cell�v���O���~���O�����Ⴂ�Ȃ�3
|
|
|
2 �F�f�t�H���g�̖����������F2008/07/07(��) 08:56:25
Cell Broadband Engine �Z�p�����J
http://cell.scei.co.jp/
PLAYSTATION3 Linux Information Site
http://cell.fixstars.com/ps3linux/index.php
The Cell Processor - PukiWiki
http://cell.fixstars.com/pukiwiki/index.php
developerWorks : Cell Broadband Engine resource center(IBM��Cell�Z�p���)
http://www-128.ibm.com/developerworks/power/cell/
Cell Broadband Engine Architecture forum (Cell�v���O���~���O�̌f����)
http://www.ibm.com/developerworks/forums/dw_forum.jsp?forum=739&cat=46
Multicore Programming Primer: PS3 Cell Programming
(�}�T�`���[�Z�b�c�H�ȑ�w��PS3���g�����}���`�R�A�v���O�������K�B�\�[�X�R�[�h�ȂǗL��)
http://cag.csail.mit.edu/ps3/
CellPerformance
http://www.cellperformance.com/articles/
http://cell.scei.co.jp/
PLAYSTATION3 Linux Information Site
http://cell.fixstars.com/ps3linux/index.php
The Cell Processor - PukiWiki
http://cell.fixstars.com/pukiwiki/index.php
developerWorks : Cell Broadband Engine resource center(IBM��Cell�Z�p���)
http://www-128.ibm.com/developerworks/power/cell/
Cell Broadband Engine Architecture forum (Cell�v���O���~���O�̌f����)
http://www.ibm.com/developerworks/forums/dw_forum.jsp?forum=739&cat=46
Multicore Programming Primer: PS3 Cell Programming
(�}�T�`���[�Z�b�c�H�ȑ�w��PS3���g�����}���`�R�A�v���O�������K�B�\�[�X�R�[�h�ȂǗL��)
http://cag.csail.mit.edu/ps3/
CellPerformance
http://www.cellperformance.com/articles/
3 �F�f�t�H���g�̖����������F2008/07/07(��) 08:57:33
�ꉞ���ĂĂ݂����̂̃X���^�C�݂������^�i�Oo�O�j�_
4 �F�f�t�H���g�̖����������F2008/07/07(��) 17:47:02
>>1 ���B�v���Ԃ�ɘb�蓊�����Ă݂�B
����short�l�̔z�����āA�����log2()����悤�Ȋ����Ŏw�����~�����B
�w�������̒l�A�܂艼�����͎l�̌ܓ�����B
�܂��A�}�C�i�X�l�ƃv���X�l�͘A�������Č��ʂ��R���p�N�g�ɂ������B
��ō���Ă�v���O���������猋�ʂ̃t�H�[�}�b�g�͂���ȊO�ɕς���Ă��\��Ȃ��B
�^���R�[�h�ŏ����ƁA���܂̂Ƃ��낱��Ȋ����̎����ɂ��Ă���B
(short)round(log(abs(a))/log(2)) + (a > 0 ? 16 : 0);
�ŁA������œK���ł��Ȃ����ȂƂ����b�B
�Ƃ肠����2���l���Ă݂��̂œ\���Ă݂�B
����short�l�̔z�����āA�����log2()����悤�Ȋ����Ŏw�����~�����B
�w�������̒l�A�܂艼�����͎l�̌ܓ�����B
�܂��A�}�C�i�X�l�ƃv���X�l�͘A�������Č��ʂ��R���p�N�g�ɂ������B
��ō���Ă�v���O���������猋�ʂ̃t�H�[�}�b�g�͂���ȊO�ɕς���Ă��\��Ȃ��B
�^���R�[�h�ŏ����ƁA���܂̂Ƃ��낱��Ȋ����̎����ɂ��Ă���B
(short)round(log(abs(a))/log(2)) + (a > 0 ? 16 : 0);
�ŁA������œK���ł��Ȃ����ȂƂ����b�B
�Ƃ肠����2���l���Ă݂��̂œ\���Ă݂�B
5 �F�f�t�H���g�̖����������F2008/07/07(��) 17:48:46
vec_short8 log2_1(vec_short8 v) {
static const vec_uchar16 vPack = (vec_uchar16)
{ 2, 3, 18, 19, 6, 7, 22, 23,
10, 11, 26, 27, 14, 15, 30, 31};
vec_short8 v1 = spu_splats((int16_t)1);
vec_short8 v0x100 = spu_splats((int16_t)0x100);
vec_uint4 vEven = (vec_uint4)spu_convtf(spu_mule(v, v1), 0);
vec_uint4 vOdd = (vec_uint4)spu_convtf(spu_mulo(v, 1), 0);
vec_uint4 vExpE = spu_rlmask(vEven, -22);
vec_uint4 vExpO = spu_rlmask(vOdd, -22);
vec_short8 vExp = (vec_short8)spu_shuffle(vExpE, vExpO, vPack);
vExp = spu_rlmask(vExp + spu_and(vExp, 1), -1); // round
vExp = spu_add(spu_and(vExp, 0xff), -126)
+ spu_rlmask(spu_andc(v0x100, vExp), -4); // sign
vExp = spu_andc(vExp, (vec_short8)spu_cmpeq(v, 0));
return vExp;
}
static const vec_uchar16 vPack = (vec_uchar16)
{ 2, 3, 18, 19, 6, 7, 22, 23,
10, 11, 26, 27, 14, 15, 30, 31};
vec_short8 v1 = spu_splats((int16_t)1);
vec_short8 v0x100 = spu_splats((int16_t)0x100);
vec_uint4 vEven = (vec_uint4)spu_convtf(spu_mule(v, v1), 0);
vec_uint4 vOdd = (vec_uint4)spu_convtf(spu_mulo(v, 1), 0);
vec_uint4 vExpE = spu_rlmask(vEven, -22);
vec_uint4 vExpO = spu_rlmask(vOdd, -22);
vec_short8 vExp = (vec_short8)spu_shuffle(vExpE, vExpO, vPack);
vExp = spu_rlmask(vExp + spu_and(vExp, 1), -1); // round
vExp = spu_add(spu_and(vExp, 0xff), -126)
+ spu_rlmask(spu_andc(v0x100, vExp), -4); // sign
vExp = spu_andc(vExp, (vec_short8)spu_cmpeq(v, 0));
return vExp;
}
6 �F�f�t�H���g�̖����������F2008/07/07(��) 17:50:12
vec_short8 log2_2(vec_short8 v) {
static const vec_uchar16 vPack = (vec_uchar16)
{ 2, 3, 18, 19, 6, 7, 22, 23,
10, 11, 26, 27, 14, 15, 30, 31};
vec_ushort8 v1 = spu_splats((uint16_t)1);
vec_ushort8 vIsPos = spu_cmpgt(v, 0);
vec_ushort8 vAbs = (vec_ushort8)spu_sel(-v, v, vIsPos);
vec_ushort8 vRound = (vAbs & ~spu_rlmask(vAbs, -2)) + spu_rlmask(vAbs, -1);
vec_uint4 vEven = spu_mule(vRound, v1);
vec_uint4 vOdd = spu_mulo(vRound, 1);
vec_uint4 vExpE = spu_sub(32, spu_cntlz(vEven));
vec_uint4 vExpO = spu_sub(32, spu_cntlz(vOdd));
vec_short8 vExp = (vec_short8)spu_shuffle(vExpE, vExpO, vPack);
vExp += (vec_short8)spu_and(vIsPos, 16); // sign
return vExp;
}
static const vec_uchar16 vPack = (vec_uchar16)
{ 2, 3, 18, 19, 6, 7, 22, 23,
10, 11, 26, 27, 14, 15, 30, 31};
vec_ushort8 v1 = spu_splats((uint16_t)1);
vec_ushort8 vIsPos = spu_cmpgt(v, 0);
vec_ushort8 vAbs = (vec_ushort8)spu_sel(-v, v, vIsPos);
vec_ushort8 vRound = (vAbs & ~spu_rlmask(vAbs, -2)) + spu_rlmask(vAbs, -1);
vec_uint4 vEven = spu_mule(vRound, v1);
vec_uint4 vOdd = spu_mulo(vRound, 1);
vec_uint4 vExpE = spu_sub(32, spu_cntlz(vEven));
vec_uint4 vExpO = spu_sub(32, spu_cntlz(vOdd));
vec_short8 vExp = (vec_short8)spu_shuffle(vExpE, vExpO, vPack);
vExp += (vec_short8)spu_and(vIsPos, 16); // sign
return vExp;
}
7 �F�f�t�H���g�̖����������F2008/07/08(��) 00:21:46
>>6
������32�ȏ�˂����߂�Ȃ��҂̕����ǂ���
������32�ȏ�˂����߂�Ȃ��҂̕����ǂ���
8 �F�f�t�H���g�̖����������F2008/07/08(��) 00:25:46
�������k���ȁH
nop / lq
nop / shufb
csflt / shufb
csflt / shufb
nop / shufb
rlmaskbyte
�Ƃ��ϑz���Ă݂�
nop / lq
nop / shufb
csflt / shufb
csflt / shufb
nop / shufb
rlmaskbyte
�Ƃ��ϑz���Ă݂�
9 �F�f�t�H���g�̖����������F2008/07/08(��) 07:35:05
10 �F�f�t�H���g�̖����������F2008/07/10(��) 23:47:30
>>9
�p�b�N���ŏ\������
�p�b�N���ŏ\������
11 �F�f�t�H���g�̖����������F2008/07/15(��) 00:31:59
CUDA�{�i�I�ɂȂ��ĂȂ�G���W�����n�ɗ��������
12 �F�f�t�H���g�̖����������F2008/07/15(��) 11:10:40
>>11
�悭�킩��ˁ[�悗
�悭�킩��ˁ[�悗
13 �F�f�t�H���g�̖����������F2008/07/16(��) 00:45:58
>>11
���v�A�X�p�[�X�G���W���Ȃ�čŏ������痧�ꂪ�Ȃ�����B
���v�A�X�p�[�X�G���W���Ȃ�čŏ������痧�ꂪ�Ȃ�����B
14 �F�f�t�H���g�̖����������F2008/07/17(��) 05:09:34
Cell �� GPU �ɓG���i���𑱂����邩�͕ʂ����B
���������� HPC �I���_���ACell �͒�����v���Z�b�T�ł���AGPU �̓n�C�p�[SIMD/MIMD �Ȃ킯���B
���ꂼ��ɓ��ӂȕ��삪���邩��A�ǂ��炪�ł�łǂ��炪�h����Ƃ����b�ł͂Ȃ��B
�łȂ��Ƃ�����Ȃ����B
���������� HPC �I���_���ACell �͒�����v���Z�b�T�ł���AGPU �̓n�C�p�[SIMD/MIMD �Ȃ킯���B
���ꂼ��ɓ��ӂȕ��삪���邩��A�ǂ��炪�ł�łǂ��炪�h����Ƃ����b�ł͂Ȃ��B
�łȂ��Ƃ�����Ȃ����B
15 �F�f�t�H���g�̖����������F2008/07/17(��) 14:44:19
���ۖ��A������v���Z�b�T���Ă����Ă��A�n�C�p�[SIMD/MIMD�ƕς��Ȃ��悤�ȗp�r�ł����g���ĂȂ����낤�B
�v���Z�b�T�������������āA���������Ƃ����ł���BLinux��SPE�Ɏd������U���悤�ɂł��Ȃ�Ȃ��B
�v���Z�b�T�������������āA���������Ƃ����ł���BLinux��SPE�Ɏd������U���悤�ɂł��Ȃ�Ȃ��B
16 �F�f�t�H���g�̖����������F2008/07/17(��) 15:29:40
�u���[�h�o���h�G���W���͓������ꂽ�z�X�gCPU��Pen4���x�̒ᐫ�\�A
�X�p�[�X�G���W���͕���x������������Ƀz�X�gCPU���O�t���B
�^�ł̖ڎw�������͂ǂ��Ȃ��B
�X�p�[�X�G���W���͕���x������������Ƀz�X�gCPU���O�t���B
�^�ł̖ڎw�������͂ǂ��Ȃ��B
17 �F�f�t�H���g�̖����������F2008/07/18(��) 00:24:09
>>15
> ���ۖ��A������v���Z�b�T���Ă����Ă��A�n�C�p�[SIMD/MIMD�ƕς��Ȃ��悤�ȗp�r�ł����g���ĂȂ����낤�B
���ɂ͒P�ɁAGPU �ł̏����Ɍ������A�v���P�[�V�����́A����R���s���[�^����̒u���������A�܂��܂��i��ł��Ȃ������̂悤�̎v����B
�����������Ӗ��Ŗ����Ȃ�A���̒m��Ȃ�����̂��Ƃ������Ă���悤������A�����Ă����ƗL���B
> ���ۖ��A������v���Z�b�T���Ă����Ă��A�n�C�p�[SIMD/MIMD�ƕς��Ȃ��悤�ȗp�r�ł����g���ĂȂ����낤�B
���ɂ͒P�ɁAGPU �ł̏����Ɍ������A�v���P�[�V�����́A����R���s���[�^����̒u���������A�܂��܂��i��ł��Ȃ������̂悤�̎v����B
�����������Ӗ��Ŗ����Ȃ�A���̒m��Ȃ�����̂��Ƃ������Ă���悤������A�����Ă����ƗL���B
18 �F�f�t�H���g�̖����������F2008/07/18(��) 01:41:44
�[���������MIMD�ł������Ȃ����B
19 �F�f�t�H���g�̖����������F2008/07/19(�y) 17:18:45
Cell�v���O���~���O����낤�Ǝv��
PS3�ɂ�Ubuntu������Synaptic�p�b�P�[�W�}�l�[�W����Cell-sdk��binfbinfmts-support�����܂����B
spu-gcc ��hello world
PS3�ɂ�Ubuntu������Synaptic�p�b�P�[�W�}�l�[�W����Cell-sdk��binfbinfmts-support�����܂����B
spu-gcc ��hello world
20 �F�f�t�H���g�̖����������F2008/07/19(�y) 17:21:01
�r���ő��M���Ă��܂��܂���
Cell�v���O���~���O����낤�Ǝv��
PS3�ɂ�Ubuntu������Synaptic�p�b�P�[�W�}�l�[�W����Cell-sdk��binfbinfmts-support�����܂����B
spu-gcc ��hello world��\������v���O����������R���p�C��������Ƃ���܂ł͂ł����̂ł���
�������s���Ă݂��
spu_create(): no such file or directory
spe_create_single: Bad address
�ƂłĂ��܂����s�ł��܂���ł����B
���낢�뒲�ׂĂ������̂ł�������Ƃ�����������������炸�r���ɂ���Ă��܂��B
�����������m�̕�����������Ⴂ�܂����狳���Ă��������Ȃ��ł��傤���B
Cell�v���O���~���O����낤�Ǝv��
PS3�ɂ�Ubuntu������Synaptic�p�b�P�[�W�}�l�[�W����Cell-sdk��binfbinfmts-support�����܂����B
spu-gcc ��hello world��\������v���O����������R���p�C��������Ƃ���܂ł͂ł����̂ł���
�������s���Ă݂��
spu_create(): no such file or directory
spe_create_single: Bad address
�ƂłĂ��܂����s�ł��܂���ł����B
���낢�뒲�ׂĂ������̂ł�������Ƃ�����������������炸�r���ɂ���Ă��܂��B
�����������m�̕�����������Ⴂ�܂����狳���Ă��������Ȃ��ł��傤���B
21 �F�f�t�H���g�̖����������F2008/07/19(�y) 17:28:49
�f����fedora��Yellowdog�ɂ���B
22 �F�f�t�H���g�̖����������F2008/07/19(�y) 17:36:35
���X�L��������܂�
��Ubuntu���ƌ���Cell���̂ɂ͖�葽����ł����ˁE�E�E
�y�����Ęb������ł����ǁB���������Ȃ�Fedora�ɂ��Ƃ��܂��B
��Ubuntu���ƌ���Cell���̂ɂ͖�葽����ł����ˁE�E�E
�y�����Ęb������ł����ǁB���������Ȃ�Fedora�ɂ��Ƃ��܂��B
23 �F�f�t�H���g�̖����������F2008/07/19(�y) 20:07:23
PS3�ŊJ�����ĕӂ肪���\�������ۂ��B
�����N���X�J�����Ȃ��̂��˂��B
�����N���X�J�����Ȃ��̂��˂��B
24 �F�f�t�H���g�̖����������F2008/07/19(�y) 20:19:10
SPU�p�̃o�C�i���̃t�@�C����������Ă邩����ĂȂ��̂ł́H
���̂Ƃ���x����Ȃ�Ubuntu7.10�����ǖ��Ȃ��Z���t�J���ł��Ă�
���̂Ƃ���x����Ȃ�Ubuntu7.10�����ǖ��Ȃ��Z���t�J���ł��Ă�
25 �F�f�t�H���g�̖����������F2008/07/19(�y) 22:21:43
26 �F�f�t�H���g�̖����������F2008/07/20(��) 04:17:30
�f���Ɉ�U�Q�[�����ɍs���悗
27 �F�f�t�H���g�̖����������F2008/07/21(��) 14:59:52
>> 20
������xubuntu�ŏ�肭�s���Ă�B24�̎w�E�ʂ�ł͂Ȃ��ł��傤���B
������xubuntu�ŏ�肭�s���Ă�B24�̎w�E�ʂ�ł͂Ȃ��ł��傤���B
28 �F�f�t�H���g�̖����������F2008/07/21(��) 16:22:12
>>24,27
���X���肪�Ƃ��������܂��B
�͂��߂Ɏ��s�����Ƃ�cannot execute binary file �ƕ\�����ꂽ�̂�SPU�p�̃o�C�i����������������܂���B
������������邽�߂�binfbinfmts-support�����Ă݂��̂ł����E�E�E�����ɂ͂Ȃ��ĂȂ�������������Ȃ��ł��ˁB
SPU�p�̃o�C�i���ɂ��ĕ��s���ł��܂�悭�킩��Ȃ��̂Œ��ׂĂ݂����Ǝv���܂��B
���X���肪�Ƃ��������܂��B
�͂��߂Ɏ��s�����Ƃ�cannot execute binary file �ƕ\�����ꂽ�̂�SPU�p�̃o�C�i����������������܂���B
������������邽�߂�binfbinfmts-support�����Ă݂��̂ł����E�E�E�����ɂ͂Ȃ��ĂȂ�������������Ȃ��ł��ˁB
SPU�p�̃o�C�i���ɂ��ĕ��s���ł��܂�悭�킩��Ȃ��̂Œ��ׂĂ݂����Ǝv���܂��B
SPU �͕̂��ʂ͒��ڋN���ł����C�N������̂� PPU �p�̃o�C�i���D
�������� spe_image_open �� spe_program_load �g���� load ����D
����� thread �� 6�n���� spe_context_create, spe_context_run ����D
SPU �p�̃o�C�i���ߍ��Ⴆ�� _open �̕��͗v��Ȃ��D
��Cspu-gcc �̃I�v�V������ -standalone ���w�肷��C
���ڋN���ł���v���O���������Ă��ꂽ�͂��D
�������� spe_image_open �� spe_program_load �g���� load ����D
����� thread �� 6�n���� spe_context_create, spe_context_run ����D
SPU �p�̃o�C�i���ߍ��Ⴆ�� _open �̕��͗v��Ȃ��D
��Cspu-gcc �̃I�v�V������ -standalone ���w�肷��C
���ڋN���ł���v���O���������Ă��ꂽ�͂��D
30 �F�f�t�H���g�̖����������F2008/07/21(��) 22:19:00
�{����SPU�����p�������Ȃ�A
�g���闧��ɂ���Ȃ�SPURS�Ƃ��A
MARS,Ctk,���̂ق���
SPU�����J�[�l���݂����Ȃ̂𗧂Ă�
����ɃW���u�𓊂��������y����B
�g���闧��ɂ���Ȃ�SPURS�Ƃ��A
MARS,Ctk,���̂ق���
SPU�����J�[�l���݂����Ȃ̂𗧂Ă�
����ɃW���u�𓊂��������y����B
31 �F�f�t�H���g�̖����������F2008/07/22(��) 17:07:48
�d���ł���Ȃ炻������
32 �F�f�t�H���g�̖����������F2008/07/25(��) 17:42:28
33 �F�f�t�H���g�̖����������F2008/07/25(��) 17:46:45
34 �F�f�t�H���g�̖����������F2008/07/25(��) 20:04:08
���������z�������B
35 �F�f�t�H���g�̖����������F2008/07/25(��) 21:36:54
�N���t�@�C������ɂ��Ă�C�̐��䕶�H�iprintf�̂悤�Ȃ��́j�m��Ȃ��H
�m���Ă镪�����`�����Ăق����ł�
�m���Ă镪�����`�����Ăق����ł�
36 �F�f�t�H���g�̖����������F2008/07/25(��) 22:18:18
>>35
�X���Ⴂ�B
�X���Ⴂ�B
37 �F�f�t�H���g�̖����������F2008/07/25(��) 22:20:24
MARS���ăR���e�L�X�g�ʌ��点�邾���H
38 �F�f�t�H���g�̖����������F2008/07/26(�y) 16:27:04
MARS�ł���悤�Ȃ��Ƃ́AGPGPU���Ƃ��Ԃ����Ǝv���B�����������Ƃɂ����ACell�̋��݂������Ȃ����ȁB
���ۂǂꂾ���g����悤�ɂȂ��Ă���̂�����肾�B
���ۂǂꂾ���g����悤�ɂȂ��Ă���̂�����肾�B
39 �F�f�t�H���g�̖����������F2008/07/26(�y) 17:09:50
�f�[�^�̓���ւ��ɂ͑Ή����ĂȂ��݂������ȁB(�܂�)
40 �F�f�t�H���g�̖����������F2008/07/26(�y) 18:03:22
CPU�̏ȃG�l�A���(CELL�ABG/L���Q�l�ɍl����B)
http://www.ne.jp/asahi/comp/tarusan/main190.htm
�d�͏���ʓI��LS�͂悢�ƁB���܂�������̘b�����ǁB
���ꂶ�Ⴀ�A�L���b�V����LS�������āA�g������������̂��Ƃ��v�����ǁA
�Q�̎g��������c�����Ȃ��Ƃ����Ȃ�����A�ς킵����������ƁB
http://www.ne.jp/asahi/comp/tarusan/main190.htm
�d�͏���ʓI��LS�͂悢�ƁB���܂�������̘b�����ǁB
���ꂶ�Ⴀ�A�L���b�V����LS�������āA�g������������̂��Ƃ��v�����ǁA
�Q�̎g��������c�����Ȃ��Ƃ����Ȃ�����A�ς킵����������ƁB
41 �F�f�t�H���g�̖����������F2008/07/31(��) 11:56:30
�u5�N�͒ǂ����Ȃ��ł��傤�v�������ł����AV�m�[�g�̐V���������`�EQosmio G50�̊v�V���Ƃ�
ttp://journal.mycom.co.jp/articles/2008/07/30/qosmio/001.html
�ʏ�
ttp://journal.mycom.co.jp/photo/articles/2008/07/30/qosmio/images/005l.jpg
supers engine
ttp://journal.mycom.co.jp/photo/articles/2008/07/30/qosmio/images/006l.jpg
����͌��\�����ȁB
ttp://journal.mycom.co.jp/articles/2008/07/30/qosmio/001.html
�ʏ�
ttp://journal.mycom.co.jp/photo/articles/2008/07/30/qosmio/images/005l.jpg
{kind=link}
supers engine
ttp://journal.mycom.co.jp/photo/articles/2008/07/30/qosmio/images/006l.jpg
{kind=link}
����͌��\�����ȁB
42 �F�f�t�H���g�̖����������F2008/08/01(��) 12:39:21
���̓m�[�g�ł����܂ł̗v�������邩����
43 �F�f�t�H���g�̖����������F2008/08/01(��) 13:31:07
�f��D���̐l�Ƃ��A���\�A�{�C�ŗ~�������Ȃ����H
����Ŏg���f�X�N�m�[�g�Ƃ��āB�܂��A�����܂Ń}�j�A���v���ȁB
�ł��A���ԓI�ɈӊO�Ƃ���Ȃ�ʼn�������Ƃ����肦�����ȋC�����邪�B
Qosmio��Supers�͒��ڂ�����Ȃ��炵����A����Ⴂ�����ǂˁB
����Ŏg���f�X�N�m�[�g�Ƃ��āB�܂��A�����܂Ń}�j�A���v���ȁB
�ł��A���ԓI�ɈӊO�Ƃ���Ȃ�ʼn�������Ƃ����肦�����ȋC�����邪�B
Qosmio��Supers�͒��ڂ�����Ȃ��炵����A����Ⴂ�����ǂˁB
44 �F�f�t�H���g�̖����������F2008/08/01(��) 18:24:08
�A�v���͎���p�̃J�[�h�ɏ��Ȃ�����F�X�ȃ��[�J�[�Ɋ��҂�����āc�c
����p�J�[�h�o���Ă��A�G�R�V�X�e�������قǃA�v�����o�Ă���v���Ȃ��ȁB
����p�J�[�h�o���Ă��A�G�R�V�X�e�������قǃA�v�����o�Ă���v���Ȃ��ȁB
45 �F�f�t�H���g�̖����������F2008/08/09(�y) 21:36:42
Qosmio G50�V����ASpursEngine���X�S�����錏�y�O�ҁz
http://ascii.jp/elem/000/000/157/157525/
Nvidia��GPU�܂킹�ASpursEngine����Ȃ���c�B
http://ascii.jp/elem/000/000/157/157525/
Nvidia��GPU�܂킹�ASpursEngine����Ȃ���c�B
46 �F�f�t�H���g�̖����������F2008/08/09(�y) 21:38:57
The Barcelona Supercomputing Center has a new prototype
to investigate the supercomputing of the future
http://www.bsc.es/media/1762.pdf
Roadrunner����Cell�X�p�R�����ł���炵���B
to investigate the supercomputing of the future
http://www.bsc.es/media/1762.pdf
Roadrunner����Cell�X�p�R�����ł���炵���B
47 �F�f�t�H���g�̖����������F2008/08/09(�y) 21:52:37
���Ƀx�[����E����Intel��CPU&GPU�n�C�u���b�h�uLarrabee�v
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
Intel��Cell�Ƃ����ȂƂ���ő�����Ă��܂��ȁBCell�Ƃ��������ǁAGPU�Ƃ���
�o�ꂷ��Ƃ���͑傫�ȈႢ�ł���A�H�ł�����B
http://pc.watch.impress.co.jp/docs/2008/0804/kaigai457.htm
Intel��Cell�Ƃ����ȂƂ���ő�����Ă��܂��ȁBCell�Ƃ��������ǁAGPU�Ƃ���
�o�ꂷ��Ƃ���͑傫�ȈႢ�ł���A�H�ł�����B
48 �F�f�t�H���g�̖����������F2008/08/09(�y) 22:01:41
���낻��Cell��������̃o�[�W�����̏ڍׂ��łĂ��邾�낤���B2PPE+32SPE���ł�
���Ă������͂łĂ邯�ǁA����ȏ�̘b�͂܂��Ȃ��āA���܂��Ɍ������Ȃ낤�B
Sony�����������C���ŁAToshiba������������ɐi�݂���AIBM��HPC�H���œ˂��i��ł���B
�܂��APS3�̏́A������Cell�ɑ傫���ւ���Ă���낤�BPS3�̏͂悭�Ȃ���邪�A
�܂������������B������Ɍ����ē����o���Ƃ����̂Ƃ��ɁA���̂悤�ȕs�����ȏł��邱�Ƃ��A
�������Cell�Ɉ�̂ǂ���p���邩�c�BSony�̋��S�͂���܂邱�ƂŁA���IBM�哱�̃A�[�L�e�N�`����
�i�ނ̂��낤���H�ʂ����āc�B
���Ă������͂łĂ邯�ǁA����ȏ�̘b�͂܂��Ȃ��āA���܂��Ɍ������Ȃ낤�B
Sony�����������C���ŁAToshiba������������ɐi�݂���AIBM��HPC�H���œ˂��i��ł���B
�܂��APS3�̏́A������Cell�ɑ傫���ւ���Ă���낤�BPS3�̏͂悭�Ȃ���邪�A
�܂������������B������Ɍ����ē����o���Ƃ����̂Ƃ��ɁA���̂悤�ȕs�����ȏł��邱�Ƃ��A
�������Cell�Ɉ�̂ǂ���p���邩�c�BSony�̋��S�͂���܂邱�ƂŁA���IBM�哱�̃A�[�L�e�N�`����
�i�ނ̂��낤���H�ʂ����āc�B
49 �F�f�t�H���g�̖����������F2008/08/10(��) 01:51:45
>>45
> Qosmio G50�V����ASpursEngine���X�S�����錏�y�O�ҁz
> http://ascii.jp/elem/000/000/157/157525/
>
> Nvidia��GPU�܂킹�ASpursEngine����Ȃ���c�B
GPU�ł܂��Ƃ���C/C++�g������������炻�������ˁB
> Qosmio G50�V����ASpursEngine���X�S�����錏�y�O�ҁz
> http://ascii.jp/elem/000/000/157/157525/
>
> Nvidia��GPU�܂킹�ASpursEngine����Ȃ���c�B
GPU�ł܂��Ƃ���C/C++�g������������炻�������ˁB
50 �F�f�t�H���g�̖����������F2008/08/10(��) 04:02:39
MS������XBOX��Larrabee�g����
51 �F�f�t�H���g�̖����������F2008/08/10(��) 09:51:21
>>49
CUDA�ł�����ˁB
CUDA�ł�����ˁB
52 �F�f�t�H���g�̖����������F2008/08/10(��) 10:02:33
>>51
> >>49
> CUDA�ł�����ˁB
�u�܂��Ƃ���C/C++�v�Ƃ����̂�CUDA�ւ̔������w
Cell�̕����͂邩�ɍ��₷���B
�܂����₷���ȏ�̓��@�����邩��CUDA���g���Ă���킯�����ǁB
> >>49
> CUDA�ł�����ˁB
�u�܂��Ƃ���C/C++�v�Ƃ����̂�CUDA�ւ̔������w
Cell�̕����͂邩�ɍ��₷���B
�܂����₷���ȏ�̓��@�����邩��CUDA���g���Ă���킯�����ǁB
53 �F�f�t�H���g�̖����������F2008/08/10(��) 10:05:28
�O�p�����S���g���Ȃ��Ă��A�œK�����n���ł��A�������]�����߂���x���ł�����������Ă��Ȃ��Ă��A
����ł�Cell�̕����͂邩�ɍ��₷����ł��ˁA����܂��B
����ł�Cell�̕����͂邩�ɍ��₷����ł��ˁA����܂��B
54 �F�f�t�H���g�̖����������F2008/08/10(��) 10:15:24
���z���g����͕̂֗�����ȁB
����ȊO�̃c�b�R�~�͓I�O��B
����ȊO�̃c�b�R�~�͓I�O��B
55 �F�f�t�H���g�̖����������F2008/08/10(��) 10:41:47
���z���Ȃ�āi�ׂ��������t���Ȃ���j�ȒP�Ɏ����ł��邾��H
�������ȂH
�������ȂH
56 �F�f�t�H���g�̖����������F2008/08/10(��) 11:31:49
�����n�[�h�Œ��z���̉��Z�펝���Ă���Ă��������ꂵ������B
57 �F�f�t�H���g�̖����������F2008/08/10(��) 14:27:13
�n�[�h�E�F�A�̒��z�����ăX���[�v�b�g��5�T�C�N�����炢�Ȃ�ł���H
4�v�f�v�Z���Ă�20�T�C�N���A�n������������Ȃ����B
4�v�f�v�Z���Ă�20�T�C�N���A�n������������Ȃ����B
58 �F�f�t�H���g�̖����������F2008/08/10(��) 15:16:58
���z���[��sqrt������Ώ\�����ȁB1/sqrt�ł��ǂ����ǁB
59 �F�f�t�H���g�̖����������F2008/08/10(��) 16:28:14
>>52
LS�̗e�ʐ�����C++�͂��ɂ����낤�B���ʓI��Cell��CUDA������Ȃɕς���Ǝv�����B
LS�̗e�ʐ�����C++�͂��ɂ����낤�B���ʓI��Cell��CUDA������Ȃɕς���Ǝv�����B
60 �F�f�t�H���g�̖����������F2008/08/11(��) 01:27:06
>>59
�����������Ƃ͂ǂ���������Ă݂Ă��猾���Ă���B
�����������Ƃ͂ǂ���������Ă݂Ă��猾���Ă���B
61 �F�f�t�H���g�̖����������F2008/08/11(��) 11:15:00
�ǂ�����C�Ƃ�����Ƃ̊g���ŏ�������x������˂��B���������Ȃ�ǂ����������܂ő卷�Ȃ����B
���͍œK���̒i�K���ȁB�ł��A������R�c���o���āA���������̍œK���ł�����Ȃ炻��Ȃɂ͋�J���Ȃ��Ǝv���B
�l�I�Ȋ��z�ł́ACUDA�̃���������̍œK����������Ɠ�肩�BCell�͍ŏ�����A���C�������g�Ƃ�Ȃ��Ƃ�������
DMA�]���ł��Ȃ��悤�ɂȂ��Ă��邩��A����܂�l����K�v�Ȃ����ACUDA�̏ꍇ�́A�X���b�h���Ƃ�DRAM�ւ̃A�N�Z�X�p�^�[����
�l���Ȃ��ƑʖڂƂ����̂��A���`��B����shared memory�̃o���N�R���t���N�g���l���Ȃ��ƁA�Ƃ�ł��Ȃ����Ƃ�
�Ȃ�Ƃ�������B������ւ���A�R���p�C�����n�[�h�łȂ�Ƃ����Ă����Ƃ����ǁB
���͍œK���̒i�K���ȁB�ł��A������R�c���o���āA���������̍œK���ł�����Ȃ炻��Ȃɂ͋�J���Ȃ��Ǝv���B
�l�I�Ȋ��z�ł́ACUDA�̃���������̍œK����������Ɠ�肩�BCell�͍ŏ�����A���C�������g�Ƃ�Ȃ��Ƃ�������
DMA�]���ł��Ȃ��悤�ɂȂ��Ă��邩��A����܂�l����K�v�Ȃ����ACUDA�̏ꍇ�́A�X���b�h���Ƃ�DRAM�ւ̃A�N�Z�X�p�^�[����
�l���Ȃ��ƑʖڂƂ����̂��A���`��B����shared memory�̃o���N�R���t���N�g���l���Ȃ��ƁA�Ƃ�ł��Ȃ����Ƃ�
�Ȃ�Ƃ�������B������ւ���A�R���p�C�����n�[�h�łȂ�Ƃ����Ă����Ƃ����ǁB
62 �F�f�t�H���g�̖����������F2008/08/22(��) 21:02:45
Qosmio G50�V����ASpursEngine���X�S�����錏�y��ҁz
http://ascii.jp/elem/000/000/162/162488/index-3.html
�~�ʐE�l�̖���������
http://ascii.jp/elem/000/000/162/162488/index-3.html
�~�ʐE�l�̖���������
63 �F�f�t�H���g�̖����������F2008/08/25(��) 12:11:23
�O�O���Ă��炱��Ȃ�߂�����
http://www.ibm.com/developerworks/jp/power/library/j_pa-asmvis/
�� 1 �� asmVis �������Ă݂悤
http://www.ibm.com/developerworks/jp/power/library/j_pa-asmvis2/
�� 2 �� �p�C�v���C�����œK������
http://www.ibm.com/developerworks/jp/power/library/j_pa-asmvis/
�� 1 �� asmVis �������Ă݂悤
http://www.ibm.com/developerworks/jp/power/library/j_pa-asmvis2/
�� 2 �� �p�C�v���C�����œK������
64 �F�f�t�H���g�̖����������F2008/09/10(��) 10:54:28
���[�h�e�b�N�A���ł̃��f�B�A�v���Z�b�T
�uSpursEngine�v����PCIe�g���J�[�h
http://pc.watch.impress.co.jp/docs/2008/0910/leadtek.htm
�uSpursEngine�v����PCIe�g���J�[�h
http://pc.watch.impress.co.jp/docs/2008/0910/leadtek.htm
65 �F�f�t�H���g�̖����������F2008/09/10(��) 23:28:57
�i߇�߁j���
66 �F�f�t�H���g�̖����������F2008/09/19(��) 18:29:04
�����炭�炢�ɂȂ�H
67 �F�f�t�H���g�̖����������F2008/09/19(��) 19:06:43
���ŁA'09�H�ɔ�����Cell TV�̍����f���������f��
http://av.watch.impress.co.jp/docs/20080918/toshiba7.htm
45nm��ςނ�ȁB
http://av.watch.impress.co.jp/docs/20080918/toshiba7.htm
45nm��ςނ�ȁB
68 �F�f�t�H���g�̖����������F2008/09/24(��) 00:02:00
������CELL��4PPE+32SPE��
368: 2008/09/22 22:10:38 RPIGcU63O [sage]
>>364
MAC������ł����Ǥ������CELL�̸ۯ���3.8GHz�~�܂�ł��
> 6/10�̾�Ű��������������@���Ă����玟����CELL�ɂ��Č��y�����ʂ̂����������
> http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_Strat_JHC_Japan.pdf
> �@��]���^Cell/B.E.��2009�N��45nm��۾���
> �@��ȑO��۰��ϯ�߂ɂ�����2*PPE + 32*SPE��"PowerXCell 32ii"����ݾ١�����
> �@�@4*PPE + 32*SPE��"PowerXCell 32iv"�֡
> �@�PowerXCell 32iv�̐����PPE�Ɏ������ -> PPE' ��
> �@�������SPE��"eSPE"�ɐi��
> �@��ۯ����グ�餁`3.8GHz
> �@����̑�PowerXCell 32iv����̓���������L�̒ʂ�
> �@�@- 100% backward compatible
> �@�@- PPE���\��啝����
> �@�@- SPE��V���ߒlj��ȊO�팻��� (�V���߾�Ă��g�p�����Ă�啝�ɐ��\����)
> �@�@- SPE�Ԃ̒ʐMڲ�ݼ�팸
> �@�@- More on-chip memory (LS���ʂ�?)
> �@�@- Ҳ���ر����̑�敝������ڲ�ݼ�팸
368: 2008/09/22 22:10:38 RPIGcU63O [sage]
>>364
MAC������ł����Ǥ������CELL�̸ۯ���3.8GHz�~�܂�ł��
> 6/10�̾�Ű��������������@���Ă����玟����CELL�ɂ��Č��y�����ʂ̂����������
> http://www-06.ibm.com/jp/solutions/deepcomputing/events/pdf/080610_Cell_Strat_JHC_Japan.pdf
> �@��]���^Cell/B.E.��2009�N��45nm��۾���
> �@��ȑO��۰��ϯ�߂ɂ�����2*PPE + 32*SPE��"PowerXCell 32ii"����ݾ١�����
> �@�@4*PPE + 32*SPE��"PowerXCell 32iv"�֡
> �@�PowerXCell 32iv�̐����PPE�Ɏ������ -> PPE' ��
> �@�������SPE��"eSPE"�ɐi��
> �@��ۯ����グ�餁`3.8GHz
> �@����̑�PowerXCell 32iv����̓���������L�̒ʂ�
> �@�@- 100% backward compatible
> �@�@- PPE���\��啝����
> �@�@- SPE��V���ߒlj��ȊO�팻��� (�V���߾�Ă��g�p�����Ă�啝�ɐ��\����)
> �@�@- SPE�Ԃ̒ʐMڲ�ݼ�팸
> �@�@- More on-chip memory (LS���ʂ�?)
> �@�@- Ҳ���ر����̑�敝������ڲ�ݼ�팸
69 �F�f�t�H���g�̖����������F2008/09/25(��) 04:02:42
mars�������Ƀo�[�W����Up
70 �F�f�t�H���g�̖����������F2008/09/25(��) 08:23:16
>>68
���ꉽ���o��H
���v���Z�X�ō�����猻���I�Ȃ�B
��ȋ�����������A�g���{�[�h���o�����A����̃A���ȓ_���C������
�}�C�i�[�A�b�v�o�[�W�����o���������ǂ��Ǝv�����B
���ꉽ���o��H
���v���Z�X�ō�����猻���I�Ȃ�B
��ȋ�����������A�g���{�[�h���o�����A����̃A���ȓ_���C������
�}�C�i�[�A�b�v�o�[�W�����o���������ǂ��Ǝv�����B
71 �F�f�t�H���g�̖����������F2008/09/25(��) 11:45:22
�g���{�[�h���ĂȂH
����ȓ_�Ƃ́H
����ȓ_�Ƃ́H
72 �F�f�t�H���g�̖����������F2008/09/25(��) 18:34:33
>>70
�������i��K�͂��g�傷��͓̂�����O�̘b�B�T�[�o�p��CPU�Ȃ���B
����ɏ]����Cell�̉��ǔłȂ�A���ɐ��i������Ă��B
�������i��K�͂��g�傷��͓̂�����O�̘b�B�T�[�o�p��CPU�Ȃ���B
����ɏ]����Cell�̉��ǔłȂ�A���ɐ��i������Ă��B
73 �F�f�t�H���g�̖����������F2008/09/25(��) 19:21:37
>>68���o����PS3�݂����ɕs�ǃR�A�������炩�E���Ă���č\��Ȃ����������ɓ���Ȃ����Ȃ��B
�����A���� Cell.B.E �� 90nm �������̂��B
��������A4�{��(+LS����)+���Ȃ炠�肦��b���B���߂�B
�ǂ���ɂ���APS3 �����Ԃ��ᗬ�s���ȁB
Atom + GeForce �̕������₷�����B
��������A4�{��(+LS����)+���Ȃ炠�肦��b���B���߂�B
�ǂ���ɂ���APS3 �����Ԃ��ᗬ�s���ȁB
Atom + GeForce �̕������₷�����B
75 �F�f�t�H���g�̖����������F2008/09/25(��) 21:04:32
�����Atom�̕������͏o�邾�낤���ǁA���������������ĂȂ�����B
ttp://www-06.ibm.com/systems/jp/bladecenter/hardware/qs22/
ttp://www-06.ibm.com/systems/jp/bladecenter/hardware/qs22/
76 �F�f�t�H���g�̖����������F2008/09/26(��) 15:13:55
Cell�̏�����Sony��IBM�Ɠ��ł����ꂼ��Ⴄ����ł̎g������z�肵
�قȂ�J���v��������Ă邩��A�u�ǂ̉�Ђ̌v��Ȃ̂��H�v��
�w�肵�Ȃ��Ƙb���X���Ⴂ���܂���Ȃ�ȁB
Sony:�Q�[���@�iPS3�y�т��̌�p�j
���ŁF�Ɠd�i�摜�����j���m�[�gPC�p�R�v���Z�b�T�iSpursEngine�j
IBM�F�u���[�h�T�[�o�[��HPC�pCPU
�قȂ�J���v��������Ă邩��A�u�ǂ̉�Ђ̌v��Ȃ̂��H�v��
�w�肵�Ȃ��Ƙb���X���Ⴂ���܂���Ȃ�ȁB
Sony:�Q�[���@�iPS3�y�т��̌�p�j
���ŁF�Ɠd�i�摜�����j���m�[�gPC�p�R�v���Z�b�T�iSpursEngine�j
IBM�F�u���[�h�T�[�o�[��HPC�pCPU
77 �F�f�t�H���g�̖����������F2008/09/26(��) 16:25:38
BD�G���R�[�_�Ƃ��ABD�G���R�[�_�Ƃ��E�E�E
78 �F�f�t�H���g�̖����������F2008/09/26(��) 18:06:51
Cell�G���Ă݂�����
�d���ł͐�₾����
�d���ł͐�₾����
79 �F�f�t�H���g�̖����������F2008/09/26(��) 18:40:58
>>78
�d����SuperEngine�G�邩�������
�d����SuperEngine�G�邩�������
80 �F�f�t�H���g�̖����������F2008/09/26(��) 21:15:49
������Super�ł���
81 �F�f�t�H���g�̖����������F2008/10/16(��) 14:54:02
helloworld�v���O������������̂ł����A���s������ƁB
spu_create(): Invalid argument
spe_context_create: Bad address�Ƃł܂��B
�v���O�����\�[�X��fixstars�̃`���[�g���A���ǂ���ŁA
PS3�ɂ�Fedora7�ASDK��3.0�����܂����B
������>>20����̎���Ƃقڂ��Ԃ��Ă���̂͂킩��̂ł����A�����킩��܂���B
>>24����̂����A�o�C�i���̃t�@�C��������Ă���A�������͍���Ă��Ȃ��ꍇ�͂ǂ��������낵���̂ł��傤���H
spu_create(): Invalid argument
spe_context_create: Bad address�Ƃł܂��B
�v���O�����\�[�X��fixstars�̃`���[�g���A���ǂ���ŁA
PS3�ɂ�Fedora7�ASDK��3.0�����܂����B
������>>20����̎���Ƃقڂ��Ԃ��Ă���̂͂킩��̂ł����A�����킩��܂���B
>>24����̂����A�o�C�i���̃t�@�C��������Ă���A�������͍���Ă��Ȃ��ꍇ�͂ǂ��������낵���̂ł��傤���H
82 �F�f�t�H���g�̖����������F2008/10/16(��) 19:08:19
83 �F�f�t�H���g�̖����������F2008/10/18(�y) 00:24:16
�q���g: ���ƕ��̕�
84 �F�f�t�H���g�̖����������F2008/10/18(�y) 10:04:21
>>81
fixstars�̃`���[�g���A����3.2�͂ɂ���\�[�X�iPPE/SPE�p�j���R���p�C�������Ƃ������Ƃł���ˁB
���̊��ł́AFedora7 + SDK3(�����ɂ�3.0.0.3�ł����W�Ȃ��ł��傤�j�A�Ŗ��Ȃ����s�ł��܂��B
PS3 linux���mount�����s�����ۂɁAspufs�̓}�E���g����Ă��܂����H
Linux������̖��̂悤�ȋC�����܂��B
fixstars�̃`���[�g���A����3.2�͂ɂ���\�[�X�iPPE/SPE�p�j���R���p�C�������Ƃ������Ƃł���ˁB
���̊��ł́AFedora7 + SDK3(�����ɂ�3.0.0.3�ł����W�Ȃ��ł��傤�j�A�Ŗ��Ȃ����s�ł��܂��B
PS3 linux���mount�����s�����ۂɁAspufs�̓}�E���g����Ă��܂����H
Linux������̖��̂悤�ȋC�����܂��B
85 �F�f�t�H���g�̖����������F2008/10/18(�y) 18:11:22
GT200�Ƃ�Larrabee�Ƃ��̃j���[�X���Ђƒi�����āA�ŋ߁A�V�����b���Ȃ��đދ����B
���낻��A����Cell�̘b���łĂ��Ă����͂�����ȁB
���낻��A����Cell�̘b���łĂ��Ă����͂�����ȁB
86 �F�f�t�H���g�̖����������F2008/10/18(�y) 18:40:44
����Cell�͏o������́A9�R�A�������Ȃ�������āA�ƊE�ɂ���Ȃ�̃C���p�N�g�A�e����^�����Ǝv���B
����Cell��2010�N�㔼��36�R�A�����ǁA�ǂ��Ȃ邾�낤���B
��������32��SPE������ƁA�{���I�ɍ��܂łƕς���Ă��邱�Ƃ��o�Ă���B
�܂��A��Ԗ��Ȃ̂̓������̑ш悾�낤�B����ł��ш�͉��Z�ɒǂ����Ă��Ȃ����A
�����܂Ō������v��������A�v���P�[�V��������łȂ��̂ŁA���p�ɂ͖��Ȃ��B
�������A����Cell�ł̓R�A�����ŁA�ш�s���������ɂȂ��Ȃ����낤���B
IBM�͂��������ӂ͍l������Őv���Ă邩��A�������Ă�̂��낤�B���̉�����
�d�����ǂ�����Ă���̂��������Ă݂����B
���ɁA���\�̃X�P�[���r���e�B��32SPE�ł����Ȃ��ۂĂ�̂��ǂ������B
����̓������̘b�Ƃ��W���Ă��邱�Ƃł͂��邯�ǁB����Cell�ł�8�R�A��
�قڃ��j�A�ɃX�P�[������Ƃ����b���悭������ACell�̈�̔���ɂȂ��Ă����B
2Cell��16SPE�ł��X�P�[������Ȃ�Ęb���������悤�ȋC�����邪�A����Cell�ł�
�ǂ����낤���B
���ꂪ�A32SPE���炢�܂ł�������X�P�[����������A32SPE�ɐv���܂���
�Ƃ����Ă����̂��A������100���炢�܂ł����邱�Ƃ��m�F���Ă���̂��A20���炢��
���E�ŁA���Ƃ͕ʗp�r�œ������s���Ă����������Ă����̂��A���ɏd�v���B
Cell�̃X�P�[���r���e�B���悢�Ƃ����̂́A���̔����̃��[�J�[�����ڂ��Ă���͂��ŁA
30���炢�ł����\�ł�߂ǂ�����ƂȂ�����A�����^�����ĒǏ]�������Ă��傤���Ȃ����낤�B
8�R�A���炢�܂ł����p�̏���Ȃ�Ęb�����邩��A������ӂ̌��ɂ߂��������͂����B
�܂��A�A�v���P�[�V�����ɂ�邯�ǁB�ł�MARS��32SPE�Ō��ʓI�ɓ������ĂȂ�����A�������
������Ȃ����낤���H
����Cell��2010�N�㔼��36�R�A�����ǁA�ǂ��Ȃ邾�낤���B
��������32��SPE������ƁA�{���I�ɍ��܂łƕς���Ă��邱�Ƃ��o�Ă���B
�܂��A��Ԗ��Ȃ̂̓������̑ш悾�낤�B����ł��ш�͉��Z�ɒǂ����Ă��Ȃ����A
�����܂Ō������v��������A�v���P�[�V��������łȂ��̂ŁA���p�ɂ͖��Ȃ��B
�������A����Cell�ł̓R�A�����ŁA�ш�s���������ɂȂ��Ȃ����낤���B
IBM�͂��������ӂ͍l������Őv���Ă邩��A�������Ă�̂��낤�B���̉�����
�d�����ǂ�����Ă���̂��������Ă݂����B
���ɁA���\�̃X�P�[���r���e�B��32SPE�ł����Ȃ��ۂĂ�̂��ǂ������B
����̓������̘b�Ƃ��W���Ă��邱�Ƃł͂��邯�ǁB����Cell�ł�8�R�A��
�قڃ��j�A�ɃX�P�[������Ƃ����b���悭������ACell�̈�̔���ɂȂ��Ă����B
2Cell��16SPE�ł��X�P�[������Ȃ�Ęb���������悤�ȋC�����邪�A����Cell�ł�
�ǂ����낤���B
���ꂪ�A32SPE���炢�܂ł�������X�P�[����������A32SPE�ɐv���܂���
�Ƃ����Ă����̂��A������100���炢�܂ł����邱�Ƃ��m�F���Ă���̂��A20���炢��
���E�ŁA���Ƃ͕ʗp�r�œ������s���Ă����������Ă����̂��A���ɏd�v���B
Cell�̃X�P�[���r���e�B���悢�Ƃ����̂́A���̔����̃��[�J�[�����ڂ��Ă���͂��ŁA
30���炢�ł����\�ł�߂ǂ�����ƂȂ�����A�����^�����ĒǏ]�������Ă��傤���Ȃ����낤�B
8�R�A���炢�܂ł����p�̏���Ȃ�Ęb�����邩��A������ӂ̌��ɂ߂��������͂����B
�܂��A�A�v���P�[�V�����ɂ�邯�ǁB�ł�MARS��32SPE�Ō��ʓI�ɓ������ĂȂ�����A�������
������Ȃ����낤���H
87 �F�f�t�H���g�̖����������F2008/10/18(�y) 19:19:41
����Cell�̃X�P�[������LS�̃R�q�[�����V���l����K�v���Ȃ����Ƃ��{����������A
����Cell�A���̎���Cell(120�R�A���炢?)�ŁA���̌��ʂ��w�����I�ɏo�Ă���͂��B
��������ƁALS�̍ĕ]���݂����Ȃ̂��N���Ă����Ȃ����낤���B
����LS�ɑ�������GPU��shared memory�͂��̐��肩������Ȃ����A��������
���j�[�R�A�̕K�R�Ƃ��ē����A�[�L�e�N�`���ɂ��ǂ�����Ƃ�����̂�������Ȃ��H
�܂��A�X�N���b�`�p�b�h�Ȃ�Đ̂��炠��������A����ȂɈ̂����킩��Ȃ����ǁB
LS�Ƃ����A�v���O���}�݂͂�ȗe�ʂ𑝂��邱�Ƃ��A����Cell�ł͊��҂��Ă��邾�낤�B
Cell�̃X�s�[�h�`�������W�ō��N�D�������l�́ALS�̗e�ʂ��{���I�Ɍv�Z�̍�����
�ƊW����悤�Ȃ��Ƃ������Ă��B�v���O�������y�Ƃ��������Ƃł͂Ȃ��B
LS�̗e�ʂ������ASPE���Ƃ̃��[�J���e�B�̍����A���S���Y���ɕύX�ł��邱�Ƃ�����
�Ƃ����悤�Ȃ��Ƃ炵���B
Cell���łĂ����Ԃ݂Ȃ��l���ɂȂ邱�ƂŁALS�̗e�ʂ͂��ꂭ�炢����ׂ��Ƃ����̂��A
���[�U�[���炠�������BLS�̑����͓��R�g�����W�X�^�\�Z��H���킯�ŁASPE���𑝂₷
�ق��������̂��ALS�𑝂₷�ق��������̂��̓V���ɂ邵�āA����LS�̗e�ʂ����܂�낤�B
�������Cell�Ŗʔ����̂́A��������GPU�����݂���Ȃ��ł̃f�r���[�ɂȂ�ALarrabee�Ƃ̋�����
���������̂ɂȂ邾�낤���Ƃ��B
����Cell�A���̎���Cell(120�R�A���炢?)�ŁA���̌��ʂ��w�����I�ɏo�Ă���͂��B
��������ƁALS�̍ĕ]���݂����Ȃ̂��N���Ă����Ȃ����낤���B
����LS�ɑ�������GPU��shared memory�͂��̐��肩������Ȃ����A��������
���j�[�R�A�̕K�R�Ƃ��ē����A�[�L�e�N�`���ɂ��ǂ�����Ƃ�����̂�������Ȃ��H
�܂��A�X�N���b�`�p�b�h�Ȃ�Đ̂��炠��������A����ȂɈ̂����킩��Ȃ����ǁB
LS�Ƃ����A�v���O���}�݂͂�ȗe�ʂ𑝂��邱�Ƃ��A����Cell�ł͊��҂��Ă��邾�낤�B
Cell�̃X�s�[�h�`�������W�ō��N�D�������l�́ALS�̗e�ʂ��{���I�Ɍv�Z�̍�����
�ƊW����悤�Ȃ��Ƃ������Ă��B�v���O�������y�Ƃ��������Ƃł͂Ȃ��B
LS�̗e�ʂ������ASPE���Ƃ̃��[�J���e�B�̍����A���S���Y���ɕύX�ł��邱�Ƃ�����
�Ƃ����悤�Ȃ��Ƃ炵���B
Cell���łĂ����Ԃ݂Ȃ��l���ɂȂ邱�ƂŁALS�̗e�ʂ͂��ꂭ�炢����ׂ��Ƃ����̂��A
���[�U�[���炠�������BLS�̑����͓��R�g�����W�X�^�\�Z��H���킯�ŁASPE���𑝂₷
�ق��������̂��ALS�𑝂₷�ق��������̂��̓V���ɂ邵�āA����LS�̗e�ʂ����܂�낤�B
�������Cell�Ŗʔ����̂́A��������GPU�����݂���Ȃ��ł̃f�r���[�ɂȂ�ALarrabee�Ƃ̋�����
���������̂ɂȂ邾�낤���Ƃ��B
88 �F�f�t�H���g�̖����������F2008/10/19(��) 02:08:02
PPE�F3
SPE�F21
LS�e�ʁF12MB
���ꂭ�炢�������B
SPE�F21
LS�e�ʁF12MB
���ꂭ�炢�������B
89 �F�f�t�H���g�̖����������F2008/10/20(��) 17:17:47
90 �F�f�t�H���g�̖����������F2008/10/24(��) 11:44:38
mars1.0.0�Ƀo�[�W�����A�b�v
91 �F�f�t�H���g�̖����������F2008/10/27(��) 11:35:38
�Ƃ肠�������b�N�t���[�L���[�őS�������ւ��Ȃ���mutex�吙
92 �F�f�t�H���g�̖����������F2008/10/27(��) 14:01:17
93 �F�f�t�H���g�̖����������F2008/11/04(��) 17:49:52
����Ȃ�ł����ASDK3.0�����Ă��A�R���p�C���G���[���o�āA
gcc�̓C���X�g�[������Ă��܂���Ƃł��̂ł����A
�ǂ��œ��肵����悢�̂ł��傤���H
gcc�̓C���X�g�[������Ă��܂���Ƃł��̂ł����A
�ǂ��œ��肵����悢�̂ł��傤���H
94 �F�f�t�H���g�̖����������F2008/11/04(��) 18:15:30
�p�X�͂����Ɛݒ肵�Ă���̂�? ������ɂ��Ă��Acell�v���O���~���O�ƊW�Ȃ������B
95 �F�f�t�H���g�̖����������F2008/11/05(��) 07:30:28
�����̑ԓx�ł������ȓz
96 �F�f�t�H���g�̖����������F2008/11/05(��) 08:11:16
���O�������Ȃ�
97 �F�f�t�H���g�̖����������F2008/11/08(�y) 00:31:51
Fedora9��SDK3.1�ƃV�~�����[�^���C���X�g�[�����܂����B
SDK�t����eclipse�ォ��A�V�~�����[�^�����s����ƁA�J�[�l����ǂݍ����
�����オ�����Ƃ���ŁA�R�}���h���͑҂��ɂȂ�A��ɐi�܂Ȃ��Ȃ��Ă��܂��܂��B
�����ݒ肵�Ȃ���Ȃ�Ȃ����ړ�������̂ł��傤���H
SDK�t����eclipse�ォ��A�V�~�����[�^�����s����ƁA�J�[�l����ǂݍ����
�����オ�����Ƃ���ŁA�R�}���h���͑҂��ɂȂ�A��ɐi�܂Ȃ��Ȃ��Ă��܂��܂��B
�����ݒ肵�Ȃ���Ȃ�Ȃ����ړ�������̂ł��傤���H
98 �F�f�t�H���g�̖����������F2008/11/08(�y) 01:34:37
�R�}���h���͑҂��ɂȂ�Ȃ�A�R�}���h����͂���������?
