1 :
132人目の素数さん :
2005/08/13(土) 10:33:29 2 :
1 :2005/08/13(土) 10:42:40
他にも関連スレがあったら教えて。
3 :
132人目の素数さん :2005/08/13(土) 10:46:26
3get!!
4 :
132人目の素数さん :2005/08/13(土) 13:48:09
最小二乗法とかわけわかめ
5 :
132人目の素数さん :2005/08/13(土) 14:04:51
教科書読めとしか言いようがない。教科書をやさしめのやつに変えたら?
6 :
132人目の素数さん :2005/08/13(土) 14:08:18
安い感動だな
7 :
132人目の素数さん :2005/08/13(土) 14:54:04
工学部だけど正規分布やΧ二乗分布、F分布などの導出って覚えておくべき
8 :
132人目の素数さん :2005/08/13(土) 14:55:20
覚えることがまず第一。余力があれば導出も。
9 :
132人目の素数さん :2005/08/13(土) 15:09:52
Covarianceの定義って
>>9 前者は標本共分散、後者は確率変数の共分散。
後段は質問の体を成していないんで何が聞きたいのかは知らんが、最後の2行は、
σ^2≧Σ(|Xi-m|≧ε)≧ε^2Pr(|Xi-m|≧ε)
ゆえにσ^2/ε^2≧Pr(|Xi-m|≧ε)
だね。君の表記法に従えば。
11 :
132人目の素数さん :2005/08/13(土) 15:46:27
>>11 確率。(=Probability)
PだけよりもPrを使う方が一般的だと思うよ。
13 :
132人目の素数さん :2005/08/13(土) 22:27:22
Pは普通、確率空間の測度として使われるので、σー代数上での測度。
>>13 そだね。統計屋は確率空間上の確率測度よりは、確率変数に関する確率(というか分布の確率というかR上の確率というか)がメインだから、このスレにおいては一般的と書いてみた。
統計学の参考書を読んでたら
>>15 普通の母比率の検定。
帰無仮説:p=1/37
Z=|(140/3700)-p|/√((1/37)(1-1/37)/3700)
=4.0…
で帰無仮説は棄却。イカサマ。
下のほうに書いてるじゃん。
19 :
132人目の素数さん :2005/08/19(金) 08:28:29
age
>>18 そうかとおもって実際に計算してみたのですがうまくいきませんでした
tα / n はTINV(n,α)のことではないのでしょうか?
何度もすみません
>>22 TINVって、両側じゃないの?
Rで計算したら青木先生のものと一致しました。
って、青木先生も多分Rで計算したんだろうね。
>>22 だからTINV(2α/n,n-2)だな。これで合わないか?
25 :
132人目の素数さん :2005/08/19(金) 15:36:42
証明が丁寧で具体例も豊富な統計の本でおすすめなのはありますか?
>>23 ,24
TINVって両側だったんですね
失念しておりました。。。
無事計算することができました
どうもありがとうございました
>>25 数理統計学 稲垣宣生 裳華房
がいいんじゃなかろうか。
28 :
132人目の素数さん :2005/08/20(土) 03:11:03
>>27 ありがとうございます。
早速本屋で見てます。
早まるな! どの定理でもいいから証明を立ち読みしてみよ。
30 :
132人目の素数さん :2005/08/20(土) 20:25:11
下の問題の考え方がわかりません。
32 :
132人目の素数さん :2005/08/23(火) 01:25:52
質問
33 :
132人目の素数さん :2005/08/23(火) 01:54:11
東京大学教養学部統計学教室の「統計学入門」と同レベルな洋書の候補を
McGrowHill inrto2statics
ガンマ分布Γ(α,β)のパラメータをモーメント法を用いて推定したいのですが
>>36 標本モーメントが母集団モーメントに等しいという方程式を作って解けばいい。
38 :
GiantLeaves ◆6fN.Sojv5w :2005/08/24(水) 19:46:19
talk:
>>32 388^3998/389^4000*7998000
39 :
132人目の素数さん :2005/08/24(水) 23:59:35
ホーエルの数理統計学ってどう?
>>39 英語で読もうとしてるか?
自分が読んだ英語版が何版なのか忘れたが、一部で数式にミスがあった気がする。
まぁこの本だけに言えたことではないので、ある意味間違いを見抜く訓練にはなったが。
>>40 .41
thx
邦訳を読もうとしてます。
統計の本は応用志向ばかりで純粋数学なのはあんまりないですね。
43 :
132人目の素数さん :2005/08/26(金) 11:59:56
禿なんでまったくわからないんです。教えてください。
>>43 どちらも非常に答えづらい。
Aは検定をしたいのか推定をしたいのかわからんし、Bは最低限の基準もわからん。
それこそ、Aは1回ひいて0回、Bは1回、なんて答えでもその質問に対する答えとして間違いとはいえないから。
こっちで勝手に前提をおいて、~ということならこうだよ、って答えることもできるがめんどくさいし、前提の説明にまた労力がいる。
まずは「推定」、「検定」、「母比率の推定」、「母比率の検定」とかで検索してみな。
この場合は推定でしょうね。
疑問Bのほうはモデル選択(尤度の比較)なんてのもありそうです。
しかし、やはり
>>44 の言うとおり「母比率の推定」を調べてみてはいかがか。
46 :
132人目の素数さん :2005/08/28(日) 01:20:02
>>44 >>45 お答えありがとうございます。
どうやら問題があいまいすぎるみたいでしたね。
簡単な導き出し方があるのかなと思っていました。
75%の当選確率なら、100回抽選で60回~90回当選すれば
95%の確率で75%は正しいといえる。とか。
でも調べるべきものを教えていただいただけでも収穫です。
ありがとうございました。
47 :
132人目の素数さん :2005/09/01(木) 17:48:29
ベイズ統計学を研究に活用している方いらっしゃいますか?
48 :
132人目の素数さん :2005/09/02(金) 11:35:24
>47
49 :
132人目の素数さん :2005/09/03(土) 12:14:50
自由度があるから実務に向いているということかも
50 :
132人目の素数さん :2005/09/03(土) 12:55:38
accuracyって日本語でなんですか?
文脈によっていろいろだろ。
52 :
132人目の素数さん :2005/09/06(火) 01:48:08
主成分分析でQモードの主成分析とはどのようなものですか?
Mardia's Testについての詳細が書かれた書籍,WebPage等
統計学って数学なのか?
違うんじゃない?米国の大学だと数学科(部)とは独立して統計学科(部)があるのが普通。
工学
57 :
132人目の素数さん :2005/09/09(金) 23:14:02
今、イラスト・図解 確率・統計のしくみがわかる本―わからなかったことがよくわかる、確率・統計入門
>>58 すみません。他に適切なスレがどこにも無かったのでこちらで聞かせてもらいました。
どなたかお願いします。
61 :
名無しさん@そうだ選挙に行こう :2005/09/10(土) 22:10:01
標本分散の公式の、普通のやつと、簡単なやつ(エックスバーを使った、標本平均を使ったほう)
>61
63 :
名無しさん@そうだ選挙に行こう :2005/09/11(日) 19:21:02
教えてください。
判別分析について学習しているのですが,自分で実際にデータを使ってやってみたいと思っています
65 :
132人目の素数さん :2005/09/14(水) 07:40:26
マンガでわかる統計学の表紙の女の子がかわいい
いいんじゃね?
67 :
132人目の素数さん :2005/09/14(水) 18:59:46
>>65 俺あれ読んだけど、おすすめはしない。
図書館で借りてみたら?
確かに最初はわかりやすけど途中から話が一気に飛ぶから。
イラストばっかり使ってるからどうしても詳細な説明が抜けてる感じがする。
本当に勉強しようと思うなら数学的に解説している本1冊とエクセルを使って
演習する本両方で勉強したほうがいいと思う。特にエクセル使って演習すると
飛躍的に理解できるよ。
>>67 Excel 使うと理解が増すというのは、信じられないなー。
まぁ、そういう人がいてもおかしくないけどー。
だって、わざわざ手を使って Excel 動かさなくても、
頭の中で Excel 動かせば十分じゃないかー。
手と紙で例題をやるよりも、
70 :
GiantLeaves ◆6fN.Sojv5w :2005/09/14(水) 22:29:13
talk:
>>68 そんなことできるんだったら、コンピュータは要らないんだよ。
71 :
132人目の素数さん :2005/09/14(水) 22:45:34
少し質問させてください.
72 :
132人目の素数さん :2005/09/16(金) 07:28:09
今年の統計学会はどうでしたか?
73 :
132人目の素数さん :2005/09/16(金) 08:53:35
しょぼかったっす。
74 :
132人目の素数さん :2005/09/17(土) 07:08:08
と優香、毎年の統計学会退会者が多いと思わないか?
75 :
132人目の素数さん :2005/09/18(日) 21:52:21
すいません門外漢なので教えて下さい。
regression coefficient
77 :
75 :2005/09/18(日) 22:47:45
どうも有り難うございましたです。
78 :
132人目の素数さん :2005/09/19(月) 15:48:00
例えば、試料Aと試料Bをそれぞれ10回ずつ測定して、平均値と標準偏差がそれぞれ
検定すればわかると思います(きっぱり)。
「微妙だ」とか「適切」とかいう言葉を使っている時点でねぇ・・
僕も統計初心者なんですが、おそらく“スチューデント”のt検定とかでできるんじゃないでしょうか。
>>81 おそらく2標本t検定でいいとは思いますが、あなたの計算式はめちゃくちゃです。
83 :
132人目の素数さん :2005/09/20(火) 22:57:35
多変量解析をちゃんと勉強したいんですけど
>>83 奥野他「多変量解析法」が省略なしで丁寧だけど、嫌になっちゃうかも(レベル高いし)。
85 :
132人目の素数さん :2005/09/21(水) 00:37:47
>>84 39です。
他にもおすすめあれば教えてください。
86 :
132人目の素数さん :2005/09/21(水) 06:22:20
統計学を勉強しようと思います。
87 :
81 :2005/09/21(水) 08:37:57
あれれ? t = (x1 - x2) / (v1 - v2)だと思ってましたが・・・。
>>86 高橋信:『マンガでわかる統計学』(オーム社、2004)。
とにかく萌える。可愛い見掛けの割に意外と正攻法。
不評もあるがおれは名著だと思う。
89 :
132人目の素数さん :2005/09/21(水) 14:11:18
会社員だが。統計学を系統的に学べるところってないのでしょうか?
確率統計の教科書で名著と呼ばれているのは?
東大出版会の三部作あたりを挙げとけば無難か。
>>90 応用が念頭にあるのならば
>>91 でいいかもしれないけど、
統計学そのものに興味があるのなら稲垣宣生の「数理統計学」がおすすめ。
でも、本当に「名著」と呼ばれているのは和書には無いと思うし、洋書にも無いかも。
「確率統計」というと広すぎて...
確率論の教科書なら、Chung の A course in probability theory が断トツで有名かと。
94 :
132人目の素数さん :2005/09/25(日) 17:47:20
質問なんですが、今統計を勉強し始めました。今使ってるのは単位が取れるシリーズの統計ノートです。資格試験に使うのですが、この後どのような問題集をやればいいでしょうか。一応、サイエンス社の統計は以前本屋で見てきたんですが・・。
95 :
mik :2005/09/25(日) 23:01:48
質問なんですけど加法モデルと乗法モデルの違いてなんですか?
96 :
132人目の素数さん :2005/09/25(日) 23:39:23
>>95 まったく理解していないと思われ。
足し算モデルと掛け算モデルだよ?
理解していたらそんな質問は絶対にしね。
97 :
132人目の素数さん :2005/09/26(月) 18:39:54
質問なんですが,統計方法毎に,検定結果の記載(表現)例文が掲載されている
どんなときにはどの手法を使う、そして報告の仕方はこうだ、ってのが書いてある本を本屋で見かけたことがある。
あらゆる学部に統計の研究者がいてばらばらに研究してますな。
鳥居さんの「はじめての統計学」を読んで統計を独学中の者です。
成山堂「生物資源統計学」
102 :
◆Mjk4PcAe16 :2005/09/29(木) 22:56:19
コーシー分布の平均が中心極限定理に従わないのはなぜですか
>>103 中心極限定理なのだから直接の問題は平均が存在しないのが原因だと思うが・・・
分散は関係なくないけど関係ないべ
TVで「運命の数字」とかいう確率・統計バラエティ?番組を、休日に偶然
107 :
132人目の素数さん :2005/10/02(日) 06:40:21
純粋な統計学でなくて、応用統計ってどう学ぶ?
108 :
132人目の素数さん :2005/10/02(日) 07:55:21
統計学そのものが、かなーり応用的なものだと思うんだけど……
ものすごい応用統計ですかw
ものすごい応用統計って、統計学じゃないの?
>>111 それ三部作で一番ダメな奴、なぜにⅠとⅢ薦めずにⅡを薦めるかね
心理統計学とか社会統計学という本が出ているよ。
114 :
132人目の素数さん :2005/10/03(月) 19:46:36
すいません、今大学の授業で共分散構造分析とfishbeinモデルについて
統計的に見て多数って言うのはどのくらいのサンプルを取ってどのくらいの割合なら多数と言われるのでしょうか。
116 :
132人目の素数さん :2005/10/04(火) 21:00:40
今、統計入門の標準偏差のところを読んでいるのですが、意味がわからなくて…。・゚・(ノД`)・゚・。
>>115 手法ごとに「オススメのサンプル数」というのがある場合がある。
脱線するけど、自動的に多数のサンプルが取れてしまうような場合
(コンビニのレジとか、ネットワークのログとか)に、
サンプル数がむちゃくちゃ多くなって、
普通の検定だと何しても有意になってしまう。
こういう場合はどうすればいいんだー。
>>116 それだけの情報じゃ何がなんだか分からんけど、
標準偏差×ネイピア数(39.3×2.7183)が107くらい。
119 :
115 :2005/10/04(火) 22:03:24
>>117 ありがとうございます。
ついでにそういうお勧めのサンプル数。というのが乗っているサイトか本を教えてはいただけないでしょうか?
120 :
116 :2005/10/04(火) 23:06:00
>>118 ネイピア数ってどういったものなんでしょうか?
標準偏差の意味を考えた時、その根拠として正規分布があげられているのですが、(エックスバー-S,エックスバー+S)の区間に107個のデータが入り、その割合が107/143であるということを、正規分布表を用いて求めたのでしょうか?
>>117 サンプルが大量に取れてかつ、有意な結果とは思えない状況になっているなら
サンプルが一様に取れているかどうか確かめてみそ
検定の前提が上手く機能していない可能性大です
>>117 そんなときこそデータマイニングなのでは?
という答えじゃダメかな。
123 :
132人目の素数さん :2005/10/05(水) 10:07:40
>>117 まあ、
>>121 の言ってることにつきるけど、
外挿予測をしてみたり、Cross Validation で確かめてみたら?
124 :
117 :2005/10/05(水) 21:32:32
>>121-123 ありがとうございます。
なんせ自動ログなので、
一人の人間が何度もサンプル対象になっているかもしれないですし、
偏りがある可能性は大きいと思います。
個人情報に気を配る必要があって、
個人を識別できる情報は一切取れないのです。
データマイニングにも興味があるので、ちょっと書籍をあさってみます。
>>119 各手法の本に「この手法ならこのくらいサンプルを集めなさい」
というようなことが書いてあることがあります。
多次元尺度法であれば「10項目に対して行う場合は被験者は12人~15人以上」とか。
著者によってそこらへんはまちまちだったりするけど。
125 :
115 :2005/10/05(水) 21:36:48
>>124 ありがとうございます。
著者によってまちまち、という事は割と適当なんですね。
>>125 それこそ統計を確り勉強するだよ、必要な個数を計算するのは必ず入ってるから。
例えば母集団の平均を知りたいとします、精度と母集団の分布でコロコロ必要な個数は変わるので、精度が高い必要があるときには沢山データが必要だし、
もし母集団の分布が小さい範囲に集中しているなら、必要な個数は少なくても高い精度がでるのでOKといった感じです。
そして、母集団のもっと別のパラメータ、たとえば分散を知りたいとかなるとまたちょっと色々出てくるわけです。
127 :
132人目の素数さん :2005/10/05(水) 23:54:54
>>125 >126に概ね同意だが、若干補足。
>126も言っているが、とりあえず、推定量だけでなく、
その分散も計算したほうがいいということ。
そうすれば、サンプル数に応じた精度が分かるわけだし。
ただし、各サンプルの独立性などが満たされない場合、
分散は過小評価されこともあるので注意。
あと、t-分布やカイ二乗分布等を正規分布で近似する場合は、
ある程度サンプルがないと良い近似が得られない。
その場合、t-分布やカイ二乗分布等を直接計算するのも手だが、
面倒だったら、一般的に言われているサンプル数の
下限を目安にするのも手。
128 :
132人目の素数さん :2005/10/05(水) 23:59:02
πのn番目の数字をanとする。anの漸化式をたてて。
>>127 うーんどうかな、もし分かっているパラメータがあるならそれは計算するより固定してしまう方が個人的には好み
そして、こういう固定化可能なパラメータを沢山作り出すことが精度アップの第一歩だと思うんです。
そのためにはまず、現物のデータなり、データを作り出す対象を調べ上げる必要があると思うので、対象に対する深い考察が統計の第一歩だと考えています。
なんでもかんでも計算ばっかりやっていると、結果が何言っているのか分からない状態になることが多々あります、統計なんて所詮仮定・仮定そしてまた仮定と仮定ばっかりで、これを減らさないと良い物にはなりません。
それどころかトンデモ結論に達していること多々ありです、計算するよりもまずヒストグラムにするとかして、それを確認してから計算方法は決めるべきだと思います。
130 :
127 :2005/10/06(木) 12:27:46
>>129 モデルのパラメーターを決めないとモデルが使えない、というような
意味で言っているのなら分かるけど、ここではそんな多段階の推計が
問題になってるの?
少なくとも、パラメータを計算したときには(あとで固定するにしても)、
その分散推定量くらいはを出しておく必要があるし、また、最終的な推計
結果に推定誤差を示していない調査・研究は、appliedであっても、とても
まともとは思えない。
初めは、グラフを目で見て起っていることを確かめるのは当然だが、
むしろ計算ばっかりの結果っていうのは、誤差やモデルの前提条件の確認
をおざなりにした結果、結論が妥当でないというパターンが多い気が
するぞ。
131 :
132人目の素数さん :2005/10/06(木) 13:14:23
質問です。
132 :
132人目の素数さん :2005/10/06(木) 15:58:11
インターネットのアンケートの様な全体の何%が投票したのかも分からず
>>131 4回しか比較をしないのなら、有意水準を 1/4 にする、という方法で問題はありません。
ただ、ボンフェローニを使う必要があるか(もっと洗練された多重比較の方法があるのでは)?という気はします。
>>132 無限母集団を仮定できるのなら全体の何%かはあまり問題ではないが、
一人で何票でもというのは扱いにくい。
また、利用目的にもよるが、例えば「日本国民全体」を調べたい場合には、
一人一票でも「そのサイトにアクセスし、かつそのアンケートに積極的に投票したがる人」
というバイアスがかかってしまうと思う。
135 :
132人目の素数さん :2005/10/07(金) 03:46:36
>134
136 :
132人目の素数さん :2005/10/07(金) 13:09:29
何らかの属性情報(性別、住所、年収、135の例なら宗教など)
137 :
131 :2005/10/07(金) 14:00:51
>>133 亀レスだけど、返信ありがと。
確かにボンフェローニよりも適した方法があると思いますが、とりあえず間違いでなければ問題ありません。
まあインターネットのアンケートで投票回数を一人一回に制限するのは
しょうもない質問で恐縮なのですが、お暇でしたら答えてください。
専門家じゃないけど、答えていいかな
>>140 全体数は大きく異なります(因みにこれはDVDレコーダー販売シェア)。
うーん、じゃあ21%って微妙に意味分からん数字だよね
>>140 > 常識的には8.7%の減少って言うんじゃない?
日本語の場合パーセンテージの差分は普通「ポイント」と言います
(二つの百分率の値を比べた時の差:広辞苑)。つまり「8.7ポイントの減少」
統計の問題じゃないよね。
例えばシェアが10%から20%になったとすれば、+10ptというより、倍になったことを強調するため、シェア前年比+100%、なんていう言い方をすることもなくはないと思う。
ただ、
>>143 のいうようにパーセンテージの前年比較をする場合は差を+~pt(ポイント)という言い方を普通はするよ、経験上も。
上場企業のアニュアルレポートとかを見てみるといい。ちょっとソニーあたりを見てみたが、
「原価率は78.9%から2.9ポイント上昇して、81.8%になりました。」とかそういう表現になってるね、やっぱり。
シャピロ・ウィルク検定を勉強しているのですが
146 :
132人目の素数さん :2005/10/10(月) 10:44:17
たとえば3科目の中から2科目選択をさせて
147 :
132人目の素数さん :2005/10/10(月) 17:04:12
ベイズ推定って、ベイズの定理つかって事後確率だして
148 :
132人目の素数さん :2005/10/10(月) 18:44:58
質問が続いているところにまた質問で恐縮ですが……
>>146 得点を調整するのでなく、
そもそもの偏差値の合計で順位をつけるとか。
150 :
146 :2005/10/10(月) 22:17:35
>149
151 :
132人目の素数さん :2005/10/10(月) 22:26:34
>>148 正規分布はいいですか?
正規分布する確率変数(測定値)にある変換を施すことにより、t分布、カイ二乗分布、F分布に従う確率変数が得られます。
いずれも、いろいろな検定を行う上で必要になります。
まれにしか生じないイベントの個数はポアソン分布で近似されます。
放射性同位元素を観測しはじめてから崩壊するまでの時間は指数分布で近似されます。
コインを一定回数投げたとき、表が出る回数は二項分布に従います。
これらは全て、(適当な仮定を置くことにより)理論的に導かれます。
152 :
132人目の素数さん :2005/10/10(月) 22:42:43
1)26個の既知距離行列(90×90)がある。これらを最適化した行列を求めたい。
153 :
132人目の素数さん :2005/10/10(月) 22:43:27
また、この距離行列には欠損値があり、その扱いは除外する方向で
154 :
132人目の素数さん :2005/10/11(火) 16:03:55
>>151 なるほど。いろいろと実例をありがとうございます。
「t分布は、正規分布に関係している」といった断片的な知識はあったのですが……
どうもぼくは、まだ基本ができていないようなので、頂いた情報を元に、まずは正規分布から勉強を始めていきたいと思います。
ありがとうございました。
155 :
149 :2005/10/11(火) 20:06:34
>>150 必修科目があろうとなかろうと、偏差値だけで
ランク付けしてかまわないような気もします。
センター試験の得点調整だって、
けっこういい加減じゃなかったっけ。
統計のやり方について教えてください。
157 :
146 :2005/10/12(水) 21:22:31
>149
158 :
146 :2005/10/12(水) 21:26:28
以下が抜けました。補足します。
160 :
149 :2005/10/12(水) 22:51:47
ちょっと計算してみたけど、
161 :
146 :2005/10/15(土) 22:59:39
>159、160
162 :
132人目の素数さん :2005/10/17(月) 07:09:10
すみません卒論でSD法を使っているものなのですが、
163 :
132人目の素数さん :2005/10/17(月) 07:20:43
164 :
132人目の素数さん :2005/10/18(火) 14:07:50
統計処理の方法についてお尋ねします。
165 :
132人目の素数さん :2005/10/19(水) 21:54:01
標準偏差と標準誤差はどのように比べたらよいのでしょうか?
166 :
132人目の素数さん :2005/10/22(土) 23:43:00
すみません、相関係数の求め方に関してお尋ねします。
167 :
132人目の素数さん :2005/10/23(日) 23:17:58
各国の統計を調べていたら、
なんかある小学校の生徒を無作為に抽出してテストした結果で
>>167 心理学板の方にも書き込んでいやがったな、こいつ。
自分の宿題は自分でやれ。
ちょい逃避したいんで。
>>165 文脈がよくわからんけど、
標準誤差は単に標準偏差をサンプル数の平方根で割っただけ
のものとちゃうか。
>>166 理論値って何?
回帰直線 y=a+bx の予測値ってことなら、
その回帰直線の決定係数の平方根に b の符号をつけた値が
求めたい相関係数になっとるよ。
>>167 相関と因果は別物ってことかな。
171 :
132人目の素数さん :2005/10/25(火) 05:53:28
>>167 たとえば,だけどね,
1)癌=長生きしないと顕在化しない病気,貧しい国では他の死因のほうが優勢
⇒ 癌の死亡率と所得に正の相関
2)牛乳の消費量は所得と正の相関
が正しいとすれば,牛乳と癌の相関は見せかけの回帰になるね.
ネックは仮説1)が正しいかどうかだな.
172 :
132人目の素数さん :2005/10/25(火) 06:58:00
BSEは食べるとき肉片を細かくすれば感染する確率は減るよ
173 :
132人目の素数さん :2005/10/25(火) 21:23:41
2×2分割表で二つの変数が無関係(独立)である場合のデータのパターンとして下記が与えられています。
174 :
132人目の素数さん :2005/10/25(火) 23:45:34
すいません。
>>173 は解決しました。
別の疑問なんですけど、連関係数Qが1となるようなオッズ比ψの値って、どんな値ですか?
