Intelの次世代CPUについて語ろう 18
Intel製品の値段が安くなったり、性能が向上するのは
AMDのおかげででもあるんだぞ。
AMDが終わったら競争がなくなって、Intelはぼったくりはじめるぞ。
AMDのおかげででもあるんだぞ。
AMDが終わったら競争がなくなって、Intelはぼったくりはじめるぞ。
>>898
独占市場を維持する程度の経営努力(例:M$)はすると思うが。
独占市場を維持する程度の経営努力(例:M$)はすると思うが。
>>898
そうですね。
今は逆にIntelに頑張ってもらわないといけない次期ですけど、
実際、Socket370時代はAMDの恩恵を受けてましたしね。
今は性能その他がアレだからIntelのCPUは買わないけど、
今後、IntelからいいCPUが出たら買う可能性ありますからね。
そうですね。
今は逆にIntelに頑張ってもらわないといけない次期ですけど、
実際、Socket370時代はAMDの恩恵を受けてましたしね。
今は性能その他がアレだからIntelのCPUは買わないけど、
今後、IntelからいいCPUが出たら買う可能性ありますからね。
チップセットについても頑張っていただきたい
903 :Socket774:2005/11/09(水) 17:02:12 ID:xcAo18ar
IDF Tel Aviv 2005 Coverage
ttp://www.hardwaresecrets.com/article/242/1
>especially the new Merom/Conroe/Woodcrest family,
>the new Monahans cell phone application CPU and a little bit about the forthcoming 45 nm technology,
>since all these technologies are being developed in Israel.
組込マイコンから次々期45nmプロセサまで全てイスラエルだなw
ttp://www.hardwaresecrets.com/article/242/1
>especially the new Merom/Conroe/Woodcrest family,
>the new Monahans cell phone application CPU and a little bit about the forthcoming 45 nm technology,
>since all these technologies are being developed in Israel.
組込マイコンから次々期45nmプロセサまで全てイスラエルだなw
>>894
C3でも使ってれば?
C3でも使ってれば?
905 :Socket774:2005/11/09(水) 18:40:03 ID:47YRYQdN
Dempsey男
ID:uxs9uH//は他スレで雑音認定がどうとかAAアム厨がどうとか言ってるが
もしかして
もしかして
googleの「もしかして:ふたなりプリキュア」
を思い出した。
を思い出した。
>>886
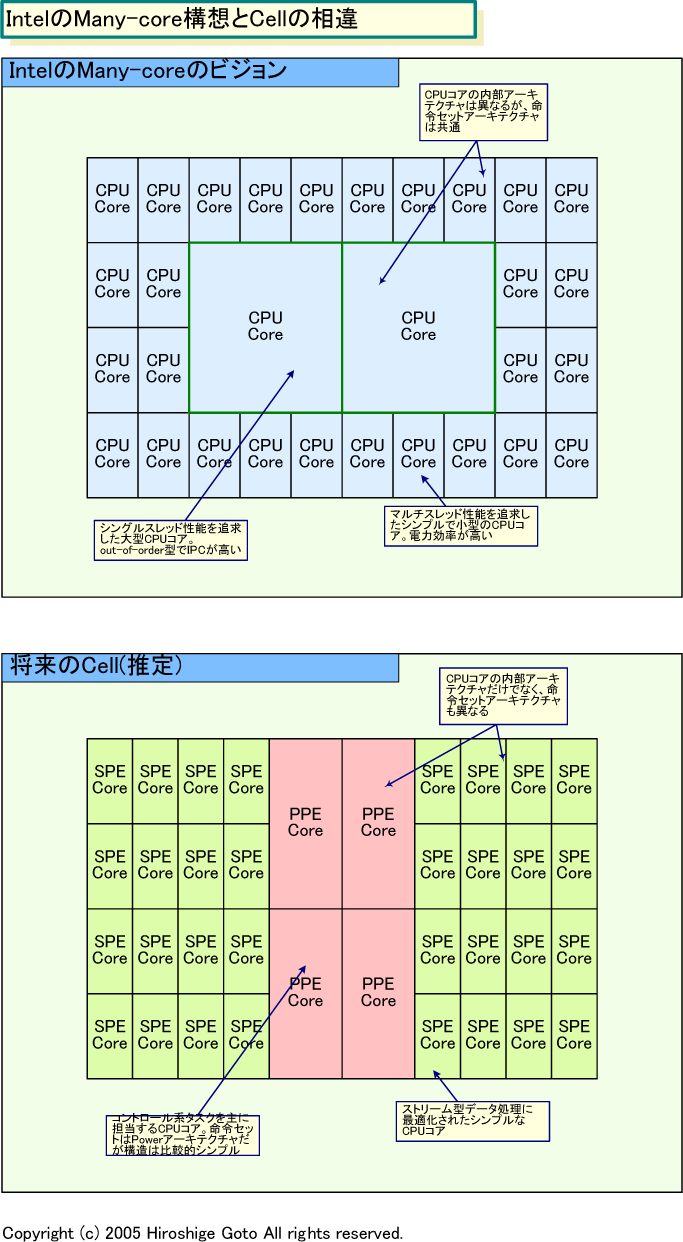
>ただし、同一の命令セットを使うコアでは、浮動小数点演算を強化したコアと
>通常のコア、のような混載はあり得るとした。
mycomだとこうなってるね
これだと分かりやすいけどね
SIMD特化コアとか
>ただし、同一の命令セットを使うコアでは、浮動小数点演算を強化したコアと
>通常のコア、のような混載はあり得るとした。
mycomだとこうなってるね
これだと分かりやすいけどね
SIMD特化コアとか
>>886
