AMD�̎�����CPU�ɂ��Č�낤 ��36����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��35����
http://pc11.2ch.net/test/read.cgi/jisaku/1270329471/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��35����
http://pc11.2ch.net/test/read.cgi/jisaku/1270329471/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 43
http://pc11.2ch.net/test/read.cgi/jisaku/1270976684/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
|
|
|
���ߋ��X���ꗗ
34 ttp://pc11.2ch.net/test/read.cgi/jisaku/1267796312/
33 ttp://pc11.2ch.net/test/read.cgi/jisaku/1265866982/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1263352294/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
34 ttp://pc11.2ch.net/test/read.cgi/jisaku/1267796312/
33 ttp://pc11.2ch.net/test/read.cgi/jisaku/1265866982/
32 ttp://pc11.2ch.net/test/read.cgi/jisaku/1263352294/
31 ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
���O�Z��܂�����̂��ȁH
AMD����Ȃ���ATi Stream�ȂȁB
�ł�����NV���ăV�F�A�Ƃ��Ă���[��肨�����Ƃ��Ă邩��
�c�q�͖�����GPGPU���ق߂Ȃ��Ă����̂�
�c�q�͖�����GPGPU���ق߂Ȃ��Ă����̂�
�����@��CUDA�����̂���Ȃ�
10 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 08:04:19 ID:E/cWbyEH
�J�߂Ă˂�
GPGPU�Ȃ�Ă͉̂ߓn���̋Z�p�ł����čŏI�I�Ɏc��͕̂��v���O���~���O����E�t���[�����[�N���B
Intel��AMD���ߒ��͈Ⴆ�ǍŏI�I�ɖڎw���Ă�̂̓O���t�B�b�N�����ɂ��ėp�R���s���[�e�B���O�ɂ��g����
���C�h�ȃx�N�^�G���W����CPU�Ɋ��S�������邱�Ƃ����B
���������̓n�[�h�ʂ��\�t�g�ʂ������n���ĂȂ��B
�܂��ė��v���̍������CPU/�`�b�v�Z�b�g���f�B�X�N���[�gGPU�Ɉˑ����Ă���APCIe 3.0�ւ�
�Ή����i�߂Ă��錻��ŁAIGP���s��V�F�A�̑唼�������Ă��܂��V�i���I��Intel����]��łȂ�����B
x86�Ɋւ���Intel���哱���������Ă���ȏ�ALarrabee��SIMD���߂��ŏI�I�Ɋe�Ћ��ʂ�
�v���O���~���O�C���^�[�t�F�C�X�ɂȂ�\���͍����Ƃ͎v���Ă邩��A
��������҂ł���NVIDIA�̈����~�����̂͂��Ɩ��Ӗ����ȂƁB
GPGPU�Ȃ�Ă͉̂ߓn���̋Z�p�ł����čŏI�I�Ɏc��͕̂��v���O���~���O����E�t���[�����[�N���B
Intel��AMD���ߒ��͈Ⴆ�ǍŏI�I�ɖڎw���Ă�̂̓O���t�B�b�N�����ɂ��ėp�R���s���[�e�B���O�ɂ��g����
���C�h�ȃx�N�^�G���W����CPU�Ɋ��S�������邱�Ƃ����B
���������̓n�[�h�ʂ��\�t�g�ʂ������n���ĂȂ��B
�܂��ė��v���̍������CPU/�`�b�v�Z�b�g���f�B�X�N���[�gGPU�Ɉˑ����Ă���APCIe 3.0�ւ�
�Ή����i�߂Ă��錻��ŁAIGP���s��V�F�A�̑唼�������Ă��܂��V�i���I��Intel����]��łȂ�����B
x86�Ɋւ���Intel���哱���������Ă���ȏ�ALarrabee��SIMD���߂��ŏI�I�Ɋe�Ћ��ʂ�
�v���O���~���O�C���^�[�t�F�C�X�ɂȂ�\���͍����Ƃ͎v���Ă邩��A
��������҂ł���NVIDIA�̈����~�����̂͂��Ɩ��Ӗ����ȂƁB
12 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 08:18:32 ID:E/cWbyEH
��������
13 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 08:30:50 ID:E/cWbyEH
AVX�֘A�̃\�t�g�Z�p�͓���������Ƃ����т̎�Ȃ��
���������̂��q����ɂ�GPGPU�]�X�͌����o���Ȃ��ŗ~��������
���i�K�ł́B
���������̂��q����ɂ�GPGPU�]�X�͌����o���Ȃ��ŗ~��������
���i�K�ł́B
14 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 08:42:04 ID:E/cWbyEH
���A�ʂɂ���ȗ��R�Ńf�B�X���Ă�킯����Ȃ�
���������̂͐��_�Ȃ̈�҂Ƃ�������肵�ĂĂ���
���ǂ͎��
�ǂ���C��ɂ��Ă���
�ǂ���C��ɂ��Ă���
��҂����Ƃ����Â��Ȃ���
����܂ł�����PC�W�̃R�~��������ӂ̏������j�̎q����Q����
�Ƃ��ɃV���^�ɂ͑�����Ă��J���y�L�ƍ߂���
����܂ł�����PC�W�̃R�~��������ӂ̏������j�̎q����Q����
�Ƃ��ɃV���^�ɂ͑�����Ă��J���y�L�ƍ߂���
>>10
> �J�߂Ă˂�
> GPGPU�Ȃ�Ă͉̂ߓn���̋Z�p�ł����čŏI�I�Ɏc��͕̂��v���O���~���O����E�t���[�����[�N���B
GPGPU��GPU�Ƃ����n�[�h�E�F�A�ŕ������s�������Ă��������t�݂����Ȃ���
�����t���[�����[�N�Ɠ��������Řb���Ă��Ӗ��������Ǝv����
> Intel��AMD���ߒ��͈Ⴆ�ǍŏI�I�ɖڎw���Ă�̂̓O���t�B�b�N�����ɂ��ėp�R���s���[�e�B���O�ɂ��g����
> ���C�h�ȃx�N�^�G���W����CPU�Ɋ��S�������邱�Ƃ����B
���̉ߒ��Ŋe�Ђ��I�̂��A
Intel��CPU�̃R�A���ɕt������SIMD�G���W���̊g����SSE��AVX�A
Nvidia�͊O�����j�b�g�Ƃ��Ă̑�^GPU�̊g����Tesla
AMD��CPU�R�A�Ƃ͓Ɨ�����GPU�R�A�̊g���ƃI���_�C�����끨FireStream��Fusion
���ꂼ��꒷��Z���邩���T�ɂǂꂪ�D�G�Ƃ͌����Ȃ�
> ���������̓n�[�h�ʂ��\�t�g�ʂ������n���ĂȂ��B
> �܂��ė��v���̍������CPU/�`�b�v�Z�b�g���f�B�X�N���[�gGPU�Ɉˑ����Ă���APCIe 3.0�ւ�
> �Ή����i�߂Ă��錻��ŁAIGP���s��V�F�A�̑唼�������Ă��܂��V�i���I��Intel����]��łȂ�����B
IGP�Ƃ����T�O���o���Ĉȍ~������IGP���V�F�A�̑唼�������Ă��邾��A�f�B�X�N���[�g�ȂS�̂̐������x�ł�������
> x86�Ɋւ���Intel���哱���������Ă���ȏ�ALarrabee��SIMD���߂��ŏI�I�Ɋe�Ћ��ʂ�
> �v���O���~���O�C���^�[�t�F�C�X�ɂȂ�\���͍����Ƃ͎v���Ă邩��A
> ��������҂ł���NVIDIA�̈����~�����̂͂��Ɩ��Ӗ����ȂƁB
X86�͖w�NJW�Ȃ��Ǝv����
�Ǝ�����CUDA��Tesla��HPC�s��Ől�C����H
Nvidia���D�ꂽ�n�[�h���J����������Α����ł����
> �J�߂Ă˂�
> GPGPU�Ȃ�Ă͉̂ߓn���̋Z�p�ł����čŏI�I�Ɏc��͕̂��v���O���~���O����E�t���[�����[�N���B
GPGPU��GPU�Ƃ����n�[�h�E�F�A�ŕ������s�������Ă��������t�݂����Ȃ���
�����t���[�����[�N�Ɠ��������Řb���Ă��Ӗ��������Ǝv����
> Intel��AMD���ߒ��͈Ⴆ�ǍŏI�I�ɖڎw���Ă�̂̓O���t�B�b�N�����ɂ��ėp�R���s���[�e�B���O�ɂ��g����
> ���C�h�ȃx�N�^�G���W����CPU�Ɋ��S�������邱�Ƃ����B
���̉ߒ��Ŋe�Ђ��I�̂��A
Intel��CPU�̃R�A���ɕt������SIMD�G���W���̊g����SSE��AVX�A
Nvidia�͊O�����j�b�g�Ƃ��Ă̑�^GPU�̊g����Tesla
AMD��CPU�R�A�Ƃ͓Ɨ�����GPU�R�A�̊g���ƃI���_�C�����끨FireStream��Fusion
���ꂼ��꒷��Z���邩���T�ɂǂꂪ�D�G�Ƃ͌����Ȃ�
> ���������̓n�[�h�ʂ��\�t�g�ʂ������n���ĂȂ��B
> �܂��ė��v���̍������CPU/�`�b�v�Z�b�g���f�B�X�N���[�gGPU�Ɉˑ����Ă���APCIe 3.0�ւ�
> �Ή����i�߂Ă��錻��ŁAIGP���s��V�F�A�̑唼�������Ă��܂��V�i���I��Intel����]��łȂ�����B
IGP�Ƃ����T�O���o���Ĉȍ~������IGP���V�F�A�̑唼�������Ă��邾��A�f�B�X�N���[�g�ȂS�̂̐������x�ł�������
> x86�Ɋւ���Intel���哱���������Ă���ȏ�ALarrabee��SIMD���߂��ŏI�I�Ɋe�Ћ��ʂ�
> �v���O���~���O�C���^�[�t�F�C�X�ɂȂ�\���͍����Ƃ͎v���Ă邩��A
> ��������҂ł���NVIDIA�̈����~�����̂͂��Ɩ��Ӗ����ȂƁB
X86�͖w�NJW�Ȃ��Ǝv����
�Ǝ�����CUDA��Tesla��HPC�s��Ől�C����H
Nvidia���D�ꂽ�n�[�h���J����������Α����ł����
19 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 09:59:46 ID:E/cWbyEH
> X86�͖w�NJW�Ȃ��Ǝv����
�����̓����v���Z�b�T��x86��SIMD���߂ڎ��s���邱�Ƃ��}�j�t�F�X�g�Ƃ��Čf�����̂�AMD�����B
�����Swift��SSE5���̂��̂����s�ł���Ɗ��Ⴂ�����z���������̂����N���炢�̘b�B
�����̓����v���Z�b�T��x86��SIMD���߂ڎ��s���邱�Ƃ��}�j�t�F�X�g�Ƃ��Čf�����̂�AMD�����B
�����Swift��SSE5���̂��̂����s�ł���Ɗ��Ⴂ�����z���������̂����N���炢�̘b�B
�V���^�z���Ƃ̉Ԓd�ł̓R�[�h�l�[��Swift��SSE5�����s�o���Ȃ����ƂɂȂ��Ă��́H
���ŁH
���ŁH
�uSSE5���̂��̂��v���ď����Ă��������
�\�[�X�����ɂ��܂�����������肾��������
�O�O������SSE5���̂�Swift�܂�K10���X���[��Bull���瓋�ڂ���ˁ[��
�\�[�X�����ɂ��܂�����������肾��������
�O�O������SSE5���̂�Swift�܂�K10���X���[��Bull���瓋�ڂ���ˁ[��
22 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 10:20:24 ID:E/cWbyEH
�ƁA�܂��r���̐l���������܂���
>>19
1�N�O�̘b�ȂN���o���Ăˁ[��
�Z�p�v�V��s�ꓮ���A�J���̐i���ŕ��j�]���Ȃ�ē��풃�ю��̋ƊE�Ń}�j�t�F�X�g�ɈӖ��ȂȂ�
���ꌾ������Intel�����Ă悭��邾��A1�N�O����Larrabee�ő�R�����Ă���������ˁH
���O�����q�̂������ƌ����Ă���ȁA����Larrabee�͍��ǂ��Ȃ��Ă�A�����ɂ������ĂȂ�����H
1�N�O�̘b�ȂN���o���Ăˁ[��
�Z�p�v�V��s�ꓮ���A�J���̐i���ŕ��j�]���Ȃ�ē��풃�ю��̋ƊE�Ń}�j�t�F�X�g�ɈӖ��ȂȂ�
���ꌾ������Intel�����Ă悭��邾��A1�N�O����Larrabee�ő�R�����Ă���������ˁH
���O�����q�̂������ƌ����Ă���ȁA����Larrabee�͍��ǂ��Ȃ��Ă�A�����ɂ������ĂȂ�����H
google�搶�ł�����o�Ă��˂�������
������
AMD
x86�R�A�����������Ƃ�
��86�R�A�𑀂�̂��ŏI�ڕW
Intel
x86�f�R�[�_�Ă���ɂ������Ԃ���R�A����ނ�
�w�e�����`������̂��ŏI�ڕW
NVIDIA
���̂Ƃ���x86���W
�Ă��Ƃ�> X86�͖w�NJW�Ȃ��Ǝv�����@�͕ʂɊԈ���Ė�����ˁH
AMD
x86�R�A�����������Ƃ�
��86�R�A�𑀂�̂��ŏI�ڕW
Intel
x86�f�R�[�_�Ă���ɂ������Ԃ���R�A����ނ�
�w�e�����`������̂��ŏI�ڕW
NVIDIA
���̂Ƃ���x86���W
�Ă��Ƃ�> X86�͖w�NJW�Ȃ��Ǝv�����@�͕ʂɊԈ���Ė�����ˁH
26 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 10:36:03 ID:E/cWbyEH
>>24
�搶�Ɍ����Ă��Ȃ��́H
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
SSE�͂�胏�C�h�ȃx�N�g���ɑΉ��ł���悤�ɖ��߃Z�b�g���g������K�v�����邵
GPU�͂��f�[�^���x������x�������Ȃ���Ȃ�Ȃ��B
�����������i�K��ʼn\�ɂȂ�ƌ����b�ŁARadeon��K10���_�C�ɍڂ��Ă�����
SSE���߂�GPU�Ŕ��s�o����Ƃ����b�ł͂Ȃ��B
�搶�Ɍ����Ă��Ȃ��́H
http://journal.mycom.co.jp/articles/2007/09/15/barcelona/004.html
SSE�͂�胏�C�h�ȃx�N�g���ɑΉ��ł���悤�ɖ��߃Z�b�g���g������K�v�����邵
GPU�͂��f�[�^���x������x�������Ȃ���Ȃ�Ȃ��B
�����������i�K��ʼn\�ɂȂ�ƌ����b�ŁARadeon��K10���_�C�ɍڂ��Ă�����
SSE���߂�GPU�Ŕ��s�o����Ƃ����b�ł͂Ȃ��B
�������ASwift��SSE5�����s�]�X�̏�������
Radeon��K10���_�C�ɍڂ��Ă����ɃR�v���Ƃ��đ����悤�ɂ����Ƃ��Ă�
��x86��GPU�͈ꐶSSE�Ȃǔ��s���Ȃ��̂��������E
��x86��GPU�͈ꐶSSE�Ȃǔ��s���Ȃ��̂��������E
�[�����ꂾ��
>21-22�̃����[�h�A�łł�
����́u�~�X�����v�����݂̂ɔ������Ă邾����
���e�S���������ĂȂ���
>27
���m�ȋL���͖�������
���̌��̔����͂���Ȃ�ɂ�����
>21-22�̃����[�h�A�łł�
����́u�~�X�����v�����݂̂ɔ������Ă邾����
���e�S���������ĂȂ���
>27
���m�ȋL���͖�������
���̌��̔����͂���Ȃ�ɂ�����
GPU��X86��SSE�g�킹�邮�炢�Ȃ�CPU��SIMD���������邾�낤�����
31 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 10:54:15 ID:E/cWbyEH
> ���ꌾ������Intel�����Ă悭��邾��A1�N�O����Larrabee�ő�R�����Ă���������ˁH
> ���O�����q�̂������ƌ����Ă���ȁA����Larrabee�͍��ǂ��Ȃ��Ă�A�����ɂ������ĂȂ�����H
���M���Ȃ��Ă�̂�H
Larrabee�͍ŏ����瓝���v���Z�b�T���O��Ńf�B�X�N���[�g�͋����̌����̂��߂����Ă͍̂ŏ����疾�炩��������B
��������K�v���̂������Ȃ��Ă��܂�����o�����R���Ȃ����낤�B
�����Ă邾��n�[�h�͖{������Ȃ��Ė��̓\�t�g���ƁB
���N�̍���AMD��AVX�T�|�[�g��\���������ƂŁALarrabee�̖��߃Z�b�g���܂߁A�����ɂ킽����
Intel�Ƃ̖��߃Z�b�g�݊����ێ�����\���������Ȃ����B
x86����GPU�ɃA�N�Z�X�ł��閽�߃Z�b�g���K�v�Ȃ̂�AMD��������Intel�ɕ������킹���ق�����������ȁB
��킸�ɏ��̂��ŗǂ̕��@�����H
�l�I�������炷��Ύc�O�ł͂��邯�ǂȁB
> ���O�����q�̂������ƌ����Ă���ȁA����Larrabee�͍��ǂ��Ȃ��Ă�A�����ɂ������ĂȂ�����H
���M���Ȃ��Ă�̂�H
Larrabee�͍ŏ����瓝���v���Z�b�T���O��Ńf�B�X�N���[�g�͋����̌����̂��߂����Ă͍̂ŏ����疾�炩��������B
��������K�v���̂������Ȃ��Ă��܂�����o�����R���Ȃ����낤�B
�����Ă邾��n�[�h�͖{������Ȃ��Ė��̓\�t�g���ƁB
���N�̍���AMD��AVX�T�|�[�g��\���������ƂŁALarrabee�̖��߃Z�b�g���܂߁A�����ɂ킽����
Intel�Ƃ̖��߃Z�b�g�݊����ێ�����\���������Ȃ����B
x86����GPU�ɃA�N�Z�X�ł��閽�߃Z�b�g���K�v�Ȃ̂�AMD��������Intel�ɕ������킹���ق�����������ȁB
��킸�ɏ��̂��ŗǂ̕��@�����H
�l�I�������炷��Ύc�O�ł͂��邯�ǂȁB
�܁[������Ȃ����Ƃ��̒c�q�`��V���[���n�܂�����
AMD�̏ꍇGPU�R�A��CPU�R�A���Ɨ����Ă��邩��x86�ɍS��K�v���Ȃ����
�Ԃ����ႯARM��Power�ASparc�R�A�Ɠ��������邱�Ƃ��ł���
AMD��ARM��Power�̃��C�Z���X���邩�A���Ђ�GPU�R�A�̃��C�Z���X���邩���������
����AMD��Fusion�\�z�̂��Ȃ��̓W�J������AX86�ł�Fusion�͂��̑������肾�Ǝv��
���̈�ႪSnapdragon�B
�܂��R�A�͔��p�������烉�C�Z���X����Ȃ����ǁA����ȕ���GPU�R�A�̃��C�Z���X�����ƂƂ��ė����グ��Ζʔ��������B
�n�[�h�Ƃ��Ă̐�����͂���킯�����A���ɂ��g�������Ƃ��낪�o�Ă����Ȃ����ȁB
�t��Intel��x86�ƈ�@��A�Ȃ�CPU�R�A�Ɩ��ڂɗZ�����Ă��邩�瑼�̃R�A�ւ̓]�p�͂قڕs�\
�Ԃ����ႯARM��Power�ASparc�R�A�Ɠ��������邱�Ƃ��ł���
AMD��ARM��Power�̃��C�Z���X���邩�A���Ђ�GPU�R�A�̃��C�Z���X���邩���������
����AMD��Fusion�\�z�̂��Ȃ��̓W�J������AX86�ł�Fusion�͂��̑������肾�Ǝv��
���̈�ႪSnapdragon�B
�܂��R�A�͔��p�������烉�C�Z���X����Ȃ����ǁA����ȕ���GPU�R�A�̃��C�Z���X�����ƂƂ��ė����グ��Ζʔ��������B
�n�[�h�Ƃ��Ă̐�����͂���킯�����A���ɂ��g�������Ƃ��낪�o�Ă����Ȃ����ȁB
�t��Intel��x86�ƈ�@��A�Ȃ�CPU�R�A�Ɩ��ڂɗZ�����Ă��邩�瑼�̃R�A�ւ̓]�p�͂قڕs�\
�`����Ă��������N�a�ɂ��������Ȃ���
>>31
> Larrabee�͍ŏ����瓝���v���Z�b�T���O��Ńf�B�X�N���[�g�͋����̌����̂��߂����Ă͍̂ŏ����疾�炩��������B
> ��������K�v���̂������Ȃ��Ă��܂�����o�����R���Ȃ����낤�B
���̂͌����悤����w
�\�t�g�����O�_�O�_���������Ęb�����ADX10�ł���܂Ƃ��ɓ����Ȃ������炵����
> �����Ă邾��n�[�h�͖{������Ȃ��Ė��̓\�t�g���ƁB
> ���N�̍���AMD��AVX�T�|�[�g��\���������ƂŁALarrabee�̖��߃Z�b�g���܂߁A�����ɂ킽����
> Intel�Ƃ̖��߃Z�b�g�݊����ێ�����\���������Ȃ����B
> x86����GPU�ɃA�N�Z�X�ł��閽�߃Z�b�g���K�v�Ȃ̂�AMD��������Intel�ɕ������킹���ق�����������ȁB
�܂��A�V�F�A�I�Ɏ����悤�Ȋg���������Ă������͔Z��������ˌ݊��H���͎d���Ȃ���
�����ABull�ł̎���������ƁA�݊��H���͐��\����Ȃ背�x���ŕЎ�Ԃ��Ċ�������
> ��킸�ɏ��̂��ŗǂ̕��@�����H
> �l�I�������炷��Ύc�O�ł͂��邯�ǂȁB
AMD��Intel�݊�(SSE/AVX)��GPGPU�ǂ���ɏd���������Ă邩�͉������薾�炩����H
�v�͂܂�����Ă����Ȃ��Ƃ������Ƃ��B
���N��Llano vs Sandy�����̏���Ƃ������邵�A����܂Ŗϑz�Ŋy���߂�����B
> Larrabee�͍ŏ����瓝���v���Z�b�T���O��Ńf�B�X�N���[�g�͋����̌����̂��߂����Ă͍̂ŏ����疾�炩��������B
> ��������K�v���̂������Ȃ��Ă��܂�����o�����R���Ȃ����낤�B
���̂͌����悤����w
�\�t�g�����O�_�O�_���������Ęb�����ADX10�ł���܂Ƃ��ɓ����Ȃ������炵����
> �����Ă邾��n�[�h�͖{������Ȃ��Ė��̓\�t�g���ƁB
> ���N�̍���AMD��AVX�T�|�[�g��\���������ƂŁALarrabee�̖��߃Z�b�g���܂߁A�����ɂ킽����
> Intel�Ƃ̖��߃Z�b�g�݊����ێ�����\���������Ȃ����B
> x86����GPU�ɃA�N�Z�X�ł��閽�߃Z�b�g���K�v�Ȃ̂�AMD��������Intel�ɕ������킹���ق�����������ȁB
�܂��A�V�F�A�I�Ɏ����悤�Ȋg���������Ă������͔Z��������ˌ݊��H���͎d���Ȃ���
�����ABull�ł̎���������ƁA�݊��H���͐��\����Ȃ背�x���ŕЎ�Ԃ��Ċ�������
> ��킸�ɏ��̂��ŗǂ̕��@�����H
> �l�I�������炷��Ύc�O�ł͂��邯�ǂȁB
AMD��Intel�݊�(SSE/AVX)��GPGPU�ǂ���ɏd���������Ă邩�͉������薾�炩����H
�v�͂܂�����Ă����Ȃ��Ƃ������Ƃ��B
���N��Llano vs Sandy�����̏���Ƃ������邵�A����܂Ŗϑz�Ŋy���߂�����B
�c�q��\���ɂ��Ă�̂ɂ����J�ɕЂ��[������p���Ă���n��������ȁB
37 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 11:17:33 ID:E/cWbyEH
>>30
�H���ACPU��SIMD���������Ă��ꕔ�̉Ȋw�Z�p�v�Z��Q�[���ɂ����g���Ȃ�㩁B
�ł�GPU�Ɖ��Z���\�[�X�����L���Ă��A�O���t�B�b�N���g�������̃v���O�����ʼn��Z���\�[�X��
�L���Ɏg����@�������BFusion�̔��z�͂������痈�Ă�B
�t�����g�G���h��x86����GPU���ŕʁX�ɂ��ăo�b�N�G���h�i���Z���j�b�g�j�̂��L�Ƃ������f�����Ƃ��Ă������B
������Larrabee�̂悤��GPU���̂��uSIMD��������x86�v�ō\������K�v�͂Ȃ����낤�B
���������Z���j�b�g��x86�̓����I�y���[�V�����������悭���s�o����悤�ɍ��ւ���K�v������B
�ǂ݂̂������悤�ȂƂ���ɂ���������B
�H���ACPU��SIMD���������Ă��ꕔ�̉Ȋw�Z�p�v�Z��Q�[���ɂ����g���Ȃ�㩁B
�ł�GPU�Ɖ��Z���\�[�X�����L���Ă��A�O���t�B�b�N���g�������̃v���O�����ʼn��Z���\�[�X��
�L���Ɏg����@�������BFusion�̔��z�͂������痈�Ă�B
�t�����g�G���h��x86����GPU���ŕʁX�ɂ��ăo�b�N�G���h�i���Z���j�b�g�j�̂��L�Ƃ������f�����Ƃ��Ă������B
������Larrabee�̂悤��GPU���̂��uSIMD��������x86�v�ō\������K�v�͂Ȃ����낤�B
���������Z���j�b�g��x86�̓����I�y���[�V�����������悭���s�o����悤�ɍ��ւ���K�v������B
�ǂ݂̂������悤�ȂƂ���ɂ���������B
38 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 11:29:06 ID:E/cWbyEH
> ���N��Llano vs Sandy�����̏���Ƃ������邵�A����܂Ŗϑz�Ŋy���߂�����B
���x�������_���ς����Č����Ă邱�Ƃ������肪�A�[�L�̉��ǂ��킦�Ă�̂ɁA
4�R�A��Westmere 2�R�A�ɂ��珟�ĂȂ��A�[�L�����̂܂g���Ă鎞�_��Llano�͍ŏ����畉���Ă邾��B
GPU�Ȃ�ăf�B�X�N���[�gGPU�łȂ�Ƃł��Ȃ�BCPU���\�̕s���͊g���J�[�h�ŕ₦�Ȃ��B
�N�\�ł����荞�ނ悤�ȃ}�[�P�e�B���O�Z���X������Ȃ�ʂ������ɔ��荞�߂�v�f�Ȃ��B
���������Ȃ�Ń��[�G���h�`�~�b�h�����W��Sandy Bridge�̃_�C��GMA�i�j�ɖт�������GPU�R�A�ڂ邩�킩���Ă�́H
�R���V���[�}�p�r��AVX��L���Ɏg����v���O�������o��܂ł́AVertex Shader��ւƂ��Ďg���̂�
��ԃ��\�[�X�̖��ʂ��Ȃ����炾��B
�P���v�Z��VS�̐��\��Arrandale��2�`4�{�ɂȂ�킯�����炻��Ȃ�Ɏg����̂ł́H
���l�͂��܂�C�ɓ���B
Llano�Ə������邽�߂���Ȃ��B����ɉ��z�G�ɂ���ȁB
���x�������_���ς����Č����Ă邱�Ƃ������肪�A�[�L�̉��ǂ��킦�Ă�̂ɁA
4�R�A��Westmere 2�R�A�ɂ��珟�ĂȂ��A�[�L�����̂܂g���Ă鎞�_��Llano�͍ŏ����畉���Ă邾��B
GPU�Ȃ�ăf�B�X�N���[�gGPU�łȂ�Ƃł��Ȃ�BCPU���\�̕s���͊g���J�[�h�ŕ₦�Ȃ��B
�N�\�ł����荞�ނ悤�ȃ}�[�P�e�B���O�Z���X������Ȃ�ʂ������ɔ��荞�߂�v�f�Ȃ��B
���������Ȃ�Ń��[�G���h�`�~�b�h�����W��Sandy Bridge�̃_�C��GMA�i�j�ɖт�������GPU�R�A�ڂ邩�킩���Ă�́H
�R���V���[�}�p�r��AVX��L���Ɏg����v���O�������o��܂ł́AVertex Shader��ւƂ��Ďg���̂�
��ԃ��\�[�X�̖��ʂ��Ȃ����炾��B
�P���v�Z��VS�̐��\��Arrandale��2�`4�{�ɂȂ�킯�����炻��Ȃ�Ɏg����̂ł́H
���l�͂��܂�C�ɓ���B
Llano�Ə������邽�߂���Ȃ��B����ɉ��z�G�ɂ���ȁB
Llano�Ɠo�ꎞ�������Ԃ邩��A�ǂ����Ă���r�����Ǝv����
CPU�͗D�G�AGPU�͏o�����Ȃ� vs CPU�͒l�i�Ȃ�AGPU���D�G�@�݂����ɂ�
CPU�͗D�G�AGPU�͏o�����Ȃ� vs CPU�͒l�i�Ȃ�AGPU���D�G�@�݂����ɂ�
>>36
�c�q���ꕔ�̃��c���猩����^�V�����I���`���݂��������B
��ꂽ�e�[�v�Ɠ��ꂾ���Ď����c�����ƁB�R�����R�e�����ȁB
�c�q���ꕔ�̃��c���猩����^�V�����I���`���݂��������B
��ꂽ�e�[�v�Ɠ��ꂾ���Ď����c�����ƁB�R�����R�e�����ȁB
��r����邾�낤���ǁALlano�̕���GPU���\�������Ă������o�邩�Ƃ����Ƌ^�₪�B
42 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 11:53:52 ID:E/cWbyEH
Westmere��Sandy Bridge�̉��Ǔ_
�P�DAVX�ɑΉ�����256�r�b�gSIMD�G���W������
�Q�DLoad���j�b�g�̔{��
�R�DMacro OPs Fusion�̑Ώۖ��ߊg��
�S�DROB/RS�̃G���g������
�T�DLoop Stream Detector�ōė��p�ł����OPs���̊g��
>>39
G45��780G���x�ɂ͔�r����邩���ˁA�S��AMD�ɒǂ����ɂȂ��ĂȂ����ǂ�����
�Ƃ���ŁA���Ƃ���DDR3 1066MHz��2GB 1���h���ł��\���ȑш�m�ۂł���́H
NEC��x�m�ʂ̗������f���Ń�����2���h�����Ėw�ǖ�����H
�P�DAVX�ɑΉ�����256�r�b�gSIMD�G���W������
�Q�DLoad���j�b�g�̔{��
�R�DMacro OPs Fusion�̑Ώۖ��ߊg��
�S�DROB/RS�̃G���g������
�T�DLoop Stream Detector�ōė��p�ł����OPs���̊g��
>>39
G45��780G���x�ɂ͔�r����邩���ˁA�S��AMD�ɒǂ����ɂȂ��ĂȂ����ǂ�����
�Ƃ���ŁA���Ƃ���DDR3 1066MHz��2GB 1���h���ł��\���ȑш�m�ۂł���́H
NEC��x�m�ʂ̗������f���Ń�����2���h�����Ėw�ǖ�����H
G45��780G���x�ȏ�ɊJ�������邼
������Intel��GMA��1���ʂ���GMA�o���ŕ����ĂȂ���߰ق�����
�����ȃV�i���I����
������Intel��GMA��1���ʂ���GMA�o���ŕ����ĂȂ���߰ق�����
�����ȃV�i���I����
44 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 12:07:07 ID:E/cWbyEH
�R�������Ă��܂����B�\����Ȃ��B
NEC��2010��f��
http://121ware.com/psp/PA121/LEARN/ENTP/h/?tab=LRN_Z_TOP
LaVie
�@L : Core i5/i3
�@S : Core i5/i3
�@M : Core 2 Duo / Celeron
�@Light : Atom
VALUESTAR
�@N : Core i5/i3, Celeron (���o�C����CPU)
�@W : Core i5/i3
�@L : Core i7 8xx
AMD�S�������ĂȂ��B
�x�m�ʂ͌��킸�����ȁB
NEC��2010��f��
http://121ware.com/psp/PA121/LEARN/ENTP/h/?tab=LRN_Z_TOP
LaVie
�@L : Core i5/i3
�@S : Core i5/i3
�@M : Core 2 Duo / Celeron
�@Light : Atom
VALUESTAR
�@N : Core i5/i3, Celeron (���o�C����CPU)
�@W : Core i5/i3
�@L : Core i7 8xx
AMD�S�������ĂȂ��B
�x�m�ʂ͌��킸�����ȁB
45 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 12:12:14 ID:E/cWbyEH
>>43
������A�z���ȁB���K�v�ˁ[�����B
�������̉��i�̍��z�Ńf�B�X�N���[�g�h���邵����
NEC/�x�m�ʂ�Intel�I�����[�ɂȂ������Ƃœ��{�̉Ɠd���͊��S��AMD�����������\�}�ɂȂ����킯�����ǂǂ��v�����H
������A�z���ȁB���K�v�ˁ[�����B
�������̉��i�̍��z�Ńf�B�X�N���[�g�h���邵����
NEC/�x�m�ʂ�Intel�I�����[�ɂȂ������Ƃœ��{�̉Ɠd���͊��S��AMD�����������\�}�ɂȂ����킯�����ǂǂ��v�����H
���f�B�X�N���[�g�h���邵����
���߂��A�R�X�g�A�b�v��������
���߂��A�R�X�g�A�b�v��������
Llano�̎���̓m�[�g���X����➑̂̃f�X�N�g�b�v�����肾���
48 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 12:23:54 ID:E/cWbyEH
1600MHz���W���[����2���h���Ȃ�Ă�����R�X�g�A�b�v�A�P�`������
���|�I�ȁE�E�E�E�ш�s��
�^�C�������_�x�[�X�Ń������ш��]��H��Ȃ�GPU���J�����Ă����ׂ��������ˁi��
���A�d�l�m�F��������LaVie�͂������Intel HDG/GMA������
���|�I�ȁE�E�E�E�ш�s��
�^�C�������_�x�[�X�Ń������ш��]��H��Ȃ�GPU���J�����Ă����ׂ��������ˁi��
���A�d�l�m�F��������LaVie�͂������Intel HDG/GMA������
>>46
�����r�̎c�[�����āA������sell�����|�I�Ɏg���Ă�o�b�Ԃ��q���{�[�h�Ƃ�
�����r�ɂ͖�����������B�o�ꎞ����10�N�قǑ����C�͂���B
�����r�̎c�[�����āA������sell�����|�I�Ɏg���Ă�o�b�Ԃ��q���{�[�h�Ƃ�
�����r�ɂ͖�����������B�o�ꎞ����10�N�قǑ����C�͂���B
�����������Ƃ������������Ȃ������Ƃ����b������
Llano�Ȃ�č��̖��͂������m�[�g�������C���i�b�v�ɑI�������ł��邾���ł����肪����
�f�X�N�g�b�v�����ł��R�X�g�I�ɗL�������炠����x����邾�낤��
�f�X�N�g�b�v�����ł��R�X�g�I�ɗL�������炠����x����邾�낤��
52 �F,,�E�L�́M�E,,�j��-�������F2010/05/05(��) 12:55:58 ID:E/cWbyEH
AMD�̎Ј�����ANEC/Fujitsu�̃��S������ƖY��Ă��
http://www.amd.com/jp-ja/Processors/ComputingSolutions/0,,30_288_3091_3100,00.html
http://www.amd.com/jp-ja/Processors/ComputingSolutions/0,,30_288_3091_3098,00.html
���̉�Ђɂ͖�����Ȃ��ȁB
http://www.amd.com/jp-ja/Processors/ComputingSolutions/0,,30_288_3091_3100,00.html
http://www.amd.com/jp-ja/Processors/ComputingSolutions/0,,30_288_3091_3098,00.html
���̉�Ђɂ͖�����Ȃ��ȁB
53 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 12:59:29 ID:E/cWbyEH
�������炢�͂���ł��t���Ă�����
�����ɂ͖������������� (:D)rz ��
http://hissi.org/read.php/jisaku/20100502/cmdJZytxczk.html
http://hissi.org/read.php/jisaku/20100503/SVMzK3Bjc1g.html
http://hissi.org/read.php/jisaku/20100505/RS9jV2J5RUg.html
http://hissi.org/read.php/jisaku/20100502/cmdJZytxczk.html
http://hissi.org/read.php/jisaku/20100503/SVMzK3Bjc1g.html
http://hissi.org/read.php/jisaku/20100505/RS9jV2J5RUg.html
55 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 13:07:35 ID:E/cWbyEH
>>51
Acer��DOSPARA�̃m�[�gPC���I�����ɏオ��l���́A���{�̏���҂ɂ͏��Ȃ��Ǝv���B
AMD�ɊS���Ȃ��l�͂킴�킴����Ȃ�����B
CPU�����V����Ȃ�AMD�ɖ��͂��Ȃ�����NEC���x�m�ʂ����������Ǝv����B
Acer��DOSPARA�̃m�[�gPC���I�����ɏオ��l���́A���{�̏���҂ɂ͏��Ȃ��Ǝv���B
AMD�ɊS���Ȃ��l�͂킴�킴����Ȃ�����B
CPU�����V����Ȃ�AMD�ɖ��͂��Ȃ�����NEC���x�m�ʂ����������Ǝv����B
�ނ�����V����ĂȂ��R�A�����E�I�q�b�g�Ƃ���
2010�N�ɂȂ��Ă�Celeron��PentiumDC���܂��܂����
Core2���łĂ���4�N���炢�o���Ă�
Core2���łĂ���4�N���炢�o���Ă�
NEC��x�m�ʂ͒m��Ȃ��Ԃ�AMD���ڃp�\�R�����o���Ȃ��錾�����Ă����̂��E�E�E
59 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 13:50:05 ID:E/cWbyEH
���N�O�A�^�Ɠd�ʔ̓X�̃m�[�gPC�����̎����̔�
Intel���Ƒ�̂���
�uCPU��Intel�̃f���A���R�A�ICore 2 Duo�𓋍ڂ��Ă���܂��I�v
���ꂪAMD�@����
�u�ꗬ���[�J�[NEC�̃m�[�g�p�\�R���ł��I�O�����[�J�[���ገ���Ă���܂���I�ꗬ���[�J�[��NEC�ł��I�v
����r�F�����̎��b�B�F�m�x�̈Ⴂ�Ƃ������̂��ȁB
���A���ɒn���v�f���炯����Ȃ���
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
> �@�܂��AIntel�̓p���[�Q�[�e�B���O�̂��߂ɁACPU�R�A�̃X�e�C�g��ێ�������ʂ�SRAM��CPU�Ɏ����A
> �p���[�I�t����̕��A�������������B�������AAMD�̎����ł́ACPU�R�A�̃X�e�C�g�́ACPU�O����
> DRAM�ɑҔ������B���̂��߁A�����I��Intel�̃p���[�Q�[�e�B���O���A�I���I�t�̃��C�e���V�������B
> ���ۂ̋@��ł́A�p���[�I�t����̕��A�Ɏ��Ԃ������邱�ƂɂȂ�A�ǂ̒��x���p��������̂��́A
> �܂��킩��Ȃ��B
�̊����x�i�j�����������ȁB
Intel���Ƒ�̂���
�uCPU��Intel�̃f���A���R�A�ICore 2 Duo�𓋍ڂ��Ă���܂��I�v
���ꂪAMD�@����
�u�ꗬ���[�J�[NEC�̃m�[�g�p�\�R���ł��I�O�����[�J�[���ገ���Ă���܂���I�ꗬ���[�J�[��NEC�ł��I�v
����r�F�����̎��b�B�F�m�x�̈Ⴂ�Ƃ������̂��ȁB
���A���ɒn���v�f���炯����Ȃ���
http://pc.watch.impress.co.jp/docs/column/kaigai/20100215_348705.html
> �@�܂��AIntel�̓p���[�Q�[�e�B���O�̂��߂ɁACPU�R�A�̃X�e�C�g��ێ�������ʂ�SRAM��CPU�Ɏ����A
> �p���[�I�t����̕��A�������������B�������AAMD�̎����ł́ACPU�R�A�̃X�e�C�g�́ACPU�O����
> DRAM�ɑҔ������B���̂��߁A�����I��Intel�̃p���[�Q�[�e�B���O���A�I���I�t�̃��C�e���V�������B
> ���ۂ̋@��ł́A�p���[�I�t����̕��A�Ɏ��Ԃ������邱�ƂɂȂ�A�ǂ̒��x���p��������̂��́A
> �܂��킩��Ȃ��B
�̊����x�i�j�����������ȁB
>>58
�ϑz�ɕt�������̂��ǂ����Ƃ�
�ϑz�ɕt�������̂��ǂ����Ƃ�
NEC���x�m�ʂ��N�Ԑ��Y��2�`300���䂾����AAMD���̗p���ă��C���𑝂₵�Ă��R�X�g���オ�邾����
��قǂ̂��Ƃ���������̗p���Ȃ����낤
��قǂ̂��Ƃ���������̗p���Ȃ����낤
1. GMA�ŏ\�����Ǝv���Ă�ЂƁ�Intel+����GPU
2. GMA�������Ǝv���Ă�ЂƁ�Intel+�f�B�X�N���[�gGPU
3. GMA�͋������f�B�X�N���[�g�̃R�X�g�A�b�v�͌��ACPU�̐��\�͂��������ł��� �� Llano
1���啔���̃��[�U�ł����2�������A3�͈�ԃj�b�`�B
�}�[�P�e�B���O�łЂ�����Ԃ���\����0�ł͂Ȃ�����ǁA
AMD�̗��j�Ƀ}�[�P�e�B���O�Ő��������ߋ��͂Ȃ��B
2. GMA�������Ǝv���Ă�ЂƁ�Intel+�f�B�X�N���[�gGPU
3. GMA�͋������f�B�X�N���[�g�̃R�X�g�A�b�v�͌��ACPU�̐��\�͂��������ł��� �� Llano
1���啔���̃��[�U�ł����2�������A3�͈�ԃj�b�`�B
�}�[�P�e�B���O�łЂ�����Ԃ���\����0�ł͂Ȃ�����ǁA
AMD�̗��j�Ƀ}�[�P�e�B���O�Ő��������ߋ��͂Ȃ��B
63 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 14:11:00 ID:E/cWbyEH
�y����z
���N���ĂȂ�PC�Q�[�ŃL���[�^�C�g�������������H
Intel�̃C���e�O���[�g�Ő��\�s������悤�ȁB
�t�@�~�ʂŁu�T���V���C���q��v�̋L�����g�܂��悤�Ȏ���ł�����ˁB
���܂ǂ��̃J�W���A���Q�[�}�[�w�����߂�̂́umixi�A�v�����X�g���X��������PC�v���Ǝv�����B
Flash�Q�[�̃p�t�H�[�}���X�͂قƂ��CPU�̃V���O���X���b�h���\�ˑ��B
���GPU��GMA�ł��\���B
CPU���\���������Ă������o���郆�[�U�[�͋��Ȃ��͂��B
�����ׂ��ƈႤ��������B
���N���ĂȂ�PC�Q�[�ŃL���[�^�C�g�������������H
Intel�̃C���e�O���[�g�Ő��\�s������悤�ȁB
�t�@�~�ʂŁu�T���V���C���q��v�̋L�����g�܂��悤�Ȏ���ł�����ˁB
���܂ǂ��̃J�W���A���Q�[�}�[�w�����߂�̂́umixi�A�v�����X�g���X��������PC�v���Ǝv�����B
Flash�Q�[�̃p�t�H�[�}���X�͂قƂ��CPU�̃V���O���X���b�h���\�ˑ��B
