AMD�̎�����CPU�ɂ��Č�낤
AMD�̃v���Z�b�T�E���[�h�}�b�v
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_608,00.html
http://www.amd.com/us-en/assets/content_type/styleone/33275A-0_roadmap.gif
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_608,00.html
http://www.amd.com/us-en/assets/content_type/styleone/33275A-0_roadmap.gif
{kind=link}
|
|
|
2 �F�������G�� ��yGAhoNiShI �F2005/08/20(�y) 22:01:27 ID:TTT3DgDh
������낤���I�I
�����m���
�����m���
���Ƃ��Ă͎����̂��Ƃ��������u�Ԃ�2�Q�b�g����
���Ƃ��e�Ղ��B
�����������A������l���B
�M�l��ɂ��u������������A���ł�2�Q�b�g�ł����Ⴄ�����`�H�I�v���Ċ��҂�
�����Ȃ��Ɖ��������ȁB2�Q�b�^�[��1���ɂ��ĂȂ炸�B
�������i���[�o���h����́A������J�������������B
>>4�������(�@�L,_�T`)�߯ �Ƃ���ꂽ���Ƃ�����B�����������Ȃ�
������������z���A�S�̏���w�����Ă݂�Ȃ����h����u2�Q�b�g�v�̃��X���ł���킯���B
�������A���͂���ȑf�l�ɂ́u2�v�͏���Ȃ��B�Ȃ��̂Q�Q�b�^�[���13���ɂȂ�B
�����܂ł̒����������Ă��]�T�ł݂�Ȃ̓���u2�v�̓Q�b�g�ł���B
2�Q�b�g�I
���Ƃ��e�Ղ��B
�����������A������l���B
�M�l��ɂ��u������������A���ł�2�Q�b�g�ł����Ⴄ�����`�H�I�v���Ċ��҂�
�����Ȃ��Ɖ��������ȁB2�Q�b�^�[��1���ɂ��ĂȂ炸�B
�������i���[�o���h����́A������J�������������B
>>4�������(�@�L,_�T`)�߯ �Ƃ���ꂽ���Ƃ�����B�����������Ȃ�
������������z���A�S�̏���w�����Ă݂�Ȃ����h����u2�Q�b�g�v�̃��X���ł���킯���B
�������A���͂���ȑf�l�ɂ́u2�v�͏���Ȃ��B�Ȃ��̂Q�Q�b�^�[���13���ɂȂ�B
�����܂ł̒����������Ă��]�T�ł݂�Ȃ̓���u2�v�̓Q�b�g�ł���B
2�Q�b�g�I
>>3
(�@�L,_�T`)�߯
(�@�L,_�T`)�߯
AMD�̔��M���ɂ��Č��X���͂����ł���
6 �F�������G�� ��yGAhoNiShI �F2005/08/20(�y) 22:18:49 ID:TTT3DgDh
����1.4G�͎�����ǂ������M�d�l�ł�����
Merom/Conroe���o�鍠���炢�ɂ��킹��AMD���ȓd�͂Ƀt�H�[�J�X����CPU�����
Conroe�Ƀ{�������������E�E�E�B
65nm�v���Z�X�ȍ~�͂����H 2006�N���`2007�N�͂��߂����肾�����������H
Conroe�Ƀ{�������������E�E�E�B
65nm�v���Z�X�ȍ~�͂����H 2006�N���`2007�N�͂��߂����肾�����������H
8 �FSocket774�F2005/08/20(�y) 22:44:32 ID:cqJLZd+q
AMDuser�ɂ�
�A�t�H�̈��~�݂����ɁA�܂��肩�łȂ�������CPU�ɂ��Ėϑz�����҂͂����B
��@���@�ā@���@�́@�X�@���@�́@�I�@���@�B
�A�t�H�̈��~�݂����ɁA�܂��肩�łȂ�������CPU�ɂ��Ėϑz�����҂͂����B
��@���@�ā@���@�́@�X�@���@�́@�I�@���@�B
9 �F�������G�� ��yGAhoNiShI �F2005/08/20(�y) 22:45:13 ID:TTT3DgDh
��M2��DDR2���g�������4G�z����ڎw���܂��B
�������FX�ł���DUAL�R�A�ƂȂ�Aʲ����CPU��AMD�A
�������ݼ�ϰ����CPU�����قƐF��������܂��B
���̌��ʂƂ��Ă������͍��̂܂ܕς��܂��c
�������FX�ł���DUAL�R�A�ƂȂ�Aʲ����CPU��AMD�A
�������ݼ�ϰ����CPU�����قƐF��������܂��B
���̌��ʂƂ��Ă������͍��̂܂ܕς��܂��c
�����ǂ��낶��Ȃ���
http://www.tomshardware.com/cpu/20050725/athlon_64_fx-02.html
�V���O���R�A��100W�˔j
FX�V���[�Y�͋����E�M���M����
http://www.tomshardware.com/cpu/20050725/athlon_64_fx-02.html
�V���O���R�A��100W�˔j
FX�V���[�Y�͋����E�M���M����
��yGAhoNiShI �@�Â��r�炵�̃g���b�v�g���ė���������ȁB�{�P
12 �F�������G�� ��yGAhoNiShI �F2005/08/20(�y) 23:03:13 ID:TTT3DgDh
���ق����j�]������������ĕʂɂ���ɏ]�����Ƃ��Ȃ��ł���B
����������CG��FX-55��E4��FX-55������TDP104W�ɂ��Ă���̂�
TDP�̕t�������������ɓK��������Ǝv�����B
TDP�̕t�������������ɓK��������Ǝv�����B
FX-55�����i���Ƃ��đ�����̂ł�
�}�U�[��FX-55�Ή���搂��Ȃ��TDP104W�ɑΉ����Ă��Ȃ���Ȃ�܂���
�}�U�[��FX-55�Ή���搂��Ȃ��TDP104W�ɑΉ����Ă��Ȃ���Ȃ�܂���
15 �FSocket774�F2005/08/21(��) 13:11:15 ID:YR1rQrn4
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �Q�Q�Q�Q�Q�Q�Q�Q_ �@�@�@Intel���L���ɂȂ�ƒ��q�ɂ̂���
�@�@�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@�_.�@�@�����i�@�@�@| | �@�@�@�ڂ������艿�i
::::::::�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@�@ �_�Q�Q�Q_�@�@�@.| |�@�@�@���ꂪ�@It's AMD Quality.
:::::::::::::::::::�@�@�@�@�@�@�@�@�@ �@ �@ �@ �^|�Q�Q�@�b�@ �@| | �@�@�@�@�@�R(߁��)ɱ�ˬ�ˬ
:::::::::::::::::::::::::::: �@�@ �@�@�@�@�@�@�@�^�@ |� �́B|�|�@�@�@| |�@�@�@�@
:::::::::::::::::::::::::::::::::::�@�@�@�@�@�@�@�@|�@�@�b6_4_|__.|�@�@�@| |�@�@�@�@�@�@�@�@�@::::::::::::::::::
:::::::::::::::::::::::::::::::::::::::::::::::.�@�@�@ �@|�@��[���@�^�_ �@| |�@�@�@�@�@�@�@:::::::::::::::::::::::::::::::::
�@�@:::::::::::::::::::::::::::::::::::::::::::::.�@�@�@|�Q�Q�Q_�^�@�@�@�_| |�@�@�@::::::::::::::::::::::::::::::::::::::::�@�@�@::::::::::::::::::::::::::
:::::::::::::::::::::::::::::::::::�@�@�@�@�@�@ �@�@�@�@�@�@�@�@ �@ �@ �@.| |�@�@�@�@�@�@�@�@::::::::::::::::::::::::::::::::::::::::::::
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ /�@�j �@�@�@�@:::::::::::::::::::::::::::::::::::::::::::
�@�@�@�@�@�@::::::::::::::::::::::::::::::::::::::::::::::::::�@�@�@�@�@�@�@/ /|_|
�@�@�@�@�@�@�@�@�@�@�@::��::::::::::::::::::::::::::::�@�@�@�@�@/ /
�@�@�@�@�@ �ȁQ�� �@ | |�@�@�@�@�@�@�@�@�@�@�@�@�i�@(
�@�@�@�@�@�i�@�@'A`�j�^./�@�@�@�@�@�@ �@�@��_�ȁ@�R �R�@�@ �ȁQ��
�@�@�@�@�^Sempron�@�@�@�@��_��m9(�O�D�O)�@�@ �@�_�_�i�O�D�O�@�j�@ �@ �@ ��
�@�@�@�@�@�@�@�ȁQ�ȁ@�@�@�i�@�O�́O�j�s�k �@�@�@�@�R�@�@ �@�@ �_�@�@ �i E�j��
�@�@�@�@�@ �@�i�@� ���E�j�@�@�^ �@�@�@_�_�@�m�@�@�@�@�@�@�@|�@AMD/�R �R_�^.�^ | .|
�@(^�R,�@�@�^�@�@�@�@�R�A/�@, Athlon �@�@�@�@�@�@�@�@�@�@|�@�@�@ Ɂ@. �__�^�@�@| .|�@. ��_��
�@�@�_�_/ ,Opteron,�.�i�@( �@�@�@(^�i�M�D�L�j'^)�@�@ �@�@ l�@�@�@ l�@�@�@�@�@�@�@ �R �_<`�D�L�@>
�@�@�@ �R_,Ɂ@|�@�@�@�@|�@ �R��R��@�@)�@64�@/�L�@�@�@�@�@ /�@�@�^�@�@�@�@�@�@�@�@�@ �_�w�@ �Q�@�_
�@�@�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@�_.�@�@�����i�@�@�@| | �@�@�@�ڂ������艿�i
::::::::�@�@�@�@�@�@�@ �@�@�@�@�@�@�@�@�@ �_�Q�Q�Q_�@�@�@.| |�@�@�@���ꂪ�@It's AMD Quality.
:::::::::::::::::::�@�@�@�@�@�@�@�@�@ �@ �@ �@ �^|�Q�Q�@�b�@ �@| | �@�@�@�@�@�R(߁��)ɱ�ˬ�ˬ
:::::::::::::::::::::::::::: �@�@ �@�@�@�@�@�@�@�^�@ |� �́B|�|�@�@�@| |�@�@�@�@
:::::::::::::::::::::::::::::::::::�@�@�@�@�@�@�@�@|�@�@�b6_4_|__.|�@�@�@| |�@�@�@�@�@�@�@�@�@::::::::::::::::::
:::::::::::::::::::::::::::::::::::::::::::::::.�@�@�@ �@|�@��[���@�^�_ �@| |�@�@�@�@�@�@�@:::::::::::::::::::::::::::::::::
�@�@:::::::::::::::::::::::::::::::::::::::::::::.�@�@�@|�Q�Q�Q_�^�@�@�@�_| |�@�@�@::::::::::::::::::::::::::::::::::::::::�@�@�@::::::::::::::::::::::::::
:::::::::::::::::::::::::::::::::::�@�@�@�@�@�@ �@�@�@�@�@�@�@�@ �@ �@ �@.| |�@�@�@�@�@�@�@�@::::::::::::::::::::::::::::::::::::::::::::
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ /�@�j �@�@�@�@:::::::::::::::::::::::::::::::::::::::::::
�@�@�@�@�@�@::::::::::::::::::::::::::::::::::::::::::::::::::�@�@�@�@�@�@�@/ /|_|
�@�@�@�@�@�@�@�@�@�@�@::��::::::::::::::::::::::::::::�@�@�@�@�@/ /
�@�@�@�@�@ �ȁQ�� �@ | |�@�@�@�@�@�@�@�@�@�@�@�@�i�@(
�@�@�@�@�@�i�@�@'A`�j�^./�@�@�@�@�@�@ �@�@��_�ȁ@�R �R�@�@ �ȁQ��
�@�@�@�@�^Sempron�@�@�@�@��_��m9(�O�D�O)�@�@ �@�_�_�i�O�D�O�@�j�@ �@ �@ ��
�@�@�@�@�@�@�@�ȁQ�ȁ@�@�@�i�@�O�́O�j�s�k �@�@�@�@�R�@�@ �@�@ �_�@�@ �i E�j��
�@�@�@�@�@ �@�i�@� ���E�j�@�@�^ �@�@�@_�_�@�m�@�@�@�@�@�@�@|�@AMD/�R �R_�^.�^ | .|
�@(^�R,�@�@�^�@�@�@�@�R�A/�@, Athlon �@�@�@�@�@�@�@�@�@�@|�@�@�@ Ɂ@. �__�^�@�@| .|�@. ��_��
�@�@�_�_/ ,Opteron,�.�i�@( �@�@�@(^�i�M�D�L�j'^)�@�@ �@�@ l�@�@�@ l�@�@�@�@�@�@�@ �R �_<`�D�L�@>
�@�@�@ �R_,Ɂ@|�@�@�@�@|�@ �R��R��@�@)�@64�@/�L�@�@�@�@�@ /�@�@�^�@�@�@�@�@�@�@�@�@ �_�w�@ �Q�@�_
���m�Ŕn�����킬�����|���Ȃ�AMD�~���Ɏ�����CPU�k�`�Ȃ�Ė�������w ��߂Ƃ�w
AMD�͂܂��܂�Intel�ɂ͉����y�Ȃ���(�L�́M)
PentiumXE840�@10,9450�~
(Pentium4/541*2)�@(23,360�~*2)134%UP����
Athlon64X2/4800+�@11,7714�~
(Athlon64/4000+*2)�@(44,800�~*2)31%UP����
PentiumXE840�@10,9450�~
(Pentium4/541*2)�@(23,360�~*2)134%UP����
Athlon64X2/4800+�@11,7714�~
(Athlon64/4000+*2)�@(44,800�~*2)31%UP����
18 �F�P�P�P�P�P�P�P�PV�P�P�P�P�P�P�P�P�P�P�F2005/08/21(��) 14:43:05 ID:R/SkiCsa
�@ |�@�@�@�@�@|�Q|�Q|�Q|�Q|
�@ |;;;;;;;;;;�m�� �@�_,) ,,�^ �R
�@ |::�i 6�� (��) �@ (��)�@�j
�@ |�m�@�@�i��,,�m(�A_, )�R�A���j
�@ |�@��<�@���@�@ �R�@��j
�@�@�_�@�@�@�@�@�@�@ �܁@�m�Q�Q�Q�Q�Q_�@
�@�@�@�@�_�Q�Q�Q�Q_�^�@| �@ |�P�P�_�@�_�@
�Q�Q_�^�@�@�@�@�@�@ �_�@ |�@�@|�@�@�@�@|�P�P|
|:::::::/�@�@�_����Q�Q�_ | 2ch��p .|�Q�Q|�@
|:::::::|�@�_�Q�Q�Q�Q|����|�Q_|�Q�Q�^�@�^�@
|:::::/�@�@�@�@�@�@�@�@|�P�P�P�P|�@�@�k�P�P�l
�@ |;;;;;;;;;;�m�� �@�_,) ,,�^ �R
�@ |::�i 6�� (��) �@ (��)�@�j
�@ |�m�@�@�i��,,�m(�A_, )�R�A���j
�@ |�@��<�@���@�@ �R�@��j
�@�@�_�@�@�@�@�@�@�@ �܁@�m�Q�Q�Q�Q�Q_�@
�@�@�@�@�_�Q�Q�Q�Q_�^�@| �@ |�P�P�_�@�_�@
�Q�Q_�^�@�@�@�@�@�@ �_�@ |�@�@|�@�@�@�@|�P�P|
|:::::::/�@�@�_����Q�Q�_ | 2ch��p .|�Q�Q|�@
|:::::::|�@�_�Q�Q�Q�Q|����|�Q_|�Q�Q�^�@�^�@
|:::::/�@�@�@�@�@�@�@�@|�P�P�P�P|�@�@�k�P�P�l
>>18
�M�҉�
�ǂ����~������AMD��Intel�ɂ͉����y�Ȃ���(�L�́M)�v�v
PentiumXE840�@1.200-1.400V(125A)60%UP����
(Pentium4/541)(1.200-1.425V)(78A)
Athlon64X24800+�@1.35-1.400V(78.6A)23%UP����
(Athlon64/4000+)(1.35-1.400V)(63.6A)
�M�҉�
�ǂ����~������AMD��Intel�ɂ͉����y�Ȃ���(�L�́M)�v�v
PentiumXE840�@1.200-1.400V(125A)60%UP����
(Pentium4/541)(1.200-1.425V)(78A)
Athlon64X24800+�@1.35-1.400V(78.6A)23%UP����
(Athlon64/4000+)(1.35-1.400V)(63.6A)
PentiumXE840��Pentium4 541���\�Ⴂ��
3200+���x����H
3200+���x����H
�ڂ��������͂������ɉ����y�Ȃ���
23,360�~*2��10,9450�~������
23,360�~*2��10,9450�~������
�����ȂƂ���A�V��悪���o�邩�ō��V�����X�R�X�őg�ޕK�v�����邩�A�����
�l2�͗��N5������o�n�߂āA���C���X�g���[�����u�������̂�10�����B
�܂��܂��悾�A�S�z����ȁB
�܂��܂��悾�A�S�z����ȁB
24 �FSocket774�F2005/08/23(��) 15:01:06 ID:EQMdDBZg
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
[�z���G������p������]�@�@�~� �R�R�R�R���Ƀm�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ �@�@�@�@�@�@�@�@�@�@l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@�v�@�@�@��'�@'�܁@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@�@�@�@�@�@�@�@�@�@�@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |�@�@�������y����
�@ �@�@�@�@�@�@�@�@�@�@�@�@ �� �@�@�@ �R�jƿ�@�@�@l
�@�@�@�@�@�@�@�@�@�@�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
[�z���G������p������]�@�@�~� �R�R�R�R���Ƀm�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ �@�@�@�@�@�@�@�@�@�@l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@�v�@�@�@��'�@'�܁@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@�@�@�@�@�@�@�@�@�@�@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |�@�@�������y����
�@ �@�@�@�@�@�@�@�@�@�@�@�@ �� �@�@�@ �R�jƿ�@�@�@l
�@�@�@�@�@�@�@�@�@�@�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
25 �FSocket774�F2005/08/23(��) 15:09:18 ID:9ZKzl9kc
���̓Z������D�ŗV�ԂƂ��ł��ADDR2�������[�̌`����������������
DDR2�̃}�C�N���}�U�[945G�Ƃ�������A
��������łĂ�Gb�W�������Ƃ���
DDR2�̃}�C�N���}�U�[945G�Ƃ�������A
��������łĂ�Gb�W�������Ƃ���
Yonah�ւ́g�h�q�h�Ƃ��ē��������
AMD�̃f���A���R�ATurion 64
http://pc.watch.impress.co.jp/docs/2005/0824/ubiq120.htm
AMD�̃f���A���R�ATurion 64
http://pc.watch.impress.co.jp/docs/2005/0824/ubiq120.htm
���ǁAK10�Ă̂͂ǂ��Ȃ����́H
���Ȃ�AMD����K8�x�[�X�ɉ��ǂ��Ă���������OK���Ǝv�����ǁA
�ė��N������̉B�����������낻��`���b�Ɨ����ė~�����B
�u���͊���Quad�R�A�������Ă܂��v
�Ƃ��B
���Ȃ�AMD����K8�x�[�X�ɉ��ǂ��Ă���������OK���Ǝv�����ǁA
�ė��N������̉B�����������낻��`���b�Ɨ����ė~�����B
�u���͊���Quad�R�A�������Ă܂��v
�Ƃ��B
Athlon64�̎���Opteron�x�[�X�ɂȂ���Ė{���H
K5��K6��K7��K8�܂łɔ�ׂāA
K8��K9��K10���ď�Ȃ��Ȃ�?
����ȍ��ׂȕύX�Ő�����i�߂�Ȃƌ��������B
K8��K9��K10���ď�Ȃ��Ȃ�?
����ȍ��ׂȕύX�Ő�����i�߂�Ȃƌ��������B
PenPro��PenII��PenIII���Ԃ����Ⴏ���������ύX�����Ƃ������Ă����ǁA
����͗���Ԃ��Ώo���̂����R�A��������Ɍ��������������K�v�������Ƃ������ƁB
AMD������PenPro����ɓ��ꂽ�Ƃ������Ƃł��B
����͗���Ԃ��Ώo���̂����R�A��������Ɍ��������������K�v�������Ƃ������ƁB
AMD������PenPro����ɓ��ꂽ�Ƃ������Ƃł��B
����͑S���܂Ƃ߂�P6�ł����ȁB
33 �FSocket774�F2005/08/26(��) 21:08:56 ID:es9+CW/4
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
[�z���G������p������]�@�@�~� �R�R�R�R���Ƀm�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ �@�@�@�@�@�@�@�@�@�@l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@�v�@�@�@��'�@'�܁@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@�@�@�@�@�@�@�@�@�@�@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |�@�@�����͂����܂�
�@ �@�@�@�@�@�@�@�@�@�@�@�@ �� �@�@�@ �R�jƿ�@�@�@l
�@�@�@�@�@�@�@�@�@�@�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
[�z���G������p������]�@�@�~� �R�R�R�R���Ƀm�m
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ �@�@�@�@�@�@�@�@�@�@l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@�v�@�@�@��'�@'�܁@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@�@�@�@�@�@�@�@�@�@�@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |�@�@�����͂����܂�
�@ �@�@�@�@�@�@�@�@�@�@�@�@ �� �@�@�@ �R�jƿ�@�@�@l
�@�@�@�@�@�@�@�@�@�@�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�@�@�@�@�@�@�@�@�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
Intel�����̃R�A�Ŗ��߂̕����u�펞�v�S�ɂ���iK8�́u�ő�Łv�R�j�Ȃ�A
���߂̕��ȂQ���炢�ł�������K6�R�A��16���炢
���ׂ��������������I�@�Ƃ����q�����z�͂ǂ����H
���߂̕��ȂQ���炢�ł�������K6�R�A��16���炢
���ׂ��������������I�@�Ƃ����q�����z�͂ǂ����H
>>34
�h��I������̂��H
�h��I������̂��H
36 �FSocket774�F2005/08/27(�y) 18:26:58 ID:aNJMVXe7
����B
���̃R�A�������Ă��܂���BDDR2�Ή������H�v���Z�b�T�Ƃ��Ẳ��P�͂Ȃ��́H
�w�e���W�j�A�X�����Ƃ��A���̃R�A�̉��P���ꂽ�̂������Ă��Ȃ��ł��B
���܂����H
���̃R�A�������Ă��܂���BDDR2�Ή������H�v���Z�b�T�Ƃ��Ẳ��P�͂Ȃ��́H
�w�e���W�j�A�X�����Ƃ��A���̃R�A�̉��P���ꂽ�̂������Ă��Ȃ��ł��B
���܂����H
959 Socket774 2005/08/27(�y) 17:10:34 ID:rONMclPA
>>955
�j�W�̍���̐i��
2006�N�@�V�\�P�b�g�ڍs�i�\�P�b�g�e�C�l�Q�C�r�P�j
�@�@�@�@�@�@�c�c�q�Q�������Ή�
�@�@�@�@�@�@�R�A�P�ʂ̏ȓd�͋@�\�H
�@�@�@�@�@�@���z���Ή��iPacifica�j
�@�@�@�@�@�@�Í����Ή�(Presidio)
2007�N�@65nm�v���Z�X�ڍs
�@�@�@�@�@�@DDR3�������Ή�
�@�@�@�@�@�@��e�ʁi2-4MB�j�̋��p�^�L���b�V���@
�@�@�@�@�@�@4�R�A���iOp�̂݁H�j
�@�@�@�@�@�@�{����HT2.0�iOp�̂݁H�j
>>955
�j�W�̍���̐i��
2006�N�@�V�\�P�b�g�ڍs�i�\�P�b�g�e�C�l�Q�C�r�P�j
�@�@�@�@�@�@�c�c�q�Q�������Ή�
�@�@�@�@�@�@�R�A�P�ʂ̏ȓd�͋@�\�H
�@�@�@�@�@�@���z���Ή��iPacifica�j
�@�@�@�@�@�@�Í����Ή�(Presidio)
2007�N�@65nm�v���Z�X�ڍs
�@�@�@�@�@�@DDR3�������Ή�
�@�@�@�@�@�@��e�ʁi2-4MB�j�̋��p�^�L���b�V���@
�@�@�@�@�@�@4�R�A���iOp�̂݁H�j
�@�@�@�@�@�@�{����HT2.0�iOp�̂݁H�j
�r���L���b�V���͂ǂ�����낤�ˁH�������낻��~�߂�̂��ȁH
�܂��A�r���L���b�V���~�߂Ă��x���`�̃X�R�A�オ�邮�炢���낯�ǁB
�܂��A�r���L���b�V���~�߂Ă��x���`�̃X�R�A�オ�邮�炢���낯�ǁB
DDR�Q�Ή���������܂��ł���
2007�N�ɋ��p�^�L���V���H
2007�N�ɋ��p�^�L���V���H
AMD 2005 Analyst Day
ttp://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_10383,00.html
ttp://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_10383,00.html
���NDDR2�Ή��ɂȂ��Ă��A�������R���g���[����DDR���T�|�[�g��������H
SocketM2��DDR�g����}�U�{�o�邩�ȁB
SocketM2��DDR�g����}�U�{�o�邩�ȁB
42 �FSocket774�F2005/08/29(��) 02:14:19 ID:96RCGFwa
���܂̃R�A�̂܂܂Ȃ́H
�C���e���Ɣ�ׂĂ܂�Ȃ���`
�C���e���Ɣ�ׂĂ܂�Ȃ���`
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�A���h
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�A���h
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N
�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\�N�\
>>43 ����A���O�����������߂ă}�}�ɂ��˂��肵���Y�����Ȃ̂͗ǂ������������A
�����͂`�l�c�X�������瑃�ɂ��A�肗����
�����͂`�l�c�X�������瑃�ɂ��A�肗����
45 �FSocket774�F2005/08/29(��) 20:46:32 ID:3K033M8F
�ʂɃC���e����AMD�͕��������킹�ĊJ�����Ă�킯�ł��Ȃ�ł��Ȃ��B
Am286�̎��ォ��AMD�ƃC���e���̊W�̓C���e�����V�A�[�L�e�N�`������
��AMD�͈�����őR��AMD�V�A�[�L�e�N�`�������Œl�i�߂��A�̌J��Ԃ�����
���̓l�b�g�o�[�X�g�̎������s�����邩��C���e���̐V�A�[�L�e�N�`�����b���
�Ȃ�B���K8�͓��������I����Ă��ꂩ��s�[�N���}���悤���Ď����B
�Ƃ͂����A��ʐl���x���i����G�������肷��̂����������j�ɂ͖{����AMD��
�V�A�[�L�e�N�`���̘b���ĕ������Ă��Ȃ��ˁB��������K9�L�����Z�����炢�H
Am286�̎��ォ��AMD�ƃC���e���̊W�̓C���e�����V�A�[�L�e�N�`������
��AMD�͈�����őR��AMD�V�A�[�L�e�N�`�������Œl�i�߂��A�̌J��Ԃ�����
���̓l�b�g�o�[�X�g�̎������s�����邩��C���e���̐V�A�[�L�e�N�`�����b���
�Ȃ�B���K8�͓��������I����Ă��ꂩ��s�[�N���}���悤���Ď����B
�Ƃ͂����A��ʐl���x���i����G�������肷��̂����������j�ɂ͖{����AMD��
�V�A�[�L�e�N�`���̘b���ĕ������Ă��Ȃ��ˁB��������K9�L�����Z�����炢�H
�f���A���R�A�͍����Ă�������
XP�����̂悤�ɃV���O�������肫�ڂ��
XP�����̂悤�ɃV���O�������肫�ڂ��
�f���A���R�A�����}���`�v���Z�b�T�Ή��V���O���R�A�̕��������I���Ǝv�����ǁB
�}�U�[�͊�{�I�Ƀf���A���ȏオ�W���ŁA�V���O���ŗǂ��l�̓V���O���Ŏg���A
�f���A���̐��\���~�����l�͂������CPU���B
�}�U�[�͊�{�I�Ƀf���A���ȏオ�W���ŁA�V���O���ŗǂ��l�̓V���O���Ŏg���A
�f���A���̐��\���~�����l�͂������CPU���B
�EM/B�A�Ђ��Ă�PC�S�̂����^���o����
�E�V���O��CPU��2�ڂ�����͏ȓd��
�Ƃ����������ŁA���Ȃ��炸�����b�g�͗L��͂��B
�ȓd�́E�ȃX�y�[�X�E���p�t�H�[�}���X�̃o�����X���厖�B
���������f���A���R�A�́A����N���b�N���v���悤�ɏグ���Ȃ��̂�
��ւ̐��\����ĂƂ��ċ}���ɕ��y�����悤�Ƃ��Ă��W���}�C�J�H
�}���`�v���Z�b�T�������l�ɁA�}���`�v���Z�b�T�Ή��}���`�R�A��
�嗬�ɂȂ��Ă����Ǝv���B
�E�V���O��CPU��2�ڂ�����͏ȓd��
�Ƃ����������ŁA���Ȃ��炸�����b�g�͗L��͂��B
�ȓd�́E�ȃX�y�[�X�E���p�t�H�[�}���X�̃o�����X���厖�B
���������f���A���R�A�́A����N���b�N���v���悤�ɏグ���Ȃ��̂�
��ւ̐��\����ĂƂ��ċ}���ɕ��y�����悤�Ƃ��Ă��W���}�C�J�H
�}���`�v���Z�b�T�������l�ɁA�}���`�v���Z�b�T�Ή��}���`�R�A��
�嗬�ɂȂ��Ă����Ǝv���B
48�̃A�z���͌v��m��Ȃ�
>>49
�u�����`OS�IOS�I�I
�u�����`OS�IOS�I�I
52 �FSocket774�F2005/08/30(��) 09:35:12 ID:wvMkzsl7
AMD�͍�������ꂮ�炢�̃X�P�W���[�����O�����Ă��Ȃ��́H
Fab 30�͂Ȃ�����Ȃɏ����Ȃ̂�
http://pc.watch.impress.co.jp/docs/article/20001207/kaigai01.htm
Fab 30�͂Ȃ�����Ȃɏ����Ȃ̂�
http://pc.watch.impress.co.jp/docs/article/20001207/kaigai01.htm
>52
���̋L�����߂ēǂB���̋L�����ǂB
�W���E�h�[���������������I
���̋L�����߂ēǂB���̋L�����ǂB
�W���E�h�[���������������I
ITmedia PCUPdate�FAMD�̃f���A���R�A�Ń��o�C��CPU��2006�N��1�l����������
ttp://www.itmedia.co.jp/pcupdate/articles/0508/29/news006.html
ttp://www.itmedia.co.jp/pcupdate/articles/0508/29/news006.html
35W�g����1.8GHz���炢�����x��
�ł��\�P�b�g�ς�邩��A�f�X�N�g�b�v�ł͎g���Ȃ���ˁE�E�E
SocketA�ŁA���[�[�[�[�[�[���ƃA�b�v�O���[�h�o�������オ����������
SocketA�ŁA���[�[�[�[�[�[���ƃA�b�v�O���[�h�o�������オ����������
AMD���V���O���R�A�̐��\����͑ł��~�߁H
�\�P�b�g�ς��Ȃ��Ă�
�ǂ����݂�DDR2�Ή��}�U�{�Ɋ������
�ǂ����݂�DDR2�Ή��}�U�{�Ɋ������
>>57
64�v������A�ޱٺ��Ή����Ă��킯�ŁA�ł��~�߂͐D�荞�ݍς݂��ƁB
64�v������A�ޱٺ��Ή����Ă��킯�ŁA�ł��~�߂͐D�荞�ݍς݂��ƁB
60 �FT.A. ��Vr3ZLNzp5. �F2005/08/30(��) 20:24:18 ID:bFezT0ai
>>57
�ǂ�����H65nm�̏o�����悾�Ƃ͎v�����ǁA����������܂ł͍s�������ȋC������B
K7�F�`700MHz(250nm)
K75�F�`1.0GHz(180nm)
Thunderbird�F�`1.4GHz(180nm)
Palomino�F�`1.73GHz(180nm)
Thoroughbred�F�`2.25GHz(130nm)
ClawHammer�F�`2.6GHz(130nm)
�Ɨ��Ă邩��A�m���Ƀv���Z�X�����ɂ�铮��N���b�N����͓݂��Ȃ��Ă邯�ǁA�ŏ�ʃN���b�N��
�قڈ��肵���y�[�X�����肵���Ԋu(�T��400MHz����)�ŏオ���ė��Ă邩��ˁB
����90nm����͎���Athlon64FX�ł����炭��3.0GHz�ɓ��B���邾�낤����A����������Ƃ͍s�����Ȃ��H
NetBurst��Northwood�̃N���b�N����y�[�X���ُ킾�����̂ƁAPrescott�ł��Ȃ������̂���ۓI����������
����ő����ȍ��o�������Ă�Ǝv����B
Pentium-M�n���n���ɓ���N���b�N���グ�ė��Ă邵�B
�ǂ�����H65nm�̏o�����悾�Ƃ͎v�����ǁA����������܂ł͍s�������ȋC������B
K7�F�`700MHz(250nm)
K75�F�`1.0GHz(180nm)
Thunderbird�F�`1.4GHz(180nm)
Palomino�F�`1.73GHz(180nm)
Thoroughbred�F�`2.25GHz(130nm)
ClawHammer�F�`2.6GHz(130nm)
�Ɨ��Ă邩��A�m���Ƀv���Z�X�����ɂ�铮��N���b�N����͓݂��Ȃ��Ă邯�ǁA�ŏ�ʃN���b�N��
�قڈ��肵���y�[�X�����肵���Ԋu(�T��400MHz����)�ŏオ���ė��Ă邩��ˁB
����90nm����͎���Athlon64FX�ł����炭��3.0GHz�ɓ��B���邾�낤����A����������Ƃ͍s�����Ȃ��H
NetBurst��Northwood�̃N���b�N����y�[�X���ُ킾�����̂ƁAPrescott�ł��Ȃ������̂���ۓI����������
����ő����ȍ��o�������Ă�Ǝv����B
Pentium-M�n���n���ɓ���N���b�N���グ�ė��Ă邵�B
�A�X�����̏ꍇ�̓N���b�N���ゾ������Ȃ��āA
���オ�ς�邲�Ƃ�1�N���b�N������̐��\���オ���Ă�̂��|�C���g�����Ǝv���B
�ςɃN���b�N�グ�����ɑ��炸�ɂ������̘H����i�߂��̂͐挩�̖����������Ǝv����B
���オ�ς�邲�Ƃ�1�N���b�N������̐��\���オ���Ă�̂��|�C���g�����Ǝv���B
�ςɃN���b�N�グ�����ɑ��炸�ɂ������̘H����i�߂��̂͐挩�̖����������Ǝv����B
>>60
250nm��180nm�@+1000MHz �ix2.6�j
180nm��130nm�@+900MHz�@�ix1.5�j
130nm�� 90nm�@ +400MHz? �ix1.2�j
�����Rev.F��3.6GHz���炢�܂ŏオ�����Ƃ��Ă�������1.4�|�B
����σy�[�X�����Ă�B
250nm��180nm�@+1000MHz �ix2.6�j
180nm��130nm�@+900MHz�@�ix1.5�j
130nm�� 90nm�@ +400MHz? �ix1.2�j
�����Rev.F��3.6GHz���炢�܂ŏオ�����Ƃ��Ă�������1.4�|�B
����σy�[�X�����Ă�B
���f���`�F���W�P�ʂŌ��邱�Ǝ��̈Ӗ��������C������B
�v���Z�X���[���������ł��v���ς��ΈႤ��łȂ������H
�ɒ[�ȗ�Ō�����AMD��Intel�œ����v���Z�X���[���ŃN���b�N��
1.5�{���炢�̍������邵�B
�ɒ[�ȗ�Ō�����AMD��Intel�œ����v���Z�X���[���ŃN���b�N��
1.5�{���炢�̍������邵�B
�ǂ����̃T�C�g��Hammer��K7�Ɣ�ׂč��N���b�N�u�������������o�����A�[�L�e�N�`���Ƃ�����������������Ȃ�
�ǂ�������������
�ǂ�������������
2�i���炢���₵����
>67
�p�C�v���C���ɂ��Ă悭�m���̂ŁA�������Ă��������B
�O�O�����͈͓��̒m���ł���
����P �� 5
P3 �� 10
P4 �� 20
P4 Prescott �� 30
Banias �� 12
Merom �� 14
Athlon �� ����10�A��������15
Athlon64 �� ����12�A��������17
Efficeon �� ����6�A��������8�i���������[�h/�X�g�A��6�j
�\�[�X�͂��̂ւ�
ttp://pc.watch.impress.co.jp/docs/article/20011102/kaigai01.htm
ttp://www.atmarkit.co.jp/fpc/special/pentium4arch/pentium4arch01.html
ttp://pc.watch.impress.co.jp/docs/2003/1016/kaigai033.htm
�ŁA�C���e���̂������ƕ��������ɕ�����ĂȂ��̂͂Ȃ��Ȃ�ł��傤�H
�p�C�v���C���ɂ��Ă悭�m���̂ŁA�������Ă��������B
�O�O�����͈͓��̒m���ł���
����P �� 5
P3 �� 10
P4 �� 20
P4 Prescott �� 30
Banias �� 12
Merom �� 14
Athlon �� ����10�A��������15
Athlon64 �� ����12�A��������17
Efficeon �� ����6�A��������8�i���������[�h/�X�g�A��6�j
�\�[�X�͂��̂ւ�
ttp://pc.watch.impress.co.jp/docs/article/20011102/kaigai01.htm
ttp://www.atmarkit.co.jp/fpc/special/pentium4arch/pentium4arch01.html
ttp://pc.watch.impress.co.jp/docs/2003/1016/kaigai033.htm
�ŁA�C���e���̂������ƕ��������ɕ�����ĂȂ��̂͂Ȃ��Ȃ�ł��傤�H
conroe������������AMD��������ȁBIPC���S�����B
64����IPC�R�����������H
AMD���d�͌����������R�AK10�J�����Ă�낤���B
64����IPC�R�����������H
AMD���d�͌����������R�AK10�J�����Ă�낤���B
>>68
�C���e�������R�A�����ƕ��������ł̓p�C�v���C���i���͈قȂ�B
�p�C�v���C���͂P�ʂ肶��Ȃ��B
���߂ɂ���Ēʉ߂���p�C�v���C���͈قȂ�B
�p�C�v���C���̂ǂ�����ǂ��܂ł𐔂���̂��ɂ���Ă��قȂ�B
�C���e����AMD�ł͕\���Ă���p�C�v���C���i���̈Ӗ����قȂ�̂ŁA
�����̑召�������r���Ă��Ӗ��������Ȃ��B
�C���e�������R�A�����ƕ��������ł̓p�C�v���C���i���͈قȂ�B
�p�C�v���C���͂P�ʂ肶��Ȃ��B
���߂ɂ���Ēʉ߂���p�C�v���C���͈قȂ�B
�p�C�v���C���̂ǂ�����ǂ��܂ł𐔂���̂��ɂ���Ă��قȂ�B
�C���e����AMD�ł͕\���Ă���p�C�v���C���i���̈Ӗ����قȂ�̂ŁA
�����̑召�������r���Ă��Ӗ��������Ȃ��B
>70
���肪�Ƃ��������܂��B
������������ɍX�ɃO�O���ė�����[�߂܂��B
���肪�Ƃ��������܂��B
������������ɍX�ɃO�O���ė�����[�߂܂��B
> conroe������������AMD��������ȁBIPC���S�����B
IPC4 ���Č������͂�߂����������Ǝv�����ǂȁB
4 issue �Ȃ̂͐������Z�݂̂̉\��������炵�����A��������
x86�A�[�L�e�N�`���Ō�����IPC 4��B������͔̂��ɍ����B
������ӂɂ������Ă��邯�ǁA
ttp://pc.watch.impress.co.jp/docs/2002/1122/kaigai01.htm
�ʐ����ƁA�X�[�p�X�J���ł͕��� 3 IPC�����E�ƌ����Ă�킯�����B
(4 issue �ɂ͈Ӗ����Ȃ��ƌ����Ă�킯����Ȃ��B���� 3 IPC ��B��
����ɂ́A3 issue �ł͑���Ȃ��̂� 4 issue �ɂ͈Ӗ�������)
> 64����IPC�R�����������H
3 ����̃f�R�[�_�A3�̉��Z��Ƃ����Ӗ��ł� 3�B
�ł��A����� 3 IPC �ƌĂԂ̂͊ԈႢ�B�u���_�I�ő�l�Ƃ��� 3IPC�v
�Ƃ����������Ȃ�܂������邯�ǁB
IPC4 ���Č������͂�߂����������Ǝv�����ǂȁB
4 issue �Ȃ̂͐������Z�݂̂̉\��������炵�����A��������
x86�A�[�L�e�N�`���Ō�����IPC 4��B������͔̂��ɍ����B
������ӂɂ������Ă��邯�ǁA
ttp://pc.watch.impress.co.jp/docs/2002/1122/kaigai01.htm
�ʐ����ƁA�X�[�p�X�J���ł͕��� 3 IPC�����E�ƌ����Ă�킯�����B
(4 issue �ɂ͈Ӗ����Ȃ��ƌ����Ă�킯����Ȃ��B���� 3 IPC ��B��
����ɂ́A3 issue �ł͑���Ȃ��̂� 4 issue �ɂ͈Ӗ�������)
> 64����IPC�R�����������H
3 ����̃f�R�[�_�A3�̉��Z��Ƃ����Ӗ��ł� 3�B
�ł��A����� 3 IPC �ƌĂԂ̂͊ԈႢ�B�u���_�I�ő�l�Ƃ��� 3IPC�v
�Ƃ����������Ȃ�܂������邯�ǁB
>>72
Athlon XP�ƈ���āA�}�C�N��Ops�̈ˑ��W���p�b�N�X�e�[�W�ʼn������Ă邩��A
���_�I�ő�l3IPC�Ɍ���Ȃ��߂����ɐ���̂ł́H
Athlon XP�ƈ���āA�}�C�N��Ops�̈ˑ��W���p�b�N�X�e�[�W�ʼn������Ă邩��A
���_�I�ő�l3IPC�Ɍ���Ȃ��߂����ɐ���̂ł́H
>>73
�}�C�N��Ops�̈ˑ��W���p�b�N�X�e�[�W�ʼn�������Ƃ����̂�
AMD�̌����Ȑ����H
�p�b�N�X�e�[�W�́AK8�ŐV�݂��ꂽDirectPath Double���߂�
2��DirectPath�f�R�[�_�ŕ����f�R�[�h������A�p�b�N���邾������
�l�I�ɂ͎v�����ǁB
�}�C�N��Ops�̈ˑ��W���p�b�N�X�e�[�W�ʼn�������Ƃ����̂�
AMD�̌����Ȑ����H
�p�b�N�X�e�[�W�́AK8�ŐV�݂��ꂽDirectPath Double���߂�
2��DirectPath�f�R�[�_�ŕ����f�R�[�h������A�p�b�N���邾������
�l�I�ɂ͎v�����ǁB
>>72
���ߊԂɈˑ��W�������ĕ�����s���s�\��������AL2�L���b�V��
�҂���A�������A�N�Z�X�҂��ł�邱�Ƃ��Ȃ��Ȃ����肷�邱�Ƃ�
����̂ŁA��ʘ_�Ƃ��� 3 IPC �͖����B
�J���J���Ƀ`���[����������ȃR�[�h�Ȃ玞�ɂ͉\�����ǁB
���ߊԂɈˑ��W�������ĕ�����s���s�\��������AL2�L���b�V��
�҂���A�������A�N�Z�X�҂��ł�邱�Ƃ��Ȃ��Ȃ����肷�邱�Ƃ�
����̂ŁA��ʘ_�Ƃ��� 3 IPC �͖����B
�J���J���Ƀ`���[����������ȃR�[�h�Ȃ玞�ɂ͉\�����ǁB
mov eax,[ebp-12]
mov ebx,[eax]
call [ebx]
���z���Ȃ�ăX�g�[�����܂���ōň��̗ނ��낤�ȁB
mov ebx,[eax]
call [ebx]
���z���Ȃ�ăX�g�[�����܂���ōň��̗ނ��낤�ȁB
���܂ǂ��͐����̌p�������p�����^���C�Y�̎����
�v���~�e�B�u�̕����̓C�����C�����z���Ȃ�ł���������
�Â��̂͂��߂���
�v���~�e�B�u�̕����̓C�����C�����z���Ȃ�ł���������
�Â��̂͂��߂���
DLL �Ăт������āA�K���ԐڃR�[���ɂȂ�ł���B
Windows API �Ƃ��S�ł���Ȃ�?
Windows API �Ƃ��S�ł���Ȃ�?
�����^�C�����C�u�����g�킸CopyMemory�Ƃ����ڌĂяo���̂͑f�l
�^�C�g���[�v�̓����Ń��_��API�ĂԂ̂͂������ɖ�肠�肷��
�t�Ƀ��[�v���Ȃ����DLL�̃I�[�o�[�w�b�h�Ȃ�ě��͓̉�
�^�C�g���[�v�̓����Ń��_��API�ĂԂ̂͂������ɖ�肠�肷��
�t�Ƀ��[�v���Ȃ����DLL�̃I�[�o�[�w�b�h�Ȃ�ě��͓̉�
��IDirect3D
COM�C���^�[�t�F�[�X�̃��\�b�h�͑S�����z���e�[�u�����B
����ɂ�����炸�A�������ォ��_��ɕύX���邽�߂ɂ�
���z���͂Ȃ��Ȃ�Ȃ��Ǝv���܂��B
COM�C���^�[�t�F�[�X�̃��\�b�h�͑S�����z���e�[�u�����B
����ɂ�����炸�A�������ォ��_��ɕύX���邽�߂ɂ�
���z���͂Ȃ��Ȃ�Ȃ��Ǝv���܂��B
�܂��A���������p�C�v���C���������P�[�X�́A
�p�C�v���C���̒Z�� AMD�n�� PenM �̕����܂�
�y�i���e�B�����Ȃ��āANetBurst ���͗y����
�}�V�Ȃ��ǂˁB
���ƁA�������R���g���[�������̊W�ŁA������
�A�N�Z�X�̃��C�e���V�� Athlon 64 70ns �ɑ��A
NetBurst 120ns �ƁA�啝�ɈႤ����A���̓_�ł�
AMD �L���B
IPC �̓_�ł́APenM �n���f�X�N�g�b�v�ɏオ����
���� Conroe �̐���ɂȂ�ƁAIntel �L���ɂȂ�
���ǁA�L���b�V�����͂������ꍇ�̃��C�e���V��
�_�ł́AConroe �̂���Ɏ�����ɂȂ�܂ŁA
AMD �L�����������B
3 IPC�A3GHz �� CPU ��������A120-70=50ns �̍��́A
450���ߕ��̋��ɑ�������킯�ŁB
3 IPC 3GHz ���ƁA1�b�ԂɎ��s�ł��閽�ߐ���
3*3G = 9000000000����/�b�B
L2 cache �q�b�g���� 99.9% ���Ƃ���� (������
�Ⴂ�Ǝv������)�A1�b�ԂɃ~�X����͂��悻
9000000000 �~ (1-0.999) = 9000000 ����x?
�Ƃ���ƁA450���߂̋��ǂꂾ���̖��ߐ���
���ɂȂ邩�Ƃ����ƁA
450 ���߁~9000000��/�b = 4050000000 ����/�b
9000000000����/�b �\�Ȃ̂�
4050000000����/�b ��������A
���ۂɏo��p�t�H�[�}���X�͔����Ƃ������ƂɂȂ�B
����́A4 issue �� 3 issue �Ő����鍷�����傫���B
���߂ɕ���x������ꍇ�ɂ́A�������҂��̏ꍇ��
���̌v�Z�𑱂����邱�Ƃ�����̂ŁA����͔���
��G�c�Ȍv�Z�ɉ߂��Ȃ����ǁA���͂����Ă�Ǝv������A
�������R���g���[�������ɂȂ�܂ŁAAMD�L���͓���
�Ȃ��Ǝv����B
�p�C�v���C���̒Z�� AMD�n�� PenM �̕����܂�
�y�i���e�B�����Ȃ��āANetBurst ���͗y����
�}�V�Ȃ��ǂˁB
���ƁA�������R���g���[�������̊W�ŁA������
�A�N�Z�X�̃��C�e���V�� Athlon 64 70ns �ɑ��A
NetBurst 120ns �ƁA�啝�ɈႤ����A���̓_�ł�
AMD �L���B
IPC �̓_�ł́APenM �n���f�X�N�g�b�v�ɏオ����
���� Conroe �̐���ɂȂ�ƁAIntel �L���ɂȂ�
���ǁA�L���b�V�����͂������ꍇ�̃��C�e���V��
�_�ł́AConroe �̂���Ɏ�����ɂȂ�܂ŁA
AMD �L�����������B
3 IPC�A3GHz �� CPU ��������A120-70=50ns �̍��́A
450���ߕ��̋��ɑ�������킯�ŁB
3 IPC 3GHz ���ƁA1�b�ԂɎ��s�ł��閽�ߐ���
3*3G = 9000000000����/�b�B
L2 cache �q�b�g���� 99.9% ���Ƃ���� (������
�Ⴂ�Ǝv������)�A1�b�ԂɃ~�X����͂��悻
9000000000 �~ (1-0.999) = 9000000 ����x?
�Ƃ���ƁA450���߂̋��ǂꂾ���̖��ߐ���
���ɂȂ邩�Ƃ����ƁA
450 ���߁~9000000��/�b = 4050000000 ����/�b
9000000000����/�b �\�Ȃ̂�
4050000000����/�b ��������A
���ۂɏo��p�t�H�[�}���X�͔����Ƃ������ƂɂȂ�B
����́A4 issue �� 3 issue �Ő����鍷�����傫���B
���߂ɕ���x������ꍇ�ɂ́A�������҂��̏ꍇ��
���̌v�Z�𑱂����邱�Ƃ�����̂ŁA����͔���
��G�c�Ȍv�Z�ɉ߂��Ȃ����ǁA���͂����Ă�Ǝv������A
�������R���g���[�������ɂȂ�܂ŁAAMD�L���͓���
�Ȃ��Ǝv����B
�ʔ������Ȃ̂ʼn����p�x��ς��Čv�Z���Ă݂��B
���g��f��CPU�ł�1���߂̏������Ԃ͕����Ȃǂ������1/f�B
�������҂����C�e���V�ɑO�q��70ns���g���ƁA2GHz��CPU��CPU��100���ʼn���Ă�Ƃ�
�X�g�[�����Ă��鎞�Ԃ̊�����
�������� ����
2G = 0.5ns 0.999
70ns 0.001
(70 x 0.001) / (0.5 x 0.999 + 70 x 0.001) = 0.12
12%���̎��Ԃ�҂����ԂƂ��Ė��ʂɏ���Ă���悤���B
����2GHz�Ń������҂����C�e���V��130ns�̏ꍇ20�������ʂɏ�����B
IPC���������ς�������A������g�����オ��Ƃ��̐��l�͂����Ƒ傫���Ȃ�B
�������Ȃ�\����L2�~�X�̃��C�e���V�Ȃǂ̍l��������B
���g��f��CPU�ł�1���߂̏������Ԃ͕����Ȃǂ������1/f�B
�������҂����C�e���V�ɑO�q��70ns���g���ƁA2GHz��CPU��CPU��100���ʼn���Ă�Ƃ�
�X�g�[�����Ă��鎞�Ԃ̊�����
�������� ����
2G = 0.5ns 0.999
70ns 0.001
(70 x 0.001) / (0.5 x 0.999 + 70 x 0.001) = 0.12
12%���̎��Ԃ�҂����ԂƂ��Ė��ʂɏ���Ă���悤���B
����2GHz�Ń������҂����C�e���V��130ns�̏ꍇ20�������ʂɏ�����B
IPC���������ς�������A������g�����オ��Ƃ��̐��l�͂����Ƒ傫���Ȃ�B
�������Ȃ�\����L2�~�X�̃��C�e���V�Ȃǂ̍l��������B
84 �FSocket774�F2005/09/07(��) 15:28:26 ID:FPc8Gttc
��������XDR��XDR2�ɑΉ����Ăق���
85 �FSocket774�F2005/09/10(�y) 10:13:54 ID:N4Mfy0UR
�@�@�@ A�QA �@ �^�P�P�P�P
�@ A�i�@�E�́E�j���@����
�@�i�E�� �@64�@�� �_�Q�Q�Q�Q
�@�i�@�@�m �m
�@�b�i_�Q�j�Q�j
�@�i_�Q�j�Q�j
�@ A�i�@�E�́E�j���@����
�@�i�E�� �@64�@�� �_�Q�Q�Q�Q
�@�i�@�@�m �m
�@�b�i_�Q�j�Q�j
�@�i_�Q�j�Q�j
86 �F���������������I���ɍs�����F2005/09/10(�y) 20:08:26 ID:+1mzZi9r
���ߎ��s���ł�
K5
�f�R�[�_4�i���S�ɓ���j
��x�Ƀf�R�[�h�ł��邘86���߂̑g�ݍ��킹�ɐ����Ȃ��B
�����̋Z�p�ł͂��܂�ɂ����G�����邽�߃N���b�N��
�����炸OUT
K6
�f�R�[�_4�i�V���[�g*2�A�����O�A�x�N�^�j
��86���ߒ��̑g�ݍ��킹��K6�f�R�[�_�̑g�ݍ��킹��
����̏ꍇ�̂�4���ߓ������s
�����X�[�p�[�p�C�v���C���̗p�����A500MHz���傢�ŏI���B
K7
3�i�K�f�R�[�h
�v���f�R�[�h��MOPS�i�f�R�[�_3����j��OPS�i�f�R�[�_6�H�j
K8�ȍ~���Ăǂ��Ȃ̂�H
����K5������炯�����������������肵�āB
K5
�f�R�[�_4�i���S�ɓ���j
��x�Ƀf�R�[�h�ł��邘86���߂̑g�ݍ��킹�ɐ����Ȃ��B
�����̋Z�p�ł͂��܂�ɂ����G�����邽�߃N���b�N��
�����炸OUT
K6
�f�R�[�_4�i�V���[�g*2�A�����O�A�x�N�^�j
��86���ߒ��̑g�ݍ��킹��K6�f�R�[�_�̑g�ݍ��킹��
����̏ꍇ�̂�4���ߓ������s
�����X�[�p�[�p�C�v���C���̗p�����A500MHz���傢�ŏI���B
K7
3�i�K�f�R�[�h
�v���f�R�[�h��MOPS�i�f�R�[�_3����j��OPS�i�f�R�[�_6�H�j
K8�ȍ~���Ăǂ��Ȃ̂�H
����K5������炯�����������������肵�āB
87 �F���������������I���ɍs�����F2005/09/10(�y) 21:26:20 ID:kGhCVY4B
K5����2��ނȂ����ˁH
88 �F���������������I���ɍs�����F2005/09/10(�y) 22:04:32 ID:jlgC2Lfs
>>86
K8=�U�Sbit������K7�R�A�{�������R���g���[���{HyperTransport
K8=�U�Sbit������K7�R�A�{�������R���g���[���{HyperTransport
89 �F���������������I���ɍs�����F2005/09/10(�y) 22:40:38 ID:+1mzZi9r
K8���ŏ��ɃA�i�E���X���������̓t���X�N���b�`
�ł܂������V�����v�������Ƃ������̂̓L�����Z���H
���Ă��Ƃ�K9���V�v���H
�ł܂������V�����v�������Ƃ������̂̓L�����Z���H
���Ă��Ƃ�K9���V�v���H
90 �F���������������I���ɍs�����F2005/09/10(�y) 22:52:30 ID:SJdMumue
�ʂɊԈႢ�ł��Ȃ����B
���������t���X�N���b�`���Đ��������āA
�S���܂�����ȐV�v�ȂL�肦��Ǝv�����B�B�B
���������t���X�N���b�`���Đ��������āA
�S���܂�����ȐV�v�ȂL�肦��Ǝv�����B�B�B
91 �F���������������I���ɍs�����F2005/09/10(�y) 23:20:29 ID:+8LLO+H3
92 �F���������������I���ɍs�����F2005/09/11(��) 00:10:15 ID:9YFCMc6u
���łɌ�����K9�̓L�����Z��or�f���A���R�A�ȁB
93 �F���������������I���ɍs�����F2005/09/11(��) 01:17:40 ID:Gqcxe2nM
�R��̋L���ł́A������K8�̓t���X�N���b�`�������͂��B
�����ǃ`�[�t�A�[�L�e�N�g�����������ς�������ŁA
����K7���ɂȂ������ăI�`��������K�X�B
�ŁAK10�͂ǂ��Ȃ����H
�����ǃ`�[�t�A�[�L�e�N�g�����������ς�������ŁA
����K7���ɂȂ������ăI�`��������K�X�B
�ŁAK10�͂ǂ��Ȃ����H
94 �F���������������I���ɍs�����F2005/09/11(��) 01:30:58 ID:KVxOwZxS
���̃A�[�L�e�N�g�̓T���_�[�X�Ɲ��߂Ď��߂���ł͂Ȃ��������ȁH
�ǂ����Ńu���b�N�}�܂Ō��J����Ă����A���ꂪ�V�vK8�̂��̂��������ǂ����͕�����Ȃ��B
�ǂ����Ńu���b�N�}�܂Ō��J����Ă����A���ꂪ�V�vK8�̂��̂��������ǂ����͕�����Ȃ��B
95 �F���������������I���ɍs�����F2005/09/11(��) 03:14:07 ID:8rpnnAg3
�ǂ��ł��������ǁA�t���X�N���b�`���Ęa���p�ꂶ��Ȃ�?(�܂�ԈႢ)
from scratch ���������Ǝv���B�킴�ƊԈႦ�Ă�Ȃ�X�}���B
from scratch ���������Ǝv���B�킴�ƊԈႦ�Ă�Ȃ�X�}���B
96 �F���������������I���ɍs�����F2005/09/11(��) 08:04:25 ID:s93fEjXb
�ʂ���Ⴂ����
97 �F���������������I���ɍs�����F2005/09/11(��) 08:14:48 ID:OWReHqed
�a���p����ē��{��ł���H
�ԈႢ����Ȃ������
�ԈႢ����Ȃ������
98 �F���������������I���ɍs�����F2005/09/11(��) 08:15:12 ID:E5HKi+75
�킴�ƊԈႤ�������蒅���Ă���ق��ʂ͎g���Ǝv�����Ȃ��B
���{�l���m�Řa���p��w�E����̂��������ˁ[���Ƃ����B
�܂����O������ł��f�p�[�g�Ƃ��|�X�g�Ƃ������Ȃ��^�C�v�Ȃ͔̂������B�@�@�@�@�@�@�@�E�E�E�}�W�łǂ��ł��ǂ��ȁB
���{�l���m�Řa���p��w�E����̂��������ˁ[���Ƃ����B
�܂����O������ł��f�p�[�g�Ƃ��|�X�g�Ƃ������Ȃ��^�C�v�Ȃ͔̂������B�@�@�@�@�@�@�@�E�E�E�}�W�łǂ��ł��ǂ��ȁB
99 �F���������������I���ɍs�����F2005/09/11(��) 08:16:35 ID:E5HKi+75
���������t�ނ�Ă邶��ˁ[���B����Ȃ̂ɒނ���̂͘R�ꂾ�����ƁB orz
100 �F���������������I���ɍs�����F2005/09/11(��) 08:53:04 ID:WuloKfB1
20�N�O����K���v������Ă�l�ŁA
�L�b�g�������i�ꂩ��쐬�����ꍇ�t���X�N���b�`
���Č����Ă��ȁ[�B
�L�b�g�������i�ꂩ��쐬�����ꍇ�t���X�N���b�`
���Č����Ă��ȁ[�B
101 �F���������������I���ɍs�����F2005/09/11(��) 10:28:21 ID:nr5gFk/s
K8�ŃX�P�W���[���[��2�i��������Ȃ����������H
102 �F���������������I���ɍs�����F2005/09/11(��) 11:19:49 ID:6WPfheKk
�ǃX���n�b�P�\�i�|�|
K7��K8�̓t���X�N���b�`����낤
�K�������t���X�N���b�`���Ă܂�ňႤ���̂ɂ͂Ȃ�Ȃ�
�v�z�����������Ȃ����H�}�����Ă�̂����R����
P6���l�g�o�͎v�z���܂�ňႤ����t���X�N���b�`���ʕ�
P6���o�j�A�X�͎v�z�����Ă邩��t���X�N���b�`=���nj^
�Ɍ�����̂ƈꏏ
�v�z�������R�������Ƃ��f�R�[�_�̐��ƌ����Ӗ�����Ȃ�
����畨�������́u��i�v�A�ړI�Ǝ�i�̊W����
���s��K8�̑O�ɘb�����ɏI�����K8�炵�����̂�
���ǂȂ����낤�ˁE�E�E
K7��K8�̓t���X�N���b�`����낤
�K�������t���X�N���b�`���Ă܂�ňႤ���̂ɂ͂Ȃ�Ȃ�
�v�z�����������Ȃ����H�}�����Ă�̂����R����
P6���l�g�o�͎v�z���܂�ňႤ����t���X�N���b�`���ʕ�
P6���o�j�A�X�͎v�z�����Ă邩��t���X�N���b�`=���nj^
�Ɍ�����̂ƈꏏ
�v�z�������R�������Ƃ��f�R�[�_�̐��ƌ����Ӗ�����Ȃ�
����畨�������́u��i�v�A�ړI�Ǝ�i�̊W����
���s��K8�̑O�ɘb�����ɏI�����K8�炵�����̂�
���ǂȂ����낤�ˁE�E�E
103 �F���������������I���ɍs�����F2005/09/11(��) 11:45:39 ID:34TFVjwR
�P����K7��K8�͎��s���j�b�g��9�œ��������
104 �F���������������I���ɍs�����F2005/09/11(��) 12:05:56 ID:gsFKib1q
�܂��ł�������������t���X�N���b�`�ł͂Ȃ��Ƃ�
���s���j�b�g���������Ȃ炻�̑��S�Ă��ς���Ă��t���X�N���b�`�ł͂Ȃ�
�t�Ɏ��s���j�b�g������ł��ς����̑��S�Ă������ł��t���X�N���b�`���Ď����Ȏ����ȁH
���s���j�b�g���������Ȃ炻�̑��S�Ă��ς���Ă��t���X�N���b�`�ł͂Ȃ�
�t�Ɏ��s���j�b�g������ł��ς����̑��S�Ă������ł��t���X�N���b�`���Ď����Ȏ����ȁH
105 �F���������������I���ɍs�����F2005/09/11(��) 12:27:01 ID:6WPfheKk
��������v���Ă̂��t���X�N���b�`���ĈӖ����Ǝv���Ă�
�����܂Ōl�I�ɂ�����٘_�����邩������
��������l���Ă���������ɂȂ鎖�������
�S�R�ʕ������邶��낤���ĈӖ�����
�܂������ʕ�=�t���X�N���b�`�ƂƂ炦����
����CPU�͑S���ߋ��v�̈��p���͑�Ȃ菬�Ȃ�
���Ă��Ő������ł��Ȃ��Ȃ����Ⴄ�l�F
�����܂Ōl�I�ɂ�����٘_�����邩������
��������l���Ă���������ɂȂ鎖�������
�S�R�ʕ������邶��낤���ĈӖ�����
�܂������ʕ�=�t���X�N���b�`�ƂƂ炦����
����CPU�͑S���ߋ��v�̈��p���͑�Ȃ菬�Ȃ�
���Ă��Ő������ł��Ȃ��Ȃ����Ⴄ�l�F
106 �F���������������I���ɍs�����F2005/09/11(��) 15:00:05 ID:Njh78elu
>>102
�����i�K��K8��CELL�̂悤�ȃw�e���W�j�A�X�^�}���`�R�A��
�u�����Ă����炵���E�E�E�E
���i�f�r���[�������Dual�R�A�̑Ή��v�悪�\���ł����̂́A
���̖��c��E�E�E
�����i�K��K8��CELL�̂悤�ȃw�e���W�j�A�X�^�}���`�R�A��
�u�����Ă����炵���E�E�E�E
���i�f�r���[�������Dual�R�A�̑Ή��v�悪�\���ł����̂́A
���̖��c��E�E�E
107 �F���������������I���ɍs�����F2005/09/11(��) 15:20:33 ID:YRiw77pg
�h���X�f���ƈꏏ�ɐ��ɗ����Ă��܂����̂���
108 �F���������������I���ɍs�����F2005/09/11(��) 16:55:51 ID:DoA+rrh4
>�����i�K��K8��CELL�̂悤�ȃw�e���W�j�A�X�^�}���`�R�A��
����̓C���e������ˁ[�́H
AMD�̋Z�p�w�̓C���^�r���[�����閈�ɁA��Ώ̌^�̃R�A��
�W�ς��鎖�͋����Ȃ��Ƃ����Č����Ă邵�A�㓡����̃��|�ł�
AMD�͍��@�\�E�����\�E���R�A�w�������Ďw�E���Ă�B
�C���e����CPU�p���[��20�����߂镡�G�ȏ����Ƀ}�b�V�u�R�A��
���蓖�ĂāA�c��80���̌y�������p�ɒP���ȃR�A���ǂ�����ڂ�
�ő��20�R�A�܂ōs���悤�ȋZ�p�u����������ă��|�o�Ă��Ă邵�B
����̓C���e������ˁ[�́H
AMD�̋Z�p�w�̓C���^�r���[�����閈�ɁA��Ώ̌^�̃R�A��
�W�ς��鎖�͋����Ȃ��Ƃ����Č����Ă邵�A�㓡����̃��|�ł�
AMD�͍��@�\�E�����\�E���R�A�w�������Ďw�E���Ă�B
�C���e����CPU�p���[��20�����߂镡�G�ȏ����Ƀ}�b�V�u�R�A��
���蓖�ĂāA�c��80���̌y�������p�ɒP���ȃR�A���ǂ�����ڂ�
�ő��20�R�A�܂ōs���悤�ȋZ�p�u����������ă��|�o�Ă��Ă邵�B
109 �F���������������I���ɍs�����F2005/09/11(��) 19:19:33 ID:2tHwultP
>>106
�ȂႻ��႗ �\�[�X�����悗
�ȂႻ��႗ �\�[�X�����悗
110 �F���������������I���ɍs�����F2005/09/11(��) 20:14:52 ID:aGK5rVZh
�㓡����́A�����ŋ߂̋L���ł̓t�����X�N���b�`���ď����Ă��B
�C����?