1〜2issueでインオーダ実行な、小さなコアを複数搭載するって意味じゃないのか?
スレッドレベル並列化が進めば1コアあたりの性能を稼ぐよりはコアをシンプルにして大量搭載したほうが
効率が良いからね。
まあ、バス帯域の問題なんかもあるから、今の現状ではMeromみたいにコアをリッチにするのが最適解らしい。
1〜2issueでインオーダ実行な、小さなコアを複数搭載するって意味じゃないのか?
スレッドレベル並列化が進めば1コアあたりの性能を稼ぐよりはコアをシンプルにして大量搭載したほうが
効率が良いからね。
まあ、バス帯域の問題なんかもあるから、今の現状ではMeromみたいにコアをリッチにするのが最適解らしい。
http://www.atmarkit.co.jp/fsys/zunouhoudan/050zunou/multicore.html
マルチコア・マルチプロセッサ化が進むと、x86は互換性維持のための
「OS専用プロセッサ」か「メンテナンス・プロセッサ」になってしまう
マルチコア・マルチプロセッサ化が進むと、x86は互換性維持のための
「OS専用プロセッサ」か「メンテナンス・プロセッサ」になってしまう
>>910
別に今に始まったことでは(ry
別に今に始まったことでは(ry
>>910
なかなか面白い考え方だね。
>>908 のようなケースも含めて考えると、
シンメトリーなマルチプロセッサはもう古いという時代が来るのかもしれないね。
ただ、「OS専用プロセッサ」というのはおかしいと思う。
むしろOSこそどんな命令セットのCPUでもいい部分で、
実際にx86の命令セットが必要なのはアプリケーションだと思う。
はっきり言って、x86を捨てられない最大の理由は膨大なソフト資産によるものだし。
なかなか面白い考え方だね。
>>908 のようなケースも含めて考えると、
シンメトリーなマルチプロセッサはもう古いという時代が来るのかもしれないね。
ただ、「OS専用プロセッサ」というのはおかしいと思う。
むしろOSこそどんな命令セットのCPUでもいい部分で、
実際にx86の命令セットが必要なのはアプリケーションだと思う。
はっきり言って、x86を捨てられない最大の理由は膨大なソフト資産によるものだし。
そこでドットニートですよ
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai_1l.gif
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai_3.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai_3.jpg
{kind=link}
性能電力比的には、Niagara みたいな in-order one issue が
最適なんだけど、それぐらいシンプルにしちゃうと、x86 デコーダ
のトランジスタ数が重荷になって、RISC命令をネイティブに実行
するプロセッサの方が、性能電力比でさらに有利になっちゃうんだよね。
じゃあそういう RISC プロセッサとのヘテロになるかっていうと、
x86 系の最大の財産である豊富なソフトウェアを生かせなくなるので、
ヘテロにはならない気がするんだけど。
最適なんだけど、それぐらいシンプルにしちゃうと、x86 デコーダ
のトランジスタ数が重荷になって、RISC命令をネイティブに実行
するプロセッサの方が、性能電力比でさらに有利になっちゃうんだよね。
じゃあそういう RISC プロセッサとのヘテロになるかっていうと、
x86 系の最大の財産である豊富なソフトウェアを生かせなくなるので、
ヘテロにはならない気がするんだけど。
Dempsyやけに速いなあ。どうなってるんだろ
今はRISCもμ命令に分解してるしなぁ
チップセット大丈夫かなぁ?