何じゃ他のデータって
すいません、標本統計法の概要を説明してるHPとかないでしょうか?
177 :
132人目の素数さん :2005/10/26(水) 10:20:50
>>175 完全に独立であると言えるための(製品購入の有無、CM試聴の有無に関わらず、同じ割合になる)、期待値を求める式という解釈でよいですか?
>完全に独立であると言えるための
179 :
132人目の素数さん :2005/10/26(水) 22:13:04
与えられたデータでは、
180 :
132人目の素数さん :2005/10/26(水) 22:41:12
基本中の基本の質問で非常に恐縮なのですが・・
181 :
132人目の素数さん :2005/10/27(木) 04:59:22
しょぼい質問だと思うんですがお願いします。
182 :
132人目の素数さん :2005/10/27(木) 06:41:22
経済学で,母集団が1万を超えてるなら,
>>182 どうもありがとうございます。
時間があればきっちり勉強できるのですがいかんせん時間がなかったので、力技で
メルセンヌツイスターまで用意して乱数を大量発生させるプログラムを作成して
シミュレーションしてみたところ母集団12000ですとおおむね
上記の式でも問題ないことが確認できました。
他のチームと同じなんじゃないかしら
186 :
132人目の素数さん :2005/10/28(金) 22:59:48
標本標準偏差から母標準偏差を推定するのに
187 :
132人目の素数さん :2005/10/29(土) 01:22:30
っていうか何で2chで質問すんの?誰も応えちゃくれねえぞ。
何それ?
189 :
132人目の素数さん :2005/10/29(土) 07:24:01
>>186 掛けるのは sqrt(n/(n-1)) のはずなんだけど。
教科書、読み間違ってませんか?
190 :
132人目の素数さん :2005/10/29(土) 14:44:43
質問させてください。
>>190 ごく個人的な憶測で、調べもせずにレスします。
"degree of freedom"
力学の分野から借りた言葉だとすると機械要素の連結(リンク)の話かな?
間接の自由度とかね。自由度を抑えないと、プラプラして制御に困っちゃうみたいな。
193 :
132人目の素数さん :2005/10/29(土) 20:23:44
>>190 カイ二乗分布の自由度は理解していますか?
自由度=いくつの(正規分布に従う)確率変数から成るか、ということ。
好き勝手に値をとる(すなわち、「自由な」)正規確率変数の個数です。
間違いなく言えることは、興味のある確率変数(カイ二乗分布に従う)の
自由度が判らなければ、分布が特定されない(計算ができない)ということ。
F分布でも事情は同じ。
正規分布における平均、標準偏差と同様に、
分布を特定するパラメータのひとつ、という理解もありです。
単にパラメータの個数、と思っといていいんじゃ?
195 :
132人目の素数さん :2005/10/30(日) 00:23:15
信頼区間て何ですか?
196 :
132人目の素数さん :2005/10/30(日) 00:51:10
191~194さん、レスありがとうございます。身に覚えのないプロクシ
197 :
132人目の素数さん :2005/10/30(日) 11:07:08
自由度が20だからと言って、パラメータが20
198 :
132人目の素数さん :2005/10/30(日) 11:08:16
(続き)
個ある、というわけではないから、ちょっと違うと思う。
>>194 199 :
132人目の素数さん :2005/10/30(日) 20:25:44
任意の時間解像度の単位時間当たり分散1のブラウン運動を生成するプログラムを作りたいと思っているのですが、構造上適当な区間を適当に分割してゆく方法にしたいです。
200 :
132人目の素数さん :2005/10/30(日) 20:38:58
あのう…、この記号ってどんな意味ですか?
同じだよ。
202 :
132人目の素数さん :2005/10/30(日) 21:51:21
同じなんですか?
同義語はどれか一つで用が足りるから。慣れるしかない。
204 :
132人目の素数さん :2005/10/30(日) 22:41:46
統計学では>の下に_のほうを使う習慣があるというわけではなく、≧でもどちらでも構わないのですか?
二本書くのはめんどくさいので大学教官(特に数学の人?)は一本で書く
数学会の習慣。
207 :
132人目の素数さん :2005/10/31(月) 21:25:38
少し違うのでレス。
209 :
132人目の素数さん :2005/10/31(月) 22:27:26
210 :
132人目の素数さん :2005/10/31(月) 23:14:08
確率変数は、せいぜい標準偏差ぐらいの大きさしかないとはどういう意味ですか?
>数の大小の正式な記号
>>208 >教科書もそうなってるでしょうが。
中高の教科書ではなってないだろ。
213 :
132人目の素数さん :2005/11/01(火) 00:28:08
すいません、文系の駄目社員ですが場違いな職場で苦しんでおります。質問してもいいでしょうか?
>>208 大学の入試問題作成時、2本線にしなきゃいけなく
通常一本棒なので、苦労します。
文科省の指導要領は二本ですね。
大学の講義で使う本は殆ど2本です。
時々、一本と二本の不等式の意味が違うのかと
質問する学生いますが、
同じです。
と答えます。
215 :
214 :2005/11/01(火) 06:59:29
訂正
>213
>>213 品質管理のS管理図書いて…
この結果から全体分かるわけ無いでしょ。
218 :
132人目の素数さん :2005/11/01(火) 13:08:03
>213
219 :
132人目の素数さん :2005/11/01(火) 15:29:54
再質問しますが、そもそも
>>219 >「確率変数は、せいぜい標準偏差ぐらいの大きさしかない」というのは事実ですか?
事実でない。
>また、こういった性質はどのようなときに使われるのですか?
そんな命題、初めて聞いた。
>>219 220の言うとおりですが、もし、
「確率変数は、せいぜい標準偏差ぐらいの大きさしかない」というのは事実
ならば、
チェビシェフの不等式、正規分布の1σを超える値…
統計・確率理論、破綻します。
3σとか6σとか言うのは一般的だし、どこから1σという話が出るんでしょうね。
「確率変数は、平均を中心としてせいぜいプラス・マイナス標準偏差ぐらいの
大きさしか変動ない」というなら、1σの話になるのですが。
222 :
132人目の素数さん :2005/11/01(火) 22:50:04
相関係数を求める式の分子のSxyですが、
>>222 それは定義から計算していけば出ると思うけど
224 :
132人目の素数さん :2005/11/01(火) 23:11:41
>>223 わからないから聞いているのです。
ウワァァァン! ヽ(`Д´)ノ
Σ(xi-x~)(yi-y~)
226 :
132人目の素数さん :2005/11/01(火) 23:31:46
*ってなんですか?
227 :
213 :2005/11/02(水) 02:35:40
皆様レスありがとうございます
228 :
132人目の素数さん :2005/11/02(水) 05:42:39
>>200 おそらく元々アメリカ式の表記法なんでしょう。
連中メンド臭がり屋で(笑)、簡易表記が好きで、時々日本式表記と違った記述をするから面食らう事もあります(笑)。
ちなみにアメリカの数学の教科書では、
<や>の下に_がついてるやつ
が教科書に正式記号として使われてます。(つまり連中は二本線のは知らないのです。)
日本の大学の先生も、留学とかの経緯で、その『簡略表記』に馴れているから使用するのでしょう。
書く線減ればラクですしね(笑)。
正式なのは_が斜めのやつ?それとも水平なやつ?w
230 :
132人目の素数さん :2005/11/02(水) 12:37:12
>227
各月ごとのサンプル数と平均値が分かれば、
232 :
231 :2005/11/02(水) 16:54:54
233 :
132人目の素数さん :2005/11/03(木) 16:21:14
Aさん、Bさん、Cさんの三人でジャンケンをします。
234 :
132人目の素数さん :2005/11/03(木) 16:56:25
>230-232 および 227
235 :
234 :2005/11/03(木) 16:57:15
(続き)
236 :
234 :2005/11/03(木) 16:58:40
あ、答えの0.075は、σの値です。
237 :
230 :2005/11/03(木) 18:12:42
>>234 結局はトータルの二乗和とトータルの平均が判れば済む話だよな。
238 :
208 :2005/11/03(木) 23:30:28
不等号でこんなに盛り上がるとは。
239 :
132人目の素数さん :2005/11/03(木) 23:52:50
大学生向けの参考書でも、和書だと二本棒が標準だなぁ。
240 :
228 :2005/11/04(金) 03:03:25
ちなみに日本での正式な不等号の使われ方は
確かに正式だ
242 :
234 :2005/11/04(金) 04:28:37
>237
≥ ≤
244 :
233 :2005/11/04(金) 14:47:37
すみません。
245 :
132人目の素数さん :2005/11/04(金) 14:58:21
>>244 「あいこは無し」とすると,1が負けない<=>2が勝つ <=>CがAにもBにも
勝つ
よって答えは1/9
でどうでしょう。
246 :
245 :2005/11/04(金) 14:59:26
ごめんなさい。
>>245 は間違いです。もうちょっと考えます。
つーかスレ違いだ
248 :
245 :2005/11/04(金) 15:07:22
>>244 「あいこ」の扱いを明らかにして,他の質問スレに問題をageで書いて
くれませんか?
249 :
233 :2005/11/04(金) 19:08:42
>>248 すみません。
「わからない問題はここに書いてね 178 」
の340番に書きました。
「あいこ」の場合は考えず、勝負が決着する場合だけで考えます。
200見て思い出したんだけど、< のしたに斜めの棒があるのは200
でいわれている不等号とどう違うんですか? それとも同じ?
>>238 では同じみたいに書かれているけど...
tex のコマンドでいうと \leqslant とかで表示されるやつです。
251 :
132人目の素数さん :2005/11/04(金) 20:15:22
spatial statistics(空間統計学)という分野は、
252 :
208 :2005/11/04(金) 21:24:49
>>250 斜めのものは標準ではないと思うのですが、数の順序でも
使われていますね。(数以外の何かの順序で使うと思ってました。)
どういう区別で使っているのかあるいは単なる好みなのかは
私には分かりませんでした。
< の下に斜め一本棒は、溝畑茂「偏微分方程式論」に記述がある。
254 :
132人目の素数さん :2005/11/05(土) 23:20:18
お尋ねします。
256 :
254 :2005/11/06(日) 13:06:01
>>255 Windows用なのですが、グラフ自体は特殊なので独自描画する予定です。
言語はC系なんですが、RはCから呼び出す事は可能でしょうか。
自前で計算するのはかなり大変な事なのでしょうか?
Excelに関数があるようなので、できれば避けたいのですがExcelをプログラム内部から呼び出して関数を使うしかないかな、と考えています・・
258 :
132人目の素数さん :2005/11/06(日) 18:57:28
すみません。Kernelって何ですか?
核のこと
260 :
258 :2005/11/06(日) 19:30:06
261 :
132人目の素数さん :2005/11/06(日) 19:41:14
独立と排反はどう違うの?
262 :
132人目の素数さん :2005/11/06(日) 20:22:53
f(Kerf)=0
263 :
132人目の素数さん :2005/11/06(日) 20:25:05
P(A and B)=P(A)+P(B)
>>258 行列の話ですか?
普通代数系のある特定の準同型写像で、
0に移る元の集まりのことを指しますが、、
265 :
132人目の素数さん :2005/11/06(日) 23:10:40
母回帰の信頼区間を出す式がわかりません。
>>261 独立independentとは、まったく関係がないこと
例えば大きいサイコロと小さいサイコロを振ったときに
大で素数が出るって事象(≒出来事)と小で偶数が出るという事象の関係
背反disjointとは同時には起き得ないこと
例えば小で1が出る事象eventと小で偶数が出る事象の関係
267 :
258 :2005/11/06(日) 23:36:22
>>264 いいえ、そのKernelではなく、
Kernel Estimatorのことです。
(ノンパラメトリック推定量が云々とあります・・・)
268 :
132人目の素数さん :2005/11/07(月) 00:15:07
>>267 核関数(Kernel)を使った確率密度関数の推定です。
たとえばガウシアンカーネルとかを使います。
270 :
132人目の素数さん :2005/11/07(月) 00:27:02
グリーン関数とかデストリビューションで使っている意味での
271 :
132人目の素数さん :2005/11/08(火) 00:35:54
一般化最小二乗法は、どうして分散共分散行列(のようなもの?)
272 :
132人目の素数さん :2005/11/08(火) 10:26:19
誤差が独立ではないからです。
273 :
132人目の素数さん :2005/11/08(火) 11:30:49
カーネル推定:
274 :
132人目の素数さん :2005/11/08(火) 11:32:25
ちなみに,経験分布F_nをカーネル関数Kで平滑化するには
275 :
271 :2005/11/08(火) 18:49:40
>>272 誤差が独立でないなら、どうして一般化最小二乗法を用いて
一致推定量が求められるのでしょうか。
この辺の直感的な意味合いが良くわかりません。
276 :
132人目の素数さん :2005/11/08(火) 23:21:20
>>275 分散共分散行列の逆行列のルートみたいなものを掛けることにより、「独立にする」んです。
277 :
271 :2005/11/08(火) 23:40:44
>>276 その操作を行う意味はわかりますが、
なぜ独立になるんですか?
ベクトル空間で見た場合、
どう解釈できますか?
279 :
132人目の素数さん :2005/11/10(木) 15:59:07
質問させてください。
280 :
132人目の素数さん :2005/11/10(木) 17:08:38
極値統計ってどういうものなのでしょう?普通に使われている言葉だけど意味がよく分かりません・・・どなたか詳しく教えていただけないでしょうか?
>>280 ピーク値がどのような値をとるかとかそういうのです、例えば
3,1,4,1,5
という実現値がでたら、最大は 5 最小は 1
これがどういう分布になりますか?という話です。
>279
283 :
132人目の素数さん :2005/11/11(金) 09:37:54
>280
284 :
132人目の素数さん :2005/11/11(金) 12:45:11
>>282 x^p だと負の値に適用できないですよね。
全て非負として、歪度を0にするpを求める方法はありますか?
285 :
132人目の素数さん :2005/11/12(土) 19:51:48
確率変数、X1,X2,・・・Xaが独立で指数分布,Ex(λ)に従うならば
287 :
132人目の素数さん :2005/11/13(日) 19:15:51
いい教科書教えれ
288 :
GiantLeaves ◆6fN.Sojv5w :2005/11/13(日) 21:48:46
talk:
>>287 私はお前のことは知らない。よって、自分で本を選ぶのがいいだろう。
289 :
132人目の素数さん :2005/11/13(日) 22:13:23
こんなときどうしたらいいですか?
290 :
132人目の素数さん :2005/11/14(月) 22:24:28
左に歪んだ分布って現実に存在しますか?
291 :
132人目の素数さん :2005/11/14(月) 22:25:58
平均年収は?
292 :
132人目の素数さん :2005/11/14(月) 22:35:47
年収はむしろ右に歪んでませんか?
ある作業を完了させるまでにかかる時間の分布なんてどうよ。
なるほど…サンクスです。
>>293 え?それも右に歪んでいるのでは?
左に歪んでいるって歪度が負ということですよね?
たとえば、平均点のやたらと高いテスト結果だと左に歪むでしょう。
左か右かよくわからなくなるよね
じゃあ平均点がやたら低いテスト結果でいいじゃん
298 :
132人目の素数さん :2005/11/15(火) 07:37:57
確率密度関数のグラフが確率分布のグラフでいいんでしょうか?
299 :
132人目の素数さん :2005/11/15(火) 20:43:55
二つの銘柄(AとB)の赤ワインをそれぞれ5杯づつ用意し、でたらめな順序で味見させる。
301 :
132人目の素数さん :2005/11/15(火) 21:23:11
∈
くちばし。
こんな風に使ったりします(^∈^)
305 :
132人目の素数さん :2005/11/15(火) 21:47:30
>>305 ◎読み方
……に属する, in
◎意味
集合に属すること
◎解説
「x ∈ S」は、x が集合 S の元であることを意味する。必要に応じて「S ∋ x」とも書くが、こちらには S が主語であるようなニュアンスを伴うこともある。
「¬(x ∈ S)」を「x ? S」と書く。
とwikiでは説明してるよ。
>>306 「x ? S」と書く。
の?は縦長の長方形記号。[]こんな感じ。
「x []S」
[]は「属さない」という意味だそうです。
∈の否定ってことみたい。
特殊な記号でフォントがないから、縦長の長方形で代わりに表示されてると思われ。
310 :
132人目の素数さん :2005/11/15(火) 23:45:27
>>299 本質的には『選択肢が2つの問題が5問あって、4問以上正解である確率はいくらでしょう?』って問題と変わらないと思います。
と言うのも、5杯選んだ時点でもう5杯がはじき出される、って意味ですから。
要するに総試行回数が5回の2項分布を考えれば事足りる問題なのじゃないか、と思います。
エクセルの書式で書くと、
=binomdist(5,5,0.5,true)-binomdist(3,5,0.5,true)
が答えになるのではないでしょうか?
間違ってたらゴメン。
>308-309
312 :
301 :2005/11/17(木) 00:04:45
みなさん、ありがとうございました。
313 :
132人目の素数さん :2005/11/17(木) 20:53:04
与えられた平均、分散、歪度、尖度を満たす、分布関数を
>>313 いっぱい作れるのでありません。
ベータ分布に工夫を加えて作ってみたらどうでしょうか?
>>313 この4つの量で特性関数の最初の4つの係数が
決まりまります。
5つ目以降を適当に決めて、反転公式に入れる。
一つ分布、求めろと言われてもやりたくない。
316 :
132人目の素数さん :2005/11/17(木) 22:24:06
>>314-315 ありがとうございます。どうも、簡単な方法はなさそうですね。
もともとほしいのは、標本集合から、分布関数の近似式を
得る方法です。
必要な条件は、
・単峰
・連続
・(-∞,+∞)で常に正
・正規分布近似より正確
・なるべく少ない計算量
です。
いいほうほうはないでしょうか。
317 :
132人目の素数さん :2005/11/18(金) 03:06:10
>>正規分布近似より正確
>>316 単に経験分布関数使った方が統計学的に説得力が
あるような気がします。
>>316 計算が難しいというか、意味的にヤバイというかんじ
定義域を有限にすればもう少しましになるかも知れない、無限だと変な物がいっぱい考えられるから。
320 :
誰かいませんか? :2005/11/18(金) 21:55:58
正規分布に関する問題が解けません orz
>>320 標本平均の標準誤差 SE は
SE = 母集団の標準偏差÷√(標本数)
= 7 ÷ √100
= 0.7
よって、1ポンドは 1÷0.7=1.43 SE に相当。
標本平均が母集団平均から 1.43 SE 以上大きい/小さい確率は、
正規分布表より、それぞれ 0.076(=7.6%)。
よって、標本平均が母集団平均から1ポンド以上異なる確率は、
7.6×2=15.2%
322 :
320 :2005/11/19(土) 01:29:30
>>321 ありがとうございました。標準誤差を使う問題だったんですね。
全く気づかなかった orz
323 :
321 :2005/11/19(土) 01:54:27
>>322 すまん、ちょっと修正。
標本平均が母集団平均から 1.43 SE 以上大きい/小さい確率は、
正規分布表より、それぞれ 0.0764(=7.64%)。
よって、標本平均が母集団平均から1ポンド以上異なる確率は、
7.64×2=15.3%
324 :
320 :2005/11/19(土) 03:07:30
>>323 愚問かもしれませんが、標準誤差を使わずに解く方法はありますか?
標準誤差は授業で取り扱われなかったもので・・・
325 :
321 :2005/11/19(土) 03:25:15
>>324 > 愚問かもしれませんが、標準誤差を使わずに解く方法はありますか?
ない。
そもそも貴殿の聞き漏らしではないですか?
中心極限定理とか信頼区間とか習いませんでしたか?
でなければ、授業担当者の出題ミスでしょう。
だいたいポンドってなんやねん。アメリカの院生か?
327 :
132人目の素数さん :2005/11/19(土) 14:31:08
カプラン・マイヤ推定量を求めようと思っているのですが、
328 :
320 :2005/11/19(土) 17:07:01
>>325 中心極限定理は習いましたが、理解できていなっかたと思います。
中心極限定理をσを導くためのものだとおもっていたので、
『μが分からんと問題解けないじゃないか』とずっとおもっていました。
くだらぬ質問にお答えいただき、お手間を取らせてしまったことをお詫び申し上げます。
>>326 私は文型の学部生で留学経験はありません。
久しく数学から離れていたせいもありまして
数式の理解にも、たびたび苦労している始末です。
厚かましい事この上ありませんが、どうかご容赦ください。
問題文中でポンドを使用したのは教科書の原文通りの表記を
したことに起因しています。P.G.ホーエル著作 で翻訳された
ものを使用しているためです。申し訳ありませんでした。
>>327 全て投入してかまいません。
こんぴゅーたーの性能に問題がないならば。
逆に、データを部分的にしか使わないとしたら、「なぜ」部分的にしか使わないかを説明する必要があります。
あと、サンプル数という言葉は間違いです。
サンプルサイズ(サンプルの大きさ)といいましょう。
330 :
132人目の素数さん :2005/11/19(土) 20:50:05
本当に全部投入していいのか??
331 :
132人目の素数さん :2005/11/20(日) 04:43:32
すいません.質問です.
ネットで見る限り「上側検定(upper side test)」「下側検定(lower side tes)」
333 :
332 :2005/11/20(日) 11:49:11
「t」が抜けたのはタイポ。
334 :
132人目の素数さん :2005/11/20(日) 15:01:13
Xを離散分布、Nを連続分布とするとき、
335 :
331 :2005/11/20(日) 15:43:33
>>332 ありがとうございます.参考になりました.
336 :
132人目の素数さん :2005/11/20(日) 15:44:23
母集団ΠからのランダムサンプルをX1,X2,X3とするとき次をものをもとめよ。
337 :
132人目の素数さん :2005/11/20(日) 15:47:31
すいません4つめの答えはδ^2(δ^2+2μ^2)でした。
338 :
132人目の素数さん :2005/11/20(日) 17:04:53
>>337 (1)は公式「E(X+Y)=E(X)+E(Y)」を使う。
(2)は公式「X,Yが独立ならばE(XY)=E(X)E(Y)」を使う。
(3)は公式「X,Yが独立ならばV(X+Y)=V(X)+V(Y)」を使う。
(4)は公式「V(X)=E(X^2)-E(X)^2」と(2)の公式から
V(X1・X2・X3)=E(X1^2・X2^2・X3^2)-(E(X1・X2・X3))^2
=E(X1^2)・E(X2^2)・E(X3^2)-(E(X1)・E(X2)・E(X3))^2
と変形して、もういちど公式「E(X^2)=V(X)+E(X)^2」を使うと、
(σ^2+μ)^3-(μ^3)^2となる。
σ^2(σ^2+2μ^2)という答は(σ^2+μ^2)^2-(μ^2)^2なので、V(X1・X2)の間違い
であろう。
339 :
337 :2005/11/20(日) 17:09:46
スマソ、「^2」が一箇所抜けていた(すぐわかるのでどこかは言わない)
340 :
132人目の素数さん :2005/11/20(日) 17:48:42
>>339 ありがとうございます!
しっかり考えてみます!
キム カセツ って人の名前ですか ?
MS-IMEで kimukasetu と入力して、
kimukasetu→金仮設
345 :
132人目の素数さん :2005/11/21(月) 18:51:17
統計学の本を読みました。
ガンマ分布G(α,β)およびF分布(n1,n2)の尖度と歪度の式を
>345
348 :
132人目の素数さん :2005/11/22(火) 01:55:13
確率変数Xでの正規分布N(170,8^2)からPr(X>170)、Pr(160<X<175)等の確率を求めることは出来るのですが
>>346 ガンマ分布の平均の回りのj次モーメントは
\frac{\Gamma(r+j)}{\lambda^j\Gamma (r)}
F分布の平均の回りのr次モーメントは
(\frac nm)^r\frac{\Gamma(m/2+r)\Gamma(n/2-r)}{\Gamma(m/2)\Gamm(n/2)}
から計算して。
面倒だったので、記号は貴方のものに合わせていません。
>>348 「x個から出たXの平均XXがある時の」意味分かんない…
標本をn個取り、nが確率変数という話かな、と想像してますが…
350 :
132人目の素数さん :2005/11/22(火) 17:55:15
>>347 やはり求められるんですね。ありがとうございます。導出を考えて見ます。
本に載ってないのは重要性が低いからと理解していいでしょうか?
統計ソフトSPSSで
T.W.Andersonを見ながら、相関係数のz変換の所考えていました。
353 :
352 :2005/11/22(火) 21:27:36
漸近分散はn-3でなく、1/(n-3)でした。
355 :
352 :2005/11/23(水) 10:04:59
>>354 Thx!
T.W.Andersonというのは
An Introduction to Multivariate Statistical Analysis 2nd edition
のことです。120ページからの話です。
竹内啓
数理統計学 東洋経済
138ページにあったのですが、結局最後にはz変換したものzに対する
E(z)\approx \zeta+\frac \rho{2(n-1)}
Var(z)\approx \frac 1{n-3}
から漸近分散が
\frac 1{n-3}
とするようですね。
356 :
132人目の素数さん :2005/11/23(水) 16:34:30
実務家です。いつも参考にさせて頂いております。実務寄りの質問なのですが、どの板、どのスレに質問するべきか迷ったため、
358 :
132人目の素数さん :2005/11/24(木) 10:03:35
>>356 季節ダミーを入れても駄目ですか?