ttp://pc.watch.impress.co.jp/docs/2005/0822/kaigai204.htm
ttp://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
������ȑO�͂قڑS�ăt���X�N���b�`���ď����Ă�B(w
�C����?
ttp://pc.watch.impress.co.jp/docs/2005/0822/kaigai204.htm
ttp://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
������ȑO�͂قڑS�ăt���X�N���b�`���ď����Ă�B(w
111 �F���������������I���ɍs�����F2005/09/11(��) 20:23:32 ID:f6QIyI6P
�X�N���b�`������
���{��ŏ��������̂ɂˁB
���{��ŏ��������̂ɂˁB
112 �F���������������I���ɍs�����F2005/09/11(��) 21:11:34 ID:QbLJLijy
�ꂩ���蒼���H
K8���ăN���b�N���Ă����オ���̂ȁH
�ǂ����Ƀ}�[�P�b�g��o���K�v���Ȃ�����o���Ȃ��Ƃ�
�����Ă������ǁB
�C���e���̐��\����������獂�N���b�N�̂�o���Ȃ��̂��ȁH
�ǂ����Ƀ}�[�P�b�g��o���K�v���Ȃ�����o���Ȃ��Ƃ�
�����Ă������ǁB
�C���e���̐��\����������獂�N���b�N�̂�o���Ȃ��̂��ȁH
�f���A���R�A�ɂ����ق��������Ď|������Ȃ��B
116 �FSocket774�F2005/09/12(��) 21:33:50 ID:cnDtg+9b
>>82
>�A�N�Z�X�̃��C�e���V�� Athlon 64 70ns �ɑ��A
>NetBurst 120ns �ƁA�啝�ɈႤ����A���̓_�ł�
�@�����PCWeb�̑匴�Y��̋L�����Q�l�ɂ������l���Ǝv�����A�����PC-2700��������
Opteron240�̑g�ݍ��킹�̎��̃��C�e���V�ŁA���ƂȂ��Ă͌Â��̂ł́H
�@Opteron240��1.4GHz�̂��߁A�������N���b�N��1400��9��155.6MHz�ƁAPC-2700�̒�i��
166.7MHz�����Ⴍ�Ȃ��Ă����B
�@K8�R�A�̃����R���̓������C�e���V��22/27�N���b�N������A
�@(2.5+3+3)��155.6MHz�{27��1.4GHz��73.93ns�@�@�ɂȂ�B
�@���݂̎嗬�ł���PC-3200��������2.4GHz��Athlon64/Opteron�̑g�ݍ��킹���ƁA
�@(3+3+3)��200MHz�{27��2.4GHz��56.25ns�@�@�ɂȂ锤�B
>�A�N�Z�X�̃��C�e���V�� Athlon 64 70ns �ɑ��A
>NetBurst 120ns �ƁA�啝�ɈႤ����A���̓_�ł�
�@�����PCWeb�̑匴�Y��̋L�����Q�l�ɂ������l���Ǝv�����A�����PC-2700��������
Opteron240�̑g�ݍ��킹�̎��̃��C�e���V�ŁA���ƂȂ��Ă͌Â��̂ł́H
�@Opteron240��1.4GHz�̂��߁A�������N���b�N��1400��9��155.6MHz�ƁAPC-2700�̒�i��
166.7MHz�����Ⴍ�Ȃ��Ă����B
�@K8�R�A�̃����R���̓������C�e���V��22/27�N���b�N������A
�@(2.5+3+3)��155.6MHz�{27��1.4GHz��73.93ns�@�@�ɂȂ�B
�@���݂̎嗬�ł���PC-3200��������2.4GHz��Athlon64/Opteron�̑g�ݍ��킹���ƁA
�@(3+3+3)��200MHz�{27��2.4GHz��56.25ns�@�@�ɂȂ锤�B
117 �FSocket774�F2005/09/12(��) 21:42:11 ID:aRz7zY7b
>>116
�G�x���X�g�̎�������X2 4800+��PC3200��62.2ns
�G�x���X�g�̎�������X2 4800+��PC3200��62.2ns
�f���A���R�A�͈ꎞ�̖���
���̐斢�����Ȃ����Ƃɕς��͂Ȃ�
���̐斢�����Ȃ����Ƃɕς��͂Ȃ�
���>>116���̌v�Z�ǂ���̐��l���łĂ�̂�
���`�b�v�Z�b�g�̓k�b�t�H�b�t�H4�@�N���b�N��200�ɒ����Ă���v��
�f���A����1�s����ł�
���`�b�v�Z�b�g�̓k�b�t�H�b�t�H4�@�N���b�N��200�ɒ����Ă���v��
�f���A����1�s����ł�
>>120
�����R���̉��ǂŃ��C�e���V�͊m��Winchester�̕���������Ȃ����������B
�ł����i�т������Venice��sandiego���X2�̕����������A�N�Z�X�������Ƃ����̂��������Ƃ�����B
�����R���̉��ǂŃ��C�e���V�͊m��Winchester�̕���������Ȃ����������B
�ł����i�т������Venice��sandiego���X2�̕����������A�N�Z�X�������Ƃ����̂��������Ƃ�����B
�R������3Ghz�ŗ��Ă����v�ł��傤���H
K10�����ƊJ�����Ă��ł��傤���H
�N���b�N�AIPC�Ƃ��ɕ�������
���x�����ׂ�Ă��܂��܂����B
K10�����ƊJ�����Ă��ł��傤���H
�N���b�N�AIPC�Ƃ��ɕ�������
���x�����ׂ�Ă��܂��܂����B
��������X2�����������邩��
>>123
1��i���炢�łԂ�Ă��獡��intel�Ԃ�Ă�
�̂��畉�����Ƃ��납��X�^�[�g�Ȃ̂���AMD
�ŏ��Ȃ��intel�ɂ����Ă���Ɨ��܂�Č݊�CPU���n�߂�����
�����intel�����鐫�\�����ăV�F�A�̖����l��
�ȁ[��Ď��ʂقnjÂ��b�����邼
32bit�ɂȂ��Ă���͂܂�intel���D����
AMD���݊��b�o�t������Ă���
������\�P�b�g�ύX���ė�����intel���Ɛ肵��
���ꂩ�炾��AMD��intel���\�P�b�g�ς�����̂͂�
1��i���炢�łԂ�Ă��獡��intel�Ԃ�Ă�
�̂��畉�����Ƃ��납��X�^�[�g�Ȃ̂���AMD
�ŏ��Ȃ��intel�ɂ����Ă���Ɨ��܂�Č݊�CPU���n�߂�����
�����intel�����鐫�\�����ăV�F�A�̖����l��
�ȁ[��Ď��ʂقnjÂ��b�����邼
32bit�ɂȂ��Ă���͂܂�intel���D����
AMD���݊��b�o�t������Ă���
������\�P�b�g�ύX���ė�����intel���Ɛ肵��
���ꂩ�炾��AMD��intel���\�P�b�g�ς�����̂͂�
>>123
FSB�ŏ����Ă��Ȃ����H
FSB�ŏ����Ă��Ȃ����H
127 �F���r�� ��iBFoFMKK5M �F2005/09/13(��) 16:57:50 ID:SUslgCBD
�ɂ��������玩��̓ǂݕ��u���Ă���
�i���q�l�����ǂݕ� I�N�Ƃ`�N 1/2�j
�̂���Ƃ���ɂo�����Ƃ�����������܂���
�܂��V�����o�������ň��|�I�Ƀp��������܂���ł���
�h�N���p�������o�c���邱�Ƃɂ��܂���
�ŏ��͂h�N�����ō���Ă܂����������͎����ʂ�
��肫��܂���ł����h�N�ɂ̓W���������g�����������̂ł�
�h�N�͍ŏ��`�N�Ƀp������点��
���X�̈ꕔ��݂��Ē��ǂ��c�Ƃ��Ă܂���
�h�N�̓W�����ł��ׂ���̂ł���ł��悩�����̂ł�
I�N�͍��̂��Ƃ������l���Ă܂���
�������h�N���`�N�̂ق������Ƃ��ƃp������邾���͂��܂������̂�
�h�N�̃p���ƕ��Ԕ���s���ɂȂ�܂���
�h�N�͊�@���������ĐV�����p�����J�������Ɠ����ɂa�N�����X����
�������o���܂����B
�`�N�͎d���Ȃ��V�����p�����J�X���܂���
�i���͂h�N�ɂ��Ȃ�Ȃ����Lj����̂ł݂�ȂɊ��܂���
�������`�N�͐V�����o�����p�����Ȃ̂ő��Ƀt�����X�p���[���̘b�͒��܂���ł���
�i���q�l�����ǂݕ� I�N�Ƃ`�N 1/2�j
�̂���Ƃ���ɂo�����Ƃ�����������܂���
�܂��V�����o�������ň��|�I�Ƀp��������܂���ł���
�h�N���p�������o�c���邱�Ƃɂ��܂���
�ŏ��͂h�N�����ō���Ă܂����������͎����ʂ�
��肫��܂���ł����h�N�ɂ̓W���������g�����������̂ł�
�h�N�͍ŏ��`�N�Ƀp������点��
���X�̈ꕔ��݂��Ē��ǂ��c�Ƃ��Ă܂���
�h�N�̓W�����ł��ׂ���̂ł���ł��悩�����̂ł�
I�N�͍��̂��Ƃ������l���Ă܂���
�������h�N���`�N�̂ق������Ƃ��ƃp������邾���͂��܂������̂�
�h�N�̃p���ƕ��Ԕ���s���ɂȂ�܂���
�h�N�͊�@���������ĐV�����p�����J�������Ɠ����ɂa�N�����X����
�������o���܂����B
�`�N�͎d���Ȃ��V�����p�����J�X���܂���
�i���͂h�N�ɂ��Ȃ�Ȃ����Lj����̂ł݂�ȂɊ��܂���
�������`�N�͐V�����o�����p�����Ȃ̂ő��Ƀt�����X�p���[���̘b�͒��܂���ł���
128 �F���r�� ��iBFoFMKK5M �F2005/09/13(��) 16:58:32 ID:SUslgCBD
(���q�l�����ǂݕ� 2/2)
�����ĔN���͂Ȃ���
�`�N�̘r�͂���ɂ�����A�����ɃW�����J���\�͂Ȃ��̂�m���Ă���
�p�����̏��i��̂ɂ�4�l�̒��Ԃ��ł��Ă��܂���
�W�������[�J��4�l�ł��r�N�Ƃm�N�Ƃt�N�Ƃu�N�ł�
�`�N���W�����͍���Ă܂������悤�₭���ɓ������悤�ɂȂ����̂�
���̑��p�t�����X�p����p�W���������̂Ő���t�������̂ł�
������h�N�p���̊J���Ɏ��s���܂���
�����t���`�[�Y���g��Ȃ��ƐH���Ȃ��Ƃ����قǂ܂����T���h�C�b�`�ł�
�`�[�Y���͂��ނƔ��������̂Ƀ`�[�Y�͍��������܂���
�����Ăh�N����킵�ăW�����̊J�������낻���ɂȂ��Ă����܂���
�������h�N�͂`�N�̗F�B�u�N�ɃW����������Ă��炤���Ƃɂ��܂���
�u�N�͓����҂ő�R�W���������܂�����僁�[�J�Ȃ̂Ŗ����ǂ�
�h�N���V�������i���o�����Ƃ��ɂ͎����p�̃p���̃W�����̔�����
�u�N�̐��i�x���҂ɂȂ��Ă��܂���
�h�N�͍l���܂����W�����̕��̔���グ�����Ƃ����Ȃ����
�������h�N�ɂ͍��̂��Ƃ�肨�����厖�ɂȂ��Ă��܂���
�����Ă`�N�̂��X��`���Č��܂���
���悭���i������Ă��܂����B
�h�N�͂����������������~�����Ȃ����̂Ńp���ƃW�������ɔ����Ă����l��
�L���b�V���o�b�N�T�[�r�X�Ƃh�N�̃p����������Ȃ���Ƃɓ��ʊ�����
���n�߂܂���
���Ƃ��Ƃ��˂�����h�N�Ȃ̂Ŗׂ����t�ɂ���������܂�����
���̍��ɂ͈��ӂ��炠��܂���
���̌����痣�ꂽ�`�炵�߂Ă�낤�Ƃ���v���Ă��܂���
�݂�݂�`�N�̃p���̔���s���͉������čs���܂���
����ł��Ԃ�Ȃ��`�N�̃p�����������h�N�͂����
�`�N�̗��݂Ƃ���W�����E�l�ɊJ�����˗����܂���
�����h�N�͈Ӓn�ɂȂ��Ă��܂���
�a�N�ɂ̓p���ł͐�Ε����Ȃ���
�E�E�E��
�����ĔN���͂Ȃ���
�`�N�̘r�͂���ɂ�����A�����ɃW�����J���\�͂Ȃ��̂�m���Ă���
�p�����̏��i��̂ɂ�4�l�̒��Ԃ��ł��Ă��܂���
�W�������[�J��4�l�ł��r�N�Ƃm�N�Ƃt�N�Ƃu�N�ł�
�`�N���W�����͍���Ă܂������悤�₭���ɓ������悤�ɂȂ����̂�
���̑��p�t�����X�p����p�W���������̂Ő���t�������̂ł�
������h�N�p���̊J���Ɏ��s���܂���
�����t���`�[�Y���g��Ȃ��ƐH���Ȃ��Ƃ����قǂ܂����T���h�C�b�`�ł�
�`�[�Y���͂��ނƔ��������̂Ƀ`�[�Y�͍��������܂���
�����Ăh�N����킵�ăW�����̊J�������낻���ɂȂ��Ă����܂���
�������h�N�͂`�N�̗F�B�u�N�ɃW����������Ă��炤���Ƃɂ��܂���
�u�N�͓����҂ő�R�W���������܂�����僁�[�J�Ȃ̂Ŗ����ǂ�
�h�N���V�������i���o�����Ƃ��ɂ͎����p�̃p���̃W�����̔�����
�u�N�̐��i�x���҂ɂȂ��Ă��܂���
�h�N�͍l���܂����W�����̕��̔���グ�����Ƃ����Ȃ����
�������h�N�ɂ͍��̂��Ƃ�肨�����厖�ɂȂ��Ă��܂���
�����Ă`�N�̂��X��`���Č��܂���
���悭���i������Ă��܂����B
�h�N�͂����������������~�����Ȃ����̂Ńp���ƃW�������ɔ����Ă����l��
�L���b�V���o�b�N�T�[�r�X�Ƃh�N�̃p����������Ȃ���Ƃɓ��ʊ�����
���n�߂܂���
���Ƃ��Ƃ��˂�����h�N�Ȃ̂Ŗׂ����t�ɂ���������܂�����
���̍��ɂ͈��ӂ��炠��܂���
���̌����痣�ꂽ�`�炵�߂Ă�낤�Ƃ���v���Ă��܂���
�݂�݂�`�N�̃p���̔���s���͉������čs���܂���
����ł��Ԃ�Ȃ��`�N�̃p�����������h�N�͂����
�`�N�̗��݂Ƃ���W�����E�l�ɊJ�����˗����܂���
�����h�N�͈Ӓn�ɂȂ��Ă��܂���
�a�N�ɂ̓p���ł͐�Ε����Ȃ���
�E�E�E��
129 �F���r�� ��iBFoFMKK5M �F2005/09/13(��) 17:00:00 ID:SUslgCBD
�����̓��A���^�C���̎����̐i��Ɩ{�l���ɂȂ�ł�
130 �F���r�� ��iBFoFMKK5M �F2005/09/13(��) 17:02:56 ID:SUslgCBD
�a�N�ɂ̓p���ł͐�Ε����Ȃ���
���`�N�ɂ̓p���ł͐�܂��Ȃ���
��A������orz
���`�N�ɂ̓p���ł͐�܂��Ȃ���
��A������orz
���R�͕�����Ȃ����A����ł���Ă��X�����c�����ŋ����v���o����
�܂�20�N�O����
�V���O�����s���l�܂聨�}���`�����Z�p�v�V���V���O����
���ČJ��Ԃ��Ă���炻�̂����Ȃ�Ƃ����Ă����ׁ`�ƊÂ����҂����Ă���
���K�C��
�V���O�����s���l�܂聨�}���`�����Z�p�v�V���V���O����
���ČJ��Ԃ��Ă���炻�̂����Ȃ�Ƃ����Ă����ׁ`�ƊÂ����҂����Ă���
���K�C��
>>119
�����ăR�A���唚����
�����ăR�A���唚����
Niagara��32����ڂ�������
>119
�}���`�R�A�ƃn�[�h�E�F�A���z���Ɍ�����OS���ς��Ă���
http://pc.watch.impress.co.jp/docs/2005/0912/kaigai211.htm
�}���`�R�A�ƃn�[�h�E�F�A���z���Ɍ�����OS���ς��Ă���
http://pc.watch.impress.co.jp/docs/2005/0912/kaigai211.htm
�{���j�b�`�ȋZ�p�����C���X�g���[���Ɏ����Ă��Ȃ��Ⴂ���Ȃ����炢
�l�^�s���Ȕ����̋ƊE�͂����I����d�ˁB
�l�^�s���Ȕ����̋ƊE�͂����I����d�ˁB
���z������Ă�����x86�͂���Ȃ��Ȃ邩��
>>137
�܂���������܂���B
�܂���������܂���B
Athlon64X2�ɏd��ȕs�
http://news19.2ch.net/test/read.cgi/news/1126540601/
http://news19.2ch.net/test/read.cgi/news/1126540601/
�܂��X���^�C���x���ꂽ���z�Ȑl��
>>126
�R����1333Mhz�ł��邩����D�Z�p�I�ɖ������������ȁD
���Ȃ��Ƃ�1066�ł͂��邶���H
���C���X�g���[����800�������C�����邪�D
���Ȃ��Ƃ�IPC�ŕ����Ȃ��ŗ~�����D
HT��FSB�̎��g�����y�U�Ŕ�ׂĂ������̂��ȁH
HT�̕��������悳�������D
�R����1333Mhz�ł��邩����D�Z�p�I�ɖ������������ȁD
���Ȃ��Ƃ�1066�ł͂��邶���H
���C���X�g���[����800�������C�����邪�D
���Ȃ��Ƃ�IPC�ŕ����Ȃ��ŗ~�����D
HT��FSB�̎��g�����y�U�Ŕ�ׂĂ������̂��ȁH
HT�̕��������悳�������D
HT1000��1600�Ɋg�債��DDR2 800�f���A���ɂ����FSB1600�����H
���Ɖ��肪�ʐ����Ă����ł�
HT�̕�������������Ȃ��H
HT�̕�������������Ȃ��H
HT = 16bit 1GHz DDR �㉺��
FSB = 64bit 800MHz (200MHz QDR)�@�㉺���L
���Ɖ����P���ɍ��v�����ш��
HT 8GByte/sec
FSB 6.4GByte/sec
�Ƃ͂����Ă����C���������̑ш悪�ʂ��Ƃ��A�o�X�̃v���g�R���I�[�o�[�w�b�h���Ƃ�
���낢�날�肻�������B
FSB = 64bit 800MHz (200MHz QDR)�@�㉺���L
���Ɖ����P���ɍ��v�����ш��
HT 8GByte/sec
FSB 6.4GByte/sec
�Ƃ͂����Ă����C���������̑ш悪�ʂ��Ƃ��A�o�X�̃v���g�R���I�[�o�[�w�b�h���Ƃ�
���낢�날�肻�������B
K9���Ă��L�����Z�������܂����́H
K9����DDR2�A���z���Z�p�����������Ȃ������H
K9����DDR2�A���z���Z�p�����������Ȃ������H
�Ƃ�ł��Ȃ��b������邪�A���C�e���V��100ns�������Ă���
����X�g�[�����ē��삷��Ƃ�����10MHz�ɂȂ�E�E�E
�ȏ���L�B
����X�g�[�����ē��삷��Ƃ�����10MHz�ɂȂ�E�E�E
�ȏ���L�B
K10���o������H
SocketM2�ŏ���CPU��DDR2�̂����ł��傤���H
DDR2-667?
DDR2-667?
>>149
667����Ȃ��BAMD��667�ȏザ��Ȃ��Ə�芷����Ӗ����Ȃ���
���������B
800��400�̎��̂悤�ɕ��y���邩�ǂ����킩��ȁB
DD2��667�ŃX�g�b�v�����ˁB
667����Ȃ��BAMD��667�ȏザ��Ȃ��Ə�芷����Ӗ����Ȃ���
���������B
800��400�̎��̂悤�ɕ��y���邩�ǂ����킩��ȁB
DD2��667�ŃX�g�b�v�����ˁB
151 �FSocket774�F2005/09/23(��) 23:22:55 ID:sgcsxlFV
>>1 ����ł������̃X���͎���ƁA
�ǂ������W������̂ł����H �S���W�Ȃ��Ǝv���܂����c
�ǂ������W������̂ł����H �S���W�Ȃ��Ǝv���܂����c
�������ˁB�S���W�Ȃ�����N�͗��Ȃ��Ă�����B
>>152
���łɂ������̃X���ɂ������������Ă����B
��
Intel�̎�����CPU�ɂ��Č�낤 17�v����
http://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
���łɂ������̃X���ɂ������������Ă����B
��
Intel�̎�����CPU�ɂ��Č�낤 17�v����
http://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
���̃X���𗧂Ă�ɂ������āA�@�����Ɗ؍��ɋ������̂ł����H���ĂȂ��ł���H
K10���\�P�b�gM2�������肵�āB
DDR2/3���s���݊��݂���������AHyperTransport�̃N���b�N����C�ɏオ�����肵�Ȃ�����
�݊�����ꂻ���ȋC�����邪�B
�݊�����ꂻ���ȋC�����邪�B
K10�̓T�[�o��p�Ńf�X�N�g�b�v��m�[�g�ɂ͕ʃR�A�g�������Ȋ����ł����邪�B
K9���č��N���b�N���˂���Ă������݂��������ǁA
���L�����Z���ɂȂ����̂��킩��A
���ۂǂ��������킩��ȁB
�P��K9�̔�������������L�����Z���������ȁB
���L�����Z���ɂȂ����̂��킩��A
���ۂǂ��������킩��ȁB
�P��K9�̔�������������L�����Z���������ȁB
K9K9����p
�A�X�e���C�h�x���g��
�A�E�g���[���k�������R�X�������W���[K9�B
�F����ԁ@�˂�����̂��@�u���C�T���_�[
�u���C�T���_�[
�\�����N
�������߂��A��ь����u���C�X�^�[ �g����v���Y�}
�M�������������
�E�b�E�b�E���t�́`�}�[�N�@�������[�����́`
K9���Ēm���Ă邩���H
���Semp�@���Semp�@�u���C�K�[
�ǂ������ǂ������I�ǂ������ǂ������I
173 �FSocket774�F2005/10/03(��) 11:57:02 ID:juk5v6pu
�i���N�́j�r�O��A�N����邼�E�E�E
�S�����̂��Ƃ������ł��Ȃ��R��͂܂��܂�������ȁA����B
�R���ܶ�ȁ@
���H���Ǝv������������
���H���Ǝv������������
���܂�Ȃ���
���̐����P���A�Ł@��(����)�̏��������܂���
�����琯�ɋ����l�́@�ܔw�����ĉF���̎n��
��͐����u���C�K�[�@���ĂтƂ���Α��Q��
�����琯�ɋ����l�́@�ܔw�����ĉF���̎n��
��͐����u���C�K�[�@���ĂтƂ���Α��Q��
�b�_���C�K�[�Ȃ�킩����E�E�E�B
�b�_�T���_vs�K�C��
�u���C�K�[�͋L���ɗL�邯�ǁA�o�N�V���K�[�͋L���ɖ����B
���Ō��Ȃ������낤�E�E�E�B
���Ō��Ȃ������낤�E�E�E�B
�����ADDR2-533��M2�ł͎g����̂��A�A�A(�L��֥`)
WOOOOW�E�E�E�E�I ���܂�Ȃ����n�j�n�j
�́A�����A�߂���A�r�[�g�H
185 �FSocket774�F2005/10/06(��) 21:55:20 ID:vNxWtQ66
���F�T�C�R�[
K9���b�܂����ێ���ł邵����
K9���b�܂����ێ���ł邵����
�Ȃ��̃X��
187 �FSocket774�F2005/10/08(�y) 17:24:24 ID:EC2AKOtf
������ƁA������CPU�̘b���o���Ă݂邩�B
������CPU�ł́APCIExpress�R���g���[�����������ˁB
���[�����GPU-CPU�Ԃ̒ʐM���x�A������x�オ�邾��[���A�`�b�v�Z�b�g�P���ōςނ悤�ɂȂ�͂������B
������CPU�ł́APCIExpress�R���g���[�����������ˁB
���[�����GPU-CPU�Ԃ̒ʐM���x�A������x�オ�邾��[���A�`�b�v�Z�b�g�P���ōςނ悤�ɂȂ�͂������B
HyperTransport 2.0���m��Ȃ��z��
����������Ƃ͕Е��ɂ�
����������Ƃ͕Е��ɂ�
���C�\�e���֘A�̎���������܂����B
http://1000yenkigan.fc2web.com/mudai_050308_01.pdf
http://1000yenkigan.fc2web.com/mudai_050308_01.pdf
16bit�~16bit�����N��4GB/s
32bit�~32bit�����N��8GB/s
32bit�~32bit�����N��8GB/s
>>187
op�̎��̃��f����PC�wI�R���g���[����������Ȃ����Ƃ����\������킯�����B
op�̎��̃��f����PC�wI�R���g���[����������Ȃ����Ƃ����\������킯�����B
�����Ă����MediaGX�ɋ߂Â��čs���킯��
HyperTransport 2.0���m��Ȃ��z��
����������Ƃ͕Е��ɂ�
����������Ƃ͕Е��ɂ�
HT���ăV���A���ɂ��ڍs�ł�������H
�Ӗ��s��
CPU�����C���������ȊO�̂��̂ɃA�N�Z�X�ɍs���ƁA
���̂������T�C�N�����E�F�C�g�Ŗ��ʎg������̂��A
�Ȃ�Ƃ����ׂ����Ǝv���B
�������ACPU���ǂ�Ȃɍ����ł��낤�ƁA
CPU���̂̑��x�ɊW�Ȃ��A
��莞��CPU�������ł��Ȃ��Ȃ�
���Ă������̂�����A������CPU�������ɂ��Ă��A
���ړI�ɂ͉������Ȃ��B
�悭�A�I�`�b�v��LAN��CPU���ׂ��E�E�E�Ƃ��������ǁA
���ۂɂ�CPU�̂��d���������̂ł͂Ȃ��A
CPU���I�`�b�v�ɕp�ɂɃA�N�Z�X���ɍs���̂ŁA
CPU�����x�݂ɂȂ邱�Ƃ������̂��B
���̃`�b�v�́ACPU���`�b�v�ɃA�N�Z�X����̂�����A
�`�b�v�ւ̕����̎w�������C���������ɏ�������ł����A
���̃A�h���X���`�b�v�ɋ�����ƁA
�`�b�v�����C���������ɂ���w����ǂ�œ����A
�Ƃ����d�|���ɂȂ��Ă���B
���̂������T�C�N�����E�F�C�g�Ŗ��ʎg������̂��A
�Ȃ�Ƃ����ׂ����Ǝv���B
�������ACPU���ǂ�Ȃɍ����ł��낤�ƁA
CPU���̂̑��x�ɊW�Ȃ��A
��莞��CPU�������ł��Ȃ��Ȃ�
���Ă������̂�����A������CPU�������ɂ��Ă��A
���ړI�ɂ͉������Ȃ��B
�悭�A�I�`�b�v��LAN��CPU���ׂ��E�E�E�Ƃ��������ǁA
���ۂɂ�CPU�̂��d���������̂ł͂Ȃ��A
CPU���I�`�b�v�ɕp�ɂɃA�N�Z�X���ɍs���̂ŁA
CPU�����x�݂ɂȂ邱�Ƃ������̂��B
���̃`�b�v�́ACPU���`�b�v�ɃA�N�Z�X����̂�����A
�`�b�v�ւ̕����̎w�������C���������ɏ�������ł����A
���̃A�h���X���`�b�v�ɋ�����ƁA
�`�b�v�����C���������ɂ���w����ǂ�œ����A
�Ƃ����d�|���ɂȂ��Ă���B
>>197
����̓h���C�o�̍�����Ӄf�o�C�X�̖�肾�ȁB
����̓h���C�o�̍�����Ӄf�o�C�X�̖�肾�ȁB
>>197
����𒆓r���[�Ȓm���Œm�������B�ƌ����B
����𒆓r���[�Ȓm���Œm�������B�ƌ����B
ttp://www.behardware.com/news/7626/AMD-s-plans-for-2006-2007.html
AMD��2006�`2007�N�̃��[�h�}�b�v
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013145_1.jpg
�f�X�N�g�b�v�̃��[�h�}�b�v�E�E�E2007�N�܂�K8�������邾��
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013149_1.jpg
���o�C���̃��[�h�}�b�v�E�E�E2007�N�܂�K8�������邾��
K9�L�����Z���ŁAK10�͂��ɂȂ�����o����̂�����S���s���B
������CPU�̉e���`�������Ȃ����牽�����Ȃ���)�߹ׯ��
AMD��2006�`2007�N�̃��[�h�}�b�v
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013145_1.jpg
{kind=link}
�f�X�N�g�b�v�̃��[�h�}�b�v�E�E�E2007�N�܂�K8�������邾��
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013149_1.jpg
{kind=link}
���o�C���̃��[�h�}�b�v�E�E�E2007�N�܂�K8�������邾��
K9�L�����Z���ŁAK10�͂��ɂȂ�����o����̂�����S���s���B
������CPU�̉e���`�������Ȃ����牽�����Ȃ���)�߹ׯ��
201 �F�������G�� ��yGAhoNiShI �F2005/10/10(��) 01:08:27 ID:2VsfyfPi
�����݂͕��ʂ�K9�ɍs����Ȃ��́H
�����̃f�X�N�g�b�vCPU�͂ǂ��ł�������
�����̃f�X�N�g�b�vCPU�͂ǂ��ł�������
K9�̓L�����Z��
�f�X�N�g�b�v�����ł��N���b�N�������D�� (Conroe, 2006)
�܂Ƃ��ȃf���A���R�A���� (Yona, Merom, 2006)
�������R���g���[������ (Whitefield, 2007)
�ȂǂȂǁAIntel �����㐔�N�����Ă��悤�Ȃ��Ƃ��A����
���N���O�Ɏ�����������Ă邩����Ȃ��悤�Ȋ�K�X�B
�Ă䂤���AIntel �挩�̖��Ȃ������B
�܂Ƃ��ȃf���A���R�A���� (Yona, Merom, 2006)
�������R���g���[������ (Whitefield, 2007)
�ȂǂȂǁAIntel �����㐔�N�����Ă��悤�Ȃ��Ƃ��A����
���N���O�Ɏ�����������Ă邩����Ȃ��悤�Ȋ�K�X�B
�Ă䂤���AIntel �挩�̖��Ȃ������B
>>198
�������B
1�R�A�Ń}���`�X���b�h����������悤�ɂ���A���ʎg��������B
>>199
�����Ƃ����������Ă��當�匾����A���匾�������̋��Y�}�݂����ȖV��B
�������B
1�R�A�Ń}���`�X���b�h����������悤�ɂ���A���ʎg��������B
>>199
�����Ƃ����������Ă��當�匾����A���匾�������̋��Y�}�݂����ȖV��B
>>203
intel�ɏo����AMD�ɏo���Ȃ������Č�������A�n�C�p�[�X���b�f�B���O�ʂ��B
���ȏ�ɑ���CPU��AMD�����ɂ́A�ǂ���������낤�B
�ǂ��������āA�������Z���j�b�g�Ȃ�A����G���R�[�h��p�`�b�v�Ȃ�AGPU���j�b�g�⏕�`�b�v��CPU�ɍڂ�����悤�ɂ���̂��낤���H
���ȏ�ɐ��\���グ����@�Ƃ�������A������p�`�b�v���ڂ��邭�炢�����A���ɂ͎v�����Ȃ����ǁB
�c�c���������Ȃ�����A�n�C�G���h�p�\�R�����S��������p�@�Ƃ��ɂȂ肻�����ȁB
intel�ɏo����AMD�ɏo���Ȃ������Č�������A�n�C�p�[�X���b�f�B���O�ʂ��B
���ȏ�ɑ���CPU��AMD�����ɂ́A�ǂ���������낤�B
�ǂ��������āA�������Z���j�b�g�Ȃ�A����G���R�[�h��p�`�b�v�Ȃ�AGPU���j�b�g�⏕�`�b�v��CPU�ɍڂ�����悤�ɂ���̂��낤���H
���ȏ�ɐ��\���グ����@�Ƃ�������A������p�`�b�v���ڂ��邭�炢�����A���ɂ͎v�����Ȃ����ǁB
�c�c���������Ȃ�����A�n�C�G���h�p�\�R�����S��������p�@�Ƃ��ɂȂ肻�����ȁB
>>203
���\�Ə���d�̘͂b�����S�ɔ����Ă�ȁB
�s��ł�Pentium D�ɂ��������Ă�K8�ŁA
����͐��\������d�͂������Ă��܂����ƂɂȂ�̂ɁA
����ȏ�Ԃ�2008�N�܂ň��������Ă�
�N��K8�Ȃ�Ĕ���Ȃ��Ȃ��B
Intel��Tejas�L�����Z�����Ă��A�C�X���G���̊J���`�[����
������CPU����������o���������A
AMD�̕���K9�L�����Z�����Ă��̊ԉ����o�Ă��Ȃ��ᑊ���܂�������B
���\�Ə���d�̘͂b�����S�ɔ����Ă�ȁB
�s��ł�Pentium D�ɂ��������Ă�K8�ŁA
����͐��\������d�͂������Ă��܂����ƂɂȂ�̂ɁA
����ȏ�Ԃ�2008�N�܂ň��������Ă�
�N��K8�Ȃ�Ĕ���Ȃ��Ȃ��B
Intel��Tejas�L�����Z�����Ă��A�C�X���G���̊J���`�[����
������CPU����������o���������A
AMD�̕���K9�L�����Z�����Ă��̊ԉ����o�Ă��Ȃ��ᑊ���܂�������B
>CPU�����C���������ȊO�̂��̂ɃA�N�Z�X�ɍs����
���܂��A�ǂ��OS�g���Ă���B
���܂��A�ǂ��OS�g���Ă���B
>>207
�܂��A��낤�Ǝv�����ł��o���邾��B�d��Turion���ŁA�S�R�A��CPU�Ȃ�āB
���ƁA�Ȃ�ł��O���C���e���C�X���G���`�[�����A��Ɂu�X�P�W���[��������Ĉ�̃o�O�̖���CPU�����o����v���Ēf���ł���̂��A�킩��Ȃ��B
�C�X���G���l���l�Ԃ����B
�܂��A��낤�Ǝv�����ł��o���邾��B�d��Turion���ŁA�S�R�A��CPU�Ȃ�āB
���ƁA�Ȃ�ł��O���C���e���C�X���G���`�[�����A��Ɂu�X�P�W���[��������Ĉ�̃o�O�̖���CPU�����o����v���Ēf���ł���̂��A�킩��Ȃ��B
�C�X���G���l���l�Ԃ����B
> ����͐��\������d�͂������Ă��܂����ƂɂȂ�̂ɁA
����d�͂͂����炭 Intel �̕����L�����낤���A
���\��N���b�N�̕��� Intel �����邩�ǂ����͌����_�ł�
�Ȃ�Ƃ��������B
���ɁA�ŋ߂̃I���S���`�[���̎��s����������ƂˁB
(Conroe �̓I���S���ł���)
�����_��AMD�̓������o���h������Intel�ɕ����Ă�킯�����A
����ł����\�͏����Ă�B���N�ɂȂ�ƃ������o���h����
���͂Ȃ��Ȃ�A�����ă��������C�e���V�̓_�ł͏��Ȃ��Ƃ�
2007�N�ɂȂ�܂�AMD�̃��[�h�������BConroe�ŁA���\��
�t�]���ł���ƐM�������C�����͕����邪�A�������o�����_��
�������肷�邩����B
����d�͂͂����炭 Intel �̕����L�����낤���A
���\��N���b�N�̕��� Intel �����邩�ǂ����͌����_�ł�
�Ȃ�Ƃ��������B
���ɁA�ŋ߂̃I���S���`�[���̎��s����������ƂˁB
(Conroe �̓I���S���ł���)
�����_��AMD�̓������o���h������Intel�ɕ����Ă�킯�����A
����ł����\�͏����Ă�B���N�ɂȂ�ƃ������o���h����
���͂Ȃ��Ȃ�A�����ă��������C�e���V�̓_�ł͏��Ȃ��Ƃ�
2007�N�ɂȂ�܂�AMD�̃��[�h�������BConroe�ŁA���\��
�t�]���ł���ƐM�������C�����͕����邪�A�������o�����_��
�������肷�邩����B
>>207
������>>200�ɏo���������N���2007�N��New Core�Ə�����Ă�ł���B
���ʂ͂��ꂪK10�ƍl���邯�ǁA2008�N�܂�K8������������Ăǂ��������ƁH
�������K8�̐��Y���̂͏��Ȃ��Ƃ�2010�N�܂ł͑������Ƃ͊m�肵�Ă邯�ǁB
������>>200�ɏo���������N���2007�N��New Core�Ə�����Ă�ł���B
���ʂ͂��ꂪK10�ƍl���邯�ǁA2008�N�܂�K8������������Ăǂ��������ƁH
�������K8�̐��Y���̂͏��Ȃ��Ƃ�2010�N�܂ł͑������Ƃ͊m�肵�Ă邯�ǁB
>�s��ł�Pentium D�ɂ��������Ă�K8��
PenD���ĎI��10%�A�f�X�N�g�b�v��20%������Ă�́H
PenD���ĎI��10%�A�f�X�N�g�b�v��20%������Ă�́H
>intel�ɏo����AMD�ɏo���Ȃ������Č�������A�n�C�p�[�X���b�f�B���O�ʂ��B
XP�̎���ɂ��ł�SMT�͏o���Ă����ĕ������C������B�ł����\�⑼�̗��R��
�ς܂Ȃ������Ƃ��B����HTT�̓��������Ă��AMD�����ˁB
>���ȏ�ɑ���CPU��AMD�����ɂ́A�ǂ���������낤�B
�r���L���b�V���~�߂�x���`�͖Œ��ꒃ�����Ȃ�Ǝv���B���s���\�ɂǂꂾ��
���ʂ��邩���J������w
XP�̎���ɂ��ł�SMT�͏o���Ă����ĕ������C������B�ł����\�⑼�̗��R��
�ς܂Ȃ������Ƃ��B����HTT�̓��������Ă��AMD�����ˁB
>���ȏ�ɑ���CPU��AMD�����ɂ́A�ǂ���������낤�B
�r���L���b�V���~�߂�x���`�͖Œ��ꒃ�����Ȃ�Ǝv���B���s���\�ɂǂꂾ��
���ʂ��邩���J������w
>>210
>�����_��AMD�̓������o���h������Intel�ɕ����Ă�킯����
HyperTransport2.0��12.8GB/sec�T�|�[�g����Aintel��FSB�������H
>�����_��AMD�̓������o���h������Intel�ɕ����Ă�킯����
HyperTransport2.0��12.8GB/sec�T�|�[�g����Aintel��FSB�������H
>>212
�T�[�o��10%�͂Ȃ��ˁB��������PenD���āA�T�[�o�pCPU����Ȃ����A1�\�P�b�g
�ł��������Ȃ����B
>>213
�����r���L���b�V���͂��낻���߂����������Ǝv���BL2�����������������
�Ӗ������������ǁA���́c�B���� L2 1MB �̃`�b�v�ł͂�߂Ăق����B
>>214
>>210 �Ō����Ă�̂́AFSB�̃X�s�[�h����Ȃ��� DDR2 ���T�|�[�g���ĂȂ�����
�Ӗ��ˁB����� Socket M �҂��ł���?
���ƁA12.8GB/s �T�|�[�g���邽�߂ɂ́A1.6GHz �N���b�N�� HyperTransport ��
�K�v�Ȕ������AHyperTransport 2.0 �̋K�i�� 1.6GHz ���Ă���������?
1.4GHz �܂ł������悤�Ȋo�����c
�܂� 1.6GHz �ɂ��Ȃ��Ă��A32bit ������� 800MHz �ł� 12.8GB/s �ɂȂ邪�B
����Ɍ����_�ł� 16bit �N���b�N 1GHz �Ȃ̂ŁA�o���� 8GB/s �ŁA�J�^���O
�X�y�b�N�I�ɂ� Intel �� FSB �ɕ����Ă�B�܂��A���L FSB �������� P2P ��
�����I�[�o�w�b�h�����Ȃ��̂ŁA�������\���Ƃ܂�������Ƙb�͕ς�邪�c
�T�[�o��10%�͂Ȃ��ˁB��������PenD���āA�T�[�o�pCPU����Ȃ����A1�\�P�b�g
�ł��������Ȃ����B
>>213
�����r���L���b�V���͂��낻���߂����������Ǝv���BL2�����������������
�Ӗ������������ǁA���́c�B���� L2 1MB �̃`�b�v�ł͂�߂Ăق����B
>>214
>>210 �Ō����Ă�̂́AFSB�̃X�s�[�h����Ȃ��� DDR2 ���T�|�[�g���ĂȂ�����
�Ӗ��ˁB����� Socket M �҂��ł���?
���ƁA12.8GB/s �T�|�[�g���邽�߂ɂ́A1.6GHz �N���b�N�� HyperTransport ��
�K�v�Ȕ������AHyperTransport 2.0 �̋K�i�� 1.6GHz ���Ă���������?
1.4GHz �܂ł������悤�Ȋo�����c
�܂� 1.6GHz �ɂ��Ȃ��Ă��A32bit ������� 800MHz �ł� 12.8GB/s �ɂȂ邪�B
����Ɍ����_�ł� 16bit �N���b�N 1GHz �Ȃ̂ŁA�o���� 8GB/s �ŁA�J�^���O
�X�y�b�N�I�ɂ� Intel �� FSB �ɕ����Ă�B�܂��A���L FSB �������� P2P ��
�����I�[�o�w�b�h�����Ȃ��̂ŁA�������\���Ƃ܂�������Ƙb�͕ς�邪�c
>>211
AMD��New Core���ėǂ���������Winchester��Venice���hNew Core�h�����A����K8�̂܂�܁B
��������2007�N�����Ƀf�X�N�g�b�v�p��K10���o�Ă��������r�b�O�j���[�X�ɂȂ��Ă��ȁB
�����Ȃ��AMD�̊J���̏������猾���ăT�[�o�[�p�ɂ�2006�N��K10���o�ĂȂ��ƊԂɍ���Ȃ��Ȃ邪�A
�T�[�o�p�̃��[�h�}�b�v���Ă��A2007�N�ɂ����Ă�K8�̃}���`�R�A�������o�Ă��ĂȂ��B
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013144_1.jpg
�Ƃ������ƂŁAK10�͉e���`��������ԁB
AMD��New Core���ėǂ���������Winchester��Venice���hNew Core�h�����A����K8�̂܂�܁B
��������2007�N�����Ƀf�X�N�g�b�v�p��K10���o�Ă��������r�b�O�j���[�X�ɂȂ��Ă��ȁB
�����Ȃ��AMD�̊J���̏������猾���ăT�[�o�[�p�ɂ�2006�N��K10���o�ĂȂ��ƊԂɍ���Ȃ��Ȃ邪�A
�T�[�o�p�̃��[�h�}�b�v���Ă��A2007�N�ɂ����Ă�K8�̃}���`�R�A�������o�Ă��ĂȂ��B
ttp://www.hardware.fr/medias/photos_news/00/13/IMG0013144_1.jpg
{kind=link}
�Ƃ������ƂŁAK10�͉e���`��������ԁB
>>215
Conroe���o�Ă��鍠�ɂ́ASocketM��HT��1GHz32bit���T�|�[�g���邾��
Conroe���o�Ă��鍠�ɂ́ASocketM��HT��1GHz32bit���T�|�[�g���邾��
>>216
Winchester��Venice�N���X��New Core�Ȃ�ʂɓ��L����K�v�͂Ȃ��ł��傤�B
����Ƀr�b�O�j���[�X�ɂȂ�ĂȂ邩�ȁH
�Ⴆ��1�N�O��Conroe���r�b�O�j���[�X�ɂȂ��Ă��L���͂Ȃ����ǁB
�r�b�O�j���[�X�Ƃ������킩��Ȃ�����Ȃ�Ƃ������Ȃ����ǂˁB
���ƁA�V�R�A�̓T�[�o�ƃf�X�N�g�b�v/���o�C���ŕʂ̂��̂Ƃ�����������B
���Ȃ��Ƃ������̌����{�݂Ń��o�C���p��CPU��ʂɐv���Ă�̂͊ԈႢ�Ȃ��B
�i�܂��������K9�̂悤�ɃL�����Z�������\���͂�����ǁj
Winchester��Venice�N���X��New Core�Ȃ�ʂɓ��L����K�v�͂Ȃ��ł��傤�B
����Ƀr�b�O�j���[�X�ɂȂ�ĂȂ邩�ȁH
�Ⴆ��1�N�O��Conroe���r�b�O�j���[�X�ɂȂ��Ă��L���͂Ȃ����ǁB
�r�b�O�j���[�X�Ƃ������킩��Ȃ�����Ȃ�Ƃ������Ȃ����ǂˁB
���ƁA�V�R�A�̓T�[�o�ƃf�X�N�g�b�v/���o�C���ŕʂ̂��̂Ƃ�����������B
���Ȃ��Ƃ������̌����{�݂Ń��o�C���p��CPU��ʂɐv���Ă�̂͊ԈႢ�Ȃ��B
�i�܂��������K9�̂悤�ɃL�����Z�������\���͂�����ǁj
>>217
�Ȃ����Ă邱�Ƃ��ς�����ȁB(w
1GHz 32bit ���Ƒo������ 16GB/s �ɂȂ�ȁB�������� Socket M ��
32bit ������悤�ȋC�����Ă�B�̂� HyperTransport 2.0 �ŁA1.1
�̔{�����T�|�[�g������Č����Ă��̂ɁA���� 1.6GHz �̓T�|�[�g�O
�ɂȂ������Ă��ƂŁA���Ƃ� P2P �ł����N���b�N�͑�ςȂȂ��Ɓc
�܂��A�V���O���\�P�b�g�Ȃ�A�������g���t�B�b�N�͂قƂ�� Hyper
Transport ��ʂ�Ȃ��킯������A�f�X�N�g�b�v�����Ɋւ��ẮA
����ق� HyperTrasnport �������̕K�v���͂Ȃ����ǂˁB
�Ƃ������A>>210 �ŏ������悤�ɁAAMD �͌��R�A�̂܂܂ł��A�܂�
�������o���h���̓_�� ���Ȃ����̗]�n������킯�ŁAConroe ��
�P���� K8 �������Ɖ��肷��̂͂����ԊÂ�����Ă��ƂŁB
�Ȃ����Ă邱�Ƃ��ς�����ȁB(w
1GHz 32bit ���Ƒo������ 16GB/s �ɂȂ�ȁB�������� Socket M ��
32bit ������悤�ȋC�����Ă�B�̂� HyperTransport 2.0 �ŁA1.1
�̔{�����T�|�[�g������Č����Ă��̂ɁA���� 1.6GHz �̓T�|�[�g�O
�ɂȂ������Ă��ƂŁA���Ƃ� P2P �ł����N���b�N�͑�ςȂȂ��Ɓc
�܂��A�V���O���\�P�b�g�Ȃ�A�������g���t�B�b�N�͂قƂ�� Hyper
Transport ��ʂ�Ȃ��킯������A�f�X�N�g�b�v�����Ɋւ��ẮA
����ق� HyperTrasnport �������̕K�v���͂Ȃ����ǂˁB
�Ƃ������A>>210 �ŏ������悤�ɁAAMD �͌��R�A�̂܂܂ł��A�܂�
�������o���h���̓_�� ���Ȃ����̗]�n������킯�ŁAConroe ��
�P���� K8 �������Ɖ��肷��̂͂����ԊÂ�����Ă��ƂŁB
>>218
�Ȃ����ȉ����������Ă邯�ǁA�����̓\�[�X����낵���B
�Ȃ����ȉ����������Ă邯�ǁA�����̓\�[�X����낵���B
221 �FSocket774�F2005/10/10(��) 04:02:17 ID:DTPFCHUw
�@�@ �@ A�QA �@�@n�@ �@
�@�@ �i�@�E�́E �j(E) ))�@���ް�ɐ�����[�I
�@�@ �i/Op�@__�m
�@ �n�i�@�@�@�m
�@�@ /�@ ./
ttp://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
�@�@ �i�@�E�́E �j(E) ))�@���ް�ɐ�����[�I
�@�@ �i/Op�@__�m
�@ �n�i�@�@�@�m
�@�@ /�@ ./
ttp://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
>>220
������ӂɁAnew core �̘b���ڂ��Ă��B
ttp://www.extremetech.com/article2/0,1697,1826657,00.asp
ttp://www.extremetech.com/article2/0,1697,1826658,00.asp
DDR-3, ��� PCI Express, HyperTransport 3.0, quad-core,
new multimedia-specific instructions, ����� additional
enhancements to the floating-point architecture ���������B
"cluster based multithreading," a technology specifically designed
for large enterprise clusters. The technology would allow other
microprocessors to share specific blocks on the chip, such as the
floating-point unit. Designing this technology in will cost an
additional 50 percent in die resources, but yield an additional 80
percent improvement in performance, Moore said.
���ĂȂ�낤�B
������ӂɁAnew core �̘b���ڂ��Ă��B
ttp://www.extremetech.com/article2/0,1697,1826657,00.asp
ttp://www.extremetech.com/article2/0,1697,1826658,00.asp
DDR-3, ��� PCI Express, HyperTransport 3.0, quad-core,
new multimedia-specific instructions, ����� additional
enhancements to the floating-point architecture ���������B
"cluster based multithreading," a technology specifically designed
for large enterprise clusters. The technology would allow other
microprocessors to share specific blocks on the chip, such as the
floating-point unit. Designing this technology in will cost an
additional 50 percent in die resources, but yield an additional 80
percent improvement in performance, Moore said.
���ĂȂ�낤�B
>>220
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20040625/146372/
����Ƃ���OK�H
�T�[�o�ƃf�X�N�g�b�v/���o�C�����ʃR�A�Ƃ����̂͂��ꂱ��>>200����̗ސ�����B
�S�R�Ⴄ���̂Ɍ����Ȃ��H
>>222
���������b�̃l�^�ɂȂ��Ă�p�l����
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_10383,00.html
��pdf�ł��邯�ǁA������Chuck Moore�̂������������ڂ�������������B
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20040625/146372/
����Ƃ���OK�H
�T�[�o�ƃf�X�N�g�b�v/���o�C�����ʃR�A�Ƃ����̂͂��ꂱ��>>200����̗ސ�����B
�S�R�Ⴄ���̂Ɍ����Ȃ��H
>>222
���������b�̃l�^�ɂȂ��Ă�p�l����
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_10383,00.html
��pdf�ł��邯�ǁA������Chuck Moore�̂������������ڂ�������������B
�I���ă^���o�K�j�H
�^���o�K�j����������ˁB
�^���o�K�j����������ˁB
����I�������B��ǂ�����B
P7,P8���L�����Z�����ꂽ���ƂɂȂ��Ă�ȁB
NetBurst��P15����Ȃ���P-1���Ǝv���Ă��邻��ȉ��lPenM�h
>>222-223
float4�Adouble2��1���߂ŏ����ł���悤�ɂȂ�̂��ȁH
�i�͂����茾���Č��|���|����64�r�b�g�j�R�C�`��128�r�b�gSIMD�����ُ͈�j
NetBurst��P15����Ȃ���P-1���Ǝv���Ă��邻��ȉ��lPenM�h
>>222-223
float4�Adouble2��1���߂ŏ����ł���悤�ɂȂ�̂��ȁH
�i�͂����茾���Č��|���|����64�r�b�g�j�R�C�`��128�r�b�gSIMD�����ُ͈�j
���o������sossaman��yonah������
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
Yonah����Ɠ��N���b�N����K8�̕������\����ۂ��ȁB
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
Yonah����Ɠ��N���b�N����K8�̕������\����ۂ��ȁB
>>228
�V���O���R�A�ł��N���b�N������Ȃ�Athlon64����L���ȃx���`�Ȃ�łǂ��Ƃ������Ȃ��ˁB
http://akiba.ascii24.com/akiba/column/latestparts/2005/02/03/imageview/images764854.gif.html
�V���O���R�A�ł��N���b�N������Ȃ�Athlon64����L���ȃx���`�Ȃ�łǂ��Ƃ������Ȃ��ˁB
http://akiba.ascii24.com/akiba/column/latestparts/2005/02/03/imageview/images764854.gif.html
{kind=link}
Athlon 64 X4�@����H�҂�����Ȃ��ăC���C�����܂����Ă���I
AMD�̛��ăR�A�͂܂��ł����E
233 �FSocket774�F2005/10/10(��) 19:47:27 ID:IR37PXvq
�t���Z�b�g�A�\�V�A�e�B�u������CPU�̕����_�C���N�g�}�b�v������
CPU��荂���Ƀv���O���������s�ł���̂͂ǂ�ȏꍇ�ł����H�H
�������������i���Q���j
CPU��荂���Ƀv���O���������s�ł���̂͂ǂ�ȏꍇ�ł����H�H
�������������i���Q���j
234 �FSocket774�F2005/10/10(��) 19:51:38 ID:IR37PXvq
�L���b�V���������Ńu���b�N�T�C�Y���P�U�o�C�g�A���v�u���b�N����
�Q�O�S�W�u���b�N�ł���B
�_�C���N�g�}�b�v�L���b�V��������CPU�ɂ����āA�L���b�V����������
�@�\�����Ԃ�16*2048��32768�o�C�g�̃v���O�����������B���ׂĂ�
���߂��S�o�C�g���Ɏ��܂�Ƃ��A���̃v���O�����Ɏ��s�ɂ͉��N���b�N
�����邩�H
�E�E�E�Ƃ�����肪�ǂ����Ă������܂���B�B�B
�����������A�ǂ��������Ă���������
�Q�O�S�W�u���b�N�ł���B
�_�C���N�g�}�b�v�L���b�V��������CPU�ɂ����āA�L���b�V����������
�@�\�����Ԃ�16*2048��32768�o�C�g�̃v���O�����������B���ׂĂ�
���߂��S�o�C�g���Ɏ��܂�Ƃ��A���̃v���O�����Ɏ��s�ɂ͉��N���b�N
�����邩�H
�E�E�E�Ƃ�����肪�ǂ����Ă������܂���B�B�B
�����������A�ǂ��������Ă���������
Cinebench 2003 Rendering
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
http://akiba.ascii24.com/akiba/column/latestparts/2005/06/01/images/images775460.gif
http://pcweb.mycom.co.jp/articles/2004/08/07/xeon/images/graph13l.gif
1005�@ Opteron 875�~2�@2.2GHz
884�@�@Sossaman�~2�@2GHz
668�@�@Xeon�@3.6GHz
583�@�@Opteron 875�@2.2GHz
206�@�@Sossaman�iSC�j�@1.5GHz
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
http://akiba.ascii24.com/akiba/column/latestparts/2005/06/01/images/images775460.gif
{kind=link}
http://pcweb.mycom.co.jp/articles/2004/08/07/xeon/images/graph13l.gif
{kind=link}
1005�@ Opteron 875�~2�@2.2GHz
884�@�@Sossaman�~2�@2GHz
668�@�@Xeon�@3.6GHz
583�@�@Opteron 875�@2.2GHz
206�@�@Sossaman�iSC�j�@1.5GHz
�f���A���R�A��AMD���܂��܂������Ȃ肻����
Intel�͏���d�͂�����Ǝg���郌�x���ɉ����邯��
Intel�͏���d�͂�����Ǝg���郌�x���ɉ����邯��
SSE2���g����悤�ɂȂ�܂ő҂��Ă�����
����A�g�������Ȃ�g������āB
�����ƒP���x��MMX/3DNOW!�̂ق����������������ŁB
�����ƒP���x��MMX/3DNOW!�̂ق����������������ŁB
>>233
cache line������ɂȂ�ꍇ�����鎞
fully associative cache������
>>234
���̍��ڂ��킩��Ȃ�����s�\
�E1���߂̎��s�ɉ��N���b�N�����邩�s��
�E�L���b�V���~�X�����ꍇ�̃y�i���e�B���s��
�E�L���b�V���q�b�g�����ꍇ�̃A�N�Z�X�T�C�N�����s��
�E����\�����͖������Ă悢�̂��s��
�E1�T�C�N���ɉ����߃t�F�b�`����̂��s��
�E1�T�C�N���ɉ����ߔ��s�E���s����̂��s��
�E�v���O�����̃A�h���X���z�i�Ƃ������R���g���[���t���[�j��
�ǂ̂悤�ɂȂ��Ă��邩�s��
�E�f�[�^�A�N�Z�X�͗��z�I�Ƃ��Ă悢�̂��s��
cache line������ɂȂ�ꍇ�����鎞
fully associative cache������
>>234
���̍��ڂ��킩��Ȃ�����s�\
�E1���߂̎��s�ɉ��N���b�N�����邩�s��
�E�L���b�V���~�X�����ꍇ�̃y�i���e�B���s��
�E�L���b�V���q�b�g�����ꍇ�̃A�N�Z�X�T�C�N�����s��
�E����\�����͖������Ă悢�̂��s��
�E1�T�C�N���ɉ����߃t�F�b�`����̂��s��
�E1�T�C�N���ɉ����ߔ��s�E���s����̂��s��
�E�v���O�����̃A�h���X���z�i�Ƃ������R���g���[���t���[�j��
�ǂ̂悤�ɂȂ��Ă��邩�s��
�E�f�[�^�A�N�Z�X�͗��z�I�Ƃ��Ă悢�̂��s��
>>234
��w�̏h��Ȃ� 8192clock ���낤(���z����z�肷��n�Y)
�������Ȃ���A���ۂ� >>239 �������Ă邱�Ƃ�z�肵�Ȃ��Ƃ킩����B
���ɂ��V���O���^�X�N�Ȃ̂��}���`�^�X�N�Ȃ̂����荞�ݔ����̗L���Ƃ�
�S�z�Ȃ�u���s���̑O��������s�����Ă��邽�߉ł��Ȃ��v�Ɖ�
���Ȃ���B
��w�̏h��Ȃ� 8192clock ���낤(���z����z�肷��n�Y)
�������Ȃ���A���ۂ� >>239 �������Ă邱�Ƃ�z�肵�Ȃ��Ƃ킩����B
���ɂ��V���O���^�X�N�Ȃ̂��}���`�^�X�N�Ȃ̂����荞�ݔ����̗L���Ƃ�
�S�z�Ȃ�u���s���̑O��������s�����Ă��邽�߉ł��Ȃ��v�Ɖ�
���Ȃ���B
�܂����������͂Ђǂ��C���^�[�l�b�g�ł���
�F����͂ЂƂ̒ɂ݂��킩��Ȃ��̂ł��傤��
����������Ƃ����Ė��ӔC�Ȕ������������܂���I�I
��Q�҂̐l���͂ǂ��ł��ǂ��Ƃ����̂ł��傤���H
�j���[�X�X�e�[�V�����̒}�����A�C���^�[�l�b�g�̂��Ƃ��A
�֏��̃g�C�����Č����Ă���̂�m���Ă܂��H���Ȃ�������
�ǂ����j���[�X�����Ȃ�����m��Ȃ��Ƒ����܂����B
�Ƃ��Ƃ��A�{�C�ŕ���Ă��܂��B��������A�ǂ�ǂ�H��
��ʂ�`���ɂ��܂����B���ꂩ��A���Ƃ���������܂����B
���̂U����A�������܂����B���Ȃ������́A�䂪�Ƃɏ��Ă��܂��B
�ƂĂ�������ł��B�Ƒ��݂�Ȃ��A���̐l��������������
���������˂��āA�݂��ɔl�荇���Ă��܂��B����������́A
�����R�N�ƂɋA���Ă��Ă܂��A�K����������������������ˁA
���ĉ]���Ǝv���܂���B�ǂ��ł��H���Ɏӂ�Ȃ�A���̂����ł���B
���͂���ł��C�������ق��Ȃ�ł��B�܂��R����A�����ɗ��܂��B���肪�Ƃ��������܂����B
�F����͂ЂƂ̒ɂ݂��킩��Ȃ��̂ł��傤��
����������Ƃ����Ė��ӔC�Ȕ������������܂���I�I
��Q�҂̐l���͂ǂ��ł��ǂ��Ƃ����̂ł��傤���H
�j���[�X�X�e�[�V�����̒}�����A�C���^�[�l�b�g�̂��Ƃ��A
�֏��̃g�C�����Č����Ă���̂�m���Ă܂��H���Ȃ�������
�ǂ����j���[�X�����Ȃ�����m��Ȃ��Ƒ����܂����B
�Ƃ��Ƃ��A�{�C�ŕ���Ă��܂��B��������A�ǂ�ǂ�H��
��ʂ�`���ɂ��܂����B���ꂩ��A���Ƃ���������܂����B
���̂U����A�������܂����B���Ȃ������́A�䂪�Ƃɏ��Ă��܂��B
�ƂĂ�������ł��B�Ƒ��݂�Ȃ��A���̐l��������������
���������˂��āA�݂��ɔl�荇���Ă��܂��B����������́A
�����R�N�ƂɋA���Ă��Ă܂��A�K����������������������ˁA
���ĉ]���Ǝv���܂���B�ǂ��ł��H���Ɏӂ�Ȃ�A���̂����ł���B
���͂���ł��C�������ق��Ȃ�ł��B�܂��R����A�����ɗ��܂��B���肪�Ƃ��������܂����B
>>239-240
>>234�̓}���`�ł�����A�������̃X���ɂ��������Ə����Ă�
http://pc7.2ch.net/test/read.cgi/jisaku/1128543843/l50
>>234�̓}���`�ł�����A�������̃X���ɂ��������Ə����Ă�
http://pc7.2ch.net/test/read.cgi/jisaku/1128543843/l50
������AMDCPU��Intel�X��������p�����
������ӂɁAnew core �̘b���ڂ��Ă��B
ttp://www.extremetech.com/article2/0,1697,1826657,00.asp
ttp://www.extremetech.com/article2/0,1697,1826658,00.asp
DDR-3, ��� PCI Express, HyperTransport 3.0, quad-core,
new multimedia-specific instructions, ����� additional
enhancements to the floating-point architecture ���������B
�Ƃ������Ƃ炵���ȁB�܂��A�O����\�͂��������B
�Ȃ�Ƃ������A�}�j�A���Ȃ�AMD�̎�����R�A�Ƃ������B
PCI-E��������Ƃ��������肩��AMD�̏����I�ȓW�J��������B
���`�b�v�Z�b�g�x���_�[�ւ̈ˑ����Ȃ����A
�p�t�H�[�}���X�����コ���悤�Ƃ����_�����낤�B
�����_�ł�PCI-Ex�̎����̓v���Z�X�Z�p�̓_����`�b�v�x���_�[�ɂ͌������i�炵���j�B
AMD�ɂ͍Ő�[�v���Z�X��Fab�����邩�炱�����ł�����ق��������L�����B
������PCI-E���R���g���[����CPU�̊Ǘ����ɂ�����̂ŁA�s�v�ȃX�g�[��������邱�Ƃ��ł��������B
�����I�Ɍ���ƁAx86CPU�͂Ȃ�������Ă���̂��A���l���A
x86CPU�iAMD��CPU�j�͂��ꂩ�甄�ꑱ���邽�߂ɂǂ�����悢�̂����l���Ȃ���Ȃ�Ȃ��B
���ݔ��ꑱ���Ă��闝�R��Microsoft��Windows�ɍ̗p���Ă��邩��A
����Ɖߋ��̖L�x�Ȏ��Y�����邩�炾�B
�������A������Ă��ꂩ�甄�ꑱ���闝�R�ɂ��Ă͂Ƃ�ł��Ȃ��S�ׂ����̂���Ȃ����낤���B
Java��.net�̂悤�ȃA�[�L�e�N�`���Ɉˑ����Ȃ��v���O�����������Ă����B
������GPU�̐��܂��������ɂ��A�}���`�X���b�h�R���s���[�e�B���O�ł͂Ƃ���GPU�̂ق������\�������B
�͂����݂Ŏs������Intel�ɔ�ׂāAx86����܂����Ƃ���ꂽ�Ƃ���1�`�b�v�ł��낢��ł��܂��A
�Ƃ��A�ėpIO���낢�날��܂��A�Ƃ�����AMD�̂ق�����i�I�ł͂Ȃ��낤���Ǝv�����������̂���B
�ȏ���L�����B
������ӂɁAnew core �̘b���ڂ��Ă��B
ttp://www.extremetech.com/article2/0,1697,1826657,00.asp
ttp://www.extremetech.com/article2/0,1697,1826658,00.asp
DDR-3, ��� PCI Express, HyperTransport 3.0, quad-core,
new multimedia-specific instructions, ����� additional
enhancements to the floating-point architecture ���������B
�Ƃ������Ƃ炵���ȁB�܂��A�O����\�͂��������B
�Ȃ�Ƃ������A�}�j�A���Ȃ�AMD�̎�����R�A�Ƃ������B
PCI-E��������Ƃ��������肩��AMD�̏����I�ȓW�J��������B
���`�b�v�Z�b�g�x���_�[�ւ̈ˑ����Ȃ����A
�p�t�H�[�}���X�����コ���悤�Ƃ����_�����낤�B
�����_�ł�PCI-Ex�̎����̓v���Z�X�Z�p�̓_����`�b�v�x���_�[�ɂ͌������i�炵���j�B
AMD�ɂ͍Ő�[�v���Z�X��Fab�����邩�炱�����ł�����ق��������L�����B
������PCI-E���R���g���[����CPU�̊Ǘ����ɂ�����̂ŁA�s�v�ȃX�g�[��������邱�Ƃ��ł��������B
�����I�Ɍ���ƁAx86CPU�͂Ȃ�������Ă���̂��A���l���A
x86CPU�iAMD��CPU�j�͂��ꂩ�甄�ꑱ���邽�߂ɂǂ�����悢�̂����l���Ȃ���Ȃ�Ȃ��B
���ݔ��ꑱ���Ă��闝�R��Microsoft��Windows�ɍ̗p���Ă��邩��A
����Ɖߋ��̖L�x�Ȏ��Y�����邩�炾�B
�������A������Ă��ꂩ�甄�ꑱ���闝�R�ɂ��Ă͂Ƃ�ł��Ȃ��S�ׂ����̂���Ȃ����낤���B
Java��.net�̂悤�ȃA�[�L�e�N�`���Ɉˑ����Ȃ��v���O�����������Ă����B
������GPU�̐��܂��������ɂ��A�}���`�X���b�h�R���s���[�e�B���O�ł͂Ƃ���GPU�̂ق������\�������B
�͂����݂Ŏs������Intel�ɔ�ׂāAx86����܂����Ƃ���ꂽ�Ƃ���1�`�b�v�ł��낢��ł��܂��A
�Ƃ��A�ėpIO���낢�날��܂��A�Ƃ�����AMD�̂ق�����i�I�ł͂Ȃ��낤���Ǝv�����������̂���B
�ȏ���L�����B
>>243
x86����Ȃ����A���ł�PCI-E�������f���A���R�ACPU��90nm�v���Z�X�ő��݂���B
���ꂼ��̃R�A�ɃM�K�r�b�g�C�[�T�ƃ������R���g���[���ARapid IO�R���g���[���APCI-Ex8���[�������Ă���
���{�ꂾ�Ƃ������킩��₷��
ttp://www.freescale.co.jp/media/news/mpc8641.html
���͂��ꂭ�炢�����m��Ȃ����A�g�ݍ������ł͑��ɂ����肻������
>�͂����݂Ŏs������Intel�ɔ�ׂāAx86����܂����Ƃ���ꂽ�Ƃ���1�`�b�v�ł��낢��ł��܂��A
>�Ƃ��A�ėpIO���낢�날��܂��A�Ƃ�����AMD�̂ق�����i�I�ł͂Ȃ��낤���Ǝv�����������̂���B
x86�܂ޑS�Ă̔����̃V�F�A�ŁA�C���e���̓g�b�v�Ȃ��
x86���C���e���̃��C���Ȃ̂͊ԈႢ�Ȃ��Ǝv�����AAMD�͂��̃����N�t�����Ƃ��Ȃ艺�ŁAx86�s��Ɍ���2�ʁA�݂����Ȋ���
��i�I�ȍl�����������Ă�̂͂������Ƃ��Ǝv�����Ax86����܂����ƌ���ꂽ�Ƃ��ɐ�ɂ�����̂�AMD
x86����Ȃ����A���ł�PCI-E�������f���A���R�ACPU��90nm�v���Z�X�ő��݂���B
���ꂼ��̃R�A�ɃM�K�r�b�g�C�[�T�ƃ������R���g���[���ARapid IO�R���g���[���APCI-Ex8���[�������Ă���
���{�ꂾ�Ƃ������킩��₷��
ttp://www.freescale.co.jp/media/news/mpc8641.html
���͂��ꂭ�炢�����m��Ȃ����A�g�ݍ������ł͑��ɂ����肻������
>�͂����݂Ŏs������Intel�ɔ�ׂāAx86����܂����Ƃ���ꂽ�Ƃ���1�`�b�v�ł��낢��ł��܂��A
>�Ƃ��A�ėpIO���낢�날��܂��A�Ƃ�����AMD�̂ق�����i�I�ł͂Ȃ��낤���Ǝv�����������̂���B
x86�܂ޑS�Ă̔����̃V�F�A�ŁA�C���e���̓g�b�v�Ȃ��
x86���C���e���̃��C���Ȃ̂͊ԈႢ�Ȃ��Ǝv�����AAMD�͂��̃����N�t�����Ƃ��Ȃ艺�ŁAx86�s��Ɍ���2�ʁA�݂����Ȋ���
��i�I�ȍl�����������Ă�̂͂������Ƃ��Ǝv�����Ax86����܂����ƌ���ꂽ�Ƃ��ɐ�ɂ�����̂�AMD
>244
�g�b�v�Ȃ̂��E�E�E�E
�����炱���A�͂�����Intel�A�l�ꔪ�ꂷ��AMD�ȂȁB
�[�������B
�g�b�v�Ȃ̂��E�E�E�E
�����炱���A�͂�����Intel�A�l�ꔪ�ꂷ��AMD�ȂȁB
�[�������B
>>244
�Ȃ�ł��������ʔ����R�A����̂ɱ�߰��PPC�̂Ă�낤�ˁE�E�E
�ǂ����Ȃ炻�������R�A�g����PC�ł͏o���Ȃ��l�ȃ}�V���o���Ă�����
�R����߰�����̂ɂȁE�E�E
�Ȃ�ł��������ʔ����R�A����̂ɱ�߰��PPC�̂Ă�낤�ˁE�E�E
�ǂ����Ȃ炻�������R�A�g����PC�ł͏o���Ȃ��l�ȃ}�V���o���Ă�����
�R����߰�����̂ɂȁE�E�E
MAC�I�^����
>>247
�c�O�Ȃ���B
���̃X�X��������������B
�����c��������ĂȂ�Ƃ�����̂͂ǂ��ł��ꏏ�B
AMD���낤���A�����̉�Ђ��낤���A�������낤���B
��Ђ��A�����Ă����̕������A�����������獡�����������Ƃ����l���Ȃ��ăi
�ŁA�d�����A���{�̍s�����[�Ȃ�čl���Ă�A�����������Ȗ�Y�ł���B
�c�O�Ȃ���B
���̃X�X��������������B
�����c��������ĂȂ�Ƃ�����̂͂ǂ��ł��ꏏ�B
AMD���낤���A�����̉�Ђ��낤���A�������낤���B
��Ђ��A�����Ă����̕������A�����������獡�����������Ƃ����l���Ȃ��ăi
�ŁA�d�����A���{�̍s�����[�Ȃ�čl���Ă�A�����������Ȗ�Y�ł���B
>>244
��������x86�̐��̘_����IA-64�Őg�������Ēm���Ă邩��ȁAintel��
��������x86�̐��̘_����IA-64�Őg�������Ēm���Ă邩��ȁAintel��
>>203
>Intel �����㐔�N�����Ă��悤�Ȃ��Ƃ��A����
>���N���O�Ɏ�����������Ă���Ă��Ƃ���
�t��intel��������S�Ď��������Ƃ��ɂ́A
AMD�͂܂��V�������炩���C���v�������g���Ă����Ȃ���
Գާ����ƂɂȂ�A�Ƃ������ƂȂ̂ł�?
