A������������
>>900
SMT�Ή�����Ȃ�SMP�Ή�����H
SMT�Ή�����Ȃ�SMP�Ή�����H
�����Ɏg����SMTP�ł����H
EHLO
Bloomfield�Ȃv��������Agena�̉��^������ˁ[���B
�Ă��Ȃ��amd�͐挩�̖�������̂�intel�ɏo����������I�������I
�Ă��Ȃ��amd�͐挩�̖�������̂�intel�ɏo����������I�������I
����Ȃ̂�K5���ɔ��\���Ƃ��Ȃ���P6���ɏo���ꂽ������ς���ĂȂ�����Ȃ���
�����������̖�Y�͂Ȃɂ��Ƃ����Ƀp�N��₪��B��o���ł������[�Ƃ��S�������Ă��Ⴀ�����Ă�B���������B
�v���C�h�͂Ȃ��̂��ˁH���̃A�C�f�A�n�R�͂�[�B�܂�Ŗ^�����ԃ��[�J�[�݂Ă������A���I
�v���C�h�͂Ȃ��̂��ˁH���̃A�C�f�A�n�R�͂�[�B�܂�Ŗ^�����ԃ��[�J�[�݂Ă������A���I
AMD Live�I�Ƃ��������Ȃ̂��H
MMX�Ƃ�SSE�Ȃǂ̖��߃Z�b�g�́A������AMD����ǂ����Ȃ����������H
i7�́AAMD���̗p���Ă��Ȃ�HTT��SSE4.2�������
i7�́AAMD���̗p���Ă��Ȃ�HTT��SSE4.2�������
Tolapai�h�]�[
�yET2008�zIntel�Ђ�SoC�uEP80579�v�𓋍ڂ���
CPU�{�[�h�A�A�h�o�l�b�g���o�W
http://www.ednjapan.com/content/l_news/2008/11/u0o6860000013fjm.html
�yET2008�zIntel�Ђ�SoC�uEP80579�v�𓋍ڂ���
CPU�{�[�h�A�A�h�o�l�b�g���o�W
http://www.ednjapan.com/content/l_news/2008/11/u0o6860000013fjm.html
�܂�x64��TFP��SSE2���̂��̂����B
911 �F,,�E�L�́M�E,,�j��-�������F2008/11/25(��) 22:12:55 ID:P8ZTmbPf
�ŏ��͓Ǝ��̖��߃Z�b�g��������B
3D Now!��Opcode��Ԃ�3�I�y�����h�̕����������߂�lj�����\�肾�����B
���̌�̕ϑJ����Ɩʔ�����
��SSE�x�[�X�ɒu�������܂��i�������AAthlonXP��SSE�T�|�[�g�j
��SSE��SSE2�̕����������������T�|�[�g���܂�
��SSE2�܂őS���T�|�[�g���܂�
���̂ւ��MS�����܂�������ɉ�����������Ǝv���Ă�
3D Now!��Opcode��Ԃ�3�I�y�����h�̕����������߂�lj�����\�肾�����B
���̌�̕ϑJ����Ɩʔ�����
��SSE�x�[�X�ɒu�������܂��i�������AAthlonXP��SSE�T�|�[�g�j
��SSE��SSE2�̕����������������T�|�[�g���܂�
��SSE2�܂őS���T�|�[�g���܂�
���̂ւ��MS�����܂�������ɉ�����������Ǝv���Ă�
>>911
����ǂ��Ȃ��ł��傤�ˁAAMD��SSE5���̗p���ASSSE3������Intel��
���߃Z�b�g�͍̗p����\���͒�߂ł����HAVX��Intel�������ɑΉ�����
�A�v���𑝂₵���ꍇ�́A����ς�AMD�����̂����̗p����悤�ɂȂ�\��
�������̂ł��傤���H
����ǂ��Ȃ��ł��傤�ˁAAMD��SSE5���̗p���ASSSE3������Intel��
���߃Z�b�g�͍̗p����\���͒�߂ł����HAVX��Intel�������ɑΉ�����
�A�v���𑝂₵���ꍇ�́A����ς�AMD�����̂����̗p����悤�ɂȂ�\��
�������̂ł��傤���H
AVX�͂Ƃ�����SSE4.2�܂ł͕��ʂɍ̗p�����Ȃ��̂��E�E�E
���Ȃ�����BSSE4a���炵�Ė�����̕����֓˂������Ă邵
915 �F,,�E�L�́M�E,,�j��-�������F2008/11/25(��) 23:14:16 ID:P8ZTmbPf
