Intel uPs Info
1 �Fu�F
Intel���}�C�N���v���Z�b�T�̏��ǃX���b�h�ł��B
��e��낵���ł��BIntel�v���Z�b�T�̘̐b��OK�B
�����Intel�X���ɕ����Ȃ��悤�ɂ��悤�B
���ϑz�A�����E���_�A�֒��\���͍T���߂ɁB
��������A������AIBM�������̏������݂͂��������������B
����������h�~�̂��߁A�Ӑ}�I�ɂ킩��ɂ����^�C�g���ɂ��Ă��܂��B���������������B
�������܂��傤�B
��e��낵���ł��BIntel�v���Z�b�T�̘̐b��OK�B
�����Intel�X���ɕ����Ȃ��悤�ɂ��悤�B
���ϑz�A�����E���_�A�֒��\���͍T���߂ɁB
��������A������AIBM�������̏������݂͂��������������B
����������h�~�̂��߁A�Ӑ}�I�ɂ킩��ɂ����^�C�g���ɂ��Ă��܂��B���������������B
�������܂��傤�B
|
|
|
����Ȃ��ȁB
���Ȃ݂Ɏ���PC���[�U�ł����A�ǂ�����낵���B
���Ȃ݂Ɏ���PC���[�U�ł����A�ǂ�����낵���B
�ŋ߂̃j���[�X
Intel�AYonah�v���Z�b�T�̏ڍׂ����J
ttp://pcweb.mycom.co.jp/articles/2005/07/14/yonah/
Net Burst�̏I���FIntel�A�����A�[�L�e�N�`��CPU���[�h�}�b�v�����J
ttp://www.expertspc.com/index.asp?Language=JP&DataId=193&Status=Reports
Intel��OEM�W�҂ɑ��A2006�N�㔼�ɐV�A�[�L�e�N�`����CPU��
�T�[�o�[�E���[�N�X�e�[�V������f�X�N�g�b�v�A���o�C���s��ɓ������邱�Ƃ𖾂炩�ɂ����B
����́A�J���R�[�h���gMerom�h�ƌĂ�郂�o�C���R�A���x�[�X�ɁA
�e�v���b�g�t�H�[���ɍœK�������̂ƂȂ�B
�ƊE�W�҂ɂ��AIntel�͂�����CPU���g�������ꂽ�R�A�iConverged Core�j�h�Ə̂��A
����܂ł�CPU�Ƌ�ʂ��Ă���悤���B
�����ɁA���̂��Ƃ́ANet Burst�A�[�L�e�N�`�������ɏI�����}���邱�Ƃ��Ӗ����Ă���B
Intel���ŐV��OEM�������[�h�}�b�v�ɒlj������̂́A���o�C��CPU�́gMerom�h�A
�f�X�N�g�b�vCPU�́gConroe�h�A�T�[�o�[�E���[�N�X�e�[�V����������2way CPU�gWoodcrest�h�̎O�B
Merom�͌��sPentium-M�̃A�[�L�e�N�`�����g�����AEM64T��Hyper-Threading�Ƃ������Z�p�荞�݂A
�f���A���R�A�A�}���`�R�ACPU�ւ̍œK�����s�Ȃ������̂ƌ����Ă���B
���̐����v���Z�X�́A�������o�C��CPU�́gYonah�h�Ɠ���65nm�v���Z�X���̗p���A
��̃R�A�ő�e�ʂ�L2�L���b�V�������L����A�[�L�e�N�`����Yonah�ƕς��Ȃ��B
�������AOEM�W�҂ɂ��AMerom����ł�CPU�R�A���m�����ԃC���^�[�t�F�[�X��������A
�f���A���R�A�����̌����������グ��ƂƂ��ɁA�����d�͉�����������ƌ����B
����Merom�R�A���x�[�X�Ƃ���f�X�N�g�b�vCPU��Conroe�ɂ́A
2MB��4MB��L2�L���b�V���𓋍ڂ���2���i���p�ӂ���錩�ʂ����B
Intel�AYonah�v���Z�b�T�̏ڍׂ����J
ttp://pcweb.mycom.co.jp/articles/2005/07/14/yonah/
Net Burst�̏I���FIntel�A�����A�[�L�e�N�`��CPU���[�h�}�b�v�����J
ttp://www.expertspc.com/index.asp?Language=JP&DataId=193&Status=Reports
Intel��OEM�W�҂ɑ��A2006�N�㔼�ɐV�A�[�L�e�N�`����CPU��
�T�[�o�[�E���[�N�X�e�[�V������f�X�N�g�b�v�A���o�C���s��ɓ������邱�Ƃ𖾂炩�ɂ����B
����́A�J���R�[�h���gMerom�h�ƌĂ�郂�o�C���R�A���x�[�X�ɁA
�e�v���b�g�t�H�[���ɍœK�������̂ƂȂ�B
�ƊE�W�҂ɂ��AIntel�͂�����CPU���g�������ꂽ�R�A�iConverged Core�j�h�Ə̂��A
����܂ł�CPU�Ƌ�ʂ��Ă���悤���B
�����ɁA���̂��Ƃ́ANet Burst�A�[�L�e�N�`�������ɏI�����}���邱�Ƃ��Ӗ����Ă���B
Intel���ŐV��OEM�������[�h�}�b�v�ɒlj������̂́A���o�C��CPU�́gMerom�h�A
�f�X�N�g�b�vCPU�́gConroe�h�A�T�[�o�[�E���[�N�X�e�[�V����������2way CPU�gWoodcrest�h�̎O�B
Merom�͌��sPentium-M�̃A�[�L�e�N�`�����g�����AEM64T��Hyper-Threading�Ƃ������Z�p�荞�݂A
�f���A���R�A�A�}���`�R�ACPU�ւ̍œK�����s�Ȃ������̂ƌ����Ă���B
���̐����v���Z�X�́A�������o�C��CPU�́gYonah�h�Ɠ���65nm�v���Z�X���̗p���A
��̃R�A�ő�e�ʂ�L2�L���b�V�������L����A�[�L�e�N�`����Yonah�ƕς��Ȃ��B
�������AOEM�W�҂ɂ��AMerom����ł�CPU�R�A���m�����ԃC���^�[�t�F�[�X��������A
�f���A���R�A�����̌����������グ��ƂƂ��ɁA�����d�͉�����������ƌ����B
����Merom�R�A���x�[�X�Ƃ���f�X�N�g�b�vCPU��Conroe�ɂ́A
2MB��4MB��L2�L���b�V���𓋍ڂ���2���i���p�ӂ���錩�ʂ����B
�T�[�o�p�v���Z�b�T�ɂ�P/N�����\��B
ttp://www.x86-secret.com/index.php?option=newsd&nid=898
Itanium2
Itanium2 9055: Montecino 1.8(2.0) Ghz/24M L3
Itanium2 9040: Montecino 1.6(1.8) Ghz/18M L3 *
Itanium2 9030: Montecino 1.7(1.8) Ghz/8M L3 *
Itanium2 9020: Montecino 1.4(1.6) Ghz/12M L3 *
Itanium2 9018: Montecino LV 1.2(1.4) Ghz/12M L3
Itanium2 9010: Montecino 1.6(1.8) Ghz/6M L3 *
* Proc Number +1 for FSB667 instead of 400/533
Xeon MP
Xeon MP 7041: Paxville 3.00 GHz/2*2MB L2/FSB800
Xeon MP 7040: Paxville 3.00 GHz/2*2MB L2/FSB667
Xeon MP 7030: Paxville 2.80 GHz/2*1MB L2/FSB800
Xeon MP 7020: Paxville 2.67 GHz/2*1MB L2/FSB667
Xeon DP
Xeon DP 5xxx: Dempsey TBD/2*2MB L2/FSB667/1066
Xeon DP 5xxx: Dempsey MV TBD/2*2MB L2/FSB667/1066
Xeon DP 5xxx: Sossaman TBD/2MB L2/FSB667
Conroe��P/N�́A950, 940, 930, 920�B���N�㔼�����[�X�\��B
ttp://www.theinquirer.net/?article=24586
ttp://www.x86-secret.com/index.php?option=newsd&nid=898
Itanium2
Itanium2 9055: Montecino 1.8(2.0) Ghz/24M L3
Itanium2 9040: Montecino 1.6(1.8) Ghz/18M L3 *
Itanium2 9030: Montecino 1.7(1.8) Ghz/8M L3 *
Itanium2 9020: Montecino 1.4(1.6) Ghz/12M L3 *
Itanium2 9018: Montecino LV 1.2(1.4) Ghz/12M L3
Itanium2 9010: Montecino 1.6(1.8) Ghz/6M L3 *
* Proc Number +1 for FSB667 instead of 400/533
Xeon MP
Xeon MP 7041: Paxville 3.00 GHz/2*2MB L2/FSB800
Xeon MP 7040: Paxville 3.00 GHz/2*2MB L2/FSB667
Xeon MP 7030: Paxville 2.80 GHz/2*1MB L2/FSB800
Xeon MP 7020: Paxville 2.67 GHz/2*1MB L2/FSB667
Xeon DP
Xeon DP 5xxx: Dempsey TBD/2*2MB L2/FSB667/1066
Xeon DP 5xxx: Dempsey MV TBD/2*2MB L2/FSB667/1066
Xeon DP 5xxx: Sossaman TBD/2MB L2/FSB667
Conroe��P/N�́A950, 940, 930, 920�B���N�㔼�����[�X�\��B
ttp://www.theinquirer.net/?article=24586
���N�㔼�AMerom���������A�N���b�N2.33GHz�AFSB667MHz�B
http://www.tomshardware.com/hardnews/20050714_135731.html
http://www.tomshardware.com/hardnews/20050714_135731.html
�d�����ǂ�������
�y�ܗ��zPowerPC to Intel �����X�� 10�y�����z
http://pc7.2ch.net/test/read.cgi/mac/1121143275/
�y�ܗ��zPowerPC to Intel �����X�� 10�y�����z
http://pc7.2ch.net/test/read.cgi/mac/1121143275/
�����͂h���������}�C�N���v���Z�b�T���Ɍ��X���b�h�Ȃ̂ŏd������Ȃ��ł���B
�������͖ϑz���ۂ����B
�������͖ϑz���ۂ����B
http://pcweb.mycom.co.jp/articles/2005/07/14/yonah/002.html
���Ȃ݂ɂ��̋L���A
Dothan��1��4000�����Đ������A�o�E�g�ɔ��\����Ă邾�����Ǝv���܂����A
�����v�Z���Ȃ��Ă��BYonah��Banias��ŁAMerom��Dothan��ȕ����Ȃ������
���Ȃ݂ɂ��̋L���A
Dothan��1��4000�����Đ������A�o�E�g�ɔ��\����Ă邾�����Ǝv���܂����A
�����v�Z���Ȃ��Ă��BYonah��Banias��ŁAMerom��Dothan��ȕ����Ȃ������
sage�i�s�ł��肢���܂�
������HKEPC��Yonah�̃T���v����摜���c�B
ttp://www.hkepc.com/bbs/viewthread.php?tid=428812
Intel Advances Itanium 2 Lineup with New Chips.
ttp://www.xbitlabs.com/news/cpu/display/20050718225240.html
FSB667MHz�̐VItanium2�������[�X����܂����B
ttp://www.hkepc.com/bbs/viewthread.php?tid=428812
Intel Advances Itanium 2 Lineup with New Chips.
ttp://www.xbitlabs.com/news/cpu/display/20050718225240.html
FSB667MHz�̐VItanium2�������[�X����܂����B
���}����P�̃��r�L�^�X���ǁ�
�Ȃ�Yonah��EM64T�ɑΉ����Ȃ��̂�
http://pc.watch.impress.co.jp/docs/2005/0720/ubiq119.htm
Yonah��64bit�ɑΉ����Ȃ��̂́A�P�ɐv���Ԃɍ����ĂȂ�����ł��ˁB
Yonah�̊J�������ł́AAMD64�݊���EM64T���g�����ǂ�������܂��Ă��Ȃ��������A
Prescott�����[�X����AEM64T�͂��炭�g��Ȃ��\��ł�������B
���͑O�|���ŋ�������64bit��ON�ɂȂ��Ă邾��Ȃ��B
����ɂ��Ă��A64bit�����ƃ_�C���ł����Ȃ肷����͋���ȉR�ł��ˁB
���ł�Merom�̃_�C�����\�������Ƃ����\���Ȃ���Ă܂����B
�Ȃ�Yonah��EM64T�ɑΉ����Ȃ��̂�
http://pc.watch.impress.co.jp/docs/2005/0720/ubiq119.htm
Yonah��64bit�ɑΉ����Ȃ��̂́A�P�ɐv���Ԃɍ����ĂȂ�����ł��ˁB
Yonah�̊J�������ł́AAMD64�݊���EM64T���g�����ǂ�������܂��Ă��Ȃ��������A
Prescott�����[�X����AEM64T�͂��炭�g��Ȃ��\��ł�������B
���͑O�|���ŋ�������64bit��ON�ɂȂ��Ă邾��Ȃ��B
����ɂ��Ă��A64bit�����ƃ_�C���ł����Ȃ肷����͋���ȉR�ł��ˁB
���ł�Merom�̃_�C�����\�������Ƃ����\���Ȃ���Ă܂����B
Intel has dual PCIe 16X slot boards
http://www.theinquirer.net/?article=24766
>The board is equipped with i955X/iCH7R chipset, USB 2.0, Firewire 800, Gb LAN,S-ATA 300 RAID, two times PCIe x16,
> one PCIe 1X, 3x PCI.
Intel���f���A��PCIe 16x��i955X�x�[�X�}�U�[�������B
http://www.theinquirer.net/?article=24766
>The board is equipped with i955X/iCH7R chipset, USB 2.0, Firewire 800, Gb LAN,S-ATA 300 RAID, two times PCIe x16,
> one PCIe 1X, 3x PCI.
Intel���f���A��PCIe 16x��i955X�x�[�X�}�U�[�������B
14 �F���̖��ݒ��F2005/07/20(��) 20:08:48 ID:ed4Qyzeq
�ŁA�Ȃ�Mac�ł��̂��Ƃ������Ƃ�
Intel Readies New 90nm Dual-Core Processors.
http://www.xbitlabs.com/news/cpu/display/20050791210923.html
�Ȃ��10����Smithfield PenD/XE��B0�V�X�e�b�s���O�ł��o��B
�d�C�d�l��TDP���ς��݂����ł���B
>>14
Mac��IntelCPU�̃X���������ĕs�����ł����H
������Mac�d�l�ɂ��傫���W���Ă���̂ɁB
http://www.xbitlabs.com/news/cpu/display/20050791210923.html
�Ȃ��10����Smithfield PenD/XE��B0�V�X�e�b�s���O�ł��o��B
�d�C�d�l��TDP���ς��݂����ł���B
>>14
Mac��IntelCPU�̃X���������ĕs�����ł����H
������Mac�d�l�ɂ��傫���W���Ă���̂ɁB
���܂�
AMD to integrate PCIe
http://www.theinquirer.net/?article=24756
�������R���g���[���ɑ�����PCIe�������v�撆�H
AMD is plumbum free
http://www.theinquirer.net/?article=24756
���������ĐM���������邩��A�ڋq�ɂƂ��Ă͈������Ƃ����Ȃ���ȁB
AMD to integrate PCIe
http://www.theinquirer.net/?article=24756
�������R���g���[���ɑ�����PCIe�������v�撆�H
AMD is plumbum free
http://www.theinquirer.net/?article=24756
���������ĐM���������邩��A�ڋq�ɂƂ��Ă͈������Ƃ����Ȃ���ȁB
Intel's Merom misses tape out by a month
http://www.theinquirer.net/?article=24788
Merom���\����1���������e�[�v�A�E�g�����݂����ł���B�B
���Ɛ��T�ԂŃt�@�[�X�g�V���R�����Ƃ��炵���B
���Ƃ�65nm�v���Z�X�������ɗ����オ���Ă����Η��NQ3�ɂ͔q�߂܂����ˁc�B
Intel's new instructions to Rockton round the clock
http://www.theinquirer.net/?article=24781
Intel�̐V*Ts�̈�A"RT"�ɂ��āB
.NET��Java�̂悤��JIT�ȃ\�t�g�������������邽�߂́A�\�t�g&�n�[�h����݂̐V�Z�p�炵���B
uP���ɂ͖��ߒlj��̌`�Ŏ��������悤���B
�ʂ�����Merom�ɂ͕����I�Ɏ���������ł����ˁH���Ȃ�������Ǝv�����ǁc�B
��������A�́AIA-64�֘A�̌����ʼn��z���e�[�u����CPU���ɂ��Ƃ������̂��������悤�ȁB
http://www.theinquirer.net/?article=24788
Merom���\����1���������e�[�v�A�E�g�����݂����ł���B�B
���Ɛ��T�ԂŃt�@�[�X�g�V���R�����Ƃ��炵���B
���Ƃ�65nm�v���Z�X�������ɗ����オ���Ă����Η��NQ3�ɂ͔q�߂܂����ˁc�B
Intel's new instructions to Rockton round the clock
http://www.theinquirer.net/?article=24781
Intel�̐V*Ts�̈�A"RT"�ɂ��āB
.NET��Java�̂悤��JIT�ȃ\�t�g�������������邽�߂́A�\�t�g&�n�[�h����݂̐V�Z�p�炵���B
uP���ɂ͖��ߒlj��̌`�Ŏ��������悤���B
�ʂ�����Merom�ɂ͕����I�Ɏ���������ł����ˁH���Ȃ�������Ǝv�����ǁc�B
��������A�́AIA-64�֘A�̌����ʼn��z���e�[�u����CPU���ɂ��Ƃ������̂��������悤�ȁB
Intel�fs Dual-Core Shipments on Track
http://www.xbitlabs.com/news/cpu/display/20050720210604.html
�f���A���R�A�v���Z�b�T�A����v�ŋ�풆�B
http://www.xbitlabs.com/news/cpu/display/20050720210604.html
�f���A���R�A�v���Z�b�T�A����v�ŋ�풆�B
�C���e��(R) Itanium(R) 2 �v���Z�b�T�̐V���i�\
http://www.intel.co.jp/jp/intel/pr/press2005/050719.htm
�C���e���AFSB 667MHz�Ή�Itanium 2�\
http://pc.watch.impress.co.jp/docs/2005/0719/intel.htm
http://www.intel.co.jp/jp/intel/pr/press2005/050719.htm
�C���e���AFSB 667MHz�Ή�Itanium 2�\
http://pc.watch.impress.co.jp/docs/2005/0719/intel.htm
High end Intel Montecito delayed
http://www.theinquirer.net/?article=24842
Montecito 2.0GHz/24MB��8�����̒x��B
���N3���܂Ŕq�߂Ȃ��Ȃ�炵���ł��B
http://www.theinquirer.net/?article=24842
Montecito 2.0GHz/24MB��8�����̒x��B
���N3���܂Ŕq�߂Ȃ��Ȃ�炵���ł��B
>>15�̋L���̏ڍׂŁAIntel�̌����T�C�g���猏��PCN�����Ƃ���悤�ɂȂ��Ă��܂��B
ttp://developer.intel.com/design/pcn/Processors/D0105224.pdf
IntelR PentiumR processor Extreme Edition 840 and IntelR PentiumR D processors 840, 830, 820, will
undergo the following changes for the A-0 to the B-0 core processor stepping change:
�E CPUID will change from F44 to F47
�E B-0 is pin compatible with A-0
�E New S-Specs for converting products
ttp://developer.intel.com/design/pcn/Processors/D0105224.pdf
IntelR PentiumR processor Extreme Edition 840 and IntelR PentiumR D processors 840, 830, 820, will
undergo the following changes for the A-0 to the B-0 core processor stepping change:
�E CPUID will change from F44 to F47
�E B-0 is pin compatible with A-0
�E New S-Specs for converting products
Intel to discuss Magpie, Paxville, Twincastle at Hot Chips
ttp://www.eetimes.com/news/semi/showArticle.jhtml?articleID=166401382
>Intel engineers are expected to present five papers at the conference including presentations of �gMagpie�h,
> described as a real-time �gmilliflow aggregation processor�h, together with �gPaxville�h a Xeon-based multiprocessor
> and �gTwincastle�h a chipset for servers in support of multiprocessors. The company is also going to present on
>�gFoxton�h, Intel�fs approach to dynamically optimized power saving.
������Hot Chips��Intel��5�̐V�Z�p�\����݂����ł��B
�gMagpie�h �Ɓgmilliflow aggregation processor�h�͏��߂Ăł��傤���c�B
ttp://www.eetimes.com/news/semi/showArticle.jhtml?articleID=166401382
>Intel engineers are expected to present five papers at the conference including presentations of �gMagpie�h,
> described as a real-time �gmilliflow aggregation processor�h, together with �gPaxville�h a Xeon-based multiprocessor
> and �gTwincastle�h a chipset for servers in support of multiprocessors. The company is also going to present on
>�gFoxton�h, Intel�fs approach to dynamically optimized power saving.
������Hot Chips��Intel��5�̐V�Z�p�\����݂����ł��B
�gMagpie�h �Ɓgmilliflow aggregation processor�h�͏��߂Ăł��傤���c�B
>>22�́Amilliflow aggregation processor=Magpie�݂����ł��ˁB��ǂ��܂����B
Intel�̃��r���e�B�헪�͂ǂ��������̂�
��Intel�A�`�����h���V�[�J���В��ɕ���
ttp://enterprise.watch.impress.co.jp/cda/ohkawara/2005/07/22/5783.html
Apple��Intel�̗p�ɂ��Ă��R�����g����Ă��܂��ˁB�B
��Intel�A�`�����h���V�[�J���В��ɕ���
ttp://enterprise.watch.impress.co.jp/cda/ohkawara/2005/07/22/5783.html
Apple��Intel�̗p�ɂ��Ă��R�����g����Ă��܂��ˁB�B
���̂Ƃ���A�P�Ȃ�j���[�X�X���b�h�ɂȂ��Ă��܂��Ă��܂����A
�_���I���q�ϓI�ȕ��͂��ł���l���]�~�͑劽�}�ł���B
���������l�͂��������݂��Ă���������B
�_���I���q�ϓI�ȕ��͂��ł���l���]�~�͑劽�}�ł���B
���������l�͂��������݂��Ă���������B
Intel Preps �gEntry-Level�h Dual-Core Processor
http://www.xbitlabs.com/news/cpu/display/20050722085026.html
Intel�A2.66GHz/533MHzFSB��Pentium D 805�������B
http://www.xbitlabs.com/news/cpu/display/20050722085026.html
Intel�A2.66GHz/533MHzFSB��Pentium D 805�������B
China's BLX unveils 64-bit processor
ttp://eetimes.com/news/design/technology/showArticle.jhtml?articleID=161500026
������BLX IC�f�U�C�����ĉ�Ђ��AMIPS�x�[�X��64bit�v���Z�b�TGodson-2�������[�X����炵���ł���B
�p�t�H�[�}���X��PenIII�ɕC�G����悤�ł��B���N��0.13um�炵������A2���キ�炢Intel�ɒx��Ă��܂��ˁB
�Ƃ�����R10000�̃N���[�����i���B
ttp://eetimes.com/news/design/technology/showArticle.jhtml?articleID=161500026
������BLX IC�f�U�C�����ĉ�Ђ��AMIPS�x�[�X��64bit�v���Z�b�TGodson-2�������[�X����炵���ł���B
�p�t�H�[�}���X��PenIII�ɕC�G����悤�ł��B���N��0.13um�炵������A2���キ�炢Intel�ɒx��Ă��܂��ˁB
�Ƃ�����R10000�̃N���[�����i���B
Intel's Merom is going to rock
http://www.theinquirer.net/?article=24932
Merom�́A65nm�v���Z�X�A�f���A���R�A��
�Vu�A�[�L�e�N�`����Banias�A�[�L�x�[�X��PenM�Ɣ�r����20-30%�����BbyINQ
http://www.theinquirer.net/?article=24932
Merom�́A65nm�v���Z�X�A�f���A���R�A��
�Vu�A�[�L�e�N�`����Banias�A�[�L�x�[�X��PenM�Ɣ�r����20-30%�����BbyINQ
Intel�A�Ԃ��Ȃ��f���A���R�A�̐V���i�\��
http://www.itmedia.co.jp/enterprise/articles/0507/26/news075.html
Intel�A�A���]�i�B��45nm�v���Z�X����300mm�E�F�n�H�������
http://pc.watch.impress.co.jp/docs/2005/0726/intel2.htm
�C���e���APentium M/Celeron M�̍ŏ�ʃ��f��
http://pc.watch.impress.co.jp/docs/2005/0726/intel.htm
http://www.itmedia.co.jp/enterprise/articles/0507/26/news075.html
Intel�A�A���]�i�B��45nm�v���Z�X����300mm�E�F�n�H�������
http://pc.watch.impress.co.jp/docs/2005/0726/intel2.htm
�C���e���APentium M/Celeron M�̍ŏ�ʃ��f��
http://pc.watch.impress.co.jp/docs/2005/0726/intel.htm
���㓡�O��Weekly�C�O�j���[�X��
Intel�f�X�N�g�b�vCPU���[�h�}�b�v�A�b�v�f�[�g
�`Conroe��Merom�����[�h�}�b�v�ɐ����o��
http://pc.watch.impress.co.jp/docs/2005/0728/kaigai200.htm
�v�X�ɁA�㓡����IntelCPU���������Ă��܂��B
>���ہA���N�̑����i�K�ł��ł�Merom�̎Г��T���v���͊������Ă����ƋƊE�W�҂͓`����B
���[��A���܂ł̃��[�}�[�ƈႤ��ɁA�����������ł��ˁc�B�ǂ��Ȃ�ł��傤�c�B
Intel�f�X�N�g�b�vCPU���[�h�}�b�v�A�b�v�f�[�g
�`Conroe��Merom�����[�h�}�b�v�ɐ����o��
http://pc.watch.impress.co.jp/docs/2005/0728/kaigai200.htm
�v�X�ɁA�㓡����IntelCPU���������Ă��܂��B
>���ہA���N�̑����i�K�ł��ł�Merom�̎Г��T���v���͊������Ă����ƋƊE�W�҂͓`����B
���[��A���܂ł̃��[�}�[�ƈႤ��ɁA�����������ł��ˁc�B�ǂ��Ȃ�ł��傤�c�B
Sources: Intel to move up MP Paxville launch to 4Q 2005
http://www.digitimes.com/news/a20050812A6031.html
�f���A���R�AXeon MP7000�V���[�Y�̂�Paxville�����NQ1����A
���N��Q4�ɑO�|�������[�X����邩������Ȃ��炵���ł��B
http://www.digitimes.com/news/a20050812A6031.html
�f���A���R�AXeon MP7000�V���[�Y�̂�Paxville�����NQ1����A
���N��Q4�ɑO�|�������[�X����邩������Ȃ��炵���ł��B
Intel to detail new chips at conference
http://news.zdnet.com/2100-9584_22-5829313.html
8/23��IDF�ŁAMerom/Conroe/Woodcrest�̏ڍׂ\����݂����ł��B
�����[�X�̈�N���O�ɐV�A�[�L�e�N�`���̏ڍ��J����Ȃ�āA���܂Ŗ��������ł��ˁB
�v�������Ȃ̂͂������ǂ����Ƃ��������Ă�悤�ȁc�B
http://news.zdnet.com/2100-9584_22-5829313.html
8/23��IDF�ŁAMerom/Conroe/Woodcrest�̏ڍׂ\����݂����ł��B
�����[�X�̈�N���O�ɐV�A�[�L�e�N�`���̏ڍ��J����Ȃ�āA���܂Ŗ��������ł��ˁB
�v�������Ȃ̂͂������ǂ����Ƃ��������Ă�悤�ȁc�B
Intel�AIDF Fall 2005�̎��O��������J��
�`Merom/Conroe�̃A�[�L�e�N�`���ɒ��ڂ�
http://pc.watch.impress.co.jp/docs/2005/0812/intel.htm
PC Watch�ɂ����Ă܂����B
�`Merom/Conroe�̃A�[�L�e�N�`���ɒ��ڂ�
http://pc.watch.impress.co.jp/docs/2005/0812/intel.htm
PC Watch�ɂ����Ă܂����B
35 �F���̖��ݒ��F2005/08/12(��) 18:48:12 ID:6HLrmdd7
ttp://macandpal.blogspot.com/2005/08/mac_11.html
���̘b��S�R�������ĂȂ��̂ł����A���v�Ȃ�ł���mac os
p2p�ŏo����ăh�U�ɘM����̂ق�Ƃɂ�Ȃ�ł����ǁB
���̘b��S�R�������ĂȂ��̂ł����A���v�Ȃ�ł���mac os
p2p�ŏo����ăh�U�ɘM����̂ق�Ƃɂ�Ȃ�ł����ǁB
���܂�
AMD Announces Low-Power Dual-Core Processors.
http://www.xbitlabs.com/news/cpu/display/20050811204921.html
>Dual-core AMD Opteron family of processors for embedded applications consists
> of processor models 165, 265 and 865 clocked at 1.80GHz as well as the lower-power
> 55W version of each. AMD Opteron processors feature dual-channel PC3200 memory
> controller, 2MB L2 cache (1MB of L2 cache per core), SSE3 technology and are to be
> made using 90nm process technology.
AMD��Intel�ɐ�s���ċ߁X�f���A���R�AOpteron�̃��[�p���[�ł������[�X����͗l�B
AMD Announces Low-Power Dual-Core Processors.
http://www.xbitlabs.com/news/cpu/display/20050811204921.html
>Dual-core AMD Opteron family of processors for embedded applications consists
> of processor models 165, 265 and 865 clocked at 1.80GHz as well as the lower-power
> 55W version of each. AMD Opteron processors feature dual-channel PC3200 memory
> controller, 2MB L2 cache (1MB of L2 cache per core), SSE3 technology and are to be
> made using 90nm process technology.
AMD��Intel�ɐ�s���ċ߁X�f���A���R�AOpteron�̃��[�p���[�ł������[�X����͗l�B
Intel's next generation processors revealed
http://www.theinquirer.net/?article=25349
TheINQ���摖���āA������CPU�ɂ��Č���Ă��܂���B
IDF�l�^�o�����ӁB
Mac OS X for Intel
ttp://www.concretesurf.co.nz/osx86/viewtopic.php?t=177
http://www.theinquirer.net/?article=25349
TheINQ���摖���āA������CPU�ɂ��Č���Ă��܂���B
IDF�l�^�o�����ӁB
Mac OS X for Intel
ttp://www.concretesurf.co.nz/osx86/viewtopic.php?t=177
���̒��q���ƁAMac����Ȃ��Ă�����@�ŃN���b�N��MacOS X���l��
���B���������Ȃ��B�������傤�Ԃ��@>Apple
���B���������Ȃ��B�������傤�Ԃ��@>Apple
Intel to trim power consumption of desktop CPUs in half by H2 2006
http://www.tomshardware.com/hardnews/20050808_190135.html
Conroe��TDP60-70W��HT�Ȃ��݂����ł��ˁB
http://www.tomshardware.com/hardnews/20050808_190135.html
Conroe��TDP60-70W��HT�Ȃ��݂����ł��ˁB
40 �F���̖��ݒ��F2005/08/14(��) 16:36:37 ID:uVataZjO
���R�W
�����ȂƂ���AThinkpad��OS X�����Ȃ�~������ł����ǁB
�����ȂƂ���AThinkpad��OS X�����Ȃ�~������ł����ǁB
41 �F���̖��ݒ��F2005/08/14(��) 16:41:26 ID:P2Rd7FKS
>>40
ttp://macandpal.blogspot.com/2005/08/tiger-pc.html
ttp://macandpal.blogspot.com/2005/08/mac-os-xvaio.html
�S�R���蓾��
�܂��łނ����N���b�N�������
����ɋr���ݓ���₪����
ttp://macandpal.blogspot.com/2005/08/tiger-pc.html
ttp://macandpal.blogspot.com/2005/08/mac-os-xvaio.html
�S�R���蓾��
�܂��łނ����N���b�N�������
����ɋr���ݓ���₪����
42 �F3�͊w����N ��BJ3GET/Ezc �F2005/08/14(��) 20:01:04 ID:Eu61fWrm
�ʔ�����
43 �F���̖��ݒ��F2005/08/14(��) 20:03:16 ID:FLt7rZrd
���[��
�M�҂̐���AMacOSX
�M�҂̐���AMacOSX
44 �F���̖��ݒ��F2005/08/14(��) 20:05:21 ID:brcESCcR
>>41
�����Ԃ���{�ꂪ�s���R�Ȃ悤�ŁB
�����Ԃ���{�ꂪ�s���R�Ȃ悤�ŁB
Conroe lance a 2.93 GHz
http://www.x86-secret.com/index.php?option=newsd&nid=909
Conroe���o�ꎞ�A2.93GHz��FSB1066MHz�B
Merom��Yonah�ƃs���R���p�`��FSB667MHz�������ł���B
���[��A65nm�Ƃ͂���PenM�N���X�̃p�C�v���C���i���ŏ������r�W������2.93GHz���ł邩�Ȃ��B
�������A2.93GHz�������Ȃ肾����Plesler��3.6GHz����Ђ����ڂɌ��Ă����\�̃W�����v���������킯�����ǁA
�����Ȃ肻���܂ł�����烁�[�J�[�Ƃ��Ă͂��������Ȃ��Ƃ������AIntel�͂�肻���ɂȂ��悤�ȁc�B
http://www.x86-secret.com/index.php?option=newsd&nid=909
Conroe���o�ꎞ�A2.93GHz��FSB1066MHz�B
Merom��Yonah�ƃs���R���p�`��FSB667MHz�������ł���B
���[��A65nm�Ƃ͂���PenM�N���X�̃p�C�v���C���i���ŏ������r�W������2.93GHz���ł邩�Ȃ��B
�������A2.93GHz�������Ȃ肾����Plesler��3.6GHz����Ђ����ڂɌ��Ă����\�̃W�����v���������킯�����ǁA
�����Ȃ肻���܂ł�����烁�[�J�[�Ƃ��Ă͂��������Ȃ��Ƃ������AIntel�͂�肻���ɂȂ��悤�ȁc�B
���㓡�O��Weekly�C�O�j���[�X��
Intel��Hyper-Threading���̂�!?
http://pc.watch.impress.co.jp/docs/2005/0816/kaigai203.htm
Intel��Hyper-Threading���̂�!?
http://pc.watch.impress.co.jp/docs/2005/0816/kaigai203.htm
��Intel���f���A���R�AXeon�X�P�W���[����O�|���A2005�N�����\��
http://pcweb.mycom.co.jp/news/2005/08/16/004.html
http://pcweb.mycom.co.jp/news/2005/08/16/004.html
48 �F3�͊w����N ��BJ3GET/Ezc �F2005/08/17(��) 01:02:57 ID:breb9rU+ BE:393379698-#
�������͉ߑa�����Ă�Ȃ�
���Ă������Amac�̐l�͂���܂��������̋����Ȃ���ł����ˁB
����Ƃ����܂�IntelCPU�Ɋւ��ĕ��s���ŁA������Ƙb��ɂ��Ă����Ȃ��̂��B
���тꂫ�炵�Ė{�X���ɏ������������B
����Ƃ����܂�IntelCPU�Ɋւ��ĕ��s���ŁA������Ƙb��ɂ��Ă����Ȃ��̂��B
���тꂫ�炵�Ė{�X���ɏ������������B
50 �F3�͊w����N ��BJ3GET/Ezc �F2005/08/17(��) 01:22:39 ID:breb9rU+ BE:98345063-#
>>46
�������A�㓡���̋L���̏��������������ȁB
��������Merom��Nehalem��HT�Ȃ����ŁA�_�C�ʐςɂ̓P�`��Ȃ��Ă�65nm�ȍ~�ł͗]�T�����邵�A
���̌�́ACSI�x�[�X�̃����O�ڑ��C���^�[�R�l�N�g��Many�R�A�Ɍ������\�肾����A
���Ȃ��Ă�PC�����ł́AHT�Ȃ�č��㓱�����錄�������b�g���Ȃ��킯�ł���B
���̕ӂ̂Ƃ����������x��͂����ĂĂ킩���Ă�낤���ǁA�����ɕs�m�����Ȃ�����A
SMT�Ȃ��Ȃ�Ƃ��������āA���Ƃŗ\�z�����������݂����ɂ����ł��傤�c�B���������܂��B
�������A�㓡���̋L���̏��������������ȁB
��������Merom��Nehalem��HT�Ȃ����ŁA�_�C�ʐςɂ̓P�`��Ȃ��Ă�65nm�ȍ~�ł͗]�T�����邵�A
���̌�́ACSI�x�[�X�̃����O�ڑ��C���^�[�R�l�N�g��Many�R�A�Ɍ������\�肾����A
���Ȃ��Ă�PC�����ł́AHT�Ȃ�č��㓱�����錄�������b�g���Ȃ��킯�ł���B
���̕ӂ̂Ƃ����������x��͂����ĂĂ킩���Ă�낤���ǁA�����ɕs�m�����Ȃ�����A
SMT�Ȃ��Ȃ�Ƃ��������āA���Ƃŗ\�z�����������݂����ɂ����ł��傤�c�B���������܂��B
52 �F���̖��ݒ��F2005/08/17(��) 13:50:17 ID:8miSNRlW
53 �F���̖��ݒ��F2005/08/17(��) 14:29:05 ID:4zXKeO+S
�����̃X��������オ��Ȃ����R���A�i���l���j�u���s���ŁA������Ƙb��ɂ��Ă����Ȃ��v�Ȃ�čl����v�l��H�͐����Ǝv���B
54 �F���̖��ݒ��F2005/08/17(��) 15:18:24 ID:MORGhDHi
�����悤�ȃX���͑��ɂ��邵�˂��B
�܂��}�J�ɂƂ��Ă͌����I�Șb�ł͂Ȃ����B
�������������炨��͂����ŕ������Ă��炤�悗
�܂��}�J�ɂƂ��Ă͌����I�Șb�ł͂Ȃ����B
�������������炨��͂����ŕ������Ă��炤�悗
MAC�I�^�̗\���I
Intel to sample Conroe processor in Q1 2006
http://www.tomshardware.com/hardnews/20050816_113912.html
Conroe
-> Q1 2006����T���v���J�n
-> ���킹�ăV���O���R�A�ł�Allendale���o��
-> ��p�`�v�Z�g��Broadwater
Broadwater�`�v�Z�g
->Conroe����̃f�X�N�g�b�v�����`�v�Z�g
->HDMI
->iAMT (Active Power Management)
->Dual DDR2-800������
->��4���㓝���O���t�B�N�X GDDR3 256MB�����
1�N���Mac�������Ă��܂�����B
http://www.tomshardware.com/hardnews/20050816_113912.html
Conroe
-> Q1 2006����T���v���J�n
-> ���킹�ăV���O���R�A�ł�Allendale���o��
-> ��p�`�v�Z�g��Broadwater
Broadwater�`�v�Z�g
->Conroe����̃f�X�N�g�b�v�����`�v�Z�g
->HDMI
->iAMT (Active Power Management)
->Dual DDR2-800������
->��4���㓝���O���t�B�N�X GDDR3 256MB�����
1�N���Mac�������Ă��܂�����B
8��14���t���ő�^�v���C�X�J�b�g������܂����B
Intel�v���Z�b�T�v���C�X���X�g�@
http://www.intel.com/intel/finance/pricelist/
Intel�v���Z�b�T�v���C�X���X�g�@
http://www.intel.com/intel/finance/pricelist/
The hidden currents powering Intel's next gen chips
http://www.theinquirer.net/?article=25496
�V�����X�^�b�t���ȁH�Ђǂ��ϑz�ł��ˁB�ǂ܂Ȃ��Ă悵�B
Intel word of the day revealed
http://www.theinquirer.net/?article=25501
Merom��45nm�V�������N�ł�Penryn�Ƃ����R�[�h�l�[���炵���ł���B
http://www.theinquirer.net/?article=25496
�V�����X�^�b�t���ȁH�Ђǂ��ϑz�ł��ˁB�ǂ܂Ȃ��Ă悵�B
Intel word of the day revealed
http://www.theinquirer.net/?article=25501
Merom��45nm�V�������N�ł�Penryn�Ƃ����R�[�h�l�[���炵���ł���B
Intel logo of DRM Forking plan emerges
http://www.theinquirer.net/?article=25524
Intel��East Fork(�v���b�g�t�H�[����̂̃}�[�P�e�B���O)�헪�̃��S�̘b�ł��B
IntelMac�͍ŏ�����East Fork�}�[�P�e�B���O�ɂ̂������Ă���Ƃ�������̂ŁA
���̃��S�V�[���̂���Mac��IntelMac�̖ڈ�ɂȂ肻���ł���B
http://www.theinquirer.net/?article=21559
Quad Xeon MP 8M & E8500
http://www.x86-secret.com/popups/articleswindow.php?id=126
Potomac Xeon + E8500 ��4�v���Z�b�T�V�X�e���̃x���`�}�[�N��
X86-secret���f�ڂ��Ă��܂���B
Intel 45 nanometre process is good to go
http://www.theinquirer.net/?article=25512
������IDF�ł�45nm�v���Z�X�Ɋւ��Ă����y������悤�ł���B
65nm�v���Z�X�ł́A���[�N�d����90nm���������������Ƃ̂��Ƃł��B
�����āA�����45nm�v���Z�X�ł̓��[�N�d�����������ł���ƕ����\�[�X���`���Ă���悤�ł��B
http://www.theinquirer.net/?article=25524
Intel��East Fork(�v���b�g�t�H�[����̂̃}�[�P�e�B���O)�헪�̃��S�̘b�ł��B
IntelMac�͍ŏ�����East Fork�}�[�P�e�B���O�ɂ̂������Ă���Ƃ�������̂ŁA
���̃��S�V�[���̂���Mac��IntelMac�̖ڈ�ɂȂ肻���ł���B
http://www.theinquirer.net/?article=21559
Quad Xeon MP 8M & E8500
http://www.x86-secret.com/popups/articleswindow.php?id=126
Potomac Xeon + E8500 ��4�v���Z�b�T�V�X�e���̃x���`�}�[�N��
X86-secret���f�ڂ��Ă��܂���B
Intel 45 nanometre process is good to go
http://www.theinquirer.net/?article=25512
������IDF�ł�45nm�v���Z�X�Ɋւ��Ă����y������悤�ł���B
65nm�v���Z�X�ł́A���[�N�d����90nm���������������Ƃ̂��Ƃł��B
�����āA�����45nm�v���Z�X�ł̓��[�N�d�����������ł���ƕ����\�[�X���`���Ă���悤�ł��B
62 �F���̖��ݒ��F2005/08/19(��) 20:33:51 ID:HZj1JwWW
>>61
>���̃��S�V�[���̂���Mac��IntelMac�̖ڈ�ɂȂ肻���ł���B
>http://www.theinquirer.net/?article=21559
���ق��Ă���悗��������
>���̃��S�V�[���̂���Mac��IntelMac�̖ڈ�ɂȂ肻���ł���B
>http://www.theinquirer.net/?article=21559
���ق��Ă���悗��������
Intel ���ȁ[�A���낻�� x86 �A�[�L�e�B�N�`����߂Ă܂Ƃ���
�v�̃v���Z�b�T���Ȃ����Ȃ��B�����v���Z�X�Ȃ牽������
�����Ȃ�Ǝv�����ǁB
�v�̃v���Z�b�T���Ȃ����Ȃ��B�����v���Z�X�Ȃ牽������
�����Ȃ�Ǝv�����ǁB
64 �F���̖��ݒ��F2005/08/20(�y) 03:51:07 ID:H7/6GFTo
��������
���̃X���l�C�Ȃ��ˁB
�Ƃ肠����IDF�Ŕ��\���ꂽ�VCPU�l�^�͂���������Ɨ��������Ă����낤���ȁc�B
Intel Merom is designed from the ground up
http://www.theinquirer.net/?article=25623
�Ƃ肠����Merom�́A
14stage, full 4uops pipeline, OOO�R�A
�Ƃ������Ƃł��ˁB
P6�ł́ASimple Instruction�f�R�[�_(1uops/clk)��2�AComplex Instruction�f�R�[�_(max. 4uops/clk)
��1�̃f�R�[�_�\�����Ƃ��Ă��܂�������A����ꂽ�����ɂ����āA�ő�3���߃f�R�[�h�A6uops���s�ł����B
�܂��ADispatch�ɂ��Ă�5���߃|�[�g�p�ӂ���Ă���A5uops�������s�\�ł����B�B
�������A���^�C�A�ɂ��Ă͕��ϓI�Ɏ��s�\��uops����3uops/clk���x�Ƃ������ƂŁA3uops/clk�Ő�������Ă���A
�S�̂Ƃ���3uops/clk�̃p�C�v���C���\���ł����B
NetBurst�ɂ��Ă̓V���O���T�C�N���̃f�R�[�_��1�����p�ӂ���Ă��炸�A�g���[�X�L���b�V��
�ł�����J�o�[����\��������Ă���A�������g���[�X�L���b�V���̃t�F�b�`�ш悪3uops/clk�ł����B
Dispatch�ɂ��Ă͖��߃|�[�g��4�|�[�g�ōő�6uops�������s�\�ł������A�A
���^�C�A�ш�͂�͂�3uops/clk�ɐ�������Ă���A��͂�S�̂Ƃ���3uops/clk�̃p�C�v���C���\���ł��B
Merom�ł́A�p�C�v���C���̏ڍׂ͕s���ł����A���s���烊�^�C�A�܂ł̑ш悪4uops/clk���ێ��ł���悤��
�v����Ă��āAALU���߃|�[�g���������Ă���Ƃ̂��Ƃł��B
14�i�Ƃ����X�e�[�W�����Aoverall pipe�Ȃ̂�critical pipe�Ȃ̂��͂悭�킩��Ȃ��ƋL���ł͂����Ă��܂��ˁB
overall����P6�Ɠ������炢�ȃX�e�[�W���ŁA������P6�̕������ш�v�Ȃ̂Ŏ�����Merom�̕���
��N���b�N�Ȑv�Ƃ����ӂ��ɂȂ�܂����Acritical pipe�Ȃ�ł����ˁB
���Ă���̂ŁA���̑��̏ڍׂɂ��Ă͏T�����炢�Ɂc�B
http://www.theinquirer.net/?article=25623
�Ƃ肠����Merom�́A
14stage, full 4uops pipeline, OOO�R�A
�Ƃ������Ƃł��ˁB
P6�ł́ASimple Instruction�f�R�[�_(1uops/clk)��2�AComplex Instruction�f�R�[�_(max. 4uops/clk)
��1�̃f�R�[�_�\�����Ƃ��Ă��܂�������A����ꂽ�����ɂ����āA�ő�3���߃f�R�[�h�A6uops���s�ł����B
�܂��ADispatch�ɂ��Ă�5���߃|�[�g�p�ӂ���Ă���A5uops�������s�\�ł����B�B
�������A���^�C�A�ɂ��Ă͕��ϓI�Ɏ��s�\��uops����3uops/clk���x�Ƃ������ƂŁA3uops/clk�Ő�������Ă���A
�S�̂Ƃ���3uops/clk�̃p�C�v���C���\���ł����B
NetBurst�ɂ��Ă̓V���O���T�C�N���̃f�R�[�_��1�����p�ӂ���Ă��炸�A�g���[�X�L���b�V��
�ł�����J�o�[����\��������Ă���A�������g���[�X�L���b�V���̃t�F�b�`�ш悪3uops/clk�ł����B
Dispatch�ɂ��Ă͖��߃|�[�g��4�|�[�g�ōő�6uops�������s�\�ł������A�A
���^�C�A�ш�͂�͂�3uops/clk�ɐ�������Ă���A��͂�S�̂Ƃ���3uops/clk�̃p�C�v���C���\���ł��B
Merom�ł́A�p�C�v���C���̏ڍׂ͕s���ł����A���s���烊�^�C�A�܂ł̑ш悪4uops/clk���ێ��ł���悤��
�v����Ă��āAALU���߃|�[�g���������Ă���Ƃ̂��Ƃł��B
14�i�Ƃ����X�e�[�W�����Aoverall pipe�Ȃ̂�critical pipe�Ȃ̂��͂悭�킩��Ȃ��ƋL���ł͂����Ă��܂��ˁB
overall����P6�Ɠ������炢�ȃX�e�[�W���ŁA������P6�̕������ш�v�Ȃ̂Ŏ�����Merom�̕���
��N���b�N�Ȑv�Ƃ����ӂ��ɂȂ�܂����Acritical pipe�Ȃ�ł����ˁB
���Ă���̂ŁA���̑��̏ڍׂɂ��Ă͏T�����炢�Ɂc�B
IDF Fall 2005 - �f�W�^���z�[����u��: �f�W�^�����f�B�A�E�e�N�m���W�̐V�u�����h�uViiv�v
http://pcweb.mycom.co.jp/articles/2005/08/25/idf1/
Apple��Viiv�헪�ɂǂꂾ����������Ă��邩�͔������ȁc�B
http://pcweb.mycom.co.jp/articles/2005/08/25/idf1/
Apple��Viiv�헪�ɂǂꂾ����������Ă��邩�͔������ȁc�B
����ɖ��炩�ɂȂ���Yonah�̎p
�`�g�����ꂽC4�X�e�[�g�ł���Ȃ�ȓd�͂�
http://pc.watch.impress.co.jp/docs/2005/0825/ubiq121.htm
Yonah
-> Mobile Pentium / Celeron
-> �f���A���R�APentium M
-> Mobile Intel 945 Express "Calistoga"�`�v�Z�g Napa�v���b�g�t�H�[��
-> 151,600,000Tr/90.3sqmm@65nm, CMOS
-> Jan. 5th, 2006@US
-> FSB667MHz@�ʏ�/LV��, 533MHz@ULV��
-> uBGA479 / uPGA568 �p�b�P�[�W
-> TDP31W@�ʏ��, 5.5W@ULV��
-> VT, SSE3�̃T�|�[�g
-> 2MB L2�L���b�V�� on-chip
-> �R�A�ԋ��L�^L2, �X�}�[�g�L���b�V���@�\
-> Enhanced Deeper Sleep (DC4)�X�e�[�g(L2�̓d�����I�~��)
-> SSE���߂�Micro Ops Fusion
-> SIMD��p���Z����������ASSE�̃p�t�H�[�}���X���ő�30%���P
-> [email protected]
�ŋ߂̉\���܂߂������܂Ƃ߂�Ƃ���Ȋ����ł����ˁB
�`�g�����ꂽC4�X�e�[�g�ł���Ȃ�ȓd�͂�
http://pc.watch.impress.co.jp/docs/2005/0825/ubiq121.htm
Yonah
-> Mobile Pentium / Celeron
-> �f���A���R�APentium M
-> Mobile Intel 945 Express "Calistoga"�`�v�Z�g Napa�v���b�g�t�H�[��
-> 151,600,000Tr/90.3sqmm@65nm, CMOS
-> Jan. 5th, 2006@US
-> FSB667MHz@�ʏ�/LV��, 533MHz@ULV��
-> uBGA479 / uPGA568 �p�b�P�[�W
-> TDP31W@�ʏ��, 5.5W@ULV��
-> VT, SSE3�̃T�|�[�g
-> 2MB L2�L���b�V�� on-chip
-> �R�A�ԋ��L�^L2, �X�}�[�g�L���b�V���@�\
-> Enhanced Deeper Sleep (DC4)�X�e�[�g(L2�̓d�����I�~��)
-> SSE���߂�Micro Ops Fusion
-> SIMD��p���Z����������ASSE�̃p�t�H�[�}���X���ő�30%���P
-> [email protected]
�ŋ߂̉\���܂߂������܂Ƃ߂�Ƃ���Ȋ����ł����ˁB
Yonah
-> Mobile Pentium / Celeron
-> �f���A���R�APentium M
-> Mobile Intel 945 Express "Calistoga"�`�v�Z�g Napa�v���b�g�t�H�[��
-> 151,600,000Tr/90.3sqmm@65nm, CMOS
-> Jan. 5th, 2006@US
-> FSB667MHz@�ʏ�/LV��, 533MHz@ULV��
-> uBGA479 / uPGA568 �p�b�P�[�W
-> TDP31W@�ʏ��, 5.5W@ULV��
-> VT, SSE3�̃T�|�[�g
-> 13stage�p�C�v�A�ꕔ�̖��߂̑������^�C�A(8th stage)
-> 2MB L2�L���b�V�� on-chip
-> �R�A�ԋ��L�^L2, �X�}�[�g�L���b�V���@�\
-> Enhanced Deeper Sleep (DC4)�X�e�[�g(L2�̓d�����I�~��)
-> SSE���߂�Micro Ops Fusion�@(ld+op)
-> SIMD��p���Z����������ASSE�̃p�t�H�[�}���X���ő�30%���P
-> [email protected]
-> Mobile Pentium / Celeron
-> �f���A���R�APentium M
-> Mobile Intel 945 Express "Calistoga"�`�v�Z�g Napa�v���b�g�t�H�[��
-> 151,600,000Tr/90.3sqmm@65nm, CMOS
-> Jan. 5th, 2006@US
-> FSB667MHz@�ʏ�/LV��, 533MHz@ULV��
-> uBGA479 / uPGA568 �p�b�P�[�W
-> TDP31W@�ʏ��, 5.5W@ULV��
-> VT, SSE3�̃T�|�[�g
-> 13stage�p�C�v�A�ꕔ�̖��߂̑������^�C�A(8th stage)
-> 2MB L2�L���b�V�� on-chip
-> �R�A�ԋ��L�^L2, �X�}�[�g�L���b�V���@�\
-> Enhanced Deeper Sleep (DC4)�X�e�[�g(L2�̓d�����I�~��)
-> SSE���߂�Micro Ops Fusion�@(ld+op)
-> SIMD��p���Z����������ASSE�̃p�t�H�[�}���X���ő�30%���P
-> [email protected]
�Ƃ̃T�C�g��Yonah/Sossaman(Yonah�̃T�[�o��)�̃x���`�X�R�A���f�ڂ��Ă��܂����B
IDF: Benchmarks von Sossaman und Yonah
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
IDF: Benchmarks von Sossaman und Yonah
http://www.computerbase.de/news/hardware/prozessoren/intel/2005/august/idf_benchmarks_sossaman_yonah/
http://www.geocities.jp/andosprocinfo/wadai05/20050827.htm
��������IDF�̓��e�ɂ��ďڍׂȉ�����Ă��B
�ā[���A������Ȃ������͍̂ŏ����炱��˂炢�������肵�āi�E�́E�j���
��������IDF�̓��e�ɂ��ďڍׂȉ�����Ă��B
�ā[���A������Ȃ������͍̂ŏ����炱��˂炢�������肵�āi�E�́E�j���
����ɂ��Ă�IPF��IDF�ł��w�ǘb��ɂ̂��ĂȂ����A
���悢��t�F�[�h�A�E�g�������ȋC�z����Ȃ���������Ȃ��H
�Z�����������c(;�L�D�M)
���悢��t�F�[�h�A�E�g�������ȋC�z����Ȃ���������Ȃ��H
�Z�����������c(;�L�D�M)
74 �F���̖��ݒ��F2005/08/27(�y) 23:51:50 ID:nud9gR7W
>>72
���̐l�̓��{��A�����[�ǂ݂ɂ�����ł����B
���̐l�̓��{��A�����[�ǂ݂ɂ�����ł����B
�������ȁB���ʂɓǂ߂�Ƃ��������ǁB
�ł��A��������Merom TDP5W���܂������ĐM��������Ă�̂��c(;�L�D�M)
�ł��A��������Merom TDP5W���܂������ĐM��������Ă�̂��c(;�L�D�M)
http://www.theinquirer.net/?article=25746
Conroe�̃p�b�P�[�W�ʐ^�̂��Ă�B
�ڎZ��Prescott���͑傫�����ǁAConroe���͏�����������Ȃ��H
�N���摜���͂̃v����낵���B
Conroe�̃p�b�P�[�W�ʐ^�̂��Ă�B
�ڎZ��Prescott���͑傫�����ǁAConroe���͏�����������Ȃ��H
�N���摜���͂̃v����낵���B
Conroe����Ȃ���Smithfield���_�C��������������Ȃ��H���Ęb�B
�Ԃ������AMerom�̃}�C�N���A�[�L�́A�X�[�p�[�p�C�v���C��+�X�[�p�[�X�J��+OOO�Ƃ���RISC�S����
�Ɋm�����ꂽ�n�C�G���h�v���Z�b�T�̊�{�I�ȍ\�������̂܂܌p�����āAP6�ȍ~�̃{�����[��
�A�b�v��������ɂ����Ȃ���ˁB
���Ƃׂ̍����A�[�L�v�f�͐o���ς���ΎR�ƂȂ�I�ȋ����ŁA���܂�ڗ��������\���P�ɂ͂Ȃ�Ȃ����B
ʷ�����čŋ߂̃v���Z�b�T�͂����R�A���̃}�C�N���A�[�L�e�N�`���ǂ������̘b���Ă��܂�Ȃ��ˁB
Merom�A�[�L�ň�ԖڐV�����|�C���g���}�C�N���A�[�L�ł͂Ȃ��A�u���s���j�b�g���j�b�g�̓d���I�t�v���Ǝv���B
�Ɋm�����ꂽ�n�C�G���h�v���Z�b�T�̊�{�I�ȍ\�������̂܂܌p�����āAP6�ȍ~�̃{�����[��
�A�b�v��������ɂ����Ȃ���ˁB
���Ƃׂ̍����A�[�L�v�f�͐o���ς���ΎR�ƂȂ�I�ȋ����ŁA���܂�ڗ��������\���P�ɂ͂Ȃ�Ȃ����B
ʷ�����čŋ߂̃v���Z�b�T�͂����R�A���̃}�C�N���A�[�L�e�N�`���ǂ������̘b���Ă��܂�Ȃ��ˁB
Merom�A�[�L�ň�ԖڐV�����|�C���g���}�C�N���A�[�L�ł͂Ȃ��A�u���s���j�b�g���j�b�g�̓d���I�t�v���Ǝv���B
79 �F���̖��ݒ��F2005/08/28(��) 03:01:13 ID:aRczAU0C
>OEM�x���_�̏��Ɋ��A�������̐V�����g�����߂����������\��ł���A
>���f�B�A�����\�͂�����ɋ�������邱�ƂɂȂ�B
�����I�ɂ݂āA�P�ɂ܂�Merom�̏ڍׂ�
�B���Ă邾���ȋC������E�E�E
>���f�B�A�����\�͂�����ɋ�������邱�ƂɂȂ�B
�����I�ɂ݂āA�P�ɂ܂�Merom�̏ڍׂ�
�B���Ă邾���ȋC������E�E�E
80 �F���̖��ݒ��F2005/08/28(��) 03:02:16 ID:46vPR5Zn
AltiVec�������PowerPC����ڍs�������AIntel��CPU�������ƃ��f�B�A�����\�͂�
�������Ă����Ă���Ȃ��Ɗm���ɍ���܂��ȁB
�������Ă����Ă���Ȃ��Ɗm���ɍ���܂��ȁB
IDF Fall 2005 Report link�W
http://www.itmedia.co.jp/news/topics/idffall_2005.html
http://www.itmedia.co.jp/news/topics/idffall_2005.html
�t���[�X�P�[���ЂƃA�b�v���Ђ��V�_��A
PowerPC�̋�����2008�N�܂Ōp��
http://www.eetimes.jp/contents/200508/2125_2_20050829122914.cfm
>��Apple Computer�i�A�b�v���R���s���[�^�j�Ђ�2005�N8��26���i�č����ԁj�A
>��Freescale Semiconductor�i�t���[�X�P�[���E�Z�~�R���_�N�^�j�Ђ���uPowerPC�v�v���Z�b�T
>�̋�����2008�N�܂Ŏ�_�������ł������Ƃ�ď،�����ψ���iSEC�j�ɕ����B
>����ɂ��AApple�Ђ���Intel�А��̃v���Z�b�T�Ɉڍs����v��́A�����̌��ʂ����x��
>�錩���݂ł���B
2008�N�܂łɊ��SIntel�ڍs�ł���Ώ\�������Ǝv�����A
�ǂ������\�����Ă��낤���c�B
PowerPC�̋�����2008�N�܂Ōp��
http://www.eetimes.jp/contents/200508/2125_2_20050829122914.cfm
>��Apple Computer�i�A�b�v���R���s���[�^�j�Ђ�2005�N8��26���i�č����ԁj�A
>��Freescale Semiconductor�i�t���[�X�P�[���E�Z�~�R���_�N�^�j�Ђ���uPowerPC�v�v���Z�b�T
>�̋�����2008�N�܂Ŏ�_�������ł������Ƃ�ď،�����ψ���iSEC�j�ɕ����B
>����ɂ��AApple�Ђ���Intel�А��̃v���Z�b�T�Ɉڍs����v��́A�����̌��ʂ����x��
>�錩���݂ł���B
2008�N�܂łɊ��SIntel�ڍs�ł���Ώ\�������Ǝv�����A
�ǂ������\�����Ă��낤���c�B
���z���Ή��A���^�K�i�A�i��������PCI Express
http://pc.watch.impress.co.jp/docs/2005/0827/hot382.htm
http://pc.watch.impress.co.jp/docs/2005/0827/hot382.htm
Banias�J���҂ɕ����AIntel�̎�����ȓd��CPU�Z�p
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
>ITmedia�@Merom�̃}�C�N���A�[�L�e�N�`���ł́A�������Z������4���ߓ������s�ł���A
>���o�b�t�@�̐[���p�C�v���C���ɂȂ�ƃA�i�E���X����Ă��܂��B�����̎��s���j�b�g�Ɋւ��Đ��͓����Ȃ̂ł����H
>�܂��X�e�[�W���̔�r�ł͂�葽���Ȃ�̂ł��傤���H
>�G�f�����@�u�X�e�[�W����14�i�ł��B���Ȃ݂�Pentium III��11�X�e�[�W�ł����i�������j���[�X�����[�X�ł�
>12�X�e�[�W�ƂȂ��Ă���j�B�܂��f���A���R�A�v�ƂȂ���Yonah�́A�R�A�Ԃ̓�����L���b�V���̊Ǘ��Ȃ�
>�����邽�߁ABanias��Dothan�����������₵�Ă��܂��B���s���j�b�g�̐��ɂ��ẮA��胏�C�h�ɂ͂Ȃ�
>�܂��������_�ł͓������܂���v
ALU 4��ƍl���ėǂ��̂��ȁH
PenIII��11�ɑ���Merom��14���c�B
�ŋ߂�Intel�̃p�C�v���C���X�e�[�W�̃J�E���g�@���悭�킩���B
>���o�b�t�@�̐[���p�C�v���C���ɂȂ�ƃA�i�E���X����Ă��܂��B�����̎��s���j�b�g�Ɋւ��Đ��͓����Ȃ̂ł����H
>�܂��X�e�[�W���̔�r�ł͂�葽���Ȃ�̂ł��傤���H
>�G�f�����@�u�X�e�[�W����14�i�ł��B���Ȃ݂�Pentium III��11�X�e�[�W�ł����i�������j���[�X�����[�X�ł�
>12�X�e�[�W�ƂȂ��Ă���j�B�܂��f���A���R�A�v�ƂȂ���Yonah�́A�R�A�Ԃ̓�����L���b�V���̊Ǘ��Ȃ�
>�����邽�߁ABanias��Dothan�����������₵�Ă��܂��B���s���j�b�g�̐��ɂ��ẮA��胏�C�h�ɂ͂Ȃ�
>�܂��������_�ł͓������܂���v
ALU 4��ƍl���ėǂ��̂��ȁH
PenIII��11�ɑ���Merom��14���c�B
�ŋ߂�Intel�̃p�C�v���C���X�e�[�W�̃J�E���g�@���悭�킩���B
Intel����������A�œK�̓d�����䂪�ł��鎟����`�b�v�Ƃ�
http://www.itmedia.co.jp/news/articles/0508/29/news066.html
CMOS�`�b�v�d���ɂ��āB
http://www.itmedia.co.jp/news/articles/0508/29/news066.html
CMOS�`�b�v�d���ɂ��āB
87 �F���̖��ݒ��F2005/08/30(��) 23:27:36 ID:9aVVeDCn
���̃X���{���ɖʔ����Ȃ��ˁc�B
�K���Ƀj���[�X�T�C�g�����Ă�Ύ�ɓ���������肾���B
������inteler����̓Ǝ��̈ӌ�������ΐ���オ���Ȃ��́H
�K���Ƀj���[�X�T�C�g�����Ă�Ύ�ɓ���������肾���B
������inteler����̓Ǝ��̈ӌ�������ΐ���オ���Ȃ��́H
IDF Fall 2005 - Merom/Conroe/Woodcrest�̓o��
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/
�匴����̋L���͑��ς�炸�A���Ⴂ�A�ϑz���������Ă��̂����ȁi�E�́E�j
�L���̓��e�Ɋւ��Ă̐����͌�ł�邱�Ƃɂ������B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/
�匴����̋L���͑��ς�炸�A���Ⴂ�A�ϑz���������Ă��̂����ȁi�E�́E�j
�L���̓��e�Ɋւ��Ă̐����͌�ł�邱�Ƃɂ������B
LInux�ł悭Win��DLL�Ƃ��g���Ă邯�ǁA������ăv���Z�b�T���݊������邩�炻�̂܂g������Ă��ƁH
90 �Finteler �F2005/09/06(��) 02:59:54 ID:n2RyWvO4
�@�\�g���̊��ɏ�����Yonah�̃R�A
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
�㓡����̋L�������ς�炸�A���Ⴂ�A�ϑz���������Ă��̂����ȁi�E�́E�j
�L���̓��e�Ɋւ��Ă̐����͌�ł�邱�Ƃɂ������B
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
�㓡����̋L�������ς�炸�A���Ⴂ�A�ϑz���������Ă��̂����ȁi�E�́E�j
�L���̓��e�Ɋւ��Ă̐����͌�ł�邱�Ƃɂ������B
91 �Finteler �F2005/09/11(��) 03:06:01 ID:6w9rH4M3
�@�_i�"�U�^( _ �l ,;���" i�;;::.�_�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�Q/
)�S �m�@�@�� ,,:;:''�@�@,;�@;,�@,;.,�@�f.�ځ@�R�A�Q�ʼnΗ͂��Q�{�B�B�I�@��
�@�@�@�@�_�@�@�@���ׁ@�@�@�@�^.�^�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�_
�@�@| �_ �@ |�P �l ,��ɁP| �Q ..:| : :.�P�@/�@�^��|�@/�v�_�@�@/�_|�_�@ .|�@
:. ,: |::: : | �@|: :::::|����|::::::|�@�R: ::::::::|/�^�@�@�@|/�@�@ �@ �_/�@�@ �@ �_|
,)�',|::: : | �@|�@,;'"PenD"���In�Q??.::::::::|
�m;ɁS;, ., ( _ �l ,���" i� i�@( �G�M�D�L) ::::::|�@(:
�i. ,.�i ,;�@�@/�@�@�@�@�@�@�@ �@/�Y�� :::::::|.:��,�@�ް�ް
�l:. �S,��@�i.�@�@�@�@�@�@ �@ �i_�� Ɂ@�@�@�@,;;'�l,,�m
�@�i;.�@�i:, �@,�j::. �@ �@ �@ �@ �@ ���L�@;,��@,;�� .:;.�i
)�S �m�@�@�� ,,:;:''�@�@,;�@;,�@,;.,�@�f.�ځ@�R�A�Q�ʼnΗ͂��Q�{�B�B�I�@��
�@�@�@�@�_�@�@�@���ׁ@�@�@�@�^.�^�Q�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�_
�@�@| �_ �@ |�P �l ,��ɁP| �Q ..:| : :.�P�@/�@�^��|�@/�v�_�@�@/�_|�_�@ .|�@
:. ,: |::: : | �@|: :::::|����|::::::|�@�R: ::::::::|/�^�@�@�@|/�@�@ �@ �_/�@�@ �@ �_|
,)�',|::: : | �@|�@,;'"PenD"���In�Q??.::::::::|
�m;ɁS;, ., ( _ �l ,���" i� i�@( �G�M�D�L) ::::::|�@(:
�i. ,.�i ,;�@�@/�@�@�@�@�@�@�@ �@/�Y�� :::::::|.:��,�@�ް�ް
�l:. �S,��@�i.�@�@�@�@�@�@ �@ �i_�� Ɂ@�@�@�@,;;'�l,,�m
�@�i;.�@�i:, �@,�j::. �@ �@ �@ �@ �@ ���L�@;,��@,;�� .:;.�i
Intel���i�̐V�����v���Z�b�T�i���o�ɂ���
Intel to dump numbering scheme, start new one
http://www.theinquirer.net/?article=26362
Yonah
T1x00 - Normal
L1x00 - Low Voltage
U1x00 - ULV
Conroe
S5x00
Allendale
S2x00
Merom
T4x00?
T6x00?
����ł������l�^�ꂵ�������Ȃ��c�B
Intel to dump numbering scheme, start new one
http://www.theinquirer.net/?article=26362
Yonah
T1x00 - Normal
L1x00 - Low Voltage
U1x00 - ULV
Conroe
S5x00
Allendale
S2x00
Merom
T4x00?
T6x00?
����ł������l�^�ꂵ�������Ȃ��c�B
93 �Finteler �F2005/10/01(�y) 21:21:27 ID:7SxvEJF3
PowerMac�ɂ͉���ςނ낤�BWoodcrest�H
���}����P�̃��r�L�^�X���ǁ�
Intel�AInternational CES�ŐV�u�����f�B���O�헪���\��
�`Pentium�u�����h�p�~�A�VIntel���S�o��
http://pc.watch.impress.co.jp/docs/2005/1021/ubiq129.htm
Pentium�u�����h�p�~���c�B
Apple�Ƃ��Ă͍D�s������ˁB
Intel�AInternational CES�ŐV�u�����f�B���O�헪���\��
�`Pentium�u�����h�p�~�A�VIntel���S�o��
http://pc.watch.impress.co.jp/docs/2005/1021/ubiq129.htm
Pentium�u�����h�p�~���c�B
Apple�Ƃ��Ă͍D�s������ˁB
Intel Merom to Be Pin-to-Pin Compatible with Yonah ? Intel Exec.
http://www.xbitlabs.com/news/mobile/display/20051020095852.html
Merom��Yonah�ƃs���R���p�`�ŁANapa�v���b�g�t�H�[������
BIOS�̃A�b�v�f�[�g�őΉ��ł���悤���BFSB667MHz�B
http://www.xbitlabs.com/news/mobile/display/20051020095852.html
Merom��Yonah�ƃs���R���p�`�ŁANapa�v���b�g�t�H�[������
BIOS�̃A�b�v�f�[�g�őΉ��ł���悤���BFSB667MHz�B
NVIDIA Dropping 975X Support and More Yonah Tidbits
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2569
Fortunately, many manufacturers are already working on two different chipsets
to succeed the existing mobile on desktop (MOD) motherboards. The first of
these, 945GT, is nearly an identical revision to Intel's 945G, but will feature the
new Yonah specific socket. As with other Intel CPUs, the 945 and 955 North
Bridges are required to enable both cores. 945GT will show up for several small
form factor and HTPC PCs, but vendors tell us there are no full scale ATX
motherboard designs in the works.
Intel's 945GM is a follow up chip to 945GT, but will feature SO-DIMM DDR2.
945GM will be used mainly for laptops and ultra portables, but we will also see
set-top DVRs based on the 945GM as well due to the profile advantages.
Other interesting Yonah tidbits we've picked up over the last few days include:
*There will be single core and Celeron versions of Yonah - but Celeron M won't
show up until H2'06.
*945GM and 945GT will cost about the same as 955X does on the chipset level.
Centrino will have a slightly newer logo (due apparently to legal counsel).
*Most Yonah models will feature VT, but the ultra low voltage and low voltage
designs geared for ultra portables will have it disabled.
*Merom (Yonah's successor) will feature 64-bit extensions, but Yonah will not.
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2569
Fortunately, many manufacturers are already working on two different chipsets
to succeed the existing mobile on desktop (MOD) motherboards. The first of
these, 945GT, is nearly an identical revision to Intel's 945G, but will feature the
new Yonah specific socket. As with other Intel CPUs, the 945 and 955 North
Bridges are required to enable both cores. 945GT will show up for several small
form factor and HTPC PCs, but vendors tell us there are no full scale ATX
motherboard designs in the works.
Intel's 945GM is a follow up chip to 945GT, but will feature SO-DIMM DDR2.
945GM will be used mainly for laptops and ultra portables, but we will also see
set-top DVRs based on the 945GM as well due to the profile advantages.
Other interesting Yonah tidbits we've picked up over the last few days include:
*There will be single core and Celeron versions of Yonah - but Celeron M won't
show up until H2'06.
*945GM and 945GT will cost about the same as 955X does on the chipset level.
Centrino will have a slightly newer logo (due apparently to legal counsel).
*Most Yonah models will feature VT, but the ultra low voltage and low voltage
designs geared for ultra portables will have it disabled.
*Merom (Yonah's successor) will feature 64-bit extensions, but Yonah will not.
Intel prepares to roll out 65 nano Pentium 4s
Desktop Road Maps
http://www.theinquirer.net/?article=26071
Intel prices up Presler as top end desktop chips change
Desktop Roadmaps
http://www.theinquirer.net/?article=26870
Intel intros new numbering system for chips
Notebook Roadmaps
http://www.theinquirer.net/?article=26867
Intel predicts wattage for future server chips
Server Roadmaps
http://www.theinquirer.net/?article=26887
Desktop Road Maps
http://www.theinquirer.net/?article=26071
Intel prices up Presler as top end desktop chips change
Desktop Roadmaps
http://www.theinquirer.net/?article=26870
Intel intros new numbering system for chips
Notebook Roadmaps
http://www.theinquirer.net/?article=26867
Intel predicts wattage for future server chips
Server Roadmaps
http://www.theinquirer.net/?article=26887
Yonah CPU 667MHz front side bus
YonahDC T1600 2.16GHz 667 2MB L2 $640
YonahDC T1500 2GHz 667 2MB L2 $420
YonahDC T1400 1.83GHz 667 2MB L2 $295
YonahDC T1300 1.66GHz 667 2MB L2 $240
YonahSC 756 1.66GHz 667 2MB L2 $210
Yonah CPU 667MHz front side bus LV (low voltage)
Yonah DC L1400 1.66GHz 667 2MB L2 $315
Yonah DC L1300 1.5GHz 667 2MB L2 $284
Yonah CPU 533MHz front side bus ULV (ultra low voltage)
Yonah SC 1200 1.2GHz 533 2MB L2 $260
Yonah SC 1100 1.06GHz 533 2MB L2 $240
Intel PRO/wireless 3945 ABG $26
YonahDC T1600 2.16GHz 667 2MB L2 $640
YonahDC T1500 2GHz 667 2MB L2 $420
YonahDC T1400 1.83GHz 667 2MB L2 $295
YonahDC T1300 1.66GHz 667 2MB L2 $240
YonahSC 756 1.66GHz 667 2MB L2 $210
Yonah CPU 667MHz front side bus LV (low voltage)
Yonah DC L1400 1.66GHz 667 2MB L2 $315
Yonah DC L1300 1.5GHz 667 2MB L2 $284
Yonah CPU 533MHz front side bus ULV (ultra low voltage)
Yonah SC 1200 1.2GHz 533 2MB L2 $260
Yonah SC 1100 1.06GHz 533 2MB L2 $240
Intel PRO/wireless 3945 ABG $26
100 �F���̖��ݒ��F2005/10/22(�y) 17:11:33 ID:fLkH+XCM
�ŁAinteler����͉������������́H
����Ȃ�R�����g�Ȃ菑���Ă���Ȃ��Ɩʔ����Ȃ���B
����Ȃ�R�����g�Ȃ菑���Ă���Ȃ��Ɩʔ����Ȃ���B
���̃X���̓����ƃ����N�W�ɂ��邱�Ƃɂ��܂����i�E�́E�j
�ŋߖZ�����Ă���Ă��Ȃ��B
���[�}�[�T�C�g���ǂގ��Ԃ��Ȃ��ˁB
���[�}�[�T�C�g���ǂގ��Ԃ��Ȃ��ˁB
�ȑO�AThe Inq.�ł�Yonah�p�̃\�P�b�g�Ƃ���mPGA479��mPGA568��
����ƌ����Ă�����(��A�̉\����)�A����������945GT��mPGA568�g���̂��ȁB
Merom��Yonah�ƃs���݊��Ƃ����̂�IDF�̑O�ォ�猾���Ă������A
mPGA479�̓T�|�[�g�����낤���c�B
����ƌ����Ă�����(��A�̉\����)�A����������945GT��mPGA568�g���̂��ȁB
Merom��Yonah�ƃs���݊��Ƃ����̂�IDF�̑O�ォ�猾���Ă������A
mPGA479�̓T�|�[�g�����낤���c�B
�v���I�ȃG���b�^�ŃA�b�v���|�Y�̊�@�B
�}�C�N���R�[�h�X�V�ł��ő�15�p�[�Z���g��
�p�t�H�[�}���X�ቺ�Ƃ����L�l�B
�}�C�N���R�[�h�X�V�ł��ő�15�p�[�Z���g��
�p�t�H�[�}���X�ቺ�Ƃ����L�l�B
Intel Boosts Storage Performance with NAND Flash Cache.
http://www.xbitlabs.com/news/storage/display/20051018191439.html
Intel����pIDF��Robston Technology���f�������悤���B
RobstonTechnology�Ƃ́AHDD��64MB�`4GB�̃t���b�V���������̃R���r�l�[�V����
(�y�ѐ�p�\�t�g�E�G�A)�ɂ��X�g���[�W�Z�p�B
128MB��Robston�𓋍ڂ���Centrino�m�[�gPC�ł́A
Adobe Reader�̋N�����Ԃ�Robston�Ȃ��̃m�[�g�ɔ�ׁA5.4sec��0.4sec�ɒZ�k�B
Qicken�̋N���ł�8.0sec��2.9sec�ɒZ�k���ꂽ�悤���B
����ɋ���ȃt���b�V���𓋍ڂ���X�g���[�W�̏���d�͍팸�ɂ����ʂ�����炵���B
http://www.xbitlabs.com/news/storage/display/20051018191439.html
Intel����pIDF��Robston Technology���f�������悤���B
RobstonTechnology�Ƃ́AHDD��64MB�`4GB�̃t���b�V���������̃R���r�l�[�V����
(�y�ѐ�p�\�t�g�E�G�A)�ɂ��X�g���[�W�Z�p�B
128MB��Robston�𓋍ڂ���Centrino�m�[�gPC�ł́A
Adobe Reader�̋N�����Ԃ�Robston�Ȃ��̃m�[�g�ɔ�ׁA5.4sec��0.4sec�ɒZ�k�B
Qicken�̋N���ł�8.0sec��2.9sec�ɒZ�k���ꂽ�悤���B
����ɋ���ȃt���b�V���𓋍ڂ���X�g���[�W�̏���d�͍팸�ɂ����ʂ�����炵���B
106 �F���̖��ݒ��F2005/10/22(�y) 19:13:17 ID:GSLuVFKE
intel�͂���������ł����H
imac�������Ǝv���Ă��ł�����
�ǂ����Ȃ�intel�ɂȂ��Ă��甃�����Ǝv���āE�E�E�B
imac�������Ǝv���Ă��ł�����
�ǂ����Ȃ�intel�ɂȂ��Ă��甃�����Ǝv���āE�E�E�B
107 �F���̖��ݒ��F2005/10/22(�y) 19:52:17 ID:fLkH+XCM
���N�Z���̗\��B
�ȏ�B
�ȏ�B
108 �F���̖��ݒ��F2005/10/22(�y) 20:21:05 ID:XlYdpnx4
Cedarmill���X�e�b�s���O�X�V�ő����܂��ɂȂ��Ă鍠���ȁH
YonahLV�ł��������m�[�g���L�{���B
YonahLV�ł��������m�[�g���L�{���B
109 �F���̖��ݒ��F2005/10/22(�y) 22:25:21 ID:GSLuVFKE
�U�����E�E�E�܂��܂��悾�ȁE�E�E
�����������Ƃ�����낤���E�E�E
�܂�imac�����Ȃ��ȁE�E�Eorz
�����������Ƃ�����낤���E�E�E
�܂�imac�����Ȃ��ȁE�E�Eorz
HP�̎�����90nm NetBurst�̐������������̂����A
�����ȕ�����31stage�̃p�C�v���C���Ɩ��L����Ă���̂͏��߂Č��܂����B
ttp://h20000.www2.hp.com/bc/docs/support/SupportManual/c00164255/c00164255.pdf
*Extended hyper-pipeline (31 stages versus 20 stages) to enable high CPU core frequencies
�����ȕ�����31stage�̃p�C�v���C���Ɩ��L����Ă���̂͏��߂Č��܂����B
ttp://h20000.www2.hp.com/bc/docs/support/SupportManual/c00164255/c00164255.pdf
*Extended hyper-pipeline (31 stages versus 20 stages) to enable high CPU core frequencies
�C���e���AItanium�`�b�v�̃����[�X��摗��--Xeon�̉��ǂ��v��
http://japan.cnet.com/news/ent/story/0,2000047623,20089535,00.htm
Intel server strategy crashes as Xeon roadmap changes
http://www.theinquirer.net/?article=27192
Intel�t�@���ɔ߂������m�点�c(;�L�D�M)
��̃T�[�o�`�b�v���[�h�}�b�v�ύX�̃j���[�X�����ǁA
Cnet�̋L������ތ���ł͂����ł��Ȃ����ATheINQ�̋L������ނ�
���Ȃ�̈�厖���ȁB�p��L���͓ǂ݂����Ȃ����ǁA�ǂ�ł��܂������B
CSI��TT��������L�����Z���ɂȂ�����TheINQ�͌��Ă���悤���B
(Xbit�̕��͂킩��Ȃ��Ƃ����Ă���悤���B)
Tingerton�̃V�X�e����Whitefield�̂������������Intel�͂����Ă���悤�����A
�Z�p�I�ɂ̓g�[���_�E������Ȃ��̂��낤���B
����Ȃ�Itanium�c�B
*CSI�cIntel��Tukwila�p�ɊJ�������C���^�[�R�l�N�g�p�V���A���o�X�B
�@�@�@�@ P2P�Ń����O�^�g�|���W�Ƃ����\�B���ۃL�����Z���ɂȂ�����Tukwila
�@�@�@�@ �̓����O�ڑ��̃}���`�R�A�������B
�@�@�@�@ CSI��Whitefield�ɂ��̗p����AWhitefield��Tukwila�̃v���b�g�t�H�[��
�@�@�@�@ �͋��ʂƂȂ�͂�������(���A����L�����Z�����ꂽ)�B
*TT�cCSI�̗̍p�ɔ����A�������o�X��CPU-�`�v�Z�g�Ԃ̐ڑ�����Ɨ����邽�߁A
�@�@�@�@�������R���g���[����CPU���ɓ�������邱�ƂɂȂ邪�A���̋Z�p��
�@�@�@�@�V*Ts�̈�Ƃ���"TT"�ƌĂԂ炵��(���A����L�����Z�����ꂽ)�B
http://japan.cnet.com/news/ent/story/0,2000047623,20089535,00.htm
Intel server strategy crashes as Xeon roadmap changes
http://www.theinquirer.net/?article=27192
Intel�t�@���ɔ߂������m�点�c(;�L�D�M)
��̃T�[�o�`�b�v���[�h�}�b�v�ύX�̃j���[�X�����ǁA
Cnet�̋L������ތ���ł͂����ł��Ȃ����ATheINQ�̋L������ނ�
���Ȃ�̈�厖���ȁB�p��L���͓ǂ݂����Ȃ����ǁA�ǂ�ł��܂������B
CSI��TT��������L�����Z���ɂȂ�����TheINQ�͌��Ă���悤���B
(Xbit�̕��͂킩��Ȃ��Ƃ����Ă���悤���B)
Tingerton�̃V�X�e����Whitefield�̂������������Intel�͂����Ă���悤�����A
�Z�p�I�ɂ̓g�[���_�E������Ȃ��̂��낤���B
����Ȃ�Itanium�c�B
*CSI�cIntel��Tukwila�p�ɊJ�������C���^�[�R�l�N�g�p�V���A���o�X�B
�@�@�@�@ P2P�Ń����O�^�g�|���W�Ƃ����\�B���ۃL�����Z���ɂȂ�����Tukwila
�@�@�@�@ �̓����O�ڑ��̃}���`�R�A�������B
�@�@�@�@ CSI��Whitefield�ɂ��̗p����AWhitefield��Tukwila�̃v���b�g�t�H�[��
�@�@�@�@ �͋��ʂƂȂ�͂�������(���A����L�����Z�����ꂽ)�B
*TT�cCSI�̗̍p�ɔ����A�������o�X��CPU-�`�v�Z�g�Ԃ̐ڑ�����Ɨ����邽�߁A
�@�@�@�@�������R���g���[����CPU���ɓ�������邱�ƂɂȂ邪�A���̋Z�p��
�@�@�@�@�V*Ts�̈�Ƃ���"TT"�ƌĂԂ炵��(���A����L�����Z�����ꂽ)�B
112 �Finteler@�R�����F2005/10/26(��) 22:40:56 ID:3bmtLo/3
Montecito�́A
FoxtonTechnology�̐M�����ɖ�肪����A�����B
����Ƃ͊W�Ȃ��ɁA
Tukwila����Alpha�`�[������HP�`�[���̐v�Ɍォ��ύX���ꂽ��A
CSI����Ŏ肱����2008�N�ɉ����B
Montvale��Montecito��Tukwila�̊Ԃɋ��܂��`�ʼn����B
����ɁAWhitefiled�́ATukwila������ŁACSI���ʃv���b�g�t�H�[���v�悪
���т�or�����߂ɉ����B
FoxtonTechnology�̐M�����ɖ�肪����A�����B
����Ƃ͊W�Ȃ��ɁA
Tukwila����Alpha�`�[������HP�`�[���̐v�Ɍォ��ύX���ꂽ��A
CSI����Ŏ肱����2008�N�ɉ����B
Montvale��Montecito��Tukwila�̊Ԃɋ��܂��`�ʼn����B
����ɁAWhitefiled�́ATukwila������ŁACSI���ʃv���b�g�t�H�[���v�悪
���т�or�����߂ɉ����B
113 �F���̖��ݒ��F2005/10/26(��) 22:43:21 ID:6y6Xw7wG
�قƂ�Ǔǂ�ł܂��ǁA�v�����IA-64�̓L�����Z�������Ƃ������Ƃł����H
IA-64�̓L�����Z������Ȃ�(HP�͍ŋ߂܂��ݾ��������Ă邵)���A
�v��̒x��ɂ��A�������[�h�}�b�v���z�肳��Ă������\���傫��������B
�܂��A����AXeon��Itanium�̃v���b�g�t�H�[�����ꉻ�v�悪����Ă��܂������߁A
���[�G���h�T�[�o�s��ւ̐i�o�͂܂��܂��������Ȃ����B
(���̑���Xeon�n�̃p�t�H�[�}���X�͏オ�邩������Ȃ��悤��)
���XWhitefield�̌�p�`�b�v�Ƃ����Ă����ADunnington��CSI�ł͂Ȃ�
���̂ɃR�[�h�l�[�������u���Œu��������ꂽ�悤���B
�v��̒x��ɂ��A�������[�h�}�b�v���z�肳��Ă������\���傫��������B
�܂��A����AXeon��Itanium�̃v���b�g�t�H�[�����ꉻ�v�悪����Ă��܂������߁A
���[�G���h�T�[�o�s��ւ̐i�o�͂܂��܂��������Ȃ����B
(���̑���Xeon�n�̃p�t�H�[�}���X�͏オ�邩������Ȃ��悤��)
���XWhitefield�̌�p�`�b�v�Ƃ����Ă����ADunnington��CSI�ł͂Ȃ�
���̂ɃR�[�h�l�[�������u���Œu��������ꂽ�悤���B
���Ȃ݂�Tukwila��p��Poulson�͊J���\�Z���폜���ꂽ�Ƃ����L����
�O�ɓǂ̂Ŋ��S�ɐ����Ă��܂����\���������B
�O�ɓǂ̂Ŋ��S�ɐ����Ă��܂����\���������B
116 �F���̖��ݒ��F2005/10/26(��) 23:05:44 ID:ey/WWo5h
ttp://www.intel.com/products/motherboard/d101ggc/
���ʂ��炱�ꌩ�������H�h���C�����Ă݁B�l�^����Ȃ���B
���ꂪiMac�Ƃ��ɍڂ�Ƒz������Ƃ����Ƃ���ˁB
����Ȃ��Intel�Ɉڍs���đ��v���ˁB
���ʂ��炱�ꌩ�������H�h���C�����Ă݁B�l�^����Ȃ���B
���ꂪiMac�Ƃ��ɍڂ�Ƒz������Ƃ����Ƃ���ˁB
����Ȃ��Intel�Ɉڍs���đ��v���ˁB
117 �F���̖��ݒ��F2005/10/26(��) 23:10:11 ID:6y6Xw7wG
���ꂪ�o�J�}�J�̎���
���̃}�U�[�{�[�h�悭���ăC���e�����ǂ�ȉ�Ђɐ��艺��������
�悭��������
���̃}�U�[�{�[�h�悭���ăC���e�����ǂ�ȉ�Ђɐ��艺��������
�悭��������
119 �F���̖��ݒ��F2005/10/27(��) 15:05:04 ID:AvjhEySQ
�u�����̌����������Ƃ��`���Ȃ��̂́A���肪���������v�Ǝv���Ă锜�ނƂ͂��b�͂ł��܂���ˁB
120 �F���̖��ݒ��F2005/10/27(��) 17:46:29 ID:1p+8R9ls
�����̎���I�ɂ����č��x�͑��l�̂����ɂ��Ă��w
����Ƃ�1����1000�܂Ő������Ă��Ȃ��Ɖ���������Ȃ��̂��ȁH���̃o�J�ɂ�
����Ƃ�1����1000�܂Ő������Ă��Ȃ��Ɖ���������Ȃ��̂��ȁH���̃o�J�ɂ�
���㓡�O��Weekly�C�O�j���[�X��
Intel�̃T�[�o�[CPU�v��ɑ啝�Ȓx��
http://pc.watch.impress.co.jp/docs/2005/1027/kaigai219.htm
�㓡�������{��ł܂Ƃ߂Ă����B
TheINQ����ԏڂ������ǁB
Intel�̃T�[�o�[CPU�v��ɑ啝�Ȓx��
http://pc.watch.impress.co.jp/docs/2005/1027/kaigai219.htm
�㓡�������{��ł܂Ƃ߂Ă����B
TheINQ����ԏڂ������ǁB
Intel's 65nm Processors: Overclocking Preview
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2578&p=1
AnandTech��65nm���i(CedarMill��Presler)�̃T���v���̃��r���[�����Ă���B
���ʂ́A�܂��A65nm�Ȃ炱��Ȃ���˂Ƃ������Ƃ��납�i��ͥ�j
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2578&p=1
AnandTech��65nm���i(CedarMill��Presler)�̃T���v���̃��r���[�����Ă���B
���ʂ́A�܂��A65nm�Ȃ炱��Ȃ���˂Ƃ������Ƃ��납�i��ͥ�j
New Intel desktop CPUs expected soon
http://www.digitimes.com/news/a20051027A7038.html
11/13�ɁAVT=Virtualization Technology���ڂ�Prescott 2M��65nm���i��
��s���ă����[�X�����悤���B
November 13
Prescott 2M Pentium4 672 3.8GHz $605
Prescott 2M Pentium4 662 3.6GHz $401
http://www.digitimes.com/news/a20051027A7038.html
11/13�ɁAVT=Virtualization Technology���ڂ�Prescott 2M��65nm���i��
��s���ă����[�X�����悤���B
November 13
Prescott 2M Pentium4 672 3.8GHz $605
Prescott 2M Pentium4 662 3.6GHz $401
Fall Processor Forum 2005 - �x�m�ʂ̎�����SPARC64�v���Z�b�T�u�I�����p�X�v�u�W���s�^�[�v
http://pcweb.mycom.co.jp/articles/2005/10/28/fpf1/
�x�m�ʂ̎�����SPARC�ɂ��Ă̋L���B
400sqmm�I�[�o�[�̃_�C��4�R�A+2Thread�̓��I�I���I�t�\��VMT���A
�ŐV�Z�p�Ă��肾�ȁc�B
���ю��̋L���͋Z�p�I�ȗv�����������Ă��Ė��ʂ��Ȃ�����悢�B
http://pcweb.mycom.co.jp/articles/2005/10/28/fpf1/
�x�m�ʂ̎�����SPARC�ɂ��Ă̋L���B
400sqmm�I�[�o�[�̃_�C��4�R�A+2Thread�̓��I�I���I�t�\��VMT���A
�ŐV�Z�p�Ă��肾�ȁc�B
���ю��̋L���͋Z�p�I�ȗv�����������Ă��Ė��ʂ��Ȃ�����悢�B
�������z�t�j�̏T��PC�z�b�g���C����
�T�n�֒ǂ������Itanium
http://pc.watch.impress.co.jp/docs/2005/1028/hot390.htm
������v���������Ă���Ƃ͎v���Ȃ��ϑz�n�L�����o��B
���̂����C���t���[���p�ɒǂ����ꂽ���ƂɂȂ��Ă���Itanium�B
�T�n�֒ǂ������Itanium
http://pc.watch.impress.co.jp/docs/2005/1028/hot390.htm
������v���������Ă���Ƃ͎v���Ȃ��ϑz�n�L�����o��B
���̂����C���t���[���p�ɒǂ����ꂽ���ƂɂȂ��Ă���Itanium�B
IBM highlights Power chip power savings
http://news.zdnet.com/2100-9584_22-5913921.html
IBM��Fall Processor Forum�ŁA970MP��power saving�ɂ���
������炵���B
�s�[�N�d��60W�́AIntel��Conroe�����Ⴂ�ƍl���ėǂ��̂��ȁH
http://news.zdnet.com/2100-9584_22-5913921.html
IBM��Fall Processor Forum�ŁA970MP��power saving�ɂ���
������炵���B
�s�[�N�d��60W�́AIntel��Conroe�����Ⴂ�ƍl���ėǂ��̂��ȁH
�N���b�N���A�Ⴕ���͎l���̈�ɗ��Ƃ������Ƀs�[�N�d�͂����ꂼ��60W�A40W�ɂȂ���Ă��Ƃ���
�悭�ǂ߂�
�悭�ǂ߂�
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04.htm
>�ŏ��ɐ��i�������uPWRficient 1682M�v�`�b�v�̓����u���b�N�B2MB��2���L���b�V���A
>2��DDR2�������R���g���[���A8��PCI Express�C���^�[�t�F�C�X�A2��10Gbit Ethernet(XAUI)
>�C���^�[�t�F�C�X�Ȃǂ𓋍ڂ���
PC�Ń��j�B�R�A�͗��s��Ȃ��B���ꂩ��͓���!����!�̎���ł���i��ͥ�j
x86�����ǁA���̘H���ɂȂ�ƘR��͗\�z���܂��B
�ڍׂ͂����火
The Craft of Building Truly Powerful Computers
PWRficient-based Supercomputing
ttp://progressive.playstream.com/news_events/progressive/pa_semi_high_performance_computing_wp.pdf
>�ŏ��ɐ��i�������uPWRficient 1682M�v�`�b�v�̓����u���b�N�B2MB��2���L���b�V���A
>2��DDR2�������R���g���[���A8��PCI Express�C���^�[�t�F�C�X�A2��10Gbit Ethernet(XAUI)
>�C���^�[�t�F�C�X�Ȃǂ𓋍ڂ���
PC�Ń��j�B�R�A�͗��s��Ȃ��B���ꂩ��͓���!����!�̎���ł���i��ͥ�j
x86�����ǁA���̘H���ɂȂ�ƘR��͗\�z���܂��B
�ڍׂ͂����火
The Craft of Building Truly Powerful Computers
PWRficient-based Supercomputing
ttp://progressive.playstream.com/news_events/progressive/pa_semi_high_performance_computing_wp.pdf
���[�Ă˂�
Dothan�̏ꍇVCC*ICC=33.5W���x��TDP27W��25%�������x������
���������Ƃ���܂�PenM�x�[�X��Conroe������Ă������
TDP65W��Peak80W���x�Ɏ��܂��Ȃ����Ǝv�����A�ǂ��Ȃ邩�͒m���
Dothan�̏ꍇVCC*ICC=33.5W���x��TDP27W��25%�������x������
���������Ƃ���܂�PenM�x�[�X��Conroe������Ă������
TDP65W��Peak80W���x�Ɏ��܂��Ȃ����Ǝv�����A�ǂ��Ȃ邩�͒m���
131 �FMAC�I�^��inteler �����F2005/10/29(�y) 00:08:58 ID:Zs5FZNDW
>>129
�@�@-----------------------
�@�@�ŁA�����s�[�N100W���B
�@�@-----------------------
100W [email protected] dual��(��)
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04_15.jpg
���łɂ���ȏ����B
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04_16.jpg
�@�@-----------------------
�@�@�� Memory coherence maintained through the North Bridge
�@�@-----------------------
Pentium D���}�������ď����q�g���āB�B�B
�@�@-----------------------
�@�@�ŁA�����s�[�N100W���B
�@�@-----------------------
100W [email protected] dual��(��)
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04_15.jpg
{kind=link}
���łɂ���ȏ����B
http://pc.watch.impress.co.jp/docs/2005/1028/fpf04_16.jpg
{kind=link}
�@�@-----------------------
�@�@�� Memory coherence maintained through the North Bridge
�@�@-----------------------
Pentium D���}�������ď����q�g���āB�B�B
>>130
Conroe�̓f���A���R�A������ATDP�ƃs�[�N�̔�͑傫���Ȃ��Ă��邾�낤�ȁB
�܂��A�ȓd�͋Z�p���i������ɂ�ĊJ���X���ɂ���킯������A�R���
�s�[�N��100W�I�[�o�[���o�債�Ă��邯�ǂˁB
Conroe�̓f���A���R�A������ATDP�ƃs�[�N�̔�͑傫���Ȃ��Ă��邾�낤�ȁB
�܂��A�ȓd�͋Z�p���i������ɂ�ĊJ���X���ɂ���킯������A�R���
�s�[�N��100W�I�[�o�[���o�債�Ă��邯�ǂˁB
���ꂵ�Ă������U�����ă����N�W������̂����\�����ǁAx86�̘b�ȊO���������̂Ȃ�APowerPC�X���b�h�ł�
���ł����}���B
���ł����}���B
Intel�ȊO�̘b�͂��܂�ɂ��������Ȃ��̂ł�����Ǝ��グ�Ă݂��������B
PPC�X���b�h�́A�Q�[�n�[�ɂ͋������Ȃ�����w�ǒ��߂Ă��邾�����ȁB
970FX�ŁAMax.��Typ.��25%���̌X��������A970MP�ł͍Œ�ł�2.5GHz@125W���炢��
�s�������Ƃ������Ƃ��ȁB970MP=PPC��Smithfield�������ƁB
PPC�X���b�h�́A�Q�[�n�[�ɂ͋������Ȃ�����w�ǒ��߂Ă��邾�����ȁB
970FX�ŁAMax.��Typ.��25%���̌X��������A970MP�ł͍Œ�ł�2.5GHz@125W���炢��
�s�������Ƃ������Ƃ��ȁB970MP=PPC��Smithfield�������ƁB
HotChip�̃T�C�g����HotChip16�̃v���[�������������N�B
Montecito - The next product in the Itanium(R) Processor Family, Cameron McNairy (Intel), Rohit Bhatia (HP)
ttp://www.hotchips.org/archives/hc16/3_Tue/13_HC16_Sess10_Pres1_bw.pdf
Intel Pentium(R) 4 Processor(R) on 90nm Technology, Ronak Singhal (Intel)
ttp://www.hotchips.org/archives/hc16/3_Tue/15_HC16_Sess10_Pres3_bw.pdf
Montecito - The next product in the Itanium(R) Processor Family, Cameron McNairy (Intel), Rohit Bhatia (HP)
ttp://www.hotchips.org/archives/hc16/3_Tue/13_HC16_Sess10_Pres1_bw.pdf
Intel Pentium(R) 4 Processor(R) on 90nm Technology, Ronak Singhal (Intel)
ttp://www.hotchips.org/archives/hc16/3_Tue/15_HC16_Sess10_Pres3_bw.pdf
136 �FMAC�I�^��inteler �����F2005/10/30(��) 00:25:23 ID:f+0ANxei
>>135
�ꌾ�A�u���N�́vHot Chips�Ə����Ɛe���Ǝv�����B
�ꌾ�A�u���N�́vHot Chips�Ə����Ɛe���Ǝv�����B
���㓡�O��Weekly�C�O�j���[�X��
�����N���Ă���Intel�̃V���A��FSB��FB-DIMM�v���W�F�N�g
http://pc.watch.impress.co.jp/docs/2005/1031/kaigai221.htm
�㓡�������߂�CSI�ɂ��Č��y�B
����ς����ɋL���ɍڂ����Ȃ����͂�����������Ă���悤���B
�R��I�ȐV����HP��Tukwila�̃}�C�N���A�[�L��Montecito�x�[�X�ł���Ƃ������Ƃ��ȁB
(�܂�2001�N��McKinley����7�N�ԃ��W���[�A�b�v�f�[�g���Ȃ����ƂɂȂ�)
�����N���Ă���Intel�̃V���A��FSB��FB-DIMM�v���W�F�N�g
http://pc.watch.impress.co.jp/docs/2005/1031/kaigai221.htm
�㓡�������߂�CSI�ɂ��Č��y�B
����ς����ɋL���ɍڂ����Ȃ����͂�����������Ă���悤���B
�R��I�ȐV����HP��Tukwila�̃}�C�N���A�[�L��Montecito�x�[�X�ł���Ƃ������Ƃ��ȁB
(�܂�2001�N��McKinley����7�N�ԃ��W���[�A�b�v�f�[�g���Ȃ����ƂɂȂ�)
138 �F���̖��ݒ��F2005/11/02(��) 23:43:46 ID:NxmL+TTC
�㓡�̋L����ǂ�ł�Ώ\��������A���̃X���v��Ȃ���B
>>138
�C�O���[�}�[�T�C�g������ǂ�ł�l�͕ʂƂ��Ă��A
�㓡���̋L���͂��������Ԃ肪��������ǂ����Ȃ��B
���̃X���̂�2�����x�[�X�ŘR�ꂪ�����Ȃ��͎̂��グ�Ȃ�
�܂Ƃ܂肪�������A��{�I�Ɍ㓡����葬���̂����c�B(�����A�����ő�������)
�㓡���̋L����ǂ�ł���悢�Ƃ����l��age���ɃX���[���Ă���Č��\���B
���ɘR��̌l�����X���Ɖ����Ă��Ă��邱�̃X�������A
�ߋ��ɃL�����Z���ɂȂ���Nehalem�̃}�C�N���A�[�L�ɂ��Ă�
���E�ł����̃X���ł����ǂ߂Ȃ��א��͔��N�キ�炢��������
��肽���Ǝv��(�m
�C�O���[�}�[�T�C�g������ǂ�ł�l�͕ʂƂ��Ă��A
�㓡���̋L���͂��������Ԃ肪��������ǂ����Ȃ��B
���̃X���̂�2�����x�[�X�ŘR�ꂪ�����Ȃ��͎̂��グ�Ȃ�
�܂Ƃ܂肪�������A��{�I�Ɍ㓡����葬���̂����c�B(�����A�����ő�������)
�㓡���̋L����ǂ�ł���悢�Ƃ����l��age���ɃX���[���Ă���Č��\���B
���ɘR��̌l�����X���Ɖ����Ă��Ă��邱�̃X�������A
�ߋ��ɃL�����Z���ɂȂ���Nehalem�̃}�C�N���A�[�L�ɂ��Ă�
���E�ł����̃X���ł����ǂ߂Ȃ��א��͔��N�キ�炢��������
��肽���Ǝv��(�m
Intel to Ship High-End Next-Gen Xeon MP for Evaluation Before Year End.
Server Makers to Test Intel�fs Xeon MP �gTulsa�h with 16MB Cache in 2005
http://www.xbitlabs.com/news/cpu/display/20051102044154.html
Tulsa�̕]���p�`�b�v��N���܂łɏo�ׂ���݂������ˁB
Tulsa
XeonMP
H2 2006
65nm
Paxville MP(90nm)�̌�p
DualCore
FSB667/800MHz
���L�^16MB L3cache
Tigerton will be based on the next-generation architecture from Intel,
whereas Caneland will bring in a new bus for processors as well as support for Fully-Buffered
Dual In-Line Memory Modules (FB-DIMMs) to multi-processor servers.
Server Makers to Test Intel�fs Xeon MP �gTulsa�h with 16MB Cache in 2005
http://www.xbitlabs.com/news/cpu/display/20051102044154.html
Tulsa�̕]���p�`�b�v��N���܂łɏo�ׂ���݂������ˁB
Tulsa
XeonMP
H2 2006
65nm
Paxville MP(90nm)�̌�p
DualCore
FSB667/800MHz
���L�^16MB L3cache
Tigerton will be based on the next-generation architecture from Intel,
whereas Caneland will bring in a new bus for processors as well as support for Fully-Buffered
Dual In-Line Memory Modules (FB-DIMMs) to multi-processor servers.