99 �F�f�t�H���g�̖����������F2008/11/08(�y) 01:46:11
Run→Open Run Dialog...�E�C���h�E��Target�^�u�ŁA�N�������V�~�����[�^���w�肷������ł���
100 �F�f�t�H���g�̖����������F2008/11/10(��) 08:20:40
101 �F�f�t�H���g�̖����������F2008/11/11(��) 20:41:20
102 �F�f�t�H���g�̖����������F2008/11/12(��) 10:16:13
http://www.ie.u-ryukyu.ac.jp/~kono/papers/kono/2008/gongo-sigos2008.pdf
http://www.ie.u-ryukyu.ac.jp/~kono/papers/kono/2008/akira-vld.pdf
����Ȃ̂�����
http://www.ie.u-ryukyu.ac.jp/~kono/papers/kono/2008/akira-vld.pdf
����Ȃ̂�����
103 �F�f�t�H���g�̖����������F2008/11/12(��) 15:31:40
>>102
�����^�BCell�̊J���ɓ��ł̖��O�������B
�����^�BCell�̊J���ɓ��ł̖��O�������B
104 �F�f�t�H���g�̖����������F2008/11/12(��) 21:11:45
Hack the Cell 2009�ɎQ�����悤����
�ق�Ƃɐ}�������炦��Ȃ���C�o������
�ق�Ƃɐ}�������炦��Ȃ���C�o������
105 �F�f�t�H���g�̖����������F2008/11/12(��) 21:17:07
�Ј���
106 �F�f�t�H���g�̖����������F2008/11/12(��) 21:29:31
���X������
���ǐ}���J�[�h����ˁH���Ęb�Ȃ�����������
���ǐ}���J�[�h����ˁH���Ęb�Ȃ�����������
107 �F�f�t�H���g�̖����������F2008/11/13(��) 10:25:46
���債����Hack the Cell 2008�ɎQ�����肪�Ƃ����Č���ꂽ���ǂ����̂��낤��
108 �F�f�t�H���g�̖����������F2008/11/13(��) 11:34:08
>>102
�g���������ǁA��̕��͓���Cell Broadband Engine�̐�����SPE��7�Ƃ�6�Ƃ�����������Ă鎞�_�ŃA�C�^�^�^�B
������ĂȂ����PS3�Ɍ��肵�Ȃ���ʓI�Ȑ����Ƃ��Ă͂ǂ������Ԉ���Ă�w
�g���������ǁA��̕��͓���Cell Broadband Engine�̐�����SPE��7�Ƃ�6�Ƃ�����������Ă鎞�_�ŃA�C�^�^�^�B
������ĂȂ����PS3�Ɍ��肵�Ȃ���ʓI�Ȑ����Ƃ��Ă͂ǂ������Ԉ���Ă�w
109 �F�f�t�H���g�̖����������F2008/11/13(��) 16:30:46
PS3��OpenCV on the Cell�Ƃ���
��F���̃T���v���v���O���������Ă݂����̂ł����A
fixstars�̒ʂ�ɃC���X�g�[�����Ă��I�����삵�܂���B
�iSPE�������Ă���C�z�Ȃ��j
http://cell.fixstars.com/opencv/index.php/How_to_Build
���Ԃ�p�X�������ƒʂ��Ă܂���B
�ǂȂ��������@�������Ă��������I�I�I
��F���̃T���v���v���O���������Ă݂����̂ł����A
fixstars�̒ʂ�ɃC���X�g�[�����Ă��I�����삵�܂���B
�iSPE�������Ă���C�z�Ȃ��j
http://cell.fixstars.com/opencv/index.php/How_to_Build
���Ԃ�p�X�������ƒʂ��Ă܂���B
�ǂȂ��������@�������Ă��������I�I�I
110 �F�f�t�H���g�̖����������F2008/11/14(��) 02:08:31
Hack the Cell 2009���Ă���̂��Ƃ��B
cell�v���O���~���O�̃R���e���X��
http://cell.fixstars.com/challenge/index.html
�Ȃ��>>107��2008�ɎQ�����肪�Ƃ����Č���ꂽ��
�w���ƎЉ�l�ŕ��啪����Ă邯�ǁE�E
�ǂ���ɂ����Ă͂܂�Ȃ��ꍇ�ɂ͂ǂ��Ȃ�H
cell�v���O���~���O�̃R���e���X��
http://cell.fixstars.com/challenge/index.html
�Ȃ��>>107��2008�ɎQ�����肪�Ƃ����Č���ꂽ��
�w���ƎЉ�l�ŕ��啪����Ă邯�ǁE�E
�ǂ���ɂ����Ă͂܂�Ȃ��ꍇ�ɂ͂ǂ��Ȃ�H
111 �F�f�t�H���g�̖����������F2008/11/14(��) 17:20:37
���肠�����Ă܂���܂����B
112 �F�f�t�H���g�̖����������F2008/11/15(�y) 20:53:05
�ŋ߂b����̕��n�߂������肾���ǁAHack the Cell���ĎQ�����đ��v���ȁH
�o�g�o�Ȃ炩�Ȃ蓾�ӂȂ��ǁB
�ł��A�D�����Ă��ꏏ�ɊC�O���s�ɍs���悤�ȗF�l���Ȃ��Ȃ��B
�o�g�o�Ȃ炩�Ȃ蓾�ӂȂ��ǁB
�ł��A�D�����Ă��ꏏ�ɊC�O���s�ɍs���悤�ȗF�l���Ȃ��Ȃ��B
113 �F�f�t�H���g�̖����������F2008/11/15(�y) 21:59:26
�ǁ[���Ȃ� ioccc �ŏ����Ƃ�
114 �F�f�t�H���g�̖����������F2008/11/15(�y) 23:12:54
PHP�����ӂ�C���o���Ȃ��l�Ԃ��ăI�u�W�F�N�g�w���Ƃ��m���Ă�̂��C�ɂȂ�
115 �F�f�t�H���g�̖����������F2008/11/15(�y) 23:38:33
Cell�̒m�����Ă�����g���r�A����ˁB
116 �F�f�t�H���g�̖����������F2008/11/15(�y) 23:56:22
2�N�߂��Ő�[�ł���ꂽ�̂ł���Ӗ��𗧂����B
117 �F�f�t�H���g�̖����������F2008/11/16(��) 06:40:32
����A�ƒ������ŐH���Ă�l�△�E�ł��Q���ł���낤���H
�w���ȊO�͑S���Љ��l������ĂȂ��Ă邯�ǁA��Ж��Ƃ��������Ƃ��K�{���ڂ߂��Ȃ����B
�f���ɉ�Ж��u�e�̉Ɓv�����u����x���v���ď����Ă����̂��H
�w���ȊO�͑S���Љ��l������ĂȂ��Ă邯�ǁA��Ж��Ƃ��������Ƃ��K�{���ڂ߂��Ȃ����B
�f���ɉ�Ж��u�e�̉Ɓv�����u����x���v���ď����Ă����̂��H
118 �F�f�t�H���g�̖����������F2008/11/16(��) 11:12:01
�Ȃ����܂��͂����ڋ��Ȃ�
����x�����Ɍւ������
����x�����Ɍւ������
119 �F�f�t�H���g�̖����������F2008/11/16(��) 11:42:28
�o�g�o�Ȃ�ق�Ƃ��Ȃ蓾�ӂ���
���O��̂o�b�n�b�N���炢�͑S�R�]�T
�b�������������ȒP�Ɏg�����Ȃ���Ǝv��
���O��̂o�b�n�b�N���炢�͑S�R�]�T
�b�������������ȒP�Ɏg�����Ȃ���Ǝv��
120 �F�f�t�H���g�̖����������F2008/11/16(��) 14:43:10
�ނ�͑����ł��
121 �F�f�t�H���g�̖����������F2008/11/16(��) 16:17:18
122 �F�f�t�H���g�̖����������F2008/11/16(��) 18:17:17
123 �F�f�t�H���g�̖����������F2008/11/16(��) 20:19:39
124 �F�f�t�H���g�̖����������F2008/11/17(��) 00:53:39
>>110
>�Љ�l����
>
>�w������ɊY�����Ȃ��l���ׂĂ̕����ΏۂƂȂ�܂��B
�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`
>�l��������2���ł̃`�[�����傪�\�ł��B
�����͐����ǂ߂悗
>�Љ�l����
>
>�w������ɊY�����Ȃ��l���ׂĂ̕����ΏۂƂȂ�܂��B
�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`�`
>�l��������2���ł̃`�[�����傪�\�ł��B
�����͐����ǂ߂悗
125 �F�f�t�H���g�̖����������F2008/11/19(��) 23:23:22
Cell2 Broadband Engine
� 3PPE (Power Processor Element)
�4.2Ghz
�@�2 threads (can run at same time)
�L1 cache:32KB data + 32KB instruction
�L2 cache:512KB
�Memory bus width:64bit (serial)
�VMX (Altivec) instruction set support
�Full IEEE-745 compliant
�18 SPE (Synergistic Processing Element)
�4.2Ghz
�2 SPE disabled to improve chip yield
�1 SPE dedicated for hypervisor security
�256KB local store per SPE
�128 registers per SPE
�Dual Issue (Each SPE can execute 2 instructions per clock)
�IEEE-754 compliant in double precision (single precision round-towards-zero instead of round-towards-even)
PS4�̽�߯��\�z
http://www.edepot.com/playstation4.html
� 3PPE (Power Processor Element)
�4.2Ghz
�@�2 threads (can run at same time)
�L1 cache:32KB data + 32KB instruction
�L2 cache:512KB
�Memory bus width:64bit (serial)
�VMX (Altivec) instruction set support
�Full IEEE-745 compliant
�18 SPE (Synergistic Processing Element)
�4.2Ghz
�2 SPE disabled to improve chip yield
�1 SPE dedicated for hypervisor security
�256KB local store per SPE
�128 registers per SPE
�Dual Issue (Each SPE can execute 2 instructions per clock)
�IEEE-754 compliant in double precision (single precision round-towards-zero instead of round-towards-even)
PS4�̽�߯��\�z
http://www.edepot.com/playstation4.html
126 �F�f�t�H���g�̖����������F2008/11/20(��) 12:02:06
120%���肦�Ȃ�
127 �F�f�t�H���g�̖����������F2008/11/25(��) 22:47:41
>126
�����H Cell�Ɋւ��Ă͂���ȂɂԂ����ł����Ȃ��A
�ނ��뉸���ȗ\�����Ǝv�����B
PPE��3���ςނ��͂�����Ƌ^�₾���ǁB
SPE�̃��[�J���X�g�A�͂�͂�256KB�����E�Ȃ̂��Ȃ��H
�A�[�L�e�N�`����͂����Ƒ��₹��悤�Ɏv�����A
�_�C�̖ʐϓI�ɋꂵ�����낤���H
�����H Cell�Ɋւ��Ă͂���ȂɂԂ����ł����Ȃ��A
�ނ��뉸���ȗ\�����Ǝv�����B
PPE��3���ςނ��͂�����Ƌ^�₾���ǁB
SPE�̃��[�J���X�g�A�͂�͂�256KB�����E�Ȃ̂��Ȃ��H
�A�[�L�e�N�`����͂����Ƒ��₹��悤�Ɏv�����A
�_�C�̖ʐϓI�ɋꂵ�����낤���H
128 �F�f�t�H���g�̖����������F2008/11/25(��) 23:59:01
>>127
��Cell B.E.��eDRAM�̑�e�ʃ��������ڂ̓����J����
ttp://pc.watch.impress.co.jp/docs/2007/0216/kaigai338.htm
��Cell B.E.��eDRAM�̑�e�ʃ��������ڂ̓����J����
ttp://pc.watch.impress.co.jp/docs/2007/0216/kaigai338.htm
129 �F�f�t�H���g�̖����������F2008/11/27(��) 13:08:12
130 �F�f�t�H���g�̖����������F2008/11/29(�y) 19:43:30
SpursEngine��SDK�̉��������炵��
SpursEngine�̃C�x���g�𓌎ł����T���{�ASDK�̉����\�t�g�e�Ђ̃A�s�[����
http://www.watch.impress.co.jp/akiba/hotline/20081129/etc_toshiba.html
SpursEngine�̃C�x���g�𓌎ł����T���{�ASDK�̉����\�t�g�e�Ђ̃A�s�[����
http://www.watch.impress.co.jp/akiba/hotline/20081129/etc_toshiba.html
131 �F�f�t�H���g�̖����������F2008/12/02(��) 23:47:15
XLC �ōs�����I: �� 3 �� �����炩�̎����͂���ς�K�v
ttp://www.ibm.com/developerworks/jp/power/library/j_pa-xlc03/
ttp://www.ibm.com/developerworks/jp/power/library/j_pa-xlc03/
132 �F�f�t�H���g�̖����������F2008/12/06(�y) 01:55:30
�\�j�[���炱��Ȃ�o�Ă܂��ȁB
ttp://pc.watch.impress.co.jp/docs/2008/1205/sony.htm
ttp://www.ecat.sony.co.jp/business/video_production/products/index.cfm?PD=33164&KM=BCU-100
�f���ҏW�p�@�툵�������ǂǂ�Ȏg������z�肵�Ă�낤���H�@OS�ʂ����B
���������̂������͖��������m��Ȃ����APC�p�g���{�[�h�̌`��
�������iXDR-DRAM)��������x�ς߂Ă������������z�𑁂��o���ė~�����B
PS3�������ƃ���������������~�����Ǝv���Ƃ����Ȃ�100���~�R�[�X��
�Ȃ�̂͂��낻�늨�ق��Ă��������B
ttp://pc.watch.impress.co.jp/docs/2008/1205/sony.htm
ttp://www.ecat.sony.co.jp/business/video_production/products/index.cfm?PD=33164&KM=BCU-100
�f���ҏW�p�@�툵�������ǂǂ�Ȏg������z�肵�Ă�낤���H�@OS�ʂ����B
���������̂������͖��������m��Ȃ����APC�p�g���{�[�h�̌`��
�������iXDR-DRAM)��������x�ς߂Ă������������z�𑁂��o���ė~�����B
PS3�������ƃ���������������~�����Ǝv���Ƃ����Ȃ�100���~�R�[�X��
�Ȃ�̂͂��낻�늨�ق��Ă��������B
133 �F�f�t�H���g�̖����������F2008/12/08(��) 14:31:24
>>132 ���܂����A�킩���Ȃ��E�E�E�E�E�E
���ǂ�����Ċ�炮�炢�̂�����̂ŁA�ǂ̒��x�̎��܂Ŏ肪��낤�H�H�H
�ȂA��ǂ��ł������������łĂȂ��ĂȂ��B
����Ȃ�PS3�̍ɏ����Ƃ��ĂȂ낤���H
���ǂ�����Ċ�炮�炢�̂�����̂ŁA�ǂ̒��x�̎��܂Ŏ肪��낤�H�H�H
�ȂA��ǂ��ł������������łĂȂ��ĂȂ��B
����Ȃ�PS3�̍ɏ����Ƃ��ĂȂ낤���H
134 �F��������W���B�B�B�F2008/12/08(��) 17:27:13
Cell�h����SpursEngine��PCIe�{�[�h����������Ă��邪SDK��N���ɖ����z�z���邻����
�Ȃ�SpursEngine���A�Ǝv������SPE�̊J����(eclipse)���Ƃ̒Ńf�o�b�K���t���炵��
http://www.watch.impress.co.jp/akiba/hotline/20081206/image/sstod8.jpg
�z�X�g��(PC��)��Visual Studio�œ��{��h�L�������g���p�ӂ����炵��
http://www.watch.impress.co.jp/akiba/hotline/20081206/image/sstod7.jpg
SpursEngine�̃{�[�h���̂�3�����炢������PS3��������Ęb�����邯�ǂ�
�Ȃ�SpursEngine���A�Ǝv������SPE�̊J����(eclipse)���Ƃ̒Ńf�o�b�K���t���炵��
http://www.watch.impress.co.jp/akiba/hotline/20081206/image/sstod8.jpg
{kind=link}
�z�X�g��(PC��)��Visual Studio�œ��{��h�L�������g���p�ӂ����炵��
http://www.watch.impress.co.jp/akiba/hotline/20081206/image/sstod7.jpg
{kind=link}
SpursEngine�̃{�[�h���̂�3�����炢������PS3��������Ęb�����邯�ǂ�
135 �F�f�t�H���g�̖����������F2008/12/09(��) 00:19:00
>134
SpursEngine���ڃJ�[�h�͂��낢��o�Ă������A�̐S��Cell���ڃJ�[�h��
������҂��Ă��o�ė��Ȃ��ȁi100�}�\�R�[�X�̃{�b�^�N��Card�͏����j
XDR-DRAM�e�ʂ�256MB����1GB���炢�܂őI�ׂĂ��ł�DDR2-DRAM��
1GB���炢���ڂł���5������20�����x�̃J�[�h���Ȃ��o����H
�������C���^�[�t�F�[�X��PCI-Express x 16�ŁB
��p�t�@���̓S�c�C�����v�肻���ł͂���ȁB
RSX�͎g���悤��������ŗv��Ȃ��B
�A�}�`���A�v���O���}�̊S�͂����ς�GPGPU�Ɍ������Ă��܂����B
��������������ׂ�PS3��ł����Ă��HFixStars����B
SpursEngine���ڃJ�[�h�͂��낢��o�Ă������A�̐S��Cell���ڃJ�[�h��
������҂��Ă��o�ė��Ȃ��ȁi100�}�\�R�[�X�̃{�b�^�N��Card�͏����j
XDR-DRAM�e�ʂ�256MB����1GB���炢�܂őI�ׂĂ��ł�DDR2-DRAM��
1GB���炢���ڂł���5������20�����x�̃J�[�h���Ȃ��o����H
�������C���^�[�t�F�[�X��PCI-Express x 16�ŁB
��p�t�@���̓S�c�C�����v�肻���ł͂���ȁB
RSX�͎g���悤��������ŗv��Ȃ��B
�A�}�`���A�v���O���}�̊S�͂����ς�GPGPU�Ɍ������Ă��܂����B
��������������ׂ�PS3��ł����Ă��HFixStars����B
136 �F,,�E�L�́M�E,,�j��-�������F2008/12/09(��) 00:27:49
http://cellbe-cygwin.cvs.sourceforge.net/viewvc/cellbe-cygwin/cellbe-cygwin/ppu-gcc-c%2B%2B-4.1.1-5.cygwin.i686.rpm?view=log
PPE�����܂߂�Windows�ŃN���X�J���͂ł���ɂȂ������ǂˁB
PPE�����܂߂�Windows�ŃN���X�J���͂ł���ɂȂ������ǂˁB
137 �F�f�t�H���g�̖����������F2008/12/09(��) 19:47:54
>>135
�������Ƃ��BPC�ɂ�����Ƃ������Ƃ��A���͈�ԋC�y�ȋ߂���i�ȂƁA������������B
�Q�[���@�ɃC���X�g�[���ł�����Ă̂́A��y�����Ŏ��̓o���A������B
Nvidia�͂�����ւ��m���Ă��m�炸���A���Ȃ�{�C�Ŋ��o���Ă���̂��������B������T�|�[�g
���Ђǂ��Ƃ͂����AWindowsPC�Ŏg���āAVC�܂Ŏg����������낦�邾���ŏ\�����͂�����B
�Ђǂ����{��Ƃ͂����h�L�������g�����낦�āA�J���җp�����̌f��������āA���邱�Ƃ�����Ă���B
Cell�͂Ȃ�3�Ђ�����̂ɁA���������̂��ł��Ȃ��̂��c�B3�Ђ��˂���Ă��邩����ċC������ȁB
�������Ƃ��BPC�ɂ�����Ƃ������Ƃ��A���͈�ԋC�y�ȋ߂���i�ȂƁA������������B
�Q�[���@�ɃC���X�g�[���ł�����Ă̂́A��y�����Ŏ��̓o���A������B
Nvidia�͂�����ւ��m���Ă��m�炸���A���Ȃ�{�C�Ŋ��o���Ă���̂��������B������T�|�[�g
���Ђǂ��Ƃ͂����AWindowsPC�Ŏg���āAVC�܂Ŏg����������낦�邾���ŏ\�����͂�����B
�Ђǂ����{��Ƃ͂����h�L�������g�����낦�āA�J���җp�����̌f��������āA���邱�Ƃ�����Ă���B
Cell�͂Ȃ�3�Ђ�����̂ɁA���������̂��ł��Ȃ��̂��c�B3�Ђ��˂���Ă��邩����ċC������ȁB
138 �F�f�t�H���g�̖����������F2008/12/09(��) 22:13:19
nVidia���K���Ȃ���
139 �F,,�E�L�́M�E,,�j��-�������F2008/12/09(��) 22:48:12
���ʂ͏o�Ă镪�}�V����B
140 �F,,�E�L�́M�E,,�j��-�������F2008/12/09(��) 23:16:20
GPU�ŒP���x��500GFLOPS�o��r�f�I�J�[�h��2�����x�Ŕ����邲������
�撣���Ă�200GFLOPS�o�邩�łȂ����̑㕨��4�����o���Ĕ�������Ȑl�Ԃ������������Ȃ�����ȁB
SpursEngine������MPEG2/H.264�̃G���R�[�_�E�f�R�[�_�Ɗ������C�u���������邩�炱���̂��̂�
SPE�����������炢����SDK�p�ӂ��Ă��N���H�����Ȃ������낤��B
���ۖ��A���[�h�e�b�N�̃A���͐H�����������̂��ǂ����͒m���B
���ꏈ���n�Ƃ���CUDA���D��Ă�̂́ASIMD�ƃ}���`�R�A�Ƃ����T�O��SPMD���f���ɂ�����
�X���b�h�̊T�O�ł��܂��B�����Ă邱�ƁB������Ƃ��Ă͔��ɃV���v���ł킩��₷���B
�撣���Ă�200GFLOPS�o�邩�łȂ����̑㕨��4�����o���Ĕ�������Ȑl�Ԃ������������Ȃ�����ȁB
SpursEngine������MPEG2/H.264�̃G���R�[�_�E�f�R�[�_�Ɗ������C�u���������邩�炱���̂��̂�
SPE�����������炢����SDK�p�ӂ��Ă��N���H�����Ȃ������낤��B
���ۖ��A���[�h�e�b�N�̃A���͐H�����������̂��ǂ����͒m���B
���ꏈ���n�Ƃ���CUDA���D��Ă�̂́ASIMD�ƃ}���`�R�A�Ƃ����T�O��SPMD���f���ɂ�����
�X���b�h�̊T�O�ł��܂��B�����Ă邱�ƁB������Ƃ��Ă͔��ɃV���v���ł킩��₷���B
141 �F�f�t�H���g�̖����������F2008/12/09(��) 23:41:14
�Ō�̓�s�A�c�O�Ȃ���c�q�ɓ��ӁB�Ƃ͌������̂́A�X���Ⴂ����w
142 �F�f�t�H���g�̖����������F2008/12/09(��) 23:44:52
SCE�͂��ꂮ�炢����Ă�������ˁH
�EPLAYSTATION�����y�[�W�ŁuPS3�łł��邱�Ɓv��Linux�̂��Ƃ������Ə���
�Ƃɂ���������PS3��Linux���C���X�g�[���ł��邱�Ƃ�PS3���[�U�[�ɂ���m���ĂȂ��B�����ɃA�i�E���X���Ȃ�����B
�T�|�[�g�ΏۊO�̋@�\�ł��A�ł�������B�u�ց[����Ȃ��Ƃ��ł���v�Ǝv���Ă�������炻�ꂾ���ŕt�����l2���~�����炢�A�b�v����Ǝv���B
�t�B�b�N�X�^�[�Y��YDL�̃����[�X�ɍ��킹�ăC���X�g�[��DVD�t���̃��b�N�{���o���ė~�����B
����I�ɁB���e�͖���قƂ�Ǔ����ł���������B���������f�B�X�N�t����HOWTO�{���o�Ȃ��ƐV�K���[�U�[�͑����Ă����Ȃ��B
�G���h���[�U�[�������Ȃ���Cell�r�W�l�X���������Ȃ���H
���łƃ\�j�[��Cell�p�\�R������Ă�OS��Linux�ŁBGPU�̓`�b�v�Z�b�g�������x���ł����B�O���t�B�b�N��SPE�ł���������B���[�R�X�g�d���ŁA�ׂ���������^�C�v�̏��i�ɂ��ė~�����B
������������������������A�ǂ�ǂ�O�o���Ă��������B
�EPLAYSTATION�����y�[�W�ŁuPS3�łł��邱�Ɓv��Linux�̂��Ƃ������Ə���
�Ƃɂ���������PS3��Linux���C���X�g�[���ł��邱�Ƃ�PS3���[�U�[�ɂ���m���ĂȂ��B�����ɃA�i�E���X���Ȃ�����B
�T�|�[�g�ΏۊO�̋@�\�ł��A�ł�������B�u�ց[����Ȃ��Ƃ��ł���v�Ǝv���Ă�������炻�ꂾ���ŕt�����l2���~�����炢�A�b�v����Ǝv���B
�t�B�b�N�X�^�[�Y��YDL�̃����[�X�ɍ��킹�ăC���X�g�[��DVD�t���̃��b�N�{���o���ė~�����B
����I�ɁB���e�͖���قƂ�Ǔ����ł���������B���������f�B�X�N�t����HOWTO�{���o�Ȃ��ƐV�K���[�U�[�͑����Ă����Ȃ��B
�G���h���[�U�[�������Ȃ���Cell�r�W�l�X���������Ȃ���H
���łƃ\�j�[��Cell�p�\�R������Ă�OS��Linux�ŁBGPU�̓`�b�v�Z�b�g�������x���ł����B�O���t�B�b�N��SPE�ł���������B���[�R�X�g�d���ŁA�ׂ���������^�C�v�̏��i�ɂ��ė~�����B
������������������������A�ǂ�ǂ�O�o���Ă��������B
143 �F�f�t�H���g�̖����������F2008/12/09(��) 23:59:02
nVidia���撣���Ă��鎖��CUDA���ǂ��ł��Ă��鎖�����ӂȂ�
���i�����Ŋ������W�̈Ⴄ���̂ɂ������Ƃ������Ă�̂��ɂ�����B
Cell�ɖ��������邩�͂Ƃ������B
���i�����Ŋ������W�̈Ⴄ���̂ɂ������Ƃ������Ă�̂��ɂ�����B
Cell�ɖ��������邩�͂Ƃ������B
144 �F,,�E�L�́M�E,,�j��-�������F2008/12/10(��) 00:24:27
���t�B�b�N�X�^�[�Y��YDL�̃����[�X�ɍ��킹�ăC���X�g�[��DVD�t���̃��b�N�{���o���ė~�����B
�t�B�b�N�X�^�[�Y�i��Terrasoft�j�Ƃ��Ă͗L���T�|�[�g�肽�����낤���炱��͖�������B
�Ԃ����Ⴏ�A�yLinux�C���X�g�[���f�B�X�N�ɍL���t���̎��̑��鏤���z�͍����I�n�܂���
2�N���炢�Ńr�W�l�X���f���Ƃ��Ĕj�]�����B
�X�|���T�[�s�݂Ƃ������A�X�|���T�[�ɑ������ҕs�݁B
Software Design�݂����ȍd�h�ȎG���Ƃ͈���āA�m���T�|�[�g��Linux��CD-ROM�t�^
�y���݂ɂ��Ă�̂͂��������l���[�U�[���炢�������B
��ƃ��[�U�[�����̃J���[�����߂�ƁA�����܂ŃN���C�A���gOS�Ƃ��Ċy���݂���
�l���u���Ă��ڂ�H�炤�B�͂Ȃ����ƃ��[�U�[�͂��܂���Ă��ĂȂ������B
���[�^�Ƃ����z���\�����[�V�����Ƃ�����ɂ��Ă�����҂��t���Ă��Ȃ��킯��B
�ŁA�L�������Ȃ�����ǂ�ǂ������Ȃ��Ă������B
�ǂ�������������悤�Ƀu���[�h�o���h��CD-R�����y�������������A�G����
�����Ӗ����Ȃ��Ȃ���������B
Linux Magagine�̂܂��Ƃ䂫�Ђ뎁�̘A�ڂ͍D�����������ǂ��B
�A�ڑł����Ă��甃���y���݂��Ȃ��Ȃ����ȁB
�܂�PC�G���S�ʂɌ����邱�Ƃ����ǁB
�ǂ������킯��Mac�G�������͍������l�C���ւ��Ă�B���ꂾ���͗���s�\�B
>>143
���������̊z�ʂ����ɒ��ڂ������\�E�R�X�g�p�t�H�[�}���X�Ɋւ��Ă�GeForce 8800�V���[�Y�o�ꎞ�_��
���ɔ�����������B�܂菉���[��������B���̏�Q�[�����Ƃ����܂��̗l�����B
�����Ɍ�����GPU�ł��邱�Ƃ�Cell��SPE�̂�������p�r��I�Ԃ��������̐�����������B
�������ꏈ���n�Ƃ��Ă̂Ƃ����₷���̖ʂł�CUDA�͂���Ȃ�ɂ͗ǂ����̂��B
�v�����Cell���i���͎ア�̂͂��̕ӂ��ˁB
�܂��AOpenCL�ɑΉ�����������Ă��܂���ǂ��Ȃ����ł��Ȃ����ȁB
�t�B�b�N�X�^�[�Y�i��Terrasoft�j�Ƃ��Ă͗L���T�|�[�g�肽�����낤���炱��͖�������B
�Ԃ����Ⴏ�A�yLinux�C���X�g�[���f�B�X�N�ɍL���t���̎��̑��鏤���z�͍����I�n�܂���
2�N���炢�Ńr�W�l�X���f���Ƃ��Ĕj�]�����B
�X�|���T�[�s�݂Ƃ������A�X�|���T�[�ɑ������ҕs�݁B
Software Design�݂����ȍd�h�ȎG���Ƃ͈���āA�m���T�|�[�g��Linux��CD-ROM�t�^
�y���݂ɂ��Ă�̂͂��������l���[�U�[���炢�������B
��ƃ��[�U�[�����̃J���[�����߂�ƁA�����܂ŃN���C�A���gOS�Ƃ��Ċy���݂���
�l���u���Ă��ڂ�H�炤�B�͂Ȃ����ƃ��[�U�[�͂��܂���Ă��ĂȂ������B
���[�^�Ƃ����z���\�����[�V�����Ƃ�����ɂ��Ă�����҂��t���Ă��Ȃ��킯��B
�ŁA�L�������Ȃ�����ǂ�ǂ������Ȃ��Ă������B
�ǂ�������������悤�Ƀu���[�h�o���h��CD-R�����y�������������A�G����
�����Ӗ����Ȃ��Ȃ���������B
Linux Magagine�̂܂��Ƃ䂫�Ђ뎁�̘A�ڂ͍D�����������ǂ��B
�A�ڑł����Ă��甃���y���݂��Ȃ��Ȃ����ȁB
�܂�PC�G���S�ʂɌ����邱�Ƃ����ǁB
�ǂ������킯��Mac�G�������͍������l�C���ւ��Ă�B���ꂾ���͗���s�\�B
>>143
���������̊z�ʂ����ɒ��ڂ������\�E�R�X�g�p�t�H�[�}���X�Ɋւ��Ă�GeForce 8800�V���[�Y�o�ꎞ�_��
���ɔ�����������B�܂菉���[��������B���̏�Q�[�����Ƃ����܂��̗l�����B
�����Ɍ�����GPU�ł��邱�Ƃ�Cell��SPE�̂�������p�r��I�Ԃ��������̐�����������B
�������ꏈ���n�Ƃ��Ă̂Ƃ����₷���̖ʂł�CUDA�͂���Ȃ�ɂ͗ǂ����̂��B
�v�����Cell���i���͎ア�̂͂��̕ӂ��ˁB
�܂��AOpenCL�ɑΉ�����������Ă��܂���ǂ��Ȃ����ł��Ȃ����ȁB
145 �F,,�E�L�́M�E,,�j��-�������F2008/12/10(��) 00:53:49
PS3�����i�����ʼn��i�����Ă����Ηǂ��������ˁB2���~�䂭�炢�ɁB
�ŏ����琻����������B
�X�Ƀ_���s���O�K���@���ł��āA�����Ȓl�������ł��Ȃ��Ȃ����B
�\�t�g���[�J�[�����Ă��ĂȂ��̂Ƀn�[�h�����Ă��d���Ȃ��ʂ�����B
�ŋ߂�NVIDIA���n�[�h��s�̊��͂��邪�A�Ȃɂ��ɐ̂���Q�[���\�t�g�J���ɑ���x���͎���������B
�@�ނ�C�u�����̒Ƃ��ȁB
���W���[��PC�����Q�[���^�C�g���ɂ͕K��NVIDIA�̍L�������邾��H
CUDA�ł������悤�ɋZ�p�x������Ă��B���ꂱ���l�J���̃\�t�g�ɂ܂ŁB
�����SCE��PS3�����\�t�g�̖����̌��ł��_�E�����[�h���ɉ����ă\�t�g���[�J�[�ɉۋ��Ƃ��A
���蓾�Ȃ���������@�����{���B
�����������Ƃ͎s�ꏶ�����ėL�������킹�Ȃ���Ԃɂ��Ă��炷����B
DS�Ƃ�Wii�Ƃ�360�Ƃ����ɓ����ꂪ�����Ԃł���Ă邩��ȁB����ł͓��������B
�ŎZ�I�Ȉ��s�͑��ɂ����邪�B
�uPS3�𒆐S�Ƃ���Cell�x�[�X�̃G�R�V�X�e���v�̉\��������ׂ��Ă��܂����B
�ŏ����琻����������B
�X�Ƀ_���s���O�K���@���ł��āA�����Ȓl�������ł��Ȃ��Ȃ����B
�\�t�g���[�J�[�����Ă��ĂȂ��̂Ƀn�[�h�����Ă��d���Ȃ��ʂ�����B
�ŋ߂�NVIDIA���n�[�h��s�̊��͂��邪�A�Ȃɂ��ɐ̂���Q�[���\�t�g�J���ɑ���x���͎���������B
�@�ނ�C�u�����̒Ƃ��ȁB
���W���[��PC�����Q�[���^�C�g���ɂ͕K��NVIDIA�̍L�������邾��H
CUDA�ł������悤�ɋZ�p�x������Ă��B���ꂱ���l�J���̃\�t�g�ɂ܂ŁB
�����SCE��PS3�����\�t�g�̖����̌��ł��_�E�����[�h���ɉ����ă\�t�g���[�J�[�ɉۋ��Ƃ��A
���蓾�Ȃ���������@�����{���B
�����������Ƃ͎s�ꏶ�����ėL�������킹�Ȃ���Ԃɂ��Ă��炷����B
DS�Ƃ�Wii�Ƃ�360�Ƃ����ɓ����ꂪ�����Ԃł���Ă邩��ȁB����ł͓��������B
�ŎZ�I�Ȉ��s�͑��ɂ����邪�B
�uPS3�𒆐S�Ƃ���Cell�x�[�X�̃G�R�V�X�e���v�̉\��������ׂ��Ă��܂����B
146 �F�f�t�H���g�̖����������F2008/12/10(��) 01:14:53
���b�N�{���̂Ŗׂ���Ȃ��Ă�������B
�G���h���[�U�[�𑝂₷���Ƃ��ړI������B
�G���h���[�U�[���������Cell���̂̒m���x�⒍�ړx���オ���ăr�W�l�X�ł̗̍p�������邾�낤���A
�����̎Ј��̗{���A�Z�p�҂̃��x���̒�グ���ł���B
������t�B�b�N�X�^�[�Y�͂��ׂ�����B
�G���h���[�U�[�𑝂₷���Ƃ��ړI������B
�G���h���[�U�[���������Cell���̂̒m���x�⒍�ړx���オ���ăr�W�l�X�ł̗̍p�������邾�낤���A
�����̎Ј��̗{���A�Z�p�҂̃��x���̒�グ���ł���B
������t�B�b�N�X�^�[�Y�͂��ׂ�����B
147 �F�f�t�H���g�̖����������F2008/12/10(��) 07:32:08
���ꂮ�炢���Ȃ���Ă��
ttp://www.playstation.com/ps3-openplatform/jp/index.html
ttp://cell.fixstars.com/ps3linux/index.php/MARS
ttp://www.playstation.com/ps3-openplatform/jp/index.html
ttp://cell.fixstars.com/ps3linux/index.php/MARS
OpenCL�̍���ɂ�IBM�����Ȃ�����Ă�Cell�ɑΉ�������ۂ����琶�g����������Ă�B
149 �F�f�t�H���g�̖����������F2008/12/10(��) 18:47:23
OpenCL�������Ƀ����[�X����Ă��ł��g����悤�ɂȂ�����ł�
Cell�������[�Y�i�u����PC�p�g���J�[�h���o�Ȃ��āA�N��Cell�p
OpenCL���g���Ȃ������Ƃ�����Ȃ��Ȃ�������ȁB
Cell�������[�Y�i�u����PC�p�g���J�[�h���o�Ȃ��āA�N��Cell�p
OpenCL���g���Ȃ������Ƃ�����Ȃ��Ȃ�������ȁB
150 �F�f�t�H���g�̖����������F2008/12/10(��) 18:56:38
Cell�������c�邩�̓A��������IBM��Opteron+Cell���Ă͈̂����Ȃ��Ǝv���B
���ꂼ�꓾�ӕ��삪�S���Ⴄ�킯�ŁB
���z�I�ɂ�CPU+Cell+GPU�ɂȂ�ׂ��B
���̂��߂�OpenCL���Ǝv�����ˁB
CPU�ł�DSP�ł�GPU�ł������悤�ɋL�q�ł��āA�ȒP�ɐ�ւ�/�����g�p�o����悤�ɂȂ��Ă�B
���R���ӕ��삪�Ⴄ�킯������t���[�܂œ����悤�ɋL�q�����琫�\�͐������Ȃ����A
��������ŋL�q�ł��āA�Ƃ肠�������������̂͑傫���B
���ꂼ�꓾�ӕ��삪�S���Ⴄ�킯�ŁB
���z�I�ɂ�CPU+Cell+GPU�ɂȂ�ׂ��B
���̂��߂�OpenCL���Ǝv�����ˁB
CPU�ł�DSP�ł�GPU�ł������悤�ɋL�q�ł��āA�ȒP�ɐ�ւ�/�����g�p�o����悤�ɂȂ��Ă�B
���R���ӕ��삪�Ⴄ�킯������t���[�܂œ����悤�ɋL�q�����琫�\�͐������Ȃ����A
��������ŋL�q�ł��āA�Ƃ肠�������������̂͑傫���B
151 �F�f�t�H���g�̖����������F2008/12/10(��) 22:11:42
��AMD��STI���Ē��ԂȂ́H
152 �F�f�t�H���g�̖����������F2008/12/10(��) 22:43:37
STI?
�X�o���e�N�j�J�C���^�[�i�V���i����AMD�������W������Ƃ�
�������������ȁB
�X�o���e�N�j�J�C���^�[�i�V���i����AMD�������W������Ƃ�
�������������ȁB
153 �F�f�t�H���g�̖����������F2008/12/11(��) 15:37:08
>>150
>���z�I�ɂ�CPU+Cell+GPU�ɂȂ�ׂ��B
���̗��z���Ă����͉̂��Ɏg������Ȃ́H�������ɁAGPU�œ��ӂȂƂ����Cell�œ��ӂȂƂ��낪
�₦��Ƃ����Ӗ��ł͗��z��������Ȃ����A����ȕ��G�ȃV�X�e�����g�������Ă����l���
�{���Ɍ����Ă���Ǝv���B
�v�Z�@�Z���^�[�ŁA�����Ȑl�ɑΉ����鋤�L�v�Z�@�Ȃ�܂��킩�邪�A����Ȃ�g���l���邩�ǂ����c�B
>���z�I�ɂ�CPU+Cell+GPU�ɂȂ�ׂ��B
���̗��z���Ă����͉̂��Ɏg������Ȃ́H�������ɁAGPU�œ��ӂȂƂ����Cell�œ��ӂȂƂ��낪
�₦��Ƃ����Ӗ��ł͗��z��������Ȃ����A����ȕ��G�ȃV�X�e�����g�������Ă����l���
�{���Ɍ����Ă���Ǝv���B
�v�Z�@�Z���^�[�ŁA�����Ȑl�ɑΉ����鋤�L�v�Z�@�Ȃ�܂��킩�邪�A����Ȃ�g���l���邩�ǂ����c�B
154 �F�f�t�H���g�̖����������F2008/12/11(��) 16:45:34
ATI��AMD���������B�ǂ��������������Ǝv����B
155 �F�f�t�H���g�̖����������F2008/12/11(��) 22:05:49
>>151�̌����Ă�STI���Ă���Ɂ[�E�Ɓ[���i�j�EIBM�̂��Ƃ���H
45nm�v���Z�X�̊J���ŋ��͂Ƃ����Ƃ����Ȃ����������B
45nm�v���Z�X�̊J���ŋ��͂Ƃ����Ƃ����Ȃ����������B
156 �F�f�t�H���g�̖����������F2008/12/11(��) 22:47:09
Sony Toshiba IBM�̎O�Ђ��܂Ƃ߂�STI�Ɨ����̂͏��߂ĕ����ȁB
AMD��IBM(���ɂ����Ђ�)�������̃v���Z�X�J��
�i����SOI�v���Z�X�j�ŃA���C�A���X��g��ł�̂͗L�������B
AMD��IBM(���ɂ����Ђ�)�������̃v���Z�X�J��
�i����SOI�v���Z�X�j�ŃA���C�A���X��g��ł�̂͗L�������B
157 �F�f�t�H���g�̖����������F2008/12/11(��) 22:54:11
ttp://en.wikipedia.org/wiki/Cell_(microprocessor)
Cell is a microprocessor architecture jointly developed by Sony Computer Entertainment, Toshiba, and IBM, an alliance known as "STI".
Cell is a microprocessor architecture jointly developed by Sony Computer Entertainment, Toshiba, and IBM, an alliance known as "STI".
158 �F�f�t�H���g�̖����������F2008/12/11(��) 23:05:46
�w�[�w�[�w�[�I�@���߂Ēm�������B
159 �F�f�t�H���g�̖����������F2008/12/11(��) 23:40:05
����������STI�͍���̋��Z��@�ł��Ȃ�̒Ɏ���Ăă��X�g����]�V�Ȃ�����Ă邯�ǁA
Microsoft��Intel�����͂Ȃ����s���R�ȂقǏ����B�B�B
Microsoft��Intel�����͂Ȃ����s���R�ȂقǏ����B�B�B
160 �F�f�t�H���g�̖����������F2008/12/12(��) 04:01:59
Intel��Atom�n�����ꂾ��������ȁB�������ĕ����܂���������i������A�������J����Ζׂ���B
MS��Vista�s�l�C�͍��Ɏn�܂������Ƃ���Ȃ��B
�\�t�g���Ǝ��́A���Ƃ��Ɨ��v���������܂������B
�\���ȗ��v���ŏ\���ȘJ���҂��ق��邾���̒��~������B
���{��Ƃ��ƔC�V�������X�g���m�炸�Ȃ̂Ɠ����B
Xbox���Ƃ��������獕���v�サ�Ă�̂��傫���ˁi�ݐς��Ƃ܂��܂��Ԃ����ǁj
�h�����͒Z���I�ɂ͊O�݉҂��Ƀv���X�ɓ����B
MS��Vista�s�l�C�͍��Ɏn�܂������Ƃ���Ȃ��B
�\�t�g���Ǝ��́A���Ƃ��Ɨ��v���������܂������B
�\���ȗ��v���ŏ\���ȘJ���҂��ق��邾���̒��~������B
���{��Ƃ��ƔC�V�������X�g���m�炸�Ȃ̂Ɠ����B
Xbox���Ƃ��������獕���v�サ�Ă�̂��傫���ˁi�ݐς��Ƃ܂��܂��Ԃ����ǁj
�h�����͒Z���I�ɂ͊O�݉҂��Ƀv���X�ɓ����B
161 �F�f�t�H���g�̖����������F2008/12/12(��) 21:36:06
�������ASTI�ł�
��Ԃ��������Ƃ����IBM�������Ă����ƁBPC����̔��莞�����܂�������
HDD���E�E�EIBM�͂����[��B
��Ԃ��������Ƃ����IBM�������Ă����ƁBPC����̔��莞�����܂�������
HDD���E�E�EIBM�͂����[��B
162 �F�f�t�H���g�̖����������F2008/12/21(��) 21:03:41
/proc/cpuinfo��timebase����sysctl�Ƃ��œǂ߂Ȃ��̂ł��傤���H
163 �F,,�E�L�́M�E,,�j��-�������F2008/12/21(��) 21:26:17
���XCell�p�̃R�[�h�����Ă݂���
ttp://tripper.kousaku.in/20081217.html#p01
ttp://tripper.kousaku.in/20081217.html#p01
164 �F�f�t�H���g�̖����������F2008/12/25(��) 23:17:21
Hack the Cell�̉ۑ蔭�\���ꂽ
http://cell.fixstars.com/challenge/challenge.html
�ۑ�̓����Z���k�E�c�C�X�^�̍œK��
�g�pSPE1��ALS256KB�̂���210KB���g�p�֎~�B
http://cell.fixstars.com/challenge/challenge.html
�ۑ�̓����Z���k�E�c�C�X�^�̍œK��
�g�pSPE1��ALS256KB�̂���210KB���g�p�֎~�B
165 �F�f�t�H���g�̖����������F2008/12/26(��) 08:25:47
����܂�H�v�̂��ǂ��낪�����C���c
166 �F�f�t�H���g�̖����������F2008/12/26(��) 12:45:53
ttp://ftp.uk.linux.org/pub/linux/Sony-PS3/mars/latest/
�o�[�W����1.1
�o�[�W����1.1
167 �F�f�t�H���g�̖����������F2008/12/26(��) 14:14:24
>>164
�����c�q����Ɋ���
�����c�q����Ɋ���
168 �F�f�t�H���g�̖����������F2008/12/26(��) 16:01:05
�܂�ł��̂��߂ɗp�ӂ����悤�ȉۑ�
�O����������
�����܂����瑸�h���Ă��
�O����������
�����܂����瑸�h���Ă��
169 �F,,�E�L�́M�E,,�j��-�������F2008/12/27(�y) 18:34:18
�����f��
170 �F�f�t�H���g�̖����������F2008/12/27(�y) 21:03:06
�������c�q����I
171 �F�f�t�H���g�̖����������F2008/12/30(��) 22:35:11
����Ȃ̂ł����ACell SDK �̃C���X�g�[������Ă���Fedora 9 �ɂāA
SPE�p�̂b�\�[�X�v���O�����ォ��pthread_create���ŃX���b�h�����o���܂����H
�v�����SPE�̃v���O�����̓}���`�X���b�h���o���邩�ǂ����ƌ������ƂȂ̂ł����A
�茳��Cell�����Ȃ��̂ŋ����Ă��������B
SPE�p�̂b�\�[�X�v���O�����ォ��pthread_create���ŃX���b�h�����o���܂����H
�v�����SPE�̃v���O�����̓}���`�X���b�h���o���邩�ǂ����ƌ������ƂȂ̂ł����A
�茳��Cell�����Ȃ��̂ŋ����Ă��������B
172 �F�f�t�H���g�̖����������F2008/12/30(��) 23:28:20
>>171
SPE�ŁA�܂Ƃ��ȃv���O���~���O���ł���ƌ����Â����z�͂Ƃ��ƂƎ̂Ă܂��傤�B
POSIX�͂��납�AC�W���̊��ł����w�ǎg���܂���B
�[���A�Ȃ�ŃX���b�h�����Ȃ�Ĕ��z��?
����Ȃ̂́APPE�ɂ�点��SPE�͌v�Z�ɐ�O����̂�CBE�̊�{�ł����B
SPE�ŁA�܂Ƃ��ȃv���O���~���O���ł���ƌ����Â����z�͂Ƃ��ƂƎ̂Ă܂��傤�B
POSIX�͂��납�AC�W���̊��ł����w�ǎg���܂���B
�[���A�Ȃ�ŃX���b�h�����Ȃ�Ĕ��z��?
����Ȃ̂́APPE�ɂ�点��SPE�͌v�Z�ɐ�O����̂�CBE�̊�{�ł����B
173 �F�f�t�H���g�̖����������F2008/12/31(��) 00:01:37
>>172
���鏈�����s�������ŁASPE����PPE�ɏ������ރf�[�^��50��悮�炢����܂��āA
tag�ԍ���32�܂ł����Ȃ��̂ŁA�ʃX���b�h�Ńf�[�^�𑗂낤�Ǝv�����̂ł����E�E�E�B
�f�[�^�̔z�u��A���I�ɂȂ�悤�ɍl�����������Ǝv���܂��B
���鏈�����s�������ŁASPE����PPE�ɏ������ރf�[�^��50��悮�炢����܂��āA
tag�ԍ���32�܂ł����Ȃ��̂ŁA�ʃX���b�h�Ńf�[�^�𑗂낤�Ǝv�����̂ł����E�E�E�B
�f�[�^�̔z�u��A���I�ɂȂ�悤�ɍl�����������Ǝv���܂��B
174 �F�f�t�H���g�̖����������F2008/12/31(��) 02:34:46
>>173
DMA�^�O�����[�e�[�V���������ē]���������炢���Ǝv��
DMA�^�O�����[�e�[�V���������ē]���������炢���Ǝv��
175 �F�f�t�H���g�̖����������F2008/12/31(��) 02:45:01
176 �F,,�E�L�́M�E,,�j��-�������F2009/01/02(��) 18:37:45
���[������SPE�ŊȒP�ȃx���`�}�[�N�Ƃ낤�Ƃ���time.h���Ȃ��Đ�����
177 �F�f�t�H���g�̖����������F2009/01/02(��) 20:30:28
����ᓖ����O���ȁB
�p�\�R�����C��time�W�̊������ʂɎg����̂�PC��
�n�[�h�E�F�A�Ń��A���^�C���E�N���b�N�������Ă邩�炾�B
�ŁACPU���璼�ړǂ߂��ԂɃ��W�X�^��u���Ă���B
�n�[�h�E�F�A�̃��A���^�C���E�N���b�N���Ȃ����
�ႦPC��CPU�ł����Ă��ǂ����悤�������B
�p�\�R�����C��time�W�̊������ʂɎg����̂�PC��
�n�[�h�E�F�A�Ń��A���^�C���E�N���b�N�������Ă邩�炾�B
�ŁACPU���璼�ړǂ߂��ԂɃ��W�X�^��u���Ă���B
�n�[�h�E�F�A�̃��A���^�C���E�N���b�N���Ȃ����
�ႦPC��CPU�ł����Ă��ǂ����悤�������B
178 �F,,�E�L�́M�E,,�j��-�������F2009/01/02(��) 20:57:46
�܂��g�������͎̂������͎��Ԍv���Ȃ��ǂ�
������SPU Decrementer���܂��g���đ�p���ė~����������
PS3��Cell�̓x�[�X�N���b�N��79.8MHz������
��������Linux�ォ��͂Ƃ�Ă�݂���������
������SPU Decrementer���܂��g���đ�p���ė~����������
PS3��Cell�̓x�[�X�N���b�N��79.8MHz������
��������Linux�ォ��͂Ƃ�Ă�݂���������
179 �F�f�t�H���g�̖����������F2009/01/02(��) 21:48:24
�����������������v���ł��Ȃ�Decrementer����肭�g���Ƃ��B
180 �F�f�t�H���g�̖����������F2009/01/02(��) 22:31:32
clock()�ł��������Ă����Ă����Ίy�Ȃ��ǂ˂��B
�܂��A���v���Ԍv���͂ǂ����݂����ˑ�������̂Ǝv���Ă��邩�疢�������̂�����ǁB
�܂��A���v���Ԍv���͂ǂ����݂����ˑ�������̂Ǝv���Ă��邩�疢�������̂�����ǁB
181 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 07:42:35
182 �F�f�t�H���g�̖����������F2009/01/03(�y) 19:31:43
>>181
���傷��ɂ͍Œ�10�{�����ȁB���Ă��āB
���傷��ɂ͍Œ�10�{�����ȁB���Ă��āB
183 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 20:41:32
184 �F,,�E�L�́M�E,,�j��-�������F2009/01/03(�y) 23:48:52
�ǂ������Ƃ����ƃR�[�h�T�C�Y�����̒��łǂꂾ���A�����[�����邩���Ă����e�[�}�ɂȂ肻��
185 �F�f�t�H���g�̖����������F2009/01/04(��) 00:22:09
���₢��A���͎Q�����ĂȂ���B����������������A���܂̏��������AFixstars�̃T�C�g��10�{�����ď����Ȃ������H
186 �F�f�t�H���g�̖����������F2009/01/04(��) 01:46:51
>>184
SFMT�����̂܂܈ڐA���Ă�H
SFMT�����̂܂܈ڐA���Ă�H
187 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 01:53:36
>>184
����͐��������ʕ������炻�������g�����ɂȂ�Ȃ��B
�������ӊO�ƕ��ł���ˁB���ꂱ���A�����[�����܂���B
Makefile�͘M������ʖڂ�����#pragma�͎g���Ă�����H
����͐��������ʕ������炻�������g�����ɂȂ�Ȃ��B
�������ӊO�ƕ��ł���ˁB���ꂱ���A�����[�����܂���B
Makefile�͘M������ʖڂ�����#pragma�͎g���Ă�����H
188 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 01:55:14
>>186��
189 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 01:56:50
movdqu�݂����ȋC�̗������~�X�A���C���f�[�^���������郆�[�e�B���e�B�����Ȃ��Ă����[�Ǝv���܂���
shufb�ł��܂������ǁB
shufb�ł��܂������ǁB
190 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 05:48:26
7�{�܂ł������B
�R���p�C���̎w��Ƃ�����́H�����g���Ă�̂�SDK3.1
IBM���o���Ă�g���[�X�c�[���ł��g��������
�R���p�C���̎w��Ƃ�����́H�����g���Ă�̂�SDK3.1
IBM���o���Ă�g���[�X�c�[���ł��g��������
191 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 05:50:39
�����̎�Ɛ������闐����̒��������߂�seed_table�Ɋ܂܂��f�[�^�͗�ł��B ���ۂ̌v�����͕ύX����ꍇ������܂��B�C�ӂ̒l�œ��삷��悤�ɂ��Ă��������B
�������A�ȉ��̓�_�͉��肵�č\���܂���B
- num_rand��4�̔{��
- num_rand��10000�ȏ�
�ȁ[�A���肵�ėǂ������̂�
�������A�ȉ��̓�_�͉��肵�č\���܂���B
- num_rand��4�̔{��
- num_rand��10000�ȏ�
�ȁ[�A���肵�ėǂ������̂�
192 �F�f�t�H���g�̖����������F2009/01/04(��) 05:54:04
GCC4.3��XLC���Ăǂ������͂₢�낤�B���͂��낢�날����XLC�h�B
193 �F�f�t�H���g�̖����������F2009/01/04(��) 05:58:40
�������A�R���e�X�g��2������̂ɂ��̉ߑa��悤�c�B����������Ɛ���オ���Ă�
�����悤�ȋC�����邺���B
�����悤�ȋC�����邺���B
194 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 07:35:56
GCC4.3�̓f���R�[�h�͂��܂ɐ_���������œK��������Ă������ǃs�[�L�[���ȁB
�����Ȃ�����x���Ȃ�����B
�œK���t���O�̎w����@�ɂ���ĕς�邩��A1�����ɍׂ����œK���I�v�V�������w�肵�Ă����K�v������B
�����Cell�Ɍ��炸�����ǁB
�����Ȃ�����x���Ȃ�����B
�œK���t���O�̎w����@�ɂ���ĕς�邩��A1�����ɍׂ����œK���I�v�V�������w�肵�Ă����K�v������B
�����Cell�Ɍ��炸�����ǁB
195 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 08:51:06
196 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 08:53:09
���[�Ȃ�قǁA����̂�
197 �F�f�t�H���g�̖����������F2009/01/04(��) 15:04:23
>>193
������̃R���e�X�g���ĉ��H
������̃R���e�X�g���ĉ��H
198 �F,,�E�L�́M�E,,�j��-�������F2009/01/04(��) 16:36:14
��ׁ[���D�������Ⴄ����
199 �F�f�t�H���g�̖����������F2009/01/04(��) 17:00:49
200 �F�f�t�H���g�̖����������F2009/01/05(��) 09:27:32
>>198
���v�A�����Ƃ݂�Ȃ������v���Ă���B
���v�A�����Ƃ݂�Ȃ������v���Ă���B
201 �F,,�E�L�́M�E,,�j��-�������F2009/01/05(��) 18:10:03
���I�ł͂Ȃ����̂́A������ƘM���Ă݂������ł�1�����炢���C�Ő��\�L�т��
202 �F�f�t�H���g�̖����������F2009/01/06(��) 20:14:22
��ځA7Mticks�����B
������ɏ��Ă�C�͂��Ȃ����ǁA���D����ڎw���B
������ɏ��Ă�C�͂��Ȃ����ǁA���D����ڎw���B
203 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 04:24:06
�����܂ł͌y��������̂��B����ς�B
���������̕ϑԃe�N�j�b�N���ǂ��܂Œʗp����̂��͂킩���B
�{�i�I�ɕǂɂԂ�������������g���閽�߂��Ȃ����蓖���莟��ɒT���Ă�Ƃ���B
���n���Ȃ��悤�Ȃ�Ƃ肠������o��ԏ�肳���Ă��炤��B
�b�肾���ǃ��|�[�g��������������B
����ȏ�͎��Ԃ����Ă����ʂ����Ǝv���Ă���B
�}�C�N���b�P�ʂ̏����Ɏ����Ă�����Ɛ��������B���낢��蔲�����Ă镔���������Ă�����
���������̕ϑԃe�N�j�b�N���ǂ��܂Œʗp����̂��͂킩���B
�{�i�I�ɕǂɂԂ�������������g���閽�߂��Ȃ����蓖���莟��ɒT���Ă�Ƃ���B
���n���Ȃ��悤�Ȃ�Ƃ肠������o��ԏ�肳���Ă��炤��B
�b�肾���ǃ��|�[�g��������������B
����ȏ�͎��Ԃ����Ă����ʂ����Ǝv���Ă���B
�}�C�N���b�P�ʂ̏����Ɏ����Ă�����Ɛ��������B���낢��蔲�����Ă镔���������Ă�����
>>203
�Ȃ����s���l�����B
>>202�̂��Ƃ����낢���������ǁA���ꂩ��ǂ����Ă� 7M ��Ȃ��B
�����H�v���Ă��t�ɒx���Ȃ�B
�A�Z���u���ŏ����� >>202 �����邩������Ȃ����ǁA�����܂ł���C�͖͂�����B
odd �p�C�v��������ˁB even �p�C�v�� add �� shift �����ł��t���Ă����Ə�����̂ɁB
�Ȃ����s���l�����B
>>202�̂��Ƃ����낢���������ǁA���ꂩ��ǂ����Ă� 7M ��Ȃ��B
�����H�v���Ă��t�ɒx���Ȃ�B
�A�Z���u���ŏ����� >>202 �����邩������Ȃ����ǁA�����܂ł���C�͖͂�����B
odd �p�C�v��������ˁB even �p�C�v�� add �� shift �����ł��t���Ă����Ə�����̂ɁB
�܂�7Mtics���悤�ɂȂ����B
���[�v�����}�N���ɂ��ď\�����ׂ���Ƃ��A�����܂肾�ȁB
���������A�������낻�냌�|�[�g�������B
���[�v�����}�N���ɂ��ď\�����ׂ���Ƃ��A�����܂肾�ȁB
���������A�������낻�냌�|�[�g�������B
206 �F�f�t�H���g�̖����������F2009/01/07(��) 12:28:37
������o�������������Ƃ�����́H�H�H
207 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 13:00:22
�Ȃ��ˁB
�l���ē����������郂���ł��Ȃ���
�l�������Ďd������ɕt���Ȃ��Ȃ邭�炢�Ȃ���߂����������B
�l���ē����������郂���ł��Ȃ���
�l�������Ďd������ɕt���Ȃ��Ȃ邭�炢�Ȃ���߂����������B
208 �F�f�t�H���g�̖����������F2009/01/07(��) 16:22:11
7Mtics�Ă�����30�{�ȏォ�����[��
�A���S���Y���͊�{�̂܂܂ł����܂ł�����́H
�A���S���Y���͊�{�̂܂܂ł����܂ł�����́H
>>208
�A���S���Y���͂��̂܂܂����ǁA���������������`�F�b�N�T���v�Z�������Ē�����
�̂���ƁA���p��������đ��x���҂��ł�B
�A���S���Y���͂��̂܂܂����ǁA���������������`�F�b�N�T���v�Z�������Ē�����
�̂���ƁA���p��������đ��x���҂��ł�B
210 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 16:50:59
�������Ǝv���������I
�r�b�g�X���C�X���ď������������ˁH
�i���������悤�Ƃ��Ă邩�炠�ځ[���j
�r�b�g�X���C�X���ď������������ˁH
�i���������悤�Ƃ��Ă邩�炠�ځ[���j
211 �F�f�t�H���g�̖����������F2009/01/07(��) 17:11:43
�Ԃ����ႯCell���ď������͂ǂ��Ȃ́H
�Ȃ�PC��GPU�Ńg���b�v�v�Z��Cell��10�{�̐��\�������o�����Ƃ�
����������
�Ȃ�PC��GPU�Ńg���b�v�v�Z��Cell��10�{�̐��\�������o�����Ƃ�
����������
212 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 17:21:24
45nm��32�R�A�{PPE2�R�A��Cell���o���
����̉��ǔ�Bitslice DES���g���ƁAPS3��SPE 6�R�A�����g����12MTrips/sec���x�͂�����B
32�R�A�S���g����64MTrips/sec���x�͏o��
�ł�����32�R�ACell�̓A�z�݂����ɍ�����������������
����̉��ǔ�Bitslice DES���g���ƁAPS3��SPE 6�R�A�����g����12MTrips/sec���x�͂�����B
32�R�A�S���g����64MTrips/sec���x�͏o��
�ł�����32�R�ACell�̓A�z�݂����ɍ�����������������
213 �F�f�t�H���g�̖����������F2009/01/07(��) 18:14:43
���������͂Ȃ肻�����Ȃ����˂��B
>>210
spu_sel() ?
�����g����� (���
7M�܂ŋ�J�����̂ɁA�u�����܂ł͌y���v�Ƃ��������Ⴄ�l���A����ɑ����Ȃ�̂��E�E�E
�Ђ���Ƃ���6M���Ă�H
spu_sel() ?
