Proxomitron フィルター作成スレッド Part6
1 :ミスターオミトロン:
このスレは作成依頼されたフィルタを有志により作るスレッドPart4です
アップローダー
http://wind.prohosting.com/proxmine/cgi-bin/uploader/
http://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/upload.html
Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/
Thinking Archive(仮)
http://vird2002.s8.xrea.com/
CastleCops Proxomitron Filters
http://www.castlecops.com/f65-Proxomitron_Filters.html
>>2-10にいろいろと
アップローダー
http://wind.prohosting.com/proxmine/cgi-bin/uploader/
http://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/upload.html
Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/
Thinking Archive(仮)
http://vird2002.s8.xrea.com/
CastleCops Proxomitron Filters
http://www.castlecops.com/f65-Proxomitron_Filters.html
>>2-10にいろいろと
|
|
|
2 :ミスターオミトロン:2006/11/13(月) 17:01:48 ID:oCAoIukD0
【関連スレ】
Proxomitron Part27
http://pc8.2ch.net/test/read.cgi/win/1145863257/
■■■■Proxomitron入門スレッド■■■■5
http://pc7.2ch.net/test/read.cgi/pcqa/1107577736/
ブラクラにProxomitronで対抗するスレPart5
http://pc7.2ch.net/test/read.cgi/software/1060792740/
【過去スレ】
Proxomitron フィルタ作成スレッド
http://pc5.2ch.net/test/read.cgi/software/1083337210/
Proxomitron フィルター作成スレッド Part2
http://pc8.2ch.net/test/read.cgi/software/1100052614/
Proxomitron フィルター作成スレッド Part4
http://pc7.2ch.net/test/read.cgi/software/1138069706/
Proxomitron フィルター作成スレッド Part5
http://pc7.2ch.net/test/read.cgi/software/1152479379/
Proxomitron Part27
http://pc8.2ch.net/test/read.cgi/win/1145863257/
■■■■Proxomitron入門スレッド■■■■5
http://pc7.2ch.net/test/read.cgi/pcqa/1107577736/
ブラクラにProxomitronで対抗するスレPart5
http://pc7.2ch.net/test/read.cgi/software/1060792740/
【過去スレ】
Proxomitron フィルタ作成スレッド
http://pc5.2ch.net/test/read.cgi/software/1083337210/
Proxomitron フィルター作成スレッド Part2
http://pc8.2ch.net/test/read.cgi/software/1100052614/
Proxomitron フィルター作成スレッド Part4
http://pc7.2ch.net/test/read.cgi/software/1138069706/
Proxomitron フィルター作成スレッド Part5
http://pc7.2ch.net/test/read.cgi/software/1152479379/
3 :ミスターオミトロン:2006/11/13(月) 17:03:24 ID:oCAoIukD0
【関連サイト】
Proxomitron-J
http://www.pluto.dti.ne.jp/~tengu/proxomitron/
日本語訳ヘルプ
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Contents.html
AD Killer(広告消し)、Add Link(h抜きURL等をリンク化) (wahaha さん)
http://proxomitron.at.infoseek.co.jp/
Meta-X Extension (ブラウザをコマンド入力で操作出来るようにするフィルタ)
http://www.geocities.co.jp/SiliconValley-SanJose/6740/
やたら手の込んだフィルタ群、詳細不明 (英語)
http://www.jd5000.net/proxo/
sidki | proxomitron
http://www.geocities.com/sidki3003/prox.html
現在proxomitronで使われているリスト一覧を見る
http://local.ptron/.pinfo/lists/
proxomitronが記録した履歴を見る
http://local.ptron/.pinfo/urls/
ENV Checker ( 環境変数のチェックに )
http://www.cybersyndrome.net/evc.html
Proxomitron-J
http://www.pluto.dti.ne.jp/~tengu/proxomitron/
日本語訳ヘルプ
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Contents.html
AD Killer(広告消し)、Add Link(h抜きURL等をリンク化) (wahaha さん)
http://proxomitron.at.infoseek.co.jp/
Meta-X Extension (ブラウザをコマンド入力で操作出来るようにするフィルタ)
http://www.geocities.co.jp/SiliconValley-SanJose/6740/
やたら手の込んだフィルタ群、詳細不明 (英語)
http://www.jd5000.net/proxo/
sidki | proxomitron
http://www.geocities.com/sidki3003/prox.html
現在proxomitronで使われているリスト一覧を見る
http://local.ptron/.pinfo/lists/
proxomitronが記録した履歴を見る
http://local.ptron/.pinfo/urls/
ENV Checker ( 環境変数のチェックに )
http://www.cybersyndrome.net/evc.html
4 :ミスターオミトロン:2006/11/13(月) 17:05:56 ID:oCAoIukD0
【本体いろいろ】
本体(N4.5May)とその日本語化パッチ、OpenSSLライブラリのダウンロード
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/download.html
4.5June+shift_jis誤爆回避日本語化+RWIN32768回避+バイパス赤icon+有難屋icon な本体
ttp://wind.prohosting.com/proxmine/cgi-bin/uploader/download.cgi?PmU_0338.zip
【4.5june+sjis誤爆回避日本語化+RWIN32768回避+win9x対応赤アイコン】 な本体
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0001.zip.html
>>1の
>このスレは作成依頼されたフィルタを有志により作るスレッドPart4です
は、Part6の間違いです。すみません。
それでは引き続きよろしくお願いします。
本体(N4.5May)とその日本語化パッチ、OpenSSLライブラリのダウンロード
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/download.html
4.5June+shift_jis誤爆回避日本語化+RWIN32768回避+バイパス赤icon+有難屋icon な本体
ttp://wind.prohosting.com/proxmine/cgi-bin/uploader/download.cgi?PmU_0338.zip
【4.5june+sjis誤爆回避日本語化+RWIN32768回避+win9x対応赤アイコン】 な本体
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0001.zip.html
>>1の
>このスレは作成依頼されたフィルタを有志により作るスレッドPart4です
は、Part6の間違いです。すみません。
それでは引き続きよろしくお願いします。
5 :名無しさん@お腹いっぱい。:2006/11/13(月) 17:50:02 ID:w72sMec60
---- 文字コード変換 (全角文字を認識させるために必要)
Proxomitron用 文字コード変換
ttp://vird2002.s8.xrea.com/php/getcode.php
文字コード変換スクリプト (IE推奨)
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
文字コード表記変換アプリ StrHex ver 1.0 (文字 <-> 文字コード の相互変換)
ttp://www.pleasuresky.co.jp/strhex.php3
---- 情報表示用の特別なURL
ブロックリスト一覧
ttp://local.ptron/.pinfo/lists/
履歴URL
ttp://local.ptron/.pinfo/urls/
---- 環境変数のチェック
ENV Checker
ttp://www.cybersyndrome.net/evc.html
診断くん
ttp://taruo.net/e/
---- Proxomitronの競合ソフト
【Proxomitron】 proximodo 【後継】
ttp://pc7.2ch.net/test/read.cgi/software/1110563904/
Privoxyスレ
ttp://pc7.2ch.net/test/read.cgi/software/1097621024/
Proxomitron用 文字コード変換
ttp://vird2002.s8.xrea.com/php/getcode.php
文字コード変換スクリプト (IE推奨)
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
文字コード表記変換アプリ StrHex ver 1.0 (文字 <-> 文字コード の相互変換)
ttp://www.pleasuresky.co.jp/strhex.php3
---- 情報表示用の特別なURL
ブロックリスト一覧
ttp://local.ptron/.pinfo/lists/
履歴URL
ttp://local.ptron/.pinfo/urls/
---- 環境変数のチェック
ENV Checker
ttp://www.cybersyndrome.net/evc.html
診断くん
ttp://taruo.net/e/
---- Proxomitronの競合ソフト
【Proxomitron】 proximodo 【後継】
ttp://pc7.2ch.net/test/read.cgi/software/1110563904/
Privoxyスレ
ttp://pc7.2ch.net/test/read.cgi/software/1097621024/
>>5でInternet ArchiveのURLを貼り間違えました。m(_ _)m
---- FAQ
PRXFAQ
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
---- 文字コード変換 (全角文字を認識させるために必要)
Proxomitron用 文字コード変換
ttp://vird2002.s8.xrea.com/php/getcode.php
JSで文字コード変換 (IE推奨)
ttp://web.archive.org/web/20050901004339/http://www2.wbs.ne.jp/~go-to/prx/getcode.html
文字コード表記変換アプリ StrHex ver 1.0 (文字 <-> 文字コード の相互変換)
ttp://www.pleasuresky.co.jp/strhex.php3
---- 情報表示用の特別なURL
ブロックリスト一覧
ttp://local.ptron/.pinfo/lists/
履歴URL
ttp://local.ptron/.pinfo/urls/
---- 環境変数のチェック
ENV Checker
ttp://www.cybersyndrome.net/evc.html
診断くん
ttp://taruo.net/e/
---- Proxomitronの競合ソフト
【Proxomitron】 proximodo 【後継】
ttp://pc7.2ch.net/test/read.cgi/software/1110563904/
Privoxyスレ
ttp://pc7.2ch.net/test/read.cgi/software/1097621024/
---- FAQ
PRXFAQ
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
---- 文字コード変換 (全角文字を認識させるために必要)
Proxomitron用 文字コード変換
ttp://vird2002.s8.xrea.com/php/getcode.php
JSで文字コード変換 (IE推奨)
ttp://web.archive.org/web/20050901004339/http://www2.wbs.ne.jp/~go-to/prx/getcode.html
文字コード表記変換アプリ StrHex ver 1.0 (文字 <-> 文字コード の相互変換)
ttp://www.pleasuresky.co.jp/strhex.php3
---- 情報表示用の特別なURL
ブロックリスト一覧
ttp://local.ptron/.pinfo/lists/
履歴URL
ttp://local.ptron/.pinfo/urls/
---- 環境変数のチェック
ENV Checker
ttp://www.cybersyndrome.net/evc.html
診断くん
ttp://taruo.net/e/
---- Proxomitronの競合ソフト
【Proxomitron】 proximodo 【後継】
ttp://pc7.2ch.net/test/read.cgi/software/1110563904/
Privoxyスレ
ttp://pc7.2ch.net/test/read.cgi/software/1097621024/
7 :think ◆MM0nnAOCiQ :2006/11/13(月) 18:09:07 ID:w72sMec60
>>1
スレ立てお疲れ様です。
本スレッドから有用そうなURLを抜き出してみましたが、URL記述を間違えたり、一部重複していたり…でかえってまとまりがなくなったような気もします。(汗)
出しゃばってしまって、すみませんでした。m(_ _)m
# 以下を参考にさせていただきました。
Proxomitron Part27
ttp://pc8.2ch.net/test/read.cgi/win/1145863257/2
スレ立てお疲れ様です。
本スレッドから有用そうなURLを抜き出してみましたが、URL記述を間違えたり、一部重複していたり…でかえってまとまりがなくなったような気もします。(汗)
出しゃばってしまって、すみませんでした。m(_ _)m
# 以下を参考にさせていただきました。
Proxomitron Part27
ttp://pc8.2ch.net/test/read.cgi/win/1145863257/2
8 :名無しさん@お腹いっぱい。:2006/11/13(月) 18:48:30 ID:Vc2PoI1Z0
9 :名無しさん@お腹いっぱい。:2006/11/13(月) 23:06:49 ID:EUL7Ubnx0
どの文字コードのページでもマルチバイト文字を挿入
http://abc.s65.xrea.com/prox/ncr.php
http://abc.s65.xrea.com/prox/ncr.php
10 :名無しさん@お腹いっぱい。:2006/11/14(火) 00:00:31 ID:bSdezmVN0
>>9
なにこれ?w
なにこれ?w
11 :think ◆MM0nnAOCiQ :2006/11/14(火) 00:24:37 ID:wmVqBQ9Y0
>>10
Proxomitronの置換表現でマルチバイト文字を挿入するためのPHPスクリプトです。
マルチバイト文字を実体参照に置換します。
Shift_JIS/EUC-JP/JIS/UTF-8 どの文字コードのページでもProxomitronなどでマルチバイト文字を挿入する
ttp://abc.s65.xrea.com/prox/wiki/TIPS/#n22f5801
面白そうなスクリプトなので、私も挑戦してみたいと思っていることの一つです。
Proxomitronの置換表現でマルチバイト文字を挿入するためのPHPスクリプトです。
マルチバイト文字を実体参照に置換します。
Shift_JIS/EUC-JP/JIS/UTF-8 どの文字コードのページでもProxomitronなどでマルチバイト文字を挿入する
ttp://abc.s65.xrea.com/prox/wiki/TIPS/#n22f5801
面白そうなスクリプトなので、私も挑戦してみたいと思っていることの一つです。
12 :名無しさん@お腹いっぱい。:2006/11/14(火) 00:50:42 ID:Rh+rmFg00
UTF-16のページには挿入できないかも 試してないけど
13 :名無しさん@お腹いっぱい。:2006/11/14(火) 01:04:43 ID:Rh+rmFg00
[Patterns]
Name = "New HTML filter"
Active = TRUE
Limit = 256
Match = "<([%00])\0b[%00]o[%00]d[%00]y*>[%00]&&\1"
Replace = "\1&\0#\0x\06\03\06\05\0;\0"
やっぱりUTF-16では↑みたいに0x00も挿入しないと駄目だった
Name = "New HTML filter"
Active = TRUE
Limit = 256
Match = "<([%00])\0b[%00]o[%00]d[%00]y*>[%00]&&\1"
Replace = "\1&\0#\0x\06\03\06\05\0;\0"
やっぱりUTF-16では↑みたいに0x00も挿入しないと駄目だった
14 :名無しさん@お腹いっぱい。:2006/11/14(火) 07:15:51 ID:kziJ5yQE0
>>9がなんかのフィルターが悪さしてるらしく、ものすごい勢いでぶっ壊れるなぁ。
15 :名無しさん@お腹いっぱい。:2006/11/14(火) 12:24:15 ID:o/zavw2M0
>>13
googleのトップページのソースをUTF-16で保存してバイナリエディタで覗いてみたら 「x00」 が
一文字に1つずつ入ってたw 3バイトの文字もあるらしいから 「x00」 じゃマッチしない場合もあるってことか。
それとファイルの先頭に 「FE FF 00」 という3バイトが勝手に挿入されたけど、これはUTF-16の
お約束事かな、後で調べてみます。
googleのトップページのソースをUTF-16で保存してバイナリエディタで覗いてみたら 「x00」 が
一文字に1つずつ入ってたw 3バイトの文字もあるらしいから 「x00」 じゃマッチしない場合もあるってことか。
それとファイルの先頭に 「FE FF 00」 という3バイトが勝手に挿入されたけど、これはUTF-16の
お約束事かな、後で調べてみます。
16 :名無しさん@お腹いっぱい。:2006/11/14(火) 13:07:17 ID:89JuPRle0
前スレの995です。
(4.5June+shift_jis誤爆回避日本語化+RWIN32768回避+バイパス赤icon+有難屋
これ使っても バグが出るんですね。
前スレの998さん 色々とありがとうございました。
(4.5June+shift_jis誤爆回避日本語化+RWIN32768回避+バイパス赤icon+有難屋
これ使っても バグが出るんですね。
前スレの998さん 色々とありがとうございました。
>>16
どうもです。
>これ使っても バグが出るんですね。
それでも出ますね、このバグは一番悪影響のあるバグなので作者さんに直して欲しいところ
なんですが、作者さんは既に・・。(ー人ー)
>色々とありがとうございました。
お役に立てたようで嬉しいです。(^^)ノシ
>>15
>「FE FF 00」
これは BOM(Byte Order Mark) というものだそうです。
参照 ttp://seclan.dll.jp/ccutffaq.htm
どうもです。
>これ使っても バグが出るんですね。
それでも出ますね、このバグは一番悪影響のあるバグなので作者さんに直して欲しいところ
なんですが、作者さんは既に・・。(ー人ー)
>色々とありがとうございました。
お役に立てたようで嬉しいです。(^^)ノシ
>>15
>「FE FF 00」
これは BOM(Byte Order Mark) というものだそうです。
参照 ttp://seclan.dll.jp/ccutffaq.htm
18 :名無しさん@お腹いっぱい。:2006/11/15(水) 13:03:26 ID:9/nG3bZb0
19 :名無しさん@お腹いっぱい。:2006/11/15(水) 17:38:25 ID:ezYrAZI50
Google: Kill ad [2006/09/24]入れてみたけど、広告表示されるんだけどうちだけ?
20 :think ◆MM0nnAOCiQ :2006/11/15(水) 18:01:10 ID:gu93Fua+0
>>19
Google系フィルタの「使い方」の説明を修正するのを忘れていました。m(_ _)m
ブロックリスト「GoogleSearch」は登録済みでしょうか?
未登録でしたら以下をインポートして、"GoogleSearch.txt" をProxomitronのListフォルダにコピーしてみてください。
[Blocklists]
List.GoogleSearch = "..\Lists\GoogleSearch.txt"
Google系フィルタの「使い方」の説明を修正するのを忘れていました。m(_ _)m
ブロックリスト「GoogleSearch」は登録済みでしょうか?
未登録でしたら以下をインポートして、"GoogleSearch.txt" をProxomitronのListフォルダにコピーしてみてください。
[Blocklists]
List.GoogleSearch = "..\Lists\GoogleSearch.txt"
21 :名無しさん@お腹いっぱい。:2006/11/15(水) 19:59:35 ID:zqqqohm00
Google: High Light 1 [2006/06/04]・2 [2006/06/27]だけど、
着色が始まったワードの最初4byte分が文字化けしちゃう
Google High Light以外のフィルタを全部非アクティブにしても同じ
なんなんだろ
着色が始まったワードの最初4byte分が文字化けしちゃう
Google High Light以外のフィルタを全部非アクティブにしても同じ
なんなんだろ
22 :think ◆MM0nnAOCiQ :2006/11/15(水) 21:58:05 ID:gu93Fua+0
>>21
> 着色が始まったワードの最初4byte分が文字化けしちゃう
私の環境では文字化けしていませんが、全てのワードで文字化けしますか?
簡単に思いつくところでは、「oe=sjis で不正にマッチしている」ということが考えられますが…。
# "URL: Google transfer" で回避できます。
現象が再現するURLを教えていただければ、検証できるかもしれません。
> 着色が始まったワードの最初4byte分が文字化けしちゃう
私の環境では文字化けしていませんが、全てのワードで文字化けしますか?
簡単に思いつくところでは、「oe=sjis で不正にマッチしている」ということが考えられますが…。
# "URL: Google transfer" で回避できます。
現象が再現するURLを教えていただければ、検証できるかもしれません。
23 :名無しさん@お腹いっぱい。:2006/11/15(水) 22:02:43 ID:fjdP0RiG0
ティンコさん大忙しだな
25 :名無しさん@お腹いっぱい。:2006/11/15(水) 22:29:28 ID:zqqqohm00
>>22
URL: Google transferは入れてます。
Googleの検索結果はどのページでも全てのワードで再現します。
例えば ttp://www.google.co.jp/search?q=proxomitron+%E5%85%AC%E5%BC%8F が
ttp://bebe.run.buttobi.net/up/src/be_0071.jpg
こんな感じ。
一つ気づいたのは、なぜかリロードの度に文字の化け方が変わるみたいです
URL: Google transferは入れてます。
Googleの検索結果はどのページでも全てのワードで再現します。
例えば ttp://www.google.co.jp/search?q=proxomitron+%E5%85%AC%E5%BC%8F が
ttp://bebe.run.buttobi.net/up/src/be_0071.jpg
{kind=link}
こんな感じ。
一つ気づいたのは、なぜかリロードの度に文字の化け方が変わるみたいです
26 :think ◆MM0nnAOCiQ :2006/11/15(水) 23:03:59 ID:gu93Fua+0
>>25
何かこう…小動物に見つめられているような文字化けですねw
同じ検索語で試してみましたが、以下のように文字化けは発生しませんでした。
ttp://vird2002.s8.xrea.com/temp/ie7.png
ttp://vird2002.s8.xrea.com/temp/sylera.png
再現できる状況にないので、後は想像になってしまいますが、私が同じ状況に立てば以下の点を確認してみます。
・Webブラウザのキャッシュ破損
・ユーザスタイルシート
・外部のProxyを通していないかどうか
・その他、関係ありそうな設定
想像するに、ブラウザの拡張機能と干渉しているような気がしますが…。
何かこう…小動物に見つめられているような文字化けですねw
同じ検索語で試してみましたが、以下のように文字化けは発生しませんでした。
ttp://vird2002.s8.xrea.com/temp/ie7.png
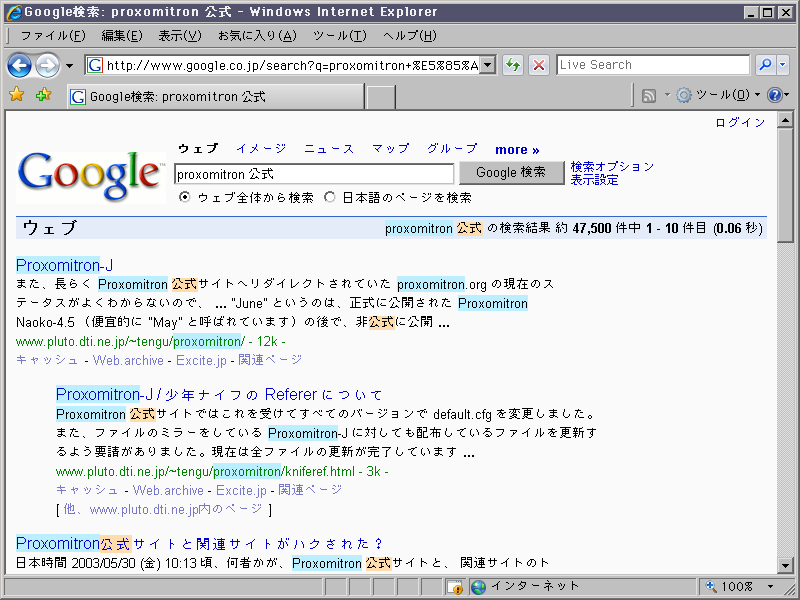{kind=link}
ttp://vird2002.s8.xrea.com/temp/sylera.png
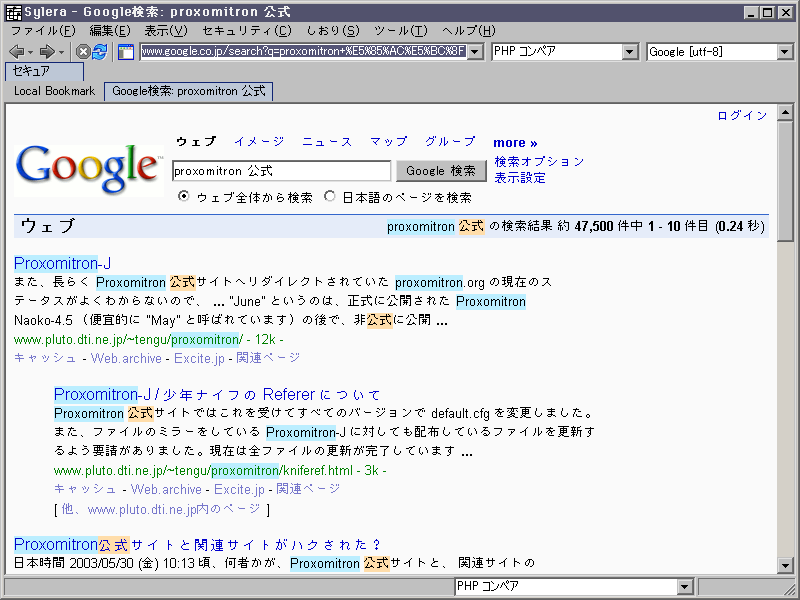{kind=link}
再現できる状況にないので、後は想像になってしまいますが、私が同じ状況に立てば以下の点を確認してみます。
・Webブラウザのキャッシュ破損
・ユーザスタイルシート
・外部のProxyを通していないかどうか
・その他、関係ありそうな設定
想像するに、ブラウザの拡張機能と干渉しているような気がしますが…。
27 :名無しさん@お腹いっぱい。:2006/11/15(水) 23:10:14 ID:H+1RCAyR0
28 :名無しさん@お腹いっぱい。:2006/11/15(水) 23:22:36 ID:zqqqohm00
>>26
うちの環境の問題みたいですね。もうちょっと試行錯誤してみます。
ありがとうございました。
>>27
freetype版はX-Finderでの文字化けが酷かったんで非freetype版使ってます。
gdi++外して試しても変化無かったんで、gdi++は関係ないみたいです。
うちの環境の問題みたいですね。もうちょっと試行錯誤してみます。
ありがとうございました。
>>27
freetype版はX-Finderでの文字化けが酷かったんで非freetype版使ってます。
gdi++外して試しても変化無かったんで、gdi++は関係ないみたいです。
29 :名無しさん@お腹いっぱい。:2006/11/16(木) 00:36:55 ID:I3soafo10
試したけどうちでも化けた。
だから多分、キャッシュCSSProxyは関係なし。
後で他のフィルタとがっちんこしてないか見てみるわ。
もしgoogle highlightがおかしいとしたらフィルタ1の方だと思われる。
フィルタ数100を超えると管理が大変だよねぇw
だから多分、キャッシュCSSProxyは関係なし。
後で他のフィルタとがっちんこしてないか見てみるわ。
もしgoogle highlightがおかしいとしたらフィルタ1の方だと思われる。
フィルタ数100を超えると管理が大変だよねぇw
30 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:13:07 ID:n+jzEDpm0
多分初歩的な事なので 怒らないで教えてください。
"Google"で"proxomitron"を検索した時に ログウインドを出していても
New Message Log Window....
BlockList 182: in Bypass, line 79
+++GET 182+++
GET /search?hl=ja&q=proxomitron&btnG=Google+%E6%A4%9C%E7%B4%A2&lr= HTTP/1.0
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, */*
Referer: http://www.google.co.jp/webhp?hl=ja
Accept-Language: ja
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)
Host: www.google.co.jp
Cookie: PREF=ID=da8439db0b57b436:TM=1163645442:LM=1163645442:S=1hJiAq-KOnYjGjqB
Connection: keep-alive
+++RESP 182+++
HTTP/1.0 200 OK
Cache-Control: private
Content-Type: text/html; charset=UTF-8
Server: GWS/2.1
Transfer-Encoding: chunked
Date: Thu, 16 Nov 2006 04:08:32 GMT
+++CLOSE 182+++
これだけしか出ず マッチしません。
Google: High Light とかも入っていてチェックも入っています。
何がいけないのでしょうか?
"Google"で"proxomitron"を検索した時に ログウインドを出していても
New Message Log Window....
BlockList 182: in Bypass, line 79
+++GET 182+++
GET /search?hl=ja&q=proxomitron&btnG=Google+%E6%A4%9C%E7%B4%A2&lr= HTTP/1.0
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, */*
Referer: http://www.google.co.jp/webhp?hl=ja
Accept-Language: ja
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)
Host: www.google.co.jp
Cookie: PREF=ID=da8439db0b57b436:TM=1163645442:LM=1163645442:S=1hJiAq-KOnYjGjqB
Connection: keep-alive
+++RESP 182+++
HTTP/1.0 200 OK
Cache-Control: private
Content-Type: text/html; charset=UTF-8
Server: GWS/2.1
Transfer-Encoding: chunked
Date: Thu, 16 Nov 2006 04:08:32 GMT
+++CLOSE 182+++
これだけしか出ず マッチしません。
Google: High Light とかも入っていてチェックも入っています。
何がいけないのでしょうか?
31 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:19:32 ID:tgDqHzbg0
バイパスリストに入ってるってメッセージでてるやん
79行目をみれば済むでしょ
79行目をみれば済むでしょ
32 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:24:16 ID:ItNCUX5I0
バイパスしてるんじゃないの?
>BlockList 182: in Bypass, line 79
>BlockList 182: in Bypass, line 79
33 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:29:07 ID:fAnCXB530
すげー、よくわかるな
34 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:37:25 ID:n+jzEDpm0
35 :名無しさん@お腹いっぱい。:2006/11/16(木) 13:41:58 ID:YCmjIULv0
>>34
([^/]++.|)goo.ne.jp/
([^/]++.|)goo.ne.jp/
36 :名無しさん@お腹いっぱい。:2006/11/16(木) 14:04:01 ID:n+jzEDpm0
>>35
こんな私のために 大変ありがとうございます。
こんな私のために 大変ありがとうございます。
37 :名無しさん@お腹いっぱい。:2006/11/16(木) 19:53:32 ID:J6B4unk10
>>29
果たしてこういう使い方をして良いのか分からないけど、
Google: High Light 1 [2006/06/04]
Google: High Light 2 [2005.10.21]
の組み合わせだと文字化けは起こらなかった
うちの文字化けにはGoogle: High Light 2 [2006/06/27]が関係あるっぽい?
果たしてこういう使い方をして良いのか分からないけど、
Google: High Light 1 [2006/06/04]
Google: High Light 2 [2005.10.21]
の組み合わせだと文字化けは起こらなかった
うちの文字化けにはGoogle: High Light 2 [2006/06/27]が関係あるっぽい?
38 :think ◆MM0nnAOCiQ :2006/11/16(木) 22:35:14 ID:ER6xdwGh0
>>29
もし、他のフィルタと干渉しているとしたら、Multi を有効にしているフィルタを疑ってみてください。
デバッグモードを使えば、特定できると思います。
"Google: High Light 1" でtitle要素から検索語を抽出し、"Google: High Light 2" で抽出した検索語にマッチさせます。
"Google: High Light 1" に問題があるとしたら、検索語の抽出が不完全なために、"Google: High Light 2" で不正にマッチしてしまうケースだと思います。
"Google: High Light 2" で不具合が発生するとしたら、検索語へのマッチングが不正(2バイト文字の1バイト分しかマッチしないとか)であるか、他のフィルタでマッチした語句に対して、"Google: High Light 2" がマッチしている可能性があります。
Multi が有効なフィルタは他のフィルタからの検索対象になりますので、不具合の温床となりやすいです。
一応、私の自作フィルタの中には Multi が有効なフィルタはありません。
# 再帰的な動作に興味があって一時期試したことがありますが、「マッチング回数を制限しにくい」「複数回マッチするため、速度低下」の性質からあまり魅力を感じませんでした…。
>>37
> うちの文字化けにはGoogle: High Light 2 [2006/06/27]が関係あるっぽい?
過去の版は取り置きしてないので、 [2005.10.21] がどんなフィルタか判りません。(苦笑)
"Google: High Light 2" で最近(2006年)の大きな更新は、「2006/01/19 部分一致に対応」だと思います。
# アスタリスクに対応するために、(^$TST(Key1)|$TST(Key2)...) の表現を付け加えました。
# 例) ttp://www.google.com/search?ie=eucjp&lr=lang_ja&q=%b2%e6%a4%ac%c7%da*%c7%ad%a4%c7%a4%a2%a4%eb
もし、他のフィルタと干渉しているとしたら、Multi を有効にしているフィルタを疑ってみてください。
デバッグモードを使えば、特定できると思います。
"Google: High Light 1" でtitle要素から検索語を抽出し、"Google: High Light 2" で抽出した検索語にマッチさせます。
"Google: High Light 1" に問題があるとしたら、検索語の抽出が不完全なために、"Google: High Light 2" で不正にマッチしてしまうケースだと思います。
"Google: High Light 2" で不具合が発生するとしたら、検索語へのマッチングが不正(2バイト文字の1バイト分しかマッチしないとか)であるか、他のフィルタでマッチした語句に対して、"Google: High Light 2" がマッチしている可能性があります。
Multi が有効なフィルタは他のフィルタからの検索対象になりますので、不具合の温床となりやすいです。
一応、私の自作フィルタの中には Multi が有効なフィルタはありません。
# 再帰的な動作に興味があって一時期試したことがありますが、「マッチング回数を制限しにくい」「複数回マッチするため、速度低下」の性質からあまり魅力を感じませんでした…。
>>37
> うちの文字化けにはGoogle: High Light 2 [2006/06/27]が関係あるっぽい?
過去の版は取り置きしてないので、 [2005.10.21] がどんなフィルタか判りません。(苦笑)
"Google: High Light 2" で最近(2006年)の大きな更新は、「2006/01/19 部分一致に対応」だと思います。
# アスタリスクに対応するために、(^$TST(Key1)|$TST(Key2)...) の表現を付け加えました。
# 例) ttp://www.google.com/search?ie=eucjp&lr=lang_ja&q=%b2%e6%a4%ac%c7%da*%c7%ad%a4%c7%a4%a2%a4%eb
39 :名無しさん@お腹いっぱい。:2006/11/16(木) 23:32:09 ID:J6B4unk10
なるほど、確かにアスタリスクがあると着色されないです
でもそれ以外特に問題もなさそうだし、[2005.10.21]のを使うことにします
#念のためGoogle: High Light 2 [2005.10.21]を貼っときます
[Patterns]
Name = "Google: High Light 2 [2005.10.21]"
Active = TRUE
URL = "(www|images|news|groups).google.co(m|.jp)/(search|images|news|groups)\? $TYPE(htm)"
Limit = 256
Match = "($NEST(<b>,(^...)\#,</b>)(<br>\s+|\s$SET(#= )|)\2)++{1,*}"
"$SET(Temp=\@)"
"($TST(Temp=($TST(Key1))\1 )$SET(0=#bbeeff)"
"|$TST(Temp=($TST(Key2))\1 )$SET(0=#ffddaa)"
"|$TST(Temp=($TST(Key3))\1 )$SET(0=#88ebaa)"
"|$TST(Temp=($TST(Key4))\1 )$SET(0=#ccbbff)"
"|$TST(Temp=($TST(Key5))\1 )$SET(0=#ffaaaa)"
"|$TST(Temp=($TST(Key6))\1 )$SET(0=#99ccff)"
"|$TST(Temp=($TST(Key7))\1 )$SET(0=#eebbaa)"
"|$SET(Temp=)$TST(9=null))"
Replace = "<span style="background-color: \0">\1</span>\2$SET(Temp=)"
でもそれ以外特に問題もなさそうだし、[2005.10.21]のを使うことにします
#念のためGoogle: High Light 2 [2005.10.21]を貼っときます
[Patterns]
Name = "Google: High Light 2 [2005.10.21]"
Active = TRUE
URL = "(www|images|news|groups).google.co(m|.jp)/(search|images|news|groups)\? $TYPE(htm)"
Limit = 256
Match = "($NEST(<b>,(^...)\#,</b>)(<br>\s+|\s$SET(#= )|)\2)++{1,*}"
"$SET(Temp=\@)"
"($TST(Temp=($TST(Key1))\1 )$SET(0=#bbeeff)"
"|$TST(Temp=($TST(Key2))\1 )$SET(0=#ffddaa)"
"|$TST(Temp=($TST(Key3))\1 )$SET(0=#88ebaa)"
"|$TST(Temp=($TST(Key4))\1 )$SET(0=#ccbbff)"
"|$TST(Temp=($TST(Key5))\1 )$SET(0=#ffaaaa)"
"|$TST(Temp=($TST(Key6))\1 )$SET(0=#99ccff)"
"|$TST(Temp=($TST(Key7))\1 )$SET(0=#eebbaa)"
"|$SET(Temp=)$TST(9=null))"
Replace = "<span style="background-color: \0">\1</span>\2$SET(Temp=)"
40 :think ◆MM0nnAOCiQ :2006/11/17(金) 00:01:48 ID:ER6xdwGh0
>>39
ふむふむ。大体、予想通りですが、このフィルタだと
Google検索: Windows:XP
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=Windows%3aXP
にマッチしません。( <b>Windows XP</b> にマッチできない)
あまり頻度は高くありませんが、記号を含んだ検索語でマッチしなくなるケースがあると思います。
他は特に問題はなさそうですね。
ふむふむ。大体、予想通りですが、このフィルタだと
Google検索: Windows:XP
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=Windows%3aXP
にマッチしません。( <b>Windows XP</b> にマッチできない)
あまり頻度は高くありませんが、記号を含んだ検索語でマッチしなくなるケースがあると思います。
他は特に問題はなさそうですね。
41 :名無しさん@お腹いっぱい。:2006/11/18(土) 00:06:04 ID:qHY53OAh0
質問させてください。偽装リファラーやリファラー隠すフィルターはあるのでしょうか?
42 :名無しさん@お腹いっぱい。:2006/11/18(土) 00:30:04 ID:2mCB8qmG0
あります
43 :名無しさん@お腹いっぱい。:2006/11/20(月) 23:35:57 ID:dhcpKh950
>>29だけど、think氏のgoogle highlightオンリーの状態でも化けたよ。
該当部分の検索単語の文字コードの先頭部分が破壊されてるね。
時間有ったからちょっと頑張ってみたけど、元々正規表現が苦手なのもあって、
さすがに複雑なフィルタのバグ探しは俺には無理だった。
申し訳ないが他の人頼む。
Google: High Light 2が多分原因な気がするけど、ちょっと自信なし。
それにしてもオミトロン有りの状態でなれてると、
無しの状態はバナーが邪魔だったり、機能が不便すぎて困る。
検証しててものすごく身にしみた。
該当部分の検索単語の文字コードの先頭部分が破壊されてるね。
時間有ったからちょっと頑張ってみたけど、元々正規表現が苦手なのもあって、
さすがに複雑なフィルタのバグ探しは俺には無理だった。
申し訳ないが他の人頼む。
Google: High Light 2が多分原因な気がするけど、ちょっと自信なし。
それにしてもオミトロン有りの状態でなれてると、
無しの状態はバナーが邪魔だったり、機能が不便すぎて困る。
検証しててものすごく身にしみた。
44 :名無しさん@お腹いっぱい。:2006/11/20(月) 23:53:07 ID:7cit4xxy0
45 :名無しさん@お腹いっぱい。:2006/11/21(火) 00:06:19 ID:9FLgOsK00
エディタでソース開いても壊れてるから、ブラウザは関係ないかも。
一応晒しとくね。
Win2kSP4
Opera9.0.2 Build8573
Syrela3.0.11 SeaMonkey1.0.2
Sleipnir2.4.8 + IE6
オミトロンはver4.5 Naoko 2003-5-22
Webページ、ヘッダの両方とも余分なフィルタは全て無しの状態で検証
一応晒しとくね。
Win2kSP4
Opera9.0.2 Build8573
Syrela3.0.11 SeaMonkey1.0.2
Sleipnir2.4.8 + IE6
オミトロンはver4.5 Naoko 2003-5-22
Webページ、ヘッダの両方とも余分なフィルタは全て無しの状態で検証
46 :名無しさん@お腹いっぱい。:2006/11/21(火) 00:51:42 ID:/UDEfx3r0
うちもこんな感じで。フィルターはこの2つだけ
<Match: Google: High Light 1 [2006/06/04] >
<title>proxomitron - Google 検索</title>
</Match>
<title>Google検索: proxomitron </title><style><!--
<Match: Google: High Light 2 [2006/06/27] >
<b>proxomitron</b>
</Match>
<span style='background-color: #bbeeff'>???omitron</span> の検索結果のうち
win2k SP4
Sylera/3.0.13 SeaMonkey/1.1b
Opera9.0.0 Build8501
<Match: Google: High Light 1 [2006/06/04] >
<title>proxomitron - Google 検索</title>
</Match>
<title>Google検索: proxomitron </title><style><!--
<Match: Google: High Light 2 [2006/06/27] >
<b>proxomitron</b>
</Match>
<span style='background-color: #bbeeff'>???omitron</span> の検索結果のうち
win2k SP4
Sylera/3.0.13 SeaMonkey/1.1b
Opera9.0.0 Build8501
47 :名無しさん@お腹いっぱい。:2006/11/21(火) 01:30:20 ID:KzByW+A90
>>21だけど、うちはWin2kSP4で、
Opera9.0.2 Build8653
Syrela3.0.13 SeaMonkey1.1b
KIKI 1.0.8
IE6
Proxomitronは>>4の有難屋iconの奴
ひょっとしてWinXPじゃないと化けるとか?
Opera9.0.2 Build8653
Syrela3.0.13 SeaMonkey1.1b
KIKI 1.0.8
IE6
Proxomitronは>>4の有難屋iconの奴
ひょっとしてWinXPじゃないと化けるとか?
48 :名無しさん@お腹いっぱい。:2006/11/22(水) 11:40:27 ID:nBMod6cy0
ユーザスタイルを書くとき、
例えば onclick 属性をセレクタに入れようとすると、ちょっと面倒。
CSS で [onclick] と書いた場合は onclick="属性値" の場合しか適用されない。
(onClick="属性値" などと書かれていると適用されない。ちなみに、Firefox 2.0 の場合)
そこで試しに
([%4F]n[%43]lick|[%4F]nclick|on[%43]lick)=$SET(1=onclick=)
というマッチを書いてみたものの、
Proxomitron 側では大文字だろうと小文字だろうとマッチしてしまうのね……。
最初から全部小文字で書かれたものにはマッチさせても無駄な処理なので、
大文字のときだけマッチさせられればよいものの、そういうのは無理なのかな。
あるいは、[onclick] と書いただけで onClick="属性値" などに適用されれば、
それでも解決されるのだけれど。むしろ、そっちの方が理想的。
ブラウザの開発側に要望を出した方がよいのかな。
例えば onclick 属性をセレクタに入れようとすると、ちょっと面倒。
CSS で [onclick] と書いた場合は onclick="属性値" の場合しか適用されない。
(onClick="属性値" などと書かれていると適用されない。ちなみに、Firefox 2.0 の場合)
そこで試しに
([%4F]n[%43]lick|[%4F]nclick|on[%43]lick)=$SET(1=onclick=)
というマッチを書いてみたものの、
Proxomitron 側では大文字だろうと小文字だろうとマッチしてしまうのね……。
最初から全部小文字で書かれたものにはマッチさせても無駄な処理なので、
大文字のときだけマッチさせられればよいものの、そういうのは無理なのかな。
あるいは、[onclick] と書いただけで onClick="属性値" などに適用されれば、
それでも解決されるのだけれど。むしろ、そっちの方が理想的。
ブラウザの開発側に要望を出した方がよいのかな。
49 :think ◆MM0nnAOCiQ :2006/11/22(水) 20:54:58 ID:tagApU8a0
---- Proxomitron Filter
Google: High Light 1 [2006/06/04]
Google: High Light 2 [2006/06/27]
---- OS
Windows XP Professional SP2
---- Proxomitron
Proxomitron Version Naoko 4.5(2003-6-1)+3
Proxomitron Version Naoko 4.5(2003-5-22)
---- Browser
Sylera 3.0.11 (GRE 1.8.0.7_1)
Opera v9.02 Build 8585
IE6 SP2
IE7_Standalone
以上の環境で検証しましたが、不具合を確認できませんでした。
今のところ不具合報告が上がっているOSは「Windows2000SP4」だけのようですが、OS依存の不具合だとするとちょっと手が出せません…。
関係ないかもしれませんが、以前にどうしてもRefererを消せない環境があって、悩んだ末にKerioのWebフィルタが作用していたことがありました。
ユーザが気がつかないところで別のソフトが作用していることもありますので、念のため、現在常駐しているソフトにも目を向けてみてください。
(もし、Win2k限定なら、Win2k限定で動作するソフトorサービスがあるかもしれません)
今までに報告いただいたところでは、「Google: High Light」しか文字化けの現象が出ていないようなので、>39のようにフィルタの表現を操作することで問題を回避できる可能性はあると思います。
以下、>39より、「Windows:XP」の検索語を認識するようにした版です。
Google: High Light 1 [2006/06/04]
Google: High Light 2 [2006/06/27]
---- OS
Windows XP Professional SP2
---- Proxomitron
Proxomitron Version Naoko 4.5(2003-6-1)+3
Proxomitron Version Naoko 4.5(2003-5-22)
---- Browser
Sylera 3.0.11 (GRE 1.8.0.7_1)
Opera v9.02 Build 8585
IE6 SP2
IE7_Standalone
以上の環境で検証しましたが、不具合を確認できませんでした。
今のところ不具合報告が上がっているOSは「Windows2000SP4」だけのようですが、OS依存の不具合だとするとちょっと手が出せません…。
関係ないかもしれませんが、以前にどうしてもRefererを消せない環境があって、悩んだ末にKerioのWebフィルタが作用していたことがありました。
ユーザが気がつかないところで別のソフトが作用していることもありますので、念のため、現在常駐しているソフトにも目を向けてみてください。
(もし、Win2k限定なら、Win2k限定で動作するソフトorサービスがあるかもしれません)
今までに報告いただいたところでは、「Google: High Light」しか文字化けの現象が出ていないようなので、>39のようにフィルタの表現を操作することで問題を回避できる可能性はあると思います。
以下、>39より、「Windows:XP」の検索語を認識するようにした版です。
50 :think ◆MM0nnAOCiQ :2006/11/22(水) 20:55:32 ID:tagApU8a0
[Patterns]
Name = "Google: High Light 2 [2006/06/27] remake test1"
Active = TRUE
URL = "$LST(GoogleSearch)$TYPE(htm)"
Limit = 256
Match = "($NEST(<b>(^...| </b>),([^<]+)\0,</b>)"
"(<br> $SET(Temp=$GET(Temp)\0)|"
"\s $SET(Temp=$GET(Temp)\0 )|"
"$SET(Temp=$GET(Temp)\0))\9"
")++{1,*}"
""
"($TST(Temp=("
"($TST(Key1))\1"
"$SET(#=<span style='background-color: #bbeeff'>\1</span>)|"
"($TST(Key2))\2"
"$SET(#=<span style='background-color: #ffddaa'>\2</span>)|"
"($TST(Key3))\3"
"$SET(#=<span style='background-color: #88ebaa'>\3</span>)|"
"($TST(Key4))\4"
"$SET(#=<span style='background-color: #ccbbff'>\4</span>)|"
"($TST(Key5))\5"
"$SET(#=<span style='background-color: #ffaaaa'>\5</span>)|"
"($TST(Key6))\6"
"$SET(#=<span style='background-color: #99ccff'>\6</span>)|"
"($TST(Key7))\7"
"$SET(#=<span style='background-color: #eebbaa'>\7</span>)|"
"(\s)\#)+{1,*}"
")|"
"(^<b>)$SET(Temp=)$TST(\0=(^?)))"
"$SET(Temp=)"
Replace = "\@\9"
Name = "Google: High Light 2 [2006/06/27] remake test1"
Active = TRUE
URL = "$LST(GoogleSearch)$TYPE(htm)"
Limit = 256
Match = "($NEST(<b>(^...| </b>),([^<]+)\0,</b>)"
"(<br> $SET(Temp=$GET(Temp)\0)|"
"\s $SET(Temp=$GET(Temp)\0 )|"
"$SET(Temp=$GET(Temp)\0))\9"
")++{1,*}"
""
"($TST(Temp=("
"($TST(Key1))\1"
"$SET(#=<span style='background-color: #bbeeff'>\1</span>)|"
"($TST(Key2))\2"
"$SET(#=<span style='background-color: #ffddaa'>\2</span>)|"
"($TST(Key3))\3"
"$SET(#=<span style='background-color: #88ebaa'>\3</span>)|"
"($TST(Key4))\4"
"$SET(#=<span style='background-color: #ccbbff'>\4</span>)|"
"($TST(Key5))\5"
"$SET(#=<span style='background-color: #ffaaaa'>\5</span>)|"
"($TST(Key6))\6"
"$SET(#=<span style='background-color: #99ccff'>\6</span>)|"
"($TST(Key7))\7"
"$SET(#=<span style='background-color: #eebbaa'>\7</span>)|"
"(\s)\#)+{1,*}"
")|"
"(^<b>)$SET(Temp=)$TST(\0=(^?)))"
"$SET(Temp=)"
Replace = "\@\9"
51 :名無しさん@お腹いっぱい。:2006/11/22(水) 22:02:22 ID:xcYKG8+70
>>49
お疲れさまです
残念ながら>>50でも文字化けしました。
>>21はOSインストール直後で、ほとんどソフトをインストールしていない状態でした
不要なサービスを切りNIS等疑わしいソフトを切ってテストしてたんで、
OS依存の不具合の確率が高そうです
お疲れさまです
残念ながら>>50でも文字化けしました。
>>21はOSインストール直後で、ほとんどソフトをインストールしていない状態でした
不要なサービスを切りNIS等疑わしいソフトを切ってテストしてたんで、
OS依存の不具合の確率が高そうです
52 :名無しさん@お腹いっぱい。:2006/11/22(水) 22:33:11 ID:IeiskbXA0
think氏のサイトがわからん・・・
53 :名無しさん@お腹いっぱい。:2006/11/22(水) 23:02:12 ID:B1gUfDsc0
数日前からgoogle検索の結果の、各トップへのリンクの文字のサイズが大きくなりましたよね。
これを以前のように、内容紹介の文字と同じサイズにするフィルタをお願いできますでしょうか?
これを以前のように、内容紹介の文字と同じサイズにするフィルタをお願いできますでしょうか?
54 :名無しさん@お腹いっぱい。:2006/11/22(水) 23:16:03 ID:xcYKG8+70
55 :名無しさん@お腹いっぱい。:2006/11/23(木) 13:43:25 ID:+P8TU40N0
>>53
それだけでいいなら、これでいけるはず。
[Patterns]
Name = "Google: title font-size normalizer"
Active = TRUE
URL = "www.google.(com|co.jp)/"
Limit = 256
Match = ".r{font-size:*}"
Replace = ".r{font-size:100%}"
見ての通りの単能フィルターなので、
もっとスマートな汎用フィルターを待った方がいいかも。
それだけでいいなら、これでいけるはず。
[Patterns]
Name = "Google: title font-size normalizer"
Active = TRUE
URL = "www.google.(com|co.jp)/"
Limit = 256
Match = ".r{font-size:*}"
Replace = ".r{font-size:100%}"
見ての通りの単能フィルターなので、
もっとスマートな汎用フィルターを待った方がいいかも。
56 :名無しさん@お腹いっぱい。:2006/11/23(木) 15:31:21 ID:wbuxJo560
どうでも良さそうだけど、WinXP環境がないもんでVistaRC1(Build5600)で試してみた
Vistaインストール->Proxomitron起動->Opera9.10 Build8653インストール
->ProxomitronからGoogle High Light関連以外全部フィルタoff
で、OperaでGoogleの検索結果に飛んでみた
結果、着色開始位置から最初の2byteが文字化けしました
Vistaインストール->Proxomitron起動->Opera9.10 Build8653インストール
->ProxomitronからGoogle High Light関連以外全部フィルタoff
で、OperaでGoogleの検索結果に飛んでみた
結果、着色開始位置から最初の2byteが文字化けしました
57 :名無しさん@お腹いっぱい。:2006/11/23(木) 16:57:19 ID:pAZD4gKH0
>>55
ありがとうございます。
自分でも作ってみたんですけど↓でも上手くいきました。
[Patterns]
Name = "Google font"
Active = TRUE
URL = "www.google.(com|co.jp)/"
Limit = 256
Match = "<h2 class=r>|</h2>|<font size=-1>"
ありがとうございます。
自分でも作ってみたんですけど↓でも上手くいきました。
[Patterns]
Name = "Google font"
Active = TRUE
URL = "www.google.(com|co.jp)/"
Limit = 256
Match = "<h2 class=r>|</h2>|<font size=-1>"
58 :名無しさん@お腹いっぱい。:2006/11/25(土) 19:27:19 ID:6LZDwYL40
ttp://tomizawa-web.hp.infoseek.co.jp/event.htm
ここに書かれているようなスクリプト関連の属性にマッチさせ、
なおかつ通常は「onclick」にマッチさせないようにするには
どう書けばよいのでしょうか。
onclick属性にもマッチさせたいときは、$KEYCHKを使用するつもりです。
(*(on[a-z]+)&*(^onclick)=)\1
こんな感じで書いてみたのですが、onclickにもマッチしてしまいます。
ここに書かれているようなスクリプト関連の属性にマッチさせ、
なおかつ通常は「onclick」にマッチさせないようにするには
どう書けばよいのでしょうか。
onclick属性にもマッチさせたいときは、$KEYCHKを使用するつもりです。
(*(on[a-z]+)&*(^onclick)=)\1
こんな感じで書いてみたのですが、onclickにもマッチしてしまいます。
59 :名無しさん@お腹いっぱい。:2006/11/25(土) 19:38:09 ID:YUzVJ0fa0
>>58
つ on(^click)[a-z]+{3,20}=
つ on(^click)[a-z]+{3,20}=
60 :名無しさん@お腹いっぱい。:2006/11/26(日) 16:21:57 ID:q/copbjI0
61 :名無しさん@お腹いっぱい。:2006/11/26(日) 19:52:12 ID:q/copbjI0
>>56
なるほど、VMware+VistaRC1で再現出来そう。 スペック的にうちでは無理だけど。
なるほど、VMware+VistaRC1で再現出来そう。 スペック的にうちでは無理だけど。
62 :名無しさん@お腹いっぱい。:2006/11/26(日) 20:16:42 ID:q/copbjI0
あ、マルチブートでいいじゃんw
>59
どうもありがとうございます。否定を先に書いておけばよいのですね。
属性名は最長で18文字のようなので {3,16} で十分かなとも思うのですが、
ちょっと余裕があったほうがよいのでしょうか。さっそく使ってみます。
どうもありがとうございます。否定を先に書いておけばよいのですね。
属性名は最長で18文字のようなので {3,16} で十分かなとも思うのですが、
ちょっと余裕があったほうがよいのでしょうか。さっそく使ってみます。
グローバル変数ではなくローカル変数で文字化けを回避出来るかも知れないので
試しに作ってみました。 これで動くなら乗り換え推奨です。
Google: High Light 2 [2006/11/27 - 817]
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0053.txt
試しに作ってみました。 これで動くなら乗り換え推奨です。
Google: High Light 2 [2006/11/27 - 817]
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0053.txt
65 :名無しさん@お腹いっぱい。:2006/11/27(月) 05:11:48 ID:1UZtU9sA0
migemoのログを2chブラウザに入れてログ検索したらこんなやり取りが出てきました。
Proxomitron フィルター作成スレッド Part4
http://pc7.2ch.net/test/read.cgi/software/1138069706/
143 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/03/05(日) 21:17:51 ID:iwuQps7B0
そういえば、google high light の最新版は文字化けするな。
古いのに戻したいのに見つからないよ。
144 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/03/05(日) 22:28:00 ID:D06bOlrz0
うちは化けないよ。
Proxomitron フィルター作成スレッド Part4
http://pc7.2ch.net/test/read.cgi/software/1138069706/
143 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/03/05(日) 21:17:51 ID:iwuQps7B0
そういえば、google high light の最新版は文字化けするな。
古いのに戻したいのに見つからないよ。
144 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/03/05(日) 22:28:00 ID:D06bOlrz0
うちは化けないよ。
66 :名無しさん@お腹いっぱい。:2006/11/27(月) 15:54:34 ID:aS6yLCHU0
>>64
&はいらない模様。
テストウインドウ = "ABC"
Name = "test1"
Active = TRUE
Limit = 256
Match = "A(*)\0C$SET(0=D)"
Replace = "1\03"
Name = "test2"
Active = TRUE
Limit = 256
Match = "A\0C$SET(0=D)"
Replace = "1\03"
Name = "test3"
Active = TRUE
Limit = 256
Match = "A(\0)C$SET(0=D)"
Replace = "1\03"
test1だけBのまま。 (...)\0で取り込む場合は&がいる。
&はいらない模様。
テストウインドウ = "ABC"
Name = "test1"
Active = TRUE
Limit = 256
Match = "A(*)\0C$SET(0=D)"
Replace = "1\03"
Name = "test2"
Active = TRUE
Limit = 256
Match = "A\0C$SET(0=D)"
Replace = "1\03"
Name = "test3"
Active = TRUE
Limit = 256
Match = "A(\0)C$SET(0=D)"
Replace = "1\03"
test1だけBのまま。 (...)\0で取り込む場合は&がいる。
67 :名無しさん@お腹いっぱい。:2006/11/27(月) 17:25:14 ID:HWzFKkOW0
>>64
残念、化けた。
残念、化けた。
68 :名無しさん@お腹いっぱい。:2006/11/27(月) 19:30:43 ID:Uj1Sm9EE0
ばけらった
すみません、遅くなりました。m(_ _)m
>>66
どうもです。 &が無くても中身が更新されるんですね。
$NEST、$TST、Bounds欄ではどういう挙動をするか気に
なるので後で調べてみます。
>>67-68
確認ありがとうございました。m(_ _)m
動きませんでしたか、すみません..。 これでダメだということは
グローバル変数経由でないと\@は出力出来ないということです
ね、ちょっとショック..。
>>64のはアプロダから削除しておきます。 もう1つのほうも
これ以上は検証するネタがないのでthink氏が対応版を出す
などして用済みになれば削除する予定です、では。
>>66
どうもです。 &が無くても中身が更新されるんですね。
$NEST、$TST、Bounds欄ではどういう挙動をするか気に
なるので後で調べてみます。
>>67-68
確認ありがとうございました。m(_ _)m
動きませんでしたか、すみません..。 これでダメだということは
グローバル変数経由でないと\@は出力出来ないということです
ね、ちょっとショック..。
>>64のはアプロダから削除しておきます。 もう1つのほうも
これ以上は検証するネタがないのでthink氏が対応版を出す
などして用済みになれば削除する予定です、では。
肉ちゃんの過去ログ読んでたら面白い代入方法を見つけたので晒し。
[Patterns]
Name = "(^^)"
Active = FALSE
Limit = 256
Match = "<b>*1$SET(#=^)</b>"
Replace = "(\@)"
サンプルテキスト : <b>11</b>
結果 : (^^)
↓これの応用
# increment リストの2つ目
# 「9のみで構成される数値」をインクリメント (+1)
$TST(Num=9++9$SET(Ntmp=$GET(Ntmp)0)(^?))$SET(Num=1$GET(Ntmp))$SET(Ntmp=)
[Patterns]
Name = "(^^)"
Active = FALSE
Limit = 256
Match = "<b>*1$SET(#=^)</b>"
Replace = "(\@)"
サンプルテキスト : <b>11</b>
結果 : (^^)
↓これの応用
# increment リストの2つ目
# 「9のみで構成される数値」をインクリメント (+1)
$TST(Num=9++9$SET(Ntmp=$GET(Ntmp)0)(^?))$SET(Num=1$GET(Ntmp))$SET(Ntmp=)
71 :名無しさん@お腹いっぱい。:2006/11/30(木) 10:21:03 ID:rfBw1woi0
Google High Light 1 (2006/06/04)
Google High Light 2 (2006/06/27)
ttp://vird2002.s8.xrea.com/download/#filter_kill_ad_type-list
を使っているのですが 検索の文字列の間が全角スペースの時に
うまくハイライトしません 何処を書き換えれば良いでしょうか?
hoge[半角スペース]ほげ の時OK
hoge[全角スペース]ほげ の時駄目
宜しくお願いします。
Google High Light 2 (2006/06/27)
ttp://vird2002.s8.xrea.com/download/#filter_kill_ad_type-list
を使っているのですが 検索の文字列の間が全角スペースの時に
うまくハイライトしません 何処を書き換えれば良いでしょうか?
hoge[半角スペース]ほげ の時OK
hoge[全角スペース]ほげ の時駄目
宜しくお願いします。
72 :名無しさん@お腹いっぱい。:2006/11/30(木) 14:19:51 ID:/I61tEMd0
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Google transfer (Out) [2005.10.18] beta"
Match = "(http://www.google.co(m|.jp)/search)\#(^(^\?))\#(([?&])\#oe=[^&]+(\&|)|([&?]q=)\#(([^&]++)\#(%81%40|%a1%a1|%e3%80%80|%21%21$SET(#=%1b%28B)$SET(2=%1b%24B))$SET(#=+\2))+{1,*}) \#"
Replace = "$JUMP(\@)"
In = FALSE
Out = TRUE
Key = "URL: Google transfer (Out) [2005.10.18] beta"
Match = "(http://www.google.co(m|.jp)/search)\#(^(^\?))\#(([?&])\#oe=[^&]+(\&|)|([&?]q=)\#(([^&]++)\#(%81%40|%a1%a1|%e3%80%80|%21%21$SET(#=%1b%28B)$SET(2=%1b%24B))$SET(#=+\2))+{1,*}) \#"
Replace = "$JUMP(\@)"
73 :名無しさん@お腹いっぱい。:2006/11/30(木) 14:36:33 ID:rfBw1woi0
ありがとうございます。
74 :名無しさん@お腹いっぱい。:2006/12/01(金) 16:40:05 ID:xWBEfpDA0
youtubeって、www4とかあったんだね。
気が付かなかった。
気が付かなかった。
更新お疲れ様です >think氏
817A/B版はお役御免につきアプロダから削除しておきました。
817A/B版はお役御免につきアプロダから削除しておきました。
76 :名無しさん@お腹いっぱい。:2006/12/06(水) 21:36:18 ID:nC6dhwpd0
http://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0046.txt
↑のうたまっぷ用が上手く表示されません・・・
どうにかなりませんか?
↑のうたまっぷ用が上手く表示されません・・・
どうにかなりませんか?
77 :名無しさん@お腹いっぱい。:2006/12/07(木) 00:53:20 ID:gF13/8nK0
wikiをutamapで検索
78 :名無しさん@お腹いっぱい。:2006/12/07(木) 01:00:56 ID:NjyDIVKn0
ここで試したら普通に効いたよ。
ttp://www.utamap.com/showtop.php?surl=B19196
>think氏
>$NEST を使用しているので、この処理は不要かもしれません
(^?)を消してデバックモードで見ると違いが分かります。
ttp://www.utamap.com/showtop.php?surl=B19196
>think氏
>$NEST を使用しているので、この処理は不要かもしれません
(^?)を消してデバックモードで見ると違いが分かります。
79 :名無しさん@お腹いっぱい。:2006/12/07(木) 04:07:23 ID:ACnTOB1q0
>>78
上のURLだと
http://www.utamap.com/showtop.php?surl=B19196
普通に検索から行くと
http://www.utamap.com/showkasi.php?surl=B19196
でURLが違うんですが・・・
どういうことですか?
上のURLだと
http://www.utamap.com/showtop.php?surl=B19196
普通に検索から行くと
http://www.utamap.com/showkasi.php?surl=B19196
でURLが違うんですが・・・
どういうことですか?
取り合えずフィルターのURL書き換えで解決しました。
>>79
URLが2つあるけどオリジナルはshowkasiにしか対応してなくて、前スレの584氏が修正したものは
showtopにしか対応してなかった。 ・・ということみたい。 ということで両方のURL対応版。
[Patterns]
Name = "Uta-map swf -> txt part1 (2006_12_07)"
Active = TRUE
URL = "www.utamap.com/(show(top|kasi).php\?surl=|phpflash/flashfalsephp.php\?unum=)"
Limit = 32767
Match = " $NEST(<object\s,*<embed\s[^>]++src=$AV(phpflash/showkasi.swf\?ucode=([a-z0-9]+)\0)*,</object>) "
"|"
"<NOSCRIPT*</NOSCRIPT>"
"|"
"<SCRIPT*</SCRIPT>"
"|"
"test[0-9]+=[0-9]+\&test[0-9]+="
Replace = "$TST(\0=[a-z0-9]*)"
"<iframe src="http://www.utamap.com/phpflash/flashfalsephp.php?unum=\0?" height="400" width="600">\r\n"
"This filter use IFrame Tag! your browser cant't use this Tag.\r\n"
"</iframe>\r\n</TABLE></TABLE></BODY></HTML>\k"
読み込みがいつまでも止まらないので強制的に読み込みを停止する処理を入れときました。
URLが2つあるけどオリジナルはshowkasiにしか対応してなくて、前スレの584氏が修正したものは
showtopにしか対応してなかった。 ・・ということみたい。 ということで両方のURL対応版。
[Patterns]
Name = "Uta-map swf -> txt part1 (2006_12_07)"
Active = TRUE
URL = "www.utamap.com/(show(top|kasi).php\?surl=|phpflash/flashfalsephp.php\?unum=)"
Limit = 32767
Match = " $NEST(<object\s,*<embed\s[^>]++src=$AV(phpflash/showkasi.swf\?ucode=([a-z0-9]+)\0)*,</object>) "
"|"
"<NOSCRIPT*</NOSCRIPT>"
"|"
"<SCRIPT*</SCRIPT>"
"|"
"test[0-9]+=[0-9]+\&test[0-9]+="
Replace = "$TST(\0=[a-z0-9]*)"
"<iframe src="http://www.utamap.com/phpflash/flashfalsephp.php?unum=\0?" height="400" width="600">\r\n"
"This filter use IFrame Tag! your browser cant't use this Tag.\r\n"
"</iframe>\r\n</TABLE></TABLE></BODY></HTML>\k"
読み込みがいつまでも止まらないので強制的に読み込みを停止する処理を入れときました。
82 :名無しさん@お腹いっぱい。:2006/12/07(木) 05:13:10 ID:ACnTOB1q0
83 :名無しさん@お腹いっぱい。:2006/12/07(木) 05:33:33 ID:NjyDIVKn0
(ё▽ё)ノシ
84 :名無しさん@お腹いっぱい。:2006/12/07(木) 08:32:13 ID:aiAW0M3n0
(◕∀◕)ノシ
85 :名無しさん@お腹いっぱい。:2006/12/07(木) 08:54:49 ID:YjNK8s9d0
d(゚Д゚)☆スペシャルサンクス☆( ゚Д゚)b
86 :名無しさん@お腹いっぱい。:2006/12/08(金) 23:14:53 ID:QEZq1mOz0
>>81
おつ
おつ
87 :名無しさん@お腹いっぱい。:2006/12/09(土) 00:42:58 ID:TZXbep1x0
4.5にしたら、pcが落ちるようになってしまったんだが、何が怪しいでしょうか?
4.4からの移行です。レジストリとか??
ブラウザでどっかのページみようとした瞬間に落ちる。(ランダム)
4.4からの移行です。レジストリとか??
ブラウザでどっかのページみようとした瞬間に落ちる。(ランダム)
88 :名無しさん@お腹いっぱい。:2006/12/09(土) 01:07:05 ID:4aBuCChb0
レジストリは使ってない筈
ウイルスじゃね?CRCかMD5を
ウイルスじゃね?CRCかMD5を
89 :名無しさん@お腹いっぱい。:2006/12/09(土) 01:21:55 ID:MrCYpI9z0
4.5のパグだから素直に4.4使っておいたほうがいいよ
90 :名無しさん@お腹いっぱい。:2006/12/09(土) 02:17:21 ID:WRh2Yu790
ありがとうございます。crcなどはどこに乗ってるんですか?
4.4とは別フォルダをしようして、新規に4.5juneをいれて、exeをろだの+5に
したんですが・・・。(+3も少し使用。それと、9x版も少し起動したかも)
デフォルトcfgファイルは4.4および4.5とも同じ形式ですか?それなら
4.5の設定を4.4に移そうかな。こっちの設定の方がいろいろ便利だったので。
一応、ウェブキャッシュを消して見た。
4.4とは別フォルダをしようして、新規に4.5juneをいれて、exeをろだの+5に
したんですが・・・。(+3も少し使用。それと、9x版も少し起動したかも)
デフォルトcfgファイルは4.4および4.5とも同じ形式ですか?それなら
4.5の設定を4.4に移そうかな。こっちの設定の方がいろいろ便利だったので。
一応、ウェブキャッシュを消して見た。
91 :名無しさん@お腹いっぱい。:2006/12/09(土) 04:11:35 ID:fQH69PRH0
peercast、ロダのパス…。 作者の普段の行動が手に取るように分かってしまうんだけどなんて魔法?
92 :名無しさん@お腹いっぱい。:2006/12/09(土) 04:27:13 ID:HdE0FRAA0
?
( ゚д゚ )
( ゚д゚ )
93 :名無しさん@お腹いっぱい。:2006/12/09(土) 04:40:18 ID:fQH69PRH0
つ Wiki
94 :名無しさん@お腹いっぱい。:2006/12/13(水) 19:03:17 ID:2qmfn3Zo0
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Cookie: 29ch html2dat (out)"
URL = "$OHDR(User-Agent: Monazilla/1.00)"
Replace = "text=dat<>1<>0<>false<>mycss=<>0<>-1<>3000<><><><>"
In = FALSE
Out = TRUE
Key = "URL: 2ch - 29ch kakolog Redirect (Out)"
URL = "$OHDR(User-Agent: Monazilla/1.00)"
Match = "http://(([^.]+)\2.2ch.net|(www(2|)\0$SET(2=bbspink\0)|([^.]+)\0$SET(2=bbspink-\0)).bbspink.com)(:80|)/([^/]+)\3/((kako/([0-9]+{4})\4/\4([0-9])\5/
\4\5([0-9]+{5})\6|dat/([0-9]+{4})\4([0-9])\5([0-9]+{5})\6)$SET(7=\4\5\6)|(kako/([0-9]+{3})\4/\4([0-9]+{6})\5|dat/([0-9]+{3})\4([0-9]+{6})\5)$SET(7=\4\5)).dat"
Replace = "$RDIR(http://makimo.to/2ch/\2_\3/\4/\7.html)$FILTER(false)"
In = FALSE
Out = TRUE
Key = "Cookie: 29ch html2dat (out)"
URL = "$OHDR(User-Agent: Monazilla/1.00)"
Replace = "text=dat<>1<>0<>false<>mycss=<>0<>-1<>3000<><><><>"
In = FALSE
Out = TRUE
Key = "URL: 2ch - 29ch kakolog Redirect (Out)"
URL = "$OHDR(User-Agent: Monazilla/1.00)"
Match = "http://(([^.]+)\2.2ch.net|(www(2|)\0$SET(2=bbspink\0)|([^.]+)\0$SET(2=bbspink-\0)).bbspink.com)(:80|)/([^/]+)\3/((kako/([0-9]+{4})\4/\4([0-9])\5/
\4\5([0-9]+{5})\6|dat/([0-9]+{4})\4([0-9])\5([0-9]+{5})\6)$SET(7=\4\5\6)|(kako/([0-9]+{3})\4/\4([0-9]+{6})\5|dat/([0-9]+{3})\4([0-9]+{6})\5)$SET(7=\4\5)).dat"
Replace = "$RDIR(http://makimo.to/2ch/\2_\3/\4/\7.html)$FILTER(false)"
95 :名無しさん@お腹いっぱい。:2006/12/15(金) 04:43:09 ID:7YuBUavy0
googleの検索結果のソースが改悪されて異常に使いにくくなった。
・「○○の検索結果」と書かれていたのが、ただの「検索結果」に。
・イメージ検索やキーワードなどが、適当な場所のセルに独立して収められるようになった。
・検索結果の表示される横幅が狭くなった。
こんなところかな?
ユーザスタイルも書き直さなければならない。
どうしよう、これ。なんでこんな使いにくいシステムにせにゃならんのか理解に苦しむ。
・「○○の検索結果」と書かれていたのが、ただの「検索結果」に。
・イメージ検索やキーワードなどが、適当な場所のセルに独立して収められるようになった。
・検索結果の表示される横幅が狭くなった。
こんなところかな?
ユーザスタイルも書き直さなければならない。
どうしよう、これ。なんでこんな使いにくいシステムにせにゃならんのか理解に苦しむ。
96 :名無しさん@お腹いっぱい。:2006/12/15(金) 13:58:32 ID:ueMJjD770
>>95
え?
え?
97 :名無しさん@お腹いっぱい。:2006/12/15(金) 15:25:01 ID:tYSMVP9x0
デフォルトフィルターの”Set-cookie: Make all cookies session only (in)”が効いていないみたいなのですが、SyleraなどGeckoではつかえないのでしょうか?
ごめん。なんか勘違いしたみたいだ。
後で同じキーワードで検索してみたけど、>95のようにはならなかったよ。
それなら、あのとき見たものは何だったんだろうな。
またそういうことがあったら、何か法則などがないか試してみる。
後で同じキーワードで検索してみたけど、>95のようにはならなかったよ。
それなら、あのとき見たものは何だったんだろうな。
またそういうことがあったら、何か法則などがないか試してみる。
99 :名無しさん@お腹いっぱい。:2006/12/15(金) 22:42:21 ID:eP7Z7Ywu0
たまに実験してるからそれに当たったんじゃね?
何時の間にかなおってるとか何度か有ったし。
何時の間にかなおってるとか何度か有ったし。
100 :名無しさん@お腹いっぱい。:2006/12/16(土) 03:14:23 ID:/YOGWH+A0
ヘッダフィルタ(out?)で、GETメソッドのURL内の任意の文字列を全て置換するには、どうしたらいいんでしょうか?
Unicodeのページで、全角空白%E3%80%80を半角空白%20に全て変換したのですが。
ぶっちゃけグーグルですが。
Unicodeのページで、全角空白%E3%80%80を半角空白%20に全て変換したのですが。
ぶっちゃけグーグルですが。
101 :名無しさん@お腹いっぱい。:2006/12/16(土) 08:26:09 ID:a25lr4PN0
>>100
以前私が作ったもので良ければ..。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: del double-byte space and out-encode (out)"
URL = "www.google.co(.jp|m)/*\?*q="
Match = "http://(\#(%E3%80%80$SET(#=+)|([?&])\#oe=[^&]+\&+))+{1,*}\#"
Replace = "$JUMP(http://\@)"
以前私が作ったもので良ければ..。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: del double-byte space and out-encode (out)"
URL = "www.google.co(.jp|m)/*\?*q="
Match = "http://(\#(%E3%80%80$SET(#=+)|([?&])\#oe=[^&]+\&+))+{1,*}\#"
Replace = "$JUMP(http://\@)"
102 :名無しさん@お腹いっぱい。:2006/12/19(火) 04:54:02 ID:47XuO8PM0
任意のサイトに google の検索フォームを追加するフィルタのα版。
現在開いているサイト内のみを検索対象にする。
ただし、サブドメインや独自ドメインなどでないサイトではだめかも。
とりあえず書いてみましたというところで。
Name = "insert search form (2006.12.19)"
Active = TRUE
URL = "$KEYCHK(g)"
Limit = 16
Match = "(^(^</body>))"
Replace = "\r\n\r\n<form action="http://www.google.co.jp/search" method="get">\r\n"
"<p><input type="text" name="q" size="50" value="Google" \r\n"
"onfocus="if(this.value=='Google'){this.value=''};" \r\n"
"onblur="if(this.value==''){this.value='Google'}">\r\n"
"<input type="submit" name="btnG" value="Google Search">\r\n"
"<input type="hidden" name="hl" value="ja">\r\n"
"<!-- input type="hidden" name="ie" value="Shift_JIS" -->\r\n"
"<!-- input type="hidden" name="oe" value="Shift_JIS" -->\r\n"
"<input type="hidden" name="num" value="20">\r\n"
"<input type="hidden" name="as_sitesearch" value="\h"></p>\r\n"
"</form>\r\n\r\n$STOP"
$STOP が効かない。
$KEYCHK のキーを押している間は無限にマッチするので危険。
$STOP は置換テキストでも使えるそうだけど、
なぜかただのテキストとして扱われているもよう。なぜだろう?
現在開いているサイト内のみを検索対象にする。
ただし、サブドメインや独自ドメインなどでないサイトではだめかも。
とりあえず書いてみましたというところで。
Name = "insert search form (2006.12.19)"
Active = TRUE
URL = "$KEYCHK(g)"
Limit = 16
Match = "(^(^</body>))"
Replace = "\r\n\r\n<form action="http://www.google.co.jp/search" method="get">\r\n"
"<p><input type="text" name="q" size="50" value="Google" \r\n"
"onfocus="if(this.value=='Google'){this.value=''};" \r\n"
"onblur="if(this.value==''){this.value='Google'}">\r\n"
"<input type="submit" name="btnG" value="Google Search">\r\n"
"<input type="hidden" name="hl" value="ja">\r\n"
"<!-- input type="hidden" name="ie" value="Shift_JIS" -->\r\n"
"<!-- input type="hidden" name="oe" value="Shift_JIS" -->\r\n"
"<input type="hidden" name="num" value="20">\r\n"
"<input type="hidden" name="as_sitesearch" value="\h"></p>\r\n"
"</form>\r\n\r\n$STOP"
$STOP が効かない。
$KEYCHK のキーを押している間は無限にマッチするので危険。
$STOP は置換テキストでも使えるそうだけど、
なぜかただのテキストとして扱われているもよう。なぜだろう?