�Ƃ�����Agner��AMD�t�H�[�����ł���ȃl�^����Ă��B
http://forums.amd.com/forum/messageview.cfm?catid=203&threadid=98392&messid=908906&parentid=904989&FTVAR_FORUMVIEWTMP=Single
AVX��FMA(vmaddps�Ȃ�)��SSE5��FMA(maddps�Ȃǁj�ɂ킴�Ɩ��O�킹�����ۂ���
Intel�Ƃ��Ă��Ӑ}�I�Ȃ���ł���
�ŁA���̃t�H�[�����ł�AVX�̏����͊m���AMD�͂ǂ̓�AVX���T�|�[�g����H�ڂɂł���
���Ă̂�O��Ƃ��āASSE5��VEX�G���R�[�f�B���O�ł��ǂ����邩���ċc�_���Ă�B
SSE5��AVX�ŋ@�\�������̂�AVX�̂ق����D��Ă�̂͂����Ƃ��Ă�
SSE5�ɂ����Ȃ����߂��������邩���
http://forums.amd.com/forum/messageview.cfm?catid=203&threadid=98392&messid=908906&parentid=904989&FTVAR_FORUMVIEWTMP=Single
AVX��FMA(vmaddps�Ȃ�)��SSE5��FMA(maddps�Ȃǁj�ɂ킴�Ɩ��O�킹�����ۂ���
Intel�Ƃ��Ă��Ӑ}�I�Ȃ���ł���
�ŁA���̃t�H�[�����ł�AVX�̏����͊m���AMD�͂ǂ̓�AVX���T�|�[�g����H�ڂɂł���
���Ă̂�O��Ƃ��āASSE5��VEX�G���R�[�f�B���O�ł��ǂ����邩���ċc�_���Ă�B
SSE5��AVX�ŋ@�\�������̂�AVX�̂ق����D��Ă�̂͂����Ƃ��Ă�
SSE5�ɂ����Ȃ����߂��������邩���
916 �F,,�E�L�́M�E,,�j��-�������F2008/11/25(��) 23:16:51 ID:P8ZTmbPf
>>914
popcnt��SSE4.2�Ɣ���Ă邵
lzcnt���邢�͗ގ��̖��߂�Larrabee�ł��T�|�[�g����Ƃ��B
movntss/sd�́AIntel�������Ă��ǂ��ˁB
extraq/insertq�́A���Ɏg���H
popcnt��SSE4.2�Ɣ���Ă邵
lzcnt���邢�͗ގ��̖��߂�Larrabee�ł��T�|�[�g����Ƃ��B
movntss/sd�́AIntel�������Ă��ǂ��ˁB
extraq/insertq�́A���Ɏg���H
���y�̌����݂̖��������Ȃ͎̂��O��
���D����MS���e���ʂ̑Ή��ɍ������đ��̍����~�߂Ă���邳
���肷��ᐻ�i�̌������o��O�Ɏ��S�m���
���D����MS���e���ʂ̑Ή��ɍ������đ��̍����~�߂Ă���邳
���肷��ᐻ�i�̌������o��O�Ɏ��S�m���
MS�̃T�|�[�g���ĉ��H
VS�̃R���p�C���H
VS�̃R���p�C���H
SSE5�Ȃ�Ė��O��t����AMD�͍ō��ɃA�z
�m���ɂ���͗i�삵�悤���Ȃ���}�W�ŁB
�ł����܂���deneb�͔�����H�����o��������ȁB
AM3�ꎮ��V�K�w�������Ȃ畁�ʂ�Nehalem������c
����Ə������ރX���Ԉ���Ă܂���
����Ə������ރX���Ԉ���Ă܂���
AMD�̐��i���A�Ȃ�Ă����I�����͂����̏Z�l�ɂ͖���������߂�
����ȕ����l�Ԃ��肶��Ȃ���B������CPU�g���Ă邵�X�����������Ă�
�w�r�[�ȃW�T�J�[�Ȃ�A�ǂ��������̏㎩���Ŕ�r���邾��B
���܂��AMD�ɕ��Ă���̂Ŏ���Intel�ɂ��悤�Ǝv����
���̂�AMD���肪�����Ă���
���̂�AMD���肪�����Ă���
�ӂ�������ȏ�͂���Ⴂ�Ȃ̂ōŌ�ɂ��邪
http://en.expreview.com/2008/11/26/amd-phenom-ii-bring-us-no-exciting-improvements.html
����A���̐��\���B
http://en.expreview.com/2008/11/26/amd-phenom-ii-bring-us-no-exciting-improvements.html