���GPU��GMA�ł��\���B
CPU���\���������Ă������o���郆�[�U�[�͋��Ȃ��͂��B
�����ׂ��ƈႤ��������B
�Q�[���̎��͒m���mixi���ă��o�C�������Q�[���H
MMORPG�Ȃ�Llano�ŏ\��
Intel��GMA�̃V�F�A�����\�̊��ɍ����̂��āA
�P��GPU�̐��\�Ȃ�Ăǂ��ł��悢�����[���p��
Intel�Z�b�g����ʂɍ̗p����Ă��邩�炶��Ȃ��́H
�P��GPU�̐��\�Ȃ�Ăǂ��ł��悢�����[���p��
Intel�Z�b�g����ʂɍ̗p����Ă��邩�炶��Ȃ��́H
���[�J�[PC���ƂقƂ��GMA����Ȃ����B�������Ă���l�Ԃ��炷��S�~������
69 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 14:38:18 ID:E/cWbyEH
�������PC�̎��v��7����GPU���\�̎��v�̂قƂ�ǂȂ��@�l��������B
�����������A�z�[�����[�X������GPU���\������Ȃ�����ɂȂ����B
http://it.nikkei.co.jp/digital/column/gamescramble.aspx?n=MMITew000027112009&cp=1
���Ȃ��Ƃ����{�ɂ͊��ɉƓd�����Q�[�}�[����PC������Ĕ����悤�ȓy��͂Ȃ��Ȃ����ȁB
�����������A�z�[�����[�X������GPU���\������Ȃ�����ɂȂ����B
http://it.nikkei.co.jp/digital/column/gamescramble.aspx?n=MMITew000027112009&cp=1
���Ȃ��Ƃ����{�ɂ͊��ɉƓd�����Q�[�}�[����PC������Ĕ����悤�ȓy��͂Ȃ��Ȃ����ȁB
>>62���uGMA�ŏ\�����Ǝv���Ă���v����GMA�ł͂Ȃ��āA
1.������PC��GMA�����������B
���������낤�ȁB���g��m���Ă���u2�v���u3�v�ɂ����Ȃ�Ȃ��B
1.������PC��GMA�����������B
���������낤�ȁB���g��m���Ă���u2�v���u3�v�ɂ����Ȃ�Ȃ��B
GMA�w����������z�͗��ɂ��Ȃ����낤����Ȃ�
>>70
�܂�����ł��������A������ɂ���uGMA����������AMD��CPU�����v�Ƃ͂Ȃ�Ȃ��B
���ʂ�Radeon�Ȃ�GeForce�Ȃ蓋�ڂ���PC������I�ԁB
3�ɌĂэ��ނɂ͋��͂ȃ}�[�P�e�B���O���K�v�Ȃ̂�B
�܂�����ł��������A������ɂ���uGMA����������AMD��CPU�����v�Ƃ͂Ȃ�Ȃ��B
���ʂ�Radeon�Ȃ�GeForce�Ȃ蓋�ڂ���PC������I�ԁB
3�ɌĂэ��ނɂ͋��͂ȃ}�[�P�e�B���O���K�v�Ȃ̂�B
73 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 14:44:32 ID:E/cWbyEH
AMD�w����������Ҏ҃L�{��
��������
�������t�@�~�ʓǎ҂�����
�������t�@�~�ʓǎ҂�����
>>62�͎���er���_����
>>72
�u����ł����v�̂ł͂Ȃ��āA�u����ł����Ȃ��v�킯�����B
���ƁA
>�uGMA����������AMD��CPU�����v�Ƃ͂Ȃ�Ȃ��B
>���ʂ�Radeon�Ȃ�GeForce�Ȃ蓋�ڂ���PC������I�ԁB
�R�����R�B��ʐl�͗^����ꂽ���������ŁA
GPU�Ȃ�ċC�ɂ��Ȃ��B�I���B"����I�^"��A
���胁�[�J�[�M�҂̖ϑz�Ƃ͎v�l��H���Ⴄ�B
�u���i�v�Ɓu��`����v�������������ł������������B
���g�Ȃ�ċC�ɂ��Ȃ��B�Ⴆ�����\�������Ƃ��Ă��A
�����Ɂu�w���ӗ~�Ɍ���������`����v������Δ��������B
�����AAMD�����[�J�[�T�C�h�ւ̃}�[�P�e�B���O���ア�͓̂��ӁB
�����Ǎ���̓`�b�v�Z�b�g�����ЁiGF�j���Y�ɂȂ�A
�Z�b�g�̔��ł̗l�X�Ȋ��������T�͕t���₷���Ȃ�̂ŁA
OEM�����̃}�[�P�e�B���O�I�ɂ����₷���Ȃ��Ă����Ȃ��H
GPU+�`�b�v�Z�b�g�Ő��Y�\����[�i�\�������Ă₷���Ȃ邵�B
�u����ł����v�̂ł͂Ȃ��āA�u����ł����Ȃ��v�킯�����B
���ƁA
>�uGMA����������AMD��CPU�����v�Ƃ͂Ȃ�Ȃ��B
>���ʂ�Radeon�Ȃ�GeForce�Ȃ蓋�ڂ���PC������I�ԁB
�R�����R�B��ʐl�͗^����ꂽ���������ŁA
GPU�Ȃ�ċC�ɂ��Ȃ��B�I���B"����I�^"��A
���胁�[�J�[�M�҂̖ϑz�Ƃ͎v�l��H���Ⴄ�B
�u���i�v�Ɓu��`����v�������������ł������������B
���g�Ȃ�ċC�ɂ��Ȃ��B�Ⴆ�����\�������Ƃ��Ă��A
�����Ɂu�w���ӗ~�Ɍ���������`����v������Δ��������B
�����AAMD�����[�J�[�T�C�h�ւ̃}�[�P�e�B���O���ア�͓̂��ӁB
�����Ǎ���̓`�b�v�Z�b�g�����ЁiGF�j���Y�ɂȂ�A
�Z�b�g�̔��ł̗l�X�Ȋ��������T�͕t���₷���Ȃ�̂ŁA
OEM�����̃}�[�P�e�B���O�I�ɂ����₷���Ȃ��Ă����Ȃ��H
GPU+�`�b�v�Z�b�g�Ő��Y�\����[�i�\�������Ă₷���Ȃ邵�B
> ��ʐl�͗^����ꂽ���������ŁAGPU�Ȃ�ċC�ɂ��Ȃ��B
���̑w��1����ˁBLlano�ɂ͍s���Ȃ��BIntel�u�����h�͂ł����B
���̑w��1����ˁBLlano�ɂ͍s���Ȃ��BIntel�u�����h�͂ł����B
���{�̏ꍇ���Ƃ���PC�̃I�����C���Q�[�����g�уQ�[���̕����s��K�͂��傫��
���O���I�̎s��K�͂ɂ��Ă͒m���
���{�����胁�[�J�[��3D�Q�[������PC���o���]�n�͍ŏ����疳������
���O���I�̎s��K�͂ɂ��Ă͒m���
���{�����胁�[�J�[��3D�Q�[������PC���o���]�n�͍ŏ����疳������
79 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 15:05:08 ID:E/cWbyEH
>>74
���̍�����������Ƃ����b��ɂȂ��Ă�����ǂ�ˁB
�Ԃ����Ⴏ�A�����Ԃ��䂾���㓙�̗m�Q�[���Ɠd����PC�̔��グ��������������ē��{�ɑ��݂��Ȃ���Ȃ��́H
Sandy Bridge��IGP�ł�����Ƃ����Ȃ���Llano�Ŗ����o����l�g�Q����MHF������H
������ɏI����Ă�C�����邪�B
���̍�����������Ƃ����b��ɂȂ��Ă�����ǂ�ˁB
�Ԃ����Ⴏ�A�����Ԃ��䂾���㓙�̗m�Q�[���Ɠd����PC�̔��グ��������������ē��{�ɑ��݂��Ȃ���Ȃ��́H
Sandy Bridge��IGP�ł�����Ƃ����Ȃ���Llano�Ŗ����o����l�g�Q����MHF������H
������ɏI����Ă�C�����邪�B
�u�����h�헪�������ɑ厖������NVIDIA������킵�Ă����ȁE�E�E
>>42
1�ȊO�͑��������������ƂȂ���A�x�X�g�p�^�[���ł��N���b�N�����肹�����������̌��ゾ�낤
����ƁA����������2�R�A��Ontario�̑��ݖY��Ă����H
�n�C�G���h������4�R�A�A�����ł�ȓd�͌�����2�R�A��Ontario
���Ȃ݂�2�R�A�łɂ�20W�ȉ��̃��C���i�b�v������炵��
���C���i�b�v�͂���Ȃ��낤
�l�b�g�u�b�N�F10W�ȉ���Ontario
10���~�ȉ���CULV�Ή��F2�R�ALlano
10���~�ȏ��Q�[���m�[�g�F4�R�ALlano
�S��Win7�̍ŐVDX11�Ή�
���C���i�b�v�Ƃ��Ă������肵�Ă��ăX�L�����Ђ����������ȍ\������
�������O���o�X�I�ɂ͑S��DDR3+PCie+�f�B�X�v���C�o�͂œ��ꂳ��āA
�Ⴂ�͑��x��Pin�����炢�̊J���̂��₷��
���FNvidia��Ion��Geforce�ɗ��炴������Ȃ�Intel��i3/i5��Sandy�Ȃ�������ɂ��Ȃ�낤��
1�ȊO�͑��������������ƂȂ���A�x�X�g�p�^�[���ł��N���b�N�����肹�����������̌��ゾ�낤
����ƁA����������2�R�A��Ontario�̑��ݖY��Ă����H
�n�C�G���h������4�R�A�A�����ł�ȓd�͌�����2�R�A��Ontario
���Ȃ݂�2�R�A�łɂ�20W�ȉ��̃��C���i�b�v������炵��
���C���i�b�v�͂���Ȃ��낤
�l�b�g�u�b�N�F10W�ȉ���Ontario
10���~�ȉ���CULV�Ή��F2�R�ALlano
10���~�ȏ��Q�[���m�[�g�F4�R�ALlano
�S��Win7�̍ŐVDX11�Ή�
���C���i�b�v�Ƃ��Ă������肵�Ă��ăX�L�����Ђ����������ȍ\������
�������O���o�X�I�ɂ͑S��DDR3+PCie+�f�B�X�v���C�o�͂œ��ꂳ��āA
�Ⴂ�͑��x��Pin�����炢�̊J���̂��₷��
���FNvidia��Ion��Geforce�ɗ��炴������Ȃ�Intel��i3/i5��Sandy�Ȃ�������ɂ��Ȃ�낤��
�������c�q��Intel���̓}�[�P�e�B���O�}���Z�[����������
>>61
���͏��Ȃ�����NEC������AMD�̗p���Ă����A������p������
���C���i�b�v�����Ȃ��̂͒m���x��T�|�[�g�̎��A���x�[�g�Ȃ̍����낤��
�t�Ɍ����ƁA���̂ւ��P������C���i�b�v�͑�����Ƃ������Ƃ�
>>61
���͏��Ȃ�����NEC������AMD�̗p���Ă����A������p������
���C���i�b�v�����Ȃ��̂͒m���x��T�|�[�g�̎��A���x�[�g�Ȃ̍����낤��
�t�Ɍ����ƁA���̂ւ��P������C���i�b�v�͑�����Ƃ������Ƃ�
84 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 15:37:07 ID:E/cWbyEH
�uVAIO�̃p�\�R�����������v��AMD��F�m������͓̂��
> ���͏��Ȃ�����NEC������AMD�̗p���Ă����A������p������
���̂Ȃ��Ȃ��̗̍p�����獡���V���f���́u�[���v�Ȃ�ł����B
> ���͏��Ȃ�����NEC������AMD�̗p���Ă����A������p������
���̂Ȃ��Ȃ��̗̍p�����獡���V���f���́u�[���v�Ȃ�ł����B
���{�ŁAGMA�ł͖����ɓ����Ȃ��i�P�i�r�f�I�J�[�g�v�����郌�x���j
��PC�Q�[�������s��Ȃ��̂́A�g�т��̓Q�[����p�@�̑��݂��傫������B
�����āA���ƃQ�[���Ɋւ������A�C�O�̃Z���X�͓��{�Ƙ������Ă邩��
�m�Q�[�A���������Ĉꕔ�}�j�A�ȊO�͐G�낤�Ƃ����Ȃ����B
��PC�Q�[�������s��Ȃ��̂́A�g�т��̓Q�[����p�@�̑��݂��傫������B
�����āA���ƃQ�[���Ɋւ������A�C�O�̃Z���X�͓��{�Ƙ������Ă邩��
�m�Q�[�A���������Ĉꕔ�}�j�A�ȊO�͐G�낤�Ƃ����Ȃ����B
���ς�炸�ϑz����������
�V�F�A�_�c�Ƃ�����
���鑤��Intel�F8�AAMD�F2�̊����Ŕ����Ă邩��A�w���҂̃V�F�A��8�F2���ĂȂ���
���g�ȂقƂ�ǂ̓z�͋C�ɂ��Ȃ��A���������l�i�ƃ��j�^�̃T�C�Y���炢��
��ƌ����Ȃw�ǃ`�b�v�̈����荇�킾��
�@�\��\�ȂW�Ȃ��A�����Ɉ����d������邩���Ă���
���R�Ԏ��Ő����ʂ����Ȃ�AMD����ʂɗ��v�Ȃ��Ŕ[���o�������Ȃ�
�ȓd�͂�o�b�e���[���Ԃ͂���Ȃ�ɂ���������x�Ń��C���̗��R�ł�����
���鑤��Intel�F8�AAMD�F2�̊����Ŕ����Ă邩��A�w���҂̃V�F�A��8�F2���ĂȂ���
���g�ȂقƂ�ǂ̓z�͋C�ɂ��Ȃ��A���������l�i�ƃ��j�^�̃T�C�Y���炢��
��ƌ����Ȃw�ǃ`�b�v�̈����荇�킾��
�@�\��\�ȂW�Ȃ��A�����Ɉ����d������邩���Ă���
���R�Ԏ��Ő����ʂ����Ȃ�AMD����ʂɗ��v�Ȃ��Ŕ[���o�������Ȃ�
�ȓd�͂�o�b�e���[���Ԃ͂���Ȃ�ɂ���������x�Ń��C���̗��R�ł�����
>>86
�c�q�̖ϑz���������͖̂��x�̂��ƁB
�c�q�̖ϑz���������͖̂��x�̂��ƁB
>>77
> ���̑w��1����ˁBLlano�ɂ͍s���Ȃ��BIntel�u�����h�͂ł����B
�m����AMD���y���ɂł���
�ł������y���ɒ�����ق�NEC��x�m�ʁA�\�j�[�̃u�����h�̕����d�v
�D��x
1.���[�J�[�̃u�����h
2.�l�i
3.�f�B�X�v���C�̃T�C�Y
4.�t���\�t�g��@�\
Intel���ǂ����͂�������5�Ԗڂ��炢�A�������炷��Ɛ�%�ł����Ȃ����낤
> ���̑w��1����ˁBLlano�ɂ͍s���Ȃ��BIntel�u�����h�͂ł����B
�m����AMD���y���ɂł���
�ł������y���ɒ�����ق�NEC��x�m�ʁA�\�j�[�̃u�����h�̕����d�v
�D��x
1.���[�J�[�̃u�����h
2.�l�i
3.�f�B�X�v���C�̃T�C�Y
4.�t���\�t�g��@�\
Intel���ǂ����͂�������5�Ԗڂ��炢�A�������炷��Ɛ�%�ł����Ȃ����낤
90 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 15:53:43 ID:E/cWbyEH
�C�O�����낻�뒪�������ǂˁB�L���Q�[���X�^�W�I�������|�Y���Ă邩��B
�J����͍�������̂Ƀp�C�͏��Ȃ��Ȃ������B
���{�ŗ��s���Ă�mixi�A�v�����́A���������k�Ă�Facebook��2�Ԑ����������肷��B
DX11�Ή����ǂ��̂����̂����Ă鎞�_�Ŋ��ɏ����h�̎v�l���[�`���B
iApp�̂ق�������ۂǏ�����������B1�N�ƌo���Ȃ��Ԃ�PSP�̃V�F�A��������������B
�J����͍�������̂Ƀp�C�͏��Ȃ��Ȃ������B
���{�ŗ��s���Ă�mixi�A�v�����́A���������k�Ă�Facebook��2�Ԑ����������肷��B
DX11�Ή����ǂ��̂����̂����Ă鎞�_�Ŋ��ɏ����h�̎v�l���[�`���B
iApp�̂ق�������ۂǏ�����������B1�N�ƌo���Ȃ��Ԃ�PSP�̃V�F�A��������������B
���Y�ʂ̌��I�ȑ�����������ǂ��ɂ��Ȃ���
�Ⴆ��ƃI�[���d���Z��݂����Ȃ���
�������̂�����������̂��K�X�̕��������̂����A�d�C�ƃK�X��2�n�����L��Ɗ�{������2�n������������
����Ȃ�d�C��{�ɍi���Ċ�{��������{�ɍi���������A�g�[�^���ł͈����ς�
�Ⴆ��ƃI�[���d���Z��݂����Ȃ���
�������̂�����������̂��K�X�̕��������̂����A�d�C�ƃK�X��2�n�����L��Ɗ�{������2�n������������
����Ȃ�d�C��{�ɍi���Ċ�{��������{�ɍi���������A�g�[�^���ł͈����ς�
���E�I�ȕs�����l������ƂˁA�J����̈����Q�[���ɂȂ����͎̂��R���낤��
���イ��mixi�A�v�����̂�AVX��DX11���K�v�Ȃ��ȁA�ނ��Ⴍ�����˒c�q
94 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:00:21 ID:E/cWbyEH
> �ł������y���ɒ�����ق�NEC��x�m�ʁA�\�j�[�̃u�����h�̕����d�v
����>>59�Ȃ킯���Ȃ�����
���Ȃ݂ɂ��̓X���A�uAMD Sempron�v�̖��O�͈�؏o���Ȃ�����������
����>>59�Ȃ킯���Ȃ�����
���Ȃ݂ɂ��̓X���A�uAMD Sempron�v�̖��O�͈�؏o���Ȃ�����������
PC�Q�[���̎s��K�͎��͓̂��{�ł��C�O�ł����������Ă邯�ǂ�
���̊Ԃ̂̕s�����͂������Ƀy�[�X�͓݂���������ł���������
�Q�[���̎��I�ȕω��ɂ��Ă͒m���
���̊Ԃ̂̕s�����͂������Ƀy�[�X�͓݂���������ł���������
�Q�[���̎��I�ȕω��ɂ��Ă͒m���
MW2�Ƃ�GMA�ŏo����́H
97 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:03:47 ID:E/cWbyEH
>>93
�K�v�Ȃ��ˁB�V���O���X���b�h���\�d��������ˁB
�L����������畦���悤�ȃA�v���͌y�����ʁB
�ǂ������Ƃ�����Turbo Boost�ŃN���b�N���ǂꂾ���オ�邩���d�v������
�������ǂ�����Bu�i���̂悤��IPC������Ȃ�Ă͎̂��ōs�ׁB
�K�v�Ȃ��ˁB�V���O���X���b�h���\�d��������ˁB
�L����������畦���悤�ȃA�v���͌y�����ʁB
�ǂ������Ƃ�����Turbo Boost�ŃN���b�N���ǂꂾ���オ�邩���d�v������
�������ǂ�����Bu�i���̂悤��IPC������Ȃ�Ă͎̂��ōs�ׁB
98 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:05:11 ID:E/cWbyEH
>>95
SNS�ƘA�g������{�����̃u���E�U�Q�[�̑䓪���v���B
SNS�ƘA�g������{�����̃u���E�U�Q�[�̑䓪���v���B
>>84
���A����AMD����VAIO�����ɂ����Ă���ǂȂɂ��H
�����A���ʂɂo�b�����z�͂b�o�t���ǂ����ł�windows����������
���A����AMD����VAIO�����ɂ����Ă���ǂȂɂ��H
�����A���ʂɂo�b�����z�͂b�o�t���ǂ����ł�windows����������
mixi�̃A�v���Ȃ�Ă߂��Ⴍ����y������
Atom�ł��ł�����[��
Atom�ł��ł�����[��
101 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:13:41 ID:E/cWbyEH
>>100
�y���̂�������ĂȂ�����B
�����̂���Ă�̂̓z�[����\�����������ŕЃR�A��CPU�g�p����100%�ɂ͂���B
�ꉞ30���l���炢�o�^���Ă�A�v���B
�y���̂�������ĂȂ�����B
�����̂���Ă�̂̓z�[����\�����������ŕЃR�A��CPU�g�p����100%�ɂ͂���B
�ꉞ30���l���炢�o�^���Ă�A�v���B
>>99
�n���ɂ͈�ʐl��CPU���ǂ��̂��Ȃ�ĊW�Ȃ��̂������ł��Ȃ��悗
�n���ɂ͈�ʐl��CPU���ǂ��̂��Ȃ�ĊW�Ȃ��̂������ł��Ȃ��悗
103 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:19:14 ID:E/cWbyEH
�T���V���C���q��̒{�Y�L�������������Ƃ�����x���o�C�ˁB���Ȃ��Ƃ�Atom�������B
�ǂ�ȃQ�[������100%�ɂ͂���u���E�U�Q�[���Ă̂�
�����������K�ɗV�ׂ�̂���
�����������K�ɗV�ׂ�̂���
105 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:21:20 ID:E/cWbyEH
�I�u�W�F�N�g�������atom���Ⴋ����
���Ă����t���b�V������Ȃ��́H��
���Ă����t���b�V������Ȃ��́H��
Flash��GPU�x�����Ăǂ��Ȃ��Ă�̂���
�u���E�U�Q�[���Ƃ��͂��Ȃ����画���
�u���E�U�Q�[���Ƃ��͂��Ȃ����画���
�t���b�V����GPU�x������
���悾������Ȃ���
���悾������Ȃ���
110 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:27:07 ID:E/cWbyEH
>>106
���̏ꍇ�z�[���ɓ����I�u�W�F�N�g��ʔz�u���Ă邩���˂�����
���͂�CPU���׃e�X�g������
>>107
�`��Ώۂ̃I�u�W�F�N�g���点����Ȃɏd���͂Ȃ���
>>108
�����h.264�̍Đ��x�������������ActionScript���ǂ������ł�����̂���Ȃ��B
���̏ꍇ�z�[���ɓ����I�u�W�F�N�g��ʔz�u���Ă邩���˂�����
���͂�CPU���׃e�X�g������
>>107
�`��Ώۂ̃I�u�W�F�N�g���点����Ȃɏd���͂Ȃ���
>>108
�����h.264�̍Đ��x�������������ActionScript���ǂ������ł�����̂���Ȃ��B
>>105
�e�w�������͒m��Ȃ����A�����o�b������n�߂����Ȃ�Ăo�b98�ȊO�͑ʍ삾�Ǝv���Ă���
���g��intel+ATI��A�l�c�Ȃ�Ă����̌݊��b�o�t���Ǝv���Ă�����ȁB
�m�������̂�����łƂ܂��Ă�l���܂�����������낤
�e�w�������͒m��Ȃ����A�����o�b������n�߂����Ȃ�Ăo�b98�ȊO�͑ʍ삾�Ǝv���Ă���
���g��intel+ATI��A�l�c�Ȃ�Ă����̌݊��b�o�t���Ǝv���Ă�����ȁB
�m�������̂�����łƂ܂��Ă�l���܂�����������낤
113 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:41:07 ID:E/cWbyEH
�C���^�v���^������CPU���ׂ̕����傫������GPU���\�ł͍����o�Ȃ�
���߂ĕʑ��ŕ\�����Ă�Flash���炢�X���b�h���ė~�������B
���߂ĕʑ��ŕ\�����Ă�Flash���炢�X���b�h���ė~�������B
114 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 16:46:37 ID:E/cWbyEH
�uAMD�͂�߂Ă��������v���Č������S���҂�20��㔼����
�܂����̏�i�����̔N���Ȃ낤���ǂ�
�܂����̏�i�����̔N���Ȃ낤���ǂ�
>>110
�ϑz����̏����ɍu�����邱�Ƃ��炵�Ȃ��V���^�J�u��
�ϑz����̏����ɍu�����邱�Ƃ��炵�Ȃ��V���^�J�u��
���{��Intel�D������������
���{�͐��E�ōł�����Itanium�����Ă邾�낤
���{�͐��E�ōł�����Itanium�����Ă邾�낤
>A�l�c�Ȃ�Ă����̌݊��b�o�t���Ǝv���Ă�����ȁB
�������̂�
�������̂�
�V�F�A�ŗ��A�u�����h�ŗ��A���\������݊��i�̖����͖��S�Ȃ��̂��B
>>117
�u���ɑ��Č݊����v�ɂ��BAMD��
�uIntel�̌݊�CPU�v�����Ă����̂͐̂����B
>>118
�F�X�Ȑl�̃c�b�R�~�ɉ�������Ȃ��āA
���ǂ��ꂪ�Ō�̈ꌾ���B�i�D�����ȁB
�u���ɑ��Č݊����v�ɂ��BAMD��
�uIntel�̌݊�CPU�v�����Ă����̂͐̂����B
>>118
�F�X�Ȑl�̃c�b�R�~�ɉ�������Ȃ��āA
���ǂ��ꂪ�Ō�̈ꌾ���B�i�D�����ȁB
AMD�̗p�𑝂₷�ɂ͍����̊�Ƃ������ɔ�������Ȃ��ƂȖ�����
Windows�݊�CPU�Ƃ����̂��������藈��
x86�̎��_��Intel�݊����낤��
>>122
���ꂾ��Intel��AMD64�݊�������AMD�݊�CPU�ƌ����Ă��܂�
���ꂾ��Intel��AMD64�݊�������AMD�݊�CPU�ƌ����Ă��܂�
�ǂ��������H
�ǂ�������RISC86����
64bit��AMD�݊������ǂ�
���ASSSE3,SSE4���Ή��������݊���
������A�ǂ��Ⴄ��
�����Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
���ꂪ�H
>>130
���̒��x�𗝉����Ă��炱�̃X���ɗ��Ă��������B
�r���ړI�������瑊��ɂ����������āA
�ނ�錾���������Ƃɏ����Ă��������B
���̒��x�𗝉����Ă��炱�̃X���ɗ��Ă��������B
�r���ړI�������瑊��ɂ����������āA
�ނ�錾���������Ƃɏ����Ă��������B
Intel�݊�����Ȃ����Ă�Ȃ�
x86�g���Ȃ�
x86�g���Ȃ�
135 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 18:04:38 ID:E/cWbyEH
>>131
Atom�E�E�E
Atom�E�E�E
>>134
�}�W�ŁuIntel�݊��v�Ɓu��86�݊��v�ꎋ�c���āA
���܂��ɂ���Ȏc�O�m���l�����܂��Ɏ���ɂ����c�B
�R���̓��o�C�B�}�W�Ń��o�C�B�ʔ������ă��o�C�B
�}�W�ŁuIntel�݊��v�Ɓu��86�݊��v�ꎋ�c���āA
���܂��ɂ���Ȏc�O�m���l�����܂��Ɏ���ɂ����c�B
�R���̓��o�C�B�}�W�Ń��o�C�B�ʔ������ă��o�C�B
�y�����y�����J�I�X���K���̂͂��ꂩ�炾��
AMD�̐��Y�\�͂̓��C���X�g���[���ȏ�Ɍ����Ă�����2�N��3�{�ɂȂ�
����Ƃ͕ʂ�Bobcat������
GF��AMD�ȊO�̐��i���������Ȃ��Ⴂ���Ȃ����炻�̔\�͂̑S�Ă�CPU�Ɋ������Ƃ͏o���Ȃ���
�L���p�V�e�B�[�I�ɂ�2012�N�ɂ��傤��Intel�ɕC�G���鎖�ɂȂ�
��Bobcat���o���N�ł̏ꍇ�̘b
�܂�Ƃ�ł��Ȃ������ߏ���
����͊y����
AMD�̐��Y�\�͂̓��C���X�g���[���ȏ�Ɍ����Ă�����2�N��3�{�ɂȂ�
����Ƃ͕ʂ�Bobcat������
GF��AMD�ȊO�̐��i���������Ȃ��Ⴂ���Ȃ����炻�̔\�͂̑S�Ă�CPU�Ɋ������Ƃ͏o���Ȃ���
�L���p�V�e�B�[�I�ɂ�2012�N�ɂ��傤��Intel�ɕC�G���鎖�ɂȂ�
��Bobcat���o���N�ł̏ꍇ�̘b
�܂�Ƃ�ł��Ȃ������ߏ���
����͊y����
����Intel�p�N���ł�����
>>137
bobcat����GF����Ȃ����H
bobcat����GF����Ȃ����H
>>139
�ǂ��łǂ�ȃv���Z�X�ō����̂��m��Ȃ�
GF�Ń��C���X�g���[��CPU�Ɠ����H��ō��悤�Ȃ�
Bull��Llano�ƂƃE�F�n�̎�荇���ɂȂ邩�琶�Y�ʂ�Intel�ɂ͋y�Ȃ�
�ǂ��łǂ�ȃv���Z�X�ō����̂��m��Ȃ�
GF�Ń��C���X�g���[��CPU�Ɠ����H��ō��悤�Ȃ�
Bull��Llano�ƂƃE�F�n�̎�荇���ɂȂ邩�琶�Y�ʂ�Intel�ɂ͋y�Ȃ�
�������Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
�ŁH
�ŁH
>>138
AMD�́ux86�݊�CPU�������[�J�[�v�B����͗h�邪�Ȃ��B
Intel�Ɂux86���߃Z�b�g�v���g�p����̂ɋ������Ă��邵�A
���Ȃ݂�Intel�D�ʂȂ���u�N���X���C�Z���X�v������ł�����B
������AMD���J������"x86-64"�Ȃ�Ė��߃Z�b�g���A
Intel�ɂ��̗p���ꂽ�肷��B���Ȃ݂ɖ����c�������͂��B
�����NjM���̖ϑz��ے肷��悤�ň������ǁA
�c�O�Ȃ���uIntel CPU�݊��������[�J�[�v�ł͂Ȃ��B
�����Intel��AMD��CPU��x86���߃Z�b�g���������邱�Ƃ͂ł��邪�A
����CPU���m�͓����I�ɂ��o�X�I�ɂ��݊����͑S�����݂��Ȃ�����B
�����A�uIntel�̃p�N���v��������uIntel�݊�CPU�v�������肵���ꍇ�ɂ́A
Intel��AMD��i�����珟�Ă�B
�Ƃ������BAMD���u�Ɛ�֎~�@�ɒ�G����I�v���čٔ����N�������Ƃ��ɂł��A
AMD�ɑ��āu�m�I���C�Z���X�̐N�Q�v�ői����A�b�͏I������B
����Ȋ����B�uIntel�݊��v�Ɓux86�݊��v����������̂͒p���������B
AMD�́ux86�݊�CPU�������[�J�[�v�B����͗h�邪�Ȃ��B
Intel�Ɂux86���߃Z�b�g�v���g�p����̂ɋ������Ă��邵�A
���Ȃ݂�Intel�D�ʂȂ���u�N���X���C�Z���X�v������ł�����B
������AMD���J������"x86-64"�Ȃ�Ė��߃Z�b�g���A
Intel�ɂ��̗p���ꂽ�肷��B���Ȃ݂ɖ����c�������͂��B
�����NjM���̖ϑz��ے肷��悤�ň������ǁA
�c�O�Ȃ���uIntel CPU�݊��������[�J�[�v�ł͂Ȃ��B
�����Intel��AMD��CPU��x86���߃Z�b�g���������邱�Ƃ͂ł��邪�A
����CPU���m�͓����I�ɂ��o�X�I�ɂ��݊����͑S�����݂��Ȃ�����B
�����A�uIntel�̃p�N���v��������uIntel�݊�CPU�v�������肵���ꍇ�ɂ́A
Intel��AMD��i�����珟�Ă�B
�Ƃ������BAMD���u�Ɛ�֎~�@�ɒ�G����I�v���čٔ����N�������Ƃ��ɂł��A
AMD�ɑ��āu�m�I���C�Z���X�̐N�Q�v�ői����A�b�͏I������B
����Ȋ����B�uIntel�݊��v�Ɓux86�݊��v����������̂͒p���������B
�܁A���݂�̓p�b�P�[�W�Ȃ�Ď����ĂȂ����낤����
ttp://www.agenda.co.jp/news/2009/08/atn2010-20090825.html
Pentium?�ȏ�mPentium?III�ȏ�𐄏��n
���Œ�ł��A�g�p����OS�̈ȉ��̍Œ�N���b�N���K�v�ł��B
[WindowsVista] 1000MHz �ȏ��32�r�b�gIntel�݊�CPU
[WindowsXP] 300MHz �ȏ��Intel�݊�CPU
[Windows2000] 133MHz �ȏ��Intel�݊�CPU
ttp://www.justsystems.com/jp/news/2010f/news/j01201.html
Pentium�iR�j 1GHz�ȏ��Intel�݊�CPU
�iWindows XP�̏ꍇ��733MHz�ȏ�j
��
���iCD�N������1GHz�ȏ�𐄏����܂��B
ttp://www.tsuzuki.co.jp/jigyo/sup_ser/ppointer.html
Intel�݊�CPU�@2.0GHz �����ȏ�
Intel�݊�CPU�@1.0GHz �����ȏ�
ttp://www.agenda.co.jp/news/2009/08/atn2010-20090825.html
Pentium?�ȏ�mPentium?III�ȏ�𐄏��n
���Œ�ł��A�g�p����OS�̈ȉ��̍Œ�N���b�N���K�v�ł��B
[WindowsVista] 1000MHz �ȏ��32�r�b�gIntel�݊�CPU
[WindowsXP] 300MHz �ȏ��Intel�݊�CPU
[Windows2000] 133MHz �ȏ��Intel�݊�CPU
ttp://www.justsystems.com/jp/news/2010f/news/j01201.html
Pentium�iR�j 1GHz�ȏ��Intel�݊�CPU
�iWindows XP�̏ꍇ��733MHz�ȏ�j
��
���iCD�N������1GHz�ȏ�𐄏����܂��B
ttp://www.tsuzuki.co.jp/jigyo/sup_ser/ppointer.html
Intel�݊�CPU�@2.0GHz �����ȏ�
Intel�݊�CPU�@1.0GHz �����ȏ�
���̗���AVIA�����ɂ͌��Ȃ��ȁI
�N�炪���Ⴂ���Ă�̂�Socket7�ȑO�̃o�X���x���̌݊���
�Z�J���h�\�[�X����̂��Ƃ���Ȃ���
�������Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
�ŁH
�Z�J���h�\�[�X����̂��Ƃ���Ȃ���
�������Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
�ŁH
���łɂ����AIntel��AMD�̌_��̒��ɁA
�uAMD�͎��ЍH���x86�݊�CPU������Ă�����v���Ă̂��������炵���A
���ꂪ���N�������N�����Ɉꎞ�b��ɂȂ����A
�uGF�͎��ЍH�ꂶ��Ȃ�����I�@x86���C�Z���X���~���Ă��I�v
����Intel���̑i���Ɍq�������킯�ł����c�B
���̂��b�̌����͓������ɑ����Ă����u�Ɛ�֎~�@�ٔ��v�̌����B
�uIntel��AMD�ɘa�������x�����v�̂��܂��̂悤�ɂ����������ǁA
���d�v�����B�ux86���C�Z���X�̌p���v���Ă������܂��܂ł��ď��i�B
�Ă������B�u�a���������Ȃ��v���Ęb�͊m���ɂ��������ǁA
�ux86���C�Z���X�p���v����������A���Ȃ��ǂ���̘b����ˁ[������
>>144
�ԈႦ�������������ꂽ�p�b�P�[�W�ł͂Ȃ��āA
Windows�p�b�P�[�W�̃V�X�e���v���ł����߂Ă낗
�uAMD�͎��ЍH���x86�݊�CPU������Ă�����v���Ă̂��������炵���A
���ꂪ���N�������N�����Ɉꎞ�b��ɂȂ����A
�uGF�͎��ЍH�ꂶ��Ȃ�����I�@x86���C�Z���X���~���Ă��I�v
����Intel���̑i���Ɍq�������킯�ł����c�B
���̂��b�̌����͓������ɑ����Ă����u�Ɛ�֎~�@�ٔ��v�̌����B
�uIntel��AMD�ɘa�������x�����v�̂��܂��̂悤�ɂ����������ǁA
���d�v�����B�ux86���C�Z���X�̌p���v���Ă������܂��܂ł��ď��i�B
�Ă������B�u�a���������Ȃ��v���Ęb�͊m���ɂ��������ǁA
�ux86���C�Z���X�p���v����������A���Ȃ��ǂ���̘b����ˁ[������
>>144
�ԈႦ�������������ꂽ�p�b�P�[�W�ł͂Ȃ��āA
Windows�p�b�P�[�W�̃V�X�e���v���ł����߂Ă낗
�A�C�^�j�E���ǂ��Ȃ��Ă��܂���H
Itanium�͖��ƂƂ���Nehalem-EX�Ɉ����p���ꂽ��
intel�݊�cpu
�������Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
�ŁH
�������Intel��x86���߃Z�b�g���l�C�e�B�u�ŏ�������CPU�Ȃ�āA�������ĂȂ�����B
�ŁH
��2�@Intel�݊�CPU�͓���Ώۂł����AAMD�Ђ̈ꕔ�̋��^CPU�ɂ��Ă�Silverlight����ΏۊO�ƂȂ�܂��B
Intel�Ђƌ݊����̂���CPU�Ȃ�ق炱�̒ʂ�
�؋����މ�₂�A���s�i���F�l���C�y�Ɏ��s�o���܂��I
�ł���������ł��傤�H
���ꂪ����(ry
�؋����މ�₂�A���s�i���F�l���C�y�Ɏ��s�o���܂��I
�ł���������ł��傤�H
���ꂪ����(ry
>>148
���̖��́A���n�ɍl����Εʂ̌������o���邩�ƁB
���Ƃ��ƃC���e����AMD�̊Ԃɂ͓Ƌ֖@�ᔽ�̌W�����������B
Intel�ɂ��Ă݂�ň��P�[�X�ł͊�ƕ��������肤��s����v�����B
AMD�̋Ɛш������[���������Ƃ��AAMD�̓A���u���{�̏o��������A
�Ԏ��œ������܂܂Ȃ�Ȃ�������������ɞ����ꂷ�邱�Ƃɂ����B
���x�����킹�邽�߂Ƀt�@�E���h�����Ƃւ̎Q�������߂��B
�ʂ�AMD�͕��Љ�����K�v�͂Ȃ������ɂ��ւ�炸(���Ƃ��T���X���͉�Ђ�
�ꕔ��Ƃ��ăt�@�E���h�����Ƃ��s���Ă���)�A���������GF�Ƃ��ĕ��Љ������B
�����ŁAAMD�ɂ�x86�̐������C�Z���X����������Ƃ����s����v�����������B
������Intel��AMD�́A(�����炩�̌����ƂƂ���)���݂��̕s����v�����o�[�^�[����
���Ƃɍ��ӂ����BAMD��x86�̐������s�����������������ێ�����̂ƈ��������ɁA
Intel��Ƌ֖@�ᔽ�ōU�����錠�����������B
���C�Z���X���̉������āAAMD�͐�������̕��Љ�������ɉ����i�߁A
���Z����GF�����A�����]�����ʂ������B
AMD�̐Ԏ��������p���`�ɂȂ���GF�͔���J��Ƃ�����A���Z�̐�����(�Ԏ����낤�Ƃ����ȊO)
�O������͂킩��Ȃ��B
�a���ɂ��x86�������C�Z���X�̎擾�͏����ł͂Ȃ��A
GF���Љ��ȊO�ō����]���ł��Ȃ��Ɋׂ����厸����A
�Ƌ֖@�ᔽ�Ƃ���(��҂̋��͂�)����ƈ��������ɃC�[�u���ɖ߂����ɉ߂��Ȃ��A
�Ƃ����̂������̌����B
���̖��́A���n�ɍl����Εʂ̌������o���邩�ƁB
���Ƃ��ƃC���e����AMD�̊Ԃɂ͓Ƌ֖@�ᔽ�̌W�����������B
Intel�ɂ��Ă݂�ň��P�[�X�ł͊�ƕ��������肤��s����v�����B
AMD�̋Ɛш������[���������Ƃ��AAMD�̓A���u���{�̏o��������A
�Ԏ��œ������܂܂Ȃ�Ȃ�������������ɞ����ꂷ�邱�Ƃɂ����B
���x�����킹�邽�߂Ƀt�@�E���h�����Ƃւ̎Q�������߂��B
�ʂ�AMD�͕��Љ�����K�v�͂Ȃ������ɂ��ւ�炸(���Ƃ��T���X���͉�Ђ�
�ꕔ��Ƃ��ăt�@�E���h�����Ƃ��s���Ă���)�A���������GF�Ƃ��ĕ��Љ������B
�����ŁAAMD�ɂ�x86�̐������C�Z���X����������Ƃ����s����v�����������B
������Intel��AMD�́A(�����炩�̌����ƂƂ���)���݂��̕s����v�����o�[�^�[����
���Ƃɍ��ӂ����BAMD��x86�̐������s�����������������ێ�����̂ƈ��������ɁA
Intel��Ƌ֖@�ᔽ�ōU�����錠�����������B
���C�Z���X���̉������āAAMD�͐�������̕��Љ�������ɉ����i�߁A
���Z����GF�����A�����]�����ʂ������B
AMD�̐Ԏ��������p���`�ɂȂ���GF�͔���J��Ƃ�����A���Z�̐�����(�Ԏ����낤�Ƃ����ȊO)
�O������͂킩��Ȃ��B
�a���ɂ��x86�������C�Z���X�̎擾�͏����ł͂Ȃ��A
GF���Љ��ȊO�ō����]���ł��Ȃ��Ɋׂ����厸����A
�Ƌ֖@�ᔽ�Ƃ���(��҂̋��͂�)����ƈ��������ɃC�[�u���ɖ߂����ɉ߂��Ȃ��A
�Ƃ����̂������̌����B
>>154
�Ɛ�֎~�@�Ƃ����Ă��s�������h�~�@�Ɣ��g���X�g�@�͓��e���S�R�Ⴄ
Intel���i����ꂽ�͔̂��g���X�g�@����Ȃ��ĕs�������h�~�@
��ƕ����͊W�Ȃ���Ȃ���
�Ɛ�֎~�@�Ƃ����Ă��s�������h�~�@�Ɣ��g���X�g�@�͓��e���S�R�Ⴄ
Intel���i����ꂽ�͔̂��g���X�g�@����Ȃ��ĕs�������h�~�@
��ƕ����͊W�Ȃ���Ȃ���
�����Ęa����AAMD�͍����ƂȂ����̂ł������B
����������ƕ⑫���Ƃ���
�Ɛ�֎~�@�͑�܂��ɕ�����
�@��@�ȍs�ׂɂ�苣������ɕs���v��^����s���ȋ�����h�~�������
�A�ߓx�ȓƐ��h�~���邽�߂̂���
��2���
Intel���i����ꂽ�͇̂@�̕��̕s���s�ׂɂ�鐳���ȋ����̖W�Q�ł�����
�s��̓Ɛ��i����ꂽ���ł͂Ȃ�
�Ɛ�֎~�@�͑�܂��ɕ�����
�@��@�ȍs�ׂɂ�苣������ɕs���v��^����s���ȋ�����h�~�������
�A�ߓx�ȓƐ��h�~���邽�߂̂���
��2���
Intel���i����ꂽ�͇̂@�̕��̕s���s�ׂɂ�鐳���ȋ����̖W�Q�ł�����
�s��̓Ɛ��i����ꂽ���ł͂Ȃ�
�a�����ō����Ƃ�
����ƋC�t����
�a�����ʂɌ������B
����ō����Ƃ�
������NVIDIA�͐Ԏ����������Ɋg�債���̂ł������B
�ʂɐԎ��ł��ǂ���(�g�債���Ⴄ�̂͂܂�����)
�����������ƌ��t�̂悤�ɂ��������ɗ���Ă�����܂��̂�
�����A���炳��ɗ���Ȃ����ԂɊׂ邱�Ƃ����Ă����A���Ƃ������ł���
���������Ƃ��͖{�i�I�ɂ���A�����|�Y���Ă��������ɂȂ�Ԃ��N�����Ⴄ
�����������ƌ��t�̂悤�ɂ��������ɗ���Ă�����܂��̂�
�����A���炳��ɗ���Ȃ����ԂɊׂ邱�Ƃ����Ă����A���Ƃ������ł���
���������Ƃ��͖{�i�I�ɂ���A�����|�Y���Ă��������ɂȂ�Ԃ��N�����Ⴄ
�����|�Y�͔ߎS�����
�܂��A�L���b�V���������Ă���������ǂȂ��Ȃ�������
�܂��A�L���b�V���������Ă���������ǂȂ��Ȃ�������
�C�������}�~�͂Ǝv���Ă��Ȃ�����
>>165
���[�s�[�n���R����
���[�s�[�n���R����
�����u������Ȃɋ��낵���`���a���Ƃ͎v���ĂȂ�����
�h�u��ЊQ��̗\�Z���K�v�ɂȂ�Ƃ͎v���ĂȂ�����
�h�u��ЊQ��̗\�Z���K�v�ɂȂ�Ƃ͎v���ĂȂ�����
�A�~�����������Ȃ��Ȃ��āA�܂��������Ⴂ�̕����ɑ��肾�����ȁB
�y�{��z �ł܂������u�^���@�E�����ΏہA�R�����ɔ��遚�T
http://tsushima.2ch.net/test/read.cgi/newsplus/1273033812/
http://tsushima.2ch.net/test/read.cgi/newsplus/1273033812/
������x86_64�ł�Intel��AMD�݊��ɐ��艺�������̂ł�?