�����g����� (���
7M�܂ŋ�J�����̂ɁA�u�����܂ł͌y���v�Ƃ��������Ⴄ�l���A����ɑ����Ȃ�̂��E�E�E
�Ђ���Ƃ���6M���Ă�H
215 �F�f�t�H���g�̖����������F2009/01/07(��) 19:58:30
>>202
�~�X���[�h���Ă��邼�B�u�����܂ł͌y���������Ⴄ�v�̂͂��̂��Ƃ���B�c�q�͎����̂��Ƃ��Ƃ͏����ĂȂ����B
�~�X���[�h���Ă��邼�B�u�����܂ł͌y���������Ⴄ�v�̂͂��̂��Ƃ���B�c�q�͎����̂��Ƃ��Ƃ͏����ĂȂ����B
216 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 20:08:47
>>215
������́A 1/4 �� ttp://tripper.kousaku.in/20090104.html#p01 �܂ł����ĂāA
1/5 �� >>201 �Ƃ������Ă邩��A 7M �͐��Ă�n�Y�B
�Ƃ����O��̌��ɁA 7M �ꂽ�I �ƌ�������A�u�����܂ł͌y���v�ƕԂ��ꂽ�̂ŁA
6M�܂ł����Ă�̂��ȁA�ƁB
6M�������ƁA�t�������Ă����Ă�C�����Ȃ��B
������́A 1/4 �� ttp://tripper.kousaku.in/20090104.html#p01 �܂ł����ĂāA
1/5 �� >>201 �Ƃ������Ă邩��A 7M �͐��Ă�n�Y�B
�Ƃ����O��̌��ɁA 7M �ꂽ�I �ƌ�������A�u�����܂ł͌y���v�ƕԂ��ꂽ�̂ŁA
6M�܂ł����Ă�̂��ȁA�ƁB
6M�������ƁA�t�������Ă����Ă�C�����Ȃ��B
218 �F�f�t�H���g�̖����������F2009/01/07(��) 20:51:36
32�R�A�ł��V�^GPU��8�`10���g�����W�X�^�A
�_�C�T�C�Y�͓������炢�ɂȂ邾��
�����܂藦�͂܂��A���œ����Ƃ��āA
SPE�����ł��{����5�`6GHz�œ�������Ȃ�A�h�o���e�[�W�ɂȂ��
�������ш���g�����Ȃ��Ƃ���܂�Ӗ��Ȃ�����
�_�C�T�C�Y�͓������炢�ɂȂ邾��
�����܂藦�͂܂��A���œ����Ƃ��āA
SPE�����ł��{����5�`6GHz�œ�������Ȃ�A�h�o���e�[�W�ɂȂ��
�������ш���g�����Ȃ��Ƃ���܂�Ӗ��Ȃ�����
219 �F�f�t�H���g�̖����������F2009/01/07(��) 20:53:28
�������g�������ۂ̒[�q���l�����XDR���L�ш���������Ȃ��
220 �F,,�E�L�́M�E,,�j��-�������F2009/01/07(��) 21:03:54
�ƊE�̖�莙RAMBUS
221 �F�f�t�H���g�̖����������F2009/01/07(��) 21:25:09
>>218
������Ė{���H
���Ⴀ�A32�R�ACell��GPU�ƃg�����W�X�^�����͓����ŁA���s�̎��g���ł������\�ɂȂ�́H
���o�I�ɁAGPU�̂ق����P���ȍ\��������A�����g�����W�X�^���Ȃ�s�[�N�̐��\��GPU���ォ�Ǝv���Ă����B
���������Ȃ�ALS�̗e�ʂ̑傫�������\������Ă����ŁACell�̋��݂͂��łɂ����ˁB���Ɣ{���x����ɂȂ�B
���i�͑S�R���߂��߂��낤���ǁB
������Ė{���H
���Ⴀ�A32�R�ACell��GPU�ƃg�����W�X�^�����͓����ŁA���s�̎��g���ł������\�ɂȂ�́H
���o�I�ɁAGPU�̂ق����P���ȍ\��������A�����g�����W�X�^���Ȃ�s�[�N�̐��\��GPU���ォ�Ǝv���Ă����B
���������Ȃ�ALS�̗e�ʂ̑傫�������\������Ă����ŁACell�̋��݂͂��łɂ����ˁB���Ɣ{���x����ɂȂ�B
���i�͑S�R���߂��߂��낤���ǁB
222 �F�f�t�H���g�̖����������F2009/01/07(��) 21:30:25
����̉��ǂƂ������ƂŁALS1MB�Ƃ��ASPE�̃X�J�����\�A�b�v�Ƃ��APPE�̋����Ƃ����������猋�\�������̂ɂȂ邾�낤�ȁB
�ł��APPE���������炢���������I�ɖ������낤���ǁB
�܂��AIBM�̂��Ƃ����炻���������ȓ_�͂��������Power�ɔ��f���Ă��邾�낤�ȂƗ\���B
�ł��APPE���������炢���������I�ɖ������낤���ǁB
�܂��AIBM�̂��Ƃ����炻���������ȓ_�͂��������Power�ɔ��f���Ă��邾�낤�ȂƗ\���B
223 �F�f�t�H���g�̖����������F2009/01/07(��) 22:03:08
224 �F�f�t�H���g�̖����������F2009/01/07(��) 23:37:17
odd���߂�even���߂ɐ�ւ����B
�Ƃ������A���̖��߂�even���߂��ƒm��Ȃ������B
���ɂ�6M�������Ă����B
�Ƃ������A���̖��߂�even���߂��ƒm��Ȃ������B
���ɂ�6M�������Ă����B
226 �F�f�t�H���g�̖����������F2009/01/08(��) 02:12:54
spu-gcc43 �ɕύX����Ă� �� FAQ�lj�����Ƃ�B
227 �F ��eZQcaIaFJs �F2009/01/08(��) 02:30:19
odd��even�̈Ⴂ���������Ă��āA���Ƃ�7Mtick�ꂽ@gcc43�B
# �ۑ�̍Ē�o���ďo����낤���c�B�t���C���O�������Ď��s���Ă�����orz
# �ۑ�̍Ē�o���ďo����낤���c�B�t���C���O�������Ď��s���Ă�����orz
228 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 04:15:43
�͂₭��o���ē����邱�ƂȂ�Ă���̂��H
�t�B�b�N�X�^�[�Y����̃X�J�E�g�ł��_���Ă�́H
�t�B�b�N�X�^�[�Y����̃X�J�E�g�ł��_���Ă�́H
229 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 04:20:50
�[���A���̈Ӑ}��������spu-gcc43�ȂH
��������50�{��������������
�Ȃ��Ȃ�I���W�i���̂ق����x���Ȃ�������
��������50�{��������������
�Ȃ��Ȃ�I���W�i���̂ق����x���Ȃ�������
spu-gcc43 �ɂ�����AORIGINAL���x���Ȃ��āA40�{�ȏ㕽�C�ŏo��Ȃ�
�E�E�E�悵�A6M
�E�E�E�悵�A6M
231 �F�f�t�H���g�̖����������F2009/01/08(��) 11:20:52
�Ē�o�ɂȂ��Ă�B��FAQ
���Ă���������̓����[�g�J������ scp �ł��Ȃ������ŕ������B
�݂�ȏo���Ă�̂��Ȃ��H�H�H
���Ă���������̓����[�g�J������ scp �ł��Ȃ������ŕ������B
�݂�ȏo���Ă�̂��Ȃ��H�H�H
232 �F�f�t�H���g�̖����������F2009/01/08(��) 11:34:07
>>228
�t�B�b�N�X�^�[�Y����̃X�J�E�g�ł��_���Ă�́H
�t�B�b�N�X�^�[�Y����̃X�J�E�g�ł��_���Ă�́H
233 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 11:38:57
�ǂ����ɂ���Ē�o���x���ł���Ȃ�A���Ȃ����͂�������������
234 �F�f�t�H���g�̖����������F2009/01/08(��) 11:40:07
50�{��������www
��������C�����˂��B������ɕ��ׂĂ���������ȁB
��������C�����˂��B������ɕ��ׂĂ���������ȁB
234=202
236 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 12:05:25
��������ORIGINAL�����R���R���ς�邩��Ȃ�
�܂��A��邱�Ƃ̓R���p�C���̋@�����̍�Ƃ���
�܂��A��邱�Ƃ̓R���p�C���̋@�����̍�Ƃ���
237 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 12:47:32
����CUDA�Ɏ�肩���邩��
238 �F�f�t�H���g�̖����������F2009/01/08(��) 15:34:46
�Ƃ���Ŋ�Ɩ��O�N���ĕ\����ɗ��́H
239 �F�f�t�H���g�̖����������F2009/01/08(��) 16:33:45
���Ă��A�Ж����N�����̂��Ȃ��c
240 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 18:21:39
>>239
��Ж��Ő\�����̂��H
��Ж��Ő\�����̂��H
241 �F�f�t�H���g�̖����������F2009/01/08(��) 19:33:21
�������ɕK�{���ڂʼnR�����̂��݂��������B
242 �F�f�t�H���g�̖����������F2009/01/08(��) 21:05:22
�ǂ�������50�{�Ƃ��t�J�V����H
�Ȃ����R�t���Č��ǂ͒�o���Ȃ��ƌ����B
�R���e�X�g�I����ɂ����\�[�X���J���Ȃ�������t�J�V�m��
�Ȃ����R�t���Č��ǂ͒�o���Ȃ��ƌ����B
�R���e�X�g�I����ɂ����\�[�X���J���Ȃ�������t�J�V�m��
243 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 21:43:17
���̒��̐l���{�������߂�l�Ԃ�
���Ƃ����A�w������̗D���҂��ď��w����N60���~���炦��ł���B
�Љ�l�g�ł�������42�C���`�̃e���r���Ă�����15���~�����̃M�t�g���D���_�����́A
���z���傫���w���g�ŕ��������̂�����y�ɓ���m�b�����ق�����
���Ă̂͋ɘ_�B�������A���ɏ����Ƃɂ͍S���ĂȂ��B
���Ȃ݂ɗD������5x�{�̈��|�I�Ȑ��\���������o������Ŋ��ɒ�o�ς݂��ď��Ȃ炠���B
�r�b�g���Z�̘_�������x���ōœK���������|�[�g���Ђ������āA�ˁB
�����₳��̃}�C�~�N�ɃK�`�̃t�B�b�N�X�^�[�Y�Ј������܂��B����̏o��҂����ˁH
���Ƃ����A�w������̗D���҂��ď��w����N60���~���炦��ł���B
�Љ�l�g�ł�������42�C���`�̃e���r���Ă�����15���~�����̃M�t�g���D���_�����́A
���z���傫���w���g�ŕ��������̂�����y�ɓ���m�b�����ق�����
���Ă̂͋ɘ_�B�������A���ɏ����Ƃɂ͍S���ĂȂ��B
���Ȃ݂ɗD������5x�{�̈��|�I�Ȑ��\���������o������Ŋ��ɒ�o�ς݂��ď��Ȃ炠���B
�r�b�g���Z�̘_�������x���ōœK���������|�[�g���Ђ������āA�ˁB
�����₳��̃}�C�~�N�ɃK�`�̃t�B�b�N�X�^�[�Y�Ј������܂��B����̏o��҂����ˁH
244 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 21:54:38
>>238-239�͂��Ԃ�Cell Speed Challenge�̂ق�����B����͑�w�E��ƑΌ��̈Ӗ��������������瓖�R���B
�t�B�b�N�X�^�[�Y�̂ق��͉�Ђ̖��`�������K�v���Ȃ��̂Ŏ���x�����ł��牞��\�ł��B
�t�B�b�N�X�^�[�Y�̂ق��͉�Ђ̖��`�������K�v���Ȃ��̂Ŏ���x�����ł��牞��\�ł��B
�ȂS����ɂȂ��Ă邗
���|�I�Ȑ��\���āA�A�A������� 5x�{�ł���[�ɁB
�����D�����łȂ��Ƃ���ƁA���͏��D�����烀���|�����A
�ꉞ50�{�������̂ŏI����\�[�X���J�����B
���|�I�Ȑ��\���āA�A�A������� 5x�{�ł���[�ɁB
�����D�����łȂ��Ƃ���ƁA���͏��D�����烀���|�����A
�ꉞ50�{�������̂ŏI����\�[�X���J�����B
246 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 22:06:44
���Ă�����IPC����l����Θ_�������x���Ŏ�����Ȃ�������E�˔j�͕s�\
247 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 23:16:35
���Ȃ݂Ɂu�c�q�~�v�͗D���]�X�ȑO�ɎQ���o�^���炵�Ă܂���̂ŁB
�U���͂܂����炵������ˁB
2�l�܂ł̃`�[���Q��OK�Ȃ̒m���Ă��H
����͂��₳��ł͂Ȃ���\���`�ŁA�����������ł���Ă܂��B
�D�������D���ɂȂ�����PS3��ނɂ�������Ă��ƂŎ��ł����B
�U���͂܂����炵������ˁB
2�l�܂ł̃`�[���Q��OK�Ȃ̒m���Ă��H
����͂��₳��ł͂Ȃ���\���`�ŁA�����������ł���Ă܂��B
�D�������D���ɂȂ�����PS3��ނɂ�������Ă��ƂŎ��ł����B
248 �F,,�E�L�́M�E,,�j��-�������F2009/01/08(��) 23:57:17
���Ă������A�D�G�҂̃R�[�h��BSD���C�Z���X�Ō��J����邱�ƂɂȂ��Ă邩��
�I����Ɍ��J���Ă̂����Ӗ����Ǝv���B
�A�Z���u���o�͂Ǝ��s�`���ꎮ���Í���ZIP�ŃA�b�v���[�h����
�R���e�X�g�I����Ƀp�X���[�h���J������Ă̂͂ǂ����ȁH
�I����Ɍ��J���Ă̂����Ӗ����Ǝv���B
�A�Z���u���o�͂Ǝ��s�`���ꎮ���Í���ZIP�ŃA�b�v���[�h����
�R���e�X�g�I����Ƀp�X���[�h���J������Ă̂͂ǂ����ȁH
249 �F�f�t�H���g�̖����������F2009/01/09(��) 00:12:41
�ŁA�݂�Ȃ� pikazip challenge �ł��ˁB�킩��܂��B
250 �F�f�t�H���g�̖����������F2009/01/09(��) 00:13:52
������܂����ʂɕ����������łP�O�{�̏��… orz
�T�O�{�͂���ǂ������Ȃ��B���A�� gcc 4.1 �Ȃ��ǁA
4.3 �ɂ�����ǂ炢�Ⴄ��? 4.3 �̃I���W�i������
�� ticks ���炢�H
�T�O�{�͂���ǂ������Ȃ��B���A�� gcc 4.1 �Ȃ��ǁA
4.3 �ɂ�����ǂ炢�Ⴄ��? 4.3 �̃I���W�i������
�� ticks ���炢�H
251 �F,,�E�L�́M�E,,�j��-�������F2009/01/09(��) 00:16:43
4.3�ł��B
252 �F,,�E�L�́M�E,,�j��-�������F2009/01/09(��) 00:17:14
��ԏオ29Mticks���炢
253 �F227 ��eZQcaIaFJs �F2009/01/09(��) 00:17:58
���Ƃ�6MTick�˔j�Bspu_timing �����������Ƌl�߂�ꂻ���ȋC������c�B
���ꂩ��h���A�[�K�̒��p���ĐQ��B
>>228
����3D�v���O���~���O�����ɏW���������Ǝv���Ă���������܂��B
���ꂩ��h���A�[�K�̒��p���ĐQ��B
>>228
����3D�v���O���~���O�����ɏW���������Ǝv���Ă���������܂��B
254 �F�f�t�H���g�̖����������F2009/01/09(��) 00:21:06
spu_timing ���ĂȂ�ł����H�ƃO�O�炸�ɕ����Ă݂�e�X�g�B
255 �F,,�E�L�́M�E,,�j��-�������F2009/01/09(��) 00:35:28
�����Ɖ���I�ȃ����g����
http://up2.viploader.net/pic3/src/vl2_092246.gif
http://up2.viploader.net/pic3/src/vl2_092246.gif
{kind=link}
>>252
�ǂ��B29M ���Ď��́A50 �{���Ƃ���ςƂ肠�����̖ڕW�� 6M �Ȃ̂ˁB
���܁A������Ƃ������ [email protected] �ɂ͂Ȃ����B�������� 20M�B
����ɔ��������B����œK���ł��鏊�������Ă����Ȃ��B
�ǂ��B29M ���Ď��́A50 �{���Ƃ���ςƂ肠�����̖ڕW�� 6M �Ȃ̂ˁB
���܁A������Ƃ������ [email protected] �ɂ͂Ȃ����B�������� 20M�B
����ɔ��������B����œK���ł��鏊�������Ă����Ȃ��B
�A�����[�����O���܂�������x���Ȃ��āA�A�Z���u������ƃ��[�J���ϐ���LS�ɓǂݏ������Ă�E�E�E
�R���p�C�����o�J�Ȃ̂��A���W�X�^128����p�C�v���C���l�߂��Ȃ��̂��A�悭�����B
�R���p�C�����o�J�Ȃ̂��A���W�X�^128����p�C�v���C���l�߂��Ȃ��̂��A�悭�����B
258 �F�f�t�H���g�̖����������F2009/01/09(��) 11:02:56
5.6M������
�����[�A5M�䑝���Ă����ȁB
�݂�Ȃ����[�B
�݂�Ȃ����[�B
�g���b�v�t���āA�R�[�h�̃R�����g�Ƀg���b�v�p�X����Ƃ����������ȁB
�c�q�搶(��)�Ɠ����`�[���������肵�܂��B
263 �F�f�t�H���g�̖����������F2009/01/09(��) 11:58:18
>>262
���O�݂���PS3���Q�b�g��_���Ă�l��
>>247�̏������݂݂�ƁC�w�����傶��Ȃ��Љ�l����ŎQ�����Ă�̂�
�Ƃ����Cell�`��������Ă�l�͂��Ȃ��̂���
�����w�����Ȃ��ˁH
���O�݂���PS3���Q�b�g��_���Ă�l��
>>247�̏������݂݂�ƁC�w�����傶��Ȃ��Љ�l����ŎQ�����Ă�̂�
�Ƃ����Cell�`��������Ă�l�͂��Ȃ��̂���
�����w�����Ȃ��ˁH
264 �F�f�t�H���g�̖����������F2009/01/09(��) 13:47:18
�g���b�v�� mt_mine.c �� sha1sum ��������ǂ��Ⴂ�������
265 �F,,�E�L�́M�E,,�j��-�������F2009/01/09(��) 17:17:15
�ؖ�����C�ȂǍX�X�Ȃ���
���̐l�͒��̐l���`�ŕʂ̊�������Ă邩�炱�����̖��O�ŋZ�p�I�������Ă����̃����b�g���Ȃ����B
���₳��Ƃ͏��F�u�L���v���Btanasinn�Ȃ݂ɑޔp�I�ȊT�O���B
�Ȃɂ��ł���肷�����A���₳���
���̐l�͒��̐l���`�ŕʂ̊�������Ă邩�炱�����̖��O�ŋZ�p�I�������Ă����̃����b�g���Ȃ����B
���₳��Ƃ͏��F�u�L���v���Btanasinn�Ȃ݂ɑޔp�I�ȊT�O���B
�Ȃɂ��ł���肷�����A���₳���
>>264
��x�g���b�v�t������A���̌�\�[�X���ςł��Ȃ��Ȃ邶���B
��x�g���b�v�t������A���̌�\�[�X���ςł��Ȃ��Ȃ邶���B
��H�H���ς�����܂��V�����̏������߂����H
268 �F�f�t�H���g�̖����������F2009/01/10(�y) 01:09:01
>212
�u45nm��32�R�A�{PPE2�R�A��Cell�v���ǂ����Ŕ��\���ꂽ�́H
�_���v���Ă݂������Ƃ������b����Ȃ��A����`�b�v���炢���ꂽ�H
�����������nj�����Ȃ������̂ō����x���Ȃ���\�[�X�������Ă���B
�u45nm��32�R�A�{PPE2�R�A��Cell�v���ǂ����Ŕ��\���ꂽ�́H
�_���v���Ă݂������Ƃ������b����Ȃ��A����`�b�v���炢���ꂽ�H
�����������nj�����Ȃ������̂ō����x���Ȃ���\�[�X�������Ă���B
269 �F�f�t�H���g�̖����������F2009/01/10(�y) 03:45:46
270 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 03:46:09
���Ⴂ�������B�����͗��N�i2010�N�j����炵����B
271 �F227 ��eZQcaIaFJs �F2009/01/10(�y) 04:50:14
�����ƌ��j�x���o�Ζ��߂��o���ƌ����̂ɁA����Ȏ��Ԃ܂Ō�����������
���܂��ėǂ��̂��낤���c�B
>>255
�����̌|�p�I�ȉ�ʁB�������͈��ʕ��Б������Ƃ��L���ł�����
>>258
�悤�₭�ǂ������A���ǎ��ɂ��ׂ����������Ă��Ȃ�㩁B
���܂��ėǂ��̂��낤���c�B
>>255
�����̌|�p�I�ȉ�ʁB�������͈��ʕ��Б������Ƃ��L���ł�����
>>258
�悤�₭�ǂ������A���ǎ��ɂ��ׂ����������Ă��Ȃ�㩁B
272 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 07:05:00
����Y��ȂƂ��댩���Ă�Ɍ��܂��Ă邶��B
Odd���Ń��C�e���V1�Ȃ̂�lnop��hbr���Ǝv���Ă�����B
Odd���Ń��C�e���V1�Ȃ̂�lnop��hbr���Ǝv���Ă�����B
5.6M�����Ƃ���ɕǂ�����̂��ȁH
274 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 13:16:46
�Ȃ�ő����Ȃ����̂��킩��ˁ[�����_���E�ɂ܂�����߂Â���
275 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 17:56:53
>>273
1���グ��̂����Ζ����ȋ��n�ɒB�����B
1���グ��̂����Ζ����ȋ��n�ɒB�����B
>>275
mjd!? �D�����u�`�������Ȃ��H
�������D���ȏ�ڎw���Ċ撣�낤�B
�v���C�x�[�g���S�^�S�^���܂����ĂāA���������̋x�݂Ȃ̂ɖw�ǘM��ˁ[�B
mjd!? �D�����u�`�������Ȃ��H
�������D���ȏ�ڎw���Ċ撣�낤�B
�v���C�x�[�g���S�^�S�^���܂����ĂāA���������̋x�݂Ȃ̂ɖw�ǘM��ˁ[�B
277 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 18:32:08
����������
�R�A���[�v�̓����̕Е��p�C�v�����S�����Ԗ������܂��������
����ȏ�ǂ����悤���Ȃ����
�O�����ǂ��ɂ�����Ƃ��������x���ł̃`���[�������ł��Ȃ��B
�Ƃ͂����Ă�Tick����10�Ƃ�20�ς�郌�x���Ȃ���
�R�A���[�v�̓����̕Е��p�C�v�����S�����Ԗ������܂��������
����ȏ�ǂ����悤���Ȃ����
�O�����ǂ��ɂ�����Ƃ��������x���ł̃`���[�������ł��Ȃ��B
�Ƃ͂����Ă�Tick����10�Ƃ�20�ς�郌�x���Ȃ���
278 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 20:29:05
�D�������Ă̂̓I���̃`�[���Ɍ��܂��Ă邾��
>>278
���傗�A>>243�̗D�������Ēc�q���g�������̂��悗����
���l�̃X�R�A�����[�N����fixstars�Ј�������̂��Ǝv������B
���傗�A>>243�̗D�������Ēc�q���g�������̂��悗����
���l�̃X�R�A�����[�N����fixstars�Ј�������̂��Ǝv������B
280 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 22:18:04
281 �F�f�t�H���g�̖����������F2009/01/10(�y) 22:24:15
>>280
�̂��̒c�q���ɂ��ƁA�������^�̃X�^�[�g���C���������Ƃ����B
�̂��̒c�q���ɂ��ƁA�������^�̃X�^�[�g���C���������Ƃ����B
282 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 22:48:46
�X�^�[�g���C���ɗ����Ă�l�Ԃ����炢��낤�ȁH
���[�v���ŕЕ��̃p�C�v�S�����܂��Ă��ԂȂ��B
���߂�̂���ǂ������B�A�Z���u���g�킸�ɂ�����ȁB
���[�v���ŕЕ��̃p�C�v�S�����܂��Ă��ԂȂ��B
���߂�̂���ǂ������B�A�Z���u���g�킸�ɂ�����ȁB
283 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:00:01
�Ƃ����R�����g���������݁A�c�q���͂ӂƋC�t�����B
�u�A�Z���u�����g������c�v
�u�A�Z���u�����g������c�v
284 �F,,�E�L�́M�E,,�j��-�������F2009/01/10(�y) 23:05:56
���Ⴀ���₵�Ă��Ă�B
�A�Z���u���g���Ă������ǂ���
���Ă������ϐ�����������̂߂�ǂ�����
�A�Z���u���g���Ă������ǂ���
���Ă������ϐ�����������̂߂�ǂ�����
285 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:16:34
�Ƃ����R�����g���c���Ă���A
���@�͖����ɕs���B
�ł́A���̃j���[�X�ł��B
���@�͖����ɕs���B
�ł́A���̃j���[�X�ł��B
286 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:17:57
�܂����A�����܂ŕ��ʂ��Ȃ����낤�B
�����A���ʂ͂��Ȃ��B
�������ACell��������l�Ȑl��ɏ펯�͒ʗp���Ȃ��̂��B
�����A���ʂ͂��Ȃ��B
�������ACell��������l�Ȑl��ɏ펯�͒ʗp���Ȃ��̂��B
287 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:22:24
���܂łȂ�ƂȂ��A�S�ɂڂ���Ƃ������A�^�₪�]�����悬��B
"�Ȃ��AMT�̌���ꂽ�œK���ŁALS�̗e�ʂ���������Ƃ����A����Ȃɂ����������̉ۑ�Ȃ̂��B"
�����B���͗v�����x���́A���̗̈�ɂ������̂��B
"�Ȃ��AMT�̌���ꂽ�œK���ŁALS�̗e�ʂ���������Ƃ����A����Ȃɂ����������̉ۑ�Ȃ̂��B"
�����B���͗v�����x���́A���̗̈�ɂ������̂��B
288 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:30:06
�X�^�[�g�n�_�ɗ��Ă��l�Ԃ́A�����͑����Ȃ��B�������A�����܂ōs���������̂͊m���ɁA"��"�ɋC�Â����B
�����A�����̐l�ԂƂ͕ʂɁA�����ꕔ�A���߂��炻�̓���i��ł������̂������B
�����āA���̐�ɂ́A����Ȃ�g�����҂��Ă����B
�����A�����̐l�ԂƂ͕ʂɁA�����ꕔ�A���߂��炻�̓���i��ł������̂������B
�����āA���̐�ɂ́A����Ȃ�g�����҂��Ă����B
289 �F�f�t�H���g�̖����������F2009/01/10(�y) 23:48:48
���Ă������A1 tick ���ĉ� cycle ���炢�Ȃ́H
��������t�Z����ƁA5.6 M �̎����ĕ��ω� cycle / 32bit �������炢�H
��������t�Z����ƁA5.6 M �̎����ĕ��ω� cycle / 32bit �������炢�H
>270
�[�������B
�[�������B
���Ȃ݂ɁA�ǂ�����@���v���������B
�P�D��Ɏ��s���ꂽ�͂���ORIGINAL�̌��ʂ����W�X�^����T���Ă���
2. �`���l���ɏ������߂Ȃ��Ȃ�A���Ăяo���O�ɕۑ������f�N�������^�̒l��
�@�@����������B
���ꂩ�l�^�ł���Ă���Ȃ����Ȃ�
�P�D��Ɏ��s���ꂽ�͂���ORIGINAL�̌��ʂ����W�X�^����T���Ă���
2. �`���l���ɏ������߂Ȃ��Ȃ�A���Ăяo���O�ɕۑ������f�N�������^�̒l��
�@�@����������B
���ꂩ�l�^�ł���Ă���Ȃ����Ȃ�
293 �F�f�t�H���g�̖����������F2009/01/11(��) 02:36:26
>>289, 291
40cycle/1tick����B5.6M����3.85cycle/32bit���炢���B
�Œ��SIMD�������Ƃ���15.4cycle/128bit�B
unroll�����Ă�Ƃ���16�`7cycle/128bit���炢���B
�z���g�ɂ���Ȃ�ŏo����H�H�H
40cycle/1tick����B5.6M����3.85cycle/32bit���炢���B
�Œ��SIMD�������Ƃ���15.4cycle/128bit�B
unroll�����Ă�Ƃ���16�`7cycle/128bit���炢���B
�z���g�ɂ���Ȃ�ŏo����H�H�H
294 �F227 ��eZQcaIaFJs �F2009/01/11(��) 02:45:23
>>282
���Ȃ�����100���炢�Ă�̂ŁA�S���l�߂����0.25MTick���c�B
�R���p�C�������Ȃ� asm volatile ���g���Ď蓮�X�P�W���[�����O�ł�
���悤���ƍl�����ł��B
>>292
while( spu_read_decrementer() < ~16384 ) rand();
���Ȃ�����100���炢�Ă�̂ŁA�S���l�߂����0.25MTick���c�B
�R���p�C�������Ȃ� asm volatile ���g���Ď蓮�X�P�W���[�����O�ł�
���悤���ƍl�����ł��B
>>292
while( spu_read_decrementer() < ~16384 ) rand();
295 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 04:57:09
SPU_Decrementer�͓����I�Ƀ`�����l���g���Ă܂��B
296 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 05:07:17
�z��Ƀ}�V����L�q���Ă̂ǂ����ȁH
���肪���ȕ��@���ȁB
�����Ȃ��v���O���}�ۏo��
���肪���ȕ��@���ȁB
�����Ȃ��v���O���}�ۏo��
297 �F202�F2009/01/11(��) 07:55:31
>>293
unroll����Ƃ��Ă����肩��A�������A�����܂ł̐����͐������Ǝv����B
15.4�Ƃ������l���łĂ����Ƃ���ƁA15cycle+0.4cycle��0.4���I�[�o�[�w�b�h�ɂȂ�B
�I�[�o�[�w�b�h��1%���炢�ɗ}����������A�ڕW��5.51Mticks��邱�ƁB
�g�b�v�N���X�͂��̂�����ɂ���ǂɂǂ��܂ŋ߂Â��邩�Ƃ����`�L�����[�X���B
�Ƃ����Ƃ���܂Ő����ł����Ⴄ����A�݂��ticks���͗L�������ꌅ�����o���Ȃ��������ǁA
�����L�������̏����o���Ă����̂́A�ucycle���ŕ���Ă��ǂ܂ł̋߂��Ȃ�
�����Ȃ��v�Ƃ����ӎv�\�����ȁB�J�b�R�C�C�B
unroll����Ƃ��Ă����肩��A�������A�����܂ł̐����͐������Ǝv����B
15.4�Ƃ������l���łĂ����Ƃ���ƁA15cycle+0.4cycle��0.4���I�[�o�[�w�b�h�ɂȂ�B
�I�[�o�[�w�b�h��1%���炢�ɗ}����������A�ڕW��5.51Mticks��邱�ƁB
�g�b�v�N���X�͂��̂�����ɂ���ǂɂǂ��܂ŋ߂Â��邩�Ƃ����`�L�����[�X���B
�Ƃ����Ƃ���܂Ő����ł����Ⴄ����A�݂��ticks���͗L�������ꌅ�����o���Ȃ��������ǁA
�����L�������̏����o���Ă����̂́A�ucycle���ŕ���Ă��ǂ܂ł̋߂��Ȃ�
�����Ȃ��v�Ƃ����ӎv�\�����ȁB�J�b�R�C�C�B
���i�g���Ă�̂ƈႤPC�ŏ������݂�����sage�Y�ꂽ�B�X�}�\�B
299 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 08:15:21
��unroll�����Ă�Ƃ���16�`7cycle/128bit���炢���B
���ꂪ�Ӗ��s���Ȃ��ǂˁB
�A�����[�����悤�������悤�����Z���j�b�g��������킯����Ȃ��B
���Z���j�b�g�̉ғ�����������܂ŋl�߂邩���ĉۑ�Ȃ킯�ŁB
���ꂪ�Ӗ��s���Ȃ��ǂˁB
�A�����[�����悤�������悤�����Z���j�b�g��������킯����Ȃ��B
���Z���j�b�g�̉ғ�����������܂ŋl�߂邩���ĉۑ�Ȃ킯�ŁB
300 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 08:29:36
��������
�u15�T�C�N���v���ċ�̓I�Ȑ������o�Ă������ǁA�{���ɂ���ł����̂��A��������l���Ȃ��Ƃ����Ȃ��B
�u15�T�C�N���v���ċ�̓I�Ȑ������o�Ă������ǁA�{���ɂ���ł����̂��A��������l���Ȃ��Ƃ����Ȃ��B
301 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 08:42:54
128bit������A15�T�C�N���̃X���[�v�b�g�ōςނƉ��肵�āA�I�[�o�[�w�b�h�����̃X���[�v�b�g��5.47M�邭�炢�H�ł����̂��ȁH
���[�ƁA��]����������Ă������ȁH
�y�Ƃ����ɐ��Ă��z
�t�ɂǂ��Ɍ��E������̂��킩��Ȃ��Ȃ��Ă�����B
���[�ƁA��]����������Ă������ȁH
�y�Ƃ����ɐ��Ă��z
�t�ɂǂ��Ɍ��E������̂��킩��Ȃ��Ȃ��Ă�����B
302 �F�f�t�H���g�̖����������F2009/01/11(��) 10:45:57
���ɏ��ɂ�tempering�̖��ߐ����炷���Ƃ�{�C�ōl�����ق����ǂ��B
�������瓹���J����Ǝv���B
�A�����[�����ă^�C�~���O�l�߂�̂͂��ꂩ��ł��x���Ȃ��B
�������瓹���J����Ǝv���B
�A�����[�����ă^�C�~���O�l�߂�̂͂��ꂩ��ł��x���Ȃ��B
>>301
��m��ˁ[�ȁB�ł����v�A���̒��x�Ő�]���Ȃ���B
5.5M���킢�ɎQ�킷��G�𑝂₵�����Ȃ���������A>>297�ł�>>293�̐��l�����Ƃɘb���Ă��B
�܂�gcc�̓f���R�[�h�ɖ|�M����Ă邯�ǁA5.5�̕ǂ̐�̐��E�����邱�Ƃ͗������Ă���B
�E�E�E�ł��A�������>>227��������ɒǂ��������Ȃ�ȁE�E�E
�����������T���܂����āA�ǂ������������Ǝv�����獡���u�����\�����܂�Ă܂����v�ƘA����orz
�����x�����ۈ���g���Ă�����Ɠ������E�ɍs�������B
��m��ˁ[�ȁB�ł����v�A���̒��x�Ő�]���Ȃ���B
5.5M���킢�ɎQ�킷��G�𑝂₵�����Ȃ���������A>>297�ł�>>293�̐��l�����Ƃɘb���Ă��B
�܂�gcc�̓f���R�[�h�ɖ|�M����Ă邯�ǁA5.5�̕ǂ̐�̐��E�����邱�Ƃ͗������Ă���B
�E�E�E�ł��A�������>>227��������ɒǂ��������Ȃ�ȁE�E�E
�����������T���܂����āA�ǂ������������Ǝv�����獡���u�����\�����܂�Ă܂����v�ƘA����orz
�����x�����ۈ���g���Ă�����Ɠ������E�ɍs�������B
>>302
�G���₵�����Ȃ������̓I�Șb�͂������������ǂ��B
�����������>>227������A�Ƃ����ɂ��̃��x���ŏo���鎖�͂���Ă�B
���̒��x�ł͏��ĂȂ���B
�G���₵�����Ȃ������̓I�Șb�͂������������ǂ��B
�����������>>227������A�Ƃ����ɂ��̃��x���ŏo���鎖�͂���Ă�B
���̒��x�ł͏��ĂȂ���B
305 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 12:34:59
�ŁA��ʂ����̃X������ł�̂͊m���Ԃ�
306 �F�f�t�H���g�̖����������F2009/01/11(��) 13:00:56
�c�q3�Z��
307 �F�f�t�H���g�̖����������F2009/01/11(��) 13:01:52
�X���ŏ����z�C�z�C�������ނ悤�Ȑl���g�b�v�Ƃ��낤���c
308 �F�f�t�H���g�̖����������F2009/01/11(��) 13:12:48
��̓I�ȕ��@�_�͒N�����J���ĂȂ����B
5M��@���o���Ă�l�̓A���S���Y�����x���ł͖w�Ǔ����R�[�h�ɂȂ��Ă�Ǝv���B�K�R�I�ɁB
���Ƃ�0.1�p�[�Z���g�P�ʂ̃`���[�����Ă��ƂɂȂ�킯����
�Ō�܂ŔS���������ɂȂ肻�����ȁB
5M��@���o���Ă�l�̓A���S���Y�����x���ł͖w�Ǔ����R�[�h�ɂȂ��Ă�Ǝv���B�K�R�I�ɁB
���Ƃ�0.1�p�[�Z���g�P�ʂ̃`���[�����Ă��ƂɂȂ�킯����
�Ō�܂ŔS���������ɂȂ肻�����ȁB
309 �F�f�t�H���g�̖����������F2009/01/11(��) 16:46:40
���Ă������A15cycle �Ƃ��z���g�ɏo����́H
���Ă��A�݂�ȃ}�W�ł���ȂƂ��ɏ����Ă�́Hw
���Ă��A�݂�ȃ}�W�ł���ȂƂ��ɏ����Ă�́Hw
310 �F�f�t�H���g�̖����������F2009/01/11(��) 17:22:25
�Ƃ肠�����A�ǂ������������̃X���ɏ������܂ꂽ���ƂŁA������ӂ̐��\��
�X�^���_�[�h�ɂȂ��Ă��܂����ȁB
�܂�2�����߂����邵�ˁB
�X�^���_�[�h�ɂȂ��Ă��܂����ȁB
�܂�2�����߂����邵�ˁB
311 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:24:06
�����Ȃ�Ȃ��Ɩʔ����Ȃ�����H
312 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:33:15
ORIGNAL: sum=3c927c56, 294426736 ticks
MINE: sum=3c927c56, 5470853 ticks
ORIGNAL: sum=2e987a4d, 424726988 ticks
MINE: sum=2e987a4d, 7891991 ticks
ORIGNAL: sum=ef1b6aef, 312523179 ticks
MINE: sum=ef1b6aef, 5807115 ticks
ORIGNAL: sum=eedd2516, 290445788 ticks
MINE: sum=eedd2516, 5396877 ticks
ORIGNAL: sum=f7e967a8, 14386174 ticks
MINE: sum=f7e967a8, 267359 ticks
ORIGNAL: sum=1f37a7db, 214504754 ticks
MINE: sum=1f37a7db, 3985803 ticks
ORIGNAL: sum=c7d41f36, 295361550 ticks
MINE: sum=c7d41f36, 5488220 ticks
ORIGNAL: sum=aa9d2e9f, 259914712 ticks
MINE: sum=aa9d2e9f, 4829583 ticks
ORIGNAL: sum=8abd398a, 251182134 ticks
MINE: sum=8abd398a, 4667315 ticks
ORIGNAL: sum=a374bd58, 6118517 ticks
MINE: sum=a374bd58, 113731 ticks
���̃X�R�A�������ɎN������ĈӖ��𗝉����Ă���B
MINE: sum=3c927c56, 5470853 ticks
ORIGNAL: sum=2e987a4d, 424726988 ticks
MINE: sum=2e987a4d, 7891991 ticks
ORIGNAL: sum=ef1b6aef, 312523179 ticks
MINE: sum=ef1b6aef, 5807115 ticks
ORIGNAL: sum=eedd2516, 290445788 ticks
MINE: sum=eedd2516, 5396877 ticks
ORIGNAL: sum=f7e967a8, 14386174 ticks
MINE: sum=f7e967a8, 267359 ticks
ORIGNAL: sum=1f37a7db, 214504754 ticks
MINE: sum=1f37a7db, 3985803 ticks
ORIGNAL: sum=c7d41f36, 295361550 ticks
MINE: sum=c7d41f36, 5488220 ticks
ORIGNAL: sum=aa9d2e9f, 259914712 ticks
MINE: sum=aa9d2e9f, 4829583 ticks
ORIGNAL: sum=8abd398a, 251182134 ticks
MINE: sum=8abd398a, 4667315 ticks
ORIGNAL: sum=a374bd58, 6118517 ticks
MINE: sum=a374bd58, 113731 ticks
���̃X�R�A�������ɎN������ĈӖ��𗝉����Ă���B
313 �F�f�t�H���g�̖����������F2009/01/11(��) 17:39:55
������Ƃ��̃\�[�X�N���Ă����H
�R����������B
�R����������B
314 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:43:14
�N���邩�{�P
315 �F227 ��eZQcaIaFJs �F2009/01/11(��) 17:43:29
���ꂩ��p�C�v���C���̋����炢�܂ŋl�߂�ꂽ���ǁA
�R���p�C�������łǂ��ɂ��Ȃ�Ȃ���ԁB
.L9: ; ���C�����[�v�̐擪
lqr $81,mt+X
lqr $84,mt+X
lqr $53,mt+X
lqr $41,mt+X
lqr $47,mt+X
lqr $48,mt+X
lqr $59,mt+X
lqr $68,mt+X
lqr $24,mt+X
lqr $71,mt+X
lqr $113,mt+X
lqr $42,mt+X
lqr $43,mt+X
lqr $45,mt+X
lqr $46,mt+X
lqr $58,mt+X
lqr $55,mt+X
lqr $93,mt+X
lqr $104,mt+X
shufb $106,$73,$81,$127
>>312
�����O�̃X�R�A�ł����H
�R���p�C�������łǂ��ɂ��Ȃ�Ȃ���ԁB
.L9: ; ���C�����[�v�̐擪
lqr $81,mt+X
lqr $84,mt+X
lqr $53,mt+X
lqr $41,mt+X
lqr $47,mt+X
lqr $48,mt+X
lqr $59,mt+X
lqr $68,mt+X
lqr $24,mt+X
lqr $71,mt+X
lqr $113,mt+X
lqr $42,mt+X
lqr $43,mt+X
lqr $45,mt+X
lqr $46,mt+X
lqr $58,mt+X
lqr $55,mt+X
lqr $93,mt+X
lqr $104,mt+X
shufb $106,$73,$81,$127
>>312
�����O�̃X�R�A�ł����H
>>313
���傗��������͂�肷�����낗
>>312���X�^���_�[�h�ɂȂ��Ă��܂���
>>312 �Ȃ�ǂ����鎩�M�����邯�ǁA���������ǂ��܂ōs�����낤�ˁB�B�B
���傗��������͂�肷�����낗
>>312���X�^���_�[�h�ɂȂ��Ă��܂���
>>312 �Ȃ�ǂ����鎩�M�����邯�ǁA���������ǂ��܂ōs�����낤�ˁB�B�B
317 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:46:08
318 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:47:55
15clk���{���Ȃ�>>312��99���˔j���Ă�킯����
319 �F�f�t�H���g�̖����������F2009/01/11(��) 17:51:59
���������ł���w
320 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 17:53:24
�Ē�o�㓙
�X�R�A�X�V����x�Ƀt�B�b�N�X�^�[�Y�ɑ�����Ă�邺���
�X�R�A�X�V����x�Ƀt�B�b�N�X�^�[�Y�ɑ�����Ă�邺���
321 �F�f�t�H���g�̖����������F2009/01/11(��) 17:58:41
���̃X���Ŋ����O�ɍő��R�[�h�����J���āA�R���e�X�g�������āA�����ē`���ցc
�Ȃ�ăX�g�[���[������̂��ȂƖϑz���Ă���B2ch���ۂ����B���₢��A�S�R���߂ĂȂ�������Ȃ��łˁB
����A�ł��A�Ȃ��Ȃ��R����W�J���ȁB�����A�c�q�R�Z��B
�Ȃ�ăX�g�[���[������̂��ȂƖϑz���Ă���B2ch���ۂ����B���₢��A�S�R���߂ĂȂ�������Ȃ��łˁB
����A�ł��A�Ȃ��Ȃ��R����W�J���ȁB�����A�c�q�R�Z��B
322 �F�f�t�H���g�̖����������F2009/01/11(��) 18:18:54
58156364 / 4(SIMD) * 15(cycle) / 40(ticks) = 5452159.125 ���B
���ꂩ 15cycle �̕ǂ���Ԃ��Ă���w
���ꂩ 15cycle �̕ǂ���Ԃ��Ă���w
323 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 18:22:23
tempering���e�[�u���Q�ƂŁE�E�E
���āA���\GB���������K�v�ɂȂ�܂���
���āA���\GB���������K�v�ɂȂ�܂���
324 �F�f�t�H���g�̖����������F2009/01/11(��) 18:34:45
325 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 18:40:19
9%��90%��99%��99.9$���E�E�E
�ł��ˁB�킩��܂�
�ł��ˁB�킩��܂�
>>322
������15��j��邱�ƃo��������������牴���o�������ǁA
15�͐����O�ɂ����j���Ă��B
�R���p�C���̓f���R�[�h����낵���Ȃ��āA�����̎��Ԃ����ĂȂ������B
>>325
99.9$ �E�E�E 9000�~���炢�H
������15��j��邱�ƃo��������������牴���o�������ǁA
15�͐����O�ɂ����j���Ă��B
�R���p�C���̓f���R�[�h����낵���Ȃ��āA�����̎��Ԃ����ĂȂ������B
>>325
99.9$ �E�E�E 9000�~���炢�H
327 �F�f�t�H���g�̖����������F2009/01/11(��) 19:43:14
�������Ă��̃X���ł���Ȃ�Cell�v���O���~���O�����s�������Ƃ����������낤���A����Ȃ�
328 �F�f�t�H���g�̖����������F2009/01/11(��) 19:51:07
�������A���̏T�����x�ɂɂȂ����̂�PS3�͉�Ђ̂����玖�����ɒu�����ςȂ����c�c
�ނ��A���N�ȏ���u���Ă��邩�獡�X�����߂�Ȃ����ǂˁB
�ނ��A���N�ȏ���u���Ă��邩�獡�X�����߂�Ȃ����ǂˁB
>>328
���v�A���Ȃ��Cell�v���O���~���O�͏��߂Ă��B
�����[�g�̊J�������p�ӂ��Ă�����B
�E�E�E�ׁA�ʂɗU���Ă�킯����Ȃ�����˂��I
�ǂ��������Ă����ƃ��C�o����������ƍ������˂��I
���v�A���Ȃ��Cell�v���O���~���O�͏��߂Ă��B
�����[�g�̊J�������p�ӂ��Ă�����B
�E�E�E�ׁA�ʂɗU���Ă�킯����Ȃ�����˂��I
�ǂ��������Ă����ƃ��C�o����������ƍ������˂��I
330 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 23:06:20
>>326
�����̂�16�i���Ă�����18�j����Ȃ��āH
�ǂ���4�v�f����spu_add���čŌ�ɍ��v�𐅕����Z���Ă������H
���Z��Even�p�C�v����B
�����̂�16�i���Ă�����18�j����Ȃ��āH
�ǂ���4�v�f����spu_add���čŌ�ɍ��v�𐅕����Z���Ă������H
���Z��Even�p�C�v����B
331 �F�f�t�H���g�̖����������F2009/01/11(��) 23:42:30
����܂��̓I�Șb������̂́A�P�`�Q�l�ŎQ���Ƃ�����|�ɔ������
�v����B
�v����B
332 �F,,�E�L�́M�E,,�j��-�������F2009/01/11(��) 23:54:01
���[�A�ۂB�����ς�����B�������܂�� unroll �ɂƂ肩���邺w
>>325,326
�����獡 unroll ���ĂȂ���Ԃ� 16cycle ������A�߂����Ȃ��A�ƁB
>>330
18���ĂȂɁH�Ƃ�����A�Ȃ�Ƃ� even �����ƈ�k�߂�����Ȃ��c
>>331
�ǂ���������\������łȂ����[�B���Ă����O&�Ж��o���˂�w
>>325,326
�����獡 unroll ���ĂȂ���Ԃ� 16cycle ������A�߂����Ȃ��A�ƁB
>>330
18���ĂȂɁH�Ƃ�����A�Ȃ�Ƃ� even �����ƈ�k�߂�����Ȃ��c
>>331
�ǂ���������\������łȂ����[�B���Ă����O&�Ж��o���˂�w
>>334
���Ă��Aeven 15 ���Ă�̂�������_�Ȋ�K�X
>>322 �ɏ��������ǁA������� 15 �͐��ĂȂ���B
�ǂꂾ���_�����E(15)�ɋ߂Â��邩�̏����ł���B
���ꂩ�N���� 15 ��邩w
���Ă��Aeven 15 ���Ă�̂�������_�Ȋ�K�X
>>322 �ɏ��������ǁA������� 15 �͐��ĂȂ���B
�ǂꂾ���_�����E(15)�ɋ߂Â��邩�̏����ł���B
���ꂩ�N���� 15 ��邩w
���A>>301 �� 5.47M �͊ԈႢ���Ǝv���
337 �F227 ��eZQcaIaFJs �F2009/01/12(��) 01:43:39
338 �F,,�E�L�́M�E,,�j��-�������F2009/01/12(��) 01:47:40
>>312��2���O�̐��ʁB�������Ɂi�킸���Ȃ���ł͂��邪�j���\�͐L�тĂ�
339 �F,,�E�L�́M�E,,�j��-�������F2009/01/12(��) 07:40:11
���_�X���[�v�b�g15�ɂȂ���@�v�������Ƃ��͉�SUGEEEEEEEEEE���Ďv��������
�����܂ł͈ĊO�݂�ȋC�Â��̑��������ȁB
�����܂ł͈ĊO�݂�ȋC�Â��̑��������ȁB
>>335
even? odd ����ˁH tempering �I�Ɍ����āB
>>339
�Ă�����15�T�C�N�������Ǝv�������ǁA�{�C��15�T�C�N���̃R�[�h��
���̃X�R�A�����̂��B�����[�ȁB
even? odd ����ˁH tempering �I�Ɍ����āB
>>339
�Ă�����15�T�C�N�������Ǝv�������ǁA�{�C��15�T�C�N���̃R�[�h��
���̃X�R�A�����̂��B�����[�ȁB
341 �F,,�E�L�́M�E,,�j��-�������F2009/01/12(��) 09:40:14
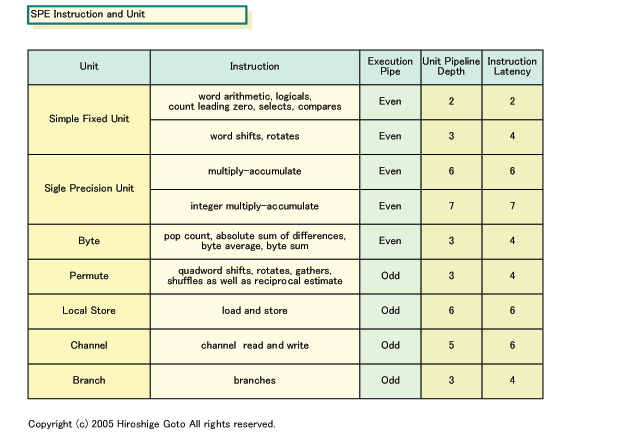{kind=link}
342 �F,,�E�L�́M�E,,�j��-�������F2009/01/12(��) 09:41:24
���Ă�����15�T�C�N�������Ǝv�������ǁA�{�C��15�T�C�N���̃R�[�h��
����͔閧�B
�����A�����I�Ɏ��̕ό`�͂��Ă�B�������̂��߂ɂǂ����Ă��K�v�������B
����͔閧�B
�����A�����I�Ɏ��̕ό`�͂��Ă�B�������̂��߂ɂǂ����Ă��K�v�������B
>>341
�����������������I
���Av = mt[k] �Ƃ��� //e ���āA spu_and() �Ƃ��� //o ���ăR�����g�t���Ă��I
�p�������[�I
�����������������I
���Av = mt[k] �Ƃ��� //e ���āA spu_and() �Ƃ��� //o ���ăR�����g�t���Ă��I
�p�������[�I
344 �F�f�t�H���g�̖����������F2009/01/12(��) 12:33:46
�Ǒf�l�ł����ǁA�b�d�k�k�Ɉ���ꓬ���Ă���X�Ɏ���B
�b�d�k�k�̃������\���̈����ɂ������āA�����k�r�̗e�ʂ�������
�e�r�o�t������̎d���ɐ�S����悤�ɂȂ�����A����ق�
�傫�ȑ������ɂȂ�Ȃ��C�������ł����ǁA�ǂ��ł��傤���H
���͂k�r�̗e�ʂ����Ȃ����āA�p�ɂɏ����������K�v�����璴�ʓ|�����ǁB
�N�^�͂����܂ōl���āA�k�r�ɂ�����Ȃ���ł��傤���H
�b�d�k�k�̃������\���̈����ɂ������āA�����k�r�̗e�ʂ�������
�e�r�o�t������̎d���ɐ�S����悤�ɂȂ�����A����ق�
�傫�ȑ������ɂȂ�Ȃ��C�������ł����ǁA�ǂ��ł��傤���H
���͂k�r�̗e�ʂ����Ȃ����āA�p�ɂɏ����������K�v�����璴�ʓ|�����ǁB
�N�^�͂����܂ōl���āA�k�r�ɂ�����Ȃ���ł��傤���H
345 �F�f�t�H���g�̖����������F2009/01/12(��) 13:52:21
�Ȃ������݂��Q�n�L��������ׂ����u�A��ȁv�ƌ����ׂ����������B
�N�^�����ɏœ_�Ă�Ȃ�APS3��v���Ă���Œ��ɁuLS����������v�������͍̂l����Ε�����b�����?
�N�^�����ɏœ_�Ă�Ȃ�APS3��v���Ă���Œ��ɁuLS����������v�������͍̂l����Ε�����b�����?
346 �F�f�t�H���g�̖����������F2009/01/12(��) 14:19:49
�ق�ƃQ�n�L����w
>>344
������ Hack the Cell ���悤�Ȑl�͈����ɂ����Ƃ��v���ĂȂ����H
�����ɂ������ĂȂ�̂́A�v���W�F�N�g���傫���Ȃ��� C# �������
�ւ���v���O���}���g��Ȃ��Ⴂ���Ȃ��Ȃ���������Ȃ����ȁH
Hack the Cell ���悤�ȐE�l�ɂƂ��Ă� LS �̗e�ʂ����Ȃ��Ē��ʓ|����
���͂Ȃ���(������Ɩʓ|���炢w)�A�ւ���ɂƂ��Ă� LS �̗e�ʂ������Ă��A
�w�e���������� cache ����Ȃ�������̎��_�Œ��ʓ|�ȂƎv���B
���������� Larrabee �݂����ȕ��������Ɍ��܂��Ă������B
>>344
������ Hack the Cell ���悤�Ȑl�͈����ɂ����Ƃ��v���ĂȂ����H
�����ɂ������ĂȂ�̂́A�v���W�F�N�g���傫���Ȃ��� C# �������
�ւ���v���O���}���g��Ȃ��Ⴂ���Ȃ��Ȃ���������Ȃ����ȁH
Hack the Cell ���悤�ȐE�l�ɂƂ��Ă� LS �̗e�ʂ����Ȃ��Ē��ʓ|����
���͂Ȃ���(������Ɩʓ|���炢w)�A�ւ���ɂƂ��Ă� LS �̗e�ʂ������Ă��A
�w�e���������� cache ����Ȃ�������̎��_�Œ��ʓ|�ȂƎv���B
���������� Larrabee �݂����ȕ��������Ɍ��܂��Ă������B
���������� => �������������
348 �F�f�t�H���g�̖����������F2009/01/12(��) 16:55:22
Larrabee����Cell�����̂̓}���h�N�Z�b�Ǝv���Ă�
�w�^���i�ƌ������PC��CPU�݈̂�������Ă���j
�v���O���}�Ɏ���Ă͂����ɂ������₷�����Ɍ����邪
�L���b�V�����x���ŏ���ɓ���������鎖��ǂ�����
���X���b�h�̂��������ŕp�ɂɓ��������v���O������
�����Ă��܂��Ă��ꂪ�L���b�V���p�����O�H�o�X�̑ш��
�������ăp�t�H�[�}���X���o�Ȃ��ƌ���㩂Ɋׂ肻���Ȋ�K�X�B
�w�^���i�ƌ������PC��CPU�݈̂�������Ă���j
�v���O���}�Ɏ���Ă͂����ɂ������₷�����Ɍ����邪
�L���b�V�����x���ŏ���ɓ���������鎖��ǂ�����
���X���b�h�̂��������ŕp�ɂɓ��������v���O������
�����Ă��܂��Ă��ꂪ�L���b�V���p�����O�H�o�X�̑ш��
�������ăp�t�H�[�}���X���o�Ȃ��ƌ���㩂Ɋׂ肻���Ȋ�K�X�B
349 �F�f�t�H���g�̖����������F2009/01/12(��) 17:12:05
��������Q�n�ɋA���
350 �F�f�t�H���g�̖����������F2009/01/12(��) 17:14:32
>>348
�������Ă�����B�܂��x86������PC��CPU�݂����Ȍ��������Ȃ���ȁB
�[���ALarrabee��Cell��Ō�邱�Ǝ��̂��ǂ������Ă���B
�������Ă�����B�܂��x86������PC��CPU�݂����Ȍ��������Ȃ���ȁB
�[���ALarrabee��Cell��Ō�邱�Ǝ��̂��ǂ������Ă���B
>349
���͎c�O�Ȃ���>344����Ȃ����Q�n���痈���킯�ł�������B
���͎c�O�Ȃ���>344����Ȃ����Q�n���痈���킯�ł�������B
352 �F�f�t�H���g�̖����������F2009/01/12(��) 17:30:51
>350
�lj�͖����ˁA�A�i�^�B
�lj�͖����ˁA�A�i�^�B
353 �F�f�t�H���g�̖����������F2009/01/12(��) 19:15:57
�������A���X�Ȃ���C�Â��������݁A�s��Ŕ����Ă���
PC��CPU�͂��͂�A�قƂ�ǑS��x86�Ȃ�ȁB
Apple(Macintosh)��Intel CPU�̗̍p���n�߂Ă���́B
�ƌ�����x86�ȊO��PC�p�i�ƌĂׂ�jCPU���v�����Ȃ��B
PC��CPU�͂��͂�A�قƂ�ǑS��x86�Ȃ�ȁB
Apple(Macintosh)��Intel CPU�̗̍p���n�߂Ă���́B
�ƌ�����x86�ȊO��PC�p�i�ƌĂׂ�jCPU���v�����Ȃ��B
354 �F�f�t�H���g�̖����������F2009/01/12(��) 20:50:56
CBE
�Ӂ[�A�ڕW�� 6M �˔j�B�Ǝv�����炷�������ɂȂ��Ă��w�@5.47M ����www
���������� spu-gcc43 �̍œK�������Ƃ̍���ׂ��ۂ��Ȃ��c orz
���Ă������œK���n���߂�w �s�v�ȏ������߂�!! �t���A�Z�ŏ�������!!!!w
���������� spu-gcc43 �̍œK�������Ƃ̍���ׂ��ۂ��Ȃ��c orz
���Ă������œK���n���߂�w �s�v�ȏ������߂�!! �t���A�Z�ŏ�������!!!!w
356 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 08:21:08
>>355
�������}�V�����z��ɏ�������H������
SPU�͌����Ȏ��s�����Ǘ��Ƃ����Ȃ����玩�ȏ��������Ƃ��ȒP�ɓ������肷���B
���ۖ��I�[�o�[���C���Ď��ȏ��������Ǝ����悤�Ȃ����B
�����k�ł�������
�������}�V�����z��ɏ�������H������
SPU�͌����Ȏ��s�����Ǘ��Ƃ����Ȃ����玩�ȏ��������Ƃ��ȒP�ɓ������肷���B
���ۖ��I�[�o�[���C���Ď��ȏ��������Ǝ����悤�Ȃ����B
�����k�ł�������
�ǂ����Ă�0.3���߂��炢�̓I�[�o�[�w�b�h�������Ȃ��B
15.3 * 100 /15 = 102 ������A2%���I�[�o�[�w�b�h���B
�R���p�C����99%�ȏ�̌����̃R�[�h��f���o�����邾����͐_�B
15.3 * 100 /15 = 102 ������A2%���I�[�o�[�w�b�h���B
�R���p�C����99%�ȏ�̌����̃R�[�h��f���o�����邾����͐_�B
>>355
������Ƒ҂��Ă�Afixstars�ɃC�����C���A�Z���u���g���ėǂ����ǂ����u���Ă���B
������ɏ��ɂ͂������ꂵ���Ȃ���K�X�B
������Ƒ҂��Ă�Afixstars�ɃC�����C���A�Z���u���g���ėǂ����ǂ����u���Ă���B
������ɏ��ɂ͂������ꂵ���Ȃ���K�X�B
>>358
�����I��낵�����ނ����I�ł��������Ƀ_���ȋC������w
�����獡 1.66% �̃I�[�o�[�w�b�h�܂ł����B5.54M
�ł��ȂS�R�{������Ȃ��������ł�����Ƌ������c orz
�����I��낵�����ނ����I�ł��������Ƀ_���ȋC������w
�����獡 1.66% �̃I�[�o�[�w�b�h�܂ł����B5.54M
�ł��ȂS�R�{������Ȃ��������ł�����Ƌ������c orz
360 �F�f�t�H���g�̖����������F2009/01/13(��) 13:45:11
���ꂩ��`���[�g���A���ǂݎn�߂���ǁA10�{���炢�Ȃ炢���邩��
5M�䉽�l����̂�����Ȃ��Ȃ��Ă����ȁB
5.6M���Ă�̂����̃X����4�l���炢����̂��ȁH
5.6M���Ă�̂����̃X����4�l���炢����̂��ȁH
>>322,324 ����Afixstars�Ј��ł��ˁA�킩��܂��B
363 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 17:52:24
VISEO MDT243W��������2�ʂ������Ȃ��ȂƎv���Ă���B
���Ă��A42�C���`�̃e���r�Ȃ�Ďg��ˁ[
PC���j�^�Ƃ��Ă����ɂ͂ł������邵�B
���Ă��A42�C���`�̃e���r�Ȃ�Ďg��ˁ[
PC���j�^�Ƃ��Ă����ɂ͂ł������邵�B
364 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 21:17:18
15���ߐ���@�v�����������m��Ȃ�
365 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 21:27:21
���͂�������
�݂Ȃ����Ă�����������������������
�Ƃ肠�����ڕW�C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@5M�ȁI
�݂Ȃ����Ă�����������������������
�Ƃ肠�����ڕW�C��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@5M�ȁI
366 �F�f�t�H���g�̖����������F2009/01/13(��) 21:28:57
�Ǝv������A��������ɂ� spu_and ���K�v�����猸��Ȃ��ȁ[
wwwwwwwwww
�тт点�₪���āI
�тт点�₪���āI
368 �F�f�t�H���g�̖����������F2009/01/13(��) 21:31:56
����A>>366 �͓K���ɏ��������������Ă�
�����ɃC�����C���A�Z���u�������Ă݂����ǁA
asm("lqr $50, mt+16")
�݂����ɂ���ƁA�R���p�C���ɓ{����B mt+ ���ď����͎g���Ȃ��H
asm("lqr $50, mt+16")
�݂����ɂ���ƁA�R���p�C���ɓ{����B mt+ ���ď����͎g���Ȃ��H
�����������
������ɒǂ��������I
������ɒǂ��������I
�C�����C���A�Z���u�������łǂ������5M�����悤��
372 �F�f�t�H���g�̖����������F2009/01/13(��) 21:35:43
202 ����͌��i�K�Ŕ����Ă��́H
���Ԃ�ˁB15cycle �͏����O�ɓ˔j���Ă�B >>326
������C�Â��ĂȂ����ۂ���������A���̌�� 15cycle�O��ʼn�b���Ă��B
gcc43�ɍs�����j�܂�āA���_�l�ɑS�R�߂Â��ĂȂ����ǁA>>316 �̎��_��
>>312 �͔����Ă��B
������C�Â��ĂȂ����ۂ���������A���̌�� 15cycle�O��ʼn�b���Ă��B
gcc43�ɍs�����j�܂�āA���_�l�ɑS�R�߂Â��ĂȂ����ǁA>>316 �̎��_��
>>312 �͔����Ă��B
374 �F�f�t�H���g�̖����������F2009/01/13(��) 21:57:26
���Ď��́A>>357 �͖{���� 14.3 ���Ă��ƁH
>>374
����A���́A�A�Z���u����������������ȒP�ȃv���O���������āA
���̏o�͂����R�[�h�i���e�X�g�j�̃T�C�N�����̘b�B15�̓E�\�B
�{���̃I�[�o�[�w�b�h��0.3�ǂ��낶��Ȃ��B�����ƃf�J�C�B
��ŁA�A�Z���u���֎~���ꂽ�B
... ���₵�Ȃ����ǂ�����orz
����A���́A�A�Z���u����������������ȒP�ȃv���O���������āA
���̏o�͂����R�[�h�i���e�X�g�j�̃T�C�N�����̘b�B15�̓E�\�B
�{���̃I�[�o�[�w�b�h��0.3�ǂ��낶��Ȃ��B�����ƃf�J�C�B
��ŁA�A�Z���u���֎~���ꂽ�B
... ���₵�Ȃ����ǂ�����orz
376 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:15:21
�Ƃ����킯�ʼn��������̃X�e�b�v�ɐ����\��
377 �F�f�t�H���g�̖����������F2009/01/13(��) 22:15:31
�A�Z���u���֎~�Ӗ��s���B�ő� Hack The spu-gcc43 �����B
378 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:17:56
�p�C�v���C���߂����l�������Ȃ��Ƃ����Ȃ��ȁB
379 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:19:54
����́E�E�E����Ȃ��ꂪ�B
380 �F�f�t�H���g�̖����������F2009/01/13(��) 22:25:49
>>377 ���܂����@�܂��������̂Ƃ��肾�Ƃ���
381 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:25:50