103 :名無しさん@お腹いっぱい。:2006/12/19(火) 07:40:57 ID:tTszulTD0
>$STOP が効かない。
ワロタw
ワロタw
104 :名無しさん@お腹いっぱい。:2006/12/19(火) 08:21:07 ID:47XuO8PM0
ワラワレタ
105 :名無しさん@お腹いっぱい。:2006/12/19(火) 08:31:51 ID:tTszulTD0
$STOPの使い方を日本語訳サイトで確認しるw
106 :名無しさん@お腹いっぱい。:2006/12/19(火) 08:58:23 ID:47XuO8PM0
$STOP → $STOP()
アフォ杉
あー。せっかく赤字で書かれていたのに気づかなかった。
>105
どうもありがとう。
アフォ杉
あー。せっかく赤字で書かれていたのに気づかなかった。
>105
どうもありがとう。
107 :名無しさん@お腹いっぱい。:2006/12/20(水) 17:02:28 ID:ILwXjZfq0
「`ー'′/ / ヽ、 \ \ ヽl}::.:)、 \
l_,ィ / / l l 、 l `、 {:|}く\ヽ/
ノ ,′ ! { | l| | l ):|} ノ|:「´
. ヽ∧| , | | l | l| | l| {:|!::)|:
|::l| | | l 、 | l | _,厶| j| {::|}::} |」
l:::| `、!| \ ヽ、 |,.イ,斗予 | |{K!j | >>106
〈:;小、ヽヽ、T,Zニミヽj ^ヾrシ | |ァ1 | いい子ね…
| \ヽN {ヾtク | ト |_| |
. | | l \ `- /!| |::..::.`:┴-、
. | | | | > 、 __ /::..::|| |::..::..::..::..::..:ト、
| j /| l/::..::..::..::..rクニミ::../| |::..::..::..::..::./::..`ヽ、
. l ! //l l::..::..::..::/;ハミZシ//| |::..::..::..::..:/::..::.`ー┴―-ォ
j レ'∧! ,'::..::..::.〃::..::..::.レ'/::| |::..::..::..::r'::..::..::..::..::..::..::/::|
/ / / /| ハ::..::..::..::..::..::. /l ト、| |::..::..::..::{ー-::.ハ::..::..:: /::..|
. / / |{::.| ||::.\::..::..::..::../::.| l::.| |::..::..::./::..::..::/::..\::./:ヽ:j
( 真紅氏 )
l_,ィ / / l l 、 l `、 {:|}く\ヽ/
ノ ,′ ! { | l| | l ):|} ノ|:「´
. ヽ∧| , | | l | l| | l| {:|!::)|:
|::l| | | l 、 | l | _,厶| j| {::|}::} |」
l:::| `、!| \ ヽ、 |,.イ,斗予 | |{K!j | >>106
〈:;小、ヽヽ、T,Zニミヽj ^ヾrシ | |ァ1 | いい子ね…
| \ヽN {ヾtク | ト |_| |
. | | l \ `- /!| |::..::.`:┴-、
. | | | | > 、 __ /::..::|| |::..::..::..::..::..:ト、
| j /| l/::..::..::..::..rクニミ::../| |::..::..::..::..::./::..`ヽ、
. l ! //l l::..::..::..::/;ハミZシ//| |::..::..::..::..:/::..::.`ー┴―-ォ
j レ'∧! ,'::..::..::.〃::..::..::.レ'/::| |::..::..::..::r'::..::..::..::..::..::..::/::|
/ / / /| ハ::..::..::..::..::..::. /l ト、| |::..::..::..::{ー-::.ハ::..::..:: /::..|
. / / |{::.| ||::.\::..::..::..::../::.| l::.| |::..::..::./::..::..::/::..\::./:ヽ:j
( 真紅氏 )
108 :名無しさん@お腹いっぱい。:2006/12/21(木) 06:49:07 ID:WNysFY4U0
Name = "google 2ch to mimizun"
Active = TRUE
URL = "$TYPE(htm) [^.]+.google.co(.jp|m)/search"
Limit = 2048
Match = "($NEST($NEST(<a\s,*href=$AV(http://([^.]+.2ch.net)\2/test/read.cgi/([^/]+)\1/([0-9]+)\3*)*,>),</a>))\9"
Replace = "\9<a href="http://mimizun.com:81/log/2ch/\1/\2/\1/dat/\3.dat>m</a>"
googleでヒットしたもののうち2chへのリンクにmimizunのdatへの直リンも追加するフィルタなのですが、
このフィルタをオンにすると画面がおかしくなります。
ソースは思った通りにできあがってるのでどうもJAVA SCRIPTがじゃまをしているように見えるんですが、
どうにかこれを使い物にできないでしょうか。
Name = "google 2ch to mimizun 2"
Active = FALSE
URL = "$TYPE(htm) [^.]+.google.co(.jp|m)/search"
Limit = 2048
Match = "($NEST(<span\s,*class=$AV(a)*,>)([^.]+.2ch.net)\2/test/read.cgi/([^/]+)\1/([0-9]+)\3*</span><nobr>$NEST($NEST(<a\s,>),</a>)[^<]+$NEST($NEST(<a\s,>),</a>))\9"
Replace = "\9 <a href="http://mimizun.com:81/log/2ch/\1/\2/\1/dat/\3.dat>mimizun</a>"
こっちは苦肉の策で
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ
↑を
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ mimizun
に書き換えるようなフィルタなのですが、やはりこれもソースでみるとうまく行っているのに描画されたものはおかしいです。
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k mimizun キャッシュ - 関連ページ
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - mimizun - 関連ページ mimizun
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ
というような置き方も試してみましたが、ことごとく失敗しました。
Active = TRUE
URL = "$TYPE(htm) [^.]+.google.co(.jp|m)/search"
Limit = 2048
Match = "($NEST($NEST(<a\s,*href=$AV(http://([^.]+.2ch.net)\2/test/read.cgi/([^/]+)\1/([0-9]+)\3*)*,>),</a>))\9"
Replace = "\9<a href="http://mimizun.com:81/log/2ch/\1/\2/\1/dat/\3.dat>m</a>"
googleでヒットしたもののうち2chへのリンクにmimizunのdatへの直リンも追加するフィルタなのですが、
このフィルタをオンにすると画面がおかしくなります。
ソースは思った通りにできあがってるのでどうもJAVA SCRIPTがじゃまをしているように見えるんですが、
どうにかこれを使い物にできないでしょうか。
Name = "google 2ch to mimizun 2"
Active = FALSE
URL = "$TYPE(htm) [^.]+.google.co(.jp|m)/search"
Limit = 2048
Match = "($NEST(<span\s,*class=$AV(a)*,>)([^.]+.2ch.net)\2/test/read.cgi/([^/]+)\1/([0-9]+)\3*</span><nobr>$NEST($NEST(<a\s,>),</a>)[^<]+$NEST($NEST(<a\s,>),</a>))\9"
Replace = "\9 <a href="http://mimizun.com:81/log/2ch/\1/\2/\1/dat/\3.dat>mimizun</a>"
こっちは苦肉の策で
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ
↑を
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ mimizun
に書き換えるようなフィルタなのですが、やはりこれもソースでみるとうまく行っているのに描画されたものはおかしいです。
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k mimizun キャッシュ - 関連ページ
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - mimizun - 関連ページ mimizun
pc8.2ch.net/test/read.cgi/win/1149050460/-100 - 35k キャッシュ - 関連ページ
というような置き方も試してみましたが、ことごとく失敗しました。
109 :名無しさん@お腹いっぱい。:2006/12/21(木) 09:34:26 ID:MCqs2/450
>>108
<a href=">
<a href=">
110 :名無しさん@お腹いっぱい。:2006/12/23(土) 12:18:14 ID:0r3xAbKG0
フィルターの作成をおながいしたいです。
ホモサイトでアレなんですが、
http://bbs01.apricot-fizz.net/nonkeoyaji/
と
http://bbs01.apricot-fizz.net/nonkeoyaji/?command=GRPVIEW&num=29514
の、一番下に出てくる「無料体験実施中なんたら」ってある
画像の広告を削除できるフィルターを作っていただけないでしょうか?
(どんびきしたらスマソ)
どうかよろしくおながいします。m(__)m
ホモサイトでアレなんですが、
http://bbs01.apricot-fizz.net/nonkeoyaji/
と
http://bbs01.apricot-fizz.net/nonkeoyaji/?command=GRPVIEW&num=29514
の、一番下に出てくる「無料体験実施中なんたら」ってある
画像の広告を削除できるフィルターを作っていただけないでしょうか?
(どんびきしたらスマソ)
どうかよろしくおながいします。m(__)m
111 :名無しさん@お腹いっぱい。:2006/12/23(土) 12:39:52 ID:k9zqbMl70
>>110
[Patterns]
Name = "( apricot-fizz.net ) kill bottom ad"
Active = TRUE
URL = "bbs01.apricot-fizz.net/$TYPE(htm)"
Limit = 19
Match = "<hr><center><iframe"
Replace = "</div><p><br><br></p></body></html>\k"
[Patterns]
Name = "( apricot-fizz.net ) kill bottom ad"
Active = TRUE
URL = "bbs01.apricot-fizz.net/$TYPE(htm)"
Limit = 19
Match = "<hr><center><iframe"
Replace = "</div><p><br><br></p></body></html>\k"
112 :名無しさん@お腹いっぱい。:2006/12/23(土) 12:45:40 ID:0r3xAbKG0
113 :名無しさん@お腹いっぱい。:2006/12/23(土) 13:10:23 ID:0r3xAbKG0
>>111
あ、正確に言うと、二つ目の、
http://bbs01.apricot-fizz.net/nonkeoyaji/?command=GRPVIEW&num=29501
のほうが消えないです。
もしよかったら、お手数ですが、
こちらのほうの消去フィルターの作成も、おながいします。m(__)m
あ、正確に言うと、二つ目の、
http://bbs01.apricot-fizz.net/nonkeoyaji/?command=GRPVIEW&num=29501
のほうが消えないです。
もしよかったら、お手数ですが、
こちらのほうの消去フィルターの作成も、おながいします。m(__)m
114 :名無しさん@お腹いっぱい。:2006/12/23(土) 14:48:29 ID:k9zqbMl70
>>113
すまそ、トップしか見てなかった。 ついでに元画像を表示させるようにした。
それと後からいろいろ追加出来るように出力するものは\9に入れる仕様に変更。
[Patterns]
Name = "( apricot-fizz.net ) kill bottom ad +alpha"
Active = TRUE
URL = "bbs01.apricot-fizz.net/$TYPE(htm)"
Limit = 1024
Match = "$NEST(<iframe,</iframe>)|<a\shref=$AV(./\?command=GRPVIEW*)([^>]+> <img\s[^>]++src=)\0"
"$AV((./grpview.php/[0-9]+.)\1[0-9]+.([0-9]+.[a-z]+{3,4})\2)$SET(9=<a href="\1\2"\0"\1\2")"
Replace = "\9"
すまそ、トップしか見てなかった。 ついでに元画像を表示させるようにした。
それと後からいろいろ追加出来るように出力するものは\9に入れる仕様に変更。
[Patterns]
Name = "( apricot-fizz.net ) kill bottom ad +alpha"
Active = TRUE
URL = "bbs01.apricot-fizz.net/$TYPE(htm)"
Limit = 1024
Match = "$NEST(<iframe,</iframe>)|<a\shref=$AV(./\?command=GRPVIEW*)([^>]+> <img\s[^>]++src=)\0"
"$AV((./grpview.php/[0-9]+.)\1[0-9]+.([0-9]+.[a-z]+{3,4})\2)$SET(9=<a href="\1\2"\0"\1\2")"
Replace = "\9"
115 :名無しさん@お腹いっぱい。:2006/12/23(土) 18:25:53 ID:8I3p70DB0
116 :名無しさん@お腹いっぱい。:2006/12/23(土) 20:19:57 ID:k9zqbMl70
(^-^;)ノシ
117 :名無しさん@お腹いっぱい。:2006/12/23(土) 22:18:06 ID:k9zqbMl70
[Patterns]
Name = "image inline ext (+2ch) [2006.12.23]"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "$NEST(<a\s[^>]+>,</a>)"
Limit = 4096
Match = "([^>]++href=)\0$AV((([^/]+//)\1(ime.nu/|ime.st/|pinktower.com/|www2.ime.st/|)|)(\2)"
".(jpg|gif|bmp|png)\3(.html+|)\4)([^>]+>\s+[^<]*</a>)\5($OHDR(User-Agent:*Opera)$SET(6=\\x2F)|)"
Replace = "\0"\1\2.\3\4" \5\r\n<span><a onclick="this.parentNode.innerHTML="
"(this.parentNode.innerHTML.match(/\\x2D\\x3Cbr\6\\x3E\\x3Cimg/i)!=null)?"
"this.parentNode.innerHTML.replace(/\\x2D\\x3Cbr\6\\x3E\\x3Cimg.*\\x3E/i,'\\x2B'):"
"this.parentNode.innerHTML.replace(/\\x2B/i,'\\x2D\\x3Cbr\6\\x3E\\x3Cimg src=\1\2.\3 border=0\\x3E');"
"return(false);" href="javascript:"> [\3]</a>+</span>\r\n"
ttp://tmp.2chan.net/img2/futaba.htm ですごいことになる問題を修正。
Name = "image inline ext (+2ch) [2006.12.23]"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "$NEST(<a\s[^>]+>,</a>)"
Limit = 4096
Match = "([^>]++href=)\0$AV((([^/]+//)\1(ime.nu/|ime.st/|pinktower.com/|www2.ime.st/|)|)(\2)"
".(jpg|gif|bmp|png)\3(.html+|)\4)([^>]+>\s+[^<]*</a>)\5($OHDR(User-Agent:*Opera)$SET(6=\\x2F)|)"
Replace = "\0"\1\2.\3\4" \5\r\n<span><a onclick="this.parentNode.innerHTML="
"(this.parentNode.innerHTML.match(/\\x2D\\x3Cbr\6\\x3E\\x3Cimg/i)!=null)?"
"this.parentNode.innerHTML.replace(/\\x2D\\x3Cbr\6\\x3E\\x3Cimg.*\\x3E/i,'\\x2B'):"
"this.parentNode.innerHTML.replace(/\\x2B/i,'\\x2D\\x3Cbr\6\\x3E\\x3Cimg src=\1\2.\3 border=0\\x3E');"
"return(false);" href="javascript:"> [\3]</a>+</span>\r\n"
ttp://tmp.2chan.net/img2/futaba.htm ですごいことになる問題を修正。
118 :名無しさん@お腹いっぱい。:2006/12/23(土) 22:21:31 ID:k9zqbMl70
ふたば見てると切断バグの発生がすごい。
POSTの場合は発生しやすいのかも。
POSTの場合は発生しやすいのかも。
119 :名無しさん@お腹いっぱい。:2006/12/25(月) 17:19:41 ID:TqH+QEZr0
フィルターの作成をお願いします。
現在、>>1でダウンロードした、サイト別adkiller(新聞社など)と、
Youtubeの動画ダウンローダーを導入しています。
他の機能は切っています。
この状態で、「阪急リネア」のサイト(下のURL)を見ることができません。
http://dentetsu.hankyu.co.jp/linea/linea0107/welcome.htm
具体的には、
トップページの画像が表示されない。
リンクされているコンテンツページをクリックすると、
"HTTP 404 NotFound"となってしまう。
という症状です。
(ためしにFirefoxで表示したところ、ちゃんと見られました。)
これらを解決するフィルターあるいは方法があったら、
どうかご教示ください。お願いいたします。
現在、>>1でダウンロードした、サイト別adkiller(新聞社など)と、
Youtubeの動画ダウンローダーを導入しています。
他の機能は切っています。
この状態で、「阪急リネア」のサイト(下のURL)を見ることができません。
http://dentetsu.hankyu.co.jp/linea/linea0107/welcome.htm
具体的には、
トップページの画像が表示されない。
リンクされているコンテンツページをクリックすると、
"HTTP 404 NotFound"となってしまう。
という症状です。
(ためしにFirefoxで表示したところ、ちゃんと見られました。)
これらを解決するフィルターあるいは方法があったら、
どうかご教示ください。お願いいたします。
120 :名無しさん@お腹いっぱい。:2006/12/26(火) 11:00:56 ID:citWPD1Z0
一番簡単なところではSafeList.txtにdentetsu.hankyu.co.jpを追加する、とかが考えられるな。
もちろんそれだけの情報でははっきりとは言えないが。
SafeList.txtにかかれているURLにはProxomitronがOFFになるようになってるから何らかのフィルタが悪さをしているなら
それを止めることが可能だ。
もう少し確かなことを知りたいならどのフィルタが原因か突き止めて、かつそのフィルタを示さなきゃ誰も答えられんよ。
もちろんそれだけの情報でははっきりとは言えないが。
SafeList.txtにかかれているURLにはProxomitronがOFFになるようになってるから何らかのフィルタが悪さをしているなら
それを止めることが可能だ。
もう少し確かなことを知りたいならどのフィルタが原因か突き止めて、かつそのフィルタを示さなきゃ誰も答えられんよ。
>>120
回答、ありがとうございます。
Safelistへの追加を試みたところ、同様の症状のままでした。
もしやと思い、Proxomitronを切って、Proxyもなしで再接続したところ、
やはり同様の症状でした。
どうやら、Proxomitronのフィルターが原因ではなく、
Web側に問題があって、Vista+IE7.0では表示されないようです。
サイト側に、他の閲覧者にも、同じような症状が出ているケースがあるようだったら、
対応してもらえるように、との申し出を入れました。
お騒がせして、失礼いたしました。
回答に再感謝いたします。
回答、ありがとうございます。
Safelistへの追加を試みたところ、同様の症状のままでした。
もしやと思い、Proxomitronを切って、Proxyもなしで再接続したところ、
やはり同様の症状でした。
どうやら、Proxomitronのフィルターが原因ではなく、
Web側に問題があって、Vista+IE7.0では表示されないようです。
サイト側に、他の閲覧者にも、同じような症状が出ているケースがあるようだったら、
対応してもらえるように、との申し出を入れました。
お騒がせして、失礼いたしました。
回答に再感謝いたします。
122 :名無しさん@お腹いっぱい。:2006/12/28(木) 19:51:06 ID:RXroac770
携帯電話用のサイトを見るためにはどうすればよいのでしょうか。
下のではだめのようです。UAをただ書き換えるだけではだめなのかな。
In = FALSE
Out = TRUE
Key = "User-Agent: test (2006.12.17) (out)"
URL = "$KEYCHK(x)"
Match = "*"
Replace = "DoCoMo"
下のではだめのようです。UAをただ書き換えるだけではだめなのかな。
In = FALSE
Out = TRUE
Key = "User-Agent: test (2006.12.17) (out)"
URL = "$KEYCHK(x)"
Match = "*"
Replace = "DoCoMo"
123 :名無しさん@お腹いっぱい。:2006/12/28(木) 20:19:55 ID:N+Q9M+aB0
>携帯電話用のサイト
一口にこう言っても携帯用のサイトにはいろいろな種類があってな・・・(以下略
一口にこう言っても携帯用のサイトにはいろいろな種類があってな・・・(以下略
124 :名無しさん@お腹いっぱい。:2006/12/29(金) 11:34:23 ID:nZI37Q3P0
UAをみて弾くサイトとIPから判断して弾くサイトがあるからな。
前者なら適当なUAを偽装すれば見れるが、後者の場合は偽装だけじゃ見れん。
携帯を使って接続すれば見れるかもしれないから、そこまでして見たいサイトならやってみては?
前者なら適当なUAを偽装すれば見れるが、後者の場合は偽装だけじゃ見れん。
携帯を使って接続すれば見れるかもしれないから、そこまでして見たいサイトならやってみては?
125 :名無しさん@お腹いっぱい。:2006/12/29(金) 12:07:48 ID:k/SJwbGE0
携帯をサーバー化するソフトってあるかな
126 :名無しさん@お腹いっぱい。:2006/12/29(金) 14:59:55 ID:nZI37Q3P0
すごく古いauの機種だけどそれだと充電するための穴にケーブルを指してPCに接続できるようだが。
携帯のデータをPCにバックアップするときにも使うだろうからどの機種も付いてるんじゃないかな。
詳しくはスレ違いだから適当な板で聞くのが早いかと。
携帯のデータをPCにバックアップするときにも使うだろうからどの機種も付いてるんじゃないかな。
詳しくはスレ違いだから適当な板で聞くのが早いかと。
127 :名無しさん@お腹いっぱい。:2006/12/29(金) 15:52:47 ID:fVQnfO1N0
もう「モデム」を知らない世代なのか…
どうもありがとうございます。
IPで弾いていたとしたらどうしようもないですね……。
携帯は持っていないうえに使う気もさらさらないので、
UA偽装でだめならおとなしくあきらめるしかありません。
IPで弾いていたとしたらどうしようもないですね……。
携帯は持っていないうえに使う気もさらさらないので、
UA偽装でだめならおとなしくあきらめるしかありません。
129 :名無しさん@お腹いっぱい。:2007/01/02(火) 17:13:36 ID:Ny7Bu6X50
前フィルター投下してくれた人、ありがとう。
今日初めてmixiの足跡殺せたよ。
フィルター入れといて良かった。
↓アクセスする時は気をつけてくれ。
www.nishishi.com/blog/2006/05/perl_use_strict.html
www.nishishi.com/pt/sp/mr.gif
今日初めてmixiの足跡殺せたよ。
フィルター入れといて良かった。
↓アクセスする時は気をつけてくれ。
www.nishishi.com/blog/2006/05/perl_use_strict.html
www.nishishi.com/pt/sp/mr.gif
130 :名無しさん@お腹いっぱい。:2007/01/02(火) 17:47:35 ID:BXgdmXvS0
fc2web.com の上下のバナー広告消すフィルター作ったんだけど、
どうも、Limitのサイズを8kにしている辺りが、スマートじゃない気がするんだけど
他にやりようがあるカナ?
Name = "Kill fc2web ad"
Active = TRUE
URL = "*.fc2web.com"
Limit = 8192
Match = "<!-- St-HP-*<!-- En-HP-*-->"
Replace = "<!-- Kill fc2web ad -->"
どうも、Limitのサイズを8kにしている辺りが、スマートじゃない気がするんだけど
他にやりようがあるカナ?
Name = "Kill fc2web ad"
Active = TRUE
URL = "*.fc2web.com"
Limit = 8192
Match = "<!-- St-HP-*<!-- En-HP-*-->"
Replace = "<!-- Kill fc2web ad -->"
131 :think ◆MM0nnAOCiQ :2007/01/02(火) 22:05:32 ID:Oi/Tv9CC0
明けましておめでとうございます。
今年もよろしくお願いします。
>>130
fc2webはヘッダ(上部)とフッタ(下部)の2通りの広告が挿入されています(現在ヘッダは挿入されていない風味)が、フッタは \k を使うことで通信を節約できますですです。
ttp://vird2002.s8.xrea.com/proxomitron/meta_character/m-chara_backslash_k.html
今年もよろしくお願いします。
>>130
fc2webはヘッダ(上部)とフッタ(下部)の2通りの広告が挿入されています(現在ヘッダは挿入されていない風味)が、フッタは \k を使うことで通信を節約できますですです。
ttp://vird2002.s8.xrea.com/proxomitron/meta_character/m-chara_backslash_k.html
132 :名無しさん@お腹いっぱい。:2007/01/02(火) 22:48:22 ID:BXgdmXvS0
133 :名無しさん@お腹いっぱい。:2007/01/02(火) 22:53:14 ID:YpOxUjl60
>>129
ノシ mixi.jp/show_friend.pl?id=1741100 にアクセスしようとするね、きめぇ。
ノシ mixi.jp/show_friend.pl?id=1741100 にアクセスしようとするね、きめぇ。
134 :think ◆MM0nnAOCiQ :2007/01/02(火) 23:16:52 ID:Oi/Tv9CC0
>>132
> でも、fc2web は何故か、</body> 要素の中に入っちゃってるんだよね
確かに、当該コメントはbody要素の内容としてありますが、<!-- St-HP-F -->...<!-- En-HP-F --> に限っては </body> の手前に挿入されるようなので
Match = "<!-- St-HP-F -->"
Replace = "\k</body></html>"
は有りだと思います。。
> でも、fc2web は何故か、</body> 要素の中に入っちゃってるんだよね
確かに、当該コメントはbody要素の内容としてありますが、<!-- St-HP-F -->...<!-- En-HP-F --> に限っては </body> の手前に挿入されるようなので
Match = "<!-- St-HP-F -->"
Replace = "\k</body></html>"
は有りだと思います。。
135 :名無しさん@お腹いっぱい。:2007/01/03(水) 00:22:18 ID:+dM3kPeo0
>>134
え〜と…それだと、フッターしか対象にしないよね。
>>130で、俺が言いたかったのは、ヘッダー、フッター *両方* に対して一つのフィルターで
俺が作った奴より効率のいい方法は無いか?と、言う事なんだが…
え〜と…それだと、フッターしか対象にしないよね。
>>130で、俺が言いたかったのは、ヘッダー、フッター *両方* に対して一つのフィルターで
俺が作った奴より効率のいい方法は無いか?と、言う事なんだが…
136 :名無しさん@お腹いっぱい。:2007/01/03(水) 00:25:28 ID:iVi9hXFe0
>>135
正月からうぜーな。 これでどうよ。
Active = TRUE
URL = "[^/]++.fc2web.com/"
Limit = 16
Match = "<!-- St-HP-[HF] -->"
Replace = "<!-- St-HP-F \r\n"
正月からうぜーな。 これでどうよ。
Active = TRUE
URL = "[^/]++.fc2web.com/"
Limit = 16
Match = "<!-- St-HP-[HF] -->"
Replace = "<!-- St-HP-F \r\n"
137 :名無しさん@お腹いっぱい。:2007/01/03(水) 05:56:31 ID:XUoIAkGl0
纏めると低速になるよ
138 :名無しさん@お腹いっぱい。:2007/01/03(水) 22:05:55 ID:iVi9hXFe0
火消し成功。
139 :名無しさん@お腹いっぱい。:2007/01/04(木) 09:03:00 ID:oS3wYhPc0
>>136 動かないフィルター貼られてもねぇ…
140 :名無しさん@お腹いっぱい。:2007/01/04(木) 12:20:51 ID:OoyVhxNC0
アダルト系で申し訳ないんだけど
artemiswebの広告除去出来るフィルターないかな
ttp://imgbbs1.artemisweb.jp/
例えばこういうトップページに戻るより下にあるゴチャゴチャしたの全部消したいんだ
artemiswebの広告除去出来るフィルターないかな
ttp://imgbbs1.artemisweb.jp/
例えばこういうトップページに戻るより下にあるゴチャゴチャしたの全部消したいんだ
141 :名無しさん@お腹いっぱい。:2007/01/04(木) 15:31:02 ID:F+UwuCN50
>>140
こんなんでどう?
Active = TRUE
URL = "[^/]++.artemisweb.jp/"
Limit = 128
Match = "<script[^>]+> <!-- var jwdflt2_setting"
Replace = "\k"
こんなんでどう?
Active = TRUE
URL = "[^/]++.artemisweb.jp/"
Limit = 128
Match = "<script[^>]+> <!-- var jwdflt2_setting"
Replace = "\k"
142 :名無しさん@お腹いっぱい。:2007/01/04(木) 15:36:03 ID:F+UwuCN50
>>139
動いてるようですが・・。
動いてるようですが・・。
143 :名無しさん@お腹いっぱい。:2007/01/04(木) 16:31:28 ID:OoyVhxNC0
144 :名無しさん@お腹いっぱい。:2007/01/04(木) 19:14:11 ID:My96A3dP0
>>142
動いた、すまない。
動いた、すまない。
145 :名無しさん@お腹いっぱい。:2007/01/04(木) 19:46:58 ID:j7bKq4IG0
146 :名無しさん@お腹いっぱい。:2007/01/04(木) 19:52:19 ID:j7bKq4IG0
147 :名無しさん@お腹いっぱい。:2007/01/04(木) 20:30:17 ID:oS3wYhPc0
148 :名無しさん@お腹いっぱい。:2007/01/04(木) 23:36:32 ID:j7bKq4IG0
>>147
おまえだよ。 上に広告無いだろ? 目か頭おかしいの? 両方?
おまえだよ。 上に広告無いだろ? 目か頭おかしいの? 両方?
149 :名無しさん@お腹いっぱい。:2007/01/05(金) 00:36:59 ID:4J6i3H5O0
確かに
<!-- St-HP-H -->
<!-- En-HP-H -->
はあるけど中身はからっぽだなw
ad bloackedって表示されるようにしてたから最初空なのに気づかなかった。
<!-- St-HP-H -->
<!-- En-HP-H -->
はあるけど中身はからっぽだなw
ad bloackedって表示されるようにしてたから最初空なのに気づかなかった。
150 :名無しさん@お腹いっぱい。:2007/01/05(金) 00:40:41 ID:qyRztfz10
/::::::/::::::::::::::::\/ |:::::/|:::::| |::::::| |::::|::::::::|:::::::::::::|::::::::::\:::::::::::::::
:::::::/::::::::::::::::::/ ヽ、 |::/ |::::| |::::::| |::::ト、:::::|、:::::::::::|:::::::::::::::ヽ:::::::::::
:::::/::::::::/::::::/ ,==>ト{_, |:::| |::::::| |::::| \|\::::::::|::::::::::::::::::|::::::::::
/|::::::/|:::::::| イ /( )、ヽ |:::| l`'十┼┼-----‐<「:::::::::::|:::::|::::::::::
|:::/::o::::::| | {::::::l|l|::!| V |:::::! レ/´,ィ´ ̄`ヽ::::ト、::::::::|:::::|::::::::::
レ'.:::::|::o::! ヽヾ、:::ノノ ヾ、| | /::ヽ、_ノレ' ヽ:::::::|:::::|::::::::::
/.:::゚:::∧:::::|(__)ニ==ニ | |::::::l|l|l:::::::| ト、::::!::::。:::::::::
.::::::::::/::::ハ:::| ´ ̄ ̄` ヽヾ、;;;;;;;;;;ノ O::::o::::::::::::::::
::::::::/::::/ .:ヾ、 .::: ´ ̄ ==‐- 二つ /:::::::::::::::::::::::::::
:::::/::::/ .::::∧ ` /::::::::/::::::::|:::::::::
::/::::/ .:::::/::∧ ヽ`'ー--- 、 /.::::/:::::::::::|::::::::: あやまれ!
/:::/ .:::::/.::/.::.ヽ |:::::::::; -‐::::.ヽ /.::::/:::::::::::::::::|:::::::::
::::;' .:::::/ .::i:::::::::.\ !:::/7:::::::::::::::::i /.::::/:::::::::::::::::::::::|:::::::: ちんこにあやまれ!!:
.:::! .:::/ .:::::!:::::::::::::/\ V〈::::::::::::::::::::| ∠:::::/:::::::::::::/.:::/::::::|:::::::::
::::|:::/ .:::::::l::::::::::::/.::::::.\ \ヽ、_// /::::::::::::::::/::::/|:::::::|:::::::::
::::レ' .::::::::/::::::::::/.::::::::::::::.\ `'ー--‐' _,. ‐'"/.::::::::::::/.::::/::|:::::::l\::::
:::::::::::::/.::::::/.::::::::::::::::::::::.`'ー--‐''"´ヽ /.:::::::::/.:::::/::::|:::::::| \
:::::::/::::::::::::::::::/ ヽ、 |::/ |::::| |::::::| |::::ト、:::::|、:::::::::::|:::::::::::::::ヽ:::::::::::
:::::/::::::::/::::::/ ,==>ト{_, |:::| |::::::| |::::| \|\::::::::|::::::::::::::::::|::::::::::
/|::::::/|:::::::| イ /( )、ヽ |:::| l`'十┼┼-----‐<「:::::::::::|:::::|::::::::::
|:::/::o::::::| | {::::::l|l|::!| V |:::::! レ/´,ィ´ ̄`ヽ::::ト、::::::::|:::::|::::::::::
レ'.:::::|::o::! ヽヾ、:::ノノ ヾ、| | /::ヽ、_ノレ' ヽ:::::::|:::::|::::::::::
/.:::゚:::∧:::::|(__)ニ==ニ | |::::::l|l|l:::::::| ト、::::!::::。:::::::::
.::::::::::/::::ハ:::| ´ ̄ ̄` ヽヾ、;;;;;;;;;;ノ O::::o::::::::::::::::
::::::::/::::/ .:ヾ、 .::: ´ ̄ ==‐- 二つ /:::::::::::::::::::::::::::
:::::/::::/ .::::∧ ` /::::::::/::::::::|:::::::::
::/::::/ .:::::/::∧ ヽ`'ー--- 、 /.::::/:::::::::::|::::::::: あやまれ!
/:::/ .:::::/.::/.::.ヽ |:::::::::; -‐::::.ヽ /.::::/:::::::::::::::::|:::::::::
::::;' .:::::/ .::i:::::::::.\ !:::/7:::::::::::::::::i /.::::/:::::::::::::::::::::::|:::::::: ちんこにあやまれ!!:
.:::! .:::/ .:::::!:::::::::::::/\ V〈::::::::::::::::::::| ∠:::::/:::::::::::::/.:::/::::::|:::::::::
::::|:::/ .:::::::l::::::::::::/.::::::.\ \ヽ、_// /::::::::::::::::/::::/|:::::::|:::::::::
::::レ' .::::::::/::::::::::/.::::::::::::::.\ `'ー--‐' _,. ‐'"/.::::::::::::/.::::/::|:::::::l\::::
:::::::::::::/.::::::/.::::::::::::::::::::::.`'ー--‐''"´ヽ /.:::::::::/.:::::/::::|:::::::| \
151 :名無しさん@お腹いっぱい。:2007/01/05(金) 01:11:23 ID:Ewxj51VQ0
htmlソースも見ないで、吠えてるのがいるなw
152 :名無しさん@お腹いっぱい。:2007/01/05(金) 12:16:55 ID:BtaVp2M00
新年早々から荒れるなよ、こんなんじゃ次のクリスマスが思いやられるぞ。
ゴメンナサイの言えない馬鹿ってどこにでもいるからな。
ゴメンナサイの言えない馬鹿ってどこにでもいるからな。
153 :名無しさん@お腹いっぱい。:2007/01/05(金) 12:52:58 ID:mMVMHAOb0
また基地外コテが暴れてるのか
154 :名無しさん@お腹いっぱい。:2007/01/06(土) 02:40:05 ID:lK3UTB0W0
Opera使ってると>>117で画像開いた後、-クリックしても画像を折り畳めないと思ったら、
Opera9.02(Build:8585)だと画像閉じれたのに9.10(Build:8679)で閉じれなくなっちゃったのね
Opera9.02(Build:8585)だと画像閉じれたのに9.10(Build:8679)で閉じれなくなっちゃったのね
155 :名無しさん@お腹いっぱい。:2007/01/08(月) 05:50:55 ID:Lh/7yKxz0
ITmediaへ直リンしても見れるフィルタって無いですかね?
自作しようと頑張ったんですが、どうにも出来ませんでした
自作しようと頑張ったんですが、どうにも出来ませんでした
>>155
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: ==ITmedia== add Referer (Out)"
URL = "image.itmedia.co.jp/"
Match = "$URL(http://image.itmedia.co.jp/(l/im/|)(\0))"
Replace = "http://image.itmedia.co.jp/l/im/\0"
おまけでもう1つ。
ttp://image.itmedia.co.jp/l/im/pcuser/articles/0701/07/l_kn_ces06utilnive.jpg
上みたいなURLにアクセスしようとすると画像URLに直接ジャンプするフィルタ。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: ==ITmedia== Jump to Image (Out)"
Match = "http://image.itmedia.co.jp/l/im/\0"
Replace = "$JUMP(http://image.itmedia.co.jp/\0)"
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: ==ITmedia== add Referer (Out)"
URL = "image.itmedia.co.jp/"
Match = "$URL(http://image.itmedia.co.jp/(l/im/|)(\0))"
Replace = "http://image.itmedia.co.jp/l/im/\0"
おまけでもう1つ。
ttp://image.itmedia.co.jp/l/im/pcuser/articles/0701/07/l_kn_ces06utilnive.jpg
{kind=link}
上みたいなURLにアクセスしようとすると画像URLに直接ジャンプするフィルタ。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: ==ITmedia== Jump to Image (Out)"
Match = "http://image.itmedia.co.jp/l/im/\0"
Replace = "$JUMP(http://image.itmedia.co.jp/\0)"
157 :名無しさん@お腹いっぱい。:2007/01/08(月) 06:58:58 ID:Lh/7yKxz0
158 :名無しさん@お腹いっぱい。:2007/01/08(月) 23:54:08 ID:s7eX/uWC0
>>118
超遅レス マジでそうかも
超遅レス マジでそうかも
159 :名無しさん@お腹いっぱい。:2007/01/09(火) 23:28:29 ID:orMYx3x10
FirefoxだとHTMLソースがmetaタグ1つのページで止まるからげっこ系の問題かも。
リダイレクトさせたいならHTTPヘッダ使ってくれ。 >ふたば
リダイレクトさせたいならHTTPヘッダ使ってくれ。 >ふたば
160 :名無しさん@お腹いっぱい。:2007/01/10(水) 00:50:56 ID:NIzkCggh0
アクセスしたURL、アクセスした日時を列挙した履歴ファイルが欲しいのですが
ttp://local.ptron/.pinfo/urls/でそれを得ることはできますか?
またはそれが得られるように設定とかフィルタを書くことは可能ですか?
ttp://local.ptron/.pinfo/urls/でそれを得ることはできますか?
またはそれが得られるように設定とかフィルタを書くことは可能ですか?
161 :名無しさん@お腹いっぱい。:2007/01/10(水) 01:20:11 ID:8tJoeJyU0
$LOG()
>>160
1、↓を access.txt というファイル名で保存しProxomitronのListsフォルダに置く。
-------------access.txt-------------
# LOGFILE
-------------access.txt-------------
2、↓をインポートして登録。
[Blocklists]
List.glog = "..\Lists\access.txt"
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Access Log Get (out)"
Replace = "$ADDLST(access, \u $DTM([Y/M/D H:m s]))"
1、↓を access.txt というファイル名で保存しProxomitronのListsフォルダに置く。
-------------access.txt-------------
# LOGFILE
-------------access.txt-------------
2、↓をインポートして登録。
[Blocklists]
List.glog = "..\Lists\access.txt"
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Access Log Get (out)"
Replace = "$ADDLST(access, \u $DTM([Y/M/D H:m s]))"
163 :名無しさん@お腹いっぱい。:2007/01/10(水) 04:12:34 ID:yv1a8TYZ0
こうなると、ファイル名を日、月毎に分けたくなるな…
訂正。
[Blocklists]
List.access = "..\Lists\access.txt"
[Blocklists]
List.access = "..\Lists\access.txt"
165 :名無しさん@お腹いっぱい。:2007/01/10(水) 09:41:50 ID:NIzkCggh0
>>164
できました、ありがとうございます。
ちなみに>>163のようにするとこはできるんですか?
まあある程度ファイルが大きくなったら手動でaccess.txtの部分を
適当に書き換えればよさそうですが。
できました、ありがとうございます。
ちなみに>>163のようにするとこはできるんですか?
まあある程度ファイルが大きくなったら手動でaccess.txtの部分を
適当に書き換えればよさそうですが。
166 :名無しさん@お腹いっぱい。:2007/01/10(水) 11:12:54 ID:yv1a8TYZ0
言い出した本人が言うのも何だけど、結論から言えば無理。
恐らくこれはセキュリティの観点からオミトロンから勝手にファイル生成できないようにしてるんだと思う。
$ADDLST の第1パラメーターに指定するのは、「リスト名」であって、ファイル名では無い。
なおかつ、リストに登録されたファイルは前もって作られていなければならない
(ファイルサイズが0でも、ファイルが存在していなければならない)
恐らくこれはセキュリティの観点からオミトロンから勝手にファイル生成できないようにしてるんだと思う。
$ADDLST の第1パラメーターに指定するのは、「リスト名」であって、ファイル名では無い。
なおかつ、リストに登録されたファイルは前もって作られていなければならない
(ファイルサイズが0でも、ファイルが存在していなければならない)
167 :名無しさん@お腹いっぱい。:2007/01/10(水) 11:40:41 ID:XC/2KTIq0
[Patterns]
Name = "Title URL Logger"
Active = TRUE
Limit = 256
Match = "<title>\1</title>"
Replace = "<title>\1</title>$ADDLST(access,$DTM([Y/M/D H:m s])\n\1\n\u\n\n )"
ついでにタイトルも記録するやつ
文字コード全く考慮無しなので化けまくる
Name = "Title URL Logger"
Active = TRUE
Limit = 256
Match = "<title>\1</title>"
Replace = "<title>\1</title>$ADDLST(access,$DTM([Y/M/D H:m s])\n\1\n\u\n\n )"
ついでにタイトルも記録するやつ
文字コード全く考慮無しなので化けまくる
168 :名無しさん@お腹いっぱい。:2007/01/10(水) 20:02:17 ID:paIXEo8X0
HTMLタグの属性の値をテストしたいのですが、アンパサンドで区切って取得した後方の
属性の値のテストに必ず失敗します。何が悪いのでしょうか?
例:
<tag(*a=$AV(\1)*&*b=$AV(\2)*)>$TST(\2=value_b)
という条件で
<tag a="value_a" b="value_b">
にマッチして欲しいのですが失敗します。
・$TSTコマンドを削除するとマッチします
・(*b=$AV(\2)*&*a=$AV(\1)*) のように位置を入れ替える事でマッチします
実際には$TST内の条件を複雑にしたいです。分かり辛いかも知れませんが
答えて頂けたら嬉しいです。よろしくお願いします。
属性の値のテストに必ず失敗します。何が悪いのでしょうか?
例:
<tag(*a=$AV(\1)*&*b=$AV(\2)*)>$TST(\2=value_b)
という条件で
<tag a="value_a" b="value_b">
にマッチして欲しいのですが失敗します。
・$TSTコマンドを削除するとマッチします
・(*b=$AV(\2)*&*a=$AV(\1)*) のように位置を入れ替える事でマッチします
実際には$TST内の条件を複雑にしたいです。分かり辛いかも知れませんが
答えて頂けたら嬉しいです。よろしくお願いします。
>>165
>>166氏の言う通り新しくファイルを作成する機能はありません。
ただ、日曜日なら sun.txt、月曜日なら mon.txt 、火曜日なら ... という具合に
曜日や日時によって保存先のリストを換えることは出来ます。
もし外部プログラムを作るスキルがある場合はaccess.txtに保存されたログを振り分ける
プログラムを作って解決することが出来ます。 ( JScriptやVBScriptを使えば
正規表現を使った文字列操作、ファイル作成などが手軽に行えます )
>>168
Match = "( A & B ) C"
という検索表現の場合、処理される順番は A -> C -> B となります。
つまり、 $TST(\2=value_b) をテストする瞬間にはまだ \2 への代入は行われて
いないのでマッチしないわけです。
>>166氏の言う通り新しくファイルを作成する機能はありません。
ただ、日曜日なら sun.txt、月曜日なら mon.txt 、火曜日なら ... という具合に
曜日や日時によって保存先のリストを換えることは出来ます。
もし外部プログラムを作るスキルがある場合はaccess.txtに保存されたログを振り分ける
プログラムを作って解決することが出来ます。 ( JScriptやVBScriptを使えば
正規表現を使った文字列操作、ファイル作成などが手軽に行えます )
>>168
Match = "( A & B ) C"
という検索表現の場合、処理される順番は A -> C -> B となります。
つまり、 $TST(\2=value_b) をテストする瞬間にはまだ \2 への代入は行われて
いないのでマッチしないわけです。
>>169
なるほどそう言う訳ですか。ありがとうございます。助かりました !
なるほどそう言う訳ですか。ありがとうございます。助かりました !
171 :名無しさん@お腹いっぱい。:2007/01/12(金) 19:03:39 ID:wKo4gAUA0
[^<]+に変わる表現ってない?
172 :名無しさん@お腹いっぱい。:2007/01/13(土) 05:58:42 ID:qE1KNOkr0
ジパング語でおk
173 :名無しさん@お腹いっぱい。:2007/01/13(土) 10:14:26 ID:6BMPJKY+0
倭語
174 :名無しさん@お腹いっぱい。:2007/01/13(土) 22:46:01 ID:WYonyKGE0
Impressのサイトで記事の折り返しをワイドな画面に合わせて変えるフィルタを作ったけど
ウィンドウサイズを変えたら自動的に比率を変えられるようにしたい。
自分の腕では決めうち(620)しかうまくいかないので、誰か直してくれない?
[Patterns]
Name = "Impress Article Width Changer"
Active = TRUE
Multi = TRUE
URL = "[^/]++.impress.co.jp/$TYPE(htm)"
Bounds = "<(table|td)*<(tr|/td)>"
Limit = 1024
Match = "\1 width=[#400:499]\2 \3"
Replace = "\1 width="620" \3"
ウィンドウサイズを変えたら自動的に比率を変えられるようにしたい。
自分の腕では決めうち(620)しかうまくいかないので、誰か直してくれない?
[Patterns]
Name = "Impress Article Width Changer"
Active = TRUE
Multi = TRUE
URL = "[^/]++.impress.co.jp/$TYPE(htm)"
Bounds = "<(table|td)*<(tr|/td)>"
Limit = 1024
Match = "\1 width=[#400:499]\2 \3"
Replace = "\1 width="620" \3"
175 :名無しさん@お腹いっぱい。:2007/01/14(日) 01:01:36 ID:SyKEodRB0
[Patterns]
Name = "Impress Article Width Changer (JS)"
Active = TRUE
URL = "[^/]++.impress.co.jp/"
Limit = 128
Match = "<end>"
Replace = "<script type="text/javascript">window.onload = function(){"
"prx_tbl_width = document.body.clientWidth - 160 - 300 - 30;"
"prx_tbl = document.getElementsByTagName('TABLE');"
"for (i=0; prx_tbl[i]; ++i)"
" if (400 < prx_tbl[i].width && prx_tbl[i].width < 499)"
" prx_tbl[i].width = prx_tbl_width;"
"};"
"window.onresize = prxResize;"
"function prxResize() {"
"for (i=0; prx_tbl[i]; ++i)"
" if (prx_tbl[i].width == prx_tbl_width)"
" prx_tbl[i].width = document.body.clientWidth - 160 - 300 - 30;"
"prx_tbl_width = document.body.clientWidth - 160 - 300 - 30;"
"}"
"</script>"
作った よければWikiにもフィルタ投稿してね
Name = "Impress Article Width Changer (JS)"
Active = TRUE
URL = "[^/]++.impress.co.jp/"
Limit = 128
Match = "<end>"
Replace = "<script type="text/javascript">window.onload = function(){"
"prx_tbl_width = document.body.clientWidth - 160 - 300 - 30;"
"prx_tbl = document.getElementsByTagName('TABLE');"
"for (i=0; prx_tbl[i]; ++i)"
" if (400 < prx_tbl[i].width && prx_tbl[i].width < 499)"
" prx_tbl[i].width = prx_tbl_width;"
"};"
"window.onresize = prxResize;"
"function prxResize() {"
"for (i=0; prx_tbl[i]; ++i)"
" if (prx_tbl[i].width == prx_tbl_width)"
" prx_tbl[i].width = document.body.clientWidth - 160 - 300 - 30;"
"prx_tbl_width = document.body.clientWidth - 160 - 300 - 30;"
"}"
"</script>"
作った よければWikiにもフィルタ投稿してね
176 :名無しさん@お腹いっぱい。:2007/01/14(日) 04:06:13 ID:BeBqwSdb0
>174
Firefox でしかテストしてない(Gecko系以外では絶対だめ)上に、
余計なのとか入っているけど、こんなのでよければ。フィルタじゃないよ。
@-moz-document domain("watch.impress.co.jp") {
body > table:first-child,
body > table:first-child + table > tbody > tr > td > div,
body > table:first-child + table > tbody > tr > td > hr + table,
body > table:first-child + table > tbody > tr > td > hr + table + hr,
/*body > table:first-child + table > tbody > tr > td:last-child,*/
table[bgcolor="orange"],
td[width="1"], td[width="10"], td[width="20%"], td[width="148"],
td[width="111"], td[width="127"], td[width="160"],
td.body-text > div, td.body-text > p[align="right"],
p + div {
display: none !important;
}
td.body-text {
padding: 1.5em !important;
}
td[width="111"] + td > table > tbody > tr > td {
padding: 0 1.5em !important;
}
}
Firefox でしかテストしてない(Gecko系以外では絶対だめ)上に、
余計なのとか入っているけど、こんなのでよければ。フィルタじゃないよ。
@-moz-document domain("watch.impress.co.jp") {
body > table:first-child,
body > table:first-child + table > tbody > tr > td > div,
body > table:first-child + table > tbody > tr > td > hr + table,
body > table:first-child + table > tbody > tr > td > hr + table + hr,
/*body > table:first-child + table > tbody > tr > td:last-child,*/
table[bgcolor="orange"],
td[width="1"], td[width="10"], td[width="20%"], td[width="148"],
td[width="111"], td[width="127"], td[width="160"],
td.body-text > div, td.body-text > p[align="right"],
p + div {
display: none !important;
}
td.body-text {
padding: 1.5em !important;
}
td[width="111"] + td > table > tbody > tr > td {
padding: 0 1.5em !important;
}
}
177 :名無しさん@お腹いっぱい。:2007/01/14(日) 04:16:08 ID:BeBqwSdb0
table や td は、width を指定しなければ(既定値の)auto になるはず。
フィルタを使うのならば、width 属性を削除すればいいんじゃないかな。
フィルタを使うのならば、width 属性を削除すればいいんじゃないかな。
178 :名無しさん@お腹いっぱい。:2007/01/14(日) 05:14:48 ID:+liiWOsH0
179 :名無しさん@お腹いっぱい。:2007/01/14(日) 15:08:50 ID:EndJP6hS0
あるよ
180 :名無しさん@お腹いっぱい。:2007/01/14(日) 15:14:46 ID:i+rtodRK0
円満解決!
>>175-177
レスサンクス。wikiにも投稿したよ。
とりあえず>>177のいうように、widthを削除してみた。
イメージしてた仕様に近づいた感じ。
Name = "Impress Article Width Changer"
Active = TRUE
Multi = TRUE
URL = "[^/]++.impress.co.jp/$TYPE(htm)"
Bounds = "<(table|td)*<(tr|/td)>"
Limit = 1024
Match = "\1 width=([#400:499]|[#900:999])\2 \3"
Replace = "\1 \3"
>>175のやつで、ウィンドウ幅を小さくすると、記事欄が小さくなり過ぎちゃうので
prx_tbl[i].widthの下限を450ぐらいにすれば、俺が作ったのよりいいかも。
レスサンクス。wikiにも投稿したよ。
とりあえず>>177のいうように、widthを削除してみた。
イメージしてた仕様に近づいた感じ。
Name = "Impress Article Width Changer"
Active = TRUE
Multi = TRUE
URL = "[^/]++.impress.co.jp/$TYPE(htm)"
Bounds = "<(table|td)*<(tr|/td)>"
Limit = 1024
Match = "\1 width=([#400:499]|[#900:999])\2 \3"
Replace = "\1 \3"
>>175のやつで、ウィンドウ幅を小さくすると、記事欄が小さくなり過ぎちゃうので
prx_tbl[i].widthの下限を450ぐらいにすれば、俺が作ったのよりいいかも。
182 :名無しさん@お腹いっぱい。:2007/01/14(日) 17:57:39 ID:SyKEodRB0
widthを削除した方が断然良いな ショック
183 :名無しさん@お腹いっぱい。:2007/01/14(日) 19:57:09 ID:2roywZ5h0
$ADDLST コマンドでリスト(ここでは Deny)にURLから[ホスト名+パス]を
登録させたい場合、[ホスト名+パス]部分を指定する置換テキストはどの
ようになりますでしょうか。
$ADDLST(Deny,\h\q) とやると、リストにはホスト部分までしか反映され
ません。フルパスを登録させるのでしたら“ /u ”を使用すればいいので
しょうけど… どなたか、お助けください。
登録させたい場合、[ホスト名+パス]部分を指定する置換テキストはどの
ようになりますでしょうか。
$ADDLST(Deny,\h\q) とやると、リストにはホスト部分までしか反映され
ません。フルパスを登録させるのでしたら“ /u ”を使用すればいいので
しょうけど… どなたか、お助けください。
184 :名無しさん@お腹いっぱい。:2007/01/14(日) 20:33:39 ID:SyKEodRB0
パスは\p
185 :名無しさん@お腹いっぱい。:2007/01/14(日) 23:21:12 ID:OOrNpFsL0
google image (061103) +jsが、Opera9.0.2から9.1に乗り換えたら、
開いた後閉じれなくなったんだけど、
該当部分のソースを抜き出してローカルで試してみると閉じれる。
何でだろう?
同じ問題おきてる人って居る?
もし、解決策があったら教えてもらえると嬉しい。
開いた後閉じれなくなったんだけど、
該当部分のソースを抜き出してローカルで試してみると閉じれる。
何でだろう?
同じ問題おきてる人って居る?
もし、解決策があったら教えてもらえると嬉しい。
186 :名無しさん@お腹いっぱい。:2007/01/14(日) 23:52:14 ID:C1LWPu2m0
Kill off-site Imagesで使われてる
http://(^\h) 表示サイトのホスト以外のこの表現、
指定から漏れることが結構あるけどこれProxomitron側のバグかな?
いろいろやり方変えてみたけどなぜかサイト以外なのに同一に判定される場合がある。
どなたか詳しい人検証してほしい
http://(^\h) 表示サイトのホスト以外のこの表現、
指定から漏れることが結構あるけどこれProxomitron側のバグかな?
いろいろやり方変えてみたけどなぜかサイト以外なのに同一に判定される場合がある。
どなたか詳しい人検証してほしい
187 :名無しさん@お腹いっぱい。:2007/01/15(月) 18:31:54 ID:AZHWP8Dh0
うpろだの広告キラーを入れて使ってますが、
gooのトップページの、右側と上に出てくる、
flashの広告が消えません。
これを消すフィルターを作ってくださいましな。
おながいしますだ。
gooのトップページの、右側と上に出てくる、
flashの広告が消えません。
これを消すフィルターを作ってくださいましな。
おながいしますだ。
188 :名無しさん@お腹いっぱい。:2007/01/16(火) 07:49:16 ID:+wMFIvzu0
>>186
うろ覚えなんだが\hって
セカンドレベルドメインまでしか判定してないんじゃなかったっけ?
www1.host.comもwww2.host.comも同一ドメインと見なすある意味便利な機能だが
yahoo.co.jpもgoogle.co.jpも同一ドメインと見なされてしまう欠陥機能でもある。
うろ覚えなんだが\hって
セカンドレベルドメインまでしか判定してないんじゃなかったっけ?
www1.host.comもwww2.host.comも同一ドメインと見なすある意味便利な機能だが
yahoo.co.jpもgoogle.co.jpも同一ドメインと見なされてしまう欠陥機能でもある。
189 :名無しさん@お腹いっぱい。:2007/01/16(火) 08:49:56 ID:+wMFIvzu0
>>187
[Patterns]
Name = "goo AD killer"
Active = TRUE
URL = "[^.]+.goo.ne.jp/"
Limit = 7000
Match = "$NEST(<!-- ((h02|banner02|osusume|top_text|ad|ad_focus|pr)\0|Sniffer Code for Flash version=60) -->,<!-- /($TST(\0)|html.ng/cat=*) -->)"
[Patterns]
Name = "goo AD killer"
Active = TRUE
URL = "[^.]+.goo.ne.jp/"
Limit = 7000
Match = "$NEST(<!-- ((h02|banner02|osusume|top_text|ad|ad_focus|pr)\0|Sniffer Code for Flash version=60) -->,<!-- /($TST(\0)|html.ng/cat=*) -->)"
190 :187:2007/01/16(火) 12:18:37 ID:9uCC6V930
191 :名無しさん@お腹いっぱい。:2007/01/19(金) 00:01:14 ID:r0W7w4ag0
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.2ch.net) (in)"
Match = "$RESP(302*)http://([^.]+.(2ch.net|bbspink.com))\1/test/read.cgi/\2/([^/]+)\3(/\4|)"
Replace = "$JUMP(http://p2.2ch.net/p2/read.php?host=\1&bbs=\2&key=\3&ls=\4)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (snapshot.publog.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://snapshot.publog.net/dat.php?url=\u)"
↑の二つが働かないので、修正をお願いします。
↓の二つは大丈夫です。
In = TRUE
Out = FALSE
Key = "URL: 2ch redirector (oo.2ch2.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://oo.2ch2.net/?q=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.chbox.jp) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://p2.chbox.jp/read.php?url=\u)"
Out = FALSE
Key = "URL: 2ch redirector (p2.2ch.net) (in)"
Match = "$RESP(302*)http://([^.]+.(2ch.net|bbspink.com))\1/test/read.cgi/\2/([^/]+)\3(/\4|)"
Replace = "$JUMP(http://p2.2ch.net/p2/read.php?host=\1&bbs=\2&key=\3&ls=\4)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (snapshot.publog.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://snapshot.publog.net/dat.php?url=\u)"
↑の二つが働かないので、修正をお願いします。
↓の二つは大丈夫です。
In = TRUE
Out = FALSE
Key = "URL: 2ch redirector (oo.2ch2.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://oo.2ch2.net/?q=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.chbox.jp) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://p2.chbox.jp/read.php?url=\u)"
192 :名無しさん@お腹いっぱい。:2007/01/19(金) 05:34:19 ID:l92jSPOX0
サンプルがあれば直すのもできるが。
どんなURLに対してどんなURLへリダイレクトしたいのかが分からんからね。
どんなURLに対してどんなURLへリダイレクトしたいのかが分からんからね。
193 :名無しさん@お腹いっぱい。:2007/01/19(金) 10:27:19 ID:Cdaf7IxG0
>>191
これたしか俺の作ったフィルタだったような気がする。
人大杉の時にオンライン2chビューアにリダイレクトするフィルタ。
1番上のフィルタは普通に動いてる。
一時的な鯖落ちとかで使えなくなってたんじゃないかな?
2番目のはサイト自体が閉鎖になったっぽい。よって修正不可能。
これたしか俺の作ったフィルタだったような気がする。
人大杉の時にオンライン2chビューアにリダイレクトするフィルタ。
1番上のフィルタは普通に動いてる。
一時的な鯖落ちとかで使えなくなってたんじゃないかな?
2番目のはサイト自体が閉鎖になったっぽい。よって修正不可能。
194 :名無しさん@お腹いっぱい。:2007/01/19(金) 15:45:30 ID:DrA0NWks0
>>2
windows98質問レスから来ました。win98でyahoo動画を見るフィルターを教えていただきました。
一度は見れたのですが再度起動したら、テスト画像は見れるのに本編はスタートのクリックができなくて
見られません。proxomitronを再編集しようにも窓が開きません。どうなっているのでしょうか。
windows98質問レスから来ました。win98でyahoo動画を見るフィルターを教えていただきました。
一度は見れたのですが再度起動したら、テスト画像は見れるのに本編はスタートのクリックができなくて
見られません。proxomitronを再編集しようにも窓が開きません。どうなっているのでしょうか。
195 :名無しさん@お腹いっぱい。:2007/01/19(金) 15:49:05 ID:e/te59kE0
196 :名無しさん@お腹いっぱい。:2007/01/19(金) 16:55:41 ID:e/te59kE0
>>194
フィルタの出来がいまいちだったから手直しした。 この2つだけで動くはず。
正常に動けば白いウインドウが新しく開いてそこに動画へのリンクが表示される。
うまくいかない場合は他のフィルタを全部オフにしてProxomitronの更新ボタン押して
ブラウザのキャッシュを消してからもう一度試すと見れるかも。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "User-Agent: YahooDOUGA for Win9x (out)"
URL = "streaming.yahoo.co.jp/|player.streaming.yahoo.co.jp/"
Replace = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.40607; .NET CLR 1.0.3705)"
[Patterns]
Name = "YahooDOUGA for Win9x (fix 2007/01/19 16:00)"
Active = TRUE
URL = "player.streaming.yahoo.co.jp/player/js/player.js | player.streaming.yahoo.co.jp/player/makeAsx.php\?"
Limit = 2048
Match = "if\(!chkEnvData\(\)\){ return false; }|//window.open\(url\);$SET(\0=window.open\(url\);)"
"|<ASX version="3.0">*<Ref HREF=$AV(mms://\1)*</ASX>$SET(0=Video URL = <a href="mms://\1">mms://\1</a>)"
Replace = "\0"
フィルタの出来がいまいちだったから手直しした。 この2つだけで動くはず。
正常に動けば白いウインドウが新しく開いてそこに動画へのリンクが表示される。
うまくいかない場合は他のフィルタを全部オフにしてProxomitronの更新ボタン押して
ブラウザのキャッシュを消してからもう一度試すと見れるかも。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "User-Agent: YahooDOUGA for Win9x (out)"
URL = "streaming.yahoo.co.jp/|player.streaming.yahoo.co.jp/"
Replace = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.40607; .NET CLR 1.0.3705)"
[Patterns]
Name = "YahooDOUGA for Win9x (fix 2007/01/19 16:00)"
Active = TRUE
URL = "player.streaming.yahoo.co.jp/player/js/player.js | player.streaming.yahoo.co.jp/player/makeAsx.php\?"
Limit = 2048
Match = "if\(!chkEnvData\(\)\){ return false; }|//window.open\(url\);$SET(\0=window.open\(url\);)"
"|<ASX version="3.0">*<Ref HREF=$AV(mms://\1)*</ASX>$SET(0=Video URL = <a href="mms://\1">mms://\1</a>)"
Replace = "\0"
197 :名無しさん@お腹いっぱい。:2007/01/19(金) 17:10:37 ID:CGmrM71A0
>>193
ありがとうございます。
ありがとうございます。
198 :名無しさん@お腹いっぱい。:2007/01/19(金) 21:55:43 ID:DrA0NWks0
>>196
有難うございます。前のより少し変わりましたね。前のときは確かに保存しておりませんでした。
プロシキを設定するのは初めてでいい勉強になります。
質問です。このフィルターのみ設定すると、一般のwebページを開くときにはプロシキをはずさないといけないよのでしょうか。
proxomitronはPCの電源を落として長時間しないと編集できないのでしょうか
有難うございます。前のより少し変わりましたね。前のときは確かに保存しておりませんでした。
プロシキを設定するのは初めてでいい勉強になります。
質問です。このフィルターのみ設定すると、一般のwebページを開くときにはプロシキをはずさないといけないよのでしょうか。
proxomitronはPCの電源を落として長時間しないと編集できないのでしょうか
199 :名無しさん@お腹いっぱい。:2007/01/19(金) 22:17:55 ID:knNLy8q20
おもしろいねえ、ちみw
200 :名無しさん@お腹いっぱい。:2007/01/19(金) 22:47:45 ID:Rvp3+Jhz0
楽しんで貰えたようで何よりです
201 :名無しさん@お腹いっぱい。:2007/01/19(金) 22:48:52 ID:L8t+bRXy0
フロシキオミトロン
ピロシキオミトロン
オミトロンを風呂敷と呼ぶのも悪くない。
ピロシキオミトロン
オミトロンを風呂敷と呼ぶのも悪くない。
202 :名無しさん@お腹いっぱい。:2007/01/19(金) 23:17:45 ID:+/UPOcxc0
フロシキオミトロン
ピロシキオミトロン
ヒロユキオミトロン
もう2chって呼ぼうぜ
ピロシキオミトロン
ヒロユキオミトロン
もう2chって呼ぼうぜ
203 :名無しさん@お腹いっぱい。:2007/01/20(土) 05:56:12 ID:YRBAQm0e0
>>198
どっちもいいえ。
どっちもいいえ。
204 :名無しさん@お腹いっぱい。:2007/01/21(日) 13:55:53 ID:bgSztaYs0
Yahoo!動画をwin98で見るフィルタを更新してうpしておきました。
今度はリンクを表示するのではなくプレイヤーが自動起動するようにしました。
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0062.txt
あとオリジナルの作者さんGJ!
今度はリンクを表示するのではなくプレイヤーが自動起動するようにしました。
ttp://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0062.txt
あとオリジナルの作者さんGJ!
205 :名無しさん@お腹いっぱい。:2007/01/21(日) 14:50:44 ID:qsJSKksj0
>>204>>203
皆さんから3通りのフィルターを教えていただきました。ただただ人の作ったものを利用するだけのレベルの者に対しても丁寧に応対してくださることに
感謝します。こうしている内にだんだんと分かってくるのが,何とも言えないくらい楽しいのです。これからも切り捨てることなくよろしくお願いしします。
2度成功したのですが、今、私のパソコンはデスクトッップのproxonのアイコンをクリックしても設定画面が出てこくなりました。
それで新しいのを試せないのが残念です
皆さんから3通りのフィルターを教えていただきました。ただただ人の作ったものを利用するだけのレベルの者に対しても丁寧に応対してくださることに
感謝します。こうしている内にだんだんと分かってくるのが,何とも言えないくらい楽しいのです。これからも切り捨てることなくよろしくお願いしします。
2度成功したのですが、今、私のパソコンはデスクトッップのproxonのアイコンをクリックしても設定画面が出てこくなりました。
それで新しいのを試せないのが残念です
206 :名無しさん@お腹いっぱい。:2007/01/21(日) 15:58:46 ID:AyfIWyTh0
207 :名無しさん@お腹いっぱい。:2007/01/21(日) 18:31:54 ID:qsJSKksj0
>>204
やっとproxomitronを再インストールして、設定をしなおしました。これで完全に動画を見るボタンをクリックすることが出来ます。
ここ数日、仕事から帰ってパソコンをいじるのが楽しみでした。出費を惜しまず2000やXPやはたまたvistaにするのもよし、
はたまた、こうして古いなじみのパソコンを手探りでいじるのも味わい深いものです。理屈がわかればもっと楽しいのでしょうが。
今 夜逃げや本舗を視聴しております。有難うございました
やっとproxomitronを再インストールして、設定をしなおしました。これで完全に動画を見るボタンをクリックすることが出来ます。
ここ数日、仕事から帰ってパソコンをいじるのが楽しみでした。出費を惜しまず2000やXPやはたまたvistaにするのもよし、
はたまた、こうして古いなじみのパソコンを手探りでいじるのも味わい深いものです。理屈がわかればもっと楽しいのでしょうが。
今 夜逃げや本舗を視聴しております。有難うございました
208 :名無しさん@お腹いっぱい。:2007/01/21(日) 19:16:32 ID:t1bHow280
改行しろよ
209 :名無しさん@お腹いっぱい。:2007/01/21(日) 20:27:06 ID:mEOuzJy10
改行なんてただの飾りです
210 :名無しさん@お腹いっぱい。:2007/01/21(日) 21:23:23 ID:zpW2JNwf0
エロイ人にはそれが・・・一番大事〜♪(槙原)
211 :名無しさん@お腹いっぱい。:2007/01/21(日) 21:27:00 ID:Jr8sS6wH0
212 :名無しさん@お腹いっぱい。:2007/01/21(日) 21:31:46 ID:zpW2JNwf0
まずくない
213 :名無しさん@お腹いっぱい。:2007/01/21(日) 22:02:55 ID:M1jxy/iz0
美味
214 :名無しさん@お腹いっぱい。:2007/01/21(日) 22:14:01 ID:DxIFNmtE0
この流れ嫌いじゃないぜ
215 :名無しさん@お腹いっぱい。:2007/01/22(月) 12:16:34 ID:Pmm7KXkJ0
他人に何から何まで任せておいて
それで楽しいとか言われてもカチンと来る
それで楽しいとか言われてもカチンと来る
>>質問者さん
害虫がわいてますがお気になさらず。
害虫がわいてますがお気になさらず。
217 :名無しさん@お腹いっぱい。:2007/01/22(月) 13:10:36 ID:zso0DEDP0
218 :名無しさん@お腹いっぱい。:2007/01/23(火) 14:26:49 ID:k9Y8Z01V0
Yahoo動画に変更があったようなのでフィルタをちょっと書きかえ。
[Patterns]
Name = "YahooDOUGA for Win9x (07/01/23)"
Active = TRUE
URL = "i.yimg.jp/images/streaming/js/stream_env_func.js|player.streaming.yahoo.co.jp/player/js/player.js|player.streaming.yahoo.co.jp/player/makeAsx.php\?"
Limit = 2048
Match = "function isStreamingEnvCheck\(\) {$SET(\0=\kfunction isStreamingEnvCheck\(\){return true;})"
"|if\(!chkEnvData\(\)\){ return false; }|//window.open\(url\);$SET(\0=window.open\(url\);)"
"|<ASX version="3.0">*<Ref HREF=$AV(mms://\1)*</ASX>"
"$SET(0=<ASX version="3.0">\r\n<Entry>\r\n<ref HREF="mms://\1"/>\r\n</Entry>\r\n</ASX>\r\n)"
Replace = "\0"
[Patterns]
Name = "YahooDOUGA for Win9x (07/01/23)"
Active = TRUE
URL = "i.yimg.jp/images/streaming/js/stream_env_func.js|player.streaming.yahoo.co.jp/player/js/player.js|player.streaming.yahoo.co.jp/player/makeAsx.php\?"
Limit = 2048
Match = "function isStreamingEnvCheck\(\) {$SET(\0=\kfunction isStreamingEnvCheck\(\){return true;})"
"|if\(!chkEnvData\(\)\){ return false; }|//window.open\(url\);$SET(\0=window.open\(url\);)"
"|<ASX version="3.0">*<Ref HREF=$AV(mms://\1)*</ASX>"
"$SET(0=<ASX version="3.0">\r\n<Entry>\r\n<ref HREF="mms://\1"/>\r\n</Entry>\r\n</ASX>\r\n)"
Replace = "\0"
219 :名無しさん@お腹いっぱい。:2007/01/23(火) 15:54:16 ID:rJYgr5bJ0
ヤフーオークション用のフィルタがあったら教えてください
一応検索はしたのですが
今のフィルターでは入札のフォームまで消えてしまって困ってます
一応検索はしたのですが
今のフィルターでは入札のフォームまで消えてしまって困ってます
220 :名無しさん@お腹いっぱい。:2007/01/23(火) 20:49:42 ID:r8DPwIH30
>>219
何をフィルタリングしたいの
何をフィルタリングしたいの
221 :名無しさん@お腹いっぱい。:2007/01/23(火) 21:05:51 ID:VIIXYjtU0
>>220
私の過去をフィルタリングしたいんです。
私の過去をフィルタリングしたいんです。
222 :名無しさん@お腹いっぱい。:2007/01/24(水) 07:59:08 ID:kTo/hI+b0
Googleイメージがまた変わった?
223 :名無しさん@お腹いっぱい。:2007/01/24(水) 09:39:22 ID:kChnhVkm0
みたい なお巣のめんどくせー
224 :名無しさん@お腹いっぱい。:2007/01/24(水) 14:14:25 ID:UhO8OXuD0
>>219
どういうフィルターだよ〜セニョリータ
どういうフィルターだよ〜セニョリータ
226 :名無しさん@お腹いっぱい。:2007/01/24(水) 15:25:23 ID:VcmclMnp0
>>225
その「今のフィルター」ってのはいったい何なんだ
その「今のフィルター」ってのはいったい何なんだ
227 :名無しさん@お腹いっぱい。:2007/01/24(水) 15:44:02 ID:VWFikHoe0
228 :名無しさん@お腹いっぱい。:2007/01/24(水) 18:00:58 ID:kTo/hI+b0
あぷろだにあるkoukoku eraserに
Yahoo AD Killerっていうフィルタが含まれてるから
それ使ってみたら?
Yahoo AD Killerっていうフィルタが含まれてるから
それ使ってみたら?
229 :名無しさん@お腹いっぱい。:2007/01/24(水) 18:34:59 ID:VWFikHoe0
230 :名無しさん@お腹いっぱい。:2007/01/24(水) 20:28:36 ID:pDBZ8GX90
こんなのでよかったら。
[Patterns]
Name = "YahooAuction ad killer"
Active = TRUE
Multi = TRUE
URL = "[^.]+.auctions.yahoo.co.jp/$TYPE(htm)"
Limit = 6000
Match = "<td\s[^>]++>\n<!--\nLEFT COLUMN\n-->*<!--\n/LEFT COLUMN\n-->\n</td>|"
"<a href="http://ard.yahoo.co.jp/*</a>|"
"<script language=$AV(JavaScript|javascript)>*</noscript>|"
"<img\s[^>]++src=$AV(http://ai.yimg.jp/[^>]++gif)[^>]+>|"
"$NEST(<map name=,</map>)"
Replace = "<!-- Kill Yahoo! ad -->"
[Patterns]
Name = "YahooAuction ad killer"
Active = TRUE
Multi = TRUE
URL = "[^.]+.auctions.yahoo.co.jp/$TYPE(htm)"
Limit = 6000
Match = "<td\s[^>]++>\n<!--\nLEFT COLUMN\n-->*<!--\n/LEFT COLUMN\n-->\n</td>|"
"<a href="http://ard.yahoo.co.jp/*</a>|"
"<script language=$AV(JavaScript|javascript)>*</noscript>|"
"<img\s[^>]++src=$AV(http://ai.yimg.jp/[^>]++gif)[^>]+>|"
"$NEST(<map name=,</map>)"
Replace = "<!-- Kill Yahoo! ad -->"
231 :名無しさん@お腹いっぱい。:2007/01/24(水) 20:50:27 ID:VWFikHoe0
232 :名無しさん@お腹いっぱい。:2007/01/28(日) 21:42:08 ID:WrnzFfO80
Sn Uploader系のアップローダーでDLKey→[DownLoad]ボタンを押した直後に自動的に出る
ファイルのダウンロードダイアログを出現させなくするフィルターはありますでしょうか。
「飛ばない場合はこちらから」を自発的にクリックしたとき初めて
ファイルのダウンロードダイアログが出るようになれば、と思ってます。
ファイルのダウンロードダイアログを出現させなくするフィルターはありますでしょうか。
「飛ばない場合はこちらから」を自発的にクリックしたとき初めて
ファイルのダウンロードダイアログが出るようになれば、と思ってます。
233 :名無しさん@お腹いっぱい。:2007/01/29(月) 00:37:08 ID:WcdzCDB/0
だ、誰か、、、新googleイメージに対応して、、、く、、、れ、 、、 、、、、ガクッ
234 :名無しさん@お腹いっぱい。:2007/01/29(月) 04:32:07 ID:TUvaYD2w0
>>233
パソコン遊戯のTOPで公開されてる。 ちゃんと動くかは知らん。
ちなみにmixiに自動ログインするフィルターもTOPにあるが入れないほうがいい。
これ入れるとmixi以外のウェブページ側からmixiのログインパスを盗まれる危険がある。
つまり今のNoriya氏のmixi用メアド、Passは取ろうと思えば取れるw
パソコン遊戯のTOPで公開されてる。 ちゃんと動くかは知らん。
ちなみにmixiに自動ログインするフィルターもTOPにあるが入れないほうがいい。
これ入れるとmixi以外のウェブページ側からmixiのログインパスを盗まれる危険がある。
つまり今のNoriya氏のmixi用メアド、Passは取ろうと思えば取れるw
235 :名無しさん@お腹いっぱい。:2007/01/29(月) 05:21:37 ID:qErXV2rI0
>234
見てみた。mixiのあれって、なんで盗まれるかもしれないの?
Noriya氏はいろんな検索エンジンを使っているのかな。
自分はGoogleしか使わないから、Google用のユーザスタイルだけで十分。
@-moz-document domain("google.co.jp"), domain("google.com") {
div.ch, p.e,
body > br, noscript + div,
body > center > div[align="right"],
table.bt td:first-child,
table[align="right"],
div#navbar ~ center,
body > div + center, body > div + center ~ center,
body > br, body > br ~ center {
display: none !important;
}
いらないところを消すだけならこんな感じで。
見てみた。mixiのあれって、なんで盗まれるかもしれないの?
