ヽ / /⌒\
/ヽヽ|/⌒\ii|\
/ /ヾゞ///\\|
|/ |;;;;;;|/ハ \|
|;;;;//⌒ヽ
|;/( ^ω^)
>>1 おっおっおっ乙枯ー
. |{ ∪ ∪
|;;ヾ.,____,ノ
|;;; |
|;;;;;|
|;;;;;|
前スレ埋まりました。
GJ!
2ch閉鎖したらどーすんの?
大原が入稿してからついに一週間経つのにまだ掲載されてないなんて
珍しいなム板で500KB制限って
このスレとは関係ないけど
サーバーを意識した設計だがRASは無い
俺はnopは実行ユニット使ってると思っていた。そこで実験。Dothanで。
lp:
計算式や正規表現のようなユーザから来る可変な表現からプログラムを生成。
Cの関数のような表記のアセンブラといえば、CELLのもそうじゃなかったっけ?
あれはもともとIntelコンパイラの組み込み関数
>>16 正規表現か。難しそうだな。
結局、定数書き換え以上のことやろうとすると、コンパイラみたいなのを
自作してプログラムに入れないといけないんだよな。
ぶっちゃけ定数埋め込みだけでも意義は大きいと思うし、
最後に0.99をかける処理をする/しないの選択みたいな要素が8個あれば
高速化を考えれば普通なら256通りのコードを用意する必要があるわけだから、
そういうのに使ってもいい。
>>17 べつにmov(ecx, n); でmov ecx, n を実行するわけじゃなくて、
将来実行するコードにmov ecx, n のマシン語を追加しているのだ。
単なる表記法の話とは違う。
>20
正規表現は動的にDFAを構築するlazy evaluationがナウなヤングにバカウケ
> そうなると、そうすると
俺くどいwwwwwwwwwwwwwwwwwwww
26 :
デフォルトの名無しさん :2007/01/21(日) 04:13:03
http://journal.mycom.co.jp/column/sopinion/190/ REV.FのDualCore 2MB L2で227.4Mトランジスタ
1MB L2で、153.8Mトランジスタと言われている。
つまり、227.4-153.8=73.6Mトランジスタが、1MB L2の容量と思われる。
2MBだとx2で147.2
227.4-147.2=80.2がL2を除いたトランジスタ数。
41.1Mが1コアあたりのトランジスタ数となる。
ちなみに、512KBのシングルコアは81.1Mと言われているので
81.1-36.8=44.3ほどDualCoreの数値と比べ、少し多いが、
後述するメモコンなどの共用部分は、1コアでも1つ持つので、割とあってるかもしれない。
ここから大原氏のいうL1キャッシュの容量7Mを差し引いて34.1Mトランジスタ
さらにメモコン部分のL2以外のダイ面積に占める割合からすると14%なので、
単純計算で5.75M、これを両コアで共有するため、半分として2.88Mトランジスタ。
34.1-2.875=31.22Mである。
メモコンのトランジスタ数については、前述の数値で言えば、
DualCoreとSingleCoreでコア辺り3.2Mの差があるので、
あたらずも遠からずかな。
27 :
デフォルトの名無しさん :2007/01/21(日) 04:15:27
つづき
http://journal.mycom.co.jp/column/sopinion/190/ これと同じことをCore2でやると
Core2 4MB版が291M
Core2 2MB版が167M
であるから、(291-167)*2で248Mトランジスタ
(291-248)/2=21.5M
過去のP6アーキテクチャのくらべると、両コアの共用部分を差し引いても少ないように思う。
その他Core2のキャッシュ計算法から、過去のCPUのトランジスタ数を推定すると
2MBのCoreDuoが、(151.6-124M)/2=13.8M
2MBのドタン,PentiumMが、140-124M=16M
1MBのバニアス,PentiumMが、77M-62M=15M
256KBのPentium3が、28.1M-15.5=12.6M
L2外付けのPentium3が、95M
Penteium4だと
プレセラで(376-248)/2=64M
プレスコットで125-62=63M
割といい感じと言うか、ほぼぴったり!
しかしトランジスタ数がCore2の3倍に達することになるが。
長々と書いたが、半分大原氏に向けて書いたつもり。
ここをみてる様だから。
参考文献
http://www.sandpile.org/index.htm 大原なんてどうでも良い
「モノ書くってレベルじゃねーぞ」
30 :
デフォルトの名無しさん :2007/01/21(日) 14:47:40
大原氏の検証が正しいどうかかわからないが、Core2のトランジスタ数が少ないのは事実であろう。いずれにせよ、Core2のトランジスタ効率はかなり良い。
その上整数パイプラインとFP/SIMDパイプラインに分かれてる。
その代わりK8はスレッド数が増えても急激な性能の低下はないね。
ソース希望。共有キャッシュだから若干遅くなるのは予想できるが、
単純に1スレッドだけだと2MB~4MBのキャッシュを占有できるからじゃないの?
Intelの共有キャッシュ = 再構成可能キャッシュ
36 :
デフォルトの名無しさん :2007/01/21(日) 15:59:52
そうだね。
何言ってんの?K8といえば今やX2だろう。
>>23 4issueのCPUで演算パイプラインが常時IPC4で回るとかあり得ないのは
当然のことだと思うのだが、意図的に間違えてるのか?
そういう意味じゃCore2もK8もIPC3すら全く達成できてない/する気がない。
それとは別に、パイプラインを3→4に強化すれば高速化するのは間違いない。
その高速化に対して、IPC4+のケースがあることも、そうじゃないことも貢献している。
その他色々な強化を積み重ねて、Core2はあのスピードを手に入れたのだ。
K8だってCore2だって、IPCが1.4のところを1.5にしようと必死に頑張って作ったはず。
あと、俺はむしろK8の演算器((ALU+L/S)*3)が過剰でバランスが悪いと感じる。
もっとも、これがK8のパワーの源だとも思うし、実際にはそう悪くないのだろう。
よく言われることだけど、ALUが過剰とかキャッシュだけ多いとかいうのは
設計思想の違いで、どちらが良い悪いというものではない。
バランスが悪いとダメだけど、K8やCore2がそこまでバランスが悪いとは思わない。
ところで、大原さんは別にCore2を貶してるわけじゃないんだよね。
ただ、「Core2は(x86命令で)IPC4を狙った設計ではない」と主張してるだけで、
4issueは無駄だとか、K8より性能が劣るとか、設計が悪いとかは、言ってない。
なぜそう主張したいのかが、さっぱりわからないんだけど。
今度のK8Lは、「より確実にIPC3を出し続けることを狙ったCPU」だと思う。
このK8Lと、「IPC4を狙ってデコード・スケジュールでつまづく」Core2の戦いは楽しみだ。
K8では整数パイプとFP/SIMDパイプにディスパッチする手前でデコードしてたのを
>>39 SIMDの方にディスパッチしてから64bit単位で命令を解釈し、
ある程度トランジスタを割いてうまくスケジュールして、
同じピークSIMD性能のCore2を超える実性能を叩き出す、
というのが俺の希望だが、実際どうだろね。
ディスパッチ前の命令の単位が64bitから128bitに変わったことが
影響していると考えていいと思うけど。
そそ、Intel processorが特別ピーキーで(絶妙な)設計なだよなー(・∀・)
Intelerお久
どこが優っていて、どこが劣っているとか、
読んだ。
おはようございます。
>>43 論旨には賛同するが、メモリ帯域やレイテンシ計測は是非やって欲しいよ。
もちろん、そういう計測をそのままCPUの性能と思ってしまうのは論外だが、
「自分はこの処理をさせたいが、どのCPUがいいだろう?」と思ったときに
一般アプリの実性能ベンチだけではイマイチ検討のしようがない。
まあ、こういうのは最近の流行りじゃないんだろうねぇ。
確かに俺も、とりあえず帯域ベンチやっときましたみたいな記事を見ると、
色々誤解が広まりそうで嫌な感じはする。
CPUの性能を調べることと素性を調べることの差って感じか
周波数特性だけで盲目的に音質を語るな
>>47 そうだね。
あと、ベンチって結果から製品を選ぶのが目的と見せかけて
むしろ好奇心を満たすものという面が大きい。
性能より素性を知りたい人が少ないってのが寂しい。
>>48 そういう意味じゃ、CPUは速いのが正義だから、まだ簡単だ。
MP3とACCの比較とか、ありゃあ泥沼になるわけだ。
>>50 実際にどっちを買うべきかという話ではなくて、CPUメーカーがシングルコア路線を続けた方が
動画エンコしない一般ユーザーは(今までは)幸せだったんじゃないかという話だね。
結局、俺は使ったことがないからわからないんだよな。
それに、Pen4からCore2Duoに乗り換えた人は、
Coreアーキだから速いのか、デュアルコアだから速いのか、Pen4が遅かっただけなのか、
何が原因だか容易には知ることができないだろう。
俺は前から、体感したYonahの速さからデュアルコアをすすめる人の多くが、
CoreSoloでも同じ速さを感じるのではないかと思っていたが、これも確かめるのが難しい。
一方、Intelとすれば、シングルでも非常に高速なYonahやConroeで
デュアルコアをスタートさせたため、商売としては成功したと言えるだろう。
(いや、ネトバのデュアルはスタート以前というか・・・それでもエンコは強かった)
>CPUメーカーがシングルコア路線を続けた方が動画エンコしない一般ユーザーは(今までは)幸せだったんじゃないかという話
>>52 AdaptabilityやDMTの意味がわからないが、
前提となるコストと熱設計の中で最も性能の高いものを作るだけじゃないの?
開発期間の隙間と言っても、開発が済んだらコアを減らすわけでもないだろうし。
Speculative MultiThreadingによってILPの壁を突き破れるようになるまで
SpMTが高めるのはMLPだ。
>>56 > Speculative MultiThreadingによってILPの壁を突き破れるようになる
の「ILPの壁」というのは、「シングルスレッド処理のIPC向上の壁」と言えばいいんじゃない?
ILPと言うと、メモリ以外の命令同士の依存関係を何とかするみたいな感じを受けるから。
#メモリアクセスもI(命令)だと言われればそうだけど。
俺は、メモリ以外のILPの問題の方が本質的だと思うので、ここではILPという言葉は使わない。
手動でプリフェッチすれば同等の性能が出るであろう技術には個人的に萌えない。
しかし、SpMTによって、手動でprefetch命令を入れたのに匹敵する効果が得られるなら、
これこそプログラマに優しい、「逃げない」技術なのかもしれないとも思った。
> 投機実行
それは、文脈からして条件分岐命令に対する投機実行のことだから、
投機的マルチスレッディングとは関係ないと思われる。
>>54 逃げなきゃいけない状況なら逃げないといけないね。
何事もバランス、中庸。
>>53 ではああ言ったが、最後の2行は同意。単純に対応ソフトの普及促進にもなるし。
大腹自身の記事かよw
61 :
デフォルトの名無しさん :2007/01/28(日) 00:54:47
>>59 それは読んだよ。
しかし、大原氏の計算方式だと、、同じコアのキャッシュ容量違いで、コアトランジスタの数が変わる理由が説明できない。
たとえば、X2の512KBと、1MB版は
512KB 15380万個 1MB 22740万個だが
コアトランジスタの数は
512KB 5708万個 1MB 4859万個となり、900万個の差が説明できない。
あと、K8の場合、24KBのプリデコードビットもキャッシュ量として計算すべきじゃないか?とか思ったり
で、整合性を持たせた結果、個人的に”こんなものか”とはじき出した数字がこれくらい。
初代 K7 1360万
初代 K8 1770万
90nm K8 2660万
Rev.F K8 DualCore 2870万
Rev.F K8 SingleCore 2990万
Pentium3 773万
PentiumM (130nm) 1146万
PentiumM (90nm) 1246万
CoreDuo 1326万
Core2 Duo 2096万
過去のCPUの傾向から言うと
1バイトあたりのトランジスタ数はK8が約70個、PentiumMが約60個という傾向も見えてきた。
なかには40個台のもあるが、これでは6トランジスタでは作れないので、(6トランジスタで作るには、最低54個必要)、4トランジスタで作っているか、公式発表の数字がうそか、どちらかだろう。
まあ大原もここのスレ住人も、ほとんどが確たるウラをとらずに好き
PenMが4トランジスタSRAMってのは間違い。
そろそろclock計測の話題に戻ろうよ。
素人が個人ブログや掲示板に自己満足記事投稿するのと
クロック数計測してもTr数はわからんし。
>>66 大企業メディアの情報の質、正確性、量、速度が
個人サイトの集合を上回っているとはいえなくなりつつある
ネット社会の現代、こういうライター稼業のなんてもう流行らないのかも。
しかし、それにしても国内のハードウエアレビューは質が低い。
AnandTechやTom's, INQなどは個人サイトが反映しても死ぬ気がしないんだけど、
国内ではそのような優良サイトがない。情報も一方的だし、ライターの記事は情報が少なく、遅い。
この計算はあってるの?
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2915&p=3 If we assume that 288M transistors (6T SRAM) will be used by the 6MB cache,
that leaves 122M transistors for L1 cache and the rest of the core.
Applying the same calculation to Conroe gives us 99M transistors left over,
meaning that there are roughly 23% more core-logic,
control and L1 transistors being used in Penryn than in Conroe.
>>70 なんかどうみても、これスレを読んでいて、且つこのスレに対して
言い訳してるようにしか読めないな。
大原氏には悪いけど。
>>70 話の持っていきかたの無理矢理感が・・・・・
どんな下手な書き方してもIPC=3を出せるハードという意味なら永久に無理に決まってる。
そこでEPIC
4IPCを狙ったアーキじゃないって論は云々はどっちかというと
この人の記事を読んで真に受けただけじゃなかろうか
http://www.ne.jp/asahi/comp/tarusan/main147.htm 別に ALU+Load, ALU, ALU, Store
もしくは ALU, ALU, ALU, Load or Store
でもx86換算4命令になるわけだがな。
インオーダで実行するわけじゃないんだから、3IPC以上出せないというのは
大きな間違いだよね。
従来のアーキテクチャではストア命令が来る度に、格納先が確定するまで
後続のロードとそれに依存する命令を発行できないという縛りがあるわけで、
レジスタが少なくロードストア頻度の高いx86でIPC=3を実現する上で大きな縛りになってる。
Core 2で導入されたMemory Disambiguationはそのへんを解決してる。
大原氏はCore 2で平均IPCを引き上げるためのその辺の機構を正当に見てない希ガス。
安藤壽茂氏なんかの記事はちゃんとそのへんも触れてる。
キャッシュラインサイズが256Bというのもその辺考えてるのかもな。
>>76 キャッシュラインサイズが256Bって何?
P6,Netburstでは、unknown store-addressがあってもそれ以降の別のストアはアドレス計算できれば発行可能。
またunknown load-addressがあってもそれ以降の(アドレス計算可能な)ロードやストアは発行可能。
唯一できなかったパターンがunknown store-address以降の(アドレス計算可能な)ロード発行で、
これはCore 2で可能になった。
これに対してK7,K8では、unknown store-addresがあるとそれ以降のロードやストアは発行できない。
またunknown load-addressがあってもそれ以降のロードやストアを発行できない。
ロードやストアのAGU命令はインオーダー発行になっているようだ。
K8Lでロードのアウトオブオーダー発行が実装されるが、
どの程度のアウトオブオーダーなのか、またそれによってどの程度性能が向上するのか、
楽しみではある。
計測情報源:
http://www.realworldtech.com/forums/index.cfm?action=detail&id=73407&threadid=73407&roomid=11 今回のは何を言いたいのかさっぱい伝わってこないのだが…
Vista 64bit版も出た事だし、そろそろx86-64の話題が欲しいですね。
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2915&p=3 Penrynはdual coreだ。そしてquad coreはただそれらを二つパッケージに封入しただけだ。
ただ、あとからシングルダイの製品が登場するかもしれない。
トランジスタ数が4億1000万なので、Penrynが6MBの共有L2 cacheを持つと予想できる。
Penrynのロジック部はConroeの進化形になるだろう。
キャッシュの増量分以上の機能的・性能的追加が期待できる。
2億8800万トランジスタが6T-SRAMの共有L2キャッシュに利用されているとすれば
残り1億2200万トランジスタはL1キャッシュとコアに費やされていることになる。
同じ計算をConroeに適用すると、9千9百万のトランジスタがコアとL1 cacheに割り当てられている。
これらの事実はPenrynではConroeと比較して23%多いトランジスタがL1 cache, 論理, 制御に
使用されるのを意味する。
追加される機能が不明である現時点でさえ、SSE4のサポートがそれらのトランジスタの
かなりの部分を占めると予想するだろう。またIntelが45nmでクロックを上げるので
Penrynが3GHzよりも高いクロックで登場するのを容易に予想できる。
Conroeのオーバークロック耐性を考えると、Penrynのクロックが非常に良いのを見ても
そんなに驚かないだろう。
> Penrynの世代でHyper-Threadingが搭載されるという。
今回のこれは大原を弄るのは酷かもな…
89 :
デフォルトの名無しさん :2007/02/05(月) 01:17:24
つーか、なんか論点がずれてるというか、大雑把な主張になってきたな。
このシリーズはいつまで続くんじゃー!
Core2がIPC=4じゃないとする主張の理由の中に
元々はCoreMAとK8のIPC向上に対するアプローチの違いを言いたかったような気がするが。
>>89 Meromと果物のmelonをかけてるのだろうか?