�����15cycle���Ȃ��R�[�h�̍ō��X�R�A���B�������A�Z���u���Ȃǎg���ĂȂ��B
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294035297 ticks
MINE: sum=3c927c56, 5466192 ticks
ORIGNAL: sum=2e987a4d, 424162315 ticks
MINE: sum=2e987a4d, 7885270 ticks
ORIGNAL: sum=ef1b6aef, 312107681 ticks
MINE: sum=ef1b6aef, 5802168 ticks
ORIGNAL: sum=eedd2516, 290059639 ticks
MINE: sum=eedd2516, 5392281 ticks
ORIGNAL: sum=f7e967a8, 14367047 ticks
MINE: sum=f7e967a8, 267131 ticks
ORIGNAL: sum=1f37a7db, 214219571 ticks
MINE: sum=1f37a7db, 3982409 ticks
ORIGNAL: sum=c7d41f36, 294968868 ticks
MINE: sum=c7d41f36, 5483545 ticks
ORIGNAL: sum=aa9d2e9f, 259569157 ticks
MINE: sum=aa9d2e9f, 4825469 ticks
ORIGNAL: sum=8abd398a, 250848188 ticks
MINE: sum=8abd398a, 4663339 ticks
ORIGNAL: sum=a374bd58, 6110381 ticks
MINE: sum=a374bd58, 113635 ticks
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294035297 ticks
MINE: sum=3c927c56, 5466192 ticks
ORIGNAL: sum=2e987a4d, 424162315 ticks
MINE: sum=2e987a4d, 7885270 ticks
ORIGNAL: sum=ef1b6aef, 312107681 ticks
MINE: sum=ef1b6aef, 5802168 ticks
ORIGNAL: sum=eedd2516, 290059639 ticks
MINE: sum=eedd2516, 5392281 ticks
ORIGNAL: sum=f7e967a8, 14367047 ticks
MINE: sum=f7e967a8, 267131 ticks
ORIGNAL: sum=1f37a7db, 214219571 ticks
MINE: sum=1f37a7db, 3982409 ticks
ORIGNAL: sum=c7d41f36, 294968868 ticks
MINE: sum=c7d41f36, 5483545 ticks
ORIGNAL: sum=aa9d2e9f, 259569157 ticks
MINE: sum=aa9d2e9f, 4825469 ticks
ORIGNAL: sum=8abd398a, 250848188 ticks
MINE: sum=8abd398a, 4663339 ticks
ORIGNAL: sum=a374bd58, 6110381 ticks
MINE: sum=a374bd58, 113635 ticks
�����A�����A���̃X�e�b�v�͂Ȃ��B
Hack the spu-gcc 4.3 '09
�D�������̃X�e�[�W�ɁA���܁A���Ƃ��������Ă���B
���̃X�e�[�W�𐧂���̂́A�����A�����A�͂��܂��V���Ȃ�
�`�������W���[���I�I�I
Hack the spu-gcc 4.3 '09
�D�������̃X�e�[�W�ɁA���܁A���Ƃ��������Ă���B
���̃X�e�[�W�𐧂���̂́A�����A�����A�͂��܂��V���Ȃ�
�`�������W���[���I�I�I
383 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:33:16
��Ȃ��狰�낵���B15clk/QWORD�ɑ����������99.74���̊�n�O�X�P�W���[�����O
���ɏ��Ă邩�ȃN�N�N
���ɏ��Ă邩�ȃN�N�N
384 �F,,�E�L�́M�E,,�j��-�������F2009/01/13(��) 22:43:37
�q���g�F�œK�������Ȃ�A�����ɂ����������Ȃ�
385 �F�f�t�H���g�̖����������F2009/01/13(��) 23:46:28
���X�H
386 �F�f�t�H���g�̖����������F2009/01/13(��) 23:58:15
���̉ۑ�����ŃC�����C���A�Z���u���֎~�Ȃ�A
pragma ���g�p�֎~�ł��傤�ȁB
pragma ���g�p�֎~�ł��傤�ȁB
387 �F�f�t�H���g�̖����������F2009/01/14(��) 00:03:42
������āA�Ȃ�ăR���p�C���n�b�L���O�Q�[��?w
388 �F227 ��eZQcaIaFJs �F2009/01/14(��) 00:41:47
��������悤�₭>>282�̃X�^�[�g���C���ɗ��Ă��̂ňꉞ�B
���Ȃ݂ɁA���̂��R���p�C���̍œK�������ɂ�����R�[�h�̎����ǂ��Ȃ��Ă邵�A
�R���p�C���Ƃ̐킢�̈Ӗ������̕��������悤�ȋC������Ȃ��c�B
���Ȃ݂ɁA���̂��R���p�C���̍œK�������ɂ�����R�[�h�̎����ǂ��Ȃ��Ă邵�A
�R���p�C���Ƃ̐킢�̈Ӗ������̕��������悤�ȋC������Ȃ��c�B
389 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 01:01:21
�n�b�L���O�Ȃǂ��ĂȂ�
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 295486875 ticks
MINE: sum=3c927c56, 5093390 ticks
ORIGNAL: sum=2e987a4d, 426256300 ticks
MINE: sum=2e987a4d, 7347483 ticks
ORIGNAL: sum=ef1b6aef, 313648483 ticks
MINE: sum=ef1b6aef, 5406455 ticks
ORIGNAL: sum=eedd2516, 291491590 ticks
MINE: sum=eedd2516, 5024518 ticks
ORIGNAL: sum=f7e967a8, 14437972 ticks
MINE: sum=f7e967a8, 248913 ticks
ORIGNAL: sum=1f37a7db, 215277119 ticks
MINE: sum=1f37a7db, 3710802 ticks
ORIGNAL: sum=c7d41f36, 296425055 ticks
MINE: sum=c7d41f36, 5109559 ticks
ORIGNAL: sum=aa9d2e9f, 260850588 ticks
MINE: sum=aa9d2e9f, 4496367 ticks
ORIGNAL: sum=8abd398a, 252086563 ticks
MINE: sum=8abd398a, 4345293 ticks
ORIGNAL: sum=a374bd58, 6140545 ticks
MINE: sum=a374bd58, 105884 ticks
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 295486875 ticks
MINE: sum=3c927c56, 5093390 ticks
ORIGNAL: sum=2e987a4d, 426256300 ticks
MINE: sum=2e987a4d, 7347483 ticks
ORIGNAL: sum=ef1b6aef, 313648483 ticks
MINE: sum=ef1b6aef, 5406455 ticks
ORIGNAL: sum=eedd2516, 291491590 ticks
MINE: sum=eedd2516, 5024518 ticks
ORIGNAL: sum=f7e967a8, 14437972 ticks
MINE: sum=f7e967a8, 248913 ticks
ORIGNAL: sum=1f37a7db, 215277119 ticks
MINE: sum=1f37a7db, 3710802 ticks
ORIGNAL: sum=c7d41f36, 296425055 ticks
MINE: sum=c7d41f36, 5109559 ticks
ORIGNAL: sum=aa9d2e9f, 260850588 ticks
MINE: sum=aa9d2e9f, 4496367 ticks
ORIGNAL: sum=8abd398a, 252086563 ticks
MINE: sum=8abd398a, 4345293 ticks
ORIGNAL: sum=a374bd58, 6140545 ticks
MINE: sum=a374bd58, 105884 ticks
390 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 01:02:58
��ׂ������������Ƃ܂�ˁ[����������
�����ꂽ�E�E�E���s��orz
392 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 01:19:03
��H�܂�������i�K��������
5M�ꂻ���H
���������A5088682 �������ȂȁB
395 �F�f�t�H���g�̖����������F2009/01/14(��) 01:34:03
396 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 01:34:04
����
397 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 01:35:32
398 �F227 ��eZQcaIaFJs �F2009/01/14(��) 02:09:28
399 �F�f�t�H���g�̖����������F2009/01/14(��) 02:14:08
ttp://cell.fixstars.com/ps3linux/index.php/3.8%E3%80%80%E6%BC%94%E7%BF%92%E5%95%8F%E9%A1%8C_(3-3)_%E5%8C%BA%E5%88%86%E6%B1%82%E7%A9%8D%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%A0_(%E8%A7%A3%E7%AD%94)
400 �F�f�t�H���g�̖����������F2009/01/14(��) 02:17:55
�r���œ��e���Ă������E�E�E
http://cell.fixstars.com/ps3linux/index.php/
�����ɂ���v���O���~���O�`���[�g���A���̉��K�R�|�R�̉ŁASPE�̌���ς�������ł���
#define NUM_SPE * ��*�����ς��Ă����߂ł���ˁE�E�E
���\���ǂ�Ȃ��݂�����ł����c�ǂ̓_��ύX����悢�̂����������������܂���ł��傤��
http://cell.fixstars.com/ps3linux/index.php/
�����ɂ���v���O���~���O�`���[�g���A���̉��K�R�|�R�̉ŁASPE�̌���ς�������ł���
#define NUM_SPE * ��*�����ς��Ă����߂ł���ˁE�E�E
���\���ǂ�Ȃ��݂�����ł����c�ǂ̓_��ύX����悢�̂����������������܂���ł��傤��
401 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 02:20:52
2�ׂ̂���Ȃ炢����Ȃ��́H
�e�L�g�[�Ɍ����Ă݂邯�ǁB
�e�L�g�[�Ɍ����Ă݂邯�ǁB
402 �F�f�t�H���g�̖����������F2009/01/14(��) 09:07:02
403 �F�f�t�H���g�̖����������F2009/01/14(��) 12:06:10
>>389
SFMT��葬����ˁH
SFMT��葬����ˁH
404 �F�f�t�H���g�̖����������F2009/01/14(��) 12:42:54
>>401-402
���肪�Ƃ��������܂��B
�ύX�ӏ��͂�����ł����Ă���݂����ł���
�^�C�����𗘗p���ď������Ԃ𑪒肵�Ă��A�t��SPE�𗘗p�����ق������Ԃ����тĂ��܂��܂��B
���_��ł�SPE�P����SPE4�ɂ�����1/4�ɂȂ�͂��ł���ˁH
ppe�̃��C�����ɂ���result���������đ��肵�Ă���̂ł����K�ł͂Ȃ��̂���
���݂܂���A�o�͂ɗv�������Ԃ𑪒肷��ɂ͂ǂ����K�Ȃ̂ł��傤
http://cell.fixstars.com/pukiwiki/index.php?tips_timebase �^�C�����͂�����g�p���Ă��܂�
���肪�Ƃ��������܂��B
�ύX�ӏ��͂�����ł����Ă���݂����ł���
�^�C�����𗘗p���ď������Ԃ𑪒肵�Ă��A�t��SPE�𗘗p�����ق������Ԃ����тĂ��܂��܂��B
���_��ł�SPE�P����SPE4�ɂ�����1/4�ɂȂ�͂��ł���ˁH
ppe�̃��C�����ɂ���result���������đ��肵�Ă���̂ł����K�ł͂Ȃ��̂���
���݂܂���A�o�͂ɗv�������Ԃ𑪒肷��ɂ͂ǂ����K�Ȃ̂ł��傤
http://cell.fixstars.com/pukiwiki/index.php?tips_timebase �^�C�����͂�����g�p���Ă��܂�
405 �F�f�t�H���g�̖����������F2009/01/14(��) 13:21:25
>>404
�����������̖����Ă���ȑ�K�͂Ȑ����v�Z���ĂȂ�����
�����SPE���₷�ƃf�[�^�]�����Ԃ�炻�̑�������낪������
�t�ɒx���Ȃ�\���̂ق���������
�����������̖����Ă���ȑ�K�͂Ȑ����v�Z���ĂȂ�����
�����SPE���₷�ƃf�[�^�]�����Ԃ�炻�̑�������낪������
�t�ɒx���Ȃ�\���̂ق���������
406 �F�f�t�H���g�̖����������F2009/01/14(��) 14:42:22
�����ł����c�킩��܂����B���肷��v���O�������̂��ԈႢ��������ł�����
���\�����邽�߂ɓK�����v���O�����E�E�E�ǂ�������܂����ˁH
�T���Ă݂܂��B
���\�����邽�߂ɓK�����v���O�����E�E�E�ǂ�������܂����ˁH
�T���Ă݂܂��B
407 �F�f�t�H���g�̖����������F2009/01/14(��) 16:03:39
����ł��B
�b�d�k�k��Larrabee ���Ăǂ̒��x���\���������ł����H
�債�Đ��\�����Ȃ��Ƃ�����A���ɂo�r�S���o��Ƃ��āA
�\�j�[���b�d�k�k�ɍS��Ӗ����āA���͂△���̂ł́H
�ނ���o�b�̐��E�Ŏ嗬�ɂȂ�ł��낤�ALarrabee��
��ւ��������R�X�g�I�ɂ��L���Ȃ̂ł́H
�b�d�k�k��Larrabee ���Ăǂ̒��x���\���������ł����H
�債�Đ��\�����Ȃ��Ƃ�����A���ɂo�r�S���o��Ƃ��āA
�\�j�[���b�d�k�k�ɍS��Ӗ����āA���͂△���̂ł́H
�ނ���o�b�̐��E�Ŏ嗬�ɂȂ�ł��낤�ALarrabee��
��ւ��������R�X�g�I�ɂ��L���Ȃ̂ł́H
408 �F�f�t�H���g�̖����������F2009/01/14(��) 16:50:01
�Q�n�ɂ��A�肭�������B
409 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 17:16:08
>>403
�t���I�����ǁA���Z��O��ɂ����ꍇ�A���̓I���W�i����MT�̂ق�������x�̍���
�i�������Ȃ��Ɛ��\�̏o�Ȃ��j�A�[�L�e�N�`���Ɍ����Ă���Ă̂͂���B
MT�̔z��̂����A�擪����224�A�c���400�͕��Z�\���B
�����CUDA�̎����ɂ��Ă̐����B
�\�[�X��CUDA SDK�̃T���v���ɂ������Ă�B
http://developer.download.nvidia.com/compute/cuda/sdk/website/projects/MersenneTwister/doc/MersenneTwister.pdf
����ɑ��āA����SFMT��4�v�f�i��128�r�b�g�j�̌v�Z�����Ȃ��Ƃ��̎���4�v�f�̌v�Z���ł��Ȃ��B
�v����Ɉˑ��W�������āA128�r�b�g���\���o�Ȃ��B
�e���߂̃��C�e���V���傫����SFMT�͑��ΓI�ɕs�������Ă��ƂɂȂ邩���ˁB
�t���I�����ǁA���Z��O��ɂ����ꍇ�A���̓I���W�i����MT�̂ق�������x�̍���
�i�������Ȃ��Ɛ��\�̏o�Ȃ��j�A�[�L�e�N�`���Ɍ����Ă���Ă̂͂���B
MT�̔z��̂����A�擪����224�A�c���400�͕��Z�\���B
�����CUDA�̎����ɂ��Ă̐����B
�\�[�X��CUDA SDK�̃T���v���ɂ������Ă�B
http://developer.download.nvidia.com/compute/cuda/sdk/website/projects/MersenneTwister/doc/MersenneTwister.pdf
����ɑ��āA����SFMT��4�v�f�i��128�r�b�g�j�̌v�Z�����Ȃ��Ƃ��̎���4�v�f�̌v�Z���ł��Ȃ��B
�v����Ɉˑ��W�������āA128�r�b�g���\���o�Ȃ��B
�e���߂̃��C�e���V���傫����SFMT�͑��ΓI�ɕs�������Ă��ƂɂȂ邩���ˁB
410 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 17:18:53
�~ �v����Ɉˑ��W�������āA128�r�b�g���\���o�Ȃ��B
�~ �v����Ɉˑ��W�������āA128�r�b�gSIMD���Z���C�e���V�Ŏ��s�ł���A�[�L�łȂ��Ƃ��o�Ȃ��B
�~ �v����Ɉˑ��W�������āA128�r�b�gSIMD���Z���C�e���V�Ŏ��s�ł���A�[�L�łȂ��Ƃ��o�Ȃ��B
411 �F�f�t�H���g�̖����������F2009/01/14(��) 17:38:23
�����݂�����
412 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 17:44:30
�ǂ���
����̉ۑ��MT��SFMT�Ɣ�ׂă��C�e���V�߂邽�߂̃e�N�j�b�N���g���₷���͎̂�������B
���Ă������N��CUDA��SFMT�ڐA���Ă����H4�_���X���b�h����������s�ł��Ȃ��ߎS�Ȃ��ƂɂȂ�B
����̉ۑ��MT��SFMT�Ɣ�ׂă��C�e���V�߂邽�߂̃e�N�j�b�N���g���₷���͎̂�������B
���Ă������N��CUDA��SFMT�ڐA���Ă����H4�_���X���b�h����������s�ł��Ȃ��ߎS�Ȃ��ƂɂȂ�B
413 �F�f�t�H���g�̖����������F2009/01/14(��) 17:45:45
����A�ǂ������~�ȂƂ���ɂȂ���
414 �F,,�E�L�́M�E,,�j��-�������F2009/01/14(��) 17:48:20
�� �v����Ɉˑ��W�������āA128�r�b�gSIMD���Z���C�e���V�Ŏ��s�ł���A�[�L�łȂ��Ɛ��\���o�Ȃ��B
�^�C�s���O���������F�≊�ɂȂ肻��
�^�C�s���O���������F�≊�ɂȂ肻��
415 �F�f�t�H���g�̖����������F2009/01/14(��) 18:36:35
>407
Larrabee�͂܂����̒��ɏo�Ă��Ȃ��̂ŒN�ɂ�������܂���B
���\��r�͗p�r�ɂ���ĕς��̂ō��ACell���g���Ă���p�r��
���̂܂�Larrabee���g��ꂽ��ǂ��Ȃ邩�Ȃ�ĉ���̘b��
Intel�̒��̐l�ł��番����Ȃ��ł��傤�B
�܂�PC�p��CPU�̐��E��Larrabee�̂悤��
�V���v���ȃR�A����������W�ς������j�[�R�A��
�����ɗ��s�鎖�������ł��傤�B
���s��Ƃ��Ă������Ԑ�̘b�i10�N�悩20�N�悩�H�j
Larrabee�͂܂����̒��ɏo�Ă��Ȃ��̂ŒN�ɂ�������܂���B
���\��r�͗p�r�ɂ���ĕς��̂ō��ACell���g���Ă���p�r��
���̂܂�Larrabee���g��ꂽ��ǂ��Ȃ邩�Ȃ�ĉ���̘b��
Intel�̒��̐l�ł��番����Ȃ��ł��傤�B
�܂�PC�p��CPU�̐��E��Larrabee�̂悤��
�V���v���ȃR�A����������W�ς������j�[�R�A��
�����ɗ��s�鎖�������ł��傤�B
���s��Ƃ��Ă������Ԑ�̘b�i10�N�悩20�N�悩�H�j
416 �F�f�t�H���g�̖����������F2009/01/14(��) 20:19:04
>>409
�����������_�������D��Ă���Ȃ�Ē����ǂ������Ȃ����Ƃ͎v���Ă����B
�ӂ[�Ȃ�A�ǂ������̂͂�������ȁB�����Ђǂ��Ȃ�����́B
�����������_�������D��Ă���Ȃ�Ē����ǂ������Ȃ����Ƃ͎v���Ă����B
�ӂ[�Ȃ�A�ǂ������̂͂�������ȁB�����Ђǂ��Ȃ�����́B
417 �F227 ��eZQcaIaFJs �F2009/01/14(��) 22:15:12
99%���������[
418 �F�f�t�H���g�̖����������F2009/01/15(��) 10:44:32
http://cell.fixstars.com/challenge/faq.html#kadai4
> �C�����C���A�Z���u���͎g�p���Ă��悢�ł����H
> �C�����C���A�Z���u���͋֎~�Ƃ��Ă��܂������A�g�p���Ă��������č\���܂���B(1/15 �X�V)
> �C�����C���A�Z���u���͎g�p���Ă��悢�ł����H
> �C�����C���A�Z���u���͋֎~�Ƃ��Ă��܂������A�g�p���Ă��������č\���܂���B(1/15 �X�V)
419 �F�f�t�H���g�̖����������F2009/01/15(��) 10:46:52
���̐l���̃X�����Ă�ȁB
420 �F�f�t�H���g�̖����������F2009/01/15(��) 11:23:12
�ȂA�����Ȃ苣���̃��[�����ς���Ă��܂����ȁB
421 �F�f�t�H���g�̖����������F2009/01/15(��) 11:33:29
�����������[���Ȃ�čĊm�F���Ȃ����낤����A���̃X�����ĂȂ��l�����z����ȁB
422 �F�f�t�H���g�̖����������F2009/01/15(��) 11:38:36
�������Ă�ȁB
�A�Z���u�����x����Cell���n�m���ĂȂ��l�Ԃɂ̓`�����X��^���Ȃ������ɐ���ʂĂ��B
�R���p�C���I�v�V�����ύX�����Ȃ��Ӗ������ɖ����B
�A�Z���u�����x����Cell���n�m���ĂȂ��l�Ԃɂ̓`�����X��^���Ȃ������ɐ���ʂĂ��B
�R���p�C���I�v�V�����ύX�����Ȃ��Ӗ������ɖ����B
423 �F�f�t�H���g�̖����������F2009/01/15(��) 11:58:29
>�A�Z���u�����x����Cell���n�m���ĂȂ��l�Ԃɂ̓`�����X��^���Ȃ������ɐ���ʂĂ��B
���̃��x���̐l�ɂ͌��X�u���v�`�����X�͖����Ǝv���܂��B
�Q�����鎖�ɈӋ`������B
���̃��x���̐l�ɂ͌��X�u���v�`�����X�͖����Ǝv���܂��B
�Q�����鎖�ɈӋ`������B
424 �F�f�t�H���g�̖����������F2009/01/15(��) 12:05:30
�A�Z���u�������̂͊��}�����A����Ȃ��Ƃ�����
�u��҂͍ŏ����猈�߂Ă�������I�v
�ƌ���ꂩ�˂Ȃ��B
�u��҂͍ŏ����猈�߂Ă�������I�v
�ƌ���ꂩ�˂Ȃ��B
425 �F�f�t�H���g�̖����������F2009/01/15(��) 12:11:38
>>�A�Z���u�����x����Cell���n�m���ĂȂ��l�Ԃɂ̓`�����X��^���Ȃ������ɐ���ʂĂ��B
>���̃��x���̐l�ɂ͌��X�u���v�`�����X�͖����Ǝv���܂��B
202����A������
>���̃��x���̐l�ɂ͌��X�u���v�`�����X�͖����Ǝv���܂��B
202����A������
426 �F�f�t�H���g�̖����������F2009/01/15(��) 12:18:14
>>425
���₢��A202�͊��ɏn�m�u�����v����B
���₢��A202�͊��ɏn�m�u�����v����B
427 �F�f�t�H���g�̖����������F2009/01/15(��) 12:19:00
���[��A�m���ɃR���e�X�g���n�߂Ă��烋�[����ς���̂͂Ȃ��ȁB
�Ē�o�̃`�����X������Ƃ͌����ǁB
��Î҂̓��[�����ς�����������[���ȂǂŎ��m�O�ꂷ�ׂ����낤�B
�Ē�o�̃`�����X������Ƃ͌����ǁB
��Î҂̓��[�����ς�����������[���ȂǂŎ��m�O�ꂷ�ׂ����낤�B
����A���ɂȂ����̂���I�I
�A�Z���u��������X�N���v�g��C�\�[�X�f���悤�ɉ��ς��āA
�ǂ�����čœK������ɂ��f�`���[�����瓦��邩���s���낵�Ă��̂ɁI
#pragma GCC optimize ("-O0") ���A __attribute__ ((optimize(0))) ���g���Ȃ��A
�ϐ���volatile�ɂ�����X�^�b�N��push/pop���邩�璴�x���Aetcetc�A�A�A
����2���Ԃ������[�[�I
�A�Z���u��������X�N���v�g��C�\�[�X�f���悤�ɉ��ς��āA
�ǂ�����čœK������ɂ��f�`���[�����瓦��邩���s���낵�Ă��̂ɁI
#pragma GCC optimize ("-O0") ���A __attribute__ ((optimize(0))) ���g���Ȃ��A
�ϐ���volatile�ɂ�����X�^�b�N��push/pop���邩�璴�x���Aetcetc�A�A�A
����2���Ԃ������[�[�I
�܂��A�ł��{���� Hack the spu-gcc43 �ɂȂ��Ă�����ȁc
������� 4.1 ���Ƃ��܂��������œK���}����@���A4.3 ����
�g���Ȃ������肵�Č��\�������Ȃ��Ă�����悩���������B
������� 4.1 ���Ƃ��܂��������œK���}����@���A4.3 ����
�g���Ȃ������肵�Č��\�������Ȃ��Ă�����悩���������B
430 �F,,�E�L�́M�E,,�j��-�������F2009/01/15(��) 12:48:42
���������B
���܂ł̂͑S��C���B
���܂ł̂͑S��C���B
���A�R���e�X�g�I�������ł�������A�����ǂ������
�œK���}�����Ă��̂������Ăق��������B�����炪����Ă��̂�
4.3 �ɂ����� even �ɂ܂Ŗ��ߒlj�����Ďg���Ȃ����������B
�œK���}�����Ă��̂������Ăق��������B�����炪����Ă��̂�
4.3 �ɂ����� even �ɂ܂Ŗ��ߒlj�����Ďg���Ȃ����������B
432 �F�f�t�H���g�̖����������F2009/01/15(��) 12:54:18
�ǂ����A�����܂ł���Ȃ�R���p�C���I�v�V�������ύX�\�ɂ���
���ł��A���A���̏����ŋ��������ė~�����B
���ł��A���A���̏����ŋ��������ė~�����B
>>432
�C�����C���A�Z���u������=���ł��A������B
�ʂ̃R���p�C���ŁA�ʂ̃R���p�C���I�v�V�����ŃA�Z���u���\�[�X�f�����āA
������C�����C���A�Z���u���Ŗ��ߍ��߂Ηǂ�����B
�C�����C���A�Z���u������=���ł��A������B
�ʂ̃R���p�C���ŁA�ʂ̃R���p�C���I�v�V�����ŃA�Z���u���\�[�X�f�����āA
������C�����C���A�Z���u���Ŗ��ߍ��߂Ηǂ�����B
���A���߂�B
�����Ȃ�ł��A���Ȃ�A�{���ɉ��ł��A���ɂ��Ă�����Ă����Ӗ��ˁB
�����Ȃ�ł��A���Ȃ�A�{���ɉ��ł��A���ɂ��Ă�����Ă����Ӗ��ˁB
437 �F�f�t�H���g�̖����������F2009/01/15(��) 13:00:04
>433
����A��������͂�Ӗ��̖����`�������̃R���p�C���I�v�V������
������Ȃƌ���������O��������������₷������H
����A��������͂�Ӗ��̖����`�������̃R���p�C���I�v�V������
������Ȃƌ���������O��������������₷������H
438 �F�f�t�H���g�̖����������F2009/01/15(��) 13:19:20
���Ȃ� mt_mine.c �����I�v�V�����������Ȃ��ƁA
�I���W�i���̑��x�Ƃ��e�X�g�x���`�ɂ܂ʼne�����c
�I���W�i���̑��x�Ƃ��e�X�g�x���`�ɂ܂ʼne�����c
439 �F,,�E�L�́M�E,,�j��-�������F2009/01/15(��) 18:47:17
SPU�̃A�Z���u������͂�����Ƃ����ǂ߂邯�ǂ��ꂾ���̃R�[�h���܂Ƃ��ɏ�����C�����Ȃ��B
���܂������Ȃ点��spu-gcc43�����ŋ��̍����A�Z���u��
���܂������Ȃ点��spu-gcc43�����ŋ��̍����A�Z���u��
������ 4.3 �͎����Ȃ炵�����킩��Battribute �Ƃ�����Ȃ���ˁH
���āA�R���e�X�g�O�Ȃ��畷���Ă�ꍇ����Ȃ�����
������� asm �s�����ǁA�������C�ɂȂ��ċC�ɂȂ��āB
���Ȃ݂� 4.1 �Ȃ� >>383 �̗������܂���!! �Ӗ��Ȃ����ǂ�
������� asm �s�����ǁA�������C�ɂȂ��ċC�ɂȂ��āB
���Ȃ݂� 4.1 �Ȃ� >>383 �̗������܂���!! �Ӗ��Ȃ����ǂ�
442 �F,,�E�L�́M�E,,�j��-�������F2009/01/15(��) 20:54:44
443 �F�f�t�H���g�̖����������F2009/01/15(��) 20:59:19
�Ȃ�ł��������̖ق��Ă��Ȃ��낤�B
444 �F�f�t�H���g�̖����������F2009/01/15(��) 21:07:59
��SUGEEEEEEEEEE �����炶���H��
445 �F�f�t�H���g�̖����������F2009/01/15(��) 21:12:55
���߂Ē��ߐ��Ă���ɂ�����ǂ����ˁB
446 �F�f�t�H���g�̖����������F2009/01/15(��) 21:33:05
���،�t�J�V������������āu���Q�����Ăˁ[���v�Ƃ����������Ȋ���
447 �F�f�t�H���g�̖����������F2009/01/15(��) 21:37:21
������ŗi�삪�������Ȋ���
448 �F�f�t�H���g�̖����������F2009/01/15(��) 23:48:57
���₢�������������Ǝv���Ă�����݂��
Cell�v���O���~���O�ɊW���Ă邾���}�V���Ǝv���Ă����ǁA
�E�U�������H
���ɂȂb�肠��H
�E�U�������H
���ɂȂb�肠��H
450 �F�f�t�H���g�̖����������F2009/01/16(��) 00:34:34
���c�q�ɉa��^����̂͂������Ȃ��̂��B���������B
451 �F,,�E�L�́M�E,,�j��-�������F2009/01/16(��) 03:09:49
>>446
����Ȃ炻��Ń\�[�X�R�[�h���J�ł�����ǂˁB
�s���Ƃ͗����ɒN�ɂ��C�Â���邱�Ƃ��Ȃ��D������V�i���I��]��ł�B
�������Ă�ȁB
����Ȃ炻��Ń\�[�X�R�[�h���J�ł�����ǂˁB
�s���Ƃ͗����ɒN�ɂ��C�Â���邱�Ƃ��Ȃ��D������V�i���I��]��ł�B
�������Ă�ȁB
�C�����C���A�Z���u���œ������B
�����͂��ꂩ��l�߂Ă������ǁA�Ƃ肠�����K���ȋl�ߕ��ł�98%�s���B
�f�o�b�O�����ʓ|�������B
���ꂩ��C�����C���A�Z���u���Ɏ���o���l�Ƀq���g�B
.balign 16
�Ƃ����f�B���N�e�B�u���g���āA���߂̃A�h���X��16byte���E��align���Ȃ��ƁA
Dual-issue �˂���Ă����߂��S��single-issue �ɂȂ��Ă��܂��B
�߂�����x���Ȃ��āA�Ԉ���ă��[�v�J�E���^�����Ǝv�����B
�����͂��ꂩ��l�߂Ă������ǁA�Ƃ肠�����K���ȋl�ߕ��ł�98%�s���B
�f�o�b�O�����ʓ|�������B
���ꂩ��C�����C���A�Z���u���Ɏ���o���l�Ƀq���g�B
.balign 16
�Ƃ����f�B���N�e�B�u���g���āA���߂̃A�h���X��16byte���E��align���Ȃ��ƁA
Dual-issue �˂���Ă����߂��S��single-issue �ɂȂ��Ă��܂��B
�߂�����x���Ȃ��āA�Ԉ���ă��[�v�J�E���^�����Ǝv�����B
453 �F227 ��eZQcaIaFJs �F2009/01/16(��) 21:47:01
���T���͂Q���ԂƂ������ɋx�ގ��ɂ�����ŁA�C�����C���A�Z���u���ɂł�
���t���Ă݂܂��i���Ȃ݂�VC�̓z�͌o���L�邯�ǁAGCC�̓z�͏��j�B
98%�������S�l���鎖���������Ă���̂ŁA�܂��܂��`�L�����[�X�����܂��悗
>>428
�C�����C���A�Z���u�����ւ��ꂽ�̂ŁA���ɈӖ������Ȃ������ł������B
volatile�ɂ�鐧��́A�������A�N�Z�X�̏��Ԃ���鐧��ł��L��܂��B
�g�ݍ��݃v���O���~���O�Ń�������Ԃ��O���o�X�Ƀ}�b�s���O����Ă�ƁA
�A�N�Z�X���Ԃ��������o�O�A�Ƃ����������Ɍq�����Ă����ł��B
>>439
gcc �̃R�[�h����ёւ��邾���ŏI���悤�ȗ\���B
���t���Ă݂܂��i���Ȃ݂�VC�̓z�͌o���L�邯�ǁAGCC�̓z�͏��j�B
98%�������S�l���鎖���������Ă���̂ŁA�܂��܂��`�L�����[�X�����܂��悗
>>428
�C�����C���A�Z���u�����ւ��ꂽ�̂ŁA���ɈӖ������Ȃ������ł������B
volatile�ɂ�鐧��́A�������A�N�Z�X�̏��Ԃ���鐧��ł��L��܂��B
�g�ݍ��݃v���O���~���O�Ń�������Ԃ��O���o�X�Ƀ}�b�s���O����Ă�ƁA
�A�N�Z�X���Ԃ��������o�O�A�Ƃ����������Ɍq�����Ă����ł��B
>>439
gcc �̃R�[�h����ёւ��邾���ŏI���悤�ȗ\���B
>>453
�������Č��g�ݍ��݉����Bvolatile�̈Ӗ����炢�m���Ă�B
�ł��A�Ђ���Ƃ�����Aregister volatile vector unsigned va; �Ƃ���������Ava���K����
���W�X�^�ɌŒ�Ń}�b�s���O����Ă���Ȃ����ȂƎv���Ď������Ă݂����Ȃ�͔̂��邾��B
�������Č��g�ݍ��݉����Bvolatile�̈Ӗ����炢�m���Ă�B
�ł��A�Ђ���Ƃ�����Aregister volatile vector unsigned va; �Ƃ���������Ava���K����
���W�X�^�ɌŒ�Ń}�b�s���O����Ă���Ȃ����ȂƎv���Ď������Ă݂����Ȃ�͔̂��邾��B
455 �F227 ��eZQcaIaFJs �F2009/01/16(��) 22:16:02
>>454
���̓��̃v���̕��ł������B����͎��炢�����܂����B
> va���K���ȃ��W�X�^�ɌŒ�Ń}�b�s���O����Ă���Ȃ�����
���n�b�L���O���D���ȃQ�[����������ƌ����āA���荞�݂���
���C���X���b�h�̃��W�X�^����悤�Ȏ��͂�������Ɩ����Ȃ��c�B
���̓��̃v���̕��ł������B����͎��炢�����܂����B
> va���K���ȃ��W�X�^�ɌŒ�Ń}�b�s���O����Ă���Ȃ�����
���n�b�L���O���D���ȃQ�[����������ƌ����āA���荞�݂���
���C���X���b�h�̃��W�X�^����悤�Ȏ��͂�������Ɩ����Ȃ��c�B
456 �F,,�E�L�́M�E,,�j��-�������F2009/01/16(��) 22:49:32
SPU��ABI�d�l���ǂ�ł݂�Ɩʔ����ˁB
vector�^�������o�Ɏ��\���̂��A���W�X�^�{���ɗ]�T��������背�W�X�^��ɓW�J�ł���B
����ɂ���ĕ����̕Ԓl�������Ƃ��ł���B
SSE(VC++)���ƍ\���̂�Ԓl�ɂ���Ɩ������ŃX�^�b�N�Ԃ��ɂȂ��Ă��悤�ȁB
vector�^�������o�Ɏ��\���̂��A���W�X�^�{���ɗ]�T��������背�W�X�^��ɓW�J�ł���B
����ɂ���ĕ����̕Ԓl�������Ƃ��ł���B
SSE(VC++)���ƍ\���̂�Ԓl�ɂ���Ɩ������ŃX�^�b�N�Ԃ��ɂȂ��Ă��悤�ȁB
457 �F�f�t�H���g�̖����������F2009/01/17(�y) 02:14:37
������������ȂɊy�������̂��Ƃ͒m��Ȃ������B
�ǂ�ǂ��Ȃ��Ă����͉̂������ˁB
�ǂ�ǂ��Ȃ��Ă����͉̂������ˁB
458 �F227 ��eZQcaIaFJs �F2009/01/17(�y) 02:31:13
�Ȃ�l�܂�̗\��orz
mt_mine.c:93: internal compiler error: Segmentation fault
Please submit a full bug report,
with preprocessed source if appropriate.
See <http://gcc.gnu.org/bugs.html> for instructions.
make: *** [mt_mine.o] Error 1
mt_mine.c:93: internal compiler error: Segmentation fault
Please submit a full bug report,
with preprocessed source if appropriate.
See <http://gcc.gnu.org/bugs.html> for instructions.
make: *** [mt_mine.o] Error 1
459 �F227 ��eZQcaIaFJs �F2009/01/17(�y) 03:57:00
�g���A�Z���u���������Ă����ۂ������ł��B���W�X�^�̑Ҕ��܂Ŏ蓮�ł���
���v�ɂȂ�̂��Ȃ��c�H
���v�ɂȂ�̂��Ȃ��c�H
460 �F,,�E�L�́M�E,,�j��-�������F2009/01/17(�y) 14:30:48
�܂��Ƀ`�L�����[�X���ȁB
���ɓI�ɂ͗����̃p�C�v�߂���܂ł��낱��B
���ɓI�ɂ͗����̃p�C�v�߂���܂ł��낱��B
461 �Fsage�F2009/01/17(�y) 14:58:35
�c�q����͍��ǂ�ȃX�R�A�ł����H
���܂ł̐�������4.5M���Ă��肵�āc
���܂ł̐�������4.5M���Ă��肵�āc
462 �F,,�E�L�́M�E,,�j��-�������F2009/01/17(�y) 15:40:52
���낻��l����
463 �F�f�t�H���g�̖����������F2009/01/17(�y) 16:17:21
���܂Ŏd����HTC�ł��Ȃ��������獡����{�C�o��
ASM�֎~�����ւ̂��������̊ԂɎ���o���Ȃ������̂͋t�ɏ����g�Ȃ��
ASM�֎~�����ւ̂��������̊ԂɎ���o���Ȃ������̂͋t�ɏ����g�Ȃ��
464 �F�f�t�H���g�̖����������F2009/01/17(�y) 16:27:20
465 �F,,�E�L�́M�E,,�j��-�������F2009/01/17(�y) 16:31:54
���Ԃ��ԏ�̍��ڂ�5M���炢�o����Ώ��D���_����Ǝv����
�D���͖������낤���ǂˁB
�D���͖������낤���ǂˁB
>>465
SUGEEEEEEEEEE���M�����ǎ����͂ǂꂭ�炢�܂ōs�������Ȃ́H
�������D������ł��Ȃ������牽���Ă����́H
�܂������7M��̂Ő���t������W�Ȃ����ǁB�B�B
SUGEEEEEEEEEE���M�����ǎ����͂ǂꂭ�炢�܂ōs�������Ȃ́H
�������D������ł��Ȃ������牽���Ă����́H
�܂������7M��̂Ő���t������W�Ȃ����ǁB�B�B
>>465
�܂�A�������5M�����Ƃ�
�܂�A�������5M�����Ƃ�
468 �F,,�E�L�́M�E,,�j��-�������F2009/01/17(�y) 19:19:57
��������͂ǂ�����
���Ȃ��Ƃ��ׂ����`���[���ł̑Ό��Ɏ������߂Ώ��Ă鎩�M������E�E�E��������Ȃ���
���Ȃ��Ƃ��ׂ����`���[���ł̑Ό��Ɏ������߂Ώ��Ă鎩�M������E�E�E��������Ȃ���
469 �F�f�t�H���g�̖����������F2009/01/17(�y) 20:54:41
60�{�z������ł��ˁB�킩��܂��B
������̗D���͂������莖���Ȃ̂��B�B�B
471 �F227 ��eZQcaIaFJs �F2009/01/18(��) 00:43:53
�C�����C���A�Z���u������g���Ă�>>389�ɏ��ĂȂ��Ƃ�������orz
��������A�Z���u���G���Ă݂āAgcc43�̐������������܂����B
��������A�Z���u���G���Ă݂āAgcc43�̐������������܂����B
�A�C�f�A�o�����тɃK���K�������Ȃ��Ă������ƈ���āA5M�߂��ɂ��ǂ蒅����
��s�ɂȂ��Ă����ȁB
1%�����̒����͓����o���Ē�o���鎞�������B
���n�]�ł́A1�ʂ�����ŁA2�ʂ͉���>>227�̑Ό����B
�`�L���Ȃ̂ʼn���ticks���͏����Ȃ��B
��s�ɂȂ��Ă����ȁB
1%�����̒����͓����o���Ē�o���鎞�������B
���n�]�ł́A1�ʂ�����ŁA2�ʂ͉���>>227�̑Ό����B
�`�L���Ȃ̂ʼn���ticks���͏����Ȃ��B
473 �F227 ��eZQcaIaFJs �F2009/01/18(��) 01:13:21
474 �F�f�t�H���g�̖����������F2009/01/18(��) 04:12:17
�D���Ɏg���Ă������W�X�^���ĉ��ԁ`���Ԃ�����
�ȂR���p�C�����\�Ă�Ƃ��Ƃ��������C��������ǂǂ̎����������̂��Y��Ă��܂���
�ȂR���p�C�����\�Ă�Ƃ��Ƃ��������C��������ǂǂ̎����������̂��Y��Ă��܂���
475 �F�f�t�H���g�̖����������F2009/01/18(��) 05:59:54
>>474
ttp://cell.scei.co.jp/j_download.html
�uSPU Application Binary Interface Specification�v�� �u2.2.1 ���W�X�^�v(���{�ꂾ�� P8) �̕\
ttp://cell.scei.co.jp/j_download.html
�uSPU Application Binary Interface Specification�v�� �u2.2.1 ���W�X�^�v(���{�ꂾ�� P8) �̕\
476 �F�f�t�H���g�̖����������F2009/01/18(��) 06:08:38
>>475
���肪��
���ʂ�R80�`���g���Ă�
�Ȃ��ʂɓ����Ă邯�ǂ��܂��܂Ȃ̂��R���p�C�����ޔ����Ă���Ă�̂��c
�ł��邾��R10�`79�ʂ��g���l�ɂ��邩��
���肪��
���ʂ�R80�`���g���Ă�
�Ȃ��ʂɓ����Ă邯�ǂ��܂��܂Ȃ̂��R���p�C�����ޔ����Ă���Ă�̂��c
�ł��邾��R10�`79�ʂ��g���l�ɂ��邩��
>>476
�g���C�����C���A�Z���u���\���������Ɨǂ���B
�R���p�C���ɂǂ̃��W�X�^�g����������ƁA�ϐ����蓖�Ă����Ԃ�Ȃ��悤��
���Ă��ꂽ��A�K�v�Ȃ烌�W�X�^�ޔ�������Ă����B
�g���C�����C���A�Z���u���\���������Ɨǂ���B
�R���p�C���ɂǂ̃��W�X�^�g����������ƁA�ϐ����蓖�Ă����Ԃ�Ȃ��悤��
���Ă��ꂽ��A�K�v�Ȃ烌�W�X�^�ޔ�������Ă����B
478 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 12:15:37
���������B
���ɂ͖����B
���ɂ͖����B
479 �F227 ��eZQcaIaFJs �F2009/01/18(��) 18:13:28
nop/lnop ������Ƒ����Ȃ��B���W�X�^�̈ˑ��W�͖��������₵�A
LS�̑ш搧���Ƃ������B��d�l�ł��L��̂��Ȃ��c�B
LS�̑ш搧���Ƃ������B��d�l�ł��L��̂��Ȃ��c�B
480 �F�f�t�H���g�̖����������F2009/01/18(��) 18:39:43
�B��d�l�Ȃ���Ȃ���B�����ƕ����܂��傤�B
481 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 19:01:48
����ȏ㐫�\�L���ɂ�Odd�p�C�v�̖��ߐ��팸������@��{�C�ōl���Ȃ��Ƃ����Ȃ��Ȃ����B
���g�b�v��ڎw���Ă�l�͂ǂ��������킩���ȁH
���g�b�v��ڎw���Ă�l�͂ǂ��������킩���ȁH
>>481
��������
��������
>>479
dual-issue�Ƃ�����Ȃ��H
dual-issue�Ƃ�����Ȃ��H
484 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 19:29:49
��͂���B����Ȃ��̂̓������B
485 �F227 ��eZQcaIaFJs �F2009/01/18(��) 19:49:31
>>483
������ƈႤ���ۂ��Bnop+lnop������ƂP�N���b�N�̃��X�ōςނ��̂́A
��������Ȃ��ƂQ�N���b�N�X�g�[�����Ă�悤�Ȋ����ł��B
>>481
���̂Ƃ��� Odd �]���Ă��₯�ǂȂ��c�B�܂������E�˔j�����Ƃ�orz
������ƈႤ���ۂ��Bnop+lnop������ƂP�N���b�N�̃��X�ōςނ��̂́A
��������Ȃ��ƂQ�N���b�N�X�g�[�����Ă�悤�Ȋ����ł��B
>>481
���̂Ƃ��� Odd �]���Ă��₯�ǂȂ��c�B�܂������E�˔j�����Ƃ�orz
486 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 19:51:25
���[�v�㔼�̂ǂ��ł������悤�ȂƂ��낵���]���ĂȂ��B
�����ɂȂ������ꂽ��t�ɐ��\�ቺ���邵�A���낻��ʂ̕��j���K�v���ۂ�
���Ӓn�ł�C�ł���邼
�����ɂȂ������ꂽ��t�ɐ��\�ቺ���邵�A���낻��ʂ̕��j���K�v���ۂ�
���Ӓn�ł�C�ł���邼
487 �F�f�t�H���g�̖����������F2009/01/18(��) 20:04:38
>>485
�q���g�~�����Hw
�q���g�~�����Hw
488 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:12:08
���Ȃ猾�����ǁA>>394�͌��E�ł͂Ȃ�
���`�F�N���Ƃ��������Ђ��܂Ƃ߂�SPU���߂̃��C�e���V�ꗗ��������œ\���Ă����܂��ˁB
�Ȃ�ł��������킩��₷�������������ɖ����̂��^��B
http://www.insomniacgames.com/tech/articles/0907/spu_instruction_cheat_sheet.php
���`�F�N���Ƃ��������Ђ��܂Ƃ߂�SPU���߂̃��C�e���V�ꗗ��������œ\���Ă����܂��ˁB
�Ȃ�ł��������킩��₷�������������ɖ����̂��^��B
http://www.insomniacgames.com/tech/articles/0907/spu_instruction_cheat_sheet.php
489 �F�f�t�H���g�̖����������F2009/01/18(��) 20:15:02
�܁[���A�t�J�V���n�܂�����c �Ȃ�Ŗق��Ă��Ȃ��낤�B
490 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:24:07
�ʂɐM���Ȃ��Ă��������A����������Ȃ���D���������A���ꂾ���̘b���B
������͂܂��p�C�v���C���ɗ]�T���������Ƃ��̃X�R�A�B
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294032967 ticks
MINE: sum=3c927c56, 4967580 ticks
ORIGNAL: sum=2e987a4d, 424158953 ticks
MINE: sum=2e987a4d, 7165990 ticks
ORIGNAL: sum=ef1b6aef, 312105208 ticks
MINE: sum=ef1b6aef, 5272912 ticks
ORIGNAL: sum=eedd2516, 290057341 ticks
MINE: sum=eedd2516, 4900408 ticks
ORIGNAL: sum=f7e967a8, 14366933 ticks
MINE: sum=f7e967a8, 242775 ticks
ORIGNAL: sum=1f37a7db, 214217873 ticks
MINE: sum=1f37a7db, 3619145 ticks
ORIGNAL: sum=c7d41f36, 294966530 ticks
MINE: sum=c7d41f36, 4983349 ticks
ORIGNAL: sum=aa9d2e9f, 259567100 ticks
MINE: sum=aa9d2e9f, 4385307 ticks
ORIGNAL: sum=8abd398a, 250846200 ticks
MINE: sum=8abd398a, 4237963 ticks
ORIGNAL: sum=a374bd58, 6110333 ticks
MINE: sum=a374bd58, 103279 ticks
������͂܂��p�C�v���C���ɗ]�T���������Ƃ��̃X�R�A�B
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294032967 ticks
MINE: sum=3c927c56, 4967580 ticks
ORIGNAL: sum=2e987a4d, 424158953 ticks
MINE: sum=2e987a4d, 7165990 ticks
ORIGNAL: sum=ef1b6aef, 312105208 ticks
MINE: sum=ef1b6aef, 5272912 ticks
ORIGNAL: sum=eedd2516, 290057341 ticks
MINE: sum=eedd2516, 4900408 ticks
ORIGNAL: sum=f7e967a8, 14366933 ticks
MINE: sum=f7e967a8, 242775 ticks
ORIGNAL: sum=1f37a7db, 214217873 ticks
MINE: sum=1f37a7db, 3619145 ticks
ORIGNAL: sum=c7d41f36, 294966530 ticks
MINE: sum=c7d41f36, 4983349 ticks
ORIGNAL: sum=aa9d2e9f, 259567100 ticks
MINE: sum=aa9d2e9f, 4385307 ticks
ORIGNAL: sum=8abd398a, 250846200 ticks
MINE: sum=8abd398a, 4237963 ticks
ORIGNAL: sum=a374bd58, 6110333 ticks
MINE: sum=a374bd58, 103279 ticks
491 �F�f�t�H���g�̖����������F2009/01/18(��) 20:30:40
����ȂƂ��ɏ��o���܂���z�ɂ��D���͂Ȃ��Ǝv��w
492 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:32:00
���낤�ˁB�p�S�[�������ɌÂ����������o���Ă�B
493 �F�f�t�H���g�̖����������F2009/01/18(��) 20:32:48
����ő��v�Ǝv���Ă��̒��̊^�͕�����Ǝv��w
494 �F�f�t�H���g�̖����������F2009/01/18(��) 20:33:22
���O��Ђ��݂݂͂��Ƃ��Ȃ���
495 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:33:44
���������N�ɕ�������āH
496 �F227 ��eZQcaIaFJs �F2009/01/18(��) 20:36:40
497 �F�f�t�H���g�̖����������F2009/01/18(��) 20:36:47
�䁁2ch
�^���c�q
�^���c�q
498 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:38:49
�����Č����A����͏o�����[�X���B
499 �F�f�t�H���g�̖����������F2009/01/18(��) 20:43:09
���������̌�����ł��ˁB�킩��܂��B
500 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:45:33
��H�����������������������ǂ�����Ċm�F����C���H������������
���Ⴀ�\�z�������Ă������B
�D���҂́A13clk/qword���A��B
���Ⴀ�\�z�������Ă������B
�D���҂́A13clk/qword���A��B
501 �F�f�t�H���g�̖����������F2009/01/18(��) 20:46:17
�܂������
502 �F�f�t�H���g�̖����������F2009/01/18(��) 20:51:00
2�l�Q�����D�����Ă���܂��c�q����w
503 �F�f�t�H���g�̖����������F2009/01/18(��) 20:52:47
�ȂE�E�E�C���p�N�g�Ɍ�����\�z���ȁE�E�E
504 �F227 ��eZQcaIaFJs �F2009/01/18(��) 20:53:02
505 �F�f�t�H���g�̖����������F2009/01/18(��) 20:54:00
2�l�Q�����D��������A�������O���Ж��o���悤��fixstars�ɓ��������悤��w
506 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 20:55:19
>>504
�����ق��̖��߂ЂƂ��炷�̂ɁA���Ȃ��ق��̖��߂�3���炢������ߎS�Ȏ��ԂɊׂ��Ă܂����B
�����ق��̖��߂ЂƂ��炷�̂ɁA���Ȃ��ق��̖��߂�3���炢������ߎS�Ȏ��ԂɊׂ��Ă܂����B
507 �F�f�t�H���g�̖����������F2009/01/18(��) 21:01:59
���Ă��A2�l�Q���̕Њ��ꂪfixstars�̊W�҂����m��Ȃ��ˁH
>>507
fixstars �W�҂͎Q���ł��Ȃ���B
���̐l�́A�d���̕Ў�Ԃɉ���҂�葬���R�[�h��ڎw���Ď������B
���Ԃ�܂�5M��ĂȂ��B
���̃X���݂ăK�N�u�����Ă�悗
fixstars �W�҂͎Q���ł��Ȃ���B
���̐l�́A�d���̕Ў�Ԃɉ���҂�葬���R�[�h��ڎw���Ď������B
���Ԃ�܂�5M��ĂȂ��B
���̃X���݂ăK�N�u�����Ă�悗
510 �F�f�t�H���g�̖����������F2009/01/18(��) 21:14:45
�Q���ł��Ȃ�����A�Q�����ĂȂ������ؖ����Ȃ���_������B
���Ă��Ƃ́A�`�[���̏ꍇ���������O���Ж��o���Ȃ��ƁB
���Ă��Ƃ́A�`�[���̏ꍇ���������O���Ж��o���Ȃ��ƁB
511 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 21:45:34
512 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 21:48:52
���[�ށE�E�E���͂��l�܂肩
>>511
�ʂɔ�W�ґ����ĎQ�킵�Ă�Ƃ����[��[��Ȃ��āA�����ɗV�т�
���킵�Ă�炵����B
Cell�̃v���t�F�b�V���i���Ƃ��Ẵv���C�h�����������V�т�w
�}�C�~�N��fixstars�Ј��Ɂu�Г���5M�����z����H�v���Đu���Ă݂���H
�ʂɔ�W�ґ����ĎQ�킵�Ă�Ƃ����[��[��Ȃ��āA�����ɗV�т�
���킵�Ă�炵����B
Cell�̃v���t�F�b�V���i���Ƃ��Ẵv���C�h�����������V�т�w
�}�C�~�N��fixstars�Ј��Ɂu�Г���5M�����z����H�v���Đu���Ă݂���H
514 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 22:08:32
�܂��v�������ɕ�����킯�ɂ͂����낤���Ȃ�
����A������4.8M���Ă�̂��B�X�Q�[�I
516 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 22:31:34
�����͋����Ƃ��낶��Ȃ�
�܂���͂����ˁH���ƂȂ��B
�܂���͂����ˁH���ƂȂ��B
517 �F227 ��eZQcaIaFJs �F2009/01/18(��) 22:52:28
518 �F,,�E�L�́M�E,,�j��-�������F2009/01/18(��) 22:56:16
���₳��s�[���`
519 �F227 ��eZQcaIaFJs �F2009/01/18(��) 23:02:30
>>518
�����������B14cycle�̎��͂P�ʂƂ̍���10000tick�s�����s���Ȃ����̏��܂�
�l�߂�ꂽ���ǁA�����܂ŗ���Ƃ������Ɏ��M�����Ȃ��c�B
�����������B14cycle�̎��͂P�ʂƂ̍���10000tick�s�����s���Ȃ����̏��܂�
�l�߂�ꂽ���ǁA�����܂ŗ���Ƃ������Ɏ��M�����Ȃ��c�B
520 �F�f�t�H���g�̖����������F2009/01/19(��) 00:24:58
>>479
���͍ڂ��Ă�Ƃ��돭�Ȃ�����8�T�C�N���ȏ�ʘA���Ń��[�h/�X�g�A���悤�Ƃ���ƃX�g�[�������L��������
�����ł�������Ԃ�������odd�ł���ȊO�̎����邩�����Ă��܂������������Ȃ�����Ƃ�
���������N�����ƂƂ��C�Â������ƂȂ�Ō����Ȏ��͊o���ĂȂ�����
���͍ڂ��Ă�Ƃ��돭�Ȃ�����8�T�C�N���ȏ�ʘA���Ń��[�h/�X�g�A���悤�Ƃ���ƃX�g�[�������L��������
�����ł�������Ԃ�������odd�ł���ȊO�̎����邩�����Ă��܂������������Ȃ�����Ƃ�
���������N�����ƂƂ��C�Â������ƂȂ�Ō����Ȏ��͊o���ĂȂ�����
521 �F�f�t�H���g�̖����������F2009/01/19(��) 00:52:56
���̐����͂W�T�C�N�����͒�����B�ł� 227 �͂���� load/store �͂��ĂȂ��Ǝv���B
523 �F�f�t�H���g�̖����������F2009/01/19(��) 01:10:02
>>520
SPE��LS�̓|�[�g����������̂ŁADMA��load,store���p������ƁA���߃t�F�b�`���ł��Ȃ��Ȃ�ꍇ������B
Handbook �� 3.1.1.3 �ɁA�D��x�́A DMA > load,store > ���߃t�F�b�` �Ə����Ă���B
���߃t�F�b�`���K�v�ȏꍇ�́Ahbrp���߂���ƗD��x���グ����B
�ڍׂ́A
ttp://cell.scei.co.jp/j_download.html
�u�v���Z�b�T�ɂ����閽�ߌ͊��ɋN������ Synergistic Processor Element�̖����X�g�[���̖h�~�ɂ��āv
������ɏ����Ă���C�����邪�A�ǂ�ł��悭�킩���B
SPE��LS�̓|�[�g����������̂ŁADMA��load,store���p������ƁA���߃t�F�b�`���ł��Ȃ��Ȃ�ꍇ������B
Handbook �� 3.1.1.3 �ɁA�D��x�́A DMA > load,store > ���߃t�F�b�` �Ə����Ă���B
���߃t�F�b�`���K�v�ȏꍇ�́Ahbrp���߂���ƗD��x���グ����B
�ڍׂ́A
ttp://cell.scei.co.jp/j_download.html
�u�v���Z�b�T�ɂ����閽�ߌ͊��ɋN������ Synergistic Processor Element�̖����X�g�[���̖h�~�ɂ��āv
������ɏ����Ă���C�����邪�A�ǂ�ł��悭�킩���B
524 �F227 ��eZQcaIaFJs �F2009/01/19(��) 01:16:02
�Ƃ肠�����l�܂��Ă݂����ǁAasmvis ���Ă��ǂ��ŃX�g�[�����N���Ă�̂�
������Ȃ���ԁB�Ђ��[���� nop/lnop ����Č�����̂����corz
>>521
�J����16��20�Ƃ݂��B���q�ɏ���ă��[�v�W�J���܂����Ă�����������A
�m��Ȃ��ԂɃ��~�b�g��ǂ��Ă��܂����̂�������܂���ˁB
������Ȃ���ԁB�Ђ��[���� nop/lnop ����Č�����̂����corz
>>521
�J����16��20�Ƃ݂��B���q�ɏ���ă��[�v�W�J���܂����Ă�����������A
�m��Ȃ��ԂɃ��~�b�g��ǂ��Ă��܂����̂�������܂���ˁB
>>524
����q���g���߂̃��C�e���V��15cycle������A����ȉ��̉\���������B
12cycle=24���߂�8cycle=16���ߕ��ŃI�`���Ȃ����ȁB
����q���g���߂̃��C�e���V��15cycle������A����ȉ��̉\���������B
12cycle=24���߂�8cycle=16���ߕ��ŃI�`���Ȃ����ȁB
526 �F�f�t�H���g�̖����������F2009/01/19(��) 01:42:57
>>523
DMA �p�� load/store & ifetch �p�̂Q�|�[�g��������K�X�B
����� DMA �W�Ȃ����ǁADMA �͑҂������Ȃ�����ˁB
�ŁAload/store �� ifetch �Ń|�[�g���L���Ă邩��Aifetch ��
�X�g�[�����Ȃ��悤�ɁAload/store �͑������Ⴞ�߂�A�ƁB
DMA �p�� load/store & ifetch �p�̂Q�|�[�g��������K�X�B
����� DMA �W�Ȃ����ǁADMA �͑҂������Ȃ�����ˁB
�ŁAload/store �� ifetch �Ń|�[�g���L���Ă邩��Aifetch ��
�X�g�[�����Ȃ��悤�ɁAload/store �͑������Ⴞ�߂�A�ƁB
527 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 08:09:41
��̃f�`���[���i�j�Ő��\���P���ꂽ�����ɂȂ�ȁB
������������
������������
528 �F�f�t�H���g�̖����������F2009/01/19(��) 12:42:42
�w���ł���Ă邯��10�{����L�c��
�A�Z���u�����߂ƕ����P���߂őΉ����Ă���g�ݍ��ݖ��߂�
�ǂ̒��x�R���p�C���ɂ��œK���̉e������́H
��b�I�Ȓm�������|�I�ɑ���Ă��Ȃ������orz
�A�Z���u�����߂ƕ����P���߂őΉ����Ă���g�ݍ��ݖ��߂�
�ǂ̒��x�R���p�C���ɂ��œK���̉e������́H
��b�I�Ȓm�������|�I�ɑ���Ă��Ȃ������orz
529 �F,,�E�L�́M�E,,�j��[���̓J���[]�F2009/01/19(��) 12:44:00
�v�����128�o�C�g���̖��߁i32���߁j�����Ȃ��Ԃ�8�T�C�N���ȏ�
LS�Ƀ��[�h�E�X�g�A���Ȃ��^�C�~���O���m�ۂ�������炵���B
���S��Even/Odd���������s����Ă�ꍇ�̓��[�h�E�X�g�A��1�o�b�t�@������8���߂��z����ƃA�E�g�B
2���ߓ������s�ł��Ȃ��T�C�N�����������肷���1�o�b�t�@���g������T�C�N������17�ȏ�ɉ��т�̂ŁA���̕��͉��т�B
���Ƃ���Even��20���߁A���[�h�E�X�g�A12���߂�32���߂ł��A�o�b�t�@�̃t�B���ɕK�v��8�T�C�N�����m�ۂł���B
LS�Ƀ��[�h�E�X�g�A���Ȃ��^�C�~���O���m�ۂ�������炵���B
���S��Even/Odd���������s����Ă�ꍇ�̓��[�h�E�X�g�A��1�o�b�t�@������8���߂��z����ƃA�E�g�B
2���ߓ������s�ł��Ȃ��T�C�N�����������肷���1�o�b�t�@���g������T�C�N������17�ȏ�ɉ��т�̂ŁA���̕��͉��т�B
���Ƃ���Even��20���߁A���[�h�E�X�g�A12���߂�32���߂ł��A�o�b�t�@�̃t�B���ɕK�v��8�T�C�N�����m�ۂł���B
530 �F�f�t�H���g�̖����������F2009/01/19(��) 14:13:31
>>529
Handbook �ɂ���
�uSPU instruction prefetches are 128 bytes per cycle.�v
�炵���̂ŁA32���ߒ���1�T�C�N������������͂��B
Handbook �ɂ���
�uSPU instruction prefetches are 128 bytes per cycle.�v
�炵���̂ŁA32���ߒ���1�T�C�N������������͂��B
531 �F�f�t�H���g�̖����������F2009/01/19(��) 14:14:19
>>528
���ʂ�������Ȃ�o�J�����ɁuSIMD��MT�v����������K�v���Ȃ�
���ʂ�������Ȃ�o�J�����ɁuSIMD��MT�v����������K�v���Ȃ�
532 �F�f�t�H���g�̖����������F2009/01/19(��) 14:17:58
>>530
bit����Ȃ���byte����
bit����Ȃ���byte����
533 �F�f�t�H���g�̖����������F2009/01/19(��) 14:30:33
����������DMA�Ɩ��߃t�F�b�`�������o�X�Ȃ�Ă��Ƃ������Ă���悤��
534 �F�f�t�H���g�̖����������F2009/01/19(��) 15:24:33
535 �F�f�t�H���g�̖����������F2009/01/19(��) 15:45:38
536 �F�f�t�H���g�̖����������F2009/01/19(��) 16:12:20
>>530,532
LS �̓ǂݏ����P�ʂ� 128byte ������ˁA�������B
�����A�ǂݍ��ݎ��̂� 1cycle �ŏI����Ă��ASPU �� pipeline ��
���\�[���āA15cycle ���炢�O�� fetch ����ĂȂ��ƃ_���Ȃ͂��B
���ɂ� ifetch �N�������Ƃ��F�X�����B�ǂ����Ɏ��������
�v�����ǁA�����N�Ƃ�����Ȃ��ł݂�Ȏ��͂Ŋ撣�낤����
LS �̓ǂݏ����P�ʂ� 128byte ������ˁA�������B
�����A�ǂݍ��ݎ��̂� 1cycle �ŏI����Ă��ASPU �� pipeline ��
���\�[���āA15cycle ���炢�O�� fetch ����ĂȂ��ƃ_���Ȃ͂��B
���ɂ� ifetch �N�������Ƃ��F�X�����B�ǂ����Ɏ��������
�v�����ǁA�����N�Ƃ�����Ȃ��ł݂�Ȏ��͂Ŋ撣�낤����
537 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 18:04:15
{kind=link}
538 �F�f�t�H���g�̖����������F2009/01/19(��) 18:47:38
���A������O�ł́H
539 �F�f�t�H���g�̖����������F2009/01/19(��) 19:50:30
�����Q�����������ǁA�ǂ����Ȃ�1��2�ʂ𑈂������B
�ł��c�q������݂����ȉɐl����Ȃ����珟�Ă�킯���Ȃ��̂ō��݂̌����B
�ł��c�q������݂����ȉɐl����Ȃ����珟�Ă�킯���Ȃ��̂ō��݂̌����B
540 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 19:51:04
�Ђ܂���Ƃ͂��ꂢ��
541 �F�f�t�H���g�̖����������F2009/01/19(��) 20:30:21
>>531
����l���Ă���ǎv�����Ȃ����
�A���S���Y�������̂܂g�����߂̓���ւ��ƕ��ёւ���15�T�C�N���܂ł͗��ꂽ����
���������ጄ�Ԃ͎c���Ă�̂Ɉˑ����ŋl�߂��Ȃ��Ƃ��낪�����Ă��������Ȃ�
�����ɂ���D����₳���͎Љ�l���傾�ƐM���Ă�
����l���Ă���ǎv�����Ȃ����
�A���S���Y�������̂܂g�����߂̓���ւ��ƕ��ёւ���15�T�C�N���܂ł͗��ꂽ����
���������ጄ�Ԃ͎c���Ă�̂Ɉˑ����ŋl�߂��Ȃ��Ƃ��낪�����Ă��������Ȃ�
�����ɂ���D����₳���͎Љ�l���傾�ƐM���Ă�
542 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 21:46:33
__builtin_expect()�g���Ă��Ӗ��ˁ[
���x���Ȃ�
���x���Ȃ�
543 �F�f�t�H���g�̖����������F2009/01/19(��) 21:49:36
�I�I�I���܂܂Ŏg���ĂȂ������I�I�I��
544 �F�f�t�H���g�̖����������F2009/01/19(��) 21:50:14
������H
__builtin_expect�ł�����Ⴛ��Ȏ���o�Ă��邾��B
__builtin_expect�ł�����Ⴛ��Ȏ���o�Ă��邾��B
545 �Fv127251.ppp.asahi-net.or.jp �F2009/01/19(��) 21:54:45
�������[
546 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 21:59:07
�ӂ�[����[�˂�����H
547 �F227 ��eZQcaIaFJs �F2009/01/19(��) 22:00:15
���[�v�����̍œK���͓����o���āA�O���̐��`��ƂɈڂ�Ƃ��܂����B
�m��Ȃ��ԂɃ��A�����Q���}�C���X�g�[���Ƃ����������ꒃ�Ȏ���
�Ȃ��Ă���ŁA�������������X�ɂ��Ƃ��Ȃ��ƃ}�W�Ń��o�C�����B�B�B
�m��Ȃ��ԂɃ��A�����Q���}�C���X�g�[���Ƃ����������ꒃ�Ȏ���
�Ȃ��Ă���ŁA�������������X�ɂ��Ƃ��Ȃ��ƃ}�W�Ń��o�C�����B�B�B
548 �F�f�t�H���g�̖����������F2009/01/19(��) 22:00:49
�Ȃ�ŁA����ȂƂ���ɐߌ�������́H
549 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 22:03:18
���̓��L�̓��A��GateKeeper���悭�ǂ�ł邯�ǂ�
550 �F227 ��eZQcaIaFJs �F2009/01/19(��) 22:12:55
���X�ɂȂ���>>389���Č��ł��Ă���orz �������������Ə��Ă�C�����Ȃ��c�B
551 �F,,�E�L�́M�E,,�j��-�������F2009/01/19(��) 23:17:44
15,000tick�팸����
������Ƃ���܂ł�邩
������Ƃ���܂ł�邩
552 �F227 ��eZQcaIaFJs �F2009/01/20(��) 00:57:49
�Ƃ肠�����A>>389�̈����O�܂ł��ǂ蒅�����̂͗ǂ���₯�ǁA������
�Ȃ��Ċg���A�Z���u�����g�����ɂȂ�Ȃ�(>>458)�����n���f�ɂȂ��Ă���
�Ƃ͎v��Ȃ�����orz
>>551
�܂��R���قNJy���߂����ł��悗
�Ȃ��Ċg���A�Z���u�����g�����ɂȂ�Ȃ�(>>458)�����n���f�ɂȂ��Ă���
�Ƃ͎v��Ȃ�����orz
>>551
�܂��R���قNJy���߂����ł��悗
553 �F227 ��eZQcaIaFJs �F2009/01/20(��) 01:35:27
554 �F�f�t�H���g�̖����������F2009/01/20(��) 01:38:13
>>517 �͉��������́Hw
555 �F227 ��eZQcaIaFJs �F2009/01/20(��) 01:56:24
556 �F�f�t�H���g�̖����������F2009/01/20(��) 02:17:10
557 �F�f�t�H���g�̖����������F2009/01/20(��) 11:58:58
�f�l�����ǎQ��
���ߏ��������Ƃ��A�Ȃ��Ȃ���肭�����Ȃ����NJy������R����
���ߏ��������Ƃ��A�Ȃ��Ȃ���肭�����Ȃ����NJy������R����
558 �F�f�t�H���g�̖����������F2009/01/20(��) 16:16:18
>>557
���ߎ��ȏ�������(self modification)���Ă�́H
�d�l���ɏ����Ă��邯�ǁA���̏ꍇ�� sync ���Ȃ���
���߂����炠��ܑ����Ȃ�Ȃ��C������Ȃ��c
���ߎ��ȏ�������(self modification)���Ă�́H
�d�l���ɏ����Ă��邯�ǁA���̏ꍇ�� sync ���Ȃ���
���߂����炠��ܑ����Ȃ�Ȃ��C������Ȃ��c
559 �F,,�E�L�́M�E,,�j��-�������F2009/01/20(��) 17:53:14
�yOdd�́z���ߐ��팸�@�v������
560 �F�f�t�H���g�̖����������F2009/01/20(��) 19:24:19
�����߂��炢�̏��Ŋ撣���Ă�낤�H
�����͂�������ȏ����C�����Ȃ����ǁc
�����͂�������ȏ����C�����Ȃ����ǁc
�����̂���4M�肻�����Ȃ�
����A�ł�4.7M�̕ǂ͍��܂ł̕ǂƔ�ׂĂ������L�c�C�ȁB
��o���܂Ŋ撣���Ă��������Ȃ��C�����Ă����B
��o���܂Ŋ撣���Ă��������Ȃ��C�����Ă����B
563 �F,,�E�L�́M�E,,�j��-�������F2009/01/20(��) 20:45:21
�Ȃ�ł���4.7M�̕ǂ���
565 �F,,�E�L�́M�E,,�j��-�������F2009/01/20(��) 22:03:02
�t�ɒx���Ȃ���orz
566 �F�f�t�H���g�̖����������F2009/01/20(��) 22:08:50
���D���ł��Ȃ�������u���O���̕����ł悳�����Ȃ̂��ȁH
567 �F,,�E�L�́M�E,,�j��-�������F2009/01/20(��) 22:13:22
�Ȃ�ł�˂�
�t�ɗD�������Ⴄ�Ƃ��낢��܂������ƂȂ炠�邪
�t�ɗD�������Ⴄ�Ƃ��낢��܂������ƂȂ炠�邪
568 �F�f�t�H���g�̖����������F2009/01/20(��) 22:23:08
3M�̕ǂ��E�E�E�B�C�`�����蒼�����E�E�Eorz
569 �F�f�t�H���g�̖����������F2009/01/20(��) 22:30:49
16G���炢�������g������ł����Hw
>>568
3M���āA�A�A����Ɠ�����Ȃ牻�����X�R�A���ȁB
3M���āA�A�A����Ɠ�����Ȃ牻�����X�R�A���ȁB
571 �F227 ��eZQcaIaFJs �F2009/01/20(��) 23:29:48
572 �F,,�E�L�́M�E,,�j��-�������F2009/01/20(��) 23:34:44
30M�̊��Ⴂ�̗\��
573 �F227 ��eZQcaIaFJs �F2009/01/20(��) 23:59:18
���̊Ԃɂ� FAQ �X�V����Ă����
> �f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
> ����̏o��̎�|�ɔ�����̂ŕs�\�Ƃ��܂��B
> �f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
> ����̏o��̎�|�ɔ�����̂ŕs�\�Ƃ��܂��B
574 �F�f�t�H���g�̖����������F2009/01/21(��) 00:03:08
�s�\�ł͂Ȃ��Ǝv���B
575 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 00:06:04
�{���̝s��
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294422087 ticks
MINE: sum=3c927c56, 4694973 ticks
ORIGNAL: sum=2e987a4d, 424720276 ticks
MINE: sum=2e987a4d, 6772739 ticks
ORIGNAL: sum=ef1b6aef, 312518235 ticks
MINE: sum=ef1b6aef, 4983550 ticks
ORIGNAL: sum=eedd2516, 290441206 ticks
MINE: sum=eedd2516, 4631487 ticks
ORIGNAL: sum=f7e967a8, 14385949 ticks
MINE: sum=f7e967a8, 229457 ticks
ORIGNAL: sum=1f37a7db, 214501370 ticks
MINE: sum=1f37a7db, 3420537 ticks
ORIGNAL: sum=c7d41f36, 295356889 ticks
MINE: sum=c7d41f36, 4709875 ticks
ORIGNAL: sum=aa9d2e9f, 259910600 ticks
MINE: sum=aa9d2e9f, 4144655 ticks
ORIGNAL: sum=8abd398a, 251178167 ticks
MINE: sum=8abd398a, 4005396 ticks
ORIGNAL: sum=a374bd58, 6118425 ticks
MINE: sum=a374bd58, 97617 ticks
spu-gcc43 -std=gnu99 -O3 -g -c -o mt_mine.o mt_mine.c
spu-gcc43 -Wl,-Map,mt_kadai.map mt_kadai.o mt_mine.o mt19937ar.sep/mt19937ar.o -o mt_kadai
./mt_kadai
ORIGNAL: sum=3c927c56, 294422087 ticks
MINE: sum=3c927c56, 4694973 ticks
ORIGNAL: sum=2e987a4d, 424720276 ticks
MINE: sum=2e987a4d, 6772739 ticks
ORIGNAL: sum=ef1b6aef, 312518235 ticks
MINE: sum=ef1b6aef, 4983550 ticks
ORIGNAL: sum=eedd2516, 290441206 ticks
MINE: sum=eedd2516, 4631487 ticks
ORIGNAL: sum=f7e967a8, 14385949 ticks
MINE: sum=f7e967a8, 229457 ticks
ORIGNAL: sum=1f37a7db, 214501370 ticks
MINE: sum=1f37a7db, 3420537 ticks
ORIGNAL: sum=c7d41f36, 295356889 ticks
MINE: sum=c7d41f36, 4709875 ticks
ORIGNAL: sum=aa9d2e9f, 259910600 ticks
MINE: sum=aa9d2e9f, 4144655 ticks
ORIGNAL: sum=8abd398a, 251178167 ticks
MINE: sum=8abd398a, 4005396 ticks
ORIGNAL: sum=a374bd58, 6118425 ticks
MINE: sum=a374bd58, 97617 ticks
576 �F227 ��eZQcaIaFJs �F2009/01/21(��) 00:19:26
���������A����Ɛ������������o���B
�g���C�����C���A�Z���u���A���Ȃ��̓�����B
���W�X�^��������A�ǂ̃��W�X�^�����Ғl�ƈႤ�̂������B
�N�������̂�����Ȃ��A�Z���u���̃f�o�b�O���Ȃ��疽�ߍ����A
C����̏�ň�ł������̃A�C�f�A����������������Ό����I���B
�g���C�����C���A�Z���u���A���Ȃ��̓�����B
���W�X�^��������A�ǂ̃��W�X�^�����Ғl�ƈႤ�̂������B
�N�������̂�����Ȃ��A�Z���u���̃f�o�b�O���Ȃ��疽�ߍ����A
C����̏�ň�ł������̃A�C�f�A����������������Ό����I���B
579 �F�f�t�H���g�̖����������F2009/01/21(��) 01:05:57
���k�B
�ۑ�́AMT�̍œK���ł͂Ȃ��A���v�̌v�Z�̍œK���ȂȁB
��i�� tempering �� mt[] �ɉe����^���Ȃ��̂ŁAtempering ���
�l�����v�����ɁAtempering �O�́u�Ƃ���l�v���W�v����BGF(2)�̒��ŁB
����ƁAtempering (�����̑���)�͈��ōςށB
�����܂�����
�c�q�u�X�^�[�g���C���v���Ă���̂��Ƃ���H
���ɁA�u�Ƃ���l�v���W�v���邾���̖ړI�ł���� mt[] ���u�^�ʖڂɁv
�v�Z����K�v�͂Ȃ����āA���Ȃ�[�܂��B(���ɁA�[�܂��Čv�Z����
mt[] �� pmt[]�Ƃ���)
�ǂ̌v�Z���[�܂�邩�A���܌v�Z���Ă���Ƃ���B
����������������
�Ō�ɁAnum_rand % 624 �̒[���Ԃ���ǂ��v�Z���邩�Ŏ�l�܂�C���B
pmt[] ���� mt[] ���v�Z���������Ƃ���ƁAmt[] ���ŏ�����v�Z����
�̂Ƃ��܂�R�X�g���ς��Ȃ����@�����v�����Ȃ� orz
�������Amt19937ar.c �� mt[] �� LS ����T���Ă��܂������B
�܂��Anum_rand % 624 �ƂȂ��Ă��� mti ��T���āA�݂����� mt[]
���� pmt[] �����肷��B
�ǂ����ȁB
�ۑ�́AMT�̍œK���ł͂Ȃ��A���v�̌v�Z�̍œK���ȂȁB
��i�� tempering �� mt[] �ɉe����^���Ȃ��̂ŁAtempering ���
�l�����v�����ɁAtempering �O�́u�Ƃ���l�v���W�v����BGF(2)�̒��ŁB
����ƁAtempering (�����̑���)�͈��ōςށB
�����܂�����
�c�q�u�X�^�[�g���C���v���Ă���̂��Ƃ���H
���ɁA�u�Ƃ���l�v���W�v���邾���̖ړI�ł���� mt[] ���u�^�ʖڂɁv
�v�Z����K�v�͂Ȃ����āA���Ȃ�[�܂��B(���ɁA�[�܂��Čv�Z����
mt[] �� pmt[]�Ƃ���)
�ǂ̌v�Z���[�܂�邩�A���܌v�Z���Ă���Ƃ���B
����������������
�Ō�ɁAnum_rand % 624 �̒[���Ԃ���ǂ��v�Z���邩�Ŏ�l�܂�C���B
pmt[] ���� mt[] ���v�Z���������Ƃ���ƁAmt[] ���ŏ�����v�Z����
�̂Ƃ��܂�R�X�g���ς��Ȃ����@�����v�����Ȃ� orz
�������Amt19937ar.c �� mt[] �� LS ����T���Ă��܂������B
�܂��Anum_rand % 624 �ƂȂ��Ă��� mti ��T���āA�݂����� mt[]
���� pmt[] �����肷��B
�ǂ����ȁB
580 �F�f�t�H���g�̖����������F2009/01/21(��) 01:07:43
>>575
�l�Ԃ����W�X�^���Ǘ����邱�ƂȂ�Ċ��ɕs�\�ƋC�Â���B
�l�Ԃ����W�X�^���Ǘ����邱�ƂȂ�Ċ��ɕs�\�ƋC�Â���B
581 �F�f�t�H���g�̖����������F2009/01/21(��) 01:12:12
>>579
���[���AGF(2) �Ƃ��o���Ă���Ȃ�w
�c�q�́u�X�^�[�g���C���v�͑S�R��������Ȃ����āB
��˂̒��Ŗ������Ă�z�ɉa�^�����Ⴞ�߂�����w
���[���AGF(2) �Ƃ��o���Ă���Ȃ�w
�c�q�́u�X�^�[�g���C���v�͑S�R��������Ȃ����āB
��˂̒��Ŗ������Ă�z�ɉa�^�����Ⴞ�߂�����w
582 �F�f�t�H���g�̖����������F2009/01/21(��) 01:16:35
��˂̒���
>>579
���[���u���C�J�[�������H
tempering�O�ɉ������W�v���āE�E�E�Ƃ������Ƃ��ł���Ό��I��
�����Ȃ�Ƃ������z�͂��������A������������Ǝv���Ă���ĂȂ���B
�w���Ȃ�����ŁAGF����Wikipedia�Œ��ׂāA����ς�Ӗ��s���������B
���[���u���C�J�[�������H
tempering�O�ɉ������W�v���āE�E�E�Ƃ������Ƃ��ł���Ό��I��
�����Ȃ�Ƃ������z�͂��������A������������Ǝv���Ă���ĂȂ���B
�w���Ȃ�����ŁAGF����Wikipedia�Œ��ׂāA����ς�Ӗ��s���������B
>>580
Python�ŃX�N���v�g�g��ŁA�A�Z���u���R�[�h�������������Ă邩��A
���܂������Ă�Ƃ��͖��Ȃ��B
��x�v�Z���ʂ������ƁA�ǂ����Ԉ���Ă�̂��S�R����Ȃ��Ȃ�B
Python�ŃX�N���v�g�g��ŁA�A�Z���u���R�[�h�������������Ă邩��A
���܂������Ă�Ƃ��͖��Ȃ��B
��x�v�Z���ʂ������ƁA�ǂ����Ԉ���Ă�̂��S�R����Ȃ��Ȃ�B
585 �F�f�t�H���g�̖����������F2009/01/21(��) 01:46:28
>>202
Matsutomo et al.1994 �ɂ��AMK-tempering �� GF(2) �s��̊|���Z���A
�Ə����Ă���ł���B
���ꂩ��AMT���Í������Ƃ��ĐƎ�Ȃ��Ƃ� Matsumoto ���F�߂邱�Ƃ�B
���������Ȃ��Ăǁ[���邗
������ ACM ������ MT �ɔᔻ�I�Ș_���ŁB
Matsutomo et al.1994 �ɂ��AMK-tempering �� GF(2) �s��̊|���Z���A
�Ə����Ă���ł���B
���ꂩ��AMT���Í������Ƃ��ĐƎ�Ȃ��Ƃ� Matsumoto ���F�߂邱�Ƃ�B
���������Ȃ��Ăǁ[���邗
������ ACM ������ MT �ɔᔻ�I�Ș_���ŁB
�Ƃ������A�[���̏����������ł��Ȃ������牴�̕����B
587 �F�f�t�H���g�̖����������F2009/01/21(��) 02:04:10
>>579
�c�q�͉�������Ȃ����Ă��Ƃɂ܂��C�t���ĂȂ��B�B�B
�c�q�͉�������Ȃ����Ă��Ƃɂ܂��C�t���ĂȂ��B�B�B
588 �F�f�t�H���g�̖����������F2009/01/21(��) 02:07:03
589 �F�f�t�H���g�̖����������F2009/01/21(��) 02:25:40
��������˂�
590 �F�f�t�H���g�̖����������F2009/01/21(��) 03:40:48
591 �F�f�t�H���g�̖����������F2009/01/21(��) 04:11:57
>>590
�|�C���g�͂����ł����Hw �� �u6.5.2 �ǂ����t�[���G�ϊ���˂�v
�|�C���g�͂����ł����Hw �� �u6.5.2 �ǂ����t�[���G�ϊ���˂�v
592 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 09:33:19
�܁@���@���@��@���@�́@�y���@��@���@���@��z�@��
�Z�p�t�̉ԉ��ւ悤����
�Z�p�t�̉ԉ��ւ悤����
593 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 10:18:06
���������Amt19937ar.c �� mt[] �� LS ����T���Ă��܂������B
���̃��x���̃l�^�ł����Ȃ�A
num_rand��seed�̑g�����߂����ɂ��āAswitch(num_rand) { } �Ōv�Z�ς݂̌��ʕԂ��悤�ɂ�����H
�ύX�����炵�����ǂ�����
�A�z�̌����Ă邱�Ƃ͗v����ɂ��̃��x���B
�����̔�����₳��͌v�Z�@�Ŕ@���������邩�Ƃ����_�_�������Ă�B
�]�k�܂łɏ��{�������֓����̂r�e�l�s���I���W�i���̂l�s�Ɣ�ׂĔ@���Ⴄ�����āA�ő�̈Ⴂ��
Tempering�̌��ʂ�s�x�i32bit�~4�v�f���P�ʂŁjmt[]�Ƀt�B�[�h�o�b�N���Ă邱�ƁB
����ł��܂���Ƀr�b�g���x���Ő��l���炯�Ă����B
�t�ɂ���ňˑ��W���N����128�r�b�g���z����r�h�l�c�ł͌����I�Ɏ��s�ł��Ȃ��킯�����B
>>580
�����ȁB���W�X�^�Ǘ����ǂ��Ƃ��Ȃ�Č����ĂȂ�����B
�����܂őS���R���p�C���ɂ�点�Ă邵
���̃��x���̃l�^�ł����Ȃ�A
num_rand��seed�̑g�����߂����ɂ��āAswitch(num_rand) { } �Ōv�Z�ς݂̌��ʕԂ��悤�ɂ�����H
�ύX�����炵�����ǂ�����
�A�z�̌����Ă邱�Ƃ͗v����ɂ��̃��x���B
�����̔�����₳��͌v�Z�@�Ŕ@���������邩�Ƃ����_�_�������Ă�B
�]�k�܂łɏ��{�������֓����̂r�e�l�s���I���W�i���̂l�s�Ɣ�ׂĔ@���Ⴄ�����āA�ő�̈Ⴂ��
Tempering�̌��ʂ�s�x�i32bit�~4�v�f���P�ʂŁjmt[]�Ƀt�B�[�h�o�b�N���Ă邱�ƁB
����ł��܂���Ƀr�b�g���x���Ő��l���炯�Ă����B
�t�ɂ���ňˑ��W���N����128�r�b�g���z����r�h�l�c�ł͌����I�Ɏ��s�ł��Ȃ��킯�����B
>>580
�����ȁB���W�X�^�Ǘ����ǂ��Ƃ��Ȃ�Č����ĂȂ�����B
�����܂őS���R���p�C���ɂ�点�Ă邵
>>558
���A�����Ȃ́H
�d�l������܂��ǂ�łȂ�����킩��Ȃ�����
��������Ă�̂͗Ⴆ��odd���߂�even���߂ɒu���������肵��
�������s�𑣂��Ƃ����������̂Ȃ̂����ǥ��
���A�����Ȃ́H
�d�l������܂��ǂ�łȂ�����킩��Ȃ�����
��������Ă�̂͗Ⴆ��odd���߂�even���߂ɒu���������肵��
�������s�𑣂��Ƃ����������̂Ȃ̂����ǥ��
595 �F,,�E�L�́M�E,,�j��[�^�~�t��]�F2009/01/21(��) 10:45:30
odd��even����B���l�͂�������i�K����Ȃ��ȁB
�Ă��A���̂n�������̖��ߐ��팸�@�A���ۂ�낤�Ƃ���ƃ��C�e���V�`�F�C�����L�т�
�A�����[�����郌�W�X�^����Ȃ��Ȃ�㩁B�{���]�|�B
�C���t���G���U�ł��������H
�Ă��A���̂n�������̖��ߐ��팸�@�A���ۂ�낤�Ƃ���ƃ��C�e���V�`�F�C�����L�т�
�A�����[�����郌�W�X�^����Ȃ��Ȃ�㩁B�{���]�|�B
�C���t���G���U�ł��������H
596 �F,,�E�L�́M�E,,�j��[�^�~�t��]�F2009/01/21(��) 10:55:31
597 �F�f�t�H���g�̖����������F2009/01/21(��) 12:02:37
����ς���C�łȂ�����A���w�I��@�ւ̒���͂�߂Ƃ��B
���W�X�^��Ɉ�u�Ƃ͂����ړI�̗������o�����鉴��c�q����ɔ�ׂāA
���w�I��@���ƈ�u����Ƃ��ړI�̗������o�����Ȃ�����A
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
�̏����Ɉᔽ���Ă���Ƃ������R�� reject ����鋰������邵�ˁB
�R�[�h�������āA���|�[�g�����āA��o�����Ⴈ���B
���W�X�^��Ɉ�u�Ƃ͂����ړI�̗������o�����鉴��c�q����ɔ�ׂāA
���w�I��@���ƈ�u����Ƃ��ړI�̗������o�����Ȃ�����A
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
�̏����Ɉᔽ���Ă���Ƃ������R�� reject ����鋰������邵�ˁB
�R�[�h�������āA���|�[�g�����āA��o�����Ⴈ���B
599 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 12:18:46
���W�X�^��Ɉ�u�Ƃ͂����ړI�̗������o�����鉴��c�q����ɔ�ׂāA
���H�A�����ďo�Ă���Č����̂��ȁH
���̓f�[�^�\���I�ɂ��₵�����Ƃ���Ă邯�ǁB
���H�A�����ďo�Ă���Č����̂��ȁH
���̓f�[�^�\���I�ɂ��₵�����Ƃ���Ă邯�ǁB
600 �F�f�t�H���g�̖����������F2009/01/21(��) 12:20:02
>>593
���ǎ����ŊǗ����Ȃ��ŃR���p�C���C������Ȃ����B
���W�X�^�������ς����邩��Ƃ����Ď����őS�ĊǗ��ł���͂��͂Ȃ����ǁB
���ǎ����ŊǗ����Ȃ��ŃR���p�C���C������Ȃ����B
���W�X�^�������ς����邩��Ƃ����Ď����őS�ĊǗ��ł���͂��͂Ȃ����ǁB
�Ђ���Ƃ��Ă܂��߂ɗ�������ă`�F�b�N�T������Ă�̉��������H�H
�����c�q����ɓG��Ȃ��̂����̂����H�H�H
�����c�q����ɓG��Ȃ��̂����̂����H�H�H
602 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 12:31:58
603 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 12:47:36
>>601
���Ȃ݂ɁA�ނ̒����_�ʼn��Z���Ԃ̒Z�k��}��ɂ͒����������̍\���̃��W�X�^�≉�Z���j�b�g���K�v�������肷�邩��C�ɂ���Ȃ�������
���Ȃ݂ɁA�ނ̒����_�ʼn��Z���Ԃ̒Z�k��}��ɂ͒����������̍\���̃��W�X�^�≉�Z���j�b�g���K�v�������肷�邩��C�ɂ���Ȃ�������
604 �F�f�t�H���g�̖����������F2009/01/21(��) 13:08:44
�c�q���V�ˁB�͂��B������������܂�
605 �F�f�t�H���g�̖����������F2009/01/21(��) 13:43:41
>>604
�N�����܂��H�X�s�[�h���I�^�N�̕��ۂŒ��q�ɏ��ȁB
�N�����܂��H�X�s�[�h���I�^�N�̕��ۂŒ��q�ɏ��ȁB
606 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 14:01:25
MT�z��͋��ȏ��ʂ�̌��ʂɂȂ�悤�ɓs�x�X�V���Ă邯��tempering���܂��Ƃ��ȕ��@�ł���Ă鎩�M�͂Ȃ��ȁB
607 �F�f�t�H���g�̖����������F2009/01/21(��) 14:48:01
>>603
���������AGF(2) �n�̉��Z�̍�������ȑf���̓R���s���[�^�̓��ӕ��삾���H
�����̈Í��Ȃ瓖����O�̎�����B�����������Ȃ��̂��H
���������AGF(2) �n�̉��Z�̍�������ȑf���̓R���s���[�^�̓��ӕ��삾���H
�����̈Í��Ȃ瓖����O�̎�����B�����������Ȃ��̂��H
608 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 14:49:59
��������������Ă݂��
����̋�_�͂��Ȃ������ς�
����̋�_�͂��Ȃ������ς�
609 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 14:56:08
������N�͒[������������̂Ƀ`�[�g���Ȃ��Ɩ��������Č����Ă��H
�Ȃ�ǂ݂̂��肪�Ȃ����@���B
�Ȃ�ǂ݂̂��肪�Ȃ����@���B
610 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 15:07:30
> GF(2) �n�̉��Z�̍�������ȑf����
������B
MT[]�̃f�[�^��Ԃɖ������N���Ȃ��͈͂łȁB���ꂪ�o���Ȃ��Ȃ獡��̃R���e�X�g�͒��߂�B
������B
MT[]�̃f�[�^��Ԃɖ������N���Ȃ��͈͂łȁB���ꂪ�o���Ȃ��Ȃ獡��̃R���e�X�g�͒��߂�B
611 �F�f�t�H���g�̖����������F2009/01/21(��) 15:21:50
�ؗ��ĂȂ��ŗ��������B
�ǂ��̃X���ł��ɂ�����B���������������Ă��邩�ǂ�������Ȃ��āB
�����ė~�������₩��͓�����̂ɒ@����Ƃ���͂ǂ��ł������Ƃ���܂ł��Ⴕ���o�Ă���B
�ǂ��̃X���ł��ɂ�����B���������������Ă��邩�ǂ�������Ȃ��āB
�����ė~�������₩��͓�����̂ɒ@����Ƃ���͂ǂ��ł������Ƃ���܂ł��Ⴕ���o�Ă���B
612 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 15:35:50
�Ȃ����ė~����������āH
613 �F�f�t�H���g�̖����������F2009/01/21(��) 15:35:58
�Q�n�~�w��~�ɉ������Ă���x��
�b��ς�邯�ǁAspu-gdb���Ăǂ�����Ďg���́H
elfspe�g����spe�p�̃o�C�i���ڎ��s�ł�����ǁA
spu-gdb mt_kadai �Ƃ�����Ă��f�o�b�O�ł��Ȃ��B
���܂Ńf�o�b�O�͑S���R�[�h�C���X�y�N�V�����ƁAmt[]�̃_���v�����
�o�O�̉ӏ��𐄑������2��ނ����őS������Ă��B
elfspe�g����spe�p�̃o�C�i���ڎ��s�ł�����ǁA
spu-gdb mt_kadai �Ƃ�����Ă��f�o�b�O�ł��Ȃ��B
���܂Ńf�o�b�O�͑S���R�[�h�C���X�y�N�V�����ƁAmt[]�̃_���v�����
�o�O�̉ӏ��𐄑������2��ނ����őS������Ă��B
615 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 15:40:07
�������̉��i��
616 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 15:43:17
>>614
SPU�̎��s�C���[�W��PPE����ǂݏo�����[�_�[�ł����Ηǂ��̂ł́H
http://cell.fixstars.com/ps3linux/index.php/Libspe�v���O�����̃f�o�b�O
SPU�̎��s�C���[�W��PPE����ǂݏo�����[�_�[�ł����Ηǂ��̂ł́H
http://cell.fixstars.com/ps3linux/index.php/Libspe�v���O�����̃f�o�b�O
>>612
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
�̈Ӗ��ɂ��āA
1. �v���O��������mt[]�̓��e���v�Z���Ă�����ǂ��̂��A
2. �S����word�ɂ���tempering��̒l���v�Z���Ă��Ȃ��Ƃ����Ȃ��̂��A
3. ����Ƃ��`�F�b�N�T�����������Ă�Ȃ�ł��A���Ȃ̂��A
�����₵�Ă݂āA���₵�ĉ�2���ƃ��o�C�H
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
�̈Ӗ��ɂ��āA
1. �v���O��������mt[]�̓��e���v�Z���Ă�����ǂ��̂��A
2. �S����word�ɂ���tempering��̒l���v�Z���Ă��Ȃ��Ƃ����Ȃ��̂��A
3. ����Ƃ��`�F�b�N�T�����������Ă�Ȃ�ł��A���Ȃ̂��A
�����₵�Ă݂āA���₵�ĉ�2���ƃ��o�C�H
618 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 15:46:17
���ɕ����ȁB
���Ȃ݂ɉ���genrand_mine���J��Ԃ��Ă�ł����S�Ȃ悤�ɐv���Ă�B
�Ԃ����Ⴏ�O���̍œK���̓T�{���Ă�
���Ȃ݂ɉ���genrand_mine���J��Ԃ��Ă�ł����S�Ȃ悤�ɐv���Ă�B
�Ԃ����Ⴏ�O���̍œK���̓T�{���Ă�
619 �F�f�t�H���g�̖����������F2009/01/21(��) 19:26:33
620 �F�f�t�H���g�̖����������F2009/01/21(��) 19:29:02
�@���X���Ȓc�q�B
621 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 19:41:11
�茳�ɂ���ŐV�̃R�[�h���킴�ƈ������ʂ�\���Ă�͖̂{���B
�N�����s���ʂ͑O�̃o�[�W������������A�킴�ƃf�`���[��������A�F�X�B
�N�����s���ʂ͑O�̃o�[�W������������A�킴�ƃf�`���[��������A�F�X�B
622 �F�f�t�H���g�̖����������F2009/01/21(��) 19:47:57
�ȂQ���܂��邵�A�ɂ��������Ă݂悤����
�v���O�����S�R�����Ȃ�����
���̃X�����Ȃ���y��������Ă݂悤
�v���O�����S�R�����Ȃ�����
���̃X�����Ȃ���y��������Ă݂悤
>>593
>switch(num_rand) { } �Ōv�Z�ς݂̌��ʕԂ��悤�ɂ�����H
�S�R�l�^�̃��x����������Ȃ����낗
>�ύX�����炵�����ǂ�����
���̏�ł̃l�^�Ȃ킯�����B
>�ő�̈Ⴂ��Tempering�̌��ʂ�s�x�i32bit�~4�v�f���P�ʂŁj
>mt[]�Ƀt�B�[�h�o�b�N���Ă邱�ƁB
�n�Y���B
�]�k�ɗ]�k���d�˂�ƁAMT �� SFMT �� GFSR �ł���_�œ���B
tempering �̃R�X�g�� MT �̍X�V���ɐU���������B
>�t�ɂ���ňˑ��W���N����128�r�b�g���z����r�h�l�c�ł�
������Ⴄ�ȁB
MT �̑Q������ g(w)_MT = w_0 A + w_1 B + w_M �Ȃ킯�����A
SFMT �� g(w)_SFMT = w_0 A + w_M B + w_{N-2} C + w_{N-1} D
�ɕύX����Ă���B
���ꂪ�����Ă���̂́A���W�X�^���ł͂Ȃ��ނ������v�Z����B
>switch(num_rand) { } �Ōv�Z�ς݂̌��ʕԂ��悤�ɂ�����H
�S�R�l�^�̃��x����������Ȃ����낗
>�ύX�����炵�����ǂ�����
���̏�ł̃l�^�Ȃ킯�����B
>�ő�̈Ⴂ��Tempering�̌��ʂ�s�x�i32bit�~4�v�f���P�ʂŁj
>mt[]�Ƀt�B�[�h�o�b�N���Ă邱�ƁB
�n�Y���B
�]�k�ɗ]�k���d�˂�ƁAMT �� SFMT �� GFSR �ł���_�œ���B
tempering �̃R�X�g�� MT �̍X�V���ɐU���������B
>�t�ɂ���ňˑ��W���N����128�r�b�g���z����r�h�l�c�ł�
������Ⴄ�ȁB
MT �̑Q������ g(w)_MT = w_0 A + w_1 B + w_M �Ȃ킯�����A
SFMT �� g(w)_SFMT = w_0 A + w_M B + w_{N-2} C + w_{N-1} D
�ɕύX����Ă���B
���ꂪ�����Ă���̂́A���W�X�^���ł͂Ȃ��ނ������v�Z����B
>>603
�����������̍\�����ĂȂ悗
>>606
���̋��ȏ��ɂ́Aw �� n �K�� (T)GFSR �� 1 �K������� nw ����
GFSR �ɂȂ��āA1 �K���`�Q�����ɋA������Ƃ͏����ĂȂ����������H
>>609
>�[������������̂Ƀ`�[�g���Ȃ��Ɩ��������Č����Ă��H
�N���������ƌ�������
�v�����Ȃ��������Ȃ̂��H
>>610
> > GF(2) �n�̉��Z�̍�������ȑf����
>������B
MT �̓����͑S�� GF(2) �Ȃ킯�����B
����܂��ĊO����@���� GF(2) �̏�Ɏ����Ă������̘b���B
�����������̍\�����ĂȂ悗
>>606
���̋��ȏ��ɂ́Aw �� n �K�� (T)GFSR �� 1 �K������� nw ����
GFSR �ɂȂ��āA1 �K���`�Q�����ɋA������Ƃ͏����ĂȂ����������H
>>609
>�[������������̂Ƀ`�[�g���Ȃ��Ɩ��������Č����Ă��H
�N���������ƌ�������
�v�����Ȃ��������Ȃ̂��H
>>610
> > GF(2) �n�̉��Z�̍�������ȑf����
>������B
MT �̓����͑S�� GF(2) �Ȃ킯�����B
����܂��ĊO����@���� GF(2) �̏�Ɏ����Ă������̘b���B
>>598=202
�q���g�F �O���� sum += ������ sum ^= ���Ƃ�����H
> ��������������Ă��������B�̏����Ɉᔽ���Ă���
���傗����
���Ƃ�����
>tempering���܂��Ƃ��ȕ��@�ł���Ă鎩�M�͂Ȃ�
>MT[]�̃f�[�^��Ԃɖ������N���Ȃ��͈͂łȁB
�c�q���A�ꂾ�ȁB
�q���g�F �O���� sum += ������ sum ^= ���Ƃ�����H
> ��������������Ă��������B�̏����Ɉᔽ���Ă���
���傗����
���Ƃ�����
>tempering���܂��Ƃ��ȕ��@�ł���Ă鎩�M�͂Ȃ�
>MT[]�̃f�[�^��Ԃɖ������N���Ȃ��͈͂łȁB
�c�q���A�ꂾ�ȁB
�b��߂��ƁA�ۑ�(MT��sum�����߂�)�́A���̂悤�ɕ����ł���B
1. mt[] ���� pmt[] �ւ̐��`�ʑ������߂�B
2. for (num_rand / N) �s�^�ʖڂȌv�Z�B
3. pmt[] ����(num_rand / N�������) mt[] ��߂��B
4. for (num_rand % N) �^�ʖڂȌv�Z�B
5. tempering
�����Ɍ����Amt[] �� num_rand ����s�^�ʖڂȌv�Z������
O(1) �� sum �����߂鎖�����_�I�ɂ͉\�B���A���̗��_��
��͂��Ă��鎞�Ԃ͂Ȃ��킯�B
���A������ 32N �������x�� GF(2) ��̃x�N�g���ł���A2 ��
�s�^�ʖڂȌv�Z���@�B�I�ɋ��߂邱�Ƃ����I�ł͂Ȃ��B
���܂������͂��Ă���Ƃ���B
���Ƃ��Ă���̂� 3 �̑���ŁApmt[] �� mt[] �̐��`�ʑ���
����ȏ�A���S�� mt[] �����ɖ߂����Ƃ̓����B4 �̌v�Z��
�s�^�ʖډ�����悢�̂�����ǁA���̂܂܂ł� num_rand % N ��
������ N ��ނ̕s�^�ʖڌv�Z���@���������Ă��܂��ăR�[�h
�T�C�Y�I�Ƀ����B
�Ȃ̂ŁA�ʂ̕��@�ł̕s�^�ʖڌv�Z���l���Ă���Ƃ���B
O((num_rand % N) ^ 2) �ł���Ή��͌��������B���A���ꂾ��
�����unum_rand �� 10000 �ȏ�v�ɑ��ăR�X�g�E���X�N�傫�����B
�܂��A1��ڂ̕s�^�ʖڌv�Z����͂ł���A����������Â鎮��
���܂��Ȃ����Ɗy�ώ����Ă���B
�Ƃ������A���܂͉�͌��ʑ҂��B
1. mt[] ���� pmt[] �ւ̐��`�ʑ������߂�B
2. for (num_rand / N) �s�^�ʖڂȌv�Z�B
3. pmt[] ����(num_rand / N�������) mt[] ��߂��B
4. for (num_rand % N) �^�ʖڂȌv�Z�B
5. tempering
�����Ɍ����Amt[] �� num_rand ����s�^�ʖڂȌv�Z������
O(1) �� sum �����߂鎖�����_�I�ɂ͉\�B���A���̗��_��
��͂��Ă��鎞�Ԃ͂Ȃ��킯�B
���A������ 32N �������x�� GF(2) ��̃x�N�g���ł���A2 ��
�s�^�ʖڂȌv�Z���@�B�I�ɋ��߂邱�Ƃ����I�ł͂Ȃ��B
���܂������͂��Ă���Ƃ���B
���Ƃ��Ă���̂� 3 �̑���ŁApmt[] �� mt[] �̐��`�ʑ���
����ȏ�A���S�� mt[] �����ɖ߂����Ƃ̓����B4 �̌v�Z��
�s�^�ʖډ�����悢�̂�����ǁA���̂܂܂ł� num_rand % N ��
������ N ��ނ̕s�^�ʖڌv�Z���@���������Ă��܂��ăR�[�h
�T�C�Y�I�Ƀ����B
�Ȃ̂ŁA�ʂ̕��@�ł̕s�^�ʖڌv�Z���l���Ă���Ƃ���B
O((num_rand % N) ^ 2) �ł���Ή��͌��������B���A���ꂾ��
�����unum_rand �� 10000 �ȏ�v�ɑ��ăR�X�g�E���X�N�傫�����B
�܂��A1��ڂ̕s�^�ʖڌv�Z����͂ł���A����������Â鎮��
���܂��Ȃ����Ɗy�ώ����Ă���B
�Ƃ������A���܂͉�͌��ʑ҂��B
628 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 21:30:52
�ϑz�͂�������B
> �q���g�F �O���� sum += ������ sum ^= ���Ƃ�����H
���u���蓾�Ȃ�����������o���v
������k�ق́����ӏ��ɂ���������
�܂������_�����o���Ă�������������߂땉����
������ˁ[�R���e�X�g�Ȃ�Ėڂ���ˁ[���B
> �q���g�F �O���� sum += ������ sum ^= ���Ƃ�����H
���u���蓾�Ȃ�����������o���v
������k�ق́����ӏ��ɂ���������
�܂������_�����o���Ă�������������߂땉����
������ˁ[�R���e�X�g�Ȃ�Ėڂ���ˁ[���B
629 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 21:35:49
> ���̋��ȏ��ɂ́Aw �� n �K�� (T)GFSR �� 1 �K������� nw ����
> GFSR �ɂȂ��āA1 �K���`�Q�����ɋA������Ƃ͏����ĂȂ����������H
�ŁA�����SPU�̖��߂��g���ĉ����߂Ŏ����ł��܂����H
> �v�����Ȃ��������Ȃ̂��H
���F���O�͌��������ȁB
�n�b�^���͉����o���Ȃ��l�Ԃ̂��߂ɂ�����̂����B
�ǂ����~���Ă����O�ɂ͂ł��Ȃ��B
> GFSR �ɂȂ��āA1 �K���`�Q�����ɋA������Ƃ͏����ĂȂ����������H
�ŁA�����SPU�̖��߂��g���ĉ����߂Ŏ����ł��܂����H
> �v�����Ȃ��������Ȃ̂��H
���F���O�͌��������ȁB
�n�b�^���͉����o���Ȃ��l�Ԃ̂��߂ɂ�����̂����B
�ǂ����~���Ă����O�ɂ͂ł��Ȃ��B
630 �F�f�t�H���g�̖����������F2009/01/21(��) 21:38:07
631 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 21:39:12
�����A���Ȃ݂ɍŏ����炢��1�r�b�g�~128����̃r�b�g�X���C�X�����v����������
�S�R�����Ȃ�������B
�S�R�����Ȃ�������B
632 �F�f�t�H���g�̖����������F2009/01/21(��) 21:39:43
����͂ǂꂮ�炢���x�Ȑ��w���K�v�ȂH
633 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 21:41:31
��������k�ق͕����ĕ����
634 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 21:58:01
>>632
����ǂ�ʼn������Ă��邩������x�B���̂܂�܂����ǁB
http://www.kurims.kyoto-u.ac.jp/~kyodo/kokyuroku/contents/pdf/1441-14.pdf
1 ticks = 40clk�ŁAPLAYSTATION 3��SPU�̃N���b�N����3192MHz����ł��B
num_rand = 58156364�̂Ƃ��Agenrand_mine�̎��s���Ԃ�4.7MTicks���x������܂����B
���̂Ƃ��Agenrand_mine�̎��s���Ԃ͉��b���������ł��傤�H
����͊ȒP�Ȃ����i�j�̖��
�ł��Apmt[]�i�j���߂�̂ɉ��\�b������̂��˂�������
������i�j�͌v�Z���Ԃ������炩���邩�A��������������K�v�����������ϓ_�����@���Ă邩�獢��B
���̏����_������ׂ�B�ł��邱�Ƃ����Ȃ��B������ł��Ȃ��B
�܂��A���Ԃ������肷����SPU Decrementer�����b�v�A���E���h���Ă���A�����ڂ�Tick���́i����
����ǂ�ʼn������Ă��邩������x�B���̂܂�܂����ǁB
http://www.kurims.kyoto-u.ac.jp/~kyodo/kokyuroku/contents/pdf/1441-14.pdf
1 ticks = 40clk�ŁAPLAYSTATION 3��SPU�̃N���b�N����3192MHz����ł��B
num_rand = 58156364�̂Ƃ��Agenrand_mine�̎��s���Ԃ�4.7MTicks���x������܂����B
���̂Ƃ��Agenrand_mine�̎��s���Ԃ͉��b���������ł��傤�H
����͊ȒP�Ȃ����i�j�̖��
�ł��Apmt[]�i�j���߂�̂ɉ��\�b������̂��˂�������
������i�j�͌v�Z���Ԃ������炩���邩�A��������������K�v�����������ϓ_�����@���Ă邩�獢��B
���̏����_������ׂ�B�ł��邱�Ƃ����Ȃ��B������ł��Ȃ��B
�܂��A���Ԃ������肷����SPU Decrementer�����b�v�A���E���h���Ă���A�����ڂ�Tick���́i����
635 �F�f�t�H���g�̖����������F2009/01/21(��) 21:59:50
����A������A�c�q�͂���ł�������ق��Ă�ₗ
>���u���蓾�Ȃ�����������o���v
�������ȒP�ɍl���邽�߂̉I��H���BTT800����n�߂Ă�B
>�ŁA�����SPU�̖��߂��g���ĉ����߂Ŏ����ł��܂����H
�������͒������Č����Ă邾�낤���B
��͌��ʁH�o�Ăˁ[��B
�ۑ�A�i��(����)�� prolog �Ŏ������������~�X���B����͔F�߂�B
vsz �͏�����(?)�����Ă����Ă邩��A���� 2,3 ���ق��Ƃ��Ă݂邩�B
�������ȒP�ɍl���邽�߂̉I��H���BTT800����n�߂Ă�B
>�ŁA�����SPU�̖��߂��g���ĉ����߂Ŏ����ł��܂����H
�������͒������Č����Ă邾�낤���B
��͌��ʁH�o�Ăˁ[��B
�ۑ�A�i��(����)�� prolog �Ŏ������������~�X���B����͔F�߂�B
vsz �͏�����(?)�����Ă����Ă邩��A���� 2,3 ���ق��Ƃ��Ă݂邩�B
637 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:12:27
59ms�ゾ��B
�O�炵�ăA�z����
MT[n]��sum��Tempering�������̂� TemperingFunction(MT[n])��sum�͑S���̕ʕ�
��ŁA���ア�q�͉��Z���߂�XOR��AND�ɕ������ă\�t�g�I�ɉ��Z��������Ǝv���Ă邾��H
���W�X�^�����H�ނ��냁���������H
���Ă������A�]�݂�����Ă�H
�O�炵�ăA�z����
MT[n]��sum��Tempering�������̂� TemperingFunction(MT[n])��sum�͑S���̕ʕ�
��ŁA���ア�q�͉��Z���߂�XOR��AND�ɕ������ă\�t�g�I�ɉ��Z��������Ǝv���Ă邾��H
���W�X�^�����H�ނ��냁���������H
���Ă������A�]�݂�����Ă�H
638 �F�f�t�H���g�̖����������F2009/01/21(��) 22:15:06
>>634
�Ȃ�ƂȂ�������܂����B���x�Ȑ��w�Ƃ��������V�N�ȃA���S���Y���ɋC�������ǂ����̖�肾���A�f����T���v���W�F�N�g�ƂȂ��Ă܂��ˁB
�Ȃ�ƂȂ�������܂����B���x�Ȑ��w�Ƃ��������V�N�ȃA���S���Y���ɋC�������ǂ����̖�肾���A�f����T���v���W�F�N�g�ƂȂ��Ă܂��ˁB
639 �F�f�t�H���g�̖����������F2009/01/21(��) 22:22:43
�c�q�͂��������A
>>637
>���W�X�^�����H�ނ��냁���������H
>
>���Ă������A�]�݂�����Ă�H
����͏��Ă��܂����B���A���₵���B
>>637
>���W�X�^�����H�ނ��냁���������H
>
>���Ă������A�]�݂�����Ă�H
����͏��Ă��܂����B���A���₵���B
640 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:24:26
�Ȃ�ɂ���10000��num_rand��UINT_MAX������Ȃ�
���\�N������v�Z�𐔊w�I��͂ɂ���ĒZ�k�]�X�Ȃ牿�l�͂��邪
���\ms���x�ŏI���v�Z����ɃX�s�[�h�������A�v���[�`�Ƃ��Ă͖��d��ʂ�z���Ĕn������
5�i�K��1�i�K�ڂ����Ŋ��ɏI����Ă��K�X�B
������UNIX crypt(3)�̃n�b�V���l����L�[���_�C���N�g�ɋ��߂�A���S���Y���ł��𖾂��ĉ������悗����
���\�N���̉ۑ�ł�����
���\�N������v�Z�𐔊w�I��͂ɂ���ĒZ�k�]�X�Ȃ牿�l�͂��邪
���\ms���x�ŏI���v�Z����ɃX�s�[�h�������A�v���[�`�Ƃ��Ă͖��d��ʂ�z���Ĕn������
5�i�K��1�i�K�ڂ����Ŋ��ɏI����Ă��K�X�B
������UNIX crypt(3)�̃n�b�V���l����L�[���_�C���N�g�ɋ��߂�A���S���Y���ł��𖾂��ĉ������悗����
���\�N���̉ۑ�ł�����
641 �F�f�t�H���g�̖����������F2009/01/21(��) 22:25:19
fixstars���ɏ\���Ȑ��w�̒m��������l������
�Ȃ����R���e�X�g�Ő��ݏo�����R�[�h����X�̖��ɗ����̂ł����Ăق����Ɗ���Ă���̂Ȃ�
�f���ɗ���������ĉ��Z����̂���ԑ����Ȃ�悤�Ȗ��ɂȂ��Ă���͂��A
�ƐM������
�Ȃ����R���e�X�g�Ő��ݏo�����R�[�h����X�̖��ɗ����̂ł����Ăق����Ɗ���Ă���̂Ȃ�
�f���ɗ���������ĉ��Z����̂���ԑ����Ȃ�悤�Ȗ��ɂȂ��Ă���͂��A
�ƐM������
>>637
�������ȁB���O�� cite ���������ɏ����Ă��邶���B
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
�������ȁB���O�� cite ���������ɏ����Ă��邶���B
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> MT �̉𑜓x�͍ő�\�ȉ𑜓x�Ɣ�ׂ�Ƃ��Ȃ舫���Ȃ��Ă���
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
> ���̌Œ肳��Ă��܂��� j_1,...,j_L �������̎������߂�̂����A���ꂪ���������Ȃ��B
643 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:30:54
�������͉��i�������͒B�҂���
��ŁA�v�Z���Ԃ͋�̓I�ɂ�����ł����H
O(n)�̃A�v���[�`�̂ق��������Ƃ������Ƃ�����܂���B
> 1. mt[] ���� pmt[] �ւ̐��`�ʑ������߂�B
�ǂ������ꂾ���œV���w�I�Ȏ��Ԃ������H��
��ŁA�v�Z���Ԃ͋�̓I�ɂ�����ł����H
O(n)�̃A�v���[�`�̂ق��������Ƃ������Ƃ�����܂���B
> 1. mt[] ���� pmt[] �ւ̐��`�ʑ������߂�B
�ǂ������ꂾ���œV���w�I�Ȏ��Ԃ������H��
���`�ʑ����߂邾���œV���w�I�Ȃ�āA�ǂ��܂ł��Ԕ��Ȃ��H
645 �F�f�t�H���g�̖����������F2009/01/21(��) 22:35:19
�M���E�E�E�M�������O��
�����������Ƃ��
�����������Ƃ��
647 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:36:36
�E������210KB���g�p�֎~
�E�`���l���g�p�s�i���C���������Ԃ�DMA���������s�j
�܂��Ƃ肠�����]�����_�̓u���O�ł��B
�E�`���l���g�p�s�i���C���������Ԃ�DMA���������s�j
�܂��Ƃ肠�����]�����_�̓u���O�ł��B
648 �F�f�t�H���g�̖����������F2009/01/21(��) 22:38:54
���`�ʑ� = ���@����A����
��� = ���O��ƁA�ᑬ
��� = ���O��ƁA�ᑬ
649 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:40:06
����̋�_�ɂ�
�uTempering�̓����_���e�[�u�����b�N�A�b�v��1��̑���ōs�����Ƃ��ł��܂����A
4Byte�~2^32 = 16GByte�̃��������K�v�ł��v
�݂����ȃI�`�������
�uTempering�̓����_���e�[�u�����b�N�A�b�v��1��̑���ōs�����Ƃ��ł��܂����A
4Byte�~2^32 = 16GByte�̃��������K�v�ł��v
�݂����ȃI�`�������
650 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:42:01
>>648
> ���`�ʑ� = ���@����A����
> ��� = ���O��ƁA�ᑬ
���́u���`�ʑ��v�Ȃ��ǁA46KB�����̃�������ԂŊm�ۂł���LUT��
��̂Ȃɂ��ł���̂�������
> ���`�ʑ� = ���@����A����
> ��� = ���O��ƁA�ᑬ
���́u���`�ʑ��v�Ȃ��ǁA46KB�����̃�������ԂŊm�ۂł���LUT��
��̂Ȃɂ��ł���̂�������
651 �F�f�t�H���g�̖����������F2009/01/21(��) 22:42:56
���`�ʑ��̈Ӗ��킩���Ă�H
652 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:45:43
���`�ʑ�������������@���\�t�g�E�F�A�H�w�ł�LUT�i���b�N�A�b�v�e�[�u���j���Č�����B
Cell�̓��[�J���������������������ʓI�ɂ͕s�����ƌ�����B
Cell�̓��[�J���������������������ʓI�ɂ͕s�����ƌ�����B
653 �F�f�t�H���g�̖����������F2009/01/21(��) 22:47:26
�ق��ق��A���Ⴛ��̓A���S���Y���Ŏ������邱�Ƃ͂ł��Ȃ��ȁH��
654 �F�f�t�H���g�̖����������F2009/01/21(��) 22:47:47
���������c�q������A���Z��"����"�����蒼������ǂ��Ȃ̂�
655 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:50:24
���ق��ق��A���Ⴛ��̓A���S���Y���Ŏ������邱�Ƃ͂ł��Ȃ��ȁH��
�N�́u�A���S���Y���v�������w���̂��킩��܂���
LUT���A���S���Y���̈�ł�
�N�́u�A���S���Y���v�������w���̂��킩��܂���
LUT���A���S���Y���̈�ł�
656 �F�f�t�H���g�̖����������F2009/01/21(��) 22:51:42
���܂�A�uLUT �łȂ��A���Z�ŋ��߂邱�Ƃ́A�ł��Ȃ��ȁH���v���B
657 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:53:19
�e�[�u���̃I�t�Z�b�g���A�h���X�����߂Ēl�����[�h����̂��u���Z�v�ł��B
658 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 22:56:17
�ނ���NOP�n�̖��߈ȊO�͑S�ĉ��Z�Ȃ�Ȃ��́H
659 �F�f�t�H���g�̖����������F2009/01/21(��) 22:58:02
�܁A���ł����[��B���`�ʑ����k�t�s�ˁBtempering �� LUT �ł���Ă��ꂗ
660 �F�f�t�H���g�̖����������F2009/01/21(��) 23:04:17
�����v���H �� �C���t���G���U
661 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:04:22
�߯
�܂����r�b�g�_�����Z�̑g�ݍ��킹�����ł�낤�Ƃ��Ă�̂��H
����͂���ʼn����p�t�H�[�}���X��̗D�ʐ��ˁ[��
�܂������A�z�����āA���ǂ̂Ƃ���>>637�Ȃ���
�܂����r�b�g�_�����Z�̑g�ݍ��킹�����ł�낤�Ƃ��Ă�̂��H
����͂���ʼn����p�t�H�[�}���X��̗D�ʐ��ˁ[��
�܂������A�z�����āA���ǂ̂Ƃ���>>637�Ȃ���
>>656
���͐�呲�Ȃ̂œ�����w�͔���Ȃ��̂����A
���̌v�Z�����̂��uLUT�ł͂Ȃ����@�v�ŁA
���Ǔ���p��������o���Ă鐔�w���̌����Ă邱�Ƃ�
�u���̌v�Z���Ɠ�������������Z���ʂ̌v�Z��������������v
�����H
����Ȃ�A�ŏ��Ɍv�Z���Ƃɂ�߂������āA�u���ɂ͖����v�Ɣ��f���Ă�B
Prolog�ʼn����ł���̂��m��Ȃ����ǁA���̌v�Z�����v�Z�ʂ̏��Ȃ�
�����o�Ă�����Ă������������w���ɂ͂���́H
���͐�呲�Ȃ̂œ�����w�͔���Ȃ��̂����A
���̌v�Z�����̂��uLUT�ł͂Ȃ����@�v�ŁA
���Ǔ���p��������o���Ă鐔�w���̌����Ă邱�Ƃ�
�u���̌v�Z���Ɠ�������������Z���ʂ̌v�Z��������������v
�����H
����Ȃ�A�ŏ��Ɍv�Z���Ƃɂ�߂������āA�u���ɂ͖����v�Ɣ��f���Ă�B
Prolog�ʼn����ł���̂��m��Ȃ����ǁA���̌v�Z�����v�Z�ʂ̏��Ȃ�
�����o�Ă�����Ă������������w���ɂ͂���́H
663 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:05:31
664 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:07:00
MT�̏����l���Œ肳��Ă����牽����ł��j�锲���������肻���ȋC�����邯�ǁA
init_genrand() �̈����� num_rand �����m�̏ꍇ�A�u�����̃`�F�b�N�T���v�̌v�Z��
�V���[�g�J�b�g����͖̂��������Ƃ����̂��\�t�g���̒����B
���w���ƈ���ĉ��̍������Ȃ����A�����ł�����ȂɐM���ĂȂ����������ǂȁB
init_genrand() �̈����� num_rand �����m�̏ꍇ�A�u�����̃`�F�b�N�T���v�̌v�Z��
�V���[�g�J�b�g����͖̂��������Ƃ����̂��\�t�g���̒����B
���w���ƈ���ĉ��̍������Ȃ����A�����ł�����ȂɐM���ĂȂ����������ǂȁB
666 �F�f�t�H���g�̖����������F2009/01/21(��) 23:12:40
>�u���̌v�Z���Ɠ�������������Z���ʂ̌v�Z��������������v
�����������Ƃ��BTempering ���Z���ʑ�����������n�j�B
���āATempering ���\���Z�����疳�����ۂ����ǂȁ[��
�����������Ƃ��BTempering ���Z���ʑ�����������n�j�B
���āATempering ���\���Z�����疳�����ۂ����ǂȁ[��
667 �F�f�t�H���g�̖����������F2009/01/21(��) 23:13:08
�\��Ă���̂͂��ł���
668 �F�f�t�H���g�̖����������F2009/01/21(��) 23:14:37
���͒��C���t���G���U
669 �F�f�t�H���g�̖����������F2009/01/21(��) 23:16:59
���̐l��l���Đ���S���ƃv���O���~���O�S��������R�e�̐l�͂��邢�Ǝv���܂��B
670 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:17:29
>>666
���Ƃ���
A XOR (B AND C)
��������Ƃ���MUX���g���Ď��ό`����Ƃǂ��Ȃ�H
���āA���̃��x���̎��݂͉����Ƃ����ɂ���Ă�킯�����B
���Ƃ���
A XOR (B AND C)
��������Ƃ���MUX���g���Ď��ό`����Ƃǂ��Ȃ�H
���āA���̃��x���̎��݂͉����Ƃ����ɂ���Ă�킯�����B
671 �F�f�t�H���g�̖����������F2009/01/21(��) 23:19:12
>>669
�R�l����ˁH��������������K�X
�R�l����ˁH��������������K�X
672 �F�f�t�H���g�̖����������F2009/01/21(��) 23:20:22
>>671
�c�q�O�Z������
�c�q�O�Z������
673 �F�f�t�H���g�̖����������F2009/01/21(��) 23:24:56
����ȂɕK���ɂȂ�Ȃ��Ă����v����A�c�q�����蓪�̈����l�����Ă����ς����邩��
674 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:28:06
>>673�Ƃ���
>>674
�܂��A�{���̂��Ƃ����牽�������Ȃ����ǂ�
�܂��A�{���̂��Ƃ����牽�������Ȃ����ǂ�
676 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:31:53
B = A XOR D
����������Ƃ�
A XOR (B AND C)�@���@spu_sel(A, D, C)
����A���m����
����������Ƃ�
A XOR (B AND C)�@���@spu_sel(A, D, C)
����A���m����
677 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:44:40
���_���猾����>>676�͍���g���Ƃ���͂ǂ��ɂ�����܂���B
���Ƃ���Ȃ�ARPG�œł̏��ɓ����Ă��_���[�W���Ȃ���������ɓ��ꂽ����
���̐�ŏ��Ȃ�Ăǂ��ɂ�����܂�����Ċ������ȁB
��
����̌��l�^�������z�͉��̃h�b�y���Q���K�[
���Ƃ���Ȃ�ARPG�œł̏��ɓ����Ă��_���[�W���Ȃ���������ɓ��ꂽ����
���̐�ŏ��Ȃ�Ăǂ��ɂ�����܂�����Ċ������ȁB
��
����̌��l�^�������z�͉��̃h�b�y���Q���K�[
678 �F�f�t�H���g�̖����������F2009/01/21(��) 23:52:10
>>676
���������̂�㐔�w�̒m���ŏؖ��ł���悤�ɂȂ肽��
���������̂�㐔�w�̒m���ŏؖ��ł���悤�ɂȂ肽��
679 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:52:33
�m���Ă�Ǝv�����ǒc�q�̒��̐l�͍L��̏��{�������ƃ��[�����Ƃ肵�����Ƃ�����B
���_��������seed��num_rand����pmt(��)�����߂邽�߂̈�ӂȘ_�����Ȃ�đ��݂��Ȃ���B
�����Ă��v�Z���ԁE�������e�ʓI�Ɏ��p�I�ȃ��m�ł͂Ȃ��B
���_��������seed��num_rand����pmt(��)�����߂邽�߂̈�ӂȘ_�����Ȃ�đ��݂��Ȃ���B
�����Ă��v�Z���ԁE�������e�ʓI�Ɏ��p�I�ȃ��m�ł͂Ȃ��B
680 �F,,�E�L�́M�E,,�j��-�������F2009/01/21(��) 23:53:34
>>678
�J���m�[�}�����Έꔭ����Ȃ���
�J���m�[�}�����Έꔭ����Ȃ���
681 �F�f�t�H���g�̖����������F2009/01/22(��) 00:02:26
>��ӂȘ_�����Ȃ�đ��݂��Ȃ���B
����A���݂͂�����ĂB���p�I�Ȃ̂�������Ȃ����Ă����ŁB
����A���݂͂�����ĂB���p�I�Ȃ̂�������Ȃ����Ă����ŁB
682 �F�f�t�H���g�̖����������F2009/01/22(��) 00:04:44
Cell�g���Ă���݂Ԃ��ɒT�����Ⴆ�H
683 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 00:05:41
���̏�A�[������������̂Ƀ`�[�g���Ȃ��Ǝ��p�I�Ȑ��\�o�Ȃ���H
���˂����̂ɂ�����
����ɔ�ׂ�����Ƃ�܂��V��݂����Ȃ���B
���˂����̂ɂ�����
����ɔ�ׂ�����Ƃ�܂��V��݂����Ȃ���B
684 �F�f�t�H���g�̖����������F2009/01/22(��) 00:11:57
�ǂ���MT���������Ȃ�A���łɑ��ϗʐ��K�����܂ł���Ă����
�f�L�o�C�ɂ���Ă͋��o����
�f�L�o�C�ɂ���Ă͋��o����
685 �F�f�t�H���g�̖����������F2009/01/22(��) 00:15:40
�o���h��?