Noriya氏はいろんな検索エンジンを使っているのかな。
自分はGoogleしか使わないから、Google用のユーザスタイルだけで十分。
@-moz-document domain("google.co.jp"), domain("google.com") {
div.ch, p.e,
body > br, noscript + div,
body > center > div[align="right"],
table.bt td:first-child,
table[align="right"],
div#navbar ~ center,
body > div + center, body > div + center ~ center,
body > br, body > br ~ center {
display: none !important;
}
いらないところを消すだけならこんな感じで。
236 :名無しさん@お腹いっぱい。:2007/01/29(月) 08:36:07 ID:lc8AiyX60
google image (061103) +js+の改良お願いします。
237 :名無しさん@お腹いっぱい。:2007/01/29(月) 08:53:23 ID:VrEljtzt0
それがどんなフィルタか分からんけどwikiのやつじゃないの?
238 :名無しさん@お腹いっぱい。:2007/01/29(月) 10:35:06 ID:48/vG0j40
Google image redirector [061103] の修正お願いします。
これ、四天王フィルタの一つなんです…。
これ、四天王フィルタの一つなんです…。
239 :名無しさん@お腹いっぱい。:2007/01/29(月) 15:58:10 ID:YehxWyo00
"四天王"なら自分で修正する術を身に付けたら?
まさか、これからもその"四天王"とやらのどれかが効かなくなるたびに駆込み寺よろしくここに書き込むつもりか?
まさか、これからもその"四天王"とやらのどれかが効かなくなるたびに駆込み寺よろしくここに書き込むつもりか?
240 :名無しさん@お腹いっぱい。:2007/01/29(月) 16:38:20 ID:48/vG0j40
そうです。依頼スレですから。
241 :名無しさん@お腹いっぱい。:2007/01/29(月) 16:45:58 ID:lc8AiyX60
>>237
236です。
googleイメージで画像の上に画像への直リンと画像のあるサイトのurlへの別窓で開くリンクが出来、
画像をクリックすると実サイズで表示、再度クリックで元のサイズに戻るというフィルターだったと思います。
wikiにあるGoogle Image: Image Change (070124)がそれそのものでした。
教えてくださってありがとうございました。作成された方も感謝いたします。
ただ画像のサイズがカーソルを当てないと見られないようになったのは残念です。
236です。
googleイメージで画像の上に画像への直リンと画像のあるサイトのurlへの別窓で開くリンクが出来、
画像をクリックすると実サイズで表示、再度クリックで元のサイズに戻るというフィルターだったと思います。
wikiにあるGoogle Image: Image Change (070124)がそれそのものでした。
教えてくださってありがとうございました。作成された方も感謝いたします。
ただ画像のサイズがカーソルを当てないと見られないようになったのは残念です。
242 :名無しさん@お腹いっぱい。:2007/01/29(月) 16:46:05 ID:/jTYo2F70
この依頼は絶対受けないと心に決めた。
243 :名無しさん@お腹いっぱい。:2007/01/29(月) 18:34:47 ID:48/vG0j40
黙ってスルーすればいいでしょう。
説教もウザイだけですよ。
説教もウザイだけですよ。
244 :名無しさん@お腹いっぱい。:2007/01/29(月) 18:42:20 ID:1Jw0goy60
依頼やクレクレは許されてないわけじゃないが作成するのが主旨のスレであって
自分の態度ぐらいはわきまえてほしいもんだ
自分の態度ぐらいはわきまえてほしいもんだ
245 :名無しさん@お腹いっぱい。:2007/01/29(月) 18:45:28 ID:48/vG0j40
246 :名無しさん@お腹いっぱい。:2007/01/29(月) 19:49:53 ID:4fTZaltd0
このスレは作成依頼されたフィルタを有志により作るスレッドだから何の問題もないよ
247 :名無しさん@お腹いっぱい。:2007/01/29(月) 19:54:16 ID:/jTYo2F70
>244
NGIDにぶち込んでおけ。相手にする価値はない。
NGIDにぶち込んでおけ。相手にする価値はない。
248 :名無しさん@お腹いっぱい。:2007/01/29(月) 19:54:38 ID:TUvaYD2w0
249 :名無しさん@お腹いっぱい。:2007/01/29(月) 20:15:57 ID:48/vG0j40
250 :名無しさん@お腹いっぱい。:2007/01/29(月) 22:44:59 ID:TUvaYD2w0
Noriya氏修正入れたね。 何の説明もなくこっそり "/" を追加するのはどうかと。
251 :名無しさん@お腹いっぱい。:2007/01/29(月) 22:47:38 ID:WcdzCDB/0
Google Image: Image Change (070124)がGoogle Image: Image Changeと同じように動くのを確認。
書いてくれた人GJ!
書いてくれた人GJ!
252 :名無しさん@お腹いっぱい。:2007/01/30(火) 00:07:42 ID:3s5eFhU00
>248
修正前がどうなっていたかわからないけど、納得した。
どうもありがとう。
URLマッチって、そんな穴というか注意点があるのね。
修正前がどうなっていたかわからないけど、納得した。
どうもありがとう。
URLマッチって、そんな穴というか注意点があるのね。
253 :名無しさん@お腹いっぱい。:2007/01/30(火) 00:31:37 ID:TjsVwVUn0
>>252
修正前
URL = "mixi.jp$TYPE(htm)"
修正後
URL = "mixi.jp/$TYPE(htm)"
何も知らずに修正前のを使ってる人は切り捨てっぽい。 無責任だなぁ。
修正前
URL = "mixi.jp$TYPE(htm)"
修正後
URL = "mixi.jp/$TYPE(htm)"
何も知らずに修正前のを使ってる人は切り捨てっぽい。 無責任だなぁ。
254 :名無しさん@お腹いっぱい。:2007/01/30(火) 01:57:04 ID:FcSv1uu70
責任取れって言われても困る
255 :名無しさん@お腹いっぱい。:2007/01/30(火) 02:41:21 ID:R33CAw8k0
責任なんてない
256 :名無しさん@お腹いっぱい。:2007/01/30(火) 07:15:48 ID:aHo/HheL0
[Patterns]
Name = "Google image redirector [070130]"
Active = TRUE
URL = "images.google."
Limit = 512
Match = "<script*>$SET(9=<script defer="defer" language="null">)"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
Name = "Google image redirector [070130]"
Active = TRUE
URL = "images.google."
Limit = 512
Match = "<script*>$SET(9=<script defer="defer" language="null">)"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
257 :名無しさん@お腹いっぱい。:2007/01/30(火) 11:14:35 ID:9+c6/Dfa0
所詮はしょぼスキル自慢の自己満サイトだしな。
258 :名無しさん@お腹いっぱい。:2007/01/30(火) 18:07:54 ID:TJIKRZn20
>>256
検索結果に画像やリンクが一切表示されません><
検索結果に画像やリンクが一切表示されません><
259 :名無しさん@お腹いっぱい。:2007/01/30(火) 18:53:14 ID:LmaNxWmb0
BannerBlasterが効いてるんじゃねーの?
260 :名無しさん@お腹いっぱい。:2007/01/30(火) 19:16:10 ID:bh1+l+dr0
http://www.watch.impress.co.jp/
で画像の取りこぼしが出ないフィルタをお願いします
で画像の取りこぼしが出ないフィルタをお願いします
261 :名無しさん@お腹いっぱい。:2007/01/30(火) 21:50:29 ID:izvs/DMb0
専用アップローダーのホストエラー画面編集パッチで4.5に対応したのってないかな?
262 :名無しさん@お腹いっぱい。:2007/01/31(水) 01:19:38 ID:3cMwvv4B0
263 :名無しさん@お腹いっぱい。:2007/01/31(水) 01:26:05 ID:yDhWXYhu0
264 :名無しさん@お腹いっぱい。:2007/01/31(水) 04:44:19 ID:RUeX8l0s0
mixiのオートログインって何のためにいるの?
http://mixi.jp/login.pl?next_url=/home.pl&email=○○&password=○○
でブックマークすればそれでいいじゃん。
http://mixi.jp/login.pl?next_url=/home.pl&email=○○&password=○○
でブックマークすればそれでいいじゃん。
265 :名無しさん@お腹いっぱい。:2007/01/31(水) 05:42:20 ID:J5qJOQDK0
その作業を自動化するだけだよ
必要ないならそれでいい
必要ないならそれでいい
266 :名無しさん@お腹いっぱい。:2007/01/31(水) 07:36:39 ID:j58JZ3Dn0
[Patterns]
Name = "Google image redirector [070131]"
Active = TRUE
URL = "images.google."
Limit = 800
Match = "<script*>$SET(9=<script defer="defer" language="null">)"
"|"
"<noscript>|</noscript>"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
Name = "Google image redirector [070131]"
Active = TRUE
URL = "images.google."
Limit = 800
Match = "<script*>$SET(9=<script defer="defer" language="null">)"
"|"
"<noscript>|</noscript>"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
267 :名無しさん@お腹いっぱい。:2007/01/31(水) 07:59:24 ID:IEiplPeo0
268 :名無しさん@お腹いっぱい。:2007/01/31(水) 10:47:14 ID:IuQqNg+D0
269 :名無しさん@お腹いっぱい。:2007/01/31(水) 11:31:34 ID:UWCCvoHn0
270 :名無しさん@お腹いっぱい。:2007/01/31(水) 11:41:18 ID:c+Lq47V40
俺は"google image (060810_kai) +js+"ってやつでずっと使えてるな
271 :名無しさん@お腹いっぱい。:2007/01/31(水) 12:26:18 ID:QhtT0xdc0
google imageはヘッダフィルタの方使ってるから、こちらもみんなが騒いでる中で
二年ぐらいはなんも書き換えずにそのまま利用できてるなぁ・・・
単純にダイレクトで飛べればいいだけなおいらには、これで十分だ
二年ぐらいはなんも書き換えずにそのまま利用できてるなぁ・・・
単純にダイレクトで飛べればいいだけなおいらには、これで十分だ
272 :名無しさん@お腹いっぱい。:2007/01/31(水) 13:54:58 ID:j58JZ3Dn0
[Patterns]
Name = "Google image redirector [070131a]"
Active = TRUE
URL = "images.google."
Limit = 800
Match = "<a href="\+e\+b.n\+"><img"
"$SET(9=<a target=_blank href="+decodeURIComponent(b.p.match(/[^&]+/))+">Ref</a>"
"<a target=_blank href="+(b.c.indexOf("://")<0?"http://":"")+decodeURIComponent(b.c)+"><img)"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
Name = "Google image redirector [070131a]"
Active = TRUE
URL = "images.google."
Limit = 800
Match = "<a href="\+e\+b.n\+"><img"
"$SET(9=<a target=_blank href="+decodeURIComponent(b.p.match(/[^&]+/))+">Ref</a>"
"<a target=_blank href="+(b.c.indexOf("://")<0?"http://":"")+decodeURIComponent(b.c)+"><img)"
"|"
"<a href=/imgres\?imgurl=\0\&imgrefurl=\1\&h=*>"
"$SET(9=<a href=$UESC(\1) target=_blank>Link</a><a href=$UESC(\0) target=_blank>)"
Replace = "\9"
273 :名無しさん@お腹いっぱい。:2007/01/31(水) 14:21:54 ID:vbgFULxO0
google image 大人気だな
274 :名無しさん@お腹いっぱい。:2007/01/31(水) 17:51:17 ID:UWCCvoHn0
275 :名無しさん@お腹いっぱい。:2007/01/31(水) 23:45:19 ID:sLMkpCXq0
2chの専ブラみたいにあらゆるサイトにNGワードを指定したいんですが、
何か良い方法はありますか?
あるNG文字列をあらかじめ指定した別の文字列に置き換えることさえ出来たらいいんですが。
普通に指定しただけでは2chのスレタイトル程度なら置き換え可能なんですが、
他のサイトには適応できないのですが。
何か良い方法はありますか?
あるNG文字列をあらかじめ指定した別の文字列に置き換えることさえ出来たらいいんですが。
普通に指定しただけでは2chのスレタイトル程度なら置き換え可能なんですが、
他のサイトには適応できないのですが。
276 :名無しさん@お腹いっぱい。:2007/02/01(木) 00:08:40 ID:8XkNqH/e0
>275
Matchに「NGワード」を並べて書き、Replaceに「別の文字列」を書く。
あらゆるフィルタの中でも、もっとも簡単な部類に入る。
そのくらいなら自分で書けるようになった方が自分のためだと思うが……。
自分で書く気がないなら、NGワードの例を出してほしい。
あと、下の2行の意味がなからない。
Matchに「NGワード」を並べて書き、Replaceに「別の文字列」を書く。
あらゆるフィルタの中でも、もっとも簡単な部類に入る。
そのくらいなら自分で書けるようになった方が自分のためだと思うが……。
自分で書く気がないなら、NGワードの例を出してほしい。
あと、下の2行の意味がなからない。
277 :名無しさん@お腹いっぱい。:2007/02/01(木) 02:03:41 ID:RQx5IB6e0
278 :名無しさん@お腹いっぱい。:2007/02/01(木) 02:07:18 ID:+vUmzVaZ0
>>276
例えば「ブラウザ」という言葉をNGワードにして、「NG」という文字列に置き換えようとしたら
今は以下のようにやってます。
[Patterns]
Name = "NGword"
Active = TRUE
Limit = 256
Match = "[%83][%75][%83][%89][%83][%45][%83][%55]"
""
Replace = "NG"
上のフィルターでは↓の2chのスレ一覧のようなサイトでは「ブラウザ」という言葉が確かに「NG」という言葉に入れ替わってて、
フィルターが効いてるのが分かるのですが。
http://pc9.2ch.net/software/subback.html
でも出来ればこういったフィルターをあらゆるサイトに適応したいのです。
今のままでは一般のサイト、
例えば↓のようなサイトでは、
http://japan.cnet.com/column/pers/story/0,2000055923,20085434,00.htm
「ブラウザ」という言葉が「NG」という文字列に入れ替わらないのです。
何かいい方法はあるでしょうか?
例えば「ブラウザ」という言葉をNGワードにして、「NG」という文字列に置き換えようとしたら
今は以下のようにやってます。
[Patterns]
Name = "NGword"
Active = TRUE
Limit = 256
Match = "[%83][%75][%83][%89][%83][%45][%83][%55]"
""
Replace = "NG"
上のフィルターでは↓の2chのスレ一覧のようなサイトでは「ブラウザ」という言葉が確かに「NG」という言葉に入れ替わってて、
フィルターが効いてるのが分かるのですが。
http://pc9.2ch.net/software/subback.html
でも出来ればこういったフィルターをあらゆるサイトに適応したいのです。
今のままでは一般のサイト、
例えば↓のようなサイトでは、
http://japan.cnet.com/column/pers/story/0,2000055923,20085434,00.htm
「ブラウザ」という言葉が「NG」という文字列に入れ替わらないのです。
何かいい方法はあるでしょうか?
279 :名無しさん@お腹いっぱい。:2007/02/01(木) 02:08:23 ID:SBsOKr/c0
Google image redirector いいなあ。
280 :名無しさん@お腹いっぱい。:2007/02/01(木) 02:26:17 ID:8XkNqH/e0
>278
ん? ちゃんとマッチしたよ。
改善点は、日本語の場合、Shift_JIS以外の文字コードにも対応させること。
EUC-JPとUTF-8ね。ISO-2022-JPはProxomitronと相性が悪いようだから、
正常に動作するかはわからないけど、たぶんOKだろうと思う。
あとは、NGワードがたくさんあるようならば、$LSTを使った方がいい。
Limitももっと減らしていい。
ん? ちゃんとマッチしたよ。
改善点は、日本語の場合、Shift_JIS以外の文字コードにも対応させること。
EUC-JPとUTF-8ね。ISO-2022-JPはProxomitronと相性が悪いようだから、
正常に動作するかはわからないけど、たぶんOKだろうと思う。
あとは、NGワードがたくさんあるようならば、$LSTを使った方がいい。
Limitももっと減らしていい。
281 :名無しさん@お腹いっぱい。:2007/02/01(木) 03:20:33 ID:jKsRxV8d0
ヘッダフィルタでcharsetを見てフラグを立てて
そのフラグが例えば1だったらshift-jis、2だったらEUC-JPとかにして
マッチ欄でスイッチすればいいのかも
マッチさせるワードは>>5のコード変換スクリプトで
そのフラグが例えば1だったらshift-jis、2だったらEUC-JPとかにして
マッチ欄でスイッチすればいいのかも
マッチさせるワードは>>5のコード変換スクリプトで
282 :名無しさん@お腹いっぱい。:2007/02/01(木) 04:10:38 ID:jKsRxV8d0
そこまでしなくていいのか
試してないけど、とりあえずmatch欄を
[%1B][%24][%62][%25][%56][%25][%69][%25][%26][%25][%36][%1B][%28][%42]|
[%83][%75][%83][%89][%83][%45][%83][%55]|
[%A5][%D6][%A5][%E9][%A5][%A6][%A5][%B6]|
[%E3][%83][%96][%E3][%83][%A9][%E3][%82][%A6][%E3][%82][%B6]|
[%30][%D6][%30][%E9][%30][%A6][%30][%B6]|
[%D6][%30][%E9][%30][%A6][%30][%B6][%30]
にしたらいいんじゃ?
上からISO-2022-JP(JIS)、Shift_JIS、EUC-JP、UTF-8、UTF-16BE、UTF-16LE
試してないけど、とりあえずmatch欄を
[%1B][%24][%62][%25][%56][%25][%69][%25][%26][%25][%36][%1B][%28][%42]|
[%83][%75][%83][%89][%83][%45][%83][%55]|
[%A5][%D6][%A5][%E9][%A5][%A6][%A5][%B6]|
[%E3][%83][%96][%E3][%83][%A9][%E3][%82][%A6][%E3][%82][%B6]|
[%30][%D6][%30][%E9][%30][%A6][%30][%B6]|
[%D6][%30][%E9][%30][%A6][%30][%B6][%30]
にしたらいいんじゃ?
上からISO-2022-JP(JIS)、Shift_JIS、EUC-JP、UTF-8、UTF-16BE、UTF-16LE
283 :名無しさん@お腹いっぱい。:2007/02/01(木) 04:33:50 ID:P+90d2Py0
すみません、
http://rainbow.sakuratan.com/
http://rainbow2.sakuratan.com/
URLが↑の部分に一致した場合にCoralを使って、.nyud.net:8090を加えて
例えば、http://rainbow2.sakuratan.com/img/rainbow2nd00000.jpg を
http://rainbow2.sakuratan.com.nyud.net:8090/img/rainbow2nd00000.jpg に
変換してアクセスするフィルタをお願いします。
$JUMP使うんだろうなとやってはみたのですが、おいらには無理ですた。
http://rainbow.sakuratan.com/
http://rainbow2.sakuratan.com/
URLが↑の部分に一致した場合にCoralを使って、.nyud.net:8090を加えて
例えば、http://rainbow2.sakuratan.com/img/rainbow2nd00000.jpg を
{kind=link}
http://rainbow2.sakuratan.com.nyud.net:8090/img/rainbow2nd00000.jpg に
{kind=link}
変換してアクセスするフィルタをお願いします。
$JUMP使うんだろうなとやってはみたのですが、おいらには無理ですた。
284 :名無しさん@お腹いっぱい。:2007/02/01(木) 09:13:37 ID:fBgpczrI0
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: rainbow.sakuratan.com (out)"
Match = "http://rainbow(2|)\0.sakuratan.com/\1"
Replace = "$JUMP(http://rainbow\0.sakuratan.com.nyud.net:8090/\1)"
In = FALSE
Out = TRUE
Key = "URL: rainbow.sakuratan.com (out)"
Match = "http://rainbow(2|)\0.sakuratan.com/\1"
Replace = "$JUMP(http://rainbow\0.sakuratan.com.nyud.net:8090/\1)"
285 :名無しさん@お腹いっぱい。:2007/02/01(木) 14:06:16 ID:P+90d2Py0
286 :名無しさん@お腹いっぱい。:2007/02/01(木) 18:19:44 ID:+vUmzVaZ0
287 :名無しさん@お腹いっぱい。:2007/02/01(木) 20:02:48 ID:N6/IPVDA0
>>280-282というアンカーの付け方を覚えような
288 :名無しさん@お腹いっぱい。:2007/02/02(金) 03:10:10 ID:0N0Xwy8o0
便乗で質問なんですが>>278のような場合で
特定の文字のあるサイトを、完全に非表示にさせたい場合はどうすれば良いですか?
特定の文字のあるサイトを、完全に非表示にさせたい場合はどうすれば良いですか?
289 :名無しさん@お腹いっぱい。:2007/02/02(金) 05:05:15 ID:nsQ2fZGS0
ベタですが
Limit = 32767
Match="<html*NGな文字列"
Replace ="\k"
とか?
Limit = 32767
Match="<html*NGな文字列"
Replace ="\k"
とか?
290 :名無しさん@お腹いっぱい。:2007/02/02(金) 06:26:00 ID:BZ0cWc8X0
$TST使ったことないからよくわからんけど。
NGワードにマッチしたら $SET(NGword=true)。
$TST(NGword=true) のときに html, body { display: none } になるよう、
<html>か<body>あたりを書き換える。
ただ、これだとなんで非表示になったのかわからないから、
適当な背景画像やCSSの content あたりを使ってわかるようにするか、
あるいはどこかにリダイレクトしてもいいし、\kしてもいいかも。
NGワードにマッチしたら $SET(NGword=true)。
$TST(NGword=true) のときに html, body { display: none } になるよう、
<html>か<body>あたりを書き換える。
ただ、これだとなんで非表示になったのかわからないから、
適当な背景画像やCSSの content あたりを使ってわかるようにするか、
あるいはどこかにリダイレクトしてもいいし、\kしてもいいかも。
291 :名無しさん@お腹いっぱい。:2007/02/02(金) 07:20:12 ID:0N0Xwy8o0
292 :名無しさん@お腹いっぱい。:2007/02/02(金) 07:28:57 ID:OVU0v0RQ0
リダイレクトが一番手っ取り早そうだな。
検出するときはこんな感じで。
Limit = 16384
Match="$NEST(>,*NGWARD*,<)"
Replace ="\k"
検出するときはこんな感じで。
Limit = 16384
Match="$NEST(>,*NGWARD*,<)"
Replace ="\k"
293 :名無しさん@お腹いっぱい。:2007/02/02(金) 17:19:59 ID:9vWGIiWo0
Google image redirector [070130] を使っています。
イメージで検索すると、イメージが全く表示されません。
(下のGoooooogle→ は、表示される)
一度、バイパスにして、リロードすると、画像が表示され、
バイパスを外して、リロードすると、今度は普通に表示され、
画像の左に、Link と、表示されます。
バイパス前後で、URLを比較してみると、最後に、
&ei=W_HCRczoLMWsJP-bpZ4O&gbv=1
が、付いていない場合、表示されないようです。
これは、なぜこのような動作になってしまうのでしょうか?
ログと、デバッグで見てみましたが、わかりませんでした。
イメージで検索すると、イメージが全く表示されません。
(下のGoooooogle→ は、表示される)
一度、バイパスにして、リロードすると、画像が表示され、
バイパスを外して、リロードすると、今度は普通に表示され、
画像の左に、Link と、表示されます。
バイパス前後で、URLを比較してみると、最後に、
&ei=W_HCRczoLMWsJP-bpZ4O&gbv=1
が、付いていない場合、表示されないようです。
これは、なぜこのような動作になってしまうのでしょうか?
ログと、デバッグで見てみましたが、わかりませんでした。
294 :名無しさん@お腹いっぱい。:2007/02/02(金) 18:48:41 ID:W8YpnX540
js off と認識されたらそれが付くみたいよ
295 :名無しさん@お腹いっぱい。:2007/02/02(金) 22:04:39 ID:c4Ondbdf0
Google image redirector [070130]は
非Javascript版のGoogleイメージでしか使えないよ。
>>266のGoogle image redirector [070131]か
>>272のGoogle image redirector [070131a]だと
問題なく動くのでこっち使ってみたらどう?
非Javascript版のGoogleイメージでしか使えないよ。
>>266のGoogle image redirector [070131]か
>>272のGoogle image redirector [070131a]だと
問題なく動くのでこっち使ってみたらどう?
296 :名無しさん@お腹いっぱい。:2007/02/02(金) 22:08:27 ID:UcPFGIJe0
フィルターの製作をおながいします。
NIKKEINET:
ttp://www.nikkei.co.jp/
の各ページ(主要、経済、各企業etc.)の
バナー&フラッシュ広告を削除するフィルターを作ってください。
よろしくお願いします。<(_ _)>
NIKKEINET:
ttp://www.nikkei.co.jp/
の各ページ(主要、経済、各企業etc.)の
バナー&フラッシュ広告を削除するフィルターを作ってください。
よろしくお願いします。<(_ _)>
297 :名無しさん@お腹いっぱい。:2007/02/03(土) 10:42:12 ID:qkmUNYlQ0
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL-Killer: NIKKEI AD KILLER (out)"
URL = "gavit.nikkei.co.jp/js.ng/"
Replace = "\k"
In = FALSE
Out = TRUE
Key = "URL-Killer: NIKKEI AD KILLER (out)"
URL = "gavit.nikkei.co.jp/js.ng/"
Replace = "\k"
298 :296:2007/02/03(土) 12:33:02 ID:2RLsb/q/0
299 :名無しさん@お腹いっぱい。:2007/02/04(日) 02:39:42 ID:6Eu6Gprl0
フィルターの製作をお願いしたいのですが、
http://www.aucfan.com/
の検索結果に出てくる広告、
今まではさほど気にならなかったのですが、
急に広告が増量されて見づらくなってしまいました。
広告を消すフィルターをどうかよろしくお願いします。
http://www.aucfan.com/
の検索結果に出てくる広告、
今まではさほど気にならなかったのですが、
急に広告が増量されて見づらくなってしまいました。
広告を消すフィルターをどうかよろしくお願いします。
300 :名無しさん@お腹いっぱい。:2007/02/04(日) 03:34:15 ID:av2NYkCr0
報酬を聞こうか
301 :名無しさん@お腹いっぱい。:2007/02/04(日) 04:37:37 ID:DsV96qAf0
>299
ck.jp.ap.valuecommerce.com/ を\kする。
あとはインラインフレームを消せば、ほとんどの広告は消えそうだ。
ck.jp.ap.valuecommerce.com/ を\kする。
あとはインラインフレームを消せば、ほとんどの広告は消えそうだ。
302 :名無しさん@お腹いっぱい。:2007/02/04(日) 09:41:21 ID:aKwvo5/a0
[Patterns]
Name = "aucfan.com ad killer"
Active = TRUE
URL = "[^.]+.aucfan.com/"
Limit = 2560
Match = "<!-- [%A5][%A2][%A5][%C9][%A5][%BB][%A5][%F3][%A5][%B9] -->*<!-- /+[%A5][%A2][%A5][%C9][%A5][%BB][%A5][%F3][%A5][%B9]([%bd][%aa][%ce][%bb]|) -->"
"|<!-- 88\*88 [%a5][%d0][%a5][%ca][%a1][%bc][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->*<!-- /88\*88 [%a5][%d0][%a5][%ca][%a1][%bc][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->"
"|<!-- 468\*60 [%b9][%ad][%b9][%f0] -->*<!-- /468\*60 [%b9][%ad][%b9][%f0] -->"
"|<!-- SUPER_REACH_TEXT_AUCFAN [%b9][%ad][%b9][%f0] -->*<!-- /SUPER_REACH_TEXT_AUCFAN [%b9][%ad][%b9][%f0] -->"
"|<!-- 200\*200 [%b9][%ad][%b9][%f0] -->*<!-- /200\*200 [%b9][%ad][%b9][%f0] -->"
"|<!-- [%b9][%ad][%b9][%f0][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->*<!-- [%b9][%ad][%b9][%f0][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->"
Name = "aucfan.com ad killer"
Active = TRUE
URL = "[^.]+.aucfan.com/"
Limit = 2560
Match = "<!-- [%A5][%A2][%A5][%C9][%A5][%BB][%A5][%F3][%A5][%B9] -->*<!-- /+[%A5][%A2][%A5][%C9][%A5][%BB][%A5][%F3][%A5][%B9]([%bd][%aa][%ce][%bb]|) -->"
"|<!-- 88\*88 [%a5][%d0][%a5][%ca][%a1][%bc][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->*<!-- /88\*88 [%a5][%d0][%a5][%ca][%a1][%bc][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->"
"|<!-- 468\*60 [%b9][%ad][%b9][%f0] -->*<!-- /468\*60 [%b9][%ad][%b9][%f0] -->"
"|<!-- SUPER_REACH_TEXT_AUCFAN [%b9][%ad][%b9][%f0] -->*<!-- /SUPER_REACH_TEXT_AUCFAN [%b9][%ad][%b9][%f0] -->"
"|<!-- 200\*200 [%b9][%ad][%b9][%f0] -->*<!-- /200\*200 [%b9][%ad][%b9][%f0] -->"
"|<!-- [%b9][%ad][%b9][%f0][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->*<!-- [%b9][%ad][%b9][%f0][%a5][%b9][%a5][%da][%a1][%bc][%a5][%b9] -->"
303 :名無しさん@お腹いっぱい。:2007/02/04(日) 13:07:51 ID:AcpWn5Bc0
304 :名無しさん@お腹いっぱい。:2007/02/04(日) 16:47:05 ID:tn0QTiVt0
ユーザースタイルシートをブラウザではなく、Proxomitoronで指定させる方法はありますか?
よろしくお願いします
よろしくお願いします
305 :名無しさん@お腹いっぱい。:2007/02/05(月) 00:27:43 ID:TSp+vltp0
>>304
俺はこういうの使ってる
[Patterns]
Name = "Apply my style sheet"
Active = TRUE
URL = "$LST(CSS-List)"
Limit = 1
Match = "<start>"
Replace = "<link rel="stylesheet" href="file:///C:\\Progra~1\\ProxN\\html\\white.css">"
俺はこういうの使ってる
[Patterns]
Name = "Apply my style sheet"
Active = TRUE
URL = "$LST(CSS-List)"
Limit = 1
Match = "<start>"
Replace = "<link rel="stylesheet" href="file:///C:\\Progra~1\\ProxN\\html\\white.css">"
306 :名無しさん@お腹いっぱい。:2007/02/05(月) 00:48:13 ID:yTjSLT5a0
>>305 俺のとほとんど同じだ
$LSTでスタイルシートを使い分けられるのが便利だよね
あと俺は\dを使って href="\dhtml/Hiragino.css" にして
最後に$STOP()を入れてるけど$STOP()は蛇足かな?
$LSTでスタイルシートを使い分けられるのが便利だよね
あと俺は\dを使って href="\dhtml/Hiragino.css" にして
最後に$STOP()を入れてるけど$STOP()は蛇足かな?
307 :名無しさん@お腹いっぱい。:2007/02/05(月) 02:10:20 ID:oVE+Ue5C0
特定のURLをクリックしたら、そのURLを違うのに置き換えて違うアプリに渡す事って出来ますか?
ってのも、ニコニコ動画のURLをクリックしたらその元になったYouTubeのURLを
TubePlayerってアプリに渡したいんですよ。
ってのも、ニコニコ動画のURLをクリックしたらその元になったYouTubeのURLを
TubePlayerってアプリに渡したいんですよ。
308 :名無しさん@お腹いっぱい。:2007/02/05(月) 03:48:32 ID:ev+hu6il0
初めてフィルタを作りますた。
[Patterns]
Name = "JWord Popup killer (5 Feb 2007)"
Active = TRUE
Multi = TRUE
Bounds = "<script*</script>"
Limit = 512
Match = "*(jword|jwd)*"
Replace = "\n<!-- JWord Popup killer -->\n"
[Patterns]
Name = "JWord Popup killer (5 Feb 2007)"
Active = TRUE
Multi = TRUE
Bounds = "<script*</script>"
Limit = 512
Match = "*(jword|jwd)*"
Replace = "\n<!-- JWord Popup killer -->\n"
309 :名無しさん@お腹いっぱい。:2007/02/05(月) 03:50:04 ID:oVE+Ue5C0
FAQ等を穴が空く程見た結果、>>307の様な事は出来ないみたいですね。
そこで
http://www.nicovideo.jp/watch?v=ut**********
というリンクがあったら
http://www.nicovideo.jp/watch?v=ut**********の横に
http://www.youtube.com/watch?v=**********というリンクを追加するフィルタを作ってはいただけないでしょうか。
自分で頑張ってみた結果、テストでは成功したのに実際に適用されませんでした。
そこで
http://www.nicovideo.jp/watch?v=ut**********
というリンクがあったら
http://www.nicovideo.jp/watch?v=ut**********の横に
http://www.youtube.com/watch?v=**********というリンクを追加するフィルタを作ってはいただけないでしょうか。
自分で頑張ってみた結果、テストでは成功したのに実際に適用されませんでした。
310 :名無しさん@お腹いっぱい。:2007/02/05(月) 05:28:35 ID:9MDRIgP10
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: nicovideo to yotube (out)"
Match = "http://www.nicovideo.jp/watch?v=ut\0"
Replace = "$JUMP(http://www.youtube.com/watch?v=\0)"
でも、コメント見たいような時はこういうほうが良くない?
[Patterns]
Name = "to yotube from nicovideo"
Active = TRUE
URL = "([^/]++.|)nicovideo.jp"
Limit = 1024
Match = "<table border="0" cellspacing="4" cellpadding="0">\1"
"value=\"http://www.nicovideo.jp/watch\?v=ut\0\""
"\2</table>"
Replace = "<table border="0" cellspacing="4" cellpadding="0">\1"
"value="http://www.youtube.com/watch?v=\0""
"\2<a href="http://www.youtube.com/watch?v=\0">youtube</a></table>"
In = FALSE
Out = TRUE
Key = "URL: nicovideo to yotube (out)"
Match = "http://www.nicovideo.jp/watch?v=ut\0"
Replace = "$JUMP(http://www.youtube.com/watch?v=\0)"
でも、コメント見たいような時はこういうほうが良くない?
[Patterns]
Name = "to yotube from nicovideo"
Active = TRUE
URL = "([^/]++.|)nicovideo.jp"
Limit = 1024
Match = "<table border="0" cellspacing="4" cellpadding="0">\1"
"value=\"http://www.nicovideo.jp/watch\?v=ut\0\""
"\2</table>"
Replace = "<table border="0" cellspacing="4" cellpadding="0">\1"
"value="http://www.youtube.com/watch?v=\0""
"\2<a href="http://www.youtube.com/watch?v=\0">youtube</a></table>"
311 :名無しさん@お腹いっぱい。:2007/02/05(月) 05:47:21 ID:ErlZFXgT0
313 :名無しさん@お腹いっぱい。:2007/02/05(月) 12:08:06 ID:JksNLc5i0
>307
たぶんだけど新しいスキームを作って、そのスキームにポチエスのURL版を関連づければいいんじゃないかな。
どうやってそれを加工してTubePlayerに渡すかという問題が残るが。
たぶんだけど新しいスキームを作って、そのスキームにポチエスのURL版を関連づければいいんじゃないかな。
どうやってそれを加工してTubePlayerに渡すかという問題が残るが。
314 :名無しさん@お腹いっぱい。:2007/02/05(月) 13:51:20 ID:pMFKTk5j0
某所では偽プロトコル?とか言ってたな
315 :名無しさん@お腹いっぱい。:2007/02/05(月) 16:02:31 ID:O3aVo9FA0
>>310
リンク元に直接YouTubeのリンクも欲しいのよ
だもんで、頑張ってこんなの作ってみました。
一応は動いてる。もし良かったらもっと良い感じにしてくれると嬉しい
[Patterns]
Name = "nicovideo ==> YouTube"
Active = TRUE
Multi = TRUE
Bounds = "<a*</a>"
Limit = 256
Match = "(<a href="http://(|ime.nu/)www.nicovideo.jp/watch?v=ut\1"*</a>)\9"
Replace = "\9 <a href="http://www.youtube.com/watch?v=\1" target=_blank><font color="red" size="-2">YouTube</font></a>"
>>313
そういう難しいのよく分からないから、SleipnirのURIアクションで渡す事にしました。
リンク元に直接YouTubeのリンクも欲しいのよ
だもんで、頑張ってこんなの作ってみました。
一応は動いてる。もし良かったらもっと良い感じにしてくれると嬉しい
[Patterns]
Name = "nicovideo ==> YouTube"
Active = TRUE
Multi = TRUE
Bounds = "<a*</a>"
Limit = 256
Match = "(<a href="http://(|ime.nu/)www.nicovideo.jp/watch?v=ut\1"*</a>)\9"
Replace = "\9 <a href="http://www.youtube.com/watch?v=\1" target=_blank><font color="red" size="-2">YouTube</font></a>"
>>313
そういう難しいのよく分からないから、SleipnirのURIアクションで渡す事にしました。
316 :名無しさん@お腹いっぱい。:2007/02/05(月) 20:24:36 ID:05vrgQwq0
フィルターの作成依頼でございます。
Exiteの「ニュース」の各ページの、バナー広告とFlashを殺すフィルターを、
どうか作っていただきたくおながいします。
(おじぎ)
Exiteの「ニュース」の各ページの、バナー広告とFlashを殺すフィルターを、
どうか作っていただきたくおながいします。
(おじぎ)
317 :名無しさん@お腹いっぱい。:2007/02/06(火) 00:44:44 ID:Qi34bLYl0
まずは既存のよくできた汎用広告除去フィルタを試したのかな。
個別にフィルタを作るまでもなく、たいがいのフィルタ機能は既に存在しているので
(場合によっては手を加える必要がある可能性もあるが)
まずはthinkingさんのところやアップローダをよく見てみることを勧める。
個別にフィルタを作るまでもなく、たいがいのフィルタ機能は既に存在しているので
(場合によっては手を加える必要がある可能性もあるが)
まずはthinkingさんのところやアップローダをよく見てみることを勧める。
318 :名無しさん@お腹いっぱい。:2007/02/06(火) 00:50:36 ID:XkM+asqz0
(ねごと)
320 :名無しさん@お腹いっぱい。:2007/02/06(火) 02:16:12 ID:qTo28GH/0
すまん、既に試してたのね
>>317
たびたびすいません。
既存のフィルターをいろいろと試していたら、
何とか消すことができました。
ちゃんと確かめないでカキコしてごめんなさい。
これからは注意します。
またわからないことがあったら、
調べられるところはちゃんと確かめて、
それでもわからないときにだけ質問しますので、
教えてくださいね。
ありがとうございました。
たびたびすいません。
既存のフィルターをいろいろと試していたら、
何とか消すことができました。
ちゃんと確かめないでカキコしてごめんなさい。
これからは注意します。
またわからないことがあったら、
調べられるところはちゃんと確かめて、
それでもわからないときにだけ質問しますので、
教えてくださいね。
ありがとうございました。
323 :名無しさん@お腹いっぱい。:2007/02/06(火) 17:39:38 ID:pGgI1Jpm0
http://www.amazon.co.jp/?&tag=
↑の広告を消すフィルタってないですか・・・
↑の広告を消すフィルタってないですか・・・
324 :名無しさん@お腹いっぱい。:2007/02/06(火) 22:49:19 ID:vWqTPSbl0
YouTubeで全画面表示から次の動画を選んだときに
次の動画も全画面で表示するようなフィルターを作っていただけませんか。
前のアドレスがwatch_fullscreenだったら
次もwatch_fullscreenにするようなやつ。
次の動画も全画面で表示するようなフィルターを作っていただけませんか。
前のアドレスがwatch_fullscreenだったら
次もwatch_fullscreenにするようなやつ。
325 :名無しさん@お腹いっぱい。:2007/02/09(金) 17:40:50 ID:t4bWrHbi0
326 :名無しさん@お腹いっぱい。:2007/02/09(金) 21:40:17 ID:cGqbxPYH0
クレクレ君をスルーするスレにようそこ。
327 :名無しさん@お腹いっぱい。:2007/02/10(土) 02:51:37 ID:WGTkmpWl0
before/afterのサンプルを出すなら別だが、わざわざ見もしないURLを他人のために踏んでソース見て……なんて普通はせんわな。
このスレは無報酬労働者の溜まり場じゃねーよって話だ。
このスレは無報酬労働者の溜まり場じゃねーよって話だ。
328 :名無しさん@お腹いっぱい。:2007/02/10(土) 09:16:42 ID:2y6NySyi0
あっそ
329 :名無しさん@お腹いっぱい。:2007/02/10(土) 15:28:48 ID:6IzS+fNt0
作成依頼じゃなくて添削依頼お願いします。
いくつかあったフィルタを纏めてたんですが、上の方のマッチを纏めるのが上手く行きません。
また、一部のリンクには効かないようなので手を加えて頂ければと思います。
行数足りないので、下にフィルタを貼ります。&は半角です。
いくつかあったフィルタを纏めてたんですが、上の方のマッチを纏めるのが上手く行きません。
また、一部のリンクには効かないようなので手を加えて頂ければと思います。
行数足りないので、下にフィルタを貼ります。&は半角です。
330 :名無しさん@お腹いっぱい。:2007/02/10(土) 15:29:20 ID:6IzS+fNt0
Name = "Amazon Associates Killer3"
Active = TRUE
Bounds = "<a * >"
Limit = 512
Match = "<a * href="http://www.amazon.co.jp/gp/product/\w\1\?\w">|"
"<a * href="http://www.amazon.co.jp/exec/obidos/ASIN/\1/\2">|"
"<a * href="http://www.amazon.co.jp/exec/obidos/redirect\?path\=ASIN/\1\&amp;\2>"
Replace = "<a href="http://www.amazon.co.jp/gp/product/\1" title="AA_Killed3">"
Name = "Amazon Associates Killer6"
Active = TRUE
Bounds = "<a * >"
Limit = 512
Match = "<a href=("|)http://www.amazon.co.jp/\1(\&|\?|\&amp;)\2tag=\3\&\4>"
Replace = "<a href="http://www.amazon.co.jp/\1\2tag=\&\4" title="AA_Killed6">"
Active = TRUE
Bounds = "<a * >"
Limit = 512
Match = "<a * href="http://www.amazon.co.jp/gp/product/\w\1\?\w">|"
"<a * href="http://www.amazon.co.jp/exec/obidos/ASIN/\1/\2">|"
"<a * href="http://www.amazon.co.jp/exec/obidos/redirect\?path\=ASIN/\1\&amp;\2>"
Replace = "<a href="http://www.amazon.co.jp/gp/product/\1" title="AA_Killed3">"
Name = "Amazon Associates Killer6"
Active = TRUE
Bounds = "<a * >"
Limit = 512
Match = "<a href=("|)http://www.amazon.co.jp/\1(\&|\?|\&amp;)\2tag=\3\&\4>"
Replace = "<a href="http://www.amazon.co.jp/\1\2tag=\&\4" title="AA_Killed6">"
331 :名無しさん@お腹いっぱい。:2007/02/10(土) 18:14:09 ID:x/oTTU950
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: byebye kusokkasu (Out)"
Match = "?"
Replace = "\k"
In = FALSE
Out = TRUE
Key = "Referer: byebye kusokkasu (Out)"
Match = "?"
Replace = "\k"
332 :名無しさん@お腹いっぱい。:2007/02/10(土) 21:15:21 ID:5nGHBRPX0
高スキルの人がいなくなったスレにようそこ。
333 :名無しさん@お腹いっぱい。:2007/02/11(日) 00:30:18 ID:jUmLfwXG0
<a * href="http://www.amazon.co.jp/exec/obidos/redirect\?path\=ASIN/\1\&amp;\2>
このままだと\2の中に'"'が含まれる。
それからhref属性はちゃんと$AV()使っておいたほうがいい。
ローカル変数やアスタリスクなんかは$NEST()や$AV()などで効く範囲が限定された場所で使うべきだ。
一つめのフィルタのマッチ欄はこれを参考にして完成させてみれ。
$NEST(<a\s,\1href=$AV(http://www.amazon.co.jp/(ここをOR関数を使って適当に埋める))\2,>)
ちなみに\2は$AV()の中に対応しているわけじゃないので注意。
このままだと\2の中に'"'が含まれる。
それからhref属性はちゃんと$AV()使っておいたほうがいい。
ローカル変数やアスタリスクなんかは$NEST()や$AV()などで効く範囲が限定された場所で使うべきだ。
一つめのフィルタのマッチ欄はこれを参考にして完成させてみれ。
$NEST(<a\s,\1href=$AV(http://www.amazon.co.jp/(ここをOR関数を使って適当に埋める))\2,>)
ちなみに\2は$AV()の中に対応しているわけじゃないので注意。
334 :名無しさん@お腹いっぱい。:2007/02/11(日) 16:53:56 ID:c7C8u/0E0
>>326-327
ここは元々Windows板の本スレからクレクレ君を隔離したスレだドアホ。
ここは元々Windows板の本スレからクレクレ君を隔離したスレだドアホ。
335 :名無しさん@お腹いっぱい。:2007/02/11(日) 22:30:22 ID:xLtsgn710
それを承知の上で書いてるんだドアホ。
336 :名無しさん@お腹いっぱい。:2007/02/12(月) 06:31:51 ID:gWBgRQZL0
>>333
サンクス。マッチングコマンドってあんま使ったこと無いんで、後でリファレンス読んでみます。
サンクス。マッチングコマンドってあんま使ったこと無いんで、後でリファレンス読んでみます。
337 :名無しさん@お腹いっぱい。:2007/02/12(月) 06:47:55 ID:GPwgnVer0
>>334-335
自演の臭い
自演の臭い
338 :名無しさん@お腹いっぱい。:2007/02/12(月) 08:56:58 ID:kXp1N8wL0
>>331
とんくす
とんくす
339 :名無しさん@お腹いっぱい。:2007/02/14(水) 02:57:35 ID:AYzdg3rK0
kasamatusanの画像ファイルが見れません
http://pc7.2ch.net/test/read.cgi/software/1152479379/229
あたりで紹介された設定を入れて一度はうまく行っていたのですが、
最近また何か変更があったようです
サンプル
http://kasamatusan.sakura.ne.jp/cgi-bin2/src/ichi74902.jpg.html
http://pc7.2ch.net/test/read.cgi/software/1152479379/229
あたりで紹介された設定を入れて一度はうまく行っていたのですが、
最近また何か変更があったようです
サンプル
http://kasamatusan.sakura.ne.jp/cgi-bin2/src/ichi74902.jpg.html
{kind=link}
340 :名無しさん@お腹いっぱい。:2007/02/14(水) 03:48:00 ID:q2P9kiOF0
こちとら慈善事業でフィルタ作成してんじゃねぇんだ
DAT落ちログなんか見れるかよ!
まさに外道
DAT落ちログなんか見れるかよ!
まさに外道
341 :名無しさん@お腹いっぱい。:2007/02/14(水) 04:09:39 ID:A1ueMnqT0
{kind=link}
342 :名無しさん@お腹いっぱい。:2007/02/14(水) 09:08:07 ID:AYzdg3rK0
失礼しました。当該書き込みの内容は以下のとおりです。
229 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/08/16(水) 14:25:27 ID:uWVqRDUT0
>>228
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Cookie: kasamatusan 1MB (Out)"
URL = "kasamatusan.sakura.ne.jp(:80|)/"
Match = "^?"
Replace = "0810imageview=ok"
229 名前:名無しさん@お腹いっぱい。[sage] 投稿日:2006/08/16(水) 14:25:27 ID:uWVqRDUT0
>>228
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Cookie: kasamatusan 1MB (Out)"
URL = "kasamatusan.sakura.ne.jp(:80|)/"
Match = "^?"
Replace = "0810imageview=ok"
343 :名無しさん@お腹いっぱい。:2007/02/14(水) 09:14:02 ID:AYzdg3rK0
参考になるか判りませんが、Cookiesの内容です
SN_USER
hXQiw6L4KOzeM<>1
kasamatusan.sakura.ne.jp/cgi-bin2/
1600
406055296
31593874
4235352032
29838233
*
SN_USER
hXQiw6L4KOzeM<>1
kasamatusan.sakura.ne.jp/cgi-bin2/
1600
406055296
31593874
4235352032
29838233
*
344 :名無しさん@お腹いっぱい。:2007/02/14(水) 11:13:48 ID:AYzdg3rK0
解決しました
345 :名無しさん@お腹いっぱい。:2007/02/14(水) 14:41:38 ID:k9GIn0gc0
999 名前:名無しさん@お腹いっぱい。[sage] 投稿日:9/09(水) 14:25:27 ID:uWVqRDUT0
の14:25:27←ここの部分だけを消したいのですが正規表現が分かりません。
誰かお願いします。
の14:25:27←ここの部分だけを消したいのですが正規表現が分かりません。
誰かお願いします。
346 :名無しさん@お腹いっぱい。:2007/02/14(水) 22:24:01 ID:LaaHunlN0
2007があるものとして
URL = "([^/]++.|)(2ch.net|bbspink.com)"
Match = "(200?/??/??\(??\))\0\s[#0:24]:[#0:60]:[#0:60]"
Replace = "\0"
URL = "([^/]++.|)(2ch.net|bbspink.com)"
Match = "(200?/??/??\(??\))\0\s[#0:24]:[#0:60]:[#0:60]"
Replace = "\0"
347 :名無しさん@お腹いっぱい。:2007/02/14(水) 22:46:32 ID:6+rv4nlX0
>>339
頭が悪いと大変だね、死ぬまでがんばれ。
頭が悪いと大変だね、死ぬまでがんばれ。
348 :名無しさん@お腹いっぱい。:2007/02/14(水) 23:44:00 ID:TxjerRle0
>>345
神様ありがとう。これで快適な2ちゃんライフがおくれます。
神様ありがとう。これで快適な2ちゃんライフがおくれます。
349 :名無しさん@お腹いっぱい。:2007/02/15(木) 05:03:24 ID:um1ZphUT0
URL = "([^/]++.|)(2ch.net|bbspink.com)"
Match = "200?/((1?)\0|0(?)\0)/(0(?)\1|(??)\1)\((??)\3\)\s[#0:24]:[#0:60]:[#0:60]"
Replace = "\0/\1 (\3)"
こんなのはどうだろう。年は消えてしまうが必要がないのなら。
Match = "200?/((1?)\0|0(?)\0)/(0(?)\1|(??)\1)\((??)\3\)\s[#0:24]:[#0:60]:[#0:60]"
Replace = "\0/\1 (\3)"
こんなのはどうだろう。年は消えてしまうが必要がないのなら。
350 :名無しさん@お腹いっぱい。:2007/02/15(木) 13:22:33 ID:y1yACXHd0
Jane系なら2chブラウザのスキン弄れば出来そうな。
351 :名無しさん@お腹いっぱい。:2007/02/15(木) 21:32:57 ID:Gbf/ktOp0
このフィルタ2chの仕様変更で効かなくなりました。
どなたか改訂版をお願いいたします。
Name = "2ch thread list Tabler [HOME]-R subback"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body> <font size=2>)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</body>$SET(0=</td></tr></table></body>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
どなたか改訂版をお願いいたします。
Name = "2ch thread list Tabler [HOME]-R subback"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body> <font size=2>)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</body>$SET(0=</td></tr></table></body>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
352 :名無しさん@お腹いっぱい。:2007/02/15(木) 23:53:26 ID:f/tPnEPj0
143 名前:名無し~3.EXE sage 投稿日:2007/02/13(火) 23:06:32 ID:xcI1/tg5
今日辺りから突然このフィルタが効かなくなりました。
非常に重宝していたのですが・・・
Name = "2ch thread list Tabler [HOME]-R subback"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body> <font size=2>)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</body>$SET(0=</td></tr></table></body>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
どなたか、改訂版をお願いいたします。
今日辺りから突然このフィルタが効かなくなりました。
非常に重宝していたのですが・・・
Name = "2ch thread list Tabler [HOME]-R subback"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body> <font size=2>)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</body>$SET(0=</td></tr></table></body>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
どなたか、改訂版をお願いいたします。
353 :名無しさん@お腹いっぱい。:2007/02/15(木) 23:56:59 ID:KQ0MEgQJ0
マルチ課よ
354 :名無しさん@お腹いっぱい。:2007/02/16(金) 06:01:10 ID:xbTrLM300
とりあえず修正してみた。これでいいのかな?
[Patterns]
Name = "2ch thread list Tabler [HOME]-R subback [070216]"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body><div><small id="trad">)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</small></div>$SET(0=</td></tr></table></small></div>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
[Patterns]
Name = "2ch thread list Tabler [HOME]-R subback [070216]"
Active = TRUE
URL = "[^/]++.(2ch.net|bbspink.com)/[^/]+/subback.html"
Limit = 900
Match = "</head>$SET(0="
"</head><style>"
"a:link{font-size:9pt;text-decoration:none;color:#0000ff}"
"a:visited{text-decoration:none;color:#550088}"
"a:hover{color:red}"
"</style>\n)|"
"(<body><div><small id="trad">)\1$SET(0="
"\1<TABLE width="85%" border="1" cellspacing="5""
" cellpadding="5" bgcolor="#DDFFDD" align="center">"
"<TR><TD valign="top">)|"
"</small></div>$SET(0=</td></tr></table></small></div>)|"
"/l50$SET(0=/l10)|"
"(\)</a>)\1$SET(0=\1<br>\n)|"
"(50:*\)</a>)\1$SET(0=\1</td><td valign=top>)|"
"(00:*\)</a>)\1$SET(0=\1</td></tr><tr><td valign=yop>)|"
" (<a href=)\1$SET(0=\1)"
Replace = "\0"
355 :名無しさん@お腹いっぱい。:2007/02/16(金) 08:10:13 ID:duQ3RLzw0
2ch/JBBS changer for popupが効かなくなってるね。
とりあえず
<html>*<font size=$AV(\+1) color=*</font> な部分を
↓
<html>*(<h1 style="*">*</h1>|<font size=$AV(\+1) color=*</font>)
に変えて応急処置した。
とりあえず
<html>*<font size=$AV(\+1) color=*</font> な部分を
↓
<html>*(<h1 style="*">*</h1>|<font size=$AV(\+1) color=*</font>)
に変えて応急処置した。
356 :名無しさん@お腹いっぱい。:2007/02/16(金) 15:08:16 ID:xbTrLM300
Popup Anchorの最新版をインフォシークのほうのアプロダにうpしました。
http://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0066.zip
ちなみに>>355のやり方だと仕様が古いままの板では不具合が出るようです。
http://proxo.hp.infoseek.co.jp/cgi-bin/sn_uploader/src/pr0066.zip
ちなみに>>355のやり方だと仕様が古いままの板では不具合が出るようです。
357 :名無しさん@お腹いっぱい。:2007/02/16(金) 20:23:18 ID:duQ3RLzw0
>>356 乙
358 :名無しさん@お腹いっぱい。:2007/02/16(金) 22:51:31 ID:j7duRJr10
359 :名無しさん@お腹いっぱい。:2007/02/17(土) 00:14:13 ID:E2Ij0om/0
恥を忍んで添削をお願いします……。
youtube検索結果の動画ページリンクの横に、どの動画を直接ダウンロードするリンクを付加したいです。
[Patterns]
Name = "YouTube Results DL [07/02/16]"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/results\?search_query=*"
Limit = 512
Match = "<a href="/watch\?v=\1" rel="nofollow" onclick="_hbLink('','VidHorz');">\2</a>"
Replace = "<a href="/watch\?v=\1" rel="nofollow" onclick="_hbLink('','VidHorz');">\2</a> <a href="http://youtube.com/get_video.php?video_id=\1" title="\2">[DL]</a>\n"
youtube検索結果の動画ページリンクの横に、どの動画を直接ダウンロードするリンクを付加したいです。
[Patterns]
Name = "YouTube Results DL [07/02/16]"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/results\?search_query=*"
Limit = 512
Match = "<a href="/watch\?v=\1" rel="nofollow" onclick="_hbLink('','VidHorz');">\2</a>"
Replace = "<a href="/watch\?v=\1" rel="nofollow" onclick="_hbLink('','VidHorz');">\2</a> <a href="http://youtube.com/get_video.php?video_id=\1" title="\2">[DL]</a>\n"
360 :名無しさん@お腹いっぱい。:2007/02/17(土) 02:46:52 ID:rmgiWJaD0
URL欄は前方一致なので最後の * はいりません。
361 :名無しさん@お腹いっぱい。:2007/02/17(土) 07:05:10 ID:T90IyW2S0
362 :名無しさん@お腹いっぱい。:2007/02/17(土) 10:04:40 ID:sZXKor/P0
YouTubeが文字化けします。
Bypass List に www.youtube.com/* を入れると文字化けしません。
YouTubeの調子のいいフィルターが使えないので困っています。
どうすれば 文字化けしなくなりますか?
Log貼ったほうがいいのかな?
偉い人教えてください。
Bypass List に www.youtube.com/* を入れると文字化けしません。
YouTubeの調子のいいフィルターが使えないので困っています。
どうすれば 文字化けしなくなりますか?
Log貼ったほうがいいのかな?
偉い人教えてください。
363 :名無しさん@お腹いっぱい。:2007/02/17(土) 10:24:40 ID:sZXKor/P0
自己解決しました。
ヘッダの「Content-Type: character set filter (in)」が効いていた模様です。
スレ汚ししません。
ヘッダの「Content-Type: character set filter (in)」が効いていた模様です。
スレ汚ししません。
364 :名無しさん@お腹いっぱい。:2007/02/17(土) 21:25:12 ID:G9w7zrRG0
IDを色で識別するフィルタ作ってみました。
パソと携帯の0とOの識別も。
寒色系の背景に合わせてます。
指摘あればよろしく。
パソと携帯の0とOの識別も。
寒色系の背景に合わせてます。
指摘あればよろしく。
365 :名無しさん@お腹いっぱい。:2007/02/17(土) 21:27:00 ID:G9w7zrRG0
Name = "2ch ID: colored [070217]"
Active = TRUE
URL = "([^/]++.|)(2ch.net|bbspink.com)(|*:[0-9]+{1,*})"
Limit = 16
Match = "ID\:((([a-f0-9])\9|([g-i])$SET(9=e)|([j-l])$SET(9=d)|([m-n])$SET(9=c)|([o-q])$SET(9=b)|([r-t])$SET(9=a)|([u-w])$SET(9=9)|([x-z])$SET(9=8)|([/+.])$SET(9=d))"
"(([a-f0-9])\8|([g-i])$SET(8=e)|([j-l])$SET(8=d)|([m-n])$SET(8=c)|([o-q])$SET(8=b)|([r-t])$SET(8=a)|([u-w])$SET(8=9)|([x-z])$SET(8=8)|([/+.])$SET(8=d))"
"(([a-f0-9])\7|([g-i])$SET(7=e)|([j-l])$SET(7=d)|([m-n])$SET(7=c)|([o-q])$SET(7=b)|([r-t])$SET(7=a)|([u-w])$SET(7=9)|([x-z])$SET(7=8)|([/+.])$SET(7=d))"
"(([a-f0-9])\6|([g-i])$SET(6=e)|([j-l])$SET(6=d)|([m-n])$SET(6=c)|([o-q])$SET(6=b)|([r-t])$SET(6=a)|([u-w])$SET(6=9)|([x-z])$SET(6=8)|([/+.])$SET(6=d))"
"(([a-f0-9])\5|([g-i])$SET(5=e)|([j-l])$SET(5=d)|([m-n])$SET(5=c)|([o-q])$SET(5=b)|([r-t])$SET(5=a)|([u-w])$SET(5=9)|([x-z])$SET(5=8)|([/+.])$SET(5=d))"
"(([a-f0-9])\4|([g-i])$SET(4=e)|([j-l])$SET(4=d)|([m-n])$SET(4=c)|([o-q])$SET(4=b)|([r-t])$SET(4=a)|([u-w])$SET(4=9)|([x-z])$SET(4=8)|([/+.])$SET(4=d))"
"??)\0((0)$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font><font color=#bbe417>0</font>)|(O)$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font><font color=#ef20ef>O</font>)|"
"$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font>))|"
"ID\:(\?\?\?)\0O$SET(1=ID:\0<font color=#ef20ef>O</font>)|"
"ID\:(\?\?\?)\00$SET(1=ID:\0<font color=#bbe417>0</font>)"
Replace = "\1"
Active = TRUE
URL = "([^/]++.|)(2ch.net|bbspink.com)(|*:[0-9]+{1,*})"
Limit = 16
Match = "ID\:((([a-f0-9])\9|([g-i])$SET(9=e)|([j-l])$SET(9=d)|([m-n])$SET(9=c)|([o-q])$SET(9=b)|([r-t])$SET(9=a)|([u-w])$SET(9=9)|([x-z])$SET(9=8)|([/+.])$SET(9=d))"
"(([a-f0-9])\8|([g-i])$SET(8=e)|([j-l])$SET(8=d)|([m-n])$SET(8=c)|([o-q])$SET(8=b)|([r-t])$SET(8=a)|([u-w])$SET(8=9)|([x-z])$SET(8=8)|([/+.])$SET(8=d))"
"(([a-f0-9])\7|([g-i])$SET(7=e)|([j-l])$SET(7=d)|([m-n])$SET(7=c)|([o-q])$SET(7=b)|([r-t])$SET(7=a)|([u-w])$SET(7=9)|([x-z])$SET(7=8)|([/+.])$SET(7=d))"
"(([a-f0-9])\6|([g-i])$SET(6=e)|([j-l])$SET(6=d)|([m-n])$SET(6=c)|([o-q])$SET(6=b)|([r-t])$SET(6=a)|([u-w])$SET(6=9)|([x-z])$SET(6=8)|([/+.])$SET(6=d))"
"(([a-f0-9])\5|([g-i])$SET(5=e)|([j-l])$SET(5=d)|([m-n])$SET(5=c)|([o-q])$SET(5=b)|([r-t])$SET(5=a)|([u-w])$SET(5=9)|([x-z])$SET(5=8)|([/+.])$SET(5=d))"
"(([a-f0-9])\4|([g-i])$SET(4=e)|([j-l])$SET(4=d)|([m-n])$SET(4=c)|([o-q])$SET(4=b)|([r-t])$SET(4=a)|([u-w])$SET(4=9)|([x-z])$SET(4=8)|([/+.])$SET(4=d))"
"??)\0((0)$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font><font color=#bbe417>0</font>)|(O)$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font><font color=#ef20ef>O</font>)|"
"$SET(1=ID:<font color="#\9\8\7\6\5\4">\0</font>))|"
"ID\:(\?\?\?)\0O$SET(1=ID:\0<font color=#ef20ef>O</font>)|"
"ID\:(\?\?\?)\00$SET(1=ID:\0<font color=#bbe417>0</font>)"
Replace = "\1"
366 :名無しさん@お腹いっぱい。:2007/02/17(土) 23:21:00 ID:TADx1M6H0
URL欄の(|*:[0-9]+{1,*})はあっても無くても同じだからイラネ。:に\はイラネ。
367 :名無しさん@お腹いっぱい。:2007/02/17(土) 23:38:29 ID:G9w7zrRG0
>>366 ども
ほんとですね
ほんとですね
368 :名無しさん@お腹いっぱい。:2007/02/18(日) 02:07:40 ID:yl8Igbxg0
369 :名無しさん@お腹いっぱい。:2007/02/18(日) 02:15:11 ID:yl8Igbxg0
>>368
あ、すみません自己解決しました。
あ、すみません自己解決しました。
370 :名無しさん@お腹いっぱい。:2007/02/18(日) 04:32:39 ID:9V28jqDL0
一度質問したんだから、解決したなら解決済みのフィルター書くのが礼儀。
運がよければアドバイスも貰えるかもしれないし。
運がよければアドバイスも貰えるかもしれないし。
>>370
omitronのバージョン違いでした。
omitronのバージョン違いでした。
372 :名無しさん@お腹いっぱい。:2007/02/18(日) 16:47:08 ID:Ad13aOLe0
ttp://web.archive.org/web/20050203201413/www.hirax.net/scraps/tabi/index.html
↑のように Internet archive で日本語ページを見ると文字化けするのは、
ヘッダに charset=UTF-8 と書いてあるからだと思ったので
次のようなフィルターを書いた。でも化け直らず。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "web.archive.org charset (Out)"
URL = "*web.archive.org"
Match = "charset=UTF-8"
Replace = "charset=Shift_JIS"
そもそもの着眼点が間違ってるかもだけど
とりあえずフィルタの書き方は合ってる……?
↑のように Internet archive で日本語ページを見ると文字化けするのは、
ヘッダに charset=UTF-8 と書いてあるからだと思ったので
次のようなフィルターを書いた。でも化け直らず。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "web.archive.org charset (Out)"
URL = "*web.archive.org"
Match = "charset=UTF-8"
Replace = "charset=Shift_JIS"
そもそもの着眼点が間違ってるかもだけど
とりあえずフィルタの書き方は合ってる……?
373 :名無しさん@お腹いっぱい。:2007/02/18(日) 17:19:00 ID:xJ9Dcg+D0
>>372
確かに素のIEで見ると文字化けしてるんで調べてみたら
In = TRUE
Out = FALSE
Key = "Content-Type: charset deleter (2006.09.09) (in)"
URL = "web.archive.org/"
Match = "text/html; charset=*"
Replace = "text/html"
これが効いてたよ
確かに素のIEで見ると文字化けしてるんで調べてみたら
In = TRUE
Out = FALSE
Key = "Content-Type: charset deleter (2006.09.09) (in)"
URL = "web.archive.org/"
Match = "text/html; charset=*"
Replace = "text/html"
これが効いてたよ
374 :名無しさん@お腹いっぱい。:2007/02/19(月) 01:22:09 ID:7BUQV5gZ0
375 :名無しさん@お腹いっぱい。:2007/02/19(月) 01:22:32 ID:s3bBYpWe0
/::^'´::::::::::::i、::::::::::::::::::::::::::::\
‐'7::::::::::::::::::::::::ハ:ハ::|ヽ:::;、::::::::::::丶
/::::::::::::::/!i::/|/ ! ヾ リハ:|;!、:::::::l
/´7::::::::::〃|!/_,,、 ''"゛_^`''`‐ly:::ト
/|;ィ:::::N,、‐'゛_,,.\ ´''""'ヽ !;K
! |ハト〈 ,r''"゛ , リイ)| 死ねばいいと思うよ
`y't ヽ' //
! ぃ、 、;:==ヲ 〃
`'' へ、 ` ‐ '゜ .イ
`i;、 / l
〉 ` ‐ ´ l`ヽ
/ ! レ' ヽ_
376 :名無しさん@お腹いっぱい。:2007/02/19(月) 03:51:43 ID:JCVsqpGD0
>373
それ、自分が書いたやつですな。
>372
それだと書き換えている意味がないわな。化けて当然。
Shift_JISだろうとUTF-8だろうと、
文書の中身とヘッダの文字コードが一致していなければ化ける。
web.archive.org の管理者が適当にUTF-8を指定しているのが原因なので、
web.archive.org の管理者が改善してくれればいいのだが。
それ、自分が書いたやつですな。
>372
それだと書き換えている意味がないわな。化けて当然。
Shift_JISだろうとUTF-8だろうと、
文書の中身とヘッダの文字コードが一致していなければ化ける。
web.archive.org の管理者が適当にUTF-8を指定しているのが原因なので、
web.archive.org の管理者が改善してくれればいいのだが。
377 :名無しさん@お腹いっぱい。:2007/02/19(月) 04:57:29 ID:3/veHM8c0
おまえが書いたから何なんだ
378 :名無しさん@お腹いっぱい。:2007/02/19(月) 05:20:58 ID:Z4fMRv340
自己主張したい年頃なのさ。
379 :名無しさん@お腹いっぱい。:2007/02/19(月) 06:10:58 ID:ZEWRH1fl0
答えてくれてるのに何故叩く?
文句言うなら、何のレスも返さない372のほうだろ。
文句言うなら、何のレスも返さない372のほうだろ。
380 :名無しさん@お腹いっぱい。:2007/02/19(月) 15:09:53 ID:Jr1TlpmL0
YouTubeのタイトル文字化けを直すフィルタってありませんか?
381 :名無しさん@お腹いっぱい。:2007/02/20(火) 11:00:51 ID:QUSe3g/S0
叩きたいお年頃なのさ。
チェック怠ってて済みません。
>>373
わざわざ調べてくれてありがとう……! 感無量です。バッチリです。
>>374
……出直してきますっ。
>>376
そもそもの間違いは、フィルタ名に Content-Type: が入ってなかったことでした。鬱死。
以下のフィルタで特定の日本語ページの Internet Archive は文字化けしなくなりましたが、
ドイツ語ページとかだと当然のように化けます。役立たず。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: web.archive.org charset (in)"
URL = "web.archive.org/"
Match = "text/html; charset=UTF-8"
Replace = "text/html; charset=Shift_JIS"
>>373
わざわざ調べてくれてありがとう……! 感無量です。バッチリです。
>>374
……出直してきますっ。
>>376
そもそもの間違いは、フィルタ名に Content-Type: が入ってなかったことでした。鬱死。
以下のフィルタで特定の日本語ページの Internet Archive は文字化けしなくなりましたが、
ドイツ語ページとかだと当然のように化けます。役立たず。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: web.archive.org charset (in)"
URL = "web.archive.org/"
Match = "text/html; charset=UTF-8"
Replace = "text/html; charset=Shift_JIS"
383 :名無しさん@お腹いっぱい。:2007/02/21(水) 23:44:53 ID:n3eFdYWu0
質問なんだけど、Yahooの広告を消す場合、Yahooの広告だけを消すフィルターを入れるのと、リストがたのフィルターで登録しておくのではどちらが処理的にかるいのでしょうか?
384 :名無しさん@お腹いっぱい。:2007/02/22(木) 01:04:13 ID:1euCCJ0E0
自 分 で 調 べ ろ
385 :名無しさん@お腹いっぱい。:2007/02/22(木) 01:19:28 ID:eNeppJ8q0
どうなんだろう。
1GHz超えなら$LSTであらゆるmatchぶち込んでも全然気にならないけど。
場合わけしてみると
1. URLマッチングでyahoo.co.jpだけでTXT内では$URL(http://tv.yahoo.co.jp)とは書かないであらゆる*.yahoo.co.jpにmatchさせる。
2. URLマッチングでyahoo.co.jpだけにして$LSTのTXT内で$URL(http://tv.yahoo.co.jp)
として分岐させる。
3.$LST使わないでtv.yahoo.co.jp、weather.yahoo.co.jp各々フィルタ作成。
俺はわからない・・w
1GHz超えなら$LSTであらゆるmatchぶち込んでも全然気にならないけど。
場合わけしてみると
1. URLマッチングでyahoo.co.jpだけでTXT内では$URL(http://tv.yahoo.co.jp)とは書かないであらゆる*.yahoo.co.jpにmatchさせる。
2. URLマッチングでyahoo.co.jpだけにして$LSTのTXT内で$URL(http://tv.yahoo.co.jp)
として分岐させる。
3.$LST使わないでtv.yahoo.co.jp、weather.yahoo.co.jp各々フィルタ作成。
俺はわからない・・w
386 :名無しさん@お腹いっぱい。:2007/02/22(木) 01:59:37 ID:zkphvezb0
Google Image: Image Change (070124)
また駄目になりました。
お願いします。
また駄目になりました。
お願いします。
387 :名無しさん@お腹いっぱい。:2007/02/22(木) 02:03:49 ID:XwojGfDn0
[Patterns]
Name = "Google Image: Image Change (070115)"
Active = TRUE
URL = "images.google.co(m|.jp)/"
Limit = 128
Match = "<a href="\+e\+b.m\+"><img"
Replace = ""+(b.a=b.c='')+""
"<a target=\\"_blank\\" href=\\""+decodeURIComponent(e.match(/[?&]imgrefurl=([^&]+)/)[1])+"\\">ref</a> / "
"<a target=\\"_blank\\" href=\\""+(b.b.indexOf("://")<0?"http://":"")+b.b+"\\">img</a>"
"<br><img ondblclick=\\""
" this.src = '';"
" this.style.display = 'none'"
"\\" onclick = \\""
" if (this.a) {"
" this.src = this.a;"
" this.a = 0"
"} else {"
" this.a = this.src;"
" this.src = '"+(b.b.indexOf("://")<0?"http://":"")+b.b+"'"
"}\\"$STOP()"
Name = "Google Image: Image Change (070115)"
Active = TRUE
URL = "images.google.co(m|.jp)/"
Limit = 128
Match = "<a href="\+e\+b.m\+"><img"
Replace = ""+(b.a=b.c='')+""
"<a target=\\"_blank\\" href=\\""+decodeURIComponent(e.match(/[?&]imgrefurl=([^&]+)/)[1])+"\\">ref</a> / "
"<a target=\\"_blank\\" href=\\""+(b.b.indexOf("://")<0?"http://":"")+b.b+"\\">img</a>"
"<br><img ondblclick=\\""
" this.src = '';"
" this.style.display = 'none'"
"\\" onclick = \\""
" if (this.a) {"
" this.src = this.a;"
" this.a = 0"
"} else {"
" this.a = this.src;"
" this.src = '"+(b.b.indexOf("://")<0?"http://":"")+b.b+"'"
"}\\"$STOP()"
388 :名無しさん@お腹いっぱい。:2007/02/22(木) 02:06:09 ID:N4Nfl5NR0
googleイメージがまた戻ってるw
ふるいの消しちゃったよ・・・
ふるいの消しちゃったよ・・・
389 :名無しさん@お腹いっぱい。:2007/02/22(木) 02:08:21 ID:N4Nfl5NR0
ってログ読んでるうちに書き込みが!
ばっちり動いたよ。GJ!
ばっちり動いたよ。GJ!
390 :名無しさん@お腹いっぱい。:2007/02/22(木) 02:25:52 ID:zkphvezb0
>>387
ありがとう。でもうちの環境だと駄目みたいです。
それでこれに戻したらいけました。
[Patterns]
Name = "google image (061103) +js+"
Active = TRUE
URL = "images.google.co(.jp|m)/"
Limit = 1024
Match = "var\ e=\"/imgres\?imgurl=\"\+\0\+\"\&imgrefurl=\"\+\1\+[^;]+;c\+=[^;]+;[^;]+;[^;]+;$STOP()"
"$SET(9=var e=unescape(\1.match(/^[^&]+/));var proxvar=\0;"
"c+="<a href="+e+" target=_blank>imgref</a> / <a target=_blank href="+unescape(proxvar)+">img</a><br>"
"<img ondblclick='this.src="+'"";this.style.display="none"'"
"+"' onclick='if(this.a){this.src=this.a;this.a=0}else{this.a=this.src;this.src="+'"http://'+unescape(proxvar)+'"}'"
"+"' src=/images?q=tbn:"+b.d+proxvar+">";)"
"|"
"<a href=/imgres\?imgurl=[^&]+\&imgrefurl=([^&]+)\0[^>]+> <img[^>]++(src=/images\?q\=tbn:[^:]+:([^ >]+)\2)\1*</a>"
"$SET(9=<a href="$UESC(\0)" target="_blank">imgref</a> / <a href="\2" target="_blank">img</a><br>"
"<img ondblclick="this.src='';this.style.display='none'" onclick="if(this.a){this.src=this.a;this.a=0}else{this.a=this.src;this.src='\2'}"\1</a>)"
Replace = "\9"
ありがとう。でもうちの環境だと駄目みたいです。
それでこれに戻したらいけました。
[Patterns]
Name = "google image (061103) +js+"
Active = TRUE
URL = "images.google.co(.jp|m)/"
Limit = 1024
Match = "var\ e=\"/imgres\?imgurl=\"\+\0\+\"\&imgrefurl=\"\+\1\+[^;]+;c\+=[^;]+;[^;]+;[^;]+;$STOP()"
"$SET(9=var e=unescape(\1.match(/^[^&]+/));var proxvar=\0;"
"c+="<a href="+e+" target=_blank>imgref</a> / <a target=_blank href="+unescape(proxvar)+">img</a><br>"
"<img ondblclick='this.src="+'"";this.style.display="none"'"
"+"' onclick='if(this.a){this.src=this.a;this.a=0}else{this.a=this.src;this.src="+'"http://'+unescape(proxvar)+'"}'"
"+"' src=/images?q=tbn:"+b.d+proxvar+">";)"
"|"
"<a href=/imgres\?imgurl=[^&]+\&imgrefurl=([^&]+)\0[^>]+> <img[^>]++(src=/images\?q\=tbn:[^:]+:([^ >]+)\2)\1*</a>"
"$SET(9=<a href="$UESC(\0)" target="_blank">imgref</a> / <a href="\2" target="_blank">img</a><br>"
"<img ondblclick="this.src='';this.style.display='none'" onclick="if(this.a){this.src=this.a;this.a=0}else{this.a=this.src;this.src='\2'}"\1</a>)"
Replace = "\9"
391 :名無しさん@お腹いっぱい。:2007/02/22(木) 18:51:13 ID:n67R39dJ0
このソフトで、http://www.google.com/analytics/への記録を残さないために、
該当するスクリプトを読み込まないようにとかって可能ですか?