�C���e��
�}���`�v���Z�b�T�E�T�[�o������
�f���A���R�A�Ή��T�[�o�E�v���b�g�t�H�[���V���i�\
http://www.intel.co.jp/jp/intel/pr/press2005/051102a.htm
Paxville MP�������[�X����܂����B
>(4) �R�A�E�v���Z�b�T�ł���uTigerton�v�i�J���R�[�h���j���܂܂�܂��B
>�uCaneland�v�v���b�g�t�H�[���ł́A�e�v���Z�b�T�����ڃ`�b�v�Z�b�g�ɐڑ�����
>�C���^�[�t�F�[�X������p�̍����C���^�[�R�l�N�g�ɂ��A�啝�ȃp�t�H�[�}���X
>���オ���҂���܂��B����ɁA�uCaneland�v�ł́AFully-Buffered Dual In-Line Memory Module (FB-DIMM)
> �ƌĂ��V�����������E�A�[�L�e�N�`�����T�|�[�g���A���e�N�m���W�ɂ���ĉ\�ƂȂ�
>�e�ʂ̑����ɑΉ��ł���悤�A4 �̃������E�C���^�[�R�l�N�g������\��ł��B
���A���{��Ō����ɏ����Ă��邵�B
�㓡���̑O��̋L���ł͏]���^FSB�������ɂȂ�Ɨ\�z���Ă����̂����A
����̋L���ł͏]���^FSB��CSI�Ƃ�"���ԉ�"�ɂȂ���Ęb�ɂ�������ς���Ă���ˁB
��������Tukwila�ƌ݊����Ƃ�K�v�Ȃ��Ȃ����킯�����A�ň�4S�V�X�e��
�����Ώ\���Ȃ���A�V���A���������Ƃ��Ă�CSI���͂����ƕ~�����Ⴂ�킯�Łc�B
�R��͂����ƕ\�X���Ő�p�o�X���ď����Ă܂�����i��ͥ�j���
�}���`�v���Z�b�T�E�T�[�o������
�f���A���R�A�Ή��T�[�o�E�v���b�g�t�H�[���V���i�\
http://www.intel.co.jp/jp/intel/pr/press2005/051102a.htm
Paxville MP�������[�X����܂����B
>(4) �R�A�E�v���Z�b�T�ł���uTigerton�v�i�J���R�[�h���j���܂܂�܂��B
>�uCaneland�v�v���b�g�t�H�[���ł́A�e�v���Z�b�T�����ڃ`�b�v�Z�b�g�ɐڑ�����
>�C���^�[�t�F�[�X������p�̍����C���^�[�R�l�N�g�ɂ��A�啝�ȃp�t�H�[�}���X
>���オ���҂���܂��B����ɁA�uCaneland�v�ł́AFully-Buffered Dual In-Line Memory Module (FB-DIMM)
> �ƌĂ��V�����������E�A�[�L�e�N�`�����T�|�[�g���A���e�N�m���W�ɂ���ĉ\�ƂȂ�
>�e�ʂ̑����ɑΉ��ł���悤�A4 �̃������E�C���^�[�R�l�N�g������\��ł��B
���A���{��Ō����ɏ����Ă��邵�B
�㓡���̑O��̋L���ł͏]���^FSB�������ɂȂ�Ɨ\�z���Ă����̂����A
����̋L���ł͏]���^FSB��CSI�Ƃ�"���ԉ�"�ɂȂ���Ęb�ɂ�������ς���Ă���ˁB
��������Tukwila�ƌ݊����Ƃ�K�v�Ȃ��Ȃ����킯�����A�ň�4S�V�X�e��
�����Ώ\���Ȃ���A�V���A���������Ƃ��Ă�CSI���͂����ƕ~�����Ⴂ�킯�Łc�B
�R��͂����ƕ\�X���Ő�p�o�X���ď����Ă܂�����i��ͥ�j���
E. Rotenberg, S. Bennett, and J. E. Smith : Trace cache: a low latency approach to high bandwidth
instruction fetching. Proc. of the 29th Annual ACM/IEEE International Symposium on Microarchitecture
, pp.24.34 (December 1996)
ttp://www.eecs.harvard.edu/~dbrooks/cs146/micro.trace-cache.pdf
TraceCache�Ɋւ���ŏ��̘_���B
1996�N12�����BP6�̊J���`�[���́APenPro�����[�X��A������NetBurst�̊J����
���肵�����Ă����Ă邯�ǁA���̍��ɂ̓A�[�L�e�N�`����`�Ƃ��͑�v�i��ł����낤�ȁB
���l��Nehalem�ɂ��Ă��֘A�������Ș_����2001�N���ɂłĂ�����B
instruction fetching. Proc. of the 29th Annual ACM/IEEE International Symposium on Microarchitecture
, pp.24.34 (December 1996)
ttp://www.eecs.harvard.edu/~dbrooks/cs146/micro.trace-cache.pdf
TraceCache�Ɋւ���ŏ��̘_���B
1996�N12�����BP6�̊J���`�[���́APenPro�����[�X��A������NetBurst�̊J����
���肵�����Ă����Ă邯�ǁA���̍��ɂ̓A�[�L�e�N�`����`�Ƃ��͑�v�i��ł����낤�ȁB
���l��Nehalem�ɂ��Ă��֘A�������Ș_����2001�N���ɂłĂ�����B
AMD's K10 is delayed or dead
http://www.theinquirer.net/?article=27421
AMD��K10���x��Ă���悤���B
���Ȃ��Ƃ�2008�N�܂œo�ꂵ�Ȃ�or�ň��L�����Z�������悤���B
���̑���K8L�Ƃ����`�b�v���p�ӂ����悤���B
K8L�͏��Ȃ��Ƃ�Quad Core�ł�����8 Core�Ɉڍs����炵���B
K8�����XNexGen�`�[��������Ă��̂��v�ɂȂ��āA
���̂���Alpha�`�[����K7�x�[�X�ɂŋ}篗p�ӂ����̂��A
����Opteron/Athlon64�̃A�[�L�B
���ꂩ��AK9(8 issue core)�����\�O�L�����Z���ɂȂ����̂ō���
�͂��Ȃ�Ɏ肾�낤�B
2006�N���炵�炭��Merom/Conroe�A�[�L�̗D�ʂ��������ȁB
http://www.theinquirer.net/?article=27421
AMD��K10���x��Ă���悤���B
���Ȃ��Ƃ�2008�N�܂œo�ꂵ�Ȃ�or�ň��L�����Z�������悤���B
���̑���K8L�Ƃ����`�b�v���p�ӂ����悤���B
K8L�͏��Ȃ��Ƃ�Quad Core�ł�����8 Core�Ɉڍs����炵���B
K8�����XNexGen�`�[��������Ă��̂��v�ɂȂ��āA
���̂���Alpha�`�[����K7�x�[�X�ɂŋ}篗p�ӂ����̂��A
����Opteron/Athlon64�̃A�[�L�B
���ꂩ��AK9(8 issue core)�����\�O�L�����Z���ɂȂ����̂ō���
�͂��Ȃ�Ɏ肾�낤�B
2006�N���炵�炭��Merom/Conroe�A�[�L�̗D�ʂ��������ȁB
>>144�̋L����A�Q�[���s�������TDP 50W�N���X��Yohah-E���K�v�Ƃ���Ă�Ƃ����b�Ȃ��ǁA
����OC����Dothan����N���b�N��TDP���グ���������Pentium-M�R�A��AMD�̃n�C�G���h�v���Z�b�T��
�Q�[���\�t�g�̐��\�őR�ł��邱�Ƃ��ؖ�����Ă��邷�B
http://www.tomshardware.com/cpu/20050525/pentium4-10.html
���e�I�ɂ�A���ɐV��������b���ᖳ�����B
����OC����Dothan����N���b�N��TDP���グ���������Pentium-M�R�A��AMD�̃n�C�G���h�v���Z�b�T��
�Q�[���\�t�g�̐��\�őR�ł��邱�Ƃ��ؖ�����Ă��邷�B
http://www.tomshardware.com/cpu/20050525/pentium4-10.html
���e�I�ɂ�A���ɐV��������b���ᖳ�����B
146 �F���̖��ݒ��F2005/11/03(��) 22:26:54 ID:ZssWHlLT
���Ȃ݂ɁA�n�[�h�E�F�A�ő��{���x���������_�ɑΉ����Ă�CPU���������狳���Ă���Ȃ��H
�ƁA���̂�������������Ă��B
�ƁA���̂�������������Ă��B
147 �FMAC�I�^��146 �����F2005/11/03(��) 22:39:05 ID:2WTEF8GY
148 �F146����MAC�I�^�F2005/11/03(��) 22:40:58 ID:ZssWHlLT
���ӂ��邷�B
���āA�ȑO�\�����Ȃ���T�{���Ă����匴����̋L���̐����ł����邩�c�B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
>�EBanias/Dothan: 12�i�̃p�C�v���C��
>�EYonah: 13�i�̃p�C�v���C��
>�E�VMicroArchitecture: 14�i�̃p�C�v���C��
>�Ƃ������ƂɂȂ邾�낤�B
�e�`�b�v�̃p�C�v���C���i���ɂ��ẮA���܂ł̉\�Ȃǂ𑍍�����ƁA
���̉��߂���ԑÓ��Ȑ����낤�B�����܂ł͂悢�̂����A
���̎��ŁA���̐�����������o��Bʷ�����ĈӖ��s���Ȃ��ǁc�B
>Complex Decoder�̓��C�e���V���ٗl�ɑ傫���A���X���[�v�b�g��1�ł͂Ȃ����߁A
>�p�C�v���C���͎�����2�{�ő���Ă����B�Ƃ��낪Yonah�ł�SSE/SSE2���߂��X���[�v�b�g3
>�ŏ��������Ƃ�������ǂ߂�킯�ŁA�����Ȃ��SSE/SSE2�̎��s���j�b�g��3�Ȃ��Ƃ���
>�������ɂȂ�B�ŁAYonah�͑S�Ă̐������Z���j�b�g��SSE/SSE2�����s�ł��邱�Ƃ����Ɍ�
>�J����Ă��邩��A�܂萮�����Z�Ɋւ��Ă̓p�C�v���C����3�{�Ƃ������ƂɂȂ�B
>�]����Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i���₳��Ă���v�Z�ɂȂ�킯���B
>�p�C�v���C���͎�����2�{�ő���Ă���
�� P6��Decode�X�e�[�W�̃p�C�v���C����2�{�Ȃ�Ď����͂Ȃ����c�B
>SSE/SSE2���߂��X���[�v�b�g3�ŏ��������
�� Decoder�̑ш悪SSE/SSE2�n�ł�3uops/clk���Ă�������c�B
>�����Ȃ��SSE/SSE2�̎��s���j�b�g��3�Ȃ��Ƃ�������
�� Decoder Bandwidth�Ǝ��s���j�b�g�̐��͕ʂł��������������͂Ȃ��B
�@ �匴����͉��̂��p�C�v���C������Decoder�Ǝ��s���j�b�g���Z�b�g�ōl���Ă��܂��Ă���悤���B
>�]����Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i���₳��Ă���v�Z�ɂȂ�킯��
�� ���܂ł̉�����p�C�v���C����1�i�����邱�Ƃ̐����ɂǂ����т��Ă���̂�
�@�@�S�R���m�ɂȂ��ĂȂ��B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
>�EBanias/Dothan: 12�i�̃p�C�v���C��
>�EYonah: 13�i�̃p�C�v���C��
>�E�VMicroArchitecture: 14�i�̃p�C�v���C��
>�Ƃ������ƂɂȂ邾�낤�B
�e�`�b�v�̃p�C�v���C���i���ɂ��ẮA���܂ł̉\�Ȃǂ𑍍�����ƁA
���̉��߂���ԑÓ��Ȑ����낤�B�����܂ł͂悢�̂����A
���̎��ŁA���̐�����������o��Bʷ�����ĈӖ��s���Ȃ��ǁc�B
>Complex Decoder�̓��C�e���V���ٗl�ɑ傫���A���X���[�v�b�g��1�ł͂Ȃ����߁A
>�p�C�v���C���͎�����2�{�ő���Ă����B�Ƃ��낪Yonah�ł�SSE/SSE2���߂��X���[�v�b�g3
>�ŏ��������Ƃ�������ǂ߂�킯�ŁA�����Ȃ��SSE/SSE2�̎��s���j�b�g��3�Ȃ��Ƃ���
>�������ɂȂ�B�ŁAYonah�͑S�Ă̐������Z���j�b�g��SSE/SSE2�����s�ł��邱�Ƃ����Ɍ�
>�J����Ă��邩��A�܂萮�����Z�Ɋւ��Ă̓p�C�v���C����3�{�Ƃ������ƂɂȂ�B
>�]����Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i���₳��Ă���v�Z�ɂȂ�킯���B
>�p�C�v���C���͎�����2�{�ő���Ă���
�� P6��Decode�X�e�[�W�̃p�C�v���C����2�{�Ȃ�Ď����͂Ȃ����c�B
>SSE/SSE2���߂��X���[�v�b�g3�ŏ��������
�� Decoder�̑ш悪SSE/SSE2�n�ł�3uops/clk���Ă�������c�B
>�����Ȃ��SSE/SSE2�̎��s���j�b�g��3�Ȃ��Ƃ�������
�� Decoder Bandwidth�Ǝ��s���j�b�g�̐��͕ʂł��������������͂Ȃ��B
�@ �匴����͉��̂��p�C�v���C������Decoder�Ǝ��s���j�b�g���Z�b�g�ōl���Ă��܂��Ă���悤���B
>�]����Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i���₳��Ă���v�Z�ɂȂ�킯��
�� ���܂ł̉�����p�C�v���C����1�i�����邱�Ƃ̐����ɂǂ����т��Ă���̂�
�@�@�S�R���m�ɂȂ��ĂȂ��B
150 �Finteler@�����F2005/11/05(�y) 22:42:31 ID:UFKLFbos
�~Decoder�̑ш悪SSE/SSE2�n�ł�3uops/clk���Ă�������c�B
��Decoder�̑ш悪SSE/SSE2�n�ł�3x86-Inst./clk���Ă�������c�B
��Decoder�̑ш悪SSE/SSE2�n�ł�3x86-Inst./clk���Ă�������c�B
>Mobile�͒P��\���ŁA�����炭��4MB�L���b�V����Dual Core�B
>Mobility TDP Envelope�͂����炭30W�O��(���ꂪ���C���X�g���[��)��15W(���ꂪLow Voltage)�A
>�����5W�O��(���ꂪUltra Low Voltage)�ɂȂ邾�낤�B���Desktop��TDP��65W�ŌŒ肾���A
>Photo11�̃_�C�̐}��M����Mobile�̃T�C�Y���琄������Ȃ�A�L���b�V����4MB��8MB��2��ށB
>Server�͌��݂�Xeon��130W�̃����W�ɒB���Ă��邩��A40%�팸�����78W�ƂȂ�A�ق�80W�Ƃ������Ƃ��납?
> �������2�R�A�E8MB�L���b�V����Woodcrest�ƁA4�R�A�E32MB(!)�L���b�V����Whitefield�Ƃ����\���ɂȂ�B
>80W�̃����W�͂����炭4�R�A��Whitefield�ɓK�p�������̂ɂȂ邾�낤�B
���̋L����L2�e�ʗ\���͂͂��ꂾ�낤�B�\�z�̔����������B
���ꂩ��AMerom��TDP35W@�ʏ�ŁATDP9W@ULV�łƂ����\�ł����B
>Mobility TDP Envelope�͂����炭30W�O��(���ꂪ���C���X�g���[��)��15W(���ꂪLow Voltage)�A
>�����5W�O��(���ꂪUltra Low Voltage)�ɂȂ邾�낤�B���Desktop��TDP��65W�ŌŒ肾���A
>Photo11�̃_�C�̐}��M����Mobile�̃T�C�Y���琄������Ȃ�A�L���b�V����4MB��8MB��2��ށB
>Server�͌��݂�Xeon��130W�̃����W�ɒB���Ă��邩��A40%�팸�����78W�ƂȂ�A�ق�80W�Ƃ������Ƃ��납?
> �������2�R�A�E8MB�L���b�V����Woodcrest�ƁA4�R�A�E32MB(!)�L���b�V����Whitefield�Ƃ����\���ɂȂ�B
>80W�̃����W�͂����炭4�R�A��Whitefield�ɓK�p�������̂ɂȂ邾�낤�B
���̋L����L2�e�ʗ\���͂͂��ꂾ�낤�B�\�z�̔����������B
���ꂩ��AMerom��TDP35W@�ʏ�ŁATDP9W@ULV�łƂ����\�ł����B
152 �FMAC�I�^��inteler �����F2005/11/05(�y) 23:31:17 ID:tWrmGhny
>>149
���ӓI�Ȍ�ǂ�����悤�ȋC�����邷�B
�@�@-----------------------
�@�@�p�C�v���C���͎�����2�{�ő���Ă����B
�@�@-----------------------
�����A���s���j�b�g�̃p�C�v���C���̂��Ƃ��w���悤�ɂ����ǂ߂Ȃ����BYonah/Merom�ł�A�f�R�[�_��
�����ɍ��킹�Ă����胏�C�h�ɂȂ�Ƃ���A3�{�̎��s�p�C�v���C���Ƃ����̂�Ó��Ȑ������B
���ӓI�Ȍ�ǂ�����悤�ȋC�����邷�B
�@�@-----------------------
�@�@�p�C�v���C���͎�����2�{�ő���Ă����B
�@�@-----------------------
�����A���s���j�b�g�̃p�C�v���C���̂��Ƃ��w���悤�ɂ����ǂ߂Ȃ����BYonah/Merom�ł�A�f�R�[�_��
�����ɍ��킹�Ă����胏�C�h�ɂȂ�Ƃ���A3�{�̎��s�p�C�v���C���Ƃ����̂�Ó��Ȑ������B
153 �FMAC�I�^���⑫�F2005/11/05(�y) 23:36:51 ID:tWrmGhny
�f�R�[�_�̃X���[�v�b�g�Ǝ��s���j�b�g���̊W�Ƃ��āA�ň��̉��肪�u�f�R�[�h�������߂��S�ĒP��
�������Z���߁v�ƂȂ�ꍇ�ŁA���ۂɂ푼�̉��Z���j�b�g���g�p���閽�߂��}������邽�߂ɂ�����
�P�����Z���߂�issue���팸�邷�B
�܂�T�C�N���������issue�����A�P���������Z���j�b�g�̐��������̂�P�Ȃ閳�ʂƂ������ƂɂȂ邷�B
�������Z���߁v�ƂȂ�ꍇ�ŁA���ۂɂ푼�̉��Z���j�b�g���g�p���閽�߂��}������邽�߂ɂ�����
�P�����Z���߂�issue���팸�邷�B
�܂�T�C�N���������issue�����A�P���������Z���j�b�g�̐��������̂�P�Ȃ閳�ʂƂ������ƂɂȂ邷�B
>>152
������x�ǂݒ����Ă݂��̂����A���s���j�b�g�̃p�C�v�Ƃ�����SSE�Ŏg���閽�߃|�[�g��
2�|�[�g�Ƃ����Ӗ��ŏ����Ă�݂������ȁB
�������A������ɂ���Decorder���ő�3 SSE-Inst/clk�����ł���悤�ɂȂ�������Ƃ����āA
SSE�̃|�[�g��3�ɑ��₷�Ƃ����\���͂��Ȃ薳���������Ȃ��́H
P6�n�A�[�L�̏ꍇ�A���C��ALU��SSE�ƂŖ��߃|�[�g�����ʂȂ̂ŁA
�匴����I�ɂ͐������Z���j�b�g��3�ɑ����Ă���Ƃ̑�_�\�������A
�R��͂��蓾�Ȃ��Ǝv��(�m
������x�ǂݒ����Ă݂��̂����A���s���j�b�g�̃p�C�v�Ƃ�����SSE�Ŏg���閽�߃|�[�g��
2�|�[�g�Ƃ����Ӗ��ŏ����Ă�݂������ȁB
�������A������ɂ���Decorder���ő�3 SSE-Inst/clk�����ł���悤�ɂȂ�������Ƃ����āA
SSE�̃|�[�g��3�ɑ��₷�Ƃ����\���͂��Ȃ薳���������Ȃ��́H
P6�n�A�[�L�̏ꍇ�A���C��ALU��SSE�ƂŖ��߃|�[�g�����ʂȂ̂ŁA
�匴����I�ɂ͐������Z���j�b�g��3�ɑ����Ă���Ƃ̑�_�\�������A
�R��͂��蓾�Ȃ��Ǝv��(�m
Apple�́A������u�����v�ɂȂ��Ă��܂��̂��H
�Ȃ��Ă��܂��A��MAC�I�^�͊뜜���Ă������ǁAinteler����̌����͂ǂ���B
�Ȃ��Ă��܂��A��MAC�I�^�͊뜜���Ă������ǁAinteler����̌����͂ǂ���B
�R�������������Ǝv�����ǂȁB
157 �FMAC�I�^��inteler �����F2005/11/06(��) 00:41:52 ID:D0D4WAtk
>>154
�@�@----------------------
�@�@SSE�̃|�[�g��3�ɑ��₷�Ƃ����\���͂��Ȃ薳���������Ȃ��́H
�@�@----------------------
>>153�ɏ������悤�ɃV���O���T�C�N���̎��s���j�b�g����issue����葝�₷�K�v�햳��������A
SSE�̃|�[�g�̍ő吔��3���B����2�ŁA�����葝����Ƃ������ƂȂ�A�I������3���������Ǝv�������ǁB�B�B
�@�@----------------------
�@�@�������Z���j�b�g��3�ɑ����Ă���Ƃ̑�_�\�������A
�@�@----------------------
G4+�ł�4-instructions/cycle�̖��߃t�F�b�`��simple IU x 3, complex IU x 1������A��_�ȗ\���Ƃ��v��Ȃ����B
�@�@----------------------
�@�@SSE�̃|�[�g��3�ɑ��₷�Ƃ����\���͂��Ȃ薳���������Ȃ��́H
�@�@----------------------
>>153�ɏ������悤�ɃV���O���T�C�N���̎��s���j�b�g����issue����葝�₷�K�v�햳��������A
SSE�̃|�[�g�̍ő吔��3���B����2�ŁA�����葝����Ƃ������ƂȂ�A�I������3���������Ǝv�������ǁB�B�B
�@�@----------------------
�@�@�������Z���j�b�g��3�ɑ����Ă���Ƃ̑�_�\�������A
�@�@----------------------
G4+�ł�4-instructions/cycle�̖��߃t�F�b�`��simple IU x 3, complex IU x 1������A��_�ȗ\���Ƃ��v��Ȃ����B
����PowerPC970�n�́A����ȏ�i�������Ȃ̂��ȁB
>>157
>SSE�̃|�[�g�̍ő吔��3���B����2�ŁA�����葝����Ƃ������ƂȂ�A�I������3���������Ǝv�������ǁB�B�B
���̘b�͖���������ȁB
���������ADecoder��"�X���[�v�b�g����=SSE���j�b�g�̑���"���Ă������߂��ԈႢ�B
SSE/SSE2���j�b�g�́ANetBurst�ł��������s���S������A����PenM�n�ł͐��𑝂₷�O�ɁA
���������b�`�ɂ��āA�e���s���j�b�g�̃X���[�v�b�g���P��������悾�Ǝv�����ǁB
>SSE�̃|�[�g�̍ő吔��3���B����2�ŁA�����葝����Ƃ������ƂȂ�A�I������3���������Ǝv�������ǁB�B�B
���̘b�͖���������ȁB
���������ADecoder��"�X���[�v�b�g����=SSE���j�b�g�̑���"���Ă������߂��ԈႢ�B
SSE/SSE2���j�b�g�́ANetBurst�ł��������s���S������A����PenM�n�ł͐��𑝂₷�O�ɁA
���������b�`�ɂ��āA�e���s���j�b�g�̃X���[�v�b�g���P��������悾�Ǝv�����ǁB
160 �FMAC�I�^��inteler �����F2005/11/06(��) 00:57:35 ID:D0D4WAtk
>>159
�@�@------------------
�@�@�e���s���j�b�g�̃X���[�v�b�g���P��������悾�Ǝv�����ǁB
�@�@------------------
SSE���simple IU����issue���ƍ��킹��Ƃ����v�f���傫���Ǝv���邷�BSSE��IU�̃|�[�g�����p�Ȃ�
���RSSE���ꏏ��3�ɂȂ�Ƃ����̂����R�ȉ��߂��Ǝv�����B
�@�@------------------
�@�@�e���s���j�b�g�̃X���[�v�b�g���P��������悾�Ǝv�����ǁB
�@�@------------------
SSE���simple IU����issue���ƍ��킹��Ƃ����v�f���傫���Ǝv���邷�BSSE��IU�̃|�[�g�����p�Ȃ�
���RSSE���ꏏ��3�ɂȂ�Ƃ����̂����R�ȉ��߂��Ǝv�����B
161 �Finteler@�⑫�F2005/11/06(��) 01:02:00 ID:lwAPrTr7
>>160
>SSE���simple IU����issue���ƍ��킹��Ƃ����v�f���傫����
�P�������n��Decode�ш��Yonah�ŕς���ĂȂ��͂���(�m
�ς�����̂�SSE����B
���C��ALU�𑝂₷�ƁA�p�C�v���C����w�Ǎ�蒼���ɂȂ��Ă��܂��̂ŁA
�e���j�b�g�̎��������P��������A�y���ɃX�}�[�g�B
Yonah��Merom�Ƀo�g���^�b�`�����炷��������킯�����A
�_�C�T�C�Y��g�����W�X�^�����炢���Ă�����ȑ傪����ȕύX�͂Ȃ����B
�Ƃ��������蓾�Ȃ��B
>SSE���simple IU����issue���ƍ��킹��Ƃ����v�f���傫����
�P�������n��Decode�ш��Yonah�ŕς���ĂȂ��͂���(�m
�ς�����̂�SSE����B
���C��ALU�𑝂₷�ƁA�p�C�v���C����w�Ǎ�蒼���ɂȂ��Ă��܂��̂ŁA
�e���j�b�g�̎��������P��������A�y���ɃX�}�[�g�B
Yonah��Merom�Ƀo�g���^�b�`�����炷��������킯�����A
�_�C�T�C�Y��g�����W�X�^�����炢���Ă�����ȑ傪����ȕύX�͂Ȃ����B
�Ƃ��������蓾�Ȃ��B
162 �FMAC�I�^��inteler �����F2005/11/06(��) 01:05:15 ID:D0D4WAtk
>>161
���ꂪ���S�ɉR���Ă��Ƃ����H
�@�@------------------------
�@�@�܂��A4 issue�̃X�[�p�[�X�P�[���ł��邪�A����͌�Ŋm�F�ł����b�����������Z�u�̂݁v
�@�@------------------------
�u���҂��b���Ă������e���A���₵�ĉ�����ꂽ���e�̂悤�Ɏv���邷���ǁB�B�B
���ꂪ���S�ɉR���Ă��Ƃ����H
�@�@------------------------
�@�@�܂��A4 issue�̃X�[�p�[�X�P�[���ł��邪�A����͌�Ŋm�F�ł����b�����������Z�u�̂݁v
�@�@------------------------
�u���҂��b���Ă������e���A���₵�ĉ�����ꂽ���e�̂悤�Ɏv���邷���ǁB�B�B
MAC�I�^�����ǂ̒��xIntel�v���Z�b�T��c�����Ă���̂��m��ǁA
4issue��Merom�̘b��(�m
Merom��Yonah�̓}�C�N���A�[�L�e�N�`�����x���Őv���Ⴄ�̂�Yonah�̘b�Ƃ͊W�Ȃ��B
Yonah�͊�{�I�ȂƂ����Dothan�̕ς���ĂȂ����Ă����̂͊��ɂ悭�m���Ă���̂ŁA
���̍ہA�͂����肢�����Ⴄ���ǁA�匴�\�z�;�������蓾�Ȃ����i�E�́E�j
4issue��Merom�̘b��(�m
Merom��Yonah�̓}�C�N���A�[�L�e�N�`�����x���Őv���Ⴄ�̂�Yonah�̘b�Ƃ͊W�Ȃ��B
Yonah�͊�{�I�ȂƂ����Dothan�̕ς���ĂȂ����Ă����̂͊��ɂ悭�m���Ă���̂ŁA
���̍ہA�͂����肢�����Ⴄ���ǁA�匴�\�z�;�������蓾�Ȃ����i�E�́E�j
164 �FMAC�I�^���⑫ �����F2005/11/06(��) 01:10:55 ID:D0D4WAtk
���Ȃ݂Ɏ��AMerom�̘b�����Ă���肷�B�匴���̋L���ł��A
�@�@--------------------
�@�@Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i[MAC�I�^��: ����1�{�̌��]���₳��Ă���v�Z��
�@�@�Ȃ�킯���B
�@�@--------------------
�Ƃ���悤�ɁA���Z���j�b�g�̑�����Merom����̘b���B
�@�@--------------------
�@�@Yonah��Merom�ł͐������Z�̃p�C�v���C����1�i[MAC�I�^��: ����1�{�̌��]���₳��Ă���v�Z��
�@�@�Ȃ�킯���B
�@�@--------------------
�Ƃ���悤�ɁA���Z���j�b�g�̑�����Merom����̘b���B
MAC�I�^���̂����������Ƃ��悭�킩��A
�匴���̃l�^�͈�x�Y���Ƃ��āA�P������(���C��ALU)�Ɋւ��Ă����ƁA
P6�`Yonah��2issue
Merom��4issue
�Ȃ�ł���BMerom�̐�����issue�ш�͔{�ɋ�������Ă���B
(�O�]���ŃN���b�N������30%���̐��\�Ƃ����̂��[���ł���)
�����l�^�ő����̃��X�������̂͏�x�d���̂��̃X����
��|�ɔ�����̂ł��̃l�^�͂��J���Ƃ������ƂŁB
�匴���̃l�^�͈�x�Y���Ƃ��āA�P������(���C��ALU)�Ɋւ��Ă����ƁA
P6�`Yonah��2issue
Merom��4issue
�Ȃ�ł���BMerom�̐�����issue�ш�͔{�ɋ�������Ă���B
(�O�]���ŃN���b�N������30%���̐��\�Ƃ����̂��[���ł���)
�����l�^�ő����̃��X�������̂͏�x�d���̂��̃X����
��|�ɔ�����̂ł��̃l�^�͂��J���Ƃ������ƂŁB
166 �FMAC�I�^��inteler �����F2005/11/06(��) 08:17:36 ID:D0D4WAtk
>>165
�@�@-------------------
�@�@�匴���̃l�^�͈�x�Y���Ƃ��āA
�@�@-------------------
�匴�L����ᔻ������������Ȃ������B�B�B�@���ꂾ�������Ə�x���Ⴂ�Ɠ{��ꂻ������(��)
����c�_�ɂȂ��Ă���v���[��������A��������_�E�����[�h�ł��邷�B
https://www28.cplan.com/cv82/sessions_catalog.jsp?ilc=82-9&ilg=english&ip=yes
�@�@-------------------
�@�@�匴���̃l�^�͈�x�Y���Ƃ��āA
�@�@-------------------
�匴�L����ᔻ������������Ȃ������B�B�B�@���ꂾ�������Ə�x���Ⴂ�Ɠ{��ꂻ������(��)
����c�_�ɂȂ��Ă���v���[��������A��������_�E�����[�h�ł��邷�B
https://www28.cplan.com/cv82/sessions_catalog.jsp?ilc=82-9&ilg=english&ip=yes
id��pass�Ȃ��Ⴈ�Ƃ��ˁ[�����
168 �FMAC�I�^��167 �����F2005/11/06(��) 22:32:55 ID:D0D4WAtk
>>167
IDF�����O���idf/spring05�Ń_�E�����[�h�ł��������ǁA�ʂ�Ȃ��Ȃ��Ă邷�ˁB
11���ȍ~�Ɉ�ʌ��J���ď����Ă��邷����A�����N�����o���Ă����Ηǂ��Ǝv�����B
���Ȃ݂ɑ匴���̃��|�[�g��ADPIS010�̃Z�b�V�����𒆐S�Ɍ���Ă��邷�B
IDF�����O���idf/spring05�Ń_�E�����[�h�ł��������ǁA�ʂ�Ȃ��Ȃ��Ă邷�ˁB
11���ȍ~�Ɉ�ʌ��J���ď����Ă��邷����A�����N�����o���Ă����Ηǂ��Ǝv�����B
���Ȃ݂ɑ匴���̃��|�[�g��ADPIS010�̃Z�b�V�����𒆐S�Ɍ���Ă��邷�B
�I�^���A�������̃X�������ނ�B
�Ȃ�Mac�̃r�f�I�J�[�h�͕n��Ȃ̂�
http://pc7.2ch.net/test/read.cgi/mac/1128605380/
�Ȃ�Mac�̃r�f�I�J�[�h�͕n��Ȃ̂�
http://pc7.2ch.net/test/read.cgi/mac/1128605380/
170 �F���̖��ݒ��F2005/11/07(��) 09:08:08 ID:oJTGBkX8
���N���ɂ�Intel iMac���o������H
CPU�͑���Yonah���낤���ǁA�N���b�N�͂ǂꂮ�炢�ɂȂ�Ǝv����H
CPU�͑���Yonah���낤���ǁA�N���b�N�͂ǂꂮ�炢�ɂȂ�Ǝv����H
2.17GHz@T1600@launch(Jan. 1st, 2006@US)
2.33GHz@T1700@2H 2006
������A���N�O���ɂł�Ƃ��āA2.17GHz���ƁB
2.33GHz@T1700@2H 2006
������A���N�O���ɂł�Ƃ��āA2.17GHz���ƁB
Exklusiv: Erster Test! Xeon 5000 Dempsey mit FB-DIMM
http://www.tecchannel.de/server/hardware/432957/index.html
�Ƃ�TechChannel��Dempsey�̃��r���[�����Ă���悤���B
���ʂ͑����̃x���`�}�[�N��Paxville�͂��납Opteron 280������悤���B
INQ��Dempsey�݂���Paxville�����Ȃ�Ă��肦�ˁ[�݂����ȋL�������Ă����A
���̃x���`������Ɣ[���ł���B
A: 2x Dempsey 3.2GHz + 4ch FB-DIMM DDR2-533
B: 2x Opteron 280(2.4GHz) + DDR400
C: 2x Paxville 2.8GHz + DDR400
�@ SPECint_base_rate SPECfp_base_rate
A: 70.0�@�@�@�@�@�@�@�@�@57.3
B: 62.9�@�@�@�@�@�@�@�@�@42.4
C: 58.1�@�@�@�@�@�@�@�@�@35.9
http://www.tecchannel.de/server/hardware/432957/index.html
�Ƃ�TechChannel��Dempsey�̃��r���[�����Ă���悤���B
���ʂ͑����̃x���`�}�[�N��Paxville�͂��납Opteron 280������悤���B
INQ��Dempsey�݂���Paxville�����Ȃ�Ă��肦�ˁ[�݂����ȋL�������Ă����A
���̃x���`������Ɣ[���ł���B
A: 2x Dempsey 3.2GHz + 4ch FB-DIMM DDR2-533
B: 2x Opteron 280(2.4GHz) + DDR400
C: 2x Paxville 2.8GHz + DDR400
�@ SPECint_base_rate SPECfp_base_rate
A: 70.0�@�@�@�@�@�@�@�@�@57.3
B: 62.9�@�@�@�@�@�@�@�@�@42.4
C: 58.1�@�@�@�@�@�@�@�@�@35.9
Intel�t�F���[ ���g�i�[���A�����Ɍ����������J�����e�����
http://pc.watch.impress.co.jp/docs/2005/1108/intel.htm
Virtualizing Transactional Memory
ttp://www.cs.wisc.edu/~isca2005/papers/08A-02.PDF
http://pc.watch.impress.co.jp/docs/2005/1108/intel.htm
Virtualizing Transactional Memory
ttp://www.cs.wisc.edu/~isca2005/papers/08A-02.PDF
�C���e���A���j�[�R�A���ւ̎��g�݂ȂǁA���������Ɋւ����������J��
http://pcweb.mycom.co.jp/news/2005/11/09/003.html
MYCOM�̕����悭�܂Ƃ܂��Ă�ȁB
100MHz CMOS���M�����[�^�G���i�E�́E�j
http://pcweb.mycom.co.jp/news/2005/11/09/003.html
MYCOM�̕����悭�܂Ƃ܂��Ă�ȁB
100MHz CMOS���M�����[�^�G���i�E�́E�j
PowerPC Power Mac��4-way�̃}�V�����o�Ă��܂����̂ŁAIntel Power Mac��4-way��
������Ȃ��Ǝv����ł����A�����Ȃ�ƁA�l�i���v�ł����ˁB
�f���A���v���Z�b�T�Ή��̃f���A���R�A��Intel CPU���Ēl�i�߂����ፂ�����A���炭
������T�|�[�g����`�b�v�Z�b�g���������낤���B
inteler�����MAC�I�^����̈ӌ��������B
������Ȃ��Ǝv����ł����A�����Ȃ�ƁA�l�i���v�ł����ˁB
�f���A���v���Z�b�T�Ή��̃f���A���R�A��Intel CPU���Ēl�i�߂����ፂ�����A���炭
������T�|�[�g����`�b�v�Z�b�g���������낤���B
inteler�����MAC�I�^����̈ӌ��������B
176 �FMAC�I�^��175 �����F2005/11/10(��) 20:34:35 ID:PjLRNRen
>>175
����Apple��v���Z�b�T��PC�x���_�ƍ��ʉ���}��K�v���̂��̂������Ȃ���������A2007�N���_�ł�
����PC�x���_�̃��C���i�b�v������Ă����̘b���B
Dell���}���`�v���Z�b�T��PC���[�N�X�e�[�V������K���Ŕ���Ȃ�AApple���R���i���o����
���������Z�O�����g�̐��i�����݂��Ȃ��Ȃ�AApple������Ȏs��햳��������Ă������Ǝv�����B
����Apple��v���Z�b�T��PC�x���_�ƍ��ʉ���}��K�v���̂��̂������Ȃ���������A2007�N���_�ł�
����PC�x���_�̃��C���i�b�v������Ă����̘b���B
Dell���}���`�v���Z�b�T��PC���[�N�X�e�[�V������K���Ŕ���Ȃ�AApple���R���i���o����
���������Z�O�����g�̐��i�����݂��Ȃ��Ȃ�AApple������Ȏs��햳��������Ă������Ǝv�����B
>>175
Xeon�v���b�g�t�H�[���́A���i�����Ȃ�v���Ă���قǍ����Ȃ��B
Dual Core XeonDP�̒��`���̕��̃N���b�N�ŁA
�T�|�[�g��M���������[�N�X�e�[�V�����łȂ���PC���x���ł悢�̂Ȃ�A
4way��Mac�Ƒ卷�Ȃ��l�i�ł������Ȃ����Ȃ��B
Apple�̂��C����ŁASossaman��Woodcrest��Mac�͂��蓾��Ǝv���B
��:
ttp://www.dospara.co.jp/bto/bto_f.php?gm=346&gs=16&gf=0
Xeon�v���b�g�t�H�[���́A���i�����Ȃ�v���Ă���قǍ����Ȃ��B
Dual Core XeonDP�̒��`���̕��̃N���b�N�ŁA
�T�|�[�g��M���������[�N�X�e�[�V�����łȂ���PC���x���ł悢�̂Ȃ�A
4way��Mac�Ƒ卷�Ȃ��l�i�ł������Ȃ����Ȃ��B
Apple�̂��C����ŁASossaman��Woodcrest��Mac�͂��蓾��Ǝv���B
��:
ttp://www.dospara.co.jp/bto/bto_f.php?gm=346&gs=16&gf=0
�ϯ��i�E�́E�j ����������Ȃ�A
�ŏ�����PC���[�N�X�e�[�V�����Ɠ��������Ŕ���\���̕������肩�c�B
���㓡�O��Weekly�C�O�j���[�X��
��������Intel��5�`10�N���CPU�A�[�L�e�N�`��
�`�z���W�j�A�X���߃Z�b�g&�w�e���W�j�A�X�}�C�N���A�[�L�e�N�`����
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
�ŏ�����PC���[�N�X�e�[�V�����Ɠ��������Ŕ���\���̕������肩�c�B
���㓡�O��Weekly�C�O�j���[�X��
��������Intel��5�`10�N���CPU�A�[�L�e�N�`��
�`�z���W�j�A�X���߃Z�b�g&�w�e���W�j�A�X�}�C�N���A�[�L�e�N�`����
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
���Xsankusu�ł��B
>>176
�u����PC�x���_��4-way�}�V�����i�荠�Ȓl�i�Łj�o���Ă��Ȃ����ǁAApple�͊����ďo���v
�Ƃ����I�����͂��蓾�Ȃ��A�Ƃ����\�z�ł��ˁB
�������AApple��4-way�}�V�����o���Ȃ��ƁA�ȉ��̂悤�ȓ_�����Ȃ̂ł́B
�EPowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�E4-way�}�V�����o���Ă����瓾���Ă�����������Ȃ����v�i���Ƃ��A�f������ɂ�����
�@���荞�߂Ă�����������Ȃ��A���j���������ƂɂȂ�
>>177
�₷���I
�v�킸�~�����Ȃ�܂����悗
>>176
�u����PC�x���_��4-way�}�V�����i�荠�Ȓl�i�Łj�o���Ă��Ȃ����ǁAApple�͊����ďo���v
�Ƃ����I�����͂��蓾�Ȃ��A�Ƃ����\�z�ł��ˁB
�������AApple��4-way�}�V�����o���Ȃ��ƁA�ȉ��̂悤�ȓ_�����Ȃ̂ł́B
�EPowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�E4-way�}�V�����o���Ă����瓾���Ă�����������Ȃ����v�i���Ƃ��A�f������ɂ�����
�@���荞�߂Ă�����������Ȃ��A���j���������ƂɂȂ�
>>177
�₷���I
�v�킸�~�����Ȃ�܂����悗
>>178
���߃Z�b�g�́A����\�N�i�Ђ���Ƃ����炻��ȏ�A�Ƃ��������i�v�I�ɁH�jx86�ōs���A����
���Ƃł����ˁB�ǂ����������A������Intel���Ċ����B
���߃Z�b�g�́A����\�N�i�Ђ���Ƃ����炻��ȏ�A�Ƃ��������i�v�I�ɁH�jx86�ōs���A����
���Ƃł����ˁB�ǂ����������A������Intel���Ċ����B
�Q�l�܂ł�Paxville�̏���d�́B
����ȏ�M��Intel�v���Z�T�͂������炭�͔q�߂Ȃ������Ȃ��B
Paxville DP
Clock: 2.8GHz@launch~eol
TDP: 135W
Max. Power: 150W
Core Voltage: 1.2875V~1.4125V
Icc-max: 120A
Paxville MP
Clock: 2.66GHz@launch, 3GHz@Q1 2006
TDP: [email protected]
Max. Power: [email protected]
Core Voltage: 1.2625V~1.4125V
Icc-max: 150A
����ȏ�M��Intel�v���Z�T�͂������炭�͔q�߂Ȃ������Ȃ��B
Paxville DP
Clock: 2.8GHz@launch~eol
TDP: 135W
Max. Power: 150W
Core Voltage: 1.2875V~1.4125V
Icc-max: 120A
Paxville MP
Clock: 2.66GHz@launch, 3GHz@Q1 2006
TDP: [email protected]
Max. Power: [email protected]
Core Voltage: 1.2625V~1.4125V
Icc-max: 150A
182 �FMAC�I�^��180 �����F2005/11/11(��) 23:25:16 ID:Q9XoNfl8
>>180
Intel��x86�̖��_���F�����Ă������C�ڍs���l���Ă�������B
x86���Y�Ƀ^�J�����������ɉ��炵��64-bit�Ή��܂ł����������̂�p�N����AMD���B
�R��CIntel���������܂ꂽ�B�B�B��
Intel��x86�̖��_���F�����Ă������C�ڍs���l���Ă�������B
x86���Y�Ƀ^�J�����������ɉ��炵��64-bit�Ή��܂ł����������̂�p�N����AMD���B
�R��CIntel���������܂ꂽ�B�B�B��
�R���s���[�^�A�[�L�e�N�`���̘b
��4��}���`�R�A�v���Z�T�̏���d��
http://pcweb.mycom.co.jp/column/architecture/004/
�Ў�ԂŃ��C�^�[�f�r���[���ʂ����Ă��܂�������������(�Z�p�҂Ƃ��Ă̊i�͉���������c)�A
�A�[�L�e�N�`���̘b�Ƃ������Ȃ���A6��ڂ܂ł͂قƂ��CMOS�̘b�ɂȂ��Ă�Ƃ��낪���X�B
-------------
�}���`�R�A�ʼn��̏���d�͂���������̂��H
�@�}���`�R�A�ł̓N���b�N�Ɠd�����������邩��
�A�R�A�̓��엦�����ቺ���邩��
�}���`�R�A�̃f�����b�g
�B�ʐς��傫��
-------------
���̌��_�͐��������ł���c�B
��4��}���`�R�A�v���Z�T�̏���d��
http://pcweb.mycom.co.jp/column/architecture/004/
�Ў�ԂŃ��C�^�[�f�r���[���ʂ����Ă��܂�������������(�Z�p�҂Ƃ��Ă̊i�͉���������c)�A
�A�[�L�e�N�`���̘b�Ƃ������Ȃ���A6��ڂ܂ł͂قƂ��CMOS�̘b�ɂȂ��Ă�Ƃ��낪���X�B
-------------
�}���`�R�A�ʼn��̏���d�͂���������̂��H
�@�}���`�R�A�ł̓N���b�N�Ɠd�����������邩��
�A�R�A�̓��엦�����ቺ���邩��
�}���`�R�A�̃f�����b�g
�B�ʐς��傫��
-------------
���̌��_�͐��������ł���c�B
�I�^����A�ǂ��炩�Ƃ�����>>179�փ��X���~�������i��
>>183 inteler ����
�����A���피���̃l�^�������ɓ������ăv���Z�X�T�C�Y�^�����d���ƃX�C�b�`���O���x�^����d�͂�
���ւ��������̂ɋꗶ���Ă���������A����������b�������Ă����q�g������ƌ��ꂽ���ƂɊ���
���Ă��邷�B(�ނ���A���������˂�����ʼn�����ė~�����Ƃ����̂��{����)
�[���A���̕Ӓm�炸�ɒm�������Ԃ�J�}���Ă�q�g���đ��������B�B�B
>>184 VCYg9z+4 ����
�@�E����Ȏs�ꂪ�\���傫���Ȃ瑼�̉�Ђ��Q�����Ă邷�B
�@�E�T�|�[�g������ۏ��K���ȃV���b�v�u�����h�Ɛ��E���Apple���ׂ��Ⴂ���Ȃ����B�������A��L��
�@�@�s�ꂪ�������Ȃ�A����ȘA���ł��T�|�[�g�ł���Ǝv�����B
�����A���피���̃l�^�������ɓ������ăv���Z�X�T�C�Y�^�����d���ƃX�C�b�`���O���x�^����d�͂�
���ւ��������̂ɋꗶ���Ă���������A����������b�������Ă����q�g������ƌ��ꂽ���ƂɊ���
���Ă��邷�B(�ނ���A���������˂�����ʼn�����ė~�����Ƃ����̂��{����)
�[���A���̕Ӓm�炸�ɒm�������Ԃ�J�}���Ă�q�g���đ��������B�B�B
>>184 VCYg9z+4 ����
�@�E����Ȏs�ꂪ�\���傫���Ȃ瑼�̉�Ђ��Q�����Ă邷�B
�@�E�T�|�[�g������ۏ��K���ȃV���b�v�u�����h�Ɛ��E���Apple���ׂ��Ⴂ���Ȃ����B�������A��L��
�@�@�s�ꂪ�������Ȃ�A����ȘA���ł��T�|�[�g�ł���Ǝv�����B
�ǂ����ł��B
�ł��A
�EPowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�Ƃ����_���A�܂������������ł���B
������Ƃ��ẮA
�uPowerPC Power Mac��4-way�������̂ɁAIntel Power Mac��2-way����I ����˂��I�v
�Ǝv���Ă��܂��̂ł́H
�ł��A
�EPowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�Ƃ����_���A�܂������������ł���B
������Ƃ��ẮA
�uPowerPC Power Mac��4-way�������̂ɁAIntel Power Mac��2-way����I ����˂��I�v
�Ǝv���Ă��܂��̂ł́H
187 �FMAC�I�^��VCYg9z+4 �����F2005/11/12(�y) 14:25:33 ID:23aeHcHU
>>186
�@�@--------------------------
�@�@PowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�@�@--------------------------
Jobs�Ƃ��Ă�AIntel��IBM�̃��[�h�}�b�v������ׂ���ŁA�Ȃ�Ƃ��Ȃ錩���݂�����̂ňڍs�����߂������B
�����������Ƃ����邷����A����Jobs�̑I����M���邷�B
http://pc7.2ch.net/test/read.cgi/mac/1124631110/917
�@�@--------------------------
�@�@PowerPC Power Mac (Quad)�ɑ��鐫�\�ʂł̃A�h�o���e�[�W���ア
�@�@--------------------------
Jobs�Ƃ��Ă�AIntel��IBM�̃��[�h�}�b�v������ׂ���ŁA�Ȃ�Ƃ��Ȃ錩���݂�����̂ňڍs�����߂������B
�����������Ƃ����邷����A����Jobs�̑I����M���邷�B
http://pc7.2ch.net/test/read.cgi/mac/1124631110/917
>>166�̃����N��A��ʌ����Ƀ_�E�����[�h�ł���悤��id��pass���NjL���ꂽ���B
189 �F���̖��ݒ��F2005/11/14(��) 15:31:52 ID:987As5x6
>Apple Insider���AApple��Intel Mac�̓�����\���葁�߂�悤���Ɠ`����
>���܂����BMacworld Conference & Expo/San Francisco 2006�ŁA
>iMac��PowerBook G4 (15-inch)�\���A�t���ɂ́AiBook 13�C���`���f����
>Mac mini�𓊓����AIntel�ւ̈ȍ~���A2006�N�̏H���i2006�N�x��v���j��
>��������v��̂悤���Ɠ`���Ă��܂����B
�ق�܂�����
>���܂����BMacworld Conference & Expo/San Francisco 2006�ŁA
>iMac��PowerBook G4 (15-inch)�\���A�t���ɂ́AiBook 13�C���`���f����
>Mac mini�𓊓����AIntel�ւ̈ȍ~���A2006�N�̏H���i2006�N�x��v���j��
>��������v��̂悤���Ɠ`���Ă��܂����B
�ق�܂�����
������Ƃ����Insider�\�z���Ă����Ƃ���������
Intel Bensley Platform Preview - Page 1/8
http://www.2cpu.com/review.php?id=110&page=1
Dempsey�̃��r���[�B
http://www.2cpu.com/review.php?id=110&page=1
Dempsey�̃��r���[�B
Intel Core, Centrino Duo et logos
http://www.x86-secret.com/?option=newsd&nid=916
����Intel�V���S���p����������i�E�́E�j
http://www.x86-secret.com/?option=newsd&nid=916
����Intel�V���S���p����������i�E�́E�j
http://www.pcpop.com/doc/0/116/116657.shtml
�e���œ\���Ă���Yonah�̃x���`�B
���ʂ͂��Ă����A�\�N�ȏ�O�ɃR���p�C�����ꂽ�x���`�}�[�N(Boland C 4.0?)��������
���\�]���ɂ����Ă���PC�I�^���E���āc�B
P5����UV�̔�Ώ̂ȃp�C�v�ɁA�낭�Ƀp�C�v���C��������ĂȂ�FPU��1�{����������ȁH
����Ȏ���̍œK����������ĂȂ���A�ŋ߃}�C�N���A�[�L�̐��\��ɂ͂ƂĂ��g���Ȃ���c�B
�e���œ\���Ă���Yonah�̃x���`�B
���ʂ͂��Ă����A�\�N�ȏ�O�ɃR���p�C�����ꂽ�x���`�}�[�N(Boland C 4.0?)��������
���\�]���ɂ����Ă���PC�I�^���E���āc�B
P5����UV�̔�Ώ̂ȃp�C�v�ɁA�낭�Ƀp�C�v���C��������ĂȂ�FPU��1�{����������ȁH
����Ȏ���̍œK����������ĂȂ���A�ŋ߃}�C�N���A�[�L�̐��\��ɂ͂ƂĂ��g���Ȃ���c�B
194 �F���̖��ݒ��F2005/11/15(��) 00:30:20 ID:zjG/0QQb
PCMark�Ƃ��ő������x���`�͖��������H
Intel May Delay New Dual-Core Chips Because of Instability
http://www.digitimes.com/mobos/a20051115A7035.html
Presler���s����Ȃ��ߒx��邩������Ȃ��悤���B
Yonah�͖��Ȃ��悤���B
���܂��Ƃ��āAi975�p��955/945�ł͓����Ȃ�Presler XE�̃T���v����3����O��
i865(AsRock)�ł̓`�F�b�N���Ȃ����ߓ������炵���悤���B(���̃T���v���͓d���Ⴂ�ˁc)
ttp://www.hkepc.com/bbs/viewthread.php?tid=506271
http://www.digitimes.com/mobos/a20051115A7035.html
Presler���s����Ȃ��ߒx��邩������Ȃ��悤���B
Yonah�͖��Ȃ��悤���B
���܂��Ƃ��āAi975�p��955/945�ł͓����Ȃ�Presler XE�̃T���v����3����O��
i865(AsRock)�ł̓`�F�b�N���Ȃ����ߓ������炵���悤���B(���̃T���v���͓d���Ⴂ�ˁc)
ttp://www.hkepc.com/bbs/viewthread.php?tid=506271
Intel to debut Broadwater 965 chipsets in 2Q 2006
ttp://www.digitimes.com/NewsShow/NewsSearch.asp?DocID=5D2C955D3B07B525482570B600455390&query=BROADWATER
Q2 2006��Broadwater�`�v�Z�g�𓊓��\��B
Presler/Conroe�p�Ȃ̂ŁA�ŏ��̃f�X�N�g�b�vx86 Mac�ɂ��ꂪ�g����\���傩�ȁB
G965
- Broadwater-GC
- 533/800/1066MHz FSB
- Dual-channel DDR2 800, Intel GMA
- $42
P965
- Broadwater-P
- 533/800/1066MHz FSB
- Dual-channel DDR2 800
- $38
Enterprise market
Q965
- Broadwater-G
- 533/800/1066MHz FSB
- Dual-channel DDR2 800, Intel GMA, Dual-display output, iAMT, SIPP
- $42
Q963
- Broadwater-GF
- 533/800/1066MHz FSB
- Dual-channel DDR2 533/667, Intel GMA, SIPP
- $39
iAMT = Intel Active Management Technology
SIPP = Stable Image Platform Program
ttp://www.digitimes.com/NewsShow/NewsSearch.asp?DocID=5D2C955D3B07B525482570B600455390&query=BROADWATER
Q2 2006��Broadwater�`�v�Z�g�𓊓��\��B
Presler/Conroe�p�Ȃ̂ŁA�ŏ��̃f�X�N�g�b�vx86 Mac�ɂ��ꂪ�g����\���傩�ȁB
G965
- Broadwater-GC
- 533/800/1066MHz FSB
- Dual-channel DDR2 800, Intel GMA
- $42
P965
- Broadwater-P
- 533/800/1066MHz FSB
- Dual-channel DDR2 800
- $38
Enterprise market
Q965
- Broadwater-G
- 533/800/1066MHz FSB
- Dual-channel DDR2 800, Intel GMA, Dual-display output, iAMT, SIPP
- $42
Q963
- Broadwater-GF
- 533/800/1066MHz FSB
- Dual-channel DDR2 533/667, Intel GMA, SIPP
- $39
iAMT = Intel Active Management Technology
SIPP = Stable Image Platform Program
�ȑO���J����Ă����p�b�P�[�W�ʐ^����_�C�T�C�Y�𐄑����Ă݂��B
Conroe: 148sqmm
Presler: 80sqmm*2
�����v���̎d���ŁASmithfield 216sqmm, Yonah��91sqmm����������A
����X�e�b�s���O�̐i��Ń_�C�T�C�Y���ς��\�������邪�A
���Ȃ�߂��������Ă�̂ł͂Ȃ����ƁB
Conroe: 148sqmm
Presler: 80sqmm*2
�����v���̎d���ŁASmithfield 216sqmm, Yonah��91sqmm����������A
����X�e�b�s���O�̐i��Ń_�C�T�C�Y���ς��\�������邪�A
���Ȃ�߂��������Ă�̂ł͂Ȃ����ƁB
Yonah�͓����A�ǂꂮ�炢�̎��g���ŏo�Ă��錩���݂����H
�ǂ����肪�ƁB
iMac�ɂ̓f���A���R�A���ڂ�̂��˂��B�V���O���R�A��������V���{���k���ȁc
iMac�ɂ̓f���A���R�A���ڂ�̂��˂��B�V���O���R�A��������V���{���k���ȁc
�ŐV��TheINQ�L���ł�Proc. Number���ύX�ɂȂ��Ă���݂����Ȃ̂ōX�V�B
ULV�ł͌���4���ɂȂ����悤���B
Intel decides on clock speeds for Yonah processors
Notebook Roadmaps
http://www.theinquirer.net/?article=27770
No. GHz FSB Cache Cash
Yonah DC T2600 2.16 667 2MB $640
Yonah DC T2500 2 667 2MB $420
Yonah DC T2400 1.83 667 2MB $295
Yonah DC T2300 1.66 667 2MB $240
Yonah SC T1300 1.66 667 2MB $210
Yonah LV DC L2400 1.66 667 2MB $325
Yonah LV DC L2300 1.5 667 2MB $285
ULV�ł͌���4���ɂȂ����悤���B
Intel decides on clock speeds for Yonah processors
Notebook Roadmaps
http://www.theinquirer.net/?article=27770
No. GHz FSB Cache Cash
Yonah DC T2600 2.16 667 2MB $640
Yonah DC T2500 2 667 2MB $420
Yonah DC T2400 1.83 667 2MB $295
Yonah DC T2300 1.66 667 2MB $240
Yonah SC T1300 1.66 667 2MB $210
Yonah LV DC L2400 1.66 667 2MB $325
Yonah LV DC L2300 1.5 667 2MB $285
202 �F���̖��ݒ��F2005/11/19(�y) 20:44:18 ID:6HvRYlqW
Yonah�̓R�[�h�l�[���Ȃ̂Ŏ��ۂ͂����Ȃ�
Core Duo T2600 2.16 667 2MB $640
Core Duo T2500 2 667 2MB $420
Core Duo T2400 1.83 667 2MB $295
Core Duo T2300 1.66 667 2MB $240
Core Solo T1300 1.66 667 2MB $210
Core Duo LV L2400 1.66 667 2MB $325
Core Duo LV L2300 1.5 667 2MB $285
Core Duo T2600 2.16 667 2MB $640
Core Duo T2500 2 667 2MB $420
Core Duo T2400 1.83 667 2MB $295
Core Duo T2300 1.66 667 2MB $240
Core Solo T1300 1.66 667 2MB $210
Core Duo LV L2400 1.66 667 2MB $325
Core Duo LV L2300 1.5 667 2MB $285
203 �FMAC�I�^��inteler �����F2005/11/19(�y) 22:04:25 ID:rPuhCKuv
>>201
�@�@------------------
�@�@No. GHz FSB Cache Cash
�@�@------------------
���i��"cash"����Ȃ���"price"�����ē˂�����ŗǂ������H
�@�@------------------
�@�@No. GHz FSB Cache Cash
�@�@------------------
���i��"cash"����Ȃ���"price"�����ē˂�����ŗǂ������H
����������������ATheINQ���W���[�N�Ŏg���Ă邾�����Ɓc�B
AMD bumps up quad core road map
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=173603258
Phil Hester, corporate vice president and CTO, said by 2007 AMD will introduce processors
that will contain at least four cores and scale to up to 32 sockets. The processors will be coupled
with L3 cache; an improved memory technology, presumable Fully Buffered DIMM (FBDIMM);
and Hypertransport 3.0 that will include support for fault tolerant I/O.
AMD��2007�N��Quad Core���i��p�ӂ��Ă���悤���B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=173603258
Phil Hester, corporate vice president and CTO, said by 2007 AMD will introduce processors
that will contain at least four cores and scale to up to 32 sockets. The processors will be coupled
with L3 cache; an improved memory technology, presumable Fully Buffered DIMM (FBDIMM);
and Hypertransport 3.0 that will include support for fault tolerant I/O.
AMD��2007�N��Quad Core���i��p�ӂ��Ă���悤���B
206 �FMAC�I�^��inteler �����F2005/11/19(�y) 23:06:54 ID:rPuhCKuv
>>205
���Ƌ������Ǝv�����BAMD��Analyst Meeting, Nov.2005�̃v���[���e�[�V����������A�������痎�Ƃ��邷�B
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_13588,00.html
�p��ŕ����������A�������webcast���ǂ����B
http://phx.corporate-ir.net/phoenix.zhtml?p=irol-eventDetails&c=74093&eventID=1118535
���Ƌ������Ǝv�����BAMD��Analyst Meeting, Nov.2005�̃v���[���e�[�V����������A�������痎�Ƃ��邷�B
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_13588,00.html
�p��ŕ����������A�������webcast���ǂ����B
http://phx.corporate-ir.net/phoenix.zhtml?p=irol-eventDetails&c=74093&eventID=1118535
Intel, Micron Form Flash Joint-Venture.
http://www.xbitlabs.com/news/memory/display/20051121222716.html
Intel��Micron��������Flash�̐V��Ђ𗧂��グ��悤���B
�gThe creation of this new company supports Intel�fs intent to maintain its industry-leading position in
nonvolatile memory and enables us to rapidly enter a fast-growing portion of the flash market segment.
We are looking forward to working with Micron, and are extremely pleased to have Apple broaden its
relationship with us,�h said Paul Otellini, Intel president and chief executive.
http://www.xbitlabs.com/news/memory/display/20051121222716.html
Intel��Micron��������Flash�̐V��Ђ𗧂��グ��悤���B
�gThe creation of this new company supports Intel�fs intent to maintain its industry-leading position in
nonvolatile memory and enables us to rapidly enter a fast-growing portion of the flash market segment.
We are looking forward to working with Micron, and are extremely pleased to have Apple broaden its
relationship with us,�h said Paul Otellini, Intel president and chief executive.
���㓡�O��Weekly�C�O�j���[�X��
Intel���V�u�����h�uIntel Core�v�ƁuIntel Centrino Duo�v��1���ɔ��\
http://pc.watch.impress.co.jp/docs/2005/1122/kaigai225.htm
Intel��Micron�ANAND�t���b�V�������̍��ى�Ђ�ݗ�
�`Apple�ɑ����ʂ�����
http://pc.watch.impress.co.jp/docs/2005/1122/intel.htm
�}����P�̃��r�L�^�X����
Intel�A�V�f���A���R�A�̃u�����h�l�[�����gINTEL CORE�h�Ɩ�����
http://pc.watch.impress.co.jp/docs/2005/1121/ubiq131.htm
Intel���V�u�����h�uIntel Core�v�ƁuIntel Centrino Duo�v��1���ɔ��\
http://pc.watch.impress.co.jp/docs/2005/1122/kaigai225.htm
Intel��Micron�ANAND�t���b�V�������̍��ى�Ђ�ݗ�
�`Apple�ɑ����ʂ�����
http://pc.watch.impress.co.jp/docs/2005/1122/intel.htm
�}����P�̃��r�L�^�X����
Intel�A�V�f���A���R�A�̃u�����h�l�[�����gINTEL CORE�h�Ɩ�����
http://pc.watch.impress.co.jp/docs/2005/1121/ubiq131.htm
>>208
--
�����Ƃ��AIntel�́AIA-32�A�[�L�e�N�`������菬���ȃf�o�C�X�ɓ��ڂ��邱�Ƃ��l���Ă���A
���̂��߂ɁA�������d�͂�IA-32 CPU���J�����Ă���B���̃��[�p���[�v���Z�b�T����������ƁA
��W���CPU���i�̃����W�͂�����̃A�[�L�e�N�`�����J�o�[����悤�ɂȂ邩������Ȃ��B
���[�p���[�v���Z�b�T�́A���ł�R&D���傩�玖�ƕ��ւƈڊǂ���A�{�i�I�ȊJ���t�F�C�Y��
�����Ă���ƌ�����B
--
Flash�ł̒�g�Ƃ���Apple�̖{���̑_���͂������̕��������肵�āc�B
--
�����Ƃ��AIntel�́AIA-32�A�[�L�e�N�`������菬���ȃf�o�C�X�ɓ��ڂ��邱�Ƃ��l���Ă���A
���̂��߂ɁA�������d�͂�IA-32 CPU���J�����Ă���B���̃��[�p���[�v���Z�b�T����������ƁA
��W���CPU���i�̃����W�͂�����̃A�[�L�e�N�`�����J�o�[����悤�ɂȂ邩������Ȃ��B
���[�p���[�v���Z�b�T�́A���ł�R&D���傩�玖�ƕ��ւƈڊǂ���A�{�i�I�ȊJ���t�F�C�Y��
�����Ă���ƌ�����B
--
Flash�ł̒�g�Ƃ���Apple�̖{���̑_���͂������̕��������肵�āc�B
{kind=link}
�Ȃo���̈����R���݂�������
212 �Finteler@�]�k�F2005/11/24(��) 00:03:00 ID:8CgQ/J4h
�����A"microprocessor"�̂��Ƃ�"MPU"�Ɨ����͓̂��{�̵��ݐ��ギ�炢�Ȃ̂ł�߂悤�B
���W�b�NIC�n�̃f�[�^�V�[�g��ǂދ@�����l�Ȃ番����Ǝv�����A
�C�O�̋Z�p�n�h�L�������g�ł́A"microprocessor"�������Ă�"��P"�Ƃ���̂����ʂ��B
http://h71028.www7.hp.com/enterprise/cache/81308-0-0-0-121.html
>Central Processing Unit (CPU):
>An older term used for processor.
CPU���Â��炵����(�m
���W�b�NIC�n�̃f�[�^�V�[�g��ǂދ@�����l�Ȃ番����Ǝv�����A
�C�O�̋Z�p�n�h�L�������g�ł́A"microprocessor"�������Ă�"��P"�Ƃ���̂����ʂ��B
http://h71028.www7.hp.com/enterprise/cache/81308-0-0-0-121.html
>Central Processing Unit (CPU):
>An older term used for processor.
CPU���Â��炵����(�m
213 �F���̖��ݒ��F2005/11/24(��) 15:14:40 ID:5+iVlSdi
����@�����ˁA���̂l�o�t�́A�b�h�r�b�͂q�h�r�b�̋Z�p��
�@�@�@�@�@�@�ǂ�ǂ����������ŁA�q�h�r�b�`�b�v���̂�
�@�@�@�@�@�@���ߐ����ǂ�ǂ₷�Ƃ��A�b�h�r�b�ɋ߂Â��Ă���悤�ȏ�ԂŁA
�@�@�@�@�@�@�q�h�r�b���b�h�r�b���A�Ƃ����_���͖��Ӗ���
�@�@�@�@�@�@�Ȃ����͎̂����ł���B
�V�c�@�����Ȃ�ł��B���ǂ̂Ƃ���⑺�������l�������̂̈�́A
�@�@�@�@�@�@���l�ȗp�r�����ɍ��ꂽ�l�X�Ȏ�ނ̂l�o�t���A
�@�@�@�@�@�@���������ꂽ�d�]���̒��ŃX���[�Y�ɖ��߂������ł��邽�߂́A
�@�@�@�@�@�@�������̂��閽�߃Z�b�g�̓���Ȃ�ł��B
�@�@�@�@�@�@�����瓖���̃��[�N�X�e�[�V�����̗p�r�ɍ�����
�@�@�@�@�@�@���߃Z�b�g�𐧌�����͍̂���ƁB
�@�@�@�@�@�@���̃��[�N�X�e�[�V�����ł���u�}���`���f�B�A�@�\�v�Ƃ���
�@�@�@�@�@�@�t�����K�v�ɂȂ��āA���ߐ��𑝂₵�Ăb�h�r�b�ɋ߂Â��Ă���̂́A
�@�@�@�@�@�@�⑺�����̌��ʂ��������������Ƃ����؋�����Ȃ��ł��傤���B
�@�@�@�@�@�@�ǂ�ǂ����������ŁA�q�h�r�b�`�b�v���̂�
�@�@�@�@�@�@���ߐ����ǂ�ǂ₷�Ƃ��A�b�h�r�b�ɋ߂Â��Ă���悤�ȏ�ԂŁA
�@�@�@�@�@�@�q�h�r�b���b�h�r�b���A�Ƃ����_���͖��Ӗ���
�@�@�@�@�@�@�Ȃ����͎̂����ł���B
�V�c�@�����Ȃ�ł��B���ǂ̂Ƃ���⑺�������l�������̂̈�́A
�@�@�@�@�@�@���l�ȗp�r�����ɍ��ꂽ�l�X�Ȏ�ނ̂l�o�t���A
�@�@�@�@�@�@���������ꂽ�d�]���̒��ŃX���[�Y�ɖ��߂������ł��邽�߂́A
�@�@�@�@�@�@�������̂��閽�߃Z�b�g�̓���Ȃ�ł��B
�@�@�@�@�@�@�����瓖���̃��[�N�X�e�[�V�����̗p�r�ɍ�����
�@�@�@�@�@�@���߃Z�b�g�𐧌�����͍̂���ƁB
�@�@�@�@�@�@���̃��[�N�X�e�[�V�����ł���u�}���`���f�B�A�@�\�v�Ƃ���
�@�@�@�@�@�@�t�����K�v�ɂȂ��āA���ߐ��𑝂₵�Ăb�h�r�b�ɋ߂Â��Ă���̂́A
�@�@�@�@�@�@�⑺�����̌��ʂ��������������Ƃ����؋�����Ȃ��ł��傤���B
Intel�fs Chips to Boost Processor System Bus Speed.
http://www.xbitlabs.com/news/cpu/display/20051125034416.html
Dempsey�͂ɂ�1066MHz�ƐV���� 1333MHz FSB���T�|�[�g�����悤���B
http://www.xbitlabs.com/news/cpu/display/20051125034416.html
Dempsey�͂ɂ�1066MHz�ƐV���� 1333MHz FSB���T�|�[�g�����悤���B
Intel to Manufacture Chipsets Using 90nm Process Technology.
http://www.xbitlabs.com/news/chipsets/display/20051124214142.html
Broadwater(x965 Express)�`�v�Z�g��90nm�v���Z�X���g����悤���B
http://www.xbitlabs.com/news/chipsets/display/20051124214142.html
Broadwater(x965 Express)�`�v�Z�g��90nm�v���Z�X���g����悤���B
Intel adds follow-up series to 915 chipset family
http://www.digitimes.com/mobos/a20051125A2007.html
Intel��i915�̃o�����[�]�[���̌�p�Ƃ���Q2 2006��946�`�v�Z�g�𓊓�����悤���B
Broadwater�Ɠ������ɓ�������A���ݕ������Ȃ����͗l�B
�f�X�N�g�b�v������Yonah�p�`�v�Z�g�ł�
945GT�ɉ����A�r�f�I�����^��945GZ�����C���i�b�v�ɉ����悤���B
http://www.digitimes.com/mobos/a20051125A2007.html
Intel��i915�̃o�����[�]�[���̌�p�Ƃ���Q2 2006��946�`�v�Z�g�𓊓�����悤���B
Broadwater�Ɠ������ɓ�������A���ݕ������Ȃ����͗l�B
�f�X�N�g�b�v������Yonah�p�`�v�Z�g�ł�
945GT�ɉ����A�r�f�I�����^��945GZ�����C���i�b�v�ɉ����悤���B
217 �FMAC�I�^��inteler �����F2005/11/27(��) 18:04:46 ID:St2Mb+Vm
>>215
inteler����̑匙���ȑ匴���̋L���̈��p�ň��������ǁAPCI Express���g������`�b�v�Z�b�g���v���Z�b�T
�Ɠ��l�̃v���Z�X�Ő������邱�Ƃ�K�R�Ȃ�B
http://pcweb0.pc.mycom.co.jp/column/sopinion/100/
�@�@--------------------
�@�@PCI-Express���t���t�@���N�V�����ŃC���v�������g���悤�Ƃ���ƁAPHY�Ɋւ��Ă�Standard��0.18��m
�@�@�v���Z�X�ł������ł��邪�AMAC���ƂĂ�0.18��m�v���Z�X�ł͎��܂肫�ꂸ�A�Œ�0.13��m�v���Z�X��
�@�@�K�v�B���L�����y�ɂ͋��炭90nm�v���Z�X���K�v�Ƃ�������������A���݂̃v���Z�X�ł͈����ɍ\�z
�@�@����̂��s�\�����炾�B
�@�@--------------------
����2003�N�Ɋ��ɓ����w�E���s���Ă���̂������������m���B
http://pcweb0.pc.mycom.co.jp/column/sopinion/050/
inteler����̑匙���ȑ匴���̋L���̈��p�ň��������ǁAPCI Express���g������`�b�v�Z�b�g���v���Z�b�T
�Ɠ��l�̃v���Z�X�Ő������邱�Ƃ�K�R�Ȃ�B
http://pcweb0.pc.mycom.co.jp/column/sopinion/100/
�@�@--------------------
�@�@PCI-Express���t���t�@���N�V�����ŃC���v�������g���悤�Ƃ���ƁAPHY�Ɋւ��Ă�Standard��0.18��m
�@�@�v���Z�X�ł������ł��邪�AMAC���ƂĂ�0.18��m�v���Z�X�ł͎��܂肫�ꂸ�A�Œ�0.13��m�v���Z�X��
�@�@�K�v�B���L�����y�ɂ͋��炭90nm�v���Z�X���K�v�Ƃ�������������A���݂̃v���Z�X�ł͈����ɍ\�z
�@�@����̂��s�\�����炾�B
�@�@--------------------
����2003�N�Ɋ��ɓ����w�E���s���Ă���̂������������m���B
http://pcweb0.pc.mycom.co.jp/column/sopinion/050/
>>182
Apple��x86���Y�ɂ�����͂��߂��p�N����Ƃ��B
Apple��x86���Y�ɂ�����͂��߂��p�N����Ƃ��B
219 �F���̖��ݒ��F2005/11/29(��) 20:55:39 ID:6KJC7PQI
Mac mini�ɂ�Core Solo���ڂ����ˁH
�ł��A���ꂾ�ƃN���b�N���c
�ł��A���ꂾ�ƃN���b�N���c
220 �F���̖��ݒ��F2005/11/30(��) 08:37:41 ID:lJzzLrnx
���H��A100TFLOPS�̃X�p�R���iOpteron 10000�R�A�j
http://pc.watch.impress.co.jp/docs/2005/1130/titech.htm
�ł��ASIMD�A�N�Z�����[�^�{�[�h�̏����\�͂��܂߂�100TFLOPS���B
�ǂ�Ȃ���ł����ˁc�B
http://pc.watch.impress.co.jp/docs/2005/1130/titech.htm
�ł��ASIMD�A�N�Z�����[�^�{�[�h�̏����\�͂��܂߂�100TFLOPS���B
�ǂ�Ȃ���ł����ˁc�B
221 �F���̖��ݒ��F2005/11/30(��) 14:50:05 ID:jH/79kXG
>987 ���O�F ���̖��ݒ� Mail�F sage ���e���F 05/11/30(��) 13:58:00 ID�F 76G4JF90
>
>AppleInsider�ɍŐV�r���h��Rosetta��Velocity Engine�ɑΉ��Ƃ������Ă�����
>�{�����Ƃ����Ȃ��B
Velocity Engine���߂�SSE���߂ɕϊ������ł����ˁB
�ł���̂��Ȃ��B
>
>AppleInsider�ɍŐV�r���h��Rosetta��Velocity Engine�ɑΉ��Ƃ������Ă�����
>�{�����Ƃ����Ȃ��B
Velocity Engine���߂�SSE���߂ɕϊ������ł����ˁB
�ł���̂��Ȃ��B
Intel Yonah Performance Preview - Part I: The Exclusive First Look at Yonah
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2627
Yonah�̃x���`�ł܂Ƃ��Ȃ̂����܂����B
��̑������āAAthlon 3800+�ɂ��y�Ȃ��͗l�B
FPU/SSE���͋�������Ă��邽�߁ADothan�ɑ���A�h�o���e�[�W�͂��Ȃ肠�肻�����B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2627
Yonah�̃x���`�ł܂Ƃ��Ȃ̂����܂����B
��̑������āAAthlon 3800+�ɂ��y�Ȃ��͗l�B
FPU/SSE���͋�������Ă��邽�߁ADothan�ɑ���A�h�o���e�[�W�͂��Ȃ肠�肻�����B
���Ȃ݂�Intel x86�v���Z�b�T�ŏ��߂ďȓd�͂��ӎ����āA
��X�I�ɃN���b�N�Q�[�e�B���O�������̂��ANetBurst�A�[�L�ŁA
PenM�́AP6��NetBurst�����̏ȓd�͋@�\�����Ƃ���lj��������̂ŁA
���͂����������Ƃ��Ȃ��B
uOPs-Fusion�ɂ��Ă�P6���ォ��ꕔ����Ă���\����
�w�E����悤�ȃ\�[�X������A�ǂ����炪PenIII��PenM�ł̐V�����Ȃ̂��͐��������ȂƂ����B
�Ƃ����������w�E����Ǝ���ł�PenM&AMD�M�҂������̂ō��܂Ŗق��Ă܂����B
��X�I�ɃN���b�N�Q�[�e�B���O�������̂��ANetBurst�A�[�L�ŁA
PenM�́AP6��NetBurst�����̏ȓd�͋@�\�����Ƃ���lj��������̂ŁA
���͂����������Ƃ��Ȃ��B
uOPs-Fusion�ɂ��Ă�P6���ォ��ꕔ����Ă���\����
�w�E����悤�ȃ\�[�X������A�ǂ����炪PenIII��PenM�ł̐V�����Ȃ̂��͐��������ȂƂ����B
�Ƃ����������w�E����Ǝ���ł�PenM&AMD�M�҂������̂ō��܂Ŗق��Ă܂����B
���}����P�̃��r�L�^�X���ǁ�
Intel�A�uCentrino Duo�v��1��5���ɔ��\��
�`�啝�ɏ���d�͂�������Napa�v���b�g�t�H�[��
http://pc.watch.impress.co.jp/docs/2005/1128/ubiq132.htm
���悢��Yonah�Ɋւ��Ă͍����̃��f�B�A�̕�����[�����Ă����ȁB
�����������̃X���Ŏ��グ��K�v���͔���Ă����悤���B
Intel�A�uCentrino Duo�v��1��5���ɔ��\��
�`�啝�ɏ���d�͂�������Napa�v���b�g�t�H�[��
http://pc.watch.impress.co.jp/docs/2005/1128/ubiq132.htm
���悢��Yonah�Ɋւ��Ă͍����̃��f�B�A�̕�����[�����Ă����ȁB
�����������̃X���Ŏ��グ��K�v���͔���Ă����悤���B
���㓡�O��Weekly�C�O�j���[�X��
Core�u�����h���ƃN�A�b�h�R�A������������Intel�f�X�N�g�b�vCPU
http://pc.watch.impress.co.jp/docs/2005/1125/kaigai226.htm
>Intel�͔r�M�ɂ��Đ���\�����[�V�������^���Ɍ������Ă���Ƃ����B
>���C���X�g���[��PC��TDP��Conroe��65W�ւƉ�������̂́A�n�C�G���h�̃��C����
>��TDP�H�����ێ�����B�N�A�b�h�R�A��TDP������ɓ���Ă��邽�߂��ƌ����B
�V���c�B
>Conroe�n�ł́A�h���i(Derivative)�Ƃ��āA�����̃R�[�h�l�[�����`�����Ă���B
Conroe�̔h���i(Desktop)�ɂ���
- Millivile
-- Desktop Celeron
-- 2007
- Allendale
-- Mainstream Desktop (Single Core)
-- Conroe�̗����łŁACedarMill�̌�p�`�b�v
-- S2xxx
-- H2 2006
Core�u�����h���ƃN�A�b�h�R�A������������Intel�f�X�N�g�b�vCPU
http://pc.watch.impress.co.jp/docs/2005/1125/kaigai226.htm
>Intel�͔r�M�ɂ��Đ���\�����[�V�������^���Ɍ������Ă���Ƃ����B
>���C���X�g���[��PC��TDP��Conroe��65W�ւƉ�������̂́A�n�C�G���h�̃��C����
>��TDP�H�����ێ�����B�N�A�b�h�R�A��TDP������ɓ���Ă��邽�߂��ƌ����B
�V���c�B
>Conroe�n�ł́A�h���i(Derivative)�Ƃ��āA�����̃R�[�h�l�[�����`�����Ă���B
Conroe�̔h���i(Desktop)�ɂ���
- Millivile
-- Desktop Celeron
-- 2007
- Allendale
-- Mainstream Desktop (Single Core)
-- Conroe�̗����łŁACedarMill�̌�p�`�b�v
-- S2xxx
-- H2 2006
- Kentsfield
-- Desktop Extreme Edition
-- mid-2007
- Ridgefield
-- 45nm
-- Performance Desktop
-- 2007
-- Conroe�̃V�������N��
-- FSB1333MHz, 4MB-6MB L2�L���b�V��
- Wolfdale
-- 45nm
-- Mainstream Desktop
-- Ridgefield�̗����łŁAAllendale�̌�p�`�b�v
-- 2007
-- Desktop Extreme Edition
-- mid-2007
- Ridgefield
-- 45nm
-- Performance Desktop
-- 2007
-- Conroe�̃V�������N��
-- FSB1333MHz, 4MB-6MB L2�L���b�V��
- Wolfdale
-- 45nm
-- Mainstream Desktop
-- Ridgefield�̗����łŁAAllendale�̌�p�`�b�v
-- 2007
Intel to take 'Averill' to market as Centrino-like platform
http://www.theregister.co.uk/2005/11/29/intel_averill_platform_plan/
Centrino, Viiv�ɑ����A��3�̃v���b�g�t�H�[���u�����h�v�撆�炵���B
�R�[�h�l�[����Averill�BBroadwater�`�v�Z�g�̓�����ɂł�炵���B
����ܕς���ĂȂ��̂ɐV�������O�������X���āA
����Ȃ��Ă��炻�̂�������҂̊S�Ȃ��Ȃ����Ⴄ��Ȃ��c(;�L�D`)
������˂��`�B
http://www.theregister.co.uk/2005/11/29/intel_averill_platform_plan/
Centrino, Viiv�ɑ����A��3�̃v���b�g�t�H�[���u�����h�v�撆�炵���B
�R�[�h�l�[����Averill�BBroadwater�`�v�Z�g�̓�����ɂł�炵���B
����ܕς���ĂȂ��̂ɐV�������O�������X���āA
����Ȃ��Ă��炻�̂�������҂̊S�Ȃ��Ȃ����Ⴄ��Ȃ��c(;�L�D`)
������˂��`�B
228 �F���̖��ݒ��F2005/11/30(��) 22:57:35 ID:1f3O6poP
�v���b�g�t�H�[����Viiv(���@�C�u)�͂Ȃ������{���ე�B�[�u���ČĂԂ�
Intel's 65nm Extreme Edition arrives late to party
http://www.theinquirer.net/?article=28074
Presler Pentium Extreme Edition 955(3.46GHz, 1066MHz FSB) ��12/27�Ƀ����[�X����邱�ƂɂȂ����悤���B
�ŏ���65nm���i��Presler�Ƃ������ƂɂȂ肻�����B
http://www.theinquirer.net/?article=28074
Presler Pentium Extreme Edition 955(3.46GHz, 1066MHz FSB) ��12/27�Ƀ����[�X����邱�ƂɂȂ����悤���B
�ŏ���65nm���i��Presler�Ƃ������ƂɂȂ肻�����B
Intel�A�C�X���G����45nm�v���Z�X/300mm�E�G�n�Ή��́uFab 28�v�V��
http://pcweb.mycom.co.jp/news/2005/12/02/101.html
http://pcweb.mycom.co.jp/news/2005/12/02/101.html
>�������l����Ƃ���A������1980�N�Ƀ}�C�N���v���Z�b�T�\�\
>�{���I�ɂ̓R���s���[�^�E�I���E�`�b�v�\�\�����C���t���[���v���Z�b�T��������ɂ���
>���Ɠ����悤�ȁA�V���ȋZ�p�̓]���_�ɂ���B�����́A���́u�}�C�N���V�X�e���v�\�\
>�{���I�ɂ̓T�[�o�E�I���E�`�b�v�\�\���}�C�N���v���Z�b�T������x��ɂ���ƌ��B
�S���R��Ɠ����������̖ϑz���ȁB
�����`�b�v�\���̃��C���t���[��CPU���A���͓d��p�ɂ����Ȃ������P��`�b�v��uP��
�쒀���ꂽ�̂Ɠ��������x�̓V�X�e�����x���N���肻���ȋC�z���Y���Ă����B
�����A�N���C�A���gPC�ł́A��K�͂ȃ}���`�R�A�̓}�C�N���V�X�e���̉��ɂ͂Ȃ�Ȃ�
�Ƃ����̂��R��̍l���B
>�{���I�ɂ̓R���s���[�^�E�I���E�`�b�v�\�\�����C���t���[���v���Z�b�T��������ɂ���
>���Ɠ����悤�ȁA�V���ȋZ�p�̓]���_�ɂ���B�����́A���́u�}�C�N���V�X�e���v�\�\
>�{���I�ɂ̓T�[�o�E�I���E�`�b�v�\�\���}�C�N���v���Z�b�T������x��ɂ���ƌ��B
�S���R��Ɠ����������̖ϑz���ȁB
�����`�b�v�\���̃��C���t���[��CPU���A���͓d��p�ɂ����Ȃ������P��`�b�v��uP��
�쒀���ꂽ�̂Ɠ��������x�̓V�X�e�����x���N���肻���ȋC�z���Y���Ă����B
�����A�N���C�A���gPC�ł́A��K�͂ȃ}���`�R�A�̓}�C�N���V�X�e���̉��ɂ͂Ȃ�Ȃ�
�Ƃ����̂��R��̍l���B
EPI �̐���ɂ�� CMP �̒��������{�g���l�b�N�̉���
http://www.intel.co.jp/jp/developer/technology/magazine/research/EPI-throttling-1005.htm
�\�X���Ŗʔ����\�[�X����������B
http://www.intel.co.jp/jp/developer/technology/magazine/research/EPI-throttling-1005.htm
�\�X���Ŗʔ����\�[�X����������B
233 �Finteler@�R�ꃁ���F2005/12/04(��) 13:38:39 ID:aJeY3YnE0
��̘_���̑O��ł�AMP(Asymmetric Multiprocessor, ��Ώ̃}���`�v���Z�b�T)�\��
�̃}���`�R�A�Z�p�ŁAAmdahl�̖@�������z������Ǝ咣���Ă���݂����B
Amdahl�̖@���ł́A�V�X�e��������������Ă��R�[�h�̒��������̏�������
���������������Đ��\�����サ�Ȃ��킯�����AAMP�ł́A�����������K�̓R�A�A
���������K�̓R�A�����ꂼ��S������悤�ɏ�����U�蕪����B
����ɂ�蒀�������ƕ����̗���������������AAmdahl�̖@���ɂ��
��������z������Ƃ������̂炵���B
�ŏ�L�̘_���ł́AAMP�\���̑�K�̓}���`�R�A�v���Z�b�T�����̓d�͔͈�
�œ��삳���邽�߂̓d�͊Ǘ��Z�p�ɂ��ďq�ׂ��Ă���킯�����c�B
�ʓ|�Ȃ̂ő����͌�ŁB
�̃}���`�R�A�Z�p�ŁAAmdahl�̖@�������z������Ǝ咣���Ă���݂����B
Amdahl�̖@���ł́A�V�X�e��������������Ă��R�[�h�̒��������̏�������
���������������Đ��\�����サ�Ȃ��킯�����AAMP�ł́A�����������K�̓R�A�A
���������K�̓R�A�����ꂼ��S������悤�ɏ�����U�蕪����B
����ɂ�蒀�������ƕ����̗���������������AAmdahl�̖@���ɂ��
��������z������Ƃ������̂炵���B
�ŏ�L�̘_���ł́AAMP�\���̑�K�̓}���`�R�A�v���Z�b�T�����̓d�͔͈�
�œ��삳���邽�߂̓d�͊Ǘ��Z�p�ɂ��ďq�ׂ��Ă���킯�����c�B
�ʓ|�Ȃ̂ő����͌�ŁB
Top Secret Intel Processor Plans Uncovered
http://www.tomshardware.com/cpu/20051203/index.html
�\�X����MAC�I�^���\����Intel���[�h�}�b�v�B
����͂������c(;�L�D`)
�ڍׂ́AMAC�I�^���撣���Ă܂Ƃ߂Ă邩��\�X�����݂�ׂ��B
�R��̃��[�J���������啝�X�V�ł���B
http://www.tomshardware.com/cpu/20051203/index.html
�\�X����MAC�I�^���\����Intel���[�h�}�b�v�B
����͂������c(;�L�D`)
�ڍׂ́AMAC�I�^���撣���Ă܂Ƃ߂Ă邩��\�X�����݂�ׂ��B
�R��̃��[�J���������啝�X�V�ł���B
235 �FMAC�I�^��inteler �����F2005/12/04(��) 14:47:22 ID:wazvlmiz0
>>234
����������������ŁA�����N���炢�\���Ă��ꂽ�����������������B
http://pc7.2ch.net/test/read.cgi/jisaku/1131783188/730-733n
����������������ŁA�����N���炢�\���Ă��ꂽ�����������������B
http://pc7.2ch.net/test/read.cgi/jisaku/1131783188/730-733n
Bloomfield�̒Ԃ肪�Ԉ���Ă��邷��B
237 �FMAC�I�^��inteler �����F2005/12/04(��) 14:59:58 ID:wazvlmiz0
>>236
���w�E���ӂ��邷�B�ł��Q�����˂�̏������݂�ҏW�ł��Ȃ���ŁA������ɂ������Ă�����Ɗ���Ǝv�����B
���w�E���ӂ��邷�B�ł��Q�����˂�̏������݂�ҏW�ł��Ȃ���ŁA������ɂ������Ă�����Ɗ���Ǝv�����B
238 �F���̖��ݒ��F2005/12/07(��) 21:58:39 ID:NY+vk46k0
���悢����v���Z�b�T�̎��シ�B
�d�q�v���Z�b�T�͎���x��ɂȂ邷�B
�k�r�h�����u���v�Ŕz���@�m�d�b�J���A�����͂P�O�O�{��
http://www.asahi.com/business/update/1206/069.html
�d�q�v���Z�b�T�͎���x��ɂȂ邷�B
�k�r�h�����u���v�Ŕz���@�m�d�b�J���A�����͂P�O�O�{��
http://www.asahi.com/business/update/1206/069.html
239 �Finteler@�]�k�F2005/12/07(��) 23:44:54 ID:VqWRLdYd0
�{���ɗ]�k�ł����A�Z�p�_���Ƃ͂���������͐l�ԂȂ̂ŁA���̎咣����ɐ������킯�ł͂Ȃ��B
����Ɗ֘A���āA�v���Z�b�T�Ɋւ���_���̎咣�ł́A�ܖ������ꂪ�������₷���̂Œ��ӂ��K�v�B
�����̃v���Z�b�T�ō̗p����ł��낤�Z�p�̓|�W�e�B�u�ɁA����ɑR����Z�p�̓l�K�e�B�u��
�������ʂ��܂Ƃ߂�͓̂��R�̂��ƁB
�܂��A�����Z�p�̐i������ŁA�e�N�m���W�ɂ�����g�����W�X�^�����傫���ω����邽�߁A
�͖̂��ʂƘ_���Ŏ咣����Ă����������A���̂��肠�܂郊�\�[�X�Ȃ����Č��ʂ���Ƃ������Ƃ��悭����B
�g�����h�̈ڂ�ς��͌������̂Łc�B
�X�[�p�[�X�J���֘A�̘b�����������ǁA�_��������ۂ̐��i��\������I�^�N�̈�e�N�j�b�N�Ƃ���
�m���Ă����������悢���Ǝv���܂��B
����Ɗ֘A���āA�v���Z�b�T�Ɋւ���_���̎咣�ł́A�ܖ������ꂪ�������₷���̂Œ��ӂ��K�v�B
�����̃v���Z�b�T�ō̗p����ł��낤�Z�p�̓|�W�e�B�u�ɁA����ɑR����Z�p�̓l�K�e�B�u��
�������ʂ��܂Ƃ߂�͓̂��R�̂��ƁB
�܂��A�����Z�p�̐i������ŁA�e�N�m���W�ɂ�����g�����W�X�^�����傫���ω����邽�߁A
�͖̂��ʂƘ_���Ŏ咣����Ă����������A���̂��肠�܂郊�\�[�X�Ȃ����Č��ʂ���Ƃ������Ƃ��悭����B
�g�����h�̈ڂ�ς��͌������̂Łc�B
�X�[�p�[�X�J���֘A�̘b�����������ǁA�_��������ۂ̐��i��\������I�^�N�̈�e�N�j�b�N�Ƃ���
�m���Ă����������悢���Ǝv���܂��B
240 �FMAC�I�^��inteler �����F2005/12/08(��) 05:16:26 ID:ZrPdzFxs0
>>239
���ǂ̂���_���ŕۏ����̂�A���̒��x���B
�@�E�g���f��������Ȃ�(��)
�@�E�w�i�ƂȂ闝�_�Ƙ_���W�J�ɐ�����������
�@�E�f�[�^�ɉR������
���ɒ��҂̍l�@��猋�_���Ɏ�����K�v�햳�����B
�悭�A�u�X�g���N�g�Ɛ}�\�������Ȃ����Ęb�����������ǁA���ǁA��X���x���`�}�[�N�L�������鎞�ƈꏏ����B
�[���̂����Ȃ����ʂ�����Ă���ƁA������������߂ēǂݒ����Ƃ��B�B�B
���ǂ̂���_���ŕۏ����̂�A���̒��x���B
�@�E�g���f��������Ȃ�(��)
�@�E�w�i�ƂȂ闝�_�Ƙ_���W�J�ɐ�����������
�@�E�f�[�^�ɉR������
���ɒ��҂̍l�@��猋�_���Ɏ�����K�v�햳�����B
�悭�A�u�X�g���N�g�Ɛ}�\�������Ȃ����Ęb�����������ǁA���ǁA��X���x���`�}�[�N�L�������鎞�ƈꏏ����B
�[���̂����Ȃ����ʂ�����Ă���ƁA������������߂ēǂݒ����Ƃ��B�B�B
>>85
P6�p�C�v���C���͗v��ƁA
�t�F�b�`�@2
�f�R�[�h 3
�X�P�W���[�� 3
���s 1(1uops�̒P������)
���^�C�A 3
�Ȃ킯�����A�閧��P6�p�C�v���C���ڍ׃��\�[�X���݂�ƁA
���߂ɂ���ẮA���U�x�[�V�����X�e�[�V�����ւ̏������݂ŃX�P�W���[���X�e�[�W���lj���1�͂���炵��
�̂ŁA�f�R�[�_�`���^�C�A�܂ł̃p�C�v���C����11�Ɠǂ߂��(�t�F�b�`�Ȃǂ͓���Ȃ�)�B
���Ȃ݂ɁANetBurst�o��ȍ~�ɂ悭��������悤�ɂȂ����AMisprediction-Pipe�̐}�ł́A
�t�F�b�`������s�܂ł�10�X�e�[�W�̐}�������B
P6�A�[�L����ɂ悭���������A12�X�e�[�W���ł́A
�t�F�b�`���烊�^�C�A�܂łŁA��̃��U�x�[�V�����X�e�[�V�����ւ̏������݃X�e�[�W�͊܂܂Ȃ��B
�܂��A�����܂ōׂ������Ƃɂ�������Ă�̂͐��E�ł��R�ꂾ�����炢��������Ȃ��̂ŁA
�ǂ��ł��悢�ł����ˁB
�v�́AMerom�ł́A�f�R�[�h���烊�^�C�A�܂łŁA14����Ȃ����낤���Ƃ������Ƃł��B
P6�p�C�v���C���͗v��ƁA
�t�F�b�`�@2
�f�R�[�h 3
�X�P�W���[�� 3
���s 1(1uops�̒P������)
���^�C�A 3
�Ȃ킯�����A�閧��P6�p�C�v���C���ڍ׃��\�[�X���݂�ƁA
���߂ɂ���ẮA���U�x�[�V�����X�e�[�V�����ւ̏������݂ŃX�P�W���[���X�e�[�W���lj���1�͂���炵��
�̂ŁA�f�R�[�_�`���^�C�A�܂ł̃p�C�v���C����11�Ɠǂ߂��(�t�F�b�`�Ȃǂ͓���Ȃ�)�B
���Ȃ݂ɁANetBurst�o��ȍ~�ɂ悭��������悤�ɂȂ����AMisprediction-Pipe�̐}�ł́A
�t�F�b�`������s�܂ł�10�X�e�[�W�̐}�������B
P6�A�[�L����ɂ悭���������A12�X�e�[�W���ł́A
�t�F�b�`���烊�^�C�A�܂łŁA��̃��U�x�[�V�����X�e�[�V�����ւ̏������݃X�e�[�W�͊܂܂Ȃ��B
�܂��A�����܂ōׂ������Ƃɂ�������Ă�̂͐��E�ł��R�ꂾ�����炢��������Ȃ��̂ŁA
�ǂ��ł��悢�ł����ˁB
�v�́AMerom�ł́A�f�R�[�h���烊�^�C�A�܂łŁA14����Ȃ����낤���Ƃ������Ƃł��B
242 �Finteler@�������F2005/12/09(��) 00:12:56 ID:DvtNPgsu0
�����ԈႦ�Ă����̂ŏC�����܂����B
>>85
P6�p�C�v���C���͗v��ƁA
�t�F�b�`�@2
�f�R�[�h 3
�X�P�W���[�� 3 or 4
���s 1(1uops�̒P������)
���^�C�A 3
���߂ɂ���ẮA���U�x�[�V�����X�e�[�V�����ւ̏������݂ŃX�P�W���[���X�e�[�W���lj���1�͂���炵��
�̂ŁA�f�R�[�_�`���^�C�A�܂ł̃p�C�v���C����11�Ɠǂ߂��(�t�F�b�`�Ȃǂ͓���Ȃ�)�B
���Ȃ݂ɁANetBurst�o��ȍ~�ɂ悭��������悤�ɂȂ����AMisprediction-Pipe�̐}�ł́A
�t�F�b�`������s�܂ł�10�X�e�[�W�̐}�������B
P6�A�[�L����ɂ悭���������A12�X�e�[�W���ł́A
�t�F�b�`���烊�^�C�A�܂łŁA��̃��U�x�[�V�����X�e�[�V�����ւ̏������݃X�e�[�W�͊܂܂Ȃ��B
�܂��A�����܂ōׂ������Ƃɂ�������Ă�̂͐��E�ł��R�ꂾ�����炢��������Ȃ��̂ŁA
�ǂ��ł��悢�ł����ˁB
�v�́AMerom�ł́A�f�R�[�h���烊�^�C�A�܂łŁA14����Ȃ����낤���Ƃ������Ƃł��B
>>85
P6�p�C�v���C���͗v��ƁA
�t�F�b�`�@2
�f�R�[�h 3
�X�P�W���[�� 3 or 4
���s 1(1uops�̒P������)
���^�C�A 3
���߂ɂ���ẮA���U�x�[�V�����X�e�[�V�����ւ̏������݂ŃX�P�W���[���X�e�[�W���lj���1�͂���炵��
�̂ŁA�f�R�[�_�`���^�C�A�܂ł̃p�C�v���C����11�Ɠǂ߂��(�t�F�b�`�Ȃǂ͓���Ȃ�)�B
���Ȃ݂ɁANetBurst�o��ȍ~�ɂ悭��������悤�ɂȂ����AMisprediction-Pipe�̐}�ł́A
�t�F�b�`������s�܂ł�10�X�e�[�W�̐}�������B
P6�A�[�L����ɂ悭���������A12�X�e�[�W���ł́A
�t�F�b�`���烊�^�C�A�܂łŁA��̃��U�x�[�V�����X�e�[�V�����ւ̏������݃X�e�[�W�͊܂܂Ȃ��B
�܂��A�����܂ōׂ������Ƃɂ�������Ă�̂͐��E�ł��R�ꂾ�����炢��������Ȃ��̂ŁA
�ǂ��ł��悢�ł����ˁB
�v�́AMerom�ł́A�f�R�[�h���烊�^�C�A�܂łŁA14����Ȃ����낤���Ƃ������Ƃł��B
243 �F���̖��ݒ��F2005/12/09(��) 09:30:32 ID:fdNmBMsv0
Merom�֘A�̏��l�^�ϑz
- Memory Disambiguation~
Speculative Load�̈��ŁA�p�C�v���C����FrontEnd�i�K�ŁA�������̈ˑ��W���������Ă��܂��B
�X�g�A���߂̌��ʂ�҂O�ɁAValue Predictor�Ȃǂ�p���āA
�㑱�̃��[�h���߂̃A�h���X�����肵�A���[�h�I�y���[�V�����𓊋@�I�ɔ��s�A��ǂ݁B
���ʂ̌����̓��^�C�A���ɍs���B
(�������A�N�Z�X���Ԃ�Z�k���A�p�C�v���C���X�g�[����}����B)
- Macro OP Fusion
x86���߂���̃f�R�[�_�ŕ��������ł���悤�ɁA�������Ă��܂��B
(FrontEnd�̃��\�[�X�ߖ�ƒ����d�͉�)
- Memory Disambiguation~
Speculative Load�̈��ŁA�p�C�v���C����FrontEnd�i�K�ŁA�������̈ˑ��W���������Ă��܂��B
�X�g�A���߂̌��ʂ�҂O�ɁAValue Predictor�Ȃǂ�p���āA
�㑱�̃��[�h���߂̃A�h���X�����肵�A���[�h�I�y���[�V�����𓊋@�I�ɔ��s�A��ǂ݁B
���ʂ̌����̓��^�C�A���ɍs���B
(�������A�N�Z�X���Ԃ�Z�k���A�p�C�v���C���X�g�[����}����B)
- Macro OP Fusion
x86���߂���̃f�R�[�_�ŕ��������ł���悤�ɁA�������Ă��܂��B
(FrontEnd�̃��\�[�X�ߖ�ƒ����d�͉�)
���܂�
The Real Story about Sun's Niagara
http://h71028.www7.hp.com/ERC/cache/280124-0-0-0-121.html
HP��HP���Niagara���o�J�ɂ��Ă���B
�T�[�o�Ƃ͂����V���O���X���b�h���\�͏d�v�B
The Real Story about Sun's Niagara
http://h71028.www7.hp.com/ERC/cache/280124-0-0-0-121.html
HP��HP���Niagara���o�J�ɂ��Ă���B
�T�[�o�Ƃ͂����V���O���X���b�h���\�͏d�v�B
>>243 ����
�������ݏグ�Ă���̂�m�������ǁAP6�A�[�L�e�N�`���ɂ��Ă�A�܂��l�b�g��ɏ����̂�
���ʂ��ᖳ������PetiumPro����Ɍ��s������Ă��邷�B���ɂȂ��ċ�J���Đ̘̂_����T���ēǂ�ł�
�ނ�}�����Ⴂ���Ȃ����B
>>244 inteler����
8����Fall IDF 2005�̘b������̍��X�B�B�B���Ă̂�u���ĂāA�ʓ|�L�����ĎQ�l�����������Ȃ�
�Ȃ�����A���ꃋ�[�}�[�H���꒼���Ȃ�ŏ����l�������ė~�������B
���Ԃɂ�u���\�[�X�v�Ɓu�Q�l�����v�̋�ʂ�����Ȃ����n��������̂������Ȃ��ǁB�B�B
�������ݏグ�Ă���̂�m�������ǁAP6�A�[�L�e�N�`���ɂ��Ă�A�܂��l�b�g��ɏ����̂�
���ʂ��ᖳ������PetiumPro����Ɍ��s������Ă��邷�B���ɂȂ��ċ�J���Đ̘̂_����T���ēǂ�ł�
�ނ�}�����Ⴂ���Ȃ����B
>>244 inteler����
8����Fall IDF 2005�̘b������̍��X�B�B�B���Ă̂�u���ĂāA�ʓ|�L�����ĎQ�l�����������Ȃ�
�Ȃ�����A���ꃋ�[�}�[�H���꒼���Ȃ�ŏ����l�������ė~�������B
���Ԃɂ�u���\�[�X�v�Ɓu�Q�l�����v�̋�ʂ�����Ȃ����n��������̂������Ȃ��ǁB�B�B
MAC�I�^�͂��̃X���Ɉ�̉����ɗ��Ă�H
����Ō����Ⴂ�c�_�ł�����Ă�Ⴂ�������B
>8����Fall IDF 2005�̘b������̍��X�B�B�B���Ă̂�u���ĂāA�ʓ|�L�����ĎQ�l�����������Ȃ�
>�Ȃ�����A���ꃋ�[�}�[�H���꒼���Ȃ�ŏ����l�������ė~�������B
�R��͓��{��T�C�g�Ō���Ă��Ȃ����e�́A�V���Ɋւ�炸�������Ƃɂ��Ă�B
�ϑz�Ƃ����Ă���̂͘R��̑啔�����l�\�z�Ȃ̂ŁA�\�[�X�͂Ȃ��Ƃ����Ӗ��B
���̃X�����Ă�l�Ȃ�āAmac�ł��ꈬ��Ȃ̂ŁA���ꃋ�[�}�[�ɂ͂Ȃ�ƁB
P6����ɃI�^�N������Ă������ƂȂ�ĉR������Ȃ̂ŁB
NetBurst����ł���R����Ȃ̂ŁAweb��̏������Đ�������͉̂��l������܂��B
����Ō����Ⴂ�c�_�ł�����Ă�Ⴂ�������B
>8����Fall IDF 2005�̘b������̍��X�B�B�B���Ă̂�u���ĂāA�ʓ|�L�����ĎQ�l�����������Ȃ�
>�Ȃ�����A���ꃋ�[�}�[�H���꒼���Ȃ�ŏ����l�������ė~�������B
�R��͓��{��T�C�g�Ō���Ă��Ȃ����e�́A�V���Ɋւ�炸�������Ƃɂ��Ă�B
�ϑz�Ƃ����Ă���̂͘R��̑啔�����l�\�z�Ȃ̂ŁA�\�[�X�͂Ȃ��Ƃ����Ӗ��B
���̃X�����Ă�l�Ȃ�āAmac�ł��ꈬ��Ȃ̂ŁA���ꃋ�[�}�[�ɂ͂Ȃ�ƁB
P6����ɃI�^�N������Ă������ƂȂ�ĉR������Ȃ̂ŁB
NetBurst����ł���R����Ȃ̂ŁAweb��̏������Đ�������͉̂��l������܂��B
248 �F���̖��ݒ��F2005/12/10(�y) 21:17:07 ID:cux6PYiT0
Fall IDF 2005 - Day 1: Intel's New Architecture Details Revealed
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2504
>Intel is also introducing speculative data loads with the new architecture,
> loads to be executed ahead of stores if a dependency is predicted to not exist between the two.
x86���߂̏��v�N���b�N�v���X���Ɏ���𓊂�����ł������̂�
�ǂ��Ԃ��Ă��邩���̂��݂��Ȃ��i�E�́E�j
x86���߂̏��v�N���b�N�v���X��
http://pc8.2ch.net/test/read.cgi/tech/1103609337/901-
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2504
>Intel is also introducing speculative data loads with the new architecture,
> loads to be executed ahead of stores if a dependency is predicted to not exist between the two.
x86���߂̏��v�N���b�N�v���X���Ɏ���𓊂�����ł������̂�
�ǂ��Ԃ��Ă��邩���̂��݂��Ȃ��i�E�́E�j
x86���߂̏��v�N���b�N�v���X��
http://pc8.2ch.net/test/read.cgi/tech/1103609337/901-
250 �FMAC�I�^��inteler �����F2005/12/10(�y) 22:13:09 ID:ws5TpkLg0
>>247
�@�@---------------------
�@�@�ϑz�Ƃ����Ă���̂͘R��̑啔�����l�\�z�Ȃ̂ŁA�\�[�X�͂Ȃ��Ƃ����Ӗ��B
�@�@---------------------
�{�C�Ŗϑz�Ǝv������ł�Ȃ��̑ł��l�����������ǁA����Ȃ��Ɩ����Ǝv�����B���������ǁA
>>244�킱���������ɏ����ׂ����ƁB�B�B
�@�@---------------------
�@�@�ϑz�Ƃ����Ă���̂͘R��̑啔�����l�\�z�Ȃ̂ŁA�\�[�X�͂Ȃ��Ƃ����Ӗ��B
�@�@---------------------
�{�C�Ŗϑz�Ǝv������ł�Ȃ��̑ł��l�����������ǁA����Ȃ��Ɩ����Ǝv�����B���������ǁA
>>244�킱���������ɏ����ׂ����ƁB�B�B
251 �FMAC�I�^�������F2005/12/10(�y) 22:15:05 ID:ws5TpkLg0
Intel��Fall IDF 2005��Merom/Conroe�̃A�[�L�e�N�`���ɂ��Ď�̃L�[���[�h�������Ă��邷�B
���̃v���[���摜�����肪�Q�l�ɂȂ邷���ˁB
http://pcweb.mycom.co.jp/photo/articles/2005/08/31/idf1/images/009l.jpg
���̒��Ō�����Ȃ��p��Ƃ���"memory disambiguation"���Ă̂����邷���ǁA����퓊�@�I������
�A�N�Z�X�Z�p�̈���B��̓I�Ȑ�����A���̘_���ɋL����Ă��邷�B
http://www.c.csce.kyushu-u.ac.jp/lab_db/papers/paper/pdf/2002/metsugi02_1.pdf
�@�@----------------------------
�@�@(1) �������E�A�h���X�̈�v�^�s��v���
�@�@�@�@(memory disambiguation, alias analysis)�F
�@�@��ʂɁC���[�h�^�X�g�A���߂̃������E�A�h���X�ɂ͎��s���ɂȂ�Ȃ��Ɣ���
�@�@���Ȃ����̂����݂���D���̏ꍇ�C���ܒ��ڂ��Ă��郍�[�h�^�X�g�A���߂�����
�@�@��s���郍�[�h�^�X�g�A���߂ɑ��ăf�[�^�ˑ��W�����Ă��邩�ۂ��͎��s��
�@�@�ɂȂ�܂ŕ�����Ȃ��D���ǁC���郍�[�h�^�X�g�A���߂ɒ��ڂ����ꍇ�C���̐�s
�@�@���邷�ׂẴ��[�h�^�X�g�A���߂̃������E�A�h���X���������C���C���Y���[
�@�@�h�^�X�g�A���߂̃������E�A�h���X���������ăf�[�^�ˑ��W�̗L�����m�F�����
�@�@�܂œ��Y���[�h�^�X�g�A���߂͎��s�ł��Ȃ��D����ɑ��āC���炩�̕��@��
�@�@�������E�A�h���X�̈�v�^�s��v���\�߉�͂ł���C���̂悤�Ȑ���͊ɘa�ł���D
�@�@----------------------------
�v����Ƀ��[�h���߂Ɋ܂܂��|�C���^��I�t�Z�b�g�̒l��\������@�\��lj����āA���[�h�̓��@�I���s
��}��Ǝv���邷�B
���̃v���[���摜�����肪�Q�l�ɂȂ邷���ˁB
http://pcweb.mycom.co.jp/photo/articles/2005/08/31/idf1/images/009l.jpg
{kind=link}
���̒��Ō�����Ȃ��p��Ƃ���"memory disambiguation"���Ă̂����邷���ǁA����퓊�@�I������
�A�N�Z�X�Z�p�̈���B��̓I�Ȑ�����A���̘_���ɋL����Ă��邷�B
http://www.c.csce.kyushu-u.ac.jp/lab_db/papers/paper/pdf/2002/metsugi02_1.pdf
�@�@----------------------------
�@�@(1) �������E�A�h���X�̈�v�^�s��v���
�@�@�@�@(memory disambiguation, alias analysis)�F
�@�@��ʂɁC���[�h�^�X�g�A���߂̃������E�A�h���X�ɂ͎��s���ɂȂ�Ȃ��Ɣ���
�@�@���Ȃ����̂����݂���D���̏ꍇ�C���ܒ��ڂ��Ă��郍�[�h�^�X�g�A���߂�����
�@�@��s���郍�[�h�^�X�g�A���߂ɑ��ăf�[�^�ˑ��W�����Ă��邩�ۂ��͎��s��
�@�@�ɂȂ�܂ŕ�����Ȃ��D���ǁC���郍�[�h�^�X�g�A���߂ɒ��ڂ����ꍇ�C���̐�s
�@�@���邷�ׂẴ��[�h�^�X�g�A���߂̃������E�A�h���X���������C���C���Y���[
�@�@�h�^�X�g�A���߂̃������E�A�h���X���������ăf�[�^�ˑ��W�̗L�����m�F�����
�@�@�܂œ��Y���[�h�^�X�g�A���߂͎��s�ł��Ȃ��D����ɑ��āC���炩�̕��@��
�@�@�������E�A�h���X�̈�v�^�s��v���\�߉�͂ł���C���̂悤�Ȑ���͊ɘa�ł���D
�@�@----------------------------
�v����Ƀ��[�h���߂Ɋ܂܂��|�C���^��I�t�Z�b�g�̒l��\������@�\��lj����āA���[�h�̓��@�I���s
��}��Ǝv���邷�B
�]�������̏��Ȃ���A����Ȃ̏����悤�Ȃ�����B
Speculative Load�Ƃ�����x86�Ȃ�ǂ����̂�?