686 �F�f�t�H���g�̖����������F2009/01/22(��) 00:16:46
���[���ꂾ
���{���肾����
���{���肾����
687 �F�f�t�H���g�̖����������F2009/01/22(��) 00:21:04
> �����Ƃ�܂��V��݂����Ȃ���B
13cycle �ꂽ��ł�����܂��ɂ�
13cycle �ꂽ��ł�����܂��ɂ�
688 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 00:26:07
���Ƃ����A
�ugenrand_mine���Ă��O�ɂ́A�K��init_genrand_mine�����Ɖ��肵�Ă��܂�Ȃ��v
�Ƃ͂��邪�A�����ĂԒ��O��init_genrand_mine���ĂԂȂ�Č����ĂȂ����B
���Ƃ��ɒ[�Șb�A
init_genrand_mine(seed);
hash = genrand_mine(num_rand) + genrand_mine(num_rand2);
�݂����ȋS�{�ȏ����ł̑���ɂ��Ă��āA�T�}���l�s�����Ŏ��i���o�ɂȂ邩������Ȃ����H
���͂ǂ��]��ł������悤�ɒ��J�Ȏ������Ă邯�ǁA
���肵�č\��Ȃ����Č����Ă邱�ƈȊO�͉��肵����ʖڂ��Ǝv�����B
�Ƃ肠�����N�����₵�Ă��Ă�
�ugenrand_mine���Ă��O�ɂ́A�K��init_genrand_mine�����Ɖ��肵�Ă��܂�Ȃ��v
�Ƃ͂��邪�A�����ĂԒ��O��init_genrand_mine���ĂԂȂ�Č����ĂȂ����B
���Ƃ��ɒ[�Șb�A
init_genrand_mine(seed);
hash = genrand_mine(num_rand) + genrand_mine(num_rand2);
�݂����ȋS�{�ȏ����ł̑���ɂ��Ă��āA�T�}���l�s�����Ŏ��i���o�ɂȂ邩������Ȃ����H
���͂ǂ��]��ł������悤�ɒ��J�Ȏ������Ă邯�ǁA
���肵�č\��Ȃ����Č����Ă邱�ƈȊO�͉��肵����ʖڂ��Ǝv�����B
�Ƃ肠�����N�����₵�Ă��Ă�
689 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 00:27:52
690 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 00:30:14
����12clk/qword��̓����Ȃ��H
691 �F�f�t�H���g�̖����������F2009/01/22(��) 00:36:13
692 �F227 ��eZQcaIaFJs �F2009/01/22(��) 01:08:36
������Even13clock�̕ǂ�˔j�ł��Ȃ������B�Ȃɑ�_�ɒB���Ă�悤��
�C������̂ŁA�ǂ��܂Ŗ߂��ΐ��������ɖ߂�邩�T���Ă鏊�ł��B
�C������̂ŁA�ǂ��܂Ŗ߂��ΐ��������ɖ߂�邩�T���Ă鏊�ł��B
693 �F�f�t�H���g�̖����������F2009/01/22(��) 01:15:57
�R�A�̕�����Even:12.5�AOdd12.1�T�C�N����
�v�V���Ȃ����肱��ȏ�ǂ��ɂ��Ȃ�C�����Ȃ�
�v�V���Ȃ����肱��ȏ�ǂ��ɂ��Ȃ�C�����Ȃ�
694 �F227 ��eZQcaIaFJs �F2009/01/22(��) 01:18:27
>>580
���W�X�^�P�Q�U�g�����ŁA�J���[�����O�̕K�v����������y�ł���B
>>614
stqr + printf �Ńf�o�b�O���Ă܂��B�o�O���o���Ƃ��� svn diff�B
���W�X�^�P�Q�U�g�����ŁA�J���[�����O�̕K�v����������y�ł���B
>>614
stqr + printf �Ńf�o�b�O���Ă܂��B�o�O���o���Ƃ��� svn diff�B
695 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 01:24:15
>>693
���[�v�̓����X�J�X�J�������肷�邾��H
���[�v�̓����X�J�X�J�������肷�邾��H
696 �F�f�t�H���g�̖����������F2009/01/22(��) 01:31:34
697 �F�f�t�H���g�̖����������F2009/01/22(��) 01:32:40
�S���A�Z���u���ŋl�߂Ă邩�猄�ԂȂ��150�T�C�N���̊Ԃ�Odd4���邾������
698 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 01:36:34
>>696
���R
���R
699 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 02:13:27
even����12����@�v��������Odd�����낵�����ƂɂȂ�
700 �F�f�t�H���g�̖����������F2009/01/22(��) 03:57:56
���߂Ȍߌ�̐l�� hack the cell �n�߂Ă�` �����������Ă���ۂ��B
����[�A����������Ė������ŁA�Ȃ��S�[�������B
����[�A����������Ė������ŁA�Ȃ��S�[�������B
701 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 04:13:25
�����Aherumi���̂��Ƃ��B
��������Ȃ��Ǝv����B
���A��Google�Ј��̐l�̓��L�i�������̂��Ɓj���Đ^�����n�߂��炵���B
�𗬂����邻���ȁB
���N���炢�����A�̂���胒�`���Ă邯��
����@�o�g�Ƌ���@�o�g�̓��]�o�g���͌��ĂĖʔ����B
�f���炵������Ȃ����B
����herumi���Ɛ킦��Ȃ畉���Ă������͂Ȃ��B
���W�Q���ł�Xbyak��Atom�V���ߑΉ��p�b�`�܂�������Ă�邩���
��������Ȃ��Ǝv����B
���A��Google�Ј��̐l�̓��L�i�������̂��Ɓj���Đ^�����n�߂��炵���B
�𗬂����邻���ȁB
���N���炢�����A�̂���胒�`���Ă邯��
����@�o�g�Ƌ���@�o�g�̓��]�o�g���͌��ĂĖʔ����B
�f���炵������Ȃ����B
����herumi���Ɛ킦��Ȃ畉���Ă������͂Ȃ��B
���W�Q���ł�Xbyak��Atom�V���ߑΉ��p�b�`�܂�������Ă�邩���
702 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 04:29:35
�܂Ă�
60�{�]�X���āE�E�E���̃J�L�R�����o�̏������Ȃ��E�E�E��������
�܂����̐l�͉��̓��L�ǂ�ł邩���
60�{�]�X���āE�E�E���̃J�L�R�����o�̏������Ȃ��E�E�E��������
�܂����̐l�͉��̓��L�ǂ�ł邩���
703 �F�f�t�H���g�̖����������F2009/01/22(��) 04:46:51
��[�A�킩���B�N����H > real google �̐l
&���L�X�V���Ă���ˁB15cycle �� latency �̘b�����ǁA
6cycle �Ȃ͖̂��ߎ��s�� LS �ɔ��f�����܂ł� latency
������A���߉��߂�� register file ����e���Z��� latch
�ւ̓]���Ƃ��� 15cycle �Ƃ͕ʕ�����[�B�}�W������w
&���L�X�V���Ă���ˁB15cycle �� latency �̘b�����ǁA
6cycle �Ȃ͖̂��ߎ��s�� LS �ɔ��f�����܂ł� latency
������A���߉��߂�� register file ����e���Z��� latch
�ւ̓]���Ƃ��� 15cycle �Ƃ͕ʕ�����[�B�}�W������w
704 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 04:51:42
��������イherumi�������L�̃l�^�ɂ��Ă邶��Ȃ���
�q���g�F�uyajit�v
�q���g�F�uyajit�v
�������߂ăA�Z���u���G�������@��MMX�ʼn摜�����������I�ŁA
�ւ�݂���̃T�C�g�ɎU�X�����b�ɂȂ����B
�Ȃ��S�[���ȁ[�B
�ւ�݂���̃T�C�g�ɎU�X�����b�ɂȂ����B
�Ȃ��S�[���ȁ[�B
>>704
�`�[���Q��^��ICFP�v���R���ŁA�l�ŏ�ʂ�������Ⴄ���̕��ł��ˁA�킩��܂��B
�`�[���Q��^��ICFP�v���R���ŁA�l�ŏ�ʂ�������Ⴄ���̕��ł��ˁA�킩��܂��B
707 �F�f�t�H���g�̖����������F2009/01/22(��) 16:11:09
�������T�{���̃^�~�t�����A���̂����ƂȂ�����
708 �F�f�t�H���g�̖����������F2009/01/22(��) 16:16:48
�Ă�o�Ă����܂�����I��
709 �F�f�t�H���g�̖����������F2009/01/22(��) 20:26:42
�����[�A13 ��˂� orz
13�������Ă��Ă�̂��������ЂȂ��E�E�E
693�A���A������13���ĂāA227��709��13��
693�A���A������13���ĂāA227��709��13��
>>640
>������UNIX crypt(3)�̃n�b�V���l����L�[���_�C���N�g��
>���߂�A���S���Y���ł��𖾂��ĉ������悗����
�Í������ƃ����e�J���������͕ʕ����Ɖ��x�������Ă��邾��o�J
>>647
>�܂��Ƃ肠�����]�����_�̓u���O�ł��B
�u���O�ɏ����قǂ̓��e�ł��Ȃ����炱���ɏ����Ă���킯������
>>657
>�e�[�u���̃I�t�Z�b�g���A�h���X�����߂Ēl�����[�h����̂��u���Z�v�ł��B
����͒ɂ����邾��Btempering �����`�ʑ��Ȃ킯�����B
>>683
>����ɔ�ׂ�����Ƃ�܂��V��݂����Ȃ���B
�V��̈Ӗ��m���Ă�H
>������UNIX crypt(3)�̃n�b�V���l����L�[���_�C���N�g��
>���߂�A���S���Y���ł��𖾂��ĉ������悗����
�Í������ƃ����e�J���������͕ʕ����Ɖ��x�������Ă��邾��o�J
>>647
>�܂��Ƃ肠�����]�����_�̓u���O�ł��B
�u���O�ɏ����قǂ̓��e�ł��Ȃ����炱���ɏ����Ă���킯������
>>657
>�e�[�u���̃I�t�Z�b�g���A�h���X�����߂Ēl�����[�h����̂��u���Z�v�ł��B
����͒ɂ����邾��Btempering �����`�ʑ��Ȃ킯�����B
>>683
>����ɔ�ׂ�����Ƃ�܂��V��݂����Ȃ���B
�V��̈Ӗ��m���Ă�H
�ǂ����c�q�����ł��Ȃ����낤���狳���Ă���B
���̑O�� md5sum = 770e20e29056b7e5d420fc46bdc5ee6a
>>637
>��ŁA���ア�q�͉��Z���߂�XOR��AND�ɕ������ă\�t�g�I��
>���Z��������Ǝv���Ă邾��H
>���W�X�^�����H�ނ��냁���������H
���O�����܂���������ĉ��ƈꏏ�ɂ���ȁB
���l�̕\�L�@�� n �i�\�L��������Ȃ����H
�~�����̂� 2 �i�\�L�� sum �Ȃ킯�����A�ŏI�I�ɕϊ��\��
����Γr���o�߂̕\�L�@�͉������č\��Ȃ��B��Ԃ����Ă����B
���Ȃ̂́Amod 2^32 ���K���A�̂ł͂Ȃ����Ƃ��B
���̑O�� md5sum = 770e20e29056b7e5d420fc46bdc5ee6a
>>637
>��ŁA���ア�q�͉��Z���߂�XOR��AND�ɕ������ă\�t�g�I��
>���Z��������Ǝv���Ă邾��H
>���W�X�^�����H�ނ��냁���������H
���O�����܂���������ĉ��ƈꏏ�ɂ���ȁB
���l�̕\�L�@�� n �i�\�L��������Ȃ����H
�~�����̂� 2 �i�\�L�� sum �Ȃ킯�����A�ŏI�I�ɕϊ��\��
����Γr���o�߂̕\�L�@�͉������č\��Ȃ��B��Ԃ����Ă����B
���Ȃ̂́Amod 2^32 ���K���A�̂ł͂Ȃ����Ƃ��B
���[�v�̓������K���A�̂ŁA�O�����K���A�̂ł͂Ȃ�������A
�����v������͔̂�������낤�B��������A2^33 �̃K���A
�g��̂̏�Ōv�����Ă݂悤�Ƃ������z�ɂ͂Ȃ��̂����H
33 �� M �n��̐��������� (33, 13) ���g���A�\�����p�I���B
���̌n�� 1 ���v��������@���l����Ζ��炩�B
�O���̃��[�v�� ^= �ɂȂ�������H
>>628
>���u���蓾�Ȃ�����������o���v
�n�����B
�����炨�O�ł��A�K���A�g��̏�ł̌v����O��Ƃ��Ă����A
tempering �����[�v�̊O���ɏo���邱�Ƃ������l����킩�邾��H
�����āA�Ō�ɃV���h���[���v�Z����� 2 �i�\�L�ɖ߂���B
�����v������͔̂�������낤�B��������A2^33 �̃K���A
�g��̂̏�Ōv�����Ă݂悤�Ƃ������z�ɂ͂Ȃ��̂����H
33 �� M �n��̐��������� (33, 13) ���g���A�\�����p�I���B
���̌n�� 1 ���v��������@���l����Ζ��炩�B
�O���̃��[�v�� ^= �ɂȂ�������H
>>628
>���u���蓾�Ȃ�����������o���v
�n�����B
�����炨�O�ł��A�K���A�g��̏�ł̌v����O��Ƃ��Ă����A
tempering �����[�v�̊O���ɏo���邱�Ƃ������l����킩�邾��H
�����āA�Ō�ɃV���h���[���v�Z����� 2 �i�\�L�ɖ߂���B
>>631
>�����A���Ȃ݂ɍŏ����炢��1�r�b�g�~128����̃r�b�g�X���C�X
>�����v���������ǑS�R�����Ȃ�������B
�n���͂����Œ��߂�B
�K���A�g��̏�ł̌v���́A�r�b�g�X���C�X�ōs��������������
�ǂ��͖��炩�B���Amt[] �̍X�V���r�b�g�X���C�X�ōs���̂͂�������
������B����́AMT �� "�r�b�g�X���C�X�ł͂Ȃ�" �v�Z�@�ł̌�����
�_�������̂Ȃ̂œ��R�Ƃ����Γ��R�B
�r�b�g�X���C�X�ł͂Ȃ��v�Z�@�ň���������I�Ȑ��`�ʑ��́A
�s�� [[0ii,0ij]T,[Iij,Ojj]T] (�܂�r�b�g�V�t�g) �̊|���Z��
�v�f�ǂ����̊|���Z(AND)�Ƒ����Z(XOR)�A���̑g�ݍ��킹���B
����ɑ��āA�r�b�g�X���C�X�ň����₷�����`�ʑ��̏����́A
�s�� "1" �̏o���p�x�����Ȃ����́B���ɓ��R�B
�Ȃ�A�ŏ��� mt[] ��ʂ̋�ԂɎʑ����Ă����āA���̋�Ԃ�
�X�V�s��� "1" �����Ȃ��Ȃ�悤�ɐv���������ł�
(���ꂱ���V���)�����͉��P�����B
>�����A���Ȃ݂ɍŏ����炢��1�r�b�g�~128����̃r�b�g�X���C�X
>�����v���������ǑS�R�����Ȃ�������B
�n���͂����Œ��߂�B
�K���A�g��̏�ł̌v���́A�r�b�g�X���C�X�ōs��������������
�ǂ��͖��炩�B���Amt[] �̍X�V���r�b�g�X���C�X�ōs���̂͂�������
������B����́AMT �� "�r�b�g�X���C�X�ł͂Ȃ�" �v�Z�@�ł̌�����
�_�������̂Ȃ̂œ��R�Ƃ����Γ��R�B
�r�b�g�X���C�X�ł͂Ȃ��v�Z�@�ň���������I�Ȑ��`�ʑ��́A
�s�� [[0ii,0ij]T,[Iij,Ojj]T] (�܂�r�b�g�V�t�g) �̊|���Z��
�v�f�ǂ����̊|���Z(AND)�Ƒ����Z(XOR)�A���̑g�ݍ��킹���B
����ɑ��āA�r�b�g�X���C�X�ň����₷�����`�ʑ��̏����́A
�s�� "1" �̏o���p�x�����Ȃ����́B���ɓ��R�B
�Ȃ�A�ŏ��� mt[] ��ʂ̋�ԂɎʑ����Ă����āA���̋�Ԃ�
�X�V�s��� "1" �����Ȃ��Ȃ�悤�ɐv���������ł�
(���ꂱ���V���)�����͉��P�����B
�������A���ꂾ�����ƃr�b�g�X���C�X��p���鍪���Ƃ��Ă͂܂�
�����ア�B����́Amt[] �̃T�C�Y�����W�X�^���Ɣ�r���đ傫��
(load, store ���X�P�W���[������̂����)�̂ƁA"1" �̊�����
���点���Ƃ��Ă��s�̂��傫���̂ŁA�K�R�I�Ɍv�Z�ʂ͑����܂܁B
�����ŁAmt[] ���̂����������邱�Ƃ��l���悤�B
���A�c�O�Ȃ��Ƃ� MT �� mt[](19968 bit)�̂����A19937 bit ��
�������Ă��邱�Ƃ����_�I�ɏؖ�����Ă���B
���āA�ǂ����悤�H
>>640
>�Ȃ�ɂ���10000��num_rand��UINT_MAX������Ȃ�
���������Ă��邶��Ȃ����[���BINT_MAX �����ǂȁB
�܂�A32bit �� seed ����n�܂� 31bit �̋�Ԃ́A19937bit ��
��Ԃ̒��ŁA���ɏ����ȕ�����Ԃł����Ȃ��B
���̏����ȕ�����Ԃł́A19937bit �̑啔�����������Ă��Ȃ��B
�������Ă��Ȃ��r�b�g�́A���ꂱ���v�Z����K�v�͂Ȃ��B
�ۑ�A�i��(����)�̐��̂́A�������Ă��Ȃ��r�b�g��T��������̂�
���Ȃ�Ȃ��B
�����ア�B����́Amt[] �̃T�C�Y�����W�X�^���Ɣ�r���đ傫��
(load, store ���X�P�W���[������̂����)�̂ƁA"1" �̊�����
���点���Ƃ��Ă��s�̂��傫���̂ŁA�K�R�I�Ɍv�Z�ʂ͑����܂܁B
�����ŁAmt[] ���̂����������邱�Ƃ��l���悤�B
���A�c�O�Ȃ��Ƃ� MT �� mt[](19968 bit)�̂����A19937 bit ��
�������Ă��邱�Ƃ����_�I�ɏؖ�����Ă���B
���āA�ǂ����悤�H
>>640
>�Ȃ�ɂ���10000��num_rand��UINT_MAX������Ȃ�
���������Ă��邶��Ȃ����[���BINT_MAX �����ǂȁB
�܂�A32bit �� seed ����n�܂� 31bit �̋�Ԃ́A19937bit ��
��Ԃ̒��ŁA���ɏ����ȕ�����Ԃł����Ȃ��B
���̏����ȕ�����Ԃł́A19937bit �̑啔�����������Ă��Ȃ��B
�������Ă��Ȃ��r�b�g�́A���ꂱ���v�Z����K�v�͂Ȃ��B
�ۑ�A�i��(����)�̐��̂́A�������Ă��Ȃ��r�b�g��T��������̂�
���Ȃ�Ȃ��B
716 �F�f�t�H���g�̖����������F2009/01/22(��) 21:23:46
�����S�T��̊���Ŋ����X��������������
717 �F�f�t�H���g�̖����������F2009/01/22(��) 21:33:32
>>579
�Ȃ�ł���ȑ厖�Ȃ��Ƃ炵���Ⴄ�́H��
�Ȃ�ł���ȑ厖�Ȃ��Ƃ炵���Ⴄ�́H��
�ꉞ�A�݂�Ȕ����Ă�Ǝv�����AHack the Cell �̉ۑ肪�����m�F���Ă����B
ttp://cell.fixstars.com/challenge/challenge.html
�ۑ�́A�����Z���k�E�c�C�X�^�̍œK���ł��B
���ӎ���
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
ttp://cell.fixstars.com/challenge/challenge.html
�ۑ�́A�����Z���k�E�c�C�X�^�̍œK���ł��B
���ӎ���
����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
719 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 21:39:22
��̂Ȃ����@���肪�Ȃ��Ɗ����\�͂����������l�Ԃ̉��i���͂ނȂ����̂�
720 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 21:42:03
721 �F�f�t�H���g�̖����������F2009/01/22(��) 21:45:16
>>710
����H202 �� 13 ���Ă��́H >>598-599 �̂���茩�āA
�܂����ĂȂ��Ǝv���Ă��悗
>>720
������ >>599 �����Ă͂܂�Ƃ����Ȃ��́H��
����H202 �� 13 ���Ă��́H >>598-599 �̂���茩�āA
�܂����ĂȂ��Ǝv���Ă��悗
>>720
������ >>599 �����Ă͂܂�Ƃ����Ȃ��́H��
�A�����e����������������
�Ō�ɁA�[�����ǂ����邩���B
���̑O�ɁA���Ă����B���̃A�i���͂������Z�t�F�[�Y�ɓ��������H
��������� pmt[] �̍ň��l�����ς���n�߂������珟�Z�͂�����
�킯�����A��͌��ʂ�����Ƒz���ȏ�ɏ������B
���ꂪ�����Ӗ����邩�킩��ȁH
���ɁAmt[](pmt[]) �̍X�V�͂ق� O(rn^2) �̃R�X�g�ł��邱�ƁB
r �͐��`�ʑ��s��Ɋ܂܂�� "1" �̊����Bn �͍s��̃T�C�Y�B
���ɁApmt[] ����v���x�N�g���ւ̎ʑ��s��� N-1 ��ނ܂�܂�
�p�ӂ��Ă��������T�C�Y�I�ɗ]�T���ł������ƁB
���܂���}�l���悤�Ƃ��Ă��A��͂̕��@�Ȃ�đz�������Ȃ�����H
���O�͂������� 59ms �A�i���ł��ƂȂ����S���T���ł����Ă��낗
���[�āA���낻������ł��n�߂܂���������
�Ō�ɁA�[�����ǂ����邩���B
���̑O�ɁA���Ă����B���̃A�i���͂������Z�t�F�[�Y�ɓ��������H
��������� pmt[] �̍ň��l�����ς���n�߂������珟�Z�͂�����
�킯�����A��͌��ʂ�����Ƒz���ȏ�ɏ������B
���ꂪ�����Ӗ����邩�킩��ȁH
���ɁAmt[](pmt[]) �̍X�V�͂ق� O(rn^2) �̃R�X�g�ł��邱�ƁB
r �͐��`�ʑ��s��Ɋ܂܂�� "1" �̊����Bn �͍s��̃T�C�Y�B
���ɁApmt[] ����v���x�N�g���ւ̎ʑ��s��� N-1 ��ނ܂�܂�
�p�ӂ��Ă��������T�C�Y�I�ɗ]�T���ł������ƁB
���܂���}�l���悤�Ƃ��Ă��A��͂̕��@�Ȃ�đz�������Ȃ�����H
���O�͂������� 59ms �A�i���ł��ƂȂ����S���T���ł����Ă��낗
���[�āA���낻������ł��n�߂܂���������
723 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 21:50:46
>>721
�P����MT�̎���MT��32�r�b�g�~4���������̂ł͂Ȃ��Ƃ������Ƃ���B
�z���ԂƃT�}���̒l�������ɂȂ�͈͂ō������o������@�͑S�ċ�g���Ă�B
������邱�Ƃ͏I����Ă����������悩�ȁB
�����I�ɃX�J�X�J�ȕ������������肷��̂Ń��[�v�S�̂����Ė��ߐ�������悤�Ƀo�����X�������K�v���B
�P����MT�̎���MT��32�r�b�g�~4���������̂ł͂Ȃ��Ƃ������Ƃ���B
�z���ԂƃT�}���̒l�������ɂȂ�͈͂ō������o������@�͑S�ċ�g���Ă�B
������邱�Ƃ͏I����Ă����������悩�ȁB
�����I�ɃX�J�X�J�ȕ������������肷��̂Ń��[�v�S�̂����Ė��ߐ�������悤�Ƀo�����X�������K�v���B
>������邱�Ƃ͏I����Ă����������悩�ȁB
�V�䂶��Ȃ������̂���
�V�䂶��Ȃ������̂���
726 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 21:52:40
>>722
����̋�_�͌��ʂ��o���Ă��猾�����Ƃ�
����̋�_�͌��ʂ��o���Ă��猾�����Ƃ�
727 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 21:53:13
>>724������Ƃ���
728 �F�f�t�H���g�̖����������F2009/01/22(��) 21:53:27
729 �F�f�t�H���g�̖����������F2009/01/22(��) 22:00:14
����>>579����������
���Ȃ��Ƃ��c�_�̑�ɏ������
�����H�w�n�����班�Ȃ��Ƃ����n�ł͂�������������Ă�̂��S���킩���
�Ƃ肠�����T�C�N���̘b�͂���܂肵�Ȃ����������Ƃ�����
�T�C�N���̘b���������łǂ��̍œK������ĂĂǂ��̍œK������ĂȂ����z���ł��邵
���Ȃ��Ƃ��c�_�̑�ɏ������
�����H�w�n�����班�Ȃ��Ƃ����n�ł͂�������������Ă�̂��S���킩���
�Ƃ肠�����T�C�N���̘b�͂���܂肵�Ȃ����������Ƃ�����
�T�C�N���̘b���������łǂ��̍œK������ĂĂǂ��̍œK������ĂȂ����z���ł��邵
730 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:00:24
������579���A�{�[�����X�g�ɒlj����Ƃ�����
�ނ͑S�R���ɗ����Ȃ����Ƃ��������ĂȂ��B
�܂������Ȃ��G�Ɛ���Ă�n�������瑊��ɂ����
�ނ͑S�R���ɗ����Ȃ����Ƃ��������ĂȂ��B
�܂������Ȃ��G�Ɛ���Ă�n�������瑊��ɂ����
>>717
�ǂ����c�q�����ł��Ȃ�����H
>>718
>����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ���
>������������������B
���������āu�����v�Ƃ��邩�A���B
tempering �O�̐��l�� tempering ��̐��l���A�\�L�@��
�قȂ邾���ŁA�������l�Ȃ킯���Btempering ��������
�����e�J�����ɗp�����ł͍D�s���Ȏ��������̂�
���Ă��邾���B
>3. ����Ƃ��`�F�b�N�T�����������Ă�Ȃ�ł��A���Ȃ̂��A
>1. �v���O��������mt[]�̓��e���v�Z���Ă�����ǂ��̂��A
>2. �S����word�ɂ���tempering��̒l���v�Z���Ă��Ȃ��Ƃ����Ȃ��̂��A
���ꂪ 2 ��������A�o��҂����̈Ӑ}�������Ă��Ȃ��� orz
1 �̔��f�͔��������A���� 1 ���Ƃ���Ƃł��鎖�͌����Ă���A
�܂肻��ȃR���e�N���o�Ă����ʂ͈ꏏ�B�c�}���l�B
�ǂ����c�q�����ł��Ȃ�����H
>>718
>����������́A�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ���
>������������������B
���������āu�����v�Ƃ��邩�A���B
tempering �O�̐��l�� tempering ��̐��l���A�\�L�@��
�قȂ邾���ŁA�������l�Ȃ킯���Btempering ��������
�����e�J�����ɗp�����ł͍D�s���Ȏ��������̂�
���Ă��邾���B
>3. ����Ƃ��`�F�b�N�T�����������Ă�Ȃ�ł��A���Ȃ̂��A
>1. �v���O��������mt[]�̓��e���v�Z���Ă�����ǂ��̂��A
>2. �S����word�ɂ���tempering��̒l���v�Z���Ă��Ȃ��Ƃ����Ȃ��̂��A
���ꂪ 2 ��������A�o��҂����̈Ӑ}�������Ă��Ȃ��� orz
1 �̔��f�͔��������A���� 1 ���Ƃ���Ƃł��鎖�͌����Ă���A
�܂肻��ȃR���e�N���o�Ă����ʂ͈ꏏ�B�c�}���l�B
732 �F�f�t�H���g�̖����������F2009/01/22(��) 22:06:35
�n�C�@�����炢�B
http://pc11.2ch.net/test/read.cgi/tech/1158559031/l50
SSE���s�ł��Ȃ�Cell��SSE�̎����������Ƃ����s���̏u�Ԃ���������
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
����Ȋ����ŌJ��Ԃ��Έꉞ�����̃��C�e���V�͌v���ł�����
�ŁA���N���b�N������̂��ȁH
�����ĂˁB����蓪�����q�Ȃ炷���킩��͂��B
�����Ƃ����͎������ʂ��邯��
866 ���O�F �f�t�H���g�̖��������� [sage] ���e���F 2007/06/17(��) 16:26:12
Cell��SSE����
http://pc11.2ch.net/test/read.cgi/tech/1158559031/l50
SSE���s�ł��Ȃ�Cell��SSE�̎����������Ƃ����s���̏u�Ԃ���������
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
movd xmm0, eax
movd eax, xmm0
����Ȋ����ŌJ��Ԃ��Έꉞ�����̃��C�e���V�͌v���ł�����
�ŁA���N���b�N������̂��ȁH
�����ĂˁB����蓪�����q�Ȃ炷���킩��͂��B
�����Ƃ����͎������ʂ��邯��
866 ���O�F �f�t�H���g�̖��������� [sage] ���e���F 2007/06/17(��) 16:26:12
Cell��SSE����
>>721
>>689�͒�������B
���\��J���ăA�Z���u�����������ˁB
>>721(=>>693?)����������Atempering��̒l���܂��߂Ɍv�Z����
add ���J��Ԃ��Ă��Ȃ��̂��E�E�E
�Ƃ肠�����A�`�F�b�N�T�����������Ă��OK�Ȃ̂��u���Ă݂āA
OK�Ȃ�܂��������ɒ��킵�Ă݂��B
>>689�͒�������B
���\��J���ăA�Z���u�����������ˁB
>>721(=>>693?)����������Atempering��̒l���܂��߂Ɍv�Z����
add ���J��Ԃ��Ă��Ȃ��̂��E�E�E
�Ƃ肠�����A�`�F�b�N�T�����������Ă��OK�Ȃ̂��u���Ă݂āA
OK�Ȃ�܂��������ɒ��킵�Ă݂��B
735 �F�f�t�H���g�̖����������F2009/01/22(��) 22:09:26
693������tempering�͖������Ă�
�Ƃ�����������7����tempering
��������
�Ƃ�����������7����tempering
��������
736 �F�f�t�H���g�̖����������F2009/01/22(��) 22:15:59
�b�̍�������ň�����
tempering���ĂȂH
tempering���ĂȂH
737 �F�f�t�H���g�̖����������F2009/01/22(��) 22:17:17
���ނ�!��
738 �F�f�t�H���g�̖����������F2009/01/22(��) 22:20:06
���ŏo�Ă���������32bit��Ԃŕ肪�����l�ɍă}�b�s���O���Ă�Ə���Ɏv���Ă�
739 �F�f�t�H���g�̖����������F2009/01/22(��) 22:21:20
�}�[�W�����p��ł�
�e���p�C ���y���v�z
�����ŁA���ƈꖇ�K�v�Ȕv����������邱�Ƃ̂ł����ԁB
���ꂪ�A�]���ĉ������𐬂������悤�Ƃ����Ƃ��̍ŏI�i�K�A�A�҂��̏�ԂɂȂ����Ƃ��Ɏg���P�[�X������܂��B
�Ă�ς�A�Ă�ς��Ă�B
�X�^����i�X�^���o�C����j�A�A�ȂǂƓ����a����ł��ˁB
�e���p�C ���y���v�z
�����ŁA���ƈꖇ�K�v�Ȕv����������邱�Ƃ̂ł����ԁB
���ꂪ�A�]���ĉ������𐬂������悤�Ƃ����Ƃ��̍ŏI�i�K�A�A�҂��̏�ԂɂȂ����Ƃ��Ɏg���P�[�X������܂��B
�Ă�ς�A�Ă�ς��Ă�B
�X�^����i�X�^���o�C����j�A�A�ȂǂƓ����a����ł��ˁB
���Ă��āB
����Â����Ǝv���Ă������A�c�q�o��B�c�q�͂���قlj���
�A�i�����D���ȂȂ��@���ނ���Q���ݏP���Ă���Ȃ�B
���̎�̍�킾�Ǝ�������ɂ����������������킯�����A
���ʏo���o���E���Z�[������邩��A���͂��낻������n�߂�
���Ƃɂ����B
���̑O�ɃN�\���ĐQ��B
����Â����Ǝv���Ă������A�c�q�o��B�c�q�͂���قlj���
�A�i�����D���ȂȂ��@���ނ���Q���ݏP���Ă���Ȃ�B
���̎�̍�킾�Ǝ�������ɂ����������������킯�����A
���ʏo���o���E���Z�[������邩��A���͂��낻������n�߂�
���Ƃɂ����B
���̑O�ɃN�\���ĐQ��B
741 �F�f�t�H���g�̖����������F2009/01/22(��) 22:23:20
742 �F�f�t�H���g�̖����������F2009/01/22(��) 22:27:12
���������ςɁAMT�ŗ��������ׂ̈ɍs���A���S���Y���Ńr�b�g�V�t�g���s������̂��Ƃ���
tempering
tempering
743 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:30:00
>>729
�Í��_�̐��E�ɂ�������ǖ@�Ȃ�Ă̂������āA�r�b�g�̕��т̓������牉�Z���V���[�g�J�b�g����
���@�Ɋւ��Ă͉����g�����낢�뎎�������Ƃ������ĂˁB
��ŁA����͂��������V���[�g�J�b�g�͑S�������Ė��ɗ����Ȃ��B
MT��Tempering�̓t�F�C�X�e�C���^�Í��ł����Ƃ���̈���S-box�݂����Ȃ��B
RISC�I�y���[�V������10���ߒ��x�̃r�b�g�_�����Z�ō\���ł���Ƃ͂����A
�����������܂���Ƀr�b�g���炯��悤�ɍl���Ă���B
���Z���Ă��A�ȈՓI�ɂ�XOR��AND�̑g�ݍ��킹�ō���킯�����ǁA
�L�����[�A�b�v��́A1�r�b�g�ׂ����B
Tempering�O�ƌザ�Ⴛ��1�r�b�g�ׂ���S�R�ʕ��ɂȂ����Ⴄ��ˁB
������Tempering�O�̒l��������u���Z�v���Ă����Ӗ��ȂB
Tempering�͏��Ȃ����ߐ��Ȃ���A���܂��l���Ă���Ǝv����B
�Í��̎����̘b�ɂȂ邯�ǁAAltiVec��VPERM��SPU��SHUFB��AES��S-Box��16����ŏ�������
���Ƃ��ł��邯�ǁASSE���Ɠ��l�̃V���b�t�����߂ł���pshufb���߂Ȃ��g�����ʂ̕��@�̂ق��������B
����̉ۑ�͂��������ϓ_�ʼn����œK�ȃA���S���Y�������l������l�łȂ��Ɠ���Ǝv���B
�Í��_�̐��E�ɂ�������ǖ@�Ȃ�Ă̂������āA�r�b�g�̕��т̓������牉�Z���V���[�g�J�b�g����
���@�Ɋւ��Ă͉����g�����낢�뎎�������Ƃ������ĂˁB
��ŁA����͂��������V���[�g�J�b�g�͑S�������Ė��ɗ����Ȃ��B
MT��Tempering�̓t�F�C�X�e�C���^�Í��ł����Ƃ���̈���S-box�݂����Ȃ��B
RISC�I�y���[�V������10���ߒ��x�̃r�b�g�_�����Z�ō\���ł���Ƃ͂����A
�����������܂���Ƀr�b�g���炯��悤�ɍl���Ă���B
���Z���Ă��A�ȈՓI�ɂ�XOR��AND�̑g�ݍ��킹�ō���킯�����ǁA
�L�����[�A�b�v��́A1�r�b�g�ׂ����B
Tempering�O�ƌザ�Ⴛ��1�r�b�g�ׂ���S�R�ʕ��ɂȂ����Ⴄ��ˁB
������Tempering�O�̒l��������u���Z�v���Ă����Ӗ��ȂB
Tempering�͏��Ȃ����ߐ��Ȃ���A���܂��l���Ă���Ǝv����B
�Í��̎����̘b�ɂȂ邯�ǁAAltiVec��VPERM��SPU��SHUFB��AES��S-Box��16����ŏ�������
���Ƃ��ł��邯�ǁASSE���Ɠ��l�̃V���b�t�����߂ł���pshufb���߂Ȃ��g�����ʂ̕��@�̂ق��������B
����̉ۑ�͂��������ϓ_�ʼn����œK�ȃA���S���Y�������l������l�łȂ��Ɠ���Ǝv���B
744 �F�f�t�H���g�̖����������F2009/01/22(��) 22:31:58
> �t�F�C�X�e�C���^�Í��ł����Ƃ���̈���S-box�݂����Ȃ��B
���E���E��
���E���E��
745 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:34:09
746 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:36:08
>>744
������t�F�C�X�e�C���^�Í���S-box�̓r�b�g�_�����Z�̑g�ݍ��킹�����Ŏ����ł���̒m���Ă�H
������t�F�C�X�e�C���^�Í���S-box�̓r�b�g�_�����Z�̑g�ݍ��킹�����Ŏ����ł���̒m���Ă�H
747 �F�f�t�H���g�̖����������F2009/01/22(��) 22:37:44
�����ӂ� bitslice ���H�@����� s-box �̈Ӌ`�͑S�R�ʕ������H
748 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:39:16
�t�F�C�X�e�C���^�Í��ɂ�����S-box�̖����́A�ȒP�Ɍ����ƑO��̃r�b�g�̕��т̑�����j�邽�߂̎d�g�݁B
MT��Tempering���ATempering���Ȃ��č��v�l���v�Z���悤�Ƃ��Ă��o���Ȃ��悤�ɂ�����x�ɂ͑�����j��ł��Ă�B
MT��Tempering���ATempering���Ȃ��č��v�l���v�Z���悤�Ƃ��Ă��o���Ȃ��悤�ɂ�����x�ɂ͑�����j��ł��Ă�B
749 �F�f�t�H���g�̖����������F2009/01/22(��) 22:45:37
�����A�Í����[���������g�U���ĈӖ��ł͂Ȃ��Ċg�U�����A
�قƂ�ǂ��_�����Z�̑g�ݍ��킹�Ŏ����ł��邾�낤��B
���̒��x�̈Ӗ��ŁAfeistel �� s-box �Ɠ������Č������̂��H
�قƂ�ǂ��_�����Z�̑g�ݍ��킹�Ŏ����ł��邾�낤��B
���̒��x�̈Ӗ��ŁAfeistel �� s-box �Ɠ������Č������̂��H
750 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 22:53:59
Tempering���u�����v
�X�C�[�c�i�j�p��ł����ƃ`���R���[�g�R�[�e�B���O�̕\�ʂ����炩�ɂ��邽�߂̍s���B
�������A���̂܂�܂̈Ӗ��ʼn��߂��Ă��Ӗ��͂Ȃ��B
�r�b�g�̕��т̑�����������x�j�邱�ƂɈӖ�������B
MT�ɂ����ẮA���ւ�j�邱�Ƃ��A�r�b�g�̏o���m���̋ψꉻ�iTempering�j�ɂȂ�B
S-Box��S��substitution
�悤����Ƀe�[�u�����b�N�A�b�v�Ȃ킯�����B
��������Tempering��S-box�͕ʂ̒P�ꂾ���A���t�����̂܂ܑ����Ă��Ӗ��͂Ȃ��B
�{���𗝉����Ȃ��Ƃ����Ȃ��B
�e�[�u�����b�N�A�b�v���g��Ȃ��Í��E�n�b�V���A���S���Y���̎����ł�
�قƂ��MT��Tempering�݂����ȊȒP�ȃV�t�g�{�r�b�g�_�����Z������Ă�B
������{���I�ɓ��������Č�������B
�X�C�[�c�i�j�p��ł����ƃ`���R���[�g�R�[�e�B���O�̕\�ʂ����炩�ɂ��邽�߂̍s���B
�������A���̂܂�܂̈Ӗ��ʼn��߂��Ă��Ӗ��͂Ȃ��B
�r�b�g�̕��т̑�����������x�j�邱�ƂɈӖ�������B
MT�ɂ����ẮA���ւ�j�邱�Ƃ��A�r�b�g�̏o���m���̋ψꉻ�iTempering�j�ɂȂ�B
S-Box��S��substitution
�悤����Ƀe�[�u�����b�N�A�b�v�Ȃ킯�����B
��������Tempering��S-box�͕ʂ̒P�ꂾ���A���t�����̂܂ܑ����Ă��Ӗ��͂Ȃ��B
�{���𗝉����Ȃ��Ƃ����Ȃ��B
�e�[�u�����b�N�A�b�v���g��Ȃ��Í��E�n�b�V���A���S���Y���̎����ł�
�قƂ��MT��Tempering�݂����ȊȒP�ȃV�t�g�{�r�b�g�_�����Z������Ă�B
������{���I�ɓ��������Č�������B
751 �F�f�t�H���g�̖����������F2009/01/22(��) 23:07:52
>�e�[�u�����b�N�A�b�v���g��Ȃ��Í��E�n�b�V���A���S���Y���̎����ł�
>�قƂ��MT��Tempering�݂����ȊȒP�ȃV�t�g�{�r�b�g�_�����Z������Ă�B
�ց[�A�������Ȃ��B����ALUT ���g��Ȃ��������W���Ƃ��v��Ȃ��ق����������H
�Í�����Ă���͊ȒP�ȃV�t�g�{�r�b�g�_�����Z�ŋ��߂��Ȃ��悤�� sbox ��
�������Ă�̂ɁA�Ȃ��z�ɂȂ��Ă����Ⴄ��B
�܂��m���ɖ{���I�ɂ͗����g�U�����瓯�������Ȃ�
>�قƂ��MT��Tempering�݂����ȊȒP�ȃV�t�g�{�r�b�g�_�����Z������Ă�B
�ց[�A�������Ȃ��B����ALUT ���g��Ȃ��������W���Ƃ��v��Ȃ��ق����������H
�Í�����Ă���͊ȒP�ȃV�t�g�{�r�b�g�_�����Z�ŋ��߂��Ȃ��悤�� sbox ��
�������Ă�̂ɁA�Ȃ��z�ɂȂ��Ă����Ⴄ��B
�܂��m���ɖ{���I�ɂ͗����g�U�����瓯�������Ȃ�
752 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 23:30:18
>>751
RSA��Rivest Cipher(RC)�V���[�Y�Ƃ�MD5�Ȃ��S-box���g�킸�ɃX���b�v���J��Ԃ�
�Í��E�n�b�V���A���S���Y���̑�\�i�Ȃ킯�����H
RC6��AES�̍ŏI���܂Ŏc�������B
RSA��Rivest Cipher(RC)�V���[�Y�Ƃ�MD5�Ȃ��S-box���g�킸�ɃX���b�v���J��Ԃ�
�Í��E�n�b�V���A���S���Y���̑�\�i�Ȃ킯�����H
RC6��AES�̍ŏI���܂Ŏc�������B
753 �F�f�t�H���g�̖����������F2009/01/22(��) 23:36:19
�Ȃ�Ō����ݗ����Ă��āA�� feistel �����Ȃ̂��l���悤����
754 �F�f�t�H���g�̖����������F2009/01/22(��) 23:37:45
755 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 23:42:56
>>754
�Œ�������邱�Ƃ́ASPU�ɂ͔C�ӂ̈ʒu�̃r�b�g�ɃL�����[�A�b�v���Ă����悤�ȓ���ȎZ�p���Z���߂͂Ȃ��Ƃ������Ƃ��B
�܂������������Ƃ��B
�n�[�h�E�F�A�ɕs�����Ȃ��Ƃ���点�Đ��\���o�����Ƃ��������ԈႢ�B
�Œ�������邱�Ƃ́ASPU�ɂ͔C�ӂ̈ʒu�̃r�b�g�ɃL�����[�A�b�v���Ă����悤�ȓ���ȎZ�p���Z���߂͂Ȃ��Ƃ������Ƃ��B
�܂������������Ƃ��B
�n�[�h�E�F�A�ɕs�����Ȃ��Ƃ���点�Đ��\���o�����Ƃ��������ԈႢ�B
756 �F�f�t�H���g�̖����������F2009/01/22(��) 23:49:49
�Ȃ��悭�킩��܂��A�悭�킩��܂����B
���肪�Ƃ��������܂����B
���肪�Ƃ��������܂����B
757 �F,,�E�L�́M�E,,�j��-�������F2009/01/22(��) 23:55:21
�W�Ȃ�����JNB�̃g�[�N�����ĈÍ��`���Ȃ��������H
758 �F�f�t�H���g�̖����������F2009/01/22(��) 23:59:44
���낻���k�ق́��������ŁY�Ă���
759 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 00:06:08
>>753
������AES�����A�ɒ��������B
AES�����E�I�ɑI��Ă�̂�AES��AES�����炾�B
AES�ɑI��Ȃ�����feistel�Í��̐M������ۏ��鍪���ɂ���̂͊ԈႢ���ȁB
�Ƃ����Ɏ��͂���DES�����̂������^�C���p�X���[�h�Ƃ��Č����Ŏg���Ă��肷�邭�炢�����B
���̃��x���Ō����Ȃ�MD5��RC4�����Ė����Ɏg���Ă���B
i�����Ȃ��j���e���h�[DS����Wi-Fi��WEP�iRC4�j������������������
����ɔ�ׂ���Y�Í���MISTY�Ƃ�Camellia�Ȃ�Ă܂��܂��}�C�i�[���B
���䂳��ɂ͈������B
������AES�����A�ɒ��������B
AES�����E�I�ɑI��Ă�̂�AES��AES�����炾�B
AES�ɑI��Ȃ�����feistel�Í��̐M������ۏ��鍪���ɂ���̂͊ԈႢ���ȁB
�Ƃ����Ɏ��͂���DES�����̂������^�C���p�X���[�h�Ƃ��Č����Ŏg���Ă��肷�邭�炢�����B
���̃��x���Ō����Ȃ�MD5��RC4�����Ė����Ɏg���Ă���B
i�����Ȃ��j���e���h�[DS����Wi-Fi��WEP�iRC4�j������������������
����ɔ�ׂ���Y�Í���MISTY�Ƃ�Camellia�Ȃ�Ă܂��܂��}�C�i�[���B
���䂳��ɂ͈������B
760 �F�f�t�H���g�̖����������F2009/01/23(��) 00:11:09
��H DES �� Feistel ����H MISTY1 �� Camellia �� NESSIE �Ƃ��Ă邪�B
�� MD5 �� RC4 �����ꂩ��V�K�ɍ̗p����K�i������������������H
�� MD5 �� RC4 �����ꂩ��V�K�ɍ̗p����K�i������������������H
761 �F�f�t�H���g�̖����������F2009/01/23(��) 00:17:04
���Ȃ݂ɁASHA-3 �R���y�ł� feistel �g���Ă邼��
762 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 00:18:28
������O�̂��ƌ����Ăǂ����B�����l���Ă��̂������B
���������ɏo���Ȃ�RC6�����肾��B
Rijndael��AES�ɑI�ꂽ�̂͂��̈�Ƃ���DES�݂����ȕ��G�ȃr�b�g�V���b�t�����Z���Ȃ���
��p�n�[�h�E�F�A�łȂ��Ă������R�X�g���y�����炾�B
�ʂ�RC6�̈Í����x���ے肳�ꂽ�킯�ł͂Ȃ��B
���������ɏo���Ȃ�RC6�����肾��B
Rijndael��AES�ɑI�ꂽ�̂͂��̈�Ƃ���DES�݂����ȕ��G�ȃr�b�g�V���b�t�����Z���Ȃ���
��p�n�[�h�E�F�A�łȂ��Ă������R�X�g���y�����炾�B
�ʂ�RC6�̈Í����x���ے肳�ꂽ�킯�ł͂Ȃ��B
763 �F�f�t�H���g�̖����������F2009/01/23(��) 00:30:55
���܂�A������Ɠǂ݈Ⴆ�Ă��B���A���Ԃ��Ȃ��B�܂����xw
���A���� RC6 �̈Í����x��ے肷�����͖ѓ��Ȃ���B
���A���� RC6 �̈Í����x��ے肷�����͖ѓ��Ȃ���B
764 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 00:33:43
���������ʂ�LUT���r�b�g���Z�̂ق����R�X�g�p�t�H�[�}���X���D��Ă�Ȃ�Č����C�͂Ȃ��B
�s��
�����Tempering��ʂ��O�ɃT�}���v�Z���o���邩�ǂ�������
���p�I�Ȍv�Z���Ԃ��͂����o���̂́u�����v�ƌ����郌�x���̑����̔j��͒B���ł��Ă�Ƃ����̂�
���̌����B
���l�͍��Y�Í��}���Z�[�̗���Ȃ̂ŌN�ɕt��������RSA�̕���̗i�삷��C���Ȃ��B
���Ȃ݂�SHA-3���Ƃ��ĉ������ڂ��Ă�̂͂���
http://ehash.iaik.tugraz.at/uploads/5/5c/Lesamnta.pdf
������AES�͌����ɂ�SPNS�ł�����Feistel�ɂ͕��ނ���Ȃ��B
�s��
�����Tempering��ʂ��O�ɃT�}���v�Z���o���邩�ǂ�������
���p�I�Ȍv�Z���Ԃ��͂����o���̂́u�����v�ƌ����郌�x���̑����̔j��͒B���ł��Ă�Ƃ����̂�
���̌����B
���l�͍��Y�Í��}���Z�[�̗���Ȃ̂ŌN�ɕt��������RSA�̕���̗i�삷��C���Ȃ��B
���Ȃ݂�SHA-3���Ƃ��ĉ������ڂ��Ă�̂͂���
http://ehash.iaik.tugraz.at/uploads/5/5c/Lesamnta.pdf
������AES�͌����ɂ�SPNS�ł�����Feistel�ɂ͕��ނ���Ȃ��B
765 �F�f�t�H���g�̖����������F2009/01/23(��) 00:37:12
���{��ł���
766 �F�f�t�H���g�̖����������F2009/01/23(��) 00:39:15
������O�̂��ƌ����Ăǂ����B
767 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 00:43:44
�l�I��Camellia��SSE4���������Ƃ��J����
���ꏼ�䂳��D������
��Fixstars����
���N�̉ۑ��Camellia�ł��肢���܂��B
���ꏼ�䂳��D������
��Fixstars����
���N�̉ۑ��Camellia�ł��肢���܂��B
>>764
���̌����́A�g�U���ĈӖ��ł� tempering �� sbox ���������Ă̂ɂ͓��ӁB
�����A�V�t�g�{�r�b�g�_�����Z�ł͂ł��Ȃ� substitution ���������邽�߂�
sbox �����Ă���A��������Ղɓ���Ɉ����̂͗����ł���B
���A���Y�}���Z�[�͉����ꏏ�B���N Camellia �����˂�w
���̌����́A�g�U���ĈӖ��ł� tempering �� sbox ���������Ă̂ɂ͓��ӁB
�����A�V�t�g�{�r�b�g�_�����Z�ł͂ł��Ȃ� substitution ���������邽�߂�
sbox �����Ă���A��������Ղɓ���Ɉ����̂͗����ł���B
���A���Y�}���Z�[�͉����ꏏ�B���N Camellia �����˂�w
769 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 02:09:19
�܁A�Ƃ肠�������̏�̂ЂƂN���Ă�����B
�Í��A���S���Y���y�ъ֘A�Z�p�̕]����
http://cryptrec.nict.go.jp/cryptrec_03_0424_outrep.htm
S-box���g��Ȃ�RC6�͂��Ȃ荂���]���Ă��B
��ʓI�ȃo�C�g�}�V���E���[�h�}�V���Ńr�b�g���Z�ł������߂��Ⴍ����R�X�g�����鉉�Z��
LUT�Ȃ�ȒP�Ɏ����o�����肷��BS-box�̑����́ARISC�v���Z�b�T�̃r�b�g���Z�ɂ��̂܂�ܓW�J�����
�Ƃ�ł��Ȃ����Z�������������肷����A����͈Í����_�I�Ȍ��S���̍����Ƃ��Ă͎ア�Ǝv����B
�o�C�g�}�V���E���[�h�}�V������Ȃ��āA�r�b�g�}�V���Ƃ�ASIC�EFPGA��������H
���Ƃ���DES��S-box��AND/OR/NOT/XOR�̊�{�I��1�r�b�g�_�����Z��
�������̕���56�Q�[�g�ō\���o����B
����͋�̓I�ɂ�����32�r�b�g���[�h�̑S���Z��H�ɕK�v�ȃg�����W�X�^���������Ȃ菭�Ȃ��B
AES��S-box�́E�E�E�����ɂ��Ă̘_�����������ǁA�����炾�������Y�ꂽ�B
�i��������ōŒZ����������v���O�������茳�ɂ��邯��8�r�b�g�~8�r�b�g��S-box�͌v�Z���ԓI�ɗ��ɂ����j
������ς��悤��
AES��Camellia��S-box�������ADES��IP�EE�EP�EFP�ł���Ă�悤�ȕ��G�ȃr�b�g�P�ʂ�
���a��������炸�ɁA���E�ō������̈��S�����������Ă�킯���B
�X�ɂ����ƁACamellia��S-box�͎����I��8�r�b�g���́~8�r�b�g�o�͂̂��̂�������1���������Ȃ��B
���̓_�ł݂ă\�t�g�E�F�A�ł̎����̕��G���ƈÍ��I�ȋ��x�͕ʃ��m�ƍl���Ă�B
�Í��A���S���Y���y�ъ֘A�Z�p�̕]����
http://cryptrec.nict.go.jp/cryptrec_03_0424_outrep.htm
S-box���g��Ȃ�RC6�͂��Ȃ荂���]���Ă��B
��ʓI�ȃo�C�g�}�V���E���[�h�}�V���Ńr�b�g���Z�ł������߂��Ⴍ����R�X�g�����鉉�Z��
LUT�Ȃ�ȒP�Ɏ����o�����肷��BS-box�̑����́ARISC�v���Z�b�T�̃r�b�g���Z�ɂ��̂܂�ܓW�J�����
�Ƃ�ł��Ȃ����Z�������������肷����A����͈Í����_�I�Ȍ��S���̍����Ƃ��Ă͎ア�Ǝv����B
�o�C�g�}�V���E���[�h�}�V������Ȃ��āA�r�b�g�}�V���Ƃ�ASIC�EFPGA��������H
���Ƃ���DES��S-box��AND/OR/NOT/XOR�̊�{�I��1�r�b�g�_�����Z��
�������̕���56�Q�[�g�ō\���o����B
����͋�̓I�ɂ�����32�r�b�g���[�h�̑S���Z��H�ɕK�v�ȃg�����W�X�^���������Ȃ菭�Ȃ��B
AES��S-box�́E�E�E�����ɂ��Ă̘_�����������ǁA�����炾�������Y�ꂽ�B
�i��������ōŒZ����������v���O�������茳�ɂ��邯��8�r�b�g�~8�r�b�g��S-box�͌v�Z���ԓI�ɗ��ɂ����j
������ς��悤��
AES��Camellia��S-box�������ADES��IP�EE�EP�EFP�ł���Ă�悤�ȕ��G�ȃr�b�g�P�ʂ�
���a��������炸�ɁA���E�ō������̈��S�����������Ă�킯���B
�X�ɂ����ƁACamellia��S-box�͎����I��8�r�b�g���́~8�r�b�g�o�͂̂��̂�������1���������Ȃ��B
���̓_�ł݂ă\�t�g�E�F�A�ł̎����̕��G���ƈÍ��I�ȋ��x�͕ʃ��m�ƍl���Ă�B
770 �F227 ��eZQcaIaFJs �F2009/01/23(��) 02:17:31
771 �F�f�t�H���g�̖����������F2009/01/23(��) 02:34:03
772 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 02:44:12
Camellia�̋��ȏ��I���������p�B
���͂Ȃ�ł����AES�Ȃ݂̋��x��������̂��^�₾������B
#define SBOX1(n) SBOX[(n)]
#define SBOX2(n) (Byte)((SBOX[(n)]>>7^SBOX[(n)]<<1)&0xff)
#define SBOX3(n) (Byte)((SBOX[(n)]>>1^SBOX[(n)]<<7)&0xff)
#define SBOX4(n) SBOX[((n)<<1^(n)>>7)&0xff]
2��3��1�̏o�͒l�����[�e�[�g���Ă邾���B4�͓��͒l�����[�e�[�g���Ă邾���B
�Ȃ�ł���ŁuAES�Ȃ݂̈Í����x�������ł���v�i���̐l�k�j�̂�
>>771
�Ƃ������A�ǂ���牴���������œK�����@�͊��ɂ��̃X����13clk�����A���͌����Ă�Ǝv����B
���Ƃ͎��������Ȃ킯�����A�A�Z���u�������C�ŏ��Ă�C�͂��Ȃ��B
��̓I�ɂ����ƌ����_�ł�>>693���͒x���B�K�`�B
�i�Ă����̐l���ő����ۂ��j
�������ɂƂ��Ă͍���̒���͂ǂ��܂ł�Hack the spu-gcc43�Ȃ̂��B
�A�Z���u���g��Ȃ��ƗD���ł��Ȃ��̂͂킩���Ă邪�A�A�Z���u�����g���͉̂��I�ɕ����Ȃ̂ł���B
C�݂̂Œ��킷��l�����ɓ��ʏ܂ł��p�ӂ��Ă����Ȃ牴�͊��ŕ\����ɂ������Ă�邺�B
�iherumi�����Q�킵�Ă������ƂŁA����ł��畉����C�����Ă����j
���͂Ȃ�ł����AES�Ȃ݂̋��x��������̂��^�₾������B
#define SBOX1(n) SBOX[(n)]
#define SBOX2(n) (Byte)((SBOX[(n)]>>7^SBOX[(n)]<<1)&0xff)
#define SBOX3(n) (Byte)((SBOX[(n)]>>1^SBOX[(n)]<<7)&0xff)
#define SBOX4(n) SBOX[((n)<<1^(n)>>7)&0xff]
2��3��1�̏o�͒l�����[�e�[�g���Ă邾���B4�͓��͒l�����[�e�[�g���Ă邾���B
�Ȃ�ł���ŁuAES�Ȃ݂̈Í����x�������ł���v�i���̐l�k�j�̂�
>>771
�Ƃ������A�ǂ���牴���������œK�����@�͊��ɂ��̃X����13clk�����A���͌����Ă�Ǝv����B
���Ƃ͎��������Ȃ킯�����A�A�Z���u�������C�ŏ��Ă�C�͂��Ȃ��B
��̓I�ɂ����ƌ����_�ł�>>693���͒x���B�K�`�B
�i�Ă����̐l���ő����ۂ��j
�������ɂƂ��Ă͍���̒���͂ǂ��܂ł�Hack the spu-gcc43�Ȃ̂��B
�A�Z���u���g��Ȃ��ƗD���ł��Ȃ��̂͂킩���Ă邪�A�A�Z���u�����g���͉̂��I�ɕ����Ȃ̂ł���B
C�݂̂Œ��킷��l�����ɓ��ʏ܂ł��p�ӂ��Ă����Ȃ牴�͊��ŕ\����ɂ������Ă�邺�B
�iherumi�����Q�킵�Ă������ƂŁA����ł��畉����C�����Ă����j
773 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 02:47:12
�܂��A�ǂ�����ăR���p�C���̕���p��}�����̂����Ă����̂̓\�[�X�ɂт����菑���Ă��肷�邩��
������ʂɎc���Ă���Q�l�ɂ��Ă���A�I�ȁB
������ʂɎc���Ă���Q�l�ɂ��Ă���A�I�ȁB
774 �F�f�t�H���g�̖����������F2009/01/23(��) 02:55:35
>>769
���̌����������� >>768 �Ō��������A�u�� feistel �����v�Ƃ���
�C�ɐH��Ȃ��ȁH sbox �� ���S�ƌ����Ă��ł͂Ȃ��āA���S����
���x�𗼗�����̂� sbox �������Ă�ƌ������������Ȃ��B
�V�t�g�{�r�b�g�_�����Z�����œ����̌��S����������������A
sbox �̕����������Ղ����A�����������Ղ����ė����Ȃ��ǁB
������ NIST �ɂ��� NESSIE �ɂ���Afeistel �n�����Ȃ�ł���B
���ꂾ���ʕ������牴�ɂ� tempering �� sbox ��ɂ͈�����B
�ȏ�B
���̌����������� >>768 �Ō��������A�u�� feistel �����v�Ƃ���
�C�ɐH��Ȃ��ȁH sbox �� ���S�ƌ����Ă��ł͂Ȃ��āA���S����
���x�𗼗�����̂� sbox �������Ă�ƌ������������Ȃ��B
�V�t�g�{�r�b�g�_�����Z�����œ����̌��S����������������A
sbox �̕����������Ղ����A�����������Ղ����ė����Ȃ��ǁB
������ NIST �ɂ��� NESSIE �ɂ���Afeistel �n�����Ȃ�ł���B
���ꂾ���ʕ������牴�ɂ� tempering �� sbox ��ɂ͈�����B
�ȏ�B
775 �F�f�t�H���g�̖����������F2009/01/23(��) 02:55:47
>>772
���̓A�Z���u������Ȃ��Ɛ�ɏo���Ȃ����Ƃ�����Ă邩�瑼�̓_�̎������ꏏ�Ȃ�L�����������
�����Șb���̃X���Ō��\�Ȑ��̃q���g��������炱�ꂪ�Ȃ��ƕ����Ă�
���̓A�Z���u������Ȃ��Ɛ�ɏo���Ȃ����Ƃ�����Ă邩�瑼�̓_�̎������ꏏ�Ȃ�L�����������
�����Șb���̃X���Ō��\�Ȑ��̃q���g��������炱�ꂪ�Ȃ��ƕ����Ă�
776 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 03:46:15
���̒��x�Ȃ炠��܂�e�����Ă������x���ŁAC�őg�ސl�ɃA�h�o�C�X�B
�i�Ƃ�����C�{�g�ݍ��݊��ʼn��ɒ������ƍl���Ă�z�͗��ɂ��Ȃ����낤�j
���ɃC���C�������̂́Aeven���̖��ߌ��炵�����̂ɒl�̃��[�h��immidiate load�ieven���[�h)�ɏ���ɓW�J���₪�邱�ƁB
qword�^�ł��Ă�̂�immidiate load�B
�ǂ����QWORD�̑S�v�f������̒l���Ə����imm load�ɓW�J���₪��炵���B
��ŁAvolatile�ɂ�����A�h���X���烍�[�h�iOdd�j�ɓW�J���Ă����悤�ɂȂ����B
�Ƃ��A���낢��B
���ƁAAND/OR/XOR�ȂǂŎg���l��halfword�ɑ��l�w�肷��Ζ��ߐ������点��B
���Ƃ��Ă͂܂����j��ς��ăp�C�v���C�����l�ߒ������Ǝv���Ă���B
�����_�ŕЕ��̃p�C�v���S�����܂�Ƃ���܂�C�ŋl�߂邱�Ƃ��ł��Ă�킯��
>>774
�c�O�������ӂł��Ȃ��B
�W���K�i�ɂ����ă_���g�c�̃g�b�v�ɌN�Ղ���AES��Feistel�n�A���S���Y���Ƃ�����Ǝ��Ă邪���ޏ�ʕ��B
���Ǝ������Ƃ���ACamellia�͕��ʂ�Feistel�^�Í��ŏ]��4�ȏ��LUT�iS-Box�j���K�v�ȏ�����
1��LUT�ƃ��[�e�[�g�Ő��������Ă邯�ǁA���̓_�ŋ��x�ɖ�肪����Ƃ���ꂽ���Ƃ͖����B
�P���S-box�Ƀr�b�g���Z�������g�ݍ��킹�邾���ŁA���x��̂ɕK�v��S-box�̐���
�����I�Ɍ��炷���Ƃ��ł���̂�����A�V�t�g�E�_�����Z�E�萔�̑g�ݍ��킹��S-box���g�킸��
���\�Ƌ��x��̂��s�\�Ƃ͎v���B
���ۖ��AS-box���g��Ȃ�RC6�͑�����Feistel�Í���荂���ŁA�Ȃ����\���Ȍ��S��������B
S-box���n�[�h�E�F�A�̕��S�����������Ă��Ǝ��̓��ӂł��Ȃ��B
���o�C�������̃v���Z�b�T�ɂ�AES��S-box����f�[�^�L���b�V���Ɏ��܂肫��Ȃ����炢���������̂�����B
Camellia��SBOX���ŏ��̎����ł�������256�o�C�g��LUT�����ō\���o����悤�ɔz������Ă�̂�
�~�����b�g�N���X�̑g�ݍ���CPU�ł̎���������ɓ���Ă邩�炾�B
Camellia��S-box�����������Ƃ́A�L���b�V�����������������A�[�L�e�N�`���ɂ₳�����Ƃ������Ƃł�����
�ŁA����ł��ď\���ȋ��x�Ƃ����]���Ă���B
�i�Ƃ�����C�{�g�ݍ��݊��ʼn��ɒ������ƍl���Ă�z�͗��ɂ��Ȃ����낤�j
���ɃC���C�������̂́Aeven���̖��ߌ��炵�����̂ɒl�̃��[�h��immidiate load�ieven���[�h)�ɏ���ɓW�J���₪�邱�ƁB
qword�^�ł��Ă�̂�immidiate load�B
�ǂ����QWORD�̑S�v�f������̒l���Ə����imm load�ɓW�J���₪��炵���B
��ŁAvolatile�ɂ�����A�h���X���烍�[�h�iOdd�j�ɓW�J���Ă����悤�ɂȂ����B
�Ƃ��A���낢��B
���ƁAAND/OR/XOR�ȂǂŎg���l��halfword�ɑ��l�w�肷��Ζ��ߐ������点��B
���Ƃ��Ă͂܂����j��ς��ăp�C�v���C�����l�ߒ������Ǝv���Ă���B
�����_�ŕЕ��̃p�C�v���S�����܂�Ƃ���܂�C�ŋl�߂邱�Ƃ��ł��Ă�킯��
>>774
�c�O�������ӂł��Ȃ��B
�W���K�i�ɂ����ă_���g�c�̃g�b�v�ɌN�Ղ���AES��Feistel�n�A���S���Y���Ƃ�����Ǝ��Ă邪���ޏ�ʕ��B
���Ǝ������Ƃ���ACamellia�͕��ʂ�Feistel�^�Í��ŏ]��4�ȏ��LUT�iS-Box�j���K�v�ȏ�����
1��LUT�ƃ��[�e�[�g�Ő��������Ă邯�ǁA���̓_�ŋ��x�ɖ�肪����Ƃ���ꂽ���Ƃ͖����B
�P���S-box�Ƀr�b�g���Z�������g�ݍ��킹�邾���ŁA���x��̂ɕK�v��S-box�̐���
�����I�Ɍ��炷���Ƃ��ł���̂�����A�V�t�g�E�_�����Z�E�萔�̑g�ݍ��킹��S-box���g�킸��
���\�Ƌ��x��̂��s�\�Ƃ͎v���B
���ۖ��AS-box���g��Ȃ�RC6�͑�����Feistel�Í���荂���ŁA�Ȃ����\���Ȍ��S��������B
S-box���n�[�h�E�F�A�̕��S�����������Ă��Ǝ��̓��ӂł��Ȃ��B
���o�C�������̃v���Z�b�T�ɂ�AES��S-box����f�[�^�L���b�V���Ɏ��܂肫��Ȃ����炢���������̂�����B
Camellia��SBOX���ŏ��̎����ł�������256�o�C�g��LUT�����ō\���o����悤�ɔz������Ă�̂�
�~�����b�g�N���X�̑g�ݍ���CPU�ł̎���������ɓ���Ă邩�炾�B
Camellia��S-box�����������Ƃ́A�L���b�V�����������������A�[�L�e�N�`���ɂ₳�����Ƃ������Ƃł�����
�ŁA����ł��ď\���ȋ��x�Ƃ����]���Ă���B
777 �F�f�t�H���g�̖����������F2009/01/23(��) 04:24:16
���[��A�_�_���ǂ��Ȃ��C�}�C�`�����B
feistel �� sbox �� spn �� sbox �͕ʕ��Ȃ̂��H
�����s�\�Ƃ͎v���ĂȂ����ے�����Ȃ��恄RC6
���S���������Ƃ��v���ĂȂ��B���S���Ƌ��ɁA����
�o���邱�Ƃ����������鎖���\�Ȃ̂��d�v�Ȃ����B
AES �� sbox �� 256 �������Ǝv���̂����Ⴄ�̂��H
���ɂ� tempering �� sbox ��Ɉ����̂͗���
�ł��Ȃ����A�u�݂����Ȃ���v�Ȃ�Đ����ɂ͓���
���ӂł���ق͏����邪�A�ʂɒc�q�������
�Ԉ���ĂȂ����Ďv���̂͂ǁ[�ł����[��B
���Ă��A����Șb�N�����Ă��ˁ[���w
�ł����[�A�c�q�� sbox �n�ƃV�t�g�E�_�����Z�n��
�Y��ɕʂ��Ăˁ[��w�@����ϕʂȂ�ˁHw
feistel �� sbox �� spn �� sbox �͕ʕ��Ȃ̂��H
�����s�\�Ƃ͎v���ĂȂ����ے�����Ȃ��恄RC6
���S���������Ƃ��v���ĂȂ��B���S���Ƌ��ɁA����
�o���邱�Ƃ����������鎖���\�Ȃ̂��d�v�Ȃ����B
AES �� sbox �� 256 �������Ǝv���̂����Ⴄ�̂��H
���ɂ� tempering �� sbox ��Ɉ����̂͗���
�ł��Ȃ����A�u�݂����Ȃ���v�Ȃ�Đ����ɂ͓���
���ӂł���ق͏����邪�A�ʂɒc�q�������
�Ԉ���ĂȂ����Ďv���̂͂ǁ[�ł����[��B
���Ă��A����Șb�N�����Ă��ˁ[���w
�ł����[�A�c�q�� sbox �n�ƃV�t�g�E�_�����Z�n��
�Y��ɕʂ��Ăˁ[��w�@����ϕʂȂ�ˁHw
778 �F�f�t�H���g�̖����������F2009/01/23(��) 05:11:28
780 �F�f�t�H���g�̖����������F2009/01/23(��) 09:41:39
>>778
���v�A�������̕ӂō��܂����B�[���A�O����w
���v�A�������̕ӂō��܂����B�[���A�O����w
>>693���A58156364 / 4 * 12.5 / 40 = 4543466 ���B
���̐��l���o���Ă��牴��葬���B
>>775 �̈Ӗ�������B
�����_�ł��̃X�����ƁA
�D���A���D����� : >>693 , ��
�D�������\���̂���q�g: >>568, >>579
������� >>579 �̘b�ɂ͂��Ă����Ȃ��������A
�Ƃ肠���� >>579 �� Prolog �������o������@�̃T�C�N������
�o��܂ł̓C�����C���A�Z���u���Ō��E�܂ōs�����ҏ������ۂ��ȁB
���̐��l���o���Ă��牴��葬���B
>>775 �̈Ӗ�������B
�����_�ł��̃X�����ƁA
�D���A���D����� : >>693 , ��
�D�������\���̂���q�g: >>568, >>579
������� >>579 �̘b�ɂ͂��Ă����Ȃ��������A
�Ƃ肠���� >>579 �� Prolog �������o������@�̃T�C�N������
�o��܂ł̓C�����C���A�Z���u���Ō��E�܂ōs�����ҏ������ۂ��ȁB
782 �F�f�t�H���g�̖����������F2009/01/23(��) 11:13:19
�܁[���ʂɍl���Ă��A�����ɏ�������łȂ���ŗD�ꂽ�z�����邾��`����
�D���������̃X�����ōi����Ă̂�����������Ǝv�����ǂ�
�D���������̃X�����ōi����Ă̂�����������Ǝv�����ǂ�
>>782
������̉\���͔ے肵�Ȃ��B���̃X����ǂ܂Ȃ��ƁA�u���ߐ��ǂ��܂Ō��点��v�Ƃ���
�w�W���Ȃ���ԂŃ`�L�����[�X�ɎQ�����Ȃ��Ƃ����Ȃ�����L�c�C���ǁA���̃X����ROM���Ă�Ȃ�
���ߐ����ǂ��܂Ō��点�邩����ˁB
������̉\���͔ے肵�Ȃ��B���̃X����ǂ܂Ȃ��ƁA�u���ߐ��ǂ��܂Ō��点��v�Ƃ���
�w�W���Ȃ���ԂŃ`�L�����[�X�ɎQ�����Ȃ��Ƃ����Ȃ�����L�c�C���ǁA���̃X����ROM���Ă�Ȃ�
���ߐ����ǂ��܂Ō��点�邩����ˁB
784 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 11:59:48
>>781
�����A���l��D���E���D���̉\������͂����ȁI
����O���Ă�������B���������̎�̓��͖������킯�ɂ͂����Ȃ�
�Ƃ肠�����J�[�h�͎c���Ă�B
�����A���l��D���E���D���̉\������͂����ȁI
����O���Ă�������B���������̎�̓��͖������킯�ɂ͂����Ȃ�
�Ƃ肠�����J�[�h�͎c���Ă�B
785 �F�f�t�H���g�̖����������F2009/01/23(��) 12:06:20
>784
�����ċT�c�Z��I�|�W�V���������
�����ċT�c�Z��I�|�W�V���������
787 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 12:16:58
788 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 12:27:55
mt[n] = mt[m] ^ (x >> 1) ^ (((x & 1) == 1)? 0x9908b0dfUL : 0);
��
x = rotr(x, 1);
mt[n] = mt[m] ^ x ^ ((x > 0x7FFFFFFF)? (0x1908b0dfUL) : 0);
��������g���Ă��`�L�����[�X�ɂ͎Q���ł��܂���B�ۑ肪�ʃ��m�Ȃ�L�p����������
��������J����Ă���3�����炢�ōl�����l�^�����ǁA�ŏI�I�ɍ������̌��Ƃ��Ă͊O�ꂽ���@�����犸���ďЉ�Ă����B
���ƃu���b�N�P�ʂ���Ȃ��ăX�J���P�ʂŎ��o���ꍇ�͂������̂ق���������������Ȃ��B���C�e���V�I�ȈӖ��ŁB
��
x = rotr(x, 1);
mt[n] = mt[m] ^ x ^ ((x > 0x7FFFFFFF)? (0x1908b0dfUL) : 0);
��������g���Ă��`�L�����[�X�ɂ͎Q���ł��܂���B�ۑ肪�ʃ��m�Ȃ�L�p����������
��������J����Ă���3�����炢�ōl�����l�^�����ǁA�ŏI�I�ɍ������̌��Ƃ��Ă͊O�ꂽ���@�����犸���ďЉ�Ă����B
���ƃu���b�N�P�ʂ���Ȃ��ăX�J���P�ʂŎ��o���ꍇ�͂������̂ق���������������Ȃ��B���C�e���V�I�ȈӖ��ŁB
789 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 12:44:24
^ x ^
�����̂ւނ���
>>787
even�̖��ߐ��팸�͖��ӎ�������A�ǂ�������� even18 �ɂȂ邩�Y�B
andc �Ƃ�������߂��g�����c���H
������̖��߂ŗ\��ᔽ���Ă邯�ǁA������SPU�œ����Ȃ��Ȃ��Ă�
�\��Ȃ��Ɣ��f������B
even�̖��ߐ��팸�͖��ӎ�������A�ǂ�������� even18 �ɂȂ邩�Y�B
andc �Ƃ�������߂��g�����c���H
������̖��߂ŗ\��ᔽ���Ă邯�ǁA������SPU�œ����Ȃ��Ȃ��Ă�
�\��Ȃ��Ɣ��f������B
andc����Ȃ���sel�ł��ǂ��̂��B
792 �F�f�t�H���g�̖����������F2009/01/23(��) 13:48:27
>>202 �ȂɌ����ĂHw
�������A�g�b�v�����J�[�ɂ͖��Ӗ��ȏ����o�������Ⴆ�B
spu_and( matrix_a, spu_cmpeq( spu_and( x , 1 ) , 1 ) )
��
spu_andc( matrix_a, spu_subx( z, z, x ) )
spu_and( matrix_a, spu_cmpeq( spu_and( x , 1 ) , 1 ) )
��
spu_andc( matrix_a, spu_subx( z, z, x ) )
794 �F�f�t�H���g�̖����������F2009/01/23(��) 13:58:00
�R���e�X�g�Q�����Ă�̂��O�炾������ˁ[��
�����͍l����
�����͍l����
795 �F�f�t�H���g�̖����������F2009/01/23(��) 14:00:30
���Ă��A202 �ɂ� >>788 �̓����͌����ĂȂ��̂��H
797 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 14:03:11
>>793
���@�@��@�@�ȁ@�@���@�@�@�@�@���@�@���@�@���@�@���@�@�́@�@��
���I�y�����h�j�閽�߂͂��܂��l���Ďg��Ȃ��ƍ����ˁB
>>788�������Ƃ��͉�SUGEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE���Ďv����
���@�@��@�@�ȁ@�@���@�@�@�@�@���@�@���@�@���@�@���@�@�́@�@��
���I�y�����h�j�閽�߂͂��܂��l���Ďg��Ȃ��ƍ����ˁB
>>788�������Ƃ��͉�SUGEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE���Ďv����
798 �F�f�t�H���g�̖����������F2009/01/23(��) 14:06:19
>>797 ����Ȃ̂Ŏv����!w
799 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 21:14:51
8bit�~4�̐������Z�Ƃ����邯�lj��Ɏg���R��
SSE��PSADBW/MPSADBW�Ɠ������A����̓������o�Ƃ��Ɏg����H
���ꂵ���v�����Ȃ��B
�߂������Ƃɍ���̉ۑ�ł����ɗ����Ȃ��B
�@���������Ă��������Z�̂ق������\�o��B
���ꂪ������Odd�ŏ��������Ȃ�܂��g��������������ǁB
SSE��PSADBW/MPSADBW�Ɠ������A����̓������o�Ƃ��Ɏg����H
���ꂵ���v�����Ȃ��B
�߂������Ƃɍ���̉ۑ�ł����ɗ����Ȃ��B
�@���������Ă��������Z�̂ق������\�o��B
���ꂪ������Odd�ŏ��������Ȃ�܂��g��������������ǁB
800 �F�f�t�H���g�̖����������F2009/01/23(��) 21:23:56
absdb/avgb/sumb ������͓���̂��߂����ȁB
ORIGNAL: sum=26842941, 20235458 ticks
MINE: sum=26842941, 296432 ticks
ORIGNAL: sum=ff298dc7, 29209150 ticks
MINE: sum=ff298dc7, 416484 ticks
ORIGNAL: sum=e41976b4, 21287451 ticks
MINE: sum=e41976b4, 359310 ticks
ORIGNAL: sum=1d20a3cf, 19895914 ticks
MINE: sum=1d20a3cf, 271577 ticks
ORIGNAL: sum=7ab6f153, 1012083 ticks
MINE: sum=7ab6f153, 80442 ticks
ORIGNAL: sum=d528faae, 14662211 ticks
MINE: sum=d528faae, 226395 ticks
ORIGNAL: sum=f2e9b16f, 20421921 ticks
MINE: sum=f2e9b16f, 285473 ticks
ORIGNAL: sum=c38c3ffb, 17745083 ticks
MINE: sum=c38c3ffb, 312869 ticks
ORIGNAL: sum=4a476dd4, 17155127 ticks
MINE: sum=4a476dd4, 268986 ticks
ORIGNAL: sum=817388cd, 412802 ticks
MINE: sum=817388cd, 60522 ticks
�ۑ�A�i��(����)�ԈႦ�Ă����� orz
�Ƃ���ŁA���܂ł����̂��ƃA�i�����������Ȃ̂ŁA�������̂�
�n�b�Nthe�A�i���Ɍ��߂���B���łɏ����n�Ǝ������ς������ǁB
MINE: sum=26842941, 296432 ticks
ORIGNAL: sum=ff298dc7, 29209150 ticks
MINE: sum=ff298dc7, 416484 ticks
ORIGNAL: sum=e41976b4, 21287451 ticks
MINE: sum=e41976b4, 359310 ticks
ORIGNAL: sum=1d20a3cf, 19895914 ticks
MINE: sum=1d20a3cf, 271577 ticks
ORIGNAL: sum=7ab6f153, 1012083 ticks
MINE: sum=7ab6f153, 80442 ticks
ORIGNAL: sum=d528faae, 14662211 ticks
MINE: sum=d528faae, 226395 ticks
ORIGNAL: sum=f2e9b16f, 20421921 ticks
MINE: sum=f2e9b16f, 285473 ticks
ORIGNAL: sum=c38c3ffb, 17745083 ticks
MINE: sum=c38c3ffb, 312869 ticks
ORIGNAL: sum=4a476dd4, 17155127 ticks
MINE: sum=4a476dd4, 268986 ticks
ORIGNAL: sum=817388cd, 412802 ticks
MINE: sum=817388cd, 60522 ticks
�ۑ�A�i��(����)�ԈႦ�Ă����� orz
�Ƃ���ŁA���܂ł����̂��ƃA�i�����������Ȃ̂ŁA�������̂�
�n�b�Nthe�A�i���Ɍ��߂���B���łɏ����n�Ǝ������ς������ǁB
$ diff mt19937ar.sep/mt19937ar.c~ mt19937ar.sep/mt19937ar.c
52c52
< #define MATRIX_A 0x9908b0dfUL /* constant vector a */
---
> #define MATRIX_A 0x9908b0cfUL /* constant vector a */
$ uname -mrsv
Linux 2.6.18-6-powerpc64 #1 SMP Fri Dec 12 23:54:31 UTC 2008 ppc64
$ cat /proc/cpuinfo
processor : 0
cpu : PPC970FX, altivec supported
clock : 2700.000000MHz
revision : 3.1 (pvr 003c 0301)
processor : 1
cpu : PPC970FX, altivec supported
clock : 2700.000000MHz
revision : 3.1 (pvr 003c 0301)
timebase : 33333333
platform : PowerMac
machine : PowerMac7,3
motherboard : PowerMac7,3 MacRISC4 Power Macintosh
detected as : 336 (PowerMac G5)
pmac flags : 00000000
L2 cache : 512K unified
pmac-generation : NewWorld
�ł����A�����H
52c52
< #define MATRIX_A 0x9908b0dfUL /* constant vector a */
---
> #define MATRIX_A 0x9908b0cfUL /* constant vector a */
$ uname -mrsv
Linux 2.6.18-6-powerpc64 #1 SMP Fri Dec 12 23:54:31 UTC 2008 ppc64
$ cat /proc/cpuinfo
processor : 0
cpu : PPC970FX, altivec supported
clock : 2700.000000MHz
revision : 3.1 (pvr 003c 0301)
processor : 1
cpu : PPC970FX, altivec supported
clock : 2700.000000MHz
revision : 3.1 (pvr 003c 0301)
timebase : 33333333
platform : PowerMac
machine : PowerMac7,3
motherboard : PowerMac7,3 MacRISC4 Power Macintosh
detected as : 336 (PowerMac G5)
pmac flags : 00000000
L2 cache : 512K unified
pmac-generation : NewWorld
�ł����A�����H
���Ȃ݂ɁA������ C99 �ȁB�{���̈Ӗ��ł̂ȁBaltivec ���g���Ă��Ȃ��B
32bit �r�b�g�X���C�X���ł��̒��x�B�[���̏����͂܂������œK�����Ă��Ȃ��B
SIMD ������������Ƒ����Ȃ邩�Ȃ��i�_
>>720
>�˂����݂ǂ���̃f�p�[�g�B�k�ق̏W�听�B
�ŁA
>>729
>������Tempering�O�̒l��������u���Z�v���Ă����Ӗ��ȂB
�����������Ƃ͂��ꂾ���H
>>579
>tempering �O�́u�Ƃ���l�v���W�v����BGF(2)�̒��ŁB
>����ƁAtempering (�����̑���)�͈��ōςށB
�N�� tempering �O�̒l���u���̂܂܁v���Z����Ƃ͌����Ă��Ȃ����H
���Z����Ƃ������Ă��Ȃ��B�����т��Ă邾��H
>>730
>�ނ͑S�R���ɗ����Ȃ����Ƃ��������ĂȂ��B
�ϴ�Ű
>>771
����Ȃɉ��̃A�i���傫���H
>>781=202
���H�D������\���H�Ȃ���B�o�Ȃ�����
32bit �r�b�g�X���C�X���ł��̒��x�B�[���̏����͂܂������œK�����Ă��Ȃ��B
SIMD ������������Ƒ����Ȃ邩�Ȃ��i�_
>>720
>�˂����݂ǂ���̃f�p�[�g�B�k�ق̏W�听�B
�ŁA
>>729
>������Tempering�O�̒l��������u���Z�v���Ă����Ӗ��ȂB
�����������Ƃ͂��ꂾ���H
>>579
>tempering �O�́u�Ƃ���l�v���W�v����BGF(2)�̒��ŁB
>����ƁAtempering (�����̑���)�͈��ōςށB
�N�� tempering �O�̒l���u���̂܂܁v���Z����Ƃ͌����Ă��Ȃ����H
���Z����Ƃ������Ă��Ȃ��B�����т��Ă邾��H
>>730
>�ނ͑S�R���ɗ����Ȃ����Ƃ��������ĂȂ��B
�ϴ�Ű
>>771
����Ȃɉ��̃A�i���傫���H
>>781=202
���H�D������\���H�Ȃ���B�o�Ȃ�����
804 �F�f�t�H���g�̖����������F2009/01/23(��) 21:56:21
805 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 22:05:25
�悭�ł����s������
�ł��^�[�Q�b�g�͂o��������PC����Ȃ��āuSPU�v
�ł��^�[�Q�b�g�͂o��������PC����Ȃ��āuSPU�v
806 �F�f�t�H���g�̖����������F2009/01/23(��) 22:08:25
��A�悭�o���Ă�̂��H��
807 �F�f�t�H���g�̖����������F2009/01/23(��) 22:09:26
> ���H�D������\���H�Ȃ���B�o�Ȃ�����
����������̂͂���������Ƃ��Ƃ̕����ʔ����������Ȃ�
����������̂͂���������Ƃ��Ƃ̕����ʔ����������Ȃ�
808 �F�f�t�H���g�̖����������F2009/01/23(��) 22:09:33
809 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 22:11:27
�Q�n�Ŕ������Ă�A�X�y���N������Ɋ��Ⴂ�����������낻��
810 �F�f�t�H���g�̖����������F2009/01/23(��) 22:12:40
�������ɉ��������v���B�c�q�̓E�U�C���� >>732 �͖��߁B
�����������̂��B�c�q���߂�
812 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 22:16:23
PPU��SPU�������R�[�h�V�[�P���X�Ŏ��s�ł���Ƃ��A�z�Ȃ��ƌ����₪����
�o�o�t��18issue�̖��ߑш悪�K�v�ɂȂ邼���Č�������A�\���Ƃ������₪�邵
���܂��ɂ́ASSE����86�̃t�H�[�}�b�g�Ƃ͂�������Ă�Ƃ�������
���̖��߃t�H�[�}�b�g����86�łȂ��ĂȂ�Ȃ�
�o�o�t��18issue�̖��ߑш悪�K�v�ɂȂ邼���Č�������A�\���Ƃ������₪�邵
���܂��ɂ́ASSE����86�̃t�H�[�}�b�g�Ƃ͂�������Ă�Ƃ�������
���̖��߃t�H�[�}�b�g����86�łȂ��ĂȂ�Ȃ�
813 �F�f�t�H���g�̖����������F2009/01/23(��) 22:37:38
���v����B���̃R�s�y�Œc�q�͊Ԉ���ĂȂ����Ă݂�ȕ������Ă邩��B
�c�q���ԈႢ��F�߂Ȃ��ăE�U���������Ȃ肠�邪�ȁB
���Ɛړ����̂悤�ɕt���Ă���u�m�荇���ɒN�X������v���ĉ�����E�U���B
�m�荇�����L���Ȃ����ŁA�ʂɃX�l�v���̂��킯����Ȃ����낤�B
�c�q���ԈႢ��F�߂Ȃ��ăE�U���������Ȃ肠�邪�ȁB
���Ɛړ����̂悤�ɕt���Ă���u�m�荇���ɒN�X������v���ĉ�����E�U���B
�m�荇�����L���Ȃ����ŁA�ʂɃX�l�v���̂��킯����Ȃ����낤�B
814 �F�f�t�H���g�̖����������F2009/01/23(��) 22:38:02
�u�T�}���������߂�V���[�g�T�[�L�b�g�֎~�v
�Ƃ��������Q�ĂČ����o������u�����ȁB
���o��҂������܂�邢���Ă��ƂɂȂ邪�B
�Ƃ��������Q�ĂČ����o������u�����ȁB
���o��҂������܂�邢���Ă��ƂɂȂ邪�B
815 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 22:45:01
�������낻��g�����U���i�j���������Ⴈ������
���낻�늨�̂����l�͋ȕ��@������������������ƂɋC�Â��Ă邩���m��Ȃ�������
>>814
��������O��MT�̔z��ɏ����߂���������Γ����Ȏ����ł����܂�Ȃ��̂ł́H
���낻�늨�̂����l�͋ȕ��@������������������ƂɋC�Â��Ă邩���m��Ȃ�������
>>814
��������O��MT�̔z��ɏ����߂���������Γ����Ȏ����ł����܂�Ȃ��̂ł́H
816 �F�f�t�H���g�̖����������F2009/01/23(��) 22:59:23
���[�������{�ύX�����Ɛ����߂����B�����ăL�c���B
�P�Ȃ�`�L�����[�X�Ȃ�~���B
�P�Ȃ�`�L�����[�X�Ȃ�~���B
817 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 23:18:26
�ۑ茩�����ʼn����Ƃ��ɂȂ�����ʔ����B
MT�̔z����r�߂�K�v���Ȃ��O��Ȃ�g�����U���i�j�\�Ȃ��Ƃ͋C�Â��Ă��B
��������ƃA���S���Y�������{����ς�邯��
�R�A���[�v�����Ă���MT�z��ɏ����߂������ƍĎ��s���\�B
MT�̔z����r�߂�K�v���Ȃ��O��Ȃ�g�����U���i�j�\�Ȃ��Ƃ͋C�Â��Ă��B
��������ƃA���S���Y�������{����ς�邯��
�R�A���[�v�����Ă���MT�z��ɏ����߂������ƍĎ��s���\�B
818 �F�f�t�H���g�̖����������F2009/01/23(��) 23:32:24
>>734�̌����Ƃ���ɂȂ�����
819 �F,,�E�L�́M�E,,�j��-�������F2009/01/23(��) 23:39:57
�������W�b�N�W�F�l���[�^�����������낻�둖�点�悤����
�e�L�g�[�ɓ�����t�����p�^�[�����ċA�őS�������n���ȕ��@�g���Ă邩��œK�ɋ߂����@������̂�1�������炢������B
���̎��Z����
�e�L�g�[�ɓ�����t�����p�^�[�����ċA�őS�������n���ȕ��@�g���Ă邩��œK�ɋ߂����@������̂�1�������炢������B
���̎��Z����
���߂�A�����v���O�����͏����Ȃ�����A���킹�Ă���B
>>816
���������A�ۑ�͗����������œK������Ƃ������̂ŁA�ŏ�����ǂ��܂ŃT�C�N������
���点�邩�Ƃ����`�L�����[�X�Ȃ��H
>>579�̕��@�͂����̃`�[�g�ŁA���[�����u�`�F�b�N�T�������Ă�Η����������Ȃ��Ă��ǂ��v
���ĂȂ����炻�ꂱ�����{�I�ȃ��[���ύX���B
����Hack the Cell�ɎQ�������B�P�Ȃ鐔�w�R���e�X�g�Ȃ�~���B
>>816
���������A�ۑ�͗����������œK������Ƃ������̂ŁA�ŏ�����ǂ��܂ŃT�C�N������
���点�邩�Ƃ����`�L�����[�X�Ȃ��H
>>579�̕��@�͂����̃`�[�g�ŁA���[�����u�`�F�b�N�T�������Ă�Η����������Ȃ��Ă��ǂ��v
���ĂȂ����炻�ꂱ�����{�I�ȃ��[���ύX���B
����Hack the Cell�ɎQ�������B�P�Ȃ鐔�w�R���e�X�g�Ȃ�~���B
821 �F�f�t�H���g�̖����������F2009/01/24(�y) 00:18:10
�l�X�ȕ���ɑ���m�������߂���A���ꂾ���̂��Ƃ���Ȃ���?