該当するスクリプトを読み込まないようにとかって可能ですか?
392 :名無しさん@お腹いっぱい。:2007/02/22(木) 21:40:12 ID:doWBmrzQ0
[HTTP headers]
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (oo.2ch2.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://oo.2ch2.net/?q=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.2ch.net) (in)"
Match = "$RESP(302*)http://([^.]+.(2ch.net|bbspink.com))\1/test/read.cgi/\2/([^/]+)\3(/\4|)"
Replace = "$JUMP(http://p2.2ch.net/p2/read.php?host=\1&bbs=\2&key=\3&ls=\4)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.chbox.jp) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://p2.chbox.jp/read.php?url=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (snapshot.publog.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://snapshot.publog.net/dat.php?url=\u)"
↑が効かないみたいですので、修正お願いします。
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (oo.2ch2.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://oo.2ch2.net/?q=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.2ch.net) (in)"
Match = "$RESP(302*)http://([^.]+.(2ch.net|bbspink.com))\1/test/read.cgi/\2/([^/]+)\3(/\4|)"
Replace = "$JUMP(http://p2.2ch.net/p2/read.php?host=\1&bbs=\2&key=\3&ls=\4)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (p2.chbox.jp) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://p2.chbox.jp/read.php?url=\u)"
In = FALSE
Out = FALSE
Key = "URL: 2ch redirector (snapshot.publog.net) (in)"
Match = "$RESP(302*)http://[^.]+.(2ch.net|bbspink.com)/test/read.cgi/"
Replace = "$JUMP(http://snapshot.publog.net/dat.php?url=\u)"
↑が効かないみたいですので、修正お願いします。
393 :名無しさん@お腹いっぱい。:2007/02/22(木) 22:43:54 ID:doWBmrzQ0
すいません。見れました。↑は無視してくださいゥ。
394 :名無しさん@お腹いっぱい。:2007/02/23(金) 18:52:01 ID:AiikQHrw0
http://www.youtube.com/watch?v=c3-b0dnGscg
はバイパスしたいけど、
http://www.youtube.com/watch?v=c3-b0dnGscg&session=〜
はバイパスしたくないってのが書けないので助けてください
*youtube.com/watch\?v=([A-Za-z0-9_-]&[^\&])+
これで&が入ってるものを除外できるかと思ったんだけど
書き方が悪いのかそもそもを理解してないのかも分からんのです
何かと除外のところで躓いてあきらめてる
はバイパスしたいけど、
http://www.youtube.com/watch?v=c3-b0dnGscg&session=〜
はバイパスしたくないってのが書けないので助けてください
*youtube.com/watch\?v=([A-Za-z0-9_-]&[^\&])+
これで&が入ってるものを除外できるかと思ったんだけど
書き方が悪いのかそもそもを理解してないのかも分からんのです
何かと除外のところで躓いてあきらめてる
395 :名無しさん@お腹いっぱい。:2007/02/23(金) 20:32:36 ID:En/mF5T00
www.youtube.com/watch?v=(^*[&])
だと簡単すぎるかな
だと簡単すぎるかな
396 :名無しさん@お腹いっぱい。:2007/02/23(金) 20:42:26 ID:k6yS9SQt0
[^/]++youtube.com/watch\?=[^&]+(^?)
とすれば「URLは?を含むことがない」という条件を与えられる
(^?)は「もう何も続きませんよ」という印
もしかしたら[^\&]としないと動かないかもしれないけど、それは自分で検証してくれ
とすれば「URLは?を含むことがない」という条件を与えられる
(^?)は「もう何も続きませんよ」という印
もしかしたら[^\&]としないと動かないかもしれないけど、それは自分で検証してくれ
397 :名無しさん@お腹いっぱい。:2007/02/23(金) 21:57:27 ID:1mJJ69aB0
*youtube.com/watch\?v=[^&]+(^?)
398 :名無しさん@お腹いっぱい。:2007/02/23(金) 21:58:27 ID:1mJJ69aB0
1時間パソコンほったらかしにしてるあいだにかぶったorz
399 :名無しさん@お腹いっぱい。:2007/02/23(金) 22:06:10 ID:AiikQHrw0
あんがと!!!
なんとかできた!
これで夕立がまた使えそうです
なんとかできた!
これで夕立がまた使えそうです
400 :名無しさん@お腹いっぱい。:2007/02/25(日) 00:51:04 ID:SRmz9w6X0
>>391
ADListに www.google-analytics.com/urchin.js を追加。
ADListに www.google-analytics.com/urchin.js を追加。
401 :名無しさん@お腹いっぱい。:2007/02/25(日) 01:24:02 ID:7eejlz4U0
>>354
"2ch thread list Tabler [HOME]-R subback [070216]"
何故かまた効かなくなりました。
ページソースを見ても問題ないような気がするのですが・・・
お手数ですが、再び改訂版をお願いいたします。
"2ch thread list Tabler [HOME]-R subback [070216]"
何故かまた効かなくなりました。
ページソースを見ても問題ないような気がするのですが・・・
お手数ですが、再び改訂版をお願いいたします。
402 :名無しさん@お腹いっぱい。:2007/02/25(日) 18:04:00 ID:K9lZt87Q0
>>401
俺の環境ではちゃんと動いてるんだが
俺の環境ではちゃんと動いてるんだが
403 :名無しさん@お腹いっぱい。:2007/02/25(日) 22:53:43 ID:FZ67Frsr0
390のフィルター、一昨日はいけたけどまたダメになってるね…
なんなんだGoogle image
なんなんだGoogle image
404 :名無しさん@お腹いっぱい。:2007/02/25(日) 23:33:03 ID:ddW5q+L40
387は問題なく使えてる
405 :名無しさん@お腹いっぱい。:2007/02/26(月) 00:16:46 ID:EbqblFqF0
406 :名無しさん@お腹いっぱい。:2007/02/26(月) 00:30:43 ID:Fn52+iDi0
なにか他のフィルタが干渉してるのでは?
例えばAdd Link
例えばAdd Link
407 :名無しさん@お腹いっぱい。:2007/03/02(金) 12:05:17 ID:dihVs1M00
静かですね
408 :名無しさん@お腹いっぱい。:2007/03/02(金) 17:04:14 ID:eAbtRiGR0
409 :名無しさん@お腹いっぱい。:2007/03/02(金) 18:51:02 ID:KOh5VbwA0
スクリプトタグ無いの
urchinTracker();
って部分だけフィルターで消したいのですが、
タグ内の一部分だけ消す方法が良くわかりません。
どなたか教えてくれませんか?
urchinTracker();
って部分だけフィルターで消したいのですが、
タグ内の一部分だけ消す方法が良くわかりません。
どなたか教えてくれませんか?
410 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:18:25 ID:fhmIoiDy0
>>387とか>>390って何?
Googleイメージで検索して出た画像クリックするとホームページじゃなしに
元のサイズで画像を表示するってフィルタ↓使ってたんだけど、使えなくなった
これの新しいのってあります?>>387>>390は違うみたいでした
Name = "Google: Replace natural sized img [2006.04.20]"
Active = TRUE
URL = "images.google.co(m|.jp)/im(ag|gr)es\? $TYPE(htm)"
Limit = 512
Match = "(<a\s[^>]++href=)\#$AV((/imgres\?imgurl=[^&]+(^*\&frame=small)?+)\0)(^(^[ >]))"
"$SET(#="\0&frame=small")|"
"<a\s[^>]++href=$AV((http(://|s://)?+)\0)[^>]+>"
" <img\s[^>]++src=$AV(/images\?q=tbn:[^:]+:$TST(\0))[^>]+> </a>"
"$SET(#=<img style="margin: 5px; border-style: none" src="\0">)$STOP()"
Replace = "\@\r\n"
Googleイメージで検索して出た画像クリックするとホームページじゃなしに
元のサイズで画像を表示するってフィルタ↓使ってたんだけど、使えなくなった
これの新しいのってあります?>>387>>390は違うみたいでした
Name = "Google: Replace natural sized img [2006.04.20]"
Active = TRUE
URL = "images.google.co(m|.jp)/im(ag|gr)es\? $TYPE(htm)"
Limit = 512
Match = "(<a\s[^>]++href=)\#$AV((/imgres\?imgurl=[^&]+(^*\&frame=small)?+)\0)(^(^[ >]))"
"$SET(#="\0&frame=small")|"
"<a\s[^>]++href=$AV((http(://|s://)?+)\0)[^>]+>"
" <img\s[^>]++src=$AV(/images\?q=tbn:[^:]+:$TST(\0))[^>]+> </a>"
"$SET(#=<img style="margin: 5px; border-style: none" src="\0">)$STOP()"
Replace = "\@\r\n"
411 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:33:19 ID:HkvjeHx70
ようつべの認証が必要なページをスルーする方法ない?
412 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:34:32 ID:HkvjeHx70
ちなみに直接flvにリダイレクトすればflv動画保存はできた。
でも動画タイトルとか説明とか載ってるページが見たい
でも動画タイトルとか説明とか載ってるページが見たい
413 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:42:55 ID:YSlvBEF80
>>410
387を使ってるけどクリックすると元画像サイズになるよ
>>409
文面通りの意味だと
Limit 1024 (適当)
Match <script\s\0urchinTracker\(\);\1</script>
Replace <script \0\1</script>
こういう事?
もっと深い意味があるのかな
387を使ってるけどクリックすると元画像サイズになるよ
>>409
文面通りの意味だと
Limit 1024 (適当)
Match <script\s\0urchinTracker\(\);\1</script>
Replace <script \0\1</script>
こういう事?
もっと深い意味があるのかな
414 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:45:52 ID:fhmIoiDy0
>>413
ありがとう
マジですか、俺>>387、>>390ともに試したけど全然だめでした
もしかして、Javaとかオンじゃないとだめなのかなあ
>>410のはJavaなしでもいけたんだけど、う〜ん
もう一度試してきます
ありがとう
マジですか、俺>>387、>>390ともに試したけど全然だめでした
もしかして、Javaとかオンじゃないとだめなのかなあ
>>410のはJavaなしでもいけたんだけど、う〜ん
もう一度試してきます
415 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:53:36 ID:fhmIoiDy0
だめだ、出来ないorz
Firefox使ってるんだけど、もしかしてIE限定かな?
Firefox使ってるんだけど、もしかしてIE限定かな?
416 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:55:22 ID:YSlvBEF80
417 :名無しさん@お腹いっぱい。:2007/03/02(金) 20:56:49 ID:YSlvBEF80
ちなみに私はIEエンジンのタブブラウザですね
418 :名無しさん@お腹いっぱい。:2007/03/02(金) 21:00:20 ID:fhmIoiDy0
>>416
そうなんだ
Firefox2.0.0.2でJavaオフ = 普通にホームページに飛ばされる
Firefox2.0.0.2でJavaオン = サムネイル画像すら表示されず、なすすべなし(泣)
誰かFirefox用の>>410のフィルタ作ってくださいm(_ _)m
そうなんだ
Firefox2.0.0.2でJavaオフ = 普通にホームページに飛ばされる
Firefox2.0.0.2でJavaオン = サムネイル画像すら表示されず、なすすべなし(泣)
誰かFirefox用の>>410のフィルタ作ってくださいm(_ _)m
419 :名無しさん@お腹いっぱい。:2007/03/02(金) 21:14:30 ID:RWK0oXTa0
FxならgreasemonkeyいれてGreased Lightbox使った方が便利だと思う
GoogleImage以外でも使えるし。
GoogleImage以外でも使えるし。
420 :名無しさん@お腹いっぱい。:2007/03/02(金) 21:46:35 ID:WUebI47X0
このスレはOperaユーザが多いからそのせいもあるんじゃない?
421 :名無しさん@お腹いっぱい。:2007/03/02(金) 22:51:58 ID:fhmIoiDy0
422 :409 :2007/03/02(金) 23:04:03 ID:KOh5VbwA0
>>413
どうもです。
狙いはその通りで、試してみましたが、
ロード時に読み込まれるので、後ろの</script>が読み込まれる前に
urchinTracker()を呼び出そうとするみたいで、
とりあえず、後ろの</script>を削って
Match <script\s\0urchinTracker\(\);\1
でやってみたら動いてるようです。
こんな感じでいいんでしょうか?
どうもです。
狙いはその通りで、試してみましたが、
ロード時に読み込まれるので、後ろの</script>が読み込まれる前に
urchinTracker()を呼び出そうとするみたいで、
とりあえず、後ろの</script>を削って
Match <script\s\0urchinTracker\(\);\1
でやってみたら動いてるようです。
こんな感じでいいんでしょうか?
423 :名無しさん@お腹いっぱい。:2007/03/03(土) 00:09:34 ID:kMgiw1TB0
>>422
ん、テストページが無いので良くわからない。
入れ子でおかしくなるかもなので
Match
$NEST(<script\s[^>]\0+>,\1urchinTracker\(\);\2,</script>)
Replace
<script \0>\1\2</script>
のほうが安全かな。
ん、テストページが無いので良くわからない。
入れ子でおかしくなるかもなので
Match
$NEST(<script\s[^>]\0+>,\1urchinTracker\(\);\2,</script>)
Replace
<script \0>\1\2</script>
のほうが安全かな。
424 :名無しさん@お腹いっぱい。:2007/03/03(土) 06:33:14 ID:KNGGVaeK0
425 :名無しさん@お腹いっぱい。:2007/03/03(土) 06:34:55 ID:KNGGVaeK0
↑フィルターが正しく動いてればの話ね。 limitが足りなかったとかそういう原因かも知れない。
426 :名無しさん@お腹いっぱい。:2007/03/03(土) 06:53:45 ID:UgcnQ/NE0
ttp://dat.2chan.net/l/futaba.htm
上の掲示板への特定のIPからの書き込みを返信の場合はそれのみ
投稿の場合は広告、画像から子ツリーまですべて
痕跡も残さず消せるフィルターを作ってもらえないでしょうか
おねがいします
上の掲示板への特定のIPからの書き込みを返信の場合はそれのみ
投稿の場合は広告、画像から子ツリーまですべて
痕跡も残さず消せるフィルターを作ってもらえないでしょうか
おねがいします
427 :名無しさん@お腹いっぱい。:2007/03/03(土) 07:07:54 ID:KNGGVaeK0
ふたばのオミトロンスレ見れよ
428 :名無しさん@お腹いっぱい。:2007/03/03(土) 07:13:16 ID:UgcnQ/NE0
気づきませんでした
いってきます
いってきます
429 :409 :2007/03/03(土) 09:31:45 ID:fwIzo8pg0
>>423
>>424
どうもです。
いろいろ勘違いがあったみたいです。
とりあえず以下のようにしました。
まれに
urchinTracker();
に引数が入ってるのがあるのでMatchに*を入れてみました。
後はBounds指定ってこれだと意味ないんでしょうか?
[Patterns]
Name = "Kill urchinTracker"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<script($INEST(<script,</script)</script>|*)"
Limit = 1024
Match = "<script\s\0urchinTracker\(*\);\1</script>"
Replace = "<script \0\1</script>"
>>424
どうもです。
いろいろ勘違いがあったみたいです。
とりあえず以下のようにしました。
まれに
urchinTracker();
に引数が入ってるのがあるのでMatchに*を入れてみました。
後はBounds指定ってこれだと意味ないんでしょうか?
[Patterns]
Name = "Kill urchinTracker"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<script($INEST(<script,</script)</script>|*)"
Limit = 1024
Match = "<script\s\0urchinTracker\(*\);\1</script>"
Replace = "<script \0\1</script>"
430 :名無しさん@お腹いっぱい。:2007/03/03(土) 11:08:29 ID:KNGGVaeK0
inestの使い道が違う。 この場合はnest。
$NEST(<script,\1urchinTracker\(\);\2,</script>)
これで十分だからboundsはいりません。
$NEST(<script,\1urchinTracker\(\);\2,</script>)
これで十分だからboundsはいりません。
431 :名無しさん@お腹いっぱい。:2007/03/03(土) 19:14:24 ID:7WHuJ2Be0
432 :409 :2007/03/03(土) 19:43:56 ID:fwIzo8pg0
>>430
ありがとうございます。NESTの件、了解しました。
また別件というか別パターンが出てきました。
<a href="/index.html" onclick="javascript:urchinTracker('/sample/2007/misc/');">
みたいな感じでタグのイベント属性で追加されるパターンがあるみたいです。
なんかこのパターンを考えるとキリが無いのですが、
このパターンも消すとするとフィルターは別途書く必要があるので負荷が高くなるので、
ダミーのスクリプトを入れるフイルターを作った方が良いかと思うようになりました。
<head>タグの直後あたりにスクリプトブロック込みでダミーのurchinTracker()ファンクションを入れる
事で対応しようかと思い、以下の感じで作りましたが、なんか手抜きというか情けないような内容です。
アドバイスいただけますでしようか。
[Patterns]
Name = "New HTML filter"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<head>"
Replace = "<head>"
"<script type="text/javascript">function urchinTracker(){};</script>"
ありがとうございます。NESTの件、了解しました。
また別件というか別パターンが出てきました。
<a href="/index.html" onclick="javascript:urchinTracker('/sample/2007/misc/');">
みたいな感じでタグのイベント属性で追加されるパターンがあるみたいです。
なんかこのパターンを考えるとキリが無いのですが、
このパターンも消すとするとフィルターは別途書く必要があるので負荷が高くなるので、
ダミーのスクリプトを入れるフイルターを作った方が良いかと思うようになりました。
<head>タグの直後あたりにスクリプトブロック込みでダミーのurchinTracker()ファンクションを入れる
事で対応しようかと思い、以下の感じで作りましたが、なんか手抜きというか情けないような内容です。
アドバイスいただけますでしようか。
[Patterns]
Name = "New HTML filter"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<head>"
Replace = "<head>"
"<script type="text/javascript">function urchinTracker(){};</script>"
433 :名無しさん@お腹いっぱい。:2007/03/03(土) 20:41:14 ID:kMgiw1TB0
ひとつのフィルタに纏める事できるよ
match欄
matchpattern1 $SET(9=replacepattern1)|
matchpattern2 $SET(9=replacepattern2)
replace欄
\9
みたいな感じ
match欄
matchpattern1 $SET(9=replacepattern1)|
matchpattern2 $SET(9=replacepattern2)
replace欄
\9
みたいな感じ
434 :名無しさん@お腹いっぱい。:2007/03/03(土) 20:59:36 ID:kMgiw1TB0
具体的に書くと
例えばこんな感じ。
これだとurchinTrackerの記述のあるscriptタグ全部消しちゃうけど。
Match
$NEST(<a\s[^>]++href=$AV(*urchinTracker*),</a>) $SET(9=)|
$NEST(<script\s[^>]+>,*urchinTracker*,</script>) $SET(9=)
Replace
\9
>>432なんだけど
空の関数の後に実際のソースに実態があれば効かないんじゃない?
テストしてないからわからないけど
例えばこんな感じ。
これだとurchinTrackerの記述のあるscriptタグ全部消しちゃうけど。
Match
$NEST(<a\s[^>]++href=$AV(*urchinTracker*),</a>) $SET(9=)|
$NEST(<script\s[^>]+>,*urchinTracker*,</script>) $SET(9=)
Replace
\9
>>432なんだけど
空の関数の後に実際のソースに実態があれば効かないんじゃない?
テストしてないからわからないけど
435 :名無しさん@お腹いっぱい。:2007/03/03(土) 21:01:30 ID:NAXtb9SN0
>>432
その方法なら1ページにつき一度のマッチングで済むので$STOPコマンドが使えますよ。
その方法なら1ページにつき一度のマッチングで済むので$STOPコマンドが使えますよ。
436 :名無しさん@お腹いっぱい。:2007/03/03(土) 21:24:52 ID:jp1tAzDC0
<script\s[^>]+>
437 :名無しさん@お腹いっぱい。:2007/03/03(土) 21:26:50 ID:jp1tAzDC0
早漏した
<script\s[^>]+>って<script>にマッチしたっけか
こっちで確認した限りではしないようだが
<script\s[^>]+>って<script>にマッチしたっけか
こっちで確認した限りではしないようだが
438 :名無しさん@お腹いっぱい。:2007/03/03(土) 21:36:53 ID:pF+sHsLa0
あぁ
<script>だけの場合? それは想定外でした。
<script>だけの場合? それは想定外でした。
439 :名無しさん@お腹いっぱい。:2007/03/04(日) 00:06:25 ID:tBx8TrfH0
↓これじゃだめなの?
400 :名無しさん@お腹いっぱい。:2007/02/25(日) 00:51:04 ID:SRmz9w6X0
>>391
ADListに www.google-analytics.com/urchin.js を追加。
400 :名無しさん@お腹いっぱい。:2007/02/25(日) 00:51:04 ID:SRmz9w6X0
>>391
ADListに www.google-analytics.com/urchin.js を追加。
440 :名無しさん@お腹いっぱい。:2007/03/04(日) 00:19:46 ID:73lxeMGz0
これがONになっているとアマゾンで検索したときに画像が出ません。
どうしてですか?
Name = "Banner Blaster (limit text)"
Active = TRUE
Multi = TRUE
Bounds = "<a\s[^>]++href=*</a>|<input*>|<ilayer*</ilayer>|<iframe*</iframe>|<object*</object>"
Limit = 900
Match = "(<(ilayer|iframe|object)*|\1<i(mg|mage|nput)*src=$AV(*)*>\3)"
"&(*(href|src)=$AV($LST(AdKeys)*)|"
"*http://*<i(mg|mage|nput)\s(*>&&"
"(*width=[#460-480]&*height=[#55-60]*)|"
"(*width=[#88]&*height=[#31]*)))"
"&(*alt=$AV((?+{18})\2*|\2)|$SET(2=Ad))"
どうしてですか?
Name = "Banner Blaster (limit text)"
Active = TRUE
Multi = TRUE
Bounds = "<a\s[^>]++href=*</a>|<input*>|<ilayer*</ilayer>|<iframe*</iframe>|<object*</object>"
Limit = 900
Match = "(<(ilayer|iframe|object)*|\1<i(mg|mage|nput)*src=$AV(*)*>\3)"
"&(*(href|src)=$AV($LST(AdKeys)*)|"
"*http://*<i(mg|mage|nput)\s(*>&&"
"(*width=[#460-480]&*height=[#55-60]*)|"
"(*width=[#88]&*height=[#31]*)))"
"&(*alt=$AV((?+{18})\2*|\2)|$SET(2=Ad))"
441 :409 :2007/03/04(日) 01:13:16 ID:9b7LgS8o0
>>434
本物の関数は常に別ファイルで読み込まれるので、AdlistでBlockしてます。
>>435
どうもです。
HEADなんで$STOPは効果的ですね。
>>439
それだけだと、関数の呼び出しが残っているので、
Javascriptエラーが毎回でるので。
結果はこんな感じでにしました。
[Patterns]
Name = "Kill urchinTracker"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<head*>$STOP()"
Replace = "<head>"
"<script type="text/javascript">function urchinTracker(){};</script>"
このフィルターは他人の所に足跡を残したくないのではなくて、
自分が管理してるサイトの分析に自身のアクセス記録を入れない為なので、
実際にはURLには実サイト名が入ってます。
Googgle Anlytics側にもフィルターがあるのですが、
出先で内容を確認したりする時のまでフォローしきれないので。
本物の関数は常に別ファイルで読み込まれるので、AdlistでBlockしてます。
>>435
どうもです。
HEADなんで$STOPは効果的ですね。
>>439
それだけだと、関数の呼び出しが残っているので、
Javascriptエラーが毎回でるので。
結果はこんな感じでにしました。
[Patterns]
Name = "Kill urchinTracker"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<head*>$STOP()"
Replace = "<head>"
"<script type="text/javascript">function urchinTracker(){};</script>"
このフィルターは他人の所に足跡を残したくないのではなくて、
自分が管理してるサイトの分析に自身のアクセス記録を入れない為なので、
実際にはURLには実サイト名が入ってます。
Googgle Anlytics側にもフィルターがあるのですが、
出先で内容を確認したりする時のまでフォローしきれないので。
442 :名無しさん@お腹いっぱい。:2007/03/04(日) 07:26:16 ID:2pUUjDDU0
OperaでUAがMozilla含まれてないからこれでUA変更してるんだけど
バージョン変わるたびに修正するの面倒だから変更するときに
変更元のUAのバージョンつけられないかな?
今こんな感じの設定
key:User-Agent: Opera 9 (out)
URL:
Match:Opera
Replace:Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.1; U; ja) Opera/9.10
バージョン変わるたびに修正するの面倒だから変更するときに
変更元のUAのバージョンつけられないかな?
今こんな感じの設定
key:User-Agent: Opera 9 (out)
URL:
Match:Opera
Replace:Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.1; U; ja) Opera/9.10
443 :名無しさん@お腹いっぱい。:2007/03/04(日) 13:29:48 ID:hlyDBHQO0
[HTTP headers]
In = FALSE
Out = TRUE
Key = "User-Agent: Opera (out)"
Match = "Opera/\0(\s|(^?))"
Replace = "Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.1; U; ja) Opera/\0"
In = FALSE
Out = TRUE
Key = "User-Agent: Opera (out)"
Match = "Opera/\0(\s|(^?))"
Replace = "Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.1; U; ja) Opera/\0"
444 :名無しさん@お腹いっぱい。:2007/03/04(日) 13:41:01 ID:2pUUjDDU0
>>443
ありがとうございます〜
ありがとうございます〜
445 :名無しさん@お腹いっぱい。:2007/03/05(月) 23:25:27 ID:4aRF74xu0
446 :名無しさん@お腹いっぱい。:2007/03/05(月) 23:36:20 ID:E9YpSH1g0
華麗にスルー
447 :名無しさん@お腹いっぱい。:2007/03/05(月) 23:41:29 ID:2RxO/zSP0
www.jtw.zaq.ne.jp/animesong/y.js への接続を遮断するだけ
448 :名無しさん@お腹いっぱい。:2007/03/05(月) 23:42:34 ID:gh6EZIJM0
>>445
from
<BODY BGCOLOR="#CCFF99" onselectstart="return false" oncontextmenu="return false">
to
<BODY BGCOLOR="#CCFF99" onselectstart="return true" oncontextmenu="return true">
from
<BODY BGCOLOR="#CCFF99" onselectstart="return false" oncontextmenu="return false">
to
<BODY BGCOLOR="#CCFF99" onselectstart="return true" oncontextmenu="return true">
449 :名無しさん@お腹いっぱい。:2007/03/06(火) 12:11:59 ID:iB1jvKZy0
任意のタグ群から任意の要素群を除去するフィルタを書いてみた。
とりあえずはbodyとimgからoncontextmenu, onselectstaart, oncopyを除去できる感じに。
ひどいスパデティ状態だけど要は<body >みたいなスペースが入らないようにしたかったので。
[Patterns]
Name = "oncontextmenu deleter"
Active = TRUE
Limit = 256
Match = "$NEST(<(body(^(^\s))|img(^(^\s)))\#,((\s|)on(contextmenu|selectstart|copy)=$AV(*)|((\s|)[^=\s]+(=$AV(*)|))\#)+,>)"
Replace = "<\@>"
とりあえずはbodyとimgからoncontextmenu, onselectstaart, oncopyを除去できる感じに。
ひどいスパデティ状態だけど要は<body >みたいなスペースが入らないようにしたかったので。
[Patterns]
Name = "oncontextmenu deleter"
Active = TRUE
Limit = 256
Match = "$NEST(<(body(^(^\s))|img(^(^\s)))\#,((\s|)on(contextmenu|selectstart|copy)=$AV(*)|((\s|)[^=\s]+(=$AV(*)|))\#)+,>)"
Replace = "<\@>"
450 :名無しさん@お腹いっぱい。:2007/03/06(火) 12:13:41 ID:iB1jvKZy0
書き忘れてたけどサンプル
before : <body onselectstart="return false" oncontextmenu="return false" bgcolor="#ccff99">
after : <body bgcolor="#ccff99">
before : <body onselectstart="return false" oncontextmenu="return false" bgcolor="#ccff99">
after : <body bgcolor="#ccff99">
451 :名無しさん@お腹いっぱい。:2007/03/06(火) 14:43:34 ID:9zhYO6rw0
Firefox のように、ブラウザ側で
コンテキストメニューを強制的に使用可能にする手もある。フィルタ不要だし。
コンテキストメニューを強制的に使用可能にする手もある。フィルタ不要だし。
452 :名無しさん@お腹いっぱい。:2007/03/06(火) 19:03:44 ID:mTAaejSY0
>>449
要望者ではないがGJ
要望者ではないがGJ
453 :名無しさん@お腹いっぱい。:2007/03/06(火) 20:12:47 ID:5wFR0ABi0
454 :think ◆MM0nnAOCiQ :2007/03/06(火) 20:57:29 ID:74I35w2I0
>>449-450
そのフィルタは <body bgcolor="#ccff99"> にもマッチしてしまう問題を持っていますね。
((\s|)[^=\s]+(=$AV(*)|))\# を (([^>]++)\#\son(contextmenu|selectstart|copy)=$AV(*))+{1,*} に変更してはどうでしょうか?
[Patterns]
Name = "oncontextmenu deleter type2 [2007/03/06]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<(body|img)\#(^(^\s))"
"(([^>]++)\#\son(contextmenu|selectstart|copy)=$AV(*))+{1,*}"
Replace = "<\@"
そのフィルタは <body bgcolor="#ccff99"> にもマッチしてしまう問題を持っていますね。
((\s|)[^=\s]+(=$AV(*)|))\# を (([^>]++)\#\son(contextmenu|selectstart|copy)=$AV(*))+{1,*} に変更してはどうでしょうか?
[Patterns]
Name = "oncontextmenu deleter type2 [2007/03/06]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "<(body|img)\#(^(^\s))"
"(([^>]++)\#\son(contextmenu|selectstart|copy)=$AV(*))+{1,*}"
Replace = "<\@"
455 :名無しさん@お腹いっぱい。:2007/03/06(火) 22:42:58 ID:+rFDbjSB0
Proxymoitronのフィルターなんですけど 以下のレスを参考にしたんですが、
もう少しキレイにするならどうしたらいいでしょう。
>【デボジット】Google AdSense初心者スレ 8PIN目
>http://pc9.2ch.net/test/read.cgi/affiliate/1171772889/370
>
>370 名前:クリックで救われる名無しさんがいる[] 投稿日:2007/03/05(月) 08:17:45 ID:5uG+lPlH0
>こんなの見つけたんだけど便利かな?
>ttp://isawseashell.blogspot.com/2007/02/adsense.html
>
>俺にはちょっとハードル高いんだけど、安心感が得られるならやろうかと思ってる。
[Patterns]
Name = "Adsense"
Active = TRUE
URL = "*.googlesyndication.com/$TYPE(htm)"
Limit = 1024
Match = "<a\s\0href="*123456789012"
Replace = "<a \0 href="about:blank"
これでやると、about:blank&nm=13 みたいに about:blnakの後ろにパラか残ってしまうんです。
実際のURLは
http://pagead2.googlesyndication.com/pagead/iclk?sa=l&ai=&num=1&adurl=http://hoge.hoge/&client=ca-pub-123456789012&nm=17
みたいに入ってきてるんですが、タグ全体がフレームの中なので見えなくて どうやったら調べたりしたらいいかわからず困ってます。
もう少しキレイにするならどうしたらいいでしょう。
>【デボジット】Google AdSense初心者スレ 8PIN目
>http://pc9.2ch.net/test/read.cgi/affiliate/1171772889/370
>
>370 名前:クリックで救われる名無しさんがいる[] 投稿日:2007/03/05(月) 08:17:45 ID:5uG+lPlH0
>こんなの見つけたんだけど便利かな?
>ttp://isawseashell.blogspot.com/2007/02/adsense.html
>
>俺にはちょっとハードル高いんだけど、安心感が得られるならやろうかと思ってる。
[Patterns]
Name = "Adsense"
Active = TRUE
URL = "*.googlesyndication.com/$TYPE(htm)"
Limit = 1024
Match = "<a\s\0href="*123456789012"
Replace = "<a \0 href="about:blank"
これでやると、about:blank&nm=13 みたいに about:blnakの後ろにパラか残ってしまうんです。
実際のURLは
http://pagead2.googlesyndication.com/pagead/iclk?sa=l&ai=&num=1&adurl=http://hoge.hoge/&client=ca-pub-123456789012&nm=17
みたいに入ってきてるんですが、タグ全体がフレームの中なので見えなくて どうやったら調べたりしたらいいかわからず困ってます。
456 :名無しさん@お腹いっぱい。:2007/03/06(火) 23:18:09 ID:ToBVIAPe0
マッチの部分をhref=$AV(*12345678912*)
にすりゃいいのでは。about:blnakはともかくProxymoitronってなんやねん。
にすりゃいいのでは。about:blnakはともかくProxymoitronってなんやねん。
457 :名無しさん@お腹いっぱい。:2007/03/07(水) 17:22:42 ID:/8mO2Jfl0
$NEST(<a\s(*href=$AV(\1)*|)&(*title=$AV(\3)*|)&(^(*(href|title)*)\7|)[^>]+>,\0,</a>)
aタグのhrefとtitleの値を\1,\3に順不同で入れるのには成功したんですが、
それ以外のものを\7に入れる事ができません。
とりあえず(^(*(href|title)*)\7|)としてますが効きません。
助言お願いします。
ソース例
<a href="/aaa/bbb/ここは1に" title="これは3に" class="これは7に">ここは0に</a>
aタグのhrefとtitleの値を\1,\3に順不同で入れるのには成功したんですが、
それ以外のものを\7に入れる事ができません。
とりあえず(^(*(href|title)*)\7|)としてますが効きません。
助言お願いします。
ソース例
<a href="/aaa/bbb/ここは1に" title="これは3に" class="これは7に">ここは0に</a>
思ったよりも反響があったようでビックリ。
>453
なるほど、そういうケースもあり得るのでしたら汎用フィルタとした使うためには手を加える必要がありますね。
手っ取り早いのは$AV(*)を使う代わりに [^=]+=[^ ]+ とすることでしょうか。
これでもまだ誤爆例がありましたら教えてください。
#ところで今までずっと[^\s]としていたのですがこれは大きな誤りであると分かりましたorz
>454
確かに、例えば <body> で終わらない全てのbodyタグに(極端な例では<body >にも)マッチしますが、そこに何か問題があるとは思えません。
<body bgcolor="#ccff99"> を挙げれば、それ全体を\#に代入して<\@>で出力しているので一見してムダではありますが。
そこで試しにプロファイルで速度比較をしてみました。
私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
<img alt="hogehoge" src="hogehoge.jpeg"> を29986バイト分だけコピペしたサンプルでの計測です。
<img alt="hogehoge" src="hogehoge.jpeg" oncopy="hogehoge"> とした場合も速度比はほぼ同じでした。
もしマッチングさせたくないという場合にはver2を選択すると良いでしょう。
>453
なるほど、そういうケースもあり得るのでしたら汎用フィルタとした使うためには手を加える必要がありますね。
手っ取り早いのは$AV(*)を使う代わりに [^=]+=[^ ]+ とすることでしょうか。
これでもまだ誤爆例がありましたら教えてください。
#ところで今までずっと[^\s]としていたのですがこれは大きな誤りであると分かりましたorz
>454
確かに、例えば <body> で終わらない全てのbodyタグに(極端な例では<body >にも)マッチしますが、そこに何か問題があるとは思えません。
<body bgcolor="#ccff99"> を挙げれば、それ全体を\#に代入して<\@>で出力しているので一見してムダではありますが。
そこで試しにプロファイルで速度比較をしてみました。
私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
<img alt="hogehoge" src="hogehoge.jpeg"> を29986バイト分だけコピペしたサンプルでの計測です。
<img alt="hogehoge" src="hogehoge.jpeg" oncopy="hogehoge"> とした場合も速度比はほぼ同じでした。
もしマッチングさせたくないという場合にはver2を選択すると良いでしょう。
459 :名無しさん@お腹いっぱい。:2007/03/07(水) 18:16:46 ID:eYPYjnoZ0
肝心の445が出てこない件
460 :名無しさん@お腹いっぱい。:2007/03/07(水) 18:23:04 ID:JUv0ENxk0
>457
目的がよく分からなんのですが、\1と\2と\3と\0に属性値を入れるわけですね。
\1はhrefに対応しなければならないんですか?
たいていの場合は必ずしもそういう対応関係を成り立たせなければならないわけではないと思いますが。
例えば
(href|title|((^(href|title)[^=])+))\1=$AV(\2) \s (href|title|((^(href|title)[^=])+))\3=$AV(\4) \s (href|title|((^(href|title)[^=])+))\5=$AV(\6)
とでもすれば\1と\2や\3と\4はセットなので、何が入ろうともかまわないということになります。
これで問題があるかはフィルタで何をしたいかによります。
ちなみにアスタリスク"*"をそういうふうに使う場合は
aタグを$NEST()で独立させたほうが良いです。
$NEST($NEST(<a\s,*hogehoge*,>),\0,</a>)
もう一度フィルタの目的をよく考えてから作り直しては?
目的がよく分からなんのですが、\1と\2と\3と\0に属性値を入れるわけですね。
\1はhrefに対応しなければならないんですか?
たいていの場合は必ずしもそういう対応関係を成り立たせなければならないわけではないと思いますが。
例えば
(href|title|((^(href|title)[^=])+))\1=$AV(\2) \s (href|title|((^(href|title)[^=])+))\3=$AV(\4) \s (href|title|((^(href|title)[^=])+))\5=$AV(\6)
とでもすれば\1と\2や\3と\4はセットなので、何が入ろうともかまわないということになります。
これで問題があるかはフィルタで何をしたいかによります。
ちなみにアスタリスク"*"をそういうふうに使う場合は
aタグを$NEST()で独立させたほうが良いです。
$NEST($NEST(<a\s,*hogehoge*,>),\0,</a>)
もう一度フィルタの目的をよく考えてから作り直しては?
>458について日本語のミスがありましたorz
>私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
1.5倍の時間が掛かる、もしくは0.5倍多くの時間が掛かる、に訂正します。
例えばver1で2sec要する場合にver2はおよそ3sec要します。
>私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
1.5倍の時間が掛かる、もしくは0.5倍多くの時間が掛かる、に訂正します。
例えばver1で2sec要する場合にver2はおよそ3sec要します。
462 :名無しさん@お腹いっぱい。:2007/03/07(水) 18:36:28 ID:/8mO2Jfl0
>>460
目的はtitle欄にhref以下のurlその他をぶち込んでマウスを当てると見えるようにするためです。
ORで分岐すると順不同(hrefの前にtitleが来たり)のとき面倒なので&を使ってます。
ですから>>457の場合だとreplece欄でtitle="\1 \3"みたいに続けて記述します。
目的はtitle欄にhref以下のurlその他をぶち込んでマウスを当てると見えるようにするためです。
ORで分岐すると順不同(hrefの前にtitleが来たり)のとき面倒なので&を使ってます。
ですから>>457の場合だとreplece欄でtitle="\1 \3"みたいに続けて記述します。
463 :名無しさん@お腹いっぱい。:2007/03/07(水) 18:46:47 ID:JUv0ENxk0
>462
つまりtitle要素があれば中身をhrefで書き換え、title要素がない場合はtitle="href属性値"を追加するということ?
言い換えればtitle要素があれば除去し、title="href属性値"を追加する、とでもすればうまくいきそうですな。
やり方はいくつもあると思うけど私ならこうやります。
その場合は&を使うよりはスタックを使ったほうがよさそうです。
つまりtitle要素があれば中身をhrefで書き換え、title要素がない場合はtitle="href属性値"を追加するということ?
言い換えればtitle要素があれば除去し、title="href属性値"を追加する、とでもすればうまくいきそうですな。
やり方はいくつもあると思うけど私ならこうやります。
その場合は&を使うよりはスタックを使ったほうがよさそうです。
464 :名無しさん@お腹いっぱい。:2007/03/07(水) 18:57:41 ID:JUv0ENxk0
チープな>449の焼き回しですが、一例として
マッチ欄
$NEST(<a(^(^\s)),(\s(title=$AV(*)|href=$AV(\0)|([^= ]+=$AV(*))\#))+,>)
置換テキスト
<a href="\0" title="\0" \@)
サンプル例
before : <a href="ljilfejalfejla" src="ljfiejlajflea" title="fea.fae">
after : <a href="ljilfejalfejla" title="ljilfejalfejla" src="ljfiejlajflea")
マッチ欄
$NEST(<a(^(^\s)),(\s(title=$AV(*)|href=$AV(\0)|([^= ]+=$AV(*))\#))+,>)
置換テキスト
<a href="\0" title="\0" \@)
サンプル例
before : <a href="ljilfejalfejla" src="ljfiejlajflea" title="fea.fae">
after : <a href="ljilfejalfejla" title="ljilfejalfejla" src="ljfiejlajflea")
465 :名無しさん@お腹いっぱい。:2007/03/07(水) 19:06:34 ID:/8mO2Jfl0
>>463
あらかじめtitleの無い場合は,titleにhrefを入れます。
titleのある場合は、既にあるtitle+hrefにします。
具体的には
<a href ="\1" title="\3 \1" \7>\0</a>
3は既にあるタイトルで空の場合もとりあえず入れときますw
記述してくださった$NESTの入れ子を試してみたところ7にその他のものが入ってくれました。
$NEST($NEST(<(a|area)\s,(*href=$AV(\1)*|)&(*title=$AV(\3)*|) \7,>),\0,</a>)
ただこれだと\7に既にあるhrefやtitleも入ってしまいますが
<a href ="\1" \7 title="\3 \1" >\0</a>
こうすれば大丈夫みたいです。
ありがとうございました。
あらかじめtitleの無い場合は,titleにhrefを入れます。
titleのある場合は、既にあるtitle+hrefにします。
具体的には
<a href ="\1" title="\3 \1" \7>\0</a>
3は既にあるタイトルで空の場合もとりあえず入れときますw
記述してくださった$NESTの入れ子を試してみたところ7にその他のものが入ってくれました。
$NEST($NEST(<(a|area)\s,(*href=$AV(\1)*|)&(*title=$AV(\3)*|) \7,>),\0,</a>)
ただこれだと\7に既にあるhrefやtitleも入ってしまいますが
<a href ="\1" \7 title="\3 \1" >\0</a>
こうすれば大丈夫みたいです。
ありがとうございました。
466 :think ◆MM0nnAOCiQ :2007/03/07(水) 19:37:31 ID:O0RWiz+R0
>>456
> そこに何か問題があるとは思えません。
"oncontextmenu deleter" でマッチすると、他のフィルタで <body> にマッチしなくなるという問題がありますが、"oncontextmenu deleter" を優先するなら些細な問題かもしれませんね。
アプローチの仕方が違うだけとも言えるので、好みの問題だと思います。
> 私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
検証お疲れ様です。
>454は読み取るバイト数が少ないので、速いと思っていましたが $NEST の方が速くなるんですね。
せっかくなので、速度重視で最適化してみました。(下記の状況で、+{1,*} が効かない理由は解りません)
[Patterns]
Name = "oncontextmenu deleter type3.1 [2007/03/07]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "$NEST(<(body|img)\#(^(^\s)),"
"\#\son(contextmenu|selectstart|copy)=$AV(*)"
"(\#\son(contextmenu|selectstart|copy)=$AV(*))+"
"\#,>)"
Replace = "<\@>"
ところで、>454で示したフィルタは "type2" であって、「最新のフィルタ」として掲示したわけではないですよ。(^^;
449氏の作成したフィルタを引き継いで改良したなんて、おこがましいことは言えません。
私の経験,ポリシーに則って作成した別のフィルタだと思っています。
> そこに何か問題があるとは思えません。
"oncontextmenu deleter" でマッチすると、他のフィルタで <body> にマッチしなくなるという問題がありますが、"oncontextmenu deleter" を優先するなら些細な問題かもしれませんね。
アプローチの仕方が違うだけとも言えるので、好みの問題だと思います。
> 私のver1とthinkさんのver2では、ver2がver1の1.5倍多くの時間が掛かるようです。
検証お疲れ様です。
>454は読み取るバイト数が少ないので、速いと思っていましたが $NEST の方が速くなるんですね。
せっかくなので、速度重視で最適化してみました。(下記の状況で、+{1,*} が効かない理由は解りません)
[Patterns]
Name = "oncontextmenu deleter type3.1 [2007/03/07]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "$NEST(<(body|img)\#(^(^\s)),"
"\#\son(contextmenu|selectstart|copy)=$AV(*)"
"(\#\son(contextmenu|selectstart|copy)=$AV(*))+"
"\#,>)"
Replace = "<\@>"
ところで、>454で示したフィルタは "type2" であって、「最新のフィルタ」として掲示したわけではないですよ。(^^;
449氏の作成したフィルタを引き継いで改良したなんて、おこがましいことは言えません。
私の経験,ポリシーに則って作成した別のフィルタだと思っています。
467 :名無しさん@お腹いっぱい。:2007/03/07(水) 20:02:01 ID:JUv0ENxk0
>466
一度マッチした部分にはほかのフィルタはマッチしないというのは不覚にも知りませんでした。
ちょっとしたテストをしてみましたが、確かにそのようです。
フィルタ同士でループしないようにとのことでしょう。
こうだと分かると何でもかんでもマッチングしてしまう>>449のフィルタは曲者ですね。
thinkさんの>466が正当な改良版だと思いますよ。
>456の段階では単にver違いという意味で書いたのですが。
一度マッチした部分にはほかのフィルタはマッチしないというのは不覚にも知りませんでした。
ちょっとしたテストをしてみましたが、確かにそのようです。
フィルタ同士でループしないようにとのことでしょう。
こうだと分かると何でもかんでもマッチングしてしまう>>449のフィルタは曲者ですね。
thinkさんの>466が正当な改良版だと思いますよ。
>456の段階では単にver違いという意味で書いたのですが。
468 :think ◆MM0nnAOCiQ :2007/03/07(水) 23:41:26 ID:O0RWiz+R0
>>467
> 一度マッチした部分にはほかのフィルタはマッチしない
これは下記URLの「再帰的なマッチングを使う方法」を読むと、よく理解できると思います。
Tips and Tricks
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html
> >456の段階では単にver違いという意味で書いたのですが。
それは失礼しました。
ただ、ver違いというニュアンスだと後継版と受け取られがちなので、念のため釈明させていただきました。
> 一度マッチした部分にはほかのフィルタはマッチしない
これは下記URLの「再帰的なマッチングを使う方法」を読むと、よく理解できると思います。
Tips and Tricks
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html
> >456の段階では単にver違いという意味で書いたのですが。
それは失礼しました。
ただ、ver違いというニュアンスだと後継版と受け取られがちなので、念のため釈明させていただきました。
469 :think ◆MM0nnAOCiQ :2007/03/07(水) 23:43:05 ID:O0RWiz+R0
>>465
仰ることが正確に掴めていませんが...
> $NEST($NEST(<(a|area)\s,(*href=$AV(\1)*|)&(*title=$AV(\3)*|) \7,>),\0,</a>)
> <a href ="\1" \7 title="\3 \1" >\0</a>
どちらの表現でも、
<a id="test" title="string" href="URL">
のHTMLソースにマッチしないという問題が残っているようです。
>464の表現を使い回しするとこれに対応できますが、「全てのa要素にマッチしてしまう」という問題がまだ残ります。
HTML4.01仕様書によれば、
------------
ユーザエージェントは、CDATA型属性値の、冒頭あるいは末尾の空白文字を無視してよい。
(例えば「 myval 」を「myval」として解釈してよい。)
著者は、冒頭あるいは末尾に空白文字のある属性値を宣言することを避けるべきである。
http://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/types.html#type-cdata
------------
とあり、空白文字のみの属性値によるUAの動作を明示していません。(「してよい」は「しなくてもよい」とも受け取れる表現だからです。)
可能なら、「空の属性値」「空白のみの属性値」は避けるべきだと思います。
仰ることが正確に掴めていませんが...
> $NEST($NEST(<(a|area)\s,(*href=$AV(\1)*|)&(*title=$AV(\3)*|) \7,>),\0,</a>)
> <a href ="\1" \7 title="\3 \1" >\0</a>
どちらの表現でも、
<a id="test" title="string" href="URL">
のHTMLソースにマッチしないという問題が残っているようです。
>464の表現を使い回しするとこれに対応できますが、「全てのa要素にマッチしてしまう」という問題がまだ残ります。
HTML4.01仕様書によれば、
------------
ユーザエージェントは、CDATA型属性値の、冒頭あるいは末尾の空白文字を無視してよい。
(例えば「 myval 」を「myval」として解釈してよい。)
著者は、冒頭あるいは末尾に空白文字のある属性値を宣言することを避けるべきである。
http://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/types.html#type-cdata
------------
とあり、空白文字のみの属性値によるUAの動作を明示していません。(「してよい」は「しなくてもよい」とも受け取れる表現だからです。)
可能なら、「空の属性値」「空白のみの属性値」は避けるべきだと思います。
470 :think ◆MM0nnAOCiQ :2007/03/07(水) 23:52:20 ID:O0RWiz+R0
>469の続き。
この条件なら二重に$NESTを使うまでもなく、</a> までマッチさせずとも、<a> の開始タグのみにマッチさせるだけで十分だと思います。
期待する動作を、「href属性のあるa要素があったとき、title属性にhref属性値を挿入する」とすると。
[Patterns]
Name = "Insert <a> title [2007/03/07] test2"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "$NEST((<a(rea|)\s)\#(^(^[^>]++href=$AV(\0))),"
"(\#)title=$AV(\1)$SET(2=\1 \0)\#|"
"$SET(2=\0)\#"
",>)"
Replace = "\@ title="\2">"
(^(^[^>]++href=$AV(\0))) は & に読み替えてもらっても構いません。
(\#) は置換スタックのバグ回避のための暫定措置です。
ttp://abc.s65.xrea.com/prox/wiki/MatchingRules/#stack-bug
| と $SET を組み合わせているのは、title属性値の先頭に空白を含めないためですが、title属性値を格納した変数を $TST で判定して分岐させてもよいかもしれません。
この条件なら二重に$NESTを使うまでもなく、</a> までマッチさせずとも、<a> の開始タグのみにマッチさせるだけで十分だと思います。
期待する動作を、「href属性のあるa要素があったとき、title属性にhref属性値を挿入する」とすると。
[Patterns]
Name = "Insert <a> title [2007/03/07] test2"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "$NEST((<a(rea|)\s)\#(^(^[^>]++href=$AV(\0))),"
"(\#)title=$AV(\1)$SET(2=\1 \0)\#|"
"$SET(2=\0)\#"
",>)"
Replace = "\@ title="\2">"
(^(^[^>]++href=$AV(\0))) は & に読み替えてもらっても構いません。
(\#) は置換スタックのバグ回避のための暫定措置です。
ttp://abc.s65.xrea.com/prox/wiki/MatchingRules/#stack-bug
| と $SET を組み合わせているのは、title属性値の先頭に空白を含めないためですが、title属性値を格納した変数を $TST で判定して分岐させてもよいかもしれません。
471 :457,462,465:2007/03/08(木) 00:30:23 ID:yKKFo5Ex0
>>469-470
まだ理解してませんが、参考になります。
titleにあらゆる属性をつっこもうとしてまして
(例えばaタグの後にimgタグが来た場合のhrefも)。
470を検討してみます。ありがとうございます。
まだ理解してませんが、参考になります。
titleにあらゆる属性をつっこもうとしてまして
(例えばaタグの後にimgタグが来た場合のhrefも)。
470を検討してみます。ありがとうございます。
472 :名無しさん@お腹いっぱい。:2007/03/08(木) 00:45:41 ID:4XFeP5Uk0
aタグ内にimgがある場合に対応させようとするなら↓のようにすればいいよ
$NEST($NEST(<a\s,*hogehoge*,>),
\0((<img[^>]++src=$AV(\3)[^>]+>)\1\2|),
</a>)
で置換部分は <a>\0\1\2<\a> とすれば良いし、srcの属性値は\3に入っている。
>(例えばaタグの後にimgタグが来た場合のhrefも)。
但し、これをhrefじゃなくてsrcのことだと解釈しての話。
*hogehoge* を>470に置き換えればそのまま動くはず。
$NEST($NEST(<a\s,*hogehoge*,>),
\0((<img[^>]++src=$AV(\3)[^>]+>)\1\2|),
</a>)
で置換部分は <a>\0\1\2<\a> とすれば良いし、srcの属性値は\3に入っている。
>(例えばaタグの後にimgタグが来た場合のhrefも)。
但し、これをhrefじゃなくてsrcのことだと解釈しての話。
*hogehoge* を>470に置き換えればそのまま動くはず。
473 :名無しさん@お腹いっぱい。:2007/03/08(木) 00:54:47 ID:yKKFo5Ex0
>>472
ありがとう。やってみますね。
ありがとう。やってみますね。
474 :名無しさん@お腹いっぱい。:2007/03/08(木) 01:16:31 ID:7b1HZB3B0
ぶった切ってすみませんが、YOUTUBEで再生のデフォルトを、
全画面にするフィルター(リンク追加でもかまいません)がもしできたらお願いします。
全画面にするフィルター(リンク追加でもかまいません)がもしできたらお願いします。
475 :名無しさん@お腹いっぱい。:2007/03/08(木) 07:26:27 ID:2LOjLWQX0
>>474
[Patterns]
Name = "YouTube fullscreen"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?"
Limit = 256
Match = "<!DOCTYPE$SET(0=<!--)"
"|"
"-->"
"|"
"new\sSWFObject\(\"/player2.swf\?(video_id=[^"]+)\1\""
"$SET(0=--><meta http-equiv="refresh" content="0;url=http://www.youtube.com/player2.swf?\1">\k)"
Replace = "\0"
[Patterns]
Name = "YouTube fullscreen"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?"
Limit = 256
Match = "<!DOCTYPE$SET(0=<!--)"
"|"
"-->"
"|"
"new\sSWFObject\(\"/player2.swf\?(video_id=[^"]+)\1\""
"$SET(0=--><meta http-equiv="refresh" content="0;url=http://www.youtube.com/player2.swf?\1">\k)"
Replace = "\0"
476 :名無しさん@お腹いっぱい。:2007/03/08(木) 16:21:59 ID:vBpwNiv90
ところで>>445のフィルタまだ?
477 :名無しさん@お腹いっぱい。:2007/03/08(木) 16:52:03 ID:BEkyhjCe0
JavaScriptをOFFにすればいいんじゃね?
478 :名無しさん@お腹いっぱい。:2007/03/08(木) 18:34:06 ID:2LOjLWQX0
>>476
超適当だけど一応作ってみた
[Patterns]
Name = "www.jtw.zaq.ne.jp/animesong/ kasi kopipe"
Active = TRUE
URL = "www.jtw.zaq.ne.jp/animesong/"
Limit = 256
Match = "<script type="text/javascript" src="../../y.js"></script>"
"|"
"<NOSCRIPT><META HTTP-EQUIV="Refresh" CONTENT="0;URL=index.html"></NOSCRIPT>"
"|"
"on(selectstart|contextmenu)="return false""
超適当だけど一応作ってみた
[Patterns]
Name = "www.jtw.zaq.ne.jp/animesong/ kasi kopipe"
Active = TRUE
URL = "www.jtw.zaq.ne.jp/animesong/"
Limit = 256
Match = "<script type="text/javascript" src="../../y.js"></script>"
"|"
"<NOSCRIPT><META HTTP-EQUIV="Refresh" CONTENT="0;URL=index.html"></NOSCRIPT>"
"|"
"on(selectstart|contextmenu)="return false""
479 :名無しさん@お腹いっぱい。:2007/03/08(木) 19:18:02 ID:K/9AXNBV0
480 :名無しさん@お腹いっぱい。:2007/03/08(木) 23:09:23 ID:yKKFo5Ex0
>>470,>>472を使ってあれこれいじってましたが
$NESTを使うと<img*>の記述のある場合と無い場合でうまくいかなかったので
単純にして全部作り直してしまいました ;;
リンクをクリックすれば_selfで、右に出るblanktab.gifをクリックすれば_blankで開きます。
(blanktab.gifはなんでもいいです)
>>470,>>472はかなり参考になりました。またよろしくお願いします。
おかしなところ多々あると思いますが、以下source
$NESTを使うと<img*>の記述のある場合と無い場合でうまくいかなかったので
単純にして全部作り直してしまいました ;;
リンクをクリックすれば_selfで、右に出るblanktab.gifをクリックすれば_blankで開きます。
(blanktab.gifはなんでもいいです)
>>470,>>472はかなり参考になりました。またよろしくお願いします。
おかしなところ多々あると思いますが、以下source
481 :名無しさん@お腹いっぱい。:2007/03/08(木) 23:11:26 ID:OXZVhBSr0
\(^^)/ ←ソース
482 :名無しさん@お腹いっぱい。:2007/03/08(木) 23:11:58 ID:yKKFo5Ex0
Name = "Insert title & blankGIF [2007/03/08]"
Active = TRUE
Bounds = "<(a|area)\s[^>]+>(^(\>|click here|<dd>|ID:))*</a>"
Limit = 2048
Match = "<(a(rea|))\9\s(*(*href=$AV(\1)*|)&(*title=$AV(\2)*|) *)\5[^>]+>"
"\7((<img\s(*src=$AV(\3)*|)&(*alt=$AV(\4)*|) *[^>]+>)\6|)"
"</(a(rea|))>"
Replace = "<\9 target="_self" \5 target="_self" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">\7\6\8</\9>"
"<\9 target="_blank" \5 target="_blank" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">"
"<img border="0" src="http://Local.ptron/blanktab.gif" alt="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4"></\9>"
Active = TRUE
Bounds = "<(a|area)\s[^>]+>(^(\>|click here|<dd>|ID:))*</a>"
Limit = 2048
Match = "<(a(rea|))\9\s(*(*href=$AV(\1)*|)&(*title=$AV(\2)*|) *)\5[^>]+>"
"\7((<img\s(*src=$AV(\3)*|)&(*alt=$AV(\4)*|) *[^>]+>)\6|)"
"</(a(rea|))>"
Replace = "<\9 target="_self" \5 target="_self" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">\7\6\8</\9>"
"<\9 target="_blank" \5 target="_blank" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">"
"<img border="0" src="http://Local.ptron/blanktab.gif" alt="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4"></\9>"
{kind=link}
483 :名無しさん@お腹いっぱい。:2007/03/08(木) 23:13:17 ID:yKKFo5Ex0
>>481
間違えました
間違えました
484 :名無しさん@お腹いっぱい。:2007/03/09(金) 01:00:08 ID:bjxVpHmZ0
誤爆ありまくりなので$NESTつけました・・
Name = "Insert title & blankgif set [2007/03/08]"
Active = TRUE
Bounds = "<a(rea|)\s[^>]+>(^(\>|click here|<dd>|ID:))*</a(rea|)>"
Limit = 1024
Match = "$NEST(<(a(rea|))\9\s,(*(*href=$AV(\1)*|)&(*title=$AV(\2)*|) *)\5,>"
"\7((<img\s(*src=$AV(\3)*|)&(*alt=$AV(\4)*|) *[^>]+>)\6|)"
"</(a(rea|))>)"
Replace = "<\9 target="_self" \5 target="_self" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">\7\6</\9>"
"<\9 target="_blank" \5 target="_blank" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">
"<img border="0" src="http://Local.ptron/blanktab.gif" alt="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4"></\9>"
Name = "Insert title & blankgif set [2007/03/08]"
Active = TRUE
Bounds = "<a(rea|)\s[^>]+>(^(\>|click here|<dd>|ID:))*</a(rea|)>"
Limit = 1024
Match = "$NEST(<(a(rea|))\9\s,(*(*href=$AV(\1)*|)&(*title=$AV(\2)*|) *)\5,>"
"\7((<img\s(*src=$AV(\3)*|)&(*alt=$AV(\4)*|) *[^>]+>)\6|)"
"</(a(rea|))>)"
Replace = "<\9 target="_self" \5 target="_self" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">\7\6</\9>"
"<\9 target="_blank" \5 target="_blank" title="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4">
"<img border="0" src="http://Local.ptron/blanktab.gif" alt="[URL]\1\r\[TITLE]\2\r[SRC]\3\r[ALT]\4"></\9>"
485 :名無しさん@お腹いっぱい。:2007/03/09(金) 02:11:39 ID:3Cl7ivfL0
自分で考えてフィルタを作りたいならもう少しプログラミング(論理学でもいい)の基礎を勉強したほうがいいよ。
もしくはほかの人がこれまでに書いてきたものを読んで理解したほうがいい。
例えば <a(rea|)>...</a(rea|)> としたんじゃ
<a>...</area> にも <area>....</a> にもマッチするし、たぶんそれは意図していないマッチングだろう。
もう一つだけど最初のうちはアスタリスクを乱用しないほうがいい。
初心者にとってのアスタリスクというのはおそらく面倒なことをブラックボックスに詰め込んでどっかにやるためのツールなんだろうけど
それじゃ何も上達しないし理解もすすまないだろう。
>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
これなんかはアスタリスク乱用の好例だね。
やりたいことはhrefがあればその属性値を\1に代入し、titleがあればその属性値を\2に代入する、ということなんだろうけど
hrefとtitle以外の属性値をすべて無視してしまえば、もっとシンプルな場合わけができるはずだ。
<a>, <a href>, <a href title>, <a title>, <a title href> というように。
あとはこのスペースを[^>]++で置き換えてやればhrefとtitle以外の属性値を上手に無視することができる。
例えばこうなる。
<a\s ([^>]++href=$AV(*)([^>]++title=$AV(*)|)[^>]+>|[^>]++title=$AV(*)([^>]++href=$AV(*)|)[^>]+>|[^>]+>)
#これは<a>にはマッチしないけど、現実的にはそれでも問題はないだろう。
>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
は初心者の好むブラックボックス化で
><a\s ([^>]++href=$AV(*)([^>]++title=$AV(*)|)[^>]+>|[^>]++title=$AV(*)([^>]++href=$AV(*)|)[^>]+>|[^>]+>)
は論理的思考にある程度慣れた人が好むブラックボックス化だと考えてくれてもいいと思う。(優劣の問題にあらず)
論理学的には中身はまったく一緒だけどよりシンプルでより破綻しづらいのは後者。 { (A|B)&(C|D) = (AC|AD|BC|BD) }
Proxomitronでのアスタリスクは賢い上に速度も最速な便利な道具だけど慣れるまでは上記のようなスタンスで取り組んだほうがいい。
高速化チューニングはその後からやってもいいんだから。
もしくはほかの人がこれまでに書いてきたものを読んで理解したほうがいい。
例えば <a(rea|)>...</a(rea|)> としたんじゃ
<a>...</area> にも <area>....</a> にもマッチするし、たぶんそれは意図していないマッチングだろう。
もう一つだけど最初のうちはアスタリスクを乱用しないほうがいい。
初心者にとってのアスタリスクというのはおそらく面倒なことをブラックボックスに詰め込んでどっかにやるためのツールなんだろうけど
それじゃ何も上達しないし理解もすすまないだろう。
>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
これなんかはアスタリスク乱用の好例だね。
やりたいことはhrefがあればその属性値を\1に代入し、titleがあればその属性値を\2に代入する、ということなんだろうけど
hrefとtitle以外の属性値をすべて無視してしまえば、もっとシンプルな場合わけができるはずだ。
<a>, <a href>, <a href title>, <a title>, <a title href> というように。
あとはこのスペースを[^>]++で置き換えてやればhrefとtitle以外の属性値を上手に無視することができる。
例えばこうなる。
<a\s ([^>]++href=$AV(*)([^>]++title=$AV(*)|)[^>]+>|[^>]++title=$AV(*)([^>]++href=$AV(*)|)[^>]+>|[^>]+>)
#これは<a>にはマッチしないけど、現実的にはそれでも問題はないだろう。
>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
は初心者の好むブラックボックス化で
><a\s ([^>]++href=$AV(*)([^>]++title=$AV(*)|)[^>]+>|[^>]++title=$AV(*)([^>]++href=$AV(*)|)[^>]+>|[^>]+>)
は論理的思考にある程度慣れた人が好むブラックボックス化だと考えてくれてもいいと思う。(優劣の問題にあらず)
論理学的には中身はまったく一緒だけどよりシンプルでより破綻しづらいのは後者。 { (A|B)&(C|D) = (AC|AD|BC|BD) }
Proxomitronでのアスタリスクは賢い上に速度も最速な便利な道具だけど慣れるまでは上記のようなスタンスで取り組んだほうがいい。
高速化チューニングはその後からやってもいいんだから。
486 :名無しさん@お腹いっぱい。:2007/03/09(金) 02:47:07 ID:3Cl7ivfL0
属性値と要素を混同している部分があるけど、適宜読み替えてほしい。
<a(rea|)>...</a(rea|)> について。
残念ながらProxomitronの仕様ではこれに多少の修正を加えることで「意図」通りに動かすということはできない。
方法は二つ。
一つは括弧を閉じないやり方。
Proxomitronからすれば一番合理的なやり方だけど、人間からすれば読みづらいしフィルタサイズが大きくなるわ追加・修正が面倒だわ。
<a(rea...>...</area> | ...>....</a>)
もう一つはTSTを利用するやり方。
<a(rea...>(\1)<\area> | ...>(\1)<\a>)$TST(\1=foobar)
これなら人間にとって把握しやすいし修正が楽になるというメリットがある。
後者は同じようなことをANDやBoundsを使って表現することもできる。
ANDとBoundsとTSTでどれが一番早いかは……不明。
<a(rea|)>...</a(rea|)> について。
残念ながらProxomitronの仕様ではこれに多少の修正を加えることで「意図」通りに動かすということはできない。
方法は二つ。
一つは括弧を閉じないやり方。
Proxomitronからすれば一番合理的なやり方だけど、人間からすれば読みづらいしフィルタサイズが大きくなるわ追加・修正が面倒だわ。
<a(rea...>...</area> | ...>....</a>)
もう一つはTSTを利用するやり方。
<a(rea...>(\1)<\area> | ...>(\1)<\a>)$TST(\1=foobar)
これなら人間にとって把握しやすいし修正が楽になるというメリットがある。
後者は同じようなことをANDやBoundsを使って表現することもできる。
ANDとBoundsとTSTでどれが一番早いかは……不明。
487 :名無しさん@お腹いっぱい。:2007/03/09(金) 03:15:52 ID:3Cl7ivfL0
簡単なテストでANDとDOUBLEANDとTSTの速度比較をしてみた。
AND : <a\s([^>]+>&href=$AV(*))
TST : <a\s([^>]+)\0>$TST(\0=*href=$AV(*)*)
DAND : <a\s([^>]+>&&*href=$AV(*)*)
フィルタとしては考え得る限りで同一の動作をすると思う。
結果から言うと所要時間は AND ≒ DAND < TST でした。
TSTが一番遅いだろうとは思ってたけどANDとDANDがほぼ同じというのは少し意外。
#もちろんサンプルによっては結果は異なると思うので、本来なら色々なサンプルでテストしてみるべきところだが
#今回は二つのサンプルでほぼ同一の結果(所要時間の比率)を得たのでよしとした。
AND/DANDとTSTの速度差は数回の平均を取った場合で0.7%。
ANDとDANDの差は誤差範囲内。
ちなみに <a\s[^>]++href=$AV(*)[^>]+> は上記三つの約7倍の速さだった。
[^>]++をアスタリスクに置換すると更に6%早くなった。(但しこのアスタリスクの使い方は非推奨)
長い文字列に対しては$NESTを使うことで更に早くなる場合もあるがそれはケースバイケース。
AND : <a\s([^>]+>&href=$AV(*))
TST : <a\s([^>]+)\0>$TST(\0=*href=$AV(*)*)
DAND : <a\s([^>]+>&&*href=$AV(*)*)
フィルタとしては考え得る限りで同一の動作をすると思う。
結果から言うと所要時間は AND ≒ DAND < TST でした。
TSTが一番遅いだろうとは思ってたけどANDとDANDがほぼ同じというのは少し意外。
#もちろんサンプルによっては結果は異なると思うので、本来なら色々なサンプルでテストしてみるべきところだが
#今回は二つのサンプルでほぼ同一の結果(所要時間の比率)を得たのでよしとした。
AND/DANDとTSTの速度差は数回の平均を取った場合で0.7%。
ANDとDANDの差は誤差範囲内。
ちなみに <a\s[^>]++href=$AV(*)[^>]+> は上記三つの約7倍の速さだった。
[^>]++をアスタリスクに置換すると更に6%早くなった。(但しこのアスタリスクの使い方は非推奨)
長い文字列に対しては$NESTを使うことで更に早くなる場合もあるがそれはケースバイケース。
488 :名無しさん@お腹いっぱい。:2007/03/09(金) 04:45:32 ID:hFs8erHf0
ニコニコ動画から直接.flvをDLできるフィルタきぼん
489 :名無しさん@お腹いっぱい。:2007/03/09(金) 05:15:16 ID:edKiCEkR0
間接キスでガマンして
490 :名無しさん@お腹いっぱい。:2007/03/09(金) 05:36:25 ID:TLLxfe8n0
素人な人は、ここで質問して作ってもらったフィルターは、すぐに試さない方がいいかもしれない。
半日程度寝かして、否定的なコメントが出ないぐらいまで待った方が良いかもね。
とんでもないスクリプトを混ぜられるかもしれん。
半日程度寝かして、否定的なコメントが出ないぐらいまで待った方が良いかもね。
とんでもないスクリプトを混ぜられるかもしれん。
491 :名無しさん@お腹いっぱい。:2007/03/09(金) 07:20:42 ID:bjxVpHmZ0
492 :名無しさん@お腹いっぱい。:2007/03/10(土) 03:18:00 ID:uXHetq1x0
<a(rea|)>...</a(rea|)> についてすっかり忘れていたことがあったので追記します。
>残念ながらProxomitronの仕様ではこれに多少の修正を加えることで「意図」通りに動かすということはできない。
これはまったくの誤りで実はもう一つの(比較的小規模な修正で意図通りに動かせる)方法がある。
第三の方法は変数をフラグとして用いてOR関数で分岐させるというもの。
例:
<a(\s$SET(flag=0)|real\s$SET(flag=1))[^>]+>*<($TST(flag=0)/a|$TST(flag=1)/area)>
但しこの手法ではローカル変数は使えないので、グローバル変数を使うことになるが使用後に解放することを忘れずに。
解放のやりかたは不要になった段階で$SET(flag=)というように空でSETすれば良い。
グローバル変数自体は基本的にほかのフィルタに値を渡すために使うためのもので、フラグとして使うというのはトリッキーな部類に属すのだが
Proxomitronの仕様上、ローカル変数をフラグとして利用することができない(一度使ったローカル変数をマッチ欄で再度使うことができない)ので仕方がない。
>残念ながらProxomitronの仕様ではこれに多少の修正を加えることで「意図」通りに動かすということはできない。
これはまったくの誤りで実はもう一つの(比較的小規模な修正で意図通りに動かせる)方法がある。
第三の方法は変数をフラグとして用いてOR関数で分岐させるというもの。
例:
<a(\s$SET(flag=0)|real\s$SET(flag=1))[^>]+>*<($TST(flag=0)/a|$TST(flag=1)/area)>
但しこの手法ではローカル変数は使えないので、グローバル変数を使うことになるが使用後に解放することを忘れずに。
解放のやりかたは不要になった段階で$SET(flag=)というように空でSETすれば良い。
グローバル変数自体は基本的にほかのフィルタに値を渡すために使うためのもので、フラグとして使うというのはトリッキーな部類に属すのだが
Proxomitronの仕様上、ローカル変数をフラグとして利用することができない(一度使ったローカル変数をマッチ欄で再度使うことができない)ので仕方がない。
493 :名無しさん@お腹いっぱい。:2007/03/10(土) 03:35:34 ID:650fW3oU0
ttp://vipup.org/
このサイトの広告を消すフィルタを作っていただけないでしょうか。よろしくお願いします。
このサイトの広告を消すフィルタを作っていただけないでしょうか。よろしくお願いします。
494 :名無しさん@お腹いっぱい。:2007/03/10(土) 04:37:51 ID:Q+Oc8G1J0
Name = "3d>>>2d"
Active = TRUE
URL = "$TYPE(htm)vipup.org/"
Limit = 256
Match = "$NEST(<a\shref=$AV(http://click.t2z.jp/*),</a>)|"
"<a\shref=$AV(http://ofuda.cc/)*</a>"
Active = TRUE
URL = "$TYPE(htm)vipup.org/"
Limit = 256
Match = "$NEST(<a\shref=$AV(http://click.t2z.jp/*),</a>)|"
"<a\shref=$AV(http://ofuda.cc/)*</a>"
495 :名無しさん@お腹いっぱい。:2007/03/10(土) 06:38:33 ID:650fW3oU0
>>494
遅くなりましたが、ありがとうございます。
遅くなりましたが、ありがとうございます。
496 :名無しさん@お腹いっぱい。:2007/03/10(土) 08:02:57 ID:pr+9tzs+0
firefoxのadblockplusで^http://click\.とofuda.cc/を弾いてる漏れには無縁
497 :名無しさん@お腹いっぱい。:2007/03/10(土) 10:08:04 ID:FcJ4cSpA0
オミトロン入れてるのにadblockplusとかアホちやうかと思う。
498 :名無しさん@お腹いっぱい。:2007/03/10(土) 10:57:17 ID:v1L9WvH00
>>492
一生懸命なとこ申し訳ないけど、日本語訳ヘルプサイトのマッチングコマンドページの
$TSTの説明文のところにそれと同じことをローカル変数で実現する例が載ってる。
あとその方法でやるなら$TSTはもっと後ろに置くべき。 </a>、</area>の後ろで。
>>470
置換スタックに代入するためだけに先頭の<aを()で囲うのは
処理速度の低下になるから高速化に拘るのであれば避けるべき。
一生懸命なとこ申し訳ないけど、日本語訳ヘルプサイトのマッチングコマンドページの
$TSTの説明文のところにそれと同じことをローカル変数で実現する例が載ってる。
あとその方法でやるなら$TSTはもっと後ろに置くべき。 </a>、</area>の後ろで。
>>470
置換スタックに代入するためだけに先頭の<aを()で囲うのは
処理速度の低下になるから高速化に拘るのであれば避けるべき。
499 :名無しさん@お腹いっぱい。:2007/03/10(土) 14:15:10 ID:uXHetq1x0
>498
$TST(\0)の存在を完全に忘れてた。使い所はまだあまり思い浮かばないけど参考になったよ。
<([a-z]+)\1*</$TST(\1)>
すごく……スマートです。
>置換スタックに代入するためだけに先頭の<aを()で囲うのは
>処理速度の低下になるから高速化に拘るのであれば避けるべき。
該当部分を $NEST(<a(\s|rea\s)\#, .....) に変えて
置換テキストの先頭に <a を加えたほうが良いということ?
前後での速度変化は検知すら不可能な気がするけど調べてないから何とも言えない。
しかし個人的には修正するときに弄る箇所が多くなる可能性があるフィルタというのは使い勝手がよくないと思う。
$TST(\0)の存在を完全に忘れてた。使い所はまだあまり思い浮かばないけど参考になったよ。
<([a-z]+)\1*</$TST(\1)>
すごく……スマートです。
>置換スタックに代入するためだけに先頭の<aを()で囲うのは
>処理速度の低下になるから高速化に拘るのであれば避けるべき。
該当部分を $NEST(<a(\s|rea\s)\#, .....) に変えて
置換テキストの先頭に <a を加えたほうが良いということ?
