Intel�̎�����CPU�ɂ��Č�낤 25
1 �FSocket774�F
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 24
http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B
�@�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
Intel�̎�����CPU�ɂ��Č�낤 24
http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B
�@�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
|
|
|
���ߋ��X��
24 http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 http://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ��ށB
21 http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
24 http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 http://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ��ށB
21 http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
����
��Intel Core Microarchitecture
Intel's Next Generation Microarchitecture Unveiled
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Into the Core: Intel's next-generation microarchitecture
http://arstechnica.com/articles/paedia/cpu/core.ars
���ĂɂȂ����uCore Microarchitecture�v�̑S�e
http://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
Intel��Core Microarchitecture
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
Intel's Next Generation Microarchitecture Unveiled
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Into the Core: Intel's next-generation microarchitecture
http://arstechnica.com/articles/paedia/cpu/core.ars
���ĂɂȂ����uCore Microarchitecture�v�̑S�e
http://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
Intel��Core Microarchitecture
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
6 �FSocket774�F2006/05/14(��) 03:57:57 ID:fLYvJJ5k
�ێ�
8 �FSocket774�F2006/05/15(��) 07:04:53 ID:PdgvSy1g
age
9 �F�V�X��age�F2006/05/15(��) 07:10:20 ID:LsLSrsnM
>1����
�O�X�X���̂W������̂��ƂȂ��A
20���̃N���b�N�A�b�v��10���ŏI����Ƃ�8���ōςނƂ��Ȃ�Ƃ�������B
10���̂���8���ŏI��邩��20������Ɣ]���ōl���Ă邾���Łc�ȉ���
20���̃N���b�N�A�b�v��10���ŏI����Ƃ�8���ōςނƂ��Ȃ�Ƃ�������B
10���̂���8���ŏI��邩��20������Ɣ]���ōl���Ă邾���Łc�ȉ���
�Ȃ�Athlon64�������������̂��H�Ƃ�
������ւ�m�肽�����ǁE�E�E
������ւ�m�肽�����ǁE�E�E
Athlon64�̎�����I��肩�B
>>11
�Ԃ����Ⴏ�Aintel��K8��AMD�̐��{�������č��������w
�Ԃ����Ⴏ�Aintel��K8��AMD�̐��{�������č��������w
>>11
�������̃v���t�F�`�����Ɠ��@�I���[�h���낤
�v���t�F�`�S����ƁA���x�����ȉ��ɂȂ鏈������
K8���v���t�F�`����������A10�`20%���炢��
�y�ɑ����Ȃ�Ǝv��
����K8��conroe�ɕ����Ă邯�ǁARev.G��
FPU�̕���x���{�ɂȂ��āA�����ɂ���Ă�conroe��
�����邱�Ƃ��\�z�����̂ł���܂ł܂Ƃ�
�������̃v���t�F�`�����Ɠ��@�I���[�h���낤
�v���t�F�`�S����ƁA���x�����ȉ��ɂȂ鏈������
K8���v���t�F�`����������A10�`20%���炢��
�y�ɑ����Ȃ�Ǝv��
����K8��conroe�ɕ����Ă邯�ǁARev.G��
FPU�̕���x���{�ɂȂ��āA�����ɂ���Ă�conroe��
�����邱�Ƃ��\�z�����̂ł���܂ł܂Ƃ�
FPU���������Ȃ��Ă�����܂肤�ꂵ���Ȃ��킯�����B
�[������Rev.G�ɖ��݂͂Ȃ���B�ǂ������I�ɂ͕ς���B
�[������Rev.G�ɖ��݂͂Ȃ���B�ǂ������I�ɂ͕ς���B
�����`��
Conroe��sse unit��128bit������
�Ђ���Ƃ����
via��isaiah�̂悤�ɂ�������FPU�����p����Ȃ��̂���
�܂��悭�ǂ�łȂ����B
Conroe��sse unit��128bit������
�Ђ���Ƃ����
via��isaiah�̂悤�ɂ�������FPU�����p����Ȃ��̂���
�܂��悭�ǂ�łȂ����B
���L�L���b�V���ƃv���t�F�b�`���̓}�W���G�Ȃ��K8�ɂ͂�������Ƃ͐ς߂Ȃ��B
�x���`�������ł́��̓����R��������K8�Ƃł͂قڑ��E�Ɨ\�z�B
����ϓ��@���[�h�ɗ\���@�\�t�������Ƃ��opsFusion�̍v���x���������B
�Ԃ����Ⴐ���������_���Z�͍œK�����܂�������p�v���Z�b�T�ɂ�点�Ă������c
�Ǝv�����͎���x��Ȃ납�B
�x���`�������ł́��̓����R��������K8�Ƃł͂قڑ��E�Ɨ\�z�B
����ϓ��@���[�h�ɗ\���@�\�t�������Ƃ��opsFusion�̍v���x���������B
�Ԃ����Ⴐ���������_���Z�͍œK�����܂�������p�v���Z�b�T�ɂ�点�Ă������c
�Ǝv�����͎���x��Ȃ납�B
19 �FSocket774�F2006/05/17(��) 16:03:00 ID:E4Ak1zB3
CPU���Ă܂��܂��œK���̗]�n������́H
conroe���o����Ȃ�����Ƒ����o������Ċ����Ȃ��ǁB
����Ƃ����\������ɓn���Ď��������邽�߂ɁA
�œK���̗]�n���c���Ă���Ƃ��H
conroe���o����Ȃ�����Ƒ����o������Ċ����Ȃ��ǁB
����Ƃ����\������ɓn���Ď��������邽�߂ɁA
�œK���̗]�n���c���Ă���Ƃ��H
�����̂��āA����͂��߂Ă��犮������܂Ő��S�H���A���J�������邩���
���ŏ��̏o�ׂɂ��Ȃ��đq�ɂɍɐς�ł鎞���Ȃ낤
���ŏ��̏o�ׂɂ��Ȃ��đq�ɂɍɐς�ł鎞���Ȃ낤
>>20
�J�������Ȃ�T�N�ȏォ����
�J�������Ȃ�T�N�ȏォ����
24 �FSocket774�F2006/05/17(��) 21:13:01 ID:E4Ak1zB3
>>20
���Ȃ��̂��������œK�����Ăǂ������Ӗ�������B
���Ȃ��̂��������œK�����Ăǂ������Ӗ�������B
ATI�ł����Ƃ��̃`�[�g
26 �FSocket774�F2006/05/17(��) 21:40:52 ID:hINkEH5q
�h���N�G�ł����Ƃ��̂ӂ��됮��
�����o���Ȃ�����o�Ă��Ȃ������AConroe��65nm�v���Z�X�ł���B
�����v���Z�X���i��ł��Ȃ��ƁA�N���b�N�͒Ⴂ�A�R�A�͈�A�L���b�V���e�ʂ͏��Ȃ����Ď��ɂȂ�B
�����v���Z�X���i��ł��Ȃ��ƁA�N���b�N�͒Ⴂ�A�R�A�͈�A�L���b�V���e�ʂ͏��Ȃ����Ď��ɂȂ�B
965�`�b�v�Z�b�g���s���ďo���ė~�����Ƃ��낾
Conroe��975�ȑO�̃`�b�v�Z�b�g�ɂ͑Ή����邱�Ƃ͂Ȃ��̂��ȁH
�Ȃ�Ƃ�LGA775����̃`�b�v�Z�b�g�ɂ͑Ή����ė~���������B
�̂�ODP�Ȃ�Ĕ��z�ŏ������Ă���Ă��̂ɂȂ��A�C���e���B
�Ȃ�Ƃ�LGA775����̃`�b�v�Z�b�g�ɂ͑Ή����ė~���������B
�̂�ODP�Ȃ�Ĕ��z�ŏ������Ă���Ă��̂ɂȂ��A�C���e���B
>>29
�`�b�v�Z�b�g�Ƃ������VRM(�d���W)�̖�肾�Ƃ������ƂŁA
http://www.hkepc.com/bbs/news.php?tid=593760
�����i865G�œ����Ă���炵���BVRM���������B
�܂������Conroe�Ή��Ɩ������Ă���MB�����ǁB
���ʂ��o�āA���ł������悤�ɂȂ�A��������Ȃ��E�E�B
�`�b�v�Z�b�g�Ƃ������VRM(�d���W)�̖�肾�Ƃ������ƂŁA
http://www.hkepc.com/bbs/news.php?tid=593760
�����i865G�œ����Ă���炵���BVRM���������B
�܂������Conroe�Ή��Ɩ������Ă���MB�����ǁB
���ʂ��o�āA���ł������悤�ɂȂ�A��������Ȃ��E�E�B
�p�^�[���J�b�g�{VID������ł����邩�ȁH
>>29
975X�͑Ή�����B���[�N�X�e�[�V���������W�����̃`�b�v�Z�b�g������͂Ȃ�����ˁB
���̃`�b�v�Z�b�g�͗��N�炵�����B
������>>30�̒ʂ�AVRM��������C����Conroe�Ή���975X�}�U�[�{�[�h���K�v�B
���Ƃ��C���e���̃}�U�[D975XBXLKR�ł́A���b�g�i���o�[304�ȍ~���K�v�B
975X�͑Ή�����B���[�N�X�e�[�V���������W�����̃`�b�v�Z�b�g������͂Ȃ�����ˁB
���̃`�b�v�Z�b�g�͗��N�炵�����B
������>>30�̒ʂ�AVRM��������C����Conroe�Ή���975X�}�U�[�{�[�h���K�v�B
���Ƃ��C���e���̃}�U�[D975XBXLKR�ł́A���b�g�i���o�[304�ȍ~���K�v�B
33 �FSocket774�F2006/05/21(��) 18:24:52 ID:P3Qpe8Ew
Intel to intro WoodCrest on June 19th
http://www.theinquirer.net/?article=31843
5110 - 1.60 GHz clock, 1066 MHz FSB, $230 per 1K CPU
5120 - 1.86 GHz clock, 1066 MHz FSB, $270 per 1K CPU
5130 - 2.00 GHz clock, 1333 MHz FSB, $330 per 1K CPU
5140 - 2.33 GHz clock, 1333 MHz FSB, $470 per 1K CPU
5150 - 2.67 GHz clock, 1333 MHz FSB, $700 per 1K CPU
5160 - 3.00 GHz clock, 1333 MHz FSB, $851 per 1K CPU
Woodcrest 6/19�����[�X�B
���̋L�������Ă�Theo���Ă�ɂ��ƁA
Woodcrest��Northbridge��10-30W�d�͐H���Ƃ��AK8L�͍��N�������N��Q1�ɂł�炵��(�m
���ƁAWoodcrest��4MB+4MB=8MB L2�Ƃ������Ă邵�B�����Ɣc�����ď�����ƁB
http://www.theinquirer.net/?article=31843
5110 - 1.60 GHz clock, 1066 MHz FSB, $230 per 1K CPU
5120 - 1.86 GHz clock, 1066 MHz FSB, $270 per 1K CPU
5130 - 2.00 GHz clock, 1333 MHz FSB, $330 per 1K CPU
5140 - 2.33 GHz clock, 1333 MHz FSB, $470 per 1K CPU
5150 - 2.67 GHz clock, 1333 MHz FSB, $700 per 1K CPU
5160 - 3.00 GHz clock, 1333 MHz FSB, $851 per 1K CPU
Woodcrest 6/19�����[�X�B
���̋L�������Ă�Theo���Ă�ɂ��ƁA
Woodcrest��Northbridge��10-30W�d�͐H���Ƃ��AK8L�͍��N�������N��Q1�ɂł�炵��(�m
���ƁAWoodcrest��4MB+4MB=8MB L2�Ƃ������Ă邵�B�����Ɣc�����ď�����ƁB
FB-DIMM4ch����30W�Ƃ��H���Ă��s�v�c����Ȃ��悤�ȁB
yonah��
http://www.xbitlabs.com/images/mainboards/asus-n4lvm-dh/power-1.png
http://www.xbitlabs.com/images/mainboards/asus-n4lvm-dh/power-2.png
http://www.xbitlabs.com/images/mainboards/asus-n4lvm-dh/power-1.png
{kind=link}
http://www.xbitlabs.com/images/mainboards/asus-n4lvm-dh/power-2.png
{kind=link}
PenD�ེ
Athlon�����\��
ttp://journal.mycom.co.jp/articles/2006/05/19/spf3/
���̋L����
ttp://journal.mycom.co.jp/articles/2006/05/19/spf3/002.html
�����Ă���T�C�g�̏���d�͑��肪�܂��܂��M�p�o���Ȃ��Ȃ��Ă����B
����d�͂̑�����Ăق�Ɠ����Ȃ��B
���̋L����
ttp://journal.mycom.co.jp/articles/2006/05/19/spf3/002.html
�����Ă���T�C�g�̏���d�͑��肪�܂��܂��M�p�o���Ȃ��Ȃ��Ă����B
����d�͂̑�����Ăق�Ɠ����Ȃ��B
{kind=link}
Intel to Offer "Special Edition" Chips for Servers.
http://www.xbitlabs.com/news/cpu/display/20060521232933.html
Intel�̓T�[�o�[�p��Standard��SKU�i5110��1.60GH���`5160��3.00GH���j �ɉ����āA
"Special Edition" ��Chips�����邻�����ȁB
http://www.xbitlabs.com/news/cpu/display/20060521232933.html
Intel�̓T�[�o�[�p��Standard��SKU�i5110��1.60GH���`5160��3.00GH���j �ɉ����āA
"Special Edition" ��Chips�����邻�����ȁB
Intel Nehalem will have lots of interconnect links
http://www.theinquirer.net/?article=31860
��̎�����Nehalem(Conroe�̎��A�[�L�j�ɂ��Ă����ACharlie Demerjian����
���݊J����Ă�Spring Processor Forum�Ŏd����Ă������ɂ��ƁA
�ȑO���皑����Ă�CSI link�����A'Enterprise' versions��Nehalem��8�{�����Ă邻�����B
http://www.theinquirer.net/?article=31860
��̎�����Nehalem(Conroe�̎��A�[�L�j�ɂ��Ă����ACharlie Demerjian����
���݊J����Ă�Spring Processor Forum�Ŏd����Ă������ɂ��ƁA
�ȑO���皑����Ă�CSI link�����A'Enterprise' versions��Nehalem��8�{�����Ă邻�����B
>>41
PCIe�݂�����CSIx1,CSIx2�ɂ��Ďg���̂��ȁH
PCIe�݂�����CSIx1,CSIx2�ɂ��Ďg���̂��ȁH
CSI��{������̑ш�́H
Xeon 5160 3.0GHz Dual core TPC-C : 169,360tpmC / 2.90 $/tpmC
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=106052202
2processor/4core/4thread �� woodcrest�B
TPC-C �͎v�����قǂł��Ȃ��B
http://www.tpc.org/tpcc/results/tpcc_result_detail.asp?id=106052202
2processor/4core/4thread �� woodcrest�B
TPC-C �͎v�����قǂł��Ȃ��B
45 �FMAC�I�^��44 �����F2006/05/24(��) 00:58:22 ID:hfyI0XzM
>>44
�@�@--------------------
�@�@TPC-C �͎v�����قǂł��Ȃ��B
�@�@--------------------
���m�̍l�����̈Ⴂ�����ˁH�ėp�`�b�v�Z�b�g���g����4-way x86�T�[�o�[�Ƃ��Ă팋�\�Ȑ��\���Ǝv�����B
�@�@Woodcrest x 2�@�@�@�@�@�@�F 169,360 [tpmC] ($2.93/tpmC)
�@�@SingleCore Opteron x 4�F 138,845 [tpmC] ($3.04/tpmC)
�@�@DualCore Opteron x 2�@�F 113,628 [tpmC] ($2.99/tpmC)
�@�@--------------------
�@�@TPC-C �͎v�����قǂł��Ȃ��B
�@�@--------------------
���m�̍l�����̈Ⴂ�����ˁH�ėp�`�b�v�Z�b�g���g����4-way x86�T�[�o�[�Ƃ��Ă팋�\�Ȑ��\���Ǝv�����B
�@�@Woodcrest x 2�@�@�@�@�@�@�F 169,360 [tpmC] ($2.93/tpmC)
�@�@SingleCore Opteron x 4�F 138,845 [tpmC] ($3.04/tpmC)
�@�@DualCore Opteron x 2�@�F 113,628 [tpmC] ($2.99/tpmC)
TPC-C������Ɏ���I�ɉ������Ǝv�������ǤTechReport�������ƕ��ʂ̊���Woodcrest/3GHz��
���r���[���Ă��邷�B
http://www.techreport.com/onearticle.x/10021
���r���[���Ă��邷�B
http://www.techreport.com/onearticle.x/10021
47 �FMAC�I�^�������F2006/05/24(��) 01:01:31 ID:hfyI0XzM
������SPEC�ɂ��o�^����锤�����ǤIntel�̌��J����Woodcrest��SPEC2000�̌��ʂ��B
http://www.intel.com/performance/server/xeon/intspd.htm
Woodcrest/3.0GHz, 4MB L2, 1.33GHz FSB
�@�ESPECint_base2000: 3012
�@�ESPECint_rate_base2000: 123 (2-socket/4-way)
�@�ESPECfp_base2000: 2602(Windows), 2783(Linux)
�@�ESPECfp_rate_base2000: 79.3(Windows), 83(Linux)
FB-DIMM���ڂ�Woodcrest�ł��̐��т����礓���SPECint��Conroe�̐��\��X�ɍ����Ȃ�Ƃ����̂�
���ق��B�B�B
http://www.intel.com/performance/server/xeon/intspd.htm
Woodcrest/3.0GHz, 4MB L2, 1.33GHz FSB
�@�ESPECint_base2000: 3012
�@�ESPECint_rate_base2000: 123 (2-socket/4-way)
�@�ESPECfp_base2000: 2602(Windows), 2783(Linux)
�@�ESPECfp_rate_base2000: 79.3(Windows), 83(Linux)
FB-DIMM���ڂ�Woodcrest�ł��̐��т����礓���SPECint��Conroe�̐��\��X�ɍ����Ȃ�Ƃ����̂�
���ق��B�B�B
�Ƃ���ŁAYonah��2���L���b�V���̃o�X����Dothan�̓�{�ŁA
Merom��Yonah�̓�{�Ƃ������ƂȂ��A���ۂ͍���bit���炢�Ȃ낤�H
Merom��Yonah�̓�{�Ƃ������ƂȂ��A���ۂ͍���bit���炢�Ȃ낤�H
�f�[�^�o�X����256bit
52 �F�E�́E�j��-������ ��toBASh.... �F2006/05/25(��) 01:20:45 ID:4Fd4rFOi
Netburst���lLoad/Store�e128bit�͂قڊm���ƌ��Ă悢�悤�ł���
54 �F�E�́E�j��-������ ��toBASh.... �F2006/05/25(��) 01:43:53 ID:4Fd4rFOi
�u128bit SSE�v���s���Ȃ�Ȃ��@�����Ȃ낤�Ƃ͎v������
SIMD����ALU�E�V�t�g�E���̑���S�Ċ܂ނ̂�3�Ȃ̂��A���������܂��Ă�̂�
SIMD����ALU�E�V�t�g�E���̑���S�Ċ܂ނ̂�3�Ȃ̂��A���������܂��Ă�̂�
Core2 XE��3GHz���Ǝv���Ă����A����2.93GHz�ɂȂ����炵���B
3.33GHz�͍l�����Ȃ��Ǝv���Ă������AFSB1.33GHz���Ȃ��͎̂₵��
���ꂩ���Athlon64 FX�X�^�C���ɂȂ邩�ȁB
2.93GHz��Core2�ɍ~��Ă��āAXE��3.2GHz�ɂȂ�A���Ċ������ȁB
3.33GHz�͍l�����Ȃ��Ǝv���Ă������AFSB1.33GHz���Ȃ��͎̂₵��
���ꂩ���Athlon64 FX�X�^�C���ɂȂ邩�ȁB
2.93GHz��Core2�ɍ~��Ă��āAXE��3.2GHz�ɂȂ�A���Ċ������ȁB
Nehalem��Core�R�A�{�����R���{CSI�ɂȂ�̂��ȁH
X6800���ăl�^�݂����ȃv���Z�b�T�i���o�[����
>>49
Woodcrest�X�S�X
DELL���T�[�o�[�ō��XAMD���̗p����炵������ǁA���\�I�ɂ�
����d�͂�AMD�̗p���闝�R�Ȃ�Ė����悤�ȁB
Woodcrest�X�S�X
DELL���T�[�o�[�ō��XAMD���̗p����炵������ǁA���\�I�ɂ�
����d�͂�AMD�̗p���闝�R�Ȃ�Ė����悤�ȁB
�ߑa��߂�
�V�����A�[�L�e�N�`���o����������Ńl�^�Ȃ����낗
�Q�N���ƂɃA�[�L�e�N�`���ς��Ă����炵����
�Q�N��ǂ��Ȃ��H�Ƃ����Ă��l�^�Ȃ����B
�Q�N���ƂɃA�[�L�e�N�`���ς��Ă����炵����
�Q�N��ǂ��Ȃ��H�Ƃ����Ă��l�^�Ȃ����B
>>49
�t��Dempsey�̌����Ԃ�ɋ������B
PenD������ʃp�t�H�[�}���X���o�Ă�����ǂ������̂ɁB
�`�b�v�Z�b�g���]�����͂Ȃ̂��ˁB
�t��Dempsey�̌����Ԃ�ɋ������B
PenD������ʃp�t�H�[�}���X���o�Ă�����ǂ������̂ɁB
�`�b�v�Z�b�g���]�����͂Ȃ̂��ˁB
>>49
�悤�킩���B�x���`�}�[�N�̃O���t�Ƃ��Ȃ��́H
�悤�킩���B�x���`�}�[�N�̃O���t�Ƃ��Ȃ��́H
Nehalem won't have eight CSI links
http://www.theinquirer.net/?article=31912
���Ȃ����̂͊ԈႢ�ŁAFBD links��8�炵���ƁB
Tukwila�Ɠ����悤��CPU���FB-DIMM�������R���g���[�����ڂ��āA
���{���͒m��Ȃ����ǁACSI���ڂ�Ƃ����������Ǝv�����ǁB
�T�[�o�����͂��������\���Ȃ낤�ˁB
http://www.theinquirer.net/?article=31912
���Ȃ����̂͊ԈႢ�ŁAFBD links��8�炵���ƁB
Tukwila�Ɠ����悤��CPU���FB-DIMM�������R���g���[�����ڂ��āA
���{���͒m��Ȃ����ǁACSI���ڂ�Ƃ����������Ǝv�����ǁB
�T�[�o�����͂��������\���Ȃ낤�ˁB
��������4.74GHz�ŃΏĂ�10�b�䂾�Ƃ�B
http://u-san.net/c-board/file/X6800-4739_10s750.gif
http://u-san.net/c-board/file/X6800-4739_10s750.gif
{kind=link}
��������܂�SSE4�̏ڍׂɂ��Ă͏o�ĂȂ���Ȃ��H
Intel 2006 Desktop CPU Roadmap Update
http://www.dailytech.com/Article.aspx?newsid=2547
�@�@�@�@�@�@�@�@�@Clock �@�@�@FSB �@Cache Launch Price@Launch
C2E X6800 2.93GHz / 1066MHz 4MB�@23-Jul�@ $999
C2D E6700 2.67GHz / 1066MHz 4MB�@23-Jul �@$530
C2D E6600 2.40GHz / 1066MHz 4MB�@23-Jul �@$316
C2D E6400 2.13GHz / 1066MHz 2MB�@23-Jul �@$224
C2D E6300 1.86GHz / 1066MHz 2MB�@23-Jul �@$183
Intel 2006 Mobile CPU Roadmap Update
http://www.dailytech.com/article.aspx?newsid=254
�@�@�@�@�@�@�@�@�@Clock�@�@�@FSB Cache Price
C2D T7600�@2.33GHz �@667MHz 4MB $637
C2D T7400�@2.16GHz �@667MHz 4MB $423
C2D T7200�@2.0GHz�@�@ 667MHz 4MB $294
C2D 5600�@�@1.83GHz�@ 667MHz 2MB $240
C2D 5500�@�@1.66GHz�@ 667MHz 2MB $209
Core Duo (Yonah) CPU this June 25th with a 2.33GHz clock.
http://www.dailytech.com/Article.aspx?newsid=2547
�@�@�@�@�@�@�@�@�@Clock �@�@�@FSB �@Cache Launch Price@Launch
C2E X6800 2.93GHz / 1066MHz 4MB�@23-Jul�@ $999
C2D E6700 2.67GHz / 1066MHz 4MB�@23-Jul �@$530
C2D E6600 2.40GHz / 1066MHz 4MB�@23-Jul �@$316
C2D E6400 2.13GHz / 1066MHz 2MB�@23-Jul �@$224
C2D E6300 1.86GHz / 1066MHz 2MB�@23-Jul �@$183
Intel 2006 Mobile CPU Roadmap Update
http://www.dailytech.com/article.aspx?newsid=254
�@�@�@�@�@�@�@�@�@Clock�@�@�@FSB Cache Price
C2D T7600�@2.33GHz �@667MHz 4MB $637
C2D T7400�@2.16GHz �@667MHz 4MB $423
C2D T7200�@2.0GHz�@�@ 667MHz 4MB $294
C2D 5600�@�@1.83GHz�@ 667MHz 2MB $240
C2D 5500�@�@1.66GHz�@ 667MHz 2MB $209
Core Duo (Yonah) CPU this June 25th with a 2.33GHz clock.
Intel 2006 Mobile CPU Roadmap Update
�~http://www.dailytech.com/article.aspx?newsid=254
��http://www.dailytech.com/article.aspx?newsid=2546
�~http://www.dailytech.com/article.aspx?newsid=254
��http://www.dailytech.com/article.aspx?newsid=2546
>>48�̃f�[�^�Dell��SPEC�ɓo�^�������̂����J����Ă��邷�B
SPECint2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
SPECfp2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05956.html
SPECint rate2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060501-05940.html
�@�EPrecision WS 690 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05942.html
SPECfp rate2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060501-05939.html
�@�EPrecision WS 690 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05941.html
SPECint2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05955.html
SPECfp2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05956.html
SPECint rate2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060501-05940.html
�@�EPrecision WS 690 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05942.html
SPECfp rate2000
�@�EPowerEdge 2950 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060501-05939.html
�@�EPrecision WS 690 http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060502-05941.html
71 �FMAC�I�^�������F2006/05/27(�y) 20:29:00 ID:4tEIfxwj
��̏�������SPECint2000��SPECfp2000���
�@PowerEdge 2950 -> Precision WS 690
�̊ԈႢ���B
�@PowerEdge 2950 -> Precision WS 690
�̊ԈႢ���B
72 �F�E�́E�j��-������ ��toBASh.... �F2006/05/27(�y) 22:16:43 ID:pd3KKQ07
>>67
�����������̖ϑz�e�L�X�g�Ƃ��̈��p�T�C�g��Google�̏�ʂ��ď͑ŊJ���ė~�����B
�Ԃ����Ⴏ�A�������̖��߂̒lj����̂͑傫�ȃu���C�N�X���[����Ȃ���
���Z���j�b�g�̑����ɂ�鐫�\����͂���Ǝv���B
�����������̖ϑz�e�L�X�g�Ƃ��̈��p�T�C�g��Google�̏�ʂ��ď͑ŊJ���ė~�����B
�Ԃ����Ⴏ�A�������̖��߂̒lj����̂͑傫�ȃu���C�N�X���[����Ȃ���
���Z���j�b�g�̑����ɂ�鐫�\����͂���Ǝv���B
73 �F�E�́E�j��-������ ��toBASh.... �F2006/05/27(�y) 22:19:08 ID:pd3KKQ07
>>59
�������ш�E���C�e���V�ň��|���Ă邤����Web�T�[�o�݂����ȗp�r����Opteron�D���ȋC��
�������ш�E���C�e���V�ň��|���Ă邤����Web�T�[�o�݂����ȗp�r����Opteron�D���ȋC��
74 �FSocket774�F2006/05/27(�y) 23:41:49 ID:YftZe/6i BE:671789186-
Power Mac (Mac Pro?) �ɂ�Woodcrest���ڂ邷���H
X6800�ă}���n�b�^���I�H
����conroe��9���Ȃ̂��H
77 �FMAC�I�^��76 �����F2006/05/28(��) 00:48:59 ID:26X60QWa
>>76
�@�@--------------
�@�@����conroe��9���Ȃ̂��H
�@�@--------------
�����v�����݂����A����������B�B�B���Ă�������(��)
�@�@--------------
�@�@����conroe��9���Ȃ̂��H
�@�@--------------
�����v�����݂����A����������B�B�B���Ă�������(��)
����2������ɂ�Conroe�������ザ��Ȃ��Ȃ��Ă�̂��c�B
�ȓd�͋@�\�͂ǂ��Ȃ��Ă��?
�ȓd�͋@�\�͂ǂ��Ȃ��Ă��?
���C���i�b�v����3.33GHz���������̂�
�}�[�P�e�B���O�I�ɏo���}���Ȃ����炩�Ǝv���Ă����ǁA
���ۂ̂Ƃ����₾�Ƃ���܂����Ȃ��݂������B
>> ����������ł��ˁB
>> NetBurst����Ȃ��̂Ɂi�[����i�N���b�N�͉��H�j�B
>
>��i�́A266*11=2.93G�ł����A����i�d��(1.34v?)�ł�OC�}�[�W����
>10���ʂ납�Ȃ�Ȃ������E�E(^^;;
>�s�̂�3.33G�Ȃ�āA�܂��܂����Ċ����ł��B
�}�[�P�e�B���O�I�ɏo���}���Ȃ����炩�Ǝv���Ă����ǁA
���ۂ̂Ƃ����₾�Ƃ���܂����Ȃ��݂������B
>> ����������ł��ˁB
>> NetBurst����Ȃ��̂Ɂi�[����i�N���b�N�͉��H�j�B
>
>��i�́A266*11=2.93G�ł����A����i�d��(1.34v?)�ł�OC�}�[�W����
>10���ʂ납�Ȃ�Ȃ������E�E(^^;;
>�s�̂�3.33G�Ȃ�āA�܂��܂����Ċ����ł��B
Itanium�n�̎�����͂ǂ��Ȃ�́H
�܂��ł��肶��Ȃ���ˁH
�܂��ł��肶��Ȃ���ˁH
�R�����X���̐���オ��ɔ�ׂĂ����́c
���̽ڂ���������͏��Intel�̎�����CPU�ł����炵��
nehalem�̖��ł��݂܂��傤���ˁB
parrot�Ɠ��@�I�}���`�X���b�f�B���O�͎������Ă���̂��ˁB
�ǂ�����anti-HTT���Ƃ������Ύ������݂��l�[�~���O�ւ̈�̉��A�̂͂��Ȃ��B
�����SMT�ɂ���Ď������Ă�����ő�̔���B
parrot�Ɠ��@�I�}���`�X���b�f�B���O�͎������Ă���̂��ˁB
�ǂ�����anti-HTT���Ƃ������Ύ������݂��l�[�~���O�ւ̈�̉��A�̂͂��Ȃ��B
�����SMT�ɂ���Ď������Ă�����ő�̔���B
PARROT�Ɠ��@�I�}���`�X���b�f�B���O���ċ�������̂��H
87 �FSocket774�F2006/05/29(��) 19:19:24 ID:5b9DxuvM
4�R�A���ڂ���Core2�͂ǂ�Ȗ��O�ɂȂ�H
�ɍl�����Core2 Quartetto�����ǁc�c
�ɍl�����Core2 Quartetto�����ǁc�c
Core4����ˁH��
>>87
Solo��Duo�ɔ�ׂĒ��߂��B
Solo��Duo�ɔ�ׂĒ��߂��B
90 �F�E�́E�j��-������ ��toBASh.... �F2006/05/29(��) 19:29:53 ID:M2f5LDr1
���ʂ�Core2 eXtreme Edition�ȋC��
Core2Quo�ł�����ł�
92 �F�E�́E�j��-������ ��toBASh.... �F2006/05/29(��) 20:40:25 ID:M2f5LDr1
����Oct�ł��̎���Hexa�H�i16�i����Hex�Ƃ����̂Ɉ���Łj
Intel Core 2 Quartet
Intel Core 2 Octet
Intel Core 2 Orchestra
Intel Core 2 Octet
Intel Core 2 Orchestra
Tulsa��4CPU����Woodcrest2CPU�ɏ��Ă�̂��H
�y�������ƃE���t�f�[���҂�
Intel Core 2 Qoo
http://www.qoo.jp/
http://www.qoo.jp/
Kentsfield��TDP����g����FSB���g���̗\�z�l���āA�ǂ����ɏ���ł����H
TDP�͒P����Conroe�̓�{�ɂȂ�̂��Ȃ��B
TDP�͒P����Conroe�̓�{�ɂȂ�̂��Ȃ��B
KentsField��Core XE��FSB1066/TDP130W/3GHz�O��A�Ƃ̂��ƁB���Ԃ�2.93GHz����
>>97-98
������
������
130W���c�B�������ɂ�����ƃL�c���ȁB
CPU Power Consumption (Burn), W
ttp://www.xbitlabs.com/images/cpu/amd-socket-am2/charts/power.png
Athlon64 FX-62 [2.8GHz dual L2=1MBx2](rev.F) : 135.6W
Pentium XE 965 [3.73GHz dual L2=2MBx2] (rev.C1) : 132W
Pentium D 960 [3.6GHz duall L2=2MBx2] (rev.C1) : 124W
ttp://www.xbitlabs.com/images/cpu/amd-socket-am2/charts/power.png
{kind=link}
Athlon64 FX-62 [2.8GHz dual L2=1MBx2](rev.F) : 135.6W
Pentium XE 965 [3.73GHz dual L2=2MBx2] (rev.C1) : 132W
Pentium D 960 [3.6GHz duall L2=2MBx2] (rev.C1) : 124W
>>87
Core2 Quad ?
Core2 Quad ?
Athlon64 3700+���āAPentium4 3.6GHz������ɏ�芷������ƃT�C�t���K���ɂȂꂻ���ȉ��i����
rev.C1�}�W�ŃC�C�����c
CederMill(C1)��HT��UD������������
CederMill(C1)��HT��UD������������
HyperThreading��UD�̓|�C���g��{�AResult�������ĂƂ��낾��������
106 �FSocket774�F2006/06/02(��) 14:35:09 ID:Lhknc6UD
Northwood 130nm�@�V���O���R�A�A�g�s�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
Prescott�@�@90nm�@�V���O���R�A�A�g�s�A�V�A�[�L�e�N�`���[�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@���MCPU
Smithfield�@ 90nm�@�f���A���R�A�APrescott ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�@�����MCPU
Cedar Mill�@ 65nm�@�V���O���R�A�A�g�s�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
Presler�@�@�@65nm�@�f���A���R�A�ACedar Mill ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�@���b�T��CPU
Conroe�@�@�@65nm�@�f���A���R�A�A�V�A�[�L�e�N�`���[�A�^�̃f���A���R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
Kentsfield�@ 65nm�@�N�A�b�h�R�A�AConroe ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�@�@�@�@�@45nm�@�N�A�b�h�R�A�AKentsfield ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�@���b�T��CPU
���Q�@�@�@�@�@45nm�@�N�A�b�h�R�A�A�V�A�[�L�e�N�`���[�A�^�̃N�A�b�h�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���R�@�@�@�@�@45nm�@�W�R�A�A���Q ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���S�@�@�@�@�@32nm�@�W�R�A�A���R ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���T�@�@�@�@�@32nm�@�W�R�A�A�V�A�[�L�e�N�`���[�A�^�̂W�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���U�@�@�@�@�@32nm�@�P�U�R�A�A���T ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���V�@�@�@�@�@22nm�@�P�U�R�A�A���U ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���W�@�@�@�@�@22nm�@�P�U�R�A�A�V�A�[�L�e�N�`���[�A�^�̂P�U�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���X�@�@�@�@�@22nm�@�R�Q�R�A�A���W ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
Prescott�@�@90nm�@�V���O���R�A�A�g�s�A�V�A�[�L�e�N�`���[�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@���MCPU
Smithfield�@ 90nm�@�f���A���R�A�APrescott ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�@�����MCPU
Cedar Mill�@ 65nm�@�V���O���R�A�A�g�s�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
Presler�@�@�@65nm�@�f���A���R�A�ACedar Mill ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�@���b�T��CPU
Conroe�@�@�@65nm�@�f���A���R�A�A�V�A�[�L�e�N�`���[�A�^�̃f���A���R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
Kentsfield�@ 65nm�@�N�A�b�h�R�A�AConroe ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�@�@�@�@�@45nm�@�N�A�b�h�R�A�AKentsfield ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�@���b�T��CPU
���Q�@�@�@�@�@45nm�@�N�A�b�h�R�A�A�V�A�[�L�e�N�`���[�A�^�̃N�A�b�h�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���R�@�@�@�@�@45nm�@�W�R�A�A���Q ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���S�@�@�@�@�@32nm�@�W�R�A�A���R ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���T�@�@�@�@�@32nm�@�W�R�A�A�V�A�[�L�e�N�`���[�A�^�̂W�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���U�@�@�@�@�@32nm�@�P�U�R�A�A���T ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���V�@�@�@�@�@22nm�@�P�U�R�A�A���U ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���W�@�@�@�@�@22nm�@�P�U�R�A�A�V�A�[�L�e�N�`���[�A�^�̂P�U�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���X�@�@�@�@�@22nm�@�R�Q�R�A�A���W ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�O�@�@�@�@16nm�@�R�Q�R�A�A���X ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���P�P�@�@�@�@16nm�@�R�Q�R�A�A�V�A�[�L�e�N�`���[�A�^�̂R�Q�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�Q�@�@�@�@16nm�@�U�S�R�A�A���P�P ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�R�@�@�@�@11nm�@�U�S�R�A�A���P�Q ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���P�S�@�@�@�@11nm�@�U�S�R�A�A�V�A�[�L�e�N�`���[�A�^�̂U�S�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�T�@�@�@�@11nm�@�P�Q�W�R�A�A���P�S ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�U�@�@�@�@ 8nm�@�P�Q�W�R�A�A���P�T ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���P�V�@�@�@�@ 8nm�@�P�Q�W�R�A�A�V�A�[�L�e�N�`���[�A�^�̂P�Q�W�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�W�@�@�@�@ 8nm�@�Q�T�U�R�A�A���P�V ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�P�@�@�@�@16nm�@�R�Q�R�A�A�V�A�[�L�e�N�`���[�A�^�̂R�Q�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�Q�@�@�@�@16nm�@�U�S�R�A�A���P�P ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�R�@�@�@�@11nm�@�U�S�R�A�A���P�Q ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���P�S�@�@�@�@11nm�@�U�S�R�A�A�V�A�[�L�e�N�`���[�A�^�̂U�S�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�T�@�@�@�@11nm�@�P�Q�W�R�A�A���P�S ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
���P�U�@�@�@�@ 8nm�@�P�Q�W�R�A�A���P�T ������CPU�̃_�C�A�����v���Z�X�V�������N�@�E�E�E�E�E�E�E�E�E�E�@���b�T��CPU
���P�V�@�@�@�@ 8nm�@�P�Q�W�R�A�A�V�A�[�L�e�N�`���[�A�^�̂P�Q�W�R�A�@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�D��CPU
���P�W�@�@�@�@ 8nm�@�Q�T�U�R�A�A���P�V ������CPU�̃_�C��2�����������́@�E�E�E�E�E�E�E�E�E�E�E�E�E�E�E�@�����MCPU
�@+-->�@���b�T��CPU�@----->�@�D��CPU�@----->�@�����MCPU�@--+
�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |
�@+------------------------------------------------------+
���̃M���O����
32core�ɃA���~�̌��E������
�@�@�@�@�@�@�@�@�@�@�@ ������
�@�@�@�@�@�@�@�@�@ �^�@�@�@�@�@�@�_
�@�@�@�@�@�@�@�@ ���@�@�@�@�@�@�@�@��
�@�@�@�@�@+--> ���@�D��CPU�@ ���@--+
�@�@�@�@�@|�@�@�@���@�@�@�@�@�@�@�@���@�@�@|
�@�@�@�@�@|�@�@�@�@�_�@�@�@�@�@�@�^�@�@�@�@|
�@�@�@�@�@|�@�@�@�@�@�@�������@�@�@�@�@�@ |
�@�@�@�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|
�@�@�@�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@v
�@�@�@�������@�@�@�@�@�@�@�@�@�@�@�@�@������
�@�^�@�@�@�@�@�@�_�@�@�@�@�@�@�@�@�^�@�@�@�@�@�@�_
���@�@�@�@�@�@�@�@���@�@�@�@�@�@���@�@�@�@�@�@�@�@��
�����b�T��CPU���@<-----�@�� �����MCPU ��
���@�@�@�@�@�@�@�@���@�@�@�@�@�@���@�@�@�@�@�@�@�@��
�@�_�@�@�@�@�@�@�^�@�@�@�@�@�@�@�@�_�@�@�@�@�@�@�^
�@�@�@�������@�@�@�@�@�@�@�@�@�@�@�@�@������
��������PenD���^��(ry����Ȃ��Ƃ�������j�_!��ID:4etqU9Kb���K���ł���
114 �FSocket774�F2006/06/02(��) 20:09:55 ID:5TnjiW3z
�����������Ƃ͕����������痎������
����̒@�V���ɂ��v���싅�̔M���g���I�@
����A�k���A�M�z�n�������_�Ƃ����싅�̓Ɨ����[�O�����̍\�z�����\����܂����B
�싅�D���̖l�ɂƂ��ėx�肾���قǂ��ꂵ���j���[�X�B
�V���s�͑��N���싅�̃`�[�������S���g�b�v�N���X�B�싅�D���̑����y�n���Ȃ�ł��B
�T�b�J�[�ł����[�����炱���܂ŃA���r��傫�������V���B
�싅���V����������������ɈႢ�Ȃ��I�k�M�z���[�O�ɑ����^�ڂ��I
�V���Ƀv���싅�I�@�A���r�̂悤�ɉ������悤�I
�^���H���H���[�͓y�j���܂ŁI
http://www.banana.gg/index1.asp
����A�k���A�M�z�n�������_�Ƃ����싅�̓Ɨ����[�O�����̍\�z�����\����܂����B
�싅�D���̖l�ɂƂ��ėx�肾���قǂ��ꂵ���j���[�X�B
�V���s�͑��N���싅�̃`�[�������S���g�b�v�N���X�B�싅�D���̑����y�n���Ȃ�ł��B
�T�b�J�[�ł����[�����炱���܂ŃA���r��傫�������V���B
�싅���V����������������ɈႢ�Ȃ��I�k�M�z���[�O�ɑ����^�ڂ��I
�V���Ƀv���싅�I�@�A���r�̂悤�ɉ������悤�I
�^���H���H���[�͓y�j���܂ŁI
http://www.banana.gg/index1.asp
116 �F�E�́E�j��-������ ��toBASh.... �F2006/06/02(��) 20:43:52 ID:UpYDIr3/
���傗������
������tmmintrin.h�ɐG��Ă�l���ĈӊO�Ə��Ȃ����
������tmmintrin.h�ɐG��Ă�l���ĈӊO�Ə��Ȃ����
>>108
8nm�̎���5nm��6nm�ǂ����Ȃ́H
8nm�̎���5nm��6nm�ǂ����Ȃ́H
Core�͏���ň���������d�̘͂g�ɂ��]�T������Ƃ������
���̗]�T��Xeon��4core��Core2��2core���N���b�N�ɐU�蕪����̂��낤
������AMD�̔������n�܂�Rev.H�Ƃقړ������ɗ���45nm��DST�����������킯����
�ǂ̂��炢���\�����シ�邩�C�ɂȂ�Ƃ���
���肵����Nehalem�͏o�Ԃ����������˂�
���̗]�T��Xeon��4core��Core2��2core���N���b�N�ɐU�蕪����̂��낤
������AMD�̔������n�܂�Rev.H�Ƃقړ������ɗ���45nm��DST�����������킯����
�ǂ̂��炢���\�����シ�邩�C�ɂȂ�Ƃ���
���肵����Nehalem�͏o�Ԃ����������˂�
DST���ĂȂ��H
120 �F�E�́E�j��-������ ��toBASh.... �F2006/06/05(��) 04:45:58 ID:i0q+5brU
�T�}�[�^�C��
intel��soi�̎����ȁB
Depleted Substrate Transistor
Intel ���J������ SOI �Z�p�̈��B����܂ł� SOI �Z�p�Ɣ�r���Đ≏�w�������C
ON ���ɂ͓d�����ő���X���[�X�ɂ��COFF ���ɂ̓��[�N����ʓI�� SOI �Z�p�̂P���ɗ}������炵���B
�܂胊�[�N�d����SOI��100����1�ɂł���(�Ȃɂ����ĂȂ��V���R������ׂ���1000����1)
Intel ���J������ SOI �Z�p�̈��B����܂ł� SOI �Z�p�Ɣ�r���Đ≏�w�������C
ON ���ɂ͓d�����ő���X���[�X�ɂ��COFF ���ɂ̓��[�N����ʓI�� SOI �Z�p�̂P���ɗ}������炵���B
�܂胊�[�N�d����SOI��100����1�ɂł���(�Ȃɂ����ĂȂ��V���R������ׂ���1000����1)
FDSOI����
�ŋ߂̃n�C�G���hGPU�͓d�͐H���߂��B
���b�g������̐��\�蕶��ɂ��o�����C���e���ɁA�f�B�X�N���[�g�^GPU������Ăق����B
���b�g������̐��\�蕶��ɂ��o�����C���e���ɁA�f�B�X�N���[�g�^GPU������Ăق����B
ttp://plusd.itmedia.co.jp/pcuser/articles/0606/03/news001.html
�����ǂޕ��ɂ̓��b�g���\��AMD�ɑR���Ďd���Ȃ�����Ă銴����
�����{�C�Ȃ�merom�p�����f�X�N�g�b�v�}�U�[�o���ł���
�Ƃ����Intel���r�f�I�J�[�h�s��ɗ������ĉ\�̓}�W��������?
�����ǂޕ��ɂ̓��b�g���\��AMD�ɑR���Ďd���Ȃ�����Ă銴����
�����{�C�Ȃ�merom�p�����f�X�N�g�b�v�}�U�[�o���ł���
�Ƃ����Intel���r�f�I�J�[�h�s��ɗ������ĉ\�̓}�W��������?