171 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 23:17:37 ID:E/cWbyEH
�����v�����z���A�uIntel��SSE5���̗p���Ȃ��̂�AMD�ɑ��邢�₪�点���I�v�ƌ����Ⴂ�̂��Ƃ������Ă���
�Ƃ���Ńe�w�ƒc�q�͓���l��? �@�ȑO�g���b�v�������������ǁc�B
�܂�AMD�̃X���Ŗ���intel�̘b�����o���ė���z�������̃X���^�C�I�ɂǂ����Ƃ͎v������
174 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 23:31:01 ID:E/cWbyEH
���~���܂��t�@�r�����Ă�̂��H
������X����Intel�̑i�גn���̕�����Ȃ̘b���Ă��܂��
�ǂ��������̌݊��Ƃ������ǂ��ł���������H
AMD��Intel�����ジ����X86CPU���J���E�̔����Ă������Ƃɂ͕ς��Ȃ������
�g���ƃW�F�[���[�݂����ɒ��ǂ����܂��Ă������
�܂��A�������匋��Intel����ɒ��N�Ԏ������ŋ�킵�Ă��Ă������߂��Ƃ����y�d��ŁA
ATI�����A�A�u�_�r�̎x���A�H�ꕪ���A�a����X86�p���A�啝�ȍ������Ƃ�����Ղ̕����𐋂���AMD�͑f���ɂ������Ǝv����
���������N�͐V�v���Z�X���g�����VCPU�ƐVGPU�ő唽�����s����
��s���`�����Ղ̕����A�����đ唽���Ƃ������̏��N���悾��w
���̃X�g�[���[�������ɂ�����m���ɂ��s����`���������2ch������̗����낤��
���ʂ͂��̂܂ܑ�t�]���ăn�b�s�[�G���h�����ǁA�܂��������낤��
������X����Intel�̑i�גn���̕�����Ȃ̘b���Ă��܂��
�ǂ��������̌݊��Ƃ������ǂ��ł���������H
AMD��Intel�����ジ����X86CPU���J���E�̔����Ă������Ƃɂ͕ς��Ȃ������
�g���ƃW�F�[���[�݂����ɒ��ǂ����܂��Ă������
�܂��A�������匋��Intel����ɒ��N�Ԏ������ŋ�킵�Ă��Ă������߂��Ƃ����y�d��ŁA
ATI�����A�A�u�_�r�̎x���A�H�ꕪ���A�a����X86�p���A�啝�ȍ������Ƃ�����Ղ̕����𐋂���AMD�͑f���ɂ������Ǝv����
���������N�͐V�v���Z�X���g�����VCPU�ƐVGPU�ő唽�����s����
��s���`�����Ղ̕����A�����đ唽���Ƃ������̏��N���悾��w
���̃X�g�[���[�������ɂ�����m���ɂ��s����`���������2ch������̗����낤��
���ʂ͂��̂܂ܑ�t�]���ăn�b�s�[�G���h�����ǁA�܂��������낤��
177 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/05(��) 23:55:26 ID:E/cWbyEH
ARM�Ȃ݂Ă݂�Ή��邪�݊����[�J�[�̊g����{�Ƃ��t�̗p���邱�Ƃ͕ʂɒ��������Ƃ���Ȃ�
��������x64����IA-32���߃Z�b�g�̏�ʌ݊���AMD�I���W�i���̕����Ȃ�ĂقڊF��
GF�̕����̍ۂ̂��������ł��AIntel�̃��C�Z���X���Ȃ����AMD�́uAMD64�v����邱�Ƃ�
�܂܂Ȃ�Ȃ��Ƃ����x�z�W�͉��߂Ċm�F�ł�����H
��������x64����IA-32���߃Z�b�g�̏�ʌ݊���AMD�I���W�i���̕����Ȃ�ĂقڊF��
GF�̕����̍ۂ̂��������ł��AIntel�̃��C�Z���X���Ȃ����AMD�́uAMD64�v����邱�Ƃ�
�܂܂Ȃ�Ȃ��Ƃ����x�z�W�͉��߂Ċm�F�ł�����H
GW�I��
179 �F,,�E�L�́M�E,,�j��/<()���ݛ�< �F2010/05/06(��) 00:08:58 ID:usoqWTp7
�؋����L���\�����Ƃ���
��������̂Ɉ�ԏd�v�ȁA�n�C�p�t�H�[�}���XCPU�Ƃ����s�[�X�������Ă���̂����B
���C�Z���X�Ƃ������A�v���O�����R�[�h�E�b�o�t�\���i�l�l�t�̑���ȂǂˁB�@�����\���͊܂܂Ȃ��j�ɑ���
���쌠�̖�肾��B
���쌠�̖�肾��B
>>180
> ��������̂Ɉ�ԏd�v�ȁA�n�C�p�t�H�[�}���XCPU�Ƃ����s�[�X�������Ă���̂����B
Bulldozer 8�R�A/16�R�A���n�C�p�t�H�[�}���X����Ȃ��̂��AIntel��Sandy16�R�A�ł��p�ӂ��Ă���̂��H
> ��������̂Ɉ�ԏd�v�ȁA�n�C�p�t�H�[�}���XCPU�Ƃ����s�[�X�������Ă���̂����B
Bulldozer 8�R�A/16�R�A���n�C�p�t�H�[�}���X����Ȃ��̂��AIntel��Sandy16�R�A�ł��p�ӂ��Ă���̂��H
��Bulldozer 8�R�A/16�R�A
����̓��[�p�t�H�[�}���X���R�A
sandy 8core�ŏ\��
����̓��[�p�t�H�[�}���X���R�A
sandy 8core�ŏ\��
12/16�̓T�[�o�[
6/8�̓R���V���[�}
6/8�̓R���V���[�}
�����E�����_
�X�J���E�x�N�^
��ʏo����m�\�͂��Ƃ��
���x���Ă��m������t���Ȃ��V���^�J�u���i�����ی��55�i���炢�������H�j�j
�X�J���E�x�N�^
��ʏo����m�\�͂��Ƃ��
���x���Ă��m������t���Ȃ��V���^�J�u���i�����ی��55�i���炢�������H�j�j
186 �FSocket774�F2010/05/06(��) 08:42:26 ID:MpTmikb7
sandy�����߂ƂȂ�������ɂ�BULL�Ɋ��҂��邵���Ȃ��B
>>182
AMD���̐������ł͎��s���j�b�g�̑O�H����
�R�A����1/2������ȁB
�I��HPC�p�r�݂�����
�펞�s�[�N�t�߂Ńu�����삾��
�ǂ�����Ă�100%������B
AMD���̐������ł͎��s���j�b�g�̑O�H����
�R�A����1/2������ȁB
�I��HPC�p�r�݂�����
�펞�s�[�N�t�߂Ńu�����삾��
�ǂ�����Ă�100%������B
���ꂩ��̓p���[���
����d�͂������
����10�{�����ł�����
����1/10�d�C�H��Ȃ��悤�ɏo���邩
�����Čg�тɎ���Ă����邩��
�����c��̃J�M����
����d�͂������
����10�{�����ł�����
����1/10�d�C�H��Ȃ��悤�ɏo���邩
�����Čg�тɎ���Ă����邩��
�����c��̃J�M����
�Ȃg���̃Z���X�܂ŎG���Ɏ��Ă邗
>�����Čg�тɎ���Ă����邩��
>�����c��̃J�M����
���������̂��ˁH
ttp://pc.watch.impress.co.jp/docs/news/20100506_365603.html
>Intel�A�X�}�[�g�t�H������SoC�uAtom Z6xx�v
>�����c��̃J�M����
���������̂��ˁH
ttp://pc.watch.impress.co.jp/docs/news/20100506_365603.html
>Intel�A�X�}�[�g�t�H������SoC�uAtom Z6xx�v
>>187
�ʂ����Ă������Ғʂ�ɕ����Ă���邩�c��������肾�ȁB
�ʂ����Ă������Ғʂ�ɕ����Ă���邩�c��������肾�ȁB
�e�w���c�͑��ς�炸���_�����ςȂ�������
��86�͌g�ь����ɐi�o�͂ł��Ȃ���
ARM�̏ȓd�͂�Atom���ች���ǂ��撣���Ă��ǂ����Ȃ������
ARM�̏ȓd�͂�Atom���ች���ǂ��撣���Ă��ǂ����Ȃ������
ARM����6502�V���J�Ȃ�ȁH
>>187
���ʂ̃A�v���ƈ���āA������������p�r����
�\�t�g������������Ԃ�������邩��Ȃ��B
��ʌ����Ȃ�u���̊������Ő����Ȃ�B
���ʂ̃A�v���ƈ���āA������������p�r����
�\�t�g������������Ԃ�������邩��Ȃ��B
��ʌ����Ȃ�u���̊������Ő����Ȃ�B
�\�t�g�����猩���烂�W���[����R�A���Ȃǂ��ł��悭�āA�X���b�h������Ȃ̂����d�v�B
OS���猩���i7��8�X���b�h�AGulftown��12�X���b�h�ŔF������X�P�W���[�����O����邩��ˁB
�w�ǂ̏ꍇ�AIntel��HTT�̂悤�ɃX���b�h�ԂŐ��\�����傫�����̂����A
Bulldozer�̂悤�ɃX���b�h�Ԃ̐��\�ɍ����Ȃ��ق��������Ղ��B
OS���猩���i7��8�X���b�h�AGulftown��12�X���b�h�ŔF������X�P�W���[�����O����邩��ˁB
�w�ǂ̏ꍇ�AIntel��HTT�̂悤�ɃX���b�h�ԂŐ��\�����傫�����̂����A
Bulldozer�̂悤�ɃX���b�h�Ԃ̐��\�ɍ����Ȃ��ق��������Ղ��B
>>196-197
����������
����������
199 �FSocket774�F2010/05/07(��) 02:31:36 ID:ryUHGWyB
BULL�ŋ��Ƃ������ł��ˁB
200 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 02:38:41 ID:ls/Tt+fy
�T�[�o�͓e���p�A�N���C�A���g�E�z�[�����[�U�[������4�X���b�h�ȏ�g���\�t�g�Ȃ�Ă��������ˁ[���ǂȁB
OS�̃T�[�r�X�Ɋ��蓖�Ă�CPU���ԂȂ�Č����Ă����
�������s�X���b�h���̓N���C�A���g�̃R���e�N�X�g���p�ɂɐ�ւ��Ȃ����x�ɂ���Ώ\��
OS�̃T�[�r�X�Ɋ��蓖�Ă�CPU���ԂȂ�Č����Ă����
�������s�X���b�h���̓N���C�A���g�̃R���e�N�X�g���p�ɂɐ�ւ��Ȃ����x�ɂ���Ώ\��
�c�q���t�ɓǂ߂Ό��c���Ƃ������Ă����Ȃ̂��Ȃ��̔n��
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/264
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/272
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/281
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/310
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/379
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/387
AMD�̎�����CPU�ɂ��Č�낤 ��34����
http://pc11.2ch.net/test/read.cgi/jisaku/1267796312/
�@864 ���O�F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o [sage] ���e���F2010/04/02(��) 04:26:06 ID:VnW/HhAl
�@�@�E�����Č�����̋C�ɂ��Ă���
�@�@�R���v���b�N�X�h�������������
�e�w�G���c�q������܂�����
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/272
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/281
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/310
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/379
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/387
AMD�̎�����CPU�ɂ��Č�낤 ��34����
http://pc11.2ch.net/test/read.cgi/jisaku/1267796312/
�@864 ���O�F,,�E�L�́M�E,,�j��-�������� ��OhjIkO1O8o [sage] ���e���F2010/04/02(��) 04:26:06 ID:VnW/HhAl
�@�@�E�����Č�����̋C�ɂ��Ă���
�@�@�R���v���b�N�X�h�������������
�e�w�G���c�q������܂�����
146 ���O�FSocket774[sage] ���e���F2007/09/23(��) 02:16:45 ID:uqQtZWII
�G����������炸�������o���Ă�ȁ[�B
148 ���O�F���͌��c��[sage] ���e���F2007/09/23(��) 02:41:12 ID:/aojbA/5
>>146
> �G����������炸�������o���Ă�ȁ[�B
�܂��ȁA�o�J�͒����ɒᑭ�ւƓ����đ������瑊��ɂ������˂����ǂ܂���ɂ͗ǂ�����w
�y������z�G�����{��Part44�y�����z
http://mamono.2ch.net/test/read.cgi/tubo/1270998379/
�e�w���c���ƎG���̃v���O�����m���ɒE�X
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
�G����������炸�������o���Ă�ȁ[�B
148 ���O�F���͌��c��[sage] ���e���F2007/09/23(��) 02:41:12 ID:/aojbA/5
>>146
> �G����������炸�������o���Ă�ȁ[�B
�܂��ȁA�o�J�͒����ɒᑭ�ւƓ����đ������瑊��ɂ������˂����ǂ܂���ɂ͗ǂ�����w
�y������z�G�����{��Part44�y�����z
http://mamono.2ch.net/test/read.cgi/tubo/1270998379/
�e�w���c���ƎG���̃v���O�����m���ɒE�X
http://z-temp.hp.infoseek.co.jp/2ch/Prescott699-.html
�P��CMT�ɐU�邾������Ȃ��āA
���Ƃ��v���Z�b�T���x����Cilk��spawn/sync�������Ɏ��s�ł���悤�Ȗ��߂�ς�ʔ����Ǝv�����A
���������v�V���������̂��܂�Ȃ��ł��Ȃ��B
���Ƃ��v���Z�b�T���x����Cilk��spawn/sync�������Ɏ��s�ł���悤�Ȗ��߂�ς�ʔ����Ǝv�����A
���������v�V���������̂��܂�Ȃ��ł��Ȃ��B
205 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 03:56:29 ID:ls/Tt+fy
���łɌ���������ɋψ�ɃX���b�h�������Ă��闝�z��ԂȂ�Power-Gate & Turbo-Boost�Ȃ�Ď��ɋ@�\����B
�w�r�[�ȃX���b�h�̐������Ȃ����ɁA�@���ɍ����ɏ����ł��邩���d�v����B
�ꕔ�̃R�A�̃N���b�N�������グ��̂͗L�������A����{�����K�v���ȁB
�E2��̃X�J���������Z���j�b�g�iSandy Bridge��3��j
�E2���FP/SIMD���j�b�g�iSandy Bridge��3��j
�E�e��16KB, �ш�32B/clk��L1�f�[�^�L���b�V���iSandy Bridge��32KB, 48B/clk�j
���X���b�h���̃X���[�v�b�g�ŗD�ʂ�ۂɂ͈��|�I�ɃN���b�N���オ��Ȃ��ƌ������Ǝv�����ǂȁB
4�X���b�h�ȉ��̏ꍇ�ɗL���ȗv�f���Ȃ��B
i7�͂����Ƃ��Ă��AK10���V���O���X���b�h���\�������ǂ������^��B
5�N����10�N������̃g�����h���ǂ݂���̂͂����h���������]���ɂ��đS�Ă��������琢�b�Ȃ��B
�w�r�[�ȃX���b�h�̐������Ȃ����ɁA�@���ɍ����ɏ����ł��邩���d�v����B
�ꕔ�̃R�A�̃N���b�N�������グ��̂͗L�������A����{�����K�v���ȁB
�E2��̃X�J���������Z���j�b�g�iSandy Bridge��3��j
�E2���FP/SIMD���j�b�g�iSandy Bridge��3��j
�E�e��16KB, �ш�32B/clk��L1�f�[�^�L���b�V���iSandy Bridge��32KB, 48B/clk�j
���X���b�h���̃X���[�v�b�g�ŗD�ʂ�ۂɂ͈��|�I�ɃN���b�N���オ��Ȃ��ƌ������Ǝv�����ǂȁB
4�X���b�h�ȉ��̏ꍇ�ɗL���ȗv�f���Ȃ��B
i7�͂����Ƃ��Ă��AK10���V���O���X���b�h���\�������ǂ������^��B
5�N����10�N������̃g�����h���ǂ݂���̂͂����h���������]���ɂ��đS�Ă��������琢�b�Ȃ��B
������2ch�ɒ���t���j�[�g��V�N�Ŏ��̔N��8500��
�X�[�p�[�����ی�v���O���}�[�̂������Ƃ͈Ⴄ��
�X�[�p�[�����ی�v���O���}�[�̂������Ƃ͈Ⴄ��
���łɌ����ΏĂ����g���Ȃ��Ȃ�������3�l�����剉�͓���̂���
���c����o�������[���I
���c����o�������[���I
�N���C�A���g�ŏd�v�Ȃ̂̓V���O���p�t�H�[�}���X
�x���`�ł��Ȃ�����
�x���`�ł��Ȃ�����
�Ȃ��̃V���O���^�X�N�̃p�t�H�[�}���X������قǏd�v����Ȃ��C���ŋ߂��Ă���
�@�d�v����Ȃ��Ƃ������A�O�a���Ă��ˁB
211 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 05:42:24 ID:ls/Tt+fy
�X�g���[�W�����܂�ɒx�����炾��B
�Ƃ������A�R���V���[�}�����Ƃ��Ă̓\�t�g���̂��l�^��C�����ȁB
�L�[�{�[�h�������ă}�E�X�������Ĕ��������ĉ�ʂ������āE�E�E�̔��e�łł��邱�Ƃ�
���s���������͂���B�Q�[�����܂߁B
�Ƃ������A�R���V���[�}�����Ƃ��Ă̓\�t�g���̂��l�^��C�����ȁB
�L�[�{�[�h�������ă}�E�X�������Ĕ��������ĉ�ʂ������āE�E�E�̔��e�łł��邱�Ƃ�
���s���������͂���B�Q�[�����܂߁B
�m�\�w��-200�̃V���^�J�u��������
Atom 128core�ł��ς߂����̂�
�Ȃ�ł����܂ŋɒ[�ɘb���U�邩�Ȃ�
�܂Ƃ��ɘb�����Ƃ��o���Ȃ�����Ȃ���
�܂Ƃ��ɘb�����Ƃ��o���Ȃ�����Ȃ���
�@Bull�̕��������Ó��ł���Ƃ������_�ɒB�������Ȃ�����ł���B
>>214
�ł��Q�R�A���炢�����g���Ȃ��Ƃ���
�ł��Q�R�A���炢�����g���Ȃ��Ƃ���
>>214���ɒ[�E�E�E�H
>215�͐V�Q���H
�V���^�J�u���i�G���Ƃ��������̃X���̔S���R�e�Q�j�Ȃ�
�ɒ[�Ȃ�܂�������ɖŒ��ꒃ����
>215�͐V�Q���H
�V���^�J�u���i�G���Ƃ��������̃X���̔S���R�e�Q�j�Ȃ�
�ɒ[�Ȃ�܂�������ɖŒ��ꒃ����
219 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 07:07:08 ID:ls/Tt+fy
�܂��A���������A���ς�炸�ǂމ��l�̂Ȃ����X�����肾�ȁB
�܂�2�X���b�h��4���ߓ������s�ɂ͕ς��Ȃ���
���̏�Bulldozer�̐�����8�R�A��Sandy Bridge��4�R�A�i�[��8�R�A�j�Ɨǂ��Ăǂ������̐��\�����B
����łȂ��Ƃ�6�R�A12�X���b�h�ɂ͏��Ă낤�B
AMD�̎������X�y�b�N�\�z���ƁAInteragos 16�R�A�ł��痝�_���\�l��INT/FP����Magny-Cours��1.3�{���x�B
�s���������܂ł��Ȃ����ɏI�����Ƃ�B
�ʂɃR���V���[�}�p�r�ł��������A�Q�[���i�j�Ȃ�CPU�R�A���̎��v���̂��O�a���Ă邼��
���Ƃ���Crysis�ň�̉��X���b�h�����Ă�H
�܂�PC�̃Q�[���s��͊J���҂��ڋq����R�X�g�ȃu���E�U�Q�[���ɗ����
D3D��OpenGL�g�������b�`��3D�Q�[���̎s��k���Ȃ̂͊���H�������̂��B
DX11��GPGPU���}���`�R�A���Ƒ������Ă��Ƃ���Ń\�t�g�����낭�Ɍ����������Ȃ���ǂ����悤���Ȃ��B
���ς�炸����G���R�[�h�����肪���݂Ȃ�ˁH
���������ʂ̓l�b�g�u�b�N��X�}�[�g�t�H�������s���Ă��O�Ŏ����o���čĐ�����Ƃ��̎��v�͑������������B
�܂�2�X���b�h��4���ߓ������s�ɂ͕ς��Ȃ���
���̏�Bulldozer�̐�����8�R�A��Sandy Bridge��4�R�A�i�[��8�R�A�j�Ɨǂ��Ăǂ������̐��\�����B
����łȂ��Ƃ�6�R�A12�X���b�h�ɂ͏��Ă낤�B
AMD�̎������X�y�b�N�\�z���ƁAInteragos 16�R�A�ł��痝�_���\�l��INT/FP����Magny-Cours��1.3�{���x�B
�s���������܂ł��Ȃ����ɏI�����Ƃ�B
�ʂɃR���V���[�}�p�r�ł��������A�Q�[���i�j�Ȃ�CPU�R�A���̎��v���̂��O�a���Ă邼��
���Ƃ���Crysis�ň�̉��X���b�h�����Ă�H
�܂�PC�̃Q�[���s��͊J���҂��ڋq����R�X�g�ȃu���E�U�Q�[���ɗ����
D3D��OpenGL�g�������b�`��3D�Q�[���̎s��k���Ȃ̂͊���H�������̂��B
DX11��GPGPU���}���`�R�A���Ƒ������Ă��Ƃ���Ń\�t�g�����낭�Ɍ����������Ȃ���ǂ����悤���Ȃ��B
���ς�炸����G���R�[�h�����肪���݂Ȃ�ˁH
���������ʂ̓l�b�g�u�b�N��X�}�[�g�t�H�������s���Ă��O�Ŏ����o���čĐ�����Ƃ��̎��v�͑������������B
DX11�ɂ��Ă��A�قƂ�nj����ڂ��ς���̂���
�R�X�g�ɑ�����ʂ��ΐ����I�����
�n�[�h�I�ɂ��\�t�g�I�ɂ�
�R�X�g�ɑ�����ʂ��ΐ����I�����
�n�[�h�I�ɂ��\�t�g�I�ɂ�
���������Ă�̂́A����́@Intel�@����B
AMD�̂͐����B
AMD�̂͐����B
������ƕ\�����ԈႦ������
>214�͋ɒ[�Ƃ������I�O��Ȃ����̔n��
�V���^�J�u���iID:ls/Tt+fy�j�͖Œ��ꒃ�Ƃ������
�E�ǂꂾ�����Ă����\�Z�o�ɉ��Z�퐔�Ŋ|���Z����̂���߂Ȃ�
�E�ǂꂾ�����Ă�����GPU��SIMD���j�b�g��x86�f�R�[�_���t���Ă�ƐM���ċ^��Ȃ�
�E�ǂꂾ�����Ă��u���܂�Pentium4�ɂ�L1D�������v
�E�ǂꂾ�����Ă������i��������j����ړ��Ăł��̃X���ɔS��
�Ƃ����悤�Ƀz���S�J�Ɩϑz�S�J�ƃo�O�S�J�R�s�y���ӊO�Ɋ�p�ɐD�������
�l�b�g��ʂ��Ă��L���Ă���قNjC���������C�J�L���S�L�u����
>214�͋ɒ[�Ƃ������I�O��Ȃ����̔n��
�V���^�J�u���iID:ls/Tt+fy�j�͖Œ��ꒃ�Ƃ������
�E�ǂꂾ�����Ă����\�Z�o�ɉ��Z�퐔�Ŋ|���Z����̂���߂Ȃ�
�E�ǂꂾ�����Ă�����GPU��SIMD���j�b�g��x86�f�R�[�_���t���Ă�ƐM���ċ^��Ȃ�
�E�ǂꂾ�����Ă��u���܂�Pentium4�ɂ�L1D�������v
�E�ǂꂾ�����Ă������i��������j����ړ��Ăł��̃X���ɔS��
�Ƃ����悤�Ƀz���S�J�Ɩϑz�S�J�ƃo�O�S�J�R�s�y���ӊO�Ɋ�p�ɐD�������
�l�b�g��ʂ��Ă��L���Ă���قNjC���������C�J�L���S�L�u����
223 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 07:57:05 ID:ls/Tt+fy
1�R�A������3���߂Ƃ�4���߂Ƃ��������s�ł���R�A���{����8�Ȃ���16����Ȃ�e���p
2�̐����N���X�^�ōő�4���߂̃f�R�[�_���L�����L���Ă�̂�2�R�A�ƌ����Ă邾������B
�R�A���̐������ƌ����Ă��d���Ȃ��B
���Ƃ́A2�̃X���b�h�ŋ��L���Ă�4����/clk�̕��Z���\�[�X���A
���ׂɉ�����3:1�Ƃ�4:0�Ƃ��ɂ����I�Ɋ��蓖�Ă���iSandy Bridge�j��
���邢�̓N���X�^���̉��Z���\�[�X���œ��ł��iBullDOZEr�j���A�ǂ������}�V���ƌ����b����
2�̐����N���X�^�ōő�4���߂̃f�R�[�_���L�����L���Ă�̂�2�R�A�ƌ����Ă邾������B
�R�A���̐������ƌ����Ă��d���Ȃ��B
���Ƃ́A2�̃X���b�h�ŋ��L���Ă�4����/clk�̕��Z���\�[�X���A
���ׂɉ�����3:1�Ƃ�4:0�Ƃ��ɂ����I�Ɋ��蓖�Ă���iSandy Bridge�j��
���邢�̓N���X�^���̉��Z���\�[�X���œ��ł��iBullDOZEr�j���A�ǂ������}�V���ƌ����b����
224 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 07:57:46 ID:ls/Tt+fy
��2�̐����N���X�^�ōő�4���߂̃f�R�[�_�����L���Ă�̂�2�R�A�ƌ����Ă邾������B
�܂��G����A���̃R�e�͕ʐl�L�����̐ݒ�Ȃ̂��H
>>223
Sandy Bridge�̉��Z���\�[�X�̓|�[�g6�ŁA�ő�6����/clk���낤�BALU��3��
C++�ŏ����ꂽ�I�p�v���O�������ƁA���Z���\�[�X����Ȃ���L1D$�̃��C�e���V�E�ш�ɐ������ꂻ���ȋC������
������u�R�A�v���Ƃ�L1D$������Bulldozer�͐����n�x���`�ňӊO�ƑP�킷�邩�������
Sandy Bridge�̉��Z���\�[�X�̓|�[�g6�ŁA�ő�6����/clk���낤�BALU��3��
C++�ŏ����ꂽ�I�p�v���O�������ƁA���Z���\�[�X����Ȃ���L1D$�̃��C�e���V�E�ш�ɐ������ꂻ���ȋC������
������u�R�A�v���Ƃ�L1D$������Bulldozer�͐����n�x���`�ňӊO�ƑP�킷�邩�������
>>220
>DX11�ɂ��Ă��A�قƂ�nj����ڂ��ς���̂���
�m���ɂ���͂��邗
�Q�[������Ă鎞�ɂ��̈Ⴂ�ɋC�t���͖̂�������
�����R�X�g�Ɍ�����Ȃ��Ɣ��f���ꂽ��ǂ�ȋK�i���p���
>DX11�ɂ��Ă��A�قƂ�nj����ڂ��ς���̂���
�m���ɂ���͂��邗
�Q�[������Ă鎞�ɂ��̈Ⴂ�ɋC�t���͖̂�������
�����R�X�g�Ɍ�����Ȃ��Ɣ��f���ꂽ��ǂ�ȋK�i���p���
DX11�͊J���Җڐ��ō��肳�ꂽ����������(���₷���d���Ƃ����Ӗ���)�B�\���̌���̓e�b�Z���[�V�������炢����
229 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 08:50:52 ID:ls/Tt+fy
>>226
���m�Ɍ����Ɠ����ш��1�N���b�N������4 Fused-��OPs��
Fusion�ł��Ȃ���OPs�̑g�ݍ��킹������̂ŕK������6�|�[�g�ɓ������s�o����킯�ł͂Ȃ��B
���[�h�E�X�g�A�́u�ш�v���Č������Ⴄ��SSE�O��ɂȂ��Ă��܂������s�̂ق����d�v�ł́H
���Ȃ݂ɖ^�������ɁA��ʓI�ȃR�[�h�ŕ��ς���ƃ��[�h�I�y���[�V�����̔��s�p�x��
�R�[�h�V�[�P���X�S�̂�1/5�A�X�g�A�͍X�ɂ���1/4���x�B
Load���j�b�g1�{�ł��d���Ă����A2�{�ɂȂ������Ƃ�Load���삪������x�W�����Ă��Ή��ł���悤�ɂȂ�̂ł́H
1�̃X�P�W���[����2�̃X���b�h�̃X�P�W���[�������̂͂���Ȃ�ɗL������B
2�̖��߃X�g���[���Ԃ̈ˑ��W�͏�ɑ��݂��Ȃ����A���C�e���V�̂����閽�߂��݂���
�C���^�[���[�u���邱�Ƃŏ[�U�������߂邱�Ƃ��ł���B
Bulldozer�̓N���X�^��������Ă镪�A���ꂼ���Integer�X�P�W���[���͂��ꂼ��ŕʁX�ɁA
���ꖽ�߃X�g���[���Ԃŏ�������o���镔���𒊏o���A���בւ��Ȃ���Ȃ�Ȃ��B
�{���ɋ��ЂɂȂ�͍̂X��SMT�i1���W���[����4�X���b�h�������s�j�����o���������Ǝv���B
���m�Ɍ����Ɠ����ш��1�N���b�N������4 Fused-��OPs��
Fusion�ł��Ȃ���OPs�̑g�ݍ��킹������̂ŕK������6�|�[�g�ɓ������s�o����킯�ł͂Ȃ��B
���[�h�E�X�g�A�́u�ш�v���Č������Ⴄ��SSE�O��ɂȂ��Ă��܂������s�̂ق����d�v�ł́H
���Ȃ݂ɖ^�������ɁA��ʓI�ȃR�[�h�ŕ��ς���ƃ��[�h�I�y���[�V�����̔��s�p�x��
�R�[�h�V�[�P���X�S�̂�1/5�A�X�g�A�͍X�ɂ���1/4���x�B
Load���j�b�g1�{�ł��d���Ă����A2�{�ɂȂ������Ƃ�Load���삪������x�W�����Ă��Ή��ł���悤�ɂȂ�̂ł́H
1�̃X�P�W���[����2�̃X���b�h�̃X�P�W���[�������̂͂���Ȃ�ɗL������B
2�̖��߃X�g���[���Ԃ̈ˑ��W�͏�ɑ��݂��Ȃ����A���C�e���V�̂����閽�߂��݂���
�C���^�[���[�u���邱�Ƃŏ[�U�������߂邱�Ƃ��ł���B
Bulldozer�̓N���X�^��������Ă镪�A���ꂼ���Integer�X�P�W���[���͂��ꂼ��ŕʁX�ɁA
���ꖽ�߃X�g���[���Ԃŏ�������o���镔���𒊏o���A���בւ��Ȃ���Ȃ�Ȃ��B
�{���ɋ��ЂɂȂ�͍̂X��SMT�i1���W���[����4�X���b�h�������s�j�����o���������Ǝv���B
DirectX������������㎀����z�ƁuDX11�̖����ɂ��āv������Ă��Ӗ��Ȃ�
������������i��������j�����D���ȋC���������V���^�J�u���̋Ɍ��I�Ȓm�\�̒Ⴓ�ɂ����Q�̂ق����y���ɖ��
������������i��������j�����D���ȋC���������V���^�J�u���̋Ɍ��I�Ȓm�\�̒Ⴓ�ɂ����Q�̂ق����y���ɖ��
231 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 09:31:23 ID:ls/Tt+fy
>>228
�g�уQ�[���Ń��[�V�����Z���T��}���`�^�b�`�p�l���A����3D�t���iDS������@�j���g����̂ɔ�ׂ��
�����ς�����̂��A����Ҏ��_�ʼn���Â炢��ȁB
���E�I�Ɍ��Ă�PC�Q�[���̎s��Ő������Ă�̂�Mac�EFirefox�ł������Ē�R�X�g�ȃu���E�U�Q�[��
��X�y�b�N�ł�����MMO���炢�ŁA�f�B�X�N���[�g���K�v�ȃN���X�͐��E�I�ɂ����ނ��Ă�B
�����炱���̔�Q�[���p�r�̃j�[�Y�J��iGPGPU�j������A1�l�ɕ��������킹���肵�Ă�킯�ŁB
GPGPU���Ē��xDSP�Ń��f���@�\���������Ă݂܂����A�݂����ȃ����ł���H
�ő��������邱�Ƃ������Ȃ����T�E���h�J�[�h�Ɠ������𒅎��ɕ���ł�B
�g�уQ�[���Ń��[�V�����Z���T��}���`�^�b�`�p�l���A����3D�t���iDS������@�j���g����̂ɔ�ׂ��
�����ς�����̂��A����Ҏ��_�ʼn���Â炢��ȁB
���E�I�Ɍ��Ă�PC�Q�[���̎s��Ő������Ă�̂�Mac�EFirefox�ł������Ē�R�X�g�ȃu���E�U�Q�[��
��X�y�b�N�ł�����MMO���炢�ŁA�f�B�X�N���[�g���K�v�ȃN���X�͐��E�I�ɂ����ނ��Ă�B
�����炱���̔�Q�[���p�r�̃j�[�Y�J��iGPGPU�j������A1�l�ɕ��������킹���肵�Ă�킯�ŁB
GPGPU���Ē��xDSP�Ń��f���@�\���������Ă݂܂����A�݂����ȃ����ł���H
�ő��������邱�Ƃ������Ȃ����T�E���h�J�[�h�Ɠ������𒅎��ɕ���ł�B
>>229
�������ɐ������Z���[�N���[�h��L1D$�̃��[�h�E�X�g�A�u�ш�v�̓N���e�B�J���łȂ���������
�����[�h�E�X�g�A�́u�ш�v���Č������Ⴄ��SSE�O��ɂȂ��Ă��܂������s�̂ق����d�v�ł́H
SSE���K�V�K�V�g���v���O�����ł́A���ߔ��s�ш���L2�`L3�`���C���������ш�ɐ�������邱�Ƃ�����
SSE�n�x���`�ł�HT������Sandy Bridge�Ɣ��R�A������Bulldozer�̐킢�ɂȂ�Ǝv�����A
���̕���ł̓L���b�V���e�ʁE�ш�̋Z�p�ɏG�ł�Intel��AMD�͏��ĂȂ����낤��
�������ɐ������Z���[�N���[�h��L1D$�̃��[�h�E�X�g�A�u�ш�v�̓N���e�B�J���łȂ���������
�����[�h�E�X�g�A�́u�ш�v���Č������Ⴄ��SSE�O��ɂȂ��Ă��܂������s�̂ق����d�v�ł́H
SSE���K�V�K�V�g���v���O�����ł́A���ߔ��s�ш���L2�`L3�`���C���������ш�ɐ�������邱�Ƃ�����
SSE�n�x���`�ł�HT������Sandy Bridge�Ɣ��R�A������Bulldozer�̐킢�ɂȂ�Ǝv�����A
���̕���ł̓L���b�V���e�ʁE�ш�̋Z�p�ɏG�ł�Intel��AMD�͏��ĂȂ����낤��
>>231
�S���E��PC�Q�[���s��K�͂̐��ڂ��Ăǂ�Ȋ����Ȃ�H
�S���E��PC�Q�[���s��K�͂̐��ڂ��Ăǂ�Ȋ����Ȃ�H
Bulldozer��1�R�A������1��128bit��SIMD���L����
���W���[������1�R�A���~�߂鎖�ɈӖ�������̂�
���W���[������1�R�A���~�߂鎖�ɈӖ�������̂�
PC�Q�[���͐��ނ��Ă�ƌ������ǔ���I�ɂ͂ǂ��Ȃ́H
�R���V���[�}�@�̔��㊄���������Ă�̂͊m�����낤���ǂ�
Modern Warfare 2�͔������T�̔����PC�łʼnߋ��ō��������炵����(���̌�͒m���)
�R���V���[�}�@�̔��㊄���������Ă�̂͊m�����낤���ǂ�
Modern Warfare 2�͔������T�̔����PC�łʼnߋ��ō��������炵����(���̌�͒m���)
2009�N�܂ł̒i�K�ł́A�f�B�X�N���[�gGPU�s�ꂪ���ނ��Ă�����ăf�[�^�͖������낤
���C�g��PC�Q�[����PC�Q�[���̃p�C���L���邱�Ƃɖ𗧂��Ă��邪
�w�r�[�ȃQ�[���̎s���H�����̂ł͂Ȃ�
�ƌ��������A���C�g��PC�Q�[�����D���Ă���s��Ƃ����̂�TV�␘�u�^�̉ƒ�p�Q�[���@�Ȃǂł�����
PC�Q�[���̎s����L���鎖�ɖ��ɗ����Ă���
���C�g��PC�Q�[����PC�Q�[���̃p�C���L���邱�Ƃɖ𗧂��Ă��邪
�w�r�[�ȃQ�[���̎s���H�����̂ł͂Ȃ�
�ƌ��������A���C�g��PC�Q�[�����D���Ă���s��Ƃ����̂�TV�␘�u�^�̉ƒ�p�Q�[���@�Ȃǂł�����
PC�Q�[���̎s����L���鎖�ɖ��ɗ����Ă���
�I���{�̐��\���������Ă���̂�PC�Q�[���Ƃ��Ă͑劽�}
Llano��790GX����ׂ�Ƃǂ̒��x�Q�[���̃X�R�A�����ł����ȂȁH
����Ƃ���̏�ƁALlano�̂ق����f�R��̐��\