�Ƃ����̂��Ȃ�����U��i���čl�������ʂł���i�E�́E�j
Speculative Load�Ƃ�����x86�Ȃ�ǂ����̂�?
�Ƃ����̂��Ȃ�����U��i���čl�������ʂł���i�E�́E�j
253 �FMAC�I�^��inteler �����F2005/12/10(�y) 23:23:20 ID:ws5TpkLg0
>>252
�@�@--------------------
�@�@Speculative Load�Ƃ�����x86�Ȃ�ǂ����̂�?
�@�@--------------------
�ϑz����܂ł������A������Speculative load��Petium4�Ŋ��Ɏ�������Ă��邷�B
http://www.intel-inside.fr/jp/developer/technology/itj/2004/volume08issue01/art01_microarchitecture/p04_new.htm
�@�@====================
�@�@Intel NetBurst? �}�C�N���A�[�L�e�N�`���̃C���v�������e�[�V�����ł́A���[�h - ���[�Y�E���C�e���V��
�@�@�ŏ�������悤�ɐv����܂��B�܂�A�������z�A�h���X�E�}�b�`���O�ɂ���āA���[�h���L���b�V����
�@�@�q�b�g���邩�~�X���邩���p�C�v���C���̏����̒i�K�Ō��o����悤�ɂ��Ă���̂ł��B
�@�@====================
�@�@--------------------
�@�@Speculative Load�Ƃ�����x86�Ȃ�ǂ����̂�?
�@�@--------------------
�ϑz����܂ł������A������Speculative load��Petium4�Ŋ��Ɏ�������Ă��邷�B
http://www.intel-inside.fr/jp/developer/technology/itj/2004/volume08issue01/art01_microarchitecture/p04_new.htm
�@�@====================
�@�@Intel NetBurst? �}�C�N���A�[�L�e�N�`���̃C���v�������e�[�V�����ł́A���[�h - ���[�Y�E���C�e���V��
�@�@�ŏ�������悤�ɐv����܂��B�܂�A�������z�A�h���X�E�}�b�`���O�ɂ���āA���[�h���L���b�V����
�@�@�q�b�g���邩�~�X���邩���p�C�v���C���̏����̒i�K�Ō��o����悤�ɂ��Ă���̂ł��B
�@�@====================
>>253
�����Speculative Load�Ƃ͂����B
�L���b�V���ɂ����邩������Ȃ������X�P�W���[���Ƀq���g�œn�������ł���B
���@���[�h�I�y���[�V�����s����Ȃ�Ăǂ��ɂ������ĂȂ������B
�����Speculative Load�Ƃ͂����B
�L���b�V���ɂ����邩������Ȃ������X�P�W���[���Ƀq���g�œn�������ł���B
���@���[�h�I�y���[�V�����s����Ȃ�Ăǂ��ɂ������ĂȂ������B
255 �FMAC�I�^��inteler �����F2005/12/11(��) 01:27:01 ID:UaGYQnoT0
>>254
Pentium4��uL1�q�b�g�����肷��v�Ƃ������h�ȓ��@���[�h�@�\�����邷�B
���{��̎������ƁA���ꂷ���ˁB�B�B
http://applause.elfmimi.jp/diary/m200506.shtml
�@�@--------------------
�@�@ 9.�@ �ŏ��̃��[�h���߂�L1�L���b�V���Ƀq�b�g���Ȃ�������ǂ��Ȃ�̂��H
�@�@�@�@L2�L���b�V����7�N���b�N�̒x���Ȃ̂ŁA�������f�[�^���͂����ɂ́A���߂͊Ԉ�����I�y�����h�Ōv�Z
�@�@�@�@���I���Ă��܂��Ă���B�������Ȃ��Ƃ͋�����Ȃ��B
�@�@10.�@���̂��߂�Pentium4�ɂ͓��ʂȎd�|�����p�ӂ���Ă��āA���������s���邽�߂̂��V���Ă��o��
�@�@�@�@�Ȃ��������߂̓p�C�v���C������ǂ��o����Areplay�Ƃ��������ɑ���ꂽ��A������x�p�C�v���C����
�@�@�@�@����悤�ɂȂ��Ă���B
�@�@11.�@ replay�ɑ���ꂽ���߂́A�ւ�`���悤�ɂ��ăp�C�v���C �̓�����ɖ߂邪���̗ւ̒��������傤��
�@�@�@�@L2�L���b�V���̃��C�e���V�ɍ����Ă���Breplay����̖��߂��������ɂ̓X�P�W���[������̖��߂͑���
�@�@�@�@��Ȃ��B
�@�@--------------------
Pentium4��uL1�q�b�g�����肷��v�Ƃ������h�ȓ��@���[�h�@�\�����邷�B
���{��̎������ƁA���ꂷ���ˁB�B�B
http://applause.elfmimi.jp/diary/m200506.shtml
�@�@--------------------
�@�@ 9.�@ �ŏ��̃��[�h���߂�L1�L���b�V���Ƀq�b�g���Ȃ�������ǂ��Ȃ�̂��H
�@�@�@�@L2�L���b�V����7�N���b�N�̒x���Ȃ̂ŁA�������f�[�^���͂����ɂ́A���߂͊Ԉ�����I�y�����h�Ōv�Z
�@�@�@�@���I���Ă��܂��Ă���B�������Ȃ��Ƃ͋�����Ȃ��B
�@�@10.�@���̂��߂�Pentium4�ɂ͓��ʂȎd�|�����p�ӂ���Ă��āA���������s���邽�߂̂��V���Ă��o��
�@�@�@�@�Ȃ��������߂̓p�C�v���C������ǂ��o����Areplay�Ƃ��������ɑ���ꂽ��A������x�p�C�v���C����
�@�@�@�@����悤�ɂȂ��Ă���B
�@�@11.�@ replay�ɑ���ꂽ���߂́A�ւ�`���悤�ɂ��ăp�C�v���C �̓�����ɖ߂邪���̗ւ̒��������傤��
�@�@�@�@L2�L���b�V���̃��C�e���V�ɍ����Ă���Breplay����̖��߂��������ɂ̓X�P�W���[������̖��߂͑���
�@�@�@�@��Ȃ��B
�@�@--------------------
>>255
�����������ꂥ(�m
����͈ꉞ���@���[�h�ł͂��邪�A���\�ቺ�v���Ȃ킯���B
���h�ȓ��@���[�h����Ȃ��āA�P�Ȃ�Ë����[�h����Ȃ���(�m
�悭�݂���>>253�ɂ������Ă���ˁB
Prescott�ł́A"�Ë����[�h���o���邾�����Ȃ�"���߂̗\����܂ł��Ă�炵��(�m
-------------------------------------------
����A���[�h�́A�]���A�X�g�A�E�f�[�^��op �Ƃ͔��ɃX�P�W���[������Ă��܂����B
���������āA���[�h���X�g�A�̃f�[�^���t�H���[�h���Ă��炤�K�v������ꍇ���A
�X�g�A�E�f�[�^��op �̑O�Ƀ��[�h�����s����邱�Ƃ�����܂��B
���̏ꍇ�A�X�g�A�E�f�[�^��op �̊�����Ƀ��[�h���Ď��s���Ȃ���Ȃ�܂���B
���̌��ʁA�X�g�A�E�f�[�^��op �Ƃ���Ɉˑ����郍�[�h�̍ŏ����C�e���V�͍Ď��s���ꂽ
���[�h�̒ʏ�̃��C�e���V�Ƃ͈قȂ邽�߁A�x�����������邱�Ƃ�����܂��B
����Ɉ������ƂɁA���[�h���Ď��s���Ȃ���Ȃ�Ȃ����߁A
�M�d�ȃ��[�h���Z�̃��\�[�X�ʂɂ��Ă��܂��܂��B��������2�̖����y�����邽�߂ɁA
���郍�[�h��op ���f�[�^�̃t�H���[�h��v����\���ƁA���̏ꍇ�̌��ɂȂ�X�g�A�ׂ�
�ȒP�ȗ\���@�\��lj����܂����B���̏�����ɁA���[�h�E�X�P�W���[���́A�t�H���[�f�B���O���\������郍�[�h���A
���ꂪ�K�v�Ƃ���f�[�^�����X�g�A�E�f�[�^��op ���X�P�W���[�������܂ŃX�P�W���[�����ɕێ�����悤�ɂ����̂ł��B
--------------------------------------------
�����������ꂥ(�m
����͈ꉞ���@���[�h�ł͂��邪�A���\�ቺ�v���Ȃ킯���B
���h�ȓ��@���[�h����Ȃ��āA�P�Ȃ�Ë����[�h����Ȃ���(�m
�悭�݂���>>253�ɂ������Ă���ˁB
Prescott�ł́A"�Ë����[�h���o���邾�����Ȃ�"���߂̗\����܂ł��Ă�炵��(�m
-------------------------------------------
����A���[�h�́A�]���A�X�g�A�E�f�[�^��op �Ƃ͔��ɃX�P�W���[������Ă��܂����B
���������āA���[�h���X�g�A�̃f�[�^���t�H���[�h���Ă��炤�K�v������ꍇ���A
�X�g�A�E�f�[�^��op �̑O�Ƀ��[�h�����s����邱�Ƃ�����܂��B
���̏ꍇ�A�X�g�A�E�f�[�^��op �̊�����Ƀ��[�h���Ď��s���Ȃ���Ȃ�܂���B
���̌��ʁA�X�g�A�E�f�[�^��op �Ƃ���Ɉˑ����郍�[�h�̍ŏ����C�e���V�͍Ď��s���ꂽ
���[�h�̒ʏ�̃��C�e���V�Ƃ͈قȂ邽�߁A�x�����������邱�Ƃ�����܂��B
����Ɉ������ƂɁA���[�h���Ď��s���Ȃ���Ȃ�Ȃ����߁A
�M�d�ȃ��[�h���Z�̃��\�[�X�ʂɂ��Ă��܂��܂��B��������2�̖����y�����邽�߂ɁA
���郍�[�h��op ���f�[�^�̃t�H���[�h��v����\���ƁA���̏ꍇ�̌��ɂȂ�X�g�A�ׂ�
�ȒP�ȗ\���@�\��lj����܂����B���̏�����ɁA���[�h�E�X�P�W���[���́A�t�H���[�f�B���O���\������郍�[�h���A
���ꂪ�K�v�Ƃ���f�[�^�����X�g�A�E�f�[�^��op ���X�P�W���[�������܂ŃX�P�W���[�����ɕێ�����悤�ɂ����̂ł��B
--------------------------------------------
�R���xbit�̂��̋L���́A�����ƑO����u�b�N�}�[�N���Ă����ǁA
������Ƃ݂Ă悭�킩��Ȃ���������ۗ����Ă���ȁB
x86���߂̏��v�N���b�N�v���X���ɂ��O�Ƀ����N�\���Ă��������ǁA
>>1�͂��ł�̂��Ȃ��c�B
������Ƃ݂Ă悭�킩��Ȃ���������ۗ����Ă���ȁB
x86���߂̏��v�N���b�N�v���X���ɂ��O�Ƀ����N�\���Ă��������ǁA
>>1�͂��ł�̂��Ȃ��c�B
258 �FMAC�I�^��inteler �����F2005/12/11(��) 12:01:38 ID:UaGYQnoT0
>>257
�@�@-----------------
�@�@������Ƃ݂Ă悭�킩��Ȃ���������ۗ����Ă���ȁB
�@�@-----------------
�����ł��AIntel������X���łł����₷��Ηǂ�����B�f���펩���̈ꕨ���I����ꏊ���Ė�Ȃ����B
�@�@-----------------
�@�@������Ƃ݂Ă悭�킩��Ȃ���������ۗ����Ă���ȁB
�@�@-----------------
�����ł��AIntel������X���łł����₷��Ηǂ�����B�f���펩���̈ꕨ���I����ꏊ���Ė�Ȃ����B
�����œǂ�ŗ����ł��Ȃ��\�[�X������Ă���MAC�I�^�����������c�B
����̎�����CPU�X���Ȃ�ē��ĂɂȂ��c�B���Ⴂ�ʃ��X���肾��B
�R����Â�����̏Z�l������悭�������B
Part.11-16�̏������݂̖�10%�����͘R��̏�������(�m
����̎�����CPU�X���Ȃ�ē��ĂɂȂ��c�B���Ⴂ�ʃ��X���肾��B
�R����Â�����̏Z�l������悭�������B
Part.11-16�̏������݂̖�10%�����͘R��̏�������(�m
���܂�A10%�͂Ȃ������B�X���ɂ���Ă͂��̂��炢�����Ă�̂����邯�ǁB
261 �FMAC�I�^��inteler �����F2005/12/11(��) 14:09:52 ID:UaGYQnoT0
>>259
�@�@--------------------
�@�@����̎�����CPU�X���Ȃ�ē��ĂɂȂ��c�B���Ⴂ�ʃ��X���肾��B
�@�@--------------------
�f�����荇�����ł����āA���Ăɂ��郂�����ᖳ�����B�ʃX����@�Ƃ������Ƃ��āA�ǂ����Ⴂ�Ȃ̂�
����������Ă̂��f���ŃR�~���j�P�[�V�����\�͂��Ǝv�����B���l�̎��_���Ă̂��ʔ������m����B
�@�@--------------------
�@�@����̎�����CPU�X���Ȃ�ē��ĂɂȂ��c�B���Ⴂ�ʃ��X���肾��B
�@�@--------------------
�f�����荇�����ł����āA���Ăɂ��郂�����ᖳ�����B�ʃX����@�Ƃ������Ƃ��āA�ǂ����Ⴂ�Ȃ̂�
����������Ă̂��f���ŃR�~���j�P�[�V�����\�͂��Ǝv�����B���l�̎��_���Ă̂��ʔ������m����B
262 �FMAC�I�^���⑫�F2005/12/11(��) 14:11:58 ID:UaGYQnoT0
���Ȃ݂Ɏ���A�������u�m���Ă���b�v��������邽�߂ɎQ�l�ƂȂ郊���N���E���Ă��邷�B
���ɜ��ӓI�ȏ����莦���B�B�B�Ɣᔻ����鏊�Ȃ�����(��)
���ɜ��ӓI�ȏ����莦���B�B�B�Ɣᔻ����鏊�Ȃ�����(��)
�܂��A�R���MAC�I�^���������CPU�X���̗����m��s�����Ă��邩��ȁB
����ł́A�C�O�\�[�X�̏���\���Ă��قƂ�Ǔǂ܂�Ȃ����A
���ǁAImpress������̍����L���łƂ肠���Ă���c�_���n�܂�B
�������ϑz���e�̕���������炵���B
�����������Ă��A�����ł��Ȃ��w�������āA���ʁB
��r�I�Ƃ����₷���㓡�L�������Ă����N�\���Ă�̂�
�ςȗ������Ă�z�������ł���B
�R����ߋ��ɂ͂����Ƌc�_������Ă邯�ǁA
�S���ŊԈႢ�F�߂��Ȃ��l�Ƃ��A����͂̂Ȃ��l�Ƃ�������B
������CPU�X����Part.6�����肩��Q�����Ă邯�ǁA���̍��ɂ͂قƂ�ǃ��X�̓X���[���j�B
�~�[��100�l��肠�܂��Ă��������_�����A���[�}�[��̕����厖
�Ȃ̂����̃X���̊�{���j�ł��B
�R��͏��������ɗ��Ă���̂ł����āA�Z�p�k�`�͖ړI�ł͂���܂���B
�������̃R�~���j�P�[�V�����Ƃ�炪��D���Ȑl�͎���łǂ����B
�Ƃ����킯�ŁA�X�����{��ƈ���Ă��Ă���̂ŁA���낻�뗬���߂��ė~�����̂����B
����ł́A�C�O�\�[�X�̏���\���Ă��قƂ�Ǔǂ܂�Ȃ����A
���ǁAImpress������̍����L���łƂ肠���Ă���c�_���n�܂�B
�������ϑz���e�̕���������炵���B
�����������Ă��A�����ł��Ȃ��w�������āA���ʁB
��r�I�Ƃ����₷���㓡�L�������Ă����N�\���Ă�̂�
�ςȗ������Ă�z�������ł���B
�R����ߋ��ɂ͂����Ƌc�_������Ă邯�ǁA
�S���ŊԈႢ�F�߂��Ȃ��l�Ƃ��A����͂̂Ȃ��l�Ƃ�������B
������CPU�X����Part.6�����肩��Q�����Ă邯�ǁA���̍��ɂ͂قƂ�ǃ��X�̓X���[���j�B
�~�[��100�l��肠�܂��Ă��������_�����A���[�}�[��̕����厖
�Ȃ̂����̃X���̊�{���j�ł��B
�R��͏��������ɗ��Ă���̂ł����āA�Z�p�k�`�͖ړI�ł͂���܂���B
�������̃R�~���j�P�[�V�����Ƃ�炪��D���Ȑl�͎���łǂ����B
�Ƃ����킯�ŁA�X�����{��ƈ���Ă��Ă���̂ŁA���낻�뗬���߂��ė~�����̂����B
264 �F���̖��ݒ��F2005/12/11(��) 15:38:47 ID:gAiCPTxx0
�������Ainteler�ɔ�ׂ��MAC�I�^���܂Ƃ��Ȑl�ԂɌ����邗
265 �Finteler@�⑫�F2005/12/11(��) 16:03:48 ID:+wj+MCsY0
MAC�I�^���̏ꂵ�̂����k�ق���ׂĂ��邾���ł��̂ŁA�^�ɎȂ��悤�Ɂc�B
���������x����������A���N�O���炩��݂���Ă����A���ꂭ�炢������܂��B
>�f�����荇�����ł����āA���Ăɂ��郂�����ᖳ�����B�ʃX����@�Ƃ������Ƃ��āA�ǂ����Ⴂ�Ȃ̂�
>����������Ă̂��f���ŃR�~���j�P�[�V�����\�͂��Ǝv�����B���l�̎��_���Ă̂��ʔ������m����B
21 �FMAC�I�^ �F02/11/01 18:03
�����������ራ�������ǁA�q�g�����Ȃ��Ȃ�̂�R���e���c���R�~���j�e�B���Ȃ����炷�B
�����f���ɃR�~���j�e�B���Ȃ��̂퓖�R������A���ǂ̂Ƃ���R���e���c�̖�肷�ˁB
����ɂ��ނȂ琢�E���ł����ł����ǂ߂Ȃ��b�������ׂ����B���ꂪ�s�\�Ȃ烊�A����
�A����ł����J���āAOFF��ł��P��I�ɊJ�������Ȃ���ł햳�������H
�r��Ă��ǂ��Ȃ�u���ꃋ�[�}�[�v�X���b�h�������ŕ��������Ă��ǂ�������(��)
���������x����������A���N�O���炩��݂���Ă����A���ꂭ�炢������܂��B
>�f�����荇�����ł����āA���Ăɂ��郂�����ᖳ�����B�ʃX����@�Ƃ������Ƃ��āA�ǂ����Ⴂ�Ȃ̂�
>����������Ă̂��f���ŃR�~���j�P�[�V�����\�͂��Ǝv�����B���l�̎��_���Ă̂��ʔ������m����B
21 �FMAC�I�^ �F02/11/01 18:03
�����������ራ�������ǁA�q�g�����Ȃ��Ȃ�̂�R���e���c���R�~���j�e�B���Ȃ����炷�B
�����f���ɃR�~���j�e�B���Ȃ��̂퓖�R������A���ǂ̂Ƃ���R���e���c�̖�肷�ˁB
����ɂ��ނȂ琢�E���ł����ł����ǂ߂Ȃ��b�������ׂ����B���ꂪ�s�\�Ȃ烊�A����
�A����ł����J���āAOFF��ł��P��I�ɊJ�������Ȃ���ł햳�������H
�r��Ă��ǂ��Ȃ�u���ꃋ�[�}�[�v�X���b�h�������ŕ��������Ă��ǂ�������(��)
266 �FMAC�I�^��inteler �����F2005/12/11(��) 16:38:04 ID:UaGYQnoT0
>>265
�R�~���j�e�B�ƃR�~���j�P�[�V�����̈Ⴂ���炢�펫���Œ��ׂČ���Ηǂ��Ǝv�������ǁB�B�B
�R�~���j�e�B�ƃR�~���j�P�[�V�����̈Ⴂ���炢�펫���Œ��ׂČ���Ηǂ��Ǝv�������ǁB�B�B
267 �F���̖��ݒ��F2005/12/13(��) 17:24:31 ID:9ErrZI+f0
AMD�A�g�f���A���R�A�Ό��h��Intel�ɏ���
��AMD��13��(���n����)�A8��23��(��)��Intel�ɑ�������@�������udual-core
duel�v(�f���A���R�A�Ό�)�ŏ��������Ɣ��\�����B�����[�X���Łg���C�o���̓����O�ɓ����
�����ۂ����h�ƕ\�����Ă���B
���̒����́AAMD�̃f���A���R�AOpteron 2xx/8xx�V���[�Y�ƁA���Z�O�����g��Intel
Xeon�Ƃ��O�҂̒��������@�ւŋƊE�W���x���`�}�[�N�����{���Ĕ�r���A���b�g����
�萫�\�̕]���������ɍs�Ȃ��Ƃ������́B
�g�p���ꂽ�x���`�}�[�N��SPECint rate2000�ASPECfp rate 2000�ASPECjbb 2005
�ȂǂŁA�f���A���R�A��Opteron 280�̐�ΐ��\�́A�f���A���R�A��Xeon 2.80GHz��
���ׂĂ̌��ʂ�����A���b�g�����萫�\�Ɋ��Z�����200%�D���Ƃ����B
����̏����錾�́A�č�����San Francisco Chronicle�ASan Jose Mercury News�A
Austin American-Statesman�ȂǂɑS�ʍL���Ōf�ڂ����B
http://pc.watch.impress.co.jp/docs/2005/1213/amd.htm
��AMD��13��(���n����)�A8��23��(��)��Intel�ɑ�������@�������udual-core
duel�v(�f���A���R�A�Ό�)�ŏ��������Ɣ��\�����B�����[�X���Łg���C�o���̓����O�ɓ����
�����ۂ����h�ƕ\�����Ă���B
���̒����́AAMD�̃f���A���R�AOpteron 2xx/8xx�V���[�Y�ƁA���Z�O�����g��Intel
Xeon�Ƃ��O�҂̒��������@�ւŋƊE�W���x���`�}�[�N�����{���Ĕ�r���A���b�g����
�萫�\�̕]���������ɍs�Ȃ��Ƃ������́B
�g�p���ꂽ�x���`�}�[�N��SPECint rate2000�ASPECfp rate 2000�ASPECjbb 2005
�ȂǂŁA�f���A���R�A��Opteron 280�̐�ΐ��\�́A�f���A���R�A��Xeon 2.80GHz��
���ׂĂ̌��ʂ�����A���b�g�����萫�\�Ɋ��Z�����200%�D���Ƃ����B
����̏����錾�́A�č�����San Francisco Chronicle�ASan Jose Mercury News�A
Austin American-Statesman�ȂǂɑS�ʍL���Ōf�ڂ����B
http://pc.watch.impress.co.jp/docs/2005/1213/amd.htm
Intel�fs Dual-Core Xeon First Look
http://www.anandtech.com/IT/showdoc.aspx?i=2644
Dempsey/Bensley�v���b�g�t�H�[���̃��r���[�B
Opteron 280����Ƀp�t�H�[�}���X�ł͑P�킵�Ă���悤�����A
����d�͂ł͂�͂��s���Ă���悤���B
http://www.anandtech.com/IT/showdoc.aspx?i=2644
Dempsey/Bensley�v���b�g�t�H�[���̃��r���[�B
Opteron 280����Ƀp�t�H�[�}���X�ł͑P�킵�Ă���悤�����A
����d�͂ł͂�͂��s���Ă���悤���B
ttp://timesofindia.indiatimes.com/articleshow/msid-1333869,curpg-1.cms
������ƑO�ɃL�����Z���ɂȂ���Whitefield���J�����Ă����C���h�`�[�������A
�܂��Anew multi-core processor platform�����炵���B
������ƑO�ɃL�����Z���ɂȂ���Whitefield���J�����Ă����C���h�`�[�������A
�܂��Anew multi-core processor platform�����炵���B
Intel gets knickers in a twist over Tanglewood ��
http://www.theinquirer.net/?article=28298
CSI�ɂ��āB
�v��ƁA
��CSI�́A���Ƃ��Ƃ��ׂĂɂ�����HT�����邱�Ƃ�ڕW�ɂ��Đv����Ă������A
�ڕW���������Ė����������AWhitefield�⋌Tukwila���L�����Z���ɂȂ������Ɏ���ł����炵���B
�ŁA����CSI�͌����H���ōăX�^�[�g�������̂ŁARAS�@�\�͍���HT���͂͂邩�ɗD��Ă��邪�A
���x��1333MHz FSB x4��Caneland�ɑ��đ債���A�h�o���e�[�W�͂Ȃ��Ƃ̂��ƁB
AMD��HT���o�[�W�������������Ă����̂ŁARAS��2008�N�ɂ͑債���A�h�o���e�[�W�ɂ͂Ȃ�Ȃ��B
(�p������FSB x4���R�X�g�͂͂邩�Ɉ����ς�)
http://www.theinquirer.net/?article=28298
CSI�ɂ��āB
�v��ƁA
��CSI�́A���Ƃ��Ƃ��ׂĂɂ�����HT�����邱�Ƃ�ڕW�ɂ��Đv����Ă������A
�ڕW���������Ė����������AWhitefield�⋌Tukwila���L�����Z���ɂȂ������Ɏ���ł����炵���B
�ŁA����CSI�͌����H���ōăX�^�[�g�������̂ŁARAS�@�\�͍���HT���͂͂邩�ɗD��Ă��邪�A
���x��1333MHz FSB x4��Caneland�ɑ��đ債���A�h�o���e�[�W�͂Ȃ��Ƃ̂��ƁB
AMD��HT���o�[�W�������������Ă����̂ŁARAS��2008�N�ɂ͑債���A�h�o���e�[�W�ɂ͂Ȃ�Ȃ��B
(�p������FSB x4���R�X�g�͂͂邩�Ɉ����ς�)
Intel reschedules launch of Conroe and 965-chipset to July 2006, say mobo makers
http://www.digitimes.com/mobos/a20051221A1001.html
Intel will push up the launch of its desktop Conroe CPU and delay the debut of its
965-series chipset so that both will hit the market at the same time in July 2006
in a demand-boosting strategy, according to sources at motherboard makers in Taiwan
Intel���AConroe�O�|����7���Ƀ����[�X���邱�Ƃɂ����炵���B
965�͋t��Conroe�̃����[�X�ɕ����Ēx���͗l�c�B
http://www.digitimes.com/mobos/a20051221A1001.html
Intel will push up the launch of its desktop Conroe CPU and delay the debut of its
965-series chipset so that both will hit the market at the same time in July 2006
in a demand-boosting strategy, according to sources at motherboard makers in Taiwan
Intel���AConroe�O�|����7���Ƀ����[�X���邱�Ƃɂ����炵���B
965�͋t��Conroe�̃����[�X�ɕ����Ēx���͗l�c�B
ntel to turn tables on AMD on desktop front
http://www.theinquirer.net/?article=28602
2006�N�̃f�X�N�g�b�vCPU�AConroe��Athlon��F-Step�ɂ��āB
Charlie Demerjian���̗\�z�ɂ��Ɨ��N��AMD����X�^�[�g���A�O���́AAMD�������B
���̌�AConroe���o�ꂷ�邪�AIntel���d��Ȃւ܂���炩���Ȃ�����́A�N���ɂ͂킸���Ȃ���Intel�����Ƃ��Ȃ�Ƃ��B
Conroe�́A2.66GHz�ŃX�^�[�g���A�N����3GHz�ɓ��B����̂����݂̃v�����̂悤�����A
Yonah�����X2.5GHz�O��̗\�肾�����̂ɁAunderdelivering���ꂽ���Ƃ���AConroe�����҂��Ȃ������悢�B
AMD��65nm�����܂�ǂ��\�������ĂȂ����炱���邩������Ȃ��B
���[�h�}�b�v��^�Ɏ��\��������ƁA
Athlon X2 F-Step��Athlon X2���110%��IPC(core improvement + DDR2)�A
Conroe��Athlon X2��A125%��IPC�ŊT�Z���āA2.66GHz�ŃX�^�[�g������A
Athlon X2 = 3.52 INU vs Conroe = 3.75 INU �ƂȂ���Conroe�����[�h�B
(INU: Inq Nebulous Units)
����d�͂ɂ��ẮAAthlon�̃��[�h�͐Z�H����邪�A
North�̕����l���ɂ����Ȃ�A�v���łɂ͂Ȃ����Ă��B
-----
�S�̓I��AMD�т������[���AIntel�s�M�a�Ȋ����̋L�����ȁc(;�L�D�M)
Conroe�͗\����Ⴂ�N���b�N�łł����Ȃ̂ɂ͓��ӂ����A
��������Conroe����������łĂ������肳��Ȃ�Athlon�̗\��������Ȃ��B
http://www.theinquirer.net/?article=28602
2006�N�̃f�X�N�g�b�vCPU�AConroe��Athlon��F-Step�ɂ��āB
Charlie Demerjian���̗\�z�ɂ��Ɨ��N��AMD����X�^�[�g���A�O���́AAMD�������B
���̌�AConroe���o�ꂷ�邪�AIntel���d��Ȃւ܂���炩���Ȃ�����́A�N���ɂ͂킸���Ȃ���Intel�����Ƃ��Ȃ�Ƃ��B
Conroe�́A2.66GHz�ŃX�^�[�g���A�N����3GHz�ɓ��B����̂����݂̃v�����̂悤�����A
Yonah�����X2.5GHz�O��̗\�肾�����̂ɁAunderdelivering���ꂽ���Ƃ���AConroe�����҂��Ȃ������悢�B
AMD��65nm�����܂�ǂ��\�������ĂȂ����炱���邩������Ȃ��B
���[�h�}�b�v��^�Ɏ��\��������ƁA
Athlon X2 F-Step��Athlon X2���110%��IPC(core improvement + DDR2)�A
Conroe��Athlon X2��A125%��IPC�ŊT�Z���āA2.66GHz�ŃX�^�[�g������A
Athlon X2 = 3.52 INU vs Conroe = 3.75 INU �ƂȂ���Conroe�����[�h�B
(INU: Inq Nebulous Units)
����d�͂ɂ��ẮAAthlon�̃��[�h�͐Z�H����邪�A
North�̕����l���ɂ����Ȃ�A�v���łɂ͂Ȃ����Ă��B
-----
�S�̓I��AMD�т������[���AIntel�s�M�a�Ȋ����̋L�����ȁc(;�L�D�M)
Conroe�͗\����Ⴂ�N���b�N�łł����Ȃ̂ɂ͓��ӂ����A
��������Conroe����������łĂ������肳��Ȃ�Athlon�̗\��������Ȃ��B
����
3.52 INU (X2 3.2GHz) vs 3.75 INU (Conroe 3GHz)
��Q4�̗\���ł����B
Conroe@lanuch@early Q3�̗\�����ƁA
3.3 INU (X2 3.0GHz) vs 3.325 INU (Conroe 2.66GHz)
���A����INQ�\���͂܂�������Ȃ��Ǝv����̂ŃX���[��OK�B
3.52 INU (X2 3.2GHz) vs 3.75 INU (Conroe 3GHz)
��Q4�̗\���ł����B
Conroe@lanuch@early Q3�̗\�����ƁA
3.3 INU (X2 3.0GHz) vs 3.325 INU (Conroe 2.66GHz)
���A����INQ�\���͂܂�������Ȃ��Ǝv����̂ŃX���[��OK�B
�㓡�����F�X�Ɩϑz���L���Ċy����ł���悤�����ANehalem�́AMerom(4core)+CSI+��
���Ă����ȑO�̏�璆�g�͂��܂�ς���ĂȂ����낤�B
�f�X�N�g�b�v����Bloomfield�ȍ~��Nehalem�x�[�X�B
Bleemfield�͍��N��2�������o�Ă����B
CSI���̂�>>270�̒ʂ�A�����̗\���肨�ƂȂ����Ȃ��Ă���͗l�B
http://www.theinquirer.net/?article=21380
And then there's Bloomfield, another X86 product with cores a-plenty.
This design, say the sources, is being subject to continued re-definition,
as people higher up the chain look at how Bloomfield fits into the overall Intel marketing plan.
TraceCache�Ɋւ��錤����Israel�ł�Oregon�ł��s���Ă��āA
Nehalem�����̎��̃A�[�L�ŁAACCMP(��Ώ̃N���X�^�[�`�b�v�}���`�v���Z�T)������O�ɕ�������\�����������B
issue rate��8 issue���ŋ߂͓d�͖ʂ���݂čœK�Ƃ�Intel�͂����Ă邩��A�V���O���X���b�h���\��
�������A���͂�����߂ĂȂ����A�ƔN����_�ϑz���Ă݂�e�X�c�B
���Ă����ȑO�̏�璆�g�͂��܂�ς���ĂȂ����낤�B
�f�X�N�g�b�v����Bloomfield�ȍ~��Nehalem�x�[�X�B
Bleemfield�͍��N��2�������o�Ă����B
CSI���̂�>>270�̒ʂ�A�����̗\���肨�ƂȂ����Ȃ��Ă���͗l�B
http://www.theinquirer.net/?article=21380
And then there's Bloomfield, another X86 product with cores a-plenty.
This design, say the sources, is being subject to continued re-definition,
as people higher up the chain look at how Bloomfield fits into the overall Intel marketing plan.
TraceCache�Ɋւ��錤����Israel�ł�Oregon�ł��s���Ă��āA
Nehalem�����̎��̃A�[�L�ŁAACCMP(��Ώ̃N���X�^�[�`�b�v�}���`�v���Z�T)������O�ɕ�������\�����������B
issue rate��8 issue���ŋ߂͓d�͖ʂ���݂čœK�Ƃ�Intel�͂����Ă邩��A�V���O���X���b�h���\��
�������A���͂�����߂ĂȂ����A�ƔN����_�ϑz���Ă݂�e�X�c�B
ACCMP�ɂ��āB
Performance, Power Efficiency and Scalability of Asymmetric Cluster Chip Multiprocessors
ttp://www.cs.virginia.edu/~tcca/2005/morad_jul05.pdf
Performance, Power Efficiency and Scalability of Asymmetric Cluster Chip Multiprocessors
ttp://www.cs.virginia.edu/~tcca/2005/morad_jul05.pdf
276 �F���̖��ݒ��F2006/01/03(��) 23:03:01 ID:e6k8X4zi0
�Ȃ��Yonah��EM64T�ɑΉ����ĂȂ���ł����H
���̂�������a�����o����̂ł����B
���̂�������a�����o����̂ł����B
Intel's great 'leap' forward boosts Apple
http://www.eetimes.com/showArticle.jhtml?articleID=175800134
>Intel is developing motherboards for the new Apple models at its Intel Oregon facilities.
Intel��Oregon��Mac�p�}�U�[���J�����B
http://www.eetimes.com/showArticle.jhtml?articleID=175800134
>Intel is developing motherboards for the new Apple models at its Intel Oregon facilities.
Intel��Oregon��Mac�p�}�U�[���J�����B
AnandTech���APresler��Cedar Mill�̃_�C�T�C�Y�ƃg�����W�X�^���̏�����肵�Ă���͗l�B
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2658
While Smithfield weighed in at a whopping 230M transistors, Presler is now up to 376M.
The move to 65nm has actually made the chip smaller at 162 mm2, down from 206 mm2.
With a smaller die size, Presler is actually cheaper for Intel to make than Smithfield, despite having
twice the cache. Equally impressive is that Cedar Mill, the single core version, measures in at a
meager 81 mm2.
Presler
- 162sqmm
Cedar Mill
- 81sqmm
-----
197 ���O�Finteler[sage] ���e���F2005/11/16(��) 21:36:44 ID:uqDu0pWZ
�ȑO���J����Ă����p�b�P�[�W�ʐ^����_�C�T�C�Y�𐄑����Ă݂��B
Conroe: 148sqmm
Presler: 80sqmm*2
-----
>>197�ŘR�ꂪ������_�C�T�C�Y�̐��������\�����������Ă邱�Ƃ��킩��㩁i��ͥ�j
ttp://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2658
While Smithfield weighed in at a whopping 230M transistors, Presler is now up to 376M.
The move to 65nm has actually made the chip smaller at 162 mm2, down from 206 mm2.
With a smaller die size, Presler is actually cheaper for Intel to make than Smithfield, despite having
twice the cache. Equally impressive is that Cedar Mill, the single core version, measures in at a
meager 81 mm2.
Presler
- 162sqmm
Cedar Mill
- 81sqmm
-----
197 ���O�Finteler[sage] ���e���F2005/11/16(��) 21:36:44 ID:uqDu0pWZ
�ȑO���J����Ă����p�b�P�[�W�ʐ^����_�C�T�C�Y�𐄑����Ă݂��B
Conroe: 148sqmm
Presler: 80sqmm*2
-----
>>197�ŘR�ꂪ������_�C�T�C�Y�̐��������\�����������Ă邱�Ƃ��킩��㩁i��ͥ�j
280 �F���̖��ݒ��F2006/01/04(��) 10:10:04 ID:Rj5MwiY3O
http://pc.watch.impress.co.jp/docs/2006/0104/intel02l.gif
http://pc.watch.impress.co.jp/docs/2006/0104/intel03l.gif
�m���ɂ������̕����C���[�W������
{kind=link}
http://pc.watch.impress.co.jp/docs/2006/0104/intel03l.gif
{kind=link}
�m���ɂ������̕����C���[�W������
281 �FMAC�I�^��inteler �����F2006/01/04(��) 21:55:24 ID:76EFc/kW0
>>278
���g�ǂ�ł邷���H���p����Ă���\�[�X�핅�ꃋ�[�}�[�T�C�g���B
���g�ǂ�ł邷���H���p����Ă���\�[�X�핅�ꃋ�[�}�[�T�C�g���B
282 �F���̖��ݒ��F2006/01/04(��) 22:03:22 ID:UavedBwz0
Intel Mac mini�i���j�ɓ��ڂ����CPU�́AT1300�ƌ��ĊԈႢ�Ȃ������ˁH
�i�����������Əڂ����Ȃ��l�ւ̕t�L�F
�@T1300 = Yonah Single Core, 1666MHz�B�����v���Z�X��65nm�AOEM���i��209�h���B
�@ttp://pc.watch.impress.co.jp/docs/2006/0103/intel.htm�j
�i�����������Əڂ����Ȃ��l�ւ̕t�L�F
�@T1300 = Yonah Single Core, 1666MHz�B�����v���Z�X��65nm�AOEM���i��209�h���B
�@ttp://pc.watch.impress.co.jp/docs/2006/0103/intel.htm�j
Intel Mac mini�i���j�ɃV���O���R�A��ς������A���i�͓X���Ŕ����邩��ςݑւ������s��낤��
>>282
LV�łƂ���?
LV�łƂ���?
LV��CPU�����Ō��݂�mini�{�̂��炢�̂��l�i�Ȃ̂ŁE�E�E
Apple notebook using Intel Robson cache technology may be launched this month
ttp://www.digitimes.com/news/a20060105A5020.html
>sources now claim that Apple Computer will launch a notebook computer in the middle of this month
>that utilizes the NAND flash based cache memory technology.
ttp://www.digitimes.com/news/a20060105A5020.html
>sources now claim that Apple Computer will launch a notebook computer in the middle of this month
>that utilizes the NAND flash based cache memory technology.
287 �F���̖��ݒ��F2006/01/05(��) 20:48:50 ID:X2XWTSwY0
���s��Mac mini�����ʋ@��Ə�ʋ@��ŃN���b�N���Ⴄ�̂�����A
Intel Mac mini�ł��A���ʋ@��̓V���O���R�A�A��ʋ@��̓f���A���R�A�Ƃ������Ƃ͍l�����Ȃ����B
T1300��T2300��32�h���������Ȃ����B
ttp://pc.watch.impress.co.jp/docs/2006/0103/intel.htm
iMac�Ƃ̍��ʉ��̂��߂ɂ́AiMac�ɂ�T2400��T2500�𓋍ڂ����낵���B
Intel Mac mini�ł��A���ʋ@��̓V���O���R�A�A��ʋ@��̓f���A���R�A�Ƃ������Ƃ͍l�����Ȃ����B
T1300��T2300��32�h���������Ȃ����B
ttp://pc.watch.impress.co.jp/docs/2006/0103/intel.htm
iMac�Ƃ̍��ʉ��̂��߂ɂ́AiMac�ɂ�T2400��T2500�𓋍ڂ����낵���B
288 �F���̖��ݒ��F2006/01/05(��) 20:49:25 ID:X2XWTSwY0
���݂܂���A�X���딚���܂����B
Yonah�R�A�̗p�̃��o�C�������f���A���R�ACPU��6�����甭��
http://www.watch.impress.co.jp/akiba/hotline/20060107/etc_yonah.html
����A�Ȃ����[���B
http://www.watch.impress.co.jp/akiba/hotline/20060107/etc_yonah.html
����A�Ȃ����[���B
290 �F���̖��ݒ��F2006/01/05(��) 22:14:58 ID:ur7o+/660
>>289
�Ђ���Ƃ��āACPU�P�̂ł̓X�����i�ƁA���PC���[�J�[�ւ̉����i�������Ǝv���Ă�H
�Ђ���Ƃ��āACPU�P�̂ł̓X�����i�ƁA���PC���[�J�[�ւ̉����i�������Ǝv���Ă�H
���܂łł��A�����Ƃ����v���Ȃ��������݂����������ȁB
292 �F���̖��ݒ��F2006/01/05(��) 22:28:53 ID:nT3RccbRO
T1300����209�AT2300����241������1000�`���炾���牽���P�ʂŔ��������炳����ׁB
����T2300���ڂ�HDD�̗e�ʂ��炢�̈Ⴂ���Ǝv���B�V���O���R�A�ƃf���A���R�A�ňႢ�����Ȃ����낤���B
����T2300���ڂ�HDD�̗e�ʂ��炢�̈Ⴂ���Ǝv���B�V���O���R�A�ƃf���A���R�A�ňႢ�����Ȃ����낤���B
mini�AiBook�̓V���O���R�A
iMac�APowerBook�̓f���A���R�A
PowerMac�̓f���A���~2
���̂��炢�łŗ���������Ȃ���
iMac�APowerBook�̓f���A���R�A
PowerMac�̓f���A���~2
���̂��炢�łŗ���������Ȃ���
�������ƁA���낻��MAC�I�^��Inteler���Ƃ��o���Ă������ł����H
������DOSV�n�G����945GT�͎���Apple�p�ɊJ���������Ęb���ڂ��Ă��B
Mac mini iBook�̓��i�f���A���R�A�̒�N���b�N
iMac Power Book�̓��i�f���A���R�A�̍��N���b�N�����
Power Mac�̓��o�C�������͎g��Ȃ�
����Ȋ������Ǝv���B
iMac Power Book�̓��i�f���A���R�A�̍��N���b�N�����
Power Mac�̓��o�C�������͎g��Ȃ�
����Ȋ������Ǝv���B
297 �F���̖��ݒ��F2006/01/07(�y) 09:06:52 ID:R2TIN2pj0
>>296
�قړ��ӌ����B
������ɁAMac mini�̒ቿ�i�o�[�W�����ɂ�Yonah �V���O���R�A���ڂ�Ǝv���B
Power Mac��Conroe�~2���낤�B
�قړ��ӌ����B
������ɁAMac mini�̒ቿ�i�o�[�W�����ɂ�Yonah �V���O���R�A���ڂ�Ǝv���B
Power Mac��Conroe�~2���낤�B
�m�[�g��LV�ł��낤��15W�@�@1.5-1.6mhz�@
299 �F���̖��ݒ��F2006/01/07(�y) 15:04:33 ID:R2TIN2pj0
>>295
945GT���āA���O����z������ƁAGPU�����`�b�v�Z�b�g�H
�f�B�X�N���[�gGPU�Ō����A�ǂꂮ�炢�̃N���X�ɑ�������낤�B
945GT���āA���O����z������ƁAGPU�����`�b�v�Z�b�g�H
�f�B�X�N���[�gGPU�Ō����A�ǂꂮ�炢�̃N���X�ɑ�������낤�B
i945GTm-HIL M/B
http://www.cesweb.org/press/new_products/rd_new_product_details.asp?prodid=7621
����ɂ���Ȃ̂��\���Ă������B
Apple�͂ǂ��Ȃ�̂��ȁB
http://www.cesweb.org/press/new_products/rd_new_product_details.asp?prodid=7621
����ɂ���Ȃ̂��\���Ă������B
Apple�͂ǂ��Ȃ�̂��ȁB
>>297
conroe����4way�g�߂Ȃ��ᖳ���낤���B
���s��4way�\�Ȃ�xeon�ł���Bconroe�͂����܂�pentium�����̈ʒu�t���Ȃ̂ł́B
conroe����4way�g�߂Ȃ��ᖳ���낤���B
���s��4way�\�Ȃ�xeon�ł���Bconroe�͂����܂�pentium�����̈ʒu�t���Ȃ̂ł́B
�A�b�v�����]�ނȂ�A�����������`�b�v�Z�b�g���o�邩����B
Vista��CPU���̐������ς�邩���m��B�@�@conroe�ɂ��Ă͂ǂ��Ȃ�̂� �܂���������
Vista��CPU���̐������ς�邩���m��B�@�@conroe�ɂ��Ă͂ǂ��Ȃ�̂� �܂���������
Woodcrest�������ނ�Conroe�Ȃ̂ł�����g����낵���B
PowerMac = �}���`�v���Z�b�T���Ă̂�A�����i�т�x86�ƑR����Ƃ����Ȃ�B�B�B���Ĉȏ�̘b���ᖳ�����B
x86���̗p������Ă��Ƃ�A�����l�i��PC���V���O���v���Z�b�T�Ȃ�Mac���V���O���v���Z�b�T�BXeon�N���X��
MP���~������A80���~��o�債����Ă��ƂɂȂ邷�B
x86���̗p������Ă��Ƃ�A�����l�i��PC���V���O���v���Z�b�T�Ȃ�Mac���V���O���v���Z�b�T�BXeon�N���X��
MP���~������A80���~��o�債����Ă��ƂɂȂ邷�B
80���Ȃ�Ă��Ȃ�������ہB
306 �F���̖��ݒ��F2006/01/07(�y) 21:14:44 ID:1o5oT0bJ0
MAC�I�^�A�܂�����Ȃ��ƌ����Ă�̂��c
Fast Conroe�~1�@25��
Faster Conroe�~2�@30��
Ultimate Woodcrest�~2�@80���H
���̍\���͂��蓾�Ȃ���
Faster Conroe�~2�@30��
Ultimate Woodcrest�~2�@80���H
���̍\���͂��蓾�Ȃ���
308 �F���̖��ݒ��F2006/01/07(�y) 21:53:11 ID:j9jAjO5D0
�uConroe�~2�͂��蓾�Ȃ��v
�u4-way��PowerMac���o��Ȃ�80���~����v
MAC�I�^�����������������ƁA�݂�ȃ������Ă������I
�u4-way��PowerMac���o��Ȃ�80���~����v
MAC�I�^�����������������ƁA�݂�ȃ������Ă������I
���̂Ƃ���ADualCPU�Ή���XeonDP��Pentium�ƒl�i�͂���قǕς��Ȃ�
Quad�܂őΉ���XeonMP�͂�����
�ŁA���s��PowerMacG5��4way�Ȃ�AXeonDP�ɂ�����Woodcrest��DualCore������
�����DualCPU�ł����A���s��PowerMacG5���炢�̒l�i�łł��Ȃ��낤��
SingleCPU�ł��AKentsfield�Ƃ�����DualCore���1�̃\�P�b�g�̂ɍڂ����̂Ȃ�
4way��CPU�̒l�i�������ɗ}�����邩������Ȃ�
Quad�܂őΉ���XeonMP�͂�����
�ŁA���s��PowerMacG5��4way�Ȃ�AXeonDP�ɂ�����Woodcrest��DualCore������
�����DualCPU�ł����A���s��PowerMacG5���炢�̒l�i�łł��Ȃ��낤��
SingleCPU�ł��AKentsfield�Ƃ�����DualCore���1�̃\�P�b�g�̂ɍڂ����̂Ȃ�
4way��CPU�̒l�i�������ɗ}�����邩������Ȃ�
310 �F���̖��ݒ��F2006/01/14(�y) 21:55:38 ID:kGe6fsfo0
Merom��Yonah���āA�N���b�N������̐��\�͂ǂꂮ�炢�Ⴄ��ł����H
���ƁAMerom/Conroe�͂ǂꂮ�炢�̎��g������X�^�[�g�ł����H
���ƁAMerom/Conroe�͂ǂꂮ�炢�̎��g������X�^�[�g�ł����H
>>310
Conroe 2.66GHz�ŃX�^�[�g@7��
Merom�̓N���b�N���܂����܂��ĂȂ��炵���B9���ȍ~�o��B
Woodcrest��Conroe���l�O�|�������悤���B
�ȏオ�ŐV�̗\����B�������A���͏�ɍX�V����܂��B
INQ�\�[�X�ł́AMerom��Yonah���30%���̃N���b�N�����萮�����Z���\�B
// ��\�z���m����̐��l�ɓ��Ɍl�I�Ȕ��_�͂Ȃ��B
���A�\�X���ɂ͂��Ă�����3.33GHz�Ƃ������̂�
���ꃋ�[�}�[���Ǝv����̂ŃX���[��OK�B
// �]�k
// Merom/Conroe��ALU port���啝�ɑ�����Ƃ̏�������邪�A
// FPU/SIMD���̏��͑S���Ƃ����Ă����قǂȂ��B
// ALU���������邵�A����d�͂̂��Ƃ��l���Ă�Intel�����ӂ̃A����
// �ӂ�ɂ���Ă���̂��A
// ����Ƃ��܂��V�v�f��FPU/SIMD���ɉB���Ă���̂��B
// �R���Conroe�̃_�C�T�C�Y��FPU/SIMD�������ALU�̂��Ƃ�
// �g������̂ɏ\���ȑ傫���Ƃ͂��܂�v��Ȃ��B
// �������AMerom/Conroe�̃��f�B�A���Z���\���Ⴂ�Ƃ����̂�
// ��ʓI�ȗ\�z�ł͂���܂���̂Řb�����ɁB
Conroe 2.66GHz�ŃX�^�[�g@7��
Merom�̓N���b�N���܂����܂��ĂȂ��炵���B9���ȍ~�o��B
Woodcrest��Conroe���l�O�|�������悤���B
�ȏオ�ŐV�̗\����B�������A���͏�ɍX�V����܂��B
INQ�\�[�X�ł́AMerom��Yonah���30%���̃N���b�N�����萮�����Z���\�B
// ��\�z���m����̐��l�ɓ��Ɍl�I�Ȕ��_�͂Ȃ��B
���A�\�X���ɂ͂��Ă�����3.33GHz�Ƃ������̂�
���ꃋ�[�}�[���Ǝv����̂ŃX���[��OK�B
// �]�k
// Merom/Conroe��ALU port���啝�ɑ�����Ƃ̏�������邪�A
// FPU/SIMD���̏��͑S���Ƃ����Ă����قǂȂ��B
// ALU���������邵�A����d�͂̂��Ƃ��l���Ă�Intel�����ӂ̃A����
// �ӂ�ɂ���Ă���̂��A
// ����Ƃ��܂��V�v�f��FPU/SIMD���ɉB���Ă���̂��B
// �R���Conroe�̃_�C�T�C�Y��FPU/SIMD�������ALU�̂��Ƃ�
// �g������̂ɏ\���ȑ傫���Ƃ͂��܂�v��Ȃ��B
// �������AMerom/Conroe�̃��f�B�A���Z���\���Ⴂ�Ƃ����̂�
// ��ʓI�ȗ\�z�ł͂���܂���̂Řb�����ɁB
312 �F310�F2006/01/15(��) 05:47:39 ID:Pet1mO+N0
thx.
�N���b�N������̐��\��G4��荂��Pentium M��荂��Yonah��荂��Conroe/Merom���B
�I�����N���N���������I
�N���b�N������̐��\��G4��荂��Pentium M��荂��Yonah��荂��Conroe/Merom���B
�I�����N���N���������I
IntelR Fortran Compiler for Mac OS
IntelR C++ Compiler for Mac OS
IntelR Math Kernel Library for Mac OS
IntelR Integrated Performance Primitives for Mac OS
Intel Software Development Products for Mac OS* Beta
Available Now!
Development Support for Intel-Based Mac
http://www.intel.com/cd/ids/developer/asmo-na/eng/255716.htm
�e��\�t�g�J���c�[����Beta�ŁB
Intel-Based Mac���c�B
IntelR C++ Compiler for Mac OS
IntelR Math Kernel Library for Mac OS
IntelR Integrated Performance Primitives for Mac OS
Intel Software Development Products for Mac OS* Beta
Available Now!
Development Support for Intel-Based Mac
http://www.intel.com/cd/ids/developer/asmo-na/eng/255716.htm
�e��\�t�g�J���c�[����Beta�ŁB
Intel-Based Mac���c�B
���}����P�̃��r�L�^�X���ǁ�
Intel�̎�����v���b�g�t�H�[���gSanta Rosa�h
http://pc.watch.impress.co.jp/docs/2006/0116/ubiq145.htm
Intel�̎�����v���b�g�t�H�[���gSanta Rosa�h
http://pc.watch.impress.co.jp/docs/2006/0116/ubiq145.htm
315 �F���̖��ݒ��F2006/01/28(�y) 13:39:16 ID:2icG+wxU0
���[���A�݂�Ȃǂ��֍s�����H
�����̌��_�B �Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q���݂܂���ł���orz�B�B
�C���e��CPU���ڂ̐V�^�}�b�N�́u�����v���H(��)
http://hotwired.goo.ne.jp/news/technology/story/20060127301.html
�C���e��CPU���ڂ̐V�^�}�b�N�́u�����v���H(��)
http://hotwired.goo.ne.jp/news/technology/story/20060127301.html
Intel readies E6xxx Conroe desktop chips for fall
http://www.theinquirer.net/?article=29504
E6700 2.67GHz L2 4MB FSB1066MHz $529
E6600 2.40GHz L2 4MB FSB1066MHz $315
Exxxx 2.67GHz L2 2MB FSB1066MHz $xxx
Exxxx 2.40GHz L2 2MB FSB1066MHz $xxx
E6400 2.13GHz L2 2MB FSB1066MHz $240
E6300 1.83GHz L2 2MB FSB1066MHz $210
�Ђ��т��ɂ܂Ƃ��ȐV������Ȃ��B
http://www.theinquirer.net/?article=29504
E6700 2.67GHz L2 4MB FSB1066MHz $529
E6600 2.40GHz L2 4MB FSB1066MHz $315
Exxxx 2.67GHz L2 2MB FSB1066MHz $xxx
Exxxx 2.40GHz L2 2MB FSB1066MHz $xxx
E6400 2.13GHz L2 2MB FSB1066MHz $240
E6300 1.83GHz L2 2MB FSB1066MHz $210
�Ђ��т��ɂ܂Ƃ��ȐV������Ȃ��B
- Conroe (Core Duo, 1066MHz FSB, 4MB L2)
-- E6700 2.67GHz $529
-- E6600 2.40GHz $315
- Conroe (Core Duo, 1066MHz FSB, 2MB L2)
-- Exxxx 2.67GHz $xxx
-- Exxxx 2.40GHz L$xxx
-- E6400 2.13GHz $240
-- E6300 1.83GHz $210
Intel prices up Xeon Woodcrest server chips
http://www.theinquirer.net/?article=29510
- Woodcrest (Xeon DP, 1333MHz FSB, 4MB L2)
-- 5160 3GHz $850
-- 5150 2.66GHz $700
-- 5140 2.33GHz $470
-- 5130 2GHz $330
-- 5120 1.86GHz $270
-- 5110 1.6GHz $230
-- E6700 2.67GHz $529
-- E6600 2.40GHz $315
- Conroe (Core Duo, 1066MHz FSB, 2MB L2)
-- Exxxx 2.67GHz $xxx
-- Exxxx 2.40GHz L$xxx
-- E6400 2.13GHz $240
-- E6300 1.83GHz $210
Intel prices up Xeon Woodcrest server chips
http://www.theinquirer.net/?article=29510
- Woodcrest (Xeon DP, 1333MHz FSB, 4MB L2)
-- 5160 3GHz $850
-- 5150 2.66GHz $700
-- 5140 2.33GHz $470
-- 5130 2GHz $330
-- 5120 1.86GHz $270
-- 5110 1.6GHz $230
319 �Finteler@�����F2006/02/06(��) 22:46:03 ID:prOJ0e2c0
���A��ׁA���̐�����ǂ��Ă��B
Intel readies E6xxx Conroe desktop chips for fall
http://www.theinquirer.net/?article=29504
- Conroe (Core Duo, 1066MHz FSB, 4MB L2)
-- E6700 2.67GHz $529
-- E6600 2.40GHz $315
- Conroe (Core Duo, 1066MHz FSB, 2MB L2)
-- E6400 2.13GHz $240
-- E6300 1.83GHz $210
Intel prices up Xeon Woodcrest server chips
http://www.theinquirer.net/?article=29510
- Woodcrest (Xeon DP, 1333MHz FSB, 4MB L2)
-- 5160 3GHz $850
-- 5150 2.66GHz $700
-- 5140 2.33GHz $470
-- 5130 2GHz $330
-- 5120 1.86GHz $270
-- 5110 1.6GHz $230
Intel readies E6xxx Conroe desktop chips for fall
http://www.theinquirer.net/?article=29504
- Conroe (Core Duo, 1066MHz FSB, 4MB L2)
-- E6700 2.67GHz $529
-- E6600 2.40GHz $315
- Conroe (Core Duo, 1066MHz FSB, 2MB L2)
-- E6400 2.13GHz $240
-- E6300 1.83GHz $210
Intel prices up Xeon Woodcrest server chips
http://www.theinquirer.net/?article=29510
- Woodcrest (Xeon DP, 1333MHz FSB, 4MB L2)
-- 5160 3GHz $850
-- 5150 2.66GHz $700
-- 5140 2.33GHz $470
-- 5130 2GHz $330
-- 5120 1.86GHz $270
-- 5110 1.6GHz $230
Intel Merom chips get numbers, specs
http://www.theinquirer.net/?article=29514
- Merom (667MHz FSB, 4MB L2, FCPGA6)
-- T7600 2.33GHz
-- T7400 2.16GHz
-- T7200 2GHz
-- T5600 1.83GHz Solo
ProcNum �� Merom > Conroe�ȂƂ��낪���X���ȁB
�N���b�N�������ĕς���Ȃ��B
http://www.theinquirer.net/?article=29514
- Merom (667MHz FSB, 4MB L2, FCPGA6)
-- T7600 2.33GHz
-- T7400 2.16GHz
-- T7200 2GHz
-- T5600 1.83GHz Solo
ProcNum �� Merom > Conroe�ȂƂ��낪���X���ȁB
�N���b�N�������ĕς���Ȃ��B
321 �F���̖��ݒ��F2006/02/07(��) 07:52:35 ID:D1n+ergt0
�ŁA�������Ƃ����ē��ڂ�Mac�͂�����o��́H
>>321
Q3
Intel's Ultra Mobile PC on track for Q1 release
http://www.tgdaily.com/2006/02/06/intel_umpc/
UMPC(Ultra Mobile PC)�ɂ��āB
�ڂ����̓\�[�X�Q�ƁB
�������݂����A
Intel���n���h�g�b�v��PC�����l�������ɗ\��BQ2�����肩�琔���o��B
������0.5W�̏���d�͂̐V�����J�e�S���̃v���Z�b�T�𓋍ڂ���\�肾�����悤�����A
���Ȃ��Ƃ��ŏ��̃o�[�W������90nm ULV Dothan�ŏo��B
���Ȃ݂ɂ��̃\�[�X�ɂ��ƐV�}�C�N���A�[�L��CPU��9���B
Q3
Intel's Ultra Mobile PC on track for Q1 release
http://www.tgdaily.com/2006/02/06/intel_umpc/
UMPC(Ultra Mobile PC)�ɂ��āB
�ڂ����̓\�[�X�Q�ƁB
�������݂����A
Intel���n���h�g�b�v��PC�����l�������ɗ\��BQ2�����肩�琔���o��B
������0.5W�̏���d�͂̐V�����J�e�S���̃v���Z�b�T�𓋍ڂ���\�肾�����悤�����A
���Ȃ��Ƃ��ŏ��̃o�[�W������90nm ULV Dothan�ŏo��B
���Ȃ݂ɂ��̃\�[�X�ɂ��ƐV�}�C�N���A�[�L��CPU��9���B
323 �F���̖��ݒ��F2006/02/07(��) 21:10:50 ID:9+gpO+fR0
Q1���ĉ�������Ȃ́H�@1���H�@4���H
�č���������A1�����琔���܂��B
325 �F���̖��ݒ��F2006/02/07(��) 21:25:59 ID:9+gpO+fR0
���N�̋^�₪�X�����܂����B
���肪���₠�肪����B
���肪���₠�肪����B
Yonah T2600(2.17GHz)��SPEC CPU�����o�^�X�R�A�B
Lenovo Thinkpad T60 Type 1951-IXU( 2.167 GHz, Intel(R) Core Duo processor T2600)
SPECint2000 = 1754
SPECint_base2000 = 1748
SPECfp2000 = 1580
SPECfp_base2000 = 1581
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05370.html
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05371.html
Lenovo Thinkpad T60 Type 1951-IXU( 2.167 GHz, Intel(R) Core Duo processor T2600)
SPECint2000 = 1754
SPECint_base2000 = 1748
SPECfp2000 = 1580
SPECfp_base2000 = 1581
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05370.html
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05371.html
Intel shows off multi-threaded Xeon chip
http://www.theinquirer.net/?article=29540
�Ō��NetBurst�`�b�v�ATulsa(Xeon MP)�ɂ��āB
Tulsa
- 3.4GHz
- 1MB L2 + 16MB L3 On-Chip
- 150W [email protected]
- 65nm, 1328MTr., 435sqmm
- 667/800MHz 3load FSB
�_�C�T�C�Y�����܂ł�Xeon�Ƃ���ׂĂ����Ȃ�ł����ȁB
Conroe��3�{�߂�����Ȃ����c(;�L�D`)
http://www.theinquirer.net/?article=29540
�Ō��NetBurst�`�b�v�ATulsa(Xeon MP)�ɂ��āB
Tulsa
- 3.4GHz
- 1MB L2 + 16MB L3 On-Chip
- 150W [email protected]
- 65nm, 1328MTr., 435sqmm
- 667/800MHz 3load FSB
�_�C�T�C�Y�����܂ł�Xeon�Ƃ���ׂĂ����Ȃ�ł����ȁB
Conroe��3�{�߂�����Ȃ����c(;�L�D`)
L2 1MB�̓R�A������BL3�͋��L�B
329 �F���̖��ݒ��F2006/02/07(��) 22:46:16 ID:0j7vOijG0
>>326
SPEC_rate���B
Lenovo Thinkpad T60 Type 1951-IXU( 2.167 GHz, Intel(R) Core Duo processor T2600)
SPECint_rate_base2000 = 34.9
SPECfp_rate_base2000 = 27.4
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05373.html
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05372.html
SPEC_rate���B
Lenovo Thinkpad T60 Type 1951-IXU( 2.167 GHz, Intel(R) Core Duo processor T2600)
SPECint_rate_base2000 = 34.9
SPECfp_rate_base2000 = 27.4
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05373.html
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060110-05372.html
ISSCC 2006 - �C���e���A������Xeon MP�uTulsa�v�̊T�v�����\
http://pcweb.mycom.co.jp/articles/2006/02/07/isscc3/
http://pcweb.mycom.co.jp/articles/2006/02/07/isscc3/
Intel Merom delayed to 2007, claim
http://www.digitimes.com/systems/a20060208A7034.html
DIGITIMES claimed Intel's 64-32 Merom processor won't now be introduced into 2007.
The wire quotes local Taiwanese notebook makers as saying that the delay is due to market timing,
with Microsoft Vista being a contributory factor, meaning that we won't see "Santa Rose" notebooks
until this time next year.
Intel�fs new notebook platform Santa Rosa to come in March 2007,
expected to boost notebook shipments
http://www.digitimes.com/systems/a20060208A7034.html
����́AINQ�̑��Ƃ��肩�c�i��ͥ�j???
�x���̂�Santa Rosa�����̂悤����(Merom��Napa����ł�����)�B
http://www.digitimes.com/systems/a20060208A7034.html
DIGITIMES claimed Intel's 64-32 Merom processor won't now be introduced into 2007.
The wire quotes local Taiwanese notebook makers as saying that the delay is due to market timing,
with Microsoft Vista being a contributory factor, meaning that we won't see "Santa Rose" notebooks
until this time next year.
Intel�fs new notebook platform Santa Rosa to come in March 2007,
expected to boost notebook shipments
http://www.digitimes.com/systems/a20060208A7034.html
����́AINQ�̑��Ƃ��肩�c�i��ͥ�j???
�x���̂�Santa Rosa�����̂悤����(Merom��Napa����ł�����)�B
>>329
Intel�����N��IDF�Ŏ��̂悤�Ȕ��\�����Ă���B
XeonDP�̐��\��(SPECint_rate, 2chip)
Irwindale + Lindenhurst (2chip, 2core)�ɑ��āA
Dempsey + Bensley (2chip, 4core) �ł� +88%
Woodcrest + Bensley (2chip, 4core) �ł͍X�� +52%
�̐��\�B
�ŁA���т͂Ƃ����ƁA
Irwindale + Lindenhurst �̃X�R�A SPECint_rate 38.3
http://www.spec.org/cpu2000/results/res2005q3/cpu2000-20050616-04288.html
�ɑ��āA>>172��Dempsey+Bensley�� SPECint_rate [email protected](+82%)�B
Dempsey��3.46GHz�̃o�[�W����������̂łقڒB���ł��Ă���ƍl���ėǂ����ƁB
�Ȃ̂ŁA[email protected](2chip, 4core)�́ASPECint_rate 109(est.)���炢�̃X�R�A�Ǝv���Ă����悢�B
Intel�����N��IDF�Ŏ��̂悤�Ȕ��\�����Ă���B
XeonDP�̐��\��(SPECint_rate, 2chip)
Irwindale + Lindenhurst (2chip, 2core)�ɑ��āA
Dempsey + Bensley (2chip, 4core) �ł� +88%
Woodcrest + Bensley (2chip, 4core) �ł͍X�� +52%
�̐��\�B
�ŁA���т͂Ƃ����ƁA
Irwindale + Lindenhurst �̃X�R�A SPECint_rate 38.3
http://www.spec.org/cpu2000/results/res2005q3/cpu2000-20050616-04288.html
�ɑ��āA>>172��Dempsey+Bensley�� SPECint_rate [email protected](+82%)�B
Dempsey��3.46GHz�̃o�[�W����������̂łقڒB���ł��Ă���ƍl���ėǂ����ƁB
�Ȃ̂ŁA[email protected](2chip, 4core)�́ASPECint_rate 109(est.)���炢�̃X�R�A�Ǝv���Ă����悢�B
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04974.html
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04975.html
���Ȃ݂ɁADempsey(NetBurst DualCore Xeon)�̏ꍇ�A2chip��4chip�ł̃X�R�A��1.86�{���炢��
�Ȃ邱�Ƃ�O���ɂ��āADual Yonah(=Sossman) 2.17GHz�̃X�R�A�𐄑�����ƁA
Dual Yonah(=Sossman) 2.17GHz SPECint_rate 65(est.)
�����P���v�Z��Woodcrest�̎��g���Ɋ��Z����ƁA
Dual Yonah(=Sossman) 2.93GHz SPECint_rate 88(est.)
@SPECint_rate: Dual Woodcrest / Dual Yonah = 88 / 109 = 1.24 (est.)
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04975.html
���Ȃ݂ɁADempsey(NetBurst DualCore Xeon)�̏ꍇ�A2chip��4chip�ł̃X�R�A��1.86�{���炢��
�Ȃ邱�Ƃ�O���ɂ��āADual Yonah(=Sossman) 2.17GHz�̃X�R�A�𐄑�����ƁA
Dual Yonah(=Sossman) 2.17GHz SPECint_rate 65(est.)
�����P���v�Z��Woodcrest�̎��g���Ɋ��Z����ƁA
Dual Yonah(=Sossman) 2.93GHz SPECint_rate 88(est.)
@SPECint_rate: Dual Woodcrest / Dual Yonah = 88 / 109 = 1.24 (est.)
335 �Finteler@�����F2006/02/08(��) 23:10:00 ID:QId3ntrg0
�~ ���Ȃ݂ɁADempsey(NetBurst DualCore Xeon)�̏ꍇ
�� ���Ȃ݂ɁAPaxville(NetBurst DualCore Xeon)�̏ꍇ
�� ���Ȃ݂ɁAPaxville(NetBurst DualCore Xeon)�̏ꍇ
���㓡�O��Weekly�C�O�j���[�X��
Intel�̎�����CPU�uConroe�v��2.66GHz�ő�3�l�����ɓo��
http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241.htm
�㓡�����܂Ƃ߂Ă����ȁB
Intel�̎�����CPU�uConroe�v��2.66GHz�ő�3�l�����ɓo��
http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241.htm
�㓡�����܂Ƃ߂Ă����ȁB
337 �Finteler@�����F2006/02/09(��) 23:55:58 ID:6yD/WhF90
>>334�ɂ܂����Ă���A���������̂ŗ�̂��Ƃ����������܂����B
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04974.html
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04975.html
���Ȃ݂ɁAPaxville(NetBurst DualCore Xeon)�̏ꍇ�A1chip(2core)��2chip(4core)�ł̃X�R�A��1.86�{���炢��
�Ȃ邱�Ƃ�O���ɂ��āADual Yonah(=Sossman 2chip, 4core) 2.17GHz�̃X�R�A�𐄑�����ƁA
Dual Yonah(=Sossman) 2.17GHz SPECint_rate 65(est.)
�����P���v�Z��Woodcrest�̎��g���Ɋ��Z����ƁA
Dual Yonah(=Sossman) 2.93GHz SPECint_rate 88(est.)
@SPECint_rate: Dual Woodcrest 2.93GHz / Dual Yonah 2.93GHz = 88 / 109
= 1.24 (est.)
�� SPECint�ɂ����铯�N���b�N�ł̐���R�A���\��
Sossman�̃X�R�A���o�^���ꂽ������Ɛ��x�̗ǂ��\�������Ă�ꂻ���B
�Ƃ����������_������ŁA��̓I�Ȑ��l�����ė\�z����̂͌������̂Řb�����ɁB
(Paxville����Ȃ��Ă��߂�Dempsey�������Ă�Ȃ��c)
���ɂ�INQ��Charlie����Woodcrest SPECint/fp_rate�X�R�A�\�z�Ȃǂ����邼�B
�R��̂��ʖڗ\�z���Ǝv�����ǂ��i��ͥ�j
AMD-Intel server market faces Woodcrest vs F-Step scrap
http://www.theinquirer.net/?article=28639
Woodcrest, if it comes out at 2.66/1333, will beat that handily on Int, and most likely at least tie it on FP.
I would expect low hundreds in FP_Rate and high 80s on Int_Rate. If Intel comes out with the cores on time,
they will at least be caught up, and when AMD goes to 3.2 as expected in Q4 and Intel hits 3.0, the gap will
widen in Intel's favor.
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04974.html
http://www.spec.org/cpu2000/results/res2005q4/cpu2000-20051027-04975.html
���Ȃ݂ɁAPaxville(NetBurst DualCore Xeon)�̏ꍇ�A1chip(2core)��2chip(4core)�ł̃X�R�A��1.86�{���炢��
�Ȃ邱�Ƃ�O���ɂ��āADual Yonah(=Sossman 2chip, 4core) 2.17GHz�̃X�R�A�𐄑�����ƁA
Dual Yonah(=Sossman) 2.17GHz SPECint_rate 65(est.)
�����P���v�Z��Woodcrest�̎��g���Ɋ��Z����ƁA
Dual Yonah(=Sossman) 2.93GHz SPECint_rate 88(est.)
@SPECint_rate: Dual Woodcrest 2.93GHz / Dual Yonah 2.93GHz = 88 / 109
= 1.24 (est.)
�� SPECint�ɂ����铯�N���b�N�ł̐���R�A���\��
Sossman�̃X�R�A���o�^���ꂽ������Ɛ��x�̗ǂ��\�������Ă�ꂻ���B
�Ƃ����������_������ŁA��̓I�Ȑ��l�����ė\�z����̂͌������̂Řb�����ɁB
(Paxville����Ȃ��Ă��߂�Dempsey�������Ă�Ȃ��c)
���ɂ�INQ��Charlie����Woodcrest SPECint/fp_rate�X�R�A�\�z�Ȃǂ����邼�B
�R��̂��ʖڗ\�z���Ǝv�����ǂ��i��ͥ�j
AMD-Intel server market faces Woodcrest vs F-Step scrap
http://www.theinquirer.net/?article=28639
Woodcrest, if it comes out at 2.66/1333, will beat that handily on Int, and most likely at least tie it on FP.
I would expect low hundreds in FP_Rate and high 80s on Int_Rate. If Intel comes out with the cores on time,
they will at least be caught up, and when AMD goes to 3.2 as expected in Q4 and Intel hits 3.0, the gap will
widen in Intel's favor.
338 �F���̖��ݒ��F2006/02/10(��) 08:28:25 ID:GVKetmqp0
>>337
>@SPECint_rate: Dual Woodcrest 2.93GHz / Dual Yonah 2.93GHz = 88 / 109
>= 1.24 (est.)
���q�ƕ��ꂪ�r���ŋt�ɂȂ��Ă�B
>@SPECint_rate: Dual Woodcrest 2.93GHz / Dual Yonah 2.93GHz = 88 / 109
>= 1.24 (est.)
���q�ƕ��ꂪ�r���ŋt�ɂȂ��Ă�B
339 �Finteler@�ϑz�F2006/02/11(�y) 00:53:20 ID:miMS+59o0
//�������Ⴂ�Ⴂ�ƒQ���̐�(�Ɗ���̐�)���������Ă���Conroe�̃N���b�N�ɂ��Ă����A
//�R��l�̊��z��2.66GHz�ł����C�B
//Merom��2.33GHz�Ƃ�Woodcrest��3GHz�Ȃǂ͗\��ʂ�o��̂����Ȃ�^���Ă�c�B
//>>336�̐V���
//�@�@Conroe XE��Q3�ɂł�B
//�A�@Launch��A���Ȃ��Ƃ�3�l�����̓N���b�N���オ��Ȃ��B
//�@�@�悭�킩��Ȃ����A�\�����������Ȃ̂�Woodcrest�����i(3GHz,1333MHz,TDP70W-80W)�̃��l�[���̔��B
//�A �{����3�l�������N���b�N���オ��Ȃ����ǂ����͂��Ȃ�^��B
//�@�@���C�o���̊撣�莟��ł́A���\�I�~�����}�����ꂸ�A����ɏ�̃p���[�N���X�Łc�B
//�R��l�̊��z��2.66GHz�ł����C�B
//Merom��2.33GHz�Ƃ�Woodcrest��3GHz�Ȃǂ͗\��ʂ�o��̂����Ȃ�^���Ă�c�B
//>>336�̐V���
//�@�@Conroe XE��Q3�ɂł�B
//�A�@Launch��A���Ȃ��Ƃ�3�l�����̓N���b�N���オ��Ȃ��B
//�@�@�悭�킩��Ȃ����A�\�����������Ȃ̂�Woodcrest�����i(3GHz,1333MHz,TDP70W-80W)�̃��l�[���̔��B
//�A �{����3�l�������N���b�N���オ��Ȃ����ǂ����͂��Ȃ�^��B
//�@�@���C�o���̊撣�莟��ł́A���\�I�~�����}�����ꂸ�A����ɏ�̃p���[�N���X�Łc�B
Intel promises quad server chips for Q1 2007
http://www.theinquirer.net/?article=29617
Intel��Clovertown(2chip- 4core MCM Woodcrest Xeon)+Bensley/Glidewell��Q1 2007��OEM��ɓ`�����B
Woodcrest�͑��ς�炸Q3�B���Ղɂ�Montecito���BTulsa��Q3-Q4�B
http://www.theinquirer.net/?article=29617
Intel��Clovertown(2chip- 4core MCM Woodcrest Xeon)+Bensley/Glidewell��Q1 2007��OEM��ɓ`�����B
Woodcrest�͑��ς�炸Q3�B���Ղɂ�Montecito���BTulsa��Q3-Q4�B
>>339
���l�[���������AConroe4M��Woodcrest�͂قړ������̂���Ȃ��H
���l�[���������AConroe4M��Woodcrest�͂قړ������̂���Ȃ��H
342 �F���̖��ݒ��F2006/02/11(�y) 13:59:38 ID:XJ4tFjTb0
Intel Power Mac�i���j��4-way�ŏo�邷���ˁH
4Socket��XeonMP�͂ƂĂ������̂Ň_
2core��2Socket��XeonDP��Mac�͂ł邩���B
2core��2Socket��XeonDP��Mac�͂ł邩���B
iMac�ɺ�ۂ��̂�̂���݂ɂȂ�̂�
���ꂪ�C�ɂȂ鍡�����̍��ł�
���ꂪ�C�ɂȂ鍡�����̍��ł�
iMac�͏����ł��ቿ�i�ɂ���ׁA�Ƃ���yonah�Ɨ\�z���Ă�B�@2007�N�̒ቿ�i��conroe/merom�łǂ����ςނ��ȁA
346 �F���̖��ݒ��F2006/02/12(��) 17:55:21 ID:LQJzUk8o0
Yonah��Merom/Conroe�̃R�A���g�����ACeleron�N���X�̐��i���ďo��\��͖������ˁB
347 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/12(��) 18:00:50 ID:nSYAEhQq0
CoreSolo����Mac-mini�o�Ă��Ă�������ˁB
���ƁA�M�x�A�{�[���͐����B
���ƁA�M�x�A�{�[���͐����B
���㓡�O��Weekly�C�O�j���[�X��
���o�C��CPU�uMerom�v�͔N������ɓo��
http://pc.watch.impress.co.jp/docs/2006/0210/kaigai242.htm
Intel Merom for mobile pushed out to Q4
http://www.theinquirer.net/?article=29605
Intel roadmap update: Conroe to launch with up to 2.66 GHz
http://www.tgdaily.com/2006/02/11/intel_conroe_to_launch_in_q3/
Intel pushes Conroe Extreme Edition, Viiv, Averill Pro and Vista
http://www.theinquirer.net/?article=29599
>>332�̘b�Ƃ͂܂��Ⴄ�悤�����AMerom������Q4�ɒx���(TGdaily�\�z�ł�10��)�B
Merom�x�[�XCeleron M��Q1 2007�BSanta Rosa��Mar. 2007�B
- Merom
-- T7600 2.33GHz 4MB L2 667MHz FSB $640
-- T7400 2.16GHz 4MB L2 667MHz FSB $420
-- T7200 2.00GHz 4MB L2 667MHz FSB $295
-- T5600 1.83GHz 2MB L2 667MHz FSB $240
���o�C��CPU�uMerom�v�͔N������ɓo��
http://pc.watch.impress.co.jp/docs/2006/0210/kaigai242.htm
Intel Merom for mobile pushed out to Q4
http://www.theinquirer.net/?article=29605
Intel roadmap update: Conroe to launch with up to 2.66 GHz
http://www.tgdaily.com/2006/02/11/intel_conroe_to_launch_in_q3/
Intel pushes Conroe Extreme Edition, Viiv, Averill Pro and Vista
http://www.theinquirer.net/?article=29599
>>332�̘b�Ƃ͂܂��Ⴄ�悤�����AMerom������Q4�ɒx���(TGdaily�\�z�ł�10��)�B
Merom�x�[�XCeleron M��Q1 2007�BSanta Rosa��Mar. 2007�B
- Merom
-- T7600 2.33GHz 4MB L2 667MHz FSB $640
-- T7400 2.16GHz 4MB L2 667MHz FSB $420
-- T7200 2.00GHz 4MB L2 667MHz FSB $295
-- T5600 1.83GHz 2MB L2 667MHz FSB $240
>>346 >>348
Clovertown��Q1 2007������AKentsfield(Conroe XE: 2chip 4core MCM Conroe)���ӊO�ɑ��������B
Kentsfield���ł��4way�ɂ��ẮA������Ƃ܂Ă�1S�ł�����B
Xeon DP�Ȃ�8way������ɂ͂��邪��������MCM�n�͉��i�����\���������B
Clovertown��Q1 2007������AKentsfield(Conroe XE: 2chip 4core MCM Conroe)���ӊO�ɑ��������B
Kentsfield���ł��4way�ɂ��ẮA������Ƃ܂Ă�1S�ł�����B
Xeon DP�Ȃ�8way������ɂ͂��邪��������MCM�n�͉��i�����\���������B
Montecito��4�����̗\��炵���B
Intel prices up 24MB dual core Itanium
http://www.theinquirer.net/?article=29569
- Montecito (dual core, Itanium 2, 1MB+256KB L2 I+D/core)
-- 9050 1.6GHz L3 24MB $3,650
-- 9040 1.6GHz L3 18MB $1,990
-- 9030 1.6GHz L3 8MB $1,570
-- 9020 1.42GHz L3 12MB $950
-- 9010 1.6GHz L3 8MB single-core $950
Intel prices up 24MB dual core Itanium
http://www.theinquirer.net/?article=29569
- Montecito (dual core, Itanium 2, 1MB+256KB L2 I+D/core)
-- 9050 1.6GHz L3 24MB $3,650
-- 9040 1.6GHz L3 18MB $1,990
-- 9030 1.6GHz L3 8MB $1,570
-- 9020 1.42GHz L3 12MB $950
-- 9010 1.6GHz L3 8MB single-core $950
351 �F���̖��ݒ��F2006/02/12(��) 18:45:23 ID:dAaUW5og0
DirectX 10�����GPU�ł́AGPGPU�I�Ȏg���������Ȃ�o����悤�ɂȂ�݂��������ǁA
GPGPU�p�r��API���ǂ����L�͂Ȋ�ƂȂ�c�̂Ȃ肪����ĕ��y�����Ă������̂��ˁB
GPGPU�p�r��API���ǂ����L�͂Ȋ�ƂȂ�c�̂Ȃ肪����ĕ��y�����Ă������̂��ˁB
Dempsey delay is not Intel's fault
http://www.theinquirer.net/?article=29576
�Ȃ��Ȃ��łȂ��Ȃ��Ƃ������Ă���A5���ɒx��Ă��̂�Dempsey�B
�x��̌�����FB-DIMM�̖͗l�B
http://www.theinquirer.net/?article=29576
�Ȃ��Ȃ��łȂ��Ȃ��Ƃ������Ă���A5���ɒx��Ă��̂�Dempsey�B
�x��̌�����FB-DIMM�̖͗l�B
First Lab Tests: iMac with Intel Core Duo processor
Intel-based iMacs are fast, but gains don�ft match Apple�fs claims
http://www.macworld.com/2006/01/features/imaclabtest1/index.php
���X���Ŋ��o��������AIntel Core Duo 2.0GHz vs iMac G5 2.1GHz�B
Universal�A�v���ł́AIntel Mac�̕��������ݍ��������A
PPC Binary + Rosetta �̃A�v���ł́A40%���炢���\�B
Intel-based iMacs are fast, but gains don�ft match Apple�fs claims
http://www.macworld.com/2006/01/features/imaclabtest1/index.php
���X���Ŋ��o��������AIntel Core Duo 2.0GHz vs iMac G5 2.1GHz�B
Universal�A�v���ł́AIntel Mac�̕��������ݍ��������A
PPC Binary + Rosetta �̃A�v���ł́A40%���炢���\�B
�}���`�X���b�h�ȃA�v���P�[�V�����ő����Ȃ�̂͂���Ӗ����R������
�Е��̃R�A���~�����Ĕ�r���ė~����
�Е��̃R�A���~�����Ĕ�r���ė~����
355 �F���̖��ݒ��F2006/02/12(��) 20:09:58 ID:dAaUW5og0
����Ȕ�r�͖��Ӗ�
>>354
Core Duo�̕Е���Core���~�߂��e�X�g�BG5�L�������ǁA����Intel�n��
�ǂꂮ�炢���シ��̂��ǂ����B
Inside Intel: Updated Lab Tests and Analysis
http://www.macworld.com/2006/02/firstlooks/imacbench2/index.php
Page 11�ӂ肩��B
Apple Makes the Switch: iMac G5 vs. iMac Core Duo
http://www.anandtech.com/mac/showdoc.aspx?i=2685
�ǂ�����512MB�����ς�łȂ���ˁB
Core Duo�̕Е���Core���~�߂��e�X�g�BG5�L�������ǁA����Intel�n��
�ǂꂮ�炢���シ��̂��ǂ����B
Inside Intel: Updated Lab Tests and Analysis
http://www.macworld.com/2006/02/firstlooks/imacbench2/index.php
Page 11�ӂ肩��B
Apple Makes the Switch: iMac G5 vs. iMac Core Duo
http://www.anandtech.com/mac/showdoc.aspx?i=2685
�ǂ�����512MB�����ς�łȂ���ˁB
>>356
����ς�V���O���X���b�h���\��G5�ɑ��Ĉ��|�I�ȗD�ʐ��͖����ˁB
PowerMac�̑�ւ͂܂��悩�A����Ƃ�dual corex2�ɂ��邩�B
����ς�V���O���X���b�h���\��G5�ɑ��Ĉ��|�I�ȗD�ʐ��͖����ˁB
PowerMac�̑�ւ͂܂��悩�A����Ƃ�dual corex2�ɂ��邩�B
Intel Kentsfield is four core gaming chip
http://www.theinquirer.net/?article=29735
Intel attempts dragging quad core Clovertown into 2006
http://www.theinquirer.net/?article=29749
Clovertown��Q1 2007���獡�N��Q4�ɑO�|������邩������Ȃ��͗l�B
Kentsfield��mid-2007����early-2007�Ɉڂ�����������Ȃ��͗l�B
http://www.theinquirer.net/?article=29735
Intel attempts dragging quad core Clovertown into 2006
http://www.theinquirer.net/?article=29749
Clovertown��Q1 2007���獡�N��Q4�ɑO�|������邩������Ȃ��͗l�B
Kentsfield��mid-2007����early-2007�Ɉڂ�����������Ȃ��͗l�B
�ECPUID will change from F62 to F64
�EC-1 is pin compatible with B-1
�ENew S-specs for converting products
�EThe advanced power management features Enhanced HALT State and Enhanced Intel SpeedStep� Technology will be enabled
�EThe Pentium D Processor 940 change from the 2005 Performance FMB (130W) to the 2005 Mainstream FMB (95W)
�EPentium D Processor 950 will also change from the 2005 Performance FMB (130W) to the 2005 Mainstream FMB (95W)
Presler�̃G���b�^���������ꂽ�͗l�BTDP��95W�܂Ō���܂����B
�EC-1 is pin compatible with B-1
�ENew S-specs for converting products
�EThe advanced power management features Enhanced HALT State and Enhanced Intel SpeedStep� Technology will be enabled
�EThe Pentium D Processor 940 change from the 2005 Performance FMB (130W) to the 2005 Mainstream FMB (95W)
�EPentium D Processor 950 will also change from the 2005 Performance FMB (130W) to the 2005 Mainstream FMB (95W)
Presler�̃G���b�^���������ꂽ�͗l�BTDP��95W�܂Ō���܂����B
���Ɨ]�k�����ǁC>>317-320�Ɏ�����Ă���悤��Intel�̉��i�̌n�������x86��PowerPC�̃}���`�v��
�Z�b�T����̈Ⴂ�������Ă��邷�B
���̒��̏펯�Ƃ��āu���m��C�܂Ƃ߂Ĕ����ƈ�����Ƃ��u2�����̂�C1������肨����Ƃ����̂������
���ǁCx86�̐��E��C���̏펯�����藧���Ȃ����B�Ⴆ�C
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)E6700 2.67GHz $529
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5150 2.66GHz $700
�@�@---------------------------
�s�v�c�Ȃ��Ƃɕ����������Ƃ��O��ɂȂ��Ă���MP�Ή��v���Z�b�T�̂ق��������Ȃ��Ă��邷�BAMD�ł�
����퓯�����B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� Opteron 180 $637
�@�@�f���A���v���Z�b�T�Ή� Opteron 280 $851
�@�@�}���`�v���Z�b�T�Ή��@ Opteron 880 $1,514
�@�@---------------------------
�Z�b�T����̈Ⴂ�������Ă��邷�B
���̒��̏펯�Ƃ��āu���m��C�܂Ƃ߂Ĕ����ƈ�����Ƃ��u2�����̂�C1������肨����Ƃ����̂������
���ǁCx86�̐��E��C���̏펯�����藧���Ȃ����B�Ⴆ�C
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)E6700 2.67GHz $529
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5150 2.66GHz $700
�@�@---------------------------
�s�v�c�Ȃ��Ƃɕ����������Ƃ��O��ɂȂ��Ă���MP�Ή��v���Z�b�T�̂ق��������Ȃ��Ă��邷�BAMD�ł�
����퓯�����B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� Opteron 180 $637
�@�@�f���A���v���Z�b�T�Ή� Opteron 280 $851
�@�@�}���`�v���Z�b�T�Ή��@ Opteron 880 $1,514
�@�@---------------------------
361 �FMAC�I�^@�����F2006/02/18(�y) 15:48:17 ID:m1PjHMUN0
���G4��G5��PowerPC��ŏ����炷�ׂă}���`�v���Z�b�T�Ή��ŁCx86�̐��E�Ō�����悤��
���ȉ��i�̌n�푶�݂��Ȃ����B������P���ɑ�R�����قLj����Ȃ邷�B
Apple��Power Mac�����MP�H���ɑ������̂�C�R�A������̐��\���߂�Ƃ�������ȊO��
�������������炩�ȃR�X�g�I�ȗv�������邷�B
x86�Ɉڍs�����ȏ�C���܂łƂ�v���Z�b�T���i�̑̌n���̂��̂��قȂ邱�Ƃ햾�炩�ŁC�ȑO���珑���Ă���
�悤�ɁC2-core x �f���A����4-way�Ȃ�đ㕨������܂���҂ł��Ȃ�(��������C�����ȃv���~�A���i�ɂȂ�)��
�Ă̂햾�炩�Șb���B
���ȉ��i�̌n�푶�݂��Ȃ����B������P���ɑ�R�����قLj����Ȃ邷�B
Apple��Power Mac�����MP�H���ɑ������̂�C�R�A������̐��\���߂�Ƃ�������ȊO��
�������������炩�ȃR�X�g�I�ȗv�������邷�B
x86�Ɉڍs�����ȏ�C���܂łƂ�v���Z�b�T���i�̑̌n���̂��̂��قȂ邱�Ƃ햾�炩�ŁC�ȑO���珑���Ă���
�悤�ɁC2-core x �f���A����4-way�Ȃ�đ㕨������܂���҂ł��Ȃ�(��������C�����ȃv���~�A���i�ɂȂ�)��
�Ă̂햾�炩�Șb���B
�\�X�����]��
Intel Desktop CPU Roadmap 2006
http://www.dailytech.com/article.aspx?newsid=787
222 ���O�FMAC�I�^[sage] ���e���F2006/02/18(�y) 15:28:12 ID:XDVb5DOw
�u���o������Ől�C�̃v���Z�b�T�A�[�L�e�N�g�CMooly Eden�����܂��ʔ������ƌ����Ă邷�B
http://news.com.com/2100-1006_3-6041120.html
�@�@-------------------------
�@�@Instead, Intel will count on its microarchitectural improvements and a faster front-side bus to
�@�@deliver the 20 percent improvement in performance over AMD's chips, based on standard benchmarks,
�@�@Eden said.
�@�@-------------------------
Merom/Conroe��Hammer���20%��ǂ����\���o�邻�����B�ڍׂ허����IDF�Ŗ��炩�ɂȂ邻���Ȃ��
�y���݂���(��)
Intel Desktop CPU Roadmap 2006
http://www.dailytech.com/article.aspx?newsid=787
222 ���O�FMAC�I�^[sage] ���e���F2006/02/18(�y) 15:28:12 ID:XDVb5DOw
�u���o������Ől�C�̃v���Z�b�T�A�[�L�e�N�g�CMooly Eden�����܂��ʔ������ƌ����Ă邷�B
http://news.com.com/2100-1006_3-6041120.html
�@�@-------------------------
�@�@Instead, Intel will count on its microarchitectural improvements and a faster front-side bus to
�@�@deliver the 20 percent improvement in performance over AMD's chips, based on standard benchmarks,
�@�@Eden said.
�@�@-------------------------
Merom/Conroe��Hammer���20%��ǂ����\���o�邻�����B�ڍׂ허����IDF�Ŗ��炩�ɂȂ邻���Ȃ��
�y���݂���(��)
>>360-361
�܂��܂��BXeon��Pentium�͓������̂���Ȃ����A�o���f�[�V�����̃R�X�g���S�R�Ⴄ�̂�����
�}���`�v���Z�b�T�V�X�e���pCPU���f�X�N�g�b�vCPU�Ɣ�ׂč����I���Ă̂͂���͌��������肾��B
Xeon����Op���̂����đ�ʂɂ܂Ƃ߂Ĕ����Ȃ�l�����͂��Ă����킯�ł��B
PPC�̒l�i�̓}���`�v���Z�b�T�V�X�e���p�̃o���f�[�V�����̃R�X�g���܂�ł���킯�ŁA
�V���O���v���Z�b�T�����g��Ȃ��ڋq�͎g�������Ȃ��}���`�v���Z�b�T�̋@�\�̂��߂�
�������Ă���čl���邱�Ƃ��ł���B
�܂��A�ǂ����ł��������ǂ��B���Ƃ�Xeon��5150���̗p���Ă�80���͂����Ȃ����낤���ˁB
�܂��܂��BXeon��Pentium�͓������̂���Ȃ����A�o���f�[�V�����̃R�X�g���S�R�Ⴄ�̂�����
�}���`�v���Z�b�T�V�X�e���pCPU���f�X�N�g�b�vCPU�Ɣ�ׂč����I���Ă̂͂���͌��������肾��B
Xeon����Op���̂����đ�ʂɂ܂Ƃ߂Ĕ����Ȃ�l�����͂��Ă����킯�ł��B
PPC�̒l�i�̓}���`�v���Z�b�T�V�X�e���p�̃o���f�[�V�����̃R�X�g���܂�ł���킯�ŁA
�V���O���v���Z�b�T�����g��Ȃ��ڋq�͎g�������Ȃ��}���`�v���Z�b�T�̋@�\�̂��߂�
�������Ă���čl���邱�Ƃ��ł���B
�܂��A�ǂ����ł��������ǂ��B���Ƃ�Xeon��5150���̗p���Ă�80���͂����Ȃ����낤���ˁB
364 �FMAC�I�^��363 �����F2006/02/19(��) 19:52:09 ID:OBh36tmv0
>>363
�@�@----------------------
�@�@�o���f�[�V�����̃R�X�g���S�R�Ⴄ�̂�����
�@�@----------------------
���ʁC�V�X�e���̃o���f�[�V�����탆�[�U��Ƃ���邷�BPC��Ƃ픠���Ɖ����Ă��ŁC�v���Z�b�T�x���_��
�o���f�[�V�������܂ރR�X�g������Ă�Ƃ������@��(��)�@
�]���āC
�@�@----------------------
�@�@PPC�̒l�i�̓}���`�v���Z�b�T�V�X�e���p�̃o���f�[�V�����̃R�X�g���܂�ł���킯��
�@�@----------------------
�����R�����Ƃ������ƂɂȂ邷�B�d�l�ƃo���f�[�V�����̈Ⴂ�ʂ퓥�܂��Ă����������ǂ��Ǝv�����B
�@�@----------------------
�@�@�o���f�[�V�����̃R�X�g���S�R�Ⴄ�̂�����
�@�@----------------------
���ʁC�V�X�e���̃o���f�[�V�����탆�[�U��Ƃ���邷�BPC��Ƃ픠���Ɖ����Ă��ŁC�v���Z�b�T�x���_��
�o���f�[�V�������܂ރR�X�g������Ă�Ƃ������@��(��)�@
�]���āC
�@�@----------------------
�@�@PPC�̒l�i�̓}���`�v���Z�b�T�V�X�e���p�̃o���f�[�V�����̃R�X�g���܂�ł���킯��
�@�@----------------------
�����R�����Ƃ������ƂɂȂ邷�B�d�l�ƃo���f�[�V�����̈Ⴂ�ʂ퓥�܂��Ă����������ǂ��Ǝv�����B
���₢�₢��B�}���`�v���Z�b�T�pCPU������Ă郁�[�J�[�Ō������Ȃ����[�J�[�͂��Ȃ����낤�ƁB
���Ƃ��ŏ����ɂ��Ă��ˁB
���Ƃ��ŏ����ɂ��Ă��ˁB
PPC��CPU�͑S���}���`�v���Z�b�T�Ή�����������I�Ƃ͌������A
�`�b�v�Z�b�g���O�ō������e�X�g�����肵�Ȃ��Ⴂ���Ȃ��Ȃ�g�[�^���ł͂���܂�����Ȃ��킯�ŁA
���̓_x86�͏\���g����`�b�v�Z�b�g���Z�b�g�Ńv���Z�b�T���[�J�[�����Ă����킯�ŁA
CPU�P�̂̒l�i�̕t�����������Ăǂ����������̂͂������ȃ��m���Ǝv���킯�ł���B
���ꂱ�����i�̌n���Ⴄ�킯������E�E�E���B
�`�b�v�Z�b�g���O�ō������e�X�g�����肵�Ȃ��Ⴂ���Ȃ��Ȃ�g�[�^���ł͂���܂�����Ȃ��킯�ŁA
���̓_x86�͏\���g����`�b�v�Z�b�g���Z�b�g�Ńv���Z�b�T���[�J�[�����Ă����킯�ŁA
CPU�P�̂̒l�i�̕t�����������Ăǂ����������̂͂������ȃ��m���Ǝv���킯�ł���B
���ꂱ�����i�̌n���Ⴄ�킯������E�E�E���B
367 �FMAC�I�^��365 �����F2006/02/19(��) 20:13:54 ID:OBh36tmv0
>>365
PowerPC��errata���X�g��IBM��Motorola�̃T�C�g����_�E�����[�h���ēǂ�Ō���Ɨǂ����Ǝv�����B
MP��snoop����W�̖��킻��Ȃ�Ɍ����邷�B
��������ver.1.0�̒i�K�őΉ��`�b�v�Z�b�g���疳����Ԃł��������o�O������̂��C������Apple�������B
PowerPC��errata���X�g��IBM��Motorola�̃T�C�g����_�E�����[�h���ēǂ�Ō���Ɨǂ����Ǝv�����B
MP��snoop����W�̖��킻��Ȃ�Ɍ����邷�B
��������ver.1.0�̒i�K�őΉ��`�b�v�Z�b�g���疳����Ԃł��������o�O������̂��C������Apple�������B
>>367
���₳�A���������f�[�^�V�[�g�ɖ�肪�L�ڂ���Ă�Ƃ������Ƃ͂����ƌ�������Ă���Ă��Ƃ���Ȃ����B
���₳�A���������f�[�^�V�[�g�ɖ�肪�L�ڂ���Ă�Ƃ������Ƃ͂����ƌ�������Ă���Ă��Ƃ���Ȃ����B
369 �FMAC�I�^��366 �����F2006/02/19(��) 20:16:50 ID:OBh36tmv0
>>366
�@�@--------------------
�@�@�`�b�v�Z�b�g���O�ō������e�X�g�����肵�Ȃ��Ⴂ���Ȃ�
�@�@--------------------
�S�����̒ʂ�̗��R�ŁC�V���O���v���Z�b�T�ƃ}���`�v���Z�b�T�̃V�X�e���ŊJ���R�X�g��傫�����Ȃ��������B
���ꂪPower Mac��MP�H���̌o�ϓI�ȗ��t���Ƃ������Ƃ��B
�@�@--------------------
�@�@�`�b�v�Z�b�g���O�ō������e�X�g�����肵�Ȃ��Ⴂ���Ȃ�
�@�@--------------------
�S�����̒ʂ�̗��R�ŁC�V���O���v���Z�b�T�ƃ}���`�v���Z�b�T�̃V�X�e���ŊJ���R�X�g��傫�����Ȃ��������B
���ꂪPower Mac��MP�H���̌o�ϓI�ȗ��t���Ƃ������Ƃ��B
���Ȃ݂ɂ��̃X���b�h�A�c�_��5���X�ȓ��Ƃ����Öق̃��[�������݂��邷�B�B�B
371 �FMAC�I�^��368 �����F2006/02/19(��) 20:19:56 ID:OBh36tmv0
>>368
�@�@--------------------
�@�@�����ƌ�������Ă���Ă��Ƃ���Ȃ����B
�@�@--------------------
�ڋq���o�O����邷���ǁB�B�B�@�Ⴆ�C
http://www.powerlogix.com/products/g3_zif/
�@�@====================
�@�@PowerLogix opted for the IBM PowerPC 750GX for these upgrades, instead of the Motorola G4s,
�@�@due to a bug we discovered in 2001 (not even Motorola knew about this bug..it even existed in
�@�@their evaluation boards.) The 745x chip is incompatible with the Motorola bridge chip used on
�@�@these motherboards.
�@�@====================
�@�@--------------------
�@�@�����ƌ�������Ă���Ă��Ƃ���Ȃ����B
�@�@--------------------
�ڋq���o�O����邷���ǁB�B�B�@�Ⴆ�C
http://www.powerlogix.com/products/g3_zif/
�@�@====================
�@�@PowerLogix opted for the IBM PowerPC 750GX for these upgrades, instead of the Motorola G4s,
�@�@due to a bug we discovered in 2001 (not even Motorola knew about this bug..it even existed in
�@�@their evaluation boards.) The 745x chip is incompatible with the Motorola bridge chip used on
�@�@these motherboards.
�@�@====================
>>370
���߂�ˁB
���߂�ˁB
Intel's next next next gen mobile is called....
http://www.theinquirer.net/?article=29775
���X�X���ヂ�o�C���v���b�g�t�H�[����
�R�[�h�l�[����Gesher?
http://www.theinquirer.net/?article=29775
���X�X���ヂ�o�C���v���b�g�t�H�[����
�R�[�h�l�[����Gesher?
�}���`�v���Z�b�T�p�`�b�v�ɂ͍����������K�������ŕs���R����Ȃ�
���v�Ƌ����ʼn��i�����܂�Ƃ������
Power��UltraSparc�W�͂����ƍ���
���v�Ƌ����ʼn��i�����܂�Ƃ������
Power��UltraSparc�W�͂����ƍ���
woodcreat��clovertown�̃R�A���\�������̂͊ԈႢ�Ȃ����낤���ǁA
SMP���\�͂ǂ��Ȃ�̂��ȁA��
xeon MP��xeon7XX0���Aopteron�ɑ卷�����Ă邱�Ƃ��l�����
�ʖڂȋC������
SMP���\�͂ǂ��Ȃ�̂��ȁA��
xeon MP��xeon7XX0���Aopteron�ɑ卷�����Ă邱�Ƃ��l�����
�ʖڂȋC������
�A�J�L�R���܂�
>>375�ŁA���x���o�i�C��������ď��������ǁAFSB���x�A�{���Ƃ�
�����邩����v����
����2�\�P�b�g�͂Ȃ�Ƃ��Ȃ�Ƃ��āA4�\�P�b�g�ɂ�
�ǂ��Ή�����낤?
65nm����ł��ASMP�ł̓R�X�g���܂߂��D�ʐ���AMD���ɂ���낤�ȁA
�Ǝv��
>>375�ŁA���x���o�i�C��������ď��������ǁAFSB���x�A�{���Ƃ�
�����邩����v����
����2�\�P�b�g�͂Ȃ�Ƃ��Ȃ�Ƃ��āA4�\�P�b�g�ɂ�
�ǂ��Ή�����낤?
65nm����ł��ASMP�ł̓R�X�g���܂߂��D�ʐ���AMD���ɂ���낤�ȁA
�Ǝv��
�ް��MP��FSB�͏オ���Ă���������1066MHz������A
1FSB������2�\�P�b�g��B���ł����4Socket�������ł���B
1FSB������2�\�P�b�g��B���ł����4Socket�������ł���B
ttp://pcweb.mycom.co.jp/photo/news/2005/12/13/002el.jpg
�EQuad High Speed Interconnect
�ELarge Memory Snoop Filter
�撣����Bus4�{�i4Socket�j�o���܂��B
{kind=link}
�EQuad High Speed Interconnect
�ELarge Memory Snoop Filter
�撣����Bus4�{�i4Socket�j�o���܂��B
Conroe aims to trump Athlon's processing performance
http://www.tgdaily.com/2006/02/21/conroe_athlon/
Conroe��PECI�iPlatform Environment Control Interface)�ƌĂ��
one-wire bus interface������Ă���悤���B
http://www.tgdaily.com/2006/02/21/conroe_athlon/
Conroe��PECI�iPlatform Environment Control Interface)�ƌĂ��
one-wire bus interface������Ă���悤���B
Detailed Platform Analysis in RightMark Memory Analyzer. Part 10: Intel Core Duo (Yonah)
http://www.digit-life.com/articles2/cpu/rmma-yonah.html
Dothan��Yonah�̔�r�B
Decoder�����P����Ă�悤���B
http://www.digit-life.com/articles2/cpu/rmma-yonah.html
Dothan��Yonah�̔�r�B
Decoder�����P����Ă�悤���B
381 �F���̖��ݒ��F2006/02/25(�y) 02:02:53 ID:NdlrOU8+0
>>308����Ƃ���Conroe�f���A���̉\����������čl���Ă�݂����ł����ǁA�\�[�X����́H
Intel�̃��C���i�b�v���ƁAPentium�u�����h�iConroe�ł͕ς�邾�낤���ǁj�̓��j�v���Z�b�T�AXeon DP�u�����h�iWoodcrest�͑�������j�̓f���A���v���Z�b�T��Pentium��肿����ƍ������Ċ������Ǝv�����B
���Ȃ݂�
�� �u4-way��PowerMac���o��Ȃ�80���~����v
����́g4-way�h���g4�R�A�h���ĈӖ��Ȃ�A80�������Ȃ��Ǝv���܂��B
����Ɋւ��Ă�>>308����ɓ��ӁB
Intel�̃��C���i�b�v���ƁAPentium�u�����h�iConroe�ł͕ς�邾�낤���ǁj�̓��j�v���Z�b�T�AXeon DP�u�����h�iWoodcrest�͑�������j�̓f���A���v���Z�b�T��Pentium��肿����ƍ������Ċ������Ǝv�����B
���Ȃ݂�
�� �u4-way��PowerMac���o��Ȃ�80���~����v
����́g4-way�h���g4�R�A�h���ĈӖ��Ȃ�A80�������Ȃ��Ǝv���܂��B
����Ɋւ��Ă�>>308����ɓ��ӁB
Conroe�͈�ʂ�1�\�P�b�g�}�V�[������������2�\�P�b�g�@�ɍ̗p����邱���Ȃ��ł���B
��������Intel�������Ă͂���Ȃ����낤�B
�`�b�v�Ƃ��Ă͂قƂ�Ǔ�����Woodcrest Xeon�Ńf���A���\�P�b�g��Mac���o�邩������Ȃ��Ƃ����̂�
Mac���͂Ȃ�ł��ے肵������ˁB80�������Ƃ������Ă邵�B
Intel��4�R�A��Clovertown(XeonDP)��Kentsfield(Core XE)�Ƃ����邯��ǂ��A������2007�N�B
��҂�XE��Core���g����4�R�A�A1�\�P�b�g��Mac�B�����80�����Ȃ����낤�B
�O�҂�4�R�A��Xeon���g����4�R�A�A1�\�P�b�g��Mac�i�Ӗ������邩�ǂ����͕ʂƂ��āj�B�����80���͂��Ȃ����낤�B
4�R�AXeon��2�\�P�b�g��Mac�́A�o��Ƃ����炩�Ȃ荂���Ȃ肻�����B
G5�ł��܂łЂ��ς�́H�Ƃ��A
4�R�A�Ȃ���G5Quad�Ɣ�r���ăp�t�H�[�}���X�I�ɔ�������Ȃ��H�Ƃ��A�]�X�B
��������Intel�������Ă͂���Ȃ����낤�B
�`�b�v�Ƃ��Ă͂قƂ�Ǔ�����Woodcrest Xeon�Ńf���A���\�P�b�g��Mac���o�邩������Ȃ��Ƃ����̂�
Mac���͂Ȃ�ł��ے肵������ˁB80�������Ƃ������Ă邵�B
Intel��4�R�A��Clovertown(XeonDP)��Kentsfield(Core XE)�Ƃ����邯��ǂ��A������2007�N�B
��҂�XE��Core���g����4�R�A�A1�\�P�b�g��Mac�B�����80�����Ȃ����낤�B
�O�҂�4�R�A��Xeon���g����4�R�A�A1�\�P�b�g��Mac�i�Ӗ������邩�ǂ����͕ʂƂ��āj�B�����80���͂��Ȃ����낤�B
4�R�AXeon��2�\�P�b�g��Mac�́A�o��Ƃ����炩�Ȃ荂���Ȃ肻�����B
G5�ł��܂łЂ��ς�́H�Ƃ��A
4�R�A�Ȃ���G5Quad�Ɣ�r���ăp�t�H�[�}���X�I�ɔ�������Ȃ��H�Ƃ��A�]�X�B
���Ȃ݂�Inq�̃��^�L���Ȃ̂ł��ĂɂȂ�Ȃ�
http://www.theinquirer.net/?article=26433
Apple seeking Intel's Woodcrest and Merom chips early?
http://www.theinquirer.net/?article=26433
Apple seeking Intel's Woodcrest and Merom chips early?