>>821
�ۑ��100��ǂ�ł�B�@�� http://cell.fixstars.com/challenge/challenge.html
�ǂ��Ɂu�����̃`�F�b�N�T�����v�Z���Ă��������v���ď����Ă���H
�u�ۑ�́A�����Z���k�E�c�C�X�^�̍œK���ł��B�v
�u�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B�v
�ۑ��100��ǂ�ł�B�@�� http://cell.fixstars.com/challenge/challenge.html
�ǂ��Ɂu�����̃`�F�b�N�T�����v�Z���Ă��������v���ď����Ă���H
�u�ۑ�́A�����Z���k�E�c�C�X�^�̍œK���ł��B�v
�u�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B�v
823 �F�f�t�H���g�̖����������F2009/01/24(�y) 00:25:25
������Cell���Ė{���ɑ����H�g�������ƂȂ�����
�t�B�N�^�[�̃T�C�g�ɂ���p�t�H�[�}�X��Ɠ���������Xeon�őg��ł݂���
10�{�����̂ł������E�E�E
�t�B�N�^�[�̃T�C�g�ɂ���p�t�H�[�}�X��Ɠ���������Xeon�őg��ł݂���
10�{�����̂ł������E�E�E
824 �F�f�t�H���g�̖����������F2009/01/24(�y) 00:29:55
>>693������
�Ȃ��Ŗ{�C�o���Ă�Ԃɂ��ʖ郂�[�h�ɂȂ��Ƃ�
�Ƃ肠����12.0�܂ł͂���
�܂�0.3�ʂ͋l�߂�邩������Ȃ�
�ŁA���~�Ƃ����[���ύX�Ƃ��Ȃ����炨��͂ǂ����������
�Ȃ��Ŗ{�C�o���Ă�Ԃɂ��ʖ郂�[�h�ɂȂ��Ƃ�
�Ƃ肠����12.0�܂ł͂���
�܂�0.3�ʂ͋l�߂�邩������Ȃ�
�ŁA���~�Ƃ����[���ύX�Ƃ��Ȃ����炨��͂ǂ����������
825 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 00:30:33
>>820
������
> ���[�����u�`�F�b�N�T�������Ă�Η����������Ȃ��Ă��ǂ��v
�����Ȃ�ď��F�[���I�ȃ��m�ł��B
mt[]�̔z��ȊO�̃��[�N��������ʂɊm�ۂ��āA���̏�ŗ������������
���ꂪ�F�߂���Ȃ獂�����͂�����ł����悤������B
CUDA��1SM������̃��W�X�^�{����32�r�b�g�~8192��32KB
�z��̗v�f��S�����W�X�^�Ɋ��蓖�ĂČv�Z���A���ƂŃ��������mt[]�ɏ����߂������������������B
mt[]�̔z������W�X�^�Ɋ��蓖�ĂČv�Z������MT�݊��ł͂Ȃ��̂��H�����Ă���Ȃ��Ƃł͂Ȃ��B
���W�X�^�ɗ]�T������A�[�L�e�N�`���ł́A�œK���̉ߒ��ł���Ȃ��Ƃ͎����ł���Ă����
�����n�����݂���B
�y�Ƃ����킯�Łz
mt[]���r�߂邱�Ƃ�����߂�A�����炩�͍������̗]�n�������B
���Ƃ��A�R�A���[�v�̓�����mt[]�̂��������W�X�^�Ɋ��蓖�ĂĂ��܂��āA
�S�����W�X�^��ł��ˉƂ���A128�r�b�g�~156�{�̃��W�X�^���K�v�ɂȂ�ASPU��128�{�{���ł͑���Ȃ��B
����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B�����������[�h�E�X�g�A�����邭�炢�������p���͂Ȃ���
�A�����[���Ɏg���郏�[�N���W�X�^�������I�Ɍ����Ă��܂��ċt�ɐ��\�ቺ�ɂȂ肩�˂Ȃ��B
�����ł��A���W�X�^��ߖA�X���[�v�b�g���҂���悤�ɁA�f�[�^�̃��C�A�E�g���̂��̂�M���Ă��܂�������Ȃ����ƁB
���[�N�������̓��W�X�^�Ɋ����đ�����K�v�͂Ȃ��ALS��̋ɃX���b�v���Ă����B
�������A����͂�����ł͂Ȃ��A�v�Z�@���Ƃ��Ă̗������B
�ǂ��܂ł������łǂ����炪�ד��Ȃ̂��A���p�Ȑ�������]���ō���Ă��܂��Ă��u�����v�͂Ȃ��킯��
�Ƃ肠�������̐l�ɖ��m�����Ă��炢�����Ƃ��낾�B
����gcc43���Ďw�肵�Ă���̂ɃA�Z���u���g�p�ɂȂ������_�ōő����[���Ȃ�ĂȂ����Ǝv�������B
������
> ���[�����u�`�F�b�N�T�������Ă�Η����������Ȃ��Ă��ǂ��v
�����Ȃ�ď��F�[���I�ȃ��m�ł��B
mt[]�̔z��ȊO�̃��[�N��������ʂɊm�ۂ��āA���̏�ŗ������������
���ꂪ�F�߂���Ȃ獂�����͂�����ł����悤������B
CUDA��1SM������̃��W�X�^�{����32�r�b�g�~8192��32KB
�z��̗v�f��S�����W�X�^�Ɋ��蓖�ĂČv�Z���A���ƂŃ��������mt[]�ɏ����߂������������������B
mt[]�̔z������W�X�^�Ɋ��蓖�ĂČv�Z������MT�݊��ł͂Ȃ��̂��H�����Ă���Ȃ��Ƃł͂Ȃ��B
���W�X�^�ɗ]�T������A�[�L�e�N�`���ł́A�œK���̉ߒ��ł���Ȃ��Ƃ͎����ł���Ă����
�����n�����݂���B
�y�Ƃ����킯�Łz
mt[]���r�߂邱�Ƃ�����߂�A�����炩�͍������̗]�n�������B
���Ƃ��A�R�A���[�v�̓�����mt[]�̂��������W�X�^�Ɋ��蓖�ĂĂ��܂��āA
�S�����W�X�^��ł��ˉƂ���A128�r�b�g�~156�{�̃��W�X�^���K�v�ɂȂ�ASPU��128�{�{���ł͑���Ȃ��B
����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B�����������[�h�E�X�g�A�����邭�炢�������p���͂Ȃ���
�A�����[���Ɏg���郏�[�N���W�X�^�������I�Ɍ����Ă��܂��ċt�ɐ��\�ቺ�ɂȂ肩�˂Ȃ��B
�����ł��A���W�X�^��ߖA�X���[�v�b�g���҂���悤�ɁA�f�[�^�̃��C�A�E�g���̂��̂�M���Ă��܂�������Ȃ����ƁB
���[�N�������̓��W�X�^�Ɋ����đ�����K�v�͂Ȃ��ALS��̋ɃX���b�v���Ă����B
�������A����͂�����ł͂Ȃ��A�v�Z�@���Ƃ��Ă̗������B
�ǂ��܂ł������łǂ����炪�ד��Ȃ̂��A���p�Ȑ�������]���ō���Ă��܂��Ă��u�����v�͂Ȃ��킯��
�Ƃ肠�������̐l�ɖ��m�����Ă��炢�����Ƃ��낾�B
����gcc43���Ďw�肵�Ă���̂ɃA�Z���u���g�p�ɂȂ������_�ōő����[���Ȃ�ĂȂ����Ǝv�������B
826 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 00:33:09
���߂������ɔ����Ă�
�~����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B
��224�v�f���炢�܂ł����蓖�Ă�ɂ��Ă��A����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B
�~����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B
��224�v�f���炢�܂ł����蓖�Ă�ɂ��Ă��A����Ȃ��Ƃ�SPU�Ŏ��ۂ���56�{�Œ�ŐH�����܂��B
>>825
�ʂɁAmt[] ��������ȂƂ͌����ĂȂ����A�ꕔ�̌v�Z���������ザ��Ȃ��ă��W�X�^���
���͉̂�������Ă�B
�����A>>579�͂�������MT�[�������̐������̑S������ĂȂ��悤�Ɏv�����B
mt[]��ό`����MT�[�����������Ă��邾���Ȃ牴�̊��Ⴂ���B���ݕt���ăX�}���B
�ʂɁAmt[] ��������ȂƂ͌����ĂȂ����A�ꕔ�̌v�Z���������ザ��Ȃ��ă��W�X�^���
���͉̂�������Ă�B
�����A>>579�͂�������MT�[�������̐������̑S������ĂȂ��悤�Ɏv�����B
mt[]��ό`����MT�[�����������Ă��邾���Ȃ牴�̊��Ⴂ���B���ݕt���ăX�}���B
828 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 00:41:37
�l�^�炵�����Ⴄ����13�����z�݂͂�ȕ����I��8����Ƃ�16����Ƃ�����Ă邾��H
spu_shuffle�g���ăp�b�N�E�A���p�b�N���Ă���Ă邾��H
���ꂪ�A���Ȃ牽�ł��A������B
���Ƃ����A32�r�b�g�̋^�������̏��16�r�b�g�Ɖ���16�r�b�g���ʁX�̃��W�X�^��ɕ�����Ă���A��������Ȃ��́H
��ŁA�㉺�������ꂽ��ԂŕʁX�ɍ��v�l�̌v�Z���Ă�������ˁH
���ꂪ�������ǂ����͕ʂɂ��āi���Ă�����carry�̌v�Z�������镪�����Ȃ��j
spu_shuffle�g���ăp�b�N�E�A���p�b�N���Ă���Ă邾��H
���ꂪ�A���Ȃ牽�ł��A������B
���Ƃ����A32�r�b�g�̋^�������̏��16�r�b�g�Ɖ���16�r�b�g���ʁX�̃��W�X�^��ɕ�����Ă���A��������Ȃ��́H
��ŁA�㉺�������ꂽ��ԂŕʁX�ɍ��v�l�̌v�Z���Ă�������ˁH
���ꂪ�������ǂ����͕ʂɂ��āi���Ă�����carry�̌v�Z�������镪�����Ȃ��j
>>828
���߂�A����C�Â��Ȃ������킗������
�Ă��A�R���e�X�g�Q���҂ł܂�13cycle���ĂȂ��A���ꂩ��撣��l���������A
�l�^�炵�͎~�߂悤���B
���߂�A����C�Â��Ȃ������킗������
�Ă��A�R���e�X�g�Q���҂ł܂�13cycle���ĂȂ��A���ꂩ��撣��l���������A
�l�^�炵�͎~�߂悤���B
���́A >>598 �� >>601 �ł����Ă�Ƃ���A�܂��߂� genrand_int32() �̖߂�l��
�v�Z������Ń`�F�b�N�T�����Ƃ��Ă�B
�������̃��W�X�^�ɕ�������̂͂ǂ��Ȃ낤�ȁH
���܂��ꏊ������Ă��邾���ŁA�r�b�g�P�ʂł͌��̗��������Ă�����A
�ʂɂ����C�����邪�A�A�A�O���[���ȁB
�v�Z������Ń`�F�b�N�T�����Ƃ��Ă�B
�������̃��W�X�^�ɕ�������̂͂ǂ��Ȃ낤�ȁH
���܂��ꏊ������Ă��邾���ŁA�r�b�g�P�ʂł͌��̗��������Ă�����A
�ʂɂ����C�����邪�A�A�A�O���[���ȁB
831 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 00:58:17
���Ⴀ���̃O���[�ȕ��@���g�킹�Ă��炤��B
x86��64�r�b�g�������ǂ�����Ĉ����Ă邩�m���Ă�H
����32�r�b�g��eax�A��ʂ�edx���B
�����������̂�2�i�łȂ��Ƃ����Ƃ���BCD�łಲ�Ǝv���킯
���������̉�������23�r�b�g��\�����Ă������B
�Ȃ��ɁAgenrand_int32()�̌`���ŗv�f�𒊏o����API��ʓr�p�ӂ���Ζ��Ȃ�
x86��64�r�b�g�������ǂ�����Ĉ����Ă邩�m���Ă�H
����32�r�b�g��eax�A��ʂ�edx���B
�����������̂�2�i�łȂ��Ƃ����Ƃ���BCD�łಲ�Ǝv���킯
���������̉�������23�r�b�g��\�����Ă������B
�Ȃ��ɁAgenrand_int32()�̌`���ŗv�f�𒊏o����API��ʓr�p�ӂ���Ζ��Ȃ�
832 �F227 ��eZQcaIaFJs �F2009/01/24(�y) 01:26:29
�Ƃ肠�����X�g�[���n������̒E�o�ɐ����B
�������o������>>824�ڎw���Ċ撣��B
�Ƃ���ŁA
for (int i = 0; i < num_rand; i+=2) {
sum += genrand_int32();
sum -= genrand_int32();
}
�Ƃ�����Ă݂���`�[�g��ɂȂ����肵�Ȃ��̂��ȁH���ȁH
�������o������>>824�ڎw���Ċ撣��B
�Ƃ���ŁA
for (int i = 0; i < num_rand; i+=2) {
sum += genrand_int32();
sum -= genrand_int32();
}
�Ƃ�����Ă݂���`�[�g��ɂȂ����肵�Ȃ��̂��ȁH���ȁH
833 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 01:27:20
���̓`�[�g�͂��Ȃ���
834 �F�f�t�H���g�̖����������F2009/01/24(�y) 01:56:42
init_genrand_mine ��ύX����ȂƂ͏����Ă��邯�ǁA
init_genrand_mine �ŏ��������ꂽ�x�N�^�Ńe�X�g����Ƃ�
�����ĂȂ��킯�����B
init_genrand_mine �ŏ��������ꂽ�x�N�^�Ńe�X�g����Ƃ�
�����ĂȂ��킯�����B
835 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 02:00:54
�g�����U�����ʏ��3�{�̐��\
���Ƃ͂킩��ȁH
���Ƃ͂킩��ȁH
836 �F�f�t�H���g�̖����������F2009/01/24(�y) 02:00:58
�����������l�^��Ђǂ�����
13�͐��Ă邯�ǁA>>828�̕��@�͎g���ĂȂ�
�����V�˂Ȃ̂͌��\�����ǁA�R���e�X�g�I����Ă���ɂ����
13�͐��Ă邯�ǁA>>828�̕��@�͎g���ĂȂ�
�����V�˂Ȃ̂͌��\�����ǁA�R���e�X�g�I����Ă���ɂ����
837 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 02:04:33
�c�O�������̕��@�ɂ͉�͖����悤���B
�U�X�l�|�������ǔނɂ͊��ӂ��Ȃ��Ƃ����Ȃ��B
�Ȃ��ɁA�P���ȗ�����������B
�U�X�l�|�������ǔނɂ͊��ӂ��Ȃ��Ƃ����Ȃ��B
�Ȃ��ɁA�P���ȗ�����������B
838 �F�f�t�H���g�̖����������F2009/01/24(�y) 02:25:51
Hack the Cell �ƌ����|���� Hack the spu-gcc43�A
�Ǝv������ Hack the MT �������ł�����B
�Ǝv������ Hack the MT �������ł�����B
839 �F�f�t�H���g�̖����������F2009/01/24(�y) 02:32:37
�c���f���H
840 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 02:34:18
����
841 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 02:46:25
���̃u���C�N�X���[�́A����Ӗ���Cell�̓������ő�������������̂ɂȂ�B
�������MT�̌݊����E�Ď��s�����ۏ�ł���B
�܂�A�A�Z���u���Ȃ�čŏ�����K�v�Ȃ�������B
����A����ł��l�߂�ɂ͕K�v������
�������MT�̌݊����E�Ď��s�����ۏ�ł���B
�܂�A�A�Z���u���Ȃ�čŏ�����K�v�Ȃ�������B
����A����ł��l�߂�ɂ͕K�v������
842 �F�f�t�H���g�̖����������F2009/01/24(�y) 02:48:32
��������̂Ƌɂ߂�͕̂ʕ��������
843 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 03:01:18
������A�Ō�ɂ�SIMDer�����炱���ł���e�N�j�b�N�����̂������Ǝv����B
844 �F�f�t�H���g�̖����������F2009/01/24(�y) 03:28:16
�ȂF�X�䖳�����ˁB>>321 �̗\�z�ʂ�Ƃ��������ˁB
845 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 03:44:22
�ǂ݂̂��ő��Ŗ����i��mt[]���r�߂邾���j�̕��@�͋߁X���̓��L�Ō��J���Ă�낤�Ǝv���Ă���B
Fixstars�͂Ȃ��mt[]��vec_uint4�Ƃ̋��p�̂ɂ��Ƃ��Ă���Ȃ������̂��H
���͂����ɓ������������̂��B
Fixstars�͂Ȃ��mt[]��vec_uint4�Ƃ̋��p�̂ɂ��Ƃ��Ă���Ȃ������̂��H
���͂����ɓ������������̂��B
846 �F�f�t�H���g�̖����������F2009/01/24(�y) 03:49:22
>>845
���ɋC�t���Ă�l�Ԃ��炵����A�Œ��ꒃ���f�Ȃ�ł����ǁB
���ɋC�t���Ă�l�Ԃ��炵����A�Œ��ꒃ���f�Ȃ�ł����ǁB
847 �F�f�t�H���g�̖����������F2009/01/24(�y) 03:50:25
��������
����܂肢��Ƃ����
12�T�C�N���ɓ��B���ĂȂ��l�Ԃ̓w�͂͑S�ے肩
���ł�10�{���ŎQ���o���Ȃ��Ⴂ���Ȃ�Fixsters�̐g�ɂ��Ȃ��
����܂肢��Ƃ����
12�T�C�N���ɓ��B���ĂȂ��l�Ԃ̓w�͂͑S�ے肩
���ł�10�{���ŎQ���o���Ȃ��Ⴂ���Ȃ�Fixsters�̐g�ɂ��Ȃ��
848 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 03:55:15
>>847
10�{���B�����l�������ꍇ�͏�ʂ�����ă��[�����������͂�
�ǂ݂̂��D���s�\�ȃR�[�h�Ȃ��當�喳������H
�������Ȃ���ǂ�����ʎҁiBSD���C�Z���X�Ń\�[�X���J�j�̓A�Z���u���������̃R�[�h�ɂȂ��H
�A�Z���u���̃R�[�h�Ȃ�Č��J����Ă��\�[�X�̍ė��p���Ƃ����ʂł͈Ӗ���������B
�������̃e�N�j�b�N���A�A�C�f�B�A���ė��p���̍����`�Ő��ɏo���K�v������B
���͉��̐M�O�ŁA�A�Z���u��������Fixstars���������낷
10�{���B�����l�������ꍇ�͏�ʂ�����ă��[�����������͂�
�ǂ݂̂��D���s�\�ȃR�[�h�Ȃ��當�喳������H
�������Ȃ���ǂ�����ʎҁiBSD���C�Z���X�Ń\�[�X���J�j�̓A�Z���u���������̃R�[�h�ɂȂ��H
�A�Z���u���̃R�[�h�Ȃ�Č��J����Ă��\�[�X�̍ė��p���Ƃ����ʂł͈Ӗ���������B
�������̃e�N�j�b�N���A�A�C�f�B�A���ė��p���̍����`�Ő��ɏo���K�v������B
���͉��̐M�O�ŁA�A�Z���u��������Fixstars���������낷
849 �F�f�t�H���g�̖����������F2009/01/24(�y) 05:55:21
�A�Z���u�������Ȃ玩�����ő��ŁA�����Ƃ��D�ꂽ�e�N�j�b�N��A�C�f�B�A�������Ă�Ǝv���Ă邠���肪�ɂ���ȁc�c
850 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 06:14:29
�V�����R�[�h����Tempering����������0.5����/Word�����B
�ʂ̂Ƃ��낪����������Ă��ł����ǂˁB
��������H�g�����U������������āB
�ʂ̂Ƃ��낪����������Ă��ł����ǂˁB
��������H�g�����U������������āB
851 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 06:48:26
���܂�A�ق��Ă����B
���͉����v�����Ă܂���B�����
���͉����v�����Ă܂���B�����
852 �F�f�t�H���g�̖����������F2009/01/24(�y) 07:47:25
�y���ŃG�l���M�[�g���ʂ����Ď��������ł��ˁA������܂�
853 �F�f�t�H���g�̖����������F2009/01/24(�y) 07:53:17
�z���g����u���v�����B�c�q�ɂ����B
�ł�����͒������{�l�����F�߂����狖���B
�����Ƃ��B
�ł�����͒������{�l�����F�߂����狖���B
�����Ƃ��B
�{���ɖ��f���邩����J�͂�߂Ă���
���̂���Ȃ��Ƃ�����
���̂���Ȃ��Ƃ�����
855 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 08:04:54
���Ⴀ���،�Ɍ��J�����B
�ǂ�����o���Ȃ��R�[�h���B
�ǂ�����o���Ȃ��R�[�h���B
856 �F�f�t�H���g�̖����������F2009/01/24(�y) 08:22:01
>>848�ɏq�ׂ��Ă���Ƃ���̕K�v��������J����Ƃ����Ȃ�
�܂��̓t�B�b�N�X�^�[�Y�ɒ��ڕ��匾���Ă����
���̌�ŃR���e�X�g�I����ɔ�A�Z���u���̃R�[�h�����J�������
����ɂ���Ă��Ȃ��̌����u�ė��p���v�̗v���͒B�������̂ł́H
�m���ɍė��p�\�ȃR�[�h�ƃA�C�f�B�A�̌��J�͕K�v�ȗv�f���Ǝv�����^�����邯��
�ʂɃR���e�X�g���ɂ�����s���ċ��Z��ׂ��Ȃ���ΒB���ł��Ȃ��ړI�ł͂Ȃ��Ǝv��
�����Ɏ����̐M�O������J�ɓ��ݐ낤�Ƃ���̂Ȃ�A�������ė~����
�܂��A����ȉ\���͖����Ƃ͎v�������ӂ⎩�Ȍ����~���炻����s�����Ƃ���͎̂~�߂ė~����
����Ȃ��Ƃ͕��ʂ̂Ȃ��q���̂��邱�Ƃ����A���炭�M���͎q���ł͂Ȃ��̂ŁB
�܂��̓t�B�b�N�X�^�[�Y�ɒ��ڕ��匾���Ă����
���̌�ŃR���e�X�g�I����ɔ�A�Z���u���̃R�[�h�����J�������
����ɂ���Ă��Ȃ��̌����u�ė��p���v�̗v���͒B�������̂ł́H
�m���ɍė��p�\�ȃR�[�h�ƃA�C�f�B�A�̌��J�͕K�v�ȗv�f���Ǝv�����^�����邯��
�ʂɃR���e�X�g���ɂ�����s���ċ��Z��ׂ��Ȃ���ΒB���ł��Ȃ��ړI�ł͂Ȃ��Ǝv��
�����Ɏ����̐M�O������J�ɓ��ݐ낤�Ƃ���̂Ȃ�A�������ė~����
�܂��A����ȉ\���͖����Ƃ͎v�������ӂ⎩�Ȍ����~���炻����s�����Ƃ���͎̂~�߂ė~����
����Ȃ��Ƃ͕��ʂ̂Ȃ��q���̂��邱�Ƃ����A���炭�M���͎q���ł͂Ȃ��̂ŁB
857 �F�f�t�H���g�̖����������F2009/01/24(�y) 08:24:13
>>855
���A�����Ȃ̂��B���肪�Ƃ�
�K��������>>856�݂����Ȓ����������̂��p��������
�C�����Q���Ă��܂�����\����Ȃ��ł�
���A�����Ȃ̂��B���肪�Ƃ�
�K��������>>856�݂����Ȓ����������̂��p��������
�C�����Q���Ă��܂�����\����Ȃ��ł�
858 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 08:35:03
�܂��A�R���e�X�g�̏�ʂ�_���ɂ͂ǂ����ɂ���u���ɗ����Ȃ��v�Ǝv�����ǂˁB
���J�\��̃R�[�h�͂����J�����������B
���ʂ��Ƃ킩�������Ƃ͂��Ȃ��B
���J�\��̃R�[�h�͂����J�����������B
���ʂ��Ƃ킩�������Ƃ͂��Ȃ��B
859 �F�f�t�H���g�̖����������F2009/01/24(�y) 09:34:56
���ʂł����킷��̂����}������?
�܂��A�R���e�X�g�ׂ��͂����߂��Ȃ��B
# ����ɂ��ẮA�u�����Ƃ��v�Ƃ͎v��Ȃ����Ȃ���w
�܂��A�R���e�X�g�ׂ��͂����߂��Ȃ��B
# ����ɂ��ẮA�u�����Ƃ��v�Ƃ͎v��Ȃ����Ȃ���w
860 �F�f�t�H���g�̖����������F2009/01/24(�y) 10:48:45
�܂����l�Ƀt�F�A�ł���ׂ������
861 �F�f�t�H���g�̖����������F2009/01/24(�y) 12:11:49
>>848
>�������Ȃ���ǂ�����ʎҁiBSD���C�Z���X�Ń\�[�X���J�j�̓A�Z���u���������̃R�[�h�ɂȂ��H
>�A�Z���u���̃R�[�h�Ȃ�Č��J����Ă��\�[�X�̍ė��p���Ƃ����ʂł͈Ӗ���������B
�ɂ�����Ȃ�
�Q���ґS�����\�[�X���J�̋������Ă������A�^�c���̔��f��
�S���̃\�[�X�R�[�h���擾�\�ɂȂ�Ƃ��A�ő��̃R�[�h�̑��ɂ��\�������ĉǐ��̗ǂ��\�[�X��
���J�����Ƃ����\�������邾��B
>�������̃e�N�j�b�N���A�A�C�f�B�A���ė��p���̍����`�Ő��ɏo���K�v������B
������厖�����A���̎Q���҂��h�����ōl���āh�X�L���������厖�Ȃ��Ƃ���H
���܂��������͔̂F�߂Ă��邩��A�l�́h�l����h�y���݂�D���Ȃ�B
>�������Ȃ���ǂ�����ʎҁiBSD���C�Z���X�Ń\�[�X���J�j�̓A�Z���u���������̃R�[�h�ɂȂ��H
>�A�Z���u���̃R�[�h�Ȃ�Č��J����Ă��\�[�X�̍ė��p���Ƃ����ʂł͈Ӗ���������B
�ɂ�����Ȃ�
�Q���ґS�����\�[�X���J�̋������Ă������A�^�c���̔��f��
�S���̃\�[�X�R�[�h���擾�\�ɂȂ�Ƃ��A�ő��̃R�[�h�̑��ɂ��\�������ĉǐ��̗ǂ��\�[�X��
���J�����Ƃ����\�������邾��B
>�������̃e�N�j�b�N���A�A�C�f�B�A���ė��p���̍����`�Ő��ɏo���K�v������B
������厖�����A���̎Q���҂��h�����ōl���āh�X�L���������厖�Ȃ��Ƃ���H
���܂��������͔̂F�߂Ă��邩��A�l�́h�l����h�y���݂�D���Ȃ�B
862 �F�f�t�H���g�̖����������F2009/01/24(�y) 16:32:27
���S���̃\�[�X�R�[�h���擾�\�ɂȂ�Ƃ��A�ő��̃R�[�h�̑��ɂ��\�������ĉǐ��̗ǂ��\�[�X��
�����J�����Ƃ����\�������邾��B
���߂ł��������āB
�����܂��������͔̂F�߂Ă��邩��A�l�́h�l����h�y���݂�D���Ȃ�B
�l����\�͂̒Ⴂ�z�Ɍ����Ă���������ˁB
�[���\�͂�����Ȃ�A�ڂ̑O�ɃS�[���ւ̒n�}�������Ă����̉ߒ����y���ނ��Ƃ��ł���̂ɁB
�����J�����Ƃ����\�������邾��B
���߂ł��������āB
�����܂��������͔̂F�߂Ă��邩��A�l�́h�l����h�y���݂�D���Ȃ�B
�l����\�͂̒Ⴂ�z�Ɍ����Ă���������ˁB
�[���\�͂�����Ȃ�A�ڂ̑O�ɃS�[���ւ̒n�}�������Ă����̉ߒ����y���ނ��Ƃ��ł���̂ɁB
>>838
���͍ŏ����� Hack the MT ���Ƃ����Ă���B
�^�ʖڂɗ������������@�ɂ��ẮAIBM �� SCE ���ő��̃R�[�h��
(�������ؖ�����)�����Ă���̂ł͂Ȃ����Ǝv����킯���BCELL �̐v��
����ۂɂ��̂��炢�̌����͂��Ă��邾�낤�B
���ꂩ��A����͓��Ă����ۂ�������ǁAFolding@Home �̗����� MT �ł́H
���Ƃ���ƁASCE �͍L������|���čœK�����Ă���͂��B�����ڂȂ��ˁB
�Ȃ�AC ������(SIMD �g�킸��)�ő���������ʔ�����ˁH �Ǝv�����B
���ۖ��A������s���ɂ́u�ۑ�v�����Ȃ�ȉ����Ȃ��Ɩ����Ȃ킯�����A
�����͐��w���ƕ������̃X�^���X�̈Ⴂ�ł���킯���B
�ŏ��͂����v���Ă������ǁA�������ω������̂͗ǂ��������� >>628�B
���w�͉�㈂̊w��B�S�Ă͐^���ł���Əؖ����ꂽ���Ƃ��瓱����Ȃ����
�Ȃ�Ȃ��B�Ƃ����Ӗ��ł́A
>���u���蓾�Ȃ�����������o���v������k�ق́����ӏ��ɂ���������
���̎w�E�͐������B
�Ђ�A�����͋A�[�̊w��B�S�Ă͊ϑ��Ɋ�Â��B�����Ƃ��炵���ƕ]�����ꂽ
�u�����v�́A�������ϑ����Ȃ���Ȃ�����u�����v�ł���Ƃ���B
�����Ď��ɂ͑Ë�������B�������́A�u���肦�Ȃ�����v�͂悭�p����B
�u���z�d���v���t���炢�͕��������Ƃ��邾��H
���͍ŏ����� Hack the MT ���Ƃ����Ă���B
�^�ʖڂɗ������������@�ɂ��ẮAIBM �� SCE ���ő��̃R�[�h��
(�������ؖ�����)�����Ă���̂ł͂Ȃ����Ǝv����킯���BCELL �̐v��
����ۂɂ��̂��炢�̌����͂��Ă��邾�낤�B
���ꂩ��A����͓��Ă����ۂ�������ǁAFolding@Home �̗����� MT �ł́H
���Ƃ���ƁASCE �͍L������|���čœK�����Ă���͂��B�����ڂȂ��ˁB
�Ȃ�AC ������(SIMD �g�킸��)�ő���������ʔ�����ˁH �Ǝv�����B
���ۖ��A������s���ɂ́u�ۑ�v�����Ȃ�ȉ����Ȃ��Ɩ����Ȃ킯�����A
�����͐��w���ƕ������̃X�^���X�̈Ⴂ�ł���킯���B
�ŏ��͂����v���Ă������ǁA�������ω������̂͗ǂ��������� >>628�B
���w�͉�㈂̊w��B�S�Ă͐^���ł���Əؖ����ꂽ���Ƃ��瓱����Ȃ����
�Ȃ�Ȃ��B�Ƃ����Ӗ��ł́A
>���u���蓾�Ȃ�����������o���v������k�ق́����ӏ��ɂ���������
���̎w�E�͐������B
�Ђ�A�����͋A�[�̊w��B�S�Ă͊ϑ��Ɋ�Â��B�����Ƃ��炵���ƕ]�����ꂽ
�u�����v�́A�������ϑ����Ȃ���Ȃ�����u�����v�ł���Ƃ���B
�����Ď��ɂ͑Ë�������B�������́A�u���肦�Ȃ�����v�͂悭�p����B
�u���z�d���v���t���炢�͕��������Ƃ��邾��H
���w���ƕ������A�ǂ��炪�ゾ�����Ƙ_�������͖ѓ��Ȃ����A>>628 ��
����u�Z�p�t�v�Ɩ����A�l���u�������v�ƌĂԁu�c�q�v�ɋ������ڂ����B
�u���蓾�Ȃ�����v���u���蓾�Ȃ��v�Ƃ���̂́A�c�q�́u����v�ł����Ȃ��B
���̉���́A��㈂̊w��Ƃ��Ă͐��������@�ł͂Ȃ��B
������A>>713 �ł��̉��肪�ԈႦ�Ă��邱�Ƃ��ؖ������B����ł��c�q��
�u����̋�_�v�Ƃ����ď���Ȃ��B
�����Ŋ��S�ɋ������������B
�c�q�Ƃ����l����m�����C�ɂȂ��Ă����B�u���w�����������������Z�p�t�v
�Ƃ����������u�ϑ����ꂽ�v�Ǝv���Ă����B
���A�����ɗ��Ăǂ����낤�B�ŋ߂̒c�q�A���Ɠ������ƌ����Ă��Ȃ����H
�܂�A�ŏ����牴�͒c�q�ɏ悹���Ă����ȁB
���s�B
�R�[�h�͒c�q���l�A���ߐ��Ɍ��J���邱�Ƃɂ����B�����悤�ȃ��W�b�N��
SIMD �g��ꂽ�珟�Ă�C�����Ȃ��B
���߂�ȁB
����u�Z�p�t�v�Ɩ����A�l���u�������v�ƌĂԁu�c�q�v�ɋ������ڂ����B
�u���蓾�Ȃ�����v���u���蓾�Ȃ��v�Ƃ���̂́A�c�q�́u����v�ł����Ȃ��B
���̉���́A��㈂̊w��Ƃ��Ă͐��������@�ł͂Ȃ��B
������A>>713 �ł��̉��肪�ԈႦ�Ă��邱�Ƃ��ؖ������B����ł��c�q��
�u����̋�_�v�Ƃ����ď���Ȃ��B
�����Ŋ��S�ɋ������������B
�c�q�Ƃ����l����m�����C�ɂȂ��Ă����B�u���w�����������������Z�p�t�v
�Ƃ����������u�ϑ����ꂽ�v�Ǝv���Ă����B
���A�����ɗ��Ăǂ����낤�B�ŋ߂̒c�q�A���Ɠ������ƌ����Ă��Ȃ����H
�܂�A�ŏ����牴�͒c�q�ɏ悹���Ă����ȁB
���s�B
�R�[�h�͒c�q���l�A���ߐ��Ɍ��J���邱�Ƃɂ����B�����悤�ȃ��W�b�N��
SIMD �g��ꂽ�珟�Ă�C�����Ȃ��B
���߂�ȁB
>>820
>�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
mt19937ar.c �́A���`�����@�Ő��������ŏ��̎킩�炵�������ł��Ȃ�����H
�ۑ�Ƃ��ẮAmt19937ar.c �Ɠ����������ł���Ηǂ��A�Ɠǂ߂�B
�����āAmt[] �̏����l�𓊓�������폜���ꂿ����Ă������B
>>834
init_genrand_mine() �̓��e������ɕύX���ꂽ��A����� mt19937ar.c ��
��������(�ł���)������Ȃ���ˁB����ȕ��Ƀ��[���ύX���ꂽ��
���ꂱ���A���t�F�A����Ȃ������H
���ꂩ��A�C�ӂ̐�������������������̍��v���v�Z�ł���Ƃ������Ƃ́A
�C�ӂ̉ӏ��Ő�������闐�����v�Z�ł���(num_rand - 1 �Ōv�Z�������v��
�����Z����悢)�B�܂�A�u���������ł���v�̂Ɠ����Ӗ��ɂȂ�B
�����āA�R���e�X�g�� sum ���v�Z���鑬���ŋ����A�Ə����Ă���B
>>825
>�����Ȃ�ď��F�[���I�ȃ��m�ł��B
�܂��ɁB
�����āA�[�������́u�g�����v�̎���������܂��B
����́A�u���v���v�Z���邽�߂Ɂv�[���������������B
���ꂾ���̎����B
>>830
������x�^�ʖڂɌv�Z����ɂ��Ă��A�������Z�͍Ō��1��H
>�����Z���k�E�c�C�X�^�̎��� mt19937ar.c �Ɠ�������������Ă��������B
mt19937ar.c �́A���`�����@�Ő��������ŏ��̎킩�炵�������ł��Ȃ�����H
�ۑ�Ƃ��ẮAmt19937ar.c �Ɠ����������ł���Ηǂ��A�Ɠǂ߂�B
�����āAmt[] �̏����l�𓊓�������폜���ꂿ����Ă������B
>>834
init_genrand_mine() �̓��e������ɕύX���ꂽ��A����� mt19937ar.c ��
��������(�ł���)������Ȃ���ˁB����ȕ��Ƀ��[���ύX���ꂽ��
���ꂱ���A���t�F�A����Ȃ������H
���ꂩ��A�C�ӂ̐�������������������̍��v���v�Z�ł���Ƃ������Ƃ́A
�C�ӂ̉ӏ��Ő�������闐�����v�Z�ł���(num_rand - 1 �Ōv�Z�������v��
�����Z����悢)�B�܂�A�u���������ł���v�̂Ɠ����Ӗ��ɂȂ�B
�����āA�R���e�X�g�� sum ���v�Z���鑬���ŋ����A�Ə����Ă���B
>>825
>�����Ȃ�ď��F�[���I�ȃ��m�ł��B
�܂��ɁB
�����āA�[�������́u�g�����v�̎���������܂��B
����́A�u���v���v�Z���邽�߂Ɂv�[���������������B
���ꂾ���̎����B
>>830
������x�^�ʖڂɌv�Z����ɂ��Ă��A�������Z�͍Ō��1��H
>>837
>�c�O�������̕��@�ɂ͉�͖����悤���B
>�U�X�l�|�������ǔނɂ͊��ӂ��Ȃ��Ƃ����Ȃ��B
>�Ȃ��ɁA�P���ȗ�����������B
�Ō�Ɏ̂đ䎌�f���Ă�����B
���̔����ɂ͏��X�u�R�v�����荞�܂�Ă���B�v�l�̉ߒ���
�u����Ⴞ�߂��v�ƍs���l�������̂ȁB
�R���������ނ̂��c�q�̏퓅��i����H
�������N�_�Ƃ��ď����l����A�c�q�ȊO�̂�͋C�Â���
�v���Ă����B�����āA�c�q�͋C�Â��Ȃ����낤�Ǝv���Ă����B
�Ȃ��ɁA�P���ȗ�������B
>�c�O�������̕��@�ɂ͉�͖����悤���B
>�U�X�l�|�������ǔނɂ͊��ӂ��Ȃ��Ƃ����Ȃ��B
>�Ȃ��ɁA�P���ȗ�����������B
�Ō�Ɏ̂đ䎌�f���Ă�����B
���̔����ɂ͏��X�u�R�v�����荞�܂�Ă���B�v�l�̉ߒ���
�u����Ⴞ�߂��v�ƍs���l�������̂ȁB
�R���������ނ̂��c�q�̏퓅��i����H
�������N�_�Ƃ��ď����l����A�c�q�ȊO�̂�͋C�Â���
�v���Ă����B�����āA�c�q�͋C�Â��Ȃ����낤�Ǝv���Ă����B
�Ȃ��ɁA�P���ȗ�������B
867 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 17:36:51
���͋^�킵���͔�����A�O���P���̑㐔�������������炿������
���w�L���Ƃ��ǂ�ł����i�[��p�̓��ꕶ���̗���ɂ��������Ȃ��킯��
�ł������ȉ�@�ōĎ������Ă݂Ă邪
�e�����̉��Z�R�X�g���f�������S�ɋt�]���Ă��܂����B
�}�W��XOR�ƃV�t�g���������Ȃ����E����
���w�L���Ƃ��ǂ�ł����i�[��p�̓��ꕶ���̗���ɂ��������Ȃ��킯��
�ł������ȉ�@�ōĎ������Ă݂Ă邪
�e�����̉��Z�R�X�g���f�������S�ɋt�]���Ă��܂����B
�}�W��XOR�ƃV�t�g���������Ȃ����E����
868 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 17:39:41
> ���̔����ɂ͏��X�u�R�v�����荞�܂�Ă���B�v�l�̉ߒ���
> �u����Ⴞ�߂��v�ƍs���l�������̂ȁB
�����܂��ɉ��̏퓅��i��
> �u����Ⴞ�߂��v�ƍs���l�������̂ȁB
�����܂��ɉ��̏퓅��i��
869 �F�f�t�H���g�̖����������F2009/01/24(�y) 19:40:59
�Ȃイ�~�[�̉�b��w
�u����������v�������Ӗ�����̂��́AFixstars�Ɏ��Ⓤ��������҂��B
>>865
>�ۑ�Ƃ��ẮAmt19937ar.c �Ɠ����������ł���Ηǂ��A�Ɠǂ߂�B
����A��������������鑬�x�������Ă��ˁB
�ŁA>>579�̕��@�ł́A������������Ă�́H
�u��������Γ��������o����v�Ƃ���������A���������������Ԃ��o���ĂˁH
>������x�^�ʖڂɌv�Z����ɂ��Ă��A�������Z�͍Ō��1��H
������H
���������������̂��ۑ�ŁA�ۑ��������Ń`�F�b�N�T������鏇�ԂȂ�Ď��R����H
>>865
>�ۑ�Ƃ��ẮAmt19937ar.c �Ɠ����������ł���Ηǂ��A�Ɠǂ߂�B
����A��������������鑬�x�������Ă��ˁB
�ŁA>>579�̕��@�ł́A������������Ă�́H
�u��������Γ��������o����v�Ƃ���������A���������������Ԃ��o���ĂˁH
>������x�^�ʖڂɌv�Z����ɂ��Ă��A�������Z�͍Ō��1��H
������H
���������������̂��ۑ�ŁA�ۑ��������Ń`�F�b�N�T������鏇�ԂȂ�Ď��R����H
���x���������ǁA�ۑ�͓���������̐����ŁA�`�F�b�N�T���͂����܂ł������������
�������Ă��邩���m�F�����i�ɉ߂��Ȃ��B
�f�N�������^�����Ԃ��v�������i�ɂ����߂��Ȃ��̂Ɠ����B
>�f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
>����̏o��̎�|�ɔ�����̂ŕs�Ƃ��܂��B
����FAQ�Ɠ����B
�X�^�b�N��͂���ORIGINAL�̌v�Z���ʂ�T���Ƃ��Agenrand_mine() ���Ăяo���O�̃f�N�������^��
�l������������Ƃ��A mt_kadai �̓���ɑ���n�b�N�͊�����邯�ǁA���ꂪ����̉ۑ��
�Ƃ��ĔF�߂����ł͂Ȃ��B
�����������Ȃ��Ń`�F�b�N�T�������v�Z���悤�Ƃ��Ă郄�c�́A�l�b�g�Q�[���Ńo�O�Z�����āA
�u�o�O���d�l�̂����v�Ƃ��ʂ����ăQ�[����Œ��ꒃ�ɂ���^�C�v���H
�������Ă��邩���m�F�����i�ɉ߂��Ȃ��B
�f�N�������^�����Ԃ��v�������i�ɂ����߂��Ȃ��̂Ɠ����B
>�f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
>����̏o��̎�|�ɔ�����̂ŕs�Ƃ��܂��B
����FAQ�Ɠ����B
�X�^�b�N��͂���ORIGINAL�̌v�Z���ʂ�T���Ƃ��Agenrand_mine() ���Ăяo���O�̃f�N�������^��
�l������������Ƃ��A mt_kadai �̓���ɑ���n�b�N�͊�����邯�ǁA���ꂪ����̉ۑ��
�Ƃ��ĔF�߂����ł͂Ȃ��B
�����������Ȃ��Ń`�F�b�N�T�������v�Z���悤�Ƃ��Ă郄�c�́A�l�b�g�Q�[���Ńo�O�Z�����āA
�u�o�O���d�l�̂����v�Ƃ��ʂ����ăQ�[����Œ��ꒃ�ɂ���^�C�v���H
>>870
�������ǂȁB
sum ���v�Z�ł��邱�ƂƁA�������ł��邱�Ƃ� >>865 �ɏ������ʂ�
���w�I�ɂ͍����ȂB
�����āAmt19937ar.c �� capability �͂��Ȃ�����Ă���B
>mt19937ar.c �Ɠ�������������Ă��������B
�܂�Amt19937ar.c �������ł��Ȃ������͐�������K�v���Ȃ��B
���ɁA>>688 �̂悤�ȕ]�����@���̂�ꂽ�Ƃ��Ă��A�Ō�� seed �� mti
�����ۑ����Ă����A�[���Ԃ�� sum ���L�����Z�����đ����� sum ��
�v�Z��������B
�������A�L�����Z������Ԃ�̃R�X�g�͊|���邪�Anum_rand >= 100000
�Ƃ�������������������Ώ\���ɃR�X�g�͉���ł���B
>>>579�̕��@�͂����̃`�[�g�ŁA���[�����u�`�F�b�N�T�������Ă�Η���
>�������Ȃ��Ă��ǂ��v ���ĂȂ����炻�ꂱ�����{�I�ȃ��[���ύX���B
�����l�����`�[�g�́A�S�ĉۑ���n�l������ł̂��Ƃ��B
���̒i�K�ŁAmt19937ar.c �� capability ��ύX���邱�Ƃ�����A�����
fixtars �̏���ȃ��[���ύX�ł����āA���ꂱ�����{�I�ȃ��[���ύX���B
���߂�ȁB�c�q�ɓ���m�b�����܂����͉̂����B
�������ǂȁB
sum ���v�Z�ł��邱�ƂƁA�������ł��邱�Ƃ� >>865 �ɏ������ʂ�
���w�I�ɂ͍����ȂB
�����āAmt19937ar.c �� capability �͂��Ȃ�����Ă���B
>mt19937ar.c �Ɠ�������������Ă��������B
�܂�Amt19937ar.c �������ł��Ȃ������͐�������K�v���Ȃ��B
���ɁA>>688 �̂悤�ȕ]�����@���̂�ꂽ�Ƃ��Ă��A�Ō�� seed �� mti
�����ۑ����Ă����A�[���Ԃ�� sum ���L�����Z�����đ����� sum ��
�v�Z��������B
�������A�L�����Z������Ԃ�̃R�X�g�͊|���邪�Anum_rand >= 100000
�Ƃ�������������������Ώ\���ɃR�X�g�͉���ł���B
>>>579�̕��@�͂����̃`�[�g�ŁA���[�����u�`�F�b�N�T�������Ă�Η���
>�������Ȃ��Ă��ǂ��v ���ĂȂ����炻�ꂱ�����{�I�ȃ��[���ύX���B
�����l�����`�[�g�́A�S�ĉۑ���n�l������ł̂��Ƃ��B
���̒i�K�ŁAmt19937ar.c �� capability ��ύX���邱�Ƃ�����A�����
fixtars �̏���ȃ��[���ύX�ł����āA���ꂱ�����{�I�ȃ��[���ύX���B
���߂�ȁB�c�q�ɓ���m�b�����܂����͉̂����B
873 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:06:45
�D���_���Ă�Ȃ�Ƃ������A�����̍D���ȕ��@�ōD���ɑg�߂��������
�ʂɌ��I�g�D���J���Ă�����Ă킯����Ȃ�����A�S�z�Ȃ珃���ȍœK���Ɛ��w�I�ȕ��@�̂Q�o�[�W���������Ƃ������肶��ˁH
�_����������E�E�i�m�F�͕K�v���ȁj
�ʂɌ��I�g�D���J���Ă�����Ă킯����Ȃ�����A�S�z�Ȃ珃���ȍœK���Ɛ��w�I�ȕ��@�̂Q�o�[�W���������Ƃ������肶��ˁH
�_����������E�E�i�m�F�͕K�v���ȁj
874 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:13:04
�M���Ȃ肷����
�҂ĂΖ�������
���Ƀf�N�������^�����������ĂȂ�Ƃ��Ƃ͓���ɂ͏o���낤
������Ɛ��w�I�ɏؖ����ꂽ�A���S���Y�����������Ă邾���Ȃ���
����͂�����11.6�܂ł͂�����
���͓������Ƃ̃A���S���Y���̂܂܂ŋɗ����������10����ڎw���Ċ撣�邺
�҂ĂΖ�������
���Ƀf�N�������^�����������ĂȂ�Ƃ��Ƃ͓���ɂ͏o���낤
������Ɛ��w�I�ɏؖ����ꂽ�A���S���Y�����������Ă邾���Ȃ���
����͂�����11.6�܂ł͂�����
���͓������Ƃ̃A���S���Y���̂܂܂ŋɗ����������10����ڎw���Ċ撣�邺
875 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:14:37
>>871
�t�ɕ�����
mt[]�̃f�[�^���C�A�E�g��mt19937ar.c�Ɗ��S�݊��ł���K�v���邩�H
mt[]�̔z�Ďv�������ǁA������肽���Ďd�����Ȃ�������B
union {
�@�@�@vec_uint vec[N/4];
�@�@�@unsigned int scl[N];
} MT_Array;
#define mt MT_Array.scl
���Ǖʂ̕��@�l������łǂ��ł��ǂ��Ȃ����B
����͂��Ă����A��������ėǂ��ĉ���������炢���Ȃ����H���̐��������ĒN�����́H
���܂�ɌŒ�ϔO�ɔ���ꂷ���Ă��Ȃ����ƁH
���f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
�݂����Ș_�O�Ȏ��₾����FAQ�ɂ������Ă���A�����ł��邩�ǂ�����
�������炢����Ȃ��́H
���������̖��p�Ȓlj����[��������Ă��܂��Ă����ł����Ȃ�
�t�ɕ�����
mt[]�̃f�[�^���C�A�E�g��mt19937ar.c�Ɗ��S�݊��ł���K�v���邩�H
mt[]�̔z�Ďv�������ǁA������肽���Ďd�����Ȃ�������B
union {
�@�@�@vec_uint vec[N/4];
�@�@�@unsigned int scl[N];
} MT_Array;
#define mt MT_Array.scl
���Ǖʂ̕��@�l������łǂ��ł��ǂ��Ȃ����B
����͂��Ă����A��������ėǂ��ĉ���������炢���Ȃ����H���̐��������ĒN�����́H
���܂�ɌŒ�ϔO�ɔ���ꂷ���Ă��Ȃ����ƁH
���f�N�������^�̃I�[�o�[�t���[�𗘗p���邱�Ƃ͉\�ł����H
�݂����Ș_�O�Ȏ��₾����FAQ�ɂ������Ă���A�����ł��邩�ǂ�����
�������炢����Ȃ��́H
���������̖��p�Ȓlj����[��������Ă��܂��Ă����ł����Ȃ�
>>872
>sum ���v�Z�ł��邱�ƂƁA�������ł��邱�Ƃ� >>865 �ɏ������ʂ�
>���w�I�ɂ͍����ȂB
���w�I�ɓ����ł��邩�牽�H����͐��w�R���e�X�g����Ȃ��čœK���R���e�X�g����H
������������Ȃ�A���ۂɓ��������������āA���̎��Ԃ��v�����āB
�������A >>579 �̓R���e�X�g�ɎQ�����Ȃ��炵������A���w�I�ȋ�������ۑ�Ƃ͈Ⴄ��@��
������͕̂ʂɖ��Ȃ���B
�ł��A�Q�����郄�c�́A�����Ɖۑ�ǂ��藐���������悤���B
>sum ���v�Z�ł��邱�ƂƁA�������ł��邱�Ƃ� >>865 �ɏ������ʂ�
>���w�I�ɂ͍����ȂB
���w�I�ɓ����ł��邩�牽�H����͐��w�R���e�X�g����Ȃ��čœK���R���e�X�g����H
������������Ȃ�A���ۂɓ��������������āA���̎��Ԃ��v�����āB
�������A >>579 �̓R���e�X�g�ɎQ�����Ȃ��炵������A���w�I�ȋ�������ۑ�Ƃ͈Ⴄ��@��
������͕̂ʂɖ��Ȃ���B
�ł��A�Q�����郄�c�́A�����Ɖۑ�ǂ��藐���������悤���B
877 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:19:26
�ǂ��Ȃ邩�ˁB���鑤���Y��ł��ˁH��
�v���O�����̍œK�����������ŁA�C���t��������ɍ��x�Ȑ��w�m�����������l����
��ʓ��܂ł��Ȃ����Ă����̂��Ȃ��Ȃ�
�v���O�����̍œK�����������ŁA�C���t��������ɍ��x�Ȑ��w�m�����������l����
��ʓ��܂ł��Ȃ����Ă����̂��Ȃ��Ȃ�
>�u����������v�������Ӗ�����̂��́AFixstars�Ɏ��Ⓤ��������҂��B
�{���ɂ��߂�ȁB����̂́A���������� fixstars �́u�ݖ�~�X�v�Ȃ�B
>>865 �ɏ������u�[�������́w�g�����x�̎���������܂��v�͂��������Ӗ��B
���̒i�K�Őݖ��ύX���邽�߂ɂ́A�Z���^�[�������l�u�S���ɎQ���o���܂��v
���炢�̊o�傪�K�v�B
�Ⴆ�A�u�E�H�[���X�̃����_���E�H�[�N�v�����肵�āu�����{�v�R���e�X�g��
�s����B�������A���������͐��`�����@�Ɛ錾����Ă���B
�������A�݂�Ȑ��`�����@�������`�[�g������킯���B��������ˑR�A
�u���������� MT �ɂ��܂��v�B����Ȋ����B
�{���ɂ��߂�ȁB����̂́A���������� fixstars �́u�ݖ�~�X�v�Ȃ�B
>>865 �ɏ������u�[�������́w�g�����x�̎���������܂��v�͂��������Ӗ��B
���̒i�K�Őݖ��ύX���邽�߂ɂ́A�Z���^�[�������l�u�S���ɎQ���o���܂��v
���炢�̊o�傪�K�v�B
�Ⴆ�A�u�E�H�[���X�̃����_���E�H�[�N�v�����肵�āu�����{�v�R���e�X�g��
�s����B�������A���������͐��`�����@�Ɛ錾����Ă���B
�������A�݂�Ȑ��`�����@�������`�[�g������킯���B��������ˑR�A
�u���������� MT �ɂ��܂��v�B����Ȋ����B
>>874
��������>>579�̍l�������@�́A���w�I�ɐ������炵�����A���̕��@�����߂���̂͐����Ǝv���B
�ł��A���@�������Ă������Ȃ��Ă��A�u���������������v�Ƃ����ۑ�����ĂȂ��ȏ�A
����̃R���e�X�g�̉Ƃ��Ă͕s�K����H
�f�N�������^�̃I�[�o�[�t���[�Ɠ���Ɉ����ĉ��̖�肪����H
��������>>579�̍l�������@�́A���w�I�ɐ������炵�����A���̕��@�����߂���̂͐����Ǝv���B
�ł��A���@�������Ă������Ȃ��Ă��A�u���������������v�Ƃ����ۑ�����ĂȂ��ȏ�A
����̃R���e�X�g�̉Ƃ��Ă͕s�K����H
�f�N�������^�̃I�[�o�[�t���[�Ɠ���Ɉ����ĉ��̖�肪����H
880 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:25:11
�_�����Z���œK�����邽�߂̃u�[���㐔�w�����w�̈����B
�u^ x ^�v�̃A�������Đ��w�I�m���Ɋ�Â����m�����ǁA�`�[�g�Ȃ́H
������ό`��ԂŐ���������ʖڂ��Ȃ�ď����ĂȂ��Ǝv�����B
���̕ӂ̗Z�ʂ������Ȃ��ƁA��ԓ��̕��������𐳋K�`�Ń_�C���N�g�ɐ�������dSFMT�́A��������Ȃ��݂����Șb�ɂȂ����܂��B
�u^ x ^�v�̃A�������Đ��w�I�m���Ɋ�Â����m�����ǁA�`�[�g�Ȃ́H
������ό`��ԂŐ���������ʖڂ��Ȃ�ď����ĂȂ��Ǝv�����B
���̕ӂ̗Z�ʂ������Ȃ��ƁA��ԓ��̕��������𐳋K�`�Ń_�C���N�g�ɐ�������dSFMT�́A��������Ȃ��݂����Șb�ɂȂ����܂��B
>>877
>�v���O�����̍œK�����������ŁA�C���t��������ɍ��x�Ȑ��w�m�����������l����
>��ʓ��܂ł��Ȃ����Ă����̂��Ȃ��Ȃ�
���Ԃ�ˁA
>>819
>�e�L�g�[�ɓ�����t�����p�^�[�����ċA�őS�������n���ȕ��@�g���Ă邩��
>�œK�ɋ߂����@������̂�1�������炢������B
�ɏ����Ă���ʂ�B
�N���X�^�v�Z�@�����������D������B
���͂��Ȃ�Ë������B
>�v���O�����̍œK�����������ŁA�C���t��������ɍ��x�Ȑ��w�m�����������l����
>��ʓ��܂ł��Ȃ����Ă����̂��Ȃ��Ȃ�
���Ԃ�ˁA
>>819
>�e�L�g�[�ɓ�����t�����p�^�[�����ċA�őS�������n���ȕ��@�g���Ă邩��
>�œK�ɋ߂����@������̂�1�������炢������B
�ɏ����Ă���ʂ�B
�N���X�^�v�Z�@�����������D������B
���͂��Ȃ�Ë������B
882 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:28:18
�悵�ACell�̃N���X�^�[�������ď������悤�I
883 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:31:41
�y���֘b�z
Twisted-GFSR�̃��[�v���ʼn�������W�v�ł���̂�Tempering���MSB�ɑ�������r�b�g�ȊO�v��������Ȃ������B
���Z��XOR 1�Œu����������̂�MSB�����Ȃ�����H�L�����[�̌v�Z�Ƃ��߂�ǂ���B
��ł�����Unslicing��Tempering�{���Z�̃T�C�N���ɐD�荞��ň�C�ɂ�����܂����ق����G���K���g�������ƌ������_�ɒB�����B
SPU�ɂ͂���������ɂ�邽�߂ɗL�p�Ȗ��߂����݂���B