スロープのダミーで.
359 :
356 :2005/11/25(金) 02:32:48
>>357 フリーソフトのRですね。話には聞くのですが、まだ使ったことはありません。
コマンドだけ読むと、なにか分析してくれて数値とか表示されそうな予感がします。
週末に時間使って試してみます、ありがとうございました。
>>358 時系列分析は今回初めてなので、手探り状態です。手元にある石村貞夫さんの
テキストでは、どの本を読んでも「季節変動の分解は難しいのでSPSS Trendsを使います」
と書いており、まったく参考になりません。いろんなサイトを読んでみて、0と1のダミーを
入れることで季節変動を代入できることはなんとなく分かるのですが、手元にある
時系列データが表す季節変動分を、正しく数量化Ⅰ類で求めた式に反映させる方法が
よく分からず困っています。
360 :
132人目の素数さん :2005/11/25(金) 14:52:45
確率変数のオーダーが1(つまりO_{p}(1))であるとは、
362 :
360 :2005/11/26(土) 02:38:03
364 :
132人目の素数さん :2005/11/26(土) 17:22:43
あるサイトで、下記のような質問がありました。
365 :
132人目の素数さん :2005/11/26(土) 17:42:35
>>360 標本数nを増やしても,少なくとも発散はしない,ということ.
定数か確率変数に収束するならO_p(1).
>>364 相関係数の二乗なら,「決定係数(coefficient of determination)」
だけどね.
366 :
132人目の素数さん :2005/11/26(土) 17:56:45
>>365 :132人目の素数さん
さっそく、ご返事を大変ありがとうございます。
顔も見えない他人の私に、ご親切に時間を割いて書き込んでくださいまして
本当に感謝します。 m(_ _)m
367 :
132人目の素数さん :2005/11/26(土) 23:31:39
昨シーズンを2 割8 分の打率で終わった打者が,今シーズンもこの確率でヒットを打つものとし,450 回打
漏れなら「四死球と犠打、犠飛の確率が提示されていないので解けません」とだけ答えに書く
369 :
367 :2005/11/27(日) 02:15:09
>>368 打席=打数 四死球と犠打、犠飛はなしとして考えてます。
>>367 p=0.28の二項分布 B(n,0.28) を使う。すなわち、確率変数Xをこの打者の今
シーズンの総ヒット数とすると、XはB(n,0.28)に従う。
(1)n=450だから、XはB(450,0.28)に従うとして、r≧450×0.3=135となる確率P(X≧135)を求めればよい。
(2)XはB(n,0.28)に従うとして、P(X≧0.3n)≧0.2となるnを求めればよい。
二項分布の公式:P(X=r)=(nCr)(p^r)(1-p)^(n-r)
しかしこの計算は大変(Excelを使うという手もあるが)。
そこでnが大きいことを使って、正規分布で近似する。
定理:nが大きいとき、二項分布B(n,p)は正規分布N(np,np(1-p))で近似できる。
(1)np=126, np(1-p)=90.72だから、XはN(126, 90.72)に従う。ということは、
Z=(X-126)/√90.72は標準正規分布N(0,1)に従う。
P(X≧135)=P(Z≧0.95)=1-P(Z≦0.95)だから、あとはP(Z≦x)が載っている標
準正規分布表でP(Z≦0.95)の値を調べる。
(2)np=0.28n, np(1-p)=0.2016nだから、XはN(0.28n,0.2016n)に従う。ということは、
Z=(X-0.28n)/√(0.2016n)は標準正規分布に従う。
P(X≧0.3n)=P(Z≧0.02/(0.45√n))だから、これが≧0.3となるnを求めればよい。
標準正規分布表で、P(Z≧x)=1-P(Z≦x)=0.3となるxを探し、x=0.02/(0.45√n)を
みたすnを求めれば、そのn以上が答。すなわちn≧0.02/(0.45x)
371 :
370 :2005/11/27(日) 02:39:56
一番最後、2乗が抜けた
372 :
370 :2005/11/27(日) 07:14:30
>>370 の最後から3行目「これが≧0.3となるnを求めればよい」は「これが≧0.2と
なるnを求めればよい」の間違い。以下、それに応じて修正のこと。
373 :
132人目の素数さん :2005/11/27(日) 10:30:21
>>370 乙
> P(X≧0.3n)=P(Z≧0.02/(0.45√n))だから
のところあってます?
というか、2割8分の打者だったら、たくさん打席に立てば立つほど
3割以上打てる確率ちいさくならないのかな?
374 :
132人目の素数さん :2005/11/27(日) 10:33:34
すいません
375 :
370 :2005/11/27(日) 11:34:24
>> P(X≧0.3n)=P(Z≧0.02/(0.45√n))だから
376 :
370 :2005/11/27(日) 11:58:52
nが十分大きくないと(せめてn≧25くらい)正規近似自体がだめになるので、
377 :
132人目の素数さん :2005/11/27(日) 12:10:27
>>374 期待値との差の二乗の期待値を計算して、平方根をとる
378 :
132人目の素数さん :2005/11/27(日) 12:18:08
>>370 どうもです。ここまでくると手計算じゃめんどくさいねw
>>367 下のどれなのか、結果の報告期待してます
1. 出題ミス
2. 367の転記ミス
3.
>>376 のような考察をさせるための問題
4. 「世の中問題そのものが間違っていることだってあるんだよ」
ということを判らせるための、教育的配慮に満ちた問題w
379 :
367 :2005/11/27(日) 12:28:03
みなさん、ありまとー
手計算でって指示なんで、
コツコツやってみます
>>378 さん、
2.コピペしたんで、転記ミスはないとおもいます。
こんな問題出すヤツにおそるおそるゴラァーって言ってみます。
4、 この先生、わざと、間違えて生徒に訂正させようとします。
380 :
132人目の素数さん :2005/11/27(日) 12:30:13
どうか、よろしくお願いします
>>380 10回分の測定値の平均Xは、正規母集団N(0,0.1)からの大きさ10の標本平均だから、
N(0, 0.1/10)にしたがう。
それがわかればあとは正規分布の単純計算問題だ
382 :
132人目の素数さん(380) :2005/11/27(日) 13:00:12
383 :
381 :2005/11/27(日) 13:10:19
>>382 (1)はもうできてるよね。
(2)は、XがN(0,0.01)にしたがうとき、P(|X-100|>0.3)を求めよってこと。
これができないようじゃ救いにくいなあ
μ=0,σ=√0.01の正規分布でしょ? Z=(X-μ)/σが標準正規分布N(0,1)に従うという
ことは判ってる? あと手元に標準正規分布表はある?
なら(2)はもう解けるはず。
(3)はXがN(0,0.01/n)にしたがう、つまりμ=0, σ=0.01/√nのときにP(|X-100|<0.1)≧0.9
となるnを求めればいい。標準正規分布でP(-x<Z<x)≧0.9となるxを表から探すのが先決だ。
たのむから正規分布くらい勉強してくれ…
384 :
383 :2005/11/27(日) 13:14:02
× (3)はXがN(0,0.01/n)にしたがう、つまりμ=0, σ=0.01/√nのときにP(|X-100|<0.1)≧0.9
385 :
380 :2005/11/27(日) 13:27:21
381、383さん、おバカなあたいにご親切に、
>>385 N(0,0,1)というのは「誤差」だけでの分布で、問では「測定値」そのものを
問題にしているので、
>>381 ,
>>383 は少し間違ってる。
測定値の平均XはN(100,0.01)にしたがう、つまりμ=0でなくμ=100
387 :
380 :2005/11/27(日) 22:34:27
385-386さんありがとうございました。
388 :
みっち :2005/11/27(日) 23:02:13
明日までのレポートなんです・・(>_<)だれかたすけてー!
>>388 ...,、 - 、
,、 ' ヾ 、 丶,、 -、
/ ヽ ヽ \\:::::ゝ
/ヽ/ i i ヽ .__.ヽ ヽ::::ヽ
ヽ:::::l i. l ト ヽ ヽ .___..ヽ 丶::ゝ
r:::::イ/ l l. i ヽ \ \/ノノハ ヽ
l:/ /l l. l i ヽ'"´__ヽ_ヽリ }. ', ',
'l. i ト l レ'__ '"i:::::i゙〉l^ヾ |.i. l
. l l lミ l /r'!:::ヽ '‐┘ .} / i l l / ̄ ̄ ̄ ̄ ̄ ̄ ̄
l l l.ヾlヽ ゝヾ:ノ , !'" i i/ i< 図書館で待ってます。
iハ l (.´ヽ _ ./ ,' ,' ' | 本を開いてください・・・・・
|l. l ` ''丶 .. __ イ \_______
ヾ! l. ├ァ 、
/ノ! / ` ‐- 、
/ ヾ_ / ,,;'' /:i
/,, ',. ` / ,,;'''/:.:.i
392 :
132人目の素数さん :2005/11/28(月) 13:27:30
質問です。
393 :
132人目の素数さん :2005/11/28(月) 15:45:05
可能です.ただし(もちろん平均と分散に依存しますが)
394 :
392 :2005/11/28(月) 16:25:13
>>393 なるほど、ありがとうございます。急激に変化する範囲が3σなのですね。
395 :
393 :2005/11/29(火) 02:15:12
ううん?そういっても間違いじゃないのかもしれないけど...
396 :
132人目の素数さん :2005/11/30(水) 20:45:50
問題
398 :
396 :2005/11/30(水) 21:42:13
8以上異なる場合の標準誤差がわからないんです。
SE=7/√100=0.7
8/0.7=11.4
これでいいのでしょうか?
正規分布表は4くらいまでしか載っていないのに
このような値がでてくるのは何か間違っているのでは、と思っています。
本当に解きたい問題は別にあるのですが、それは自力で解きたいと思い
>>320 の問題を引用しています。
質問です。
Q:データ x1,x2.......xnが2項分布B(n,p)の実現値とする。
401 :
132人目の素数さん :2005/12/02(金) 07:12:08
>>400
>>400 Q:データ x1,x2.......xnが2項分布B(n,p)の実現値とする。
と書くと、nが2回出てきてなにか気持ち悪い。
Q:データ x1,x2.......xmが2項分布B(n,p)の実現値とする。
と書いた方がいいね。
401が言ったことが1回分のXとなり、これをm回繰り返すという
ことですね。
>>398 > SE=7/√100=0.7
> 8/0.7=11.4
それで正解です。
z値が11.4なので、確率は限りなくゼロに近くになりますが、ゼロではありません。
>>399 母集団と標本の違いを勉強してから出直しておいで。
405 :
400 :2005/12/02(金) 22:44:09
答えてくれた方ありがとうございました
406 :
132人目の素数さん :2005/12/02(金) 22:59:40
407 :
405 :2005/12/03(土) 00:10:04
>>406 大学の授業で扱ったものです。
イマイチよくわからなくて・・・・
408 :
405 :2005/12/03(土) 00:12:55
誤字が多いので訂正
>>408 何だろね~~~。
(a)>またなぜ2項分布に従う確率変数で考えるのかが妥当なのかその根拠を述べよ。
これなんかは答え様ないんじゃないかしら?
どう言うモデル(この場合ニ項分布?)に適合してるかどうか、って『思う』のは分析者の主観であり、勝手な判断だからね。
取り合えず想定できるモデルを設定してみて、そのモデルに対する適合度を検定してみる。
帰無仮説にそのモデル採用を設定して、検定統計量が棄却域に入ってるかどうか調べてみる。
入ってなかったら『まあ、じゃあ取り合えずコレで分析でもしてみようか』って消極的な理由により二項分布を使う。
それが一応流れだと思うんですが・・・・・・。
他にAIC使って『より良いモデル』を探してみる手もあります。それで二項分布が一番適してたらそれを採用、とかね。
特に合理的な根拠なんてないんじゃないかなあ。
(b)>pをどのように推定するのがいいだろうか、またその根拠を述べよ。
確率分布使用するなら最尤推定量でしょう。これが一番いいと言われている筈です。
ただ、それは(a)との絡みで何指してるんだか分かんないや。
データ例としてはこんな問題がありますよ。
1条に10粒ずつ,60条に農作物の種子をまいて発芽の実験を行ったところ
次の結果を得た.発芽状況は二項分布に合っているといえるか,危険率5%で
検定せよ.
1条の発芽数 |0 1 2 3 4 5 6 7 8 9 10 計
実測した条の数 |5 6 12 18 9 5 2 2 0 1 0 60
410 :
405 :2005/12/03(土) 02:32:01
>>409 レスありがとうございます
とりあえず参考書見ながら自分でやってみますね!
単に,「n回の独立同一なベルヌーイ試行の成功回数」であることを
412 :
132人目の素数さん :2005/12/03(土) 14:08:30
大変基本的な質問です。
413 :
132人目の素数さん :2005/12/03(土) 14:54:56
「何の」分散なのかをはっきりさせないと...
>>413 多分『二項分布を制する者は統計を制す』から・・・・・・・ホントか(笑)?
415 :
412 :2005/12/03(土) 15:25:29
御回答ありがとうございます。
>>412 回帰分析を知りたいだけなら二項分布は飛ばしてOK
大数の法則と中心極限定理だけ押さえとけば大丈夫
小標本特性も要らないから,F分布だのt分布だのも
スキップ.正規分布とカイ二乗分布は重要.
>>416 t分布は知っておいていただかないと困る。
418 :
412 :2005/12/03(土) 17:40:26
>>416-417 ありがとうございます。統計学は分析ツールとして必須と考えています。
あまり賢くないですが頑張ります。時々アドバイス願いします。
>プロになるなら全部
>>420 当然そうですが、研究者なら当然新しい手法等も考えてるでしょうしね。
他にAICで検定代わり、とかQ値っての使って多重検定、って方法やら色々あるようですが、これ等を含めて全て網羅するのは
アマチュアにはちょっと厳しい、と言った意味です。
>>419 さん、ありがとうございます。
>参考書では『マンガでわかる統計学~回帰分析編』(オーム社)がお薦めです。
実はそれで勉強してるんですよ(笑)。それで回帰式で予測するところまでいったのですが、回帰係数の検定でつまづいたのです。
P.84のところで帰無仮説と対立仮説が出てきますね?あそこでつまづいてしまいました。
ちなみに、マンガでわかる統計学も持ってますよ。マンガのストーリーはこちらの方が面白いですね。
回帰分析は無理矢理なストーリーです。次はフーリエ解析がでるそうですよ。正規分布の関数の式で、対数関数が弱いのでこちらも楽しみです。
ほかには基本統計学(宮川公男)という昔から増刷を重ねてる本で勉強してます。「はじめての統計学」もありますけど。今は本棚に。。
>勉強する側にとっても『取り合えずどの部分を割り切って(不問として)書いているのか?』が非常に大事だと思うからです
私もそう思います。色々アドバイスありがとうございます。
>>422 ああ、『マンガでわかる統計学』ご使用してるんですね。
『二項分布は無視した』ってんでヘンだなあ、とか思ってたんですが、なるほど確かに(笑)。
第1弾は基本的に正規分布とχ^2分布しか扱ってなかったですからね(笑)。
p.84って言うと単回帰のところですね?そこの単回帰係数の検定、と。
多分そこの『検定』自体は大して問題が無いと思うんです。おそらく悩んでいるのはF分布の存在ではないでしょうか?
本文にこんな事が書いてあります。
Step5:おこなおうとしてるのは「回帰係数の検定」である.。『したがって』検定統計量は・・・・・・。
とか書いています。この『したがって』で引っ掛かってるのではないでしょうか?なんでこの検定統計量が『したがって』いきなり
出てくるのか分からない。多分そんなところではないかと思うんですが・・・・・・・・・。
まあ、ハッキリ言うと理由なんてどうでもいいんですよね(笑)。僕も数冊統計関係の書籍持ってますけど、大体F分布紹介してますけど、
『F分布ってなんぞや?』ってのは書いてないんですよ(笑)。従って、『検定統計量』ってのはケースバイケースで天下りに覚えるしかないです。
(ですから、先程“アマチュアはその度検定手法を調べざるを得ない”って書いたんです。)
取り合えず今回用いてる検定統計量(a^2)/(1-S_xx)÷S_e/(個体の個数-2)ってのはF分布上の確率変数なんです。(と言うか確率変数に
なるように捏造した、と言うべきでしょうか。)
例えば手元にある教科書ですと、次のように書いています。
>>419 さん、詳しいお返事ありがとうございます。私なんかよりも遙かに詳しい方のようですね。
>この『したがって』で引っ掛かってるのではないでしょうか?なんでこの検定統計量が『したがって』いきなり
>出てくるのか分からない。多分そんなところではないかと思うんですが・・・・・・・・・。
そうなんですよ、ここは式からして訳ワカメです。仕方ないので気にせず読み進めます。
P.88の式も訳わからんです、ハイ。
http://ssl.ohmsha.co.jp/cgi-bin/menu.cgi?ISBN=4-274-06617-7 今度のストーリーは女子高生バンド結成をネタにフーリエ解析にもっていくそうです(爆笑)。
ちなみに11月刊行だったのですが、12月に延期になり、HP上では発売日が??になってしまいました。
>>425 『マンガでわかる統計学~回帰分析編』は、『マンガでわかる統計学』のp.106でちょっと紹介されていた
t分布を全く使用しないで説明しよう、と言う試みで書かれているようです。
統計初学者に対して『アレに対してはあの分布を、コレに対してはこの分布を』等と言った混乱を招く
ような記述をしたくなかったのでしょう。著者の努力は並大抵ではないはずです。
必要最小限に押えた分布の数でなるたけ一貫したパースペクティブを貫こうとしています。
が・・・・・・。
問題は『マンガでわかる統計学』第1作で具体的に扱われていなかった『区間推定』が今回の『回帰分析編』
で初めて登場した事。また、抽象的なF分布より直観的に分かり易いt分布を排したことで、p88、及びp.92が
直観的には分かりづらくなっちゃっているんですよね。(通常どっちもt分布で記述されているのです。かつイメージ
的にはt分布を利用した普通の区間推定は比較的分かり易いんですが、『マンガ』では排除されています。)
そんなわけで、もし、その辺りが分かりづらかったら、取り合えずお持ちの基本統計学(宮川公男)か「はじめての
統計学」でt分布を利用した推定に関する知識を補完した方が宜しいと思います。あくまで感覚的な話ですが。
>今度のストーリーは女子高生バンド結成をネタにフーリエ解析にもっていくそうです(爆笑)。
>>425 =426
「マンガでシリーズ」だけでやろうとすると分かったつもりになるだけかも知れないですね。
数学的な説明はできないけど、なんとなく直感的に分かったというのが本書の中でも大事と指摘されています。
セリフでの説明は分かりやすいのですが、式が出てくると突飛な感じがしちゃうんですよ。
その辺のところは基本書で補わないといけないですね。
>>417 さんも、t分布は知っておかなくてはダメとの御助言でしたし。
フーリエ解析の方も、何故バンドなのかというのはちゃんと理由があるようですね!
しかし、女子高生ネタがつづくと我々読者それで釣ってるようで複雑な心境ですね。
といいながら楽しみにしている私・・。
429 :
132人目の素数さん :2005/12/05(月) 00:54:24
こんばんは。回帰分析についてアドバイスをお願いします。
>>429 取り合えず知ってる範囲で答えると手順が逆。
まずは散布図を作る⇒回帰と言う手順が流れ。
回帰式作ってからプロットしてみる、なんてのは全然逆です。
(あとで外れ値発見、ってのはおかしいです。)
取り合えず初歩的な方法論としては外れ値を除去してみて回帰をやりなおした方がいいでしょう。
それから寄与率R^2をもう一回見て下さい。
>Q:R2乗値は最低どれくらいあればいいものなのでしょうか?
統計学的には基準は特にありません。0.1でさえ『わずかながらでも』相関していると言えるからです。
(数学的にはどんな回帰直線でも描けてしまうのです。)
一応経験的には0.5以上、とも言えますが、これは慣習であって、特に根拠があるわけではないのです。
あとはエロイ人が書いてくれると思います(笑)。
あともう一つだけ。
432 :
132人目の素数さん :2005/12/05(月) 18:30:18
t検定などのパラメトリックな検定はなぜ母集団の正規性を仮定しているのですか?
>>432 中心極限定理は、小標本の場合には使えないから。
あと、(平均だけでなく)分散の推定量の分布もt分布に帰着する上で問題になるから。
434 :
132人目の素数さん :2005/12/05(月) 20:33:42
aX1、2aX2、3aX3、…naXn(aは定数)
>>434 Σを使って表す、と言うのが意味不明。
題意は別に和を表しているわけではないので。
436 :
132人目の素数さん :2005/12/05(月) 21:07:30
既出ならすみません。
>>436 >どのような手順で集計すれば良いかわかりません。
と言う質問自体が意味が分かりません。
『××分析をしたい』ってのならまだしも、単にデータベースの作り方が分からない、って質問に思えるのですが・・・・・・。
基本的に最初は
質問① 質問② 質問③・・・・・・・・・
被質問者A
被質問者B
・
・
・
って表を作ってアンケートの結果を入力したデータベースを作ってから色々考えた方がイイでしょう。
質問①、②、③、の下にそれぞれ選択肢があるでしょうから、選択肢の項目をそれぞれの質問の下に設置して、
○を付けたものに1、それ以外を0と言うダミー変数にしておけば、その後の分析もやり易くなるんではないでしょうか?
438 :
132人目の素数さん :2005/12/05(月) 22:29:33
>>438 了解。
でも大して難しい問題じゃないよ。
ΣiaX_i (iは1からnまでの和)
でエエんちゃうん?
ここで係数のaはiの値に無関係なんで、
aΣiX_i (iは1からnまでの和)
と書いてもいいかもしれない。
440 :
132人目の素数さん :2005/12/06(火) 06:42:51
>>439 ありがとうございます。
iって、Xiとかにしか使っちゃいけないのか、他の表し方があるのかと悩んでたんですよー。
あー、すっきりー。
>>436 >>437 に補足するが、仮に
Q. 以下の中で、あなたの好きなものを挙げてください(複数回答可)。
1.みかん
2.うな重
3.ハンバーグ
4.ざるそば
という設問があった場合、
みかん うな重 ハンバーグ ざるそば
回答者1 0 1 1 0
回答者2 1 1 1 0
というような表を作って、言及があった場合は1、ない場合は0とすれば良い。
あとは因子分析なりクラスター分析なりご自由に。
442 :
132人目の素数さん :2005/12/06(火) 10:56:56
>>441 ありがとうございます。
とても丁寧で分かりやすいです、早速作ってみます。
現在の大学の偏差値を10年前と比較したら5~7くらい下がってるなんて
>>443 10年前と現在の大学入試問題が同一水準である。
大学の構成数は変化していない。
等の仮定を設ければ比較しても差し支えないんじゃない?
>>443 単純に上下差がつまってきている、とは解釈できる。
上が落ちてるとか下が下がってるとかは言えない。
>>443 単純に上下差がつまってきている、とは解釈できる。
上が落ちてるとか下が上がってるとかは言えない。
ミスすまそ
>>443 偏差値が下がってるってのは多分意味不明でしょう。
ただし、10年前と現在の大学入試の成績がそれぞれ正規分布に従っていると仮定して、
母平均値の差の検定を行う事は可能だとは思います。
片側検定なら、『上がってる/下がってる』とは言えるでしょうね。
ただし、そもそも偏差値ってのは『テストの成績が正規分布に従ってる』と仮定して出してる
数値なんですが、実際は山が二つのヒストグラムになってしまって、とても『正規分布で
近似できる』ような状態ではないそうですが。
同世代人口が減っても定員はあまり減ってないので、一部の難関以外は
>>443 大学の偏差値っていうのがそれだけではよく意味分かりませんけど
母集団がそれぞれその世代の若者集団なら、
10年前の偏差値と比較してもしょうがない気はしますね
まあ相対的なレベルが下がっているということは言えると思いますけど
仮に同じ問題(あるいは水準がほぼ同等の問題)で、
大学入学後に学力調査をした結果とかだったら、意味はあると思います
451 :
132人目の素数さん :2005/12/08(木) 04:28:35
日本計算機統計学とは、どういう分野ですか?
452 :
451 :2005/12/08(木) 04:29:16
日本計算機統計学→計算機統計学
454 :
408 :2005/12/08(木) 08:34:55
>>454 コイン投げの確率なんて1/2って昔から決まっている。
ってのはだめだろうな。
pの決定は実験によってでしかえられない
数多く投下して表が出たら1裏が出たら0としてその期待値は1/2に近づく。
456 :
408 :2005/12/08(木) 08:45:22
あっ(c)だけで大丈夫です。根拠は最尤推定量とお聞きしましたので
>>456 二項分布が最大となるのはpがいくつのときだ?
失礼。
460 :
408 :2005/12/08(木) 09:02:04
質問がわかりにくくてすみません。
461 :
132人目の素数さん :2005/12/08(木) 09:35:10
>>460 観測値の平均をなぜnでわる??