DP�V�X�e���P����UP�V�X�e���P����荂���̂́A
�v���Z�T�����Ȃ炻����ł��Ȃ����낤���A
�\������V�X�e���p�[�c�������ɂȂ��Ă��܂�����B
�ŏ�ȃV�X�e���\���Ƃ��ɂ���A80���������낤���A
����Ȃ�ȍ\���ɗ}����A40�����x�ɂ͎��܂��Ȃ����B
�v���Z�T�����Ȃ炻����ł��Ȃ����낤���A
�\������V�X�e���p�[�c�������ɂȂ��Ă��܂�����B
�ŏ�ȃV�X�e���\���Ƃ��ɂ���A80���������낤���A
����Ȃ�ȍ\���ɗ}����A40�����x�ɂ͎��܂��Ȃ����B
Apple��PowerMac�̍\���݂����ǁA
�K�v�ŏ����ȍ\���ł��̃v���C�X�݂���������A
Woodcrest��Mac�͏\���\�ł���B
�K�v�ŏ����ȍ\���ł��̃v���C�X�݂���������A
Woodcrest��Mac�͏\���\�ł���B
>>378->>380�̋U������
����\���Ă����̂͌��\�Ȃ��Ƃ����A�ʂ̖��O�ł���ė~�����ˁB
����\���Ă����̂͌��\�Ȃ��Ƃ����A�ʂ̖��O�ł���ė~�����ˁB
AMD has a response to Intel Woodcrest server chips
http://www.theinquirer.net/?article=29890
AMD��K8L��2007�ɏo�ׂ���BK8L��K8���l�����̃Z�O�����g�o���G�[�V��������Ȃ�B
2x��FP Unit�������A1.5x�̃p�t�H�[�}���X�ɂȂ�B
Woodcrest is going to be an Int monster, but slightly weaker on the FP side.
This chip, be it K8L or a new code name, should blow Woody out of the FP waters.
Wodcrest��INT�����X�^�[�ɂȂ邾�낤���AFP�͎ア�B
http://www.theinquirer.net/?article=29890
AMD��K8L��2007�ɏo�ׂ���BK8L��K8���l�����̃Z�O�����g�o���G�[�V��������Ȃ�B
2x��FP Unit�������A1.5x�̃p�t�H�[�}���X�ɂȂ�B
Woodcrest is going to be an Int monster, but slightly weaker on the FP side.
This chip, be it K8L or a new code name, should blow Woody out of the FP waters.
Wodcrest��INT�����X�^�[�ɂȂ邾�낤���AFP�͎ア�B
388 �Finteler@�ϑz�F2006/02/25(�y) 10:39:10 ID:NZcXNuJc0
// Charlie Demerjian����AMD�т��������č���Ȃ��B
// K8L�̃T�[�o�`�b�v�A4 core = 2x FPU�Ƃ����Ӗ����낤�B
// Woodcrest����Clovertown�Ƃ̔�r�����ׂ����낤�B
// Woodcrest��int���\����ア�Ƃ����̂́A�M���Ă��ǂ����낤�B
// Server�p�`�b�v�ł́Ax86�ȊO�ł������Ȃ��̂����ꂩ�瓊�������킯�ŁA
// K8L�T�[�o��FP�����X�^�[�ȂǂƂ����͖̂��炩�Ɍ��������B
// K8L�̃T�[�o�`�b�v�A4 core = 2x FPU�Ƃ����Ӗ����낤�B
// Woodcrest����Clovertown�Ƃ̔�r�����ׂ����낤�B
// Woodcrest��int���\����ア�Ƃ����̂́A�M���Ă��ǂ����낤�B
// Server�p�`�b�v�ł́Ax86�ȊO�ł������Ȃ��̂����ꂩ�瓊�������킯�ŁA
// K8L�T�[�o��FP�����X�^�[�ȂǂƂ����͖̂��炩�Ɍ��������B
389 �Finteler@�ϑz�F2006/02/25(�y) 10:42:14 ID:NZcXNuJc0
// int���\�� �� fp���\��
390 �F���̖��ݒ��F2006/02/25(�y) 15:09:03 ID:NdlrOU8+0
���������AWoodcrest��FPU���肪�S�R���炩�ɂȂ��Ă��Ȃ��̂ɔ�r���Ă����Ӗ��B
����FPU�̏��������Ă���Ȃ�A�������������ė~�������̂ł��B
����FPU�̏��������Ă���Ȃ�A�������������ė~�������̂ł��B
391 �FMAC�I�^��382 �����F2006/02/25(�y) 18:21:02 ID:4jzqH5E90
>>382
�@�@--------------------
�@�@Woodcrest Xeon�Ńf���A���\�P�b�g��Mac���o�邩������Ȃ��Ƃ����̂�
�@�@Mac���͂Ȃ�ł��ے肵������ˁB
�@�@--------------------
�ے�킵�Ȃ����B�P�ɉ��i���}���`�\�P�b�g��PC�Ɠ����x���ɂȂ�Ƃ��������̘b���B���łɌ����C
���̃N���X�̏���PC���[�N�X�e�[�V�����������s��K�͂��傫�����ǂ������^�₷�B
�@�@--------------------
�@�@Woodcrest Xeon�Ńf���A���\�P�b�g��Mac���o�邩������Ȃ��Ƃ����̂�
�@�@Mac���͂Ȃ�ł��ے肵������ˁB
�@�@--------------------
�ے�킵�Ȃ����B�P�ɉ��i���}���`�\�P�b�g��PC�Ɠ����x���ɂȂ�Ƃ��������̘b���B���łɌ����C
���̃N���X�̏���PC���[�N�X�e�[�V�����������s��K�͂��傫�����ǂ������^�₷�B
dell�̃T�C�g�ŁAPowerEdge 1850 �I�����C������p�b�P�[�W��
�f���A���R�Axeon2.8GHZz*2������Ă݂���A52��������
AppleStore���i�Ȃ�Awoodcrest*2�ł��A60�����炢�ŏo�����łȂ���?
mac�̃n�C�G���h���[�U���Ă̂́A���ł����邾�낤����
�s��I�ɂ����Ȃ��Ǝv����
�f���A���R�Axeon2.8GHZz*2������Ă݂���A52��������
AppleStore���i�Ȃ�Awoodcrest*2�ł��A60�����炢�ŏo�����łȂ���?
mac�̃n�C�G���h���[�U���Ă̂́A���ł����邾�낤����
�s��I�ɂ����Ȃ��Ǝv����
�[���A�����l�^������ł����B
>>175�����肩��Kentsfield���������ȊO���������V�����Ȃ��āA�b���w�ǂ�����Ƃ��̂Ɂc(;�L�D`)
>>175�����肩��Kentsfield���������ȊO���������V�����Ȃ��āA�b���w�ǂ�����Ƃ��̂Ɂc(;�L�D`)
394 �F���̖��ݒ��F2006/02/25(�y) 20:26:28 ID:NdlrOU8+0
>>392����ɓ��ӁB
> ���i���}���`�\�P�b�g��PC�Ɠ����x��
�Ȃ�AOS�E���j�^��������덞�݂łU�O���ď�����Ȃ��B
80���͂��Ȃ��ł��傤�B
>���̃N���X�̏���PC���[�N�X�e�[�V�����������s��K�͂��傫�����ǂ������^��
�����PowerMac�̎s��͖����ł����H
> ���i���}���`�\�P�b�g��PC�Ɠ����x��
�Ȃ�AOS�E���j�^��������덞�݂łU�O���ď�����Ȃ��B
80���͂��Ȃ��ł��傤�B
>���̃N���X�̏���PC���[�N�X�e�[�V�����������s��K�͂��傫�����ǂ������^��
�����PowerMac�̎s��͖����ł����H
395 �F���̖��ݒ��F2006/02/25(�y) 20:32:00 ID:NdlrOU8+0
�A���J�L�R���܂�ł��B
Conroe3.33GHz��Kentsfield��Extreme Edition���C���ɂȂ肻���ł����APowerMac���Ăǂ����𓋍ڂ����ł��傤�H
���̗\�z�ł́APowerPC��2.8GHz2�R�A��2.5GHz��4�R�A�݂����ɋ������邩���A�Ǝv���̂ł����B
Conroe3.33GHz��Kentsfield��Extreme Edition���C���ɂȂ肻���ł����APowerMac���Ăǂ����𓋍ڂ����ł��傤�H
���̗\�z�ł́APowerPC��2.8GHz2�R�A��2.5GHz��4�R�A�݂����ɋ������邩���A�Ǝv���̂ł����B
396 �Finteler@�ϑz�F2006/02/25(�y) 20:47:17 ID:NZcXNuJc0
// XE 3.33GHz�l�^�͐M���Ȃ������g�̂��߁BXbit�����ꃋ�[�}�[���悭�������Ă�B
// Apple�̃`���C�X�ȑO�ɁAKentsfield���O�|�����ꂽ���Ƃɂ��A���ʉ������Â炢2 core�ł�Conroe XE�v��
// �͂Ȃ��Ȃ�AKentsfield����XE���X�^�[�g����\���������Ȃ��Ă����\���B
// Apple�̃`���C�X�ȑO�ɁAKentsfield���O�|�����ꂽ���Ƃɂ��A���ʉ������Â炢2 core�ł�Conroe XE�v��
// �͂Ȃ��Ȃ�AKentsfield����XE���X�^�[�g����\���������Ȃ��Ă����\���B
397 �FMAC�I�^��392 �����F2006/02/25(�y) 20:50:10 ID:4jzqH5E90
>>392
�@�@---------------------
�@�@�f���A���R�Axeon2.8GHZz*2������Ă݂���A52��������
�@�@---------------------
PowerPC 970MP�̍ō��N���b�N��2.5GHz�BXeon�̍ō��N���b�N��3.8GHz���B
�ŁC2.8GHz���Ă̂�C���Ȃ��̔]���̉��Ɣ�r��������������(��)
�@�@---------------------
�@�@�f���A���R�Axeon2.8GHZz*2������Ă݂���A52��������
�@�@---------------------
PowerPC 970MP�̍ō��N���b�N��2.5GHz�BXeon�̍ō��N���b�N��3.8GHz���B
�ŁC2.8GHz���Ă̂�C���Ȃ��̔]���̉��Ɣ�r��������������(��)
398 �FMAC�I�^�o�E�ψ����F2006/02/25(�y) 21:29:05 ID:E9QW68Dq0
399 �F���̖��ݒ��F2006/02/25(�y) 21:31:16 ID:NdlrOU8+0
>>396����
Xbit��theINQ�̗����ɏ����Ă���������M���Ă܂����B
�V���O���X���b�h�d����3.33GHz���~����������ł����ǂ˂��B
>>397����
����A���̔]���ɂ��������̂�����܂��� �i�j
���Ȃ݂ɁAXeon DP��**�f���A���R�A��**�ō��N���b�N��2.8GHz�ł��B
��r����Ȃ�APowerPC�f���A���R�A��Xeon�f���A���R�A���APowerPC�V���O���R�A��Xeon�V���O���R�A���r���ׂ����Ǝv���̂ł����B
���Ȃ������APowerPC�f���A���R�A��Xeon�V���O���R�A���r��������ł����H
Xbit��theINQ�̗����ɏ����Ă���������M���Ă܂����B
�V���O���X���b�h�d����3.33GHz���~����������ł����ǂ˂��B
>>397����
����A���̔]���ɂ��������̂�����܂��� �i�j
���Ȃ݂ɁAXeon DP��**�f���A���R�A��**�ō��N���b�N��2.8GHz�ł��B
��r����Ȃ�APowerPC�f���A���R�A��Xeon�f���A���R�A���APowerPC�V���O���R�A��Xeon�V���O���R�A���r���ׂ����Ǝv���̂ł����B
���Ȃ������APowerPC�f���A���R�A��Xeon�V���O���R�A���r��������ł����H
970MP�̑��x���āAxeon2.8Ghz�Ɠ�����������Ƒ������x����
�\�t�g���Ⴄ����P���ɔ�r�ł��Ȃ�����
�\�t�g���Ⴄ����P���ɔ�r�ł��Ȃ�����
401 �F���̖��ݒ��F2006/02/25(�y) 21:38:16 ID:NdlrOU8+0
�Ђ���Ƃ���Mac�I�^������āAHyper-Threading�ƃf���A���R�A�̋�ʂ��t���ĂȂ��H
Dell Precision Workstation�Ŏ�������
Xeon3.8Ghz��970MP�Ɠ����悤�ȍ\����49���B
Xeon3.6Ghz��43���B
�܂��A�Ȃ�Ƃ��Ȃ��Ȃ��B
Xeon3.8Ghz��970MP�Ɠ����悤�ȍ\����49���B
Xeon3.6Ghz��43���B
�܂��A�Ȃ�Ƃ��Ȃ��Ȃ��B
xeon�}�V���������Ȃ�����
PowerMacG5���o���Ƃ��́A���b�`�Ȏd�l�ň����������̂�
PowerMacG5���o���Ƃ��́A���b�`�Ȏd�l�ň����������̂�
404 �F���̖��ݒ��F2006/02/25(�y) 21:44:44 ID:NdlrOU8+0
Xeon�Ƃ���APrestonia�̍��Ƀf���A���}�V����g�ȁB
���̍��́ASETI@home��4�����ɓ������Ċ��ł��B
���̍��́ASETI@home��4�����ɓ������Ċ��ł��B
405 �F���̖��ݒ��F2006/02/25(�y) 21:47:12 ID:pO1MKif10
�@�@�@�@�@�@�@�@�@_,,..
�@�@�@�@�@�@�@ /�L�E::�M�� �@�@�@�܂��l�^�͂�߂�
�@�@�@�@�@�@�@/:::::(,,߄D�)�@�@������]���c��ɑ��ʂ����炽���ł͍ς܂���
�@�@�@�@�@�@�@|::::| �@ �@ }�R
�@�@�@�@�@�@�@��'�@ �@ �@�pJ
�@�@�@�@�@�@�@ �T�@,��@<
�@�@�@ �@ �@�@ �L�܁L �M��
�@�@�@�@�@�@�@ /�L�E::�M�� �@�@�@�܂��l�^�͂�߂�
�@�@�@�@�@�@�@/:::::(,,߄D�)�@�@������]���c��ɑ��ʂ����炽���ł͍ς܂���
�@�@�@�@�@�@�@|::::| �@ �@ }�R
�@�@�@�@�@�@�@��'�@ �@ �@�pJ
�@�@�@�@�@�@�@ �T�@,��@<
�@�@�@ �@ �@�@ �L�܁L �M��
�Ƃ肠�����]���ϑz��age�Ő��ꗬ���Ȃ��ł�������
�\����Ȃ��B
����C�����܂��B
����C�����܂��B
�Ƃ��ɁAMAC�I�^����̔��_�͂܂����ȁH
���Ȃ��Ƌ��Ȃ��Ŏ₵���̂����B������Ƃ����B
���Ȃ��Ƌ��Ȃ��Ŏ₵���̂����B������Ƃ����B
�EIrwindale
-- 3.80 GHz �@�iw/L2 2M cache 800 MHz FSB�j - $851
-- 3.60E GHz �iw/L2 2M cache 800 MHz FSB�j -$690
-- 3.40E GHz �iw/L2 2M cache 800 MHz FSB�j -$455
-- 3.20E GHz �iw/L2 2M cache 800 MHz FSB�j -$316
-- 3E GHz�@�@ �iw/L2 2M cache 800 MHz FSB�j -$247
-- 2.80E GHz �iw/L2 2M cache 800 MHz FSB�j - $193
�EWoodcrest
-- 5160 �iw/L2 4MB 1333MHz FSB�j 3GHz�@�@ - $850
-- 5150 �iw/L2 4MB 1333MHz FSB�j 2.66GHz - $700
-- 5140 �iw/L2 4MB 1333MHz FSB�j 2.33GHz - $470
-- 5130 �iw/L2 4MB 1333MHz FSB�j 2GHz - $330
-- 5120 �iw/L2 4MB 1333MHz FSB�j 1.86GHz - $270
-- 5110 �iw/L2 4MB 1333MHz FSB�j 1.6GHz�@- $230
-- 3.80 GHz �@�iw/L2 2M cache 800 MHz FSB�j - $851
-- 3.60E GHz �iw/L2 2M cache 800 MHz FSB�j -$690
-- 3.40E GHz �iw/L2 2M cache 800 MHz FSB�j -$455
-- 3.20E GHz �iw/L2 2M cache 800 MHz FSB�j -$316
-- 3E GHz�@�@ �iw/L2 2M cache 800 MHz FSB�j -$247
-- 2.80E GHz �iw/L2 2M cache 800 MHz FSB�j - $193
�EWoodcrest
-- 5160 �iw/L2 4MB 1333MHz FSB�j 3GHz�@�@ - $850
-- 5150 �iw/L2 4MB 1333MHz FSB�j 2.66GHz - $700
-- 5140 �iw/L2 4MB 1333MHz FSB�j 2.33GHz - $470
-- 5130 �iw/L2 4MB 1333MHz FSB�j 2GHz - $330
-- 5120 �iw/L2 4MB 1333MHz FSB�j 1.86GHz - $270
-- 5110 �iw/L2 4MB 1333MHz FSB�j 1.6GHz�@- $230
���Ȃ݂Ƀv���Z�T�̉��i�̌n���̂͌�Xeon�ƕς��Ȃ��̂ŁA
Woodcrest�ł������悤�ȃV�X�e�����i�ɂȂ�Ǝv���B
Woodcrest�ł������悤�ȃV�X�e�����i�ɂȂ�Ǝv���B
ISSCC 2006�ɂ݂�}�C�N���v���Z�T�ƃf�B�W�^����H�Z�p�̓���
http://pcweb.mycom.co.jp/articles/2006/02/23/isscc/
���������������Ƃ������ɐ����ȁA����c(;�L�D�M)
http://pcweb.mycom.co.jp/articles/2006/02/23/isscc/
���������������Ƃ������ɐ����ȁA����c(;�L�D�M)
Tulsa�̃L���b�V���̘b�Ƃ����A9GHz�̐������Z���j�b�g�̘b�Ƃ����AIntel���Č��\�n���ɓw�͂��Ă�B
���̌o�����AMerom�^Conroe�^Woodcrest�Ƀt�B�[�h�o�b�N����Ă���Ǝv�������B
���̌o�����AMerom�^Conroe�^Woodcrest�Ƀt�B�[�h�o�b�N����Ă���Ǝv�������B
>>409����̕⑫
�EPaxville DP
�|�| 2.80 GHz �iw/ 2x2M cache 800 MHz FSB�j - $1,043
�Ђ���Ƃ�����AWoodcrest�ł̓V�X�e�����i�������邩���B
�v���b�g�t�H�[���͋��ʂ��Ęb�����B
�� ��ɂ���āA�`�b�v�Z�b�g�͋��ʂ����ǃ}�U�[�̍Đv���K�v�ɂȂ邩������B
�EPaxville DP
�|�| 2.80 GHz �iw/ 2x2M cache 800 MHz FSB�j - $1,043
�Ђ���Ƃ�����AWoodcrest�ł̓V�X�e�����i�������邩���B
�v���b�g�t�H�[���͋��ʂ��Ęb�����B
�� ��ɂ���āA�`�b�v�Z�b�g�͋��ʂ����ǃ}�U�[�̍Đv���K�v�ɂȂ邩������B
���R����c���E��̔����̃��[�J�[����
�������ȁB���̒ʂ肾�B
�h��ȃA�v���[�`�������̂ŁA��������Y��Ă���B
�h��ȃA�v���[�`�������̂ŁA��������Y��Ă���B
MAC���^�܂��[��H
>>413
����APaxville DP�͌��s�`�v�Z�g��E7520�iLindenhurst�j��B
Dempsey��Woodcrest��Blackford�ɂȂ�B
���Ȃ݂�Blackford�ł̓`�v�Z�g�����������\�P�b�g���V�K�ɂȂ�܂��B
Intel Socket 771 Unmasked
http://www.dailytech.com/article.aspx?newsid=946
The Future of DDR Memory is Serial
http://www.dailytech.com/article.aspx?newsid=350
�V�X�e�����i�Ɋւ��Ă�FBDIMM���ǂ̒��x�Ő��ڂ��邩�ő����e�����邩���B
����APaxville DP�͌��s�`�v�Z�g��E7520�iLindenhurst�j��B
Dempsey��Woodcrest��Blackford�ɂȂ�B
���Ȃ݂�Blackford�ł̓`�v�Z�g�����������\�P�b�g���V�K�ɂȂ�܂��B
Intel Socket 771 Unmasked
http://www.dailytech.com/article.aspx?newsid=946
The Future of DDR Memory is Serial
http://www.dailytech.com/article.aspx?newsid=350
�V�X�e�����i�Ɋւ��Ă�FBDIMM���ǂ̒��x�Ő��ڂ��邩�ő����e�����邩���B
������ �i��
�������A�܂�Dempsey���������B
�w�E�T���N�X�B
�������A�܂�Dempsey���������B
�w�E�T���N�X�B
419 �F���̖��ݒ��F2006/02/27(��) 16:22:10 ID:mEpyZn0JO
intel������Ƃ�����ʂŗD��Ă邪
�L���b�V���̖��x�A����d�͂ł͑������|���Ă�C��
�L���b�V���̖��x�A����d�͂ł͑������|���Ă�C��
�������
Launch of Intel's Santa Rosa notebook platform now expected in 2Q 2007, paper says
http://www.digitimes.com/systems/a20060303PB200.html
The launch of Intel�fs Santa Rosa notebook platform, originally expected in the first quarter of 2007,
will not happen until the second quarter, according to sources in Taiwan cited by a Chinese-language
Commercial Times report today.
Santa Rosa�v���b�g�t�H�[����Q2�ɉ����B
http://www.digitimes.com/systems/a20060303PB200.html
The launch of Intel�fs Santa Rosa notebook platform, originally expected in the first quarter of 2007,
will not happen until the second quarter, according to sources in Taiwan cited by a Chinese-language
Commercial Times report today.
Santa Rosa�v���b�g�t�H�[����Q2�ɉ����B
Intel Developer Forum
http://www.intel.com/idf/us/spring2006/
���T3/7-3/9��IDF Spring 2006�B
�Ƃ����킯�ŁA�R��͍��o�Ă�����Ɋւ��Ă͐[���l���Ȃ����Ƃɂ���i��ͥ�j
http://www.intel.com/idf/us/spring2006/
���T3/7-3/9��IDF Spring 2006�B
�Ƃ����킯�ŁA�R��͍��o�Ă�����Ɋւ��Ă͐[���l���Ȃ����Ƃɂ���i��ͥ�j
423 �Finteler@�ϑz�F2006/03/04(�y) 22:24:26 ID:Jr5Ih9lt0
���́AMerom�A�[�L�ł�FP���\�����܂�����������Ȃ��v�Ȃ̂��A�ϑz����P�o���Ă݂邱�Ƃɂ܂����B
// Merom�͌��́ATejas�f�X�N�g�b�v����̃��o�C���Z�O�����gCPU�Ƃ��Čv�悳��Ă����B
// Yonah��Prescott�����̃t�B�[�`��������Ă���̂Ɠ��l�AMerom��Tejas�����̋@�\�������Ă��邪�A
// Tejas���L�����Z���ɂȂ�A�}�Merom�̐v��Desktop/Server�ł��g�����ƂɁc(;�L�D�M)
// Tejas/NetBurst�̌�p�Ƃ��ẮANehalem�Ƃ���Super-NetBurst�ȃA�[�L���v�悵�Ă������A
// �����Tejas�����O�ɃL�����Z���ɂȂ��Ă���A���̌�ASuper-Merom�ȃA�[�L�̐VNehalem�Ɍv��ύX���ꂽ�B
// + Merom�ł̓��o�C����p�̏ȓd�̓A�[�L�Ƃ������ꂩ��AFPU/SIMD�n�[�h�E�G�A�ւ̓����͍T���߂ŁA
//�@�@Int�����������Ȃ炢�������A�Ƃ������j�Ō��X�v����Ă����B
// + Tejas�L�����Z���ȍ~�ATejas/Nehalem�̊J���w�́A�VNehalem�̊J���Ɉڂ����B
// �VNehalem�́AMerom����2�N�x�ꂭ�炢�X�P�W���[���Ȃ̂ŁAFP/SIMD�́ANehalem����Ŋg������悭�A
// Merom����ł͋}���Ȃ��Ă��悢�Ƃ������f�B
// + ���f�B�A���Z���\�́A�����I�ɂ͂ɂ�ACCMP�̏��K�̓R�A�ő啝�ɉ����������獡�͂ނ���T���߂ł悢�Ƃ����l���B
// + Intel�̓v���b�g�t�H�[���d���̃}�[�P�e�B���O�ɏ��o���AIntel��965�`�b�v�Z�b�g�ȍ~�́AGPU���p�ɐϋɓI�B
// CPU������FP/SIMD�͍���A���͏d�v����Ȃ���������Ȃ��Ƃ����l���B
// Merom�͌��́ATejas�f�X�N�g�b�v����̃��o�C���Z�O�����gCPU�Ƃ��Čv�悳��Ă����B
// Yonah��Prescott�����̃t�B�[�`��������Ă���̂Ɠ��l�AMerom��Tejas�����̋@�\�������Ă��邪�A
// Tejas���L�����Z���ɂȂ�A�}�Merom�̐v��Desktop/Server�ł��g�����ƂɁc(;�L�D�M)
// Tejas/NetBurst�̌�p�Ƃ��ẮANehalem�Ƃ���Super-NetBurst�ȃA�[�L���v�悵�Ă������A
// �����Tejas�����O�ɃL�����Z���ɂȂ��Ă���A���̌�ASuper-Merom�ȃA�[�L�̐VNehalem�Ɍv��ύX���ꂽ�B
// + Merom�ł̓��o�C����p�̏ȓd�̓A�[�L�Ƃ������ꂩ��AFPU/SIMD�n�[�h�E�G�A�ւ̓����͍T���߂ŁA
//�@�@Int�����������Ȃ炢�������A�Ƃ������j�Ō��X�v����Ă����B
// + Tejas�L�����Z���ȍ~�ATejas/Nehalem�̊J���w�́A�VNehalem�̊J���Ɉڂ����B
// �VNehalem�́AMerom����2�N�x�ꂭ�炢�X�P�W���[���Ȃ̂ŁAFP/SIMD�́ANehalem����Ŋg������悭�A
// Merom����ł͋}���Ȃ��Ă��悢�Ƃ������f�B
// + ���f�B�A���Z���\�́A�����I�ɂ͂ɂ�ACCMP�̏��K�̓R�A�ő啝�ɉ����������獡�͂ނ���T���߂ł悢�Ƃ����l���B
// + Intel�̓v���b�g�t�H�[���d���̃}�[�P�e�B���O�ɏ��o���AIntel��965�`�b�v�Z�b�g�ȍ~�́AGPU���p�ɐϋɓI�B
// CPU������FP/SIMD�͍���A���͏d�v����Ȃ���������Ȃ��Ƃ����l���B
424 �F���̖��ݒ��F2006/03/04(�y) 22:33:10 ID:8xcAsTk80
AMD�̎�����R�A���Ăǂ��Ȃ�́H
>>424
��Ȃ��Ƃ�������������ˁ[��
��Ȃ��Ƃ�������������ˁ[��
426 �F���̖��ݒ��F2006/03/04(�y) 23:02:27 ID:Lqtr1Zz/0
�Ƃ���ŊF����Intel Mac mini�̒l�i�����āux86�̗p�ň����Ȃ飂��Ėϑz�����o�߂������H
>>424
���̂Ƃ���A�ǂ��ɂ��Ȃ��ĂȂ��B
���̂Ƃ���A�ǂ��ɂ��Ȃ��ĂȂ��B
429 �Finteler@�����F2006/03/05(��) 00:59:52 ID:r38pTEr20
The Case for the Reduced Instruction Computer (1980)
ttp://courses.ece.uiuc.edu/ece511/papers/Patterson.1980.CAN.pdf
�ŏ���RISC�̘_���B
���҂͂���Patterson�����ƁATransmeta�n�n�҂�David R.Ditzel�B
http://www.candc.or.jp/kensyo/2004nendo/prof_david_a_patterson.htm
ttp://courses.ece.uiuc.edu/ece511/papers/Patterson.1980.CAN.pdf
�ŏ���RISC�̘_���B
���҂͂���Patterson�����ƁATransmeta�n�n�҂�David R.Ditzel�B
http://www.candc.or.jp/kensyo/2004nendo/prof_david_a_patterson.htm
MacBook Pro: Review
http://arstechnica.com/reviews/hardware/macbookpro.ars/1
http://arstechnica.com/reviews/hardware/macbookpro.ars/1
>>424�@������Intel�B
AMD�̎�����CPU�ɂ��Č�낤 3������
http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/204-
204 ���O�FMAC�I�^[sage] ���e���F2006/03/04(�y) 21:25:03 ID:9igVid/W
TheInquirer��K8�̉����v��i�̉\)��Ă��邷�B
http://www.theinquirer.net/?article=30042
�@�Erev F - Santa Rosa (2006)
�@�@DDR2-800 �T�|�[�g
�@�@��������RAS����
�@�@Quad-core �T�|�[�g�̃N���X�o�[��H
�@�@���N���b�N��10%���x�̐��\���ォ�H
�@�Erev G - Deerhound (2007)
�@�@1207-pin
�@�@Quad-core
�@�@�VPacifica
�@�@dual 64-bit FPU
�@�@48-bit�����A�h���X�C1GB�y�[�W�T�|�[�g
�@�Erev H - Cerebus (2xx/8xx) / Wolfhound (1xx) (2008)
�@�@2.6GHz HyperTransport & 3D�g�[���X�\���T�|�[�g
�@�@�C���^�R�l�N�g�����ɂ��16-socket(x4��64-way)�T�|�[�g
�@�@6MB L3
�@�@RAS����
AMD�̎�����CPU�ɂ��Č�낤 3������
http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/204-
204 ���O�FMAC�I�^[sage] ���e���F2006/03/04(�y) 21:25:03 ID:9igVid/W
TheInquirer��K8�̉����v��i�̉\)��Ă��邷�B
http://www.theinquirer.net/?article=30042
�@�Erev F - Santa Rosa (2006)
�@�@DDR2-800 �T�|�[�g
�@�@��������RAS����
�@�@Quad-core �T�|�[�g�̃N���X�o�[��H
�@�@���N���b�N��10%���x�̐��\���ォ�H
�@�Erev G - Deerhound (2007)
�@�@1207-pin
�@�@Quad-core
�@�@�VPacifica
�@�@dual 64-bit FPU
�@�@48-bit�����A�h���X�C1GB�y�[�W�T�|�[�g
�@�Erev H - Cerebus (2xx/8xx) / Wolfhound (1xx) (2008)
�@�@2.6GHz HyperTransport & 3D�g�[���X�\���T�|�[�g
�@�@�C���^�R�l�N�g�����ɂ��16-socket(x4��64-way)�T�|�[�g
�@�@6MB L3
�@�@RAS����
>>423
���㓡�O��Weekly�C�O�j���[�X��
IDF�ł��悢����J�uMerom�A�[�L�e�N�`���v
http://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
>���������ꂽ���������_���ZSIMD���Z���j�b�g
>���Z���j�b�g���ł́ASSE SIMD(Single Instruction, Multiple Data)���Z���j�b�g���啝�Ɋg�[���ꂽ�B
>4�̒P���x(32bit)���������_�f�[�^�ō\�������128bit SIMD�f�[�^�ɑ��āA
>1�T�C�N���X���[�v�b�g��1��̐Ϙa���Z�����s�ł���悤�ɂȂ����B
>�܂�A�I�y���[�V�������ł�1�T�C�N����8���������_�I�y���[�V�����Ƃ������ƂɂȂ�B
>�C�X���G���`�[����CPU�́ABanias����Yonah�ŕ��������_���Z���\�����P���ꂽ���AMerom�ł͂����2�{�ɋ��������B
>NetBurst�n��2�T�C�N���X���[�v�b�g�Ȃ̂ŁANetBurst�n�Ɣ�r���Ă�2�{�̌����ƂȂ�B
>Intel CPU�́A���������_���Z���\���ォ�������AMerom�A�[�L�e�N�`���ł͂悤�₭���̕��������ǂ���邱�ƂɂȂ�B
���㓡�O��Weekly�C�O�j���[�X��
IDF�ł��悢����J�uMerom�A�[�L�e�N�`���v
http://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
>���������ꂽ���������_���ZSIMD���Z���j�b�g
>���Z���j�b�g���ł́ASSE SIMD(Single Instruction, Multiple Data)���Z���j�b�g���啝�Ɋg�[���ꂽ�B
>4�̒P���x(32bit)���������_�f�[�^�ō\�������128bit SIMD�f�[�^�ɑ��āA
>1�T�C�N���X���[�v�b�g��1��̐Ϙa���Z�����s�ł���悤�ɂȂ����B
>�܂�A�I�y���[�V�������ł�1�T�C�N����8���������_�I�y���[�V�����Ƃ������ƂɂȂ�B
>�C�X���G���`�[����CPU�́ABanias����Yonah�ŕ��������_���Z���\�����P���ꂽ���AMerom�ł͂����2�{�ɋ��������B
>NetBurst�n��2�T�C�N���X���[�v�b�g�Ȃ̂ŁANetBurst�n�Ɣ�r���Ă�2�{�̌����ƂȂ�B
>Intel CPU�́A���������_���Z���\���ォ�������AMerom�A�[�L�e�N�`���ł͂悤�₭���̕��������ǂ���邱�ƂɂȂ�B
>>432
�܂��AIDF�̏�܂����J���ꂽ�킯����Ȃ����痎�������đ҂āB
�܂��AIDF�̏�܂����J���ꂽ�킯����Ȃ����痎�������đ҂āB
434 �F���̖��ݒ��F2006/03/07(��) 18:45:09 ID:xzyfD3b50
������CPU�uConroe�v�̓����\�������炩��
http://pc.watch.impress.co.jp/docs/2006/0307/idf01.htm
Power Mac G5�̌�p�@��iMac Pro?�j��Kentsfield���ڂŌ��܂肷�ˁB
http://pc.watch.impress.co.jp/docs/2006/0307/idf01.htm
Power Mac G5�̌�p�@��iMac Pro?�j��Kentsfield���ڂŌ��܂肷�ˁB
4 ALU�̓f�}���������c�BIDF�I������甽�ȉ���Ȃ���c(;�L�D`)
�Ȃς��ƌ�K8�Ɏ��Ă�ȁB
PreDecode�͓��@���[�h�ADecode�̑O�̃L���[������̂�MacroOPFusion�̂���?
���̐}����Â������W���^���U�x�͔p�~�ɂȂ������Ƃ��炢�����������B
���������đ�����܂Ƃ��c(;�L�D�M)
�Ȃς��ƌ�K8�Ɏ��Ă�ȁB
PreDecode�͓��@���[�h�ADecode�̑O�̃L���[������̂�MacroOPFusion�̂���?
���̐}����Â������W���^���U�x�͔p�~�ɂȂ������Ƃ��炢�����������B
���������đ�����܂Ƃ��c(;�L�D�M)
�C���e��(R) Core(TM) �}�C�N���A�[�L�e�N�`���[�ƂƂ��Ɏn�܂�
�d�͌����A���\�A�f�U�C�����ɗD�ꂽ�C���e���E�x�[�X�̃R���s���[�e�B���O
http://www.intel.co.jp/jp/intel/pr/press2006/060308a.htm
�E�C���e��(R) ���C�h�E�_�C�i�~�b�N�E�G�O�[�L���[�V�����F
�@1 �N���b�N�T�C�N���ŁA��葽���̖��߂����s���A���������Ɠd�͌��������߂܂��B�@
�@14 �i�̃p�C�v���C�����g�p���A������ 4 �̃t���E�C���X�g���N�V���������s���邱�Ƃ��ł��܂�
�E�C���e��(R) �C���e���W�F���g�E�p���[�E�P�C�p�r���e�B�[�F
�@�X�̃��W�b�N�E�T�u�V�X�e���ɕK�v�Ȏ������A�C���e���W�F���g�ɓd�͂��������A����d�͂�����ɍ팸���܂�
�E�C���e��(R) �A�h�o���X�h�E�X�}�[�g�E�L���b�V���F
�@���L�^�� 2 ���L���b�V���ŁA�������[�g���t�B�b�N���ŏ����ɂ��邱�Ƃŏ���d�͂�}�����A
�@�܂��A����̃R�A���A�C�h�����̏ꍇ�A�R�A�̃L���b�V�����ׂĂ𗘗p�\�ɂ��Đ��\�����コ���邱�Ƃ��ł��܂�
�E�C���e��(R) �X�}�[�g�E�������[�E�A�N�Z�X�F
�@�������[�E���C�e���V�[���B�����ƂŃV�X�e�����\���グ�A�������[�E�T�u�V�X�e���ւ̏o�͎��̃f�[�^�ш�̗��p�����œK�����܂�
�E�C���e��(R) �A�h�o���X�h�E�f�W�^���E���f�B�A�E�u�[�X�g�F
�@128 �r�b�g SSE�ASSE2�A����� SSE3 �C���X�g���N�V�����̂��ׂĂ̖��߂� 1 �T�C�N���Ŏ��s�����邱�Ƃ��ł��܂��B
�@����ɂ��A�}���`���f�B�A��O���t�B�b�N�X�E�A�v���P�[�V�����ōL���g���Ă��邱���̖��߂̏������x�������I�ɔ{�������邱�Ƃ��ł��܂�
�d�͌����A���\�A�f�U�C�����ɗD�ꂽ�C���e���E�x�[�X�̃R���s���[�e�B���O
http://www.intel.co.jp/jp/intel/pr/press2006/060308a.htm
�E�C���e��(R) ���C�h�E�_�C�i�~�b�N�E�G�O�[�L���[�V�����F
�@1 �N���b�N�T�C�N���ŁA��葽���̖��߂����s���A���������Ɠd�͌��������߂܂��B�@
�@14 �i�̃p�C�v���C�����g�p���A������ 4 �̃t���E�C���X�g���N�V���������s���邱�Ƃ��ł��܂�
�E�C���e��(R) �C���e���W�F���g�E�p���[�E�P�C�p�r���e�B�[�F
�@�X�̃��W�b�N�E�T�u�V�X�e���ɕK�v�Ȏ������A�C���e���W�F���g�ɓd�͂��������A����d�͂�����ɍ팸���܂�
�E�C���e��(R) �A�h�o���X�h�E�X�}�[�g�E�L���b�V���F
�@���L�^�� 2 ���L���b�V���ŁA�������[�g���t�B�b�N���ŏ����ɂ��邱�Ƃŏ���d�͂�}�����A
�@�܂��A����̃R�A���A�C�h�����̏ꍇ�A�R�A�̃L���b�V�����ׂĂ𗘗p�\�ɂ��Đ��\�����コ���邱�Ƃ��ł��܂�
�E�C���e��(R) �X�}�[�g�E�������[�E�A�N�Z�X�F
�@�������[�E���C�e���V�[���B�����ƂŃV�X�e�����\���グ�A�������[�E�T�u�V�X�e���ւ̏o�͎��̃f�[�^�ш�̗��p�����œK�����܂�
�E�C���e��(R) �A�h�o���X�h�E�f�W�^���E���f�B�A�E�u�[�X�g�F
�@128 �r�b�g SSE�ASSE2�A����� SSE3 �C���X�g���N�V�����̂��ׂĂ̖��߂� 1 �T�C�N���Ŏ��s�����邱�Ƃ��ł��܂��B
�@����ɂ��A�}���`���f�B�A��O���t�B�b�N�X�E�A�v���P�[�V�����ōL���g���Ă��邱���̖��߂̏������x�������I�ɔ{�������邱�Ƃ��ł��܂�
Spring IDF 2006 Conroe Preview: Intel Regains the Performance Crown
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=1
AnandTech��������IDF�Ŏ������ꂽ�x���`�X�R�A���l�^�ɋL�������Ă�B
A = Intel Conroe 2.66GHz
B = AMD Athlon X2 2.8GHz
- benchName
A B A:B A:B(per cycle)
--------------------------------
- Quake 4 - r_useSMP=0
184.3 143.6 1.28 1.35
- Quake 4 - r_useSMP=1
238.4 207.5 1.15 1.21
- Half Life 2 - Lost Coast
147.6 112.8 1.31 1.38
- Unreal Tournament 2004
191.8 160.4 1.20 1.26
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2713&p=1
AnandTech��������IDF�Ŏ������ꂽ�x���`�X�R�A���l�^�ɋL�������Ă�B
A = Intel Conroe 2.66GHz
B = AMD Athlon X2 2.8GHz
- benchName
A B A:B A:B(per cycle)
--------------------------------
- Quake 4 - r_useSMP=0
184.3 143.6 1.28 1.35
- Quake 4 - r_useSMP=1
238.4 207.5 1.15 1.21
- Half Life 2 - Lost Coast
147.6 112.8 1.31 1.38
- Unreal Tournament 2004
191.8 160.4 1.20 1.26
- F.E.A.R - Minimum Frame Rate
186 132 1.41 1.48
- F.E.A.R - Maximum Frame Rate
532 350 1.52 1.60
- Windows Media Encorder 9 with Advanced Profile
66 75 1.14 1.20
- DivX 6.1 - Unconstrained / Balanced Codec Settings
31 44 1.42 1.49
- iTunes
6.0.1.3 65 73 1.12 1.18
186 132 1.41 1.48
- F.E.A.R - Maximum Frame Rate
532 350 1.52 1.60
- Windows Media Encorder 9 with Advanced Profile
66 75 1.14 1.20
- DivX 6.1 - Unconstrained / Balanced Codec Settings
31 44 1.42 1.49
- iTunes
6.0.1.3 65 73 1.12 1.18
���㓊���\��̎�����G���^�[�v���C�Y�E�v���b�g�t�H�[�����Љ�
�` �}���`�R�A�E�v���b�g�t�H�[���ɂ��A�����\�ƗD�ꂽ�d�͌��������˔������v�V�I�ȃA�[�L�e�N�`����� �`
http://www.intel.co.jp/jp/intel/pr/press2006/060308b.htm
�E�������d�̓v���Z�b�T�[�uSossaman�i�J���R�[�h���j�v�́A�u���[�h�T�[�o�[��X�g���[�W�@��A
�@�ʐM�@���ΏۂƂ��A�o�J�n�𗈏T�ɗ\�肵�Ă��܂��B
�E�uDempsey�i�J���R�[�h���j�v�́A�C���e��(R) Xeon(R) �v���Z�b�T�[���ڂ̐V�����v���b�g�t�H�[���uBensley�i�J���R�[�h���j�v������
�@�ŏ��̃v���Z�b�T�[�ŁA�������܂łɏo�J�n����\��ł��B
�E2006 �N�� 3 �l�����ɂ́A�C���e���� Bensley �v���b�g�t�H�[�������ɁA�R���s���[�e�B���O���\�� 80���ȏ���コ�������A
�@����d�͂��ő� 35���팸 ����v���Z�b�T�[�uWoodcrest�i�J���R�[�h���j�v�𓊓����ABensley �v���b�g�t�H�[������V���܂��B
�E�C���e���̎����㉼�z���Z�p�uDirected I/O �����C���e��(R) �o�[�`�����C�[�[�V�����E�e�N�m���W�[�i�C���e��(R) VTd�j�v�́A
�@I/O �f�o�C�X�̃o�[�`�����E�}�V���ւ̊��蓖�Ă��\�ɂ��� I/O �̉��z�����������A���z���V�X�e���ɂ�茘�S�������\�ȃv���b�g�t�H�[������܂��B
�@�C���e���͂܂��A�C���e�� VT-d �ɑΉ����������̐��i�̕]���E�v���s���J���Ҍ����̎d�l���ɒ���Ɣ��\���܂����B
�` �}���`�R�A�E�v���b�g�t�H�[���ɂ��A�����\�ƗD�ꂽ�d�͌��������˔������v�V�I�ȃA�[�L�e�N�`����� �`
http://www.intel.co.jp/jp/intel/pr/press2006/060308b.htm
�E�������d�̓v���Z�b�T�[�uSossaman�i�J���R�[�h���j�v�́A�u���[�h�T�[�o�[��X�g���[�W�@��A
�@�ʐM�@���ΏۂƂ��A�o�J�n�𗈏T�ɗ\�肵�Ă��܂��B
�E�uDempsey�i�J���R�[�h���j�v�́A�C���e��(R) Xeon(R) �v���Z�b�T�[���ڂ̐V�����v���b�g�t�H�[���uBensley�i�J���R�[�h���j�v������
�@�ŏ��̃v���Z�b�T�[�ŁA�������܂łɏo�J�n����\��ł��B
�E2006 �N�� 3 �l�����ɂ́A�C���e���� Bensley �v���b�g�t�H�[�������ɁA�R���s���[�e�B���O���\�� 80���ȏ���コ�������A
�@����d�͂��ő� 35���팸 ����v���Z�b�T�[�uWoodcrest�i�J���R�[�h���j�v�𓊓����ABensley �v���b�g�t�H�[������V���܂��B
�E�C���e���̎����㉼�z���Z�p�uDirected I/O �����C���e��(R) �o�[�`�����C�[�[�V�����E�e�N�m���W�[�i�C���e��(R) VTd�j�v�́A
�@I/O �f�o�C�X�̃o�[�`�����E�}�V���ւ̊��蓖�Ă��\�ɂ��� I/O �̉��z�����������A���z���V�X�e���ɂ�茘�S�������\�ȃv���b�g�t�H�[������܂��B
�@�C���e���͂܂��A�C���e�� VT-d �ɑΉ����������̐��i�̕]���E�v���s���J���Ҍ����̎d�l���ɒ���Ɣ��\���܂����B
�yIDF�z��Intel�A�V�A�[�L�e�N�`���Ɋ�Â��}�C�N���v���Z�T�̃��[�h�}�b�v�𖾂炩��
http://itpro.nikkeibp.co.jp/article/USNEWS/20060308/231945/?ST=ep1
2007�N�ɂ́A�f�X�N�g�b�v�����Ɠ��l�ɁA4��CPU�R�A����������uClovertown�v�����B
Clovertown�̏���d�͂́A�n�C�G���h������120W�ȉ��A���C���X�g���[��������80W�A�����d�͔ł�40W�������ށB
IDF Spring 2006 - Day 0 - Research, Development and Architecture
http://www.hardwarezone.com.au/reviews/view.php?cid=18&id=1837
IDF Spring 2006 - Next Generation Microarchitecture Revealed
http://www.hardwarezone.com.au/reviews/view.php?cid=18&id=1838
http://itpro.nikkeibp.co.jp/article/USNEWS/20060308/231945/?ST=ep1
2007�N�ɂ́A�f�X�N�g�b�v�����Ɠ��l�ɁA4��CPU�R�A����������uClovertown�v�����B
Clovertown�̏���d�͂́A�n�C�G���h������120W�ȉ��A���C���X�g���[��������80W�A�����d�͔ł�40W�������ށB
IDF Spring 2006 - Day 0 - Research, Development and Architecture
http://www.hardwarezone.com.au/reviews/view.php?cid=18&id=1837
IDF Spring 2006 - Next Generation Microarchitecture Revealed
http://www.hardwarezone.com.au/reviews/view.php?cid=18&id=1838
SSE1/2/3�����ׂ�1cycle�Ŏ��s�ł�����Ă���ȁc�i��ͥ�j
���S128bit���͂悢�Ƃ��Ă���̂ǂ������������Ă��?
>>432�̋L���̃u���b�N�}�����Ȃ�ȗ�������Ă���ۂ����A
FPU/SIMD���ӂ͂܂��悭�킩��Ȃ��ˁB
FPU�|�[�g�̃N���X�^����4�߂�ALU���B��Ă��肷��\�������Ă���Ȃ��ȁB
�e��x���`��Intel�̃`���C�X�ɂ����̂�����A���Ɠ��ӌn�ł��߂Ă�낤���A
Core�}�C�N���A�[�L�ւ̍œK�����i��łȂ����Ƃ����邵�A�܂��܂��y���݂��ȁB
���ꂩ��AMacroFusion�͒P�Ȃ�f�R�[�_�̕��y���p���Ƃ������Ă����ǁA
�V���O���T�C�N�����s�̂��߂Ƃ������Ă���ˁB
���S128bit���͂悢�Ƃ��Ă���̂ǂ������������Ă��?
>>432�̋L���̃u���b�N�}�����Ȃ�ȗ�������Ă���ۂ����A
FPU/SIMD���ӂ͂܂��悭�킩��Ȃ��ˁB
FPU�|�[�g�̃N���X�^����4�߂�ALU���B��Ă��肷��\�������Ă���Ȃ��ȁB
�e��x���`��Intel�̃`���C�X�ɂ����̂�����A���Ɠ��ӌn�ł��߂Ă�낤���A
Core�}�C�N���A�[�L�ւ̍œK�����i��łȂ����Ƃ����邵�A�܂��܂��y���݂��ȁB
���ꂩ��AMacroFusion�͒P�Ȃ�f�R�[�_�̕��y���p���Ƃ������Ă����ǁA
�V���O���T�C�N�����s�̂��߂Ƃ������Ă���ˁB
Conroe������
>>441
�悤�₭SIMD��AltiVec���݂ɂȂ������ĂƂ��납
�悤�₭SIMD��AltiVec���݂ɂȂ������ĂƂ��납
�ꉞMac�Ȃ̂ɖY��Ă��c(;�L�D`) >AltiVec
445 �F���̖��ݒ��F2006/03/09(��) 13:28:18 ID:WUJ/+gab0
�R���������ȁBAMD����ˁH
�u�Ȃ��AMD����Ȃ���Intel�͕��v�Ƃ������Ă��z�炪�������͂��ƂȂ����Ȃ�������肪�Ƃ�
�X���[�v�b�g�ƃ��C�e���V�̋�ʂ������ɕ��������_���Z�����C�e���V1�Ŏ��s�ł���
�Ȃ�ăg���f������M�����Ⴄ�q�g�����Ȃ����Ƃ��F����肷(��)
�Ȃ�ăg���f������M�����Ⴄ�q�g�����Ȃ����Ƃ��F����肷(��)
���㓡�O��Weekly�C�O�j���[�X��
Intel�̎�����CPU�A�[�L�e�N�`���uCore Microarchitecture�v
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
Intel�̎�����CPU�A�[�L�e�N�`���uCore Microarchitecture�v
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
Inside Intel Core Microarchitecture
ftp://download.intel.com/technology/architecture/new_architecture_06.pdf
ftp://download.intel.com/technology/architecture/new_architecture_06.pdf
Intel finally set to smash AMD in performance stakes
http://www.hexus.net/content/item.php?item=4843&page=4
PCMark - CPU�x���`���ƁA
Conroe 2.66GHz��Athlon FX60 2.8GHz�ɑ���20%���̐��\�B
http://www.hexus.net/content/item.php?item=4843&page=4
PCMark - CPU�x���`���ƁA
Conroe 2.66GHz��Athlon FX60 2.8GHz�ɑ���20%���̐��\�B
451 �F���̖��ݒ��F2006/03/09(��) 23:23:25 ID:7+8FUQus0
����AAMD���o���Ⴂ�܂��́H
�ׂ��ł����[�B
�ׂ��ł����[�B
Intel's Next Generation Microarchitecture Unveiled
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Core Microarchitecture�̏ڍׂƌ��sx86 Microarchitecture�Ƃ̔�r�B
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Core Microarchitecture�̏ڍׂƌ��sx86 Microarchitecture�Ƃ̔�r�B
>>452-453
�i�C�X�ȃ\�[�X�����肪�Ƃ��i�E�́E�j���I
�i�C�X�ȃ\�[�X�����肪�Ƃ��i�E�́E�j���I
�悤�₭x86�Ŏg�����Ȃ������Ȃ�CPU���o���B���N���N
456 �F���̖��ݒ��F2006/03/12(��) 14:09:21 ID:kT4nC4jP0
>>MAC�I�^
>>inteler
Banias��Yonah��Merom��P6�x�[�X�Ȃ�ł��A�Ƃ����ӌ��ɑ��Ăǂ��v���H
>>inteler
Banias��Yonah��Merom��P6�x�[�X�Ȃ�ł��A�Ƃ����ӌ��ɑ��Ăǂ��v���H
457 �FMAC�I�^��456 �����F2006/03/12(��) 17:37:51 ID:wXE3ifwK0
>>456
CNET�̃C���^�r���[�ŁC�S�Ă�m�肦�闧��ɂ���Mooly Eden�������Ă��邷�B
http://news.com.com/2008-1006_3-6047173-2.html
�@�@-------------------------
�@�@Part of it is based on previous architecture and part of it looks forward. It
�@�@resembled (Pentium III) architecture to some extent, but (there are) a lot of
�@�@different features inside.
�@�@Can you give performance improvement based on the same architecture? Are
�@�@you taking things from the previous architecture? Yes. Did Yonah not take from
�@�@Dothan alone? Did Merom take from Yonah? Much less, but to call it Pentium III
�@�@architecture I believe is doing an injustice to the hundreds of people that delivered
�@�@Banias.
�@�@-------------------------
[MAC�I�^��] ������O�̘b�����ǁC�O����̃`�b�v��������p��������������C
�V�K�ɓ������ꂽ�A�C�f�A��������Ă��Ƃ���B�m����Pentium III�ƃA�[�L�e�N�`��
�I�ɗǂ����Ă��镔���͂��邯�ǁC�����I�ɂ͑S�R����Ă���Ƃ�������X�������
���Ƃ��B
��������������̃A�[�L�e�N�`���̂܂܂ŁC�ǂꂾ�����\���グ����Ǝv���H
Pentium III�̃A�[�L�e�N�`�����p�����Ă��镔�������邩�ƕ������C�������
�C�G�X���BDothan����Yonah���J������ߒ��ŐV���ɕt��������ꂽ�����͑S��
���猩��Ώ����ȕω������CYonah����Merom�ł̒lj��������悤�ɑS�ʓI�ȍ��V
���Ėᖳ���B�ł�Banias���uP6�A�[�L�e�N�`���̂܂܂��v���Č����̂́C�J����
�g��������S�l�̃X�^�b�t�ɑ��Ď�����Ă��̂���Ȃ����ȁB
CNET�̃C���^�r���[�ŁC�S�Ă�m�肦�闧��ɂ���Mooly Eden�������Ă��邷�B
http://news.com.com/2008-1006_3-6047173-2.html
�@�@-------------------------
�@�@Part of it is based on previous architecture and part of it looks forward. It
�@�@resembled (Pentium III) architecture to some extent, but (there are) a lot of
�@�@different features inside.
�@�@Can you give performance improvement based on the same architecture? Are
�@�@you taking things from the previous architecture? Yes. Did Yonah not take from
�@�@Dothan alone? Did Merom take from Yonah? Much less, but to call it Pentium III
�@�@architecture I believe is doing an injustice to the hundreds of people that delivered
�@�@Banias.
�@�@-------------------------
[MAC�I�^��] ������O�̘b�����ǁC�O����̃`�b�v��������p��������������C
�V�K�ɓ������ꂽ�A�C�f�A��������Ă��Ƃ���B�m����Pentium III�ƃA�[�L�e�N�`��
�I�ɗǂ����Ă��镔���͂��邯�ǁC�����I�ɂ͑S�R����Ă���Ƃ�������X�������
���Ƃ��B
��������������̃A�[�L�e�N�`���̂܂܂ŁC�ǂꂾ�����\���グ����Ǝv���H
Pentium III�̃A�[�L�e�N�`�����p�����Ă��镔�������邩�ƕ������C�������
�C�G�X���BDothan����Yonah���J������ߒ��ŐV���ɕt��������ꂽ�����͑S��
���猩��Ώ����ȕω������CYonah����Merom�ł̒lj��������悤�ɑS�ʓI�ȍ��V
���Ėᖳ���B�ł�Banias���uP6�A�[�L�e�N�`���̂܂܂��v���Č����̂́C�J����
�g��������S�l�̃X�^�b�t�ɑ��Ď�����Ă��̂���Ȃ����ȁB
458 �FMAC�I�^���⑫�F2006/03/12(��) 17:41:01 ID:wXE3ifwK0
Eden���Ƃ��Ă�C���ʂƂ���Intel���~���C�ނ̃L�����A���P���������̂ɂ���
Banias�ɂ�C�����Ȏv�����ꂪ����悤���ˁB
Banias�ɂ�C�����Ȏv�����ꂪ����悤���ˁB
>>457
456����Ȃ����ǁAGJ!
456����Ȃ����ǁAGJ!
Banias�J���҂ɕ����AIntel�̎�����ȓd��CPU�Z�p (2/2)
http://www.itmedia.co.jp/news/articles/0508/29/news008_2.html
>�uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i�����Ă���Ƃ���ƁA
>Dothan����Yonah�ւ̐i���͂��̐��{���̑傫�ȍ�������܂��B
>Yonah����Merom�̐i���������ď������͂���܂��ADothan����Yonah�ւ̕ω�
>�قǑ傫�Ȃ��̂ł͂���܂���v
Banias�`Yonah��P6�A�[�L�x�[�X�B
Merom�ȍ~��Core�A�[�L�Ƃ��ĘR��͘b��i�߂܂��B
Eden���̎咣�Ȃ�ăI�^�N�ɂƂ��Ă���ʐl�ɂƂ��Ă��ǂ��ł��ǂ�����B
�����IDF�ł̐V�}�C�N���A�[�L�̐�`���Ղ肪���̏ؖ��B
http://www.itmedia.co.jp/news/articles/0508/29/news008_2.html
>�uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i�����Ă���Ƃ���ƁA
>Dothan����Yonah�ւ̐i���͂��̐��{���̑傫�ȍ�������܂��B
>Yonah����Merom�̐i���������ď������͂���܂��ADothan����Yonah�ւ̕ω�
>�قǑ傫�Ȃ��̂ł͂���܂���v
Banias�`Yonah��P6�A�[�L�x�[�X�B
Merom�ȍ~��Core�A�[�L�Ƃ��ĘR��͘b��i�߂܂��B
Eden���̎咣�Ȃ�ăI�^�N�ɂƂ��Ă���ʐl�ɂƂ��Ă��ǂ��ł��ǂ�����B
�����IDF�ł̐V�}�C�N���A�[�L�̐�`���Ղ肪���̏ؖ��B
ALU���{���C�p�C�v���C���i�������B�B�B�Ȃ�Ă̂�CNorthwood -> Prescott�ł��s��ꂽ����
�Ȃ��ǁC�s�v�c�Ȃ��Ƃ�Prescott��V�A�[�L�e�N�`���ƌĂԃq�g��C���Ȃ����B
�v���Z�b�T�A�[�L�e�N�g�̋�J���C�m�������Ԃ�̑f�l�ǂ��ɗ��������Ƃ����Ȃ��D�Ⴗ�ˁB�B�B
�Ȃ��ǁC�s�v�c�Ȃ��Ƃ�Prescott��V�A�[�L�e�N�`���ƌĂԃq�g��C���Ȃ����B
�v���Z�b�T�A�[�L�e�N�g�̋�J���C�m�������Ԃ�̑f�l�ǂ��ɗ��������Ƃ����Ȃ��D�Ⴗ�ˁB�B�B
The PentiumR II/III Processor �gCompiler on a Chip Compiler on a Chip�h
Ronny Ronen, Senior Principal Engineer Director of Architecture
Research Intel Labs --Haifa
ttp://www.cs.tau.ac.il/~afek/p6tx050111.pdf
>Most significant, major improvement over P6 architecture ever
������PenM=P6�x�[�X�ł����ʷ�ؔF�߂Ă���͗l�i�m
>>2
���̃\�[�X�ɂ��Dothan�̃g�����W�X�^����140M�ł͂Ȃ�127M��FA�ł��邱�Ƃ������B
���R�A�����̃g�����W�X�^���ł݂Ă��AMerom�ő啝�ɃW�����v���邱�Ƃ��\�z����܂��B
Ronny Ronen, Senior Principal Engineer Director of Architecture
Research Intel Labs --Haifa
ttp://www.cs.tau.ac.il/~afek/p6tx050111.pdf
>Most significant, major improvement over P6 architecture ever
������PenM=P6�x�[�X�ł����ʷ�ؔF�߂Ă���͗l�i�m
>>2
���̃\�[�X�ɂ��Dothan�̃g�����W�X�^����140M�ł͂Ȃ�127M��FA�ł��邱�Ƃ������B
���R�A�����̃g�����W�X�^���ł݂Ă��AMerom�ő啝�ɃW�����v���邱�Ƃ��\�z����܂��B
Pentium M�̕��ADavid Perlmutter���ɐq�˂�
http://pcweb.mycom.co.jp/news/2003/03/13/43.html
�q�ϓI�Ɍ��Ăǂ������Ă��ƂƂ͕ʂɁA�C�X���G���`�[���𗦂��Ă���
�����B���炷��Ɓu�I���S������������̂ɏ����ǂ��{�������́v
�Ƃ��đ������邱�Ƃɉ䖝�Ȃ�Ȃ��A�Ƃ������ƂȂ�ł��傤�ȁB
http://pcweb.mycom.co.jp/news/2003/03/13/43.html
�q�ϓI�Ɍ��Ăǂ������Ă��ƂƂ͕ʂɁA�C�X���G���`�[���𗦂��Ă���
�����B���炷��Ɓu�I���S������������̂ɏ����ǂ��{�������́v
�Ƃ��đ������邱�Ƃɉ䖝�Ȃ�Ȃ��A�Ƃ������ƂȂ�ł��傤�ȁB
���₢��A�A�[�L�̏ڍׂ����J���ꂽ���Ƃ����A����͎��ƕ��Ƃ��Ă�Core�A�[�L�̕���
���荞��ł����������낤����A�ȍ~�������Ȃ��������̂悤�Ɉ�ʌ������f�B�A�ɑ��Ă��A
P6��PenM�x�[�X�ł����݂����Ȍ����\�[�X���łĂ����肵�Ăȁc�i�E�́E�j
���荞��ł����������낤����A�ȍ~�������Ȃ��������̂悤�Ɉ�ʌ������f�B�A�ɑ��Ă��A
P6��PenM�x�[�X�ł����݂����Ȍ����\�[�X���łĂ����肵�Ăȁc�i�E�́E�j
CeBIT06: Intel zeigt, wie schlecht Paxville ist
http://www.computerbase.de/news/hardware/prozessoren/intel/2006/maerz/cebit06_intel_paxville/
Dempsey�AWoodcrest�i&LV�j��Spec�T�Z�O���t�����\�����B
CeBIT06: Benchmarks vom Intel Merom
http://www.computerbase.de/news/hardware/prozessoren/intel/2006/maerz/cebit06_benchmarks_intel_merom/
���N���b�N��Yonah��Merom��Quake 4�x���`�B
http://www.computerbase.de/news/hardware/prozessoren/intel/2006/maerz/cebit06_intel_paxville/
Dempsey�AWoodcrest�i&LV�j��Spec�T�Z�O���t�����\�����B
CeBIT06: Benchmarks vom Intel Merom
http://www.computerbase.de/news/hardware/prozessoren/intel/2006/maerz/cebit06_benchmarks_intel_merom/
���N���b�N��Yonah��Merom��Quake 4�x���`�B
http://pcweb.mycom.co.jp/articles/2006/03/18/cebit8/
>���Ȃ݂ɖ^���[�J�[�̒S���҂������Ă����̂����AConroe�̓I�[�o�[�N���b�N���\���ǂ��A
>30%���x�̃}�[�W��������̂��������B
���� 2.6GHz*1.3=3.38GHz �Ƃ����
�ȑO�o��XE��3.3GH���͉\�Ɏv����B
>���Ȃ݂ɖ^���[�J�[�̒S���҂������Ă����̂����AConroe�̓I�[�o�[�N���b�N���\���ǂ��A
>30%���x�̃}�[�W��������̂��������B
���� 2.6GHz*1.3=3.38GHz �Ƃ����
�ȑO�o��XE��3.3GH���͉\�Ɏv����B
>>465->>466
�U�҉��B�\�[�X�͂悢���A�ʂ̖��O�ł���Ă����B
�U�҉��B�\�[�X�͂悢���A�ʂ̖��O�ł���Ă����B
Core�A�[�L�ɂ��Ă���̂��Ƃ��ϑz������̔F�����ɂ����˂�⍑���T�C�g�𒆐S�ɍL�����Ă����킯�����B
���IDF�����p�̊ȗ������ꂽ�u���b�N�}���̂܂ܓǂނȂ�Ɓc�B�������̉���Ƃ������Ȃ�A�������B
�����Best����܂�RealWorldTech�ł���?�i�E�́E�j
���IDF�����p�̊ȗ������ꂽ�u���b�N�}���̂܂ܓǂނȂ�Ɓc�B�������̉���Ƃ������Ȃ�A�������B
�����Best����܂�RealWorldTech�ł���?�i�E�́E�j
�܂��AMerom�̐��\�Ɋւ��ď������낢�날��킯�����A
�Ԃ����Ⴏ�A(P6�jBanias��Yonah�܂ŁA�R�A���̂͑S���ς���ĂȂ��킯�ŁA
����ɔ�ׂ�AYonah��Merom�̃R�A�ύX�͑S�R�傫���킯�ŁA
���ʂ�Intel�����\���Ă�悤�Ȃ��̂����ł��A�Z�߂�Α����I�ɁA20%�������炢���������B
���X�APenM�̓��o�C���Ƃ��Đ��\�͊�����ĊJ������Ă��킯�ŁA
���̕����̃l�b�N��n���ɒׂ��Ă��������ł����Ȃ���ʂ��������B
��́A�������ʼn�%�A�L���b�V�����ʼn�%�Ƃ������Ă鐢�E�ŁA
���ꂾ��Core�M���Č��サ�Ȃ��������������Ǝv���B
�Ԃ����Ⴏ�A(P6�jBanias��Yonah�܂ŁA�R�A���̂͑S���ς���ĂȂ��킯�ŁA
����ɔ�ׂ�AYonah��Merom�̃R�A�ύX�͑S�R�傫���킯�ŁA
���ʂ�Intel�����\���Ă�悤�Ȃ��̂����ł��A�Z�߂�Α����I�ɁA20%�������炢���������B
���X�APenM�̓��o�C���Ƃ��Đ��\�͊�����ĊJ������Ă��킯�ŁA
���̕����̃l�b�N��n���ɒׂ��Ă��������ł����Ȃ���ʂ��������B
��́A�������ʼn�%�A�L���b�V�����ʼn�%�Ƃ������Ă鐢�E�ŁA
���ꂾ��Core�M���Č��サ�Ȃ��������������Ǝv���B
�킯�ŁA���ȉ�͍ė��T���炢�ɗ\��i�E�́E�j
��������R��Ȃ�ɍl���Ă݂��B
http://www.geocities.jp/andosprocinfo/wadai06/20060311.htm
http://www.geocities.jp/andosprocinfo/wadai06/20060318.htm
> 1.2 ���s�p�C�v���C��
> ���s�p�C�v���C���́C���Z�n�̃p�C�v���C����3�{����C�����ALU�CMMX/SSE�CFP Move�����s�ł���
�����Z�n���߃|�[�g��3�̊ԈႢ�B�|�[�g�̐�ɂ͕����̎��s���j�b�g(�p�C�v)�A�T�u���j�b�g������B
���߃|�[�g�Ƃ����T�O��P6�ȍ~��Intel�̓`���B
> ��ʂɂ́C�X�g�A�̃A�h���X�����܂������_�ŁC���s�J�n���ꂽ�㑱�̃��[�h���߂̃A�h���X�Ɣ�r���s���C
> ��v�������̂�����Ƃ��̃��[�h���߂Ƃ���ȍ~�̖��߂̎��s�𒆒f���C�X�g�A���߂����s����Ă��烍�[�h
> ���߂Ƃ���ȍ~�̖��߂̎��s����蒼���Ƃ������@���p�����܂��B
�� �ȈՓI�ȃX�g�A�ǂ��z����NetBurst��PenM�ł��������͂��B
�����Dynamic Alias Predictor��p���ē��I�\�����ӂ܂��Ă���Ă���͗l�B
> 1.5 Advanced Smart Cache
> ���ʃL���b�V�����ɂ��C�����̖�肪��������Əq�ׂĂ��܂����C
> ���X���蔲���ŁC����ē��R�Ƃ��������ŁC�����Markitecute�ł��B
�� ���̃n�C�G���h�v���Z�b�T�̌��画�f���Ă��i��ł�����Ȃ̂Ɏ茵�����ł��ˁB
��������R��Ȃ�ɍl���Ă݂��B
http://www.geocities.jp/andosprocinfo/wadai06/20060311.htm
http://www.geocities.jp/andosprocinfo/wadai06/20060318.htm
> 1.2 ���s�p�C�v���C��
> ���s�p�C�v���C���́C���Z�n�̃p�C�v���C����3�{����C�����ALU�CMMX/SSE�CFP Move�����s�ł���
�����Z�n���߃|�[�g��3�̊ԈႢ�B�|�[�g�̐�ɂ͕����̎��s���j�b�g(�p�C�v)�A�T�u���j�b�g������B
���߃|�[�g�Ƃ����T�O��P6�ȍ~��Intel�̓`���B
> ��ʂɂ́C�X�g�A�̃A�h���X�����܂������_�ŁC���s�J�n���ꂽ�㑱�̃��[�h���߂̃A�h���X�Ɣ�r���s���C
> ��v�������̂�����Ƃ��̃��[�h���߂Ƃ���ȍ~�̖��߂̎��s�𒆒f���C�X�g�A���߂����s����Ă��烍�[�h
> ���߂Ƃ���ȍ~�̖��߂̎��s����蒼���Ƃ������@���p�����܂��B
�� �ȈՓI�ȃX�g�A�ǂ��z����NetBurst��PenM�ł��������͂��B
�����Dynamic Alias Predictor��p���ē��I�\�����ӂ܂��Ă���Ă���͗l�B
> 1.5 Advanced Smart Cache
> ���ʃL���b�V�����ɂ��C�����̖�肪��������Əq�ׂĂ��܂����C
> ���X���蔲���ŁC����ē��R�Ƃ��������ŁC�����Markitecute�ł��B
�� ���̃n�C�G���h�v���Z�b�T�̌��画�f���Ă��i��ł�����Ȃ̂Ɏ茵�����ł��ˁB
> �O���IDF�ł̔��\�ł́CL1$�Ԃ̃f�[�^�]�������ڍs����(Direct L1 to L1 cache transfer)�Ƃ����L�q���������̂ł����C
> ����̔��\�ł͐G����Ă��Ȃ����C�u���b�N�}�ɂ����̂悤�ȃp�X�͑��݂��Ă��܂���BPCWeb�ɏ������悤�ɁC
> ���̋@�\�͂��������ȂƎv���Ă����̂ł����C�Ă̒�C����̔��\�ł͖����Ȃ��Ă��܂����B
�� ���big/little endian�ȃu���b�N�}�ɂ����Ɓ̂�������Ă�B
�@�@�O���IDF���_�ł��łɃe�[�v�A�E�g���ς�ł����̂ŁA���������R�̔��\�Ȃ�Ă���킯�Ȃ����B
> ��T�Љ��Intel��Core Microarchitecture��Pentium 4��Netburst�A�[�L�Ɣ�ׂ��1�T�C�N��������̐��\�������C
> AMD��Athlon/Opteron�A�[�L�ɂЂ������Ȃ��Ǝv���܂����C��߂̃N���b�N�łQ�O���̍���t����Ƃ����͎̂�o�������ŁC
> �����̃A�v���ł́CSSE���Z��2�T�C�N������1�T�C�N���ɉ��P�����_�ƁCDDR2-667�̃������o���h���������Ă���悤�Ɏv���܂��B
�� ���ʂɍl����Core�̕���K8�������C�h�BSPEC�x���`�o�^��̈������̔������y���݁i�E�́E�j
472 �F���̖��ݒ��F2006/03/21(��) 16:54:48 ID:ITaZGgML0
�A���X�\�t�g�̃I���W�i��iPod nano���f��
http://www.alicesoft.com/user/ipod/index.html
��������������(߁��)������������ !!!!!
http://www.alicesoft.com/user/ipod/index.html
��������������(߁��)������������ !!!!!
473 �FMAC�I�^��inteler �����F2006/03/21(��) 22:31:35 ID:2IeJbMIx0
>>471
�@�@-------------------
�@�@�� ���big/little endian�ȃu���b�N�}�ɂ����Ɓ̂�������Ă�B
�@�@-------------------
�u���b�N�}��C�����܂Ŋȗ��}������CL1-L2�Ԃ̓]���s��2�{�����̂��T�{�����������Ǝv�����B
�����C�������̕������Ⴂ�����邩�Ǝv�����B
http://pcweb.mycom.co.jp/column/architecture/021/
�@�@===================
�@�@����A���ʂ̍��ł́A���R�A��1���L���b�V�����~�X����Ƌ��p��2���L���b�V���ɃA�N�Z�X���A
�@�@����R�A��1���L���b�V���Ƀf�[�^������ꍇ�́AInclusion Cache�ł����2���L���b�V���Ƀq�b�g���A
�@�@��������f�[�^���ǂ܂��B�킴�킴�A���ړ]���ƌ����Ă���̂ŁA����2���L���b�V������̓]����
�@�@��ׂă����b�g���Ȃ���Ȃ�Ȃ�
�@�@===================
�����C�����܂�L1�L���b�V����POWER4/PPC970�̂悤��write-through�̏ꍇ���B�ׂ������\�A�b�v��
�C���g��Intel�̓`������l���Ă�L1��copy-back������CL1�Ԃ̃L���b�V�������`�F�b�N��f�[�^�]��
�̂��߂̒����o�X��C�L���Ƃ������K�{�̃��x���Ƃ������ƂɂȂ邷�B
��{�I��Intel��AMD(�����ĕt��������ƁC���Ă�Motorola)��C�{�����[���̏o��v���Z�b�T��v����
����W��IBM�̂悤�Ɂu�����ɐv�R�X�g���P�`�邩��Ƃ����ϓ_��D��x���Ⴂ������C�킸���ł����\
����ɂȂ�Ɣ����Ă�����m�̋Z�p��C���R�̂悤�ɑg�ݍ���ł��邷�ˁB
�@�@-------------------
�@�@�� ���big/little endian�ȃu���b�N�}�ɂ����Ɓ̂�������Ă�B
�@�@-------------------
�u���b�N�}��C�����܂Ŋȗ��}������CL1-L2�Ԃ̓]���s��2�{�����̂��T�{�����������Ǝv�����B
�����C�������̕������Ⴂ�����邩�Ǝv�����B
http://pcweb.mycom.co.jp/column/architecture/021/
�@�@===================
�@�@����A���ʂ̍��ł́A���R�A��1���L���b�V�����~�X����Ƌ��p��2���L���b�V���ɃA�N�Z�X���A
�@�@����R�A��1���L���b�V���Ƀf�[�^������ꍇ�́AInclusion Cache�ł����2���L���b�V���Ƀq�b�g���A
�@�@��������f�[�^���ǂ܂��B�킴�킴�A���ړ]���ƌ����Ă���̂ŁA����2���L���b�V������̓]����
�@�@��ׂă����b�g���Ȃ���Ȃ�Ȃ�
�@�@===================
�����C�����܂�L1�L���b�V����POWER4/PPC970�̂悤��write-through�̏ꍇ���B�ׂ������\�A�b�v��
�C���g��Intel�̓`������l���Ă�L1��copy-back������CL1�Ԃ̃L���b�V�������`�F�b�N��f�[�^�]��
�̂��߂̒����o�X��C�L���Ƃ������K�{�̃��x���Ƃ������ƂɂȂ邷�B
��{�I��Intel��AMD(�����ĕt��������ƁC���Ă�Motorola)��C�{�����[���̏o��v���Z�b�T��v����
����W��IBM�̂悤�Ɂu�����ɐv�R�X�g���P�`�邩��Ƃ����ϓ_��D��x���Ⴂ������C�킸���ł����\
����ɂȂ�Ɣ����Ă�����m�̋Z�p��C���R�̂悤�ɑg�ݍ���ł��邷�ˁB
474 �FMAC�I�^���⑫�F2006/03/21(��) 22:38:16 ID:2IeJbMIx0
�v����IBM�̃P�`�P�`�v�̍ň��̗��CPOWER4/PPC970�̃��C�e���V2�̈ˑ��������Z���B
Stream Benchmark�ŗL����McCalpin���̌��ł�C�u�ˑ����߂�2�̃p�C�v���C���̂ǂ���𗬂�Ă��邩
����ʂ��āC���C�e���V1�Ŏ��s�\�ȏꍇ�͂�������B�B�B�Ƃ����I�������������C����قǐ��\��ς��Ȃ�
�̂Ŏ~�߂���Ƃ������b�����ǁC���̕ӂ�IBM���̃v���Z�b�T���Ŕʂ�̐��\���o�Ȃ��v�����Ǝv�����B
Stream Benchmark�ŗL����McCalpin���̌��ł�C�u�ˑ����߂�2�̃p�C�v���C���̂ǂ���𗬂�Ă��邩
����ʂ��āC���C�e���V1�Ŏ��s�\�ȏꍇ�͂�������B�B�B�Ƃ����I�������������C����قǐ��\��ς��Ȃ�
�̂Ŏ~�߂���Ƃ������b�����ǁC���̕ӂ�IBM���̃v���Z�b�T���Ŕʂ�̐��\���o�Ȃ��v�����Ǝv�����B
475 �F���̖��ݒ��F2006/03/21(��) 22:42:23 ID:7YaGxPwJ0
1���L���b�V����1MB���炢�ɂ���A���������\�悭�Ȃ��ˁH
�����ēV�ˁH
�����ēV�ˁH
476 �FMAC�I�^��475 �����F2006/03/21(��) 22:55:56 ID:2IeJbMIx0
����A�}�W���X����܂��Ă��c�B
�Ƃ���ŁAx86��PowerPC�ŁA�ꎟ�L���b�V����MB�P�ʂ܂ő��₵���Ƃ�����A�ǂꂮ�炢
���\���オ�����߂邷���ˁH
�Ƃ���ŁAx86��PowerPC�ŁA�ꎟ�L���b�V����MB�P�ʂ܂ő��₵���Ƃ�����A�ǂꂮ�炢
���\���オ�����߂邷���ˁH
�Ă��ADirect L1 to L1 cache transfer���āAYonah������ɓ�������Ă��悤�ȋC���������E�E�E
�O���o�X�g��Ȃ����ĈӖ��ŁB�B�B
�O���o�X�g��Ȃ����ĈӖ��ŁB�B�B
���낻��N�����̂�������ɃC���^�r���[���Ă���
ftp://download.intel.com/pressroom/images/bios/perlumuttera.jpg
ftp://download.intel.com/pressroom/images/bios/perlumutterb.jpg
ftp://download.intel.com/pressroom/images/bios/perlumuttera.jpg
{kind=link}
ftp://download.intel.com/pressroom/images/bios/perlumutterb.jpg
{kind=link}
480 �FMAC�I�^��479 �����F2006/03/22(��) 00:22:11 ID:+n1MgpD80
481 �FMAC�I�^���⑫�F2006/03/22(��) 00:25:27 ID:+n1MgpD80
���������ŋ߂̂��̂����ǁC�p��
http://www.tgdaily.com/2005/11/08/q_and_a_intel_dadi_perlmutter/index.html
http://www.tgdaily.com/2005/11/08/q_and_a_intel_dadi_perlmutter/index.html
>>252 ����͒m���Ă�B�[���A������463�ł������N�������B
>>479��Core Microarchitecture���\�ȍ~�ŁA���ĈӖ��ˁB
>>479��Core Microarchitecture���\�ȍ~�ŁA���ĈӖ��ˁB
Mac�ł�Pure Video�Ƃ�AVIVO�Ƃ��g���Ȃ��́H
QuickTime�o�R�Ƃ��Ŏg��������Ǝv�����ǁB
QuickTime�o�R�Ƃ��Ŏg��������Ǝv�����ǁB
�L���ǂ�ł����ЂƂӖ�������Ȃ������ǁA���̎ʐ^��PowerBook�̃o�b�e�����ʂ��Ă邷���H
"Apple notebook could end up using AMD Turion"
http://www.theinquirer.net/?article=30545
"Apple notebook could end up using AMD Turion"
http://www.theinquirer.net/?article=30545
GPU�̔ėp�����i��ł���ƌ����Ă��邷���ǁA
GPU�œ���̃G���R�[�h�╡�G�Ȍv�Z���ł���悤�ɂȂ�̂͂��������H
DirectX 10����H
GPU�œ���̃G���R�[�h�╡�G�Ȍv�Z���ł���悤�ɂȂ�̂͂��������H
DirectX 10����H
GPU���āA�O���t�B�b�N�X�ȊO�́A����ܐ��\�łȂ��炵��
�{����CPU�̃}���`�R�A����Ȃ����ȁH
4�R�A�ɂȂ�ƁA�P���x��100GFlops�����邵
�{����CPU�̃}���`�R�A����Ȃ����ȁH
4�R�A�ɂȂ�ƁA�P���x��100GFlops�����邵
4�R�A���c�B
Kentsfield����Mac���Ă����o���ł����ˁB��MAC�I�^�Ainteler����
Kentsfield����Mac���Ă����o���ł����ˁB��MAC�I�^�Ainteler����
xtremesystesm�f���̓��e�ɂ��ƁAMac mini��Merom��ES�i���ڂ��Č�����A�����Ɠ��삵���������B
http://www.xtremesystems.org/forums/showthread.php?t=91758
�H��Merom�������[�X���ꂽ��A����y�����u�[���̍ė��ɂȂ肻������(��)
http://www.xtremesystems.org/forums/showthread.php?t=91758
�H��Merom�������[�X���ꂽ��A����y�����u�[���̍ė��ɂȂ肻������(��)
�ŐV�̃��[�}�[���ɂ��ƁA
Conroe��9���B
Merom��10�� or 11���B
Kentsfield��1�����B
���Ƃ́AApple�̔��f����œ����ɏo�����A���������x��Ăł邩�����c�B
���Ȃ݂�Kentsfield��Vista�̃����[�X���ɂ��킹�Ă���͗l���B
Conroe��9���B
Merom��10�� or 11���B
Kentsfield��1�����B
���Ƃ́AApple�̔��f����œ����ɏo�����A���������x��Ăł邩�����c�B
���Ȃ݂�Kentsfield��Vista�̃����[�X���ɂ��킹�Ă���͗l���B
492 �Finteler@�R�s�y�F2006/03/32(�y) 10:31:59 ID:oHgNYCJg0
617 ���O�FMAC�I�^[sage] ���e���F2006/03/31(��) 17:16:25 ID:1E6U8MQb
OEM������Conroe��ES�i���o���n�߂��炵�����Bxtremesystems�f���ɓ��e���ꂽConroe/2GHz��
Sandra multimedia�x���`�}�[�N�̌��ʂ��B
http://www.xtremesystems.org/forums/showpost.php?s=959eaadecf76016346dbf39bf50342a3&p=1364871&postcount=234
�Q�l�܂ł�Athlon64 FX-60�̌���
http://www.hothardware.com/image_popup.cfm?image=big_sanmmfx60.png&articleid=767&t=a
�ESandra CPU Multi-Media Benchmark
�@�@�@�@�@�@�@�@�@�@�@�@�@�@Int�@�@�@�@�@FP
Coroe/2.0GHz:�@�@�@�@108162�@�@59254
Athlon64/2.6GHz:�@�@�@49557�@�@53865
618 ���O�FMAC�I�^[sage] ���e���F2006/03/31(��) 17:19:33 ID:1E6U8MQb
������xtremesystems�f�����FutureMark�̃T�C�g�ɓo�^���ꂽMerom��3DMark�̌��ʂ��B
http://www.xtremesystems.org/forums/showpost.php?s=8a794a746edc948bfe89ad303a06b431&p=1365564&postcount=297
619 ���O�FSocket774[sage] ���e���F2006/03/31(��) 17:39:32 ID:mL5kDraE
ttp://www.xtremesystems.org/forums/showpost.php?p=1365564
�����p�����[�^�͔������悢��
----
�������A���������T���v�����肵�Ă�̂ɁA�Ȃ�ł��̎�̃I�^�N����Sandra�Ƃ�PI�Ƃ�
���������ɑ����ĂȂ��x���`�����葪�肷��낤�Ȃ��c(;�L�D�M)
OEM������Conroe��ES�i���o���n�߂��炵�����Bxtremesystems�f���ɓ��e���ꂽConroe/2GHz��
Sandra multimedia�x���`�}�[�N�̌��ʂ��B
http://www.xtremesystems.org/forums/showpost.php?s=959eaadecf76016346dbf39bf50342a3&p=1364871&postcount=234
�Q�l�܂ł�Athlon64 FX-60�̌���
http://www.hothardware.com/image_popup.cfm?image=big_sanmmfx60.png&articleid=767&t=a
{kind=link}
�ESandra CPU Multi-Media Benchmark
�@�@�@�@�@�@�@�@�@�@�@�@�@�@Int�@�@�@�@�@FP
Coroe/2.0GHz:�@�@�@�@108162�@�@59254
Athlon64/2.6GHz:�@�@�@49557�@�@53865
618 ���O�FMAC�I�^[sage] ���e���F2006/03/31(��) 17:19:33 ID:1E6U8MQb
������xtremesystems�f�����FutureMark�̃T�C�g�ɓo�^���ꂽMerom��3DMark�̌��ʂ��B
http://www.xtremesystems.org/forums/showpost.php?s=8a794a746edc948bfe89ad303a06b431&p=1365564&postcount=297
619 ���O�FSocket774[sage] ���e���F2006/03/31(��) 17:39:32 ID:mL5kDraE
ttp://www.xtremesystems.org/forums/showpost.php?p=1365564
�����p�����[�^�͔������悢��
----
�������A���������T���v�����肵�Ă�̂ɁA�Ȃ�ł��̎�̃I�^�N����Sandra�Ƃ�PI�Ƃ�
���������ɑ����ĂȂ��x���`�����葪�肷��낤�Ȃ��c(;�L�D�M)
ttp://www.xtremesystems.com/modules.php?op=modload&name=News&file=article&sid=655&mode=thread&order=0&thold=0
������Merom��SuperPI(mod)�X�R�A�B
- [email protected]
������Merom��SuperPI(mod)�X�R�A�B
- [email protected]
>>487
x965�`�b�v�Z�b�g���ォ��́AIntel��GPU���p�ɐϋɓI�݂����B
Intel Clear Video Technology�ł́AHW�x���̃G���R�[�h�Ȃǂ��ł���͗l�B
�R��͏ڍׂ̓t�H���[���ĂȂ��̂ŁA���Ƃ͎����Œ��ׂĂ݂Ă���B
Intel Clear Video Technology
http://wwww.vr-zone.com/index.php?i=3239
x965�`�b�v�Z�b�g���ォ��́AIntel��GPU���p�ɐϋɓI�݂����B
Intel Clear Video Technology�ł́AHW�x���̃G���R�[�h�Ȃǂ��ł���͗l�B
�R��͏ڍׂ̓t�H���[���ĂȂ��̂ŁA���Ƃ͎����Œ��ׂĂ݂Ă���B
Intel Clear Video Technology
http://wwww.vr-zone.com/index.php?i=3239
>>453��Real World Tech�̏��Օ������ւȂ��傱�v�Ă݂�(�㔼�͖ʓ|�ɂȂ����̂ł�߂�)�B
�����AIntel�������炻�̂����_���ƍœK���}�j���A���ł����Ɛ��m�ȏ�������ł��邾�낤���A�ԈႢ�̎w�E�Ȃǂ͂���܂���B
Intel's Next Generation Microarchitecture Unveiled
By: David KanterUpdated: 03-09-2006
-----------------
*** Introduction
Intel�̍ŐV�̃}�C�N���A�[�L��Israel�ŊJ�����ꂽYonah�R�A�ł��邪�A
���̃}�C�N���A�[�L�́AP6�̐v�ɗR������B
Intel��Merom-Based�R�A�͗l�X�Ȗ���(NGMA��)�ŌĂ�Ă������A
Core�}�C�N���A�[�L�e�N�`���Ɩ������ꂽ�B
Merom��Laptop, Conroe��Desktop, Woodcrest�́A1S-2S�̃T�[�o�����̃��@���G�[�V�����B
*** Rounding the Dual Core (Wood) Crest
Chip Multi-Processing (CMP)�̐^�̗̂��v�̓L���b�V���R�q�[�����V�̌������ł���B
Core�ɂ����ẮAL1D�L���b�V���ԂŃf�[�^�̒��ړ]�����\�����A
Intel�̃A�[�L�e�N�g�B�́A���̏ڍׂɂ��Ă͌��Ȃ������B
(�}1�́AYonah, Core, Dempsey�̃V�X�e���̑�܂��Ȕ�r������)
ttp://www.realworldtech.com/includes/images/articles/merom-1.gif
Core�ł́AYonah��CMP�A�v���[�`���p������Ɠ����ɁADempsey�̑ш�ɋ߂Â��Ă���B
Intel�́AWoodcrest���܂�early-Q3�Ƀ����[�X���āA���ꂩ��Conroe��Q3���ɁAQ4��Merom���o�ׂ��邾�낤�B
*** Where Ever I Merom
Core�}�C�N���A�[�L�̊T�v�B
dual core, 64 bit, 4 issue moderately pipelined out-of-order superscalar�B
36bit�̕�����������48bit�̉��z�������A���ׂĂ�Intel *Ts�̃T�|�[�g(��HT�͂Ȃ�����)�B
�e�R�A��32KB L1I + DP 32KB L1D �L���b�V�������B4MB L2�͋��ʁB
�N���b�N�͌��s�ōő�3.0GHz�B�������A�����炭3.33GHz�܂ŏオ�邾�낤�B
TDP�� Woodcrest 80W, Conroe 65W, Merom 35W�BLV Woodcrest��40W�B
�����AIntel�������炻�̂����_���ƍœK���}�j���A���ł����Ɛ��m�ȏ�������ł��邾�낤���A�ԈႢ�̎w�E�Ȃǂ͂���܂���B
Intel's Next Generation Microarchitecture Unveiled
By: David KanterUpdated: 03-09-2006
-----------------
*** Introduction
Intel�̍ŐV�̃}�C�N���A�[�L��Israel�ŊJ�����ꂽYonah�R�A�ł��邪�A
���̃}�C�N���A�[�L�́AP6�̐v�ɗR������B
Intel��Merom-Based�R�A�͗l�X�Ȗ���(NGMA��)�ŌĂ�Ă������A
Core�}�C�N���A�[�L�e�N�`���Ɩ������ꂽ�B
Merom��Laptop, Conroe��Desktop, Woodcrest�́A1S-2S�̃T�[�o�����̃��@���G�[�V�����B
*** Rounding the Dual Core (Wood) Crest
Chip Multi-Processing (CMP)�̐^�̗̂��v�̓L���b�V���R�q�[�����V�̌������ł���B
Core�ɂ����ẮAL1D�L���b�V���ԂŃf�[�^�̒��ړ]�����\�����A
Intel�̃A�[�L�e�N�g�B�́A���̏ڍׂɂ��Ă͌��Ȃ������B
(�}1�́AYonah, Core, Dempsey�̃V�X�e���̑�܂��Ȕ�r������)
ttp://www.realworldtech.com/includes/images/articles/merom-1.gif
{kind=link}
Core�ł́AYonah��CMP�A�v���[�`���p������Ɠ����ɁADempsey�̑ш�ɋ߂Â��Ă���B
Intel�́AWoodcrest���܂�early-Q3�Ƀ����[�X���āA���ꂩ��Conroe��Q3���ɁAQ4��Merom���o�ׂ��邾�낤�B
*** Where Ever I Merom
Core�}�C�N���A�[�L�̊T�v�B
dual core, 64 bit, 4 issue moderately pipelined out-of-order superscalar�B
36bit�̕�����������48bit�̉��z�������A���ׂĂ�Intel *Ts�̃T�|�[�g(��HT�͂Ȃ�����)�B
�e�R�A��32KB L1I + DP 32KB L1D �L���b�V�������B4MB L2�͋��ʁB
�N���b�N�͌��s�ōő�3.0GHz�B�������A�����炭3.33GHz�܂ŏオ�邾�낤�B
TDP�� Woodcrest 80W, Conroe 65W, Merom 35W�BLV Woodcrest��40W�B
�}�̐����B
�}2��Core�̃u���b�N�_�C�A�O�����B
�F�����̐����B���́AFrontEnd�ɂ����閽�߃t�F�b�`�ƁA����\���B�I�����W�́Ax86 �� uop �ւ̕ϊ��u���b�N�B
�N���[���n?�̐F�́Auop�̂��߂̓����o�b�t�@�ƁA�X�P�W���[�����O/OOO�u���b�N�B�͎��s���j�b�g�B�̓������V�X�e���B
�D�F�̓v���O����������݂����ۂ̃��W�X�^�t�@�C���̏�Ԃ������B
ttp://www.realworldtech.com/includes/images/articles/merom-2.gif
�}3, �}4�͔�r�p��Yonah�A�[�L, Pentium 4(NetBurst)�A�[�L�̃u���b�N�}�ł���(Core�̐}2����ڍדx��������)�B
ttp://www.realworldtech.com/includes/images/articles/merom-3.gif
ttp://www.realworldtech.com/includes/images/articles/merom-4.gif
�e�R�A�ɂ��āA1cycle������̖��߃t�F�b�`�T�C�Y�́A���Ȃ��Ƃ�160bit�ȏ�(Intel�͐��m�ȃt�F�b�`�T�C�Y�𖾂炩�ɂ��Ȃ�����)�B
���㓡�L���ł́A6��x86���߂��t�F�b�`�Ƃ̂��ƁB
- �ȉ��A�e�X�e�[�W�̑ш�
Fetch �c 160bit+ (x86���� 6����?)
Decode�@�c 1+4 (complex+simple) x86���߂��f�R�[�h�B
Decode �c 4+3 uops�s�B
Rename & Reorder �c 4 uops
Dispatch �c 6 uops
Retire �c 4uops
���ׂẴX�e�[�W��Pen4��Yonah���y���ɍL�ш�B
�Ȍ�ڍׂɓ���܂��B
�}2��Core�̃u���b�N�_�C�A�O�����B
�F�����̐����B���́AFrontEnd�ɂ����閽�߃t�F�b�`�ƁA����\���B�I�����W�́Ax86 �� uop �ւ̕ϊ��u���b�N�B
�N���[���n?�̐F�́Auop�̂��߂̓����o�b�t�@�ƁA�X�P�W���[�����O/OOO�u���b�N�B�͎��s���j�b�g�B�̓������V�X�e���B
�D�F�̓v���O����������݂����ۂ̃��W�X�^�t�@�C���̏�Ԃ������B
ttp://www.realworldtech.com/includes/images/articles/merom-2.gif
{kind=link}
�}3, �}4�͔�r�p��Yonah�A�[�L, Pentium 4(NetBurst)�A�[�L�̃u���b�N�}�ł���(Core�̐}2����ڍדx��������)�B
ttp://www.realworldtech.com/includes/images/articles/merom-3.gif
{kind=link}
ttp://www.realworldtech.com/includes/images/articles/merom-4.gif
{kind=link}
�e�R�A�ɂ��āA1cycle������̖��߃t�F�b�`�T�C�Y�́A���Ȃ��Ƃ�160bit�ȏ�(Intel�͐��m�ȃt�F�b�`�T�C�Y�𖾂炩�ɂ��Ȃ�����)�B
���㓡�L���ł́A6��x86���߂��t�F�b�`�Ƃ̂��ƁB
- �ȉ��A�e�X�e�[�W�̑ш�
Fetch �c 160bit+ (x86���� 6����?)
Decode�@�c 1+4 (complex+simple) x86���߂��f�R�[�h�B
Decode �c 4+3 uops�s�B
Rename & Reorder �c 4 uops
Dispatch �c 6 uops
Retire �c 4uops
���ׂẴX�e�[�W��Pen4��Yonah���y���ɍL�ш�B
�Ȍ�ڍׂɓ���܂��B
*** The Front End (4/11)
Core�}�C�N���A�[�L�́AP6��Pen4���y���Ƀ��C�h�ł���B�}4�́AIntel�}�C�N���A�[�L�e�N�`����
Fetch/Decode�̏ڍׂȔ�r�������BIntel�͐��m�ȃt�F�b�`�ш�������炩�ɂ��Ȃ������B
�������A���ς�x86���ߒ���32bit�ł��邱�Ƃ��炵�āA���Ȃ��Ƃ�5���߂T�C�N��
�t�F�b�`�ł��邾�낤�B�����̖��߂�PreDecode��FetchBuffer(Instruction Que)�ɑ�����B
FetcheBuffer�́A�f��x86���߂݂̂ł͂Ȃ��A���ߒ��E�f�R�[�h�̋��E�ɂ��Ă̏����܂�ł���B
FetchBuffer�́A���Ȃ��Ƃ�10���߈ȏ���i�[�ł���(Intel�͐��m�Ȑ��͖��炩�ɂ��Ȃ�����)�B
�ނ��v�f������TraceCache�́A4��x86�f�R�[�_�ɒu��������ꂽ�B3��Simple Decoder�e�X���A
x86���߂̒��ŒP���uop�ɒu�������\�Ȃ��̂���������B����AComplex Decoder�́A
1-4uops������x86���߂ɑ��Ă���舵��(���������āADecode�p�^�[����4-1-1-1�ł���)�B
MicrocodeSequenser�́A��̐v�Ɠ��l�A4��葽��uop������x86���߂ɑ��ăf�R�[�h�A
�������̓A�V�X�g���邽�߂ɂ���BYonah�̂悤�ɁA�S�Ă�SSE���߂�P���uop�̐����ɂ����Simple Decoder��
��舵�����Ƃ��\�ł���B
����ɁA�}4�������ʂ�AIntel Core FrontEnd��Macro-op Fusion�ƌĂ��V�����t�B�[�`��������B
Intel�̏ꍇ�A�������߂�uops�ƌĂ�A�܂��Ax86���߂�Macro-ops�ƌĂ��B
Macro-op Fusion�́ADecoder��2��Macro-op��P���uop�ւƌ���������B
���ɁAx86 compare/test���߂�x86 jump���߂Ƃ��P���uop�ɗZ�������B
�܂��A�e�ǂ̃f�R�[�_�����̍œK�����s�����Ƃ��\�����A�ecycle�ɂ��A(�S�̂ł�)1��Macro-op Fusion�݂̂�
�s�Ȃ����Ƃ��\�ł���B�Ƃǂ̂܂�Amax issue bandwidth�� 4+1 x86inst/cycle�ł���BMacro-op fusion�́A
��蕪�����Ɉ�ʓI�ȃv���O���~���O�ł���if-then-else�X�e�[�g�����g�ɏ�肭�K������BIntel�̓R�����g���T�������A
�������̐����ł�Macro-op fusion�́Auops�̐���10%�팸���邱�Ƃ������Ă���B
Core�}�C�N���A�[�L�́AP6��Pen4���y���Ƀ��C�h�ł���B�}4�́AIntel�}�C�N���A�[�L�e�N�`����
Fetch/Decode�̏ڍׂȔ�r�������BIntel�͐��m�ȃt�F�b�`�ш�������炩�ɂ��Ȃ������B
�������A���ς�x86���ߒ���32bit�ł��邱�Ƃ��炵�āA���Ȃ��Ƃ�5���߂T�C�N��
�t�F�b�`�ł��邾�낤�B�����̖��߂�PreDecode��FetchBuffer(Instruction Que)�ɑ�����B
FetcheBuffer�́A�f��x86���߂݂̂ł͂Ȃ��A���ߒ��E�f�R�[�h�̋��E�ɂ��Ă̏����܂�ł���B
FetchBuffer�́A���Ȃ��Ƃ�10���߈ȏ���i�[�ł���(Intel�͐��m�Ȑ��͖��炩�ɂ��Ȃ�����)�B
�ނ��v�f������TraceCache�́A4��x86�f�R�[�_�ɒu��������ꂽ�B3��Simple Decoder�e�X���A
x86���߂̒��ŒP���uop�ɒu�������\�Ȃ��̂���������B����AComplex Decoder�́A
1-4uops������x86���߂ɑ��Ă���舵��(���������āADecode�p�^�[����4-1-1-1�ł���)�B
MicrocodeSequenser�́A��̐v�Ɠ��l�A4��葽��uop������x86���߂ɑ��ăf�R�[�h�A
�������̓A�V�X�g���邽�߂ɂ���BYonah�̂悤�ɁA�S�Ă�SSE���߂�P���uop�̐����ɂ����Simple Decoder��
��舵�����Ƃ��\�ł���B
����ɁA�}4�������ʂ�AIntel Core FrontEnd��Macro-op Fusion�ƌĂ��V�����t�B�[�`��������B
Intel�̏ꍇ�A�������߂�uops�ƌĂ�A�܂��Ax86���߂�Macro-ops�ƌĂ��B
Macro-op Fusion�́ADecoder��2��Macro-op��P���uop�ւƌ���������B
���ɁAx86 compare/test���߂�x86 jump���߂Ƃ��P���uop�ɗZ�������B
�܂��A�e�ǂ̃f�R�[�_�����̍œK�����s�����Ƃ��\�����A�ecycle�ɂ��A(�S�̂ł�)1��Macro-op Fusion�݂̂�
�s�Ȃ����Ƃ��\�ł���B�Ƃǂ̂܂�Amax issue bandwidth�� 4+1 x86inst/cycle�ł���BMacro-op fusion�́A
��蕪�����Ɉ�ʓI�ȃv���O���~���O�ł���if-then-else�X�e�[�g�����g�ɏ�肭�K������BIntel�̓R�����g���T�������A
�������̐����ł�Macro-op fusion�́Auops�̐���10%�팸���邱�Ƃ������Ă���B
Macro-op Fusion�̗��_�͗e�Ղɗ����ł���Buops���̍팸���A2�̕��@�Ńp�t�H�[�}���X�����P�����炷�B
��1�ɂ́A��菭���̖��ߎ��s�ōςނƂ������Ƃł���A����͐��\����ɒ�������B��2�ɂ́Ascheduling window��
�v���O��������x�ɂ����ʓI�Ɍ������邱�Ƃ��ł��A��薽�߃��x������(ILP, Instruction Level Prallelism)������
���邱�Ƃ��ł��邽�߁Aout-of-order���s�����L���ɂȂ邱�Ƃł���B�������A�����̗��_�́Auop-fusion�����
���_�ɔ��ɂ悭���Ă��邪�A���߂̈قȂ�N���X�ɑ��ĉ��P���Ă���B�B���炭�ł�����Ȃ��Ƃ́A�������̓_�ŁA
Macro-op fusion��uop-fusion�Ƃ�x86�v���Z�b�T���A��������CISC-like�ɂ��A���RISC-like�łȂ����Ă���Ƃ������Ƃł���B
Core�}�C�N���A�[�L�̕���\���́A�����̂悭����\�����p���āA���߃t�F�b�`���j�b�g�̓����Ŕ�������B
Pentium M�x�[�X�̐v�ł́APentium 4���̏]���^Branch Target Buffer(BTB)�ABranch Address Calculator(BAC)�A
Return Address Stack(RAS)������Ă������A�܂��A2�̐V�����\����������Ă����BLoop Detector(Loop Detector, LD)�́A
���m�Ƀ��[�v�̒E�o��\������B�܂��AIndirect Branch Predictor(IBP)�́A���I�ȗ����Ɋ�Â��ĕ�����I�����A
�Z�o���ꂽ�A�h���X�ւ̕�����x������BCore�}�C�N���A�[�L�ł́A�����̗\����̑S�Ă��g�p���Ȃ���A
�V�����t�B�[�`����������Ă���B��̐v�ł́A����ꂽ���A��Ƀp�C�v���C�����փV���O���T�C�N���̃o�u����}�����Ă����B
Core�}�C�N���A�[�L�ł́A�����\����Ɩ��߃t�F�b�`�̊Ԃ�queue��������ꂽ���Ƃɂ���āA�w�ǂ����̖A���B�����邱�Ƃ��ł���B
��1�ɂ́A��菭���̖��ߎ��s�ōςނƂ������Ƃł���A����͐��\����ɒ�������B��2�ɂ́Ascheduling window��
�v���O��������x�ɂ����ʓI�Ɍ������邱�Ƃ��ł��A��薽�߃��x������(ILP, Instruction Level Prallelism)������
���邱�Ƃ��ł��邽�߁Aout-of-order���s�����L���ɂȂ邱�Ƃł���B�������A�����̗��_�́Auop-fusion�����
���_�ɔ��ɂ悭���Ă��邪�A���߂̈قȂ�N���X�ɑ��ĉ��P���Ă���B�B���炭�ł�����Ȃ��Ƃ́A�������̓_�ŁA
Macro-op fusion��uop-fusion�Ƃ�x86�v���Z�b�T���A��������CISC-like�ɂ��A���RISC-like�łȂ����Ă���Ƃ������Ƃł���B
Core�}�C�N���A�[�L�̕���\���́A�����̂悭����\�����p���āA���߃t�F�b�`���j�b�g�̓����Ŕ�������B
Pentium M�x�[�X�̐v�ł́APentium 4���̏]���^Branch Target Buffer(BTB)�ABranch Address Calculator(BAC)�A
Return Address Stack(RAS)������Ă������A�܂��A2�̐V�����\����������Ă����BLoop Detector(Loop Detector, LD)�́A
���m�Ƀ��[�v�̒E�o��\������B�܂��AIndirect Branch Predictor(IBP)�́A���I�ȗ����Ɋ�Â��ĕ�����I�����A
�Z�o���ꂽ�A�h���X�ւ̕�����x������BCore�}�C�N���A�[�L�ł́A�����̗\����̑S�Ă��g�p���Ȃ���A
�V�����t�B�[�`����������Ă���B��̐v�ł́A����ꂽ���A��Ƀp�C�v���C�����փV���O���T�C�N���̃o�u����}�����Ă����B
Core�}�C�N���A�[�L�ł́A�����\����Ɩ��߃t�F�b�`�̊Ԃ�queue��������ꂽ���Ƃɂ���āA�w�ǂ����̖A���B�����邱�Ƃ��ł���B
�Z�s���炢�ɗv�Ă���B
Spring IDF 2006: Introducing Intel's new Core processors
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2711&p=4
>Both AMD and Intel have announced that they would have quad-core processors in 2007,
>however Rattner mentioned that there's no reason to expect 8-core processors in 2008
> but rather further improvements on the ILP level to each one of those 2 or 4 cores.
IDF��Rattner�������̂悤�Ȕ��������Ă������B
2007�N�܂�core�͔{�X�ő����邱�ƂɂȂ邪�A8core������荂ILP����������core���D��Ƃ��c�i�E�́E�j
Nehalem����ōX�ɍ�IPC���̉��P�����ƍl���Ă悳�����ȁB
ttp://www.anandtech.com/tradeshows/showdoc.aspx?i=2711&p=4
>Both AMD and Intel have announced that they would have quad-core processors in 2007,
>however Rattner mentioned that there's no reason to expect 8-core processors in 2008
> but rather further improvements on the ILP level to each one of those 2 or 4 cores.