前後での速度変化は検知すら不可能な気がするけど調べてないから何とも言えない。
しかし個人的には修正するときに弄る箇所が多くなる可能性があるフィルタというのは使い勝手がよくないと思う。
500 :名無しさん@お腹いっぱい。:2007/03/10(土) 14:16:49 ID:nGbrcGZM0
myspace(例えばhttp://www.myspace.com/hellogoodbye)で
一番上に出る"今週のお勧めアーティスト"のバナーを消したいのと、
おそらくインターネットオプションの言語が日本語だと
メニューが中途半端に日本語になるのがいやなのですが(英語のままがいいです)、
フィルターで解決できますでしょうか?
もしできるのであればどなたか作っていただけませんか?
よろしくおねがいします。
一番上に出る"今週のお勧めアーティスト"のバナーを消したいのと、
おそらくインターネットオプションの言語が日本語だと
メニューが中途半端に日本語になるのがいやなのですが(英語のままがいいです)、
フィルターで解決できますでしょうか?
もしできるのであればどなたか作っていただけませんか?
よろしくおねがいします。
501 :think ◆MM0nnAOCiQ :2007/03/10(土) 14:58:13 ID:iZYl65vB0
>>498
> 置換スタックに代入するためだけに先頭の<aを()で囲うのは処理速度の低下になる
今回はa要素かarea要素かを覚え込ませる必要があるので、置換スタックを使わざるを得ませんでした。
(rea|) で変数に格納した方が望ましいということでしょうか?
> 置換スタックに代入するためだけに先頭の<aを()で囲うのは処理速度の低下になる
今回はa要素かarea要素かを覚え込ませる必要があるので、置換スタックを使わざるを得ませんでした。
(rea|) で変数に格納した方が望ましいということでしょうか?
502 :think ◆MM0nnAOCiQ :2007/03/10(土) 15:00:25 ID:iZYl65vB0
ところで、何の前提も無しに私がフィルタを作成しようと思ったら、$NESTは使わないと思います。
$NESTを使用すると、最小限のマッチが実現しにくくなる(マッチしなくても良いところまでマッチする)場合があり、今回はその状況なので…。
[Patterns]
Name = "Insert <a> title [2007/03/10] test4"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "(<a(rea|)\s)\#(^(^[^>]++href=$AV(\2)))"
"(([^>]++)\#title=$AV(\1)$SET(#=title="<a title>: \1\r\n<a href>: \2)|"
"$SET(#=title="<a href>: \2))"
"("
"[^>]+>(^<img\s[^>]++title=)"
"(<img\s("
"[^>]++src=$AV(\3)$SET(#=\r\n<img src>: \3)&"
"([^>]++alt=$AV(\4)$SET(#=\r\n<img alt>: \4)|)"
")|)"
")\9"
Replace = "\@"\9"
---- サンプルソース
<a id="a_id" title="a_title" href="a_href"><img alt="img_alt" src="img_src" title="img_title" /></a>
<a id="a_id" title="a_title" href="a_href"><img alt="img_alt" src="img_src" /></a>
<a id="a_id" title="a_title" href="a_href">text</a>
IE7とSyleraで検証したところ、img要素のtitle属性が存在するときは、img要素のtitle属性がツールチップに表示されるようです。
そのため、img要素のtitle属性が存在する状況ではマッチしないようにしてあります。
どうせなら、img要素用のフィルタがあっても良いかもしれません。
$NESTを使用すると、最小限のマッチが実現しにくくなる(マッチしなくても良いところまでマッチする)場合があり、今回はその状況なので…。
[Patterns]
Name = "Insert <a> title [2007/03/10] test4"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "(<a(rea|)\s)\#(^(^[^>]++href=$AV(\2)))"
"(([^>]++)\#title=$AV(\1)$SET(#=title="<a title>: \1\r\n<a href>: \2)|"
"$SET(#=title="<a href>: \2))"
"("
"[^>]+>(^<img\s[^>]++title=)"
"(<img\s("
"[^>]++src=$AV(\3)$SET(#=\r\n<img src>: \3)&"
"([^>]++alt=$AV(\4)$SET(#=\r\n<img alt>: \4)|)"
")|)"
")\9"
Replace = "\@"\9"
---- サンプルソース
<a id="a_id" title="a_title" href="a_href"><img alt="img_alt" src="img_src" title="img_title" /></a>
<a id="a_id" title="a_title" href="a_href"><img alt="img_alt" src="img_src" /></a>
<a id="a_id" title="a_title" href="a_href">text</a>
IE7とSyleraで検証したところ、img要素のtitle属性が存在するときは、img要素のtitle属性がツールチップに表示されるようです。
そのため、img要素のtitle属性が存在する状況ではマッチしないようにしてあります。
どうせなら、img要素用のフィルタがあっても良いかもしれません。
503 :think ◆MM0nnAOCiQ :2007/03/10(土) 15:06:46 ID:iZYl65vB0
>502の続き。
「最小限のマッチ」を最優先で考えるならば、>502のフィルタは \9 ではなく「肯定先読み」を使うべきですが、それでは置換スタックに該当テキストが代入されませんでした。
仕方がないので、ローカル変数で代替えしていますが、他に良い手段があれば改善したい部分です。
「最小限のマッチ」を最優先で考えるならば、>502のフィルタは \9 ではなく「肯定先読み」を使うべきですが、それでは置換スタックに該当テキストが代入されませんでした。
仕方がないので、ローカル変数で代替えしていますが、他に良い手段があれば改善したい部分です。
504 :名無しさん@お腹いっぱい。:2007/03/10(土) 17:25:14 ID:S0lPbdUa0
ニコニコ動画から直接.flvをDLできるフィルタきぼん
505 :think ◆MM0nnAOCiQ :2007/03/10(土) 17:52:21 ID:iZYl65vB0
>>325
遅レスですが、作成したのを忘れていました。(汗)
[Patterns]
Name = "Mooter: Kill ad [2007/02/09] test1"
Active = TRUE
URL = "$TYPE(htm)www.mooter.co.jp/moot/\?"
Limit = 2048
Match = "$NEST(<td[ >],[^>]++bgcolor=$AV(*)*<div\s[^>]++id=$AV(sponsor)*,</td>)"
"$SET(0=\r\n<!-- Kill Mooter ad -->\r\n)|"
"<div(^(^\s[^>]++id=$AV(sp)))$SET(0=<div style="display: none")$STOP()"
Replace = "\0"
参考までに、どんな時に「Mooter」で検索するのか、聞かせていただけると嬉しいです。
遅レスですが、作成したのを忘れていました。(汗)
[Patterns]
Name = "Mooter: Kill ad [2007/02/09] test1"
Active = TRUE
URL = "$TYPE(htm)www.mooter.co.jp/moot/\?"
Limit = 2048
Match = "$NEST(<td[ >],[^>]++bgcolor=$AV(*)*<div\s[^>]++id=$AV(sponsor)*,</td>)"
"$SET(0=\r\n<!-- Kill Mooter ad -->\r\n)|"
"<div(^(^\s[^>]++id=$AV(sp)))$SET(0=<div style="display: none")$STOP()"
Replace = "\0"
参考までに、どんな時に「Mooter」で検索するのか、聞かせていただけると嬉しいです。
506 :名無しさん@お腹いっぱい。:2007/03/11(日) 01:45:50 ID:QC5rXZw90
みなさんのアドバイスをいただきたいです。
http://proxo.hp.infoseek.co.jp./cgi-bin/sn_uploader/src/pr0071.txt
相対リンクを絶対リンクに直すリストを作ったのですが、思ったように動きません。
相対リンクなら絶対リンクに直し、絶対リンクならそのままにグローバル変数ABSにURLを格納するのですが
それを正しく呼び出すことができません。
$SET(ABS=\8\9) のようにセットしているのですが $GET(ABS)と\8\9が一致していないということです。
置換テキストで $GET(ABS) の代わりに\8\9を使うとこちらの環境では大部分のウェブサイトで動作を確認できました。
http://proxo.hp.infoseek.co.jp./cgi-bin/sn_uploader/src/pr0071.txt
相対リンクを絶対リンクに直すリストを作ったのですが、思ったように動きません。
相対リンクなら絶対リンクに直し、絶対リンクならそのままにグローバル変数ABSにURLを格納するのですが
それを正しく呼び出すことができません。
$SET(ABS=\8\9) のようにセットしているのですが $GET(ABS)と\8\9が一致していないということです。
置換テキストで $GET(ABS) の代わりに\8\9を使うとこちらの環境では大部分のウェブサイトで動作を確認できました。
507 :名無しさん@お腹いっぱい。:2007/03/11(日) 02:41:41 ID:LLusi//q0
パスを変換するフィルタはときどき話題になるけど、面倒な問題だと思う。
自分も以前考えたことがあったけど、
わざわざパスを変換しなくても目的さえ達成できればいいかと考えて、
まったく別の見方からフィルタを書くことで解決した。
パスを書き換えることが本当に必要なのかを考え直すのも手だと思う。
自分も以前考えたことがあったけど、
わざわざパスを変換しなくても目的さえ達成できればいいかと考えて、
まったく別の見方からフィルタを書くことで解決した。
パスを書き換えることが本当に必要なのかを考え直すのも手だと思う。
508 :名無しさん@お腹いっぱい。:2007/03/11(日) 02:45:15 ID:woTiePuf0
>>499>>501
>置換テキストの先頭に <a を加えたほうが良い
>(rea|) で変数に格納した方が望ましい
そうです。 でもこれは’高速化を重視する場合は’という条件での
話なので必ずこう書かなければいけないということではないです。
>>470は高速化のために$NESTを使ってると思ったので>>498のレスを
付けたんですが、>>502を読むとどうやら違ったみたいです。
こちらの勘違いだったようなのですみませんが忘れて下さい。
>置換テキストの先頭に <a を加えたほうが良い
>(rea|) で変数に格納した方が望ましい
そうです。 でもこれは’高速化を重視する場合は’という条件での
話なので必ずこう書かなければいけないということではないです。
>>470は高速化のために$NESTを使ってると思ったので>>498のレスを
付けたんですが、>>502を読むとどうやら違ったみたいです。
こちらの勘違いだったようなのですみませんが忘れて下さい。
510 :名無しさん@お腹いっぱい。:2007/03/11(日) 15:31:59 ID:LSOWJrEn0
511 :名無しさん@お腹いっぱい。:2007/03/11(日) 17:50:01 ID:0EO6G7xs0
title要素内の改行をスペースに置換するにはどうしたらいいでしょう。
512 :名無しさん@お腹いっぱい。:2007/03/11(日) 20:45:54 ID:LSOWJrEn0
513 :511:2007/03/11(日) 21:44:41 ID:0EO6G7xs0
>>512
それは知っています。
それは知っています。
514 :名無しさん@お腹いっぱい。:2007/03/11(日) 21:57:38 ID:qs13JhQR0
アメーバ動画をDLできるフィルタきぼん
515 :名無しさん@お腹いっぱい。:2007/03/11(日) 23:37:09 ID:LSOWJrEn0
516 :511:2007/03/12(月) 00:16:20 ID:/2yG7ZeG0
>>515
違います。
私は既存のどのフィルターに対しても言及していません。
ただ、私のやりたいことについて言っているのです。
改行をスペースに置換する方法は知ってるんです。
それをtitle要素に限定する方法がわからないのです。
違います。
私は既存のどのフィルターに対しても言及していません。
ただ、私のやりたいことについて言っているのです。
改行をスペースに置換する方法は知ってるんです。
それをtitle要素に限定する方法がわからないのです。
517 :think ◆MM0nnAOCiQ :2007/03/12(月) 00:32:23 ID:zgeKaTdr0
>>510
ローカル変数で万事OKでした。多謝。
# まさか、置換スタックの制限だったとは…。$SET が使えないものと想定していました。
[Patterns]
Name = "Insert <a> title [2007/03/12] test4.1"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "(<a(rea|)\s)\#(^(^[^>]++href=$AV(\2)))"
"(([^>]++)\#title=$AV(\1)$SET(#=title="<a title>: \1\r\n<a href>: \2)|"
"$SET(#=title="<a href>: \2))"
"(^(^"
"[^>]+>(^<img\s[^>]++title=)"
"(<img\s("
"[^>]++src=$AV(\3)$SET(\8=\r\n<img src>: \3)&"
"([^>]++alt=$AV(\4)$SET(\9=\r\n<img alt>: \4)|)"
")|)"
"))"
Replace = "\@\8\9""
>>511,513,516
$NEST でマッチ範囲を制限してみてはどうでしょうか?
ローカル変数で万事OKでした。多謝。
# まさか、置換スタックの制限だったとは…。$SET が使えないものと想定していました。
[Patterns]
Name = "Insert <a> title [2007/03/12] test4.1"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 256
Match = "(<a(rea|)\s)\#(^(^[^>]++href=$AV(\2)))"
"(([^>]++)\#title=$AV(\1)$SET(#=title="<a title>: \1\r\n<a href>: \2)|"
"$SET(#=title="<a href>: \2))"
"(^(^"
"[^>]+>(^<img\s[^>]++title=)"
"(<img\s("
"[^>]++src=$AV(\3)$SET(\8=\r\n<img src>: \3)&"
"([^>]++alt=$AV(\4)$SET(\9=\r\n<img alt>: \4)|)"
")|)"
"))"
Replace = "\@\8\9""
>>511,513,516
$NEST でマッチ範囲を制限してみてはどうでしょうか?
518 :名無しさん@お腹いっぱい。:2007/03/12(月) 00:46:37 ID:awFCazQV0
どなたかSHOUTcast Song HistoryをShift-JISで表示する
ヘッダフィルタをお願いしマス
ヘッダフィルタをお願いしマス
519 :think ◆MM0nnAOCiQ :2007/03/12(月) 00:52:44 ID:zgeKaTdr0
>>511,513,516
もしくは、「title要素の開始タグから次のタグまでの文字列」に制限する方法ですね。
<title>[^<]++[\r\n]...
title要素は、内容モデルで文字列のみを許可しているので、HTMLに即した書き方である限り、他のタグが現れることはありません。
ttp://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/struct/global.html#h-7.4.2
最も、"<>" を文字列としてそのまま書いたりするサイトもあるので(本来は実体参照で書くべきところです)、$NESTの方が確実ではあります…。
見やすいフィルタを作るなら、Bounds でも良いです。
もしくは、「title要素の開始タグから次のタグまでの文字列」に制限する方法ですね。
<title>[^<]++[\r\n]...
title要素は、内容モデルで文字列のみを許可しているので、HTMLに即した書き方である限り、他のタグが現れることはありません。
ttp://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/struct/global.html#h-7.4.2
最も、"<>" を文字列としてそのまま書いたりするサイトもあるので(本来は実体参照で書くべきところです)、$NESTの方が確実ではあります…。
見やすいフィルタを作るなら、Bounds でも良いです。
520 :511:2007/03/12(月) 01:35:35 ID:/2yG7ZeG0
>>517,519
ありがとうございます。
私、$NEST()の使い方がどうもわからないのです。
Match = "$NEST(<title*>,\r\n,</title>)"
Replace = " "
と書いてみたんですが、駄目でした。おそらくこれは間違った書き方なんでしょう。
正しい書き方をご教示願います。
ありがとうございます。
私、$NEST()の使い方がどうもわからないのです。
Match = "$NEST(<title*>,\r\n,</title>)"
Replace = " "
と書いてみたんですが、駄目でした。おそらくこれは間違った書き方なんでしょう。
正しい書き方をご教示願います。
521 :think ◆MM0nnAOCiQ :2007/03/12(月) 02:28:08 ID:zgeKaTdr0
>>520
"$NEST(<title*>,\r\n,</title>)" は "<title>\r\n</title>" にマッチします。
$NEST の第二引数 (上例では "\r\n") は完全一致ですので、「改行を含む文字列」を指定してやれば良いでしょう。
「改行を含む文字列」の簡単な例は
*(\r\n|[\r\n])*
ですが、これでは一つの改行しか置換できません。
複数の改行を置換するためには、「グループ化を利用して、再帰的にマッチ」させる必要があります。
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html (「再帰的なマッチングを使わない方法」を参照)
(*(\r\n|[\r\n]))+{1,*}*
この表現で期待通りにマッチすると思います。
後は、置換スタックに格納して、変換してあげてください。
改行が見つかったときに、$SET で置換スタックに半角空白を格納するのがポイントです。
"$NEST(<title*>,\r\n,</title>)" は "<title>\r\n</title>" にマッチします。
$NEST の第二引数 (上例では "\r\n") は完全一致ですので、「改行を含む文字列」を指定してやれば良いでしょう。
「改行を含む文字列」の簡単な例は
*(\r\n|[\r\n])*
ですが、これでは一つの改行しか置換できません。
複数の改行を置換するためには、「グループ化を利用して、再帰的にマッチ」させる必要があります。
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html (「再帰的なマッチングを使わない方法」を参照)
(*(\r\n|[\r\n]))+{1,*}*
この表現で期待通りにマッチすると思います。
後は、置換スタックに格納して、変換してあげてください。
改行が見つかったときに、$SET で置換スタックに半角空白を格納するのがポイントです。
522 :think ◆MM0nnAOCiQ :2007/03/12(月) 02:38:10 ID:zgeKaTdr0
今更ですが。
title要素内の「空白」と「改行」は同様に「空白としてWebブラウザに解釈される」ので、ブラウザの挙動を変更したいのなら、ご希望のフィルタは期待通りに動作しません。
今回は別の意図が質問者さんにあるのかと思っていたのですが、やはり、気になってしまいました…。
title要素内の「空白」と「改行」は同様に「空白としてWebブラウザに解釈される」ので、ブラウザの挙動を変更したいのなら、ご希望のフィルタは期待通りに動作しません。
今回は別の意図が質問者さんにあるのかと思っていたのですが、やはり、気になってしまいました…。
523 :511:2007/03/12(月) 06:33:53 ID:/2yG7ZeG0
thinkさんのレスを参考にして、title要素内の改行をスペースに置換するフィルターを作りました。
[Patterns]
Name = "Opera History Saver"
Active = TRUE
Multi = TRUE
Bounds = "<title(\s*|)>*</title>"
Limit = 256
Match = "(\#(\r\n|[\r\n])$SET(\#= ))+\1"
Replace = "\@\1"
これで適切なのかどうか不安ですが、テストをした限りでは私の望み通り働いてくれます。
thinkさんありがとうございました。
なぜtitle要素内の改行を空白に置換したかったのかといいますと…
Operaの履歴ファイルがたまに破損するから調べてみると、原因はタイトルに含まれる改行らしい。
そこで、Proxomitronを使って、改行を空白に置換してしまえと思ったわけです。
でもですね、もっとよく調べてみると、メディアタイプがapplication/xhtml+xmlの場合において
タイトルに改行を含むと履歴ファイルが破損するらしく、text/htmlならセーフみたいなんです。
だからHTTPヘッダーフィルターでapplication/xhtml+xmlをtext/htmlに書き換えれば済む話でした。
せっかく作った "Opera History Saver" ですが、存在意義がなさそうです…。
[Patterns]
Name = "Opera History Saver"
Active = TRUE
Multi = TRUE
Bounds = "<title(\s*|)>*</title>"
Limit = 256
Match = "(\#(\r\n|[\r\n])$SET(\#= ))+\1"
Replace = "\@\1"
これで適切なのかどうか不安ですが、テストをした限りでは私の望み通り働いてくれます。
thinkさんありがとうございました。
なぜtitle要素内の改行を空白に置換したかったのかといいますと…
Operaの履歴ファイルがたまに破損するから調べてみると、原因はタイトルに含まれる改行らしい。
そこで、Proxomitronを使って、改行を空白に置換してしまえと思ったわけです。
でもですね、もっとよく調べてみると、メディアタイプがapplication/xhtml+xmlの場合において
タイトルに改行を含むと履歴ファイルが破損するらしく、text/htmlならセーフみたいなんです。
だからHTTPヘッダーフィルターでapplication/xhtml+xmlをtext/htmlに書き換えれば済む話でした。
せっかく作った "Opera History Saver" ですが、存在意義がなさそうです…。
524 :名無しさん@お腹いっぱい。:2007/03/12(月) 12:32:18 ID:sFZoAlND0
以前このスレでYahooBlog検索の右側にあるニュースとかを消すフィルターを作ってもらったものですが
Name = "test"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 50
Match = "(<!-- [%b1][%a6]\w --> )\1<td [^>]+>$SET(#=\1<td style="display: none;">)"
Replace = "\@"
これがいつのまのか通用しなくなってしまいました。どこをどう変えればいいのかご教示してくれれば幸いです。
Name = "test"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 50
Match = "(<!-- [%b1][%a6]\w --> )\1<td [^>]+>$SET(#=\1<td style="display: none;">)"
Replace = "\@"
これがいつのまのか通用しなくなってしまいました。どこをどう変えればいいのかご教示してくれれば幸いです。
525 :名無しさん@お腹いっぱい。:2007/03/12(月) 12:55:47 ID:tVcyCE360
IEが受け取れないメディアタイプを指定するほどのニッチなウェブサイトがタイトル要素に改行を含めるなんてなかなか飲み込めない話だね。
もしかしてインデントでもしてるのかな。
どちらにしろそんなウェブサイトは見る価値がないだろうと思うのでURL killfile.txtに追加するのも一つ。
<title>
タイトル
</title>
もしかしてインデントでもしてるのかな。
どちらにしろそんなウェブサイトは見る価値がないだろうと思うのでURL killfile.txtに追加するのも一つ。
<title>
タイトル
</title>
526 :名無しさん@お腹いっぱい。:2007/03/12(月) 14:44:55 ID:aCYQ5JIW0
>>485
>もう一つだけど最初のうちはアスタリスクを乱用しないほうがいい。
>初心者にとってのアスタリスクというのはおそらく面倒なことをブラックボックスに詰め込ん>>でどっかにやるためのツールなんだろうけど
>それじゃ何も上達しないし理解もすすまないだろう。
>>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
>これなんかはアスタリスク乱用の好例だね。
Tips and Tricks
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html
アンパサンド「&」を使用すれば、タグの属性を、見つけた順番に関係なく
取り込むことができます。
たとえば、「<img ... >」タグを書き換えて、あなたが持っている画像と置き換え、
元の「width」と「height」の値はそのまま残す、という例を考えてみましょう。
その場合、以下のようにします...
Matching: <img ( (*(height=\w)\1*| ) & (*(width=\w)\2*| ) ) >
この表現真似したんだろ。少し意地悪過ぎないか?
>もう一つだけど最初のうちはアスタリスクを乱用しないほうがいい。
>初心者にとってのアスタリスクというのはおそらく面倒なことをブラックボックスに詰め込ん>>でどっかにやるためのツールなんだろうけど
>それじゃ何も上達しないし理解もすすまないだろう。
>>(*href=$AV(\1)*|)&(*title=$AV(\2)*|)
>これなんかはアスタリスク乱用の好例だね。
Tips and Tricks
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Tips_And_Tricks.html
アンパサンド「&」を使用すれば、タグの属性を、見つけた順番に関係なく
取り込むことができます。
たとえば、「<img ... >」タグを書き換えて、あなたが持っている画像と置き換え、
元の「width」と「height」の値はそのまま残す、という例を考えてみましょう。
その場合、以下のようにします...
Matching: <img ( (*(height=\w)\1*| ) & (*(width=\w)\2*| ) ) >
この表現真似したんだろ。少し意地悪過ぎないか?
527 :511:2007/03/12(月) 21:51:58 ID:xzItuT7B0
>>525
私のOperaの履歴が破損する原因だったサイトは――こんな言い方するとそのサイトが悪い見たいだけど、
もちろん悪いのはOperaのバグ――IEからのリクエストが来たらtext/htmlを吐くように配慮しているサイトでした。
ところで「ニッチなウェブサイト」って何でしょう。
私のOperaの履歴が破損する原因だったサイトは――こんな言い方するとそのサイトが悪い見たいだけど、
もちろん悪いのはOperaのバグ――IEからのリクエストが来たらtext/htmlを吐くように配慮しているサイトでした。
ところで「ニッチなウェブサイト」って何でしょう。
528 :名無しさん@お腹いっぱい。:2007/03/12(月) 23:09:22 ID:Xw0bZVnJ0
>ニッチ【niche】
>西洋建築で,壁面を半円または方形にくぼめた部分。
>彫刻などを飾ったり噴水を設けたりする。壁龕(へきがん)。
>転じて,広く,隙間をいう。
スキマ産業的Webサイト???
>西洋建築で,壁面を半円または方形にくぼめた部分。
>彫刻などを飾ったり噴水を設けたりする。壁龕(へきがん)。
>転じて,広く,隙間をいう。
スキマ産業的Webサイト???
529 :名無しさん@お腹いっぱい。:2007/03/12(月) 23:26:51 ID:Tn7hpqvH0
ニッチもサッチもどうにもこうにもブルドッグ
530 :名無しさん@お腹いっぱい。:2007/03/12(月) 23:30:23 ID:IhbXMcJV0
>525 ttp://www.faireal.net/
application/xhtml+xml の際のソース参照。
application/xhtml+xml の際のソース参照。
531 :名無しさん@お腹いっぱい。:2007/03/13(火) 02:12:22 ID:O2zL+zL90
google imageまたダメになった?
532 :名無しさん@お腹いっぱい。:2007/03/13(火) 02:35:52 ID:mu+tlPQe0
>>531
Google Image: Image Change (070115)だったら
<a href="\+e\+b.m\+"><imgを
<a href="\+e\+b.n\+"><imgにすればいいよ
Google Image: Image Change (070115)だったら
<a href="\+e\+b.m\+"><imgを
<a href="\+e\+b.n\+"><imgにすればいいよ
533 :名無しさん@お腹いっぱい。:2007/03/13(火) 02:38:39 ID:O2zL+zL90
>>532
おお、ありがとう。
おお、ありがとう。
534 :名無しさん@お腹いっぱい。:2007/03/13(火) 13:37:19 ID:6oKDUNzC0
>>524
とりあえず作り直してみた。
Name = "Yahoo blog search"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 80
Match = "<td [^>]+>( <!-- [%a5][%c8])\1$SET(#=<td style="display: none;">\1)"
Replace = "\@"
とりあえず作り直してみた。
Name = "Yahoo blog search"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 80
Match = "<td [^>]+>( <!-- [%a5][%c8])\1$SET(#=<td style="display: none;">\1)"
Replace = "\@"
535 :名無しさん@お腹いっぱい。:2007/03/13(火) 19:16:45 ID:POt57Fu+0
>>534
ありがとうございます・・・しかし私の環境では右側のキーワードの注目度、評判、ニュース記事などが消えませんでした。
http://blog-search.yahoo.co.jp/search?ei=UTF-8&fr=sfp&p=%E6%88%B8%E7%94%B0%E6%81%B5%E6%A2%A8%E9%A6%99
ありがとうございます・・・しかし私の環境では右側のキーワードの注目度、評判、ニュース記事などが消えませんでした。
http://blog-search.yahoo.co.jp/search?ei=UTF-8&fr=sfp&p=%E6%88%B8%E7%94%B0%E6%81%B5%E6%A2%A8%E9%A6%99
536 :名無しさん@お腹いっぱい。:2007/03/13(火) 22:36:25 ID:+r6UlnCI0
xhtmlって要素内に改行入れちゃいけないの?
ってそんなことあるわけないか。
ってそんなことあるわけないか。
537 :名無しさん@お腹いっぱい。:2007/03/14(水) 08:04:48 ID:nHF3h8Zy0
>>535
トップページがEUCで検索した後のページがUTF8 …… なのか?
これで動くはず。
Name = "Yahoo blog search"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 80
Match = "<td [^>]+>( <!-- [%a5][%c8][%a5][%d4])\1$SET(#=<td style="display: none;">\1)"
"|</head>$SET(#=<style>\n<!--\ntd#rightcol { display: none; }\n-->\n</style>\n</head>)"
Replace = "\@"
トップページがEUCで検索した後のページがUTF8 …… なのか?
これで動くはず。
Name = "Yahoo blog search"
Active = TRUE
URL = "blog-search.yahoo.co.jp/"
Limit = 80
Match = "<td [^>]+>( <!-- [%a5][%c8][%a5][%d4])\1$SET(#=<td style="display: none;">\1)"
"|</head>$SET(#=<style>\n<!--\ntd#rightcol { display: none; }\n-->\n</style>\n</head>)"
Replace = "\@"
538 :think ◆MM0nnAOCiQ :2007/03/14(水) 08:25:50 ID:VvDEM1HD0
おはようございます。
最近、書くだけ書いて投稿を忘れてしまうことが多い気が…(汗)。遅レスですみません。
>>523
なるほど、そういう訳でしたか。
> これで適切なのかどうか不安ですが、テストをした限りでは私の望み通り働いてくれます。
比較的、良くできていると思います。少しアドバイスしますと
-- <title(\s*|)> を <title(\s[^>]+|)> に変更
アスタリスクは制限された領域でない限り、2つ連続で使わない方がよいです。
ttp://vird2002.s8.xrea.com/proxomitron/meta_character/m-chara_asterisk.html
-- \1 を \# に変更
置換テキストを \@ のみにできます。
-- Multi を外す。
私の書き方も悪かったのですが、このやり方はProxomitronHelp記述上の「再帰的なマッチングを使わない方法」です。
ヘルプ上のマッチという表現は「フィルタのマッチ」を指していると思われますが、私は「ある表現部分のマッチ」という意味で用いていましたので、ややこしくなっていました…。
Multiに依存しない表現を使う場合は、Multi を外した方が高速化されますし、誤爆を最小限に抑えられます。
最近、書くだけ書いて投稿を忘れてしまうことが多い気が…(汗)。遅レスですみません。
>>523
なるほど、そういう訳でしたか。
> これで適切なのかどうか不安ですが、テストをした限りでは私の望み通り働いてくれます。
比較的、良くできていると思います。少しアドバイスしますと
-- <title(\s*|)> を <title(\s[^>]+|)> に変更
アスタリスクは制限された領域でない限り、2つ連続で使わない方がよいです。
ttp://vird2002.s8.xrea.com/proxomitron/meta_character/m-chara_asterisk.html
-- \1 を \# に変更
置換テキストを \@ のみにできます。
-- Multi を外す。
私の書き方も悪かったのですが、このやり方はProxomitronHelp記述上の「再帰的なマッチングを使わない方法」です。
ヘルプ上のマッチという表現は「フィルタのマッチ」を指していると思われますが、私は「ある表現部分のマッチ」という意味で用いていましたので、ややこしくなっていました…。
Multiに依存しない表現を使う場合は、Multi を外した方が高速化されますし、誤爆を最小限に抑えられます。
539 :think ◆MM0nnAOCiQ :2007/03/14(水) 09:16:00 ID:VvDEM1HD0
>>536
br要素のことでしたら、XHTML1.1 でも使用できます。
<p> で括るべきところで <br /> を使うのはNGですが、論理構造にそってマークアップされていれば仕様上は問題ありません。
最も、「論理要素でないbr要素は非推奨」というポリシーの方もいるようで、それも納得できる話ですけど…。
余談ですが、XHTML2.0 では br要素 は廃止され、新しい要素として l要素 ("line"を意味し、空要素ではなくなります) が導入される見込みです。
ですので、前方互換性を考慮するなら、br要素は使わない方が良いと思います。
>>537
> トップページがEUCで検索した後のページがUTF8 …… なのか?
Yahoo!ブログ検索 - 「Proxomitron」の検索結果
ttp://blog-search.yahoo.co.jp/search?p=Proxomitron
↑の検索結果はEUC-JPで出力されているようですが、そのフィルタではコメント部分がマッチしていないようです。
つまり、<td ... id="rightcol"> へのスタイルのみが適用されているわけですが、これで必要条件を満たしているように思えます。
[%a5][%c8][%a5][%d4] をデコードしてみると、"トピ" となりましたがこれはどの部分にマッチさせようとしているのでしょうか?
Proxomitronによる改変前のhtmlソースを検索してみましたが、HITしませんでした。
br要素のことでしたら、XHTML1.1 でも使用できます。
<p> で括るべきところで <br /> を使うのはNGですが、論理構造にそってマークアップされていれば仕様上は問題ありません。
最も、「論理要素でないbr要素は非推奨」というポリシーの方もいるようで、それも納得できる話ですけど…。
余談ですが、XHTML2.0 では br要素 は廃止され、新しい要素として l要素 ("line"を意味し、空要素ではなくなります) が導入される見込みです。
ですので、前方互換性を考慮するなら、br要素は使わない方が良いと思います。
>>537
> トップページがEUCで検索した後のページがUTF8 …… なのか?
Yahoo!ブログ検索 - 「Proxomitron」の検索結果
ttp://blog-search.yahoo.co.jp/search?p=Proxomitron
↑の検索結果はEUC-JPで出力されているようですが、そのフィルタではコメント部分がマッチしていないようです。
つまり、<td ... id="rightcol"> へのスタイルのみが適用されているわけですが、これで必要条件を満たしているように思えます。
[%a5][%c8][%a5][%d4] をデコードしてみると、"トピ" となりましたがこれはどの部分にマッチさせようとしているのでしょうか?
Proxomitronによる改変前のhtmlソースを検索してみましたが、HITしませんでした。
540 :名無しさん@お腹いっぱい。:2007/03/14(水) 14:35:09 ID:2lOdeE9F0
>>537
完璧です!本当にありがとうございました。お手数をおかけしました。
完璧です!本当にありがとうございました。お手数をおかけしました。
>>539
やはりOKでしたか、どうもありがとう。
やはりOKでしたか、どうもありがとう。
542 :名無しさん@お腹いっぱい。:2007/03/14(水) 18:49:24 ID:PpkryFJv0
>>542
よっ大将!見事ですね。
よっ大将!見事ですね。
543 :名無しさん@お腹いっぱい。:2007/03/15(木) 04:00:02 ID:ridcyRuU0
( ´ー`)。oO(…ぬう、何者かがいきなり自画自賛を・・・・)
>>539
> トップページがEUCで検索した後のページがUTF8 …… なのか?
↑ この文字コード云々……というコメントは全然関係なくて、自分の勘違いでした。
> つまり、<td ... id="rightcol"> へのスタイルのみが適用されているわけですが、これで必要条件を満たしているように思えます。
検索結果のページの右側の部分には <td valign="top" id="rightcol"> という風に idが振られているんですが、
トップページ ttp://blog-search.yahoo.co.jp/ の同じ <td>タグの箇所にはidとかclassが無いんですよ。
それで仕方なく後続のコメント(<!--トピックス関連検索-->)にマッチするような書き方になりました。
> トップページがEUCで検索した後のページがUTF8 …… なのか?
↑ この文字コード云々……というコメントは全然関係なくて、自分の勘違いでした。
> つまり、<td ... id="rightcol"> へのスタイルのみが適用されているわけですが、これで必要条件を満たしているように思えます。
検索結果のページの右側の部分には <td valign="top" id="rightcol"> という風に idが振られているんですが、
トップページ ttp://blog-search.yahoo.co.jp/ の同じ <td>タグの箇所にはidとかclassが無いんですよ。
それで仕方なく後続のコメント(<!--トピックス関連検索-->)にマッチするような書き方になりました。
545 :名無しさん@お腹いっぱい。:2007/03/15(木) 13:02:15 ID:M2i2oHhr0
そうそう、質問しに来たんですが……
ttp://www.amazon.co.jp/dp/4480062858/
たとえばこのページに行って、「マーケットプレイスに出品する」のボタンを押して、次の画面で
ALT + 1キーを押すと「商品説明」のフォームにフォーカスが行くようにしたいんです。
それで以下のようなフィルタを書いたんですが、上手くいきません。
Name = "test"
Active = TRUE
URL = "s1.amazon.co.jp/"
Limit = 100
Match = "(name=$AV(sdp-sai-condition-comments))\1$SET(#=accesskey="1" \1)"
Replace = "\@"
テスト画面ではちゃんとマッチするのですが、実際の画面ではマッチしてないようです。何が原因でしょうか?
ttp://www.amazon.co.jp/dp/4480062858/
たとえばこのページに行って、「マーケットプレイスに出品する」のボタンを押して、次の画面で
ALT + 1キーを押すと「商品説明」のフォームにフォーカスが行くようにしたいんです。
それで以下のようなフィルタを書いたんですが、上手くいきません。
Name = "test"
Active = TRUE
URL = "s1.amazon.co.jp/"
Limit = 100
Match = "(name=$AV(sdp-sai-condition-comments))\1$SET(#=accesskey="1" \1)"
Replace = "\@"
テスト画面ではちゃんとマッチするのですが、実際の画面ではマッチしてないようです。何が原因でしょうか?
546 :think ◆MM0nnAOCiQ :2007/03/15(木) 20:22:58 ID:ZDvtMegz0
>>544
トップページも考慮していたのですか。納得しました。
>>545
掲示されたフィルタをAmazonでテストしてみましたが、期待通りにマッチし、[Alt + 1] キーでフォーカスが移動しました。
インターネットキャッシュが残っているのではないでしょうか?
# そのままでも支障はありませんが、そのフィルタは置換スタックを使わなくとも、置換テキストに accesskey="1" を記述するだけで機能します
トップページも考慮していたのですか。納得しました。
>>545
掲示されたフィルタをAmazonでテストしてみましたが、期待通りにマッチし、[Alt + 1] キーでフォーカスが移動しました。
インターネットキャッシュが残っているのではないでしょうか?
# そのままでも支障はありませんが、そのフィルタは置換スタックを使わなくとも、置換テキストに accesskey="1" を記述するだけで機能します
>>546
>>545 のフィルタで上手くいきますか?
自分の環境では CTRL + F5 で強制リロードしても、「インターネットオプション」の
「インターネット一時ファイル」でキャッシュを削除しても変わらないです。
いったい何が悪いのやら……
ともかく、検証してもらってありがとうございました。
>>545 のフィルタで上手くいきますか?
自分の環境では CTRL + F5 で強制リロードしても、「インターネットオプション」の
「インターネット一時ファイル」でキャッシュを削除しても変わらないです。
いったい何が悪いのやら……
ともかく、検証してもらってありがとうございました。
548 :名無しさん@お腹いっぱい。:2007/03/15(木) 22:13:02 ID:3+4y6iBM0
他のフィルターに邪魔されてるのかも。 デバックモードを試してみれば分かります。
549 :think ◆MM0nnAOCiQ :2007/03/15(木) 22:47:52 ID:ZDvtMegz0
>>547
ええ、動作の上でもhtmlソースを見ても正常動作を確認しています。
>548氏の指摘が当たっているかもしれませんね。
フィルタは早い者勝ちなので、ある範囲にフィルタがマッチすると他のフィルタがマッチできなくなります。
Multiを有効にすることでこの制限を外せますが、動作が重くなるのと複雑なロジックなので、このオプションはあまり使わない方がよいです。
ええ、動作の上でもhtmlソースを見ても正常動作を確認しています。
>548氏の指摘が当たっているかもしれませんね。
フィルタは早い者勝ちなので、ある範囲にフィルタがマッチすると他のフィルタがマッチできなくなります。
Multiを有効にすることでこの制限を外せますが、動作が重くなるのと複雑なロジックなので、このオプションはあまり使わない方がよいです。
550 :名無しさん@お腹いっぱい。:2007/03/15(木) 22:59:36 ID:5XjJlvKV0
アクセスキーは例えば、検索画面等で
[Mat] $NEST(<input\s,\0name=$AV((query|p|q)\1)\2,>)
[Rep] <input \0name="\1"\2 accesskey="1">
pはyahoo,qはgoogle
な感じで色々使えそうな気がする。
[Mat] $NEST(<input\s,\0name=$AV((query|p|q)\1)\2,>)
[Rep] <input \0name="\1"\2 accesskey="1">
pはyahoo,qはgoogle
な感じで色々使えそうな気がする。
551 :think ◆MM0nnAOCiQ :2007/03/15(木) 23:00:00 ID:ZDvtMegz0
と、対処法を書き忘れました。
フィルタは上に配置してあるものの優先度が高いので、特定のURLにのみ適用させるフィルタ等、出来るだけ有効にしたいフィルタは上に配置してください。
基本的に、上に配置してあるフィルタから作用しますが、マッチングパターンによっては下のフィルタが先に働く場合もあります。
例えば、以下の状況があるとします。
---- htmlソース
<a href="http://test.com/">TestLink</a>
---- フィルタ
Name="test filter1"
Match="TestLink"
Name="test filter2"
Match="$NEST(<a\s[^>]++href=$AV(http://test.com/),</a>)"
「test filter1」は「test filter2」より上に配置しています。
但し、Proxomitronはファイルの先頭から1バイトずつ読み込んでフィルタに合致する状況かどうかテストしています。
ですので、初めにマッチするのはa要素から始まる「test filter2」です。
「test filter1」を優先させたい場合は、
Match="<a\s[^>]+>[^<]++TestLink"
と書きます。
「test filter1」と「test filter2」はa要素から始まるパターンを持っている事になります。
同じ状況のフィルタが2つある場合は、優先度の高いフィルタから働きます。
フィルタは上に配置してあるものの優先度が高いので、特定のURLにのみ適用させるフィルタ等、出来るだけ有効にしたいフィルタは上に配置してください。
基本的に、上に配置してあるフィルタから作用しますが、マッチングパターンによっては下のフィルタが先に働く場合もあります。
例えば、以下の状況があるとします。
---- htmlソース
<a href="http://test.com/">TestLink</a>
---- フィルタ
Name="test filter1"
Match="TestLink"
Name="test filter2"
Match="$NEST(<a\s[^>]++href=$AV(http://test.com/),</a>)"
「test filter1」は「test filter2」より上に配置しています。
但し、Proxomitronはファイルの先頭から1バイトずつ読み込んでフィルタに合致する状況かどうかテストしています。
ですので、初めにマッチするのはa要素から始まる「test filter2」です。
「test filter1」を優先させたい場合は、
Match="<a\s[^>]+>[^<]++TestLink"
と書きます。
「test filter1」と「test filter2」はa要素から始まるパターンを持っている事になります。
同じ状況のフィルタが2つある場合は、優先度の高いフィルタから働きます。
552 :名無しさん@お腹いっぱい。:2007/03/15(木) 23:19:06 ID:uLDWt/T60
>551
下に置いたフィルタが先にマッチする現象は、ずっと前から疑問に思ってた。
Proxomitron の仕様なのね。
フィルタを書き直すなどしないとだめなのか……。
優先度を設定することができるといいんだけど。
下に置いたフィルタが先にマッチする現象は、ずっと前から疑問に思ってた。
Proxomitron の仕様なのね。
フィルタを書き直すなどしないとだめなのか……。
優先度を設定することができるといいんだけど。
553 :名無しさん@お腹いっぱい。:2007/03/16(金) 07:41:06 ID:kg1cd2iM0
そいうのは「仕様」とはいわないだろ。
むしろどうしてそれを疑問に思えるのかが疑問なくらいに
至極当たり前の挙動だ。
むしろどうしてそれを疑問に思えるのかが疑問なくらいに
至極当たり前の挙動だ。
554 :名無しさん@お腹いっぱい。:2007/03/16(金) 09:13:53 ID:+6j5jdaH0
555 :名無しさん@お腹いっぱい。:2007/03/16(金) 10:31:21 ID:9J0GOQta0
まさに、仕様。
556 :名無しさん@お腹いっぱい。:2007/03/16(金) 14:29:20 ID:Lin+siRH0
仕様であってると思うよ。 これが至極当たり前の挙動と思ってるほうがおかしい。
検索アルゴリズムにはいろいろあるがオミトロンのこの方式はその中の1つでしかない。
検索アルゴリズムにはいろいろあるがオミトロンのこの方式はその中の1つでしかない。
557 :名無しさん@お腹いっぱい。:2007/03/16(金) 14:30:04 ID:8/GkMkD20
まぁ確かに
0 < 1 と評価するのはProxomitronの仕様なのね
みたいなこと言われたら
日本語として見ても主張の内容として見ても100%正しいけど
なんか妙だなって違和感は覚える
どちらの言いたいことも分かるが
0 < 1 と評価するのはProxomitronの仕様なのね
みたいなこと言われたら
日本語として見ても主張の内容として見ても100%正しいけど
なんか妙だなって違和感は覚える
どちらの言いたいことも分かるが
558 :think ◆MM0nnAOCiQ :2007/03/16(金) 18:53:48 ID:Hi6v4zHb0
>>552
「現在のProxomitronの動作」と「>552氏が求めるProxomitronの動作」をまとめると以下のようになると思います。
---- 現在のProxomitronの動作 (以降、「動作A」とする)
1. ファイルの先頭の1バイト目から読み込み、優先度の高いフィルタから順番にテスト
2. 1バイト進み、優先度の高いフィルタから順番にテスト
3. 「3. の動作」をファイルの末尾([EOF])まで続ける
---- 「フィルタの優先度」を最優先した場合のProxomitronの動作 (以降、「動作B」とする)
1. ファイルの先頭の1バイト目から読み込み、「優先度の最も高いフィルタ」をテスト
2. 1バイト進み、「優先度の最も高いフィルタ」をテスト
3. 「2. の動作」をファイルの末尾([EOF])まで続ける
4. ファイルの先頭の1バイト目から読み込み、「前回テストしたフィルタの次に優先度の高いフィルタ」をテスト
5. 1バイト進み、「4. でテストしたフィルタ」をテスト
6. 「4. 〜 5. の動作」をファイルの末尾([EOF])まで続ける
ここで、フィルタテストに必要とするバイト数に注目してみてください。
動作A … 「フィルタテストするバイト数 = 読み込んだファイルのサイズ」
動作B … 「フィルタテストするバイト数 = 読み込んだファイルのサイズ×フィルタの数」
このことから、「動作B」はフィルタの数が多ければ多いほど、Proxomitronの動作が顕著に重くなるでしょう。
「動作A」でもフィルタの数が多いほど、Proxomitronの動作が重くなりますが、フィルタテストするバイト数はファイルサイズ分だけに留まるため、「動作A」の負荷は「動作B」程には大きくならないと想像できます。
日本語としては私も「仕様」であっていると思いますが、上のところの内部事情を知っているか否かで見方が変わってきます。
特に、「フィルタの優先度」という表現は、如何にも「最優先されそうな設定」ですから、勘違いがあっても致し方ない気がします。
# 余談ですが、2chブラウザ「JaneDoe View」の ReplaceStr.txt は「動作B」に近い動作になっていると思われます。
「現在のProxomitronの動作」と「>552氏が求めるProxomitronの動作」をまとめると以下のようになると思います。
---- 現在のProxomitronの動作 (以降、「動作A」とする)
1. ファイルの先頭の1バイト目から読み込み、優先度の高いフィルタから順番にテスト
2. 1バイト進み、優先度の高いフィルタから順番にテスト
3. 「3. の動作」をファイルの末尾([EOF])まで続ける
---- 「フィルタの優先度」を最優先した場合のProxomitronの動作 (以降、「動作B」とする)
1. ファイルの先頭の1バイト目から読み込み、「優先度の最も高いフィルタ」をテスト
2. 1バイト進み、「優先度の最も高いフィルタ」をテスト
3. 「2. の動作」をファイルの末尾([EOF])まで続ける
4. ファイルの先頭の1バイト目から読み込み、「前回テストしたフィルタの次に優先度の高いフィルタ」をテスト
5. 1バイト進み、「4. でテストしたフィルタ」をテスト
6. 「4. 〜 5. の動作」をファイルの末尾([EOF])まで続ける
ここで、フィルタテストに必要とするバイト数に注目してみてください。
動作A … 「フィルタテストするバイト数 = 読み込んだファイルのサイズ」
動作B … 「フィルタテストするバイト数 = 読み込んだファイルのサイズ×フィルタの数」
このことから、「動作B」はフィルタの数が多ければ多いほど、Proxomitronの動作が顕著に重くなるでしょう。
「動作A」でもフィルタの数が多いほど、Proxomitronの動作が重くなりますが、フィルタテストするバイト数はファイルサイズ分だけに留まるため、「動作A」の負荷は「動作B」程には大きくならないと想像できます。
日本語としては私も「仕様」であっていると思いますが、上のところの内部事情を知っているか否かで見方が変わってきます。
特に、「フィルタの優先度」という表現は、如何にも「最優先されそうな設定」ですから、勘違いがあっても致し方ない気がします。
# 余談ですが、2chブラウザ「JaneDoe View」の ReplaceStr.txt は「動作B」に近い動作になっていると思われます。
559 :名無しさん@お腹いっぱい。:2007/03/16(金) 20:42:00 ID:HCDQ1kIb0
Jane板見たけど、結構大変そうなことやるつもりみたいだねぇ。
ガンガレ。
ガンガレ。
560 :名無しさん@お腹いっぱい。:2007/03/16(金) 21:13:39 ID:Lin+siRH0
JaneViewのReplaceStr.txtをオミトロン方式にしたら早くなるのではとViewスレに書き込んだら
複数の人に否定されたことがある。 何故なのか未だに分からない。
複数の人に否定されたことがある。 何故なのか未だに分からない。
561 :名無しさん@お腹いっぱい。:2007/03/16(金) 22:31:20 ID:1wcXUPwP0
>558
ややっ、詳しい解説ありがとうございます。
そういう事情があると極めて妥当な動作ですね。
今後は、優先度を高くしたいフィルタは
ほかのフィルタと競合しても問題ないように努力します。
ややっ、詳しい解説ありがとうございます。
そういう事情があると極めて妥当な動作ですね。
今後は、優先度を高くしたいフィルタは
ほかのフィルタと競合しても問題ないように努力します。
562 :名無しさん@お腹いっぱい。:2007/03/17(土) 03:30:08 ID:AadC9Up90
TOK2のWebスペースの広告が激しくUzeeeee!!
消すこと自体は簡単なんだが、
こちらが対応した数日〜1週間後に10〜数百バイトくらいずつ増やして、
バイト制限を潜り抜けてきやがる。
このまま増やし続ける気か(#゚Д゚)ゴラァ!
消すこと自体は簡単なんだが、
こちらが対応した数日〜1週間後に10〜数百バイトくらいずつ増やして、
バイト制限を潜り抜けてきやがる。
このまま増やし続ける気か(#゚Д゚)ゴラァ!
563 :名無しさん@お腹いっぱい。:2007/03/17(土) 05:21:53 ID:RWq7G/0N0
>562
自分の場合、limit は16384(16KB)になってる。
1回につき最低でも512バイト、最大で2KBくらい増やして、
いったい何回 limit を増やしたことか。
自分の場合、limit は16384(16KB)になってる。
1回につき最低でも512バイト、最大で2KBくらい増やして、
いったい何回 limit を増やしたことか。
564 :名無しさん@お腹いっぱい。:2007/03/17(土) 05:26:11 ID:RWq7G/0N0
いま思いついたけど、
<!-- tok2_top --> → <div class="tok2-ad">
<!-- tok2_top_end --> → </div>
こんな感じで置き換えて、
div.tok2-ad { display: none !important }
こうすれば消える。
バイト制限を増やす必要がなさそうだし、動作も軽くなるかも。
<!-- tok2_top --> → <div class="tok2-ad">
<!-- tok2_top_end --> → </div>
こんな感じで置き換えて、
div.tok2-ad { display: none !important }
こうすれば消える。
バイト制限を増やす必要がなさそうだし、動作も軽くなるかも。
565 :名無しさん@お腹いっぱい。:2007/03/17(土) 11:02:34 ID:HIHHgHWL0
567 :名無しさん@お腹いっぱい。:2007/03/17(土) 13:22:55 ID:AadC9Up90
568 :名無しさん@お腹いっぱい。:2007/03/17(土) 18:08:19 ID:MjkjkU7H0
569 :名無しさん@お腹いっぱい。:2007/03/17(土) 18:37:53 ID:jVQSctLy0
570 :名無しさん@お腹いっぱい。:2007/03/18(日) 07:59:30 ID:s5Pb2Uih0
571 :名無しさん@お腹いっぱい。:2007/03/18(日) 11:52:02 ID:x92h/snR0
572 :名無しさん@お腹いっぱい。:2007/03/18(日) 16:33:15 ID:4oJ5D+yI0
573 :名無しさん@お腹いっぱい。:2007/03/18(日) 19:50:17 ID:UeHdvFS20
URLの最後が.jpgで終わっててContent-Type: がimage/jpegで、中身が普通のhtmlになってると
WEBページフィルタ適応されないんですが対処方法ありませんか?
WEBページフィルタ適応されないんですが対処方法ありませんか?
574 :名無しさん@お腹いっぱい。:2007/03/18(日) 21:08:43 ID:YcHYPNb90
>>562
とりあえず作ってみた。
広告部分にidが振ってあったのでCSSで消したよ。
Name = "TOK2"
Active = TRUE
URL = "[^/]++.tok2.com/$TYPE(htm)"
Limit = 120
Match = "(<script * </script> && *(prego.jp)*)"
"|</head>$SET(#=<style>\n<!--\n"
"#TOK2-TOP-BANNER, #TOK2-SIDE-BANNER, #TOK2-SEO { display: none; }\n"
"-->\n</style>\n</head>\n)"
Replace = "\@"
とりあえず作ってみた。
広告部分にidが振ってあったのでCSSで消したよ。
Name = "TOK2"
Active = TRUE
URL = "[^/]++.tok2.com/$TYPE(htm)"
Limit = 120
Match = "(<script * </script> && *(prego.jp)*)"
"|</head>$SET(#=<style>\n<!--\n"
"#TOK2-TOP-BANNER, #TOK2-SIDE-BANNER, #TOK2-SEO { display: none; }\n"
"-->\n</style>\n</head>\n)"
Replace = "\@"
575 :名無しさん@お腹いっぱい。:2007/03/18(日) 21:09:27 ID:YcHYPNb90
>>572
Name = "1rk"
Active = TRUE
URL = "www.1rk.net/$TYPE(htm)"
Limit = 80
Match = "(<img *> && *(image.jpg)*)"
"|</head>$SET(#=<style>\n<!--\n"
".ad, p.ads, p.adw { display: none; }\n-->\n</style>\n</head>)"
Replace = "\@"
Name = "1rk"
Active = TRUE
URL = "www.1rk.net/$TYPE(htm)"
Limit = 80
Match = "(<img *> && *(image.jpg)*)"
"|</head>$SET(#=<style>\n<!--\n"
".ad, p.ads, p.adw { display: none; }\n-->\n</style>\n</head>)"
Replace = "\@"
576 :名無しさん@お腹いっぱい。:2007/03/18(日) 21:35:26 ID:qf1arYv00
イメージファイルの中にアドビのタグ?が入っていると
誤爆するのを防ぐにはどうしたらよいですか
誤爆するのを防ぐにはどうしたらよいですか
577 :名無しさん@お腹いっぱい。:2007/03/18(日) 21:56:22 ID:WywTxmu/0
>>573
Content-Type: をimage/jpegからtext/htmlに置換するフィルタで対処。
URL欄を使ってフィルタが動作するサイトを絞ってから使うといいよ。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: image to html (In)"
URL = "www.hoge.com/"
Match = "image/jpeg"
Replace = "text/html"
>>576
画像ファイルはデフォルトではフィルタリング対象外のはず。
その画像を見れば対策方法が分かるかも。
Content-Type: をimage/jpegからtext/htmlに置換するフィルタで対処。
URL欄を使ってフィルタが動作するサイトを絞ってから使うといいよ。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: image to html (In)"
URL = "www.hoge.com/"
Match = "image/jpeg"
Replace = "text/html"
>>576
画像ファイルはデフォルトではフィルタリング対象外のはず。
その画像を見れば対策方法が分かるかも。
>>506
これで期待通りに動くようです。
# NoAddURL
(#?+)\9$URL(\8)$SET(ABS=\8\9)
./(?+)\9($TST(SWITCH1=1)$SET(ABS=$GET(CURRENTURL)\9)|
$URL(([^:]+://*/([^/]+/)+)\8)$SET(CURRENTURL=\8)$SET(SWITCH1=1)$SET(ABS=\8\9))
/(?+)\9$URL(([^:]+://*/)\8)$SET(ABS=\8\9)
../($TST(SWITCH2=1)$SET(NUM=$GET(LEVEL))|$URL([^:]+://*/$SET(NUM=1)
([^/]+/$LST(increment))+)$SET(SWITCH2=1)$SET(LEVEL=$GET(NUM)))
($LST(decrement)../)+$URL(([^:]+://*/([^/]+/$LST(decrement)
$TST(NUM=[^0]*))+)\8)(?+)\9$SET(ABS=\8\9)
([a-z]+:?+)\9$SET(ABS=\9)
(?+)\9$URL(([^:]+://*/([^/]+/)+)\8)$SET(ABS=\8\9)
これで期待通りに動くようです。
# NoAddURL
(#?+)\9$URL(\8)$SET(ABS=\8\9)
./(?+)\9($TST(SWITCH1=1)$SET(ABS=$GET(CURRENTURL)\9)|
$URL(([^:]+://*/([^/]+/)+)\8)$SET(CURRENTURL=\8)$SET(SWITCH1=1)$SET(ABS=\8\9))
/(?+)\9$URL(([^:]+://*/)\8)$SET(ABS=\8\9)
../($TST(SWITCH2=1)$SET(NUM=$GET(LEVEL))|$URL([^:]+://*/$SET(NUM=1)
([^/]+/$LST(increment))+)$SET(SWITCH2=1)$SET(LEVEL=$GET(NUM)))
($LST(decrement)../)+$URL(([^:]+://*/([^/]+/$LST(decrement)
$TST(NUM=[^0]*))+)\8)(?+)\9$SET(ABS=\8\9)
([a-z]+:?+)\9$SET(ABS=\9)
(?+)\9$URL(([^:]+://*/([^/]+/)+)\8)$SET(ABS=\8\9)
579 :名無しさん@お腹いっぱい。:2007/03/19(月) 00:42:49 ID:tQMpuigO0
>>575
遅くなりましたが、ありがとうございます。
遅くなりましたが、ありがとうございます。
580 :名無しさん@お腹いっぱい。:2007/03/19(月) 00:45:50 ID:NXCUdEyC0
本スレが不毛な言い争いの場に…
DOCTYPE宣言があればそのまま、無ければ付加ってフィルタを作ろうと思ったのに
前者が実現できなくて問答無用に付加されてしまう
有効リストなり無効リストなりを作ってマッチさせる手もあるけど
それじゃ汎用性が落ちるからなぁ
DOCTYPE宣言があればそのまま、無ければ付加ってフィルタを作ろうと思ったのに
前者が実現できなくて問答無用に付加されてしまう
有効リストなり無効リストなりを作ってマッチさせる手もあるけど
それじゃ汎用性が落ちるからなぁ
>>506
$GET(ABS)と\8\9が一致しない原因は以下のフィルターを試せば分かります。
テストウインドウに"abc"と書いて下の3つのフィルターを試して下さい。
Name = "$SET test1"
Active = FALSE
Limit = 256
Match = "*"
Replace = "<match>"
Name = "$SET test2"
Active = FALSE
Limit = 256
Match = "*$SET(\0=text)"
Replace = "<match>"
Name = "$SET test3"
Active = FALSE
Limit = 256
Match = "?+$SET(\0=text)"
Replace = "<match>"
1と2の違いは$SET(\0=text)が付いてるかどうかの違いしかありませんが結果が
変わっていると思います。 3では2で起きた問題を修正するために*を?+に書き換えています。
$GET(ABS)と\8\9が一致しない原因は以下のフィルターを試せば分かります。
テストウインドウに"abc"と書いて下の3つのフィルターを試して下さい。
Name = "$SET test1"
Active = FALSE
Limit = 256
Match = "*"
Replace = "<match>"
Name = "$SET test2"
Active = FALSE
Limit = 256
Match = "*$SET(\0=text)"
Replace = "<match>"
Name = "$SET test3"
Active = FALSE
Limit = 256
Match = "?+$SET(\0=text)"
Replace = "<match>"
1と2の違いは$SET(\0=text)が付いてるかどうかの違いしかありませんが結果が
変わっていると思います。 3では2で起きた問題を修正するために*を?+に書き換えています。
>>506
何故こうなるかというと、*は後ろに何かがあれば最短一致として動作、無ければ
最長一致として動作するためです。 *の後ろに$SETコマンドがあると*は最短一致として
動作するようになってしまうので2のようにカラにマッチしてしまうわけです。
そこで後ろに何があっても最長一致をする?+を使うことでこの問題を回避しています。
>>580
こんな感じですかね。
Active = FALSE
Limit = 256
Match = "("
"(^(^ <!DOCTYPE))"
"|"
"$SET(0=<!DOCTYPE ....)"
")"
"$STOP()"
Replace = "\0"
何故こうなるかというと、*は後ろに何かがあれば最短一致として動作、無ければ
最長一致として動作するためです。 *の後ろに$SETコマンドがあると*は最短一致として
動作するようになってしまうので2のようにカラにマッチしてしまうわけです。
そこで後ろに何があっても最長一致をする?+を使うことでこの問題を回避しています。
>>580
こんな感じですかね。
Active = FALSE
Limit = 256
Match = "("
"(^(^ <!DOCTYPE))"
"|"
"$SET(0=<!DOCTYPE ....)"
")"
"$STOP()"
Replace = "\0"
>>582
お、これはありがとうごぜぇやす
ブックマークから適当に踏んで試してみたらXML宣言ありなページで誤爆したんで
回避する為に”(^(^ *<;!DOCTYPE))”に変えてしばらく使ってみるっす
そこでSTOPかけるのを思い付かんかったのと
宣言文に続く<HTML〜まで見るようにしてたのが敗因か
お、これはありがとうごぜぇやす
ブックマークから適当に踏んで試してみたらXML宣言ありなページで誤爆したんで
回避する為に”(^(^ *<;!DOCTYPE))”に変えてしばらく使ってみるっす
そこでSTOPかけるのを思い付かんかったのと
宣言文に続く<HTML〜まで見るようにしてたのが敗因か
584 :名無しさん@お腹いっぱい。:2007/03/19(月) 18:06:50 ID:WHlPa9sf0
>>577
ども
URL: Filter image extension をブラクラ用にオンにしてます
ログに Protect Contents except HTML が出てます
ttp://www.mxtv.co.jp/goji/ ここの画像がそうなります
ども
URL: Filter image extension をブラクラ用にオンにしてます
ログに Protect Contents except HTML が出てます
ttp://www.mxtv.co.jp/goji/ ここの画像がそうなります
585 :名無しさん@お腹いっぱい。:2007/03/20(火) 16:44:20 ID:0LIwAOV50
>>584
Protect Contents except HTMLというフィルタが誤爆しているようなので
このフィルターを修正するしかないですが、ログを検索してみてもこのフィルターを
配布しているところが見つかりません。
よろしければここに貼るか、うpして頂けないでしょうか。
問題が起こるところがそのサイトだけならば (^([^/]++.|)mxtv.co.jp/) をそのフィルターの
URL欄の先頭に入れれば回避出来ますが、根本的な解決にはなりません。
Protect Contents except HTMLというフィルタが誤爆しているようなので
このフィルターを修正するしかないですが、ログを検索してみてもこのフィルターを
配布しているところが見つかりません。
よろしければここに貼るか、うpして頂けないでしょうか。
問題が起こるところがそのサイトだけならば (^([^/]++.|)mxtv.co.jp/) をそのフィルターの
URL欄の先頭に入れれば回避出来ますが、根本的な解決にはなりません。
587 :名無しさん@お腹いっぱい。:2007/03/20(火) 20:49:41 ID:PJkWD4Ws0
>>585
ヘボくてすんません、おかしかったら誰か直してやってください
勉強させていただきやす。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.3.1"
URL = "www.amazon.co.jp/\w(ASIN(/|=)|obidos/|product/)[0-9A-Z]+{10}?"
Match = "*([0-9A-Z]+{10})\0"
Replace = "$JUMP(http://www.amazon.co.jp/o/ASIN/\0)$LOG(R[Amazon] http://www.amazon.co.jp/o/ASIN/\0)"
http://www.amazon.co.jp/gp/product/ じゃなくて
http://www.amazon.co.jp/o/ASIN/ に飛ばす仕様なんだけど
これだとまずいのかなぁ。飛べない商品とかあるかもしれない。
Amazonの仕様自体イマイチわかってないからそこも不安…。
ヘボくてすんません、おかしかったら誰か直してやってください
勉強させていただきやす。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.3.1"
URL = "www.amazon.co.jp/\w(ASIN(/|=)|obidos/|product/)[0-9A-Z]+{10}?"
Match = "*([0-9A-Z]+{10})\0"
Replace = "$JUMP(http://www.amazon.co.jp/o/ASIN/\0)$LOG(R[Amazon] http://www.amazon.co.jp/o/ASIN/\0)"
http://www.amazon.co.jp/gp/product/ じゃなくて
http://www.amazon.co.jp/o/ASIN/ に飛ばす仕様なんだけど
これだとまずいのかなぁ。飛べない商品とかあるかもしれない。
Amazonの仕様自体イマイチわかってないからそこも不安…。
588 :名無しさん@お腹いっぱい。:2007/03/20(火) 23:25:12 ID:4ptHUCsg0
>>585
www.amazon.co.jp/商品名/dp/*
という形式の商品名の部分が長くなる原因。
この商品名の部分は実は何でも良かったりする。削除しても良し。
これをを削除するだけなら>>587を改造してこうすれば良いと思う。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer (out)"
Match = "http://www.amazon.co.jp/[^/]+/dp/\0"
Replace = "$JUMP(http://www.amazon.co.jp/dp/\0)"
www.amazon.co.jp/商品名/dp/*
という形式の商品名の部分が長くなる原因。
この商品名の部分は実は何でも良かったりする。削除しても良し。
これをを削除するだけなら>>587を改造してこうすれば良いと思う。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer (out)"
Match = "http://www.amazon.co.jp/[^/]+/dp/\0"
Replace = "$JUMP(http://www.amazon.co.jp/dp/\0)"
589 :名無しさん@お腹いっぱい。:2007/03/20(火) 23:33:47 ID:0LIwAOV50
>587-588
ありがとうございました。
俺もそろそろ自分でフィルター作れるように勉強しないとな・・
ありがとうございました。
俺もそろそろ自分でフィルター作れるように勉強しないとな・・
590 :名無しさん@お腹いっぱい。:2007/03/21(水) 00:13:13 ID:1/lCY91m0
>>588
dpでいけるんですか…!
dpでいけるんですか…!
591 :名無しさん@お腹いっぱい。:2007/03/21(水) 00:53:03 ID:1/lCY91m0
ん、あれ?dpの商品名部分が削れればそれでOK?
>>587だと、(私の知る限りの)全ての形式のURIに対応、
かつASIN以降を全て消し去るという方向で書いてます。
お好きな方をお好みで、かな。
と思いきや、肝心の/dp/に対応してなかったので修正。
その他、商品画像ページ対応、ジャンプ先URIを更に短縮など。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.4 (out)"
URL = "(www.|)amazon(.co|).jp/\w((ASIN|obidos|dp|product(/images|))(/|=))[0-9A-Z]+{10}?"
Match = "*((images/|)([0-9A-Z]+{10}))\0"
Replace = "$JUMP(http://amazon.jp/dp/\0)"
アカウントサービス内での誤爆が一番恐い。
URIに含まれる文字列と[0-9A-Z]+{10}?でのASIN探しで
一応の防御はしてるつもりなんだけど。
>>587だと、(私の知る限りの)全ての形式のURIに対応、
かつASIN以降を全て消し去るという方向で書いてます。
お好きな方をお好みで、かな。
と思いきや、肝心の/dp/に対応してなかったので修正。
その他、商品画像ページ対応、ジャンプ先URIを更に短縮など。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.4 (out)"
URL = "(www.|)amazon(.co|).jp/\w((ASIN|obidos|dp|product(/images|))(/|=))[0-9A-Z]+{10}?"
Match = "*((images/|)([0-9A-Z]+{10}))\0"
Replace = "$JUMP(http://amazon.jp/dp/\0)"
アカウントサービス内での誤爆が一番恐い。
URIに含まれる文字列と[0-9A-Z]+{10}?でのASIN探しで
一応の防御はしてるつもりなんだけど。
592 :名無しさん@お腹いっぱい。:2007/03/21(水) 01:05:18 ID:d4dDjrEw0
>>591
せっかく作ってもらってるのに贅沢は言えません。
コピーする時に後ろ削れば良いだけですし、確かにASIN以降削れればよりよいことは確かですが
そのフィルターだとASINが「hoge1-hoge2-hoge3」と言う形式だと「hoge1」と認識してしまうようです
http://www.amazon.co.jp/b/ref=amb_link_18877906_34/249-2893728-4624309?ie=UTF8&node=3245331
確認用
せっかく作ってもらってるのに贅沢は言えません。
コピーする時に後ろ削れば良いだけですし、確かにASIN以降削れればよりよいことは確かですが
そのフィルターだとASINが「hoge1-hoge2-hoge3」と言う形式だと「hoge1」と認識してしまうようです
http://www.amazon.co.jp/b/ref=amb_link_18877906_34/249-2893728-4624309?ie=UTF8&node=3245331
確認用
593 :名無しさん@お腹いっぱい。:2007/03/21(水) 01:35:35 ID:1/lCY91m0
>>592
これは恥ずかしい…。
URLマッチばっかり気にして実際のマッチを手抜きしてたのが原因でした。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.4.5 (out)"
URL = "(www.|)amazon(.co|).jp/\w((ASIN|obidos|dp|product(/images|))(/|=))[0-9A-Z]+{10}?"
Match = "\w((ASIN|obidos|dp|product)(/|=))((images/|)([0-9A-Z]+{10}))\0"
Replace = "$JUMP(http://amazon.jp/dp/\0)"
まだまだ弄ってみたら、今のところ不具合が
・ユーズド商品関連に対応できない
・商品画像ページで他のカラーが見れない
どんどん冗長になってくし、やっぱり>>588ぐらいシンプルな方が
機能的にも精神衛生的にもいいみたいです。勉強になりました。
これは恥ずかしい…。
URLマッチばっかり気にして実際のマッチを手抜きしてたのが原因でした。
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Amazon URI Simplizer alpha.1.4.5 (out)"
URL = "(www.|)amazon(.co|).jp/\w((ASIN|obidos|dp|product(/images|))(/|=))[0-9A-Z]+{10}?"
Match = "\w((ASIN|obidos|dp|product)(/|=))((images/|)([0-9A-Z]+{10}))\0"
Replace = "$JUMP(http://amazon.jp/dp/\0)"
まだまだ弄ってみたら、今のところ不具合が
・ユーズド商品関連に対応できない
・商品画像ページで他のカラーが見れない
どんどん冗長になってくし、やっぱり>>588ぐらいシンプルな方が
機能的にも精神衛生的にもいいみたいです。勉強になりました。
594 :think ◆MM0nnAOCiQ :2007/03/21(水) 01:55:04 ID:lHqDQGV30
Amazonの商品紹介ページ(URL)をいくつか見ました。
どうやら、/dp/ の手前は「メーカー名-商品型番-備考」で構成されているようなので、以下の形でどうでしょうか?
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Omit Amazon URL [2007/03/21] test1"
Match = "http://(www.|)amazon.(co.|)jp/[\%0-9a-z]+{1,*}(-[\%0-9a-z]+)+{1,*}/(dp/[^/]+/)\0"
Replace = "$JUMP(http://www.amazon.co.jp/\0)"
# 商品紹介(ASIN)
http://www.amazon.co.jp/o/ASIN/商品コード/...
↓
http://www.amazon.co.jp/o/ASIN/商品コード/
# リダイレクタ
http://www.amazon.co.jp/gp/redirect.html%3F...&location=/o/ASIN/商品コード%25...
↓
http://www.amazon.co.jp/o/ASIN/商品コード/
他にも亜種がいくつかあるようですが、最近は /dp/ に統一しようとしている流れに見えますね。
どうやら、/dp/ の手前は「メーカー名-商品型番-備考」で構成されているようなので、以下の形でどうでしょうか?
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: Omit Amazon URL [2007/03/21] test1"
Match = "http://(www.|)amazon.(co.|)jp/[\%0-9a-z]+{1,*}(-[\%0-9a-z]+)+{1,*}/(dp/[^/]+/)\0"
Replace = "$JUMP(http://www.amazon.co.jp/\0)"
# 商品紹介(ASIN)
http://www.amazon.co.jp/o/ASIN/商品コード/...
↓
http://www.amazon.co.jp/o/ASIN/商品コード/
# リダイレクタ
http://www.amazon.co.jp/gp/redirect.html%3F...&location=/o/ASIN/商品コード%25...
↓
http://www.amazon.co.jp/o/ASIN/商品コード/
他にも亜種がいくつかあるようですが、最近は /dp/ に統一しようとしている流れに見えますね。
595 :名無しさん@お腹いっぱい。:2007/03/21(水) 04:23:54 ID:pz60mXe50
タブブラウザでJavascriptが有効だとアドレス短くならないよね?
IEだと短くなるね
IEだと短くなるね
596 :名無しさん@お腹いっぱい。:2007/03/21(水) 19:42:09 ID:/5cB5deu0
>>593-594
ありがとうございます。便利になりました。
私はこれで十分ですが発見した不具合でも
・Amazon外部からのURLが反応しない
・>>593はページを右上の「Would you like to see this page in English?」が効かなくなる
(ただし、外部から飛んできた時これをクリックするとURLが短くなるので英語を必要としない場合逆に便利)
http://www.google.co.jp/search?q=Windows+site%3aamazon.co.jp
確認用
ありがとうございます。便利になりました。
私はこれで十分ですが発見した不具合でも
・Amazon外部からのURLが反応しない
・>>593はページを右上の「Would you like to see this page in English?」が効かなくなる
(ただし、外部から飛んできた時これをクリックするとURLが短くなるので英語を必要としない場合逆に便利)
http://www.google.co.jp/search?q=Windows+site%3aamazon.co.jp
確認用
597 :名無しさん@お腹いっぱい。:2007/03/21(水) 22:05:22 ID:xaNVUTV40
アマゾンのアフィリエイトをやっている身としては、
アソシエイトIDまで削られるのは遺憾だな。
アソシエイトIDまで削られるのは遺憾だな。
598 :名無しさん@お腹いっぱい。:2007/03/21(水) 23:22:57 ID:NszwPh7m0
オミトロン使うような奴ならアフィは全殺しするだろ・・・常識的に考えて
599 :名無しさん@お腹いっぱい。:2007/03/21(水) 23:30:02 ID:8H5gmtUL0
確かアフィIDを指定のものに書き換えるフィルタっていうのも以前あったな
600 :名無しさん@お腹いっぱい。:2007/03/22(木) 00:55:58 ID:fq9nmX0b0
アマゾンのアフィリエイトは真っ先に殺す。
601 :名無しさん@お腹いっぱい。:2007/03/22(木) 08:11:08 ID:LPlM1PA70
アフィが見えなくなるのは別に構わないけどさ、
でも自ら進んで踏んだものは有効にしようよ。
でも自ら進んで踏んだものは有効にしようよ。
602 :名無しさん@お腹いっぱい。:2007/03/22(木) 16:25:24 ID:uFlrt95P0
htaccessを無効にするフィルタ希望
ていうかhttp://karen.saiin.net/~g-kaizou/を表示させるフィルタ希望
ていうかhttp://karen.saiin.net/~g-kaizou/を表示させるフィルタ希望
603 :名無しさん@お腹いっぱい。:2007/03/22(木) 16:37:01 ID:IfmMON990
( ゜σ・・ ゜) ホジホジ
604 :名無しさん@お腹いっぱい。:2007/03/22(木) 16:58:02 ID:h6gQqGsT0
>>602
Content-Encoding: text/html; charset=csiso2022kr
Content-Encoding: text/html; charset=csiso2022kr
605 :名無しさん@お腹いっぱい。:2007/03/22(木) 17:12:43 ID:IfmMON990
つ SJIS
606 :名無しさん@お腹いっぱい。:2007/03/22(木) 20:49:05 ID:i23UPNfh0
>602に行ってみたけど、
ヘッダで文字コードを詐称されると、フィルタがまったく効かなくなるね。
これは Proxomitron を無効化させるための手段になる。危険だな。
ヘッダで文字コードを詐称されると、フィルタがまったく効かなくなるね。
これは Proxomitron を無効化させるための手段になる。危険だな。
607 :名無しさん@お腹いっぱい。:2007/03/22(木) 21:03:40 ID:HF+LFNrU0
変なContent-Encodingは消したほうが良いみたいだな
gzip, chunk 以外知らんけど
gzip, chunk 以外知らんけど
608 :名無しさん@お腹いっぱい。:2007/03/22(木) 21:10:10 ID:CuyAqdZm0
>>599
それ教えて( ゚д゚) ホスィ・・・
それ教えて( ゚д゚) ホスィ・・・
609 :名無しさん@お腹いっぱい。:2007/03/22(木) 21:43:52 ID:h6gQqGsT0
>>602
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill Content-Encoding (in)"
Match = "*"
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: Kill charset (in)"
Match = "text/html; charset="
Replace = "text/html;"
>>606-607
ですね。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill Content-Encoding (in)"
Match = "*"
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: Kill charset (in)"
Match = "text/html; charset="
Replace = "text/html;"
>>606-607
ですね。
610 :名無しさん@お腹いっぱい。:2007/03/22(木) 22:24:29 ID:LqIcExhd0
Match = "(^gzip|x-gzip)?"