240 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 10:45:24 ID:ls/Tt+fy
>>233
���ʂ̂͒m���B
PC�̃p�b�P�[�W�Q�[���s���Crytek���R���V���[�}�ɓ����锭������������Ŋ��ɏI���̎n�܂肾�����B
��ŁA����PC�Q�[�����̓������������R���V���[�}�Q�[���s�ꎩ�̂���[���ȕs���B
�Ă������������V����̂ق��������͂��邾��
http://www.itmedia.co.jp/news/articles/1002/17/news087.html
���ʂ̂͒m���B
PC�̃p�b�P�[�W�Q�[���s���Crytek���R���V���[�}�ɓ����锭������������Ŋ��ɏI���̎n�܂肾�����B
��ŁA����PC�Q�[�����̓������������R���V���[�}�Q�[���s�ꎩ�̂���[���ȕs���B
�Ă������������V����̂ق��������͂��邾��
http://www.itmedia.co.jp/news/articles/1002/17/news087.html
241 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 10:51:55 ID:ls/Tt+fy
>>236
�w�r�[�ȃQ�[���Ƀ��C�g�w�����Ă��Ă��ꂽ����\�t�g���[�J�[�͋������܂��z���Ă��킯�����H
�������_�ŁuDX11�̃Q�[����������v�ƌ����Ă���̂��A���ɏI����Ă�B
�w�r�[�ȃQ�[���Ƀ��C�g�w�����Ă��Ă��ꂽ����\�t�g���[�J�[�͋������܂��z���Ă��킯�����H
�������_�ŁuDX11�̃Q�[����������v�ƌ����Ă���̂��A���ɏI����Ă�B
���C�g�Q�[���ɗ��ꂴ��Ȃ��Ȃ����̂�2007�N�ȍ~�̕s���E�s���̗��Ȃ��
���͂܂����Ă����Ă�3D����Ă��A�L�����قłȂ�Ƃ�����Ă����邪
���̑��A�命���̒������[�J�[�͂�肽���Ă����Ȃ����Ă��ŁA�Ȃ�Ƃ������c�낤�ƕK��
���͂܂����Ă����Ă�3D����Ă��A�L�����قłȂ�Ƃ�����Ă����邪
���̑��A�命���̒������[�J�[�͂�肽���Ă����Ȃ����Ă��ŁA�Ȃ�Ƃ������c�낤�ƕK��
243 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 11:25:52 ID:ls/Tt+fy
�\���ł���O���t�B�b�N�����ׂɂȂ�Ȃ�قǃR�X�g�͒��ˏオ�邶���B
�e�N�X�`���̉𑜓x����������ǁA�V�F�[�_�v���O���}�̐l������ɂȂ��B
�R���V���[�}�@�ł����Ȃ�PS2����ɂ͕��ϊJ�����5���~���x�������Ă����̂�PS3/Xbox�ł�30���~���x�����邻���ȁB
��ł����ă��[�U�[��5�`6�{�ɑ�����Ȃ�܂������p�C�����Ă邶���B
���ɖڂ�������J�W���A���ȃQ�[���v���b�g�t�H�[���̂ق������s���Ă�B
������n�C�G���h�Q�[���}�j�A���]��ł��A�\�t�g���[�J�[�������B
�e�N�X�`���̉𑜓x����������ǁA�V�F�[�_�v���O���}�̐l������ɂȂ��B
�R���V���[�}�@�ł����Ȃ�PS2����ɂ͕��ϊJ�����5���~���x�������Ă����̂�PS3/Xbox�ł�30���~���x�����邻���ȁB
��ł����ă��[�U�[��5�`6�{�ɑ�����Ȃ�܂������p�C�����Ă邶���B
���ɖڂ�������J�W���A���ȃQ�[���v���b�g�t�H�[���̂ق������s���Ă�B
������n�C�G���h�Q�[���}�j�A���]��ł��A�\�t�g���[�J�[�������B
�܂��G����A���̃R�e�͕ʐl�L�����̐ݒ�Ȃ̂��H
����Řb������z���Č������Ƃ�����悗
��v���̍����͂���Ƃ͕ʂ���
��v���̍����͂���Ƃ͕ʂ���
246 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 12:01:24 ID:ls/Tt+fy
�N�ƒN�����ꂩ�]�X����Ȃ��ē��e�ɓ˂����߂�
���₳��̐^��͍s���ɂ���Ď������
���₳��̐^��͍s���ɂ���Ď������
�J������Ă��������ꂭ�炢�ł���
�@PS3�F3.9���~
�@360�F1.9���~
�@Wii�F1.3���~
�@PS3�F3.9���~
�@360�F1.9���~
�@Wii�F1.3���~
�^��ɉ��l������������S���Ă�����Ƃ���
249 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 12:18:15 ID:ls/Tt+fy
�����\�t�g�̃G���W���g���ŗ}�����߂���Ȃ����ˁB
���̓C�j�V�����R�X�g�B
������͂�����DX11�g�����ėp�Q�[���G���W�����ĒN���J������́H
DX10����DX9�Ɩw�Ǎ����Ȃ������C��������B
�i�̈ӂ�XP/DX9���ŃI�v�V�����𐧌����������̃\�t�g�Ȃ炢�������������ǁj
����UnrealEngine��Tim�̔������炷��Ǝ��̃R���V���[�}�Q�[�����o�鍠�܂ʼn����������C������
���̓C�j�V�����R�X�g�B
������͂�����DX11�g�����ėp�Q�[���G���W�����ĒN���J������́H
DX10����DX9�Ɩw�Ǎ����Ȃ������C��������B
�i�̈ӂ�XP/DX9���ŃI�v�V�����𐧌����������̃\�t�g�Ȃ炢�������������ǁj
����UnrealEngine��Tim�̔������炷��Ǝ��̃R���V���[�}�Q�[�����o�鍠�܂ʼn����������C������
�C���������z���S�L�u�����Ă̂�
�N�ɂ��ǂ܂�Ȃ��ϑz���������܂����ĒN�ɂ��@����Ȃ��Ƃ��ꂾ���ő������Ė\��܂��邩��
���ۑS�ׂ̈ɂ��Ȃ�ׂ����̃S�L�u�������Ȓm�\�̋C���������V���^�z����n���ɂ���ׂ��Ȃ낤����
����ς�l���̖��ʎg��������ȁ`
���Ƃ��Ȃ����E�E�E
�N�ɂ��ǂ܂�Ȃ��ϑz���������܂����ĒN�ɂ��@����Ȃ��Ƃ��ꂾ���ő������Ė\��܂��邩��
���ۑS�ׂ̈ɂ��Ȃ�ׂ����̃S�L�u�������Ȓm�\�̋C���������V���^�z����n���ɂ���ׂ��Ȃ낤����
����ς�l���̖��ʎg��������ȁ`
���Ƃ��Ȃ����E�E�E
251 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 12:37:47 ID:ls/Tt+fy
���l�͓��������̂ʼn������_�ł��܂���
���ǂ�
���ǂ�
���R���s���[�^�[�Q�[���s��Ńp�C�����肻���Ȃ͉̂ƒ�p�Q�[���@����
�g�уQ�[���@�͂܂��L�тĂ邪�A���u�^�Q�[���@�͂������N�s��K�͉͂����̂܂�
�����u���^�Q�[���@���S�����������́wTV�̑O�x�̃|�W�V�������D�킾����
�ł�����30�Α�ȉ���TV�ł͂Ȃ�PC�̑O�ł������i30��ȉ���40��ȏ�ŌX��������I�ɈقȂ�j
�܂�A���́wPC�̑O�x�̃|�W�V�����̑��D��ł���A���u�^�Q�[���@�̏������͂��Ȃ茵����
���v���b�g�t�H�[���̋K�͂��������Ȃ��s��ŃQ�[����ɂ�
�@����҂Ɂu�Q�[���{�Q�[���@�v�𗼕����킹����̖��͂̂���Q�[�������Ȃ����
�@���ɉƒ�p�Q�[���@��1�@���1�s��ƍl�����ꍇ��PC�Q�[���s����͂邩�ɏ�����
�g�ь^�Q�[���@���I�ɂ͎��Ă邪�A�������͌g�ѓd�b�̋@�\����荞�߂�Ή\���͖����͖���
�g�уQ�[���@�͂܂��L�тĂ邪�A���u�^�Q�[���@�͂������N�s��K�͉͂����̂܂�
�����u���^�Q�[���@���S�����������́wTV�̑O�x�̃|�W�V�������D�킾����
�ł�����30�Α�ȉ���TV�ł͂Ȃ�PC�̑O�ł������i30��ȉ���40��ȏ�ŌX��������I�ɈقȂ�j
�܂�A���́wPC�̑O�x�̃|�W�V�����̑��D��ł���A���u�^�Q�[���@�̏������͂��Ȃ茵����
���v���b�g�t�H�[���̋K�͂��������Ȃ��s��ŃQ�[����ɂ�
�@����҂Ɂu�Q�[���{�Q�[���@�v�𗼕����킹����̖��͂̂���Q�[�������Ȃ����
�@���ɉƒ�p�Q�[���@��1�@���1�s��ƍl�����ꍇ��PC�Q�[���s����͂邩�ɏ�����
�g�ь^�Q�[���@���I�ɂ͎��Ă邪�A�������͌g�ѓd�b�̋@�\����荞�߂�Ή\���͖����͖���
253 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 12:58:37 ID:ls/Tt+fy
�p�b�P�[�W�\�t�g�r�W�l�X�s�т̎s��̒��ŃT�[�o�W���^�̃T�[�r�X�Ő����������߂�
�؍��̃Q�[����ЂȂ�痂����Ǝv���ˁB
iPhone�̂���͐�ΓI�ȃn�[�h���y�䐔���܂��܂����Ȃ����炻��قNj��ЂɂȂ��ĂȂ���
�X�ɃA�}�`���A�̎Q����ǂ��X�ɒႢAndroid���{�i�I�ɗ����オ��ΔC�V�������ׂ���Ȃ�
�؍��̃Q�[����ЂȂ�痂����Ǝv���ˁB
iPhone�̂���͐�ΓI�ȃn�[�h���y�䐔���܂��܂����Ȃ����炻��قNj��ЂɂȂ��ĂȂ���
�X�ɃA�}�`���A�̎Q����ǂ��X�ɒႢAndroid���{�i�I�ɗ����オ��ΔC�V�������ׂ���Ȃ�
�����������{�ɂ�
����ȃX�L���̗L��A�}�`���A�Ȃ�Ă��Ȃ�����
��������A��肪�����Ȃ����낤��
���̎����ɓƗ�����o�J�͂��Ȃ�
����ȃX�L���̗L��A�}�`���A�Ȃ�Ă��Ȃ�����
��������A��肪�����Ȃ����낤��
���̎����ɓƗ�����o�J�͂��Ȃ�
255 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 13:11:16 ID:ls/Tt+fy
���{�̃A�}�`���AFlash�E�l�ƌ_�ĊC�O�A�[�e�B�X�g�̃v�����[�V�����r�f�I��������L�����y�����Ђ������Ă��ȁE�E�E�B
�Q�[�����ΐ�Ȃ獂�x��AI�Ȃ�ĕK�v�Ȃ����炿����ƃv���O�����������w���ł��ȒP�ɍ�ꂿ�Ⴄ�̂�����H���̗��R
�����}���I��|�P������藬�s���i���o�Ă��邩�Ƃ����ƁA�����ȋC������
�Q�[�����ΐ�Ȃ獂�x��AI�Ȃ�ĕK�v�Ȃ����炿����ƃv���O�����������w���ł��ȒP�ɍ�ꂿ�Ⴄ�̂�����H���̗��R
�����}���I��|�P������藬�s���i���o�Ă��邩�Ƃ����ƁA�����ȋC������
>>254
���{�̃v���O���}�ւ̑ҋ������炵�����ǂ�
������˔\���W�܂�Ȃ�
IQ50�������U�v���O���}��
����ȏ�Ȃ�Ȃ��H���ăC���[�W
���̎d�����Ȃ����ł���Ă�z�̂ق����X�L��������
���{�̃v���O���}�ւ̑ҋ������炵�����ǂ�
������˔\���W�܂�Ȃ�
IQ50�������U�v���O���}��
����ȏ�Ȃ�Ȃ��H���ăC���[�W
���̎d�����Ȃ����ł���Ă�z�̂ق����X�L��������
ID:uIYAJENY
����͂Ђǂ�
����͂Ђǂ�
�N�ɂ��ǂ܂�Ȃ��ϑz�����̗�
http://pc11.2ch.net/test/read.cgi/jisaku/1272985619/250
http://pc11.2ch.net/test/read.cgi/jisaku/1272985619/250
259 �FSocket774�F2010/05/07(��) 14:00:26 ID:j7r2atdW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWW
canvas3d��o3d�Ƃ��u���E�U��Ŏ�y��3d������API���o�ꂵ�n�߂Ă邩��
�J�W���A���ȃu���E�U�Q�[�ł�3d������̎嗬�ɂȂ�̂͊ԈႢ�Ȃ���
�����炭HTML5�ƈꏏ�ɕ��y����͂�
�Ƃ͂����Ă�FF14��FPS�݂����ȃn�C�G���h�u���̂��̂���Ȃ�
�}���I��݂�S���̂悤�ȃf�t�H�������ꂽ���̂��낤����
�������C���X�R�s�v�Ńu���E�U��Ŏ�y�ɗV�ׂ�悤�ɂȂ��
���[�U�[���₷�`�����X�Ƒ����ĐϋɓI�ɃR���e���c�����������͂�
����ǂ��납website�ł����Ӗ���3d�g���Ƃ����o�Ă���
����flash�\��܂���̃T�C�g�̂悤�ɂ˂�
Llano�͍���web�̏��猩���GPU���ߏ�Ȑ��\�Ɍ����邩������Ȃ���
������l����Ƃ��̃��x���͍Œ���ɂȂ邩������Ȃ�
�J�W���A���ȃu���E�U�Q�[�ł�3d������̎嗬�ɂȂ�̂͊ԈႢ�Ȃ���
�����炭HTML5�ƈꏏ�ɕ��y����͂�
�Ƃ͂����Ă�FF14��FPS�݂����ȃn�C�G���h�u���̂��̂���Ȃ�
�}���I��݂�S���̂悤�ȃf�t�H�������ꂽ���̂��낤����
�������C���X�R�s�v�Ńu���E�U��Ŏ�y�ɗV�ׂ�悤�ɂȂ��
���[�U�[���₷�`�����X�Ƒ����ĐϋɓI�ɃR���e���c�����������͂�
����ǂ��납website�ł����Ӗ���3d�g���Ƃ����o�Ă���
����flash�\��܂���̃T�C�g�̂悤�ɂ˂�
Llano�͍���web�̏��猩���GPU���ߏ�Ȑ��\�Ɍ����邩������Ȃ���
������l����Ƃ��̃��x���͍Œ���ɂȂ邩������Ȃ�
��������c�q���Z�l�Ƃ��Ē蒅���Ă��
>>220
�u�����ځv�����Ɍ����Ă�����DX10�Ői���͂قƂ�ǎ~�܂��Ă�B
�u�����ځv�����Ɍ����Ă�����DX10�Ői���͂قƂ�ǎ~�܂��Ă�B
>>262
�����v�X��AMD�����\��Intel�ɏ����������������l�K�L�����ɕK���Ȃ낤��w
�����v�X��AMD�����\��Intel�ɏ����������������l�K�L�����ɕK���Ȃ낤��w
DX10.1�ȍ~�͉��ʌ݊���������̂�
11�̉摜���債�Đi�����Ă��Ȃ�����Ƃ�����10�ɂ킴�킴���܂�K�v�͂قƂ�ǂȂ�
GeForce�̕��͈�C�ɕς���Ă��܂����̂ŕ�����Ȃ���
Radeon��5�V���[�Y�Ɋւ��Ă͑債�ăg�����W�X�^���������ĂȂ��悤������
11�̉摜���債�Đi�����Ă��Ȃ�����Ƃ�����10�ɂ킴�킴���܂�K�v�͂قƂ�ǂȂ�
GeForce�̕��͈�C�ɕς���Ă��܂����̂ŕ�����Ȃ���
Radeon��5�V���[�Y�Ɋւ��Ă͑債�ăg�����W�X�^���������ĂȂ��悤������
266 �F,,�E�L�́M�E,,�j��-�������F2010/05/07(��) 19:26:04 ID:ls/Tt+fy
>>264
Atom���Phenom X6�̂ق����������낤���ǂ��ꂪ�ǂ������H
Atom���Phenom X6�̂ق����������낤���ǂ��ꂪ�ǂ������H
�����ŏ����Ă��Č����������炩�ɂ��������̂ɋC������
�����ς���Ă��ŐQ���
�����ς���Ă��ŐQ���
DirectX10���i�܂Ȃ��̂�MS�̐ӔC����B
��l����XP�ł��Ή������Ă��܂��悩������B
��l����XP�ł��Ή������Ă��܂��悩������B
�Ή������Ă����h���͑債�ĕς����
MS�I�ɂ�DirectX10���g���悤���g���܂���Windows����������ł�������ȁB
���y���i�܂Ȃ����őΉ��O���t�B�b�N�J�[�h�����Ӗ��ɂȂ낤���m�������Ƃł͂Ȃ����낤�B
���y���i�܂Ȃ����őΉ��O���t�B�b�N�J�[�h�����Ӗ��ɂȂ낤���m�������Ƃł͂Ȃ����낤�B
�Ƃ���őO�̃G�C�v�����t�[���˂���Bulldozer�̃t�F�C�N�摜������������
���̒���4KB�̃g���[�X�L���b�V�����ă�ops���Z���Ƃǂ�ʂ̗e�ʁH
���̒���4KB�̃g���[�X�L���b�V�����ă�ops���Z���Ƃǂ�ʂ̗e�ʁH
�d���Ȃ��Ȓc�q��{���N��������
�����ǂ��Ƃ�����Ȃ��A5�N��10�N�゠�邢�͍X�ɂ��̐�̐��E�̃Q�[�����A
DX9�x�[�X�̍��Ɖ����ς���ڂ��O���t�B�b�N�ƃQ�[�����̂܂܂��Ǝv���Ă���̂���
�v���Z�b�T�̐��\��𑜓x�A�ʐM�ш�Ȃ����邱�Ƃ͂����Ă�����ێ��Ȃ�Ă��Ƃ͂Ȃ��̂ɂ�
10�N��Ȃ͂ǂ���R�������̔{�ȏ�A���m�ɂ���Ă�10�{���炢�ɐi�����Ă��邾�낤��
������������������z���Ēi�K�I�Ƀn�[�h���\�t�g���i�����Ă���Œ����덡��
�c�q���D���ȃu���E�U�Q�[��Ipad�Ƃ������āA
�����I�ɂ�DX11���x����API�g����GPU�ɂ��A�N�Z�����[�V�������o���鍂�x�Ȃ��̂��o�Ă��邾�낤
����ǂ�ȋZ�p�v�V��u�[�������邩��������Ȃ��̂ɁA������̋K�i�ɔ���ꂽ�܂܂ł����Ƃ��v�l��~�ɂ��قǂ�����
�����ǂ��Ƃ�����Ȃ��A5�N��10�N�゠�邢�͍X�ɂ��̐�̐��E�̃Q�[�����A
DX9�x�[�X�̍��Ɖ����ς���ڂ��O���t�B�b�N�ƃQ�[�����̂܂܂��Ǝv���Ă���̂���
�v���Z�b�T�̐��\��𑜓x�A�ʐM�ш�Ȃ����邱�Ƃ͂����Ă�����ێ��Ȃ�Ă��Ƃ͂Ȃ��̂ɂ�
10�N��Ȃ͂ǂ���R�������̔{�ȏ�A���m�ɂ���Ă�10�{���炢�ɐi�����Ă��邾�낤��
������������������z���Ēi�K�I�Ƀn�[�h���\�t�g���i�����Ă���Œ����덡��
�c�q���D���ȃu���E�U�Q�[��Ipad�Ƃ������āA
�����I�ɂ�DX11���x����API�g����GPU�ɂ��A�N�Z�����[�V�������o���鍂�x�Ȃ��̂��o�Ă��邾�낤
����ǂ�ȋZ�p�v�V��u�[�������邩��������Ȃ��̂ɁA������̋K�i�ɔ���ꂽ�܂܂ł����Ƃ��v�l��~�ɂ��قǂ�����
>>229
��ڈȍ~�ɓ��@�}���`�X���b�f�B���O����肻�����Ęb���o�Ă��܂���
����Bulldozer�̃s�[�N�����\�͂�SandyBridge�ƒ��荇���͓̂���ł����ˁH
��ڈȍ~�ɓ��@�}���`�X���b�f�B���O����肻�����Ęb���o�Ă��܂���
����Bulldozer�̃s�[�N�����\�͂�SandyBridge�ƒ��荇���͓̂���ł����ˁH
Bulldozer�̐F��ȉ���L���ǂ�Ŏv�������ǁA
�����AMD��CPU�J���̕����������\������ȓd�͐��̌�������Ȃ�ӎ����Ă���悤�Ɍ�����B
�p�C�v���C����3way��2way�ւ̍팸��AVX���j�b�g��2�R�A�ł̋��L�́A
���ʂɍl�����琫�\��Intel�̎�����ȍ~��CPU�ɑ��Ă��܂�ɂ������邩��ˁB
�c�q���w�E����悤�ɐ��\��r�ŏ��Ă�v�f�͖w�ǂȂ��ƌ����Ă������B
���\�ŏ��C�������Ȃ�A�_���͒�R�X�g(�����E�̔�)���ȓd�͂��ɂȂ�B
�R�A���V���v�������^�����āA�ȓd�͋@�\���ӂ�ɐ��荞�݁A
���o�C�����̏ȓd�͉����ʂ������Ƃ��Ă���̂�Bulldozer�ł���Bobcat�Ȃ낤�B
�Ⴆ��Ȃ�A
K10=PenD�ANehalem=X2�ABull=Core2�̋t�Č���ژ_��ł���C������B
�����AMD��CPU�J���̕����������\������ȓd�͐��̌�������Ȃ�ӎ����Ă���悤�Ɍ�����B
�p�C�v���C����3way��2way�ւ̍팸��AVX���j�b�g��2�R�A�ł̋��L�́A
���ʂɍl�����琫�\��Intel�̎�����ȍ~��CPU�ɑ��Ă��܂�ɂ������邩��ˁB
�c�q���w�E����悤�ɐ��\��r�ŏ��Ă�v�f�͖w�ǂȂ��ƌ����Ă������B
���\�ŏ��C�������Ȃ�A�_���͒�R�X�g(�����E�̔�)���ȓd�͂��ɂȂ�B
�R�A���V���v�������^�����āA�ȓd�͋@�\���ӂ�ɐ��荞�݁A
���o�C�����̏ȓd�͉����ʂ������Ƃ��Ă���̂�Bulldozer�ł���Bobcat�Ȃ낤�B
�Ⴆ��Ȃ�A
K10=PenD�ANehalem=X2�ABull=Core2�̋t�Č���ژ_��ł���C������B
RADEON�͏��^�����ăn�C�G���h�̓~�h���~2�őR
CPU�ł�����Ɠ������Ƃ����悤�Ƃ��Ă��
CPU�ł�����Ɠ������Ƃ����悤�Ƃ��Ă��
�{���ɏȓd�͂��Ƃ������˂�
���낢�떲������������^GPU�̂悤�ɗ~����Ȃ������Ȃ�ɂł����Ȃ�
K10�R�A2��Sandy�R�A1�̑傫��
�܂�V���R���̑傫���������SIMD���j�b�g�̔\�͎͂����悤�ȕ�
�����V���R���̘g��
�@Bull �F�X�J���R�A2��SIMD���j�b�g1����
�@Sandy�F�̓X�J���R�A1��HTT��2�X���b�h�ɂ�SIMD���j�b�g����
���Ęb
�܂�V���R���̑傫���������SIMD���j�b�g�̔\�͎͂����悤�ȕ�
�����V���R���̘g��
�@Bull �F�X�J���R�A2��SIMD���j�b�g1����
�@Sandy�F�̓X�J���R�A1��HTT��2�X���b�h�ɂ�SIMD���j�b�g����
���Ęb
>>256
>���̎d�����Ȃ����ł���Ă�z�̂ق����X�L��������
�����Řb���o���郌�x���̓z�ŁA����͂Ȃ����낤�B
������ł���Ă��邪�B
>���̎d�����Ȃ����ł���Ă�z�̂ق����X�L��������
�����Řb���o���郌�x���̓z�ŁA����͂Ȃ����낤�B
������ł���Ă��邪�B
>>249
> �����\�t�g�̃G���W���g���ŗ}�����߂���Ȃ����ˁB
> ���̓C�j�V�����R�X�g�B
>
> ������͂�����DX11�g�����ėp�Q�[���G���W�����ĒN���J������́H
> DX10����DX9�Ɩw�Ǎ����Ȃ������C��������B
> �i�̈ӂ�XP/DX9���ŃI�v�V�����𐧌����������̃\�t�g�Ȃ炢�������������ǁj
>
> ����UnrealEngine��Tim�̔������炷��Ǝ��̃R���V���[�}�Q�[�����o�鍠�܂ʼn����������C������
���\����Ă�̂̓R�����炢����
Frostbite 2 FPS
Unigine
Vision Engine MMORPG
CryEngine 3 FPS
EGO (game engine) Racing
X-Ray v1.6 (game engine) FPS
4A Engine FPS
Esenthel Engine MMORPG, RPG, FPS
Neutron 3D Engine
���Ȃ݂ɃJ�v�R����MTFW2���ꉞ�Ή����Ă���炵��
DX10�Ή��G���W����DX11�Ή��ɂ���̂͂������ē���������炵�����A�����ȏ��������Ă���Ǝv����
> �����\�t�g�̃G���W���g���ŗ}�����߂���Ȃ����ˁB
> ���̓C�j�V�����R�X�g�B
>
> ������͂�����DX11�g�����ėp�Q�[���G���W�����ĒN���J������́H
> DX10����DX9�Ɩw�Ǎ����Ȃ������C��������B
> �i�̈ӂ�XP/DX9���ŃI�v�V�����𐧌����������̃\�t�g�Ȃ炢�������������ǁj
>
> ����UnrealEngine��Tim�̔������炷��Ǝ��̃R���V���[�}�Q�[�����o�鍠�܂ʼn����������C������
���\����Ă�̂̓R�����炢����
Frostbite 2 FPS
Unigine
Vision Engine MMORPG
CryEngine 3 FPS
EGO (game engine) Racing
X-Ray v1.6 (game engine) FPS
4A Engine FPS
Esenthel Engine MMORPG, RPG, FPS
Neutron 3D Engine
���Ȃ݂ɃJ�v�R����MTFW2���ꉞ�Ή����Ă���炵��
DX10�Ή��G���W����DX11�Ή��ɂ���̂͂������ē���������炵�����A�����ȏ��������Ă���Ǝv����
>>275
�G�l���M�[�������悯��A���N���b�N�̗]�n��������Ď��ł��B
�C���e����HTT�����́A�p�C�v���C�������܂�g���Ă��Ȃ����̏؋�
�G�l���M�[�������悯��A���N���b�N�̗]�n��������Ď��ł��B
�C���e����HTT�����́A�p�C�v���C�������܂�g���Ă��Ȃ����̏؋�
���T�^�I�ȑf�l�R�����g
�Ⴄ�̂ł����H
���̃X���̌��l�͍r�炵�R�e�̑��݂Ɏ����C���ɂȂ��ăl�^�ɑ���
�}�W���X���Ă�z�͑f�l
�}�W���X���Ă�z�͑f�l
287 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 05:22:01 ID:gX+S8d8a
> �G�l���M�[�������悯��A���N���b�N�̗]�n��������Ď��ł��B
�����̏�ł͓���A�[�L�e�N�`���ł̏���d�͂̓N���b�N��3��ɔ�Ⴕ�đ傫���Ȃ邩��
�i���[�N�d�����͕ʁj�オ���Ă����ǂ�����Ă�B
Cell�̃��C���R�A�iPPE�j�Ȃ�3.2GHz�ƍ��N���b�N�������̖��߂������C�e���V�ŁA
����1.6GHz��Atom�Ƃǂ������̐��\���������ł��Ȃ������B
���C�e���V��Z������ɂ͂�荂���ȃg�����W�X�^�Ń��W�b�N���\������K�v������A
����d�͂��オ�邵�A�N���b�N���オ��Ȃ��B
���債�����C�e���V���i�L�`�́jSMT�Ŗ��߂����L�������AAMD�͂��������v�ɂȂ��ĂȂ��B
> �C���e����HTT�����́A�p�C�v���C�������܂�g���Ă��Ȃ����̏؋�
�ꕔ�̃v���O�����Ɍ���ΐ��������A�T�[�o�v���O�����ł��点������2�`3���̐��\����ɗ��܂��Ă���B
�t�Ɍ����Ɨ����_�ɑ���80%���x�̏[�U���͒B���ł��Ă���Ƃ������ƁB
�����̏�ł͓���A�[�L�e�N�`���ł̏���d�͂̓N���b�N��3��ɔ�Ⴕ�đ傫���Ȃ邩��
�i���[�N�d�����͕ʁj�オ���Ă����ǂ�����Ă�B
Cell�̃��C���R�A�iPPE�j�Ȃ�3.2GHz�ƍ��N���b�N�������̖��߂������C�e���V�ŁA
����1.6GHz��Atom�Ƃǂ������̐��\���������ł��Ȃ������B
���C�e���V��Z������ɂ͂�荂���ȃg�����W�X�^�Ń��W�b�N���\������K�v������A
����d�͂��オ�邵�A�N���b�N���オ��Ȃ��B
���債�����C�e���V���i�L�`�́jSMT�Ŗ��߂����L�������AAMD�͂��������v�ɂȂ��ĂȂ��B
> �C���e����HTT�����́A�p�C�v���C�������܂�g���Ă��Ȃ����̏؋�
�ꕔ�̃v���O�����Ɍ���ΐ��������A�T�[�o�v���O�����ł��点������2�`3���̐��\����ɗ��܂��Ă���B
�t�Ɍ����Ɨ����_�ɑ���80%���x�̏[�U���͒B���ł��Ă���Ƃ������ƁB
>>286
�������
�������
289 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 05:31:17 ID:gX+S8d8a
�H��x86�ő�̔M�����f�R�[�_����
Intel��Complex Decoder��1��ɗ��߂Ă邪Bulldozer��1���W���[��������4��
�����ABulldozer��Sandy Bridge���ȓd�͂Ƃ����N���b�N�Ƃ��ɂ��₷�����R���v�������Ȃ���
Intel��Complex Decoder��1��ɗ��߂Ă邪Bulldozer��1���W���[��������4��
�����ABulldozer��Sandy Bridge���ȓd�͂Ƃ����N���b�N�Ƃ��ɂ��₷�����R���v�������Ȃ���
>K10�R�A2��Sandy�R�A1�̑傫��
>�܂�V���R���̑傫���������SIMD���j�b�g�̔\�͎͂����悤�ȕ�
�܂�llano��sandy bridge��GPU�����͓��K�͂Ȃ̂Ŕ\�͎͂����悤�ȕ�
�������ǂ��Ƃ�����Ȃ��A5�N��10�N�゠�邢�͍X�ɂ��̐�̐��E�̃Q�[�����A
��DX9�x�[�X�̍��Ɖ����ς���ڂ��O���t�B�b�N�ƃQ�[�����̂܂܂��Ǝv���Ă���̂���
�ܔN�O�ƍ��łǂ��ς������
>�܂�V���R���̑傫���������SIMD���j�b�g�̔\�͎͂����悤�ȕ�
�܂�llano��sandy bridge��GPU�����͓��K�͂Ȃ̂Ŕ\�͎͂����悤�ȕ�
�������ǂ��Ƃ�����Ȃ��A5�N��10�N�゠�邢�͍X�ɂ��̐�̐��E�̃Q�[�����A
��DX9�x�[�X�̍��Ɖ����ς���ڂ��O���t�B�b�N�ƃQ�[�����̂܂܂��Ǝv���Ă���̂���
�ܔN�O�ƍ��łǂ��ς������
���c�q���D���ȃu���E�U�Q�[��Ipad�Ƃ������āA
�������I�ɂ�DX11���x����API�g����GPU�ɂ��A�N�Z�����[�V�������o���鍂�x�Ȃ��̂��o�Ă��邾�낤
������ǂ�ȋZ�p�v�V��u�[�������邩��������Ȃ��̂ɁA������̋K�i�ɔ���ꂽ�܂܂ł����Ƃ��v�l��~�ɂ��قǂ�����
���̘J�͂ɑ��Ă̌��ʂ��Ⴂ���Ă��b�Ȃ�
�������I�ɂ�DX11���x����API�g����GPU�ɂ��A�N�Z�����[�V�������o���鍂�x�Ȃ��̂��o�Ă��邾�낤
������ǂ�ȋZ�p�v�V��u�[�������邩��������Ȃ��̂ɁA������̋K�i�ɔ���ꂽ�܂܂ł����Ƃ��v�l��~�ɂ��قǂ�����
���̘J�͂ɑ��Ă̌��ʂ��Ⴂ���Ă��b�Ȃ�
292 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 06:07:48 ID:gX+S8d8a
�R���V���[�}�Q�[���@��16�r�b�g����32�r�b�g�ɂȂ����Ƃ���2D����3D�ւ̕ω�����������
�A�Z���u���őg��ł��v���O������C/C++�ŏ�����悤�ɂȂ������Ƃł�����x�R�X�g�E�ł����B
���̓R�X�g����������������������^�[�������鎞�ザ��Ȃ�����ȁB
���Ƃ��A�g�ѓd�b�ւ�SFC�^�C�g���̃x�^�ڐA���DX11�̂ق�����R�X�g�ōςނȂ�
���Ŕ�т����낤��B
�ǂ��̉�Ђ����̎�̈ڐA���̂͐l����̈��������̊J����Ђɓ����Ă��B
�������̃��x���܂ŋZ�p�P�����Ƃ��Ȃ��Ƃ���Ă��Ȃ��B
�V�F�[�_�v���O���}1�l����100���Ƃ��Ōق��Ă�]�T�Ȃ�ĂȂ��B
�A�Z���u���őg��ł��v���O������C/C++�ŏ�����悤�ɂȂ������Ƃł�����x�R�X�g�E�ł����B
���̓R�X�g����������������������^�[�������鎞�ザ��Ȃ�����ȁB
���Ƃ��A�g�ѓd�b�ւ�SFC�^�C�g���̃x�^�ڐA���DX11�̂ق�����R�X�g�ōςނȂ�
���Ŕ�т����낤��B
�ǂ��̉�Ђ����̎�̈ڐA���̂͐l����̈��������̊J����Ђɓ����Ă��B
�������̃��x���܂ŋZ�p�P�����Ƃ��Ȃ��Ƃ���Ă��Ȃ��B
�V�F�[�_�v���O���}1�l����100���Ƃ��Ōق��Ă�]�T�Ȃ�ĂȂ��B
�Ⴆ��
4-5km�̓��̂��20km/h���x�ŏ��q����Ȃ�
1.5���~�̃}�}�`�����ł�
30���~�̃G���g���[���x�����[�h�o�C�N�ł�
150���~�̃n�C�G���h���[�h�o�C�N�ł��ς��Ȃ�
�̗͓I�ɂ����w�����x���ł��܂�Ȃ�
50-100km�̓��̂��30-40km/h���x�ŏ��q����Ȃ�
1.5���~�̃}�}�`�����͘_�O����
30���~�̃G���g���[���x�����[�h�o�C�N�ł�
150���~�̃n�C�G���h���[�h�o�C�N�ł��ς��Ȃ�
�̗͍͂��Z���̉^�������x�����K�v
150-250km�̓��̂��40-50km/h���x�ŏ��q����Ȃ�
30���~�̃G���g���[���x�����[�h�o�C�N��
150���~�̃n�C�G���h���[�h�o�C�N�ňႢ���o��
�̗͂͂悭�g���[�j���O��ς�w�����x�����K�v
4-5km�̓��̂��20km/h���x�ŏ��q����Ȃ�
1.5���~�̃}�}�`�����ł�
30���~�̃G���g���[���x�����[�h�o�C�N�ł�
150���~�̃n�C�G���h���[�h�o�C�N�ł��ς��Ȃ�
�̗͓I�ɂ����w�����x���ł��܂�Ȃ�
50-100km�̓��̂��30-40km/h���x�ŏ��q����Ȃ�
1.5���~�̃}�}�`�����͘_�O����
30���~�̃G���g���[���x�����[�h�o�C�N�ł�
150���~�̃n�C�G���h���[�h�o�C�N�ł��ς��Ȃ�
�̗͍͂��Z���̉^�������x�����K�v
150-250km�̓��̂��40-50km/h���x�ŏ��q����Ȃ�
30���~�̃G���g���[���x�����[�h�o�C�N��
150���~�̃n�C�G���h���[�h�o�C�N�ňႢ���o��
�̗͂͂悭�g���[�j���O��ς�w�����x�����K�v
>>293
������ƃ}�W���X���邪�A
> 50-100km�̓��̂��30-40km/h���x�ŏ��q����Ȃ�
> �̗͍͂��Z���̉^�������x�����K�v
���̒��x�̃��x���ł͖����B�W�c���s���O��B
> 150-250km�̓��̂��40-50km/h���x�ŏ��q����Ȃ�
> �̗͂͂悭�g���[�j���O��ς�w�����x�����K�v
�W�c���s��O��Ȃ�150km�Ȃ�\���낤���A
250km�͑�w�����x���ł͖����B
�v���ł��������B
����Ă��Ƃ��ɂȂ��Ă��Ȃ��B
������ƃ}�W���X���邪�A
> 50-100km�̓��̂��30-40km/h���x�ŏ��q����Ȃ�
> �̗͍͂��Z���̉^�������x�����K�v
���̒��x�̃��x���ł͖����B�W�c���s���O��B
> 150-250km�̓��̂��40-50km/h���x�ŏ��q����Ȃ�
> �̗͂͂悭�g���[�j���O��ς�w�����x�����K�v
�W�c���s��O��Ȃ�150km�Ȃ�\���낤���A
250km�͑�w�����x���ł͖����B
�v���ł��������B
����Ă��Ƃ��ɂȂ��Ă��Ȃ��B
295 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 06:31:08 ID:gX+S8d8a
Half Life 2�o�Ă��炩��5�N�����炢�H
����ς����Ă��PC�Q�[�́B
����ς����Ă��PC�Q�[�́B
�\�ł�
>�����ABulldozer��Sandy Bridge���ȓd�͂Ƃ����N���b�N�Ƃ��ɂ��₷�����R���v�������Ȃ���
���܂��̃A�^�}�̒��ŕ����Ԃ��ǂ����ȂS�~���ǂ��ł������B
�����ɉ����o�Ă��邩�������d�v�B
�������g���̂ă\�P�b�g�}�}���̊Q����Ƃ͐l�ނ̓G
���܂��̃A�^�}�̒��ŕ����Ԃ��ǂ����ȂS�~���ǂ��ł������B
�����ɉ����o�Ă��邩�������d�v�B