IDF��Rattner�������̂悤�Ȕ��������Ă������B
2007�N�܂�core�͔{�X�ő����邱�ƂɂȂ邪�A8core������荂ILP����������core���D��Ƃ��c�i�E�́E�j
Nehalem����ōX�ɍ�IPC���̉��P�����ƍl���Ă悳�����ȁB
SMT�����Ƃ����߂ɑg�ݍ��ގ����ďo���Ȃ��́H
�w�ǂ̃X�e�[�W��1���ߕ��ш悪�������������Ƃ�������܂ł��ȁB
P6��Core
-----
- Fetch
128bit �� 160bit+
- Decode
1+2 uops �� 1+3 uops (complex + simple
- Decode (issue
4+2 uops �� 4+3 uops (complex + simple
- Rename & Reorder
3 upos �� 4 uops
- Dispatch
5 uops �� 6 uops
- Retire
3 uops �� 4uops
- Execution Units (���K�� ��LS, SIMD)
P6 5
Banias 7
Yonah 9
K7/K8 9
NetBurst 7
Core 11
Ita2 16
P6��Core
-----
- Fetch
128bit �� 160bit+
- Decode
1+2 uops �� 1+3 uops (complex + simple
- Decode (issue
4+2 uops �� 4+3 uops (complex + simple
- Rename & Reorder
3 upos �� 4 uops
- Dispatch
5 uops �� 6 uops
- Retire
3 uops �� 4uops
- Execution Units (���K�� ��LS, SIMD)
P6 5
Banias 7
Yonah 9
K7/K8 9
NetBurst 7
Core 11
Ita2 16
>>500
http://pcweb.mycom.co.jp/articles/2006/03/08/idf2/001.html
>2006�N�̓f���A���R�A���y�̔N�ƂȂ�A45nm�����v���Z�X�ւƈڍs����2007�N�ɂ̓N�A�b�h�R�A�������Ă���B
>�ƂȂ�ƁA2008�N�ɂ͂���ɔ{�ɑ�����̂��c�c�Ƃ������҂����܂邪�A���j�C�R�A����ɂ����Ă�1�̃R�A��
>1�̃X���b�h���d������Ƃ����p���͕ς��Ȃ����߁A�u�����炭2008�N�̔{���͂Ȃ����낤�v��Rattner���͏q�ׂ��B
���{��ł��������B���j�B�R�A����ł��V���O���X���b�h���\�͏d������炵���B
http://pcweb.mycom.co.jp/articles/2006/03/08/idf2/001.html
>2006�N�̓f���A���R�A���y�̔N�ƂȂ�A45nm�����v���Z�X�ւƈڍs����2007�N�ɂ̓N�A�b�h�R�A�������Ă���B
>�ƂȂ�ƁA2008�N�ɂ͂���ɔ{�ɑ�����̂��c�c�Ƃ������҂����܂邪�A���j�C�R�A����ɂ����Ă�1�̃R�A��
>1�̃X���b�h���d������Ƃ����p���͕ς��Ȃ����߁A�u�����炭2008�N�̔{���͂Ȃ����낤�v��Rattner���͏q�ׂ��B
���{��ł��������B���j�B�R�A����ł��V���O���X���b�h���\�͏d������炵���B
�قȂ��ނ̃R�A���W�ς����i�w�e���W�j�A�X�ȁj�v���Z�b�T�́A�o��Ƃ��Ă�������ɂȂ肻�����ˁc
Intel�̈̂��l���A
�u�R�A���w�e���W�j�A�X�ɂȂ邱�Ƃ͂��邩������Ȃ����A���߃Z�b�g�̓z���W�j�A�X����ۂv
�Ƃ������Ă��悤�ȋC�����邯�ǁA�\�[�X�Y�ꂽ�B
Intel�̈̂��l���A
�u�R�A���w�e���W�j�A�X�ɂȂ邱�Ƃ͂��邩������Ȃ����A���߃Z�b�g�̓z���W�j�A�X����ۂv
�Ƃ������Ă��悤�ȋC�����邯�ǁA�\�[�X�Y�ꂽ�B
Merom 2.0GHz vs Yonah 2.16GHz
ttp://www.computerbase.de/news/hardware/prozessoren/intel/2006/april/neue_benchmarks_intels_core_duo_merom/
Core�X������E�������B�\�[�X��xtremesystems����c�B
ttp://www.computerbase.de/news/hardware/prozessoren/intel/2006/april/neue_benchmarks_intels_core_duo_merom/
Core�X������E�������B�\�[�X��xtremesystems����c�B
���g�i�[�̃g�[�����ς���Ă��Ă�B
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
Rattner�� �u5�N��ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://pc.watch.impress.co.jp/docs/2006/0310/config096.htm
Rattner�� �u��������ɃR�A�𑝂₵�Ă������j�͂Ȃ��v
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
Rattner�� �u5�N��ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤�B�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://pc.watch.impress.co.jp/docs/2006/0310/config096.htm
Rattner�� �u��������ɃR�A�𑝂₵�Ă������j�͂Ȃ��v
>>504
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
�u��X�̓z���W�j�A�X��ISA�Ƀt�H�[�J�X���Ă���B�~�N�X�h���߃Z�b�g
�@�A�[�L�e�N�`���́A���łɕ���v���O�������̂��߂ɕ��G�ȏ�
�@�Ȃ��Ă���v���O�������ɁA����ɗ]�v�ȕ��G���������Ă��܂��ƍl���Ă���B
�@�������A�z���W�j�A�X�t���[�����[�N�̒��ŁA���ꉻ�ƍœK�������čs���B
�@�����炭�A�P�ꖽ�߃Z�b�g�A�[�L�e�N�`���́A�~�N�X�h�v���Z�b�T�R�A�ɂȂ邾�낤�v
http://pc.watch.impress.co.jp/docs/2005/1110/kaigai222.htm
�u��X�̓z���W�j�A�X��ISA�Ƀt�H�[�J�X���Ă���B�~�N�X�h���߃Z�b�g
�@�A�[�L�e�N�`���́A���łɕ���v���O�������̂��߂ɕ��G�ȏ�
�@�Ȃ��Ă���v���O�������ɁA����ɗ]�v�ȕ��G���������Ă��܂��ƍl���Ă���B
�@�������A�z���W�j�A�X�t���[�����[�N�̒��ŁA���ꉻ�ƍœK�������čs���B
�@�����炭�A�P�ꖽ�߃Z�b�g�A�[�L�e�N�`���́A�~�N�X�h�v���Z�b�T�R�A�ɂȂ邾�낤�v
>>506
����˂��i�E�́E�j
ACCMP�̘_���݂Ă��A���y���Ă��A
���݂�SIMD�̂悤�Ȉʒu�Â�(���R�A)�ɂ����Ȃ肦�Ȃ����c�B
����σ��j�B�R�A�͓�����c�B
����͂����ƁA�\�X����Conroe�R�[�h�l�[�����o���̉ߋ����O�݂��狃���Ă����c(��_;)
http://itl.jisakuita.net/next_generation_cpu/1076749130.html#R310
����˂��i�E�́E�j
ACCMP�̘_���݂Ă��A���y���Ă��A
���݂�SIMD�̂悤�Ȉʒu�Â�(���R�A)�ɂ����Ȃ肦�Ȃ����c�B
����σ��j�B�R�A�͓�����c�B
����͂����ƁA�\�X����Conroe�R�[�h�l�[�����o���̉ߋ����O�݂��狃���Ă����c(��_;)
http://itl.jisakuita.net/next_generation_cpu/1076749130.html#R310
�Ԃ����Ⴏ�AGPU�����������Ői�����Ă����ĐF��Ȃ��Ƃ��ł���悤�ɂȂ�ƁA
�w�e���W�j�A�X�}���`�R�A�͕K�v�Ȃ��Ȃ�悤�Ȋ�K�X
�w�e���W�j�A�X�}���`�R�A�͕K�v�Ȃ��Ȃ�悤�Ȋ�K�X
http://pc.watch.impress.co.jp/docs/2006/0314/kaigai251.htm
�u�imany-core�ɑ��ājAMD����̓I�ɐv��i�߂Ă���Ƃ������A�܂������̒i�K���낤�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�{
>>457�́A�L���b�V���̏d�v����Macro-op fusion���̐V�Z�p�ɂ��Đ����AEden���̃C���^�r���[
���̂Q����A���g�i�[���̔������ω����Ă������R�������ł���B
�E �܂��܂����j�C�R�A�Ɍ����Ă̋Z�p�i�g�����U�N�V���i����������
�@�L�ш�o�X�A�J�����E�~�h���E�F�A���X�j�̃��h�����Ȃ��B
�E Eden�����͂��ߊJ���T�C�h����TLP����ILP�̏d�v����i��������ꂽ�B
�ł�Nehalem��Gilo����肭�����Ȃ��悤�Ȃ�A�܂��u100�R�A100�R�A�v�����o���\���B
�u�imany-core�ɑ��ājAMD����̓I�ɐv��i�߂Ă���Ƃ������A�܂������̒i�K���낤�v
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�{
>>457�́A�L���b�V���̏d�v����Macro-op fusion���̐V�Z�p�ɂ��Đ����AEden���̃C���^�r���[
���̂Q����A���g�i�[���̔������ω����Ă������R�������ł���B
�E �܂��܂����j�C�R�A�Ɍ����Ă̋Z�p�i�g�����U�N�V���i����������
�@�L�ш�o�X�A�J�����E�~�h���E�F�A���X�j�̃��h�����Ȃ��B
�E Eden�����͂��ߊJ���T�C�h����TLP����ILP�̏d�v����i��������ꂽ�B
�ł�Nehalem��Gilo����肭�����Ȃ��悤�Ȃ�A�܂��u100�R�A100�R�A�v�����o���\���B
Intel�̌����u100�R�A�v�Ƃ����Ă̂́A
�E�����ɁA����Ȃ�ɐ��\�̍����R�A���l�`�����炢�z�u
�E���ӂɁACell��SPE�݂����Ȃ̂𑽐��z�u
���Ċ��������H�i���������߃Z�b�g�͗��R�A�Ƃ�x86�j
�E�����ɁA����Ȃ�ɐ��\�̍����R�A���l�`�����炢�z�u
�E���ӂɁACell��SPE�݂����Ȃ̂𑽐��z�u
���Ċ��������H�i���������߃Z�b�g�͗��R�A�Ƃ�x86�j
>>511
http://pc.watch.impress.co.jp/docs/2006/0307/idf01_04.jpg
���̃C���[�W����Cell�Ƌt�ŁA�����܂Ŕėp�R�A����œ���R�A�͂��܂��݂����Ȉ������ȁB
http://pc.watch.impress.co.jp/docs/2006/0307/idf01_04.jpg
{kind=link}
���̃C���[�W����Cell�Ƌt�ŁA�����܂Ŕėp�R�A����œ���R�A�͂��܂��݂����Ȉ������ȁB
�i�f�b�h���b�N��\�[�X�����╉�ו��U���l�������j�X���b�h�̃X�P�W���[�����O��
�_�l������ɂ���Ă����Ƃ����O��ŏ��߂Đ��藧���j�C�R�A���K�N�F�����B
�_�l������ɂ���Ă����Ƃ����O��ŏ��߂Đ��藧���j�C�R�A���K�N�F�����B
���L����������߂ă��b�Z�[�W�p�V���O�ɂ���Ƃ�
���L�������ł��A�g�����U�N�V�������Ń������̐��������Ƃ�Ƃ�
���j�C�R�A���A�v���O���~���O�I�ɂ��n�[�h�̎����̖ʂł�
�ȒP�ɂ�����@�͂�����ł�����Ǝv��
���L�������ł��A�g�����U�N�V�������Ń������̐��������Ƃ�Ƃ�
���j�C�R�A���A�v���O���~���O�I�ɂ��n�[�h�̎����̖ʂł�
�ȒP�ɂ�����@�͂�����ł�����Ǝv��
���s��iMac���āA�v���Z�b�T��Conroe�ɍڂ��ւ����܂����H
���ƁA�r�f�I�J�[�h���A�b�v�O���[�h�ł��܂����H
���̓�_���C�|����ŁA�w���ł����ɂ��܂��B
���ƁA�r�f�I�J�[�h���A�b�v�O���[�h�ł��܂����H
���̓�_���C�|����ŁA�w���ł����ɂ��܂��B
���肪�Ƃ�
PCI Express�ڑ�������Ƃ����ăI���{�[�h����Ȃ��Ƃ͌���Ȃ����c�c���ۂǂ��Ȃ��Ă�낤�B
�g���������̂Ȃ�A��l����Power Mac�̌�p��҂̂��g���c�c
�g���������̂Ȃ�A��l����Power Mac�̌�p��҂̂��g���c�c
PowerMac��Intel�ł�Conroe�҂����Ď��Ȃ�A
����܂ł̊ԂɁA
������x�̊g���������������ACore Duo���ڂ́A�����߂̃f�X�N�g�b�v�o���Ă���Ȃ����ȁB
mini��mini�ł������ǁA�m�[�g���X�y�b�N�T���߂��Ă��������ς�Ȃ��B
iMac�͒�������Ȃ��Ȃ������B
����܂ł̊ԂɁA
������x�̊g���������������ACore Duo���ڂ́A�����߂̃f�X�N�g�b�v�o���Ă���Ȃ����ȁB
mini��mini�ł������ǁA�m�[�g���X�y�b�N�T���߂��Ă��������ς�Ȃ��B
iMac�͒�������Ȃ��Ȃ������B
Intel preps quad-core mobile chip, new CPU architecture for 2008 - analyst
http://www.tgdaily.com/2006/04/14/intel_quad_core/
According to McGregor, Intel is also planning a quad-core mobile processor,
"but [the company] is providing few details" at this time. He indicated that this processor may be
introduced in the not too distant future and in fact may be a processor that is compatible with
the "Santa Rosa" platform
Quad-Core�̃��o�C���v���Z�b�T���ӊO�ɑ����o�ꂷ�邩������Ȃ��͗l�B
�������Santa Rosa platform�x�[�X�ɏ��͗l�B
http://www.tgdaily.com/2006/04/14/intel_quad_core/
According to McGregor, Intel is also planning a quad-core mobile processor,
"but [the company] is providing few details" at this time. He indicated that this processor may be
introduced in the not too distant future and in fact may be a processor that is compatible with
the "Santa Rosa" platform
Quad-Core�̃��o�C���v���Z�b�T���ӊO�ɑ����o�ꂷ�邩������Ȃ��͗l�B
�������Santa Rosa platform�x�[�X�ɏ��͗l�B
�����_�ł�����ł̓o�ꎞ���܂Ƃ߁B
-- May
Dempsey (NetBurst-based, DP Server 5000 series)
-- Jul
Woodcrest (Woodcrest, DP Server 5100 series)
-- Sep
Conroe (Conroe, Desktop)
-- Oct-Nov
Merom (Merom, Mobile)
- 2007
-- Jan 2006
Kentsfield (4-core MCM, Allendale-die*2, XE-Desktop)
- Q4 2006 - Q1 2007
Clovertown (4-core MCM, Allendale-die*2, DP Server 5100 series)
- 2007
Tigerton (4-core, dedicated-interconnect, MP Server 7000 series)
- 2008
Dunniungton (4-core, dedicated-interconnect, MP Server 7000 series)
Tukwila (4-core, CSI, IA64 Server)
-2009
Paulson (4-core+, CSI, IA64 Server)
-- May
Dempsey (NetBurst-based, DP Server 5000 series)
-- Jul
Woodcrest (Woodcrest, DP Server 5100 series)
-- Sep
Conroe (Conroe, Desktop)
-- Oct-Nov
Merom (Merom, Mobile)
- 2007
-- Jan 2006
Kentsfield (4-core MCM, Allendale-die*2, XE-Desktop)
- Q4 2006 - Q1 2007
Clovertown (4-core MCM, Allendale-die*2, DP Server 5100 series)
- 2007
Tigerton (4-core, dedicated-interconnect, MP Server 7000 series)
- 2008
Dunniungton (4-core, dedicated-interconnect, MP Server 7000 series)
Tukwila (4-core, CSI, IA64 Server)
-2009
Paulson (4-core+, CSI, IA64 Server)
524 �Finteler@�����F2006/04/16(��) 14:17:21 ID:RED2I5hp0
Jan 2006 -> Jan 2007
�Ȃ��A�����Z�̂��߁A�������ݕp�x�����ꂩ��啝�ɗ�����̂ł�낵���B
�Ȃ��A�����Z�̂��߁A�������ݕp�x�����ꂩ��啝�ɗ�����̂ł�낵���B
>>515
Conroe�fs Incompatibility Issues with Contemporary Mainboards Revealed
http://www.xbitlabs.com/news/cpu/display/20060202133551.html
���s�}�U�[�ł�Conroe�͓����Ȃ��Ǝv���B
Intel 965 & VRM11 �ȐV�}�U�[�҂����ƁB
Conroe�fs Incompatibility Issues with Contemporary Mainboards Revealed
http://www.xbitlabs.com/news/cpu/display/20060202133551.html
���s�}�U�[�ł�Conroe�͓����Ȃ��Ǝv���B
Intel 965 & VRM11 �ȐV�}�U�[�҂����ƁB
Conroe��ConroeEX�͉����Ⴄ�̂ł���
2 core�ŏo���Ƃ��āA�N���b�N��FSB�̈Ⴂ�A
���ꂩ��ȓd�͋@�\�̂����肪�ア�Ƃ����炢�Œ��g�͕ς��Ȃ���Ȃ���?
// �R���Kentsfield�܂�XE�͂łȂ����낤�h�����ǁB
���ꂩ��ȓd�͋@�\�̂����肪�ア�Ƃ����炢�Œ��g�͕ς��Ȃ���Ȃ���?
// �R���Kentsfield�܂�XE�͂łȂ����낤�h�����ǁB
Intel Woodcrest is an 80W part
http://www.theinquirer.net/?article=31131
- Cloverton xxxx / x.xxGHz / 4+4MB L2 / 1066MHz FSB / 4 core
- Woodcrest 5160 / 3.00GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5150 / 2.66GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5140 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5130 / 2.00GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5120 / 1.86GHz / 4MB L2 / 1066MHz FSB / 2 core
- Woodcrest 5110 / 1.60GHz / 4MB L2 / 1066MHz FSB / 2 core
- Woodcrest LV 5148 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core
http://www.theinquirer.net/?article=31131
- Cloverton xxxx / x.xxGHz / 4+4MB L2 / 1066MHz FSB / 4 core
- Woodcrest 5160 / 3.00GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5150 / 2.66GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5140 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5130 / 2.00GHz / 4MB L2 / 1333MHz FSB / 2 core
- Woodcrest 5120 / 1.86GHz / 4MB L2 / 1066MHz FSB / 2 core
- Woodcrest 5110 / 1.60GHz / 4MB L2 / 1066MHz FSB / 2 core
- Woodcrest LV 5148 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core
Intel Kentsfield Has 2 x 4MB L2 Cache
http://www.vr-zone.com/?i=3559
The successor to Kentsfield, a Quad Core processor slated for later date will have 8MB of shared L2 cache.
Kentsfield�iMCM�j��p�Ƃ��āAShared Cache�\����Quad Core���v�悵�Ă���悤���B
http://www.vr-zone.com/?i=3559
The successor to Kentsfield, a Quad Core processor slated for later date will have 8MB of shared L2 cache.
Kentsfield�iMCM�j��p�Ƃ��āAShared Cache�\����Quad Core���v�悵�Ă���悤���B
Mac mini��Merom���ڂ��ē��������Ƃ������|�[�g�����邻���ł����A
���s��Intel iMac��Merom���ڂ������邱�Ƃ��\�����ˁH
���s��Intel iMac��Merom���ڂ������邱�Ƃ��\�����ˁH
���Ɍ݊������������Ƃ��Ă��ABIOS����EFI�����̃A�b�v�f�[�g���K�v�ɂȂ��Ȃ��́B
Intel Woodcrest to ship in June, Conroe July, Merom August
http://www.theinquirer.net/?article=31316
�e���Ŏ��グ���Ă��邪�A
Woodcrest��6��
Conroe��7��
Merom��8��
�ɂ��ꂼ��O�|������܂����B
http://www.theinquirer.net/?article=31316
�e���Ŏ��グ���Ă��邪�A
Woodcrest��6��
Conroe��7��
Merom��8��
�ɂ��ꂼ��O�|������܂����B
The Intel word of the day is....
http://www.theinquirer.net/?article=31323
Intel�̐^��Quad-Core���i(1chip, 4core)�́ABloomfield(Bloomfield)�Ƃ����R�[�h�l�[���B
Bus�������ɂȂ�Kentsfield�̎�_�����P�����B
// "Core"�x�[�X��"Nehalem"�x�[�X���͂��̋L���ł͕s���B
// ����"Core"�x�[�X���Ƃ����CSI�ł͂Ȃ��̂����B
// Bloomfield�́A>>274�ɏ����Ă���ʂ�A"Nehalem"����Ƃ���������ƑO�ɂ��������A
// �R���1chip, 4core���ォ��"Nehalem"�Ŗw�Ǔ��ꂳ���v�������Ɖ��߂��Ă��邯�ǂȁi�E�́E�j
http://www.theinquirer.net/?article=31323
Intel�̐^��Quad-Core���i(1chip, 4core)�́ABloomfield(Bloomfield)�Ƃ����R�[�h�l�[���B
Bus�������ɂȂ�Kentsfield�̎�_�����P�����B
// "Core"�x�[�X��"Nehalem"�x�[�X���͂��̋L���ł͕s���B
// ����"Core"�x�[�X���Ƃ����CSI�ł͂Ȃ��̂����B
// Bloomfield�́A>>274�ɏ����Ă���ʂ�A"Nehalem"����Ƃ���������ƑO�ɂ��������A
// �R���1chip, 4core���ォ��"Nehalem"�Ŗw�Ǔ��ꂳ���v�������Ɖ��߂��Ă��邯�ǂȁi�E�́E�j
Woodcrest��6�����c�BPMG5��6���ɂ����Ȃ蔭�\���ꂿ�Ⴄ���Ă̂��A�����˂��BWWDC�͔��������ǁB
Core, Nehalem, Gesher.
http://www.xbitlabs.com/news/cpu/display/20060428162855.html
�V�F�A�D���_��Intel�̃v���b�g�t�H�[���헪
http://pc.watch.impress.co.jp/docs/2006/0428/hot422.htm
�����2�N���ƂɃV�������N�łƐV�}�C�N���A�[�L���o��̂��\��B
2006 "Core"
2007 "Penryn"
2008 "Nehalem"
2009 "Nehalem-C"
2010 "Gesher"
// ����܂��A�������������܂��܂Ƃ܂��ĂȂ����B
// �����A�]���̏��ʂ�APenryn�̓��o�C���p�����̃R�[�h�l�[����
// �f�X�N�g�b�v��Conroe�V�������N�ł�Ridgefield�B
// Nehalem, Gesher�͂悭�킩��Ȃ����A��͂�]���̏��ǂ��蓯��A�[�L�e�N�`����
// ���i�t�@�~���̑��̃R�[�h�l�[���Ƃ������Ƃʼn��߂��Ă����Ȃ��Ɣ]��DB���������Ƃ�Ȃ��ȁi�E�́E�j
http://www.xbitlabs.com/news/cpu/display/20060428162855.html
�V�F�A�D���_��Intel�̃v���b�g�t�H�[���헪
http://pc.watch.impress.co.jp/docs/2006/0428/hot422.htm
�����2�N���ƂɃV�������N�łƐV�}�C�N���A�[�L���o��̂��\��B
2006 "Core"
2007 "Penryn"
2008 "Nehalem"
2009 "Nehalem-C"
2010 "Gesher"
// ����܂��A�������������܂��܂Ƃ܂��ĂȂ����B
// �����A�]���̏��ʂ�APenryn�̓��o�C���p�����̃R�[�h�l�[����
// �f�X�N�g�b�v��Conroe�V�������N�ł�Ridgefield�B
// Nehalem, Gesher�͂悭�킩��Ȃ����A��͂�]���̏��ǂ��蓯��A�[�L�e�N�`����
// ���i�t�@�~���̑��̃R�[�h�l�[���Ƃ������Ƃʼn��߂��Ă����Ȃ��Ɣ]��DB���������Ƃ�Ȃ��ȁi�E�́E�j
���Ȃ良���B
2006 "65nm Core" Merom/m, Conroe/d, Woodcrest/xd, Clovertown/xd, Tigerton/xm
2007 "45nm Core" Penryn/m, Ridgefield/d, Harpertown/xd, Dunnington/xm
2008 "45nm Nehalem" Bloomfield/d, Granestown/xd
2009 "32nm Nehalem"
2010 "32nm Gesher" (Gilo?/m)
2006 "65nm Core" Merom/m, Conroe/d, Woodcrest/xd, Clovertown/xd, Tigerton/xm
2007 "45nm Core" Penryn/m, Ridgefield/d, Harpertown/xd, Dunnington/xm
2008 "45nm Nehalem" Bloomfield/d, Granestown/xd
2009 "32nm Nehalem"
2010 "32nm Gesher" (Gilo?/m)
>>530
Merom�́AYonah�ƃs���R���p�`�Ȃ̂œ����\���͍����킯�B
Merom�́AYonah�ƃs���R���p�`�Ȃ̂œ����\���͍����킯�B
Technology@Intel Magazine
Inside IntelR Core? Microarchitecture:
Setting New Standards for Energy-Efficient Performance
http://www.intel.com/technology/magazine/computing/core-architecture-0306.htm
http://www.intel.co.jp/jp/developer/technology/magazine/computing/core-architecture-0306.htm ���{��
Intel�������炷�ł�Core�}�C�N���A�[�L�̉�����łĂ����B
���e��IDF�ʼn��������ƂقƂ�Ǔ��������B
���Ƃ͍œK���}�j���A�����炢���������̏ڂ�������o�Ă��Ȃ������Ȃ��B
Inside IntelR Core? Microarchitecture:
Setting New Standards for Energy-Efficient Performance
http://www.intel.com/technology/magazine/computing/core-architecture-0306.htm
http://www.intel.co.jp/jp/developer/technology/magazine/computing/core-architecture-0306.htm ���{��
Intel�������炷�ł�Core�}�C�N���A�[�L�̉�����łĂ����B
���e��IDF�ʼn��������ƂقƂ�Ǔ��������B
���Ƃ͍œK���}�j���A�����炢���������̏ڂ�������o�Ă��Ȃ������Ȃ��B
>>460
Intel P6 - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Intel_P6
Intel Core Microarchitecture - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Intel_Core_Microarchitecture
wiki�̒��̐l�� "P6" = P6�`Yonah �Ƃ������߂̂��l�q�B
Intel P6 - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Intel_P6
Intel Core Microarchitecture - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Intel_Core_Microarchitecture
wiki�̒��̐l�� "P6" = P6�`Yonah �Ƃ������߂̂��l�q�B
>>537
Intel Core����iMac�n�[�h�E�F�A���|�[�g
http://pc.watch.impress.co.jp/docs/2006/0117/imac01.htm
���X���蔲���������B
���Ƃ��ƌ��siMac��i945GM�Ȃ̂Ō��XConroe�͓����킯�Ȃ������B
Merom�Ȃ�BIOS�Ƃ��̕ύX�͕K�v��������Ȃ��������Ă����������Ȃ������B
�ł��d������݂̘b�́A���i�����[�X1�����܂����炢�ɂȂ��Ă���
�˔@�����Ƃ������̂��悭����̂ň��S�͂ł��Ȃ��B
����Ƃ͕ʂ�Conroe�͓d�͊Ǘ��̃����W�◱�x���ׂ����Ȃ邽�߁A
�f�X�N�g�b�v�ł����sPen4/D/XE�}�U�[��VRM�ł͑Ή��s�Ƃ������Ƃ������B
Intel Core����iMac�n�[�h�E�F�A���|�[�g
http://pc.watch.impress.co.jp/docs/2006/0117/imac01.htm
���X���蔲���������B
���Ƃ��ƌ��siMac��i945GM�Ȃ̂Ō��XConroe�͓����킯�Ȃ������B
Merom�Ȃ�BIOS�Ƃ��̕ύX�͕K�v��������Ȃ��������Ă����������Ȃ������B
�ł��d������݂̘b�́A���i�����[�X1�����܂����炢�ɂȂ��Ă���
�˔@�����Ƃ������̂��悭����̂ň��S�͂ł��Ȃ��B
����Ƃ͕ʂ�Conroe�͓d�͊Ǘ��̃����W�◱�x���ׂ����Ȃ邽�߁A
�f�X�N�g�b�v�ł����sPen4/D/XE�}�U�[��VRM�ł͑Ή��s�Ƃ������Ƃ������B
541 �Finteler@�����F2006/04/29(�y) 15:04:35 ID:3HCor+uq0
�~Granestown �� Gainestown
// �ŋ߁A���͂���Ȃɂ���߂��Ⴍ���Ⴞ�Ȃ��c(;�L�D�M)
// �l�^�͂�������̂����A�Y��Ȃ������������݂��悤�Ǝv���ďł肷������i�E�́E�j
// �ŋ߁A���͂���Ȃɂ���߂��Ⴍ���Ⴞ�Ȃ��c(;�L�D�M)
// �l�^�͂�������̂����A�Y��Ȃ������������݂��悤�Ǝv���ďł肷������i�E�́E�j
Intel�fs hurry to launch Woodcrest, Conroe and Merom not impressing industry, but neither is AMD�fs AM2 platform
http://www.digitimes.com/mobos/a20060428PR213.html
>>532����̑O�|���Ɋւ��đ�p�x���_�[�͗��₩�Ȕ����̂��l�q�B
http://www.digitimes.com/mobos/a20060428PR213.html
>>532����̑O�|���Ɋւ��đ�p�x���_�[�͗��₩�Ȕ����̂��l�q�B
i975X Based Mainboards Acquire Conroe Support.
http://www.xbitlabs.com/news/mainboards/display/20060425175704.html
i975X�́AConore���T�|�[�g���Ă���͗l�B
�悭���łȂ����ǁA�}�U�[�{�[�h�x���_�[���A
Conroe�T�|�[�g�̉��Ǖi�}�U�[�{�[�h���������݂����B
New Launching Schedule for Core Microarchitecture Based Processors.
http://www.xbitlabs.com/news/cpu/display/20060428155928.html
Woodcrest 6/26
Conroe 7���̑��T�����O�T
��launch�����āB�ʗ�ɏ]���āAXE�ł������Ƃ���s����͗l�B
// ���ǁA2core XE�ł�̂���c(;�L�D�M)
http://www.xbitlabs.com/news/mainboards/display/20060425175704.html
i975X�́AConore���T�|�[�g���Ă���͗l�B
�悭���łȂ����ǁA�}�U�[�{�[�h�x���_�[���A
Conroe�T�|�[�g�̉��Ǖi�}�U�[�{�[�h���������݂����B
New Launching Schedule for Core Microarchitecture Based Processors.
http://www.xbitlabs.com/news/cpu/display/20060428155928.html
Woodcrest 6/26
Conroe 7���̑��T�����O�T
��launch�����āB�ʗ�ɏ]���āAXE�ł������Ƃ���s����͗l�B
// ���ǁA2core XE�ł�̂���c(;�L�D�M)
intel��975X�}�U�[��Conroe�T�|�[�g�ȃ��r�W�����͂����̔�����Ďn�߂Ă�݂����ˁB
�N���b�h�R�A����A�S���l�n�[�������Ă̂͂Ȃ�����
�V�R�A�ŁAconroe���_�C�T�C�Y���傫���Ȃ�킯������
�V�R�A�ŁAconroe���_�C�T�C�Y���傫���Ȃ�킯������
546 �Finteler@�ϑz�F2006/04/29(�y) 20:19:34 ID:3HCor+uq0
Intel Nehalem : Premieres Informations 07-06-2005 13:15:30 - Samuel D.
http://www.x86-secret.com/index.php?option=newsd&nid=887
Nehalem��4 core���x�[�X�Ƃ����̂͂��Ȃ�ȑO���炢���Ă��āA
���܂�ς�����C�z���Ȃ����Ȃ�ȁB
65nm Merom��150sqmm���炢�Ȃ���A
45nm�Ȃ�Merom*4+CSI�Ƃ����\���ł��A200mm�ȓ��Ɏ��܂邾�낤�B
���ꂩ��+���̕������ǂꂭ�炢�H�����������ǁANehalem����ł�PenM��Merom�̂悤��
�啝�Ȏ��s���j�b�g�̑����Ȃǂ͂Ȃ��Ǝv���Ă���̂ŁB�B
http://www.x86-secret.com/index.php?option=newsd&nid=887
Nehalem��4 core���x�[�X�Ƃ����̂͂��Ȃ�ȑO���炢���Ă��āA
���܂�ς�����C�z���Ȃ����Ȃ�ȁB
65nm Merom��150sqmm���炢�Ȃ���A
45nm�Ȃ�Merom*4+CSI�Ƃ����\���ł��A200mm�ȓ��Ɏ��܂邾�낤�B
���ꂩ��+���̕������ǂꂭ�炢�H�����������ǁANehalem����ł�PenM��Merom�̂悤��
�啝�Ȏ��s���j�b�g�̑����Ȃǂ͂Ȃ��Ǝv���Ă���̂ŁB�B
�H P6 P7 P8 �H
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748
Woodcrest/Cloverton�@�� Harpertown@2007H2
Bensley/Greencreek �� Stoakley@2007H2
2007 H2 / Tigerton / Dual Core Intel Xeon 7xxx
- 4 core (mcm?) / 65nm / MP Server / Caneland�v���b�g�t�H�[�� / Clarksboro�`�v�Z�g or OEM�`�v�Z�g / dedicated interconnect
2007 H2 / Harpertown / Dual Core Intel Xeon 5xxx
- 4 core (mcm?) / 65nm or 45nm? / DP Server / Stoakley�v���b�g�t�H�[�� / Seaburg�`�v�Z�g /
2008 / Dunnington (Xeon MP)
- 4+ core (mcm?)/ 45nm / MP Server / Caneland�v���b�g�t�H�[�� / Clarksboro�`�v�Z�g, OEM�`�v�Z�g/ dedicated interconnect
http://www.mshk.com/hk/windowsserversystem/branchoffice/docs/PT101_Herbert_Hon.pdf�@[���\�[�X����]
Bensley/Greencreek �� Stoakley@2007H2
2007 H2 / Tigerton / Dual Core Intel Xeon 7xxx
- 4 core (mcm?) / 65nm / MP Server / Caneland�v���b�g�t�H�[�� / Clarksboro�`�v�Z�g or OEM�`�v�Z�g / dedicated interconnect
2007 H2 / Harpertown / Dual Core Intel Xeon 5xxx
- 4 core (mcm?) / 65nm or 45nm? / DP Server / Stoakley�v���b�g�t�H�[�� / Seaburg�`�v�Z�g /
2008 / Dunnington (Xeon MP)
- 4+ core (mcm?)/ 45nm / MP Server / Caneland�v���b�g�t�H�[�� / Clarksboro�`�v�Z�g, OEM�`�v�Z�g/ dedicated interconnect
http://www.mshk.com/hk/windowsserversystem/branchoffice/docs/PT101_Herbert_Hon.pdf�@[���\�[�X����]
>>547
���e�͔Z�����AConclusion�Ƃ����X�����݂ǂ��낪�����ȍ����AnandTech����́B
Yonah��"Core"��80%�߂��A�[�L�v�Ɖ�H�v�����Ȃ������炵���ˁB
���e�͔Z�����AConclusion�Ƃ����X�����݂ǂ��낪�����ȍ����AnandTech����́B
Yonah��"Core"��80%�߂��A�[�L�v�Ɖ�H�v�����Ȃ������炵���ˁB
550 �FMAC�I�^��548 �����F2006/05/03(��) 20:31:48 ID:Iao1rgSY0
>>548
����PDF�google��HTML�ł��c���Ă邷�B
http://72.14.207.104/search?q=cache:0d1HGo5N42cJ:www.mshk.com/hk/windowsserversystem/branchoffice/docs/PT101_Herbert_Hon.pdf+PT101_Herbert_Hon.pdf
����PDF�google��HTML�ł��c���Ă邷�B
http://72.14.207.104/search?q=cache:0d1HGo5N42cJ:www.mshk.com/hk/windowsserversystem/branchoffice/docs/PT101_Herbert_Hon.pdf+PT101_Herbert_Hon.pdf
551 �Finteler@�R�s�y�F2006/05/05(��) 19:27:26 ID:wYk0Mnf20
SPECint_rate�̃X�R�A
system procname cores chips cores/chip base peak
-----------
TYAN Thunder K8SD Pro (S2882-D), AMD Opteron(TM) 285 4 cores, 2 chips, 2 cores/chip 69.2 79.6
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060220-05637.html
TYAN Thunder K8QW (S4881), AMD Opteron(TM) 856 4 cores, 4 chips, 1 core/chip 79.7 90.5
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060321-05802.html
Dell PowerEdge 2950 (3.73GHz Intel Xeon processor 5080) 4 cores, 2 chips, 2 cores/chip (Hyper-Threading Technology enabled) 80.5 81.0
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060219-05624.html
>>333��Dempsey 3.2GHz�X�R�A��70.0�������B
70.0 *( 3.20GHz / 3.73GHz ) = 81.6
�ɂȂ��ŁA�w�ǂ܂�܃X�P�[���v�Z�ň�v����킯(�����ł͓��ɈӖ��Ȃ�)�B
system procname cores chips cores/chip base peak
-----------
TYAN Thunder K8SD Pro (S2882-D), AMD Opteron(TM) 285 4 cores, 2 chips, 2 cores/chip 69.2 79.6
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060220-05637.html
TYAN Thunder K8QW (S4881), AMD Opteron(TM) 856 4 cores, 4 chips, 1 core/chip 79.7 90.5
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060321-05802.html
Dell PowerEdge 2950 (3.73GHz Intel Xeon processor 5080) 4 cores, 2 chips, 2 cores/chip (Hyper-Threading Technology enabled) 80.5 81.0
http://www.spec.org/cpu2000/results/res2006q1/cpu2000-20060219-05624.html
>>333��Dempsey 3.2GHz�X�R�A��70.0�������B
70.0 *( 3.20GHz / 3.73GHz ) = 81.6
�ɂȂ��ŁA�w�ǂ܂�܃X�P�[���v�Z�ň�v����킯(�����ł͓��ɈӖ��Ȃ�)�B
���x��SPECint(rate����Ȃ����)��Dempsey 3.73GHz�̃X�R�A�����ꁫ
ProLiant DL380 G5 (3.73GHz, Intel Xeon Processor 5080) 1 core, 1 chip, 2 cores/chip (Hyper-Threading Technology disabled) 1764 1771
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060320-05779.html
�ŁA���+52%�v�Z��X�シ��ƁA
@SPECint Woodcrest 2.93GHz score = 1764* 1.52(+52%) = 2681(est.)
�Ƃ������Ȃ肷�����X�R�A���B�ȑO�̐���v�Z���A�����v���b�g�t�H�[���Ȃ̂ŗǂ��������Ă�Ǝv���B
�������A���L�L���b�V����SingleThread�ł͗ǂ������ɂ͂��炭�̂ŁA���ۂ͂������̃X�R�A�����肤��B
ProLiant DL380 G5 (3.73GHz, Intel Xeon Processor 5080) 1 core, 1 chip, 2 cores/chip (Hyper-Threading Technology disabled) 1764 1771
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060320-05779.html
�ŁA���+52%�v�Z��X�シ��ƁA
@SPECint Woodcrest 2.93GHz score = 1764* 1.52(+52%) = 2681(est.)
�Ƃ������Ȃ肷�����X�R�A���B�ȑO�̐���v�Z���A�����v���b�g�t�H�[���Ȃ̂ŗǂ��������Ă�Ǝv���B
�������A���L�L���b�V����SingleThread�ł͗ǂ������ɂ͂��炭�̂ŁA���ۂ͂������̃X�R�A�����肤��B
553 �Finteler@�ϑz�F2006/05/05(��) 19:51:25 ID:wYk0Mnf20
ttp://www.aceshardware.com/forums/read_post.jsp?id=115162890&forumid=1
In short what I gathered from a first look:
- the FPU's functional units are widened to 128 bit, number is the same as in K8
- there are 128 bit uOps as well as 64 bit ones
- portions of the functional units might work together or independently (e.g. two 64 bit FMULs executed in parallel in one FU)
- would still work with present 3 decoders then
Hammer-Info�ɂ��\���Ă��AAMD�̓����̂�B
FPU��128bit�Ŏ������āA128bit�pups��64bit���Z��2�ł���B
K8L(>>387)�ł��ꂪ�̗p���ꂽ�Ƃ���ƁA128bit�Ƃ����_�ł�"Core"�ɒǂ����ɂ��Ă��A
FP���j�b�g�̐��͑S��or�w�ǂ����낤����A��߰؋ꂵ�������������B
"Core"��FP/SSE���������NetBurst�ɍœK�����ꂽ���ł͐^�����ł��ĂȂ��킯�ŁA
AMD�����LL2, L3, 128bit SSE�Ȃǂ�p�ӂ��Ă��錄�ɂ��AIntel�̓n�[�h�ւ̓����[���ŃX�R�A��10%-20%���炢
�L�т�͍̂��܂ł̃p�^�[�����炢�ď\�����蓾��B
AMD�͍����J�����Ȃ��悤�ɂ���̂�����ƂƂ����̂������ȋC������c(;�L�D�M)
In short what I gathered from a first look:
- the FPU's functional units are widened to 128 bit, number is the same as in K8
- there are 128 bit uOps as well as 64 bit ones
- portions of the functional units might work together or independently (e.g. two 64 bit FMULs executed in parallel in one FU)
- would still work with present 3 decoders then
Hammer-Info�ɂ��\���Ă��AAMD�̓����̂�B
FPU��128bit�Ŏ������āA128bit�pups��64bit���Z��2�ł���B
K8L(>>387)�ł��ꂪ�̗p���ꂽ�Ƃ���ƁA128bit�Ƃ����_�ł�"Core"�ɒǂ����ɂ��Ă��A
FP���j�b�g�̐��͑S��or�w�ǂ����낤����A��߰؋ꂵ�������������B
"Core"��FP/SSE���������NetBurst�ɍœK�����ꂽ���ł͐^�����ł��ĂȂ��킯�ŁA
AMD�����LL2, L3, 128bit SSE�Ȃǂ�p�ӂ��Ă��錄�ɂ��AIntel�̓n�[�h�ւ̓����[���ŃX�R�A��10%-20%���炢
�L�т�͍̂��܂ł̃p�^�[�����炢�ď\�����蓾��B
AMD�͍����J�����Ȃ��悤�ɂ���̂�����ƂƂ����̂������ȋC������c(;�L�D�M)
Filtering Techniques to Improve Trace-Cache Efficiency
Roni Rosner, Avi Mendelson and Ronny Ronen
Microprocessor Research Lab, Israel Design Center Intel Corporation
ttp://www.ee.ryerson.ca/~courses/ee8207/trace_filtering.pdf
2001�N��Intel�̘_���B
Trace Cache���AFliter Trace Cache(FTC)��Main Trace Cache(MTC)�ɕ����B
trace�̎g�p�p�x�̍������̂����AMTC�Ɋi�[���āATC�̌��������߂�B
����ɁAL2 Trace Cache��lj������ꍇ�̌��ʂɂ��Ă����ׂĂ�B
// Nehalem�ł́ATrace Cache�������������Ƃ����b��N���\�z�ł��������ǁA
// PARROT�̓_�C�T�C�Y�I�ɓ���Ă��A���MTC/FTC���q�߂�\���͑傩�ƁB
// L2TC�́A�����Ȃ��Ǝv��(TC���e�ʉ��̘_��������̂�)
Roni Rosner, Avi Mendelson and Ronny Ronen
Microprocessor Research Lab, Israel Design Center Intel Corporation
ttp://www.ee.ryerson.ca/~courses/ee8207/trace_filtering.pdf
2001�N��Intel�̘_���B
Trace Cache���AFliter Trace Cache(FTC)��Main Trace Cache(MTC)�ɕ����B
trace�̎g�p�p�x�̍������̂����AMTC�Ɋi�[���āATC�̌��������߂�B
����ɁAL2 Trace Cache��lj������ꍇ�̌��ʂɂ��Ă����ׂĂ�B
// Nehalem�ł́ATrace Cache�������������Ƃ����b��N���\�z�ł��������ǁA
// PARROT�̓_�C�T�C�Y�I�ɓ���Ă��A���MTC/FTC���q�߂�\���͑傩�ƁB
// L2TC�́A�����Ȃ��Ǝv��(TC���e�ʉ��̘_��������̂�)
555 �Finteler@�ϑz�F2006/05/05(��) 20:17:06 ID:wYk0Mnf20
����ɁA�\�X���̈��p�B
Gelssinger:
I don�ft think we know how many there will be. That�fs a topic of both research and product and
market understanding. We�fre on track. We have lots of duals out already, and we have quads and
octs under development. Each of those cores can support multiple threads of execution. You can
have 16 or 32 threads each.
SMT�͂������炭�Ȃ��Ƃ������Ă��B
�[���A4-8 core���ăf�X�N�g�b�v�ł͂����ł������ʂȂ킯(����8core)�B
Gelssinger���̂����Ă���悤�ȉ��p�\�t�g������2-3�N�ŐZ���������Ȃ��������A
���Ȃ���������ǁAʷ�����Ă邩��M�p���邱�Ƃɂ���i�E�́E�j
Nehalem Microarchitecture = ( 4issueMerom + MTC/FTC + 2/4way-SMT ) * 4 + CSI
�Ƃ������Ȃ�A���ȃA�[�L���ϑz�ł���킯�����B
Gelssinger:
I don�ft think we know how many there will be. That�fs a topic of both research and product and
market understanding. We�fre on track. We have lots of duals out already, and we have quads and
octs under development. Each of those cores can support multiple threads of execution. You can
have 16 or 32 threads each.
SMT�͂������炭�Ȃ��Ƃ������Ă��B
�[���A4-8 core���ăf�X�N�g�b�v�ł͂����ł������ʂȂ킯(����8core)�B
Gelssinger���̂����Ă���悤�ȉ��p�\�t�g������2-3�N�ŐZ���������Ȃ��������A
���Ȃ���������ǁAʷ�����Ă邩��M�p���邱�Ƃɂ���i�E�́E�j
Nehalem Microarchitecture = ( 4issueMerom + MTC/FTC + 2/4way-SMT ) * 4 + CSI
�Ƃ������Ȃ�A���ȃA�[�L���ϑz�ł���킯�����B
556 �Finteler@�ϑz�F2006/05/05(��) 20:22:51 ID:wYk0Mnf20
�⑫
8 core�ȏ��SMT��Rattner�������Ă�悤�ɂ��炭��̘b�����B
Nehalem = ( Merom + TC ) * 4 + CSI���Ƃ��āAGesher����32nm�� 4 or 8issue PARROT��Dual�ł�
�_�C�T�C�Y�I�ɒ��]�T���������炱�̂����肩���Ώ�ManyCore�̒����������Ă������B
8 core�ȏ��SMT��Rattner�������Ă�悤�ɂ��炭��̘b�����B
Nehalem = ( Merom + TC ) * 4 + CSI���Ƃ��āAGesher����32nm�� 4 or 8issue PARROT��Dual�ł�
�_�C�T�C�Y�I�ɒ��]�T���������炱�̂����肩���Ώ�ManyCore�̒����������Ă������B
Intel�fs Tukwila Confirmed to be Quad Core
http://www.realworldtech.com/page.cfm?NewsID=361&date=05-05-2006#361
��(�X)����Itanium��Tukwila�ɂ��āB
Tukwila
- 4 core
- L2 ��shared�A6MB/core, total 24MB
- on-die FB-DIMM Memory Controller, support 4+ channel
- 4 Full Width + 2 Half Width CSI Controller����
- CSI router + cache coherency directories����
- total 40GFlops, 10GFlops/core, 2.5GHz(est.)
- �`1.3x scalar performance vs Montecito
- Enhanced RAS
- Server *Ts
CSI (Common System Interconnect)
- low latency, point to point, serial interconnect
- 6.4GT/s/dir + 4.8GT/s/dir, @Full Width
- Full Width �� 2D torus topology chip�ԗp, Half Width �� I/O�p
L2��Montecito��菬�����BCSI��DEC EV7�Z�p�̉e���B
Montecito��1.3�{�̃V���O���X���b�h���\�͎₵�����c(;�L�D�M)
http://www.realworldtech.com/page.cfm?NewsID=361&date=05-05-2006#361
��(�X)����Itanium��Tukwila�ɂ��āB
Tukwila
- 4 core
- L2 ��shared�A6MB/core, total 24MB
- on-die FB-DIMM Memory Controller, support 4+ channel
- 4 Full Width + 2 Half Width CSI Controller����
- CSI router + cache coherency directories����
- total 40GFlops, 10GFlops/core, 2.5GHz(est.)
- �`1.3x scalar performance vs Montecito
- Enhanced RAS
- Server *Ts
CSI (Common System Interconnect)
- low latency, point to point, serial interconnect
- 6.4GT/s/dir + 4.8GT/s/dir, @Full Width
- Full Width �� 2D torus topology chip�ԗp, Half Width �� I/O�p
L2��Montecito��菬�����BCSI��DEC EV7�Z�p�̉e���B
Montecito��1.3�{�̃V���O���X���b�h���\�͎₵�����c(;�L�D�M)
Intel Brands Next-Gen Client Processors, Cuts Prices On Existing Parts
ttp://www.crn.com/sections/breakingnews/dailyarchives.jhtml?articleId=187200861
The Conroe desktop processors, scheduled to ship in June, and Merom,
Intel's next batch of mobile processors planned for an August release,
will both be branded Core Duo 2. Intel will also call its highest end desktop processors
Intel Core 2 Extreme.
Conroe => Intel Core Duo 2
Conroe XE => Intel Core 2 Extreme
����2����c�B
��ʂ̐l�A�Ȃ��2����Ȃ̂Ƃ��v�����肵�Ȃ��̂��c(;�L�D�M)
ttp://www.crn.com/sections/breakingnews/dailyarchives.jhtml?articleId=187200861
The Conroe desktop processors, scheduled to ship in June, and Merom,
Intel's next batch of mobile processors planned for an August release,
will both be branded Core Duo 2. Intel will also call its highest end desktop processors
Intel Core 2 Extreme.
Conroe => Intel Core Duo 2
Conroe XE => Intel Core 2 Extreme
����2����c�B
��ʂ̐l�A�Ȃ��2����Ȃ̂Ƃ��v�����肵�Ȃ��̂��c(;�L�D�M)
The iXBT.com / Digit-Life.com Procedure for Testing Processor Performance, Version 2.0RC (2006)
http://www.digit-life.com/articles2/cpu/method-2006-2-0-rc.html
iXBT���A���sx86 CPU�̃x���`��r����Ă�B
Conroe�o��O�̊m�F�l�^�Ƃ��Ă͂悢�����B
http://www.digit-life.com/articles2/cpu/method-2006-2-0-rc.html
iXBT���A���sx86 CPU�̃x���`��r����Ă�B
Conroe�o��O�̊m�F�l�^�Ƃ��Ă͂悢�����B
4Ghz�Ƃ�8�R�A����啝�Ɍ�ނ���
CSI�̐��\���A�����̗\��ȉ����낤
SMP�g�|���W���A2D�g�[���X���Ă��Ƃ����ǁA
�N���X�o�[�X�C�b�`�łȂ��x���_�[���o�邾�낤��
�l�I�ɂ́AFB-DIMM 4ch���Ă̂́A�ア�Ǝv��
8�`16ch�ɂ��Ƃ������̂�
CSI�̐��\���A�����̗\��ȉ����낤
SMP�g�|���W���A2D�g�[���X���Ă��Ƃ����ǁA
�N���X�o�[�X�C�b�`�łȂ��x���_�[���o�邾�낤��
�l�I�ɂ́AFB-DIMM 4ch���Ă̂́A�ア�Ǝv��
8�`16ch�ɂ��Ƃ������̂�
�R��̔]���T�Z�ł́Aint/fp�Ƃ��ɓ�������POWER�͂��납Xeon�ɂ��畉����\���傾�ȁB
Common System�ŁAIPF => Xeon�փA�b�v�O���[�h���˂���Ă��肵�āi�E�́E�j
CSI����x���̂́A>>270�ł������Ƃ���B2D�g�[���X�Ͷ������ǂȁB
Common System�ŁAIPF => Xeon�փA�b�v�O���[�h���˂���Ă��肵�āi�E�́E�j
CSI����x���̂́A>>270�ł������Ƃ���B2D�g�[���X�Ͷ������ǂȁB
���X�J�����\�̘b
Intel invents server Super Socket ��
http://www.theinquirer.net/?article=28392
INQ�̂�����ƑO�̋L���B
�v��
-----------
Monty(Montecito)�͒x��邱�ƂȂ�A�����͎�菜����A
�T���Ė��c�����AMontvale�́A2~3�N�x��A�d�͂��������āA�w��Montecito�ɂȂ��Ă��܂����B
�ł����āATukwila the elder�͘A��߂���A���Y���ꂽ�B�V����Tukwila���x�ꂽ��ɁA��������Ă��܂����B
�ŁAPaulson�́A�����J��ɋꂵ��ł���B
����ł́AIntel�������ɑ��Ă��ׂ����Ƃ͉���?�����Super Socket���B
����Super Socket�͊�{�I��Intel����C�ɒǂ������߂̋Z�p�B
MCM���2��Core�Abit�������CSI�̑ш敝�̌���B
����́AClovertown��Paxville���A�ш敝�̌͊���啝�ɏ��Ȃ����邱�Ƃ��낤�B
�ǂ��ʂł́ASuper Socket�̃`�b�v��8��Core(2��Tukwila)�������A
2.5-3.0GHz�ʂ̃N���b�N�ł���B�d�͂́A�P��Die��Tukwila��130W�����r���āA170W�ɃZ�b�g����Ă���B
�X�P�W���[����Ŕ��f�������APower6�ɑ��Ă��Ȃ�L�͂ȑR�n�ɂȂ邾�낤�B
-----------
MCM�ł悤�₭8�R�A�BXeon�ł�MCM���炢��邩��Tukwila�Ȃ����ē��R���낤���ǁB
Intel invents server Super Socket ��
http://www.theinquirer.net/?article=28392
INQ�̂�����ƑO�̋L���B
�v��
-----------
Monty(Montecito)�͒x��邱�ƂȂ�A�����͎�菜����A
�T���Ė��c�����AMontvale�́A2~3�N�x��A�d�͂��������āA�w��Montecito�ɂȂ��Ă��܂����B
�ł����āATukwila the elder�͘A��߂���A���Y���ꂽ�B�V����Tukwila���x�ꂽ��ɁA��������Ă��܂����B
�ŁAPaulson�́A�����J��ɋꂵ��ł���B
����ł́AIntel�������ɑ��Ă��ׂ����Ƃ͉���?�����Super Socket���B
����Super Socket�͊�{�I��Intel����C�ɒǂ������߂̋Z�p�B
MCM���2��Core�Abit�������CSI�̑ш敝�̌���B
����́AClovertown��Paxville���A�ш敝�̌͊���啝�ɏ��Ȃ����邱�Ƃ��낤�B
�ǂ��ʂł́ASuper Socket�̃`�b�v��8��Core(2��Tukwila)�������A
2.5-3.0GHz�ʂ̃N���b�N�ł���B�d�͂́A�P��Die��Tukwila��130W�����r���āA170W�ɃZ�b�g����Ă���B
�X�P�W���[����Ŕ��f�������APower6�ɑ��Ă��Ȃ�L�͂ȑR�n�ɂȂ邾�낤�B
-----------
MCM�ł悤�₭8�R�A�BXeon�ł�MCM���炢��邩��Tukwila�Ȃ����ē��R���낤���ǁB
fp��xeon�ɕ����Ȃ��ł���
�X�J���Ƃ������A�x�N�g�����Z���̓��e������
�J��Ԃ����ǁAFB DIMM��8ch�ACSI���Е���32bit�ɂ��Ƃ��ׂ�����
����Ȃ��ƁAXEON��Power�Ƌ����ł��Ȃ�
�X�J���Ƃ������A�x�N�g�����Z���̓��e������
�J��Ԃ����ǁAFB DIMM��8ch�ACSI���Е���32bit�ɂ��Ƃ��ׂ�����
����Ȃ��ƁAXEON��Power�Ƌ����ł��Ȃ�
CSI 4�{�Ƃ�FB-DIMM 4ch�Ƃ����Ȃ�T���߂���ˁB����������߂Ă�Ȃ����Ǝv�����܂��B
Madison 9M 1.6GHz��spec fp�X�R�A������BWoodcrest�ł�2500���炢�͂������낤����A
Monty��3000��Tukwila�ŁA����4000���炢�������Ƃ��Ă��A2008�N��Nehalem�����Xeon�ɏ��Ă邩�ǂ����́c(;�L�D�M)
HP Integrity rx4640-8 (1.6GHz/9MB Itanium 2) 1 core, 1 chip, 1 core/chip 2712 2712
http://www.spec.org/cpu2000/results/res2004q4/cpu2000-20041101-03482.html
Madison 9M 1.6GHz��spec fp�X�R�A������BWoodcrest�ł�2500���炢�͂������낤����A
Monty��3000��Tukwila�ŁA����4000���炢�������Ƃ��Ă��A2008�N��Nehalem�����Xeon�ɏ��Ă邩�ǂ����́c(;�L�D�M)
HP Integrity rx4640-8 (1.6GHz/9MB Itanium 2) 1 core, 1 chip, 1 core/chip 2712 2712
http://www.spec.org/cpu2000/results/res2004q4/cpu2000-20041101-03482.html
���㓡�O��Weekly�C�O�j���[�X��
2�N�T�C�N���ŃA�[�L�e�N�`�������V����Intel
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268.htm
�㓡�����A>>535�̃l�^�ɂ��ċL���������Ă���B
�����đÓ��ȃ��C���̉��߂��Ȃ���Ă�L�����Ƃ������B
Nehalem�AGesher�̃A�[�L�ɂ��ẮA���̃X���ɔ�ׂ�Ƃ�����ƊÂ����ǂȁi�E�́E�j
2�N�T�C�N���ŃA�[�L�e�N�`�������V����Intel
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268.htm
�㓡�����A>>535�̃l�^�ɂ��ċL���������Ă���B
�����đÓ��ȃ��C���̉��߂��Ȃ���Ă�L�����Ƃ������B
Nehalem�AGesher�̃A�[�L�ɂ��ẮA���̃X���ɔ�ׂ�Ƃ�����ƊÂ����ǂȁi�E�́E�j
�u2007�N��Itanium2������RISC�s���5�������v�AItanium�A�������͊W������
http://itpro.nikkeibp.co.jp/article/NEWS/20060207/228765/
>�ăC���e���̃T�[�o�[�p�v���Z�T�uItanium2�v�p�A�v���P�[�V�����J���x���g�D�uItanium Solutions Alliance�iISA�j�v��
>2��7���A2007�N�܂łɍ���RISC�T�[�o�[�s��i���㍂�j��5�����l������Ƃ����ڕW��\�������B
>ISA�͍�N9���A�C���e���𒆐S��Itanium2�𓋍ڂ����^�T�[�o�[����|����BULL�A�x�m�ʁA
>���x�m�ʁE�V�[�����X�E�R���s���[�^�Y�A�������쏊�A�ăq���[���b�g�E�p�b�J�[�h�ANEC�A��SGI�A
>�ă��j�V�X���W�܂��Ĕ��������B�\�t�g�x���_�[���܂߁A�X�^�[�g����23�Ђ������Q����Ƃ�
>40�Ђ܂ő����Ă���B1�����ɂ́AItanium2���y�Ɍ�����ISV�x����Ƃ��āA�����J����s���Y�A
>�c�ƁA�}�[�P�e�B���O�����ɑ��z100���h���𓊎����邱�Ƃ�\�����Ă���B
���{��Ɖ]�X��INQ�l�^�͂��̃X���ł͓\��Ȃ��������ǁA�n�[�h��Itanium�X���ɂ͂łĂ��B
�����������Ƃ������̂��ƁB�ł��AMontecito���ATukwila�C�}�C�`�����Ȃ��B
http://itpro.nikkeibp.co.jp/article/NEWS/20060207/228765/
>�ăC���e���̃T�[�o�[�p�v���Z�T�uItanium2�v�p�A�v���P�[�V�����J���x���g�D�uItanium Solutions Alliance�iISA�j�v��
>2��7���A2007�N�܂łɍ���RISC�T�[�o�[�s��i���㍂�j��5�����l������Ƃ����ڕW��\�������B
>ISA�͍�N9���A�C���e���𒆐S��Itanium2�𓋍ڂ����^�T�[�o�[����|����BULL�A�x�m�ʁA
>���x�m�ʁE�V�[�����X�E�R���s���[�^�Y�A�������쏊�A�ăq���[���b�g�E�p�b�J�[�h�ANEC�A��SGI�A
>�ă��j�V�X���W�܂��Ĕ��������B�\�t�g�x���_�[���܂߁A�X�^�[�g����23�Ђ������Q����Ƃ�
>40�Ђ܂ő����Ă���B1�����ɂ́AItanium2���y�Ɍ�����ISV�x����Ƃ��āA�����J����s���Y�A
>�c�ƁA�}�[�P�e�B���O�����ɑ��z100���h���𓊎����邱�Ƃ�\�����Ă���B
���{��Ɖ]�X��INQ�l�^�͂��̃X���ł͓\��Ȃ��������ǁA�n�[�h��Itanium�X���ɂ͂łĂ��B
�����������Ƃ������̂��ƁB�ł��AMontecito���ATukwila�C�}�C�`�����Ȃ��B
Intel claims 40% performance gain with new Core 2 Extreme processor
http://www.tgdaily.com/2006/05/11/intel_makes_its_core2extreme_gaming_case/
Core 2 Extreme����Conroe XE�́A���sPentium XE��蕽��40%�����B
http://www.tgdaily.com/2006/05/11/intel_makes_its_core2extreme_gaming_case/
Core 2 Extreme����Conroe XE�́A���sPentium XE��蕽��40%�����B
Intel�fs Mainstream �f08 Chips ? Still Dual-Core.
http://www.xbitlabs.com/news/cpu/display/20060511233736.html
Intel��2008�N�̃��C���X�g���[���́ADual Core�B
���̋L���ɂ���
45nm�����"Core"�A�[�L���i��early-2008�N�̓o��ŁAMobile��Penryn, Desktop��Wolfdale�B
�^��Quad Core��Bloomfield��2008�N�B
�܂��ABloomfield�Ƃ͕ʂ�2008�N��Nehalem�n�̐��i���o��Ƃ����b�B
// ���܂ł̏�ƁAPerformance��Ridgefield�AMainstream��Wolfdale�AValue��Milliville
// �Ƃ����b���������ǁB
// �����������T�C�g�������o�Ă�����2�N�悭�炢�܂ł̃��[�h�}�b�v���͂����肵�Ă������B
http://www.xbitlabs.com/news/cpu/display/20060511233736.html
Intel��2008�N�̃��C���X�g���[���́ADual Core�B
���̋L���ɂ���
45nm�����"Core"�A�[�L���i��early-2008�N�̓o��ŁAMobile��Penryn, Desktop��Wolfdale�B
�^��Quad Core��Bloomfield��2008�N�B
�܂��ABloomfield�Ƃ͕ʂ�2008�N��Nehalem�n�̐��i���o��Ƃ����b�B
// ���܂ł̏�ƁAPerformance��Ridgefield�AMainstream��Wolfdale�AValue��Milliville
// �Ƃ����b���������ǁB
// �����������T�C�g�������o�Ă�����2�N�悭�炢�܂ł̃��[�h�}�b�v���͂����肵�Ă������B
���ƁA>>568�̋L���ł́ANehalem��2�R�A��4�R�A���͂͂����肵�Ȃ��Ƃ̂��ƁB
570 �Finteler@�����F2006/05/13(�y) 01:31:19 ID:YrKwn+Xy0
�~Milliville �� ��Millville
Intel stays on dual-core track through 2008
http://news.com.com/Intel+stays+on+dual-core+track+through+2008/2100-1006_3-6071046.html
>>568�Ɠ����悤�ȓ��e��CNet�L���B
������ł�ƁA
Merom -> Penryn
Conroe -> Wolfdale
Kentsfield -> Ridgefield -> Bloomfield
���Ă�������ʼn��߂���̂��K�������Ƃ����������Ă����B
multi chip package, intergrated quad core
http://news.com.com/Intel+stays+on+dual-core+track+through+2008/2100-1006_3-6071046.html
>>568�Ɠ����悤�ȓ��e��CNet�L���B
������ł�ƁA
Merom -> Penryn
Conroe -> Wolfdale
Kentsfield -> Ridgefield -> Bloomfield
���Ă�������ʼn��߂���̂��K�������Ƃ����������Ă����B
multi chip package, intergrated quad core
AMD 2007, 2008 quad core CPUs thrifty on the cache front
http://www.theinquirer.net/?article=31649
>the 2008 "Bloomfield" native quad-core part with Nehalem (Core 3?) cores inside...
INQ�ł́ABloomfield��Nehalem�x�[�X��native Quad Core�Ƃ����Ă�B
�R��̍��܂ł̉��߂ƑS�������B
http://www.theinquirer.net/?article=31649
>the 2008 "Bloomfield" native quad-core part with Nehalem (Core 3?) cores inside...
INQ�ł́ABloomfield��Nehalem�x�[�X��native Quad Core�Ƃ����Ă�B
�R��̍��܂ł̉��߂ƑS�������B
Intel to Speed Up New Core 2-Based Xeon Introduction.
http://www.xbitlabs.com/news/cpu/display/20060518070503.html
Woodcrest���܂��܂���T�Ԃ��炢�O�|�����ꂽ��������Ȃ����l�q�B6/19��X�f�[�B
Woodcrest looks much better than planned
http://www.theinquirer.net/?article=31789
Woodcrest�̃X�e�b�s���O���v�������ǂ������ɐi��ł���炵���A
��q�̑O�|���ɉ����āA�o�O���قƂ�ǂȂ��A�\�z��荂�N���b�N�i���Ƃ�A
TDP��������80W����Conroe���x����65W�ɂ�����Ƃ����b���c(;�L�D�M)
http://www.xbitlabs.com/news/cpu/display/20060518070503.html
Woodcrest���܂��܂���T�Ԃ��炢�O�|�����ꂽ��������Ȃ����l�q�B6/19��X�f�[�B
Woodcrest looks much better than planned
http://www.theinquirer.net/?article=31789
Woodcrest�̃X�e�b�s���O���v�������ǂ������ɐi��ł���炵���A
��q�̑O�|���ɉ����āA�o�O���قƂ�ǂȂ��A�\�z��荂�N���b�N�i���Ƃ�A
TDP��������80W����Conroe���x����65W�ɂ�����Ƃ����b���c(;�L�D�M)
AMD's Next Gen MPU
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=67239&threadid=67239&roomid=11
K8L�̊T�v�B
0. Native quad core
1. Hypertransport up to 5.2GT/s
2. Better coherency
3. Private L2, shared L3 cache that scales up.
4. Separate power planes and pstates for north bridge and CPU
5. 128b FPUs - see 14,15
6. 48b virtual/physical addressing and 1GB pages
7. Support for DDR2, eventually DDR3
8. Support for FBD1 and 2 eventually
9. I/O virtualization and nested page tables
10. Memory mirroring, data poisoning, HT retry protocol support
11. 32B instead of 16B ifetch
12. Indirect branch predictors
13. OOO load execution - similar to memory disambiguation
14. 2x 128b SSE units
15. 2x 128b SSE LDs/cycle
16. Several new instructions
Native Quad Core�ȂƂ���AHT�Ȃ�������Ȃ��āA���Ȃ�̑���C���s���Ă��邲�l�q�B
OOO load execution(=Memory Disambiguation), Indirect branch predictor�ȂǁA
"Core"�Ƃ��Ȃ�N���\�c�Ȋ����B
HT��Native Quad�Ȃ��Ƃɉ����āA
Fetch�ш�Ȃǂ�"Core"��20-24B�������Ă���B2x 128bit SSE�͎������悩�c�B
�L���b�V��������ш�Ȃǂ�"Core"�̕�����B
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=67239&threadid=67239&roomid=11
K8L�̊T�v�B
0. Native quad core
1. Hypertransport up to 5.2GT/s
2. Better coherency
3. Private L2, shared L3 cache that scales up.
4. Separate power planes and pstates for north bridge and CPU
5. 128b FPUs - see 14,15
6. 48b virtual/physical addressing and 1GB pages
7. Support for DDR2, eventually DDR3
8. Support for FBD1 and 2 eventually
9. I/O virtualization and nested page tables
10. Memory mirroring, data poisoning, HT retry protocol support
11. 32B instead of 16B ifetch
12. Indirect branch predictors
13. OOO load execution - similar to memory disambiguation
14. 2x 128b SSE units
15. 2x 128b SSE LDs/cycle
16. Several new instructions
Native Quad Core�ȂƂ���AHT�Ȃ�������Ȃ��āA���Ȃ�̑���C���s���Ă��邲�l�q�B
OOO load execution(=Memory Disambiguation), Indirect branch predictor�ȂǁA
"Core"�Ƃ��Ȃ�N���\�c�Ȋ����B
HT��Native Quad�Ȃ��Ƃɉ����āA
Fetch�ш�Ȃǂ�"Core"��20-24B�������Ă���B2x 128bit SSE�͎������悩�c�B
�L���b�V��������ш�Ȃǂ�"Core"�̕�����B
SSE*2�����Ă��A���Z*1�A��Z*1���낤
conroe�ƈꏏ
����SSE���[�h�A2/cycle���ق�ƂȂ�f�G
conroe�ƈꏏ
����SSE���[�h�A2/cycle���ق�ƂȂ�f�G
K8L�̃A�[�L�e�N�g�͌����`�[���Ȃ�H
���ʂɌ�K8�`�[������Ȃ��́B
���[���������ς���ȁB
����������K8�`�[�����E�E�E
����������K8�`�[�����E�E�E
Intel Server Technology Update
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Europe051706PrudentialBache.pdf
�ECanelandPlatform - MP�iTigerton�CQuadcore�C2007�j�̊T���������o�Ă�B
FSB BW�@�@�@ - 34GB/s �i34GB/s / 4�{ �� 8.5GB/s�i1066MHz�E8B�H)/1FSB�ӂ�Ȋ������j
Memory BW�@- 32GB/s
Memory Cpa - 128GB/s
���̑�Roadmap
ttp://pda.tweakers.net/?nieuws/42100/Vernieuwde-roadmap-van-Intels-serverprocessors.html
ttp://80.81.172.37/microsoft/Mika_Kamppinen_Antti_Kirmanen_Asali_klo1215.pdf�@(finland)
ftp://download.intel.com/intel/finance/presentations/PDF_Files/Europe051706PrudentialBache.pdf
�ECanelandPlatform - MP�iTigerton�CQuadcore�C2007�j�̊T���������o�Ă�B
FSB BW�@�@�@ - 34GB/s �i34GB/s / 4�{ �� 8.5GB/s�i1066MHz�E8B�H)/1FSB�ӂ�Ȋ������j
Memory BW�@- 32GB/s
Memory Cpa - 128GB/s
���̑�Roadmap
ttp://pda.tweakers.net/?nieuws/42100/Vernieuwde-roadmap-van-Intels-serverprocessors.html
ttp://80.81.172.37/microsoft/Mika_Kamppinen_Antti_Kirmanen_Asali_klo1215.pdf�@(finland)
�E�����Roadmap�̂܂Ƃ�
Xeon MP
�ETluland PF�i���s�j
�v���Z�T - Paxville(2core�j�@�@�@�@ �@ �� Tulsa(2core�j
�`�v�Z�g�@- E8500�i667MHz�C2FSB�j �� E8501(800MHz�C2FSB�j
�@�@�@�@�@�@��
�ECaneland PF�i2007�CH2�j
�v���Z�T - Tigerton(4core�j �@�@�@�@�@�@�@�@ �� Dunnington(4core�j
�`�v�Z�g�@- Clarksboro�i1066MHz�C4FSB�j �� Clarksboro+(1333MHz?�C4FSB�j
Xeon DP
�EBensley PF�i���s�j
�v���Z�T - Dempsey��Woodcrest(2core�j�@�@�@ �@�@�@ �� Cloverton(4core�j
�`�v�Z�g�@- Blackford�i1066MHz��1333MHz�C2FSB�j �� Blackford(1066MHz�C2FSB�j
�@�@�@�@�@�@��
�EStoakley PF(2007�CH2)
�v���Z�T - Harpertown�i4core�j
�`�v�Z�g�@- Seaburg�i1333MH��?�C2FSB�j
�EFuture PF�i2008�`9�j
IA��CSI(Common System Interconnect)�ɓ����B>>557�Q�l�B
CSI4�{�[�ƁANovakovic����MCM�̓z�Ƃ��܂���肻�����ȁE�E�E
ttp://www.theinquirer.net/?article=30968
Xeon MP
�ETluland PF�i���s�j
�v���Z�T - Paxville(2core�j�@�@�@�@ �@ �� Tulsa(2core�j
�`�v�Z�g�@- E8500�i667MHz�C2FSB�j �� E8501(800MHz�C2FSB�j
�@�@�@�@�@�@��
�ECaneland PF�i2007�CH2�j
�v���Z�T - Tigerton(4core�j �@�@�@�@�@�@�@�@ �� Dunnington(4core�j
�`�v�Z�g�@- Clarksboro�i1066MHz�C4FSB�j �� Clarksboro+(1333MHz?�C4FSB�j
Xeon DP
�EBensley PF�i���s�j
�v���Z�T - Dempsey��Woodcrest(2core�j�@�@�@ �@�@�@ �� Cloverton(4core�j
�`�v�Z�g�@- Blackford�i1066MHz��1333MHz�C2FSB�j �� Blackford(1066MHz�C2FSB�j
�@�@�@�@�@�@��
�EStoakley PF(2007�CH2)
�v���Z�T - Harpertown�i4core�j
�`�v�Z�g�@- Seaburg�i1333MH��?�C2FSB�j
�EFuture PF�i2008�`9�j
IA��CSI(Common System Interconnect)�ɓ����B>>557�Q�l�B
CSI4�{�[�ƁANovakovic����MCM�̓z�Ƃ��܂���肻�����ȁE�E�E
ttp://www.theinquirer.net/?article=30968
���Ȃ݂ɃN���C�A���g��CSI���������ɂ��ẮA���o�C����45nmMerom�iPenryn�j����Ƃ����b������B
�u����IntelCPU�͍L�p������FSB�̂��߁ACPU�̔z�u�̎��R���������A
�m�[�g�x���_�͋�J���Đv���Ă�B
FSB��CSI�ɂȂ�ƁAPCI-E�Ɠ��l�A�z���̎��R�x�������B
���̂��߃m�[�gPC�x���_�ɂ�CSI�����͊��}����Ă���Ƃ���ƊE�W�҂͌����B
���̂܂܂̃v�����Ő�����45nmMerom�œ������ꂻ�����B�v�@
by�@�㓡�iWinPC��������������������K���ɔ������j
�u����IntelCPU�͍L�p������FSB�̂��߁ACPU�̔z�u�̎��R���������A
�m�[�g�x���_�͋�J���Đv���Ă�B
FSB��CSI�ɂȂ�ƁAPCI-E�Ɠ��l�A�z���̎��R�x�������B
���̂��߃m�[�gPC�x���_�ɂ�CSI�����͊��}����Ă���Ƃ���ƊE�W�҂͌����B
���̂܂܂̃v�����Ő�����45nmMerom�œ������ꂻ�����B�v�@
by�@�㓡�iWinPC��������������������K���ɔ������j
Intel to intro WoodCrest on June 19th
http://www.theinquirer.net/?article=31843
5110 - 1.60 GHz clock, 1066 MHz FSB, $230 per 1K CPU
5120 - 1.86 GHz clock, 1066 MHz FSB, $270 per 1K CPU
5130 - 2.00 GHz clock, 1333 MHz FSB, $330 per 1K CPU
5140 - 2.33 GHz clock, 1333 MHz FSB, $470 per 1K CPU
5150 - 2.67 GHz clock, 1333 MHz FSB, $700 per 1K CPU
5160 - 3.00 GHz clock, 1333 MHz FSB, $851 per 1K CPU
Woodcrest 6/19�����[�X�B
���̋L�������Ă�Theo���Ă�ɂ��ƁA
Woodcrest��Northbridge��10-30W�d�͐H���Ƃ��AK8L�͍��N�������N��Q1�ɂł�炵��(�m
���ƁAWoodcrest��4MB+4MB=8MB L2�Ƃ������Ă邵�B�����Ɣc�����ď�����ƁB
http://www.theinquirer.net/?article=31843
5110 - 1.60 GHz clock, 1066 MHz FSB, $230 per 1K CPU
5120 - 1.86 GHz clock, 1066 MHz FSB, $270 per 1K CPU
5130 - 2.00 GHz clock, 1333 MHz FSB, $330 per 1K CPU
5140 - 2.33 GHz clock, 1333 MHz FSB, $470 per 1K CPU
5150 - 2.67 GHz clock, 1333 MHz FSB, $700 per 1K CPU
5160 - 3.00 GHz clock, 1333 MHz FSB, $851 per 1K CPU
Woodcrest 6/19�����[�X�B
���̋L�������Ă�Theo���Ă�ɂ��ƁA
Woodcrest��Northbridge��10-30W�d�͐H���Ƃ��AK8L�͍��N�������N��Q1�ɂł�炵��(�m
���ƁAWoodcrest��4MB+4MB=8MB L2�Ƃ������Ă邵�B�����Ɣc�����ď�����ƁB
>>579�̎����ɂ��ƁAWoodcrest��Dempsey��2S���̐��\���
@SPECint_rate: Woodcrest 3GHz / Dempsey 3.73GHz = 1.41
@SPECint_rate: Woodcrest 3GHz / Dempsey 3.73GHz = 1.35
Woodcrest 2S
SPECint_rate = 113 (est.)
SPECfp_rate = 90 (est.)
���炢�̂��l�q�BFP���\�͂���قǂł��Ȃ��Ƃ����A�ȑO�̏��͎��͐����������킯���B
rate����Ȃ����͂܂��킩��Ȃ��B�����̓��b�`�Ȃ̂ŁA�œK������ł�FP�����\�ς���Ă������ł͂��邪�B
>>552�ł�+52%�Ōv�Z�������ǁADempsey������3.46GHz�܂ł̌v�悾�����̂ō����傫�������̂�Y��Čv�Z����
�̂����邯�ǂ����艺�����Ă��邲�l�q�B
@SPECint_rate: Woodcrest 3GHz / Dempsey 3.73GHz = 1.41
@SPECint_rate: Woodcrest 3GHz / Dempsey 3.73GHz = 1.35
Woodcrest 2S
SPECint_rate = 113 (est.)
SPECfp_rate = 90 (est.)
���炢�̂��l�q�BFP���\�͂���قǂł��Ȃ��Ƃ����A�ȑO�̏��͎��͐����������킯���B
rate����Ȃ����͂܂��킩��Ȃ��B�����̓��b�`�Ȃ̂ŁA�œK������ł�FP�����\�ς���Ă������ł͂��邪�B
>>552�ł�+52%�Ōv�Z�������ǁADempsey������3.46GHz�܂ł̌v�悾�����̂ō����傫�������̂�Y��Čv�Z����
�̂����邯�ǂ����艺�����Ă��邲�l�q�B
584 �Finteler@�����F2006/05/21(��) 17:51:26 ID:BYo0Cgp/0
@SPECfp_rate: Woodcrest 3GHz / Dempsey 3.73GHz = 1.35
fp
fp
ipc cpu date
----------------
0.11 i386DX 1988
0.24 i486DX4 1994
0.25 i486DX 1989
0.26 i486DX2 1992
0.51 P54CS 1996
0.51 P5 1993
0.56 P54CQS 1995
0.56 P54VRT 1994
0.56 P55C 1997
0.58 P54C 1994
0.62 PPC604 1995
0.67 Deschutes 1998
0.67 Willamette 2000
0.70 Katmai 1999
0.70 Mendocino 1998
0.71 Klamath 1997
0.72 Northwood 2002
0.74 PPC604e 1997
----------------
0.11 i386DX 1988
0.24 i486DX4 1994
0.25 i486DX 1989
0.26 i486DX2 1992
0.51 P54CS 1996
0.51 P5 1993
0.56 P54CQS 1995
0.56 P54VRT 1994
0.56 P55C 1997
0.58 P54C 1994
0.62 PPC604 1995
0.67 Deschutes 1998
0.67 Willamette 2000
0.70 Katmai 1999
0.70 Mendocino 1998
0.71 Klamath 1997
0.72 Northwood 2002
0.74 PPC604e 1997
0.77 K75 2000
0.77 K7 1999
0.77 P6 1996
0.81 Prescott 2003
0.82 Merced 2000
0.85 Coppermine 1999
0.94 PA-7200 1994
0.94 Cedar Mill 2006
1.19 Opteron280 2005
1.24 PA-8200 1997
1.26 Opteron154 2005
1.40 PA-8700+ 2002
1.48 POWER5 2005
1.54 Yonah 2006
1.55 McKinley 2001
1.55 Dothan 2005
1.90 Madison 9M 2004
SPECint�̗��X�R�A����l�`�l�`�v�Z�����N���b�N�����萫�\�\�B�l�́AIPF��IA64��IPC(����)����B
0.77 K7 1999
0.77 P6 1996
0.81 Prescott 2003
0.82 Merced 2000
0.85 Coppermine 1999
0.94 PA-7200 1994
0.94 Cedar Mill 2006
1.19 Opteron280 2005
1.24 PA-8200 1997
1.26 Opteron154 2005
1.40 PA-8700+ 2002
1.48 POWER5 2005
1.54 Yonah 2006
1.55 McKinley 2001
1.55 Dothan 2005
1.90 Madison 9M 2004
SPECint�̗��X�R�A����l�`�l�`�v�Z�����N���b�N�����萫�\�\�B�l�́AIPF��IA64��IPC(����)����B
Woodcrest��6/19���B
�����A������Power Mac�̌�p�@�픭�\���Ă̂͌��肩�ȁB
�����A������Power Mac�̌�p�@�픭�\���Ă̂͌��肩�ȁB
��AMDᢓ���?�P? Intel DT CPU��~�J
http://www.hkepc.com/bbs/news.php?tid=604489
Conroe�X������Ƃ��Ă����B
Intel�̃v���C�X���[�h�}�b�v�B
Pen4�̖\�����Ղ肪�������ȁc(;�L�D�M)
Conroe XE�̐��̂͒P�Ȃ�2.93GHz�ł�Conroe�������B
���O��XE�Ȃ����B3.33GHz�����ꃋ�[�}�[�����Ă��Ƃ�����Əؖ����ꂽ�킯���B
�����A�^��XE��Q1'07��Kentsfield�܂ł��a���B
http://www.hkepc.com/bbs/news.php?tid=604489
Conroe�X������Ƃ��Ă����B
Intel�̃v���C�X���[�h�}�b�v�B
Pen4�̖\�����Ղ肪�������ȁc(;�L�D�M)
Conroe XE�̐��̂͒P�Ȃ�2.93GHz�ł�Conroe�������B
���O��XE�Ȃ����B3.33GHz�����ꃋ�[�}�[�����Ă��Ƃ�����Əؖ����ꂽ�킯���B
�����A�^��XE��Q1'07��Kentsfield�܂ł��a���B
48 ���O�FMAC�I�^[sage] ���e���F2006/05/24(��) 08:29:57 ID:hfyI0XzM
������SPEC�ɂ��o�^����锤�����ǤIntel�̌��J����Woodcrest��SPEC2000�̌��ʂ��B
http://www.intel.com/performance/server/xeon/intspd.htm
Woodcrest/3.0GHz, 4MB L2, 1.33GHz FSB
�@�ESPECint_base2000: 3012
�@�ESPECint_rate_base2000: 123 (2-socket/4-way)
�@�ESPECfp_base2000: 2602(Windows), 2783(Linux)
�@�ESPECfp_rate_base2000: 79.3(Windows), 83(Linux)
FB-DIMM���ڂ�Woodcrest�ł��̐��т����礓���SPECint��Conroe�̐��\��X�ɍ����Ȃ�Ƃ����̂�
���ق��B�B�B
------------------
�\�X������̃R�s�y�B
Woodcrest��SPEC�x���`�X�R�A�B
>>579, >>583�̎�������̐����Ƒ啪�Ⴄ���l�q�c(;�L�D�M)
>>586�ɒlj�
1.90 Madison 9M 2004
1.92 Woodcrest 2006
Woodcrest���AItanium 2����IPC�ł����E�ō��Ɂc(;�L�D�M)
��������ΐ��\(�����X�J��)�ł��_���g�c�g�b�v���B
������SPEC�ɂ��o�^����锤�����ǤIntel�̌��J����Woodcrest��SPEC2000�̌��ʂ��B
http://www.intel.com/performance/server/xeon/intspd.htm
Woodcrest/3.0GHz, 4MB L2, 1.33GHz FSB
�@�ESPECint_base2000: 3012
�@�ESPECint_rate_base2000: 123 (2-socket/4-way)
�@�ESPECfp_base2000: 2602(Windows), 2783(Linux)
�@�ESPECfp_rate_base2000: 79.3(Windows), 83(Linux)
FB-DIMM���ڂ�Woodcrest�ł��̐��т����礓���SPECint��Conroe�̐��\��X�ɍ����Ȃ�Ƃ����̂�
���ق��B�B�B
------------------
�\�X������̃R�s�y�B
Woodcrest��SPEC�x���`�X�R�A�B
>>579, >>583�̎�������̐����Ƒ啪�Ⴄ���l�q�c(;�L�D�M)
>>586�ɒlj�
1.90 Madison 9M 2004
1.92 Woodcrest 2006
Woodcrest���AItanium 2����IPC�ł����E�ō��Ɂc(;�L�D�M)
��������ΐ��\(�����X�J��)�ł��_���g�c�g�b�v���B
590 �FIntelerFan�F2006/05/27(�y) 00:22:39 ID:E2RQ+oj30
>>588
��?��1333MHz FSB�ݘH Bearlake���Бg�v�c����
http://www.hkepc.com/bbs/news.php?tid=604851
Weybridge, Bear Lake join Intel road map
http://www.theinquirer.net/?article=31988
1333MHz�̃`�b�v�Z�b�g��Kentsfield�ɍ��킹�ďo�Ă��邻���������A
����܂�1333MHz�͂��a���������H
��?��1333MHz FSB�ݘH Bearlake���Бg�v�c����
http://www.hkepc.com/bbs/news.php?tid=604851
Weybridge, Bear Lake join Intel road map
http://www.theinquirer.net/?article=31988
1333MHz�̃`�b�v�Z�b�g��Kentsfield�ɍ��킹�ďo�Ă��邻���������A
����܂�1333MHz�͂��a���������H
>>590
i965�̌�p�`�b�v�̏����Ƃł����c�B
i965�̌�p���ABare Lake�`�v�Z�g�ŁA
i975X�̌�p���AWeybridge Pro�`�v�Z�g��1333MHz FSB�T�|�[�g���B
����������Q2 2007�݂������ȁBINQ�ɂ�2H���Ă����Ă��邯�ǁB
����܂ł́A1333MHz FSB��Woodcrest Xeon����̂��l�q�B
i965�̌�p�`�b�v�̏����Ƃł����c�B
i965�̌�p���ABare Lake�`�v�Z�g�ŁA
i975X�̌�p���AWeybridge Pro�`�v�Z�g��1333MHz FSB�T�|�[�g���B
����������Q2 2007�݂������ȁBINQ�ɂ�2H���Ă����Ă��邯�ǁB
����܂ł́A1333MHz FSB��Woodcrest Xeon����̂��l�q�B
592 �FIntelerFan�F2006/05/27(�y) 00:43:55 ID:E2RQ+oj30
3loads��Kentsfield�撣����1333MHz�œ���������������ˁB�B�B�H
Core2��
Clovertown��1066MHz FSB�������B
1S��Kentsfield�Ȃ�A1333MHz��MCM 2chip 4core�͂����ɉ\�Ƃ������Ƃ��Ȃ��B
����Intel�f����?�iᢓW �l�j�SClovertown�K�i��
http://www.hkepc.com/bbs/news.php?tid=603854
Woodcrest 40W/65W/80W
Clovertown 80W/<120W
�̃��C���i�b�v���c�B�ڂ����̓\�[�X�Q�ƁB
1S��Kentsfield�Ȃ�A1333MHz��MCM 2chip 4core�͂����ɉ\�Ƃ������Ƃ��Ȃ��B
����Intel�f����?�iᢓW �l�j�SClovertown�K�i��
http://www.hkepc.com/bbs/news.php?tid=603854
Woodcrest 40W/65W/80W
Clovertown 80W/<120W
�̃��C���i�b�v���c�B�ڂ����̓\�[�X�Q�ƁB
Intel Nehalem will have lots of interconnect links
http://www.theinquirer.net/?article=31860
It looks like the big 'Enterprise' versions of Nehalem will all sport eight CSI links.
This means that every chip could be connected to every chip in an 8S configuration,
or you could have enough peripherals on it to make an Altix owner jealous.
Nehalem��MP�ł�CSI 8�{?
http://www.theinquirer.net/?article=31860
It looks like the big 'Enterprise' versions of Nehalem will all sport eight CSI links.
This means that every chip could be connected to every chip in an 8S configuration,
or you could have enough peripherals on it to make an Altix owner jealous.
Nehalem��MP�ł�CSI 8�{?
Intel bumps 45 nanometre process back
http://www.theinquirer.net/?article=31861
Intel��45nm�v���Z�X���A2007 Q4����Q1 2008�ɒx���B
// ���x�̂��ƁBNehalem���x���j���[�X���̂������邾�낤�ȁc�i�E�́E�j
http://www.theinquirer.net/?article=31861
Intel��45nm�v���Z�X���A2007 Q4����Q1 2008�ɒx���B
// ���x�̂��ƁBNehalem���x���j���[�X���̂������邾�낤�ȁc�i�E�́E�j
Intel to cut notebook chip prices twice in a month
http://www.theinquirer.net/?article=31989
Yonah
name p/n clock �@�@�@�@�@�@now 5/28 6/25
Core Duo T2700 2.33GHz $--- $--- $637
Core Duo T2600 2.16GHz $637 $423
Core Duo T2500 2.0GHz $423 $294
Core Duo T2400 1.83GHz $294 $241
Core Duo T2300 1.66GHz $241 $---
Core Duo T2300E 1.66GHz $209 $209
Core Solo T1400 1.83GHz $209 $209
Core Solo T1300 1.66GHz $209 $---
Core Duo U2500 1.06GHz $--- $---
5/28��Yonah�l�����B
6/25�ɁAYonah Core Duo T2700��U2500���o��B
http://www.theinquirer.net/?article=31989
Yonah
name p/n clock �@�@�@�@�@�@now 5/28 6/25
Core Duo T2700 2.33GHz $--- $--- $637
Core Duo T2600 2.16GHz $637 $423
Core Duo T2500 2.0GHz $423 $294
Core Duo T2400 1.83GHz $294 $241
Core Duo T2300 1.66GHz $241 $---
Core Duo T2300E 1.66GHz $209 $209
Core Solo T1400 1.83GHz $209 $209
Core Solo T1300 1.66GHz $209 $---
Core Duo U2500 1.06GHz $--- $---
5/28��Yonah�l�����B
6/25�ɁAYonah Core Duo T2700��U2500���o��B
599 �Finteler@�����F2006/05/27(�y) 11:41:52 ID:2GntxSRn0
Yonah
name p/n clock �@�@�@�@�@�@now 5/28 6/25
Core Duo T2700 2.33GHz $--- $--- $637
Core Duo T2600 2.16GHz $637 $423
Core Duo T2500 2.0GHz $423 $294
Core Duo T2400 1.83GHz $294 $241
Core Duo T2300 1.66GHz $241 $---
Core Duo T2300E 1.66GHz $209
Core Solo T1400 1.83GHz $209
Core Solo T1300 1.66GHz $209 $---
Core Duo U2500 1.06GHz $--- $---
name p/n clock �@�@�@�@�@�@now 5/28 6/25
Core Duo T2700 2.33GHz $--- $--- $637
Core Duo T2600 2.16GHz $637 $423
Core Duo T2500 2.0GHz $423 $294
Core Duo T2400 1.83GHz $294 $241
Core Duo T2300 1.66GHz $241 $---
Core Duo T2300E 1.66GHz $209
Core Solo T1400 1.83GHz $209
Core Solo T1300 1.66GHz $209 $---
Core Duo U2500 1.06GHz $--- $---
Weybridge, Bear Lake join Intel desktop road map
http://www.theinquirer.net/?article=31988
- Conroe (Core 2 Duo, DualCore, Desktop, Core-uarch, 1066MHz FSB)
launch@2006/7/23
p/n clock price cache brand
----
X6800 2.93GHz $999 4MB C2E
E6700 2.67GHz $530 4MB C2D
E6600 2.40GHz $316 4MB C2D
E6400 2.13GHz $224 2MB C2D
E6300 1.86GHz $183 2MB C2D
----
* C2E = Core 2 Extreme
* C2D = Core 2 Duo
- chipset
H2 2007 975X -> Weybridge + ICH9 (1333MHz FSB?)
H2 2007 965 -> Bearlake + ICH9 (1333MHz FSB)
http://www.theinquirer.net/?article=31988
- Conroe (Core 2 Duo, DualCore, Desktop, Core-uarch, 1066MHz FSB)
launch@2006/7/23
p/n clock price cache brand
----
X6800 2.93GHz $999 4MB C2E
E6700 2.67GHz $530 4MB C2D
E6600 2.40GHz $316 4MB C2D
E6400 2.13GHz $224 2MB C2D
E6300 1.86GHz $183 2MB C2D
----
* C2E = Core 2 Extreme
* C2D = Core 2 Duo
- chipset
H2 2007 975X -> Weybridge + ICH9 (1333MHz FSB?)
H2 2007 965 -> Bearlake + ICH9 (1333MHz FSB)
Intel prices up Woodcrest, Tulsa server chips
http://www.theinquirer.net/?article=31990
- Tulsa 7140M / 3.40GHz / 16MB L3 / 800MHz / 2 core / 150W / $3160 / Q4 2006
- Tulsa 7130M / 3.20GHz / 8MB L3 / 800MHz / 2 core / 150W / $1980 / Q4 2006
- Tulsa 7120M / 3.00GHz / 4MB L3 / 800MHz / 2 core / 150W / $1180 / Q4 2006
- Tulsa 7110M / 2.60GHz / 4MB L3 / 800MHz / 2 core / 150W / $850 / Q4 2006
- Tulsa 7140N / 3.33GHz / 16MB L3 / 667MHz / 2 core / 95W / $3160 / Q4 2006
- Tulsa 7130N / 3.16GHz / 8MB L3 / 667MHz / 2 core / 95W / $1980 / Q4 2006
- Tulsa 7120N / 3.00GHz / 4MB L3 / 667MHz / 2 core / 95W / $1180 / Q4 2006
- Tulsa 7110N / 2.50GHz / 4MB L3 / 667MHz / 2 core / 95W / $850 / Q4 2006
- Woodcrest 5160 / 3.00GHz / 4MB L2 / 1333MHz FSB / 2 core / 80W / $850
- Woodcrest 5150 / 2.66GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $690
- Woodcrest 5140 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $455
- Woodcrest 5130 / 2.00GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $320
- Woodcrest 5120 / 1.86GHz / 4MB L2 / 1066MHz FSB / 2 core / 65W / $260
- Woodcrest 5110 / 1.60GHz / 4MB L2 / 1066MHz FSB / 2 core / 65W / $210
- Woodcrest LV 5148T / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core / 40W / $520
Pellston = Cache Safe Technology
http://www.theinquirer.net/?article=31990
- Tulsa 7140M / 3.40GHz / 16MB L3 / 800MHz / 2 core / 150W / $3160 / Q4 2006
- Tulsa 7130M / 3.20GHz / 8MB L3 / 800MHz / 2 core / 150W / $1980 / Q4 2006
- Tulsa 7120M / 3.00GHz / 4MB L3 / 800MHz / 2 core / 150W / $1180 / Q4 2006
- Tulsa 7110M / 2.60GHz / 4MB L3 / 800MHz / 2 core / 150W / $850 / Q4 2006
- Tulsa 7140N / 3.33GHz / 16MB L3 / 667MHz / 2 core / 95W / $3160 / Q4 2006
- Tulsa 7130N / 3.16GHz / 8MB L3 / 667MHz / 2 core / 95W / $1980 / Q4 2006
- Tulsa 7120N / 3.00GHz / 4MB L3 / 667MHz / 2 core / 95W / $1180 / Q4 2006
- Tulsa 7110N / 2.50GHz / 4MB L3 / 667MHz / 2 core / 95W / $850 / Q4 2006
- Woodcrest 5160 / 3.00GHz / 4MB L2 / 1333MHz FSB / 2 core / 80W / $850
- Woodcrest 5150 / 2.66GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $690
- Woodcrest 5140 / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $455
- Woodcrest 5130 / 2.00GHz / 4MB L2 / 1333MHz FSB / 2 core / 65W / $320
- Woodcrest 5120 / 1.86GHz / 4MB L2 / 1066MHz FSB / 2 core / 65W / $260
- Woodcrest 5110 / 1.60GHz / 4MB L2 / 1066MHz FSB / 2 core / 65W / $210
- Woodcrest LV 5148T / 2.33GHz / 4MB L2 / 1333MHz FSB / 2 core / 40W / $520
Pellston = Cache Safe Technology
602 �Finteler@�ϑz�F2006/05/27(�y) 17:40:57 ID:2GntxSRn0
>>596 >>557
Nehalem Xeon MP: FB-DIMM 8ch
Tukwila: FB-DIMM 4ch
IPF�̕����������X�y�b�N�Ⴂ�����!?�͂ǂ����߂�����悢�̂�?
�ϑz�Ă�P�o���Ă݂܂����B
(CSI�X�y�b�N��Nehalem XeonMP�̕����ゾ�Ƃ�������ȑO��Ɋ�Â�)
>>596�ł����Ă�Enterprise Version��Nehalem Xeon MP�Ƃ����̂́A
��̓I�ȃ����[�X�����A�R�[�h�l�[���͕s�������ACSI�v���Z�b�T�Ƃ��ẮA
��2����ɑ�������R�A���Ƃ������߂��Ó���������Ȃ��B
CSI��1�����Xeon�͌��XWhitefield�̂͂��ŁA�����Tukwila�Ƌ���PF�̂͂��������̂����A
���X�ɃL�����Z���ɂ�A�ێ�I�ȃo�X�A�[�L��Tigerton�ɒu���������Ă���B
(���łɂ��̎���Nehalem��2�����Dunnington���u���������Ă���)
�����ŁACSI Xeon�́A�����Ȃ�CSI��2���㐻�i����̃X�^�[�g�ɂȂ��Ă��܂���̓I�ȃ����[�X�����͕s�������A
2008�N��Bloomfield��Tukwila�Ȃǂ�����������ƌ�ɓo�ꂷ��̂�������Ȃ�(2009�N�Ƃ�)�B
���݂ł��AXeon MP��Desktop��XeonDP�ɂ���ׂāA1-2����x��̃R�A�������Ă��āA
Q4��NetBurst�x�[�X��Tulsa������Əo�Ă��āA"Core"�x�[�X��Tigerton+Caneland�͗��N�㔼�܂ł��a���Ȃ��炢������B
�������ACSI��MP Server�ł����d�v�Ȃ킯�ł��̕ӂ͔����ł����B
����ŁATukwila��2008�N�܂Œx�������̂ŁA�����[�X����������Nehalem Xeon MP�Ƒ卷�Ȃ��Ȃ��āA
����̂悤��IPF�̕����X�y�b�N�Ⴂ�����݂����ȋC������̂����B
�ł��A�P�ɑ�K��SMP���l������IPF��4ch�ɉ������Ă�̂�������ǂ��B
�W�Ȃ�����Tukwila��cache coherency directory����L2/L3�Ƃ͓Ɨ�������p�L���b�V���Ƃ��Ď����Ă�݂������ȁB
Nehalem Xeon MP: FB-DIMM 8ch
Tukwila: FB-DIMM 4ch
IPF�̕����������X�y�b�N�Ⴂ�����!?�͂ǂ����߂�����悢�̂�?
�ϑz�Ă�P�o���Ă݂܂����B
(CSI�X�y�b�N��Nehalem XeonMP�̕����ゾ�Ƃ�������ȑO��Ɋ�Â�)
>>596�ł����Ă�Enterprise Version��Nehalem Xeon MP�Ƃ����̂́A
��̓I�ȃ����[�X�����A�R�[�h�l�[���͕s�������ACSI�v���Z�b�T�Ƃ��ẮA
��2����ɑ�������R�A���Ƃ������߂��Ó���������Ȃ��B
CSI��1�����Xeon�͌��XWhitefield�̂͂��ŁA�����Tukwila�Ƌ���PF�̂͂��������̂����A
���X�ɃL�����Z���ɂ�A�ێ�I�ȃo�X�A�[�L��Tigerton�ɒu���������Ă���B
(���łɂ��̎���Nehalem��2�����Dunnington���u���������Ă���)
�����ŁACSI Xeon�́A�����Ȃ�CSI��2���㐻�i����̃X�^�[�g�ɂȂ��Ă��܂���̓I�ȃ����[�X�����͕s�������A
2008�N��Bloomfield��Tukwila�Ȃǂ�����������ƌ�ɓo�ꂷ��̂�������Ȃ�(2009�N�Ƃ�)�B
���݂ł��AXeon MP��Desktop��XeonDP�ɂ���ׂāA1-2����x��̃R�A�������Ă��āA
Q4��NetBurst�x�[�X��Tulsa������Əo�Ă��āA"Core"�x�[�X��Tigerton+Caneland�͗��N�㔼�܂ł��a���Ȃ��炢������B
�������ACSI��MP Server�ł����d�v�Ȃ킯�ł��̕ӂ͔����ł����B
����ŁATukwila��2008�N�܂Œx�������̂ŁA�����[�X����������Nehalem Xeon MP�Ƒ卷�Ȃ��Ȃ��āA
����̂悤��IPF�̕����X�y�b�N�Ⴂ�����݂����ȋC������̂����B
�ł��A�P�ɑ�K��SMP���l������IPF��4ch�ɉ������Ă�̂�������ǂ��B
�W�Ȃ�����Tukwila��cache coherency directory����L2/L3�Ƃ͓Ɨ�������p�L���b�V���Ƃ��Ď����Ă�݂������ȁB
603 �Finteler@�ϑz�F2006/05/27(�y) 18:17:08 ID:2GntxSRn0
>>556
���܂ł̏��ŁANehalem�͂���ς�AMerom-Based�ȃR�A��native quad-core+CSI+��
�Ƃ������ƂɂȂ肻���B
�ŁA+���̒��g�̌��́A���̂Ƃ���Trace Cache, Chip-Multithreading, SIMD���ӂ̊g���Ƃ����B
>>556�ł́ASMT���Ă��Ƃŏ��������ǂ���ρASMT�͍l�������Ă���ϖ��ʂ��Ǝv�����B
SMT�́ANetBurst�̗�ł����ƁA3uops/cycle�����Ȃ��M�d��NetBurst��Trace Cache Fetch, Retire�̑ш��
�����ɕ������āA2thread���������Ă���(SMT�ł́ASingleThread���\�����Ƌ]���ɂȂ�̂͂�ނȂ�)�B
�ق��ɂ�SMT�p�ɑ��d������Ă��Ȃ��p�C�v��̃��\�[�X��2thread�ԂŒD�������ɂȂ��Ă����B
Nehalem�ł́ATraceCache������̂��Ȃ��̂��͂܂��킩��Ȃ����A
������ɂ���SMT���̗p�����ꍇ�AiFetch�ш�ȂǁA�����ш��Thread��2�����A4����������A
���܂�����Ă���荇���ɂȂ����肷��̂ŁA�^�_�ł����A4 core���v���Z�b�T�R�A�������āA
Single Thread���\�̕����M�d���Ǝv����̂ɕ���p���ł��������Ȃ����ƁB
�Q�����̂�����MT�Z�p�́AMontecito��SoEMT�݂�����Coarse Grained��MT�Z�p�̕���
����p�����Ȃ�����SMT���\���������Ȃ�Ȃ����Ǝv���Ă݂���B
Trace Cache�͌��X��wide band�Ȗ���Fetch�̂��߂̋Z�p�Ȃ̂ŁA
�ނ��덂IPC��Energy Efficient�ȃA�[�L�ŗL�]�Ȃ킯�B
NetBurst�ł́A��q�̒ʂ�3ups/cycle��TC Fetch�ш悵���Ƃ�ĂȂ��āA
deep�ɂȂ肷�����p�C�v�̂��߂�Decoded Cache�Ƃ��Ă̕������ڂ���Ă��܂��ăC���[�W�������ǁB
���܂ł̏��ŁANehalem�͂���ς�AMerom-Based�ȃR�A��native quad-core+CSI+��
�Ƃ������ƂɂȂ肻���B
�ŁA+���̒��g�̌��́A���̂Ƃ���Trace Cache, Chip-Multithreading, SIMD���ӂ̊g���Ƃ����B
>>556�ł́ASMT���Ă��Ƃŏ��������ǂ���ρASMT�͍l�������Ă���ϖ��ʂ��Ǝv�����B
SMT�́ANetBurst�̗�ł����ƁA3uops/cycle�����Ȃ��M�d��NetBurst��Trace Cache Fetch, Retire�̑ш��
�����ɕ������āA2thread���������Ă���(SMT�ł́ASingleThread���\�����Ƌ]���ɂȂ�̂͂�ނȂ�)�B
�ق��ɂ�SMT�p�ɑ��d������Ă��Ȃ��p�C�v��̃��\�[�X��2thread�ԂŒD�������ɂȂ��Ă����B
Nehalem�ł́ATraceCache������̂��Ȃ��̂��͂܂��킩��Ȃ����A
������ɂ���SMT���̗p�����ꍇ�AiFetch�ш�ȂǁA�����ш��Thread��2�����A4����������A
���܂�����Ă���荇���ɂȂ����肷��̂ŁA�^�_�ł����A4 core���v���Z�b�T�R�A�������āA
Single Thread���\�̕����M�d���Ǝv����̂ɕ���p���ł��������Ȃ����ƁB
�Q�����̂�����MT�Z�p�́AMontecito��SoEMT�݂�����Coarse Grained��MT�Z�p�̕���
����p�����Ȃ�����SMT���\���������Ȃ�Ȃ����Ǝv���Ă݂���B
Trace Cache�͌��X��wide band�Ȗ���Fetch�̂��߂̋Z�p�Ȃ̂ŁA
�ނ��덂IPC��Energy Efficient�ȃA�[�L�ŗL�]�Ȃ킯�B
NetBurst�ł́A��q�̒ʂ�3ups/cycle��TC Fetch�ш悵���Ƃ�ĂȂ��āA
deep�ɂȂ肷�����p�C�v�̂��߂�Decoded Cache�Ƃ��Ă̕������ڂ���Ă��܂��ăC���[�W�������ǁB
Core Microarchitecture Performance: Woodcrest Preview
http://www.realworldtech.com/includes/templates/articles.cfm?ArticleID=RWT052306090721&mode=print
Intel's Woodcrest processor previewed
The Bensley server platform debuts
http://www.techreport.com/etc/2006q2/woodcrest/index.x?pg=1
TechReport��RealWorldTech��Woodcrest�̃��r���[����Ă��B
�����ǂ߂���Woodcrest�}�j�A�̗\���i�E�́E�j
����"Core"�A�[�L�̃x���`�A���r���[���O���C���Ȃ��炢�����ɂ�������ǂ����B
http://www.realworldtech.com/includes/templates/articles.cfm?ArticleID=RWT052306090721&mode=print
Intel's Woodcrest processor previewed
The Bensley server platform debuts
http://www.techreport.com/etc/2006q2/woodcrest/index.x?pg=1
TechReport��RealWorldTech��Woodcrest�̃��r���[����Ă��B
�����ǂ߂���Woodcrest�}�j�A�̗\���i�E�́E�j
����"Core"�A�[�L�̃x���`�A���r���[���O���C���Ȃ��炢�����ɂ�������ǂ����B
Tanglewood�⋌Nehalem�ŗ\�z����Ă����v�V�I�Z�p�Ő����c���Ă�����̂͂���̂ł��傤���H
>>606
��Nehalem�����������z���H
Mitosis: speculative threads
http://techreport.com/etc/2005q3/idf/index.x?pg=4
��Nehalem�����������z���H
Mitosis: speculative threads
http://techreport.com/etc/2005q3/idf/index.x?pg=4
Mitosis�͂��܂�m���ĂȂ�Intel�o���Z���i�`�[�����������Ă��ŁA
����Gesher������̐��ザ��Ȃ����ƁB��Nehalem�Ƃ͊W�Ȃ��Ǝv���B
���A�����͂����Q��B
����Gesher������̐��ザ��Ȃ����ƁB��Nehalem�Ƃ͊W�Ȃ��Ǝv���B
���A�����͂����Q��B
>����Gesher������̐��ザ��Ȃ����ƁB
�̗p���ꂽ�Ƃ��Ă��ˁB
�̗p���ꂽ�Ƃ��Ă��ˁB
610 �Finteler@�ϑz �F2006/05/28(��) 12:43:02 ID:xg9MR68Z0
>>603�̘b�͂����܂Ŗϑz�Ă̈�B�ϑz�̓}���`�V�i���I�`���ł���B
SMT��Trace Cache��낵���A�����̃��x��������킯�ŁA�H�v����ł̓��X�N���}�����邾�낤���A
��Ώ̂����Ȃ�����Ȃ����A�\���͂Ȃ��Ȃ��ł��傤�B
�ł��A���@�X���b�h�n�͍����ȊO�̃n�[�h�E�G�A�A���[�}�[�T�C�g�ł͂���قǘb��ɂȂ��ĂȂ��悤�����A
�R���Tejas�A��Nehalem�ł������̗p����Ƃ����ϑz�͂Ƃ������A���݂͂����ƋL�����Ȃ��B
����Nehalem�ŁASMT, SpMT�n�̂���������炢������Ƃ��Ă��A
Israel��Gesher����ł͂܂��܂��S���������̈قȂ�g���ɂȂ��āA��ߐ��̑����ɂȂ�\���B
SMT��Trace Cache��낵���A�����̃��x��������킯�ŁA�H�v����ł̓��X�N���}�����邾�낤���A
��Ώ̂����Ȃ�����Ȃ����A�\���͂Ȃ��Ȃ��ł��傤�B
�ł��A���@�X���b�h�n�͍����ȊO�̃n�[�h�E�G�A�A���[�}�[�T�C�g�ł͂���قǘb��ɂȂ��ĂȂ��悤�����A
�R���Tejas�A��Nehalem�ł������̗p����Ƃ����ϑz�͂Ƃ������A���݂͂����ƋL�����Ȃ��B
����Nehalem�ŁASMT, SpMT�n�̂���������炢������Ƃ��Ă��A
Israel��Gesher����ł͂܂��܂��S���������̈قȂ�g���ɂȂ��āA��ߐ��̑����ɂȂ�\���B
Parrot�͉������ɂȂ肻���������H
��AParrot�Ƒ��̋Z�p�i�}���`�X���f�B���O�Ƃ��j�Ƃ��̑����������āB
��AParrot�Ƒ��̋Z�p�i�}���`�X���f�B���O�Ƃ��j�Ƃ��̑����������āB
Parrot��Gesher�ɂ͊Ԃɍ���Ȃ��Ǝv��
196MAC�I�^sage2006/04/15(�y) 16:01:57 ID:JAuAcVprAnandtech�̃��C�^�[�A
Johan De Gelas����AcesHardware�f����Core�A�[�L�e�N�`���Ɋւ��鎟��̋L��
�̎�ނœ�����������������Ă���Ă��邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=115161295&forumid=1
�@�EParrot�̌����͌p�����Ă��邪����������s��
�@�E�g���[�X�L���b�V�������������\��
�@�E512-bit��SIMD�̂悤�ȃx�N�g���v���Z�b�T�I�g���̗\��햳��
�@�EISA�g���ɂ����Č��ʂ��㏑�����Ȃ�3-ops�^�C�v�̖��߃Z�b�g�������̗\��햳��
Johan De Gelas����AcesHardware�f����Core�A�[�L�e�N�`���Ɋւ��鎟��̋L��
�̎�ނœ�����������������Ă���Ă��邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=115161295&forumid=1
�@�EParrot�̌����͌p�����Ă��邪����������s��
�@�E�g���[�X�L���b�V�������������\��
�@�E512-bit��SIMD�̂悤�ȃx�N�g���v���Z�b�T�I�g���̗\��햳��
�@�EISA�g���ɂ����Č��ʂ��㏑�����Ȃ�3-ops�^�C�v�̖��߃Z�b�g�������̗\��햳��
614 �F���̖��ݒ��F2006/05/29(��) 13:02:51 ID:AuUObKHg0
���AOS10.2��UPS�i�I��������BX35F�j�g���Ă܂��B
�Ă��g���Ă܂���BOSX���̊��Ȃ̂ŏ��X�d���������悤��
�ǂ����Ď�����܂�����VPC�T�œ����Ă���W2K�̓d���Ȃ�ˁB
VPC�̐ݒ��USB�o�R��UPS���͕\���������̂́A�Ȃ�����
�I�����Ă������ɉ�������Ă��܂��܂��B
�Ȃ̂ŁA���RW2K�ł�UPS��F���ł��܂���B
�����l�Ȍ��ۂ̐l���܂��H
�Ă��g���Ă܂���BOSX���̊��Ȃ̂ŏ��X�d���������悤��
�ǂ����Ď�����܂�����VPC�T�œ����Ă���W2K�̓d���Ȃ�ˁB
VPC�̐ݒ��USB�o�R��UPS���͕\���������̂́A�Ȃ�����
�I�����Ă������ɉ�������Ă��܂��܂��B
�Ȃ̂ŁA���RW2K�ł�UPS��F���ł��܂���B
�����l�Ȍ��ۂ̐l���܂��H
>>614
�����������w �m����uPs�����ǂ�
�����������w �m����uPs�����ǂ�
�G���Ō㓡�L�������ǂ݂���o��
Gesher�̓R�A�Ԃ̃C���^�[�R�l�N�g�ɓ���ȋZ�p���̗p���Ă���
�R�A�Ԃ͍��x�ɓ��������E�E�E�Ȃ�炩���
Gesher�̓R�A�Ԃ̃C���^�[�R�l�N�g�ɓ���ȋZ�p���̗p���Ă���
�R�A�Ԃ͍��x�ɓ��������E�E�E�Ȃ�炩���
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=1&v=1&if=0&ncf=1&nct=256&cpcf=1&cpct=2&mf=200&mt=3800&o=0&o=1&start=20
Woodcrest�̈����Ԃ�ɂ́c(;�L�D�M)
Woodcrest�̈����Ԃ�ɂ́c(;�L�D�M)
2006 Technology Analyst Day
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_14047,00.html
AMD�̃A�i���X�g�f�C�̎����͂������痎�Ƃ��܂��B
http://www.amd.com/us-en/Corporate/InvestorRelations/0,,51_306_14047,00.html
AMD�̃A�i���X�g�f�C�̎����͂������痎�Ƃ��܂��B
Intel single cores speed towards chip gulag
http://www.theinquirer.net/?article=32023
Conroe-L = Core 2 Solo�́A65nm�ASingle Core�A800MHz FSB�A512kB-1MB L2�AVT�Ȃ���"Core"���i�ŁA
H2 2007�o��B�����A�ȑO�̏�炵�āAConroe-L = Millville�B
http://www.theinquirer.net/?article=32023
Conroe-L = Core 2 Solo�́A65nm�ASingle Core�A800MHz FSB�A512kB-1MB L2�AVT�Ȃ���"Core"���i�ŁA
H2 2007�o��B�����A�ȑO�̏�炵�āAConroe-L = Millville�B
Benchmarking Conroe: First Look at Core 2 Extreme
http://www.extremetech.com/article2/0,1697,1970192,00.asp
Core 2 Extreme�̃x���`�B
http://www.extremetech.com/article2/0,1697,1970192,00.asp
Core 2 Extreme�̃x���`�B
Intel's LaGrande security platform to arrive in H2 2007
http://www.tgdaily.com/
> According to sources, the upcoming Averill Pro (desktop, due in Q3 2006) and Santa Rosa (mobile, due in Q2 2007)
> platforms will support LT through the new ICH8 southbridge, but complementing trusted platform modules (TPM)
> will not be available until the following chipset generation.