126 �FSocket774�F2006/06/05(��) 16:19:37 ID:6z1I8pYk
��ɕ�����F�߂Ȃ���~�� m9(�O�D�O)�����߷ެ��
>>125
���b�g���\�́A��ΐ��\���グ�邽�߂ɕK�v������A
Intel��AMD�����b�g���\���グ�悤�Ƃ���͓̂��R�B
�����A���b�g���\�̓N���b�N����������ΊȒP�ɏオ�邩��A
��N���b�N��K8�ƒʏ�N���b�N��Core2�����b�g���\�Ŕ�ׂ�ȂƂ������Ƃł���B
���b�g���\�́A��ΐ��\���グ�邽�߂ɕK�v������A
Intel��AMD�����b�g���\���グ�悤�Ƃ���͓̂��R�B
�����A���b�g���\�̓N���b�N����������ΊȒP�ɏオ�邩��A
��N���b�N��K8�ƒʏ�N���b�N��Core2�����b�g���\�Ŕ�ׂ�ȂƂ������Ƃł���B
>>125
Intel�̃r�f�I�J�[�h�s�ꗐ�����ă}�W�H
�\�[�X����������B
�ci740���v���o������Ȃ��B
�ȃG�l�ᔭ�M�Ȃ�ˌ�����I(�M��֥�L)
Intel�̃r�f�I�J�[�h�s�ꗐ�����ă}�W�H
�\�[�X����������B
�ci740���v���o������Ȃ��B
�ȃG�l�ᔭ�M�Ȃ�ˌ�����I(�M��֥�L)
http://www.famitsu.com/game/etc/2006/06/02/239,1149226543,54264,0,0.html
>����5�D�v���C�X�e�[�V����3�̉��i�i�n�[�h�f�B�X�N�h���C�u20GB���f���F62790�~[�ō�]�A
>60GB���f���F�I�[�v�����i�j�ɂ��Ď���ł��B�v���C�X�e�[�V����3�̓Q�[���@�Ƃ��Ă͍�
>�z�ȉ��i�ݒ�ƂȂ��Ă��܂����A�n�C�G���hPC�Ȃ݂̍��X�y�b�N�A�����チ�f�B�A"�u���[���C
>�f�B�X�N"�̍Đ��@�\�ȂǃQ�[���̘g���z�����@�\�����ڂ���Ă��܂��B�����̋@�\�ʂ�
>��Q�[���@�Ƃ��Ăł͂Ȃ��A�����㑍���Ɠd�Ƃ��Č����ꍇ�̉��i�̈�ۂ́H
���܂���APS3�̓n�C�G���hPC���݂̃X�y�b�N�Ƃ������Ă܂���B
>����5�D�v���C�X�e�[�V����3�̉��i�i�n�[�h�f�B�X�N�h���C�u20GB���f���F62790�~[�ō�]�A
>60GB���f���F�I�[�v�����i�j�ɂ��Ď���ł��B�v���C�X�e�[�V����3�̓Q�[���@�Ƃ��Ă͍�
>�z�ȉ��i�ݒ�ƂȂ��Ă��܂����A�n�C�G���hPC�Ȃ݂̍��X�y�b�N�A�����チ�f�B�A"�u���[���C
>�f�B�X�N"�̍Đ��@�\�ȂǃQ�[���̘g���z�����@�\�����ڂ���Ă��܂��B�����̋@�\�ʂ�
>��Q�[���@�Ƃ��Ăł͂Ȃ��A�����㑍���Ɠd�Ƃ��Č����ꍇ�̉��i�̈�ۂ́H
���܂���APS3�̓n�C�G���hPC���݂̃X�y�b�N�Ƃ������Ă܂���B
inq�����ɍs������AXScale���E�E�E
http://www.yukan-fuji.com/archives/2006/06/post_5898.html
>�v�����̓e���r�����R���̂悤�ȃR���g���[�����A�N�V�����̂悤�Ɏg����̂�
>�����ŁA���ɖʔ����ł��ˁB
>����A�o�r�R�͏d��Ԃł͂Ȃ����Ǝv���悤�Ȃ��������̂ŁA
>�d���͂T�L���O���������邻���ł��B
>�������l�i�͏���ō��݂łU���Q�V�X�O�~�B
>����͎q���̃Q�[���@�ł͂���܂���ˁB
>�I�^�N�p�̐��}�V���ł��B
�I�^�N�p�̐��}�V���ł����B
>�v�����̓e���r�����R���̂悤�ȃR���g���[�����A�N�V�����̂悤�Ɏg����̂�
>�����ŁA���ɖʔ����ł��ˁB
>����A�o�r�R�͏d��Ԃł͂Ȃ����Ǝv���悤�Ȃ��������̂ŁA
>�d���͂T�L���O���������邻���ł��B
>�������l�i�͏���ō��݂łU���Q�V�X�O�~�B
>����͎q���̃Q�[���@�ł͂���܂���ˁB
>�I�^�N�p�̐��}�V���ł��B
�I�^�N�p�̐��}�V���ł����B
The PS3 GPU is not fast enough yet
http://www.theinquirer.net/?article=32159
RSX�̃X�y�b�N�_�E���͊m��H
�R�A�N���b�N�@�@550MHz��420MHz
�������N���b�N�@700MHz��600MHz
������256MB�@128bit�ڑ�(9.6GB/s)
GPU��360�ȉ�w
PS3�V���{�߂��Ȃ̂Ɂ�
�쐼���Ɏ�ނ������̘b�ł́A
�uPS3�ł̏o�͂́A1080p�ɗ��܂炸4K/2K(4,000�~2,000�h�b�g�j��_���v
�Ƃ̂��Ƃ������̂ŁA�g�����Ȃ������̗]�͂́A�m���ɂ��Ȃ肠�肻�����B
http://www.watch.impress.co.jp/av/docs/20060511/rt003.htm
��������
http://www.theinquirer.net/?article=32159
RSX�̃X�y�b�N�_�E���͊m��H
�R�A�N���b�N�@�@550MHz��420MHz
�������N���b�N�@700MHz��600MHz
������256MB�@128bit�ڑ�(9.6GB/s)
GPU��360�ȉ�w
PS3�V���{�߂��Ȃ̂Ɂ�
�쐼���Ɏ�ނ������̘b�ł́A
�uPS3�ł̏o�͂́A1080p�ɗ��܂炸4K/2K(4,000�~2,000�h�b�g�j��_���v
�Ƃ̂��Ƃ������̂ŁA�g�����Ȃ������̗]�͂́A�m���ɂ��Ȃ肠�肻�����B
http://www.watch.impress.co.jp/av/docs/20060511/rt003.htm
��������
BD��50GB�Ȃ̂ɓ���HDD��20GB���ď��Ȃ����Ȃ����H
��o����������360�̐��{�̍����\�ŏo���ė~�����B
��o����������360�̐��{�̍����\�ŏo���ė~�����B
>>134
http://www.theinquirer.net/?article=32171
�c�O�Ȃ���A�{�̉��i�ŁA�����̐��\�ŁA��N�x��̂悤���E�E�E�B
RSX�̃g���C�A���O���Z�b�g�A�b�v���[�g���AXenos�̔����i����
���[�J����������read���A16�uM�vB/s����(ry)
no ,this isn't typo.......���āA��A����Ȃ��̂��i����
http://www.theinquirer.net/?article=32171
�c�O�Ȃ���A�{�̉��i�ŁA�����̐��\�ŁA��N�x��̂悤���E�E�E�B
RSX�̃g���C�A���O���Z�b�g�A�b�v���[�g���AXenos�̔����i����
���[�J����������read���A16�uM�vB/s����(ry)
no ,this isn't typo.......���āA��A����Ȃ��̂��i����
�������ɂ���͋ƊE�ԐV�����K�Z�l�^�͂܂��ꂽ���ēz����˂��H
GHz �N���X�� CPU �̃��[�J���������� 16MB/sec ���āA�ނ���B��
����̂�����Ȓx�����낤�B(w
GHz �N���X�� CPU �̃��[�J���������� 16MB/sec ���āA�ނ���B��
����̂�����Ȓx�����낤�B(w
�[��Write���Read���x�����_�Ńl�^�m��@
�펯�I�ɂ͌v�����̕s��Ƃ݂čăe�X�g���邾��
�펯�I�ɂ͌v�����̕s��Ƃ݂čăe�X�g���邾��
>>136
SPE�̃��[�J������������Ȃ���B
RSX����VRAM�ւ̃A�N�Z�X�B���̕\��Local Memory����
������������ɂ����ȁB
����ł�16MB/sec���ăA���G�i�X�����ǁB�Ă�SPE��RSX�A�g��
�p�^�[�������Ȃ����ꂻ���B�]���̗\�z�����B
�X���Ⴂ�Ȃ�ł��̕ӂŁB
SPE�̃��[�J������������Ȃ���B
RSX����VRAM�ւ̃A�N�Z�X�B���̕\��Local Memory����
������������ɂ����ȁB
����ł�16MB/sec���ăA���G�i�X�����ǁB�Ă�SPE��RSX�A�g��
�p�^�[�������Ȃ����ꂻ���B�]���̗\�z�����B
�X���Ⴂ�Ȃ�ł��̕ӂŁB
���[�ARSX �����猩�� local memory ���ĈӖ��Ȃ̂��B�Ȃ�قǁB
������ 16MB/sec �˂��B�ǂ��䂤�������Ă���B
read ��� write �̃o���h����D�悷�邱�Ǝ��͕̂����邯�ǂ˂��B
������ 16MB/sec �˂��B�ǂ��䂤�������Ă���B
read ��� write �̃o���h����D�悷�邱�Ǝ��͕̂����邯�ǂ˂��B
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2770&p=7
���ꌩ���965��nForce���̃q�[�g�V���N���g���Ă��邯��nj��\
�M���o����Ă��Ƃ��ȁH
975�̓q�[�g�V���N�����̃}�U�[����̂ɂ��ꂶ�႟��������CPU
������d�͗����Ă��Ȃ�
���ꌩ���965��nForce���̃q�[�g�V���N���g���Ă��邯��nj��\
�M���o����Ă��Ƃ��ȁH
975�̓q�[�g�V���N�����̃}�U�[����̂ɂ��ꂶ�႟��������CPU
������d�͗����Ă��Ȃ�
Write�͏������ςȂ�������Read�̓f�[�^���������Ă���܂�
�҂��Ȃ���Ȃ��Read�̂ق����x����ˁH
�҂��Ȃ���Ȃ��Read�̂ق����x����ˁH
�������ςȂ��ł��鍂���ȃo�b�t�@������ɂ���ΐ��\�ɍv�����邯�ǁA
�ш�ɂ͂���܂�W�Ȃ��Ǝv����B
�ш�ɂ͂���܂�W�Ȃ��Ǝv����B
>>140
���А��̔��o�Ă���܂łȂ�Ƃ�������ȁB
���̃`�b�v�Z�b�g�A���q�[�g�p�C�v&�t�@���́A�ꕔ���[�J�[�̕t�����l�@�\�����B
�Ƃ͂���965�V���[�Y��90nm�v���Z�X�����Ȃ��Ƃ�����A�����͂��ƂȂ��s���ɂȂ�̂͊m����(w
���А��̔��o�Ă���܂łȂ�Ƃ�������ȁB
���̃`�b�v�Z�b�g�A���q�[�g�p�C�v&�t�@���́A�ꕔ���[�J�[�̕t�����l�@�\�����B
�Ƃ͂���965�V���[�Y��90nm�v���Z�X�����Ȃ��Ƃ�����A�����͂��ƂȂ��s���ɂȂ�̂͊m����(w
144 �FSocket774�F2006/06/07(��) 02:51:31 ID:ZVNbXPSR
CeleronD3.2GHz��Pentium4�ɗႦ��Ɖ�GHz���炢
�Ȃ�ł����ˁH
�Ȃ�ł����ˁH
�t�@������Ȃ��B�t�B���������corz
>>144
�����ɂ���ĈقȂ邪�ő���Pen4��90���A�����ɂ���Ă�50�`60�����x�Ƃ�����
�������A���ׂĂ�CeleronD�͓��N���b�N��WillamettePentium4��葽��������
SedarMillCeleronD�ɂ������Ă�NorthwoodPentium4��FSB533�łƃN���b�N�������ł���ΐ��\�͂قړ����ł���
�����N���b�N�̐��i�͑��݂��Ȃ����ǂˁBNorthwoodPentium4�ł�HTT����(FSB800��FSB533��3.06GH��)�͗�O
��CeleronD��萫�\�͏�B����͂Q���L���b�V���̗e�ʂ�FSB�̑��x�ɂ����̂�
�����Pentium4�Ƃ����Ă��s������Ȃ̂ň�T�ɂ͔�ׂ��Ȃ�
�����ɂ���ĈقȂ邪�ő���Pen4��90���A�����ɂ���Ă�50�`60�����x�Ƃ�����
�������A���ׂĂ�CeleronD�͓��N���b�N��WillamettePentium4��葽��������
SedarMillCeleronD�ɂ������Ă�NorthwoodPentium4��FSB533�łƃN���b�N�������ł���ΐ��\�͂قړ����ł���
�����N���b�N�̐��i�͑��݂��Ȃ����ǂˁBNorthwoodPentium4�ł�HTT����(FSB800��FSB533��3.06GH��)�͗�O
��CeleronD��萫�\�͏�B����͂Q���L���b�V���̗e�ʂ�FSB�̑��x�ɂ����̂�
�����Pentium4�Ƃ����Ă��s������Ȃ̂ň�T�ɂ͔�ׂ��Ȃ�
�R�����[���Ă������������́H
��������
���͑O����
���͑O����
149 �FSocket774�F2006/06/07(��) 12:52:44 ID:53zcTtoa
>>146
>SedarMillCeleronD�ɂ������Ă�NorthwoodPentium4��FSB533�łƃN���b�N�������ł���ΐ��\�͂قړ����ł���
Prescott�Ńp�C�v���C���i�����������̖Y��ĂȂ��H
���N���b�N�E��FSB�ł�L2�L���b�V�����{�ɂ��ւ�炸Northwood���͂��ɑ�����������A�L���b�V���܂œ����Ȃ�
�m���ɗ��͂����B�E�E�E�ƌ����Ă��ɒ[�ȍ��ł͂Ȃ����낤���ȁB
>SedarMillCeleronD�ɂ������Ă�NorthwoodPentium4��FSB533�łƃN���b�N�������ł���ΐ��\�͂قړ����ł���
Prescott�Ńp�C�v���C���i�����������̖Y��ĂȂ��H
���N���b�N�E��FSB�ł�L2�L���b�V�����{�ɂ��ւ�炸Northwood���͂��ɑ�����������A�L���b�V���܂œ����Ȃ�
�m���ɗ��͂����B�E�E�E�ƌ����Ă��ɒ[�ȍ��ł͂Ȃ����낤���ȁB
���܂�Asage�Y�ꂽ�B
151 �F�������G�� ��HkEgRy0Iso �F2006/06/07(��) 12:54:31 ID:QG2NOJe3
64Bit�A�Ή��ɂȂ�̂́A���ȂH�����H�n�Q�����B���ˁB
>>149
�킷��Ă��A����Northwood��Prescott�̍����͂�����������قړ������čl���ŊԈ���ĂȂ��Ȃ����H
�킷��Ă��A����Northwood��Prescott�̍����͂�����������قړ������čl���ŊԈ���ĂȂ��Ȃ����H
153 �FSocket774�F2006/06/07(��) 19:10:54 ID:+PzfC7Ru
>>152
������65nm Celeron�̃L���b�V����Northwood�̔{�ɂȂ�����ł����H
������65nm Celeron�̃L���b�V����Northwood�̔{�ɂȂ�����ł����H
Pen4���Z�����i�ɂȂ����V�_�Z�������̂��A�z����
>>146
HTT�t���͂��̃X���ł͕������
HTT�t���͂��̃X���ł͕������
���̃X���ł�HTT�̗L�����̔ے�Ȃ�Ē���ɂȂ��ĂȂ�����
�T�[�o�[�n�ł̏����Ƃ̑����̈����Ƃ���O�I�Ȏ���͂��邯�ǂ�
�T�[�o�[�n�ł̏����Ƃ̑����̈����Ƃ���O�I�Ȏ���͂��邯�ǂ�
����̃R�[�h�ł́A����B
�ʏ�̃}���`�X���b�h�ł�HTT�Ȃ����������B
�ʏ�̃}���`�X���b�h�ł�HTT�Ȃ����������B
����̃R�[�h�Œx���Ȃ��Ă͖{���]�|���Ƃ͎v��Ȃ��̂��ȁH��
Stream�R�[�h�������Ȃ�A�G���R�������ėǂ������
P6��PenM�ł�������̃R�[�h�Œx���Ȃ邪�H
>>153
���ꂾ�Ƃ܂�L2���{������Ɛ��\�������邩�ǂ����ɂ��Ă���
�l���Ȃ��ƂȂ�Ȃ��Ȃ��Ȃ����H
Prescott��Prescott-2M�ł͊m�������Ȃ���̂ƒx���Ȃ���̂����邩��
�g���g���������Ǝv����
���ꂾ�Ƃ܂�L2���{������Ɛ��\�������邩�ǂ����ɂ��Ă���
�l���Ȃ��ƂȂ�Ȃ��Ȃ��Ȃ����H
Prescott��Prescott-2M�ł͊m�������Ȃ���̂ƒx���Ȃ���̂����邩��
�g���g���������Ǝv����
>>164
�b�̗����S���������Ă��烌�X���悤�ˁB
�b�̗����S���������Ă��烌�X���悤�ˁB
���v���X�R��3.2Gh���g���Ă邯�ǃR�����[�ł�3.2Gh���o��炵���B
�ǂ�ʑ����Ȃ�H
2�{�������ȁH
�ǂ�ʑ����Ȃ�H
2�{�������ȁH
INTEL�̃f���̋L�������̂܂܉L�ۂ݂ɂ����
��̂��̂��炢�����E�E�E
���ۂɂ�6~7�������������Ƃ��낾�Ǝv����
��̂��̂��炢�����E�E�E
���ۂɂ�6~7�������������Ƃ��낾�Ǝv����
�}���`�X���b�h�O��Ȃ�2�{�ȏ�ɂȂ��Ȃ��B
�hCore 2 Duo�h��3�{����!
FX60@E6700�Ɠ��N���b�N�@Vs E6700�œ���G���R�[�h��Excel�̌v�Z���Ɏ��s�̌���Conroe�͂R�{����
> ttp://ascii24.com/news/i/topi/article/2006/06/07/662715-000.html
> ���̌�AAMD�́wAthlon 64 FX-60�x���I�[�o�[�N���b�N���āgCore 2 Duo�h�̃��f���i���o�[�gE6700�h��
> �����̓�����g���ɂ������̌��ʂ��Љ�B�wiTunes 6.04�x��wPC Mark05�x�Ȃ�5�̃G���R�[�h���x�̃O���t�������Ȃ���A
> �wAthlon 64 FX-60�x����1.1�`1.5�{�͍����ɓ��삷��Ɛ��������B�܂��A�gAthnlon 64 FX�h�ƁgCore 2 Duo�h���̃N���b�N�ɍ��킹�A
> ����G���R�[�h��Excel�̌v�Z���Ɏ��s���A���x�����ۂɌv���������(�e�X�g���͕s��)���s�Ȃ�ꂽ�B
> ���ʂ́gAthlon 64 FX�h��36�b�ɑ��āgCore 2 Duo�h��11�b�ƂȂ�A
> ����ɂ������{�l�L�҂���́u���i���o�ꂵ����A���Ќ����Ă݂Ȃ���v�Ƃ������t���R��Ă����B
FX60@E6700�Ɠ��N���b�N�@Vs E6700�œ���G���R�[�h��Excel�̌v�Z���Ɏ��s�̌���Conroe�͂R�{����
> ttp://ascii24.com/news/i/topi/article/2006/06/07/662715-000.html
> ���̌�AAMD�́wAthlon 64 FX-60�x���I�[�o�[�N���b�N���āgCore 2 Duo�h�̃��f���i���o�[�gE6700�h��
> �����̓�����g���ɂ������̌��ʂ��Љ�B�wiTunes 6.04�x��wPC Mark05�x�Ȃ�5�̃G���R�[�h���x�̃O���t�������Ȃ���A
> �wAthlon 64 FX-60�x����1.1�`1.5�{�͍����ɓ��삷��Ɛ��������B�܂��A�gAthnlon 64 FX�h�ƁgCore 2 Duo�h���̃N���b�N�ɍ��킹�A
> ����G���R�[�h��Excel�̌v�Z���Ɏ��s���A���x�����ۂɌv���������(�e�X�g���͕s��)���s�Ȃ�ꂽ�B
> ���ʂ́gAthlon 64 FX�h��36�b�ɑ��āgCore 2 Duo�h��11�b�ƂȂ�A
> ����ɂ������{�l�L�҂���́u���i���o�ꂵ����A���Ќ����Ă݂Ȃ���v�Ƃ������t���R��Ă����B
>>167
���ς���2.5�{���炢�����Ȃ��
���ς���2.5�{���炢�����Ȃ��
�̊��ł͌����25�{�Ƃ����Ă������قǂ̑������B
��AMD�A��Intel�ɒ����
http://enterprise.watch.impress.co.jp/cda/topic/2005/08/24/6000.html
AMD�A�g�f���A���R�A�Ό��h��Intel�ɏ���
http://pc.watch.impress.co.jp/docs/2005/1213/amd.htm
���ǂ���Ȃ����낤
http://enterprise.watch.impress.co.jp/cda/topic/2005/08/24/6000.html
AMD�A�g�f���A���R�A�Ό��h��Intel�ɏ���
http://pc.watch.impress.co.jp/docs/2005/1213/amd.htm
���ǂ���Ȃ����낤
���v���A�Ȃ��ނȂ����G���ȁc
����ɂ��Ă��炦�Ȃ������悤�Ɍ�����c
����ɂ��Ă��炦�Ȃ������悤�Ɍ�����c
���̃X����Intel�D���Ȑl�������͓̂��R���������
���C�o����n���ɂ���悤�ȕi�̖������Ƃ͂���������߂悤�ȁB
�@������Ȃ����炳�B
���C�o����n���ɂ���悤�ȕi�̖������Ƃ͂���������߂悤�ȁB
�@������Ȃ����炳�B
���Ă������A��1�N 64 X2 �������Ă邶���B
Intel���D���ł��BAMD���D���ł��B�ł�VIA�̂ق��������ƍD���ł��I�I
>>176
���̕i�̖������Ƃ��i���Ƃ���Ă���̂�AMD�ЂȂ��E�E�E
���̕i�̖������Ƃ��i���Ƃ���Ă���̂�AMD�ЂȂ��E�E�E
���܂���AMD�̖��O���o�邾���ŋ���������
���ި�(�G߁��)=3ѯʰ
�F�c���f���Ȃ�AAMD�ɑ���
http://plusd.itmedia.co.jp/pcuser/articles/0606/07/news078.html
����ǂނƁACore 2 Duo ���o���܂ł͕��������Ă܂��A����intel���̂������Ă���B
�������蕉������A�����������Ă��ꂽ�ق����g�����͂��肪�����B
����ǂނƁACore 2 Duo ���o���܂ł͕��������Ă܂��A����intel���̂������Ă���B
�������蕉������A�����������Ă��ꂽ�ق����g�����͂��肪�����B
>>178
���װ��Core2�����グ��̂ɂ������ޒ@�����Ƃ��ė������Ă��������Ǝv����
�Ƃ�����Intel�̒��̐l�͂����������肾
���ޔ����Ă�̂ɂ�����Ƒ�������C�͂��邯�ǂ�
���װ��Core2�����グ��̂ɂ������ޒ@�����Ƃ��ė������Ă��������Ǝv����
�Ƃ�����Intel�̒��̐l�͂����������肾
���ޔ����Ă�̂ɂ�����Ƒ�������C�͂��邯�ǂ�
186 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 00:30:49 ID:0FGizYM2
Intel�A�[�L�e�N�`���œK���}�j���A���ŐV�̂܂��ł����H
SSE����̃`���[�j���O��肽���̂�B
SSE����̃`���[�j���O��肽���̂�B
http://www.theregister.co.uk/2006/06/08/intel_gelsinger_stanford/page2.html
>Intel will adopt the on-chip memory controller anyway.
>"Yes, we will do it at some point," Gelsinger said.
>Gelsinger also confirmed the obvious by saying Intel will start producing eight-core processors
>when it moves to a 45nm manufacturing process in 2008
>Gelsinger went on to confirm that Intel will re-introduce Hyperthreading in the generation of chips
>that follow "Core," which will add to the software adventure.
Gelsinger��Stanford�ł̍u���炵���ȁB
>Intel will adopt the on-chip memory controller anyway.
>"Yes, we will do it at some point," Gelsinger said.
>Gelsinger also confirmed the obvious by saying Intel will start producing eight-core processors
>when it moves to a 45nm manufacturing process in 2008
>Gelsinger went on to confirm that Intel will re-introduce Hyperthreading in the generation of chips
>that follow "Core," which will add to the software adventure.
Gelsinger��Stanford�ł̍u���炵���ȁB
Hyper-Threading�����H
189 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 01:45:56 ID:0FGizYM2
Merom/Conroe�Ŏ�������Ȃ��̂͂�͂�M���x���C�ɂ����̂ł��傤��
�܂�SMT�Ȃ̂��˂��BCGMT�ł����������ċC�͂����
PARROT�n���������@�I�}���`�X���b�a���O�X�����낤��
���̕ӂ�͎Г�����������ł���悤�������G���ȁB
���̕ӂ�͎Г�����������ł���悤�������G���ȁB
���ʂɍ��ډ\���Ǝv���AParrot��SMT�B
�Г������̘b�ɂȂ�Ƃ��Ă��A�ǂ���Ƃ��Ă�intel��CPU�������ł����������ǂ���ł��邩��
������čō����ڎw���A���炢�̉�Ђł����ė~�����Ƃ͎v���B
��������(enable�̃^�C�~���O�Ȃ�)�����炷�A�Ƃ����l�����ӂ�ɂ܂Ƃ܂�\���B
HyperThreading��@���l�������ǁA���ꎩ�͓̂��ɂ��܂�Ȃ��Ǝv���Ă���B
�V���O���X���b�h�̍�����>>>>>>�}���`�X���b�h�̉��b�A�Ƃ����l�����邵�A
����intel��SMT���������ɃZ�L�����e�B�����������킯�����B
�����A����ƈꏏ������SMT���̂܂Ŕے肵�������Ƃ�炪�����č���B
�w�}���`�R�A�ɂȂ������玗��f���A��(߇��)��ȁx�A�Ƃ���������̂͂ǂ����Ǝv���B
�Г������̘b�ɂȂ�Ƃ��Ă��A�ǂ���Ƃ��Ă�intel��CPU�������ł����������ǂ���ł��邩��
������čō����ڎw���A���炢�̉�Ђł����ė~�����Ƃ͎v���B
��������(enable�̃^�C�~���O�Ȃ�)�����炷�A�Ƃ����l�����ӂ�ɂ܂Ƃ܂�\���B
HyperThreading��@���l�������ǁA���ꎩ�͓̂��ɂ��܂�Ȃ��Ǝv���Ă���B
�V���O���X���b�h�̍�����>>>>>>�}���`�X���b�h�̉��b�A�Ƃ����l�����邵�A
����intel��SMT���������ɃZ�L�����e�B�����������킯�����B
�����A����ƈꏏ������SMT���̂܂Ŕے肵�������Ƃ�炪�����č���B
�w�}���`�R�A�ɂȂ������玗��f���A��(߇��)��ȁx�A�Ƃ���������̂͂ǂ����Ǝv���B
> ����intel��SMT���������ɃZ�L�����e�B�����������킯�����B
����P�Ɍ��t�V�т̃��x�����������ȁB
���ۂ͕s�\�B
����P�Ɍ��t�V�т̃��x�����������ȁB
���ۂ͕s�\�B
��[�A�ł����������̕ύX�ŕ����I�ɂ����̉����o�Ȃ��قǕs�\�ɏo����킯�����A
MS�̃Z�L�����e�B���낵���A�����l���������Ă��ꂽ���͌��Ƃ��ĔF�����č���ɐ����������B
���O��HyperThreading��������Ȃ����ǁA���������͑啪�X�}�[�g�ɂȂ��ċA���Ă���Ɨ\�z���Ă݂�B
�����Ƀg���[�X�L���b�V�����J���o�b�N����\���B
���ꂪ������d�͌����ɃV�t�g�����I���S�����̐VNehalem�Ȃ̂���!?
MS�̃Z�L�����e�B���낵���A�����l���������Ă��ꂽ���͌��Ƃ��ĔF�����č���ɐ����������B
���O��HyperThreading��������Ȃ����ǁA���������͑啪�X�}�[�g�ɂȂ��ċA���Ă���Ɨ\�z���Ă݂�B
�����Ƀg���[�X�L���b�V�����J���o�b�N����\���B
���ꂪ������d�͌����ɃV�t�g�����I���S�����̐VNehalem�Ȃ̂���!?
2004�N�i���Ăł�2005�N�j�ɔ��������wGRAN TURISMO �S�iGT4�j�x�������x���A
���𑜓x��������ŁA�������̋@�\��lj�����
�u�v���C�X�e�[�V���� �R�iPS�R�j�v�ɈڐA�����t���v���C�A�u���o�[�W�����ł��B
�wGRAN TURISMO HD�x�̍ő�̓����́A�t��HD�𑜓x�i1920�~1080-60p�j�ŕ`���o�����f���ł��B
���̍��𑜓x�̉f�����ƒ�p�e���r�ł��̂悤�ɓW�����ꂽ�̂͂���������Ɛ��E�ŏ��߂Ă�������܂���B
�����݂ł͍ŐV�̃n�C�r�W�����E�e���r�ł����f���o�����Ƃ��o���Ȃ��قǍ����X�y�b�N���������܂����B
���Ȃ݂Ɍ��݂̈�ʓI�ȃn�C�r�W���������̋L�^�𑜓x��1450�~1080i �ł��B
���������́wGRAN TURISMO�x�̓n�C�X�y�b�N�ȃe���r��Ȃ��ƗV�ׂȂ��A�Ƃ����킯�ł͂���܂���B
�wGRAN TURISMO�x�͏�ɍŐ�[�Z�p��O���ɐ��삵�Ă��܂��B
���𑜓x�����܂��u�v���C�X�e�[�V���� �R�v�ɂ��i���̌��ʂȂ̂ł��B
1920�~1080-60p �̏��ʂ��ǂꂭ�炢�Ȃ̂��A�ȒP�ɂ��������܂��傤�B
1997�N�ɔ��������wGT1�x�A����́@320�~240i �ŕ\������Ă��܂����B
�O��wGT4�x�́@640�~480i �ł����B
�O�q�����悤��HD�R���e���c����̃X�^���_�[�hVTR�t�H�[�}�b�g�ł���HDCAM��
�B�e�E���������n�C�r�W���������͋L�^�𑜓x1450�~1080i �ł��B
�掿�̍������̎ʐ^�Ŕ�r���Ă��������B
1�b�Ԃ�����̏��ʂ��r���Ă݂܂��傤�B
�wGT4�x�ɔ�ׂ�ƁA�wGRAN TURISMO HD�x�̏��ʂ�13.5�{�ł��B
�O���t
http://www.gran-turismo.com/jp/binary/images/nws11496773066968902.jpg
�L��
http://www.gran-turismo.com/jp/sp/detail.do?article_id=165
�摜
http://www.gran-turismo.com/jp/sp/detail.do?article_id=167
���𑜓x��������ŁA�������̋@�\��lj�����
�u�v���C�X�e�[�V���� �R�iPS�R�j�v�ɈڐA�����t���v���C�A�u���o�[�W�����ł��B
�wGRAN TURISMO HD�x�̍ő�̓����́A�t��HD�𑜓x�i1920�~1080-60p�j�ŕ`���o�����f���ł��B
���̍��𑜓x�̉f�����ƒ�p�e���r�ł��̂悤�ɓW�����ꂽ�̂͂���������Ɛ��E�ŏ��߂Ă�������܂���B
�����݂ł͍ŐV�̃n�C�r�W�����E�e���r�ł����f���o�����Ƃ��o���Ȃ��قǍ����X�y�b�N���������܂����B
���Ȃ݂Ɍ��݂̈�ʓI�ȃn�C�r�W���������̋L�^�𑜓x��1450�~1080i �ł��B
���������́wGRAN TURISMO�x�̓n�C�X�y�b�N�ȃe���r��Ȃ��ƗV�ׂȂ��A�Ƃ����킯�ł͂���܂���B
�wGRAN TURISMO�x�͏�ɍŐ�[�Z�p��O���ɐ��삵�Ă��܂��B
���𑜓x�����܂��u�v���C�X�e�[�V���� �R�v�ɂ��i���̌��ʂȂ̂ł��B
1920�~1080-60p �̏��ʂ��ǂꂭ�炢�Ȃ̂��A�ȒP�ɂ��������܂��傤�B
1997�N�ɔ��������wGT1�x�A����́@320�~240i �ŕ\������Ă��܂����B
�O��wGT4�x�́@640�~480i �ł����B
�O�q�����悤��HD�R���e���c����̃X�^���_�[�hVTR�t�H�[�}�b�g�ł���HDCAM��
�B�e�E���������n�C�r�W���������͋L�^�𑜓x1450�~1080i �ł��B
�掿�̍������̎ʐ^�Ŕ�r���Ă��������B
1�b�Ԃ�����̏��ʂ��r���Ă݂܂��傤�B
�wGT4�x�ɔ�ׂ�ƁA�wGRAN TURISMO HD�x�̏��ʂ�13.5�{�ł��B
�O���t
http://www.gran-turismo.com/jp/binary/images/nws11496773066968902.jpg
{kind=link}
�L��
http://www.gran-turismo.com/jp/sp/detail.do?article_id=165
�摜
http://www.gran-turismo.com/jp/sp/detail.do?article_id=167
SMT���ă_�C�T�C�Y���قƂ�Ǒ��₳���������ł���킯������
���ڂ���ق��������͕��ʂɂȂ邾��
Pentium4�͂Ȃ�����O�I�ɑ����Ȃ�Ȃ��������ǂ�
���ڂ���ق��������͕��ʂɂȂ邾��
Pentium4�͂Ȃ�����O�I�ɑ����Ȃ�Ȃ��������ǂ�
197 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 23:15:43 ID:0FGizYM2
��O�I�ɂ��Č������A���[�h�E�X�g�A���l�b�N�ɂȂ邵���ߑш����������ȁB
�œK�����Ă����ƐL���]�n���Ȃ��Ȃ��Ă��邵�B
�œK�����Ă����ƐL���]�n���Ȃ��Ȃ��Ă��邵�B
>>195
�R��̓��[�X�Q�[���͂�����x�𑜓x������݂ȓ������Ǝv���Ă�B
�����x��̊�����悤�ɂȂ�Ȃ��ƍ��ȏ�̃��[�X�Q�[���͗v��Ȃ��B
�R��̓��[�X�Q�[���͂�����x�𑜓x������݂ȓ������Ǝv���Ă�B
�����x��̊�����悤�ɂȂ�Ȃ��ƍ��ȏ�̃��[�X�Q�[���͗v��Ȃ��B
199 �F�E�́E�j��-������ ��toBASh.... �F2006/06/10(�y) 23:35:57 ID:0FGizYM2
�|�b�h���[�X�Ƃ��H������������
�A���O���Ƃ���ʃT�C�Y�ɂ���Ă͑��x�����Ȃ��Ȃ���
�A���O���Ƃ���ʃT�C�Y�ɂ���Ă͑��x�����Ȃ��Ȃ���
�Ⴂ�������[�X�Q�[�������𑜓x�͕K�v�ł���B�Տꊴ���C������Ⴄ�B
�Z�K�̃o�[�`�����[�V���O�Ƃ�����������Ɛςݖ؍H�݂����ȉf�����A���̓����͊����I
�����������ꂩ������������f���I�i���͕K�v���Ǝv���B
�Z�K�̃o�[�`�����[�V���O�Ƃ�����������Ɛςݖ؍H�݂����ȉf�����A���̓����͊����I
�����������ꂩ������������f���I�i���͕K�v���Ǝv���B
>>200
������^➑́i24�C���`�ň֎q���O���Ɉړ�����j����Ă�����
32X�̕����ǂ�������B
��ʂ����������ǁA����i�����j�̏�^����e���̓f�J�C�B
������^➑́i24�C���`�ň֎q���O���Ɉړ�����j����Ă�����
32X�̕����ǂ�������B
��ʂ����������ǁA����i�����j�̏�^����e���̓f�J�C�B
**�G��**
* INTEL���i�𗊂܂�����Ȃ��̂ɗi��/�ݾ������C�o�����i���U������
* ���AMD��CPU�@����NOD32�y��PestPatrol�ȊO�̃\�t�g�@���Ɉٗl�Ɏ���
* �Z�L���A����PC�APC��ʁADTV�A���V�X�e���A�܂����۸��ϔȂǂɏo�v
* �b����v���O���~���O�͂��납SIMD(MMX,SSE�Ȃǂ̏����n)��SIMM�Ə��������A ����������
�v���O������肳���������Ȃ��A���S�ȃv���O���~���O�f�l
* BlackIc�APrescotte�A�V���v���I�u�x�X�g�A�`�b���{�`�b�v�A�������ˁAMEMTEST86+��/onecpu�AOutLock�ȂǑz����₷��ԈႢ��Ƃ��B
�@���_�F�������������B
* ���鎩���̖��m���N���Ĉȗ��������A�ʃR�e�Ŏ��쎩��
ttp://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
ttp://66.102.7.104/search?q=cache:yFC7aJM6xCgJ:l-lab.org/pukiwiki/pukiwiki.php
�ߋ���o�v���͂������
�y���@�́H�z�G�����{��Part34�y�l�g�o������z
http://tmp6.2ch.net/test/read.cgi/tubo/1145644897/
* INTEL���i�𗊂܂�����Ȃ��̂ɗi��/�ݾ������C�o�����i���U������
* ���AMD��CPU�@����NOD32�y��PestPatrol�ȊO�̃\�t�g�@���Ɉٗl�Ɏ���
* �Z�L���A����PC�APC��ʁADTV�A���V�X�e���A�܂����۸��ϔȂǂɏo�v
* �b����v���O���~���O�͂��납SIMD(MMX,SSE�Ȃǂ̏����n)��SIMM�Ə��������A ����������
�v���O������肳���������Ȃ��A���S�ȃv���O���~���O�f�l
* BlackIc�APrescotte�A�V���v���I�u�x�X�g�A�`�b���{�`�b�v�A�������ˁAMEMTEST86+��/onecpu�AOutLock�ȂǑz����₷��ԈႢ��Ƃ��B
�@���_�F�������������B
* ���鎩���̖��m���N���Ĉȗ��������A�ʃR�e�Ŏ��쎩��
ttp://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
ttp://66.102.7.104/search?q=cache:yFC7aJM6xCgJ:l-lab.org/pukiwiki/pukiwiki.php
�ߋ���o�v���͂������
�y���@�́H�z�G�����{��Part34�y�l�g�o������z
http://tmp6.2ch.net/test/read.cgi/tubo/1145644897/
�����Ȃ��ĂȂ��킯�ł��Ȃ��Ǝv�����ǂȂ�
�Ǝv���ăX�[�p�[�p�C������Ă݂�
HTT�L��V���O����44�b
HTT�����V���O����44�b
HTT�L��f���A����1��05�b
HTT�����f���A����1��27�b
�܂�����Ȃ��c�S��104������
�Ǝv���ăX�[�p�[�p�C������Ă݂�
HTT�L��V���O����44�b
HTT�����V���O����44�b
HTT�L��f���A����1��05�b
HTT�����f���A����1��27�b
�܂�����Ȃ��c�S��104������
HTT�͓���Ȋ��荞�ݏ����𑽗p����Q�[���@����
�G�~�����[�^�ł͐��Ȍ��ʂ�����ƕ��������Ƃ�����
�G�~�����[�^�ł͐��Ȍ��ʂ�����ƕ��������Ƃ�����
SMT�ŃV���O���X���b�h���\�͏オ���
206 �F�E�́E�j��-������ ��toBASh.... �F2006/06/11(��) 05:51:14 ID:ZPZj2sL2
>>207
�Z�K�T�^�[���G�~����SSF�̍�҂���Ȃ̓n�b�L���ƌ��ʂ������
�q�ׂ����HTT�t��P4�����ɃX���b�h�𑽗p�����R�[�h�������Ă�����ł����E�E�E
http://www7a.biglobe.ne.jp/%7Ephantasy/ssf/record/20040719.html
�Z�K�T�^�[���G�~����SSF�̍�҂���Ȃ̓n�b�L���ƌ��ʂ������
�q�ׂ����HTT�t��P4�����ɃX���b�h�𑽗p�����R�[�h�������Ă�����ł����E�E�E
http://www7a.biglobe.ne.jp/%7Ephantasy/ssf/record/20040719.html
�܂�������CPU���撣���Ă��AOS���̂��̂�MT�ɂȂ��ĂȂ��ƈӖ������悤�ȋC�����邪�B
KernelMT��OS����Solaris�ȊO�͉���������������...
KernelMT��OS����Solaris�ȊO�͉���������������...
>>196-197,203
�M��HT�͂����ł���������L1I�����������ɂȂ�̂��ɂ��悤�Ȋ�K�X
�M��HT�͂����ł���������L1I�����������ɂȂ�̂��ɂ��悤�Ȋ�K�X
>>210
����������̂łȂ�Ȃ��B
����������̂łȂ�Ȃ��B
>>208
�P�ʎ��Ԃ�����̃p�C�v���C���[�U�������オ�����
�u�n�b�L���ƌ��ʂ�����v�Ɍ��܂��Ă邾�낤�B
��������͖{���̃}���`�X���b�h�Ƃ͕ʂȘb���B
�P�ʎ��Ԃ�����̃p�C�v���C���[�U�������オ�����
�u�n�b�L���ƌ��ʂ�����v�Ɍ��܂��Ă邾�낤�B
��������͖{���̃}���`�X���b�h�Ƃ͕ʂȘb���B
HTT�̐��\�E�Z�L�����e�B��@�����̂�FreeBSD����
HTT����Pen4�����S�ȃV���O���R�ACPU�Ƃ������������A�Z�L�����e�B�z�[�����o�㑦����HTT���ɂ���
HTT����Pen4�����S�ȃV���O���R�ACPU�Ƃ������������A�Z�L�����e�B�z�[�����o�㑦����HTT���ɂ���
Hyper-Threading�̗L�p��
http://dj.st44.arena.ne.jp/xwin2/mainhtml/xwinii/startm200201b.html
http://dj.st44.arena.ne.jp/xwin2/mainhtml/xwinii/startm200202a.html
http://dj.st44.arena.ne.jp/xwin2/mainhtml/xwinii/startm200201b.html
http://dj.st44.arena.ne.jp/xwin2/mainhtml/xwinii/startm200202a.html
HT�͒x���Ȃ�Ȃ����Ă̂����_���Ǝv�����H
>>213
�@���ĂȂ��B
�����v���Z�X�̕����X���b�h����HTT�̌��ʂ��ő�������o���邵
�ʃv���Z�X�ł��������[�U�[�ł���Z�L�����e�B�I�ɖ��͂Ȃ�����
���݂�FreeBSD�̃X�P�W���[���ł͂�������������������������
���������܂ł̊Ԗ����ɂ���Ƃ��������̘b�B
�@���ĂȂ��B
�����v���Z�X�̕����X���b�h����HTT�̌��ʂ��ő�������o���邵
�ʃv���Z�X�ł��������[�U�[�ł���Z�L�����e�B�I�ɖ��͂Ȃ�����
���݂�FreeBSD�̃X�P�W���[���ł͂�������������������������
���������܂ł̊Ԗ����ɂ���Ƃ��������̘b�B
FreeBSD��SMP�Ή���Linux���������s���Ă������A���̂������^���}���`�R�A�Ƃ͑�������������
>>211
���X�����A������ƃ����^
���X�����A������ƃ����^
219 �F�E�́E�j��-������ ��toBASh.... �F2006/06/12(��) 21:56:59 ID:H7hw6RLh
Crystal CPUID��SSE4��Merom/Conroe���o�ɑΉ����Ă�Ƃ����d�g���L���b�`����
�\�[�X�ǂ�ł݂���ACPU���f���l��
0x6F(Yonah=0x6E�̎�)�Ȃ�ł����ǁH
���ꂪ�����Ȃ炠���܂�P6�t�@�~���[�Ƃ��������ł����̂�
�܂��A�f���������g��Model�l�g���܂�Family=6�͎g����킯�ŁB
�\�[�X�ǂ�ł݂���ACPU���f���l��
0x6F(Yonah=0x6E�̎�)�Ȃ�ł����ǁH
���ꂪ�����Ȃ炠���܂�P6�t�@�~���[�Ƃ��������ł����̂�
�܂��A�f���������g��Model�l�g���܂�Family=6�͎g����킯�ŁB
�}�W���B�ӊO���ȁB�t���X�N���b�`�Ȃ̂ɁB
����Ƃ��A�����ɔԍ����������Ă����H
����Ƃ��A�����ɔԍ����������Ă����H
Merom���ǂ���Yonah���ǔł��낤�A�Ƃ͌����Ă����ǁAFamily=6�Ȃ̂���B
Crystal CPUID�͂Ƃ������AIntel���}�W��06xF�ɂ��Ă�̂��H
�c���A�Ȃ�CPU-Z��0x6F�ɂ��Ă���B
�}�W���ۂ��ˁB
���܂ŋC�t���Ȃ������c
Crystal CPUID�͂Ƃ������AIntel���}�W��06xF�ɂ��Ă�̂��H
�c���A�Ȃ�CPU-Z��0x6F�ɂ��Ă���B
�}�W���ۂ��ˁB
���܂ŋC�t���Ȃ������c
Penryn���Ă��o��́H
Conroe����̉��P�_�͂ǂ�Ȋ����H
Conroe����̉��P�_�͂ǂ�Ȋ����H
�܂��AFamily��6�Ȃ͈̂����Ӗ�����Ȃ����낤�ȁB
���\�I�ɂ�Yonah��傫�������鎩�M��Intel�ɂ͂���݂��������B
�D�G������P6�R�A�Ɍh�ӂ�\���Ă��Ȃ����B
���\�I�ɂ�Yonah��傫�������鎩�M��Intel�ɂ͂���݂��������B
�D�G������P6�R�A�Ɍh�ӂ�\���Ă��Ȃ����B
>>222
Penryn��45nm�ɐ�w����B
Penryn��45nm�ɐ�w����B
��Penryn��45nm�̐�w����B
intel�I�ɂ��A�[�L�e�B�N�`�����V�ő�̊��҂�Nehalem�Ƃ������ƂȂ̂��[�[�[�[�[�[�[�[�[�b!?
�Ə���Ɋ��҂��Ă݂�B
�Ə���Ɋ��҂��Ă݂�B
�������ɑ҂ĂȂ��������F�ł����悗
�n�[���������҂͂��Ă邯�ǂ��B
�n�[���������҂͂��Ă邯�ǂ��B
45nm�ł�Core2Duo���ǂ̒��x�R�����[�������ƈ���Ă��邩�y����
TDP�������Ȃ�҂������Ȃ�
�����l�n�����͂������ɑ҂ĂȂ��患
TDP�������Ȃ�҂������Ȃ�
�����l�n�����͂������ɑ҂ĂȂ��患
�U�X�K�C�V���c�����Ǎ����̃w�b�h���C����45nm�̘b�藈�Ă܂���
ttp://journal.mycom.co.jp/news/2006/06/13/300.html
ttp://journal.mycom.co.jp/news/2006/06/13/300.html
�`�b�v�Z�b�g�헪��]�����AGPU�x���_�[�ɒ���Intel
http://pc.watch.impress.co.jp/docs/2006/0613/kaigai280.htm
http://pc.watch.impress.co.jp/docs/2006/0613/kaigai280.htm
>>230
�u�����́A32�i�m���[�g�����邢��22�i�m���[�g���̃m�[�h�ŁA
�iTri-Gate�g�����W�X�^�́j�̗p����������d�v�ȋ@�����ƍl���Ă���v�B
(CNET�L��)�ł���B
�u�����́A32�i�m���[�g�����邢��22�i�m���[�g���̃m�[�h�ŁA
�iTri-Gate�g�����W�X�^�́j�̗p����������d�v�ȋ@�����ƍl���Ă���v�B
(CNET�L��)�ł���B
TI��45nm�͉t�Z�I���������ŁB
SRAM�̖��x���������B
SRAM�̖ʐς�
Intel�@0.346������m
TI�@0.24������m
AMD���m��Intel��肿����Ƒ傫�������C������B
SRAM�̖��x���������B
SRAM�̖ʐς�
Intel�@0.346������m
TI�@0.24������m
AMD���m��Intel��肿����Ƒ傫�������C������B
�̂���R��̓C���e���́i�����ȊO�́j�f�o�t�ɎQ������ׂ����Ƃ����ӌ��������Ă����ǂȁE�E�E
���ʂƂ��Ăf�o�t���[�J�[���`�b�v�Z�b�g�Ƃ��o���Ă����킯�����E�E�E
nvidia��ATi���A����������GPU�o���ė~�����Ȃ��`
���ʂƂ��Ăf�o�t���[�J�[���`�b�v�Z�b�g�Ƃ��o���Ă����킯�����E�E�E
nvidia��ATi���A����������GPU�o���ė~�����Ȃ��`
740�ŃR�P������T�d���������
Vista����K�R�ł�����A���傤�Ǘǂ��_�@�ł�����낤
IA-64�AEM64T�AHTT�ƎU�XMS�ɑ�����������ꂽIntel�����v���Ԃ�ɒǂ����������̂��ˁB
Vista��95�I��OS�Ȃ�ʼn��ƂȂ����ȗ\�������邪�B
Vista��95�I��OS�Ȃ�ʼn��ƂȂ����ȗ\�������邪�B
>>239
95�I�Ƃ����̂́AWin32��WinFX�̋��n��(Win95�ł͉��z�}�V��)�Ƃ����Ӗ��ŁA
�{����VISTA��pOS�ƍl���Ă����̂ł����H�@VISTA�ɂ͓����AWinFX��WinFS
���Ԃɍ���Ȃ��Ƃ������܂����B
95�I�Ƃ����̂́AWin32��WinFX�̋��n��(Win95�ł͉��z�}�V��)�Ƃ����Ӗ��ŁA
�{����VISTA��pOS�ƍl���Ă����̂ł����H�@VISTA�ɂ͓����AWinFX��WinFS
���Ԃɍ���Ȃ��Ƃ������܂����B
241 �F�E�́E�j��-������ ��toBASh.... �F2006/06/13(��) 22:55:16 ID:iBWWpuCe
http://aceshardware.com/forums/read_post.jsp?id=120057200&forumid=1
�����ɂ����Ă��邱�Ƃ��Y�Ƃł܂Ƃ߂��
�uMMX�Ńv���O���������Ă鍁��t��
�Ƃ肠����SSE2�ŏ��������B
�Ƃ��Ă��K���ɂȂ�܂��您�܂���v
�����ɂ����Ă��邱�Ƃ��Y�Ƃł܂Ƃ߂��
�uMMX�Ńv���O���������Ă鍁��t��
�Ƃ肠����SSE2�ŏ��������B
�Ƃ��Ă��K���ɂȂ�܂��您�܂���v
>>240
WinFX���Ԃɍ���Ȃ��A�Ƃ����̂͏����Ȃ��B
WinFX���Ԃɍ���Ȃ��A�Ƃ����̂͏����Ȃ��B
���߃Z�b�g�ō���������Ȃ��CISC����̉������B
244 �F�E�́E�j��-������ ��toBASh.... �F2006/06/14(��) 01:57:08 ID:tGGGEShd
�����疽�߃Z�b�g�̒lj�������������(128bit SIMD����)�̃X���[�v�b�g�̉��ǂɏd�_��������Ă�킯����
��̂ɕ����I�ɉ��Z���j�b�g��64bit��������������ĂȂ��̂�128bit�̖��߃Z�b�g���lj�����Ă����Ƃ̂ق���
������������B
�i�t�ɂ��̂ւ��ISA�ƃ}�C�N���A�[�L�e�N�`���̈Ⴂ����肭�z�����Ă���Ă�̂����_��x86�݊��A�[�L�e�N�`���̗ǂ��ł�����j
Core2�̔���͕���������������˂��B������128�r�b�g�p�b�N�h�_��/�����Z���Q���ߓ������s�ł��鉻�������B
AltiVec�Ƃ�����������������Ȃ��B
��̂ɕ����I�ɉ��Z���j�b�g��64bit��������������ĂȂ��̂�128bit�̖��߃Z�b�g���lj�����Ă����Ƃ̂ق���
������������B
�i�t�ɂ��̂ւ��ISA�ƃ}�C�N���A�[�L�e�N�`���̈Ⴂ����肭�z�����Ă���Ă�̂����_��x86�݊��A�[�L�e�N�`���̗ǂ��ł�����j
Core2�̔���͕���������������˂��B������128�r�b�g�p�b�N�h�_��/�����Z���Q���ߓ������s�ł��鉻�������B
AltiVec�Ƃ�����������������Ȃ��B
�_�����Z&���W�X�^�R�s�[��3���ߓ����Ɏ��s�ł���݂���
����́ASSE-ALU��2���� + SSE-Shift���j�b�g��1���߂���?
����́ASSE-ALU��2���� + SSE-Shift���j�b�g��1���߂���?
>>242
���m�ɂ́u�{����WinFX�͊Ԃɍ���Ȃ��v�Ƃ������Ƃ���Ȃ�����
Win32 API��u��������\�肾�������ǁA���ǒf�O����
Win32 API�̏�ɔ킳�郉�C�u�����Ƃ��Ď�������邱�ƂɁB
�v�����Vista=WinXP+.Net Framework3.0
WinFX�̃u�����h�l�[����.Net Framework3.0�֕ύX�����B
���m�ɂ́u�{����WinFX�͊Ԃɍ���Ȃ��v�Ƃ������Ƃ���Ȃ�����
Win32 API��u��������\�肾�������ǁA���ǒf�O����
Win32 API�̏�ɔ킳�郉�C�u�����Ƃ��Ď�������邱�ƂɁB
�v�����Vista=WinXP+.Net Framework3.0
WinFX�̃u�����h�l�[����.Net Framework3.0�֕ύX�����B
>>244
packed arithmetic �Ȃ�ĉߋ��̈╨���Ǝv���Ă��B
Cobol�n�iCobol���̂��̂���Ȃ��āAFortran�n�ɑ��錾�t�ˁj�̏����ł�
���\�З͂����邩�ȁB
�܂��A�����n�i�R���p�C�����j�����̂悤�ɍ���Ă���A�̘b�����B
packed arithmetic �Ȃ�ĉߋ��̈╨���Ǝv���Ă��B
Cobol�n�iCobol���̂��̂���Ȃ��āAFortran�n�ɑ��錾�t�ˁj�̏����ł�
���\�З͂����邩�ȁB
�܂��A�����n�i�R���p�C�����j�����̂悤�ɍ���Ă���A�̘b�����B
248 �FSocket774�F2006/06/14(��) 18:12:51 ID:KP+vxoih
>>247
�ނ肩�HGPU�̃s�N�Z���p�C�v���C���Ȃ�ĂقƂ��SIMD����B
Intel��SIMD���߂�f��Fortran�R���p�C���͏o���Ă邪COBOL�R���p�C���͏o���ĂȂ����B
�ނ肩�HGPU�̃s�N�Z���p�C�v���C���Ȃ�ĂقƂ��SIMD����B
Intel��SIMD���߂�f��Fortran�R���p�C���͏o���Ă邪COBOL�R���p�C���͏o���ĂȂ����B
247��packed10�i��(BCD)�̉��Z�̂��Ƃ������Ă�낤�ȁB
�������SSE���߂Ƃ͊W�Ȃ��B
�������SSE���߂Ƃ͊W�Ȃ��B
250 �F�E�́E�j��-������ ��toBASh.... �F2006/06/14(��) 21:11:54 ID:tGGGEShd
�낷������������������������������
>���߃Z�b�g�ō���������Ȃ��CISC����̉������B
���ꂾ�����G��剻����������CPU��
CISC��RISC���A�Ȃ�ČÏL��������ōl���Ă�
���܂��̔��z�ͶŰ؉��Ή����Ƃ�B
���ꂾ�����G��剻����������CPU��
CISC��RISC���A�Ȃ�ČÏL��������ōl���Ă�
���܂��̔��z�ͶŰ؉��Ή����Ƃ�B
�̂��炠���č�������ISA�݂͂�ȑ����ꏭ�Ȃ��ꖽ�߂̒lj��A�g���A�C��������Ă��ł͂Ȃ������[�B
�����̘A���͂ق�Ƃɂ܂��B
�Ȃ��Ȃ��ނ�Ă���Ȃ��B
��ݽ�!
�Ȃ��Ȃ��ނ�Ă���Ȃ��B
��ݽ�!
>>253
�v���v���r�[��(�Х�ͥ)��!!
�v���v���r�[��(�Х�ͥ)��!!
>>254
4�R�A�v���Z�b�T1�`�b�v�Ƀt�c�[��MCH��1�����ڑ��\�Ƃ���������
�����������т�Ȃ�������낰�邱�Ƃ��ł���������
�܂��ACPU--MCH�Ԃ̒ʐM��100GB/Sec�Ƃ��������炨�������т邩�������B
4�R�A�v���Z�b�T1�`�b�v�Ƀt�c�[��MCH��1�����ڑ��\�Ƃ���������
�����������т�Ȃ�������낰�邱�Ƃ��ł���������
�܂��ACPU--MCH�Ԃ̒ʐM��100GB/Sec�Ƃ��������炨�������т邩�������B
���炢��I
CPU-MCH�Ԃ�100GB/sec���Ă��Ƃ́ADDR2-800�ł�6.4GB/sec������
��������16���P�ʂōڂ��邱�ƂɂȂ�ȁB
��������16���P�ʂōڂ��邱�ƂɂȂ�ȁB
>>254
>�Ƃ͂����AIntel�͏����I�ɂ̓������R���g���[�����v���Z�b�T�ɑg�ݍ��ނ��낤�ƃo���_�[�J�[���͕t���������B���������͏ڂ��������͍T�����B
>���l�ɁAIntel�̓O���t�B�b�N�X�R���g���[�����v���Z�b�T�ɓ������邱�Ƃ��l���Ă��邪�A�X�P�W���[���͂܂����܂��Ă��Ȃ��ƃo���_�[�J�[����
>�q�ׂ��B
����̓_�C�ɓ�������̂��A����Ƃ�SIP��MCH�̂悤�ȃ\�����[�V�����Ȃ̂��H
>�Ƃ͂����AIntel�͏����I�ɂ̓������R���g���[�����v���Z�b�T�ɑg�ݍ��ނ��낤�ƃo���_�[�J�[���͕t���������B���������͏ڂ��������͍T�����B
>���l�ɁAIntel�̓O���t�B�b�N�X�R���g���[�����v���Z�b�T�ɓ������邱�Ƃ��l���Ă��邪�A�X�P�W���[���͂܂����܂��Ă��Ȃ��ƃo���_�[�J�[����
>�q�ׂ��B
����̓_�C�ɓ�������̂��A����Ƃ�SIP��MCH�̂悤�ȃ\�����[�V�����Ȃ̂��H
100GB/sec����256bit���iECC���݂�288bit���j��������A��3GTPS �ƂȂ�̂ŁA
double data rate�Ȃ�1.6GHz�����]�����ł���Ηǂ��킯���B
Athlon64/Opteron��HTT��1GTPS�����炠�Ƃ��傢�Ȃ��ȁB
�܂��A���ۂɂ͂��̑��x��288bit���X�L���[�����������邩�ǂ��������B
double data rate�Ȃ�1.6GHz�����]�����ł���Ηǂ��킯���B
Athlon64/Opteron��HTT��1GTPS�����炠�Ƃ��傢�Ȃ��ȁB
�܂��A���ۂɂ͂��̑��x��288bit���X�L���[�����������邩�ǂ��������B
256bit���Ƃ����肦��c
�����ł��s�тȑш敝�_��?