Penrynに、L2キャッシュ増量とSSE4実装以外の目立った改善があるのか気になるね。
遅くなるプリフィックスと64bitでのマクロフュージョン、シャッフル系SSE命令などが考えられる。
まあ、このうち1つも対応されない可能性も大きいとは思うが。
命令フェッチ幅を32byteにするのはいずれ必要だけど、Penrynの次のアーキ辺りが妥当か。
Windows生ハム
AMDの方は L3キャッシュだろ。もうどうなる事やら。
トランジスタ増やしすぎたらいくら微細化してるとしても
そういえばK8LのL3は面積からしてZ-RAMじゃないな
Opteron146(Socket939 core=Venus)の結果をば。
Pentium 4 630 Prescott 90 nm
Pentium 4 631 CedarMill 65nm
Athlon XP-M 1800+ Thoroughbred Low Power
動かしてみるに吝かではないのだけれど、CPUの情報もプログラムで拾って表示してくれると便利だと思う。
Celeron 1.7GHz(Willamette-128K)
Opteron144(Venus)だけど
>>100 と同じ結果
Pentium II
Conroe
みなさんありがとう。
小さい数の割り算だと速くなるのはPenM~Core2だけみたいだね。
Pen4はステッピングが進むにつれて遅くなってくなあ。これがネトバだよな。好きだ。
K7/K8が、PenMの遅いところと同等程度。意外と速くないが、整数はこんなものか。
K6-2は低クロックとはいえさすが。今にして思えば味のある石だった。
PenIIがPenMと似た数字なのが面白い。PenMも地味にいい改良してるよなあ。
>>104 ↓こういうのを表示できるようにして、後でアップします。
GenuineIntel Family:6 Model:D Stepping:6
Linuxは誰かにコンパイルしてもらいたいが、それにしてもVC++のインラインアセンブラはまずい。
アセンブラ部をNASM用にすることは可能だと思うので、ちょっと挑戦してみる。
>>108 あれ!?ConroeのrdtscってFSBクロックとか聞いたけどちゃんと測れるのか。
PenMの改善点を洗練させた感じだ。
基本的に被除数が32bitに収まる場合を高速化してるみたいだな。
Yonahのときに、割り算が速くなるという話があったが、Core2も同じか?
持ってる人Yonahの測定お願いします。
YonahとBaniasの計測がほしいね。それで完璧。
GCCなら-masm=intelオプションでほぼそのまんま移植できた希ガス
ほれPentium M(Banias)
今までの計測結果を見ると、
いや、除数側の改良もDothanからか。
>>99 の測定は、下のコードと、そこからdiv ebxを抜かしたコードとの
差をdiv命令のレイテンシとしている。
lp:
add eax,xa ; xa,xdはメモリ
mov edx,xd ; 被除数は毎回破壊されるので毎回読み込む
div ebx
mov esi,eax ; レジスタをクリアして、かつ依存関係を保たせるあがき
neg eax
add eax,esi
dec ecx
jnz lp
いちおうPenMでは正しい結果を出してると思うけど(以前の測定でも散々追試してるし)、
ループ処理がそれなりに重いのでCPUによっては微妙かもしれないと不安になってきた。
もう少しいい処理・わかりやすいループのアイデアある?
まず、ループをアンロールというのはやろうと思う。
>>115 いや、Yonahの発表からすると、Yonahの時点でCore2の速さだったんじゃない?
どうも新しいCPUはレイテンシが微増する傾向があるみたいなので、
Yonah(PenMと同じ世代)がCore2(新しい)より速いということも考えられる。
>>108 を見ると、PenMを改良したものからピッタリ2clk遅くなっている感じだ。
>>116 コンパイラの対応からK8Lの特徴を読み取ろうというのか。
costを見ればいいのかな。コンパイラに必要な情報というのはいい情報かも。。
Merom T5600
>>109 > あれ!?ConroeのrdtscってFSBクロックとか聞いたけどちゃんと測れるのか。
C1E等でクロック倍率が下がっている時でも
FSB1カウントにつきTSCは最高クロック倍率(
E6600なら9)ずつカウントアップする仕様みたい。
どんな時でもrdtscを2回実行すると、その差は必ず
(E6600の場合)9の倍数になる。
2コアでほぼ同時にrdtscを実行すると2コアともほぼ近い値が返ってきたが、
MBのBIOSをアップデートしたら、2コアで全く異なる値が返るようになってしまった。
その後、WinXPのデュアルコアパッチを入れたら2コアでほぼ近い値が返るようになった。
>>120 なるほど!数字としては今までと同じで、精度がコアの倍率分だけ悪くなっているのか。
2コアで同じ時計を持てるのは嬉しいが、やはりクロック単位の測定にはちょっと痛いな。
カウンタはどこにあるのだろう?
マザーボードのBIOSで影響するということはCPUの外だとも思えるが、
それだと2コアで異なる値が返ることがあるという現象に説明がつかない。
カウンタはコア毎にあって、CPUが起動するときに合わせるのかな?
>>99 CPUIDを表示するのと、
>>117 で言ったアンロール(2回)をやったのをアップし直した。
アドレスは同じ。
Core Duo T2400 1.83GHz
123 :
122 :2007/02/07(水) 08:45:22
更新されてたの気づかなかった
>>100 を本日アップ分で再計測
AuthenticAMD Family:1 Model:7 Stepping:F
除数大↓ 被除数大→
39 39 39 39 39 - - -
39 39 39 39 39 39 - -
39 39 39 39 39 39 39 -
39 39 39 39 39 39 39 39
ソース読んだ
Core 2 Duo E6300
>>126 この結果ってCPUのクロック倍率が落ちた状態じゃないかな?
EISTやC1Eで自動的にクロック倍率が落ちるので、
FSB同期のrdtscでクロック数を計測するのはいろいろと面倒かも。
Merom T5600
>>103 再計測。やっぱFamilyとStepping逆だね。
AuthenticAMD Family:6 Model:8 Stepping:1
除数大↓ 被除数大→
39 39 39 39 39 - - -
39 39 39 39 39 39 - -
39 39 39 39 39 39 39 -
39 39 39 39 39 39 39 39
AuthenticAMD Family:5 Model:8 Stepping:C
除数大↓ 被除数大→
18 18 18 18 18 - - -
18 18 18 18 18 18 - -
18 18 18 18 18 18 18 -
18 18 18 18 18 18 18 18
GenuineIntel Family:6 Model:8 Stepping:6
>>123 二度手間ごめん。しかも結果違うorz
おそらく>123の方が正解。
これで、Core2のdivはYonahを2clk遅くしたものだとわかった。
Banias→荒削りのDothan→完成形のYonah→Meromの変化が面白い。
>>124 >>129 これも結果が異なるのか。やはり測定法に問題ありだな。
>>123 >>130 とは逆にクロック数が減っているが、ALUパワーの差、かな。
K6-2も(当時としては)ALUが強い。対してP6系は総合的に速い割にALUは弱い。
2つのループの差からクロック数を求めているため、div以外の特徴も混ざってしまう。。
>>125 うあ~!俺のDothanはFamilyとSteppingが同じだから気がつかなかったよ。
指摘サンクス。後でこっそり修正しておきます。
>>127 確かに>126は2割、>128は1割だけクロック数が増えているな。
CPUのクロックが落ちても(今までのCPUと違って)rdtscのクロックは変わらないということか。
ただ、誤差が1~2割というのはSpeedStepにしては少ない感じがする。
ある程度のタイミングで補正はしてくるのか?
測定した人たちへ:毎度ヘボプログラムでごめんなさい。
>>126-127 >>131 EIST と C1E を切って測定してみました。
GenuineIntel Family:6 Model:F Stepping:6
除数大↓ 被除数大→
18 26 34 42 42 - - -
11 18 26 34 42 42 - -
11 11 18 26 42 42 42 -
11 11 11 18 42 42 42 42
>>133 順当な結果ですね。
単純にedx=0, eax=1, ebx=1としてdiv ebxを連続実行すれば
1÷1のレイテンシが求まるから、それを基準にすればいいかな。
でも、大体結果は出ているし、またバグ出すと嫌なので
ここらで手を引きます。
後藤弘茂によると、ノート用Core 2 ExtremeはIDAナシのようだ。
こういうところからIDAの思想が若干見えるか?
YorkfieldでHTが有効ってことになると、Nehalemがトレースキャッシュ型
SMTの実装にトレースキャッシュが必須ってこたないでしょ。
>>135 命令の切り出しの方がネックじゃなかったっけ?
>>134 多分 HTT有効だと一部のアプリの性能が低下する ってのと同じ問題が起きるよなあ
厳密には IDAがあるのに上手く活かされずシングルスレッド性能が向上しない だけど
至極真っ当且つナイスな技術なのにソフトウェアが台無しにするという。。。
ユーザーがHALT命令を制御できればなあー
将来的にはハイエンドサーバーみたいにCPUパーティションの動的な変更もできる様になると尚良し
>>138 HLTをユーザモードに解放するメリットは何?
計測目的ならDOSとかRING0で計測すればいいだけだし、
OSスケジューラの都合ならHLTでコアを止めるよりもsleepしてOSに任せたほうがいいし。
PentiumってOutOfOrderだったっけ?
P5はインオーダー
in-order発行のtypoだと信じておこうw
out-of-order終了w
>鼎の軽重
連載オワタよ
↓次のネタ大胆予想
「Core Microarchitectureをさらにもう少し」
>>149 今回のことで懲りたので、たぶん非PCの話題とか、誰にも突っ込まれ
ない(というか誰も興味ない)話題でお茶を濁すと見た。
> Pentium Proの世代は、命令の発行とその実行まではOut-of-Orderながら、
ハイパースレッディングは考え様によってはOut-of-Order完了だな
Out-Of-Order完了www
>>153 NetBurstはそれでもいいけど、Baniasは違うよなあ
もうなんか大原って中途半端な知識で言い切るんだよね。だから色々
初心に戻ろうと思い、裸になって学校へ行こうと電車に乗ったら捕まりました。
>>156 それがライターの仕事
後藤や本田や(中略)安藤だって(以下略
ブログとセカンドオピニオンで補足するだけマシじゃね
>>158 それでも後藤と大原じゃ、大きく違うがな。
二人が同じに見えるなら、それはそれで見る目が無いよ。
161 :
158 :2007/02/19(月) 00:48:00
何だか、何を書いても叩かれそうだからライターの格付けはしないが。
素人にわかるように説明するのに「~かも知れない」ばっか使うわけにはいかないよねって話。
でも、あの特集記事が叩かれるのもわかるんだよね。
「K8はそんなに悪くない。むしろよく見える。」な結論ありき丸出しの記事だったもん。
IPCなんて言葉は使わずに
>>38 >>41 >>43-44 みたいなことを適当に書いておけば良かった。
まぁ、でもネタを提供してくれる分にはとてもありがたく思ってるよ。
>> 162
>>148 結局、Core2のIPCが3だという主張以外はまっとうで普通な内容だったな。
本来ならば、この記事を肴にしてSSE4やそれ以降の命令の実装についてとか
32byteフェッチ3命令パイプのK8Lと16byteフェッチ4命令パイプのCore2の比較とか
色々このスレで議論できたはずなのに、ちょっと惜しい感じだ。
プロならちゃんとやれとも思うが、色々事情があってこういう格好になってしまったのだろう。
数年前と比べて、CPUの話題が減ってきてるような気がするんだよなあ・・・。
時代の流れか、それとも単に俺が手持ちのPentiumMに飽きてきただけか。
みっなおそう、みなおそう、CPUを見直そう
4gamerの第5回目以降の下書きメモ帳代わりにmycomを利用した大原たん
4gamerの記事は比較的よくできているね。
168 :
デフォルトの名無しさん :2007/02/21(水) 09:27:01
【ネガティブ派遣根性チェック】
169 :
デフォルトの名無しさん :2007/02/24(土) 00:32:24
「もうすこし」ではないから安心しろ。
>誰を恨むわけにもいかないんですが
大原先生ごめんなさいw
ぬこ成分だけで全て許してしまえる
iいろんな意味で役に立ってるから今度ファンレター送るね。
生活支援てw
> 他所様の出版社から出ている内容をここで引用するわけにもいきませんので
182 :
デフォルトの名無しさん :2007/03/07(水) 16:07:02
そこは絶望しないと
>Intelは80386以降で、4レベルのProtection Ringという概念を導入した(Photo01)。
相変わらずツッコミきっつー
VAX/VMS が仮想記憶をインプリメントした初めてのOSだとか [1]、
80386の仮想記憶ってほとんどMULTICSそのままだよな。
80386は仮想記憶やページングのアーキテクチャだけは割と新しいからな
>>188 話の流れを分かってない。
MULTICS由来ってのは286から導入されたセグメンテーション機構の話。
386から入ったページング機構はインテルにしては(?)素直で作りで良い
んだが、TLBにASIDがないのがちと古い感じ。
流れ断ち切るようでスマソ。質問。
スタックの先頭は通常キャッシュにのってるから速いが
スタックを大量に使うこと自体はそんなに問題じゃないと思う
>>192 ヒープに載っけても結局同じだけメモリ食うんだがw
まだ直線的に並んでたほうがassociativityの制約に引っかかりにくいw
机上論だがw
call by value -> call by reference
ここは計測スレなのに最近自作○C板のCPUスレと同種の話ばっかりじゃない?
しかしAgner氏の計測を覆すような発見もそうそう無いんだよな
マジでダンゴ来た・・・もうオワリだ・・・
最初からいるだろ
早く貼れ
いや、やっぱり貼るな
トリップ外すな、ハゲ。
○◎●であぼーんは基本だろ?
>>181 実際狂ったように測定していなくてゴメン。
>>190 アセンブラレベルでは、sub esp, ローカル変数のサイズ分 は ただの引き算だから、
1clkで終わってしまう簡単な処理だ。
でも、マルチタスクOSで動かす以上、Windows側のメモリ管理で時間がかかるとか?
今時間ないので後で実測したい。
>>202 256KBのLSのレイテンシとピーク帯域、FP_SIMDのレイテンシ・スループットを希望。
x86じゃないけど、自分で実測したデータなら誰も文句言わんでしょ。
>>206 レイテンシ測定はここ。
http://journal.mycom.co.jp/special/2007/x2-65nm/013.html 何で生データを載せてくれないだ。くそっ。意味わからんグラフばっか載せやがって・・・。
キャッシュラインサイズの64byte以下のstrideで速くなるのは当然として、
それ以上のstrideで変化しているのは単にCPUの機嫌が悪かっただけと予想。
内部構造が変わったかどうかはわからないが、レイテンシが増えたのは確実だ。
コンパイラの出力を見て初めて知ったこと。
or ecx, -1 (83 c9 ff) という3byteでecxに32bitの-1を入れることができる。
1byteの-1は32bitに符号拡張される。
まあ、xor ecx,-1 はnot ecx でいいし、高速化に使う機会はないかな。
>>196 ネタ切れ、というのが主な原因なんだけど、
実際クロック測定は、何を測定するか考えて、実際に測定して、考察して書き込む、
という手順を踏まなければならない。
そして、そのそれぞれが、思った以上にめんどくさい/難しい。
そこで、何を測定するかだけでも思いついたら書いてくれ、って前から言ってるけど。。
あと、cpu-zのレイテンシ測定の全CPU分を集結させたいと思っている。
このスレでも何度か上がってるけど、いざ90nmK8のデータが欲しいと思っても、
どこにあったかわからなかったので。
http://www.wikihouse.com/x86clocker/index.php?plugin=attach&pcmd=open&file=cpuz.zip&refer=Upload とりあえずここに、手元にあった分だけ固めてアップしておく。
あとでちゃんと整形して上げます。
スループットなら倍精度以外はほとんど1だよ。
てか、IBMの図におもっきし51.2GBって書いてあるじゃんww
レジスタが128本だから1レジスタ指定に7ビット。
80286の間違いは訂正なしか。だめだなこりゃ。
精度の高い除算のやり方はは3DNow/SSEと同じ。
なんつーか、普通のプロセッサ用に書いたコードがことごとく使えない
spe_printf()は遅い悪寒。
ネタがないな
暇ならXLATの所要クロックについて語ってくれ。
x86_64命令の所要クロック計測まだー
同じじゃねーかwwww(NetBurst以外
>>209 レスが遅れてすまん。
まあ、大体素直な感じだな。
x86のキャッシュはマルチタスクに対応するための複雑なメモリ管理や
L1L2(ものによってはL3も)の多重階層で、かなりレイテンシが増えているよな。
それを考えればCellのLSは順当な性能だ。
x86にLSを載せたらどうだろう。
256KBでレイテンシ6、128bit/clkという性能で、更にL1L2キャッシュは今まで通りとする。
LSは新SSE命令で明示的に使う必要があるが、使えば効果は大きいと思う。
(L1とLSの両方に高速な配線をつなぐのは技術的に困難か?)