���Ƀ������R���g���[�������̌��ʂ͂ǂ�����CPU�����Ă����炩�Ȃ悤����('��`)
������C���v�������g���Ă���̂�NetBurst����̉��ǂ���Ȃ��A�Ƃ����_��
���Ҋ��̍������R�̈���ƁB
�܂�����͒u���Ƃ��āB
AMD��65nm�v���Z�X�Ȃ�̂͂��H
>Intel �����㐔�N�����Ă��悤�Ȃ��Ƃ��A����
>���N���O�Ɏ�����������Ă���Ă��Ƃ���
�t��intel��������S�Ď��������Ƃ��ɂ́A
AMD�͂܂��V�������炩���C���v�������g���Ă����Ȃ���
Գާ����ƂɂȂ�A�Ƃ������ƂȂ̂ł�?
���Ƀ������R���g���[�������̌��ʂ͂ǂ�����CPU�����Ă����炩�Ȃ悤����('��`)
������C���v�������g���Ă���̂�NetBurst����̉��ǂ���Ȃ��A�Ƃ����_��
���Ҋ��̍������R�̈���ƁB
�܂�����͒u���Ƃ��āB
AMD��65nm�v���Z�X�Ȃ�̂͂��H
>>250
�ǂ�����CPU���Ă̂�Efficion�̂��Ƃ��I
�ǂ�����CPU���Ă̂�Efficion�̂��Ƃ��I
>>250
Fab36�̉ғ��Ɠ������ɂȂ邾�낤�B
�j���[�X�T�C�g�������
2004�N5��18���@AMD�AFab36�̌���������
2004�N12��16���@AMAT�AAMD��Fab36�������u�̎��l��
Fab36�́A2005�N���ɉғ����J�n�����\��
Fab36�̃p�C���b�g���Y�J�n��2005�N�㔼�A�ʎY�o�ׂ�2006�N�ȍ~�ƂȂ��Ă���
�ȂǂȂǁB
�Ó��ȂƂ����2006�N���`10�����炢���B
�x���\���͔ے�ł��Ȃ����B
Intel�͗��N�n�߂������ȁB
Fab36�̉ғ��Ɠ������ɂȂ邾�낤�B
�j���[�X�T�C�g�������
2004�N5��18���@AMD�AFab36�̌���������
2004�N12��16���@AMAT�AAMD��Fab36�������u�̎��l��
Fab36�́A2005�N���ɉғ����J�n�����\��
Fab36�̃p�C���b�g���Y�J�n��2005�N�㔼�A�ʎY�o�ׂ�2006�N�ȍ~�ƂȂ��Ă���
�ȂǂȂǁB
�Ó��ȂƂ����2006�N���`10�����炢���B
�x���\���͔ے�ł��Ȃ����B
Intel�͗��N�n�߂������ȁB
�@�@�@�V�� �ȁQ��
�@�@�@���܁i �@�E�ցE�j�@�@�͂��͂��o���X�o���X
�@�@�@�@ �M�R_����/�܂�
�@�@�@���܁i �@�E�ցE�j�@�@�͂��͂��o���X�o���X
�@�@�@�@ �M�R_����/�܂�
AMD��Opteron/Athlon�AIntel��Pentium 4�Ƃ��A���̔��W�̗��j��
DEC��Alpha AXP�̔��W�̐Ղ��Ȃ����Ă����ɉ߂��Ȃ��B
Alpha AXP���I�����������̂ŁA�V�@�\�̌��l�^�������Ȃ���������B
�c��啨�́A21364��NUMA�ڑ��@�\���炢��?
DEC��Alpha AXP�̔��W�̐Ղ��Ȃ����Ă����ɉ߂��Ȃ��B
Alpha AXP���I�����������̂ŁA�V�@�\�̌��l�^�������Ȃ���������B
�c��啨�́A21364��NUMA�ڑ��@�\���炢��?
�ŏI�I�ɂ���т��c�݂����ɂȂ������
>243
PCI-Ex���Â��v���Z�X�ł͓̒�����R�͂��̕ӂ��琔��ɕ����ď�����Ă����
ttp://pcweb.mycom.co.jp/column/sopinion/100/
I/O�p�Ɏg���Ă���HT����hop�����邾�낤����Op�̕����������W�J����
Athlon�͎�����ł����܂�������w
PCI-Ex���Â��v���Z�X�ł͓̒�����R�͂��̕ӂ��琔��ɕ����ď�����Ă����
ttp://pcweb.mycom.co.jp/column/sopinion/100/
I/O�p�Ɏg���Ă���HT����hop�����邾�낤����Op�̕����������W�J����
Athlon�͎�����ł����܂�������w
CPU��PCI-Ex��������������\�����������H
SocketF��1207pin������PCI-Ex�Ɏg���邩���H���Ăȗ\�z�����������Ƃ��������B
SocketF��1207pin������PCI-Ex�Ɏg���邩���H���Ăȗ\�z�����������Ƃ��������B
�Ƃ�[�����AAMD�Ƃ��Ă݂��ꍇ�A�헪�܂������ĂȂ����H
PCI Express���ꐶ���������Ăǂ�����̂�H
AMD���撣��ȃA�J���̂�HyperTransport����Ȃ��̂��H
PCI Express���ꐶ���������Ăǂ�����̂�H
AMD���撣��ȃA�J���̂�HyperTransport����Ȃ��̂��H
259 �FSocket774�F2005/10/12(��) 17:02:25 ID:QdW+bkab
>>239,240
���肪�Ƃ��������܂����B
���|�[�g�������i?�j��o�ł��܂����I�I
�A�[�L�e�N�`���̒P�ʗ��Ƃ������ȋC�����܂��B�B�B
���肪�Ƃ��������܂����B
���|�[�g�������i?�j��o�ł��܂����I�I
�A�[�L�e�N�`���̒P�ʗ��Ƃ������ȋC�����܂��B�B�B
PCI-E��pin�g�����炢��������A
HT�̊g���̂��߂�pin�g���������ǂ���
HT�̊g���̂��߂�pin�g���������ǂ���
�m�[�X���S�ɓ������Ă�C
����PowerMac G5�����f���`�F���W����킯�����AHT2.0�͍̗p�����̂���
����Ƃ��A�܂�HT2.0���̏��������ĂȂ����ȁH
���s�@�킪HT1.35GHz�����ǁA����ɏオ��̂��A����Ƃ�PPC970MP�̗p����1.25GHz�ɂȂ�̂��E�E�E
����Ƃ��A�܂�HT2.0���̏��������ĂȂ����ȁH
���s�@�킪HT1.35GHz�����ǁA����ɏオ��̂��A����Ƃ�PPC970MP�̗p����1.25GHz�ɂȂ�̂��E�E�E
�����x86������̃X�^���_�[�h�ł������A�ǂ��ł�����������
���́A�ь炾�� �o����64bit x 1.35GHz �̍����\ HTbus �������o���āA
���� AMD64�i�o����32bit x 1GH����ˁH�j �͏o���Ȃ��H
����͈�d�ɗь�̋Z�p���G�킾����Ȃ̂��낤���H
���� AMD64�i�o����32bit x 1GH����ˁH�j �͏o���Ȃ��H
����͈�d�ɗь�̋Z�p���G�킾����Ȃ̂��낤���H
�݊����������Đ�������Ă��d���Ȃ�����B
�ь�݂����ȑS�Ď��������Ŋ������鐢�E�Ȃ�Ƃ������B
�ь�݂����ȑS�Ď��������Ŋ������鐢�E�Ȃ�Ƃ������B
�����������ʂȂ��̂�M/B�������Ȃ邾��B
>>266
HT���{�g���l�b�N�ɂȂ��Ă�p�r�A�Ȃ��ĂȂ��p�r�B
HT��o����64bit����o����32bit�ɕς���Ƃ���ɕt�����ĉ���ύX���鎖�ɂȂ邩�A
�Ƃ�������ƍl����Η��R�Ȃ�ă{���{���o�Ă���Ǝv�����H
HT���{�g���l�b�N�ɂȂ��Ă�p�r�A�Ȃ��ĂȂ��p�r�B
HT��o����64bit����o����32bit�ɕς���Ƃ���ɕt�����ĉ���ύX���鎖�ɂȂ邩�A
�Ƃ�������ƍl����Η��R�Ȃ�ă{���{���o�Ă���Ǝv�����H
Uni �� Athlon �͑���قǕK�v�Ȃ������m��A
MP �� Opteron �͂��Ȃ���ʂ���ł���B
MP �� Opteron �͂��Ȃ���ʂ���ł���B
���̂��A�ь��FSB����HT����Ȃ��ł���B
�����675MHzDDR��1.35GHz�B
AMD��HT��1GHzDDR��2GHz�B
�����675MHzDDR��1.35GHz�B
AMD��HT��1GHzDDR��2GHz�B
>>272
1CPU�̑ш��32bit x1.35GHz x2 =10.8GB/s�����ˁB
HT���ǂ����͒m��Ȃ����ǁB
Opteron���������Ă�̂́A16bit x2GHz(or 1.6GHz) x2=8GB/s(or 6.4GB/s)��3�n���B
����ɁAMemory bus��64bit x400MHz x2 = 6.4GB/s�B
�V�X�e���̑ш�̈Ⴂ���悭�l����B>>266
1CPU�̑ш��32bit x1.35GHz x2 =10.8GB/s�����ˁB
HT���ǂ����͒m��Ȃ����ǁB
Opteron���������Ă�̂́A16bit x2GHz(or 1.6GHz) x2=8GB/s(or 6.4GB/s)��3�n���B
����ɁAMemory bus��64bit x400MHz x2 = 6.4GB/s�B
�V�X�e���̑ш�̈Ⴂ���悭�l����B>>266
CPU���ǂ�������BSystem Controller������HT���낤���ǁB
ttp://www.apple.com/powermac/architecture.html
�m���Ă�Ȃ炻���͂����肵�Ă���B
ttp://www.apple.com/powermac/architecture.html
�m���Ă�Ȃ炻���͂����肵�Ă���B
>>205
CPU�̃A�[�L�e�N�`���̘b������X���ŁA�킩��Ȃ��A���Ă����͕̂s����I�ɏグ�Ă�Ǝv���B
>>208
Windows�ł�Linux�ł��A�h���C�o�̓��C���������ȊO�̂��̂ɃA�N�Z�X�ɍs���܂���B
>>224
�I�`�b�v�ɃA�N�Z�X���鎞�ACPU�͂قƂ�Njx��ł��܂��B�d�����Ă��܂���B
>>227
P7�͑厸�s���Itanium�ł���B
CPU�̃A�[�L�e�N�`���̘b������X���ŁA�킩��Ȃ��A���Ă����͕̂s����I�ɏグ�Ă�Ǝv���B
>>208
Windows�ł�Linux�ł��A�h���C�o�̓��C���������ȊO�̂��̂ɃA�N�Z�X�ɍs���܂���B
>>224
�I�`�b�v�ɃA�N�Z�X���鎞�ACPU�͂قƂ�Njx��ł��܂��B�d�����Ă��܂���B
>>227
P7�͑厸�s���Itanium�ł���B
> �Ȃ�Ƃ������A�}�j�A���Ȃ�AMD�̎�����R�A�Ƃ������B
> �t��intel��������S�Ď��������Ƃ��ɂ́A
> AMD�͂܂��V�������炩���C���v�������g���Ă����Ȃ���
������āAIntel�X������Ȃ��āA���̃X����>>222����B
�����>222�ɂ��� cluster based multithreading �������Ă܂���B
����� enhancements to the floating-point architecture ��
�������̂��ȁH
�P���ɉ��߂���ƁAHT�o�R�ő��̃\�P�b�g�ɂ��鉉�Z�u���b�N��
���p�ł�����̂̂悤�ȋC�����邪�A����ȂƂ�ł��Ȃ����Ƃ�
��������Ȃ�A���R�A�}���`�R�A�̏ꍇ�ɁA�قȂ�R�A�Ԃ�
���Z�u���b�N�����L�ł���悤�ɂ��Ȃ��Ă�͂��B
(�R�A�Ԃł̃��j�b�g�̋��L�́A������IBM��POWER�Ői�߂�ƌ���
�Ă��悤�ȁc)
�Ƃ������Ƃ́A���Ƃ�1�R�A������3�Z�b�g�̃f�R�[�_�^���Z��Ƃ���
�\�����ς��Ȃ��Ă��A�R�A�Ԃŕ���x�ɕ肪����ꍇ�ɂ́A
1�R�A������3��葽���̖��߂������s�ł���������肷�邱�Ƃ�
�Ȃ�BMerom/Conroe�݂����ɒP���ɉ��Z��𑝂₷�Ɛ��\/����
�d�͔�I�ɕs���ɂȂ邪�A���̕��@���Ƃ��̖�肪�y�������B
�Ƃ����킯�ŁAintel���ǂ�������(������2007�N)�ɂ́AAMD��
���ɐ�ɍs���Ă邩���ˁB
> �t��intel��������S�Ď��������Ƃ��ɂ́A
> AMD�͂܂��V�������炩���C���v�������g���Ă����Ȃ���
������āAIntel�X������Ȃ��āA���̃X����>>222����B
�����>222�ɂ��� cluster based multithreading �������Ă܂���B
����� enhancements to the floating-point architecture ��
�������̂��ȁH
�P���ɉ��߂���ƁAHT�o�R�ő��̃\�P�b�g�ɂ��鉉�Z�u���b�N��
���p�ł�����̂̂悤�ȋC�����邪�A����ȂƂ�ł��Ȃ����Ƃ�
��������Ȃ�A���R�A�}���`�R�A�̏ꍇ�ɁA�قȂ�R�A�Ԃ�
���Z�u���b�N�����L�ł���悤�ɂ��Ȃ��Ă�͂��B
(�R�A�Ԃł̃��j�b�g�̋��L�́A������IBM��POWER�Ői�߂�ƌ���
�Ă��悤�ȁc)
�Ƃ������Ƃ́A���Ƃ�1�R�A������3�Z�b�g�̃f�R�[�_�^���Z��Ƃ���
�\�����ς��Ȃ��Ă��A�R�A�Ԃŕ���x�ɕ肪����ꍇ�ɂ́A
1�R�A������3��葽���̖��߂������s�ł���������肷�邱�Ƃ�
�Ȃ�BMerom/Conroe�݂����ɒP���ɉ��Z��𑝂₷�Ɛ��\/����
�d�͔�I�ɕs���ɂȂ邪�A���̕��@���Ƃ��̖�肪�y�������B
�Ƃ����킯�ŁAintel���ǂ�������(������2007�N)�ɂ́AAMD��
���ɐ�ɍs���Ă邩���ˁB
������CPU��
�v���O�����ʼn�H��ύX���A�V�������߃Z�b�g�ɑΉ��o����l�Ȃ�B
�Ɨǂ��ȁB
�v���O�����ʼn�H��ύX���A�V�������߃Z�b�g�ɑΉ��o����l�Ȃ�B
�Ɨǂ��ȁB
>>276
>�I�`�b�v�ɃA�N�Z�X���鎞�ACPU�͂قƂ�Njx��ł��܂��B�d�����Ă��܂���B
�x��ł͂Ȃ���A���ʂȃ������R�s�[�ɖZ���������Ă�c
�ŏ��̃|�X�g���炿����ƕς��Ȃ��Ǝv���Ă���ǁA
�Ȃ�����ĂȂ�? �ق�ƂɃh���C�o���������Ƃ���?
�Ȃ�ɂ���A�I�݂����ȃf�o�C�X�ɑ��������́AI/O���ɂ܂Ƃ���
DMA��H��ςނ��Ƃł����āACPU�X���Ƃ��Ă̓I�t�g�s���Ǝv����B
>�I�`�b�v�ɃA�N�Z�X���鎞�ACPU�͂قƂ�Njx��ł��܂��B�d�����Ă��܂���B
�x��ł͂Ȃ���A���ʂȃ������R�s�[�ɖZ���������Ă�c
�ŏ��̃|�X�g���炿����ƕς��Ȃ��Ǝv���Ă���ǁA
�Ȃ�����ĂȂ�? �ق�ƂɃh���C�o���������Ƃ���?
�Ȃ�ɂ���A�I�݂����ȃf�o�C�X�ɑ��������́AI/O���ɂ܂Ƃ���
DMA��H��ςނ��Ƃł����āACPU�X���Ƃ��Ă̓I�t�g�s���Ǝv����B
PCI�Ȃǃ��C���������ɔ�ׂăA�N�Z�X�Ɍ��������Ԃ�������Ⴞ���łȂ��A
���C���������ł������A�L���b�V���~�X����ACPU�͎d�����ł��Ȃ��x�ނ��ƂɂȂ�܂��B
�قƂ�ǃL���b�V���Ƀq�b�g����̂�����C�ɂ��Ȃ��Ă����A�Ȃ�Ă��Ƃ͂���܂���B
�����ɁA�R�X�g�������ăL���b�V���e�ʂ𑝂₵�ď����ł��q�b�g�������߂���A
�v���t�F�b�`���߂Ȃǂ�p�ӂ��Ă���̂́A�L���b�V���Ƀq�b�g���Ȃ��ƔߎS�Ȃ��ƂɂȂ邩��ł��B
���Ƃ���Opteron��2GHz�̏ꍇ�A�L���b�V���~�X����ƁA
���[�J���̃������Ȃ�140�N���b�N�A�����[�g�̃������Ȃ�200�N���b�N�A
CPU�͉��������ɋx�ނ��ƂɂȂ�܂��B
�L���b�V���̃q�b�g����99%�̏ꍇ�A
100��̂���99���1�N���b�N�����v99�N���b�N
100��̂���1���140�N���b�N�����v140�N���b�N
�Ƃ�����ŁA58%�̎��Ԃ�CPU���x��ł��܂��B
���x�����߂�̂̓��C���������̃��C�e���V�Ȃ̂ł��B
���C���������̃��C�e���V��Z�����邽�߂Ƀ������R���g���[������������̂��A���̂��߂ł��B
CPU�̃N���b�N��2GHz����4GHz�Ɉ����グ�āA���������{�̑ш�ɂȂ����Ƃ��Ă��A
�������̃��C�e���V�͕ς��Ȃ��ł��傤�B�L���b�V���~�X�����280�`400�N���b�N���x�݂ł��B
�L���b�V���̃q�b�g����99%�̏ꍇ�A
100��̂���99���1�N���b�N�����v99�N���b�N
100��̂���1���280�N���b�N�����v280�N���b�N
74%�̎��Ԃ�CPU���x��ł��܂��B
2GHz�̏ꍇ�A239�N���b�N
4GHz�̏ꍇ�A379�N���b�N
���������āA�N���b�N��2�{�ɂ��Ă��A�������Ԃ�2�������Z�k�ł��܂���B
140�N���b�N�Ƃ�240�N���b�N���̊ԁA�������Ȃ��ŋx��ł��邭�炢�Ȃ�A
�R���e�L�X�g�̐�ւ��ɁA���Ƃ�20�N���b�N���������Ƃ��Ă��A
�҂��Ă���Ԃɕʂ̃X���b�h�����s�����ق��������ł��傤�B
�Ƃ肠���������ɂł���}���`�R�A�̓S�[���ł͂Ȃ��Ǝv���܂��B
�}���`�R�A�ɂ�����ŁA�}���`�X���b�h�ɂ��Ă���Ǝv���܂��B
���C���������ł������A�L���b�V���~�X����ACPU�͎d�����ł��Ȃ��x�ނ��ƂɂȂ�܂��B
�قƂ�ǃL���b�V���Ƀq�b�g����̂�����C�ɂ��Ȃ��Ă����A�Ȃ�Ă��Ƃ͂���܂���B
�����ɁA�R�X�g�������ăL���b�V���e�ʂ𑝂₵�ď����ł��q�b�g�������߂���A
�v���t�F�b�`���߂Ȃǂ�p�ӂ��Ă���̂́A�L���b�V���Ƀq�b�g���Ȃ��ƔߎS�Ȃ��ƂɂȂ邩��ł��B
���Ƃ���Opteron��2GHz�̏ꍇ�A�L���b�V���~�X����ƁA
���[�J���̃������Ȃ�140�N���b�N�A�����[�g�̃������Ȃ�200�N���b�N�A
CPU�͉��������ɋx�ނ��ƂɂȂ�܂��B
�L���b�V���̃q�b�g����99%�̏ꍇ�A
100��̂���99���1�N���b�N�����v99�N���b�N
100��̂���1���140�N���b�N�����v140�N���b�N
�Ƃ�����ŁA58%�̎��Ԃ�CPU���x��ł��܂��B
���x�����߂�̂̓��C���������̃��C�e���V�Ȃ̂ł��B
���C���������̃��C�e���V��Z�����邽�߂Ƀ������R���g���[������������̂��A���̂��߂ł��B
CPU�̃N���b�N��2GHz����4GHz�Ɉ����グ�āA���������{�̑ш�ɂȂ����Ƃ��Ă��A
�������̃��C�e���V�͕ς��Ȃ��ł��傤�B�L���b�V���~�X�����280�`400�N���b�N���x�݂ł��B
�L���b�V���̃q�b�g����99%�̏ꍇ�A
100��̂���99���1�N���b�N�����v99�N���b�N
100��̂���1���280�N���b�N�����v280�N���b�N
74%�̎��Ԃ�CPU���x��ł��܂��B
2GHz�̏ꍇ�A239�N���b�N
4GHz�̏ꍇ�A379�N���b�N
���������āA�N���b�N��2�{�ɂ��Ă��A�������Ԃ�2�������Z�k�ł��܂���B
140�N���b�N�Ƃ�240�N���b�N���̊ԁA�������Ȃ��ŋx��ł��邭�炢�Ȃ�A
�R���e�L�X�g�̐�ւ��ɁA���Ƃ�20�N���b�N���������Ƃ��Ă��A
�҂��Ă���Ԃɕʂ̃X���b�h�����s�����ق��������ł��傤�B
�Ƃ肠���������ɂł���}���`�R�A�̓S�[���ł͂Ȃ��Ǝv���܂��B
�}���`�R�A�ɂ�����ŁA�}���`�X���b�h�ɂ��Ă���Ǝv���܂��B
>>279
> ���ʂȃ������R�s�[�ɖZ���������Ă�
�������A�����Ă��܂���B
CPU�������Ń������R�s�[���������قǁACPU�͖��ʂȋx�݂������Ȃ�܂��B
> ���ʂȃ������R�s�[�ɖZ���������Ă�
�������A�����Ă��܂���B
CPU�������Ń������R�s�[���������قǁACPU�͖��ʂȋx�݂������Ȃ�܂��B
SMT (��VMT) �����������C�e���V���B������̂ɗL���Ƃ����̂�
�S�����������A����������̂ɊI���o���Ă�͕̂ς��Ǝv���ȁB
�I�̏ꍇ�̐�����������́A�f�o�C�X���̂܂Ƃ���DMA����B
CPU�őΏ������Ȃ��āA�܂Ƃ��ȃf�o�C�X���g���ׂ��B
CPU���łǂ��Ώ������Ƃ���ŁA�܂Ƃ���DMA��H���ڂ���NIC�ɂ�
���Ȃ�Ȃ�����B
�����Ax86�v���Z�b�T�ŏ��� SMT ����������\���͂���Ǝv���Ă��
�ł͂���B���̌��ɂ��Ĕ����Ă���킯����Ȃ��B�ꉞ�O�̂��߁B
�S�����������A����������̂ɊI���o���Ă�͕̂ς��Ǝv���ȁB
�I�̏ꍇ�̐�����������́A�f�o�C�X���̂܂Ƃ���DMA����B
CPU�őΏ������Ȃ��āA�܂Ƃ��ȃf�o�C�X���g���ׂ��B
CPU���łǂ��Ώ������Ƃ���ŁA�܂Ƃ���DMA��H���ڂ���NIC�ɂ�
���Ȃ�Ȃ�����B
�����Ax86�v���Z�b�T�ŏ��� SMT ����������\���͂���Ǝv���Ă��
�ł͂���B���̌��ɂ��Ĕ����Ă���킯����Ȃ��B�ꉞ�O�̂��߁B
�������A�N�Z�X�̃��C�e���V��CPU���������Ԃ��x�݂ɂȂ��Ƃ��āA
���C����������胁�����}�b�v�hIO�̂ق����A�����ŕ�����₷�����Ȃ��A�ƁB
����ł́ACPU���������}�b�v�hIO��@���̂́A���C�e���V�����܂�ɑ傫�����邩��A
�f�o�C�X����DMA�������ăC���e���W�F���g�ɓ����ׂ����Ƃ����̂ɂ́A�٘_�͂Ȃ��ł��B
�������A�������A�N�Z�X�ő҂��Ă���ԂɁA���̃X���b�h�����s�ł���悤�ɂȂ�A
�Ȃ������ꂪ�A2�X���b�h�Ƃ��ł͂Ȃ��A�����Ƒ����̃X���b�h�Ƃ������ƂɂȂ�A
���C�e���V���ƂĂ��傫���������}�b�v�hIO��CPU���@���Ă��\��Ȃ��Ȃ�܂��B
CPU���������R���g���[����������Ă��Ȃ��������́A
�������}�b�v�hIO��CPU
CPU��������
�ŁA�����o�X��2��ʂ�̂ŁA���Ƀ��C�e���V��0�ł����Ă��ADMA���ׂ��ł����B
CPU���������R���g���[����������邱�ƂŁA
�������}�b�v�hIO��CPU��������
�ƂȂ�A�o�X��1���ʂ�܂��ACPU������Ă��ADMA�ł���Ă��A�����ł��B
���C����������胁�����}�b�v�hIO�̂ق����A�����ŕ�����₷�����Ȃ��A�ƁB
����ł́ACPU���������}�b�v�hIO��@���̂́A���C�e���V�����܂�ɑ傫�����邩��A
�f�o�C�X����DMA�������ăC���e���W�F���g�ɓ����ׂ����Ƃ����̂ɂ́A�٘_�͂Ȃ��ł��B
�������A�������A�N�Z�X�ő҂��Ă���ԂɁA���̃X���b�h�����s�ł���悤�ɂȂ�A
�Ȃ������ꂪ�A2�X���b�h�Ƃ��ł͂Ȃ��A�����Ƒ����̃X���b�h�Ƃ������ƂɂȂ�A
���C�e���V���ƂĂ��傫���������}�b�v�hIO��CPU���@���Ă��\��Ȃ��Ȃ�܂��B
CPU���������R���g���[����������Ă��Ȃ��������́A
�������}�b�v�hIO��CPU
CPU��������
�ŁA�����o�X��2��ʂ�̂ŁA���Ƀ��C�e���V��0�ł����Ă��ADMA���ׂ��ł����B
CPU���������R���g���[����������邱�ƂŁA
�������}�b�v�hIO��CPU��������
�ƂȂ�A�o�X��1���ʂ�܂��ACPU������Ă��ADMA�ł���Ă��A�����ł��B
284 �FSocket774�F2005/10/15(�y) 00:33:00 ID:QWu2tyVZ
{kind=link}
> CPU���������R���g���[����������邱�ƂŁA
> �������}�b�v�hIO��CPU��������
> �ƂȂ�A�o�X��1���ʂ�܂��ACPU������Ă��ADMA�ł���Ă��A�����ł��B
��������Ȃ��ł���B
DMA �ł���A�������R���g���[���͌o�R���邪�ACPU�� load/store unit ��
�ʂ�Ȃ��B
CPU �ł��ƁA�������R���g���[����������Ȃ��� load/store unit ��ʂ�
�̂ŁA�����̖��ʎg���B
load/store unit �̐������Č����Ă����AI/O �ȂɘQ��ׂ�
����Ȃ���B�g�����W�X�^���]������ɂ��鍡��́AI/O �Ɋւ��鏈���́A
�ނ���A�ǂ�ǂ� CPU ����o�Ă��������ł���B
> �������}�b�v�hIO��CPU��������
> �ƂȂ�A�o�X��1���ʂ�܂��ACPU������Ă��ADMA�ł���Ă��A�����ł��B
��������Ȃ��ł���B
DMA �ł���A�������R���g���[���͌o�R���邪�ACPU�� load/store unit ��
�ʂ�Ȃ��B
CPU �ł��ƁA�������R���g���[����������Ȃ��� load/store unit ��ʂ�
�̂ŁA�����̖��ʎg���B
load/store unit �̐������Č����Ă����AI/O �ȂɘQ��ׂ�
����Ȃ���B�g�����W�X�^���]������ɂ��鍡��́AI/O �Ɋւ��鏈���́A
�ނ���A�ǂ�ǂ� CPU ����o�Ă��������ł���B
AMD Fab36�O�����h�I�[�v�j���O���|�[�g
�`AMD�̐����L���p�V�e�B�͔{�ȏ��
http://pc.watch.impress.co.jp/docs/2005/1015/amd.htm
�`AMD�̐����L���p�V�e�B�͔{�ȏ��
http://pc.watch.impress.co.jp/docs/2005/1015/amd.htm
>>277
cluster based multithreading ���Ă̂͑����N���X�^�T�[�o��z�肵�����O
���������_���Z��ӂ���R�A�Ԃŋ��L���Ă��̕��R�A�𑝂₻�����Ęb���Ǝv����
cluster based multithreading ���Ă̂͑����N���X�^�T�[�o��z�肵�����O
���������_���Z��ӂ���R�A�Ԃŋ��L���Ă��̕��R�A�𑝂₻�����Ęb���Ǝv����
���̓��C�����������C�e���V��
PC98��������x���Ȃ��Ă�Ƃ����Ռ��̎���
PC98��������x���Ȃ��Ă�Ƃ����Ռ��̎���
> ���������_���Z��ӂ���R�A�Ԃŋ��L����
allow other microprocessors to share specific blocks on the chip,
�� other microprocessors ���āA����\�P�b�g�̑��̃R�A�ȂȁB
����Ƃ����A���̃\�P�b�g? other core ����Ȃ��� other microprocessors
���ď����Ă���Ă��Ƃ́A���̃\�P�b�g���Ɠǂ��LjႤ?
�ǂ���ɂ���A����\�P�b�g�Ȃ�ԈႢ�Ȃ��A���̃R�A�̉��Z��𗬗p
�ł���悤�ɂ�����Ă��肾��ˁB
���ƁAsuch as the floating-point unit ���ď����Ă��邩�畂�������_
���Z������L�ł���悤�ɂ���̂͊ԈႢ�Ȃ����ǁA���̃��j�b�g��
���L����C�����肻���ȏ���������Ȃ��H
allow other microprocessors to share specific blocks on the chip,
�� other microprocessors ���āA����\�P�b�g�̑��̃R�A�ȂȁB
����Ƃ����A���̃\�P�b�g? other core ����Ȃ��� other microprocessors
���ď����Ă���Ă��Ƃ́A���̃\�P�b�g���Ɠǂ��LjႤ?
�ǂ���ɂ���A����\�P�b�g�Ȃ�ԈႢ�Ȃ��A���̃R�A�̉��Z��𗬗p
�ł���悤�ɂ�����Ă��肾��ˁB
���ƁAsuch as the floating-point unit ���ď����Ă��邩�畂�������_
���Z������L�ł���悤�ɂ���̂͊ԈႢ�Ȃ����ǁA���̃��j�b�g��
���L����C�����肻���ȏ���������Ȃ��H
�Ȃ��9���̃A�����J�̃f�X�N�g�b�vPC����グ��AMD��Intel����������
ttp://www.digitimes.com/mobos/a20051014PR202.html
����͂т�����B
VIA Notepad�o�R
ttp://www.digitimes.com/mobos/a20051014PR202.html
����͂т�����B
VIA Notepad�o�R
HT �o�R���Ɠ��R�x���Ȃ邾�낤���ǁA�����`�b�v���ł���A
�K���������C�e���V�������Ȃ�Ƃ͌����̂���Ȃ��H
���ɁA�ŏ����炻���������ɐv����Ă���ꍇ�Ȃ�A
���C�e���V�̒����Ȃ镔�����L���[�\���ɂ��ă��C�e���V��
�B��������ċZ���g����\��������Ǝv���B
HyperThreading/SMT ���Ă̂́A�R�A�̐����������̉��z
�v���Z�b�T��p�ӂ��āA���Z���V���Ȃ��悤�ɂ�����Ă���
�Z�p�������킯�����A�R�A�Ƃ����敪��B���ɂ���4�̉��z
�v���Z�b�T���ʂ̉��Z�� (4�R�A�������� 12�Z�b�g���炢?)
�ŏ���������Č���������ƁA�{���I�ɂ���Ă邱�Ƃ�
���܂�ς��Ȃ��C������ˁB����2�N��ɂ��������v���Z�b�T
�����邩�ǂ����͂Ƃ������A�ŏI�I�ɂ͂��������\����
�Ȃ��Ă����C�����邪�A�ǂ���B
�K���������C�e���V�������Ȃ�Ƃ͌����̂���Ȃ��H
���ɁA�ŏ����炻���������ɐv����Ă���ꍇ�Ȃ�A
���C�e���V�̒����Ȃ镔�����L���[�\���ɂ��ă��C�e���V��
�B��������ċZ���g����\��������Ǝv���B
HyperThreading/SMT ���Ă̂́A�R�A�̐����������̉��z
�v���Z�b�T��p�ӂ��āA���Z���V���Ȃ��悤�ɂ�����Ă���
�Z�p�������킯�����A�R�A�Ƃ����敪��B���ɂ���4�̉��z
�v���Z�b�T���ʂ̉��Z�� (4�R�A�������� 12�Z�b�g���炢?)
�ŏ���������Č���������ƁA�{���I�ɂ���Ă邱�Ƃ�
���܂�ς��Ȃ��C������ˁB����2�N��ɂ��������v���Z�b�T
�����邩�ǂ����͂Ƃ������A�ŏI�I�ɂ͂��������\����
�Ȃ��Ă����C�����邪�A�ǂ���B
>>285
HT�̑ш敝�����A�������̑ш敝�����A
CPU�̃��[�h�X�g�A���j�b�g�̑ш敝�̂ق����A1�����炢�L����B
HT������̑ш敝����Ƀl�b�N�ɂȂ�̂ŁA
CPU�̃��[�h�X�g�A���j�b�g�̗]�蕪���g���Ă��\��Ȃ��ł��傤�B
�������̃��C�e���V���\���ɉB�����邾�������̃X���b�h�𑖂点��Ƃ������Ƃ́A
���̑唼�̃X���b�h�̏�Ԃ́A���[�h�X�g�A���j�b�g�̏����҂��ɂȂ��Ă��܂��B
�Ƃ������Ƃ́A����������Ⴂ�̐��̃��[�h�X�g�A���j�b�g�����邱�ƂɂȂ�B
�����Ȃ�AI/O�ɏ������炢�g�������č\���₵�Ȃ��B
�ނ���I/O�������ɂ���āA�S���̃X���b�h�����[�h�X�g�A�̏����҂��ŁA
������邱�Ƃ��Ȃ��Ȃ��Ă��܂��A�Ƃ������Ƃ̂ق���S�z���ׂ����낤�B
HT�̑ш敝�����A�������̑ш敝�����A
CPU�̃��[�h�X�g�A���j�b�g�̑ш敝�̂ق����A1�����炢�L����B
HT������̑ш敝����Ƀl�b�N�ɂȂ�̂ŁA
CPU�̃��[�h�X�g�A���j�b�g�̗]�蕪���g���Ă��\��Ȃ��ł��傤�B
�������̃��C�e���V���\���ɉB�����邾�������̃X���b�h�𑖂点��Ƃ������Ƃ́A
���̑唼�̃X���b�h�̏�Ԃ́A���[�h�X�g�A���j�b�g�̏����҂��ɂȂ��Ă��܂��B
�Ƃ������Ƃ́A����������Ⴂ�̐��̃��[�h�X�g�A���j�b�g�����邱�ƂɂȂ�B
�����Ȃ�AI/O�ɏ������炢�g�������č\���₵�Ȃ��B
�ނ���I/O�������ɂ���āA�S���̃X���b�h�����[�h�X�g�A�̏����҂��ŁA
������邱�Ƃ��Ȃ��Ȃ��Ă��܂��A�Ƃ������Ƃ̂ق���S�z���ׂ����낤�B
> CPU�̃��[�h�X�g�A���j�b�g�̑ш敝�̂ق����A1�����炢�L����B
���������Ƃ܂�Ń��[�h�X�g�A���j�b�g���V��ł���݂�����
�����邪�A���͂�������Ȃ��B���[�h�X�g�A���j�b�g�̑Ώۂ�
�Ȃ�̂� L1 �ł����āAL1 �̑ш敝�̓��������1�������B
����A���[�h�X�g�A���j�b�g�͂���قljɂ��Ă��Ȃ��B
> �����Ȃ�AI/O�ɏ������炢�g�������č\���₵�Ȃ��B
���ɏ��������ǁA����̓g�����h�Ɋ��S�ɋt�s���Ă�B
PC �̃f�B�X�N���������� PIO��UDMA �ƕω����Ă��邵�A
NIC���APIO�����������L(CPU���������R�s�[)��DMA��TSO��TOE
�Ƃ����i���̓r������B
���̐i�����t�s����Ɨ\������̂͌����͂��ꂾ��B
CPU�ł��Ȃ��ėǂ��d���� CPU�ł��̂́A�P�ɖ��ʁB
I/O���łł��邱�Ƃ�I/O���ł��̂��A���\�d�͔�̓_�ł�
�D�����B
���������Ƃ܂�Ń��[�h�X�g�A���j�b�g���V��ł���݂�����
�����邪�A���͂�������Ȃ��B���[�h�X�g�A���j�b�g�̑Ώۂ�
�Ȃ�̂� L1 �ł����āAL1 �̑ш敝�̓��������1�������B
����A���[�h�X�g�A���j�b�g�͂���قljɂ��Ă��Ȃ��B
> �����Ȃ�AI/O�ɏ������炢�g�������č\���₵�Ȃ��B
���ɏ��������ǁA����̓g�����h�Ɋ��S�ɋt�s���Ă�B
PC �̃f�B�X�N���������� PIO��UDMA �ƕω����Ă��邵�A
NIC���APIO�����������L(CPU���������R�s�[)��DMA��TSO��TOE
�Ƃ����i���̓r������B
���̐i�����t�s����Ɨ\������̂͌����͂��ꂾ��B
CPU�ł��Ȃ��ėǂ��d���� CPU�ł��̂́A�P�ɖ��ʁB
I/O���łł��邱�Ƃ�I/O���ł��̂��A���\�d�͔�̓_�ł�
�D�����B
��������
>>276�̌����uCPU�v���Ă̂́u���Z��v�P�̂��w���Ă��
>>276�̌����uCPU�v���Ă̂́u���Z��v�P�̂��w���Ă��
���`��...
>PC �̃f�B�X�N���������� PIO��UDMA �ƕω����Ă��邵�A
�f�B�X�N�́ADMA��PIO��UDMA����Ȃ���
>NIC���APIO�����������L(CPU���������R�s�[)��DMA��TSO��TOE
�ނ�����PIO��NIC���āA�����Ō��肶��Ȃ����H
3COM�Ƃ�DEC��NIC�͂ǂ��������́H
Realtek�Ƃ��I�Ƃ��́A10BASE����ɂ�PIO���������ǂ��B
>PC �̃f�B�X�N���������� PIO��UDMA �ƕω����Ă��邵�A
�f�B�X�N�́ADMA��PIO��UDMA����Ȃ���
>NIC���APIO�����������L(CPU���������R�s�[)��DMA��TSO��TOE
�ނ�����PIO��NIC���āA�����Ō��肶��Ȃ����H
3COM�Ƃ�DEC��NIC�͂ǂ��������́H
Realtek�Ƃ��I�Ƃ��́A10BASE����ɂ�PIO���������ǂ��B
> �f�B�X�N�́ADMA��PIO��UDMA����Ȃ���
DMA ���� PIO �ɖ߂����̂͌��\����ȗ�Ȃ��B
i8257 �� DMA �� PIO ���x���Ƃ�������������������ȁB
> �ނ�����PIO��NIC���āA�����Ō��肶��Ȃ����H
> 3COM�Ƃ�DEC��NIC�͂ǂ��������́H
3COM Etherlink III �� PIO ���B�]�����\�����͑�������
�x���`�}�[�N�͂������ACPU �͐H�����A���̊��荞�݂�
�~�߂ē������Ȃ��� underrun ���邵�A�T�[�o��������Ȃ������B
������ PC �����̊�`�`�b�v���ȁB
DEC �́AEtherWORKS III (DE203, DE204, DE205) ������́A
�h���C�o��ǂތ���APIO �̂��̂Ƌ��L�������̂��̂��������悤���B
�ǂꂪ�ǂꂩ�͒m���BDE500 �̐���� busmaster DMA�B
DMA ���� PIO �ɖ߂����̂͌��\����ȗ�Ȃ��B
i8257 �� DMA �� PIO ���x���Ƃ�������������������ȁB
> �ނ�����PIO��NIC���āA�����Ō��肶��Ȃ����H
> 3COM�Ƃ�DEC��NIC�͂ǂ��������́H
3COM Etherlink III �� PIO ���B�]�����\�����͑�������
�x���`�}�[�N�͂������ACPU �͐H�����A���̊��荞�݂�
�~�߂ē������Ȃ��� underrun ���邵�A�T�[�o��������Ȃ������B
������ PC �����̊�`�`�b�v���ȁB
DEC �́AEtherWORKS III (DE203, DE204, DE205) ������́A
�h���C�o��ǂތ���APIO �̂��̂Ƌ��L�������̂��̂��������悤���B
�ǂꂪ�ǂꂩ�͒m���BDE500 �̐���� busmaster DMA�B
�����̃h���C�o�����Ă����A3C503 �� 3C505 �͋��L�������������B
3C509 �͂���Ӗ��މ����Ă��Ȃ��B�܂� 3C509 ���o�������͂܂�
ISA �ł��������킯�ŁA�����̐���̒��Ő��\���o�����߂ɉ������
�g���̂��d�����Ȃ����Ėʂ��������낤�ȁB
PCI �ł����ɂȂ��� 3COM EtherLink XL (3C905) �̐���ɂȂ�ƁA
bus master DMA �ɂȂ��āA�������ɂ܂Ƃ��B
3C509 �͂���Ӗ��މ����Ă��Ȃ��B�܂� 3C509 ���o�������͂܂�
ISA �ł��������킯�ŁA�����̐���̒��Ő��\���o�����߂ɉ������
�g���̂��d�����Ȃ����Ėʂ��������낤�ȁB
PCI �ł����ɂȂ��� 3COM EtherLink XL (3C905) �̐���ɂȂ�ƁA
bus master DMA �ɂȂ��āA�������ɂ܂Ƃ��B
>>289 ���C�X�}�\�C�Q�Ă��܂���
���ɑ��̃\�P�b�g���Ă͖̂����Ǝv���D���Z�탌�x���̃o�X���\�P�b�g��
�O�ɏo���Ȃ�đ��x���Ⴂ�����邵�C���L����v���Z�b�T�̌��Ƃ��Ă�2��
�\��������킴�킴�O���̃v���Z�b�T�Ƌ��L���闝�R�͖������D
Microprosessor �Ə����Ă��闝�R�́C���ʂ͒P�� prosessor ���Č����Ƃ��낾��
�v���icore �͍���Ȃ������j���ǁC���� native ����Ȃ����番�����
���ƁC�����u�ӂ�v�Ə����Ă���悤�� floating unit �Ɍ������b����Ȃ��Ǝv����
���ɑ��̃\�P�b�g���Ă͖̂����Ǝv���D���Z�탌�x���̃o�X���\�P�b�g��
�O�ɏo���Ȃ�đ��x���Ⴂ�����邵�C���L����v���Z�b�T�̌��Ƃ��Ă�2��
�\��������킴�킴�O���̃v���Z�b�T�Ƌ��L���闝�R�͖������D
Microprosessor �Ə����Ă��闝�R�́C���ʂ͒P�� prosessor ���Č����Ƃ��낾��
�v���icore �͍���Ȃ������j���ǁC���� native ����Ȃ����番�����
���ƁC�����u�ӂ�v�Ə����Ă���悤�� floating unit �Ɍ������b����Ȃ��Ǝv����
http://pc.watch.impress.co.jp/docs/2005/1015/amd.htm
����Fab30�ł́A���t�Ɍ����ĔN�Ԃ�5,000�����j�b�g�̃}�C�N���v���Z�b�T��
�������邱�Ƃ��ł���BFab36���t���ɉғ�����悤�ɂȂ�ƁA
���̃L���p�V�e�B�͔{�ȏ�ƂȂ�A
���Ȃ��Ƃ�1�����j�b�g�̃}�C�N���v���Z�b�T���ł���悤�ɂȂ�
������ĂP�����x�ɗ}������Ă��Ƃ����
�f���A���R�A�̔䗦����������
����Fab30�ł́A���t�Ɍ����ĔN�Ԃ�5,000�����j�b�g�̃}�C�N���v���Z�b�T��
�������邱�Ƃ��ł���BFab36���t���ɉғ�����悤�ɂȂ�ƁA
���̃L���p�V�e�B�͔{�ȏ�ƂȂ�A
���Ȃ��Ƃ�1�����j�b�g�̃}�C�N���v���Z�b�T���ł���悤�ɂȂ�
������ĂP�����x�ɗ}������Ă��Ƃ����
�f���A���R�A�̔䗦����������
�L���p�V�e�B���肷����AthlonX2�����肫�ڂ��
>>301
�����̂͗ʎY����ƂȂ������Ȃ邩�B
�V�H��ݒu�E�V�Z�p�����E�J���ŋ���������
��
�����̂Y����
��
�����̎��̂̃R�X�g�͍����Ȃ��̂ŁA�ʎY���ʂōH���V�Z�p��J���������ł���悤�ɂȂ�
��
���i�̒l�i��������
���ŏ��̃X�e�b�v
�����̂͗ʎY����ƂȂ������Ȃ邩�B
�V�H��ݒu�E�V�Z�p�����E�J���ŋ���������
��
�����̂Y����
��
�����̎��̂̃R�X�g�͍����Ȃ��̂ŁA�ʎY���ʂōH���V�Z�p��J���������ł���悤�ɂȂ�
��
���i�̒l�i��������
���ŏ��̃X�e�b�v
Fab30����Fab36���̌����Ă邩��uFab25�͂ǂ��Ȃ��Ă�H�v���Ē��ׂĂ݂���A�Ƃ����̐̂Ƀt���b�V���������H��ɃN���X�_�E������Ă��ȁB
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20030715/6/
Fab25�̎{�݂����ǂ�����đI�����́A�Ȃ������̂��ˁH
�������̂���R�X�g�ōςނƎv�����B
���Ďv������A�h�C�c���{���V�H��ݗ��Ɋ�t���o���Ă��ꂽ�ȁB�Ȃ�قǁB
�����ĂāA�����ł��Ӗ��s�������Ƃ����������A�Q�����Ȃ̂œ��e���Ă݂�B
http://itpro.nikkeibp.co.jp/free/ITPro/USNEWS/20030715/6/
Fab25�̎{�݂����ǂ�����đI�����́A�Ȃ������̂��ˁH
�������̂���R�X�g�ōςނƎv�����B
���Ďv������A�h�C�c���{���V�H��ݗ��Ɋ�t���o���Ă��ꂽ�ȁB�Ȃ�قǁB
�����ĂāA�����ł��Ӗ��s�������Ƃ����������A�Q�����Ȃ̂œ��e���Ă݂�B
305 �F�a�Q�C�g ��P2l2AcvNK6 �F2005/10/15(�y) 19:55:02 ID:DPXENJ5E
�A�����J�l���Ƃ��ɍ�点��̂Ȃ�t���b�V���������ŏ\������
>>288
����N���b�N�����Ȃ��Ă���A�X���[�v�b�g�͏オ���Ă���炢�������B
����N���b�N�����Ȃ��Ă���A�X���[�v�b�g�͏オ���Ă���炢�������B
���C�e���V���������Ƙb�ɂȂ��B
�ш敝������ۂǍL�������瓊�@�I�ȓǂݍ��݂Ƃ����̂��l�����邪�B
�ш敝������ۂǍL�������瓊�@�I�ȓǂݍ��݂Ƃ����̂��l�����邪�B
>>303
����Ⴡ�����}�b�v�h I/O �̗̈�̓L���b�V������Ȃ�����
L1 �ɂ̓q�b�g���Ȃ����A���̎��Ƀ��[�h�X�g�A���j�b�g��
�Ă�Ƃ͌���Ȃ��B���ɕʂ� L1 �ɃA�N�Z�X���Ă���
�Z�����\��������B��������ƁAI/O �����҂������
�g�[�^���X���[�v�b�g��������B
����ɁA����ς�I�ɑ��Č�����Ă���悤������A�ꉞ������
�������A�I�� RTL8129/8139 ���x���̂̓������}�b�v�h I/O �̂�������
�Ȃ���B�I�� DMA �R���g���[�����A�z�ŁAOS ���̗v������ DMA ����
�������Ƃ��ł����ADMA ������Ɍ��ǂ���������R�s�[����
���Ⴂ���Ȃ����炾��B�����āAOS �ɂ��ˑ����邪�A���̃������R�s�[
�� L1 ���A�N�Z�X����\�������邺�B(��M���̓R�s�[�摤�ŁB���M��
�͗�����)
���ƁACPU��I/O����ꍇ�A�g���̂̓��[�h�X�g�A���j�b�g���������
���āA��������R��CPU������Q��邱�ƂɂȂ���A���̉e����
���ׂĖ����ł�����Ďv���Ă��? ���������ACPU��I/O���Ȃ��čς߂A
���̕��ʂ̌v�Z�X���b�h�����s�ł���킯������A�g�[�^���X���[�v�b�g
��CPU I/O ���Ȃ����������Ȃ͎̂������Ǝv�����B
����Ⴡ�����}�b�v�h I/O �̗̈�̓L���b�V������Ȃ�����
L1 �ɂ̓q�b�g���Ȃ����A���̎��Ƀ��[�h�X�g�A���j�b�g��
�Ă�Ƃ͌���Ȃ��B���ɕʂ� L1 �ɃA�N�Z�X���Ă���
�Z�����\��������B��������ƁAI/O �����҂������
�g�[�^���X���[�v�b�g��������B
����ɁA����ς�I�ɑ��Č�����Ă���悤������A�ꉞ������
�������A�I�� RTL8129/8139 ���x���̂̓������}�b�v�h I/O �̂�������
�Ȃ���B�I�� DMA �R���g���[�����A�z�ŁAOS ���̗v������ DMA ����
�������Ƃ��ł����ADMA ������Ɍ��ǂ���������R�s�[����
���Ⴂ���Ȃ����炾��B�����āAOS �ɂ��ˑ����邪�A���̃������R�s�[
�� L1 ���A�N�Z�X����\�������邺�B(��M���̓R�s�[�摤�ŁB���M��
�͗�����)
���ƁACPU��I/O����ꍇ�A�g���̂̓��[�h�X�g�A���j�b�g���������
���āA��������R��CPU������Q��邱�ƂɂȂ���A���̉e����
���ׂĖ����ł�����Ďv���Ă��? ���������ACPU��I/O���Ȃ��čς߂A
���̕��ʂ̌v�Z�X���b�h�����s�ł���킯������A�g�[�^���X���[�v�b�g
��CPU I/O ���Ȃ����������Ȃ͎̂������Ǝv�����B
CPU���O���{�̂悤�ɔ����鎞��B
�܂��A���Ȃ����낤���A�����B
���j�b�g�̋��p���i��ŁACPU���\�[�X���X���b�h���ƂɎg���悤�ɂȂ��
�V���O���A�}���`�X���b�h�����ɐ��\����Ƃ��B
�܂��A���G�ɂȂ��Đ��\�オ���Ƃ����������낤���ǁB
Athlon64 X1800
����N���b�N 3GHz
�������Z���j�b�g�@�@16
���������_���j�b�g 4
�ő�X���b�h�� 4
�e�X���b�h���߃f�R�[�_ 4
Athlon64 X1600
����N���b�N 2.6GHz
�������Z���j�b�g�@�@8
���������_���j�b�g 2
�ő�X���b�h�� 2
�e�X���b�h���߃f�R�[�_ 3
�܂��A���Ȃ����낤���A�����B
���j�b�g�̋��p���i��ŁACPU���\�[�X���X���b�h���ƂɎg���悤�ɂȂ��
�V���O���A�}���`�X���b�h�����ɐ��\����Ƃ��B
�܂��A���G�ɂȂ��Đ��\�オ���Ƃ����������낤���ǁB
Athlon64 X1800
����N���b�N 3GHz
�������Z���j�b�g�@�@16
���������_���j�b�g 4
�ő�X���b�h�� 4
�e�X���b�h���߃f�R�[�_ 4
Athlon64 X1600
����N���b�N 2.6GHz
�������Z���j�b�g�@�@8
���������_���j�b�g 2
�ő�X���b�h�� 2
�e�X���b�h���߃f�R�[�_ 3
>>308
���႟�A���������������̔ėpDMA�G���W�����������R���g���[���ɓ�������Ⴂ�������B
CPU�R�A����̃������A�N�Z�X�̍��Ԃ�D���āACPU�R�A�̎ז������Ȃ��悤�ɋ�
���p��������R�s�[��������B
�Ƃ������Ƃ�>>197�ɖ߂�B
���႟�A���������������̔ėpDMA�G���W�����������R���g���[���ɓ�������Ⴂ�������B
CPU�R�A����̃������A�N�Z�X�̍��Ԃ�D���āACPU�R�A�̎ז������Ȃ��悤�ɋ�
���p��������R�s�[��������B
�Ƃ������Ƃ�>>197�ɖ߂�B
> ���������������̔ėpDMA�G���W�����������R���g���[���ɓ�������Ⴂ�������B
�{���]�|���͂Ȃ͂������B
RTL8129/8139 �݂����Ȓᐫ�\ I/O �f�o�C�X���g��Ȃ��Ⴂ�������̘b�B
�����ꂽ���� I/O �`�b�v���T�|�[�g���邽�߂ɁACPU ���ɂ����p��
�@�\����������C?
�{���]�|���͂Ȃ͂������B
RTL8129/8139 �݂����Ȓᐫ�\ I/O �f�o�C�X���g��Ȃ��Ⴂ�������̘b�B
�����ꂽ���� I/O �`�b�v���T�|�[�g���邽�߂ɁACPU ���ɂ����p��
�@�\����������C?
�ł��A�܂�����C�����������ш�ɘb��߂����Ƃ��Ă���̂́A����l���H
>>311
�I�͌����ȗ�ɉ߂��Ȃ���B
���������������̔ėpDMA�G���W���́A�����Ƒ����̂��ƂɎg�����B
CPU�Ƀ��������R�s�[������̂́A�����I�̃h���C�o�����ł͂Ȃ�����B
�������A�������̃R�s�[�̓h���C�o�����łȂ��A�A�v�����p�ɂɂ���Ă�B
���Ȃ݂ɔC�ӂ̃A�h���X��DMA�ł������ł��A
������32�r�b�g�A�h���b�V���O�������Ƃ�����A
�o�E���X�o�b�t�@���g�����R�s�[�����������Ȃ���?
�I�͌����ȗ�ɉ߂��Ȃ���B
���������������̔ėpDMA�G���W���́A�����Ƒ����̂��ƂɎg�����B
CPU�Ƀ��������R�s�[������̂́A�����I�̃h���C�o�����ł͂Ȃ�����B
�������A�������̃R�s�[�̓h���C�o�����łȂ��A�A�v�����p�ɂɂ���Ă�B
���Ȃ݂ɔC�ӂ̃A�h���X��DMA�ł������ł��A
������32�r�b�g�A�h���b�V���O�������Ƃ�����A
�o�E���X�o�b�t�@���g�����R�s�[�����������Ȃ���?