Memory Read ����������Ε�����Ǝv�����A�ш敝�����傫���Ă����\�͌��サ�Ȃ��B
Opteron���͂܂��ɂ���A�����R�����ڂ��A�a�����𑝂₵�đS�̂̑ш敝��傫���L���Ă����Ԃ͂��Ă��Ȃ��B
> http://pc.watch.impress.co.jp/docs/2006/0605/graph4.htm
Memory Read�@16MB
[email protected] 6466.1MB/s �@ Conroe E6700(2.66GHz) 5861.2MB/s
�����͂���Ȃ��̂ł���B
���̐��l�A�ς�ł��郁�����̗��_�l�]�����x�ɂ��A�o�X�]�����x�ɂ��S���͂��ʒx���B
����܂ł�Xeon���a�����𑝂₷�ƃR�A1������̃o�X�]�����x����L���X�ɒx���Ȃ������ʁA
Opteron��IO�ш悪�r���𗁂�Opteron���D�G�Ȍ��ʂ��c���Ă����������B
INTEL�̎�����CPU�́ACPU���̂��̂̐��\����ƂƂ��Ƀt�����g�o�X�̑傫�����P���ꂽ�B
�`�b�v�Z�b�g��2�̓Ɨ�����FSB�����\�����̗p����2�\�P�b�g�܂ł���FSB�ш敝�s���ɂ�鐫�\�͂قƂ�ǂȂ��ƍl����̂����R���B
�s�K�v�ɑш敝�������L���āA���̑f���炵������犫���Ă������̐��\�͂��̌��ʂ������Ȃ��B
�{�g���l�b�N���ш悩��CPU���\�Ɉڂ������炾�B
Memory Read ����������Ε�����Ǝv�����A�ш敝�����傫���Ă����\�͌��サ�Ȃ��B
Opteron���͂܂��ɂ���A�����R�����ڂ��A�a�����𑝂₵�đS�̂̑ш敝��傫���L���Ă����Ԃ͂��Ă��Ȃ��B
> http://pc.watch.impress.co.jp/docs/2006/0605/graph4.htm
Memory Read�@16MB
[email protected] 6466.1MB/s �@ Conroe E6700(2.66GHz) 5861.2MB/s
�����͂���Ȃ��̂ł���B
���̐��l�A�ς�ł��郁�����̗��_�l�]�����x�ɂ��A�o�X�]�����x�ɂ��S���͂��ʒx���B
����܂ł�Xeon���a�����𑝂₷�ƃR�A1������̃o�X�]�����x����L���X�ɒx���Ȃ������ʁA
Opteron��IO�ш悪�r���𗁂�Opteron���D�G�Ȍ��ʂ��c���Ă����������B
INTEL�̎�����CPU�́ACPU���̂��̂̐��\����ƂƂ��Ƀt�����g�o�X�̑傫�����P���ꂽ�B
�`�b�v�Z�b�g��2�̓Ɨ�����FSB�����\�����̗p����2�\�P�b�g�܂ł���FSB�ш敝�s���ɂ�鐫�\�͂قƂ�ǂȂ��ƍl����̂����R���B
�s�K�v�ɑш敝�������L���āA���̑f���炵������犫���Ă������̐��\�͂��̌��ʂ������Ȃ��B
�{�g���l�b�N���ш悩��CPU���\�Ɉڂ������炾�B
FX-60��Conroe�̓X�R�A�t����ȁB
���ꂩ��FX-60�͗��_�l��90%�ȏ�̑��x���o�Ă�Ǝv���̂����B
���ꂩ��FX-60�͗��_�l��90%�ȏ�̑��x���o�Ă�Ǝv���̂����B
>>262
����AMP�͂ǂ��łǂ�����Ăǂ̒��x�̃o���h���Őڑ�����̂��ȁH
>>261
UltraSPARCIII�iII���炩�j�������A�N�Z�X�� 256bit �������Ǝv���B
���̕���read/write buffer �Ƃ̃C���^�t�F�[�X�̕��ł����āA�꒷�͊W�Ȃ��B
����AMP�͂ǂ��łǂ�����Ăǂ̒��x�̃o���h���Őڑ�����̂��ȁH
>>261
UltraSPARCIII�iII���炩�j�������A�N�Z�X�� 256bit �������Ǝv���B
���̕���read/write buffer �Ƃ̃C���^�t�F�[�X�̕��ł����āA�꒷�͊W�Ȃ��B
�[���A�V���A���o�X�Ɉڍs���悤�Ƃ��Ă�̂ɂ���Ȑ����Ȏ�����킯�Ȃ������B
266 �FSocket774�F2006/06/15(��) 08:34:30 ID:iF8rSJaD
�i ߄t߁j
>>265
100GB/sec �̓`�����Ă��Ƃ́A�ق�1Tbps�̓`���Ɠ������ȁB
���ꂪ�V�X�e�������ň����ɗ��p�ł��������������Ɨǂ��ˁB
�����`���H�͑S�Ċ��S��micro strip line �Ƃ��Đv����Ȃ��Ⴂ���Ȃ�����A
PCB��v�A�����ł����Ƃ͋͂��ɂȂ邾�낤�ȁB
���邢�͌��`���H���g����...
100GB/sec �̓`�����Ă��Ƃ́A�ق�1Tbps�̓`���Ɠ������ȁB
���ꂪ�V�X�e�������ň����ɗ��p�ł��������������Ɨǂ��ˁB
�����`���H�͑S�Ċ��S��micro strip line �Ƃ��Đv����Ȃ��Ⴂ���Ȃ�����A
PCB��v�A�����ł����Ƃ͋͂��ɂȂ邾�낤�ȁB
���邢�͌��`���H���g����...
>>262
���傢�Â����ǁARegatta�iIBM�j�� SuperDome�iHP�j�̂悤��SMP�V�X�e����
�ꍇ�A�V�X�e���Ƃ��Ẵo���h�����l����K�v������͂�����...
����Ƃ� >>262 �̘b��CPU�ЂƂP�ʂ̘b�H
Windows���g���Ƃ��A�G���g�����x����2�\�P�b�g�̃T�[�o�ꍇ���Ă̂Ȃ�A
���̂Ƃ��肾�Ǝv�����ǂˁB
���傢�Â����ǁARegatta�iIBM�j�� SuperDome�iHP�j�̂悤��SMP�V�X�e����
�ꍇ�A�V�X�e���Ƃ��Ẵo���h�����l����K�v������͂�����...
����Ƃ� >>262 �̘b��CPU�ЂƂP�ʂ̘b�H
Windows���g���Ƃ��A�G���g�����x����2�\�P�b�g�̃T�[�o�ꍇ���Ă̂Ȃ�A
���̂Ƃ��肾�Ǝv�����ǂˁB
�܂��A�m����MP��64bit*4��256bit���ɂȂ邾�낤���ǂ��B
>>262�̃A�z�����P��������ł����ǂ�
�����Core�Q�i6700�j����ɓ������̂͂������܂�
�l�a�������̂ŁA���������߂��̂͂��������A�����l�a�����Ȃ����Ȃ��B
965���������A�Ή��ł�945���������Ȃ��B
�l�a�������̂ŁA���������߂��̂͂��������A�����l�a�����Ȃ����Ȃ��B
965���������A�Ή��ł�945���������Ȃ��B
{kind=link}
273 �FSocket774�F2006/06/15(��) 11:12:40 ID:eTq2V+Ow
>>267
> �����`���H�͑S�Ċ��S��micro strip line �Ƃ��Đv����Ȃ��Ⴂ���Ȃ�����A
^^^^^^^^^^^^^^^^
�m�������A��
�܁A�����Ƃ�strip line�ł����`���ł�1Tbps�Ȃ�ĕs�\�Ȗ��B
�V���A���o�X���Ă̂�1�{�̐M���ő����ł͂Ȃ���B
PCIe��x16�͉����ux16�v�Ȃ̂��l���Ă݂ȁB
> �����`���H�͑S�Ċ��S��micro strip line �Ƃ��Đv����Ȃ��Ⴂ���Ȃ�����A
^^^^^^^^^^^^^^^^
�m�������A��
�܁A�����Ƃ�strip line�ł����`���ł�1Tbps�Ȃ�ĕs�\�Ȗ��B
�V���A���o�X���Ă̂�1�{�̐M���ő����ł͂Ȃ���B
PCIe��x16�͉����ux16�v�Ȃ̂��l���Ă݂ȁB
����
LVD�̐���16���邾���̘b�����
1byte����̂�16�̐����g���Ă�킯����Ȃ��B
1��B
1byte����̂�16�̐����g���Ă�킯����Ȃ��B
1��B
>>275
�������A�m����������Ă��܂�������
�ł�640Gbps��OTDM�}���`�v���N�T���x�Ȃ���Ɏs�̂���Ă邪�ȁB
����ƕ����{�̃p�������ɂ���ƁA�X�L���[��}����̂���ς���H
�r�b�g���[�g�グ�ăA�C�p�^�[�����m�ۂ���̂��y���A����Ƃ�
�X�L���[��}���ăf�[�^���[�g��}����̂��y���A�ǂ���Ȃ낤�ȁB
1ps �Ō��͖�0.3mm�i�ނ킯�����A���ꂪ8�p����125Gbps�ɂȂ����Ƃ����
2.4mm�Ⴆ�Γ����ʒu��1�o�C�g������邩��ȁB
�e�t�������Ȃ̊�g���Ό��̑��x��80%���x�͏o�邾�낤���A
����ł�2mm�����A���ۂ̃X�L���[�̋��e�͐������v�� 50%����킯
�ɂ͂����Ȃ�����B
���˂̂��ƂȂ��l���Ȃ��Ⴂ���ˁB
�������A�m����������Ă��܂�������
�ł�640Gbps��OTDM�}���`�v���N�T���x�Ȃ���Ɏs�̂���Ă邪�ȁB
����ƕ����{�̃p�������ɂ���ƁA�X�L���[��}����̂���ς���H
�r�b�g���[�g�グ�ăA�C�p�^�[�����m�ۂ���̂��y���A����Ƃ�
�X�L���[��}���ăf�[�^���[�g��}����̂��y���A�ǂ���Ȃ낤�ȁB
1ps �Ō��͖�0.3mm�i�ނ킯�����A���ꂪ8�p����125Gbps�ɂȂ����Ƃ����
2.4mm�Ⴆ�Γ����ʒu��1�o�C�g������邩��ȁB
�e�t�������Ȃ̊�g���Ό��̑��x��80%���x�͏o�邾�낤���A
����ł�2mm�����A���ۂ̃X�L���[�̋��e�͐������v�� 50%����킯
�ɂ͂����Ȃ�����B
���˂̂��ƂȂ��l���Ȃ��Ⴂ���ˁB
Xeon�������Opteron�ɔ����ł���Ԑ����������ƁA���������b�ł���
��ŁA
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �ȁ@�@�@�@�@�@�@ �ȁ@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ /�@�R�@�@�@ �@ �@ /�@�R�@�@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�R�Q�Q�Q/�@�@�@�R�@�@�@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�m�i �@�@�@�@�@�@�@ �@ �@ �@ �_
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�� �@ �� �@�@/�_�@�@�@���@�@|�@ �^�P�P�P�P�P�P
�@�@�@�@�@�@�@�@ �ց@�@�@ |�@�@ �@ �@ �@ �@�@/�@�@�_�@�@�@�@�@|���@Tulsa�܂��[�H
�@�@�@�@�@�@ �^�@�_�_�@�@�_�@ �@�@�@�@ �@/�P�P�P�_�@ �^ �@�_�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�^ �@�@�^�_�_�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�R
�J���J���J���^�^ �@�_�_/�@i�@i�@ �@�@�@�@�Q�@�@�@�@�@�@|
�@�J���J���J���@�@�@�@�@�@i�@| �a| �@�@ /�P�@�@ �R�@�@�@ /�@�Q�Q
�@�@�@�J���J���J���@�� [�P�P�P�P�P�R�@�@�@�@�@ �@�@/�P�@�@�^|
�@�@�@�_�P�P�P�P�P�P�P�^�P�P�R�Q�Q�Q�Q�Q �^�@�@�@�^�@ |
�@�@�@�@ �_������^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�@�@|
�@�@�@�@�@�@�_�Q�Q�Q�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �^�@�@�@�@ |
��ŁA
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �ȁ@�@�@�@�@�@�@ �ȁ@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@ �@ �@ �@ �@ �@ /�@�R�@�@�@ �@ �@ /�@�R�@�@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/�@�@�@�R�Q�Q�Q/�@�@�@�R�@�@�@�@�C���C���C���C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�m�i �@�@�@�@�@�@�@ �@ �@ �@ �_
�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@�@�� �@ �� �@�@/�_�@�@�@���@�@|�@ �^�P�P�P�P�P�P
�@�@�@�@�@�@�@�@ �ց@�@�@ |�@�@ �@ �@ �@ �@�@/�@�@�_�@�@�@�@�@|���@Tulsa�܂��[�H
�@�@�@�@�@�@ �^�@�_�_�@�@�_�@ �@�@�@�@ �@/�P�P�P�_�@ �^ �@�_�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�^ �@�@�^�_�_�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�R
�J���J���J���^�^ �@�_�_/�@i�@i�@ �@�@�@�@�Q�@�@�@�@�@�@|
�@�J���J���J���@�@�@�@�@�@i�@| �a| �@�@ /�P�@�@ �R�@�@�@ /�@�Q�Q
�@�@�@�J���J���J���@�� [�P�P�P�P�P�R�@�@�@�@�@ �@�@/�P�@�@�^|
�@�@�@�_�P�P�P�P�P�P�P�^�P�P�R�Q�Q�Q�Q�Q �^�@�@�@�^�@ |
�@�@�@�@ �_������^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�^�@�@�@|
�@�@�@�@�@�@�_�Q�Q�Q�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �^�@�@�@�@ |
Core3Duo�@10�������\��
Core4Duo�@2007�N1�������\��
Core5Duo�@2007�N4�������\��
Core6Duo�@2007�N7�������\��
Core4Duo�@2007�N1�������\��
Core5Duo�@2007�N4�������\��
Core6Duo�@2007�N7�������\��
PCI-E���ă��[�����Ƃɓ����z���������o���Ă��
�قȂ郌�[���Ԃł͓����z������Ȃ��Ă�������ȁB
���x�͂��邯�ǁB
�قȂ郌�[���Ԃł͓����z������Ȃ��Ă�������ȁB
���x�͂��邯�ǁB
ethernet����t�@�C�o�Ȃł́A�g�����L���O���o���h�����҂��ȒP�Ȏ�i���ˁB
�����A���̏ꍇ����M�o���ő��d���A�t���d�����Ȃ��Ⴂ���Ȃ��̂ł��̕���H��
�{�����[���͑��傷��B
�����A���̏ꍇ����M�o���ő��d���A�t���d�����Ȃ��Ⴂ���Ȃ��̂ł��̕���H��
�{�����[���͑��傷��B
�V���A�������N�����˂��Ȃ�A�f�B�t�@�����V�����̐M���̃y�A�Ԃ̃X�L���[�͂Ƃ������Ƃ��āA
�����N�Ԃ̃X�L���[�Ȃ͂���܂�C�ɂ��Ȃ��ėǂ���Ȃ��̂��B
����]���̂��тɐM���̓`�B���Ԃ��ς��Ȃ�Ă���������������܂��B
FlexPhase���g���p�����������N�ł����C�ɂ��Ȃ��ėǂ����낤���B
�����N�Ԃ̃X�L���[�Ȃ͂���܂�C�ɂ��Ȃ��ėǂ���Ȃ��̂��B
����]���̂��тɐM���̓`�B���Ԃ��ς��Ȃ�Ă���������������܂��B
FlexPhase���g���p�����������N�ł����C�ɂ��Ȃ��ėǂ����낤���B
�X�}�k�A282 �� "> ����t�@�C�o" ���Ă͍̂폜���˂����i��
���t�@�C�o�Ńg�����L���O���āA���̂������� >�R��
�ŁAPCI-E�̎d�l�͂悭�킩��Ȃ����ǁAx16 ���Ă̂�16���C����
�g�����L���O���Ȃ��A���Ďv���Ă�B
���t�@�C�o�Ńg�����L���O���āA���̂������� >�R��
�ŁAPCI-E�̎d�l�͂悭�킩��Ȃ����ǁAx16 ���Ă̂�16���C����
�g�����L���O���Ȃ��A���Ďv���Ă�B
>>283
�R�ꂪ��ŃX�L���[�̂��Ƃ��C�ɂ����̂́A�P����bit-parallel/byte-serial
�̓`����������A���čl��������i���������̘b���������̃o���h�����ĂƂ��납��
�o�Ă����b�Ȃ̂Łj�B
�Ɨ������V���A�������N�����̃g�����L���O�Ȃ�A���������ʂ�ł��B
�R�ꂪ��ŃX�L���[�̂��Ƃ��C�ɂ����̂́A�P����bit-parallel/byte-serial
�̓`����������A���čl��������i���������̘b���������̃o���h�����ĂƂ��납��
�o�Ă����b�Ȃ̂Łj�B
�Ɨ������V���A�������N�����̃g�����L���O�Ȃ�A���������ʂ�ł��B
�����FC�����\�z���Ă�����������ꌾ��
�@�@�@�@�@�@ �q��'�@ ~�@�P�L^-�A
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�����I�ɁA��������512KB������Ώ\����
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�����I�ɁA��������512KB������Ώ\����
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
288 �FSocket774�F2006/06/15(��) 21:26:27 ID:uKxJvBbq
�@�@�@�@�@�@ �q��'�@ ~�@�P�L^-�A
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�����v���Ă����������ɂ�����܂���
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�����v���Ă����������ɂ�����܂���
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
�@�@�@�@�@�@ �q��'�@ ~�@�P�L^-�A
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�ŁA�O�������������A������߂܂�
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
ttp://headlines.yahoo.co.jp/hl?a=20060616-00000102-yom-bus_all
�@�@�@�@�@�^�@�@�@�@�@�@�@�@�@�@��
�@�@�@�@/�@�@�@�@�@�@�@�@�@�@�@�@�@ɁA
�@�@�@/�@�@�^�R���c�c�c�c�c�R�R
�@�@�@|�@�@���@�@�@�@�@�@�@�@�@�@�@�~
�@�@�@|�@�c�@�Q�Q__�@�@�Q�Q__ �@�/
�@�@�@�T_/�^|�@�@�@ |��|�@�@�@ |�R�U
�@�@�@|t�T�@�@�___�^_�@ �___�^�@| |�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�RɁ@�@�@�@�^�__�^�_�@�@ |Ɂ@�@�^
�@�@�@�@�T�@�@�@/�R�������]�R�@/�@�@/
�@�@�@�@ /|�R�@�@�@�R����'�@�@ /�@���@�ŁA�O�������������A������߂܂�
�@�@�@�@/ | �@�_�@�@�@�P�@�@�^�@�@�@�_
�@ �@�^�@�R�@�@ �@�]-�@�@�@�@�@�@�@ �@�@�@�P�P�P�P�P�P�P�P
ttp://headlines.yahoo.co.jp/hl?a=20060616-00000102-yom-bus_all
290 �FSocket774�F2006/06/16(��) 21:08:13 ID:VErJGTFT
�C���e����Core2 XE�͏���d�͂����߂��A���b�g���\���Ⴂ�̂ɂ���ׂāA
AMD�Ђ̈ꕔ�̃f���A���R�A�v���Z�b�T�͏���d�͂��C���e���̃V���O���R�A��Core Solo�����ƂȂ��Ă���A
�C���e���Ђ�CPU�͂����g�����ɂȂ�Ȃ����オ�������Ă���܂��B
�����g�̓��[�J�[���ɂ�����炸�ǂ������h�������̂ł����A
�����C���e�����i�͔����Ȃ��قǁA�C���e���͑����Ă��܂��܂����B
AMD�͕s����ƌ����l���Ȃ��ɂ͂��܂����A����̓`�b�v�Z�b�g���[�J�̑Ӗ��ł��� �A
AMD�͗ǂ��v���Z�b�T�݂̂���葱����E�l�h�ł���Ƃ����܂� �BAMD�͒��ړI�ɂ͊W����܂���B
���������唼�̕s��̓��[�U�[���]���ɓ�������Ή����ł�����̂���ł��B
Intel�̐��i����IA-64��AMD64�ɂƂ��Ă�����A�͂����肢���čő������͂���܂���B
�C���e�����悤�Ȃ�
AMD�Ђ̈ꕔ�̃f���A���R�A�v���Z�b�T�͏���d�͂��C���e���̃V���O���R�A��Core Solo�����ƂȂ��Ă���A
�C���e���Ђ�CPU�͂����g�����ɂȂ�Ȃ����オ�������Ă���܂��B
�����g�̓��[�J�[���ɂ�����炸�ǂ������h�������̂ł����A
�����C���e�����i�͔����Ȃ��قǁA�C���e���͑����Ă��܂��܂����B
AMD�͕s����ƌ����l���Ȃ��ɂ͂��܂����A����̓`�b�v�Z�b�g���[�J�̑Ӗ��ł��� �A
AMD�͗ǂ��v���Z�b�T�݂̂���葱����E�l�h�ł���Ƃ����܂� �BAMD�͒��ړI�ɂ͊W����܂���B
���������唼�̕s��̓��[�U�[���]���ɓ�������Ή����ł�����̂���ł��B
Intel�̐��i����IA-64��AMD64�ɂƂ��Ă�����A�͂����肢���čő������͂���܂���B
�C���e�����悤�Ȃ�
291 �FSocket774�F2006/06/16(��) 21:11:02 ID:bgYN02jE
�ނ��
292 �FSocket774�F2006/06/16(��) 21:12:13 ID:DyzUN3CT
965�}�U�[�{�[�h�����o��H
Intel�̓n�[�h�v���t�F�b�`�@�\�̋����ʼnB�����đΉ����Ă�B
���ꐦ�������Ă���Conroe���|�I�ȍ����\���ɐ����B
���ꐦ�������Ă���Conroe���|�I�ȍ����\���ɐ����B
��{�I�Ƀ\�P�b�g�P�ʂł̃o�X���L���܂����̂ł����ăo�X�A�[�L�e�N�`���͊e�Ј꒷��Z���ȁA�ƍl���Ă�B
�܂��\�����݂ł̃o�X�A�[�L���ƌ��������͂����Ȃ���(��
�Ƃ肠����Tulsa�̋����L3 + MCH*2��FSB4�{�����̗͋Z�łǂ̒��xXeonMP�̃X�P�[���r���e�B��������������wktk���Ƃ��B
�܂��\�����݂ł̃o�X�A�[�L���ƌ��������͂����Ȃ���(��
�Ƃ肠����Tulsa�̋����L3 + MCH*2��FSB4�{�����̗͋Z�łǂ̒��xXeonMP�̃X�P�[���r���e�B��������������wktk���Ƃ��B
Intel�͑�ʐ��Y��ʔ̔��̉�Ђ�����A�t�H�[�J�X���Ă���s��̓\�P�b�g�����Q���x�܂ł��낤�B
����ȏ�́A�V�X�e�����ɔC���Ă���̂������IBM���͓Ǝ��̃`�b�v�Z�b�g������đΉ����Ă����肷��B
�����Ƃ��A���̓Ǝ��Ή�������K�v���S���Ȃ�Opteron���o����Ă���̓G���^�[�v���C�Y�s��������n�C�G���h�����
���i�j�������Ă���A�g�ݗ��ĉ������𗘂����Ă���̂�����B
�����Ƃ��g�ݗ��ĉ�����̍w�����Ə\���ȃT�|�[�g����Ȃ��ׁA�Z�����x�͂��Ȃ�x���̂����Ԃ��B
AMD�����낻��CPU���[�J�[����߂ăV�X�e�����ɂȂ�����Ǝv���������̍����B
����ȏ�́A�V�X�e�����ɔC���Ă���̂������IBM���͓Ǝ��̃`�b�v�Z�b�g������đΉ����Ă����肷��B
�����Ƃ��A���̓Ǝ��Ή�������K�v���S���Ȃ�Opteron���o����Ă���̓G���^�[�v���C�Y�s��������n�C�G���h�����
���i�j�������Ă���A�g�ݗ��ĉ������𗘂����Ă���̂�����B
�����Ƃ��g�ݗ��ĉ�����̍w�����Ə\���ȃT�|�[�g����Ȃ��ׁA�Z�����x�͂��Ȃ�x���̂����Ԃ��B
AMD�����낻��CPU���[�J�[����߂ăV�X�e�����ɂȂ�����Ǝv���������̍����B
>Intel�̓n�[�h�v���t�F�b�`�@�\�̋����ʼnB�����đΉ����Ă�B
���@�I�}���`�X���b�h������������ǂ��Ȃ��Ă��܂��̂��B
�B���Ƃ������A�����[���B
���@�I�}���`�X���b�h������������ǂ��Ȃ��Ă��܂��̂��B
�B���Ƃ������A�����[���B
298 �FSocket774�F2006/06/18(��) 02:55:00 ID:jABAllir
�F�B����AP4EE 3.46G�i���ł���������ǁA�����N�\�����H
299 �FSocket774�F2006/06/18(��) 03:10:16 ID:jABAllir
�N�\�����H�N�\�Ȃ̂����H�H
�������ˁA�v���e�C�����ˁB
�E�n�[�h�E�F�A�œ��@�X���b�h�̐����������ł���̂�
�E�o�����[�\���̐��x�͂ǂ̒��x�Ȃ̂�
�Ȃ��Ȃ���������Ȃ��Ƃ����݂�ɂ��̕ӂ��l�b�N�Ȃ�ł��傤��
�E�o�����[�\���̐��x�͂ǂ̒��x�Ȃ̂�
�Ȃ��Ȃ���������Ȃ��Ƃ����݂�ɂ��̕ӂ��l�b�N�Ȃ�ł��傤��
303 �FMAC�I�^��297 �����F2006/06/18(��) 13:41:31 ID:aEfkuQtB
>>297
�@�@--------------------
�@�@���@�I�}���`�X���b�h������������ǂ��Ȃ��Ă��܂��̂��B
�@�@�B���Ƃ������A�����[���B
�@�@--------------------
����ł퉉�Z��̂ق����]�T�L��܂���Ȃ̂Ť��������ǂ�����Ă��܂��Č��ǃ�������
�{�g���l�b�N�ɂȂ�Ƃ̂��Ƃ��B
http://www.research.ibm.com/journal/rd/491/emma.pdf
�@�@--------------------
�@�@���@�I�}���`�X���b�h������������ǂ��Ȃ��Ă��܂��̂��B
�@�@�B���Ƃ������A�����[���B
�@�@--------------------
����ł퉉�Z��̂ق����]�T�L��܂���Ȃ̂Ť��������ǂ�����Ă��܂��Č��ǃ�������
�{�g���l�b�N�ɂȂ�Ƃ̂��Ƃ��B
http://www.research.ibm.com/journal/rd/491/emma.pdf
ttp://www.watch.impress.co.jp/akiba/hotline/20060617/image/nitcm.html
�@�@�@�@�@���@�f���E�E ���߂�Ȃ���
�E�@�z���~�X�Ńg���b�N�ւő��ɍs���Ă��܂��܂����E�E�@�C���e���b�o�t�͔z���G���[���N�����܂��H
�����G���[���������܂��H�u�Łv�̘A���@�n���u�`�ցv
�E�@�@�@�@�@�@m<_ _>m�@���j�_�[�̂����j�_�@�ق����o�������Ă�j�_
�E����A���\�肾�����̂́A�@���ق����Ȃ����H
�ESuperPI�A���b�ŏI���H �Ƃ��@�����ς��I�����ς��I�ʼn��b�ŏI��鑁�R�H
�EFFBench�ŁA�P���h�y���˔j�h�Ƃ��A�ł��B�@�z���G�u�y�V�Ȃ�ă��C�u�h�A�f�p�[�g�Ŋy���˔j��������Ă���������v
�@�@�@�@�@���@�f���E�E ���߂�Ȃ���
�E�@�z���~�X�Ńg���b�N�ւő��ɍs���Ă��܂��܂����E�E�@�C���e���b�o�t�͔z���G���[���N�����܂��H
�����G���[���������܂��H�u�Łv�̘A���@�n���u�`�ցv
�E�@�@�@�@�@�@m<_ _>m�@���j�_�[�̂����j�_�@�ق����o�������Ă�j�_
�E����A���\�肾�����̂́A�@���ق����Ȃ����H
�ESuperPI�A���b�ŏI���H �Ƃ��@�����ς��I�����ς��I�ʼn��b�ŏI��鑁�R�H
�EFFBench�ŁA�P���h�y���˔j�h�Ƃ��A�ł��B�@�z���G�u�y�V�Ȃ�ă��C�u�h�A�f�p�[�g�Ŋy���˔j��������Ă���������v
>>304
���{��ł���
���{��ł���
307 �FMAC�I�^���⑫�F2006/06/18(��) 14:09:13 ID:aEfkuQtB
���ꂠ��? �����̒��̐l�̓I�[�o�[�N���b����D���l�Ԃ݂����ł���?
�{������������4GH�����H
�����[��
�����[��
>>306
�����Ƃ������ĂȂ��݂��������ǁA���x���炢�ȂH
�����L���O�̒��̐l�Ȃ̓G�A�R��+�_�N�g������p��3.7GHz�Ƃ������ǁB
�w���ʂ̋��x�Ȃ炢���Ȃ��B
�����Ƃ������ĂȂ��݂��������ǁA���x���炢�ȂH
�����L���O�̒��̐l�Ȃ̓G�A�R��+�_�N�g������p��3.7GHz�Ƃ������ǁB
�w���ʂ̋��x�Ȃ炢���Ȃ��B
311 �FMAC�I�^��310 �����F2006/06/19(��) 20:03:26 ID:8+P4+UkK
>>310
�@�@------------------
�@�@�����Ƃ������ĂȂ��݂��������ǁA���x���炢�ȂH
�@�@------------------
�����Ă��邷���ǁB�B�B
�@�@==================
�@�@so cal is like 75F now!!
�@�@no AC on in my room... about 77F
�@�@==================
�����悻25�����ĂƂ��낷���B
�@�@------------------
�@�@�����Ƃ������ĂȂ��݂��������ǁA���x���炢�ȂH
�@�@------------------
�����Ă��邷���ǁB�B�B
�@�@==================
�@�@so cal is like 75F now!!
�@�@no AC on in my room... about 77F
�@�@==================
�����悻25�����ĂƂ��낷���B
F�\�L����B
���Ă�4GHz�B���ł����Ȃ�A���̂Ƃ��낪�����݃K�X��Ƃ��ł���
3.6GHz�������B���ł��Ȃ��͉̂��̂��낤�B
�V�����X�e�b�s���O�̂��o���̂��H
���Ă�4GHz�B���ł����Ȃ�A���̂Ƃ��낪�����݃K�X��Ƃ��ł���
3.6GHz�������B���ł��Ȃ��͉̂��̂��낤�B
�V�����X�e�b�s���O�̂��o���̂��H
313 �FMAC�I�^��312 �����F2006/06/19(��) 20:36:08 ID:8+P4+UkK
>>312
�@�@----------------
�@�@�V�����X�e�b�s���O�̂��o���̂��H
�@�@----------------
�B�B�B
http://www.xtremesystems.org/forums/showpost.php?p=1517659
�@�@================
�@�@well~~ i think eat some E66 step 5 will help you out on air 3.5G XD
�@�@================
�@�@----------------
�@�@�V�����X�e�b�s���O�̂��o���̂��H
�@�@----------------
�B�B�B
http://www.xtremesystems.org/forums/showpost.php?p=1517659
�@�@================
�@�@well~~ i think eat some E66 step 5 will help you out on air 3.5G XD
�@�@================
�����������̂b�o�t�����Ȃ�S�T�i�m���[�g���v���Z�X�܂ő҂������������B
�X�O�`�U�T�i�m����̓��[�N�d�����������疳�ʂ������B
�Q�N�O�̋L�������ǃR������Ɣ������͂S�T�i�m�v���Z�X
http://www.itmedia.co.jp/news/articles/0404/09/news063.html
�X�O�`�U�T�i�m����̓��[�N�d�����������疳�ʂ������B
�Q�N�O�̋L�������ǃR������Ɣ������͂S�T�i�m�v���Z�X
http://www.itmedia.co.jp/news/articles/0404/09/news063.html
�i���������Ă邤���͑҂Ă܂قǐ��\�͂悭�Ȃ�܂����ȁB
���������Đ��\�Ƃ��邩���Ă����̘b������ȁB
�l�g�o����Ȃ�ď���d�͂┭�M�͑���ɂȂ�Ȃ�����
�ǂ�ǂ�މ����Ă��ǂ��ƃC���e���͍l���Ă��킯�����B�@
�f�X�N�g�b�v�ƃ��o�C���ƂŃA�[�L�e�N�`�������ʉ�����Ȃ��
�M�����������j�]�����Ȃ�����u�҂Ă܂قǐ��\�͂悭�Ȃ�܂����ȁv
�Ȃ�ĐQ����������悤�ȏł͂Ȃ������͖̂��炩���낤�ɁE�E�E
�l�g�o����Ȃ�ď���d�͂┭�M�͑���ɂȂ�Ȃ�����
�ǂ�ǂ�މ����Ă��ǂ��ƃC���e���͍l���Ă��킯�����B�@
�f�X�N�g�b�v�ƃ��o�C���ƂŃA�[�L�e�N�`�������ʉ�����Ȃ��
�M�����������j�]�����Ȃ�����u�҂Ă܂قǐ��\�͂悭�Ȃ�܂����ȁv
�Ȃ�ĐQ����������悤�ȏł͂Ȃ������͖̂��炩���낤�ɁE�E�E
���Ȃ��Ƃ�IPF�Ɋւ��Ắu�҂Ă܂قǐ��\�͂悭�Ȃ�܂����ȁv�Ɗm�M�������Č�����
�C���e���Ɍ��肵�Ă��܂ĂΑ҂قǐ��\�͂������Ă邯�ǁH������
�܂��ACore���o�Ă������猾����킯�ł����Ă�
CPI�iClocks per Instruction�j�ɒ��ڂ���ƁAP4�ȍ~�މ��͂��ĂȂ����̂�
�i�����S�����������Ǝv���Ă�̂͘R�ꂾ���H
�ł��A���F�̐��\�͂����[�Ȃ��B
CPI�iClocks per Instruction�j�ɒ��ڂ���ƁAP4�ȍ~�މ��͂��ĂȂ����̂�
�i�����S�����������Ǝv���Ă�̂͘R�ꂾ���H
�ł��A���F�̐��\�͂����[�Ȃ��B
>>306
�����X�e�b�s���O�̂悤�Ɍ�������E�E�E�����Ԃ�ϐ������\���Ⴄ�ȁB
ttp://www.hkepc.com/hwdb/x6800vsfx62-11.htm
�ȂAConroe�͏�������ĂĂǂꂪ�{���Ȃ̂��E�E�E
�����X�e�b�s���O�̂悤�Ɍ�������E�E�E�����Ԃ�ϐ������\���Ⴄ�ȁB
ttp://www.hkepc.com/hwdb/x6800vsfx62-11.htm
�ȂAConroe�͏�������ĂĂǂꂪ�{���Ȃ̂��E�E�E
>>319
���O�������B
���O�������B
>>319
���������������͕ω����Ȃ�����������o���Ă݂Ă����B
���������������͕ω����Ȃ�����������o���Ă݂Ă����B
�P�ɔM���o�[�X�g�������j���Ă��ƃW���}�C�J�B
�������\���オ���Ă邩�玸�s�ł��Ȃ��Ǝv�����B
�m�ƒL�ł悭���\�������Ƃ������邯�ǃv���Z�X���[���Ⴄ�i�B
�m�ƒL�ł悭���\�������Ƃ������邯�ǃv���Z�X���[���Ⴄ�i�B
>>323
�����j���Ȃɂ�Northwood�͑听������������B
�����j���Ȃɂ�Northwood�͑听������������B
http://pc.watch.impress.co.jp/docs/2006/0615/intel.htm
�X�e�b�s���O���オ��Ɠ����ɂ���Ȃ�ɗ����������ŐVNetBurst�B
Cedarmill�ɂ������Ă�TDP65W�ɂȂ�Ƃ��B
�X�e�b�s���O���オ��Ɠ����ɂ���Ȃ�ɗ����������ŐVNetBurst�B
Cedarmill�ɂ������Ă�TDP65W�ɂȂ�Ƃ��B
���@�I�}���`�X���b�f�B���O���ۂ���������_�œ�����Netburst�͎��������Ȃ���A
�v���X�R�͍��N���b�N(�[�[�x�p�C�v���C��)�𓊂��̂Ă�TraceCache��Hit����Fetch�ш�Ƀt�H�[�J�X����悩�����̂�
���Ȃ�ǂ����������͂�
�v���X�R�͍��N���b�N(�[�[�x�p�C�v���C��)�𓊂��̂Ă�TraceCache��Hit����Fetch�ш�Ƀt�H�[�J�X����悩�����̂�
���Ȃ�ǂ����������͂�
TDP100W������FX�V���[�Y�����ɂȂ�̂��H
> CPI�iClocks per Instruction�j�ɒ��ڂ���ƁAP4�ȍ~�މ��͂��ĂȂ����̂�
> �i�����S�����������Ǝv���Ă�̂͘R�ꂾ���H
�[���AIPC �I�ɂ� P4 ���� PIII ��� �啝�ɑމ����Ă邶���B
�܂��N���b�N�͏���҂ɂ͕�����₷���w�W������A�M���ł܂Â��܂ł́A
�}�[�P�I�ɂ͑听���������킯�����B
> �i�����S�����������Ǝv���Ă�̂͘R�ꂾ���H
�[���AIPC �I�ɂ� P4 ���� PIII ��� �啝�ɑމ����Ă邶���B
�܂��N���b�N�͏���҂ɂ͕�����₷���w�W������A�M���ł܂Â��܂ł́A
�}�[�P�I�ɂ͑听���������킯�����B
�R�ꂪ���������������Ƃ� >>329 �������Ă��ꂽ���A���ӂ�
�܂��A�R���P4��Netburst Celeron��Intel�̎��s�삾�Ƃ͎v���ĂȂ���B
�ނ���c�ƓI�ɂ͑听����������Ȃ����Ƃ��v���Ă�B
�ł��A����͘R��炪�~�������̂���Ă��ꂽ���ǂ����Ƃ����̂ƃC�R�[���ł͂Ȃ��ȁB
�W�T�b�J�[�Ƃ��ẮA�����AMD�̂�����ƃ��N�U�Ȑ��i�Ɏ䂩�����̂���������B
Intel�̐��i���ƁA�ŋ߂܂ł������Ă������납�����̂�PenD���炢�Ȃ��̂������B
�܂��A�R���P4��Netburst Celeron��Intel�̎��s�삾�Ƃ͎v���ĂȂ���B
�ނ���c�ƓI�ɂ͑听����������Ȃ����Ƃ��v���Ă�B
�ł��A����͘R��炪�~�������̂���Ă��ꂽ���ǂ����Ƃ����̂ƃC�R�[���ł͂Ȃ��ȁB
�W�T�b�J�[�Ƃ��ẮA�����AMD�̂�����ƃ��N�U�Ȑ��i�Ɏ䂩�����̂���������B
Intel�̐��i���ƁA�ŋ߂܂ł������Ă������납�����̂�PenD���炢�Ȃ��̂������B
IPC�����Ői���]�X��(ry
>>331
������ CPI �ɒ��ڂ���ƁA���Č����Ă邶���
���̍��ڂ����邱�Ƃ͂��邯�ǁA����A���Ƃ���MP�\���ɂ������̃�������
I/O�o���h���̌����}�邱�Ƃ��ł���悤�ȉ������Ă���H
FSB�A�[�L�e�N�`�����ƁAFSB��NB���l�b�N�ɂȂ����Ⴄ����Ȃ��B
�R���s���[�^�͏����\�͂�I/O�\�͈ȊO�Ɏw�W�ɂȂ�悤�Ȃ��͖̂�������ȁ[�B
�l�i�A����d�́A�M�����͒u���Ă����Ƃ��āB
������ CPI �ɒ��ڂ���ƁA���Č����Ă邶���
���̍��ڂ����邱�Ƃ͂��邯�ǁA����A���Ƃ���MP�\���ɂ������̃�������
I/O�o���h���̌����}�邱�Ƃ��ł���悤�ȉ������Ă���H
FSB�A�[�L�e�N�`�����ƁAFSB��NB���l�b�N�ɂȂ����Ⴄ����Ȃ��B
�R���s���[�^�͏����\�͂�I/O�\�͈ȊO�Ɏw�W�ɂȂ�悤�Ȃ��͖̂�������ȁ[�B
�l�i�A����d�́A�M�����͒u���Ă����Ƃ��āB
>>329
�ꉞ�˂�����ǂ����A�M�Ə���d�͂��ׂ�Ƌ��e�l���Ⴂ�̂͌��
Intel���R�����g����
>>332
�Ō�̈�s�����ǂ�Ń��X���Ă˂�
�ȂS�̓I�ɕ��s�����ۂ��Ȃ�
�Ƃ肠�����N��IPC�Ƃ����֗��ȒP�ʂɗx�炳�ꂷ���Ă�C������
1 + 1 �� 3 - 1�͑S���̕ʕ��������͓�����
��������Netburst��IPC���̂�TLP(ry
���A�N�������咣�������̂����܂����킩���
�ꉞ�˂�����ǂ����A�M�Ə���d�͂��ׂ�Ƌ��e�l���Ⴂ�̂͌��
Intel���R�����g����
>>332
�Ō�̈�s�����ǂ�Ń��X���Ă˂�
�ȂS�̓I�ɕ��s�����ۂ��Ȃ�
�Ƃ肠�����N��IPC�Ƃ����֗��ȒP�ʂɗx�炳�ꂷ���Ă�C������
1 + 1 �� 3 - 1�͑S���̕ʕ��������͓�����
��������Netburst��IPC���̂�TLP(ry
���A�N�������咣�������̂����܂����킩���
>>���������Đ��\�Ƃ��邩���Ă����̘b������ȁB
�Ɖ����B���h�����̂������ɖ��ʂɂȂ��Ƃ�Ȃ�
>>314-316�Ŋ������Ă�b���O�_�O�_��������߂�����
�Ɖ����B���h�����̂������ɖ��ʂɂȂ��Ƃ�Ȃ�
>>314-316�Ŋ������Ă�b���O�_�O�_��������߂�����
���e�ɂ��Ă͉����v��Ȃ���
���ǂ�"�i����"�͂ǂ����Ǝv��
���ǂ�"�i����"�͂ǂ����Ǝv��
>336
�܂��̃}�l�������Ȃ�N���Ȃ�
�܂��̃}�l�������Ȃ�N���Ȃ�
>>314
���Ȃ��Ƃ��A45nm��High-k��metal gate�͍̗p����݂������ˁB
ttp://www.dailytech.com/article.aspx?newsid=2649
>P1266, Penryn, and chips afterwards will use radically different manufacturing techniques
>-- High-k dielectrics, metal gate electrodes
>and with Nehalem-C a switch from 193nm DUV lithography to EUV 13.4nm lithography.
���Ȃ��Ƃ��A45nm��High-k��metal gate�͍̗p����݂������ˁB
ttp://www.dailytech.com/article.aspx?newsid=2649
>P1266, Penryn, and chips afterwards will use radically different manufacturing techniques
>-- High-k dielectrics, metal gate electrodes
>and with Nehalem-C a switch from 193nm DUV lithography to EUV 13.4nm lithography.
>>338
�̂�45nm�v���Z�X��Ή��o����̂�EUV�����A���Č����Ă����Ǎ��͂����ł�������
�̂�45nm�v���Z�X��Ή��o����̂�EUV�����A���Č����Ă����Ǎ��͂����ł�������
>>333
�i���������Ă��錻�݁i�y�щߋ��j�ł́A�҂ĂΑ҂قǐ��\�͏オ��Ƃ����b�B
�i���������Ă��錻�݁i�y�щߋ��j�ł́A�҂ĂΑ҂قǐ��\�͏オ��Ƃ����b�B
�厖�Ȃ̂́A���ɔ������̂łǂꂭ�炢�K�����������邩�ǂ����B
>>342
�܂��A���������A
> ����A���Ƃ���MP�\���ɂ������̃�������I/O�o���h���̌����}�邱�Ƃ�
> �ł���悤�ȉ������Ă���H
���Ă͖̂������đ��l����s���Ă�肵�Ă邵�B
�܂��AIntel�̂�����ア�Ƃ����˂�������Ȃ̂ŁA�����邱�Ƃ��ł���
�l�͏��Ȃ��낤���ǁB
�܂��A���������A
> ����A���Ƃ���MP�\���ɂ������̃�������I/O�o���h���̌����}�邱�Ƃ�
> �ł���悤�ȉ������Ă���H
���Ă͖̂������đ��l����s���Ă�肵�Ă邵�B
�܂��AIntel�̂�����ア�Ƃ����˂�������Ȃ̂ŁA�����邱�Ƃ��ł���
�l�͏��Ȃ��낤���ǁB
Conroe���FX�̕����y���ɔ��M�͍����B
INTEL�̈�Ԏア�Ƃ��납��AMD�̈�Ԏア�Ƃ���ւƎ���͈ڂ����̂������B
�ω��Ɏ��c����邱�ƂȂ��ȁB
INTEL�̈�Ԏア�Ƃ��납��AMD�̈�Ԏア�Ƃ���ւƎ���͈ڂ����̂������B
�ω��Ɏ��c����邱�ƂȂ��ȁB
http://pc7.2ch.net/test/read.cgi/jisaku/1150791167/38 96�͊ԈႢ�Ȃ����s�������ǂ�
>>342
ttp://www.kt.rim.or.jp/~abemo/pc/2004ECS.html
�����ǂ��XeonMP��IPF�̏���d�͂��l���Ă݂悤
>>343
> ����A���Ƃ���MP�\���ɂ������̃�������I/O�o���h���̌����}�邱�Ƃ�
> �ł���悤�ȉ������Ă���H
UMA�ɂ��\����̃{�g���l�b�N���w���Ă�Ȃ�AIntel��CPU�ł�NUMA�͍\�z��
�o�X�̘b�Ȃ�A����͐��̐��قǑ��݂����̐��Ɠ����������\�̓W�����v���Ă���
�Ɠ����Ă���
ttp://www.kt.rim.or.jp/~abemo/pc/2004ECS.html
�����ǂ��XeonMP��IPF�̏���d�͂��l���Ă݂悤
>>343
> ����A���Ƃ���MP�\���ɂ������̃�������I/O�o���h���̌����}�邱�Ƃ�
> �ł���悤�ȉ������Ă���H
UMA�ɂ��\����̃{�g���l�b�N���w���Ă�Ȃ�AIntel��CPU�ł�NUMA�͍\�z��
�o�X�̘b�Ȃ�A����͐��̐��قǑ��݂����̐��Ɠ����������\�̓W�����v���Ă���
�Ɠ����Ă���
>���̒l�����i�Ƃ��Ẵf�X�N�g�b�v�p�\�R���Ɏg�p�ł���b�o�t�̏���d�͂̌��E���w���Ă���悤�Ɏv����̂ł���B
>100W��CPU��1��5���Ԏg�p����ƁA�P�N������̓d�͗����́i1kWh������20�~�Ƃ��āj \3650 ���ɂ��Ȃ�B
>�܂�A�b�o�t�����̖�����t�܂Ŏg�����Ƃ���ƁA�d�͗����͂b�o�t�P�̂̂P�N�����艿�i�ɕC�G����قǂɂ܂łȂ��Ă���̂��B
>����ł́A�b�o�t�̏���d�͂Ɍ��E������͓̂��R�Ƃ�������B
>100W��CPU��1��5���Ԏg�p����ƁA�P�N������̓d�͗����́i1kWh������20�~�Ƃ��āj \3650 ���ɂ��Ȃ�B
>�܂�A�b�o�t�����̖�����t�܂Ŏg�����Ƃ���ƁA�d�͗����͂b�o�t�P�̂̂P�N�����艿�i�ɕC�G����قǂɂ܂łȂ��Ă���̂��B
>����ł́A�b�o�t�̏���d�͂Ɍ��E������͓̂��R�Ƃ�������B
�u�p�\�R���v�������
353 �F�R��͂悭�m��Ȃ����F2006/06/21(��) 20:04:39 ID:Yl9ria+5
>>351
�ނ���CPU�߯���ޏさϻ���CPU�d���������ݻ������E�ɋ߂��炵��
�ނ���CPU�߯���ޏさϻ���CPU�d���������ݻ������E�ɋ߂��炵��
>>348
�������ȉ��ȁB
> UMA�ɂ��\����̃{�g���l�b�N���w���Ă�Ȃ�AIntel��CPU�ł�NUMA�͍\�z��
���̂Ƃ���ANUMA�̓����́A�ǂ̂悤�ȃA�[�L�ł�NUMA���\�����邱�Ƃ��\��
���邱�Ƃɐs����Ǝv���B
������
>�o�X�̘b�Ȃ�A����͐��̐��قǑ��݂�
�Ƃ����̂Ȃ�A���ꂪ�ǂ̂悤�Ȍ`��Intel processor �Ɏ�������A���i�Ƃ���
������Ă���̂��낤���B
�������Intel�̐��ʂi�ɂ������̂́A�����ڂɂ������Ƃ������B
�������ȉ��ȁB
> UMA�ɂ��\����̃{�g���l�b�N���w���Ă�Ȃ�AIntel��CPU�ł�NUMA�͍\�z��
���̂Ƃ���ANUMA�̓����́A�ǂ̂悤�ȃA�[�L�ł�NUMA���\�����邱�Ƃ��\��
���邱�Ƃɐs����Ǝv���B
������
>�o�X�̘b�Ȃ�A����͐��̐��قǑ��݂�
�Ƃ����̂Ȃ�A���ꂪ�ǂ̂悤�Ȍ`��Intel processor �Ɏ�������A���i�Ƃ���
������Ă���̂��낤���B
�������Intel�̐��ʂi�ɂ������̂́A�����ڂɂ������Ƃ������B
����[����
��������
��������
>>354
�N���b�N�̌����o�X���̊g��
�v���g�R���̉���
���{�I�ȍ\�����v�ɂ���ăW�����v���Ȃ��ƃG���K���g�łȂ��Ǝv���Ȃ�
��PCI-E
FSB�̕��͈��RDRAM�ł����Ă邩�炵�炭���a��
����͑f���Ɏc�O��
�N���b�N�̌����o�X���̊g��
�v���g�R���̉���
���{�I�ȍ\�����v�ɂ���ăW�����v���Ȃ��ƃG���K���g�łȂ��Ǝv���Ȃ�
��PCI-E
FSB�̕��͈��RDRAM�ł����Ă邩�炵�炭���a��
����͑f���Ɏc�O��
>>353
VRM�͍ŋ�4�t�F�[�Y�Ƃ��o���Ă邩�瓖���͑��v�ł���
�J��d�����i����
���������AFB-DIMM���Č��\����d�͑������Ęb����
VRM�͍ŋ�4�t�F�[�Y�Ƃ��o���Ă邩�瓖���͑��v�ł���
�J��d�����i����
���������AFB-DIMM���Č��\����d�͑������Ęb����
>>356
> FSB�̕��͈��RDRAM�ł����Ă邩�炵�炭���a��
����͖{���Ɏc�O�Ȃ��Ƃ������ˁB
��{�I�Ȏv�z�͊Ԉ���ĂȂ������Ǝv�����Ȃ��B
>>357
> ���������AFB-DIMM���Č��\����d�͑������Ęb����
�܂��A���ꂾ���̑��x��72bit�쓮����킯������A�d���Ȃ��Ƃ����Ύd���Ȃ��ˁB
> FSB�̕��͈��RDRAM�ł����Ă邩�炵�炭���a��
����͖{���Ɏc�O�Ȃ��Ƃ������ˁB
��{�I�Ȏv�z�͊Ԉ���ĂȂ������Ǝv�����Ȃ��B
>>357
> ���������AFB-DIMM���Č��\����d�͑������Ęb����
�܂��A���ꂾ���̑��x��72bit�쓮����킯������A�d���Ȃ��Ƃ����Ύd���Ȃ��ˁB
>>354
> �������Intel�̐��ʂi�ɂ������̂́A�����ڂɂ������Ƃ������B
IBM��X�A�[�L�e�N�`���B
�`�b�v�Z�b�g��CPU�E���������q���A�����̃`�b�v�Z�b�g�𑊌ݐڑ��B
> �������Intel�̐��ʂi�ɂ������̂́A�����ڂɂ������Ƃ������B
IBM��X�A�[�L�e�N�`���B
�`�b�v�Z�b�g��CPU�E���������q���A�����̃`�b�v�Z�b�g�𑊌ݐڑ��B
>> ���������AFB-DIMM���Č��\����d�͑������Ęb����
AMD�̂����A�V�X�e���S�̂̏���d�́A�Ƃ����ϓ_����̎w�E���͏��Ȃ������݂����ł����B
AMD�̂����A�V�X�e���S�̂̏���d�́A�Ƃ����ϓ_����̎w�E���͏��Ȃ������݂����ł����B
�V�X�e���S�̂̏���d�͂��čl���������\�A���Ȃ�Ȃ��A�厖�Ȃ̂͂킩�邪�B
HDD����O���{�A�f�B�X�v���C����ʂĂ͓͂d���̌����܂ōl���Ȃ��Ⴂ����Ȃ��B
FBDIMM�̃R���g���[���`�b�v���5W�Ƃ�10W�Ƃ������ĂȂ��������ȁB
��������Ȃ�������ǂ�����ė�p�����A���Ďv���Ă����B
HDD����O���{�A�f�B�X�v���C����ʂĂ͓͂d���̌����܂ōl���Ȃ��Ⴂ����Ȃ��B
FBDIMM�̃R���g���[���`�b�v���5W�Ƃ�10W�Ƃ������ĂȂ��������ȁB
��������Ȃ�������ǂ�����ė�p�����A���Ďv���Ă����B
AMB��CPU���̓��쑬�x������Ȃ��B
363 �FSocket774�F2006/06/23(��) 00:08:36 ID:NxBaaBsr
>>350
P4���o�����ɔ��M�Ƃ��d�C�オ�����Ƃ��F�X����ꂽ����CPU�P�̂Ƃ��Ă͓d�����x�̏���d�͂������o����͈͂������B
���ۂɂ͌l�̌o�ϊ��o�Ƃ��������傫���Ǝv�����Ǖ��ϓI�ȋ��e�͈͂͂ǂ̒��x���Ǝv���܂����H
���I�ɂ�1���ɐ����Ԃ̎g�p�Ȃ�CPU��200W�A�p�\�R���S�̂�1000W���x�͋�����͈͂��Ǝv�����ǁB
24���Ԓʓd����Ȃ�CPU��30W�A�p�\�R���S�̂�150W�����肪���E�B
����ʂȂ�펞�ő�����Ȃ������̉Ɠd�Ɣ�r���Ă����e�͈͂��Ǝv�����ǁB
P4���o�����ɔ��M�Ƃ��d�C�オ�����Ƃ��F�X����ꂽ����CPU�P�̂Ƃ��Ă͓d�����x�̏���d�͂������o����͈͂������B
���ۂɂ͌l�̌o�ϊ��o�Ƃ��������傫���Ǝv�����Ǖ��ϓI�ȋ��e�͈͂͂ǂ̒��x���Ǝv���܂����H
���I�ɂ�1���ɐ����Ԃ̎g�p�Ȃ�CPU��200W�A�p�\�R���S�̂�1000W���x�͋�����͈͂��Ǝv�����ǁB
24���Ԓʓd����Ȃ�CPU��30W�A�p�\�R���S�̂�150W�����肪���E�B
����ʂȂ�펞�ő�����Ȃ������̉Ɠd�Ɣ�r���Ă����e�͈͂��Ǝv�����ǁB
�k�X�E�̂Ƃ��͂܂�CRT���t���ڍs���i��ł����̂ő��E����Ă���
>>338
�O�X����45nm��Metal�Q�[�g&High-k��Intel�͌����Ă����ǁA���������̂ł́H
ttp://www.sijapan.com/content/0605vol3/industry/industry_0605_1.html
�܂�Intel����45nm�v���Z�X�̏ڂ����������������ǁA
���Ђɒm��ꂽ���Ȃ��낤���B�E�E�͂攭�\���Ă���B
�O�X����45nm��Metal�Q�[�g&High-k��Intel�͌����Ă����ǁA���������̂ł́H
ttp://www.sijapan.com/content/0605vol3/industry/industry_0605_1.html
�܂�Intel����45nm�v���Z�X�̏ڂ����������������ǁA
���Ђɒm��ꂽ���Ȃ��낤���B�E�E�͂攭�\���Ă���B
>>365
��������Ƃ���A����͗ǂ����ƁB
���ɁA�Z�p�͊m���ς݂ŗʎY��@���m���ς݂��B
������������闝�R������Ƃ���A��ւ��Z�p�ŏ\���ɊԂɍ�������ł���A���̂ق����R�X�g�������Ă��ށB
�������߂���̂͏����ۛ��߂��邩��?