レジスタは128bit*128で2KBか。
こんなにあると、コーディングにまた別の感覚が必要になるなあ。
>>219 実際問題、普通にパソコン買うと32bitのWindowsVistaになっちゃうんだよね。
64bitの計測ができるのは、だいぶ先の話になりそうだ・・・。
帯域がもう少し広ければトレースキャッシュくらいに使えるんじゃないかなと思ったり。
ロード・ストア命令が16バイト単位でしか読めないから、多段階ルックアップテーブル
スレ違いだし今更気づくような内容でもないだろう。
スカラプロセッサの補助としてベクトル演算器があるのと、
>>221 > x86にLSを載せたらどうだろう
レジスタ同様にタスクスイッチ時にデータを退避するのか?
それともロックして占有するのか?
>>226 仮にやるとしたら、ロックするのがいいかな。
オーバーレイなんかも同時に2アプリで使えないことだし、
エンコやゲーム専用と考えれば。
でもやっぱりマルチタスクできないのは不便だよな。
OS側でも工夫のしようはあると思うが、
そうまでして使う価値があるかは正直疑問だし。
L1キャッシュよりレイテンシの大きいローカルストアよりも
スケジューラが詰まらないならその方がありがたいです。
リアルモードの割り込みベクタのことIDTなんていう呼び方してたっけ?
Interrupt Descriptor Table
いや、だからリアルモードの割り込みベクタテーブルとプロテクトモードのIDTはちょっと違うもんだろ、って話じゃ?
英語が理解できないのはつらそうだな。
どうして団子リオンはトリップつけてないのか。
>>230 intelの文書ではリアルモードの割り込みベクタテーブルを実アドレスモードIDTとよんでいる
ありゃ、お漏らししちゃってたのか。
Emulatorの友
> Super Shuffle Engine
スレ違いならごめん。
>>243 コードの差は出るかもしれないし出ないかもしれない。
その周辺のコードによっても変わるし、勿論コンパイラによっても変わる。
別スレ逝った方がいいよ。
>>243 速度を気にするなら条件分岐を排除
同確率の二択はほぼどちらかが失敗する
どうも有難うございました。
まぁ、そんな細かいことが気になるならc++で
細かいことが気になるならmin/max関数なんて使わない
なるほど、団子には皮肉が通じないわけだ。
つーかそれ、素で間違ったのに皮肉と言い訳してるのと見分けが
明らかに皮肉とわかるのに
>>248 みたいなことを言う馬鹿や初心者は結構いるぞ。
つまりそういう人間と君みたいな天才は区別が付かないんだよw
せっかく天才なんだから周りに勘違いされないようにした方が
幸せだと思っただけさ。気に障ったら許してくれw
どうもごめんなさいでした。
>>253 基本的に同意
でも多分std::maxとかって書いておけば最適な命令に置き換えてくれると勘違いしてる
初心者なんじゃないだろうか。
皮肉だ皮肉だとと必死に自己弁護してることからも明らか
>>254 Hacker's Delight日本語訳発行以降、
半端な知識で「MSBをシフトすれば分岐が排除できる=速い」と思いこんで
改悪コード書く厨が増えたよな。
257 :
デフォルトの名無しさん :2007/04/01(日) 14:43:29
皮肉だ皮肉だと自己弁護してるのが特にそうだね
いくら初心者でもmin,maxが最適な命令に置き換わるなんて発想はありえない。
団子が昔そうだったとか?
ダンゴの言うことはホント正しいよね
どう考えてもmin,maxが最適な命令に置き換わるなんてありえないな。
>>243 がかかるクロック数を短くしたいという目的があって質問したのは
明らかなわけだが
細かいこととは、かかる処理時間を少しでも短くすることなわけで
min/max関数が最適な命令に置き換わるという勘違いでもしてないかぎり
出来ないレスだと思うけどねこれは
248 :デフォルトの名無しさん :2007/04/01(日) 11:55:50
まぁ、そんな細かいことが気になるならc++で
min = std::min(a, b);
max = std::max(a, b);
とでもすればいいだろうよ。
>>259-260 ←見苦しい弁解だな
言葉遣いや性格には問題ありだが。。。
>>262 組み込み関数として最適化ができるアーキテクチャ・処理系はあるよ。
x86では、知る限りでは無いけど(マクロ版ならまだ最適化される余地あるかも)
>>264 まず団子が正しいことを認めろよ。
言い訳がましい。
268 :
248 :2007/04/01(日) 17:07:41
ここで真相を明かしますよ。今日の日付けを考えてみろ、と。
>>268 を翻訳
「max/minが関数名と重なってるからstd::ネームスペース指定してみたけど
二重に誤爆しちゃったみたい。俺ってお馬鹿♪」
条件付movとか、フラグ→マスクみたいな一般的な方法ではなく
>>271 団子よ、IDが出ないからといって見苦しい自演するな。
無意味な喧嘩すんなよ。
おまえ自作板見てないだろ?
O原ネタ振れよww
>>272 アホすwww
>>270 SSE2じゃなくてSSEまでのサポートで使えるけど。
CMOVならPentium Pro以上が要求される。
Pentium/PMMXは切り捨ててよくてPPro/P2は切り捨てちゃだめって基準は理解できない。
CMOVは対応する組み込み関数あったっけ?コンパイルオプションやインライン
ASMくらいしか使う手段なかったと思うが。
どうせSSE未サポートのx86互換チップなんて今後発売される見込み無いんだし
x64ではSSE2までは標準ISAに入ってるんだから覚えておいていいと思うけど。
ハードウェアの投機実行機構に任せるより下手すりゃ遅くなるような
ビットマスク生成とかの厨コーディングより、いま市場に出回ってるCPUの
大半で使える最速の方法を知ってたほうがよっぽど役に立つだろ。
この粘着力は酉付いてなくても真性だとわかる
MACヲタもそうだが酉なしで粘着する奴はもう一線越えてるからな
無能よかまし
>>270 が言ってるのはset命令だろ。
そこでSSEとかCMOVとか言ってる時点で話が見えてない。
CMOVの組み込み関数はVCの64bitモードになかったっけ。
32bitで使えないならあんま意味ないけどな。
無能は価値がないけど嘘吐きは有害
>>281 の脳内では「条件付きMOV」と「CMOV」は別モノらしい
set命令って何?
_mm_set_ssならmovssに展開されるだけだよ。
むろんemmintrin.hなんて要求されない
>>282 だよね。SSEしか要求しないのに生成コードすら読まずに
SSE2だなんていう嘘つきは要らない子だね。
今日付いたレスは全部嘘
インラインASM的にはこうか?
__asm {
movss xmm0, DWORD PTR [a]
movss xmm1, DWORD PTR [b]
movss xmm2, xmm0
maxss xmm0, xmm1
minss xmm2, xmm1
movss DWORD PTR [min], xmm0
movss DWORD PTR [max], xmm2
}
x87スタック←→XMMレジスタは普通の方法使えばメモリに書き出して読み直すので
その分オーバーヘッドが生じるが、
arch=sseでコンパイルしてれば浮動小数演算はほとんどXMMレジスタ上で行うことができる。
んで、SSE2命令なんてどこに必要なの?ねぇ、教えて?
>>286 だよね。「SSE2が必要」ってのはどーみても綿貫ネタだよね。
mov eax, [a]
相当な粘着だな
うちの団子が粘着でごめんなさいm(_)m
粘りけのない団子なんて食えたもんじゃない
と背景雑音どもが申しております
_, ._
SET命令やビット命令を最後に使ったのは何時だったか
つまらん事で荒れたのを久々に見たなぁ・・・
スレ違いな質問にも答えずにはいられないのが教えたがり君クオリティ
おまえらがつまらんことやってるからWolfdaleのESベンチの結果が違うスレに貼られたじゃないか
>>238 これは嬉しい!
>>300 速すぎて、クロック測定ルーチンがポシャってないか不安なくらい。
Intel、45nmプロセスの次期CPU「Penryn」の詳細を公開
http://pc.watch.impress.co.jp/docs/2007/0329/intel.htm とりあえずMeromとの比較まとめ。
L2キャッシュは1.5倍の6MB、12MB版もあり。ダイサイズは25%縮小。新たにSSE4が載る。
SSEのShuffle系の命令の遅さが改善される。
整数/FP共に除算の性能が上がる。FPUの平方根も高速化。
FSBクロックが上がり、プリフェッチにも手が入る。
省電力機能のDPD、シングルスレッド性能のためのEDA。
Yonahの消費電力はなぜ少ないのか
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm Deep Power Downは、YonahのEnhanced Deeper Sleepと何が違うんだ?
まさか、YonahのDC4ステートがMeromになかったのか。
Enhanced Dynamic Accelerationは、IDAの改良版だろうか。
"Radix 16"の16は何だろう。
>>300 を見ると相変わらず8bit単位でクロック数が変わっている。
命令のデコードが速くなるという記述もあるが、divのuOP数も減るのか?
今までは ちまちまやっていたのを、16bitいっぺんにやるから速いということかね。
引きずってる弱点もあるだろうけど、十分に洗練されてきたと感じる。
>>302 基数が16ってのは16進法で筆算するような感じなのかな。
クロック数の変動から、256進法と思っていたが、単に商を8bitで区切って
その区切りごとに演算を早目に終わるという感じか。
Nehalemは、単純にIPCで見て素直な上がり方をするのかなあ。
P6と違う味のするコアでPenrynを完全に超えてくれたら嬉しい。
つまりは4ビット単位の部分商を一気に計算してるんだろ
>>301 >速すぎて、クロック測定ルーチンがポシャってないか不安なくらい。
>>128 のMeromの半分だし妥当では?
>Deep Power Downは、YonahのEnhanced Deeper Sleepと何が違うんだ?
>まさか、YonahのDC4ステートがMeromになかったのか。
>Yonahの消費電力はなぜ少ないのか
>
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm >その段階に入ると、Yonahは、新たに設けられたEnhanced Deeper Sleep「DC4」と呼ばれるステイトに入る。
>これは、Deeper Sleepよりさらに電圧を下げるステイトだ。
>Enhanced Deeper Sleepでは、CPUコアを再起動しないですむ、コア保持(Core retention)レベルに最低限必要な電圧にまで下げる。
スライドを見る限りではこのコア保持レベルより更に電圧を下げるという話みたいね。
自習で暇だったからランダムなfloat値1億個の入った配列を読み出して
こいつは半端に知識ある癖してどこまで理解出来てるのかさっぱりだな。
うん、それで?
落ち着け。つくづく痛い子だな。
こんなもんで
80/32(bit)より遅いね。
>>190 のを試すのと、fsqrtとfdivのレイテンシ測定をやりたいんだが、
何かやる気出ないなあ・・・。
NehalemにはSMTが載るらしいが、数年後なら4~16スレッドに
備える意味があると踏んだのだろうか。
まあ、サーバー用途とかだろうけど。
SMTの効果だが、NetBurstと同等くらいはあるのではないだろうか。
ネトバは元々スカスカだから、SMTで資源を有効利用できる。
とはいえ、SSEのレイテンシで見ると、実はCore2よりもネトバの方が
スループットに対してレイテンシが短い(パイプライン充填率が高い)。
Nehalemでは、きっちり4命令/clkをコンスタントに供給してくるだろうし。
これはつまり、Core2の効率が悪いと言っていることになるが、
実際にあれだけ強化したCore2がK8の20%増ししか速くないのだから、
発揮できていない潜在パワーはかなりあるはずだ。
(これは別にCore2の設計が悪いという意味ではない)
命令フェッチ帯域が狭いからそれを拡充しないことにはね(Penrynでは改良してくるはず)
>>305 え、コア保持しないん!?
>>311 float1億個といったら400MBじゃんか。
それでもメモリネックにならないのか。
cmovは1個に20clk以上かかってるぞ。
比較-フラグ-移動のレイテンシが長いんだろうなあ。
いずれしても、これからの時代はFPUを使う意味がないね。
ちなみにCで書いてコンパイルしただけ。(SSEだけIntrinsicsを利用)
ソース希望。
ループの内側はこんだけ。
319 :
317 :2007/04/07(土) 09:29:14
お、THX!
どうでもいいけど_mm_min*だな
折角だから実測してみた。
わかりにくいから数字だけ書き直しとこ。
16bit整数×1億個で計測(10回回してるので10倍になってます)
VTune9キター
団子先生なら買う!!!
VTune使いこなせてない漏れもいますよ。
処で>321だけど、流石にiccだとintrinsic使わないソースでもでもmaxps使ってくれるのね。
尤も、ループ回数が4の倍数じゃないときのロジックがおまけについてくるけど。
それと、詳細の数値忘れたけど(出先の)2coreXeon(3GHz)だとicc -fastで0.12secは掛かってた。
クロック差を考えると速いんだけど、-parallelにしたら却って遅くなってやんの。
>>323 ふむ、cmovも遅いのね。
確か予測分岐はランダムな入力に対して学習しない、つまり予測を変えないから1/2の確率で的中するんだよな。
あと予測をことごとく裏切る、つまり短いスパンで規則性のある入力に対してはcmovが有効だろう。
そーいや、最大最小の問題は回数重ねると分岐パターンが収束してくわな。
CellのSPEの分岐ヒント命令っていいね
331 :
デフォルトの名無しさん :2007/04/20(金) 21:21:15
沖縄県の方へ(命に関わる注意事項です)
民主党といえば、民主党の公認候補が毎日のように22時過ぎまで駅前で名前を連呼しているんだが
>332
スレ違いだろうが
負け癖は抜けませんがみんすです
仮に開放するにしても、下手なやり方だと日本にはいいことなさそうだな。
>>337 64bitCPUなのに64bit加算が苦手なのか?
add reg64,reg64 は、さすがにレイテンシ1でできると思うけど、
内部的には32bit*2段パイプで実現しているのかもね。
PenMでpaddqは3-2とのことだが、測定してみたら2-2に見える。
padddやporと混ぜてもレイテンシが3にはならなかった。
(ただ、混ぜたときのクロック数は不規則で、素直な命令ではない様子)
Meromでも、普通の命令の中では実質レイテンシ1で使えるんじゃないかな。
pcmpgtqが実装されないなら、paddqの改善はしてない方が自然だ。
339 :
デフォルトの名無しさん :2007/04/26(木) 21:06:20
movapsにもレイテンシ2クロックかかんのかよ
> 64bitCPUなのに64bit加算が苦手なのか?
しょぼw
コアが増えるなら別にいいんじゃね。
345 :
デフォルトの名無しさん :2007/05/06(日) 18:36:40
ダンゴさんが書き込むとスレが引き締まるな
L2レイテンシ9だって?
なんかブロック図が想像してたのと違う。
適当なスレがないのでスレ違いを覚悟で質問します。
例えば分かりやすい例を挙げてみます。
MOV RCX,[RAX+imm64]みたいな命令がほしいってこと?
>>351 そうそうそんな奴があればいいなと思ってました。
まあ無くてもコンパイラが
>>350 みたいなコードに展開してくれるし
レジスタは多めなので問題はないと思うのですが、あってもいいような
気がします。
というのは私はよくCやC++のコンパイラでコンパイルしたコードをデバッグ
モードで眺めるのが好きなのですが、BSSやDATA領域の変数を
アクセスするコードが結構頻繁に出てくるのです。そういうのが
>>351 の
ように書けたらすっきりすると思うのです。
まあいろいろ解析して不要と判断したのでしょうけどね。
とくにAMD64やEM64Tは広大なメモリ領域を自由にアクセスできるように
>スタック領域に2GB超
>>353 いや、だからイミディエイトで±2GB以上のオフセットが必要なシーンがどれだけあるのよ?
使うかどうかも分からん命令を命令マップのどこにアサインするのよ?