314 �FSocket774�F2005/10/16(��) 06:34:44 ID:cE9tT7NF
�@�@ �@ A�QA �@�@n�@ �@
�@�@ �i�@�E�́E �j(E) ))�@���ް�ɐ�����[�I
�@�@ �i/Op�@__�m
�@ �n�i�@�@�@�m
�@�@ /�@ ./
ttp://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
�@�@ �i�@�E�́E �j(E) ))�@���ް�ɐ�����[�I
�@�@ �i/Op�@__�m
�@ �n�i�@�@�@�m
�@�@ /�@ ./
ttp://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
315 �FSocket774�F2005/10/16(��) 08:13:31 ID:osaaDGSf
http://support.universalcentury.net/main/index.php
�����A�����ԑ�I�I
�S�R�e�X�g�ł���˂����I�I
���q�����Ă�˂����I�I
�o�C�g�ɂ���ŁA���U���đ��삵���x����˂��I�I
�`�����ɋ��ł�����Ă�̂��I�I�I
�q���Ȃ߂Ă�˂����I�I�I�I
���̂����v����Y�̔ԑ䂪�I�I�I
���ˁI�I�����ԑ䂪�I�I�I�I�I�I�I
�E�ł��āA�\���ނ��ڂ��Ă�˂����I�I�S���[�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
�u�@�p�@�b�@�P�@���@���@�ā@�ȁ@���@���@�ǁ@�i�@�v
�����A�����ԑ�I�I
�S�R�e�X�g�ł���˂����I�I
���q�����Ă�˂����I�I
�o�C�g�ɂ���ŁA���U���đ��삵���x����˂��I�I
�`�����ɋ��ł�����Ă�̂��I�I�I
�q���Ȃ߂Ă�˂����I�I�I�I
���̂����v����Y�̔ԑ䂪�I�I�I
���ˁI�I�����ԑ䂪�I�I�I�I�I�I�I
�E�ł��āA�\���ނ��ڂ��Ă�˂����I�I�S���[�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�����J�X�ԑ䂪�I�I��Β@���ׂ��Ă�邩��ȁI�I�I�I�I�I�I�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
�Εt���ĔR�₷���S���[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
���Ԃ��I�I�h���{�[�I�I
�u�@�p�@�b�@�P�@���@���@�ā@�ȁ@���@���@�ǁ@�i�@�v
>>304
AMD�iSPANSION�j�̃t���b�V���������͍D���ƌ����Ă�����
����Ȃ����ȁB
�A�����J�A�����̍H��̕������Y���ő�pFab
�ɐ��Y�ϑ�����l�Șb���o�Ă�悤�ɋL�����Ă邵�B
CPU�Ƃ͊W�Ȃ����B
AMD�iSPANSION�j�̃t���b�V���������͍D���ƌ����Ă�����
����Ȃ����ȁB
�A�����J�A�����̍H��̕������Y���ő�pFab
�ɐ��Y�ϑ�����l�Șb���o�Ă�悤�ɋL�����Ă邵�B
CPU�Ƃ͊W�Ȃ����B
>>316
�ł��Ԏ��Ȃ�ˁH
�ł��Ԏ��Ȃ�ˁH
�t���b�V���������́A�؍����[�J�[���A�_���s���O���ċ������Ђ�ׂ��Ɛ錾���Ă邩��˂��B
Spansion��2004�N�Ńt���b�V���������ƊE��ʁB
NOR�^�ł͈�ʂ炵�����B
NOR�^�ł͈�ʂ炵�����B
�T���\����Intel����������߂�
322 �F�������G�� ��yGAhoNiShI �F2005/10/16(��) 12:21:39 ID:ljCqg4CJ
:-�: : : : : : : : : : : : : : :�R
�:. :. : : : : : : : : : : : : : : :�M�A
�R�:::::. : : : : : : : : : :-� : : �_
�@�@ �_::::::.. : : : : : : :_,. -'7 r�]��-:�\:-�__�Q__ �@ ..__
�@�@�@�@�_::::i : : : ,. - .��: : �R�@ �M�R�: : : t�@�@�@�@�@�@�M �-�@_
�@�@�@�@�@ �R::: : :/�@�@�@�b/�_�_;�� }: : : }_,,. -�\�@ _�@�@�@�@ �M �-
�@�@�@�@�@ �m: : : {�@�@�@�@l:/�@�@�M_j,.�T�\--'�_�@�@�@�@�@ �M�@�[�]- �
�@�@�@�@ /: : : : : :t�@�@ ,.�B�@�@�r^:.:.�P`�R:.:.:.:.:�M�R�@�@�@�@�@�@�@�@�@�R
�@�@�@ r'_: : : : : : : }_,.��r'�n�@�:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:�M�
.�@ �^�@ �Mt: : : : �^�@��' i��{:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:i_�@�@�@�@�@ ,. -�]�@�@CPU���傾���藣�������c
�^�@�@�@�@��-�]'�@�@�@ �@ !{` !::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.�.�r_�@�@�^:, -'��
�@�@�@,�@'�L�@�@�@�@�@�@�@�@ �S�P:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:!V:.:.�P:.:./�^
�@�@/�@�@�@�@�@,�@�@�@�@�@�@ ,�T�::::.:.:.:.:.:.:.:.:.:.:.:.:.::.:.:.:.:�n:__;;.-�]'�L
.�@/�@�@�@�@ �V�@�@�@�@�@�@{.��L:}�Oi:::.:.:.:::::::::::::::::::::�^�___,
�@���@�@�@�@{{�@ �@ �@ �@ �^...:::j���g�_:::::::::__; -'�L`�R���
/�@�@�@�@ __,.���[--�]:'�L:.:.::::�m�@/�:.�{�P�@�@�@�@�@�n
�@ �@ �@ �L�@�@ �P����\�] '�L �@ ��!:{ �
�:. :. : : : : : : : : : : : : : : :�M�A
�R�:::::. : : : : : : : : : :-� : : �_
�@�@ �_::::::.. : : : : : : :_,. -'7 r�]��-:�\:-�__�Q__ �@ ..__
�@�@�@�@�_::::i : : : ,. - .��: : �R�@ �M�R�: : : t�@�@�@�@�@�@�M �-�@_
�@�@�@�@�@ �R::: : :/�@�@�@�b/�_�_;�� }: : : }_,,. -�\�@ _�@�@�@�@ �M �-
�@�@�@�@�@ �m: : : {�@�@�@�@l:/�@�@�M_j,.�T�\--'�_�@�@�@�@�@ �M�@�[�]- �
�@�@�@�@ /: : : : : :t�@�@ ,.�B�@�@�r^:.:.�P`�R:.:.:.:.:�M�R�@�@�@�@�@�@�@�@�@�R
�@�@�@ r'_: : : : : : : }_,.��r'�n�@�:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:�M�
.�@ �^�@ �Mt: : : : �^�@��' i��{:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:i_�@�@�@�@�@ ,. -�]�@�@CPU���傾���藣�������c
�^�@�@�@�@��-�]'�@�@�@ �@ !{` !::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.�.�r_�@�@�^:, -'��
�@�@�@,�@'�L�@�@�@�@�@�@�@�@ �S�P:::.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:.:!V:.:.�P:.:./�^
�@�@/�@�@�@�@�@,�@�@�@�@�@�@ ,�T�::::.:.:.:.:.:.:.:.:.:.:.:.:.::.:.:.:.:�n:__;;.-�]'�L
.�@/�@�@�@�@ �V�@�@�@�@�@�@{.��L:}�Oi:::.:.:.:::::::::::::::::::::�^�___,
�@���@�@�@�@{{�@ �@ �@ �@ �^...:::j���g�_:::::::::__; -'�L`�R���
/�@�@�@�@ __,.���[--�]:'�L:.:.::::�m�@/�:.�{�P�@�@�@�@�@�n
�@ �@ �@ �L�@�@ �P����\�] '�L �@ ��!:{ �
�n�}�[�̒��̐l����Q�Ƃ���Ă����̂ŁA�����N���Ƃ��B
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
�ǂݒ������Ƃ��̒����ŁA�������AMD��SLI���Ǝv�����B
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
�ǂݒ������Ƃ��̒����ŁA�������AMD��SLI���Ǝv�����B
�Ԃ����Ⴏ�A�\�j�[�͂����T���X���̎P�����������������C������B
�v���X�e���ƁA���łɔ��p������ŁB
�v���X�e���ƁA���łɔ��p������ŁB
�����l�ɋ���邮�炢�Ȃ炨�ƂȂ������U���Ă��ꁄ���Ɂ[
���łɔ��p���ꂽ��u���[���C�͔p�~���ȁB
�Ж�CD/DVD�ł����Жʂ�HD-DVD�̃n�C�u���b�h�f�B�X�N������Ƃ��������ǁA
����͂���ŏ���ρB
�Ж�CD/DVD�ł����Жʂ�HD-DVD�̃n�C�u���b�h�f�B�X�N������Ƃ��������ǁA
����͂���ŏ���ρB
>>323
Hammer�̐l�̓n�[�h�͗]��m��Ȃ��݂�����
AMD�����l���Ă�̂͑���SIMD���j�b�g1��2�R�A�ŋ��L���ăR�A���𑝂₷
���ĕӂ�ł���iSIMD��������Ȃ��ăt���[�g�S����邩���m��j
���̉��Z���j�b�g���L���ă����b�g�����邩�D�D�D�H
���������ʏ퓮�쎞�ɋĂ郆�j�b�g�������L����Ӗ��͖�������
Hammer�̐l�̓n�[�h�͗]��m��Ȃ��݂�����
AMD�����l���Ă�̂͑���SIMD���j�b�g1��2�R�A�ŋ��L���ăR�A���𑝂₷
���ĕӂ�ł���iSIMD��������Ȃ��ăt���[�g�S����邩���m��j
���̉��Z���j�b�g���L���ă����b�g�����邩�D�D�D�H
���������ʏ퓮�쎞�ɋĂ郆�j�b�g�������L����Ӗ��͖�������
�@�@ �@ A�QA �@�@n�@ �@
�@�@ �i�@�E�́E �j(E) ))�@���ް�ɐ�����[�I
�@�@ �i/Op�@__�m
�@ �n�i�@�@�@�m
�@�@ /�@ ./
http://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
ttp://www.atmarkit.co.jp/fsys/keyword/016server_keyword2006/016server_keyword2006.html
> DIMM�ƃ������E�R���g���[���Ԃ�PCI Express���x�[�X�ɂ����V���A���E�C���^�[�t�F�C�X�Őڑ��\�ɂ�����̂��B
�ق��B���Ă��Ƃ�HT2.0��PCIe��荞��Opteron�ɂ͏������őΉ��ł������H
> DIMM�ƃ������E�R���g���[���Ԃ�PCI Express���x�[�X�ɂ����V���A���E�C���^�[�t�F�C�X�Őڑ��\�ɂ�����̂��B
�ق��B���Ă��Ƃ�HT2.0��PCIe��荞��Opteron�ɂ͏������őΉ��ł������H
>>327
���ŁA1�R�A�ӂ�̃f�R�[�_�[��3�Z�b�g�ŕς�薳���H
���ŁA1�R�A�ӂ�̃f�R�[�_�[��3�Z�b�g�ŕς�薳���H
>>330 ��C���̘b�H
���W�b�N���ǂ�������Ȃ���
���Z���j�b�g�����L���Ă�����issue�𑝂₷�Ƃ����͕̂��j����т��ĂȂ����
Issue�𑝂₷��Ȃ牉�Z���j�b�g�������ɑ��₳�Ȃ��ƌ��ʂ��Ȃ��ł���
���Z���j�b�g�����L���Ă�����issue�𑝂₷�Ƃ����͕̂��j����т��ĂȂ����
Issue�𑝂₷��Ȃ牉�Z���j�b�g�������ɑ��₳�Ȃ��ƌ��ʂ��Ȃ��ł���
AMD���ꂩ��搫�\������Ȃɂɗ���̂��ȁH
�N���b�N�Ɛ�p����
>>329�H
HT2.0��PCIe�Ƃ肱�H�Ȃ�̂��ƁH
PCIe(Bridge)���g����悤�Ƀ}�b�s���O���g�������Ƃ������Ƃ���B
HT��1GHz=2G Transfer/s�ȏ��APCIe bridge��HT2.0����B
����������̈ꕔ��Athlon64/Opteron��chipset��HT2.0�B
ttp://www.hypertransport.org/tech/tech_specs.cfm
ttp://www.hypertransport.org/docs/tech/HT20-Products-Aug05.pdf
HT2.0��PCIe�Ƃ肱�H�Ȃ�̂��ƁH
PCIe(Bridge)���g����悤�Ƀ}�b�s���O���g�������Ƃ������Ƃ���B
HT��1GHz=2G Transfer/s�ȏ��APCIe bridge��HT2.0����B
����������̈ꕔ��Athlon64/Opteron��chipset��HT2.0�B
ttp://www.hypertransport.org/tech/tech_specs.cfm
ttp://www.hypertransport.org/docs/tech/HT20-Products-Aug05.pdf
Athlon64 X2 5800+
TDP�͂킸��130W
TDP�͂킸��130W
���ꂶ�ፂ�N���b�N�̃v���X�R�ƕς��Ȃ������B
�܂����\�͌��Ⴂ���낤����
��Athlon64��Pen����u�����ᔭ�M�A�ȓd�͂Ȃ̂��Ē�N���b�N�Ȃ��瓖�R�Ȋ����͂��Ă���
�Ő��\UP���N���b�NUP�ɗ���Ƃ������قƕς����
������AMD����ꂿ�傿�傿�傿�傿�傤�������
�܂����\�͌��Ⴂ���낤����
��Athlon64��Pen����u�����ᔭ�M�A�ȓd�͂Ȃ̂��Ē�N���b�N�Ȃ��瓖�R�Ȋ����͂��Ă���
�Ő��\UP���N���b�NUP�ɗ���Ƃ������قƕς����
������AMD����ꂿ�傿�傿�傿�傿�傤�������
>>339
2.4GHz Quad Core Athlon64 X2 5800+
TDP�͂킸��130W
�N���b�N���炸�R�A�𑝂₵�Ă݂��Ƃ���A�����I��TDP�Ɏ��܂�܂����i�j�B
2.4GHz Quad Core Athlon64 X2 5800+
TDP�͂킸��130W
�N���b�N���炸�R�A�𑝂₵�Ă݂��Ƃ���A�����I��TDP�Ɏ��܂�܂����i�j�B
PenD���Ă��Â��ʖڂȎq�ȁE�E�E
P4��65nm�ł��N���b�N�グ���Ȃ�������
AMD���N���b�N�ȊO�Ő��\���Ղ��Ȃ��� ���낻�낫���낤��
AMD���N���b�N�ȊO�Ő��\���Ղ��Ȃ��� ���낻�낫���낤��
���̂��߂̃f���A���R�A�ł���B
�c�C���T�e���C�g�G���R�[�_�[
���[�N���Ɍ��܂łƂ��ǂ���
�����d���ŏ�������ˁH
�����d���ŏ�������ˁH
>>346
�������A���ׂ��Ⴂ�Ƃ��́A�R�A�P�ʂœd������Ă��܂��A�Ƃ����̂͂ǂ����ȁB
�������A���ׂ��Ⴂ�Ƃ��́A�R�A�P�ʂœd������Ă��܂��A�Ƃ����̂͂ǂ����ȁB
�R�A�P�ʂǂ��납�u���b�N�P�ʂœd����鎖���炢�ǂ��ł�����Ă铖��O�̋Z�p�B
�ނ���R�A�P�ʂœd���Ǘ�����̂����ꂩ��̖ڕW�ł���B
�ł�4�R�A���炢�܂łȂ炢�����ǃo�����[�����ɂ��R�A��8��16�������Ă��g�����Ȃ��邩��
�܂������Ȃ�܂łɂ͏��Ȃ��Ƃ�10�N�͂����邾�낤����
�܂������Ȃ�܂łɂ͏��Ȃ��Ƃ�10�N�͂����邾�낤����
Athlon64 X8 1.8GHz*8 6000+ 65nm
TDP�͂킸��150W
��p���Ԃɍ���Ȃ��ꍇ��A�d�����ア�ꍇ�ł��A�������̃R�A�̓d��������������܂��B
TDP�͂킸��150W
��p���Ԃɍ���Ȃ��ꍇ��A�d�����ア�ꍇ�ł��A�������̃R�A�̓d��������������܂��B
>>354
���̂���ɂ͎嗬�h����or�K�X�߂ł����B
���̂���ɂ͎嗬�h����or�K�X�߂ł����B
>>347 >>351
http://www.ne.jp/asahi/comp/tarusan/main72.htm
http://www.ne.jp/asahi/comp/tarusan/main96.htm
http://www.ne.jp/asahi/comp/tarusan/main72.htm
http://www.ne.jp/asahi/comp/tarusan/main96.htm
>>356
> Hyper-Threading�̓V���O���X���b�h�A�v���ɑ��鐫�\�ቺ���f���A���R�A��菭�Ȃ��B
�t�Ɍ����ƁAHT�̓}���`�X���b�h�ɂ�鐫�\���オ���Ȃ����Ď��ł�����B
�܂��O������Ƃ��āA�u�N���C�A���g�p�r�ł̓}���`�X���b�h�����ʂ��債���䗦�ł͂Ȃ��v
���Ă̂������Ă��邯�ǁB
�������A���̑O��������u���ƌ{�̊W�v�Ə�����Ă���B
��������܂ꂽ�ȏ�A������������܂��͕̂K�R�Ƃ������Ƃł��ˁB
> Hyper-Threading�̓V���O���X���b�h�A�v���ɑ��鐫�\�ቺ���f���A���R�A��菭�Ȃ��B
�t�Ɍ����ƁAHT�̓}���`�X���b�h�ɂ�鐫�\���オ���Ȃ����Ď��ł�����B
�܂��O������Ƃ��āA�u�N���C�A���g�p�r�ł̓}���`�X���b�h�����ʂ��債���䗦�ł͂Ȃ��v
���Ă̂������Ă��邯�ǁB
�������A���̑O��������u���ƌ{�̊W�v�Ə�����Ă���B
��������܂ꂽ�ȏ�A������������܂��͕̂K�R�Ƃ������Ƃł��ˁB
�l���AMD�͏ȃG�l���l���Ă���͂��ł��B
intel�Ƃ�������ЂƂ͈Ⴄ�̂���B
intel�Ƃ�������ЂƂ͈Ⴄ�̂���B
>>358
���͍���AMD��CPU���g���Ă��邪�A����Intel���������i���o�����炻�������Ǝv���B
�v�͂������i���������Ă��ƁB���[�J�[�ɂ͂������Ȃ��B
Intel�̂ق��������Ȃ�Intel�AAMD�̂ق��������Ȃ�AMD�B
���͓��RAMD�ł����ǂˁB
�̂�Cyrix�g���Ă���������������ǁB
���͍���AMD��CPU���g���Ă��邪�A����Intel���������i���o�����炻�������Ǝv���B
�v�͂������i���������Ă��ƁB���[�J�[�ɂ͂������Ȃ��B
Intel�̂ق��������Ȃ�Intel�AAMD�̂ق��������Ȃ�AMD�B
���͓��RAMD�ł����ǂˁB
�̂�Cyrix�g���Ă���������������ǁB
�u�ǂ����̂��o����ǂ����̂��v
�uIntel AMD �̃u�����h�ɂ������Ȃ��v
�Ƃ������Ă�z����
�z���g��Intel��AMD�������C�ɂȂ��Ă邾��
�Ȃ�ł킴�킴�ߖ����Ȃ���Ȃ��̂�
���������u�����h�M���Ă��������łȂ����
�ǂ����̂��ƐM������Ŏg���Ă���킯����
�uIntel AMD �̃u�����h�ɂ������Ȃ��v
�Ƃ������Ă�z����
�z���g��Intel��AMD�������C�ɂȂ��Ă邾��
�Ȃ�ł킴�킴�ߖ����Ȃ���Ȃ��̂�
���������u�����h�M���Ă��������łȂ����
�ǂ����̂��ƐM������Ŏg���Ă���킯����
�Ή������j�C�R�A�ɓ˂������Ă��A���@�̃R���p�C�����o�Ȃ����Ƃɂ�
>>349
���̊��ɂ̓A�C�h�����̏���d�͂��傫���ł���B
>>362
���ł�����ł��}���`�X���b�h�ɂ���K�v�͂Ȃ��Ǝv���B
���A1�R�A�Ő��\�I�ɑ���Ă�����̂܂ŁA�}���`�X���b�h�ɂ��Ȃ��Ă������B
����̏����A3D�̌v�Z�ȂǁA�d�����̂̓}���`�X���b�h�����₷���Ǝv����B
���̊��ɂ̓A�C�h�����̏���d�͂��傫���ł���B
>>362
���ł�����ł��}���`�X���b�h�ɂ���K�v�͂Ȃ��Ǝv���B
���A1�R�A�Ő��\�I�ɑ���Ă�����̂܂ŁA�}���`�X���b�h�ɂ��Ȃ��Ă������B
����̏����A3D�̌v�Z�ȂǁA�d�����̂̓}���`�X���b�h�����₷���Ǝv����B
>>360
���̎���J�[������ˁA���������X�A�[�L�e�N�`���̓��W�����ŐV�̏���w����āc�c�c
���̎���J�[������ˁA���������X�A�[�L�e�N�`���̓��W�����ŐV�̏���w����āc�c�c
�m��Ȃ��ƒp��������B
�w��̖{���̓��W�́A���Ⴂ�̐l��ΏۂƂ������{�L������B
�ŐV�̌����ɂ��ẮA�ʍ��̘_�����̂ق��Ɍf�ڂ�����B
�w��̖{���̓��W�́A���Ⴂ�̐l��ΏۂƂ������{�L������B
�ŐV�̌����ɂ��ẮA�ʍ��̘_�����̂ق��Ɍf�ڂ�����B
Mainstream�`Value�т�Personal Computer�ł̓V���O���R�Aor�f���A���R�A�������I���B
�N�A�b�h�R�A�ȏ�͖��ʁB
�N�A�b�h�R�A�ȏ�͖��ʁB
http://fw8.bookpark.ne.jp/cm/ipsj/search.asp?from=Magazine&flag=-1&keyword=Magazine,VN000046000010&page=&mode=PDF
���̕ӂɂ���z���H
�������������Ă�ȁc�B
���̕ӂɂ���z���H
�������������Ă�ȁc�B
sempron�f���A���ɂȂ邩�S�z���ȁB
Sempron X4 5000+ 1.6GHz*4
TDP�͂킸��140W�B
�f���A���R�ACeleron D�̎�������10W���Ⴂ�ł��B
�f���炵���Ǝv���܂��H
TDP�͂킸��140W�B
�f���A���R�ACeleron D�̎�������10W���Ⴂ�ł��B
�f���炵���Ǝv���܂��H
>>366
�����Ƃ�������Ȃ��Ǝv���B
�x�m�ʂ�FR1000�̂悤�ɁA�Ɠd�p��CPU�ł���4�R�A����B
�}���`���f�B�A������3D�����Ȃ�A4�R�A�ȏ�ł��g�����Ȃ���Ǝv���B
�p�\�R����2�R�A��K�v�Ƃ�����̂́A4�R�A�ȏ�ł��e�ՂɑΉ��ł��������Ǝv����B
�����Ƃ�������Ȃ��Ǝv���B
�x�m�ʂ�FR1000�̂悤�ɁA�Ɠd�p��CPU�ł���4�R�A����B
�}���`���f�B�A������3D�����Ȃ�A4�R�A�ȏ�ł��g�����Ȃ���Ǝv���B
�p�\�R����2�R�A��K�v�Ƃ�����̂́A4�R�A�ȏ�ł��e�ՂɑΉ��ł��������Ǝv����B
IPC����A�N���b�N����AL1�EL2�E���C�����������C�e���V�팸
�����͉ߋ�������������Ƃ�����A�v���P�[�V�����ō������̉��b����B
����ɑ��ă}���`�R�A����
�����͉ߋ�������������Ƃ�����A�v���P�[�V�����ō������̉��b����B
����ɑ��ă}���`�R�A����
http://www.watch.impress.co.jp/akiba/hotline/20051022/p_cpu.html
���i����̑O�����炩�AAMD�b�o�t�S�ʂ̉��i��������n�߂��ˁB
���i����̑O�����炩�AAMD�b�o�t�S�ʂ̉��i��������n�߂��ˁB
http://www.watch.impress.co.jp/akiba/hotline/20051022/graph/gi_eaa6r_329.html
������N�ʑS�R�ς���ĂȂ�������
������N�ʑS�R�ς���ĂȂ�������
>>375
��ȉ��ʃ��f������������������킯�Ȃ����낤���B
�n������Ȃ���(�G�L�t�M)
3500+�Ƃ��͉������Ă邾�낤���B
�������Ȃ��B
��ȉ��ʃ��f������������������킯�Ȃ����낤���B
�n������Ȃ���(�G�L�t�M)
3500+�Ƃ��͉������Ă邾�낤���B
�������Ȃ��B
�~��������
>>376
���H
3200+�͉��ʃ��f���ŁA3500+�͂�������Ȃ��́H
���\�����������B
�ł��A���ʃ��f���ł����ʂɉ�����Ǝv�����ǂȁB
�܂�������Ȃ��̂�Intel�̊撣�肪����Ȃ��������Ǝv�����ǁB
���H
3200+�͉��ʃ��f���ŁA3500+�͂�������Ȃ��́H
���\�����������B
�ł��A���ʃ��f���ł����ʂɉ�����Ǝv�����ǂȁB
�܂�������Ȃ��̂�Intel�̊撣�肪����Ȃ��������Ǝv�����ǁB
���Ԃ�v���X�R�Ƃ��v�����t���̂��o���Ă�Ԃ͂���܂艺����Ȃ���
Pre��Ple�ꎋ����͓̂��{�l�I���z����B
Freeze��Please���Ⴆ�Č�����Ď��Ⴆ
Freeze��Please���Ⴆ�Č�����Ď��Ⴆ
�딚�����B�B
>>376
���ʃ��f�������܂ł������Ă�������������Ǝv��
���ʃ��f�������܂ł������Ă�������������Ǝv��
>>383
Intel��CPU�ł���Ƌ������郉�C���i�b�v�����邩�炾�Ǝv���B
���sPentium4�̍ʼn��ʃ��f����3GHz�B
���sAthlon64�̍ʼn��ʃ��f����3000+(1.8GHz)�B
Intel��CPU�ł���Ƌ������郉�C���i�b�v�����邩�炾�Ǝv���B
���sPentium4�̍ʼn��ʃ��f����3GHz�B
���sAthlon64�̍ʼn��ʃ��f����3000+(1.8GHz)�B
>>372
���ꂪ�Z�p�I�ȕǂɓ˂������������������}���`�R�A�ɂȂ��Ă��
���ꂪ�Z�p�I�ȕǂɓ˂������������������}���`�R�A�ɂȂ��Ă��
���ɔM�̕�
�}���`�R�A�������M�̕ǂƂ̐킢�Ȃ킯�����B
�C���e���݂����ɋ��肵�܂����Ďd���̊��ɂ͔M���̂Ȃ�_�������A��������d�����Ă��ĔM���̂Ȃ�A�����Ǝv����B
���M2�{�ŁA���x��2�{�ɂȂ�������B
���M2�{�ŁA���x��2�{�ɂȂ�������B
�V���O���R�A�ł��}���`�R�A�ł��M�͖�肾����
�ŏI�I�ɐ��\����ł��邩�ǂ��������Ȃ킯��
IPC�͂��܂�ς��Ȃ�
�N���b�N������قƂ�nj����߂Ȃ�
�Ƃ����������
�@�@�@�@�@��
�V���O���R�A�ł͂��܂萫�\����ł��Ȃ���
�}���`�R�A�Ȃ�}���`�X���b�h�A�v���Ő��\����\
�ŏI�I�ɐ��\����ł��邩�ǂ��������Ȃ킯��
IPC�͂��܂�ς��Ȃ�
�N���b�N������قƂ�nj����߂Ȃ�
�Ƃ����������
�@�@�@�@�@��
�V���O���R�A�ł͂��܂萫�\����ł��Ȃ���
�}���`�R�A�Ȃ�}���`�X���b�h�A�v���Ő��\����\
���v�����ǁA�}���`�R�A�W�͂����ƃn�C�G���h���������ɏo���Ă�����
�o�����[�����ɂ�turion���������d�͂ɂ����݂����Ȃ���f�X�N�g�b�v������
�o���Ă�����������������Ȃ����ƁB���ɓ��{�̓n�C�G���h�i�Ƃ��������z�Ȃ́j����܂蔃��������Ȃ���ł���H
�o�����[�����ɂ�turion���������d�͂ɂ����݂����Ȃ���f�X�N�g�b�v������
�o���Ă�����������������Ȃ����ƁB���ɓ��{�̓n�C�G���h�i�Ƃ��������z�Ȃ́j����܂蔃��������Ȃ���ł���H
���A�������I
���{�s��ł́A�����ŏ��^�ŐÉ���VIA�}�V�����������A�����̂��I�I
�ǂ����A�}�W�ł�郁�[�J�[����Ȃ����Ȃ��B
���{�s��ł́A�����ŏ��^�ŐÉ���VIA�}�V�����������A�����̂��I�I
�ǂ����A�}�W�ł�郁�[�J�[����Ȃ����Ȃ��B
�����ŏ��^�ŐÉ���intel�}�V�����������A�����Ɣ�����B
�Ⴆ�ACeleM�m�[�g�Ƃ��B
�}�W�ł���Ă郁�[�J�[�FDELL�Ahp
�Ⴆ�ACeleM�m�[�g�Ƃ��B
�}�W�ł���Ă郁�[�J�[�FDELL�Ahp
�Ⴂ�ɂȂ��Ă���
VIA�ƍ������ċZ�p�Ɠ�����������ł���Ј����X�g���Ƃ��B
����ACyrix�E�E�Eorz
>>393
HP�������g�o
HP�������g�o
������łȂ���
Cyrix�Ŏv���o�������ǁAGeode�@GX�̕��̌�p
�`�b�v���Ă����łȂ��́H
�`�b�v���Ă����łȂ��́H
>> 400
AMD�A������x86�v���Z�b�T�Z�p�����C�Z���X���^
�`�g�ݍ�������d��CPU�̊J��������
ttp://pc.watch.impress.co.jp/docs/2005/1024/amd.htm
AMD�A������x86�v���Z�b�T�Z�p�����C�Z���X���^
�`�g�ݍ�������d��CPU�̊J��������
ttp://pc.watch.impress.co.jp/docs/2005/1024/amd.htm
�Ƃ肠�����AVIA����nVidia�ƍ������ė~�����h�ȉ��B
�`�b�v�Z�b�g�A�r�f�I�`�b�v
AMD�������ĂȂ��Z�p������ЁB
��������Αo���Ƀ����b�g������Ǝv�����c�c
�`�b�v�Z�b�g�A�r�f�I�`�b�v
AMD�������ĂȂ��Z�p������ЁB
��������Αo���Ƀ����b�g������Ǝv�����c�c
nVidia�̑̎��ɉ������ꂽ��
�m�I���L���ی�ŃK�`�K�`��
Linux�̃T�|�[�g����������B
�m�I���L���ی�ŃK�`�K�`��
Linux�̃T�|�[�g����������B
nVidia��AMD�F�ɐ��܂�����A�C���e����ATi�Ƒg��ł��܂��āA�V�F�A���E�E�E�B
>>390
���{��ValueCPU����g�p����̂́A�Ɠd���Ƃ�����B
���g���A�Ɠd���i�Ƃ��Ă̍��ʉ��i�o���j�̕���
���[�J�[�ɂ��Ă�����҂ɂ��Ă��d�v�������B
���{��ValueCPU����g�p����̂́A�Ɠd���Ƃ�����B
���g���A�Ɠd���i�Ƃ��Ă̍��ʉ��i�o���j�̕���
���[�J�[�ɂ��Ă�����҂ɂ��Ă��d�v�������B
����ł��H�t���E�G�ɖڂ�������A
�T�[�o�N���X��CPU�E�}�U�{����ʂɔ���V���b�v������A
�����Ɠ����ɔ����Ă����q������킯�ŁB
�T�[�o�N���X��CPU�E�}�U�{����ʂɔ���V���b�v������A
�����Ɠ����ɔ����Ă����q������킯�ŁB
http://news.goo.ne.jp/news/ism/sports/20051024/2005102401.html?C=S
F1�Ȃ�āA�قƂ�nj��Ȃ��Ȃ�������A
�S�R�m��Ȃ�������B
����Ȃ��Ƃ�����Ă��̂ˁAAMD�B
F1�Ȃ�āA�قƂ�nj��Ȃ��Ȃ�������A
�S�R�m��Ȃ�������B
����Ȃ��Ƃ�����Ă��̂ˁAAMD�B
F1���ƃw���v���łĂ�����
���N�O����t�F���[���̃X�|���T�[�������̂͒m���Ă����ǁA�����܂ŐH������ł��̂�
�t�F���[��/AMD
http://sports.yahoo.co.jp/f1/2005/teams/fer/
http://www.itmedia.co.jp/news/bursts/0202/07/06.html
http://www.itmedia.co.jp/enterprise/0403/19/epn09.html
�t�F���[���d�l�̃m�[�gPC
http://pc.watch.impress.co.jp/docs/2004/0907/acer.htm
�g���^/intel
http://sports.yahoo.co.jp/f1/2005/teams/toy/
�t�F���[��/AMD
http://sports.yahoo.co.jp/f1/2005/teams/fer/
http://www.itmedia.co.jp/news/bursts/0202/07/06.html
http://www.itmedia.co.jp/enterprise/0403/19/epn09.html
�t�F���[���d�l�̃m�[�gPC
http://pc.watch.impress.co.jp/docs/2004/0907/acer.htm
�g���^/intel
http://sports.yahoo.co.jp/f1/2005/teams/toy/
F1��CFD��͂ł�Opteron�g���Ă��
ttp://enterprise.watch.impress.co.jp/cda/special/2005/10/11/6338.html
ttp://enterprise.watch.impress.co.jp/cda/special/2005/10/11/6338.html
4GHz�o���Ȃ��̂Ɠ������R��3GHz�o���Ȃ��̂��H
FX-57��X2 4800+�̐l�C�����݂āA�Â���ɂ����Ƃ��H
�ł��A�{����������c�O
�ł��A�{����������c�O
����������FX�����A�����ɑI�ʂ��Ăł�3GHz�f���A���R�A�͌����������ȁB
�M�Ƃ������ڂł��v���X�R�Ή����̃N�[���[�Ȃ�ǂ��ɂł��Ȃ邾�낤����
�M�Ƃ������ڂł��v���X�R�Ή����̃N�[���[�Ȃ�ǂ��ɂł��Ȃ邾�낤����
�ł����������AMD���@�����͕̂K�����Ȃ�
�܁[TDP130W�ł��ANetburst��菭�Ȃ���Ή��ł�OK�̕��������A��������Ȃ����H
���̃v���Z�X���ᖳ������
��̉���CPU���OC�œ�Ȃ��s���鏊�ʂ܂ł����o�Ȃ���
��3G�܂�OC�Ȃ�Ėw�ǂȂ��ł���B
65n��M2�҂��B
��̉���CPU���OC�œ�Ȃ��s���鏊�ʂ܂ł����o�Ȃ���
��3G�܂�OC�Ȃ�Ėw�ǂȂ��ł���B
65n��M2�҂��B
FX57����3G�]�T�ōs����Ȃ����������H
3Ghz�̃V���O���R�A�͏o�Ȃ��̂��ȁH
3Ghz�̃V���O���R�A�͏o�Ȃ��̂��ȁH
>>402
�@SiS�ƍ������āA�`�b�v�Z�b�g�����Ѓu�����h�ŐϋɓI�ɔ����Ăق����B
�@SiS�ƍ������āA�`�b�v�Z�b�g�����Ѓu�����h�ŐϋɓI�ɔ����Ăق����B
>>418
Intel�������\CPU�o���Ȃ�����A�o���Ȃ��\���������Ǝv���B
�����ς������ς��̐��i�Y����̂͑�ς��낤���B
�����܂��I�ʂ��C�ɂ��Ȃ��čςނ̂͂��Ȃ�y���Ǝv���B
Intel�������\CPU�o���Ȃ�����A�o���Ȃ��\���������Ǝv���B
�����ς������ς��̐��i�Y����̂͑�ς��낤���B
�����܂��I�ʂ��C�ɂ��Ȃ��čςނ̂͂��Ȃ�y���Ǝv���B
�����O�ɗ��s���� �A���h�i�~�G�ł��B�@�̂͂悭�̂��̂��Ă���������܂����B
422 �FSocket774�F2005/10/30(��) 01:41:07 ID:ICcCg18p
�M�̕ǂ��ē��ʑ̃E�F�n�[�̂���͂ǂ��Ȃ�����
423 �FSocket774�F2005/10/30(��) 15:41:29 ID:+aMCqBeK
�@�@ �@ A�QA �@�@n�@ �@
�@�@ �i�@�E�́E �j(E) ))�@Intel�����i�^����j�̖Ғnj��I
�@�@ �i/Op�@__�m�@�@ �@ ���ް�ɐ�����[�i�P��T�[�܂Łj
�@ �n�i�@�@�@�m
�@�@ /�@ ./
http://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
�@�@ �i�@�E�́E �j(E) ))�@Intel�����i�^����j�̖Ғnj��I
�@�@ �i/Op�@__�m�@�@ �@ ���ް�ɐ�����[�i�P��T�[�܂Łj
�@ �n�i�@�@�@�m
�@�@ /�@ ./
http://www.petitra.net/cgi-bin/tvote/tvote.cgi?event=2chchar
424 �FSocket774�F2005/10/30(��) 16:09:38 ID:lxlLAEmg
������CPU�͂ق������ǁA�V�\�P�b�g�ɕς���ȁ`
�ł�����ATDP35W���炢��2GX4�R�A���炢��CPU��
939�ɏo���Ă��ꂽ�炢���̂Ɂc
�ł�����ATDP35W���炢��2GX4�R�A���炢��CPU��
939�ɏo���Ă��ꂽ�炢���̂Ɂc
4�R�A�ɂȂ����炻�ꂱ���������̑ш悪����Ȃ��Ȃ��Ă��邾�낤����
�Ȃ�����DDR2�̐V�\�P�b�g�ɂ��Ȃ��Ⴞ�߂���B
�Ȃ�����DDR2�̐V�\�P�b�g�ɂ��Ȃ��Ⴞ�߂���B
���͂ǂ����ɂ���l�q�������
427 �FSocket774�F2005/10/30(��) 22:13:59 ID:GkMjkyYc
�č��̃R���s���[�^�p�v���Z�b�T���[�J�[��AMD��10��24���A�������{�Ɏ嗬�̃v���Z�b�T�v�Z�p
X86�A�[�L�e�N�`���[�̃��C�Z���X�����^���A�����Ǝ��̃v���Z�b�T�J������������Ɣ��\�����B
�����ւ̋Z�p�ړ]�Ő��Y�R�X�g�팸�A�V�F�A�g����������A�C���e���ɑ�������\�����B
���p���F�W�F�g���@2005/10/28
http://www.jetro.go.jp/topics/37213
������AMD���i���u�^���^���v�Ƃ��ɂȂ�̂��H
���˂��c���v�Ȃ̂������ŁB
X86�A�[�L�e�N�`���[�̃��C�Z���X�����^���A�����Ǝ��̃v���Z�b�T�J������������Ɣ��\�����B
�����ւ̋Z�p�ړ]�Ő��Y�R�X�g�팸�A�V�F�A�g����������A�C���e���ɑ�������\�����B
���p���F�W�F�g���@2005/10/28
http://www.jetro.go.jp/topics/37213
������AMD���i���u�^���^���v�Ƃ��ɂȂ�̂��H
���˂��c���v�Ȃ̂������ŁB
�x�߂Ɍ����ꂵ�Ă��A�����犴�ӂȂ��Ȃ���B
�ǂ��悤�ɗ��p�����̂��I�`�B
�ǂ��悤�ɗ��p�����̂��I�`�B
���{�ȊO�ɑ��Ă��H
���{��ڂ̓G�ɂ��Ă�̂͑Γ������ɖ�肪���邩��ł���
�ǂ����Ƃ��W�Ȃ���Ȃ��́H�@���ꂪ�ΊO����̕W���炵������B
�ǂ����Ƃ��W�Ȃ���Ȃ��́H�@���ꂪ�ΊO����̕W���炵������B
>>427
������āA�v���x����������ɂ��悤���Ęb�Ȃ̂��ȁH
�m���ɁA�����̉��i�тŒ����ɔ��낤�Ƃ���Ȃ�A
�����̊O�ł���蒆�ōς܂����������オ��Ȃ낤���ǁB
�i���Y�ݔ����̂͊��ɂ��邵�j
������āA�v���x����������ɂ��悤���Ęb�Ȃ̂��ȁH
�m���ɁA�����̉��i�тŒ����ɔ��낤�Ƃ���Ȃ�A
�����̊O�ł���蒆�ōς܂����������オ��Ȃ낤���ǁB
�i���Y�ݔ����̂͊��ɂ��邵�j
>>431
Cyrix�̖Y��`����MediaGX�����C�Z���X������������B
Cyrix�̖Y��`����MediaGX�����C�Z���X������������B
�`�l�c�̂w�W�U���C�Z���X���^�Ɂu���c�v�j�~�̐���
http://news.searchina.ne.jp/disp.cgi?y=2005&d=1026&f=it_1026_003.shtml
http://news.searchina.ne.jp/disp.cgi?y=2005&d=1026&f=it_1026_003.shtml
���̃R�A�͊J������Ă���̂��ȁH
�ȑO�����Ă���K9�����̂��̂͗��N�o�邯�ǁB
�ȑO�����Ă���K9�����̂��̂͗��N�o�邯�ǁB
�V�A�[�L�e�N�`���̊J���n�߂Ă���o�ׂ���܂ŕW����4�N���炢�|����̂�
���J�����ĂȂ��������Ђ����̂����ׂ�܂��B
���J�����ĂȂ��������Ђ����̂����ׂ�܂��B
>>435
PenD�ł����A�����ɂP�N����������
PenD�ł����A�����ɂP�N����������
>>433
���匾���܂��ɂ�����ƃ��C�Z���X����ȁA�Ƃ����Ă�肽���i���
�������A�Ǝ��Z�p���i�̎p���͌��\�����ǁA
���̓Ǝ��Z�p�Ƃ��ł�Windows�͓����Ȃ��ƒm�������A
���O�͂��̃}�V�������̂��˂��H�@�g�ݍ�����������W�Ȃ��H
���匾���܂��ɂ�����ƃ��C�Z���X����ȁA�Ƃ����Ă�肽���i���
�������A�Ǝ��Z�p���i�̎p���͌��\�����ǁA
���̓Ǝ��Z�p�Ƃ��ł�Windows�͓����Ȃ��ƒm�������A
���O�͂��̃}�V�������̂��˂��H�@�g�ݍ�����������W�Ȃ��H
>438
�����Linux���Ȃɂ������Ă��Ȃ����������H
���̍��͋Z�p��������Windows�g�킹�Ȃ��Ƃ����ł���
�����Linux���Ȃɂ������Ă��Ȃ����������H
���̍��͋Z�p��������Windows�g�킹�Ȃ��Ƃ����ł���
���Y�̐퓬�@��낤�Ǝv�����疳����č����[�J�[�@�E�E�E�E(ry
�݂����Ȃ��̂ł����H
�݂����Ȃ��̂ł����H
���̍��͉��ł��R�s�[����n�߂�̂��퓹�Ȃ̂ŁA
���@�I�ɃR�s�[�����Ă����Ȃ��낱��ł��Ǝv�����B
�@�ł��S���C�ɂ��Ȃ����ǂȁB
���@�I�ɃR�s�[�����Ă����Ȃ��낱��ł��Ǝv�����B
�@�ł��S���C�ɂ��Ȃ����ǂȁB
>>442
����������ɂ���Ă̓R�s�[��E���Ă�ȁB
�R���A�F������͈�l�O�ȏ�A���{���i��ł镔��������B
�����́A�����H�͂�����ăR�s�[�����ĂƂ��납�B
���̂�����͑�p�����ɋ�������A�i���͈ӊO�ɑ������ł͂���B
����������ɂ���Ă̓R�s�[��E���Ă�ȁB
�R���A�F������͈�l�O�ȏ�A���{���i��ł镔��������B
�����́A�����H�͂�����ăR�s�[�����ĂƂ��납�B
���̂�����͑�p�����ɋ�������A�i���͈ӊO�ɑ������ł͂���B
�����̉F���J���̎����͓��{��ODA�Řd���Ă���
���āA�����̃X���H
���āA�����̃X���H
>>444
��w�̂��߂ɌR���ɂ����ē����ȊO�œ��{���D��Ă���|�C���g�������Ă���Ȃ����B
��w�̂��߂ɌR���ɂ����ē����ȊO�œ��{���D��Ă���|�C���g�������Ă���Ȃ����B
448 �FSocket774�F2005/11/02(��) 12:47:35 ID:cLX/jtP8
>>448
��s�҂����邶���
��s�҂����邶���
>>449
�A���͓��{�ɂ͐^���ł��Ȃ��ȁB
�A���͓��{�ɂ͐^���ł��Ȃ��ȁB
��s�҂��j�����㵒p�S�̂�����{�l�ɂ͊J���͓���B
���̋@����ʂ邢�R�[�����o�Ă��Ă����тň��߂��ݸ�ذ���_�������
��s�҂͖{�������g�����Ȃ�
�l�^���{�����̃A�h�o���[���グ�����ēK���ɏ㔼�g��������ʂ���Ȃ��ƂɂȂ���������炵���B
�l�^���{�����̃A�h�o���[���グ�����ēK���ɏ㔼�g��������ʂ���Ȃ��ƂɂȂ���������炵���B
�r�Ȃ�Ă����肾���Ă��Ƃ������ɂ͓`����ĂȂ������̂�
>>453
��͂�`���R�L���m���ȊO�͂��܂����������c
��͂�`���R�L���m���ȊO�͂��܂����������c
�{����2�r��Ԃŏ㕔�ɖC��t���������Ȃ̂�
�z��O�̏㔼�g���t�����������ŌҊԂɂȂ��Ă��܂����ƁB
�z��O�̏㔼�g���t�����������ŌҊԂɂȂ��Ă��܂����ƁB
�����͉��̃X���ł����H
>>445
���\�A���������������ǁA�F���J���Ƃ����s���{�Ƃ��̐��ԂȂꂵ������͋����B
���Y�}�x�z�̂�����݂��瓦��Ă�����x���R�Ɍ����ł��邩��ˁB
�����������̓_���B�������������I�Ƀ_���B
���\�A���������������ǁA�F���J���Ƃ����s���{�Ƃ��̐��ԂȂꂵ������͋����B
���Y�}�x�z�̂�����݂��瓦��Ă�����x���R�Ɍ����ł��邩��ˁB
�����������̓_���B�������������I�Ƀ_���B
���̗����AMD�Ɛ�s�҂�Get Ride!�Ƃ������t�Ō��т�����ׂĉ�������C������
461 �FSocket774�F2005/11/02(��) 22:47:27 ID:sCG/U3rV
AthlonX3�܂���������������������������������������
����̓g���v���R�A�Ƃ����Ӗ����H
463 �FSocket774�F2005/11/02(��) 23:11:17 ID:sCG/U3rV
����3�ł�4�ł����Ă��ꂗ������
�ł��낗��������������������������������������������������������
�ł��낗��������������������������������������������������������
���������̂łł��܂���
Athlon64X64
�H��������̂łł��܂���
�ȑO���� �uAMD�Ɏ�����Ȃ�Ė����v�Ǝ咣���Ă邷���ǁA�z���g�炵�����B
http://www.theinquirer.net/?article=27421
�܂��ʏ�4-5�N��v����v���Z�b�T�J�������ǁA5�N�O��AMD�̌o�c��Ԃ���l���Ăǂ�قnj����J��
�������\���������H�Ƃ����̂�A���R�̋^�₷�B
http://www.theinquirer.net/?article=27421
�܂��ʏ�4-5�N��v����v���Z�b�T�J�������ǁA5�N�O��AMD�̌o�c��Ԃ���l���Ăǂ�قnj����J��
�������\���������H�Ƃ����̂�A���R�̋^�₷�B
��荇�������ɃJ�G���I
>>469
�Ƃ肠�����m���őR�ł���悤�ɂȂ�܂ŁAROM
�Ƃ肠�����m���őR�ł���悤�ɂȂ�܂ŁAROM
{kind=link}
�y�]��z�@AMD's K10 Is delayed or dead
ttp://www.theinquirer.net/?article=27421
THE K10 LOOKS TO BE dead, or at least really really delayed.
we think it is much more likely that the core is history.
Either way, if you were expecting the K10 in 2007, don't, and maybe not in 2008 either.
Either way, this is not good news for AMD.
ttp://www.theinquirer.net/?article=27421
THE K10 LOOKS TO BE dead, or at least really really delayed.
we think it is much more likely that the core is history.
Either way, if you were expecting the K10 in 2007, don't, and maybe not in 2008 either.
Either way, this is not good news for AMD.
http://pc7.2ch.net/test/read.cgi/jisaku/1130919890/265
265 �v�� sage New! 2005/11/03(��) 19:11:42 ID:oaT6QpkJ
AMD��K10�͒x��邩����
AMD's K10 Is delayed or dead
http://www.theinquirer.net/?article=27421
K10�͂Ȃ��Ȃ����悤���A
���邢�͏��Ȃ��Ƃ��܂������{���ɒx�����鎖�ɂȂ�B
�P����1�N��2�N�x���Ƃ�������
�R�A(K10)���̂��ߋ��̂��̂ƂȂ�\���̕��������ƍ����Ǝv���B
<- K9�Ɋւ���V��H ->
�ȑO�̂����܂������G��8���ߔ��s���s��K9�̂悤��
�C�̂������ƂȂ��ď�������Ɏ��͓q�����B
������ɂ���2007�N��K10���o��Ɗ��҂��Ă���Ȃ炻��͖������B
�����炭2008�N���B
�Ȃ�Ƃ�����ɂ�K8L�Ƃ����V�`�b�v���Ԃɋ��ގ��ɂȂ�B
����������ɂ��Ă͍��̂Ƃ���قƂ�ǂ킩���Ă͂��Ȃ��B
�킩���Ă��鎖�͂��ꂪ4�R�A�ŃX�^�[�g����Ƃ��������B
�����Ă�����8�R�A�ւƈڍs����\�������Ȃ荂���B
265 �v�� sage New! 2005/11/03(��) 19:11:42 ID:oaT6QpkJ
AMD��K10�͒x��邩����
AMD's K10 Is delayed or dead
http://www.theinquirer.net/?article=27421
K10�͂Ȃ��Ȃ����悤���A
���邢�͏��Ȃ��Ƃ��܂������{���ɒx�����鎖�ɂȂ�B
�P����1�N��2�N�x���Ƃ�������
�R�A(K10)���̂��ߋ��̂��̂ƂȂ�\���̕��������ƍ����Ǝv���B
<- K9�Ɋւ���V��H ->
�ȑO�̂����܂������G��8���ߔ��s���s��K9�̂悤��
�C�̂������ƂȂ��ď�������Ɏ��͓q�����B
������ɂ���2007�N��K10���o��Ɗ��҂��Ă���Ȃ炻��͖������B
�����炭2008�N���B
�Ȃ�Ƃ�����ɂ�K8L�Ƃ����V�`�b�v���Ԃɋ��ގ��ɂȂ�B
����������ɂ��Ă͍��̂Ƃ���قƂ�ǂ킩���Ă͂��Ȃ��B
�킩���Ă��鎖�͂��ꂪ4�R�A�ŃX�^�[�g����Ƃ��������B
�����Ă�����8�R�A�ւƈڍs����\�������Ȃ荂���B
>>470
���������AMAC���͘^���ƕ��ԍr�炵�����I�m����_�c�Ȃ�đS���Ӗ��Ȃ��B
�l�̘b�����ĂȂ�����B����Ȃ̂ɋ�����ꂿ�።����B
���������AMAC���͘^���ƕ��ԍr�炵�����I�m����_�c�Ȃ�đS���Ӗ��Ȃ��B
�l�̘b�����ĂȂ�����B����Ȃ̂ɋ�����ꂿ�።����B
��b��f�B�e�[���̒m���͂��������ǎ����ߐM���]��߂��ĖT�ڂ��猩��ƃg�̎��Ȑl���Ă��ƁH
����m��������
>>474 ����
�@�@--------------------
�@�@�m����_�c�Ȃ�đS���Ӗ��Ȃ��B
�@�@--------------------
�܂����̕ӂ��A�������M�ƌ����鏊�Ȃ��Ǝv���邷(��)
>>471 ����
2000�N���������ł��B�B�B
�@�@--------------------
�@�@�m����_�c�Ȃ�đS���Ӗ��Ȃ��B
�@�@--------------------
�܂����̕ӂ��A�������M�ƌ����鏊�Ȃ��Ǝv���邷(��)
>>471 ����
2000�N���������ł��B�B�B
>>477
������N�Y���������ނȂƁB
������N�Y���������ނȂƁB
>>477
���ʂɃL���C
���ʂɃL���C
�@�@�@�@�@�@�@�@�@�@,,�\�]�D�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ r-�A�@�@�@�@�Q,--,�A
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
�킴�킴������Ă���Ă����A���ڂƂ��您�O��B
��n�Q�̓X���[���S���B
��n�Q�̓X���[���S���B
8���ߔ��s�͐��C�̍�������Ȃ���
http://pc.watch.impress.co.jp/docs/article/20001226/kaigai01.htm
�������A�����ɂ͋^�������B�Ƃ����̂́ACPU�ƊE�ł́A����1�`2�N�AILP�ɑ���^�₪
���o���Ă��邩�炾�B�Ⴆ�AILP��5����/�T�C�N���ȏオ�����I���ǂ����BIntel Microprocessor
Research Labs(MRL)��Fred Pollack�f�B���N�^��Intel Fellow���A���N10����PACT 2000��
���\���� �uNew Challenges in Microarchitecture and Compiler Design�v�̃v���[���e�[�V����
�����ɂ́A�X�^�e�B�b�N��ILP�ł͖��ߔ��s���������瑝�₵�Ă�����IPC�́A4.x����/�T�C�N����
�~�܂��Ă��܂�(�������{�g���l�b�N���S���Ȃ��ꍇ)�Ƃ����AMRL�̌������ʂ�������Ă���B
http://pc.watch.impress.co.jp/docs/article/20001226/kaigai01.htm
�������A�����ɂ͋^�������B�Ƃ����̂́ACPU�ƊE�ł́A����1�`2�N�AILP�ɑ���^�₪
���o���Ă��邩�炾�B�Ⴆ�AILP��5����/�T�C�N���ȏオ�����I���ǂ����BIntel Microprocessor
Research Labs(MRL)��Fred Pollack�f�B���N�^��Intel Fellow���A���N10����PACT 2000��
���\���� �uNew Challenges in Microarchitecture and Compiler Design�v�̃v���[���e�[�V����
�����ɂ́A�X�^�e�B�b�N��ILP�ł͖��ߔ��s���������瑝�₵�Ă�����IPC�́A4.x����/�T�C�N����
�~�܂��Ă��܂�(�������{�g���l�b�N���S���Ȃ��ꍇ)�Ƃ����AMRL�̌������ʂ�������Ă���B
>�ȑO�̂����܂������G��8���ߔ��s���s��K9�̂悤��
����Ȃ��o�Ă��H
K9�̓��e�Ȃ�ď��߂Č����B
����Ȃ��o�Ă��H
K9�̓��e�Ȃ�ď��߂Č����B
K8�x�[�X��K9���J�����Ă�Ǝv�������炶���
��ILP�Ƃ������ɓ˂�������Intel��IA-64�œV���w�I�ȋ����h�u�Ɏ̂Ă��B
AMD�͖����悢�Ă���i�K�Ŏv�����܂��������}�V�B
AMD�͖����悢�Ă���i�K�Ŏv�����܂��������}�V�B
�n��������
RealWorldTech�f����AMD�̃_���J���̗��j�����e����Ă���ŁA�]�ڂ��Ă������B
http://www.realworldtech.com/forums/index.cfm?action=detail&PostNum=3860&Thread=9&entryID=58564&roomID=11
http://www.aceshardware.com/forums/read_post.jsp?id=115144975&forumid=1
�@�@-----------------
�@�@�EK5 (���ЊJ�� AMD Texas) -> ���i��
�@�@�EK6 (���ЊJ�� AMD Texas) -> �p��
�@�@�EK6 (NexGen�̐v) -> ���i��
�@�@�EK7 (���ЊJ��+DEC�̃o�X���C�Z���X AMD Sunnyvale) -> ���i��
�@�@�EK8 (���ЊJ�� AMD Texas) -> �p��
�@�@�EK8 (���s�̒P�Ȃ�K7���ǔŁ@AMD Sunnyvale) -> ���i��
�@�@�EK9 -> �p��
�@�@�EK10 -> �p�� or ����
�@�@-----------------
http://www.realworldtech.com/forums/index.cfm?action=detail&PostNum=3860&Thread=9&entryID=58564&roomID=11
http://www.aceshardware.com/forums/read_post.jsp?id=115144975&forumid=1
�@�@-----------------
�@�@�EK5 (���ЊJ�� AMD Texas) -> ���i��
�@�@�EK6 (���ЊJ�� AMD Texas) -> �p��
�@�@�EK6 (NexGen�̐v) -> ���i��
�@�@�EK7 (���ЊJ��+DEC�̃o�X���C�Z���X AMD Sunnyvale) -> ���i��
�@�@�EK8 (���ЊJ�� AMD Texas) -> �p��
�@�@�EK8 (���s�̒P�Ȃ�K7���ǔŁ@AMD Sunnyvale) -> ���i��
�@�@�EK9 -> �p��
�@�@�EK10 -> �p�� or ����
�@�@-----------------
K9�͔p���Ƃ������K8�Ɏ�荞�܂ꂽ�������ȁB
Name: anonymous ([email protected]) 11/3/05
By tsayin (Recent posts)
MAC�I�^����@����ȕM�҂̉���Ȃ��T�C�g�������N���Ă��Ӗ�������B
By tsayin (Recent posts)
MAC�I�^����@����ȕM�҂̉���Ȃ��T�C�g�������N���Ă��Ӗ�������B
491 �FMAC�I�^��490 �����F2005/11/04(��) 22:36:48 ID:bljPNfGz
>>490
�@�@---------------
�@�@����ȕM�҂̉���Ȃ��T�C�g�������N���Ă��Ӗ�������B
�@�@---------------
�����A�Q�����˂�̂��Ƃ����H
�@�@---------------
�@�@����ȕM�҂̉���Ȃ��T�C�g�������N���Ă��Ӗ�������B
�@�@---------------
�����A�Q�����˂�̂��Ƃ����H
���̎�����B
>>488
�_���J���̗��j�����낤�Ɛ��i�����ꂽ���̂��悯��Ή������Ȃ��Ǝv�����B
�w�����牽�H�x���Ċ����B
Intel�݂����ɐ��i�����Ă�����������(PenD)�����肩�̓}�V����B
�_���J���̗��j�����낤�Ɛ��i�����ꂽ���̂��悯��Ή������Ȃ��Ǝv�����B
�w�����牽�H�x���Ċ����B
Intel�݂����ɐ��i�����Ă�����������(PenD)�����肩�̓}�V����B
>>493
�m��Y��ĂȂ����H
�m��Y��ĂȂ����H
�P�Ȃ�K7���ǔłɂ����C���e��CPU�����킢�����Ɏv���Ă���
�܊p���ځ[�Ă���烌�X����ȁI
�A������A�s���̈����L����"�ǂ܂Ȃ�" or "�M���Ȃ�"�Ƃ����C�s�ŐM����������Ă�����(��)
�m���Ɏ��̏������݂�ǂނ��Ƃ�A���`�ɔ�����̂�������Ȃ����ˁB�B�B
�m���Ɏ��̏������݂�ǂނ��Ƃ�A���`�ɔ�����̂�������Ȃ����ˁB�B�B
>>496
���������B���������Ȃ��l�����邩�炳�B
Mac�I�^�͖{���Ȃ�PentiumD�����Ĕp�����̂Ȃ̂�
�p�����ĂȂ�Intel�̕����D���炵����B
�J����p��������Ă��Ƃ́A�������̂���낤�Ƃ��錋�ʂ����Ȃ��������Ȃ̂�
�J����p�����Ȃ������ǂ������Ǝv���Ă�A�z������B
MAC�I�^����Intel�Ɠ�������ȁB
�ǂ��Ȃ����m�ł����i�����Ėׂ����ł�\���ł������Ă����l�������\�b�N�����B
�����o�c�҂Ȃ�����Ȋ�������ȁB
���������B���������Ȃ��l�����邩�炳�B
Mac�I�^�͖{���Ȃ�PentiumD�����Ĕp�����̂Ȃ̂�
�p�����ĂȂ�Intel�̕����D���炵����B
�J����p��������Ă��Ƃ́A�������̂���낤�Ƃ��錋�ʂ����Ȃ��������Ȃ̂�
�J����p�����Ȃ������ǂ������Ǝv���Ă�A�z������B
MAC�I�^����Intel�Ɠ�������ȁB
�ǂ��Ȃ����m�ł����i�����Ėׂ����ł�\���ł������Ă����l�������\�b�N�����B
�����o�c�҂Ȃ�����Ȋ�������ȁB
���̓����Z���Ƃ��A���Z�A�i���X�g�ɐ������鍠�ɂ̓n�b�L������ł���
�܂��ςȔn�����\��Ă�̂��H
���������Ă��AAthlon64X2��2.4GHz�ŏ����ςȂ���o�Ă�����B
��Ώo�Ȃ��Ɛ������ĉ���Ă�������ăt�@�r����Ȃ�ȁB�C�F�����B
���������Ă��AAthlon64X2��2.4GHz�ŏ����ςȂ���o�Ă�����B
��Ώo�Ȃ��Ɛ������ĉ���Ă�������ăt�@�r����Ȃ�ȁB�C�F�����B
�ߎS�Ȃ܂ܔ������Ď��ł����̂�K5��������ȁB
�ȍ~�̑ʖڌv��͔����O�ɏ��ł��Ă���B
���E����������Ŕh��ɃN���b�V�����Ă���ǂ����̃A������قǃ}�V����Ȃ����B
�ȍ~�̑ʖڌv��͔����O�ɏ��ł��Ă���B
���E����������Ŕh��ɃN���b�V�����Ă���ǂ����̃A������قǃ}�V����Ȃ����B
8issue�Ŏv���o�������A
�m��Alpha��EV8��8issue�������悤�Ȋ�K�X�B
���̕��ASMT��4thread���点��
CPU���\�[�X���r�W�[�ɂ���v�悾�����炵�����B
�m��Alpha��EV8��8issue�������悤�Ȋ�K�X�B
���̕��ASMT��4thread���点��
CPU���\�[�X���r�W�[�ɂ���v�悾�����炵�����B
�ĊO2�R�A��8���߂���ˁ[�̂��H��
SSE2�͌�����s���j�b�g�s���C��������AMerom�Ȃ�{�ɂł��Ȃ����4issue���炢�y�ɖ��܂邾��B
PenM�n�͑唼�̐������Z���߂̃��C�e���V��MMX���܂߂�1������ȁB
SSE2�͌�����s���j�b�g�s���C��������AMerom�Ȃ�{�ɂł��Ȃ����4issue���炢�y�ɖ��܂邾��B
PenM�n�͑唼�̐������Z���߂̃��C�e���V��MMX���܂߂�1������ȁB
>>506
�p�b�N�h�����������Z�̏ꍇ�A�{�炭���C�e���V�������̂ŁA���̐��\���]���ɂ��Ăł��N���b�N���グ���ق��������B
���̘H���ň��������Ă���NetBurst��萫�\�𗎂Ƃ��킯�ɂ͂����Ȃ�����ASIMD���j�b�g��{������킯��B
���j�b�g���{�Ȃ甼�����x�̃N���b�N�œ����x�̃X���[�v�b�g����B
�p�b�N�h�����������Z�̏ꍇ�A�{�炭���C�e���V�������̂ŁA���̐��\���]���ɂ��Ăł��N���b�N���グ���ق��������B
���̘H���ň��������Ă���NetBurst��萫�\�𗎂Ƃ��킯�ɂ͂����Ȃ�����ASIMD���j�b�g��{������킯��B
���j�b�g���{�Ȃ甼�����x�̃N���b�N�œ����x�̃X���[�v�b�g����B
���������A��OPs�ւ̕��𐔂͓��l�ɑ傫���A���̕������N���b�N�ł͂Ȃ��Rwide����
���Swide�ւƋ������邱�ƂŐ��\���҂��Ƃ����v�������l�����Ȃ��킯�ł͂Ȃ��B
���������A���ꂾ�ƕ��𒊏o����\�͂��傫�����߂��邽�߁A ������̖ʂł�
������d�͊g�傪�S�z�ł���B �Ȃ��Ȃ�A������ɕK�v�ȃn�[�h�E�G�A�ʂ�
������x�ɑ��Ĕ����ł͂Ȃ��đg�ݍ��킹�_�I�ɋ}���ɑ����邩�炾�B
���P���ȕ�����ł͐��\������ʂ�����d�͑�����ʂ������Ă��܂��A�d�͌����ʂ����
���t�ɐ��\�������Ă��܂����肷��B (�����PARROT�A�[�L�e�N�`���̘_���ł��w�E����Ă���B)
�������ILP�������グ��Ώグ��قǐ[���Ȗ��ł���B ILP�������グ��Ώグ��ق�
�����𑝂����߂̎����R�X�g�͑����A �t�Ɍ��ʂ̕��͓��ł��ɂȂ�B�����o�@�\��
���a�V�ȐV�Z�p�ł���������Ȃ�����Swide�ւ̉ߓx�Ȋ��҂͋֕��Ƃ����̂��ȑO����ς��Ȃ�
�����T�C�g�̌������B(Hyper-Threading����������Ă���Ε����o�\�͂��グ�Ȃ��ł�
������x���グ���邽�߁A �Swide���̌��ʂ������҂ł���̂��낤���D�D�D)
���Swide�ւƋ������邱�ƂŐ��\���҂��Ƃ����v�������l�����Ȃ��킯�ł͂Ȃ��B
���������A���ꂾ�ƕ��𒊏o����\�͂��傫�����߂��邽�߁A ������̖ʂł�
������d�͊g�傪�S�z�ł���B �Ȃ��Ȃ�A������ɕK�v�ȃn�[�h�E�G�A�ʂ�
������x�ɑ��Ĕ����ł͂Ȃ��đg�ݍ��킹�_�I�ɋ}���ɑ����邩�炾�B
���P���ȕ�����ł͐��\������ʂ�����d�͑�����ʂ������Ă��܂��A�d�͌����ʂ����
���t�ɐ��\�������Ă��܂����肷��B (�����PARROT�A�[�L�e�N�`���̘_���ł��w�E����Ă���B)
�������ILP�������グ��Ώグ��قǐ[���Ȗ��ł���B ILP�������グ��Ώグ��ق�
�����𑝂����߂̎����R�X�g�͑����A �t�Ɍ��ʂ̕��͓��ł��ɂȂ�B�����o�@�\��
���a�V�ȐV�Z�p�ł���������Ȃ�����Swide�ւ̉ߓx�Ȋ��҂͋֕��Ƃ����̂��ȑO����ς��Ȃ�
�����T�C�g�̌������B(Hyper-Threading����������Ă���Ε����o�\�͂��グ�Ȃ��ł�
������x���グ���邽�߁A �Swide���̌��ʂ������҂ł���̂��낤���D�D�D)
���ނ�(��)
������32�r�b�g�A�v���𑖂点�ĉ��Z���j�b�g���t���ғ�������K�v�����邩�ǂ����͋^�₾�ȁB
Intel�͂�ق�65nm����ɓ������郊�[�N�d��1/1000�Z�p�Ɏ��M������낤�B
HyperThreading�g��Ȃ����Ă̂��^�₾���ȁB�t���O�V�b�v���f���Ɍ���enable���Ă̂����肤��B
����łȂ��Ƃ��A64bit���[�h�͊�����32bit�A�v���ł͎g���Ȃ��B
�����Łu�d��Ȃ����v���ł���킯���B
�R���p�C���̃X�^�e�B�b�N�X�P�W���[�����O���݂ʼn��Z���j�b�g�𑝂₵�Ă��Ă��Ȃ��s�v�c�͂Ȃ��B
���̂��߂̃��W�X�^�g������B
Intel�͂�ق�65nm����ɓ������郊�[�N�d��1/1000�Z�p�Ɏ��M������낤�B
HyperThreading�g��Ȃ����Ă̂��^�₾���ȁB�t���O�V�b�v���f���Ɍ���enable���Ă̂����肤��B
����łȂ��Ƃ��A64bit���[�h�͊�����32bit�A�v���ł͎g���Ȃ��B
�����Łu�d��Ȃ����v���ł���킯���B
�R���p�C���̃X�^�e�B�b�N�X�P�W���[�����O���݂ʼn��Z���j�b�g�𑝂₵�Ă��Ă��Ȃ��s�v�c�͂Ȃ��B
���̂��߂̃��W�X�^�g������B
>>509
����A8issue��K9�̓L�����Z���ɂȂ����Ƃ���K9�̘b�B
�����L�����������̐l�ɂ��A�L�����Z���ɂȂ������R��
It was an 8 issue really wide and complex core.