Twisted-GFSR�̃��[�v���ʼn�������W�v�ł���̂�Tempering���MSB�ɑ�������r�b�g�ȊO�v��������Ȃ������B
���Z��XOR 1�Œu����������̂�MSB�����Ȃ�����H�L�����[�̌v�Z�Ƃ��߂�ǂ���B
��ł�����Unslicing��Tempering�{���Z�̃T�C�N���ɐD�荞��ň�C�ɂ�����܂����ق����G���K���g�������ƌ������_�ɒB�����B
SPU�ɂ͂���������ɂ�邽�߂ɗL�p�Ȗ��߂����݂���B
>>880
>�_�����Z���œK�����邽�߂̃u�[���㐔�w�����w�̈����B
>�u^ x ^�v�̃A�������Đ��w�I�m���Ɋ�Â����m�����ǁA�`�[�g�Ȃ́H
�u��������������Ă��������v�Ƃ����ۑ�Ȃ���A�Ԃłǂ�Ȑ��w���g���Ă��A
������������������OK����B
> ������ό`��ԂŐ���������ʖڂ��Ȃ�ď����ĂȂ��Ǝv�����B
�ό`�̒��x�ɂ�邾�낤���ǁA���炩�ɈႤ�r�b�g��ɂȂ��Ă���A�u���w�I�ɓ���������
���������v�Ȃ�Ă̂��k�قɕ�������B
> ���̕ӂ̗Z�ʂ������Ȃ��ƁA��ԓ��̕��������𐳋K�`�Ń_�C���N�g�ɐ�������dSFMT�́A��������Ȃ��݂����Șb�ɂȂ����܂��B
����A����̃R���e�X�g�Ƃǂ������W������̂�����Ӗ��s���Ȃ��H
dSFMT �͓���������Ȃ�����A����̉ۑ�̉Ƃ��Ă͖��炩�ɃA�E�g�����ǁA
�Ƃ��ăA�E�g���Ƃ������ƂƗ����ł��邩�ۂ��Ƃ͑S���W�Ȃ��b���B
>�_�����Z���œK�����邽�߂̃u�[���㐔�w�����w�̈����B
>�u^ x ^�v�̃A�������Đ��w�I�m���Ɋ�Â����m�����ǁA�`�[�g�Ȃ́H
�u��������������Ă��������v�Ƃ����ۑ�Ȃ���A�Ԃłǂ�Ȑ��w���g���Ă��A
������������������OK����B
> ������ό`��ԂŐ���������ʖڂ��Ȃ�ď����ĂȂ��Ǝv�����B
�ό`�̒��x�ɂ�邾�낤���ǁA���炩�ɈႤ�r�b�g��ɂȂ��Ă���A�u���w�I�ɓ���������
���������v�Ȃ�Ă̂��k�قɕ�������B
> ���̕ӂ̗Z�ʂ������Ȃ��ƁA��ԓ��̕��������𐳋K�`�Ń_�C���N�g�ɐ�������dSFMT�́A��������Ȃ��݂����Șb�ɂȂ����܂��B
����A����̃R���e�X�g�Ƃǂ������W������̂�����Ӗ��s���Ȃ��H
dSFMT �͓���������Ȃ�����A����̉ۑ�̉Ƃ��Ă͖��炩�ɃA�E�g�����ǁA
�Ƃ��ăA�E�g���Ƃ������ƂƗ����ł��邩�ۂ��Ƃ͑S���W�Ȃ��b���B
�c�O�����ǁA���w�I�Ɂu����������v�ł���ȏ�́A�ǂ��������Ă�
�u����������v�Ȃ�B
2 �i�\�L 32 �r�b�g�Ōv�����Ă� GF(2^33) �Ōv�����Ă������ł���̂ƈꏏ�B
�����ƕ�����₷�������ƁAethernet ��������Ƃ��ɕϒ������
�킯������ǁA���̕ϒ��ɂ���Ēl���ω�����킯�ł͂Ȃ��B�v�Z����
���������W�X�^�Ɋi�[����Ƃ��ACMOS �̃L���p�V�^�̃|�e���V������
�ϊ������킯������ǁA����ɂ���Ēl���ω�����킯�ł͂Ȃ��B
���łɁA�ɘ_����� MT �� GF(2^19937) �́u�J�E���^�v�ł����Ȃ��B
�u����������v�Ȃ�B
2 �i�\�L 32 �r�b�g�Ōv�����Ă� GF(2^33) �Ōv�����Ă������ł���̂ƈꏏ�B
�����ƕ�����₷�������ƁAethernet ��������Ƃ��ɕϒ������
�킯������ǁA���̕ϒ��ɂ���Ēl���ω�����킯�ł͂Ȃ��B�v�Z����
���������W�X�^�Ɋi�[����Ƃ��ACMOS �̃L���p�V�^�̃|�e���V������
�ϊ������킯������ǁA����ɂ���Ēl���ω�����킯�ł͂Ȃ��B
���łɁA�ɘ_����� MT �� GF(2^19937) �́u�J�E���^�v�ł����Ȃ��B
886 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:35:30
�����ƁA�uunslicing�v�̈Ӗ����킩���Ă�l�Ԃ͂����ɂ͖w�ǂ��Ȃ���
�ȂA���{�I�ɂ݂�ȂƊ��o���Ⴄ�C�����Ă����ȁB�B�B
�v���O���}�Ƃ��āA�u����������v�Ƃ������t���ƁA�u���� (���[�h|�o�C�g|�r�b�g) ��v�Ƃ����Ӗ�����
���߂���̂����R���Ǝv���Ă������A���w���́u���w�I�ɓ����v�Ɖ��߂���̂��H
�v���O���}�Ƃ��āA�u����������v�Ƃ������t���ƁA�u���� (���[�h|�o�C�g|�r�b�g) ��v�Ƃ����Ӗ�����
���߂���̂����R���Ǝv���Ă������A���w���́u���w�I�ɓ����v�Ɖ��߂���̂��H
889 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:41:23
���ɂP�O�O�O�Ԗڂ̗��������o���ĂƂ���ꂽ�Ƃ��ɁA�I���W�i���Ɠ����l�����o����Ȃ瓯����������Ă��Ƃł�����ˁH
890 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:42:41
Tempering�{���Z�������ɂȂ����̂͂����Ƃ���GFSR�̏����̂ق����߂�ǂ����ƂɂȂ��Ă�B�Ȃ�Ƃ��T�C�N�������点�Ȃ����̂�
�~�X�A���C�����[�h�E�X�g�A���{�g���l�b�N�ɂȂ�̂͌��Ǔ����������B�������������l���Ȃ��Ƃ����Ȃ��B
>>887
BCD�ł�2�i���ł��������������ł����l�I�ɒl��\���Ă�Ώ\���łȂ��́H
�f�[�^�\���Ȃ�Ē��ۉ����ăi���{����BC++���̍l�������ǁB
�~�X�A���C�����[�h�E�X�g�A���{�g���l�b�N�ɂȂ�̂͌��Ǔ����������B�������������l���Ȃ��Ƃ����Ȃ��B
>>887
BCD�ł�2�i���ł��������������ł����l�I�ɒl��\���Ă�Ώ\���łȂ��́H
�f�[�^�\���Ȃ�Ē��ۉ����ăi���{����BC++���̍l�������ǁB
>>888
����Ȃ���100�����m�ŁA>>887�̂悤�ɉ��߂��Ă��B
�ǂ����̉��߂����߂��Ă������́A�����̉҂����B
�Ƃ肠�����A�Öق̗������Ⴂ������̂͂悭�������B
>>579 �Ƃ͐�Ɉꏏ�Ƀv���O�������������Ȃ��B
�uutf-8�ŕ�����Ԃ��āv���Č�������A���C��utf-8��base64�G���R�[�h���ĕԂ��Ă��������B
����Ȃ���100�����m�ŁA>>887�̂悤�ɉ��߂��Ă��B
�ǂ����̉��߂����߂��Ă������́A�����̉҂����B
�Ƃ肠�����A�Öق̗������Ⴂ������̂͂悭�������B
>>579 �Ƃ͐�Ɉꏏ�Ƀv���O�������������Ȃ��B
�uutf-8�ŕ�����Ԃ��āv���Č�������A���C��utf-8��base64�G���R�[�h���ĕԂ��Ă��������B
>>887
>���w���́u���w�I�ɓ����v�Ɖ��߂���̂��H
���w�������������v���O���}���A�ړI�̂��߂ɂ͎�i�͑I�Ȃ��Ǝv���̂����B
�Ⴆ�ɂ���̂��݂��邪�AIBM �͌_�ɏ����Ă���ȏ�̎d���͐��
���Ȃ��B���{�l�I�v�l���炷��ƁA�u��������ȏ��ƌ_�邩�v�Ǝv��
���낤���A���ہA���������v�������ǁA���Љ�ł͌_�Ɍ����������
�n���B�����F�߂Ȃ��ƁA���̂܂܂̓��{�l�I�v�l�ł́A���ꂩ���A
���{�͐��ނ������B
>�u��������Γ��������o����v�Ƃ���������A
>���������������Ԃ��o���ĂˁH
�t�ɁA����͈Ӗ����Ȃ��B
�t�F���}�[�̍ŏI�藝���ؖ����ꂽ�Ƃ���ŁA��������p�ł��镪��͍��̂Ƃ���
��������Ȃ��B�������A������ؖ�����ߒ��œ���ꂽ�m���͉����ɂ��ウ������
��Ȃ��̂ł���B
>���w���́u���w�I�ɓ����v�Ɖ��߂���̂��H
���w�������������v���O���}���A�ړI�̂��߂ɂ͎�i�͑I�Ȃ��Ǝv���̂����B
�Ⴆ�ɂ���̂��݂��邪�AIBM �͌_�ɏ����Ă���ȏ�̎d���͐��
���Ȃ��B���{�l�I�v�l���炷��ƁA�u��������ȏ��ƌ_�邩�v�Ǝv��
���낤���A���ہA���������v�������ǁA���Љ�ł͌_�Ɍ����������
�n���B�����F�߂Ȃ��ƁA���̂܂܂̓��{�l�I�v�l�ł́A���ꂩ���A
���{�͐��ނ������B
>�u��������Γ��������o����v�Ƃ���������A
>���������������Ԃ��o���ĂˁH
�t�ɁA����͈Ӗ����Ȃ��B
�t�F���}�[�̍ŏI�藝���ؖ����ꂽ�Ƃ���ŁA��������p�ł��镪��͍��̂Ƃ���
��������Ȃ��B�������A������ؖ�����ߒ��œ���ꂽ�m���͉����ɂ��ウ������
��Ȃ��̂ł���B
893 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:47:37
�����^�̒l�����҂��Ă���Ƃ����float�Œl��n�������̌����Ȃ�
�P�O�D�O���P�O�ƕς��Ȃ��Ƃ�������
�P�O�D�O���P�O�ƕς��Ȃ��Ƃ�������
894 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:51:19
�ЂƂ̌f���ł����Ȃ���A���ɂ������悤�Ȃ��Ƃ���Ă��������邾�낤�B
���ǁA�O���[�o���X�^���_�[�h�́A�����ɂȂ�̂����ˁB
���ǁA�O���[�o���X�^���_�[�h�́A�����ɂȂ�̂����ˁB
>>893
7�i���ł��̐��l��\�����������n����邩���ȁB
7�i���ł��̐��l��\�����������n����邩���ȁB
897 �F�f�t�H���g�̖����������F2009/01/24(�y) 20:52:47
�܂��s�������邯�ǂ�
>�f�[�^�\���Ȃ�Ē��ۉ����ăi���{����BC++���̍l�������ǁB
�ɂ�100%���ӂ�
����̃C���v�b�g�������̃A�E�g�v�b�g���o���Ă�ȏ㕶��͌�����Ƃ�������
���͂ƌ�����fixsters�������������genrand_int32�Ɠ����ɂ��Ȃ������̂����Ȃ낤���ǂ��ꂶ�Ⴀ���x�͏o�Ȃ�����Ȃ�
����ɒ萔���Ԃ���Ȃ��ȏ�܂�������ƌ��܂����킯����Ȃ���
�������x���ŏo���邱�Ƃ����Ă�����ł�������H
�܂��܂�����������10�T�C�N���͐��
>�f�[�^�\���Ȃ�Ē��ۉ����ăi���{����BC++���̍l�������ǁB
�ɂ�100%���ӂ�
����̃C���v�b�g�������̃A�E�g�v�b�g���o���Ă�ȏ㕶��͌�����Ƃ�������
���͂ƌ�����fixsters�������������genrand_int32�Ɠ����ɂ��Ȃ������̂����Ȃ낤���ǂ��ꂶ�Ⴀ���x�͏o�Ȃ�����Ȃ�
����ɒ萔���Ԃ���Ȃ��ȏ�܂�������ƌ��܂����킯����Ȃ���
�������x���ŏo���邱�Ƃ����Ă�����ł�������H
�܂��܂�����������10�T�C�N���͐��
898 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 20:53:10
>>893
�Ԃ��̂͐����^�́u���v�l�v����H
MT�œ���ꂽ�^�������l�Ȃ�č���̒l�ł͒��Ԓl�ł����Ȃ������B
�ǂ݂̂����Ԓl�Ȃ�Č��J����K�v�Ȃ�����A�f�[�^�\�����ǂ��Ȃ��Ă邩��
���̃I���W�i����MT�́A�����闐�����r�b�O�G���f�B�A�������g���G���f�B�A��������K�肵�ĂȂ����B
�Ԃ��̂͐����^�́u���v�l�v����H
MT�œ���ꂽ�^�������l�Ȃ�č���̒l�ł͒��Ԓl�ł����Ȃ������B
�ǂ݂̂����Ԓl�Ȃ�Č��J����K�v�Ȃ�����A�f�[�^�\�����ǂ��Ȃ��Ă邩��
���̃I���W�i����MT�́A�����闐�����r�b�O�G���f�B�A�������g���G���f�B�A��������K�肵�ĂȂ����B
>>891
> >>579 �Ƃ͐�Ɉꏏ�Ƀv���O�������������Ȃ��B
����A�}�W�Șb�ˁB
���������Ă��炦��̂͊������āA�u����A��͂��O�ɔC�����v�Ƃ�������
�ӋC�g�X�ƃn�i�N�\�ق����Ă���ƁA���� 3 ���ʑO�ɋ���������ˁB
���ق��Ăق����̂����B
> >>579 �Ƃ͐�Ɉꏏ�Ƀv���O�������������Ȃ��B
����A�}�W�Șb�ˁB
���������Ă��炦��̂͊������āA�u����A��͂��O�ɔC�����v�Ƃ�������
�ӋC�g�X�ƃn�i�N�\�ق����Ă���ƁA���� 3 ���ʑO�ɋ���������ˁB
���ق��Ăق����̂����B
900 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:09:48
> �ꏏ�Ƀv���O�������������Ȃ��B
�̑Ώۂ͍���̃P�[�X�ł�fixters�̖ʁX�Ȃ�Ȃ����H
FAQ��"��|"�Ȃ�ĞB���ȕ\���ň�̉����킩����ĂD
fixters�͕��i���炱��ȕ\���g���Ďd�����Ă�̂��H
�_�C�d�l���ɂ������ȋL�q������"��|"���ď����̂��H
�̑Ώۂ͍���̃P�[�X�ł�fixters�̖ʁX�Ȃ�Ȃ����H
FAQ��"��|"�Ȃ�ĞB���ȕ\���ň�̉����킩����ĂD
fixters�͕��i���炱��ȕ\���g���Ďd�����Ă�̂��H
�_�C�d�l���ɂ������ȋL�q������"��|"���ď����̂��H
901 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:10:47
�ʔ����Ȃ��Ă�����
������l�X�ȑ��ʂ��瑨����͂��Ă̂͑厖���Ǝv��
������l�X�ȑ��ʂ��瑨����͂��Ă̂͑厖���Ǝv��
902 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 21:13:23
Cell�̃X�P�[�������b�g��d�v�Ȉʒu�Â�������PS3�����̎S��Ȃ̂�
Cell�I�����[�̃��[�f�B���O�J���p�j�[�̎��_�ŁA�ǂ����ȂƎv���Ă�B
���Z���Ƃ��Ӗ��s�������B
�����Ȃ̂��Ԏ��Ȃ̂�����ǂ߂Ȃ��B
Cell�I�����[�̃��[�f�B���O�J���p�j�[�̎��_�ŁA�ǂ����ȂƎv���Ă�B
���Z���Ƃ��Ӗ��s�������B
�����Ȃ̂��Ԏ��Ȃ̂�����ǂ߂Ȃ��B
>�_�C�d�l���ɂ������ȋL�q������"��|"���ď����̂��H
�l�g�Q�ɂ́u�����炪�z�肵���̂ƈႤ���@��...�v���ď����Ă����H
��������ƂȂ�����ڂ����͒m��B
�z��Ȃ�āA��t�łǂ��ɂł��Ȃ�B
����ȃ��x���̃R���e�X�g���Ƃ�����A�n�߂���o�鉿�l�Ȃ���B
�l�g�Q�ɂ́u�����炪�z�肵���̂ƈႤ���@��...�v���ď����Ă����H
��������ƂȂ�����ڂ����͒m��B
�z��Ȃ�āA��t�łǂ��ɂł��Ȃ�B
����ȃ��x���̃R���e�X�g���Ƃ�����A�n�߂���o�鉿�l�Ȃ���B
904 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:16:26
905 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:20:27
,,�E�L�́M�E,,�j��-������
���̂`�`�A[ �L �M ]�̕�����[, �E �E ]�̕����A�ǂ������ڂȂ�H
�O����C�ɂȂ��Ă��傤���Ȃ��B
�����܂��Ȏ�������Ȃ��
���̂`�`�A[ �L �M ]�̕�����[, �E �E ]�̕����A�ǂ������ڂȂ�H
�O����C�ɂȂ��Ă��傤���Ȃ��B
�����܂��Ȏ�������Ȃ��
579���āA�u����ɂႭ�v���ēǂ߂��ˁB
907 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:23:10
>>902
�ʔ����������猈�Z�����Ă݂���
���������v��34�S���Ƃ��邩�獕������
��������G�c�Ȍ��Z������
������Ђ̗v�����������߁A�Ƃ肠�����o���Ă邾���Ƃ������Ƃ��낾
�ʔ����������猈�Z�����Ă݂���
���������v��34�S���Ƃ��邩�獕������
��������G�c�Ȍ��Z������
������Ђ̗v�����������߁A�Ƃ肠�����o���Ă邾���Ƃ������Ƃ��낾
908 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 21:23:58
�~���[�f�B���O�J���p�j�[
�����̃��[�f�B���O�J���p�j�[
��86�Ƃ�Tesla�Ƃ���L�����܂��A�Ƃ��Ȃ牴���S�h�ꂽ
�����̃��[�f�B���O�J���p�j�[
��86�Ƃ�Tesla�Ƃ���L�����܂��A�Ƃ��Ȃ牴���S�h�ꂽ
909 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:26:52
>>906
����@�ȁ@�����@���ČĂ�ł�
����@�ȁ@�����@���ČĂ�ł�
910 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:27:13
Cell�͉Ɠd��Q�[���̂ق����Ɣ�������
�X�p�R���̕����Ƃ��Ȃ芈�Ă��邶��Ȃ�
�X�p�R���̕����Ƃ��Ȃ芈�Ă��邶��Ȃ�
906 �� 579 �ł͂���܂���B
�A�i���R���j���N���B
�A�i���R���j���N���B
>>911 �͉������A�b��߂��Ƃ��āB
>>877
>���ɍ��x�Ȑ��w�m�����������l����
�v���O���}�Ƃ����l��͍��x�Ȑ��w�I�m���������Ă����炢���Ȃ���?
���w�I�m���̂Ȃ��v���O���}�́A�����̓z�ꂾ�� orz
>>877
>���ɍ��x�Ȑ��w�m�����������l����
�v���O���}�Ƃ����l��͍��x�Ȑ��w�I�m���������Ă����炢���Ȃ���?
���w�I�m���̂Ȃ��v���O���}�́A�����̓z�ꂾ�� orz
913 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:43:42
>>912
������w�m���͕K�v�����A���ɂ��p���炢�낢�닁�߂���B
�����A����̃R���e�X�g�ɘb�����ڂ����Ƃ��ɁA�������̌v�Z�̐��w�I�ȉ�@�ɂ��ǂ蒅���Ȃ��l��
���܂̋@���^�����Ȃ��̂͂ǂ��Ȃ̂��Ęb�B
�܂��A�Q���҂̔������[���ł���Ȃ���Ȃ��Ǝv�����ǂˁB
������w�m���͕K�v�����A���ɂ��p���炢�낢�닁�߂���B
�����A����̃R���e�X�g�ɘb�����ڂ����Ƃ��ɁA�������̌v�Z�̐��w�I�ȉ�@�ɂ��ǂ蒅���Ȃ��l��
���܂̋@���^�����Ȃ��̂͂ǂ��Ȃ̂��Ęb�B
�܂��A�Q���҂̔������[���ł���Ȃ���Ȃ��Ǝv�����ǂˁB
915 �F�f�t�H���g�̖����������F2009/01/24(�y) 21:57:32
�ȂH
�������\��Ă�̂��H��
�������\��Ă�̂��H��
917 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 22:15:53
SPU�̃A�Z���u���������ŏ����̂������i���W�X�^���������č������܂���j�ȉ������ɂ�
�Ɍ���ꂽ�l�Ԃ����v�����Ȃ��悤�ȃu���C�N�X���[���K�v�������킯�����B
�t�ɁA������u�t�H�[�}�b�g�v�����܂�����ł̃A�Z���u���`�L�����[�X�ɂȂ����H
�Ɍ���ꂽ�l�Ԃ����v�����Ȃ��悤�ȃu���C�N�X���[���K�v�������킯�����B
�t�ɁA������u�t�H�[�}�b�g�v�����܂�����ł̃A�Z���u���`�L�����[�X�ɂȂ����H
���O����s��p�����鎞�̎����オ�������m��Ȃ��B
���A����Ȃ��Ƃ͂ǂ��ł��ǂ��B
�A�C�\�g�[�v���g����ŁA���������N�ɂ͑�ς����b�ɂȂ����B
�����𗝉������ŁA���w�����N�̒m���͔��ɖ��ɗ������B
�V�~�����[�V������i�߂��ŁA���{�搶(�̊J�����ꂽMT)�ɂ�
��ς����b�ɂȂ����B
���̏�ŁA����̐ݖ�́A���{�搶��n���ɂ��Ă���悤�ɂ���
�v���Ȃ��킯���B
���A����Ȃ��Ƃ͂ǂ��ł��ǂ��B
�A�C�\�g�[�v���g����ŁA���������N�ɂ͑�ς����b�ɂȂ����B
�����𗝉������ŁA���w�����N�̒m���͔��ɖ��ɗ������B
�V�~�����[�V������i�߂��ŁA���{�搶(�̊J�����ꂽMT)�ɂ�
��ς����b�ɂȂ����B
���̏�ŁA����̐ݖ�́A���{�搶��n���ɂ��Ă���悤�ɂ���
�v���Ȃ��킯���B
919 �F�f�t�H���g�̖����������F2009/01/24(�y) 22:17:38
���Ƃ��ACell�̃p�C�v���C�����悭�œK���Ƃ����_�ł́A
�Ȃɂ����Ă��Ȃ�579�̃R�[�h���A���̂悭�œK�������R�[�h��10�{�����ƂȂ����Ƃ��A
Cell�Ƃ͊W�Ȃ����ǁA�A���S���Y�����l����579����D���`�Ƃ����̂́A���ɕςȘb���B
�ł��A���ۂɑ����Ȃ疳���ł��Ȃ��B���ʏ܂ł��Ȃ�ł��������炠����������ȁH
579�̃R�[�h�ŁA������Cell���L�̍œK���𑽏����Ă�������A����Ȃ����낤���H
�Ȃɂ����Ă��Ȃ�579�̃R�[�h���A���̂悭�œK�������R�[�h��10�{�����ƂȂ����Ƃ��A
Cell�Ƃ͊W�Ȃ����ǁA�A���S���Y�����l����579����D���`�Ƃ����̂́A���ɕςȘb���B
�ł��A���ۂɑ����Ȃ疳���ł��Ȃ��B���ʏ܂ł��Ȃ�ł��������炠����������ȁH
579�̃R�[�h�ŁA������Cell���L�̍œK���𑽏����Ă�������A����Ȃ����낤���H
920 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 22:20:50
����Ȃ̂͒��̐l�����f���邱�ƁB�������邭�炢�Ȃ琸�i����
921 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 22:26:14
>>919
���Ȃ݂ɉ���Cell���L�ƌ����Ă��������߂���g���čĐv���Ă��B
���܂őS�������ĂȂ��������߂��B
�t�ɏ]���̂�������SSE�ł��ł��邱�Ƃ�������ĂȂ��B
���Ȃ݂ɉ���Cell���L�ƌ����Ă��������߂���g���čĐv���Ă��B
���܂őS�������ĂȂ��������߂��B
�t�ɏ]���̂�������SSE�ł��ł��邱�Ƃ�������ĂȂ��B
922 �F�f�t�H���g�̖����������F2009/01/24(�y) 22:29:46
923 �F�f�t�H���g�̖����������F2009/01/24(�y) 22:32:07
>>922�Ɉ�[
924 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 22:35:57
�Â����@���u���C�N�X���[�������ǂˁB
������Ă���@���A���Ȃ炱������肶�����Ċ����ŁB
�N�����Ⴄ�Ǝ�̓����ꕔ���������ƂɂȂ�̂ł��Ȃ��B�X�R�A����؏o���Ȃ��B
�����������̂�12�Ƃ�13�Ƃ��Ƃ͑S���Ӗ��̖��������ɂȂ��Ă��܂����B
�����������@���Ⴄ�B
������Ă���@���A���Ȃ炱������肶�����Ċ����ŁB
�N�����Ⴄ�Ǝ�̓����ꕔ���������ƂɂȂ�̂ł��Ȃ��B�X�R�A����؏o���Ȃ��B
�����������̂�12�Ƃ�13�Ƃ��Ƃ͑S���Ӗ��̖��������ɂȂ��Ă��܂����B
�����������@���Ⴄ�B
926 �F�f�t�H���g�̖����������F2009/01/24(�y) 22:42:57
927 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 22:49:12
>>925
����Ȃ��͖̂�������B
�����������D���L�����@�ł���Ă邵�B���ꂱ��SIMD�̃p���[�ɂ��̂��킹�����̈������@�ŁB
�z��Ȃ�ă��C�A�E�g���ς�������炢��mt[]�̃T�C�Y�ƂقƂ�Ǖς���
�����Č������Ⴄ���ǁA160 qword��
����Ȃ��͖̂�������B
�����������D���L�����@�ł���Ă邵�B���ꂱ��SIMD�̃p���[�ɂ��̂��킹�����̈������@�ŁB
�z��Ȃ�ă��C�A�E�g���ς�������炢��mt[]�̃T�C�Y�ƂقƂ�Ǖς���
�����Č������Ⴄ���ǁA160 qword��
>>927
���C�A�E�g�ς��������ŁAmt[] �Ƃ͓�������Ԃł��ȁB
���̂������ł���̂ł���A(��㈓I�ɂ�)����ɉz�������Ƃ�
�Ȃ��Ǝv���܂��B���͎��M�Ȃ���������`�[�g�������ǁB����ƂāA
fixstars �ɕ��匾����؍����͂Ȃ����ǂ�(�A�[�I�ɂ�)�B
�E�X�ł��B
���C�A�E�g�ς��������ŁAmt[] �Ƃ͓�������Ԃł��ȁB
���̂������ł���̂ł���A(��㈓I�ɂ�)����ɉz�������Ƃ�
�Ȃ��Ǝv���܂��B���͎��M�Ȃ���������`�[�g�������ǁB����ƂāA
fixstars �ɕ��匾����؍����͂Ȃ����ǂ�(�A�[�I�ɂ�)�B
�E�X�ł��B
929 �F�f�t�H���g�̖����������F2009/01/24(�y) 23:04:02
�ʂɐ��w�I�Ȃ��l���Ȃ��Ă����̌������炢�ɂ͖��ߌ��点���
�f�[�^���C�A�E�g���v��������ς�邩��a���o���Ƃ��͕ʂƂ���
��������o�����ɖ���W�J�Ƃ�����Ă��ǂ�
�f�[�^���C�A�E�g���v��������ς�邩��a���o���Ƃ��͕ʂƂ���
��������o�����ɖ���W�J�Ƃ�����Ă��ǂ�
931 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 23:09:22
�S���Z����Ȃ���n���炵�����Ă���Ƃ����
���������̔z��\���͑�D���ł�
���������̔z��\���͑�D���ł�
932 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 23:15:04
�Ƃ�����>>929�ɂ͋C�Â��ꂽ�悤��
933 �F�f�t�H���g�̖����������F2009/01/24(�y) 23:16:06
���Z���Ƃ��̕��@��tempering�ɂ�����̂�QWORD��������0.6�T�C�N������
�c�O�Ȃ��炾����2�`3���x�����ǂ�
���͂Ƃ肠�������Ƃ̕��@�ōœK���𑱂��邯�nj��Fixsters����
�c�O�Ȃ��炾����2�`3���x�����ǂ�
���͂Ƃ肠�������Ƃ̕��@�ōœK���𑱂��邯�nj��Fixsters����
934 �F�f�t�H���g�̖����������F2009/01/24(�y) 23:17:13
���܂�
�~QWORD��������0.6�T�C�N������
��WORD��������0.6�T�C�N������
�~QWORD��������0.6�T�C�N������
��WORD��������0.6�T�C�N������
�����AFixstars�̉������ł͗����o�������B�B�B
936 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 23:21:52
>>933
GF�̂ق�����荞��ł邯�ǃV���b�t���ɂ��p�b�L���O�̃T�C�N������}�����Ȃ��̂�
�g�[�^�����Ǝ�����������Ȑ��\�ɂȂ肻���ȗ\���B
�������Ō�̉��Z�͔��������ăA�h���i�����o�Ă��邺��������
GF�̂ق�����荞��ł邯�ǃV���b�t���ɂ��p�b�L���O�̃T�C�N������}�����Ȃ��̂�
�g�[�^�����Ǝ�����������Ȑ��\�ɂȂ肻���ȗ\���B
�������Ō�̉��Z�͔��������ăA�h���i�����o�Ă��邺��������
937 �F�f�t�H���g�̖����������F2009/01/24(�y) 23:30:08
579�̎v���u������̓W�J����w
938 �F�f�t�H���g�̖����������F2009/01/24(�y) 23:31:34
0.6�͌v�Z�~�X
�ǂ����0.5�ʂ��Ȃ�
�w�Ǔ������@���������
�ǂ����0.5�ʂ��Ȃ�
�w�Ǔ������@���������
939 �F,,�E�L�́M�E,,�j��-�������F2009/01/24(�y) 23:31:42
������O���B1�����������ĂȂ��B
�͋� is Justice.
�͋� is Justice.
��ׂ��A�����`�[�g�̕������������Ȃ��Ă����B
�܂�12.5cycle���ĂȂ����A�A�A
�܂�12.5cycle���ĂȂ����A�A�A
941 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 00:00:17
�`�[�g����˂�
�y�ד��z��
�y�ד��z��
942 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 00:09:26
���[��B
3�{��̶��ł����B�T�[�Z������������
3�{��̶��ł����B�T�[�Z������������
943 �F�f�t�H���g�̖����������F2009/01/25(��) 00:40:32
Fixsters����Ԏ�������܂�Cell Challenge��낤���I
944 �F�f�t�H���g�̖����������F2009/01/25(��) 01:05:59
�͊��ŃX�g�[������̂͒P�Ȃ�o�O�Ȃ̂ŁA������l�����ăA�Z���u���`���[��
����̂͂��܂萶�Y�I�ł͖����ˁB90nm�ł�Cell�ł����������Ȃ�����B
�܁A90nm�ňȊO��g�߂Ɏ�ɂ��鎖�͏����ɂ�������������Ȃ����ǂˁB(��
����̂͂��܂萶�Y�I�ł͖����ˁB90nm�ł�Cell�ł����������Ȃ�����B
�܁A90nm�ňȊO��g�߂Ɏ�ɂ��鎖�͏����ɂ�������������Ȃ����ǂˁB(��
945 �F�f�t�H���g�̖����������F2009/01/25(��) 01:11:05
�U�X�l���Č��ǂ���579�̕��@�ł���Ă�̂��H
>>945
��������A���w�ł��Ȃ����ł��ł�����@�B
��������A���w�ł��Ȃ����ł��ł�����@�B
���������A�������2��ނ���Ă�̂��B
948 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 01:21:16
3��ނ��B
949 �F�f�t�H���g�̖����������F2009/01/25(��) 01:26:45
>>984
579�̂����͊���̋�_�����Č����Ă��̂́H
579�̂����͊���̋�_�����Č����Ă��̂́H
950 �F�f�t�H���g�̖����������F2009/01/25(��) 01:38:25
950
951 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 01:38:31
���͓s�x�[�������̐������s���Ă�����Z���Ă�B���������͍S��B
952 �F�f�t�H���g�̖����������F2009/01/25(��) 01:42:17
579�Ɏӂ��c�q
953 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 01:47:13
�J��Ԃ�
�y���͓s�x�[�������̐������s���Ă�����Z���Ă�z
�ǂ�ȕ��@�ɂ���Tempering�O�ɃT�}�����߂�̂��A�����Ƃ͎v��Ȃ������
�y���͓s�x�[�������̐������s���Ă�����Z���Ă�z
�ǂ�ȕ��@�ɂ���Tempering�O�ɃT�}�����߂�̂��A�����Ƃ͎v��Ȃ������
954 �F�f�t�H���g�̖����������F2009/01/25(��) 01:51:31
����Ƃ��Ȃ��Ƃ��b�肷���ւ���Ȃ�
579�̓I�c������킢�Ƃ��\�������Ƃ������Ă���H
����̋�_����Ȃ���������ۂ�F�߂��
579�̓I�c������킢�Ƃ��\�������Ƃ������Ă���H
����̋�_����Ȃ���������ۂ�F�߂��
955 �F227 ��eZQcaIaFJs �F2009/01/25(��) 01:56:23
�����12clock�ɂȂ���@�v�������B���ǁA����������Even�����炷����
�����Ȃ��č����Ă鏊�ł��B����ς背�C�A�E�g����Ȃ��ƕǂ��z�����Ȃ�
�̂��Ȃ��c�B
>>912
���w�̋��{�������Ă��A�]�E���Ă���P�D�T�T�Ő��\���s�̍\���c�����āA
��������o�O����Ⴍ�ۂ��čs���ʂ̎��Ȃ�o���Ă܂���B
�[���A�����ɂȂ��āi�}�C���X�g�[���ꃖ���O�Ȃ̂Ɂj�R�A�ȕ�����
����ύX����Ƃ������o����i�����āA�o�O�̑Ώ����X�l���Ă��瓪��
���Ȃ��Ȃ��Ă��܂����B����R�P�Ȃ����Ƃ��F�邵�������ł���
�����Ȃ��č����Ă鏊�ł��B����ς背�C�A�E�g����Ȃ��ƕǂ��z�����Ȃ�
�̂��Ȃ��c�B
>>912
���w�̋��{�������Ă��A�]�E���Ă���P�D�T�T�Ő��\���s�̍\���c�����āA
��������o�O����Ⴍ�ۂ��čs���ʂ̎��Ȃ�o���Ă܂���B
�[���A�����ɂȂ��āi�}�C���X�g�[���ꃖ���O�Ȃ̂Ɂj�R�A�ȕ�����
����ύX����Ƃ������o����i�����āA�o�O�̑Ώ����X�l���Ă��瓪��
���Ȃ��Ȃ��Ă��܂����B����R�P�Ȃ����Ƃ��F�邵�������ł���
956 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 01:57:46
�{���̓��̎ア�q���ˁB
���̈Ӑ}�Ƃ͖��W�ɖ{�l�����肾�Ǝv���ĂȂ��킯�ł���ȏ�͉����������Ƃ͖������낤�B
�u�J�[�h�v���̂��͔̂ނ��o�ꂷ��O����p�ӂ��Ă����̂���B
���̈Ӑ}�Ƃ͖��W�ɖ{�l�����肾�Ǝv���ĂȂ��킯�ł���ȏ�͉����������Ƃ͖������낤�B
�u�J�[�h�v���̂��͔̂ނ��o�ꂷ��O����p�ӂ��Ă����̂���B
957 �F�f�t�H���g�̖����������F2009/01/25(��) 02:00:59
�ۂ�F�߂��
���Ă��炢�������
���Ă��炢�������
958 �F�f�t�H���g�̖����������F2009/01/25(��) 02:05:59
�����ア�̂�F�߂Ƃ��Ƃ���
>>���̈Ӑ}�Ƃ͖��W�ɖ{�l�����肾�Ǝv���ĂȂ�
���Ăǂ��L�Ӗ����H����܂��߂ɁB
>>���̈Ӑ}�Ƃ͖��W�ɖ{�l�����肾�Ǝv���ĂȂ�
���Ăǂ��L�Ӗ����H����܂��߂ɁB
959 �F�f�t�H���g�̖����������F2009/01/25(��) 02:16:49
960 �F�f�t�H���g�̖����������F2009/01/25(��) 02:23:21
>>958
�悤����ɒc�q�͖{���͂ł���̂킩���ĂĐ����Ă����Ă��Ƃ���B
�悭�p�����������Ȃ�����Ȍ�����ł����B���������c�q���ȁI
�悤����ɒc�q�͖{���͂ł���̂킩���ĂĐ����Ă����Ă��Ƃ���B
�悭�p�����������Ȃ�����Ȍ�����ł����B���������c�q���ȁI
961 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 02:40:23
GF(2)�̉�@���S�R�ʕ��Ƃ������Ƃ����������̂ʼn������Ŏv���߂����������Ƃ������Ƃ�
962 �F�f�t�H���g�̖����������F2009/01/25(��) 09:57:55
�g���
>>949 >>952 >>954
����͉��̕��Ƃ������ƂŁA�����A��邵�āB
>>955
�~�R�̒m���������Ă��A�������Ă���P�D�T�T�ň�����̕Ґ��c�����āA
��������v������Ⴍ�ۂ��čs���ʂ̎��Ȃ�o���Ă܂���B
�[���A�����ɂȂ��āi�O�{�܂ł��������Ȃ̂Ɂj�R�A�ȕ�����
�Ґ��ύX����Ƃ������o�����������āA�����̑Ώ����X�l���Ă��瓪��
���Ȃ��Ȃ��Ă��܂����B����R�P�Ȃ����Ƃ��F�邵�������ł���
����������Đ������Ƃ������n�߂��ł��ˁB�킩��܂��B
����͉��̕��Ƃ������ƂŁA�����A��邵�āB
>>955
�~�R�̒m���������Ă��A�������Ă���P�D�T�T�ň�����̕Ґ��c�����āA
��������v������Ⴍ�ۂ��čs���ʂ̎��Ȃ�o���Ă܂���B
�[���A�����ɂȂ��āi�O�{�܂ł��������Ȃ̂Ɂj�R�A�ȕ�����
�Ґ��ύX����Ƃ������o�����������āA�����̑Ώ����X�l���Ă��瓪��
���Ȃ��Ȃ��Ă��܂����B����R�P�Ȃ����Ƃ��F�邵�������ł���
����������Đ������Ƃ������n�߂��ł��ˁB�킩��܂��B
�~�O�{��
���c�㌳��
���c�㌳��
965 �F�f�t�H���g�̖����������F2009/01/25(��) 19:23:05
���[�ށA���͂≽�̘b�����Ă�̂�����O��̉��ɂ͕�����Ȃ��Ȃ��Ă������B
966 �F�f�t�H���g�̖����������F2009/01/25(��) 19:25:08
���b�c�R���̜f�r����
���R�j���炢�����Ƃ���
���R�j���炢�����Ƃ���
967 �F�f�t�H���g�̖����������F2009/01/25(��) 19:32:29
>>966
�m���ɁA�v���O���}�ɂ̓f�X�}�[�`�̒m�����K�v���ȁB
�m���ɁA�v���O���}�ɂ̓f�X�}�[�`�̒m�����K�v���ȁB
968 �F�f�t�H���g�̖����������F2009/01/25(��) 19:35:35
�����A���������Ӗ��Ȃ̂��A����ƕ��������B
�i����������g�������o������́j
�i����������g�������o������́j
969 �F�f�t�H���g�̖����������F2009/01/25(��) 19:36:20
�ȂA�w��~�Ɗw��Ƃݐ~�̑����݂����ȓW�J���ȁB
�����A�ǂ������ǂ����B
���w��N�w���������z�́A�����Ă��甭�����Ȃ���s�т��������̔n����Y�B
���̒��̘b����Ƃ��Ęb�����Ă�z�́A�Ƃ肠���������Ƃ̃X�����킹������ȑʖڐl�ԁB
�����A�ǂ������ǂ����B
���w��N�w���������z�́A�����Ă��甭�����Ȃ���s�т��������̔n����Y�B
���̒��̘b����Ƃ��Ęb�����Ă�z�́A�Ƃ肠���������Ƃ̃X�����킹������ȑʖڐl�ԁB
970 �F�f�t�H���g�̖����������F2009/01/25(��) 19:50:22
>579
MATRIX_A�̕ύX���d�v�Ȃ�H
MATRIX_A�̕ύX���d�v�Ȃ�H
971 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 19:54:16
MATRIX_A�̕ό`���ĈӖ��Ȃ�>>788�̕��@�ł�����Ă�ˁB
MATRIX_A�Ƃ�XOR��Mersenne Twister��Twister���鏊�Ȃ��B
�r�b�g�P�ʂ̍s����ɋA������A�Ȃ�MATRIX_A�Ȃ̂��킩�邩������Ȃ��B
MATRIX_A�Ƃ�XOR��Mersenne Twister��Twister���鏊�Ȃ��B
�r�b�g�P�ʂ̍s����ɋA������A�Ȃ�MATRIX_A�Ȃ̂��킩�邩������Ȃ��B
972 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 20:04:30
�g��̉]�X��RSA�Í��̃N���b�N�ɂ��L�p������Ă���@����
������ƃ��`�x�[�V�����ቺ�C���Ȃ�ŕ����������Ă邯�ǖʔ�������
������ƃ��`�x�[�V�����ቺ�C���Ȃ�ŕ����������Ă邯�ǖʔ�������
973 �F�f�t�H���g�̖����������F2009/01/25(��) 20:30:21
����Fixstars�ɂ͓������o���ė~�����Ƃ��낾��
���͂ǂ����ɂȂ��Ă������邯�ǒE������z����������
���͂ǂ����ɂȂ��Ă������邯�ǒE������z����������
974 �F�f�t�H���g�̖����������F2009/01/25(��) 22:45:03
>971
��������Ȃ��āA579��>>801-802�ŏ������̂�MATRIX_A��ς���MT�ƁA�ނ̕��@�̑��x��r�����B
(������sum���ς���Ă�)
�I���W�i��MT��sum������������̂͌��ǖ�����������Ȃ��́H�ƁB
��������Ȃ��āA579��>>801-802�ŏ������̂�MATRIX_A��ς���MT�ƁA�ނ̕��@�̑��x��r�����B
(������sum���ς���Ă�)
�I���W�i��MT��sum������������̂͌��ǖ�����������Ȃ��́H�ƁB
975 �F,,�E�L�́M�E,,�j��-�������F2009/01/25(��) 22:55:03
Twist������MT�Ȃ��MT����Ȃ��ł���B
MATRIX_A�̓r�b�g�X�g���[�������ς������salt�Ƃ��ċ@�\���Ă�炷��
�]�k�����uSalt��������DES�v�i2ch�̃g���b�v�Ŏg���Ă�crypt(3)�̂���j�͍�����ǂ����ɂ����Ȃ��
�����̐��w�҂������Ă���B
MATRIX_A�̓r�b�g�X�g���[�������ς������salt�Ƃ��ċ@�\���Ă�炷��
�]�k�����uSalt��������DES�v�i2ch�̃g���b�v�Ŏg���Ă�crypt(3)�̂���j�͍�����ǂ����ɂ����Ȃ��
�����̐��w�҂������Ă���B
976 �F�f�t�H���g�̖����������F2009/01/26(��) 17:33:50
���������ҁH
977 �F�f�t�H���g�̖����������F2009/01/26(��) 18:24:59
�A�C�����
978 �F227 ��eZQcaIaFJs �F2009/01/26(��) 22:32:55
�Ƃ肠���������������o��܂ŃR�[�f�B���O��Ƃ͂��x�݁B
>>967
�f�X�}�Ɋ������܂��Ƃ�Ƃ肪�������s�����s����ɂȂ��Ă����ł��ˁB
# �S���A���Ζ����Ԓ���FPS����Ă��i�Ƃ����Ĕ����������ɂȂ��Ă܂���
>>967
�f�X�}�Ɋ������܂��Ƃ�Ƃ肪�������s�����s����ɂȂ��Ă����ł��ˁB
# �S���A���Ζ����Ԓ���FPS����Ă��i�Ƃ����Ĕ����������ɂȂ��Ă܂���
979 �F,,�E�L�́M�E,,�j��-�������F2009/01/26(��) 23:19:02
salt���Ƃ͉������l����A
���{��ł����u�����w�v
�t�@�b�L�����C�g
�ݷ��
���{��ł����u�����w�v
�t�@�b�L�����C�g
�ݷ��
>>970
>>974
�A�i���ɓ˂����s�ԈႦ�Ă��������̘b�B
�n�b�Nthe�A�i���̌��ʂł�����A�ăg���C�������ʂ�����B
ORIGNAL: sum=3c927c56, 20051002 ticks
MINE: sum=3c927c56, 480600 ticks
ORIGNAL: sum=2e987a4d, 28979324 ticks
MINE: sum=2e987a4d, 680855 ticks
ORIGNAL: sum=ef1b6aef, 21517023 ticks
MINE: sum=ef1b6aef, 573675 ticks
ORIGNAL: sum=eedd2516, 19761023 ticks
MINE: sum=eedd2516, 446886 ticks
ORIGNAL: sum=f7e967a8, 981473 ticks
MINE: sum=f7e967a8, 116481 ticks
ORIGNAL: sum=1f37a7db, 14592172 ticks
MINE: sum=1f37a7db, 365659 ticks
ORIGNAL: sum=c7d41f36, 20085705 ticks
MINE: sum=c7d41f36, 465866 ticks
ORIGNAL: sum=aa9d2e9f, 17899900 ticks
MINE: sum=aa9d2e9f, 495607 ticks
ORIGNAL: sum=8abd398a, 17074673 ticks
MINE: sum=8abd398a, 434344 ticks
ORIGNAL: sum=a374bd58, 415390 ticks
MINE: sum=a374bd58, 86607 ticks
>>974
�A�i���ɓ˂����s�ԈႦ�Ă��������̘b�B
�n�b�Nthe�A�i���̌��ʂł�����A�ăg���C�������ʂ�����B
ORIGNAL: sum=3c927c56, 20051002 ticks
MINE: sum=3c927c56, 480600 ticks
ORIGNAL: sum=2e987a4d, 28979324 ticks
MINE: sum=2e987a4d, 680855 ticks
ORIGNAL: sum=ef1b6aef, 21517023 ticks
MINE: sum=ef1b6aef, 573675 ticks
ORIGNAL: sum=eedd2516, 19761023 ticks
MINE: sum=eedd2516, 446886 ticks
ORIGNAL: sum=f7e967a8, 981473 ticks
MINE: sum=f7e967a8, 116481 ticks
ORIGNAL: sum=1f37a7db, 14592172 ticks
MINE: sum=1f37a7db, 365659 ticks
ORIGNAL: sum=c7d41f36, 20085705 ticks
MINE: sum=c7d41f36, 465866 ticks
ORIGNAL: sum=aa9d2e9f, 17899900 ticks
MINE: sum=aa9d2e9f, 495607 ticks
ORIGNAL: sum=8abd398a, 17074673 ticks
MINE: sum=8abd398a, 434344 ticks
ORIGNAL: sum=a374bd58, 415390 ticks
MINE: sum=a374bd58, 86607 ticks
>>722
>��������� pmt[] �̍ň��l�����ς���n�߂������珟�Z�͂�����
>�킯�����A��͌��ʂ�����Ƒz���ȏ�ɏ������B
��������������̂́AMATRIX_A ��������A����̃U�}���B
�Ō�̕]���Ȃ�čŒፇ�i���C���� 10 �{�������Ă��Ȃ��B
�Ԃ����Ⴏ�A46KiB �̐���Ɏ��܂邩���������B
SIMD ������܂��\���͂��邩������Ȃ����ǁA���͔R���s�����B
�c�q�ɂ͂��Ȃ�Ȃ���B���������ǂȁB
>��������� pmt[] �̍ň��l�����ς���n�߂������珟�Z�͂�����
>�킯�����A��͌��ʂ�����Ƒz���ȏ�ɏ������B
��������������̂́AMATRIX_A ��������A����̃U�}���B
�Ō�̕]���Ȃ�čŒፇ�i���C���� 10 �{�������Ă��Ȃ��B
�Ԃ����Ⴏ�A46KiB �̐���Ɏ��܂邩���������B
SIMD ������܂��\���͂��邩������Ȃ����ǁA���͔R���s�����B
�c�q�ɂ͂��Ȃ�Ȃ���B���������ǂȁB
>>978
��i�̋C�������킩���ł��Ȃ��ȁB
>>202 >>227 �܂��Ⴂ�݂��������狳���Ă������ǁA�J���̌����
��ԕK�v�Ƃ���Ă���X�L���͉������킩�邩���H
�E���R�݂����ȃR�[�h��ǂݎ��X�L���ł��Ȃ��A�o�O�̏��Ȃ��ǎ���
�R�[�h�Y����X�L���ł��Ȃ��B
���������{��ƁA���e�ȋC��������B
���̂����킩��������邳�B���ނ���A���݂����ȃN�T���W�W�B�ɂ�
�Ȃ�Ȃ��ł���B
"Der Alte wuerfelt nicht."
��i�̋C�������킩���ł��Ȃ��ȁB
>>202 >>227 �܂��Ⴂ�݂��������狳���Ă������ǁA�J���̌����
��ԕK�v�Ƃ���Ă���X�L���͉������킩�邩���H
�E���R�݂����ȃR�[�h��ǂݎ��X�L���ł��Ȃ��A�o�O�̏��Ȃ��ǎ���
�R�[�h�Y����X�L���ł��Ȃ��B
���������{��ƁA���e�ȋC��������B
���̂����킩��������邳�B���ނ���A���݂����ȃN�T���W�W�B�ɂ�
�Ȃ�Ȃ��ł���B
"Der Alte wuerfelt nicht."
983 �F,,�E�L�́M�E,,�j��-�������F2009/01/27(��) 01:25:37
��H�V�~���Ǝ��@����Tick�l�̈Ӗ����Ⴄ�̂��H�H�H�H�H�H
��T5���ԘA���{����1���A�Ζ����Ԓ���LBP����Ă������������̂��Ȃ��B
>>983
���APowerPC �Ȃ�ŁBSPU �ւ̈ڐA���Ȃ�čl���Ă��Ȃ��悗
tb_get(get_tb������?)�� /usr/include/asm/time.h ���炩���ς���Ă����B
���APowerPC �Ȃ�ŁBSPU �ւ̈ڐA���Ȃ�čl���Ă��Ȃ��悗
tb_get(get_tb������?)�� /usr/include/asm/time.h ���炩���ς���Ă����B
986 �F�f�t�H���g�̖����������F2009/01/27(��) 01:47:54
���ʏo���Ă������@���悩�����̂�
987 �F,,�E�L�́M�E,,�j��-�������F2009/01/27(��) 01:49:14
�тт点��Ȃ�����������
988 �F�f�t�H���g�̖����������F2009/01/27(��) 07:47:08
579�̋\�Ԃɂ��_���S����n�܂�����
989 �F�f�t�H���g�̖����������F2009/01/27(��) 10:41:15
>>988
�܂Ă܂āA�X�J���ƍœK���ς݃x�N�^�ō��̏o�ɂ���
���ʂ� PowerPC �� >>980 ���Ƃ�����ASPU ���Ⴓ���
�S�{���J���ƌ��Ă�������B
>>287 >>288 �̒ʂ�Ȃ�ˁ[�́H
�܂Ă܂āA�X�J���ƍœK���ς݃x�N�^�ō��̏o�ɂ���
���ʂ� PowerPC �� >>980 ���Ƃ�����ASPU ���Ⴓ���
�S�{���J���ƌ��Ă�������B
>>287 >>288 �̒ʂ�Ȃ�ˁ[�́H
990 �F�f�t�H���g�̖����������F2009/01/27(��) 14:50:11
>>989
PPC970����H������ƃR�[�h�̏������ς��邾���ł����͏o���B
���[�v�͂��܂蓾�ӂł͂Ȃ��āA�^�C�g�ȕ���������A�E�g�I�u�I�[�_�ŕ�����s�ł��邩��
�A���S���Y�����x���ł����������Ƃ͖����Ă����ꂾ���Ő��\���L�тĂ��܂����Ƃ�����B
PPC970����H������ƃR�[�h�̏������ς��邾���ł����͏o���B
���[�v�͂��܂蓾�ӂł͂Ȃ��āA�^�C�g�ȕ���������A�E�g�I�u�I�[�_�ŕ�����s�ł��邩��
�A���S���Y�����x���ł����������Ƃ͖����Ă����ꂾ���Ő��\���L�тĂ��܂����Ƃ�����B
991 �F�f�t�H���g�̖����������F2009/01/27(��) 14:53:04
SIMD���Ő��\�P��4�{�ƍl����̂��������B
�~�X�A���C�����[�h�̘A���Ő��\�o�Ȃ����Ƃ����Ă���B�I���W�i��MT�������ł���悤�ɂˁB
�e�[�u����16�o�C�g�A���C��������e�ʃI�[�o�[��������Ȃ��ˁB
�~�X�A���C�����[�h�̘A���Ő��\�o�Ȃ����Ƃ����Ă���B�I���W�i��MT�������ł���悤�ɂˁB
�e�[�u����16�o�C�g�A���C��������e�ʃI�[�o�[��������Ȃ��ˁB
992 �F�f�t�H���g�̖����������F2009/01/27(��) 17:24:41
���낻��F����n�b�^���̃l�^�������Ȃ��ĐÂ��ɂȂ����Ⴂ�܂����˂�
993 �F�f�t�H���g�̖����������F2009/01/27(��) 17:39:59
10cyc��邱�Ƃ͂��肦�Ȃ�
994 �F,,�E�L�́M�E,,�j��-�������F2009/01/27(��) 18:58:49
>>993
����
����
995 �F�f�t�H���g�̖����������F2009/01/27(��) 19:15:53
996 �F,,�E�L�́M�E,,�j��-�������F2009/01/27(��) 19:39:44
�uHack the 579�R�[�h�v�̂͂��܂�ł�
997 �F�f�t�H���g�̖����������F2009/01/27(��) 19:43:25
���������>>802�̓~�X�ɂ�����łȂ��Ȃ�����W���}�C�J?
��64�r�b�g�����ŏ��������瑬���Ȃ�Ȃ�?
��64�r�b�g�����ŏ��������瑬���Ȃ�Ȃ�?
998 �F,,�E�L�́M�E,,�j��-�������F2009/01/27(��) 19:50:02
>>997
���́APPC970��64bit ALU�~2�ŁA����AltiVec�̕��Z�ł��郆�j�b�g���Ȃ�����
ALU�ł�����ق�������肪�����đ������Ƃ�����B
���́APPC970��64bit ALU�~2�ŁA����AltiVec�̕��Z�ł��郆�j�b�g���Ȃ�����
ALU�ł�����ق�������肪�����đ������Ƃ�����B
999 �F�f�t�H���g�̖����������F2009/01/27(��) 20:03:39
�������!! 8.5 cycle ����!!!
�uHack the �n�b�^���v ��Q�� -> http://pc11.2ch.net/test/read.cgi/tech/1232817361/l50
1001 �F�P�O�O�P�F
���̃X���b�h�͂P�O�O�O���܂����B
���������Ȃ��̂ŁA�V�����X���b�h�𗧂ĂĂ��������ł��B�B�B
���������Ȃ��̂ŁA�V�����X���b�h�𗧂ĂĂ��������ł��B�B�B