����A���̐��\���B
���A�͂����sPhenom���͂悳�����ʼn����ł��B
3DMark06��CPU�A2.66GHz��L2������Q9400��3GHz��PhenomII��
10%�サ�����������Ȃ����ăO���t�\���Ċy�����̂��낤���B
10%�サ�����������Ȃ����ăO���t�\���Ċy�����̂��낤���B
���܂��������������Ⴄ�Ȃ悗���������������Ƃ��Ƃ��Ă��悗������
�y������ˁH
����������ƍr�炵��AMD�̃X���ł�AMD���Ȃ���Intel�������グ
Intel�̃X���ł�Intel���Ȃ���AMD�������グ���
������"no exciting improvements"�������o���ĂȂ��悤����
����������ƍr�炵��AMD�̃X���ł�AMD���Ȃ���Intel�������グ
Intel�̃X���ł�Intel���Ȃ���AMD�������グ���
������"no exciting improvements"�������o���ĂȂ��悤����
"no exciting improvements"
����͎�ςɂ����Ȃ����E�E�E�N�̂����͒m��Ȃ����ǁI
�ڂ���45nm�ɂȂ��������ł��イ�Ԃ����Ƃ������܂�
�[������Ȓ�x���ȍr�炵��Ƃ���ˁ[���낗
����͎�ςɂ����Ȃ����E�E�E�N�̂����͒m��Ȃ����ǁI
�ڂ���45nm�ɂȂ��������ł��イ�Ԃ����Ƃ������܂�
�[������Ȓ�x���ȍr�炵��Ƃ���ˁ[���낗
125W���M�o���Ă����Ȃ���95W��CPU��
10%�サ�����������Ȃ����ăO���i����
10%�サ�����������Ȃ����ăO���i����
>>933��
�n�����ȁA>933�͉��܂킵��Nehalem�Ɠ����y�U�Ɉ�������o���ׂ��w
���������ŏ��������番�������̂͂킩�肫���Ă邩�炻�̃O���t��p�ӂ�����Ȃ����B
����ȃO���t��\������A������w
���������ŏ��������番�������̂͂킩�肫���Ă邩�炻�̃O���t��p�ӂ�����Ȃ����B
����ȃO���t��\������A������w
Q9400�Ɠ������i�тɂ��邩���r������Ȃ��̂��H
938 �F,,�E �� �E,,�j��-�������F2008/11/27(��) 20:42:48 ID:zC8HAqOY
>>882
��ׂ��A�������ł݂����A�̐S�̋L����ǂ܂��ɁAMAC�I�^����̂܂Ƃ߂����ł����
�ς��Ƃ݂ł킩���Ă��܂�������l�͈�̂Ȃ�Ȃ낤��w�@��炢���Ƃ܂�˂�www
�Ȃ̋��ׂ��Ɏg����������w
��ׂ��A�������ł݂����A�̐S�̋L����ǂ܂��ɁAMAC�I�^����̂܂Ƃ߂����ł����
�ς��Ƃ݂ł킩���Ă��܂�������l�͈�̂Ȃ�Ȃ낤��w�@��炢���Ƃ܂�˂�www
�Ȃ̋��ׂ��Ɏg����������w
939 �F,,�E �� �E,,�j��-�������F2008/11/27(��) 20:45:00 ID:zC8HAqOY
�������>>872�͒P�Ȃ�W���[�N���B
�L���ǂ܂Ȃ��ŏ����Ă邩��ȁBAnand����I�ɂ́A
AVX�́A�����\�z�����Nehalem+LRB�ւ̕z�A�����Ƃ����݂ĂȂ��B
�L���ǂ܂Ȃ��ŏ����Ă邩��ȁBAnand����I�ɂ́A
AVX�́A�����\�z�����Nehalem+LRB�ւ̕z�A�����Ƃ����݂ĂȂ��B
940 �F,,�E �� �E,,�j��-�������F2008/11/27(��) 21:29:48 ID:zC8HAqOY
941 �F,,�E�L�́M�E,,�j��-�������F2008/11/27(��) 21:50:06 ID:KVJ1xHPt
�ŁA���ǁA�듚��Anand�����nj����Ă邱�Ƃ͓����ȂˁH
���ق����B
���ق����B
����d�͂��C�ɂȂ��>Phenom II
��۰�ގ���I�ɔ�ׂĔ����Ƃ������̂������C�����邪�c