They ran simulations and found it wasn't going to be much faster than the K8,
so it died, and the K10 replaced it.
�V�~�����[�V����������A���҂������\�ɂȂ�������炾�������B
�܂��A�ق�Ƃ��ǂ����m��ǁB
����A8issue��K9�̓L�����Z���ɂȂ����Ƃ���K9�̘b�B
�����L�����������̐l�ɂ��A�L�����Z���ɂȂ������R��
It was an 8 issue really wide and complex core.
They ran simulations and found it wasn't going to be much faster than the K8,
so it died, and the K10 replaced it.
�V�~�����[�V����������A���҂������\�ɂȂ�������炾�������B
�܂��A�ق�Ƃ��ǂ����m��ǁB
>>510
I couldn't understand that you said.
I couldn't understand that you said.
>>511
�����A�Ȃ�قǁB
�ł��A���̕��͂�SMT�Ɋւ��镨�ł͖����ˁB
AMD��SMT�������������Ȃ��̂��낤���H
����Ƃ�SMT�œ�������݂̖��ł�����̂��H
�܂��́A�A�[�L�e�N�`���\����SMT���������邾���̉��l�������Ƃ��H
�����A�Ȃ�قǁB
�ł��A���̕��͂�SMT�Ɋւ��镨�ł͖����ˁB
AMD��SMT�������������Ȃ��̂��낤���H
����Ƃ�SMT�œ�������݂̖��ł�����̂��H
�܂��́A�A�[�L�e�N�`���\����SMT���������邾���̉��l�������Ƃ��H
http://pc.watch.impress.co.jp/docs/2004/1109/kaigai02.jpg
4wide����8wide����
IPC�@ �@ +16��
Energy�@+70��
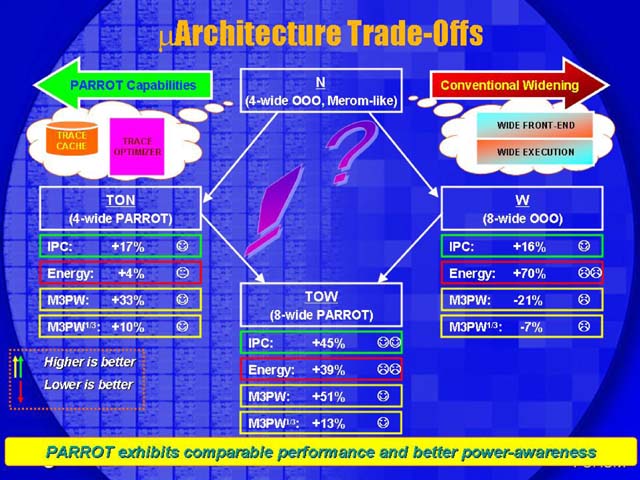{kind=link}
4wide����8wide����
IPC�@ �@ +16��
Energy�@+70��
>>516
�o�b�N�i���o�[�Ƀ����N�����������ł����B�����ł����B
�o�b�N�i���o�[�Ƀ����N�����������ł����B�����ł����B
�Ƃ���ŁA�����Intel�̘b�Ȃ킯�����ǁD�D
AMD��AMD�ł܂��ʂȘb�ɂȂ�H
AMD��AMD�ł܂��ʂȘb�ɂȂ�H
���ĕ�ꂽAMD K9/K10�ɂ��Ă̏����Ă̂�A����Ȋ������B
http://www.xbitlabs.com/news/cpu/display/20031016140742.html
�@�E�X���b�h���d���̃A�[�L�e�N�`��
�@�ECMP
�@�E��K��MP�T�|�[�g
�@�E10GHz(!)
�@�E�]�����y���ɑ�K�͂ȃX�[�p�[�X�P�[����OoOE
�@�E��e�ʃL���b�V��
�@�E�}���`���f�B�A�g�����ߒlj�
�@�E����у������v���t�F�b�`�̂��߂̃q���g���ߒlj�
�@�EGHz�N���X��I/O
�@�E���z���ƃZ�L�����e�B�@�\
�@�E�ÓI�^���I�d�͊Ǘ��@�\
�P�ɗ��s�̃L�[���[�h�𗅗������̂悤�ȋC�����邷���ǁA��{�I��NetBurst�̌�ǂ��̃��b�`�ȃR�A��
�z�肵�Ă������Ƃ햾�炩���B��������Z�p�̗��j���Ď�����ŗ��ꂪ����ւ��Ⴊ���������邷���ǁA
���炩��Intel���A�c���㕨��z�肵�Ă����Ǝv���邷�B�L�����Z�������̂����R����(��)
http://www.xbitlabs.com/news/cpu/display/20031016140742.html
�@�E�X���b�h���d���̃A�[�L�e�N�`��
�@�ECMP
�@�E��K��MP�T�|�[�g
�@�E10GHz(!)
�@�E�]�����y���ɑ�K�͂ȃX�[�p�[�X�P�[����OoOE
�@�E��e�ʃL���b�V��
�@�E�}���`���f�B�A�g�����ߒlj�
�@�E����у������v���t�F�b�`�̂��߂̃q���g���ߒlj�
�@�EGHz�N���X��I/O
�@�E���z���ƃZ�L�����e�B�@�\
�@�E�ÓI�^���I�d�͊Ǘ��@�\
�P�ɗ��s�̃L�[���[�h�𗅗������̂悤�ȋC�����邷���ǁA��{�I��NetBurst�̌�ǂ��̃��b�`�ȃR�A��
�z�肵�Ă������Ƃ햾�炩���B��������Z�p�̗��j���Ď�����ŗ��ꂪ����ւ��Ⴊ���������邷���ǁA
���炩��Intel���A�c���㕨��z�肵�Ă����Ǝv���邷�B�L�����Z�������̂����R����(��)
�^���ƕ��ԂȂ�Ƃ����Č����Ă��l�������ǁA�^�����̂܂�܂Ɍ������ł����ǁB
�{���ɕʐl�H�E������B
�{���ɕʐl�H�E������B
>>509
ttp://www.geocities.com/andrew_f_glew/cv-glew.html
�ꎞ���A��Intel�̎�v�A�[�L�e�N�g��Andy Glew�iSMT���i�ҁj�ق��Ă����炢������A
SMT�����R�A�l�����Ă���ł��傤�B
�����AK9���L�����Z���ɂȂ������Ɣނ����߂Ď~�߂����Ƃ͖��W����Ȃ��ł��傤�ȁB
ttp://www.geocities.com/andrew_f_glew/cv-glew.html
�ꎞ���A��Intel�̎�v�A�[�L�e�N�g��Andy Glew�iSMT���i�ҁj�ق��Ă����炢������A
SMT�����R�A�l�����Ă���ł��傤�B
�����AK9���L�����Z���ɂȂ������Ɣނ����߂Ď~�߂����Ƃ͖��W����Ȃ��ł��傤�ȁB
>>520
���̒����čL�����낤�H
���̒����čL�����낤�H
Mac�I�^�͖��O�̒ʂ�Mac�ȊO�S���ے肷�邩��ȁB
�ł������Ȃ߂郌�X�͂悭���邯��Mac��J�ߏ̂��郌�X���Ă���܌��Ȃ��ȁB
�Ȃ�ł���B
�ł������Ȃ߂郌�X�͂悭���邯��Mac��J�ߏ̂��郌�X���Ă���܌��Ȃ��ȁB
�Ȃ�ł���B
ttp://pcweb.mycom.co.jp/news/2005/06/18/102el.gif
���ǁASMT��comeing soon���ᖳ���Ȃ������Ď��H
{kind=link}
���ǁASMT��comeing soon���ᖳ���Ȃ������Ď��H
�L�����Z������AMD�̓G���C��ȁB
Intel�Ȃ��̏ꂵ�̂���PentiumD��邭�炢�Ȃ���B
Intel�Ȃ��̏ꂵ�̂���PentiumD��邭�炢�Ȃ���B
��x���肾�����v���W�F�N�g�𒆒f����̂��đ�ς�����ȁB
���Ɋ��ɑ����̃��\�[�X���Ԃ�����ł����Ƃ��c
���Ɋ��ɑ����̃��\�[�X���Ԃ�����ł����Ƃ��c
�܂������͂킩���
���ŋ��Ȃ̂�Athlon���Ă��Ƃ�
�������ނ�������͐��\�L�тȂ��������V�i�[
���ŋ��Ȃ̂�Athlon���Ă��Ƃ�
�������ނ�������͐��\�L�тȂ��������V�i�[
>>520
�^���͖Œ��ꒃ���������܂�l�@�������Ȃ����A�K�v�Ȏ��͎�����PC�Ńx���`
������������BMAC���͊O���̃\�[�X����ǂ�����A�\���x�̃\�[�X�������C��
�\��Ȃ���l�@����ړI�Ƀ��X������B�܂��^���̕����}�V�B
���́A�Z�p�I�Șb�Œǂ��l�߂���Ƃ����b�肸�炵����l�i�ے肩����鏊
����A�����聁MAC���@���Ǝv���B
�^���͖Œ��ꒃ���������܂�l�@�������Ȃ����A�K�v�Ȏ��͎�����PC�Ńx���`
������������BMAC���͊O���̃\�[�X����ǂ�����A�\���x�̃\�[�X�������C��
�\��Ȃ���l�@����ړI�Ƀ��X������B�܂��^���̕����}�V�B
���́A�Z�p�I�Șb�Œǂ��l�߂���Ƃ����b�肸�炵����l�i�ے肩����鏊
����A�����聁MAC���@���Ǝv���B
>>521
�����̐l�̌o��w
Intel �� AMD �� Intel
>�����AK9���L�����Z���ɂȂ������Ɣނ����߂Ď~�߂����Ƃ͖��W����Ȃ��ł��傤�ȁB
���������I
�����̐l�̌o��w
Intel �� AMD �� Intel
>�����AK9���L�����Z���ɂȂ������Ɣނ����߂Ď~�߂����Ƃ͖��W����Ȃ��ł��傤�ȁB
���������I
533 �FSocket774�F2005/11/05(�y) 14:37:33 ID:lNEDGn9w
Socket M2 Processor Roadmap; FX-62 and Athlon 64 X2 5200+
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
AMD�ŋߊJ���x���Ȃ��ł���?
>>534
���ǃE���g�����o�Ȃ�������G70�ƈꏏ�B
���ǃE���g�����o�Ȃ�������G70�ƈꏏ�B
>>535
�o�����Ǝv���ΐ��T�Ԓ��x�ŏo����G70�E���g���Ɠ����H
�o�����Ǝv���ΐ��T�Ԓ��x�ŏo����G70�E���g���Ɠ����H
K6�Ƃ�Am386�Ƃ���
K9���
������Fab30��APM3.0���z�����ċ��剻����APM4.0FX��
�h���X�f���̎s�����ÎE���Đl�މ������n�߂Ă���\���B
�h���X�f���̎s�����ÎE���Đl�މ������n�߂Ă���\���B
SMT=Surface Mount Technology�A�Ƃ����Ӗ��Ȃ�(�Ⴄ�Ǝv������)�A�ʎ����p�b�P�[�W��CPU��AMD�͒��Ă܂���
AMD������v�A�[�L�e�N�g���ǂ�ǂ��o���Ă��邷�B
�@Fred Weber http://news.softpedia.com/news/At-AMD-Phil-Hester-Will-Replace-Fred-Weber-The-Ex-CTO-7976.shtml
�@Jim Keller http://www.pasemi.com/about/team.html
���X�B�B�B
�@Fred Weber http://news.softpedia.com/news/At-AMD-Phil-Hester-Will-Replace-Fred-Weber-The-Ex-CTO-7976.shtml
�@Jim Keller http://www.pasemi.com/about/team.html
���X�B�B�B
M2��������iHyperTransport���H�j�{����
200*n��333*n�ɕς��炵���Ƃ����b�����A
���\�����ɉe������́H
200*n��333*n�ɕς��炵���Ƃ����b�����A
���\�����ɉe������́H
>546
���ꂪ�}�W�Ȃ�A939DUAL-SATAII�͂ǂ��Ȃ��B
���ꂪ�}�W�Ȃ�A939DUAL-SATAII�͂ǂ��Ȃ��B
>545
�̓ǂA���E�̖�͂̂Q���̈�߂��v���o�����B
�����̃v���C�h���ێ����邽�߂ɁA����Ɍ����@��A���ă��c�B
����Ȃ��Ƃ����Ă��A���玩���������ʒu�ɗ��Ă�킯�ł��Ȃ��̂ɂȁB
���ׂȓw�͂�������A�h��������������X���łł��Z�p�I�Ȗ��ł�����Ă��Ă���B
NetBurst��D���Ȃ�ȁA�m���B
�̓ǂA���E�̖�͂̂Q���̈�߂��v���o�����B
�����̃v���C�h���ێ����邽�߂ɁA����Ɍ����@��A���ă��c�B
����Ȃ��Ƃ����Ă��A���玩���������ʒu�ɗ��Ă�킯�ł��Ȃ��̂ɂȁB
���ׂȓw�͂�������A�h��������������X���łł��Z�p�I�Ȗ��ł�����Ă��Ă���B
NetBurst��D���Ȃ�ȁA�m���B
549 �FMAC�I�^��548 �����F2005/11/06(��) 12:22:43 ID:+LagjjC+
>>548
���������H�ȑO���������悤�Ɏ��� ���Ȃ��������Ă���Ƃ�����v���o�����B
http://www.drc-gb.org/open4all/service/open4all_presentation/Image2.jpg
"ostrich policy"�Ō������Č���̂��ǂ���������Ȃ����ˁB�B�B
���������H�ȑO���������悤�Ɏ��� ���Ȃ��������Ă���Ƃ�����v���o�����B
http://www.drc-gb.org/open4all/service/open4all_presentation/Image2.jpg
{kind=link}
"ostrich policy"�Ō������Č���̂��ǂ���������Ȃ����ˁB�B�B
�N�͂��̃X���ɕK�v�������Ă��Ƃɂ͋C�Â��Ȃ��悤�ł��ˁB
551 �FMAC�I�^���ǐL�F2005/11/06(��) 12:34:29 ID:+LagjjC+
�Ƃ���Ő��E�̖�͂��ĉ����Ǝv������A�j������(��)
�����Ȃ��ł���Ȃ��̂����茩�Ă邷����A�A�����������Ȃ����Ǝv�����B
�����Ȃ��ł���Ȃ��̂����茩�Ă邷����A�A�����������Ȃ����Ǝv�����B
�ȑO���������A�Ȃ�Ęb���o������v���o������ŕ����Ă݂邯�ǁA
���Ȃ�O�̕��̃X���ŁA
>���̒ʂ肷����Intel�̌���Maximum Power��A���̃v���Z�b�T�x���_��茵�����\�����������B
> >>781�̃����N�悪�Q�Ƃ��Ă���Intel��Socket423 Pentium4�̔M�v�K�C�h��ǂނƁA�}����Max. Power��
> �S�Ă̓d�͊Ǘ��@�\����������Ԃ̉��z�I�Ȓl�Ɍ����邷�B
> ����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
> ���Ȃ��Ƃ�PowerPC�x���_(IBM, Freescale����)�́u�ő����d�́v��A��p�A�v�����g���������l���B
> AMD���������Ƃ�����Ă�����Z��A�������Ǝv�����B
�Ƃ̎咣�ɑ��A
>���̔����̃\�[�X�͂ǂ���ɂ���̂ł��傤���H
>�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h��AMD�������Ă��鎑��������̂ł�������[���̂ŁB
�ƕԂ��ꂽ��́A�\�[�X�̒͂ǂ��Ȃ��Ă�́H
�ł��Ȃ�������A���R�s�͒P�Ȃ錾�������肾�Ǝv�����ǁB
�s���̈��������݂�����A���Ďp���́A���玦�������̊G�̒ʂ肶��Ȃ��H
���Ȃ݂ɁAAMD�Ɉ����j���[�X������͂���Ŏ~�߂��A���́B
�ʂɕK������AMD��CPU����Ȃ���C�����A���Ė�Ȃ����B
���̂Ƃ���Ԏ����̃j�[�Y�ɍ��������̂�I�Ԃ��������ˁB
�����Ȃ��������āAC3/C7�ɑ��݉��l������悤�ɁB
�����A���Ȃ��Ă��AAMD���������炱���A
Intel�̓a�l�����������Ƃ̓}�V�ɂȂ����Ƃ��v���킯�ŁB
PenM�n�������Ɏ�͂ɐ�����ꂽ�̂��AAMD�̒ǂ��グ�������Ă̎����Ǝv���B
���������Ӗ��ł́A�܂��܂�AMD�ɂ��撣���ė~�����Ǝv������ǂˁB���[�U�[�̗��v�̂��߂ɁB
�l�I�Ȍ����ł́A����̃x���_�ɌŎ�����p���������A����Ȕ��f��݂点����̂Ǝv�����ǂˁB
AMD�ɂ�����AIntel�ɂ�����A�ˁB
��������҂ɂȂ�Ȃ���B
���Ȃ�O�̕��̃X���ŁA
>���̒ʂ肷����Intel�̌���Maximum Power��A���̃v���Z�b�T�x���_��茵�����\�����������B
> >>781�̃����N�悪�Q�Ƃ��Ă���Intel��Socket423 Pentium4�̔M�v�K�C�h��ǂނƁA�}����Max. Power��
> �S�Ă̓d�͊Ǘ��@�\����������Ԃ̉��z�I�Ȓl�Ɍ����邷�B
> ����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
> ���Ȃ��Ƃ�PowerPC�x���_(IBM, Freescale����)�́u�ő����d�́v��A��p�A�v�����g���������l���B
> AMD���������Ƃ�����Ă�����Z��A�������Ǝv�����B
�Ƃ̎咣�ɑ��A
>���̔����̃\�[�X�͂ǂ���ɂ���̂ł��傤���H
>�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h��AMD�������Ă��鎑��������̂ł�������[���̂ŁB
�ƕԂ��ꂽ��́A�\�[�X�̒͂ǂ��Ȃ��Ă�́H
�ł��Ȃ�������A���R�s�͒P�Ȃ錾�������肾�Ǝv�����ǁB
�s���̈��������݂�����A���Ďp���́A���玦�������̊G�̒ʂ肶��Ȃ��H
���Ȃ݂ɁAAMD�Ɉ����j���[�X������͂���Ŏ~�߂��A���́B
�ʂɕK������AMD��CPU����Ȃ���C�����A���Ė�Ȃ����B
���̂Ƃ���Ԏ����̃j�[�Y�ɍ��������̂�I�Ԃ��������ˁB
�����Ȃ��������āAC3/C7�ɑ��݉��l������悤�ɁB
�����A���Ȃ��Ă��AAMD���������炱���A
Intel�̓a�l�����������Ƃ̓}�V�ɂȂ����Ƃ��v���킯�ŁB
PenM�n�������Ɏ�͂ɐ�����ꂽ�̂��AAMD�̒ǂ��グ�������Ă̎����Ǝv���B
���������Ӗ��ł́A�܂��܂�AMD�ɂ��撣���ė~�����Ǝv������ǂˁB���[�U�[�̗��v�̂��߂ɁB
�l�I�Ȍ����ł́A����̃x���_�ɌŎ�����p���������A����Ȕ��f��݂点����̂Ǝv�����ǂˁB
AMD�ɂ�����AIntel�ɂ�����A�ˁB
��������҂ɂȂ�Ȃ���B
�A�j���H
�ꉞ�����ł����B
����Ƃ��A�^���̓A�j����ǂނ̂��H
�ꉞ�����ł����B
����Ƃ��A�^���̓A�j����ǂނ̂��H
>>551
���̂��̃X����MAC�I�^��������Ă���̂��m��A
���܂��� PowerPC �I�^�Ȃ�H
����Ƃ�AMD�̎����オ�C�ɂȂ��Ă�A�B��AMDer�Ȃ̂�YO! w
���̂��̃X����MAC�I�^��������Ă���̂��m��A
���܂��� PowerPC �I�^�Ȃ�H
����Ƃ�AMD�̎����オ�C�ɂȂ��Ă�A�B��AMDer�Ȃ̂�YO! w
>>552
�����������ځ[�Ă�̂ɁA�킴�킴���p����Ȃ�B
�����������ځ[�Ă�̂ɁA�킴�킴���p����Ȃ�B
556 �FMAC�I�^��552 �����F2005/11/06(��) 13:26:13 ID:+LagjjC+
>>552
�@�@---------------------
�@�@�h����d�́h��AMD�������Ă��鎑��
�@�@---------------------
�b�̗���ɂ��ė��Ă����画�锤�����ǁB�B�B���Y�X���b�h��776��ǂ�ŗ~�������B�Ę^�����
�@�@---------------------
�@�@776 ���O�FSocket774 ���e���F2005/04/05(��) 19:44:40 ID:7dXOnFX8
�@�@Thermal Design Power (TDP) is measured under the conditions of TCASE Max, IDD Max, and VDD=VID_VDD,
�@�@and include all power dissipated on-die from VDD, VDDIO, VLDT, VTT, and VDDA.
�@�@ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/30430.pdf
�@�@---------------------
�@�@---------------------
�@�@�h����d�́h��AMD�������Ă��鎑��
�@�@---------------------
�b�̗���ɂ��ė��Ă����画�锤�����ǁB�B�B���Y�X���b�h��776��ǂ�ŗ~�������B�Ę^�����
�@�@---------------------
�@�@776 ���O�FSocket774 ���e���F2005/04/05(��) 19:44:40 ID:7dXOnFX8
�@�@Thermal Design Power (TDP) is measured under the conditions of TCASE Max, IDD Max, and VDD=VID_VDD,
�@�@and include all power dissipated on-die from VDD, VDDIO, VLDT, VTT, and VDDA.
�@�@ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/30430.pdf
�@�@---------------------
���ځ[��Ɉ͂܂�鐶��
>>543
>SMT=Surface Mount Technology�A�Ƃ����Ӗ��Ȃ�(�Ⴄ�Ǝv������)�A�ʎ����p�b�P�[�W��CPU��AMD�͒��Ă܂���
SMT�ASMT���Č����Ă�̂� "Simultaneous Multi Thread" ���Ă����Ӗ��Ō����Ă�̂łB
>SMT=Surface Mount Technology�A�Ƃ����Ӗ��Ȃ�(�Ⴄ�Ǝv������)�A�ʎ����p�b�P�[�W��CPU��AMD�͒��Ă܂���
SMT�ASMT���Č����Ă�̂� "Simultaneous Multi Thread" ���Ă����Ӗ��Ō����Ă�̂łB
���ӂ��H
>�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h
���ď����Ă邾��B
���A�����������ɂȂ�͔̂���������ŁA�܂Ƃ߂邯�ǁA
���̌�́A
>���Ȃ݂ɉ���>800�Ō����Ă���悤�ȏ����ł̎����l��TDP�ɗp���Ă���A
>�Ƃ����咣�ł���A���ߕ��ׂȏ�Ԃł͏���d�͂��傫���ƌ�����̂ł���A
>VID_VDD(1.50V) * IDD Max(57.4A)
>����d�͂�CPU�ŏ�����Ƃ������Ƃł��傤���H
�Ƃ����₢�ɑ��A
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
>����������u���l�Ȃ�ŁA�����̓d�͊Ǘ��@�\�t���̃v���Z�b�T�ŏ���d�͂ƃC�R�[���ɂȂ邱�Ƃ�����
>�����B
�Ɠ����Ă��ȁB
��ŁA���ꂪ���Ȃ�A
>�ł����ƁAVID_VDD * IDD Max = 1.5 * 57.4 = 86.1 W�ƂȂ�A
>and include�`�ȉ��̕��������ɉ����Ƃ��Ă��ATDP 89W���邱�Ƃ�
>���_�l�ł��قڂ��蓾�Ȃ��Ǝv���܂����B
�ƂȂ�A
���ɁA���܂����������̂��w�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h�x�������Ƃ��Ă��A
>����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
�͋U�ƂȂ�B
��ŁA���ꂪ���ƂȂ�\�[�X���o���ƌ����Ă�́B
>all
�X�}�\�[���B
>�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h
���ď����Ă邾��B
���A�����������ɂȂ�͔̂���������ŁA�܂Ƃ߂邯�ǁA
���̌�́A
>���Ȃ݂ɉ���>800�Ō����Ă���悤�ȏ����ł̎����l��TDP�ɗp���Ă���A
>�Ƃ����咣�ł���A���ߕ��ׂȏ�Ԃł͏���d�͂��傫���ƌ�����̂ł���A
>VID_VDD(1.50V) * IDD Max(57.4A)
>����d�͂�CPU�ŏ�����Ƃ������Ƃł��傤���H
�Ƃ����₢�ɑ��A
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
>����������u���l�Ȃ�ŁA�����̓d�͊Ǘ��@�\�t���̃v���Z�b�T�ŏ���d�͂ƃC�R�[���ɂȂ邱�Ƃ�����
>�����B
�Ɠ����Ă��ȁB
��ŁA���ꂪ���Ȃ�A
>�ł����ƁAVID_VDD * IDD Max = 1.5 * 57.4 = 86.1 W�ƂȂ�A
>and include�`�ȉ��̕��������ɉ����Ƃ��Ă��ATDP 89W���邱�Ƃ�
>���_�l�ł��قڂ��蓾�Ȃ��Ǝv���܂����B
�ƂȂ�A
���ɁA���܂����������̂��w�g�M�v�d�́h�ł͂Ȃ��A�h����d�́h�x�������Ƃ��Ă��A
>����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
�͋U�ƂȂ�B
��ŁA���ꂪ���ƂȂ�\�[�X���o���ƌ����Ă�́B
>all
�X�}�\�[���B
560 �FMAC�I�^��559 �����F2005/11/06(��) 14:06:51 ID:+LagjjC+
under�ȍ~�͓ǂ߂Ȃ��̂��H
562 �FMAC�I�^��561 �����F2005/11/06(��) 14:15:40 ID:+LagjjC+
>>561
�@�@---------------------
�@�@under�ȍ~�͓ǂ߂Ȃ��̂��H
�@�@---------------------
������������ɉ����ςȂƂ��낪���邷���H
Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
�Ŏ��W���ꂽ����l�ł햳�����Ƃ�������Ă��邷�B
�@�@---------------------
�@�@under�ȍ~�͓ǂ߂Ȃ��̂��H
�@�@---------------------
������������ɉ����ςȂƂ��낪���邷���H
Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
�Ŏ��W���ꂽ����l�ł햳�����Ƃ�������Ă��邷�B
������̂̃X���b�h�̘b�������o���Ȃ�AAMD��d�l���ɕ��C�ʼnR��������Ђ��ƃA�������Ԃ���
�F�����Ƃ��v���o���Ɩʔ������Ǝv�����B
�@�@-----------------------------
�@�@782 ���O�FSocket774 ���e���F2005/04/05(��) 20:03:49 ID:SdEFcWBv
�@�@>>778
�@�@�܂��A�R�ɂ͈Ⴂ�Ȃ��ȁB
�@�@��Ђ̌��Z�\�z�Ɠ����悤�ɁA���\���Ă���l��
�@�@�T���߂����炩�܂ւ�
�@�@-----------------------------
�P�ɊJ���Ҍ����T�|�[�g�̈������������ɉ߂��Ȃ������ǁB�B�B
�F�����Ƃ��v���o���Ɩʔ������Ǝv�����B
�@�@-----------------------------
�@�@782 ���O�FSocket774 ���e���F2005/04/05(��) 20:03:49 ID:SdEFcWBv
�@�@>>778
�@�@�܂��A�R�ɂ͈Ⴂ�Ȃ��ȁB
�@�@��Ђ̌��Z�\�z�Ɠ����悤�ɁA���\���Ă���l��
�@�@�T���߂����炩�܂ւ�
�@�@-----------------------------
�P�ɊJ���Ҍ����T�|�[�g�̈������������ɉ߂��Ȃ������ǁB�B�B
��ŁH
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
����ȁB
��ŁA���ɁA����TDP�������̂��̂������Ɖ��肵�Ă�(���ɂ́AIDD���̏��������̎��ɂ�
���̔��M�ɂȂ�܂��A�Ə����Ă���悤�ɂ��������Ȃ���)�A
>����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
�����ƂȂ�A�܂肱��TDP���锭�M��������Ƃ��������͎�����Ă��Ȃ����H
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
����ȁB
��ŁA���ɁA����TDP�������̂��̂������Ɖ��肵�Ă�(���ɂ́AIDD���̏��������̎��ɂ�
���̔��M�ɂȂ�܂��A�Ə����Ă���悤�ɂ��������Ȃ���)�A
>����AAMD�̌��������{�����Ƃ���Ɣނ�́u�ő�v����d�͂�A�����܂ō����M�̃A�v���P�[�V�����Ŏ���������l�ŁAIntel�́u�ő�v���Ⴛ�����B
�����ƂȂ�A�܂肱��TDP���锭�M��������Ƃ��������͎�����Ă��Ȃ����H
565 �FMAC�I�^��564 �����F2005/11/06(��) 14:38:27 ID:+LagjjC+
>>564
�@�@-----------------------
�@�@TDP���锭�M��������Ƃ�������
�@�@-----------------------
>>559�ň��p����Ă��鎄�̏������݂̒��ɉ����邷���ǂˁB�B�B
�d�͊Ǘ��@�\����������v���Z�b�T�ł�u����v���ꂽ�ő����d�͂��A(�d�͊Ǘ��𗎂Ƃ���)�u���z�I�v��
�ő�l�Ɠ����l�ɂȂ�ۏ햳�����B
�@�@-----------------------
�@�@TDP���锭�M��������Ƃ�������
�@�@-----------------------
>>559�ň��p����Ă��鎄�̏������݂̒��ɉ����邷���ǂˁB�B�B
�d�͊Ǘ��@�\����������v���Z�b�T�ł�u����v���ꂽ�ő����d�͂��A(�d�͊Ǘ��𗎂Ƃ���)�u���z�I�v��
�ő�l�Ɠ����l�ɂȂ�ۏ햳�����B
��ŁA���̉ߑ�ȏ���d�͂́A�ǂ����琶����́H
�T���v�Z�����ǁA
>�ł����ƁAVID_VDD * IDD Max = 1.5 * 57.4 = 86.1 W
�Ƃ����͎̂�����Ă��ˁB
�܂�A�d�͊Ǘ��𗎂Ƃ�����AIDD Max����d���������ƌ��������́H
�����
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
�Ɩ������Ȃ��̂����H
�T���v�Z�����ǁA
>�ł����ƁAVID_VDD * IDD Max = 1.5 * 57.4 = 86.1 W
�Ƃ����͎̂�����Ă��ˁB
�܂�A�d�͊Ǘ��𗎂Ƃ�����AIDD Max����d���������ƌ��������́H
�����
>IDD_Max��d���v�Ɏg�����l������A������邱�Ƃ햳���Ǝv�����B
�Ɩ������Ȃ��̂����H
567 �FMAC�I�^��566 �����F2005/11/06(��) 14:51:50 ID:+LagjjC+
>>566
�Ƃ肠���������ɂ펊�����݂������ˁB
�@�@------------------
�@�@�d�͊Ǘ��𗎂Ƃ�����AIDD Max����d���������
�@�@------------------
���̒ʂ肷�B�����āA���퓮�삵�Ă��鐻�i�Ƃ��Ă��̂悤�Ȃ��Ƃ�N���Ȃ�������AIDD_MAX�ɂ�
����������l������Ă��Ȃ����B�i���������d�͊Ǘ��A���ł̎����l����)
�Ƃ肠���������ɂ펊�����݂������ˁB
�@�@------------------
�@�@�d�͊Ǘ��𗎂Ƃ�����AIDD Max����d���������
�@�@------------------
���̒ʂ肷�B�����āA���퓮�삵�Ă��鐻�i�Ƃ��Ă��̂悤�Ȃ��Ƃ�N���Ȃ�������AIDD_MAX�ɂ�
����������l������Ă��Ȃ����B�i���������d�͊Ǘ��A���ł̎����l����)
568 �FMAC�I�^���⑫�F2005/11/06(��) 14:54:07 ID:+LagjjC+
�Ⴆ�u���z�I�v�ȏ̈��Ƃ��āAL2�̑S�Ă�SRAM���Ђ�����t���b�v�t���b�v���J��Ԃ��Ȃ�Ă̂�
�������邷���ǁA�v���Z�b�T�̓���Ƃ��Ă���Ȃ��ƗL�蓾�Ȃ��B
�������邷���ǁA�v���Z�b�T�̓���Ƃ��Ă���Ȃ��ƗL�蓾�Ȃ��B
>�����āA���퓮�삵�Ă��鐻�i�Ƃ��Ă��̂悤�Ȃ��Ƃ�N���Ȃ�������
���ꂪ���Ƃ���Ȃ�A�g�p���Ɍ�����TDP���鎖���Ȃ��A�Ƃ����̂��^�ɂȂ��ȁB
���ɂ���𐳂Ƃ���ƁA
>Intel�́u�ő�v���Ⴛ�����B
���U�ƂȂ�ˁB
���ɁA���e�[���N�[���[�g���Ă�EIST��������������݂������B
��ŁA����������Ă���݂��������ǁA
>Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
>�Ŏ��W���ꂽ����l�ł햳�����Ƃ�������Ă��邷�B
�ɂ��Ă͍������Ȃ��Ǝv�����ǁH
�E�`�b�v�̎d�l���ɖ��L����Ă��遁�d�͊Ǘ��@�\���܂ő�l
�Ƃ����_�����ł���A�Ƃ͂���������Ă��Ȃ����B
�܂����A�ǂ����̉�Ђ̂悤�ɁA
>���i��������A�ڋq����̗v�]�ł������������l�����J���Ă�Ǝv���邷�B���ǂ̂Ƃ���A
>PC�Ȃ�Ĉ����Ȃ��Ɣ���Ȃ����炷��(��)
>�V�X�e���x���_�Ƃ��Ă�A�]�T�����鐔�l�����������A�K�v�\���Ȃ��肬��̒l�̕����R�X�g�_�E���m��
>���E�������ĕ֗���������Ȃ������H
�Ȃ�Ă��Ƃ��l�����Ђ����݂���Ƃ͎v���Ȃ����B
���ꂪ���Ƃ���Ȃ�A�g�p���Ɍ�����TDP���鎖���Ȃ��A�Ƃ����̂��^�ɂȂ��ȁB
���ɂ���𐳂Ƃ���ƁA
>Intel�́u�ő�v���Ⴛ�����B
���U�ƂȂ�ˁB
���ɁA���e�[���N�[���[�g���Ă�EIST��������������݂������B
��ŁA����������Ă���݂��������ǁA
>Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
>�Ŏ��W���ꂽ����l�ł햳�����Ƃ�������Ă��邷�B
�ɂ��Ă͍������Ȃ��Ǝv�����ǁH
�E�`�b�v�̎d�l���ɖ��L����Ă��遁�d�͊Ǘ��@�\���܂ő�l
�Ƃ����_�����ł���A�Ƃ͂���������Ă��Ȃ����B
�܂����A�ǂ����̉�Ђ̂悤�ɁA
>���i��������A�ڋq����̗v�]�ł������������l�����J���Ă�Ǝv���邷�B���ǂ̂Ƃ���A
>PC�Ȃ�Ĉ����Ȃ��Ɣ���Ȃ����炷��(��)
>�V�X�e���x���_�Ƃ��Ă�A�]�T�����鐔�l�����������A�K�v�\���Ȃ��肬��̒l�̕����R�X�g�_�E���m��
>���E�������ĕ֗���������Ȃ������H
�Ȃ�Ă��Ƃ��l�����Ђ����݂���Ƃ͎v���Ȃ����B
���ނ���MAC�I�^�̑��肷��̂�߂Ă���B
���ځ[��o���Ȃ��B
���ځ[��o���Ȃ��B
>570��
����肪��������~�߂悤�Ǝv���Ă����ǁE�E�E
�X�}�\�B����ōŌ�ɂ���B
>569�ɒNjL
���łɌ����ƁA�w�����M�̃A�v���P�[�V�����Ŏ���������l�x�Ȃ�Ă̂��ǂ��ɂ������ĂȂ��ȁB
���ǂ��̘b�̉ߒ��ŕ����������́A
�v�����݂����Ő^���̂悤�ɏ����Ă���z�������A���Ă��Ƃ������ȁB
IDD Max���鎖������A���Ă̂��A���ǃ\�[�X�������Ȃ��A
��ʓI�Ɍ����Ă���������������A���Ă����̘b���������B
��̓I�ȃ\�[�X���Ȃ��ȏ�A�b�𑱂���̂����f���낤����A�����őł��낤�B
�X�}�\ >all
>mac�I�^��
�Ƃ肠�����A���̘b�𑱂��Ă��A���������Ƃ͕��������B
��ʘ_�͕����������A��̘_���Ȃ���Δ[���͂ł����B�ے�����Ȃ�����ǁB
����肪��������~�߂悤�Ǝv���Ă����ǁE�E�E
�X�}�\�B����ōŌ�ɂ���B
>569�ɒNjL
���łɌ����ƁA�w�����M�̃A�v���P�[�V�����Ŏ���������l�x�Ȃ�Ă̂��ǂ��ɂ������ĂȂ��ȁB
���ǂ��̘b�̉ߒ��ŕ����������́A
�v�����݂����Ő^���̂悤�ɏ����Ă���z�������A���Ă��Ƃ������ȁB
IDD Max���鎖������A���Ă̂��A���ǃ\�[�X�������Ȃ��A
��ʓI�Ɍ����Ă���������������A���Ă����̘b���������B
��̓I�ȃ\�[�X���Ȃ��ȏ�A�b�𑱂���̂����f���낤����A�����őł��낤�B
�X�}�\ >all
>mac�I�^��
�Ƃ肠�����A���̘b�𑱂��Ă��A���������Ƃ͕��������B
��ʘ_�͕����������A��̘_���Ȃ���Δ[���͂ł����B�ے�����Ȃ�����ǁB
572 �FMAC�I�^��569 �����F2005/11/06(��) 15:23:09 ID:+LagjjC+
>>569-571
�@�@-------------------------
�@�@>Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
�@�@[����] �ɂ��Ă͍������Ȃ��Ǝv�����ǁH
�@�@-------------------------
�����l�Ƃ������Ƃ�A�g�p���Ă���`�b�v��o�הłƓ������i�E�\���ł��邱�Ƃ햾�炩���B
�@�@-------------------------
�@�@�w�����M�̃A�v���P�[�V�����Ŏ���������l�x
�@�@-------------------------
���ꎩ�̂�A>>552�Ɉ��p���ꂽ���̏������݂ɗL��ʂ��ʓI�Ȏ�@�Ȃ�ŁA���ɂ��������b���ᖳ�����B
�@�@-------------------------
�@�@�Ȃ�Ă��Ƃ��l�����Ђ����݂���Ƃ͎v���Ȃ����B
�@�@-------------------------
������Intel��TDP�ɑ���]�T�i�̍��ʉ��̂��߂Ɏg����Ǝw�����Ă��邱�Ƃ�m���Ă����Ɨǂ����Ǝv�����B
�@�@-------------------------
�@�@>Idd_max��A�`�b�v�̎d�l���ɖ��L����Ă���l������A�d�͊Ǘ��@�\��S�ė��Ƃ��Ƃ����悤�Ȏ����I��
�@�@[����] �ɂ��Ă͍������Ȃ��Ǝv�����ǁH
�@�@-------------------------
�����l�Ƃ������Ƃ�A�g�p���Ă���`�b�v��o�הłƓ������i�E�\���ł��邱�Ƃ햾�炩���B
�@�@-------------------------
�@�@�w�����M�̃A�v���P�[�V�����Ŏ���������l�x
�@�@-------------------------
���ꎩ�̂�A>>552�Ɉ��p���ꂽ���̏������݂ɗL��ʂ��ʓI�Ȏ�@�Ȃ�ŁA���ɂ��������b���ᖳ�����B
�@�@-------------------------
�@�@�Ȃ�Ă��Ƃ��l�����Ђ����݂���Ƃ͎v���Ȃ����B
�@�@-------------------------
������Intel��TDP�ɑ���]�T�i�̍��ʉ��̂��߂Ɏg����Ǝw�����Ă��邱�Ƃ�m���Ă����Ɨǂ����Ǝv�����B
573 �F����Ȃ�̂����������F2005/11/06(��) 15:28:57 ID:/fbzlwkG
571�̒ʂ�Ȃ�ŁA����ȏ㔽�_�͂��Ȃ���B
���ʂ͐l�C�Ȃ�s��Ȃ肪�o���Ă���邾�낤���B�Z���I�ɂ͖����ł��B
�߁XMAC���\�肾����A
����PowerPC�̘b�ł����悤�B�ʂȃX���ŁB
���ʂ͐l�C�Ȃ�s��Ȃ肪�o���Ă���邾�낤���B�Z���I�ɂ͖����ł��B
�߁XMAC���\�肾����A
����PowerPC�̘b�ł����悤�B�ʂȃX���ŁB
���̂���ɂ�PowerPC����Ȃ��ăC���e���n�C�b�e���������肵�Ă�
575 �FMAC�I�^���⑫�F2005/11/06(��) 15:35:04 ID:+LagjjC+
Intel�̔M�v�Ɋւ���w����A����Ȋ������B
http://developer.intel.com/design/pentium4/guides/249203.htm
�@�@------------------------------
�@�@Figure 13 plots processor performance with the Thermal Control Circuit enabled versus system
�@�@cooling capability. System designers must evaluate the tradeoffs between cooling costs and risk
�@�@of processor performance loss to determine the optimum configuration for the end user.
�@�@------------------------------
http://developer.intel.com/design/pentium4/guides/249203.htm
�@�@------------------------------
�@�@Figure 13 plots processor performance with the Thermal Control Circuit enabled versus system
�@�@cooling capability. System designers must evaluate the tradeoffs between cooling costs and risk
�@�@of processor performance loss to determine the optimum configuration for the end user.
�@�@------------------------------
576 �FMAC�I�^��573 �����F2005/11/06(��) 15:41:26 ID:+LagjjC+
>>573
�@�@--------------------
�@�@�߁XMAC���\�肾����A
�@�@--------------------
���̐߂�A�܂���낵�����肢���܂��B
�@�@--------------------
�@�@�߁XMAC���\�肾����A
�@�@--------------------
���̐߂�A�܂���낵�����肢���܂��B
���ꂾ�����藧�āA���݂��Ă����āA
>���̐߂́A�܂���낵�����肢���܂��B
�͂Ȃ�����Ɓc(;�L�D�M)
>���̐߂́A�܂���낵�����肢���܂��B
�͂Ȃ�����Ɓc(;�L�D�M)
���ׂĎ������˂��B�@���ق���
�܂��y�j�X�Ȑl���Ă��́H
���肷�邾�����ʂ���B�p��܂Ƃ��ɓǂ߂ĂȂ��̂ɉp��̃\�[�X���������Ă��Ȃ�
���A���ꈫ���Ȃ�Ƃ����b���肩���邵�B�����r�炵���������ȍ���t������B
���肷�邾�����ʂ���B�p��܂Ƃ��ɓǂ߂ĂȂ��̂ɉp��̃\�[�X���������Ă��Ȃ�
���A���ꈫ���Ȃ�Ƃ����b���肩���邵�B�����r�炵���������ȍ���t������B
���̃X���}�ɕ��������ȁB
�r�炵�͑��ݎ��̂��s�v�Ȃ��B
�r�炵�͑��ݎ��̂��s�v�Ȃ��B
�v�悾�����h�Ŏ��ۂ�CPU���_���|���ƍ����ȁB
�Ƃ���������AMD�̎�����ɂ��Č��X���Ȃ̂�
MAC�I�^��Intel�̂��Ƃɂ��Č���Ă�낤�B
��(���*)�܂������{�ꂪ�ǂ߂Ȃ��́I�H
�Ƃ���������AMD�̎�����ɂ��Č��X���Ȃ̂�
MAC�I�^��Intel�̂��Ƃɂ��Č���Ă�낤�B
��(���*)�܂������{�ꂪ�ǂ߂Ȃ��́I�H
>>549
�ڂƎ����ǂ��œG����B�ꂽ�C�ɂȂ��Ă�o�J�ȓ������Ɖx�ɓ����Ă��邪
���ۂ͎��͂𒍈Ӑ[���ώ@����ׂɎ���n�ʂɕt���Ă���s�����Ƃ͋C��
�t���Ȃ��o�J�Ȏ����Ƃ������s�l�^�Ȃ�?
�ڂƎ����ǂ��œG����B�ꂽ�C�ɂȂ��Ă�o�J�ȓ������Ɖx�ɓ����Ă��邪
���ۂ͎��͂𒍈Ӑ[���ώ@����ׂɎ���n�ʂɕt���Ă���s�����Ƃ͋C��
�t���Ȃ��o�J�Ȏ����Ƃ������s�l�^�Ȃ�?
583 �FMAC�I�^��582 �����F2005/11/06(��) 21:53:25 ID:+LagjjC+
>>582
���������C�T�������āA�Ȍ�A���k�����ăR�e�n���ł������Ȃ班�����S���邷�B
�ł�>>579-581�������ǂ�ł����������Ă���Ȃ�A����ς�s���̈������Ƃɖڂ��ǂ��ł��ł�H
���������C�T�������āA�Ȍ�A���k�����ăR�e�n���ł������Ȃ班�����S���邷�B
�ł�>>579-581�������ǂ�ł����������Ă���Ȃ�A����ς�s���̈������Ƃɖڂ��ǂ��ł��ł�H
���܂���A�����ł�����ł���������������
(�L�E�ցE`) �� �U
(�L�E�ցE`) �� �U
�̎G���X���Ō������ꂾ��
�܁A�ǂ���MAC���^��������������AMD�͂���Ȃ�ɗǂ�������Ă��邾��B
������Ȃ��邾���̔n�����Ă��Ƃ��ˁB
������Ȃ��邾���̔n�����Ă��Ƃ��ˁB
>>583
�Ȃ̖��m�Ǝ��̋C�T��R�e�n���̎g�p�Ƃ͖��W���Ǝv���邪�B
�u�_�`���E�v�̓o�J���Ǝv�����������̂͌l�̎��R��������͐���
�uostrich policy�v���Ƃ͎v��Ȃ�����?
�Ȃ̖��m�Ǝ��̋C�T��R�e�n���̎g�p�Ƃ͖��W���Ǝv���邪�B
�u�_�`���E�v�̓o�J���Ǝv�����������̂͌l�̎��R��������͐���
�uostrich policy�v���Ƃ͎v��Ȃ�����?
588 �FMAC�I�^��587 �����F2005/11/06(��) 22:37:09 ID:+LagjjC+
>>587
�@�@-------------------
�@�@�u�_�`���E�v�̓o�J���Ǝv�����������̂�
�@�@-------------------
���������āA�P�Ȃ銵�p�傾���Ă��Ƃ�m��Ȃ����������B�B�B�O���P�Ē��F�肵�Ă����邷�B
�����ԂƓ����x���ɂȂ�ėǂ���������(��)
�@�@-------------------
�@�@�u�_�`���E�v�̓o�J���Ǝv�����������̂�
�@�@-------------------
���������āA�P�Ȃ銵�p�傾���Ă��Ƃ�m��Ȃ����������B�B�B�O���P�Ē��F�肵�Ă����邷�B
�����ԂƓ����x���ɂȂ�ėǂ���������(��)
�ŁA�l�i�U�����c�܂������G���Ɠ�������ŏ��邗
�킴�킴�J�b�R�t���ŏ����Ă����Ă�̂ɗ����ł��Ȃ��̂��E�E�E
�l�^�������ƍr���D�D
���Ⴀ�A�����l�^���ӂ��Ă��B
HyperTransport �� AMD-8131 PCI-X �g���l���`�b�v�����邪
����� PCIe �ɒu��������v��͖����̂��낤���H
ttp://www.amd.com/us-en/Processors/TechnicalResources/0,,30_182_739_9004,00.html
�ǂ��݂Ă�PCI-X�̓j�b�`�Ȋ�K�X
�����AAGP�܂ł���PCIe�œh��ւ�������̂�����Ȃ̂����D�D
���Ⴀ�A�����l�^���ӂ��Ă��B
HyperTransport �� AMD-8131 PCI-X �g���l���`�b�v�����邪
����� PCIe �ɒu��������v��͖����̂��낤���H
ttp://www.amd.com/us-en/Processors/TechnicalResources/0,,30_182_739_9004,00.html
�ǂ��݂Ă�PCI-X�̓j�b�`�Ȋ�K�X
�����AAGP�܂ł���PCIe�œh��ւ�������̂�����Ȃ̂����D�D
592 �FMAC�I�^��590 �����F2005/11/06(��) 22:51:27 ID:+LagjjC+
>>590
�����ăJ�b�R�t���́u�_�`���E�v�̈Ӗ����āA�����v���v��Ȃ��Ɋւ�炸�Ӗڂ��Ă��Ƃ���(��)
�]���p��œ��ʂȈӖ����t�������Ȃ�A�܂�������Ă���g�����Ƃ����肢���邷�B
�����ăJ�b�R�t���́u�_�`���E�v�̈Ӗ����āA�����v���v��Ȃ��Ɋւ�炸�Ӗڂ��Ă��Ƃ���(��)
�]���p��œ��ʂȈӖ����t�������Ȃ�A�܂�������Ă���g�����Ƃ����肢���邷�B
>>591
�T�[�h�p�[�e�B��PCI Express�`�b�v�Z�b�g�͊��ɏo�����Ă��܂��B
PCI Express tunnel��NVIDIA��ULi���o���Ă��܂��B
���ɃT�[�h�p�[�e�B����s���Ă��镪��ɍ��XAMD�̏o�Ԃ͂���܂���B
�T�[�h�p�[�e�B��PCI Express�`�b�v�Z�b�g�͊��ɏo�����Ă��܂��B
PCI Express tunnel��NVIDIA��ULi���o���Ă��܂��B
���ɃT�[�h�p�[�e�B����s���Ă��镪��ɍ��XAMD�̏o�Ԃ͂���܂���B
594 �FMAC�I�^��591 �����F2005/11/06(��) 22:52:01 ID:+LagjjC+
>>591
Apple���V�^Power Mac G5�ŁA���ɃR�����̗p���Ă��邷�B
http://www.broadcom.com/products/Enterprise-Small-Office/SystemI-O-Chips/HT-2000
Apple���V�^Power Mac G5�ŁA���ɃR�����̗p���Ă��邷�B
http://www.broadcom.com/products/Enterprise-Small-Office/SystemI-O-Chips/HT-2000
�y�j�X�͎����Łu�A�����v�Ɗ��������݂̖{���n�ɑԁX��荞��ł܂ő��肵�ė~�����݂���������
���̍s���Ɍh�ӂ������������Ă�������̂��������ċA��ł���B
>>591
���I������PCIe���ڂ��闝�R���킩���B
���̍s���Ɍh�ӂ������������Ă�������̂��������ċA��ł���B
>>591
���I������PCIe���ڂ��闝�R���킩���B
PCIe���Ɠ��쌟�ɕ��������Ԃ����肻�����ȁB
���肵�ē������Ƃ���O��ȎI�ł́APCI-X�ő����̂ł͓��Ȉ�
���肵�ē������Ƃ���O��ȎI�ł́APCI-X�ő����̂ł͓��Ȉ�
597 �FMAC�I�^��595 �����F2005/11/06(��) 22:56:12 ID:+LagjjC+
>>595
HPC�N���X�^�����Ɏg���Ă���Infiniband�J�[�h�ȂŁA����PCI-X -> PCI Express�ւ̈ڍs��
�i��ł��邷�B
http://www.mellanox.com/technology/shared/InfiniHost_Architecture_WP_160_JPN.pdf
HPC�N���X�^�����Ɏg���Ă���Infiniband�J�[�h�ȂŁA����PCI-X -> PCI Express�ւ̈ڍs��
�i��ł��邷�B
http://www.mellanox.com/technology/shared/InfiniHost_Architecture_WP_160_JPN.pdf
>>593
>���ɃT�[�h�p�[�e�B����s���Ă��镪��ɍ��XAMD�̏o�Ԃ͂���܂���B
�m����AMD���o���͍̂��X�������邩������A
���܂ł�PCI-X tunnel�̂܂܂ōs���͍̂l�������Ǝv�����D�D�D
>���ɃT�[�h�p�[�e�B����s���Ă��镪��ɍ��XAMD�̏o�Ԃ͂���܂���B
�m����AMD���o���͍̂��X�������邩������A
���܂ł�PCI-X tunnel�̂܂܂ōs���͍̂l�������Ǝv�����D�D�D
PCI-X���Ă���ȂɃj�b�`�H
����܂ވ�ʃ��[�U�����̎s��ƃT�[�o�s����ׂ��
���I�ɂ͊m���Ƀj�b�`�����ǁc
>>599
Athlon64��PCIe������Opteron��PCI-X�Ƃ������ݕ����̓_���H
����܂ވ�ʃ��[�U�����̎s��ƃT�[�o�s����ׂ��
���I�ɂ͊m���Ƀj�b�`�����ǁc
>>599
Athlon64��PCIe������Opteron��PCI-X�Ƃ������ݕ����̓_���H
������̘b�̏�A����قǐV�����l�^����Ȃ��Ď��炷�邷�BAnandTech�̂���B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
Q2'06�̎��_�ŃV���O���R�A��Athlon 64 4000+ (=2.4GHz)������BIntel��4GHz��O�ő����݂��Ă�̂�
���l�ɁAAMD���u�M�̕ǁv�ɓ˂���������3GHz��O���炿�т��я��o���ɂ���H�ڂɂȂ肻�����B�B�B
�������A�����t�B���^�ŔߊϓI�Ȍ����ɂȂ��ŁA�F����̊�]�I�ϑ����W�����B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
Q2'06�̎��_�ŃV���O���R�A��Athlon 64 4000+ (=2.4GHz)������BIntel��4GHz��O�ő����݂��Ă�̂�
���l�ɁAAMD���u�M�̕ǁv�ɓ˂���������3GHz��O���炿�т��я��o���ɂ���H�ڂɂȂ肻�����B�B�B
�������A�����t�B���^�ŔߊϓI�Ȍ����ɂȂ��ŁA�F����̊�]�I�ϑ����W�����B
�����_�ł�FX-57��2.8GHz��B�����Ă�Ƃ����͌����Ă����B
AnandTech��SocketM2�̘b�B
AnandTech��SocketM2�̘b�B
603 �FT.A. ��Vr3ZLNzp5. �F2005/11/06(��) 23:49:11 ID:BFDOuLbd
>>546-547
333MHz�x�[�X�ɂȂ�̂�HyperTransport���ꏏ�Ȃ̂��ǂ����s�������ǁE�E�E
(�R�A�N���b�N��333MHz�x�[�X�ɂȂ�̂͂قڊm���炵���B)
�����AHyperTransport��200MHz�x�[�X��333MHz�x�[�X�̓��샂�[�h�̗��Ή���
�Ȃ��Ȃ����ȁH
�ڍs���ɂ͌����̃`�b�v�Z�b�g���g���Ȃ��ƐF�X���邾�낤���B
HyperTransport�̑ш�ɂ��Ă�3DMark05�ŁA����N���b�N��ς��Ē��ׂĂ݂�����
400MHz(200MHz*2)�܂ŗ��Ƃ��ƁA�����Ȑ��\�ቺ���o�����ǂ���ȏ�͌덷���x��
�̈Ⴂ�����Ȃ���������AI/O�����N�Ƃ��ĂȂ炻��قǐ��\�ɉe���͂Ȃ����ƁB
>>598
�ނ���A����PCI-X tunnel�̂܂܂ł����悤�ȋC������E�E�E
�ڍs���ɂ�PCI-Express��PCI-X�̗������g��������������ق����������ǁA�ڍs��
������x�i�߂�PCI-X�Ȃ����嗬�ɂȂ邩��A���̏�Ԃ͗��z�I�ȏ�Ԃ��Ǝv���B
������PCI�ǂ��납ISA�������c���Ă镪������邭�炢������A�ڍs���i�s���Ă�PCI-X��
�S�ł��Ă��Ƃ͂Ȃ����낤���B
�E�E�E����ɂ��Ă����ځ`�����ς�����ȁE�E�E
333MHz�x�[�X�ɂȂ�̂�HyperTransport���ꏏ�Ȃ̂��ǂ����s�������ǁE�E�E
(�R�A�N���b�N��333MHz�x�[�X�ɂȂ�̂͂قڊm���炵���B)
�����AHyperTransport��200MHz�x�[�X��333MHz�x�[�X�̓��샂�[�h�̗��Ή���
�Ȃ��Ȃ����ȁH
�ڍs���ɂ͌����̃`�b�v�Z�b�g���g���Ȃ��ƐF�X���邾�낤���B
HyperTransport�̑ш�ɂ��Ă�3DMark05�ŁA����N���b�N��ς��Ē��ׂĂ݂�����
400MHz(200MHz*2)�܂ŗ��Ƃ��ƁA�����Ȑ��\�ቺ���o�����ǂ���ȏ�͌덷���x��
�̈Ⴂ�����Ȃ���������AI/O�����N�Ƃ��ĂȂ炻��قǐ��\�ɉe���͂Ȃ����ƁB
>>598
�ނ���A����PCI-X tunnel�̂܂܂ł����悤�ȋC������E�E�E
�ڍs���ɂ�PCI-Express��PCI-X�̗������g��������������ق����������ǁA�ڍs��
������x�i�߂�PCI-X�Ȃ����嗬�ɂȂ邩��A���̏�Ԃ͗��z�I�ȏ�Ԃ��Ǝv���B
������PCI�ǂ��납ISA�������c���Ă镪������邭�炢������A�ڍs���i�s���Ă�PCI-X��
�S�ł��Ă��Ƃ͂Ȃ����낤���B
�E�E�E����ɂ��Ă����ځ`�����ς�����ȁE�E�E
>>600
>Athlon64��PCIe������Opteron��PCI-X�Ƃ������ݕ����̓_���H
AMD�I�� Opteron �̓T�[�o���烏�[�N�X�e�[�V������͈͂ɂ��Ă�͂��Ȃ�ŁA
���[�N�X�e�[�V��������Ȃ�PCIe�̕������̉��b�������ɂ���Ǝv���̂����D�D
>Athlon64��PCIe������Opteron��PCI-X�Ƃ������ݕ����̓_���H
AMD�I�� Opteron �̓T�[�o���烏�[�N�X�e�[�V������͈͂ɂ��Ă�͂��Ȃ�ŁA
���[�N�X�e�[�V��������Ȃ�PCIe�̕������̉��b�������ɂ���Ǝv���̂����D�D
�ꉞ
google �� PCI-X �� PCI-Express �֘A�y�[�W���̔�r
PCI-Express�@8,040,000 ��
PCI-X�@�@�@�@2,090,000 ��
google �� PCI-X �� PCI-Express �֘A�y�[�W���̔�r
PCI-Express�@8,040,000 ��
PCI-X�@�@�@�@2,090,000 ��
PCI-Express �� PCI-X �̎d�l�����Ă݂悤�Ǝv����
�ȉ��ɍs����
PCI-SIG - Specifications
http://www.pcisig.com/specifications
�Ȃ��̃T�C�g�́A�����o�[�ȊO�d�l������ˁ[�̂���I
�Ȃ�Ă����������B
�ȉ��ɍs����
PCI-SIG - Specifications
http://www.pcisig.com/specifications
�Ȃ��̃T�C�g�́A�����o�[�ȊO�d�l������ˁ[�̂���I
�Ȃ�Ă����������B
����Opteron�ł�Socket F��CPU��PCI-Express������b������悤�����ǁA
����ɃO���{���q���̂ł͂Ȃ��āA�Ⴆ��SAS-HDD��
�@�@�@�@�@�@�@�@�@�@��PCI-Express�ڑ�
HDD----SAS------cpu----������
�@�@�@�@�@�@�@�@�@�@ �@�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@North
���������̂��ĈӖ�����܂����H
HDD�͐�Α��x���x������A����ő����̃��C�e���V���팸���Ă����ʂ͔������ł��傤���H
����ɃO���{���q���̂ł͂Ȃ��āA�Ⴆ��SAS-HDD��
�@�@�@�@�@�@�@�@�@�@��PCI-Express�ڑ�
HDD----SAS------cpu----������
�@�@�@�@�@�@�@�@�@�@ �@�@�@|
�@�@�@�@�@�@�@�@�@�@�@�@North
���������̂��ĈӖ�����܂����H
HDD�͐�Α��x���x������A����ő����̃��C�e���V���팸���Ă����ʂ͔������ł��傤���H
>>607
����ł�HDD���̂̑��x���x���̂ł���ȊO�𑬂߂Ă��ɂ�Ƃ�����Ƃ��E�E�E�E
�����ǂ����Ă������������������Ɩ����̂ŗ��ʂ͂قƂ�Ǖς���Ƃ����E�E
����ł�HDD���̂̑��x���x���̂ł���ȊO�𑬂߂Ă��ɂ�Ƃ�����Ƃ��E�E�E�E
�����ǂ����Ă������������������Ɩ����̂ŗ��ʂ͂قƂ�Ǖς���Ƃ����E�E
>>603
�l�I�ɂ́APCIe�������K�v�Ȃ��Ǝv���BHT-PCIe Bridge�ł����B
�^�C�~���O�ŁAMemory��FB-DIMM �R���g���[���̓����͕K�v�ɂȂ邾�낤���ǁB
�l�I�ɂ́APCIe�������K�v�Ȃ��Ǝv���BHT-PCIe Bridge�ł����B
�^�C�~���O�ŁAMemory��FB-DIMM �R���g���[���̓����͕K�v�ɂȂ邾�낤���ǁB
>>606
PCIE��HT�R��Intel�哱�ō��ꂽ�K�i������ȁB
PCIE��HT�R��Intel�哱�ō��ꂽ�K�i������ȁB
>>609
�����ȃN���X�^�g�ނƂ���PCIe��PCI-X�̃��C�e���V�����������������
�b�����邩������͌��ʂ���Ƃ�������B
�����N���X�^��HT�����̐�p�`�b�v�g������ǂ����ł��������낤���ǂ��B
�����ȃN���X�^�g�ނƂ���PCIe��PCI-X�̃��C�e���V�����������������
�b�����邩������͌��ʂ���Ƃ�������B
�����N���X�^��HT�����̐�p�`�b�v�g������ǂ����ł��������낤���ǂ��B
>>611
>PCIE��HT�R��Intel�哱�ō��ꂽ�K�i������ȁB
Intel�哱�ō��ꂽ�K�i�ł�AMD���g�p���Ă����Ȃ��킯���Ȃ��B
�K�i�Ƃ��Đ��藧���Ă���ȏ�AMD�ɂ�������̗p���錠���͂���B
�����HyperTransport��PCIe�Ɋւ��Č����ƁA
PCIe�́A���I/O�o�X�Ɍ��肵���K�i�ł���̂ɑ��āA
HyperTransport�́ACPU�o�X�AI/O�o�X�Ȃǂɕ��L���K�������K�i���B
�Ȃ̂ŁA�������Ă���̂�I/O�o�X�����݂̂ƂȂ�B
���z�I�Ȃ̂́AHyperTransport��CPU�A�`�b�v�Z�b�g�Ԃ̐�p�o�X�Ƃ��Ďg�p���A
���Ӌ@���R���g���[����ڑ�����I/O�o�X�Ԃ�PCIe�Ő��ݕ�����̂��x�X�g����ˁ[�́B
�[���A�ŏI�I�ɂ͂����Ȃ�Ǝv���B
>PCIE��HT�R��Intel�哱�ō��ꂽ�K�i������ȁB
Intel�哱�ō��ꂽ�K�i�ł�AMD���g�p���Ă����Ȃ��킯���Ȃ��B
�K�i�Ƃ��Đ��藧���Ă���ȏ�AMD�ɂ�������̗p���錠���͂���B
�����HyperTransport��PCIe�Ɋւ��Č����ƁA
PCIe�́A���I/O�o�X�Ɍ��肵���K�i�ł���̂ɑ��āA
HyperTransport�́ACPU�o�X�AI/O�o�X�Ȃǂɕ��L���K�������K�i���B
�Ȃ̂ŁA�������Ă���̂�I/O�o�X�����݂̂ƂȂ�B
���z�I�Ȃ̂́AHyperTransport��CPU�A�`�b�v�Z�b�g�Ԃ̐�p�o�X�Ƃ��Ďg�p���A
���Ӌ@���R���g���[����ڑ�����I/O�o�X�Ԃ�PCIe�Ő��ݕ�����̂��x�X�g����ˁ[�́B
�[���A�ŏI�I�ɂ͂����Ȃ�Ǝv���B
>>614
����۽
������������YO�I�@�}�W���X���Ă��������ȁB
���Ȃ݂Ɍ����Ă����ƁAPCI-SIG�͂ǂ��̃��[�J�ɂ��ˑ����ĂȂ��A
PCI�֘A�̋K�i���܂Ƃ߂Ă���c�̂ł���B
����۽
������������YO�I�@�}�W���X���Ă��������ȁB
���Ȃ݂Ɍ����Ă����ƁAPCI-SIG�͂ǂ��̃��[�J�ɂ��ˑ����ĂȂ��A
PCI�֘A�̋K�i���܂Ƃ߂Ă���c�̂ł���B
�Ƃ肠����M2�͗\��ʂ�o�����ȗ\��
�}���`�ɍڂ���CPU��K15���炢�ł����H
�t����B
HT��PCIe(3GIO)�R�����ẮB
HT��PCIe(3GIO)�R�����ẮB
>>619
�R����Ȃ��Ǝv���B
���Ȃ��Ƃ�����HyperTransport��CPU�o�X�Ƃ��Ă̎g��������ԑ����B
����ɁA
�L���o�X�������|�C���g�c�[�|�C���g�ڑ�
�ƂȂ�͎̂���̗���B
�������ӎ����Ȃ��Ă��K�R�I�ɂ����Ȃ�B
�R����Ȃ��Ǝv���B
���Ȃ��Ƃ�����HyperTransport��CPU�o�X�Ƃ��Ă̎g��������ԑ����B
����ɁA
�L���o�X�������|�C���g�c�[�|�C���g�ڑ�
�ƂȂ�͎̂���̗���B
�������ӎ����Ȃ��Ă��K�R�I�ɂ����Ȃ�B
�O���f�o�C�X��HypetTransport�ɂ����Ⴆ���đ_�����Ȃ������킯����Ȃ�����
�ꉞ�R�͂��Ă��悤�ȁB
�Ă�HyperTransport�̂�3GIO��蔭�\�悶��Ȃ���������
�ꉞ�R�͂��Ă��悤�ȁB
�Ă�HyperTransport�̂�3GIO��蔭�\�悶��Ȃ���������
�r�炷����ł�����Ȃ����ǁA���̕ӂ̘b��intel������CPU�X����
���T�ԑO�Ɍ�����K�X�E�E�E
���T�ԑO�Ɍ�����K�X�E�E�E
�F�l�A�����Ɠǂ�ʼn������B
the HyperTransport Consortium
ttp://www.hypertransport.org/
Direct Low Latency Peripheral-to-CPU Connections
ttp://www.hypertransport.org/docs/wp/HTX_wp_final.pdf
the HyperTransport Consortium
ttp://www.hypertransport.org/
Direct Low Latency Peripheral-to-CPU Connections
ttp://www.hypertransport.org/docs/wp/HTX_wp_final.pdf
>>621
�R���������А��i�̂��߂̃o�X����H
�����������Ȃ���A���O�̃o�X�Ȃ���������B
���܂ł�Alpha��EV6�o�X�����C�Z���X�Ŏg���Ă�킯�ɂ������낤���B
�I�[�v���ɂ������R�͒P���ɊJ�����S���炷���߂ł���B
�i������ЋZ�p���L�߂闝�R�����邾�낤���ǁj
�R���������А��i�̂��߂̃o�X����H
�����������Ȃ���A���O�̃o�X�Ȃ���������B
���܂ł�Alpha��EV6�o�X�����C�Z���X�Ŏg���Ă�킯�ɂ������낤���B
�I�[�v���ɂ������R�͒P���ɊJ�����S���炷���߂ł���B
�i������ЋZ�p���L�߂闝�R�����邾�낤���ǁj
��������Pin���Ɩ����Ȃ̂��ȁB
�Ȃ�LGA775�ƈ���ăS�c�S�c���Ă銴���Ɍ�����ȁB
�h�C�c���ۂ��H
�Ȃ�LGA775�ƈ���ăS�c�S�c���Ă銴���Ɍ�����ȁB
�h�C�c���ۂ��H
���悢��p�N����
�A�Ƃ��p�b�N�Ă邵
Land Grid Array (LGA)
ttp://en.wikipedia.org/wiki/Land_grid_array
ttp://en.wikipedia.org/wiki/Land_grid_array
LGA���K�v�ȂقǍ��N���b�N�ɑ���Ƃ͎v���Ȃ��̂���
>>630
�N���b�N����Ȃ��āA�������̔z���x�����C�ɂ��Ă��Ȃ��H
�N���b�N����Ȃ��āA�������̔z���x�����C�ɂ��Ă��Ȃ��H
SocketF�Ď���Opteron������APCI-Express�悹��e���łȂ��H
����m���f�[�^�N���b�N2.5GHz�A�����K�i2.0����5GHz�ɂȂ��ˁB
����m���f�[�^�N���b�N2.5GHz�A�����K�i2.0����5GHz�ɂȂ��ˁB
�������R���g���[����PCIe�R���g���[������������f���A���R�AOpteron
(; �L�D`)ʧʧ
(; �L�D`)ʧʧ
Leaked Pictures of Socket F
ttp://hardware.slashdot.org/hardware/05/11/08/1310205.shtml?tid=142&tid=137
�p����z�̂��R�s�y
The first photos of AMD's Socket F have emerged on our Gathering of Tweakers
forum. In May we wrote that AMD had a new processor socket on its roadmap. The
new footprint should have 1207 pins and is intended for multi-Opteron servers.