命令マップに座席を用意したとしても、64bitのイミディエイトを命令に
組み込めば、命令が8バイト伸びるってのも忘れちゃならんよ。
#ISAの設計の世界には「アイは高くつく」という格言があってだね...。
個人的にはイミディエイト値の扱いなんて POWER 並みで十分だと思う。
ユーザーが操作してない間は自由に動いてて構わないと思うけど。
359 :
138 :2007/05/10(木) 01:46:57
やっぱりIDAショボーンだった…
地雷の965でしか動かさせないとなると怖いなぁ・・・
>>347 (Core0-3 + L3)が独立小島でDRAMアクセスを含めた外の領域はL3を通して接続って形に見えるね。
スケーラビリティーを考えると妥当なやりかたにも思える。
コア領域とノースブリッジ領域の分離を明確にしたというか。
>>361 しかしクロックや電圧供給ってCore0-3とL3+NBで分かれてたと思うんだけどねえ。
L3の位置もコアに挟まれてるんじゃなくてダイの端だし、一番遠いコアだとアクセス効率悪すぎる気もするのだが。
●Core2Duoの結果
Opteron146でやってみた。
366 :
363 :2007/05/28(月) 00:21:12
>>365 さすがOpteronはx87で非数、∞を使っても遅くならないですね。
367 :
363 :2007/05/28(月) 00:55:04
よく見るとOpteronは正規化数 + 非正規化数 = 正規化数でも遅くならないんですね。
>>363 「現在、大変混み合っております。」ぐみゅう。
俺もレジスタを初期化せずにaddpsのレイテンシ測定とかやって、
「妙に遅いな」とか思ってたことがあったなあ。
マンデルブロ集合をSSEで計算するときも、
計算済みの場所はクリアしないとオーバーフローして遅くなる、
と思ってたが、SSEの∞加算・乗算はCore2でOKなのか。
今、PenMで測ってみても大丈夫っぽい。
上で書いたaddpsで遅くなったケースはCoppermineなので、
P6→PenMで改善されたのかもしれんね。
369 :
363 :2007/05/28(月) 20:19:35
Opteronじゃなくても結構いける
>>370 AthlonXP3200+だとSSE2はないけどx87とSSEはほぼ同じ結果。
>>369 肝心なときに役に立たないまとめサイトであった。
・PentiumM(Dothan-ULV 1.1GHz)
vender:GenuineIntel CPUID:6D6
x87 SSE SSE2
3.1 3.1 3.1 clk : 正規化数 + 正規化数 = 正規化数
5.0 4.0 5.0 clk : 正規化数 * 正規化数 = 正規化数
32.0 18.0 32.0 clk : 正規化数 / 正規化数 = 正規化数
145.5 3.1 3.0 clk : 非数 + 正規化数 = 非数
147.4 4.0 5.0 clk : 非数 * 正規化数 = 非数
151.4 9.0 9.0 clk : 非数 / 正規化数 = 非数
155.5 3.0 3.1 clk : 非数 + 非数 = 非数
157.4 4.0 5.0 clk : 非数 * 非数 = 非数
161.4 9.0 9.0 clk : 非数 / 非数 = 非数
151.5 98.0 98.0 clk : 正規化数 + 非正規化数 = 正規化数
302.8 183.4 183.4 clk : 非正規化数 + 非正規化数 = 非正規化数
302.7 185.4 187.4 clk : 非正規化数 * 正規化数 = 非正規化数
343.7 204.4 218.4 clk : 非正規化数 / 正規化数 = 非正規化数
143.5 3.1 3.1 clk : +∞ + 正規化数 = +∞
139.4 4.0 5.0 clk : +∞ * 正規化数 = +∞
150.4 9.0 9.0 clk : +∞ / 正規化数 = +∞
143.5 3.0 3.1 clk : +∞ + +∞ = +∞
139.4 4.0 5.0 clk : +∞ * +∞ = +∞
実際にこの数字が性能に影響を与えるケースはほとんどないだろうけど、
Core2の、x87はいいからSSEを高速化したいという気持ちが見えるかな。
しかし、PenM→Core2で、レイテンシは全く変わってないな(除算以外)。
#お、無負荷なのにファンが回り始めた。さっきSpeedStep切ったからだ。
FPだと、1.0001をかけ続けても全然オーバーフローしないのね。
ちょっと泣けるCeleron2GHz
AthlonXP2400 です。
AthlonXP-M 1800+でも
>>374 と同様
そしてまた空気を読まずにK6-2 400MHz
vender:AuthenticAMD CPUID:58C
x87
2.0 clk : 正規化数 + 正規化数 = 正規化数
2.0 clk : 正規化数 * 正規化数 = 正規化数
34.0 clk : 正規化数 / 正規化数 = 正規化数
4.0 clk : 非数 + 正規化数 = 非数
4.0 clk : 非数 * 正規化数 = 非数
4.0 clk : 非数 / 正規化数 = 非数
7.0 clk : 非数 + 非数 = 非数
7.0 clk : 非数 * 非数 = 非数
7.0 clk : 非数 / 非数 = 非数
3.0 clk : 正規化数 + 非正規化数 = 正規化数
20.0 clk : 非正規化数 + 非正規化数 = 非正規化数
19.0 clk : 非正規化数 * 正規化数 = 非正規化数
50.0 clk : 非正規化数 / 正規化数 = 非正規化数
4.0 clk : +∞ + 正規化数 = +∞
5.0 clk : +∞ * 正規化数 = +∞
7.0 clk : +∞ / 正規化数 = +∞
6.0 clk : +∞ + +∞ = +∞
5.0 clk : +∞ * +∞ = +∞
376 :
デフォルトの名無しさん :2007/05/29(火) 07:26:21
使われないx87が遅くても欠点ではないと思うけど、
Pentium2 です
くそ、お前らのせいでMMX Pentiumを探したくなって、
380 :
363 :2007/05/29(火) 20:51:43
たくさんの計測結果ありがとう。
Athlon64X2 3800+@939だと
>>370 と同じだった
vender:AuthenticAMD CPUID:FB1
x87 SSE SSE2
河童800
385 :
363 :2007/05/31(木) 20:38:14
>>383 あれ?CoppermineでもSSEはNaN,∞で問題ないですね…。
Tualatin(P3-s)の1.13GHz
> AMDのCPUは昔からNaN,∞に強いんですね。
つかなんでNANとINF食うとストールするんだろ
>388
MMX Pentium 166MHz
>>389 そういえばそんな物あったね、もうね、すっかり失念。
Coppermine-128K Celeron-400MHz
vender:GenuineIntel CPUID:681
x87 SSE
3.0 3.0 clk : 正規化数 + 正規化数 = 正規化数
5.0 4.0 clk : 正規化数 * 正規化数 = 正規化数
32.0 18.0 clk : 正規化数 / 正規化数 = 正規化数
104.6 3.0 clk : 非数 + 正規化数 = 非数
106.6 4.0 clk : 非数 * 正規化数 = 非数
110.6 9.0 clk : 非数 / 正規化数 = 非数
115.6 3.0 clk : 非数 + 非数 = 非数
117.6 4.0 clk : 非数 * 非数 = 非数
121.6 9.0 clk : 非数 / 非数 = 非数
113.6 77.6 clk : 正規化数 + 非正規化数 = 正規化数
215.6 133.6 clk : 非正規化数 + 非正規化数 = 非正規化数
216.6 135.6 clk : 非正規化数 * 正規化数 = 非正規化数
257.6 154.6 clk : 非正規化数 / 正規化数 = 非正規化数
103.6 3.0 clk : +∞ + 正規化数 = +∞
101.6 4.0 clk : +∞ * 正規化数 = +∞
111.6 9.0 clk : +∞ / 正規化数 = +∞
103.6 3.0 clk : +∞ + +∞ = +∞
101.6 4.0 clk : +∞ * +∞ = +∞
>>368 は、たまたま非正規化数で測ってしまって勘違いしたのかな。
>>383 とほぼ同じだ。こちらが少し速いのは、クロックの差か、ステッピングか、測定誤差か。
むしろ
>>378 に近い数字だ。
>>390 性格はP6と同じっぽいね。やはり古いだけあってクロック当たりの性能はいいけど。
小数点以下の数字が、みんな1なのが面白い。
>>376 テーマとしては面白いね。
K8に対して、Northwoodが勝つにはadd eax,eaxを繰り返せばクロック当たりで倍の性能になる。
K8に対してPentiumMが勝つには、paddd mm0,mm0を繰り返せばこれも倍。
あとは排他キャッシュの弱点をえぐり出すことかな。
Prescottが勝つのはどうするんだろ。
別にadd eax,eaxでもクロック当たりで互角だから、高クロック型のPrescottが勝ちと言えるけど、
どうせならクロック当たりの性能でも勝つのを考えたいよな。
単にL2帯域で比べてもいいが、それじゃ面白くない。K8は弱点少ないから攻めにくいねえ。
俺はAMDユーザーだからIntelに負けて欲しいな。
ららびー
そういえば団子のサイトのRSSっておかしくね?
団子ちゃんのサイトなんてあったの!?
SPAMトラックバック掃除したときに消したまんまだ
なんか記事更新すれば再生成されるからマットれ
ネタは
>>395 掃除前の記事はRSSに出ないみたいだね。
402 :
401 :2007/06/15(金) 01:43:25
P35マザーで組んだけどなんか人柱依頼ある?
>>403 こういうときのために平素から測定プログラムを作っておくんだったと後悔しきり。
とはいえ最近、自分で高速化する需要が減ってたりする。
やはり自分で何か作って、それを高速化したいとなって初めて
クロック測定の意欲が出てくるんだなあと、このごろ思うのです。
#ららびーでマンデルブロ集合描かせるくらいしか夢がない。
ちょうどVista x64動かしてるから命令長ネックの検証でもしてみるのも手だと思うけど
うお!64bitOSかよ。それを先に言え。
そこでVMwareに64bitLinuxですよ
アレってx64非対応の石でも使えたっけ?
>>408 今時amd64非対応の石なんて使ってないだろ。
32bitOSの上でも64bitOS動かせるからそうしろってこと。
動かせないよ
GeodeやCore (2じゃないほう) Duo/Soloは非対応だよ。
VMWareはx64が使えれば動かせるな
C2DだけどXP(32bit)の上ではx64版の犬がインストールできなかった
>>414 ちゃんとVTをオンにしているんだろうな。
え、VMware使ったら32bitのホストOSの上で64bitのゲストOS動かせんの?
お前の思いこみを吐露しろなんて誰もいってないぞ。
531 :Socket774:2007/06/27(水) 17:29:08 ID:7g9GfI7V
・・・Barcelonaの値段出てるみたいだけど、そんなに高くないか。
ただ、上位は消費電力も性能も値段もウンコだな。
2340 1.9GHz 95W $320
2350 2.0GHz 95W $390
2352 2.1GHz 95W $450
2354 2.2GHz 95W $610
2356 2.3GHz 95W $795
2358 2.4GHz 120W $1180
2360 2.5GHz 120W TBA
537 :Socket774:2007/06/27(水) 18:11:48 ID:V0//xVyS
>>531 登場時期も書いてやれ。
9月10日
2340 1.9GHz 95W $320
2350 2.0GHz 95W $390
10月
2352 2.1GHz 95W $450
2354 2.2GHz 95W $610
たぶん年内
2356 2.3GHz 95W $795
2358 2.4GHz 120W $1180
すぐには出ない
2360 2.5GHz 120W TBA
強気すぎるだろwwwwww
何で1PのQ6600が出てくるのか
ああ2Way Opteronか。
Various developers are busy implimenting workarounds for serious bugs in Intel's Core 2 cpu.
>>425 テオ様が痛い人なのは同意だけど、技術的な嘘を付くような人ではないと思うぞ。
OS作成者から見て嫌なバグとアプリケーション開発者からみて嫌なバグは違うし。
NHK「本日未明、ド田舎村で不発弾が発見されそれを自衛隊が処理しました。」
>>424 「日本って超危険な国家だったんだ。国外に脱出せねば。」
>>429 IntelもL$2経由で接続するし、HT経由より速いんじゃないか?
>>430 こう考えるんだ。
各種I/OもCPU内蔵キャッシュの恩恵にあずかれると。
ライトバックだったらイヤだな
vtuneの話はここでいいですかね
同じ18万ならAmiga最上位版買うな
同じ18万なら8800GTX搭載Core2Duo搭載のPC一台組むな。
440 :
デフォルトの名無しさん :2007/08/08(水) 10:58:52
age
>>441 ピークIPCこそ3のままだが、32byteフェッチとSSEがDirectPathになるのが大きい。
SSEのロードも高速化されるし、命令の流れは相当スムースになると思う。
シャッフル系SSEの性能が気になるところ。
スタックエンジンに当たるものは、Intelと少し違うように見えるが、
そもそもIntelのやつも、どの程度スタックのオーバーヘッドが残るのか知らないしな。
サーバー向け4コアをターゲットに最適化してるっぽいから、
最初の一般向けデュアルコアの勝負では微妙な感じもする。
まあ、そのうち4コアが主流になるだろうから長期的にはむしろ有利か。
#てかクロックがもうちょっと上がらないときつい気が・・・
>>442 以前から疑問だったすけど、立ち寄ったついでに質問させていただくす。
---------------------
ピークIPCこそ3のままだが、
---------------------
AMDのプロセッサの場合issue queue(x86的にわROBすか?)にわロードと演算命令が
マージされたMacro-Opsとして格納され、実行時に2つのMicro-Opsに分解されるす。
これってIPC的にわ6命令と数えないすか?
それはインテル流に言えばUPC(micro-ops per cycle)。
MACオタがマイクロアーキテクチャをよく理解していないということがわかるな。
>>1 のいっているピークIPCとはプロセッサのパイプラインにおいて
理論的に持続可能な命令レートを指しているので、IPC=3にほかならない。
あんま関係ないけど最近IPCって言葉が乱用されすぎだよね。
○○並列というのはないか。
リタイアメントuOPs数で比較する?
>>443 俺が言ったのは、1clkにつきx86命令を(持続的に)3つを超えては処理できないということ。
ところで、最近自作板でも面白い話題が少ないねー。
まあ、
>>446 みたいなことは俺も思う。
命令の単位が、x86命令か、Macro-Opsか、Micro-Opsか、スタックエンジン等は含めるのか、
好きな命令か、与えられた命令か、持続できる性能か、瞬間的な性能か、平均的な性能か、
単にIPCと書いたときは、これらのことを省略して書いたことになるわけですな。
>>442 では、このスレなら(言葉が適切かどうかはともかく)言いたいことが簡単に伝わると思って使った。
ニュアンスとしては、K8のデコード・発行・ALU・リタイヤのユニットがきれいに3つずつであるように
今度のAMDが出す新CPUも「3つずつ」という構造は同じっぽいなあ、という感じ。
わかりにくいならすまんかった。
>>449 かなり初期からMicro-ops fusion相当の機能を持つ命令処理ユニットを備えていたAMDのアーキテクチャわ、
比較的小さな進歩でx86命令換算でのIPCを上げる潜在能力を持つと思うという話だったすけど。K8Lのレベル
でわ望み薄すか。。。
--------------------------
単にIPCと書いたときは、これらのことを省略して書いたことになるわけですな。
--------------------------
ベンチマークとして広く使われるDhrystoneだと、結果の単位わMIPSでも異なるアーキテクチャを比較するために
標準システムでの結果との比を取っているだけすから、深く考える必要も無いかと思うす。
>>450 いや平均IPCは上がるでしょ。
Core2みたいなマクロフュージョンがないならピークIPCを上げることは無理だけど。
でも、ピークIPCを上げる目的は、平均IPCを上げることだから無問題。
> 深く考える必要も無いかと思うす。
Dhrystoneの話とわかっていてそのベンチ内容も知っている読み手ならいいが、
そうでないときの乱用が最近目立つから困ると言っているのだ。
白い変人ことだんごです。
これと
456 :
デフォルトの名無しさん :2007/08/22(水) 21:32:55
なんか、デジャヴが
457 :
デフォルトの名無しさん :2007/08/22(水) 21:37:00
>>455 んなもんCPUによる
少なくともP6系アーキでは前者はストールしまくりんぐ
ところで計測くらい自分でできるよな?
xchg edx, [eax] は19clkとかかかって、何でこんなに遅いんだと思ったら、
These improvements should help K10 execute programs written in high-level object-oriented code much faster.
Pentium Mで導入された間接分岐の予測器をようやく採用したのか
間接分岐の予測自体は以前からあるけどな
ICL10ちゃうの?
>>464 ICLってなに?
IntelCompilerのことなら、通常iccというと思うのだけれど。
コマンド名っしょ。
EXEの名前がicl.exe
>>466 ICCはIntel C/C++ Compilerの頭文字とったものだと思ってたが
ccがc compilerなんだからモジってようがモジってまいが
Linux/ICC,Win/ICLで使い分けることはあるにしろどっちでも通じると思ってた
確かにどっちでもいいが
oic
>少し紛らわしい
実際のところはダンゴさんにピシっと語っていただこう
オペランドが増えているのにソースの一つにメモリを指定出来るのが面白いな。
PCMOVはMMXのころから欲しかった機能だ
Intelは放置する
CMOVPS/PDがないな
CPUID EAX:80000001に定義ビットがあるようなものをIntelが採用するわけがない。
>>481 期待して自分が傷つきたくないだけでしょ。
本質的にはこうなんだよ
いや、むしろIntelのと比較するとDSPNow!だな。
確かに内積演算なんかはIntelのがリッチに見える。
ダンゴさんが語るとスレが引き締まるな
なにこいつ
Intel64に続いてSSE5の登場か・・・言ったもん勝ちだな
x64をAMD64と呼び
>>489 x64ってめちゃくちゃダサいっていうか意味不明だろ。
xってなんだ?
x86-64と書くのが自分のお気に入り。
ちょwwwそれお気に入りでもなんでもないだろ
いっそx68にすべきだったな
リトルエンディアンのアーキテクチャに68と付けるな!
Intel Core2 Duo E6800
いよいよベールを脱ぐIntelの次期CPU「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0916/kaigai386.htm Nehalemについて。
ネイティブクアッドコアということで、ノート用のデュアルコアをうまく作れるかに注目したい。
まあ、ノートは当面Core2一本で行くような気がするけど。
キャッシュは共有8MB。今のCore2は65nmで4MB、45nmのPenrynで6MBなので、
45nmから始まるNehalemでは妥当なところだろう。
拡張命令は、MeromのSSSE3、PenrynのSSE4に続いて、ATAという特定用途向けを載せる。
下の記事では、CRCチェックをすると言われている。
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm 各コアにSMTを載せているというのが驚きだ。
4コア*2で8スレッドを並列実行できることになる。
これは、Core2の弱点であった命令フェッチをかなり強化していると思っていいだろう。
「Turbo Mode」については不明ということだが、IDAの改良版だろう。
Vistaでも働くようになるかなあ。この辺りは、OSの協力も欲しいところではある。
TDPは最大のもので130W。今とあまり変わらない感じだ。
そして、ついにメモリコントローラが統合された。3チャネルのDDR3となる。
その他の入出力はIntel QuickPath interconnectというシリアルインターフェイスになる。
よくわからんが、最近のボトルネックらしいので、かなり強化される模様。
個人的には、コア数のバリエーションとキャッシュ構造が一番気になるところだ。
#最近こういう記事がなかったんで、既出情報も多いのに全然覚えてなかった。。
Intel uPs Info 2 落ちたにょ
> ついにメモリコントローラが統合された
を? 今までは非同期SRAMすら直付け出来なかったとか?