������65nm�����Ă����������c�V���R�������ŏ\���Ȑ��\���o���Ă���B
��������Ƃ���A����͗ǂ����ƁB
���ɁA�Z�p�͊m���ς݂ŗʎY��@���m���ς݂��B
������������闝�R������Ƃ���A��ւ��Z�p�ŏ\���ɊԂɍ�������ł���A���̂ق����R�X�g�������Ă��ށB
�������߂���̂͏����ۛ��߂��邩��?
������65nm�����Ă����������c�V���R�������ŏ\���Ȑ��\���o���Ă���B
���[�N��͂ǂ�����낤�B
�m���v���Z�X���[�����オ��ƍX�ɍ����Ȃ���?�A����B
�ŐV��Cedarmill��D�X�e�b�v��TDP65W�Ɏ��܂�݂��������A
�����V�������@�ł��o�����̂�����Aintel�́B
Prescott�̔ߌ����R�̂悤���B
�m���v���Z�X���[�����オ��ƍX�ɍ����Ȃ���?�A����B
�ŐV��Cedarmill��D�X�e�b�v��TDP65W�Ɏ��܂�݂��������A
�����V�������@�ł��o�����̂�����Aintel�́B
Prescott�̔ߌ����R�̂悤���B
�Q�[�g���[�N��}���邽�߂ɂ�High-k���K�v�ŁAHigh-k������Ȃ烁�^���Q�[�g���K�v�B
�������Q�[�g���[�N�͐≏���̌����𔖂����Ȃ������قǑ����Ȃ��B
����65nm��90nm�ƌ����͕ς���ĂȂ������n�Y�B
�T�u�X���V�����h���[�N��FD-SOI�ŗ}������������ȁB
�����AFinFET�ɂȂ�����ʓI�B
���\�グ�Ȃ���v���Z�X�̕ύX��TDP������̂͂܂����R�ȗ���B
�������Q�[�g���[�N�͐≏���̌����𔖂����Ȃ������قǑ����Ȃ��B
����65nm��90nm�ƌ����͕ς���ĂȂ������n�Y�B
�T�u�X���V�����h���[�N��FD-SOI�ŗ}������������ȁB
�����AFinFET�ɂȂ�����ʓI�B
���\�グ�Ȃ���v���Z�X�̕ύX��TDP������̂͂܂����R�ȗ���B
ttp://journal.mycom.co.jp/news/2003/11/05/51.html
>�����E�W�ω����i�ނɂ�āA�Z�p�҂�Y�܂���̂����[�N�d���ƔM�̖��ł���B
>���݁A�Q�[�g�≏���ɂ�SiO 2 (��_���P�C�f)���p�����Ă��邪�A�����ɔ������q�����̔����ɂȂ낤�Ƃ��Ă���B
>����Ńg�����W�X�^�̏���d�͂͑���̈�r�ł���A��܂����≏�����z���ăQ�[�g�ɓd�������ꍞ��A�\�[�X�ƃh���C���Ԃ��I�t�̏�Ԃł��d��������Ă��܂��Ƃ�����肪�o�Ă����B
>1.2nm��SiO 2�ɑ���High-k��3.0nm�B�Q�[�g�≏���ł̃��[�N�d����100����1�ȉ��ɗ}������Ƃ���
>High-k�Q�[�g�≏���́A�U�d���̍����ޗ��Ō����≏�������A�o�͓d����ۂ��Ȃ���A���[�N�d����ጸ�����悤�Ƃ������݂��B
>Intel�ł͐�����Atomic Layer Deposition�Ƃ����Z�p��p����B
>����̓u���b�N���d�˂�悤�Ɉ�w���ϑw������@�ŁA���m�ɕ��q�̑w���R���g���[���ł���Ƃ����B
>����High-k�Q�[�g�≏�����̗p�����Ŗ��ƂȂ�̂��A���݃Q�[�g�d�ɂɎg���Ă���|���V���R���Ƃ̑g�ݍ��킹�ł���B
>High-K�Q�[�g�≏��/�|���V���R���ł́A���E�ŕs����������₷���A����d�����㏸����X��������B
>����Ƀt�H�m���U���ɂ���ēd�q�̈ړ��x�ɗ�������B������High-K�Q�[�g�≏���̓������\�Ɉ����o�����߂ɁA���^���Q�[�g�d�ɂ��I�ꂽ�B
������Ə�����Ă邯��45nm�̃L���͂���
>Intel�ł͐�����Atomic Layer Deposition�Ƃ����Z�p��p����B
High-k��^���Q�[�g�͂��܂��Ƃ������ی�
>�����E�W�ω����i�ނɂ�āA�Z�p�҂�Y�܂���̂����[�N�d���ƔM�̖��ł���B
>���݁A�Q�[�g�≏���ɂ�SiO 2 (��_���P�C�f)���p�����Ă��邪�A�����ɔ������q�����̔����ɂȂ낤�Ƃ��Ă���B
>����Ńg�����W�X�^�̏���d�͂͑���̈�r�ł���A��܂����≏�����z���ăQ�[�g�ɓd�������ꍞ��A�\�[�X�ƃh���C���Ԃ��I�t�̏�Ԃł��d��������Ă��܂��Ƃ�����肪�o�Ă����B
>1.2nm��SiO 2�ɑ���High-k��3.0nm�B�Q�[�g�≏���ł̃��[�N�d����100����1�ȉ��ɗ}������Ƃ���
>High-k�Q�[�g�≏���́A�U�d���̍����ޗ��Ō����≏�������A�o�͓d����ۂ��Ȃ���A���[�N�d����ጸ�����悤�Ƃ������݂��B
>Intel�ł͐�����Atomic Layer Deposition�Ƃ����Z�p��p����B
>����̓u���b�N���d�˂�悤�Ɉ�w���ϑw������@�ŁA���m�ɕ��q�̑w���R���g���[���ł���Ƃ����B
>����High-k�Q�[�g�≏�����̗p�����Ŗ��ƂȂ�̂��A���݃Q�[�g�d�ɂɎg���Ă���|���V���R���Ƃ̑g�ݍ��킹�ł���B
>High-K�Q�[�g�≏��/�|���V���R���ł́A���E�ŕs����������₷���A����d�����㏸����X��������B
>����Ƀt�H�m���U���ɂ���ēd�q�̈ړ��x�ɗ�������B������High-K�Q�[�g�≏���̓������\�Ɉ����o�����߂ɁA���^���Q�[�g�d�ɂ��I�ꂽ�B
������Ə�����Ă邯��45nm�̃L���͂���
>Intel�ł͐�����Atomic Layer Deposition�Ƃ����Z�p��p����B
High-k��^���Q�[�g�͂��܂��Ƃ������ی�
65�����v���Z�X�ł͏ȓd�͂̉��P�͂Ȃ��́H�H�H
�S��45nm�܂ő҂��Ȃ��Ƃ����Ȃ��̂��E�E�E
���Ƃf�o�t�ɂ͎Q��������Ȃ����낤�Ȃ��B
�f�X�N�g�b�v�p�E�m�[�g�p�Ń��C�����������L�^�݂����ȁB
�������P�i�ł��Q������nVIDIA��ATi�Ɛ��\�������J��L���Ăق������̂����ǂ�
�S��45nm�܂ő҂��Ȃ��Ƃ����Ȃ��̂��E�E�E
���Ƃf�o�t�ɂ͎Q��������Ȃ����낤�Ȃ��B
�f�X�N�g�b�v�p�E�m�[�g�p�Ń��C�����������L�^�݂����ȁB
�������P�i�ł��Q������nVIDIA��ATi�Ɛ��\�������J��L���Ăق������̂����ǂ�
��ŁA45nm���o�鎞���ɂȂ�ƃg���C�Q�[�g�͂��̎�������Ƃ������킯��
�V���A���������ɂ���Ƃ��ɁA�e�r�a�Ȃǃo�X���V���A��������݂�������
�����o�X�̓R�P�Ă�킯������A�S�̓I�ɂ������ƃV���A���������ق���������Ȃ����ƁB
�������Ƃ��Ȃ��̂��ȁ[�ƁB
�����o�X�̓R�P�Ă�킯������A�S�̓I�ɂ������ƃV���A���������ق���������Ȃ����ƁB
�������Ƃ��Ȃ��̂��ȁ[�ƁB
����A�Ȃ��Nehalem�H
374 �FSocket774�F2006/06/24(�y) 00:55:11 ID:DqS5NNl3
45nm�ō̗p�����ȓd�͑��32nm��22nm�ł��L���Ȃ̂��H
>>370
65nm�v���Z�X�ł̏ȓd�͉��P�͈ȑO�̔��\�ŏo�Ă邵�A���l�I�ɂ�
�͂����肵�Ă��Ǝv�����ǁB
GPU�͂����G965�����邶�Ⴀ�Ȃ����A�Ƃ����b����Ȃ��āH
>>374
45nm�v���Z�X�ł͂܂��cSi�g�����炢������Ȃ����B�E�E�g�����W�X�^
�\���ɍH�v������Ƃ����b�����邯�ǁB
�ŁA32nm�ɂȂ�Ƃǂ��Ȃ邩�̓g���C�Q�[�g�̑I���������āA�͂����肵�ĂȂ����B
���^���Q�[�g�́A�ȑO��IEDM�ł�����Ə�����Ă����ׂ̖�肪�܂�
���S�ɃN���A����Ȃ����炶�Ⴀ����܂����B
http://journal.mycom.co.jp/articles/2005/12/07/iedm2/
65nm�v���Z�X�ł̏ȓd�͉��P�͈ȑO�̔��\�ŏo�Ă邵�A���l�I�ɂ�
�͂����肵�Ă��Ǝv�����ǁB
GPU�͂����G965�����邶�Ⴀ�Ȃ����A�Ƃ����b����Ȃ��āH
>>374
45nm�v���Z�X�ł͂܂��cSi�g�����炢������Ȃ����B�E�E�g�����W�X�^
�\���ɍH�v������Ƃ����b�����邯�ǁB
�ŁA32nm�ɂȂ�Ƃǂ��Ȃ邩�̓g���C�Q�[�g�̑I���������āA�͂����肵�ĂȂ����B
���^���Q�[�g�́A�ȑO��IEDM�ł�����Ə�����Ă����ׂ̖�肪�܂�
���S�ɃN���A����Ȃ����炶�Ⴀ����܂����B
http://journal.mycom.co.jp/articles/2005/12/07/iedm2/
>>375
���ׂ��c���Ă���悤�ɂ́A�S���ǂ߂Ȃ��̂����E�E�E
���ׂ��c���Ă���悤�ɂ́A�S���ǂ߂Ȃ��̂����E�E�E
���Q�[�g���V���T�C�h������ߒ��ŁA�Q�[�g�≏���Ƃ̋��E�����ɁA
�����ׂȃV���T�C�h������Ȃ��|�P�b�g���邢�̓O���C�����������邱�Ƃ�����A
�����ꂪ�f�o�C�X�̓����ɕϓ���^���Ă��܂��Əq�ׂĂ���B
���̕ϓ��͕����܂�ɉe�������Ȃ������B
�����ׂȃV���T�C�h������Ȃ��|�P�b�g���邢�̓O���C�����������邱�Ƃ�����A
�����ꂪ�f�o�C�X�̓����ɕϓ���^���Ă��܂��Əq�ׂĂ���B
���̕ϓ��͕����܂�ɉe�������Ȃ������B
ttp://www.xtremesystems.org/forums/showpost.php?p=1530747&postcount=2
ttp://www.xtremesystems.org/forums/showpost.php?p=1533914&postcount=59
Core Multiplexing Technology
SW Single Processor Mode
ttp://www.xtremesystems.org/forums/showpost.php?p=1533996&postcount=63
>Core multiplexing, when set to disabled, causes my PC to not boot.
>SW single CPU does indeed cause the PC to boot and use only 1 core.
ttp://www.xtremesystems.org/forums/showpost.php?p=1533914&postcount=59
Core Multiplexing Technology
SW Single Processor Mode
ttp://www.xtremesystems.org/forums/showpost.php?p=1533996&postcount=63
>Core multiplexing, when set to disabled, causes my PC to not boot.
>SW single CPU does indeed cause the PC to boot and use only 1 core.
ttp://www.xtremesystems.org/forums/showpost.php?p=1535465&postcount=84
>simulation article concerning multithreading a singular thread, co-authored by Intel,
>note the buzz words Memory Disambiguation.
>simulation article concerning multithreading a singular thread, co-authored by Intel,
>note the buzz words Memory Disambiguation.
380 �FSocket774�F2006/06/26(��) 02:04:31 ID:Xeaoag63
���F�̎��̃N���b�h�R�A���ē�ł����H�`�r�f�u�n�Q�B�����Ă�����
ttp://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
Core�}�C�N���A�[�L�e�N�`���͐i������CISC�������ȁB
Core�}�C�N���A�[�L�e�N�`���͐i������CISC�������ȁB
���\��B
ttp://pc.watch.impress.co.jp/docs/2006/0626/intel2.htm
��CPU���t�@�����X�Ȃ̂ɑ��A�������X���b�g�̏�ɂ͋���ȃt�@���B
��FB-DIMM�̔��M���傫�����Ƃ��f����
����w
CPU�̃t�@�����X�́A�P�[�X�t�@���̃G�A�t���[�ŋ��p���Ƃ����Ӗ����Ǝv���B
ttp://pc.watch.impress.co.jp/docs/2006/0626/intel2.htm
��CPU���t�@�����X�Ȃ̂ɑ��A�������X���b�g�̏�ɂ͋���ȃt�@���B
��FB-DIMM�̔��M���傫�����Ƃ��f����
����w
CPU�̃t�@�����X�́A�P�[�X�t�@���̃G�A�t���[�ŋ��p���Ƃ����Ӗ����Ǝv���B
�`�b�v�Z�b�g�Ƀt�@�����t�����悤�ɁA�����I�Ƀ��������₷�\�����[�V�����ł���Ă���̂�����B
BTX�͂��ꂪ�l������Ă����?
����ɂ��Ă��T�[�o�[CPU�t�@�����X�Ƃ����̂̓C���p�N�g����ȁB
������P�[�X�t�@���̃G�A�t���[�ŋ��p���Ƃ͂����B
>���̂ق��A�V�X�e��I/O�̃X���[�v�b�g������������A�uI/O�A�N�Z�����[�V�����E�e�N�m���W�[ (I/OAT)�v�@�\�𓋍ڂ���B
����̌���?���C�ɂȂ�B
BTX�͂��ꂪ�l������Ă����?
����ɂ��Ă��T�[�o�[CPU�t�@�����X�Ƃ����̂̓C���p�N�g����ȁB
������P�[�X�t�@���̃G�A�t���[�ŋ��p���Ƃ͂����B
>���̂ق��A�V�X�e��I/O�̃X���[�v�b�g������������A�uI/O�A�N�Z�����[�V�����E�e�N�m���W�[ (I/OAT)�v�@�\�𓋍ڂ���B
����̌���?���C�ɂȂ�B
>����ɂ��Ă��T�[�o�[CPU�t�@�����X�Ƃ����̂̓C���p�N�g����ȁB
�����A1U�Ƃ�2U���ƃt�@���t���Ă������������B�E�`�ʼnғ����Ă郉�b�N�}�E���g
�I�S���t�@�����X����B
�����A1U�Ƃ�2U���ƃt�@���t���Ă������������B�E�`�ʼnғ����Ă郉�b�N�}�E���g
�I�S���t�@�����X����B
�H�G�G�F�F(�L�t�M)�F�F�G�G�H�A�I���Ă����ȂB
�ǂ�����ė�p���Ă��ł���?
�T�[�o�[���[���������������Ƃ������b�����Ă�����
����͂�����������p�V�X�e���Ȃ̂��Ƃ���B
�ǂ�����ė�p���Ă��ł���?
�T�[�o�[���[���������������Ƃ������b�����Ă�����
����͂�����������p�V�X�e���Ȃ̂��Ƃ���B
>>387
>>386�������Ă�̂̓u���[�h�T�[�o�[�ł����������d�͂̂���B
�ڂ��Ă���CPU�������ƒᐫ�\�ŁA2U�܂ł̂���p�ӂ��ăN���X�^�������Ďg���B
Web�T�[�o�[���ł悭��������\���ŁAAPP�T�[�o�[���̃p���[�͂���Ȃ��B
>>386�������Ă�̂̓u���[�h�T�[�o�[�ł����������d�͂̂���B
�ڂ��Ă���CPU�������ƒᐫ�\�ŁA2U�܂ł̂���p�ӂ��ăN���X�^�������Ďg���B
Web�T�[�o�[���ł悭��������\���ŁAAPP�T�[�o�[���̃p���[�͂���Ȃ��B
CPU�̃V���N�ɒ��ڃt�@�����t���ĂȂ����Ă�����
�P�[�X�ɂ̓t�@���t���ē����̃G�A�t���[�m�ۂ��Ă邩��
CPU�̃V���N�ɕ����Ă�K�v�����������M�Ⴂ�Ƃ����Ӗ��ł͑S�R�Ȃ��B
�P�[�X�ɂ̓t�@���t���ē����̃G�A�t���[�m�ۂ��Ă邩��
CPU�̃V���N�ɕ����Ă�K�v�����������M�Ⴂ�Ƃ����Ӗ��ł͑S�R�Ȃ��B
�q�[�g�V���N�Ƀt�@��������t�����ĂȂ������ŁA�����߂��ɔz�u�����P�[�X�t�@���̕��Ăė�p���Ă���킯������A�A
���ۂɂ̓t�@�����X�Ƃ͌����������B
1U��2U�̏ꍇ�̓G�A�t���[��CPU�𗬂ꂽ��`�b�v�Z�b�g��DIMM���r�߂�悤�ɂ��Č���ɔ����Ă����̂ŁA
�����̗�p���ł���B
���ۂɂ̓t�@�����X�Ƃ͌����������B
1U��2U�̏ꍇ�̓G�A�t���[��CPU�𗬂ꂽ��`�b�v�Z�b�g��DIMM���r�߂�悤�ɂ��Č���ɔ����Ă����̂ŁA
�����̗�p���ł���B
1U�I�͎��۔���������
389��390�̌����ʂ�ȍ�肗
�E�`�̃}�V����8cm8000rpm�ȃt�@�����_�N�g�t����CPU�����₷���ɂȂ��Ă�
�����t�@���̉����u�I�[�Ƃ��{�H�[�[�[����Ȃ��ăW�F�b�g�@�̂悤��
�L�B�B�B�B�B�C�C�C���ł�w
�ł��q�[�g�V���N�ɂ̓t�@���t���ĂȂ�����~�܂��Ă��������Ƣ���A����
�t�@�����X�������Č�����Ǝv���B
�E�`�̃}�V����8cm8000rpm�ȃt�@�����_�N�g�t����CPU�����₷���ɂȂ��Ă�
�����t�@���̉����u�I�[�Ƃ��{�H�[�[�[����Ȃ��ăW�F�b�g�@�̂悤��
�L�B�B�B�B�B�C�C�C���ł�w
�ł��q�[�g�V���N�ɂ̓t�@���t���ĂȂ�����~�܂��Ă��������Ƣ���A����
�t�@�����X�������Č�����Ǝv���B
>>387
�P�[�X�O�ʂɑ�ʂ̍����t�@���������ƂȂ��ł��āA���ꂪ�P�[�X�O�ʁ`����Ɏ���܂ł�
�܂������ȃG�A�t���[������Ă���BCPU�ɂ���HDD�ɂ���A���̃G�A�t���[���ė�p���Ă���B
��p��CPU�t�@���͂Ȃ��B���̑���A�t�@�������ꂽ���炢�ł͎x��͐����Ȃ��B
���������悤�ȍ\�����B
ttp://www.rioworks.co.jp/motherboard/popup/h2101_img/h2101_inside_m.jpg
�܂�������ƋC�̗��������[�J�[���ƁA�t�@�����̂����W���[��������Ă��āA�ȒP�Ɍ����ł���B
�t�@�����̂��c�ɓ��ɕ��ׂď璷��������č\��������ȁB
�P�[�X�O�ʂɑ�ʂ̍����t�@���������ƂȂ��ł��āA���ꂪ�P�[�X�O�ʁ`����Ɏ���܂ł�
�܂������ȃG�A�t���[������Ă���BCPU�ɂ���HDD�ɂ���A���̃G�A�t���[���ė�p���Ă���B
��p��CPU�t�@���͂Ȃ��B���̑���A�t�@�������ꂽ���炢�ł͎x��͐����Ȃ��B
���������悤�ȍ\�����B
ttp://www.rioworks.co.jp/motherboard/popup/h2101_img/h2101_inside_m.jpg
{kind=link}
�܂�������ƋC�̗��������[�J�[���ƁA�t�@�����̂����W���[��������Ă��āA�ȒP�Ɍ����ł���B
�t�@�����̂��c�ɓ��ɕ��ׂď璷��������č\��������ȁB
�R��̓V���b�R�ȃu���A�݂����Ȍ`��̂��悭�ڂɂ��邪�B
Intel�ACore Duo 2.33GHz�́uT2700�v�ƒ���d���ŁuU2500�v
http://pc.watch.impress.co.jp/docs/2006/0628/intel2.htm
9W�̃f���A���R�A�L�^�[�I
http://pc.watch.impress.co.jp/docs/2006/0628/intel2.htm
9W�̃f���A���R�A�L�^�[�I
>>378
Intel Touts Core Multiplexing Technology.
http://www.xbitlabs.com/news/cpu/display/20060627095448.html
Intel Touts Core Multiplexing Technology.
http://www.xbitlabs.com/news/cpu/display/20060627095448.html
9W����Let'snote�ɂ͍ڂ��ȁc
��Ή��Ƃ����čڂ���Ǝv����
399 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/06/28(��) 22:29:56 ID:CJFCtgDH
���[�J�[����̈��̗v�]�������ďo�����Ƃɂ������I�ʔł�����
��������ɍڂ��Ȃ��́B
����Merom���o��Yonah�̓T�u�m�[�g�����[�G���h�݂̂̋����ɂȂ邱�Ƃ��l����ƁA
�V���O���R�A��p�}�X�N�ɂ����ق��������̂��낤���ǁA�ǂ��Ȃ낤�B
��������ɍڂ��Ȃ��́B
����Merom���o��Yonah�̓T�u�m�[�g�����[�G���h�݂̂̋����ɂȂ邱�Ƃ��l����ƁA
�V���O���R�A��p�}�X�N�ɂ����ق��������̂��낤���ǁA�ǂ��Ȃ낤�B
���̂����o���Ƃ����L�����ǂ����Ō���(��
����}�W��
����}�W��
TraceCache��Nehalem���炾�����B
���Ƃ�����3fetch�ł�Netburst�̎���肸���ƌ��ʂ��o�������ˁB
�܂�4Fetch�ȏ�ɂ͊g�����邾�낤����
���Ƃ�����3fetch�ł�Netburst�̎���肸���ƌ��ʂ��o�������ˁB
�܂�4Fetch�ȏ�ɂ͊g�����邾�낤����
�uCore���ā���������́������������}�V�v�I�ȍl���ŏo���Ă���
����ł����܂ł̐��i�S�Đ�����Ԃ��炢�̐��\�Ȃ���ǂ��Ƃ����ӁB
���܂܂ł̐��i����悵�Ă�����t�A��ɂ���Ɨǂ��Ǝv�ӁB
���܂܂ł̐��i����悵�Ă�����t�A��ɂ���Ɨǂ��Ǝv�ӁB
>>404
�Z�p�̐l�̓}���`�R�A�h�̐l�ɑ������͂��B������̃j���[�X�œǂ悤�ȁB
�ł����A�����̐e�����N�r�Ƃ��Ȃ�����ǂ�����ׁH
����l������y�X�����N�r�Ƃ������Ȃ��Ȃ��������K�C��
�Z�p�̐l�̓}���`�R�A�h�̐l�ɑ������͂��B������̃j���[�X�œǂ悤�ȁB
�ł����A�����̐e�����N�r�Ƃ��Ȃ�����ǂ�����ׁH
����l������y�X�����N�r�Ƃ������Ȃ��Ȃ��������K�C��
406 �FSocket774�F2006/06/30(��) 00:14:52 ID:6XdflqZ5
�l�g�o�́A���[�N�d�������ɂȂ�O�ɐv����n�߂�����
�d���Ȃ��BIntel�̃g�b�v�������Ă��Ă��C�Â��Ȃ����Ƃ������B
�d���Ȃ��BIntel�̃g�b�v�������Ă��Ă��C�Â��Ȃ����Ƃ������B
���ۂɃV���R��������Ă݂ă��[�N�d���̑��傪�킩�������_�ł́A
���������Ԃ��Ȃ��Ƃ���ɂ��Ă������ȁE�E
���ہA���R����������܂ł悭�撣�ꂽ���B
���������Ԃ��Ȃ��Ƃ���ɂ��Ă������ȁE�E
���ہA���R����������܂ł悭�撣�ꂽ���B
���܂��܃C�X���G���`�[�����������ȃ��o�C��CPU�𐬌������Ă�����
�Ȃ�Ƃ�Conroe�����R�ɊԂɍ��������E�E�E����PenM���Ȃ�������E�E�E('A`)
�Ȃ�Ƃ�Conroe�����R�ɊԂɍ��������E�E�E����PenM���Ȃ�������E�E�E('A`)
���ŁA�I���S���ƃT���^�N�����͍������Ă�́H
"���܂���"�ŕʃ��C���Ƀ��o�C��CPU����킯�Ȃ������E�E�E
412 �FSocket774�F2006/06/30(��) 21:04:05 ID:6XdflqZ5
���������Ӗ��ł́A�����d��CPU�̊J�������ӂ�����
�g�����X���^�̑��݂��AIntel���~�����Ƃ�������E�E�E�̂��ȁH
�g�����X���^�̑��݂��AIntel���~�����Ƃ�������E�E�E�̂��ȁH
�[���A���Ƃ��A�������Ȃ��Ă��A
������P3�̕���P4��舳�|�I�ɏȓd�͂Ȃ킯������B
������P3�̕���P4��舳�|�I�ɏȓd�͂Ȃ킯������B
>>413
���ǁAVLIW�̐�����Intel�Ɉ�ەt���āAItanium����������Ȃ������Ƃ����������E�E�E
���ǁAVLIW�̐�����Intel�Ɉ�ەt���āAItanium����������Ȃ������Ƃ����������E�E�E
Intel�C�ᔭ�M�̃��o�C���v���Z�b�T�J���ɖ{��
http://www.itmedia.co.jp/news/0008/24/mobile2.html
Intel�������d�͔Ńv���Z�b�T�̂��߂̐�C������Ґ�
http://pc.watch.impress.co.jp/docs/article/20000823/kaigai02.htm
http://pc.watch.impress.co.jp/docs/article/20000908/kaigai01.htm
�C�X���G������Intel�̎����ヂ�o�C��CPU������Ă���
http://pc.watch.impress.co.jp/docs/article/20010205/kaigai01.htm
�gBanias�h�͍ň��̃V�i���I�ɑΉ����邽�߂̑�2�v�悾!
http://ascii24.com/news/columns/10107/article/2001/12/28/632480-000.html
Pentium M��Intel����j
http://plusd.itmedia.co.jp/pcupdate/articles/0501/20/news039.html
�u2000�N���O�ɁA�����͓d�̖͂ʂŕǂɂԂ����Ă��܂����Ƃ��������Ă����B
�@�����͌o�c�w�ɂ��̂��Ƃ�[�������悤�ƌ����������v�ƃC�[�f�����B
http://www.itmedia.co.jp/news/0008/24/mobile2.html
Intel�������d�͔Ńv���Z�b�T�̂��߂̐�C������Ґ�
http://pc.watch.impress.co.jp/docs/article/20000823/kaigai02.htm
http://pc.watch.impress.co.jp/docs/article/20000908/kaigai01.htm
�C�X���G������Intel�̎����ヂ�o�C��CPU������Ă���
http://pc.watch.impress.co.jp/docs/article/20010205/kaigai01.htm
�gBanias�h�͍ň��̃V�i���I�ɑΉ����邽�߂̑�2�v�悾!
http://ascii24.com/news/columns/10107/article/2001/12/28/632480-000.html
Pentium M��Intel����j
http://plusd.itmedia.co.jp/pcupdate/articles/0501/20/news039.html
�u2000�N���O�ɁA�����͓d�̖͂ʂŕǂɂԂ����Ă��܂����Ƃ��������Ă����B
�@�����͌o�c�w�ɂ��̂��Ƃ�[�������悤�ƌ����������v�ƃC�[�f�����B
>>414
>������P3�̕���P4��舳�|�I�ɏȓd�͂Ȃ킯������B
�܂����̎��ɗv������Ă��ō��i�ڕW�j�N���b�N��
�����v���Z�X���Ⴄ�����r����̂͂ǂ����Ǝv�����B
>������P3�̕���P4��舳�|�I�ɏȓd�͂Ȃ킯������B
�܂����̎��ɗv������Ă��ō��i�ڕW�j�N���b�N��
�����v���Z�X���Ⴄ�����r����̂͂ǂ����Ǝv�����B
NetBurst�ʼn҂������̂����炩��Core Microarchitecture�̊J���ɓ��Ă�ꂽ��
�H��̊g���Ɏg��ꂽ�肵�Ă�Ǝv����
����Ȃɑ��߂��A�I���S�����B
Nehalem�ʼnؗ�ɕ�������Ɨ\�z���Ă݂�B
�d�͌����ɃV�t�g�����A�[�L�e�B�N�`�����Ƃ������B
�Ƃ����PARROT�̓C�X���G���������ǁA
SMT�Ŏ������铊�@�I�}���`�X���b�f�B���O��
�ǂ���������Ă�낤?
�H��̊g���Ɏg��ꂽ�肵�Ă�Ǝv����
����Ȃɑ��߂��A�I���S�����B
Nehalem�ʼnؗ�ɕ�������Ɨ\�z���Ă݂�B
�d�͌����ɃV�t�g�����A�[�L�e�B�N�`�����Ƃ������B
�Ƃ����PARROT�̓C�X���G���������ǁA
SMT�Ŏ������铊�@�I�}���`�X���b�f�B���O��
�ǂ���������Ă�낤?
419 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/01(�y) 00:43:04 ID:S79P94iJ
Tejas�����̎�������ōڂ���p�ӂ��������悤�ɋL���B���Ⴂ�����B
�\�t�g���̎d�����Ǝv����B�R���p�C���W�̕����������肵�āB
�\�t�g���̎d�����Ǝv����B�R���p�C���W�̕����������肵�āB
�I���S���ƃT���^�N�����@���z�͂����̃A�z
>>419
> �\�t�g���̎d�����Ǝv����B�R���p�C���W�̕����������肵�āB
�R���p�C���W�̕����Ȃ�ĂȂ�����B���ЂɊۓ������Ă����B
ttp://www.xlsoft.com/jp/products/intel/index.html
> �\�t�g���̎d�����Ǝv����B�R���p�C���W�̕����������肵�āB
�R���p�C���W�̕����Ȃ�ĂȂ�����B���ЂɊۓ������Ă����B
ttp://www.xlsoft.com/jp/products/intel/index.html
�t���[�Ő��\�̂����R���p�C���Ȃ��Ȃ��E�E�E
�� gcc
���\�I�ɂ͈����Ȃ��Ǝv�����B
���\�I�ɂ͈����Ȃ��Ǝv�����B
>>422
�A�t�H��?
�A�t�H��?
>>423
�ق���Intel�̃R���p�C�������BXcode�Ŏg������B
�ق���Intel�̃R���p�C�������BXcode�Ŏg������B
���߁A�f��mac�ƊԈႦ���B
>>422
http://www.hpc.co.jp/B-DEV/IADEV-ifc.htm
> �P�D2000�N�āAIntel�Ђ�KAI�Ђ��BKAI�Ђ�KAP�Ƃ������i���̃\�[�X�R�[�h�œK���c�[���ō����Z�p�͂������Ă����Ђł��B
> �Q�D2001�N�āAIntel�Ђ�Compaq�Ђ̃R���p�C���J���`�[�����B��DEC�Ђ���̃R���p�C���Z�p��Compaq�Ђ��o��Intel�Ђ֗��ꂽ�B
xlsoft�͓��{��ł̔̔��𐿂������Ă邾���ł���B
http://www.hpc.co.jp/B-DEV/IADEV-ifc.htm
> �P�D2000�N�āAIntel�Ђ�KAI�Ђ��BKAI�Ђ�KAP�Ƃ������i���̃\�[�X�R�[�h�œK���c�[���ō����Z�p�͂������Ă����Ђł��B
> �Q�D2001�N�āAIntel�Ђ�Compaq�Ђ̃R���p�C���J���`�[�����B��DEC�Ђ���̃R���p�C���Z�p��Compaq�Ђ��o��Intel�Ђ֗��ꂽ�B
xlsoft�͓��{��ł̔̔��𐿂������Ă邾���ł���B
>>428
���́[intel����ό����Ȃ��Ȃ��c
���́[intel����ό����Ȃ��Ȃ��c
�������Ă����l�ނ�������Ȃ��ċ�SPT�T�|�[�g�����Ȃ������͂�>>�R���p�C������
�v����CPU�̏��ɂ��A�N�Z�X�ł��邾�낤���ȁB��Intel�̃R���p�C������
�ɂ�CSI�o��Ƌ��Ɉ��ނ��ȁB
���ނ�����Common����˂�������
Intel�͂��������Ԃ�O���琢�E�ŋ��̃R���p�C��������B
Visual C++�̍œK�������Ȃ��Intell����o�����č���Ă���B
Visual C++�̍œK�������Ȃ��Intell����o�����č���Ă���B
���낻��Intel��(����IA-64��)OS���ǂ��ɂ�����B�Č������AYou!���낻�뎩�삵���Ⴂ��YO!
MS�́ANetburst + �}���`�_�C�Ɣ䂵�Ă����X���A�������V�X�e���A�[�L�e�N�`���������Ĉ�Γ���
MS�́ANetburst + �}���`�_�C�Ɣ䂵�Ă����X���A�������V�X�e���A�[�L�e�N�`���������Ĉ�Γ���
436 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/05(��) 23:18:23 ID:J77r0n59
Intel����o�����Ă銄�ɂ́AVC2005��SIMD�g�ݍ��݊��̓W�J�̕����ɂ��������������������Ă���B
���܂���SSE3�̑g���݊�����g���Ȃ����H
�܂��A�iMFC7��ATL7�Ƃ���ˑ��̃A�v����64bit���܂߂ājICC+VC2005 Standard+PSDK�łǂ��ɂł��Ȃ���邪�B
Itanium2�A�[�L�e�N�`�����C�X���G���`�[���Ƀe�R���ꂳ�����ق���������Ȃ����ȁ[�Ǝv������
���܂���SSE3�̑g���݊�����g���Ȃ����H
�܂��A�iMFC7��ATL7�Ƃ���ˑ��̃A�v����64bit���܂߂ājICC+VC2005 Standard+PSDK�łǂ��ɂł��Ȃ���邪�B
Itanium2�A�[�L�e�N�`�����C�X���G���`�[���Ƀe�R���ꂳ�����ق���������Ȃ����ȁ[�Ǝv������
>>436
�C�X���G���`�[���͈�����Ȃ��̂����B
�C�X���G���`�[���͈�����Ȃ��̂����B
�d�͌����ɃV�t�g�Ƃ�����������̉��A�ꐶ������点����
�I���S�����C�X���G�����������炢�ǂ��d���������ȋC�����邯�ǂȁB
�I���S�����C�X���G�����������炢�ǂ��d���������ȋC�����邯�ǂȁB
Core2���ďo�ׂ͂��������H
�Ȃ��C���e���͓����`�[�������Ȃ��E�E�E
�m�[�g�o�b�p�b�o�t��v���b�g�t�H�[���J����
���C�����������Ȃ̂ɁB
�m�[�g�o�b�p�b�o�t��v���b�g�t�H�[���J����
���C�����������Ȃ̂ɁB
>>440
��p�i�l����{����j�Ό��ʂ��������炾��B
��p�i�l����{����j�Ό��ʂ��������炾��B
���{�������{�B�ɂȂ�ł��邩����>>�����`�[��
>>442
����A����ł������B
���{�����ł��A���`�[�����́A���`�[�����́A�É��`�[�����̂ɂ���������p�Ό��ʍ������B
����A����ł������B
���{�����ł��A���`�[�����́A���`�[�����́A�É��`�[�����̂ɂ���������p�Ό��ʍ������B
�É��ɂ����G���W�j�A���W������Ƃ͎v���܂���
>>439
7�����o�ׁB
7�����o�ׁB
>>443
���Ȃ�ēy�n���l����������˂���
���Ȃ�ēy�n���l����������˂���
�����͂�Ȋw���s�s�Ɉ���肢���܂��B
>>444
�V�����ʋΔ�p���S�x��
�V�����ʋΔ�p���S�x��
>>448
��p�Ό��ʂ͂ǂ���������
��p�Ό��ʂ͂ǂ���������
>>449
�s�S�̔���|�É��̔��� ������������B
�s�S�̔���|�É��̔��� ������������B
�������̂��Ɩk�C�����������ɂł���Fab���Ă��Ⴆ������
PC�H��͂��邾��B
������A�Ƃ��i��ł邵�B
������A�Ƃ��i��ł邵�B
>>419
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
Tejas�̒��̐l��Xscale�ɍ��J���ꂽ�炵���悗
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
Tejas�̒��̐l��Xscale�ɍ��J���ꂽ�炵���悗
�O�[�O���l�̃��O�̃����N�͕|���Č���Ȃ�
>>458
thx
thx
���[�ł�Tejas�̒��̐l�͓����Ƃ������Ă�(�\�����܂�)�\�����������A�����Ȃ����ق�Ƃꂽ���̐l���낤��
�\����ɕԂ�炭�͓̂����������
�\����ɕԂ�炭�͓̂����������
�܂����肷��ΐ��S���g���ă|�V�������v���W�F�N�g�Ȃ킯������A���J�����̂�
�m���Ȃ悤�ȁE�E�E
�m���Ȃ悤�ȁE�E�E
>>451
��B�̓V���R���A�C�����h�ƌ����Ă邭�炢�ŁA���ł�\�j�[�̋����Fab������
���邪�A�G���W�j�A�͂قƂ�ǂ��Ȃ��B �D�G�ȃG���W�j�A�͓������ӂɔz�u���Ă���B
��B�̓V���R���A�C�����h�ƌ����Ă邭�炢�ŁA���ł�\�j�[�̋����Fab������
���邪�A�G���W�j�A�͂قƂ�ǂ��Ȃ��B �D�G�ȃG���W�j�A�͓������ӂɔz�u���Ă���B
�����e���r�ʼn�������Ă��ȁB�����̓`�����ό��q��������ł���
���Ƃ��Ă����Ėׂ����Ă邩��x���`���[��ƂƂ��̗U�v�������ǂ��ƁB
���Ƃ��Ă����Ėׂ����Ă邩��x���`���[��ƂƂ��̗U�v�������ǂ��ƁB
���{�͍��R�X�g�̑��ɒn�k�̃��X�N������B
���E�͍L���Ă����ƍD�K�ȏ��������ς�����B
���{��FAB�������Ĕ��z���ł���͓̂��{�l�����B
���E�͍L���Ă����ƍD�K�ȏ��������ς�����B
���{��FAB�������Ĕ��z���ł���͓̂��{�l�����B
>>465
fab�͑��ŊJ���`�[�������{�Ȃ�ǂ��Ȃ��Ęb
fab�͑��ŊJ���`�[�������{�Ȃ�ǂ��Ȃ��Ęb
����Ȃ疳����Intel�ł���K�v���Ȃ����낤�ɂ�
>>436
IPF�̃A�[�L�e�N�`���̂Ă�������āc��̓I�ɂǂ�����̂�?
IPF�̃A�[�L�e�N�`���̂Ă�������āc��̓I�ɂǂ�����̂�?
Intel�ЁA�`�b�v�Z�b�g�̋����s����h���邩�F�O��
http://www.ednjapan.com/content/l_news/2006/07/12_02.html
http://www.ednjapan.com/content/l_news/2006/07/12_02.html
�P�R�A
��
�Q�R�A
����
�S�R�A
����
����
�W�R�A
��������
��������
�P�U�R�A
��������
��������
��������
��������
�R�Q�R�A
����������������
����������������
����������������
����������������
��
�Q�R�A
����
�S�R�A
����
����
�W�R�A
��������
��������
�P�U�R�A
��������
��������
��������
��������
�R�Q�R�A
����������������
����������������
����������������
����������������
�U�S�R�A
����������������
����������������
����������������
����������������
����������������
����������������
����������������
����������������
�P�Q�W�R�A
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
����������������
����������������
����������������
����������������
����������������
����������������
����������������
����������������
�P�Q�W�R�A
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
�Q�T�U�R�A
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
��������������������������������
�T�P�Q�R�A
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
����������������������������������������������������������������
>>473
�ڂ̍��o�H�ق�Ƃ�512�R�A�Ɍ�������B
�ڂ̍��o�H�ق�Ƃ�512�R�A�Ɍ�������B
�R�A�̐����Ĕ{���J��Ԃ��́H
2���̎���3�����Ǝv���Ă�
2���̎���3�����Ǝv���Ă�
>>476
���w�Ƃ��ăR���s���[�^�̐��E�ł͂Q�̏搔
���w�Ƃ��ăR���s���[�^�̐��E�ł͂Q�̏搔
���̂܂ܕ��Ă����čŌ�ɂ͐����݂̂����ɂȂ�̂���
��ׁA���w���̖ϑz���x����������
��ׁA���w���̖ϑz���x����������
669 ���O: ���̖��ݒ� Mail: ���e��: 2006/07/14(��) 17:43:55 ID: marERjuH0
�d�l�Ȃ̂��A�s��Ȃ̂��킩��Ȃ����AEM64T(AMD64�݊�64bit�g��)���g����64bit���[�h���₽��ƒx���B
64bit���{���̐��\�Ȃ�Ȃ��āA32bit�����ǖ��������64bit�������܂���A�݂����Ȋ����̐��\������
�܂��AK8��SSE2�݊������̗p�����Ƃ��͑債�����ƂȂ������B
��̉��ǂŐ��\���オ��������A���邩���A����Ȃ��B
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-002.html?
�Ƃ���ŁA�C���e����Core2�̃x���`�𗬂��܂���Ƃ����b�͕��������A��͂��肢��
�d�l�Ȃ̂��A�s��Ȃ̂��킩��Ȃ����AEM64T(AMD64�݊�64bit�g��)���g����64bit���[�h���₽��ƒx���B
64bit���{���̐��\�Ȃ�Ȃ��āA32bit�����ǖ��������64bit�������܂���A�݂����Ȋ����̐��\������
�܂��AK8��SSE2�݊������̗p�����Ƃ��͑債�����ƂȂ������B
��̉��ǂŐ��\���オ��������A���邩���A����Ȃ��B
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-002.html?
�Ƃ���ŁA�C���e����Core2�̃x���`�𗬂��܂���Ƃ����b�͕��������A��͂��肢��
>>480
���̃e�X�^�[����̓������������������B
1,2��x���Ȃ�P�[�X��������64bit�̓_���Ƃ����ϑz�Ɏx�z����Ă��܂����̂��낤�B
�����������w
�l�C�e�B�u�R�[�h�̓��e�ɂ�葬���Ȃ�P�[�X������Βx���Ȃ�P�[�X������B
�����Conroe�����̌��ۂł͂Ȃ�AMD��CPU�ł����l���B
�����āAConroe���x���Ȃ���́AAMD��CPU���x���Ȃ���͔̂����ɈႤ�B
�܂��A�e�X�^�[���A�z������~�X���[�h����Ă��܂��͕̂�����ʂł��Ȃ����ȁB
���̃e�X�^�[����̓������������������B
1,2��x���Ȃ�P�[�X��������64bit�̓_���Ƃ����ϑz�Ɏx�z����Ă��܂����̂��낤�B
�����������w
�l�C�e�B�u�R�[�h�̓��e�ɂ�葬���Ȃ�P�[�X������Βx���Ȃ�P�[�X������B
�����Conroe�����̌��ۂł͂Ȃ�AMD��CPU�ł����l���B
�����āAConroe���x���Ȃ���́AAMD��CPU���x���Ȃ���͔̂����ɈႤ�B
�܂��A�e�X�^�[���A�z������~�X���[�h����Ă��܂��͕̂�����ʂł��Ȃ����ȁB
>>480
�O���t�������x���x���Ƃ����Ă��Asakura editer��������64bit�l�C�e�B�u
�A�v���ł��ő��͂ǂ����Ă�Conroe�Ȃ킯�����B
�O���t�������x���x���Ƃ����Ă��Asakura editer��������64bit�l�C�e�B�u
�A�v���ł��ő��͂ǂ����Ă�Conroe�Ȃ킯�����B
����Ȃ��Ƃ��A�������܂ŕς�錴����m�肽���B
http://www.hardware.fr/articles/623-11/intel-core-2-duo-dossier.html
Athlon64��64bit�Œx���Ȃ邱�Ƃ�����B
Athlon64��64bit�Œx���Ȃ邱�Ƃ�����B
>>480
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-000.html?
>�]���AIntel CPU�ł�SSE���߂̃X���[�v�b�g�i���߂s�\�ȊԊu�j��2�i2�N���b�N�ɂ�
>��1�j�������B���ꂪCore 2 Duo�ł�1�ɂȂ��Ă���BSSE���߂��W���I�ɕ��ԃ}���`��
>�f�B�A�����ł́A�傫�Ȑ��\���オ���҂ł���
�c�c�H
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-000.html?
>�]���AIntel CPU�ł�SSE���߂̃X���[�v�b�g�i���߂s�\�ȊԊu�j��2�i2�N���b�N�ɂ�
>��1�j�������B���ꂪCore 2 Duo�ł�1�ɂȂ��Ă���BSSE���߂��W���I�ɕ��ԃ}���`��
>�f�B�A�����ł́A�傫�Ȑ��\���オ���҂ł���
�c�c�H
>>485
�ȒP�Ɍ�����Core2Duo 2GHz��PenD 4GHz�̐��\�Ɠ������\���Ă��ƁB
�ȒP�Ɍ�����Core2Duo 2GHz��PenD 4GHz�̐��\�Ɠ������\���Ă��ƁB
ttp://journal.mycom.co.jp/articles/2006/07/14/x6800/
SSE4�̃I�y�R�[�h�͌��J����Ă���̂Ŏ����Ńv���O������
�g��Œ��ׂ�����Ǝv�����B���J����Ă��邱�Ƃ�
�C�Â��Ă��Ȃ��̂��A����Ƃ��Ƃڂ��Ă���̂��H
ttp://download.intel.com/design/Pentium4/manuals/25366720.pdf
�@APPENDIX A OPCODE MAP
�@�@A.3 ONE, TWO, AND THREE-BYTE OPCODE MAPS
�@�@�@Table A-4. Three-byte Opcode Map
SSE4�̃I�y�R�[�h�͌��J����Ă���̂Ŏ����Ńv���O������
�g��Œ��ׂ�����Ǝv�����B���J����Ă��邱�Ƃ�
�C�Â��Ă��Ȃ��̂��A����Ƃ��Ƃڂ��Ă���̂��H
ttp://download.intel.com/design/Pentium4/manuals/25366720.pdf
�@APPENDIX A OPCODE MAP
�@�@A.3 ONE, TWO, AND THREE-BYTE OPCODE MAPS
�@�@�@Table A-4. Three-byte Opcode Map
�悤�₭AltiVec���݂ɂȂ����ȁB
>>485
�X���[�v�b�g���āA���̎g�����ō����Ă�����H
�X���[�v�b�g���āA���̎g�����ō����Ă�����H
>>491
�ŋ߂͂��������g��������ʓI�B
�ŋ߂͂��������g��������ʓI�B
>>422
���傗
���傗
>>491
�X���[�v�b�g�Ƃ����P��͔��R�Ƃ����P�ʎ��Ԃ������
�����̗ǂ������Ƃ��E�E�E�B���ēK���Ȍ����Ŏg���ꍇ����������
�{���̌����Ȓ�`�Ŏg���Ƌt�Ɉ�a����������Ė��Ȏ��Ԃ�
�X���[�v�b�g�Ƃ����P��͔��R�Ƃ����P�ʎ��Ԃ������
�����̗ǂ������Ƃ��E�E�E�B���ēK���Ȍ����Ŏg���ꍇ����������
�{���̌����Ȓ�`�Ŏg���Ƌt�Ɉ�a����������Ė��Ȏ��Ԃ�
���A���^�C�����Č��t�Ɠ����ʼn��ɂ��Ęb�Ă��邩�ŒP�ʂ͕ς��B
�����͕��������������ĂȂ��Ƙb�͒ʂ��Ȃ��B
�����͕��������������ĂȂ��Ƙb�͒ʂ��Ȃ��B
�_�C�T�C�Y�����܂�ς�����CORE2DUO�Ɠ����̃R�A��512�R�A����邱�Ƃ͉\�H
�o�����Ƃ����牽�N��H
�o�����Ƃ����牽�N��H
>>496
�P�U�N��
�P�U�N��
>>498
�ǂ����낤��
http://journal.mycom.co.jp/articles/2005/03/17/idf/003.html
8nm�܂ł͍��̋Z�p�̉�����2�N���ƂɃv���Z�X�V�������N�ł����Intel�͗\�肵�Ă��
http://journal.mycom.co.jp/articles/2004/02/19/idf2/
�ǂ����낤��
http://journal.mycom.co.jp/articles/2005/03/17/idf/003.html
8nm�܂ł͍��̋Z�p�̉�����2�N���ƂɃv���Z�X�V�������N�ł����Intel�͗\�肵�Ă��
http://journal.mycom.co.jp/articles/2004/02/19/idf2/
512�R�A���c
����4nm�v���Z�X��CPU(���Č����ėǂ��V�����m�Ȃ̂����J��������)���g���ĂĂ��A
���ƕς��Ȃ����Ƃ���Ă�������ȁA��orz
����4nm�v���Z�X��CPU(���Č����ėǂ��V�����m�Ȃ̂����J��������)���g���ĂĂ��A
���ƕς��Ȃ����Ƃ���Ă�������ȁA��orz
���g��Ȃ���ŗǂ�������A5,6�N�ŏo����Ƃ������Ă��̂��ǂ����ł݂��������遄100�R�A
200����mm���x�̋���_�C��L2���ŏ����ōς܂������Ȃ���ł���B
�P���v�Z�ł�6�N��ɂ�16�R�A�ɂł���킯�ŁB
�P���v�Z�ł�6�N��ɂ�16�R�A�ɂł���킯�ŁB
�Ȃ��C���e���̓����R���������Ȃ��낗
������o�������H
2010�N�AIntel��CPU��32�R�A��
ttp://slashdot.jp/askslashdot/article.pl?sid=06/07/11/0830210
2010�N�AIntel��CPU��32�R�A��
ttp://slashdot.jp/askslashdot/article.pl?sid=06/07/11/0830210
Pen4 ��5GHz���Ƃ������Ă����̂��v���o���Ȃ��B
2010�N�A�F���̗����Ă��B
��z�͂������̂����A�C���e���ɂ͎��ۂɏo�����ł��ăz�X�B
��z�͂������̂����A�C���e���ɂ͎��ۂɏo�����ł��ăz�X�B
����945�}�U�[��C�Q�c�g������ĉ\�͂ǂ��Ȃ����H
�P���ȃN���b�N���g���ōl����ƁA�����̌��E����40GHz���x��
�V��ɂȂ�炵���ȁB�v���Z�X�V�������N�͂��łɌ��q�̑傫����
���ɂȂ�͂��߂Ă��邩��A�����Ȃ������ɓ��ł����������B
�V��ɂȂ�炵���ȁB�v���Z�X�V�������N�͂��łɌ��q�̑傫����
���ɂȂ�͂��߂Ă��邩��A�����Ȃ������ɓ��ł����������B
509 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 15:51:29 ID:myBOtHHO
�w�e���łł��B
Merom���C�N�ȋ���R�A���z���W�j�A�X�\����32�Ȃ�Ă�����Ȃ�ł����d
���[�ł����N����4�R�A������2�N���ƂɃ_�C�T�C�Y�����������Ή\�Ȃ̂�
Merom���C�N�ȋ���R�A���z���W�j�A�X�\����32�Ȃ�Ă�����Ȃ�ł����d
���[�ł����N����4�R�A������2�N���ƂɃ_�C�T�C�Y�����������Ή\�Ȃ̂�
510 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 15:54:07 ID:myBOtHHO
>>503
���ςœ������邯�ǁH
���ςœ������邯�ǁH
��ȃR�A�����葝�₳��B
���j�C�R�A�ɃA�v�����Ή�����Ƃ������Ƃ�SSE�Ƃ̐e�a�����ɂ߂č����Ȃ�Ƃ������ƁB
�R�A���Ƒ��₷���SSE�̐��\�����グ������g�����W�X�^���͂͂邩�ɏ��Ȃ��čςށB
���j�C�R�A�ɃA�v�����Ή�����Ƃ������Ƃ�SSE�Ƃ̐e�a�����ɂ߂č����Ȃ�Ƃ������ƁB
�R�A���Ƒ��₷���SSE�̐��\�����グ������g�����W�X�^���͂͂邩�ɏ��Ȃ��čςށB
513 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 16:05:31 ID:myBOtHHO
SPE���C�N��SIMD�����^�R�A���p�ӂ���̂͊m���ɗL����
100MHz���Ă�����͎̂��g�������\�݂����Ȋ��o����������
���̂����R�A�������\�݂����Ȋ��o�ɂȂ��Ă����̂��ȁB
���̂����R�A�������\�݂����Ȋ��o�ɂȂ��Ă����̂��ȁB
�R�A�����c��ɂȂ�A�\������ł��炩���߂��ꂼ��ʁX�̖��߂����s���Ă�����
���X�������Ȃ�̂��ȁc?�l�g�o����?