�������g���̂ă\�P�b�g�}�}���̊Q����Ƃ͐l�ނ̓G
�����Ȃ�ˁB
299 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 06:38:09 ID:gX+S8d8a
AMD��CPU�V�F�A�����낻�뉺���~�܂邩�ȁH
http://journal.mycom.co.jp/articles/2010/04/27/x6preview/menu.html
�匴����A�Ȃ��i7�Ɣ�r���Ȃ��́H
http://journal.mycom.co.jp/articles/2010/04/27/x6preview/menu.html
�匴����A�Ȃ��i7�Ɣ�r���Ȃ��́H
�v���O�����̃X�e�b�v���������Ȃ�Α����Ȃ�قǁA�����I�ɊJ���������
�����I�Ƀo�O�������Ȃ�A�����I�Ɏ��Ԃƃ����e�オ������B
���NJJ����Ȃ�Ė��ꂪ���܂��Ă��邩��A�����I�ɂ�����J�����}����=
�X�e�b�v����}����=�i�����悭�Ȃ����̂��o����
�ŋ߂�3D���x�����v�V�I�ɏオ��Ȃ��̂͂��̂��߁B
����ɁA�Q�[���ň�ԏd�v�ȗv�f�́u�M���ł���v�f�����邩�ǂ����v��Key�ł���
���̗v�f��3D�̕i���ƃQ�[���̓��e/��ނǂ���ɔ�d�����邩�ƌ����ƌ�ҁB
����ĊJ���҂��ǂ��Ƀ|�C���g��u���ĊJ�����邩�Ƃ����ƁA3D�̕i���ł͂Ȃ���
�Q�[���̓��e->�Q�[���̊j�ƂȂ�V�X�e���̒�`�Â��̕��ɋ������邾�낤�B
�����I�Ƀo�O�������Ȃ�A�����I�Ɏ��Ԃƃ����e�オ������B
���NJJ����Ȃ�Ė��ꂪ���܂��Ă��邩��A�����I�ɂ�����J�����}����=
�X�e�b�v����}����=�i�����悭�Ȃ����̂��o����
�ŋ߂�3D���x�����v�V�I�ɏオ��Ȃ��̂͂��̂��߁B
����ɁA�Q�[���ň�ԏd�v�ȗv�f�́u�M���ł���v�f�����邩�ǂ����v��Key�ł���
���̗v�f��3D�̕i���ƃQ�[���̓��e/��ނǂ���ɔ�d�����邩�ƌ����ƌ�ҁB
����ĊJ���҂��ǂ��Ƀ|�C���g��u���ĊJ�����邩�Ƃ����ƁA3D�̕i���ł͂Ȃ���
�Q�[���̓��e->�Q�[���̊j�ƂȂ�V�X�e���̒�`�Â��̕��ɋ������邾�낤�B
�uDX11�Ȃ�ĕs�v�v
��NV�����₭AMD���Ή����Ă��炻��ȃZ���t�f���Ȃ�
��NV�����₭AMD���Ή����Ă��炻��ȃZ���t�f���Ȃ�
> 50-100km�̓��̂��30-40km/h���x�ŏ��q����Ȃ�
> �̗͍͂��Z���̉^�������x�����K�v
���Ȃ݂ɂ���́A�����̒��ёO��
�悭�P������Ă��Ȃ���������̉���
10�����������̃N���������[�h�ł���Ă܂�
> �̗͍͂��Z���̉^�������x�����K�v
���Ȃ݂ɂ���́A�����̒��ёO��
�悭�P������Ă��Ȃ���������̉���
10�����������̃N���������[�h�ł���Ă܂�
>>299
���܂�Turbo CORE Technology�̌��ʂ͂�������������ƌ������ق����������낤�B
�������āA��AMD�v���b�g�t�H�[���Ƃ���r�����Ă݂����Ƃ��낾�B
���Ƃ����킯�ŁA���̂�����͂��̂��Ƃ̃t���o�[�W�����Ō�Љ�̗\��Ȃ̂ŁA�y���݂ɂ��Ă��Ăق����B
�܁A���������̂��邯��
ttp://www.computerbase.de/artikel/prozessoren/2010/test_amd_phenom_ii_x6_1055t_1090t_be/
���܂�Turbo CORE Technology�̌��ʂ͂�������������ƌ������ق����������낤�B
�������āA��AMD�v���b�g�t�H�[���Ƃ���r�����Ă݂����Ƃ��낾�B
���Ƃ����킯�ŁA���̂�����͂��̂��Ƃ̃t���o�[�W�����Ō�Љ�̗\��Ȃ̂ŁA�y���݂ɂ��Ă��Ăق����B
�܁A���������̂��邯��
ttp://www.computerbase.de/artikel/prozessoren/2010/test_amd_phenom_ii_x6_1055t_1090t_be/
��������870-860���x
�G���e�w���̈�l���ꂪ�͂��܂��I
>>306
���܂��͂Ȃɂ������Ă����
�������������ʂɏ��q���g���̂͂�����������
50km-100km�̎���Ȃ�Ď���̒냌�x���ł����ĉ\����
���܂��͂Ȃɂ������Ă����
�������������ʂɏ��q���g���̂͂�����������
50km-100km�̎���Ȃ�Ď���̒냌�x���ł����ĉ\����
���̔n���v�͊�R�[�X�𑖂锭�z�͂Ȃ��̂��ˁE�E�E�E
�ЂƂ����Ă������H
���̕ӂ̘b���ǂ�AMD�̎�����CPU�ɖ߂��H
���̕ӂ̘b���ǂ�AMD�̎�����CPU�ɖ߂��H
�֘A�p��g���Ă邾���̒P�Ȃ�ϑz�A���X�Ƃ����Ⴂ�͖�����
�߂��ė���Ȃ��Ă��ʂɂǂ��ł���������Ȃ���
�߂��ė���Ȃ��Ă��ʂɂǂ��ł���������Ȃ���
>>307
���������Ă��邩���āA���]�Ԃō��Z���̉^�������x�����A
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���[���[��Ƃ�������Ȃ����낤�ȁB
���ǂ��Ƃ��ɂȂ��Ă��Ȃ��Ƃ������ƁB
���������Ă��邩���āA���]�Ԃō��Z���̉^�������x�����A
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���[���[��Ƃ�������Ȃ����낤�ȁB
���ǂ��Ƃ��ɂȂ��Ă��Ȃ��Ƃ������ƁB
�T�O�_�Ɍ����_�Ԃ���Ȃ�B
�ϊ����ł�����Ƃ��B
�ϊ����ł�����Ƃ��B
�����������Ă��邩���āA���]�Ԃō��Z���̉^�������x�����A
��50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���܂��{���Ƀ`������������Ƃ���H�H
��50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���܂��{���Ƀ`������������Ƃ���H�H
�T�O�_�Ƃ��ɂ��Ȃ��ĂȂ�����B
���͐~�O�̎���260Km��8���Ԃő����Ă�����
�����������h�i�[�ԂŁB���܂��ɋA��łȂ�
100Km�ȓ��Ȃ�]�T��35Km/h�͈ێ��ł��邾��
�����������h�i�[�ԂŁB���܂��ɋA��łȂ�
100Km�ȓ��Ȃ�]�T��35Km/h�͈ێ��ł��邾��
>>313
������Ƃ̎��ԏ��q����Ƃ��������Ȃ�o�����B
�ł�50km-100km�����q������Ă����̂��܂������Șb�B
���q�Ƃ����Ӗ����킩���Ă���̂��H�����悭���邱�Ƃ����B
�o����Ƃ����Ȃ����Ă݂�B
�o����Ȃ�A�}�`���A�̃��[�h���[�X�ŏ�ʓ��o�����B
������Ƃ̎��ԏ��q����Ƃ��������Ȃ�o�����B
�ł�50km-100km�����q������Ă����̂��܂������Șb�B
���q�Ƃ����Ӗ����킩���Ă���̂��H�����悭���邱�Ƃ����B
�o����Ƃ����Ȃ����Ă݂�B
�o����Ȃ�A�}�`���A�̃��[�h���[�X�ŏ�ʓ��o�����B
���q�̐V���߂���
���q���x�i����������ǁj�Ƃ́A�q��@��D���Ȃǂ��R���̏���������ł��ǂ���Ԃňړ����鑬�x�B
�ʏ펞�̈ړ��ɗp������A�o�ϑ��x�B
���[�h���[�T�[�ȂǂŒ��������s�����郉�C�_�[�̊ԂŁA
��{�Ƃ��鑖�s���x�Ƃ��ĕ\�����邪�A
�u�����ɏ��Ȃ��G�l���M�[�ł�艓���Ɉړ����邩�v�̊T�O����������Ă���A��p�ł���B
�ʏ펞�̈ړ��ɗp������A�o�ϑ��x�B
���[�h���[�T�[�ȂǂŒ��������s�����郉�C�_�[�̊ԂŁA
��{�Ƃ��鑖�s���x�Ƃ��ĕ\�����邪�A
�u�����ɏ��Ȃ��G�l���M�[�ł�艓���Ɉړ����邩�v�̊T�O����������Ă���A��p�ł���B
���@50km-100km�����q������Ă����̂��܂������Șb�B
�r�샍�[�h�̈�{�������ł���80��������̂�(�L�E�ցE�M)
�r�샍�[�h�̈�{�������ł���80��������̂�(�L�E�ցE�M)
���������Ă��邩���āA���]�Ԃō��Z���̉^�������x�����A
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
�ł��k�C���łȂ�o����B
�k�C�����L���V����
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
�ł��k�C���łȂ�o����B
�k�C�����L���V����
���Ă����肱�̃X���͒c�q���m�����Ђ��炩�����������̃I�i�j�[�X�����Ƃ�����v���Ă����ǁA��������������ɂȂ鎖���L��ȁB
>>320
�� ���]�Ԃō��Z���̉^�������x�����A
�� 50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�
������A�R�[�X�͍r�쉈�����n�_�I�_�ŗ]�T��80km���邾��A
�̗͓I�ɂ͒��w�����x���ł��]�T�ŏo���邼����Ȃ���B
�\�[�X�͒��w����̋A��̃`�����}�j�A�̉��B
���Ȃ݂ɉ�����w�s���܂œ��Y�q���������B
�c�ɂɃJ���p��50���N���f���u�����ςȂ��Ȃ��
���������炢���炭�炢�ɂȂ��H
�� ���]�Ԃō��Z���̉^�������x�����A
�� 50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�
������A�R�[�X�͍r�쉈�����n�_�I�_�ŗ]�T��80km���邾��A
�̗͓I�ɂ͒��w�����x���ł��]�T�ŏo���邼����Ȃ���B
�\�[�X�͒��w����̋A��̃`�����}�j�A�̉��B
���Ȃ݂ɉ�����w�s���܂œ��Y�q���������B
�c�ɂɃJ���p��50���N���f���u�����ςȂ��Ȃ��
���������炢���炭�炢�ɂȂ��H
���������Ă��邩���āA���]�Ԃō��Z���̉^�������x�����A
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���������g���l���̓K���o�[�g���l���i�h��������閧����j�Ȃ̂�
�����ʂ蔲���Ėk�C���ɒ��������Z���Ȃ�]�T
����͖k�C�������̍��Z���������ڒu����鑶��
50-100km��30-40km/h���x�ŏ��q����Ȃ�Ċ�R�[�X�ł������Șb�Ȃ�B
���������g���l���̓K���o�[�g���l���i�h��������閧����j�Ȃ̂�
�����ʂ蔲���Ėk�C���ɒ��������Z���Ȃ�]�T
����͖k�C�������̍��Z���������ڒu����鑶��
324 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 08:33:31 ID:gX+S8d8a
��ڂ̓��������������X���͂����ł����H
���Ȃ݂Ƀ\�[�X�͂���
ttp://wiki.chakuriki.net/index.php/%E5%8C%97%E6%B5%B7%E9%81%93%E3%81%AF%E3%81%A7%E3%81%A3%E3%81%8B%E3%81%84%E3%81%A9%E3%81%86
ttp://wiki.chakuriki.net/index.php/%E5%8C%97%E6%B5%B7%E9%81%93%E3%81%AF%E3%81%A7%E3%81%A3%E3%81%8B%E3%81%84%E3%81%A9%E3%81%86
���ċ��Ă������Ă��邩
�p�C�v���C�������ɂ�������̖��߂��������ŕ��G�ɉ��H���ăX���[�v�b�g���グ��Intel
�P���ŕn��ȃp�C�v���C���𑽐����ׂāA���ꂾ����������ǂ��l�܂邱�ƂȂ�����Ƃ���AMD
���݂̐����n�x���`�}�[�N�ł͂قڑS�ẴV�[����AMD��Intel�ɕ����Ă���
�B��AMD�����Ă�̂͗\���̌����ɂ�������̖��x���ɒ[�ɍ����x���`�}�[�N
�e���̃L���[�ɖ��߂��o�b�t�@����Intel�̐v�ł́A�ǂ����Ă��\���~�X�y�i���e�B���傫��
�l�H�I�Ƀ��W�X�^�ǂݏo���X�g�[�����������Intel�͒x�����nj����̃v���O�����ł͋N����Ȃ�
�P���ŕn��ȃp�C�v���C���𑽐����ׂāA���ꂾ����������ǂ��l�܂邱�ƂȂ�����Ƃ���AMD
���݂̐����n�x���`�}�[�N�ł͂قڑS�ẴV�[����AMD��Intel�ɕ����Ă���
�B��AMD�����Ă�̂͗\���̌����ɂ�������̖��x���ɒ[�ɍ����x���`�}�[�N
�e���̃L���[�ɖ��߂��o�b�t�@����Intel�̐v�ł́A�ǂ����Ă��\���~�X�y�i���e�B���傫��
�l�H�I�Ƀ��W�X�^�ǂݏo���X�g�[�����������Intel�͒x�����nj����̃v���O�����ł͋N����Ȃ�
������Ȃ̂͂��܂��B
���q������Ă����̂͌����̗ǂ���Ԃňړ����鑬�x�B
�܂�l�Ԃɂ��Ƃ���ƐS������60%���x���B
�����ɐS���v�t���đ����Ă݂ȁB
�܂肾�A�C���e���̓t���p���[�Ŋ撣���ĂԂ�������ǁA
AMD�͏��q���邱�Ƃɏd�݂�u���Ă���Ƃ������Ƃ��B
���q������Ă����̂͌����̗ǂ���Ԃňړ����鑬�x�B
�܂�l�Ԃɂ��Ƃ���ƐS������60%���x���B
�����ɐS���v�t���đ����Ă݂ȁB
�܂肾�A�C���e���̓t���p���[�Ŋ撣���ĂԂ�������ǁA
AMD�͏��q���邱�Ƃɏd�݂�u���Ă���Ƃ������Ƃ��B
329 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 09:15:17 ID:gX+S8d8a
�t���p���[�Ŋ撣��Ȃ����Ƃɏd�݂�u�������ʂ��uCoolSpeed Technology�v�ł����H
�܂�����Ȗϑz�������Ă�̂�
����ł��k�C���Ȃ�E�E�E�k�C���Ȃ炫���Ɖ��Ƃ����Ă����
�g���b�N�̌��ɒ���t���Έ�ʐl�ł�����100km�Ŋy�X����邼
�M����������������]�Ԃƈ��S���u���K�v�Ȃ̂Ŏ��p���͖������E�E�E
NHK�������Ă����Ă�n�̔ԑg�Ŏ������Ă���E�E�E
�M����������������]�Ԃƈ��S���u���K�v�Ȃ̂Ŏ��p���͖������E�E�E
NHK�������Ă����Ă�n�̔ԑg�Ŏ������Ă���E�E�E
Bulldpzer�̃R�A1�̃T�C�Y�����\��K10���x���Ƃ����
Bull�̃T�C�Y�FSandy�̃T�C�Y��1�F2�@���@����d�͂̊W��1�F1.4�`1�F2�Ƃ��H�i�����͖����j
Bull�̐��\�FSandy�̐��\��1�F1.15
HKMG�̊J���ɂ���Ȃ�ɐ�������ASOI�Ƃ̕��p�������ď���d�͊W�̐��\��
���N���X�ɂȂ肻�������烏�b�g�p�t�H�[�}���X�͗ǂ����낤��
�ł����̈���ŁABull�̃N���b�N��15�������Đ��\�Œǂ������Ƃ����
����d�͂̑�������2��Ȃ�1.3�{�A3��Ȃ�1.5�{�ɂȂ��Ĕ����ȂƂ��납�ȁH
Bull�̃T�C�Y�FSandy�̃T�C�Y��1�F2�@���@����d�͂̊W��1�F1.4�`1�F2�Ƃ��H�i�����͖����j
Bull�̐��\�FSandy�̐��\��1�F1.15
HKMG�̊J���ɂ���Ȃ�ɐ�������ASOI�Ƃ̕��p�������ď���d�͊W�̐��\��
���N���X�ɂȂ肻�������烏�b�g�p�t�H�[�}���X�͗ǂ����낤��
�ł����̈���ŁABull�̃N���b�N��15�������Đ��\�Œǂ������Ƃ����
����d�͂̑�������2��Ȃ�1.3�{�A3��Ȃ�1.5�{�ɂȂ��Ĕ����ȂƂ��납�ȁH
�_���v�̌��ɒ���t����150��]�ʂ�����80km/h����o�������Ƃ͂��邪�A
�_���v���~�܂����玀�ʂȂƎv������B�Ⴉ�肵�v���o�E�E�E�E�B���f���ȁB
���������u���h�[�U�[���ăl�[�~���O���̂������Ȃ�����A
�R�A�𑝂₵�ĉ����Ă������Ă����̂�AMD�Ȃ낤�B
�����ł̓C���e���ɏ��ĂȂ���B
�_���v���~�܂����玀�ʂȂƎv������B�Ⴉ�肵�v���o�E�E�E�E�B���f���ȁB
���������u���h�[�U�[���ăl�[�~���O���̂������Ȃ�����A
�R�A�𑝂₵�ĉ����Ă������Ă����̂�AMD�Ȃ낤�B
�����ł̓C���e���ɏ��ĂȂ���B
�����X�J������x�͓��ł�
�x�N�^�ł�GPU�Ƀ{�R�{�R�̌���ł̓L���b�V�����\�����i����Ȃ��������������j������
���̃L���b�V����Bull�ł͑�ω�
���X�L���b�V�����n��Ȃ܂܂�Intel�ƒ��荇���ė���AMD������
�����ł��̃L���b�V���Ɏ�����Ăǂ��Ȃ邩���ď�
�x�N�^�ł�GPU�Ƀ{�R�{�R�̌���ł̓L���b�V�����\�����i����Ȃ��������������j������
���̃L���b�V����Bull�ł͑�ω�
���X�L���b�V�����n��Ȃ܂܂�Intel�ƒ��荇���ė���AMD������
�����ł��̃L���b�V���Ɏ�����Ăǂ��Ȃ邩���ď�
�������������ȁ[�Ǝv�������ɂ܂��������
�Ȃ�A�}�V���̉���(HD2xxx��HD3xxx��HD4xxx��HD5xxx)��
�V���[�g�J�b�g(8800GT��9800GT��GT240)�������
�Ȃ�A�}�V���̉���(HD2xxx��HD3xxx��HD4xxx��HD5xxx)��
�V���[�g�J�b�g(8800GT��9800GT��GT240)�������
�K����������Ă���G�������D���ł���
1�̒m������10�̊�]��c��܂�100�l��
���߂Ă���1�̒m���������̋��ʂ��𔘂��o�����߈ȊO�Ɏg���Ȃ����̂���
���߂Ă���1�̒m���������̋��ʂ��𔘂��o�����߈ȊO�Ɏg���Ȃ����̂���
>>333
���\�����{����1:1.15���x��������悩�����̂ɂ�
���\�����{����1:1.15���x��������悩�����̂ɂ�
340 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 14:20:59 ID:gX+S8d8a
�������ш�ˑ��x�̍����Ȃ�SPECint�ł���Nehalem(HT ON)����Barcelona�Ń_�u���X�R�A������Ȃ�
�Ǝ����Ɍ��������������ȁB���z��
342 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 14:56:27 ID:gX+S8d8a
�����ăg���v���`���l������Ȃ�Nehalem�̃X�R�A�Ƃ��Ă���
4�R�A DDR3 2ch
Fujitsu CELSIUS W280, Intel Core i7-860
Base 113
Peak 121
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09640.html
2�\�P�b�g �~ 4�R�A DDR3 2ch
Dell Inc. PowerEdge R805 (AMD Opteron 2387, 2.80 GHz)
Base 114
Peak 137
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090427-07230.html
��4�R�A��8�R�A�̔�r�ł�
4�R�A DDR3 2ch
Fujitsu CELSIUS W280, Intel Core i7-860
Base 113
Peak 121
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09640.html
2�\�P�b�g �~ 4�R�A DDR3 2ch
Dell Inc. PowerEdge R805 (AMD Opteron 2387, 2.80 GHz)
Base 114
Peak 137
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090427-07230.html
��4�R�A��8�R�A�̔�r�ł�
343 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 14:58:50 ID:gX+S8d8a
i7�̂ق���URL����
4�R�A DDR3 2ch
Fujitsu CELSIUS W280, Intel Core i7-860
Base 113
Peak 121
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09634.html
4�R�A DDR3 2ch
Fujitsu CELSIUS W280, Intel Core i7-860
Base 113
Peak 121
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09634.html
Nehalem �̃X�R�A�́H
�c�q����Nehalem��Lynnfield�̋�ʂ��t���Ȃ����x���H
346 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 15:13:27 ID:gX+S8d8a
>>333
> Bulldpzer�̃R�A1�̃T�C�Y�����\��K10���x���Ƃ����
�R�A������3way��2way�ŐF�X������̂ɓ��T�C�Y�Ƃ��ˁ[��
> Bulldpzer�̃R�A1�̃T�C�Y�����\��K10���x���Ƃ����
�R�A������3way��2way�ŐF�X������̂ɓ��T�C�Y�Ƃ��ˁ[��
Nehalem�̃X�R�A����HTT�L���ɂ�������8�R�A����
349 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 15:20:21 ID:gX+S8d8a
�������j�b�g�Ȃ�Ă����������������ʐϐH���ĂȂ�
http://www.chip-architect.com/news/K8L_floorplan.jpg
�����������l�^��Sandy Bridge��Llano�̃R�A�T�C�Y��r�A�O�҂�L2�̂Ԃ���܂ނ���҂͊܂܂Ȃ����_�Ŋ��ɂ��������B
http://www.chip-architect.com/news/K8L_floorplan.jpg
{kind=link}
�����������l�^��Sandy Bridge��Llano�̃R�A�T�C�Y��r�A�O�҂�L2�̂Ԃ���܂ނ���҂͊܂܂Ȃ����_�Ŋ��ɂ��������B
�R�A�ɐ�߂鐮�����Z��̑傫���Ȃ�Ĕ��X���镨���낤
�傫���̂������Ȃ盛���~�ł��g���Ƃ����Ċ�������
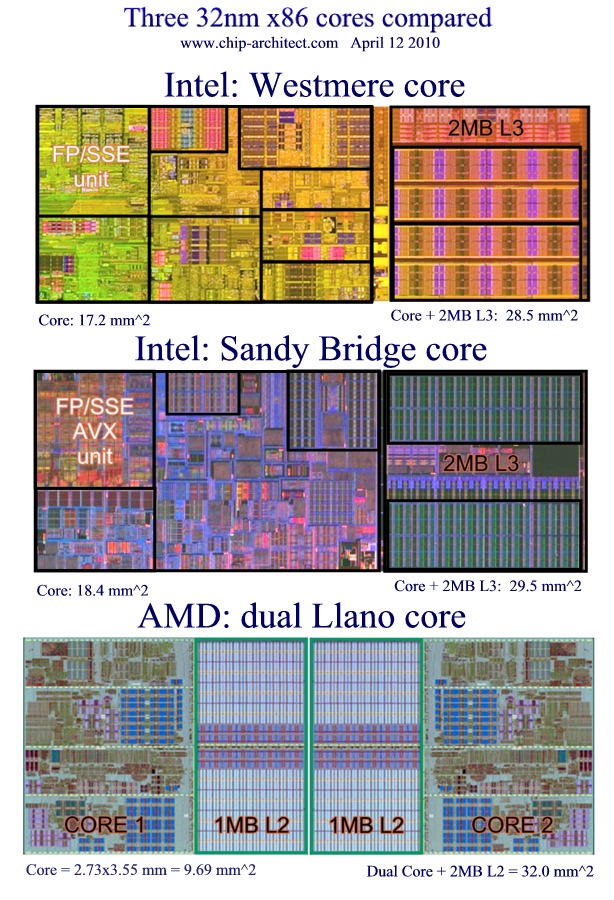{kind=link}
353 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 15:24:19 ID:gX+S8d8a
>>348
���̎���8�R�A�ɐ^��4�R�A�~2�\�P�b�g���ǂ������Ȃ��H
Bulldozer�͂������߉���8�R�A���B�m����K10��8�R�A����IPC������Ǝv�����B
���̎���8�R�A�ɐ^��4�R�A�~2�\�P�b�g���ǂ������Ȃ��H
Bulldozer�͂������߉���8�R�A���B�m����K10��8�R�A����IPC������Ǝv�����B
�Ȃ��IPC�ɕK���Ȃ����́H
355 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 15:30:34 ID:gX+S8d8a
���Ⴀ�N���b�N���ŏ�������̂�
Pentium 4����
Pentium 4����
POWER6��
�Ȃ���ꂽ�珟���Ă镔������ׂ�̂͗ǂ������̘b�����Ă��
�L���K�CAMDer�Ɠ��������
�L���K�CAMDer�Ɠ��������
Bull��IPC�ݒ�̕��j�͎��݂����ȑf�l�ɂ͗\�����悤��������
���߂ăR�A�T�C�Y�̗\���Ƃ����o��l���悤���L�邪
���߂ăR�A�T�C�Y�̗\���Ƃ����o��l���悤���L�邪
>>353
�E�V���O�����\
Nehalem>K10
�E�}���`�̌���
���R�A>HTT
�ő����I�Ɍ݊p���Ă���
�������������̂������ł��Ȃ��A�c�q�͔n���Ȃ́H
�E�V���O�����\
Nehalem>K10
�E�}���`�̌���
���R�A>HTT
�ő����I�Ɍ݊p���Ă���
�������������̂������ł��Ȃ��A�c�q�͔n���Ȃ́H
�n������
>>342
Turbo Boost���ē����̂��H
Turbo Boost���ē����̂��H
362 �FSocket774�F2010/05/08(�y) 16:38:50 ID:knXGA7+S
8�R�A��BULL��2,3���~�Ŕ�����A���ꂵ���ł͂Ȃ����B
363 �FSocket774�F2010/05/08(�y) 16:51:40 ID:JZZ71bgH
>>287
>����d�͂̓N���b�N��3��ɔ��
3��͍������D���ł���D
>>342
>2�\�P�b�g �~ 4�R�A DDR3 2ch
>Dell Inc. PowerEdge R805 (AMD Opteron 2387, 2.80 GHz)
�~DDR3
��DDR2-800
>����d�͂̓N���b�N��3��ɔ��
3��͍������D���ł���D
>>342
>2�\�P�b�g �~ 4�R�A DDR3 2ch
>Dell Inc. PowerEdge R805 (AMD Opteron 2387, 2.80 GHz)
�~DDR3
��DDR2-800
���Ԃ����
X6��1�`3���AX8��2���`5�����낤��
���i�헪�I�ɂ�Intel��Clarkdale��Lynnfield�݂����Ȋ����ɂȂ�Ǝv��
Sandybridge6�R�A�����10���~�̉��i�тł��o�邩������Ȃ�
X6��1�`3���AX8��2���`5�����낤��
���i�헪�I�ɂ�Intel��Clarkdale��Lynnfield�݂����Ȋ����ɂȂ�Ǝv��
Sandybridge6�R�A�����10���~�̉��i�тł��o�邩������Ȃ�
���Ƃ͋���ȃ^�[�{���~������
8�R�A������^�[�{�������������@��͏\���ɑ����Ȃ肻��
8�R�A������^�[�{�������������@��͏\���ɑ����Ȃ肻��
366 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 17:12:20 ID:gX+S8d8a
>>361
�S���̃R�A��g�����Ƃ��̃X���[�v�b�g�v���Ă�̂�
�ꕔ�̃R�A�����g���ĂȂ��Ƃ��ɃN���b�N�������グ��Z�p�������Ă邩�ǂ����Ƃ����̂�
���Ȏ��₾�Ǝv�����B
�V���O���^�X�N���Ƃ�������
Fujitsu CELSIUS W280, Intel Core i7-860
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09640.html
Base 32.3
Peak 35.7
Supermicro H8DA3-2 , AMD Opteron 2386 SE
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090416-07093.html
Base 17.9
Peak 21.6
����Turbo-Boost�������̃N���b�N���ȏ�̍����t���Ă�Ǝv����
�S���̃R�A��g�����Ƃ��̃X���[�v�b�g�v���Ă�̂�
�ꕔ�̃R�A�����g���ĂȂ��Ƃ��ɃN���b�N�������グ��Z�p�������Ă邩�ǂ����Ƃ����̂�
���Ȏ��₾�Ǝv�����B
�V���O���^�X�N���Ƃ�������
Fujitsu CELSIUS W280, Intel Core i7-860
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09640.html
Base 32.3
Peak 35.7
Supermicro H8DA3-2 , AMD Opteron 2386 SE
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090416-07093.html
Base 17.9
Peak 21.6
����Turbo-Boost�������̃N���b�N���ȏ�̍����t���Ă�Ǝv����
367 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 17:14:31 ID:gX+S8d8a
>>359
> �ő����I�Ɍ݊p���Ă���
�����Ă݂�u��Ԋp�����v�ŝh�R���Ă�̂��u�݊p�v���Ă����̂��B������Ƃ�v�l���ȁB
i7 9xx����Ȃ��ăf���A���`���l����8xx�Ƃ̔�r�ɂ����̂͂�����̐^�S
> �������������̂������ł��Ȃ��A�c�q�͔n���Ȃ́H
�ʂɂ��������Ȃ���B
Bulldozer��1�\�P�b�g������́u�R�A�v����{�������Ă��܂�����CPU�ɋy�Ȃ�����������₷�������ł��邾��H
K10�Ń_�u���X�R�A�����������̂�Bulldozer����ł�1�`2���������炢�ɂȂ���x
>>363
���߂�ADDR3�Ή�������Istanbul����Ȃ̂ˁB
���ႠHT����4�R�A vs 6�R�A��1�\�P�b�g�Ό��͂ǂ��H
Fujitsu CELSIUS W280, Intel Core i5-750 2.66GHz
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09630.html
Base 92.4
Peak 99.2
Hewlett-Packard Company Proliant DL165 G6 (2.6 GHz AMD Opteron 2435)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
Base 82.0
Peak 104
> �ő����I�Ɍ݊p���Ă���
�����Ă݂�u��Ԋp�����v�ŝh�R���Ă�̂��u�݊p�v���Ă����̂��B������Ƃ�v�l���ȁB
i7 9xx����Ȃ��ăf���A���`���l����8xx�Ƃ̔�r�ɂ����̂͂�����̐^�S
> �������������̂������ł��Ȃ��A�c�q�͔n���Ȃ́H
�ʂɂ��������Ȃ���B
Bulldozer��1�\�P�b�g������́u�R�A�v����{�������Ă��܂�����CPU�ɋy�Ȃ�����������₷�������ł��邾��H
K10�Ń_�u���X�R�A�����������̂�Bulldozer����ł�1�`2���������炢�ɂȂ���x
>>363
���߂�ADDR3�Ή�������Istanbul����Ȃ̂ˁB
���ႠHT����4�R�A vs 6�R�A��1�\�P�b�g�Ό��͂ǂ��H
Fujitsu CELSIUS W280, Intel Core i5-750 2.66GHz
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100212-09630.html
Base 92.4
Peak 99.2
Hewlett-Packard Company Proliant DL165 G6 (2.6 GHz AMD Opteron 2435)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
Base 82.0
Peak 104
compiler�̐��\�������X���͂����ł����H
�G���R�V�I�ɂ́A2���W���[���̍��N���b�N���f���Ɋ��ҁB
�X���̗�������ĉ�ꂽ�^���e�[�v�݂����Ɏ����̓s���̗ǂ��f�[�^�����J��Ԃ����ׁA�s����������X���[
�ŋ߂̒c�q�̍s���p�^�[�����Ă܂�܃e�w�̍s���p�^�[���Ɠ�������ˁ[��w
��͂�c�q=�e�w���c
�ŋ߂̒c�q�̍s���p�^�[�����Ă܂�܃e�w�̍s���p�^�[���Ɠ�������ˁ[��w
��͂�c�q=�e�w���c
Stream TRAID on 64 bit linux - maximaum threads
http://it.anandtech.com/show/2978/amd-s-12-core-magny-cours-opteron-6174-vs-intel-s-6-core-xeon/5
Dual Opteron 6174 2.2�E�E�E49372
Dual Xeon X5670 2.93�E�E�E35868
�����Ă݂�u��Ԋp�����v�ŝh�R���Ă�̂��u�݊p�v���Ă����̂��B������Ƃ�v�l���ȁB
http://it.anandtech.com/show/2978/amd-s-12-core-magny-cours-opteron-6174-vs-intel-s-6-core-xeon/5
Dual Opteron 6174 2.2�E�E�E49372
Dual Xeon X5670 2.93�E�E�E35868
�����Ă݂�u��Ԋp�����v�ŝh�R���Ă�̂��u�݊p�v���Ă����̂��B������Ƃ�v�l���ȁB
�ł��e�w�{�l�͑��l�����������Ă���Ɩ{�C�Ŏv������ł��邩�獢��cw
���|�����ɂ��œK�������X���ł��悱����
�������c�q���K���������
1��2�C���e�����L���ȃx���`�}�[�N�������Ă��A������ǂ��������Ęb�Ȃ�
������1090T�͔���܂����Ă��邵�Ai7����Ȃ�X6�I��ł���z�����Ȃ��炸���݂���
���������A875K�o���Ă���ق�Intel��K10�̑��R�A�����ЂɊ����Ă����
�������c�q���K���������
1��2�C���e�����L���ȃx���`�}�[�N�������Ă��A������ǂ��������Ęb�Ȃ�
������1090T�͔���܂����Ă��邵�Ai7����Ȃ�X6�I��ł���z�����Ȃ��炸���݂���
���������A875K�o���Ă���ق�Intel��K10�̑��R�A�����ЂɊ����Ă����
�قƂ�ǂ̃}���`�X���b�h�Ή��̃x���`�}�[�N��i7��X6�͐�%�̍��ŋ����Ă���
1���ȏ�̍�������̂͋Ɍ���ꂽ�ꍇ�݂̂̏ʼn�������ł����ꂵ����������
1���ȏ�̍�������̂͋Ɍ���ꂽ�ꍇ�݂̂̏ʼn�������ł����ꂵ����������
375 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 17:50:47 ID:gX+S8d8a
>>368
�ց[�A�R���p�C���ɍ�������́H
Dell Inc. PowerEdge 1950
http://www.spec.org/cpu2006/results/res2006q4/cpu2006-20060918-00109.html�@
Result 16.3 / Baseline 15.8
Hewlett-Packard Company ProLiant BL465c (3.0GHz AMD Opteron 2222)
http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070831-01930.html
Result 15.5 / Baseline 14.5
>>370
�s���������������o�����Ɛl�i�U�����Ƃ�����l���F����Ă̂��|���Ȃ��ł���
�ց[�A�R���p�C���ɍ�������́H
Dell Inc. PowerEdge 1950
http://www.spec.org/cpu2006/results/res2006q4/cpu2006-20060918-00109.html�@
Result 16.3 / Baseline 15.8
Hewlett-Packard Company ProLiant BL465c (3.0GHz AMD Opteron 2222)
http://www.spec.org/cpu2006/results/res2007q3/cpu2006-20070831-01930.html
Result 15.5 / Baseline 14.5
>>370
�s���������������o�����Ɛl�i�U�����Ƃ�����l���F����Ă̂��|���Ȃ��ł���
Globalfoundries May Acquire IBM�fs Semiconductor Fabs �H Analyst.