とかにしとかなくていいの
とかにしとかなくていいの
611 :名無しさん@お腹いっぱい。:2007/03/22(木) 22:57:21 ID:h6gQqGsT0
612 :名無しさん@お腹いっぱい。:2007/03/23(金) 00:57:41 ID:zEKCeVAb0
文字コード詐称されてフィルターが効かないと言う状態なら
ブラウザも正しく認識出来ないのだからどっちにしろ危険は無いんじゃないのか?
ブラウザも正しく認識出来ないのだからどっちにしろ危険は無いんじゃないのか?
613 :名無しさん@お腹いっぱい。:2007/03/23(金) 16:29:48 ID:3Pg7luNE0
オミトロン装備してるとどうも一部の頁が西ヨーロッパ言語になってしまうんだが、どうすればいい?
614 :名無しさん@お腹いっぱい。:2007/03/23(金) 16:33:29 ID:3Pg7luNE0
すまない。スレ違いだった。
615 :名無しさん@お腹いっぱい。:2007/03/23(金) 21:25:45 ID:+CQ+E6V20
>>609
駄目だった・・・
駄目だった・・・
616 :think ◆MM0nnAOCiQ :2007/03/24(土) 14:25:23 ID:Vct6LEbc0
>>602,615
こちらの環境では、「>609の "Content-Type: Kill charset (in)" を取り入れて、JavaScriptを有効に」すれば、支障なく閲覧できています。
万が一問題があるようでしたら、以下のフィルタを取り込んでみてください。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: Fix g-kaizou charset (in) [2007/03/24]"
URL = "karen.saiin.net/~g-kaizou/"
Match = "text/html; charset=(^shift_jis|euc-jp|iso-2022-jp|utf-(8|16))"
Replace = "text/html; charset=shift_jis"
こちらの環境では、「>609の "Content-Type: Kill charset (in)" を取り入れて、JavaScriptを有効に」すれば、支障なく閲覧できています。
万が一問題があるようでしたら、以下のフィルタを取り込んでみてください。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Type: Fix g-kaizou charset (in) [2007/03/24]"
URL = "karen.saiin.net/~g-kaizou/"
Match = "text/html; charset=(^shift_jis|euc-jp|iso-2022-jp|utf-(8|16))"
Replace = "text/html; charset=shift_jis"
617 :think ◆MM0nnAOCiQ :2007/03/24(土) 14:38:04 ID:Vct6LEbc0
>616の続き。
Content-Typeヘッダの不正が原因なわけですが、Firefox, Opera9 (IE6, IE7 は [日本語(自動選択)] にチェックONで正常に閲覧可) で閲覧不可では少なからず訪問者を逃がしてしまいます。管理人の運営方針にもよりますが、サイト側の問題と受け取れると思います。
当分は、Proxomitronで凌ぐとしても、サイト運営者に報告しておいた方がお互いの益になるのではないでしょうか。
該当Webサイトのトップページには
-------------
2007年3月18日
なぜか全ページが文字化け(原因不明)
-------------
とあるので、運営者は原因を把握していないと思われます。
おそらく、htaccess に
AddType "text/html; charset=csiso2022kr" .html .htm
の記述があるので、これを
AddType "text/html; charset=shift_jis" .html .htm
に変更すれば、問題は解消されるでしょう。
…ということを運営者に報告してあげてください。
文字化け対策としての.htaccess
ttp://www.shtml.jp/htaccess/mojibake.html
@IT:Javaの文字化け対策FAQ(1)
ttp://www.atmarkit.co.jp/fjava/rensai3/mojibake01/mojibake01.html
Content-Typeヘッダの不正が原因なわけですが、Firefox, Opera9 (IE6, IE7 は [日本語(自動選択)] にチェックONで正常に閲覧可) で閲覧不可では少なからず訪問者を逃がしてしまいます。管理人の運営方針にもよりますが、サイト側の問題と受け取れると思います。
当分は、Proxomitronで凌ぐとしても、サイト運営者に報告しておいた方がお互いの益になるのではないでしょうか。
該当Webサイトのトップページには
-------------
2007年3月18日
なぜか全ページが文字化け(原因不明)
-------------
とあるので、運営者は原因を把握していないと思われます。
おそらく、htaccess に
AddType "text/html; charset=csiso2022kr" .html .htm
の記述があるので、これを
AddType "text/html; charset=shift_jis" .html .htm
に変更すれば、問題は解消されるでしょう。
…ということを運営者に報告してあげてください。
文字化け対策としての.htaccess
ttp://www.shtml.jp/htaccess/mojibake.html
@IT:Javaの文字化け対策FAQ(1)
ttp://www.atmarkit.co.jp/fjava/rensai3/mojibake01/mojibake01.html
618 :think ◆MM0nnAOCiQ :2007/03/24(土) 15:26:50 ID:Vct6LEbc0
問題提起されている件は、
Content-Encoding: text/html; charset=csiso2022kr
でProxomitronフィルタが無効になるという現象ですね。
# Content-Typeの方はフィルタの挙動とは無関係のようです。
# 何より、Content-Typeヘッダを意図的に不正にするとWebブラウザでの閲覧の支障が出るので、そういう設定にされる可能性は低いと思います。
で、この
Content-Encoding: text/html; charset=csiso2022kr
という記述は、正しい書式なのでしょうか?
よく解らないなりに、調べてみると以下の文献が見つかり、
-----------------
内容コーディングは、section 3.5 にて定義されている。使用例を見よ。
HTTP/1.1: ヘッダフィールド定義 - 14.11 Content-Encoding
ttp://www.practical-lamp.com/LAMP/PHP/reference/rfc/html/sec14.html#sec14.11
-----------------
最初は、登録機構は以下のトークンを登録している。... gzip, conpress, deflate, identity
HTTP/1.1: プロトコルパラメータ - 3.5 内容コーディング
ttp://www.practical-lamp.com/LAMP/PHP/reference/rfc/html/sec3.html#sec3.5
-----------------
とあるので、少なくとも>602のWebサイトの出力するContent-Encodingヘッダの書式は誤っているような気がします。
Content-Encoding: text/html; charset=csiso2022kr
でProxomitronフィルタが無効になるという現象ですね。
# Content-Typeの方はフィルタの挙動とは無関係のようです。
# 何より、Content-Typeヘッダを意図的に不正にするとWebブラウザでの閲覧の支障が出るので、そういう設定にされる可能性は低いと思います。
で、この
Content-Encoding: text/html; charset=csiso2022kr
という記述は、正しい書式なのでしょうか?
よく解らないなりに、調べてみると以下の文献が見つかり、
-----------------
内容コーディングは、section 3.5 にて定義されている。使用例を見よ。
HTTP/1.1: ヘッダフィールド定義 - 14.11 Content-Encoding
ttp://www.practical-lamp.com/LAMP/PHP/reference/rfc/html/sec14.html#sec14.11
-----------------
最初は、登録機構は以下のトークンを登録している。... gzip, conpress, deflate, identity
HTTP/1.1: プロトコルパラメータ - 3.5 内容コーディング
ttp://www.practical-lamp.com/LAMP/PHP/reference/rfc/html/sec3.html#sec3.5
-----------------
とあるので、少なくとも>602のWebサイトの出力するContent-Encodingヘッダの書式は誤っているような気がします。
619 :think ◆MM0nnAOCiQ :2007/03/24(土) 15:28:47 ID:Vct6LEbc0
>618の説が正しいとすると、Content-Encodingヘッダも運営者側で修正する方が望ましいので、サイト運営者が .htaccess から
AddEncoding "text/html; charset=csiso2022kr" .html .htm
を削除するという配慮があると有り難いですね。(書式は少し自信がないです…。)
あえて、Proxomitron排除のために残すというサイトがあった場合は、以下のフィルタで回避できる…と思います。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill faulty value (in) [2007/03/24]"
Match = "(^gzip|compress|deflate|identity)"
AddEncoding "text/html; charset=csiso2022kr" .html .htm
を削除するという配慮があると有り難いですね。(書式は少し自信がないです…。)
あえて、Proxomitron排除のために残すというサイトがあった場合は、以下のフィルタで回避できる…と思います。
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill faulty value (in) [2007/03/24]"
Match = "(^gzip|compress|deflate|identity)"
620 :名無しさん@お腹いっぱい。:2007/03/25(日) 00:39:47 ID:U32bBhWY0
621 :名無しさん@お腹いっぱい。:2007/03/25(日) 00:44:01 ID:ykWCl22f0
Match = "(^gzip|compress|deflate|identity)?+"
622 :think ◆MM0nnAOCiQ :2007/03/25(日) 01:03:18 ID:sQ09AHw80
>>620-621
レス有難う御座います。
>621を取り込ませていただきました。m(_ _)m
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill faulty value (in) [2007/03/25]"
Match = "(^gzip|compress|deflate|identity)?"
> httpd.confも疑ったほうがいいですな。
>602は自宅サーバじゃないようなので、httpd.conf を編集する権限がないと思います。多分…。
レス有難う御座います。
>621を取り込ませていただきました。m(_ _)m
[HTTP headers]
In = TRUE
Out = FALSE
Key = "Content-Encoding: Kill faulty value (in) [2007/03/25]"
Match = "(^gzip|compress|deflate|identity)?"
> httpd.confも疑ったほうがいいですな。
>602は自宅サーバじゃないようなので、httpd.conf を編集する権限がないと思います。多分…。
623 :名無しさん@お腹いっぱい。:2007/03/25(日) 01:43:58 ID:U32bBhWY0
メンテの後文字化けしたんじゃなかったっけ? 運営側が何かやらかしたのでは。
624 :think ◆MM0nnAOCiQ :2007/03/25(日) 02:57:05 ID:sQ09AHw80
>>623
その可能性には思い至りませんでした。
ざっと調べてみたところ、同サービスの他のサイトでは同様の症状(Content-Type, Content-Encoding 含めて)が発生していないようです。
Google検索: site:saiin.net
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=site%3asaiin.net
一部のサイト(サーバ)だけ設定が誤っている可能性も否定出来ませんが…。
その可能性には思い至りませんでした。
ざっと調べてみたところ、同サービスの他のサイトでは同様の症状(Content-Type, Content-Encoding 含めて)が発生していないようです。
Google検索: site:saiin.net
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=site%3asaiin.net
一部のサイト(サーバ)だけ設定が誤っている可能性も否定出来ませんが…。
625 :think ◆MM0nnAOCiQ :2007/03/25(日) 03:26:51 ID:sQ09AHw80
何にしても両方チェックしておくに超したことはないですね。
その辺りも加味して、>602のサイトへ報告しておきました。
その辺りも加味して、>602のサイトへ報告しておきました。
626 :名無しさん@お腹いっぱい。:2007/03/25(日) 11:34:40 ID:civrXBG40
ローカルに保存したhtmlをこれを通して閲覧する方法はありますか?
極力改変を加えずに保存し、閲覧時には無駄な広告やflashへのリンクを
殺して動作を軽くしたいです。
極力改変を加えずに保存し、閲覧時には無駄な広告やflashへのリンクを
殺して動作を軽くしたいです。
627 :think ◆MM0nnAOCiQ :2007/03/25(日) 13:44:12 ID:sQ09AHw80
>>626
URLコマンドの file// がありますが、ローカルファイルに対して常にProxomitronを通すには他のユーティリティを利用しないと無理だと思います。
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/URL_Commands.html
他に、ローカルにWebサーバを立ち上げる方法があります。
URLコマンドの file// がありますが、ローカルファイルに対して常にProxomitronを通すには他のユーティリティを利用しないと無理だと思います。
ttp://www.pluto.dti.ne.jp/~tengu/proxomitron/help/URL_Commands.html
他に、ローカルにWebサーバを立ち上げる方法があります。
629 :think ◆MM0nnAOCiQ :2007/03/25(日) 22:23:31 ID:sQ09AHw80
>602のサイト復旧。
結果的に、"Content-Type: text/html", Content-Encodingなし の状態に落ち着いたようです。
# 匿名で報告したので、具体的な対処法(原因)は判りませんでした。
何はともあれ、>602氏の問題は解決しました。
結果的に、"Content-Type: text/html", Content-Encodingなし の状態に落ち着いたようです。
# 匿名で報告したので、具体的な対処法(原因)は判りませんでした。
何はともあれ、>602氏の問題は解決しました。
630 :think ◆MM0nnAOCiQ :2007/03/25(日) 22:28:52 ID:sQ09AHw80
失礼。
>629の件ですが、掲示板に復旧までの経緯が記載されていました。
.htaccess は無関係で、サーバの管理者に報告したのみ…ということです。
>629の件ですが、掲示板に復旧までの経緯が記載されていました。
.htaccess は無関係で、サーバの管理者に報告したのみ…ということです。
631 :名無しさん@お腹いっぱい。:2007/03/26(月) 17:25:13 ID:z4qaU8SK0
すべらない名無し(ttp://by774.blog73.fc2.com/)にある、
Brainerのテキスト広告をカットしたいのですが、下記ではうまく仕事をしてくれません。
どなたかご教授願えせんでしょうか。
[Patterns]
Name = "[User] AD @ Brainer"
Active = TRUE
Limit = 1139
Match = "$NEST(<script[^>]+>,</script>)<script[^>]++ad.brainer.jp[^>]+></script>$NEST(<iframe[^>]+>,</iframe>)"
Replace = "<!-- AD @ Brainer - Blocked by Proxomitron -->"
>>626
FirefoxならAdblockが使える。
Brainerのテキスト広告をカットしたいのですが、下記ではうまく仕事をしてくれません。
どなたかご教授願えせんでしょうか。
[Patterns]
Name = "[User] AD @ Brainer"
Active = TRUE
Limit = 1139
Match = "$NEST(<script[^>]+>,</script>)<script[^>]++ad.brainer.jp[^>]+></script>$NEST(<iframe[^>]+>,</iframe>)"
Replace = "<!-- AD @ Brainer - Blocked by Proxomitron -->"
>>626
FirefoxならAdblockが使える。
632 :think ◆MM0nnAOCiQ :2007/03/26(月) 18:51:02 ID:hy1J35Zo0
>>631
該当Webサイトのhtmlソースを拝見しました。
マッチさせたい箇所は以下の部分ですよね?
<script type="text/javascript"><!--
brainer_partner_id = "****";
...
brainer_channel = "****";
//--></script>
<script type="text/javascript" src="http://ad.brainer.jp/ad.js"></script>
## 引用元: ttp://by774.blog73.fc2.com/blog-entry-2210.html
iframe要素が見あたらないために、マッチしていないと思われます。
更に簡単に書くならば、<script type="text/javascript" src="http://ad.brainer.jp/ad.js"></script> だけにマッチさせても良いですね。
前述のscript要素の内容コードは、変数の初期化だけですので本元の処理部分をカットするだけでも広告を取り除けます。(script要素の順番に配慮しなくても良いのも利点)
細かいことをいえば、ad.brainer.jp はsrc属性値に限定した方がベターだと思います。
該当Webサイトのhtmlソースを拝見しました。
マッチさせたい箇所は以下の部分ですよね?
<script type="text/javascript"><!--
brainer_partner_id = "****";
...
brainer_channel = "****";
//--></script>
<script type="text/javascript" src="http://ad.brainer.jp/ad.js"></script>
## 引用元: ttp://by774.blog73.fc2.com/blog-entry-2210.html
iframe要素が見あたらないために、マッチしていないと思われます。
更に簡単に書くならば、<script type="text/javascript" src="http://ad.brainer.jp/ad.js"></script> だけにマッチさせても良いですね。
前述のscript要素の内容コードは、変数の初期化だけですので本元の処理部分をカットするだけでも広告を取り除けます。(script要素の順番に配慮しなくても良いのも利点)
細かいことをいえば、ad.brainer.jp はsrc属性値に限定した方がベターだと思います。
633 :名無しさん@お腹いっぱい。:2007/03/26(月) 21:21:23 ID:z4qaU8SK0
>>632
どうもありがとうがざいます。
火狐の「選択した部分のソースを表示する」を使ってしまい、確認を怠っていましたorz
今までのテストでおkなのに引っ掛からなかったフィルタも確認しなければ(´・ω・`)
前半の$NEST部分は仰るとおり必要ないのですが、
ソースを見たときに痕跡があると何故かヽ(`Д´)ノフォオオオ!となるので、
個人的にくっつけていたりいなかったり。
[Patterns]
Name = "[User] AD @ Brainer"
Active = TRUE
Limit = 640
Match = "$NEST(<script[^>]+>,</script>)<script[^>]++src="http://ad.brainer.jp/ad.js"[^>]+></script>"
Replace = "<!-- AD @ Brainer - Blocked by Proxomitron -->"
どうもありがとうがざいます。
火狐の「選択した部分のソースを表示する」を使ってしまい、確認を怠っていましたorz
今までのテストでおkなのに引っ掛からなかったフィルタも確認しなければ(´・ω・`)
前半の$NEST部分は仰るとおり必要ないのですが、
ソースを見たときに痕跡があると何故かヽ(`Д´)ノフォオオオ!となるので、
個人的にくっつけていたりいなかったり。
[Patterns]
Name = "[User] AD @ Brainer"
Active = TRUE
Limit = 640
Match = "$NEST(<script[^>]+>,</script>)<script[^>]++src="http://ad.brainer.jp/ad.js"[^>]+></script>"
Replace = "<!-- AD @ Brainer - Blocked by Proxomitron -->"
>>629-630
お疲れ様でした。 運営側のミスでしたか、こういうこともあるんですね。
>>626
ブラウザを起動してるときにProxomitronのメインウインドウに目的のhtmlファイルをD&Dすれば
フィルタリングされたページがブラウザに表示されます。 このときブラウザのアドレスバーに
表示されるURLをお気に入りに入れておくと便利かも知れません。
お疲れ様でした。 運営側のミスでしたか、こういうこともあるんですね。
>>626
ブラウザを起動してるときにProxomitronのメインウインドウに目的のhtmlファイルをD&Dすれば
フィルタリングされたページがブラウザに表示されます。 このときブラウザのアドレスバーに
表示されるURLをお気に入りに入れておくと便利かも知れません。
635 :名無しさん@お腹いっぱい。:2007/03/28(水) 07:07:18 ID:LqglA30l0
ローカルファイルに対してフィルタをかけたいんですが、うまくいきません。
具体体には、FirefoxのRSSリーダであるSageが作成するページに
フィルタリングをかけ、記事中に割り込んでくる広告を削除したいのですが。
http://file//pathでローカルファイルをWebページと同様にフィルタリングが
出来ると言うところまではわかったのですが(無論プレフィックスも設定しています)、
Webページフィルタの「URLのマッチ」の欄に、
http://file//C:/*/sage.html
と入れてもマッチしていない様なのです。
フルパスだと
http://file//C:/Docoments%20and%20Settings/Users/Application/〜/chome/sage.html
と言う感じで、フルパスで書いても同じ現象でした。
ダミーとして簡単なHTMLファイルをC:直下において、http://file/C:/test.htmlと
やってみたのですが、やはりフィルタリングされない模様です。
どこか記述や使い方など、間違っている部分があればご指摘願いたいのですが・・・。
具体体には、FirefoxのRSSリーダであるSageが作成するページに
フィルタリングをかけ、記事中に割り込んでくる広告を削除したいのですが。
http://file//pathでローカルファイルをWebページと同様にフィルタリングが
出来ると言うところまではわかったのですが(無論プレフィックスも設定しています)、
Webページフィルタの「URLのマッチ」の欄に、
http://file//C:/*/sage.html
と入れてもマッチしていない様なのです。
フルパスだと
http://file//C:/Docoments%20and%20Settings/Users/Application/〜/chome/sage.html
と言う感じで、フルパスで書いても同じ現象でした。
ダミーとして簡単なHTMLファイルをC:直下において、http://file/C:/test.htmlと
やってみたのですが、やはりフィルタリングされない模様です。
どこか記述や使い方など、間違っている部分があればご指摘願いたいのですが・・・。
636 :名無しさん@お腹いっぱい。:2007/03/28(水) 09:25:12 ID:zqd/h+Lp0
「URLのマッチ」欄では"http(s|)://"は含めないで下さい。
637 :名無しさん@お腹いっぱい。:2007/03/28(水) 13:17:57 ID:YK1sZGBa0
>>635
「URLのマッチ」の欄を消したらフィルタは期待通りに動く? 動かないなら論外。 動くのなら>>636の確認と、
Proxomitronの 「設定」 - 「アクセス」 - 「URLベースのProxomitronコマンドを無効にする」 のチェックが入っていれば外す。
あと、Firefoxで広告消すならAdblockもあるよ。 新しいコマンドが追加されてて面白そう。
【CSS】Mozilla広告ブロック【Adblock】
http://pc11.2ch.net/test/read.cgi/software/1154403706/584-585
「URLのマッチ」の欄を消したらフィルタは期待通りに動く? 動かないなら論外。 動くのなら>>636の確認と、
Proxomitronの 「設定」 - 「アクセス」 - 「URLベースのProxomitronコマンドを無効にする」 のチェックが入っていれば外す。
あと、Firefoxで広告消すならAdblockもあるよ。 新しいコマンドが追加されてて面白そう。
【CSS】Mozilla広告ブロック【Adblock】
http://pc11.2ch.net/test/read.cgi/software/1154403706/584-585
638 :名無しさん@お腹いっぱい。:2007/03/28(水) 22:54:30 ID:YK1sZGBa0
>>634の方法だとファイルパスの中の ":" が何故か "%7C" に置換されてしまう。( %7C = "|" 、正しくは %3A。)
このためページが見つからずにエラーになるのでそれを修正するURL Control系のリスト用コード。
--------------------------------------------------------------------------------------------
# ProxomitronウインドウにhtmlファイルをD&Dした時のURLを修正。 "prefix.." は各自のprefixに書き換える。
http://prefix..file//([a-z]+{1,2})\0%7C/\1&$JUMP(http://prefix..file//\0:/\1)
--------------------------------------------------------------------------------------------
この現象はデフォルトの4.5June、4.5 338で確認。
このためページが見つからずにエラーになるのでそれを修正するURL Control系のリスト用コード。
--------------------------------------------------------------------------------------------
# ProxomitronウインドウにhtmlファイルをD&Dした時のURLを修正。 "prefix.." は各自のprefixに書き換える。
http://prefix..file//([a-z]+{1,2})\0%7C/\1&$JUMP(http://prefix..file//\0:/\1)
--------------------------------------------------------------------------------------------
この現象はデフォルトの4.5June、4.5 338で確認。
639 :名無しさん@お腹いっぱい。:2007/03/29(木) 01:40:52 ID:oWBN6QKE0
>>636-637
試してみましたが、期待通りに動きませんでした・・・論外って事ですね。
フィルタ自体はテストも動くし、同一内容のhtmlをコピーして別サーバにアップして試したところ
問題なく動いたので、フィルタが間違っているわけでは無いと思うのですが・・・。
ログを見ているとローカルに対しては全くフィルタを適用しようとしていない様に見えます。
設定のチェックは外しているのですが。
諦めます・・・レスありがとうございました。
試してみましたが、期待通りに動きませんでした・・・論外って事ですね。
フィルタ自体はテストも動くし、同一内容のhtmlをコピーして別サーバにアップして試したところ
問題なく動いたので、フィルタが間違っているわけでは無いと思うのですが・・・。
ログを見ているとローカルに対しては全くフィルタを適用しようとしていない様に見えます。
設定のチェックは外しているのですが。
諦めます・・・レスありがとうございました。
640 :名無しさん@お腹いっぱい。:2007/03/29(木) 01:47:44 ID:nwH5ZQHV0
Sageは使ったことないからよく知らないけど、
広告だったら何か規則性があるんでないの?
<div class="ad"> の中に入っているとか、
<a href="広告サイトのURL"> とか。
スタイルシートで消すことが可能かもしれない。
広告だったら何か規則性があるんでないの?
<div class="ad"> の中に入っているとか、
<a href="広告サイトのURL"> とか。
スタイルシートで消すことが可能かもしれない。
641 :名無しさん@お腹いっぱい。:2007/03/29(木) 04:02:19 ID:oWBN6QKE0
ありがとうございます。
おっしゃるとおりで、普段はIEとFirefoxを使い分けているので、どちらかのブラウザに
依存する方法で広告削除はしたくなかったのですが、今回はFirefoxに依存した
問題なのだから、FirefoxのCSSで消してしまえば良かったのですよね。
Proxomitronで消す事ばかりを考えてしまって、そこに考えが至りませんでした。
件の広告はCSSを用いて無事に削除出来ました。
フィルタがローカルに適用されないというのが未だに解決していないのが
気持ちの悪いところではあるのですが、ともあれレスをくれた皆さん、
ありがとうございました。
おっしゃるとおりで、普段はIEとFirefoxを使い分けているので、どちらかのブラウザに
依存する方法で広告削除はしたくなかったのですが、今回はFirefoxに依存した
問題なのだから、FirefoxのCSSで消してしまえば良かったのですよね。
Proxomitronで消す事ばかりを考えてしまって、そこに考えが至りませんでした。
件の広告はCSSを用いて無事に削除出来ました。
フィルタがローカルに適用されないというのが未だに解決していないのが
気持ちの悪いところではあるのですが、ともあれレスをくれた皆さん、
ありがとうございました。
642 :名無しさん@お腹いっぱい。:2007/03/29(木) 07:31:26 ID:ve+QA7+t0
>>639
Ctrl+F5で強制リロードしてもダメ?
Ctrl+F5で強制リロードしてもダメ?
643 :名無しさん@お腹いっぱい。:2007/03/29(木) 07:56:26 ID:oWBN6QKE0
644 :名無しさん@お腹いっぱい。:2007/03/29(木) 09:22:28 ID:ve+QA7+t0
検索表現で改行コードを"\n"にしている。
WebにASCIIモードでアップ → 改行コードが 0Ah となり、マッチ
ローカルでフィルタリング → 改行コード 0Dh 0Ah でマッチせず
とか。(苦しいか...)
WebにASCIIモードでアップ → 改行コードが 0Ah となり、マッチ
ローカルでフィルタリング → 改行コード 0Dh 0Ah でマッチせず
とか。(苦しいか...)
645 :名無しさん@お腹いっぱい。:2007/03/29(木) 12:00:10 ID:Tylg9NKN0
>643
chrome://sage/content/feedsummary.html?uri=[URL]
URLがこういう感じの形式だからじゃないの?
chrome://sage/content/feedsummary.html?uri=[URL]
URLがこういう感じの形式だからじゃないの?
646 :名無しさん@お腹いっぱい。:2007/03/30(金) 02:27:46 ID:N5oMoR0M0
>>644
検索条件に改行コードは含んでいないです。
>>645
ロケーションバーに表示されるsageのURLは、
file:///C:/Documents%20and%20Settings/UserName/(省略)/chrome/sage.html
です。省略部分は一般のプロファイルの場所です。
レスが頂けるのは大変嬉しく勉強にもなるのですが、
流石にスレ違いな気がしてきたので、スルーしていただいて結構です・・・。
すみません、ありがとうございます。
検索条件に改行コードは含んでいないです。
>>645
ロケーションバーに表示されるsageのURLは、
file:///C:/Documents%20and%20Settings/UserName/(省略)/chrome/sage.html
です。省略部分は一般のプロファイルの場所です。
レスが頂けるのは大変嬉しく勉強にもなるのですが、
流石にスレ違いな気がしてきたので、スルーしていただいて結構です・・・。
すみません、ありがとうございます。
647 :名無しさん@お腹いっぱい。:2007/03/30(金) 03:28:46 ID:Fk+PoKNY0
FXがローカルのファイルを直接開いてるんじゃないの?
そうだとしたら対処不能
そうだとしたら対処不能
648 :名無しさん@お腹いっぱい。:2007/03/30(金) 14:55:49 ID:fRAcFZO30
ttp://www.bbsnews.jp/index.html
ここのトップだけscriptタグを範囲にしてマッチさせようとしても広告消してくれないんですが上手い方法ってあるんでしょうか?
他のランキングは消せたので原因がよくわかりません
ここのトップだけscriptタグを範囲にしてマッチさせようとしても広告消してくれないんですが上手い方法ってあるんでしょうか?
他のランキングは消せたので原因がよくわかりません
649 :think ◆MM0nnAOCiQ :2007/03/30(金) 21:43:47 ID:z1oSbQ+H0
650 :名無しさん@お腹いっぱい。:2007/03/31(土) 13:04:14 ID:qvhXZMuJ0
とりあえずのこの脆弱性対応
ttp://www.microsoft.com/japan/technet/security/advisory/935423.mspx
Name = "Cut Cursor"
Active = TRUE
Limit = 500
Match = "cursor (:|=) [^;}>]+"
超誤爆上等注意
まぁ、見ただけでアウトな脆弱性だから対応パッチが出るまでのしのぎレベルで
#私は昔から常用してるフィルタなんだけどねw
ttp://www.microsoft.com/japan/technet/security/advisory/935423.mspx
Name = "Cut Cursor"
Active = TRUE
Limit = 500
Match = "cursor (:|=) [^;}>]+"
超誤爆上等注意
まぁ、見ただけでアウトな脆弱性だから対応パッチが出るまでのしのぎレベルで
#私は昔から常用してるフィルタなんだけどねw
651 :名無しさん@お腹いっぱい。:2007/04/01(日) 00:28:32 ID:uRgnshK20
<font style="cursor:url(mailto:kuso.ani)">feffeffe</font>
652 :名無しさん@お腹いっぱい。:2007/04/01(日) 15:01:41 ID:0jf8ZLJk0
TOK2広告、4月1日現在、Limit = 13640
確実に増え続けている。
Proxomitronを意識しているとしか思えないんだが。
確実に増え続けている。
Proxomitronを意識しているとしか思えないんだが。
653 :名無しさん@お腹いっぱい。:2007/04/01(日) 15:05:11 ID:NVBogZYX0
↑馬鹿
654 :名無しさん@お腹いっぱい。:2007/04/01(日) 17:20:26 ID:EDThOvVs0
やっつけ
Match = "(c|\c)(u|\u)(r|\r)(s|\s)(o|\o)(r|\r) (:|=) [^;}>]+"
Match = "(c|\c)(u|\u)(r|\r)(s|\s)(o|\o)(r|\r) (:|=) [^;}>]+"
655 :名無しさん@お腹いっぱい。:2007/04/01(日) 17:23:40 ID:EDThOvVs0
ぐは
これでどうだ
Match = "(c|\c)(u|\u)(r|\r)(s|\s)(o|\o)(r|\r) (:|=) [^;}>]+"
これでどうだ
Match = "(c|\c)(u|\u)(r|\r)(s|\s)(o|\o)(r|\r) (:|=) [^;}>]+"
656 :名無しさん@お腹いっぱい。:2007/04/01(日) 17:29:21 ID:EDThOvVs0
これ、10進とかにも対応とか考えると重くなるだけな気がするな
$UESCの検索側版って無いのかな?
$UESCの検索側版って無いのかな?
657 :名無しさん@お腹いっぱい。:2007/04/01(日) 19:16:38 ID:CvldivIu0
CSS内の数値文字参照を本来の文字に戻してから、
他のフィルタで処理したほうが良いような
他のフィルタで処理したほうが良いような
658 :名無しさん@お腹いっぱい。:2007/04/01(日) 20:55:33 ID:NqLKJzxg0
659 :名無しさん@お腹いっぱい。:2007/04/01(日) 21:20:06 ID:YuF/sEJL0
660 :名無しさん@お腹いっぱい。:2007/04/02(月) 00:01:33 ID:BXoP6IEA0
IE6じゃ!important使えなかった希ガス
661 :名無しさん@お腹いっぱい。:2007/04/02(月) 00:48:07 ID:UKQKuB2c0
>>660
え??????
え??????
662 :名無しさん@お腹いっぱい。:2007/04/02(月) 13:43:50 ID:poYN2CYf0
663 :名無しさん@お腹いっぱい。:2007/04/02(月) 20:31:38 ID:ezmG3rBo0
664 :名無しさん@お腹いっぱい。:2007/04/03(火) 00:33:16 ID:J5HArJ7i0
>>659,663
それ、ちゃんと機能する?
IE6では駄目だった。
>>650,655の10,16進大文字小文字対応…重いかな?
実体参照の区切り文字 ; が無くても有効だ!
Match = "(c|\&#(x63|x43|67|99)(;|))"
"(u|\&#(x75|x55|85|117)(;|))"
"(r|\&#(x72|x52|82|114)(;|))"
"(s|\&#(x73|x53|83|115)(;|))"
"(o|\&#(x6F|x4F|79|111)(;|))"
"(r|\&#(x72|x52|82|114)(;|)) (:|=)[^;}>"]+"
実体参照が有効なのはインラインでのスタイル定義(>>651)だけで
.cssファイルと<style>ブロック内では無効みたいだね。
それ、ちゃんと機能する?
IE6では駄目だった。
>>650,655の10,16進大文字小文字対応…重いかな?
実体参照の区切り文字 ; が無くても有効だ!
Match = "(c|\&#(x63|x43|67|99)(;|))"
"(u|\&#(x75|x55|85|117)(;|))"
"(r|\&#(x72|x52|82|114)(;|))"
"(s|\&#(x73|x53|83|115)(;|))"
"(o|\&#(x6F|x4F|79|111)(;|))"
"(r|\&#(x72|x52|82|114)(;|)) (:|=)[^;}>"]+"
実体参照が有効なのはインラインでのスタイル定義(>>651)だけで
.cssファイルと<style>ブロック内では無効みたいだね。
665 :名無しさん@お腹いっぱい。:2007/04/03(火) 01:34:59 ID:NxFim7nS0
アニメーションカーソルはfaviconにも使えるそうだし拡張子偽装も出来るそうだから
弾くの難しいだろうね
弾くの難しいだろうね
666 :名無しさん@お腹いっぱい。:2007/04/03(火) 01:58:18 ID:+KrQYJGn0
IEを使わない。これで>665も解決できると思われ。
MIME-Type もろくに見ないようなブラウザを使うのが悪いと言わざるをえない。
favicon は、*.ico か image/x-icon を\kすればいいのかな。
MIME-Type もろくに見ないようなブラウザを使うのが悪いと言わざるをえない。
favicon は、*.ico か image/x-icon を\kすればいいのかな。
667 :名無しさん@お腹いっぱい。:2007/04/03(火) 02:49:31 ID:6wNViq4u0
うは、数字前部複数の 0 、文字間に %00 があっても有効だった。
キリがない…orz もう、これで終わりにしますぅ。>>664でした。
Match = "(c|\&#(x[0]+{0,*}(63|43)|[0]+{0,*}(67|99)) (;|)) "
"(u|\&#(x[0]+{0,*}(75|55)|[0]+{0,*}(85|117)) (;|)) "
"(r|\&#(x[0]+{0,*}(72|52)|[0]+{0,*}(82|114)) (;|)) "
"(s|\&#(x[0]+{0,*}(73|53)|[0]+{0,*}(83|115)) (;|)) "
"(o|\&#(x[0]+{0,*}(6F|4F)|[0]+{0,*}(79|111)) (;|)) "
"(r|\&#(x[0]+{0,*}(72|52)|[0]+{0,*}(82|114)) (;|)) (:|=) [^;}>"]+"
キリがない…orz もう、これで終わりにしますぅ。>>664でした。
Match = "(c|\&#(x[0]+{0,*}(63|43)|[0]+{0,*}(67|99)) (;|)) "
"(u|\&#(x[0]+{0,*}(75|55)|[0]+{0,*}(85|117)) (;|)) "
"(r|\&#(x[0]+{0,*}(72|52)|[0]+{0,*}(82|114)) (;|)) "
"(s|\&#(x[0]+{0,*}(73|53)|[0]+{0,*}(83|115)) (;|)) "
"(o|\&#(x[0]+{0,*}(6F|4F)|[0]+{0,*}(79|111)) (;|)) "
"(r|\&#(x[0]+{0,*}(72|52)|[0]+{0,*}(82|114)) (;|)) (:|=) [^;}>"]+"
668 :名無しさん@お腹いっぱい。:2007/04/03(火) 02:50:32 ID:O0ftgExI0
入れ違いになってしまった。
670 :名無しさん@お腹いっぱい。:2007/04/03(火) 02:55:49 ID:O0ftgExI0
ちなみにキミの書いているのは(文字)実体参照ではなくて数値文字参照だ。
どうでもいいけど。
どうでもいいけど。
671 :名無しさん@お腹いっぱい。:2007/04/03(火) 03:58:17 ID:u5Y7aheh0
>>667補足です。
>・・・文字間に %00 があっても有効だった。
& # x 0 0 6 3 ; u r s o r :
↑半角スペースを %00 と読み替えて下さい。
当然ながら>>667ではマッチしませんから…中途半端でスマソでした。
>>669-670
了解です。
>・・・文字間に %00 があっても有効だった。
& # x 0 0 6 3 ; u r s o r :
↑半角スペースを %00 と読み替えて下さい。
当然ながら>>667ではマッチしませんから…中途半端でスマソでした。
>>669-670
了解です。
672 :名無しさん@お腹いっぱい。:2007/04/03(火) 04:53:45 ID:+KrQYJGn0
仮に理想的なフィルタができたとしても、
よほど処理が軽くない限りは使いたくないものだな。
そこまで悪意を持ったサイトなんてあるんだかというのが知りたい。
まあ、精神的ブラクラを集めたような物好きサイトがあるのも確かだが。
よほど処理が軽くない限りは使いたくないものだな。
そこまで悪意を持ったサイトなんてあるんだかというのが知りたい。
まあ、精神的ブラクラを集めたような物好きサイトがあるのも確かだが。
673 :名無しさん@お腹いっぱい。:2007/04/04(水) 03:51:09 ID:j6rLwbwp0
674 :名無しさん@お腹いっぱい。:2007/04/04(水) 09:03:43 ID:Ww/FJYxO0
プロファイル結果...
サンプルテキスト : 30000 バイト(このスレのhtmlソース)
成功マッチ数 : 1
(5回試行した平均値)
>>650 平均時間 : 0.37 (ミリ秒)
>>655 平均時間 : 0.72 (ミリ秒)
>>664 平均時間 : 0.73 (ミリ秒)
>>667 平均時間 : 0.73 (ミリ秒)
↓平均時間 : 0.73 (ミリ秒)
Match = "(c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|)) "
"(u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|)) "
"(r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|)) "
"(s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|)) "
"(o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|)) "
"(r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|)) (:|=) [^;}>"]+"
興味本位の改変なので、突っ込まんで下され。
>>672-673
同意。
サンプルテキスト : 30000 バイト(このスレのhtmlソース)
成功マッチ数 : 1
(5回試行した平均値)
>>650 平均時間 : 0.37 (ミリ秒)
>>655 平均時間 : 0.72 (ミリ秒)
>>664 平均時間 : 0.73 (ミリ秒)
>>667 平均時間 : 0.73 (ミリ秒)
↓平均時間 : 0.73 (ミリ秒)
Match = "(c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|)) "
"(u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|)) "
"(r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|)) "
"(s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|)) "
"(o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|)) "
"(r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|)) (:|=) [^;}>"]+"
興味本位の改変なので、突っ込まんで下され。
>>672-673
同意。
675 :名無しさん@お腹いっぱい。:2007/04/04(水) 09:19:38 ID:/oqEdOnS0
<font style="cursor feffeffe:url(mailto:kuso.ani)">nmooi</font>
http://www.microsoft.com/japan/technet/security/bulletin/ms07-017.mspx
http://www.microsoft.com/japan/technet/security/bulletin/ms07-017.mspx
676 :名無しさん@お腹いっぱい。:2007/04/04(水) 09:54:55 ID:qTxRbb9j0
>>675
パッチ来たのか、今回は随分早いな。
パッチ来たのか、今回は随分早いな。
677 :名無しさん@お腹いっぱい。:2007/04/05(木) 03:37:36 ID:l42HB2fw0
678 :名無しさん@お腹いっぱい。:2007/04/05(木) 14:38:16 ID:/B+A98J/0
nico動画のID表示フィルタってありませんか?
679 :名無しさん@お腹いっぱい。:2007/04/06(金) 13:25:48 ID:/V316V1o0
URLをリストで管理する際に、ずっと感じている疑問。
href=$AV((http://|https://|//|)$LST(リストの名前)*)\1
まず最初に使い方を書いておくと、このような感じ。
疑問1。
「~」と「%7E」のどちらにもマッチさせるには (~|%7E) と書くしかないのかな。
href="http://somehost.jp/~anyname/"
href="http://somehost.jp/%7Eanyname/"
このような例はリンク先が同じになるけれども、両方にマッチさせるには、
somehost.jp/(~|%7E)anyname/
このように書いているのが現状。なんとなくメンテナンスしにくい。
$UESC が使えないかと思うものの、いい方法はないのかな。
疑問2。
href="http://www.yahoo.co.jp/"
href="http://www.yahoo.co.jp"
href="http://www.yahoo.co.jp/index.html"
など、トップページへのリンクのみにマッチさせたいときは、
www.yahoo.co.jp(/|/index.html|)(^?)
こう書いているんだけれど、これもメンテナンスが面倒。
上記は yahoo の例だけど、google に対しても同じことをしたければ、
www.google..co.jp(/|/index.html|)(^?)
やはり(各サイトごとに)このように書かなければならない。
上記2点のようなことがあると、リスト(URL)の内容が煩雑に見えるので、
もっと見やすい(煩雑に見えない)書き方があれば教えてください。
(/|/index.html|)(^?) の部分をフィルタ側に書くなど、何か工夫できるといいんだけど。
href=$AV((http://|https://|//|)$LST(リストの名前)*)\1
まず最初に使い方を書いておくと、このような感じ。
疑問1。
「~」と「%7E」のどちらにもマッチさせるには (~|%7E) と書くしかないのかな。
href="http://somehost.jp/~anyname/"
href="http://somehost.jp/%7Eanyname/"
このような例はリンク先が同じになるけれども、両方にマッチさせるには、
somehost.jp/(~|%7E)anyname/
このように書いているのが現状。なんとなくメンテナンスしにくい。
$UESC が使えないかと思うものの、いい方法はないのかな。
疑問2。
href="http://www.yahoo.co.jp/"
href="http://www.yahoo.co.jp"
href="http://www.yahoo.co.jp/index.html"
など、トップページへのリンクのみにマッチさせたいときは、
www.yahoo.co.jp(/|/index.html|)(^?)
こう書いているんだけれど、これもメンテナンスが面倒。
上記は yahoo の例だけど、google に対しても同じことをしたければ、
www.google..co.jp(/|/index.html|)(^?)
やはり(各サイトごとに)このように書かなければならない。
上記2点のようなことがあると、リスト(URL)の内容が煩雑に見えるので、
もっと見やすい(煩雑に見えない)書き方があれば教えてください。
(/|/index.html|)(^?) の部分をフィルタ側に書くなど、何か工夫できるといいんだけど。
680 :名無しさん@お腹いっぱい。:2007/04/06(金) 16:47:12 ID:Md9XOTKa0
>>679
%7Eの件はURLを$UESCしたものをグローバル変数に入れて
そのグローバル変数を$TSTでテストする。 (リストを$TSTの中に置く)
ただし速度的にかなり遅くなるので遅いマシンではもっさりしてしまうかも。
(/|/index.html|)(^?)の件はこれだけを記述したリストを別に用意して
www.google.co.jp$LST(ROOT) のように使う。
%7Eの件はURLを$UESCしたものをグローバル変数に入れて
そのグローバル変数を$TSTでテストする。 (リストを$TSTの中に置く)
ただし速度的にかなり遅くなるので遅いマシンではもっさりしてしまうかも。
(/|/index.html|)(^?)の件はこれだけを記述したリストを別に用意して
www.google.co.jp$LST(ROOT) のように使う。
681 :think ◆MM0nnAOCiQ :2007/04/06(金) 17:08:49 ID:7LcMj/ni0
>>679
> (/|/index.html|)(^?) の部分をフィルタ側に書くなど、何か工夫できるといいんだけど。
未検証の上、効率が下がりますが。
href=$AV((^(^[_0-9a-z-]+{2,*}(.[_0-9a-z-]+{2,*})+{1,*}(:[0-9]+|(^:))((^?)|/index.(html+|php|cgi)(^?))))
\0(index.(html+|php|cgi)(^?)$SET(Temp=\0)|(^?)$SET(Temp=\0/)))
$TST(Temp=$LST(リストの名前)*)
あるいは、煩雑なコードに目をつぶって、テキストエディタの一括置換でメンテナンスするぐらいでしょうか。
> (/|/index.html|)(^?) の部分をフィルタ側に書くなど、何か工夫できるといいんだけど。
未検証の上、効率が下がりますが。
href=$AV((^(^[_0-9a-z-]+{2,*}(.[_0-9a-z-]+{2,*})+{1,*}(:[0-9]+|(^:))((^?)|/index.(html+|php|cgi)(^?))))
\0(index.(html+|php|cgi)(^?)$SET(Temp=\0)|(^?)$SET(Temp=\0/)))
$TST(Temp=$LST(リストの名前)*)
あるいは、煩雑なコードに目をつぶって、テキストエディタの一括置換でメンテナンスするぐらいでしょうか。
682 :think ◆MM0nnAOCiQ :2007/04/06(金) 17:24:57 ID:7LcMj/ni0
>680氏の提案された
> %7Eの件はURLを$UESCしたものをグローバル変数に入れて
ですが、そのままアンエスケープすると、
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=%2f%26%3f
のように検索パラメータまでアンエスケープされてしまいますので、ご注意下さい。
特に、/&? のアンエスケープは予期せぬ不具合の原因となりそうな気がします。
> %7Eの件はURLを$UESCしたものをグローバル変数に入れて
ですが、そのままアンエスケープすると、
ttp://www.google.co.jp/search?ie=utf-8&lr=lang_ja&q=%2f%26%3f
のように検索パラメータまでアンエスケープされてしまいますので、ご注意下さい。
特に、/&? のアンエスケープは予期せぬ不具合の原因となりそうな気がします。
683 :名無しさん@お腹いっぱい。:2007/04/06(金) 20:48:20 ID:ZQc0Ffc80
パッチも出たことだし用済みとなりましたが…
>>650,655,664,667,674
>>651,671,675
Match = "cursor[^:=}]+(:|=) url\([^)}]+\)(;|) \1}$SET(0=\1})|"
"style=$AVQ(\1"
" (c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|))"
" (u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))"
" (s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|))"
" (o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))[^;"]+ \2"
")$SET(0=style=\1\2)"
Replace = "\0"
サンプルテキスト : 30000 バイト
平均時間 : 0.511000 (ミリ秒)
一行目を {} で括って {\1cursor[^:=}]+(:|=)[^;}]+(;|) \2}$SET(0={\1\2}) のようにすると
平均時間 : 0.881000 (ミリ秒)
a{ cursor アXXXイ ウYYYエ: url( mailto: kuso.ani オZZZ ) } ←こんなのも有効でした。
半角スペースの部分は[%00]から[%20]までマッチさせた方が望ましい。
>>650,655,664,667,674
>>651,671,675
Match = "cursor[^:=}]+(:|=) url\([^)}]+\)(;|) \1}$SET(0=\1})|"
"style=$AVQ(\1"
" (c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|))"
" (u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))"
" (s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|))"
" (o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))[^;"]+ \2"
")$SET(0=style=\1\2)"
Replace = "\0"
サンプルテキスト : 30000 バイト
平均時間 : 0.511000 (ミリ秒)
一行目を {} で括って {\1cursor[^:=}]+(:|=)[^;}]+(;|) \2}$SET(0={\1\2}) のようにすると
平均時間 : 0.881000 (ミリ秒)
a{ cursor アXXXイ ウYYYエ: url( mailto: kuso.ani オZZZ ) } ←こんなのも有効でした。
半角スペースの部分は[%00]から[%20]までマッチさせた方が望ましい。
どうもありがとうございます。
遅くなる上に誤動作の可能性ありですか。パワーのないマシンでは厳しい。
$LST(ROOT) を使う場合、中身は以下のようになるのかな。
(/|/index.html|)(^?)
(/|/index.php|)(^?)
index.php などになっているサイトもあるので。
wƾw.google.co.jp$LST(ROOT) のような場合、
ドメイン名の後に$LST(など、何かしらの文字)を書かねばならないので、
見やすくはなるものの、(/|/index.html|)(^?) を書くのとあまり変わりないかもしれない。
軽さを重視して、何より誤動作させたくないのであれば>679のままでよさそう。
余談だけど>679を書いたのは、
\kの対象などになる URL のリストが長くなったのがきっかけ。
一度登録すると削除することがなかなかないものだから、
ドメインなどのリンク切れチェックや誤爆チェックをするため、
URL を最初から書き直すことにした。
個人サイトのウェブリングや、中小規模のショップなどはリンク切れがけっこうありそう。
1年から2年に1回くらいはリストを書き直すといいかもしれない。
遅くなる上に誤動作の可能性ありですか。パワーのないマシンでは厳しい。
$LST(ROOT) を使う場合、中身は以下のようになるのかな。
(/|/index.html|)(^?)
(/|/index.php|)(^?)
index.php などになっているサイトもあるので。
wƾw.google.co.jp$LST(ROOT) のような場合、
ドメイン名の後に$LST(など、何かしらの文字)を書かねばならないので、
見やすくはなるものの、(/|/index.html|)(^?) を書くのとあまり変わりないかもしれない。
軽さを重視して、何より誤動作させたくないのであれば>679のままでよさそう。
余談だけど>679を書いたのは、
\kの対象などになる URL のリストが長くなったのがきっかけ。
一度登録すると削除することがなかなかないものだから、
ドメインなどのリンク切れチェックや誤爆チェックをするため、
URL を最初から書き直すことにした。
個人サイトのウェブリングや、中小規模のショップなどはリンク切れがけっこうありそう。
1年から2年に1回くらいはリストを書き直すといいかもしれない。
>>684
すみません、質問の内容を勘違いしてました。
$LST(ROOT) はサイトのトップだけでなくその他のURLもリストに登録するような場合に使うと便利ですが、
サイトのトップだけをリストにまとめる場合には無駄になります。
この場合はthink氏のようにフィルター側で対応するべきでした。
>$LST(ROOT)の誤動作
私の知る限りは誤動作する心配はいらないと思います。 むしろ(/|/index.html|)(^?)を書く際の
記述ミスの心配が無くなり確認もラクになるので二者択一の場面があれば私なら積極的に使います。
>>682
実際にフィルターを書く場合にはURLの一部を取り出し、そこだけ変換するような書き方になると思います。
しかしURLの一部を改変してしまうことには変わりはないので何らかの不具合は覚悟の上で使うことになります。
この方法は (~|%7E) と比べると余計に面倒なことになるのであまり現実的ではありませんね。
すみません、質問の内容を勘違いしてました。
$LST(ROOT) はサイトのトップだけでなくその他のURLもリストに登録するような場合に使うと便利ですが、
サイトのトップだけをリストにまとめる場合には無駄になります。
この場合はthink氏のようにフィルター側で対応するべきでした。
>$LST(ROOT)の誤動作
私の知る限りは誤動作する心配はいらないと思います。 むしろ(/|/index.html|)(^?)を書く際の
記述ミスの心配が無くなり確認もラクになるので二者択一の場面があれば私なら積極的に使います。
>>682
実際にフィルターを書く場合にはURLの一部を取り出し、そこだけ変換するような書き方になると思います。
しかしURLの一部を改変してしまうことには変わりはないので何らかの不具合は覚悟の上で使うことになります。
この方法は (~|%7E) と比べると余計に面倒なことになるのであまり現実的ではありませんね。
686 :think ◆MM0nnAOCiQ :2007/04/07(土) 16:55:40 ID:cyEdAINr0
>>683
流れを追い切れてませんが、お疲れ様です。
>>684
誤動作に関しては、しっかりとテストを行えば、クリアできる課題だと思います。
しかし、遅くなるのはどうしようもありませんね…。
(/|/index.html|)(^?) の書き方をする場面は限られてくると思うので、速度も気になるのでしたら、テキストエディタの「一括置換」で管理する方が用途に合うと思います。
>>685
> しかしURLの一部を改変してしまうことには変わりはないので何らかの不具合は覚悟の上で使うことになります。
>682の他に、マルチバイト文字をデコードしたときにも誤爆する可能性があることに気がつきました。
ASCII文字のみに絞ってURLエンコードされた文字列を指定すれば、誤爆を回避できそうですが、面倒なことには変わりなく。
以下の表現からの派生を考えてみましたが、思いの外、時間がかかりそうだったので中断しました。
(http://[_0-9a-z-]+{2,*}(.[_0-9a-z-]+{2,*})+{1,*}(:[0-9]+|(^:))/)\#
(([^#?/%]++)\#(((%([0-7][0-f]))+)\0$SET(#=$UESC(\0))((%[0-f]+)+[^#?/%]+)\#)+(/)\#)+\#
流れを追い切れてませんが、お疲れ様です。
>>684
誤動作に関しては、しっかりとテストを行えば、クリアできる課題だと思います。
しかし、遅くなるのはどうしようもありませんね…。
(/|/index.html|)(^?) の書き方をする場面は限られてくると思うので、速度も気になるのでしたら、テキストエディタの「一括置換」で管理する方が用途に合うと思います。
>>685
> しかしURLの一部を改変してしまうことには変わりはないので何らかの不具合は覚悟の上で使うことになります。
>682の他に、マルチバイト文字をデコードしたときにも誤爆する可能性があることに気がつきました。
ASCII文字のみに絞ってURLエンコードされた文字列を指定すれば、誤爆を回避できそうですが、面倒なことには変わりなく。
以下の表現からの派生を考えてみましたが、思いの外、時間がかかりそうだったので中断しました。
(http://[_0-9a-z-]+{2,*}(.[_0-9a-z-]+{2,*})+{1,*}(:[0-9]+|(^:))/)\#
(([^#?/%]++)\#(((%([0-7][0-f]))+)\0$SET(#=$UESC(\0))((%[0-f]+)+[^#?/%]+)\#)+(/)\#)+\#
687 :名無しさん@お腹いっぱい。:2007/04/09(月) 02:20:48 ID:zSOO4a+F0
チラシの裏。
リストの拡張子を.cfgに変更して、.cfgをメモ帳よりもちょっと高機能なエディタに関連付けした。
.txtはいまだにメモ帳を使っているけど、
リストを編集するときにはアンドゥくらいは楽にできるとよいので
拡張子変更という手段をとってみた。
タスクトレイのアイコン右クリックからでも、指定したエディタが起動してなかなかよさげ。
リストの拡張子を.cfgに変更して、.cfgをメモ帳よりもちょっと高機能なエディタに関連付けした。
.txtはいまだにメモ帳を使っているけど、
リストを編集するときにはアンドゥくらいは楽にできるとよいので
拡張子変更という手段をとってみた。
タスクトレイのアイコン右クリックからでも、指定したエディタが起動してなかなかよさげ。
688 :名無しさん@お腹いっぱい。:2007/04/09(月) 02:22:55 ID:5sO+vonU0
妙な関連付けを一般化するよりは
エデター+パラメターでショーツカッツ作った方が利口そうに思えるのだが
エデター+パラメターでショーツカッツ作った方が利口そうに思えるのだが
689 :名無しさん@お腹いっぱい。:2007/04/09(月) 02:35:43 ID:zSOO4a+F0
>688
1. 使用したいエディタのショートカットをSendToフォルダに入れる。
2. リストがあるフォルダを開いてから右クリック→送る
こういうやり方でもいいかなーと思ったけど、
タスクトレイのアイコン右クリックから開けるのが便利なので関連付けすることにした。
.cfgなんて拡張子はProxomitron以外だとあまり見かけないし、
.cfg専用にアイコンを設定しておいたので、開きたくない.cfgを誤って開くこともないかなと。
1. 使用したいエディタのショートカットをSendToフォルダに入れる。
2. リストがあるフォルダを開いてから右クリック→送る
こういうやり方でもいいかなーと思ったけど、
タスクトレイのアイコン右クリックから開けるのが便利なので関連付けすることにした。
.cfgなんて拡張子はProxomitron以外だとあまり見かけないし、
.cfg専用にアイコンを設定しておいたので、開きたくない.cfgを誤って開くこともないかなと。
690 :名無しさん@お腹いっぱい。:2007/04/09(月) 03:06:58 ID:7Je96E6Q0
いずれにせよ
100歩遅れてるぞ
100歩遅れてるぞ
691 :名無しさん@お腹いっぱい。:2007/04/09(月) 10:04:18 ID:fUCp2oiA0
それなりのエディタ持っててメモ帳使う意味が分からん。
692 :名無しさん@お腹いっぱい。:2007/04/09(月) 10:13:25 ID:f4aajwxY0
cfgはOTBEditに関連付けしてる。 関連付けして不都合でもない限りしたほうが利口だと思う。
693 :名無しさん@お腹いっぱい。:2007/04/09(月) 10:16:15 ID:bCBiMOfp0
694 :名無しさん@お腹いっぱい。:2007/04/09(月) 11:49:27 ID:Lin40nlx0
>>693
[Patterns]
Name = "nicovideo randomgif to static"
Active = TRUE
URL = "www.nicovideo.jp/random $TYPE(htm)"
Limit = 256
Match = "<script type="text/javascript" src="js/illust.js"></script></a><noscript><img src="img/tpl/head/illust/000.gif" alt=""></noscript>"
Replace = "</a><img src="img/tpl/head/illust/030.gif" alt="">"
[Patterns]
Name = "nicovideo randomgif to static"
Active = TRUE
URL = "www.nicovideo.jp/random $TYPE(htm)"
Limit = 256
Match = "<script type="text/javascript" src="js/illust.js"></script></a><noscript><img src="img/tpl/head/illust/000.gif" alt=""></noscript>"
Replace = "</a><img src="img/tpl/head/illust/030.gif" alt="">"
695 :名無しさん@お腹いっぱい。:2007/04/09(月) 12:10:25 ID:bCBiMOfp0
696 :名無しさん@お腹いっぱい。:2007/04/09(月) 12:37:48 ID:f4aajwxY0
>>695
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: niko 030.gif (out)"
Match = "http://www.nicovideo.jp/img/tpl/head/illust/(^030.gif)[0-9]+.gif(^?)"
Replace = "$JUMP(http://www.nicovideo.jp/img/tpl/head/illust/030.gif)"
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: niko 030.gif (out)"
Match = "http://www.nicovideo.jp/img/tpl/head/illust/(^030.gif)[0-9]+.gif(^?)"
Replace = "$JUMP(http://www.nicovideo.jp/img/tpl/head/illust/030.gif)"
{kind=link}
697 :名無しさん@お腹いっぱい。:2007/04/09(月) 12:43:21 ID:bCBiMOfp0
>>696
ありがと〜ございます!
ありがと〜ございます!
698 :名無しさん@お腹いっぱい。:2007/04/09(月) 13:00:49 ID:Lin40nlx0
699 :名無しさん@お腹いっぱい。:2007/04/09(月) 17:15:19 ID:kYTyr62b0
こちらこそごめんなさい。
700 :名無しさん@お腹いっぱい。:2007/04/11(水) 01:50:11 ID:1C3+uH/D0
>>683修正
Match = "$NEST({,\1cursor[^:=]+(:|=)[^;]+(;|) \2,})$SET(0={\1\2})|"
"style=$AV(\1"
" (c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|))"
" (u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))"
" (s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|))"
" (o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))[^;]+(;|) \2"
")$SET(0=style="\1\2")"
Replace = "\0"
<font style = ' cursor feffeffe : url( " mailto: kuso.ani " ) '>nmooi</font> ←に対応
1行目比較
サンプルテキスト : 30000 バイト
平均時間 : 0.571000 (ミリ秒) ← cursor[^:=}]+(:|=) url\([^)}]+\)[^;}]+(;|) \1}$SET(0=\1})
平均時間 : 0.821000 (ミリ秒) ← {\1cursor[^:=}]+(:|=)[^;}]+(;|) \2}$SET(0={\1\2})
平均時間 : 0.701000 (ミリ秒) ← $NEST({,\1cursor[^:=]+(:|=)[^;]+(;|) \2,})$SET(0={\1\2})
Match = "$NEST({,\1cursor[^:=]+(:|=)[^;]+(;|) \2,})$SET(0={\1\2})|"
"style=$AV(\1"
" (c|\& # (x (0 )+{0,*}(6 3|4 3)|(0 )+{0,*}(6 7|9 9)) (;|))"
" (u|\& # (x (0 )+{0,*}(7 5|5 5)|(0 )+{0,*}(8 5|1 1 7)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))"
" (s|\& # (x (0 )+{0,*}(7 3|5 3)|(0 )+{0,*}(8 3|1 1 5)) (;|))"
" (o|\& # (x (0 )+{0,*}(6 F|4 F)|(0 )+{0,*}(7 9|1 1 1)) (;|))"
" (r|\& # (x (0 )+{0,*}(7 2|5 2)|(0 )+{0,*}(8 2|1 1 4)) (;|))[^;]+(;|) \2"
")$SET(0=style="\1\2")"
Replace = "\0"
<font style = ' cursor feffeffe : url( " mailto: kuso.ani " ) '>nmooi</font> ←に対応
1行目比較
サンプルテキスト : 30000 バイト
平均時間 : 0.571000 (ミリ秒) ← cursor[^:=}]+(:|=) url\([^)}]+\)[^;}]+(;|) \1}$SET(0=\1})
平均時間 : 0.821000 (ミリ秒) ← {\1cursor[^:=}]+(:|=)[^;}]+(;|) \2}$SET(0={\1\2})
平均時間 : 0.701000 (ミリ秒) ← $NEST({,\1cursor[^:=]+(:|=)[^;]+(;|) \2,})$SET(0={\1\2})
701 :名無しさん@お腹いっぱい。:2007/04/11(水) 22:23:13 ID:cQGpqEHg0
特定のサイトだけUAをIEに変えるフィルターありませんか?
具体的に言うとDELL・・
具体的に言うとDELL・・
702 :名無しさん@お腹いっぱい。:2007/04/12(木) 01:55:46 ID:yoxqXBik0
そのくらい自分で
703 :名無しさん@お腹いっぱい。:2007/04/12(木) 11:03:10 ID:MOcLIRDj0
>>701
自分でやって覚えようってことで、テンプレを示してみるってのはどうかと思ったが
[HTTP headers]
In = FALSE
Out = TRUE
Key = "User-Agent: Template (out) "
URL = ""
Match = "*"
Replace = ""
ほとんど空白になったのでまぁ自分でがんばれ。
URL MatchにDELLのURLを入れて、Replaceに任意のUAを入れるんだよ。
自分でやって覚えようってことで、テンプレを示してみるってのはどうかと思ったが
[HTTP headers]
In = FALSE
Out = TRUE
Key = "User-Agent: Template (out) "
URL = ""
Match = "*"
Replace = ""
ほとんど空白になったのでまぁ自分でがんばれ。
URL MatchにDELLのURLを入れて、Replaceに任意のUAを入れるんだよ。
704 :名無しさん@お腹いっぱい。:2007/04/12(木) 14:05:18 ID:NgCTnRpZ0
ワイルドカードいらない
705 :名無しさん@お腹いっぱい。:2007/04/15(日) 09:19:20 ID:gMOTS18V0
Vectorでダウンロードのたびに、Vアップ通知画面見させられるの回避するフィルター教えてください。
JUMPとか使いそうなんですけどさっぱりわかりません。
JUMPとか使いそうなんですけどさっぱりわかりません。
706 :名無しさん@お腹いっぱい。:2007/04/15(日) 10:58:16 ID:xcMSre2P0
>>705
Vector ってゲームとソフトとで別の構成なのよね。
Vアップ通知画面を回避するという意味で、こんなのはどう?
Leeyes(WindowsNT/2000/XP / 画像&サウンド)
http://www.vector.co.jp/soft/dl/winnt/art/se381425.html
とかの、ダウンロード画面でいきなりリダイレクトするWEBページフィルタ。
[Patterns]
Name = "Vector Soft DL Redirect"
Active = TRUE
URL = "*vector.co.jp/soft/dl/"
Limit = 200
Match = "<META NAME="download" CONTENT="\0">"
"$STOP()"
Replace = "<meta http-equiv="refresh" content="0;url=\0">"
"\k"
Vector ってゲームとソフトとで別の構成なのよね。
Vアップ通知画面を回避するという意味で、こんなのはどう?
Leeyes(WindowsNT/2000/XP / 画像&サウンド)
http://www.vector.co.jp/soft/dl/winnt/art/se381425.html
とかの、ダウンロード画面でいきなりリダイレクトするWEBページフィルタ。
[Patterns]
Name = "Vector Soft DL Redirect"
Active = TRUE
URL = "*vector.co.jp/soft/dl/"
Limit = 200
Match = "<META NAME="download" CONTENT="\0">"
"$STOP()"
Replace = "<meta http-equiv="refresh" content="0;url=\0">"
"\k"
707 :名無しさん@お腹いっぱい。:2007/04/15(日) 11:48:44 ID:UGe0bqze0
[Patterns]
Name = "Vector download add link- (2007/04/15)"
Active = TRUE
URL = "www.vector.co.jp/soft/(dl/|)win"
Limit = 256
Match = "(<META NAME="download" CONTENT="http://download.\8">)\0$SET(_link=\8)|"
"(<META NAME="ve_@title" CONTENT="\8">)\0$SET(_title=\8)|"
"(<!-- soft data -->\s<table id="soft_data">)\8"
"$SET(\0=\8\n"
"<tr>\n"
" <td class="celltitle">Download : </td>\n"
" <td> <a href="ftp://ftp.$GET(_link)">FTP</a> <a href="http://download.$GET(_link)">HTTP</a> $GET(_title)</td>\n"
"</tr>\n"
")$STOP()"
Replace = "\0"
ダウンロードのリンク追加するフィルタ
Name = "Vector download add link- (2007/04/15)"
Active = TRUE
URL = "www.vector.co.jp/soft/(dl/|)win"
Limit = 256
Match = "(<META NAME="download" CONTENT="http://download.\8">)\0$SET(_link=\8)|"
"(<META NAME="ve_@title" CONTENT="\8">)\0$SET(_title=\8)|"
"(<!-- soft data -->\s<table id="soft_data">)\8"
"$SET(\0=\8\n"
"<tr>\n"
" <td class="celltitle">Download : </td>\n"
" <td> <a href="ftp://ftp.$GET(_link)">FTP</a> <a href="http://download.$GET(_link)">HTTP</a> $GET(_title)</td>\n"
"</tr>\n"
")$STOP()"
Replace = "\0"
ダウンロードのリンク追加するフィルタ
708 :名無しさん@お腹いっぱい。:2007/04/15(日) 12:12:08 ID:2puWsnLs0
漏れもメタタグを置換してリンクにしてる
709 :名無しさん@お腹いっぱい。:2007/04/15(日) 12:42:36 ID:gMOTS18V0
>>706
助かります!事前にリンク持ってくるって手もあるんですね、なるほど。
似たような例探していじってるだけだから全然応用力ない('A`)
>>707
さらに便利そうだと思って試したら何故かうちの環境じゃCPU100%で固まる・・・
助かります!事前にリンク持ってくるって手もあるんですね、なるほど。
似たような例探していじってるだけだから全然応用力ない('A`)
>>707
さらに便利そうだと思って試したら何故かうちの環境じゃCPU100%で固まる・・・
710 :名無しさん@お腹いっぱい。:2007/04/15(日) 14:11:03 ID:6jv7Rx080
うちでも固まった
どこで暴走しているんだろう
どこで暴走しているんだろう
711 :名無しさん@お腹いっぱい。:2007/04/15(日) 15:05:01 ID:UGe0bqze0
うちでは使えてるんだけどなぁ…
712 :名無しさん@お腹いっぱい。:2007/04/15(日) 15:39:19 ID:6jv7Rx080
713 :名無しさん@お腹いっぱい。:2007/04/15(日) 16:04:18 ID:BZwh9YcC0
{kind=link}
714 :名無しさん@お腹いっぱい。:2007/04/15(日) 16:11:13 ID:UGe0bqze0
715 :名無しさん@お腹いっぱい。:2007/04/15(日) 16:52:40 ID:X62yZfmp0
みんなVectorをそんなに利用しているのか。
自分はゲームの新作チェックを週1回と、
よく使うソフトの一部がたまにバージョンアップするときくらいかな。
(こっちは不定期チェック)
広告消しなら作ったけど、リダイレクトのフィルタは使ってないなあ。
自分はゲームの新作チェックを週1回と、
よく使うソフトの一部がたまにバージョンアップするときくらいかな。
(こっちは不定期チェック)
広告消しなら作ったけど、リダイレクトのフィルタは使ってないなあ。
716 :名無しさん@お腹いっぱい。:2007/04/15(日) 19:34:46 ID:xcMSre2P0
Vectorのなにもかも削ぎ落として、
直接ファイルへのリンクを張るWEBページフィルタ。
Treasure Search
http://www.vector.co.jp/soft/win95/game/se422845.html
動いたり動かなかったりだけど、とりあえず ↑みたいなソフト紹介のページ用。
[Patterns]
Name = "Vector Soft All cut"
Active = TRUE
URL = "*vector.co.jp"
Limit = 20000
Match = "<HTML>*"
"<META NAME="download" CONTENT="*/pack/\9">*"
"<META NAME="ve_@title" CONTENT="\1">*"
"<META NAME="ve_@description" CONTENT="\2">*"
""
"treeOnOff'*</script>"
"\0<div class="fr">*<!-- left -->*<!-- /left -->"
"*<!-- soft data -->*<!-- soft data -->\6 <BR clear="ALL">"
"$STOP()"
Replace = "<HTML><head><TITLE>\1</TITLE></head><BODY>"
"<table border="0" width="700" align=center><tr>"
""
"\0 <!-- directory navi -->"
"<hr noshade="noshade" />"
"<font size=6><a href ="http://my.vector.co.jp/servlet/System.FileDownload/download/http/0/407081/pack/\9">\1</a> </font> <!-- title -->"
"\6 <!-- explanation -->"
"\k"
直接ファイルへのリンクを張るWEBページフィルタ。
Treasure Search
http://www.vector.co.jp/soft/win95/game/se422845.html
動いたり動かなかったりだけど、とりあえず ↑みたいなソフト紹介のページ用。
[Patterns]
Name = "Vector Soft All cut"
Active = TRUE
URL = "*vector.co.jp"
Limit = 20000
Match = "<HTML>*"
"<META NAME="download" CONTENT="*/pack/\9">*"
"<META NAME="ve_@title" CONTENT="\1">*"
"<META NAME="ve_@description" CONTENT="\2">*"
""
"treeOnOff'*</script>"
"\0<div class="fr">*<!-- left -->*<!-- /left -->"
"*<!-- soft data -->*<!-- soft data -->\6 <BR clear="ALL">"
"$STOP()"
Replace = "<HTML><head><TITLE>\1</TITLE></head><BODY>"
"<table border="0" width="700" align=center><tr>"
""
"\0 <!-- directory navi -->"
"<hr noshade="noshade" />"
"<font size=6><a href ="http://my.vector.co.jp/servlet/System.FileDownload/download/http/0/407081/pack/\9">\1</a> </font> <!-- title -->"
"\6 <!-- explanation -->"
"\k"
717 :名無しさん@お腹いっぱい。:2007/04/15(日) 20:05:03 ID:2puWsnLs0
ttp://my.vector.co.jp/**
これだと結局リダイレクトされるから
ttp://ftp.
に置換してやる方が早いかなと思う
でも一つのページで
98用とXP用とかシェア版とフリー版とか
複数のファイルがある場合、メタタグに
URLが書かれないケースがあるんよね
これだと結局リダイレクトされるから
ttp://ftp.
に置換してやる方が早いかなと思う
でも一つのページで
98用とXP用とかシェア版とフリー版とか
複数のファイルがある場合、メタタグに
URLが書かれないケースがあるんよね
718 :名無しさん@お腹いっぱい。:2007/04/16(月) 13:54:00 ID:/FD4Gd9i0
>>717
おおっ。確かに、ラスト三行のとこははこれで十分だった。
すっきりしてよかった。ありがとう。
"<font size=6><a href ="http://ftp.vector.co.jp/pack/\9">\1</a> </font> <!-- title -->"
"\6 <!-- explanation -->"
"\k"
メタタグに書かれてないアドレスは、拾うのがめんどくさいよなー。
おおっ。確かに、ラスト三行のとこははこれで十分だった。
すっきりしてよかった。ありがとう。
"<font size=6><a href ="http://ftp.vector.co.jp/pack/\9">\1</a> </font> <!-- title -->"
"\6 <!-- explanation -->"
"\k"
メタタグに書かれてないアドレスは、拾うのがめんどくさいよなー。
719 :名無しさん@お腹いっぱい。:2007/04/22(日) 23:44:54 ID:ZzK8n97j0
ttp://vird2002.s8.xrea.com/download/#filter_web
の汎用Webフィルタ集内のReplace vlink colorフィルタなのですが
background-colorにも誤爆してしまいます
どうすれば誤爆しないように出来るのでしょう?
以下コピペ
Name = "Replace vlink color (html+css) [2005/11/24]"
Active = TRUE
URL = "$TYPE(htm)|$TYPE(css)"
Limit = 256
Match = "(<body(^[^ ]))\#("
"([^>]++\svlink=)\#$AV(\0)([^>]+>)\1&"
"[^>]++\slink=$AV($TST(\0))"
"$SET(#="purple"))|"
"(a:visited {[^}]++color : )\#([0-9a-z#]+)\0"
"([^>]++a:link {[^}]++color : $TST(\0))\1"
"$SET(#=purple)|"
"(a:link {[^}]++color : ([0-9a-z#]+)\0"
"[^>]++a:visited {[^}]++color : )\#$TST(\0)"
"$SET(#=purple)"
Replace = "\@\1$STOP()"
の汎用Webフィルタ集内のReplace vlink colorフィルタなのですが
background-colorにも誤爆してしまいます
どうすれば誤爆しないように出来るのでしょう?