�܂��L�蓾�Ȃ����낤��
��۰�ގ���I�ɔ�ׂĔ����Ƃ������̂������C�����邪�c
�܂��L�蓾�Ȃ����낤��
943 �F,,�E�L�́M�E,,�j��-�������F2008/11/27(��) 21:55:22 ID:KVJ1xHPt
>>942
�Ȃ��Ȃ��B���̃T�C�g����H
�}�V���S�̂̏���d�͂��瑫��葤��TDP������������������ۂ��B
�L���b�V���̃q�b�g�����オ��`�b�v�Z�b�g�̕��̕��ׂ����邩��g�[�^���ł�
����d�͂̍팸�ɂȂ肤�邩�炻�̂܂܈����������ł�CPU���̂̏���d�͂�
�v��Ȃ��B
�܂��g�[�^���ŏ���d�͂�������̂͂��肪�������Ƃł͂��邪�B
���ς�炸Core i7��Q9550�ȏ�Ƃ̔�r�͂�������Ȃ����낤�ȁB
�Ȃ��Ȃ��B���̃T�C�g����H
�}�V���S�̂̏���d�͂��瑫��葤��TDP������������������ۂ��B
�L���b�V���̃q�b�g�����オ��`�b�v�Z�b�g�̕��̕��ׂ����邩��g�[�^���ł�
����d�͂̍팸�ɂȂ肤�邩�炻�̂܂܈����������ł�CPU���̂̏���d�͂�
�v��Ȃ��B
�܂��g�[�^���ŏ���d�͂�������̂͂��肪�������Ƃł͂��邪�B
���ς�炸Core i7��Q9550�ȏ�Ƃ̔�r�͂�������Ȃ����낤�ȁB
944 �FSocket774�F2008/11/27(��) 22:09:57 ID:op/PNVjm
>943
>���ς�炸Core i7��Q9550�ȏ�Ƃ̔�r�͂�������Ȃ����낤�ȁB
�l�i���������ް�i�̂ݒǐ��B�ȶȷݺ
�ŒႾ�B�����킫�܂������i�ݒ肵��
�ǂ�����������������Ȃ��̂�����
>���ς�炸Core i7��Q9550�ȏ�Ƃ̔�r�͂�������Ȃ����낤�ȁB
�l�i���������ް�i�̂ݒǐ��B�ȶȷݺ
�ŒႾ�B�����킫�܂������i�ݒ肵��
�ǂ�����������������Ȃ��̂�����
945 �FSocket774�F2008/11/28(��) 01:33:19 ID:rQU93AcL
i7���Ēn���Ȃ�ł���H
�܂��n�C�p�[�Ȃ�Ƃ��Ȃ�ăE���R���������邵
���˂ƌ�������
�܂��n�C�p�[�Ȃ�Ƃ��Ȃ�ăE���R���������邵
���˂ƌ�������
946 �FSocket774�F2008/11/28(��) 01:44:23 ID:4xZwmndF
���́A�c�q����ɂ��f����������ł����ǁA�_���R�A8�����Ă��}���`�X���b�h�A�v���łȂ�����g���Ȃ��Ƃ������Ƃł����A
�����ŗL���ɃR�A���g�������ꍇ�A��������̃A�v�����g�p��������̂��ȂƂ��v���̂ł����A����̂����������ŕ����A�v���𗧂��グ���ꍇ
���[�U�[�����Ɉӎ������Ƃ��K�ɕ��ׂ����蓖�ĂĂ����̂ł��傤���H����Ƃ��蓮�Őݒ肵�Ȃ����蕡���A�v�����P�R�A�ŏ��������Ă��܂��̂ł��傤���H
�����ŗL���ɃR�A���g�������ꍇ�A��������̃A�v�����g�p��������̂��ȂƂ��v���̂ł����A����̂����������ŕ����A�v���𗧂��グ���ꍇ
���[�U�[�����Ɉӎ������Ƃ��K�ɕ��ׂ����蓖�ĂĂ����̂ł��傤���H����Ƃ��蓮�Őݒ肵�Ȃ����蕡���A�v�����P�R�A�ŏ��������Ă��܂��̂ł��傤���H
948 �F,,�E�L�́M�E,,�j��-�������F2008/11/28(��) 14:51:26 ID:/NUP3hwi
�\�t�g���������I�Ɂu���̃R�A�g���v���Ďw�肵�Ȃ�����
OS�͏������Ԃ��Ă�R�A�Ɋ���U�邩��C�ɂ����
OS�͏������Ԃ��Ă�R�A�Ɋ���U�邩��C�ɂ����
���������̂����肪�Ƃ��������܂��B����Œ��N�̋^�O����������܂����B