> Intel apparently plans to bring TPMs to the market once the chipsets "Weybridge" (desktop, H2 2007) and "Montevina"
> (mobile, H1 2008) will hit the market. Both chipsets will be based on the ICH9 southbridge and support LT with connecting
> functionality to Windows Vista's "next Generation Secure Computing Base" (NGSCB).
Intel��LaGrande�e�N�m���W�́AAverill Pro = vPro, Santa Rosa PF�ł̓T�|�[�g����Ă͂��邪�A
TPM = Trusted Platform Module�́A���̐���̃`�b�v�Z�b�g�܂ŗ��p�ł��Ȃ��B
Weybridge�`�v�Z�g (Desktop, ICH9, H2 2007)
Montevina�`�v�Z�g (Mobile, ICH9, H1 2008)
��TPM�T�|�[�g�B
���X�Ɏ��X����`�v�Z�g��o�Ă���㩁B
http://www.tgdaily.com/
> According to sources, the upcoming Averill Pro (desktop, due in Q3 2006) and Santa Rosa (mobile, due in Q2 2007)
> platforms will support LT through the new ICH8 southbridge, but complementing trusted platform modules (TPM)
> will not be available until the following chipset generation.
> Intel apparently plans to bring TPMs to the market once the chipsets "Weybridge" (desktop, H2 2007) and "Montevina"
> (mobile, H1 2008) will hit the market. Both chipsets will be based on the ICH9 southbridge and support LT with connecting
> functionality to Windows Vista's "next Generation Secure Computing Base" (NGSCB).
Intel��LaGrande�e�N�m���W�́AAverill Pro = vPro, Santa Rosa PF�ł̓T�|�[�g����Ă͂��邪�A
TPM = Trusted Platform Module�́A���̐���̃`�b�v�Z�b�g�܂ŗ��p�ł��Ȃ��B
Weybridge�`�v�Z�g (Desktop, ICH9, H2 2007)
Montevina�`�v�Z�g (Mobile, ICH9, H1 2008)
��TPM�T�|�[�g�B
���X�Ɏ��X����`�v�Z�g��o�Ă���㩁B
Intel's Secret Weapon For Kentsfield : Bad Axe 2
http://www.vr-zone.com/index.php?i=3703
>Currently, the Intel D975XBX (Bad Axe 1) rev. 304 boards out there can support the upcoming
>Conroe and even the quad-core Kentsfield since the board is based on VRD11 design guideline
>and both processors work fine with VRD11. As for thermal envelope, Conroe is 65W and Kentsfield is 95W.
�Ȃ��i975�`�v�Z�g with VRM11�ȃ}�U�[ Intel D975XBX rev.304��Kentsfield�܂őΉ��B
��p��Barelake�`�v�Z�g�̓o�ꎞ����>>591�̂悤�ɒx���̂�(Kentsfield�́A1���ʂɏo��)�A
�^�₾��������i975�ł��̂���킯���B�Ȃ�قǁi�E�́E�j
TDP
Kentsfield 95W
Conroe C2X 80W
Conroe C2D 65W
http://www.vr-zone.com/index.php?i=3703
>Currently, the Intel D975XBX (Bad Axe 1) rev. 304 boards out there can support the upcoming
>Conroe and even the quad-core Kentsfield since the board is based on VRD11 design guideline
>and both processors work fine with VRD11. As for thermal envelope, Conroe is 65W and Kentsfield is 95W.
�Ȃ��i975�`�v�Z�g with VRM11�ȃ}�U�[ Intel D975XBX rev.304��Kentsfield�܂őΉ��B
��p��Barelake�`�v�Z�g�̓o�ꎞ����>>591�̂悤�ɒx���̂�(Kentsfield�́A1���ʂɏo��)�A
�^�₾��������i975�ł��̂���킯���B�Ȃ�قǁi�E�́E�j
TDP
Kentsfield 95W
Conroe C2X 80W
Conroe C2D 65W
�ϑz�x������߂č����̂ŃX���[��OK�B
2010�N�̍ŏ�����32nm��z�肵��Gesher�}�C�N���A�[�L�B
32nm�v���Z�X���ƃ_�C�T�C�Y�I�ȗ]�T��"65nm Core"��Ŗ�4�{�Ƃ������ƂɂȂ�A
���̂������P���Ȍv�Z�ŁA�L���b�V���T�C�Y���̂܂܂ł�4 issue OOO��Merom 8 core����150sqmm����
�_�C�Ŏ����ł��Ă��܂��Ƃ����]�T���B
Intel��PARROT�֘A�̘_���ł�4-issue OOO���x�[�X���C���Ƃ���ƁA
�m��4-issue OOO+PARROT��1.4�{�A8-issue OOO+PARROT�ł�2.4�{�̃_�C�G���A�ɂȂ�Ƃ��B
�����^�Ɏčl����ƁA32nm�v���Z�X�ł́A���̋@�\�g���Ȃǂ�������x����ƍl����̂����ʂƂ��Ă��A
4-issue OOO+PARROT�ȃA�[�L�ł�4+ core�A8-issue PARROT�ł́A2+ core�ł��V�}�C�N���A�[�L�Ƃ���
�����I�ȃ_�C�T�C�Y�Ŏ����ł������B
2010�N��Nehalem�ł�PARROT�̘_���A�m��2003�N����7�N���o�߂��Ă��邱�ƂɂȂ�A�����I�ɂ�PARROT���Â����邭�炢�̗]�T������܂��B
2010�N�̍ŏ�����32nm��z�肵��Gesher�}�C�N���A�[�L�B
32nm�v���Z�X���ƃ_�C�T�C�Y�I�ȗ]�T��"65nm Core"��Ŗ�4�{�Ƃ������ƂɂȂ�A
���̂������P���Ȍv�Z�ŁA�L���b�V���T�C�Y���̂܂܂ł�4 issue OOO��Merom 8 core����150sqmm����
�_�C�Ŏ����ł��Ă��܂��Ƃ����]�T���B
Intel��PARROT�֘A�̘_���ł�4-issue OOO���x�[�X���C���Ƃ���ƁA
�m��4-issue OOO+PARROT��1.4�{�A8-issue OOO+PARROT�ł�2.4�{�̃_�C�G���A�ɂȂ�Ƃ��B
�����^�Ɏčl����ƁA32nm�v���Z�X�ł́A���̋@�\�g���Ȃǂ�������x����ƍl����̂����ʂƂ��Ă��A
4-issue OOO+PARROT�ȃA�[�L�ł�4+ core�A8-issue PARROT�ł́A2+ core�ł��V�}�C�N���A�[�L�Ƃ���
�����I�ȃ_�C�T�C�Y�Ŏ����ł������B
2010�N��Nehalem�ł�PARROT�̘_���A�m��2003�N����7�N���o�߂��Ă��邱�ƂɂȂ�A�����I�ɂ�PARROT���Â����邭�炢�̗]�T������܂��B
����AIntel�����ł́AMany Core�Z�p���̗l�X�Ȃ̂�͍����Ă���l�q�B
�ł��AGeneral/Special�ȃR�A��fablic�ɂȂ��ʼn]�X�Ƃ��AMitosis�Ƃ��́A
�{����Future�̗̈�̂悤�Ɏv���邵�A���l����͖̂��ʂ��Ǝv���̂ł�߂āA
��Ԃ��肻�����ƌl�I�Ɏv��ACCMP�ɂ��āB
ACCMP�̘_���ł́A��R�A x2 + ���R�A x4 +���R�A x16�̑g�ݍ��킹�̌v22�R�A�̔�Ώ̂ȃ}���`�R�A���ɂ��čl���Ă����B
���ۂ̐��i�ŁA�Ⴆ�Ή��̏���ɍl�����g�ݍ��킹�ł�����ƍl���Ă݂Ă��A32nm�ł͉\�����ɂ݂���
(2006�N���݂̂̃}���`�R�A�ߓn����65nm����̃R�A�̓L���b�V���ʐς��傫������ˁB)�B
�� 4-issue OOO PARROT x 2
�� 3-issue OOO P6�N���X x 4
�� 1-issue SIMD�� x 16
������A�ŏ�����32nm��z�肵���A�[�L�e�N�`���ƂȂ�Gesher�ł́AACCMP�������łȂ��Ă���K�͂�
��Ώ̂ȃ}���`�R�A�̒����������Ă���̂ł͂Ȃ����ƍl�����킯�ł��B
���Ȃ݂ɁAIntel��Dynamic Multi-threading�n�̋Z�p�́A���Ƃ���
Trace Buffer, Trace Cache���x�[�X�ɍl���Ă����߂�����A���������Ӗ��ł́A
����TC�x�[�X��PARROT�Ƃ͐e�a���͍����̂�������Ȃ��B
�ł��A�R��͍��̂Ƃ���Gesher�ł͂Ȃ��Ǝv���Ă邯�ǂȁR(�L�[�M)�m
�ł��AGeneral/Special�ȃR�A��fablic�ɂȂ��ʼn]�X�Ƃ��AMitosis�Ƃ��́A
�{����Future�̗̈�̂悤�Ɏv���邵�A���l����͖̂��ʂ��Ǝv���̂ł�߂āA
��Ԃ��肻�����ƌl�I�Ɏv��ACCMP�ɂ��āB
ACCMP�̘_���ł́A��R�A x2 + ���R�A x4 +���R�A x16�̑g�ݍ��킹�̌v22�R�A�̔�Ώ̂ȃ}���`�R�A���ɂ��čl���Ă����B
���ۂ̐��i�ŁA�Ⴆ�Ή��̏���ɍl�����g�ݍ��킹�ł�����ƍl���Ă݂Ă��A32nm�ł͉\�����ɂ݂���
(2006�N���݂̂̃}���`�R�A�ߓn����65nm����̃R�A�̓L���b�V���ʐς��傫������ˁB)�B
�� 4-issue OOO PARROT x 2
�� 3-issue OOO P6�N���X x 4
�� 1-issue SIMD�� x 16
������A�ŏ�����32nm��z�肵���A�[�L�e�N�`���ƂȂ�Gesher�ł́AACCMP�������łȂ��Ă���K�͂�
��Ώ̂ȃ}���`�R�A�̒����������Ă���̂ł͂Ȃ����ƍl�����킯�ł��B
���Ȃ݂ɁAIntel��Dynamic Multi-threading�n�̋Z�p�́A���Ƃ���
Trace Buffer, Trace Cache���x�[�X�ɍl���Ă����߂�����A���������Ӗ��ł́A
����TC�x�[�X��PARROT�Ƃ͐e�a���͍����̂�������Ȃ��B
�ł��A�R��͍��̂Ƃ���Gesher�ł͂Ȃ��Ǝv���Ă邯�ǂȁR(�L�[�M)�m
2010�N��Nehalem�ł�
2010�N��Gesher�ł�
2010�N��Gesher�ł�
>>620
XE��Foxton��Enable�����Ǝv���Ă����A�Ȃ��݂������ˁB
XE��Foxton��Enable�����Ǝv���Ă����A�Ȃ��݂������ˁB
Benchmarking Conroe: First Look at Core 2 Extreme
> ttp://www.extremetech.com/article2/0,1697,1970190,00.asp
�������ɁAConroe�̍ŏ��CPU�͂������Ȃ��B
> ttp://www.extremetech.com/article2/0,1697,1970190,00.asp
�������ɁAConroe�̍ŏ��CPU�͂������Ȃ��B
Kentsfield(4-core)���o����A�ǂ̋@��ɍ̗p����̂��Ȃ��B
Mac Pro�ɂ�Kentsfield�A����ȊO�ɂ�Core2 Duo���Ċ������H
�ł��A�ŏ���Mac Pro��Woodcrest�~2�ŏo��Ƃ�����A�Ȃ��Ȃ��ʓ|�Ȃ��ƂɂȂ肻�����B
Mac Pro�ɂ�Kentsfield�A����ȊO�ɂ�Core2 Duo���Ċ������H
�ł��A�ŏ���Mac Pro��Woodcrest�~2�ŏo��Ƃ�����A�Ȃ��Ȃ��ʓ|�Ȃ��ƂɂȂ肻�����B
ando����Woodcrest�ɂ��ăR�����g
> ����SPECint�ʼn��́C���̂悤�ȍ������\���o��̂������ł��܂���
> ����SPECint�ʼn��́C���̂悤�ȍ������\���o��̂������ł��܂���
���������Ԃ������Ĉ��p����ƁAWoodcrest��SPECint�Ń`�[�g�ł����Ă�̂��ƈ������^���Ă�悤�ɓǂ߂Ă��܂���
�����A�ŏ����猩�����Ă������Ă��Ȃ��������炾��B
��1�j�ǂ����X�}�[�g�ȃL���b�V���H
���ۂ́A���͂ȃv���t�F�b�`�@�\�ƃo�X����{�ɂ��������]���A�ȑf�ł��邪�̂ɔ��ɋ��͂��B
��2)���@���[�h�E�E�E����Ȃ̂��ĂȂ������́H
�������𗝉����Ă���Ƃ͎v���Ȃ������A�������ʂɎ��s���Ă��܂��ƃX�g�A�A�h���X�����܂�̂��x��Ă��܂��ƃp�C�v���C���͋l�܂��Ă��܂��B
���̂��Ƃ��痝�����Ă��Ȃ������ł�����B
�����A�����l�����Ƀ��[�h�������Ă����ăX�g�A�A�h���X�Ƃ̏Փ˂��Ȃ����Ƃ��m�F����Ă���p�C�v���C���֓�������Ƃł��v���Ă����̂��낤�B
���̂������INTEL���ɔ�ɂ��Ă���ǂ̂悤�ɐ���œ��@���[�h�𐧌䂵�Ă���̂��̏ڍׂ͔��\���Ă��Ȃ��B
�P�ɁA�X�g�A�A�h���X�Ƃ̏Փ˂��Ȃ����Ƃ��m�肷��܂Ń��^�C�A���Ȃ��Ƃ������������Ă��Ȃ��B
�������A���@���[�h�����s���J��Ԃ����ꍇ�̉����H�����ڂ��Ă��邱�Ƃ���A����ȒP���Ȃ��̂łȂ����Ƃ͖��炩���B
��1�j�ǂ����X�}�[�g�ȃL���b�V���H
���ۂ́A���͂ȃv���t�F�b�`�@�\�ƃo�X����{�ɂ��������]���A�ȑf�ł��邪�̂ɔ��ɋ��͂��B
��2)���@���[�h�E�E�E����Ȃ̂��ĂȂ������́H
�������𗝉����Ă���Ƃ͎v���Ȃ������A�������ʂɎ��s���Ă��܂��ƃX�g�A�A�h���X�����܂�̂��x��Ă��܂��ƃp�C�v���C���͋l�܂��Ă��܂��B
���̂��Ƃ��痝�����Ă��Ȃ������ł�����B
�����A�����l�����Ƀ��[�h�������Ă����ăX�g�A�A�h���X�Ƃ̏Փ˂��Ȃ����Ƃ��m�F����Ă���p�C�v���C���֓�������Ƃł��v���Ă����̂��낤�B
���̂������INTEL���ɔ�ɂ��Ă���ǂ̂悤�ɐ���œ��@���[�h�𐧌䂵�Ă���̂��̏ڍׂ͔��\���Ă��Ȃ��B
�P�ɁA�X�g�A�A�h���X�Ƃ̏Փ˂��Ȃ����Ƃ��m�肷��܂Ń��^�C�A���Ȃ��Ƃ������������Ă��Ȃ��B
�������A���@���[�h�����s���J��Ԃ����ꍇ�̉����H�����ڂ��Ă��邱�Ƃ���A����ȒP���Ȃ��̂łȂ����Ƃ͖��炩���B
�܂��A�������͎������v���Z�T�A�[�L�e�N�g������A
����ꂽ����̒��ł����ɐ��\�グ�鎖��������g�ɂ��݂ĕ������Ă�낤�B
ttp://journal.mycom.co.jp/articles/2006/03/21/intelcore/004.html
>20%�̉��P�Ƃ����Ƒ債�����Ƃ͖����悤�Ɏv���邩���m��Ȃ����A
>�}�C�N���A�[�L�e�N�`����20%���\���グ��Ƃ����̂́A���ƂقǍ��l�ɑ�ςȂ̂ł���B
����ꂽ����̒��ł����ɐ��\�グ�鎖��������g�ɂ��݂ĕ������Ă�낤�B
ttp://journal.mycom.co.jp/articles/2006/03/21/intelcore/004.html
>20%�̉��P�Ƃ����Ƒ債�����Ƃ͖����悤�Ɏv���邩���m��Ȃ����A
>�}�C�N���A�[�L�e�N�`����20%���\���グ��Ƃ����̂́A���ƂقǍ��l�ɑ�ςȂ̂ł���B
634 �F ��.MeromIYCE �F2006/06/05(��) 20:47:11 ID:0iNhU6590
635 �F���̖��ݒ��F2006/06/15(��) 02:07:04 ID:ZOpXj5nz0
{kind=link}
�������
>>636
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
�v�́A2007�N�㔼����2008�N�O���ɂ����āAAthlon 64��啝�g���������̂��o��Ƃ������ƁB
2006�N�㔼���_��Core2 Duo���͑�����������Ȃ��ˁB
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai272.htm
�v�́A2007�N�㔼����2008�N�O���ɂ����āAAthlon 64��啝�g���������̂��o��Ƃ������ƁB
2006�N�㔼���_��Core2 Duo���͑�����������Ȃ��ˁB
4�f�R�[�h/cykle�Ő^�ʖڂɐv���Ă�Ȃ琦�������m���
�L���b�V�����n��Ȃ�Ŋ��҂͂��Ă��Ȃ���
���X���Ⴂ
�L���b�V�����n��Ȃ�Ŋ��҂͂��Ă��Ȃ���
���X���Ⴂ
�����o����̂Ɨ��N�o�邩���������̂��r����Ă�...w
640 �F���̖��ݒ��F2006/06/16(��) 23:31:14 ID:deQtrtEt0
Mac�̃V���[�g�J�b�g�L�[�͖��炩�Ɍ���҂������Ă��Ȃ��B
�Ȃ��V���[�g�J�b�g���������̂ɗ�����g���K�v������H
���Ń}�E�X�Ɏ��L���̂��ʓ|�Ȃ̂ɁA �����͕Ў肵���g���Ȃ�����L�[�{�[�h�ō�Ƃ��Ă���̂� �����v�������H
�V���[�g�J�b�g�L�[�̊��蓖�Ă�ύX�����������Ȃ����A �C�Ⴂ�}�J�[�ǂ��͂������������B
�ނ�̊�{�́w���̃R���s���[�^�͎����̕������� �����p�ɃJ�X�^�}�C�Y����͓̂��R�x�Ƃ������W�b�N�ɂ���B
����͋M�l�̎�������ɂ��镅�ꂽ�ь炾���̘b���B
�d���Ŏg���Ȃ�A�S�Ẵ��[�U�[�̍�Ƃꉻ����K�v������B
����̃A�v���P�[�V�����ɂ�����V���[�g�J�b�g�̍쐬�Ȃ�܂������AOS������V���[�g�J�b�g��ύX���Ă�����b�ɂȂ�Ȃ��B
����͉�Ђ̃R���s���[�^�ł����ċM�l�̃Y���l�^����Ȃ��B
�Ȃ��V���[�g�J�b�g���������̂ɗ�����g���K�v������H
���Ń}�E�X�Ɏ��L���̂��ʓ|�Ȃ̂ɁA �����͕Ў肵���g���Ȃ�����L�[�{�[�h�ō�Ƃ��Ă���̂� �����v�������H
�V���[�g�J�b�g�L�[�̊��蓖�Ă�ύX�����������Ȃ����A �C�Ⴂ�}�J�[�ǂ��͂������������B
�ނ�̊�{�́w���̃R���s���[�^�͎����̕������� �����p�ɃJ�X�^�}�C�Y����͓̂��R�x�Ƃ������W�b�N�ɂ���B
����͋M�l�̎�������ɂ��镅�ꂽ�ь炾���̘b���B
�d���Ŏg���Ȃ�A�S�Ẵ��[�U�[�̍�Ƃꉻ����K�v������B
����̃A�v���P�[�V�����ɂ�����V���[�g�J�b�g�̍쐬�Ȃ�܂������AOS������V���[�g�J�b�g��ύX���Ă�����b�ɂȂ�Ȃ��B
����͉�Ђ̃R���s���[�^�ł����ċM�l�̃Y���l�^����Ȃ��B
641 �F���̖��ݒ��F2006/06/22(��) 05:17:18 ID:ORGKeL+n0
733 �F�s���ȃf�o�C�X���� �F2006/06/22(��) 03:04:40 ID:hlliXPGH
Intel Quad Core CPU previewed
Hardware Roundup 2.4GHz, 8MB cache monster is Kentsfield
http://www.theinquirer.net/?article=32555
Intel Quad Core CPU previewed
Hardware Roundup 2.4GHz, 8MB cache monster is Kentsfield
http://www.theinquirer.net/?article=32555
�y���݂ɂł��Ȃ���
Intel together forever ? or at least 2010 ? with x86
http://www.theregister.co.uk/2006/06/07/intel_x86_2010/
"We pretty much have x86 as the going assumption," said Intel's CTO Justin Rattner,
speaking here today at an Intel Labs press event. "As we talk to our partners and customers,
we get tremendous resonance around (x86)."
Rattner noted that there's a tendency to look at creating new instruction sets when things aren't
"going as well as you expect." Ultimately, many of these specialized efforts morph back into
general purpose computing parts. So, Intel now "tries to resist the natural urge to invent something new."
In the future, Intel wants to build x86 chips that consume 10x lower power than today's parts while
delivering 10x more performance, Rattner said.
x86�̎���͏I���Ȃ��B
// Intel��{�Ƃ�Santa Clara�`�[�����AIA-32�x�[�X�V�A�[�L���������炵���c(;�L�D�M)
http://www.theregister.co.uk/2006/06/07/intel_x86_2010/
"We pretty much have x86 as the going assumption," said Intel's CTO Justin Rattner,
speaking here today at an Intel Labs press event. "As we talk to our partners and customers,
we get tremendous resonance around (x86)."
Rattner noted that there's a tendency to look at creating new instruction sets when things aren't
"going as well as you expect." Ultimately, many of these specialized efforts morph back into
general purpose computing parts. So, Intel now "tries to resist the natural urge to invent something new."
In the future, Intel wants to build x86 chips that consume 10x lower power than today's parts while
delivering 10x more performance, Rattner said.
x86�̎���͏I���Ȃ��B
// Intel��{�Ƃ�Santa Clara�`�[�����AIA-32�x�[�X�V�A�[�L���������炵���c(;�L�D�M)
http://www.eweek.com/article2/0,1895,1976374,00.asp
That said, he added that Intel probably will put the memory controller on the chip at some point,
though he declined to be more specific. In the same vein, Intel also is looking at integrating the
graphics controller with the processor, though Bhandarkar said no timetable has been set.
�����́AMemory Contraller����Ȃ��ăr�f�I�����̉\���c(;�L�D�M)
>>128������ł����������ǍŏI�I�ɂ̓��j�B�R�A����
�ቿ�i�E�����d�͂̓����`�b�v�������v�Ŏ�͂ɂȂ邩����(�m
That said, he added that Intel probably will put the memory controller on the chip at some point,
though he declined to be more specific. In the same vein, Intel also is looking at integrating the
graphics controller with the processor, though Bhandarkar said no timetable has been set.
�����́AMemory Contraller����Ȃ��ăr�f�I�����̉\���c(;�L�D�M)
>>128������ł����������ǍŏI�I�ɂ̓��j�B�R�A����
�ቿ�i�E�����d�͂̓����`�b�v�������v�Ŏ�͂ɂȂ邩����(�m
4 cores in 1,Conroe E6600 8Mb Cache,Kentsfield result@MSI 975X
http://www.xtremesystems.org/forums/showthread.php?p=1527913
>>641�̃l�^���BKentsfield��ES�i��2.4GHz�������ғ����B
����͉ɂ���������Nehalem����݂̐V�l�^�̗\���i�E�́E�j
http://www.xtremesystems.org/forums/showthread.php?p=1527913
>>641�̃l�^���BKentsfield��ES�i��2.4GHz�������ғ����B
����͉ɂ���������Nehalem����݂̐V�l�^�̗\���i�E�́E�j
inteler�̓R���ǂ��v���H
�Q�e���m�e�N�m���W�����܂�����
>"Reverse(Anti)-Hyper-Threading"�Z�p���āA
>X2��2�̃R�A��������6IPC(3IPCx2��)�̃V���O���R�A���G�~�����[�g����Z�p�Ƃ̂���(CONROE��4IPC)�B
329 ���O�FSocket774[sage] ���e���F2006/06/24(�y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
�p�t�H�[�}���X�����AM2������Ȃ���B
939�ŏo����ΐ_�Ȃ̂ɂ�
336 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:38:21 ID:W3KCOSqT
Intel���������Ƃ�邻���ł���
�P���c��4�R�A��1CPU�ɂ�
98 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:33:05 ID:Utko172H
�Ȃ����悤�Ȃ̂��c
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
�Q�e���m�e�N�m���W�����܂�����
>"Reverse(Anti)-Hyper-Threading"�Z�p���āA
>X2��2�̃R�A��������6IPC(3IPCx2��)�̃V���O���R�A���G�~�����[�g����Z�p�Ƃ̂���(CONROE��4IPC)�B
329 ���O�FSocket774[sage] ���e���F2006/06/24(�y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
�p�t�H�[�}���X�����AM2������Ȃ���B
939�ŏo����ΐ_�Ȃ̂ɂ�
336 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:38:21 ID:W3KCOSqT
Intel���������Ƃ�邻���ł���
�P���c��4�R�A��1CPU�ɂ�
98 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:33:05 ID:Utko172H
�Ȃ����悤�Ȃ̂��c
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
Intel Core 2 Duo (Conroe) E6400 and E6700: A Start to Be Remembered
http://www.digit-life.com/articles2/cpu/intel-conroe-2-13-ghz.html
>>559�̑����ŁAiXBT��Conroe vs Athlon FX vs Pentium XE�̃x���`�B
���ʂ͓��N���b�N�ŁAConroe��Athlon��蕽�ς�23%�����B
Preliminary Tests of Intel Core 2 Duo in Games
http://www.digit-life.com/articles2/video/conroe.html
�������̓Q�[���̃x���`�B
http://www.digit-life.com/articles2/cpu/intel-conroe-2-13-ghz.html
>>559�̑����ŁAiXBT��Conroe vs Athlon FX vs Pentium XE�̃x���`�B
���ʂ͓��N���b�N�ŁAConroe��Athlon��蕽�ς�23%�����B
Preliminary Tests of Intel Core 2 Duo in Games
http://www.digit-life.com/articles2/video/conroe.html
�������̓Q�[���̃x���`�B
�l�q�����B3+3 IPC�͂������ɕ��ꂾ�Ǝv�����B
A New Perspective : Intel�fs �gWoodcrest�h Xeon Previewed
http://www.gamepc.com/labs/view_content.asp?id=woodcrest&page=1
GamePC��Woodcrest�̃��r���[�B5140(2.33GHz)�܂ł�������ł��Ȃ������݂����B
http://www.gamepc.com/labs/view_content.asp?id=woodcrest&page=1
GamePC��Woodcrest�̃��r���[�B5140(2.33GHz)�܂ł�������ł��Ȃ������݂����B
�[���A���������V���O���X���b�h���}���`�X���b�h�ɕ�������Ȃ�Ăł���́H
>>651
������A�}���`�X���b�h�ɕ�������Z�p�ł͂Ȃ����B
�����I��2�R�A���̃��\�[�X��1�R�A�ɉ����B
��������s�R�A�ł͓���Ǝv�����ǂȁB
������A�}���`�X���b�h�ɕ�������Z�p�ł͂Ȃ����B
�����I��2�R�A���̃��\�[�X��1�R�A�ɉ����B
��������s�R�A�ł͓���Ǝv�����ǂȁB
�Ȃ�قǁBthx.
�����炭�A�����R�A���L���ɂȂ�Ɛ��\���ቺ���Ă��܂��n�̃A�v���ŁA
���̃R�A���\�t�g�����疳���ɂł��ijϰ�Ƃ����̂��^�̖ړI�łȂ����ƁB
�����ȒP�Ƀ��\�[�X����قǃn�[�h�̐��E�͊Â��Ȃ�㩁B
���̃R�A���\�t�g�����疳���ɂł��ijϰ�Ƃ����̂��^�̖ړI�łȂ����ƁB
�����ȒP�Ƀ��\�[�X����قǃn�[�h�̐��E�͊Â��Ȃ�㩁B
Intel Touts Core Multiplexing Technology
http://www.xbitlabs.com/news/cpu/display/20060627095448.html
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=10
>The thermal sensor is used for safety and reliability features, as thermal diodes were previously.
>However, it is also rumored that it may be used to increase the frequency of the MPU
>when the sensor determines that there is thermal headroom.
http://pc.watch.impress.co.jp/docs/2006/0116/ubiq145.htm
>Santa Rosa�pMerom�ɂ͂���Ƃ͕ʂ�42W�܂ŔM�v����d�͂��g�����邱�Ƃ��ł���B
>��̓I�ɂ͂��̎��_�ł̃g�b�vSKU��Merom�800�ɂ́A
>�^�[�{���[�h�ƌĂ����̃I�[�o�[�N���b�N���[�h���p�ӂ���Ă��āA
>OEM�x���_�͂���𗘗p�����v���\�ɂȂ�Ƃ����B
Core Multiplexing Technology �� �Ȃ�ƂȂ��I�[�o�[�N���b�N���[�h�@�\���ۂ��ȁE�E�E
http://www.xbitlabs.com/news/cpu/display/20060627095448.html
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144&p=10
>The thermal sensor is used for safety and reliability features, as thermal diodes were previously.
>However, it is also rumored that it may be used to increase the frequency of the MPU
>when the sensor determines that there is thermal headroom.
http://pc.watch.impress.co.jp/docs/2006/0116/ubiq145.htm
>Santa Rosa�pMerom�ɂ͂���Ƃ͕ʂ�42W�܂ŔM�v����d�͂��g�����邱�Ƃ��ł���B
>��̓I�ɂ͂��̎��_�ł̃g�b�vSKU��Merom�800�ɂ́A
>�^�[�{���[�h�ƌĂ����̃I�[�o�[�N���b�N���[�h���p�ӂ���Ă��āA
>OEM�x���_�͂���𗘗p�����v���\�ɂȂ�Ƃ����B
Core Multiplexing Technology �� �Ȃ�ƂȂ��I�[�o�[�N���b�N���[�h�@�\���ۂ��ȁE�E�E
Montecito�ŃL�����Z�����ꂽFoxton�e�N�m���W���B
Itanium�ł����Ȃ蓊��������̓f�X�N�g�b�v�ŗl�q�������ق��������Ƃ������f���ˁB
Itanium�ł����Ȃ蓊��������̓f�X�N�g�b�v�ŗl�q�������ق��������Ƃ������f���ˁB
Merom�̓m�[�g�������ȁB
���܂�B
���܂�B
Xbits�̋L�����������肾���B
Core Multiplexing Technology�͕��i2�R�A�ŋ��L���Ă�L2�L���b�V����
�Е��̃R�A���~�߂邱�Ƃɂ��1�R�A�Ő�L�o������ċZ�p����Ȃ��̂��H
��������SingleThread�̐��\���オ��A�ƁB
Core Multiplexing Technology�͕��i2�R�A�ŋ��L���Ă�L2�L���b�V����
�Е��̃R�A���~�߂邱�Ƃɂ��1�R�A�Ő�L�o������ċZ�p����Ȃ��̂��H
��������SingleThread�̐��\���オ��A�ƁB
SW Single Processor Mode�ɂ��Ă������낤
685 �FSocket774�F2006/06/29(��) 19:14:03 ID:6lPtT+wq
http://www.itmedia.co.jp/enterprise/articles/0606/29/news068.html
AMD�̉��z���Z�p�Ɍ��ׂ������āA�ǂ�OS�ł�100�����m�s�\�ȃ}���E�F�A���쐬�\�炵��
AMD���
VT�͑��v�Ȃ̂��c?����FIX���Ȃ낤��
http://www.itmedia.co.jp/enterprise/articles/0606/29/news068.html
AMD�̉��z���Z�p�Ɍ��ׂ������āA�ǂ�OS�ł�100�����m�s�\�ȃ}���E�F�A���쐬�\�炵��
AMD���
VT�͑��v�Ȃ̂��c?����FIX���Ȃ낤��
�N�������܂ˁ[
���ɑ��x������ł͂Ȃ����R�Ń}���`�X���b�h��p����͂�������킯�ŁA
���̂悤�ȃA�v���ł́A�����R�A���L���ɂȂ����ꍇ�A�t�ɐ��\���ቺ���Ă��܂��P�[�X���ł�킯�B
(����X���b�h���ʂ邢�����������Ă��Ȃ��Ėw�ǗV��ł����肷��ꍇ�Ȃ�)
OS��CPU�ɑ��đS�m�S�\�Ȃ킯�͂Ȃ��̂ŁA
�A�v�����̗v���ŁA���I�ɂ���Ȃ��R�A���E���Đ��\���ێ�������Core Multiplexing�̂悤�ȋZ�p���L���Ȃ��Ă���킯�B
�Е��̃R�A�ɕ������̃R�A�̃��\�[�X���Ƃ����̂́A�n�[�h�v�̖�肪����̂ŁA
���s���i�ł͂��̂悤�ȋ@�\�̂��߂̓����͖w�ǂ��ĂȂ����낤�������B
"Core"�̏ꍇ�Ashared L2��L1-to-L1�̃����N�͐������ꂻ���B
(�������A�����̋@�\�͂������������R�A���E���Ȃ��Ă�Single Thread�ɂȂ�Ώ���ɓ����Ă����킯����)
����̓W�J�ł��A���s���j�b�g�A�X�P�W���[���̃��\�[�X�g���͂͂����肢���ĕs�\���Ǝv����B
�撣���Ă�Fetch, Decode�Ȃǂ̃t�����g�G���h�����x���ƁB����ł��ш摝�₵�Ȃ���x�������ɉ�������̂�
�e�Ղł͂Ȃ��̂Ń^�_�ő����͂Ȃ�܂���B
�d�́E���M�̓s������l���āA�����R�A���E���ăI�[�o�[�N���b�N�Ƃ���Foxton�n�̓W�J�͍���l������B
�[���A���\�[�X���A�I�[�o�[�N���b�N�Ő��\�҂��������A���オ��Ō��ʂ��傫����Ȃ����ƁB
>>555, >>603�ł́ANehalem�ŁA4+4 core, 4 thread / core�Ƃ������b�����������ǁA
Core Multiplexing�ŃA�v�����̓s���ŁA�_���v���Z�b�T���E���邾���E���Ă��܂���̂́A
SMT�Ȃǂ̕���p���O����Ƃ��Ă��Ȃ�g����\���B
�Ƃ����̂��R��̊��z�B
���̂悤�ȃA�v���ł́A�����R�A���L���ɂȂ����ꍇ�A�t�ɐ��\���ቺ���Ă��܂��P�[�X���ł�킯�B
(����X���b�h���ʂ邢�����������Ă��Ȃ��Ėw�ǗV��ł����肷��ꍇ�Ȃ�)
OS��CPU�ɑ��đS�m�S�\�Ȃ킯�͂Ȃ��̂ŁA
�A�v�����̗v���ŁA���I�ɂ���Ȃ��R�A���E���Đ��\���ێ�������Core Multiplexing�̂悤�ȋZ�p���L���Ȃ��Ă���킯�B
�Е��̃R�A�ɕ������̃R�A�̃��\�[�X���Ƃ����̂́A�n�[�h�v�̖�肪����̂ŁA
���s���i�ł͂��̂悤�ȋ@�\�̂��߂̓����͖w�ǂ��ĂȂ����낤�������B
"Core"�̏ꍇ�Ashared L2��L1-to-L1�̃����N�͐������ꂻ���B
(�������A�����̋@�\�͂������������R�A���E���Ȃ��Ă�Single Thread�ɂȂ�Ώ���ɓ����Ă����킯����)
����̓W�J�ł��A���s���j�b�g�A�X�P�W���[���̃��\�[�X�g���͂͂����肢���ĕs�\���Ǝv����B
�撣���Ă�Fetch, Decode�Ȃǂ̃t�����g�G���h�����x���ƁB����ł��ш摝�₵�Ȃ���x�������ɉ�������̂�
�e�Ղł͂Ȃ��̂Ń^�_�ő����͂Ȃ�܂���B
�d�́E���M�̓s������l���āA�����R�A���E���ăI�[�o�[�N���b�N�Ƃ���Foxton�n�̓W�J�͍���l������B
�[���A���\�[�X���A�I�[�o�[�N���b�N�Ő��\�҂��������A���オ��Ō��ʂ��傫����Ȃ����ƁB
>>555, >>603�ł́ANehalem�ŁA4+4 core, 4 thread / core�Ƃ������b�����������ǁA
Core Multiplexing�ŃA�v�����̓s���ŁA�_���v���Z�b�T���E���邾���E���Ă��܂���̂́A
SMT�Ȃǂ̕���p���O����Ƃ��Ă��Ȃ�g����\���B
�Ƃ����̂��R��̊��z�B
Socket M�Ŗ{Merom�|���� ���s�x��Santa Rosa����
http://www.hkepc.com/bbs/news.php?tid=623670
Merom�p�̐V�\�P�b�g�ASocket M�Ă͂�߂āA
Santa Rosa Platform@H2 2007����ASocket P���o��B
���łɓ������ɁAMerom Core 2 Duo T7700�Ȃǂ��o��B
- Socket P
-- Keyed with A1, B1 Pins removed
-- Sacrificial Corner Balls (SCB) introduced
-- Not Pin-Compatible with Intel Core(TM) 2 Duo for Napa, or Intel Core(TM) Duo T2500
http://www.hkepc.com/bbs/news.php?tid=623670
Merom�p�̐V�\�P�b�g�ASocket M�Ă͂�߂āA
Santa Rosa Platform@H2 2007����ASocket P���o��B
���łɓ������ɁAMerom Core 2 Duo T7700�Ȃǂ��o��B
- Socket P
-- Keyed with A1, B1 Pins removed
-- Sacrificial Corner Balls (SCB) introduced
-- Not Pin-Compatible with Intel Core(TM) 2 Duo for Napa, or Intel Core(TM) Duo T2500
>>663
x86�̏ꍇ�̓f�R�[�_����������邾���ł��������ʂ����肻���Ȃ�����
x86�̏ꍇ�̓f�R�[�_����������邾���ł��������ʂ����肻���Ȃ�����
ando�����㓡�����Ɍ��ܔ����Ă�
>>666
URL���]
URL���]
Chip toys with Intel's Core Multiplexing
http://www.theinquirer.net/default.aspx?article=32747
> My personal theory (and it is just that) is that one possibility is that it is something developed for
> Merom as a way of reducing the hotspots on the chip that you would get when running in single core mode,
> for example when on battery, and that it is not a performance-enhanced mode targeted at the desktop people.
> The operating system would see just one processor, but code execution would switch between one core
> and the other, in order to keep the temperatures down.
INQ��Chip Mulligan���̐��ł́A
Core Multiplexing = Hot Spot��ŁA2�R�A���X�C�b�`���Đ�ւ��Ȃ���쓮���āA
���x�㏸��}����BOS�����1�v���Z�T�Ɍ�����B
// Multiplexing = �I���̈Ӗ�������킯�ŁA���̐������������Ă邩���i�E�́E�j
What Intel is calling a 2008 Xeon MP
http://www.theinquirer.net/default.aspx?article=32733
> WHAT DO YOU call a 2008-ish multicore Xeon MP? Intel calls it Aliceton, the sequel to Tigerton.
�V����Xeon MP�n�̃R�[�h�l�[����Aliceton�Ƃ����̂��o��B
Tigerton�̌�p��2008�N�ɏo��炵���B
// Tigerton�ɂ�Dunnington�Ƃ�����p�`�b�v�����݂��邪�A����Ƃ̊W�͕s���B
http://www.theinquirer.net/default.aspx?article=32747
> My personal theory (and it is just that) is that one possibility is that it is something developed for
> Merom as a way of reducing the hotspots on the chip that you would get when running in single core mode,
> for example when on battery, and that it is not a performance-enhanced mode targeted at the desktop people.
> The operating system would see just one processor, but code execution would switch between one core
> and the other, in order to keep the temperatures down.
INQ��Chip Mulligan���̐��ł́A
Core Multiplexing = Hot Spot��ŁA2�R�A���X�C�b�`���Đ�ւ��Ȃ���쓮���āA
���x�㏸��}����BOS�����1�v���Z�T�Ɍ�����B
// Multiplexing = �I���̈Ӗ�������킯�ŁA���̐������������Ă邩���i�E�́E�j
What Intel is calling a 2008 Xeon MP
http://www.theinquirer.net/default.aspx?article=32733
> WHAT DO YOU call a 2008-ish multicore Xeon MP? Intel calls it Aliceton, the sequel to Tigerton.
�V����Xeon MP�n�̃R�[�h�l�[����Aliceton�Ƃ����̂��o��B
Tigerton�̌�p��2008�N�ɏo��炵���B
// Tigerton�ɂ�Dunnington�Ƃ�����p�`�b�v�����݂��邪�A����Ƃ̊W�͕s���B
// >>536�̂�ɂƂ肠�����lj�����Ƃ����炱��Ȋ�����?
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainestown/xd, Aliceton/mp
2009- "32nm Nehalem"
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainestown/xd, Aliceton/mp
2009- "32nm Nehalem"
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
Rumours continue Intel taking GPU route
http://www.theinquirer.net/default.aspx?article=32737
Intel���r�f�I�`�b�v�s��ɍĎQ���̉\�B
Intel postpones launch of new desktop CPUs to July 27
http://www.digitimes.com/bits_chips/a20060629A2007.html
Conroe��Launch��7/23����A7/27�ɕύX�ɂȂ������l�q�B
http://www.theinquirer.net/default.aspx?article=32737
Intel���r�f�I�`�b�v�s��ɍĎQ���̉\�B
Intel postpones launch of new desktop CPUs to July 27
http://www.digitimes.com/bits_chips/a20060629A2007.html
Conroe��Launch��7/23����A7/27�ɕύX�ɂȂ������l�q�B
�ŋ߂̘b�� 2006�N7���P��
http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
>���̋L���ł́CMicro-OP Fusion��uOP���O���[�v�����ď������邱�Ƃ�CISC����Beauty�ł���C
>���ꂪCore�A�[�L�e�N�`���̒�d�́C�����\���̎���ł���Ƃ�����|���q�ׂĂ��܂����C
>���́C���̌����ɂ͎^���ł��܂���B
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
>���Ԃ́A��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B
>�܂�ACISC���߂����Ȃ����Ƃ�Micro-OPs Fusion�̖{�����B
���̃C���^�r���[�ł��̐^�������炩�Ɂc(;�L�D�M)
http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
>���̋L���ł́CMicro-OP Fusion��uOP���O���[�v�����ď������邱�Ƃ�CISC����Beauty�ł���C
>���ꂪCore�A�[�L�e�N�`���̒�d�́C�����\���̎���ł���Ƃ�����|���q�ׂĂ��܂����C
>���́C���̌����ɂ͎^���ł��܂���B
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
>���Ԃ́A��r�I�P����CISC�^x86���߂��A1��1��Fused uOPs�ɕϊ����Ă���ɉ߂��Ȃ��B
>�܂�ACISC���߂����Ȃ����Ƃ�Micro-OPs Fusion�̖{�����B
���̃C���^�r���[�ł��̐^�������炩�Ɂc(;�L�D�M)
ttp://homepage.mac.com/mlv/iblog/yoshishin/C520947495/E20060323130600/index.html
���܂�l�T�C�g�͓\��̂͂�낵���Ȃ��Ǝv�����A���\�ǂ݂₷���ȁB
�ςɒm��������l������ʐl����̂ق����킩��₷��������B
���i�����d�����Ȃ�����Ⴑ�ꂭ�炢�ŏ\�������B
���܂�l�T�C�g�͓\��̂͂�낵���Ȃ��Ǝv�����A���\�ǂ݂₷���ȁB
�ςɒm��������l������ʐl����̂ق����킩��₷��������B
���i�����d�����Ȃ�����Ⴑ�ꂭ�炢�ŏ\�������B
>>668
���A������SSE4�Ƃ��̐��������ĂȂ��̂��A�����ȁB
�܂��A���ɖ����\�̋@�\�Ƃ��������ĂĂ��f�o�b�N�Ƃ��o���f�[�V�����Ƃ�
���Ƃ��^�C�~���O�Ƃ������S����Ȃ��āA�s�\�ɂ��Ă���Ƃ��͂悭����낤���E�E�E
�����łȂ��Ă��O�|���ŗ��Ă�킯�����B
���A������SSE4�Ƃ��̐��������ĂȂ��̂��A�����ȁB
�܂��A���ɖ����\�̋@�\�Ƃ��������ĂĂ��f�o�b�N�Ƃ��o���f�[�V�����Ƃ�
���Ƃ��^�C�~���O�Ƃ������S����Ȃ��āA�s�\�ɂ��Ă���Ƃ��͂悭����낤���E�E�E
�����łȂ��Ă��O�|���ŗ��Ă�킯�����B
// 970MP��shared L2�Ƃ����̂͂������ɒ������ׂ����c�B
�C���e���AXeon 5100�V���[�Y���\��
�`���\���[�_�[��D�҂���v���Z�b�T
http://pc.watch.impress.co.jp/docs/2006/0626/intel2.htm
�_�C�T�C�Y��142����mm�A�g�����W�X�^����2��9,100�������āB
���̂���AnandTech������̉���l�^�������Ȃ̂ŕۗ��B
�C���e���AXeon 5100�V���[�Y���\��
�`���\���[�_�[��D�҂���v���Z�b�T
http://pc.watch.impress.co.jp/docs/2006/0626/intel2.htm
�_�C�T�C�Y��142����mm�A�g�����W�X�^����2��9,100�������āB
���̂���AnandTech������̉���l�^�������Ȃ̂ŕۗ��B
�C���e���A������Core���ڂ�Woodcrest���ƁuXeon 5100�ԑ�v�𐳎����\
ttp://journal.mycom.co.jp/news/2006/06/26/006.html
>�lj����ꂽ�Ƃ݂���V���ߌQ(Merom New Instruction: SSE4)�Ɋւ���ڍ��́A
>���ЊW�҂ɂ��Ό����_�ł͕s���B
ttp://journal.mycom.co.jp/news/2006/06/26/006.html
>�lj����ꂽ�Ƃ݂���V���ߌQ(Merom New Instruction: SSE4)�Ɋւ���ڍ��́A
>���ЊW�҂ɂ��Ό����_�ł͕s���B
>>672
> ttp://homepage.mac.com/mlv/iblog/yoshishin/C520947495/E20060323130600/index.html
> iMac G5 �� Power Mac G5 ���g�p���Ă��� PowerPC G5 �� Apple ���Ă�ł��� IBM �� Power PC �v���Z�b�T�[�ł�
> ���łɃf���A���R�A�ɂ�鋤�L�^ L2 �L���b�V�����������Ă���̂ŋZ�p�I�Ȑ�i���͂���܂���B
�������A�����v���Ă���Ȃ��Ə������Ȃ��B
�ʂɐ�i�I�ł����Ă��A���̌��ʂ��������鐫�\���Ⴉ������A���\���ǂ��Ȃ��Ă��ق�̋͂��ł������肷��ƈӖ��Ȃ��B
���ǂ́A�����̋Z�p�ł��낤�ƂȂ��낤�Ƃ���Ȃ��Ƃ͂ǂ��ł��悭�A���\���ǂꂾ�����サ���̂����d�v�ł���B
���̈Ӗ��ŁA��r����Ȃ琫�\�ł��邵���Ȃ��B
�����āAx86�̘b�����Ă���̂����炻��ȊO��CPU�͖��W�B
> ttp://homepage.mac.com/mlv/iblog/yoshishin/C520947495/E20060323130600/index.html
> iMac G5 �� Power Mac G5 ���g�p���Ă��� PowerPC G5 �� Apple ���Ă�ł��� IBM �� Power PC �v���Z�b�T�[�ł�
> ���łɃf���A���R�A�ɂ�鋤�L�^ L2 �L���b�V�����������Ă���̂ŋZ�p�I�Ȑ�i���͂���܂���B
�������A�����v���Ă���Ȃ��Ə������Ȃ��B
�ʂɐ�i�I�ł����Ă��A���̌��ʂ��������鐫�\���Ⴉ������A���\���ǂ��Ȃ��Ă��ق�̋͂��ł������肷��ƈӖ��Ȃ��B
���ǂ́A�����̋Z�p�ł��낤�ƂȂ��낤�Ƃ���Ȃ��Ƃ͂ǂ��ł��悭�A���\���ǂꂾ�����サ���̂����d�v�ł���B
���̈Ӗ��ŁA��r����Ȃ琫�\�ł��邵���Ȃ��B
�����āAx86�̘b�����Ă���̂����炻��ȊO��CPU�͖��W�B
�m�C�}���A�[�L�e�N�`���Ȃ̂Ő�i���͂���܂���
peculation Techniques for Improving Load Related Instruction SchedulingAdi Yoaz, Mattan Erez, Ronny Ronen, and Stephan Jourdan
Intel Corporation Intel Israel (74) Ltd., BMD Architecture Dept., MS: IDC-3C (1999)
ttp://www.stanford.edu/~merez/papers/LoadSched_ISCA26.pdf
Memory Disambiguation�ɂ��Ă�Intel Israel�̘_���B���\�Â��ȁB
disambiguation�̎蔤�́A
load���߂��X�g���[�����Ɍ����ƁACHT(Collidiing History Table, �Փ˗����e�[�u��)���Q�Ƃ���Ascheduling window����
�S�Ă�stroe���߂ɂ���load���߂ƎQ�ƃA�h���X���Փ˂��邩���Ȃ����̌������s�����ƂŃA�h���X�Փ˗\��������B
�\���̕����́AMemory Dependence Prediction, Hit-Mis Presdiction, Bank Prediction�Ȃǂ̃A���S���Y����g�ݍ��킹�Ă���B
�A�h���X�̔�Փ˂��\��������stroe���߂̑O��load���߂����s�\�ɂȂ�B�Փ˂��\�������ꍇ�́A�S�Ă�stroe���߂��܂��Ă���
���s�����B
stroe�A�h���X�����m�ɂȂ�����A�S�Ă̓��@���s�ς݂�load���߂ɂ������āA���ۂ̏Փ˂̌��ʂ͒��ׁA�ˑ����������ꂽload�͍Ď��s����B
load���߂�retire���ɗ\���̌��ʂ�CHT�ɔ��f����B
�V�~�����[�V�������ʂ��炢���ƁAExclusive Collision Predictor���Ă������Ȃ��(�ڍׂ͘_���Q��)���A
�������Ȃ�(=�S�Ă�store adress�̊�����҂�)�ꍇ�Ƃ���ׂāASysmarkNT�ŕ��ς���15%���炢�̐��\���P�A
(���adress�̔�Փ˂����肷��Opportunistic�X�L�[�}�ɔ�ׂ��10%���炢�̉��P)�B
�ŁA"Core"�̓z�͂ǂ�������̂��Ƃ�����Ƃ悭�킩��Ȃ��킯�����B
Intel Corporation Intel Israel (74) Ltd., BMD Architecture Dept., MS: IDC-3C (1999)
ttp://www.stanford.edu/~merez/papers/LoadSched_ISCA26.pdf
Memory Disambiguation�ɂ��Ă�Intel Israel�̘_���B���\�Â��ȁB
disambiguation�̎蔤�́A
load���߂��X�g���[�����Ɍ����ƁACHT(Collidiing History Table, �Փ˗����e�[�u��)���Q�Ƃ���Ascheduling window����
�S�Ă�stroe���߂ɂ���load���߂ƎQ�ƃA�h���X���Փ˂��邩���Ȃ����̌������s�����ƂŃA�h���X�Փ˗\��������B
�\���̕����́AMemory Dependence Prediction, Hit-Mis Presdiction, Bank Prediction�Ȃǂ̃A���S���Y����g�ݍ��킹�Ă���B
�A�h���X�̔�Փ˂��\��������stroe���߂̑O��load���߂����s�\�ɂȂ�B�Փ˂��\�������ꍇ�́A�S�Ă�stroe���߂��܂��Ă���
���s�����B
stroe�A�h���X�����m�ɂȂ�����A�S�Ă̓��@���s�ς݂�load���߂ɂ������āA���ۂ̏Փ˂̌��ʂ͒��ׁA�ˑ����������ꂽload�͍Ď��s����B
load���߂�retire���ɗ\���̌��ʂ�CHT�ɔ��f����B
�V�~�����[�V�������ʂ��炢���ƁAExclusive Collision Predictor���Ă������Ȃ��(�ڍׂ͘_���Q��)���A
�������Ȃ�(=�S�Ă�store adress�̊�����҂�)�ꍇ�Ƃ���ׂāASysmarkNT�ŕ��ς���15%���炢�̐��\���P�A
(���adress�̔�Փ˂����肷��Opportunistic�X�L�[�}�ɔ�ׂ��10%���炢�̉��P)�B
�ŁA"Core"�̓z�͂ǂ�������̂��Ƃ�����Ƃ悭�킩��Ȃ��킯�����B
Advanced Smart Cache�Ƃ��������O��t���邩�炾��B
PowerPC��POWER4�x�[�X�Ȃ�ŁADualCore�������ۂ�POWER4�Ɠ������LL2�Ǝv�����낤����
Advanced Smart Cache���Ă̂��AYonah�ł�Smart Cache���advance���Ă����̃l�[�~���O���Ǝv���Ă������ǁc
intel�̃l�[�~���O�͈ȑO�̗p�����Z�p�������ł����ǂ�����傰���ɂ��Ă�̂ŁA���ꂫ���Ă��܂��Ă���
Advanced Smart Cache���Ă̂��AYonah�ł�Smart Cache���advance���Ă����̃l�[�~���O���Ǝv���Ă������ǁc
intel�̃l�[�~���O�͈ȑO�̗p�����Z�p�������ł����ǂ�����傰���ɂ��Ă�̂ŁA���ꂫ���Ă��܂��Ă���
SSE�i2�E3�E4�܁j��AltiVec���Ăǂ������悢�́H
���߃Z�b�g��SSE
�����\�͂̓��j�b�g�\���Ɋ�邯�ǂ����ނ�AltiVec
�����\�͂̓��j�b�g�\���Ɋ�邯�ǂ����ނ�AltiVec
http://pc.watch.impress.co.jp/docs/2006/0703/kaigai286.htm
> Intel��Core MA�́A4way�f�R�[�h�ɂ������ƂŁA
> �f�R�[�_���ł��Ȃ��J���Ă���l�q��������B
�ǂ̕ӂ����Ă������f�����̂��낤�H
> Intel��Core MA�́A4way�f�R�[�h�ɂ������ƂŁA
> �f�R�[�_���ł��Ȃ��J���Ă���l�q��������B
�ǂ̕ӂ����Ă������f�����̂��낤�H
�����m�肽��
�v�̋�J�Ȃ�
�v�̋�J�Ȃ�
�����Ԃ�AMD�Ɂu�z���v�����L�����ȁA�Ǝv�����B
>>684
�M
�M
�M�Ƃ������A�M���x�B
Core�̓f�R�[�_�̊����x�������Ƃ�������
complex*3�Ȃ�Ĕn��
complex*3�Ȃ�Ĕn��
Intel Oregon�`�[���́ATejas�L�����Z���Ȍ�͉�������Ă����̂�?
���炭�^�₾�������A��͂艽�����ĂȂ��킯�ł͂Ȃ��A�F�X�Ȍ��������Ă������Ɣ��o�i�E�́E�j
H. Akkary and M. A. Driscoll. "A Dynamic Multithreading Processor"
ttp://courses.ece.uiuc.edu/ece511/papers/Akkary.1998.MICRO.pdf
�܂��A1998�N��Dynamic Multitreading Processor�̘_���B
Intel Oregon�̂�ŁANetBurst�o��O�̘_���B
�������琄�@����ɁANetBurst�̉��nj^�`��p�A�[�L�őz�肵�Ă����̂����B
�������A���I�ȃ}���`�X���b�h�����͕~���������킯�ł��̌�A���@�X���b�h�Z�p�����ƍT���߂ȂȂ̂�
������Ɍ�������Ă��邲�l�q�B
�ŁA����Ƃ͕ʂɁASanta Clara�`�[���̕���IA64����݂̌����ŏo���Ă����̂��A���ꁫ
Speculative Precomputation: Long-range Prefetching of Delinquent Loads
ttp://www.intel.com/research/mrl/library/148_collins_j.pdf
2001�N�ASP(Speculative Precomputation, ���@�\�����s)�̘_���B
prefetch�p�̓��@�X���b�h�����āA���������C�e���V����������z�B
����͐ÓI�Ȏ��������̂�ŁA���݂�Intel�R���p�C���ɂ���������Ă���B
Dynamic Speculative Precomputation
ttp://www-cse.ucsd.edu/users/tullsen/dsp.pdf
����ɁA���N�ɓ����`�[�������I��SP�Z�p���������Ă������B
�������A�����Y��Ă���l�������Ǝv�����A�V�}�C�N���A�[�L�Ƃ����Ă�����Montecito/Chivano�́A
�}���`�R�A�H���ɓ]���������ƂŁA�L�����Z���ɂȂ�A���̌�A�����A�[�L��Dual Core�ȐVMontecito��
�\�肪�u����������B���ꂪ�A������18�����炢�ɂ���ƃ����[�X����邱�ƂɂȂ��Ă�킯�B
SP�͂����Hudson, MA(��DEC)�`�[���������𑱂��Ă������A���̋�Tukwila�����̂ŁA
���͂ǂ��Ȃ��Ă���̂����킩��Ȃ��B
���炭�^�₾�������A��͂艽�����ĂȂ��킯�ł͂Ȃ��A�F�X�Ȍ��������Ă������Ɣ��o�i�E�́E�j
H. Akkary and M. A. Driscoll. "A Dynamic Multithreading Processor"
ttp://courses.ece.uiuc.edu/ece511/papers/Akkary.1998.MICRO.pdf
�܂��A1998�N��Dynamic Multitreading Processor�̘_���B
Intel Oregon�̂�ŁANetBurst�o��O�̘_���B
�������琄�@����ɁANetBurst�̉��nj^�`��p�A�[�L�őz�肵�Ă����̂����B
�������A���I�ȃ}���`�X���b�h�����͕~���������킯�ł��̌�A���@�X���b�h�Z�p�����ƍT���߂ȂȂ̂�
������Ɍ�������Ă��邲�l�q�B
�ŁA����Ƃ͕ʂɁASanta Clara�`�[���̕���IA64����݂̌����ŏo���Ă����̂��A���ꁫ
Speculative Precomputation: Long-range Prefetching of Delinquent Loads
ttp://www.intel.com/research/mrl/library/148_collins_j.pdf
2001�N�ASP(Speculative Precomputation, ���@�\�����s)�̘_���B
prefetch�p�̓��@�X���b�h�����āA���������C�e���V����������z�B
����͐ÓI�Ȏ��������̂�ŁA���݂�Intel�R���p�C���ɂ���������Ă���B
Dynamic Speculative Precomputation
ttp://www-cse.ucsd.edu/users/tullsen/dsp.pdf
����ɁA���N�ɓ����`�[�������I��SP�Z�p���������Ă������B
�������A�����Y��Ă���l�������Ǝv�����A�V�}�C�N���A�[�L�Ƃ����Ă�����Montecito/Chivano�́A
�}���`�R�A�H���ɓ]���������ƂŁA�L�����Z���ɂȂ�A���̌�A�����A�[�L��Dual Core�ȐVMontecito��
�\�肪�u����������B���ꂪ�A������18�����炢�ɂ���ƃ����[�X����邱�ƂɂȂ��Ă�킯�B
SP�͂����Hudson, MA(��DEC)�`�[���������𑱂��Ă������A���̋�Tukwila�����̂ŁA
���͂ǂ��Ȃ��Ă���̂����킩��Ȃ��B
Minimal Dual-Core Speculative Multi-Threading Architecture
ttp://www.iccd-conference.org/proceedings/2004/22310360.pdf
�ŁAOregon�ɖ߂�ƁA2004�N���̘_�������ꁪ
���̎����̏͘R����w�ǖY��Ă��܂����̂����AIntel������Tejas�L�����Z�������܂��Ă������ǂ����͔����B
��Nehalem�͊��Ɏ���ł������Z�������B
���e��Dual Core���x�[�X�Ɍ����I�Ȏ�����SpMT(Speculative Multithreating)���n�[�h���Ŏ�������Ƃ������́B
Dual Core�œ��@�X���b�h�͕Е��̃R�A�����s���邱�Ƃɂ����Single Thread���\�����P����B
�ו��͓���̂ŃX���[����Ƃ��āA���ʂ͕���+19%��Single Thread���\���P�B
Minimal SpMT�́A�����I�ɂ�2008-2009�N�̐VNehalem�ɃM���M���Ԃɍ����]�[���B
Oregon�`�[���́A��K��ROB�̑�ւ���i�Ƃ���CPR(Checkpoint Processing and Recovery)�Ȃ�_����
���̘_���̂�����ƑO�ɂ����Ă���B
NetBurst���ӎ����ăV�~�����[�V�������Ă�̂͂��ꂪ�Ōォ�ȁB
CPR�́A�ǂ��炩�Ƃ�����Deeper Pipe�����̋Z�p�����A�VNehalem�ɐ�������邩�ǂ����������Ƃ������B
�����͂ł����疾���̗\��i�E�́E�j
ttp://www.iccd-conference.org/proceedings/2004/22310360.pdf
�ŁAOregon�ɖ߂�ƁA2004�N���̘_�������ꁪ
���̎����̏͘R����w�ǖY��Ă��܂����̂����AIntel������Tejas�L�����Z�������܂��Ă������ǂ����͔����B
��Nehalem�͊��Ɏ���ł������Z�������B
���e��Dual Core���x�[�X�Ɍ����I�Ȏ�����SpMT(Speculative Multithreating)���n�[�h���Ŏ�������Ƃ������́B
Dual Core�œ��@�X���b�h�͕Е��̃R�A�����s���邱�Ƃɂ����Single Thread���\�����P����B
�ו��͓���̂ŃX���[����Ƃ��āA���ʂ͕���+19%��Single Thread���\���P�B
Minimal SpMT�́A�����I�ɂ�2008-2009�N�̐VNehalem�ɃM���M���Ԃɍ����]�[���B
Oregon�`�[���́A��K��ROB�̑�ւ���i�Ƃ���CPR(Checkpoint Processing and Recovery)�Ȃ�_����
���̘_���̂�����ƑO�ɂ����Ă���B
NetBurst���ӎ����ăV�~�����[�V�������Ă�̂͂��ꂪ�Ōォ�ȁB
CPR�́A�ǂ��炩�Ƃ�����Deeper Pipe�����̋Z�p�����A�VNehalem�ɐ�������邩�ǂ����������Ƃ������B
�����͂ł����疾���̗\��i�E�́E�j
----
454 ���O�FSocket774[sage] ���e���F2006/07/09(��) 05:42:10 ID:tZypqzus
>>419
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
Tejas�̒��̐l��Xscale�ɍ��J���ꂽ�炵���悗
----
�\�X���̏������݂�ǂ�ŏd��Ȃ��ƂɋC�Â����B
454 ���O�FSocket774[sage] ���e���F2006/07/09(��) 05:42:10 ID:tZypqzus
>>419
ttp://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=W4YJQATP0HKDMQSNDLRCKHSCJUNN2JVN?articleID=188703330&pgno=3
>The Tejas design team, led by Brad Beavers, site director for Intel in Austin,
>was put to work on the ultramobile-PC processor.
>Intel's work force in Austin has increased from 500 to 800,
>including design teams working on the next-generation Xscale, an Intel Austin engineer said.
Tejas�̒��̐l��Xscale�ɍ��J���ꂽ�炵���悗
----
�\�X���̏������݂�ǂ�ŏd��Ȃ��ƂɋC�Â����B
Tejas�́AAustin, Texas�`�[���ɂ��v�Ƃ������������B wiki�Ō���ƁA
http://en.wikipedia.org/wiki/Texas
>The state name derives from a word in the Caddoan language of the Hasinai: taysha?, tecas, or tejas (the Spanish spelling);
"Texas"�̃X�y�C����̃X�y�����A"Tejas"�炵���c(;�L�D�M)
�Ƃ����킯�ŁAOR�`�[���́A�����������Tejas�ƒ��ڊW�Ȃ���������Ȃ����Ă�����������B
(���_�ATejas�L�����Z��=NetBurst�̏I���Ȃ̂�OR�`�[���ɉe�����o�Ȃ����Ƃ͂Ȃ���)
�Ȃ̂ŁA���������>>690�̓��e�͂��܂�ύX�͂Ȃ��B
// Intel��Processor��"�v"��"����"�̕��S���ǂ��Ȃ��Ă��邩��������Ƌ^��Ɏv���Ă����B
// - Santa Clara, CA
// - Folsom, CA
// - Hillsboro, OR.
// - Chandler, AR
// - Austin, TX
// - Fort Collins, CO
// - Hudson, MA
// - Haifa, Israel
// - Bangalore, India
// ����v��Intel�̃v���Z�b�T�v�`�[���炵�����A���̂����������ꏏ�ɂ���Ă�̂�Santa Clara�AHillsboro, Haifa�ȊO�ɂ͂���̂���?
// Spain�`�[���͌�����������ĂȂ����ۂ��B(Tejas = Texas + Spain�Ƃ����ۂǂ��[�ǂ݂��ł���w)
// �ŋ߂̓h�C�c���lj����ȁc�B
http://en.wikipedia.org/wiki/Texas
>The state name derives from a word in the Caddoan language of the Hasinai: taysha?, tecas, or tejas (the Spanish spelling);
"Texas"�̃X�y�C����̃X�y�����A"Tejas"�炵���c(;�L�D�M)
�Ƃ����킯�ŁAOR�`�[���́A�����������Tejas�ƒ��ڊW�Ȃ���������Ȃ����Ă�����������B
(���_�ATejas�L�����Z��=NetBurst�̏I���Ȃ̂�OR�`�[���ɉe�����o�Ȃ����Ƃ͂Ȃ���)
�Ȃ̂ŁA���������>>690�̓��e�͂��܂�ύX�͂Ȃ��B
// Intel��Processor��"�v"��"����"�̕��S���ǂ��Ȃ��Ă��邩��������Ƌ^��Ɏv���Ă����B
// - Santa Clara, CA
// - Folsom, CA
// - Hillsboro, OR.
// - Chandler, AR
// - Austin, TX
// - Fort Collins, CO
// - Hudson, MA
// - Haifa, Israel
// - Bangalore, India
// ����v��Intel�̃v���Z�b�T�v�`�[���炵�����A���̂����������ꏏ�ɂ���Ă�̂�Santa Clara�AHillsboro, Haifa�ȊO�ɂ͂���̂���?
// Spain�`�[���͌�����������ĂȂ����ۂ��B(Tejas = Texas + Spain�Ƃ����ۂǂ��[�ǂ݂��ł���w)
// �ŋ߂̓h�C�c���lj����ȁc�B
�Q�l�����͂��̋L���B
http://www.statesman.com/business/content/business/stories/technology/05/22intel.html
http://www.statesman.com/business/content/business/stories/technology/05/22intel.html
Haitham Akkary, Srikanth T. Srinivasan, Rajendar Koltur, Yogesh Patil, and Wael Refaai
Portland State University, Microarchitecture Research Lab Intel Corporation
"Perceptron-Based Branch Confidence Estimation"
ttp://webspace.ulbsibiu.ro/lucian.vintan/html/Citare_HPCA04.pdf
�Ȃ����N�悪���ł��܂����݂��������ǁAIntel OR�`�[����2004�N�̘_���B
�ŐV�̃n�C�G���h�v���Z�b�T�͑����̈قȂ�A���S���Y���̗\�����g�ݍ��킹�ĕ���\�����Ă��邪�A
�ǂ̕���\������g���ׂ���?�Ƃ����̂�\���E�I�����邽�߂̕���M���x�����(Branch Confidence Estimation)
�܂ŕK�v�ɂȂ��Ă��Ă�����ۂ��B����́A�p�[�Z�v�g�����x�[�X�ł�����������Ă���Ƃ�����B
http://ja.wikipedia.org/wiki/%E3%83%91%E3%83%BC%E3%82%BB%E3%83%97%E3%83%88%E3%83%AD%E3%83%B3
���e�͓���̂Ńp�X�����A���̘_���̃V�~�����[�V�������f����CPR�̘_���ɔ�ׂāA
�VNehalem�őz�肳���A�[�L�ɋ߂����f��(Merom+TC)�ɂȂ��Ă���C������B
Fetch/Issue/Retire width 4
ROB size 128
Load and store buffers 48 loads, 32 stores
Memory disambiguation Perfect
Scheduling window size 48 int, 24 mem and 56 fp
Execution units 3 int, 2 mem, 1 fp
Hardware data prefetch Stream-based, 16 streams
Branch predictor Combined: 16K bimodal,
64K gshare, 64K Meta
Trace cache 12K uops, 8-way
L1 DCache 32K, 8-way, 64-byte line
L2 unified cache 1M, 8-way, 64-byte line
CPR�̘_���B
Checkpoint Processing and Recovery:Towards Scalable Large Instruction Window Processors
Microprocessor Research Labs, Intel Corporation Hillsboro, Oregon 97124, USA
ttp://www.microarch.org/micro36/html/pdf/akkary-CheckpointProcessing.pdf
Portland State University, Microarchitecture Research Lab Intel Corporation
"Perceptron-Based Branch Confidence Estimation"
ttp://webspace.ulbsibiu.ro/lucian.vintan/html/Citare_HPCA04.pdf
�Ȃ����N�悪���ł��܂����݂��������ǁAIntel OR�`�[����2004�N�̘_���B
�ŐV�̃n�C�G���h�v���Z�b�T�͑����̈قȂ�A���S���Y���̗\�����g�ݍ��킹�ĕ���\�����Ă��邪�A
�ǂ̕���\������g���ׂ���?�Ƃ����̂�\���E�I�����邽�߂̕���M���x�����(Branch Confidence Estimation)
�܂ŕK�v�ɂȂ��Ă��Ă�����ۂ��B����́A�p�[�Z�v�g�����x�[�X�ł�����������Ă���Ƃ�����B
http://ja.wikipedia.org/wiki/%E3%83%91%E3%83%BC%E3%82%BB%E3%83%97%E3%83%88%E3%83%AD%E3%83%B3
���e�͓���̂Ńp�X�����A���̘_���̃V�~�����[�V�������f����CPR�̘_���ɔ�ׂāA
�VNehalem�őz�肳���A�[�L�ɋ߂����f��(Merom+TC)�ɂȂ��Ă���C������B
Fetch/Issue/Retire width 4
ROB size 128
Load and store buffers 48 loads, 32 stores
Memory disambiguation Perfect
Scheduling window size 48 int, 24 mem and 56 fp
Execution units 3 int, 2 mem, 1 fp
Hardware data prefetch Stream-based, 16 streams
Branch predictor Combined: 16K bimodal,
64K gshare, 64K Meta
Trace cache 12K uops, 8-way
L1 DCache 32K, 8-way, 64-byte line
L2 unified cache 1M, 8-way, 64-byte line
CPR�̘_���B
Checkpoint Processing and Recovery:Towards Scalable Large Instruction Window Processors
Microprocessor Research Labs, Intel Corporation Hillsboro, Oregon 97124, USA
ttp://www.microarch.org/micro36/html/pdf/akkary-CheckpointProcessing.pdf
Reducing Branch Misprediction Penalty via Selective Branch Recovery
ttp://www.hpcaconf.org/hpca10/papers/27gandhia.pdf
Intel OR�ɂ��SBR(Selective Branch Recovery)�̘_���B
����\�����~�X�����Ƃ��Ɋ��Ƀp�C�v���C�����ɓ����Ă��閽�߂͑S�Ĕj������̂����ʂ����A
�悭�킩��Ȃ����ǂ���͕���̂��ƂɎ���������̃u���b�N�̓~�X���Ă��~�X��Ȃ��Ă����ʂŎ��s����Ƃ����̂�
���p���āA�I��I���A���s���B������̃u���b�N�̖��߂͔j�����ꂸ�ɍė��p(reuse)����A
fetch��rename���Ď��s�����ɍςށB
reuse�Ƃ����͍̂ŋ߂̗��s�炵���B
������͂ɑ��錋�ʂ��e�[�u���ɕۑ����Ă����A�������͂������Ƃ��ɍĎ��s���o�C�p�X����Ƃ�����
����{�I�ȍl���BSBR�̂�͂�����ƈႤ�̂�������ǁB
ttp://www.hpcaconf.org/hpca10/papers/27gandhia.pdf
Intel OR�ɂ��SBR(Selective Branch Recovery)�̘_���B
����\�����~�X�����Ƃ��Ɋ��Ƀp�C�v���C�����ɓ����Ă��閽�߂͑S�Ĕj������̂����ʂ����A
�悭�킩��Ȃ����ǂ���͕���̂��ƂɎ���������̃u���b�N�̓~�X���Ă��~�X��Ȃ��Ă����ʂŎ��s����Ƃ����̂�
���p���āA�I��I���A���s���B������̃u���b�N�̖��߂͔j�����ꂸ�ɍė��p(reuse)����A
fetch��rename���Ď��s�����ɍςށB
reuse�Ƃ����͍̂ŋ߂̗��s�炵���B
������͂ɑ��錋�ʂ��e�[�u���ɕۑ����Ă����A�������͂������Ƃ��ɍĎ��s���o�C�p�X����Ƃ�����
����{�I�ȍl���BSBR�̂�͂�����ƈႤ�̂�������ǁB
����OR�`�[���̕���2003-2004�N���ɐF�X�Ƙ_�����o���Ă��邱�Ƃ��킩�����B
Nehalem�́A�ꉞ2008�N�\��Ȃ̂ŁA�����̘_���ň����Ă�Z�p�́A�̗p�����\������B
>>554�ł́AIntel Israel��FTC/MTC�̘_����\����Nehalem�Ŕq�߂����Ə��������ǁA
FTC/MTC�́APARROT�ւ̕z��Israel�u���Ȃ�Ȃ̂�Nehalem�ł͂���ςȂ������Ȃƍl����ς��܂����B
>>555�ł́AGel���̔����ŁAMultithreading�����Ƃ����̂����o�B
Native 4 core + 4 core��mcm�ŁA4 thread/core�Ȃ�A32 thread��1S�ŏ����ł���B
����͒����ʂ��ז����Ǝv�����ACore Multiplexing�̘b�����邵�A�\�t�g�J���҂�[�U�̑I����on/off
�ł���Ȃ炠�肩�ȂƂ��v�����B
>>603�ł́ASMT�͖��ʂȂ̂�CGMT����Ȃ��̂��Ƃ����̂��������B
Nehalem�́ANative 4 core + CSI +���Ƃ����̂����܂ł̉\����L�͂��Ǝv����킯�����A
+�������̌��͂��������Ėϑz���L����ȁi�E�́E�j
>>610�ł́ASpMT�͂Ȃ�����Ƃ����l���������̂����A>>690��Minimal DC SpMT�̘_�����݂���A
SpMT�����肩�Ǝv�����B
*** Hillsboro, Oregon
- "Nehalem" (2008)
-- Trace Cache
-- Minimal SpMT (Speculative Multi-Threading)
-- CPR (Checkpoint Processing and Recovery)
-- SBR (Selective Branch Recovery)
-- Branch Confidence Estimation
*** Haifa, Israel
- "Gesher" (2010)
-- FTC/MTC (Filter Trace Cache / Main Trace Cache)
-- PARROT (Power AwaReness thRough selective dynamically Optimized Traces)
-- ACCMP (Asymmetric Cluster Chip Multi-Processor)
Nehalem�́A�ꉞ2008�N�\��Ȃ̂ŁA�����̘_���ň����Ă�Z�p�́A�̗p�����\������B
>>554�ł́AIntel Israel��FTC/MTC�̘_����\����Nehalem�Ŕq�߂����Ə��������ǁA
FTC/MTC�́APARROT�ւ̕z��Israel�u���Ȃ�Ȃ̂�Nehalem�ł͂���ςȂ������Ȃƍl����ς��܂����B
>>555�ł́AGel���̔����ŁAMultithreading�����Ƃ����̂����o�B
Native 4 core + 4 core��mcm�ŁA4 thread/core�Ȃ�A32 thread��1S�ŏ����ł���B
����͒����ʂ��ז����Ǝv�����ACore Multiplexing�̘b�����邵�A�\�t�g�J���҂�[�U�̑I����on/off
�ł���Ȃ炠�肩�ȂƂ��v�����B
>>603�ł́ASMT�͖��ʂȂ̂�CGMT����Ȃ��̂��Ƃ����̂��������B
Nehalem�́ANative 4 core + CSI +���Ƃ����̂����܂ł̉\����L�͂��Ǝv����킯�����A
+�������̌��͂��������Ėϑz���L����ȁi�E�́E�j
>>610�ł́ASpMT�͂Ȃ�����Ƃ����l���������̂����A>>690��Minimal DC SpMT�̘_�����݂���A
SpMT�����肩�Ǝv�����B
*** Hillsboro, Oregon
- "Nehalem" (2008)
-- Trace Cache
-- Minimal SpMT (Speculative Multi-Threading)
-- CPR (Checkpoint Processing and Recovery)
-- SBR (Selective Branch Recovery)
-- Branch Confidence Estimation
*** Haifa, Israel
- "Gesher" (2010)
-- FTC/MTC (Filter Trace Cache / Main Trace Cache)
-- PARROT (Power AwaReness thRough selective dynamically Optimized Traces)
-- ACCMP (Asymmetric Cluster Chip Multi-Processor)
Montecito 1.6GHz 24MB��SPEC�x���`�X�R�A���o�^���ꂽ�͗l�B
SPECint2000 = 1474
SPECint_base2000 = 1474
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060613-06198.html
SPECfp2000 = 3017
SPECfp_base2000 = 3017
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060613-06201.html
fp�͂��肬���3000��˔j�������Aint��Madison���Ⴍ�Ȃ��Ă�̂́A����Bull�̌v�������܂��������ȁB
����͂����ƁAHP���ŋߓo�^����Woodcrest��fp_peak�̃X�R�A��Montecito/Madison�̃X�R�A������X�R�A��B���B
HP�K��Montecito�̃X�R�A�Ɋ��҂��Ȃ��BSPECfp�ł�x86��POWER, Itanium�������Ă�Ȃ�ĉ��N���O�ɂ͍l�����Ȃ������W�J���Ȃ��B
Hewlett-Packard Company ProLiant ML370 G5 (3.0GHz, Intel Xeon processor 5160)
SPECfp2000 = 3048
SPECfp_base2000 = 2803
http://www.spec.org/osg/cpu2000/results/res2006q2/cpu2000-20060612-06162.html
ttp://www.aceshardware.com/SPECmine/index.jsp?b=2&s=1&v=1&if=0&a=0&a=1&a=2&a=3&a=4&a=5&a=8&ncf=1&nct=256&cpcf=1&cpct=2&mf=1600&mt=3000&o=0&o=1&o=2&ic=0&ic=1&ic=9&ic=17&ic=18&ic=39
SPECint2000 = 1474
SPECint_base2000 = 1474
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060613-06198.html
SPECfp2000 = 3017
SPECfp_base2000 = 3017
http://www.spec.org/cpu2000/results/res2006q2/cpu2000-20060613-06201.html
fp�͂��肬���3000��˔j�������Aint��Madison���Ⴍ�Ȃ��Ă�̂́A����Bull�̌v�������܂��������ȁB
����͂����ƁAHP���ŋߓo�^����Woodcrest��fp_peak�̃X�R�A��Montecito/Madison�̃X�R�A������X�R�A��B���B
HP�K��Montecito�̃X�R�A�Ɋ��҂��Ȃ��BSPECfp�ł�x86��POWER, Itanium�������Ă�Ȃ�ĉ��N���O�ɂ͍l�����Ȃ������W�J���Ȃ��B
Hewlett-Packard Company ProLiant ML370 G5 (3.0GHz, Intel Xeon processor 5160)
SPECfp2000 = 3048
SPECfp_base2000 = 2803
http://www.spec.org/osg/cpu2000/results/res2006q2/cpu2000-20060612-06162.html
ttp://www.aceshardware.com/SPECmine/index.jsp?b=2&s=1&v=1&if=0&a=0&a=1&a=2&a=3&a=4&a=5&a=8&ncf=1&nct=256&cpcf=1&cpct=2&mf=1600&mt=3000&o=0&o=1&o=2&ic=0&ic=1&ic=9&ic=17&ic=18&ic=39
Intel Core 2 Extreme X6800 Preview from Taiwan
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2771
AnandTech���A
AMD Athlon 64 FX-62 (2.80GHz)
Intel Core 2 Extreme X6800 (2.93GHz)
�̔�r�x���`�L��������Ă�B����Ƃ܂Ƃ��Ȓ���Ό��x���`�������킯�����i�E�́E�j
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2771
AnandTech���A
AMD Athlon 64 FX-62 (2.80GHz)
Intel Core 2 Extreme X6800 (2.93GHz)
�̔�r�x���`�L��������Ă�B����Ƃ܂Ƃ��Ȓ���Ό��x���`�������킯�����i�E�́E�j
Intel��Cell��ǂ�������Ȃ�NetBurst��i����������������������낤�ȁB
Heterogeneous Multi-Core Architecture rules the future
http://www.hkepc.com/bbs/itnews.php?tid=626040
��ԉ���4Core���L�L���b�V���̃��f����Nehalem���H
http://www.hkepc.com/bbs/itnews.php?tid=626040
��ԉ���4Core���L�L���b�V���̃��f����Nehalem���H
>>669
ttp://www.tgdaily.com/2006/07/10/intel_32_core_processor/
45nm Nehalem�@�@�@Gainestown
32nm Nehalem-C�@ Gulftown�H
32nm Gesher�@�@�@�@Keifer�H
ttp://www.tgdaily.com/2006/07/10/intel_32_core_processor/
45nm Nehalem�@�@�@Gainestown
32nm Nehalem-C�@ Gulftown�H
32nm Gesher�@�@�@�@Keifer�H
Efficeon��PARROT�͑S�R�Ⴄ����c
tuka,
Parrot�W�Ȃ����B
���ɑΉ�����64bit���[�h�Ɏ�_����
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-002.html?
�@�Ƃ��ɁA�قړ��@�\�̃A�v��������Ă���uPanorama Factory�v�i�����̉摜���Ȃ���360�x�̎ʐ^�����\�t�g�j��
�usakura editor�v�i�e�L�X�g�G�f�B�^�j�A�u7-Zip�v�i�����\���k�\�t�g�j�̌��ʂ�����Ǝ��Ԃ��悭�c���ł���i�O���t15�`17�j�B
Athlon 64�͂������64bit�l�C�e�B�u�ł̂ق������\���A�b�v���Ă���̂ɑ��ACore 2 Duo�͂悭�ĉ����A
�ꍇ�ɂ���Ă�40�����A�l�C�e�B�u�A�v���̂ق����ᑬ�ɂȂ��Ă���B���̌��ʁA�u7-Zip�v�ł�32bit����
Core 2-2.4GHz���x�̑��x������FX-62���A64bit����Core 2-2.93GHz�ɔ��鐔�l�ɂȂ�A�uPanorama Factory�v�ł��A
Core 2-2.4GHz��FX-62�ɔ�����A�usakura editor�v�Ɏ����ẮA32bit�ł̓��X������FX-62����C�ɋt�]�g�b�v�������Ă���B
http://akiba.ascii24.com/akiba/column/latestparts/2006/07/14/663447-002.html?
�@�Ƃ��ɁA�قړ��@�\�̃A�v��������Ă���uPanorama Factory�v�i�����̉摜���Ȃ���360�x�̎ʐ^�����\�t�g�j��
�usakura editor�v�i�e�L�X�g�G�f�B�^�j�A�u7-Zip�v�i�����\���k�\�t�g�j�̌��ʂ�����Ǝ��Ԃ��悭�c���ł���i�O���t15�`17�j�B
Athlon 64�͂������64bit�l�C�e�B�u�ł̂ق������\���A�b�v���Ă���̂ɑ��ACore 2 Duo�͂悭�ĉ����A
�ꍇ�ɂ���Ă�40�����A�l�C�e�B�u�A�v���̂ق����ᑬ�ɂȂ��Ă���B���̌��ʁA�u7-Zip�v�ł�32bit����
Core 2-2.4GHz���x�̑��x������FX-62���A64bit����Core 2-2.93GHz�ɔ��鐔�l�ɂȂ�A�uPanorama Factory�v�ł��A
Core 2-2.4GHz��FX-62�ɔ�����A�usakura editor�v�Ɏ����ẮA32bit�ł̓��X������FX-62����C�ɋt�]�g�b�v�������Ă���B
708 �Finteler@�ϑz�F2006/07/16(��) 13:32:20 ID:unIashj50
>>702�͈ꌩGesher����̐��i�̂悤�ɂ݂��Ă����łȂ������B
- Keifer
-- 32nm, 2GHz, 32 core, 128 thread, 2S Xeon
-- 4 thread / core
-- 4 core / processing-node
-- 8 processing-node / socket
Keifer�́A1 core��4 thread�����ł��āA4 core�P�ʂŃ����O�ڑ��̃A�[�L�ł��邱�Ƃ��炵�āA
Nehalem-C�̔h���i�Ƃ������߂��Ó����ȁB
Woodcrest/Clovertown�̂Ƃ��납��O���t�̃v���b�g�_�̑Ή����悭���Ă����ƁAHarpertown��2008�N�̓��ŁA
Gainstown��2008�N�̏I���AGulftown��2009�N�̏I���ŁA2010�N��Keifer��Next�ł��邱�Ƃ��킩��(�v���b�g�_������C��)�B
Harpertown(45nm Merom-based) �� Gainstown(45nm Nehalem)
Gulftown(32nm Nehalem) �� "Next"(32nm Gesher)
�̂悤�ɐV�}�C�N���A�[�L�ɕς��Ɨ\�z�����ӏ��ł́A�k����������Ȃ��Ƃ���ɑ��Đ��\���傫���オ�邱�Ƃ��ӎ�����
�O���t������Ă��邱�Ƃ��킩��B�܂��AKeifer�́ANext = Gesher�������ɓo�ꂷ�邱�ƈӎ����Ă��邱�Ƃ��ǂݎ���B
���̂悤�ȑ����R�A�̃`�b�v�̕����V�A�[�L�ʼn��ʐ��i����ɓo�ꂷ�邱�Ƃ͍l���ɂ����̂ŁA
Keifer = �����A�[�L = Nehalem�x�[�X�Ƃ������߂ɂȂ�킯�B
- Keifer
-- 32nm, 2GHz, 32 core, 128 thread, 2S Xeon
-- 4 thread / core
-- 4 core / processing-node
-- 8 processing-node / socket
Keifer�́A1 core��4 thread�����ł��āA4 core�P�ʂŃ����O�ڑ��̃A�[�L�ł��邱�Ƃ��炵�āA
Nehalem-C�̔h���i�Ƃ������߂��Ó����ȁB
Woodcrest/Clovertown�̂Ƃ��납��O���t�̃v���b�g�_�̑Ή����悭���Ă����ƁAHarpertown��2008�N�̓��ŁA
Gainstown��2008�N�̏I���AGulftown��2009�N�̏I���ŁA2010�N��Keifer��Next�ł��邱�Ƃ��킩��(�v���b�g�_������C��)�B
Harpertown(45nm Merom-based) �� Gainstown(45nm Nehalem)
Gulftown(32nm Nehalem) �� "Next"(32nm Gesher)
�̂悤�ɐV�}�C�N���A�[�L�ɕς��Ɨ\�z�����ӏ��ł́A�k����������Ȃ��Ƃ���ɑ��Đ��\���傫���オ�邱�Ƃ��ӎ�����
�O���t������Ă��邱�Ƃ��킩��B�܂��AKeifer�́ANext = Gesher�������ɓo�ꂷ�邱�ƈӎ����Ă��邱�Ƃ��ǂݎ���B
���̂悤�ȑ����R�A�̃`�b�v�̕����V�A�[�L�ʼn��ʐ��i����ɓo�ꂷ�邱�Ƃ͍l���ɂ����̂ŁA
Keifer = �����A�[�L = Nehalem�x�[�X�Ƃ������߂ɂȂ�킯�B
709 �Finteler@�ϑz�F2006/07/16(��) 13:39:54 ID:unIashj50
�N���b�N��32nm��2GHz�ʂł��Ȃ�T���߂炵���ŁANehalem-C������d�͋쓮�ŁA
mcm���Ȃɂ��͂킩��Ȃ���1S��8 node��͋Ƃł̂���32 core, 128 thread�����s�ł���悤�ɂ������̂��ȁB
�L����ǂތ���Sun��Niagara/Rock�ɑ���R���I�Ȉʒu�Â����ۂ�����A�]����Xeon DP�Ƃ͂�����ƌn�Ⴄ�̂����B
Tukwila����ȍ~��Itanium���P�̂��X���[�v�b�g��x86�ɑR���Ă����悤�ȋC�z�Ȃ̂ŁA
IPF�Ƃ̋������\�z�����B
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/dp
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
mcm���Ȃɂ��͂킩��Ȃ���1S��8 node��͋Ƃł̂���32 core, 128 thread�����s�ł���悤�ɂ������̂��ȁB
�L����ǂތ���Sun��Niagara/Rock�ɑ���R���I�Ȉʒu�Â����ۂ�����A�]����Xeon DP�Ƃ͂�����ƌn�Ⴄ�̂����B
Tukwila����ȍ~��Itanium���P�̂��X���[�v�b�g��x86�ɑR���Ă����悤�ȋC�z�Ȃ̂ŁA
IPF�Ƃ̋������\�z�����B
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/dp
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
710 �Finteler@�����F2006/07/16(��) 14:19:10 ID:unIashj50
>>707-708�ł͏����DP�p���Ă��Ƃɂ��Ă�������͊ԈႢ�B
- Keifer
-- 2010�N, 32nm, 2GHz, 15x throughput perf.(vs woodcrest)
-- 32 core, 128 thread / socket
-- 4 thread / core
-- 4 core / processing-node
-- 8 processing-node / socket
-- 512KB L2C / core
-- 3 MB LLC / node, total 24 MB LLC / socket
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/xx
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
- Keifer
-- 2010�N, 32nm, 2GHz, 15x throughput perf.(vs woodcrest)
-- 32 core, 128 thread / socket
-- 4 thread / core
-- 4 core / processing-node
-- 8 processing-node / socket
-- 512KB L2C / core
-- 3 MB LLC / node, total 24 MB LLC / socket
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/xx
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
Keifer�̑��_�C�ʐς�450mm^2���炢��
�R����]���T�Z���Ă݂������v500sqmm�O��N���X���ȁB
���̃T�C�Y����Xeon MP/IPF�N���X�̃n�C�G���h�����`�b�v�Ȃ�single die�����肦�Ȃ����Ȃ��ȍŋ߂̃g�����h���ƁB
�����O�Œ��r���[��mcm�\�����₾���A����Many Core�Ɋւ��Ă͏璷�\���ŃR�A��ϋɓI�ɎE�����j�ł���Ε����܂���啪���P�����킯�����B
�ӊO��single die�ł����邩������Ȃ�������B
���̃T�C�Y����Xeon MP/IPF�N���X�̃n�C�G���h�����`�b�v�Ȃ�single die�����肦�Ȃ����Ȃ��ȍŋ߂̃g�����h���ƁB
�����O�Œ��r���[��mcm�\�����₾���A����Many Core�Ɋւ��Ă͏璷�\���ŃR�A��ϋɓI�ɎE�����j�ł���Ε����܂���啪���P�����킯�����B
�ӊO��single die�ł����邩������Ȃ�������B
Tera-scale Computing: Intel's Attack of the Cores
http://www.eweek.com/article2/0,1895,1978412,00.asp
http://www.eweek.com/article2/0,1895,1978412,00.asp
������x�蔲���v�Z���Ă݂��A600^mm���炢�ɂȂ肻���B
>>715
���̕��ɂ��̃X���ŋ�J���ďW�߂�����\�z����������܂Ƃ܂��Ă���B
Gainestown�͂����Nehalem*2��8core���i�E�́E�j
--
Beyond the current crop of 65nm Core 2 processors, we expect the 45nm
versions of Core 2 to launch in early 2008 with clock speeds of ~3.5 GHz,
caches sizes that are 50% larger vs the 65nm Core 2 and improved floating point
performance, an area that the 65nm Core 2 is somewhat deficient relative to its
integer performance.
Later in 2008, we expect Intel to move to its next generation architecture,
Nehalem, which we expect to more closely resemble AMD systems with an onchip
memory controller and chip-to-chip communications interface called CSI.
We also expect Intel to launch its first 8-core chip in 2008, called Gainestown
for dual-socket servers. In a similar time frame in 2008, we expect Intel to
launch its first 65nm Itanium chip called Tukwila, a quad-core with an on-chip
memory controller and CSI interface that should be similar to the Nehalem
Intel Corp. 19 June 2006
UBS 7
implementation. This could create an interesting overlap between MP x86 Xeon
and low-end Itanium systems that should benefit from the higher-volume lowercost
infrastructure that supports Xeon and the performance of Itanium.
--
Kentsfield��3.75GHz��OC�ł܂���Ă���͗l�B
http://www.xtremesystems.org/forums/showthread.php?t=107092
���̕��ɂ��̃X���ŋ�J���ďW�߂�����\�z����������܂Ƃ܂��Ă���B
Gainestown�͂����Nehalem*2��8core���i�E�́E�j
--
Beyond the current crop of 65nm Core 2 processors, we expect the 45nm
versions of Core 2 to launch in early 2008 with clock speeds of ~3.5 GHz,
caches sizes that are 50% larger vs the 65nm Core 2 and improved floating point
performance, an area that the 65nm Core 2 is somewhat deficient relative to its
integer performance.
Later in 2008, we expect Intel to move to its next generation architecture,
Nehalem, which we expect to more closely resemble AMD systems with an onchip
memory controller and chip-to-chip communications interface called CSI.
We also expect Intel to launch its first 8-core chip in 2008, called Gainestown
for dual-socket servers. In a similar time frame in 2008, we expect Intel to
launch its first 65nm Itanium chip called Tukwila, a quad-core with an on-chip
memory controller and CSI interface that should be similar to the Nehalem
Intel Corp. 19 June 2006
UBS 7
implementation. This could create an interesting overlap between MP x86 Xeon
and low-end Itanium systems that should benefit from the higher-volume lowercost
infrastructure that supports Xeon and the performance of Itanium.