観測値の和をnで割るのならば分かるが。
ちなみのこのページのnは試行回数で40がその数字に当たるかな。
462 :
132人目の素数さん :2005/12/08(木) 09:36:46
言い換えるのならば
>>460 この「平均」って単語良くないな・・・・・・。通常「母比率」と呼びます。(と言うか母比率≒最尤推定量ですが。)
ですから
最尤推定量=表が出た回数÷n
でしょうね。nは40回で構わないと思います。
最尤推定量、ってのは理論値で、それを求める場合尤度関数ってのを設定します。
二項分布の場合、尤度関数は
L(p)=Combin(n,x)*p^x*(1-p)^(n-x)
で表します。ってか単に二項分布そのままの式なんですけどね。(註:Combin(n,x)=n!/{x!*(n-x)!}の事。)
ただし、L(p)って書いてる通り、これはxの関数ではなくってpの関数と解釈します。
これをpで微分して、L(p)が最大になるpの値を「最尤推定量」として「もっとももっともらしいpの値とする」のです。
464 :
408 :2005/12/08(木) 10:19:07
すみません観測値の和と平均を勘違いしてましたw
465 :
408 :2005/12/08(木) 10:31:36
>>463 最尤推定量=表が出た回数÷n
ということは、22÷40 なのはわかりました。
L(p)=Combin(n,x)*p^x*(1-p)^(n-x)
をこの場合に当てはめるとどうなるんでしょうか?
確認したいので 本当に何度も答えていただいて恐縮です・・
>>465 通常、
L(p)=Combin(n,x)*p^x*(1-p)^(n-x)
のままじゃ微分しづらいので、両辺対数を取ります、対数を取った尤度関数を「対数尤度」と呼んだりします。
ln|L(p)|=ln|Combin(n,x)*p^x*(1-p)^(n-x) |
=ln|Combin(n,x)|+ln|p^x|+ln|(1-p)^(n-x)|
=ln|Combin(n,x)|+xln|p|+(n-x)ln|1-p|
となります。そして、pについて微分するんですが、この場合、nもxも定数をみなします。つまり微分すると第1項の
ln|Combin(n,x)|は定数なんで、pで微分すると0になります。pについての微分記号をDとすると、
Dln|L(p)|=0+x/p-(n-x)/(1-p)
=x/p-(n-x)/(1-p)
ここで二項分布の尤度関数L(p)は上に凸なのは分かりきってるので(註:二項分布は離散型確率ですが、
連続量pの関数として捉えた尤度関数は当然滑らかな連続した関数となります)、1階微分=0になる場所が
極大値となります。その時のpの値が尤度を最大にする値なのでそれを最尤推定量とします。
x/p-(n-x)/(1-p)=0
∴p=x/n
よって、二項分布の母数(パラメータ)pの最尤推定量は成功回数(表が出た回数)÷nとなります。
467 :
132人目の素数さん :2005/12/08(木) 15:53:42
統計学って気持ち悪い・・・
468 :
408 :2005/12/08(木) 15:58:56
>>466 ありがとうございます!参考になりました。
数学を避けてきた文系なので勉強し直してきます
>>467 確かに気持ち悪いですよね(笑)。
曖昧模糊とした数学(モドキ)って感覚は良く分かります。
>>468 微分のトコが分かりづらかったですか?それとも対数?
尤度関数の最大値、ってのがイマイチピンと来なかったならグラフ描いてみる事をお薦めします。
エクセルなんか使えば簡単に描画できますんで、是非ともやってみて下さい
例えばエクセルの場合ですと、二項分布は
>>470 >成功率、試行回数を定数(この場合22と40)とします。
成功数、でしたね。失礼しやした。
ごめんなちゃい。
>>467 統計学の気持ち悪さを払底したいなら、公理論的確率論をかじってみるといいかも。
数理統計学に曖昧さは微塵もないことが判るから。
でも現実的な応用はやっぱり気持ち悪いよね
気持ち悪いのは別に
476 :
436 :2005/12/09(金) 01:55:46
再びすみません。
>>476 ちょっと待ってください。
『アンケートで選択肢』だったらカテゴリー変数ではないですか?
通常『相関係数』と言うと、連続量同士の相関が問題となります。
ゆえに通常アンケートと相関係数と言うのはまるっきり関係ありません。
まず『何をやりたいのか』分かりません。あまりにも曖昧だと思います。
通常アンケートの集計ですと、まずクロス集計を行って、場合によっては
クラメールのVと言うのを求めてカテゴリー変数同士の連関関係を見たり
はするのですが、
>>476 氏が『何をやりたいのか?』あまりにも曖昧だと
思います。
479 :
132人目の素数さん :2005/12/09(金) 11:44:11
>>476 あのさ一つ重要なことを言うけど
どのような論文を書こうとしているのか
どのようなアンケートを行っているのか
何に関する相関係を知りたいのか
主張したいことは何なのかが分からないと答えられないよ。
あなたは言葉が足らない。
>>477 氏も言ってるけど、まあ、そう言ったわけで
『実験計画をやる前に統計学者に良く相談しましょう。』
ってサラ金のCMみたいなフレーズがまかり通ってるわけです(苦笑)。
でも
>>476 氏がちょっと可哀想なんで、エクセル上でクロス集計するテクニック、ちょっと紹介しておきます。
時間も足りないみたいなんで。
エクセルでクロス集計を行うにはピボットテーブル機能、と言うのを利用します。
解説はコチラ↓
http://www.daito.ac.jp/~mizutani/lecture/spreadsheet/pivot.html 取り合えずコレ使って色々と弄ってみてください。
『何と何の変数の連関を見たいのか?』
クロス集計である程度、『関係がありそうなカテゴリー変数同士』の表を作れたら、
その次の話はまたアトでやりましょう。
482 :
132人目の素数さん :2005/12/10(土) 22:04:36
μ(005)=1.645.
>>482 誤植じゃない?
何の本?文脈分かんないと。
ただの文の最後のピリオドだったりしてな
485 :
482 :2005/12/11(日) 00:55:51
問) zが標準正規分布N(0,1)にしたがう確率変数である時、
データ処理で分からない事がありますので、
487 :
132人目の素数さん :2005/12/12(月) 01:58:12
質問の意味がよくわからないんですが...
488 :
486 :2005/12/12(月) 02:56:25
>>487 レスありがとうございます。
重相関係数だけで一致具合を判断しているのですが
変数増やしてしまうと,明らかに(a,b,c)の組み合わせがおかしな時にも
重相関係数が大きくなることと、大体の理論値が分かっているので
それでやったほうが正確だと思ったからです。
統計は苦手でして、こちらの考え方とかやり方が間違っているのかもしれませんが・・・。
なにか他にもいい方法ありましたら教えていただけるとありがたいです。
えと、質問の意味ですが、
>>486 の関数に対して
(a,b,c)の組み合わせはf(t),tを与えるとただ一通りにしか決められないのか
という事です。(誤差とかバラつきとかは別として)
組み合わせがただ一通りしか存在しないのであれば
回帰分析で出てきた(a,b,c)の値を信用できますが
そうでなければ(a,b,c)の組み合わせが
本当に正しいのかどうか判断できないのではと思いましたので。
説明が下手でスイマセン。
まだ分からないかもしれませんがよろしくお願いします。
>>488 僕も
>>486 見てて意味が分からなかったんですよね・・・・・・。
まあ時系列分析やった事ないですが。
ただ、式見る限り重相関係数で一致具合判断できるのかな?
なんたって与式は線形の式ではありませんので。
全部対数とってみて重回帰やってみたのですか?
あああああ、恐らくこう言う意味かしら?
491 :
132人目の素数さん :2005/12/12(月) 04:28:21
>>486 > このデータは理論的に下の関数に乗る事が分かっています。
> f(t)=a+b*exp(c*t) a,b,c : const
> a,b はその計測値がありますが、
> 実験誤差が大きく,この値だと決める事ができません。
a,b,cを同時に推定したいのではなくて、
a,bは仮に固定した上でcを推定する、ただし、
仮に固定するa,bの組がいくつかあって、
それらの候補の中で最も良い回帰式はどれか知りたい、ということですね?
その際、a,bを仮に固定してcを推定すると、それに対応する重相関係数が出てくるのだけれども、
a,bを色々変えてみたときに、重相関係数が一番大きなものを選択するのは妥当か?という質問ですね?
もしそうなら、t, f(t)のデータを与えた元で、重相関係数をa,bの関数と見た場合に
(a,b,に対して重相関係数をプロットする3次元のグラフを想像してください)
この重相関係数に最大値が存在するのか否かを知りたいということですね?
それだったら回答のしようはある気がします。
でも問題は、a,bの測定誤差が大きいらしいというところ。
上の議論はa,bを誤差0で特定できるという文脈での話。
よって、486さんの質問が、a,bを誤差0で特定できると割り切るという前提での質問なら、
唯一解があるか否か、という質問に答えることはできますが(酔っぱらっていて計算する元気が出ないので答えはパス)、
a,bに大きな誤差が乗っていることを否定できないのなら、質問自体が適当でない可能性もある気がします。
a,bの不確実性を無視している解析方針だから。
何度も申し訳ありません。
>>489 まず、適当なa,bを仮定します。
(f(t)-a)/b=exp(cx)の形に変形して両辺の対数を取って線形回帰分析をかけています。
あとはa,bをループでまわす。得られたデータを散布図にして相関係数と、見た目で判断しました。
a,b,cは、これで得られ、目で見ても実験値と回帰曲線がいい一致を示しているのですが
この値は本当に正しいのか?という事が気になりました。
言葉足らずでしたが、正確なcの値を知りたいと思っています。
統計的なお話とはズレてしまっているのかもしれません。
計測できない真値と比較してa,bがめちゃくちゃでも、cがこの値ならあっているように見えるとか
cがめちゃくちゃでもa,bがこの値ならあって見えるとか。
Newton法で最小値を探すはずが極小値を探してしまったとか
そういう状況ではないのか?という事が気になりました。
このようなことは起こりえないのか?また、起こりうるならどうやって判断するべきなのか?
という事を考えているうちによく分からなくなってしまいました。
説明力不足を痛感しています・・・。どうかよろしくお願いします。
書き込み中にレスが・・。
ありがとうございます。
>>490 回帰分析が終わった後の事が気になっています。説明不足申し訳ないです。
>>491 ほとんどおっしゃっている通りですが、a,bの測定値があるが正確ではないというのは
"a,bが正確にわかるのであれば式はf(t)-a/B=exp(cx)となり、線形の式だから、cは一意にしか決まらないが、
a,bの特定ができないので非線形な関数となるので解(a,b,c)が一意に決まらないかもしれない"
ということです。
実験の計測値では、a,b,cが決まっていてt,f(t)を計測しますが、
その逆のt,f(t)の組み合わせからその(a,b,c)を特定できるという保障が欲しいのです。
>a,bの不確実性を無視している解析方針だから。
実測値のa,bは参考にするが解析には用いないという考えで
解析をしています(あまりにかけ離れた場合にその結果を無視するくらいの使い方)
a,bの不確実性とは、cはa,bに依存するということでしょうか?
a,bが正確にわからないのであればcを正確に特定する事はできないと。
だとしたら、a,bに対するcの依存度調べて実験値a,bがこの値だから
cはこの値の範囲~という感じで調べて見ようと思います。
線形回帰じゃなくって多項式回帰じゃダメかしら?
495 :
132人目の素数さん :2005/12/12(月) 10:00:21
e
496 :
443 :2005/12/12(月) 11:23:48
皆さんありがとうございます。返事遅くなってすいません。
二項分布の関数について
498 :
132人目の素数さん :2005/12/12(月) 17:21:14
>>497 離散的なのに微分係数として扱うとはどのような意味だ?
変化率も離散的で連続ではないぞ。
>>496 まあ、20歳くらい年上の世代は10年位前、
『最近の若者は・・・・・・』
って言ってたんだろうね(笑)。
いつでも『年喰ってる人間(世代)の方が偉い』
って人間は言いたがるもの(笑)。
多分5000年くらい前の人間も
『最近の若者は・・・・・・。』
って言ってたんではないでしょうか(笑)。
t年に生まれた人間の平均知能指数をμ(t)とすると、
題意により、
dμ(t)/dt<0
でなきゃならないハズなんだけど、科学技術は5000年前よち進歩してるし、
結論としては明らかにおかしいんですけど・・・・・・・・・(笑)。
まあ、年寄りのたわ言だと思って哀れんであげてください(笑)。
500 :
497 :2005/12/12(月) 18:55:22
二項分布の確率変数は0,1,2・・・nといった整数をとりますよね?
501 :
132人目の素数さん :2005/12/12(月) 19:00:23
>>500 ようはそれをして何がしたいのかわからないんだよ。
そのように考えるからには何かしたいんでしょ?
それが分からないと答えようが無い。
>>500 言わんとしてる事は分かるけど、やりたい事が良く分かりません。
面白いですけどね。
ただし、極限操作にはならんでしょ。
と言うのも、n=2であろうとn=10であろうと、はたまたn⇒∞であろうと、
ΔX=1って事実は変わりませんよ。
つまり、全然極限を取っていないと思います。
503 :
497 :2005/12/12(月) 23:36:09
>>501 バックグラウンドを全く書いていませんでした。すいません。
二項分布の確率関数 f(x)=nCx*p^x*(1-p)^n-x
から試行回数nを非常に大きい値にするという条件で
正規分布の確率関数 f(x)=e^-{(x-m)^2/2σ^2}/(2π)^1/2*σ
を導いてみようということで、両辺の対数をとり、ピーク値のx=mで
テイラー展開をしようとしたのですが、1階導関数に
d/dx{ln x!}とd/dx{ln (n-x)!}という項が出てきます。前に書いたような操作で
d/dx{ln x!}={ln(x+Δx)!-ln x!}/Δx = ln(x+1)!-ln x! = ln(x+1)
ここで、x
>>1 の場合と仮定して ln(x+1)=ln x
とすっきりできないものかと思いまして。
>>502 そうですね、極限ではなく平均変化率ですよね。。。
離散値の微分について勉強してみます。
504 :
132人目の素数さん :2005/12/12(月) 23:43:31
>>503 二項定理から正規分布を出したいの?
それとも中心極限定理を示したいのかな?
二項定理から正規分布を出すのはちょっと大変かな。
変だけど一般的な分布が正規分布になることを示すほうが簡単かと。
505 :
497 :2005/12/13(火) 00:35:54
>>504 二項定理から正規分布を導出したいのです。
しかし、離散的な二項分布の差分を微分のように近似して使い、二項分布から正規分布を
近似的に導出することしか出来ないような気がしてきました。
離散的な関数に対して厳密には微分不可能で、テイラー展開も適用出来ないようなので。
上記の手段で無理矢理連続な関数として近似し、得られた確率密度関数を-∞~∞で
積分すると1になるという式を用いると、正規分布の関数は出てくるのですが、どうも
しっくりこないです。
二項分布のベルヌーイ試行を大きくしたときに近似的に正規分布に置き換えれるといった
認識ではだめなのでしょうか?
506 :
132人目の素数さん :2005/12/13(火) 00:42:54
507 :
132人目の素数さん :2005/12/13(火) 00:44:37
とは言ってもあえて難しい道を選ぶあなただからモーメント関数による証明は既に
508 :
497 :2005/12/13(火) 01:06:03
>>506-507 実際に高校で習った二項分布が絡んでいるようだったので自分の興味が
そっちにばかり向いてしまっていて、他の分布が正規分布に近似される
ということはまだやっていないです。
数学の公式が出てくるとその証明が気になってしまうのでてんぱってますが
視覚的にとても見やすいです。参考になるHPを教えて頂きありがとうございます。
509 :
132人目の素数さん :2005/12/13(火) 01:12:39
大学で微積など習っていないのならば定理などは軽く飛ばして
数学の公式と統計は分けて考えた方が良いかも
511 :
132人目の素数さん :2005/12/13(火) 03:06:53
おはつです。失礼します。どうしてもわからない問題なのでカキコさせて頂きます。
512 :
132人目の素数さん :2005/12/13(火) 03:08:38
一応。6.14のPr{mx-a≦μ≦mx+a}={-a√μ/σ≦z≦a√μ/σ}を証明せよ。です。ちんぷんかんぷんなので助けてください(T_T)
513 :
132人目の素数さん :2005/12/13(火) 03:42:08
基本的な問題らしいのですがさっぱり解りません
>>497 さん
スターリングの公式
Γ(n+1)=n! ~近似~ √(2π)×n^(n+1/2)×e^(-n)
ってのがあります。これを使って、
√(2π)×n^(n+1/2)×e^(-n)×p^x*(1-p)^(n-x)
二項分布~近似~-----------------------------
√(2π)×(n-x)^(n-x+1/2)×e^(-n+x)×√(2π)×x^(x+1/2)×e^(-x)
=√{n/2πx(n-x)}×(np/x)^x×{n(1-p)/(n-x)}^(n-x)
あとはx-np=zとでもして、
(np/x)^x×{n(1-p)/(n-x)}^(n-x)
の部分を対数を取ってマクローリン展開してみて下さい。
>>513 偏差値ってのは
偏差値=(得点-平均得点)/√分散×10+50
の事です。ですから今回は
偏差値=(得点-60点)/√12点×10+50
でしょうね。
>>511 最初のPrの部分も正規分布かな?
それとも『中心極限定理で』とか書いてありますか?
518 :
132人目の素数さん :2005/12/13(火) 05:08:20
レスありがとうございます。正規分布だと思います。一応前回習ったのが中心極限定理でしたが、その前の例題でサラリーマンの平均給与を求める問題がでたので。
>>518 何かヘンな問題だなあ・・・・・・。大体mxってなんだろ?平均の実測値?
多分区間推定に絡んでいるネタだと思うんですが、通常
Pr(X-λσ/√n≦μ≦X+λσ√n)=1-α
とか書いて、λを求めたい標準正規分布上のパーセンタイルと対応させて、
危険率αを除いた範囲でのμの値を推定するんですが・・・・・・
>>518 の例題見る限り、そもそもσ/√nが逆数として扱われていますし。
おかしいですね。
エロイ人登場キボンヌ
520 :
132人目の素数さん :2005/12/13(火) 06:50:26
すみません。何分文系なもので自分にもよくわからないのが現状です。
521 :
132人目の素数さん :2005/12/13(火) 06:52:54
例題を考えないで証明するとどのようになりますか?
522 :
132人目の素数さん :2005/12/13(火) 07:01:10
すみません。最初の問題自体まちがっていました。
>>522 aって何て書いてあります?本当にaですか?αじゃなくって?
多分aってパーセンタイルに関係ある数値だと思うんですが・・・・・・。
>>519 のλに対応してませんか?
>>513 >分散が12点で正規分布に従った。
何かひかかる文章ですね。
分散の単位は点でないです。標準偏差で書いたいいんでしょうね。
多分、専門が統計でない先生でしょうね。
525 :
132人目の素数さん :2005/12/13(火) 13:16:43
523
526 :
132人目の素数さん :2005/12/13(火) 13:19:09
>>525 横槍ですまんがzは標準化か?
式変形で無理やり持っていけるがちょっと問題文があいまいだから
なんともいえないけど。。
問題がちょっと言葉足らずで分かりづらいが
528 :
132人目の素数さん :2005/12/13(火) 13:41:23
X_avは一般的に
529 :
132人目の素数さん :2005/12/13(火) 13:56:28
レスありがとうございます。
530 :
132人目の素数さん :2005/12/13(火) 14:01:01
528さんの証明を読んでいるとzは標準化というような気がしてきました。
531 :
132人目の素数さん :2005/12/13(火) 14:01:54
>>529 zが標準化で無いとするのならばちょっと・・うーん
μってのは期待値(平均)であるがこれも一つの確率変数であり
μ周りの確率を鑑みるにzとμは同じ意味とも取れるな。
母集団の平均をμ
サンプルの平均がmxならば527の証明であっていると思うが。
532 :
132人目の素数さん :2005/12/13(火) 14:26:08
レスありがとうございます。混乱させてしまい申し訳ありませんでした。今気付いたのですが、mxはサンプルで取り出したものの平均と書いてありました。大変申し訳ありませんでした。(T_T)
533 :
だれかわかる人いますか? :2005/12/13(火) 16:08:08
統計学でわからなくなってしまい誰かわかる人いませんか?
534 :
だれかわかる人いますか? :2005/12/13(火) 16:10:18
すいません。
>>533 こう言う問題の何が難しいか、と言うと、
『耐震率』
ってのが何を表しているのか分からないからなんです。
例えば、耐震率90%って言うのが、
『地震があった時ビル10000棟内1000棟倒壊』
って頻度で『耐震率』って言ってるのかどうか?
それだったら100軒中10軒『しか』倒壊しないと考えるべきか、10軒『も』倒壊する、って考えるべきなのか(笑)?
そう言う意味で考えると『耐震率90%=倒壊率10%』ってワリとデカイ感じしますよね(笑)。
それはともかく(笑)、一概に『率』って言っても必ずしも『頻度』であるとか、『比率』を表しているとは限らない、って
辺りが難しいのです。
こう言う問題は一応『耐震率』の定義を書いてあると思うんですが、どうでしょうか?
あるいは『耐震率』って名前のある種の『得点』なのでしょうか?
それによって検定手法も変わってくると思います。
>>533 氏がその問題を一番良く知っていると思いますんで、追加情報お願いします。
536 :
533 :2005/12/14(水) 02:22:25
書き込みありがとうございます
537 :
533 :2005/12/14(水) 02:30:07
追加情報です
>>537 どれが追加情報なんでしょう?
多分ある種の得点のような感じだと思うんですよね。
例えば、
『あるクラスのテストの得点について下記のような標本データを得た。
データは :87点 87点 94点 89点 91点 87点 90点 91点 90点 91点
このクラスの平均得点は90点以上といわれているが、この得られたデータは
この事実を反映しているのかどうか。検定せよ。ただし、有意水準は5%で与えられるとする。』
つまり『耐震率』ってのがこのように『100点満点中何点』って意味と同じであれば、
帰無仮説H_0:耐震率=90
対立仮説H_1:耐震率>90
としてt分布で片側検定できると思います。
一方、耐震率が言葉通りに『頻度データ』だったら、データが
>>534 じゃ足りないのです。
地震に耐えた軒数とそれぞれグルーピングされたサンプル数が必要なんです。
問題文見る限り、また与えられたデータだけを見る限り多分前者だとは思いますが・・・・・・
ハッキリわからないんですよね。『耐震率』ってのがあまりにも曖昧で。
もし有意水準が1%になった場合でこの事実が変わるかどうかも検定せよ。
ちょっと
>>538 に従ってやってみますか。
データは以下の通りですね?これを分散未知の正規母集団から無作為に取られた標本とします。
87 87 94 89 91 87 90 91 90 91
標本平均=89.7
標本不偏標準偏差=2.263232693
ここで次の帰無仮説、対立仮説を立てます。
帰無仮説H_0:耐震率=90
対立仮説H_1:耐震率>90
(註:本来だったら帰無仮説を耐震率≦90としたいトコなんですが、帰無仮説の分布がハッキリと決まらないので、最高の耐震率=90を帰無仮説とします。)
ここで検定統計量tは
t=|平均-90|/(標本不偏標準偏差/√データ数)・・・☆
となります。現在データ数は10個ですね?
さて、検定統計量tは自由度(データ数-1)のt分布に従う確率変数で、☆で求めたtが右側5パーセント点(t分布で右側から全体の面積の5%を占める値を示すtの値)より大きければ帰無仮説を棄却して対立仮説を採択します。
ここで☆式は実値代入すると、
541 :
132人目の素数さん :2005/12/15(木) 03:58:46
移動平均モデルって自己回帰モデルより先に開発されたのかな?
542 :
132人目の素数さん :2005/12/16(金) 22:37:54
独立と無相関は別物なのですか?
>542
544 :
132人目の素数さん :2005/12/18(日) 15:24:58
ふざけてるようですが、真面目にお聞きします。
>>544 ぎゃははははははは(笑)。
取り合えず回帰分析でもしてみたら?www
例えば無作為に選んだ女性の乳回りを記入してもらって、『常識テスト』でもやってもらう。
結果の散布図書いてみて相関ありそうだったら回帰してみてもいいかも。
ネタとしたら面白いですねwww
>>545 大学の偏差値ごとに一定人数の巨乳率を測るというのは有効?
それは計り方が逆じゃねえの?
標本調査理論としては面白い題材かも。
それじゃ意味がない。
以前テレビの番組かなんかで、常識テストを巨乳組、貧乳組に分けてテストしたら
>>547 まあでも、個人個人の偏差値データが仮に手元にあったとして・・・・・・。
例えば、巨乳をおうやって定義するかは知らないんですが、
『Eカップ以上を巨乳とする』
で従属変数を
『巨乳である=1』『巨乳でない=0』
として、説明変数を『偏差値』にして、最尤法でロジスティック回帰を行い、
『巨乳確率』
を偏差値から推定する事は可能かもwwwwww
偏差値聞いただけで巨乳かそうでないか判別できるwwwww
もっとも本当に巨乳率が偏差値に対してZ型に推移してるのかどうか
まずは調べないといけませんけどね。
>>551 巨乳を1と0で切り分けてしまうのは主観の問題もあるし無理がある気がする。
巨乳がというとわかりにくいが、要はカップ数と知能?との関係を調べるってことになるのではないでしょうか?