http://www.xbitlabs.com/news/other/display/20100506182520_Globalfoundries_May_Acquire_IBM_s_Semiconductor_Fab_Analyst.html
http://www.xbitlabs.com/news/other/display/20100506182520_Globalfoundries_May_Acquire_IBM_s_Semiconductor_Fab_Analyst.html
>>376
UMC�Ƃ����A�Ђ��[���甃���܂������Ȃ̂���
UMC�Ƃ����A�Ђ��[���甃���܂������Ȃ̂���
378 �F,,�E�L�́M�E,,�j��-�������F2010/05/08(�y) 18:14:46 ID:gX+S8d8a
>>371
Stream TRIAD��HPC�����̃������ш�x���`�}�[�N���ˁB
�܂��A3ch��4ch���Ⴛ�̒��x�̍��͏o�邾�낤�ˁB
�ł�Bulldozer���d���i�j���Ă�炵���������Z���\�ɂ��̎�̃x���`�͂قƂ�LjӖ����Ȃ���B
���łɂ����Ǝ��ۂ�HPC�p�r�ł��炻��قǗD�ʂȍ��ł͂Ȃ���������Ȃ��ˁB
���������[�J���e�B���ӎ����ăv���O�������`���[�j���O����̂�������O������ˁB
�����ł���MP�i4�\�P�b�g�ȏ�j�ɂ�閧�����N���X�^����DP�̑e�����N���X�^�̂ق����L���g���Ă邭�炢�����B
Stream TRIAD��HPC�����̃������ш�x���`�}�[�N���ˁB
�܂��A3ch��4ch���Ⴛ�̒��x�̍��͏o�邾�낤�ˁB
�ł�Bulldozer���d���i�j���Ă�炵���������Z���\�ɂ��̎�̃x���`�͂قƂ�LjӖ����Ȃ���B
���łɂ����Ǝ��ۂ�HPC�p�r�ł��炻��قǗD�ʂȍ��ł͂Ȃ���������Ȃ��ˁB
���������[�J���e�B���ӎ����ăv���O�������`���[�j���O����̂�������O������ˁB
�����ł���MP�i4�\�P�b�g�ȏ�j�ɂ�閧�����N���X�^����DP�̑e�����N���X�^�̂ق����L���g���Ă邭�炢�����B
�ŐV���X�ł����Ȃ�h�e����:�h��
�O�O�������������X��36��������
�ӂ����Ėϑz���ߍr�炵���Ă邾���Ȃ玀��ł���
�O�O�������������X��36��������
�ӂ����Ėϑz���ߍr�炵���Ă邾���Ȃ玀��ł���
Blender 2.5 Alpha 2 Windows
Dual Opteron 6174 2.2�E�E�E31.5
Dual Xeon X5670 2.93�E�E�E26.4
Blender 2.5 Alpha 2 Linux
Dual Opteron 6174 2.2�E�E�E18
Dual Xeon X5670 2.93�E�E�E31
*Lower is better
�Ƃ���ŁA�c�q�����http://boo.2ch.net/�ɂ��ĂȂɂ��v���Ƃ���͂���܂����H
Dual Opteron 6174 2.2�E�E�E31.5
Dual Xeon X5670 2.93�E�E�E26.4
Blender 2.5 Alpha 2 Linux
Dual Opteron 6174 2.2�E�E�E18
Dual Xeon X5670 2.93�E�E�E31
*Lower is better
�Ƃ���ŁA�c�q�����http://boo.2ch.net/�ɂ��ĂȂɂ��v���Ƃ���͂���܂����H
Bulldozer�̔ے��Intel����������ōł��͂����Ă�SCC�̔ے�ɂ��Ȃ��邩��~�߂Ƃ�
AMD���d�����Ă������Ƃ��Ă�̂͒P�Ȃ鐮�����Z���\����Ȃ��A�R�X�g�������d�͓�����ł̃}���`�X���b�h���\����
�x���`�}�[�N�ł̗D��Ȃ����������ďd�v�����ĂȂ����Ă�����
AMD���d�����Ă������Ƃ��Ă�̂͒P�Ȃ鐮�����Z���\����Ȃ��A�R�X�g�������d�͓�����ł̃}���`�X���b�h���\����
�x���`�}�[�N�ł̗D��Ȃ����������ďd�v�����ĂȂ����Ă�����
382 �FSocket774�F2010/05/08(�y) 18:44:12 ID:knXGA7+S
>>381�吳���B
383 �FSocket774�F2010/05/08(�y) 18:45:47 ID:JZZ71bgH
>>378
8ch�ł��_���Ȏq
http://www.anandtech.com/show/3648/xeon-7500-dell-r810/7
HPC��MP�ł͂Ȃ�DP���g���Ă���̂̓R�X�g�̖�肪1�Ԃ��Ǝv���D
8ch�ł��_���Ȏq
http://www.anandtech.com/show/3648/xeon-7500-dell-r810/7
HPC��MP�ł͂Ȃ�DP���g���Ă���̂̓R�X�g�̖�肪1�Ԃ��Ǝv���D
�Ƃ͂����x���`�}�[�N�Ŗ��炩�ɗ��悤�ȃA�[�L�e�N�`���ɂ͂��ĂȂ����ǂ�
�������\�∵���Ղ����d�����Ă��āA�낭�Ɏg�������Ȃ�HTT��TB�C����Nehalem�n���͐l�C�o�������B
�������\�∵���Ղ����d�����Ă��āA�낭�Ɏg�������Ȃ�HTT��TB�C����Nehalem�n���͐l�C�o�������B
�v��Ȃ��q
���łɌ����Ȃ�
AMD�͉��i�헪�ł����R�ł���
CPU�ł�GPU�ł�
Radeon�ɐ������Ȃ����璆�ؐ���tenga��Radeon������FirePro�͖���
�����̎�i�߂�s�ׂ���邵���Ȃ�
����̐��i�ł�
���łɌ����Ȃ�
AMD�͉��i�헪�ł����R�ł���
CPU�ł�GPU�ł�
Radeon�ɐ������Ȃ����璆�ؐ���tenga��Radeon������FirePro�͖���
�����̎�i�߂�s�ׂ���邵���Ȃ�
����̐��i�ł�
>>353
�H�@�������������������ς肾���c�H
�H�@�������������������ς肾���c�H
�V���O���X���b�h�ł�K10��Bull�̃��j�b�g���ω���
�f�R�[�_+1
ALU-1
SIMD�}0
���Ƃ̓L���b�V������ω�
AMD�̕فE�����ɂ���ALU��2�ɂȂ��Ă�
���\�̉����͂�������2,3%�ĂƂ���
����E�N���b�N�E�L���b�V���i�q�b�g���j�A���̖��m�̍��ڂ��炷��Ή��ł��Ȃ�
�f�R�[�_+1
ALU-1
SIMD�}0
���Ƃ̓L���b�V������ω�
AMD�̕فE�����ɂ���ALU��2�ɂȂ��Ă�
���\�̉����͂�������2,3%�ĂƂ���
����E�N���b�N�E�L���b�V���i�q�b�g���j�A���̖��m�̍��ڂ��炷��Ή��ł��Ȃ�
����̎�������f���Ă̂��헪�̈���낤��
GPU����͉��i�헪���[�������NV��������������ċt�ɒl�サ���o�܂��E�E�E
�ŋ߂ł͂ǂ����̌�����w�̋�����GTX285����GTX280�������g�����X�p�R������Ă�������ɂ��ĉ����R�����g�͂Ȃ��ł��傤���E�E�E
�ŋ߂ł͂ǂ����̌�����w�̋�����GTX285����GTX280�������g�����X�p�R������Ă�������ɂ��ĉ����R�����g�͂Ȃ��ł��傤���E�E�E
>>386
�r�f�I�J�[�h�͌��X�叟���Ă���Ƃ���������������A�����͈��S���Ă���
����ǁA���̓`�b�v�Z�b�g��CPU�E�E�E
���������撣���Ăق���
�r�f�I�J�[�h�͌��X�叟���Ă���Ƃ���������������A�����͈��S���Ă���
����ǁA���̓`�b�v�Z�b�g��CPU�E�E�E
���������撣���Ăق���
>>392
��������������ATI���ĕʂɑ叟������Ȃ���ȁH�@�ނ���c�B
��������������ATI���ĕʂɑ叟������Ȃ���ȁH�@�ނ���c�B
�������CUDA����Ȃ��Œ��ړ������̂���
�ނ�̌����ړI�́w�ėpGPU�ɂ���Ĉ����ɍ����\�ȃX�p�R�������x���Ƃɂ���
�X�p�R������錤���ł���A���������\�͂�ނ玩�g�������Ɏg����Ȃ�
Tesla��Firestream�ł͌�������Ӗ�������
�ނ�̌����ړI�́w�ėpGPU�ɂ���Ĉ����ɍ����\�ȃX�p�R�������x���Ƃɂ���
�X�p�R������錤���ł���A���������\�͂�ނ玩�g�������Ɏg����Ȃ�
Tesla��Firestream�ł͌�������Ӗ�������
�~�w�ėpGPU�ɂ���Ĉ����ɍ����\�ȃX�p�R�������x
���w��ʑ�O�����̐��i�ł���GPU�ɂ���Ĉ����ɍ����\�ȃX�p�R�������x
���w��ʑ�O�����̐��i�ł���GPU�ɂ���Ĉ����ɍ����\�ȃX�p�R�������x
3 ALU��k8��2 ALU��nano�ō����Ȃ�����
�u���������Ȃ����낤
���A�ł�nano��ALU2�͕��߂ƒP�����߂���������1.5 ALU���ĂƂ���
�u���������Ȃ����낤
���A�ł�nano��ALU2�͕��߂ƒP�����߂���������1.5 ALU���ĂƂ���
nano���āE�E�E
ttp://hamanasu.sakura.ne.jp/~yami/qandc/cpuspec.html
�������ƎU�X�Ȉ����Ȃ��E�E�E
�����X�J�������Ȃ獷�������̂��H
�܂��ǂ���ALU2�E3�i���f�R�[�_3�E4+1��SSE64�E128���X�j���ׂ��Ȃ��łƺ�ۂ���
ttp://hamanasu.sakura.ne.jp/~yami/qandc/cpuspec.html
�������ƎU�X�Ȉ����Ȃ��E�E�E
�����X�J�������Ȃ獷�������̂��H
�܂��ǂ���ALU2�E3�i���f�R�[�_3�E4+1��SSE64�E128���X�j���ׂ��Ȃ��łƺ�ۂ���
>>397
���̃T�C�g�����܂�ɂ��S�~�Ȃ����ł�
���̃T�C�g�����܂�ɂ��S�~�Ȃ����ł�
>>391
�l�オ����āATSMC�̂����Ő������Ȃ��A����(�������Ƃ�)�̍����̂�������
�l�オ����āATSMC�̂����Ő������Ȃ��A����(�������Ƃ�)�̍����̂�������
http://www.extremetech.com/image_popup/0,,iid=255433&aID=249505&sID=27867,00.asp
����Ȃ́A�J�[�N��������Ȃ��ł�
����Ȃ́A�J�[�N��������Ȃ��ł�
nano-e�ł͍X��2-3����p�t�H�[�}���X���オ��
�^�����ăR�e�ɒ�����e�w������
�Ă��E���ꂽ�̂��H�c�q
SandyBridge�Ɠ������̃����[�X�Ƃ����Ă���Bulldozer�Ȃ̂���
�܂��T���v���̉\�Ƃ������Ă��Ȃ���
�܂��T���v���̉\�Ƃ������Ă��Ȃ���
�܂��o��܂�1�N���炢���邩��̂�т�҂Ƃ���
���������A256itAVX��2�R�A���L�����ǁASSE��FPU�̓R�A�Ɠ����̓��ڂŐ��\�����サ�Ă�����ۂ�����
k10��SSE/FPU���j�b�g���āAK8��80Bit���j�b�g�Ɍ�t��64Bit�t�����������̂�����A
�\���I�Ƀ��_��\�̑����������肻�����������ǁA
Bulldozer�ł͍ŏ�����128Bit���j�b�g�Ƃ��ĐV�v����Ă��邩��A���\�������͗ǂ��Ȃ��Ă��������B
K10.5��SSE�Ɍ��炸�����ȕ�����K7����̓x�d�Ȃ�g���Ń��_���炯�ő��������炯�ȋC�����邩��A
�[���x�[�X�ŐV�K�J�����Ă���Bulldozer�R�A�́A���Ȃ�����������f�U�C��������Ă�Ǝv���B
���������A256itAVX��2�R�A���L�����ǁASSE��FPU�̓R�A�Ɠ����̓��ڂŐ��\�����サ�Ă�����ۂ�����
k10��SSE/FPU���j�b�g���āAK8��80Bit���j�b�g�Ɍ�t��64Bit�t�����������̂�����A
�\���I�Ƀ��_��\�̑����������肻�����������ǁA
Bulldozer�ł͍ŏ�����128Bit���j�b�g�Ƃ��ĐV�v����Ă��邩��A���\�������͗ǂ��Ȃ��Ă��������B
K10.5��SSE�Ɍ��炸�����ȕ�����K7����̓x�d�Ȃ�g���Ń��_���炯�ő��������炯�ȋC�����邩��A
�[���x�[�X�ŐV�K�J�����Ă���Bulldozer�R�A�́A���Ȃ�����������f�U�C��������Ă�Ǝv���B
408 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 00:25:21 ID:sNWFFdis
>>381
> Bulldozer�̔ے��Intel����������ōł��͂����Ă�SCC�̔ے�ɂ��Ȃ���
�Ȃ���ˁ[��ާ-�
�����N���X�^���X���b�h���ɕ�����Ă邾���Ńt�����g�G���h�̐����������s�X���b�h����
Sandy Bridge�ƕς��Ȃ��A���i���x���̑㕨��Intel�̃��j�[�R�A�����Ƃǂ��q����H
����Ƃ�AMD�͎����i�K�̂��̂i������̂��H�債���咣���ȁB
> Bulldozer�̔ے��Intel����������ōł��͂����Ă�SCC�̔ے�ɂ��Ȃ���
�Ȃ���ˁ[��ާ-�
�����N���X�^���X���b�h���ɕ�����Ă邾���Ńt�����g�G���h�̐����������s�X���b�h����
Sandy Bridge�ƕς��Ȃ��A���i���x���̑㕨��Intel�̃��j�[�R�A�����Ƃǂ��q����H
����Ƃ�AMD�͎����i�K�̂��̂i������̂��H�債���咣���ȁB
409 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 00:39:45 ID:sNWFFdis
>>383
���̓����y�[�W�����p����H
�����y�[�W�ɂȂ����C�e���V�̕\������̂��p�ꂭ�炢�ǂ߂邾��
�Ȃ�Xeon X7560�̃X���[�v�b�g���Ⴂ�̂������Ɛ�������Ă���B
�p��ǂ߂Ȃ��킯����Ȃ�����
���̓����y�[�W�����p����H
�����y�[�W�ɂȂ����C�e���V�̕\������̂��p�ꂭ�炢�ǂ߂邾��
�Ȃ�Xeon X7560�̃X���[�v�b�g���Ⴂ�̂������Ɛ�������Ă���B
�p��ǂ߂Ȃ��킯����Ȃ�����
410 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 00:51:12 ID:sNWFFdis
>>380
> �Ƃ���ŁA�c�q�����http://boo.2ch.net/�ɂ��ĂȂɂ��v���Ƃ���͂���܂����H
���̒ʂ�A�����Ȃ���B
���Ă��O�ꂽ�ȳާ�[�
>>379
loose coupling�̂ق��̖���u�a�����v���ĕ\�L���������̂��B
���w�E���ӂ������܂��B
> �Ƃ���ŁA�c�q�����http://boo.2ch.net/�ɂ��ĂȂɂ��v���Ƃ���͂���܂����H
���̒ʂ�A�����Ȃ���B
���Ă��O�ꂽ�ȳާ�[�
>>379
loose coupling�̂ق��̖���u�a�����v���ĕ\�L���������̂��B
���w�E���ӂ������܂��B
�Ȃ������̉����ɂ��������M�������Ă�Ȓc�q����
�������Ȃ�
�������Ȃ�
���_�̓e�w���c�̓C���e���}���Z�[�ȊO�͎t���܂�����Ă��Ƃ���H
�c�q����Ȃ��ăe�w���c�̕ʐl�i����A
�����������炪�n���ɕt�������ċ�ʂ��ČĂԕK�v�ˁ[����
�����������炪�n���ɕt�������ċ�ʂ��ČĂԕK�v�ˁ[����
414 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 01:16:16 ID:sNWFFdis
�����A��������Bulldozer���g�����W�X�^������Nj������\���Ƃ����咣�i�v�����݁j�Ɏ^�����ĂȂ��B
�Ȃ������N���X�^�Q��FP/SIMD�N���X�^��3�N���X�^�ŕʁX�ɃX�P�W���[�����O���ƂŃg�����W�X�^����������̓d�͌�����
�ǂ����シ��̂��S�R�킩���B
�Ƃ������AComplex Decoder�~4�̎��_�Ŋ��ɐ��c�ꂾ�낤
�Ȃ������N���X�^�Q��FP/SIMD�N���X�^��3�N���X�^�ŕʁX�ɃX�P�W���[�����O���ƂŃg�����W�X�^����������̓d�͌�����
�ǂ����シ��̂��S�R�킩���B
�Ƃ������AComplex Decoder�~4�̎��_�Ŋ��ɐ��c�ꂾ�낤
���ǂ��̔n���͛��������˂���܂킵��
�����Ă邱�Ƃ̓C���e���ō����������ĂȂ����
�����Ă邱�Ƃ̓C���e���ō����������ĂȂ����
>>407
�}�W����
K7/K8�� 80BitFPU��64BitSIMD�̑�������Ă��āA
SSE��128Bit������O���ƌ㔼��2��ɕ����Čv�Z���Ă����B
GF100�̒P���x�Ɣ{���x�̎����Ɠ����悤�Ȃ��́B
���������ꂶ��ACore2�ȍ~�ɑR�ł��Ȃ�����AK10�ł�FPU�ׂ̗�64Bit���j�b�g��lj����āA
128Bit�����Ōv�Z�ł���悤�ɂ����B
�}�W����
K7/K8�� 80BitFPU��64BitSIMD�̑�������Ă��āA
SSE��128Bit������O���ƌ㔼��2��ɕ����Čv�Z���Ă����B
GF100�̒P���x�Ɣ{���x�̎����Ɠ����悤�Ȃ��́B
���������ꂶ��ACore2�ȍ~�ɑR�ł��Ȃ�����AK10�ł�FPU�ׂ̗�64Bit���j�b�g��lj����āA
128Bit�����Ōv�Z�ł���悤�ɂ����B
417 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 01:36:20 ID:sNWFFdis
�܂��l�i�U�������������Ɩ����̂���
���₾�˂�AMD���ے肳���Ǝ������ے肳��Ă�悤�Ɏv�����Ⴄ���z�Ȑl��
���₾�˂�AMD���ے肳���Ǝ������ے肳��Ă�悤�Ɏv�����Ⴄ���z�Ȑl��
418 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 01:45:17 ID:sNWFFdis
���Ȃ݂�>>416�͑�̐�����
K10�̏��64�r�b�g��SIMD���j�b�g��V���ɒlj����������AMD���������\�����Ă�
�[���A�Ϙa���j�b�g�������ASSSE3, SSE4, AVX���lj��������FP/SIMD�N���X�^�͑����ȋK�͂ɂ͂Ȃ肻������
K10�̏��64�r�b�g��SIMD���j�b�g��V���ɒlj����������AMD���������\�����Ă�
�[���A�Ϙa���j�b�g�������ASSSE3, SSE4, AVX���lj��������FP/SIMD�N���X�^�͑����ȋK�͂ɂ͂Ȃ肻������
>>414
> �����A��������Bulldozer���g�����W�X�^������Nj������\���Ƃ����咣�i�v�����݁j�Ɏ^�����ĂȂ��B
3way�͖��ʂ���������2way�Ɍ��炵�Ă邵�A����ɔ����F�X�y�ʉ����Ă�Ǝv����
�����͌������サ�Ă���ƌ��ĊԈႢ�Ȃ�
> �Ȃ������N���X�^�Q��FP/SIMD�N���X�^��3�N���X�^�ŕʁX�ɃX�P�W���[�����O���ƂŃg�����W�X�^����������̓d�͌�����
> �ǂ����シ��̂��S�R�킩���B
>
> �Ƃ������AComplex Decoder�~4�̎��_�Ŋ��ɐ��c�ꂾ�낤
����d�͂��傫���f�R�[�_�[���A�R�A������X3�������̂�X2�Ɍ��邩�����d�͂͌���Ǝv�����B
�Ȃ}�t���߂ɂ�����肷���đ�ǂ�����ĂȂ��Ȓc�q����
> �����A��������Bulldozer���g�����W�X�^������Nj������\���Ƃ����咣�i�v�����݁j�Ɏ^�����ĂȂ��B
3way�͖��ʂ���������2way�Ɍ��炵�Ă邵�A����ɔ����F�X�y�ʉ����Ă�Ǝv����
�����͌������サ�Ă���ƌ��ĊԈႢ�Ȃ�
> �Ȃ������N���X�^�Q��FP/SIMD�N���X�^��3�N���X�^�ŕʁX�ɃX�P�W���[�����O���ƂŃg�����W�X�^����������̓d�͌�����
> �ǂ����シ��̂��S�R�킩���B
>
> �Ƃ������AComplex Decoder�~4�̎��_�Ŋ��ɐ��c�ꂾ�낤
����d�͂��傫���f�R�[�_�[���A�R�A������X3�������̂�X2�Ɍ��邩�����d�͂͌���Ǝv�����B
�Ȃ}�t���߂ɂ�����肷���đ�ǂ�����ĂȂ��Ȓc�q����
420 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 01:58:34 ID:sNWFFdis
>>419
> ����d�͂��傫���f�R�[�_�[���A�R�A������X3�������̂�X2�Ɍ��邩�����d�͂͌���Ǝv�����B
�H�H�H�H�H
�����X���b�h���ŏ���d�͂����闝���ł����Ă�K10��4�R�A���Bulldozer��8�R�A�̕����ȓd�́A�Ƃ����咣����Ȃ���˂����
���āA2�X���b�h��4����/clk�Ȃ̂͂킩�������Е��̃X���b�h���x�Ƃ���1�X���b�h�ōő剽���ߐ�L�ł���̂��˃f�R�[�_��
> ����d�͂��傫���f�R�[�_�[���A�R�A������X3�������̂�X2�Ɍ��邩�����d�͂͌���Ǝv�����B
�H�H�H�H�H
�����X���b�h���ŏ���d�͂����闝���ł����Ă�K10��4�R�A���Bulldozer��8�R�A�̕����ȓd�́A�Ƃ����咣����Ȃ���˂����
���āA2�X���b�h��4����/clk�Ȃ̂͂킩�������Е��̃X���b�h���x�Ƃ���1�X���b�h�ōő剽���ߐ�L�ł���̂��˃f�R�[�_��
421 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 02:00:55 ID:sNWFFdis
���������ϒ����߂̃f�R�[�_��3����/clk��4����/clk�ɑ�����̂̓��\�[�X1.33�{�Ƃ��̎�������Ȃ���
�Ȃ�ŘA������̂��̎q�A�Z�߂�Ƃ��������z�����́H
�����1�R�A������ɉ����߂܂Ŕ��s����悤�ɐݒ肳��Ă��邩������Ȃ��Ɛ������悤��������Ȃ�
�d�͂ɂ��Ă̓R�A���������N���b�N�����Ƃ��Ή��Ƃł��Ȃ�
�d�͌������厖���������������Ɛ��\���L���Ȃ�
�����intel��AMD�����������ǁA���̃o�����X�̂Ƃ���ɍ����o�Ėʔ���
�d�͌������厖���������������Ɛ��\���L���Ȃ�
�����intel��AMD�����������ǁA���̃o�����X�̂Ƃ���ɍ����o�Ėʔ���
K7�n��3���Direct Path(Intel��Simple Decoder�ɑ���)��
1���Vector Path(���G�Ȗ��ߐ�p��Decoder)�̌v4���
Decoder��������
Direct Path��Vector Path�A1���1���Complex Decoder�ɑ������邩��
Bulldozer�ɂ�
4���Direct Path��4���Vector Path�̌v8���Decoder������́H
1���Vector Path(���G�Ȗ��ߐ�p��Decoder)�̌v4���
Decoder��������
Direct Path��Vector Path�A1���1���Complex Decoder�ɑ������邩��
Bulldozer�ɂ�
4���Direct Path��4���Vector Path�̌v8���Decoder������́H
>>420
> �����X���b�h���ŏ���d�͂����闝��
����������Ă��邾���Ȃ�
>K10��4�R�A���Bulldozer��8�R�A�̕����ȓd�́A�Ƃ����咣����Ȃ���˂����
�������Ȏ咣�����o���͂��炳��Ȃ��ȁA������ǂ炻�����Ⴂ�o����̂������ė~�������炢��
�܂��ABobcat��8�R�A�Ȃ�K10 4�R�A���ȓd�͂��ۂ����ǂˁB
�l�I�\�z�� K10 4�R�A��Bulldozer 6�R�A(3���W���[��)�������x�Ƃ����Ƃ��낾�ȁB
> �����X���b�h���ŏ���d�͂����闝��
����������Ă��邾���Ȃ�
>K10��4�R�A���Bulldozer��8�R�A�̕����ȓd�́A�Ƃ����咣����Ȃ���˂����
�������Ȏ咣�����o���͂��炳��Ȃ��ȁA������ǂ炻�����Ⴂ�o����̂������ė~�������炢��
�܂��ABobcat��8�R�A�Ȃ�K10 4�R�A���ȓd�͂��ۂ����ǂˁB
�l�I�\�z�� K10 4�R�A��Bulldozer 6�R�A(3���W���[��)�������x�Ƃ����Ƃ��낾�ȁB
>>421
> ���������ϒ����߂̃f�R�[�_��3����/clk��4����/clk�ɑ�����̂̓��\�[�X1.33�{�Ƃ��̎�������Ȃ���
������Ă܂�A2�R�A�i���W���[��)���Z���� 6���߂���4���߂Ɍ���̂̓��\�[�X0.66�{�Ƃ��̎�������Ȃ����Ă��ƂɂȂ���
> ���������ϒ����߂̃f�R�[�_��3����/clk��4����/clk�ɑ�����̂̓��\�[�X1.33�{�Ƃ��̎�������Ȃ���
������Ă܂�A2�R�A�i���W���[��)���Z���� 6���߂���4���߂Ɍ���̂̓��\�[�X0.66�{�Ƃ��̎�������Ȃ����Ă��ƂɂȂ���
>>409
371�Ƃ͕ʂ̃y�[�W�ł���D
����ƃ������X���[�v�b�g���Ⴂ�̂̓������L���p�V�e�B�𑝂₵�����߂�
���C�e���V�Ƃ̊ւ��͏����ĂȂ��Ǝv���̂ł����D
�Ƃ���ł݂Ȃ����Bulldozer���ǂ̂��炢�̃N���b�N�ŏo��Ǝv���Ă��܂��H
6�R�AK10���8�R�ABulldozer�̕����f�R�[�_�ɂ���ALU�ɂ��돭�Ȃ��Ȃ邩��C
Phenom II X6 1090T���C�܂�3.2GHz���͍��N���b�N�ɂȂ�Ǝ����͎v���Ă��܂����D
Frond end��Execution�ŏ���d�͂̔����ȏ�ɂȂ�悤�ł��̂ŁD
http://citavia.blog.de/2009/10/28/more-on-power-management-7262005/
371�Ƃ͕ʂ̃y�[�W�ł���D
����ƃ������X���[�v�b�g���Ⴂ�̂̓������L���p�V�e�B�𑝂₵�����߂�
���C�e���V�Ƃ̊ւ��͏����ĂȂ��Ǝv���̂ł����D
�Ƃ���ł݂Ȃ����Bulldozer���ǂ̂��炢�̃N���b�N�ŏo��Ǝv���Ă��܂��H
6�R�AK10���8�R�ABulldozer�̕����f�R�[�_�ɂ���ALU�ɂ��돭�Ȃ��Ȃ邩��C
Phenom II X6 1090T���C�܂�3.2GHz���͍��N���b�N�ɂȂ�Ǝ����͎v���Ă��܂����D
Frond end��Execution�ŏ���d�͂̔����ȏ�ɂȂ�悤�ł��̂ŁD
http://citavia.blog.de/2009/10/28/more-on-power-management-7262005/
ttp://pc.watch.impress.co.jp/docs/2008/0428/kaigai438.htm
�������Č���ƁANehalem�ł́A�t�����g�G���h�Ƀ{�g���l�b�N�����̂܂c����Ă���悤�����A
����́A�v�̍ŏ�����D�荞�ݍς݂Ȃ̂�������Ȃ��B
x86 CPU�̌����Ƃ��ẮA3�`4���ߓ����f�R�[�h�́A����ꂽ�P�[�X�ł��������I�ł͂Ȃ��Ɗ�����Ă���Ƃ����w�E�����邩�炾�B
CPU�A�[�L�e�N�g�Ƃ���IBM���ォ��L����Glenn Henry(�O�����E�w�����[)��(President and Founder, Centaur Technology)�͎��̂悤�Ɍ��B
�u(x86 CPU�v�҂�)�N�������ӂ��Ă���̂́A3����4���߂̓����f�R�[�h�ɂ͂������̐�����Ƃ������Ƃ��B
���3����4���߂̓����f�R�[�h���ł���Ƃ́A�F�A�l���Ă��Ȃ��B
�����āA�ʏ�́A�������ȃv���t�B�b�N�X(Funny Prefixes)���A���ĂȂ��ꍇ�݂̂�z�肵�Ă���B
Intel���A�������ȃv���t�B�b�N�X���Ȃ��g�m�[�}������(Normal Instruction)�h���A3����4���߂��f�R�[�h���邱�Ƃ�O��Ƃ��Ă���͂����B
����́A��X�́wIsaiah�x(VIA Technologies/Centaur Technology�̎���CPU�A�[�L�e�N�`��)�̏ꍇ�ł��������B
����(�m�[�}������)�ȊO�̃P�[�X��(3�`4���߂̓����f�R�[�h��)�g�����悤�Ƃ���ƁA�f�R�[�_���ɒ[�ɕ��G�ɂȂ��Ă��܂����낤�v
Henry�����w�E����̂́A��[x86 CPU��3�`4���߂Ƃ������߃f�R�[�h�ш�́A�C���M�����ȃv���t�B�b�N�X�����Ă��Ȃ����߂�z�肵�Ă���A
����ȊO�̃P�[�X�ł͖��߃f�R�[�h�ш悪�����邱�Ƃ͐D�荞�ݍς݂Ƃ������Ƃ��B
3�`4���߂̃f�R�[�h�́A�����܂ł��s�[�N�ш�ŁA���ϒl�͗�����ƍl���Ă���Ɛ��肳���B
���Ƃ�����A�㗬�̃t�F�b�`&�v���f�R�[�h�Ƀ{�g���l�b�N�������Ă����ł͂Ȃ��Ȃ�B
Nehalem�̐����̒ʂ肾�Ƃ���ƁA�d�͌������l�����ꍇ�A�����ɖ��߃v���f�R�[�h&�f�R�[�h���g�����邱�Ƃ͓���ł͂Ȃ����ƂɂȂ�B
��������ƁA���R�A����̉�����Ƃ��đz�肳���̂́A�u���߃t�F�b�`����f�R�[�h�܂ł��ł��邾���X�L�b�v���邱�Ɓv�ɂȂ�B
������Intel��PC����CPU�̔��W�́A�������������������Ă䂭�̂����m��Ȃ��B
�������Č���ƁANehalem�ł́A�t�����g�G���h�Ƀ{�g���l�b�N�����̂܂c����Ă���悤�����A
����́A�v�̍ŏ�����D�荞�ݍς݂Ȃ̂�������Ȃ��B
x86 CPU�̌����Ƃ��ẮA3�`4���ߓ����f�R�[�h�́A����ꂽ�P�[�X�ł��������I�ł͂Ȃ��Ɗ�����Ă���Ƃ����w�E�����邩�炾�B
CPU�A�[�L�e�N�g�Ƃ���IBM���ォ��L����Glenn Henry(�O�����E�w�����[)��(President and Founder, Centaur Technology)�͎��̂悤�Ɍ��B
�u(x86 CPU�v�҂�)�N�������ӂ��Ă���̂́A3����4���߂̓����f�R�[�h�ɂ͂������̐�����Ƃ������Ƃ��B
���3����4���߂̓����f�R�[�h���ł���Ƃ́A�F�A�l���Ă��Ȃ��B
�����āA�ʏ�́A�������ȃv���t�B�b�N�X(Funny Prefixes)���A���ĂȂ��ꍇ�݂̂�z�肵�Ă���B
Intel���A�������ȃv���t�B�b�N�X���Ȃ��g�m�[�}������(Normal Instruction)�h���A3����4���߂��f�R�[�h���邱�Ƃ�O��Ƃ��Ă���͂����B
����́A��X�́wIsaiah�x(VIA Technologies/Centaur Technology�̎���CPU�A�[�L�e�N�`��)�̏ꍇ�ł��������B
����(�m�[�}������)�ȊO�̃P�[�X��(3�`4���߂̓����f�R�[�h��)�g�����悤�Ƃ���ƁA�f�R�[�_���ɒ[�ɕ��G�ɂȂ��Ă��܂����낤�v