���X�������Ȃ�̂��ȁc?�l�g�o����?
517 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 16:35:13 ID:myBOtHHO
518 �FSocket774�F2006/07/16(��) 16:47:24 ID:HtpL0lY/
�Ȃ�Ƃ��Ȃ�Ȃ��`�`��
519 �FSocket774�F2006/07/16(��) 17:04:52 ID:HtpL0lY/
����ł���A���̎��̒i�K�͔��R���s���[�^�Ȃ̂ł���`
�]�͐��\�w���c�̎��g���̒����U�����Ȃ���B
�f�l�I�ɂ͕��U���������ɂ܂��܂��\��������B
�f�l�I�ɂ͕��U���������ɂ܂��܂��\��������B
������D���̊F�l�B�ǂ����A��w���������B
http://journal.mycom.co.jp/news/2002/10/24/17.html
http://www.kumikomi.net/article/news/2004/03/21_02.html
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
http://ext.ricoh.co.jp/LSI/product_assp/ri20/b5v870-1028/
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
http://www.itmedia.co.jp/news/articles/0604/05/news038.html
http://journal.mycom.co.jp/news/2002/10/24/17.html
http://www.kumikomi.net/article/news/2004/03/21_02.html
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
http://ext.ricoh.co.jp/LSI/product_assp/ri20/b5v870-1028/
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
http://www.innotech.co.jp/products/product_list/lsi/dsp/linedancer.html
http://www.itmedia.co.jp/news/articles/0604/05/news038.html
522 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 17:40:32 ID:myBOtHHO
>>515
IA64�Ȃł͂������邽�߂ɂ��ꂾ�����W�X�^�𑝂₵��
�\���̓��������ق��̌��ʂ��������ɏ������ނ��ƂŁA���\���҂��ł�B
���W�X�^�����Ȃ����߂Ƀ������ǂݏ������p������x86-ISA�ŁA
�i���K�V�[�����Ƃ����O��Łj��������̂͂����Ǝv���̂ł����B
�e�p�X���Ƀ�������Ԃ̉��z�����ł���Ή\�����Ȃ��ł���������
���₪��ς���
Itanium��IA32-EL�͈��̐��ʂ͏グ�Ă邵�A���\���オ���Ă�����[�G���h�T�[�o�ł�
Xeon�̑�ւƂ��Ă͎g����悤�ɂȂ邩��
IA64�Ȃł͂������邽�߂ɂ��ꂾ�����W�X�^�𑝂₵��
�\���̓��������ق��̌��ʂ��������ɏ������ނ��ƂŁA���\���҂��ł�B
���W�X�^�����Ȃ����߂Ƀ������ǂݏ������p������x86-ISA�ŁA
�i���K�V�[�����Ƃ����O��Łj��������̂͂����Ǝv���̂ł����B
�e�p�X���Ƀ�������Ԃ̉��z�����ł���Ή\�����Ȃ��ł���������
���₪��ς���
Itanium��IA32-EL�͈��̐��ʂ͏グ�Ă邵�A���\���オ���Ă�����[�G���h�T�[�o�ł�
Xeon�̑�ւƂ��Ă͎g����悤�ɂȂ邩��
64bit���ɂ܂�x86�����������Ă���AMD�̍߂͑傫���Ɗ�����
524 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 18:14:04 ID:myBOtHHO
mixi��SSE���g���đS�p�X�������s�Ȃ�čr�Ƃ��Љ�Ă�l�͂��܂���
������x�A�V�K��CPU���J��������IA64�Ƃ͈Ⴄ��@�ō����\��ڎw���̂��ȁH
����Ƃ����ł�IA64���œK���Ȃ̂��H
����Ƃ����ł�IA64���œK���Ȃ̂��H
528 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 20:28:53 ID:myBOtHHO
MS�ɂԂ��ꂽYamhill��IA64�ł�AMD64�݊��ł��Ȃ���R��64bit�����������炵������
NetBurst�̑�ʂ̃��W�X�^�t�@�C���ƒ����p�C�v���C���Ƃ̐e�a���̍���ISA�������\�����B
���Ƃ��A��葽���̘_�����W�X�^�i�R�Q�{���炢�H�j�łR�`�S�I�y�����h���炢�̖��߃Z�b�g�B
���ߒ��͒����Ȃ邪�A���W�X�^���\���ɂ���̂Ń��[�h�E�X�g�A�̕p�x�͌��点��̂Ō��ʓI�ɂ�
�R�[�h�̓R���p�N�g�ɂ܂Ƃ܂邩���H
�f�R�[�_��x86��Yamhill ISA�ŕʁX�ɂ��邪�A��OPs���x���ł͌݊��B
����̗����̃p�X�����s�Ȃ�Ă��Ƃ͂���̕��ŁA�����p�C�v���C���i���̃f�����b�g���z���\�B
�Ƃ��]�X�B
AMD64��MS�Ɏx������Yamhill���R��ꂽ���_��NetBurst�͏I����Ă��̂��������ˁB
NetBurst�̑�ʂ̃��W�X�^�t�@�C���ƒ����p�C�v���C���Ƃ̐e�a���̍���ISA�������\�����B
���Ƃ��A��葽���̘_�����W�X�^�i�R�Q�{���炢�H�j�łR�`�S�I�y�����h���炢�̖��߃Z�b�g�B
���ߒ��͒����Ȃ邪�A���W�X�^���\���ɂ���̂Ń��[�h�E�X�g�A�̕p�x�͌��点��̂Ō��ʓI�ɂ�
�R�[�h�̓R���p�N�g�ɂ܂Ƃ܂邩���H
�f�R�[�_��x86��Yamhill ISA�ŕʁX�ɂ��邪�A��OPs���x���ł͌݊��B
����̗����̃p�X�����s�Ȃ�Ă��Ƃ͂���̕��ŁA�����p�C�v���C���i���̃f�����b�g���z���\�B
�Ƃ��]�X�B
AMD64��MS�Ɏx������Yamhill���R��ꂽ���_��NetBurst�͏I����Ă��̂��������ˁB
>>527
�ȓd�́E���g�����W�X�^�ɂ����ƐU����CPU�ɂȂ邾�낤�ˁB
i860�݂����ȁA�����Ə��K�͂�VLIW�̂ق����悩�����B�E�E����̓o�O��������
���ł�����������ǁB�Ƃ������A���l������Ƃ��Ɖ�͖��������낤�B
�z���g�͊��S�ɃA�[�L�e�N�`���̈Ⴄ�R�A�̓������w�e���W�j�A�X�R�A��intel������āA
���̃w�e�������݂̂ł����삷��悤�ɂ��Ă����āA�ŏI�I��x86������Ӓ��Ƃ���
��Ƃ����V�i���I������ė~���������Borz
�ȓd�́E���g�����W�X�^�ɂ����ƐU����CPU�ɂȂ邾�낤�ˁB
i860�݂����ȁA�����Ə��K�͂�VLIW�̂ق����悩�����B�E�E����̓o�O��������
���ł�����������ǁB�Ƃ������A���l������Ƃ��Ɖ�͖��������낤�B
�z���g�͊��S�ɃA�[�L�e�N�`���̈Ⴄ�R�A�̓������w�e���W�j�A�X�R�A��intel������āA
���̃w�e�������݂̂ł����삷��悤�ɂ��Ă����āA�ŏI�I��x86������Ӓ��Ƃ���
��Ƃ����V�i���I������ė~���������Borz
�\�Z5���~�E�J������10�N���炢�ŁA���S�Ƀ[������CPU��v������A�ǂꂮ�炢�̐��\�ɂȂ��B
�J������10�N�Ă̂����ʁB
�N��10�N��Ȃ�ė\���ł��Ȃ��B
�N��10�N��Ȃ�ė\���ł��Ȃ��B
>>530
Intel��10�N��̃v���Z�b�T�����̐��\
Intel��10�N��̃v���Z�b�T�����̐��\
534 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/16(��) 23:45:31 ID:myBOtHHO
���킽��������
Fab�P��邾���łR�O�O�O���~�قǂ����邼
Yamhill�̊T�v��m���Ă��邪�c�q�̗\�z�͊O��܂��肾�B�ƌ����Ă����B
538 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 14:23:22 ID:zbUstSrv
>>537
���[�Ȃ��H����ς�x86�̊g���������ƁH
���[�Ȃ��H����ς�x86�̊g���������ƁH
540 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 15:54:10 ID:zbUstSrv
�c�O�Ȃ��炤���̎���ɂ�IDF�Ƃ��ɘA��Ă��Ă����悤�ȏ�i�͂���܂ւ��
�w����炢�Ȃ�ǂ݂��Ă܂����ȁB
�������ɋɒ[��NetBurst�̓����A�[�L�Ɉˑ������悤�Ȗ��߃Z�b�g����
P6�A�[�L�̉�����Merom�ł͎����������
������ɂ���Intel�ɂ�IA64�Ƃ͕ʂ�64bit�g��ISA�̍\�z�������āA
NetBurst��CMA���������������v�悾�����킯������
NetBurst�͍��x�ɉ��z���ł��Ă�����uAMD64�݊��v�ɐ�ւ���Ă�
�_��Ƀ`���[�j���O�ł������ǁACMA�̓o�����X�̕�������߂��̂�����āA
���ʁA����̂悤��EM64T�Ńp�t�H�[�}���X�ቺ�Ƃ����\�����l���Ă݂���B
������ɂ���AIA64�̕��y��W����Ǝv���Ă����Ўd�l��x86 64bit�g����
������Ɣ��荞��ł����Ȃ�����Intel�̎��s�ł��ȁB
�n�C�G���h�R���s���[�e�B���O�����POWER�ɑR�ł���v���Z�b�T��D�悷��̂�
�ǂ������̂��APC�s���AMD����������̂��ǂ������̂��A���̕ӂ͂킩�肩��Ƃ���ł���
�w����炢�Ȃ�ǂ݂��Ă܂����ȁB
�������ɋɒ[��NetBurst�̓����A�[�L�Ɉˑ������悤�Ȗ��߃Z�b�g����
P6�A�[�L�̉�����Merom�ł͎����������
������ɂ���Intel�ɂ�IA64�Ƃ͕ʂ�64bit�g��ISA�̍\�z�������āA
NetBurst��CMA���������������v�悾�����킯������
NetBurst�͍��x�ɉ��z���ł��Ă�����uAMD64�݊��v�ɐ�ւ���Ă�
�_��Ƀ`���[�j���O�ł������ǁACMA�̓o�����X�̕�������߂��̂�����āA
���ʁA����̂悤��EM64T�Ńp�t�H�[�}���X�ቺ�Ƃ����\�����l���Ă݂���B
������ɂ���AIA64�̕��y��W����Ǝv���Ă����Ўd�l��x86 64bit�g����
������Ɣ��荞��ł����Ȃ�����Intel�̎��s�ł��ȁB
�n�C�G���h�R���s���[�e�B���O�����POWER�ɑR�ł���v���Z�b�T��D�悷��̂�
�ǂ������̂��APC�s���AMD����������̂��ǂ������̂��A���̕ӂ͂킩�肩��Ƃ���ł���
IA64�ōs���\�肾�������AAMD���E�E�E
Yamhill�̘b�����ւ��Ă�ł���
ttp://pc.watch.impress.co.jp/docs/2004/0225/kaigai067.htm
ttp://pc.watch.impress.co.jp/docs/2004/0225/kaigai067.htm
�����Nehalem�܂ő҂��c
�܂�ȯ��ް�ĂƂ��������������̂���
�܂�ȯ��ް�ĂƂ��������������̂���
545 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 21:06:20 ID:zbUstSrv
128bit�Œ蒷���߂�IA64��Prescott/Tejas�ł˂�
�Ԃ����Ⴏx86�Ƃ͎��Ă������ʖ��߃Z�b�g�Ȃ�ł���
IA64��ł�x86�iP7�A�[�L�e�N�`���j�̂��Ƃł����H
�Ԃ����Ⴏx86�Ƃ͎��Ă������ʖ��߃Z�b�g�Ȃ�ł���
IA64��ł�x86�iP7�A�[�L�e�N�`���j�̂��Ƃł����H
>>543
Yamhill��Prescott�ɍڂ���\�肾����64bit�g���ŁATejas�͂��̌�̃v���W�F�N�g����Ȃ������H
http://www.aceshardware.com/read.jsp?id=50000243
�����ɏ�����Ă��� IA32+ ��Yamhill�ŁA
Tejas - evaluated support for IA64 within a mainstream IA32 processor.�Ƃ͕ʂ��ƁB
Yamhill��Prescott�ɍڂ���\�肾����64bit�g���ŁATejas�͂��̌�̃v���W�F�N�g����Ȃ������H
http://www.aceshardware.com/read.jsp?id=50000243
�����ɏ�����Ă��� IA32+ ��Yamhill�ŁA
Tejas - evaluated support for IA64 within a mainstream IA32 processor.�Ƃ͕ʂ��ƁB
�j��ō��̖��߃Z�b�g���ĉ����Ǝv���H
���ƃ��C�h
������H
���[�����ŋ߃}�N���^���݂܂���ˁB
���㓡�O��Weekly�C�O�j���[�X��
32bit�ł͈��|�I����64bit�͂�����Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
32bit�ł͈��|�I����64bit�͂�����Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
552 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 23:44:15 ID:zbUstSrv
>>550
WWDC���\�O�����炶��ˁH
����Ȃ��ƌ����ĊO�����́A��t���ōu�ߐ��ꂽ�ق��������킯��
http://amb.sakura.ne.jp/hanyou/img-box/img20060705023955.jpg
WWDC���\�O�����炶��ˁH
����Ȃ��ƌ����ĊO�����́A��t���ōu�ߐ��ꂽ�ق��������킯��
http://amb.sakura.ne.jp/hanyou/img-box/img20060705023955.jpg
{kind=link}
553 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/17(��) 23:47:44 ID:zbUstSrv
> �@���Ƃ��ƁAIntel�̃I���W�i����64bit�g���uYamhill(�����q��)�v�́A���W�X�^�g�����܂܂Ȃ��A
> �A�h���X�g�������̃e�N�m���W�������ƌ����Ă���B���ꂪ�A���݂�EM64T(Clackamas:�N���J�}�X)��
> �ς����2003�N�㔼�̒i�K�ŁAAMD64�݊��ƂȂ背�W�X�^�g�����������ƌ����Ă���B
> CPU�J���T�C�N����4�`5�N�Ȃ̂ŁA�����I�ɂ́A���̎��_�ł�Core MA�̏㗬�v�͏I���A
> ���łɕ����v���i��ł����͂��BEM64T�Ƃ̂��荇�킹���r������s�Ȃ�ꂽ�Ƃ��Ă�
> �s�v�c�ł͂Ȃ��B
Yamhill ISA���Ȃ�ƂȂ������ł���
> �A�h���X�g�������̃e�N�m���W�������ƌ����Ă���B���ꂪ�A���݂�EM64T(Clackamas:�N���J�}�X)��
> �ς����2003�N�㔼�̒i�K�ŁAAMD64�݊��ƂȂ背�W�X�^�g�����������ƌ����Ă���B
> CPU�J���T�C�N����4�`5�N�Ȃ̂ŁA�����I�ɂ́A���̎��_�ł�Core MA�̏㗬�v�͏I���A
> ���łɕ����v���i��ł����͂��BEM64T�Ƃ̂��荇�킹���r������s�Ȃ�ꂽ�Ƃ��Ă�
> �s�v�c�ł͂Ȃ��B
Yamhill ISA���Ȃ�ƂȂ������ł���
> �A�h���X�g������
�{��ALU�ɂƂ��Ă͓s�����ǂ��B
�{��ALU�ɂƂ��Ă͓s�����ǂ��B
�{�����[��ALU�̌v�Z��0.5�N���b�N�łP����ĈӖ����������ƁB
ALU�����{�̃N���b�N�ʼn��킯����Ȃ��B
ALU�����{�̃N���b�N�ʼn��킯����Ȃ��B
556 �FMAC�I�^���c�q �����F2006/07/18(��) 03:21:07 ID:aFOWSjDQ
>>552-553
Apple�Ɋւ���b��A��������ǂ���(��)
http://pc7.2ch.net/test/read.cgi/mac/1121683774/722-727
x86�Ɋւ���b���A���Ȃ��₤���̔�inteler���b��̓_�ł����߂̓_�ł�
����Ȃ�̃��m�������Ă��邷����A���ɏo�Ԃ햳�����ˁB�B�B
�����AIntel�̏��v���W�X�^���ɂ��Ă̍l����A�������Andy Glew���̈ӌ����Q�l
�ɂȂ邩�Ǝv�����B
http://groups.google.co.jp/group/comp.arch/browse_thread/thread/d5def6efe58e9de9/c85f4f125889419b
��K��OOoE�v���Z�b�T + SMT�ł�X���b�h������̐�L���W�X�^�������炷���ƂŁA
�@�E������s�\�Ȃ悤�ɕ������W�X�^������t���₷���Ȃ�
�@�E�����̂��̂̒��o���y
�Ƃ�������������݂������ˁB�B�B
C2D�R�A�Ɍ��炸�ASPECint�ɂ�����x86�̏����탌�W�X�^�������\�ɒ������Ȃ��Ƃ���
��̏ؖ��Ȃ̂�������Ȃ����B
Apple�Ɋւ���b��A��������ǂ���(��)
http://pc7.2ch.net/test/read.cgi/mac/1121683774/722-727
x86�Ɋւ���b���A���Ȃ��₤���̔�inteler���b��̓_�ł����߂̓_�ł�
����Ȃ�̃��m�������Ă��邷����A���ɏo�Ԃ햳�����ˁB�B�B
�����AIntel�̏��v���W�X�^���ɂ��Ă̍l����A�������Andy Glew���̈ӌ����Q�l
�ɂȂ邩�Ǝv�����B
http://groups.google.co.jp/group/comp.arch/browse_thread/thread/d5def6efe58e9de9/c85f4f125889419b
��K��OOoE�v���Z�b�T + SMT�ł�X���b�h������̐�L���W�X�^�������炷���ƂŁA
�@�E������s�\�Ȃ悤�ɕ������W�X�^������t���₷���Ȃ�
�@�E�����̂��̂̒��o���y
�Ƃ�������������݂������ˁB�B�B
C2D�R�A�Ɍ��炸�ASPECint�ɂ�����x86�̏����탌�W�X�^�������\�ɒ������Ȃ��Ƃ���
��̏ؖ��Ȃ̂�������Ȃ����B
>>555
������Ȃɂ����������́H
������Ȃɂ����������́H
>>481
>>���̃e�X�^�[����̓������������������B
���������̂͌N�̕��������˂��I��������
���㓡�O��Weekly�C�O�j���[�X��
32bit�ł͈��|�I����64bit�͂�����Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
>>���̃e�X�^�[����̓������������������B
���������̂͌N�̕��������˂��I��������
���㓡�O��Weekly�C�O�j���[�X��
32bit�ł͈��|�I����64bit�͂�����Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
���̋��?�Ȑ��i�̃g�b�v�N���X�ƁA���ӂȐ��i�̃g�b�v�N���X���r����
�ǂ��炪�������̂������Ă݂��B
sakura editor�ő���۽
�ǂ��炪�������̂������Ă݂��B
sakura editor�ő���۽
sakura editor��AMD�M�҂̐S�̂��ǂ���
�Ђǂ������L������B
���̋L���̉��̕��ɏ����Ă��邯�ǁA
�����Core MicroArchitecture�̎�_�ł���Ɠ�����x86�̖���ł�����݂����ł��ˁB
�f�R�[�_�[�̌��Trace Cache���������NetBurst�̂悤�ɏ�肭�B���ł���̂��ȁB
�����Core MicroArchitecture�̎�_�ł���Ɠ�����x86�̖���ł�����݂����ł��ˁB
�f�R�[�_�[�̌��Trace Cache���������NetBurst�̂悤�ɏ�肭�B���ł���̂��ȁB
K7,K8�݂����Ƀv���f�R�[�h�ς݂̖��߂�L1�L���b�V���ɓ������@������B
>>563
Conroe�͓����Ă��B
Conroe�͓����Ă��B
�����Ă�H�H�ړI�ꂪ�킩��܂���B
Conroe�̖��߃L���b�V����
�v���f�R�[�h�Ƃ����ĂȂ�
�f�̃f�[�^�������Ă��ˁH
�v���f�R�[�h�Ƃ����ĂȂ�
�f�̃f�[�^�������Ă��ˁH
>>567
������A������L1�֏����o���Ă��B
������A������L1�֏����o���Ă��B
�v���f�R�[�h���Ă邩�疽�߃L���b�V���Ȃ�c
>>570
����Ȃ��Ƃ͂Ȃ��B
���߂ƃf�[�^���ɓǂޕK�v������Ƃ�
���߂͏����������قƂ�NjN����Ȃ��Ȃǂ̗��R��
�f�[�^�L���b�V���ƕ�����������������
���߃L���b�V��������̂��B
>>571
�E�E�E
����Ȃ��Ƃ͂Ȃ��B
���߂ƃf�[�^���ɓǂޕK�v������Ƃ�
���߂͏����������قƂ�NjN����Ȃ��Ȃǂ̗��R��
�f�[�^�L���b�V���ƕ�����������������
���߃L���b�V��������̂��B
>>571
�E�E�E
>>558�������v���f�R�[�_��L1���߃L���b�V���̌�ɂ�����ǂ˂��B
�܂��AL1�̑O�Ƀv���f�R�[�_������L2�̃��C�e���V���ߎS�Ȏ��ɂȂ邩���w
>>572
�Ⴄ�B
���Ƀt�@�C�h�^�L���b�V���̓t�F�b�`��v���f�R�[�h�̌����𗎂Ƃ�����Ƃ����A
L1�Ƃ��Ēv���I�Ȏ�_�����邩��n�[�o�[�h�A�[�L�Ȃ̂��B
�b�͕ς�邪>>567,>>572��???�������̂Œ��ׂĂ݂���AMD�̓v���f�R�[�h��L1�̑O�ɂ���ˁB
AMD�ɂ͂܂����������Ȃ����������ɂȂ����B
���_�A���b�`�Ȗ��߃L���[�ƃv���f�R�[�h�^�L���b�V���A���ꂾ���ł͂ǂ��炪�D��Ă��邩�͔��f�ł��Ȃ����B
�Ⴄ�B
���Ƀt�@�C�h�^�L���b�V���̓t�F�b�`��v���f�R�[�h�̌����𗎂Ƃ�����Ƃ����A
L1�Ƃ��Ēv���I�Ȏ�_�����邩��n�[�o�[�h�A�[�L�Ȃ̂��B
�b�͕ς�邪>>567,>>572��???�������̂Œ��ׂĂ݂���AMD�̓v���f�R�[�h��L1�̑O�ɂ���ˁB
AMD�ɂ͂܂����������Ȃ����������ɂȂ����B
���_�A���b�`�Ȗ��߃L���[�ƃv���f�R�[�h�^�L���b�V���A���ꂾ���ł͂ǂ��炪�D��Ă��邩�͔��f�ł��Ȃ����B
�����Ă邱�Ƃ͓����Ɏv����B
�܂��f�[�^�̕��ɋǏ����������ꍇ�͖��߂��������������Ă��Ƃ����邩������B
�܂��f�[�^�̕��ɋǏ����������ꍇ�͖��߂��������������Ă��Ƃ����邩������B
�����v���̂����E�E�E�B
�݂ǂ��ł���ȕ����Ă���H
�݂ǂ��ł���ȕ����Ă���H
Conroe��45nm�����H
45nm�ł̓V�������N���Ȃ��ŕʐv�ɂȂ�́H
45nm�ł̓V�������N���Ȃ��ŕʐv�ɂȂ�́H
45nm��08Q1��Core2�̃V�������N�Ŏn�܂�
���̌�_�C���N�g�R�l�N�g��CSI�ƃ����R�������̟��ςŐV�v���b�g�t�H�[�����n�܂�B
�\��B
���A2�N����̗\�肪���̂܂��s���ꂽ���ȂǂȂ��̂�
����܍l���Ă����傤���Ȃ��B
���̌�_�C���N�g�R�l�N�g��CSI�ƃ����R�������̟��ςŐV�v���b�g�t�H�[�����n�܂�B
�\��B
���A2�N����̗\�肪���̂܂��s���ꂽ���ȂǂȂ��̂�
����܍l���Ă����傤���Ȃ��B
Conroe�̎��̓n�b�L�������ĂȂ����Ă��Ƃ�
���i����Ȃ�ĂȂ���������
���i����Ȃ�ĂȂ���������
���{��ł�k
Penryn�ł�64bit���\�̃e�R����͂����̂��ˁH
584 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 00:24:40 ID:1bCHDZNj
Nehalem�A�[�L�e�N�`�����T���Ă�炵���̂ŁA����܂�傫�ȉ��ǂ͂Ȃ�����
�[���A64bit�ɂ�����炸32bit�ł�16byte�̃t�F�b�`���v���f�R�[�h�ш���Č����čL���Ƃ͌����Ȃ���ˁB
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268_01l.gif
�[���A64bit�ɂ�����炸32bit�ł�16byte�̃t�F�b�`���v���f�R�[�h�ш���Č����čL���Ƃ͌����Ȃ���ˁB
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268_01l.gif
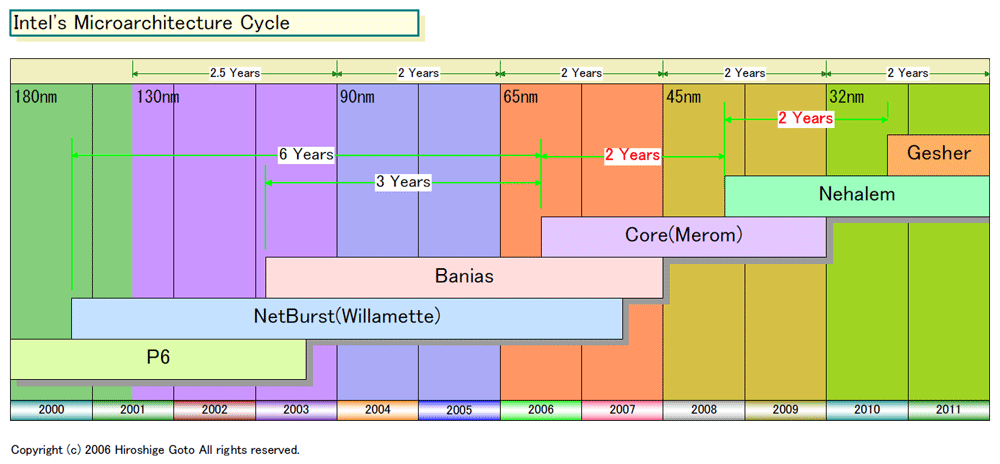{kind=link}
�@ ,j;;;;;j,. ---�� �M �@�\--�]�_ l;;;;;;�@�@�@
�@�o;;;;;;�T T�i� i �@ �@f'�j�@�@ !i;;;;;�@�@�@Nehalem��20GHz
�@ �S;;;ʁ@�@�@�@Ɂ@�@�@�@�@�@�@.::!l�;;r�
�@�@ `Z;i�@�@�@�q.,_..,.�@�@�@�@�@�@�;;;;;;;;>�@�@����Ȃӂ��ɍl���Ă���������
�@ �@,;��ʁA�@�_,.�-�_',. �@ �@,���: Y;;f �@�@�@���ɂ�����܂���
�@�@ ~''���R �@ �M��L �@�@ r'�L:::.�@`!
�@�o;;;;;;�T T�i� i �@ �@f'�j�@�@ !i;;;;;�@�@�@Nehalem��20GHz
�@ �S;;;ʁ@�@�@�@Ɂ@�@�@�@�@�@�@.::!l�;;r�
�@�@ `Z;i�@�@�@�q.,_..,.�@�@�@�@�@�@�;;;;;;;;>�@�@����Ȃӂ��ɍl���Ă���������
�@ �@,;��ʁA�@�_,.�-�_',. �@ �@,���: Y;;f �@�@�@���ɂ�����܂���
�@�@ ~''���R �@ �M��L �@�@ r'�L:::.�@`!
���邠�邗
5GHz��4���Ȃ獇�v20GHz�ɂȂ邶���
�撣��Ζ�������Ȃ���
�撣��Ζ�������Ȃ���
2.5GHz��8-core�̂ق��������I����ˁH
���N���b�N���Ƃ܂��d�͖�肾��
���N���b�N���Ƃ܂��d�͖�肾��
589 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 02:13:10 ID:1bCHDZNj
�l�b�g���[���h�A�C���e��CPU��Solaris/SPARC�p�A�v�����ғ�������\�t�g
http://enterprise.watch.impress.co.jp/cda/software/2006/07/18/8265.html
Opteron����Ȃ���Xeon��Itanium2�p���Ă̂��Ȃ�Ƃ��B
http://enterprise.watch.impress.co.jp/cda/software/2006/07/18/8265.html
Opteron����Ȃ���Xeon��Itanium2�p���Ă̂��Ȃ�Ƃ��B
591 �FSocket774�F2006/07/19(��) 03:08:41 ID:8QdS/7yD
�܁A�f�l�͂����l�����ȁB
>>589
�����ɂ����[�g��SUN�̃V�X�e�������邯�ǁA���������ƈ����Ȃ�ȁB
����Ȃ璆�Ô����Ă��Ă��܂������ق��������B
�����������Ԃ͎����悤�Ȃ��낤���B
�����ɂ����[�g��SUN�̃V�X�e�������邯�ǁA���������ƈ����Ȃ�ȁB
����Ȃ璆�Ô����Ă��Ă��܂������ق��������B
�����������Ԃ͎����悤�Ȃ��낤���B
>>580
Core2 65nm�łQ�N���Ď��͎��g���Ƃ��܂��]�T�ŃN���b�N�A�b�v�ł����o���̂��H
Core2 65nm�łQ�N���Ď��͎��g���Ƃ��܂��]�T�ŃN���b�N�A�b�v�ł����o���̂��H
Kents��Presler���ă_�C�T�C�Y�����ɂȂ��ȁE�E�E
�v���Ď��߂Ă�̂��ȁH
�v���Ď��߂Ă�̂��ȁH
�Ǝv����������
Tom�̓z�Ԉ���Ă��
Tom�̓z�Ԉ���Ă��
�ނ���LGA775��Yonah�j�R�C�`��Core Quad�Ƃ��o���ė~�����ȁB
FSB1333�Ȃ炫�ꂢ�ɕ���ł���B
FSB1333�Ȃ炫�ꂢ�ɕ���ł���B
FSB1333MHz��MCM�͓��
���ŁAConroe��Merom�̕����A�h���X����36bit�H
599 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 22:50:18 ID:1bCHDZNj
CPUID����킩���ˁH
XP x64��16GB�܂ŁAVista�ł����̔{���x�����牼��64GB���Ƃ��Ă��x��͂Ȃ����ǂȁB
�����܂Ń������ς߂�PC�p�}�U�[���Ȃ����낤����f����Xeon�ł��������낤���B
XP x64��16GB�܂ŁAVista�ł����̔{���x�����牼��64GB���Ƃ��Ă��x��͂Ȃ����ǂȁB
�����܂Ń������ς߂�PC�p�}�U�[���Ȃ����낤����f����Xeon�ł��������낤���B
NetBurst�������A�h���X36bit���ᖳ�����������H
����������ꔭ��40bit�Əo����
602 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/19(��) 23:02:07 ID:1bCHDZNj
�v���X�R/�m�R�i�̏������r�W������x86-64�̎d�l�ێʂ���36bit�����Ȃ��̂�40bit������������
�m���ɂ���������Irwindale����40bit�Ə����Ă��邪�A�����z�̋L�������c
�uMontecito�v�̊J���ӔC�҂ɕ��䗠����
http://techon.nikkeibp.co.jp/article/NEWS/20060719/119268/
Tukwila�R�A�́AMontecito�Ɗ�{�I�ɂ͓����R�A���Ƃ������ƂŁA
�ȑOINQ�ɂ�����������������ƁB
�����i���ƂɃR�A��ς��Ă�����C�R���p�C���̊J������ςɂȂ�B
����͑OTukwila�̗��Y���R���ȁB
http://techon.nikkeibp.co.jp/article/NEWS/20060719/119268/
Tukwila�R�A�́AMontecito�Ɗ�{�I�ɂ͓����R�A���Ƃ������ƂŁA
�ȑOINQ�ɂ�����������������ƁB
�����i���ƂɃR�A��ς��Ă�����C�R���p�C���̊J������ςɂȂ�B
����͑OTukwila�̗��Y���R���ȁB
Tukwila��CSI�ɂȂ���������H
�C���e���A�N�A�h�R�A�v���Z�b�T��N�����\��--AMD�̐搧�ڎw��
ttp://japan.cnet.com/news/ent/story/0,2000056022,20175767,00.htm
Intel�{�C���ȁB
�܂�Conroe�����܂��s���Ă��܂Ƃ߂ď悹�邾��������ȒP�Ȃ��ǂ��B
����������AMD���\��𑁂߂Ă��肷��̂��Ȃ��B
ttp://japan.cnet.com/news/ent/story/0,2000056022,20175767,00.htm
Intel�{�C���ȁB
�܂�Conroe�����܂��s���Ă��܂Ƃ߂ď悹�邾��������ȒP�Ȃ��ǂ��B
����������AMD���\��𑁂߂Ă��肷��̂��Ȃ��B
Tulsa��8/26�炵��
>>605
4FBDlink���Ƃ�
���N�x���Nehalem��8link������2009�N�ɂ�8link�ȏ�̊g���ł��o���ė~������
�܂���Ȃ��i�ނ��Ƃ̂ق������������\�\�\
>>605
4FBDlink���Ƃ�
���N�x���Nehalem��8link������2009�N�ɂ�8link�ȏ�̊g���ł��o���ė~������
�܂���Ȃ��i�ނ��Ƃ̂ق������������\�\�\
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288_01.jpg
���̐}�����ċ��������AMacro-Fusion����CMP+JGE�݂����ȕ����L��̑召��r�������
�t���[�W�����ł��Ȃ��ˁB
{kind=link}
���̐}�����ċ��������AMacro-Fusion����CMP+JGE�݂����ȕ����L��̑召��r�������
�t���[�W�����ł��Ȃ��ˁB
>>605
�I���_�C�����R���{CSI
>>607
Nehalem������FBD8ch�Ȃ̂��Ƃ����ƁAMCM�i4ch*2�jVer�����邩�炾���炾�낤�B
Tukwila��MCM Ver�����邻��������A�ς��낤�B
�I���_�C�����R���{CSI
>>607
Nehalem������FBD8ch�Ȃ̂��Ƃ����ƁAMCM�i4ch*2�jVer�����邩�炾���炾�낤�B
Tukwila��MCM Ver�����邻��������A�ς��낤�B
>>606
�{�C�Œ@���ׂ��C�Ȃ̂��c
�{�C�Œ@���ׂ��C�Ȃ̂��c
���߁AConroe�̔��\�����Ă��������H
7��28���B
thx.
615 �FSocket774�F2006/07/27(��) 00:23:58 ID:19S6ih5Z
age
E6300��1.86Hz�ɂȂ��Ă邪�ǂ�Ȗ��̐��E�Ȃ낤
http://pc.watch.impress.co.jp/docs/2006/0714/tawada79.htm
http://pc.watch.impress.co.jp/docs/2006/0714/tawada79.htm
����X�n��E�n�͎��g�����Ⴄ�����Ȃ̂��H
618 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/27(��) 20:57:41 ID:cE04IxGu
PenXE 965��Ath64 FX-62�قǂ������ȉ��i�ݒ肶��Ȃ�����B
619 �FSocket774�F2006/07/28(��) 03:43:12 ID:Xyo+qCp4
���ɍ��������Conroe��������CPU�ł͖����Ȃ����킯���B
620 �FSocket774�F2006/07/28(��) 03:51:28 ID:BhLY8/jU
Core 2 Quad�܂����H
�^�ł�Nehalem�B
totoro?anata,totorotteyuunone.
�f�p�ȋ^��Ȃ��ǁA
C2D���ĂƂ��Ă��œK������Ă��đf���炵�����ǁA
����Ȃɂ�������������āA�X���[�Y�ɃR�A���₵����
�ʎ�R�A�Ƃ̃}���`�Ƃ��̊g�����X���[�Y�ɏo����̂��ȁH
C2D���ĂƂ��Ă��œK������Ă��đf���炵�����ǁA
����Ȃɂ�������������āA�X���[�Y�ɃR�A���₵����
�ʎ�R�A�Ƃ̃}���`�Ƃ��̊g�����X���[�Y�ɏo����̂��ȁH
�ǂ��ł�FX�����̂�(6700�j�Ƃ�����R��������FX�������i�ڂ�������j����������6700��������������̂���
�y�K�V�X�ATMPGEnc 4.0 XPress��Core 2 Duo�Ή�
�|5�`18%�������BH.264��2�p�X�G���R�[�h��
ttp://www.watch.impress.co.jp/av/docs/20060727/pegasys.htm
������āASSE4�ɑΉ�����������5�`18���������������Ă��ƁH
���Ƃ����猋�\�X�S�X
�|5�`18%�������BH.264��2�p�X�G���R�[�h��
ttp://www.watch.impress.co.jp/av/docs/20060727/pegasys.htm
������āASSE4�ɑΉ�����������5�`18���������������Ă��ƁH
���Ƃ����猋�\�X�S�X
>>625
����ASSE�̃X���[�v�b�g���{�ɋ������ꂽ���߁A
���C�e���V�̊��S�ȉB��������Ȃ����B
���̐��\�������o�����߂̃`���[�j���O�Ƃ��l������B
�܂��ASSE4�����̉\�������邪�A���ɂ͂ǂ��������킩���B
����ASSE�̃X���[�v�b�g���{�ɋ������ꂽ���߁A
���C�e���V�̊��S�ȉB��������Ȃ����B
���̐��\�������o�����߂̃`���[�j���O�Ƃ��l������B
�܂��ASSE4�����̉\�������邪�A���ɂ͂ǂ��������킩���B
�܂��A�����ł���B
���ɂ��AC2D�Ή��ւׂ̍��ȃ`���[�j���O������ł��傤�B
���ɂ��AC2D�Ή��ւׂ̍��ȃ`���[�j���O������ł��傤�B
Core2��SSE3���S��炵����
SSE2�ƕς��Ȃ��炵��
��Cpre2�����̊g�����߂�p�ӂ�����
SSE2�ƕς��Ȃ��炵��
��Cpre2�����̊g�����߂�p�ӂ�����
629 �FSocket774�F2006/07/28(��) 14:09:49 ID:w+8WFqXb
�炵����
�炵��
�炵��
Intel�A�Ė{�Ђ�Core 2 Duo�̃��[���`�C�x���g���J��
ttp://pc.watch.impress.co.jp/docs/2006/0728/intel.htm
�� �I����ɍs��ꂽQ&A�Z�b�V�����ł́AAMD�ɂ��ATI�����Ɋ֘A����
�� �uCPU��GPU���������i�ɂ��Ă̏����̓W�]�́v�Ƃ������������яo�������A
�� �I�b�e���[�j�В��́u�P���ɓ�����Ȃ�A����́g�C�G�X�h���B
�� �ł��A���܂͂���ȏ�̓�����Ԃ����Ƃ͏o���Ȃ���(��)�v�Ɩ����͔����Ă���B
ttp://pc.watch.impress.co.jp/docs/2006/0728/intel.htm
�� �I����ɍs��ꂽQ&A�Z�b�V�����ł́AAMD�ɂ��ATI�����Ɋ֘A����
�� �uCPU��GPU���������i�ɂ��Ă̏����̓W�]�́v�Ƃ������������яo�������A
�� �I�b�e���[�j�В��́u�P���ɓ�����Ȃ�A����́g�C�G�X�h���B
�� �ł��A���܂͂���ȏ�̓�����Ԃ����Ƃ͏o���Ȃ���(��)�v�Ɩ����͔����Ă���B
TG Daily interviews Intel Senior VP: "Core is changing the game"
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
632 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/28(��) 21:11:43 ID:zUjJered
>>628
���Ƃ���Tejas�ɍڂ�\��̖��߂��������Core2�ׂ̖̈��߂���Ȃ�
�������唼�͕���������������Ȃ��Đ�������������SSE3���g�����閽�߂���Ȃ�
���Ƃ���Tejas�ɍڂ�\��̖��߂��������Core2�ׂ̖̈��߂���Ȃ�
�������唼�͕���������������Ȃ��Đ�������������SSE3���g�����閽�߂���Ȃ�
�C�X���G���������̓n�C�t�@�ɂ����ˁB�S�z�ł͂���B
���̃G���R�[�_�Ɗr�ׂĐM���������قǒx��TMPGENC��2�������Ȃ������Ă��܂�
�g�������Ƃ͎v���Ȃ�
������Avisynth�̔{�͒x�����E�E�E
�g�������Ƃ͎v���Ȃ�
������Avisynth�̔{�͒x�����E�E�E
Avisynth�͉掿��������_�O
>>635
���̏ꍇ�́A�����̎d����t�B���^�[�I�т��ǂ��Ȃ��B
AviSource�ł���C������ׂ��I�v�V����������B
�������A�܂Ƃ��ȃt�B���^�[��G���R�[�_��I�Ԃ�
Avisynth������Ȃ�ɒx���Ȃ��Ă��܂��B
�Ƃ���ŁAAvisynth�̓G���R�[�_����Ȃ���B
���̏ꍇ�́A�����̎d����t�B���^�[�I�т��ǂ��Ȃ��B
AviSource�ł���C������ׂ��I�v�V����������B
�������A�܂Ƃ��ȃt�B���^�[��G���R�[�_��I�Ԃ�
Avisynth������Ȃ�ɒx���Ȃ��Ă��܂��B
�Ƃ���ŁAAvisynth�̓G���R�[�_����Ȃ���B
�ǂ��ł������AMPEG�ҏW�����g���
638 �FSocket774�F2006/07/30(��) 13:45:43 ID:o7VD2f1j
>>620
�\���A�f���I��������J���e�b�g����Ȃ��́H
�\���A�f���I��������J���e�b�g����Ȃ��́H
Core3Duo�Ƃ�Core4Duo����
Core ��3�Ȃ̂� Duo ���H Core ��4�Ȃ̂� Duo ���H
�����B
�����B
X6800�͗�p���������Ƃ�
>>638
Quatoro����
Quatoro����
>>638
���O�A�p���������Ȃ�
���O�A�p���������Ȃ�
Solo�ADuo�̗���ł�������Quartet����������Ȃ�
�R���>>642������Ă���A�C�Â������ق��Ă���
�R���>>642������Ă���A�C�Â������ق��Ă���
Core��2������Core2���Ă킯����Ȃ����B
Pentium�݂�����Core3,4���ė��ꂩ��
Pentium�݂�����Core3,4���ė��ꂩ��
Core�@�l�H����
Core2�@�l�H����2
�݂����Ȋ���
Core2�@�l�H����2
�݂����Ȋ���
647 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/07/30(��) 21:30:27 ID:U7lEAKSJ
45nm�v���Z�X��L2��1.5�{�炵��
http://www.geocities.jp/andosprocinfo/wadai05/20051210.htm
�C�����̈������₵������
http://www.geocities.jp/andosprocinfo/wadai05/20051210.htm
�C�����̈������₵������
Kentsfield��Conroe�̃j�R�C�`������Core D Duo
>>650
>>645�������Ă���̂́ACore2 �� 2 �́ACore Duo �ɑ�����2�e��CPU���Ӗ�
������Ă������Ƃ���B������Ȃ��̂Ȃ�A��������������˂��J�L�R����Ȃ�B
�R�A�̐���\���̂́ASolo �Ƃ� Duo ���낤���B
>>645�������Ă���̂́ACore2 �� 2 �́ACore Duo �ɑ�����2�e��CPU���Ӗ�
������Ă������Ƃ���B������Ȃ��̂Ȃ�A��������������˂��J�L�R����Ȃ�B
�R�A�̐���\���̂́ASolo �Ƃ� Duo ���낤���B
�オ���Ă�����i�ۏo���ł����p���̂������Ă��̓X���[�����B
������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A ��
������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 4 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 7 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ��
������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ��
������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A ��
������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 4 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 7 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ��
������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ��
������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ��
������������������������������������������������������������������
��core11.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���@ �U�S�@��
������������������������������������������������������������������
��core12.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���@ �U�S�@��
������������������������������������������������������������������
������������������������������������������������������������������
��core12.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���@ �U�S�@��
������������������������������������������������������������������
2�������\������
����������������������������������������������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A �� 128�R�A .�� 256�R�A .�� 512�R�A .��1024�R�A.��
����������������������������������������������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 4 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �R�Q�@���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �U�S�@���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A �� 128�R�A .�� 256�R�A .�� 512�R�A .��1024�R�A.��
����������������������������������������������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 4 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �R�Q�@���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �U�S�@���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 7 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���@ �U�S�@���@ �P�Q�W�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �U�S�@���@ �P�Q�W�@.���@ �Q�T�U�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�Q�W�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�P�O�Q�S�@��
����������������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �U�S�@���@ �P�Q�W�@.���@ �Q�T�U�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�Q�W�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�P�O�Q�S�@��
����������������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A �� 128�R�A .�� 256�R�A .�� 512�R�A .��1024�R�A.��
����������������������������������������������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 4 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
���@�@�@�@ �� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��64�R�A �� 128�R�A .�� 256�R�A .�� 512�R�A .��1024�R�A.��
����������������������������������������������������������������������������������������������������������
��core�@ ,���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 2 ���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 3 ���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 4 ���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 5 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 6 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 7 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���@ �U�S�@���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �U�S�@���@ �P�Q�W�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�Q�W�@.���@ �Q�T�U�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core11.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@ �T�P�Q�@ ���@�P�O�Q�S�@��
����������������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������������
��core 8 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �U�S�@���@ �P�Q�W�@.���@�@�|�@�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core 9 ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�Q�W�@.���@ �Q�T�U�@.���@�@�|�@�@.���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core10.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@ �Q�T�U�@.���@ �T�P�Q�@ ���@�@�|�@�@.��
����������������������������������������������������������������������������������������������������������
��core11.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@�@�|�@�@.���@�@�|�@�@.���@ �T�P�Q�@ ���@�P�O�Q�S�@��
����������������������������������������������������������������������������������������������������������
4�R�A�ȍ~�ɋ��{�̌��E��������
�ǂ���4�R�A�ȍ~�Ŗ��O�ς��邾��
���{�̌��E
���e�̌��E�H
���e�̌��E�H
2CPU+2GPU����ɂ���4�R�A�Ȃ�ǂ�
2GPU���āE�E�E
�Q�R�AGPU�̈Ӗ�����Ȃ��H
2GPU�Ȃ�AGeForce7950X2
668 �FSocket774�F2006/07/31(��) 22:57:23 ID:FAwUSen+
Millwall���Ă̂��f�����ĕ��������ǂǂ��Ȃ́H
669 �FSocket774�F2006/07/31(��) 22:58:27 ID:FAwUSen+
�G���Ō�������4�R�A��45nm�������C�����邯�ǂǂ��Ȃ́H
Core3Duo�܂����[
���N�A���ق͉������鎖�L��́H�ۯ�age�̂݁H
672 �FSocket774�F2006/07/31(��) 23:32:42 ID:FAwUSen+
45nm�Ȃ�ďo�Ă��N������
����������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��
����������������������������������������������������������������
��core�@ .(65nm)���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������
��core 2 (65nm)���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���^�̃f���A���R�A
����������������������������������������������������������������
��core 3 (45nm)���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 4 (45nm)���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���^�̃N�A�b�h�R�A
����������������������������������������������������������������
��core 5 (32nm)���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 6 (32nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���^�̂W�R�A
����������������������������������������������������������������
��core 7 (22nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 8 (22nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���^�̂P�U�R�A
����������������������������������������������������������������
��core 9 (16nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@�������v���Z�X�V�������N
����������������������������������������������������������������
��core10.(16nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���^�̂R�Q�R�A
����������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��
����������������������������������������������������������������
��core�@ .(65nm)���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������
��core 2 (65nm)���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���^�̃f���A���R�A
����������������������������������������������������������������
��core 3 (45nm)���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 4 (45nm)���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���^�̃N�A�b�h�R�A
����������������������������������������������������������������
��core 5 (32nm)���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 6 (32nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���^�̂W�R�A
����������������������������������������������������������������
��core 7 (22nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ �������v���Z�X�V�������N
����������������������������������������������������������������
��core 8 (22nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���^�̂P�U�R�A
����������������������������������������������������������������
��core 9 (16nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@�������v���Z�X�V�������N
����������������������������������������������������������������
��core10.(16nm)���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���^�̂R�Q�R�A
����������������������������������������������������������������
����������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��
����������������������������������������������������������������������
��Pen4�@ (90nm 512KB)�� North ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��Pen4/D(90nm 1MB)�@��Presco�� Smith ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��Pen4/D(65nm 2MB)�@��Presc.2��Presler���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��core�@ .(65nm 1MB)�@.���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��core 2 (65nm 2MB)�@.���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���^�̃f���A���R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 3 (45nm 3MB)�@.���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�� 1�R�A .�� 2�R�A .�� 4�R�A .�� 8�R�A .��16�R�A ��32�R�A ��
����������������������������������������������������������������������
��Pen4�@ (90nm 512KB)�� North ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��Pen4/D(90nm 1MB)�@��Presco�� Smith ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��Pen4/D(65nm 2MB)�@��Presc.2��Presler���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��core�@ .(65nm 1MB)�@.���@Solo .���@Duo�@���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ��
����������������������������������������������������������������������
��core 2 (65nm 2MB)�@.���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ ���^�̃f���A���R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 3 (45nm 3MB)�@.���@ �|�@ ���@Duo�@�� Quad .���@ �|�@ ���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core 4 (45nm 4MB)�@.���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ ���^�̃N�A�b�h�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 5 (32nm 6MB)�@.���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core 6 (32nm 8MB)�@.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���^�̂W�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 7 (22nm 12MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core 8 (22nm 16MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���^�̂P�U�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 9 (16nm 24MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@�������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core10.(16nm 32MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���^�̂R�Q�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
����������������������������������������������������������������������
��core 5 (32nm 6MB)�@.���@ �|�@ ���@ �|�@ �� Quad .���@Oct�@���@ �|�@ ���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core 6 (32nm 8MB)�@.���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ ���^�̂W�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 7 (22nm 12MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@Oct�@���@ �P�U�@���@ �|�@ �������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core 8 (22nm 16MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@���^�̂P�U�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
��core 9 (16nm 24MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �P�U�@���@ �R�Q�@�������v���Z�X�V�������N�A�N���b�N�A�b�v
����������������������������������������������������������������������
��core10.(16nm 32MB) .���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �|�@ ���@ �R�Q�@���^�̂R�Q�R�A�A�N���b�N�_�E��
����������������������������������������������������������������������
�r�炵������
�j�R�C�`�Ȃ���ăN�@�b�h�R�A�����Ă����ĂȂ������H
���X�����AConroe����Family:6�ȂȁcPen�V�x�[�X���Ď���
>>647
2�ׂ̂���łȂ��̂́A�����炭4way��6way�ɂ���݂����ȑ��₵���Ȃ낤�B
way�����̂܂܂Ŕ{�̗e�ʂɂ����萫�\�͂ނ���オ��P�[�X�������Ǝv���B
2�ׂ̂���łȂ��̂́A�����炭4way��6way�ɂ���݂����ȑ��₵���Ȃ낤�B
way�����̂܂܂Ŕ{�̗e�ʂɂ����萫�\�͂ނ���オ��P�[�X�������Ǝv���B
>>676
��������1024�R�A�܂ł���B
��������1024�R�A�܂ł���B
������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@ ���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@ ��
������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Prescott (2MB)�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo (1MB)�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Duo (1MB�~2=2MB)�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo (2MB�~2=4MB)�@�@�@�@�@�@�@�@�@.��4�R�A Quad (2MB�~4=8MB)�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo (3MB�~2=6MB)�@�@�@�@�@�@�@�@�@.��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@ ���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@ ��
������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Prescott (2MB)�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo (1MB)�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��2�R�A Duo (1MB�~2=2MB)�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo (2MB�~2=4MB)�@�@�@�@�@�@�@�@�@.��4�R�A Quad (2MB�~4=8MB)�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo (3MB�~2=6MB)�@�@�@�@�@�@�@�@�@.��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 4 (45nm)����down��4�R�A Quad (2MB�~4=8MB)�@�@�@�@�@�@�@�@ ��8�R�A Oct (2MB�~8=16MB)�@�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct (2MB�~8=16MB)�@�@�@�@�@�@�@�@ ��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@ ��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct (2MB�~8=16MB)�@�@�@�@�@�@�@�@ ��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@.��
������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@ ��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������
��core10.(16nm)����down��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@.��64�R�A �U�S (2MB�~64=128MB)�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��core11.(11nm)����up�@ ��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@.��64�R�A �U�S (3MB�~64=192MB)�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��core12.(11nm)����down��64�R�A �U�S (2MB�~64=128MB)�@�@�@�@�@�@ ��128�R�A �P�Q�W (2MB�~128=256MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core13.(8nm) .����up�@ ��64�R�A �U�S (3MB�~64=192MB)�@�@�@�@�@�@ ��128�R�A �P�Q�W (3MB�~128=384MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core14.(8nm) .����down��128�R�A �P�Q�W (2MB�~128=256MB)�@�@�@�@��256�R�A �Q�T�U (2MB�~256=512MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core15.(6nm) .����up�@ ��128�R�A �P�Q�W (3MB�~128=384MB)�@�@�@�@��256�R�A �Q�T�U (3MB�~256=768MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������
��core11.(11nm)����up�@ ��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@.��64�R�A �U�S (3MB�~64=192MB)�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������
��core12.(11nm)����down��64�R�A �U�S (2MB�~64=128MB)�@�@�@�@�@�@ ��128�R�A �P�Q�W (2MB�~128=256MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core13.(8nm) .����up�@ ��64�R�A �U�S (3MB�~64=192MB)�@�@�@�@�@�@ ��128�R�A �P�Q�W (3MB�~128=384MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core14.(8nm) .����down��128�R�A �P�Q�W (2MB�~128=256MB)�@�@�@�@��256�R�A �Q�T�U (2MB�~256=512MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core15.(6nm) .����up�@ ��128�R�A �P�Q�W (3MB�~128=384MB)�@�@�@�@��256�R�A �Q�T�U (3MB�~256=768MB)�@�@�@�@��
������������������������������������������������������������������������������������������������
��core16.(6nm) .����down��256�R�A �Q�T�U (2MB�~256=512MB)�@�@�@�@��512�R�A �T�P�Q (2MB�~512=1024MB)�@�@�@.��
������������������������������������������������������������������������������������������������
��core17.(4nm) .����up�@ ��256�R�A �Q�T�U (3MB�~256=768MB)�@�@�@�@��512�R�A �T�P�Q (3MB�~512=1536MB)�@�@�@.��
������������������������������������������������������������������������������������������������
��core18.(4nm) .����down��512�R�A �T�P�Q (2MB�~512=1024MB)�@�@�@ ��1024�R�A �P�O�Q�S (2MB�~1024=2048MB) .��
������������������������������������������������������������������������������������������������
��core19.(3nm) .����up�@ ��512�R�A �T�P�Q (3MB�~512=1536MB)�@�@�@ ��1024�R�A �P�O�Q�S (3MB�~1024=3072MB) .��
������������������������������������������������������������������������������������������������
��core20.(3nm) .����down��1024�R�A �P�O�Q�S (2MB�~1024=2048MB)�@��2048�R�A �Q�O�S�W (2MB�~2048=4096MB) .��
������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������
��core17.(4nm) .����up�@ ��256�R�A �Q�T�U (3MB�~256=768MB)�@�@�@�@��512�R�A �T�P�Q (3MB�~512=1536MB)�@�@�@.��
������������������������������������������������������������������������������������������������
��core18.(4nm) .����down��512�R�A �T�P�Q (2MB�~512=1024MB)�@�@�@ ��1024�R�A �P�O�Q�S (2MB�~1024=2048MB) .��
������������������������������������������������������������������������������������������������
��core19.(3nm) .����up�@ ��512�R�A �T�P�Q (3MB�~512=1536MB)�@�@�@ ��1024�R�A �P�O�Q�S (3MB�~1024=3072MB) .��
������������������������������������������������������������������������������������������������
��core20.(3nm) .����down��1024�R�A �P�O�Q�S (2MB�~1024=2048MB)�@��2048�R�A �Q�O�S�W (2MB�~2048=4096MB) .��
������������������������������������������������������������������������������������������������
�j�āA�Ă��B
689 �FSocket774�F2006/08/03(��) 15:37:22 ID:k8wOyABb
4�R�A�Ȃ�Ă����ė����Ă�ڂ�OS�ɂ͌䗘�v���Ȃ�
������4�R�A�t���ғ������Ă����G���Q���o�Ă��O�����Ă���邳��
�����Ɋ��҂�
2CPU���ł���Ȃ�4CPU��8CPU���ȒP���ˁB
�n���V���~�����[�^��葬���o�\�R�����Q�O�P�O�N���ɂ͓o�ꂷ�邩���ȁB
�n���V���~�����[�^��葬���o�\�R�����Q�O�P�O�N���ɂ͓o�ꂷ�邩���ȁB
693 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/04(��) 03:23:51 ID:XE18wMND
���ӁB�Q�X���b�h�����ł���A���Ƃ͂S�X���b�h���낤�ƂW�X���b�h���낤�ƕ|���Ȃ�
���̍��ɂ͒n���V���~�����[�^�͂����Ƒ����Ȃ��Ă邾�낗
�p�\�R���͓o�ꂷ�邩������A�o�\�R���͒m����
http://pc.watch.impress.co.jp/docs/2006/0731/kaigai292_02l.gif
���悢��A���s�p������FSB���AKentsfiled����Ɍ��`�v�Z�g�X�V�iBarelake�j���āA
�I��肩�ȁE�E�E
{kind=link}
���悢��A���s�p������FSB���AKentsfiled����Ɍ��`�v�Z�g�X�V�iBarelake�j���āA
�I��肩�ȁE�E�E
�ėp�R�A4��
���ɗp���܂����H
���ɗp���܂����H
��͉Ǝ�
������͘J��
�O�߂͖�����̂��߂ɉ�������
�Ō�̈����������̈��̂��߂Ɏg�����B
���̖��́c
������͘J��
�O�߂͖�����̂��߂ɉ�������
�Ō�̈����������̈��̂��߂Ɏg�����B
���̖��́c
OS������Ɍ��߂�A�Ƃ����F������ʖڂȂ�?