Yorkfieldは買うじぇ
こいつは既出?
http://softwarecommunity.intel.com/articles/eng/1193.htm SDK for 45nm Next Generation IntelR Core?2 Processor Family and IntelR SSE4 (Penryn SDK)
をDLして味噌。
SSE4開発のためのPDF一式とか、SSSE3とSSE4のMASM用のマクロ定義とか。
あと、SSE4までのインストラクションをトラップしてエミュレーションで実行するDLLが入ってる。
実クロックの計測は無理だけど一応動作は確認できる。
>>505 これはスゲエ。
Barcelonaは相変わらずSIMD論理演算のレイテンシが2だな。
addssとかのスループットも1clkに1命令を超えるのは無理か。
Crusoeの変態モーフィングも面白いなあ。
さて、これを全部まとめてExcelの表にするにはどうしたらいいかな・・・。
へたくそだけど
シャッフル演算のレイテンシが1ってとこに注目
SSE2のPMAX/MINのスループットは0.5だが
命令長が長くなるから自重
なにげにAMDのmovntss/dが速いな
ダンゴさんが連投すると盛り上がるな
盛大に盛り上がってるね。
うるしぁバールのようなものぶつけんぞ
すごい盛り上がりだね。
516 :
デフォルトの名無しさん :2007/10/13(土) 21:56:56
じゃあ上げとくか
気がついたら 同じ言い訳ばかりしてる
気が付いたら 振り子が揺れてる
こういうのって本当におもろいと思って書いてるのかなぁ。
酒が入っていれば何でも楽しい
酒が入ったときは「うんこ」でも爆笑するやつは居る。
( ´ー`) ?
Yorkfield買った猛者は現れるかな。
525 :
デフォルトの名無しさん :2007/11/14(水) 17:22:00
IntelのIntelR 64 and IA-32 Architectures Optimization Reference Manual
>>526 ストアの改良だけをえぐり出すベンチは作るのが大変そうだな。
良く言えば完成度が高い、悪く言えば無難。
>>525 のレイテンシとスループットの表を見てもそうだ。
Comroeで「遅い」と感じた命令が遅くなくなっている(糞のように速い命令はない)。
それにしてもL2は24wayか。
どこに欲しいデータがあるのか探すのに24回もアドレス比較が必要だからな。
データ位置によってレイテンシが変わったりするんだろうか。
tetsuya komuroかと思った
529 :
デフォルトの名無しさん :2007/11/19(月) 02:49:34
>データ位置によってレイテンシが変わったりするんだろうか。
Phenom買ってきたからこのスレ的な計測を色々しようかと思ったけど手持ちのマザーで動かんかった。
マザーも買うしかないな。
BIOSは?
>>531 UNKNOWNでも動くかと思ったんだが。
BIOS画面すら拝めなかったよ。
AM2+マザーはSB700が出るまで待ちたいんだがなあ。
なんか買ってしまいそうだ。
>>532 今のところ対応BIOSは無し。
AM2+マザーでも微妙に不具合あるみたいだから出るとしても一ヶ月くらいは待たされそうだ。
ASUSのAMD690G板じゃ動いたらしいが。
イヨッ良い漢。
S3Hで動かないかなぁ
さて、マザーを買ってきたわけだが。
ドキドキ…(゚Д゚;)
規制食らったのでしばらく書き込めねー。
規制解除って長いのかな。
キャッシュやメモリの設定を変えてやってみた。
本当は同一条件でRev.Gのコアとの比較もしたいところなんだけど、さすがに時間かかるので断念。
見ると試してみたくなる。
>>543 年内にx64版用意しようかと思ってたけど急いだほうがいい?
VS2008のPGO試してみたいから俺も実機買うしかないか
>>545 64bit環境無いし…。
でもどれくらい速度上がるのかは調べてみたい。
環境揃えようかなあ。
ちなみにPhenomとK8じゃSSE2利用でPhenomの方が1.5倍くらい速かった。
1~4スレッドまで綺麗にスケールしたし。
C2Qには同クロックで10%くらいは劣る模様。
K8とC2Qのデータはそんなに正確じゃないけどね。
>541と>544もクロック差を考慮するとFPU以外はCore2Duoの方が速いな。
>>548 残念ながら俺はマウスをクリックすることしか出来んのだよ。
自作板からの出張者なのでプログラムに関しては何も…。
550 :
548 :2007/11/25(日) 09:56:08
Test 1 -- Loading before unknown load address:
552 :
548 :2007/11/25(日) 10:32:13
>>551 ありがとう御座います。
Out-of-Orderになったのはload before loadのケースだけみたいですね。
554 :
544 :2007/11/25(日) 11:45:00
くどい?
--
Test 1 -- Loading before unknown load address:
Loading before unknown load address: 11 cycles
Loading before known load address: 11 cycles
Loading before unknown load address: Yes!
Test 2 -- Loading before unknown store address:
Loading before unknown store address: 11 cycles
Loading before known store address: 11 cycles
Loading before unknown store address: Yes!
Test 3 -- Storeing before unknown load address:
Storeing before unknown load address: 11 cycles
Storeing before known load address: 11 cycles
Storeing before unknown load address: Yes!
Test 4 -- Storeing before unknown store address:
Storeing before unknown store address: 11 cycles
Storeing before known store address: 12 cycles
Storeing before unknown store address: Yes!
Finished.
--
>>553 数字と比較したいポイントが判ればグラフにするのは請け負いますよ。
>>554 上でごちゃごちゃ言いましたが、結局特集に出てたデータ全部纏めました。
どのデータをグラフ化するかはお任せします。
CSV吐いてくれたので慣れた人がやればグラフ化は簡単だと思います。
だるかったらやっぱやめてもおkです。
http://www-2ch.net:8080/up/download/1195964178823974.MbX2GM?dl そしてせっかく纏めたので他の人にも提供。(パスは"phenom")
何かの参考資料としてどうぞ。
グラフ化歓迎w
そのうちまた大原特集が組まれると思いますけど。
RMMAで取ったデータは他にもありますので、項目調べて欲しいと言ってくれれば用意するかもしれません。
うpしたのはGangedのデータですが、Ungangedのデータも一応あります。
個人的にCacheの帯域にちょっとびっくり。
>>541 貴重なデータをありがとう。
マンデルブロ集合は、PenMでチューンしたので相性があるかもしれないが、
やはりSSE性能は、PenM<Phenom<Core2。FPU性能は大差なし。
Phenomは、実行ユニットはK8の倍あるから、コードを変えればもう少し伸びると思う。
キャッシュレイテンシは意外と素直だね。
L3のレイテンシは長いから、メモリベンチでは平凡な結果になると思うけど、
共有のデータ置き場があってコア間通信もK8以上なら、実性能は期待できる。
>>553 生データだけでもすごく嬉しいのですよ。
それにしても、
>>556 。L1は本当に32byte/clk近く出るのだね。
558 :
544 :2007/11/25(日) 18:56:59
>>558 サンクス。
しかし改めて並べて見るとCoreに全然引けを取ってないから凄いな。
むしろ上回る部分も多いし。
L1 hit時なんかK8の4倍だけど、これはSSE Unaligned Load-Executeってのが効いてるのかな。
K8でも64bitの2ロードではあったから。
L3も役に立ってはいるけど量が少ないのが惜しい。Shanghaiは期待出来るだろうか。
560 :
デフォルトの名無しさん :2007/11/26(月) 04:01:14
PhenomのD-CACHE LATENCY 見てたら、特性が、なんかCore2に似てきた感じだね。
あとはどれだけ各種コンパイラが頑張ってくれるかですかねぇ・・・
SandraのCache & Memory Benchmark見る限りK10よりCoreMAの方がスコア高いけどRMMAの結果と矛盾しない?
>>559 > L1 hit時なんかK8の4倍だけど、これはSSE Unaligned Load-Executeってのが効いてるのかな。
> K8でも64bitの2ロードではあったから。
前スレでも話題に上ったけど、
K8ではmovdqa xmm,memはFMISCでしか実行できないという制限があり、
RMMAはmovdqa xmm,memを羅列して帯域計測しているので、
K8本来のL1速度(16byte/clk)の半分8byte/clkという結果になっている。
K10では理論値(32byte/clk)に近い結果が出ているので、
おそらくK10ではmovdqa xmm,memをFMISCだけでなくFADDやFMULでも
実行可能になったと考えられる。
>>562 RMMAはロードのみを行った場合の帯域。
Sandraはロードとストアをミックスした場合の、リードとライトの帯域の合計。
>>563 K8ではXMM(128bit)へのロードはFMISCのみへのDouble Issueだったものが
K10では3ユニットいずれかへのSingle Issueになっているね。
K8でもMMX(64bit)へのロードは3ユニットで処理可能だった。
実際にはL/S Unitが2基しかないけどね。
この場合はロード帯域がカタログスペック通りになるね。
K10改良点としてXMM to XMMコピーがFMISCでも処理可能に
なったことがあるけど、性能向上にどれくらい寄与するんだろう?
>>563 ロードストアの合計だったのか。納得。
CoreMAは128bitロードストア同時に出来るもんな。
>>563 命令処理の差でしたか。
>>564 そこら辺の改良の効果も測ってみたいですねえ。
メモリのGangedとUngangedの差を調べてたみた。
けどいい加減スレ違いかな。
ここってCPUコアの話がメインっぽいし。
Phenom実機で追試。
>>567 Nontempral Storeの測定もお願いします
>>567 これは興味深い結果だね。
独立したロード・ストアでも並べ方に注意って事か。
>>568 個人的にメモリストリーミングにあまり興味がないので
調べた事がなかった
MOVNT ってキャッシュ迂回するんだっけ?
訳あってシステムがDual Channel構成じゃないので
ここで回しても有意な結果が得られないかもしれん。
マンデルブロ集合ベンチをもう少し。
以下はすべてクロック当たりの性能の話です。
前スレでK7で測ってもらったものと
>>541 を比較すると、FPUはK7が0.5%遅い程度。
>>541 でキャッシュ設定を変えると微差が出たが、それと同じ種類の差だろう。
つまりFPUコアは全く変わっていない。
IntelのCPUと比べると遅いが、これはP6向けのコードだから当然の結果。
PenMとCore2のFPU比較では少し様子が違う。
z^2+cの計算では2%ほど速くなっているが、z^3はほぼ同じ、z^4では6%遅くなっている。
FPUの実行ユニットは同じ性能で、スケジューラが強化されたのが影響したのだろう。
強化されれば速くなるはずだが、P6向けにチューンされたコードだから相性が出たのだと思う。
#1%単位で語っても、CPUの周波数の誤差が0.5%くらいはあるんだが。
SSEでは、元々K7(皿)とPenMが、性格は違うが大体同じ性能だった。
それがPhenomでは、また性格が違うけど10%程度性能アップした感じだ。
また、SSE2の結果が、SSEのちょうど倍よりほんの少し速いのもPhenomの特徴だ。
つまり、4並列のaddpsと2並列のaddpdの負荷が全く同じということだろう。
微妙な差は、分岐予測かメモリ関係が原因と思われる。
逆にCore2は、SSE2の結果が、SSEのちょうど倍より少し遅い。
それも、Phenomと違ってバラつきがある。
もしやと思って命令リファレンス調べたら、addpsはaddpdより命令長が1byte短い!
巷でデコードが弱いと言われるだけのことはあるねえ。
Core2のSSEはPenMと性格が全く違い(レイテンシ据え置きなので)、10~40%の高速化。
このコードでは、レイテンシの効果が大きい。
SSE2のスループットがSSEより悪いPenMでも、SSE2はSSEの半分に近い性能を出している。
16個のxmmレジスタを使ったり、SMTを使ったりすると、新しいCPUは更に速くなるはずだ。
#マルチコアの性能を測る目的ではないベンチなので、コアは1つしか使いません。
AMD CodeAnalystにはまだ、K10のPipeline simulationが実装されていない…!!
AMDの資料に MMX MOVQ reg,regの実行ユニットが FADD/FMUL と書いてあるので
libpngはいまだにMMX版が主流じゃなかったっけ?
誤爆?
AMDのMMXはまずレイテンシがネックぢゃん
分ってきてるじゃん。
頭のおかしい人に勘違いで油を注ぐなよ・・・・・
空気を読まずにPhenomのネタ投下。
π焼きを同時に1~4個までやってみた結果。
それぞれ5回計測したうちの真ん中3つのデータを平均した時間です。
だから計測誤差は小さいと思うけど、それでもGangedだとかなりばらついた。
Super PI mod 1.5 - 8M
Unganged
1 : 6m37.781s 100.0%
2 : 6m49.003s 102.8%
3 : 7m02.712s 106.3%
4 : 7m20.039s 110.6%
Ganged
1 : 6m40.912s 100.0%
2 : 6m56.842s 104.0%
3 : 7m17.154s 109.0%
4 : 7m41.908s 115.2%
http://journal.mycom.co.jp/photo/articles/2007/09/15/barcelona/images/Photo02l.jpg ここによるとUngangedになれば10%は性能向上するらしいが、今回は良くて5%くらい。
以前Phenomスレで1Mのデータを投下したけどあのときは4個同時でも3%くらいの向上だった。
サーバのようにもっと大きな仕事をさせれば10%くらいはいくのかもしれん。
EM64T より AMD64 の方が
具体的な数字を出してください
CPUID + RDTSC の発行で
>>580 ia32_arh_dev_man_vol2a_i.pdfより抜粋。
>CPUID命令はどの特権レベルでも実行でき、命令の実行をシリアル化することができ
>る。命令の実行をシリアル化することにより、前の命令においてフラグ、レジスタ、
>メモリに対して修正が行われた場合、それらの修正がすべて完了してから、次の命令
>がフェッチされて実行されることが保証される。
そういう事。
>>583 AMD64 でも CPUID は非特権のシリアル化命令じゃないの?
CPUIDは知らんが
よく分からん
バスクロックじゃなくてコアクロックがダイナミックに下がっているだけじゃねーの?
>>586 OSの作り方によっては、影響を出せる。
>保護モード例外
>#GP(0) CR4 レジスタのTSD フラグがセットされていて、CPL が0 より大きい場合。
>実アドレスモード例外
>なし。
>仮想8086 モード例外
>#GP(0) CR4 レジスタのTSD フラグがセットされた場合。
で、わざわざ CR4 の TSD フラグをセットして一般保護例外を発生させて
つまりC2D RDTSCの挙動はBIOS,OSによって変わるということだな?
BIOSでも変わるだろうし、マイクロコード書き換えでも変わるだろうし、
593 :
582 :2007/12/12(水) 00:36:40
とりあえずもう少し詳しく調べてきたよ
Xeon 5140 (2.33 GHz)
rdtsc : 70 クロック
"movl %eax, %cr2" + rdtsc: 112 クロック
cpuid + rdtsc : 308 クロック
Athlon 64 3000+ (2 GHz)
rdtsc : 8 クロック
cpuid + rdtsc : 65 クロック
cr2 ~ ってのは特権命令使い放題な環境でも試せたから
特権シリアル化命令として CR2 へ書き込んでみた
http://journal.mycom.co.jp/special/2007/penryn/ EM64T の RDTSC の遅さはこの記事の "Faster OS Primitive Support" ってので改善されるのかねえ
594 :
582 :2007/12/12(水) 00:42:41
>>590 おおトン
とりあえず Xeon 5140 (2.33 GHz) では RDTSC は 7 クロック刻みだったわ
333 MHz * 7 = 2.33 GHz ってことかな
Pentium 4 (Prescott 2M) 3.40GHz でも 17 クロック刻みだった
これも 200 MHz * 17 GHz ってことかも
>>505 のサイトより
RDTSCのスループット
K6:7.67
K7: 11.00
K8: 6.50
Barcelona: 65.00
Coppermine: 31.00
Banias: 40.00
Dothan: 42.00
Yonah: 98.42
Merom: 64.17
Yorkfield: 28.00
596 :
デフォルトの名無しさん :2007/12/14(金) 21:15:16
この質問がスレに相応しいか判りませんが、
Intel 64 と Intel Architecture 64 ってぱっと見分かりにくいな
IA-64はIntelAMD-64の略
IntelはIA-64よりもIPFって言ってるな。
来年は順調にいけば
Larrabeeも思い出してあげて
Larrabeeって来年に出たっけ?
知らんけどIntelはこのテラスケールプロセッサはより高度なWiiライクなゲームを将来実現するために重要だとか言ってますよ。
>>340 のマニュアルでは, 128 bitのシャッフル/パック/アンパック等の
レイテンシは2 cycleだけど,
>>505 の測定結果だと3 cycleになっている.
追加されているRev.B2の測定結果でも3 cycleだし、エラッタにも該当する
ものがないから仕様なのか?
45nmのShanghaiで改善されたりするのだろうか?
×箱に関わってるのか,Intel?