Henry�����w�E����̂́A��[x86 CPU��3�`4���߂Ƃ������߃f�R�[�h�ш�́A�C���M�����ȃv���t�B�b�N�X�����Ă��Ȃ����߂�z�肵�Ă���A
����ȊO�̃P�[�X�ł͖��߃f�R�[�h�ш悪�����邱�Ƃ͐D�荞�ݍς݂Ƃ������Ƃ��B
3�`4���߂̃f�R�[�h�́A�����܂ł��s�[�N�ш�ŁA���ϒl�͗�����ƍl���Ă���Ɛ��肳���B
���Ƃ�����A�㗬�̃t�F�b�`&�v���f�R�[�h�Ƀ{�g���l�b�N�������Ă����ł͂Ȃ��Ȃ�B
Nehalem�̐����̒ʂ肾�Ƃ���ƁA�d�͌������l�����ꍇ�A�����ɖ��߃v���f�R�[�h&�f�R�[�h���g�����邱�Ƃ͓���ł͂Ȃ����ƂɂȂ�B
��������ƁA���R�A����̉�����Ƃ��đz�肳���̂́A�u���߃t�F�b�`����f�R�[�h�܂ł��ł��邾���X�L�b�v���邱�Ɓv�ɂȂ�B
������Intel��PC����CPU�̔��W�́A�������������������Ă䂭�̂����m��Ȃ��B
x86�̖��߃Z�b�g���{�g���l�b�N�����Ęb�͐̂��炠���āA
RISC���Ƃ�Itanium�Ƃ�������킯�����A�Fx86�ɔs�k�����B
�p�t�H�[�}���X�ł��d�͌����ł��B
RISC���Ƃ�Itanium�Ƃ�������킯�����A�Fx86�ɔs�k�����B
�p�t�H�[�}���X�ł��d�͌����ł��B
�����i��������j����LOVE�ȃV���^�z���̖ړI��
���̎q���Ƃ��炠�炵���������邱�Ƃł���
���ꂪ�I�悵������ɉ�����[�d�ł��C���X
���t���ς���������2���Ԃ����Ƒ�i���̃X���j�{���ōr�炵���
�����i��������j�����Ȃ��Ɣ����đގU�����悤�ł�
�ł��s��������܂��������悤�Ɨ��邾�낤��
���̎q���Ƃ��炠�炵���������邱�Ƃł���
���ꂪ�I�悵������ɉ�����[�d�ł��C���X
���t���ς���������2���Ԃ����Ƒ�i���̃X���j�{���ōr�炵���
�����i��������j�����Ȃ��Ɣ����đގU�����悤�ł�
�ł��s��������܂��������悤�Ɨ��邾�낤��
>>428
4GHz�ŏo��Ƒf�G�B
4GHz�ŏo��Ƒf�G�B
433 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 06:45:48 ID:sNWFFdis
>>425
Vector Path��Direct Path�͔r�������瓯���ɓ������Ƃ͂Ȃ���B
>>427
> ������Ă܂�A2�R�A�i���W���[��)���Z���� 6���߂���4���߂Ɍ���̂̓��\�[�X0.66�{�Ƃ��̎�������Ȃ����Ă��ƂɂȂ���
���O�͉��������Ă�iAA����
1�̖��߃X�g���[������6���ߓ����Ɏ��o���ăf�R�[�h����K�v�͂Ȃ��̂�6���߂Ƃ��������ɈӖ��͂Ȃ��B
���́A1���߃X�g���[������4����/clk�����o���ăf�R�[�h�ł��邩�Ƃ������ƁB
���������Ȃ烊�\�[�X�͎w���O���t�Ƃ͂���Ȃ��܂ł��P����1.33�{���͊m���ɑ����邵�A
3���߁~2�R�A��胊�\�[�X������Ƃ�������Ȃ��B
���̗���������Ȃ��Ȃ牽���������Ƃ͂Ȃ���B
���x���������ǁA�Œ蒷���߂���Ȃ��̂�
>>429
�R���p�C���̓f���Ȃ��v���t�B�b�N�X�̏������ǂ������Ȃ�Ď蓮�ŃA�Z���u��ϑԂ������ΑS���W�̂Ȃ���肾
�㓡�͓ڒ�������
Vector Path��Direct Path�͔r�������瓯���ɓ������Ƃ͂Ȃ���B
>>427
> ������Ă܂�A2�R�A�i���W���[��)���Z���� 6���߂���4���߂Ɍ���̂̓��\�[�X0.66�{�Ƃ��̎�������Ȃ����Ă��ƂɂȂ���
���O�͉��������Ă�iAA����
1�̖��߃X�g���[������6���ߓ����Ɏ��o���ăf�R�[�h����K�v�͂Ȃ��̂�6���߂Ƃ��������ɈӖ��͂Ȃ��B
���́A1���߃X�g���[������4����/clk�����o���ăf�R�[�h�ł��邩�Ƃ������ƁB
���������Ȃ烊�\�[�X�͎w���O���t�Ƃ͂���Ȃ��܂ł��P����1.33�{���͊m���ɑ����邵�A
3���߁~2�R�A��胊�\�[�X������Ƃ�������Ȃ��B
���̗���������Ȃ��Ȃ牽���������Ƃ͂Ȃ���B
���x���������ǁA�Œ蒷���߂���Ȃ��̂�
>>429
�R���p�C���̓f���Ȃ��v���t�B�b�N�X�̏������ǂ������Ȃ�Ď蓮�ŃA�Z���u��ϑԂ������ΑS���W�̂Ȃ���肾
�㓡�͓ڒ�������
����60ڽ�����Ă�z����T������
����������
>380�ɋ��~�߂�ꂽ�����œ��t�ς��܂ŏo�ė���Ȃ������킯��
��ŏo�ė����r�[��>420
���R�A������X3�������̂�X2
��
��K10��4�R�A���Bulldozer��8�R�A
��
�uK10��4*3���Bull��8*2�̂ق������Ȃ��Ƃ������_�Ƃ͒������Ȃ���ˁv
���ς�炸�]���X�����Ă܂���
12���16�̂ق��������͓̂�����O
���̃X���ɂ͋C���������z���̃S�L�u���ƌ������������Ă鏭�N�ȂNj��Ȃ�
���������w�h���̒��ɋA���
����ł����Ȃ炻�̂ق�������������
>380�ɋ��~�߂�ꂽ�����œ��t�ς��܂ŏo�ė���Ȃ������킯��
��ŏo�ė����r�[��>420
���R�A������X3�������̂�X2
��
��K10��4�R�A���Bulldozer��8�R�A
��
�uK10��4*3���Bull��8*2�̂ق������Ȃ��Ƃ������_�Ƃ͒������Ȃ���ˁv
���ς�炸�]���X�����Ă܂���
12���16�̂ق��������͓̂�����O
���̃X���ɂ͋C���������z���̃S�L�u���ƌ������������Ă鏭�N�ȂNj��Ȃ�
���������w�h���̒��ɋA���
����ł����Ȃ炻�̂ق�������������
436 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 07:10:00 ID:sNWFFdis
�܂����Ƃ������Ă�̂�
�ϑz����܂��
�ϑz����܂��
����
�l�ԂȂ�]���X�͕��ʂɍ݂邯��
�����͕��ʂɖ�����������Ȃ�
�������͕̂����Ă����Ȃ������
�l�ԂȂ�]���X�͕��ʂɍ݂邯��
�����͕��ʂɖ�����������Ȃ�
�������͕̂����Ă����Ȃ������
���t���ς��܂Ŗ������Ŋ撣���Ă������
bulldozer�̃f�R�[�_�b�e>>429�ŕ��G�ɂȂ肷���Č�������������intel,centaur�����Ȃ����Č����Ă�
4x complex decoder�Ȃ̂��ˁH
nehalem�ł���1 comp,3x simple�Ȃ̂���H
4x complex decoder�Ȃ̂��ˁH
nehalem�ł���1 comp,3x simple�Ȃ̂���H
440 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 08:07:53 ID:sNWFFdis
���Ƃ���4�o�C�g�Œ蒷�̖��߃Z�b�g�Ȃ�A4����f�R�[�h�͂���Ȃɑ傫�Ȗ�肶��Ȃ���B
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�FIP+4
�@�@�f�R�[�_�R�FIP+8
�@�@�f�R�[�_�S�FIP+12
�@�@���̃T�C�N���FIP��IP+16
�Ƃ��낪�ϒ����Ɩ��߂̖������m��ł��Ȃ���Ύ��̖��߂̓��o���͂ł��Ȃ�
AMD�̃A�[�L�e�N�`����L1I�Ƀt�F�b�`���鎞�_�Ŗ��ߒ����o�����O�ɂ���Ă��܂����Ƃ�
�f�R�[�_�̕��S�𑽏����炵�Ă͂��邪�A����ς�Œ蒷�Ɠ����Ƃ͂����Ȃ��B
���O�ɖ��ߒ������ꍇ�́A���߂̓��o���͂���Ȋ����ɂȂ�
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�F IP + inst1.length
�@�@�f�R�[�_�R�F IP + inst1.length + inst2.length
�@�@���̃T�C�N���FIP �� IP + inst1.length + inst2.length + inst3.length
��ŁA���ꂪ4���ߓ����f�R�[�h�ɂȂ�Ƃ����Ȃ�
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�F IP + inst1.length
�@�@�f�R�[�_�R�F IP + inst1.length + inst2.length
�@�@�f�R�[�_�S�F IP + inst1.length + inst2.length + inst3.length
�@�@���̃T�C�N���FIP + inst1.length + inst2.length + inst3.length + inst4.length
������ʂ�1�T�C�N���Ŋ��������Ȃ��Ƃ����Ȃ��B
����ɑς����鍂���쓮�̉��Z��H���K�v�ɂȂ�B1.33�{�̃��\�[�X����Ƃ͌����Ȃ����Ă̂͂����������ƁB
���̃|�C���^���v���f�R�[�h�^�O�ɂ���Ă��������H����͂���ŃL���b�V����t�����g�G���h����ςȂ��ƂɂȂ�B
�����ۂ�Intel�`���̃v���f�R�[�h�����͐��̖��߃X�g���[���𓊋@�I�ɕ���X�L��������
���ߒ��̊m�莞�_�œ��o�����s�������̂�j������B
���߃t�F�b�`�ш敪�̃X�L���i���K�v�ɂȂ�̂ňꌩAMD��荂�R�X�g�Ɍ����邪�A���o��������
1�X�e�[�W�Ŋ���������K�v���Ȃ��̂ł������Ă��₷���ʂ�����B
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�FIP+4
�@�@�f�R�[�_�R�FIP+8
�@�@�f�R�[�_�S�FIP+12
�@�@���̃T�C�N���FIP��IP+16
�Ƃ��낪�ϒ����Ɩ��߂̖������m��ł��Ȃ���Ύ��̖��߂̓��o���͂ł��Ȃ�
AMD�̃A�[�L�e�N�`����L1I�Ƀt�F�b�`���鎞�_�Ŗ��ߒ����o�����O�ɂ���Ă��܂����Ƃ�
�f�R�[�_�̕��S�𑽏����炵�Ă͂��邪�A����ς�Œ蒷�Ɠ����Ƃ͂����Ȃ��B
���O�ɖ��ߒ������ꍇ�́A���߂̓��o���͂���Ȋ����ɂȂ�
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�F IP + inst1.length
�@�@�f�R�[�_�R�F IP + inst1.length + inst2.length
�@�@���̃T�C�N���FIP �� IP + inst1.length + inst2.length + inst3.length
��ŁA���ꂪ4���ߓ����f�R�[�h�ɂȂ�Ƃ����Ȃ�
�@�@�f�R�[�_�P�FIP
�@�@�f�R�[�_�Q�F IP + inst1.length
�@�@�f�R�[�_�R�F IP + inst1.length + inst2.length
�@�@�f�R�[�_�S�F IP + inst1.length + inst2.length + inst3.length
�@�@���̃T�C�N���FIP + inst1.length + inst2.length + inst3.length + inst4.length
������ʂ�1�T�C�N���Ŋ��������Ȃ��Ƃ����Ȃ��B
����ɑς����鍂���쓮�̉��Z��H���K�v�ɂȂ�B1.33�{�̃��\�[�X����Ƃ͌����Ȃ����Ă̂͂����������ƁB
���̃|�C���^���v���f�R�[�h�^�O�ɂ���Ă��������H����͂���ŃL���b�V����t�����g�G���h����ςȂ��ƂɂȂ�B
�����ۂ�Intel�`���̃v���f�R�[�h�����͐��̖��߃X�g���[���𓊋@�I�ɕ���X�L��������
���ߒ��̊m�莞�_�œ��o�����s�������̂�j������B
���߃t�F�b�`�ш敪�̃X�L���i���K�v�ɂȂ�̂ňꌩAMD��荂�R�X�g�Ɍ����邪�A���o��������
1�X�e�[�W�Ŋ���������K�v���Ȃ��̂ł������Ă��₷���ʂ�����B
���Ƃ��� �܂œǂ�
442 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 08:34:24 ID:sNWFFdis
>>439
���ۖ���Code ROM�Q�Ƃ��K�v�ȃf�R�[�h�������Ƃǂ݂̂���OPs�����傷��̂�4����ł��Ӗ����Ă���܂�Ȃ���ˁB
����PPro�`Pen3�Ńl�b�N���������������[�h�{�_���Z�p���Z�̖��߂�Simple Decoder�ł�1�T�C�N���ŏ����ł���悤�ɂȂ��Ă�
���ʂɍl�����VectorPath 1��4�͕s������ˁB
AVX��DirectPath�ŏ�������]�T���Ȃ��̂Ŏd���Ȃ�DirectPath�𑝂₵���Ƃ�����
K7��SSE���ɒ[�ɒx���������̓�̓Q�܂Ȃ����߂ɂ͂��̂��炢�͕K�v�Ȃ̂����ˁB
256�r�b�g���߂Ȃ班�Ȃ��Ƃ�2��OPs�ɕ�������K�v�����邩���
���ۖ���Code ROM�Q�Ƃ��K�v�ȃf�R�[�h�������Ƃǂ݂̂���OPs�����傷��̂�4����ł��Ӗ����Ă���܂�Ȃ���ˁB
����PPro�`Pen3�Ńl�b�N���������������[�h�{�_���Z�p���Z�̖��߂�Simple Decoder�ł�1�T�C�N���ŏ����ł���悤�ɂȂ��Ă�
���ʂɍl�����VectorPath 1��4�͕s������ˁB
AVX��DirectPath�ŏ�������]�T���Ȃ��̂Ŏd���Ȃ�DirectPath�𑝂₵���Ƃ�����
K7��SSE���ɒ[�ɒx���������̓�̓Q�܂Ȃ����߂ɂ͂��̂��炢�͕K�v�Ȃ̂����ˁB
256�r�b�g���߂Ȃ班�Ȃ��Ƃ�2��OPs�ɕ�������K�v�����邩���
443 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 08:35:33 ID:sNWFFdis
�~AVX��DirectPath�ŏ�������]�T���Ȃ��̂Ŏd���Ȃ�DirectPath�𑝂₵���Ƃ�����
��AVX��DirectPath�ŏ�������]�T���Ȃ��̂Ŏd���Ȃ�VectorPath�𑝂₵���Ƃ�����
��AVX��DirectPath�ŏ�������]�T���Ȃ��̂Ŏd���Ȃ�VectorPath�𑝂₵���Ƃ�����
���������Ԃb�L��������Ă����ȁA�n�������܂����Ă�
�L�����ݒ肪�j�]���������Ă邵�A����͂������E����
�L�����ݒ肪�j�]���������Ă邵�A����͂������E����
�������������ꗬ���Ă邪���ǃC���e���ō����������ĂȂ���Ȃ�����
�f�R�[�_�͂��Ȃ�䂾��
ttp://www.life-lab.com/amd-lab/amd686.html
�ł̓V���[�g�E�����O�E�x�N�^��3�킠��Ƃ��Ă���
P6�̓V���[�g��3��K7�̓����O��3�A�l�g�o�������O������������
Bull���u�S���o����f�R�[�_4�v���Ă̂��ߋ����O�ň�x�����o���\��
�V���^�z���E���R�J�u�����Εa���ĘA�Ă��Ă邾���Ȃ�Ȃ����H
�܂��ڂ����\�[�X�o�ĂȂ�����
�V���O���X���b�h�Ŋ��S4�f�R�[�h
�}���`��0�`4�i���i��2�j�_��ɏo�����炻��ᐦ�����ǂ�
ttp://www.life-lab.com/amd-lab/amd686.html
�ł̓V���[�g�E�����O�E�x�N�^��3�킠��Ƃ��Ă���
P6�̓V���[�g��3��K7�̓����O��3�A�l�g�o�������O������������
Bull���u�S���o����f�R�[�_4�v���Ă̂��ߋ����O�ň�x�����o���\��
�V���^�z���E���R�J�u�����Εa���ĘA�Ă��Ă邾���Ȃ�Ȃ����H
�܂��ڂ����\�[�X�o�ĂȂ�����
�V���O���X���b�h�Ŋ��S4�f�R�[�h
�}���`��0�`4�i���i��2�j�_��ɏo�����炻��ᐦ�����ǂ�
GW�x�^�t���A���ɂ�鎖�Ȃ��̂���
5��2���Fhttp://hissi.org/read.php/jisaku/20100502/cmdJZytxczk.html
5��3���Fhttp://hissi.org/read.php/jisaku/20100503/SVMzK3Bjc1g.html
5��5���Fhttp://hissi.org/read.php/jisaku/20100505/RS9jV2J5RUg.html
5��7���Fhttp://hissi.org/read.php/jisaku/20100507/bHMvVHQrZnk.html
5��8���Fhttp://hissi.org/read.php/jisaku/20100508/Z1grUzhkOGE.html
5��9���Fhttp://hissi.org/read.php/jisaku/20100509/c05XRkZkaXM.html
5��2���Fhttp://hissi.org/read.php/jisaku/20100502/cmdJZytxczk.html
5��3���Fhttp://hissi.org/read.php/jisaku/20100503/SVMzK3Bjc1g.html
5��5���Fhttp://hissi.org/read.php/jisaku/20100505/RS9jV2J5RUg.html
5��7���Fhttp://hissi.org/read.php/jisaku/20100507/bHMvVHQrZnk.html
5��8���Fhttp://hissi.org/read.php/jisaku/20100508/Z1grUzhkOGE.html
5��9���Fhttp://hissi.org/read.php/jisaku/20100509/c05XRkZkaXM.html
X�l�g�o�������O����
O�l�g�o���V���[�g������
��
O�l�g�o���V���[�g������
��
�c�q�c���S�ɃL�������e�w�ɖ߂��Ă����w
�ꐶ�������������Ă��uIntel�ō��I�v�Ƃ��������Ă��܂�œ������������Ȃ��Ȃ�ĉ��z
���ǂ̂Ƃ���A�c�q�����͂Ȃ́H
����Ă邱�Ƃ͓������Ȃ�
453 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 08:55:14 ID:sNWFFdis
���߂�AK10�̎��_��Vector Path��3mops/clk��
����A���܂��炪�s�����Ȃ̂͂킩���Ă��
���_�ł��邱�ƂȂ�ĉ�����������l�i�U�������ɂ��Ă�̂�
����A���܂��炪�s�����Ȃ̂͂킩���Ă��
���_�ł��邱�ƂȂ�ĉ�����������l�i�U�������ɂ��Ă�̂�
���_�ł��邱�ƂȂ�ĉ�����������l�i�U�������ɂ��Ă�̂�
�s���̈������Ƃɂ������Ă��猾���Ă݂�悗
�A�z������Ȃ����͂�
�s���̈������Ƃɂ������Ă��猾���Ă݂�悗
�A�z������Ȃ����͂�
455 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:01:58 ID:sNWFFdis
���s���̈������Ƃɂ������Ă��猾���Ă݂�悗
�������̑䎌��
�������̑䎌��
���ɂ���intel�}���Z�[�����т��������Ȃ�X���`���ȁB
���ӂ̋����g���Ȃ��̂͂炢�Ȓc�q
�����͂����uintel�}���Z�[�v���u�����}���Z�[�v����
�����̏u�Ԃ͉����u�����i��������j����P�c�}���R�[�v����
����������
�����̏u�Ԃ͉����u�����i��������j����P�c�}���R�[�v����
����������
459 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:09:41 ID:sNWFFdis
�u�}���Z�[�v���Č����Ă�悤�ɂ����������Ȃ��l�Ɖ�b�͐������Ȃ���
���N��12�����͂܂�Bulldozer�i��ɂ܂���Ă�������J�����ɂꗬ�ɗi��ł��Ȃ��Ȃ����B
>>381��SCC�����������ɏo���Ă邪AMD��SCC���Ă̂͂���Ӗ������Ȃ̂����i���i���ł��郌�x���łȂ��Ƃ����Ӗ��Łj
���N��12�����͂܂�Bulldozer�i��ɂ܂���Ă�������J�����ɂꗬ�ɗi��ł��Ȃ��Ȃ����B
>>381��SCC�����������ɏo���Ă邪AMD��SCC���Ă̂͂���Ӗ������Ȃ̂����i���i���ł��郌�x���łȂ��Ƃ����Ӗ��Łj
�����u���X��������
461 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:20:46 ID:sNWFFdis
�����A�A�z���Εa���Ă�̂�����̂��D����
�����Ɋ���_�ŕԂ����炻�̎��_�Ŋ��ɕ����ł���
�����Ɋ���_�ŕԂ����炻�̎��_�Ŋ��ɕ����ł���
Bulldozer���āA���W���[������2�̃R�A�̂����A�Е��̃R�A�����N���b�N��ς�����~�߂���o����̂���
>>408�ł��łɒc�q����̕����ł����
��荇��������Ƃ��Ēc�q�͑��ݎ��̂����̃X���ɑ��ăX���Ⴂ�ƌ������͕��������B
465 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:34:23 ID:sNWFFdis
�����ŕԂ��Ă邶������ł��H
�c�q�͑��ݎ��̂����̃X���ɑ��ăX���Ⴂ
���{�ꂪ�����ł��Ȃ��n�������璣��t���Ă�
�n���͋~�����Ȃ���Ȃ�
���{�ꂪ�����ł��Ȃ��n�������璣��t���Ă�
�n���͋~�����Ȃ���Ȃ�
467 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:39:29 ID:sNWFFdis
���̎w�E�ɑ��Ė����ɋZ�p�I���_���o���Ȃ��N�͂��̃X���ɕK�v�Ȃ���
4*3<8*2�܂�12<16���Z���̐��E�Ŋm�莖�����Ƃ������Ƃ�������������
����͂Ȃ���VIA�������グ�Ă����A�ނ��Ⴍ���Ⴞ���c�q
����
�������Ȃ��Ă���
���炩�ɕs�\�Ȃ��Ƃ���������͖���
�ł����߂ā@�@�o�@�@���@�@��
�������Ȃ��Ă���
���炩�ɕs�\�Ȃ��Ƃ���������͖���
�ł����߂ā@�@�o�@�@���@�@��
471 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:43:53 ID:sNWFFdis
�����͂��������ǂ�
����d�́FBarcelona 4�R�A��Nehalem 4�R�A
�X���[�v�b�g�FBarcelona 8�R�A��Nehalem 4�R�A
����d�́FBarcelona 4�R�A��Nehalem 4�R�A
�X���[�v�b�g�FBarcelona 8�R�A��Nehalem 4�R�A
472 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:44:42 ID:sNWFFdis
>>469
���ǂ���VIA�������グ���H
���ǂ���VIA�������グ���H
>>467
���������̒m���Ȃ�������������ɗ��ĂĂ݂Ȃ��H����ȊO�ł�
���ʂɎh�X�����q�ϐ��ɂ�����悤�ȕ��������Α�����ق邾�낤��
���e�ɂ��\���Ȑ����͂�����A�Ƃ����O��͂��邯�ǂ�
���������̒m���Ȃ�������������ɗ��ĂĂ݂Ȃ��H����ȊO�ł�
���ʂɎh�X�����q�ϐ��ɂ�����悤�ȕ��������Α�����ق邾�낤��
���e�ɂ��\���Ȑ����͂�����A�Ƃ����O��͂��邯�ǂ�
474 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 09:52:46 ID:sNWFFdis
Intel�R���p�C�������瑬���ƌ����Ă��l�ɃG�T������B
Xeon�͏����R���p�C�������ĂȂ��Ƃ���ȔߎS�Ȍ��ʂ�����
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1 (internal build 39.0)
SPECintR_rate2006 = 253
SPECint_rate_base2006 = 238
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090414-07079.html
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
Xeon�͏����R���p�C�������ĂȂ��Ƃ���ȔߎS�Ȍ��ʂ�����
Sun Microsystems
Sun Blade X6275 (Intel Xeon X5570 2.93GHz)
Compiler: Sun Studio 12 Update 1 (internal build 39.0)
SPECintR_rate2006 = 253
SPECint_rate_base2006 = 238
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090414-07079.html
Sun Microsystems
Sun Blade X6440 (AMD Opteron 8389 2.9GHz)
Compiler: PGI Server Complete Version 8.0 x86 Open64 4.2.2 Compiler Suite (from AMD)�@��AMD����
SPECintR_rate2006 = 292
SPECint_rate_base2006 = 226
http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090914-08593.html
>>473
���Ă̒ʂ�A�����͒c�q�ɂƂ��Ēm�����Ђ��炩�������}�X�^�[�x�[�V�����̏�ɂȂ��Ă��邩��A����������������
�|���鎖�͑����������Ǝv��
���Ă̒ʂ�A�����͒c�q�ɂƂ��Ēm�����Ђ��炩�������}�X�^�[�x�[�V�����̏�ɂȂ��Ă��邩��A����������������
�|���鎖�͑����������Ǝv��
�o�O���ڃR�s�y�Ƃ����T���a�ŗ����i��������j��������т��ăE�z�낤�Ƃ����n�b�e���o����
�����ɂ͋��Ȃ�����ނ��킯������
�����ɂ͋��Ȃ�����ނ��킯������
���̌�����߂��c�q
���c(�c�q)�̌��������Ă���ƌ����_�ł�AMD>Intel���Ƃ������Ƃ��c�B
�����ŋ߂̌��c�̃t�@�r�����̓v���X�R���A�X64�Ƀt���{�b�R�ɂ���Ă�������̌��c���v���o����B
�����ŋ߂̌��c�̃t�@�r�����̓v���X�R���A�X64�Ƀt���{�b�R�ɂ���Ă�������̌��c���v���o����B
479 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 10:53:51 ID:sNWFFdis
��������Opteron��Xeon���S�s����>>474
http://www.stickam.jp/
�c�q�̑�D����DX11�̉����
�c�q�̑�D����DX11�̉����
>>478
�s�����V���v�������番����₷��
�s�����V���v�������番����₷��
484 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 11:38:25 ID:sNWFFdis
> ���̃y�[�W�͉~����4���������A���S���Y��bbp�@�Ōv�Z�������̃����L���O�ł��B
4�����Ȃ��Atom�ł�1�b������Ȃ�������x���A���S���Y���ʼn�����ł��˂킩��܂�
4�����Ȃ��Atom�ł�1�b������Ȃ�������x���A���S���Y���ʼn�����ł��˂킩��܂�
��������AMD�̎�����CPU�ɕt���Č���
ttp://xs.to/image-6568_4BE6210E.jpg
ttp://xs.to/image-A04C_4BE6210E.jpg
396 �FSocket774 [��] �F2010/05/08(�y) 20:23:52 ID:awUi9idF
3 ALU��k8��2 ALU��nano�ō����Ȃ�����
�u���������Ȃ����낤
���A�ł�nano��ALU2�͕��߂ƒP�����߂���������1.5 ALU���ĂƂ���
401 �FSocket774 [��] �F2010/05/08(�y) 21:00:54 ID:awUi9idF
nano-e�ł͍X��2-3����p�t�H�[�}���X���オ��
{kind=link}
ttp://xs.to/image-A04C_4BE6210E.jpg
{kind=link}
396 �FSocket774 [��] �F2010/05/08(�y) 20:23:52 ID:awUi9idF
3 ALU��k8��2 ALU��nano�ō����Ȃ�����
�u���������Ȃ����낤
���A�ł�nano��ALU2�͕��߂ƒP�����߂���������1.5 ALU���ĂƂ���
401 �FSocket774 [��] �F2010/05/08(�y) 21:00:54 ID:awUi9idF
nano-e�ł͍X��2-3����p�t�H�[�}���X���オ��
�{���]�|�ȐQ��
>>474
> Compiler: Sun Studio 12 Update 1 (internal build 39.0)
�����N��ɂ�
Compiler: Intel C++ and Fortran Compiler 11.0 for Linux Build 20080930
�Ə����Ă��邪�H
> Compiler: Sun Studio 12 Update 1 (internal build 39.0)
�����N��ɂ�
Compiler: Intel C++ and Fortran Compiler 11.0 for Linux Build 20080930
�Ə����Ă��邪�H
484 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2010/05/09(��) 11:38:25 ID:sNWFFdis (24��)
�@> ���̃y�[�W�͉~����4���������A���S���Y��bbp�@�Ōv�Z�������̃����L���O�ł��B
�@4�����Ȃ��Atom�ł�1�b������Ȃ�������x���A���S���Y���ʼn�����ł��˂킩��܂�
super�����ĕ��x���\�t�g����ȁA����ȃS�~�v�Z��CPU�̐��\����Ă�z����Ĕn���Ȃ�Ȃ�
�@> ���̃y�[�W�͉~����4���������A���S���Y��bbp�@�Ōv�Z�������̃����L���O�ł��B
�@4�����Ȃ��Atom�ł�1�b������Ȃ�������x���A���S���Y���ʼn�����ł��˂킩��܂�
super�����ĕ��x���\�t�g����ȁA����ȃS�~�v�Z��CPU�̐��\����Ă�z����Ĕn���Ȃ�Ȃ�
>>484
�܂������̓s���ɗǂ�����������o���ăt�@�r���Ă܂��ˁc�B����Ƃ����̃x���`�̎�|���{�C�ʼn���Ȃ��Ƃ�?
�܂����X>>483�̃y���`�������Ď����o�����̂͒c�q�̍s�ׂ�^�������Ă���������������ǂ�w
�܂莩���ɂƂ��ēs���̂悢���ʂ��������I���ăJ�L�R����s�ׂ��ˁB
�v�����>>483�̔ے�͎������g�̍s����ے肵�Ă���Ƃ���������B�킩��?
�܂������̓s���ɗǂ�����������o���ăt�@�r���Ă܂��ˁc�B����Ƃ����̃x���`�̎�|���{�C�ʼn���Ȃ��Ƃ�?
�܂����X>>483�̃y���`�������Ď����o�����̂͒c�q�̍s�ׂ�^�������Ă���������������ǂ�w
�܂莩���ɂƂ��ēs���̂悢���ʂ��������I���ăJ�L�R����s�ׂ��ˁB
�v�����>>483�̔ے�͎������g�̍s����ے肵�Ă���Ƃ���������B�킩��?