カップであれば、10cmから2.5cm刻みでデータがあるので、客観的で使いやすいような気がするのですが・・
それだと従属変数の分類が恣意的になるから、
554 :
553 :2005/12/19(月) 01:42:24
と思ったが、C65とC80じゃ違うよな。
ブラはアンダー70が一番多いらしい(つまり日本女性の平均的アンダーサイズ)。
乳で白熱(爆)!!!
いや・・・・・・ネーミングがイマイチ・・・・・・。
乳スティック回帰もいいかも。
ボイン分布
560 :
132人目の素数さん :2005/12/20(火) 01:27:06
バカ度との相関はさておいてもブラのメーカーなんかは乳に関していろんな統計取ってるんだろうな。
561 :
132人目の素数さん :2005/12/20(火) 02:11:14
インテリにデブは少ない + 痩せた人に巨乳は少ない
562 :
GiantLeaves ◆6fN.Sojv5w :2005/12/20(火) 19:26:50
女性を無作為に集めて計算能力のテストをしたところ、
563 :
GiantLeaves ◆6fN.Sojv5w :2005/12/20(火) 19:36:52
さて、10分間たった。答えを書こう。
100マス計算なら 8歳♀ > 20歳♀ だろ。
ガンマ分布の定理で、
Pr(X1+X2<z)=\int_{i=0}^{z} Pr(X1<i)Pr(X2<z-i) なので、ガンマ分布の密度関数の積を積分しましょう。であってると思うのですが、識者の意見を乞う。
567 :
132人目の素数さん :2005/12/22(木) 02:40:54
>>565 一番簡単な方法は、特性関数を使う方法。
X1とX2は独立だから、X1+X2の特性関数は
E{exp(it(X1+X2))}=E{exp(itX1)*exp(itX2)}=E(exp(itX1))E(exp(itX2))。
あとは、ガンマの特性関数代入すると、X1+X2はガンマ(α1+α2、β)
に従うことわかるよね。
こうすると、簡単だね。
100個の製品があって、20個を検査した結果異常がなければ
統計的指標は全体の半分が目安になってるのはなぜでしょう
幾何分布G(P)の平均E(X)の導き方教えてもらえませんか?
>>570 E(X) = Σ[k=0,∞] kp(1-p)^k
= p(1-p)Σ[k=0,∞] kr^(k-1) (r=1-p)
= p(1-p)Σ[k=0,∞] (d/dr)r^k
= p(1-p)(d/dr)Σ[k=0,∞] r^k
= p(1-p)(d/dr){1/(1-r)}
= p(1-p)*{1/(1-r)^2}
= (1-p)/p
572 :
GiantLeaves ◆pZJkTrYCYA :2005/12/23(金) 11:48:58
562 :GiantLeaves ◆6fN.Sojv5w :2005/12/20(火) 19:26:50
女性を無作為に集めて計算能力のテストをしたところ、
胸の大きい人の方が計算問題の正答率が高かった。
さて、それは何故か?
563 :GiantLeaves ◆6fN.Sojv5w :2005/12/20(火) 19:36:52
さて、10分間たった。答えを書こう。
胸の大きい人は8歳以上しか居ないからだ。
talk:
>>562-563 お前だろ?俺の名前語って物理板を荒らしてるのは?
あのな、俺はいつも「talk」ってちゃんと付けるんだよ
ついに尻尾を出したなこの偽者め!さっさと数学板から出て逝け
573 :
GiantLeaves ◆6fN.Sojv5w :2005/12/23(金) 17:56:38
talk:
>>572 お前に何が分かるというのか?
574 :
570 :2005/12/23(金) 21:46:38
575 :
132人目の素数さん :2005/12/24(土) 02:28:51
来週には118円mid迄余裕で行くだろ
576 :
132人目の素数さん :2005/12/24(土) 12:07:44
あるデータが正規分布に従うとき
578 :
570 :2005/12/24(土) 22:44:08
もうひとつとき方を教えていただきたいのですが、
579 :
132人目の素数さん :2005/12/24(土) 22:48:46
>>578 Z = X+Y とでもおいて
f(z) を計算。
それは、Y = Z - Xから
X = x の時 Y = z -x となるような確率。
あとは、 -∞ < x < ∞ で積分
580 :
570 :2005/12/25(日) 00:37:59
>>579 あつかましいようですが、もう少し詳しくお願いできないでしょうか?
おしえておしえて
584 :
582 :2005/12/27(火) 21:02:11
それです。。。統計用語じゃ無さそうですね・・・失礼しました!
585 :
132人目の素数さん :2005/12/28(水) 16:48:10
クロス集計ってのが意味不明なんだけどなんなんだ?
共分散分析と多重回帰分析ってどう違うんですか?
588 :
132人目の素数さん :2005/12/29(木) 10:13:14
すいませんが 教えてください。
589 :
132人目の素数さん :2005/12/29(木) 15:25:58
>>588 1.ある数字(たとえば、3)になるまで待つ。
2.引く。以上。
おそらく、あなたの求める答えではないでしょうけれど。
590 :
132人目の素数さん :2005/12/31(土) 01:25:58
とある事情で統計学を独学しなければならなくなってしまって困っています。
>>590 F=(X1/14)/(X2/20) がF分布に従うから
P(X1≧fX2) = P(X1/X2≧f) = P(F≧14/20*f) = 0.01
14/20*f = 3.13
f = 4.47
でいいと思う。
592 :
591 :2005/12/31(土) 04:03:00
逆だった・・・
593 :
590 :2005/12/31(土) 19:28:45
どうもありがとうございます!
701
595 :
132人目の素数さん :2006/01/02(月) 19:54:27
>>578 と似たものでZ=aX+bYと一般に一次結合になっている場合の
証明はどうすればいいですか?
596 :
132ぬんめ :2006/01/04(水) 18:08:13
>>595 XがN(m1,v1)に従うとき,aXはN(am1,a^2v1)に従うので以下略.
>>595 既に解決しているかも知れないが,
XがN(m1,v1)に従うとき,aXはN(am1,a^2v1)に従うので以下略.
海面温度の研究で英語のサイト見てるんですが、
>>598 correction か collection かを
まずはっきりさせようね。
次の問題わかりますか?進級かかってるんですけどどうしても解けなくて…
大学で習うレベルなんで簡単だとは思うのですが…
すいません、0が一個多かった。
603 :
132人目の素数さん :2006/01/07(土) 00:29:02
すみません。
x^2+y^2+z^2 <= 20^2 となる確率。すなわち、
>>603 それ、統計の問題じゃない。微積分学の問題。
a, b の値がどの範囲にあるかによって答は違うので、きっちり場合分けすること。
606 :
603 :2006/01/07(土) 00:48:44
605さん
>>604 そうか、μは-100と100の中間(原点)の0として、S^2=x^2、y^2、z^2と置けるんですね。
まだχ^2検定自体を完全に理解できてはいませんが、ひとまずこの問題は解けました。
本当にありがとうございました!!
608 :
◆M2TLe2H2No :2006/01/08(日) 01:35:17
e
609 :
fw.jta03.roonets.co.jp :2006/01/08(日) 01:35:49
2
どこに質問すればいいのかわからないので、まずはここで。
611 :
132人目の素数さん :2006/01/08(日) 20:43:49
>>610 その二冊を読んだあとであれば、統計学の前提知識としては十分だと思います。
ご専門にもよりますが、「統計学入門」の次でも、
読み進めることは可能なように書かれている気がしますよ。
確率過程について網羅的にカバーする本ではないですが、逆にポイントを
絞って全体像を把握できるように書いてあるので、読みやすいと感じました。
612 :
誰か説明できる人いますか? :2006/01/08(日) 21:55:58
もしわかる人がいるのであれば教えていただけませんか?
2変数間に相関関係があるかどうかの前に、
>>611 親切丁寧なレスしてもらえて嬉しいです。
>ご専門にもよりますが
やはり、こちらの情報も書いておくべきでした。
独学で経済学の勉強している過程で、上記の本を本屋で見つけて
面白そうなので読みたいと思っている素人です。
今のところ、線形代数と微積分、微分方程式の入門書を読んだ程度です。
>「統計学入門」の次でも、読み進めることは可能なように書かれている気がしますよ。
おお!そうですか。前提知識として必要と思って統計学の本を立ち読みしてて、
>>610 の2冊もかなり面白そうだったので、どちらにしろ読もうとは思っています。
他の「確率論」と言われるジャンルの教科書を読むには、
ルベーグ積分が必要知識というのを見かけて、恐怖していたのですが、良かったです。
>逆にポイントを絞って全体像を把握できるように書いてあるので、読みやすいと感じました。
他の人の感想とかやはり聞きたいもので、それも教えてくれて、ほんと感謝です。
615 :
132人目の素数さん :2006/01/10(火) 02:58:32
誰か助けてください(;´Д`)
616 :
132人目の素数さん :2006/01/10(火) 08:16:18
>>615 標本が少ないことも問題ですが、このデータの取り方では
(615に書いてある内容を読む限りは)
AとBのどちらの方法が良いかを判定することは厳密にはできないです。
元々きれいに治しやすい人がどちらか一方に偏っていたかもしれないからです。
どうですか?
それと、この調査はAとBの比較以外に目的があって、
その目的のために患者さんの情報を一般の人に見せる必要性があって、
そのことについて患者さんの同意を得ているのですよね?
(私はそうであることを信じたいと思っています)
データを集める前に解析方法を決めましょうと言われているのは、
集めては見たもののデータが解析に使えなかった('A`) 、では困るからです。
617 :
615 :2006/01/10(火) 11:12:09
>616さん
618 :
132人目の素数さん :2006/01/10(火) 14:54:34
非線形回帰のr^2値やF検定は可能ですか?
問、(X,Y)は一般の2次元正規分布に従うとする。
自分も質問です。
T薬品の総合鼻炎薬Bの新商品の有効性を検証するために、鼻炎患者110人に処方した。
622 :
132人目の素数さん :2006/01/10(火) 19:08:13
お願い本当に誰か助けて↑(>_<)
>>619 同時分布の密度関数は
p(x,y)={1/(2πσ1σ2√(1-ρ^2))}exp[-{1/(2(1-ρ^2))}{((x-m1)/σ1)^2-2ρ((x-m1)/σ1)((y-m2)/σ2)+((y-m2)/σ2)^2}]
exp の中は -{1/(2(1-ρ^2))}{((x-m1)/σ1)-ρ((y-m2)/σ2)}^2 - (1/2)((y-m2)/σ2)^2
∫[-∞→∞]exp[-{1/(2(1-ρ^2))}{((x-m1)/σ1)-ρ((y-m2)/σ2)}^2]dx
= ∫[-∞→∞]exp[-{1/(2(1-ρ^2))}(x/σ1)^2]dx (平行移動)
= {σ1√(1-ρ^2)}∫[-∞→∞]exp{-(1/2)x^2}dx (置換)
= σ1√(2(1-ρ^2)π) だから
Py(y)=∫[-∞→∞]p(x,y)dx
= σ1√(2(1-ρ^2)π) * {1/(2πσ1σ2√(1-ρ^2))}exp{-(1/2)((y-m2)/σ2)^2}
= {1/(√(2π)σ2)} * exp{-(1/2)((y-m2)/σ2)^2}
質問です。
626 :
GiantLeaves ◆6fN.Sojv5w :2006/01/10(火) 21:58:14
627 :
132人目の素数さん :2006/01/10(火) 22:21:49
統計はちょっとかじったくらいの素人です。
628 :
616 :2006/01/11(水) 00:30:35
>>617 さんへ
厳密な解析ではないですが、
患者さん毎に10人のお医者さんの順位の平均あるいは和を計算して、
その値に関してWilcoxon順位和検定(Wilcoxonの一標本検定)で
AとBの群間比較をしてはどうですか。検出力は非常に低いと思いますが。
もちろんAが行われた患者さんとBが行われた患者さんの元々の骨格
(シルエット)に偏りがないのが前提です。
たとえば、仮に術式Bを行いやすい骨格の人がいて、
そういう骨格の人が優先的にBを受けているなどということがあれば、
元々の骨格のちがいを比較をしているのかAとBの比較をしているのか
区別出来なくなります(なので、介入研究であればランダム化をしたり、
観察研究であればマッチングをとったりするわけです)。
さて、学生さんの評価と一般の人の評価をどう使いましょうか。
お医者さんの評価で群間差が無くて、学生さんの評価で群間差があった場合、
どう解釈すればいいかわからなくなりませんか?
お医者さんの評価で群間差があるけれども、
学生さんの評価では群間差がないということであれば、
学生さんの判定がぶれているためかもしれないという可能性が考えられますが・・・。
妥当な標本数(証明込みで)を算出する(複数の)手法で最も一般的なものを教えてください。
630 :
619 :2006/01/11(水) 18:39:21
>>624 さんどうもありがとうございます。大変助かりました。
もうひとつ教えてもらいたいのですが、
問、E[Xi]=mx,E[Yi]=my,V(Xi)=σ1^2,V(Yi)=σ2^2,Cov(Xi,Yi)=p*σ1*σ2 を用い
2次元データ(Xi,Yi))(1以上i以下n)の統計量は
Xバー=1/n*Σ[i=1,n]Xi,Yバー=1/n*Σ[i=1,n]
Sxx=1/n*Σ[i=1,n](Xi-Xバー)^2である。
よって、E[Sxx]=(n-1)/n*σ1^2を証明せよ。
この証明を教えていただけませんか?
よろしくお願いします。
>>627 どういうデータでしょうか?
見るからに連続値ではないので、t検定を行うことは適切ではないと思いますが、
どういう解析をすべきかはデータの種類によります。
>>630 n*Sxx = Σ[i=1,n](Xi-X~)^2 = Σ[i=1,n]{(Xi-mx)-(X~-mx)}^2
=Σ[i=1,n](Xi-mx)^2 - 2Σ[i=1,n](Xi-mx)(X~-mx) + Σ[i=1,n](X~-mx)^2
=Σ[i=1,n](Xi-mx)^2 - 2(X~-mx)Σ[i=1,n](Xi-mx) + n*(X~-mx)^2
=Σ[i=1,n](Xi-mx)^2 - 2(X~-mx)*n(X~-mx) + n*(X~-mx)^2
=Σ[i=1,n](Xi-mx)^2 - n(X~-mx)^2
=Σ[i=1,n](Xi-mx)^2 - n*(1/n^2)*{Σ[i=1,n](Xi-mx)}^2
=Σ[i=1,n](Xi-mx)^2 - (1/n)*Σ[i=1,n]Σ[j=1,n](Xi-mx)(Xj-mx)
=Σ[i=1,n](Xi-mx)^2 - (1/n)*{Σ[i=1,n](Xi-mx)^2 + 2Σ[i<j](Xi-mx)(Xj-mx)}
E[n*Sxx] = n*σ1^2 - (1/n)*n*σ1^2 - 2Σ[i<j] E[(Xi-mx)]*E[(Xj-mx)] = (n-1)σ1^2
E[Sxx] = {(n-1)/n}σ1^2
633 :
627 :2006/01/12(木) 00:59:24
>>631 ありがとうございました。
そうですよね。そもそもこのデータ自体がt検定に適していませんよね。
検定内容は、集団1の環境と集団2の環境においてある条件を満たす語数の比較です。
このセットがいくつかあり、他のセットでは問題なく検定できるのですが、
このセットだけ一方の集団が全部同じ値になってしまって困っているのです。
同じようにt検定している先行研究との兼ね合いもあり、t検定する必要があるのです。
この場合は「t検定はできない」と言ってしまっていいのでしょうか。
また、その場合はどういう理由をつければいいのでしょうか。
「正規分布をしていないから」? 「分散がゼロであるから」?
ご教示いただけますと助かります。
634 :
615 :2006/01/12(木) 02:21:42
>628
635 :
616 :2006/01/12(木) 04:15:17
マン・ホイットニーのU検定とウィルコクソン順位和検定は同じです。
なので、患者さん毎にお医者さん10人分の評点(=順位)の平均か和をだして、
U検定すればOKです。
>>634 > たぶん、医者の評価は、頼めばあと10人は増やせると思うのですが、それで
> もう少しはマシな検出力にすることができるでしょうか。
お医者さんの評価を新たに追加して増える情報は、
評価者間のばらつきに関する情報です。
理屈の上ではお医者さん(=評価者)を増やすことで
患者さん毎の評点(=順位)の平均が安定するので
検出力が上がる余地は0ではないです。
ただし、お医者さんの評価がさほどばらつかないときには影響無しですし、
ばらつく場合であっても、データは80(患者8人×医師10人)から160に増えますが、
解析に使うのがN=8のままですから、結果として検出力は殆ど変わらないと思います。
636 :
132人目の素数さん :2006/01/13(金) 00:23:35
617と619には回答ありか。
637 :
615 :2006/01/13(金) 13:25:18
>635
638 :
132人目の素数さん :2006/01/13(金) 14:15:19
当方大学生ですが高校確率統計(昭和2年)の教科書に載ってる問題をふと、みましたが
統計学スレに書いている時点ですでに大恥
640 :
132人目の素数さん :2006/01/13(金) 18:13:13
マンホイットニーのU検定と
641 :
616 :2006/01/13(金) 23:10:51
>>640 ありがとうございます。
確かに検定統計量の見た目は違いますが、同値になりませんか。
良かったら後学のために違うところを教えてもらえると嬉しいです。
642 :
132人目の素数さん :2006/01/14(土) 00:07:36
U値、実はあんまりよく分かってません(;´Д`)
643 :
984 :2006/01/14(土) 00:21:13
>>630 どうもありがとうございました。理解できました。
644 :
132人目の素数さん :2006/01/14(土) 00:43:04
U値で検索すると一箇所だけ正しいものにヒットする。
645 :
132人目の素数さん :2006/01/14(土) 00:47:09
順位が次のようになっているとする:
646 :
132人目の素数さん :2006/01/14(土) 00:48:33
標本Ⅰ Ⅱ
647 :
132人目の素数さん :2006/01/14(土) 00:50:05
この数字を小さい順に並べると
648 :
132人目の素数さん :2006/01/14(土) 00:52:49
ⅠのU値は
649 :
616 :2006/01/14(土) 03:43:47
1,2,3,4,5をⅠとⅡに分けるパターンは以下の10通りあります
650 :
616 :2006/01/14(土) 03:44:30
帰無仮説の元でのⅡ群のU値の分布
651 :
132人目の素数さん :2006/01/14(土) 11:26:31
助けてください・・
652 :
132人目の素数さん :2006/01/14(土) 12:48:20
>>651 特性関数の定義に基づいて計算すればいいと思います。
654 :
132人目の素数さん :2006/01/14(土) 13:44:53
>>640 ,646-648さん
>>635 の
「患者さん毎にお医者さん10人分の評点(=順位)の平均か和をだして、
U検定すればOKです。」
という書き方が悪かったのかもしれませんね。
一行目の「(=順位)の平均か和」は検定の過程での検定統計量の計算ではなくて、
検定する前のデータ処理の話です。
長々と失礼しました。名無しに戻ります。
655 :
132人目の素数さん :2006/01/14(土) 13:56:05
658 :
132人目の素数さん :2006/01/16(月) 01:06:41
ウィルコクソンの順位和検定 と
659 :
132人目の素数さん :2006/01/16(月) 01:29:07 BE:362688285-
エクセル2003によるF検定は両側検定がないのですが(片側検定しかない)、
660 :
132人目の素数さん :2006/01/16(月) 02:42:39
>>658 違うものです。
>>642 の通り。
>>659 手計算かも。両側とか片側という言い方が適当かどうか判りませんが。
便宜的に分散比>1になるように群を入れ替えて計算してしまうというのはだめですかね?
661 :
132人目の素数さん :2006/01/16(月) 18:58:47
どなたか助けてください。お願いします。
662 :
132人目の素数さん :2006/01/16(月) 22:00:58
E[(Xi-μ)^2 ]=σ^2 であるから、∑(Xi-μ)^2/n が σ^2の不偏推定量であることは当たり前。
663 :
132人目の素数さん :2006/01/16(月) 22:10:00
i=/=j ならば E[Xi Xj]=E[Xi] E[Xj]=μ^2
664 :
132人目の素数さん :2006/01/16(月) 22:58:08
よって、E[ X~^2]= { n(n-1)μ^2 + n(σ^2+μ^2) }/n^2 = μ^2 + ( σ^2/n )
665 :
132人目の素数さん :2006/01/16(月) 23:08:09
ところで、E[Xi^2]= σ^2+μ^2 であったから、
666 :
132人目の素数さん :2006/01/16(月) 23:09:50
663+664+665が問2の答え。
667 :
132人目の素数さん :2006/01/16(月) 23:20:40
>>666 ありがとうございました。
ひとつだけ気になったのですが、j=/=k←という記述は≠のことでしょうか?
668 :
132人目の素数さん :2006/01/17(火) 00:12:50
そう。
669 :
132人目の素数さん :2006/01/17(火) 01:08:55
>>668 わかりました。
本当にありがとうございました。
670 :
132人目の素数さん :2006/01/18(水) 20:32:22
統計学は専門ではありませんが
671 :
670 :2006/01/18(水) 20:43:40
すみません。間違えました。
672 :
132人目の素数さん :2006/01/18(水) 20:46:55
最近統計学について勉強を始めたのですが、偏差と分散の定義がわかりません。
673 :
132人目の素数さん :2006/01/18(水) 23:04:22
674 :
670 :2006/01/18(水) 23:19:45
たびたびすみません。再度訂正です。
>>672 偏差ってのは言ってるように、平均と各変量の差。
各変量とはいってもひとつの変量に注目してることに注意。
例えば平均10である変量が3だったら7がその偏差ってこと。
分散は偏差を全部あつめてそれぞれの二乗和をとって1/nしたもの。
標準偏差はその分散のルートをとったもの。
荒い説明ですが。
あ、ミス。7じゃなくて-7が偏差です。
677 :
672 :2006/01/19(木) 01:05:06
>>673 ,675
丁寧なご回答、ありがとうございました!
偏差は、標準偏差のことです。ご指摘ありがとうございます。
678 :
132人目の素数さん :2006/01/19(木) 11:53:20
すみません。どなたか教えてください。①は自力で出したのですが、②のやり方が
簡単な問題なんでしょうが、僕には難しい_| ̄|○
>>678 >Y=家計消費、Y=可処分所得
両方ともYなの?
>ケインズ型消費関数C=a+Cy
ケインズ型消費関数ってのは知らんけど、式これでいいのですか?
>>679 >両者の相関係数は0.878229
これは両者の関係がかなり高い、って意味です。
相関係数自体は-1から1の範囲を取りますが、問題文は絶対値を指しているのかどうかは分かりません。
なお、+の場合を正の相関といい、-の場合を負の相関と言います。
仮に問題文が絶対値を表してないのなら、これは正の相関で、『地価が高ければ高いほど家賃が高くなる』
と言った関係を示唆しています。
>有意確率pは0.00001よりも小さかった
これは相関係数が0である確率を示しています。つまり、今回たまたま相関係数が0.878229だったけれども、
仮想として無限にデータ(この場合は地価と家賃ですよね)を取った場合、ひょっとして相関関係がない(相関係数
が0)かもしれない。
そこでこの問題の場合、t分布を利用して理論上、相関係数が0である確率を求めているわけです。
『有意確率pは0.00001よりも小さかった』と言う意味は『相関係数が無限抽出でも0である確率が
0.00001以下』、つまり『相関係数が0になる可能性は“ほとんどない”』と判定してるわけです。
そこで、普遍的に相関係数が0.878229と言う値を示さないにせよ、ある程度の相関は『常に存在する(確率が
高いだろう)』と言えます、と。
つまり『地価と家賃』はどんなデータでもほぼ相関がある、と保証しているわけです。
682 :
678 :2006/01/19(木) 16:36:41
680さん、ごめんなさい。
>>681 ありがとうです!
帰無仮説、対立仮説の意味がわからんとです
あと、両側検定、右側検定ってなんですか?