初代×箱のCPUはCoppermine-128Kの733MHzだよ。
ぉ,確かに, thanks
今更だけどSSE5の16ビット浮動小数→単精度相互変換命令についてAMD-ATiの今後について妄想してみるのもありかと。
お邪魔します。別スレから誘導されてまいりました。
>>613 > 因みにPen3(1GHz)の場合、リアルでもプロテクトでも大差ないことは確認しており、
> AthlonXPでは リアルでの速度(Pen2,100M程度) << プロテクトでの速度 です。
これはどうやって検証したの?
検証用のコードがあるのなら、アップしてPen4を持っている人に実行してもらって
結果を報告してもらえばいいのでは?
Pen4で頑張って動かすより、Xeonで力任せに動かす方が余程速いんだが。
>>613 検証プログラムをUpすればこのスレの暇なPen4ユーザが計測してくれるぞ。
過去にもいろいろ計測人柱が計測しているのがこのスレ。
漏れはあいにくNetBurstな環境は持ってないから計測できないが。
>>615 世の中いろんな人がいるんだからそれを言うのは無粋。
Core 2じゃ駄目な理由が聞きたい。
619 :
デフォルトの名無しさん :2008/01/05(土) 01:32:36
団子がうぜーからじゃね?
ワロス
>620
PenDはまだまだしぶとく残ってるな
623 :
デフォルトの名無しさん :2008/01/05(土) 21:05:38
Core2は64Bit専用レジスタを持っていないので、32Bitでも64Bitでも消費電力も発熱量も変わらないと思われるが、Phenomは64Bit専用レジスタを持っており、これには32Bitでは動いていない物がある。
>>623 ひどいバカがいた物だな。どこの掲示板?
>ついでに64Bit環境でPhenomが健闘している
626 :
デフォルトの名無しさん :2008/01/06(日) 01:00:44
http://northwood.blog60.fc2.com/blog-entry-1555.html#more Core2は64Bit専用レジスタを持っていないので、32Bitでも64Bitでも消費電力も発熱量も変わらないと思われるが、Phenomは64Bit専用レジスタを持っており、これには32Bitでは動いていない物がある。
このレジスタが動き出し、発熱量が増加したとすれば、限界が下がる事は十分にあり得る。
ついでに64Bit環境でPhenomが健闘している事が、32Bitより64Bitの方が向いているという証にはなるわけだが、同周波数で同程度であっても、周波数の差で負けているのが何とも…
64ビット専用レジスタwwwwwwww
馬鹿が気が触れてますな
630 :
デフォルトの名無しさん :2008/01/06(日) 09:29:13
>馬鹿が気が触れてますな
気が触れた馬鹿は最悪だ
気が触れない馬鹿はただの馬鹿だ。
633 :
デフォルトの名無しさん :2008/01/08(火) 17:03:53
>>1 QX9650の結果です。
ただ定格ではなく、333*7@2.33GHzの結果。
FPU 1.917sec 3.611sec 4.825sec
SSE 0.437sec 0.912sec 1.161sec
SSE2 1.015sec 1.923sec 2.377sec
>>633 多少ブレはあるけど、おそらくこのベンチに関しては65nmの
>>544 から変わってないね。
デコーダの改良もない感じで、予想された通りの結果だ。
Q9450を買うか
636 :
デフォルトの名無しさん :2008/01/11(金) 13:56:39
購入宣言age
ばーるのようなものやさんのPCはWolfdale/Yorkfield Readyになりますた。
638 :
デフォルトの名無しさん :2008/01/12(土) 16:33:14
これからこのスレは
E8500買いました
買ったんかよ
641 :
デフォルトの名無しさん :2008/01/20(日) 16:06:27
それからそれから?
>PCケースをバールのようなものでこじ開ける
644 :
デフォルトの名無しさん :2008/01/20(日) 22:17:12
さぁさぁ、遠慮せずお続けになって。
プログラミングする人には重要な情報
>>643 構造上LGA775でスッポンはないと思うが。
いっぺん負荷かけてから外すと簡単に外れる。
647 :
デフォルトの名無しさん :2008/01/20(日) 23:57:00
スレ主降臨age
ダンゴさんの連投でスレが一気に加熱したな
誉め殺し乙
とりあえず割り算ベンチやってよ。
>>650 GenuineIntel Family:6 Model:7 Stepping:6
除数大↓ 被除数大→
14 19 20 22 24 - - -
14 14 19 20 22 24 - -
14 14 14 19 20 22 24 -
14 14 14 14 19 20 22 24
ずいぶん高性能なKatmaiだな(棒)
SSE4の66hを取ったら未定義オぺコード例外が発生するのかな?
さあ、間違ってもMMレジスタに作用することはなさそうだが。
>>651 これが、Radix-16 dividerの実力ですか。
>>108 とかと比べると、32bit境界が見えなくなっていて、一つ64bitっぽくなったな。
2倍は言いすぎにしても、本当にそれに近いくらいの力はありそうだ。
マザー謹製ツールが軒並み問題だらけなんでもっと人集めた方がいいかもね
>>655 単なるエイプリルフールねたのつもりよ(・∀・)
誰もやってないので
--- GogoBench 3.13a (May 25 2004) ---
○SSE4で
katmai Dual / 3Ghzで鼻からトマトジュースが出てくるところだったw
>>658 お、IntelCPUと計算方法が違うみたいですな。
商の桁数が多い場合でも早く終わるのか、
それとも、商の桁数が少ない場合でも時間がかかるのか。
どちらにしても、最遅で47clkというのは、むしろIntelっぽいクロック数だ。
さて、各社Penrynモデルが出揃って来ましたね~。
pi_fftc6のpi_cs_thread.exe を64ビットで最適化ビルド。
↑これほとんどスカラだった。
>>665 128bit精度の浮動小数点演算というのは書き間違い?
FPのレイテンシが3というのは大したもんだ(単精度の加算だけとか言うなよ)。
L1が64KB+64KBでL2が1MBだが、これだと排他制御が無駄に見える。
仕様が豪華になった分、ダイサイズが増えているのは残念。
性能的にはクロック当たりでCeleronMくらいだろうか。
温度に余裕があるときは、クロックを上げるのではなく
電圧を下げるというのがナイス。
容量を捨てて寿命を延ばしたエネループと同じような思想だね。
667 :
665 :2008/01/24(木) 21:07:02
>>667 書いてあったのか。ありがとう。
倍精度のスループットは仕方ないけど、加算のレイテンシ2はすごいな。
> world-record
確かK6のfaddがレイテンシ2、スループット2だったと思うけどw
それにしても、この短いレイテンシで2GHzとか出るとしたらすごいな。
個人的にはIn-Orderのままでデュアルコアとかやってほしかったけどな。
(まあ、正直それはバランス悪いんだけど)
これからもVIAらしい萌える石を作っていってほしいです。
すっかりCNのこと忘れてた。
Latency 4 の 2GHz より 5 の 3GHz の方が速いんだけど...
倍精度遅いんか。。。
672 :
デフォルトの名無しさん :2008/01/25(金) 15:24:47
日記あげ
ダンゴさんがCELLの話題をはじめると盛り上がるな
ところでなんで団子さんは職業プログラミンガーから
X2のG2ってL2レイテンシとか変わってるんだろうかとふと思った
latency.exeだと20cyclesの判定
Penrynって64ビットもMeromのときに言われたほど遅くない。むしろ速い。
遅いとか騒いだ連中は猫基地外の記事を希望含む視点で読んでしまったアホだけだから。
先月のWinPCの記事はひどかったなぁ
683 :
デフォルトの名無しさん :2008/02/05(火) 23:34:17
毎度の事だが、この手の基本スペックは優れているなK8、K10。
K8は元々のコンセプトが直線ばっか速いIntelより峠だぜ!って感じを受けるよな。
>単体で見れば愕然と遅くなるわけで
2スレッド分負荷かけると、全体で120%になるけど単体は60%でしょ、と言いたいのでは
日本語でおk
>>685 686さんの説明の通りだけど、P4はOoOじゃなかったっけ?
今後IntelはSMT+InOrderにするっつー話じゃなかった?
不確かな情報ばかりでスマン。
>今後IntelはSMT+InOrderにするっつー話じゃなかった?
SDRAMの最大帯域って理論上の値だから
その理論値の出ない理由が知りたい。
車がどれだけ速くなっても、ドア開けて乗り込んでエンジンかけてシートベルト締めて…なんて時間はたいして変わらない。
DRAMだから。
DRAMコマンドとかバスプロトコルの問題じゃなく構造の問題でしょ。
レイテンシ考えた1サイクルあたりの速度だとDDR1やSDRのCL2のものが今でも最速だからね。
帯域の話でレイテンシの話はしてないだろ。
君はバースト転送一回分だけというまったく意味のない帯域の話をしたいのか?
1GB転送するベンチマークでレイテンシも糞もなくね?
そもそもHTとメモコンは別個だろ
>>700 もしかしてコマンド一発出したら1GB送られてくる、と思ってる?
>>702 逆に1GB転送してもバースト転送一回分なの?
どんな事情であれ、プログラマとしてはあんな6.4GBx2/secなんて詐欺ではなくて
正確にクロックとか帯域を計算する方法は無いのかって話なんだが。
理論的に何処まで出せるか、どうしたら出せるかって議論は重要。
CPUが一度に取り込むのはキャッシュライン単位に決まってるだろう。
あと、Ring0で実行して計測云々ならまだしも、どうせユーザーモードで触って計ってるんだろ
Ring0(笑)
DRAM の仕組みをお勉強してね(はぁと
ばーか
>キャッシュライン単位に決まってるだろう。
MEM_PHYSICAL
最大バースト長が8だから
>>710 AWEサポートしてない環境は無視って素敵だね
Ring0(笑)
黙れスイーツ(笑)
わざわざ鯖OS入れるくらいならDOSなり自作OSなりで特権命令触ったほうが楽でしょ
そんなもの誰が使うの
本当にDOSや自作OS(wが楽だと思ってんのかw
自作OSの本を読んでみたが、うぎゃーって感じだった。
719 :
デフォルトの名無しさん :2008/02/08(金) 16:43:45
はいはい団子あげ団子あげ
サーバOSを入れるほうがよほど「楽」だと思うがなぁ。
俺のPCだと、Dothan-1.1GHzとPC2100で1700MB/secくらいが限界かな。
>>693 に同意なのだが、DRAMはプリチャージとか複雑で小難しくて、
最近は、原理は妥協して振る舞いを完全に知ろうというスタンスだ。
情けない状況だ。
>>703 確かに詐欺だね。
どっかで、インターネットが100Mbpsと宣伝しているのにレンタルのモデムだかが
ボトルネックになるから絶対に100Mbpsが出ないということで
宣伝の仕方がおかしいという話を見たことがあるが、それと似てる。
それを言ったら SATA だってそうだし.P2P の転送路を持つデバイスは皆アウトじゃない?
Hardware ってのはそういうもの,あるいはそういう約束,で FA.
ディスクデバイスは帯域がいくら上がったところでディスクの性能が追いつかないっしょ。
>>724 > LANはノイズが入るから転送効率何%とかちゃんと数値があるっしょ。
ないよ。少なくともノイズがどうこういうだけで転送効率は定まらない。
> Phenom9900でさえ4.5GB/secしか出てないわけで、35%しか出てない。
CPUはDRAMにとって好ましい最適な転送パターンを行わない。
#HDDでランダムシークばかりして「スピードでねー」とほざくのと同じ。
理想的パターンで読むデバイスをFPGAかなにかで作ればそれなりの速度で
読み出せると思うよ。
その為のバースト転送なんじゃないの?
>>724 バスプロトコルから算出した理論的な数字は理想的な特性のメモリを用いた場合等で
算出できるだろうけど、実際にはそんなメモリ無いしあまり意味ないような・・・
実運用での効率を掛けた数字なら、実効帯域とかいう言葉が昔からあるし。
DRAM の動作をきちんと理解しろ.話はそれからだ.
>>728 理解できないから困ってるんだよヽ(`Д´)ノ
>>728 お前、理解してないだろ。
なぜならDRAMの動作だけを理解しても
>>1 の疑問は解決しないからな。
それよりバスの通信の基本を学び、12.8GB/secのデータが常に流れ続けるというのが
ありえることなのか、考え直してみれば普通にわかる。実際はピークでは帯域がでている。
SATAにしろUSBにしろ実効値が遅いというのは帯域という言葉の指し示す範囲が
理解されていないからだ。
CPUとメモリのやりとりと言っても、通信というのは結局、ある記憶域(ラッチやキャパシタの集まり)か
らある記憶域へと情報がコピーされているだけなのよ。12.8GB/sec流れ続けるというイメージを
持っている人は送り先がの構造を記憶域(CPUでいえばラッチ/レジスタ)だということが頭にイメージできて
ないだけ。それ以外にもプロトコル上で帯域というのがどこを指しているのかという問題があるが、
>>1 の疑問の範疇からは多分外れていると思う。
メモリからメモリへコピーする場合はかなり理想の帯域に近い数字がだせるだろう。
>>731-
>>733 には大嘘が3割含まれている。これは自分で考え、学習して、
真の理解へ至らせるためのトリックだ。
>>731 ヘッダ長は大した長さじゃないだろうし、同期に時間がかかるってことかな?
それにしても35%は酷過ぎやしない?
>>732 ニホンゴムズカシイネ。でもここが肝な気がする。
>>733 L3の話ではないよね。
HTが16GB/secだってのは決まってるわけだし、仮に64KBしか無かったとしても
ループバッファみたいにどんどん上書きしていけば連続して読み出すだけなら出来るし。
CPUの記憶域というのは、何かバッファがあるって事?
俺は DRAM の cycle time がボトルネックなんじゃないかと思ってるんだが
理想モデルと実物モデルを比較されても困るという話・・・
>>724 Streamベンチマークで、10GB/s出たよ。
スレッド数増やしてコア同士で帯域食い合いさせると、
トータルの帯域は上がる。Phenomは特にそんな気がする。
storeはmovntpdにすると速くなる。
環境は9500にDDR2-1066。
金銀バール
>>736 Phenomはきちんとしたサイクルでアクセス出来るって書いてあったような。
>>737 ノイズが激しすぎるって事?
>>738 kwsk。Sandraだって複数コアでアクセスするんだがなあ。
>>739 カスラックから来ました
例えば、普通にmovqでシーケンシャルアクセスすると、64byteのロードに47clk、
ちょっと命令を並べ替えると44clk、プリフェッチ命令を使うと39clk。
デコードや実行ユニット関係の、「メモリ以前」の問題もある(微差とは思うが)。
これは古いノートPCだから大して差がないけど、Phenomレベルだとどうなんだろう。
あと、もう一つの「メモリ以前」の問題として、ベンチマークはアテにならないというのがある。
変に実用コードっぽくなってたり、帯域を引き出す工夫が微妙だったりするかもしれない。
>>737 理想の通りに動くのがコンピュータだろうが!
・・・すみません。自分の立ち位置を言っただけです。
ベンチマークは実性能を反映するように求められてるし、
PC側は機能を肥大化させて実性能を少しでも上げようとしている。
クロック測定を通じてアーキテクチャを知るには辛い時代だ。
WinRing0はどうかね?
DRAM - chipset - CPU
>>742 お前の大好きな「自作OS」を紹介してやれよw
>>741 結果を見ると、どうしてもMulti-Media Int x4の成績に行ってしまうが、
これはSandraの問題。Core 2 QuadはSSE3 Moduleで、
Athlon 64 X2やPhenomではSSE Moduleでテストを行うためで、これはイーブンな条件とは言えない。
みたいな事が大原記事でようやく言われましたからねぇ…
とりあえず本当にメモリの帯域調べたいなら
DRAMのスループット以上が出せる設計の上で自分でFPGAなりいじるしか無いのではないでしょうか。
まぁx86の枠外れて完全にスレチになっちゃいますが。
ダンゴさんのインテリジェンスあふれるレスが望まれるところだ
だから、メモリアクセスってのは断続的で、ソフトでいくら帯域志向なコードを書いても
OSのCPU使用率がCPUリソースの本質的な使用率を表しているのではないように
>>745 FPGAで頑張るまでしなくてもピークで帯域が出ているか確認するだけなら、
高価なオシロやロジアナつなげば直ぐにわかることだが。結論からいうと出ているんだけど。
団子屋さんの団子さんによる団子屋さんのための自作OS「DANGOS」近日公開予定
団子屋さんに特化したOSってどんなだろう
今の SDRAM 系の cycle time ってどの位? まだ 50ns 切ってない?
cycle timeはおまいの脳内でどうやって定義しているの?
どうやったr理想的な実効値が出せるんだろうというのを考えてみたりするのがこのスレだったような
USB2.0みたいに480Mbpsのうち一部が制御信号に使われるとかはあるのか?
DRAMのアクセスの並列化数に限界があってレイテンシが隠蔽できないのか?
メモリコントローラがネックで並列化数が増やせないのか?
>>747 送受信している時間とそうでない時間があるのは何の性能が低いためか?
>>749 の言うようにフルな性能は原理的に出せるものなのか?
>>754 原理を知らないと、どうしても最適化アイデアに抜けがでちゃうからさ。
まあ、本当に極限まで最適化をできた人は原理を知っているのと同等だとも思う。
>>755 32bitWindows使いながら64bitコードを実行できるような仮想OSキボンヌ。
>>756 > 32bitWindows使いながら64bitコードを実行できるような仮想OSキボンヌ。
32bitWindowsに仮想マシン乗せてその上で64bitWindowsを動かして64bitコードを動かせば解決。
Win64s出せばおk。
64bitWindowsに32bitWindowsってラベルを貼って
>>1 に渡せばいいんじゃないかな?