���S����core i7-965 Extreme �d�������������A�@Rampage II Extreme�A�@X25-E Extreme SATA �r�r�c�A�@Windows �������������܂Ƃ߂č��������ɂ����Ă��܂��B
�{���ɂ��肪�Ƃ��������܂����B
���S����core i7-965 Extreme �d�������������A�@Rampage II Extreme�A�@X25-E Extreme SATA �r�r�c�A�@Windows �������������܂Ƃ߂č��������ɂ����Ă��܂��B
�{���ɂ��肪�Ƃ��������܂����B
>>949
�����܂Ŏv����Ȃ�Vista��64�ɂ����[
�����܂Ŏv����Ȃ�Vista��64�ɂ����[
951 �FSocket774�F2008/11/28(��) 15:16:23 ID:Uw9RQGXp
pen�V����̏抷���Ȃ̂Ŏv���莟��������������Ǝv���܂��B���ADDR3������Ȃ��Ⴂ���Ȃ������B
�I�i�֔��N�Ԃ�̎ː������낤�ȁc
>>951
�O���t�B�b�N�{�[�h���K�v����Ȃ����H�`�f�o(?)�ł���H
�Q�t�H��9800�f�s�w+�ʔ����Ă����H(�d���͒m���)
�O���t�B�b�N�{�[�h���K�v����Ȃ����H�`�f�o(?)�ł���H
�Q�t�H��9800�f�s�w+�ʔ����Ă����H(�d���͒m���)
http://techon.nikkeibp.co.jp/article/NEWS/20081117/161306/
Intel��11nm����ւ�ArF�����Ɏ��M
���́u�v�Z�@���\�O���t�B�v���Ă����̂́A���̃}�X�N���̉������Ǝv�����ǁA
����ł����������G�Ȃ��̂��A����ɖ��@�̂悤�Ɍ��̉�܂𐧌�ł���̂����A�ƁB
�܂�����ˁB�v�Z�ʂ͂��̂�������������悤�����ǁB
http://www.sijapan.com/issue/2007/07/u3eqp3000001akyx.html
�́A�u�e�N�m���W�[�m�[�h���Ƃ�CPU�v�����v�̂悤��
EUV��22nm�ł̓p�X�ŁA16nm�ł����₵���̂��ȁB���͐i��ł�炵�����B
Intel��11nm����ւ�ArF�����Ɏ��M
���́u�v�Z�@���\�O���t�B�v���Ă����̂́A���̃}�X�N���̉������Ǝv�����ǁA
����ł����������G�Ȃ��̂��A����ɖ��@�̂悤�Ɍ��̉�܂𐧌�ł���̂����A�ƁB
�܂�����ˁB�v�Z�ʂ͂��̂�������������悤�����ǁB
http://www.sijapan.com/issue/2007/07/u3eqp3000001akyx.html
�́A�u�e�N�m���W�[�m�[�h���Ƃ�CPU�v�����v�̂悤��
EUV��22nm�ł̓p�X�ŁA16nm�ł����₵���̂��ȁB���͐i��ł�炵�����B
�t�N���\�O���t�B�Ă̂��ǂ����Ō����悤��
956 �FMAC�I�^��+++ �����F2008/11/28(��) 20:25:55 ID:CBkootPP
>>954
���炭�O��IBM�����l�̔��\�����Ă��邷�B
http://www.semiconductor.net/article/CA6597205.html
"Computational Scaling"�ƌĂ��}�X�N�̐v�v�Z��A�X�[�p�[�R���s���[�e�B���O��
���p����Ƃ̂��Ƃ��B
���炭�O��IBM�����l�̔��\�����Ă��邷�B
http://www.semiconductor.net/article/CA6597205.html
"Computational Scaling"�ƌĂ��}�X�N�̐v�v�Z��A�X�[�p�[�R���s���[�e�B���O��
���p����Ƃ̂��Ƃ��B
Intel�͍���Pixelated�ʑ��}�X�N�g���Ă邵�ȁB
k1�t�@�N�^�[�͂ǂ��܂ŗ��Ƃ���̂��˂��B
k1�t�@�N�^�[�͂ǂ��܂ŗ��Ƃ���̂��˂��B
958 �F,,�E �� �E,,�j��-�������F2008/11/28(��) 21:32:48 ID:c7UaGo5d