To make possible a processor with support for DDR memory on a DDR2-footprint
and vice-versa a new socket was needed. The extra pins that are available are
according to reports for an integrated PCI-Express controller on the
processors. Noticeable in the photos is the clear separation in the middle of
the socket. This seems to indicate that each core of the dual-core Opteron has
its own group of pins, and so works as two processors.
ttp://hardware.slashdot.org/hardware/05/11/08/1310205.shtml?tid=142&tid=137
�p����z�̂��R�s�y
The first photos of AMD's Socket F have emerged on our Gathering of Tweakers
forum. In May we wrote that AMD had a new processor socket on its roadmap. The
new footprint should have 1207 pins and is intended for multi-Opteron servers.
To make possible a processor with support for DDR memory on a DDR2-footprint
and vice-versa a new socket was needed. The extra pins that are available are
according to reports for an integrated PCI-Express controller on the
processors. Noticeable in the photos is the clear separation in the middle of
the socket. This seems to indicate that each core of the dual-core Opteron has
its own group of pins, and so works as two processors.
AMD��Intel�݂����ɔ��M�A�����d�͂ɂ͑���Ȃ���ˁH�H�H
Socket F photos
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0015ep.jpg
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0024yp.jpg
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0032cd.jpg
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0015ep.jpg
{kind=link}
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0024yp.jpg
{kind=link}
ttp://img259.imageshack.us.nyud.net:8090/my.php?image=0032cd.jpg
{kind=link}
>>635
http://www.tomshardware.com/cpu/20050725/images/sockets.gif
http://www.pcper.com/images/reviews/129/powercooling.gif
http://www.tomshardware.com/cpu/20050725/images/sockets.gif
{kind=link}
http://www.pcper.com/images/reviews/129/powercooling.gif
{kind=link}
AMDuser�ɂ�
�A�t�H�̈��~�݂����ɁA�܂��肩�łȂ�������CPU�ɂ��Ėϑz�����҂͂����B
��@���@�ā@���@�́@�X�@���@�́@�I�@���@�B
�A�t�H�̈��~�݂����ɁA�܂��肩�łȂ�������CPU�ɂ��Ėϑz�����҂͂����B
��@���@�ā@���@�́@�X�@���@�́@�I�@���@�B
�ĊJ
�ʂɌ��l�Ԃ�AMDuser�ł���K�v�͂Ȃ��킯�ŁB
���x��AMD�����M�A�ᐫ�\�ɂȂ邩���ȁB
���҂Ƃ��d�͓�����̐��\���d�����Ă���͂�������A
����͂Ȃ���Ȃ��B
���M�A�����\��ڎw���Ȃ�P�Ȃ�o�J���Ƃ����������ǁB
�K�v�Ȏ��ȊO�̓N���b�N�����Ďg�����炢����Ȃ��H
���҂Ƃ��d�͓�����̐��\���d�����Ă���͂�������A
����͂Ȃ���Ȃ��B
���M�A�����\��ڎw���Ȃ�P�Ȃ�o�J���Ƃ����������ǁB
�K�v�Ȏ��ȊO�̓N���b�N�����Ďg�����炢����Ȃ��H
�K�v�ȂƂ��ӊO�̓N���b�N��������͓̂d�C��I�ɂ͗ǂ��̂����A
�����ǂ�ȂƂ��ɓd�����ő�ɂȂ�̂��\�z�ł��Ȃ����A
���_�ɑ傫�ȃ}�[�W�����Ƃ����d���e�ʂƗ�p�̕��ʂ��K�v�Ȃ��Ƃ͕ς���B
�����ǂ�ȂƂ��ɓd�����ő�ɂȂ�̂��\�z�ł��Ȃ����A
���_�ɑ傫�ȃ}�[�W�����Ƃ����d���e�ʂƗ�p�̕��ʂ��K�v�Ȃ��Ƃ͕ς���B
>>641
AMD�����s�Ɠ����x����ۂ����܂ܐ��\���グ���ɂ��ւ�炸�A�C���e��CPU�����M�����������Ƃɂ��AMD�����ΓI�ɔ��M�ɂȂ����A
�Ƃ�����ꂽ���۽
AMD�����s�Ɠ����x����ۂ����܂ܐ��\���グ���ɂ��ւ�炸�A�C���e��CPU�����M�����������Ƃɂ��AMD�����ΓI�ɔ��M�ɂȂ����A
�Ƃ�����ꂽ���۽
x86�A�[�L�e�N�`���ɂ�Foxton Technology���K�v���ȁB
HyperTransport��PCI Express�̌��̂ЂƂ�������B
����PCI-SIG��Intel�̎x�z���ɂ���̂Ŏ������Ȃ����������ŁB
LGA���̗p����̂̓s�����x���グ�邽�߁B�����g�����̓\�P�b�g���g������PGA�ƕς��Ȃ��B
����PCI-SIG��Intel�̎x�z���ɂ���̂Ŏ������Ȃ����������ŁB
LGA���̗p����̂̓s�����x���グ�邽�߁B�����g�����̓\�P�b�g���g������PGA�ƕς��Ȃ��B
>>642
������N���b�N�ϋZ�p�͕��ϓd�͂������邽�߂ɓ������ꂽ�Z�p��B
�����A���̎�̋Z�p����VRM���}�U�[�ɂ��邽�߁A
�L���ׂ��ɐ���s�\�i���b�T���j�����ACPU�i�R�A���łȂ��j�P�ʂɂȂ��Ă��܂��B
970MP�̓R�A������\�炵�����A�ǂ��Ȃ��Ă�̂��ȁB
�}�U�[�ɃR�A��VRAM���ڂ��Ă�̂��ȁB
������N���b�N�ϋZ�p�͕��ϓd�͂������邽�߂ɓ������ꂽ�Z�p��B
�����A���̎�̋Z�p����VRM���}�U�[�ɂ��邽�߁A
�L���ׂ��ɐ���s�\�i���b�T���j�����ACPU�i�R�A���łȂ��j�P�ʂɂȂ��Ă��܂��B
970MP�̓R�A������\�炵�����A�ǂ��Ȃ��Ă�̂��ȁB
�}�U�[�ɃR�A��VRAM���ڂ��Ă�̂��ȁB
http://www.hkepc.com/bbs/viewthread.php?tid=503057
SocketF��2007�N�������ď����Ă��邪�A����Ȃɒx�����������H
���ꂪ�{���Ȃ�DDR2��Pacifica�͌��s�\�P�b�g�ŏo���̂��ȁB
SocketF��2007�N�������ď����Ă��邪�A����Ȃɒx�����������H
���ꂪ�{���Ȃ�DDR2��Pacifica�͌��s�\�P�b�g�ŏo���̂��ȁB
���͂������N�̉Ă̏I��肠����ɏo���ق������Ƃɂ����B
>>647
ttp://pcweb.mycom.co.jp/articles/2005/10/30/fpf1/
ttp://pcweb.mycom.co.jp/photo/articles/2005/10/30/fpf1/images/008l.jpg
�ꉞ�A�ʏ퓮���Doze�i�����d�̓��[�h�j������Core���ɓƗ����Ă�炵���ȁB
C1Core�̓I�t�ɂ��o����݂��������B
ttp://pcweb.mycom.co.jp/articles/2005/10/30/fpf1/
ttp://pcweb.mycom.co.jp/photo/articles/2005/10/30/fpf1/images/008l.jpg
{kind=link}
�ꉞ�A�ʏ퓮���Doze�i�����d�̓��[�h�j������Core���ɓƗ����Ă�炵���ȁB
C1Core�̓I�t�ɂ��o����݂��������B
��ʓI�ȃf�X�N�g�b�v�ɐς߂�CPU��TDP����
�C���e�����킩���Ă��Ȃ������̂��ȁH
P6�n�����M�����Ȃ�����Ȃ̂��H
���TDP���ŃN���b�N��������̂ɍ��ꂽ�̂��A
netburst���ȂƎv�����ǁB
�����ȍ~AMD���܂葝���Ă��Ȃ�����
AMD�̕������ǂޗ͂����邩�������ȁB
���ǂ͏��TDP�܂ōs���ďȓd�͂̃R�A�����Ƃ����_�ł͓��������ǁB
P6�n�����|�I�ɏ���d�͂����Ȃ������̂�����낤���B
�C���e�����킩���Ă��Ȃ������̂��ȁH
P6�n�����M�����Ȃ�����Ȃ̂��H
���TDP���ŃN���b�N��������̂ɍ��ꂽ�̂��A
netburst���ȂƎv�����ǁB
�����ȍ~AMD���܂葝���Ă��Ȃ�����
AMD�̕������ǂޗ͂����邩�������ȁB
���ǂ͏��TDP�܂ōs���ďȓd�͂̃R�A�����Ƃ����_�ł͓��������ǁB
P6�n�����|�I�ɏ���d�͂����Ȃ������̂�����낤���B
��������ʂ�ƌ������AMD�͐̂����ʗp�r��
�f�X�N�g�b�v�V���O��CPU��TDP70W�g��
�����e���A�̂̋L���̋L���Ȃ�Ń\�[�X�Y�ꂽ
���R���悭�o���ĂȂ�(�p��L���������L�K�X��)
��ɂ��Ă��\���O��Ŏd�l���߂Ă��͂�
(�ŋ߂̃f���A���Ή��Ȃ�܂ł͕��TDP80W�v)
����AMD��CPU���ׂĖ��X�BK7�̖����R�A�Ƃ�
�ꕔ�������Ă�������C���X�g���[����
70W�g�͎���Ă��n�Y
�t�ɂ�����70W���Ȃ�Ȃ�ł������I���o���������
vsP6����͔M���M������ꂽ�킯�����E�E�E
intel��130W�g�i�m���A�����E������������
����͂킩���Ă���
�l�g�o�̌�Z�̓V�������N���Ă����Ă����[�N��������
�v�����悤�ɓd�͐��������Ȃ�������
�f�X�N�g�b�v�V���O��CPU��TDP70W�g��
�����e���A�̂̋L���̋L���Ȃ�Ń\�[�X�Y�ꂽ
���R���悭�o���ĂȂ�(�p��L���������L�K�X��)
��ɂ��Ă��\���O��Ŏd�l���߂Ă��͂�
(�ŋ߂̃f���A���Ή��Ȃ�܂ł͕��TDP80W�v)
����AMD��CPU���ׂĖ��X�BK7�̖����R�A�Ƃ�
�ꕔ�������Ă�������C���X�g���[����
70W�g�͎���Ă��n�Y
�t�ɂ�����70W���Ȃ�Ȃ�ł������I���o���������
vsP6����͔M���M������ꂽ�킯�����E�E�E
intel��130W�g�i�m���A�����E������������
����͂킩���Ă���
�l�g�o�̌�Z�̓V�������N���Ă����Ă����[�N��������
�v�����悤�ɓd�͐��������Ȃ�������
>>653
�ŁA�f���A���R�A�����y���Ă������ŁAAMD�������E�ւ܂�������H
�ŁA�f���A���R�A�����y���Ă������ŁAAMD�������E�ւ܂�������H
65nm�ɂȂ�܂�X2�����C���X�g���[���ɍ~��Ă��鎖�͂Ȃ��悤��
���������A�ڊo�߂Ăق���
>>653
AMD��K7���o��������70W���炢�ɂȂ�悤�ɍ���Ă����̂��B
P6�̎��͔��M�Ƃ����Ă��āAnetburst���o�Ă��Ă���
�������D�ʂɂȂ����킯�����A
�܂�P6�n�̌�p��merom���o�Ă�����܂�P6����̂悤��
�s���ɂȂ��Ȃ����ȁB
intel��130W�o��������AAMD�����̂���130W���o��������B
����Ӗ��Aintel��AMD���ڂ��o�܂�����������Ȃ��ȁB
AMD��K7���o��������70W���炢�ɂȂ�悤�ɍ���Ă����̂��B
P6�̎��͔��M�Ƃ����Ă��āAnetburst���o�Ă��Ă���
�������D�ʂɂȂ����킯�����A
�܂�P6�n�̌�p��merom���o�Ă�����܂�P6����̂悤��
�s���ɂȂ��Ȃ����ȁB
intel��130W�o��������AAMD�����̂���130W���o��������B
����Ӗ��Aintel��AMD���ڂ��o�܂�����������Ȃ��ȁB
SocketM2��TDP����125W����Ȃ����������H
�ō��N���b�N�Ńf���A���R�A��FX�����邵�B
�ō��N���b�N�Ńf���A���R�A��FX�����邵�B
>>658
FX��XE�݂����Ȃ̂͂Ƃɂ������\�d��������A
����TDP�����Ă����Ȃ��Ǝv���B
�t�ɁA���y�тł���m�[�}����Athlon64 or X2�iintel�Ȃ�PentiumD or 4�j��TDP�͂�����x�ɉ��������܂Ȃ��ƍ���B
FX��XE�݂����Ȃ̂͂Ƃɂ������\�d��������A
����TDP�����Ă����Ȃ��Ǝv���B
�t�ɁA���y�тł���m�[�}����Athlon64 or X2�iintel�Ȃ�PentiumD or 4�j��TDP�͂�����x�ɉ��������܂Ȃ��ƍ���B
M2�̎d�l�͒m��Ȃ����Ǎ���939��TDP110W�Ƃ�������������
M2�Ȃ��Ă��ŏ���90nm�Ńf���A�����Ⴉ��TDP��
939�Ƃ������ĕς��Ȃ��v��
X2�R�A�����C���X�g���[���~��Ă���̂�65nm���ォ�炶��낤
65nm����Ȃ��X2�ł�TDP�͗}���Ă��邾�낤��
����X2���Vfab���\�蓹���������Đ��Y�L���p������̌��z����
�o�����Ǝv���A�\���葁�������������킯�����B
>657
K7�ŔM���M���ƕ��傢��ꂽ����K8�Ő�������Ă�
TDP�͂�������炸���Ⴏ��CnQ���ʏ�̃R�A�ł�
�C�l�[�u���Ȃ����̂͑傫���A�p���~�m�̍���
���o�C���n����Ȃ��Ɠ��l�̋@�\��off����Ă���
�̘b�Ȃ����ǃ��[�J�[�pOEM�i�Ȃ�M�n�̖��O���ĂȂ�
���ʂ�XP�Ȃ̂Ƀp���i�E���ڕi�Ƃ�������
����s��ɏo���ĂƎv��������orz
M2�Ȃ��Ă��ŏ���90nm�Ńf���A�����Ⴉ��TDP��
939�Ƃ������ĕς��Ȃ��v��
X2�R�A�����C���X�g���[���~��Ă���̂�65nm���ォ�炶��낤
65nm����Ȃ��X2�ł�TDP�͗}���Ă��邾�낤��
����X2���Vfab���\�蓹���������Đ��Y�L���p������̌��z����
�o�����Ǝv���A�\���葁�������������킯�����B
>657
K7�ŔM���M���ƕ��傢��ꂽ����K8�Ő�������Ă�
TDP�͂�������炸���Ⴏ��CnQ���ʏ�̃R�A�ł�
�C�l�[�u���Ȃ����̂͑傫���A�p���~�m�̍���
���o�C���n����Ȃ��Ɠ��l�̋@�\��off����Ă���
�̘b�Ȃ����ǃ��[�J�[�pOEM�i�Ȃ�M�n�̖��O���ĂȂ�
���ʂ�XP�Ȃ̂Ƀp���i�E���ڕi�Ƃ�������
����s��ɏo���ĂƎv��������orz
>>658
�\�P�b�g��TDP��CPU��TDP�͕ʂȂ�Ȃ��H
����ł��AFX��X2��ʂ͍���TDP�ɂ���Ă邯�ǁA�V���O���R�A�͕��ʂŁA
��������Ăǂ�����ڂ�����}�U�[�͍��������������Ȃ��Ⴂ���Ȃ��A�ƁB
�c���肫�������Ƃ��̂����ɏ����čς܂�
�\�P�b�g��TDP��CPU��TDP�͕ʂȂ�Ȃ��H
����ł��AFX��X2��ʂ͍���TDP�ɂ���Ă邯�ǁA�V���O���R�A�͕��ʂŁA
��������Ăǂ�����ڂ�����}�U�[�͍��������������Ȃ��Ⴂ���Ȃ��A�ƁB
�c���肫�������Ƃ��̂����ɏ����čς܂�
�\�P�b�g��TDP�͕�v��̓d�͋������E��ϔM���E�̎w��l�������
�܂肻��ȉ���OK�Őv���Ă�����Ď��A���ۂ̏�����M��CPU�ˑ�
�\�P�`��TDP80W
�\�P754��TDP80W
�\�P939�O����TDP80W
�\�P939�����TDP110W?
�\�PM�Q��TDP125W?
�܂肻��ȉ���OK�Őv���Ă�����Ď��A���ۂ̏�����M��CPU�ˑ�
�\�P�`��TDP80W
�\�P754��TDP80W
�\�P939�O����TDP80W
�\�P939�����TDP110W?
�\�PM�Q��TDP125W?
�ł����A110w�̐v����݂�30�`50w��CPU�g���Ă�Ƃ�����ƈ��S���������ˁB
���X�ɍ����J���Ă����������B
SuperPI-1M
�@�EYonah/2GHz: 30sec. http://img2.pcpop.com/ArticleImages/0x0/0/172/000172093.jpg
�@�EAthlon64/2.57GHz(OC): 32sec. http://bigsky.in.arena.ne.jp/myrecord/pi64-32.gif
SuperPI-1M
�@�EYonah/2GHz: 30sec. http://img2.pcpop.com/ArticleImages/0x0/0/172/000172093.jpg
{kind=link}
�@�EAthlon64/2.57GHz(OC): 32sec. http://bigsky.in.arena.ne.jp/myrecord/pi64-32.gif
{kind=link}
>>664
�ق�
�ōςނ͕̂��ʂ̐l�Ԃ��낤���A���̃X�����Ƃ����ς��ނꂻ�����Ȃ�
3000+��7455���[�U�[�����ǂ��ł�������
�������ނ�ꂻ��
�ق�
�ōςނ͕̂��ʂ̐l�Ԃ��낤���A���̃X�����Ƃ����ς��ނꂻ�����Ȃ�
3000+��7455���[�U�[�����ǂ��ł�������
�������ނ�ꂻ��
���ځ`�ǂ������܂������H��
{kind=link}
668 �FMAC�I�^���⑫�F2005/11/12(�y) 18:34:44 ID:yO0W/Gf5
������pcpop.com��1MB L2��Athlon64 FX-57�̌��ʂ����������B
http://www.pcpop.com/doc/0/98/98501_7.shtml
SuperPI-1M
�@�EYonah/2GHz: 30sec. http://img2.pcpop.com/ArticleImages/0x0/0/172/000172093.jpg
�@�EAthlon64/2.57GHz(OC): 32sec. http://bigsky.in.arena.ne.jp/myrecord/pi64-32.gif
�@�EAthlon64-FX/2.8GHz: 31sec. http://img2.pcpop.com/ArticleImages/0x0/0/86/000086924.jpg
http://www.pcpop.com/doc/0/98/98501_7.shtml
SuperPI-1M
�@�EYonah/2GHz: 30sec. http://img2.pcpop.com/ArticleImages/0x0/0/172/000172093.jpg
�@�EAthlon64/2.57GHz(OC): 32sec. http://bigsky.in.arena.ne.jp/myrecord/pi64-32.gif
�@�EAthlon64-FX/2.8GHz: 31sec. http://img2.pcpop.com/ArticleImages/0x0/0/86/000086924.jpg
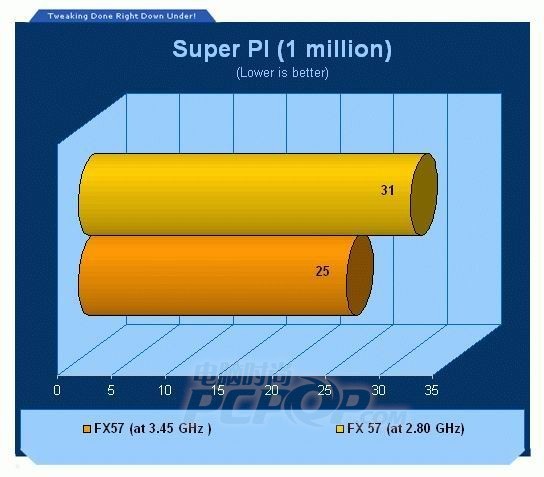{kind=link}
mac�I�^�K�����Ȃ�
�������A���̎����PenM�őg��ł݂悤���ȁB
�������A���̎����PenM�őg��ł݂悤���ȁB
Yonah�̏o�����悳�����Ȃ��Ƃ̓��f�^�C
AMD��Op���ł܂������]�T�͂��肻�������ǁA�f�X�N�g�b�v���ł�
���N�߂����\������Ƃ��������ł��ˁB
Yonah�o�邱���X2�����Ȃ�l�������邾�낤������ҁB
AMD��Op���ł܂������]�T�͂��肻�������ǁA�f�X�N�g�b�v���ł�
���N�߂����\������Ƃ��������ł��ˁB
Yonah�o�邱���X2�����Ȃ�l�������邾�낤������ҁB
�y�j�X������
���̎ʐ^�����\���āA�L���������Ȃ��悤�ɂ���ӂ�ɍ�ׂ�������B�ǁ[�ł��ǂ����B
���ƂŁA���̋L���Ŗʔ����̂͂������̊G�ˁB
ttp://www.pcpop.com/doc/App/ImageShow.aspx?category=article&sn=000172094
X2�̕��͊������邯�ǁA�������s���ɔ�r�I�傫����������ł�B
���ƂŁA���̋L���Ŗʔ����̂͂������̊G�ˁB
ttp://www.pcpop.com/doc/App/ImageShow.aspx?category=article&sn=000172094
X2�̕��͊������邯�ǁA�������s���ɔ�r�I�傫����������ł�B
673 �FMAC�I�^��672 �����F2005/11/12(�y) 21:39:15 ID:yO0W/Gf5
>>672
�@�@--------------------
�@�@�L���������Ȃ��悤�ɂ���ӂ�ɍ�ׂ�������
�@�@--------------------
�ʂɈӐ}�햳�����BX2�̓������s���̐��т�A�����Ō����邷�B
http://hirobee.jp/archives/2005/08/07/
�@�@====================
�@�@1M��1���s����ƁA35.578s
�@�@1M��2�������s����ƁA36.859s��36.797s
�@�@====================
�Ɨ�L2�Ƌ��LL2�̓������o�āA�ʔ������ʂ��Ǝv�����B
�@�@--------------------
�@�@�L���������Ȃ��悤�ɂ���ӂ�ɍ�ׂ�������
�@�@--------------------
�ʂɈӐ}�햳�����BX2�̓������s���̐��т�A�����Ō����邷�B
http://hirobee.jp/archives/2005/08/07/
�@�@====================
�@�@1M��1���s����ƁA35.578s
�@�@1M��2�������s����ƁA36.859s��36.797s
�@�@====================
�Ɨ�L2�Ƌ��LL2�̓������o�āA�ʔ������ʂ��Ǝv�����B
L2�L���b�V���̋��L���ăp�t�H�[�}���X������̂�
M2���ǂꂭ�炢�����邩���ˁc�B
�������A�����AMD�̒l����������҂ł��邩�H
�������A�����AMD�̒l����������҂ł��邩�H
>>675
��������Ȃ��āA�����A�v��2�N��������1M�������g���Ȃ�����B
2.13GHz�������Ƀ����[�X����邵���l�����ɂ�2.33GHz���o��B
64bit�Ή�����Ȃ��̂��ɂ��܂�邪�B
64bit��Merom/Conroe��4issue�̏��3GHz�߂��ɂ܂ŒB���邩��A
����肾�����_�C���N�g�ɋ����A�v���ȊO�ł́A�t�]�����҂ł���㩁B
��������Ȃ��āA�����A�v��2�N��������1M�������g���Ȃ�����B
2.13GHz�������Ƀ����[�X����邵���l�����ɂ�2.33GHz���o��B
64bit�Ή�����Ȃ��̂��ɂ��܂�邪�B
64bit��Merom/Conroe��4issue�̏��3GHz�߂��ɂ܂ŒB���邩��A
����肾�����_�C���N�g�ɋ����A�v���ȊO�ł́A�t�]�����҂ł���㩁B
>>678
X2�͂��Ƃ��ƃL���b�V�����L���ĂȂ�����V���O���X���b�h�̎���
�����Ɉ�̃R�A���g����L���b�V����1M�̂܂܂�����
Yonah�̓L���b�V�����L�^�Ō��X2M�Ȃ̂�1M�Ɍ�����Ă��Ƃł���
X2�͂��Ƃ��ƃL���b�V�����L���ĂȂ�����V���O���X���b�h�̎���
�����Ɉ�̃R�A���g����L���b�V����1M�̂܂܂�����
Yonah�̓L���b�V�����L�^�Ō��X2M�Ȃ̂�1M�Ɍ�����Ă��Ƃł���
X2�͂��Ƃ��ƃL���b�V�����L���ĂȂ�����V���O���X���b�h�̎���
�L���b�V���̔����͎d���T�{���Ă�B���������Ȃ��B
�L���b�V���̔����͎d���T�{���Ă�B���������Ȃ��B
���N�̂͂ǂ��������҂ł��������ˁB
�ǂ����̂������ȁ`��
�ǂ����̂������ȁ`��
��ӂł��̃X���b�h�ǂ��납����S�̂̋�C����ς�������(��)
683 �FSocket774�F2005/11/13(��) 13:01:28 ID:QwpzkGn2
DDR�Q/�R�Ή��`�l�c64�̐V�\�P�b�g�̂����炢
Socket S1�@�@ 638Pin�@���o�C���p(Turion64�AMobileAthlon64�AMobile Sempron)
Socket M2�@�@940Pin�@�f�X�N�b�v�p(Opteron1XX�AAthlon64X2�AAthlon64�ASempron)
http://www.expertspc.com/index.asp?Language=JP&DataId=192&Status=Reports
LGA1207�@1207Pin�@�T�[�o�p(Opteron2XX/8XX)
http://72.14.203.104/search?q=cache:1C2WQv0rnhkJ:www.beginnerspc.com/+LGA1207&hl=ja&client=firefox-a
Socket S1�@�@ 638Pin�@���o�C���p(Turion64�AMobileAthlon64�AMobile Sempron)
Socket M2�@�@940Pin�@�f�X�N�b�v�p(Opteron1XX�AAthlon64X2�AAthlon64�ASempron)
http://www.expertspc.com/index.asp?Language=JP&DataId=192&Status=Reports
LGA1207�@1207Pin�@�T�[�o�p(Opteron2XX/8XX)
http://72.14.203.104/search?q=cache:1C2WQv0rnhkJ:www.beginnerspc.com/+LGA1207&hl=ja&client=firefox-a
>>677
2.33G�o��̂͑�O�l��������
2.33G�o��̂͑�O�l��������
�ǂ�����ς��Ă�
Yonah�̓��o�C����������
Yonah�̓��o�C����������
�@�܂��AAMD���[�U�[�͖����ɂƂ��ꂸ�ǂ����̂�I�Ԃ���
AMD���g���Ă���낤����A���ۂɂ��̂��o�āA���i���܂߂�
�����I�Ɍ��ėǂ����̂ł���A���ʂɎg���Ǝv����B
AMD���g���Ă���낤����A���ۂɂ��̂��o�āA���i���܂߂�
�����I�Ɍ��ėǂ����̂ł���A���ʂɎg���Ǝv����B
���ł�PenM�őg�������ȁ[�Ǝv�������Ƃ͂������������̂ƑI�����Ȃ����ł�߂�
Yonah���f�X�N�g�b�v�ɂ͗��Ȃ���[�����A�܂����F���o����l���܂���
�����̎���@�̘b�͂Ƃ������B
AMD�Ƃ��Ă�65mm�ڍs�����N���ɏ����ɐi�ނ��ǂ������Ȃ�
���ƎI�ł�Pacifica���ǂꂭ�炢�œ����ł��邩���d�v�ɂȂ肻��
Yonah���f�X�N�g�b�v�ɂ͗��Ȃ���[�����A�܂����F���o����l���܂���
�����̎���@�̘b�͂Ƃ������B
AMD�Ƃ��Ă�65mm�ڍs�����N���ɏ����ɐi�ނ��ǂ������Ȃ�
���ƎI�ł�Pacifica���ǂꂭ�炢�œ����ł��邩���d�v�ɂȂ肻��
688 �FSocket774�F2005/11/13(��) 17:35:10 ID:aDX/4g18
65nm�͂�����AMD��2007�N��1���l������������ˁB
�N�A�b�h�R�A��2007�N��1�l���������
65nm��2006�N��
65nm��2006�N��
Yonah ��SuperPI 104�����@�Řb������オ���Ă���l�q�����B
SuperPI���Ă悭�킩��Ȃ����A�����w����Ă��Ƃ̓o�^�t���C���Z���Ȃɂ����Ă��Ƃ���H
�w�v���O�������������A�������f�͏��Ȃ��x
�w�����f�[�^�ʂ͑����x
�w�����u�͕����I�Q�ƁA�������Z�x
�f�[�^�ʂ́A104��������APenM L2 �ɂS���̂P�͓������Ⴄ���A
�������f�����Ȃ���A�Z���p�C�v���C���̂ق����L�������B
�����̑���SuperPI��A�v���O�����������ł������A�������f���������A
�L���b�V���~�X�q�b�g���Ȃǂ̃x���`�}�[�N���������Ȃ��B
��AI/O�A�N�Z�X���\���B
SuperPI���Ă悭�킩��Ȃ����A�����w����Ă��Ƃ̓o�^�t���C���Z���Ȃɂ����Ă��Ƃ���H
�w�v���O�������������A�������f�͏��Ȃ��x
�w�����f�[�^�ʂ͑����x
�w�����u�͕����I�Q�ƁA�������Z�x
�f�[�^�ʂ́A104��������APenM L2 �ɂS���̂P�͓������Ⴄ���A
�������f�����Ȃ���A�Z���p�C�v���C���̂ق����L�������B
�����̑���SuperPI��A�v���O�����������ł������A�������f���������A
�L���b�V���~�X�q�b�g���Ȃǂ̃x���`�}�[�N���������Ȃ��B
��AI/O�A�N�Z�X���\���B
692 �FMAC�I�^��690 �����F2005/11/13(��) 18:14:16 ID:g7MCVu1u
>>690
�����������������F�߂��Ȃ��ăg���f�����_��U�肩�����q�g�����ꂽ�݂�������(��)
�@�@--------------------
�@�@�������f�����Ȃ���A�Z���p�C�v���C���̂ق����L�������B
�@�@--------------------
�������f�����Ȃ��قǁA����\�����s�̍ۂɃp�C�v���C���߂Ȃ������C�e���V���������Ȃ邷����A
�����p�C�v���C�����L�����B
�����������������F�߂��Ȃ��ăg���f�����_��U�肩�����q�g�����ꂽ�݂�������(��)
�@�@--------------------
�@�@�������f�����Ȃ���A�Z���p�C�v���C���̂ق����L�������B
�@�@--------------------
�������f�����Ȃ��قǁA����\�����s�̍ۂɃp�C�v���C���߂Ȃ������C�e���V���������Ȃ邷����A
�����p�C�v���C�����L�����B
�����p�C�v���C���̒Z�������L��
�L���Ȃ͓̂�����O���Ƃ��A�������Ȃ��瓯�����Z�����s��v���ʎ̂ĂƂ��A
���ߐ�ǂ݉�H... ��H�����ɂ��p�C�v���C����... �Ƃ����H�v�����Ă����킯�Ł@
Yonah �̃o�����X�͂ǂ����ȁH�@hammer�͂���Ȃ�ɂ悩�����B
�Ƃ��������B�i���͗͂˂��`�B���߂�j
�L���Ȃ͓̂�����O���Ƃ��A�������Ȃ��瓯�����Z�����s��v���ʎ̂ĂƂ��A
���ߐ�ǂ݉�H... ��H�����ɂ��p�C�v���C����... �Ƃ����H�v�����Ă����킯�Ł@
Yonah �̃o�����X�͂ǂ����ȁH�@hammer�͂���Ȃ�ɂ悩�����B
�Ƃ��������B�i���͗͂˂��`�B���߂�j
694 �FMAC�I�^���⑫�F2005/11/13(��) 18:18:01 ID:g7MCVu1u
���ꂩ��pcpop.com�����肵���}�V����m�[�g�Ȃ��ǁA�m�[�gPC��I/O���\�ŕ�����f�X�N�g�b�v���Ă̂�
����Ƃ��v���Ȃ����B
����Ƃ��v���Ȃ����B
695 �FMAC�I�^��693 �����F2005/11/13(��) 18:21:23 ID:g7MCVu1u
>>693
�F�߂����Ȃ������Ȃ̂�������Ȃ������ǁA�������Ė��������H
�@�@----------------------
�@�@�w�v���O�������������A�������f�͏��Ȃ��x �@(>>690)
�@�@----------------------
�@�@----------------------
�@�@�����p�C�v���C���̒Z�������L��
�@�@�L���Ȃ͓̂�����O���Ƃ��A�@�@�@�@�@�@�@�@�@�@(>>693)
�@�@----------------------
�F�߂����Ȃ������Ȃ̂�������Ȃ������ǁA�������Ė��������H
�@�@----------------------
�@�@�w�v���O�������������A�������f�͏��Ȃ��x �@(>>690)
�@�@----------------------
�@�@----------------------
�@�@�����p�C�v���C���̒Z�������L��
�@�@�L���Ȃ͓̂�����O���Ƃ��A�@�@�@�@�@�@�@�@�@�@(>>693)
�@�@----------------------
>>697
Yonah�̐��т₻�̃A�[�L�e�N�`��������
AMD�����ׂ���⏫���Ɋ��҂�����̂�_����Ȃ�킩�邪
�P��Yonah���a�ɂ����l�i�U���ł͉��̐i�W���Ȃ�����H
Yonah�̐��т₻�̃A�[�L�e�N�`��������
AMD�����ׂ���⏫���Ɋ��҂�����̂�_����Ȃ�킩�邪
�P��Yonah���a�ɂ����l�i�U���ł͉��̐i�W���Ȃ�����H
���Ȃ��Mac�I�^�������ɂ���́H�@���߁APowerPC�ȍ~��Mac�I�^����H
�eCPU���[�J�[�́A�p�C�v���C�����̓N���b�N���グ�邽�߂Ɂw�������Ȃ��x
�s���Ă���.... �Ƃ������Ƃ�O��ɘb���Ă�����肾�������ǁB
�i���߂�A���͗͂Ȃ��āj
�eCPU���[�J�[�́A�p�C�v���C�����̓N���b�N���グ�邽�߂Ɂw�������Ȃ��x
�s���Ă���.... �Ƃ������Ƃ�O��ɘb���Ă�����肾�������ǁB
�i���߂�A���͗͂Ȃ��āj
700 �FMAC�I�^��699 �����F2005/11/13(��) 19:14:45 ID:g7MCVu1u
>>699
�@�@-----------------
�@�@�p�C�v���C�����̓N���b�N���グ�邽�߂Ɂw�������Ȃ��x �s���Ă���....
�@�@-----------------
���ꂪ�A�g���f�����_���B�p�C�v���C��������A���ԕ����̕��ƍl���邱�Ƃ��ł��邷�B
�����I�ȉ��Z�������������邽�߂ɍ̗p���ꂽ�Z�p���B
�@�@-----------------
�@�@�p�C�v���C�����̓N���b�N���グ�邽�߂Ɂw�������Ȃ��x �s���Ă���....
�@�@-----------------
���ꂪ�A�g���f�����_���B�p�C�v���C��������A���ԕ����̕��ƍl���邱�Ƃ��ł��邷�B
�����I�ȉ��Z�������������邽�߂ɍ̗p���ꂽ�Z�p���B
http://pc.watch.impress.co.jp/docs/article/20000218/kaigai01.htm
���p�C�v���C���́A�ו������������ق�1�i�̃Q�[�g�������邽�߁A�����I�ɍ��N���b�N�����e�ՂɂȂ�B
���p�C�v���C���́A�ו������������ق�1�i�̃Q�[�g�������邽�߁A�����I�ɍ��N���b�N�����e�ՂɂȂ�B
�X���ɍ��킹�āA���[�h�}�b�v
Athlon 64 FX-62 Windsor M2 Q2'06
Athlon 64 X2 5200+ Windsor M2 Q4'06
Athlon 64 X2 5000+ Windsor M2 Q2'06
Athlon 64 X2 4800+ Windsor M2 Q2'06
Athlon 64 X2 4600+ Windsor M2 Q2'06
Athlon 64 X2 4200+ Windsor M2 Q2'06
Athlon 64 4000+ Orleans M2 Q2'06
Athlon 64 3800+ Orleans M2 Q2'06
Athlon 64 3500+ Orleans M2 Q2'06
Sempron 3800+ Manila M2 Q3'06
Sempron 3600+ Manila M2 Q2'06
Sempron 3500+ Manila M2 Q2'06
Sempron 3400+ Manila M2 Q2'06
Sempron 3200+ Manila M2 Q2'06
Sempron 3000+ Manila M2 Q2'06
>>700
��{�I�ɂ�R3000�݂���IF RF EX MEN WB
��5�p�C�v�ōςނ��Č���������H
Athlon 64 FX-62 Windsor M2 Q2'06
Athlon 64 X2 5200+ Windsor M2 Q4'06
Athlon 64 X2 5000+ Windsor M2 Q2'06
Athlon 64 X2 4800+ Windsor M2 Q2'06
Athlon 64 X2 4600+ Windsor M2 Q2'06
Athlon 64 X2 4200+ Windsor M2 Q2'06
Athlon 64 4000+ Orleans M2 Q2'06
Athlon 64 3800+ Orleans M2 Q2'06
Athlon 64 3500+ Orleans M2 Q2'06
Sempron 3800+ Manila M2 Q3'06
Sempron 3600+ Manila M2 Q2'06
Sempron 3500+ Manila M2 Q2'06
Sempron 3400+ Manila M2 Q2'06
Sempron 3200+ Manila M2 Q2'06
Sempron 3000+ Manila M2 Q2'06
>>700
��{�I�ɂ�R3000�݂���IF RF EX MEN WB
��5�p�C�v�ōςނ��Č���������H
�܂������p�C�v���C���������Ȃ��A�[�L�e�N�`������1�N���b�N������̖��ߎ��s�ʂ͒Ⴍ�Ȃ��B
�n�C�p�[�p�C�v���C�����Ɍ��肷��Θ_�|�͐������B
�n�C�p�[�p�C�v���C�����Ɍ��肷��Θ_�|�͐������B
704 �FMAC�I�^������F2005/11/13(��) 19:30:40 ID:9qUcrFJZ
���̖��O�Ō������Ȃ��l�ɂ͑��v����
694�œ��肵���}�V�����m�[�g���Č������ƂȂ�ł����A���t�@�����X�{�[�h�łȂ����ۂ�
�m�[�g��➑̂ɓ���Ƃ���܂Ŋ����x���������Ă���̂Ȃ炷�����Ǝv���܂��B�ŁA
pcpop.com�łǂ�ȃm�[�g���ʐ^��T������ł���������܂���ł����B�ǂ�ȃX
�y�b�N�Ȃ�ł��傤�H
���ƁACPU-Z��Bus Speed��1329.5MHz���ĂȂ��Ă��ł����A�\��ł�666MHz����
�Ȃ������ł��������H�����{�œ��삵�Ă�̂Ȃ�`�b�v�Z�b�g��RAM���ɂ��炵��OC
���\���Ǝv���̂ł����A���̕\����CPU-Z���܂����Ή��Ƃ������������ƂȂ�ł��傤���H
694�œ��肵���}�V�����m�[�g���Č������ƂȂ�ł����A���t�@�����X�{�[�h�łȂ����ۂ�
�m�[�g��➑̂ɓ���Ƃ���܂Ŋ����x���������Ă���̂Ȃ炷�����Ǝv���܂��B�ŁA
pcpop.com�łǂ�ȃm�[�g���ʐ^��T������ł���������܂���ł����B�ǂ�ȃX
�y�b�N�Ȃ�ł��傤�H
���ƁACPU-Z��Bus Speed��1329.5MHz���ĂȂ��Ă��ł����A�\��ł�666MHz����
�Ȃ������ł��������H�����{�œ��삵�Ă�̂Ȃ�`�b�v�Z�b�g��RAM���ɂ��炵��OC
���\���Ǝv���̂ł����A���̕\����CPU-Z���܂����Ή��Ƃ������������ƂȂ�ł��傤���H
705 �FMAC�I�^��701 �����F2005/11/13(��) 19:33:46 ID:g7MCVu1u
>>701
1�i�̃Q�[�g��������Ƃ������Ƃ�A1�i�ʼn\�Ș_�����Z�̐�������Ƃ������Ƃ����ǁH
�X�ɃX�e�[�W�Ԃɒl��ێ����郉�b�`��H���K�v�ɂȂ邽�߁A�����S�̂ɕK�v�Ȏ��Ԃ�A��������
�����Ȃ邷�B
�p�C�v���C���������s�킸�ɁA�p�C�v���C���݂̂��ו�������Ӗ��햳�����B
1�i�̃Q�[�g��������Ƃ������Ƃ�A1�i�ʼn\�Ș_�����Z�̐�������Ƃ������Ƃ����ǁH
�X�ɃX�e�[�W�Ԃɒl��ێ����郉�b�`��H���K�v�ɂȂ邽�߁A�����S�̂ɕK�v�Ȏ��Ԃ�A��������
�����Ȃ邷�B
�p�C�v���C���������s�킸�ɁA�p�C�v���C���݂̂��ו�������Ӗ��햳�����B
������ۂ��BL2�̃��C�e���V��Dothan��茸���Ă�iIntel�̒��̐l�k�j���Ȃ̂ɂ��̎��˃x���`�̌��ʂł�
15�N���b�N���Ƃ��\������Ă����A�ǂ������\�������������\���͂���B
�T���v���Ƃ��Ă�PI�̃x���`�̂�̂ق����V������Ŗ����́B
15�N���b�N���Ƃ��\������Ă����A�ǂ������\�������������\���͂���B
�T���v���Ƃ��Ă�PI�̃x���`�̂�̂ق����V������Ŗ����́B
707 �FMAC�I�^��704 �����F2005/11/13(��) 19:41:09 ID:g7MCVu1u
>>704
���N���X�ɔ����Ȃ�A�������Ɏ���i�������Ă��s�v�c�햳�����B
�@�@-------------------
�@�@�ǂ�ȃX�y�b�N�Ȃ�ł��傤�H
�@�@-------------------
���Y�L����A���������^�C�g���Ȃ��ǁB�B�B�u�o�jPentium M�AGeforce Go 7400??�v
("Dual core Pentium M with Geforce Go 7400 Benchmark")
Geforce Go 7400���ڂ̃f�X�N�g�b�v�̃}�U�[�{�[�h���Ă��邷���H
CPU-Z�ɂ��Ă�A���Ή��ȂƎv���邷�B
���N���X�ɔ����Ȃ�A�������Ɏ���i�������Ă��s�v�c�햳�����B
�@�@-------------------
�@�@�ǂ�ȃX�y�b�N�Ȃ�ł��傤�H
�@�@-------------------
���Y�L����A���������^�C�g���Ȃ��ǁB�B�B�u�o�jPentium M�AGeforce Go 7400??�v
("Dual core Pentium M with Geforce Go 7400 Benchmark")
Geforce Go 7400���ڂ̃f�X�N�g�b�v�̃}�U�[�{�[�h���Ă��邷���H
CPU-Z�ɂ��Ă�A���Ή��ȂƎv���邷�B
>>705
NetBurst�Ɋւ��ẮA�������������S�̂ɕK�v�Ȏ��Ԃ╪��\���~�X�Ȃǂ̊e��f�����b�g��
�p�C�v���C���̍ו����ɂ��\�ɂȂ����N���b�N����ŕ₨���Ƃ����悤�ɋL�����Ă�̂ł����B
NetBurst�Ɋւ��ẮA�������������S�̂ɕK�v�Ȏ��Ԃ╪��\���~�X�Ȃǂ̊e��f�����b�g��
�p�C�v���C���̍ו����ɂ��\�ɂȂ����N���b�N����ŕ₨���Ƃ����悤�ɋL�����Ă�̂ł����B
709 �FMAC�I�^������F2005/11/13(��) 19:58:07 ID:9pWK2vEG
>>707
���ƁA�^�C�g���ɂ��Ă͂�����ł����Ă��܂����B�ŁA���ۂɐڑ�����Ă���
HDD�A�������A�����ă������C���^�[�t�F�C�X���ǂ�Ȃ��̂��Ƃ������̂��킩
��Ȃ��Ǝv�����킯�Ȃ̂ł��B
�ŁA���ۂ̂Ƃ���Bus Speed�E���������x���ǂ��Ȃ̂��Ȃ��ƁB�������ǂ�����
���\�ȃX�s�[�h�ŏo�����悳�����Ȃ��Ƃ͊�������ł��B
Athlon64X2�g���Ă�g�Ƃ��ẮA���Ƃ�EM64�ɂ��͂₭�Ή����Ăق����Ƃ���B
���ƁA�^�C�g���ɂ��Ă͂�����ł����Ă��܂����B�ŁA���ۂɐڑ�����Ă���
HDD�A�������A�����ă������C���^�[�t�F�C�X���ǂ�Ȃ��̂��Ƃ������̂��킩
��Ȃ��Ǝv�����킯�Ȃ̂ł��B
�ŁA���ۂ̂Ƃ���Bus Speed�E���������x���ǂ��Ȃ̂��Ȃ��ƁB�������ǂ�����
���\�ȃX�s�[�h�ŏo�����悳�����Ȃ��Ƃ͊�������ł��B
Athlon64X2�g���Ă�g�Ƃ��ẮA���Ƃ�EM64�ɂ��͂₭�Ή����Ăق����Ƃ���B
758 �F���������� [sage] �F2005/11/13(��) 11:00:11
SuperPI�͗v�����FFT�x���`���낤����AFPU�ƃ������E�L���b�V�������̂������͂��B
�^�X�N�}�l�[�W���Ō���ƁA100�����ł�8MB���g���悤���B
�{���A���{�����l�̌v�Z��FFT���g���Ă������_���A�N�Z�X�͉���ł���̂����A
K6�Ń��C�g�A���P�[�g���I���ɂ���ƒx���Ȃ�������SuperPI�̓����_�����C�g�������
�ǂ����œǂ��Ƃ�����B
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt006.htm
�����������B�\���Ƃ��Ă͂���Ǝv���B
���C�g�A���P�[�g���I�t���ƁAL1�q�b�g���Ȃ��������݂̂Ƃ��ɒ���L2���������ɏ����B
L2�ɑ���movntq�݂����Ȋ����B
L2��L1�̗]�v�ȃ��[�h���Ȃ��̂ōė��p���Ȃ������_�����C�g�ɂ͋����B
���ʂ̃��C�g�o�b�N���Ȃ烉�C�g�A���P�[�g���I������ȁH
FFT�̏����́A>>186�ŏ������}�[�W�\�[�g�݂����ȗ���ōs���i�������A�N�Z�X�Ɋւ��Ắj�B
�ċA�ŋǏ��I�ɏ�������ƃL���b�V���T�C�Y����r�I���j�A�Ɍ����B
�����łȂ��Ƃ��͈��ʈȉ��̃L���b�V���͂قƂ�nj����Ȃ��B
����͂������ɍċA��FFT���낤�B
Pen4���ƁAFPU�̃��C�e���V�������̂�L1�L���b�V�������������ƂŒx���Ȃ邾�낤�B
Athlon�́AL1�ƃ������Ɠ���FPU���ǂ��BL2���r���ł����Ȃ����PenM��肸���Ƒ����Ǝv���B
PenM�́A�����̑�����������L2�ōs���邽�ߑ����B���̑��̃p���[�͕��ʁB
�]�k�����AYonah�AMerom�ƁAK8�ɂƂ��ċ��ЂƂȂ�CPU���o�Ă���Ƃ��A
K8�̍Ō�̐�D��L2�L���b�V�����Ǝv���B�r��������߂Ă���B
������߂Ȃ����R������̂��낤���H
SuperPI�͗v�����FFT�x���`���낤����AFPU�ƃ������E�L���b�V�������̂������͂��B
�^�X�N�}�l�[�W���Ō���ƁA100�����ł�8MB���g���悤���B
�{���A���{�����l�̌v�Z��FFT���g���Ă������_���A�N�Z�X�͉���ł���̂����A
K6�Ń��C�g�A���P�[�g���I���ɂ���ƒx���Ȃ�������SuperPI�̓����_�����C�g�������
�ǂ����œǂ��Ƃ�����B
http://www.geocities.co.jp/SiliconValley-Bay/9439/negoto/ngt006.htm
�����������B�\���Ƃ��Ă͂���Ǝv���B
���C�g�A���P�[�g���I�t���ƁAL1�q�b�g���Ȃ��������݂̂Ƃ��ɒ���L2���������ɏ����B
L2�ɑ���movntq�݂����Ȋ����B
L2��L1�̗]�v�ȃ��[�h���Ȃ��̂ōė��p���Ȃ������_�����C�g�ɂ͋����B
���ʂ̃��C�g�o�b�N���Ȃ烉�C�g�A���P�[�g���I������ȁH
FFT�̏����́A>>186�ŏ������}�[�W�\�[�g�݂����ȗ���ōs���i�������A�N�Z�X�Ɋւ��Ắj�B
�ċA�ŋǏ��I�ɏ�������ƃL���b�V���T�C�Y����r�I���j�A�Ɍ����B
�����łȂ��Ƃ��͈��ʈȉ��̃L���b�V���͂قƂ�nj����Ȃ��B
����͂������ɍċA��FFT���낤�B
Pen4���ƁAFPU�̃��C�e���V�������̂�L1�L���b�V�������������ƂŒx���Ȃ邾�낤�B
Athlon�́AL1�ƃ������Ɠ���FPU���ǂ��BL2���r���ł����Ȃ����PenM��肸���Ƒ����Ǝv���B
PenM�́A�����̑�����������L2�ōs���邽�ߑ����B���̑��̃p���[�͕��ʁB
�]�k�����AYonah�AMerom�ƁAK8�ɂƂ��ċ��ЂƂȂ�CPU���o�Ă���Ƃ��A
K8�̍Ō�̐�D��L2�L���b�V�����Ǝv���B�r��������߂Ă���B
������߂Ȃ����R������̂��낤���H
2007�N�\���
1-Socket, Mobile��Large, Shared Cache�ɓ����\��
1-Socket, Mobile��Large, Shared Cache�ɓ����\��
�ĂH
�@�@�@�@�@�@�@�@�@�@,,�\�]�D�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ r-�A�@�@�@�@�Q,--,�A
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
�@�@�@�@�@�@�@�@�@�@,,�\�]�D�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ r-�A�@�@�@�@�Q,--,�A
�@�@�@�@�@,�\-�A�@.| ./''i����@�@r-,,,,,,,,,,,,,,,,,,,,,,,,�\��D�@�@�@ �l, �M"����ށP�O�@�@�@�_
�@�@�@ �^�@�@�@�_ �R,�'�_,/�@�@ .�l�A�@�@�@�@�@�@�@�@�@`i��@�@�@�_ _,,�\�'''/�@�@.,��'"
.,,,�A.,,i�L�@.,/�O'i��@�M'i��M�M�@�@�@�@ �M--�]'''''''''''''''"'''''''''''ށ@�@�@�@ �M�J�@�@ .���@ .,/
�o ""�@ ,/�M�@�@�R�A �M'i��@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ���@ .,/�M
.�R�A�@���@�@�@�@�_�@ .�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ,/�� �A�R,,�A
�@ �'�'"�@�@�@�@�@�@�'i��@ �ei�.r-�A�@�@�@�@�@ �Q_,,,,,,,,--�A�@�@�@�@ �^�@.,�^�_�@`'-,�A
�@�@�@�@�@�@�@�@�@�@�@�R�@�@.]�l �M����"���ށP�P�@�@�@�@�@�M'i��@�@,�^ .,,�^�@�@ .�R�@�@�_
�@�@�@�@�@�@�@�@�@�@�@�@ށR_/ .�R_.,,,,--�\�\�\�\�\�-�m_,�^�,,�^���@�@�@�@ �l�@�@ ,"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �M�@�@�@�@�@�@�@�@�@�@�@�@ ށ]''"�M�@�@�@�@�@�@�@�@�'�'"
�@���ʂɎg�����ɂ͔r���̃f�����b�g�͕\�ʉ����Ȃ��A���邢�̓����b�g�̂ق���
�傫�����炩��A���낤�ˁB�t���I�ȋ@�\������邾���Ȃ炽�₷���͂��ŁA
AMD�����������x���ł��̒��x�̎��݂����Ă��Ȃ��ƍl����ق������������B
�@�ʂ�CPU�̓x���`�̂��߂̂��̂���Ȃ��B����̃x���`�ł��܂��܃f�����b�g��
�\�ʉ����邩��Ƃ����āA��̂Ă闝�R�ɂ͂Ȃ�Ȃ���B
�傫�����炩��A���낤�ˁB�t���I�ȋ@�\������邾���Ȃ炽�₷���͂��ŁA
AMD�����������x���ł��̒��x�̎��݂����Ă��Ȃ��ƍl����ق������������B
�@�ʂ�CPU�̓x���`�̂��߂̂��̂���Ȃ��B����̃x���`�ł��܂��܃f�����b�g��
�\�ʉ����邩��Ƃ����āA��̂Ă闝�R�ɂ͂Ȃ�Ȃ���B
713����Əd�Ȃ邯��ǁA�r���̕������܂ł̃v���O���������悭���삷�����
��������Ȃ��ł��傤���B�V���Ƀv���Z�b�T�̓������l���Ȃ��珑������r������
�Ȃ��ق����l�߂�ꂻ���ł��ˁB
���Ɩϑz�����SUMO�̃X�e�[�g�̖��Ŕr���łȂ��ƍ��������ƂɂȂ�Ƃ��B
���̏�ԕ\����L1��L2�ňႤ��Ԃɂ���̂͂܂��������Ȃ����āB����Ȃ��Ƃ�
����������Ȃ����ǁB
��������Ȃ��ł��傤���B�V���Ƀv���Z�b�T�̓������l���Ȃ��珑������r������
�Ȃ��ق����l�߂�ꂻ���ł��ˁB
���Ɩϑz�����SUMO�̃X�e�[�g�̖��Ŕr���łȂ��ƍ��������ƂɂȂ�Ƃ��B
���̏�ԕ\����L1��L2�ňႤ��Ԃɂ���̂͂܂��������Ȃ����āB����Ȃ��Ƃ�
����������Ȃ����ǁB
�ꉞ�m�F���悤�Ǝv����SUMO�̏�ԕ\������������ł����A�ς��ƌ�����܂���ł����B
AMD�̎����̂ǂ����Ō����悤�Ȋo��������̂�����ǁE�E�E�E
AMD�̎����̂ǂ����Ō����悤�Ȋo��������̂�����ǁE�E�E�E
�������ΏĂ����Ă̂͑S���E�Ŏg���Ă�ȁB
�Ȃ�ƂȂ��������B
�Ȃ�ƂȂ��������B
717 �FMAC�I�^��714 �����F2005/11/13(��) 21:36:03 ID:g7MCVu1u
>>715
SUMO (Sufficiently uniform memory organization)���Ă̂�AAMD�p���NUMA�̂��Ƃ��B
�L���b�V���̃X�e�[�g�̕���MOESI (Modified Owner, Exclusive, Shared, Ivalid)���B
SUMO (Sufficiently uniform memory organization)���Ă̂�AAMD�p���NUMA�̂��Ƃ��B
�L���b�V���̃X�e�[�g�̕���MOESI (Modified Owner, Exclusive, Shared, Ivalid)���B
�v�҂̍l�����̈Ⴂ���Ǝv����B�ŗǂ̏������ōō��̃p�t�H�[�}���X�邩�A
�ň��̏������ōň��̃p�t�H�[�}���X�ɂȂ�Ȃ��悤�ɂ��邩�B
�ܘ_�r�����ᖳ�������v���O�����̏����\�͂͏オ��B�ł��APC��ł�I/O�̑҂�
��ASWAP�A���߁A�}���`�^�X�N�A���A�F�X�ȏ�����L2�Ƀq�b�g�����Ƀ������A
�}���`CPU�Ȃ瑼��CPU��L2�A�ň�HDD��O���l�b�g���[�N�̃f�[�^�܂ő҂��Ȃ�
���Ⴂ���Ȃ��ꍇ���o�Ă���B���̎���Intel���悭�������Ă邩��I�p�ɂ͂킴
�킴�x��L3�ς�����Ă�B
���������ꍇ�A�����ł�L2�����������������̃��C�e���V���B���o���ď�����
�X���[�Y�ɍs���BWeb�I��DB�I�Ȃ��Ɠ��ɏd�v�ȃt�@�N�^�[�ɂȂ��Ă��邾
�낤�B������킴�킴�x���Ȃ邵�]�v�ȏ���������̂ɔr���L���b�V���ɂ��Ă�
��Ȃ����ȁH
����ƈ�Ԃ̗v���͂���ϐ����L���p�̈Ⴂ���낤�ˁB�ܘ_AMD�����Ĕr���~�߂�
L2�h�J�b�Ɛς������\�オ��̂͗������Ă�Ǝv���B��ł��A���̌���ł�
����͖������Ǝv���B�����班���ł��L���Ɏg����悤�ɔr���L���b�V���ɂ��Ă�
��Ȃ����ȁH
�ň��̏������ōň��̃p�t�H�[�}���X�ɂȂ�Ȃ��悤�ɂ��邩�B
�ܘ_�r�����ᖳ�������v���O�����̏����\�͂͏オ��B�ł��APC��ł�I/O�̑҂�
��ASWAP�A���߁A�}���`�^�X�N�A���A�F�X�ȏ�����L2�Ƀq�b�g�����Ƀ������A
�}���`CPU�Ȃ瑼��CPU��L2�A�ň�HDD��O���l�b�g���[�N�̃f�[�^�܂ő҂��Ȃ�
���Ⴂ���Ȃ��ꍇ���o�Ă���B���̎���Intel���悭�������Ă邩��I�p�ɂ͂킴
�킴�x��L3�ς�����Ă�B
���������ꍇ�A�����ł�L2�����������������̃��C�e���V���B���o���ď�����
�X���[�Y�ɍs���BWeb�I��DB�I�Ȃ��Ɠ��ɏd�v�ȃt�@�N�^�[�ɂȂ��Ă��邾
�낤�B������킴�킴�x���Ȃ邵�]�v�ȏ���������̂ɔr���L���b�V���ɂ��Ă�
��Ȃ����ȁH
����ƈ�Ԃ̗v���͂���ϐ����L���p�̈Ⴂ���낤�ˁB�ܘ_AMD�����Ĕr���~�߂�
L2�h�J�b�Ɛς������\�オ��̂͗������Ă�Ǝv���B��ł��A���̌���ł�
����͖������Ǝv���B�����班���ł��L���Ɏg����悤�ɔr���L���b�V���ɂ��Ă�
��Ȃ����ȁH
���[���̈ӌ��Y��Ă��B
����CPU����BIOS�Ŕr���L���b�V�����悤�ɂ��Ƃ��Ă���IAMD����w
����CPU����BIOS�Ŕr���L���b�V�����悤�ɂ��Ƃ��Ă���IAMD����w
721 �FMAC�I�^�����/714�F2005/11/13(��) 21:53:30 ID:zs+m+yTe
���w�E�̒ʂ�MOESI�̕��ł����B
�I�m�ȓ˂����݇d�N�X
�I�m�ȓ˂����݇d�N�X
>>720
AMD�ސ��̃R�[�h�A�i���C�U�g���ǂ̒��x�����������Ă邩����Ǝv����B
AMD�ސ��̃R�[�h�A�i���C�U�g���ǂ̒��x�����������Ă邩����Ǝv����B
>>717
"Modified Owner Exclusive Shared Invalid"����Ȃ��̂�
"Modified Owner Exclusive Shared Invalid"����Ȃ��̂�
>>722
�L���b�V���������ق��������͓̂���O�ł͂Ȃ����B
�����x���`�}�[�N��L���b�V������ʓI�ł͖������炢�ɑ�ʂɏ���
���邲�������̃A�v�������̂��߂ɕs�K�v�ɃL���b�V���𑝂₷�킯�Ȃ�����B
AMD�͌����ƃR�X�g�����l���ɓ���Ĕr���L���b�V����I�����Ă�낤�B
�L���b�V���������ق��������͓̂���O�ł͂Ȃ����B
�����x���`�}�[�N��L���b�V������ʓI�ł͖������炢�ɑ�ʂɏ���
���邲�������̃A�v�������̂��߂ɕs�K�v�ɃL���b�V���𑝂₷�킯�Ȃ�����B
AMD�͌����ƃR�X�g�����l���ɓ���Ĕr���L���b�V����I�����Ă�낤�B
>>724
720�ł������������肾���E�E�E
720�ł������������肾���E�E�E
L1�L���b�V���~�X���̋������ȒP�ɂ܂Ƃ߂�ƁA
�yInclusive�L���b�V���iL1���C�g�o�b�N�j�̏ꍇ�z�@����T��CPU�����̕���
�P�DL1���烊�^�C���Ώۂ̃L���b�V�����C����L2�ɏ�������
�Q�D2����L1�Ƀ��[�h
�yInclusive�L���b�V���iL1���C�g�X���[�j�̏ꍇ�z�@��NetBurst�APPC G5�����̕���
�P�DL2����L1�Ƀ��[�h
�i�X�g�A���ߔ��s����L1�ւ̏��������ʂ�L2�ɂ������ɔ��f�����̂�
���߂ă��^�C������L���b�V�����C����`���߂��K�v�Ȃ��B�j
�yExclusive�L���b�V���̏ꍇ�z
�P�DL1���烊�^�C���Ώۂ̃L���b�V�����C����VictimBuffer�ɑޔ�
�Q�DL2����L1�Ƀ��[�h
�R�DVictimBuffer����L2�ɏ������݁i����L2���[�h�v�������Ȃ����肱�̎��Ԃ͉B���ł���j
AMD�̂�1�e���|�x�����肩�AVictimBuffer�̓]�����I���܂łɎ���L2����̃��[�h�v�������s������
VictimBuffer��L2�ɓ]�����I���܂ő҂��Ă���L1�̃L���b�V�����C����ޔ�������B
������L2����̘A���Q�Ƃ����̂������x���B
�yInclusive�L���b�V���iL1���C�g�o�b�N�j�̏ꍇ�z�@����T��CPU�����̕���
�P�DL1���烊�^�C���Ώۂ̃L���b�V�����C����L2�ɏ�������
�Q�D2����L1�Ƀ��[�h
�yInclusive�L���b�V���iL1���C�g�X���[�j�̏ꍇ�z�@��NetBurst�APPC G5�����̕���
�P�DL2����L1�Ƀ��[�h
�i�X�g�A���ߔ��s����L1�ւ̏��������ʂ�L2�ɂ������ɔ��f�����̂�
���߂ă��^�C������L���b�V�����C����`���߂��K�v�Ȃ��B�j
�yExclusive�L���b�V���̏ꍇ�z
�P�DL1���烊�^�C���Ώۂ̃L���b�V�����C����VictimBuffer�ɑޔ�
�Q�DL2����L1�Ƀ��[�h
�R�DVictimBuffer����L2�ɏ������݁i����L2���[�h�v�������Ȃ����肱�̎��Ԃ͉B���ł���j
AMD�̂�1�e���|�x�����肩�AVictimBuffer�̓]�����I���܂łɎ���L2����̃��[�h�v�������s������
VictimBuffer��L2�ɓ]�����I���܂ő҂��Ă���L1�̃L���b�V�����C����ޔ�������B
������L2����̘A���Q�Ƃ����̂������x���B
727 �FMAC�I�^��726 �����F2005/11/13(��) 22:41:24 ID:g7MCVu1u
>>726
���ʂ�inclusive�L���b�V���ł�victim buffer��g���Ă�Ǝv�����B
����Ƀ��^�C�A�Ώۂ̃L���b�V�����C����exclusive�ŁA�����߂��s�v�̏ꍇ�����Ȃ��Ȃ����ƁB�B�B
���ʂ�inclusive�L���b�V���ł�victim buffer��g���Ă�Ǝv�����B
����Ƀ��^�C�A�Ώۂ̃L���b�V�����C����exclusive�ŁA�����߂��s�v�̏ꍇ�����Ȃ��Ȃ����ƁB�B�B
�������e�N�j�b�N�Ƃ��āA���Z���ʃf�[�^���e�[�u���ɂ��ă����_���Q�Ƃ���̂͐̂���̏퓅��i�B
�iIntel�Ȃ�ăn�[�h���x���ł���Ă�����������B�܂��ɁA���������Ńo�O�o����Pentium����̘b�����j
Coppermine��Athlon�ƌ݊p�ɐ킦���̂͂܂���L2�̃��[�h��������������B
���������œK������Ă�A�v�����Č��\������㩁B
���̓_�APentium M��2M�����邩�烋�b�N�A�b�v�e�[�u���g���܂����킯�ŁB
�Q�Ɛ�p�Ɏg���Ȃ狤�L�L���b�V���̂ق����������������A���܂����������݂�����
�ЃR�A����ǂ݂����f�[�^�������ЃR�A���t�F�b�`�Ȃ��Ŏg����B
�iIntel�Ȃ�ăn�[�h���x���ł���Ă�����������B�܂��ɁA���������Ńo�O�o����Pentium����̘b�����j
Coppermine��Athlon�ƌ݊p�ɐ킦���̂͂܂���L2�̃��[�h��������������B
���������œK������Ă�A�v�����Č��\������㩁B
���̓_�APentium M��2M�����邩�烋�b�N�A�b�v�e�[�u���g���܂����킯�ŁB
�Q�Ɛ�p�Ɏg���Ȃ狤�L�L���b�V���̂ق����������������A���܂����������݂�����
�ЃR�A����ǂ݂����f�[�^�������ЃR�A���t�F�b�`�Ȃ��Ŏg����B
�ނ���exclusive�L���b�V���̖���AL1�L���X�g�A�E�g���������ւ̏������݂������N�����\�����傫��
���Ƃ���Ȃ������H
>>728 ����
�ŋ߃v���Z�b�T�̍œK���K�C�h�ł�A�������̃R�X�g���傫�����Ƃ���e�[�u���Q�Ƃ퓾��łȂ���
�w�����Ă��邷�B
���Ƃ���Ȃ������H
>>728 ����
�ŋ߃v���Z�b�T�̍œK���K�C�h�ł�A�������̃R�X�g���傫�����Ƃ���e�[�u���Q�Ƃ퓾��łȂ���
�w�����Ă��邷�B
Intel�����̍œK���}�j���A����Pentium M�͏���������������ĂȂ���
�u�e�[�u���Q�ƂɗL���v�Ƃ͏�����Ă���B
�܂��m���ɁA�p�ɂ�L2�������_���Q�Ƃ��ꂽ��N���b�N�Q�[�e�B���O�����ʂ����ɂ��������ȁB
�u�e�[�u���Q�ƂɗL���v�Ƃ͏�����Ă���B
�܂��m���ɁA�p�ɂ�L2�������_���Q�Ƃ��ꂽ��N���b�N�Q�[�e�B���O�����ʂ����ɂ��������ȁB
���A725��
�~�@720�ł������������肾���E�E�E
���@718�ł������������肾���E�E�E
�ł��B
�~�@720�ł������������肾���E�E�E
���@718�ł������������肾���E�E�E
�ł��B
>>728
>�Q�Ɛ�p�Ɏg���Ȃ狤�L�L���b�V���̂ق����������������A���܂����������݂�����
>�ЃR�A����ǂ݂����f�[�^�������ЃR�A���t�F�b�`�Ȃ��Ŏg����B
���ꂪ�L���b�V���̉��b�ɂȂ���Ď��͂킩�肫���Ă�B���Ă��������ׂ̈̕�����B
>�Q�Ɛ�p�Ɏg���Ȃ狤�L�L���b�V���̂ق����������������A���܂����������݂�����
>�ЃR�A����ǂ݂����f�[�^�������ЃR�A���t�F�b�`�Ȃ��Ŏg����B
���ꂪ�L���b�V���̉��b�ɂȂ���Ď��͂킩�肫���Ă�B���Ă��������ׂ̈̕�����B
���߂��Ɂu�A�h�o���X�h �g�����X�t�@�[�L���b�V���v�Ō������Ă݂���Intel�T�C�g����������Ȃ��Ȃ����ȁB
���C�e���V����Ɠd�͊Ǘ��̂��߂ɍ폜�����̂��B
���C�e���V����Ɠd�͊Ǘ��̂��߂ɍ폜�����̂��B
734 �FMAC�I�^��733 �����F2005/11/13(��) 23:06:30 ID:g7MCVu1u
>>733
����Ȃ��Ƃ�A��������B
http://www.google.co.jp/search?ie=UTF-8&q=Advanced-Transfer-Cache+site%3Aintel.com
����Ȃ��Ƃ�A��������B
http://www.google.co.jp/search?ie=UTF-8&q=Advanced-Transfer-Cache+site%3Aintel.com
�}�b�N�����͂��炭���Ȃ��Ǝv������A�b�v�����C���e���ɏ�芷���Ă��痈��悤�ɂȂ����̂�
PowerPC�{��͂������Ȃ��̂�
PowerPC�{��͂������Ȃ��̂�
Apple����芷�����\����O����Intel�V���p����Ăĕs�v�c���Ǝv���Ă����B
����ϓ��ʎ҂Ȃ̂��ȁB
����ϓ��ʎ҂Ȃ̂��ȁB
>>726
�ԈႢ�B
�yExclusive�L���b�V���̏ꍇ�z
�P�DVictimBuffer�Ńq�b�g�����L1victim��swap���ďI���B
2�DVictimBuffer�Ńq�b�g���Ȃ����L2��1block���t���b�V���B(�����ł͏I�����Ȃ��B���̃P�[�X��)
3. VictimBuffer�t���b�V���ł���AVictimBuffer�̃t���b�V�������u���b�N��}�����ď�ԕύX���ďI���B
4. L2�Ńq�b�g�����L1�ɓ]������L2�̃u���b�N���ɏI���B
5.�������ɃA�N�Z�X�B
�ł������ꍇ��1�ŏI���ɂȂ�B�ł��x���ĂT�̃P�[�X�B
�ԈႢ�B
�yExclusive�L���b�V���̏ꍇ�z
�P�DVictimBuffer�Ńq�b�g�����L1victim��swap���ďI���B
2�DVictimBuffer�Ńq�b�g���Ȃ����L2��1block���t���b�V���B(�����ł͏I�����Ȃ��B���̃P�[�X��)
3. VictimBuffer�t���b�V���ł���AVictimBuffer�̃t���b�V�������u���b�N��}�����ď�ԕύX���ďI���B
4. L2�Ńq�b�g�����L1�ɓ]������L2�̃u���b�N���ɏI���B
5.�������ɃA�N�Z�X�B
�ł������ꍇ��1�ŏI���ɂȂ�B�ł��x���ĂT�̃P�[�X�B
>>735
Apple�M�҂Ȃ�AApple�����ƌ������A���ƌ����Δ��ƌ����͓̂��R�̂��Ƃ��ƁB
Apple�M�҂Ȃ�AApple�����ƌ������A���ƌ����Δ��ƌ����͓̂��R�̂��Ƃ��ƁB
>>735
x86�������Ȃ������Ƀ}�N�ɗ����̒��̊^���́A�����Ƃ܂����Ǝv������
x86�������Ȃ������Ƀ}�N�ɗ����̒��̊^���́A�����Ƃ܂����Ǝv������
�\���S��
�Ȃ�x86���v�N���b�N�v���X���̏������݂̃R�s�y����b�����ʂɂЂ�܂��Ă��܂��Ă���
�悤�����A�L���b�V�����r�����낤���Ȃ��낤��K8�́AYonah����ɂ��肱�����Ă���悤�����A
65nm�Ɉڍs���Ă����̍���Merom/Conroe�ɏ����ڂ͂Ȃ���Ȃ����ȁB
�Ȃ�x86���v�N���b�N�v���X���̏������݂̃R�s�y����b�����ʂɂЂ�܂��Ă��܂��Ă���
�悤�����A�L���b�V�����r�����낤���Ȃ��낤��K8�́AMerom/Conroe�ɏ����ڂ͂Ȃ����낤��B
�悤�����A�L���b�V�����r�����낤���Ȃ��낤��K8�́AYonah����ɂ��肱�����Ă���悤�����A
65nm�Ɉڍs���Ă����̍���Merom/Conroe�ɏ����ڂ͂Ȃ���Ȃ����ȁB
�Ȃ�x86���v�N���b�N�v���X���̏������݂̃R�s�y����b�����ʂɂЂ�܂��Ă��܂��Ă���
�悤�����A�L���b�V�����r�����낤���Ȃ��낤��K8�́AMerom/Conroe�ɏ����ڂ͂Ȃ����낤��B
>>742
��x�����ȁB
��x�����ȁB
2��ڂ̂͂�܂т��B
���Ƃ��A���̃R�[�h�͑f���Ƀ��[�v�ŏ��������������H
int highest_bit_search( uint32_t bits )
{
�@�@const int tbl[] = { 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, };
int ret = 0;
if( bits >= 0x10000 ) { ret += 16; bits >>= 16; }
�@�@if( bits >= 0x100 ) { ret += 8 ; bits >>= 8; }
�@�@if( bits >= 0x10 ) { ret += 4; bits >>= 4; }
�@�@return ret + tbl[ bits ];
}
int highest_bit_search( uint32_t bits )
{
�@�@const int tbl[] = { 0, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, };
int ret = 0;
if( bits >= 0x10000 ) { ret += 16; bits >>= 16; }
�@�@if( bits >= 0x100 ) { ret += 8 ; bits >>= 8; }
�@�@if( bits >= 0x10 ) { ret += 4; bits >>= 4; }
�@�@return ret + tbl[ bits ];
}
>>745
�X���Ⴂ�̂悤�ȋC�����邯��ǁA���̃X���ɂ����Ă���̂�����32bit x86?