LANやサウンドもどんどんチップセット内蔵していけばいいのにさ。
もちろんCPU負荷にならないようないいもので。
・・・もうオンボードの蟹はいやだ(これが本音w)
インテルが全部やってくれれば解決してしまうのに。
LANやサウンドもどんどんチップセット内蔵していけばいいのにさ。
もちろんCPU負荷にならないようないいもので。
・・・もうオンボードの蟹はいやだ(これが本音w)
インテルが全部やってくれれば解決してしまうのに。
>インテルが全部やってくれれば
違法違法と騒がれる罠。
違法違法と騒がれる罠。
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
久しぶりに出てきましたよ、投機マルチスレッディング(Speculative Multitheading)
期待してるんだけど、いつごろ実装されるのやら。
SMTで実装してくるのか、メニーコアの中の小さなコアでも割り当てるのか。
違う記事でもあったけど、CPUそのものより、メモリ周りが性能の肝になる予感。
久しぶりに出てきましたよ、投機マルチスレッディング(Speculative Multitheading)
期待してるんだけど、いつごろ実装されるのやら。
SMTで実装してくるのか、メニーコアの中の小さなコアでも割り当てるのか。
違う記事でもあったけど、CPUそのものより、メモリ周りが性能の肝になる予感。
49 名前:Socket774投稿日:05/02/19 02:47:21 ID:g6f9WzaE
通常のプログラムでは、アドレスの決定にも前後依存性があるため、
投機スレッドが露払い的にメモリ内容を読むだけ読んで勝手に進むなんてことは出来ません。
たとえ読み捨てたとしても、その露払いの恩恵でメモリアクセス100倍速となった本スレッドに、
あっという間に追突されます。
プログラムで明示的に投機実行を制御できれば、非常に効果的でしょう。
本スレッドがループ中に、今後呼び出すであろうモジュールに投機スレッドで特攻仕掛けておくとか。
要するに、明示的な投機示唆が無い一般アプリケーションで、
いかに投機タイミングを制御できるかに、投機TLPの価値が掛かっています。
通常のプログラムでは、アドレスの決定にも前後依存性があるため、
投機スレッドが露払い的にメモリ内容を読むだけ読んで勝手に進むなんてことは出来ません。
たとえ読み捨てたとしても、その露払いの恩恵でメモリアクセス100倍速となった本スレッドに、
あっという間に追突されます。
プログラムで明示的に投機実行を制御できれば、非常に効果的でしょう。
本スレッドがループ中に、今後呼び出すであろうモジュールに投機スレッドで特攻仕掛けておくとか。
要するに、明示的な投機示唆が無い一般アプリケーションで、
いかに投機タイミングを制御できるかに、投機TLPの価値が掛かっています。
Transmetaみたいなコードモーフィングとマルチコアを合体できないかな?