core i7-965 Extreme �d�������������A�@Rampage II Extreme�A�@X25-E Extreme SATA ssd�A�@�r�f�I�J�[�hgeforce9400gt
�A�d���I�E���e�b�NM12 SS-500HM�A�@������TW3X2G1600C9DHX�A�@���w�h���C�uLF-PB371JD�A�@Windows Vista Home Premium�A�@�P�[�X�@�A���e�b�NNine Hundred AB�A���w�����܂����B
���ǁA���p�ł���p�[�c���ЂƂ������ēX���̌����邪�܂܂ɍw�����Ă��܂�����������܂��B�\�z�ȏ�̑�o��ł����B
����Ⴂ�Ƃ͎v���܂����A�S���g�݂���������Ō�Ɏʐ^�Ƌ��Ɏg�p�����A�b�v���܂��B
�A�d���I�E���e�b�NM12 SS-500HM�A�@������TW3X2G1600C9DHX�A�@���w�h���C�uLF-PB371JD�A�@Windows Vista Home Premium�A�@�P�[�X�@�A���e�b�NNine Hundred AB�A���w�����܂����B
���ǁA���p�ł���p�[�c���ЂƂ������ēX���̌����邪�܂܂ɍw�����Ă��܂�����������܂��B�\�z�ȏ�̑�o��ł����B
����Ⴂ�Ƃ͎v���܂����A�S���g�݂���������Ō�Ɏʐ^�Ƌ��Ɏg�p�����A�b�v���܂��B
���A������烌�X���Ă܂��B���ꂪ���܂܂ł̈��@�̍Ō�̃��X�ł��O�O�B
900��R2E�����
962 �F,,�E �� �E,,�j��-�������F2008/11/28(��) 21:57:40 ID:c7UaGo5d
PenIII �� i7 �Ńp�[�c�𗬗p���悤�Ƃ���>>959�̃Z���X���ꋉ�����A����Ō������̂��A
�����ȕi��������߂�X���̂����Ȃ�w�@���₢�����ǂ�w
�����ȕi��������߂�X���̂����Ȃ�w�@���₢�����ǂ�w
�d��500W�ő��v�ȂH
>�r�f�I�J�[�hgeforce9400gt
�������䂤������
�������䂤������
967 �F,,�E �� �E,,�j��-�������F2008/11/28(��) 22:39:25 ID:c7UaGo5d
�o�͌n���ʂ͒m��Ȃ��Ȃ����A�V�X�e���S�̂̓d�͂Ȃ�i7�X���ɑO���炠�������B
http://hothardware.com/Articles/Intel-Core-i7-Processors-Nehalem-and-X58-Have-Arrived/?page=16
http://hothardware.com/Articles/Intel-Core-i7-Processors-Nehalem-and-X58-Have-Arrived/?page=16
968 �F,,�E �� �E,,�j��-�������F2008/11/28(��) 22:40:34 ID:c7UaGo5d
GTX280�ł�����Ȃ���BPhenom���͑啪�}�V���ȁB
45nm+High-k�Ȃ��瓖�R����
����������C2Q Q6600������ƌ����ƂɂȂ邻�����B
http://www.digitimes.com/news/a20081126PD215.html
�@�@----------------------
�@�@Intel to phase out Core 2 Quad Q6600 CPU in 1Q09
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 27 November 2008]
�@�@�@Intel is planning to start phasing out the 65nm Core 2 Quad Q6600 in the first quarter of
�@�@2009, prompting several PC and channel vendors to start planning to cut Q6600-product
�@�@prices to clear their inventory before the end of this year, according to sources at PC vendors.