760 :
738 :2008/02/09(土) 22:30:21
3連休の1つがつぶれるのは毎度のことだが
>>756 >USB2.0みたいに480Mbpsのうち一部が制御信号に使われるとかはあるのか?
No。
アドレス線とデータ線は別系統。
ただし、read/writeでデータがかち合わないようにするためのwaitクロックは入れる必要がある。
(SDRAM以降)
>DRAMのアクセスの並列化数に限界があってレイテンシが隠蔽できないのか?
並列化はかなり多くする事も可能。 Muuti-bank-DRAMなんて物も10年以上前から提唱されてもいる。
>メモリコントローラがネックで並列化数が増やせないのか?
メモリコントローラ・DRAMチップの双方に、コストの壁がある。
バンク数を増やす=ビットコスト(コントローラコスト)の増大と考えて良い。
コストが上がると、ビット単価が安いDRAMを使っている意義に関る。
>
>>749 の言うようにフルな性能は原理的に出せるものなのか?
>まあ、本当に極限まで最適化をできた人は原理を知っているのと同等だとも思う。
プログラムの中で、同一バンクアクセス回避とか全てを前提として考えられるならある程度は
良くなる。
ただし、バンク切り替え後のアクセスタイムはある程度かかるので、x86命令に存在しない
データプリフェッチとかが必要になると思われる。(あ、それはIA64か?)
いちおうx86にもprefetch*はあるけどね
764 :
760 :2008/02/09(土) 23:22:41
ぅぅぅ
流れを読まずに書いてみる。
>>763 >最近の最適化マニュアルには馬鹿は使うなって書いてあるけど。
w。あ、それじゃ、アフォが大部分を占めるプログラマには使えない命令だな。www
使っても、使った事により効率の落ちる素晴らしい命令。wwwwwwww
αの時代に、既に実装されていたインストラクションだが、50%以上のヒットを
命令実行後のある一定期間に行わないと逆にスピードが落ちるという諸刃の刃だったような。
(大昔のことなので、実装が異なる可能性もあるけどね。)
だから賢いコンパイラ様に吐き出してもらうのでは。
ハードウェア・プリフェッチがあるからじゃね?
レイテンシの隠蔽って考え方自体がおかしい。
>>762 > ただし、read/writeでデータがかち合わないようにするためのwaitクロックは入れる必要がある。
普通のライト(ライトアロケートあり)がやたら遅いのはこのためかな。
> メモリコントローラ・DRAMチップの双方に、コストの壁がある。
意外とコストに跳ね返るのだね。むむむ。
それは普通にHT3.0になったからってだけだろ
HT3.0になってそんなに変わったのか知りたい
むしろ最近のマシンじゃエクスペリエンスインデックスは5以上が当たり前かと思ってた。
本題に戻ろう
本題とはダンゴ先生のことだが?
ここはダンゴ劇場
バールのようなものだよ
じゃあバールのようなもの劇場w
バルバルにしてやんよ
オイシスw ?
それバールだったんかw
「バールのようなもの」だ。
さあ盛り上がってまいりました
指定範囲のWORDをひたすらOR取りたいんだけど思いのほか処理が重い
こう?
宿題丸投げスレはここじゃないよ
それこそ prefetch が使えるんじゃない? SSE で十分かな
>>788 思いのほか重いってのは、どの程度の帯域を期待してて実測はどの程度ってこと?
動画のフィルタとか書いてて、そういうごく単純なシーケンシャルなメモリ
アクセスを伴う処理ではとても良い性能が出るのにびっくりした記憶があるな。
DDR2 って速いんだな、と。
>>789 残念なことに使用しているインラインアセンブラがMMX非対応なんですよ
将来的には対応させたいってのがあって、MMXも調べてはいたんですが
mov xmm0,[edi];ができないって聞いていたんでかえって遅くなると
思い込んでいたんですが、por xmm0,[edi];なら問題無いのですね
納得しました
>>792 自分はV30,V33時代にしかx86を触っていなかったんで、最近のCPUなら
超強力なストリングス命令が豊富だと思い込んでいたんです
それこそmovesdのor版とか・・・
仕方なしにor r,mで回すとクロック通りの帯域しか出ていなくって
ペアリングするとPentiumらしい速度になって目から鱗。
MMX,SSEもメモリから直接読み込めないんじゃ机上の空論だな・・・
とこれ以上の高速化を諦めていたんです。
MMXも触ってみたいんで開発環境を見直して見ます
長文失礼しました
>>793 「インラインアセンブラが」非対応ってよく分からんな。
アセンブラが非対応なら手でバイナリを直接書けばいいんじゃね?
> 自分はV30,V33時代にしかx86を触っていなかったんで、最近のCPUなら
> 超強力なストリングス命令が豊富だと思い込んでいたんです
ストリング命令なんていまどきはやらねぇっすよ。
内部でマイクロコードがシコシコ動くからかえって遅くなることもあるぐらい。
機械語は高級命令で、CPUの中にコンパイラがあるような現在では
>>793 MMXPentiumとかならまだしも、
SSEが使える最近のCPUならペアリングとか考えなくても大差ないよ。
add r1,mも、mov r2,m/add r1,r2も、速度的に大きな違いがないのが最近のCPU。
> mov xmm0,[edi];ができない
できなくはない。
movdqa xmm0,[edi] とできるが、アドレス値が16の倍数でないと使えない。
movdquならいつでも使えるが、遅い。
> por xmm0,[edi];なら問題無いのですね
porも、movdqaと同じで16byte境界に合ってないと使えないから注意。
> ペアリングするとPentiumらしい速度になって目から鱗。
MMXやSSEを使わずに、or r,mより大幅に高速化できるの?
具体的な方法とCPU名を教えてくださいまし。
lp:
or eax,[edi]
or eax,[edi+4]
or eax,[edi+8]
or eax,[edi+12]
add edi,16
dec ecx
jnz lp
このコードが、PentiumMのL1ヒットで5clk/loopくらい。
L2ミスで完全にメインメモリと思われる16MBの範囲では18.5clk/loop程度。
メモリのピーク帯域の半分以上は出ている。
単にSSE2を使うと17.6clkくらいになる。プリフェッチを使うと16.0clkになった。
漏れはこういうときって
インラインアセンブラの問題か。
>>797 LUが2基あるAMDアーキならスループット1クロックに2命令ずつ処理できる。
Intelは1load/clkなんで無意味。
無料開発環境で済ますならVisual C++2008 Expressでいいんでないの。
あと、movdquでのロードだけど、Core 2以降についてはそんなに遅くない。
>>797 ああ、忘れてた。orを取る順番は関係ないからそうするべきだね。
ちょっと測定してみたが、クロック数は変わらないようだ。
or処理はレイテンシが1で軽いからだろう。
>>799 まあ、気持ち気持ち。
できるだけ軽くしておくと、いいことあるよ。
>>793 です
>具体的な方法とCPU名を教えてくださいまし。
開発環境はAthlonXPとAthlon64 X2です
>>797 私が実際に使用しているコードもそれと同じです。
一応の最適解と考えて良いのかな?
>>799 P5以降はV,U2基だと思っていたんですが、P5だけなのかな?
>>803 P5はVパイプとUパイプで同時にload可能だったが、
P6以降はloadは専用パイプ1本のみに退化した。
逆にP5までは命令の並べ替えができないから、利用頻度の高いロードを
>>803 なんだ、Pentiumって言うからIntelだと思ってしまったよ。ごめん。
最近のCPUでは特にブランチペナルティが大きい。
>>808 ごめん、何がいいたいのかよくわからない。
コンパイラがCPUの特性を踏まえた最適なコードをはかないことがあるから、
コーディングする時は気をつけましょうってこと?
ブランチペナルティが大きいのはパイプラインの段数が多くなったからでしょ?
それを補うためのブランチプレディクションは各社力を入れてる所だと思うけど。
分岐に偏りがある場合は、分岐予測に任せても問題無いし、むしろ速い。
>>809 分岐が完全にランダムでパターンすらない場合は分岐予測は機能しないので、
分岐後の処理を代入 1 回 (setcc が使われる) に限定されるコードにすれば
最適化が弱いコンパイラでも生成バイナリの速度が速くなるってことでしょ。
808の上と下でコード眺めて a ? b : c の三項演算子部分を比較しただけの
傍観者の意見だけど。
流石にpmaxubで並列化とか使わないんだな。
808のコードで pmaxub 使える箇所あるかな?
半端だなぁ。どうせやるなら。
int hex2bin2( char *src )
>>814 L1キャッシュに収まらない規模のテーブルのランダムルックアップ1回より
小さいテーブル2・3回+論理演算のほうが速いこともある
そう、おれもこういうコード書くとき
>>813 のようにメモリ使うのと、
>>808 のようにレジスタで済ますのどちらが速いかで迷う。
昔は条件分岐によるパイプラインストールが気になって
>>813 のようなコード書いてたけど、今はキャッシュミスの方が
気になって
>>808 のように書いてる。
prefetch使えばいいのかもしれないけど。
あと、すでに知ってる人は無視してもらいたいけどgccには
builtin_expect()があって、コンパイラに静的なヒントを与えられます。
>>818 そういうものです。
CoreMAがピークで4命令/Cycleなのは本当(Fusionでそれ以上も狙えるけど)。
実際のコードでは確かに1.6命令/Cycle出ればいい方。
「3命令/Cycleを狙った」というのは単に個人の考え方だと思われる。
そもそも、IPC3という数字は狙って出せるような半端なものではない。
手でアセンブラを書いて部分的にでも出せればすごいというくらいの領域。
また、1.6命令/Cycleのコードでも、部分的には0.5命令/Cycleだったり、
あるいは4命令/Cycleだったりして、その総合が1.6命令ということだから、
ピーク能力に意味がないわけではない。
勘違い糞コテがきたことに絶望した
糞が糞を呼ぶってか
このスレもついにクソってきたか…。
というか糞化さしてるのは>823-824なのだが・・・w
大原記事のまとめはAMD信者には飴に見えてたりするんだろうか?
で、
>>821 の自作popcntの性能だけどさ
C:\Users\ばーるのようなもの\Document\test>popcnt-penryn.exe -32k
32768 B: 7676 clk (4.269B/clk)
ちなみにクロックは素のrdtscで計測。
ちなみに、本物のpopcntは32bitモードじゃいくらあがいても4byte/clkを超えることはないわけでしょ。
誰かPhenomユーザーの人いたら本物のpopcntの性能計測してくれ
ちなみに、まだ命令並べ替えたりすれば微増の可能性あり。
>>828 Phenomはあるけどコードが書けない。
バイナリくれたらいくらでもテストには協力出来る。
64bit環境も用意しようと思えば出来る。
ノドイテェ
続き。
832 :
デフォルトの名無しさん :2008/03/08(土) 09:54:33
>817
ダンゴさんのメモリベンチマークの素晴らしさに誰も口が挟めないな
>>832 勘違いしてない?
SIMDユニットが64bitだから128bitの操作をする命令が1.5命令/cycleなだけで
MMXや3D Now!, SSEのスカラ命令のデコーダスループットは最大3命令/clk
あぼーん推奨ワード:ダンゴさんの
レス番飛びまくりだと思ったらだんごきてるのかよ...。
スレ主に向かってなんということを
ハァ?
団子の駄レスでスレが伸びるくらいだったら閑古鳥の方がまし
↑こんな駄レスしてないで計測でも貼ってみろよカス
>>840 はっきり言っておまえが邪魔
団子あぼーんしてるのは勝手だがそれ以下のレスしかできない屑に価値は無いな
>>830 > 理想状態で4byte/clk
サイクル毎にpopcnt r32,m32とadd r32, r32しか
使わないからデコーダに1命令分の余裕がある
空いてるリソースでx86やSSE2で実装したpopcntを
実行できないかな?
お前ら団子に釣られすぎ
>>844 レスの価値の分別もできないお前が要らない子
クソコテだろうとパフォーマンス計測に有用なレスはOK
ただの煽りは無視だろ
愉快なインターネッツだここわ
俺団子じゃないけど俺も顔真っ赤
まあ、ただの荒らしには無視していただいたほうが都合がいいんだけど
とりあえずは
化石しか持ってないから話題についていけない
むしろ化石みたいなx86の所要クロックネタの方が貴重かもよw
> ALUとFP/SIMD並列動作で最高6IPCだ!とか言ってた人がいたけど
ダンゴさんによる自演に見せかけた荒らしも
一番恥ずかしいコテがきたよ…
団子の貢献っぷりには同意だ
権田の下のレスが飛んでる。
団子さんのベンチマークソフトはCPU泣かせだな
あぼーん推奨ワード:ダンゴ, 団子
だんごっ、だんごっ
さっきからDANGOをあぼーんにしろってレスが多いが、
バールのようなダンゴ
バールもアボーンしとけ。
ミリバール
ヘクトパスカル使え
金銀バールプレゼント
「金銀バールのようなもので…」
他の板でもバカよばわりされててワロタw
バカ呼ばわりだなんて。
ばーかばーか
ばかキターwww
ばかのようなものだよ
ばかのようなものだなんて。
バッルバッルにしてやんよ
バールのようなものだよ
2ちゃんねるで所有権も糞も無いが
団子はもうすこし
>>1 のスレを荒している自覚を持って欲しい。
ダンゴさんを見かけるスレはことごとく活気があるな
>>877 数年に渡って何度言っても無駄なんだから
あきらめも必要だよ
普通の対応で対処できると思っちゃだめ
はいはい荒らし乙
そうだぞ。クロック貼ってるダンゴさんは何をしても許されるのダ!
こいつ救えないね
>>882 ←こいつ役に立たないくせに巣食ってるね
俺以降計測結果誰も貼ってないよね
そうだそうだ!
さて、言い出しっぺが何とやらなんで
http://www.geocities.co.jp/SiliconValley-Oakland/8071/loadbench.html のWin版で movdqa と movntdqaに対応したやつの結果でも貼っておくか
なるべく正確に計るためにSetProcessAffinityMaskでコアを片方に固定。
load 帯域 計測ツール v0.4+ (だんごやさんがいじったやつ)
CPU動作クロック : 3170.2 MHz
アクセス範囲 Int32bit Float64bit MMX64bit SSE128bit SSE2-128bit SSE4.1-128bit
1KB : 11927 MB/S 22428 MB/S 23780 MB/S 47684 MB/S 47516 MB/S 47726 MB/S
2KB : 11910 MB/S 22396 MB/S 23821 MB/S 47676 MB/S 47608 MB/S 47585 MB/S
4KB : 11924 MB/S 22472 MB/S 23806 MB/S 47637 MB/S 47600 MB/S 47645 MB/S
8KB : 11904 MB/S 22430 MB/S 23819 MB/S 47613 MB/S 47661 MB/S 47725 MB/S
16KB : 11893 MB/S 22392 MB/S 23849 MB/S 47528 MB/S 47734 MB/S 47616 MB/S
32KB : 11826 MB/S 22388 MB/S 23317 MB/S 44868 MB/S 44864 MB/S 44900 MB/S
64KB : 9718 MB/S 16897 MB/S 16897 MB/S 22475 MB/S 22481 MB/S 22465 MB/S
128KB : 9723 MB/S 16862 MB/S 16878 MB/S 22402 MB/S 22420 MB/S 22450 MB/S
256KB : 9731 MB/S 16940 MB/S 16936 MB/S 22409 MB/S 22393 MB/S 22370 MB/S
512KB : 9695 MB/S 16938 MB/S 16929 MB/S 22346 MB/S 22368 MB/S 22373 MB/S
1024KB : 9746 MB/S 16883 MB/S 16901 MB/S 22394 MB/S 22374 MB/S 22340 MB/S
2048KB : 9499 MB/S 16788 MB/S 16798 MB/S 22632 MB/S 22639 MB/S 22626 MB/S
4096KB : 9476 MB/S 16483 MB/S 16610 MB/S 22257 MB/S 22492 MB/S 22593 MB/S
8192KB : 5385 MB/S 6156 MB/S 6131 MB/S 6502 MB/S 6553 MB/S 6582 MB/S
16384KB : 5310 MB/S 5844 MB/S 5905 MB/S 6145 MB/S 6134 MB/S 6140 MB/S
32768KB : 5354 MB/S 5865 MB/S 5912 MB/S 6136 MB/S 6158 MB/S 6163 MB/S
このへんはあんまり面白みのない結果だ
もう一個のレイテンシ計測ツールの改造版が面白いことになりそうだな
クロック数が乗ってないレスは全部あぼーんすればいんじゃね?
だんご本人の書き込みよりも本文に「だんご」の文字がある方がうざい(コレもな~)
じゃあバールにしよう
金銀バール
ポケットモンスター
891 :
デフォルトの名無しさん :2008/03/25(火) 10:34:55
今日もダンゴさんがスレを活性化させてるな
あなたが落としたのは、この金のバールのようなものですか?