--
Kentsfield��3.75GHz��OC�ł܂���Ă���͗l�B
http://www.xtremesystems.org/forums/showthread.php?t=107092
>>715
�[���A45nm�ł�Core 2(=Ridgefield, Wolfdale, Penryn, Harpertown��)�ł́A���int�ɑ���
��_������fp�����P�����Ƃ̐������c�B
>>423(���ǂނƌÂ�)�ł�Nehalem�̃^�C�~���O��fp��������������P�o�������ǁA
45nm Core�ł͂ǂ����c�B
----
End of DToS: Specification for Intel Xeon 3000 released
http://www.hkepc.com/bbs/itnews.php?tid=631842
���܂�UP Server�̓f�X�N�g�b�v�Ƌ��ʃu�����h(Pen4 F��)�������Ă������A
Core 2����́AIntel Xeon 3000 Series�u�����h�ł����炵���B
���g��Conroe�B�`�b�v�Z�b�g��i975X�B�R�[�h�l�[����Kaylo Platform�B
Conroe Xeon UP 3000 sequence
- Xeon 3070 / 2.67GHz / 4MB L2 / 1066MHz FSB / $530
- Xeon 3060 / 2.40GHz / 4MB L2 / 1066MHz FSB / $316
- Xeon 3050 / 2.13GHz / 2MB L2 / 1066MHz FSB / $224
- Xeon 3040 / 1.86GHz / 2MB L2 / 1066MHz FSB / $188
Q3 2007�ɂ́AKentsfield+�V�`�b�v�Z�b�g��Garlow Platform�Ɉڍs����B
�[���A45nm�ł�Core 2(=Ridgefield, Wolfdale, Penryn, Harpertown��)�ł́A���int�ɑ���
��_������fp�����P�����Ƃ̐������c�B
>>423(���ǂނƌÂ�)�ł�Nehalem�̃^�C�~���O��fp��������������P�o�������ǁA
45nm Core�ł͂ǂ����c�B
----
End of DToS: Specification for Intel Xeon 3000 released
http://www.hkepc.com/bbs/itnews.php?tid=631842
���܂�UP Server�̓f�X�N�g�b�v�Ƌ��ʃu�����h(Pen4 F��)�������Ă������A
Core 2����́AIntel Xeon 3000 Series�u�����h�ł����炵���B
���g��Conroe�B�`�b�v�Z�b�g��i975X�B�R�[�h�l�[����Kaylo Platform�B
Conroe Xeon UP 3000 sequence
- Xeon 3070 / 2.67GHz / 4MB L2 / 1066MHz FSB / $530
- Xeon 3060 / 2.40GHz / 4MB L2 / 1066MHz FSB / $316
- Xeon 3050 / 2.13GHz / 2MB L2 / 1066MHz FSB / $224
- Xeon 3040 / 1.86GHz / 2MB L2 / 1066MHz FSB / $188
Q3 2007�ɂ́AKentsfield+�V�`�b�v�Z�b�g��Garlow Platform�Ɉڍs����B
Game Over? Core 2 Duo Knocks Out Athlon 64
http://www.tomshardware.com/2006/07/14/core2_duo_knocks_out_athlon_64/index.html
Tom's��Core 2 Duo�x���`���r���[�B�x���`�����ł��Ȃ�̃{�����[�����ˁB
Processor Die-Size Transistor-Count Process
------------------------------------------
Core 2 Extreme X6800 143 mm2 291 Mio. 65 nm
Core 2 Duo E6700 143 mm2 291 Mio. 65 nm
Core 2 Duo E6600 143 mm2 291 Mio. 65 nm
Core 2 Duo E6400 111 mm2 167 Mio. 65 nm
Core 2 Duo E6300 111 mm2 167 Mio. 65 nm
Pentium D 900 280 mm2 376 Mio. 65 nm
Athlon 64 FX-62 230 mm2 227 Mio. 90 nm
Athlon 64 5000+ 183 mm2 154 Mio. 90 nm
Tom's�̃T�C�g�݂���A
C2D E6000(143sqmm)��C2D E4000(111sqmmm)�Ń_�C�T�C�Y������Ă��邱�Ƃ����o�B
Conroe = E6000 = 4MB L2, Allendale = E4000 = 2MB L2�Ƃ����悤�ɃR�[�h�l�[�����ʓr�p��
����Ă��闝�R�͂��̂��߂��c(;�L�D�M)
2MB��32sqmm�̍��Ƃ������Ƃ��o���Ă����Ɖ����̖��ɗ������B
http://www.tomshardware.com/2006/07/14/core2_duo_knocks_out_athlon_64/index.html
Tom's��Core 2 Duo�x���`���r���[�B�x���`�����ł��Ȃ�̃{�����[�����ˁB
Processor Die-Size Transistor-Count Process
------------------------------------------
Core 2 Extreme X6800 143 mm2 291 Mio. 65 nm
Core 2 Duo E6700 143 mm2 291 Mio. 65 nm
Core 2 Duo E6600 143 mm2 291 Mio. 65 nm
Core 2 Duo E6400 111 mm2 167 Mio. 65 nm
Core 2 Duo E6300 111 mm2 167 Mio. 65 nm
Pentium D 900 280 mm2 376 Mio. 65 nm
Athlon 64 FX-62 230 mm2 227 Mio. 90 nm
Athlon 64 5000+ 183 mm2 154 Mio. 90 nm
Tom's�̃T�C�g�݂���A
C2D E6000(143sqmm)��C2D E4000(111sqmmm)�Ń_�C�T�C�Y������Ă��邱�Ƃ����o�B
Conroe = E6000 = 4MB L2, Allendale = E4000 = 2MB L2�Ƃ����悤�ɃR�[�h�l�[�����ʓr�p��
����Ă��闝�R�͂��̂��߂��c(;�L�D�M)
2MB��32sqmm�̍��Ƃ������Ƃ��o���Ă����Ɖ����̖��ɗ������B
719 �Finteler@�����F2006/07/17(��) 17:40:32 ID:igF4Dfcd0
C2D E6600�ȏ�(143sqmm)��C2D E6400�ȉ�(111sqmmm)�Ń_�C�T�C�Y������Ă��邱�Ƃ����o�B
Conroe = 4MB L2
Allendale = 2MB L2
�Ƃ����悤�ɃR�[�h�l�[�����ʓr�p�ӂ���Ă��闝�R�͂��̂��߂��c(;�L�D�M)
Celeron�̂悤�ȃL���b�V���E���łł͂Ȃ��l�q�B
2MB��32sqmm�̍��Ƃ������Ƃ��o���Ă����Ɖ����̖��ɗ������B
Conroe = 4MB L2
Allendale = 2MB L2
�Ƃ����悤�ɃR�[�h�l�[�����ʓr�p�ӂ���Ă��闝�R�͂��̂��߂��c(;�L�D�M)
Celeron�̂悤�ȃL���b�V���E���łł͂Ȃ��l�q�B
2MB��32sqmm�̍��Ƃ������Ƃ��o���Ă����Ɖ����̖��ɗ������B
���㓡�O��Weekly�C�O�j���[�X��
64bit�͋���Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
�㓡�L�����܂��܂����Ȃǂ�Ȃ��ȁB
64bit�͋���Core Microarchitecture
http://pc.watch.impress.co.jp/docs/2006/0718/kaigai288.htm
�㓡�L�����܂��܂����Ȃǂ�Ȃ��ȁB
Intel Xeon 7100 16MB L3 model launch on Aug 27
http://www.hkepc.com/bbs/news.php?tid=632194&starttime=0&endtime=0
Tulsa(>>327, >>331)�́A8/27�Ƀ����[�X�B
http://www.hkepc.com/bbs/news.php?tid=632194&starttime=0&endtime=0
Tulsa(>>327, >>331)�́A8/27�Ƀ����[�X�B
�J�ł͎���Power Mac (Mac Pro?)�Ɋւ���\�ł������肷�ˁB
http://www.macrumors.com/pages/2006/07/20060714150350.shtml
�v���Z�b�T�Ƃ���Conroe���̗p�����̂��AWoodcrest���̗p�����̂��ɋ�����W��
���Ă��邷���ǁA���̓_��>>360�ŏ�����x86�̉��i�̌n�ɂ��ω��������Ă���̂ɂ�
���ڂ��Ǝv�����B
��̓I�ɂ�f�X�N�g�b�v�p�ƃT�[�o�[�p�ƕʂ̉��i�̌n�����u�}�j�A�����v�O���[�h
�̑��݂����邷�BAMD��Athlon64 FX�̗ނ��ˁB�B�B
Core2 Duo�V���[�Y�̃v���Z�b�T���]���̃f�X�N�g�b�v�����ƃT�[�o�[�����̉��i�̌n��
�Ђ����ŁA2�Z�b�g�Ŕ����DP�Ή��̃`�b�v�̕����P���������Ȃ�Ƃ����ُ�Ȓl�i��
���������Ă��邷�B�������Ȃ���A>>390��艿�i����k�܂�AXeon�ɂ퍂��FSB�̃v��
�~�A���t�����Ă��邱�Ƃ풍�ڂ��B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)E6700 2.67GHz/1066MHz FSB $530-
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5150 2.66GHz/1333MHz FSB $690-
�@�@---------------------------
http://www.macrumors.com/pages/2006/07/20060714150350.shtml
�v���Z�b�T�Ƃ���Conroe���̗p�����̂��AWoodcrest���̗p�����̂��ɋ�����W��
���Ă��邷���ǁA���̓_��>>360�ŏ�����x86�̉��i�̌n�ɂ��ω��������Ă���̂ɂ�
���ڂ��Ǝv�����B
��̓I�ɂ�f�X�N�g�b�v�p�ƃT�[�o�[�p�ƕʂ̉��i�̌n�����u�}�j�A�����v�O���[�h
�̑��݂����邷�BAMD��Athlon64 FX�̗ނ��ˁB�B�B
Core2 Duo�V���[�Y�̃v���Z�b�T���]���̃f�X�N�g�b�v�����ƃT�[�o�[�����̉��i�̌n��
�Ђ����ŁA2�Z�b�g�Ŕ����DP�Ή��̃`�b�v�̕����P���������Ȃ�Ƃ����ُ�Ȓl�i��
���������Ă��邷�B�������Ȃ���A>>390��艿�i����k�܂�AXeon�ɂ퍂��FSB�̃v��
�~�A���t�����Ă��邱�Ƃ풍�ڂ��B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)E6700 2.67GHz/1066MHz FSB $530-
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5150 2.66GHz/1333MHz FSB $690-
�@�@---------------------------
���ǁAMAC�I�^�́AMac Pro�ɂ�
�uWoodcrest���̗p�����v
�u�̗p����Ȃ��v
�ǂ������Ǝv���Ă�킯�H
�uWoodcrest���̗p�����v
�u�̗p����Ȃ��v
�ǂ������Ǝv���Ă�킯�H
724 �FMAC�I�^�������F2006/07/18(��) 01:37:18 ID:4vaZmfLg0
���>>390���Ă̂�>>360�̊ԈႢ�Ȃ�ŁA�����v���ēǂ�ŗ~�������B
�Ƃ��낪�A�Ή��`�b�v�Z�b�g�^�}�U�[�{�[�h�̊ϓ_���瓯���f�X�N�g�b�v�p�v���Z�b�T��
����Ȃ���A�ŏ㋉�O���[�h�̃`�b�v�݂̂�u�}�j�A�����v�Ƃ��ē���Ȓl�i���t�����
�Ă��邷�B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)X6800 2.93GHz/1066MHz FSB 999-
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5160 3.00GHz/1333MHz FSB $850-
�@�@---------------------------
�����ɂ���Ă�A2�Z�b�g�Ŕ���DP�Ή��̃`�b�v�̒P���������Ƃ����A���ɂ܂��Ƃ���
�l�i���B
���āA"Good", "Better", "Best"�ł��Ȃ�➑́^�}�U�[�{�[�h���g�p����Apple��
�f�X�N�g�b�v��Conroe��Woodcrest�̂ǂ�����̗p���邩��A�Ȃ��Ȃ��������
�����邷�B
�Ƃ��낪�A�Ή��`�b�v�Z�b�g�^�}�U�[�{�[�h�̊ϓ_���瓯���f�X�N�g�b�v�p�v���Z�b�T��
����Ȃ���A�ŏ㋉�O���[�h�̃`�b�v�݂̂�u�}�j�A�����v�Ƃ��ē���Ȓl�i���t�����
�Ă��邷�B
�@�@---------------------------
�@�@�V���O���v���Z�b�T�Ή� (Conroe)X6800 2.93GHz/1066MHz FSB 999-
�@�@�f���A���v���Z�b�T�Ή� (Woodcrest)5160 3.00GHz/1333MHz FSB $850-
�@�@---------------------------
�����ɂ���Ă�A2�Z�b�g�Ŕ���DP�Ή��̃`�b�v�̒P���������Ƃ����A���ɂ܂��Ƃ���
�l�i���B
���āA"Good", "Better", "Best"�ł��Ȃ�➑́^�}�U�[�{�[�h���g�p����Apple��
�f�X�N�g�b�v��Conroe��Woodcrest�̂ǂ�����̗p���邩��A�Ȃ��Ȃ��������
�����邷�B
726 �FMAC�I�^�������F2006/07/18(��) 03:04:36 ID:4vaZmfLg0
X6800��Xeon 5180�̉��i����A�n�C�G���h���f����Woodcrest���̗p����
�Ƃ����b�ɐM�ߐ���^���邷�B�������A����Best���f����Woodcrest/3GHz���̗p����
���Ƃ��l����ƁA���[�G���h���f����PC�ɑ��鉿�i�����͂��������B�������N��
Apple�����萫�̗ǂ��������̗̍p�ɍS���Ă���_���AFB-DIMM���K�v��Woodcrest
�̗p�ɋ^���������_���B
���Ă�Apple�Ȃ�Intel�`�b�v�Z�b�g�ɍS�邱�ƂȂ��A���А��Ȃ��DDR2 + Woodcrest��
�\�������������Ǝv�������ǁA����J���̃v���W�F�N�g�����݂����Ƃ��Ă����i�K��
�`�b�v���o�Ă���Ƃ�v���Ȃ����B���������Ӗ��ŁA����Power Mac����̂悤�Ȉ�ʌ���
�}���`�\�P�b�g���f�����o��Ƃ����ӌ��ɉ��^�I���B
����2-socket���f���������[�X�����Ƃ��Ă��A�f�X�N�g�b�v���f����2�ɕ�����
�@Conroe + 965�`�b�v�Z�b�g�̈�ʌ���
�@Woodcrest�̃n�C�G���h
���āA�Ƃ���Ȃ�Ȃ������ˁH��҂�^���[➑̂�XServe�ɂȂ�̂���
����Ȃ������ǁB�B�B
�Ƃ����b�ɐM�ߐ���^���邷�B�������A����Best���f����Woodcrest/3GHz���̗p����
���Ƃ��l����ƁA���[�G���h���f����PC�ɑ��鉿�i�����͂��������B�������N��
Apple�����萫�̗ǂ��������̗̍p�ɍS���Ă���_���AFB-DIMM���K�v��Woodcrest
�̗p�ɋ^���������_���B
���Ă�Apple�Ȃ�Intel�`�b�v�Z�b�g�ɍS�邱�ƂȂ��A���А��Ȃ��DDR2 + Woodcrest��
�\�������������Ǝv�������ǁA����J���̃v���W�F�N�g�����݂����Ƃ��Ă����i�K��
�`�b�v���o�Ă���Ƃ�v���Ȃ����B���������Ӗ��ŁA����Power Mac����̂悤�Ȉ�ʌ���
�}���`�\�P�b�g���f�����o��Ƃ����ӌ��ɉ��^�I���B
����2-socket���f���������[�X�����Ƃ��Ă��A�f�X�N�g�b�v���f����2�ɕ�����
�@Conroe + 965�`�b�v�Z�b�g�̈�ʌ���
�@Woodcrest�̃n�C�G���h
���āA�Ƃ���Ȃ�Ȃ������ˁH��҂�^���[➑̂�XServe�ɂȂ�̂���
����Ȃ������ǁB�B�B
727 �FMAC�I�^�������܂��F2006/07/18(��) 03:08:43 ID:4vaZmfLg0
������AMD�̈����~���̂������ŁA�f�X�N�g�b�v������2-socket���i����ʓI��
�Ȃ�"��"��o�Ă������B
http://itpro.nikkeibp.co.jp/article/USNEWS/20060602/239771/
�u�ꂵ���Ȃ��2�ڂ���v���Ă̂�A���Ă�Apple�̂��ƌ|���������ǁA�v���Z�b�T
�x���_�ł���AMD����邱�ƂŁA�u2�Z�b�g�̉��i��1��������荂���v�Ƃ���x86�s��
�ُ̈�ȉ��i�̌n��ł��j���Ă���邱�Ƃɑ傢�Ɋ��҂��邷�B
�Ȃ�"��"��o�Ă������B
http://itpro.nikkeibp.co.jp/article/USNEWS/20060602/239771/
�u�ꂵ���Ȃ��2�ڂ���v���Ă̂�A���Ă�Apple�̂��ƌ|���������ǁA�v���Z�b�T
�x���_�ł���AMD����邱�ƂŁA�u2�Z�b�g�̉��i��1��������荂���v�Ƃ���x86�s��
�ُ̈�ȉ��i�̌n��ł��j���Ă���邱�Ƃɑ傢�Ɋ��҂��邷�B
728 �F���̖��ݒ��F2006/07/18(��) 03:46:41 ID:nGvbtW/b0
PPC��Xeon���c��C�ɉ���������
�Ȃ�Ńd�A���R�AItanium����Ȃ��̂���
�Ȃ�Ńd�A���R�AItanium����Ȃ��̂���
>���А��Ȃ��DDR2 + Woodcrest�̍\�������������Ǝv��������
����Ƃ���ς�AConroe��DP�ɂ��Ă����Ȃ����Ȃ��B
�ȑOPC�̗L���}�U�[�{�[�h���[�J�[�ł��f�X�N�g�b�v������i875��������
�f���A���v���Z�b�T�p�}�U�[�{�[�h���o��������
����Ƃ���ς�AConroe��DP�ɂ��Ă����Ȃ����Ȃ��B
�ȑOPC�̗L���}�U�[�{�[�h���[�J�[�ł��f�X�N�g�b�v������i875��������
�f���A���v���Z�b�T�p�}�U�[�{�[�h���o��������
������ă`�b�v�Z�b�g�̓f�X�N�g�b�v�p�ł��\�P�b�g�̓T�[�o�[�p����B
ConroeDP�͖�����BWoodcrest���Č�������������������B
�ł����̏ꍇFSB��P2P����Ȃ��Ȃ邩��Ȃ��B
�f����Kentsfield�܂ő҂������������̂����B
ConroeDP�͖�����BWoodcrest���Č�������������������B
�ł����̏ꍇFSB��P2P����Ȃ��Ȃ邩��Ȃ��B
�f����Kentsfield�܂ő҂������������̂����B
>>663
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=70516&threadid=70516&roomid=11
core hopping �Ƃ������̂� Core Multiplexing �̎����H
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=70516&threadid=70516&roomid=11
core hopping �Ƃ������̂� Core Multiplexing �̎����H
http://pc.watch.impress.co.jp/docs/2006/0721/hot438.htm
Perlmutter�{Chandrasekher�ŋ��̗\��
Perlmutter�{Chandrasekher�ŋ��̗\��
156 ���O: Socket774 Mail: ���e��: 2006/07/16(��) 13:50:06 ID: COprQ/Sw
���O��A��ׁI
8���ƌ����Ă���Merom�̔��\�������Ȃ����悤���B�ǂ����A7/23��conroe�Ɠ������\�݂����B
http://www.hkepc.com/bbs/itnews.php?tid=631837&starttime=0&endtime=0
���O��A��ׁI
8���ƌ����Ă���Merom�̔��\�������Ȃ����悤���B�ǂ����A7/23��conroe�Ɠ������\�݂����B
http://www.hkepc.com/bbs/itnews.php?tid=631837&starttime=0&endtime=0
34W���ĉ�����I�����[��I
G4�Ɣ�r���ă��b�g���\1/3�ȉ����˂����
���ƁAP965 G965�͂���܂ł̔��M�f�X�N�g�b�v�`�b�v�Z�b�g��i975X��肳��ɓd�C��H���炵���B
G�͂܂��킩��Ȃ����ǁA�O���t�B�b�N�R�A����镪����ɔM���Ǝv��
���ƁAP965 G965�͂���܂ł̔��M�f�X�N�g�b�v�`�b�v�Z�b�g��i975X��肳��ɓd�C��H���炵���B
G�͂܂��킩��Ȃ����ǁA�O���t�B�b�N�R�A����镪����ɔM���Ǝv��
Merom�̃��b�g���\��G4�̎O���̈�ȉ��H
�m��Ȃ�������A���ɂȂ����B
�m��Ȃ�������A���ɂȂ����B
>>739
���O�͉��������Ă���H
���O�͉��������Ă���H
>>740
���O�͉������������H
���O�͉������������H
>>732
core hopping (=�}���`�R�A�ȃv���Z�b�T�ŏ���d�́E���x�Ɋ�Â����������̕��U)���ē�����
=Core Multiplexing Technology���Ƃ���ƁA>>668��Chip Mulligan���̐��Ō��ǐ������ȁB
http://www.4gamer.net/news.php?url=/review/conroe_b1/conroe_b1.shtml
>�܂��O��Ƃ��āCCore 2�V���[�Y�ł́C�uCore Multiplexing Technology�v�Ƃ����@�\�ɂ��C�Б��̃R�A���ɂ��邱�Ƃ��\���B
>����̃v���r���[�ł́C�V���O���R�A�i�ȉ�1�R�A�j����̐��\��m��ׂ��C���̋@�\�𗘗p����\�肾�����̂����C
>D975XBX��1209��BIOS�ł́C���ꂪ�Ȃ��C����ɁuSW Single Processor Mode�v�Ƃ����@�\���p�ӂ���Ă����B
���̋L���ł͒P�Ȃ�V���O���v���Z�b�T���[�h�Ƃ����Ă��邯�ǁA���Ƃ����
SW Single Processor Mode�ƒ��g���ς��Ȃ��Ȃ��Ă��܂��̂ŁA����ς�>>668�������̗\���i�E�́E�j
���Ȃ݂ɍŏ��̃\�[�X�ł�2�̃��[�h��BIOS��ŕ\������Ă���
SW Single Processor Mode = �V���O���v���Z�b�T���[�h
Core Multiplexing Technology = Hot Spot��
ttp://www.xtremesystems.org/forums/attachment.php?attachmentid=48597&stc=1&d=1151158718
core hopping (=�}���`�R�A�ȃv���Z�b�T�ŏ���d�́E���x�Ɋ�Â����������̕��U)���ē�����
=Core Multiplexing Technology���Ƃ���ƁA>>668��Chip Mulligan���̐��Ō��ǐ������ȁB
http://www.4gamer.net/news.php?url=/review/conroe_b1/conroe_b1.shtml
>�܂��O��Ƃ��āCCore 2�V���[�Y�ł́C�uCore Multiplexing Technology�v�Ƃ����@�\�ɂ��C�Б��̃R�A���ɂ��邱�Ƃ��\���B
>����̃v���r���[�ł́C�V���O���R�A�i�ȉ�1�R�A�j����̐��\��m��ׂ��C���̋@�\�𗘗p����\�肾�����̂����C
>D975XBX��1209��BIOS�ł́C���ꂪ�Ȃ��C����ɁuSW Single Processor Mode�v�Ƃ����@�\���p�ӂ���Ă����B
���̋L���ł͒P�Ȃ�V���O���v���Z�b�T���[�h�Ƃ����Ă��邯�ǁA���Ƃ����
SW Single Processor Mode�ƒ��g���ς��Ȃ��Ȃ��Ă��܂��̂ŁA����ς�>>668�������̗\���i�E�́E�j
���Ȃ݂ɍŏ��̃\�[�X�ł�2�̃��[�h��BIOS��ŕ\������Ă���
SW Single Processor Mode = �V���O���v���Z�b�T���[�h
Core Multiplexing Technology = Hot Spot��
ttp://www.xtremesystems.org/forums/attachment.php?attachmentid=48597&stc=1&d=1151158718
Intel 965GM is considerably hotter than its predecessor
http://www.theinquirer.net/default.aspx?article=33229
ChipsetName MCH ICH Total
------------------------
Calistoga 7.0W 1.7W 8.7W
Crestline 13.8W 2.4W 16.2W
Increase 97% 41% 86%
Calistoga(=945GM Express = Napa Platform�̍\��Chipset = ���s�i)
Crestline(=965GM Express = Santa Rosa Platform�̍\��Chipset = Q2 2007)
TDP��8.7W��16.2W�ւ�86%�A�b�v�B����GPU���\��50%�̐��\�A�b�v�B
CPU��34W��42W�ւƂ�����\��B
�f�X�N�g�b�v��965�̓r�f�I����������23.1W TDP�B
http://www.theinquirer.net/default.aspx?article=33229
ChipsetName MCH ICH Total
------------------------
Calistoga 7.0W 1.7W 8.7W
Crestline 13.8W 2.4W 16.2W
Increase 97% 41% 86%
Calistoga(=945GM Express = Napa Platform�̍\��Chipset = ���s�i)
Crestline(=965GM Express = Santa Rosa Platform�̍\��Chipset = Q2 2007)
TDP��8.7W��16.2W�ւ�86%�A�b�v�B����GPU���\��50%�̐��\�A�b�v�B
CPU��34W��42W�ւƂ�����\��B
�f�X�N�g�b�v��965�̓r�f�I����������23.1W TDP�B
E4200 dead in the battle againsting X2 3600+
http://www.hkepc.com/bbs/news.php?tid=632107&starttime=1152921600&endtime=1153008000
Q1 2007�ɗ����ł�Core 2 Duo E4300���o��B
- Core 2 Duo E4300 / Conroe / 1.80GHz / 2MB L2 / 800MHz FSB / no-VT
���X�́A1.6GHz�ł�E4200�����X�\�肳��Ă������A
Athlon 64 X2 3600+�֑R�̂��߁A1.8GHz�łɗ\��ύX���ꂽ�͗l�B
Q2 2007�ɂ́A����Ɉ�����Conroe-L(=Core 2��Celeron��)���o��B
http://www.hkepc.com/bbs/news.php?tid=632107&starttime=1152921600&endtime=1153008000
Q1 2007�ɗ����ł�Core 2 Duo E4300���o��B
- Core 2 Duo E4300 / Conroe / 1.80GHz / 2MB L2 / 800MHz FSB / no-VT
���X�́A1.6GHz�ł�E4200�����X�\�肳��Ă������A
Athlon 64 X2 3600+�֑R�̂��߁A1.8GHz�łɗ\��ύX���ꂽ�͗l�B
Q2 2007�ɂ́A����Ɉ�����Conroe-L(=Core 2��Celeron��)���o��B
Intel Quad-Core Pushed Up to Q4'06
http://images.anandtech.com/jcampion/article.aspx?newsid=3421
�e���Ŏ��グ���Ă��邪�A
Kentsfield, Clovertown��Q1 2007����Q4 2006�ɑO�|���ɂȂ�܂����B
http://images.anandtech.com/jcampion/article.aspx?newsid=3421
�e���Ŏ��グ���Ă��邪�A
Kentsfield, Clovertown��Q1 2007����Q4 2006�ɑO�|���ɂȂ�܂����B
Crestline: 965GM Express Chipset
-Supports Intel Core 2 Duo Processor at 667/800MHz FSB
-Dual-Channel DDR2 533/667MHz
-Intel Active Management Technology 2.5
-Integrated Graphics
-- Generation 4
-- 400MHz at 1.05V
-- DirectX 10 and OpenGL 2.0 support
-- CRT, TV-out, dual-channel 18 or single channel 24bpp LVDS
-PCI Express x16 and Dual-channel SDVO
GMCH Feature Comparison
Topic/Feature | Intel 945GM (Calistoga) | Crestline
- Package | 37.5 x 37.5mm | 35 x 35mm
- Ball Count; Pitch | 1466pins; 42mil x 34 mil | 1299pins; 31.5 mil
- Thermal Design Power | 7W | 13.8W
- FSB Addressing | 32 bit for 4GB Address Space | 36 bit for 64GB Address Space
- FSB Speed | 533/667MHz | 667/800MHz
- System Memory Speeds | 400/533/667MHz DDR2 | 533/667MHz DDR2
- System Memory Capacity | 128 MB - 4MB | 128 MB - 4MB
- Manageability Engine (AMT) | No | Yes
- Memory Technologies | 256MB, 512MB, 1GB | 256MB, 512MB,1GB, 2GB
- Max Graphics Core Speed | [email protected] | [email protected] |
- Dynamic Video Memory Tech. | 3.0 (128MB Max) | 4.0 (256MB Max) |
- Graphics Performance | 1x | 1.5x |
- Analog Monitor Resolution | Up to UXGA (1600x1200) | Up to QXGA (2048x1536) |
- 24 bpp LVDS support | No | Single Channel
- OpenGL Support | OpenGL 1.4 | OpenGL 2.0 |
- Microsoft Direct X Support | DirectX 9.0 | DirectX 10 |
-Supports Intel Core 2 Duo Processor at 667/800MHz FSB
-Dual-Channel DDR2 533/667MHz
-Intel Active Management Technology 2.5
-Integrated Graphics
-- Generation 4
-- 400MHz at 1.05V
-- DirectX 10 and OpenGL 2.0 support
-- CRT, TV-out, dual-channel 18 or single channel 24bpp LVDS
-PCI Express x16 and Dual-channel SDVO
GMCH Feature Comparison
Topic/Feature | Intel 945GM (Calistoga) | Crestline
- Package | 37.5 x 37.5mm | 35 x 35mm
- Ball Count; Pitch | 1466pins; 42mil x 34 mil | 1299pins; 31.5 mil
- Thermal Design Power | 7W | 13.8W
- FSB Addressing | 32 bit for 4GB Address Space | 36 bit for 64GB Address Space
- FSB Speed | 533/667MHz | 667/800MHz
- System Memory Speeds | 400/533/667MHz DDR2 | 533/667MHz DDR2
- System Memory Capacity | 128 MB - 4MB | 128 MB - 4MB
- Manageability Engine (AMT) | No | Yes
- Memory Technologies | 256MB, 512MB, 1GB | 256MB, 512MB,1GB, 2GB
- Max Graphics Core Speed | [email protected] | [email protected] |
- Dynamic Video Memory Tech. | 3.0 (128MB Max) | 4.0 (256MB Max) |
- Graphics Performance | 1x | 1.5x |
- Analog Monitor Resolution | Up to UXGA (1600x1200) | Up to QXGA (2048x1536) |
- 24 bpp LVDS support | No | Single Channel
- OpenGL Support | OpenGL 1.4 | OpenGL 2.0 |
- Microsoft Direct X Support | DirectX 9.0 | DirectX 10 |
ICH8-M
- Intel AMT 2.5
- Integrated GbE MAC
- 3 SATA2 Ports - 3Gbps
- 6 x1 PCI Express Ports
- 10 USB 2.0 Ports - 2 EHCU controllers (no shared bandwidth)
- Five Integrated Voltage Regulators
---
Crestline Chipset(=965GM Express, Santa Rosa Mobile PF, Q2 2007)�̎d�l�B
�\�[�X��>>743�̋L���̌��l�^�Ƃ�������HKEPC�̂�B
Details for Santa Rosa, supports DX10 and release in 07 Q2
http://www.hkepc.com/bbs/news.php?tid=630184&starttime=1152662400&endtime=1152748800
- Intel AMT 2.5
- Integrated GbE MAC
- 3 SATA2 Ports - 3Gbps
- 6 x1 PCI Express Ports
- 10 USB 2.0 Ports - 2 EHCU controllers (no shared bandwidth)
- Five Integrated Voltage Regulators
---
Crestline Chipset(=965GM Express, Santa Rosa Mobile PF, Q2 2007)�̎d�l�B
�\�[�X��>>743�̋L���̌��l�^�Ƃ�������HKEPC�̂�B
Details for Santa Rosa, supports DX10 and release in 07 Q2
http://www.hkepc.com/bbs/news.php?tid=630184&starttime=1152662400&endtime=1152748800
ICH-7��ICH-8�̔�r�͂̓^�C�v���ʓ|�Ȃ̂ł�߂܂����B
Intel Core 2 Duo X6800: The First Extreme Model with the New Core
http://www.digit-life.com/articles2/cpu/intel-core2-duo-x6800.html
iXBT��Core 2 Duo X6800�̃x���`���r���[�̋L���Ȃ̂����A
���e�[���N�[���[��GlacialTech Igloo 5071 PWM��2�̃N�[���[�Ƃ�
�X�R�A��r�������B
X6800�̃��e�[���N�[���[�ł́A��p�����܂��炵��Igloo 5071�N�[���[
�̏ꍇ���X�R�A�����m�ɗ����Ă���B
Core 2 Duo�ł́A��p�̑P�����������\�ɗ^����e������茰���ɂȂ��Ă�����ۂ��B
�t�ɂ��ꂾ���A�T�[�}���X���b�g�����O�̊����x��PenM��NetBurst�ɔ�ׂďオ���Ă��Ă���킯�B
Intel Core 2 Duo X6800: The First Extreme Model with the New Core
http://www.digit-life.com/articles2/cpu/intel-core2-duo-x6800.html
iXBT��Core 2 Duo X6800�̃x���`���r���[�̋L���Ȃ̂����A
���e�[���N�[���[��GlacialTech Igloo 5071 PWM��2�̃N�[���[�Ƃ�
�X�R�A��r�������B
X6800�̃��e�[���N�[���[�ł́A��p�����܂��炵��Igloo 5071�N�[���[
�̏ꍇ���X�R�A�����m�ɗ����Ă���B
Core 2 Duo�ł́A��p�̑P�����������\�ɗ^����e������茰���ɂȂ��Ă�����ۂ��B
�t�ɂ��ꂾ���A�T�[�}���X���b�g�����O�̊����x��PenM��NetBurst�ɔ�ׂďオ���Ă��Ă���킯�B
SPEC CPU2000. Part 26: Engineering Sample of Intel Core 2 Duo E6700 (Conroe), Intel C++/Fortran 9.1 Compilers
http://www.digit-life.com/articles2/cpu/insidespeccpu2000-part-q.html
Conroe E6700��ES�i��p�����AIntel C++/Fortran 9.1 Compiler��
�œK���I�v�V������ς����ꍇ��SPEC CPU�̃X�R�A��r�x���`�B(�悭����Ȃ��c(;�L�D�M))
���ʂ́A�V����Core 2�̂��߂ɗp�ӂ��ꂽ�I�v�V����-QxT�ŃR���p�C�������
Prescott����̃I�v�V����-QxP�ɔ�ׂė�錋�ʂɂȂ�A
�܂��A�R���p�C���̃`���[�j���O�����܂�i��ł��Ȃ��Ƃ������_�B
���łɁAQxT��T��Tejas��T�Ȃ̂ŁACore�A�[�L��Tejas�����̋@�\�������Mobile�A�[�L�Ƃ���
�v����Ă������Ƃ��킩��B
http://www.digit-life.com/articles2/cpu/insidespeccpu2000-part-q.html
Conroe E6700��ES�i��p�����AIntel C++/Fortran 9.1 Compiler��
�œK���I�v�V������ς����ꍇ��SPEC CPU�̃X�R�A��r�x���`�B(�悭����Ȃ��c(;�L�D�M))
���ʂ́A�V����Core 2�̂��߂ɗp�ӂ��ꂽ�I�v�V����-QxT�ŃR���p�C�������
Prescott����̃I�v�V����-QxP�ɔ�ׂė�錋�ʂɂȂ�A
�܂��A�R���p�C���̃`���[�j���O�����܂�i��ł��Ȃ��Ƃ������_�B
���łɁAQxT��T��Tejas��T�Ȃ̂ŁACore�A�[�L��Tejas�����̋@�\�������Mobile�A�[�L�Ƃ���
�v����Ă������Ƃ��킩��B
>>132�ł�100W�I�[�o�[�̘b�����������ǁA
Core 2 Extreme�̓s�[�N100W������114W�ŁA
Core 2 Duo�́A95W�ł��肬��Z�[�t�Ƃ������ʂɂȂ�܂����B
Core 2 Extreme (Conroe) X6900
core-voltage: 0.85V - 1.3625V
icc-max: 90A
maximum-power: 113.805W
thermal-design-power: 75W
Core 2 Duo (Conroe) E6300, E6400, E6600, E6700
core-voltage: 0.85V - 1.3625V
icc-max: 75A
maximum-power: 94.8375W
thermal-design-power: 65W
Core 2 Extreme�̓s�[�N100W������114W�ŁA
Core 2 Duo�́A95W�ł��肬��Z�[�t�Ƃ������ʂɂȂ�܂����B
Core 2 Extreme (Conroe) X6900
core-voltage: 0.85V - 1.3625V
icc-max: 90A
maximum-power: 113.805W
thermal-design-power: 75W
Core 2 Duo (Conroe) E6300, E6400, E6600, E6700
core-voltage: 0.85V - 1.3625V
icc-max: 75A
maximum-power: 94.8375W
thermal-design-power: 65W
753 �Finteler@�����F2006/07/29(�y) 13:52:38 ID:a1RHKEvt0
>>744,745
�V�K��CPU��I�Ԃɍۂ��Ė��ߑ̌^�A���W�X�^�\��������
�l�����IA-32���IA-64�̕����D��Ă���B
IA-32���I�ꂽ�͔̂��M�ʂƍ���̐��\�A�b�v���x��
�l���Ă̂��ƁB
����IA-64�����̓_���N���A���Ă����IA-64��
�I������\��������B
���ɑI�ꂽ�Ƃ��ĂȂ�������킴�킴�G�~�����[�V�����œ������K�v������H
�V�K��CPU��I�Ԃɍۂ��Ė��ߑ̌^�A���W�X�^�\��������
�l�����IA-32���IA-64�̕����D��Ă���B
IA-32���I�ꂽ�͔̂��M�ʂƍ���̐��\�A�b�v���x��
�l���Ă̂��ƁB
����IA-64�����̓_���N���A���Ă����IA-64��
�I������\��������B
���ɑI�ꂽ�Ƃ��ĂȂ�������킴�킴�G�~�����[�V�����œ������K�v������H
ttp://www.geocities.jp/andosprocinfo/wadai06/20060729.htm
�Q�DIntel��Conroe��Merom�\
�R�DCore�A�[�L�`�b�v��64�r�b�g����肩�H
�Q�DIntel��Conroe��Merom�\
�R�DCore�A�[�L�`�b�v��64�r�b�g����肩�H
Perlmutter������YO
TG Daily interviews Intel Senior VP: "Core is changing the game"
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
��memo
> ���[�U�[�̐l�B�ɂ͎��g���̐��E����R�A���̐��E�ւƈڍs���Ăق����B
> �������A���ɃN���C���g��Ԃł͑����̃R�A��ςݏグ�邱�Ƃɒ��ӂ��A
> ���ɗ����̂��������Ȃ���Ȃ�܂���B����"2"��good�ȃR�A����
> ����ƐM���Ă��܂��B"4"��high-end�ł������낢�R�A���ł��B
> �N���C���g���[�X�ɂ�����2�N���8�R�A�������Ă��邩�H�����N���I��
> ����̂Ȃ�A�v���邱�Ƃ͉\���B�������A����market needs��
> �ǂ�قǂ���̂��͋^��ł��B
TG Daily interviews Intel Senior VP: "Core is changing the game"
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
��memo
> ���[�U�[�̐l�B�ɂ͎��g���̐��E����R�A���̐��E�ւƈڍs���Ăق����B
> �������A���ɃN���C���g��Ԃł͑����̃R�A��ςݏグ�邱�Ƃɒ��ӂ��A
> ���ɗ����̂��������Ȃ���Ȃ�܂���B����"2"��good�ȃR�A����
> ����ƐM���Ă��܂��B"4"��high-end�ł������낢�R�A���ł��B
> �N���C���g���[�X�ɂ�����2�N���8�R�A�������Ă��邩�H�����N���I��
> ����̂Ȃ�A�v���邱�Ƃ͉\���B�������A����market needs��
> �ǂ�قǂ���̂��͋^��ł��B
Broadwater: Intel G/Q/P965 Express Chipset��TDP
Component / System / Bus / Memory / Tc-max / Idle Power / TDP
---------------------------------------------------------
82G965 / GMCH / 1066MHz / 800MHz / 97�� / 13W / 28W
82Q965 / GMCH / 1066MHz / 800MHz / 97�� / 13W / 28W
82Q963 / GMCH / 1066MHz / 800MHz / 97�� / 11W / 28W
82P965 / MCH / 1066MHz / 800MHz / 102�� / 10W / 19W
ICH8 / 3.0W-4.1W TDP
Component / System / Bus / Memory / Tc-max / Idle Power / TDP
---------------------------------------------------------
82G965 / GMCH / 1066MHz / 800MHz / 97�� / 13W / 28W
82Q965 / GMCH / 1066MHz / 800MHz / 97�� / 13W / 28W
82Q963 / GMCH / 1066MHz / 800MHz / 97�� / 11W / 28W
82P965 / MCH / 1066MHz / 800MHz / 102�� / 10W / 19W
ICH8 / 3.0W-4.1W TDP
>>755
Conroe and EM64T: Is There a Problem?
http://www.xbitlabs.com/articles/cpu/display/core2duo-64bit.html
http://www.xbitlabs.com/articles/cpu/display/core2duo-64bit_7.html
Core�A�[�L��64bit���\���Ⴂ�Ƃ����b�ŁA
Xbit��32bit/64bit�̔�r�x���`������Ă���B
�ŁA32bit��64bit�̌��ʂ�Core 2�ŁA���ς���+10%�����AAthlon64�ł́A+16%�����Ƃ������ʂɂȂ�A
���킪��Ă���قǂ̐��\�ቺ���܂�͂Ȃ��āAAthlon�Ɣ�ׂ�Ƃ����Ƃ��������݂����ˁB
�܂��A������ɂ���64bit�Ή������܂�Ă�����ł��Ȃ��āAMacro Fusion���g���Ȃ����A
����̉��P���K�v�Ƃ������Ƃ͂����Ȃ��ȁB
Conroe and EM64T: Is There a Problem?
http://www.xbitlabs.com/articles/cpu/display/core2duo-64bit.html
http://www.xbitlabs.com/articles/cpu/display/core2duo-64bit_7.html
Core�A�[�L��64bit���\���Ⴂ�Ƃ����b�ŁA
Xbit��32bit/64bit�̔�r�x���`������Ă���B
�ŁA32bit��64bit�̌��ʂ�Core 2�ŁA���ς���+10%�����AAthlon64�ł́A+16%�����Ƃ������ʂɂȂ�A
���킪��Ă���قǂ̐��\�ቺ���܂�͂Ȃ��āAAthlon�Ɣ�ׂ�Ƃ����Ƃ��������݂����ˁB
�܂��A������ɂ���64bit�Ή������܂�Ă�����ł��Ȃ��āAMacro Fusion���g���Ȃ����A
����̉��P���K�v�Ƃ������Ƃ͂����Ȃ��ȁB
82975X 13.5W TDP@MCH, 2.9-3.3W TDP@ICH
TDP�����̔�r�ł����ƁA975X�̕���965�������Ȃ�N�[���ŁA
Crestline����965GM���o�C���Ɠ����x�̓d�͂��ˁB
TDP�����̔�r�ł����ƁA975X�̕���965�������Ȃ�N�[���ŁA
Crestline����965GM���o�C���Ɠ����x�̓d�͂��ˁB
http://pc7.2ch.net/test/read.cgi/jisaku/1153843767/177
>177 �FSocket774 �F2006/07/28(��) 19:13:55 ID:OSWfZoH/
>Intel's future graphics tech is Power VR
>http://www.theinquirer.net/default.aspx?article=33318
>G965��GPU��Power VR��5����ڂɓ�����Muse�R�A�̋Z�p��
>SGX�Ђ��烉�C�Z���X���ꂽ�̂��g���Ă�Ɓc�܂�������ȂƂ���ɏo�Ă���Ƃ́B
>Kyro2�Ƃ��o���Ă�l����낤���H
http://pc7.2ch.net/test/read.cgi/jisaku/1067415926/891
>891 �FSocket774 �F2006/07/29(�y) 00:23:52 ID:ENeIPF+r
>915 ���O�F�Џ@[sage] ���e���F2006/07/28(��) 19:25:34 ID:FT9JY+DW
>ttp://www.imgtec.com/powervr/products/graphics/sgx/#
>���s��PowerVR SGX�i�g�ь����j�́AUnified Shader�̃n�[�h�E�F�A�A�[�L�e�N�`�����̗p
>�V�F�[�_���j�b�g�́A�V�F�[�_���f��3.0�����̃V�F�[�_�����s�ł��AOpenGL ES 2.0�ɑΉ��B
>�V�F�[�_���j�b�g�ŁAH.264���܂߂��A����̃G���R�[�h�E�f�R�[�h�Ɋւ��鏈�����s����B
>
>�g�ݍ������ŁA�撣���Ă����
>�m�[�X�u���b�W���������ɁA�Ђ���Ƃ��Ă��炭�ȓd�͂ȕ��ɂȂ邩������Ȃ��B
>
>ttp://www.imgtec.com/Investors/Presentations/Prelim06/index.asp?Slide=24
>PC�����������̗\��B
>
>Intel��PowerVR SGX�̃��C�Z���X�Ă���B
>177 �FSocket774 �F2006/07/28(��) 19:13:55 ID:OSWfZoH/
>Intel's future graphics tech is Power VR
>http://www.theinquirer.net/default.aspx?article=33318
>G965��GPU��Power VR��5����ڂɓ�����Muse�R�A�̋Z�p��
>SGX�Ђ��烉�C�Z���X���ꂽ�̂��g���Ă�Ɓc�܂�������ȂƂ���ɏo�Ă���Ƃ́B
>Kyro2�Ƃ��o���Ă�l����낤���H
http://pc7.2ch.net/test/read.cgi/jisaku/1067415926/891
>891 �FSocket774 �F2006/07/29(�y) 00:23:52 ID:ENeIPF+r
>915 ���O�F�Џ@[sage] ���e���F2006/07/28(��) 19:25:34 ID:FT9JY+DW
>ttp://www.imgtec.com/powervr/products/graphics/sgx/#
>���s��PowerVR SGX�i�g�ь����j�́AUnified Shader�̃n�[�h�E�F�A�A�[�L�e�N�`�����̗p
>�V�F�[�_���j�b�g�́A�V�F�[�_���f��3.0�����̃V�F�[�_�����s�ł��AOpenGL ES 2.0�ɑΉ��B
>�V�F�[�_���j�b�g�ŁAH.264���܂߂��A����̃G���R�[�h�E�f�R�[�h�Ɋւ��鏈�����s����B
>
>�g�ݍ������ŁA�撣���Ă����
>�m�[�X�u���b�W���������ɁA�Ђ���Ƃ��Ă��炭�ȓd�͂ȕ��ɂȂ邩������Ȃ��B
>
>ttp://www.imgtec.com/Investors/Presentations/Prelim06/index.asp?Slide=24
>PC�����������̗\��B
>
>Intel��PowerVR SGX�̃��C�Z���X�Ă���B
Final spec for G965: Q96x/946GZ are made from function disabling
http://www.hkepc.com/bbs/news.php?tid=638462&starttime=1153872000&endtime=1153958400
Direct X 9.0c and OpenGL 1.5 are told to be supported. But our sources have some more details.
Besides these, Direct X10 and Shader Model 4.0 are also supported for G965. The G965 Direct X10
driver will be ready as the same time as Direct X10 API for Vista released.
����G965�ŁAMac�Ƃ͊W�Ȃ�����DirectX10�T�|�[�g��Vista ready�̖͗l�B
Q965��DirectX9c�܂ł̃T�|�[�g�B�����O���t�B�b�N�X�h��G965�܂ł܂̂����B
http://www.hkepc.com/bbs/news.php?tid=638462&starttime=1153872000&endtime=1153958400
Direct X 9.0c and OpenGL 1.5 are told to be supported. But our sources have some more details.
Besides these, Direct X10 and Shader Model 4.0 are also supported for G965. The G965 Direct X10
driver will be ready as the same time as Direct X10 API for Vista released.
����G965�ŁAMac�Ƃ͊W�Ȃ�����DirectX10�T�|�[�g��Vista ready�̖͗l�B
Q965��DirectX9c�܂ł̃T�|�[�g�B�����O���t�B�b�N�X�h��G965�܂ł܂̂����B
Nvidia to Enable Multi-GPU Tech on Intel's Mobile Chipsets
http://www.xbitlabs.com/news/mobile/display/20060728074910.html
http://www.xbitlabs.com/news/mobile/display/20060728074910.html
Nvidia would cost $10 billion to buy
http://www.theinquirer.net/default.aspx?article=33298
Nvidia�̔����܂��`�`�`�`�`�`�`�`�`�`�`�`�`�`�H
http://www.theinquirer.net/default.aspx?article=33298
Nvidia�̔����܂��`�`�`�`�`�`�`�`�`�`�`�`�`�`�H
>>754
>����IA-64�����̓_���N���A���Ă����IA-64��
>�I������\��������B
IA-64�͂��̓_���N���A���Ă��Ȃ����A���ꂩ����N���A���Ȃ��̂ŁAIA-64���I��Ă����\���͖����B
�ȏ�B
>����IA-64�����̓_���N���A���Ă����IA-64��
>�I������\��������B
IA-64�͂��̓_���N���A���Ă��Ȃ����A���ꂩ����N���A���Ȃ��̂ŁAIA-64���I��Ă����\���͖����B
�ȏ�B
>>765
���Ⴀ�A���O�̌����u���_�v�Ƃ����܂߂āA���O�̎咣���ŏ�����Ō�܂ŏq�ׂĂ݂Ă���B
�����炭�A���O�ȊO�̐l�Ԃɂ͒N��l�Ƃ��ē`����Ă��Ȃ�����B
���Ⴀ�A���O�̌����u���_�v�Ƃ����܂߂āA���O�̎咣���ŏ�����Ō�܂ŏq�ׂĂ݂Ă���B
�����炭�A���O�ȊO�̐l�Ԃɂ͒N��l�Ƃ��ē`����Ă��Ȃ�����B
>>768
�lj�\�͂̂Ȃ���I�ɏグ�ċt�ꂩ��w
�lj�\�͂̂Ȃ���I�ɏグ�ċt�ꂩ��w
>>770
�L���ĂȂ���B�E�͂��������B
�c�_�i�Ƃ������A�I�n�i�V�j�̑O�܂�ň���Ă����ȁA�ƁB
�܂��A���l�������̌����������Ƃ�ǐS���Ă����u�lj�\�́v���]�X������A
���l�Ɏ����̌����������Ƃ�`������u�`�B�\�́v���ڂ݂����������Ǝv�����ǂˁB
�L���ĂȂ���B�E�͂��������B
�c�_�i�Ƃ������A�I�n�i�V�j�̑O�܂�ň���Ă����ȁA�ƁB
�܂��A���l�������̌����������Ƃ�ǐS���Ă����u�lj�\�́v���]�X������A
���l�Ɏ����̌����������Ƃ�`������u�`�B�\�́v���ڂ݂����������Ǝv�����ǂˁB
>>771
�͂��͂��A���͂��̂���w
�͂��͂��A���͂��̂���w
�₦�₦�`�b�v�Z�b�g�͓����o�Ȃ��̂��`�B
Itanic�~�͋������B
��킭�́A��x�Ɨ��Ȃ����Ƃ��B
��킭�́A��x�Ɨ��Ȃ����Ƃ��B
�n���ۏo������w
���߂�Ȃ����i�����j
>>742
2�R�A�œ��������Ƃ�O��Ƃ��Ă�̂�1�R�A�œ������Ƃ���Hot Spot��Ȃ�Ă��邩�ȁH
����Ȃ̂��K�v�Ȃ�2�R�A�œ������Ȃ��C�����邯�ǁB
���ƁA�R�A���ւ���Ɛ��\�����������B
>>752
���̃f�[�^���Ăǂ��ɂ���H
2�R�A�œ��������Ƃ�O��Ƃ��Ă�̂�1�R�A�œ������Ƃ���Hot Spot��Ȃ�Ă��邩�ȁH
����Ȃ̂��K�v�Ȃ�2�R�A�œ������Ȃ��C�����邯�ǁB
���ƁA�R�A���ւ���Ɛ��\�����������B
>>752
���̃f�[�^���Ăǂ��ɂ���H
Patent���Ă݂��A��������ˁ[���B
>>777
1�R�A�œ������ɂ���2�R�A�œ������ɂ����Ƀv���O�����̓��e�ɂ���Ĕ��M�������̂ŁA
���̂悤�ȍl�����o�Ă���킯�B
����͂��Ă����������݂�ƁA���\���e�����������B
core hopping = �e�R�A�̏���d�͂�M�����j�^���āA�N�[���ȃR�A�Ƀv���Z�X�����蓖�Ă�悤�ɂ�����A
>>668�̂悤�ɁA�M���Ȃ�����R�A���X���b�v������A�N�[���ȃR�A�͏����ŃN���b�N��������Ȃǂ�
������n�[�h�E�G�A�x�[�X�ōs�����������U���BOS����P��R�A�ɂ݂�����Ęb�͂Ȃ����ȁB
IntelR Core 2 Extreme Processor X6800�� and IntelR Core 2 Duo Desktop Processor E6000�� Sequence Datasheet
IntelR Core 2 Duo Desktop Processor E6000�� Sequence Thermal and Mechanical Design Guidelines
http://www.intel.co.jp/design/core2duo/documentation.htm
1�R�A�œ������ɂ���2�R�A�œ������ɂ����Ƀv���O�����̓��e�ɂ���Ĕ��M�������̂ŁA
���̂悤�ȍl�����o�Ă���킯�B
����͂��Ă����������݂�ƁA���\���e�����������B
core hopping = �e�R�A�̏���d�͂�M�����j�^���āA�N�[���ȃR�A�Ƀv���Z�X�����蓖�Ă�悤�ɂ�����A
>>668�̂悤�ɁA�M���Ȃ�����R�A���X���b�v������A�N�[���ȃR�A�͏����ŃN���b�N��������Ȃǂ�
������n�[�h�E�G�A�x�[�X�ōs�����������U���BOS����P��R�A�ɂ݂�����Ęb�͂Ȃ����ȁB
IntelR Core 2 Extreme Processor X6800�� and IntelR Core 2 Duo Desktop Processor E6000�� Sequence Datasheet
IntelR Core 2 Duo Desktop Processor E6000�� Sequence Thermal and Mechanical Design Guidelines
http://www.intel.co.jp/design/core2duo/documentation.htm
http://blogs.sun.com/roller/page/bmseer?entry=dell_woodcrest_draws_2x_to
�Ƃ��Ă��ȓd�͂�Woodcrest
�Ƃ��Ă��ȓd�͂�Woodcrest
�܂��A�V���O���R�A�����g���ĔM�����ɂȂ�قǂ̕��ׂȂ�
�R�A��ւ��Ďg�����ŏ�����f���A���œ������������ǂ�
�悤�ȋC������
�R�A��ւ��Ďg�����ŏ�����f���A���œ������������ǂ�
�悤�ȋC������
>>779
�����炳�A2�R�A���t���ɓ�������1�R�A�����M���x�オ��ł���H
���RHotSpot��1�R�A���Ɠ����ȏ�ɂ͂Ȃ�킯�����B
����Ȃ̂�HotSpot��Ƃ�����Ӗ�������̂��H���Ă��ƁB
�����炳�A2�R�A���t���ɓ�������1�R�A�����M���x�オ��ł���H
���RHotSpot��1�R�A���Ɠ����ȏ�ɂ͂Ȃ�킯�����B
����Ȃ̂�HotSpot��Ƃ�����Ӗ�������̂��H���Ă��ƁB
���2core���t���ɓ������킯����Ȃ�����B
���R�A�������Ă���v���O�����Ɉˑ����邾��B
�Е����]�T�����鎞�́A�X���b�v������A�N���b�N�グ���肷����Ď�����B
���R�A�������Ă���v���O�����Ɉˑ����邾��B
�Е����]�T�����鎞�́A�X���b�v������A�N���b�N�グ���肷����Ď�����B
HotSpot��Ƃ����\�����K���ǂ����͂����Ă����Ƃ��āA
Core 2�ł́A>>750�Ɏ�����Ă���悤�ɁA���̉��x�ɒB����ƊȒP�ɃX���b�g�����O��
�����ăp�t�H�[�}���X�������Ă��܂��̂ŁA���M�U������̂̓p�t�H�[�}���X���ێ������ł��L���Ȃ킯�B
�܂��A�É����ɂ����ʂ����邩�ƁB
���R�A>>783�������Ă�ʂ���2core���t���ғ����Ă���킯����Ȃ�����A>>779�̂悤�Ȑ��䂪�Ӗ��������Ă���킯�B
�����ɂ������Ă��邯�ǁA�e�R�A�̔��M��max�l�ȏ�ɒB����Ƃ�͂�ŏI��i�Ƃ��Ă̓X���b�g�����O�������B
desktop��蔭�M�̐�������Merom�ł͂����ƗL�������B
�����̃v���Z�b�T�ł͂���Ɋ���ǂ���̃N���b�N���x�ŏ�ɓ��삵�Ă���͂ǂ�ǂ��āA
�}���`�X���b�h�ȑO�ɃN���b�N����p�t�H�[�}���X�𐄑�����͓̂���Ȃ��Ă����ȁB
Core 2�ł́A>>750�Ɏ�����Ă���悤�ɁA���̉��x�ɒB����ƊȒP�ɃX���b�g�����O��
�����ăp�t�H�[�}���X�������Ă��܂��̂ŁA���M�U������̂̓p�t�H�[�}���X���ێ������ł��L���Ȃ킯�B
�܂��A�É����ɂ����ʂ����邩�ƁB
���R�A>>783�������Ă�ʂ���2core���t���ғ����Ă���킯����Ȃ�����A>>779�̂悤�Ȑ��䂪�Ӗ��������Ă���킯�B
�����ɂ������Ă��邯�ǁA�e�R�A�̔��M��max�l�ȏ�ɒB����Ƃ�͂�ŏI��i�Ƃ��Ă̓X���b�g�����O�������B
desktop��蔭�M�̐�������Merom�ł͂����ƗL�������B
�����̃v���Z�b�T�ł͂���Ɋ���ǂ���̃N���b�N���x�ŏ�ɓ��삵�Ă���͂ǂ�ǂ��āA
�}���`�X���b�h�ȑO�ɃN���b�N����p�t�H�[�}���X�𐄑�����͓̂���Ȃ��Ă����ȁB
�e�R�A�̔��M�� �� �e�R�A�̔��M�̍��v��
�ō����o������͉��x��������܂ő��x���Ƃ��Ȃ��Ⴂ���Ȃ��̂�
�I�[�o�[�e�C�N�{�^���݂�������
������ƈႤ��
�I�[�o�[�e�C�N�{�^���݂�������
������ƈႤ��
����̓M���O�A�������̓f�o�b�N�p�ł����@�\��
�^���ɋc�_����悤�Ȃ��̂���Ȃ��Ǝv���B
�^���ɋc�_����悤�Ȃ��̂���Ȃ��Ǝv���B
>>784
����ˁA1�R�A�ł�HotSpot�̂��߂ɃR�A���ւ��Ȃ���Ȃ�Ȃ��Ȃ�
���������\�t�g��2�{���点���Ƃ��͊m���ɂ�����Ă��Ƃł���H
2�R�A���t���ɓ��������Ă̂͂��������Ӗ��Ō������B
���M�ʎ��̂�TDP���������Ă邩���薳�����낤�ˁB
���x�̂����Ő��\�𗎂Ƃ���������Ȃ��Ƃ������͂����HotSpot�B
�ŁA�����Ƃ������Ń��e�[���N�[���[��t���ĂĂ��������\�t�g�𑖂点��
�ꍇ�ɐ��\����������Ă͍̂��\�ɋ߂��B
���ʁA���͂̉��x���K��ȓ��Ń��e�[���N�[���[���g���Ă��琫�\�ቺ�Ȃ��
�N�����Ă͂����Ȃ��B���̐��\��ۏ��邽�߂ɐF�X�K�肪����킯�����B
�����{���Ȃ�Intel�͂����ƍ��m���Ȃ��Ƃ����Ȃ��B
�����Ƃ�>>750�̃N�[���[��X6800�̃��e�[���Ƃ͈Ⴄ�݂��������ǁB
�Ƃ����킯�ŁACore Multiplexing Technology��������HotSpot�Ƃ����̂͋^��B
�������AHotSpot�̉��x����������ʂ͂��邩��A+OC�Ƃ����Ȃ�킩�邯�ǁB
�����AL1�L���b�V������ւ��邩�炻�̂܂܂��Ɛ��\�͉����邩���ˁB
>>779��core hopping�̐������{���Ȃ�A���������Ƒ�ʂ̃R�A��ς�
�Ƃ��ɂ͉\�����o�Ă���C������B2�R�A���t���ɓ������̂͊ȒP�ł�
8�R�A�Ƃ�16�R�A���t���ɓ������̂͒��X�������ˁB
����ˁA1�R�A�ł�HotSpot�̂��߂ɃR�A���ւ��Ȃ���Ȃ�Ȃ��Ȃ�
���������\�t�g��2�{���点���Ƃ��͊m���ɂ�����Ă��Ƃł���H
2�R�A���t���ɓ��������Ă̂͂��������Ӗ��Ō������B
���M�ʎ��̂�TDP���������Ă邩���薳�����낤�ˁB
���x�̂����Ő��\�𗎂Ƃ���������Ȃ��Ƃ������͂����HotSpot�B
�ŁA�����Ƃ������Ń��e�[���N�[���[��t���ĂĂ��������\�t�g�𑖂点��
�ꍇ�ɐ��\����������Ă͍̂��\�ɋ߂��B
���ʁA���͂̉��x���K��ȓ��Ń��e�[���N�[���[���g���Ă��琫�\�ቺ�Ȃ��
�N�����Ă͂����Ȃ��B���̐��\��ۏ��邽�߂ɐF�X�K�肪����킯�����B
�����{���Ȃ�Intel�͂����ƍ��m���Ȃ��Ƃ����Ȃ��B
�����Ƃ�>>750�̃N�[���[��X6800�̃��e�[���Ƃ͈Ⴄ�݂��������ǁB
�Ƃ����킯�ŁACore Multiplexing Technology��������HotSpot�Ƃ����̂͋^��B
�������AHotSpot�̉��x����������ʂ͂��邩��A+OC�Ƃ����Ȃ�킩�邯�ǁB
�����AL1�L���b�V������ւ��邩�炻�̂܂܂��Ɛ��\�͉����邩���ˁB
>>779��core hopping�̐������{���Ȃ�A���������Ƒ�ʂ̃R�A��ς�
�Ƃ��ɂ͉\�����o�Ă���C������B2�R�A���t���ɓ������̂͊ȒP�ł�
8�R�A�Ƃ�16�R�A���t���ɓ������̂͒��X�������ˁB
>>750�̂��X6800�̃��e�[������Ȃ����̂ˁB
Various disclosed embodiments re-distribute processing tasks, threads, or computations to different portions of hardware
based on power consumption and/or thermal considerations. For example, in one embodiment, processes may be switched
between different cores of a multi-core processor. Some embodiments may advantageously spread high power consumption
tasks or processes between different processing units. Such spreading or distribution of processes over different hardware
may beneficially reduce the peak temperature that is reached by a processing unit. Since some hardware components
operate more efficiently at cooler temperatures, more efficient operation (and hence less overall power consumption) may
be achieved via the resulting lower overall temperatures in some embodiments. Moreover, in some embodiments, such
advantages may be obtained while substantially maintaining performance levels because "hot" and "cool" processes may be
swapped between particular hardware units, without necessarily requiring the idling of hardware to achieve some cooling.
Additionally, in some embodiments, monitoring techniques may allow independent control of the voltages and
operational frequencies of different processing units or cores.
������x������ꉞ�A�R�ꂪ�l���Ă���悤�Ȃ��Ƃ͏����Ă�������Bmaintaining performance
Various disclosed embodiments re-distribute processing tasks, threads, or computations to different portions of hardware
based on power consumption and/or thermal considerations. For example, in one embodiment, processes may be switched
between different cores of a multi-core processor. Some embodiments may advantageously spread high power consumption
tasks or processes between different processing units. Such spreading or distribution of processes over different hardware
may beneficially reduce the peak temperature that is reached by a processing unit. Since some hardware components
operate more efficiently at cooler temperatures, more efficient operation (and hence less overall power consumption) may
be achieved via the resulting lower overall temperatures in some embodiments. Moreover, in some embodiments, such
advantages may be obtained while substantially maintaining performance levels because "hot" and "cool" processes may be
swapped between particular hardware units, without necessarily requiring the idling of hardware to achieve some cooling.
Additionally, in some embodiments, monitoring techniques may allow independent control of the voltages and
operational frequencies of different processing units or cores.
������x������ꉞ�A�R�ꂪ�l���Ă���悤�Ȃ��Ƃ͏����Ă�������Bmaintaining performance
Intel Woodcrest, AMD's Opteron and Sun's UltraSparc T1: Server CPU Shoot-out
http://www.anandtech.com/IT/showdoc.aspx?i=2772
>>780
Woodcrest��Sparc T1�̃x���`��r�Ȃ�AnandTech�̋L�����������B
http://www.anandtech.com/IT/showdoc.aspx?i=2772
>>780
Woodcrest��Sparc T1�̃x���`��r�Ȃ�AnandTech�̋L�����������B
Dell Precision Workstation 390: Core 2 Extreme Debut
http://www.itbusinessnet.com/articles/viewarticle.jsp?id=53163-1
http://www.itbusinessnet.com/articles/viewarticle.jsp?id=53163-1
Intel Core 2 �S���ʃx���`�}�[�N - �V�A�[�L�e�N�`���̐^�������ɂ߂�
ttp://journal.mycom.co.jp/special/2006/conroe/
> * ���߂̃t�F�b�` / �f�R�[�h�̐��\�Ɋւ������ACore��K8�ƊT�˓����ł��낤�B
>�@�@�ׂ�������A�܂�K8�܂Œǂ����Ă��Ȃ�������������B����Ӗ�K8�͔���
>�@�@�D�����ŁA��������Ă����Ȃ����Ȃ���ۂŁA����Core�͓���̏����ɓ�������
>�@�@�`���[�j���O�����Ă��镵�͋C��������B
> * Core�̓f�[�^��Load / Store���啝�ɋ�������Ă���AK8�̔{�߂��\�͂������Ă���B
>�@�@����Ƒ�e��L2�L���b�V����g�ݍ��킹�邱�ƂŁA�f�[�^�������������ł���ƌ�����B
> * �������A�N�Z�X�Ɋւ��Č����ACore��K8�Ɉ���y�Ȃ��B
>>683�́u�f�R�[�_����ł̋�J�v���Ă̂͂��̎����Ȃ�
ttp://journal.mycom.co.jp/special/2006/conroe/
> * ���߂̃t�F�b�` / �f�R�[�h�̐��\�Ɋւ������ACore��K8�ƊT�˓����ł��낤�B
>�@�@�ׂ�������A�܂�K8�܂Œǂ����Ă��Ȃ�������������B����Ӗ�K8�͔���
>�@�@�D�����ŁA��������Ă����Ȃ����Ȃ���ۂŁA����Core�͓���̏����ɓ�������
>�@�@�`���[�j���O�����Ă��镵�͋C��������B
> * Core�̓f�[�^��Load / Store���啝�ɋ�������Ă���AK8�̔{�߂��\�͂������Ă���B
>�@�@����Ƒ�e��L2�L���b�V����g�ݍ��킹�邱�ƂŁA�f�[�^�������������ł���ƌ�����B
> * �������A�N�Z�X�Ɋւ��Č����ACore��K8�Ɉ���y�Ȃ��B
>>683�́u�f�R�[�_����ł̋�J�v���Ă̂͂��̎����Ȃ�
�|�J�[��
>>792
Core�͐����˂��AK8�ƈ���ăv���f�R�[�h�ς݃L���b�V�������ł����܂ō����\�Ƃ͋������B
K8�͔r���L���b�V��������L1���߃L���b�V���ɓǂݍ��ޒi�K�Ńv���f�R�[�h�\�Ȃ̂ő����ē�����̑O���B
�������r���L���b�V���ł��邱�Ƃ���L1��Intel��L1�ɔ�ׂđ傫�����Ȃ��Ɛ��\�͈ێ��ł��Ȃ��B
���̃g���[�h�I�t�����邽�߁AL1�������\������͔̂��ɓ���B
K8L�Ńf�[�^�Ɩ��߃L���b�V���̑ш��Conroe���ɏグ��v�悾���A
�ш掩�̂͏オ���Ă�����ȊO�̐��\������\�����������낤����A���i���o�Ă݂�܂�Conroe���̐����ɂ܂ō������ł��邩�͕s�����B
�����s�\���낤�ȁB
����ȂɊȒP�ɐ��\���グ����̂Ȃ�N����J�͂��Ȃ����A���o����Ă���CPU�����\�������ƍ������������B
�C���N���[�h�^�ɕύX����AINTEL���̃L���b�V�����ڂ��邱�Ƃ͉\���낤���A���ꂾ�ƃv���f�R�[�h�ς݃L���b�V���ɂ��邱�Ƃ͕s�\�Ȃ̂ŁA
�f�R�[�h���\���ɒ[�ɒቺ���Ă��܂����낤�B
Core�͐����˂��AK8�ƈ���ăv���f�R�[�h�ς݃L���b�V�������ł����܂ō����\�Ƃ͋������B
K8�͔r���L���b�V��������L1���߃L���b�V���ɓǂݍ��ޒi�K�Ńv���f�R�[�h�\�Ȃ̂ő����ē�����̑O���B
�������r���L���b�V���ł��邱�Ƃ���L1��Intel��L1�ɔ�ׂđ傫�����Ȃ��Ɛ��\�͈ێ��ł��Ȃ��B
���̃g���[�h�I�t�����邽�߁AL1�������\������͔̂��ɓ���B
K8L�Ńf�[�^�Ɩ��߃L���b�V���̑ш��Conroe���ɏグ��v�悾���A
�ш掩�̂͏オ���Ă�����ȊO�̐��\������\�����������낤����A���i���o�Ă݂�܂�Conroe���̐����ɂ܂ō������ł��邩�͕s�����B
�����s�\���낤�ȁB
����ȂɊȒP�ɐ��\���グ����̂Ȃ�N����J�͂��Ȃ����A���o����Ă���CPU�����\�������ƍ������������B
�C���N���[�h�^�ɕύX����AINTEL���̃L���b�V�����ڂ��邱�Ƃ͉\���낤���A���ꂾ�ƃv���f�R�[�h�ς݃L���b�V���ɂ��邱�Ƃ͕s�\�Ȃ̂ŁA
�f�R�[�h���\���ɒ[�ɒቺ���Ă��܂����낤�B
Hound�͍œK�����ӎ����Ȃ��Ă����\���o��@���ɂ�AMD�炵���A�[�L�e�N�`�����Ċ���
�v���Z�b�T�P�̂��Ƃقڌܕ��̏����ɂȂ肻��
*Ts��FB-DIMM�̉��ǂ����̈�N�łǂ��܂ł��邩�������̕������
��IA-32e�͓��ɖ�薳������
�J�돇�������邮�炢�ŁAIPF�̕����S�z��
�v���Z�b�T�P�̂��Ƃقڌܕ��̏����ɂȂ肻��
*Ts��FB-DIMM�̉��ǂ����̈�N�łǂ��܂ł��邩�������̕������
��IA-32e�͓��ɖ�薳������
�J�돇�������邮�炢�ŁAIPF�̕����S�z��
>>794
> �C���N���[�h�^�ɕύX����AINTEL���̃L���b�V�����ڂ��邱�Ƃ͉\���낤���A
> ���ꂾ�ƃv���f�R�[�h�ς݃L���b�V���ɂ��邱�Ƃ͕s�\�Ȃ̂ŁA
�m��������
AMD�͐�(K5)����PreDecode Cache�ł��B
Exclusive Cache���̗p����O��K7�����RPreDecode Cache�B
> �C���N���[�h�^�ɕύX����AINTEL���̃L���b�V�����ڂ��邱�Ƃ͉\���낤���A
> ���ꂾ�ƃv���f�R�[�h�ς݃L���b�V���ɂ��邱�Ƃ͕s�\�Ȃ̂ŁA
�m��������
AMD�͐�(K5)����PreDecode Cache�ł��B
Exclusive Cache���̗p����O��K7�����RPreDecode Cache�B
797 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/04(��) 01:05:40 ID:bnAMu/Ic0
�����Ńg���[�X�L���b�V���ł���
>>796
�C���N���[�V�u�L���b�V���Ńv���f�R�[�h�ɂ���ƒᑬ������\���������B
�Â�CPU�Ȃ炢���m�炸�A���݂�CPU�ł���͖��d���B
>>797
�g���[�X�L���b�V�����炢�����ȁB
�C���N���[�V�u�L���b�V���Ńv���f�R�[�h�ɂ���ƒᑬ������\���������B
�Â�CPU�Ȃ炢���m�炸�A���݂�CPU�ł���͖��d���B
>>797
�g���[�X�L���b�V�����炢�����ȁB
�����K8�̓����R(ry������L2�̗e�ʂ͂���Ȃɏd�v�ł͂Ȃ��Ƃ�����|�̃��X���悭�������邪���͌����l����ȁ[
http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
�M�҂́CCore�A�[�L�̐��\����̎���́C��͂�C�S�p�C�v���C����3���ߕ���4���ߕ���
�ɋ������ꂽ�_�ƁC�����Z�b�g���߂Ə������߂�1�ɓZ�߂�MacroOP-Fusion���Ǝv���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://www.geocities.jp/andosprocinfo/wadai06/20060805.htm
�ǂ����C�e��x���`�}�[�N��Core 2 Duo��Opteron�ɏ����Ă������́C�L���b�V�����܂�
���f�[�^�A�N�Z�X���\�������_�ŁC���߃f�R�[�g�o���h���ł�Opteron�Ƒ卷�������C������
���[�e���V�ł͓����������R���g���[����Opteron�ɂ܂��C��������Ƃ������Ƃł���炵���B
�E�`�`���C���ꂪ��������CIntel���R�A�A�[�L�̐��\����Ƃ��ďq�ׂĂ���|�C���g��
�S���͂���Ƃ������ƂɂȂ�܂��B
�M�҂́CCore�A�[�L�̐��\����̎���́C��͂�C�S�p�C�v���C����3���ߕ���4���ߕ���
�ɋ������ꂽ�_�ƁC�����Z�b�g���߂Ə������߂�1�ɓZ�߂�MacroOP-Fusion���Ǝv���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://www.geocities.jp/andosprocinfo/wadai06/20060805.htm
�ǂ����C�e��x���`�}�[�N��Core 2 Duo��Opteron�ɏ����Ă������́C�L���b�V�����܂�
���f�[�^�A�N�Z�X���\�������_�ŁC���߃f�R�[�g�o���h���ł�Opteron�Ƒ卷�������C������
���[�e���V�ł͓����������R���g���[����Opteron�ɂ܂��C��������Ƃ������Ƃł���炵���B
�E�`�`���C���ꂪ��������CIntel���R�A�A�[�L�̐��\����Ƃ��ďq�ׂĂ���|�C���g��
�S���͂���Ƃ������ƂɂȂ�܂��B
���̑匴�L�����������낤���Aintel�̎咣���S���n�Y�����낤���A
����FX-62��intel�̗���CPU�ɕ����Ă�A�Ƃ��������݂̂��d�v�Ȃ̂ł����āB
�������R���g���[���������Ă�̂͑����ȃA�h�o���e�[�W���Ǝv���̂���orz
����FX-62��intel�̗���CPU�ɕ����Ă�A�Ƃ��������݂̂��d�v�Ȃ̂ł����āB
�������R���g���[���������Ă�̂͑����ȃA�h�o���e�[�W���Ǝv���̂���orz
802 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/05(�y) 15:47:31 ID:yRAezK9J0
�����߃f�R�[�g�o���h���ł�Opteron�Ƒ卷������
������m�������ǁAx86�ėp���߂��ĂP�`�Qbyte���x�Ȃ��
���l��A�h���b�V���O�𑽗p���Ȃ���4���ߎ�荞�ނɂ͏\���ȑш�͂���
������m�������ǁAx86�ėp���߂��ĂP�`�Qbyte���x�Ȃ��
���l��A�h���b�V���O�𑽗p���Ȃ���4���ߎ�荞�ނɂ͏\���ȑш�͂���
���m�̂��Ƃ�Mac Pro�����\���ꂽ���B
>>722-727�ɏ������b��C���ǃf�X�N�g�b�v�̐؎̂ĂƂ����I�`�����������B�B�B
�@�@----------------------------
�@�@����Best���f����Woodcrest/3GHz���̗p���邱�Ƃ��l����ƁA���[�G���h���f����
�@�@PC�ɑ��鉿�i�����͂��������B
�@�@----------------------------
�v����Jobs�̎v�l�평��Macintosh�ȗ��h�炮���ƂȂ��C�u�f�X�N�g�b�vPC�ɖ��ʂȊg����
��s�v�v�Ƃ������Ƃ��Ɣ[���������B
"The Rest of Us"�ɂ�iMac��MacBook (Pro)�ŏ\���Ƃ������b�Z�[�W���Ǝv�����Ƃɂ��邷�B
����������Dell�����čJ�Ō�������f�X�N�g�b�v��C�g�����F���̃X���[���t�H�[���t�@�N�^
��E���g���X���[���t�H�[���t�@�N�^➑̂����肷��(��)
>>722-727�ɏ������b��C���ǃf�X�N�g�b�v�̐؎̂ĂƂ����I�`�����������B�B�B
�@�@----------------------------
�@�@����Best���f����Woodcrest/3GHz���̗p���邱�Ƃ��l����ƁA���[�G���h���f����
�@�@PC�ɑ��鉿�i�����͂��������B
�@�@----------------------------
�v����Jobs�̎v�l�평��Macintosh�ȗ��h�炮���ƂȂ��C�u�f�X�N�g�b�vPC�ɖ��ʂȊg����
��s�v�v�Ƃ������Ƃ��Ɣ[���������B
"The Rest of Us"�ɂ�iMac��MacBook (Pro)�ŏ\���Ƃ������b�Z�[�W���Ǝv�����Ƃɂ��邷�B
����������Dell�����čJ�Ō�������f�X�N�g�b�v��C�g�����F���̃X���[���t�H�[���t�@�N�^
��E���g���X���[���t�H�[���t�@�N�^➑̂����肷��(��)
�u�f�X�N�g�b�v�̐؎̂āv���Ăǂ������Ӗ������H
�ʼn��ʃ��f���͂������������Ǝv�������ǁB
�ʼn��ʃ��f���͂������������Ǝv�������ǁB
Mac Pro��Apple�Ƃ��Ă�Desktop�ł͂Ȃ�WorkStation�̈ʒu�t�����낤���Ă��Ƃ���
��t�̗��R�Ȃ�Ăǂ��ł�����
807 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/08(��) 21:52:12 ID:z9CQu1Ex0
iMac�Ȃ�Ă��Ƃ���1000�h���O��̃o�����[�����}�V������Ȃ���
�������X
�������X
808 �F���̖��ݒ��F2006/08/12(�y) 19:39:53 ID:qYnY2VZw0
�u�Ђ�����~�����̌v�Z���������l��Core 2 Duo���Ă��������v
http://www.watch.impress.co.jp/akiba/hotline/20060812/etc_amdevent.html
http://www.watch.impress.co.jp/akiba/hotline/20060812/etc_amdevent.html
CSI�ɂ��Ă�PCI-E���C�N��RAS�ɗD�ꂽ�o�X�Ƃ������ƈȊO�͏ڂ������Ƃ͂킩���ĂȂ��̂���?
����������������������������
���@�@ �@ 8MB Shared L2�@�@�@�@��
���@�@�������������������@�@.��
���@�@�� core0 �� core3 ���@�@.��
���@�@�������������������@�@.��
���@�@�� core1 �� core2 ���@�@.��
���@�@�������������������@�@.��
���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��
����������������������������
�������������@ �������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ������ �@������������
�� core 0 �@������L1������������������������������������L1�������@ core 3 ��
�� �@ �@ �@ �@�������@ ���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@�������@ �� �@ �@ �@ �@��
�������������@�@�@.��.�@�@�@�@�@�@�@�@�@�@�@�@��. �@�@ �@ �@�@ �@ �@�@�@ ��. �@�@ ������������
�@�@�@�@�@�@�@�@�@�@�@�@���@�@ ���@CSI links Fullwidth 6.4GT/s�@���@�@��
�@�@�@�@�@�@�@�@�@�@�@�@��.�@�@�@�@�@�@�@�@�@�@�@�@���@�@�@�@�@�@�@�@�@�@ �@ ��
�������������@ �������@�@�@�@�@ �@�@ �@�@�@.���@�@ �@ �@ �@ �@�@�@�@������ �@������������
�� core 1 �@������L1���@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@�@ �@�@��L1������ core 2 �@��
�� �@ �@ �@ �@�������@ ����������������������������������.�� �@������ �@ �@ �@ �@��
�� �@ �@ �@ �@�� �@�������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �������@ �� �@ �@ �@ �@��
�������������@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�@ �@ �@�@�@�@�@ .������������
��������������������������������
���@�@�@�@ �@ 8MB Shared L2�@ �@ �@�@��
��������������������������������
���@Memory controllers.�� . Router ���@���@4*CSI links(Fullwidth) 2D torus topology�@���@Other Processor
��������������������������������
�@�@�@���������@�@�@�@�@�@�@�@�@��
�@ �@4*FBD links�@�@ �@ �@ �@ �@ ���@CSI links (Halfwidth)�@���@I/O
�V�R�A�͊�{�I��Merom�P
L1 TraceCache (16K-��OPs MainTraceCache 8K-��OPs Fliter Trace Cache)
Enhanced Intel Smart Memory Access
L1 to L1 + Core Multiplexing Technology + Foxton Technology = 1.3* boost scalar
SSE5(128bit-Optimized Instruction)
QuadCore + HTT(CGMT) = 8TLP
Enhanced Intel I/O Acceleration Technology
Enhanced Fast Memory Access
Enhanced Intel Virtualization Technology
�ȏ�B�����܂ł̂����炢������Nehalem�Ɋւ���ϑz�I���B
2-3�T�Ɉ���l�b�g�Ȃ��Ȃ�����A���������l�^�͂�������̂����A�����f���o������˂��ȁB
Optimization Manual
http://www.agner.org/optimize/
Intel�����̃}�j���A�����܂����J����ĂȂ����Ă̂ɂ��̃T�C�g�̃}�j���A����Core 2�ɂ��Ă��T�|�[�g���ꂽ�c(;�L�D�M)
�R�[�h�I�^�n�̐l�͌��Ă����Ɨǂ��B
Optimization Manual
http://www.agner.org/optimize/
Intel�����̃}�j���A�����܂����J����ĂȂ����Ă̂ɂ��̃T�C�g�̃}�j���A����Core 2�ɂ��Ă��T�|�[�g���ꂽ�c(;�L�D�M)
�R�[�h�I�^�n�̐l�͌��Ă����Ɨǂ��B
813 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/15(��) 00:14:07 ID:+TwMTlo90
Core 2�̂��Ƒ債�ď����ĂȂ������B
Core 2�̉�����̂��Ă�̂͂��̕ӂ��B
http://www.agner.org/optimize/microarchitecture.pdf
http://www.agner.org/optimize/instruction_tables.pdf
http://www.agner.org/optimize/microarchitecture.pdf
http://www.agner.org/optimize/instruction_tables.pdf
815 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/15(��) 00:41:37 ID:+TwMTlo90
pshufb�̃X���[�v�b�g�A�v������舫���Ȃ��ˁB
bswap�̑���Ɏg�����Ȃ��H
bswap�̑���Ɏg�����Ȃ��H
Oregon�̒��̐l�͉����Ă�ł����H
��Ȏ��A�݂Ă��킩�邶���B
Merom�i��p�j�n�i Nehalem�CGesher�j�ɂ̓C�X���G���̒��̐l���i����
ManyCore�ɂ̓I���S���̒��̐l���i����
Merom�i��p�j�n�i Nehalem�CGesher�j�ɂ̓C�X���G���̒��̐l���i����
ManyCore�ɂ̓I���S���̒��̐l���i����
�͂�?
{kind=link}
820 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/08/17(��) 02:05:03 ID:nAJ32XPc0
Nehalem�̓I���S������
����͓d�͂����萫�\�Ƀt�H�[�J�X����NetBurst�A�[�L�e�N�`���̍Ē�`�ł��B
Merom�̐v�f�[�^���}�[�W����Ă�Ǝv�����B
Pentium 4���͔̂��M�E�N���b�N������������\���Ȃ��̃N���b�N�����`�����B
�g���[�X�L���b�V�����̂��̂́A�ȓd�͉���IPC����𗼗�����Z�p�ɂȂ肤��B
�܂��ANetBurst�炵�������Ƃ��Čp�������̂͂��ꂭ�炢���낤�B
�C�X���G���`�[����Merom�A�[�L�e�N�`���̌�p��Gesher���B
�R�[�h�l�[��Gilo�̖��O�œx�X�L���ɏo�Ă����ˁB
����͓d�͂����萫�\�Ƀt�H�[�J�X����NetBurst�A�[�L�e�N�`���̍Ē�`�ł��B
Merom�̐v�f�[�^���}�[�W����Ă�Ǝv�����B
Pentium 4���͔̂��M�E�N���b�N������������\���Ȃ��̃N���b�N�����`�����B
�g���[�X�L���b�V�����̂��̂́A�ȓd�͉���IPC����𗼗�����Z�p�ɂȂ肤��B
�܂��ANetBurst�炵�������Ƃ��Čp�������̂͂��ꂭ�炢���낤�B
�C�X���G���`�[����Merom�A�[�L�e�N�`���̌�p��Gesher���B
�R�[�h�l�[��Gilo�̖��O�œx�X�L���ɏo�Ă����ˁB
ttp://www.tomshardware.co.uk/2006/07/27/tgdaily_interviews_david_perlmutter/page2.html
Nahalem�̘b�͂�����ӂɏ����o�Ă��
Nahalem�̘b�͂�����ӂɏ����o�Ă��
�I���S���`�[����P6�̐��݂̐e�ANetBurst�����������Ɏ��グ���Ă���悤�����A
�f���͐���ǂ��APARROT��uOPs�L���b�V�����͓�������ɏ\�����͓I�ȋZ�p�����ȁB
�f���͐���ǂ��APARROT��uOPs�L���b�V�����͓�������ɏ\�����͓I�ȋZ�p�����ȁB
>>Netburst
�������S�Ă�����Ă�������̃A�[�L������ȁc
�������S�Ă�����Ă�������̃A�[�L������ȁc
Apple Woodcrest vs G5
http://www.anandtech.com/mac/showdoc.aspx?i=2816
http://www.anandtech.com/mac/showdoc.aspx?i=2816
Intel roadmap confirms 2.67 GHz quad-core Core 2 Extreme
http://www.tgdaily.com/2006/08/17/core_2_extreme_quad_confirmed/
Intel DDR3 and Multi-GPU Desktop Chipsets Next Year
http://www.dailytech.com/Article.aspx?newsid=3830
http://www.tgdaily.com/2006/08/17/core_2_extreme_quad_confirmed/
Intel DDR3 and Multi-GPU Desktop Chipsets Next Year
http://www.dailytech.com/Article.aspx?newsid=3830
Intel Looking Forward �gHigh Performance Graphics�h Engineers.
http://www.xbitlabs.com/news/video/display/20060816030933.html
Intel gaming GPU due out in fall 2007?
http://techreport.com/onearticle.x/10549
http://www.xbitlabs.com/news/video/display/20060816030933.html
Intel gaming GPU due out in fall 2007?
http://techreport.com/onearticle.x/10549
Performance Analysis Tools: A Look at the Intel VTune Performance Analyzer
http://www.realworldtech.com/page.cfm?ArticleID=RWT080606230159
http://www.realworldtech.com/page.cfm?ArticleID=RWT080606230159
Tulsa�̃x���`�B���\�����Ȃ�uOpteron8220 SE�Ɛ킦�Ȃ����Ƃ��Ȃ��v���Ċ������ȁB
ttp://www.intel.com/performance/server_mp/xeon/intthru.htm
ttp://www.intel.com/performance/server_mp/xeon/intthru.htm
829 �F���̖��ݒ��F2006/08/24(��) 16:19:01 ID:q2ut+hJS0
�����@ �u���ꂳ�A�O�����h�N���X�H���܂��Q������H�v
�ؐ��@ �u�����v
�ΐ��@ �u�Q���v
�n���@ �u�ꉞ���܂�Ƃ��v
�C�����u���[�E�E�E����Ȃ��E�E�����]���������ɂ���˂���Ȃ��E�E�E�v
���� �@�u�}�W�H�v
�V�����u�����Ȃ��[�Ƒ�ςȂ�Ȃ��v
�y���@ �u����ȁA�������ǁ[��H�v
�������u����A����E�E�E�v
�����@ �u�ǂ�����H�v
�������u���́A����E�E�E�����ȂE�E�E�v
�C�����u�Ȃ�ŁH������������Ԃ�����H�v
�������u��������Ȃ��āE�E�E�v
���� �@�u�ȂɂȂɂȂɁA�܂������]�����?���炠�炫�Ă�ˁ[����A���͂����v
�������u�͂́E�E�E��������Ȃ���B��������Ȃ��āE�E�E����߂�v
�ؐ��@ �u����H�v
�������u�c�c�f���E�E�E�~�߂�v
�ꓯ�@ �u�c�v
�ؐ��@ �u�����v
�ΐ��@ �u�Q���v
�n���@ �u�ꉞ���܂�Ƃ��v
�C�����u���[�E�E�E����Ȃ��E�E�����]���������ɂ���˂���Ȃ��E�E�E�v
���� �@�u�}�W�H�v
�V�����u�����Ȃ��[�Ƒ�ςȂ�Ȃ��v
�y���@ �u����ȁA�������ǁ[��H�v
�������u����A����E�E�E�v
�����@ �u�ǂ�����H�v
�������u���́A����E�E�E�����ȂE�E�E�v
�C�����u�Ȃ�ŁH������������Ԃ�����H�v
�������u��������Ȃ��āE�E�E�v
���� �@�u�ȂɂȂɂȂɁA�܂������]�����?���炠�炫�Ă�ˁ[����A���͂����v
�������u�͂́E�E�E��������Ȃ���B��������Ȃ��āE�E�E����߂�v
�ؐ��@ �u����H�v
�������u�c�c�f���E�E�E�~�߂�v
�ꓯ�@ �u�c�v
�G���b�^�ł��炢������
Errata list shows for Core 2 Duo
ttp://www.theinquirer.net/default.aspx?article=33916
PDF�̓C���e���T�C�g����_�E�����[�h�\�ł��B�o�O�̂�����1�����X�g����āA
�`�h 39�͏d��ȃf�[�^�܂��̓V�X�e�����s�Ɏ��邱�Ƃ��ł��܂����ƁA�C���e�����x�����܂����B
�ǂ����܂��傤
�֘A�X��
�yConroe�zIntel Core 2 Duo Part45�yKentsfield�z
http://pc7.2ch.net/test/read.cgi/jisaku/1156190037/
Core�@2�@Duo�ɂ͎��]���A�C���e���ɂ͐�]����
http://pc7.2ch.net/test/read.cgi/jisaku/1155040263/
�yAthlon64�zCore2Duo�͂���ς胂�b�R��Part2
http://pc7.2ch.net/test/read.cgi/jisaku/1156433453/
Errata list shows for Core 2 Duo
ttp://www.theinquirer.net/default.aspx?article=33916
PDF�̓C���e���T�C�g����_�E�����[�h�\�ł��B�o�O�̂�����1�����X�g����āA
�`�h 39�͏d��ȃf�[�^�܂��̓V�X�e�����s�Ɏ��邱�Ƃ��ł��܂����ƁA�C���e�����x�����܂����B
�ǂ����܂��傤
�֘A�X��
�yConroe�zIntel Core 2 Duo Part45�yKentsfield�z
http://pc7.2ch.net/test/read.cgi/jisaku/1156190037/
Core�@2�@Duo�ɂ͎��]���A�C���e���ɂ͐�]����
http://pc7.2ch.net/test/read.cgi/jisaku/1155040263/
�yAthlon64�zCore2Duo�͂���ς胂�b�R��Part2
http://pc7.2ch.net/test/read.cgi/jisaku/1156433453/
831 �F���̖��ݒ��F2006/08/25(��) 16:23:50 ID:Cr3wdra40
X2�͒n��������
123 Bypassed Reads May Cause Data Corruption
in Dual Core Processors
Description
An internal data path allows some cache line fill requests to bypass the
DRAM read before receiving hit/miss status from the cache. Under certain
core frequencies, read data from such a request may be returned to the processor
is ready, resulting in an internal bus hang or a corrupted victim data buffer.
Potential Effect on System
Data corruption or system hang.
Suggested Workaround
Contact your AMD representative for information on a BIOS update.
123 �f���A���R�A�v���Z�b�T�ɂ����āA�o�C�p�X���[�h�ɂ��f�[�^���j���B
�����f�[�^�p�X�͂������̃L���b�V�����C�����߂�A�L���b�V������q�b�g�^�~�X��
��Ԃ��擾����O�Ƀo�C�p�X����DRAM����ǂݏo�����Ƃ�v�����܂��B
���̂Ƃ�����̃R�A���g���ɂ����āA�����炭�̓v���Z�b�T���ҋ@��ԂɂȂ�O��
���̗v���ɂ��f�[�^���ǂݏo���ꂽ�ꍇ�A�����o�X���n���O�܂���victim data buffer��
�j���ꍇ������܂��B
123 Bypassed Reads May Cause Data Corruption
in Dual Core Processors
Description
An internal data path allows some cache line fill requests to bypass the
DRAM read before receiving hit/miss status from the cache. Under certain
core frequencies, read data from such a request may be returned to the processor
is ready, resulting in an internal bus hang or a corrupted victim data buffer.
Potential Effect on System
Data corruption or system hang.
Suggested Workaround
Contact your AMD representative for information on a BIOS update.
123 �f���A���R�A�v���Z�b�T�ɂ����āA�o�C�p�X���[�h�ɂ��f�[�^���j���B
�����f�[�^�p�X�͂������̃L���b�V�����C�����߂�A�L���b�V������q�b�g�^�~�X��
��Ԃ��擾����O�Ƀo�C�p�X����DRAM����ǂݏo�����Ƃ�v�����܂��B
���̂Ƃ�����̃R�A���g���ɂ����āA�����炭�̓v���Z�b�T���ҋ@��ԂɂȂ�O��
���̗v���ɂ��f�[�^���ǂݏo���ꂽ�ꍇ�A�����o�X���n���O�܂���victim data buffer��
�j���ꍇ������܂��B
ttp://www.itmedia.co.jp/news/articles/0608/31/news026.html
>Intel�͂���ɑ����āA4�̃R�A���_�C�ɍڂ���4�R�A�v���Z�b�T��2007�N�Ƀ����[�X����B
>Intel�͂���ɑ����āA4�̃R�A���_�C�ɍڂ���4�R�A�v���Z�b�T��2007�N�Ƀ����[�X����B
Intel��45nm�v���Z�X��2008�N���ƌ����Ă�̂�
Tigerton�̂��Ƃ��낤
Tigerton�̂��Ƃ��낤
>>833
�\�X����
�\�X����
Successor of Intel 975X: Bearlake X/G+
http://www.hkepc.com/bbs/news.php?tid=653301
Q2 2007��P965/G965�`�b�v�Z�b�g�̌�p��Barelake-P/Barelake-G�`�b�v�Z�b�g�����B
���̌�AQ3 2007�ɂ�Barelake-G+/Bareake-X���ł�B
Barelake�t�@�~���ł͐V����1333MHz FSB���T�|�[�g�����B
G965�Ɠ������ABarelake-G��DirectX10�T�|�[�g�̓\�t�g�E�G�A�ɂ�邪�A
Barelake-G+�ł̓n�[�h�E�G�A�T�|�[�g�ɂȂ�\��B
Barelake-G+��Extreme��Barelake-X�ł́ADDR3-1333���T�|�[�g�����B
�X��Barelake-X�́APCIe 2.0��2x16 GFX���T�|�[�g�B
#DDR3��1.8V��1.5V�ɂȂ��āA���̃N���b�N�������邩��DDR2���
#�X�ɏ���d�͂������ijϰ�B����ł��Ƃ���45nm�̂���ł�Ƃ����Ƴϰ�i�E�́E�j
http://www.hkepc.com/bbs/news.php?tid=653301
Q2 2007��P965/G965�`�b�v�Z�b�g�̌�p��Barelake-P/Barelake-G�`�b�v�Z�b�g�����B
���̌�AQ3 2007�ɂ�Barelake-G+/Bareake-X���ł�B
Barelake�t�@�~���ł͐V����1333MHz FSB���T�|�[�g�����B
G965�Ɠ������ABarelake-G��DirectX10�T�|�[�g�̓\�t�g�E�G�A�ɂ�邪�A
Barelake-G+�ł̓n�[�h�E�G�A�T�|�[�g�ɂȂ�\��B
Barelake-G+��Extreme��Barelake-X�ł́ADDR3-1333���T�|�[�g�����B
�X��Barelake-X�́APCIe 2.0��2x16 GFX���T�|�[�g�B
#DDR3��1.8V��1.5V�ɂȂ��āA���̃N���b�N�������邩��DDR2���
#�X�ɏ���d�͂������ijϰ�B����ł��Ƃ���45nm�̂���ł�Ƃ����Ƴϰ�i�E�́E�j
- Bearlake-X
-- Q3 2007
-- PCI Express 2.0 (2.5Gbps �� 5.0Gbps)
-- 2x 16 lanes GFX
-- DDR2-800 or DDR3-1066
-- 1333MHz FSB
- Bearlake-G+
-- Q3 2007
-- Intel Clear Video
-- HDMI, HDCP
-- DDR2-800 or DDR3-1066
-- 1333MHz FSB
- Bearlake-G
-- Q2 2007
-- Intel Clear Video
-- 1333MHz FSB
- Barelake-P
-- 1333MHz FSB
-- Q3 2007
-- PCI Express 2.0 (2.5Gbps �� 5.0Gbps)
-- 2x 16 lanes GFX
-- DDR2-800 or DDR3-1066
-- 1333MHz FSB
- Bearlake-G+
-- Q3 2007
-- Intel Clear Video
-- HDMI, HDCP
-- DDR2-800 or DDR3-1066
-- 1333MHz FSB
- Bearlake-G
-- Q2 2007
-- Intel Clear Video
-- 1333MHz FSB
- Barelake-P
-- 1333MHz FSB
Intel puts beef into designing discrete graphics chip
http://www.theinquirer.net/default.aspx?article=33720
Intel��discrete��GPU�ɐ^�ʖڂɎ��g��ł���炵���B
Intel signed up most of the 3Dlabs team
http://www.theinquirer.net/default.aspx?article=33812
Intel��3Dlabs�̃G���W�j�A�̖w�ǂ��Q�b�g�����炵���B
http://www.theinquirer.net/default.aspx?article=33720
Intel��discrete��GPU�ɐ^�ʖڂɎ��g��ł���炵���B
Intel signed up most of the 3Dlabs team
http://www.theinquirer.net/default.aspx?article=33812
Intel��3Dlabs�̃G���W�j�A�̖w�ǂ��Q�b�g�����炵���B
- 5000P Chipset
-- Parameter / Value
-- Tcase_max / 105��C
-- Tcase_min / 5��C
-- TDP with 1 active memory channel / 24.7 W
-- TDP with 2 active memory channel / 26.4 W
-- TDP with 4 active memory channel / 30.0 W
- 5000V Chipset
-- Parameter / Value
-- Tcase_max / 105��C
-- Tcase_min / 5��C
-- TDP with 1 active memory channel / 23.4 W
-- TDP with 2 active memory channel / 25.1 W
- 5000X Chipset
-- Parameter / Value
-- Tcase_max 105��C
-- Tcase_min 5��C
-- TDP with 1 active memory channel 27.3 W
-- TDP with 2 active memory channel 29.0 W
-- TDP with 4 active memory channel 32.4 W
-- Parameter / Value
-- Tcase_max / 105��C
-- Tcase_min / 5��C
-- TDP with 1 active memory channel / 24.7 W
-- TDP with 2 active memory channel / 26.4 W
-- TDP with 4 active memory channel / 30.0 W
- 5000V Chipset
-- Parameter / Value
-- Tcase_max / 105��C
-- Tcase_min / 5��C
-- TDP with 1 active memory channel / 23.4 W
-- TDP with 2 active memory channel / 25.1 W
- 5000X Chipset
-- Parameter / Value
-- Tcase_max 105��C
-- Tcase_min 5��C
-- TDP with 1 active memory channel 27.3 W
-- TDP with 2 active memory channel 29.0 W
-- TDP with 4 active memory channel 32.4 W
�����IInteler�����I�I����ł���I�I
G5�̉��i�\�����J����Ă��邷�Bx86�Ɣ�r����̂��ꋻ����Ȃ������ˁB�B�B
http://www.ppcnux.com/modules.php?name=News&file=article&sid=6562
�@��970FX
�@�@2.0GHz: $161.11-, 2.2GHz: $185.28-
�@��970GX ( ) ������d�͔�
�@�@2.0GHz: $168.61-, 2.2GHz: $193.91- ($223.01-), 2.4GHz: $223.01- ($256.45-)
�@��970MP ( ) ������d�͔�
�@�@2.0GHz: $274.18- ($315.50-), 2.5GHz: $335.11- ($385.39-)
http://www.ppcnux.com/modules.php?name=News&file=article&sid=6562
�@��970FX
�@�@2.0GHz: $161.11-, 2.2GHz: $185.28-
�@��970GX ( ) ������d�͔�
�@�@2.0GHz: $168.61-, 2.2GHz: $193.91- ($223.01-), 2.4GHz: $223.01- ($256.45-)
�@��970MP ( ) ������d�͔�
�@�@2.0GHz: $274.18- ($315.50-), 2.5GHz: $335.11- ($385.39-)
843 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/03(��) 23:42:37 ID:6wxtQN7K0
FSB 533MHz�Ȃ��Celeron���Pen4�Ƃ̔�r���Ó����Ȃ���
533MHz?
PMG5�̂�CPU�̃N���b�N���g���̔�����������
PMG5�̂�CPU�̃N���b�N���g���̔�����������
970FX�̃f�[�^�V�[�g��ǂތ���ł�2:1��3:1���T�|�[�g���Ă���悤��
�Ƃ肠�����c�q��G5�̎d�l�����3���N�b�L���O�̃��V�s���o���邱��
�ǂ�����533MHz�Ȃ�Ęb���N���Ă����낤...
iMacG5��1.6GHz���[�U�[�Ȃ납
849 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/06(��) 01:18:36 ID:8xw6sqmK0
�딚�Ƀ}�W���X��������
Yonah��FSB667MHz�Ȃ�łǂ������ł��B�L���b�V���͑�������e�ʂ����ǁB
Yonah��FSB667MHz�Ȃ�łǂ������ł��B�L���b�V���͑�������e�ʂ����ǁB
�딚�Ɍ����Ȃ���
���Ƃǂ������Ȃ�
���Ƃǂ������Ȃ�
851 �F���̖��ݒ��F2006/09/09(�y) 08:24:41 ID:rZF5DzIk0
���{HP�AMontecito���ڃT�[�o�\--�G���g���[���x���̃��C���A�b�v������
http://japan.zdnet.com/news/hardware/story/0,2000056184,20225067,00.htm
>����V���ɓ��������G���g���[���x���̐V�@��́A�urx6600�v�Ɓurx3600�v�B
>����܂ŏ�ʋ@��݂̂ɓ��ڂ���Ă���HP�̓Ǝ��J���ɂ��`�b�v�Z�b�g�uHP zx2�v���������ꂽ
>
>�܂�HP�́A�G���g���[���x���̐��i�̔����������邽�߁A�T�[�o�Ƀv���Z�b�T�A�������AHDD�AOS�Ȃǂ��o���h�����A
>�V�X�e���\���̎�Ԃ��팸����ቿ�i�o���h�����i�uHP Integrity QuickValue�v�V���[�Y�\�����B
http://japan.zdnet.com/news/hardware/story/0,2000056184,20225067,00.htm
>����V���ɓ��������G���g���[���x���̐V�@��́A�urx6600�v�Ɓurx3600�v�B
>����܂ŏ�ʋ@��݂̂ɓ��ڂ���Ă���HP�̓Ǝ��J���ɂ��`�b�v�Z�b�g�uHP zx2�v���������ꂽ
>
>�܂�HP�́A�G���g���[���x���̐��i�̔����������邽�߁A�T�[�o�Ƀv���Z�b�T�A�������AHDD�AOS�Ȃǂ��o���h�����A
>�V�X�e���\���̎�Ԃ��팸����ቿ�i�o���h�����i�uHP Integrity QuickValue�v�V���[�Y�\�����B
Server duel: Xeon Woodcrest vs. Opteron Socket F
http://tweakers.net/reviews/646/
http://tweakers.net/reviews/646/
45nm�̏o��2007�NH2�ȍ~�̖ϑz
UP
Conroe-L���� 1Die L2 3MB DualCore 08Q1 45nm(Wolfdale)
E4x00���� 1Die L2 3-6MB DualCore 07Q4 45nm(Ridgefield)
E6x00���� 1Die L2 3-6MB QuadCore 07Q3 45nm
x8x00���� 2Die L2 12MB OctaCore 07Q4 45nm(Yorkfield)
DP
Xeon51xx���� 1Die L2 6MB QuadCore 07Q3 45nm
Clovertown���� 2Die L2 12MB OctaCore 07Q4 45nm(Harpertown)
MP
Tigerton���� 2Die L2 12MB OctaCore 08Q1 45nm(Dunnington)
���ʃv���b�g�t�H�[��
Itanium2 90xx���� 1Die L2 24MB QuadCore 08Q2? 65nm(Tukwila)
Dunnington���� �s�� 08Q2? 45nm(Whitefield)
���RVT����*Ts�����������
UP
Conroe-L���� 1Die L2 3MB DualCore 08Q1 45nm(Wolfdale)
E4x00���� 1Die L2 3-6MB DualCore 07Q4 45nm(Ridgefield)
E6x00���� 1Die L2 3-6MB QuadCore 07Q3 45nm
x8x00���� 2Die L2 12MB OctaCore 07Q4 45nm(Yorkfield)
DP
Xeon51xx���� 1Die L2 6MB QuadCore 07Q3 45nm
Clovertown���� 2Die L2 12MB OctaCore 07Q4 45nm(Harpertown)
MP
Tigerton���� 2Die L2 12MB OctaCore 08Q1 45nm(Dunnington)
���ʃv���b�g�t�H�[��
Itanium2 90xx���� 1Die L2 24MB QuadCore 08Q2? 65nm(Tukwila)
Dunnington���� �s�� 08Q2? 45nm(Whitefield)
���RVT����*Ts�����������
�ϑz�̌��̓R����FSB�̐��l(2Die��1Die���x���Ȃ�)
ttp://www.atmarkit.co.jp/fsys/kaisetsu/075intel_cpu2007/quadcore.jpg
���_���猾����Intel�̊�{�I�Ȑ헪��AMD�̃v���Z�b�T�ɏ�ɔ{�̃R�A�����Ԃ��邱�Ƃ��Ǝv��
ttp://www.atmarkit.co.jp/fsys/kaisetsu/075intel_cpu2007/quadcore.jpg
{kind=link}
���_���猾����Intel�̊�{�I�Ȑ헪��AMD�̃v���Z�b�T�ɏ�ɔ{�̃R�A�����Ԃ��邱�Ƃ��Ǝv��
Intel's Core 2 Quadro Kentsfield: Four Cores on a Rampage
http://www.tomshardware.com/2006/09/10/four_cores_on_the_rampage/
Kentsfield�̃��r���[
http://www.tomshardware.com/2006/09/10/four_cores_on_the_rampage/
Kentsfield�̃��r���[
Interesting Stuff Upcoming From Intel
http://www.vr-zone.com/?i=3905
���Ȃ݂Ƀf�X�N�g�b�v�Z�O�����g��07.Q3�ӂ�܂ł̃u���[�t�B���O�̂����
VT-d��LT��Bearlake����̖͗l
http://www.vr-zone.com/?i=3905
���Ȃ݂Ƀf�X�N�g�b�v�Z�O�����g��07.Q3�ӂ�܂ł̃u���[�t�B���O�̂����
VT-d��LT��Bearlake����̖͗l
KentsField��FSB1333MHz�ŏo�Ă���̂��Ȃ��E�E�E
1���[�h�Ȃ�FSB1600�܂ł͎���ɓ����Ă��݂��������ǁB
1���[�h�Ȃ�FSB1600�܂ł͎���ɓ����Ă��݂��������ǁB
>1���[�h�Ȃ�FSB1600�܂ł͎���ɓ����Ă�
�\�[�X
�\�[�X
Anandtech��Mac Pro�ɔN���̃����[�X���\�肳��Ă���4�R�A Xeon, "Clovertown"��
�G���W�j�A�����O�T���v�����ڂ��Ă݂��������B
���ʂɓ����Ƃ��B�B�B
http://anandtech.com/mac/showdoc.aspx?i=2832&p=6
�G���W�j�A�����O�T���v�����ڂ��Ă݂��������B
���ʂɓ����Ƃ��B�B�B
http://anandtech.com/mac/showdoc.aspx?i=2832&p=6
Clovertown���o����A�����Clovertown���f���A���œ��ڂ��Ă���̂��˂��B
���[�N�X�e�[�V������8�R�A�Ȃ�Ă������ɍڂ������̂悤�ȋC�����邯�ǁAApple�Ȃ���낤�ȁB
�M�̊W�ŁAiMac��Kentsfield���ڂ��邱�Ƃ��ł��Ȃ����낤����AMac Pro��iMac�̍����܂��܂��J���B
���[�N�X�e�[�V������8�R�A�Ȃ�Ă������ɍڂ������̂悤�ȋC�����邯�ǁAApple�Ȃ���낤�ȁB
�M�̊W�ŁAiMac��Kentsfield���ڂ��邱�Ƃ��ł��Ȃ����낤����AMac Pro��iMac�̍����܂��܂��J���B
861 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/14(��) 01:55:36 ID:WoIcSnNq0
�M�̊W�ȑO��iMac�ɍڂ��Ă�̂�Merom�ł�����Conroe����Ȃ�
���o�C���p��4�R�A�͏��Ȃ��Ƃ�45nm�ɂȂ�܂ł͂܂��o�Ȃ������B
�܂��A���ɕK�v�̂Ȃ��\�����[�V���������B
���o�C���p��4�R�A�͏��Ȃ��Ƃ�45nm�ɂȂ�܂ł͂܂��o�Ȃ������B
�܂��A���ɕK�v�̂Ȃ��\�����[�V���������B
864 �F���̖��ݒ��F2006/09/18(��) 13:26:12 ID:eqp9mX210
865 �FMAC�I�^��864 �����F2006/09/18(��) 19:09:12 ID:J7NfAVKb0
>>864
The Inquirer�̓��Y�L����ǂ߂Δ��邷���ǁC2008�N�܂Ŋ����R�A�̏�����(����K8L)
�ň�������Ƃ����b�Ȃ��ǁB�B�B
http://www.theinquirer.net/default.aspx?article=34433�@�@
The Inquirer�̓��Y�L����ǂ߂Δ��邷���ǁC2008�N�܂Ŋ����R�A�̏�����(����K8L)
�ň�������Ƃ����b�Ȃ��ǁB�B�B
http://www.theinquirer.net/default.aspx?article=34433�@�@
K8L >>> �z�����Ȃ��� >>>�P���c
�ǂ��l���Ă����̓��������藧��
�����ɂ͂킩��Ȃ����ˁi�j
�ǂ��l���Ă����̓��������藧��
�����ɂ͂킩��Ȃ����ˁi�j
�s�������g���Ă�̂Ɂu�����v�����B
868 �FMAC�I�^��866 �����F2006/09/18(��) 19:56:18 ID:J7NfAVKb0
>>866
K8�ŃL���b�V�����ʂ�Netburst�ɂ��珟�ĂȂ��̂ɁCL2��������K8L��Core Architecture��
�R�ł���قǃV���O���X���b�h���\���オ��Ƃ����l����C�Â����Ǝv�����B
http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/788
�@�@-----------------------------------
�@�@788 ���O�FMAC�I�^ ���e���F2006/08/18(��) 06:34:23 ID:EC30dfNH
�@�@�@�@Socket F Opteron���ߎS�ȏo�����̂悤���ˁB�B�B
�@�@�@�@4-socket/8-core�ł�SPECint2000_rate�̔�r���B
�@�@�@�@�@Xeon 7041/3GHz: 114(base)/114(peak)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060710-06446.html
�@�@�@�@�@Opteron 8220SE/2.8GHz: 146(base)/166(base)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060721-06572.html
�@�@�@�@�@Xeon 7140M(3.4GHz): 161(base)/162(peak)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060724-06780.html
�@�@-----------------------------------
���������C�^�[�Q�b�g�̎s����Ⴄ���K8L��A�����ɂ퉶�b����������(��)
�@�EKentzfield -> �f�X�N�g�b�v����
�@�EK8L -> �T�[�o�[����
K8�ŃL���b�V�����ʂ�Netburst�ɂ��珟�ĂȂ��̂ɁCL2��������K8L��Core Architecture��
�R�ł���قǃV���O���X���b�h���\���オ��Ƃ����l����C�Â����Ǝv�����B
http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/788
�@�@-----------------------------------
�@�@788 ���O�FMAC�I�^ ���e���F2006/08/18(��) 06:34:23 ID:EC30dfNH
�@�@�@�@Socket F Opteron���ߎS�ȏo�����̂悤���ˁB�B�B
�@�@�@�@4-socket/8-core�ł�SPECint2000_rate�̔�r���B
�@�@�@�@�@Xeon 7041/3GHz: 114(base)/114(peak)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060710-06446.html
�@�@�@�@�@Opteron 8220SE/2.8GHz: 146(base)/166(base)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060721-06572.html
�@�@�@�@�@Xeon 7140M(3.4GHz): 161(base)/162(peak)
�@�@�@�@�@�@�@�@http://www.spec.org/cpu/results/res2006q3/cpu2000-20060724-06780.html
�@�@-----------------------------------
���������C�^�[�Q�b�g�̎s����Ⴄ���K8L��A�����ɂ퉶�b����������(��)
�@�EKentzfield -> �f�X�N�g�b�v����
�@�EK8L -> �T�[�o�[����
HOT CHIPS�͂Ƃ����ɏI��������A
��́AIDF��eP�e�܂ł������l�^�͖����������ȁE�E�E
��́AIDF��eP�e�܂ł������l�^�͖����������ȁE�E�E
����ŃV���O���X���b�h���\���オ���Ă���ǂ���������肩��
�C���e���A�v���Z�b�T�ԒʐM�Z�p��AMD�ɑR��
http://japan.cnet.com/news/ent/story/0,2000056022,20229987,00.htm
2008�N�o���CSI�ɂ��āB
http://japan.cnet.com/news/ent/story/0,2000056022,20229987,00.htm
2008�N�o���CSI�ɂ��āB
874 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/19(��) 03:39:00 ID:KBTx25FN0
Load/Store�{����FP SIMD���j�b�g��128bit��
�����Č������̂ւB
FP���Z��Core MA�ɏ��Ă鎩�M�������Ă�B
SIMD�����͂ǂ����낤�ˁBAMD���g�[�����������B
Intel��3Way�ɂ͋y�Ȃ��������B
�����Č������̂ւB
FP���Z��Core MA�ɏ��Ă鎩�M�������Ă�B
SIMD�����͂ǂ����낤�ˁBAMD���g�[�����������B
Intel��3Way�ɂ͋y�Ȃ��������B
out-of-order�̃��[�h, 32-byte�̖���Fetch, ���̑����X�̉��Ǔ_���܂߂āA
���ς��ăR�A�P�̂Ő���+10%�O���IPC���P���ȁB
native��4 core�Ȃ̂ŁA�X���[�v�b�g�d����Server�ł͈��̃A�h�o���e�[�W����B
SPEC�x���`�̓L���b�V���T�C�Y�������đz�����قǐ��\��������Ȃ��B
�Ƃ����ϑz���˔@������ł����B
���ς��ăR�A�P�̂Ő���+10%�O���IPC���P���ȁB
native��4 core�Ȃ̂ŁA�X���[�v�b�g�d����Server�ł͈��̃A�h�o���e�[�W����B
SPEC�x���`�̓L���b�V���T�C�Y�������đz�����قǐ��\��������Ȃ��B
�Ƃ����ϑz���˔@������ł����B
Clovertown�́ADual Processor��Xeon�v���b�g�t�H�[����Apple���I�����Ă��܂����ȏ�A
Apple��Mac Pro�̃��C���i�b�v�ɂ������܉����Ȃ����R�͂Ȃ����낤�B
�������APC�ɂ���Mac�ɂ���A8 core�̃��[�U�[�ɂƂ��Ẳ��b�́w����̃}�V����CPU�R�A��8��������[�A����x
�Ƃ����C���𖡂킦�邱�Ƃ��炢�̂��̂��낤���AApple�ɂƂ��Ă�8 core�Ƃ����Ŕ�������PC���[�J�[�̍\��
�ɑ���v���~�A�Ƃ��ė~�����������낤�B
Apple��Mac Pro�̃��C���i�b�v�ɂ������܉����Ȃ����R�͂Ȃ����낤�B
�������APC�ɂ���Mac�ɂ���A8 core�̃��[�U�[�ɂƂ��Ẳ��b�́w����̃}�V����CPU�R�A��8��������[�A����x
�Ƃ����C���𖡂킦�邱�Ƃ��炢�̂��̂��낤���AApple�ɂƂ��Ă�8 core�Ƃ����Ŕ�������PC���[�J�[�̍\��
�ɑ���v���~�A�Ƃ��ė~�����������낤�B
Intel quad-cores likely to use 1333FSB
http://www.theinquirer.net/default.aspx?article=33400
>We heard that 1333FSB was a 'stretch goal', and it is looking more and more like they are going to do it.
Woodcrest�Ŋ��ɒB������Ă��邪�AIntel�́A1333MHz�̑��x�����݂�FSB�Z�p�̉����Ō��E�̃S�[����
�݂Ă���悤���B1600MHz�͂��܂�l�������Ȃ��̂��낤���B
Intel pulls back from FB-DIMMs
ttp://www.theinquirer.net/default.aspx?article=34220
Intel�͍����ŃA�c�A�c��FB-DIMM���n�C�G���h�T�[�o�̈�ȊO�ł͎g��Ȃ����j�ɓ]�������悤���B
4S�ȉ��̃T�[�o�ł́ARDIMM���Ȃ킿Registered DIMM���嗬�Ƃ��ĕ������錩�ʂ��̂悤���B
FB-DIMM�͂��Ƃ��Ƒ�e�ʂ�K�v�Ƃ���T�[�o�����̃\�����[�V�����Ƃ��ēo�ꂵ�����A
Intel�͂����ꃁ�����C���^�[�t�F�[�X���R���V���[�}�������܂߁AFB-DIMM���C�N�ȍ����V���A���ڑ��ɒu��������
��Ă������Ă���A�����A���[�G���h�T�[�o��f�X�N�g�b�vPC�ł͐V���ȑ�ւ��Z�p���o�ꂷ����̂Ǝv����B
�X��INQ�́APenryn(Merom��45nm��)����̃��o�C���v���b�g�t�H�[���ɂ����āA
XDR-DRAM�̗p�̉\���ɂ��ē`�����BIntel����̓R���V���[�}�����̃V���A���������Z�p�ɂ��Ă̘b��
�܂�������Ȃ��B���o�C���Z�O�����g�Ɋւ��ẮA�z��, ���C�A�E�g��̓s������XDR���ꎞ�I�Ɏg�p����\����
�l������B���̌�ANehalem�̐���ŃV���A���������Z�p�\����̂�������Ȃ��B
�ȏ�\�����ł����B
http://www.theinquirer.net/default.aspx?article=33400
>We heard that 1333FSB was a 'stretch goal', and it is looking more and more like they are going to do it.