PC�����Ɏg�����͐l�����߂邯�ǥ���B
PC�����Ɏg�����͐l�����߂邯�ǥ���B
700 �FSocket774�F2006/08/04(��) 13:11:41 ID:EUVprtaF
�n���V�~�����[�^��5120�R�A�������H
1024�R�A���x�ł͏��ĂȂ���B
1024�R�A���x�ł͏��ĂȂ���B
��ƂɈ��@�n���V�~�����[�^
�����ǂꂾ������悗
�]�����R�A�Ŕ��d��������H
�v�Z�v���Z�X������͂���Ɠd�C���o�Ă�����āH
ttp://www.firingsquad.com/hardware/intel_core_2_duo_e6400_review/images/quake1600.gif
E6400���čŋ������
{kind=link}
E6400���čŋ������
���̃��x���ɂȂ�Ɩ{�̂̃N���b�N����L���b�V���e�ʂ����قƂ�ǂ����Ȃ��̂�
�t�ɃL���b�V������������E6400�̂ق����悭�Ȃ�����������
�[���v���덷�͈̔�
�t�ɃL���b�V������������E6400�̂ق����悭�Ȃ�����������
�[���v���덷�͈̔�
������(�L��֥`)���ް�
>>698
�Ȃ�������I�H
�Ȃ�������I�H
ttp://www.geocities.jp/andosprocinfo/wadai06/20060729.htm
>REX Prefix��LCP�ł͂Ȃ��̂ł��̂悤�ȑ傫�ȃy�i���e�B�[�͖����̂ł����C
>�Ⴆ�C32�r�b�g�ł͖��߂̒�����4�o�C�g�ŁC16�o�C�g��4���ߓ��������̂��C
>REX������5�o�C�g�ɂȂ����̂�1�T�C�N���ɏ����ł��閽�ߐ���4����3�ɒቺ�����Ƃ����P�[�X�ł́C���\�ቺ���N���蓾�܂��B
>�������C8�̃��W�X�^�ň�ꂽ���̓������ɑޔ�����Ƃ��������ƁC16�̃��W�X�^���g�����Ƃɂ�胁�����ւ̑ޔ������炷�Ƃ��������̂ǂ��炪�����Ƃ����ƁC
>��ʓI�ɂ͌�҂̕������ŁC8�̃��W�X�^�����Ɍ��肵��REX���g��Ȃ������ǂ��Ƃ���Intel�X���C�h�̋L�q�́C�v���f�R�[�_�̓��삾���������C���܂�ɋߎ���I�Ȃ��̂Ɏv���܂��B
���XI�Ђ̕��j�ɓ�ȕt�����������Ȃ�Ȃ����Ǝv���Ă��܂����Ƃ�����B
>REX Prefix��LCP�ł͂Ȃ��̂ł��̂悤�ȑ傫�ȃy�i���e�B�[�͖����̂ł����C
>�Ⴆ�C32�r�b�g�ł͖��߂̒�����4�o�C�g�ŁC16�o�C�g��4���ߓ��������̂��C
>REX������5�o�C�g�ɂȂ����̂�1�T�C�N���ɏ����ł��閽�ߐ���4����3�ɒቺ�����Ƃ����P�[�X�ł́C���\�ቺ���N���蓾�܂��B
>�������C8�̃��W�X�^�ň�ꂽ���̓������ɑޔ�����Ƃ��������ƁC16�̃��W�X�^���g�����Ƃɂ�胁�����ւ̑ޔ������炷�Ƃ��������̂ǂ��炪�����Ƃ����ƁC
>��ʓI�ɂ͌�҂̕������ŁC8�̃��W�X�^�����Ɍ��肵��REX���g��Ȃ������ǂ��Ƃ���Intel�X���C�h�̋L�q�́C�v���f�R�[�_�̓��삾���������C���܂�ɋߎ���I�Ȃ��̂Ɏv���܂��B
���XI�Ђ̕��j�ɓ�ȕt�����������Ȃ�Ȃ����Ǝv���Ă��܂����Ƃ�����B
> ��ʓI�ɂ͌�҂̕�������
�u�f�l�̐�m�b�ł͌�҂̕������Łv�̊ԈႢ���낤?
�y�i���e�B�Ȃ��ɑ��₹��Ƃł��v���Ă���̂���?w
���ꂪ�\�Ȃ烌�W�X�^�𐔉��R���ڂ��Ƃ�����Ċ��������W
�u�f�l�̐�m�b�ł͌�҂̕������Łv�̊ԈႢ���낤?
�y�i���e�B�Ȃ��ɑ��₹��Ƃł��v���Ă���̂���?w
���ꂪ�\�Ȃ烌�W�X�^�𐔉��R���ڂ��Ƃ�����Ċ��������W
��ʓI��RISC��32�{��Register�ɔ�ׂ�IA-64��128�{�Ƃ����̂�
���ʎg���ꂸ���߂��Ƃ����邪�AX86��8�{�Ƃ����̂͏��ȉ߂���
�����ɕK�v�ȃf�[�^�ł�Memory(Cache)�ɑޔ����鑀�삪�p�ɂ�
�N����P�[�X�������Ƃ����̂͏펯�B
L1D-hit�P�[�X�ł����[�h���[�e���V3-cycle���x����Register�ǂݏo��
��1-cycle���x�ōςށB
���߃t�F�b�`���v���f�R�[�h�̌������������炢�����Ȃ��Ă��A��������
���₵��Register��16�{�t���Ɏg����������ʓI�ɗL���ł���Ƃ���
�������̈ӌ����������B
����ɂ��Ă��������͌v�Z�@��v���Z�b�T�v�̐��ƂȂ킯�����B
���ʎg���ꂸ���߂��Ƃ����邪�AX86��8�{�Ƃ����̂͏��ȉ߂���
�����ɕK�v�ȃf�[�^�ł�Memory(Cache)�ɑޔ����鑀�삪�p�ɂ�
�N����P�[�X�������Ƃ����̂͏펯�B
L1D-hit�P�[�X�ł����[�h���[�e���V3-cycle���x����Register�ǂݏo��
��1-cycle���x�ōςށB
���߃t�F�b�`���v���f�R�[�h�̌������������炢�����Ȃ��Ă��A��������
���₵��Register��16�{�t���Ɏg����������ʓI�ɗL���ł���Ƃ���
�������̈ӌ����������B
����ɂ��Ă��������͌v�Z�@��v���Z�b�T�v�̐��ƂȂ킯�����B
Intel���̔����B
> �u�����A������w�E���Ă��������B�����A���Ȃ���(�R�[�f�B���O����ۂ�)EM64T��16�{���W�X�^���K�v�Ȃ��A
> �@8�{�̃��W�X�^�ł̃I�y���[�V�����Ƀt�H�[�J�X�ł���Ȃ�AREX�v���t�B�b�N�X���g���K�v�͂Ȃ��B
> �@�Ȃ�REX�v���t�B�b�N�X���g��Ȃ����������̂��B�����REX�����ߒ������邩�炾�B
> �@���߂������Ȃ�ƃv���f�R�[�h���x���Ȃ�v
Intel�͕K�v�Ȃ���Ύg���Ȃƌ����Ă邾���B�����悤�Ȏ���AMD�̍œK���}�j���A���ɂ������Ă���B
�������ւ̑ޔ��𑝂₵�Ă���������8�̃��W�X�^�����Ɍ��肵��Ȃ�ĒN�������ĂȂ��B
> �u�����A������w�E���Ă��������B�����A���Ȃ���(�R�[�f�B���O����ۂ�)EM64T��16�{���W�X�^���K�v�Ȃ��A
> �@8�{�̃��W�X�^�ł̃I�y���[�V�����Ƀt�H�[�J�X�ł���Ȃ�AREX�v���t�B�b�N�X���g���K�v�͂Ȃ��B
> �@�Ȃ�REX�v���t�B�b�N�X���g��Ȃ����������̂��B�����REX�����ߒ������邩�炾�B
> �@���߂������Ȃ�ƃv���f�R�[�h���x���Ȃ�v
Intel�͕K�v�Ȃ���Ύg���Ȃƌ����Ă邾���B�����悤�Ȏ���AMD�̍œK���}�j���A���ɂ������Ă���B
�������ւ̑ޔ��𑝂₵�Ă���������8�̃��W�X�^�����Ɍ��肵��Ȃ�ĒN�������ĂȂ��B
���Ƃł���������������Β@����ē�����O���B
INTEL�̐����́A�v���f�R�[�h���ʂɒ������ď�����Ă���͖̂������B
���������Ɋg����߂���ʘ_�Ə̂��A�ߎ���Ă��͍����B
���̂���ߐM���߂��Ă���A�o�߂����������B
�͂����茾�킹�ĖႦ�A�����@���̋Z�ʂ�INTEL��AMD�̐v�҂̋Z�ʂɋy�Ԃ͂����Ȃ����B
INTEL�̐����́A�v���f�R�[�h���ʂɒ������ď�����Ă���͖̂������B
���������Ɋg����߂���ʘ_�Ə̂��A�ߎ���Ă��͍����B
���̂���ߐM���߂��Ă���A�o�߂����������B
�͂����茾�킹�ĖႦ�A�����@���̋Z�ʂ�INTEL��AMD�̐v�҂̋Z�ʂɋy�Ԃ͂����Ȃ����B
��������REX�Ȃ�Ă����鎞�_�Ŕ��Η����W�X�^�݂����Ȃ���B
��ʘ_�͏��F��ʘ_�B
��ʘ_�͏��F��ʘ_�B
>>712�̂悤�ɃC���e���������Ă�Ƃ������ƂȂ�A�m���Ɉ�������
�s���g���͂����Ă�ȁB���������̂悤�Ȕ������ǂ����Ă��Ă��܂���
���Ƃ����ƁA
ttp://pc.watch.impress.co.jp/docs/2006/0718/kaigai288_02.jpg
�̃X���C�h�����Ă̂��Ƃ̂悤���B
���̃X���C�h���������ł́A16�{�K�v�ȂƂ��ł�8�{�Ɍ��肵������
�ǂ��ƌ����Ă���悤�ɉ��߂���l�������ȁB
�X���C�h�͈�l�������邩��A�d�v�Ȃ��ƂȂ����Ɍ��������邽�߂ɂ�
8�{�ŊԂɍ����Ƃ���8�{�Ńv���O���~���O����Ƃ͂����菑�����ق���
�ǂ������Ǝv���ˁB
�s���g���͂����Ă�ȁB���������̂悤�Ȕ������ǂ����Ă��Ă��܂���
���Ƃ����ƁA
ttp://pc.watch.impress.co.jp/docs/2006/0718/kaigai288_02.jpg
{kind=link}
�̃X���C�h�����Ă̂��Ƃ̂悤���B
���̃X���C�h���������ł́A16�{�K�v�ȂƂ��ł�8�{�Ɍ��肵������
�ǂ��ƌ����Ă���悤�ɉ��߂���l�������ȁB
�X���C�h�͈�l�������邩��A�d�v�Ȃ��ƂȂ����Ɍ��������邽�߂ɂ�
8�{�ŊԂɍ����Ƃ���8�{�Ńv���O���~���O����Ƃ͂����菑�����ق���
�ǂ������Ǝv���ˁB
> �@8�{�̃��W�X�^�ł̃I�y���[�V�����Ƀt�H�[�J�X�ł���Ȃ�AREX�v���t�B�b�N�X���g���K�v�͂Ȃ��B
������ǂ�����Ĕ��f�����?
����ɍ��͂����ł���X�܂ł��̂܂܂Ƃ͎v���Ȃ������ꌩ�z���čl�����16�{�g����ȁB
���ւł����Ȃ��A���Ӗ��B
������ǂ�����Ĕ��f�����?
����ɍ��͂����ł���X�܂ł��̂܂܂Ƃ͎v���Ȃ������ꌩ�z���čl�����16�{�g����ȁB
���ւł����Ȃ��A���Ӗ��B
GCC�Ƃ͈Ⴄ�̂���!
GCC�Ƃ�!!
GCC�Ƃ�!!
���̈����L�������ǁA���̑匴�L���̌��ʂ���A
���\����Ƃ��ďq�ׂĂ���|�C���g�͑S���͂���A�Ƃ͌������A
���ۂɖ^�Ѓt���O�V�b�v�����X�ɐ��\������ʂ����Ă鍡�ƂȂ��Ă�
�Ȃ������A�d���̋��ł���c
���\����Ƃ��ďq�ׂĂ���|�C���g�͑S���͂���A�Ƃ͌������A
���ۂɖ^�Ѓt���O�V�b�v�����X�ɐ��\������ʂ����Ă鍡�ƂȂ��Ă�
�Ȃ������A�d���̋��ł���c
>>716
Core MA�ł̍œK����@�̐��������ɑ��Ĕn���Ȏw�E������Ȃ�B
Core MA�ł̍œK����@�̐��������ɑ��Ĕn���Ȏw�E������Ȃ�B
720 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/05(�y) 20:28:25 ID:WnBRNP9J
���悢��Apple��Intel64�v���b�g�t�H�[���Ή�Mac���\�ł���
http://www.appleinsider.com/article.php?id=1941
AMD64/EM64T ISA�̐v�~�X�́AMMX�g��Ȃ��Ȃ�SSE��66H�v���t�B�b�N�X��p�~���Ă�
�悩������Ȃ������Ă��Ƃł��ȁB
REX����1����5�o�C�g�͒ɂ��B
http://www.appleinsider.com/article.php?id=1941
AMD64/EM64T ISA�̐v�~�X�́AMMX�g��Ȃ��Ȃ�SSE��66H�v���t�B�b�N�X��p�~���Ă�
�悩������Ȃ������Ă��Ƃł��ȁB
REX����1����5�o�C�g�͒ɂ��B
kentsfield�������ꂽ��l�i�����낤�ȁE�E�E�E
����d�͍����������ȁE�E�E
����d�͍����������ȁE�E�E
Apple��Macintosh�ō̗p���Ă���ISA�͂��Ƃ��Ƃ�PC�s��ŋ쒀�����^���������킯����
����͂ǂ��Ȃ邩�ȁE�E�E�H
����͂ǂ��Ȃ邩�ȁE�E�E�H
>>721
���N���b�N���F��2�{+�����x�ŕ��������Ȃ猋�\������ˁH
�ꉞXE�ȊO�̃o�t�H�[�}���X�����C���X�g���[���Z�O�����g�ɂ��o���悤�����B
���N���b�N���F��2�{+�����x�ŕ��������Ȃ猋�\������ˁH
�ꉞXE�ȊO�̃o�t�H�[�}���X�����C���X�g���[���Z�O�����g�ɂ��o���悤�����B
kents��TDP95W����Ȃ���������
�����t������8bit SIMM��4���Z�b�g�Ŏg��Ȃ���
�����Ȃ�������ȁB���������N�A�b�h�`���l����
�Ȃ�����߂��̂��B
�����Ȃ�������ȁB���������N�A�b�h�`���l����
�Ȃ�����߂��̂��B
���������N�A�b�h�`���l���ɂȂ�ɂ�
FB-DIMM�݂����ɔz�������Ȃ��Ȃ�Ȃ��ƃ������낤�Ȃ�
���ł��啪����������̐v���������̂�
����ȏ�z�����������獂���}�U�[�������
�Ȃ����܂���(�L�E�ցE�M)
FB-DIMM�݂����ɔz�������Ȃ��Ȃ�Ȃ��ƃ������낤�Ȃ�
���ł��啪����������̐v���������̂�
����ȏ�z�����������獂���}�U�[�������
�Ȃ����܂���(�L�E�ցE�M)
Blackford�͂��ł�4ch�����
FB-DIMM������B
>>727
���̓������x���_�[�Ɍ����Ă���('A`)
���̓������x���_�[�Ɍ����Ă���('A`)
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
�@o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o o
781pin
o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o
o o o o o o o o o o o o o o o o o o o o o o o o o o o�@�@�@o o o o
��������������������������������������������������������
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o����o o o����
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o����o o o����
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o����o o o o ��
����������������������������������������������������������
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o������������������������ o o o o o o o o o ��
�� o o o o o o o o o�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o o ��
�� o o o o o o o o o o o o o o o o o o o o o o o o o o o����o o o o ��
����������������������������������������������������������
�Ȃɂ��̍q��ʐ^
�P���c�͂������ł����H
�N��
���g���̓_�E������́H
Core2Duo���ڂ̃��[�J�[PC�����\����Ȃ��˂��B
�A�b�v�����~�߂Ă�̂��Ǝv�����炻���ł��Ȃ��������B
�A�b�v�����~�߂Ă�̂��Ǝv�����炻���ł��Ȃ��������B
�H�~���f������B�������傢�҂āB
���[�JPC�̏H�~���f���̔��\��8��31������B
G965�̐����܂�����Ȃ���
�Ƃ������Ƃ́A���̓W�T�J�[�̃A�h�o���e�[�W�グ��`�����X���Ă킯���B
�~�x�݂ɂ���Ă݂悤���ȁB
�~�x�݂ɂ���Ă݂悤���ȁB
����������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@�@ .���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)�@�@�@�@�@�@�@�@�@�@�@�@�@��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Prescott/Ceder Mill (2MB)�@�@�@�@�@�@��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@�@.��
����������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah (1MB)�@�@�@�@�@�@�@�@�@�@�@ .��2�R�A Duo Yonah (1MB�~2=2MB)�@�@�@�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo Conroe/Merom (2MB�~2=4MB) .��4�R�A Quad Kentsfield (2MB�~4=8MB)�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo Penryn (3MB�~2=6MB)�@�@�@�@�@ .��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@�@ .���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)�@�@�@�@�@�@�@�@�@�@�@�@�@��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Prescott/Ceder Mill (2MB)�@�@�@�@�@�@��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@�@.��
����������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah (1MB)�@�@�@�@�@�@�@�@�@�@�@ .��2�R�A Duo Yonah (1MB�~2=2MB)�@�@�@�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo Conroe/Merom (2MB�~2=4MB) .��4�R�A Quad Kentsfield (2MB�~4=8MB)�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo Penryn (3MB�~2=6MB)�@�@�@�@�@ .��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
749 �FSocket774�F2006/08/09(��) 17:46:49 ID:GH9z3k7H
>>747
Dell���10����������w
Dell���10����������w
��core 4 (45nm)����down��4�R�A Quad Nehalem (2MB�~4=8MB)�@�@�@�@��8�R�A Oct (2MB�~8=16MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad Nehalem-C (3MB�~4=12MB)�@ .��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct Gesher (2MB�~8=16MB)�@�@�@�@�@��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@�@��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad Nehalem-C (3MB�~4=12MB)�@ .��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct Gesher (2MB�~8=16MB)�@�@�@�@�@��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@�@��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
>>747
������ȍ~�̘b�֎~
������ȍ~�̘b�֎~
����������Y��
�S
Core 2 Duo��Athlon 64 X2�̑Ό��f�������T���Ɏ��{
http://www.watch.impress.co.jp/akiba/hotline/20060812/etc_amdevpr.html
�s���Ȃ͂���AMD��CPU��Intel��Core2Duo�ɏ����ށB
�}�]�ł͂Ȃ��A���炭���Z�����邩�炾�B
���݂̖��ԁE��R�@�ւɂ��x���`�}�[�N���ʋy�ѕ]��
��32bit�ł�Core2Duo��Athlon64 FX-62�ɔ�ׂĖw�ǂ̃x���`�}�[�N�ō����ł���B
��64bit�ł́A"32bit��Core2Duo"�ɔ�ׂ�ƐL�єY�ށB�������w�ǂ̕����Athlon64�ɕ����邱�Ƃ͖����B
������d�͂ł�Intel���킸���ɏ����Ă���
���~�h���`�n�C�G���h�ł�Intel�̂ق����R�X�g�p�t�H�[�}���X�͍����B
�~���z���Z�p�ł̐��\�ł́AAMD�����|���Ă���B
�~���M�ł́A�킸����AMD�������Ă���B
�~���[�G���h��CPU�ł�AMD�̕����R�X�g�p�t�H�[�}���X�͍����B
�������I�ɂ̓��������C�e���V�Ɋւ��ẮA�����R��������AMD�������Ă���B���ŏI�I�Ȍ��ʂƂ��ďo�鑬�x�ł́c�B�Ǐ��I�x���`�}�[�N�ŗL��
http://www.watch.impress.co.jp/akiba/hotline/20060812/etc_amdevpr.html
�s���Ȃ͂���AMD��CPU��Intel��Core2Duo�ɏ����ށB
�}�]�ł͂Ȃ��A���炭���Z�����邩�炾�B
���݂̖��ԁE��R�@�ւɂ��x���`�}�[�N���ʋy�ѕ]��
��32bit�ł�Core2Duo��Athlon64 FX-62�ɔ�ׂĖw�ǂ̃x���`�}�[�N�ō����ł���B
��64bit�ł́A"32bit��Core2Duo"�ɔ�ׂ�ƐL�єY�ށB�������w�ǂ̕����Athlon64�ɕ����邱�Ƃ͖����B
������d�͂ł�Intel���킸���ɏ����Ă���
���~�h���`�n�C�G���h�ł�Intel�̂ق����R�X�g�p�t�H�[�}���X�͍����B
�~���z���Z�p�ł̐��\�ł́AAMD�����|���Ă���B
�~���M�ł́A�킸����AMD�������Ă���B
�~���[�G���h��CPU�ł�AMD�̕����R�X�g�p�t�H�[�}���X�͍����B
�������I�ɂ̓��������C�e���V�Ɋւ��ẮA�����R��������AMD�������Ă���B���ŏI�I�Ȍ��ʂƂ��ďo�鑬�x�ł́c�B�Ǐ��I�x���`�}�[�N�ŗL��
> �~���z���Z�p�ł̐��\�ł́AAMD�����|���Ă���B
����ł̓\�t�g�E�F�A�ɂ�鉼�z���̕������\�������̂ňӖ����������肷��B
VMware�̃y�[�p�[:
http://www.vmware.com/pdf/asplos235_adams.pdf
����ł̓\�t�g�E�F�A�ɂ�鉼�z���̕������\�������̂ňӖ����������肷��B
VMware�̃y�[�p�[:
http://www.vmware.com/pdf/asplos235_adams.pdf
>>754
����EIST�L���Ńx���`�}�[�N�����Ȃ�����?
EIST�L�����ƁA���ׂ̑傫�Ȃ��̂ł��ō��N���b�N�ɒB���Ȃ��\�t�g���w�ǂ�����x���`�}�[�N�ŏ��Ă�B
����ɁAEIST�L���ł��Œ�{����x6������A�C�h������X2�̂��ǂ����ʂ��ƌ��������1�[
����EIST�L���Ńx���`�}�[�N�����Ȃ�����?
EIST�L�����ƁA���ׂ̑傫�Ȃ��̂ł��ō��N���b�N�ɒB���Ȃ��\�t�g���w�ǂ�����x���`�}�[�N�ŏ��Ă�B
����ɁAEIST�L���ł��Œ�{����x6������A�C�h������X2�̂��ǂ����ʂ��ƌ��������1�[
AMD�͂b���p�Œ�d�͂��Ă��������낤�Ȃ��B
�C���e���̐^�̂S�R�A�܂����`
�Q�������������Ȃ�Ă����E�E�E
�C���e���̐^�̂S�R�A�܂����`
�Q�������������Ȃ�Ă����E�E�E
1�N�ȏ�x���Ȃ�u�^�́`�v�̓C���l
���FMCM�ł��Ȃ�AMD�̉��i������
���FMCM�ł��Ȃ�AMD�̉��i������
759 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/09(��) 23:36:26 ID:bZbCBiau
143mm^2������悤�ȃR�A��MCM�ł���Intel���Ă���ϋZ�p�͂���Ǝv��
�u�^�̃N�A�b�h�R�A�v���āA��̓I�ɂǂ�Ȃ��́H
�E4�̃R�A�œL���b�V�������L
�E�ǂ̃R�A���猩�Ă��A���̎O�̃R�A�Ƌٖ��Ɍ�������Ă���
���Ċ����H
�E4�̃R�A�œL���b�V�������L
�E�ǂ̃R�A���猩�Ă��A���̎O�̃R�A�Ƌٖ��Ɍ�������Ă���
���Ċ����H
761 �FSocket774�F2006/08/10(��) 00:19:18 ID:L5E51p4I
������Mac��AT�݊��@�������Ƃ������オ����Ƃ͖��ɂ��v��Ȃ�w
�����\����Dell������Mac�Ȃ�ĐM�������
�����\����Dell������Mac�Ȃ�ĐM�������
�G�Z�N�A�b�h�Ƃ������Ȃ�A���߂ē������ɓ������Ȃ��Ɓc
���܂�x���ƍ��x��Nehalem�ɔw����˂���鎖�ɂȂ�B
���܂�x���ƍ��x��Nehalem�ɔw����˂���鎖�ɂȂ�B
������̎�������͏�������邾������ˁH
Dell�̂��Ƃ����B
Dell�̂��Ƃ����B
765 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 01:05:27 ID:NIaDKxnG
Mac-mini��➑̂Ɏ��܂�Merom��LV�҂K�v�����鈫��
�u�����v���ōl����Ȃ�➑̃T�C�Y�̌������͕K�v���Ǝv���B
Mac mini�͂������������Œ����d�́i�������ᐫ�\�j��G4�����琬���ł������́B
���i������d�͂��オ����Yonah�̎��_�Ŋ��ɔj�]�C���B
�u�����v���ōl����Ȃ�➑̃T�C�Y�̌������͕K�v���Ǝv���B
Mac mini�͂������������Œ����d�́i�������ᐫ�\�j��G4�����琬���ł������́B
���i������d�͂��オ����Yonah�̎��_�Ŋ��ɔj�]�C���B
>>758
�ł�XP�ł�4�R�A�g���Ȃ��B
linux�g�����A����Ƃ�windows-server�Ŏg������?
>>763
�C���e���̐��ٌx�����������ꂽ����AMD�g����悤�ɂȂ�����A�S�z�Ȃ��B
���\��AMD�ɏ����Ă��鎖���m�F��ɉ��������B
�}�C�N���\�t�g��linux�̗p�����琧�ق̕��͉�������Ă��Ȃ��B
dell��OS�����ł̏o�ׂ�����t�Alinux���v���C���X�g�[��������}�C�N���\�t�g���琧�ق���B
�ł�XP�ł�4�R�A�g���Ȃ��B
linux�g�����A����Ƃ�windows-server�Ŏg������?
>>763
�C���e���̐��ٌx�����������ꂽ����AMD�g����悤�ɂȂ�����A�S�z�Ȃ��B
���\��AMD�ɏ����Ă��鎖���m�F��ɉ��������B
�}�C�N���\�t�g��linux�̗p�����琧�ق̕��͉�������Ă��Ȃ��B
dell��OS�����ł̏o�ׂ�����t�Alinux���v���C���X�g�[��������}�C�N���\�t�g���琧�ق���B
767 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 04:42:10 ID:NIaDKxnG
>>766��
XP Professional�̂��Ƃ��A���X�͎v���o���Ă����Ă��������B
XP Professional�̂��Ƃ��A���X�͎v���o���Ă����Ă��������B
XP�ł�4�R�A�g���Ȃ�(��)
769 �FSocket774�F2006/08/10(��) 05:37:16 ID:EMQNkqT4
FSB1333MHz�Ή��A�`�b�v�Z�b�g��Core2E�����Ăł�́H
http://download.microsoft.com/download/5/8/f/58fce148-01d7-457d-9a8b-52df61fb27ba/multi_core_lic102504.pdf
>���Ƃ��AWindows XP Professional ��2 �ȉ��̃v���Z�b�T�𓋍ڂ����f�X�N�g�b�v��
>�g�p���邱�Ƃ�O��ɐv����Ă���AWindows Server 2003 Standard Edition��
>SQL Server 2000 Standard Edition �� 4 �ȉ��̃v���Z�b�T�𓋍ڂ����V�X�e����
>�g�p���邱�Ƃ�O��ɐv����Ă��܂��B
>���Ƃ��AWindows XP Professional ��2 �ȉ��̃v���Z�b�T�𓋍ڂ����f�X�N�g�b�v��
>�g�p���邱�Ƃ�O��ɐv����Ă���AWindows Server 2003 Standard Edition��
>SQL Server 2000 Standard Edition �� 4 �ȉ��̃v���Z�b�T�𓋍ڂ����V�X�e����
>�g�p���邱�Ƃ�O��ɐv����Ă��܂��B
tsumannne
>>770�̌��
>�ŋߔ������ꂽ Microsoft �\�t�g�E�F�A�ɂ̓v���Z�b�T�̐��ɐ������݂����Ă��܂����A
>����ɊY������\�t�g�E�F�A�ɂ��ẮA�v���Z�b�T�Ɋ܂܂��R�A��X���b�h�̐��ɂ�����炸�A
>�e�v���Z�b�T�� 1 �̃v���Z�b�T�Ƃ��ăJ�E���g����܂��B
�Ƃ���B
Windows�̃��C�Z���X�ł̓v���Z�b�T�̐��̓\�P�b�g�P�ʂŐ�����悤������
�f���A���R�Ax2��4�R�A�ȃV�X�e���Ȃ�XP Professional�ň�����͂�����
>�ŋߔ������ꂽ Microsoft �\�t�g�E�F�A�ɂ̓v���Z�b�T�̐��ɐ������݂����Ă��܂����A
>����ɊY������\�t�g�E�F�A�ɂ��ẮA�v���Z�b�T�Ɋ܂܂��R�A��X���b�h�̐��ɂ�����炸�A
>�e�v���Z�b�T�� 1 �̃v���Z�b�T�Ƃ��ăJ�E���g����܂��B
�Ƃ���B
Windows�̃��C�Z���X�ł̓v���Z�b�T�̐��̓\�P�b�g�P�ʂŐ�����悤������
�f���A���R�Ax2��4�R�A�ȃV�X�e���Ȃ�XP Professional�ň�����͂�����
>Windows XP Professional ��2 �ȉ��̃v���Z�b�T�𓋍ڂ����f�X�N�g�b�v��
>�g�p���邱�Ƃ�O��ɐv����Ă���
�������ɐH������B
>�g�p���邱�Ƃ�O��ɐv����Ă���
�������ɐH������B
Intel�A�����̃}���`�R�A�^�}���`�X���b�h�Z�p�҈琬�ő�w�ƒ�g
ttp://www.itmedia.co.jp/news/articles/0608/09/news023.html
100�N�̌v����ό��\�����A���낻��ICC�̋������œK�ȗ��x���ێ��ł���悤�ɂ��ė~������
ttp://www.itmedia.co.jp/news/articles/0608/09/news023.html
100�N�̌v����ό��\�����A���낻��ICC�̋������œK�ȗ��x���ێ��ł���悤�ɂ��ė~������
775 �FSocket774�F2006/08/10(��) 09:19:39 ID:7PlxsKGP
>>774
���ꂪ�ł���Ȃ�OpemMP�Ȃ�ĕK�v�Ȃ��ȁB
���ꂪ�ł���Ȃ�OpemMP�Ȃ�ĕK�v�Ȃ��ȁB
>>773
���̃v���Z�b�T���̓\�P�b�g���Ƃ����Ӗ��ȁB
����AWoodcrest��4�_���v���Z�b�T�ɂ�Dempsey��8�_���v���Z�b�T�ɂ�XP Professional�őΉ��ł��Ă���B
Pro�̃J�[�l����Server�̃J�[�l���̃T�u�Z�b�g�B2�\�P�b�g�܂ł����g���Ȃ��Ȃ��Ă�̂͂����܂Ń��C�Z���X�̔��肾�B
�����XP Home��SP2�̎��_�ł��A1�\�P�b�g��2�_���v���Z�b�T�܂ł����Ή����Ȃ��B
Vista��4�_���v���Z�b�T���炢�ɂ��Ή����邩���m��ȁB
Kentsfield�����C���X�g���[���ɂ���Ă���̂�Vista���o�鍠�ɂȂ邾�낤�B
���̃v���Z�b�T���̓\�P�b�g���Ƃ����Ӗ��ȁB
����AWoodcrest��4�_���v���Z�b�T�ɂ�Dempsey��8�_���v���Z�b�T�ɂ�XP Professional�őΉ��ł��Ă���B
Pro�̃J�[�l����Server�̃J�[�l���̃T�u�Z�b�g�B2�\�P�b�g�܂ł����g���Ȃ��Ȃ��Ă�̂͂����܂Ń��C�Z���X�̔��肾�B
�����XP Home��SP2�̎��_�ł��A1�\�P�b�g��2�_���v���Z�b�T�܂ł����Ή����Ȃ��B
Vista��4�_���v���Z�b�T���炢�ɂ��Ή����邩���m��ȁB
Kentsfield�����C���X�g���[���ɂ���Ă���̂�Vista���o�鍠�ɂȂ邾�낤�B
>>776
���Ⴂ���ĂȂ�?
home��2(�_��)�Apro�͘_�������v��4�̂͂��B
����Dempsey�̓T�[�o�[/���[�N�X�e�[�V����������OS��windows-server/linux�B
�Ԉ���Ă�XP(=��������)�Ȃǎg��Ȃ��B
�����[�n���ȋ�����������Δn����邩���m��Ȃ����B
OSX��unix��XP�Ƃ͊i���Ⴄ���B
���Ⴂ���ĂȂ�?
home��2(�_��)�Apro�͘_�������v��4�̂͂��B
����Dempsey�̓T�[�o�[/���[�N�X�e�[�V����������OS��windows-server/linux�B
�Ԉ���Ă�XP(=��������)�Ȃǎg��Ȃ��B
�����[�n���ȋ�����������Δn����邩���m��Ȃ����B
OSX��unix��XP�Ƃ͊i���Ⴄ���B
>>777
�N�����Ⴂ���Ă�Ǝv����
�N�����Ⴂ���Ă�Ǝv����
Dual Xeon50x0(�_��8p�A����4p�A2�\�P�b�g�j��XP Pro�ȃ��[�N�X�e�[�V�����͕ʂɒ������Ȃ����A
PentiumD/X2(�_��2p�A����2p�A1�\�P�b�g�j��XP home��PC�����ăS���S�������ȁB
Xeon50x0�𓋍ڂ����[�N�X�e�[�V�����Ƃ��Ĕ����Ă�@�B���ƁA
Windows Server��I���ł���ق����������Ǝv�����B
PentiumD/X2(�_��2p�A����2p�A1�\�P�b�g�j��XP home��PC�����ăS���S�������ȁB
Xeon50x0�𓋍ڂ����[�N�X�e�[�V�����Ƃ��Ĕ����Ă�@�B���ƁA
Windows Server��I���ł���ق����������Ǝv�����B
����������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@�@ .���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)/Prescott 2M (2MB) ��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@�@ ��
����������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@�@�@�@�@�@�@��2�R�A Duo Yonah-DC (1MB�~2=2MB)�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo Conroe/Merom (2MB�~2=4MB) .��4�R�A Quad Kentsfield (2MB�~4=8MB)�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo Wolfdale/Penryn (3MB�~2=6MB)��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@�@�@�^�̃}���`�R�A�@�@�@�@�@�@�@�@ .���@�@�@ �^���}���`�R�A(�j�R�C�`�R�A)�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ��1�R�A Northwood (512KB)�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�|�@�@�@�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@ ��1�R�A Prescott (1MB)/Prescott 2M (2MB) ��2�R�A Smithfield (1MB�~2=2MB)�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@ ��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Presler (2MB�~2=4MB)�@�@�@�@�@�@�@�@ ��
����������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@�@�@�@�@�@�@��2�R�A Duo Yonah-DC (1MB�~2=2MB)�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��2�R�A Duo Conroe/Merom (2MB�~2=4MB) .��4�R�A Quad Kentsfield (2MB�~4=8MB)�@�@�@.��
����������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��2�R�A Duo Wolfdale/Penryn (3MB�~2=6MB)��4�R�A Quad (3MB�~4=12MB)�@�@�@�@�@�@�@�@�@��
����������������������������������������������������������������������������������������������������
��core 4 (45nm)����down��4�R�A Quad Nehalem/Gilo (2MB�~4=8MB)�@��8�R�A Oct (2MB�~8=16MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad Nehalem-C (3MB�~4=12MB)�@ .��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct Gesher (2MB�~8=16MB)�@�@�@�@�@��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@�@��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
����������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ��4�R�A Quad Nehalem-C (3MB�~4=12MB)�@ .��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 6 (32nm)����down��8�R�A Oct Gesher (2MB�~8=16MB)�@�@�@�@�@��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ��8�R�A Oct (3MB�~8=24MB)�@�@�@�@�@�@�@�@�@�@��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 8 (22nm)����down��16�R�A �P�U (2MB�~16=32MB)�@�@�@�@�@�@�@�@ ��32�R�A �R�Q (2MB�~32=64MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ��16�R�A �P�U (3MB�~16=48MB)�@�@�@�@�@�@�@�@ .��32�R�A �R�Q (3MB�~32=96MB)�@�@�@�@�@�@�@�@ .��
����������������������������������������������������������������������������������������������������
>>776 >>777 >>778
�Ƃ肠�����A����ł��ǂ����B
http://www.mnet.ne.jp/~angie/exp/hyper-threading.html
XP Professional �ɂ��Ă� G1s/bLxW �̌����ʂ� 4�_���v���Z�b�T�܂ŁB
Dempsey�� 8�_���v���Z�b�T�ɂ��Ă� HT ���� 4�_���v���Z�b�T��
�Ȃ�̂� XP professional �ł��Ή��ł���B
HT �͌��������̂悤�Ȃ��̂Ȃ̂ł������K�v���Ȃ����낤���B
���Ȃ݂ɁANT�n�J�[�l���� 32�_���v���Z�b�T�܂őΉ��ŁA�������Ă邾���B
XP home �����l�B
�J�[�l���͕������_������ʂ��ĂȂ��͂������ǁA
���C�Z���X�W�̓s���ŃV�X�e�����x���ł͋�ʂ���悤�ɕύX���ꂽ�B
�Ƃ肠�����A����ł��ǂ����B
http://www.mnet.ne.jp/~angie/exp/hyper-threading.html
XP Professional �ɂ��Ă� G1s/bLxW �̌����ʂ� 4�_���v���Z�b�T�܂ŁB
Dempsey�� 8�_���v���Z�b�T�ɂ��Ă� HT ���� 4�_���v���Z�b�T��
�Ȃ�̂� XP professional �ł��Ή��ł���B
HT �͌��������̂悤�Ȃ��̂Ȃ̂ł������K�v���Ȃ����낤���B
���Ȃ݂ɁANT�n�J�[�l���� 32�_���v���Z�b�T�܂őΉ��ŁA�������Ă邾���B
XP home �����l�B
�J�[�l���͕������_������ʂ��ĂȂ��͂������ǁA
���C�Z���X�W�̓s���ŃV�X�e�����x���ł͋�ʂ���悤�ɕύX���ꂽ�B
1�\�P�b�g�Ř_��4CPU�܂ł�CPU���Ȃ��Ƃ��̃l�^���o���ĉ����킩�����悤�Ȃ��Ƃ�w
http://pc.watch.impress.co.jp/docs/2006/0523/tawada75.htm
���a�c�͉R�����Ă��ƂȂȁA>>783�̒����ɂ���
��������悤���[���ł������Ă��w
http://pc.watch.impress.co.jp/docs/2006/0523/tawada75.htm
���a�c�͉R�����Ă��ƂȂȁA>>783�̒����ɂ���
��������悤���[���ł������Ă��w
>>783
�匴�L������Intel5000�̓��W���炢��
�匴�L������Intel5000�̓��W���炢��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@�@ �V���O���R�A�@�@�@�@�@�@���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��1�R�A Northwood (512KB)�@�@�@�@ .���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@.��1�R�A Prescott-V�@�@�@�@�@�@�@�@�@ .��1�R�A Prescott (1MB)�@�@�@�@�@�@�@.��2�R�A Smithfield (2MB)�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@Prescott 2M (2MB)�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@.��1�R�A Cedar Mill-V�@�@�@�@�@�@�@�@�@��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@ ��2�R�A Presler (4MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@�@ �V���O���R�A�@�@�@�@�@�@���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��1�R�A Northwood (512KB)�@�@�@�@ .���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@.��1�R�A Prescott-V�@�@�@�@�@�@�@�@�@ .��1�R�A Prescott (1MB)�@�@�@�@�@�@�@.��2�R�A Smithfield (2MB)�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@Prescott 2M (2MB)�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@.��1�R�A Cedar Mill-V�@�@�@�@�@�@�@�@�@��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@ ��2�R�A Presler (4MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@ �^�̃}���`�R�A�@�@�@�@�@ ���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@.��2�R�A Duo Yonah-DC (2MB)�@�@�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��1�R�A Stealey (512KB)�@�@�@�@�@�@ .��2�R�A Duo Conroe (2MB�A4MB)�@ ��4�R�A Quad Kentsfield (4MB)�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��1�R�A Millville (1MB FSB1066)�@�@ ��2�R�A Duo Merom (4MB)�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Allendale (2MB FSB800)�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��1�R�A Perryville (2MB)�@�@�@�@�@�@�@��2�R�A Duo Ridgefield (6MB)�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Wolfdale (3MB)�@�@�@�@�@�@�@ ��2�R�A Duo Wolffield (3MB)�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Duo Penryn (3MB�A6MB)�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@ �^�̃}���`�R�A�@�@�@�@�@ ���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@.��2�R�A Duo Yonah-DC (2MB)�@�@�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��1�R�A Stealey (512KB)�@�@�@�@�@�@ .��2�R�A Duo Conroe (2MB�A4MB)�@ ��4�R�A Quad Kentsfield (4MB)�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��1�R�A Millville (1MB FSB1066)�@�@ ��2�R�A Duo Merom (4MB)�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Allendale (2MB FSB800)�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 3 (45nm)����up�@ ��1�R�A Perryville (2MB)�@�@�@�@�@�@�@��2�R�A Duo Ridgefield (6MB)�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Wolfdale (3MB)�@�@�@�@�@�@�@ ��2�R�A Duo Wolffield (3MB)�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Duo Penryn (3MB�A6MB)�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 4 (45nm)����down��2�R�A Silverthorme (4MB�A8MB)�@��4�R�A Quad Nehalem�@�@�@�@�@�@�@�@��8�R�A Oct Yorkfield (12MB)�@�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Bloomfield (6MB)�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Gilo�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��4�R�A Quad Nehalem-C�@�@�@�@�@�@��8�R�A Oct �@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 6 (32nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��8�R�A Oct Gesher�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��8�R�A Oct�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 8 (22nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Bloomfield (6MB)�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Gilo�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 5 (32nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��4�R�A Quad Nehalem-C�@�@�@�@�@�@��8�R�A Oct �@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 6 (32nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��8�R�A Oct Gesher�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 7 (22nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��8�R�A Oct�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 8 (22nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 9 (16nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
Intel�APentium D 830/840/930/940�Y���~
http://pc.watch.impress.co.jp/docs/2006/0810/intel.htm
http://pc.watch.impress.co.jp/docs/2006/0810/intel.htm
790 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/10(��) 19:35:13 ID:NIaDKxnG
��������XP Professional��8�_���v���Z�b�T�����Ă܂��B
http://journal.mycom.co.jp/special/2006/blackford/005.html
�������Dempsey�o����HT�L���������ƑI�ׂ܂�
http://jpstore.dell.com/store/newstore/bsd/masterNormal.asp?iConfigID=1&iSegID=2&c_SegmName=bsd&c_ConfigType=Normal&BrandId=12037&FamilyId=7
�����ƁA���Ԃ�XP Home�����g�������Ƃ��Ȃ��l�Ȃ̂ŋ����Ă����Ă��������B
http://journal.mycom.co.jp/special/2006/blackford/005.html
�������Dempsey�o����HT�L���������ƑI�ׂ܂�
http://jpstore.dell.com/store/newstore/bsd/masterNormal.asp?iConfigID=1&iSegID=2&c_SegmName=bsd&c_ConfigType=Normal&BrandId=12037&FamilyId=7
�����ƁA���Ԃ�XP Home�����g�������Ƃ��Ȃ��l�Ȃ̂ŋ����Ă����Ă��������B
>>789
�l�g�o���ގY
�l�g�o���ގY
>>784 >>790
���[�����o���Ȃ�M$�̕����B
http://www.microsoft.com/whdc/system/CEC/HT-Windows.mspx
���̕��͂��m�F���ē��e�����B
��������A�ԈႦ���B
�܂�ő�v���Z�b�T���͑��������Ă��Ƃ��B
�Ƃ���ŁA
http://journal.mycom.co.jp/special/2006/blackford/005.html
�������̕��̃e�X�g�B
�����\�t�g�ł�CPU�ɂ���ĕ��ו��z���ɒ[�ɕς��Ă���ȁB
���[�����o���Ȃ�M$�̕����B
http://www.microsoft.com/whdc/system/CEC/HT-Windows.mspx
���̕��͂��m�F���ē��e�����B
��������A�ԈႦ���B
�܂�ő�v���Z�b�T���͑��������Ă��Ƃ��B
�Ƃ���ŁA
http://journal.mycom.co.jp/special/2006/blackford/005.html
�������̕��̃e�X�g�B
�����\�t�g�ł�CPU�ɂ���ĕ��ו��z���ɒ[�ɕς��Ă���ȁB
793 �FSocket774�F2006/08/11(��) 00:30:06 ID:auQCSbsw
�G�Z�ŗǂ��Ȃ�4�R�A�ł�16�R�A�ł��ȒP�ɍ��Ȃ��̂��H
http://www.geocities.jp/andosprocinfo/wadai05/20051210.htm
http://www.geocities.com/Tokyo/Fuji/6615/mirai.htm
http://www.geocities.com/Tokyo/Fuji/6615/mirai.htm
�I�[�o�[�w�b�h�ƃX�P�[���r���e�B�Ƃ̓g���[�h�I�t�ɂȂ�ꍇ����������
(���Ƃ����b�N���x�����������Ă��Ə�CPU���̓��b�N���삪�����Đ��\��
�����邯�ǁA��CPU���͏Փ˂���\���������Đ��\���オ��Ƃ���)
XP��2003�ł͂��̃`���[�j���O���Ⴄ���Ęb�Ȃ�Ȃ���?
(���Ƃ����b�N���x�����������Ă��Ə�CPU���̓��b�N���삪�����Đ��\��
�����邯�ǁA��CPU���͏Փ˂���\���������Đ��\���オ��Ƃ���)
XP��2003�ł͂��̃`���[�j���O���Ⴄ���Ęb�Ȃ�Ȃ���?