����Ƃ�AMD64/EM64T?�A�Z���u���E�g�ݍ��݊��͂ǂ��܂Ŏg�p�\?
�R���p�C���͉��ŃI�v�V������?
�ŁAc����Ɍ���Ƃ��Ă��A�������ǂ����Ȃ�R���p�C���ɂ���Ă͂��܂�傫��
�萔�Ŕ�r�������Ȃ��Ȃ��Ǝv������E�E�E�@���ǒނ�ꂽ�̂� orz
�X���Ⴂ�̂悤�ȋC�����邯��ǁA���̃X���ɂ����Ă���̂�����32bit x86?
����Ƃ�AMD64/EM64T?�A�Z���u���E�g�ݍ��݊��͂ǂ��܂Ŏg�p�\?
�R���p�C���͉��ŃI�v�V������?
�ŁAc����Ɍ���Ƃ��Ă��A�������ǂ����Ȃ�R���p�C���ɂ���Ă͂��܂�傫��
�萔�Ŕ�r�������Ȃ��Ȃ��Ǝv������E�E�E�@���ǒނ�ꂽ�̂� orz
���x�I�Ȗ��̓C���^�[�t�F�C�X�̈Ⴂ����Merom�������
�u���̏����Ȃ�AMD�A��������Intel�v���Ċ����ō��ׂƂ��邭�炢��
�Ȃ��Ǝv����ł����A�������AMD�ɂЂ������������ȁH
Pacifica�������������Ă�̂��Ƃ͎v���̂�����ǁA�������̂���
�悤�Ȃ��̂łȂ��̂ƁA���ʂ̃��[�U�ɂƂ��Ă͍��̂Ƃ���Ӗ��Ȃ�
�������Ƃ��낾�Ǝv���̂�����ǁB
����ł�����64bit�����B�l�I�ɂ͑�ς��������Ă�̂������w
�u���̏����Ȃ�AMD�A��������Intel�v���Ċ����ō��ׂƂ��邭�炢��
�Ȃ��Ǝv����ł����A�������AMD�ɂЂ������������ȁH
Pacifica�������������Ă�̂��Ƃ͎v���̂�����ǁA�������̂���
�悤�Ȃ��̂łȂ��̂ƁA���ʂ̃��[�U�ɂƂ��Ă͍��̂Ƃ���Ӗ��Ȃ�
�������Ƃ��낾�Ǝv���̂�����ǁB
����ł�����64bit�����B�l�I�ɂ͑�ς��������Ă�̂������w
���̃X������o�����Ă�H
http://pc8.2ch.net/test/read.cgi/tech/1103609337/
http://pc8.2ch.net/test/read.cgi/tech/1103609337/
��܂т�����B
750 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2005/11/15(��) 01:34:00 ID:OQxvnZ/I
>>745
������1�̗����Ă�ŏ�ʃr�b�g��T�����郋�[�`���Ɖ��߂������B
�}�W���X�����FP/MM��XMM�ɕ��������œ]�����Đ����œǂݏo���̂��ő��A�Ƃ����ד��ȕ��@������B
����ȕ��@�������
int nlz(unsigned int x) {
x |= (x >> 1);
x |= (x >> 2);
x |= (x >> 4);
x |= (x >> 8);
x |= (x >> 16);
return pop(~x);
}
pop�͂��̗L���ȃr�b�g�J�E���g�@�ˁB�K���ɒT���ē���Ă��������B����ŕ���Ȃ��ŕ\���\�B
������1�̗����Ă�ŏ�ʃr�b�g��T�����郋�[�`���Ɖ��߂������B
�}�W���X�����FP/MM��XMM�ɕ��������œ]�����Đ����œǂݏo���̂��ő��A�Ƃ����ד��ȕ��@������B
����ȕ��@�������
int nlz(unsigned int x) {
x |= (x >> 1);
x |= (x >> 2);
x |= (x >> 4);
x |= (x >> 8);
x |= (x >> 16);
return pop(~x);
}
pop�͂��̗L���ȃr�b�g�J�E���g�@�ˁB�K���ɒT���ē���Ă��������B����ŕ���Ȃ��ŕ\���\�B
751 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2005/11/15(��) 01:40:37 ID:OQxvnZ/I
XMM����Ȃ��Ƃ����������Ɛ����̋��p�̗p�ӂ���
int highest_bit_search( uint32_t bits )
{
union { double fp_side; unsigned int int_side[2]; } hoge = (double) bits;
�i�ȉ����j
}
int highest_bit_search( uint32_t bits )
{
union { double fp_side; unsigned int int_side[2]; } hoge = (double) bits;
�i�ȉ����j
}
752 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2005/11/15(��) 01:43:26 ID:OQxvnZ/I
hoge.fp_side = (double) bits;
���ˁB���Ƃ͕��������̎w�����𐮐��Ō��邾���B
�悭�l�����float�ł��\�������ˁB
���ˁB���Ƃ͕��������̎w�����𐮐��Ō��邾���B
�悭�l�����float�ł��\�������ˁB
�����͂����烀�ɂȂ����̂��B
>>750
�T���܂����B
ttp://blog.windy.ac/2004/05/post_36.html
���]��
inline unsigned int excellentBitCount(unsigned int i) {
�@�@i = ((i >> 1) & 0x55555555) + (i & 0x55555555);
�@�@i = ((i >> 2) & 0x33333333) + (i & 0x33333333);
�@�@i = ((i >> 4) & 0x0F0F0F0F) + (i & 0x0F0F0F0F);
�@�@i = ((i >> 8) & 0x00FF00FF) + (i & 0x00FF00FF);
�@�@return (i >> 16) + (i & 0x0000FFFF);
}
�m���ɑ������B
���������_�̎w�������g�����@��FPU����CPU�Ȃ�m���ɑ������B�ד��ł͂���܂����B
�ł��Adouble���Ə����n�ˑ��ɂȂ�܂��ˁB
double�^���̂�IEEE�{���x�Œ�`����Ă邽�ߏ����n�Ɉˑ����Ȃ����A
�G���f�B�A���̈Ⴂ�ɂ��A���p�̂�����o���Ƃ��ɖ�肠��܂��ˁB
float�^�ŏ[���Ȃ̂ŁA����Ȃ�32bit�Ɏ��܂�̂�OK�ł����B
�ł��A�{���ɑ����̂��H�Ƃ�����Ƌ^��Ɏv�����_�͂���܂��B
�E������ɕ��������_���Z���C�u�������ÖقɌĂяo�����(���Ăяo������)
�E�w�����͉��ʗ����ŁA�X��0�̏ꍇ�̃`�F�b�N���K�v(������)
�T���܂����B
ttp://blog.windy.ac/2004/05/post_36.html
���]��
inline unsigned int excellentBitCount(unsigned int i) {
�@�@i = ((i >> 1) & 0x55555555) + (i & 0x55555555);
�@�@i = ((i >> 2) & 0x33333333) + (i & 0x33333333);
�@�@i = ((i >> 4) & 0x0F0F0F0F) + (i & 0x0F0F0F0F);
�@�@i = ((i >> 8) & 0x00FF00FF) + (i & 0x00FF00FF);
�@�@return (i >> 16) + (i & 0x0000FFFF);
}
�m���ɑ������B
���������_�̎w�������g�����@��FPU����CPU�Ȃ�m���ɑ������B�ד��ł͂���܂����B
�ł��Adouble���Ə����n�ˑ��ɂȂ�܂��ˁB
double�^���̂�IEEE�{���x�Œ�`����Ă邽�ߏ����n�Ɉˑ����Ȃ����A
�G���f�B�A���̈Ⴂ�ɂ��A���p�̂�����o���Ƃ��ɖ�肠��܂��ˁB
float�^�ŏ[���Ȃ̂ŁA����Ȃ�32bit�Ɏ��܂�̂�OK�ł����B
�ł��A�{���ɑ����̂��H�Ƃ�����Ƌ^��Ɏv�����_�͂���܂��B
�E������ɕ��������_���Z���C�u�������ÖقɌĂяo�����(���Ăяo������)
�E�w�����͉��ʗ����ŁA�X��0�̏ꍇ�̃`�F�b�N���K�v(������)
>>737
�P�D�̃P�[�X�͂킩�邯�ǁA����ȍ~��>>726�Ɠ����ł͂Ȃ��́H
�Q�D�ȍ~���A�t���b�V�����Ă����̂��Ƃ��AVictimBuffer�t���b�V���Ƃ͉����Ƃ�
�Ӗ����킩��Ȃ��̂ŁA�悯��Ή�����肢���܂��B
�P�D�̃P�[�X�͂킩�邯�ǁA����ȍ~��>>726�Ɠ����ł͂Ȃ��́H
�Q�D�ȍ~���A�t���b�V�����Ă����̂��Ƃ��AVictimBuffer�t���b�V���Ƃ͉����Ƃ�
�Ӗ����킩��Ȃ��̂ŁA�悯��Ή�����肢���܂��B
�����ザ��Ȃ����ǁAIntel�̃}�[�P�e�B���O�ɂ���754��Tuiron64x2�Ƃ���������
���Ȃ��̂��ȁB���ł�754Dual�̃}�U�[�{�[�h�ȂłĂ����ƁA�����Ƃ��ꂵ����
�����ǁE�E�E
����ȕςȃ}�U�[������肻���ȃ��[�J�Ȃ��������B
���Ȃ��̂��ȁB���ł�754Dual�̃}�U�[�{�[�h�ȂłĂ����ƁA�����Ƃ��ꂵ����
�����ǁE�E�E
����ȕςȃ}�U�[������肻���ȃ��[�J�Ȃ��������B
TurionX2�͎����ヂ�o�C��CPU�ŊJ����
754Dual�͂�������HT�̖{������Ȃ��̂Ŗ�����
754Dual�͂�������HT�̖{������Ȃ��̂Ŗ�����
>>756
ttp://pc.watch.impress.co.jp/docs/article/20010727/kaigai01.htm
�}���`�v���Z�b�T�ł�HyperTransport�̎g�������悭�킩���B
754��HyperTransport 1�{�ˁB
ttp://pc.watch.impress.co.jp/docs/article/20010727/kaigai01.htm
�}���`�v���Z�b�T�ł�HyperTransport�̎g�������悭�킩���B
754��HyperTransport 1�{�ˁB
�ŋ߂ǂ�����AMD�̃X���Ō���������āA�R���ł��܂���Ă������H
����Ƃ��Q�̂��Ă邾����Dual����Ȃ��̂��ȁB
ttp://www.pconline.com.cn/diy/front/news/cpu/0411/496092.html
����Ƃ��Q�̂��Ă邾����Dual����Ȃ��̂��ȁB
ttp://www.pconline.com.cn/diy/front/news/cpu/0411/496092.html
>>760
ttp://nueda.main.jp/blog/archives/000991.html
����1�N���O�̃l�^�݂��������ǂˁB
ttp://www.madshrimps.be/forums/showthread.php?s=&threadid=10237
�ɂ�It's a good fake...�Ə����Ă��邵�B
���ɉ\���Ƃ���Ȃ�A
[CPU]---HT---[�`�b�v�Z�b�g]---HT---[CPU]
�̂悤�ɂȂ�̂��낤���A�}���`�v���Z�b�T�̏ꍇ�́A
CPU�ԂŃL���b�V���̐������Ƃ�K�v������킯�ŁA
���̂��߂̏���HT�ł���肵�Ă�B
CPU��������HyperTransport�������Ă�ꍇ�A
CPU�ƌq�����Ă鑤�ɂ��������������͗����Ȃ��͂�������A
CPU�̐v�i�K�ł��������\�����z�肳��ĂȂ��ƑΉ��ł��Ȃ��Ǝv���B
ttp://nueda.main.jp/blog/archives/000991.html
����1�N���O�̃l�^�݂��������ǂˁB
ttp://www.madshrimps.be/forums/showthread.php?s=&threadid=10237
�ɂ�It's a good fake...�Ə����Ă��邵�B
���ɉ\���Ƃ���Ȃ�A
[CPU]---HT---[�`�b�v�Z�b�g]---HT---[CPU]
�̂悤�ɂȂ�̂��낤���A�}���`�v���Z�b�T�̏ꍇ�́A
CPU�ԂŃL���b�V���̐������Ƃ�K�v������킯�ŁA
���̂��߂̏���HT�ł���肵�Ă�B
CPU��������HyperTransport�������Ă�ꍇ�A
CPU�ƌq�����Ă鑤�ɂ��������������͗����Ȃ��͂�������A
CPU�̐v�i�K�ł��������\�����z�肳��ĂȂ��ƑΉ��ł��Ȃ��Ǝv���B
AMD�̃R�A�������ǂ��Ȃ�̂��ɂȂ�`
�����R�A�ɂȂ�̂��ǂ����E�E�E�E
���Ԃj�[�R�A�ł��܂������悤�ɐv���邾�낤���ǁE�E�E
���܂Ȃɂ���Ă�̂��m�肽�����ɔ�Ȃ낤�Ȃ��B
�����R�A�ɂȂ�̂��ǂ����E�E�E�E
���Ԃj�[�R�A�ł��܂������悤�ɐv���邾�낤���ǁE�E�E
���܂Ȃɂ���Ă�̂��m�肽�����ɔ�Ȃ낤�Ȃ��B
763 �FSocket774�F2005/11/16(��) 15:38:33 ID:REjskbNY
AMD�A�i���X�gDAY�̃X���C�h�iAMD�̏������[�h�}�b�v�j
http://www.planet3dnow.de/vbulletin/showthread.php?t=243845
http://www.planet3dnow.de/vbulletin/showthread.php?t=243845
��x�V�F�A���������般��A���\���A���ł������̂́A�^�Ђ��g�������ďؖ����Ă��ꂽ����A
���̂����ɂ���܂���`�B
���̂����ɂ���܂���`�B
>>762
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai146.htm
Intel�����\�R�A��100�R�A�ȏ�𓋍ڂ��郁�j�C�R�A�Ɍ������đ���̂ɑ��āA
AMD��2�`8�R�A�̃}���`�R�A�����ʂ͓K�Ƃ����X�^���X�����B
http://pc.watch.impress.co.jp/docs/2004/1228/kaigai146.htm
Intel�����\�R�A��100�R�A�ȏ�𓋍ڂ��郁�j�C�R�A�Ɍ������đ���̂ɑ��āA
AMD��2�`8�R�A�̃}���`�R�A�����ʂ͓K�Ƃ����X�^���X�����B
�����H�Ƒ�w�A�f���A���R�AOpteron��5,240��ڂ��������ő��O���b�h
ttp://pc.watch.impress.co.jp/docs/2005/1116/titech.htm
ttp://pc.watch.impress.co.jp/docs/2005/1116/titech.htm
>>765
�ǂ��ł��B
�C���e�����ċɒ[����˂��@�������i�N���b�N�Ƃ��R�A���Ƃ��j���Č��߂�����ς��܂��邗��������
���܂̂Ƃ���`�l�c���x�X�g���ȁA����ς�B
�ǂ��ł��B
�C���e�����ċɒ[����˂��@�������i�N���b�N�Ƃ��R�A���Ƃ��j���Č��߂�����ς��܂��邗��������
���܂̂Ƃ���`�l�c���x�X�g���ȁA����ς�B
>>767
�����̕������̈Ⴂ����B
AMD�����āA8�R�A�̐悪16,32,64�R�A�ɂȂ邩������Ȃ����A���ǂ̓C���e���Ɠ��������֍s���̂�������Ȃ���
�����̕������̈Ⴂ����B
AMD�����āA8�R�A�̐悪16,32,64�R�A�ɂȂ邩������Ȃ����A���ǂ̓C���e���Ɠ��������֍s���̂�������Ȃ���
AMD�͏�����������ˁ[�����
�܂����̂����ɔ���܂����ăV�F�A�オ�����炱�������������o���Ȃ��Ȃ邯��
�܂����̂����ɔ���܂����ăV�F�A�オ�����炱�������������o���Ȃ��Ȃ邯��
AMD�����������Ȃ���Ȃ��āAIntel�������ꒃ���������Ȃ������ƁB
10GHz�s���܂���`�I�Ƃ�100�R�A�悹�܂���`�I�Ƃ������A�t�H���ƁB
���ꂩ��ǂ��N���e�B�J���ȋZ�p�▢�\�L�̕s��ɂԂ��邩��
����Ȃ��̂ɁE�E�E�E�f�^�����Ȏ������茾���Ă鷶
AMD�̕��������I�Ȗ����ł܂��}�V���Ǝv���B
10GHz�s���܂���`�I�Ƃ�100�R�A�悹�܂���`�I�Ƃ������A�t�H���ƁB
���ꂩ��ǂ��N���e�B�J���ȋZ�p�▢�\�L�̕s��ɂԂ��邩��
����Ȃ��̂ɁE�E�E�E�f�^�����Ȏ������茾���Ă鷶
AMD�̕��������I�Ȗ����ł܂��}�V���Ǝv���B
Intel�͋ƊE�̃��[�_�[�Ȃ��痦�悵�ĕǂɂԂ���ׂ��Ȃ�
�����Ă��̖����͏\���ɉʂ����Ă���
AMD��Intel�Ɏ���đ��肽���̂Ȃ炻��������������o�g���^�b�`���Ȃ���Ȃ�Ȃ�
�ǂ��Ƃ�����Ƃ����킯�ɂ͂����Ȃ�
�����Ă��̖����͏\���ɉʂ����Ă���
AMD��Intel�Ɏ���đ��肽���̂Ȃ炻��������������o�g���^�b�`���Ȃ���Ȃ�Ȃ�
�ǂ��Ƃ�����Ƃ����킯�ɂ͂����Ȃ�
�ƊE�̃��[�_�[�����炱�������Ƃ������������ׂ��Ȃ�ˁH
MS�����Ă������܂ŃA�t�H�Ȏ��͌���Ȃ�������H
MS�����Ă������܂ŃA�t�H�Ȏ��͌���Ȃ�������H
2003�N��Longhorn(Vista��)��Win32API����WinFX�Ɋ��S�ڍs���锭���Ƃ�������MS���A�t�H����
�y���_�z
�ƊE�̃V�F�ANo1�̓A�t�H�ɂȂ�B
�ƊE�̃V�F�ANo1�̓A�t�H�ɂȂ�B
���͂ł��������ǂ���B
AMD�����[�h�}�b�v�i�H�j�X�V�����̂ɂ���܃X���L�тĂȂ��ˁB
����܂�>>763���܂߂Ă̘b�Ȃ��ǎv������背�X���i��łȂ��Ɗ�������B
ttp://www.amdcompare.com/techoutlook/
���[�h�}�b�v�͂��ꂩ�ȁB
���܂ł�CPU�R�[�h�l�[�������\������������ɏo�Ă������B
AMD�̓R�[�h�l�[����\�ɏo���Ȃ��Ȃ����̂��ˁB
ttp://www.amdcompare.com/techoutlook/
���[�h�}�b�v�͂��ꂩ�ȁB
���܂ł�CPU�R�[�h�l�[�������\������������ɏo�Ă������B
AMD�̓R�[�h�l�[����\�ɏo���Ȃ��Ȃ����̂��ˁB
>>779
��荇�������N�̃��C���i�b�v
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
�\��ʂ�A�ڐV�����̂�FX-62��Dual�R�A�ɐ������ʂ�
��荇�������N�̃��C���i�b�v
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2587
�\��ʂ�A�ڐV�����̂�FX-62��Dual�R�A�ɐ������ʂ�
781 �FMAC�I�^��779 �����F2005/11/17(��) 01:18:14 ID:60JP3jS0
>>779
�ŁA����AMD��D�ӓI�Ɍ��Ă���A2008�N�Ɏ���܂�P6�R�A��PentiumPro -> Pentium iii�ɂȂ������x��
�i�������t�Ƃ������Ƃ�������������(��)
�ŁA����AMD��D�ӓI�Ɍ��Ă���A2008�N�Ɏ���܂�P6�R�A��PentiumPro -> Pentium iii�ɂȂ������x��
�i�������t�Ƃ������Ƃ�������������(��)
>>770�̊��z������
783 �FMAC�I�^��769 �����F2005/11/17(��) 01:26:34 ID:60JP3jS0
>>769
�@�@-----------------------
�@�@AMD�͏�����������ˁ[�����
�@�@-----------------------
AMD��Hammer�A�[�L�e�N�`���̔��\���A�����o��̉��N�O����z�����n�߂�����������Y��Ă�
�݂�������(��)
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_553~56635,00.html
�@�@-----------------------
�@�@AMD�͏�����������ˁ[�����
�@�@-----------------------
AMD��Hammer�A�[�L�e�N�`���̔��\���A�����o��̉��N�O����z�����n�߂�����������Y��Ă�
�݂�������(��)
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_553~56635,00.html
AMD�̌����A�B�҂Ȍ������Ȃ��قǐ؉H�l���Ă���Ƃ������邷�B
�P�Ɂu���v�D����AMD�ɏW���đ����ł��钎�����ʂɂ��āA�z���g�ɋ�������̃t�@�������F����q�g������
�����v���Ă��邷���ˁB�B�B
�P�Ɂu���v�D����AMD�ɏW���đ����ł��钎�����ʂɂ��āA�z���g�ɋ�������̃t�@�������F����q�g������
�����v���Ă��邷���ˁB�B�B
>>784
Rambus���Ń��[�h�}�b�v�ύX���Ă�intel���}�V���Ǝv�����H
���ƍ��܂�intel�����]���ĂāA����Mac��CPU��PPC����intel�ɕς��锭�\����
�ԓx180�x�ς����̒N�������H
Rambus���Ń��[�h�}�b�v�ύX���Ă�intel���}�V���Ǝv�����H
���ƍ��܂�intel�����]���ĂāA����Mac��CPU��PPC����intel�ɕς��锭�\����
�ԓx180�x�ς����̒N�������H
�͂��͂�����͂ǂ��܂�
�u���ɋA��v�ƌ��킸�ɔ��_����������ł��傤��
�R��̗\�z���ƂT���X���炢���Ȃ�����
�u���ɋA��v�ƌ��킸�ɔ��_����������ł��傤��
�R��̗\�z���ƂT���X���炢���Ȃ�����
�I�^�͐̂��� PowerPC �X���ł� intel �i�삵�Ă��̂�
�m��Ȃ����c�͑�����
�m��Ȃ����c�͑�����
��n�Q�̓A�{�[��
790 �FSocket774�F2005/11/17(��) 03:55:44 ID:2Kb8hC3c
791 �FSocket774�F2005/11/17(��) 07:34:27 ID:HtcOSSfl
���N�̐VSocket�}�U�[�͍ė��N��4-core CPU�ł��g����
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
M�@A�@C�@�n�@���@�́@�L�@�G�@��
���ʂɂ킩��Ȃ����ƁB
Intel���D�������R���B�L�͊�Ƃ�����ˁi��
AMD���D�������������B�{���͐؉H�܂��Ă��邷��i��
Intel���s����Intel�̎�����͐�������i�jAMD�Ȃڂ���Ȃ����i�j
AMD���s�������R���i�j
�����̂����炳�܂ȃG�R�q�C�L�B
Intel���D�������R���B�L�͊�Ƃ�����ˁi��
AMD���D�������������B�{���͐؉H�܂��Ă��邷��i��
Intel���s����Intel�̎�����͐�������i�jAMD�Ȃڂ���Ȃ����i�j
AMD���s�������R���i�j
�����̂����炳�܂ȃG�R�q�C�L�B
���� �G�ڟI
795 �FMAC�I�^��793 �����F2005/11/17(��) 08:10:57 ID:60JP3jS0
>>793
���펖���𗅗Ă邾���ŁA����ɑ��Ă��Ȃ�������������ۂ������Ă�����Ă����̘b���B
(�����̔���̒������ł��炭����Ă������̂�)����Hammer�X���b�h�̏�������Q�����Ă�̂�A
����̂��߂��ᖳ�������ǂˁB�B�B
���펖���𗅗Ă邾���ŁA����ɑ��Ă��Ȃ�������������ۂ������Ă�����Ă����̘b���B
(�����̔���̒������ł��炭����Ă������̂�)����Hammer�X���b�h�̏�������Q�����Ă�̂�A
����̂��߂��ᖳ�������ǂˁB�B�B
Intel���T�[�o�A�f�X�N�g�b�v�ł��̐搔�N�ł�낤�Ƃ��Ă���̂́AAMD�̂��ƒǂ��B
AMD���i�����Ȃ��Ƃ�����Ȃ�AIntel��P3����ς���Ă��Ȃ��B
Intel�����N���悤�Ƃ��Ă���̂́A760MP���x���B
AMD�����o�C���ł��̐搔�N�ł�낤�Ƃ��Ă���̂́AIntel�̂��ƒǂ��B
�ǂ��H�v���Ă��X���b�h����̃X�s�[�h�͂����Â炢�B
����ȊO�̍H�v��OS�̑Ή��ƕ��������킹�Ȃ��Ɛi�߂��Ȃ��B
AMD���i�����Ȃ��Ƃ�����Ȃ�AIntel��P3����ς���Ă��Ȃ��B
Intel�����N���悤�Ƃ��Ă���̂́A760MP���x���B
AMD�����o�C���ł��̐搔�N�ł�낤�Ƃ��Ă���̂́AIntel�̂��ƒǂ��B
�ǂ��H�v���Ă��X���b�h����̃X�s�[�h�͂����Â炢�B
����ȊO�̍H�v��OS�̑Ή��ƕ��������킹�Ȃ��Ɛi�߂��Ȃ��B
>>791
�ł����`�A�ǂ����a�h�n�r�����Ă����߁A�݂����Ȃ�����邶���B
Athlon64X2�̂Ƃ������āAVIA�Ƃ��S�ł�����H
�Ń}�U�[�����ւ��E�E�E�E
�����ˁ[�悤��`��(;�L�t��)
�ł����`�A�ǂ����a�h�n�r�����Ă����߁A�݂����Ȃ�����邶���B
Athlon64X2�̂Ƃ������āAVIA�Ƃ��S�ł�����H
�Ń}�U�[�����ւ��E�E�E�E
�����ˁ[�悤��`��(;�L�t��)
VIA�����Ǖ��ʂ�64X2�g���Ă��B�S�ł���Ȃ����āB
VIA��KX133�ł��ꕔ�d�l���������Ȃ���
�����ċp�@�\���ڃ`�b�v�Z�b�g�Ɏd�グ�Ă��ꂽ����Ȃ��E�E�E
�����ċp�@�\���ڃ`�b�v�Z�b�g�Ɏd�グ�Ă��ꂽ����Ȃ��E�E�E
�T�[�o�[�����ł�Intel�͑��ς�炸���ʂ��Â��Ǝv���B
AMD�����̃t�@�����ăR�X�g�p�t�H�[�}���X���߂Ă邾���ŁB
�Ӗ��s���ȍD�������Ƃ��W�Ȃ���B
�Ӗ��s���ȍD�������Ƃ��W�Ȃ���B
>>799-800
���������B������o�n�߂̃`�b�v�Z�b�g�ɔ�т��Ă��A
�S�R�A�ɂȂ����猋�ǃ}�U�[�����ւ��Ƃ��ˁE�E�E
�Ȃ��Ȃ��A���Ă����킯�ł���B
���������B������o�n�߂̃`�b�v�Z�b�g�ɔ�т��Ă��A
�S�R�A�ɂȂ����猋�ǃ}�U�[�����ւ��Ƃ��ˁE�E�E
�Ȃ��Ȃ��A���Ă����킯�ł���B
���Ƃ`�l�c�ɂ͂����b�o�t�N�[���[��]�����B
X2�ʼn��P���ꂽ���ǁA�܂��܂��E�E�E�E
X2�ʼn��P���ꂽ���ǁA�܂��܂��E�E�E�E
��ǂ��헪�Ŗ����ւ̓��������Ȃ��_����Ђł����Ă��A
���ݏo���Ă鐻�i���ǂ���Δ���Ă��܂��B
PC�Ȃ�Ĕ����Đ��N�Ŏ���x��ɂȂ�킯�ŁA
����s��ł͒Z���I�Ȑ��\��r�ŏ���s�������肷��̂������I���B
��Ƃɒ��ڕ��匾���̂������Ȃ̂�
�i����͐��i��Ȃ��Ƃ����`�ŒN�ł����s�ł��邵�A
����ґ��k�Z���^�[�Ƀ`�N��Ƃ�����ɂȂ�Ƃ��ł��邾�낤�j
�킴�킴2ch�̃X���ɒ���t���ďZ�l�ɓ���U�炵�A
����ɒ����I�Ȏ��_�������Ă���̂ł��ꂽ��b�ɂ����Ȃ��B
�Ƃ����Ƃ茾�B
���ݏo���Ă鐻�i���ǂ���Δ���Ă��܂��B
PC�Ȃ�Ĕ����Đ��N�Ŏ���x��ɂȂ�킯�ŁA
����s��ł͒Z���I�Ȑ��\��r�ŏ���s�������肷��̂������I���B
��Ƃɒ��ڕ��匾���̂������Ȃ̂�
�i����͐��i��Ȃ��Ƃ����`�ŒN�ł����s�ł��邵�A
����ґ��k�Z���^�[�Ƀ`�N��Ƃ�����ɂȂ�Ƃ��ł��邾�낤�j
�킴�킴2ch�̃X���ɒ���t���ďZ�l�ɓ���U�炵�A
����ɒ����I�Ȏ��_�������Ă���̂ł��ꂽ��b�ɂ����Ȃ��B
�Ƃ����Ƃ茾�B
>>804
����͂���ˁB�������Ȃ����ǁB
���ƁA�ꉞ�������ǐ��\�͊���������Ȃ��Ƃ��ˁB
�܂������VIA�Ɍ������b�ł͂Ȃ����ǁB
�������Ӗ��ł�64X2�̂Ƃ��͂��Ȃ�}�V�Ȃق����Ǝv���B
�n�Y���������l�͂��킢���������B
����͂���ˁB�������Ȃ����ǁB
���ƁA�ꉞ�������ǐ��\�͊���������Ȃ��Ƃ��ˁB
�܂������VIA�Ɍ������b�ł͂Ȃ����ǁB
�������Ӗ��ł�64X2�̂Ƃ��͂��Ȃ�}�V�Ȃق����Ǝv���B
�n�Y���������l�͂��킢���������B
�A���h�E���C�i�j
>>791
�������R���g���[������������ADDR2�Ή��Ń\�P�b�g�ς��̂͂������Ȃ��ł��ˁB
�������R���g���[������������ADDR2�Ή��Ń\�P�b�g�ς��̂͂������Ȃ��ł��ˁB
�ǂ����ė��N��DDR3�Ή��Ȃ���AM2����Ȃ��C������B
conroe�̎��̐���TDP25W�炵�����B
AMD�͂ǂ��R����̂��y���݂��ȁB
AMD�͂ǂ��R����̂��y���݂��ȁB
RAMBUS���ǂ��ɂ��ł��Ȃ��ƁA�������ۂ���
>>811
25W�Ȃ킯�ˁ[����
25W�Ȃ킯�ˁ[����
�u1�v�������Ă��܂���c
>>811
�}�W!!������Ă���ȂɌ��ʂ������
Intel�A���[�N�d����1/1000�ɂ���65nm�v���Z�X�Z�p�\
http://pcweb.mycom.co.jp/news/2005/09/21/005.html
�C���e���A�������d�͂��\�ɂ��鐻���v���Z�X�Z�p���J��
http://www.rbbtoday.com/news/20050921/25690.html
2007�N�ȍ~��65nm�v���Z�X�Ɏg����
�܂��R�����܂Ń��[�N�d���^�_�R����ۂ������ꂪ�����Ȃ�1000����1�ɂȂ����炻���ˁ[�B
�܂��y���݂ɂ��Ă܂��B
������AMD���M��̊J�����Ă܂����H
���̂܂�SOI�����ł����͖̂����Ǝv���܂����B(���̃f���A���ł��̔��M�́E�E�E)
Intel�̓��[�N�d����1000����1(SOI��4����1)�ɂ���Z�p���J���������炢�����ǁB
�}�W!!������Ă���ȂɌ��ʂ������
Intel�A���[�N�d����1/1000�ɂ���65nm�v���Z�X�Z�p�\
http://pcweb.mycom.co.jp/news/2005/09/21/005.html
�C���e���A�������d�͂��\�ɂ��鐻���v���Z�X�Z�p���J��
http://www.rbbtoday.com/news/20050921/25690.html
2007�N�ȍ~��65nm�v���Z�X�Ɏg����
�܂��R�����܂Ń��[�N�d���^�_�R����ۂ������ꂪ�����Ȃ�1000����1�ɂȂ����炻���ˁ[�B
�܂��y���݂ɂ��Ă܂��B
������AMD���M��̊J�����Ă܂����H
���̂܂�SOI�����ł����͖̂����Ǝv���܂����B(���̃f���A���ł��̔��M�́E�E�E)
Intel�̓��[�N�d����1000����1(SOI��4����1)�ɂ���Z�p���J���������炢�����ǁB
�� �u�Ձv
�C���e���~���܂��ꂱ��ł���ȁA����B���ӁB
>>817
�ł��܂��C���e���͐v�����ł���H
�C���e���̓������R���g���[���[�������ĂȂ����A�L���b�V���͋��L�ŃI�[�o�[�w�b�h����܂���B
�R��͔�r���Ă`�l�c�������Ǝv���Ă��܂��B
>>817
�ł��܂��C���e���͐v�����ł���H
�C���e���̓������R���g���[���[�������ĂȂ����A�L���b�V���͋��L�ŃI�[�o�[�w�b�h����܂���B
�R��͔�r���Ă`�l�c�������Ǝv���Ă��܂��B
���n�C�p�t�H�[�}���X�����ǔ�r�I�N�[����Prescott
http://www.watch.impress.co.jp/pc/docs/2002/0301/kaigai01.htm
>Prescott��5GHz������g����B���ł��邱�ƂɂȂ�B
>���s��Pentium 4��4GHz�œ��삳����f�����s�Ȃ�ꂽ�B
>�@Intel��90nm�v���Z�X��P1262�ŁA�u���U�d��(High-k)�Q�[�g�≏���v�f�ނ��g��
>�\��ł���B�Q�[�g�≏���̑f�ނ��]����SiO2����AHigh-k�ɕς���ƁA�g�����W�X�^
>���������Ȃ�߂������Ƃő�����X���ɂ��郊�[�N�d��(�R��d��)�����炷���Ƃ��ł�
>��B���̂��߁AIntel��90nm����CPU�́A�ҋ@���̃��[�N�d��������A�܂��ATDPtyp
>�̒l������ƌ�����B
�v���X�R���Đ����ȁI�y���݂��ȁ`��o��́I2003�N�㔼���E�E�E�E�E���ăA���H
http://www.watch.impress.co.jp/pc/docs/2002/0301/kaigai01.htm
>Prescott��5GHz������g����B���ł��邱�ƂɂȂ�B
>���s��Pentium 4��4GHz�œ��삳����f�����s�Ȃ�ꂽ�B
>�@Intel��90nm�v���Z�X��P1262�ŁA�u���U�d��(High-k)�Q�[�g�≏���v�f�ނ��g��
>�\��ł���B�Q�[�g�≏���̑f�ނ��]����SiO2����AHigh-k�ɕς���ƁA�g�����W�X�^
>���������Ȃ�߂������Ƃő�����X���ɂ��郊�[�N�d��(�R��d��)�����炷���Ƃ��ł�
>��B���̂��߁AIntel��90nm����CPU�́A�ҋ@���̃��[�N�d��������A�܂��ATDPtyp
>�̒l������ƌ�����B
�v���X�R���Đ����ȁI�y���݂��ȁ`��o��́I2003�N�㔼���E�E�E�E�E���ăA���H
����2007�N�ł���B
�@�S��������Ă�ȁB
>>821
���������Aintel��High-k�͉��������ȂH
���������Aintel��High-k�͉��������ȂH
>>821
�Ă��A���̍��̃N���b�N����\���͊F�A����Ȃ������B
IBM��Power6�ł��璴�����g��6Ghz�ȏ���ă��[�h�}�b�v���������H
�܂��APower6�͍��A�p�����Ă邩������B
�Ă��A���̍��̃N���b�N����\���͊F�A����Ȃ������B
IBM��Power6�ł��璴�����g��6Ghz�ȏ���ă��[�h�}�b�v���������H
�܂��APower6�͍��A�p�����Ă邩������B
>>824
45nm
45nm
>>826
�܂��܂��悩�c
�܂��܂��悩�c
M2�ł�4800+����2.5GHz�Ȃ��
�P��FSB�ύX�ŃL���̗ǂ����ɍ��킹��������������Ȃ���
�����͌��s���p�t�H�[�}���X��������v�f������낤���BPacifica�Ƃ�
�P��FSB�ύX�ŃL���̗ǂ����ɍ��킹��������������Ȃ���
�����͌��s���p�t�H�[�}���X��������v�f������낤���BPacifica�Ƃ�
�ǂ������Ƃ����ƌ�҂���ˁH
�����͗ǂ��Ȃ��ĂĂނ��듯�N���b�N�Ȃ�オ���Ă��������炢�Ȃ̂ɁB
MN��TB��Ƃ������ۂɂ�NetBurst��Ȃ͍̂��X�����ɂ��Č������Ƃł��Ȃ���
Cedarmill/Presler��Prescott/Smithfield���p�t�H�[�}���X���������P����Ă邩��A
�Ƃ��������ł��������Ă݂�e�X�g�B
�����͗ǂ��Ȃ��ĂĂނ��듯�N���b�N�Ȃ�オ���Ă��������炢�Ȃ̂ɁB
MN��TB��Ƃ������ۂɂ�NetBurst��Ȃ͍̂��X�����ɂ��Č������Ƃł��Ȃ���
Cedarmill/Presler��Prescott/Smithfield���p�t�H�[�}���X���������P����Ă邩��A
�Ƃ��������ł��������Ă݂�e�X�g�B
�������ĉ��P����Ă�́H
�x�[�X�N���b�N�オ���Ă�HT��1GHz�̂܂܂�����ς���Ǝv���̂����B
�x�[�X�N���b�N�オ���Ă�HT��1GHz�̂܂܂�����ς���Ǝv���̂����B
�������A�N�Z�X�̓R���g���[���[��ł��邩��W�Ȃ��B
�g�s�͂g�c�c�₻�̑��f�[�^���Ƃ�ɂ̂ݎg����B
������`�l�c�͂₢���Ă����ЂƂ̗v������Ȃ����������H�H�H
�g�s�͂g�c�c�₻�̑��f�[�^���Ƃ�ɂ̂ݎg����B
������`�l�c�͂₢���Ă����ЂƂ̗v������Ȃ����������H�H�H
Cedarmill/Presler��Prescott/Smithfield�̒P�Ȃ���w�V�������N�ŁB
���\�͂܂�������������B
���\�͂܂�������������B
�d���̋������悤����
�����Ɍ��w�I�ɃV�������N������ƁA�C���_�N�^���X�͑����A�L���p�V�^���X�͌�������̂�
���̕ӂ͎�������Ă�Ǝv���B
����ɂ��Ă܂������������ĂȂ���A����d�͂����������\�͂܂������ς��낤���ǂȁB
�����Ɍ��w�I�ɃV�������N������ƁA�C���_�N�^���X�͑����A�L���p�V�^���X�͌�������̂�
���̕ӂ͎�������Ă�Ǝv���B
����ɂ��Ă܂������������ĂȂ���A����d�͂����������\�͂܂������ς��낤���ǂȁB
Presler�̓L���b�V�����Y�̔{�ł���B
DDR2�Ή��̂��߂Ƀ������R���g���[����
�ɂ��`���[�j���O���Ă���Ƃ��B
����[���AAMD64��DDR2�ɂ�鐫�\�����m�����E�E�E
�������ш����Ő��\����������Ƃ�
���������C�e���V�����ő債�Đ��\�ς���̂��E�E�E
�ɂ��`���[�j���O���Ă���Ƃ��B
����[���AAMD64��DDR2�ɂ�鐫�\�����m�����E�E�E
�������ш����Ő��\����������Ƃ�
���������C�e���V�����ő債�Đ��\�ς���̂��E�E�E
�܂��A�}���`�R�A�̎��l������ш�͊��L���Ă�����Ȃ��ʂ�����B
�z���g����x�N�g���v���Z�b�T�����Ă����ȁB
�z���g����x�N�g���v���Z�b�T�����Ă����ȁB
�V�_�~����Prescott-2M�̃V�������N����B
�Ȃɂ���Celeron D�̃R�X�g�p�t�H�[�}���X���オ���Ă����ȗ\���B
�iPentium M�ɑ���CeleronM ��낵���L���b�V��1M���ڂƂ��j
�Ȃɂ���Celeron D�̃R�X�g�p�t�H�[�}���X���オ���Ă����ȗ\���B
�iPentium M�ɑ���CeleronM ��낵���L���b�V��1M���ڂƂ��j
�����}�b�v��������Dell�̃X�^�W�����̘r�͂�Pentium D�������B�Ȃɍl���Ă���̉�ЁB
DELL�̓C���e����������Ȃ��ł���H
�ł�64x2������`�@�܂��ŁB
�ł����N�㔼����C���e���̂�����d�͂�f���A���R�A�ɂȂ邩��
�����I�ȃr�W�l�X���l����ƃC���e���Ɩ��������ق���������Ȃ��H
�ł�64x2������`�@�܂��ŁB
�ł����N�㔼����C���e���̂�����d�͂�f���A���R�A�ɂȂ邩��
�����I�ȃr�W�l�X���l����ƃC���e���Ɩ��������ق���������Ȃ��H
AMD��SUN
Intel��DELL
�ŁA���傤�ǃo�����X�Ƃ�Ă邩��ʂɂ�����Ȃ��́B
Intel��DELL
�ŁA���傤�ǃo�����X�Ƃ�Ă邩��ʂɂ�����Ȃ��́B
>>841
AMD�G�k�X���ɂP�Q���ɏo�Ă���X�W���[�^����ł��H��
AMD�G�k�X���ɂP�Q���ɏo�Ă���X�W���[�^����ł��H��
�C���e���̃v���Z�X���Đ̂��瑼�Ђ̃v���Z�X�ɔ�ׂ�
���[�N�d������������Č����Ă���ȁB
����1000����1�Ɍ�������Z�p�ł����Ĕ��\����Ă��A
�����ǂ���B
���[�N�d������������Č����Ă���ȁB
����1000����1�Ɍ�������Z�p�ł����Ĕ��\����Ă��A
�����ǂ���B
����Ƒ��Е��݂ɂȂ�̂��ƈ��S���܂��B
���������A65nm�̃��[�N�d��
��r�����L���ǂ����ɂ�������ˁB
��r�����L���ǂ����ɂ�������ˁB
ttp://pcweb.mycom.co.jp/articles/2005/06/16/vlsi1/index.html
�Â��͂��̕ӂ��ȁB
1/1000�Ƃ����Ă�̂́A�ŏ���65nm�v���Z�X��P1264�ɑ��āA��d�͌�����
P1265���Ƃ������ƂŁA����50M SRAM���x���Ń��[�N1/300�A���i�̓o���2007�Ƃ��B
Intel���v���Z�X�I�ɂ��Ή����Ă��Ă�悤�����A�v����ւ����킯�ŁA
���\�Ɠd�͂̃o�����X�͂悭�Ȃ邾��ˁB
AMD��65nm����������ƁB
�Â��͂��̕ӂ��ȁB
1/1000�Ƃ����Ă�̂́A�ŏ���65nm�v���Z�X��P1264�ɑ��āA��d�͌�����
P1265���Ƃ������ƂŁA����50M SRAM���x���Ń��[�N1/300�A���i�̓o���2007�Ƃ��B
Intel���v���Z�X�I�ɂ��Ή����Ă��Ă�悤�����A�v����ւ����킯�ŁA
���\�Ɠd�͂̃o�����X�͂悭�Ȃ邾��ˁB
AMD��65nm����������ƁB
IEDM 2005�̃v���O���������� - 45nm�ȍ~��z�肵���v�f�Z�p�̍u�������o
http://pcweb.mycom.co.jp/news/2005/11/17/005.html
��AMD�A��IBM�Ƃ̔����̋Z�p��g���g�� - 22nm�v���Z�X�������
http://pcweb.mycom.co.jp/news/2005/11/02/102.html
http://pcweb.mycom.co.jp/news/2005/11/17/005.html
��AMD�A��IBM�Ƃ̔����̋Z�p��g���g�� - 22nm�v���Z�X�������
http://pcweb.mycom.co.jp/news/2005/11/02/102.html
>>843
�܂����ʂ�Xscale�Ȃp������A���ʂ�CPU�ɂ͊W�Ȃ������ȁB
�܂����ʂ�Xscale�Ȃp������A���ʂ�CPU�ɂ͊W�Ȃ������ȁB
XScale���č��̂Ƃ���ARM�݊������Ǐ����I��Merom�A�[�L�e�N�`���ɓ��������Ȃ���������
>>849
���
���
x86�̃��C���R�A�{XScale�̃T�u�R�A���_�C�ɂ̂��āA
CELL�R�̃w�e���W�j�A�X�}���R�`�A��������Ȃ�I�I�I�P
����͂���Ŗʔ��������Ƃ͎v��Ȃ��ł��Ȃ��B
CELL�R�̃w�e���W�j�A�X�}���R�`�A��������Ȃ�I�I�I�P
����͂���Ŗʔ��������Ƃ͎v��Ȃ��ł��Ȃ��B
>>851
����́u��������v��Ȃ��āA�u�g�ݍ��ށv�Ƃ������ƂȂ̂ł́H
�u���̂Ƃ���ARM�݊������ǁv���Č������������������B
Merom��XScale�̃R�A��g�ݍ��Ƃ��Ă��AXScale���͕̂ς��Ȃ��킯�ŁB
����́u��������v��Ȃ��āA�u�g�ݍ��ށv�Ƃ������ƂȂ̂ł́H
�u���̂Ƃ���ARM�݊������ǁv���Č������������������B
Merom��XScale�̃R�A��g�ݍ��Ƃ��Ă��AXScale���͕̂ς��Ȃ��킯�ŁB
����P����ARM�݊��v���Z�b�T�̐�����߂�Merom�A�[�L�����o�C���g�ݍ��ݗp�ɏo�����Ă���
�܂�Intel�����Ă��܂ł��uARM�݊��v���Z�b�T�v��肽���Ȃ�����B
�{��ARM��WirelessMMX�Ɣ�݊���SIMD���ڂ������_�ł��Ȃ�����ɂȂ������B
�ł������A�����܂œd�͗��Ƃ���̂��^��Ȃ��B
�܂��A�d�͂�����������猾���A���߂̕ϊ��R�X�g�̑傫��x86���
���l�C�e�B�u��RISC�v���Z�b�T�ł���ARM�̂ق��������Ǝv�����ǂȁB
�܂�Intel�����Ă��܂ł��uARM�݊��v���Z�b�T�v��肽���Ȃ�����B
�{��ARM��WirelessMMX�Ɣ�݊���SIMD���ڂ������_�ł��Ȃ�����ɂȂ������B
�ł������A�����܂œd�͗��Ƃ���̂��^��Ȃ��B
�܂��A�d�͂�����������猾���A���߂̕ϊ��R�X�g�̑傫��x86���
���l�C�e�B�u��RISC�v���Z�b�T�ł���ARM�̂ق��������Ǝv�����ǂȁB
>>853
���ʂɍl����AIntel������ARM�݊��v���Z�b�T�͍�肽������B
���ƁAMerom���ĒP�������炾�Ǝv���Ă�́H
����d�͂��Ⴍ�Ȃ���ˁH
�قƂ�ǂ̑g�ݍ��݂ɂ͌����Ȃ��Ǝv�����ǁB
���ʂɍl����AIntel������ARM�݊��v���Z�b�T�͍�肽������B
���ƁAMerom���ĒP�������炾�Ǝv���Ă�́H
����d�͂��Ⴍ�Ȃ���ˁH
�قƂ�ǂ̑g�ݍ��݂ɂ͌����Ȃ��Ǝv�����ǁB
�܂���k�͂��Ă����āA���낻��X���^�C�ǂ����ȁB
���Ⴀ�X���^�C�ɂ�����
Geode�������A6W����ł������đg�ݍ��݂ł͊���ꂪ������
Geode�������A6W����ł������đg�ݍ��݂ł͊���ꂪ������
Geode���Č����Ă�GX����NX�܂ł��邵�Ȃ��B
GX�̉��ɂ�Alchemy�����邵�B
�܂�6W���Č�������ɂ�NX���낤���ǁA�������VIA��Eden�����o�����s���_���Ă邩��ł��������Ăقǂ���Ȃ��ȁB
GX�̉��ɂ�Alchemy�����邵�B
�܂�6W���Č�������ɂ�NX���낤���ǁA�������VIA��Eden�����o�����s���_���Ă邩��ł��������Ăقǂ���Ȃ��ȁB
���̃X���A�A�i���X�g�f�C�ɑ��Ă̘b�͑S���Ȃ��B
�����ˁB
�����ˁB
�ނ��ȂďW�܂�Ɛ\���܂��ĂȁB
6����AnalystDay��2007�N�ɐV�R�A���ăX���C�h�͏o�Ă����ǂȁB
�R�v���Z�T�͍ŋߐF��ȊC�O�T�C�g�ŋL���ɂȂ��Ă����A������߂Ċm�F���ꂽ�����œ��e�Ƃ��Ă͖ڐV���������B
�R�v���Z�T�͍ŋߐF��ȊC�O�T�C�g�ŋL���ɂȂ��Ă����A������߂Ċm�F���ꂽ�����œ��e�Ƃ��Ă͖ڐV���������B
�R�v���̃A�v���[�`�͈�ɂ���ɂ��@���ɂ��āA
�\�t�g��n�[�h�x���_��������āA�Ή������邩�Ɋ|�����Ă��ˁB
�\�t�g��n�[�h�x���_��������āA�Ή������邩�Ɋ|�����Ă��ˁB
Cell��SPE���R�v���ƌĂԂ��ĂȂ���
�����͂����Ă�ł�z�炪����������
�����͂����Ă�ł�z�炪����������
EDEN���n���Ƀp���[�A�b�v����͗l����
ttp://pcweb.mycom.co.jp/articles/2005/11/16/c7/
���NGeode�̕��͂Ȃω�����̂�����
ttp://pcweb.mycom.co.jp/articles/2005/11/16/c7/
���NGeode�̕��͂Ȃω�����̂�����
�z���g��AMD���ǂ������Ă���̂��Ɩ₢�����B
���̃X���C�h�͓K�����ׂĂ邾���ŕ��������悭�����Ȃ��̂����B
L3�x�[�X��32S�V�X�e���ƁA�t�H�[���g�g�������gI/O�Ƃ�
AMD���~�h���N���X�ȏ�̃T�[�o�ɖ{�i�i�o����C�̂悤����B
>2006�N�ɂ�TCP Offload Engine�Ƃ���̂ŁC�R�v���Z�T�̃T�|�[�g�͂�����w���Ă���Ǝv���܂��B
���̃X���C�h�͓K�����ׂĂ邾���ŕ��������悭�����Ȃ��̂����B
L3�x�[�X��32S�V�X�e���ƁA�t�H�[���g�g�������gI/O�Ƃ�
AMD���~�h���N���X�ȏ�̃T�[�o�ɖ{�i�i�o����C�̂悤����B
>2006�N�ɂ�TCP Offload Engine�Ƃ���̂ŁC�R�v���Z�T�̃T�|�[�g�͂�����w���Ă���Ǝv���܂��B
�N�Ƀ��X���ĂH
����̃X���C�h��6���̎g���œ��ɖڐV��������������������d���Ȃ��낤�B
����̃X���C�h��6���̎g���œ��ɖڐV��������������������d���Ȃ��낤�B
>>867
���̈��p�����́A���̐l�̊��Ⴂ���Ǝv���B
TCP Offload�̓`�b�v�Z�b�g�Ƃ����ӊ��ŁA�����Ȃ�܂��Ƃ������ƁB
��`�b�v�R�v���Ƃ͑S�R�W�Ȃ��B
���̈��p�����́A���̐l�̊��Ⴂ���Ǝv���B
TCP Offload�̓`�b�v�Z�b�g�Ƃ����ӊ��ŁA�����Ȃ�܂��Ƃ������ƁB
��`�b�v�R�v���Ƃ͑S�R�W�Ȃ��B
turion��64���ĉ����Ⴄ�����H
�d�����Ⴄ�̂��H
�d�����Ⴄ�̂��H
Athlon64�̒�d����
�����d�͔ŁB
�����d��/���g���ɂ������ē�������d�͂���Ȃ����B
���܂̂Ƃ���R�Arev.��Turion64/mobile64��E5�ł������ˁB
�����d��/���g���ɂ������ē�������d�͂���Ȃ����B
���܂̂Ƃ���R�Arev.��Turion64/mobile64��E5�ł������ˁB
874 �FSocket774�F2005/11/25(��) 17:18:42 ID:Zs0tdjS9
�����ヂ�o�C���X�[�c�i�j
875 �FSocket774�F2005/11/25(��) 17:29:03 ID:jo0CJgtx
�މ�
������CPU���C�ɂȂ邯�ǁAAMD���g�͂���p��߾Ă͍���ă��́H
�C���e���̓��@�C��������A
�`�l�c�̓��[�^�[�Ƃ��I�i�j�[�z�[��������ł���Ȃ��H��
�`�l�c�̓��[�^�[�Ƃ��I�i�j�[�z�[��������ł���Ȃ��H��
�I�����_�R�A�ŁB
�Ȃ��AMD�͐�p�̃`�b�v�Z�b�g����Ȃ��̂ł����H
>>879
��{�I�ɂ͉Ɠ�����H�Ƃ����S�́A�l�o�c�̏��K�͎��Ə�������B
�F��Ȏ��Ɏ���L��������ƁA���r���[�ɂȂ��Čo�c�������s���Ȃ��Ȃ�B
��{�I�ɂ͉Ɠ�����H�Ƃ����S�́A�l�o�c�̏��K�͎��Ə�������B
�F��Ȏ��Ɏ���L��������ƁA���r���[�ɂȂ��Čo�c�������s���Ȃ��Ȃ�B
Intel��AMD���᎖�ƋK�͂��ꌅ���炢�Ⴄ����ȁB�K�`���R�ŏ������Đ��\�ʂ�
�����Ă錻��̂ق����A���Ȃ�ُ�ȏ�ԁB
Intel���w�^���Ƃ��������E�E�E�B
�����Ă錻��̂ق����A���Ȃ�ُ�ȏ�ԁB
Intel���w�^���Ƃ��������E�E�E�B
�u�K�`���R�ŏ�������AMD�������Ă�v�ƌ������A
intel�ɕs���ȃn���f�B�L���b�v�}�b�`����������ˁB
AMD�������G�{�Aintel���L�����^�[�ɏ����
�����Ńo�g�����Ă���悤�Ȃ��B
����ȁuAMD�ɂƂ��Ă͏����Ă�����܂��v�̏�����
�����I�ɂ͑債�������t�����ƂȂ�
�s�b�^�����ɕt���Ă���intel�A��͂苰��ׂ��B
�������ɖ����ȏ��ƋC�t���A
���������œ����y�U�ɗ�����intel��
AMD�����Ă闝�R�Ȃǁw�����Ȃ��x�B
intel�ɕs���ȃn���f�B�L���b�v�}�b�`����������ˁB
AMD�������G�{�Aintel���L�����^�[�ɏ����
�����Ńo�g�����Ă���悤�Ȃ��B
����ȁuAMD�ɂƂ��Ă͏����Ă�����܂��v�̏�����
�����I�ɂ͑債�������t�����ƂȂ�
�s�b�^�����ɕt���Ă���intel�A��͂苰��ׂ��B
�������ɖ����ȏ��ƋC�t���A
���������œ����y�U�ɗ�����intel��
AMD�����Ă闝�R�Ȃǁw�����Ȃ��x�B
884 �FT.A. ��Vr3ZLNzp5. �F2005/11/26(�y) 01:02:10 ID:anPU9Qr1
AMD vs Intel �̐킢�͂��ꂩ�炪�{�Ԃ���B
�ΐ�I�b�Y��
AMD�@�@Intel
20.0�@�F�@2.0
�ΐ�I�b�Y��
AMD�@�@Intel
20.0�@�F�@2.0
���Ă邪���������Ȃ�
�L�����^�[�œ����U�߂���A����͋��̗͂ɂ��Ƃ��낪�傫���A
�Ƃ������Ƃ���Ȃ��̂��H
�Ƃ������Ƃ���Ȃ��̂��H
AMD�̎�����햳���āAP6�̐i���̂悤�ɃL���b�V���ƃR�A���ƃ}���`���f�B�A���߂̒lj��������Ă��Ƃ�
���肵�Ă�݂����Ȃ�ŁA������(����)�̘b��Ŏ��炷�邷�B
http://www.c627627.com/AMD/Athlon64/
Socket M2�œd�͏������ɘa���āA���N���ɂ�3GHz(FX-64)���B�̗\��Ƃ��B�B�B
�ł��z���g��A3GHz��V���O���R�A�������肵��(��)
���肵�Ă�݂����Ȃ�ŁA������(����)�̘b��Ŏ��炷�邷�B
http://www.c627627.com/AMD/Athlon64/
Socket M2�œd�͏������ɘa���āA���N���ɂ�3GHz(FX-64)���B�̗\��Ƃ��B�B�B
�ł��z���g��A3GHz��V���O���R�A�������肵��(��)
���̐Ԃ��L�����^�[�ɏ���Ă�z�́I�I
2.8GHz����Q�N�߂�������3GHz��
�����Q�[�}�[����CPU Athlon64 FX��
�����Q�[�}�[����CPU Athlon64 FX��
FX�̓N���b�N�A�b�v�ł��邩��Q�[�}�[�����Ȃ��B
���ɗǂ����̂�����Ȃ炻������������B
���ɗǂ����̂�����Ȃ炻������������B
892 �FMAC�I�^��891 �����F2005/11/26(�y) 14:45:41 ID:hvusnMtE
>>891
�@�@--------------------
�@�@FX�̓N���b�N�A�b�v�ł��邩��Q�[�}�[�����Ȃ��B
�@�@--------------------
���̏����Ȃ�A����Dothan���x�X�g�Ƃ������ƂɂȂ��Ă邷(��)
http://www.tomshardware.com/cpu/20050525/pentium4-10.html
�@�@--------------------
�@�@FX�̓N���b�N�A�b�v�ł��邩��Q�[�}�[�����Ȃ��B
�@�@--------------------
���̏����Ȃ�A����Dothan���x�X�g�Ƃ������ƂɂȂ��Ă邷(��)
http://www.tomshardware.com/cpu/20050525/pentium4-10.html
2005�N�����̃g�b�v20�Ђ̗\���\
ttp://www.ebjapan.com/content/l_news/2005/11/25_top.html
ttp://www.ebjapan.com/content/l_news/2005/11/25_top.html
���Ƃ������ɂ̓f�[�^�Â��ˁH
>888
�ł��z���g��A3GHz��V���O���R�A�������肵��(��)
�̍����́H
�ł��z���g��A3GHz��V���O���R�A�������肵��(��)
�̍����́H
>>896
�ϑz�Ɍ��܂��Ă邶���B
���̃T�C�g����10���܂ł͗��NQ1�ɃV���O���R�A��3GHz���ė\�z��������ˁB
MAC�I�^�͂��̌o�܂���m��Ȃ��ƌ�����B
�ϑz�Ɍ��܂��Ă邶���B
���̃T�C�g����10���܂ł͗��NQ1�ɃV���O���R�A��3GHz���ė\�z��������ˁB
MAC�I�^�͂��̌o�܂���m��Ȃ��ƌ�����B
Opteron144/146��OC�X�����Ă�ƁA���̃v���Z�X����3.0GHz�ʂɕǂ����肻������
SocketM2��Dual�R�A�ł�3.0GHz�܂ʼn�Ηǂ��Ȃ��c
SocketM2��Dual�R�A�ł�3.0GHz�܂ʼn�Ηǂ��Ȃ��c
>>896 ����
�ǂ��l���Ă�������Ńf���A���R�A��3GHz�̃v���Z�b�T���Ă̂탄�o���������B
>>897 ����
����@���Ă�AMD�̃��[�h�}�b�v��������Ȃ�����B�J�����Ԃ��l����Ƃ�����x�ꂾ���B�B�B
�ǂ��l���Ă�������Ńf���A���R�A��3GHz�̃v���Z�b�T���Ă̂탄�o���������B
>>897 ����
����@���Ă�AMD�̃��[�h�}�b�v��������Ȃ�����B�J�����Ԃ��l����Ƃ�����x�ꂾ���B�B�B
�R�A�͓����ł�������A���������Aexclusive cache ����߂ė~�����B
IPC ���� PenM �ɕ����Ă闝�R�ɁA�C�}�C�`�[���������ĂȂ����ǁA
exclusive cache ���������Ȃ��̂��Ȃ��B