�@�@�@Intel will issue a product discontinuance notice for the Q6600 in the first quarter next
�@�@year, and call end-of-lifecycle in the second quarter.
�@�@�@Acer has reduced pricing for its Intel Core 2 Quad Q6600-based desktops to below
�@�@NT$13,900 (US$418) for the IT Month consumer show in the Taiwan market, and other
�@�@vendors are expected to follow suit.
�@�@----------------------
http://www.digitimes.com/news/a20081126PD215.html
�@�@----------------------
�@�@Intel to phase out Core 2 Quad Q6600 CPU in 1Q09
�@�@Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 27 November 2008]
�@�@�@Intel is planning to start phasing out the 65nm Core 2 Quad Q6600 in the first quarter of
�@�@2009, prompting several PC and channel vendors to start planning to cut Q6600-product
�@�@prices to clear their inventory before the end of this year, according to sources at PC vendors.
�@�@�@Intel will issue a product discontinuance notice for the Q6600 in the first quarter next
�@�@year, and call end-of-lifecycle in the second quarter.
�@�@�@Acer has reduced pricing for its Intel Core 2 Quad Q6600-based desktops to below
�@�@NT$13,900 (US$418) for the IT Month consumer show in the Taiwan market, and other
�@�@vendors are expected to follow suit.
�@�@----------------------
��������Q9400�ȉ��������ƒl��������
MS�l�̋Z�p�͂͐�����
ttp://www.engadget.com/2008/11/28/windows-7-warp-system-to-allow-for-directx-10-cpu-acceleration/
ttp://www.engadget.com/2008/11/28/windows-7-warp-system-to-allow-for-directx-10-cpu-acceleration/
Larrabee��WARP�œ����������������������肵��
974 �F,,�E�L�́M�E,,�j��-�������F2008/11/29(�y) 15:16:29 ID:d3UvztFy
>>972-973
����Ă邱�Ƃ͓�������BSoftWire�̉��p�B
�V�F�[�_����Ȃ�GPU�Œ薽�߂Ȃ��x86�{������SIMD�ɗ��Ƃ�����ŃR�[�h�I��������B
���������ACUDA2.1�ł�x86�z�X�g���ł̃J�[�l�������s�ɑΉ������Ƃ��B
����Ă邱�Ƃ͓�������BSoftWire�̉��p�B
�V�F�[�_����Ȃ�GPU�Œ薽�߂Ȃ��x86�{������SIMD�ɗ��Ƃ�����ŃR�[�h�I��������B
���������ACUDA2.1�ł�x86�z�X�g���ł̃J�[�l�������s�ɑΉ������Ƃ��B
G965�Ƃ��o���̈����I���{��Vertex Shader�̏�����
�h���C�o���Ń\�t�g�E�F�A�����_�����O���Ă�������������
����Ƃ����n�[�h�E�F�A�g����悤�ɂȂ��Ă��債�ĕς���Ƃ����I�`��������
DirectX10�ł͂���Ȓ�ӂ⋌����`�b�v��MS���i��Ŗʓ|�����Ⴄ��
�h���C�o���Ń\�t�g�E�F�A�����_�����O���Ă�������������
����Ƃ����n�[�h�E�F�A�g����悤�ɂȂ��Ă��債�ĕς���Ƃ����I�`��������
DirectX10�ł͂���Ȓ�ӂ⋌����`�b�v��MS���i��Ŗʓ|�����Ⴄ��
MS�͍�������Win7�Ɉڍs�����悤�Ƃ��Ă�̂���
800MHz���Ɖ͓���L�����肩�c
800MHz���Ɖ͓���L�����肩�c
���W�v�Z��CPU�A�h��Ԃ��̓O���t�B�b�N�J�[�h
����܂�ǂ�GPU�g���Ă���Ȃ�����2D���ォ��̓`���ɖ߂��������ł́B
����܂�ǂ�GPU�g���Ă���Ȃ�����2D���ォ��̓`���ɖ߂��������ł́B
978 �F,,�E�L�́M�E,,�j��-�������F2008/11/30(��) 01:07:48 ID:87fcriAM
���Ă������AVista�Řg�����ړ�����Ǝ��ʂقǒx���̂��������Ă�������ł�����
ttp://msdn.microsoft.com/en-us/library/dd285359.aspx#Performance
Example data:
Running Direct3D 10 Crysis at 800x600 with all the quality settings on their lowest settings
����Ȓ��x�łǂ�������ẮH
����AIntel��IGP���͂܂��Ȃ悤������
Penryn 4 Core @ 3.0GHz��
Example data:
Running Direct3D 10 Crysis at 800x600 with all the quality settings on their lowest settings
����Ȓ��x�łǂ�������ẮH
����AIntel��IGP���͂܂��Ȃ悤������
Penryn 4 Core @ 3.0GHz��
i7��8�R�A�̃X�R�A��HTT���݂̘b�Ȃ�}�W�p�l�F������
8core������16�X���b�h����
>>981
���l�ǂތ���_���R�A�����낤�A�����R�A����4�A8�X���c�h�̌��ʂ�
���l�ǂތ���_���R�A�����낤�A�����R�A����4�A8�X���c�h�̌��ʂ�
�K������w
986 �FSocket774�F2008/12/01(��) 20:53:05 ID:f1MsoL8W
http://www.fudzilla.com/index.php?option=com_content&task=view&id=10707&Itemid=1
Nehalem also has a TLB bug
Nehalem also has a TLB bug
�܂��o�O����Ȃ��ăG���b�^�����Ă����Ă���z������������
����Ȃ��Ƃ��ŋߔ������ꂽCPU���ĂقƂ��TLB�ɗ��R����Ȃ̂���������
����ɂ͉������ʂ̌����ł������?
����Ȃ��Ƃ��ŋߔ������ꂽCPU���ĂقƂ��TLB�ɗ��R����Ȃ̂���������
����ɂ͉������ʂ̌����ł������?
�v�����G�Ȃ�
�����R������
�Ƃ��������ɑ�ς݂���Ȃ���
�㓡�O��Weekly�C�O�j���[�X
CPU��GPU�̋��E���Ȃ��Ȃ鎞�オ�n�܂�2009�N�̃v���Z�b�T
http://pc.watch.impress.co.jp/docs/2008/1202/kaigai478.htm
CPU��GPU�̋��E���Ȃ��Ȃ鎞�オ�n�܂�2009�N�̃v���Z�b�T
http://pc.watch.impress.co.jp/docs/2008/1202/kaigai478.htm
�������N�̘b��
���̃t�F�C�Y�͂k��������������������gpu�������A�͂Ă��āE�E�E
��������86���߃Z�b�g�ɔ@�����Ă��S��̂ˁB
��������86���߃Z�b�g�ɔ@�����Ă��S��̂ˁB
�v���Ԃ�Ɏ���ɗ������c�ꌾ���킹�ĖႤ
CPU�ȂɃo�O�Ȃ�Ă���킯�Ȃ�����
�v���O�������d���܂�Ă�킯�ł�����܂���
CPU�ȂɃo�O�Ȃ�Ă���킯�Ȃ�����
�v���O�������d���܂�Ă�킯�ł�����܂���
���������B
���W�b�N�G���[�Ȃ�Ăǂ��ɂł�����B
���W�b�N�G���[�Ȃ�Ăǂ��ɂł�����B
>>993
�Ȃ��ă����r�[�̍ő�̗��_��x86�������
�Ȃ��ă����r�[�̍ő�̗��_��x86�������
�݊����͂����Ȃ��@PenPro�v���o���Ȃ�
10GHz�܂����`�H
999GHz
1000�Ȃ�Core2Quad�ŋ�
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/