>>777
���ɋA���
���ɋA���
199 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:53:57 5br0zUgO
�Ƃł͈�����āB
http://itpro.nikkeibp.co.jp/article/COLUMN/20060602/239826/?ST=cpu&P=2
200 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:54:16 66PhQGI2
>>193
���f���A���R�A�E�v���Z�b�T�i1�j
http://itpro.nikkeibp.co.jp/article/COLUMN/20060602/239826/
�悭�킩��ǐ��������Ă���B�R��̗���͑���Ȃ����� orz
201 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:57:21 4D1K/2KE
>>199-200
>�f���A���R�A�E�v���Z�b�T�𗘗p����ƁCWindows XP Home Edition�ł��ő�4�̘_��CPU�𗘗p�ł��邱�Ƃ��m�F�ł����B
Kents��������킯�ˁA������
202 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:59:50 qKJ75flz
> �}�C�N���\�t�g�́CWindows���Ή�����CPU�̐��Ƃ̓\�P�b�g�̐����Ӗ�����Ƃ��Ă���B
> �܂�CPentium D�̃V�X�e���ɂ�CPU�̃R�A��2���邪�C�\�P�b�g��1�Ȃ̂ŁC
> Windows XP Home Edition�ł�2�̃R�A�̋@�\���g����B
�����Ƀ\�P�b�g�Ə����Ă���B
�R�A�����͂��Ă��Ȃ��A2�R�A�܂œ��͌���o����Ă���CPU�ł̏���ł����Ȃ��A8�R�A�����Ƃ��o���8�R�A���������B
MS��OS���C�Z���X���\�P�b�g���ōs���ƌ��肵�����Ƃ��ă}���`�R�A�J�����}���ɐi�o�܂�Y��Ă͂����Ȃ��B
���ƁA���ӓ_�͌Â�OS(Windows2000��)�ł͏�L�̓K�p�͂Ȃ��B
�Ƃł͈�����āB
http://itpro.nikkeibp.co.jp/article/COLUMN/20060602/239826/?ST=cpu&P=2
200 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:54:16 66PhQGI2
>>193
���f���A���R�A�E�v���Z�b�T�i1�j
http://itpro.nikkeibp.co.jp/article/COLUMN/20060602/239826/
�悭�킩��ǐ��������Ă���B�R��̗���͑���Ȃ����� orz
201 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:57:21 4D1K/2KE
>>199-200
>�f���A���R�A�E�v���Z�b�T�𗘗p����ƁCWindows XP Home Edition�ł��ő�4�̘_��CPU�𗘗p�ł��邱�Ƃ��m�F�ł����B
Kents��������킯�ˁA������
202 ���O�FSocket774 �{���̃��X ���e���F2006/08/13(��) 19:59:50 qKJ75flz
> �}�C�N���\�t�g�́CWindows���Ή�����CPU�̐��Ƃ̓\�P�b�g�̐����Ӗ�����Ƃ��Ă���B
> �܂�CPentium D�̃V�X�e���ɂ�CPU�̃R�A��2���邪�C�\�P�b�g��1�Ȃ̂ŁC
> Windows XP Home Edition�ł�2�̃R�A�̋@�\���g����B
�����Ƀ\�P�b�g�Ə����Ă���B
�R�A�����͂��Ă��Ȃ��A2�R�A�܂œ��͌���o����Ă���CPU�ł̏���ł����Ȃ��A8�R�A�����Ƃ��o���8�R�A���������B
MS��OS���C�Z���X���\�P�b�g���ōs���ƌ��肵�����Ƃ��ă}���`�R�A�J�����}���ɐi�o�܂�Y��Ă͂����Ȃ��B
���ƁA���ӓ_�͌Â�OS(Windows2000��)�ł͏�L�̓K�p�͂Ȃ��B
798 �FSocket774�F2006/08/14(��) 08:21:00 ID:vbip1lH+
ϸ��ۂ���XPHome�͂��߂Ȃ�H
>>798
���{��ł���
���{��ł���
�E�E�E�v����������orz
Mac Pro(�\�P*2)��Mac mini�݂����ȑ��ݽ��c�[�����o�Ă�Home�g����������Ȃ����B
���ȁB
Mac Pro(�\�P*2)��Mac mini�݂����ȑ��ݽ��c�[�����o�Ă�Home�g����������Ȃ����B
���ȁB
Mac�̘b�́A�Vmac��intel�X���ɂł������Ă�n��
803 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/14(��) 22:26:13 ID:CxLnRZX6
�P�\�P�b�g�����F�����Ȃ��������Ǝv���
2010�N��32�R�A���ȁB
20GHz�ɂ���͎̂~�߂��݂������B
http://gizmodo.com/gadgets/top/intel-plans-32core-processor-by-20092010-186085.php
20GHz�ɂ���͎̂~�߂��݂������B
http://gizmodo.com/gadgets/top/intel-plans-32core-processor-by-20092010-186085.php
urasimasandesuka
Optimization Manual
http://www.agner.org/optimize/
Intel�����̃}�j���A�����܂����J����ĂȂ����Ă̂ɂ��̃T�C�g�̃}�j���A����Core 2�ɂ��Ă��T�|�[�g���ꂽ�c(;�L�D�M)
�R�[�h�I�^�n�̐l�͌��Ă����Ɨǂ��B
http://www.agner.org/optimize/
Intel�����̃}�j���A�����܂����J����ĂȂ����Ă̂ɂ��̃T�C�g�̃}�j���A����Core 2�ɂ��Ă��T�|�[�g���ꂽ�c(;�L�D�M)
�R�[�h�I�^�n�̐l�͌��Ă����Ɨǂ��B
Core 2�̉�����̂��Ă�̂͂��̕ӂ��B
http://www.agner.org/optimize/microarchitecture.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/microarchitecture.pdf
http://www.agner.org/optimize/instruction_tables.pdf
����������������������������
���@�@ �@ 8MB Shared L2�@�@�@�@��
���@�@�������������������@�@.��
���@�@�� core0 �� core3 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core1 �� core2 ���@�@.��
���@�@�������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
����������������������������
�������������@ �������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ������ �@������������
�� core 0 �@������L1������������������������������������L1�������@ core 3 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@�������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@�@�@�@�@�@�@��. �@�@ �@ �@�@ �@ �@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@���@�@ ���@CSI links Fullwidth 6.4GT/s�@���@�@��
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@ �@ ��
�������������@ �������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@������ �@������������
�� core 1 �@������L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@�@ �@�@��L1������ core 2 �@��
�� �@ �@ �@ �@�������@ ����������������������������������.�� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@ �@ �@�@�@�@�@ .������������
���@�@ �@ 8MB Shared L2�@�@�@�@��
���@�@�������������������@�@.��
���@�@�� core0 �� core3 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core1 �� core2 ���@�@.��
���@�@�������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
����������������������������
�������������@ �������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ������ �@������������
�� core 0 �@������L1������������������������������������L1�������@ core 3 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@�������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@�@�@�@�@�@�@��. �@�@ �@ �@�@ �@ �@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@���@�@ ���@CSI links Fullwidth 6.4GT/s�@���@�@��
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@ �@ ��
�������������@ �������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@������ �@������������
�� core 1 �@������L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@�@ �@�@��L1������ core 2 �@��
�� �@ �@ �@ �@�������@ ����������������������������������.�� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@ �@ �@�@�@�@�@ .������������
��������������������������������
���@�@�@�@ �@ 8MB Shared L2�@ �@ �@�@��
��������������������������������
���@Memory controllers.�� . Router ���@���@4*CSI links(Fullwidth) 2D torus topology�@���@Other Processor
��������������������������������
�@�@�@���������@�@�@�@�@�@�@�@�@��
�@ �@4*FBD links�@�@ �@ �@ �@ �@ ���@CSI links (Halfwidth)�@���@I/O
�V�R�A�͊�{�I��Merom�P
L1 TraceCache (16K-��OPs MainTraceCache 8K-��OPs Fliter Trace Cache)
Enhanced Intel Smart Memory Access
L1 to L1 + Core Multiplexing Technology + Foxton Technology = 1.3* boost scalar
SSE5(128bit-Optimized Instruction)
QuadCore + HTT(CGMT) = 8TLP
Enhanced Intel I/O Acceleration Technology
Enhanced Fast Memory Access
Enhanced Intel Virtualization Technology
�ȏ�B�����܂ł̂����炢������Nehalem�Ɋւ���ϑz�I���B
���@�@�@�@ �@ 8MB Shared L2�@ �@ �@�@��
��������������������������������
���@Memory controllers.�� . Router ���@���@4*CSI links(Fullwidth) 2D torus topology�@���@Other Processor
��������������������������������
�@�@�@���������@�@�@�@�@�@�@�@�@��
�@ �@4*FBD links�@�@ �@ �@ �@ �@ ���@CSI links (Halfwidth)�@���@I/O
�V�R�A�͊�{�I��Merom�P
L1 TraceCache (16K-��OPs MainTraceCache 8K-��OPs Fliter Trace Cache)
Enhanced Intel Smart Memory Access
L1 to L1 + Core Multiplexing Technology + Foxton Technology = 1.3* boost scalar
SSE5(128bit-Optimized Instruction)
QuadCore + HTT(CGMT) = 8TLP
Enhanced Intel I/O Acceleration Technology
Enhanced Fast Memory Access
Enhanced Intel Virtualization Technology
�ȏ�B�����܂ł̂����炢������Nehalem�Ɋւ���ϑz�I���B
The End of Wintel?
http://www.redherring.com/Article.aspx?a=17933&hed=The+End+of+Wintel%3F
http://www.redherring.com/Article.aspx?a=17933&hed=The+End+of+Wintel%3F
Nehalem�̓����R����������Ȃ��Ǝv����Ȃ��B��������
>>808
>CSI links Fullwidth 6.4GT/s
�R�s�y�ɓ˂����ނ̂��Ȃ��ǂ�����Ēx�����Ȃ��H
Netburst��L1��120GB/s���炢���������炻����傫���Ȃ�Ȃ��Ⴈ�������B
>4*CSI links(Fullwidth) 2D torus topology(>>809)
�������̐��l���Ǝv���B
>>811
���̐S�́H
>CSI links Fullwidth 6.4GT/s
�R�s�y�ɓ˂����ނ̂��Ȃ��ǂ�����Ēx�����Ȃ��H
Netburst��L1��120GB/s���炢���������炻����傫���Ȃ�Ȃ��Ⴈ�������B
>4*CSI links(Fullwidth) 2D torus topology(>>809)
�������̐��l���Ǝv���B
>>811
���̐S�́H
�N��������łȂ����ł��������
��̕��ňꐶ����AA����ĘA�����Ă�z�Ɠ���l������
��̕��ňꐶ����AA����ĘA�����Ă�z�Ɠ���l������
>>812
GT/����GB/���̈Ⴂ���낤�˂��B
GT/����GB/���̈Ⴂ���낤�˂��B
>>814
�����c�f�ŋC�t���Ȃ�������
�����c�f�ŋC�t���Ȃ�������
���A���ʂɍl���ăI���`�b�v�o�X��CSI�i�O���o�X�j�g���킯�Ȃ������A�Ǝv�����B
Bensley�̎��̃v���b�g�t�H�[����VT��PCI-E�̊g���ȊO�͂��Ȃ���?
����������������������������
���@�@�@ 16MB Shared L2�@�@�@ .��
���@�@�������������������@�@.��
���@�@�� core0 �� core4 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core1 �� core5 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core2 �� core6 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core3 �� core7 ���@�@.��
���@�@�������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
����������������������������
���@�@�@ 16MB Shared L2�@�@�@ .��
���@�@�������������������@�@.��
���@�@�� core0 �� core4 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core1 �� core5 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core2 �� core6 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core3 �� core7 ���@�@.��
���@�@�������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
����������������������������
�������������@ �������@�@�@�@ ������ �@������������
�� core 0 �@������L1����������L1�������@ core 4 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 1 �@������L1����������L1�������@ core 5 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 2 �@������L1����������L1�������@ core 6 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 3 �@������L1����������L1�������@ core 7 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@������������
�� core 0 �@������L1����������L1�������@ core 4 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 1 �@������L1����������L1�������@ core 5 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 2 �@������L1����������L1�������@ core 6 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@ ��
�������������@ �������@�@�@�@ ������ �@������������
�� core 3 �@������L1����������L1�������@ core 7 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@������������
��������������������������������������������
���@�@�@�@�@�@�@�@�@ 32MB Shared L2�@�@�@�@�@�@�@�@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core0 �� core4 �� core8 ��core12.���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core1 �� core5 �� core9 ��core13.���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core2 �� core6 ��core10.��core14���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core3 �� core7 ��core11.��core15���@�@.��
���@�@�����������������������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
��������������������������������������������
���@�@�@�@�@�@�@�@�@ 32MB Shared L2�@�@�@�@�@�@�@�@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core0 �� core4 �� core8 ��core12.���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core1 �� core5 �� core9 ��core13.���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core2 �� core6 ��core10.��core14���@�@.��
���@�@�����������������������������������@�@.��
���@�@�� core3 �� core7 ��core11.��core15���@�@.��
���@�@�����������������������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
��������������������������������������������
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core0 ������L1���� core4 ������L1���� core8 ������L1����core12������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core1 ������L1���� core5 ������L1���� core9 ������L1����core13������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core0 ������L1���� core4 ������L1���� core8 ������L1����core12������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core1 ������L1���� core5 ������L1���� core9 ������L1����core13������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core2 ������L1���� core6 ������L1����core10������L1����core14������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core3 ������L1���� core7 ������L1����core11������L1����core15������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core2 ������L1���� core6 ������L1����core10������L1����core14������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@ .��
�����������@ �����������������@ �����������������@ �����������������@ ������
�� core3 ������L1���� core7 ������L1����core11������L1����core15������L1��
�� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ���� �@ �@ �@�������@ ��
�� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@�������� �@ �@ �@�� �@������
�����������@�@�@���@ �����������@�@�@���@ �����������@�@�@���@ �����������@�@�@��
�@�@�@�@�@�@�@�@�@�@.��������������������������������������������������������
�u�w�e���W�j�A�X�}���`�R�A=���SGFLOPS=10�{�p�t�H�[�}���X�v
����I�ƂȂ����w�e���W�j�A�X�}���`�R�A�ւ̒���
ttp://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
>�\�t�g�E�F�A�̃t���[�����`���I�����
>�������A�w�e���W�j�A�X�}���`�R�A�ւ̕ω��ɂ͒ɂ݂������B����̓\�t�g�E�F�A�ʂ��B
>�w�e���W�j�A�X�}���`�R�A���ɂ���āA�\�t�g�E�F�A�J���̘J�͂���������\�������邩�炾�B
>�w�e���W�j�A�X�}���`�R�A�́A�n�[�h�E�F�A���̒ɂ݂��A�\�t�g�E�F�A���Ɏ����ė���A�v���[�`�ƍl���邱�Ƃ��ł���B
�w�e���͂�����悤�ȋC�����Ă����c
ttp://pc.watch.impress.co.jp/docs/2006/0818/kaigai295.htm
>�\�t�g�E�F�A�̃t���[�����`���I�����
>�������A�w�e���W�j�A�X�}���`�R�A�ւ̕ω��ɂ͒ɂ݂������B����̓\�t�g�E�F�A�ʂ��B
>�w�e���W�j�A�X�}���`�R�A���ɂ���āA�\�t�g�E�F�A�J���̘J�͂���������\�������邩�炾�B
>�w�e���W�j�A�X�}���`�R�A�́A�n�[�h�E�F�A���̒ɂ݂��A�\�t�g�E�F�A���Ɏ����ė���A�v���[�`�ƍl���邱�Ƃ��ł���B
�w�e���͂�����悤�ȋC�����Ă����c
�\�t�g�E�F�A���ɕ��S��������̂�Intel�̂��ƌ|�������̂����B
AMD�哱�ł��܂��ł���낤���H
�R���p�C���Z�p��Z�p�x���ȂǂŁA���̕��ʂł�Intel��AMD�ł͉_�D�̍���������B
AMD�哱�ł��܂��ł���낤���H
�R���p�C���Z�p��Z�p�x���ȂǂŁA���̕��ʂł�Intel��AMD�ł͉_�D�̍���������B
>>824
����A���ꂨ��������?
���A�w�e���ɂ��Ă�����10�{���ĈӖ��Ȃ��ˁH
�����āA���܂��A�P���ɃR�A10�ɑ��₹��10�{����
����A���ꂨ��������?
���A�w�e���ɂ��Ă�����10�{���ĈӖ��Ȃ��ˁH
�����āA���܂��A�P���ɃR�A10�ɑ��₹��10�{����
>>827
����10�{�̃p�t�H�[�}���X����菭�Ȃ��g�����W�X�^�Ŏ����ł�����Ă̂�
�w�e���̗��_���Ǝv�����E�E�E
�܂��APS3�Ƃ����w�e���̎�������Ă�ƁA�\�t�g�E�F�A�J���҂͑�ς���
����10�{�̃p�t�H�[�}���X����菭�Ȃ��g�����W�X�^�Ŏ����ł�����Ă̂�
�w�e���̗��_���Ǝv�����E�E�E
�܂��APS3�Ƃ����w�e���̎�������Ă�ƁA�\�t�g�E�F�A�J���҂͑�ς���
CELL(256Gflops)�̓��������x�����Ȃ̂ɂ������ɂ�������Ă�Ƃ��낪��
831 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/19(�y) 14:19:01 ID:5L2KVYKs
>>827
���ꂶ��w�e������Ȃ��B
1�`2issue�̐��\�̒Ⴂ�������R�A�Ƃ̍����\�����B
����������āAPARROT�̌����_���ł����Ƃ���́u�R�[���h�p�C�v�v�Ƃ����̂����B
�i���b�`��1�R�A�{������3�R�A�j�~�W�@��32�R�A�ɂȂ��ȁB
���邢�́A�@�i1�R�A�{7�R�A�j�~4�@�Ƃ��B�@
�g���[�X�L���b�V�����R�A�̃Z�b�g�Ԃŋ��L�����āA�v���t�@�C�����ʂ����Ƃɏ����̏d���X���b�h���A
Merom-Nehalem�H���̃��b�`�ȃR�A���x�[�X�Ƃ���z�b�g�p�C�v�ɁA���܂葬�x�I��
�d�v�łȂ��X���b�h�̓R�[���h�p�C�v�ɗ����B
-----------------
�����܂Ŗϑz����
�㓡���ȑO�L���ɏ����Ă邯�ǁAISA�͂����܂�x86���ۂ��ˁB
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
���ꂶ��w�e������Ȃ��B
1�`2issue�̐��\�̒Ⴂ�������R�A�Ƃ̍����\�����B
����������āAPARROT�̌����_���ł����Ƃ���́u�R�[���h�p�C�v�v�Ƃ����̂����B
�i���b�`��1�R�A�{������3�R�A�j�~�W�@��32�R�A�ɂȂ��ȁB
���邢�́A�@�i1�R�A�{7�R�A�j�~4�@�Ƃ��B�@
�g���[�X�L���b�V�����R�A�̃Z�b�g�Ԃŋ��L�����āA�v���t�@�C�����ʂ����Ƃɏ����̏d���X���b�h���A
Merom-Nehalem�H���̃��b�`�ȃR�A���x�[�X�Ƃ���z�b�g�p�C�v�ɁA���܂葬�x�I��
�d�v�łȂ��X���b�h�̓R�[���h�p�C�v�ɗ����B
-----------------
�����܂Ŗϑz����
�㓡���ȑO�L���ɏ����Ă邯�ǁAISA�͂����܂�x86���ۂ��ˁB
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
�w�e���W�j�A�X�E�}���`�R�A�ɂ�����
���ЂŃR���p�C���������A�\�t�g�E�F�A�ɑ���e���͂���r�I�傫��Intel��x86���Ŏ����A
���ЂŃR���p�C�����������A�����̃R�[�h�������ɓ����悤��CPU������Ă���AMD��x86���̗p���Ȃ��A
�Ƃ����̂͊����ɋ����[���B
���ЂŃR���p�C���������A�\�t�g�E�F�A�ɑ���e���͂���r�I�傫��Intel��x86���Ŏ����A
���ЂŃR���p�C�����������A�����̃R�[�h�������ɓ����悤��CPU������Ă���AMD��x86���̗p���Ȃ��A
�Ƃ����̂͊����ɋ����[���B
x86 everywhere�Ƃ������Ă��̂͂ǂ����������B
x86�͂Ȃ��Ȃ�Ƃ���������Ă��ł����ˁB
x86�R�A���P�ł���������ɂ�x86�����邱�ƂɁB
x86�R�A���P�ł���������ɂ�x86�����邱�ƂɁB
>>832
�����炱������B
���_���o�����B���z��茻���B
Intel�͓����Q�ގ����ɓx�Ɍ����B
>intel�Ƃ�����Ђ́A��x�ے肵���Z�p�ɂ͖ڂ�����Ȃ��Ƃ��������������Ђł���B
>�ő��ɕ����]�����Ȃ����A����Ƃ��͈�C�ɑ�]������
�����炱������B
���_���o�����B���z��茻���B
Intel�͓����Q�ގ����ɓx�Ɍ����B
>intel�Ƃ�����Ђ́A��x�ے肵���Z�p�ɂ͖ڂ�����Ȃ��Ƃ��������������Ђł���B
>�ő��ɕ����]�����Ȃ����A����Ƃ��͈�C�ɑ�]������
�@�@�@�@�@�@�@�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@�@/||�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ | /|
�@�@�@�@�@/�@| |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/ |
�@�@�@�@/�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@/�@ |
�@�@�@/�@�@�@|�@ |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ /�@�@ |
�@�@/�@�@�@�@|�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/�@�@�@�@|
�@/ �Q�Q�Q|�Q�Q|�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q|�Q/�@�@�@�@�@|
�@| �_�@�@�@|�@�@�@�@| �Q�Q�Q�Q�Q�Q�Q�Q�@|�@�^|�@�@�@�@�@|
�@|�@�@�_�@ |�@�@�@/|�@�@�@�@�@�@�@�@�@�@�@�@/| �^�@|�@�@�@�@�@|
�@|�@�@�@ �_|�@�@/�@|�@�@�@�@�@�@�@�@�@�@�@/�^|�@�@ |�@�@�@�@�@|
�@|�@�@�@�@�@|�_/�@ |�@�@�@�@�@�@�@�@�@ /�^�@|�@�@�@|�@�@�@�@�@|
�@|�@�@�@�@�@|�@ | �P|�P�P�P�P�P�P |�@�@�@|�@�@�@|�@�@�@�@�@|
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@| �Q�Q�Q�Q�Q�Q|�Q�Q|�@�@�@|�@�@�@�@�@ |
�@|�@�@�@�@�@|�Q|��/�Q�Q�Q�Q�Q�Q |�Q�Q/����| �Q�Q�Q|
�@|�@�@�@�@�@/�@|�@/�@�@�@�@�@�@�@�@�@�@|�@ /�@�P�P|�P�P�@ /
�@|�@�@�@�@/�@�@| / �@�@�@�@�@�@�@�@�@�@| /�@�@�@�@�@|�@�@�@ /
�@|�@�@�@/�@ �^ �P�P�P�P�P�P�P�P�_�@�@�@�@�@|�@�@�@/
�@|�@�@/�@�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@|�@�@/
�@|�@/ �^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@ |�@/
�@|/�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_|/
�@�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�n�C�p�[�L���[�u�E�V�X�e�� "Cosmic Cube"
�@�@�@�@�@�@/||�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ | /|
�@�@�@�@�@/�@| |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/ |
�@�@�@�@/�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@/�@ |
�@�@�@/�@�@�@|�@ |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ /�@�@ |
�@�@/�@�@�@�@|�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/�@�@�@�@|
�@/ �Q�Q�Q|�Q�Q|�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q|�Q/�@�@�@�@�@|
�@| �_�@�@�@|�@�@�@�@| �Q�Q�Q�Q�Q�Q�Q�Q�@|�@�^|�@�@�@�@�@|
�@|�@�@�_�@ |�@�@�@/|�@�@�@�@�@�@�@�@�@�@�@�@/| �^�@|�@�@�@�@�@|
�@|�@�@�@ �_|�@�@/�@|�@�@�@�@�@�@�@�@�@�@�@/�^|�@�@ |�@�@�@�@�@|
�@|�@�@�@�@�@|�_/�@ |�@�@�@�@�@�@�@�@�@ /�^�@|�@�@�@|�@�@�@�@�@|
�@|�@�@�@�@�@|�@ | �P|�P�P�P�P�P�P |�@�@�@|�@�@�@|�@�@�@�@�@|
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@|�@�@�@�@�@|�@ |�@�@| �Q�Q�Q�Q�Q�Q|�Q�Q|�@�@�@|�@�@�@�@�@ |
�@|�@�@�@�@�@|�Q|��/�Q�Q�Q�Q�Q�Q |�Q�Q/����| �Q�Q�Q|
�@|�@�@�@�@�@/�@|�@/�@�@�@�@�@�@�@�@�@�@|�@ /�@�P�P|�P�P�@ /
�@|�@�@�@�@/�@�@| / �@�@�@�@�@�@�@�@�@�@| /�@�@�@�@�@|�@�@�@ /
�@|�@�@�@/�@ �^ �P�P�P�P�P�P�P�P�_�@�@�@�@�@|�@�@�@/
�@|�@�@/�@�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@|�@�@/
�@|�@/ �^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@ |�@/
�@|/�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_|/
�@�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�n�C�p�[�L���[�u�E�V�X�e�� "Cosmic Cube"
�@�@�@�@�@�@�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@�@�@�@�@core12/||�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ | /| core14
�@�@�@�@�@�@�@�@ /�@| |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/ |
�@�@�@�@�@�@�@ /�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@/�@ |
�@�@�@�@�@�@ /�@�@�@|�@ |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ /�@�@ |
�@�@�@�@�@ /�@�@�@�@|�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/�@�@�@�@|
�@�@�@�@ / �Q�Q�Q|�Q�Q|�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q|�Q/�@�@�@�@�@|
core8�@| �_�@�@�@|�@�@�@�@| �Q�Q�Q�Q�Q�Q�Q�Q�@|�@�^|core10�@|
�@�@�@�@ |�@�@�_�@ |�@�@�@/|core4�@�@�@�@�@ core6/| �^�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@ �_|�@�@/�@|�@�@�@�@�@�@�@�@�@�@�@/�^|�@�@ |�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�_/�@ |�@�@�@�@�@�@�@�@�@ /�^�@|�@�@�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�@ | �P|�P�P�P�P�P�P |�@�@�@|�@�@�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�@ |core0�@�@�@�@ core2|�@�@�@|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@|core5�@�@�@�@�@ |core7|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@| �Q�Q�Q�Q�Q�Q|�Q�Q|�@�@�@|�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�Q|��/�Q�Q�Q�Q�Q�Q |�Q�Q/����| �Q�Q�Q|
�@�@�@�@ | core13/�@|�@/�@�@�@�@�@�@�@�@�@�@|�@ /�@�P�P|�P�P�@ / core15
�@�@�@�@ |�@�@�@�@/�@�@| /core1 �@�@�@core3| /�@�@�@�@�@|�@�@�@ /
�@�@�@�@ |�@�@�@/�@ �^ �P�P�P�P�P�P�P�P�_�@�@�@�@�@|�@�@�@/
�@�@�@�@ |�@�@/�@�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@|�@�@/
�@�@�@�@ |�@/ �^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@ |�@/
�@�@�@�@ |/�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_|/
core9�@ �P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P core11
�@�@�@�@�@core12/||�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ | /| core14
�@�@�@�@�@�@�@�@ /�@| |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/ |
�@�@�@�@�@�@�@ /�@�@|�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@/�@ |
�@�@�@�@�@�@ /�@�@�@|�@ |�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |�@ /�@�@ |
�@�@�@�@�@ /�@�@�@�@|�@�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@|�@/�@�@�@�@|
�@�@�@�@ / �Q�Q�Q|�Q�Q|�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q|�Q/�@�@�@�@�@|
core8�@| �_�@�@�@|�@�@�@�@| �Q�Q�Q�Q�Q�Q�Q�Q�@|�@�^|core10�@|
�@�@�@�@ |�@�@�_�@ |�@�@�@/|core4�@�@�@�@�@ core6/| �^�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@ �_|�@�@/�@|�@�@�@�@�@�@�@�@�@�@�@/�^|�@�@ |�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�_/�@ |�@�@�@�@�@�@�@�@�@ /�^�@|�@�@�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�@ | �P|�P�P�P�P�P�P |�@�@�@|�@�@�@|�@�@�@�@�@|
�@�@�@�@ |�@�@�@�@�@|�@ |core0�@�@�@�@ core2|�@�@�@|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@|�@�@�@�@�@�@�@�@�@ |�@�@�@|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@|core5�@�@�@�@�@ |core7|�@�@ |�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�@ |�@�@| �Q�Q�Q�Q�Q�Q|�Q�Q|�@�@�@|�@�@�@�@�@ |
�@�@�@�@ |�@�@�@�@�@|�Q|��/�Q�Q�Q�Q�Q�Q |�Q�Q/����| �Q�Q�Q|
�@�@�@�@ | core13/�@|�@/�@�@�@�@�@�@�@�@�@�@|�@ /�@�P�P|�P�P�@ / core15
�@�@�@�@ |�@�@�@�@/�@�@| /core1 �@�@�@core3| /�@�@�@�@�@|�@�@�@ /
�@�@�@�@ |�@�@�@/�@ �^ �P�P�P�P�P�P�P�P�_�@�@�@�@�@|�@�@�@/
�@�@�@�@ |�@�@/�@�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@|�@�@/
�@�@�@�@ |�@/ �^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_�@ |�@/
�@�@�@�@ |/�^�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �_|/
core9�@ �P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P�P core11
�w�e���ł��邱�Ƃƃ}���`(���j�B)�R�A�ł��邱�ƂƂ���ȊO�̂��Ƃ�
��肪��������ɂȂ��ĂĈӖ��s����
�Ƃ肠���������̊g�����߂�CPU�x���_�̗p�ӂ����R�[�h���V�X�e��
�x���_�������q���őg���ɂ��Ă邾���Ȃ̂ŁA�w�e��(��x86)�R�A��
��p���߂ł��������Ƃ��Γ����x���̃T�|�[�g�ɂ͂Ȃ�͂��B
��肪��������ɂȂ��ĂĈӖ��s����
�Ƃ肠���������̊g�����߂�CPU�x���_�̗p�ӂ����R�[�h���V�X�e��
�x���_�������q���őg���ɂ��Ă邾���Ȃ̂ŁA�w�e��(��x86)�R�A��
��p���߂ł��������Ƃ��Γ����x���̃T�|�[�g�ɂ͂Ȃ�͂��B
839 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/20(��) 14:12:37 ID:RkvenfXh
���Ƃ肠���������̊g�����߂�CPU�x���_�̗p�ӂ����R�[�h���V�X�e��
���x���_�������q���őg���ɂ��Ă邾���Ȃ̂ŁA
MMX/SSE�̂��Ƃ������Ă�Ȃ�Ax86�̖��߃t�H�[�}�b�g�ɏ]���ăl�C�e�B�u�Ŏ��s�������̂����ǁB
�v���O���}�u���V�F�[�_��x86���߂͎��s�ł��Ȃ�
ISA����x86�Ƃ���ƁA�o�C�i���t�H�[�}�b�g�͂ǂ��Ȃ�̂��ˁB
DirectX�̃v���O���}�u���V�F�[�_�݂����ȓǂݍ��ݕ��ł�����̂��ˁB
�����܂Ńt���[�����`�̌p����_����PARROT�̃A�v���[�`�Ƃ͑S�R�Ⴂ�܂��ȁB
���x���_�������q���őg���ɂ��Ă邾���Ȃ̂ŁA
MMX/SSE�̂��Ƃ������Ă�Ȃ�Ax86�̖��߃t�H�[�}�b�g�ɏ]���ăl�C�e�B�u�Ŏ��s�������̂����ǁB
�v���O���}�u���V�F�[�_��x86���߂͎��s�ł��Ȃ�
ISA����x86�Ƃ���ƁA�o�C�i���t�H�[�}�b�g�͂ǂ��Ȃ�̂��ˁB
DirectX�̃v���O���}�u���V�F�[�_�݂����ȓǂݍ��ݕ��ł�����̂��ˁB
�����܂Ńt���[�����`�̌p����_����PARROT�̃A�v���[�`�Ƃ͑S�R�Ⴂ�܂��ȁB
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�� core0 ����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�� core4 ����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
���� core1 ����L1���� core2.����L1���� core3 ����L1�������� core5 ����L1���� core6.����L1���� core7 ����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�� core0 ����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�� core4 ����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
���� core1 ����L1���� core2.����L1���� core3 ����L1�������� core5 ����L1���� core6.����L1���� core7 ����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�� core8 ����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .��core12����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
���� core9 ����L1����core10����L1����core11����L1��������core13.����L1����core14����L1����core15.����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�� core8 ����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .��core12����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
���� core9 ����L1����core10����L1����core11����L1��������core13.����L1����core14����L1����core15.����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .��core16.����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ ��core20.����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
����core17����L1����core18.����L1����core19����L1��������core21.����L1����core22����L1����core23.����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .��core16.����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ ��core20.����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
����core17����L1����core18.����L1����core19����L1��������core21.����L1����core22����L1����core23.����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .��core24.����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .��core29����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
����core25����L1����core26.����L1����core27����L1��������core29����L1����core30.����L1����core31����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .��core24.����L1���@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .��core29����L1���@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ �����@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .�����������������������������������@ �����@�@�@�@�@�@�@�@ .�����������������������������������@ ��
��������������������������������������������������������������������������������������������������������
����core25����L1����core26.����L1����core27����L1��������core29����L1����core30.����L1����core31����L1����
��������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������
�㓡��N�^���L��g�i�[�̃I�i�j�[�ɕt����������Ȃ�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core0 ����L1��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ������������������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�� core1 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�� core2 ����L1��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������������������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������������������������
�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@ �����������������@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�� core3 ����L1���@�@�@�@�@�@�@�@�@�@�@ �� core4 ����L1���@�@�@�@�@�@�@�@�@�@�@ �� core5 ����L1���@�@�@�@�@�@�@�@�@�@�@ .�� core6 ����L1��
�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@ �����������������@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@ .�������������������@�@�@�@�@�@�@�@�@�@.�������������������@�@�@�@�@�@�@�@�@�@�������������������@�@�@�@�@�@�@�@�@�@.������������������
��������������������������������������������������������������������������������������������������������������������������������
�� core7 ����L1���� core8.����L1���� core9 ����L1����core10����L1����core11.����L1����core12����L1����core13����L1����core14.����L1��
��������������������������������������������������������������������������������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core0 ����L1��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ������������������������������������������������������������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�� core1 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�� core2 ����L1��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .�����������������������������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .����������������������������������
�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@ �����������������@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�� core3 ����L1���@�@�@�@�@�@�@�@�@�@�@ �� core4 ����L1���@�@�@�@�@�@�@�@�@�@�@ �� core5 ����L1���@�@�@�@�@�@�@�@�@�@�@ .�� core6 ����L1��
�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@ �����������������@�@�@�@�@�@�@�@�@�@�@ .�����������������@�@�@�@�@�@�@�@�@�@�@ .����������������
�@�@�@�@�@�@�@�@ .�������������������@�@�@�@�@�@�@�@�@�@.�������������������@�@�@�@�@�@�@�@�@�@�������������������@�@�@�@�@�@�@�@�@�@.������������������
��������������������������������������������������������������������������������������������������������������������������������
�� core7 ����L1���� core8.����L1���� core9 ����L1����core10����L1����core11.����L1����core12����L1����core13����L1����core14.����L1��
��������������������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core0 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
���� core1 ����L1���� core2.����L1���� core3 ����L1���� core4.����L1���� core5 ����L1���� core6.����L1���� core7 ����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core0 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
���� core1 ����L1���� core2.����L1���� core3 ����L1���� core4.����L1���� core5 ����L1���� core6.����L1���� core7 ����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core8 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
���� core9 ����L1����core10����L1����core11.����L1����core12����L1����core13����L1����core14.����L1����core15����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�� core8 ����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
���� core9 ����L1����core10����L1����core11.����L1����core12����L1����core13����L1����core14.����L1����core15����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��core16.����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
����core17.����L1����core18����L1����core19����L1����core20.����L1����core21����L1����core22.����L1����core23����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��core16.����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
����core17.����L1����core18����L1����core19����L1����core20.����L1����core21����L1����core22.����L1����core23����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��core24.����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
����core25.����L1����core26����L1����core27����L1����core28.����L1����core29����L1����core30.����L1����core31����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��core24.����L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ .��
���@�@�@�@�@�@�@�@ .���������������������������������������������������������������������������������������������������@ ��
��������������������������������������������������������������������������������������������������������������������
����core25.����L1����core26����L1����core27����L1����core28.����L1����core29����L1����core30.����L1����core31����L1����
��������������������������������������������������������������������������������������������������������������������
��������������������������������������������������������������������������������������������������������������������
ID:3mu/Uvcz �E�U��
MMX���Q�[���ȊO�̎��p�A�v���ɂ܂Ƃ��Ɏg����悤�ɂȂ�܂ʼn��N����������H
GPU������̂͂����Ƃ��āA���̓���������GPU�������ɂ킽���ē��ڂ��ꍂ����
�����ۏ͂���̂��H�@CPU�ꐢ�ゾ���̍������Ȃ�ăA�v���P�[�V�����x���_��
���Ă���킯�Ȃ����B
���̓w�e�����z�����Ƃ��A����Ȃ��Ƃ���Ȃ���B
�V�ݖ��߂������ɂ킽���ăT�|�[�g����邩�ƁA�R���p�C�����炻�ꂪ�L���Ɏg���邩���B
GPU������̂͂����Ƃ��āA���̓���������GPU�������ɂ킽���ē��ڂ��ꍂ����
�����ۏ͂���̂��H�@CPU�ꐢ�ゾ���̍������Ȃ�ăA�v���P�[�V�����x���_��
���Ă���킯�Ȃ����B
���̓w�e�����z�����Ƃ��A����Ȃ��Ƃ���Ȃ���B
�V�ݖ��߂������ɂ킽���ăT�|�[�g����邩�ƁA�R���p�C�����炻�ꂪ�L���Ɏg���邩���B
>�R���p�C�����炻�ꂪ�L���Ɏg���邩��
intel�͂��̕ӂ̕ۏ�͎�������낤�B
�������ăR���p�C�����撣���Ă邵�A���@�I�}���`�X���b�f�B���O�ɂ����Ă�
�ÓI�R���p�C���̕⏕�������������u�[�X�g����\�������낤�B
AMD�Ƃ͍l�����Ƃ������A��Ƒ̗͂̈Ⴂ���炩�A�c�q�������悤��intel�͂Ȃ�ׂ��t���[�����`�̌p����_���悤�����A
���ʂ��ꂪintel���i�̒n�ʌ���ɂȂ鎖��m���Ă���A�������́A�̌����Ă������M�䂦�̕������Ƃ������B
intel���R���p�C���ɂ�����t���[�����`���ł���ꂽ����i�ׂ̑Ώۂ̈ꕔ�Ƃ��ĕ\�L���Ă��܂��ǂ����̉�ЂƂ�
���߂���͓̂����ł��A����Ɏ���܂ł̃��A�N�V�����̑���Ƃ������A���ƌ������B
�ǂ������ƂƂ��Ă͗��h�ȂƎv����B
intel�͂��̕ӂ̕ۏ�͎�������낤�B
�������ăR���p�C�����撣���Ă邵�A���@�I�}���`�X���b�f�B���O�ɂ����Ă�
�ÓI�R���p�C���̕⏕�������������u�[�X�g����\�������낤�B
AMD�Ƃ͍l�����Ƃ������A��Ƒ̗͂̈Ⴂ���炩�A�c�q�������悤��intel�͂Ȃ�ׂ��t���[�����`�̌p����_���悤�����A
���ʂ��ꂪintel���i�̒n�ʌ���ɂȂ鎖��m���Ă���A�������́A�̌����Ă������M�䂦�̕������Ƃ������B
intel���R���p�C���ɂ�����t���[�����`���ł���ꂽ����i�ׂ̑Ώۂ̈ꕔ�Ƃ��ĕ\�L���Ă��܂��ǂ����̉�ЂƂ�
���߂���͓̂����ł��A����Ɏ���܂ł̃��A�N�V�����̑���Ƃ������A���ƌ������B
�ǂ������ƂƂ��Ă͗��h�ȂƎv����B
853 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/21(��) 01:45:49 ID:s8DGGU8N
���ЂŃR���p�C������ĂȂ�AMD�ɂ͖����ł������
��x86����������I��ł�����Intel�R���p�C���ɊÂ���ƌ������Ƃ��ł��Ȃ����ˁB
�u�����Ƃ��̓Ǝ��x�N�g���v���Z�b�T�ɍœK�����Ă���Ȃ��v�Ȃ��Intel���ٔ��ői����Ȃ��
�A�z�Ȃ��Ƃ��ł��Ȃ����H
��x86����������I��ł�����Intel�R���p�C���ɊÂ���ƌ������Ƃ��ł��Ȃ����ˁB
�u�����Ƃ��̓Ǝ��x�N�g���v���Z�b�T�ɍœK�����Ă���Ȃ��v�Ȃ��Intel���ٔ��ői����Ȃ��
�A�z�Ȃ��Ƃ��ł��Ȃ����H
�t���[�����`��ł��Ȃ��Ȃ�����Ō�B
���C���X�g���[����������Ă����̂݁i�X�p�R����ꕔ�g�������͕ʁj�B
���C���X�g���[����������Ă����̂݁i�X�p�R����ꕔ�g�������͕ʁj�B
�ց[�A���Ƃ܂Ƃȕ����ɉ�b�o���Ă邶��E�E�E
�t���[�����`�������ĂȂ�̃n�[�h���ȁA�ł���B
�\�t�g�ɗ���̂��ǂ����A���ꎩ�̂��ėp����傫�����Ȃ��Ă��邱�ƂɋC���t���Ăق������̂��B
�t���[�����`�������ĂȂ�̃n�[�h���ȁA�ł���B
�\�t�g�ɗ���̂��ǂ����A���ꎩ�̂��ėp����傫�����Ȃ��Ă��邱�ƂɋC���t���Ăق������̂��B
DX10����ł́A�����m�̒ʂ�e���[�J�Ԃ̍��ق́A��{�I�Ƀp�t�H�[�}���X�݂̂ɂȂ�B
����ɁASM4.0�ł͂���܂ł̂����A�啝�Ƀv���O�����\���������B
DX10.1�ł̓O���t�B�b�N�X�`�b�v�̉��z������������AGPGPU�̎����ɂ�����
�O���t�B�b�N�X�`�b�v���R�v���Z�b�T�I�Ɋ��p�����@�������\��������B
����ɁAGPU��PC�ł���A�K�����������̂��B
�܂�A�x�N�^�v���Z�b�T�Ƃ��ẮADX10�����GPU��
�����Ƃ���ʓI�Ȃ��̂ɂȂ�Ƃ������ł��ȁB
GPGPU������ǂꂾ�����y���邩���AAMD�̐����̌��ł��ȁE�E�E
�Ȃ�ƂȂ��AMicrosoft�̉e��������B
����ɁASM4.0�ł͂���܂ł̂����A�啝�Ƀv���O�����\���������B
DX10.1�ł̓O���t�B�b�N�X�`�b�v�̉��z������������AGPGPU�̎����ɂ�����
�O���t�B�b�N�X�`�b�v���R�v���Z�b�T�I�Ɋ��p�����@�������\��������B
����ɁAGPU��PC�ł���A�K�����������̂��B
�܂�A�x�N�^�v���Z�b�T�Ƃ��ẮADX10�����GPU��
�����Ƃ���ʓI�Ȃ��̂ɂȂ�Ƃ������ł��ȁB
GPGPU������ǂꂾ�����y���邩���AAMD�̐����̌��ł��ȁE�E�E
�Ȃ�ƂȂ��AMicrosoft�̉e��������B
�ŁAGPGPU�͂��̗L��]�鉉�Z�\�͂������I�Ɏg�����ƂŃ������̃��C�e���V�͉B���ł���킯?
500Gflops�̃s�[�N���Z���\�ɑ��ă�������50GB/s���Ⴈ�b�ɂȂ�Ȃ��킯�����B
���Ȃ݂�Many Core�𐄂��i�߂�Intel�͏���Itanium�̍�����Speculative Precomputation�Ȃǂ̌�����ɂ��Ă���B
500Gflops�̃s�[�N���Z���\�ɑ��ă�������50GB/s���Ⴈ�b�ɂȂ�Ȃ��킯�����B
���Ȃ݂�Many Core�𐄂��i�߂�Intel�͏���Itanium�̍�����Speculative Precomputation�Ȃǂ̌�����ɂ��Ă���B
>>857
���ɂ��Ă�̂̓��C�e���V�Ȃ̂��]�����x�Ȃ̂��B
���C�e���V�̓n�[�h��\�t�g�̍H�v�ʼnB�����邱�Ƃ��\����
�]�����x�͂ǂ����Ȃ�B
���ɂ��Ă�̂̓��C�e���V�Ȃ̂��]�����x�Ȃ̂��B
���C�e���V�̓n�[�h��\�t�g�̍H�v�ʼnB�����邱�Ƃ��\����
�]�����x�͂ǂ����Ȃ�B
intel�͑����V���A���������𑣂���B
DDR4�ӂ�ŁB
DDR4�ӂ�ŁB
���\MB�̐�p������������ǂݏ�������̂ƁACPU�̃_�C���ł�������
��MB�̋��L�L���b�V����ǂݏ�������̂Ƃł́A�����ԈႤ�B
��Ƀ������ш悪�l�b�N�ɂȂ肩�˂Ȃ��B
XDR���������I���E���W���[���ȃX���b�g�p�b�P�[�W�ɂł�����̂��H
��MB�̋��L�L���b�V����ǂݏ�������̂Ƃł́A�����ԈႤ�B
��Ƀ������ш悪�l�b�N�ɂȂ肩�˂Ȃ��B
XDR���������I���E���W���[���ȃX���b�g�p�b�P�[�W�ɂł�����̂��H
>>858
������Intel�̓��C�e���V���ш�ɂ�������Ă���
������Intel�̓��C�e���V���ш�ɂ�������Ă���
Pentium�iR)III 700MHz�@�Ɓ@Celeron 2.4GHz
�͓����i�ł���?
�͓����i�ł���?
�����I�ɂ̓��C����������CPU�ƃI���_�C��SRAM�ɂȂ�낤�ȁB
�I���_�CSRAM�Ȃ�z���𑝂₹�邩��]���ш�͊O���������̔䂶��Ȃ����A
���j�C�R�A�ɂȂ���ꂼ��̃R�A���ƂɃ��[�J����������z�u���邱�Ƃ�
�ш������ɉ҂���B
�v���O�����͑�ς����ǂȁB
�I���_�CSRAM�Ȃ�z���𑝂₹�邩��]���ш�͊O���������̔䂶��Ȃ����A
���j�C�R�A�ɂȂ���ꂼ��̃R�A���ƂɃ��[�J����������z�u���邱�Ƃ�
�ш������ɉ҂���B
�v���O�����͑�ς����ǂȁB
866 �FSocket774�F2006/08/21(��) 13:38:00 ID:quZa4/LI
�����I�ɂ́A���L�ш�E����C�e���V���K�v�ȕ���ȊO��MRAM�ɒu�������B
���C���������i���݂�DRAM�j�ƃX�g���[�W�f�o�C�X�i���݂�HDD�j�̍��������Ȃ�A
�����Ƃ�MRAM���J�o�[����悤�ɂȂ�B
-----�����܂Ŗϑz����-----
���C���������i���݂�DRAM�j�ƃX�g���[�W�f�o�C�X�i���݂�HDD�j�̍��������Ȃ�A
�����Ƃ�MRAM���J�o�[����悤�ɂȂ�B
-----�����܂Ŗϑz����-----
�����������SMB��SRAM���I���_�C�ɂȂ���������āA���C���������ő����킯�Ȃ�����
GB�N���X�̃��������K�v�ɂȂ�ꍇ�͂ǂ�������肾
GB�P�ʂŃI���_�C�ɂȂ���Ă����̂��Hw
GB�N���X�̃��������K�v�ɂȂ�ꍇ�͂ǂ�������肾
GB�P�ʂŃI���_�C�ɂȂ���Ă����̂��Hw
>>867
���R�O���ɑ�e�ʂ�DRAM��ڑ������B
������32�R�A�ȏ�̃��j�C�R�A�ŃR�A���ꂼ��Ƀ��[�J���ڑ����ꂽSRAM��
�O��DRAM����]���ш悪�P�O�O�{�ȏ���Ⴄ�B�O��DRAM�̓��C���������Ƃ������
HDD�̃L���b�V���Ƃ������o�ɂȂ�ȁB
������v���O��������ς��ƁB
���R�O���ɑ�e�ʂ�DRAM��ڑ������B
������32�R�A�ȏ�̃��j�C�R�A�ŃR�A���ꂼ��Ƀ��[�J���ڑ����ꂽSRAM��
�O��DRAM����]���ш悪�P�O�O�{�ȏ���Ⴄ�B�O��DRAM�̓��C���������Ƃ������
HDD�̃L���b�V���Ƃ������o�ɂȂ�ȁB
������v���O��������ς��ƁB
�g�їp�̓z���ƁASoC�Ƃ�������Ă�Aintel�H
�v�͎�L�����x���̂ɂ�����ɘa����d�g�݂��p�ӂł��Ȃ��A�[�L�͑ʖڂƂ������Ƃł���H
SRAM�����SMB�`��GB�ɂȂ鍠�ɂ̓A�v���͍��ȏ�ɑ�K�͂ɂȂ��Ă邾�낤���A
�������������̉��Ƃ��Ă͂���܂�R�X�g���������Ȃ���Ȃ���
SRAM�����SMB�`��GB�ɂȂ鍠�ɂ̓A�v���͍��ȏ�ɑ�K�͂ɂȂ��Ă邾�낤���A
�������������̉��Ƃ��Ă͂���܂�R�X�g���������Ȃ���Ȃ���
�������ϑz���Ȃ�
�s�v�ȃR�[�h���I���_�C���SRAM�ɂ���ق����A���킭�x���O���������ɃX���b�v
���܂���ق����A�K�v�ȃR�[�h�����L���b�V�����Ă��錻��̎d�g�݂�肸����
�ǂ���
������OS�����Ȃ�X�}�[�g�ɂȂ�Ȃ��ƁAGB������SRAM�ɍڂ�Ȃ��悤�Ȃ�
�s�v�ȃR�[�h���I���_�C���SRAM�ɂ���ق����A���킭�x���O���������ɃX���b�v
���܂���ق����A�K�v�ȃR�[�h�����L���b�V�����Ă��錻��̎d�g�݂�肸����
�ǂ���
������OS�����Ȃ�X�}�[�g�ɂȂ�Ȃ��ƁAGB������SRAM�ɍڂ�Ȃ��悤�Ȃ�
�J�냁�C���������͏�������^��
��e�ʃL���b�V���c�cL2 64MB
�n�C�u���b�hHDD�c�c�L���b�V��20GB
��e�ʃL���b�V���c�cL2 64MB
�n�C�u���b�hHDD�c�c�L���b�V��20GB
�n�C�u���b�hHDD�ɍڂ�悤�ȃL���b�V�������C���������������\�Ȕ��Ȃ����낤?