IPC ���� PenM �ɕ����Ă闝�R�ɁA�C�}�C�`�[���������ĂȂ����ǁA
exclusive cache ���������Ȃ��̂��Ȃ��B
Dual Core Turion�����̎��̃��o�C����pCPU�͋��L�L���b�V���ɂȂ�炵��
>>MAC�I�^��
���R���͂����茾��Ȃ��Ƃ����̖ϑz�ƕς��Ȃ���[����
���R���͂����茾��Ȃ��Ƃ����̖ϑz�ƕς��Ȃ���[����
MAC�I�^�����߂�
�Ă�����60nm�Ɉڍs���Ă���̘b�����Ǝv���Ă���
�Ă�����60nm�Ɉڍs���Ă���̘b�����Ǝv���Ă���
����4800+��1.4V���Ƃ����1.35V���炢�ɉ������TDP125W�g��3GHz�f���A���R�A�͉\�������ȁB
�P���v�Z�����ǁB
��O����cSi��65nm�ł����g��Ȃ��̂��Ȃ��B
�P���v�Z�����ǁB
��O����cSi��65nm�ł����g��Ȃ��̂��Ȃ��B
>>900
�ŏ���L2�L���V��256kB��opteron�����\�肾���������
���̂悤�ɂȂ���Ă킩���Ă���Aexclusive�Ȃ�Ă���ĂȂ��������낤
����IPC ���� PenM �ɕ����Ă闝�R�ɁA�C�}�C�`�[���������ĂȂ����ǁA
����exclusive cache ���������Ȃ��̂��Ȃ��B
���낤��
�ŏ���L2�L���V��256kB��opteron�����\�肾���������
���̂悤�ɂȂ���Ă킩���Ă���Aexclusive�Ȃ�Ă���ĂȂ��������낤
����IPC ���� PenM �ɕ����Ă闝�R�ɁA�C�}�C�`�[���������ĂȂ����ǁA
����exclusive cache ���������Ȃ��̂��Ȃ��B
���낤��
906 �FMAC�I�^��900, 905 �����F2005/11/26(�y) 17:15:22 ID:hvusnMtE
>>900, >>905
�@�@---------------------
�@�@exclusive cache ���������Ȃ��̂��Ȃ��B
�@�@---------------------
����ȏ�������Ƃ��l����O��L2�������Ȃ��ƂɋC�t���ׂ��ł�H
�@�@---------------------
�@�@exclusive cache ���������Ȃ��̂��Ȃ��B
�@�@---------------------
����ȏ�������Ƃ��l����O��L2�������Ȃ��ƂɋC�t���ׂ��ł�H
>>900
���̃L���b�V��������܂߂�Banias�A�[�L�e�N�`�����̂��D��Ă��邩��B
�o�X��C�����������܂߂�ƃV�X�e���S�̂̃X���[�v�b�g��K8�̕����f�R�������ǂˁB
���̃L���b�V��������܂߂�Banias�A�[�L�e�N�`�����̂��D��Ă��邩��B
�o�X��C�����������܂߂�ƃV�X�e���S�̂̃X���[�v�b�g��K8�̕����f�R�������ǂˁB
>>891
FX�̓Q�[���ړI�Ȃ�N���b�N�A�b�v���ۏ���Ă��ł�����
FX�̓Q�[���ړI�Ȃ�N���b�N�A�b�v���ۏ���Ă��ł�����
NexGen �ŋ��B
>>906
�������A�����������ʂ����锤�����ǁA���ꂾ������Ȃ��B
���Ƃ��� SPECint �� gzip �ł��APenM �̕����N���b�N������
�̐��\���� 6% �������ǁAgzip �̏ꍇ�A1M �� L2 cache ��
�v���Z�X�S�̂����܂�Ǝv���邩��AL2 �̃T�C�Y�͑S��
�W���ĂȂ����B
���� SPECint �ł��Aeon ������� Athlon 64 �̕����A�N���b�N
������̐��\�ł��������ǂˁB
�������A�����������ʂ����锤�����ǁA���ꂾ������Ȃ��B
���Ƃ��� SPECint �� gzip �ł��APenM �̕����N���b�N������
�̐��\���� 6% �������ǁAgzip �̏ꍇ�A1M �� L2 cache ��
�v���Z�X�S�̂����܂�Ǝv���邩��AL2 �̃T�C�Y�͑S��
�W���ĂȂ����B
���� SPECint �ł��Aeon ������� Athlon 64 �̕����A�N���b�N
������̐��\�ł��������ǂˁB
AMD�̎���CPU�R�A�uK9�v��2005�N�ɓo�ꂩ
http://pc.watch.impress.co.jp/docs/2003/0912/kaigai022.htm
http://pc.watch.impress.co.jp/docs/2003/0912/kaigai022.htm
>>892
INTEL���悾���A�����������肩���͂���Ȃ�ł́B
���Ƃ͎����\����ŁB�Q�[���x���`�Ő��\���łȂ��Ȃ炠��܈Ӗ��͂Ȃ�����ˁB
>>908
�u�N���b�N�A�b�v�ݒ肪�\�v�Ȃ��Ƃ��ۏ���Ă܂��B
�������Q�[�}�[��}�j�A�̓��y�`�b�v�Ƃ����Ĕ����Ă����B
�������ǂ����͕ۏ��ĂȂ��B�t�F���[���݂����Ȃ���ł���B
INTEL���悾���A�����������肩���͂���Ȃ�ł́B
���Ƃ͎����\����ŁB�Q�[���x���`�Ő��\���łȂ��Ȃ炠��܈Ӗ��͂Ȃ�����ˁB
>>908
�u�N���b�N�A�b�v�ݒ肪�\�v�Ȃ��Ƃ��ۏ���Ă܂��B
�������Q�[�}�[��}�j�A�̓��y�`�b�v�Ƃ����Ĕ����Ă����B
�������ǂ����͕ۏ��ĂȂ��B�t�F���[���݂����Ȃ���ł���B
>>899
���Ⴊ���邶���B������łR�R�A��3.2Ghz�Ȃ���B������TMSC�����B
���Ⴊ���邶���B������łR�R�A��3.2Ghz�Ȃ���B������TMSC�����B
>>907
> ���̃L���b�V��������܂߂�Banias�A�[�L�e�N�`�����̂��D��Ă��邩��B
�P���Ƀf�R�[�_�≉�Z��̐��Ŕ�ׂ�ƁA�������A�ނ��� Athlon 64 ��
����������Ȃ��H ���ߒP�ʂ̃X���[�v�b�g��C�e���V�ł����F
�Ȃ��݂��������B
> �o�X��C�����������܂߂�ƃV�X�e���S�̂̃X���[�v�b�g��K8�̕����f�R
> �������ǂˁB
�Ƃ������P���ɃN���b�N����������A�N���b�N������Ŕ�ׂ��Ȃ��āA
��ΐ��\�Ŕ�ׂ邾���� K8 �̕����������ǁB
��������o�X���������Ȃ�A�N���b�N�������قǃN���b�N������̐��\��
�s���ɂȂ�̂����ʂ����� (����������āAXeon �̓N���b�N������̐��\
���ƁAAthlon 64 �� 2/3 �� SPECint �����o�Ȃ�)�APenM �̏ꍇ�A������
�o���h�������C�e���V���A�N���b�N��ȏ�� Athlon 64 ���x����ˁB
> ���̃L���b�V��������܂߂�Banias�A�[�L�e�N�`�����̂��D��Ă��邩��B
�P���Ƀf�R�[�_�≉�Z��̐��Ŕ�ׂ�ƁA�������A�ނ��� Athlon 64 ��
����������Ȃ��H ���ߒP�ʂ̃X���[�v�b�g��C�e���V�ł����F
�Ȃ��݂��������B
> �o�X��C�����������܂߂�ƃV�X�e���S�̂̃X���[�v�b�g��K8�̕����f�R
> �������ǂˁB
�Ƃ������P���ɃN���b�N����������A�N���b�N������Ŕ�ׂ��Ȃ��āA
��ΐ��\�Ŕ�ׂ邾���� K8 �̕����������ǁB
��������o�X���������Ȃ�A�N���b�N�������قǃN���b�N������̐��\��
�s���ɂȂ�̂����ʂ����� (����������āAXeon �̓N���b�N������̐��\
���ƁAAthlon 64 �� 2/3 �� SPECint �����o�Ȃ�)�APenM �̏ꍇ�A������
�o���h�������C�e���V���A�N���b�N��ȏ�� Athlon 64 ���x����ˁB
�[������FX��65nm���낤�H
�������3Ghz���Č��t�͓��Ă͂܂�Ȃ��Ǝv�����B
MAC�I�^�U�҂��H
�������3Ghz���Č��t�͓��Ă͂܂�Ȃ��Ǝv�����B
MAC�I�^�U�҂��H
916 �FMAC�I�^��914 �����F2005/11/26(�y) 19:40:34 ID:hvusnMtE
>>914
�@�@--------------------
�@�@��ΐ��\�Ŕ�ׂ邾���� K8 �̕����������ǁB
�@�@--------------------
�m�[�g�p�̕Ȃ�OC����ƃQ�[���ł��\�����\����PenM�����ǁA���Ȃ����������Ă���悤�ȂQ����˂���
���[�v�����Ȃ�A��i��PenM���ΐ��\���\�����B
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=0&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1
�@�@--------------------
�@�@��ΐ��\�Ŕ�ׂ邾���� K8 �̕����������ǁB
�@�@--------------------
�m�[�g�p�̕Ȃ�OC����ƃQ�[���ł��\�����\����PenM�����ǁA���Ȃ����������Ă���悤�ȂQ����˂���
���[�v�����Ȃ�A��i��PenM���ΐ��\���\�����B
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=0&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1
>>916
���ꌾ���o����P6�ł��\���Ȗ�ŁE�E�E
���ꌾ���o����P6�ł��\���Ȗ�ŁE�E�E
919 �FMAC�I�^��918 �����F2005/11/26(�y) 20:06:11 ID:hvusnMtE
>>918
�����N��ǂ�ŗ~�������BPenM�m�[�g��Athlon64 FX-55�Ƃقړ������\������B
����AFX-55�Ȃ��AMD���[�U�[�̃��[�G���h�\���Ȃ��Č�����Ύd���Ȃ�������(��)
�����N��ǂ�ŗ~�������BPenM�m�[�g��Athlon64 FX-55�Ƃقړ������\������B
����AFX-55�Ȃ��AMD���[�U�[�̃��[�G���h�\���Ȃ��Č�����Ύd���Ȃ�������(��)
>>913
XBox360�̐̂��Ƃ����Ă�H�p�C�v���C����P��������Α����͍������ł��邾�낤����
�_�����W�X�^���̏��Ȃ�x86��OoO�E���W�X�^���l�[�~���O�������ƌ�������Ȃ��́H
��������NetBurst�����ȁB�i�N���b�N�����́j�ő��̃f���A���R�ACPU������ˁB
XBox360�̐̂��Ƃ����Ă�H�p�C�v���C����P��������Α����͍������ł��邾�낤����
�_�����W�X�^���̏��Ȃ�x86��OoO�E���W�X�^���l�[�~���O�������ƌ�������Ȃ��́H
��������NetBurst�����ȁB�i�N���b�N�����́j�ő��̃f���A���R�ACPU������ˁB
921 �FMAC�I�^��920 �����F2005/11/26(�y) 20:15:31 ID:hvusnMtE
>>920
xcpu��IBM��������A��X�̒m��Ȃ��]���v���Z�b�T���Ǝv�����B
xcpu��IBM��������A��X�̒m��Ȃ��]���v���Z�b�T���Ǝv�����B
>>916
2ch ��[�v�������Ȃ�A�m���ɔ��M�����Ȃ� Pentium M �̕����������낤�ˁB
�ł��A���������p�r�ɂ� Pentium III-M �̃m�[�g���g���Ă�̂�B
AMD ���g���Ă�̂́A�\�t�g�E�F�A�J���p�r�Ȃ́B
�t���r���h�����1���Ԉȏォ����̂ŁA���Ƃ���10%�̈Ⴂ�ł����\�͏d�v
�Ȃ��ǁA���� make �́A�}���`�R�A���łقڃ��j�A�ɐ��\�����シ��
(make depend �ƃ����N�t�F�[�Y������) �킯�ŁA���� Athlon 64 X2 ���ƁA
Pentium M �ɔ�ׂāA�ԈႢ�Ȃ��{�ȏ㑬���B
Yonah ���o�Ă��A�܂��A���������p�r�Ȃ� Athlon 64 X2 �̕���
������Ȃ����ȁB����ɁAConroe ���o�Ă��A�܂����̃}�V����
�������p�͂���Ȃ��̂ŁA�����ւ��͂Ȃ��ł��B
���ƁA�����2ch��[�v���Ŏg���ĂȂ��ƌ��߂��Ȃ��悤�ɁB
2ch ��[�v�������Ȃ�A�m���ɔ��M�����Ȃ� Pentium M �̕����������낤�ˁB
�ł��A���������p�r�ɂ� Pentium III-M �̃m�[�g���g���Ă�̂�B
AMD ���g���Ă�̂́A�\�t�g�E�F�A�J���p�r�Ȃ́B
�t���r���h�����1���Ԉȏォ����̂ŁA���Ƃ���10%�̈Ⴂ�ł����\�͏d�v
�Ȃ��ǁA���� make �́A�}���`�R�A���łقڃ��j�A�ɐ��\�����シ��
(make depend �ƃ����N�t�F�[�Y������) �킯�ŁA���� Athlon 64 X2 ���ƁA
Pentium M �ɔ�ׂāA�ԈႢ�Ȃ��{�ȏ㑬���B
Yonah ���o�Ă��A�܂��A���������p�r�Ȃ� Athlon 64 X2 �̕���
������Ȃ����ȁB����ɁAConroe ���o�Ă��A�܂����̃}�V����
�������p�͂���Ȃ��̂ŁA�����ւ��͂Ȃ��ł��B
���ƁA�����2ch��[�v���Ŏg���ĂȂ��ƌ��߂��Ȃ��悤�ɁB
�肪���ׂ����B
> ���ƁA�����2ch��[�v���Ŏg���ĂȂ��ƌ��߂��Ȃ��悤�ɁB
�u�Ŏg���ĂȂ��v���u�ł����g���ĂȂ��v
�܂������ȊԈႢ�����ǁB
> ���ƁA�����2ch��[�v���Ŏg���ĂȂ��ƌ��߂��Ȃ��悤�ɁB
�u�Ŏg���ĂȂ��v���u�ł����g���ĂȂ��v
�܂������ȊԈႢ�����ǁB
�������ꂽBanias�̔閧�\�}�C�N���A�[�L�e�N�`���̋Z�p�I����
http://www.itmedia.co.jp/news/0209/11/nj00_baniasmicro.html
Banias��Pentium M�͂Ȃ������̂��H
http://ascii24.com/news/i/tech/article/2003/03/31/print/642800.html
�V���o�C���v���b�g�t�H�[�� Centrino - �p�t�H�[�}���X�E����d�́E���̂��ׂĂɔ���
http://pcweb.mycom.co.jp/special/2003/centrino/
http://www.itmedia.co.jp/news/0209/11/nj00_baniasmicro.html
Banias��Pentium M�͂Ȃ������̂��H
http://ascii24.com/news/i/tech/article/2003/03/31/print/642800.html
�V���o�C���v���b�g�t�H�[�� Centrino - �p�t�H�[�}���X�E����d�́E���̂��ׂĂɔ���
http://pcweb.mycom.co.jp/special/2003/centrino/
�����ɍڂ��Ă��� Pentium-M �̉��P�Ɠ��l�ȉ��P�́AAMD �̕��ł�
����Ă�ł���B
Dedicated Stack Manager �ɑΉ�������̂́A�Ȃ������������B
����Ă�ł���B
Dedicated Stack Manager �ɑΉ�������̂́A�Ȃ������������B
926 �F�l�`�b�I�[���X�Q�Q�����F2005/11/26(�y) 21:10:45 ID:SFafeJLl
>>922
�@�@(�@߁��)
�@�@(�@ �@�@�j�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ւ\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@ <�@<
�@�@�@ _, ,_ �@
�@�@(�@߄D�) �@
�@�@(�@ �@�@�j�@�@�@�@�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ց������\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@�@�@�@�@ <�@<
�@�@�@ _, ,_ �@
�@�@(�@߄D�) �@ �@�@�@����!!�@
�@�@(�@ �@�@�j�@�@ ��:;�@�@�@�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ց����T�h�R���\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@�@�@�@�@�@�@�@ <�@<
�@�@�@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ( ߄t� )
�@�@�@�@�@�@�@��:;�@�@�@�@�@�@�@�@�@�@�m�R�m |
���i��D����܁M�@�@�@�@.�G�Q�Qj�@<�@<
�y�j��
�@�@(�@߁��)
�@�@(�@ �@�@�j�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ւ\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@ <�@<
�@�@�@ _, ,_ �@
�@�@(�@߄D�) �@
�@�@(�@ �@�@�j�@�@�@�@�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ց������\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@�@�@�@�@ <�@<
�@�@�@ _, ,_ �@
�@�@(�@߄D�) �@ �@�@�@����!!�@
�@�@(�@ �@�@�j�@�@ ��:;�@�@�@�@�@�@�@�@�@(߄t߁@)
�@ �@|�@�ց����T�h�R���\�\�\�\�m�R�m | �@
�@ �@�� �܂i�@ �@�@�@�@�@�@�@�@�@�@�@�@ <�@<
�@�@�@ �@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ( ߄t� )
�@�@�@�@�@�@�@��:;�@�@�@�@�@�@�@�@�@�@�m�R�m |
���i��D����܁M�@�@�@�@.�G�Q�Qj�@<�@<
�y�j��
>>922
CeleronD��DirextX�J���E�e�X�g����Ă鉴�Ɏ��˂Ƃ����C���I������
���p�ł͂����ς�Pentium M������Ђ�PC������ۂǑ����B
boost�̃t���r���h���ԂŊm�F�B
>>925
�����B�����PentiumM�Ǝ��̂��́B
�p�C�v���C�������Hammer�ɂ�����Intel CPU�ɖ����@�\�Ƃ��ẮA
jcc���s�����O�ɕ���~�X�肵�Ĕj������f�[�^���ŏ����ɂ���@�\������B
��OPs�t���[�W�����ɋ߂����Ƃ͏���Athlon�������Ă��B
FSB�Ƃ��L���b�V�������Pentium III�̂ق������������B
CeleronD��DirextX�J���E�e�X�g����Ă鉴�Ɏ��˂Ƃ����C���I������
���p�ł͂����ς�Pentium M������Ђ�PC������ۂǑ����B
boost�̃t���r���h���ԂŊm�F�B
>>925
�����B�����PentiumM�Ǝ��̂��́B
�p�C�v���C�������Hammer�ɂ�����Intel CPU�ɖ����@�\�Ƃ��ẮA
jcc���s�����O�ɕ���~�X�肵�Ĕj������f�[�^���ŏ����ɂ���@�\������B
��OPs�t���[�W�����ɋ߂����Ƃ͏���Athlon�������Ă��B
FSB�Ƃ��L���b�V�������Pentium III�̂ق������������B
>927�̕����t���r���h��1���Ԃ�����p�r�Ȃ́H
>>928
�܂����̏ꍇ�͈ꉞ�������x���ˁB
�����ƃ��W���[���蕪���Ă�̂Ńt���r���h����P�[�X���̋H�����B
�e���v���[�g���ݑ��p����Ƃ��Ȃ�x���Ȃ邯�ǂ���ł�����Ȃɒx���Ȃ�Ȃ��B
Linux�J�[�l���ł�����Ȃɂł������ȁH������Ƒz���ł��Ȃ��B
�܂����̏ꍇ�͈ꉞ�������x���ˁB
�����ƃ��W���[���蕪���Ă�̂Ńt���r���h����P�[�X���̋H�����B
�e���v���[�g���ݑ��p����Ƃ��Ȃ�x���Ȃ邯�ǂ���ł�����Ȃɒx���Ȃ�Ȃ��B
Linux�J�[�l���ł�����Ȃɂł������ȁH������Ƒz���ł��Ȃ��B
> CeleronD��DirextX�J���E�e�X�g����Ă鉴�Ɏ��˂Ƃ����C���I������
�R���p�C���҂��Ŗ��ʂɂ��Ă��Ȃ�A���Ȃ� Athlon 64 X2 �����̂�
�����Ǝv����B���N�����܂ő҂��� Conroe �ł��������ǂ��B
�ł������Ȃ�A�R���p�C���҂��̓l�b�g���O���O�����鎞�Ԃ�����A
���܂�Z���Ȃ�̂��l�����̂��ȁB(w
> Linux�J�[�l���ł�����Ȃɂł������ȁH������Ƒz���ł��Ȃ��B
�J�[�l���������ƕ��P�ʂŏI��B
*BSD�n�̏ꍇ�Amake�ꔭ�ŃJ�[�l����������Ȃ��ă��[�U�����h�S��
������ǁA������t���r���h����ƈꎞ�ԉz����B
OpenOffice �͂���Ɍ����������Bmake���悤�Ƃ���ƁA�f�B�X�N��
4GB�Ƃ��A�����Ə�������B
�܂��A���ʂ͕ύX������make����������������A����Ȃɂ͂�����Ȃ����ǁB
�R���p�C���҂��Ŗ��ʂɂ��Ă��Ȃ�A���Ȃ� Athlon 64 X2 �����̂�
�����Ǝv����B���N�����܂ő҂��� Conroe �ł��������ǂ��B
�ł������Ȃ�A�R���p�C���҂��̓l�b�g���O���O�����鎞�Ԃ�����A
���܂�Z���Ȃ�̂��l�����̂��ȁB(w
> Linux�J�[�l���ł�����Ȃɂł������ȁH������Ƒz���ł��Ȃ��B
�J�[�l���������ƕ��P�ʂŏI��B
*BSD�n�̏ꍇ�Amake�ꔭ�ŃJ�[�l����������Ȃ��ă��[�U�����h�S��
������ǁA������t���r���h����ƈꎞ�ԉz����B
OpenOffice �͂���Ɍ����������Bmake���悤�Ƃ���ƁA�f�B�X�N��
4GB�Ƃ��A�����Ə�������B
�܂��A���ʂ͕ύX������make����������������A����Ȃɂ͂�����Ȃ����ǁB
X��(KDE�Ƃ�)���\�[�X����R���p�C������Ƌ����قǎ��Ԃ�����ˁB929�����������Ă݁Hw
>>931
���������ł��ꂾ���X���[�v�b�g�オ���Ă�����OP���t���[�W�����̗̍p���ꂽSSEx��
�X���[�v�b�g�������҂����Ă���ȁB�ł��炱��Ȑ����o��̂��Ƌ������炢�B
���������ł��ꂾ���X���[�v�b�g�オ���Ă�����OP���t���[�W�����̗̍p���ꂽSSEx��
�X���[�v�b�g�������҂����Ă���ȁB�ł��炱��Ȑ����o��̂��Ƌ������炢�B
���������B�����\�Ȃ͂���PentiumM����������Ȃ��B�B�B
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=0&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=50
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=0&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=50
x8664 �ł�x87�͎g���Ȃ��̂ł́H����Ȃ����amd�͓͗���Ă��Ȃ��B
>>934
SPECfp �̌��ʂ�����ł���B
���� Pentium-M �́A���������_���Z���\�͂����������ƂȂ��B
���Ԃ� Conroe �ł͒����Ă�Ǝv�����ǁB
ttp://www.spec.org/cpu2000/results/
�� SPECint2000 �� SPECfp2000 �̃����N��H��A
�������Z�ƕ��������_���Z�A���ꂼ��̌��ʂ��������B
SPECfp �̌��ʂ�����ł���B
���� Pentium-M �́A���������_���Z���\�͂����������ƂȂ��B
���Ԃ� Conroe �ł͒����Ă�Ǝv�����ǁB
ttp://www.spec.org/cpu2000/results/
�� SPECint2000 �� SPECfp2000 �̃����N��H��A
�������Z�ƕ��������_���Z�A���ꂼ��̌��ʂ��������B
���Ȃ����ŕ��ʂɓ����Ȃ��ƍ��遄x87
x87�ɂ��Ă���ӂ�Ȃ̂�64bit��Windows�����ŁA�e��PC-UNIX��x87��������ƃT�|�[�g���Ă�
x87�ɂ��Ă���ӂ�Ȃ̂�64bit��Windows�����ŁA�e��PC-UNIX��x87��������ƃT�|�[�g���Ă�
SPECint�̏���2000�z����Yonah���ȁH
��Βl�Ŕ�ׂ�����s������B����PenM�͏���d�͂��Ⴂ���瓯���d�͂Ȃ�v���Z�b�T���𑝂₹��B
�V���O���R�A�̃N���b�N�����萫�\�Ȃ�ǂ����FX�ɂ͋y�Ȃ����̂�Athlon64���͑����悤���B
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=7&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=20
�V���O���R�A�̃N���b�N�����萫�\�Ȃ�ǂ����FX�ɂ͋y�Ȃ����̂�Athlon64���͑����悤���B
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=7&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=20
>>937
�܂�SSEx����80�r�b�g���x���������g���Ȃ�����ȁBUNIX�n�͉Ȋw�Z�p���Z���邱�Ƃ����邩��ȁB
�܂�SSEx����80�r�b�g���x���������g���Ȃ�����ȁBUNIX�n�͉Ȋw�Z�p���Z���邱�Ƃ����邩��ȁB
>>938
�N���b�N������̐��\�����Ƃ����Ɠ����ł��A�\��ʂ�2.5GHz�ł�
�o��Ήz����v�Z�ɂȂ�ˁB
>>939
SPECint �� SPECfp �̂��ꂼ��ŁAPentium M �� Athlon 64 ��
��ׂČ���Ε����邯�ǁA�����Ȃ� Pentium M �́A�N���b�N������
�̐��\��������Ȃ��āA��ΐ��\�ł��������Ă��B
���������_�́A�����ɔ�ׂ�Ƃ��Ȃ藣����Ă�B
�N���b�N������̐��\�����Ƃ����Ɠ����ł��A�\��ʂ�2.5GHz�ł�
�o��Ήz����v�Z�ɂȂ�ˁB
>>939
SPECint �� SPECfp �̂��ꂼ��ŁAPentium M �� Athlon 64 ��
��ׂČ���Ε����邯�ǁA�����Ȃ� Pentium M �́A�N���b�N������
�̐��\��������Ȃ��āA��ΐ��\�ł��������Ă��B
���������_�́A�����ɔ�ׂ�Ƃ��Ȃ藣����Ă�B
�Е��̏���݂��Ĉ�ۑ����}��̂�Intel�M�҂���̈����N�Z���ˁB
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=6&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=20
http://www.aceshardware.com/SPECmine/index.jsp?b=2&s=6&v=1&if=0&if=1&a=0&a=1&a=2&a=3&a=4&a=5&a=7&ncf=1&nct=256&cpcf=1&cpct=2&mf=250&mt=3800&o=0&o=1&start=20
�܂����ӕs���ӂ�����̂͂��傤���Ȃ�����Ȃ����B
Yonah��M2��X2�̐��\���C�ɂȂ�
Yonah��M2��X2�̐��\���C�ɂȂ�
�wPenM�͕�̂�����̗̂ǂ�CPU���B�x�Ɨ_�߂�̂�BEST�B
>>942
����Ȗϑz�����ǁAYonah 2.16GHz�Œ�����Ǝv���Ă�����ǂˁB
����Ȗϑz�����ǁAYonah 2.16GHz�Œ�����Ǝv���Ă�����ǂˁB
>>922
�r���h1���Ԃ��ĕ����Đ̃R���p�C�����ԒZ�k��ړI�ɐV�s�@����������
��������v���o������
>>927
VS.NET(2003)��Banias�@�ł����X�|���X�݂���(߄t�)�ҼށA�k�X2.4CGHz��
��������������Ċ����������BAMD�͍ŋ�Op146�őg���ǎ����ĂȂ��B
JAVA�AdotNET�n�̐l�B���ĊJ���@�ǂ����Ă���ϼނŎv���B
JIT�R���p�C���ȃA�v�����S���ɂȂ�����(Vista?)�ɂ͎��s������������
�X���[�v�b�g���Ⴂ���ɑ���ɂȂ肻���Ȋ�K�X�B���������������m�V���b�N��
�܂܈��������ė~���������B
#����VC.NET�ŃA���}�l�[�W�h�R�[�h�ȓ��X�B���r���[�����邗
�r���h1���Ԃ��ĕ����Đ̃R���p�C�����ԒZ�k��ړI�ɐV�s�@����������
��������v���o������
>>927
VS.NET(2003)��Banias�@�ł����X�|���X�݂���(߄t�)�ҼށA�k�X2.4CGHz��
��������������Ċ����������BAMD�͍ŋ�Op146�őg���ǎ����ĂȂ��B
JAVA�AdotNET�n�̐l�B���ĊJ���@�ǂ����Ă���ϼނŎv���B
JIT�R���p�C���ȃA�v�����S���ɂȂ�����(Vista?)�ɂ͎��s������������
�X���[�v�b�g���Ⴂ���ɑ���ɂȂ肻���Ȋ�K�X�B���������������m�V���b�N��
�܂܈��������ė~���������B
#����VC.NET�ŃA���}�l�[�W�h�R�[�h�ȓ��X�B���r���[�����邗
948 �FMAC�I�^��931 �����F2005/11/27(��) 10:54:48 ID:OO2ZAKZn
>>931
�@�@---------------------
�@�@����g���Ȃ��Ȃ�x87���߂̂����ꂽ�Ŕ�ׂĂ��Ӗ��˂��B
�@�@---------------------
�����N�����SPECint2000�Ȃ��ǁB�B�B
���������邱�Ƃ��~�߂Ă��܂��Ɛl�Ԃ���A�����ɑމ�������Ă̂��ǂ�����R�����g���ӂ��邷�B
�@�@---------------------
�@�@����g���Ȃ��Ȃ�x87���߂̂����ꂽ�Ŕ�ׂĂ��Ӗ��˂��B
�@�@---------------------
�����N�����SPECint2000�Ȃ��ǁB�B�B
���������邱�Ƃ��~�߂Ă��܂��Ɛl�Ԃ���A�����ɑމ�������Ă̂��ǂ�����R�����g���ӂ��邷�B
>>949
�ԈႢ���w�E�����Ƃ��ꂩ��
�ԈႢ���w�E�����Ƃ��ꂩ��
>>947
Banias�Ŏg���Ă邯�ǃA�������X�|���X�݂��Ƃ͊����Ȃ����ǂȁB
IDE���Ƃ�����̊��ł��Ȃ��B
���Ǒ���肶��ˁH������256M���x�����ς�łȂ�������y�[�W���O���邩������HDD�̒x�����������B
.NET Framework 1.1��libdes�̃|�[�g�g�����ȒP�ȃx���`����Ă݂����Ƃ����邪�A
�N���b�N������ł�Banias/Dothan��Athlon�@���R���ȏ㑬�������B
���z���e�[�u���̕���\���킠��̂ƁA��{�I��VM�����̓X�^�b�N�}�V��������
��p�X�^�b�N�}�l�[�W���̂���Pentium M���L�����Ă��ƂŐ܂�ł͌������Ă�B
���ƁAWinFX(.NET Framework 2.0)�Ȃ�W�����ڂ͐摗��̂͂����B
Banias�Ŏg���Ă邯�ǃA�������X�|���X�݂��Ƃ͊����Ȃ����ǂȁB
IDE���Ƃ�����̊��ł��Ȃ��B
���Ǒ���肶��ˁH������256M���x�����ς�łȂ�������y�[�W���O���邩������HDD�̒x�����������B
.NET Framework 1.1��libdes�̃|�[�g�g�����ȒP�ȃx���`����Ă݂����Ƃ����邪�A
�N���b�N������ł�Banias/Dothan��Athlon�@���R���ȏ㑬�������B
���z���e�[�u���̕���\���킠��̂ƁA��{�I��VM�����̓X�^�b�N�}�V��������
��p�X�^�b�N�}�l�[�W���̂���Pentium M���L�����Ă��ƂŐ܂�ł͌������Ă�B
���ƁAWinFX(.NET Framework 2.0)�Ȃ�W�����ڂ͐摗��̂͂����B
�f�X�N�g�b�v�������C���i�b�v�����ׂă��o�C���v���Z�b�T�ɂȂ��Ă��܂������̂ɁE�E�E�Ǝv���B
��������ΔM���͑S����������̂ł́H
��������ΔM���͑S����������̂ł́H
�u�Q�[���ő������v���M�ł��d�C�H���ł��S�R�����B
K8�͂��̂܂܃��o�C���ɂ���ɂ͏璷�ȕ���������B
�E���͂ȕ��������_���Z���j�b�g
�E�R���v���b�N�X�f�R�[�_�~3
�t�Ɍ�����Turion�͂���ł悭�������܂ŏ���d�͂�}�����ȂƂ�������
�E���͂ȕ��������_���Z���j�b�g
�E�R���v���b�N�X�f�R�[�_�~3
�t�Ɍ�����Turion�͂���ł悭�������܂ŏ���d�͂�}�����ȂƂ�������
956 �FMAC�I�^��955 �����F2005/11/27(��) 13:41:26 ID:OO2ZAKZn
>>955
���̏璷�ȕ����Ƃ���Yonah�̓����ł����锤�����ǁA���ꃂ�o�C���v���Z�b�T���ᖳ�����������B�B�B
���̏璷�ȕ����Ƃ���Yonah�̓����ł����锤�����ǁA���ꃂ�o�C���v���Z�b�T���ᖳ�����������B�B�B
>>956
�Ƃ͌����Ă����������_���Z���j�b�g�́A���Ԃ�K8�Ƃ͂��Ȃ�K�͂��Ⴄ�ł���B
�����Yonah�͈�̂ǂ���������s�v�c�ł��傤���Ȃ����A���ꂾ�������Ȋg����
���Ă��Ȃ���A1�R�A������̃g�����W�X�^����Dothan�ȉ���Banias�Ɠ������B
���Ȃ݂�P6��PenM�i�������Yonah���j�A�V���v���f�R�[�_�~2�{�R���v���b�N�X�f�R�[�_�~1
�Ƃ͌����Ă����������_���Z���j�b�g�́A���Ԃ�K8�Ƃ͂��Ȃ�K�͂��Ⴄ�ł���B
�����Yonah�͈�̂ǂ���������s�v�c�ł��傤���Ȃ����A���ꂾ�������Ȋg����
���Ă��Ȃ���A1�R�A������̃g�����W�X�^����Dothan�ȉ���Banias�Ɠ������B
���Ȃ݂�P6��PenM�i�������Yonah���j�A�V���v���f�R�[�_�~2�{�R���v���b�N�X�f�R�[�_�~1
958 �FMAC�I�^��957 �����F2005/11/27(��) 14:09:24 ID:OO2ZAKZn
>>957
�f�R�[�_���傫�����P����Ă���̂펖�����B���ς�炸Simple x 2 + Complex x 1�Ƃ����\�����Ƃ��Ă�
Simple�f�R�[�_�Ńf�R�[�h�ł��閽�߂������Ă��������B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
�@�@-------------------
�@�@Photo10:SSE/SSE2���߂�S�Ẵf�R�[�_�ŏ����ł���Ƃ����b�����A�����Ŗ��m��
�@�@"All three decoders are..."�ƌ����Ă���A�f�R�[�_��3�ł���̂͊ԈႢ�Ȃ��������B
�@�@-------------------
�f�R�[�_���傫�����P����Ă���̂펖�����B���ς�炸Simple x 2 + Complex x 1�Ƃ����\�����Ƃ��Ă�
Simple�f�R�[�_�Ńf�R�[�h�ł��閽�߂������Ă��������B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
�@�@-------------------
�@�@Photo10:SSE/SSE2���߂�S�Ẵf�R�[�_�ŏ����ł���Ƃ����b�����A�����Ŗ��m��
�@�@"All three decoders are..."�ƌ����Ă���A�f�R�[�_��3�ł���̂͊ԈႢ�Ȃ��������B
�@�@-------------------
���߃f�R�[�_�̉��ǂɊւ��Ă͌㓡���G��Ƃ��
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
>>959
http://pcweb.mycom.co.jp/articles/2005/07/14/yonah/002.html
Banias�@�@CPU Core + L1 �� 2038�� - Bus I/F
Yonah�@�@(CPU Core + L1) * 2 �� 3836�� - Bus I/F
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
>>959
http://pcweb.mycom.co.jp/articles/2005/07/14/yonah/002.html
Banias�@�@CPU Core + L1 �� 2038�� - Bus I/F
Yonah�@�@(CPU Core + L1) * 2 �� 3836�� - Bus I/F
Yonah��Complex Decorder��1���B
�����Ax86���߂ƃ�OPs���P�F�P�őΉ������Ă��A���̕���Simple Decoder�ł��ʂ���B
�������A���s���j�b�g��RISC���̂܂�܂�����A���s�X�e�[�W�̎�O�ŕ������ĕʁX�ɉ��Z���A
�Č������ă��^�C������B��̓I�ɂ̓��W�X�^�E�������ԉ��Z�����B
���ꂪ��OP���t���[�W�����̎��ԁB
Athlon�̃f�R�[�_��DirectPath�~3��VectorPath�~1���r������Ȃ��������H
SSEx�̃p�b�N�h���Z��XP�ł�VectorPath�AK8�ł�DirectPath2���g�p���B
Athlon�̓f�R�[�_�����͂Ȃ�Ȃ��ăp�C�v���C�������͂�����f�R�[�_�̕��S�����点�Ă邾���B
���Ȃ݂�Pentium M�ł�SSE��ComplexDecorder�p�X�����烏�[�X�g�P�[�X�ł�AthlonXP��������
�i�ł�������MMX�܂ł̃V���v�����߂����f�R�[�h���邱�Ƃ͉\�j
�ŁACORE�iYonah�j��SSE�ɂ���OP���t���[�W������K�p�������߁A�S�p�X1���j�b�g�ŃX���[�v�b�g��
1�N���b�N��1���߃f�R�[�h�\������ASSE*�̃f�R�[�_�X���[�v�b�g�Ō���A������ŋ��ɂȂ�B
�i������SSE���Z�������҂����Ă�킯�����j
�܂������������j�b�g�������A����128�r�b�g������Ă����ȏ��H���̕K�v�Ȃ����ǂȁB
���ASIMD�̓f�R�[�_�̕��S�����Ȃ��̂�����Ȃ̂Ƀf�R�[�_�ōׂ����������Ȃ��Ƃ����Ȃ��͖̂{���]�|�B
�����A�f�R�[�_����͎����悤�Ȏ������Ǝv����B
Athlon�̂�����d�͍����̂́AALU��AGU��3�̃p�C�v1������U��ꂽ�肵��
�v����ɉ��Z���j�b�g�����ʂɃ��b�`�����炶��ˁ[�̂��HIntel�̓|�[�g���L���Ƃ����Č��\�P�`���������ɂ��Ă�B
���ƁAPenM�̓N���b�N�Q�[�e�B���O�������Ă邵�ˁB
�����Ax86���߂ƃ�OPs���P�F�P�őΉ������Ă��A���̕���Simple Decoder�ł��ʂ���B
�������A���s���j�b�g��RISC���̂܂�܂�����A���s�X�e�[�W�̎�O�ŕ������ĕʁX�ɉ��Z���A
�Č������ă��^�C������B��̓I�ɂ̓��W�X�^�E�������ԉ��Z�����B
���ꂪ��OP���t���[�W�����̎��ԁB
Athlon�̃f�R�[�_��DirectPath�~3��VectorPath�~1���r������Ȃ��������H
SSEx�̃p�b�N�h���Z��XP�ł�VectorPath�AK8�ł�DirectPath2���g�p���B
Athlon�̓f�R�[�_�����͂Ȃ�Ȃ��ăp�C�v���C�������͂�����f�R�[�_�̕��S�����点�Ă邾���B
���Ȃ݂�Pentium M�ł�SSE��ComplexDecorder�p�X�����烏�[�X�g�P�[�X�ł�AthlonXP��������
�i�ł�������MMX�܂ł̃V���v�����߂����f�R�[�h���邱�Ƃ͉\�j
�ŁACORE�iYonah�j��SSE�ɂ���OP���t���[�W������K�p�������߁A�S�p�X1���j�b�g�ŃX���[�v�b�g��
1�N���b�N��1���߃f�R�[�h�\������ASSE*�̃f�R�[�_�X���[�v�b�g�Ō���A������ŋ��ɂȂ�B
�i������SSE���Z�������҂����Ă�킯�����j
�܂������������j�b�g�������A����128�r�b�g������Ă����ȏ��H���̕K�v�Ȃ����ǂȁB
���ASIMD�̓f�R�[�_�̕��S�����Ȃ��̂�����Ȃ̂Ƀf�R�[�_�ōׂ����������Ȃ��Ƃ����Ȃ��͖̂{���]�|�B
�����A�f�R�[�_����͎����悤�Ȏ������Ǝv����B
Athlon�̂�����d�͍����̂́AALU��AGU��3�̃p�C�v1������U��ꂽ�肵��
�v����ɉ��Z���j�b�g�����ʂɃ��b�`�����炶��ˁ[�̂��HIntel�̓|�[�g���L���Ƃ����Č��\�P�`���������ɂ��Ă�B
���ƁAPenM�̓N���b�N�Q�[�e�B���O�������Ă邵�ˁB
>>960
���̑匴�v�Z�͂͂�����Ȃ̂ŐM���Ȃ������g�̂��߁B
���̑匴�v�Z�͂͂�����Ȃ̂ŐM���Ȃ������g�̂��߁B
{kind=link}
�͂�����Ƃ����̂͌����߂������A���ʂ̉��߂Ȃǂ��ԈႢ�B
�܂��A
Dothan��1000���P�ʂŃg�����W�X�^�������\����Ă��邪�A
Yonah��10���P�ʂŔ��\����Ă���B
���̂��Ƃ���A10���P�ʂŊe�R�A�̃g�����W�X�^���̌��ς�����o���Ĕ�r����͖̂��������邵�A
�\�[�X�̏o�����قȂ�\�������邽�߁A���̃g�����W�X�^���̃J�E���g�@���̂��̂�
�Ⴂ������\��������(����1�g�����W�X�^�Ƃ���̂����̂��Ő�[��CMOS�ł͂�����������)�B
�Ⴆ�A�����R�A�ł��J���c�[�����Ⴆ�g�����W�X�^���̃J�E���g���ς���Ă��܂��B
�܂��A���ʂ����߂���̂�Banias 2�Ƃ����̂͂ǂ��Ђ����߂ɂ݂Ă������߂��낤�B
65nm�ł͒����d�͉��̂��߂̃g�����W�X�^���ꕔ�s�v�ɂȂ�A�g�����W�X�^�����������Ƃ��A
�œK���c�[�������͂ɂȂ�A�s�v�ȃg�����W�X�^�������ʓI�ɒׂ��Ă��ꂽ
�Ƃ��̕������蓾��b���B
�܂��A
Dothan��1000���P�ʂŃg�����W�X�^�������\����Ă��邪�A
Yonah��10���P�ʂŔ��\����Ă���B
���̂��Ƃ���A10���P�ʂŊe�R�A�̃g�����W�X�^���̌��ς�����o���Ĕ�r����͖̂��������邵�A
�\�[�X�̏o�����قȂ�\�������邽�߁A���̃g�����W�X�^���̃J�E���g�@���̂��̂�
�Ⴂ������\��������(����1�g�����W�X�^�Ƃ���̂����̂��Ő�[��CMOS�ł͂�����������)�B
�Ⴆ�A�����R�A�ł��J���c�[�����Ⴆ�g�����W�X�^���̃J�E���g���ς���Ă��܂��B
�܂��A���ʂ����߂���̂�Banias 2�Ƃ����̂͂ǂ��Ђ����߂ɂ݂Ă������߂��낤�B
65nm�ł͒����d�͉��̂��߂̃g�����W�X�^���ꕔ�s�v�ɂȂ�A�g�����W�X�^�����������Ƃ��A
�œK���c�[�������͂ɂȂ�A�s�v�ȃg�����W�X�^�������ʓI�ɒׂ��Ă��ꂽ
�Ƃ��̕������蓾��b���B
�P�ʂ̂��ƂȂ�đS�R�W�Ȃ��Ǝv�����B
Banias��100���P�ʂ����B
Banias��100���P�ʂ����B
�܂�PenM�͊J�����ԒZ�k�̂��߂�P6�A�[�L�̐v�𗬗p�����̂ő������ʂȕ��������������낤��
Yonah�̊J���ɂ�2���㕪�̊��Ԃ���₳��Ă邩��A���̕ӂ̍œK�����i��ł��B
Yonah�̊J���ɂ�2���㕪�̊��Ԃ���₳��Ă邩��A���̕ӂ̍œK�����i��ł��B
Intel�̎�����CPU
Yonah���^����X���͂����ł����H
Yonah���^����X���͂����ł����H
Intel�鍑�̋t�P
>>952
>���Ǒ���肶��ˁH������256M���x�����ς�łȂ�������y�[�W���O���邩������HDD�̒x�����������B
����40GB�߯�א���ŁA�m���Ɏ蔲���肾����>HDD
��������1GB�ς�ł���FSB400MHz��SingleChannel���삾�����_�͉��P��
�]�n���邩���B����ASP.NET�������̂�IIS�AIE������ł��d�������\�����B
i815�@����VS6.0�������ł�Eclipse��VS.NET��SharpDeveroper��
�������肾����IDE���x�Ȃ瑦�ᕉ�ׂƂ������Ƃ��Ȃ����ƁB(WIndowsForm
�x�[�X�̃A�v���ŃX�e�b�v���s�|�����Ƃ�����̑��\���܂ő҂�10�b�Ƃ�)
>���z���e�[�u���̕���\���킠��̂ƁA��{�I��VM�����̓X�^�b�N�}�V��������
>��p�X�^�b�N�}�l�[�W���̂���Pentium M���L�����Ă��ƂŐ܂�ł͌������Ă�B
�R��͒P���ɗ��U�I�ȃ��\�[�X����ɎQ�Ƃ������邱�Ƃ��l�b�N�Ȃ�����
�A�[�L�̗D��𑈓_�ɂ���Ƃ��܂ł��ꍞ�܂Ȃ��Ǝv���B���ނ����i�p�C�v���C����
����₤�܂ł��Ȃ��P���ȗv��(L1��e�ʁA�����)�Œx���āA����\�����x����
�����������͂��Ȃ������݂����ɂ����ƒ�x���ȂƂ��Ō����t����������Ȃ�?
(�g���[�X�L���b�V���̗p�͌��ǃA�[�L�̖��Ȃ̂����m��Ȃ����ǂ�)
>���ƁAWinFX(.NET Framework 2.0)�Ȃ�W�����ڂ͐摗��̂͂����B
�R��S�R�����ɕt���Ă����ĂȂ��B�}�s���ׂ����ȁB
>���Ǒ���肶��ˁH������256M���x�����ς�łȂ�������y�[�W���O���邩������HDD�̒x�����������B
����40GB�߯�א���ŁA�m���Ɏ蔲���肾����>HDD
��������1GB�ς�ł���FSB400MHz��SingleChannel���삾�����_�͉��P��
�]�n���邩���B����ASP.NET�������̂�IIS�AIE������ł��d�������\�����B
i815�@����VS6.0�������ł�Eclipse��VS.NET��SharpDeveroper��
�������肾����IDE���x�Ȃ瑦�ᕉ�ׂƂ������Ƃ��Ȃ����ƁB(WIndowsForm
�x�[�X�̃A�v���ŃX�e�b�v���s�|�����Ƃ�����̑��\���܂ő҂�10�b�Ƃ�)
>���z���e�[�u���̕���\���킠��̂ƁA��{�I��VM�����̓X�^�b�N�}�V��������
>��p�X�^�b�N�}�l�[�W���̂���Pentium M���L�����Ă��ƂŐ܂�ł͌������Ă�B
�R��͒P���ɗ��U�I�ȃ��\�[�X����ɎQ�Ƃ������邱�Ƃ��l�b�N�Ȃ�����
�A�[�L�̗D��𑈓_�ɂ���Ƃ��܂ł��ꍞ�܂Ȃ��Ǝv���B���ނ����i�p�C�v���C����
����₤�܂ł��Ȃ��P���ȗv��(L1��e�ʁA�����)�Œx���āA����\�����x����
�����������͂��Ȃ������݂����ɂ����ƒ�x���ȂƂ��Ō����t����������Ȃ�?
(�g���[�X�L���b�V���̗p�͌��ǃA�[�L�̖��Ȃ̂����m��Ȃ����ǂ�)
>���ƁAWinFX(.NET Framework 2.0)�Ȃ�W�����ڂ͐摗��̂͂����B
�R��S�R�����ɕt���Ă����ĂȂ��B�}�s���ׂ����ȁB
���W�b�N���g�����W�X�^����
Yonah��64 X2�̐�����1���x�����Ȃ��̂�
����Ⴗ����
Yonah��64 X2�̐�����1���x�����Ȃ��̂�
����Ⴗ����
971 �FMAC�I�^��970 �����F2005/11/27(��) 19:03:23 ID:OO2ZAKZn
>>970
������1���Ă̂���U���Ȃ̂�u���Ă����āA�ꉞ64-bit�v���Z�b�T�̂ق����g�����W�X�^���̂퓖����O���B
������1���Ă̂���U���Ȃ̂�u���Ă����āA�ꉞ64-bit�v���Z�b�T�̂ق����g�����W�X�^���̂퓖����O���B
�����ƌv�Z���ĂȂ������B������1�Ȃ킯�Ȃ���ȁB�������炢�ł����B
7480/3836 = 1.95
AMD dual core
2��3320���@Toledo
1��5400���@Manchester
7480���@�@�@L2����
7480/3836 = 1.95
AMD dual core
2��3320���@Toledo
1��5400���@Manchester
7480���@�@�@L2����
K8�̓������R���g���[���̕��̃g�����W�X�^�����\���邩��L2�������������ᑫ��Ȃ���B
http://ascii24.com/news/i/topi/article/2005/04/22/imageview/images772076.jpg.html
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_572_573^12896~96993,00.html
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_572_573^11210,00.html
���ߕt���̎ʐ^���Ăǂ��������H
{kind=link}
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_572_573^12896~96993,00.html
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_572_573^11210,00.html
���ߕt���̎ʐ^���Ăǂ��������H
975 �FMAC�I�^��974 �����F2005/11/27(��) 21:56:46 ID:OO2ZAKZn
>>974
���̕ӂ����ˁH
http://www.rojakpot.com/editorials/img/Opteron_die.jpg
http://www.chip-architect.com/news/opteron_dualcore_make_up.jpg
http://common.ziffdavisinternet.com/util_get_image/8/0,1311,sz=1&i=81699,00.jpg
���̕ӂ����ˁH
http://www.rojakpot.com/editorials/img/Opteron_die.jpg
{kind=link}
http://www.chip-architect.com/news/opteron_dualcore_make_up.jpg
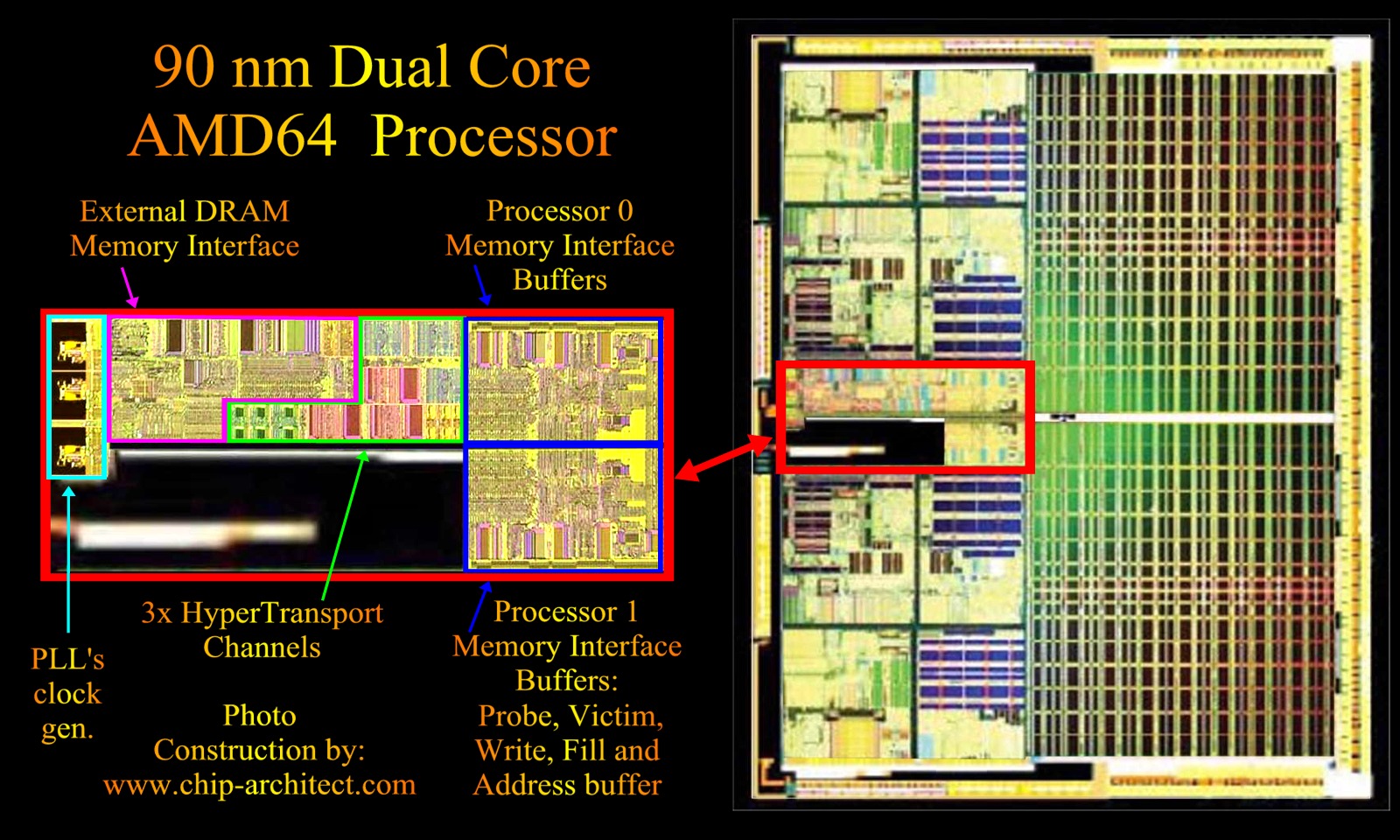{kind=link}
http://common.ziffdavisinternet.com/util_get_image/8/0,1311,sz=1&i=81699,00.jpg
{kind=link}
976 �F�l�`�b�I�[�F2005/11/27(��) 22:50:20 ID:o0jnttQN
{kind=link}
>>974
�V���O���R�A�͂�����
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai095.htm
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai06.jpg
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai07.jpg
�V���O���R�A�͂�����
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai095.htm
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai06.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2004/0609/kaigai07.jpg
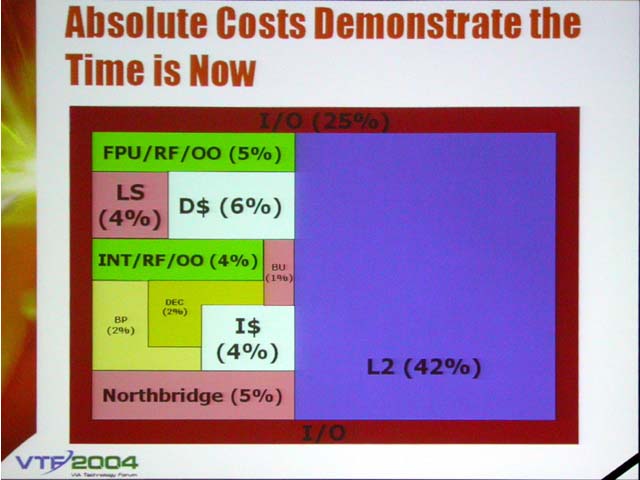{kind=link}
���̃X����MAC�I�^�Ɩ����Ȉ��~�A�Ґ~�����̃X���ƂȂ�܂���
M2��2.6GHz�̃f���A���R�A�����ǁA90nm�v���Z�X��TDP��95W�Ɏ��܂�݂����B
�܂������V�������ǂł������̂��ȁB
�o���4�����炢�H
���ꂪ�{�����Ƃ����3.0GHz�ł�����110W�g�Ɏ��܂����Ⴂ�����B
M2�ł�TDP��125W�܂ŋ������݂��������M�I�ɂ͑��v�������ȁB
�܂������V�������ǂł������̂��ȁB
�o���4�����炢�H
���ꂪ�{�����Ƃ����3.0GHz�ł�����110W�g�Ɏ��܂����Ⴂ�����B
M2�ł�TDP��125W�܂ŋ������݂��������M�I�ɂ͑��v�������ȁB
TDP��Intel��ɂȂ��˂��́H
>>981
TDP125W�ŋZ�p�I�ɂ͋�����邩������Ȃ����A���[�U�[�ɋ������́H
���ۂ�100W���x����A�Ƃ������Ă�̰݂Ƃ��������悤���Ȃ���
TDP125W�ŋZ�p�I�ɂ͋�����邩������Ȃ����A���[�U�[�ɋ������́H
���ۂ�100W���x����A�Ƃ������Ă�̰݂Ƃ��������悤���Ȃ���
�ł����[�N�d���Ȃǂւ̍��{�I�ȑ��65nm����ł���A�C���e���́B
AMD�͂ǂ��Ȃ��Ă�́H�H�H
AMD�͂ǂ��Ȃ��Ă�́H�H�H
AMD�̎�����CPU�ɂ��Č�낤�Q������
�������[�h�}�b�v
http://www.amdcompare.com/prodoutlook/
AMD���f���i���o�[�ꗗ�\
http://pc.watch.impress.co.jp/docs/article/modelno/amd.htm
�㓡2005/4/22�@�f���A���R�A�̃_�C�T�C�Y����킩��AMD��CPU�헪
http://pc.watch.impress.co.jp/docs/2005/0422/kaigai173.htm
���O�X��
1 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�������[�h�}�b�v
http://www.amdcompare.com/prodoutlook/
AMD���f���i���o�[�ꗗ�\
http://pc.watch.impress.co.jp/docs/article/modelno/amd.htm
�㓡2005/4/22�@�f���A���R�A�̃_�C�T�C�Y����킩��AMD��CPU�헪
http://pc.watch.impress.co.jp/docs/2005/0422/kaigai173.htm
���O�X��
1 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���X��
�h�������� vs �`�l�c�@part ZERO
http://pc7.2ch.net/test/read.cgi/jisaku/1114216223/l50
Pentium EE vs Athlon 64 X2 ��Live�Ō����X��(2)
http://pc7.2ch.net/test/read.cgi/jisaku/1119030161/l50
�C���e���̐��ނ�AMD�̔ɉh Part19
http://pc7.2ch.net/test/read.cgi/jisaku/1132625276/l50
Intel�̎�����CPU�ɂ��Č�낤 19
http://pc7.2ch.net/test/read.cgi/jisaku/1131783188/l50
�h�������� vs �`�l�c�@part ZERO
http://pc7.2ch.net/test/read.cgi/jisaku/1114216223/l50
Pentium EE vs Athlon 64 X2 ��Live�Ō����X��(2)
http://pc7.2ch.net/test/read.cgi/jisaku/1119030161/l50
�C���e���̐��ނ�AMD�̔ɉh Part19
http://pc7.2ch.net/test/read.cgi/jisaku/1132625276/l50
Intel�̎�����CPU�ɂ��Č�낤 19
http://pc7.2ch.net/test/read.cgi/jisaku/1131783188/l50
( �L�[�M)
(��ͥ)
(�L�E�ցE`)