Woodcrest�Ŋ��ɒB������Ă��邪�AIntel�́A1333MHz�̑��x�����݂�FSB�Z�p�̉����Ō��E�̃S�[����
�݂Ă���悤���B1600MHz�͂��܂�l�������Ȃ��̂��낤���B
Intel pulls back from FB-DIMMs
ttp://www.theinquirer.net/default.aspx?article=34220
Intel�͍����ŃA�c�A�c��FB-DIMM���n�C�G���h�T�[�o�̈�ȊO�ł͎g��Ȃ����j�ɓ]�������悤���B
4S�ȉ��̃T�[�o�ł́ARDIMM���Ȃ킿Registered DIMM���嗬�Ƃ��ĕ������錩�ʂ��̂悤���B
FB-DIMM�͂��Ƃ��Ƒ�e�ʂ�K�v�Ƃ���T�[�o�����̃\�����[�V�����Ƃ��ēo�ꂵ�����A
Intel�͂����ꃁ�����C���^�[�t�F�[�X���R���V���[�}�������܂߁AFB-DIMM���C�N�ȍ����V���A���ڑ��ɒu��������
��Ă������Ă���A�����A���[�G���h�T�[�o��f�X�N�g�b�vPC�ł͐V���ȑ�ւ��Z�p���o�ꂷ����̂Ǝv����B
�X��INQ�́APenryn(Merom��45nm��)����̃��o�C���v���b�g�t�H�[���ɂ����āA
XDR-DRAM�̗p�̉\���ɂ��ē`�����BIntel����̓R���V���[�}�����̃V���A���������Z�p�ɂ��Ă̘b��
�܂�������Ȃ��B���o�C���Z�O�����g�Ɋւ��ẮA�z��, ���C�A�E�g��̓s������XDR���ꎞ�I�Ɏg�p����\����
�l������B���̌�ANehalem�̐���ŃV���A���������Z�p�\����̂�������Ȃ��B
�ȏ�\�����ł����B
>>876
�v�������A�����ȁACovertown�B�B�B
Xeon��d�؎l�j�S?�i �ō�TDP����L50W!?
http://www.hkepc.com/bbs/news.php?tid=671363
�ETDP120W
-X5355(2.66GHz/4MB x 2 L2/1333MHz FSB) �|$1172 �|06�CO4
�ETDP80W
-E5310(1.6GHz /4MB x 2 L2/1066MHz FSB)�@�|$455�@�|06�CO4
-E5320(1.83GHz/4MB x 2 L2/1066MHz FSB)�@�|$690�@�|06�CO4
-E5345(2.33GHz/4MB x 2 L2/1333MHz FSB)�@�|$851�@�|06�CO4
�ETDP50W
-L5310�i1.6GHz�A4MB x 2 L2�@1066MHz FSB�j �|07�CO1
�v�������A�����ȁACovertown�B�B�B
Xeon��d�؎l�j�S?�i �ō�TDP����L50W!?
http://www.hkepc.com/bbs/news.php?tid=671363
�ETDP120W
-X5355(2.66GHz/4MB x 2 L2/1333MHz FSB) �|$1172 �|06�CO4
�ETDP80W
-E5310(1.6GHz /4MB x 2 L2/1066MHz FSB)�@�|$455�@�|06�CO4
-E5320(1.83GHz/4MB x 2 L2/1066MHz FSB)�@�|$690�@�|06�CO4
-E5345(2.33GHz/4MB x 2 L2/1333MHz FSB)�@�|$851�@�|06�CO4
�ETDP50W
-L5310�i1.6GHz�A4MB x 2 L2�@1066MHz FSB�j �|07�CO1
����
06�CO4��06�CQ4
07�CO1��07�CQ1
06�CO4��06�CQ4
07�CO1��07�CQ1
http://download.intel.com/design/processor/designex/31368501.pdf
IntelR Core.2 Duo desktop processor
E6000 sequence with 4 MB cache
0.38 ��C/W 35.5 ��C 1,2
IntelR Core.2 Duo desktop processor
E6000 sequence with 2 MB cache
0.40 ��C/W 35.5 ��C 1,2
NOTES:
1. The difference in the target �� ca between the IntelR Core.2 Duo desktop processor E6000
sequence with 4 MB cache and 2 MB cache is due to a slight difference in the die size.
�����Core 2��4MB L2��2MB L2�̃o�[�W�����Ń_�C�T�C�Y�̈قȂ�L�q����=Allendale�R�A�i�E�́E�j
http://www.google.co.jp/search?hl=ja&q=download.intel.com%2Fdesign%2Fprocessor%2Fdatashts%2F31327801.pdf+&btnG=Google+%E6%A4%9C%E7%B4%A2&lr=
�������[�X�O�̃f�[�^�V�[�g�̃^�C�g����Allendale�̋Z�p����B
IntelR Core.2 Duo desktop processor
E6000 sequence with 4 MB cache
0.38 ��C/W 35.5 ��C 1,2
IntelR Core.2 Duo desktop processor
E6000 sequence with 2 MB cache
0.40 ��C/W 35.5 ��C 1,2
NOTES:
1. The difference in the target �� ca between the IntelR Core.2 Duo desktop processor E6000
sequence with 4 MB cache and 2 MB cache is due to a slight difference in the die size.
�����Core 2��4MB L2��2MB L2�̃o�[�W�����Ń_�C�T�C�Y�̈قȂ�L�q����=Allendale�R�A�i�E�́E�j
http://www.google.co.jp/search?hl=ja&q=download.intel.com%2Fdesign%2Fprocessor%2Fdatashts%2F31327801.pdf+&btnG=Google+%E6%A4%9C%E7%B4%A2&lr=
�������[�X�O�̃f�[�^�V�[�g�̃^�C�g����Allendale�̋Z�p����B
�_�C�T�C�Y���قȂ�
Allendale�̋L�q����
Allendale�̋L�q����
http://www.spec.org/osg/cpu2006/results/cpu2006.html
SPEC CPU 2006��Montecito�̐��\���ǂ�������ǁc(;�L�D�M)
�X���ς�肷���B
IPC@SPECint92�`SPECint2000 (McKinley = 1.25)
ipc@specint cpu
-------------------------
0.09 i386DX
0.19 i486DX4
0.21 R4000
0.21 i486DX2
0.24 i486DX
0.24 Alpha21064
0.25 R3000
0.30 MC68040
0.41 P54CS
0.42 P5
0.42 Alpha21164A
0.44 R8000
0.45 P54CQS
0.45 P54VRT
0.45 P55C
0.45 PA-7000
0.47 P54C
0.50 PPC604
0.51 Mendocino
0.54 Deschutes
0.54 Willamette
0.57 Katmai
0.57 Mendocino
0.57 Klamath
SPEC CPU 2006��Montecito�̐��\���ǂ�������ǁc(;�L�D�M)
�X���ς�肷���B
IPC@SPECint92�`SPECint2000 (McKinley = 1.25)
ipc@specint cpu
-------------------------
0.09 i386DX
0.19 i486DX4
0.21 R4000
0.21 i486DX2
0.24 i486DX
0.24 Alpha21064
0.25 R3000
0.30 MC68040
0.41 P54CS
0.42 P5
0.42 Alpha21164A
0.44 R8000
0.45 P54CQS
0.45 P54VRT
0.45 P55C
0.45 PA-7000
0.47 P54C
0.50 PPC604
0.51 Mendocino
0.54 Deschutes
0.54 Willamette
0.57 Katmai
0.57 Mendocino
0.57 Klamath
0.58 Northwood
0.60 PPC604e
0.60 NorthwoodHT
0.60 6x86MX
0.60 Athlon XP
0.61 PPC604e
0.62 P6
0.62 K7
0.65 Prescott
0.66 Coppermine
0.66 Merced
0.67 Prescott
0.67 PPC7400
0.69 Coppermine
0.71 Tualatin-S
0.73 Dempsey
0.75 Alpha21264
0.76 PA-7200
0.76 Cedar Mill
0.83 R10000
0.93 PPC970MP
0.96 Opteron280
0.97 POWER4+
1.00 PA-8200
1.01 Opteron154
1.03 Athlon FX-57
1.04 BaniasULV
1.07 Alpha21364
1.07 SPARC64 V
1.13 PA-8700+
1.19 POWER5
0.60 PPC604e
0.60 NorthwoodHT
0.60 6x86MX
0.60 Athlon XP
0.61 PPC604e
0.62 P6
0.62 K7
0.65 Prescott
0.66 Coppermine
0.66 Merced
0.67 Prescott
0.67 PPC7400
0.69 Coppermine
0.71 Tualatin-S
0.73 Dempsey
0.75 Alpha21264
0.76 PA-7200
0.76 Cedar Mill
0.83 R10000
0.93 PPC970MP
0.96 Opteron280
0.97 POWER4+
1.00 PA-8200
1.01 Opteron154
1.03 Athlon FX-57
1.04 BaniasULV
1.07 Alpha21364
1.07 SPARC64 V
1.13 PA-8700+
1.19 POWER5
1.24 Yonah
1.25 McKinley
1.25 Dothan
1.29 R14000
1.53 Madison 9M
1.57 Woodcrest
1.63 Conroe
2.37 Montecito (2006 <-> 2K @Conroe)
1.25 McKinley
1.25 Dothan
1.29 R14000
1.53 Madison 9M
1.57 Woodcrest
1.63 Conroe
2.37 Montecito (2006 <-> 2K @Conroe)
���T��IDF Fall���B
http://www.intel.com/idf/
USA, San Francisco September 26-28
���\�e���ŊC�O���[�}�[�l�^��������悤�ɂȂ������A
���������̏��X���Ƃ��Ă̎����͂��낻��s�������ȁB
http://www.intel.com/idf/
USA, San Francisco September 26-28
���\�e���ŊC�O���[�}�[�l�^��������悤�ɂȂ������A
���������̏��X���Ƃ��Ă̎����͂��낻��s�������ȁB
>>877
Intel's Oakley apres Bensley will deck FB-DIMMs
http://www.theinquirer.net/default.aspx?article=34552
Bensley�v���b�g�t�H�[���̌�p�Ƃ��āAOakley�v���b�g�t�H�[����
Q3 2007�ɂ��o��B������FB-DIMM�͔r������Ă���͗l�c(;�L�D�M)
// �]������������c����FB-DIMM���[�U���Ĉ�́c(;�L�D�M)
// Mac Pro�����ƈ�N�ł���Ȃ�FB-DIMM���ȁB
Intel's Oakley apres Bensley will deck FB-DIMMs
http://www.theinquirer.net/default.aspx?article=34552
Bensley�v���b�g�t�H�[���̌�p�Ƃ��āAOakley�v���b�g�t�H�[����
Q3 2007�ɂ��o��B������FB-DIMM�͔r������Ă���͗l�c(;�L�D�M)
// �]������������c����FB-DIMM���[�U���Ĉ�́c(;�L�D�M)
// Mac Pro�����ƈ�N�ł���Ȃ�FB-DIMM���ȁB
>>885
�܂��܂��C�O�����҂��Ă܂�
�܂��܂��C�O�����҂��Ă܂�
>>885
�������ڂ�
�������ڂ�
�ʂɂ���Ȃ�
����C�����������Ă��ǂ�������(��)
����
>>890
itteyoshi
itteyoshi
>>890
�C�C���_���I
�C�C���_���I
�ʂɂ��̃X���I���Ƃ킢���ĂȂ����B
���ꂩ��́A���[�}�[�̓����c�������A���ߕ��ʂ̃l�^���d�����čׁX�Ƒ����\��B
���ꂩ��́A���[�}�[�̓����c�������A���ߕ��ʂ̃l�^���d�����čׁX�Ƒ����\��B
���������̂�~�߂Ƃ���(��)
>>882
Field-testing IMPACT EPIC research results in Itanium 2
ttp://www.crhc.uiuc.edu/impact/presentations/sias-isca31.pdf#search=%221.25%20Itanium%20IMPACT%20.pdf%22
SPECint IPC@McKinley = 1.25�@�Ƃ����l�͈ꉞ��̃\�[�X���Q�l�ɂ����B�T�������Ƃ����\�[�X�����肻�������ǁB
SPEC92, SPEC95�̌v���f�[�^�����Ȃ�CPU�͗����̌v���f�[�^�̂���CPU����
�K���ɌW����P�o���ă��j�A�ɃX�P�[�����O�����Ƃ����ȒP�Ȕ�r�ł��B
�܂��A���̕\��date����Y�ꂽ���ǁA���E��������Ă���10�N���炢�����ĂĂ���
�������j�A��IPC���ďオ�葱���Ă��ˁBx=�N��, y=IPC�l�ŃO���t�������PA-RISC��IA64��IPC�̐L�ш꒼�����
�Ȃ�������Ɩʔ����B
�܂��APentium Pro = 0.62�� Core Duo(Yonah) =1.24�܂ł�3 issue�̂܂܂Ŗw��2�{�܂ŏオ���Ă���킯���B
����Pentium Pro��NetBurst�����X�J�X�J�������BEnergy Efficient�ȃA�[�L�̌����̗ǂ����f����B
�܂��APentium M�Ƃ�2001-2005�N��Intel�v���Z�b�T��IPC�������Ă�̂́A
�R���p�C���ƃL���b�V���̉��b���w�ǂ��낤����܂�Ȃ����ǂȁB
>>895
�P�ɏ�����Ă���镪�ɂ�Ȃ�̖����Ȃ������ǁB�B�B
Field-testing IMPACT EPIC research results in Itanium 2
ttp://www.crhc.uiuc.edu/impact/presentations/sias-isca31.pdf#search=%221.25%20Itanium%20IMPACT%20.pdf%22
SPECint IPC@McKinley = 1.25�@�Ƃ����l�͈ꉞ��̃\�[�X���Q�l�ɂ����B�T�������Ƃ����\�[�X�����肻�������ǁB
SPEC92, SPEC95�̌v���f�[�^�����Ȃ�CPU�͗����̌v���f�[�^�̂���CPU����
�K���ɌW����P�o���ă��j�A�ɃX�P�[�����O�����Ƃ����ȒP�Ȕ�r�ł��B
�܂��A���̕\��date����Y�ꂽ���ǁA���E��������Ă���10�N���炢�����ĂĂ���
�������j�A��IPC���ďオ�葱���Ă��ˁBx=�N��, y=IPC�l�ŃO���t�������PA-RISC��IA64��IPC�̐L�ш꒼�����
�Ȃ�������Ɩʔ����B
�܂��APentium Pro = 0.62�� Core Duo(Yonah) =1.24�܂ł�3 issue�̂܂܂Ŗw��2�{�܂ŏオ���Ă���킯���B
����Pentium Pro��NetBurst�����X�J�X�J�������BEnergy Efficient�ȃA�[�L�̌����̗ǂ����f����B
�܂��APentium M�Ƃ�2001-2005�N��Intel�v���Z�b�T��IPC�������Ă�̂́A
�R���p�C���ƃL���b�V���̉��b���w�ǂ��낤����܂�Ȃ����ǂȁB
>>895
�P�ɏ�����Ă���镪�ɂ�Ȃ�̖����Ȃ������ǁB�B�B
Intel will open server chips to partners next week
http://www.theregister.co.uk/2006/09/21/intel_open_chips/
Intel��AMD��Torrenza�ɑR���āA�I�[�v�������˂���Ă���݂����B
�ڂ�����IDF Fall�Ŗ��炩�ɂȂ邾�낤���獡�̓p�X�B
Intel�炵���Ȃ��헪���Ȃ��B
http://www.theregister.co.uk/2006/09/21/intel_open_chips/
Intel��AMD��Torrenza�ɑR���āA�I�[�v�������˂���Ă���݂����B
�ڂ�����IDF Fall�Ŗ��炩�ɂȂ邾�낤���獡�̓p�X�B
Intel�炵���Ȃ��헪���Ȃ��B
899 �FMAC�I�^��inteler �����F2006/09/25(��) 00:35:40 ID:cdzKUKpN0
>>898
�}�[�P�e�B���O��A������A�Ƃ肠�����u�`�グ�Ƃ��݂�����
�}�[�P�e�B���O��A������A�Ƃ肠�����u�`�グ�Ƃ��݂�����
http://journal.mycom.co.jp/articles/2006/09/17/hotchips/005.html
>The Tulsa Processor: A Dual Core Large Shared-Cache Intel Xeon 7000 Sequence Processor for the MP Server Market Segment
>L3$���~�X���ă��������A�N�Z�X����ꍇ�̃��[�e���V��195ns�őO������15ns���x�x���Ȃ��Ă��邪�A
>60%��L3$�̃q�b�g�����l������ƕ��σ��[�e���V��117ns�ƂȂ�A���̒l�́A�O����̃v���Z�T�̖�1/3�ł���Ƃ����B
>�R�A���\��15%���x�������サ�Ă��Ȃ����A���̃������A�N�Z�X���Ԃ̒Z�k���傫����^���āA
>�O����̃v���Z�T�ɔ�ׂ�OLTP�ł�70%�߂����\���オ�����Ă���B
>Blackford: A Dual Processor Chipset for Servers and Workstations
>�A�C�h�����̃��������[�e���V�͎�������Ă�����̂́ATPC-C�̕��ϓI�ȃg���t�B�b�N�̍��G��Ԃł́A
>Lindehurst��180ns�`200ns�̃A�N�Z�X���[�e���V�ł���̂ɑ��āA115ns�`125ns�Ƒ啝�ɒZ�k����Ă���B
>The Tulsa Processor: A Dual Core Large Shared-Cache Intel Xeon 7000 Sequence Processor for the MP Server Market Segment
>L3$���~�X���ă��������A�N�Z�X����ꍇ�̃��[�e���V��195ns�őO������15ns���x�x���Ȃ��Ă��邪�A
>60%��L3$�̃q�b�g�����l������ƕ��σ��[�e���V��117ns�ƂȂ�A���̒l�́A�O����̃v���Z�T�̖�1/3�ł���Ƃ����B
>�R�A���\��15%���x�������サ�Ă��Ȃ����A���̃������A�N�Z�X���Ԃ̒Z�k���傫����^���āA
>�O����̃v���Z�T�ɔ�ׂ�OLTP�ł�70%�߂����\���オ�����Ă���B
>Blackford: A Dual Processor Chipset for Servers and Workstations
>�A�C�h�����̃��������[�e���V�͎�������Ă�����̂́ATPC-C�̕��ϓI�ȃg���t�B�b�N�̍��G��Ԃł́A
>Lindehurst��180ns�`200ns�̃A�N�Z�X���[�e���V�ł���̂ɑ��āA115ns�`125ns�Ƒ啝�ɒZ�k����Ă���B
>>898
�����͌����Ă�Tukwila�̃`�b�v�Z�b�g����Ă��炤�ɂ�
���C�Z���X���邵���Ȃ��킯��
���āA���������Ӗ�����Ȃ��̂��ȁH
�����͌����Ă�Tukwila�̃`�b�v�Z�b�g����Ă��炤�ɂ�
���C�Z���X���邵���Ȃ��킯��
���āA���������Ӗ�����Ȃ��̂��ȁH
*** ����Fetch
K8��cycle������16-byte��aligned�ȃu���b�N��L1I����ǂݍ���Decoder�ɑ��邱�Ƃ��\���B
16-byte/cycle��Fetch�ш�́A���s���镽�ς̖��ߒ���5 byte�ł���ꍇ�A3���߂�Fetch���[�g���Ӗ�����B
�������A����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y���̃v���O���������邩������Ȃ��B
���ɁASSE���߂�register-register�I�y�����h���Z�́A4-byte���ł���B
�����A���߂��ԐڃA�h���b�V���O���g�p����ꍇ�A���̒�����6-8-byte�ɂ��Ȃ��Ă��܂��B
�܂��A64bit���[�h�ɂ����āAAMD64�Ŋg�����ꂽregister���g�p����ꍇ�A1-byte��REX prefix���t�������B
�����ɂ��ASSE2���߂̖��ߒ��́A64bit mode�ł�7-9 bytes�ɂ��Ȃ��Ă��܂��B
�����������ł́A16-bytes/cycle��Fetch���[�g��3����/cycle��Decode���[�g�ɑ��ĕs�\���ł���悤�Ɏv����B
�������A���̐�����K8�v���Z�b�T�ɂ����Ă͏d�v�ł͂Ȃ��B�Ȃ��Ȃ�K8�ł́Avector SSE/SSE2��Decode���[�g�́A
2cycle��3����(=1.5����/cycle)�ŁA2x 64bit��FPU�ɋ�������̂ɂ͂���ŏ\��������ł���B
�����̃v���Z�b�T�ɂ����ẮA���Ȃ��Ƃ�3����/cycle�̃��[�g���ێ�����邾�낤�B
�������������ƁAK8L�ŃA�i�E���X����Ă���32-byte��Fetch�ш�ł���肷���Ƃ��������͂��Ȃ��B
�����A���̂悤�Ȓ������߂̘A�Ȃ肪16-byte�̗אڂ����������̃u���b�N���܂����悤�ł���A
���̏ꍇ�̕��ϓI��Fetch���[�g��3����/cycle���l���ł��Ȃ��B
�b���ς�邪�AConroe�v���Z�b�T�ł��AK8���l16-byte�u���b�N��Fetch���s���Ă���B
�]���āAConroe��4����/cycle�̖��߃X�g���[����Decode�\�Ȃ̂́A���ς̖��ߒ���4-byte�����Z���ꍇ���B
�������Ȃ���AConroe�̏ꍇ�ADecoder��4���߂͂��납3���߂��珈���ł��Ȃ��̂ł���B
�Z�����[�v�ɂ����Ă��̖��ɑΏ����邽�߁AConroe�͓����ɓ����64-bytes��(=16 bytes x 4��)��buffer�ɁA
�ő�64-bytes�̒����̃��[�v���i�[�ł���悤�ɂȂ��Ă���B����buffer���̃��[�v�ɂ����ẮA32-bytes/cycle�̃��[�g���������B
���[�v�������蒷���ꍇ�́Abuffer�Ƀ��[�v���L���b�V�����邱�Ƃ��o���Ȃ��B
K8��cycle������16-byte��aligned�ȃu���b�N��L1I����ǂݍ���Decoder�ɑ��邱�Ƃ��\���B
16-byte/cycle��Fetch�ш�́A���s���镽�ς̖��ߒ���5 byte�ł���ꍇ�A3���߂�Fetch���[�g���Ӗ�����B
�������A����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y���̃v���O���������邩������Ȃ��B
���ɁASSE���߂�register-register�I�y�����h���Z�́A4-byte���ł���B
�����A���߂��ԐڃA�h���b�V���O���g�p����ꍇ�A���̒�����6-8-byte�ɂ��Ȃ��Ă��܂��B
�܂��A64bit���[�h�ɂ����āAAMD64�Ŋg�����ꂽregister���g�p����ꍇ�A1-byte��REX prefix���t�������B
�����ɂ��ASSE2���߂̖��ߒ��́A64bit mode�ł�7-9 bytes�ɂ��Ȃ��Ă��܂��B
�����������ł́A16-bytes/cycle��Fetch���[�g��3����/cycle��Decode���[�g�ɑ��ĕs�\���ł���悤�Ɏv����B
�������A���̐�����K8�v���Z�b�T�ɂ����Ă͏d�v�ł͂Ȃ��B�Ȃ��Ȃ�K8�ł́Avector SSE/SSE2��Decode���[�g�́A
2cycle��3����(=1.5����/cycle)�ŁA2x 64bit��FPU�ɋ�������̂ɂ͂���ŏ\��������ł���B
�����̃v���Z�b�T�ɂ����ẮA���Ȃ��Ƃ�3����/cycle�̃��[�g���ێ�����邾�낤�B
�������������ƁAK8L�ŃA�i�E���X����Ă���32-byte��Fetch�ш�ł���肷���Ƃ��������͂��Ȃ��B
�����A���̂悤�Ȓ������߂̘A�Ȃ肪16-byte�̗אڂ����������̃u���b�N���܂����悤�ł���A
���̏ꍇ�̕��ϓI��Fetch���[�g��3����/cycle���l���ł��Ȃ��B
�b���ς�邪�AConroe�v���Z�b�T�ł��AK8���l16-byte�u���b�N��Fetch���s���Ă���B
�]���āAConroe��4����/cycle�̖��߃X�g���[����Decode�\�Ȃ̂́A���ς̖��ߒ���4-byte�����Z���ꍇ���B
�������Ȃ���AConroe�̏ꍇ�ADecoder��4���߂͂��납3���߂��珈���ł��Ȃ��̂ł���B
�Z�����[�v�ɂ����Ă��̖��ɑΏ����邽�߁AConroe�͓����ɓ����64-bytes��(=16 bytes x 4��)��buffer�ɁA
�ő�64-bytes�̒����̃��[�v���i�[�ł���悤�ɂȂ��Ă���B����buffer���̃��[�v�ɂ����ẮA32-bytes/cycle�̃��[�g���������B
���[�v�������蒷���ꍇ�́Abuffer�Ƀ��[�v���L���b�V�����邱�Ƃ��o���Ȃ��B
�ǂ�ȕ���̌`�Ԃł��낤�Ƃ��A����Fetch�͕���\���@�\���g�p���čs���Ă���B
K8�v���Z�b�T�ł́AConroe�Ɣ�גP���ȃA���S���Y����p���ĕ���\�������Ă����B
��Ƃ��āAK8�ł͓���ւ��Ԑڕ����\�����邱�Ƃ��ł��Ȃ�����
(�I�u�W�F�N�g�w���̃|�������t�B�Y���ȃR�[�h�̎��s�ł̓}�C�i�X�ȓ_���낤)�B
�܂��A��ɓ����K���̃p�^�[����\�����邱�Ƃ��ł��Ȃ������B����\���@�\�́AK8L�ʼn��P����邾�낤�B�������A���̏ڍׂ͂܂��`�����Ă��Ȃ��B
����e�[�u����J�E���^�͑傫���Ȃ邾�낤���A�܂��A�K���I�Ƀp�^�[��������ւ��^�C�v�̕���\���A���S���Y���͉��P����邩������Ȃ��B
K8�v���Z�b�T�ł́AConroe�Ɣ�גP���ȃA���S���Y����p���ĕ���\�������Ă����B
��Ƃ��āAK8�ł͓���ւ��Ԑڕ����\�����邱�Ƃ��ł��Ȃ�����
(�I�u�W�F�N�g�w���̃|�������t�B�Y���ȃR�[�h�̎��s�ł̓}�C�i�X�ȓ_���낤)�B
�܂��A��ɓ����K���̃p�^�[����\�����邱�Ƃ��ł��Ȃ������B����\���@�\�́AK8L�ʼn��P����邾�낤�B�������A���̏ڍׂ͂܂��`�����Ă��Ȃ��B
����e�[�u����J�E���^�͑傫���Ȃ邾�낤���A�܂��A�K���I�Ƀp�^�[��������ւ��^�C�v�̕���\���A���S���Y���͉��P����邩������Ȃ��B
X register-register�I�y�����h���Z�́A4-byte��
O register-register�I�y�����h�́A4-byte��
X ����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y���̃v���O���������邩�������
O ����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y�������邩�������
O register-register�I�y�����h�́A4-byte��
X ����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y���̃v���O���������邩�������
O ����v���O�����ł͕��ς̖��ߒ���5-byte����A���S���Y�������邩�������
>>902
>One element of the companies agenda centers around releasing extensions for PCI Express and other buses
> that will allow other companies to develop co-processors for Xeon-based motherboards.
> In addition, Intel has been trying to woo partners to build co-processors for its upcoming Common System Interface (CSI).
PCIe�̊g���ł�CSI��p�����R�v�����ł���悤�ɂȂ�炵���B
>however, would prefer to see CSI arrive first with Xeon. Although, it's looking like CSI won't get to Xeon until 2009,
>after Intel cancelled earlier versions of chips that did in fact have the technology.
>>602�̖ϑz�Ă����������Ă�\���B
>One element of the companies agenda centers around releasing extensions for PCI Express and other buses
> that will allow other companies to develop co-processors for Xeon-based motherboards.
> In addition, Intel has been trying to woo partners to build co-processors for its upcoming Common System Interface (CSI).
PCIe�̊g���ł�CSI��p�����R�v�����ł���悤�ɂȂ�炵���B
>however, would prefer to see CSI arrive first with Xeon. Although, it's looking like CSI won't get to Xeon until 2009,
>after Intel cancelled earlier versions of chips that did in fact have the technology.
>>602�̖ϑz�Ă����������Ă�\���B
IDF�̑O�̖ϑz���ł����H
>>903-904�͂��̃X���̖ϑz�l�^�ł͂Ȃ�xbit�L���̗v��ˁB
AMD's Next Generation Microarchitecture Preview: from K8 to K8L (page 2)
http://www.xbitlabs.com/articles/cpu/display/amd-k8l_2.html
AMD's Next Generation Microarchitecture Preview: from K8 to K8L (page 2)
http://www.xbitlabs.com/articles/cpu/display/amd-k8l_2.html
����A�R����֏悵�Ă�
P�AC�AX�A�R���{�̖ϑz�������B
P�AC�AX�A�R���{�̖ϑz�������B
910 �Finteler@�ϑz�F2006/09/26(��) 00:10:02 ID:uU1tjyJD0
CSI��FSB�̑ш�
- FSB@1333MHz = 64bit * 1333MHz = 8.5Gbps (��艺��ꏏ)
- FSB@Bensley = 64bit * 1333MHz x2 = 17Gbps
- FSB@�����o = 64bit * 1333MHz x4 = 34Gbps
- CSI@1ch = 6.4 Gbps + 4.8 Gbps (��� + �����)
- CSI@2ch = 12.8 Gbps + 9.6 Gbps
- CSI@4ch = 25.6 Gbps + 19.2 Gbps
- CSI@8ch = 51.2 Gbps + 38.4 Gbps
// �f�X�N�g�b�v�́ACSI��2ch�Ȃ��艺�苤��FSB������u�������Ƃ��Đ\�����Ȃ��B
// Intel�������܂Ńf�X�N�g�b�v�ɂ����Ȃ蓊���͂��Ȃ��B��Bloomfield��CSI 2ch�ŏ\���B
// 2S�ł́ACSI 4ch��FSB������B��Gainestown��CSI 4ch�\���B
// ����ł́A�G���^�[�v���C�Y�ł͂ǂ���?
// 4ch CSI�́A��艺��Ő��H���Ɨ����Ă���Ƃ��������b�g�͂��邪�A�܂Ƃ߂�ƍ����o�v���b�g�t�H�[���̕����L�ш�B
// CSI�̓��[���C�e���V�Ƃ����Ă����F�̓V���A���Ȃ̂ŁA�f�p�ȃp������FSB����C�e���V���Ƃ��v���Ȃ��B
// Whitefield(CSI 4ch��?)���L�����Z���ɂȂ����Ƃ��ɁATigerton�̕��������Ƃ����b����������(>>114)�A�����������Ƃ�?
// Xeon MP��CSI��8ch�ȏ��҂��Ȃ����Caneland�����S�ɏ���Ƃ͂����Ȃ��B��Whitefield�L�����Z��
// �l�������Ԉ���Ă�����X�}���B
- FSB@1333MHz = 64bit * 1333MHz = 8.5Gbps (��艺��ꏏ)
- FSB@Bensley = 64bit * 1333MHz x2 = 17Gbps
- FSB@�����o = 64bit * 1333MHz x4 = 34Gbps
- CSI@1ch = 6.4 Gbps + 4.8 Gbps (��� + �����)
- CSI@2ch = 12.8 Gbps + 9.6 Gbps
- CSI@4ch = 25.6 Gbps + 19.2 Gbps
- CSI@8ch = 51.2 Gbps + 38.4 Gbps
// �f�X�N�g�b�v�́ACSI��2ch�Ȃ��艺�苤��FSB������u�������Ƃ��Đ\�����Ȃ��B
// Intel�������܂Ńf�X�N�g�b�v�ɂ����Ȃ蓊���͂��Ȃ��B��Bloomfield��CSI 2ch�ŏ\���B
// 2S�ł́ACSI 4ch��FSB������B��Gainestown��CSI 4ch�\���B
// ����ł́A�G���^�[�v���C�Y�ł͂ǂ���?
// 4ch CSI�́A��艺��Ő��H���Ɨ����Ă���Ƃ��������b�g�͂��邪�A�܂Ƃ߂�ƍ����o�v���b�g�t�H�[���̕����L�ш�B
// CSI�̓��[���C�e���V�Ƃ����Ă����F�̓V���A���Ȃ̂ŁA�f�p�ȃp������FSB����C�e���V���Ƃ��v���Ȃ��B
// Whitefield(CSI 4ch��?)���L�����Z���ɂȂ����Ƃ��ɁATigerton�̕��������Ƃ����b����������(>>114)�A�����������Ƃ�?
// Xeon MP��CSI��8ch�ȏ��҂��Ȃ����Caneland�����S�ɏ���Ƃ͂����Ȃ��B��Whitefield�L�����Z��
// �l�������Ԉ���Ă�����X�}���B
��ׁA�v�Z�~�X�ƌ�A�吙�c(;�L�D�M) ��̃l�^�͂Ȃ��������Ƃɂ��Ă�(�m
912 �Finteler@�ϑz�F2006/09/26(��) 00:51:36 ID:uU1tjyJD0
CSI��FSB�̑ш�
������C���B
>>557��RWT�L���ɂ��ACSI��8bit��or16bit���Ƃ̐����B
- FSB@1333MHz = 64bit * 1333MHz = 10.6 GB/s (��艺��ꏏ)
- FSB@Bensley = 64bit * 1333MHz x2 = 21 GB/s (
- FSB@�����o = 64bit * 1333MHz x4 = 43 GB/s
- CSI@8bit��@1ch = 6.4Gtps * 8bit / 8 = 6.4GB/s + 4.8 GB/s (��艺���)
- CSI@8bit��@2ch = 12.8 GB/s + 9.6 GB/s
- CSI@8bit��@4ch = 25.6 GB/s + 19.2 GB/s
- CSI@8bit��@8ch = 51.2 GB/s + 38.4 GB/s
- CSI@16bit��@1ch = 6.4GB/s * 16bit / 8 = 12.8GB/s + 9.6 GB/s (��艺���)
- CSI@16bit��@2ch = 25.6 GB/s + 19.2 GB/s
- CSI@16bit��@4ch = 51.2 GB/s + 38.4 GB/s
- CSI@16bit��@8ch = 102.4 GB/s + 76.8 GB/s
// CSI��1ch��8bit�ꑩ���Ƃ���ƁA
// �f�X�N�g�b�v�́ACSI��2ch�Ȃ��艺�苤��FSB������u�������Ƃ��Đ\�����Ȃ��B
// Intel�������܂Ńf�X�N�g�b�v�ɂ����Ȃ蓊���͂��Ȃ��B��Bloomfield��CSI 2ch�ŏ\���B
// 2S�ł́ACSI 4ch��FSB������B��Gainestown��CSI 4ch�\���B
// ����ł́A�G���^�[�v���C�Y�ł͂ǂ���?
// 4ch CSI�́A��艺��Ő��H���Ɨ����Ă���Ƃ��������b�g�͂��邪�A�܂Ƃ߂�ƍ����o�v���b�g�t�H�[���̕����L�ш�B
// CSI�̓��[���C�e���V�Ƃ����Ă����F�̓V���A���Ȃ̂ŁA�f�p�ȃp������FSB����C�e���V���Ƃ��v���Ȃ��B
// Whitefield(CSI 4ch��?)���L�����Z���ɂȂ����Ƃ��ɁATigerton�̕��������Ƃ����b����������(>>114)�A�����������Ƃ�?
// Xeon MP��CSI��8ch�ȏ��҂��Ȃ����Caneland�����S�ɏ���Ƃ͂����Ȃ��B��Whitefield���
// CSI��1ch��16bit���Ƃ���ƁA��̍l���͂Ȃ肽���Ȃ��B
// �[���A��������I/O��Half Width�ōl���Ȃ���܂��������B
������C���B
>>557��RWT�L���ɂ��ACSI��8bit��or16bit���Ƃ̐����B
- FSB@1333MHz = 64bit * 1333MHz = 10.6 GB/s (��艺��ꏏ)
- FSB@Bensley = 64bit * 1333MHz x2 = 21 GB/s (
- FSB@�����o = 64bit * 1333MHz x4 = 43 GB/s
- CSI@8bit��@1ch = 6.4Gtps * 8bit / 8 = 6.4GB/s + 4.8 GB/s (��艺���)
- CSI@8bit��@2ch = 12.8 GB/s + 9.6 GB/s
- CSI@8bit��@4ch = 25.6 GB/s + 19.2 GB/s
- CSI@8bit��@8ch = 51.2 GB/s + 38.4 GB/s
- CSI@16bit��@1ch = 6.4GB/s * 16bit / 8 = 12.8GB/s + 9.6 GB/s (��艺���)
- CSI@16bit��@2ch = 25.6 GB/s + 19.2 GB/s
- CSI@16bit��@4ch = 51.2 GB/s + 38.4 GB/s
- CSI@16bit��@8ch = 102.4 GB/s + 76.8 GB/s
// CSI��1ch��8bit�ꑩ���Ƃ���ƁA
// �f�X�N�g�b�v�́ACSI��2ch�Ȃ��艺�苤��FSB������u�������Ƃ��Đ\�����Ȃ��B
// Intel�������܂Ńf�X�N�g�b�v�ɂ����Ȃ蓊���͂��Ȃ��B��Bloomfield��CSI 2ch�ŏ\���B
// 2S�ł́ACSI 4ch��FSB������B��Gainestown��CSI 4ch�\���B
// ����ł́A�G���^�[�v���C�Y�ł͂ǂ���?
// 4ch CSI�́A��艺��Ő��H���Ɨ����Ă���Ƃ��������b�g�͂��邪�A�܂Ƃ߂�ƍ����o�v���b�g�t�H�[���̕����L�ш�B
// CSI�̓��[���C�e���V�Ƃ����Ă����F�̓V���A���Ȃ̂ŁA�f�p�ȃp������FSB����C�e���V���Ƃ��v���Ȃ��B
// Whitefield(CSI 4ch��?)���L�����Z���ɂȂ����Ƃ��ɁATigerton�̕��������Ƃ����b����������(>>114)�A�����������Ƃ�?
// Xeon MP��CSI��8ch�ȏ��҂��Ȃ����Caneland�����S�ɏ���Ƃ͂����Ȃ��B��Whitefield���
// CSI��1ch��16bit���Ƃ���ƁA��̍l���͂Ȃ肽���Ȃ��B
// �[���A��������I/O��Half Width�ōl���Ȃ���܂��������B
- Quad Core Xeon DP
Clovertown X5355 / 2.66GHz / 1333MHz / 8MB L2 / $1172 / Q4'06
Clovertown E5345 / 2.33GHz / 1333MHz / 8MB L2 / $851 / Q4'06
Clovertown E5320 / 1.86GHz / 1066MHz / 8MB L2 / $690 / Q4'06
Clovertown E5310 / 1.60GHz / 1066MHz / 8MB L2 / $455 / Q4'06
- Quad Core Xeon UP
Kentsfield X3220 / 2.40GHz / 1066MHz / 8MB / $851 / Q1'07
Kentsfield X3210 / 2.13GHz / 1066MHz / 8MB / $690 / Q1'07
Clovertown X5355 / 2.66GHz / 1333MHz / 8MB L2 / $1172 / Q4'06
Clovertown E5345 / 2.33GHz / 1333MHz / 8MB L2 / $851 / Q4'06
Clovertown E5320 / 1.86GHz / 1066MHz / 8MB L2 / $690 / Q4'06
Clovertown E5310 / 1.60GHz / 1066MHz / 8MB L2 / $455 / Q4'06
- Quad Core Xeon UP
Kentsfield X3220 / 2.40GHz / 1066MHz / 8MB / $851 / Q1'07
Kentsfield X3210 / 2.13GHz / 1066MHz / 8MB / $690 / Q1'07
SSE4 to debut at Intel show
http://www.theinquirer.net/default.aspx?article=34622
�Ȃɂ���BMerom New Instruction����Ȃ���?
http://www.theinquirer.net/default.aspx?article=34622
�Ȃɂ���BMerom New Instruction����Ȃ���?
���݂��Ȃ����ǁA���N�ɓ�����Intel�̐l(m.khellah)����ł�on-chip serial interconnect fabric�Ș_�����������B
Reducing the data switching activity on serial link buses
http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?tp=&arnumber=1613174&isnumber=33864
// Nehalem��Native 4 core�ŁA���̌�8 core��16 core�ȏ�́A����Nehalem(=4 core)����܂Ƃ߂ŁA
// on-chip interconnect fabric�Őڑ����āA1 chip�Ŏ�������B
// �O������������(>>708-712)�AKeifer�����̎��Nehalem�x�[�X��Multi-Core�A�[�L���낤�B
// (Keifer��32 core�Ȃ̂ŁA16 core * 2��MCM����)
// �ŁAHot Chips�⍡���IDF�ł킩��悤��chip�Ԃ�CSI�Őڑ������B�X��Nehalem��Memory Controller���������Ă���B
// on-die interconnect fabric����̃R�A�ł́AIA�R�A�����łȂ��A����p�r�R�A�������Ă���킯���B
// �O�Ɍ㓡�L���ɂ������悤�ɑ召�̃R�A�̑g�ݍ��킹�͂�߂��̂����ȁB
// Nehalem��fabric��������Ƃ�Gesher��������Ă���������������Ȃ����ǁB
Reducing the data switching activity on serial link buses
http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?tp=&arnumber=1613174&isnumber=33864
// Nehalem��Native 4 core�ŁA���̌�8 core��16 core�ȏ�́A����Nehalem(=4 core)����܂Ƃ߂ŁA
// on-chip interconnect fabric�Őڑ����āA1 chip�Ŏ�������B
// �O������������(>>708-712)�AKeifer�����̎��Nehalem�x�[�X��Multi-Core�A�[�L���낤�B
// (Keifer��32 core�Ȃ̂ŁA16 core * 2��MCM����)
// �ŁAHot Chips�⍡���IDF�ł킩��悤��chip�Ԃ�CSI�Őڑ������B�X��Nehalem��Memory Controller���������Ă���B
// on-die interconnect fabric����̃R�A�ł́AIA�R�A�����łȂ��A����p�r�R�A�������Ă���킯���B
// �O�Ɍ㓡�L���ɂ������悤�ɑ召�̃R�A�̑g�ݍ��킹�͂�߂��̂����ȁB
// Nehalem��fabric��������Ƃ�Gesher��������Ă���������������Ȃ����ǁB
*** �f�R�[�h
16-bytes�u���b�N���璊�o���ꂽx86���߂����̌�macro-op�ւ�Decode�����B
Macro-op��2��micro-op����Ȃ�BInt���Z��������FP���Z��micro-op�ƃ������A�N�Z�X�̂��߂�
�A�h���X���Z��micro-op�̂ł���BMacro-op �� micro-op�ւ̕����́A���s���j�b�g��O�ŃX�P�W���[���ɂ���čs����B
�ȉ���3��ނ̖̂��߂��AK8��Decoder�ł͎��ʂ����B
- DirectPath��single���߂́A1��macro-op��
- DirectPath��double���߂́A2��macro-op��
- VectorPath���߂́A3���炻���������macro-op���}�C�N���R�[�hROM���g�p���Đ���
K8��DirectPath��VectorPath�̖��߂���Dispatch���邱�Ƃ��o���Ȃ��B
Decoder�́A3 macro-op/cycle��issue���[�g�Ō��ʂ��͂��o���Ă���B
���Ȃ킿�ADecoder�́A3��DirectPath��single���߂��A1 double���� + 1 single���߂��A
1.5��double����(3 double���߂�2 cycle�ŏ���)�̃��[�g��Decode�ł���B
VectorPath���߂ł́A1�̖��߂�3��������macro-op��Decode���ꂤ�邽�߁A���̏ꍇ�́ADecode��2 cycle�ȏ��v����B
Decoder�ɂ���Ė�cycle��������Ă���macro-op�́A�O���[�v�ɂ܂Ƃ߂��Ă����B
DirectPath��VectorPath��Decoder�̐�ւ��▽��Fetch���C�e���V�̂���������ƂȂ�A
1�`2��macro-op�����Ȃ��O���[�v���������ꂤ��B���̂悤�ȃO���[�v�͋��macro-op���l�߂邱�Ƃ�
�A�g�[�^����3 macro-op��dispatch�Ƃ���B
SSE/SSE2/SSE3��vector���Z���߂́Amacro-op�̃y�A�ւƕ�������A
128-bit SSE register�̏��/���ʂ�64-bit�̎��s���j�b�g�Ōʂɏ�������B
����́AK8��2 cycle��3 SSE���߂���Decode�ł��Ȃ����R�ƂȂ��Ă���B
K8L�ł́A����SSE���j�b�g�̕���128-bit�ւƊg�������̂ŁAvector���Z���߂�2�ɕ�������K�v���Ȃ��B
Decoder�́A3����/cycle�̃��[�g�ŁASSE���߂�P���128-bit macro-op�ւƕϊ��ł���悤�ɖ��炩�ȕύX���Ȃ����ł��낤�B
16-bytes�u���b�N���璊�o���ꂽx86���߂����̌�macro-op�ւ�Decode�����B
Macro-op��2��micro-op����Ȃ�BInt���Z��������FP���Z��micro-op�ƃ������A�N�Z�X�̂��߂�
�A�h���X���Z��micro-op�̂ł���BMacro-op �� micro-op�ւ̕����́A���s���j�b�g��O�ŃX�P�W���[���ɂ���čs����B
�ȉ���3��ނ̖̂��߂��AK8��Decoder�ł͎��ʂ����B
- DirectPath��single���߂́A1��macro-op��
- DirectPath��double���߂́A2��macro-op��
- VectorPath���߂́A3���炻���������macro-op���}�C�N���R�[�hROM���g�p���Đ���
K8��DirectPath��VectorPath�̖��߂���Dispatch���邱�Ƃ��o���Ȃ��B
Decoder�́A3 macro-op/cycle��issue���[�g�Ō��ʂ��͂��o���Ă���B
���Ȃ킿�ADecoder�́A3��DirectPath��single���߂��A1 double���� + 1 single���߂��A
1.5��double����(3 double���߂�2 cycle�ŏ���)�̃��[�g��Decode�ł���B
VectorPath���߂ł́A1�̖��߂�3��������macro-op��Decode���ꂤ�邽�߁A���̏ꍇ�́ADecode��2 cycle�ȏ��v����B
Decoder�ɂ���Ė�cycle��������Ă���macro-op�́A�O���[�v�ɂ܂Ƃ߂��Ă����B
DirectPath��VectorPath��Decoder�̐�ւ��▽��Fetch���C�e���V�̂���������ƂȂ�A
1�`2��macro-op�����Ȃ��O���[�v���������ꂤ��B���̂悤�ȃO���[�v�͋��macro-op���l�߂邱�Ƃ�
�A�g�[�^����3 macro-op��dispatch�Ƃ���B
SSE/SSE2/SSE3��vector���Z���߂́Amacro-op�̃y�A�ւƕ�������A
128-bit SSE register�̏��/���ʂ�64-bit�̎��s���j�b�g�Ōʂɏ�������B
����́AK8��2 cycle��3 SSE���߂���Decode�ł��Ȃ����R�ƂȂ��Ă���B
K8L�ł́A����SSE���j�b�g�̕���128-bit�ւƊg�������̂ŁAvector���Z���߂�2�ɕ�������K�v���Ȃ��B
Decoder�́A3����/cycle�̃��[�g�ŁASSE���߂�P���128-bit macro-op�ւƕϊ��ł���悤�ɖ��炩�ȕύX���Ȃ����ł��낤�B
K8L��Decoder�́A(�D��������)Conroe�̂悤��cycle������4-5���߂�Decode���邱�Ƃ͂ł��Ȃ���������Ȃ����A
���߂͕��ςł�3����/cycle��菭�Ȃ����[�g�Ŏ��s����Ă���̂ŁA���ɏ�Q�ɂ͂Ȃ�Ȃ����낤�B
K8�͒ʏ�x86���߂�Conroe�Ɣ�ׂď�����macro-op��Decode���Ă���B
����́A32-byte��Fetch�Ɠ��l�ɁADecoder�������I�ɂ����Ă���B
http://www.xbitlabs.com/articles/cpu/display/amd-k8l_3.html
���߂͕��ςł�3����/cycle��菭�Ȃ����[�g�Ŏ��s����Ă���̂ŁA���ɏ�Q�ɂ͂Ȃ�Ȃ����낤�B
K8�͒ʏ�x86���߂�Conroe�Ɣ�ׂď�����macro-op��Decode���Ă���B
����́A32-byte��Fetch�Ɠ��l�ɁADecoder�������I�ɂ����Ă���B
http://www.xbitlabs.com/articles/cpu/display/amd-k8l_3.html
>914
KNI -> SSE
WNI -> SSE2
PNI -> SSE3
TNI -> MNI -> Supplemental SSE3
GNI -> SSE4?
KNI -> SSE
WNI -> SSE2
PNI -> SSE3
TNI -> MNI -> Supplemental SSE3
GNI -> SSE4?
��50����?�Ƃ������Ă��邩��AMNI = SSSE3�Ƃ͂������̂��B
�Œ�ł�4�N��̃A�[�L�e�N�`���̖��߂������炩�ɂ��闝�R���킩���B
SSE3�Ɣ�ׂ��Ȃ�L�p�Ƃ̂��Ƃ炵�����B
�Œ�ł�4�N��̃A�[�L�e�N�`���̖��߂������炩�ɂ��闝�R���킩���B
SSE3�Ɣ�ׂ��Ȃ�L�p�Ƃ̂��Ƃ炵�����B
ntel�A�N�A�b�h�R�A�́uCore 2�v����сuXeon�v�V���[�Y�̏o�v������J
http://journal.mycom.co.jp/news/2006/09/27/400.html
Rackable and Intel scratch each other behind AMD's back
http://www.theregister.co.uk/2006/09/26/intel_rackable_amd/
Intel on top of the server world again
http://www.theregister.co.uk/2006/09/26/intel_fourcore_server/
�yIDF Fall 2006�z�u45nm�v���Z�X�C2007�N�̉ғ��ɕύX�Ȃ��v�CIntel�Ђ�15���i���J����
http://itpro.nikkeibp.co.jp/article/COLUMN/20060927/249066/?ST=ep1
Intel's Otellini shows off November quads, benchmarks
http://www.theinquirer.net/default.aspx?article=34641
>The first new core on 45 nanometres is Nehalem, basically a beefed up Woodcrest wih CSI.
�yIDF Fall 2006�z��Intel�̌����J�����傪�ŐV�̐��ʂ��I
http://itpro.nikkeibp.co.jp/article/USNEWS/20060926/249014/
�yIDF Fall 2006�z�u�T�[�o�[�s��̐������Ăсv��Otellini�В�
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249057/
�yIDF Fall 2006�zIntel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
http://journal.mycom.co.jp/news/2006/09/27/400.html
Rackable and Intel scratch each other behind AMD's back
http://www.theregister.co.uk/2006/09/26/intel_rackable_amd/
Intel on top of the server world again
http://www.theregister.co.uk/2006/09/26/intel_fourcore_server/
�yIDF Fall 2006�z�u45nm�v���Z�X�C2007�N�̉ғ��ɕύX�Ȃ��v�CIntel�Ђ�15���i���J����
http://itpro.nikkeibp.co.jp/article/COLUMN/20060927/249066/?ST=ep1
Intel's Otellini shows off November quads, benchmarks
http://www.theinquirer.net/default.aspx?article=34641
>The first new core on 45 nanometres is Nehalem, basically a beefed up Woodcrest wih CSI.
�yIDF Fall 2006�z��Intel�̌����J�����傪�ŐV�̐��ʂ��I
http://itpro.nikkeibp.co.jp/article/USNEWS/20060926/249014/
�yIDF Fall 2006�z�u�T�[�o�[�s��̐������Ăсv��Otellini�В�
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249057/
�yIDF Fall 2006�zIntel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
Fall IDF 2006 - Day 1: Laser FSBs, more Alan Wake, Flash in Vista & DDR3
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2841
Fall IDF 2006 - Day 1: 45/65nm, UMPC Update and Quad-Core
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2840
AnandTech��IDF�L���B��ʎ���肳�����ɏ[�����Ă���B
cnet�Ƃ�ITmedia�݂����ȃj���[�X�T�C�g�̋L�����Ă��������ȉ��ߑ�����ȁc�B
http://www.anandtech.com/tradeshows/showdoc.aspx?i=2841
Fall IDF 2006 - Day 1: 45/65nm, UMPC Update and Quad-Core
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2840
AnandTech��IDF�L���B��ʎ���肳�����ɏ[�����Ă���B
cnet�Ƃ�ITmedia�݂����ȃj���[�X�T�C�g�̋L�����Ă��������ȉ��ߑ�����ȁc�B
922 �Finteler@�����F2006/09/27(��) 20:47:17 ID:Xt+kCqtE0
>>912
AnandTech���ċC�Â�����Caneland��1066MHz x4�Ȃ̂�34GB/s�������B
AnandTech���ċC�Â�����Caneland��1066MHz x4�Ȃ̂�34GB/s�������B
Clovertown���o����A��͂�Mac Pro�ɓ��ڂ��Ă���̂��˂��B
�T�[�o���Ⴀ��܂����A���[�N�X�e�[�V������8-way�͂��܂�Ӗ��������C��������B
�T�[�o���Ⴀ��܂����A���[�N�X�e�[�V������8-way�͂��܂�Ӗ��������C��������B
Clovertown��ςނ����AWoodcrest��BTO�Ŏc���Ă��炢���i�������鎖�����҂��Ă݂����B
Supplemental SSE3����낭�ȃh�L�������g�݂����ƂȂ����Ă̂ɁA
�����������Ȃ�SSE4�̂�whitepaper���Љ�ꂽ�BSSE4��Penryn�ȍ~��Intel�v���Z�b�T�ŗ��p�\���B
Extending the�@World�fs Most Popular�@Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf
�����������Ȃ�SSE4�̂�whitepaper���Љ�ꂽ�BSSE4��Penryn�ȍ~��Intel�v���Z�b�T�ŗ��p�\���B
Extending the�@World�fs Most Popular�@Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf
�����IDF�͂������N�Ōl�I�Ɉ�Ԃ̃q�b�g���ȁi�E�́E�j
������������������Ă��Ă������l�^�ɂ���B
������������������Ă��Ă������l�^�ɂ���B
>>925
H2 2007��Nehalem�A�[�L��҂������āANative 4 core��Yorkfield���o�ꂩ�B
���܂�Native 4 core��Bloomfield�̃R�[�h�l�[�������W���[���������A���X�b���o�Ă������炱�Ƃ��炵�āA
�P��K8L�R�ŁATigerton��desktopfied����������ȁB
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Yorkfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/xx
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
���Ȃ݂�Tom's�ɈȑO�łĂ����R�[�h�l�[���I���p���[�h�ȋL����Whitefield�������c���Ă�����ƁA
�l�^���Â�or���x�������̂ł��̃X���ł͐M�p�����ɁA�ʂ̃\�[�X����̏������͂��ō\�z�������Ă�B
H2 2007��Nehalem�A�[�L��҂������āANative 4 core��Yorkfield���o�ꂩ�B
���܂�Native 4 core��Bloomfield�̃R�[�h�l�[�������W���[���������A���X�b���o�Ă������炱�Ƃ��炵�āA
�P��K8L�R�ŁATigerton��desktopfied����������ȁB
2006- "65nm Core" Merom/m, Conroe/d, Kentsfield/d, Yorkfield/d, Woodcrest/dp, Clovertown/dp, Tigerton/mp
2007- "45nm Core" Penryn/m, Wolfdale/d, Ridgefield/d, Harpertown/dp, Dunnington/mp
2008- "45nm Nehalem" Bloomfield/d, Gainstown/dp, Aliceton/mp
2009- "32nm Nehalem" Gulftown/dp, Keifer/xx
2010- "32nm Gesher"
/m = Mobile
/d = Desktop
/dp = DP Server
/mp = MP Server
���Ȃ݂�Tom's�ɈȑO�łĂ����R�[�h�l�[���I���p���[�h�ȋL����Whitefield�������c���Ă�����ƁA
�l�^���Â�or���x�������̂ł��̃X���ł͐M�p�����ɁA�ʂ̃\�[�X����̏������͂��ō\�z�������Ă�B
Intel renames AMD64 to Intel 64
http://www.theinquirer.net/default.aspx?article=34722
Intel��IPF�ւ̔z������߂�EM64T��Intel 64�Ɖ��̂��܂����B
Intel��64 bit�e�N�m���W�́A�wIntel Architecture 64�x(=IA64)�ƁwIntel 64�x��2�����݂���Ƃ���
���ɕ���킵���Ɂc(;�L�D�M)
http://www.theinquirer.net/default.aspx?article=34722
Intel��IPF�ւ̔z������߂�EM64T��Intel 64�Ɖ��̂��܂����B
Intel��64 bit�e�N�m���W�́A�wIntel Architecture 64�x(=IA64)�ƁwIntel 64�x��2�����݂���Ƃ���
���ɕ���킵���Ɂc(;�L�D�M)
Conroe���o�Ă����Ƃ��ɂ���Intel 64�͔��\����Ă�
�C���e���A�������d�͌^�`�b�v�uSteeley�v��UMPC�̒ቿ�i����ڎw��
http://japan.cnet.com/news/ent/story/0,2000056022,20250007,00.htm
�L���Ō����Ă���悤�ɁASteeley��GPU��MC���������Ǝv����B
Intel�͊J�����\�[�X���L�x�Ȃ̂ŁAGPU�̓����ƃ��j�B�R�A�����ꂼ�ꃍ�[�G���h
�ƃn�C�G���h���狲�����Ő����i�߂邱�Ƃ��o����B
���j�B�R�A�v�悪������ƁAUMPC�p�̃`�b�v���n�C�G���h�u���Ɋg������ANetBurst vs PenM�̂Ƃ��̂悤��
��������N���肤��B
AMD�̕��́AIntel�̂悤�ȕ��s�Ȃ����͏o���Ȃ��̂ŁA�͂��߂���GPU�����ɍi��������X�N�����Ȃ������I�B
�Ƃ����悤�ȓ��e�̋L�����㓡�������肪�����������c�B
Intel��AMD�����ʓI�ɂ͑債�č����Ȃ��Ƃ���ɗ��������C�����邯�ǁB
http://japan.cnet.com/news/ent/story/0,2000056022,20250007,00.htm
�L���Ō����Ă���悤�ɁASteeley��GPU��MC���������Ǝv����B
Intel�͊J�����\�[�X���L�x�Ȃ̂ŁAGPU�̓����ƃ��j�B�R�A�����ꂼ�ꃍ�[�G���h
�ƃn�C�G���h���狲�����Ő����i�߂邱�Ƃ��o����B
���j�B�R�A�v�悪������ƁAUMPC�p�̃`�b�v���n�C�G���h�u���Ɋg������ANetBurst vs PenM�̂Ƃ��̂悤��
��������N���肤��B
AMD�̕��́AIntel�̂悤�ȕ��s�Ȃ����͏o���Ȃ��̂ŁA�͂��߂���GPU�����ɍi��������X�N�����Ȃ������I�B
�Ƃ����悤�ȓ��e�̋L�����㓡�������肪�����������c�B
Intel��AMD�����ʓI�ɂ͑債�č����Ȃ��Ƃ���ɗ��������C�����邯�ǁB
>>930
>2006�N7��27���AIntel��EM64T��Intel 64�Ɩ��������Ɣ��\�����B
�S�R���Â��Ȃ��ʼn߂����Ă���A���[�}�[�ɗ��肷�����̂̕��Q���c(;�L�D�M)
>2006�N7��27���AIntel��EM64T��Intel 64�Ɩ��������Ɣ��\�����B
�S�R���Â��Ȃ��ʼn߂����Ă���A���[�}�[�ɗ��肷�����̂̕��Q���c(;�L�D�M)
�悭������ǁA����Merom���݂�TDP�g��4-core���o�Ă���̂͂�����H
>>935
Clovertown��Mac Pro�̃��C���i�b�v�ɉ����Ǝv����B�����Ă����������Q�͂Ȃ�����B
AnandTech��Penryn�Ƃ���45nm�ł�Merom�`�b�v��4 core�����Ƃ����b�����Ă����B
�R��͂���͂Ȃ��Ǝv���Ă邯�ǁB
����̃��[�h�}�b�v�ł����ƁAMerom����TDP�g��Quad��2008�N�㔼����2009�N���ߍ����Ǝv����B
��̓I�ȃR�[�h�l�[���͏オ���Ă��Ă��Ȃ����AMobile�ŏ��߂�Quad�ɂȂ肻���Ȃ̂�Nehalem-based��Mobile�ł̐��i���Ǝv����B
���̂���ɂ́AMerom�Ȃǔ�r�ɂȂ�Ȃ��قǒ����d�͂�Steeley�̕���>>935�S�������Ă���Ɨ\�z�B
Clovertown��Mac Pro�̃��C���i�b�v�ɉ����Ǝv����B�����Ă����������Q�͂Ȃ�����B
AnandTech��Penryn�Ƃ���45nm�ł�Merom�`�b�v��4 core�����Ƃ����b�����Ă����B
�R��͂���͂Ȃ��Ǝv���Ă邯�ǁB
����̃��[�h�}�b�v�ł����ƁAMerom����TDP�g��Quad��2008�N�㔼����2009�N���ߍ����Ǝv����B
��̓I�ȃR�[�h�l�[���͏オ���Ă��Ă��Ȃ����AMobile�ŏ��߂�Quad�ɂȂ肻���Ȃ̂�Nehalem-based��Mobile�ł̐��i���Ǝv����B
���̂���ɂ́AMerom�Ȃǔ�r�ɂȂ�Ȃ��قǒ����d�͂�Steeley�̕���>>935�S�������Ă���Ɨ\�z�B
>>936
�T���N�X�B���o�C����4-way��Nehalem����܂ł��a�����c�B
>Clovertown��Mac Pro�̃��C���i�b�v�ɉ����Ǝv����B�����Ă����������Q�͂Ȃ�����B
�M���������Ȃ��Ȃ����H
�܂��AApple�̂��Ƃ�����A�ڂ��Ă������ȋC�����邯�ǁB
�����������Ȃ�ƁAiMac�i�܂��́A���̌�p���C���j�ɂ�Kentsfield���ڂ��Ăق����Ȃ��B
�T���N�X�B���o�C����4-way��Nehalem����܂ł��a�����c�B
>Clovertown��Mac Pro�̃��C���i�b�v�ɉ����Ǝv����B�����Ă����������Q�͂Ȃ�����B
�M���������Ȃ��Ȃ����H
�܂��AApple�̂��Ƃ�����A�ڂ��Ă������ȋC�����邯�ǁB
�����������Ȃ�ƁAiMac�i�܂��́A���̌�p���C���j�ɂ�Kentsfield���ڂ��Ăق����Ȃ��B
����Mac Pro��1.2kW�d�����ڂ��Ă��Ȃ���X1900XT*2�͓d���e�ʂ̖��Ń_������H
����Ȃɗ]�T�Ȃ��Ȃ�Clovertown�ɂ���ƍ��x��1.5-1.7kW�d�����ڂ��Ă���̂��ˁB
����Ȃɗ]�T�Ȃ��Ȃ�Clovertown�ɂ���ƍ��x��1.5-1.7kW�d�����ڂ��Ă���̂��ˁB
4�R�AXeon�\�gClovertown�h�̍ō�FSB��1333MHz
http://northwood.blog60.fc2.com/blog-entry-193.html
�m���ɔM�̖��͂���B�����܂ł��o��Ǝv���邾��������ȁB
Clovertown 8 way Mac Pro���Ⴆ�łȂ��Ă��R��͐ӔC�Ƃ�Ȃ��̂ł��܂��ꂽ�Ƃ���߂��Ȃ��悤�ɂ�낵���i�E�́E�j
Clovertown��X5355��120W�ȊO�́A80W������Woodcrest 3GHz�Ɠ������x���ōςށB
http://northwood.blog60.fc2.com/blog-entry-193.html
�m���ɔM�̖��͂���B�����܂ł��o��Ǝv���邾��������ȁB
Clovertown 8 way Mac Pro���Ⴆ�łȂ��Ă��R��͐ӔC�Ƃ�Ȃ��̂ł��܂��ꂽ�Ƃ���߂��Ȃ��悤�ɂ�낵���i�E�́E�j
Clovertown��X5355��120W�ȊO�́A80W������Woodcrest 3GHz�Ɠ������x���ōςށB
TDP�̓N���b�N���Ƃ�����Ȃ�ɉ�������B
PentiumD�Ɠ������ȁB
PentiumD�Ɠ������ȁB
PentiumD��Kentsfield�Ɍ������b����Ȃ���
�������X
�������X
�����d�͂��Z�[���X�|�C���g�̈�������͂���Core MA���A�C������100W�I�[�o�[���c�B
���j�͌J��Ԃ��H
���j�͌J��Ԃ��H
�yIDF����z�u�����100�R�A���e�X�g���܂��v�CIntel�Ђ��}���`�R�A�̊J���̗l�q�����J
http://techon.nikkeibp.co.jp/article/NEWS/20060926/121550/
��ISMI�CLSI���Y������ƃE�G�[�n450mm���Ɍ������J���v���O�����̐i���\
http://techon.nikkeibp.co.jp/article/NEWS/20060928/121649/
http://techon.nikkeibp.co.jp/article/NEWS/20060926/121550/
��ISMI�CLSI���Y������ƃE�G�[�n450mm���Ɍ������J���v���O�����̐i���\
http://techon.nikkeibp.co.jp/article/NEWS/20060928/121649/
UMPC Update
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2840&p=8
The Core Solo/Pentium M processors used in current UMPCs use approximately 5W of power,
and by the 1st half of 2007 Intel is expecting to cut the power of these chips in half.
In another year, we'll be looking at 1/10th the power (0.5W) and 1/7th the size of today's
UMPC processors, which will hopefully lead to longer battery life and smaller form factors.
Intel gave a realistic sounding target of 7 hours of battery life for a UMPC by 2008,
much better than the 3 hours of today's best UMPCs.
ULV Core Solo��UMPC�`�b�v��5W�����A
Steeley�͂Ȃ��500mW������ȁi�E�́E�j
2008�N�ɂ̓o�b�e���[��7���Ԃ���UMPC���^�[�Q�b�g�炵���B
�p�b�P�[�W���O�����ɏ������A1/7�ł���B
// Intel�́A���Ă�XScale�̗̈��x86�ŃJ�o�[���悤�Ƃ��Ă���̂ŁA�����d�̓`�b�v�Ɉӗ~�I�B
// ������Mac mini�͂��납�AiPod����x86�����邩���i�E�́E�j
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2840&p=8
The Core Solo/Pentium M processors used in current UMPCs use approximately 5W of power,
and by the 1st half of 2007 Intel is expecting to cut the power of these chips in half.
In another year, we'll be looking at 1/10th the power (0.5W) and 1/7th the size of today's
UMPC processors, which will hopefully lead to longer battery life and smaller form factors.
Intel gave a realistic sounding target of 7 hours of battery life for a UMPC by 2008,
much better than the 3 hours of today's best UMPCs.
ULV Core Solo��UMPC�`�b�v��5W�����A
Steeley�͂Ȃ��500mW������ȁi�E�́E�j
2008�N�ɂ̓o�b�e���[��7���Ԃ���UMPC���^�[�Q�b�g�炵���B
�p�b�P�[�W���O�����ɏ������A1/7�ł���B
// Intel�́A���Ă�XScale�̗̈��x86�ŃJ�o�[���悤�Ƃ��Ă���̂ŁA�����d�̓`�b�v�Ɉӗ~�I�B
// ������Mac mini�͂��납�AiPod����x86�����邩���i�E�́E�j
�X���C�h�����
2007�N��Steeley�͏���d��1/2�Ń_�C�T�C�Y1/4
2008�N�͏���d��1/10�Ń_�C�T�C�Y1/7
������SoC
���ď����Ă��邼�B
���p����
> Intel is expecting to cut the power of these chips in half.
����
2007�N��Steeley�͏���d��1/2�Ń_�C�T�C�Y1/4
2008�N�͏���d��1/10�Ń_�C�T�C�Y1/7
������SoC
���ď����Ă��邼�B
���p����
> Intel is expecting to cut the power of these chips in half.
����
946 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/29(��) 00:51:50 ID:eO+N0eBK0
�摖����MNI��SSE4�����Đ����������E�̒p�������ɍ~��
Intel��UMPC�͗������O
http://pc.watch.impress.co.jp/docs/2006/0929/idf06.htm
�悭�ǂ�ł����B
����d�͂�1/2�A�p�b�P�[�W���O�T�C�Y��1/4�Ƃ����̂͗��N�̂͂��߂���ɂł�PenM�n�̐VUMPC�`�b�v�̂��Ƃł���B
�_�C�T�C�Y�ł͂Ȃ��p�b�P�[�W���O�̃T�C�Y��1/4�ł���B
2008�N�Ƃ����̂�Steeley���ƂŁA�p�b�P�[�W���O�T�C�Y��1/7�ŁA����d�͂�1/10����B
�p�b�P�[�W���O������������w�͂͑O���IDF�ł��łɌ��\����Ă����B
http://pc.watch.impress.co.jp/docs/2006/0929/idf06.htm
�悭�ǂ�ł����B
����d�͂�1/2�A�p�b�P�[�W���O�T�C�Y��1/4�Ƃ����̂͗��N�̂͂��߂���ɂł�PenM�n�̐VUMPC�`�b�v�̂��Ƃł���B
�_�C�T�C�Y�ł͂Ȃ��p�b�P�[�W���O�̃T�C�Y��1/4�ł���B
2008�N�Ƃ����̂�Steeley���ƂŁA�p�b�P�[�W���O�T�C�Y��1/7�ŁA����d�͂�1/10����B
�p�b�P�[�W���O������������w�͂͑O���IDF�ł��łɌ��\����Ă����B
���N�̏��߂���Ȃ����O���ˁB��N������Steeley�B
http://news.com.com/2100-1044_3-6119699.html
> The first computers based on Steeley/McCaslin will come out in late 2007,
> he said, but the serious effort to market them will begin in 2008.
�i2007�N�O����Steeley�o�ׁA�j����𓋍ڂ������i���̂�2007�N�㔼�ɏo�Ă���B
�Ɠǂ߂���ǁB
�p�b�P�[�W���O�Ɋւ����Ⴛ�̒ʂ肩���ˁB
> The first computers based on Steeley/McCaslin will come out in late 2007,
> he said, but the serious effort to market them will begin in 2008.
�i2007�N�O����Steeley�o�ׁA�j����𓋍ڂ������i���̂�2007�N�㔼�ɏo�Ă���B
�Ɠǂ߂���ǁB
�p�b�P�[�W���O�Ɋւ����Ⴛ�̒ʂ肩���ˁB
http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/295
��MAC�I�^��5000X�ɂ��X�k�[�v�t�B���^��������Č����Ă邩�猟�����Ă݂���A
http://www.hpc-technologies.co.jp/benchmarks/MemoryCacheTest-SnoopFilter.html
http://www.hpc-technologies.co.jp/benchmarks/MemoryCacheTest-SnoopFilter_5000P-5000X.html
���Ă̂����������B
���ꂪ�ǂ��܂ň�ʓI�Ɍ����邩�킩��Ȃ����A�I���I�t�ł��Ȃ�̍����ł�悤���B
��MAC�I�^��5000X�ɂ��X�k�[�v�t�B���^��������Č����Ă邩�猟�����Ă݂���A
http://www.hpc-technologies.co.jp/benchmarks/MemoryCacheTest-SnoopFilter.html
http://www.hpc-technologies.co.jp/benchmarks/MemoryCacheTest-SnoopFilter_5000P-5000X.html
���Ă̂����������B
���ꂪ�ǂ��܂ň�ʓI�Ɍ����邩�킩��Ȃ����A�I���I�t�ł��Ȃ�̍����ł�悤���B
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai305.htm
>�܂��AIntel��Clarksboro�ɂ́ACPU�̃L���b�V���X�k�[�v���t�B���^�����O���āA�X�k�[�v�g���t�B�b�N���y������X�k�[�v�t�B���^�����O�@�\������B
>Clarksboro��64MB����CPU���̃L���b�V�����g���b�N�ł���悤���B
>���̂��Ƃ́ATigerton�̌��MP�T�[�o�[����CPU�ɁA1 CPU������16MB�̃L���b�V�������ڂ���邱�Ƃ��������Ă���B
>
>���Ȃ݂ɁA�X�k�[�v�t�B���^�����O�@�\���̂́ADP���[�N�X�e�[�V���������́uGreencreek(�O���[���N���[�N)�v�`�b�v�Z�b�g�����������Ă���B
>Greencreek��16MB�܂ł̃L���b�V�����J�o�[�ł���B
http://techon.nikkeibp.co.jp/article/NEWS/20060927/121581/?SS=imgview&FD=-234061426&ad_q
>�T�[�o�[�@�����ł̓}���`�v���Z�T����Xeon 7000�ԑ�́uDunnington�v�������������m���V�b�N�^�ɂȂ�Ƃ݂���B
2008�N�ɓo���XeonMP(Dunnington)��16MB��L2Cache��4�R�A�ŋ��L���Ă��Ƃ�?
>�܂��AIntel��Clarksboro�ɂ́ACPU�̃L���b�V���X�k�[�v���t�B���^�����O���āA�X�k�[�v�g���t�B�b�N���y������X�k�[�v�t�B���^�����O�@�\������B
>Clarksboro��64MB����CPU���̃L���b�V�����g���b�N�ł���悤���B
>���̂��Ƃ́ATigerton�̌��MP�T�[�o�[����CPU�ɁA1 CPU������16MB�̃L���b�V�������ڂ���邱�Ƃ��������Ă���B
>
>���Ȃ݂ɁA�X�k�[�v�t�B���^�����O�@�\���̂́ADP���[�N�X�e�[�V���������́uGreencreek(�O���[���N���[�N)�v�`�b�v�Z�b�g�����������Ă���B
>Greencreek��16MB�܂ł̃L���b�V�����J�o�[�ł���B
http://techon.nikkeibp.co.jp/article/NEWS/20060927/121581/?SS=imgview&FD=-234061426&ad_q
>�T�[�o�[�@�����ł̓}���`�v���Z�T����Xeon 7000�ԑ�́uDunnington�v�������������m���V�b�N�^�ɂȂ�Ƃ݂���B
2008�N�ɓo���XeonMP(Dunnington)��16MB��L2Cache��4�R�A�ŋ��L���Ă��Ƃ�?
> Steeley/McCaslin�Ɋ�Â��ŏ��̃R���s���[�^��2007�N�㔼�ɏo�ė���ł��傤�A
> �Ɣނ͌����܂������A������o�����߂̖{�i�I�ȑ��2008�N�Ɏn�܂�ł��傤�B
> �Ɣނ͌����܂������A������o�����߂̖{�i�I�ȑ��2008�N�Ɏn�܂�ł��傤�B
�~�X�����B
>>951
�Ƃ肠����2008�N�̂�Steeley�Ƃ͏����ĂȂ��C��������B
����
http://www.tomshardware.com/2005/12/04/top_secret_intel_processor_plans_uncovered/page5.html
�ł͓o�ꎞ����Mid 2007�ɂȂ��Ă�B
�܂�>>928�Ō����悤�ɐM�p�ł��Ȃ��L���ƌ����邩������ǁB
>>951
�Ƃ肠����2008�N�̂�Steeley�Ƃ͏����ĂȂ��C��������B
����
http://www.tomshardware.com/2005/12/04/top_secret_intel_processor_plans_uncovered/page5.html
�ł͓o�ꎞ����Mid 2007�ɂȂ��Ă�B
�܂�>>928�Ō����悤�ɐM�p�ł��Ȃ��L���ƌ����邩������ǁB
>In the future, the UMPCs will be built around Steeley, an ultra-low-power chip coming from Intel in late 2007.
���ď����Ă邼�B
�ŁA�p����Ȃ�A
http://japan.cnet.com/news/ent/story/0,2000056022,20250007,00.htm
�Ŋ��ɖ|��L���������A�����킹�ēǂ߁B
���ď����Ă邼�B
�ŁA�p����Ȃ�A
http://japan.cnet.com/news/ent/story/0,2000056022,20250007,00.htm
�Ŋ��ɖ|��L���������A�����킹�ēǂ߁B
����ASteeley��2008�N�ɗ���Ƃ͏����ĂȂ��ˁB
���Ȃ݂�>>949�̊��ʓ���IDF�̃X���C�h��Tom����̏��𐄑����ď������킯�B
������Tom�̂Ƃ���Stealey�ɂȂ��Ă邯�ǁB
���Ȃ݂�>>949�̊��ʓ���IDF�̃X���C�h��Tom����̏��𐄑����ď������킯�B
������Tom�̂Ƃ���Stealey�ɂȂ��Ă邯�ǁB
>In the future, the UMPCs will be built around Steeley, an ultra-low-power chip coming from Intel in late 2007.
> While the chip will run Windows and Linux software like standard Intel processors,
>the design of the chip will be "dramatically different" from its contemporaries, as well as current Intel chips, Chandrasekher said.
�����܂ň��p���Ȃ��Ƃ��߂��H
�ŁASteeley��2007�N�㔼�ɍ��܂ł�CPU�ƌ��I�ɈႤ�A�ƃ`�����h���V�[�J���������Ă���B
ID:/LTfN7i10�����p���Ă�悤�ɁASteeley���̗p�������i��2008�N���낤�A�ƃ`�����h���V�[�J�͂܂������Ă���B
�ŁA������inteler�����p���Ă���Anandtech�̋L����IDF�̃X���C�h�ɂ���2007�N�h�̑O���Ɂh�_�C�E����d�͂Ƃ���
1/2�ɍ팸�̂�Steeley�ƕʂɏo�����Ă��Ƃ��l����ƁASteeley�̓`�����h���V�[�J���]���ƌ��I�ɈႤ���Č����Ă�̂ɁA
Steeley��IDF�̃X���C�h�ł�����2007�N�O����CPU��2008�N�ɓ��ڂ���Ă���CPU�̊Ԃ��Ȃ������[�t�ɂȂ�̂��H
���ʂ�2008�N�ɓ��ڂ���Ă����Steeley���Ǝv��Ȃ��H
IDF�̃X���C�h��2007�N�㔼�ɂ��Ă͓��ɏ����ĂȂ��̂ŁA������₱���������ȋC�����邪�B
> While the chip will run Windows and Linux software like standard Intel processors,
>the design of the chip will be "dramatically different" from its contemporaries, as well as current Intel chips, Chandrasekher said.
�����܂ň��p���Ȃ��Ƃ��߂��H
�ŁASteeley��2007�N�㔼�ɍ��܂ł�CPU�ƌ��I�ɈႤ�A�ƃ`�����h���V�[�J���������Ă���B
ID:/LTfN7i10�����p���Ă�悤�ɁASteeley���̗p�������i��2008�N���낤�A�ƃ`�����h���V�[�J�͂܂������Ă���B
�ŁA������inteler�����p���Ă���Anandtech�̋L����IDF�̃X���C�h�ɂ���2007�N�h�̑O���Ɂh�_�C�E����d�͂Ƃ���
1/2�ɍ팸�̂�Steeley�ƕʂɏo�����Ă��Ƃ��l����ƁASteeley�̓`�����h���V�[�J���]���ƌ��I�ɈႤ���Č����Ă�̂ɁA
Steeley��IDF�̃X���C�h�ł�����2007�N�O����CPU��2008�N�ɓ��ڂ���Ă���CPU�̊Ԃ��Ȃ������[�t�ɂȂ�̂��H
���ʂ�2008�N�ɓ��ڂ���Ă����Steeley���Ǝv��Ȃ��H
IDF�̃X���C�h��2007�N�㔼�ɂ��Ă͓��ɏ����ĂȂ��̂ŁA������₱���������ȋC�����邪�B
����IDF�̃X���C�h���������A�܂�2007�N�O��(=Steeley)��2008�N��CPU���o�Ă���ƍl���Ă�B
�V���ɓo�ꂷ��CPU��3�ł͂Ȃ�2�B
�ŁACNET������2007�N�㔼�Ƃ����̂́ASteeley�𓋍ڂ���UMPC���o�Ă��鎞���Ɗ��Ⴂ�������ȁA�Ǝv���Ă�B
���邢�̓X�P�W���[��������ɔ��f�������B
�ƌ����̂��ACNET�̋L���ׂ͍����Ƃ���͂��܂�M�p���ĂȂ��̂ŁB
�`�����h���V�[�J�̌���"���I"���Ă̂͏���d�͂��ނ���1�`�b�v�ɓ������ꂽCPU���Ď����Ǝv���B
"dramatically different"�Ȃ̂�"the design of the chip"�����B
2008�N����AMD��GPU����CPU���o���Ă��Ă����������Ȃ����A�����܂Ō��I�ƌ����邩�ǂ����B
�V���ɓo�ꂷ��CPU��3�ł͂Ȃ�2�B
�ŁACNET������2007�N�㔼�Ƃ����̂́ASteeley�𓋍ڂ���UMPC���o�Ă��鎞���Ɗ��Ⴂ�������ȁA�Ǝv���Ă�B
���邢�̓X�P�W���[��������ɔ��f�������B
�ƌ����̂��ACNET�̋L���ׂ͍����Ƃ���͂��܂�M�p���ĂȂ��̂ŁB
�`�����h���V�[�J�̌���"���I"���Ă̂͏���d�͂��ނ���1�`�b�v�ɓ������ꂽCPU���Ď����Ǝv���B
"dramatically different"�Ȃ̂�"the design of the chip"�����B
2008�N����AMD��GPU����CPU���o���Ă��Ă����������Ȃ����A�����܂Ō��I�ƌ����邩�ǂ����B
��������͂���ɖϑz���d�˂�B
�X���C�h��2008�N�̂�Steeley���Ƃ���ƁA�܂��^��Ɏv���̂�2007�N�O����CPU�̃R�[�h�l�[���́H�ƌ������ƁB
��Ɏ��X����̃R�[�h�l�[�����o�Ă���͕̂ς��ȂƁB
�����ŁATom�̃T�C�g�ɂ�Stealey��2007�N���Ղ�65nm�v���Z�X�œo��Ə����Ă���̂ł���̂��Ƃ���Ȃ����Ǝv�����킯�B
CNET�̋L�������S�ɐM����ƁASteeley�̓o���2007�N�㔼����2008�N�ł����߂̎����ɂȂ�B
�X���C�h���猩���2008�N�̂�45nm�v���Z�X���ۂ��B
�ŁA�Ȃ�ׂ�CPU�����������čH��̏��҂�i�߂��������Ɉ�������Ȃ��Ⴂ���Ȃ�CPU�����Ƃ͎v���Ȃ��B
�ƌ����킯�ŁA�X���C�h�Ō���2008�N�́A����2008�N�ł����Ȃ�㔼���낤�Ǝv���Ă�B
����Tom�̃T�C�g�ɂ�2008+��Silverhorne�Ƃ�����B
Steeley���������ꍇ�A���t�̈Ӗ��͕������ Steel �� Silver �ŋ������m�q�����Ă�Ȃ��Ƃ��v������B
�X���C�h��2008�N�̂�Steeley���Ƃ���ƁA�܂��^��Ɏv���̂�2007�N�O����CPU�̃R�[�h�l�[���́H�ƌ������ƁB
��Ɏ��X����̃R�[�h�l�[�����o�Ă���͕̂ς��ȂƁB
�����ŁATom�̃T�C�g�ɂ�Stealey��2007�N���Ղ�65nm�v���Z�X�œo��Ə����Ă���̂ł���̂��Ƃ���Ȃ����Ǝv�����킯�B
CNET�̋L�������S�ɐM����ƁASteeley�̓o���2007�N�㔼����2008�N�ł����߂̎����ɂȂ�B
�X���C�h���猩���2008�N�̂�45nm�v���Z�X���ۂ��B
�ŁA�Ȃ�ׂ�CPU�����������čH��̏��҂�i�߂��������Ɉ�������Ȃ��Ⴂ���Ȃ�CPU�����Ƃ͎v���Ȃ��B
�ƌ����킯�ŁA�X���C�h�Ō���2008�N�́A����2008�N�ł����Ȃ�㔼���낤�Ǝv���Ă�B
����Tom�̃T�C�g�ɂ�2008+��Silverhorne�Ƃ�����B
Steeley���������ꍇ�A���t�̈Ӗ��͕������ Steel �� Silver �ŋ������m�q�����Ă�Ȃ��Ƃ��v������B
Silverhorne����Ȃ���Silverthorne�������B
�n�����ȁB
�n�����ȁB
CNET�̋L�����ԈႢ�ŁAID:/LTfN7i10���������ۂ��B
959�̃R�[�h�l�[���̏��Ԃ���Ԃ̂͂�������������Ďw�E�͐����͂��邩��A
���ۃ`�����h���V�[�J���������Ă�̂��AIDF�̃T�C�g�ɂ���r�f�I�ŕ����Ă����A�����Ŋ̐S�ȂƂ��낪�����Ƃ�ˁ[w
�ʼn��x�������������̂����A�`�����h���V�[�J��IDF�Ŏ����o����UMPC��Steeley�x�[�X�̃v���g�^�C�v�ŁA���N���ꂪ�ł�A�Ƃ�������
�����Ă�悤�ȋC������B
�ŁAITmedia��
http://www.itmedia.co.jp/news/articles/0609/27/news067.html
�ȋL�����B
�܂肢����������������ԈႢ�B
959�̃R�[�h�l�[���̏��Ԃ���Ԃ̂͂�������������Ďw�E�͐����͂��邩��A
���ۃ`�����h���V�[�J���������Ă�̂��AIDF�̃T�C�g�ɂ���r�f�I�ŕ����Ă����A�����Ŋ̐S�ȂƂ��낪�����Ƃ�ˁ[w
�ʼn��x�������������̂����A�`�����h���V�[�J��IDF�Ŏ����o����UMPC��Steeley�x�[�X�̃v���g�^�C�v�ŁA���N���ꂪ�ł�A�Ƃ�������
�����Ă�悤�ȋC������B
�ŁAITmedia��
http://www.itmedia.co.jp/news/articles/0609/27/news067.html
�ȋL�����B
�܂肢����������������ԈႢ�B
>>938
>����Mac Pro��1.2kW�d�����ڂ��Ă��Ȃ���X1900XT*2�͓d���e�ʂ̖��Ń_������H
�SPCI Express�g���X���b�g�̏���d�͂̍��v��300W�܂�
http://www.apple.com/jp/macpro/specs.html
>����Mac Pro��1.2kW�d�����ڂ��Ă��Ȃ���X1900XT*2�͓d���e�ʂ̖��Ń_������H
�SPCI Express�g���X���b�g�̏���d�͂̍��v��300W�܂�
http://www.apple.com/jp/macpro/specs.html
�Ãl�^���傢����
http://pc.watch.impress.co.jp/docs/2006/0721/hot438.htm
> The Mobility Group�ł�Maloney���В��̌�C�͒u�����A
> Perlmutter���В��̃����g�b�v�t�H�[���[�V�����ƂȂ�B
> ���R�A���ƕ����ł̎��̔����͍͂��܂邱�ƂɂȂ邪�A
> ����ɂƂǂ܂炸�A�v���Z�b�T�̃}�C�N���A�[�L�e�N�`��
> �S�ʂɊւ��錈�茠������A�Ƃ̕��ꕔ�łȂ���Ă���B
http://pc.watch.impress.co.jp/docs/2006/0721/hot438.htm
> The Mobility Group�ł�Maloney���В��̌�C�͒u�����A
> Perlmutter���В��̃����g�b�v�t�H�[���[�V�����ƂȂ�B
> ���R�A���ƕ����ł̎��̔����͍͂��܂邱�ƂɂȂ邪�A
> ����ɂƂǂ܂炸�A�v���Z�b�T�̃}�C�N���A�[�L�e�N�`��
> �S�ʂɊւ��錈�茠������A�Ƃ̕��ꕔ�łȂ���Ă���B
���̐É��v��➑̂Ƀn�C�G���h�r�f�I�J�[�h��������̂́c
966 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/29(��) 21:37:26 ID:eO+N0eBK0
�_�C�E����d�͔����E�E�E�V���O���R�A��p�}�X�N��ULV Yonah�̉��ǔł���ˁH
H1 2007�Ɍ��s��UMPC�̌�p�`�b�v���ł�B1/2�̓d�͂ł���B
Tom's�̐����ł��A�����ULV Yonah��SC�łł���B(���܂ł�ULV Dothan)
�R��̐����ł�Intel������low power 65nm�v���Z�X���V���Ɏg����Ǝv����B
Second generation UMPC to debut in H1 2007
http://www.tgdaily.com/2006/09/28/second_gen_umpc/
According to the executive, the devices will not use Core 2 Duo processor, and "consume approximately
half the power of today's CPUs with approximately one-fourth the package size."
Looking at Intel's current portfolio we would speculate that the device will use a low-voltage or ultra-low
voltage Core Solo processor with 1 MB of L2 cache.
late 2007�ɁASteeley���ł�B����͐V�����A�[�L�e�N�`���ŁA����d�͂�0.5W�ł���B
Steeley��Cnet���`����Ƃ����2007�N���Ƀ����[�X�����B�{�����[�����łă}�[�P�b�g���{�i������̂�2008�N�ł���B
IDF�̃X���C�h�͂킩��₷���Ɗȗ����̂��߂�1�N���݂ŁA���̎��_�ł̃v���Z�b�T���r���Ă���ɂ������A
2008�N�Ƃ����Ă���̂�2007�N���Ƀ����[�X�����v���Z�b�T�ɂ��Ă̂��Ƃł���Ǝv����B
���߂͌o�����厖������Ȃ��B
Tom's�̐����ł��A�����ULV Yonah��SC�łł���B(���܂ł�ULV Dothan)
�R��̐����ł�Intel������low power 65nm�v���Z�X���V���Ɏg����Ǝv����B
Second generation UMPC to debut in H1 2007
http://www.tgdaily.com/2006/09/28/second_gen_umpc/
According to the executive, the devices will not use Core 2 Duo processor, and "consume approximately
half the power of today's CPUs with approximately one-fourth the package size."
Looking at Intel's current portfolio we would speculate that the device will use a low-voltage or ultra-low
voltage Core Solo processor with 1 MB of L2 cache.
late 2007�ɁASteeley���ł�B����͐V�����A�[�L�e�N�`���ŁA����d�͂�0.5W�ł���B
Steeley��Cnet���`����Ƃ����2007�N���Ƀ����[�X�����B�{�����[�����łă}�[�P�b�g���{�i������̂�2008�N�ł���B
IDF�̃X���C�h�͂킩��₷���Ɗȗ����̂��߂�1�N���݂ŁA���̎��_�ł̃v���Z�b�T���r���Ă���ɂ������A
2008�N�Ƃ����Ă���̂�2007�N���Ƀ����[�X�����v���Z�b�T�ɂ��Ă̂��Ƃł���Ǝv����B
���߂͌o�����厖������Ȃ��B
�ȉ��A�ʕ�
Cnet��IDF�̃X���C�h���Ԉ���Ă͂��Ȃ����ǁA
Tom's�̃R�[�h�l�[���L���͂Ƃ����ɏܖ���������Ă���B
���������ꍇ�AIDF�̍ŐV�̏��̕���ꡂ��ɐM�p�ł���B
�܂��A����̏ꍇ�͘b���Ⴄ���A�ʂɃR�[�h�l�[������Ɏ��X���ォ��łĂ��邱�Ƃ͕��ʂɂ���B
Yorkfield��Bloomfield�̗�Ȃǂ������B
�܂��A���I�ɂ��ƂȂ�Ƃ�������r�͖��炩�ɁA���s���i�Ɣ�r���Ă���B
2008�N���_�ŋ������Ђ��ǂ�Ȑ��i���J�����Ă悤���AIntel�̔��蕶��ɂ͊W���Ȃ��B
Cnet��IDF�̃X���C�h���Ԉ���Ă͂��Ȃ����ǁA
Tom's�̃R�[�h�l�[���L���͂Ƃ����ɏܖ���������Ă���B
���������ꍇ�AIDF�̍ŐV�̏��̕���ꡂ��ɐM�p�ł���B
�܂��A����̏ꍇ�͘b���Ⴄ���A�ʂɃR�[�h�l�[������Ɏ��X���ォ��łĂ��邱�Ƃ͕��ʂɂ���B
Yorkfield��Bloomfield�̗�Ȃǂ������B
�܂��A���I�ɂ��ƂȂ�Ƃ�������r�͖��炩�ɁA���s���i�Ɣ�r���Ă���B
2008�N���_�ŋ������Ђ��ǂ�Ȑ��i���J�����Ă悤���AIntel�̔��蕶��ɂ͊W���Ȃ��B
969 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/29(��) 23:06:26 ID:eO+N0eBK0
Steeley���o����ь�ɁuMac nano�v�ł������̂���
���삵�₷���A�����炸�A����ł��ăJ�b�R�C�C➑̂Ɋ��҂��Ă܂�
>>inteler
CNET�ɂ�Steeley��McCaslin�v���b�g�z�[���Ɋ܂܂��Ƃ���B
�����Ă���McCaslin��>>961�̋L���Ƃ��̌����ɂ�2007�N�O���ɒ����Ə����Ă���B
���ƁAIDF�̏��͐M�p�o����ƌ����A���������ɓǂݑւ��Ă�̂͋^��B
�ȗ����ׂ̈�1�N���݂����Č����Ȃ�A�킴�킴 1H'07 �ƑO�����������Ă���̂�������Ȃ��B
����ɍ��킹�� 2H'07 �ɂ���Ηǂ��̂� 2008 �Ə����Ă���̂��B
2007�N�㔼��2008�N�Ƃ���s���ƊE�̎����Ȃ�Ⴄ�B
�������������W�߂Ă�Ȃ�A���̕\�L�̈Ⴂ���炢�킩�邾�낤�ɁB
���ł�
> the design of the chip will be "dramatically different"
> from its contemporaries, as well as current Intel chips,
�����猻�s���i��������Ȃ�������̐��i�Ɣ�ׂĂ����I�ƌ����Ă�ȁB
CNET�ɂ�Steeley��McCaslin�v���b�g�z�[���Ɋ܂܂��Ƃ���B
�����Ă���McCaslin��>>961�̋L���Ƃ��̌����ɂ�2007�N�O���ɒ����Ə����Ă���B
���ƁAIDF�̏��͐M�p�o����ƌ����A���������ɓǂݑւ��Ă�̂͋^��B
�ȗ����ׂ̈�1�N���݂����Č����Ȃ�A�킴�킴 1H'07 �ƑO�����������Ă���̂�������Ȃ��B
����ɍ��킹�� 2H'07 �ɂ���Ηǂ��̂� 2008 �Ə����Ă���̂��B
2007�N�㔼��2008�N�Ƃ���s���ƊE�̎����Ȃ�Ⴄ�B
�������������W�߂Ă�Ȃ�A���̕\�L�̈Ⴂ���炢�킩�邾�낤�ɁB
���ł�
> the design of the chip will be "dramatically different"
> from its contemporaries, as well as current Intel chips,
�����猻�s���i��������Ȃ�������̐��i�Ɣ�ׂĂ����I�ƌ����Ă�ȁB
>���ƁAIDF�̏��͐M�p�o����ƌ����A���������ɓǂݑւ��Ă�̂͋^��B
>�ȗ����ׂ̈�1�N���݂����Č����Ȃ�A�킴�킴 1H'07 �ƑO�����������Ă���̂�������Ȃ��B
�ǂݑւ��ĂȂ�����B2008�N�Ƀp�b�P�[�W��1/4�ŁA����d�͂������Ƃ����̂͐������B
�X���C�h�ɏ����Ă���̂́A�v���Z�b�T���̂̃��[�h�}�b�v����Ȃ��āA�d�͂ƃp�b�P�[�W�T�C�Y�̃��[�h�}�b�v�����B
H1���킴�킴����Ă�̂͋߂����i��������������������Ȃ���?
��������́A�ϑz�̗̈�ɂȂ邪�A
Intel�͍����IDF��45nm�̐����ŁAH2 2007 45nm�̐��Y�J�n������Ƃ����Ă��邪�A
2007�N���ɁA45nm���i�������Ƃ͂����ĂȂ�(���i�������[�X�ɕK�v�ȍɂ��m�ۂ���܂ł����Ǝ��Ԃ�������B)
UMPC��Steeley(late 2007)�ɂ��Ă��{�i�I�ȃ}�[�P�b�g��2008�N�ł���B
���������b������́A45nm���i��2007�N����launch�͎��͎��M���Ȃ���Ȃ����Ǝv����B
����d�͔����́Alow power 65nm�v���Z�X��Yonah�R�A�ʼn\���Ǝv���邪�A
�������炳���1/5�́A45nm�v���Z�X�̓��������ł͖����ŁA��H�v��A�[�L���݂Ȃ�������Ȃ����ƁB
>2007�N�㔼��2008�N�Ƃ���s���ƊE�̎����Ȃ�Ⴄ�B
>�������������W�߂Ă�Ȃ�A���̕\�L�̈Ⴂ���炢�킩�邾�낤�ɁB
> the design of the chip will be "dramatically different"
> from its contemporaries, as well as current Intel chips,
���̕�����>>971�̂����Ƃ���A������Ƃ̐��i�Ƃ���r���Ă���Ƃ����̂��������B
�R�ꂪ�悭�ǂ�łȂ������B
>�ȗ����ׂ̈�1�N���݂����Č����Ȃ�A�킴�킴 1H'07 �ƑO�����������Ă���̂�������Ȃ��B
�ǂݑւ��ĂȂ�����B2008�N�Ƀp�b�P�[�W��1/4�ŁA����d�͂������Ƃ����̂͐������B
�X���C�h�ɏ����Ă���̂́A�v���Z�b�T���̂̃��[�h�}�b�v����Ȃ��āA�d�͂ƃp�b�P�[�W�T�C�Y�̃��[�h�}�b�v�����B
H1���킴�킴����Ă�̂͋߂����i��������������������Ȃ���?
��������́A�ϑz�̗̈�ɂȂ邪�A
Intel�͍����IDF��45nm�̐����ŁAH2 2007 45nm�̐��Y�J�n������Ƃ����Ă��邪�A
2007�N���ɁA45nm���i�������Ƃ͂����ĂȂ�(���i�������[�X�ɕK�v�ȍɂ��m�ۂ���܂ł����Ǝ��Ԃ�������B)
UMPC��Steeley(late 2007)�ɂ��Ă��{�i�I�ȃ}�[�P�b�g��2008�N�ł���B
���������b������́A45nm���i��2007�N����launch�͎��͎��M���Ȃ���Ȃ����Ǝv����B
����d�͔����́Alow power 65nm�v���Z�X��Yonah�R�A�ʼn\���Ǝv���邪�A
�������炳���1/5�́A45nm�v���Z�X�̓��������ł͖����ŁA��H�v��A�[�L���݂Ȃ�������Ȃ����ƁB
>2007�N�㔼��2008�N�Ƃ���s���ƊE�̎����Ȃ�Ⴄ�B
>�������������W�߂Ă�Ȃ�A���̕\�L�̈Ⴂ���炢�킩�邾�낤�ɁB
> the design of the chip will be "dramatically different"
> from its contemporaries, as well as current Intel chips,
���̕�����>>971�̂����Ƃ���A������Ƃ̐��i�Ƃ���r���Ă���Ƃ����̂��������B
�R�ꂪ�悭�ǂ�łȂ������B
����
X 2008�N�Ƀp�b�P�[�W��1/4�ŁA����d�͂������Ƃ����̂͐������B
O 2008�N�Ƀp�b�P�[�W��1/7�ŁA����d�͂�1/10�Ƃ����̂͐�����
�킩��ɂ��������̂ňꉞ�⑫�B
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai02l.gif
���̂悤�ȃv���Z�b�T���[�h�}�b�v�̃X���C�h�̊G�ƈقȂ�A
>>944�̃X���C�h�́A����TDP�ƃp�b�P�[�W�����I�ɏ������Ȃ�A�Ƃ����̂������������̂ł����āA
�����[�X�����͂���?�ɂ��ẮA�����܂Ő_�o���ɓǂݎ���Ă��d�����Ȃ��B
�p�b�P�[�W�T�C�Y��1/7�ŁA����d�͂�1/10�̃v���Z�b�T��2008�N�Ɏg���Ă��邾�낤�Ƃ��������B
X 2008�N�Ƀp�b�P�[�W��1/4�ŁA����d�͂������Ƃ����̂͐������B
O 2008�N�Ƀp�b�P�[�W��1/7�ŁA����d�͂�1/10�Ƃ����̂͐�����
�킩��ɂ��������̂ňꉞ�⑫�B
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai02l.gif
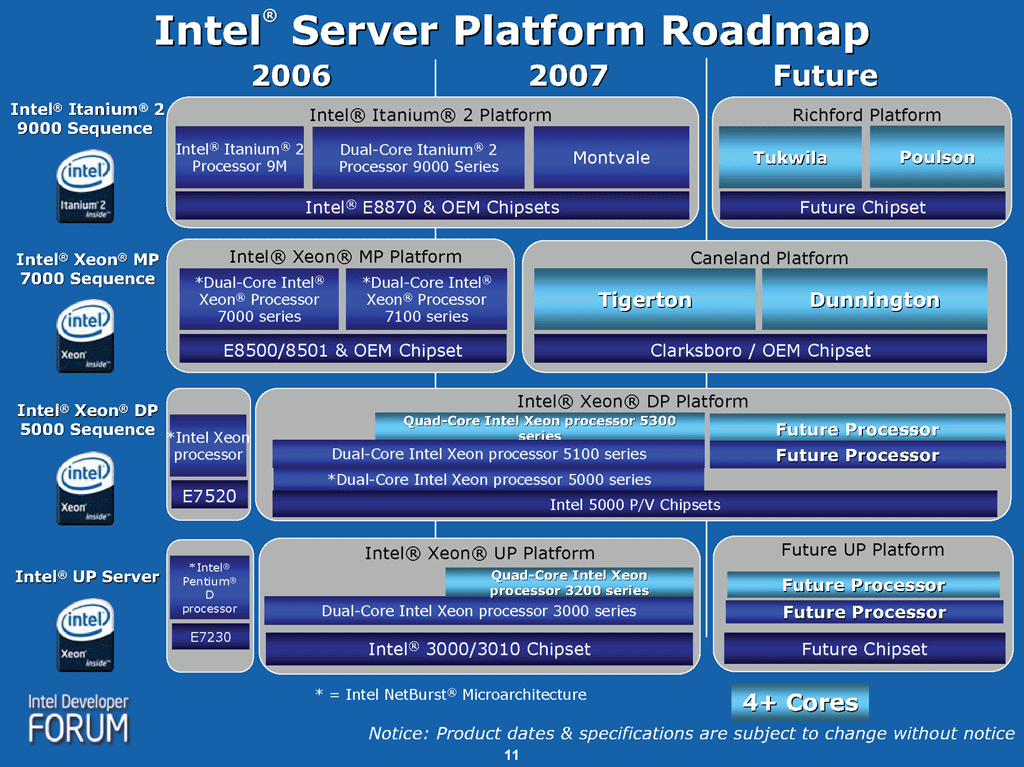{kind=link}
���̂悤�ȃv���Z�b�T���[�h�}�b�v�̃X���C�h�̊G�ƈقȂ�A
>>944�̃X���C�h�́A����TDP�ƃp�b�P�[�W�����I�ɏ������Ȃ�A�Ƃ����̂������������̂ł����āA
�����[�X�����͂���?�ɂ��ẮA�����܂Ő_�o���ɓǂݎ���Ă��d�����Ȃ��B
�p�b�P�[�W�T�C�Y��1/7�ŁA����d�͂�1/10�̃v���Z�b�T��2008�N�Ɏg���Ă��邾�낤�Ƃ��������B
974 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/30(�y) 19:52:33 ID:e4K77fgb0
�p�b�P�[�W�T�C�Y���_�C�T�C�Y
975 �FMAC�I�^��968 �����F2006/09/30(�y) 23:16:06 ID:xZmsRxfG0
>>968
�@�@--------------------
�@�@Tom's�̃R�[�h�l�[���L���͂Ƃ����ɏܖ���������Ă���B
�@�@--------------------
�v���Z�b�T�̊J���Ƃ������m�����N�̍Ό���v����傫�ȃv���W�F�N�g�ł���Ƃ������Ƃ�
�����ł��Ă���C����ȊԔ����Ȋ��z���������ނ��Ƃ햳�����Ȃ��ǁB�B�B
http://www.tomshardware.com/2005/12/04/top_secret_intel_processor_plans_uncovered/
���̋L���핅�ꃋ�[�}�[�ł��Ȃ�ł������CIntel���I���S���Ƀ��f�B�A�W�҂�������
�s�������w��̃v���[������ɂ��Ă��邷�B
�R�[�h�l�[���́u���O�v�����ɂ��������������̂Ȃ�Ƃ������CIntel���������s���Ă��邩�Ƃ���
�M�d�ȏ��Ȃ��ǂˁB�B�B
�@�@--------------------
�@�@Tom's�̃R�[�h�l�[���L���͂Ƃ����ɏܖ���������Ă���B
�@�@--------------------
�v���Z�b�T�̊J���Ƃ������m�����N�̍Ό���v����傫�ȃv���W�F�N�g�ł���Ƃ������Ƃ�
�����ł��Ă���C����ȊԔ����Ȋ��z���������ނ��Ƃ햳�����Ȃ��ǁB�B�B
http://www.tomshardware.com/2005/12/04/top_secret_intel_processor_plans_uncovered/
���̋L���핅�ꃋ�[�}�[�ł��Ȃ�ł������CIntel���I���S���Ƀ��f�B�A�W�҂�������
�s�������w��̃v���[������ɂ��Ă��邷�B
�R�[�h�l�[���́u���O�v�����ɂ��������������̂Ȃ�Ƃ������CIntel���������s���Ă��邩�Ƃ���
�M�d�ȏ��Ȃ��ǂˁB�B�B
>�v���Z�b�T�̊J���Ƃ������m�����N�̍Ό���v����傫�ȃv���W�F�N�g�ł���Ƃ������Ƃ�
>�����ł��Ă���C����ȊԔ����Ȋ��z���������ނ��Ƃ햳�����Ȃ��ǁB�B�B
�������X�c�BTom's�̋L����Intel�\�[�X�ł��邱�Ƃ��m���Ă���B
MAC�I�^�͊F�������m��������Ă���Ƃ����O��Řb��i�߂邩�獢��B
Whitefield�̓L�����Z������AYorkfield���S�����g��������Ă���B
Kentsfild��Allendale x2����AConroe x2�ɂ�����Ă��邵�ȁB
>>928���݂�킩��Ƃ���ATom's�ɂ͂Ȃ��R�[�h�l�[���������o�ꂵ�Ă���B
>�����ł��Ă���C����ȊԔ����Ȋ��z���������ނ��Ƃ햳�����Ȃ��ǁB�B�B
�������X�c�BTom's�̋L����Intel�\�[�X�ł��邱�Ƃ��m���Ă���B
MAC�I�^�͊F�������m��������Ă���Ƃ����O��Řb��i�߂邩�獢��B
Whitefield�̓L�����Z������AYorkfield���S�����g��������Ă���B
Kentsfild��Allendale x2����AConroe x2�ɂ�����Ă��邵�ȁB
>>928���݂�킩��Ƃ���ATom's�ɂ͂Ȃ��R�[�h�l�[���������o�ꂵ�Ă���B
�܂��A�C�Â��Ă����l�͋C�Â��Ă����낤���ǁA
Tom's�͍̂�N��12���ɏo���L���ŁA>>111�̋L�����݂�Ƃ킩��悤��10�����_�ł���
Whitefield�̃L�����Z���͂��łɖ��炩�ɂȂ��Ă����킯�B
�킴�ƌÂ��v��������o���Ă�����Ȃ����Ɗ������Ă��܂����炢�̃^�C�~���O��������i�E�́E�j
���̌�A������Nehalem�̊J����CSI�̊J�������炩�ɂ���A����ɂ܂�郋�[�}�[�������łĂ��Ă���̂ɁA
������Intel���������s���Ă��邩Tom's�̋L�����M�d�����Ă���Ƃ͘R��͋������B
Tom's�͍̂�N��12���ɏo���L���ŁA>>111�̋L�����݂�Ƃ킩��悤��10�����_�ł���
Whitefield�̃L�����Z���͂��łɖ��炩�ɂȂ��Ă����킯�B
�킴�ƌÂ��v��������o���Ă�����Ȃ����Ɗ������Ă��܂����炢�̃^�C�~���O��������i�E�́E�j
���̌�A������Nehalem�̊J����CSI�̊J�������炩�ɂ���A����ɂ܂�郋�[�}�[�������łĂ��Ă���̂ɁA
������Intel���������s���Ă��邩Tom's�̋L�����M�d�����Ă���Ƃ͘R��͋������B
Itanium��Solaris���������͖̂ʔ������������ɘb��͖����̂�
Montvale�Ƃ�Tukwila�Ƃ�Poulson�Ƃ�
Montvale�Ƃ�Tukwila�Ƃ�Poulson�Ƃ