���������O��
MRAM�Y��Ă邾��
MRAM�Y��Ă邾��
���������[�J�[��MRAM���X���[����炵����
876 �F866�F2006/08/21(��) 17:37:02 ID:quZa4/LI
>>874
���̖ϑz�ɂ��������Ă��������B
���̖ϑz�ɂ��������Ă��������B
�c�q����r�I�܂Ƃ��Ɍ�����
�ċx�݂��Ȃ�
�ċx�݂��Ȃ�
>>876
���ቴ���ϑz
Z-RAM�@�@�@�_�C�T�C�Y80�`90m�u
65nm�v���Z�X 256MB
45nm�v���Z�X 512MB
32nm�v���Z�X 1GB
Ath64X2(L2:�PMB) �_�C�T�C�Y90nm�v���Z�X��220m�u��45nm�v���Z�X�ō���55m�u
45nm�v���Z�XAth64X2
L1:64KB+64KB�~2
L2:1MB�~2
L3:���L512MB
�_�C�T�C�Y��145m�u
�͂��͂��ϑz�ϑz
���ቴ���ϑz
Z-RAM�@�@�@�_�C�T�C�Y80�`90m�u
65nm�v���Z�X 256MB
45nm�v���Z�X 512MB
32nm�v���Z�X 1GB
Ath64X2(L2:�PMB) �_�C�T�C�Y90nm�v���Z�X��220m�u��45nm�v���Z�X�ō���55m�u
45nm�v���Z�XAth64X2
L1:64KB+64KB�~2
L2:1MB�~2
L3:���L512MB
�_�C�T�C�Y��145m�u
�͂��͂��ϑz�ϑz
>>878
Z-RAM��SRAM��5�{�ł����Ȃ�
��32nm�v���Z�X�ɂȂ�ƍ��̃��[�G���h�r�f�I�J�[�h���ɐς߂��
TC�Ƃ�HM�݂����Ȃ̂ƍ��킹���CPU����VGA���\����I��UP���邩���B
�f�B�X�N���[�g�ł�(ry
Z-RAM��SRAM��5�{�ł����Ȃ�
��32nm�v���Z�X�ɂȂ�ƍ��̃��[�G���h�r�f�I�J�[�h���ɐς߂��
TC�Ƃ�HM�݂����Ȃ̂ƍ��킹���CPU����VGA���\����I��UP���邩���B
�f�B�X�N���[�g�ł�(ry
ttp://www.theinquirer.net/default.aspx?article=33812
>Intel signed up most of the 3Dlabs team
>Open GL 2.0 creators in Intel hands
���A����́E�E�E
>Intel signed up most of the 3Dlabs team
>Open GL 2.0 creators in Intel hands
���A����́E�E�E
Intel��2007�N�Ƀr�f�I�J�[�h�o�����ċL���̓}�W�������̂��c
http://pc.watch.impress.co.jp/docs/2006/0821/intel_01.jpg
���������Q�������A�������Ɍ��������g�Ȃ�ɂ���
{kind=link}
���������Q�������A�������Ɍ��������g�Ȃ�ɂ���
>>882
�̂̃Q�������͋��̃|�P�b�g�Ƀy���������ς��h������t�������̂Ɂc
�̂̃Q�������͋��̃|�P�b�g�Ƀy���������ς��h������t�������̂Ɂc
�Ƃ肠�������̃X�[�c�ɂ��̃l�N�^�C�͂�߂����������Ǝv���B
���̃l�N�^�C�������X�[�c�̂ق����|���B
�yHOT CHIPS����z�u�}���`�R�A�̃v���O���~���O�͖�肪�R�ς݁v�CHOT CHIPS���J��
http://techon.nikkeibp.co.jp/article/NEWS/20060821/120303/
�yHOT CHIPS����zIntel��CTO��Rattner���C�u�}���`�R�A����̃\�t�g�J�����x������v�ƌ��
http://techon.nikkeibp.co.jp/article/NEWS/20060823/120365/
http://techon.nikkeibp.co.jp/article/NEWS/20060823/120365/?SS=imgview&FD=-768184533&ad_q
>Rattner����Tera-Scale Computing�ɂ�����}�C�N���v���Z�T�̃R���Z�v�g�Ƃ��āC
>16��CPU�R�A���W��uStrawman�v��������
http://techon.nikkeibp.co.jp/article/NEWS/20060821/120303/
�yHOT CHIPS����zIntel��CTO��Rattner���C�u�}���`�R�A����̃\�t�g�J�����x������v�ƌ��
http://techon.nikkeibp.co.jp/article/NEWS/20060823/120365/
http://techon.nikkeibp.co.jp/article/NEWS/20060823/120365/?SS=imgview&FD=-768184533&ad_q
>Rattner����Tera-Scale Computing�ɂ�����}�C�N���v���Z�T�̃R���Z�v�g�Ƃ��āC
>16��CPU�R�A���W��uStrawman�v��������
strawman ���āA�@����Ƃ��A���Ă��ĈӖ��Ȃ��ǁc
�������˂��H
�������˂��H
{kind=link}
�uISA�́A���b�X�v
-----INTEL CEO�k
-----INTEL CEO�k
>Last Level Cache (Shared)
Bloomfield��8MB�ȏ�̋��LL2���Ƃ����Ȃ��c
Bloomfield��8MB�ȏ�̋��LL2���Ƃ����Ȃ��c
Last Level Cache������AL2,L3�����L������L2�͓Ɨ��ɂ���L3���������L��������ɂȂ�ȁB
���ꂾ���R�A���������Ƌ��LL2 only���Ⴕ��ǂ����B
���ꂾ���R�A���������Ƌ��LL2 only���Ⴕ��ǂ����B
strawman�@���@�m�j
PC�ƊE�̐��������A�C���e���̃o���b�g��ɕ���
http://japan.cnet.com/interview/biz/story/0,2000055955,20208087,00.htm
http://japan.cnet.com/interview/biz/story/0,2000055955,20208087,00.htm
>>891
L1��L2���킩��R�A�ʂ̃L���b�V�������ꂼ��1MB�͂Ȃ��ƌ�������
L1��L2���킩��R�A�ʂ̃L���b�V�������ꂼ��1MB�͂Ȃ��ƌ�������
����ȃG���b�^������Ă�炵���B
CPU2006���܂���
ttp://www.spec.org/cpu2006/
ttp://www.spec.org/cpu2006/
897 �FSocket774�F2006/08/26(�y) 12:00:50 ID:iXfndnpj
�e�n�X���J���𑱂��ė~���������B
�Ō��5Ghz�ŏo���Ȃ����ȁB
�Ō��5Ghz�ŏo���Ȃ����ȁB
898 �FSocket774�F2006/08/27(��) 12:33:56 ID:A+dB46il
>>896
���{���HP�Ȃ��́H
���{���HP�Ȃ��́H
899 �FSocket774�F2006/08/27(��) 20:39:46 ID:zbf22CAz
ttp://www.geocities.jp/andosprocinfo/wadai06/20060826.htm
>���\���ɓo�^���ꂽ�}�V���̒��ōō��̐��\�́CSPECint2006�ł�Fujitsu Siemens�Ђ�Celsius V830��3GHz��Opteron 256�x�[�X�̃}�V���ŁC11.9���}�[�N���Ă��܂��B
>�܂��CSPECfp2006�ł́CIntel D975XBX�}�U�[�{�[�h��3.73GHz��965EE�𓋍ڂ����V�X�e���ŁC12.7���}�[�N���Ă��܂��B
>���\���ɓo�^���ꂽ�}�V���̒��ōō��̐��\�́CSPECint2006�ł�Fujitsu Siemens�Ђ�Celsius V830��3GHz��Opteron 256�x�[�X�̃}�V���ŁC11.9���}�[�N���Ă��܂��B
>�܂��CSPECfp2006�ł́CIntel D975XBX�}�U�[�{�[�h��3.73GHz��965EE�𓋍ڂ����V�X�e���ŁC12.7���}�[�N���Ă��܂��B
Itanium3�Ƃ��H
http://pc.watch.impress.co.jp/docs/2006/0829/kaigai298.htm
>�Ⴆ�A���݂̃g�����W�X�^�́A�Q�[�g�≏����5�`6���q�����x�̌��݂����Ȃ��B
>���̂��߁A���q1���̂��(���݂̑���)�����̕\�ʂŔ�������ƁA���̏㉺�ō��v���q2���A�ő��33%(���q6��)�̂���ɂȂ��Ă��܂��B
>�����Ȃ�ƁA��������ł́A���[�N�d�������̕������10�`100�{�������Ȃ��Ă��܂��B
Intel��45nm�v���Z�X�œ�������Atomic Layer Deposition�̌��ʂ��ǂ�قǂɂȂ�̂��}�W�Ŋy���݁B
>�Ⴆ�A���݂̃g�����W�X�^�́A�Q�[�g�≏����5�`6���q�����x�̌��݂����Ȃ��B
>���̂��߁A���q1���̂��(���݂̑���)�����̕\�ʂŔ�������ƁA���̏㉺�ō��v���q2���A�ő��33%(���q6��)�̂���ɂȂ��Ă��܂��B
>�����Ȃ�ƁA��������ł́A���[�N�d�������̕������10�`100�{�������Ȃ��Ă��܂��B
Intel��45nm�v���Z�X�œ�������Atomic Layer Deposition�̌��ʂ��ǂ�قǂɂȂ�̂��}�W�Ŋy���݁B
High-K�͉������ꂽ��Ȃ�����?
>>902
�����������ׂĂ݂����͂����肵�����͂킩���ˁB
ttp://journal.mycom.co.jp/news/2006/01/26/300.html
>���̂��߁A����45nm�v���Z�X�ł́A�g�����W�X�^�̎������x�͖�2�{�ƂȂ�B
>�܂��A�g�����W�X�^�̓��������サ�Ă���A65nm�v���Z�X�ɔ�r���āA
>�I���d�������̎��ɂ̓I�t���[�N��5����1�Ɍ����A�I�t���[�N�����ɂ����Ƃ��ɂ̓g�����W�X�^�̃X�C�b�`���O�X�s�[�h��20%���サ���Ƃ����B
>�Z�p�I�ȏڍׂ͂���ȏ�w�ǖ��炩�ɂ���Ȃ�����
ttp://www.theinquirer.net/default.aspx?article=30179
>For the 45 nanometre process shrink, Intel will have already selected the equipment and made its planning decisions by the middle of this year.
ttp://techon.nikkeibp.co.jp/article/NEWS/20060310/114548/
>���Ђ�90nm/65nm���[���ł��C�Ђ���Si�̋Z�p�𗘗p���邱�ƂŁC���[�N�d����1/5�ɗ}���Ă���B
>��������45nm���[���ł��C�Ђ���Si���g���B
>����ȊO�ɂ��Chigh-k �ޗ���FUSI�Ȃǂɂ��Ă����Ђ͐ϋɓI�Ɍ������Ă��邪�C
>���ʂ́u�K�{�̋Z�p�ł͂Ȃ��B�����܂ŃI�v�V�����v�ƈʒu�Â��C���������͖��炩�ɂ��Ă��Ȃ��B
ttp://www.intel.com/pressroom/archive/releases/20060612corp.htm
>Since these transistors greatly improve performance and energy efficiency
>Intel expects tri-gate technology could become the basic building block
>for future microprocessors sometime beyond the 45nm process technology node.
�����������ׂĂ݂����͂����肵�����͂킩���ˁB
ttp://journal.mycom.co.jp/news/2006/01/26/300.html
>���̂��߁A����45nm�v���Z�X�ł́A�g�����W�X�^�̎������x�͖�2�{�ƂȂ�B
>�܂��A�g�����W�X�^�̓��������サ�Ă���A65nm�v���Z�X�ɔ�r���āA
>�I���d�������̎��ɂ̓I�t���[�N��5����1�Ɍ����A�I�t���[�N�����ɂ����Ƃ��ɂ̓g�����W�X�^�̃X�C�b�`���O�X�s�[�h��20%���サ���Ƃ����B
>�Z�p�I�ȏڍׂ͂���ȏ�w�ǖ��炩�ɂ���Ȃ�����
ttp://www.theinquirer.net/default.aspx?article=30179
>For the 45 nanometre process shrink, Intel will have already selected the equipment and made its planning decisions by the middle of this year.
ttp://techon.nikkeibp.co.jp/article/NEWS/20060310/114548/
>���Ђ�90nm/65nm���[���ł��C�Ђ���Si�̋Z�p�𗘗p���邱�ƂŁC���[�N�d����1/5�ɗ}���Ă���B
>��������45nm���[���ł��C�Ђ���Si���g���B
>����ȊO�ɂ��Chigh-k �ޗ���FUSI�Ȃǂɂ��Ă����Ђ͐ϋɓI�Ɍ������Ă��邪�C
>���ʂ́u�K�{�̋Z�p�ł͂Ȃ��B�����܂ŃI�v�V�����v�ƈʒu�Â��C���������͖��炩�ɂ��Ă��Ȃ��B
ttp://www.intel.com/pressroom/archive/releases/20060612corp.htm
>Since these transistors greatly improve performance and energy efficiency
>Intel expects tri-gate technology could become the basic building block
>for future microprocessors sometime beyond the 45nm process technology node.
�x�m�ʂ�NEC�̏H�~���f�����\���ꂽ���ǁA�f�X�N�g�b�v��Core2�قƂ��
�̗p����Ȃ������ˁB CPU������̎���͏I��������Ƃ�Ɋ����܂����B
�̗p����Ȃ������ˁB CPU������̎���͏I��������Ƃ�Ɋ����܂����B
905 �FSocket774�F2006/08/30(��) 01:13:54 ID:WLMeNraS
���ʂȂ��Ƃ��Ȃ�����Z�������ŏ\��������
�A�����J���Ƒ��ŐV��CPU���g����悤�ɂȂ���ǂȂ�
���{�̏ꍇ�ACore2Duo�ڂ�����TV�^��̉掿�̂ق���
����ۂǏd�������̂�����
���{�̏ꍇ�ACore2Duo�ڂ�����TV�^��̉掿�̂ق���
����ۂǏd�������̂�����
>>904
�q���g�FVista
�q���g�FVista
65nm�̐��Y�ݔ������Ă��ł��傤���A�����̍���CORE DUO�݂̂łȂ��A����Conroe Merom��Xeon�Y
������T�C�Y�͑傫���Ȃ��Ă�B�Z����������������A�@���Y�ʂ͑����́H
������T�C�Y�͑傫���Ȃ��Ă�B�Z����������������A�@���Y�ʂ͑����́H
65nm�p��Fab���O�������Ă邯��
Kentsfield��11���o��̖͗l
Intel�A11���Ƀf�X�N�g�b�v����4�R�ACPU����
ttp://www.itmedia.co.jp/news/articles/0608/31/news026.html
Intel�A11���Ƀf�X�N�g�b�v����4�R�ACPU����
ttp://www.itmedia.co.jp/news/articles/0608/31/news026.html
Tulsa4Way��Whitefield2Way�ɏ��Ă�̂��H
Woodcrest2Way�ɂł��������悤�ȁB
Woodcrest2Way�ɂł��������悤�ȁB
912 �FSocket774�F2006/08/31(��) 15:20:31 ID:JYhFHvrs
�P���c�o�������F�l�����肷��H
����ς肿���Ƃ����S�R�A�܂ł܂Ƃ����ȁE�E�E
�Ƃ��܂ł����Ă��ς��Ȃ��l�������Ă݂邗
�Ƃ��܂ł����Ă��ς��Ȃ��l�������Ă݂邗
1Die��4�R�A���Ă��ƂȂ�K8L�Ƃقړ������ɏo���BNehalem�͂���������݂��������ǁB
Santa Clara�܂�IA-32�̊J���ɉ�����݂�������������Intel���������Ŏ��s���邱�Ƃ͂Ȃ������B
���Ȃ݂ɍ�Itanium��S�����Ă�̂�alpha�����݂����ˁB
�ɐ~�̉��Ƃ��Ă͏����₵������Tukwila�����Ȃ肢�������Ȃ̂ŐV�A�[�L��Poulson�ɂ����҂��Ă�B
Santa Clara�܂�IA-32�̊J���ɉ�����݂�������������Intel���������Ŏ��s���邱�Ƃ͂Ȃ������B
���Ȃ݂ɍ�Itanium��S�����Ă�̂�alpha�����݂����ˁB
�ɐ~�̉��Ƃ��Ă͏����₵������Tukwila�����Ȃ肢�������Ȃ̂ŐV�A�[�L��Poulson�ɂ����҂��Ă�B
Nehalem��Core3������A�ė��N������
���X���@�p�[�g26
http://pc7.2ch.net/test/read.cgi/jisaku/1157019837/
http://pc7.2ch.net/test/read.cgi/jisaku/1157019837/
���������n��
918 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/31(��) 21:59:32 ID:PNf85pUi
>>914
Tigerton�̂��Ƃ���BDempsey��Paxville���l�ɓ����ɒ����H�����悤�ɉ��ǂ������́B
Whitefield��CSI�摗��ŏ��ŁB
Tigerton�̂��Ƃ���BDempsey��Paxville���l�ɓ����ɒ����H�����悤�ɉ��ǂ������́B
Whitefield��CSI�摗��ŏ��ŁB
>>918
Caneland��FSB��4�{���邩�疳����SingleDie�ɂ���K�v�͖����Ǝv���B
FSB�̑J�ڂ�Clovertown��Harpertown��Tigerton��Dunnington�œ���(1066��1333)�����A
�_�C�T�C�Y�I�ɂ�45nm�őS�Ă�QuadCore�v���Z�T��SingleDie�ɂ���̂ł͂Ȃ����Ɩϑz���Ă�B
Caneland��FSB��4�{���邩�疳����SingleDie�ɂ���K�v�͖����Ǝv���B
FSB�̑J�ڂ�Clovertown��Harpertown��Tigerton��Dunnington�œ���(1066��1333)�����A
�_�C�T�C�Y�I�ɂ�45nm�őS�Ă�QuadCore�v���Z�T��SingleDie�ɂ���̂ł͂Ȃ����Ɩϑz���Ă�B
Dempsey��Tulsa�Ԓ��x�̊J�����ԍ�������ASingleDie���A������
921 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/01(��) 01:06:24 ID:KiFsgqNN
L2��8MB+8MB�������B
��������Opteron�Ƃ̑R��I���_�C�̒����H�͕K�v���Ǝv���B
�܂��A�����AMCM�Œ����H�ƕ����_�C��ڑ�����Z�p�ł��m������A�h�����������G����ˁH
��������Opteron�Ƃ̑R��I���_�C�̒����H�͕K�v���Ǝv���B
�܂��A�����AMCM�Œ����H�ƕ����_�C��ڑ�����Z�p�ł��m������A�h�����������G����ˁH
>>920
���ႠFSB�͍ŏ�����1333MT/s�ł������������Ęb�ɂȂ�C�����邯�ǁB
>>921
�k����mx2�݂����Ȋ������B
ttp://www1.jpn.hp.com/products/servers/integrity/technology/images/mx2_02.gif
���ႠFSB�͍ŏ�����1333MT/s�ł������������Ęb�ɂȂ�C�����邯�ǁB
>>921
�k����mx2�݂����Ȋ������B
ttp://www1.jpn.hp.com/products/servers/integrity/technology/images/mx2_02.gif
{kind=link}
����ˁA���N��Bearlake�`�v�Z�g��1333�����炳�E�E�E�E
Bearlake-X�ɍ��킹�Ă��[�̂�
>>910�̃����N�ł��Ӗ��[�Ȃ��Ƃ����Ă邵
Bearlake-X�ɍ��킹�Ă��[�̂�
>>910�̃����N�ł��Ӗ��[�Ȃ��Ƃ����Ă邵
>>913
TDP130���b�g�炵�����B�n�Ȃ݂����
TDP130���b�g�炵�����B�n�Ȃ݂����
926 �FSocket774�F2006/09/02(�y) 16:37:04 ID:io2ltlOt
���y��4��2.4GHz���g���āA
�z�[���r�f�I��A�i���O�����̃e���r��CM�J�b�g�Ƃ��̕ҏW���Ă����
1���Ԃ̉f���ŁA���2���Ԏキ�炢������킯���B
��ŁA���̃C���e�����ƁA�G���R����ʼn��{���炢�������B
�C���e��(R) Core(TM) 2 Duo �v���Z�b�T�[ E6400 2.13GHz
�C���e��(R) Pentium(R) D �v���Z�b�T�[ 915 2.80GHz
HT�e�N�m���W�[ �C���e��(R) Pentium(R) 4 �v���Z�b�T�[ 651 3.40GHz
����Ȋ����̂͑����̂����H
��̂ł����B
������́A���g����ΐ_�b����̒m�������Ȃ�����A�悭�킩��Ȃ��̂�
�₳��������̏Z�l������A�I���ɒm�����킯�Ă���B
�z�[���r�f�I��A�i���O�����̃e���r��CM�J�b�g�Ƃ��̕ҏW���Ă����
1���Ԃ̉f���ŁA���2���Ԏキ�炢������킯���B
��ŁA���̃C���e�����ƁA�G���R����ʼn��{���炢�������B
�C���e��(R) Core(TM) 2 Duo �v���Z�b�T�[ E6400 2.13GHz
�C���e��(R) Pentium(R) D �v���Z�b�T�[ 915 2.80GHz
HT�e�N�m���W�[ �C���e��(R) Pentium(R) 4 �v���Z�b�T�[ 651 3.40GHz
����Ȋ����̂͑����̂����H
��̂ł����B
������́A���g����ΐ_�b����̒m�������Ȃ�����A�悭�킩��Ȃ��̂�
�₳��������̏Z�l������A�I���ɒm�����킯�Ă���B
ttp://www.geocities.jp/andosprocinfo/wadai06/20060902.htm
> Intel�̃R�A�A�[�L�̔��\�́C�����ƃA�J�f�~�b�N�ȓ��e�����҂��Ă�����
> �ł����C�����\�̓��e����Ŋ��҂͂���ł����BE6700�� SPEC_int_rate��
> Pentium D 960��42%�A�b�v�̐��\�Ƃ����}���������̂ŁC�N���b�N�̈Ⴂ���l
> �������IPC�ł�70%�ȏ�̌���ɂȂ��Ă���B�}�C�N���A�[�L�e�N�`���̉��P
> �Ƃ��Ĕ��\�ŏq�ׂ�ꂽ�e�@�\���ǂ̒��x��^���Ă���̂��Ƃ������������
> �̂ł����C���̎���ɓ����鏀�������Ă��Ȃ��Ƃ͂��炩����Ă��܂��܂����B
> ���\�҂̃^�C�g���̓��[�h�A�[�L�e�N�g�ƂȂ��Ă���C���[�h�A�[�L�e�N�g��
> ���̂悤�ȏd�v�Ȓl�����ɓ����ĂȂ��Ƃ��l�����Ȃ��̂ŁC���������Ȃ���
> ��������̂ł��傤�B
�匴���̐���(L1�L���b�V�����x�̊�^����)���������Ă�H
> Intel�̃R�A�A�[�L�̔��\�́C�����ƃA�J�f�~�b�N�ȓ��e�����҂��Ă�����
> �ł����C�����\�̓��e����Ŋ��҂͂���ł����BE6700�� SPEC_int_rate��
> Pentium D 960��42%�A�b�v�̐��\�Ƃ����}���������̂ŁC�N���b�N�̈Ⴂ���l
> �������IPC�ł�70%�ȏ�̌���ɂȂ��Ă���B�}�C�N���A�[�L�e�N�`���̉��P
> �Ƃ��Ĕ��\�ŏq�ׂ�ꂽ�e�@�\���ǂ̒��x��^���Ă���̂��Ƃ������������
> �̂ł����C���̎���ɓ����鏀�������Ă��Ȃ��Ƃ͂��炩����Ă��܂��܂����B
> ���\�҂̃^�C�g���̓��[�h�A�[�L�e�N�g�ƂȂ��Ă���C���[�h�A�[�L�e�N�g��
> ���̂悤�ȏd�v�Ȓl�����ɓ����ĂȂ��Ƃ��l�����Ȃ��̂ŁC���������Ȃ���
> ��������̂ł��傤�B
�匴���̐���(L1�L���b�V�����x�̊�^����)���������Ă�H
>����Ȋ����̂͑����̂����H
>��̂ł����B
�x�E�E����E�E������A�Œ��ꒃ�E�E���������܂łł́E�E�ł�����ς��Ȃ�
�������ǁE�E���₢��E�E�E�x���͂Ȃ����E�E�ł����Ȃ葬���E�E�E�����E�E
�܂��A���́E�E�ȂE�E�E��̑����ȁB
>��̂ł����B
�x�E�E����E�E������A�Œ��ꒃ�E�E���������܂łł́E�E�ł�����ς��Ȃ�
�������ǁE�E���₢��E�E�E�x���͂Ȃ����E�E�ł����Ȃ葬���E�E�E�����E�E
�܂��A���́E�E�ȂE�E�E��̑����ȁB
>>926
�yConroe�zIntel Core 2 Duo Part48�yKentsfield�z
http://pc7.2ch.net/test/read.cgi/jisaku/1157098982/
�yConroe�zIntel Core 2 Duo Part48�yKentsfield�z
http://pc7.2ch.net/test/read.cgi/jisaku/1157098982/
930 �F926�F2006/09/02(�y) 19:56:57 ID:io2ltlOt
931 �F926�F2006/09/02(�y) 20:09:58 ID:io2ltlOt
�A�����܂�B
CPU�ɂ��Ă悭�킩��Ȃ��̂ɓ����Ă��ꂽ�N�̗D�����ɂ͊��ӂ��Ă���B
�����ǁA������͔n��������A����ȌN�̐����ł��悭�킩��Ȃ��B
�����A�N�̗D�����͖l��ʖڂɂ���B
�����A�l�������E�E�E�B
CPU�ɂ��Ă悭�킩��Ȃ��̂ɓ����Ă��ꂽ�N�̗D�����ɂ͊��ӂ��Ă���B
�����ǁA������͔n��������A����ȌN�̐����ł��悭�킩��Ȃ��B
�����A�N�̗D�����͖l��ʖڂɂ���B
�����A�l�������E�E�E�B
E6600�Ŗk�X3.2�ɔ�ׂčő�4�{�̎��ԂŃG���R�ł���
933 �F926�F2006/09/02(�y) 21:54:01 ID:io2ltlOt
>>932
���肪�Ƃ��������܂��B�B
�܂�A������̖k�X2.4GHz�͎��g����HT���������Ƃ��l����ƍő��5�{�ȏ�̏����\�͂�����ƌ������Ƃ�OK�ł����H
�����ł��ˁB
�n�C�r�W�����f���̃G���R�[�h���ǂ̈ʂ�����̂��͂܂��킩��܂��A
�f�[�^�ʂ��������4�{�ȏ�Ƃ������ƂɂȂ邩��4�{�̎��Ԃ�������̂��ƌ����Ƃ킩��܂��A
�܂��܂��A�����Ȃ��ł��傤�ˁB
�����āA������̖k�X2.4GHz�͎��c����Ă䂭�E�E�E(�������[��RIMM�ł���)�B
������DVD�����ڂ����̂�������O�ɂȂ��āA�n�C�r�W��������舵��������������
��V���悤�Ƃ����������܂����B
���肪�Ƃ��������܂��B�B
�܂�A������̖k�X2.4GHz�͎��g����HT���������Ƃ��l����ƍő��5�{�ȏ�̏����\�͂�����ƌ������Ƃ�OK�ł����H
�����ł��ˁB
�n�C�r�W�����f���̃G���R�[�h���ǂ̈ʂ�����̂��͂܂��킩��܂��A
�f�[�^�ʂ��������4�{�ȏ�Ƃ������ƂɂȂ邩��4�{�̎��Ԃ�������̂��ƌ����Ƃ킩��܂��A
�܂��܂��A�����Ȃ��ł��傤�ˁB
�����āA������̖k�X2.4GHz�͎��c����Ă䂭�E�E�E(�������[��RIMM�ł���)�B
������DVD�����ڂ����̂�������O�ɂȂ��āA�n�C�r�W��������舵��������������
��V���悤�Ƃ����������܂����B
6400����Ȃ���6600����
935 �FSocket774�F2006/09/03(��) 01:35:00 ID:gvF7l5+0
>>933
Core2 Extreme���g������A�����̈Ⴄ������̊��ł��邾�낤�B
�}���`�X���b�h�Ή��A�v���Ȃ�AXeon(Woodcrest)�~2�Ƃ����̂��A�����낤�B
�x���`�͐e�ȒN�����\���Ă���邾�낤�B
�Ȃ��A�n�C�G���h��VPU����ꂽ��AHD�f���̏����͂����Ɗy�ɂȂ�B
Core2 Extreme���g������A�����̈Ⴄ������̊��ł��邾�낤�B
�}���`�X���b�h�Ή��A�v���Ȃ�AXeon(Woodcrest)�~2�Ƃ����̂��A�����낤�B
�x���`�͐e�ȒN�����\���Ă���邾�낤�B
�Ȃ��A�n�C�G���h��VPU����ꂽ��AHD�f���̏����͂����Ɗy�ɂȂ�B
936 �F926�F2006/09/03(��) 14:38:07 ID:JxgoESLU
>>935
���Ă��܂����A�G���R�[�h����CPU�̏����\�͂ɂ̂ݑ傫�����E�������̂��Ǝv���Ă����B
���ׂĂ݂����ǁAVPU���Ă̂̓n�[�h�ŃG���R�[�h�����肷��̂ł��Ȃ�d�v�炵���ł��ˁB
�������A���Ȃ�l������̂ł�����ƌ����������B
���̒��ŗ~�������Ă��鍡����Ԋy�����̂������Ȃ�ł����E�E�E�B
���Ă��܂����A�G���R�[�h����CPU�̏����\�͂ɂ̂ݑ傫�����E�������̂��Ǝv���Ă����B
���ׂĂ݂����ǁAVPU���Ă̂̓n�[�h�ŃG���R�[�h�����肷��̂ł��Ȃ�d�v�炵���ł��ˁB
�������A���Ȃ�l������̂ł�����ƌ����������B
���̒��ŗ~�������Ă��鍡����Ԋy�����̂������Ȃ�ł����E�E�E�B
�܂�X2500��2ch�ł��Ȃ�@����Ă�̂ő�������邾�낤�ȁB
�}�j�A�����̋@�\���������̂ĂāA�f�U�C���ɃR�X�g�������Ƃ��낪�������Ǝv���B
�}�j�A�����̋@�\���������̂ĂāA�f�U�C���ɃR�X�g�������Ƃ��낪�������Ǝv���B
�������딚�B ����ł��܂��B
>>936
�f�R�[�h��G�t�F�N�g��GPU�ɔC���邱�Ƃ͂����Ă�GPU�G���R�͖����̘b��
�f�R�[�h��G�t�F�N�g��GPU�ɔC���邱�Ƃ͂����Ă�GPU�G���R�͖����̘b��
940 �FSocket774�F2006/09/04(��) 12:05:28 ID:8B76cLQg
Conroe���߂��ăo���X������
941 �F926�F2006/09/04(��) 19:28:37 ID:HqmWZvTb
>>939
�ƌ������Ƃ́A
935�̃A�h�o�C�X��GPU(VPU)���f�R�[�h��G�t�F�N�g�������邩��A
���̕����K�ɂȂ�Ƃ������ƂȂ̂��ȁH
�G�t�F�N�g�͂���܂�g�p���Ȃ����ǁA�n�C�r�W�����f�����ƃf�R�[�h�����ł�
CPU�ɂ��Ȃ蕉�S��������Ƃ������ƂȂ̂��ȁH
�ƌ������Ƃ́A
935�̃A�h�o�C�X��GPU(VPU)���f�R�[�h��G�t�F�N�g�������邩��A
���̕����K�ɂȂ�Ƃ������ƂȂ̂��ȁH
�G�t�F�N�g�͂���܂�g�p���Ȃ����ǁA�n�C�r�W�����f�����ƃf�R�[�h�����ł�
CPU�ɂ��Ȃ蕉�S��������Ƃ������ƂȂ̂��ȁH
�g������͒m��Ȃ����AATI��Avivo��GPU�ŃG���R�[�h�����������Ă����B
�r�f�I�J�[�h�̓���Đ��x���@�\�������ƁA�n�C�r�W�����ǂ��납�ʏ�̓���Đ����܂܂Ȃ�Ȃ��B
�r�f�I�J�[�h�̓���Đ��x���@�\�������ƁA�n�C�r�W�����ǂ��납�ʏ�̓���Đ����܂܂Ȃ�Ȃ��B
>>942
ATI�̃A����X1000�V���[�Y���ڃ}�V���ł����g���Ȃ��悤�ɂ��Ă��邯��
���͒P�Ɏ蔲��CPU�G���R�Ŕ����Ɍ��������Ă邾������Ȃ����������H
�X���Ⴂ�ɂȂ���邪�B
ATI�̃A����X1000�V���[�Y���ڃ}�V���ł����g���Ȃ��悤�ɂ��Ă��邯��
���͒P�Ɏ蔲��CPU�G���R�Ŕ����Ɍ��������Ă邾������Ȃ����������H
�X���Ⴂ�ɂȂ���邪�B
���łɏ����
MPEG -> Windows Media Video�̕ϊ���
��30���̃\�[�X��ϊ�����̂ɂ����鎞�Ԃ�
Turion64 MT-34(1.8GHz L2 1M) + Radeon X1300LE
��16��
Athlon64 X2 4400+ (2.2GHz L2 1Mx2) + Radeon X1600XT x2(���̏ꍇ�̌��ʂ͕s���j
��2��
catalyst 6.8�ł̌��ʁB
�Q�l�܂łɁE�E�E
MPEG -> Windows Media Video�̕ϊ���
��30���̃\�[�X��ϊ�����̂ɂ����鎞�Ԃ�
Turion64 MT-34(1.8GHz L2 1M) + Radeon X1300LE
��16��
Athlon64 X2 4400+ (2.2GHz L2 1Mx2) + Radeon X1600XT x2(���̏ꍇ�̌��ʂ͕s���j
��2��
catalyst 6.8�ł̌��ʁB
�Q�l�܂łɁE�E�E
CPU��VGA�����ς����f�[�^�o����Ă��Ȃ�̎Q�l�ɂ��Ȃ��
Turion64 MT-34(1.8GHz L2 1M) + Radeon X1300LE
��10�����ȁA16����mp3�Đ����Ȃ���̌��ʁB
����CPU�����ŕϊ����Ă���̂Ȃ�
Turion MT-34��Athlon X2 4400+�̈Ⴂ���������Ă�
��5�{���̍��͏o�Ȃ��Ǝv���܂����B
X1600��X1300��pixel shader����12��4�Ŗ�3�{�̍�
GPU�ł����炩�̏������s���Ă���Ɠǂݎ���̂ł́H
��10�����ȁA16����mp3�Đ����Ȃ���̌��ʁB
����CPU�����ŕϊ����Ă���̂Ȃ�
Turion MT-34��Athlon X2 4400+�̈Ⴂ���������Ă�
��5�{���̍��͏o�Ȃ��Ǝv���܂����B
X1600��X1300��pixel shader����12��4�Ŗ�3�{�̍�
GPU�ł����炩�̏������s���Ă���Ɠǂݎ���̂ł́H
947 �FSocket774�F2006/09/05(��) 11:48:36 ID:d1Eo2aXb
�@�@ �Q�Q�Q__
�@�@|�@�@|�@�R |
�@�@|�@�@|. .��.|
�@�@|�@�@|. �F |
�@�@|�@�@|.(��)|
�@|�P|�P�P||ii~ |
�@|�@ |�@�ʁi�P�j��
�@�@�@�@�@�@�@,,, ,,,
�i�L�E�ցE�j����~~~
�ܲ��
�@�@|�@�@|�@�R |
�@�@|�@�@|. .��.|
�@�@|�@�@|. �F |
�@�@|�@�@|.(��)|
�@|�P|�P�P||ii~ |
�@|�@ |�@�ʁi�P�j��
�@�@�@�@�@�@�@,,, ,,,
�i�L�E�ցE�j����~~~
�ܲ��
�G���R�[�h���蔲������i������[�܂�j�����ł��ꂾ������������Ȃ�A
����͂���Ō��\�ȃ\�t�g�E�F�A�Z�p�ȋC������B
����͂���Ō��\�ȃ\�t�g�E�F�A�Z�p�ȋC������B
>>950��A950�̌����ʂ肾��
>>948
����܂���B
���݂�����ւ��Ă݂܂������A���Ԃ���炸�E�E�E
�p�t�H�[�}���X���͂�͂�CPU�̈Ⴂ�ɂ����̂��ۂ��ł��B
�����ƌ����l�b�g���[�N�J�[�h�̐��\�����邩���B
����܂���B
���݂�����ւ��Ă݂܂������A���Ԃ���炸�E�E�E
�p�t�H�[�}���X���͂�͂�CPU�̈Ⴂ�ɂ����̂��ۂ��ł��B
�����ƌ����l�b�g���[�N�J�[�h�̐��\�����邩���B
�����AGPU���S���g���Ă��Ȃ��̂��H���Ď��͂悭����Ȃ��E�E�E
�Ȃ��Ȃ�ABrook�ŏ����ꂽ�P��x���`�̌��ʂ�
X1600,X1300�ŁA�قړ����Ŗ�30000MFLOPS
�i�����ɂ�GeForce6100�ɑ}���z�̂ق���
CrossFire Xpress 3200�Ɏw�����z��������B�j
����Brook�ŏ����ꂽ�v���O������R5x0,RV5xx����ł���
1�X���b�h���ipixel shader 4�{�j�����g���Ă��Ȃ��Ƃ����l�@�ɂȂ�B
�i���ꂩ�AX1900�Ŏ����Ă݂Ăق����E�E�E�j
�ł��AAVIVO�̕ϊ���CPU�������ȁE�E�E
�Ȃ��Ȃ�ABrook�ŏ����ꂽ�P��x���`�̌��ʂ�
X1600,X1300�ŁA�قړ����Ŗ�30000MFLOPS
�i�����ɂ�GeForce6100�ɑ}���z�̂ق���
CrossFire Xpress 3200�Ɏw�����z��������B�j
����Brook�ŏ����ꂽ�v���O������R5x0,RV5xx����ł���
1�X���b�h���ipixel shader 4�{�j�����g���Ă��Ȃ��Ƃ����l�@�ɂȂ�B
�i���ꂩ�AX1900�Ŏ����Ă݂Ăق����E�E�E�j
�ł��AAVIVO�̕ϊ���CPU�������ȁE�E�E
>>953
GeForce6100�̓����O���t�B�b�N�Ŏ����Ă݂���H
GeForce6100�̓����O���t�B�b�N�Ŏ����Ă݂���H
>>953
���܂�A���ł�ATI�ȊO�ł͎g���͖̂ʓ|�݂������B
ttp://www.katch.ne.jp/~kakonacl/douga/avivo/avivo.html
> GPU�ɑΉ����Ă���̂�RADEON X1000�V���[�Y�����AGeForce 6000�V���[�Y�ł�
> GPU�ɂ͈ˑ�������CPU�݂̂ł����삷�邵�A���������ٓI�ɑ������x�ŃG���R�[�h
> ����Ƃ̂��Ƃ��B
> 2006�N04��12����ATI Avivo Video Converter v6.4�ƂȂ��āAATI Catalyst(x32)�h���C�o��
> �lj��C���X�g�[�����ė��p����d�l�ɂȂ����̂ŁARADEON X1000�V���[�Y��p�łƂȂ��Ă���
> �����B
> �������AATI DirectShow�֘A�̃t�B���^�[�͈ȉ��̔@���C���X�g�[�������̂ŁAGraphEdit��p
> ���ė��p���邱�Ƃ��\��
���܂�A���ł�ATI�ȊO�ł͎g���͖̂ʓ|�݂������B
ttp://www.katch.ne.jp/~kakonacl/douga/avivo/avivo.html
> GPU�ɑΉ����Ă���̂�RADEON X1000�V���[�Y�����AGeForce 6000�V���[�Y�ł�
> GPU�ɂ͈ˑ�������CPU�݂̂ł����삷�邵�A���������ٓI�ɑ������x�ŃG���R�[�h
> ����Ƃ̂��Ƃ��B
> 2006�N04��12����ATI Avivo Video Converter v6.4�ƂȂ��āAATI Catalyst(x32)�h���C�o��
> �lj��C���X�g�[�����ė��p����d�l�ɂȂ����̂ŁARADEON X1000�V���[�Y��p�łƂȂ��Ă���
> �����B
> �������AATI DirectShow�֘A�̃t�B���^�[�͈ȉ��̔@���C���X�g�[�������̂ŁAGraphEdit��p
> ���ė��p���邱�Ƃ��\��
956 �FSocket774�F2006/09/06(��) 12:11:07 ID:WyfQo1vR
�@�@ �Q�Q�Q__
�@�@|�@�@|�@�R |
�@�@|�@�@|. .��.|
�@�@|�@�@|. �F |
�@�@|�@�@|.(��)|
�@|�P|�P�P||ii~ |
�@|�@ |�@�ʁi�P�j��
�@�@�@�@�@�@�@,,, ,,,
�i�L�E�ցE�j����~~~
�ܲ��
�@�@|�@�@|�@�R |
�@�@|�@�@|. .��.|
�@�@|�@�@|. �F |
�@�@|�@�@|.(��)|
�@|�P|�P�P||ii~ |
�@|�@ |�@�ʁi�P�j��
�@�@�@�@�@�@�@,,, ,,,
�i�L�E�ցE�j����~~~
�ܲ��
AVIVO�g���Ă݂�
���C�ɂ���AAviSynth�g����ȁE�E�E
���C�ɂ���AAviSynth�g����ȁE�E�E
Celeron 2 Duo
����̂��邽��͂܂Ƃ��ȋL�����ɂ��
�ł��A�匴���̎G�L�ł̑S���ʃx���`�}�[�N�ɂ��Ă̒lj��R�����g�͓ǂ�łȂ��悤����
�ǂ�ł���A����̃l�^�͏����Ȃ��͂�
�ǂ�ł���A����̃l�^�͏����Ȃ��͂�
ttp://www.yusuke-ohara.com/weblog2/archive/2006/09/post_46.html#more
>�Ƃ�����ŁA�{�G���g���̌��_�Ƃ��āu���������ʂ�A�����͊m��ł��܂���v�Ƃ������ƂŁA���Ԏ��ɑウ�����Ă��������܂��B
>�Ƃ�����ŁA�{�G���g���̌��_�Ƃ��āu���������ʂ�A�����͊m��ł��܂���v�Ƃ������ƂŁA���Ԏ��ɑウ�����Ă��������܂��B
�匴���o�J�ȂƂ���͂���
> K7/K8��IPC=6��_����A�[�L�e�N�`�����[���ƂɂȂ����܂��܂��B
> K7/K8�͈ꉞ�f�R�[�h�i��x86���ߊ��Z�łR����/Cycle�̃f�R�[�h���\�Ȃ̂ŁA
> ���ʂɍl����Ƃ���Ȍ`�Ń�Op�����������\���͒Ⴂ�̂ł����A
> ���X�P�W���[���ɂR��Load���߂��f�[�^�҂����Ă��āA�����Ɍォ��R��ALU����(�Ⴆ��NOP)���f�R�[�_�������Ă��āA
> ���ꂪ��ĂɎ��s���j�b�g�ɓ��������ƃs�[�N���ɂ�IPC=6�Ƃ������ɂȂ�܂��B
3��Load���߂��f�[�^�҂��H
����K7/K8�̌��ו������낤�H
������3��Load���߂����s�����Ƃł��v���Ă���̂��H�A�L���b�V���������Ă邼�B
�o�J�����ȉ�H�ł͂Ȃ��A���������ȉ�H�Ń��_�Ő�������Ă��Ȃ��X�P�W���[���ƕ]�����ׂ��ӏ�����B
> K7/K8��IPC=6��_����A�[�L�e�N�`�����[���ƂɂȂ����܂��܂��B
> K7/K8�͈ꉞ�f�R�[�h�i��x86���ߊ��Z�łR����/Cycle�̃f�R�[�h���\�Ȃ̂ŁA
> ���ʂɍl����Ƃ���Ȍ`�Ń�Op�����������\���͒Ⴂ�̂ł����A
> ���X�P�W���[���ɂR��Load���߂��f�[�^�҂����Ă��āA�����Ɍォ��R��ALU����(�Ⴆ��NOP)���f�R�[�_�������Ă��āA
> ���ꂪ��ĂɎ��s���j�b�g�ɓ��������ƃs�[�N���ɂ�IPC=6�Ƃ������ɂȂ�܂��B
3��Load���߂��f�[�^�҂��H
����K7/K8�̌��ו������낤�H
������3��Load���߂����s�����Ƃł��v���Ă���̂��H�A�L���b�V���������Ă邼�B
�o�J�����ȉ�H�ł͂Ȃ��A���������ȉ�H�Ń��_�Ő�������Ă��Ȃ��X�P�W���[���ƕ]�����ׂ��ӏ�����B
963 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/06(��) 23:32:00 ID:pBJiYb0t
���^�C�������g��3����/clk������u�ԍő�Ȃ�đS�R�Ӗ��Ȃ�㩁B
����6��OPs�����s�ł��Ă����^�C���҂��ŃX�g�[�����邾���B
������FP/SIMD�p�C�v��������Ă镪���ݓI�ɂ͍���������s���\�͓�����̂�����
��������32byte/clk�̃t�F�b�`�ш�ɂ���Ȃ�A���̂ւ�͉��ǂ̗]�n�͂���̂����ǁB
����6��OPs�����s�ł��Ă����^�C���҂��ŃX�g�[�����邾���B
������FP/SIMD�p�C�v��������Ă镪���ݓI�ɂ͍���������s���\�͓�����̂�����
��������32byte/clk�̃t�F�b�`�ш�ɂ���Ȃ�A���̂ւ�͉��ǂ̗]�n�͂���̂����ǁB
�f���A���R�AItanium2���n�C�G���h����G���g���[�܂œ���
���{HP�A�f���A���R�AItanium2���ڃT�[�o�[�V���i7�@��\
http://biz.ascii24.com/biz/news/article/2006/09/07/664395-000.html
���{HP�A�f���A���R�AItanium2���ڃT�[�o�[�V���i7�@��\
http://biz.ascii24.com/biz/news/article/2006/09/07/664395-000.html
FB-DIMM�̂ق�����荂���Ϗ�Q����t���ł�����ǂ�
���M�������炷�s���v�f�̕����傫���Ƃ������f���낤��
���M�������炷�s���v�f�̕����傫���Ƃ������f���낤��
> ������3��Load���߂����s�����Ƃł��v���Ă���̂��H�A�L���b�V����
> �����Ă邼�B
�L���b�V���̌����Ȃ�HPC�n�̃A�v���Ƃ��Ȃ�A�܂��A���肤��ł���B
�A�v���Ɉˑ������b�B
> �����Ă邼�B
�L���b�V���̌����Ȃ�HPC�n�̃A�v���Ƃ��Ȃ�A�܂��A���肤��ł���B
�A�v���Ɉˑ������b�B
967 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/08(��) 01:51:46 ID:AM8zcn98
Athlon 64��L/S���j�b�g���Q��(Load/Store�������~�P�ALoad�Е����~1�j�����Ȃ�
������3���߂͂ǂ��l���Ă���������B
������3���߂͂ǂ��l���Ă���������B
�C�m�����J���@�\�������ő勉��Itanium 2�V�X�e�����ғ�
http://www.itmedia.co.jp/enterprise/articles/0609/05/news023.html
Itanium�C�C���C�C���[�i�E�́E�j
http://www.itmedia.co.jp/enterprise/articles/0609/05/news023.html
Itanium�C�C���C�C���[�i�E�́E�j
�m����Direct Path��Vecter Path��2�n���͋������ė~������
>>966
AMD�̂͋\���Ȃ�A���s���j�b�g������悤�Ɍ����|�����\����w
������ƌ����Load��������3�s����悤�Ɍ����邵�A����łȂ��Ƃ���������H�\���ɂȂ��Ă邪�A
�_���S�������Ă�悤�ɐ^�̎��s���j�b�g��3���݂��Ȃ��B
�܂�X�P�W���[�����w�{���Ă��������Ȗ�ŁA�����Ɏ��s�s�\�Ȃ̂ɓ�����3���߂Ƃ����s�p�C�v���C���֓������Ă��܂��B
����X�g�[���̌��������E�E�E
AMD�̂͋\���Ȃ�A���s���j�b�g������悤�Ɍ����|�����\����w
������ƌ����Load��������3�s����悤�Ɍ����邵�A����łȂ��Ƃ���������H�\���ɂȂ��Ă邪�A
�_���S�������Ă�悤�ɐ^�̎��s���j�b�g��3���݂��Ȃ��B
�܂�X�P�W���[�����w�{���Ă��������Ȗ�ŁA�����Ɏ��s�s�\�Ȃ̂ɓ�����3���߂Ƃ����s�p�C�v���C���֓������Ă��܂��B
����X�g�[���̌��������E�E�E
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@�@ �V���O���R�A�@�@�@�@�@�@���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��1�R�A Northwood (512KB)�@�@�@�@ .���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@.��1�R�A Prescott-V�@�@�@�@�@�@�@�@�@ .��1�R�A Prescott (1MB)�@�@�@�@�@�@�@.��2�R�A Smithfield (2MB)�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@Prescott 2M (2MB)�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@.��1�R�A Cedar Mill-V�@�@�@�@�@�@�@�@�@��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@ ��2�R�A Presler (4MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@�@ �V���O���R�A�@�@�@�@�@�@���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4�@ (90nm)����up�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��1�R�A Northwood (512KB)�@�@�@�@ .���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(90nm)����up�@.��1�R�A Prescott-V�@�@�@�@�@�@�@�@�@ .��1�R�A Prescott (1MB)�@�@�@�@�@�@�@.��2�R�A Smithfield (2MB)�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@Prescott 2M (2MB)�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��Pen4/D(65nm)���@ �|�@.��1�R�A Cedar Mill-V�@�@�@�@�@�@�@�@�@��1�R�A Ceder Mill (2MB)�@�@�@�@�@�@ ��2�R�A Presler (4MB)�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@ �^�̃}���`�R�A�@�@�@�@�@ ���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@.��2�R�A Duo Yonah-DC (2MB)�@�@�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��1�R�A Stealey (512KB)�@�@�@�@�@�@ .��2�R�A Duo Conroe (2MB�A4MB)�@ ��4�R�A Quad Kentsfield (4MB)�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��1�R�A Millville (1MB FSB1066)�@�@ ��2�R�A Duo Merom (4MB)�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Allendale (2MB FSB800)�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (45nm)����up�@ ��1�R�A Perryville (2MB)�@�@�@�@�@�@�@��2�R�A Duo Ridgefield (6MB)�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Wolfdale (3MB)�@�@�@�@�@�@�@ ��2�R�A Duo Wolffield (3MB)�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Duo Penryn (3MB�A6MB)�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .�� Clock ���@�@�@�@�@�@ �@�\����Ł@�@�@�@�@�@ .���@�@�@�@�@ �^�̃}���`�R�A�@�@�@�@�@ ���@�^���}���`�R�A(�j�R�C�`�R�A)�@ ��
������������������������������������������������������������������������������������������������������������������
��core�@ .(65nm)���@ �|�@ ��1�R�A Solo Yonah-SC (1MB)�@�@�@.��2�R�A Duo Yonah-DC (2MB)�@�@�@ ���@�@�@�@�@�@�@�@�@ �|�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (65nm)����down��1�R�A Stealey (512KB)�@�@�@�@�@�@ .��2�R�A Duo Conroe (2MB�A4MB)�@ ��4�R�A Quad Kentsfield (4MB)�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��1�R�A Millville (1MB FSB1066)�@�@ ��2�R�A Duo Merom (4MB)�@�@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Allendale (2MB FSB800)�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 2 (45nm)����up�@ ��1�R�A Perryville (2MB)�@�@�@�@�@�@�@��2�R�A Duo Ridgefield (6MB)�@�@�@�@.���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ��2�R�A Wolfdale (3MB)�@�@�@�@�@�@�@ ��2�R�A Duo Wolffield (3MB)�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��2�R�A Duo Penryn (3MB�A6MB)�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 3 (45nm)����down��2�R�A Silverthorme (4MB�A8MB)�@��4�R�A Quad Nehalem�@�@�@�@�@�@�@�@��8�R�A Oct Yorkfield (12MB)�@�@�@�@��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Bloomfield (6MB)�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Gilo�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 3 (32nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��4�R�A Quad Nehalem-C�@�@�@�@�@�@��8�R�A Oct �@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 4 (32nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��8�R�A Oct Gesher�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 4 (22nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��8�R�A Oct�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 5 (22nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 5 (16nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Bloomfield (6MB)�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
���@�@�@�@�@�@�@�@ .���@�@�@�@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.��4�R�A Quad Gilo�@�@�@�@�@�@�@�@�@�@ .���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
������������������������������������������������������������������������������������������������������������������
��core 3 (32nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��4�R�A Quad Nehalem-C�@�@�@�@�@�@��8�R�A Oct �@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 4 (32nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��8�R�A Oct Gesher�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 4 (22nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��8�R�A Oct�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 5 (22nm)����down���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ ��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
��core 5 (16nm)����up�@ ���@�@�@�@�@�@�@�@�@ �H�@�@�@�@�@�@�@�@�@ .��16�R�A �P�U�@�@�@�@�@�@�@�@�@�@�@�@�@�@��32�R�A �R�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
������������������������������������������������������������������������������������������������������������������
Intel's Core 2 Quadro Kentsfield: Four Cores on a Rampage
ttp://www.tomshardware.com/2006/09/10/four_cores_on_the_rampage/
ttp://www.tomshardware.com/2006/09/10/four_cores_on_the_rampage/
�����N���b�N���グ�Ȃ��̂ł����H
����3.8Ghz�̕ǂ�j���ė~�����̂����B
����3.8Ghz�̕ǂ�j���ė~�����̂����B
������Pentium�I���L�O��Pentium4 4GHz Premium Edtion�̓o��ł���I
PenM�`Core�h�����V�_�~���͂�����Ɗm�ۂ��Ă��������C��
����Core 2�œK�����Ă�
���ꌩ�Ă���摖�肪
ttp://jp.xlsoft.com/documents/intel/compiler/Intel_Compiler_v91_performance_indicators.PUBLIC.6-06.pdf
���ꌩ�Ă���摖�肪
ttp://jp.xlsoft.com/documents/intel/compiler/Intel_Compiler_v91_performance_indicators.PUBLIC.6-06.pdf
979 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/14(��) 00:04:28 ID:2Et8/cQK
/QxT��SSE4�g���邶���
���̂����AIntel�Ɋւ��鎿��X�����ĂȂ��́H
�����Ȃ肾���ǁc
�����Ȃ肾���ǁc
>>981
�����I
�����I
>>982
���ۃJ�[�l���T�[�r�X�������T�[�o�ł�Linux + Itanium�͘_�O����
���X����Șb���o�邮�炢������Windows�̂ق������ڂ��}�V�Ȃ�Ȃ���
���ʂ�HP-UX�I�Ԃ��낤���ǂ�
http://www.hpcwire.com/hpc/836590.html
���ۃJ�[�l���T�[�r�X�������T�[�o�ł�Linux + Itanium�͘_�O����
���X����Șb���o�邮�炢������Windows�̂ق������ڂ��}�V�Ȃ�Ȃ���
���ʂ�HP-UX�I�Ԃ��낤���ǂ�
http://www.hpcwire.com/hpc/836590.html
����A���� Woodcrest ���A�����Ȃ��� Opteron�B
���i���\��� Itanium ��舳�|�I�ɗD��Ă邵�A
gcc �ł������������\���o�邩�� Linux �ł����v�B
������� icc �̕������\���o�邪�ANetBurst �� Itanium �̏ꍇ�قǂ̍��͂Ȃ��B
���i���\��� Itanium ��舳�|�I�ɗD��Ă邵�A
gcc �ł������������\���o�邩�� Linux �ł����v�B
������� icc �̕������\���o�邪�ANetBurst �� Itanium �̏ꍇ�قǂ̍��͂Ȃ��B
i
Itanium�T�[�o�[�Ȃ�HP-UX(Windows?)
Xeon��Opteron�g��
���̓�ɂ͓��{�C�a���[���u���肪����Ǝv����
Xeon��Opteron�g��
���̓�ɂ͓��{�C�a���[���u���肪����Ǝv����
988 �FSocket774�F
i