以下コピペ
Name = "Replace vlink color (html+css) [2005/11/24]"
Active = TRUE
URL = "$TYPE(htm)|$TYPE(css)"
Limit = 256
Match = "(<body(^[^ ]))\#("
"([^>]++\svlink=)\#$AV(\0)([^>]+>)\1&"
"[^>]++\slink=$AV($TST(\0))"
"$SET(#="purple"))|"
"(a:visited {[^}]++color : )\#([0-9a-z#]+)\0"
"([^>]++a:link {[^}]++color : $TST(\0))\1"
"$SET(#=purple)|"
"(a:link {[^}]++color : ([0-9a-z#]+)\0"
"[^>]++a:visited {[^}]++color : )\#$TST(\0)"
"$SET(#=purple)"
Replace = "\@\1$STOP()"
720 :think ◆MM0nnAOCiQ :2007/04/23(月) 01:25:28 ID:OjjxmJmi0
>>719
懐かしいフィルタですねー。
CSSの表現はスマートな書き方ができなくて苦慮した覚えがあります。
> background-colorにも誤爆してしまいます
[^}]++color を ([^}]++[\t\n\r ;]|)color に変更してやれば、回避できると思います。
ご報告ありがとうございました。
[Patterns]
Name = "Replace vlink color (html+css) [2007/04/23]"
Active = TRUE
URL = "$TYPE(htm)|$TYPE(css)"
Limit = 256
Match = "(<body(^[^ ]))\#("
"([^>]++\svlink=)\#$AV(\0)([^>]+>)\1&"
"[^>]++\slink=$AV($TST(\0))"
"$SET(#="purple"))|"
"(a:visited {([^}]++[\t\n\r ;]|)color : )\#([0-9a-z#]+)\0"
"([^>]++a:link {([^}]++[\t\n\r ;]|)color : $TST(\0))\1"
"$SET(#=purple)|"
"(a:link {([^}]++[\t\n\r ;]|)color : ([0-9a-z#]+)\0"
"[^>]++a:visited {([^}]++[\t\n\r ;]|)color : )\#$TST(\0)"
"$SET(#=purple)"
Replace = "\@\1$STOP()"
懐かしいフィルタですねー。
CSSの表現はスマートな書き方ができなくて苦慮した覚えがあります。
> background-colorにも誤爆してしまいます
[^}]++color を ([^}]++[\t\n\r ;]|)color に変更してやれば、回避できると思います。
ご報告ありがとうございました。
[Patterns]
Name = "Replace vlink color (html+css) [2007/04/23]"
Active = TRUE
URL = "$TYPE(htm)|$TYPE(css)"
Limit = 256
Match = "(<body(^[^ ]))\#("
"([^>]++\svlink=)\#$AV(\0)([^>]+>)\1&"
"[^>]++\slink=$AV($TST(\0))"
"$SET(#="purple"))|"
"(a:visited {([^}]++[\t\n\r ;]|)color : )\#([0-9a-z#]+)\0"
"([^>]++a:link {([^}]++[\t\n\r ;]|)color : $TST(\0))\1"
"$SET(#=purple)|"
"(a:link {([^}]++[\t\n\r ;]|)color : ([0-9a-z#]+)\0"
"[^>]++a:visited {([^}]++[\t\n\r ;]|)color : )\#$TST(\0)"
"$SET(#=purple)"
Replace = "\@\1$STOP()"
721 :名無しさん@お腹いっぱい。:2007/04/23(月) 21:52:44 ID:9qLGs43x0
mixiの広告が書き込み後にまで出てくるのでばっさりしたいのですが
どなたかお願いできませんでしょうか
どなたかお願いできませんでしょうか
722 :名無しさん@お腹いっぱい。:2007/04/23(月) 23:45:06 ID:WunQE0DL0
ごめんなさいとか負けましたとか、相手に言わさないと気が済まないタイプだな
723 :名無しさん@お腹いっぱい。:2007/04/24(火) 00:02:18 ID:iDBm5yeQ0
ごめんくさい
724 :名無しさん@お腹いっぱい。:2007/04/24(火) 06:35:10 ID:VqzAMHe80
禿げました
725 :名無しさん@お腹いっぱい。:2007/04/24(火) 21:37:27 ID:dm3t6qtQ0
このスレ開く度に JS.WindowBomb.G 検出する
726 :名無しさん@お腹いっぱい。:2007/04/24(火) 22:08:16 ID:Iun5v+tK0
>>713のせいだろ
727 :名無しさん@お腹いっぱい。:2007/04/27(金) 00:48:04 ID:xXKAhs370
Multiを有効にしたフィルタAが動作(マッチ)した際にフラグを立て、
フラグが立っているときのみフィルタBをバイパスすることはできませんか?
$TSTを使えばよいのかと思うものの、
$TSTの使い方はいつまで経ってもよくわからない……。
フラグが立っているときのみフィルタBをバイパスすることはできませんか?
$TSTを使えばよいのかと思うものの、
$TSTの使い方はいつまで経ってもよくわからない……。
728 :名無しさん@お腹いっぱい。:2007/04/27(金) 03:24:57 ID:sTe/59Oa0
慣れれば簡単
以下はテキストエリア以外のスクリプトタグを全てテキストエリアに代えるサンプル
[Patterns]
Name = "$in_textarea = true (1/2)"
Active = TRUE
Multi = TRUE
Limit = 256
Match = "<textarea"
Replace = "$SET(in_textarea=1)<textarea"
Name = "$in_textarea = false (2/2)"
Active = TRUE
Multi = TRUE
Limit = 256
Match = "</textarea*>"
Replace = "$SET(in_textarea=0)</textarea>"
Name = "if (not $in_textarea) <scripit> to <textarea>"
Active = TRUE
Limit = 256
Match = "<(/|)\0script\1>"
"(^$TST(in_textarea=1))"
Replace = "<\0textarea rows=5 cols=100><\0script\1>"
以下はテキストエリア以外のスクリプトタグを全てテキストエリアに代えるサンプル
[Patterns]
Name = "$in_textarea = true (1/2)"
Active = TRUE
Multi = TRUE
Limit = 256
Match = "<textarea"
Replace = "$SET(in_textarea=1)<textarea"
Name = "$in_textarea = false (2/2)"
Active = TRUE
Multi = TRUE
Limit = 256
Match = "</textarea*>"
Replace = "$SET(in_textarea=0)</textarea>"
Name = "if (not $in_textarea) <scripit> to <textarea>"
Active = TRUE
Limit = 256
Match = "<(/|)\0script\1>"
"(^$TST(in_textarea=1))"
Replace = "<\0textarea rows=5 cols=100><\0script\1>"
729 :名無しさん@お腹いっぱい。:2007/05/01(火) 15:13:54 ID:XSGQ9HTn0
ニコニコ動画の広告を削除するフィルタきぼん
730 :名無しさん@お腹いっぱい。:2007/05/01(火) 16:03:37 ID:z7gVZ/0O0
ニコ動のID表示のために導入したけど
なんか面白そうだなw
なんか面白そうだなw
731 :think ◆MM0nnAOCiQ :2007/05/01(火) 16:45:44 ID:a5J7jX0x0
>>729
AdListに ad.nicovideo.jp/ を登録してください。
他、便利フィルタは「じょんじさんの日記」をウォッチしてれば、新しいフィルタが見つかると思います。
Proxomitron全角NGワードの変換方法 [日記] ニコ動画SNS
ttp://nicosns.inventor.jp/diary/1289/
AdListに ad.nicovideo.jp/ を登録してください。
他、便利フィルタは「じょんじさんの日記」をウォッチしてれば、新しいフィルタが見つかると思います。
Proxomitron全角NGワードの変換方法 [日記] ニコ動画SNS
ttp://nicosns.inventor.jp/diary/1289/
732 :名無しさん@お腹いっぱい。:2007/05/01(火) 17:01:26 ID:Dwbx2m+p0
733 :名無しさん@お腹いっぱい。:2007/05/01(火) 17:16:46 ID:YHXz+5I40
>>729
頻繁に書式変わってるから自分でメンテできないと無駄だ
頻繁に書式変わってるから自分でメンテできないと無駄だ
734 :think ◆MM0nnAOCiQ :2007/05/01(火) 17:16:58 ID:a5J7jX0x0
>>732
ニコニコ動画アカウントは最近取得しましたが、ログイン時に「02:00〜19:00間限定、80万番まで開放」という旨の警告が表示されましたよ。
公式なニュースでは、75万IDまで解放とあるようですが…。
ニコニコ動画、時間限定で75万IDまで開放--登録後すぐ利用可能に - CNET Japan
ttp://japan.cnet.com/news/media/story/0%2c2000056023%2c20347895%2c00.htm
ニコニコ動画アカウントは最近取得しましたが、ログイン時に「02:00〜19:00間限定、80万番まで開放」という旨の警告が表示されましたよ。
公式なニュースでは、75万IDまで解放とあるようですが…。
ニコニコ動画、時間限定で75万IDまで開放--登録後すぐ利用可能に - CNET Japan
ttp://japan.cnet.com/news/media/story/0%2c2000056023%2c20347895%2c00.htm
735 :think ◆MM0nnAOCiQ :2007/05/01(火) 17:26:48 ID:a5J7jX0x0
む…、>732をよく見ると「今現在時間限定開放ユーザはいません」ですね。
文章は良く読もう。orz
文章は良く読もう。orz
736 :名無しさん@お腹いっぱい。:2007/05/01(火) 18:13:43 ID:XSGQ9HTn0
737 :名無しさん@お腹いっぱい。:2007/05/01(火) 21:34:59 ID:WujtkzIE0
>>736
とりあえず……どう?
[Patterns]
Name = "nicovideo.jp UPPER AD cut"
Active = TRUE
URL = "*www.nicovideo.jp"
Limit = 250
Match = "<DIV*"
""http://ad.nicovideo.jp/*"*"
"</DIV>"
"$STOP()"
Replace = "<!-- CUTTED -->"
とりあえず……どう?
[Patterns]
Name = "nicovideo.jp UPPER AD cut"
Active = TRUE
URL = "*www.nicovideo.jp"
Limit = 250
Match = "<DIV*"
""http://ad.nicovideo.jp/*"*"
"</DIV>"
"$STOP()"
Replace = "<!-- CUTTED -->"
738 :名無しさん@お腹いっぱい。:2007/05/01(火) 21:44:40 ID:XSGQ9HTn0
739 :名無しさん@お腹いっぱい。:2007/05/02(水) 05:30:33 ID:W7TO92+P0
まあ頻繁に書式変わってるからすぐに使えなくなるけどな
740 :名無しさん@お腹いっぱい。:2007/05/02(水) 05:31:29 ID:W7TO92+P0
やっべ、寝ぼけて同じ内容書いちまったorz
741 :名無しさん@お腹いっぱい。:2007/05/02(水) 06:17:45 ID:MsarYhgY0
知らない間にニコニコ絡みで話題になってたのね。
どうせそのうちニコニコ側でIDあぼーん実装するんだろうけど、
Greasemonkey全盛の時代にこんなイベントが発生するとは。
どうせそのうちニコニコ側でIDあぼーん実装するんだろうけど、
Greasemonkey全盛の時代にこんなイベントが発生するとは。
742 :名無しさん@お腹いっぱい。:2007/05/02(水) 07:14:37 ID:IuVgBXyJ0
[Patterns]
Name = "Kill NicoNico Ad"
Active = TRUE
URL = "www.nicovideo.jp"
Limit = 256
Match = "<a href="http://ad.nicovideo.jp/*</a>"
Replace = "<!-- Kill nicovideo ad -->"
[Patterns]
Name = "Kill NicoNico Ad2"
Active = TRUE
URL = "www.nicovideo.jp"
Limit = 1024
Match = "<tr><td*<strong>dwango.jp*</td></tr>"
Replace = "<!-- Kill nicovideo ad -->"
適当に書いたんだけど一応いまは消えた
Name = "Kill NicoNico Ad"
Active = TRUE
URL = "www.nicovideo.jp"
Limit = 256
Match = "<a href="http://ad.nicovideo.jp/*</a>"
Replace = "<!-- Kill nicovideo ad -->"
[Patterns]
Name = "Kill NicoNico Ad2"
Active = TRUE
URL = "www.nicovideo.jp"
Limit = 1024
Match = "<tr><td*<strong>dwango.jp*</td></tr>"
Replace = "<!-- Kill nicovideo ad -->"
適当に書いたんだけど一応いまは消えた
743 :名無しさん@お腹いっぱい。:2007/05/02(水) 15:58:03 ID:s+ecP+200
おまえらFlash広告どうやって消してるの?
744 :名無しさん@お腹いっぱい。:2007/05/02(水) 17:22:18 ID:sUS3A/Us0
>728
遅くなりましたが、どうもありがとうございます。懲りずに練習します……。
>743
見えなくするだけだったら、
ヘッダフィルタでapplication/x-shockwave-flashを\kするとか。
CSSだったらobject[data$=".swf"], embed[src$=".swf"] { display: none !important; }とか。
遅くなりましたが、どうもありがとうございます。懲りずに練習します……。
>743
見えなくするだけだったら、
ヘッダフィルタでapplication/x-shockwave-flashを\kするとか。
CSSだったらobject[data$=".swf"], embed[src$=".swf"] { display: none !important; }とか。
745 :名無しさん@お腹いっぱい。:2007/05/02(水) 19:18:28 ID:6Ctk8iEj0
サイトのにあわせて作る
746 :think ◆MM0nnAOCiQ :2007/05/02(水) 22:10:53 ID:32+xZaXm0
>>736,738
今日、いくつかの動画閲覧しましたが、AdListの方法(>731)で広告は消えているように見えました。
キャッシュが残っているか、他のフィルタが先にマッチしているか。
そのあたりを確認してみてはどうでしょうか。
今日、いくつかの動画閲覧しましたが、AdListの方法(>731)で広告は消えているように見えました。
キャッシュが残っているか、他のフィルタが先にマッチしているか。
そのあたりを確認してみてはどうでしょうか。
747 :名無しさん@お腹いっぱい。:2007/05/02(水) 23:55:22 ID:qmLcqwLu0
オミトロンでニコニコ動画のNGIDじゃなくてNGワードって出来ないですかね・・・
748 :名無しさん@お腹いっぱい。:2007/05/03(木) 00:01:27 ID:/8nwxjhj0
とっくに出来てる
749 :think ◆MM0nnAOCiQ :2007/05/03(木) 00:29:50 ID:nPc5NiPX0
>>747
この辺を渡り歩けば、きっと見つかります。
ニコニコ動画(γ)の時間
http://nico.studio89.jp/
nikoniko027 オミトロンでニコニコ
http://nikoniko027.blog.shinobi.jp/
ニコ動画SNS - じょんじさんのプロフィール
http://nicosns.inventor.jp/profile/2790/
【教えて君は】ニコニコ動画専用オミトロン【半年ROMれ】
http://pc11.2ch.net/test/read.cgi/streaming/1177645673/
Thinking Archive(仮) - Download
http://vird2002.s8.xrea.com/download/#filter_niconico
この辺を渡り歩けば、きっと見つかります。
ニコニコ動画(γ)の時間
http://nico.studio89.jp/
nikoniko027 オミトロンでニコニコ
http://nikoniko027.blog.shinobi.jp/
ニコ動画SNS - じょんじさんのプロフィール
http://nicosns.inventor.jp/profile/2790/
【教えて君は】ニコニコ動画専用オミトロン【半年ROMれ】
http://pc11.2ch.net/test/read.cgi/streaming/1177645673/
Thinking Archive(仮) - Download
http://vird2002.s8.xrea.com/download/#filter_niconico
750 :名無しさん@お腹いっぱい。:2007/05/03(木) 00:31:57 ID:QMUIUr520
自分のID偽装は?
751 :名無しさん@お腹いっぱい。:2007/05/03(木) 00:35:08 ID:rIudHI5H0
>>749
ありがとうございます。
ありがとうございます。
752 :名無しさん@お腹いっぱい。:2007/05/03(木) 04:02:10 ID:fXOrahMQ0
>>749
wikiも載せてやれよww
http://abc.s65.xrea.com/prox/wiki/%A5%D5%A5%A3%A5%EB%A5%BF%A1%A2%A5%EA%A5%B9%A5%C8%B8%F8%B3%AB/nicovideo/
wikiも載せてやれよww
http://abc.s65.xrea.com/prox/wiki/%A5%D5%A5%A3%A5%EB%A5%BF%A1%A2%A5%EA%A5%B9%A5%C8%B8%F8%B3%AB/nicovideo/
753 :名無しさん@お腹いっぱい。:2007/05/03(木) 11:57:23 ID:5Pd/xwrv0
ttp://www.myj7000.jp-biz.net/
このサイトの左上のgif広告の絵を消したいんだけど、知識が少なくてできないっす
単純にblockfile→noimagesに追加しても駄目なんですか
gif止めるとさらに・・生理的に駄目なんです、こういう顔
このサイトの左上のgif広告の絵を消したいんだけど、知識が少なくてできないっす
単純にblockfile→noimagesに追加しても駄目なんですか
gif止めるとさらに・・生理的に駄目なんです、こういう顔
754 :think ◆MM0nnAOCiQ :2007/05/03(木) 13:49:41 ID:nPc5NiPX0
>>752
うっかりしてました。ご指摘ありがとうございます。
>>753
広告はまず、AdListを試してみてくださいな。
www.bb-chat.tv/ で消えます。
「Kill href/src ad」なら bb-chat.tv/
うっかりしてました。ご指摘ありがとうございます。
>>753
広告はまず、AdListを試してみてくださいな。
www.bb-chat.tv/ で消えます。
「Kill href/src ad」なら bb-chat.tv/
755 :名無しさん@お腹いっぱい。:2007/05/03(木) 14:05:00 ID:RdDv3z2I0
>>754
できました、ありがとう
できました、ありがとう
756 :名無しさん@お腹いっぱい。:2007/05/03(木) 15:36:36 ID:C1vsNmZH0
>>746
AdListの方法きぼん
AdListの方法きぼん
757 :名無しさん@お腹いっぱい。:2007/05/03(木) 18:31:50 ID:pgaHKdjc0
AdListってスラッシュ入れないと機能しないの?
758 :think ◆MM0nnAOCiQ :2007/05/03(木) 18:54:22 ID:nPc5NiPX0
>>756
1. Proxomitronを起動
2. $LST(AdList) を含む広告削除フィルタを無効に
3. 「Thinking Archive(仮) - Download」(http://vird2002.s8.xrea.com/download/#filter_kill_ad_type-list) へ
4. リスト型の広告除去フィルタ集をダウンロード
5. 添付テキストに従い、フィルタを適用
6. [デフォルトの設定に保存]
7. Webブラウザを終了し、キャッシュをクリア
8. ニコニコ動画 (http://www.nicovideo.jp/) へ
Google検索: ブラウザ キャッシュ クリア
http://www.google.co.jp/search?ie=euc-jp&lr=lang_ja&num=30&q=%a5%d6%a5%e9%a5%a6%a5%b6+%a5%ad%a5%e3%a5%c3%a5%b7%a5%e5+%a5%af%a5%ea%a5%a2
>>757
/ を付けると、「URLスタイル」のハッシュ化が有効になります。
「固定プレフィックス スタイル」のハッシュ化も有効なら、そちらが優先されますが。
マッチングコマンド - $LST
http://vird2002.s8.xrea.com/proxomitron/matching_command/m-cmd_lst.html
Using Blocklists
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/BlockList_Using.html
1. Proxomitronを起動
2. $LST(AdList) を含む広告削除フィルタを無効に
3. 「Thinking Archive(仮) - Download」(http://vird2002.s8.xrea.com/download/#filter_kill_ad_type-list) へ
4. リスト型の広告除去フィルタ集をダウンロード
5. 添付テキストに従い、フィルタを適用
6. [デフォルトの設定に保存]
7. Webブラウザを終了し、キャッシュをクリア
8. ニコニコ動画 (http://www.nicovideo.jp/) へ
Google検索: ブラウザ キャッシュ クリア
http://www.google.co.jp/search?ie=euc-jp&lr=lang_ja&num=30&q=%a5%d6%a5%e9%a5%a6%a5%b6+%a5%ad%a5%e3%a5%c3%a5%b7%a5%e5+%a5%af%a5%ea%a5%a2
>>757
/ を付けると、「URLスタイル」のハッシュ化が有効になります。
「固定プレフィックス スタイル」のハッシュ化も有効なら、そちらが優先されますが。
マッチングコマンド - $LST
http://vird2002.s8.xrea.com/proxomitron/matching_command/m-cmd_lst.html
Using Blocklists
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/BlockList_Using.html
759 :名無しさん@お腹いっぱい。:2007/05/03(木) 22:55:47 ID:RgqQ9N5g0
ハッシュ化というのは前から気になっているんだけど、
リストの用途によっては「/」で終わらせることができなくて悩む。
href="*click.*"
こういうものにマッチさせようとするときとか。
ドメイン名にマッチさせるときはだいたい問題ないようだけど、
ファイル名や特定の文字列にマッチさせるときは諦めるしかないのかな。
リストの用途によっては「/」で終わらせることができなくて悩む。
href="*click.*"
こういうものにマッチさせようとするときとか。
ドメイン名にマッチさせるときはだいたい問題ないようだけど、
ファイル名や特定の文字列にマッチさせるときは諦めるしかないのかな。
760 :think ◆MM0nnAOCiQ :2007/05/03(木) 23:43:36 ID:nPc5NiPX0
>>759
ファイル名や文字列にマッチさせるときには、「固定プレフィックス スタイル」のハッシュ化を利用するぐらいしかないです。
条件は「行頭から7文字目までにワイルドカードを含まない」という緩いものなので、何とか頑張って条件を満たすしか。
ファイル名や文字列にマッチさせるときには、「固定プレフィックス スタイル」のハッシュ化を利用するぐらいしかないです。
条件は「行頭から7文字目までにワイルドカードを含まない」という緩いものなので、何とか頑張って条件を満たすしか。
761 :名無しさん@お腹いっぱい。:2007/05/05(土) 00:05:45 ID:esZE5ph10
Last-Modifiedの値をSaved from URLみたいにページ内にコメント出来ますか?
できるならフィルターの作成をお願いしたのです。
できるならフィルターの作成をお願いしたのです。
762 :名無しさん@お腹いっぱい。:2007/05/05(土) 05:17:15 ID:d65anNt70
>>743
とりあえずソースを見て、script、object、embed などで検索して該当箇所を探す。
とりあえずソースを見て、script、object、embed などで検索して該当箇所を探す。
763 :名無しさん@お腹いっぱい。:2007/05/05(土) 15:02:25 ID:HXVXg19h0
ttp://level.s69.xrea.com/mozilla/index.cgi?id=20070428_LinkSelection
これ、うまくやればテキストの選択がしやすくなるかも。
CSSでやった方がいいかな。
これ、うまくやればテキストの選択がしやすくなるかも。
CSSでやった方がいいかな。
764 :名無しさん@お腹いっぱい。:2007/05/06(日) 19:59:12 ID:0RrzqTzs0
proxomitronをつかって、Adsense、Amazon広告とか消せますか?
765 :名無しさん@お腹いっぱい。:2007/05/06(日) 21:43:54 ID:v0/J9yLJ0
消せます
766 :名無しさん@お腹いっぱい。:2007/05/07(月) 01:06:36 ID:xcM0UFPs0
2ちゃんのレス内容の「w」を「・」に変えるフィルターって作れますか?
もし作れるなら作ってくれると嬉しいです。
もし作れるなら作ってくれると嬉しいです。
767 :think ◆MM0nnAOCiQ :2007/05/07(月) 02:32:12 ID:PhUD95sD0
>>766
> 2ちゃんのレス内容の「w」を「・」に変えるフィルターって作れますか?
そのフィルタを利用する「ブラウザ」は何でしょう?
それによって、回答が変わってくると思います。
ReplaceStr.txtを活用するスレ
http://jane.s28.xrea.com/test/read.cgi/bbs/1102229115/
【Proxomitron】Jane用内部Proxy設定スレ【Privoxy】
http://jane.s28.xrea.com/test/read.cgi/bbs/1156092349/
Thinking Archive(仮) - Download (2ch-BBS: Replace BlockList character)
http://vird2002.s8.xrea.com/download/download.php?type=proxomitron&file=filter_2ch
Thinking Archive(仮) - Download (ReplaceStr: BlockList)
http://vird2002.s8.xrea.com/download/#filter_web
「2ch-BBS: Replace BlockList character」はいくつか問題があるので、非推奨です。
ReplaceStr.txt の方が使い勝手が良いと思います。
> 2ちゃんのレス内容の「w」を「・」に変えるフィルターって作れますか?
そのフィルタを利用する「ブラウザ」は何でしょう?
それによって、回答が変わってくると思います。
ReplaceStr.txtを活用するスレ
http://jane.s28.xrea.com/test/read.cgi/bbs/1102229115/
【Proxomitron】Jane用内部Proxy設定スレ【Privoxy】
http://jane.s28.xrea.com/test/read.cgi/bbs/1156092349/
Thinking Archive(仮) - Download (2ch-BBS: Replace BlockList character)
http://vird2002.s8.xrea.com/download/download.php?type=proxomitron&file=filter_2ch
Thinking Archive(仮) - Download (ReplaceStr: BlockList)
http://vird2002.s8.xrea.com/download/#filter_web
「2ch-BBS: Replace BlockList character」はいくつか問題があるので、非推奨です。
ReplaceStr.txt の方が使い勝手が良いと思います。
768 :名無しさん@お腹いっぱい。:2007/05/07(月) 16:38:01 ID:xcM0UFPs0
769 :名無しさん@お腹いっぱい。:2007/05/07(月) 19:13:59 ID:KgnicPXJ0
postするデータを書き換えたいんですが
<div len="-10" ver=5 />のlen=を必ず-500にするにはどうすれば良いのでしょうか
ヘッダでオウトをonにして
[HTTP headers]
In = FALSE
Out = TRUE
Key = "New-HTTP-header"
Match = "<div\slen=$AV(-[0-9]+)
Replace = "<div len="-500"
にしてるんですが、作動していないみたいです
<div len="-10" ver=5 />のlen=を必ず-500にするにはどうすれば良いのでしょうか
ヘッダでオウトをonにして
[HTTP headers]
In = FALSE
Out = TRUE
Key = "New-HTTP-header"
Match = "<div\slen=$AV(-[0-9]+)
Replace = "<div len="-500"
にしてるんですが、作動していないみたいです
770 :名無しさん@お腹いっぱい。:2007/05/07(月) 19:15:08 ID:KgnicPXJ0
間違えた。必要な”も削ってしまった
[HTTP headers]
In = FALSE
Out = TRUE
Key = "New-HTTP-header"
Match = "<div\slen=$AV(-[0-9]+)"
Replace = "<div len="-500""
です
[HTTP headers]
In = FALSE
Out = TRUE
Key = "New-HTTP-header"
Match = "<div\slen=$AV(-[0-9]+)"
Replace = "<div len="-500""
です
771 :名無しさん@お腹いっぱい。:2007/05/07(月) 22:30:04 ID:GFsNvVxc0
最近のHTTPヘッダはHTMLタグを含むのか、すごいな
772 :名無しさん@お腹いっぱい。:2007/05/07(月) 22:38:28 ID:Fucx00y60
RFC2616始まったな
773 :名無しさん@お腹いっぱい。:2007/05/07(月) 23:32:43 ID:GFsNvVxc0
のちのHTTP/2.0である
774 :think ◆MM0nnAOCiQ :2007/05/07(月) 23:42:50 ID:BqlZ9hkC0
>>769-770
その特徴的な属性名を見ると、ニコニコ動画で得るコメント数をUPするフィルタを作ろうとしているように思えるんですが…。
> postするデータを書き換えたいんですが
ProxomitronはPOSTデータを書き換えできないので、間接的に書き換える方法を模索してください。
TIPS - Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/TIPS/#v6fd1b91
# 「JavaScriptでPOSTしている→JavaScriptのコードを書き換える」も可能だと思います、多分。
その特徴的な属性名を見ると、ニコニコ動画で得るコメント数をUPするフィルタを作ろうとしているように思えるんですが…。
> postするデータを書き換えたいんですが
ProxomitronはPOSTデータを書き換えできないので、間接的に書き換える方法を模索してください。
TIPS - Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/TIPS/#v6fd1b91
# 「JavaScriptでPOSTしている→JavaScriptのコードを書き換える」も可能だと思います、多分。
775 :名無しさん@お腹いっぱい。:2007/05/07(月) 23:46:11 ID:KgnicPXJ0
>>774
属性名変えたのにバレバレっすかw
属性名変えたのにバレバレっすかw
776 :think ◆MM0nnAOCiQ :2007/05/07(月) 23:52:52 ID:BqlZ9hkC0
>>775
某スレッドでコメント取得の話題が出たばかりですからw
某スレッドでコメント取得の話題が出たばかりですからw
777 :名無しさん@お腹いっぱい。:2007/05/08(火) 00:16:45 ID:rO/jdOj20
ttp://yp.peercast.org/
このサイトの下のほうにあるPage: 1, 2, 3, 4, 5, 6 >>>をページの
上のほうにも表示させるフィルタ作ってくれる人はいませんでしょうか。
出来れば1から8までのリンクが常に表示されるようにして頂けるととてもありがたいです。
このサイトの下のほうにあるPage: 1, 2, 3, 4, 5, 6 >>>をページの
上のほうにも表示させるフィルタ作ってくれる人はいませんでしょうか。
出来れば1から8までのリンクが常に表示されるようにして頂けるととてもありがたいです。
778 :think ◆MM0nnAOCiQ :2007/05/08(火) 21:27:01 ID:iAoRBsh/0
>>768
ごめんなさい。レスし忘れていました(汗)
「Jane Doe Style」では「2ch-BBS: Replace BlockList character」のフィルタで置換できるということしかわかりません…。(>767)
ごめんなさい。レスし忘れていました(汗)
「Jane Doe Style」では「2ch-BBS: Replace BlockList character」のフィルタで置換できるということしかわかりません…。(>767)
779 :名無しさん@お腹いっぱい。:2007/05/08(火) 23:26:39 ID:Iqon7aVp0
>>778
チカンは犯罪です。 w
チカンは犯罪です。 w
780 :名無しさん@お腹いっぱい。:2007/05/08(火) 23:42:48 ID:7lg4DeCw0
解決しましたので、このスレは削除依頼出しておきます。
答えてくださった方々、本当にありがとうございました。
答えてくださった方々、本当にありがとうございました。
781 :名無しさん@お腹いっぱい。:2007/05/09(水) 02:22:21 ID:10IZTesj0
782 :名無しさん@お腹いっぱい。:2007/05/09(水) 10:24:27 ID:7zUtyw880
変数の比較についてどうしてもうまくいかないので質問です。
\1と\2を比較して一致しているかで分岐したいのですが、
$TST(\1=\2)
と記述すると比較ではなく代入になってしまうのですが仕様なんでしょうか。
$TST(1=\2)
でもうまくいきません。今度は常にヒットしなくなります。
文字変数に代入して比較したりいろいろと工夫してみてもやっぱり駄目。
どう記述するのが正しいんでしょう?
\1と\2を比較して一致しているかで分岐したいのですが、
$TST(\1=\2)
と記述すると比較ではなく代入になってしまうのですが仕様なんでしょうか。
$TST(1=\2)
でもうまくいきません。今度は常にヒットしなくなります。
文字変数に代入して比較したりいろいろと工夫してみてもやっぱり駄目。
どう記述するのが正しいんでしょう?
783 :名無しさん@お腹いっぱい。:2007/05/09(水) 10:30:23 ID:vkCHQC3j0
$TST(\1=$TST(\2))
784 :名無しさん@お腹いっぱい。:2007/05/09(水) 11:31:08 ID:7zUtyw880
785 :名無しさん@お腹いっぱい。:2007/05/09(水) 19:52:29 ID:dnGknlhn0
>>783
感動した
感動した
786 :名無しさん@お腹いっぱい。:2007/05/11(金) 18:34:01 ID:rADFD0Jg0
http://pc11.2ch.net/test/read.cgi/software/1110563904/369
366 :名無しさん@お腹いっぱい。:2007/05/10(木) 01:28:26 ID:LPeEjSkM0
正規表現でフィルタ作れるプロクシ作ったけどいる?
gzip/deflate圧縮対応、utf-8変換機能有り
369 :名無しさん@お腹いっぱい。:2007/05/10(木) 19:34:43 ID:9b3E3OvP0
XPでしか試してない。
最低でも2000以上じゃないと動かないはず。
sageでオミトロン使いに気づかれないようにこっそり進行でお願い。
372 :369:2007/05/10(木) 20:21:47 ID:9b3E3OvP0
ttp://www-2ch.net:8080/up/download/1178795932319256.EvpoQ1?dl
パスは「dl」(小文字ででぃーえる)
ttp://www-2ch.net:8080/up/download/1178793100298275.yD9Gdz
366 :名無しさん@お腹いっぱい。:2007/05/10(木) 01:28:26 ID:LPeEjSkM0
正規表現でフィルタ作れるプロクシ作ったけどいる?
gzip/deflate圧縮対応、utf-8変換機能有り
369 :名無しさん@お腹いっぱい。:2007/05/10(木) 19:34:43 ID:9b3E3OvP0
XPでしか試してない。
最低でも2000以上じゃないと動かないはず。
sageでオミトロン使いに気づかれないようにこっそり進行でお願い。
372 :369:2007/05/10(木) 20:21:47 ID:9b3E3OvP0
ttp://www-2ch.net:8080/up/download/1178795932319256.EvpoQ1?dl
パスは「dl」(小文字ででぃーえる)
ttp://www-2ch.net:8080/up/download/1178793100298275.yD9Gdz
787 :名無しさん@お腹いっぱい。:2007/05/11(金) 19:19:18 ID:tqsDsZ1K0
>sageでオミトロン使いに
なんていうか・・・卑屈だな
そんなに仲悪いの?
なんていうか・・・卑屈だな
そんなに仲悪いの?
788 :名無しさん@お腹いっぱい。:2007/05/11(金) 19:24:41 ID:mO/La/9C0
何か嫌われてるみたいだな
789 :名無しさん@お腹いっぱい。:2007/05/11(金) 19:30:19 ID:fHP/rSL30
Arneだろ
790 :名無しさん@お腹いっぱい。:2007/05/12(土) 11:31:47 ID:zsEONeG60
そりゃこのフィルタスレ見てたってまともに自分で使えない厨房がいっぱいだし
うざいってことじゃないのかな
うざいってことじゃないのかな
どうもすみませんorz
見よう見まねで作ってみました。 上下に2列ずつページリンクが出て変だけどこれで妥協しよう。
[Patterns]
Name = "YP Link 070512"
Active = TRUE
URL = "yp.peercast.org/(\?|(^?))"
Limit = 512
Match = "(<hr\ssize="1">)\0|(Page:(([^<]|<<<)+<(/|)[ab](^[a-z])[^>]+>)+[^<]+)\3"
"$SET(4=<br><br>)$STOP()$SET(5=\r\n<style type="text/css">\r\n"
"<!--\r\nspan#pagelink { position: absolute; top: 140px; left: 340px;"
" font-size:16px; font-weight:bold; }\r\n-->\r\n</style>\r\n\r\n"
"<span id="pagelink">\r\n\3\r\n</span>\r\n\r\n)"
Replace = "$SET(6=  <a href="?from=)\0\r\n<div style="font-size: 16px;"
" font-weight:bold;">\r\n\3\4\r\nPage:\61">1</a>\r\n\621">2</a>\r\n\641">"
"3</a>\r\n\661">4</a>\r\n\681">5</a>\r\n\6101">6</a>\r\n\6121">7</a>\r\n"
"\6141">8</a>\r\n\6161">9</a>\r\n\6181">10</a>\r\n</div>\r\n\5"
ttp://yp.peercast.org/
[Patterns]
Name = "YP Link 070512"
Active = TRUE
URL = "yp.peercast.org/(\?|(^?))"
Limit = 512
Match = "(<hr\ssize="1">)\0|(Page:(([^<]|<<<)+<(/|)[ab](^[a-z])[^>]+>)+[^<]+)\3"
"$SET(4=<br><br>)$STOP()$SET(5=\r\n<style type="text/css">\r\n"
"<!--\r\nspan#pagelink { position: absolute; top: 140px; left: 340px;"
" font-size:16px; font-weight:bold; }\r\n-->\r\n</style>\r\n\r\n"
"<span id="pagelink">\r\n\3\r\n</span>\r\n\r\n)"
Replace = "$SET(6=  <a href="?from=)\0\r\n<div style="font-size: 16px;"
" font-weight:bold;">\r\n\3\4\r\nPage:\61">1</a>\r\n\621">2</a>\r\n\641">"
"3</a>\r\n\661">4</a>\r\n\681">5</a>\r\n\6101">6</a>\r\n\6121">7</a>\r\n"
"\6141">8</a>\r\n\6161">9</a>\r\n\6181">10</a>\r\n</div>\r\n\5"
ttp://yp.peercast.org/
793 :名無しさん@お腹いっぱい。:2007/05/12(土) 20:35:12 ID:hAIBizt30
2ch見ててウイルスコード書く奴が居てアンチウイルスが過剰反応するので、
このウイルスコードを読み込まない様にするフィルターが欲しいんですが。<(_ _)>
このウイルスコードを読み込まない様にするフィルターが欲しいんですが。<(_ _)>
794 :名無しさん@お腹いっぱい。:2007/05/12(土) 20:56:03 ID:50Uhoets0
アンチのほうで除外できんのか
795 :名無しさん@お腹いっぱい。:2007/05/12(土) 20:56:14 ID:1OsLhWl60
datファイルの場所を検査除外するようにすればいいだけ
796 :名無しさん@お腹いっぱい。:2007/05/12(土) 21:23:41 ID:hAIBizt30
>>794-795レスドウモデス
出来るとか出来ないとか話がありますが、これからそう言う書き込みが増えそうな予感がするのでオミトロンで出来れば遣りたいな、と思いまして。
出来るとか出来ないとか話がありますが、これからそう言う書き込みが増えそうな予感がするのでオミトロンで出来れば遣りたいな、と思いまして。
797 :名無しさん@お腹いっぱい。:2007/05/12(土) 21:34:47 ID:1OsLhWl60
ウィルスコードに共通する部分が無いと駄目かと
798 :名無しさん@お腹いっぱい。:2007/05/12(土) 21:36:20 ID:vD81c/Ks0
増えそうならますます795の方が良いと思うけどなあ。
その度にフィルタ増やすより。
その度にフィルタ増やすより。
799 :名無しさん@お腹いっぱい。:2007/05/12(土) 23:40:32 ID:QLoGUdha0
800 :名無しさん@お腹いっぱい。:2007/05/12(土) 23:45:22 ID:hAIBizt30
>>795datファイルの除外では無く、そのレスだけ除外してアンチウイルス補助(と言うか2ch対策?)
みたいな感じに使えたらと思ったんだけど。
>>797 の言う通り共通コードとか考えるとちょっと使い方違うかなとは思った。
でもフィルターだけ作っておけば後は除外コードを追加していけば・・・、
何て素人考えでいたんだけど。(^o^;; とりあえづ、除外とか対策があるのでありがとう。
みたいな感じに使えたらと思ったんだけど。
>>797 の言う通り共通コードとか考えるとちょっと使い方違うかなとは思った。
でもフィルターだけ作っておけば後は除外コードを追加していけば・・・、
何て素人考えでいたんだけど。(^o^;; とりあえづ、除外とか対策があるのでありがとう。
801 :名無しさん@お腹いっぱい。:2007/05/12(土) 23:46:23 ID:2BPV17nj0
ニコ厨
802 :名無しさん@お腹いっぱい。:2007/05/13(日) 00:30:44 ID:9GHFhxcy0
>>800
申し訳ないが仰っている意味が全くわからない
申し訳ないが仰っている意味が全くわからない
803 :名無しさん@お腹いっぱい。:2007/05/13(日) 02:07:48 ID:4aDa1u7g0
無理しなくていいよ
804 :名無しさん@お腹いっぱい。:2007/05/13(日) 02:44:46 ID:8nmUBfmr0
ウイルス対策ソフトなんて使ったことないが、オミトロンだけあれば十分でないか?
よほど凝ったしかけでもされなければ、ウイルスを入れられることはないと思うが。
(使っているフィルタにもよるけど)
あとはIEを使わないとか、ブラウザを選択するだけでもある程度の効果はあるだろう。
よほど凝ったしかけでもされなければ、ウイルスを入れられることはないと思うが。
(使っているフィルタにもよるけど)
あとはIEを使わないとか、ブラウザを選択するだけでもある程度の効果はあるだろう。
805 :名無しさん@お腹いっぱい。:2007/05/13(日) 02:47:22 ID:gLrYIWfD0
ウイルスは油断してる奴ほど引っかかりやすい。
806 :名無しさん@お腹いっぱい。:2007/05/13(日) 03:24:17 ID:gLrYIWfD0
>>800
そういうフィルタを作ることは出来るよ。 2chブラウザのNG処理みたいなことをオミトロンで
やればいいだけだから簡単。 もしかしたら既成のNGフィルタで出来るかも。
ただし、登録の仕方を工夫しないとフィルタ内のウイルスコードがアンチウイルスソフトに
ウイルス認識されてしまい、その結果オミトロンの設定ファイルがまるごと消されたり、
隔離されたりしてしまうことが考えられるので注意されたしw
余談だが、アンチウイルスの設定でdatのある場所を除外するという方法は、
この場所にウイルスが投下された場合に無防備になるという欠点があるので
これをやればいいというレスは正しいとは言えない。
今回はオミトロンで回避するにはどうすればいいかという質問なのでこれは答えになってない。
こういう場合はアンチウイルスの設定でも回避出来ることを示しつつ、
オミトロンで実現するにはどうすればいいかを書くべきだろうと思う。
そういうフィルタを作ることは出来るよ。 2chブラウザのNG処理みたいなことをオミトロンで
やればいいだけだから簡単。 もしかしたら既成のNGフィルタで出来るかも。
ただし、登録の仕方を工夫しないとフィルタ内のウイルスコードがアンチウイルスソフトに
ウイルス認識されてしまい、その結果オミトロンの設定ファイルがまるごと消されたり、
隔離されたりしてしまうことが考えられるので注意されたしw
余談だが、アンチウイルスの設定でdatのある場所を除外するという方法は、
この場所にウイルスが投下された場合に無防備になるという欠点があるので
これをやればいいというレスは正しいとは言えない。
今回はオミトロンで回避するにはどうすればいいかという質問なのでこれは答えになってない。
こういう場合はアンチウイルスの設定でも回避出来ることを示しつつ、
オミトロンで実現するにはどうすればいいかを書くべきだろうと思う。
807 :名無しさん@お腹いっぱい。:2007/05/13(日) 03:45:48 ID:No4VdHhW0
<#`∀´>ノ よっ
808 :名無しさん@お腹いっぱい。:2007/05/13(日) 06:26:16 ID:Y7joxdUo0
(-@∀@)ノ
809 :名無しさん@お腹いっぱい。:2007/05/13(日) 10:51:54 ID:jtfDIeTY0
>>806 その通りだな。
810 :名無しさん@お腹いっぱい。:2007/05/13(日) 11:05:52 ID:5QE9Ptp+0
定型文から一部当たったらその場所を適当な文字に置き換えればいいが
ただし容量が変わると次の読み込み時に読み込み開始位置がずれるので
Janeでのdatの置き換えは実用的でない
ただし容量が変わると次の読み込み時に読み込み開始位置がずれるので
Janeでのdatの置き換えは実用的でない
811 :名無しさん@お腹いっぱい。:2007/05/13(日) 11:21:20 ID:bUgHmLCf0
ウイルスが投下って、テキストなんだから投下されてもええやん。
812 :名無しさん@お腹いっぱい。:2007/05/13(日) 11:56:48 ID:j4dYgaDi0
>>811
ウィルスに感染した際に、datフォルダが作業フォルダになってしまうってことでは?
ウィルスに感染した際に、datフォルダが作業フォルダになってしまうってことでは?
813 :名無しさん@お腹いっぱい。:2007/05/13(日) 12:21:35 ID:OxtBhJpp0
何かもうチンプンカンチンだな
814 :名無しさん@お腹いっぱい。:2007/05/13(日) 14:04:52 ID:DlZ/oUSV0
おまいら日本語を勉強しなおして来い
815 :名無しさん@お腹いっぱい。:2007/05/13(日) 14:06:57 ID:lJbqJQb50
ニホンゴノ ベンキョウハ トテモ ムズカシイデス。
816 :名無しさん@お腹いっぱい。:2007/05/13(日) 15:53:48 ID:ZlFJMo5X0
>>810
Jane系ならWickedStr.txtで解決
Jane系ならWickedStr.txtで解決
817 :名無しさん@お腹いっぱい。:2007/05/14(月) 04:45:34 ID:ypZMCifm0
全角文字と半角文字を区別しないのが問題悩みの種なんですが、
たとえば検索条件に「@」を指定すると「 」(全角空白)にヒットしたりしますよね。
こういうのは根本的に解決できないんでしょうか。
たとえば検索条件に「@」を指定すると「 」(全角空白)にヒットしたりしますよね。
こういうのは根本的に解決できないんでしょうか。
818 :名無しさん@お腹いっぱい。:2007/05/15(火) 01:13:26 ID:bvbbhwzO0
プロ櫛rgx
http://pc11.2ch.net/test/read.cgi/software/1179148749/
2 :名無しさん@お腹いっぱい。:2007/05/14(月) 23:05:44 ID:WKifu00Y0
元は↓から始まったソフトproxrgxのスレ
http://pc11.2ch.net/test/read.cgi/software/1110563904/366
366 :名無しさん@お腹いっぱい。:2007/05/10(木) 01:28:26 ID:LPeEjSkM0
正規表現でフィルタ作れるプロクシ作ったけどいる?
gzip/deflate圧縮対応、utf-8変換機能有り
http://pc11.2ch.net/test/read.cgi/software/1179148749/
2 :名無しさん@お腹いっぱい。:2007/05/14(月) 23:05:44 ID:WKifu00Y0
元は↓から始まったソフトproxrgxのスレ
http://pc11.2ch.net/test/read.cgi/software/1110563904/366
366 :名無しさん@お腹いっぱい。:2007/05/10(木) 01:28:26 ID:LPeEjSkM0
正規表現でフィルタ作れるプロクシ作ったけどいる?
gzip/deflate圧縮対応、utf-8変換機能有り
819 :名無しさん@お腹いっぱい。:2007/05/15(火) 14:38:26 ID:0ysFFwet0
アクセス解析切るフィルタってどう書けばいいの?
820 :名無しさん@お腹いっぱい。:2007/05/15(火) 15:22:31 ID:rrlf/Jmg0
アクセス解析のURI切るようにすればいいんじゃない
821 :名無しさん@お腹いっぱい。:2007/05/15(火) 16:39:25 ID:0ysFFwet0
822 :名無しさん@お腹いっぱい。:2007/05/15(火) 16:52:17 ID:p9IB4x3f0
>821
そんなものができたらサーバ攻撃の踏み台になってしまうではないか。
まあ無理だと思うけど。
そんなものができたらサーバ攻撃の踏み台になってしまうではないか。
まあ無理だと思うけど。
823 :名無しさん@お腹いっぱい。:2007/05/15(火) 17:08:37 ID:rrlf/Jmg0
>>821
そのサーバにアクセスしないようにするといいよ。いやマジで
そのサーバにアクセスしないようにするといいよ。いやマジで
824 :名無しさん@お腹いっぱい。:2007/05/15(火) 17:17:05 ID:0ysFFwet0
すみませんorz
では、サーバーのアクセスログに自分のホストを残さないためには
プロキシを経由するしかないんでしょうか
proxomitronで経由させる方法を教えて下さいorz
では、サーバーのアクセスログに自分のホストを残さないためには
プロキシを経由するしかないんでしょうか
proxomitronで経由させる方法を教えて下さいorz
825 :名無しさん@お腹いっぱい。:2007/05/15(火) 17:31:47 ID:ECj21nuz0
>>824
根本から間違ってる
根本から間違ってる
826 :名無しさん@お腹いっぱい。:2007/05/15(火) 17:44:37 ID:t+ahuucv0
つか、823で答えが出てるんだけどな
827 :名無しさん@お腹いっぱい。:2007/05/15(火) 17:47:48 ID:WnjvKKRs0
>>824
プロキシと書いてあるボタンを押してプロキシサーバを登録する。
プロキシと書いてあるボタンを押してプロキシサーバを登録する。
828 :名無しさん@お腹いっぱい。:2007/05/15(火) 20:07:35 ID:K8JcRcrz0
829 :名無しさん@お腹いっぱい。:2007/05/17(木) 07:40:06 ID:TQkWKBT60
おはよ
Prox系の悪用はよく聞くが
俺が聞いたのは、プロクシ立てたよ、使ってね->ヘッダログ表示->ベーシック認証キーごっそりいただき
Prox系じゃなくてもやろうと思えばできるけど簡単にできるのはまずいね
だから外部接続は対応しないほうがいいに賛成
俺がやったいたずらは、「です。」を「でんねん」、「ます。」を「まんねん」に変換するやつ
みんな似たようなことやってるな
Prox系の悪用はよく聞くが
俺が聞いたのは、プロクシ立てたよ、使ってね->ヘッダログ表示->ベーシック認証キーごっそりいただき
Prox系じゃなくてもやろうと思えばできるけど簡単にできるのはまずいね
だから外部接続は対応しないほうがいいに賛成
俺がやったいたずらは、「です。」を「でんねん」、「ます。」を「まんねん」に変換するやつ
みんな似たようなことやってるな
830 :名無しさん@お腹いっぱい。:2007/05/17(木) 08:31:57 ID:xA2KL2ne0
「おばんです。」を「おばんでんねん」にしたのはお前か!
831 :名無しさん@お腹いっぱい。:2007/05/17(木) 14:24:22 ID:qKc8vEqj0
プロキシ経由でそういう認証する方に問題があると思うよ
832 :名無しさん@お腹いっぱい。:2007/05/20(日) 12:32:26 ID:/NeMvw7F0
流れぶったぎって
コメントタグと無関係の”-->”を削除するにはどう表記すれば良い?
--\>じゃ消せなかったんだ
コメントタグと無関係の”-->”を削除するにはどう表記すれば良い?
--\>じゃ消せなかったんだ
833 :think ◆MM0nnAOCiQ :2007/05/20(日) 12:56:14 ID:LeZXT6Rw0
>>832
こうかな?
[Patterns]
Name = "Kill incorrect comment end [2007/05/20] test1"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 4
Match = "(^(^<!--))(^$TST(Comment=start))$SET(Comment=start)|"
"(^(^-->))($TST(Comment=start)$SET(Comment=)|"
"-->$SET(Comment=incorrect end))"
こうかな?
[Patterns]
Name = "Kill incorrect comment end [2007/05/20] test1"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 4
Match = "(^(^<!--))(^$TST(Comment=start))$SET(Comment=start)|"
"(^(^-->))($TST(Comment=start)$SET(Comment=)|"
"-->$SET(Comment=incorrect end))"
834 :名無しさん@お腹いっぱい。:2007/05/20(日) 18:31:12 ID:GdzKbKKA0
Google Imageまた変わった?
835 :名無しさん@お腹いっぱい。:2007/05/20(日) 21:09:18 ID:/FLyeVGw0
Kill nest ad
で
<!-- Bar --><!-- /Bar -->
の消す書き方教えて
で
<!-- Bar --><!-- /Bar -->
の消す書き方教えて
836 :名無しさん@お腹いっぱい。:2007/05/20(日) 21:46:45 ID:0yJbN/ID0
>>834
Google Image: Image Change (070115)だったら
<a href="\+e\+b.m\+"><imgを
<a href="\+e\+b.n\+"><imgから
<a href="\+e\+b.o\+"><img
にすればいいよ
Google Image: Image Change (070115)だったら
<a href="\+e\+b.m\+"><imgを
<a href="\+e\+b.n\+"><imgから
<a href="\+e\+b.o\+"><img
にすればいいよ
837 :名無しさん@お腹いっぱい。:2007/05/20(日) 22:07:03 ID:PMhlTke70
<a href="http://
foo.bar/">
こんなソースでもリンクとして機能するとは。Firefox/2.0.0.3 で確認した。
リストでURLを管理しているんだけど、普通ならマッチするものがマッチしなかった。
// の直後にある改行を削ったらマッチした。
HTML lint だと改行は禁止されてないと書かれているけど、
この例では改行がなかったことにされてしまっているから危険。
foo.bar/">
こんなソースでもリンクとして機能するとは。Firefox/2.0.0.3 で確認した。
リストでURLを管理しているんだけど、普通ならマッチするものがマッチしなかった。
// の直後にある改行を削ったらマッチした。
HTML lint だと改行は禁止されてないと書かれているけど、
この例では改行がなかったことにされてしまっているから危険。
838 :名無しさん@お腹いっぱい。:2007/05/20(日) 22:57:01 ID:Cnpp6wc80
<img src="foo
.jpg">
とか普通に可能だよ。クォーテーション内の改行は無視される。
クォーテーション無しなら改行以降は無視。
<img src="bar.gif
.jpg">
↑ bar.gif.jpg が呼び出される
<img src=bar.gif
.jpg>
↑ bar.gif が呼び出される
.jpg">
とか普通に可能だよ。クォーテーション内の改行は無視される。
クォーテーション無しなら改行以降は無視。
<img src="bar.gif
.jpg">
↑ bar.gif.jpg が呼び出される
<img src=bar.gif
.jpg>
↑ bar.gif が呼び出される
839 :名無しさん@お腹いっぱい。:2007/05/20(日) 23:03:03 ID:GdzKbKKA0
>>836
ありがとう
ありがとう
840 :名無しさん@お腹いっぱい。:2007/05/21(月) 01:09:27 ID:SUsR8ePu0
じゃあこうすればよくね?
[Patterns]
Name = "delete break inside tag attribute value 20070521-4"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Bounds = "<[^/][^>]++=("[^"]++|'[^']++)\n"
Limit = 1024
Match = "\1\n"
Replace = "\n\1"
[Patterns]
Name = "delete break inside tag attribute value 20070521-4"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Bounds = "<[^/][^>]++=("[^"]++|'[^']++)\n"
Limit = 1024
Match = "\1\n"
Replace = "\n\1"
841 :名無しさん@お腹いっぱい。:2007/05/21(月) 02:09:59 ID:SUsR8ePu0
あ、ごめんBoundsおかしいね。
<[^/!][^>]++=("[^">]++|'[^'>]++)\n
とかで大丈夫かな。
<[^/!][^>]++=("[^">]++|'[^'>]++)\n
とかで大丈夫かな。
842 :名無しさん@お腹いっぱい。:2007/05/21(月) 02:29:41 ID:SUsR8ePu0
うへー、クォートの扱いの理解が足りなかった。
出直してくる。
出直してくる。
843 :think ◆MM0nnAOCiQ :2007/05/21(月) 03:11:04 ID:2zo606qG0
参考資料は HTML4.01 が適当かな?
Basic HTML data types (ja)
http://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/types.html#h-6.2
上の資料によると、
・a要素のhref属性値は「CDATA」に分類される。
・「CDATA」は改行文字LFを無視し、改行文字CRは1つの空白文字で置き換える。
となっています。
ところが、実際には CRLF (\r\n) がhref属性値に存在しても無視されています。
Webブラウザの挙動に合わせるなら、
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/21] type1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[^>]++\s(href=|src=))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)(^(^[ >]))"
Replace = "\@"
となるのでしょうけれど、仕様書通りに動作しないのが気になりますね…。
Basic HTML data types (ja)
http://www.asahi-net.or.jp/%7Esd5a-ucd/rec-html401j/types.html#h-6.2
上の資料によると、
・a要素のhref属性値は「CDATA」に分類される。
・「CDATA」は改行文字LFを無視し、改行文字CRは1つの空白文字で置き換える。
となっています。
ところが、実際には CRLF (\r\n) がhref属性値に存在しても無視されています。
Webブラウザの挙動に合わせるなら、
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/21] type1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[^>]++\s(href=|src=))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)(^(^[ >]))"
Replace = "\@"
となるのでしょうけれど、仕様書通りに動作しないのが気になりますね…。
844 :think ◆MM0nnAOCiQ :2007/05/21(月) 03:14:14 ID:2zo606qG0
altテキスト/titleテキスト は改行を解釈してポップアップするので、改行を取り除いてしまうと改行なしの長文が表示されてしまう可能性があります。
>843のフィルタでは、効果範囲を href属性,src属性に限定しています。
>843のフィルタでは、効果範囲を href属性,src属性に限定しています。
845 :名無しさん@お腹いっぱい。:2007/05/21(月) 10:53:39 ID:dCdyGNqN0
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/21] type ex1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[a-z][^>]++\s(href=|src=)(^(^["'])))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)"
Replace = "\@"
<a href="http://
foo.bar/"
>
Name = "Delete break inside tag attribute value [2007/05/21] type ex1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[a-z][^>]++\s(href=|src=)(^(^["'])))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)"
Replace = "\@"
<a href="http://
foo.bar/"
>
846 :名無しさん@お腹いっぱい。:2007/05/21(月) 13:22:22 ID:SUsR8ePu0
>>845
属性値の外側の改行は消さなくてもいいのでは?
属性値の外側の改行は消さなくてもいいのでは?
847 :名無しさん@お腹いっぱい。:2007/05/21(月) 13:27:57 ID:bJ0cz1h70
>844
Firefox だと title 属性値の改行は無視されるよ。(1行で表示される)
ttp://www.google.com/search?q=cache:RSRKW3BM9MYJ:www.eris.ais.ne.jp/~hiro/html/
あと、ここに改行の数値文字参照について書いてあった。
Firefox だと title 属性値の改行は無視されるよ。(1行で表示される)
ttp://www.google.com/search?q=cache:RSRKW3BM9MYJ:www.eris.ais.ne.jp/~hiro/html/
あと、ここに改行の数値文字参照について書いてあった。
848 :名無しさん@お腹いっぱい。:2007/05/21(月) 16:29:11 ID:dCdyGNqN0
849 :think ◆MM0nnAOCiQ :2007/05/21(月) 17:08:04 ID:ptycSbTw0
>>847
あ、なるほど。
Sylera3では改行されるので、Firefoxも同じだと安易に考えていました。
GREのバージョン違いかな?
>>848
属性値の外は空白として処理しないと困るケースがあります。
<a
title="test"
href="http://www.google.
com/">
それに、Proxomitronでマッチさせるだけなら、属性値の外はそれほど気にしなくて良いような気が…。
あ、なるほど。
Sylera3では改行されるので、Firefoxも同じだと安易に考えていました。
GREのバージョン違いかな?
>>848
属性値の外は空白として処理しないと困るケースがあります。
<a
title="test"
href="http://www.google.
com/">
それに、Proxomitronでマッチさせるだけなら、属性値の外はそれほど気にしなくて良いような気が…。
850 :think ◆MM0nnAOCiQ :2007/05/21(月) 17:08:45 ID:ptycSbTw0
デフォルトで有効になっているフィルタで、HTML文書先頭にスクリプトが挿入されてしまう不具合を修正しました。
[Patterns]
Name = "Kill pop-up windows [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script src="http://local.ptron/WindowOpen.js"></script>\r\n"
Name = "Suppress all JavaScript errors [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script> function NoError(){return(true);} onerror=NoError; </script>\r\n"
Name = "Stop browser window resizing [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script> function moveTo(){return true;} function resizeTo(){return true;} </script>\r\n"
他にも同様の不具合を抱えているフィルタがありますが、面倒なのでそっちは書きません。
(例) 「Stop status bar scrollers」「Kill Dynamic HTML JavaScripts」「Stop JavaScript Timers」等。
[Patterns]
Name = "Kill pop-up windows [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script src="http://local.ptron/WindowOpen.js"></script>\r\n"
Name = "Suppress all JavaScript errors [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script> function NoError(){return(true);} onerror=NoError; </script>\r\n"
Name = "Stop browser window resizing [2007/05/21] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</head>))$STOP()"
Replace = "<script> function moveTo(){return true;} function resizeTo(){return true;} </script>\r\n"
他にも同様の不具合を抱えているフィルタがありますが、面倒なのでそっちは書きません。
(例) 「Stop status bar scrollers」「Kill Dynamic HTML JavaScripts」「Stop JavaScript Timers」等。
851 :名無しさん@お腹いっぱい。:2007/05/21(月) 17:12:56 ID:Q7evb4+C0
, - ,----、
(U( )
| |∨T∨ <Google image redirectorの対応お願いします
(__)_)
852 :名無しさん@お腹いっぱい。:2007/05/21(月) 17:22:00 ID:dCdyGNqN0
853 :think ◆MM0nnAOCiQ :2007/05/21(月) 17:48:56 ID:ptycSbTw0
>>852
完全に私の勘違いでした。
申し訳ありません。m(_ _)m
>848で指摘された違いはこういうことですね。
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/21] type1.1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[^>]++\s(href=|src=))\#(^(^["']))"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)(^(^[\r\n\t >]))"
Replace = "\@"
>843は末尾に改行が存在するケースに対応していませんでした。
(^(^["'])) はクォートなしの属性値には改行を含まないため、と捉えました。
完全に私の勘違いでした。
申し訳ありません。m(_ _)m
>848で指摘された違いはこういうことですね。
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/21] type1.1"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "(<[^>]++\s(href=|src=))\#(^(^["']))"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)(^(^[\r\n\t >]))"
Replace = "\@"
>843は末尾に改行が存在するケースに対応していませんでした。
(^(^["'])) はクォートなしの属性値には改行を含まないため、と捉えました。
854 :名無しさん@お腹いっぱい。:2007/05/21(月) 21:13:09 ID:SUsR8ePu0
855 :名無しさん@お腹いっぱい。:2007/05/21(月) 23:57:57 ID:M/0UeIOj0
>>333を参考にAAKiller作ろうと思ってるんだけど参考例の中にある「,」の意味がわからない・・・
どういう用途に使ってるんでしょう
どういう用途に使ってるんでしょう
856 :think ◆MM0nnAOCiQ :2007/05/22(火) 00:35:19 ID:nSN/o3BF0
>>855
以下を参考に。
タグを「タグの始まり」「タグの終わり」「その間のタグ」に分割する役割を持つ「区切り文字」が , です。
(便宜上、タグという言葉を用います)
マッチングコマンド - $NEST
http://vird2002.s8.xrea.com/proxomitron/matching_command/m-cmd_nest.html
マッチングコマンド
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Matching_Commands.html#NEST
以下の2つはほぼ等価。(厳密には違うが、HTML文法規則に準拠したHTML文書ならば同じようにマッチする)
$NEST(<a\s,*href=$AV(http://www.amazon.co.jp/)*,>)
<a\s[^>]++href=$AV(http://www.amazon.co.jp/)[^>]+>
$NEST は入れ子を解釈するので、上の例は以下のHTML全てにマッチします。
<a href="http://www.amazon.co.jp/" <a href="http://www.amazon.co.jp/">>
<a\s で始まり、> で終わるタグの入れ子構造をチェックしていることになります。
上の書き方は通常使わないので、入れ子チェックする意味はありませんが、原理はこういう事です。
以下を参考に。
タグを「タグの始まり」「タグの終わり」「その間のタグ」に分割する役割を持つ「区切り文字」が , です。
(便宜上、タグという言葉を用います)
マッチングコマンド - $NEST
http://vird2002.s8.xrea.com/proxomitron/matching_command/m-cmd_nest.html
マッチングコマンド
http://www.pluto.dti.ne.jp/~tengu/proxomitron/help/Matching_Commands.html#NEST
以下の2つはほぼ等価。(厳密には違うが、HTML文法規則に準拠したHTML文書ならば同じようにマッチする)
$NEST(<a\s,*href=$AV(http://www.amazon.co.jp/)*,>)
<a\s[^>]++href=$AV(http://www.amazon.co.jp/)[^>]+>
$NEST は入れ子を解釈するので、上の例は以下のHTML全てにマッチします。
<a href="http://www.amazon.co.jp/" <a href="http://www.amazon.co.jp/">>
<a\s で始まり、> で終わるタグの入れ子構造をチェックしていることになります。
上の書き方は通常使わないので、入れ子チェックする意味はありませんが、原理はこういう事です。
857 :名無しさん@お腹いっぱい。:2007/05/22(火) 00:43:51 ID:6h7yiVj00
なるほど、入れ子の始まりと中と終わりを「,」で仕切るわけですね
ってよく見たらヘルプのNESTの説明中にも「,」が書いてありました
詰まってイライラしてる状態だと理解できるものも理解できなくなりますね・・・
精進します。ありがとうございました
ってよく見たらヘルプのNESTの説明中にも「,」が書いてありました
詰まってイライラしてる状態だと理解できるものも理解できなくなりますね・・・
精進します。ありがとうございました
858 :名無しさん@お腹いっぱい。:2007/05/22(火) 03:26:06 ID:5UV72l090
>>850
ありがとうございます
ttp://pc11.2ch.net/test/read.cgi/streaming/1177645673/743
にてお願いしたものです。
>他にも同様の不具合を抱えているフィルタがありますが、面倒なのでそっち
>は書きません。
>(例) 「Stop status bar scrollers」「Kill Dynamic HTML JavaScripts」
>「Stop JavaScript Timers」等。
書き換え例をみるとMatchな部分を置き換えReplaceの行頭を少しけづるだけと気づき同じように書き換えてみました。
列挙されてない残りは下記の3つなんだろうか〜?
Force pop-ups to have browser controls
Kill alert/confirm boxes
Frame Exploder
もし単純な書き換えじゃまずい場合はご指摘ください。
ありがとうございます
ttp://pc11.2ch.net/test/read.cgi/streaming/1177645673/743
にてお願いしたものです。
>他にも同様の不具合を抱えているフィルタがありますが、面倒なのでそっち
>は書きません。
>(例) 「Stop status bar scrollers」「Kill Dynamic HTML JavaScripts」
>「Stop JavaScript Timers」等。
書き換え例をみるとMatchな部分を置き換えReplaceの行頭を少しけづるだけと気づき同じように書き換えてみました。
列挙されてない残りは下記の3つなんだろうか〜?
Force pop-ups to have browser controls
Kill alert/confirm boxes
Frame Exploder
もし単純な書き換えじゃまずい場合はご指摘ください。
859 :名無しさん@お腹いっぱい。:2007/05/22(火) 04:17:48 ID:UUQ4ssVh0
デフォルトのフィルタって、改善してでも常用に耐えるほどのものなのかね?
自分でフィルタを書くようになってからは、ルールを覚えるにつれてだんだん数が減り、
現在ではヘッダフィルタのみいくつか残っている。
自分でフィルタを書くようになってからは、ルールを覚えるにつれてだんだん数が減り、
現在ではヘッダフィルタのみいくつか残っている。
860 :名無しさん@お腹いっぱい。:2007/05/22(火) 05:34:47 ID:6h7yiVj00
検索やらiframeやら検索パネルには対応してない手抜き版・・・というか誤爆が多そうな・・・
せめて[]内で小文字大文字区別してくれれば誤爆は格段に減るだろうになんでこんな仕様なんですか('A`)
[Patterns]
Name = "Amazon Affiliate Kill"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "$NEST(<a\s,[^>]++href=$AV(http://www.amazon.co.jp/[^>]++([0-9A-Z]++{10})\1*)*,>)"
Replace = "<a href="http://www.amazon.co.jp/dp/\1" title="AAK" target=_"blank">"
せめて[]内で小文字大文字区別してくれれば誤爆は格段に減るだろうになんでこんな仕様なんですか('A`)
[Patterns]
Name = "Amazon Affiliate Kill"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "$NEST(<a\s,[^>]++href=$AV(http://www.amazon.co.jp/[^>]++([0-9A-Z]++{10})\1*)*,>)"
Replace = "<a href="http://www.amazon.co.jp/dp/\1" title="AAK" target=_"blank">"
861 :名無しさん@お腹いっぱい。:2007/05/22(火) 05:55:08 ID:6h7yiVj00
Match = "$NEST(<a\s,[^>]++href=$AV(http://www.amazon.co.jp/[^>]++([0-9A-Z]++{10})\1*)*,>)"
↓
Match = "$NEST(<a\s,[^>]++href=$AV(http://www.amazon.co.jp/[^>]++([0-9A-Z]++{10})\1[^-]*)*,>)"
とりあえずこれで誤爆率少しは減るだろうけど根本から変えなきゃダメかな・・・
↓
Match = "$NEST(<a\s,[^>]++href=$AV(http://www.amazon.co.jp/[^>]++([0-9A-Z]++{10})\1[^-]*)*,>)"
とりあえずこれで誤爆率少しは減るだろうけど根本から変えなきゃダメかな・・・
862 :名無しさん@お腹いっぱい。:2007/05/22(火) 07:48:53 ID:611BnxQc0
自分は面倒だったのでインストールしたときに真っ先に既定のフィルタを切った。
863 :名無しさん@お腹いっぱい。:2007/05/22(火) 09:57:46 ID:s/TORTFf0
アフィリエイト用フィルタはURLリストでblogだけに絞れば
誤爆しても問題ないよ
誤爆しても問題ないよ
864 :名無しさん@お腹いっぱい。:2007/05/22(火) 14:09:12 ID:oSSD77tm0
865 :名無しさん@お腹いっぱい。:2007/05/22(火) 14:54:28 ID:Bg46BaNI0
リンクを書き換えるよりヘッダを書き換えたほうが簡単なんじゃ
866 :名無しさん@お腹いっぱい。:2007/05/22(火) 15:41:38 ID:Bg46BaNI0
[Patterns]
Name = "Delete break inside tag attribute value [2007/05/22] SuperLite"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "<([a-z][^>]++\s(href=|src=)(^(^["'])))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)"
Replace = "<\@"
Name = "Delete break inside tag attribute value [2007/05/22] SuperLite"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 1024
Match = "<([a-z][^>]++\s(href=|src=)(^(^["'])))\#"
"$AVQ((\#[\r\n]+{1,*})+{1,*}\#)"
Replace = "<\@"
867 :名無しさん@お腹いっぱい。:2007/05/22(火) 18:24:42 ID:4H5GdfAR0
アフィリンクはIDを無効にすることよりも、
見えなくしたり読込まないようにすることを考えた方が有意義だと思う。
アキバブログの両サイドとかiframeをOFFにすると綺麗さっぱりするよ。
アマゾン以外でアマゾンの画像表示禁止
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: Amazon images kill (out)"
URL = "([^/]++.|)images-amazon.com/"
Match = "http(s|)://(^((www.|)amazon.(co.jp|jp|com)/))*"
Replace = "\k"
見えなくしたり読込まないようにすることを考えた方が有意義だと思う。
アキバブログの両サイドとかiframeをOFFにすると綺麗さっぱりするよ。
アマゾン以外でアマゾンの画像表示禁止
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: Amazon images kill (out)"
URL = "([^/]++.|)images-amazon.com/"
Match = "http(s|)://(^((www.|)amazon.(co.jp|jp|com)/))*"
Replace = "\k"
868 :名無しさん@お腹いっぱい。:2007/05/22(火) 18:37:00 ID:PZ+Hh1SN0
>>850
Stop status bar scrollersもきぼん
Stop status bar scrollersもきぼん
869 :think ◆MM0nnAOCiQ :2007/05/22(火) 20:11:09 ID:oFNWk6Hw0
>>858
Match="(<!DOCTYPE*> |)\1"
で <script> を挿入するフィルタは全て同様の改変で問題ないと思います。
ただ、
<head>
...
<script src="hogehoge.js"></script>
</head>
のHTMLに対しては、<script> の前に置換テキストを挿入した方が良いかも?
外部JSは読み込み順が関係しているかもしれないので、JavaScriptの識者にフォローを頂きたいところ。
[Patterns]
Name = "Kill pop-up windows [2007/05/22] fixed2"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^<script[ >]|</head>))$STOP()"
Replace = "<script src="http://local.ptron/WindowOpen.js"></script>\r\n"
> 書き換え例をみるとMatchな部分を置き換えReplaceの行頭を少しけづるだけと気づき
Limitも小さくなっています。
Match="(<!DOCTYPE*> |)\1"
で <script> を挿入するフィルタは全て同様の改変で問題ないと思います。
ただ、
<head>
...
<script src="hogehoge.js"></script>
</head>
のHTMLに対しては、<script> の前に置換テキストを挿入した方が良いかも?
外部JSは読み込み順が関係しているかもしれないので、JavaScriptの識者にフォローを頂きたいところ。
[Patterns]
Name = "Kill pop-up windows [2007/05/22] fixed2"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^<script[ >]|</head>))$STOP()"
Replace = "<script src="http://local.ptron/WindowOpen.js"></script>\r\n"
> 書き換え例をみるとMatchな部分を置き換えReplaceの行頭を少しけづるだけと気づき
Limitも小さくなっています。
870 :think ◆MM0nnAOCiQ :2007/05/22(火) 20:13:56 ID:oFNWk6Hw0
HTML文書の最下部に <script> を挿入するフィルタもちょっと危ないですね。
[Patterns]
Name = "Restore pop-ups after a page loads [2007/05/22] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</html>))$STOP()"
Replace = "<script>PrxRST();</script>\r\n"
[Patterns]
Name = "Restore pop-ups after a page loads [2007/05/22] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</html>))$STOP()"
Replace = "<script>PrxRST();</script>\r\n"
871 :名無しさん@お腹いっぱい。:2007/05/22(火) 21:02:07 ID:lcJ3UX/O0
フォントがMSゴシックで指定されてるサイトで、その部分をメイリオに変更汁フィルターお願いできませんか?
置き換えのやり方はうまく理解出来なくて、ダメなんですよ私。
置き換えのやり方はうまく理解出来なくて、ダメなんですよ私。
872 :名無しさん@お腹いっぱい。:2007/05/22(火) 21:06:29 ID:5UV72l090
正規表現を1から勉強してこよう;_;
873 :名無しさん@お腹いっぱい。:2007/05/23(水) 02:37:50 ID:mFoFLFRo0
874 :名無しさん@お腹いっぱい。:2007/05/23(水) 02:52:58 ID:bXLMNBZc0
MSゴシックで表示されるからといって、MSゴシックが指定されているとは限らないよ。
body { font-family: "メイリオ" monospace !important }
メイリオが手元にないから検証してないけど、これでいいでしょ。
body でなければ、該当する要素に書き換えればよし。
あとは必要に応じて monospace を sans-serif あたりに書き換えてもよし。
ttp://d.hatena.ne.jp/jintrick/20070521
ついでに書くと、こんな話がある。
body { font-family: "メイリオ" monospace !important }
メイリオが手元にないから検証してないけど、これでいいでしょ。
body でなければ、該当する要素に書き換えればよし。
あとは必要に応じて monospace を sans-serif あたりに書き換えてもよし。
ttp://d.hatena.ne.jp/jintrick/20070521
ついでに書くと、こんな話がある。
875 :名無しさん@お腹いっぱい。:2007/05/23(水) 02:54:14 ID:bXLMNBZc0
body { font-family: "メイリオ", monospace !important }
コンマ入れ忘れ。
コンマ入れ忘れ。
876 :名無しさん@お腹いっぱい。:2007/05/23(水) 03:38:25 ID:/Pn/o+7n0
>>850
>>870
いつもありがとうございます。
この際勉強しなおそうとFAQなどから読み始めてるのですが
PRXスレFAQより
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
Name = "Kill pop-up windows(04/07/29)"
Active = TRUE
Limit = 40
Match = "<start>"
Replace = "<!-- --><script type=text/javascript>"
"function PrxKillOpen(){return(this.window);}"
"if(!window.PrxRealOpen)PrxRealOpen=window.open,"
"window.open=PrxKillOpen;"
"</script>\r\n"
Name = "Restore pop-ups after a page loads(04/07/29)"
Active = TRUE
Limit = 40
Match = "<end>"
Replace = "<!-- --><script type=text/javascript>"
"function PrxOpen(url,nam,atr){"
" if(!event||!event.type.match(/load/i))"
" return(PrxRealOpen(url,nam,atr));"
" else"
" return this.window;"
"}"
"window.open=PrxOpen;"
"</script>\r\n"
で修正版があがってるのに気づきました。thinkさまのはデフォルトのフィルタを元に修正されてますがどちらを使うのがよろしいのでしょう?
>>870
いつもありがとうございます。
この際勉強しなおそうとFAQなどから読み始めてるのですが
PRXスレFAQより
ttp://web.archive.org/web/20060519105742/http://www2.wbs.ne.jp/~go-to/prx/faq.html
Name = "Kill pop-up windows(04/07/29)"
Active = TRUE
Limit = 40
Match = "<start>"
Replace = "<!-- --><script type=text/javascript>"
"function PrxKillOpen(){return(this.window);}"
"if(!window.PrxRealOpen)PrxRealOpen=window.open,"
"window.open=PrxKillOpen;"
"</script>\r\n"
Name = "Restore pop-ups after a page loads(04/07/29)"
Active = TRUE
Limit = 40
Match = "<end>"
Replace = "<!-- --><script type=text/javascript>"
"function PrxOpen(url,nam,atr){"
" if(!event||!event.type.match(/load/i))"
" return(PrxRealOpen(url,nam,atr));"
" else"
" return this.window;"
"}"
"window.open=PrxOpen;"
"</script>\r\n"
で修正版があがってるのに気づきました。thinkさまのはデフォルトのフィルタを元に修正されてますがどちらを使うのがよろしいのでしょう?
877 :名無しさん@お腹いっぱい。:2007/05/23(水) 07:38:19 ID:Uj4jCnWm0
>>870
便乗で質問。 その"ちょっと危ない"とはどういう意味ですか?
便乗で質問。 その"ちょっと危ない"とはどういう意味ですか?