>>683 帰無仮説と言うのは、『否定される事を期待して立てる仮説』の事です。
対立仮説と言うのは帰無仮説が否定された時に採用される仮説の事です。
例えば、例
>>679 の場合、まず相関係数が0.878229 って事が分かった。
まあ、その作業はそこで終わりなんですが、問題は『今回たまたま0.878229 って
値を示しただけで、別のデータの取り方をした場合果たして相関関係がいつもあるのか』
保証できないわけですね。
そこで『相関関係が0.878229 ではないにせよ、無相関ではない』と示したいわけです。
こっちの『ホントに証明したい事』が通常対立仮説となります。しかしながら、『相関係数が
0以外である』ってのは証明が難しいのです。
と言うわけで『反証』になる部分を帰無仮説=『否定したいが為に立てる仮説』とするのです。
>>679 の場合、
相関係数はホントは0である(帰無仮説:こっちが本当は否定したい事柄。しかしながら証明はラク)
相関係数はいっつも0以外(対立仮説:こっちが本当に証明したい事柄。しかしながら直接証明は難しい)
そこで『帰無仮説を否定できれば対立仮説を採択(バンザイ!!!)となるのです。
ただし、逆は成り立たないのに注意して下さい。対立仮説を完全に否定する事は出来ないのです。
両側検定ってのは普通の検定です。
右側検定、左側検定ってのは例えば、例
>>679 で言うと、
帰無仮説:相関係数は0.5以上である
とか
帰無仮説:相関係数は0.5以下である
とか、否定したい事柄が大小関係がある場合に使われます。
これはここで書くより教科書読んだ方が早いでしょう・・・・・・。図示で理解した方が分かり易いと思います。
>>682 Call:
lm(formula = 家計消費 ~ 可処分所得)
Residuals:
1 2 3 4 5 6 7
0.1672 0.7151 0.3919 -3.0602 -1.4153 -0.1573 3.3586
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.59563 13.87260 0.043 0.967
可処分所得 0.87101 0.04881 17.844 1.01e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.162 on 5 degrees of freedom
Multiple R-Squared: 0.9845, Adjusted R-squared: 0.9814
F-statistic: 318.4 on 1 and 5 DF, p-value: 1.015e-05
多分②はCじゃなくって係数の方のcじゃないの?
>>678 パソコンでサーっとやっちゃったんですが、関数電卓でやるなら、
検定統計量=c^2/(1/xの偏差平方和)÷残差平方和/(データ数-2)
となります。
この検定統計量は第1自由度が1、第2自由度がデータ数-2のF分布での
確率変数なので、あとはF分布表のパーセント点と大小比べればいい筈です。
688 :
JIN :2006/01/19(木) 19:56:40
どなたか助けてください(;´Д`)
689 :
132人目の素数さん :2006/01/19(木) 20:49:39
>>670 難しい問題ですね。まず、2つ教えてください。
仮に、統計的に作為があるか無いかを高い確率で判断できる方法があったとします。
その方法を使って分析した結果、高い確率で作為がないという結論になったとき、
670さんは談合がなかったんだなーと判断して告発するのをやめますか?
二つめの質問です。何かの建物を作るための値段でしょうか?
公共事業のデータを見たことがないので、不自然なのかどうか判りません。
百万円単位のお金なんて日頃縁がないですし(苦笑)
670さんが、不自然ではないという入札価格の例を、
具体的な数値例として、理由とともに挙げてみてもらえますか?
「例えば、x1,x2,x3,・・・,x8という入札価格であったなら、
○○という理由で不自然ではないと思う」という例を教えてください。
690 :
678 :2006/01/19(木) 21:07:51
>>685 ,686、687さん
ありがとうございます。
申し訳ないのですが、「係数cが0である確率(有意確率)が1.01×10^-05%しかなくって」
っていうところをどう立式したのかわかりません。
691 :
132人目の素数さん :2006/01/19(木) 21:21:53
>>690 横レス失礼。p値は「相関係数が0である確率」ではありません。
「母相関係数が0である場合に」標本相関係数が0.878229を超える確率が0.00001以下(=p値)なのです。
692 :
678 :2006/01/19(木) 21:43:01
やばいです。
>>691 氏の言ってることが全然わかりません。
>>691 訂正Thanx
>>692 つまりこう言う事です。
今、
>>691 氏が言ってる事を次のようにイメージしてみて下さい。
例えば、
>>679 の問題で、『全国都道府県における地価と家賃のデータ』を集めます。
問題は全部のデータを集めたとしても、『未来永劫通用するのか?』『過去もそうだったのか?』
恒久性があるかどうかまるっきり分かりません。
実はどんなにデータを集めたとしても『標本=サンプリングである』事実は変わらないのです。
そこで仮に仮想的な母集団、こう言う場合は『無限大の母集団』としますね、それが持ってる
相関係数を0としてみるのです。母集団の相関係数(これを母相関係数と言う)が0だとすると、
ある標本(データ)をそこから取り出してもやっぱり0か0付近ではないか、と推測が付くわけです。
ところが今回相関係数が0.878229と高い数値だった。母相関係数が0だとしたら明らかに異常に
見えるわけです。まあ、確かに直観的には見えますよね。
一体、無限大の母集団の母相関係数が0なのに、あるデータを無作為にそこから取り出した場合、
相関係数が0.878229付近の値を示すのはフツーなのかやっぱり異常なのか?一体どっちなんだ、
と。
それが
>>691 氏が言ってる本当のp値の意味です。
>>690 ええとですね、方式としては
>>687 で書いた通りなんですが、普通の統計の授業では
検定統計量が(この場合は第1自由度が1、第2自由度が5)のF分布の1パーセント点
より小さいか大きいか見ます。
手元にある教科書によると・・・・・・検定統計量が22.8よりも小さければ棄却できるのかな?
確かめてないんですけど(苦笑)。
一般的にp値を普通に求めるのは難しいんですよ。Excelあれば計算できるんですが・・・・・・。
Excel持ってますか?
もうダメだ(笑)。誰か専門家呼んで来てくれ(苦笑)。
696 :
132人目の素数さん :2006/01/20(金) 00:01:46
>>690 >>691 >>693 >>694 帰無仮説:c=0(限界消費性向=0)
帰無仮説のもとで「cの推定値」/「その標準誤差」は自由度n-2のt分布に従う
cの推定値と標準誤差は、0.87101と0.04881
「cの推定値」/「その標準誤差」=17.844
自由度7-2=5のt分布で17.844より大きくなる部分と-17.844より小さくなる部分の
面積を計算すると1.015e-05。つまり、p=1.015e-05ということ。
これが0.01より小さいので1%水準で有意。
ちなみに自由度n-2のt分布にしたがう統計量を2乗した統計量は
自由度(1,n-2)のF分布にしたがいます。
というわけで、
>>678 さんのは2乗して計算した場合。数学的には同値。
697 :
132人目の素数さん :2006/01/20(金) 00:02:53
つづき。
③はこういうこと。
n=7のデータから相関係数を計算したら0.87101であった。
ここで、母集団での相関係数が0だと想像してみてください。
その母数団から7個データを取って相関係数を計算します。
また7個データを取って相関係数を計算します。
・・
これを延々繰り返すと、相関係数の分布が作れます。
容易に想像できると思いますが、0の近くの値がたくさん出て、
±1に近い値はあまり出ないです。
この分布の0.87101より大きくなる部分と-0.87101より小さくなる部分の
面積を求めるとp=1.015e-05になります。
p値というのは、
帰無仮説(相関係数=0)のもとで、
7個のデータを得る調査・実験を無限に繰り返したときに、
現実に得られている相関係数よりも極端な値が出る確率です。
>>693 さんの言う「無限」は
解析対象となるデータ数を無限に多くすることを指しているのではなく、
同様の調査・実験の回数を無限に繰り返すことを指しています。
蛇足ですが、この区別がしっかりつけられれば、
たぶん標準偏差と標準誤差の違いが理解できるようになると思います。
内閣の支持率p を「99%の確率で推定の誤差0.01 以下」で推定したい.支持率p について経験的に0.3≤ p ≤ 0.4 で
699 :
691 :2006/01/20(金) 01:15:56
>>692 本当にわかろうとしましたか?
用いられている用語の意味は調べましたか?
それすらしていないのなら、わかるわけはありません。
「わかったような気になる」ぐらいなら、わかっていないことを自覚している方がマシです。
>>695 文脈から、どのレベルで説明しているかは読み取れると思いますが...
700 :
670 :2006/01/20(金) 01:30:12
>>689 さん
ありがとうございます。
まず一点目ですが、談合の確実な証拠か内部通報(いわゆるタレコミ)がないと
告発は難しいそうです。しかし、役所が全く調査すらする気がないようなので
統計学から説明して注意喚起でも出来ないかと考えました。
二点目ですが、端数は切りますので、三桁の整数で正規分布のような形を取るのではないかと考えます。
理由は、仕様が細かく指定されるので、同じような工法、材料で積算すれば
どの会社も同じような金額になりバラつくと考えるからです。
理論的根拠はありませんが。
お示しした例では、ある会社が損をしない入札価格を先に考えて
そのあと等間隔に近い金額をつみあげて、ダミーの各会社に指示したと疑っています。
>>700 方式の詳細は知らんが、予定入札価格が公表されてるのにそれ以上の入札額があるのはどういうこと?
まぁ、それはおいとくとしても、ただ間隔が均等に散らばっているからと言って統計的におかしいとはいえないよ。過去の同様な入札の統計を取って分布を推定し、その分布からの乖離で判断すべきものでしょ。正規分布や一様分布にはならんだろ、多分。
普通は落札率(落札額/予定価格)とか入札率(入札額/予定価格)で見るんじゃないの?
予定価格公表の同じような入札の入札率の統計を取って、不自然だと言うことはできるかもね。ほとんどが談合っぽい入札になってたらどうしようもないがw
その例だとすべてが97%以上の入札額で異常だ、とか、一つだけ97%であと残り7社全部が98%以上でこれは異常だ、とか。ただ、統計的にはもちろん不自然であることが言えるだけで、確実な証拠にはならんだろうけど。
>>701 (
>>670 )
あ、
>>671 、
>>674 を見落としてた。全部が98%以上か。
まぁどっちにしろ予定価格公表で予定価格以上の入札額があるのも変だし、公表じゃないとすればいくらなんでも落札率が高すぎるわな。
703 :
132人目の素数さん :2006/01/20(金) 23:32:07
うんこ
704 :
670 :2006/01/21(土) 00:24:34
>>702 すみません。再度確かめたら、予定価格は559百万円でした。
各社の入札価格は下から543(ここが落札)
以下、544 545 547 548 550 553 555百万円です。
残念ながら談合は日常的なようです。
たとえば、入札価格の間隔のバラツキは無作為の場合計算できそうですし、
それに比べて間隔のバラツキが少ないということが
推定できないでかと素人ながら考えています。
705 :
670 :2006/01/21(土) 00:26:39
>>704 それから、予定価格は事前に公表しています。
予定価格の75%以下だとダメになるらしいです。
706 :
678 :2006/01/21(土) 03:08:56
ケインズの問題を書いたものです。
>>704 >無作為の場合計算できそうですし
のところが理論的根拠も何もないでしょ?
しかも無作為なら均等に散らばることをおかしいというのはどちらかというと不自然。
0~10の間の数を2つ選んだら、片方が3で片方が7だったとき、無作為なんだから、幅がほぼ均等なこの結果はおかしい、なんて結論づけないよね、普通。
要は元の分布を適当に仮定すれば、言いすぎかもしれないがどんな結論にももっていけるんだよ。
だから、まず前提となる分布の仮定に過去の統計的な根拠なり、理論的な根拠が無ければ、その結果として検定で出した結論に意味はない。
即ち、談合が無い場合、各入札価格がどういう分布になる場合が多いのか、が理論的に説明できなければ、「統計的におかしい」云々を論じることはできないよ。
709 :
689 :2006/01/21(土) 05:29:28
>>700 二点目についてですが、
こういう数値なら670さんの目から見ておかしくない入札結果だと思う値段の例を
具体的に挙げてください。
他の人のレスもついていますが、
>>670 さんのいう自然・不自然が正しく定式化できない限り、
かつ、その定式化が思いこみでなく合理性を持ったものでない限り、
分析できませんよ。(統計を使わなかったとしても同じです)
正規分布にしたがうというのは変だと思います。
もしそんな分布が一般的に判っているのならば、
その分布に基づいて皆が合理的だと思う値段を事前に固定して、
応募した会社のなかでくじ引きすれば入札価格の談合なんて無くなりますけど。
何の値段か判りませんが、公共的なものが破格値で落札されて、
昨今問題となっているのマンションのようなことが起きたり、
後から高いツケを払わされるシステムが導入されることの方が迷惑です。
と、考える一般市民もいるということで。
> sample(c(500:560),8,T)
>>710 >>740 の問題をRのsample関数使って何回か試行してみた。
sample関数は一応一様分布だとは思うんですが・・・・・・。
取り合えず乱数の発生範囲を500~560としてみて8つ同時に出して見る。これを8回
繰り返しました。
そうすると8つの会社が入札する状態をシミュレーションできると思ったのですが・・・・・・。
どうでしょうかこの結果は?
誰かもっといいアイディアありますか?
>>709 最後の段落はそれ以前の議論とは関係ないよね?というか,なんかおかしいよね?
談合を追及されたら困る方ですかw
まぁそれは冗談だけど,その意見は「必要なら高くても良い」ということであって
「談合(=無駄な支出)でも良い」ことにはならない。
>>711 8回繰り返すのはなぜ?
その方法だと500-560の一様分布ってことになると思うけど
やはり
>>709 が指摘するように「真の分布」がわからなければなんとも言えないのでは。
そして真の分布がわかっているならば,そこから無作為標本をとって
各社に割り当てれば「怪しくない」価格の組が出来上がってしまう。
やはりこういう問題を統計的推測で追及するのには限界がある気がする。
っていうか、一様分布ならシミュレーションなどしなくても計算で分布は出せるけどな。各期待値はちょうど均等に分割した数になる。
716 :
132人目の素数さん :2006/01/21(土) 12:37:59
>>714 困る人ですw いやウソウソ。全然困らないw
「必要なら高くても良い」≠「談合でも良い」なのは同意。
ついでに談合は良くないと思う。
670の話を突き詰めていくと、
結局いくらが妥当かという値段の下限を決める話になる。
なので先回りして書いちゃった。
670さんが社会正義を追求しているのなら、
“統計で嘘をつく方法”的アプローチは取って欲しくないし、
社会正義の追求の過程で生じる負の側面にも責任を持って欲しい、
と思ってちょっと感情的になって書きすぎました。
こういう曖昧な問題は(「無駄」という言葉の定義すら難しい)
>>708 のように、どんな結論にも持って行けるので、
統計のウソでごまかすこともいくらでもできる。
もちろん、その結論には必ずケチをつけることができる。
でも670さんを監視する人がいないし、
仮にそんな物好きが居たとしてもその人が統計を知っている可能性は小さいので、
今後670さんが「統計のウソ」を使ってもケチをつけられることは少ないと思う。
ただし、まじめにやってるのなら(レスからそう感じたので書いてるんだけど)、
統計のウソは使わないでね、と言っておきたい。
スレ違いなのでこの辺でやめます。
>>714 >8回繰り返すのはなぜ?
スレッドが長くなっちゃうからです(笑)。
当然1万回とか繰り返してもいいんですが、単に
>>670 氏が乱数で並んだ8つの数見て
『作為的だ』って感じるかどうか知りたかったんです。どうかな、と。
>やはり
>>709 が指摘するように「真の分布」がわからなければなんとも言えないのでは
僕もそう思います。
ただ、『入札価格』ってのはどう言うモデルになるのかちょっと興味あります。
一様分布じゃなくって・・・・・・公表されている入札予定価格近くから指数分布みたいになるのかな?
入札予定価格から遠く(安く)なるに従って出現確率が低くなっていく・・・・・・どうなんでしょうね?
>>670 氏が考えているモデルはどんなモデルでしょう?
>>715 一番尤もらしい状態はどう言う状態だと思いますか?
一様分布は単に『やってみただけ』なので、他に代案があれば面白そうなんですけど。
718 :
132人目の素数さん :2006/01/21(土) 20:23:24
>>688 (a)「有意水準」が書いてませんが・・・5%?
同一個体に対する対応のあるデータだから、対応のあるt検定か。
体重にばらつきがあるというのが重要で、
対応の無いデータの取り方をしたり対応を無視したデータ解析をすると
インスリン量の違いが体重の違いでかき消されてしまうんでしょうね。
(b)書いてあるとおり計算して、平均値と標準誤差を出して、信頼区間を作る
(c)QQプロットをとってみる、などが一つの方法。
ただし、体重に差があると問題に書いてあるように、
この犬だけ大きいためにインスリン量が多いのかもしれないから、
前後差に対して分析しないといけないと思う。
少し教科書的な方法からはずれますが、
ID7だけ外して散布図と信頼楕円を描き、
ID7の点が外れているかを見てみるというのもありかも。
(d)Wilcoxonの「符号つき」順位和検定のことだと思うが。
教科書の例題に殆ど同じようなものが載っているはずなので実際の計算は略。
719 :
ケインズの男 :2006/01/21(土) 21:02:49
ケインズの問題を書いたものです。
恐らくもの凄く簡単な問題なんでしょうけどいまいちノート見ても理解できない…。
>>721 即レス感謝です。どうもありがとうございました。
723 :
720 :2006/01/21(土) 23:02:35
また質問で申し訳ありません。
724 :
132人目の素数さん :2006/01/21(土) 23:02:54
>719
725 :
132人目の素数さん :2006/01/21(土) 23:05:35
ところでBayesian Statisticsってどのような物ですか? 誰か賢い人、教えてくださいな。
726 :
670 :2006/01/21(土) 23:13:44
いろいろご意見をいただきありがとうございます。
>>723 期待値と分散の定義に従って計算してみれば?
>>720 あ、良く見てみれば
>>720 って密度関数にならないよ。
1/10 :0≦y≦10
f(y)={
0 :その他の場合
全部足したら1以上になっちゃう。
定義域間違えてない?
>>728 うーん、問題文はそのようになってるんですけどね…。
出題ミスなんでしょうか?
>>728 1以上、っていうか丁度1になるから、いいんじゃないの?
>>731 ちょうど1にならないでしょ?
11/10になっちゃうと思う。
733 :
132人目の素数さん :2006/01/22(日) 01:10:35
>>726 > 公共工事の場合、入札価格がどのように決められるかは
> 非常に複雑で、積算の他に営業的な意向、技術的条件
> その他様々な要因があり私にもよくわかりません。
あ、あの・・・、入札価格がどのように決まるか判らないのに、
その入札価格を見て不自然だとか談合だとか言ってたんでつか。
監視するなら勉強してください。心の底からお願いします。
お返事つけるのもバカかもしれませんが、バカ正直に回答すると、
入札価格の桁の十分下の方(相対的に意味がないくらいに小さいところ)は
0-9までが均等に出てくるかもしれませんね。
>>732 Yが整数値だけとる離散型だとそうなるけど、
いちおう密度関数と書いてあるから、連続なんじゃないかと思ってみたり。
>>733 連続なのかな?
直観的に離散型だと思ってマシた。
735 :
132人目の素数さん :2006/01/22(日) 01:23:12
736 :
132人目の素数さん :2006/01/22(日) 01:36:35
おやすみw
>>735 >>698 n人調査したときに支持率が0.4だったとして99%信頼区間を計算する
↓
99%信頼区間が0.39-0.41に収まるnを逆算する
なんで0.4の時だけ調べればいいのか判らないときは、
0.39, 0.38,..., 0.3などと計算して確認すれば理由がなんとなく判ると思う
正確に理解したいときは二項割合の標準誤差の式をもとに、
pと標準誤差の関係をグラフに描いてみれば良い
737 :
698 :2006/01/22(日) 11:30:40
738 :
132人目の素数さん :2006/01/22(日) 12:29:43
統計的仮説検定の結果において「有意水準1%で仮説H0 が棄却されたのだから,
お尋ねしたいのですが。
740 :
739 :2006/01/22(日) 13:54:44
あ、すいませんageときます
741 :
132人目の素数さん :2006/01/22(日) 15:53:09
>>739 >t検定の数式の平均を当てはめるところに、学年全体の平均の値を当てはめていいのでしょうか?
良いか悪いかと問われたら、だめ。
でも、元々どういうことを調べたいんだろうか。
9人の成績が上がったかどうかを調べたいの?
その場合、1年生の時と2年生の時のテストの難易度が変わっていたら、意味無くない?
TOEICのような標準化されたテストなら良いんだろうけれど。
あと、本当に対応の無いデータ?
例えば、抜き出した9人だけに視点を絞って
この人達の成績が上がっているかどうかを調べたいのであれば、
さらに全体の平均に加えて標準偏差も判っているなら、
点数を偏差値に換算して1年次と2年次の偏差値について対応のあるt検定するかも。
742 :
739 :2006/01/22(日) 16:04:19
>>741 どもです。参考にさせていただきます。
ええと、調べたいこと(というか問題文)は、
「学生の、1年生時と2年生時の学力に差があるか?」です。上下ではなく、単純に差があるか。
テストの難易度とかは問題文で触れられてないので、多分標準化されてるor気にしないで良いものかと。
偏差は、全体のものは解かってません…学年全体のデータ数がいくつなのかも書いてないし。
対応に関しては、ないものとしてやれと言われてます。
743 :
670 :2006/01/22(日) 17:34:03
>>733 >あ、あの・・・、入札価格がどのように決まるか判らないのに、
その入札価格を見て不自然だとか談合だとか言ってたんでつか。
監視するなら勉強してください。心の底からお願いします。
教えていただいて感謝はしていますが、
勉強しろとの言葉にはかちんときました。
教師は、生徒の試験の点数がなぜその点数になるのか
わかっているのですか。
医者は、ある臨床データがどうして出てくるのか
完全に理解しているのですか。
むしろ、自然界のデータの分布がどうしてその形になるのかは
複雑すぎて理論的には説明できない例がほとんどだと思っていました。
過去のデータを当てはめているだけでは無いのでしょうか。
744 :
132人目の素数さん :2006/01/22(日) 17:48:17
>>742 そういうことならば、全体の平均は特に使わず、
単純に比較すれば良いんだろうね。
745 :
739 :2006/01/22(日) 18:00:49
>>744 ありがとうございます!
留年が懸かっている問題なので、すごく助かりました!
746 :
132人目の素数さん :2006/01/22(日) 18:12:59
>>745 がんばれよ!
と言いつつオレも他の単位が(笑)
お互い落ちぶれないように勉強しような!
>>743 そういうことを書くとまた
>>733 に勉強しろっていわれるよw
例えばあるクラスのある試験で全員が90点以上だったする。
各生徒の学力を大体把握している先生なら、なぜこの点数になるかが分かっている、とうよりは点数が大体どういう分布になるかは推測できる。
だから、この結果が「おかしい、不正がある可能性が高い」と結論づけるかもしれないわけだな。
が、全然生徒の学力が分かっていない人から見れば、「おかしい」と結論づけることはできない。
試験が簡単だったか、全生徒の学力が高いか、不正があったか、可能性は色々あるが、どれか分からないわけだよね。
もし、試験の難易度を知っていれば、統計的にはこの場合、全生徒の学力が高い、と「推定」することになるわけだ。
で、次に同じ試験をして全然違う結果が出れば初めて、どちらかの試験で不正がある可能性が高いと統計的に判断することができる。(これが検定)
過去のデータを当てはめる、というのは「推定」という統計学的に「理論的」なものだよ。
わからないってことは、正規分布であるか一様分布であるかとかそういうことすらわからない、ということで勝手に中心極限定理とか関係ない定理を持ち出しちゃいけない。
その推定された分布さえ無いし、今回の場合各業者の入札に対する姿勢のデータすらないのに、得られたデータを統計的な判断でおかしい云々いうことはできない、ってことだ。
最後の桁も一様分布になるとは理論的には言えないよ。当たり前だが、入札する際の最低単位を100円にしていたり、1000円にしていたり色々な業者があるかもしれないからね。
1円単位がみんなゼロだったら「おかしい」と考えるよりは、「みんな10円単位以上で丸めて入札してるんだ」と推定する方が普通なわけだね。
748 :
132人目の素数さん :2006/01/22(日) 20:46:05
>>743 まぁまぁ。落ち着いて。
レスがつくってことは、670は無視されてないってことだからさ。
>医者は、ある臨床データがどうして出てくるのか
>完全に理解しているのですか。
していないと思うよ。
でも健康な人の血液検査がどういう分布をするかは知ってるだろ。
普通の値と普通ではないかもしれない値との区別がつくから、
検査をみて病気を疑うんじゃないの?
670は談合がないときの分布はわかんないんだろ。
そうであるにもかかわらず根拠も示せずに分布がおかしいとか疑うんだったら、
どんな入札でも疑うんじゃないの?
統計学の問題としてではなく、常識的に、論理的に、変だよ。
もしかして、飲み屋で談合の話を聞いてしまった(;´Д`) 、とか、
入札の分布以外の情報がきっかけで疑ってるの?
もしそうだったら、常識的には理解できるけど、
統計学的にはもう結論でてるし、これ以上このスレッドで話す話題じゃないよ。
おしまい。
スレッドが荒れると嫌なので733は喧嘩売ったりしないでくれな。
749 :
132人目の素数さん :2006/01/22(日) 20:53:43
あ、747とかぶってしまった(;´Д`)
失礼!