すっかりクソスレになったな
話題が無い。
AVX ktkr
YMMかよwwwww
それは思った
900 :
896 :2008/04/03(木) 20:10:30
VEXプレフィックスの追加でx86のOPCODEマップがますます複雑になるな
さっそくXbyakを改造してる俺様
>>900 addpdが6サイクル、mulpdが9サイクルかかってるね。
faddのスループットが2なのもちょっと気になるか。
それにしてもAtomいいな。Atom向け最適化をしてみたい。
パワーのあるメインマシンが手に入ったら、
二台目として是非欲しい。
binutils-2.18.50.0.6が出た。
定数除算(符号なし)を考えてみた。
動機は、16bitとかのSIMDで、定数除算ができるようにしたかったから。
速度うんぬんというより、SIMDには整数除算の命令自体がないから不便だった。
http://pc11.2ch.net/test/read.cgi/tech/1103609337/400 ↑ここの、819で割るのと同じ方法でいけるようだ(除数は2以上なら何でもいい)。
変数は全てk bitの符号なし整数とする。整数しか代入しないことに注意。
「計算方法」とあるのは、kが32で、x86命令を使う場合のやり方。
「^」はベキ乗、「=」は等号または代入。
「/」は整数除算ではない。例えば、5/2=2 ではなく、5/2=2.5 である。
しかし、以下の計算では、除算の結果が全て整数になるように仕組んである。
1 < A < 2^k を満たすAを、除数とする。
2^m < A <= 2^(m+1) を満たすようにmを定める。
E := 2^(m+1) - A とする。
すると、0 <= E < 2^m < A <= 2^(m+1), 0 <= m < k が成り立つ。
(2^k)*EをAで割り、小数点以下を切り上げたものをBとする。
F := A*B - (2^k)*E とする(余りみたいなもの)。
すると、0 <= B < 2^k, 0 <= F < A が成り立つ。
#計算方法:edx = (2^k)*E、eax = A-1とし、div Aを実行、F = (a-1) - edx、B = eax とする。
ここまでで、除数Aによる定数除算の準備が完了。
ここで求めたBとmを使って定数除算ができる。
(Fは後で説明に使うだけで、求める必要はない)
0 < P < 2^k を満たすPを、被除数とする。
Dについて計算していくのだが、少し注意点を。
Dの式の中に出てきた、P/(2^k) * F/A - u - C/(2^k) について評価する。
突然落書きが始まったので驚いた。
それがどうした。
確かに>911が驚くのは勝手だな。別に「落書きするな」と指摘したわけでもないし。
分かってるなら書くなよ。
>>914 >912の指摘もあまりに無意味だな。
実態もスレタイも「
>>1 の勉強スレ」ではないのだから。
それが分かってるから>912も「元々」と頭につけざる得なかったわけだし。
そんないまさらな昔話に対しての指摘として>913は的確なものだろう。
分かってないのに書くなよ。
あの除算の効率についてコメントできるのはダンゴさんぐらいだろうな
>>918 除数に対するBとmをあらかじめ計算しておいて次のコードを実行するだけだから、
効率については特に難しくないよ。単にクロックを計算すれば、9clk前後か。
//esiに被除数、eaxにB、ecxにmが入っているとする
mul esi
sub esi, edx
shr esi, 1
add esi, edx
shr esi, cl
>>909 の方法を検証しているが、計算疲れたよ('A`)
SIMD的には、 65536/非除数 を計算しておいて pmulhwかな?
×非除数
>>921 SIMDの場合、被除数の範囲が狭いだろうから、ある程度簡単にできそうだね。
>>909 も大体証明が終わった。
あとは、四捨五入用のやり方を考えて、
MMXで、255で割るコードを作るぐらいできればいいかな。
>>909 の証明完了。
四捨五入は、除数の1/2倍(小数点以下は切捨て)を被除数に足してから処理すればいい。
除数の1/2倍を足すと、除数や被除数の制限が出てくるが、
SIMDなら問題にならないことが多いだろう。
>>909 の方法だと、被除数が2^k-1のときに分岐が必要になるのだが、
それが問題だというなら、
>>919 の方法を使えばいいし、
問題でないなら
>>909 の方法がいい。
まあ、Penrynだと、32bitの除算は14~22clkだからなあ。
うまく並列化できないと、そんなに速くはならないね。
Meromノートでpopcnt-sse3(
>>828 )を実行したら1.634byte/clkだった。
Super Shuffle Engineは偉大だな。
926 :
デフォルトの名無しさん :2008/05/10(土) 01:26:24
3
Intelがやってくれた。
このループをPMCで詳しい内訳を調べてみると、
俺もE8500だけどVista SP1で検証してみるかな。
931 :
927 :2008/05/14(水) 21:15:54
>>930 CrystalCPUIDで表示されるCPUのMicrocode IDはいくつですか?
うちの32bitWindowsXP SP3 + E8500だと、そのページのプログラム
http://journal.mycom.co.jp/column/sopinion/188/Util29.exe の"Util29 100000"の実行結果は以下のようになります。
Microcode ID : 606
Test1 100776
Test2 200203
Test3 200203
Test4 200174
Test5 300114
Test6 400102
Microcode ID : 60B
Test1 200222
Test2 200298
Test3 200317
Test4 200146
Test5 300143
Test6 400102
606だった。
933 :
927 :2008/05/14(水) 22:55:10
>>932 606ということは、VistaSP1には新マイクロコードは入ってないんですね。
PenrynにXP SP3入れるとSP2よりパフォーマンスが落ちるってことか?
ここはプログラム板なんだから、そんなアホなこと書くなよ。お里が知れるぞ。
エラッタリストに関係ありそうな記述を見つけた。
http://download.intel.com/design/processor/specupdt/318733.pdf > AW51. Short Nested Loops That Span Multiple 16-Byte Boundaries May
> Cause a Machine Check Exception or a System Hang
小さい多重ループでシステムハングを引き起こすものがあり、BIOSで対処可能との事。
LSDが効くような小さいループで多重ループをするとやばいケースがあるので、
LSDループ内ではマクロフュージョンを無効にして対処したってことかなぁ?
エラッタAW51がこの文書に追加された日は2008年2月1日と書かれており、
マイクロコードパッチID:60Bの作成日は2008年1月19日なので
時期的にも近い。
さて、もういっこパフォーマンスに関係しそうなエラッタとして
マザボの最新BIOS更新されてる。これ適用すると60Bになるんだろうな。
E0ステッピングが6/27に出荷らしいな
下記のような下手なプログラムでメモリを舐めると
>>941 >>691 以降参照。
マルチプロセッサを使って全てのバスを使い、
尚かつシーケンシャルに何百GBもかかりっきりでアクセスすると速くなるが
そんな特化したベンチマークでもスペック通りの数字は出せない。
以前Quad-ChannelをSandraで計った時は理論値の50%くらいった希ガス。
ま、現実はベンチマークじゃないんだからもっともっと遅い。
>>941 Northwoodには自動プリフェッチ機能があって、
メモリをシーケンシャルにアクセスしているストリームを検出すると、256バイト先をプリフェッチしてくれる。
インテルの資料によると、8つまでのストリームを検出できるそうなので、
あいだに別のメモリアクセスが入っても、あるいは、交互にアクセスするなどの場合でも機能するらしい。
一方、同時期の対抗馬だったAthlonXPのハードウェアプリフェッチについては・・・AMD大好きな人に譲る。
944 :
941 :2008/05/27(火) 01:26:01
>>942 ありがとう。
>>943 prefetchnta命令を使ってみたところ、
Coppermine 1GHzでは約880MB/secで、メモリバスの約87%
Northwood 2.4GHzでは約2000MB/secで、メモリバスの約79%
K7 Palomino 1.2GHzでは約780MB/secで、メモリバスの約38%
になりました。
これだけ出ていれば、ほぼメモリバスは100%稼働なのだと思います。
ちなみにprefetchntaなしでは
K7 Palomino 1.2GHzでは約450MB/secで、メモリバスの約22%
でした。
ついでに2CPUで同時に行った場合(prefetchntaあり)
Coppermine 1GHzでは約440MB/sec×2=880MB/secで、メモリバスの約87%
K7 Palomino 1.2GHzでは約650MB/sec×2=1300MB/secで、メモリバスの約64%
でした。
K7ダメダメだな。
K7もなんだかんだで中身三四回変わったよな
Slot A
> K7 Palomino 1.2GHzでは約650MB/sec×2=1300MB/secで、メモリバスの約64%
2ソケット以上なら各CPUのキャッシュ間のスヌープ制御が必要になるからそのまんまスケールするわけがないじゃん。
>>939 本当だ。Plan Fixに変わってる。
No Fixだったから、Intelはちゃんと直すつもりがないのかと思ってたが、
やっぱりちゃんと直したCPUを出すつもりなんだね。
>>949 AMD厨は幻想多いよな。
幻想→インテルはFSBが133MHzだがAMDは266MHzだ! 2倍速い。
現実→どちらも133MHzでAMDはバースト転送部分がDDR化されている。つまりオーバーヘッド部分の速度は同じ。
幻想→インテルはFSBが共有だがAMDはポイントtoポイントだ! 帯域を奪い合いしない
現実→メモリを共有するのは一緒だし、キャッシュ同期も必要。
AMD厨は
> Northwood 2.4GHzでは約2000MB/secで、メモリバスの約79%
> K7 Palomino 1.2GHzでは約650MB/sec×2=1300MB/secで、メモリバスの約64%
この現実を見るべきだ。
ちなみにOpteronもSMPでメモリアクセス性能の低下は大きい。
他のソケットの配下にあるメモリにアクセスした場合にレイテンシ増加するだけでなく、
自分のソケットの配下にあるメモリにアクセスする場合でも他のソケットと
キャッシュ同期のために通信するので、それなりに遅くなる。
夢見がちだから"真の"とか言うマーケティングで踊れるんだろう?
命令セット・演算器を拡張するのもいいけどさ、
意味わかって書いてるのかなぁ。
>>955 サンプル価格2.5万円か。
メモリ上のバイト列の並びを任意に並び替えてくれるボードがあると面白いかも。
CPUのキャッシュには入りきらないほど大きなデータを、
CPUのキャッシュより大きな高速SRAMを使って、
CPUがアクセスする順序に並び替えてやることで、
いまのCPUが苦手としている処理のうちの、いくらかで、
CPUのキャッシュのヒット率を格段に改善できるかも。
>>955 ランダムアクセスでサイクルタイムが8.0ns、I/O幅が128bit or 256bitってすごいな。
つまり、32バイト単位でのランダムアクセスで4GB/secのスループットが出るのか。
>>956 その高速SRAMをキャッシュとして使えば、
ソフトウェアの変更は、
事前にシーケンシャルにメモリを舐めておく
というだけで済むし、
他の部分でも高速化に寄与するだろう。
その高速SRAMはどこのバスにぶら下げるつもりなの?
メモリコントローラだろうな。
…はぁ。
脱線しすぎだゴルァ
>>941 のネタをすこし弄ろうか。
メインメモリの速度の話ばかりしているが、
たとえL2キャッシュに100%ヒットしていても、
そんなに速度が出ないプログラムだぞ?
プリフェッチ有での結果のMB/secを ループ回数に換算すると
Coppermine 1GHz → 880MB/sec → 220M loops/sec → 4.55 clocks/loop
Northwood 2.4GHz → 2000MB/sec → 500M loops/sec → 4.80 clocks/loop
K7 Palomino 1.2GHz → 780MB/sec → 195M loops/sec → 6.15 clocks/loop
コンパイラが何か不明だが、Cのコード上での1ループでは、
・アドレスの加算 reg1 = p + x
・ロード reg2 = [reg1]
・レジスタへ加算 sum += reg2
・アドレスの加算 x++
・比較 x < count
・条件ジャンプ
これだけのことをやるわけで。
メモリ帯域をみているのかコアの性能を見ているのか、いまいち不明瞭。
メモリ帯域を見たいなら、SIMD命令でロード & オフセットを即値にしてループ展開 すべき。
ちなみに
1Pと2Pで合計のスループットがまったく同じCoppermine 1GHzは、ある意味すばらしいな。
>>962 FSB以外にどこがあるよ?
シーケンシャルなアクセスのレイテンシは削減できないどころか、
キャッシュのために増えるかもしれない。
ランダムなアクセスのレイテンシは削減できるだろう。
全ソースどっかにplz
>>964 あー。>961のメモリコントローラってメインメモリの
メモリコントローラのことなのか。FSBの先の。紛らわしいなぁ。
で、IntelプロセッサのFSBってバースト前提のバスプロトコルだと思ったが、
その先にぶら下げて意味あるの?
一昔前のオンボードキャッシュとの違いが分からん。
>>967 そのものだろ。
オンボードキャッシュが廃れた理由を知らないのかもな。
hpのmx2のような例もあるが、あれはFSB帯域幅が足りなくなるのを補うためのものだしな。
>>965 短いのでスレに貼っちゃいます
#include <windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <xmmintrin.h>
int ReadTest(LPVOID pMem, int size) {
int* p = (int*)pMem ;
int count = size/sizeof(int) ;
int sum = 0 ;
int prefetchBytes = 512 ;
int countA = count - prefetchBytes/sizeof(int) ;
for (int x=0; x<countA;) {
_mm_prefetch((const char*)(&p[x + prefetchBytes/sizeof(int)]), _MM_HINT_NTA) ;
for (int y=0; y<32/sizeof(int); y++) {
sum += p[x] ;
x++ ;
}
}
for (; x<count; x++) {
sum += p[x] ;
}
return sum ;
}
void test(void) {
LONGLONG llSpan = liPerfCountEnd.QuadPart - liPerfCountStart.QuadPart ;
あーすみません。
こりゃまた酷いプログラムだな。
さて、Intel謹製のAtomのMini-itxマザーが来週あたりから出るらしいのだが
CPUとチップセットの写真を見てわらったよ。
チップセットを統合するのは来年だから、今年は既存のやつでお茶を濁すってところだろ。
ULPC用には新規コンパニオンチップが用意されてるだろ。
SMT面白そうだな。
981 :
980 :2008/05/30(金) 23:18:25
いけね980踏んだので次スレ立ててくる
>>974 酷いプログラムでも高速なコードにコンパイルするのがコンパイラのお仕事だし、
それを高速に実行するのがプロセッサのお仕事でしょう。
だからといって酷いプログラムを書いていいってことにはならないけどさ。
俺様のためにバッチリ最適化されたコードでないと、ちっともやる気がでないっていう
困ったプロセッサもあるみたいですけどね、あれとか。
>酷いプログラムでも高速なコードにコンパイルするのがコンパイラのお仕事だし
強引に最適化してくれるオプション付ければそうするのがお仕事ではある
インテルのコンパイラは勝手にSIMD演算してくれちゃったりするぞ。
それでSSEオンよりオフのほうが速いプログラムができたんですね。わかります。
>>985 コンパイラの最適化は普通セマンティクス保存しないぞ。
>>988 結果的には保存されるだろ
つかされないと困る
セマンティクスをどういう意味で使っているのか気になる。
「意味ワカンネーっすよ」っていうときの「意味」かも
>酷いプログラムでも高速なコードにコンパイルするのがコンパイラのお仕事だし
>>985 判る判る
for(i=0;i<8*1024*1024;i++){ ; } // 少し待つ
の行が最適化で削除されるとセマンティクスが変わっちまうよな。
このケースはコードの方がカスだと思うけど。
A = 10 + 2 * 2;
>>992 > コンパイラの仕事はコンパイルであって最適化ではない。
> オプティマイザによる最適化はオマケみたいなものである。
コンパイラとオプティマイザを厳密に分ける意味ってあるの?
>>993 でも、コーディングする時はコンパイラの最適化を意識しないとダメだよね
volatile int i;
for(i=0;i<8*1024*1024;i++){ ; } // 少し待つ
volatile最強杉
for (int x=0; x<count; x++) {
>>998 アセンブラなんて何年も前にちょこっと触った事がある
程度なんで、眉唾ものだと予め断っておくけど。
インデックス付き間接アドレッシングできないCPUとか
それを使わないコンパイラなんて今でもあるの?
今時のCPUとコンパイラなら大抵は前者が速いか、
悪くとも同等にしかならないと思っていたのだが。
1000get!
1001 :
1001 :
Over 1000 Thread このスレッドは1000を超えました。
{kind=link}
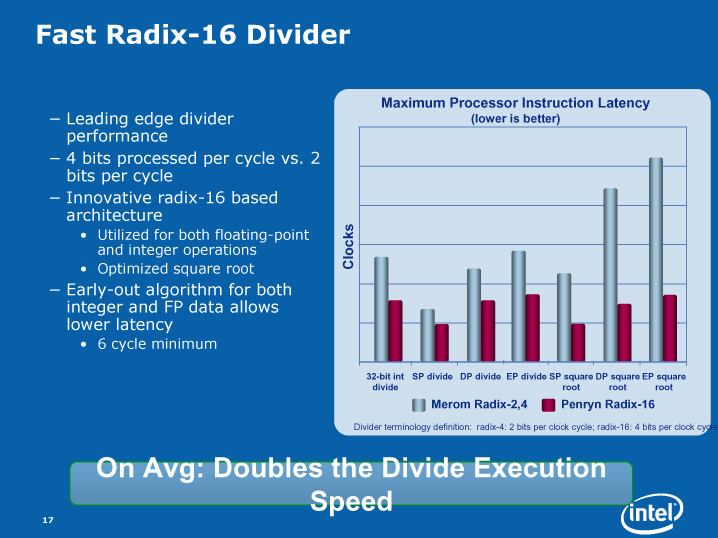{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}