878 :名無しさん@お腹いっぱい。:2007/05/23(水) 08:53:44 ID:TrgnaLDa0
>>863
巡回先にblogじゃないところも結構あるのでそれは厳しいです
>>866
ちょっと自分にはまだ理解できないです・・・。すみません
>>867
試しましたが消えるところがあったり消えないところもあったりでまだ慣れず
なので>>864の案を元に作っていたけど
$NEST(<(a\s|iframe\s)[^>]++(href=|src=)$AV(http://[^>]++amazon.(co.jp|com)/[^>]++([^/?=]++-22)\0*)*,>)\1|
(<input\s[^>]++(src=|value=)$AV([^>]++(([^?=>]++|)-22)\0)*>)\1
というところまで書いた辺りでどうやっても単なる抽出にしかならないっぽいので挫折
$SETでいけるかと思ったけどそもそも用途が違うっぽい罠。マッチングコマンドは難しい・・・
巡回先にblogじゃないところも結構あるのでそれは厳しいです
>>866
ちょっと自分にはまだ理解できないです・・・。すみません
>>867
試しましたが消えるところがあったり消えないところもあったりでまだ慣れず
なので>>864の案を元に作っていたけど
$NEST(<(a\s|iframe\s)[^>]++(href=|src=)$AV(http://[^>]++amazon.(co.jp|com)/[^>]++([^/?=]++-22)\0*)*,>)\1|
(<input\s[^>]++(src=|value=)$AV([^>]++(([^?=>]++|)-22)\0)*>)\1
というところまで書いた辺りでどうやっても単なる抽出にしかならないっぽいので挫折
$SETでいけるかと思ったけどそもそも用途が違うっぽい罠。マッチングコマンドは難しい・・・
879 :名無しさん@お腹いっぱい。:2007/05/23(水) 11:14:28 ID:Lhjw9B2V0
>>878
>>864に書いてあることをやるだけならコマンドは使う必要ないと思います。
それと、下のようにアフィID以外の部分を抽出すればアフィIDを書き換えられますよ。
Match
(<a\s[^>]++href=)\1$AV((http://(www.|)amazon.co.jp/*)\2あふぃあいでぃ\3)
Replace
\1"\2てきとうなもじれつ\3"
あとは「あふぃあいでぃ」の部分を正規表現で書き、inputタグなどにも対応させれば完成です。
追記、
フィルタを書くときに$NESTが本当に必要なケースというのは滅多にないです。
普段フィルタを書き慣れていない方が$NESTを乱用するのはあまり好ましくありません。
>>864に書いてあることをやるだけならコマンドは使う必要ないと思います。
それと、下のようにアフィID以外の部分を抽出すればアフィIDを書き換えられますよ。
Match
(<a\s[^>]++href=)\1$AV((http://(www.|)amazon.co.jp/*)\2あふぃあいでぃ\3)
Replace
\1"\2てきとうなもじれつ\3"
あとは「あふぃあいでぃ」の部分を正規表現で書き、inputタグなどにも対応させれば完成です。
追記、
フィルタを書くときに$NESTが本当に必要なケースというのは滅多にないです。
普段フィルタを書き慣れていない方が$NESTを乱用するのはあまり好ましくありません。
880 :名無しさん@お腹いっぱい。:2007/05/23(水) 17:08:54 ID:ByNRJFuF0
>>878
>>867はこれでどう?
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: Amazon images kill (out)"
URL = "(images.amazon.|([^/]++.|)images-amazon.)(co.jp|jp|com)/"
Match = "http(s|)://(^(([^/]++.|)amazon.(co.jp|jp|com)/))*"
Replace = "\k"
あとここのiFrame to dynamic linkが効果あるよ
ttp://confetto.s31.xrea.com/misc/proxomitron#IFRAME-TO-DYNAMIC-LINK
>>867はこれでどう?
[HTTP headers]
In = FALSE
Out = TRUE
Key = "Referer: Amazon images kill (out)"
URL = "(images.amazon.|([^/]++.|)images-amazon.)(co.jp|jp|com)/"
Match = "http(s|)://(^(([^/]++.|)amazon.(co.jp|jp|com)/))*"
Replace = "\k"
あとここのiFrame to dynamic linkが効果あるよ
ttp://confetto.s31.xrea.com/misc/proxomitron#IFRAME-TO-DYNAMIC-LINK
881 :think ◆MM0nnAOCiQ :2007/05/23(水) 20:02:33 ID:nCXqeKDR0
>>877
> "ちょっと危ない"とはどういう意味ですか?
デフォルトの「Restore pop-ups after a page loads」はProxomitronでフィルタを適用可能な全てのリソースの最後にスクリプトを挿入します。
しかし、<script> は HTML文書 だけで有効なので、CSSや外部JSに <script> を挿入すると誤動作を引き起こす可能性があります。
なので、URLマッチに $TYPE(htm) を追加するわけですが、これでもまだ不十分なケースがあります。
サーバから返されるContent-Typeヘッダが text/html でも、実際の中身はHTML文書ではないことがあり、このままではそれにマッチしてしまいます。
これを回避するため、「HTML文書に必ずあるタグ」にマッチさせます。
>750 は </head>
>869 は <script[ >] or </head>
>870 は </html>
にマッチさせているわけです。
> "ちょっと危ない"とはどういう意味ですか?
デフォルトの「Restore pop-ups after a page loads」はProxomitronでフィルタを適用可能な全てのリソースの最後にスクリプトを挿入します。
しかし、<script> は HTML文書 だけで有効なので、CSSや外部JSに <script> を挿入すると誤動作を引き起こす可能性があります。
なので、URLマッチに $TYPE(htm) を追加するわけですが、これでもまだ不十分なケースがあります。
サーバから返されるContent-Typeヘッダが text/html でも、実際の中身はHTML文書ではないことがあり、このままではそれにマッチしてしまいます。
これを回避するため、「HTML文書に必ずあるタグ」にマッチさせます。
>750 は </head>
>869 は <script[ >] or </head>
>870 は </html>
にマッチさせているわけです。
882 :think ◆MM0nnAOCiQ :2007/05/23(水) 20:03:15 ID:nCXqeKDR0
>881の続き。
次に、誤動作を引き起こす例を考えてみます。
・<start> <end>
タグを確認せずにマッチさせるので誤動作する可能性があります。
# <start> <end> は特別な理由がない限り、使わない方がよいと私は思います。
# HTMLはDOCTYPE宣言、XHTMLはXML宣言を先頭に記述しなければならないルールがありますし、CSSも@charsetから始まらなければなりません。
・「Kill pop-up windows」の (<!DOCTYPE*> |)
後半の分岐は「何もないところにマッチ」しますが、これは文書の先頭にマッチするのと同義です。タグを確認していないので、誤動作する可能性があります。
・サーバから受信したContent-Typeヘッダの値が正しくない
サーバの設定がいい加減なために、中身はJavaScriptであるにも関わらず、「Content-Type: text/html」が送られてくるような場合です。
「Content-Type: Fix MIME types」というフィルタで正しいContent-Typeヘッダに直すと、改善されます。
デフォルトで入っている「Content-Type: Fix MIME types」は良いフィルタとはいえないので、関連サイトで配布されているフィルタに変更してあげる必要があります。(私のサイトでも配布しています)
Content-Typeエンティティヘッダフィールドは適切なものを指定してください - Web標準普及プロジェクト
http://www.mozilla.gr.jp/standards/webtips/webtips0033.html
情報センター/MIME Content-Type 表
http://www.kyoto-su.ac.jp/ccinfo/network_service/web/mine_contenttype/index.html
コマンド一覧 - Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/%A5%B3%A5%DE%A5%F3%A5%C9%B0%EC%CD%F7/#type
Thinking Archive(仮) - Download
http://vird2002.s8.xrea.com/download/#filter_header
次に、誤動作を引き起こす例を考えてみます。
・<start> <end>
タグを確認せずにマッチさせるので誤動作する可能性があります。
# <start> <end> は特別な理由がない限り、使わない方がよいと私は思います。
# HTMLはDOCTYPE宣言、XHTMLはXML宣言を先頭に記述しなければならないルールがありますし、CSSも@charsetから始まらなければなりません。
・「Kill pop-up windows」の (<!DOCTYPE*> |)
後半の分岐は「何もないところにマッチ」しますが、これは文書の先頭にマッチするのと同義です。タグを確認していないので、誤動作する可能性があります。
・サーバから受信したContent-Typeヘッダの値が正しくない
サーバの設定がいい加減なために、中身はJavaScriptであるにも関わらず、「Content-Type: text/html」が送られてくるような場合です。
「Content-Type: Fix MIME types」というフィルタで正しいContent-Typeヘッダに直すと、改善されます。
デフォルトで入っている「Content-Type: Fix MIME types」は良いフィルタとはいえないので、関連サイトで配布されているフィルタに変更してあげる必要があります。(私のサイトでも配布しています)
Content-Typeエンティティヘッダフィールドは適切なものを指定してください - Web標準普及プロジェクト
http://www.mozilla.gr.jp/standards/webtips/webtips0033.html
情報センター/MIME Content-Type 表
http://www.kyoto-su.ac.jp/ccinfo/network_service/web/mine_contenttype/index.html
コマンド一覧 - Proxomitron等に関するWiki
http://abc.s65.xrea.com/prox/wiki/%A5%B3%A5%DE%A5%F3%A5%C9%B0%EC%CD%F7/#type
Thinking Archive(仮) - Download
http://vird2002.s8.xrea.com/download/#filter_header
883 :think ◆MM0nnAOCiQ :2007/05/23(水) 20:07:06 ID:nCXqeKDR0
>>876
それらのフィルタには、いくつか改善すべき点があると思います。
・<start> <end> は先頭/末尾にあるHTMLタグに置き換える
・URLマッチに $TYPE(htm) を加える
理由は、>881-882で説明したとおりです。
最終的にどちらのコードが良いかは、スクリプトが読めない私にはアドバイスできません…。
それらのフィルタには、いくつか改善すべき点があると思います。
・<start> <end> は先頭/末尾にあるHTMLタグに置き換える
・URLマッチに $TYPE(htm) を加える
理由は、>881-882で説明したとおりです。
最終的にどちらのコードが良いかは、スクリプトが読めない私にはアドバイスできません…。
884 :think ◆MM0nnAOCiQ :2007/05/23(水) 21:26:10 ID:nCXqeKDR0
>>860
> せめて[]内で小文字大文字区別してくれれば誤爆は格段に減るだろうになんでこんな仕様なんですか('A`)
HTML4.01では、タグの 大文字/小文字 を区別しませんから…。
ちなみに、「Far East Patch」を適用済みであれば、大文字/小文字を区別する方法はあります。
[a-z] は [a-zA-Z] に等しく、[%61-%7a] は [a-z] に等しい。
こういうやり方でどうでしょうか?
ただ、ファイル名の「大文字/小文字」の区別を活用しているサイトを見たことがありませんし、そこまで厳密にチェックする必要があるのか疑問に思うところはあります。
> せめて[]内で小文字大文字区別してくれれば誤爆は格段に減るだろうになんでこんな仕様なんですか('A`)
HTML4.01では、タグの 大文字/小文字 を区別しませんから…。
ちなみに、「Far East Patch」を適用済みであれば、大文字/小文字を区別する方法はあります。
[a-z] は [a-zA-Z] に等しく、[%61-%7a] は [a-z] に等しい。
こういうやり方でどうでしょうか?
ただ、ファイル名の「大文字/小文字」の区別を活用しているサイトを見たことがありませんし、そこまで厳密にチェックする必要があるのか疑問に思うところはあります。
885 :think ◆MM0nnAOCiQ :2007/05/23(水) 21:47:44 ID:nCXqeKDR0
【教えて君は】ニコニコ動画専用オミトロン【半年ROMれ】
http://pc11.2ch.net/test/read.cgi/streaming/1177645673/775+794+808
からの流れで、「Proxomitron-J」で配布されている「Allow right mouse click 3種セット」で誤動作を引き起こしそうな箇所を修正しました。
変更点
- URLマッチに $TYPE(htm) を追加
- <end> を (^(^</html>))$STOP() に変更した
- Limitの調整
- 微調整
[Patterns]
Name = "Allow right mouse click [2007/05/23] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 16
Match = ".(onmousedown=|captureEvents\()\1"
Replace = ".PrxOff_\1"
http://pc11.2ch.net/test/read.cgi/streaming/1177645673/775+794+808
からの流れで、「Proxomitron-J」で配布されている「Allow right mouse click 3種セット」で誤動作を引き起こしそうな箇所を修正しました。
変更点
- URLマッチに $TYPE(htm) を追加
- <end> を (^(^</html>))$STOP() に変更した
- Limitの調整
- 微調整
[Patterns]
Name = "Allow right mouse click [2007/05/23] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 16
Match = ".(onmousedown=|captureEvents\()\1"
Replace = ".PrxOff_\1"
886 :think ◆MM0nnAOCiQ :2007/05/23(水) 21:48:25 ID:nCXqeKDR0
>>885の続き。
[Patterns]
Name = "Allow right mouse click 2 [2007/05/23] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</html>))$STOP()"
Replace = "<script> document.onmousedown=null; </script>\r\n"
Name = "Allow right mouse click plus [2007/05/23] fixed"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "(<[^>]++\s)\0oncontextmenu(^(^=))"
Replace = "\0ProxAllow"
[Patterns]
Name = "Allow right mouse click 2 [2007/05/23] fixed"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 8
Match = "(^(^</html>))$STOP()"
Replace = "<script> document.onmousedown=null; </script>\r\n"
Name = "Allow right mouse click plus [2007/05/23] fixed"
Active = TRUE
Multi = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "(<[^>]++\s)\0oncontextmenu(^(^=))"
Replace = "\0ProxAllow"
887 :名無しさん@お腹いっぱい。:2007/05/24(木) 01:29:08 ID:7AkQSz8s0
今まで使ってたYoutubeにDownloadリンクを追加するフィルター効かなくなった
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: YouTube - Always jump to the permanent URI (Out)"
Match = "http://(www.|)youtube.com/watch\?v=([^&]+)\0\&*"
Replace = "$JUMP(http://www.youtube.com/watch?v=\0)"
Name = "YouTube Add Download Link [060505]"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?(|*\&)v="
Bounds = "$NEST(<script,</script>)"
Limit = 512
Match = "(*new\sSWFObject\(\"/player[0-9]+.swf\?(video_id=[^"]+)\0\"*)\1($KEYCHK(Y)"
"$SET(2=<meta http-equiv="Refresh" content="0;URL=http://youtube.com/get_video.php?\0">\k)|$SET(2=\1))"
Replace = "\2\n<div style="font-size: 20px; font-weight: bold; text-align: center;padding-bottom: 10px;">\n"
"<a href="http://youtube.com/get_video.php?\0">[[[ Download ]]]</a>\n</div>\n$STOP()"
[HTTP headers]
In = FALSE
Out = TRUE
Key = "URL: YouTube - Always jump to the permanent URI (Out)"
Match = "http://(www.|)youtube.com/watch\?v=([^&]+)\0\&*"
Replace = "$JUMP(http://www.youtube.com/watch?v=\0)"
Name = "YouTube Add Download Link [060505]"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?(|*\&)v="
Bounds = "$NEST(<script,</script>)"
Limit = 512
Match = "(*new\sSWFObject\(\"/player[0-9]+.swf\?(video_id=[^"]+)\0\"*)\1($KEYCHK(Y)"
"$SET(2=<meta http-equiv="Refresh" content="0;URL=http://youtube.com/get_video.php?\0">\k)|$SET(2=\1))"
Replace = "\2\n<div style="font-size: 20px; font-weight: bold; text-align: center;padding-bottom: 10px;">\n"
"<a href="http://youtube.com/get_video.php?\0">[[[ Download ]]]</a>\n</div>\n$STOP()"
888 :think ◆MM0nnAOCiQ :2007/05/24(木) 02:18:13 ID:PqkdgH8d0
>>887
どうぞ。
更新履歴
- script要素のチェックを外した
[Patterns]
Name = "YouTube: add download link [2007/05/24] test1"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?v\="
Limit = 256
Match = "(^(^SWFObject\($AV(/player2.swf(\?video_id=*)\0)[ +,]))"
"$SET(YTube=\0)(^$TST(YTube=?*))|"
"(^(^<div\sclass=$AV(actionsDiv)))$STOP()"
Replace = "<div class="actionRow"><a href="./get_video$GET(YTube)">Download link</a></div>"
"$SET(YTube=)"
基本的なコードは元のままですが、scriptコードが肥大化したためにマッチしていませんでした。
どうぞ。
更新履歴
- script要素のチェックを外した
[Patterns]
Name = "YouTube: add download link [2007/05/24] test1"
Active = TRUE
URL = "$TYPE(htm)(www.|)youtube.com/watch\?v\="
Limit = 256
Match = "(^(^SWFObject\($AV(/player2.swf(\?video_id=*)\0)[ +,]))"
"$SET(YTube=\0)(^$TST(YTube=?*))|"
"(^(^<div\sclass=$AV(actionsDiv)))$STOP()"
Replace = "<div class="actionRow"><a href="./get_video$GET(YTube)">Download link</a></div>"
"$SET(YTube=)"
基本的なコードは元のままですが、scriptコードが肥大化したためにマッチしていませんでした。
889 :名無しさん@お腹いっぱい。:2007/05/24(木) 10:31:10 ID:jjwUMEiY0
>>888
ありがとう!!!!!!!
ありがとう!!!!!!!
890 :名無しさん@お腹いっぱい。:2007/05/24(木) 10:47:36 ID:xJv4oJ0l0
>>888のダウソリンクを>>887のように目立たせてみた。 Replaceだけ書き換え。
Replace = "<div class="actionRow" style="font-size:25px;"><a href="./get_video$GET(YTube)">[[[ Download ]]]</a></div>"
"$SET(YTube=)"
>>888
お疲れ様です。
Replace = "<div class="actionRow" style="font-size:25px;"><a href="./get_video$GET(YTube)">[[[ Download ]]]</a></div>"
"$SET(YTube=)"
>>888
お疲れ様です。
891 :名無しさん@お腹いっぱい。:2007/05/24(木) 17:59:33 ID:Eq/iCgpl0
[HTTP headers]
In = FALSE
Out = FALSE
Key = "Content-Disposition: YouTube File ReNamer [060521] (In)"
Match = "$URL(http://(^www)[^/]++.youtube.com/get_video\?video_id=\0)"
Replace = "attachment; filename="\0.flv";"
機能しなくなってしまいました
お願いします
In = FALSE
Out = FALSE
Key = "Content-Disposition: YouTube File ReNamer [060521] (In)"
Match = "$URL(http://(^www)[^/]++.youtube.com/get_video\?video_id=\0)"
Replace = "attachment; filename="\0.flv";"
機能しなくなってしまいました
お願いします
892 :名無しさん@お腹いっぱい。:2007/05/24(木) 19:11:16 ID:xJv4oJ0l0
>>891
ちゃんと効いてるような気がする。
ちゃんと効いてるような気がする。
893 :名無しさん@お腹いっぱい。:2007/05/24(木) 19:34:55 ID:xJv4oJ0l0
>>888のだとこの動画ページでダウソリンクがページ下に隠れてしまったので
動画の直下にリンクを表示させるようにいじりました。
ttp://www.youtube.com/watch?v=5wGMn8fbmQs
[Patterns]
Name = "YouTube: add download link [2007/05/24] big link"
Active = TRUE
URL = "(www.|)youtube.com/watch\?v\= $TYPE(htm)"
Limit = 256
Match = "(^(^SWFObject\($AV(/player[0-9]+.swf(\?video_id=*)\0)[ +,]))"
"$SET(YTube=\0)(^$TST(YTube=?*))|// ]]> </script>$STOP()"
Replace = "// ]]>\r\n</script>\r\n<div style="font-size:25px; text-align:center;">\r\n"
"<a href="./get_video$GET(YTube)">[[[ Download ]]]</a>\r\n</div>$SET(YTube=)"
あとplayer2.swfがplayer3.swf等にバージョンアップしてもマッチするように修正。
動画の直下にリンクを表示させるようにいじりました。
ttp://www.youtube.com/watch?v=5wGMn8fbmQs
[Patterns]
Name = "YouTube: add download link [2007/05/24] big link"
Active = TRUE
URL = "(www.|)youtube.com/watch\?v\= $TYPE(htm)"
Limit = 256
Match = "(^(^SWFObject\($AV(/player[0-9]+.swf(\?video_id=*)\0)[ +,]))"
"$SET(YTube=\0)(^$TST(YTube=?*))|// ]]> </script>$STOP()"
Replace = "// ]]>\r\n</script>\r\n<div style="font-size:25px; text-align:center;">\r\n"
"<a href="./get_video$GET(YTube)">[[[ Download ]]]</a>\r\n</div>$SET(YTube=)"
あとplayer2.swfがplayer3.swf等にバージョンアップしてもマッチするように修正。
894 :名無しさん@お腹いっぱい。:2007/05/24(木) 20:05:26 ID:qYAvn6TG0
>>893
DLするとget_videoってなるのはようつべの仕様なの?
DLするとget_videoってなるのはようつべの仕様なの?
895 :名無しさん@お腹いっぱい。:2007/05/24(木) 20:07:20 ID:T2loM5Q20
拡張子をflvに自分で直す
896 :名無しさん@お腹いっぱい。:2007/05/24(木) 20:45:32 ID:ou7przB80
897 :名無しさん@お腹いっぱい。:2007/05/24(木) 21:58:06 ID:Ia8ewfIm0
ワラタ
898 :名無しさん@お腹いっぱい。:2007/05/24(木) 23:32:09 ID:xJv4oJ0l0
899 :名無しさん@お腹いっぱい。:2007/05/24(木) 23:37:26 ID:6ShX0m+B0
>>891
In = TURE にしてみたけど効いてない気がする
In = TURE にしてみたけど効いてない気がする
900 :名無しさん@お腹いっぱい。:2007/05/24(木) 23:43:33 ID:Wfha+YaG0
&に関する疑問。
Bounds は <meta\s*> で、
Match を以下のようにしたとき、\1の中身が違うのはどうして?
1. (*http-equiv=$AV(refresh)&*content=$AV(*)\1*)
2. (*http-equiv=$AV(refresh)&*content=$AV(\1)*)
マッチさせる対象のサンプル
<meta http-equiv="refresh" content="0;URL=index.php">
<meta content="0;URL=index.php" http-equiv="refresh">
<meta http-equiv="refresh" content="index.php">
<meta content="index.php" http-equiv="refresh">
Bounds は <meta\s*> で、
Match を以下のようにしたとき、\1の中身が違うのはどうして?
1. (*http-equiv=$AV(refresh)&*content=$AV(*)\1*)
2. (*http-equiv=$AV(refresh)&*content=$AV(\1)*)
マッチさせる対象のサンプル
<meta http-equiv="refresh" content="0;URL=index.php">
<meta content="0;URL=index.php" http-equiv="refresh">
<meta http-equiv="refresh" content="index.php">
<meta content="index.php" http-equiv="refresh">
901 :名無しさん@お腹いっぱい。:2007/05/25(金) 00:36:49 ID:58XVN4Mx0
> 1. (*http-equiv=$AV(refresh)&*content=$AV(*)\1*)
"(*)"の括弧は$AVの引数を括る括弧であって
変数\1に取り込む範囲を指定する括弧ではないぞ。
君の期待しているのは多分こうだ。
(*http-equiv=$AV(refresh)&*content=($AV(*))\1*)
勿論、その場合でも、
> \1の中身が違うのはどうして?
\1にクォートが含まれる/含まれない の違いは発生するけどな。
(君の言う「違う」はそういう事ではないだろう)
"(*)"の括弧は$AVの引数を括る括弧であって
変数\1に取り込む範囲を指定する括弧ではないぞ。
君の期待しているのは多分こうだ。
(*http-equiv=$AV(refresh)&*content=($AV(*))\1*)
勿論、その場合でも、
> \1の中身が違うのはどうして?
\1にクォートが含まれる/含まれない の違いは発生するけどな。
(君の言う「違う」はそういう事ではないだろう)
902 :名無しさん@お腹いっぱい。:2007/05/25(金) 01:21:06 ID:UqYo66iH0
903 :名無しさん@お腹いっぱい。:2007/05/25(金) 01:55:24 ID:xk9M9HKF0
904 :名無しさん@お腹いっぱい。:2007/05/25(金) 03:16:34 ID:r4Jtcvd20
>>879
bar-22で登録されてたとしてfoobar-22になれば(foobar-22が登録されてなければ)反応しないわけですね
[^>?=/]++-22の部分を消すことに躍起になっててそっちに考えが向かなかったようです
>>880
うーん何故かほぼ機能しません・・・
ログウィンドウでは大半のRefererが消えてるんですけど。ヘッダフィルタはまだよくわからない・・・
下のiframe to dynamic linkで代用しますね
>>884
ありがとうございます
書き直しでなく書き足しでもOKなら>>879の方法でやろうかと思います
bar-22で登録されてたとしてfoobar-22になれば(foobar-22が登録されてなければ)反応しないわけですね
[^>?=/]++-22の部分を消すことに躍起になっててそっちに考えが向かなかったようです
>>880
うーん何故かほぼ機能しません・・・
ログウィンドウでは大半のRefererが消えてるんですけど。ヘッダフィルタはまだよくわからない・・・
下のiframe to dynamic linkで代用しますね
>>884
ありがとうございます
書き直しでなく書き足しでもOKなら>>879の方法でやろうかと思います
905 :名無しさん@お腹いっぱい。:2007/05/25(金) 03:22:44 ID:r4Jtcvd20
[Patterns]
Name = "Amazon Affiliate Kill"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "((<a\s|input\s)[^>]++(href=|src=|value=))\1$AV((http://(www.|)amazon.co.jp/*|[^>]++.gif[^>]++|)\2([^?/>=]++-22)\3*)"
Replace = "\1"\2AAK\3""
これでいいのかな?JSにアフィ仕込んでるサイトも見かけたけど特例だろうしそっちは放置でもいいかなと
Name = "Amazon Affiliate Kill"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "((<a\s|input\s)[^>]++(href=|src=|value=))\1$AV((http://(www.|)amazon.co.jp/*|[^>]++.gif[^>]++|)\2([^?/>=]++-22)\3*)"
Replace = "\1"\2AAK\3""
これでいいのかな?JSにアフィ仕込んでるサイトも見かけたけど特例だろうしそっちは放置でもいいかなと
906 :名無しさん@お腹いっぱい。:2007/05/25(金) 03:29:24 ID:r4Jtcvd20
iframeのみのケース忘れてた
Match = "((<a\s|input\s|iframe\s)[^>]++(href=|src=|value=))\1$AV((http://(www.|rcm-jp.|)amazon.co.jp/*|[^>]++.gif[^>]++|)\2([^?/>=]++-22)\3*)"
Match = "((<a\s|input\s|iframe\s)[^>]++(href=|src=|value=))\1$AV((http://(www.|rcm-jp.|)amazon.co.jp/*|[^>]++.gif[^>]++|)\2([^?/>=]++-22)\3*)"
907 :891:2007/05/25(金) 18:14:18 ID:vzSM7iVr0
>901
どうもありがとうございます。
()は階層化のために使うものという考えがくせになってしまったようで……。
(*http-equiv=$AV(refresh)&*content=($AV(*))\1*)
だと quot が増えてしまうので、
(*http-equiv=$AV(refresh)&*content=$AV((*)\1)*)
だとよさげかもです。
どうもありがとうございます。
()は階層化のために使うものという考えがくせになってしまったようで……。
(*http-equiv=$AV(refresh)&*content=($AV(*))\1*)
だと quot が増えてしまうので、
(*http-equiv=$AV(refresh)&*content=$AV((*)\1)*)
だとよさげかもです。
909 :名無しさん@お腹いっぱい。:2007/05/25(金) 22:32:00 ID:ggSWIwPQ0
[Patterns]
Name = "kill _blank to _top +"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form|link|area)\s*[^>]+>"
Limit = 256
Match = "\1((target=|window.open)(|\())\4(*|)\2_blank\3"
Replace = "\1\4\2_top\3"
Name = "js: kill blank to top"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form|link|area)\s*[^>]+>"
Limit = 256
Match = "\1window.open[(](*|)\2_blank\3"
Replace = "\1window.open(\2_top\3"
Name = "kill blank to top"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form)\s*>"
Limit = 256
Match = "\1\starget=("|)\2_blank\3"
Replace = "\1 target=\2_top\3"
Name = "kill _blank to _top +"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form|link|area)\s*[^>]+>"
Limit = 256
Match = "\1((target=|window.open)(|\())\4(*|)\2_blank\3"
Replace = "\1\4\2_top\3"
Name = "js: kill blank to top"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form|link|area)\s*[^>]+>"
Limit = 256
Match = "\1window.open[(](*|)\2_blank\3"
Replace = "\1window.open(\2_top\3"
Name = "kill blank to top"
Active = TRUE
URL = "$TYPE(htm)"
Bounds = "<(a|base|form)\s*>"
Limit = 256
Match = "\1\starget=("|)\2_blank\3"
Replace = "\1 target=\2_top\3"
910 :名無しさん@お腹いっぱい。:2007/05/25(金) 22:32:49 ID:ggSWIwPQ0
"_blank"の書き換えについて
filter>>909
真ん中はJSのターゲット指定で効くように下をまねて書き換えたものです。
上は真ん中と下を無理やり1つにしてみました。
<a href="〜" onclick="window.open(this.href, '_blank'); return false;">
は_topにできましたが、マッチルールとかパーで適当にひっかかるようにしただけなので問題あるところの指摘、修正お願いします。
下は数年前から入れっぱなしなのでどこのかさっぱり忘れてしまいました…。Uploader?
「\1\starget」は「<a href=".html""_blank"」がアウトなので \s 消去してあります。
$AV(_blank)は "・' 等、引用符のつけ分け方法が分からないので使ってません。
というか通常リンクに書き換えてしまった方がいいのでしょうか?orz
filter>>909
真ん中はJSのターゲット指定で効くように下をまねて書き換えたものです。
上は真ん中と下を無理やり1つにしてみました。
<a href="〜" onclick="window.open(this.href, '_blank'); return false;">
は_topにできましたが、マッチルールとかパーで適当にひっかかるようにしただけなので問題あるところの指摘、修正お願いします。
下は数年前から入れっぱなしなのでどこのかさっぱり忘れてしまいました…。Uploader?
「\1\starget」は「<a href=".html""_blank"」がアウトなので \s 消去してあります。
$AV(_blank)は "・' 等、引用符のつけ分け方法が分からないので使ってません。
というか通常リンクに書き換えてしまった方がいいのでしょうか?orz
911 :名無しさん@お腹いっぱい。:2007/05/26(土) 02:49:39 ID:jxjZUNDj0
912 :名無しさん@お腹いっぱい。:2007/05/26(土) 06:43:40 ID:6r0R6OvF0
>>886の2で頭じゃなく尻の方の</html>に引っ掛けるってのは何でなんでしょ?
913 :名無しさん@お腹いっぱい。:2007/05/26(土) 07:28:41 ID:M4chxe6v0
>>912
最後に代入したのが優先されるからでしょ。
でも、</html>が無かったり、2つあるサイトがあるんだよね(ほとんどがアダルトサイト)。
さらに、</html>のあとにスクリプトを自動挿入してるところもある。
最後に代入したのが優先されるからでしょ。
でも、</html>が無かったり、2つあるサイトがあるんだよね(ほとんどがアダルトサイト)。
さらに、</html>のあとにスクリプトを自動挿入してるところもある。
>>881-882
遅くなりましたがどうもありがとうございました。
HTMLページの場合でも文書先頭に挿入してはいけない場合もあるのですね。
>>905-906
それだと"-22"を含むドメイン全てにマッチしてしまいます。 amazon以外の所にもです。
$AV()の中の表現を書くのは難しいのでamazonのアフィリエイトURLの全ての種類をここに
貼って頂けたらこちらで最適化しようと思いますがどうでしょうか。
遅くなりましたがどうもありがとうございました。
HTMLページの場合でも文書先頭に挿入してはいけない場合もあるのですね。
>>905-906
それだと"-22"を含むドメイン全てにマッチしてしまいます。 amazon以外の所にもです。
$AV()の中の表現を書くのは難しいのでamazonのアフィリエイトURLの全ての種類をここに
貼って頂けたらこちらで最適化しようと思いますがどうでしょうか。
915 :名無しさん@お腹いっぱい。:2007/05/26(土) 08:16:47 ID:M4chxe6v0
ここにある「アマゾン強制アフィリエイト検出フィルター」が役に立つと思うよ
ttp://shinshu.fm/MHz/14.30/archives/0000177192.html
ttp://shinshu.fm/MHz/14.30/archives/0000177192.html
>>914に書いた
>それだと"-22"を含むドメイン全てにマッチしてしまいます。 amazon以外の所にもです。
は間違いでした、プロトコル部分が無いのでマッチしません。 失礼しました。
>>915
どうもありがとうございます。 そのフィルタは
・ディレクトリ型
・?tag型
の2つ(+URLエンコード)に対応しているようですが、>>905-906に書かれている.gifが出てきてませんね。
この.gifとはどういうURLにマッチさせたいのかが分からないままなのでやはりURL一覧を貼って頂けると助かります。
>それだと"-22"を含むドメイン全てにマッチしてしまいます。 amazon以外の所にもです。
は間違いでした、プロトコル部分が無いのでマッチしません。 失礼しました。
>>915
どうもありがとうございます。 そのフィルタは
・ディレクトリ型
・?tag型
の2つ(+URLエンコード)に対応しているようですが、>>905-906に書かれている.gifが出てきてませんね。
この.gifとはどういうURLにマッチさせたいのかが分からないままなのでやはりURL一覧を貼って頂けると助かります。
917 :名無しさん@お腹いっぱい。:2007/05/26(土) 09:02:21 ID:M4chxe6v0
アマゾンのアフィリンクはディレクトリ型と?tag=IDの2つだけだよ。
少し前にアマゾンストアに入店しただけで紹介料が発生したけど、すぐ廃止された。
.gifなんてのは無い。
少し前にアマゾンストアに入店しただけで紹介料が発生したけど、すぐ廃止された。
.gifなんてのは無い。
919 :名無しさん@お腹いっぱい。:2007/05/26(土) 13:31:49 ID:ObhYsORF0
ニュー速+など一部の板で
2ch Back Ground Changerが効かなくなってしまいました
どこを書き換えればよいか教えて下さい
2ch Back Ground Changerが効かなくなってしまいました
どこを書き換えればよいか教えて下さい
920 :名無しさん@お腹いっぱい。:2007/05/26(土) 21:46:35 ID:6r0R6OvF0
>>913
ああ、単純に頭に置くとその先で上書きされて無効になってしまう事もありえるからですか
ああ、単純に頭に置くとその先で上書きされて無効になってしまう事もありえるからですか
921 :名無しさん@お腹いっぱい。:2007/05/27(日) 01:29:51 ID:YCzAtXSu0
>>918
なんというのかわからないけど検索ボックスと言うのかな
自分は使わないしここは意味ないのかもしれないけどソース見ててなんとなく気になったから対応させておきました
ttp://www.golgo31.net/
この中のお勧め商品リンクの上のやつですね
意味ないなら.gif云々の部分削っちゃってもいいんですけど
なんというのかわからないけど検索ボックスと言うのかな
自分は使わないしここは意味ないのかもしれないけどソース見ててなんとなく気になったから対応させておきました
ttp://www.golgo31.net/
この中のお勧め商品リンクの上のやつですね
意味ないなら.gif云々の部分削っちゃってもいいんですけど
922 :名無しさん@お腹いっぱい。:2007/05/27(日) 23:20:28 ID:HD5RdDDu0
Icestream のページでいつも文字化けします。
文字コードをShift_JISにしないといけないと駄目なんですけど、
http://203.131.199.131:80**/ のURLのとき、meta タグのcharsetを
Shift_JIS に置き換えればうまくいくのではないかと考えております。
しかし、そのフィルターが完成できません。どなたか作成願えませんでしょうか
文字コードをShift_JISにしないといけないと駄目なんですけど、
http://203.131.199.131:80**/ のURLのとき、meta タグのcharsetを
Shift_JIS に置き換えればうまくいくのではないかと考えております。
しかし、そのフィルターが完成できません。どなたか作成願えませんでしょうか
お、書き忘れてしまった(;´Д`)
** の部分のポート番号には 8000 〜 8100 の間があります。
どうかよろしくお願いしますm( )m
** の部分のポート番号には 8000 〜 8100 の間があります。
どうかよろしくお願いしますm( )m
924 :名無しさん@お腹いっぱい。:2007/05/28(月) 01:00:16 ID:OtpZuF8u0
> ** の部分のポート番号には 8000 〜 8100 の間があります。
「**の部分」、じゃなくて、ポート番号部分全体が、だよな?
(ポート番号の有効範囲は 0 〜 65535 だし)
正確に書くように。
よう分からんがXMLの文字コード宣言も書き換えんといかんのでは?
[Patterns]
Name = "(No Name)"
Active = TRUE
URL = "203.131.199.131:[#8000:8100]/"
Limit = 512
Match = "encoding="UTF-8"\?>\0charset=UTF-8" />$STOP()"
Replace = "encoding="Shift_JIS"?>\0charset=Shift_JIS" />"
(常時ではないが)本文中に複数の文字コードが混在しているようだし、
どうあれ化けるときは化けると思うけど。
「**の部分」、じゃなくて、ポート番号部分全体が、だよな?
(ポート番号の有効範囲は 0 〜 65535 だし)
正確に書くように。
よう分からんがXMLの文字コード宣言も書き換えんといかんのでは?
[Patterns]
Name = "(No Name)"
Active = TRUE
URL = "203.131.199.131:[#8000:8100]/"
Limit = 512
Match = "encoding="UTF-8"\?>\0charset=UTF-8" />$STOP()"
Replace = "encoding="Shift_JIS"?>\0charset=Shift_JIS" />"
(常時ではないが)本文中に複数の文字コードが混在しているようだし、
どうあれ化けるときは化けると思うけど。
925 :名無しさん@お腹いっぱい。:2007/05/28(月) 01:05:22 ID:POU0zOby0
書き換えないで消しちゃえば?
>>921
ありがとうございます。 なるほど、.gifは検索フォームのボタン画像のURLでしたか。
ttp://www.golgo31.net/go-button.gif?tag=golgo31-22
ちなみにこのボタンのGIF画像(GO)はゴルゴ31サイト内にある画像なので
これにアフィIDを付けてもamazonには認識されまぜん。
つまりこの画像にアフィIDを付けてもサイト主さんには何のメリットも・・。
よってフォーム部分で書き換えなければいけないのは
<input name="tag" value="golgo31-22" type="hidden">
のところだけですね。 >>915さん紹介のフィルタが秀逸なのでそれを利用させてもらって書いてみます。
ありがとうございます。 なるほど、.gifは検索フォームのボタン画像のURLでしたか。
ttp://www.golgo31.net/go-button.gif?tag=golgo31-22
{kind=link}
ちなみにこのボタンのGIF画像(GO)はゴルゴ31サイト内にある画像なので
これにアフィIDを付けてもamazonには認識されまぜん。
つまりこの画像にアフィIDを付けてもサイト主さんには何のメリットも・・。
よってフォーム部分で書き換えなければいけないのは
<input name="tag" value="golgo31-22" type="hidden">
のところだけですね。 >>915さん紹介のフィルタが秀逸なのでそれを利用させてもらって書いてみます。
>>924-925
おーー!すげぇええ!ありがとうございます!
>>924さまのフィルタと>>925さまのアイデアを合成して文字化けが見事
無くなりました。僕はこのページを訪れるたび文字コードを変換する手間
を一年以上続けていた気がします。
>「**の部分」、じゃなくて、ポート番号部分全体が、だよな?
>(ポート番号の有効範囲は 0 〜 65535 だし)
すみませんでした。 ここのページは 8000, 8010, 8020, ... というよう
にプラス10刻みで8100まで、合計10ページ(?)あるのです。
どちらにしても説明が下手糞だな(;´Д`)
ありがとうございました!
おーー!すげぇええ!ありがとうございます!
>>924さまのフィルタと>>925さまのアイデアを合成して文字化けが見事
無くなりました。僕はこのページを訪れるたび文字コードを変換する手間
を一年以上続けていた気がします。
>「**の部分」、じゃなくて、ポート番号部分全体が、だよな?
>(ポート番号の有効範囲は 0 〜 65535 だし)
すみませんでした。 ここのページは 8000, 8010, 8020, ... というよう
にプラス10刻みで8100まで、合計10ページ(?)あるのです。
どちらにしても説明が下手糞だな(;´Д`)
ありがとうございました!
928 :名無しさん@お腹いっぱい。:2007/05/28(月) 21:43:29 ID:GmjNxnj80
その悩んでいた時間をマッチングの学習時間に割り当てた方がしあわせになれる。
文字コードを強制的に変更させるのは別に難しくないしなー。
文字コードを強制的に変更させるのは別に難しくないしなー。
929 :名無しさん@お腹いっぱい。:2007/05/29(火) 09:17:06 ID:WVgml4Ke0
ニコニコダウンロード追加フィルタきぼんぬ
>>921
試作品が出来たので公開ます。 動作確認が不十分なので人柱版ということで。 効かないページがあればご報告下さい。
メンテのしやすさの面からリンクとinputを別々のフィルタにしました。
それとWEBフィルタでアフィ判定するのには限界があるので>>915さん紹介のフィルタを併用することをお勧めします。
WEBフィルタでの判定はサイト主がその気になれば簡単に回避されてしまいますので。
[Patterns]
Name = "Amazon Affiliate Kill - link [2007-05-29]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 2048
Match = "(<a\s[^>]++href=)\0$AV((http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)[?/]"
"(((e|%65)(x|%78)(e|%65)(c|%63)/(o|%6f)(b|%62)(i|%69)(d|%64)(o|%6f)(s|%73)|(o|%6f))/"
"(A|%41)(S|%53)(I|%49)(N|%4e)/[0-9A-Z%]+{10,30}/|*(\?|%26|%3f|\&(amp(;|)|))(t|%74)"
"(a|%61)(g|%67)(\=|%3d)))\1([0-9a-z_%-]++{1,*}(-|%2d)(2|%32)(2|%32)"
"(^[a-z0-9]|%((3[0-9])|[46][1-9a-f]|[57][0-9a]))*)\2)"
Replace = "\0"\1AAK\2""
[Patterns]
Name = "Amazon Affiliate Kill - Form input [2007-05-29]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "<form\s[^>]++action=$AV(http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)/*)$SET(amazonF=on)(^?)"
"|<input\s(([^>]++value=)\0$AV(\1-22)([^>]+)\2(^(^>))&&[^>]++name=$AV(tag)*)$TST(amazonF=on)"
"|</form(\s*|)(^(^>))$SET(amazonF=)(^?)"
Replace = "<input \0"AAK\1-22"\2"
試作品が出来たので公開ます。 動作確認が不十分なので人柱版ということで。 効かないページがあればご報告下さい。
メンテのしやすさの面からリンクとinputを別々のフィルタにしました。
それとWEBフィルタでアフィ判定するのには限界があるので>>915さん紹介のフィルタを併用することをお勧めします。
WEBフィルタでの判定はサイト主がその気になれば簡単に回避されてしまいますので。
[Patterns]
Name = "Amazon Affiliate Kill - link [2007-05-29]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 2048
Match = "(<a\s[^>]++href=)\0$AV((http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)[?/]"
"(((e|%65)(x|%78)(e|%65)(c|%63)/(o|%6f)(b|%62)(i|%69)(d|%64)(o|%6f)(s|%73)|(o|%6f))/"
"(A|%41)(S|%53)(I|%49)(N|%4e)/[0-9A-Z%]+{10,30}/|*(\?|%26|%3f|\&(amp(;|)|))(t|%74)"
"(a|%61)(g|%67)(\=|%3d)))\1([0-9a-z_%-]++{1,*}(-|%2d)(2|%32)(2|%32)"
"(^[a-z0-9]|%((3[0-9])|[46][1-9a-f]|[57][0-9a]))*)\2)"
Replace = "\0"\1AAK\2""
[Patterns]
Name = "Amazon Affiliate Kill - Form input [2007-05-29]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "<form\s[^>]++action=$AV(http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)/*)$SET(amazonF=on)(^?)"
"|<input\s(([^>]++value=)\0$AV(\1-22)([^>]+)\2(^(^>))&&[^>]++name=$AV(tag)*)$TST(amazonF=on)"
"|</form(\s*|)(^(^>))$SET(amazonF=)(^?)"
Replace = "<input \0"AAK\1-22"\2"
931 :名無しさん@お腹いっぱい。:2007/05/30(水) 01:27:58 ID:Sa+Rv2gj0
とりあえずみんなフィルタまとめてWikiにあげてよ。
932 :名無しさん@お腹いっぱい。:2007/05/30(水) 07:35:22 ID:Hs0/ZwZ30
どんどんいろんなフィルターが追加されて何が必要かさっぱりわからん状況・・・
最近グーグルAD更新された?結果にスポンサーの枠がよくでるようになった
最近グーグルAD更新された?結果にスポンサーの枠がよくでるようになった
おかしな挙動に遭遇したから報告。
[Patterns]
Name = "test ABC\0(^(^E))"
Active = TRUE
Limit = 256
Match = "ABC\0(^(^E))"
Replace = "ABC[\0]"
テスト用文字列: ABCDEF
結果: ABC[DEF]
結果は "ABC[D]" になるものと思っていたら何故か "F" までの文字列が代入されていた。
後ろに "E" があるかどうかの判定は出来ているが、代入時に "\0" が最長一致になっている模様。
>>929
think氏のサイトにありましたよ。>>1
[Patterns]
Name = "test ABC\0(^(^E))"
Active = TRUE
Limit = 256
Match = "ABC\0(^(^E))"
Replace = "ABC[\0]"
テスト用文字列: ABCDEF
結果: ABC[DEF]
結果は "ABC[D]" になるものと思っていたら何故か "F" までの文字列が代入されていた。
後ろに "E" があるかどうかの判定は出来ているが、代入時に "\0" が最長一致になっている模様。
>>929
think氏のサイトにありましたよ。>>1
934 :名無しさん@お腹いっぱい。:2007/05/30(水) 19:51:08 ID:yH+E72Rs0
>>933
それって、*(\0〜\9と同じ動作)は最後に使われると最長一致になるという既知の仕様じゃないかな。
http://abc.s65.xrea.com/prox/wiki/MatchingRules/#asterisk
>>930
ポート番号は80番だけでいいんじゃないかな。
それと「amazon.co.jp:000080/」とか「amazon.co.jp:/」という表現もあるよ。
>>915みたいなヘッダフィルタだとポート番号は無視されるらしいけど。
ところで>>915が少し修正されてる。
それって、*(\0〜\9と同じ動作)は最後に使われると最長一致になるという既知の仕様じゃないかな。
http://abc.s65.xrea.com/prox/wiki/MatchingRules/#asterisk
>>930
ポート番号は80番だけでいいんじゃないかな。
それと「amazon.co.jp:000080/」とか「amazon.co.jp:/」という表現もあるよ。
>>915みたいなヘッダフィルタだとポート番号は無視されるらしいけど。
ところで>>915が少し修正されてる。
>>934
私がおかしいなと思った点は "(^(^E))" が後ろにあり、かつ "(^(^E))" にマッチしているにも
関わらず最長一致になることです。 ここに違和感を感じるのは自分だけかな。
ポート番号はマッチ判定する上で重要ではないので80に絞る必要は無いです。
httpsの場合は80じゃなく443になったりしますし。 今のところこの2つに絞っても問題無いですけど。
>「amazon.co.jp:000080/」とか「amazon.co.jp:/」
こういう書き方は他にも色々出来ますが対応させてたらキリが無いので・・・。
>ヘッダフィルタだとポート番号は無視される
これは無視されません。 お使いのブラウザがURLからポート番号(80)を消してるだけだと思います。
> >>915が少し修正されてる。
あれれ、>>930は修正前のフィルタを元に書いたものなのでこちらも修正が必要かも。
私がおかしいなと思った点は "(^(^E))" が後ろにあり、かつ "(^(^E))" にマッチしているにも
関わらず最長一致になることです。 ここに違和感を感じるのは自分だけかな。
ポート番号はマッチ判定する上で重要ではないので80に絞る必要は無いです。
httpsの場合は80じゃなく443になったりしますし。 今のところこの2つに絞っても問題無いですけど。
>「amazon.co.jp:000080/」とか「amazon.co.jp:/」
こういう書き方は他にも色々出来ますが対応させてたらキリが無いので・・・。
>ヘッダフィルタだとポート番号は無視される
これは無視されません。 お使いのブラウザがURLからポート番号(80)を消してるだけだと思います。
> >>915が少し修正されてる。
あれれ、>>930は修正前のフィルタを元に書いたものなのでこちらも修正が必要かも。
936 :think ◆MM0nnAOCiQ :2007/05/31(木) 00:04:55 ID:b8t/iUm00
>>933
詳しい原理は知りませんが、「アスタリスクの後に肯定先読みor否定先読みを置いても期待通りに動作しない」という印象を持っています。
ですので、
Match = "ABC\0(^(^E))"
は
Match = "ABC\([^E]+)0(^(^E))"
と書くことで、解決するのが妥当な線だと思います。
(解決法ではなく、原理を知りたいのだと思いますが、当座の打開策として書いておきます)
詳しい原理は知りませんが、「アスタリスクの後に肯定先読みor否定先読みを置いても期待通りに動作しない」という印象を持っています。
ですので、
Match = "ABC\0(^(^E))"
は
Match = "ABC\([^E]+)0(^(^E))"
と書くことで、解決するのが妥当な線だと思います。
(解決法ではなく、原理を知りたいのだと思いますが、当座の打開策として書いておきます)
>>936
ありがとうございます。 その方法は>>930の2つ目のフィルタで使いました。(Match欄の2行目)
3行目にも使うべきところがあったので後で修正しておきます。
原理は不明ですが動作的には下の2つは同じようです。
Match = "ABC\0(^(^E))"
Match = "ABC(\0&*E)"
>Match = "ABC\([^E]+)0(^(^E))"
これは Match = "ABC([^E]+)\0(^(^E))" ですねw
ありがとうございます。 その方法は>>930の2つ目のフィルタで使いました。(Match欄の2行目)
3行目にも使うべきところがあったので後で修正しておきます。
原理は不明ですが動作的には下の2つは同じようです。
Match = "ABC\0(^(^E))"
Match = "ABC(\0&*E)"
>Match = "ABC\([^E]+)0(^(^E))"
これは Match = "ABC([^E]+)\0(^(^E))" ですねw
>>930を更新しました。 >>915のフィルタの修正に対応、その他の微修正。
[Patterns]
Name = "Amazon Affiliate Kill - link [2007-05-31]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 2048
Match = "(<a\s[^>]++href=)\0$AV((http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)[?/]"
"(((e|%65)(x|%78)(e|%65)(c|%63)/(o|%6f)(b|%62)(i|%69)(d|%64)(o|%6f)(s|%73)|(o|%6f))/"
"(A|%41)(S|%53)(I|%49)(N|%4e)/([^?]++/)++|*(\?|%26|%3f|\&(amp(;|)|))(t|%74)"
"(a|%61)(g|%67)(\=|%3d)))\1([0-9a-z_%-]++{1,*}(-|%2d)(2|%32)(2|%32)"
"(^[a-z0-9]|%((3[0-9])|[46][1-9a-f]|[57][0-9a]))*)\2)"
Replace = "\0"\1AAK\2""
[Patterns]
Name = "Amazon Affiliate Kill - Form input [2007-05-31]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "<form\s[^>]++action=$AV(http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)/*)"
"$SET(amazonF=on)(^?)|<input\s(([^>]++value=)\0$AV(\1(-|%2d)(2|%32)(2|%32))"
"([^>]+)\2(^(^>))&&[^>]++name=$AV(*(t|%74)(a|%61)(g|%67))*)$TST(amazonF=on)"
"|</form(\s[^>]+|)(^(^>))$SET(amazonF=)(^?)"
Replace = "<input \0"AAK\1-22"\2"
[Patterns]
Name = "Amazon Affiliate Kill - link [2007-05-31]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 2048
Match = "(<a\s[^>]++href=)\0$AV((http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)[?/]"
"(((e|%65)(x|%78)(e|%65)(c|%63)/(o|%6f)(b|%62)(i|%69)(d|%64)(o|%6f)(s|%73)|(o|%6f))/"
"(A|%41)(S|%53)(I|%49)(N|%4e)/([^?]++/)++|*(\?|%26|%3f|\&(amp(;|)|))(t|%74)"
"(a|%61)(g|%67)(\=|%3d)))\1([0-9a-z_%-]++{1,*}(-|%2d)(2|%32)(2|%32)"
"(^[a-z0-9]|%((3[0-9])|[46][1-9a-f]|[57][0-9a]))*)\2)"
Replace = "\0"\1AAK\2""
[Patterns]
Name = "Amazon Affiliate Kill - Form input [2007-05-31]"
Active = TRUE
URL = "$TYPE(htm)"
Limit = 512
Match = "<form\s[^>]++action=$AV(http(s|)://([^/]++.|)amazon.(co.jp|jp|com)(:[0-9]+{1,5}|)/*)"
"$SET(amazonF=on)(^?)|<input\s(([^>]++value=)\0$AV(\1(-|%2d)(2|%32)(2|%32))"
"([^>]+)\2(^(^>))&&[^>]++name=$AV(*(t|%74)(a|%61)(g|%67))*)$TST(amazonF=on)"
"|</form(\s[^>]+|)(^(^>))$SET(amazonF=)(^?)"
Replace = "<input \0"AAK\1-22"\2"
940 :名無しさん@お腹いっぱい。:2007/05/31(木) 02:10:49 ID:wK9IrGBg0
ブラクラ対策フィルタってもうないの?
よく張られてる奴は消えちゃってるんだけど
よく張られてる奴は消えちゃってるんだけど
941 :名無しさん@お腹いっぱい。:2007/05/31(木) 20:05:37 ID:tsdvSsho0
誤爆が多く使い物にはならん
素直にキルURLファイルに登録したほうが安全
素直にキルURLファイルに登録したほうが安全
942 :名無しさん@お腹いっぱい。:2007/05/31(木) 20:31:03 ID:wK9IrGBg0
tableタグが5個以上あると消すみたいなフィルタ欲しい。
table大量に書いて処理落ちさせるブラクラ怖いよ
table大量に書いて処理落ちさせるブラクラ怖いよ
943 :名無しさん@お腹いっぱい。:2007/05/31(木) 20:40:26 ID:o3TfI2Z50
どなたか、目欄が空白の書き込みを削除するフィルターを作っていただけないでしょうか?
お願いします
お願いします
944 :名無しさん@お腹いっぱい。:2007/05/31(木) 21:21:44 ID:gCj4V9Ad0
>942
table が入れ子で5つ以上ってこと?
単純に、1ページ中に table が5つ以上あったら消すってことになると
多くのサイトが消えてしまいそうだが……。
デフォルトのフィルタだったかに、多重階層の table をどうこうするフィルタがあったと思う。
"Kill Excessively Nested Tables" ってのが検索でかかったけど、これだったっけか?
table が入れ子で5つ以上ってこと?
単純に、1ページ中に table が5つ以上あったら消すってことになると
多くのサイトが消えてしまいそうだが……。
デフォルトのフィルタだったかに、多重階層の table をどうこうするフィルタがあったと思う。
"Kill Excessively Nested Tables" ってのが検索でかかったけど、これだったっけか?
945 :名無しさん@お腹いっぱい。:2007/05/31(木) 22:51:02 ID:Nw/2P6Ct0
>>943
とりあえずIEで確認。
Name = "test"
Active = TRUE
URL = "[0-9a-z]+.2ch.net/"
Limit = 100
Match = "<dt>[0-9]+ [%81][%46](^<a href=$AV(mailto:*)>)"
Replace = "<dt style="display: none;">"
とりあえずIEで確認。
Name = "test"
Active = TRUE
URL = "[0-9a-z]+.2ch.net/"
Limit = 100
Match = "<dt>[0-9]+ [%81][%46](^<a href=$AV(mailto:*)>)"
Replace = "<dt style="display: none;">"
946 :名無しさん@お腹いっぱい。:2007/05/31(木) 23:43:34 ID:9b4ITR+b0
>945
サンクス
書き忘れたんだけどfirefox+bbs2chreader新バージョン用でお願いしたいです
↓自分で変えてみたんだけどこれだとだめでした
Name = "test"
Active = TRUE
URL = "localhost:8823/"
Limit = 100
Match = "<dt>[0-9]+ [%81][%46](^<a href=$AV(mailto:*)>)"
Replace = "<dt style="display: none;">"
サンクス
書き忘れたんだけどfirefox+bbs2chreader新バージョン用でお願いしたいです
↓自分で変えてみたんだけどこれだとだめでした
Name = "test"
Active = TRUE
URL = "localhost:8823/"
Limit = 100
Match = "<dt>[0-9]+ [%81][%46](^<a href=$AV(mailto:*)>)"
Replace = "<dt style="display: none;">"
947 :名無しさん@お腹いっぱい。:2007/06/01(金) 06:04:24 ID:HnL7aYbc0
目欄が空白の書き込みとか専ブラ使おうぜ
948 :名無しさん@お腹いっぱい。:2007/06/01(金) 06:12:00 ID:eiRhC7fK0
スレ違いになっちゃうけど、専ブラだと空白の書き込みもあぼーんできるんですか?
949 :名無しさん@お腹いっぱい。:2007/06/01(金) 06:40:03 ID:HnL7aYbc0
950 :名無しさん@お腹いっぱい。:2007/06/01(金) 07:00:13 ID:d7THi53f0
ある意味専ブラだと思うよ。
bbs2chreader+Foxage2chで専ブラの機能は果たしているだろう。
bbs2chreader+Foxage2chで専ブラの機能は果たしているだろう。
951 :名無しさん@お腹いっぱい。:2007/06/01(金) 07:13:15 ID:ZSm03RpP0
>949
どうやら toc 氏のブラクラ対策フィルタの中にあったもよう。
サイト閉鎖済だし、Internet Archive にも google のキャッシュにも見つからなかった。
誰かが保存していたら転載してもらうか、新規に書くしかなさそう。
どうやら toc 氏のブラクラ対策フィルタの中にあったもよう。
サイト閉鎖済だし、Internet Archive にも google のキャッシュにも見つからなかった。
誰かが保存していたら転載してもらうか、新規に書くしかなさそう。
952 :名無しさん@お腹いっぱい。:2007/06/01(金) 08:20:46 ID:tetpjSRU0
これ?
[Patterns]
Name = "Kill Excessively Nested Tables (2002/05/14)"
Active = TRUE
URL = "^$LST(SafeList)"
Bounds = "< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*
< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>"
Limit = 2000
Match = "< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*"
"< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>"
"$SET(#=<font size=1 color=red>[Excessively Nested Tables Found]</font>\k)"
Replace = "\@"
[Patterns]
Name = "Kill Excessively Nested Tables (2002/05/14)"
Active = TRUE
URL = "^$LST(SafeList)"
Bounds = "< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*
< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>*< (/|) table [^>]+>"
Limit = 2000
Match = "< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*"
"< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>*< table [^>]+>"
"$SET(#=<font size=1 color=red>[Excessively Nested Tables Found]</font>\k)"
Replace = "\@"
953 :名無しさん@お腹いっぱい。:2007/06/01(金) 08:24:54 ID:+TUjeUXE0
toc氏って Replace = "\@" が好きだよな
懐かしい
懐かしい
954 :名無しさん@お腹いっぱい。:2007/06/01(金) 08:56:41 ID:HnL7aYbc0
>>952
ありがとう
ありがとう
955 :名無しさん@お腹いっぱい。:2007/06/01(金) 16:06:27 ID:v9japScR0
Wikiのヘッダーなんだよ
956 :think ◆MM0nnAOCiQ :2007/06/01(金) 16:50:16 ID:99X490cV0
>>952
そのフィルタ正常に動作していますか?
<table>
<table><table><table><table><table><table><table><table><table><table>
</table></table></table></table></table></table></table></table></table></table>
</table>
をテストウインドウでテストしても、マッチしないのです。
また、<table> の入れ子をチェックしていないように見えます。
# <table> が入れ子で5つ以上存在するとき、<table> を削除した上で、以降の接続を切断するフィルタをWikiに投稿しておきました。
AntiBrowserCrasher - Proxomitron等に関するWiki
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#j272fb3d
そのフィルタ正常に動作していますか?
<table>
<table><table><table><table><table><table><table><table><table><table>
</table></table></table></table></table></table></table></table></table></table>
</table>
をテストウインドウでテストしても、マッチしないのです。
また、<table> の入れ子をチェックしていないように見えます。
# <table> が入れ子で5つ以上存在するとき、<table> を削除した上で、以降の接続を切断するフィルタをWikiに投稿しておきました。
AntiBrowserCrasher - Proxomitron等に関するWiki
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#j272fb3d
957 :名無しさん@お腹いっぱい。:2007/06/01(金) 17:56:19 ID:ZSm03RpP0
変数で階層をカウントしないとだめかと思ったものの、こんなやり方があるんだね。
(^</table>)?)++
これは汎用的に使えそうなテクニックだね。
(^</table>)?)++
これは汎用的に使えそうなテクニックだね。
958 :think ◆MM0nnAOCiQ :2007/06/01(金) 20:16:38 ID:99X490cV0
mailtoストームを追記。
AntiBrowserCrasher - Proxomitron等に関するWiki
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#md6b6091
しかし、最近はブラクラを見ませんね…。
AntiBrowserCrasher - Proxomitron等に関するWiki
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#md6b6091
しかし、最近はブラクラを見ませんね…。
959 :think ◆MM0nnAOCiQ :2007/06/01(金) 20:41:53 ID:99X490cV0
「FDD/CD-ROM アタック」を追加しました。
AntiBrowserCrasher - FDD/CD-ROM アタック
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#ybdea2dc
「JavaScript でブラクラを出力する」はJavaScriptで書き換えれば回避出来そうです。
AntiBrowserCrasher - FDD/CD-ROM アタック
ttp://abc.s65.xrea.com/prox/wiki/AntiBrowserCrasher/#ybdea2dc
「JavaScript でブラクラを出力する」はJavaScriptで書き換えれば回避出来そうです。
960 :名無しさん@お腹いっぱい。:2007/06/01(金) 20:48:04 ID:v9japScR0
961 :名無しさん@お腹いっぱい。:2007/06/01(金) 20:50:25 ID:fLErzxDu0
>>958-959
Protocol src killerとLocal File Access Killerじゃダメなの?
http://www.pluto.dti.ne.jp/~tengu/proxomitron/newfilters.html
Protocol src killerとLocal File Access Killerじゃダメなの?
http://www.pluto.dti.ne.jp/~tengu/proxomitron/newfilters.html
962 :think ◆MM0nnAOCiQ :2007/06/01(金) 21:47:03 ID:99X490cV0
>>961
>958-959のブラクラは防げているので、良いと思います。
厳密には、「Local File Access Killer (2003/05/19)」で
<img title="file:///C:/test/test.html" src="./test.png">
にマッチしてしまう点が望ましくないですが…。
>958-959のブラクラは防げているので、良いと思います。
厳密には、「Local File Access Killer (2003/05/19)」で
<img title="file:///C:/test/test.html" src="./test.png">
にマッチしてしまう点が望ましくないですが…。
963 :think ◆MM0nnAOCiQ :2007/06/01(金) 21:51:11 ID:99X490cV0
「Local File Access Killer (2003/05/19)」で気になったのですが、conconクラッシャーの検出で
<img src="c:/con/contact.html">
にマッチするのは、意図通りなのでしょうか?
ファイル名(フォルダ名)が「con」と「contact」なので、conconクラッシャーにならない気がしています。
ブラウザクラッシャー - Wikipedia
ttp://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%82%A6%E3%82%B6%E3%82%AF%E3%83%A9%E3%83%83%E3%82%B7%E3%83%A3%E3%83%BC#concon_.E3.82.AF.E3.83.A9.E3.83.83.E3.82.B7.E3.83.A3.E3.83.BC
CONCON問題
ttp://web.archive.org/web/20010502030150/http://jove.prohosting.com/~freepiro/concon.htm
FAT、HPFS、NTFS ファイル システムについて
ttp://support.microsoft.com/kb/100108/ja
「Protocol src killer (2003/05/18)」の
$AV((...|http://[^/]++:[0-9]++(/|)("|>|\s))*)
も何のための表現かわかりませんでした。
<img src="c:/con/contact.html">
にマッチするのは、意図通りなのでしょうか?
ファイル名(フォルダ名)が「con」と「contact」なので、conconクラッシャーにならない気がしています。
ブラウザクラッシャー - Wikipedia
ttp://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%82%A6%E3%82%B6%E3%82%AF%E3%83%A9%E3%83%83%E3%82%B7%E3%83%A3%E3%83%BC#concon_.E3.82.AF.E3.83.A9.E3.83.83.E3.82.B7.E3.83.A3.E3.83.BC
CONCON問題
ttp://web.archive.org/web/20010502030150/http://jove.prohosting.com/~freepiro/concon.htm
FAT、HPFS、NTFS ファイル システムについて
ttp://support.microsoft.com/kb/100108/ja
「Protocol src killer (2003/05/18)」の
$AV((...|http://[^/]++:[0-9]++(/|)("|>|\s))*)
も何のための表現かわかりませんでした。
964 :名無しさん@お腹いっぱい。:2007/06/01(金) 22:06:27 ID:VIdUoGC90
think暇だな。
一体何時間張り付いてるんだよ。
一体何時間張り付いてるんだよ。
965 :名無しさん@お腹いっぱい。:2007/06/01(金) 22:14:13 ID:fLErzxDu0
>>963
conという名前のディレクトリは作れないんじゃない?
conという名前のディレクトリは作れないんじゃない?
966 :名無しさん@お腹いっぱい。:2007/06/01(金) 22:27:15 ID:+OqPkeGU0
Vectorでダウンロードする意志があったら直ちにirvineに追加するように出来ませんか?
たとえばこの画面で
http://www.vector.co.jp/soft/winnt/business/se418428.html
ダウンロード・お支払いボタンを押したらirvineに登録させるようなやつです
たとえばこの画面で
http://www.vector.co.jp/soft/winnt/business/se418428.html
ダウンロード・お支払いボタンを押したらirvineに登録させるようなやつです
967 :966:2007/06/01(金) 22:48:15 ID:+OqPkeGU0
htmlの解析は出来るんでしょうか???
ソフト紹介ページ(最初のページ)
http://www.vector.co.jp/soft/winnt/business/se418428.html
ダウンロード・お支払いのページ
http://www.vector.co.jp/soft/dl/winnt/business/se418428.html
このページの中身で、
<a class="button" href="/download/file/ で始まる部分を検索して
/download/file/winnt/business/fh428922.htmlをゲット
先頭にhttp://www.vector.co.jpを追加した先の内容から
「しばらく待ってもダウンロードが始まらない場合は」で始まる部分の後のアドレスが
ダウンしたいファイルのアドレスです・・・
ソフト紹介ページ(最初のページ)
http://www.vector.co.jp/soft/winnt/business/se418428.html
ダウンロード・お支払いのページ
http://www.vector.co.jp/soft/dl/winnt/business/se418428.html
このページの中身で、
<a class="button" href="/download/file/ で始まる部分を検索して
/download/file/winnt/business/fh428922.htmlをゲット
先頭にhttp://www.vector.co.jpを追加した先の内容から
「しばらく待ってもダウンロードが始まらない場合は」で始まる部分の後のアドレスが
ダウンしたいファイルのアドレスです・・・
968 :think ◆MM0nnAOCiQ :2007/06/01(金) 23:07:19 ID:99X490cV0
>>965
htmlにパスを書き込めれば、conconバグが誘発されるので、ディレクトリを作る必要はないと思います。
htmlにパスを書き込めれば、conconバグが誘発されるので、ディレクトリを作る必要はないと思います。
969 :名無しさん@お腹いっぱい。:2007/06/01(金) 23:10:00 ID:dovQaK750
conconクラッシャー対策って必要なのか?
NT系OSだと無効だが
NT系OSだと無効だが
970 :名無しさん@お腹いっぱい。:2007/06/01(金) 23:56:46 ID:ptD10WOa0
物理的ブラクラなんて年単位で遭遇してない気がするけど、今さら対策必要?
971 :名無しさん@お腹いっぱい。:2007/06/02(土) 00:24:23 ID:wfZMZyWs0
googleの検索結果の表示に、日本語とローマ字があった場合
ローマ字のみにクリアタイプが効いてしまって読みづらいんですが
何とかなるフィルタありませんか?
ローマ字のみにクリアタイプが効いてしまって読みづらいんですが
何とかなるフィルタありませんか?
972 :think ◆MM0nnAOCiQ :2007/06/02(土) 00:42:21 ID:+H6u/Vo80
>>969-970
対策のためというよりは、興味本位ですw
せっかく、Wikiにページが用意してあるので、空いている欄を埋めてみようと。
最近のブラウザなら特別な対策を取らなくても問題ないと私も思います。
# 「FDD/CD-ROM アタック」がIE7で有効だったことには驚きましたが…。
>>971
使用しているブラウザはIE7ですか?
IE7 メモ - ページ表示領域でアルファベット文字が滲むようになりました
http://vird2002.s8.xrea.com/web/ie7_memo.html#alphabet_blur
対策のためというよりは、興味本位ですw
せっかく、Wikiにページが用意してあるので、空いている欄を埋めてみようと。
最近のブラウザなら特別な対策を取らなくても問題ないと私も思います。
# 「FDD/CD-ROM アタック」がIE7で有効だったことには驚きましたが…。
>>971
使用しているブラウザはIE7ですか?
IE7 メモ - ページ表示領域でアルファベット文字が滲むようになりました
http://vird2002.s8.xrea.com/web/ie7_memo.html#alphabet_blur
973 :名無しさん@お腹いっぱい。:2007/06/02(土) 01:25:25 ID:wfZMZyWs0
974 :名無しさん@お腹いっぱい。:2007/06/02(土) 01:56:10 ID:zNmEYUT90
昔、特定の文字コードのページだか、
ブラウザで英語圏の言語を最優先にしてると、
英字部分がTimes New Romanになったことがある。
関係ないか。
ブラウザで英語圏の言語を最優先にしてると、
英字部分がTimes New Romanになったことがある。
関係ないか。
975 :966:2007/06/02(土) 02:34:09 ID:7UwZaQ1R0
おねがいします
976 :名無しさん@お腹いっぱい。:2007/06/02(土) 04:56:25 ID:JVcp/xGU0
リストに入ってるサーバーの場合セキュリティソフトとかで、
リファラを遮断するような設定でも強制的に
リファラを送るフィルタ見たいなのが欲しいんだけどそういうのないかな?
リファラを遮断するような設定でも強制的に
リファラを送るフィルタ見たいなのが欲しいんだけどそういうのないかな?
977 :名無しさん@お腹いっぱい。:2007/06/02(土) 07:37:01 ID:YgFS8Afj0
オミトロン→そのソフト→サーバ だとどうしようもないが、
そのソフト→オミトロン→サーバ だと、既にRefererが消えているのでどうしようもない
そのソフト→オミトロン→サーバ だと、既にRefererが消えているのでどうしようもない
>>968
ごめんそういう意味じゃない。
> <img src="c:/con/contact.html"> にマッチする意図
こんなパスは存在しないし、パスを指定している時点でそのページを疑った方が良い。
>>969
ブラクラページは1種類だけじゃなくて数十種類も仕掛けてることが多い。
ニュース速報系の板でそういのをよく見かける。
conconは目印にし易いから、その時点で\kすれば、他の未知のブラクラも防げる可能性がある。
ごめんそういう意味じゃない。
> <img src="c:/con/contact.html"> にマッチする意図
こんなパスは存在しないし、パスを指定している時点でそのページを疑った方が良い。
>>969
ブラクラページは1種類だけじゃなくて数十種類も仕掛けてることが多い。
ニュース速報系の板でそういのをよく見かける。
conconは目印にし易いから、その時点で\kすれば、他の未知のブラクラも防げる可能性がある。
979 :名無しさん@お腹いっぱい。:2007/06/02(土) 15:21:42 ID:0qg3cgFC0
>>978
なるほど、すまんかった
なるほど、すまんかった
980 :名無しさん@お腹いっぱい。:2007/06/02(土) 21:23:59 ID:sHtkwQrn0
ブラクラ発見
p://up.uppple. com/src/up3411.jpg
p://up.uppple. com/src/up3411.jpg
981 :名無しさん@お腹いっぱい。:2007/06/02(土) 21:30:25 ID:sHtkwQrn0
ソース見てみたらconconとかtelnetとか・・ 古典的すぎてワロタw
982 :名無しさん@お腹いっぱい。:2007/06/03(日) 00:16:06 ID:NcEebzvW0
フィルターまとめサイト作った方が良くないか?
983 :名無しさん@お腹いっぱい。:2007/06/03(日) 00:18:51 ID:yErYrFoM0
wkikiでいいじゃん
984 :名無しさん@お腹いっぱい。:2007/06/03(日) 00:33:24 ID:MXH6+nnd0
よろしくお願いします。
985 :名無しさん@お腹いっぱい。:2007/06/03(日) 01:10:15 ID:IrwaQ0qD0
無意味に情報を分散させるのは愚者のやること
986 :名無しさん@お腹いっぱい。:2007/06/03(日) 01:59:05 ID:NcEebzvW0
Wikiのフィルタ、リスト一覧なんて数あるフィルタの極僅かじゃん
987 :think ◆MM0nnAOCiQ :2007/06/03(日) 02:08:08 ID:q90CJcwT0
>>978
そういうことでしたか。
こちらこそ、早とちりしてすみません。
指摘された件ですが、UNIXでもデバイス名の制約を受けるのでしょうか?
制約がないとしても、Windowsのデバイス名を指定すべきではないということかもしれませんが、少し気になりました。
そういうことでしたか。
こちらこそ、早とちりしてすみません。
指摘された件ですが、UNIXでもデバイス名の制約を受けるのでしょうか?
制約がないとしても、Windowsのデバイス名を指定すべきではないということかもしれませんが、少し気になりました。
988 :名無しさん@お腹いっぱい。:2007/06/03(日) 04:41:44 ID:TU3AXuKA0
989 :名無しさん@お腹いっぱい。:2007/06/03(日) 09:25:26 ID:DXyyP9ko0
このスレの過去スレを集めたWebってないかい?
990 :名無しさん@お腹いっぱい。:2007/06/03(日) 10:29:43 ID:AAhcjta40
やってみればいいじゃん。
新しいうpろだだって最初はイラネって言われてたけど今ではこっちが主役な感じだし。
ただ、他人まかせにするつもりなら誰もやってくれないだろう。
新しいうpろだだって最初はイラネって言われてたけど今ではこっちが主役な感じだし。
ただ、他人まかせにするつもりなら誰もやってくれないだろう。
991 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:35:59 ID:RZ6xv2+x0
wkiki age
992 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:44:56 ID:K1bYT2tX0
993 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:45:15 ID:9vsiz++f0
994 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:45:37 ID:+H5gt8nA0
995 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:45:51 ID:X3G4Nv+G0
996 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:46:05 ID:NTi+Hq7Z0
997 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:46:21 ID:RWhASQyL0
998 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:46:46 ID:hT7fB/A10
999 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:47:23 ID:97JgZM3T0
↓1000取り馬鹿
1000 :名無しさん@お腹いっぱい。:2007/06/03(日) 17:53:35 ID:S9afMYMp0
\∧_ヘ / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
,,、,、,,, / \〇ノゝ∩ < 1000取り合戦、いくぞゴルァ!! ,,、,、,,,
/三√ ゚Д゚) / \____________ ,,、,、,,,
/三/| ゚U゚|\ ,,、,、,,, ,,、,、,,,
,,、,、,,, U (:::::::::::) ,,、,、,,, \オーーーーーーーッ!!/
//三/|三|\ ∧_∧∧_∧ ∧_∧∧_∧∧_∧∧_∧
∪ ∪ ( ) ( ) ( ) )
,,、,、,,, ,,、,、,,, ∧_∧∧_∧∧_∧ ∧_∧∧_∧∧_∧∧_∧
,,、,、,,, ( ) ( ) ( ) ( )
1001 :1001:
このスレッドは1000を超えました。
もう書けないので、新しいスレッドを立ててくださいです。。。
もう書けないので、新しいスレッドを立ててくださいです。。。