いじめてるわけじゃないのであしからず
>>670 750 :
747 :2006/01/22(日) 20:55:22
751 :
132人目の素数さん :2006/01/22(日) 21:13:12
>729
752 :
132人目の素数さん :2006/01/22(日) 21:13:39
Cauthy distribution{ f(x;θ)=1/{1+(x+θ)^2}のmeanとvarianceの値を教えてください(>_<)
753 :
132人目の素数さん :2006/01/22(日) 21:21:10
ある中学3年生38人のクラスの総合学力テストの成績は、平均54、標準偏
754 :
670 :2006/01/22(日) 22:07:24
>>748 >>749 分布がわからなきゃダメというのはわかりました。私も743でもそう書いています。
ただ、厳密にいうと健康な人の血液検査がどういう分布をするかもわかっていませんよ。
それぞれの測定項目によってバラバラだから、正規分布に近似しているかどうか検定くらいはするかも知れませんが
複雑すぎてそれぞれの項目の分布すらはっきりわかっていません。
また、分布がわからないのなら、分布型に依存しないノンパラメトリック統計か何かで推定が出来ないものでしょうか。
現に医学データは分布型がわからない場合にそうしているのでは。
それから、今回の入札の最低単位は全て百万単位ですので、最後の数字は一様に分布すると仮定して良いのでは。
755 :
132人目の素数さん :2006/01/22(日) 22:10:37
以下の論述が出来ずに困ってます…
>>754 モチツケw
>>747 にしろ、
>>748 にしろ構造的にどういう分布をするか、ってことが分かる、なんてことは言ってない。
だからあなたの
>入札価格がどのように決まるか判らない
というのは特に問題ある発言では無いよ。各業者全部に内通していない限りその厳密な出し方が分からないのは当たり前だから。
>>733 があおってるだけだよ、きっとw
あと、パラメトリックだろうが、ノンパラメトリックだろうが、検定するには比較する対象が必要なんだよ。
分布形が分かるかどうかの問題じゃなくて、どういう状況との違いを確かめたいのか、というのが問題。
最後の一桁も一様と仮定してもいいと思うが、各業者が最後の一桁は必ずランダムに0~9までの数を選ぶことにしている、という状況以外は構造的にそうなるわけではないよ。
これまでの経験的にそう仮定しても問題ない、ということが(厳密には検定によって)わかっている、というだけ。
ということは談合する場合は普通は最後の一桁は散らしてくるだろうから、逆に一様でない場合の方が談合が無いことの証明になるかもねw
とにかく談合する方は当然、落札価格を決めた後は残りを過去の統計からおかしいと判断できない数字を作ってくるはずなんで、統計的談合判断、というようなものは無理。
疑う基準としては、やっぱり落札価格の予定価格に対する割合が高いかどうか、で疑うのが一番だよ。95%以上の場合は調査する、とかを決めちゃえばいい。
757 :
670 :2006/01/23(月) 00:23:54
>>756 そういう憶測でものをいってはダメだよ。
入札価格のやり方がわからなければダメといっておきながら
「当然、落札価格を決めた後は残りを過去の統計から
おかしいと判断できない数字を作ってくるはず」なんて決めつけてるのが矛盾。
そもそも、彼らはそんなことを分析することはと思ってもいないよ。
町の中小企業のおやじだよ。
ちなみに、公共事業のあり方について君と議論するつもりはない。
まあ、質問が難しすぎたとは思う。
もっと単純化して、最高と最低の入札価格の間に価格がランダムに分布しているかどうかの検定は出来ないのか。
758 :
132人目の素数さん :2006/01/23(月) 00:38:38
あのさ、670さんが考える、
>>757 それは失礼しました。
後半の質問についてはできますよ。
たとえば、最も荒くいえば、533-549なら、8社すべてが中間の541以下になる確率は(1/2)^5=0.3%だから、もし全社541以下ならおかしいと判断する、とかそんな感じになるね。
もう既に
>>715 で書いてるが、ちょうど均等に並んでいる、っていうのは一様そのもので、ちょうどすぎておかしい、ということは検定では言えないですよ。
760 :
759 :2006/01/23(月) 00:47:38
>>759 訂正。(1/2)^8。
もちろん、ちょうど半分じゃなくて区間の幅を狭めて検定方式を作っても同じことね。
761 :
132人目の素数さん :2006/01/23(月) 00:52:39
そもそもは、一様になるはずではないのに一様すぎておかしい
>>755 片側と両側の違い、ってのはそもそも検定している仮説が違うってことは分かってる、ってことだな?
あと書くとすればそうだねぇ。認識として有意性があるはずなのに、有意性が無くなる検定は、そもそもの検定方式が妥当でない、あるいはサンプル数が少ない場合にそうなることがある、とかそういうことかな。
763 :
758 :2006/01/23(月) 01:19:56
>>761 そうなのか。
一様に選んだとしても、何もほぼ等間隔になってしまうなんてことはあまりに作為的な感じがするから、これを統計的におかしいと判断できないの?
って感じにも
>>670 は読めるけどな。んで、それは無理ってことは既に
>>708 や
>>715 が言ってる。
で、ランダムに選ぶ、の意味が一様に選ぶ、という意味ではないなら、
>>670 の考える「ランダム」がどういうものかが分からなければそもそも何も論じることができない、と。
もちろん、その「ランダム」が中心極限定理、正規分布云々で一般的に分かる、なんてことはない、ということですな。
おしまい。
764 :
132人目の素数さん :2006/01/23(月) 02:11:07
「平均の平均をとっても意味がない」と、
765 :
761 :2006/01/23(月) 02:16:32
>>763 758は759-763で解決済みってことで、670関係は全て終了だな? 乙
本当、憶測でものをいってはダメだね。( ´∀`)
>>752-753 はタイミング悪かったな。チャンスがあれば後日。
766 :
132人目の素数さん :2006/01/23(月) 02:33:29
少子高齢化について色々調べているんですが、将来の人口推計に興味を持ったので教えてもらいたいことがあります。
767 :
132人目の素数さん :2006/01/23(月) 03:18:57
詳しいことは判りませんが、
768 :
132人目の素数さん :2006/01/23(月) 03:34:03
>764
769 :
132人目の素数さん :2006/01/23(月) 03:49:28
>752 残念ですが、ないです。
>>768 >>764 多分、高校生に教えるぐらいだから、例えばクラスが2つあって、テストをした場合、クラスの人数が違うのに、各クラスの平均を出してそれを単純平均しても全体の平均にはならないよ、
みたいなことじゃないの?加重平均をとらないかん、という。
いや、これじゃ小中レベルかw
もしそうならついでにシンプソンのパラドックスでも教えてやれ。
771 :
768 :2006/01/23(月) 04:20:09
そういうのはあり得るかもしれないね。
ちょっとスレ違いかもしれませんがお願いします。
>>752 中央値は存在するけど、平均、分散は存在しないそうな。
775 :
132人目の素数さん :2006/01/23(月) 08:05:19
SASの本でお勧めなものはありますか?当方まったくわからないものでして・・・
778 :
132人目の素数さん :2006/01/23(月) 19:21:46
統計の問題を論述で答えるときの作法が全く解からないんですが、
779 :
132人目の素数さん :2006/01/23(月) 21:31:24
「2005年度の入学生に対して、1年次と2年次の4月に学力調査を行った。
>>670 今回のデータに関しては結論が出たみたいだけど補足。
もしこれからもデータを取る、あるいは過去のデータを調査するという気があるなら
まだ手はないこともないでしょう。
入札率に対するなんらかの分布を推定し、それを元に1回の入札で百万円単位で
同じ価格になる企業が存在しない確率を計算します。
(実際に談合があろうとこの確率の推定はなんら問題がないところがみそ。)
1回の入札でのその確率は0.9とかいうように非常に高くても、もし非常にたくさんの入札で
同じ価格が出てこないとそんなことが起こる確率は大変小さくなり談合を疑えます。
まあ同額のものを適当に混ぜると言うことをされると入札データが相当豊富にないと
分かりませんけどね。
いろいろな考え方があるはずだけれど、まずは、
>>779 決まった作法も言い回しもありません。
考慮すべきことをきちんと考慮し、思考の流れが読み取れるように書けばいいはずです。
少なくとも、あなたが「対応のあるt検定を使う」と判断した根拠は書かないとだめでしょうね。
以下のような回答で何点くれるかは知りませんが...
「学生の学力」が変化しない、という帰無仮説をおき、それを検定することにより変化の有無を検証することとした。
この帰無仮説は、(数式)のように書ける。ここで、(数式中に使用した文字の説明)である。
なお、有意水準は慣習にしたがい、x側x%とした。
・・・・・、・・・・・という仮定をおくことにより、この問題に対してはxxx検定が適用できる。
検定統計量は(数式)と表現され、実際に得られたデータより計算すると、xxxである。
この検定統計量は帰無仮説の下で自由度xのx分布に従う。
数表より読み取ると、有意確率はxxxであり、帰無仮説はxxxxxた。
よって、学力の有意な低下はxxx、xxxxxと結論される。
ここまで書いて気づいたけど、
>>781 の言われていることと同じですね。
>>781 >>782 ありがとうございます!参考にさせていただきます。
確かに、その検定を使う根拠や、言葉が足りない部分がありました。
784 :
739 :2006/01/23(月) 23:00:39
連レス失礼します。
↑番号間違えた…すいません、783です
質問があります。
787 :
132人目の素数さん :2006/01/23(月) 23:45:05
ポアソン到着についての質問です。
1. A市の食器洗い乾燥機の普及率について調査した.標本として,100世帯をランダムに抽出したところ,使用世帯は11世帯であった.
789 :
788 :2006/01/24(火) 02:13:49
解き方の方法って日本語はおかしいですねww
790 :
132人目の素数さん :2006/01/24(火) 03:29:51
学校の情報処理論というコンピューター演習の授業の宿題で、以下のキーワードを使って
791 :
132人目の素数さん :2006/01/24(火) 05:01:57
>>777 がエラーで見れません。もう一度お願いします。
792 :
132人目の素数さん :2006/01/24(火) 07:40:58
>>788 教科書を取り出す
目次か索引のページを開く
二項割合の信頼区間
二項割合に関する検定
正規分布にしたがう確率変数の平均値の信頼区間
正規分布にしたがう確率変数の平均値に関する検定
・・・について書いてあるところを探す
読む
よく分からないんだけど、教科書とか手元に無いの?
何のひねりもない問題なんだけど。
793 :
788 :2006/01/24(火) 09:08:11
>>792 ちなみにどんな感じの解答になりますかね?
テストに出るんですが、ちょうどその時だけ欠席してしまって・・・・
本当に自分勝手なんですが、よろしくお願いします。
>>777 amazonで『SAS 入門』で調べてみ。
797 :
788 :2006/01/24(火) 14:28:15
>>794 マルチみたいになってしまってすみません。
ここの方々ならば、正確な解答を出してくださると思って書き込みました。
よろしくお願いします
すみません、質問です。
>>798 >相関係数同士の有意差を出す方法
意味が分かりません。
相関係数は一つしかないのでは?
801 :
780 :2006/01/24(火) 21:36:46
>>670 >>704 もう670さんは見ていないように思うが、思いついたことを書いておく。
前回、分布を推定しないといけないと書いたが、正確な確率が必要なわけではなく
談合があったかどうかだけ知りたいのなら不等式で抑え込んで評価ができることに
気づいた。
提示されたデータでの543百万円が入札の本当の最低額だとしたらそれから559百万円
までの17通りしかない整数値で等確率に入札が生じるというのが、金額のかぶらない
確率の最大値を与える分布になる。(ただし、条件としてどの企業もこの範囲の中で
同じ分布で金額を決められることが必要になる。すなわち、企業の体力のようなものは
考えない。)
提示されたデータに当てはめるとその確率は(16/17)*・・・*(10/17)=0.14である。
したがって、提示されたデータだけでは有意な証拠とはなり得ない。
しかし、今回のような高落札率で金額のかぶらない入札が続いたなら意外と早く談合の
証拠となりそうだ。
802 :
698 :2006/01/24(火) 21:51:42
>>736 さん、
どうにか計算して、
答えが約13936人になりましたが、
あってるでしょうか?
よろしくおねがいします。
king
質問です。
805 :
132人目の素数さん :2006/01/25(水) 00:19:53
>>798 、800
例えば、今の親の年収と子どもの年収の相関係数と、
50年前の親子間の相関係数の間に有意な差があるかを調べる、
みたいな話かな。
>>802 正規近似を使って計算したら15900前後になってしまったんですが・・・。
信頼係数は正規分布の上側99.5%点から得ましたよね?
正規近似以外の方法を使って計算されました?
806 :
755 :2006/01/25(水) 02:57:20
755の答え書いたら、今度は「書き方がゴミ」と言われてしまった…
>>796 それだと20冊近く出てきてしまいます。もうちょっと絞った形で何冊かあげてほしいのですが。
808 :
798 :2006/01/25(水) 09:50:33
>>800 説明不足ですみません。
>>805 さんがおっしゃっている通りです。
今の親の年収と子どもの年収の相関係数と、
50年前の親子間の相関係数の間に有意な差があるかを調べるとして、
その際に物価の違いを統制する偏相関係数を求めたとします。
その場合、現在の親と子供の年収の偏相関係数と、
50年前の偏相関係数との間に有意差があるかどうかを調べたい場合、
相関係数の有意差を求める公式を使用しても大丈夫でしょうか?
809 :
GiantLeaves ◆6fN.Sojv5w :2006/01/25(水) 11:49:06
>>808 自由度を変えればそのまま使って多分問題ないと思う。
多分、Z変換したものが正規分布に近似できることを利用した検定をするんだと思うが、その公式の中で、「n」となってるところを「n-1」にすればそのまま使えると思う。
もちろん、他の説明変数がk個あればn-k。
>>807 20冊もでて来ないでしょ?
大体『自分に合う本/合わない本』ってのは他人に分からないよ。
何がやりたいのかも良く分からないし。
大体amazonなんか利用する場合は、
①良く売れてる
か
②書評がキチンと付いている
を目安にした方がいいと思う。
自分はSAS持ってないし触った事もないから分かりません。
でも良さそうなの見てみたら
『経済・経営分析のためのSAS入門』
ってのが良さそうに見えた。
何がイイかと言うと、中古で950円だったから(笑)。
取り合えず古本でいいので、購入してみて
『合わない』
って思ったら別の探してみれば?
812 :
798 :2006/01/25(水) 21:52:58
>>810 ありがとうございます。
はい、Z変換をした式を使用します。
では、nの部分をn-1にすれば大丈夫なのですね。
もしよければ、なぜ自由度を変えなければならないかを教えていただいてもよろしいでしょうか?
使えると知ってほっとしました。ありがとうございました。
>>801 例えば、母集団が1~10までの整数値を取るとして、
「それぞれの値を取る確率が1/10である」という仮説を検定したいとする。
で、今10個のサンプルを取った結果、1から10までがちょうど1個ずつ出たとする。
仮説が正しいとすると、ちょうど1個ずつ出る確率は
10!/(10^10)≒0.04%
しかないから、この結果はおかしい。よって仮説を棄却する…。
最後の
>提示されたデータに当てはめるとその確率は(16/17)*・・・*(10/17)=0.14である。
>したがって、提示されたデータだけでは有意な証拠とはなり得ない。
の部分を読むと、上の例の検定を正当化しているようにも見えるが、これはおかしい、というかこの検定方式は非常に好ましくない、ということは分かってるのかな?
分かってりゃいいけど。
814 :
698 :2006/01/25(水) 22:46:48
>>805 あれま。計算違いですかね?
なんでだろ~
わからん。(>_<)
>>812 (標本)偏相関係数の分布形は、単相関係数の分布と全く同じ形で、nのところが、(n-k)(kは相関を測りたい2つの変数以外の説明変数の数)になる。
これがなぜか、ってのは多変量解析とかの専門書を読んでくれ。
意味合い的には、影響を排除したい変数があるから、その変数の個数だけ多くのデータが要求される、ってとこだな。
だから、無相関検定でも、相関係数同士の検定でも、単相関係数の場合と全く同じ議論の流れで検定方式が確定できて、自由度の部分だけが変わることになるはず。
816 :
教えてください :2006/01/25(水) 23:42:29
同じ業種1000店舗の、
817 :
780 :2006/01/26(木) 00:40:55
>>813 等確率の仮説を棄却するつもりはないので分かっています。
確率が小さくなることを示しているだけ。
問題なのはその範囲内のどんな分布でも等確率の場合が
その状況が生じる確率の最大値を与えると言うこと。
818 :
132人目の素数さん :2006/01/26(木) 01:42:51
ちょっと些細な質問。
>>812 n=3として(n=3で相関係数を計算するかよ思うが、あくまでイメージしやすいようにという意味)、
(x1,y1)
(x2,y2)
(x3,y3)
の相関係数をrとする。また、
(x1,y1,z1)
(x2,y2,z2)
(x3,y3,z3)
というデータで、3番目の変数の影響を調整した偏相関係数をr_pとする。
説明1
偏相関係数は、変数xをzに回帰させたときの残差と、
yをzに回帰させたときの残差の相関を見ていることになる。
zに回帰させるときに自由度を一つ使っているので、
xの残差、yの残差ともに自由度は3-1=2になる。
>>816 正規分布の仮定が置けるのなら解ける。
Tobitモデルの応用と考えて、
測定されていない部分の尤度を積分の形で表現した尤度を書いてパラメータを推定
パラメータ推定値が得られれば売り上げ個数からパーセント点を計算できるので、
1000店の内のどの辺に位置するかは判る
と思うんだが、面倒で式を打つ気がしないので、ここまでで勘弁・・・
>>820 Z変換の分散も1/(n-k-3)になる。ご承知かと思うが念のため。
>>815 では、自由度の部分で統制する変数の数をマイナスすればいい、ということですね。
ありがとうございます。
>>819 数学専門なのではないため説明2の方は難しかったのですが、
説明1でなんとなくわかりました。
丁寧にありがとうございます。
>>821 Z変換の分散も変わる、ということは、Excelで「=FISHER」というコマンドを使わずに、
数式を入力しなければならないということになりますよね。
大変そうですが頑張ります。
みなさま、ご丁寧に教えてくださってありがとうございます。
>>822 ご指摘のとおり。書き方が紛らわしかったな。
820の話はZ変換とは無関係に自由度の説明するためのもので、
そもそも偏相関云々以前に、N=3のときにZ変換をするのは適当ではない、
ということが言いたかった。
>>804 EXCELでどうすればいいかは判らないけれども、
そのような結果になったと言うことは、
回帰係数が有意であったとしても、
統計学的に有意な差が実際上意味のある差とはいえない状況、
ってことだと思う。
帰無仮説「相関係数=0」の検定をして有意だったとして、
大きな相関があるとは限らない。
相関係数が0.01であったとしてもデータが膨大にあれば有意になるので。
そういう場合は、0でないとはいえても、相関が大きいとはいえないし、
相関があるという主張をするのは実質的に意味がない。
回帰係数と決定係数の関係も、同じこと。
>>824 FISHER関数自体はただの関数だから別にそのまま使っていいよ。
827 :
132人目の素数さん :2006/01/26(木) 23:34:51
ある人は、顔を見ただけでその人の干支をズバリ当てる超能力を持っている。
>>827 2人の干支をあてさせて、2人ともあてれば、デタラメに言ってるのではない、とする検定はできるよ。
検定方式は、帰無仮説が「干支を当てられるのが嘘。(各干支を1/12の確率でいう)」、棄却域が2人ともあてた場合で、この確率が1/144。
有意水準1/144の検定だね。対立仮説が「干支を確実に当てられる」だけなら検出力は100%。
829 :
827 :2006/01/27(金) 08:24:14
>>828 1/144ですね。 X/12として考えてました。
ありがとうございます。
830 :
132人目の素数さん :2006/01/27(金) 15:35:54
ある課題の成績について、1回目の得点を100として2回目以降の得点をそれに対する割合で表したいのです。
831 :
132人目の素数さん :2006/01/27(金) 18:01:06
ある繊維1本の破断強度の分布は平均1.2kg標準偏差0.1kg
832 :
132人目の素数さん :2006/01/28(土) 19:31:57
2件法で5種類の果物の好き嫌いを調査した。
834 :
132人目の素数さん :2006/01/29(日) 16:05:52
>>724 >時系列相関とか知ってる?
時系列相関の載っている初歩書籍って、何がありますか?
Google検索では、13万件もhitしてしまいます。
835 :
ふーみん :2006/02/01(水) 13:50:15
ある地方で200人の小学生に質問したところ、『K-1』の視聴者が50人であった。視聴率pを標本比で推定したときの誤差が5%以下である確立を0.85にしたい。およそ何人の小学生を調査する必要があるか?
小学生相手に街頭アンケートとかしたら通報されそう
838 :
132人目の素数さん :2006/02/02(木) 11:57:55
あるプリンタでデータを印刷するとき、そのなかの印刷物を抜き出して
839 :
統計学童貞 :2006/02/02(木) 20:06:25
標準偏差の求め方おしえてけろ
...,、 - 、
問い、n個の未知数 X1、X2、・・・Xnの自由度はnである。
843 :
132人目の素数さん :2006/02/05(日) 11:46:18
標準誤差って手計算だったらどうやって計算するんですか?
>>843 どうやってと言ったって…。
コンピュータで計算できるものはすべて手計算できる。
>>844 公式教えてもらいたくて・・・
できれば記号の公式じゃなくて例題みたいな感じで数字を使った感じで・・・すいません
次の証明問題教えてもらえませんか?
847 :
132人目の素数さん :2006/02/06(月) 01:05:14
すごい初歩的な質問ですみません。
848 :
132人目の素数さん :2006/02/06(月) 03:52:04
>>847 回答は連続量じゃないから正規分布に従う、って仮定は無理が生じると思うよ。
やるとしたら判別分析か数量化理論II類だと思う。
849 :
847 :2006/02/06(月) 04:42:44
>848
850 :
132人目の素数さん :2006/02/06(月) 08:17:44
>>849 >回答は数値で答えてもらうもので(「~をあと何年やりたい?」ってな設問です)
いちおう連続なのかな、と素人考えに思ったのですが・・・。
これは難しいね。
例えば『2年半』とか『3年3ヶ月』とか言う回答が可なら連続量でいいのかもしれない。
ただし、項目から選択するような形式だと、(例えば①1年②2年③3年とか言う感じ
で選択肢がある形式)むしろカテゴリー変数扱いした方が原理的には正しいかも。
>平均と標準偏差を入力する事で簡易的に回答分布を予測する
これは『予測』なの?
例えばアンケートが数問あって、『何かの予測式(例えば回帰式)』なんかを作って
やるなら確かに『予測』でしょうが、これは単に検定の問題じゃないかな?
例えばアンケート(と言ってもたった1問)で
『~をあと何年やりたい?』
って質問だけで集計するならこれは『正規分布に従っているかどうか』の仮説検証
の問題じゃない?
単にアンケート取って平均とか標準偏差で正規分布に当てはめて見るだけなら
特に『予測』ではないでしょう。
>>847 肝心なのは正規分布でよいのかということ。
また、分布の推定だけなのか、それを用いて何かするのかで
説明が異なること。
工学部なのだから統計のできる先生が必ずいるはずで実データを
持ち込んで相談する方が吉。
データもなくここで相談してもいい方には進まない。
>>849 最初からアンケート調査したい目的を
統計屋さんに伝え、調査項目を教えて
いただいて方が上手くいきます。
統計屋さんは統計処理の方法を想定して
アンケート項目作ってくださいます。
今からじゃ卒論に間に合わないね。
貴方の卒論が私の目の前に来ないことを
祈ります。
ランダムウォークS[h→τ](n)のマルコフ性、推移確立、初期値の定義を使って、
f(x)に対して、ロピタルの定理を用いて次が成り立つことを証明せよ。
855 :
132人目の素数さん :2006/02/10(金) 22:32:46
確率1/400の抽選は、何回くらい統計取れば、
856 :
132人目の素数さん :2006/02/11(土) 04:31:32
>>855 いくつか提案されているが、
x * p > 25 だと十分といえよう。
400 * 25 だから、ちょうど10000回
ぐらい統計とればよい。
多変量解析、特にPLSを紹介してる
858 :
132人目の素数さん :2006/02/11(土) 23:50:28
どなたか教えてください
860 :
858 :2006/02/12(日) 03:51:15
他板の住人なのでマルチが失礼な事程度は知っています
>>856 簡易的で面白い基準だな。どの本に載ってるんだろ?
標準誤差の観点からすると
x * p * (1-p) > 25
ということになるが、pが小さいとほとんど変わらないからな。
しかし、25では小さすぎないか?
標準誤差4%ぐらいでちょっと大きいのだが。
862 :
132人目の素数さん :2006/02/16(木) 12:55:47
すいません、質問させて下さい。
>>862 どっちも根性で四重積分かな。
一様分布は積分範囲についての場合わけを頑張ればなんとかなる。
正規分布は誤差関数の積分が沢山でてくるから、公式集でもないとやってられん。
>>863 ありがとうございます。そうですか、やっぱり根性で場合分けですか。うむ。
上のように、各項目に固有のパラメータがあって、その周囲に誤差をもって分布
するとしたとき、その各項目の順位の確率が求めやすいようなモデルの立て方っ
て、なにかありませんかね。
いや、競馬の各順位確率を求める事を想定しているわけなんですけどw
SASの技師になりたいのですが、JMPバージョン3というのは違うソフトなのですか?
>>864 簡単に分布が求まらないからシミュレーションして出すのが一番手っ取り早いよ、多分。
オレもやろうとしたことあるよ。各馬のスピード指数なり能力指数なりを平均として、たとえば各馬の時計がN(各馬の平均、各馬の分散)に従うとしたりしてな。
いつも能力どおり走る馬は分散が小さくて、ムラ馬は分散が大きくて、って感じ。正規分布にするのは多分ちょっと違うかとも思うけど。
ただ、そうやって出した結果が必ずしも儲けにつながるとはいえないし、平均と分散がそもそも間違ってれば大損の可能性もあるからな。
労力に見合わないと思ってやめたw
>>865 違います。ところで、SASの技師って何?わざ師?