未変換のコードはx86コアで実行するのと平行してCMSが変換する。
変換済みのコードは安いRISCコアが実行する。
未変換のコードはx86コアで実行するのと平行してCMSが変換する。
変換済みのコードは安いRISCコアが実行する。
ソフトウェアのCMSはオーバーヘッドが問題っしょ。
キャッシュ喰うし。
キャッシュ喰うし。
調べたらCMSって24MBも喰うらしいじゃん。
とてもキャッシュに収まらんな。
とてもキャッシュに収まらんな。
そこでCMSキャッシュ専用にSRAM搭載ですよ
結局、大きさ発熱実行速度がかわらない罠
>>923
うわ、俺の駄文がw
うわ、俺の駄文がw
う〜む、投機マルチスレッドでキャッシュの中はゴミだらけになりそうだ。w
Intelが2000年頃から研究してた投機マルチスレッディングやバリュー予測。
後藤予想では、Tejasの次のNehalem(4Thread HT)の
さらに次の世代(8Thread HT)で実装されるはずだった。
スレッド間のデータ依存性を取り去るバリュー予測機構や投機スレッドを生成する
コンパイラの開発は、Tejasキャンセル決定時点においてどれくらい進んでいたんだろうか?
実はTejasそして全NetBurstキャンセルの大きな原因は、そこにあるのではないかと邪推してみたり。
後藤予想では、Tejasの次のNehalem(4Thread HT)の
さらに次の世代(8Thread HT)で実装されるはずだった。
スレッド間のデータ依存性を取り去るバリュー予測機構や投機スレッドを生成する
コンパイラの開発は、Tejasキャンセル決定時点においてどれくらい進んでいたんだろうか?
実はTejasそして全NetBurstキャンセルの大きな原因は、そこにあるのではないかと邪推してみたり。
それはないな。
Itanium&静的コンパイルだったけど
Speculative Multitheadingでシングルスレッドの性能を?%アップ、とか言う記事あったはず。
Tejasキャンセルは関係なく研究は進んでると思われ。
Itanium&静的コンパイルだったけど
Speculative Multitheadingでシングルスレッドの性能を?%アップ、とか言う記事あったはず。
Tejasキャンセルは関係なく研究は進んでると思われ。
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2507&p=7
ttp://techreport.com/etc/2005q3/idf/index.x?pg=4
まぁ、当然、SpMTの研究開発は鋭意続けられてるだろうが。
ttp://techreport.com/etc/2005q3/idf/index.x?pg=4
まぁ、当然、SpMTの研究開発は鋭意続けられてるだろうが。
>>934
そもそもItaniumのVLIWとx86のコンパイルを同列に比較出来るの?
そもそもItaniumのVLIWとx86のコンパイルを同列に比較出来るの?
VLIWでCMSだろ
>>932
そこで投機スレッド専用にSRAM搭s(ry
そこで投機スレッド専用にSRAM搭s(ry
■後藤弘茂のWeekly海外ニュース■
Rambusの特許で揺れる次世代DIMM規格「FB-DIMM」
http://pc.watch.impress.co.jp/docs/2005/1111/kaigai223.htm
AMDが回避したのはこの為だったりして
Rambusの特許で揺れる次世代DIMM規格「FB-DIMM」
http://pc.watch.impress.co.jp/docs/2005/1111/kaigai223.htm
AMDが回避したのはこの為だったりして
Rambus May Be Taken Over ?Rumours.
http://www.xbitlabs.com/search/?query=Rambus&searchbtn=Find%21
もう、Rambus買収すれよw
http://www.xbitlabs.com/search/?query=Rambus&searchbtn=Find%21
もう、Rambus買収すれよw
いいねそれw
Rambus買収してAMDにライセンスしなければいい!!!
Rambus買収してAMDにライセンスしなければいい!!!
>>942
そして独占禁止法違反であぼーん。
そして独占禁止法違反であぼーん。
まあ、特許買収して普通にJEDECに移管すれば良いよ。
てか、Rambusが関わるとメモリベンダ不信抱くからw
てか、Rambusが関わるとメモリベンダ不信抱くからw
マジでRambusはPC業界の癌だな。
自分の金儲けしか考えて無い。
自分の金儲けしか考えて無い。