868 :
132人目の素数さん :2006/02/17(金) 00:08:50
高校程度の数学の知識と基本的な検定などの知識しか無い者です。
とある理由で無職になってしまいました。26のだめぽです。
871 :
132人目の素数さん :2006/02/17(金) 11:46:41
普通の統計の本を勉強したのですが、正規分布の統計方法しか書いてないでした。
>>87 読んだ本が悪すぎる.もっと普通の本を読め.
873 :
132人目の素数さん :2006/02/17(金) 14:35:42
>>870 理学部数学科出てるなら、SASはこれから勉強するつもりです、
って言えば、今すぐにでも製薬会社で雇ってもらえるかも。
非正規分布って言っても色々在るだろうに
ただ「途中の計算式をあまり省いてないもの」が欲しいなら
数理統計学とか書いてる本を買わないとなかなか途中の計算は載ってないんじゃないかな
小針の確率・統計入門とかはなんか如何にも数学者が書いた本って感じで面白いよ
>>870 まず「とある理由」を突っ込まれると思うけど。。
あなたに非がないなら、就職先によってはなんとかなるだろうけど
>>874 そんなにあまいことはないでしょう。
SASが自由自在に使えて統計学もばっちりです、ぐらいじゃないと。
それか統計学もしくは薬学で院を出てないと。
877 :
132人目の素数さん :2006/02/18(土) 09:26:20
age
878 :
132人目の素数さん :2006/02/18(土) 11:17:30
このスレ
879 :
132人目の素数さん :2006/02/18(土) 23:48:09
年齢x35 45 55 65 75
880 :
132人目の素数さん :2006/02/19(日) 12:50:29
>>875 レスありがとうございます。
川崎と横浜の図書館行ってみたのですが教えてもらった小針の本はありませんでした。
ある程度統計の本はあったのですが、数学と統計の基本的な知識が付いているとの前提で
大学1~2年以上をターゲットにしてる書籍が多く、数式の解説をしている本はありませんでした。
とりあえずブルーバックスの
データ分析はじめの一歩
パソコン活用3日でわかる・使える統計
推計学のすすめ
と、
統計学でリスクと向き合う
ミニマムエッセンス統計学
あと、専門書として情報処理入門コース 統計処理
を借りてきました。
でも斜め読みをした限り非正規分布の統計方法は書いてないっぽいです。。。orz
881 :
132人目の素数さん :2006/02/19(日) 13:09:37
統計・確率の演習でいい本を教えてください。
基本演習 確率統計 和田秀三 サイエンス社
883 :
870 :2006/02/19(日) 22:05:25
SASをある程度勉強してSASのバイトをしようと思います。
>>883 特定のバイト先があるなら直接聞いてみては?
向こうだって役に立たない人は雇いたくないだろうから
最低これぐらいできる人って言ってくれるように思うけど。
ところでSASを勉強するって書籍のみ?ソフトは大変高額だって
聞いたけど。
>>884 4万弱で学習用のそれが買えるみたいなので、それを買おうかと。
Rでできることを4万円でやるアホ
普通統計解析家は修士卒業程度の統計知識を必要とします。
888 :
132人目の素数さん :2006/02/20(月) 22:04:22
>>886 Rとはなんでしょうか?ちょっと気になります。
>>887 製薬メーカーじゃないんじゃないかな。
ネットで検索したら社会系の先生の手伝いとかあるみたい。
それでも相当の統計知識がいると思うけどね。
>>888 >>1 を見れ
890 :
132人目の素数さん :2006/03/01(水) 17:19:50
統計がほとんど分からないものですが、いろいろ捜しているうちに
分散は未知ですよね?なら、t検定(二標本t検定)でいいと思います。
>>891 さん。レスありがとうです。
明日、二標本t検定を調べて、やってみようと思います。
ついでに、
>>891 のレスで1つ分からないことが。
> 分散は未知ですよね?なら、
>
の文章の意味がよく分からないのですが、
二つのデータの分散をそれぞれ算出するだけでは、
分散は分かったことにならないのでしょうか?
> あと、「有為」ではなく、「有意」。
>
誤字、すいませんでした。
>>894 >母集団の分散が未知という意味でいいのでしょうか?
そうです。
現実にはほとんど有り得ないのですが、母集団の分散について知っているのなら、正規検定が可能です。
896 :
132人目の素数さん :2006/03/06(月) 16:12:54
age
897 :
132人目の素数さん :2006/03/06(月) 22:46:25
株のテクニカルチャートのボリンジャーバンドっていうのがあって、
>>897 ボリンジャーバンド自体は統計的にちゃんと有意な指標で,
株以外の分野でも(名前は違っても)広く使われてる.
無意味なのはむしろボリンジャーバンドの解釈のほう.
例えば「ボリンジャーバンド」でググって最初に出てくるページの
解釈なんかは完全に間違ってる.
899 :
132人目の素数さん :2006/03/06(月) 23:50:25
ポリンジャーバンド、聞いたこともない(私の専門は医学統計です)のでググってみました。
21日移動平均も2.5標準偏差も、経験則なんじゃないのかなぁ。
>>899 >21日平均
何日平均でも問題ない.
時系列解析を行う窓の幅を適当に取ってるだけ.
>2.5×標準偏差
何倍でも問題ない.
チェビシェフ不等式がσの定数倍で利くからσでスケーリングしてるだけ.
902 :
132人目の素数さん :2006/03/07(火) 00:57:19
至急この問題のこたえおしえてくだせー!
>>899 ・21日
経済統計に明るい人からレスがあるかもしれないが、
経済での時系列解析でよく用いられる日数のようです。
3週間ということですね。経験的に出てきたものだと思います。
・2.5倍
外れ値探索ではよく用いるので統計をやってる人なら
あまり違和感はないと思うけど。まあ役に立つかどうかは
やはり経験的なものだろう。
>>897 結論を先に書くとここで聞いても無意味だと思うがw
欧米、特にアメリカでは株価はチャートを分析すれば統計的に予測できる、
ないしΔtの価格は予想可能と言うトレーダーと株価はファンダメンタルのみで
決定される、ないしランダムウォークとの議論が延々と30年以上繰り返されてきた。
これの原因はここで書くと煽られるかもしれないが、経済学者の無知が原因。
しかし、10年ぐらい前からアメリカでヘッジファンドのトップ10を毎年
テクニカル系のなかでもシステムトレードをメインとする「同じ」人たちが
占めていることを現実として認識し始め、統計的に株価を分析できると
まともな人たちは理解を変え始めた。
そうじゃないと年利300%を15年連続とか統計的には受け入れられないしw
その中で金融工学の中でもモデル系という自分が予想してる方法だけでトレードすれば
どれだけ儲かるかをひたすらシミュレーションする方法が発達してきた。
でも、これには大きな問題があってみんなが知るとその方法は使えなくなると言う
欠点がある。
だからボリンジャーバンドも初期は使えていた。ほんとに洒落にならないほど
儲かっている人は多数いた。でも、それが公開されて一般人が使うようになると
ボリンジャーバンドのサインが出る直前に買おうとしたり、サインをわざと出して
高値掴みをさせるプロが出てくるから今は年に1割ぐらいしか儲からないよ。
ボリンジャーバンドは過去の値動きから2σなどのラインをプロットする
方法であって、それをどう利用するかはユーザー次第。21MAを使う場合もあるし
7MAの場合もある。
統計学的に計算方法としての意味はあると思うがそれと利益に相関関係は無い。
と、専業のシステムトレーダーが書いてみるw
905 :
132人目の素数さん :2006/03/07(火) 14:12:03
最小二乗法とかわけわかめ
906 :
GiantLeaves ◆6fN.Sojv5w :2006/03/07(火) 16:42:38
talk:
>>905 それでは、直線回帰とは何かは分かる?
げえむ理論みたいなことですか
909 :
GiantLeaves ◆6fN.Sojv5w :2006/03/07(火) 20:36:43
910 :
903 :2006/03/08(水) 00:19:57
>>904 分かりやすいレスありがとう!
そうか、今はやはり利益との相関は低いのか。
人と同じことをやっていては儲からないということやね。
>みんなが知るとその方法は使えなくなる
そりゃみんなが儲かりゃハッピーな世の中だな
株価はナマモノだから過去の事実のデータをいくら捏ね繰り回しても気休め程度にしかならないのね。
914 :
GiantLeaves ◆6fN.Sojv5w :2006/03/08(水) 07:14:14
talk:
>>911 資本主義の欠点とでもいうのか?
915 :
132人目の素数さん :2006/03/08(水) 22:50:51
スイマセン。相談ですが、受験人数50人の倍率10倍と
倍率だけじゃ比べられないよ
918 :
132人目の素数さん :2006/03/08(水) 23:52:22
>>907 レスアンカーのつけ方を会得したほうがよいだろう?
920 :
132人目の素数さん :2006/03/09(木) 00:22:49
>>916 そうですよね・・・やはり「質」が問われますよね。
ある意味、気が晴れました。お答えありがとうございました!
921 :
132人目の素数さん :2006/03/11(土) 17:19:42
重回帰分析についてお尋ねします。
>>921 回帰分析って基本的に「推定」ですよね?
モデルが有効かどうかのF検定のことですか?
それぞれ変数選択をしてモデルを「推定」して使えば
いくつ推定しようが多重性の問題はないと思いますけど。
923 :
921 :2006/03/12(日) 12:00:43
率と比率の違いってなぁに?
925 :
中川秀泰 :2006/03/21(火) 19:34:45
率は能率、効率、君が持っていない物の全てだよ
926 :
926 :2006/03/21(火) 20:00:39
√9*2=6
927 :
927 :2006/03/21(火) 20:02:11
9-2=7
928 :
928 :2006/03/21(火) 20:03:20
√9=log_{2}(8)
929 :
929 :2006/03/21(火) 20:04:57
√9^2=9
√9-3=0
√9/3=1
ln(9)/ln(3)=2
933 :
132人目の素数さん :2006/03/25(土) 16:03:41
あ
すいません、この問題の解き方と解答を教えてください。よろしくお願いします。
>>903 >経済での時系列解析でよく用いられる日数のよう・・・
経済変動で、3週間ってどういう区切りからきてるんだろう?
936 :
903 :2006/04/04(火) 10:51:10
ネットで調べると「21日移動平均」で多数のサイトが引っかかりますが、
937 :
132人目の素数さん :2006/04/05(水) 22:31:44
age
>>934 【1】ベイズの定理の適用についての問題。
以降、スペードが5回中3回出る事象をDとする。
また、二項分布をbinomdist(成功数,試行数、成功確率)とする。
(1)トランプAを選んだ条件の元でスペードが5回中3回出る確率をP(D|A)とすると、
P(D|A)=binomdist(3, 5, 13/52)の二項分布を計算すれば良い。
(答え)8.79%
(2)(1)と同様に、
P(D|B)=binomdist(3, 5, 26/52)
=31.25%・・・・・・(答え)
(3)単にP(D)を求める問題。
【2】(1)確率変数
>>940 訂正:
標準誤差=標準偏差÷√(サンプル数)
の間違い。
回帰分析の原理を説明しろって言われて、教科書を読んだんですが
>>942 回帰分析といっても、立てるモデルや、モデルの何を分析するかによって
めちゃくちゃ範囲が広くなるので、簡単に説明できるものじゃあない。
例えば、身長と体重の関係で、身長が1cmあがった時の体重の値の誤差が知りたいのです。
>>944 まず、回帰分析を適応するデータがどういうものか記載すること。
次に、回帰分析でなにを推測するつもりなのか記載すること。
話はそれから。おそらく、上記2点を踏まえないと、その課題を与えた人は満足しないよ。
947 :
132人目の素数さん :2006/04/09(日) 00:22:27
>>947 結論から言えば,たぶんマークは関係ない.
仮説「マークの有無は不合格数に無関係」を立てて,並び替え検定をする.
この仮説の下では,そもそも 739個の対象中,11個が不合格であって,
グループを 679 と 60 に分割したとき,60 側に1つも不合格が混じらない,
というのが観測された事象に対応する.
これが起こる確率は (728/739)*(727/738)*...*(669/680) = 0.39
これはよくあることなので,仮説は棄却できない,
949 :
947 :2006/04/09(日) 01:01:06
>>948 回答、ありがとございます。
こちらもこのデータからは、マークに関係ないしか
いえないと思っていたのですが、先日の国会で、
二階経済産業省大臣は、マークがない方は、
不合格品があるが、マークがある方は不合格品が
ないので、マーク付き製品がよいと力説されていました。
この力説の根拠を探したら、さきほどの経済産業省の
発表資料が見つかりました。
さきほどのご回答だと、大臣の力説は統計学的には
間違っていると言っていいのですね。
どうもありがとうございます。
>>949 統計学的に有意な差がないことは、関係ないということの証拠にはならない。
947のデータではマークに関係ないと判断するには検出力が十分でない。
よって、
「マークがある方が良いという主張には統計学的な裏付けはない」
という受け止め方ならば正しいけれど、
「マークがある方が良いという主張は統計学的に間違い」とか
「統計学的にはマークがあっても無くても同じ」
という受け止め方は正しくない。
念のために書いておくが、948の「たぶん」関係ないという感覚は理解できる。
951 :
132人目の素数さん :2006/04/09(日) 19:01:38
>>936 5日移動平均は一週間の株価(の終値)の平均で、
21日移動平均は一ヶ月の株価(の終値)の平均ではないですか?
一週間で市場が開いてる日は月~金の5日間だし、一ヶ月では約21日になる。
952 :
947 :2006/04/09(日) 20:17:30
>>950 こちらの書き方がまずかったみたいです。
こちらの言いたかったことは、まさに
>「マークがある方が良いという主張には統計学的な裏付けはない」
です。
二階大臣が、このデータに統計的に意味があるように
言っていたので、それは違うのではないかと。
953 :
903 :2006/04/09(日) 20:58:54
>>951 それも考えたが、それだとやはり20日移動平均の方がいい。
たとえ1日でももし週単位の周期性があったら影響を受けるから。
まあ偶数の移動平均は扱いづらいので21日なのかもしれないが、
そうすると週単位の周期性はあまり気にしていないことになる。
約1ヶ月で週単位で奇数となると25日移動平均となるが、
それは見たことがない。
昔は週6日だっただろうし、結局どれも後付の理由なんだろうな。
954 :
132人目の素数さん :2006/04/09(日) 23:12:19
相関関数を求め、その有意確率をランダムな相関のないデータを使って求めたとあるドキュメントに書いてあるのですが、その場合有意確率はどうやったら求まるのですか?
>>954 状況が全然足りないので、答えられない。
ドキュメントをうp。
>>954 帰無仮説の元での検定統計量の分布が判ればp値は求められる。
この場合は、帰無仮説は相関0で、検定統計量は相関係数。
実際に得られたデータのサンプルサイズをnと書くことにする。
相関0の二変量分布に従う乱数を発生させてn組のデータを得る
相関係数を計算する
以上を何度も(例えば1000回とか10000回)繰り返し、
帰無仮説の元での相関係数の分布を得る
この分布の、実際に得られた相関係数よりも大きな値をとる部分の割合がp値
どういう二変量分布を想定して計算したのかはドキュメントを見ないと判らん。
二変量正規分布のようなパラメトリックなものを仮定する方法もあるし、
一つの変数毎の周辺分布を実際に得られたデータの経験分布で置き換えて
二つの経験分布からそれぞれランダムにリサンプリングしたデータを
組みにしてn組のデータを得るという方法も考えられると思う。
判別分析において,2群を超える場合(n群)に正準判別を用いたんですが,
反応無し??
959 :
132人目の素数さん :2006/04/15(土) 01:33:48
age
960 :
132人目の素数さん :2006/04/15(土) 12:47:53
確率の問題について教えてください。
961 :
132人目の素数さん :2006/04/15(土) 15:29:48
>>960 例えば、
1.帰無仮説(「その会社はその国の平均レベルと自殺率が同じである」)を仮定する。
2.帰無仮説の下で、社員1万人の会社で3年連続で自殺者が3人を超える確率を計算する。
3.2.で求めた確率が0.05より小さいかどうかを見て、判断する。
962 :
132人目の素数さん :2006/04/15(土) 15:32:10
メコスジがパイパンな確率が0.05%より小さいかを見て、判断する。
963 :
132人目の素数さん :2006/04/15(土) 15:43:39
>>962 0.05に%を付けるところが面白い。
何か意味があるんだろうね。
超厳しく判定したいんだろう
965 :
132人目の素数さん :2006/04/15(土) 16:19:23
ちょっとわからない問題があるので質問させてください.
因みに推定量の導出方法がわかりません.
967 :
132人目の素数さん :2006/04/15(土) 16:33:28
>>961 >2.帰無仮説の下で、社員1万人の会社で3年連続で自殺者が3人を超える確率を計算する。
この部分が分からないんですよ。10万人当たり10人だと仮定したときに1万人だと3人になる確率ってのが
分からないです。
正規分布していると仮定して平均値と標準偏差を取らないといけないってのは予想できるのですが、
サンプルが一つしかないのに標準偏差を出すってのが分からなくて・・・
解き方を教えてもらえないでしょうか。
968 :
132人目の素数さん :2006/04/15(土) 16:45:47
>>967 正規分布ではなく、二項分布を仮定すべき。
>>967 例えば、10万人辺り10人の自殺率ってのは
p_0=10人÷10万人
=0.01%
でしょ?つまり、自殺者ってのは仮定として、二項分布B(n, 0.01%)に従うとする。
んで、帰無仮説H_0、対立仮説H_1はこうね。
帰無仮説H_0:会社の自殺率pは自殺率p_0に等しい(p=p_0)
対立仮説H_1:会社の自殺率pは自殺率p_0に等しくない(p≠p_0)
有意水準は5%とする。
さて、会社の自殺者も二項分布B(n, 0.01%)に従うとすると、3人自殺した場合のp値は
p値=1-Σb(10000, 0.01%)・・・(3人から1万人までの総和を取る)
=1.898203%
で統計的に有意である。
よって会社の自殺率は国の自殺率に一致しない。
でイイと思うんだけど?
だから、
>1万人だと3人になる確率
じゃなくって「1万人で3人以上自殺する確率」ってのが正しいと思うよ。
でもね、多分「会社の自殺率が国の自殺率より“大きい"か?」だったら、
>>970 詳しい説明ありがとうございます。
> 帰無仮説H_0:会社の自殺率pは自殺率p_0に等しい(p=p_0)
> 対立仮説H_1:会社の自殺率pは自殺率p_0に等しくない(p≠p_0)
> 有意水準は5%とする。
ここまでは理解できたのですが、
> さて、会社の自殺者も二項分布B(n, 0.01%)に従うとすると、3人自殺した場合のp値は
> p値=1-Σb(10000, 0.01%)・・・(3人から1万人までの総和を取る)
ここの式がどうしてこうなるのかが分かりませんでした。
すみませんが、できたら解説をお願いします。
2項分布なんて
4C3とかしか知らないもんで。。。
>>971 こちらの解き方は比率の差の検定でぐぐったら、
http://aoki2.si.gunma-u.ac.jp/lecture/Hiritu/diff-p-test.html のページで分かりました。
973 :
132人目の素数さん :2006/04/16(日) 15:11:22
>>972 下記の表現の方が判りやすいかと。
H_0 の下で、会社の自殺者が3人「以上」になる確率=1-会社の自殺者が2人「以下」になる確率
=1-(会社の自殺者が0人になる確率+会社の自殺者が1人になる確率+会社の自殺者が2人になる確率)
>>971 この問題の設定だと正規近似は使えないと思います。近似の精度が悪すぎて。
>>973 レスありがとうございます。
Excelで計算してみたのですが、
BINOMDIST(成功数、試行数、成功率、関数化)に代入して
=BINOMDIST(0,10000,0.0001,false)
=BINOMDIST(1,10000,0.0001,false)
=BINOMDIST(2,10000,0.0001,false)
はそれぞれ、0.367861、0.367898、0.183949となり、1から合計を引くと0.080292となってしまい、
8%となるので、棄却されません。
3人を入れると
>>970 さんの計算結果と同じになるのですが、3%も含む形にしてかまわないのでしょうか?
>>972 >2項分布なんて 4C3とかしか知らないもんで。。。
ええと、それは「二項定理」で「二項分布」そのものではありません。
まあ、二項定理ご存知でしたら、pを母比率(パラメータ)として、
f(x)=nCx*p^x*(1-p)^(n-x)
で表される確率分布が「二項分布」です。通常f(x)の代わりにB(n, p)と表現したりもします。
さて、上の二項分布はxが任意の数の場合の確率を表しているんですが、例えば
f(0)+f(1)+f(3)+・・・・・・・・+f(n)=100%
になる、ってのは何となくお分かりでしょうか?こういうのを「累積確率」と呼びます。
そうすると、x=0から任意のxまでの和を取った場合、これを「累積確率分布」と
呼びます。具体的にはF(x)として
F(x)=ΣnCx*p^x*(1-p)^(n-x)・・・・・・(x=0から任意のxまでの和)
これが
>>973 氏の示唆している事で、「3人以上になる確率」ってのは
自殺者が0人になる確率+1人になる確率+2人になる確率の累積
確率を総和である100%から引けば良い、と言った計算の元ネタに
なってます。
この計算がこの問題の場合のp値(p-value、有意確率、または確率値
等と呼ぶ)にあたります。
>>973 そうですね。こちらでも計算して確かめましたが、正規近似だと帰無仮説は
棄却されないようです。思ったより誤差が大きいですね。
まあ、パソコン全盛時代、僕個人的にもそんなに「正規近似」に拘る必要なんて
ないんじゃないか、と思っています。
二項分布ゴリゴリ計算させれば充分なんじゃなかろうか、とwww
>>974 あ、ゴメン。計算間違ってるね。
>>974 氏の計算で正しいと思いますよ。帰無仮説は棄却できないようですね。
ちなみにExcelの書式ではこの場合のp値は
=1-binomdist(2, 10000, 0.0001, true)
で計算出来ますよ。
>>977 即レスありがとうございます。
やっと理解できました。
これ実は自衛隊員の自殺率でして、自衛隊は自殺率が高いって発狂してる人にやっと対抗できますw
ここからは興味本位なのですが、もし5%を越えて統計的には有意差があるとされた場合、
どれぐらい有意差があるというのはどのように計算すればいいのでしょうか。
何倍程度という形では結果は出せなくて、有意差のあるなししか出せないのでしょうか。
>>978 愚直な方法だと、「通常の三倍自殺率が高い」を仮定して同様に検定。
何倍……ってのを増やしていって、棄却できなくなったあたりがボーダーと見る。
>>979 ということは今回の場合は2回と3回がボーダーラインだったので、2倍自殺率が高いとなるのですね。。。
ありがとうございました。
一番最初に計算したのは、実はRのRcmdrでの上側確率を計算させて、
無条件にその結果を信頼した、んですが、これっておかしな計算結果ですね。
以後気をつけます。
>>978 知ってる範囲で話をすると、原則的に「統計的仮説検定」ってのは○×式判定法
なんですよ。正確に言うと○か?なんですが。
今回「帰無仮説が棄却できなかった」って事は原則的に対立仮説が棄却されたワケ
ではなくって、あくまで
「自衛隊員の自殺率は通常より高いとも低いとも言えない。」
言い換えれば
「良く分からん」
って事です(笑)。ですから、そう言った意味では安心できないかも(笑)。
「どれくらい有意差がある」と言うのは原則的に統計的仮説検定では言えないと
思います。あくまで「○か?か」ですからね。
ただ、AIC(赤池情報量基準)ってのがありまして、それだと「どのくらい仮説が尤も
らしいか」と言った指標が計算できるらしいです。
ちょっとその辺りは僕側からはハッキリと言えないので、どなたかその話に詳しい
お方の登場を願いましょうか。
982 :
132人目の素数さん :2006/04/16(日) 19:42:13
>>980 それ、愚直すぎ。
自殺率の信頼区間を算出するのが普通だと思う。
>>982 980 は信頼区間を出すのと本質的に同じことになる。
984 :
132人目の素数さん :2006/04/16(日) 21:00:23
初歩的な質問で申し訳ありません。
985 :
132人目の素数さん :
2006/04/16(日) 23:22:06 西暦とか、経度はどうだろう?
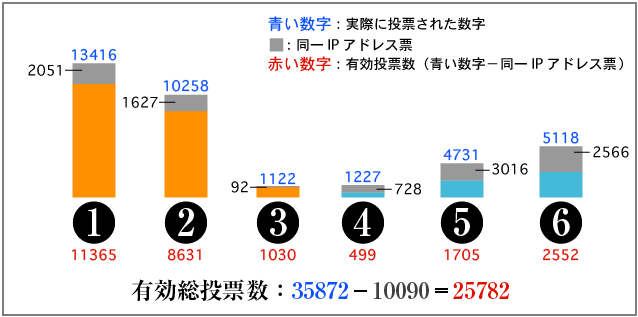{kind=link}
{kind=link}