http://www.4gamer.net/games/107/G010710/20100317030/
���Q�[���v���O������Intel HD Graphics�ɍœK�����Ăق���
�@ �_�__
:�O�=:::::::�R
:�R.�j=::��.>�M_
�O.�R= (�܁R;:;:;,.��)
�j=-�R:�R�A,��.^^���@�@�_�����B���̊肢�͐_���̗͂��Ă���B
�V,�ׁ��PƓ�P
�^;:�B�� Ƀm ,.�ցR
;:́^�P�P�P�u�R�R
�\�@ �@ �@ �@ ����|
���Q�[���v���O������Intel HD Graphics�ɍœK�����Ăق���
�@ �_�__
:�O�=:::::::�R
:�R.�j=::��.>�M_
�O.�R= (�܁R;:;:;,.��)
�j=-�R:�R�A,��.^^���@�@�_�����B���̊肢�͐_���̗͂��Ă���B
�V,�ׁ��PƓ�P
�^;:�B�� Ƀm ,.�ցR
;:́^�P�P�P�u�R�R
�\�@ �@ �@ �@ ����|
>>433
> 3���߁~2�R�A��胊�\�[�X������Ƃ�������Ȃ��B
> ���̗���������Ȃ��Ȃ牽���������Ƃ͂Ȃ���B
�v��4����/clk��3����/clk*2�̂ǂ������������������Ęb�����
�ŁABulldozer�̏ꍇ�A(2����*2)/clk�œ��������Ƃ��z�肵�Ă�����
���ꂾ���̘b���ʼn��ł���ȑ����ł�c�q��
> 3���߁~2�R�A��胊�\�[�X������Ƃ�������Ȃ��B
> ���̗���������Ȃ��Ȃ牽���������Ƃ͂Ȃ���B
�v��4����/clk��3����/clk*2�̂ǂ������������������Ęb�����
�ŁABulldozer�̏ꍇ�A(2����*2)/clk�œ��������Ƃ��z�肵�Ă�����
���ꂾ���̘b���ʼn��ł���ȑ����ł�c�q��
>>492
�O��������uAMD���Ȃ߂邱�Ɓv������B
�O��������uAMD���Ȃ߂邱�Ɓv������B
494 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 12:27:22 ID:sNWFFdis
>>490
�������Ӌ`�Ȃ�Ȃ��ȁB
�A���S���Y���ɗL�p��������ΐ��\�]���Ƃ��Ă͔��ɎQ�l�ɂȂ邪�N�\���ɂ�������
HPC�̐��E�ł͐��\�Ńn�[�h�E�F�A��I�Ԃ悤�Ƀ\�t�g�E�F�A�E���C�u�������I�Ԃ̂���B
��GMP��300�����̕����������Ǔ���N���b�N���Ȃ��̂łǂ��Ƃ������
����Ȃ��������ȃx���`�����Ђ���SPEC�Ɠ����x���Ō�邱�Ǝ��̂��G�����܂����ˁB
�Q�l�܂łɉ���SuperPI�̐��\�ŗD��������Ƃ͈�x���Ȃ���
���O������l�����Ɗ��Ⴂ���Ă�N�\�e�w�̂��ƂȂ�m���
>>488
�ނ�ꂽ���łɂ�������Ă�
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07022.html
���ƁA���̂�16�R�A�ł̌��ʂ����邩��B����Opteron��16�R�A�ƌ���ׂČ��悤��
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
������������DP��4�\�P�b�g�Ȃ��Intel���T�|�[�g���ĂȂ����Ȃ�
Sun���ǂ�ȍ\���Ƃ����̂��C�ɂȂ�
��������Sun��Intel�ŃR���p�C�����\�ɂ���Ȃɑ卷�͂Ȃ���
http://blogs.sun.com/keiichio/entry/sunstudio12u1_osol_speccpu2006
>>492
> �ŁABulldozer�̏ꍇ�A(2����*2)/clk�œ��������Ƃ��z�肵�Ă�����
���@���@��@�O�@��
2���߁~2�Ȃ炻�������t�����g�G���h�����p�ɂ���Ӗ����Ȃ�����B
���p���郁���b�g�����A���Ƃ���1�X���b�h��4����/clk���ł���悤�ȍ\�����Ƃ�Ȃ�
�n�[�h�͂����������ɐv�ɂ��Ȃ��Ƃ����Ȃ��B
���̏��>>440��ǂݒ����Ă���B�����R�X�g����C�ɏオ��̂��킩��B
�{�C�œ��������q���ˌN�́B
�������Ӌ`�Ȃ�Ȃ��ȁB
�A���S���Y���ɗL�p��������ΐ��\�]���Ƃ��Ă͔��ɎQ�l�ɂȂ邪�N�\���ɂ�������
HPC�̐��E�ł͐��\�Ńn�[�h�E�F�A��I�Ԃ悤�Ƀ\�t�g�E�F�A�E���C�u�������I�Ԃ̂���B
��GMP��300�����̕����������Ǔ���N���b�N���Ȃ��̂łǂ��Ƃ������
����Ȃ��������ȃx���`�����Ђ���SPEC�Ɠ����x���Ō�邱�Ǝ��̂��G�����܂����ˁB
�Q�l�܂łɉ���SuperPI�̐��\�ŗD��������Ƃ͈�x���Ȃ���
���O������l�����Ɗ��Ⴂ���Ă�N�\�e�w�̂��ƂȂ�m���
>>488
�ނ�ꂽ���łɂ�������Ă�
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07022.html
���ƁA���̂�16�R�A�ł̌��ʂ����邩��B����Opteron��16�R�A�ƌ���ׂČ��悤��
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090413-07024.html
������������DP��4�\�P�b�g�Ȃ��Intel���T�|�[�g���ĂȂ����Ȃ�
Sun���ǂ�ȍ\���Ƃ����̂��C�ɂȂ�
��������Sun��Intel�ŃR���p�C�����\�ɂ���Ȃɑ卷�͂Ȃ���
http://blogs.sun.com/keiichio/entry/sunstudio12u1_osol_speccpu2006
>>492
> �ŁABulldozer�̏ꍇ�A(2����*2)/clk�œ��������Ƃ��z�肵�Ă�����
���@���@��@�O�@��
2���߁~2�Ȃ炻�������t�����g�G���h�����p�ɂ���Ӗ����Ȃ�����B
���p���郁���b�g�����A���Ƃ���1�X���b�h��4����/clk���ł���悤�ȍ\�����Ƃ�Ȃ�
�n�[�h�͂����������ɐv�ɂ��Ȃ��Ƃ����Ȃ��B
���̏��>>440��ǂݒ����Ă���B�����R�X�g����C�ɏオ��̂��킩��B
�{�C�œ��������q���ˌN�́B
�����Ɋ���_�ŕԂ����炻�̎��_�Ŋ��ɕ����ł���
496 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 12:34:49 ID:sNWFFdis
�ނ����������̂͋q�ϓI�����ł��̂�
�ǂ��l���Ă��e�w=�c�q�ł���w �s���p�^�[���A�������܂�����蓯���B
���ɓ���l���ł͂Ȃ��Ƃ��Ă��e�w�̗R�s�[�ɕς��Ȃ���w
���ɓ���l���ł͂Ȃ��Ƃ��Ă��e�w�̗R�s�[�ɕς��Ȃ���w
�ł��e�w�I�ɂ͂��͓S�ǂ̃C���e���L�����Ȃ��H
499 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 12:38:55 ID:sNWFFdis
�y�����܂ł̂܂Ƃ߁z
CPU�̉��x�Z���T�[�ŋ����N���b�N�_�E������@�\��Magny-Cours�́u�ȓd�͋Z�p�v�ɉ��p����AMD�͐���
CPU�̉��x�Z���T�[�ŋ����N���b�N�_�E������@�\��Magny-Cours�́u�ȓd�͋Z�p�v�ɉ��p����AMD�͐���
>>498
����Ȑݒ肾�����B���S�ɃL�����ݒ�������������������ȁB
����Ȑݒ肾�����B���S�ɃL�����ݒ�������������������ȁB
�L�������Ă͓��
>>494
���傢�Ɣ��_�Ƃ������C�ɂȂ����_
> ����ɑς����鍂���쓮�̉��Z��H���K�v�ɂȂ�B1.33�{�̃��\�[�X����Ƃ͌����Ȃ����Ă̂͂����������ƁB
3���߁�4���߂ő��傷��͕̂�����
����3����*2����4����*1�ő��傷�邩�ǂ�������
3���߂̃��\�[�X��1�Ƃ����Ƃ��A4���߂�1.33�A3����*2��2�Ȃ�]�T�Ń��\�[�X�팸�̌��ʂ͂��邾��B
>
> �����ۂ�Intel�`���̃v���f�R�[�h�����͐��̖��߃X�g���[���𓊋@�I�ɕ���X�L��������
> ���ߒ��̊m�莞�_�œ��o�����s�������̂�j������B
> ���߃t�F�b�`�ш敪�̃X�L���i���K�v�ɂȂ�̂ňꌩAMD��荂�R�X�g�Ɍ����邪�A���o��������
> 1�X�e�[�W�Ŋ���������K�v���Ȃ��̂ł������Ă��₷���ʂ�����B
���傢�Ɣ��_�Ƃ������C�ɂȂ����_
> ����ɑς����鍂���쓮�̉��Z��H���K�v�ɂȂ�B1.33�{�̃��\�[�X����Ƃ͌����Ȃ����Ă̂͂����������ƁB
3���߁�4���߂ő��傷��͕̂�����
����3����*2����4����*1�ő��傷�邩�ǂ�������
3���߂̃��\�[�X��1�Ƃ����Ƃ��A4���߂�1.33�A3����*2��2�Ȃ�]�T�Ń��\�[�X�팸�̌��ʂ͂��邾��B
>
> �����ۂ�Intel�`���̃v���f�R�[�h�����͐��̖��߃X�g���[���𓊋@�I�ɕ���X�L��������
> ���ߒ��̊m�莞�_�œ��o�����s�������̂�j������B
> ���߃t�F�b�`�ш敪�̃X�L���i���K�v�ɂȂ�̂ňꌩAMD��荂�R�X�g�Ɍ����邪�A���o��������
> 1�X�e�[�W�Ŋ���������K�v���Ȃ��̂ł������Ă��₷���ʂ�����B
>>499
����͈��S���m�ۂ̏�ŕK�v�ȋ@�\����H
�ǂ��炩�Ƃ����ƒx��������������
�T�[�o�[��HPC�����őΉ����ĂȂ�CPU�ȂȂ�����(�m���)
����͈��S���m�ۂ̏�ŕK�v�ȋ@�\����H
�ǂ��炩�Ƃ����ƒx��������������
�T�[�o�[��HPC�����őΉ����ĂȂ�CPU�ȂȂ�����(�m���)
504 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:07:32 ID:sNWFFdis
�͂��͂��A�v����ɓǂ�łȂ��̂ˁB
����4���߂܂ł�4�̖��߂̒��������Z���Ȃ��Ƃ����Ȃ��̂��ǂꂾ���d�傩���킩��Ȃ��̂ˁB
3���߂Ȃ�2�ōς̂�2�{�����x�̉��Z�@������Ώ\����������4���߂���3�{�����K�v�ɂȂ�B
���ۂɂ̓v���f�R�[�h�r�b�g���疽�ߒ�����W�J����̂���[���R�X�g�ł͂Ȃ��B
����Ƃ�Bulldozer�̓v���f�R�[�h�L���b�V�����߂�����H
���@�I�Ȗ��ߓ��o�������ꍇ�̓p�C�v���C���i���͑����邪1�X�e�[�W�̕��S�͑����y���Ȃ邩���ˁB
����4���߂܂ł�4�̖��߂̒��������Z���Ȃ��Ƃ����Ȃ��̂��ǂꂾ���d�傩���킩��Ȃ��̂ˁB
3���߂Ȃ�2�ōς̂�2�{�����x�̉��Z�@������Ώ\����������4���߂���3�{�����K�v�ɂȂ�B
���ۂɂ̓v���f�R�[�h�r�b�g���疽�ߒ�����W�J����̂���[���R�X�g�ł͂Ȃ��B
����Ƃ�Bulldozer�̓v���f�R�[�h�L���b�V�����߂�����H
���@�I�Ȗ��ߓ��o�������ꍇ�̓p�C�v���C���i���͑����邪1�X�e�[�W�̕��S�͑����y���Ȃ邩���ˁB
505 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:08:40 ID:sNWFFdis
>>503
�t�F�C���Z�[�t�̂��߂ł͂Ȃ��Ȃ����u�ȓd�͋Z�p�v�Ȃ̂����X�ł�
�t�F�C���Z�[�t�̂��߂ł͂Ȃ��Ȃ����u�ȓd�͋Z�p�v�Ȃ̂����X�ł�
Bulldozer�A�[�L�e�N�`���̊̂́A3����*2����4����(2����*2)*1�ɕύX�������Ƃɂ���������͊ԈႢ�Ȃ�
�f�R�[�_�[���������Ȃ�A�ȍ~�̃p�C�v���C��������o�X���K�͂��������Ȃ�
�P���ɍl����ƃX���b�h�ӂ̃R�X�g����0.7�{�A���邢�͌�����1.33�{�ɂȂ�
�f�R�[�_�[���������Ȃ�A�ȍ~�̃p�C�v���C��������o�X���K�͂��������Ȃ�
�P���ɍl����ƃX���b�h�ӂ̃R�X�g����0.7�{�A���邢�͌�����1.33�{�ɂȂ�
>>504
3���߂�4���߂Ȃ�Ă��܂ɂ����Ȃ����x�̕p�x����H
�啔����2���߂��Ęb���悭��������A4���ߎ��ő��������������Ƃ��͂ǂ��ł�������
Bull�ŏd�v�Ȃ̂�(2����*2)/clk�̕����Ǝv�����Ⴄ�̂��ȁH
3���߂�4���߂Ȃ�Ă��܂ɂ����Ȃ����x�̕p�x����H
�啔����2���߂��Ęb���悭��������A4���ߎ��ő��������������Ƃ��͂ǂ��ł�������
Bull�ŏd�v�Ȃ̂�(2����*2)/clk�̕����Ǝv�����Ⴄ�̂��ȁH
508 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:14:12 ID:sNWFFdis
����ς�n������
�s�[�N�ɍ��킹�ĉ�H�v�͍s�����
�s�[�N�ɍ��킹�ĉ�H�v�͍s�����
����A507�̓A�z�߂���w
Op�X����6176SE�������l���邩��t�����[�h�ŃN���b�N�������邩�����Ă��炦����
�������N�[���[���ғ����Ă���_�E���N���b�N����Ƃ͎v����
�������N�[���[���ғ����Ă���_�E���N���b�N����Ƃ͎v����
>>505
���[�h�~�X�������~�X���͒m������t�F�C���Z�[�t�@�\����
�����܂ő����قǂ̂���ł��Ȃ���
�K�ȗ�p���Ă��č����ׂŃN���b�N�_�E���Ƃ����i�K�ŕs�̗p�@�\����
��������IBM��HP�ACray�ӂ肪����ȃN�\�@�\�����͂��͂Ȃ���
���[�h�~�X�������~�X���͒m������t�F�C���Z�[�t�@�\����
�����܂ő����قǂ̂���ł��Ȃ���
�K�ȗ�p���Ă��č����ׂŃN���b�N�_�E���Ƃ����i�K�ŕs�̗p�@�\����
��������IBM��HP�ACray�ӂ肪����ȃN�\�@�\�����͂��͂Ȃ���
512 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:24:37 ID:sNWFFdis
>>440�ɓ��Ă͂߂��3���߂̏ꍇ���Ƃ���
�y�ŏ��̃T�C�N���z
v1 = IP + inst1
v2 = inst2 + inst3
�y���̃T�C�N���z
IP = v1 + v2
��2�T�C�N���B
�����1�N���b�N�ōς܂��ɂ͏��Ȃ��Ƃ�2�{���œ������Ȃ��Ƃ����Ȃ��B
����4����/clk�ɂȂ��3�T�C�N���K�v�Ȃ̂ŁA�X�ɍ��������K�v�B
�X�ɖ��߃|�C���^���Z���j�b�g�̍��������K�v�ɂȂ�B
���߂̓��o���Ƃ����P���ȑO�����ł��炱���܂ň��|�I�ȍ��R�X�g����������̂ɁA
�P���Ƀf�R�[�_�̑��a�����ł������̂��l�����Ȃ��̂��Ė{���ɔn���Ƃ��������悤���Ȃ��B
����ł܂�����Ȃ���Ώ��w�Z�����蒼���ׂ�����B
�y�ŏ��̃T�C�N���z
v1 = IP + inst1
v2 = inst2 + inst3
�y���̃T�C�N���z
IP = v1 + v2
��2�T�C�N���B
�����1�N���b�N�ōς܂��ɂ͏��Ȃ��Ƃ�2�{���œ������Ȃ��Ƃ����Ȃ��B
����4����/clk�ɂȂ��3�T�C�N���K�v�Ȃ̂ŁA�X�ɍ��������K�v�B
�X�ɖ��߃|�C���^���Z���j�b�g�̍��������K�v�ɂȂ�B
���߂̓��o���Ƃ����P���ȑO�����ł��炱���܂ň��|�I�ȍ��R�X�g����������̂ɁA
�P���Ƀf�R�[�_�̑��a�����ł������̂��l�����Ȃ��̂��Ė{���ɔn���Ƃ��������悤���Ȃ��B
����ł܂�����Ȃ���Ώ��w�Z�����蒼���ׂ�����B
>>508
���O���n������H
�s�[�N�d���Ȃ�]����3����*2�����L��6���߁A���邢�͋�������4����*2�Ƃ��ɂ����������
2pipe��2�R�A�ŋ��L��4����/clk�f�R�[�h�Ȃ�āA�ǂ����Ă������\��2����*2���d�����Ă���
���߂̕p�x�ł�����
2���߁F8�`9��
3���߁F1�����x
4���߁F��%
���ċC�����邩�狰�炭�S�̂�1�����x��3��4���߂̃s�[�N���̐��\�͐�̂Ă��Ƃ������������ˁB
�ǂ̓�����Pipeline��2�{������������A4���߂Ȃ��2�p�X�ŏ������邵���Ȃ��Đ��\�o���Ȃ����ǂˁB
���O���n������H
�s�[�N�d���Ȃ�]����3����*2�����L��6���߁A���邢�͋�������4����*2�Ƃ��ɂ����������
2pipe��2�R�A�ŋ��L��4����/clk�f�R�[�h�Ȃ�āA�ǂ����Ă������\��2����*2���d�����Ă���
���߂̕p�x�ł�����
2���߁F8�`9��
3���߁F1�����x
4���߁F��%
���ċC�����邩�狰�炭�S�̂�1�����x��3��4���߂̃s�[�N���̐��\�͐�̂Ă��Ƃ������������ˁB
�ǂ̓�����Pipeline��2�{������������A4���߂Ȃ��2�p�X�ŏ������邵���Ȃ��Đ��\�o���Ȃ����ǂˁB
�t�����[�h�ŊȒP�ɃN���b�N��������̂Ȃ�
�x���`�̓r���ŕs���R�ȃp�t�H�[�}���X�_�E����������Ƃ��A
�N���b�N���������Ƃ����������Ă������Ǝv�����ǂȁB
�x���`�̓r���ŕs���R�ȃp�t�H�[�}���X�_�E����������Ƃ��A
�N���b�N���������Ƃ����������Ă������Ǝv�����ǂȁB
SIMD���j�b�g�͋��L�Ȃ���f�R�[�_�͊��S�ɂ͓Ɨ��������Ȃ����낤
������4���ߔ��s�̃f�R�[�_�ƕ\������Ă��邾����
�f�R�[�_�̃R�A1/�R�A2�ւ̖��ߔ��s�̐U�蕪����1�F3�A2�F2�A3�F1���x��
�Е��̃R�A�ɑ�4�̖��߂����s�͑z�肵�Ă��Ȃ���Ȃ���
������4���ߔ��s�̃f�R�[�_�ƕ\������Ă��邾����
�f�R�[�_�̃R�A1/�R�A2�ւ̖��ߔ��s�̐U�蕪����1�F3�A2�F2�A3�F1���x��
�Е��̃R�A�ɑ�4�̖��߂����s�͑z�肵�Ă��Ȃ���Ȃ���
517 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:34:57 ID:sNWFFdis
�Ȃ�Ȃ�Ńf�R�[�_�����L�Ȃ́H
���O���k�ْʂ�Ȃ�2����/clk�̃f�R�[�_��1�R�A���ŏ\������Ȃ���
���O���k�ْʂ�Ȃ�2����/clk�̃f�R�[�_��1�R�A���ŏ\������Ȃ���
518 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:36:34 ID:sNWFFdis
>>512
> ��2�T�C�N���B
> �����1�N���b�N�ōς܂��ɂ͏��Ȃ��Ƃ�2�{���œ������Ȃ��Ƃ����Ȃ��B
> ����4����/clk�ɂȂ��3�T�C�N���K�v�Ȃ̂ŁA�X�ɍ��������K�v�B
> �X�ɖ��߃|�C���^���Z���j�b�g�̍��������K�v�ɂȂ�B
>
> ���߂̓��o���Ƃ����P���ȑO�����ł��炱���܂ň��|�I�ȍ��R�X�g����������̂ɁA
> �P���Ƀf�R�[�_�̑��a�����ł������̂��l�����Ȃ��̂��Ė{���ɔn���Ƃ��������悤���Ȃ��B
���̍l������p�x�̏��Ȃ�3��4���߂�2�p�X�Ƃ��ŏ\��
���O�͕p�x�����Ȃ�4���߂�1�p�X�ŏ�������
�b�����ݍ����ĂȂ��̂́A�����d���ƃs�[�N�d���̈Ⴂ���Ă��ƂȂ�
�����A�O�Ⴆ�Ί��݂����͂�������
> ��2�T�C�N���B
> �����1�N���b�N�ōς܂��ɂ͏��Ȃ��Ƃ�2�{���œ������Ȃ��Ƃ����Ȃ��B
> ����4����/clk�ɂȂ��3�T�C�N���K�v�Ȃ̂ŁA�X�ɍ��������K�v�B
> �X�ɖ��߃|�C���^���Z���j�b�g�̍��������K�v�ɂȂ�B
>
> ���߂̓��o���Ƃ����P���ȑO�����ł��炱���܂ň��|�I�ȍ��R�X�g����������̂ɁA
> �P���Ƀf�R�[�_�̑��a�����ł������̂��l�����Ȃ��̂��Ė{���ɔn���Ƃ��������悤���Ȃ��B
���̍l������p�x�̏��Ȃ�3��4���߂�2�p�X�Ƃ��ŏ\��
���O�͕p�x�����Ȃ�4���߂�1�p�X�ŏ�������
�b�����ݍ����ĂȂ��̂́A�����d���ƃs�[�N�d���̈Ⴂ���Ă��ƂȂ�
�����A�O�Ⴆ�Ί��݂����͂�������
Jcc+CMP��Macro Fusion��2�X���b�h������
�ł���s�[�N��6����/cycle�ɂȂ�̂��H
�ł���s�[�N��6����/cycle�ɂȂ�̂��H
>>517
> �Ȃ�Ȃ�Ńf�R�[�_�����L�Ȃ́H
> ���O���k�ْʂ�Ȃ�2����/clk�̃f�R�[�_��1�R�A���ŏ\������Ȃ���
���L�̕��������悳���������A�ɋH�ɏo�Ă���3���߂�4���߂�1clk�Ńf�R�[�h���邽�߂���H
���ꂭ�炢�������
> �Ȃ�Ȃ�Ńf�R�[�_�����L�Ȃ́H
> ���O���k�ْʂ�Ȃ�2����/clk�̃f�R�[�_��1�R�A���ŏ\������Ȃ���
���L�̕��������悳���������A�ɋH�ɏo�Ă���3���߂�4���߂�1clk�Ńf�R�[�h���邽�߂���H
���ꂭ�炢�������
522 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:40:42 ID:sNWFFdis
��SIMD���j�b�g�͋��L�Ȃ���f�R�[�_�͊��S�ɂ͓Ɨ��������Ȃ����낤
����͊W�Ȃ��ȁB
�f�R�[�_���ʂł����Z���j�b�g�͋��L�ł��邵���ۂɂ����������i�͑��݂���B
����͊W�Ȃ��ȁB
�f�R�[�_���ʂł����Z���j�b�g�͋��L�ł��邵���ۂɂ����������i�͑��݂���B
>>515
����Ȏ��ᕷ�������Ɩ����ȁB���x�̉R����B
����Ȏ��ᕷ�������Ɩ����ȁB���x�̉R����B
>>518
> >>516
> �悤�₭�܂Ƃ��Ȉӌ����o���B
>
> �܂��A�o�b�N�G���h�ׂ̍��l������̒��x�ŏ\�����Ǝv����B
�o�b�N�G���h�ׂ̍��������ăs�[�N���\�ő����ł����O��������ww
> >>516
> �悤�₭�܂Ƃ��Ȉӌ����o���B
>
> �܂��A�o�b�N�G���h�ׂ̍��l������̒��x�ŏ\�����Ǝv����B
�o�b�N�G���h�ׂ̍��������ăs�[�N���\�ő����ł����O��������ww
525 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:41:58 ID:sNWFFdis
> ���̍l������p�x�̏��Ȃ�3��4���߂�2�p�X�Ƃ��ŏ\��
�A�z���Ȃ���ς�
2�p�X���������猋��2����/clk���낤��
�A�z���Ȃ���ς�
2�p�X���������猋��2����/clk���낤��
526 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 13:48:29 ID:sNWFFdis
�L���z���̓x�N�^�f�R�[�_2*2�i�\�j�Ɏ��i�Εa������
�܂�12<16���o����ق����悾��
���ꂩ�炷�����ʂ�Ȃ牽���w�͂��Ȃ��Ă�����
�܂�12<16���o����ق����悾��
���ꂩ�炷�����ʂ�Ȃ牽���w�͂��Ȃ��Ă�����
>>525
���O���A�z����
pipeline�ł̏���������
�f�R�[�_�[��pipeline����������ŃR�����g���������������ǂ�
4���ߎ��̓���
�f�R�[�_�[�F1������
Pipeline�F2�p�X
2���ߎ�
�f�R�[�_�[�F1clk��2�X���b�h��
Pipeline�F1�p�X
���O���A�z����
pipeline�ł̏���������
�f�R�[�_�[��pipeline����������ŃR�����g���������������ǂ�
4���ߎ��̓���
�f�R�[�_�[�F1������
Pipeline�F2�p�X
2���ߎ�
�f�R�[�_�[�F1clk��2�X���b�h��
Pipeline�F1�p�X
>>526
�ő�����ȂƂ���������Ȃ��̂����O��w
������ǂ������̂��Ęb����
���ǂ͑��T�[�o�[���[�J�[��ڋq���}�j�N�[���̗p���Ă��邩�������薳���@�\���Ă��Ƃ���
�ő�����ȂƂ���������Ȃ��̂����O��w
������ǂ������̂��Ęb����
���ǂ͑��T�[�o�[���[�J�[��ڋq���}�j�N�[���̗p���Ă��邩�������薳���@�\���Ă��Ƃ���
�f�R�[�h�̌��͕��G�������܂�m��Ȃ�����
AMDK7�n�̓v���f�R�[�h�Ŗ��߂ɋ��t�������̂�L1I�ɓ���Ă��Ȃ����������H
���Ƀf�R�[�_��Macro�����ɕς���
�X�P�W���[���Ńʂɕ����Ƃ����R�i�K�̃f�R�[�h
�H���z����Intel�̃f�R�[�h�̌����o�O�R�s�y���Ă�C������
AMDK7�n�̓v���f�R�[�h�Ŗ��߂ɋ��t�������̂�L1I�ɓ���Ă��Ȃ����������H
���Ƀf�R�[�_��Macro�����ɕς���
�X�P�W���[���Ńʂɕ����Ƃ����R�i�K�̃f�R�[�h
�H���z����Intel�̃f�R�[�h�̌����o�O�R�s�y���Ă�C������
�v���f�R�[�_�ɕ��G�����ڂ������ŁA���͂���܂��������Ȃ���Ȃ��́H
530�̍l�������ƁB
530�̍l�������ƁB
�L���b�V�������HL1I����
533 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 15:10:59 ID:sNWFFdis
�������������߂���
>>533
����A�����炳�A4���ߎ��̏����Ȃǂ��ł�������
�����낤���x���낤�������I�ȏ������\�ɗ^����C���p�N�g�͂����������Ƃ����������
���O���Ȃ��4���ߏ����ɍS��̂������
>>518
�ł����O���g�������Ă邾��H
Pipeline���n�ゾ����1�F3�A2�F2�A3�F1���x�ŏ\�������āB
����A�����炳�A4���ߎ��̏����Ȃǂ��ł�������
�����낤���x���낤�������I�ȏ������\�ɗ^����C���p�N�g�͂����������Ƃ����������
���O���Ȃ��4���ߏ����ɍS��̂������
>>518
�ł����O���g�������Ă邾��H
Pipeline���n�ゾ����1�F3�A2�F2�A3�F1���x�ŏ\�������āB
�����܂ň̂����ɉ��l�ԈႢ�Ȃ�������_�Ԃ����܂����Ȃ�C���e���ł�AMD�ł����Ђ��ĂĂ߁[��CPU������Ęb����ȁB
537 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 15:49:29 ID:sNWFFdis
�����ʔ�������>>440�Ŋ���
> �Ƃ��낪�ϒ����Ɩ��߂̖������m��ł��Ȃ���Ύ��̖��߂̓��o���͂ł��Ȃ�
�ɓB�����Ă�̂Ɂu2�p�X�v�ŏ�������Ƃ������Ă邱�Ƃ���˂�����
������
> 4���ߎ��̓���
> �f�R�[�_�[�F1������
> Pipeline�F2�p�X
>
> 2���ߎ�
> �f�R�[�_�[�F1clk��2�X���b�h��
> Pipeline�F1�p�X
�X���b�h�̗��p�ɂ���āy�p�C�v���C���i���z���ς��Ƃ�
�ǂ�ȃA�[�L�e�N�`��������Ă���
���̃X�e�[�W�������I�ɕς��@�\�����Ōy�����\�[�X���������Ⴂ����
> �Ƃ��낪�ϒ����Ɩ��߂̖������m��ł��Ȃ���Ύ��̖��߂̓��o���͂ł��Ȃ�
�ɓB�����Ă�̂Ɂu2�p�X�v�ŏ�������Ƃ������Ă邱�Ƃ���˂�����
������
> 4���ߎ��̓���
> �f�R�[�_�[�F1������
> Pipeline�F2�p�X
>
> 2���ߎ�
> �f�R�[�_�[�F1clk��2�X���b�h��
> Pipeline�F1�p�X
�X���b�h�̗��p�ɂ���āy�p�C�v���C���i���z���ς��Ƃ�
�ǂ�ȃA�[�L�e�N�`��������Ă���
���̃X�e�[�W�������I�ɕς��@�\�����Ōy�����\�[�X���������Ⴂ����
>440�������Ɠǂ�ł݂�Ƃ����[��
�ȑO�E���R�́u�v���f�R�[�h�łقڃf�R�[�h�����v�Ȃǂƌ����Ă��̂�
���x�́u�f�R�[�_���v���f�R�[�_�܂ł���K�v������v����
�v���f�R�[�h+�f�R�[�h��2��A���ł��Ȃ���Ȃ�Ȃ����R�́u���܂�Pentium4�ɂ�L1D�������v����ł����H
�ȑO�E���R�́u�v���f�R�[�h�łقڃf�R�[�h�����v�Ȃǂƌ����Ă��̂�
���x�́u�f�R�[�_���v���f�R�[�_�܂ł���K�v������v����
�v���f�R�[�h+�f�R�[�h��2��A���ł��Ȃ���Ȃ�Ȃ����R�́u���܂�Pentium4�ɂ�L1D�������v����ł����H
X�u�f�R�[�_���v���f�R�[�_�܂ł���K�v������v
O�u�f�R�[�_���v���f�R�[�h�܂ł���K�v������v
�������́u�f�R�[�_���v���f�R�[�_�܂Ō��C����K�v������v
O�u�f�R�[�_���v���f�R�[�h�܂ł���K�v������v
�������́u�f�R�[�_���v���f�R�[�_�܂Ō��C����K�v������v
541 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 16:05:03 ID:sNWFFdis
> ����A�����炳�A4���ߎ��̏����Ȃǂ��ł�������
�ǂ��ł��悭�Ȃ��悗
�ǂ��̐w�c���N���b�N�T�C�N���P�ʂŃX���b�h�̖��߃X�g���[�����ւ��ăt�F�b�`����@�\���̗p���Ă��B
AMD�͈Ⴄ�́H
�������������T�C�N����2�̖��߃X�g���[�����Ƀt�F�b�`���邱�ƑO��Ō���Ă邯��
����ȋ@�\���̃R�X�g������B
�펯�I�ɍl���ē������ߗ�3���߂Ȃ���4���߂��Ƀs�b�N����K�v������B
2�̖��ߗu���������v�����̂̓A�E�g�I�u�I�[�_���s�ɂ����̂�
�f�R�[�h��̘b�B
�ǂ��ł��悭�Ȃ��悗
�ǂ��̐w�c���N���b�N�T�C�N���P�ʂŃX���b�h�̖��߃X�g���[�����ւ��ăt�F�b�`����@�\���̗p���Ă��B
AMD�͈Ⴄ�́H
�������������T�C�N����2�̖��߃X�g���[�����Ƀt�F�b�`���邱�ƑO��Ō���Ă邯��
����ȋ@�\���̃R�X�g������B
�펯�I�ɍl���ē������ߗ�3���߂Ȃ���4���߂��Ƀs�b�N����K�v������B
2�̖��ߗu���������v�����̂̓A�E�g�I�u�I�[�_���s�ɂ����̂�
�f�R�[�h��̘b�B
>>537
�����đf�l�����炤�܂������o���ĂȂ��ȁA�����͂���܂��
2�p�X���Č����Ă��̂́A2��ɕ�����Pipeline�ɗ������Ă��ƁB
ABCD���Ė��߂���������AAB�𗬂������CD�𗬂����Ă�
����������ƌ����ĂȂ������\�[�X�����ĐH��Ȃ��Ǝv�����Ⴄ�̂���
>>535�ł�����������3���߂�4���ߎ��̓���Ȃx���Ă����������Ă��ǂ��ł�������
Bull�̃f�R�[�_�[��pipe�̍\�����炵��2���ߏ����ȊO�͒x���Ă��d���Ȃ���˂��Ċ�������
�����đf�l�����炤�܂������o���ĂȂ��ȁA�����͂���܂��
2�p�X���Č����Ă��̂́A2��ɕ�����Pipeline�ɗ������Ă��ƁB
ABCD���Ė��߂���������AAB�𗬂������CD�𗬂����Ă�
����������ƌ����ĂȂ������\�[�X�����ĐH��Ȃ��Ǝv�����Ⴄ�̂���
>>535�ł�����������3���߂�4���ߎ��̓���Ȃx���Ă����������Ă��ǂ��ł�������
Bull�̃f�R�[�_�[��pipe�̍\�����炵��2���ߏ����ȊO�͒x���Ă��d���Ȃ���˂��Ċ�������
�u2�̖��ߗ�i������p�C�v���C���H�j�v�̓X�[�p�[�X�J���ɂ�����
�A�E�g�I�u�I�[�_��1�̖��ߗ�ł̏����������t�i�f�[�^���[�h�������j�ɂȂ����
�Ƃ͂�������͌������E�̘b
�E���R�ƃV���^���H���Ȑ��E�̂��Ƃ͒m��܂���
���Ƃ��ł�
>538
���v���f�R�[�h+�f�R�[�h��2��A����
�n�v���f�R�[�h+�f�R�[�h��2���݂�
�A�E�g�I�u�I�[�_��1�̖��ߗ�ł̏����������t�i�f�[�^���[�h�������j�ɂȂ����
�Ƃ͂�������͌������E�̘b
�E���R�ƃV���^���H���Ȑ��E�̂��Ƃ͒m��܂���
���Ƃ��ł�
>538
���v���f�R�[�h+�f�R�[�h��2��A����
�n�v���f�R�[�h+�f�R�[�h��2���݂�
3���߂�4���߂̔����p�x�͂ǂ�Ȃ���Ȃ̂���
�l�I�ɂ�>>514�@�݂����ɑS�̂�1�����x���ė\�z���Ă��
�O�O�b�Ă����܂薳���Ƃ����悤�Ȓ��ۓI�Ȑ��������������Ȃ�
�㓡���̃R�����ł�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
���݂�PC����CPU��3�`4 x86���߃f�R�[�h&���s�̃p�C�v���C���́A
���ۂɂ̓I�[�o�[�L���ȃP�[�X������B
�������ɐ����錻��ł́A���ߊԂ̈ˑ����̂��߂ɁA
x86 ���ߊ��Z��2���ߒ��x����������s�ł��Ȃ��P�[�X�����Ȃ��Ȃ��B
uOP�ɍӂ��Ď��s����ꍇ�ł������ŁA3�`4 x86���߂̕�����s�ш�́A
�����܂ł��s�[�N�ł���A���ς͂����肩�Ȃ菭�Ȃ��Ƃ����̂��펯���Ƃ����B
���Ă��Ƃŕ��ς�2�ɋ߂��炵�����������Ă�B
����Ƃ��c�q�̌����������Ă���
�l�I�ɂ�>>514�@�݂����ɑS�̂�1�����x���ė\�z���Ă��
�O�O�b�Ă����܂薳���Ƃ����悤�Ȓ��ۓI�Ȑ��������������Ȃ�
�㓡���̃R�����ł�
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
���݂�PC����CPU��3�`4 x86���߃f�R�[�h&���s�̃p�C�v���C���́A
���ۂɂ̓I�[�o�[�L���ȃP�[�X������B
�������ɐ����錻��ł́A���ߊԂ̈ˑ����̂��߂ɁA
x86 ���ߊ��Z��2���ߒ��x����������s�ł��Ȃ��P�[�X�����Ȃ��Ȃ��B
uOP�ɍӂ��Ď��s����ꍇ�ł������ŁA3�`4 x86���߂̕�����s�ш�́A
�����܂ł��s�[�N�ł���A���ς͂����肩�Ȃ菭�Ȃ��Ƃ����̂��펯���Ƃ����B
���Ă��Ƃŕ��ς�2�ɋ߂��炵�����������Ă�B
����Ƃ��c�q�̌����������Ă���
545 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 16:26:43 ID:sNWFFdis
���_���猾���Ǝ��͓����T�C�N����2�̖��ߗ���Ƀs�b�N����@�\��݂�������R�X�g������B
�Œ蒷���߂Ȃ�t�F�b�`���j�b�g��2�d�����āA�X���b�hA����12�o�C�g�A�X���b�hB����4�o�C�g��
�t�F�b�`����R�F�P�̊����Ŏ��o�����Ƃ��ł���B
�������A��������x86�͓����o�C�g���ɉ����ߓ����Ă邩��͂���܂ʼn���Ȃ��B
����32�o�C�g���t�F�b�`���Ă�1�o�C�g���߂�32�����Ă�ꍇ�����邵�A
�������߂�3���߂��������ĂȂ��ꍇ�����肤��B
���������āA�����T�C�N����A����Q���߁AB����Q���߂݂����Ȋ������Y��Ɏ��o����悤�ȃG�X�p�[CPU�͍��悤���Ȃ��B
�ł���̂͊�T�C�N����A����32�o�C�g�A�����T�C�N����B����32�o�C�g�݂����Ȏ��o���������B
���Ƃ͖��߂̏����ɉ����ăT�C�N���̊��蓖�Ă��ς�邾���B
�Œ蒷���߂Ȃ�t�F�b�`���j�b�g��2�d�����āA�X���b�hA����12�o�C�g�A�X���b�hB����4�o�C�g��
�t�F�b�`����R�F�P�̊����Ŏ��o�����Ƃ��ł���B
�������A��������x86�͓����o�C�g���ɉ����ߓ����Ă邩��͂���܂ʼn���Ȃ��B
����32�o�C�g���t�F�b�`���Ă�1�o�C�g���߂�32�����Ă�ꍇ�����邵�A
�������߂�3���߂��������ĂȂ��ꍇ�����肤��B
���������āA�����T�C�N����A����Q���߁AB����Q���߂݂����Ȋ������Y��Ɏ��o����悤�ȃG�X�p�[CPU�͍��悤���Ȃ��B
�ł���̂͊�T�C�N����A����32�o�C�g�A�����T�C�N����B����32�o�C�g�݂����Ȏ��o���������B
���Ƃ͖��߂̏����ɉ����ăT�C�N���̊��蓖�Ă��ς�邾���B
546 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 16:32:10 ID:sNWFFdis
3�s�ł܂Ƃ߂��
��������2���߁F2���߂Ƃ�3���߁F1���߂Ȃ�Ă����p�[�e�B�V���j���O�͕s�\�ȂB
�ł���̂̓T�C�N���P�ʂŃX���b�hA��4���߂��A�X���b�hB��4���߂��A�����B
�����T�C�N���ɕʁX�̃X���b�h�̖��߂����݂���̓f�R�[�_����̃X�e�[�W�ŁA�ǂ���CPU��SMT�ł�����
��������2���߁F2���߂Ƃ�3���߁F1���߂Ȃ�Ă����p�[�e�B�V���j���O�͕s�\�ȂB
�ł���̂̓T�C�N���P�ʂŃX���b�hA��4���߂��A�X���b�hB��4���߂��A�����B
�����T�C�N���ɕʁX�̃X���b�h�̖��߂����݂���̓f�R�[�_����̃X�e�[�W�ŁA�ǂ���CPU��SMT�ł�����
ID:Yr7mfo0l�̃��X�����Ɠǂ�łȂ��̂ɃA��������
�ꉞ�����Ƃ��Ɓu�x�N�^�f�R�[�_�g���悤�Ȓ������߂̘A���x�i4���߂��ǂ��̂����́j����f�R�[�h�v��
�u���s�p�C�v���C���E�X�[�p�[�X�J���̕���x�iALU3���ȂƂ������́j�v�͕ʕ�����
�S�����e���Ԃ�Ȃ�
����ƐH��ID:sNWFFdis�z���̔����͖{���Ƀ��`���N�`��
�ꉞ�����Ƃ��Ɓu�x�N�^�f�R�[�_�g���悤�Ȓ������߂̘A���x�i4���߂��ǂ��̂����́j����f�R�[�h�v��
�u���s�p�C�v���C���E�X�[�p�[�X�J���̕���x�iALU3���ȂƂ������́j�v�͕ʕ�����
�S�����e���Ԃ�Ȃ�
����ƐH��ID:sNWFFdis�z���̔����͖{���Ƀ��`���N�`��
548 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 16:44:25 ID:sNWFFdis
�ނ��Ⴍ����̗��R�F�u�����C�ɓ���Ȃ�����v
549 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 16:51:28 ID:sNWFFdis
�Ƃ����킯�ŁA>>420�̖₢�����̓����́A�u��{�I�ɏ�ɕЕ��̃X���b�h��4���߁v�ł����Ƃ�
��������ł̓n�V�^���o���ꍇ�ɂ��������T�C�N����2�̃X���b�h�̖��߂��f�R�[�h�����\�������邯�ǂˁB
��������ł̓n�V�^���o���ꍇ�ɂ��������T�C�N����2�̃X���b�h�̖��߂��f�R�[�h�����\�������邯�ǂˁB
Bull8�R�A��4���W���[��
4���W���[���ɂ�4*4��16�f�R�[�_
4*3<4*4�Ō��Ǖς��܂���
��������Ƃ��ƂƊo�����12<16��
4���W���[���ɂ�4*4��16�f�R�[�_
4*3<4*4�Ō��Ǖς��܂���
��������Ƃ��ƂƊo�����12<16��
546�͐������ł���B
�Ă������u������������!?�v���Ă̂������ȂƂ��낾�B
�s�[�N4���ߐ�o����f�R�[�_�́A2���ߐ�o���f�R�[�_��
��{�̓d�́E�g�����W�X�^���ł͓�����܂�Ȃ��B
�����2�X���b�h�ŋ��L����Ε���2���߂�����o���Ȃ��ɂ��ւ�炸�A���B
Bulldozer�̃f�R�[�_���L�͉����̖ϑz�E����̎Y�����Ǝv����
�f�R�[�_�����{���쓮�ł��������Ȃ̂��˂��B
�Ă������u������������!?�v���Ă̂������ȂƂ��낾�B
�s�[�N4���ߐ�o����f�R�[�_�́A2���ߐ�o���f�R�[�_��
��{�̓d�́E�g�����W�X�^���ł͓�����܂�Ȃ��B
�����2�X���b�h�ŋ��L����Ε���2���߂�����o���Ȃ��ɂ��ւ�炸�A���B
Bulldozer�̃f�R�[�_���L�͉����̖ϑz�E����̎Y�����Ǝv����
�f�R�[�_�����{���쓮�ł��������Ȃ̂��˂��B
4���ߔ��s�̃f�R�[�_��A/B�̃X���b�h�����݂ɐ�L���邮�炢�Ȃ�
2���ߔ��s�̃f�R�[�_��2�p�ӂ��āA���ꂼ���A��B�̃X���b�h�Ɋ��蓖�Ă����������Ɨǂ���Ŗ�����
2���ߔ��s�̃f�R�[�_��2�p�ӂ��āA���ꂼ���A��B�̃X���b�h�Ɋ��蓖�Ă����������Ɨǂ���Ŗ�����
553 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 17:05:53 ID:sNWFFdis
>>545
�����E�E�E
�uK7�n�i�Ƃ�������ł����́H�j�̓v���f�R�[�h�ς݂̖��߂�L1I�ɓ����Ă�v
�Ă��Ƃ𖢂��ɋL���ł��Ȃ��̂�
�`���V�̗���100���Ȃ�Ȃ�Ȃ肵�ĂƂ��ƂƑS���o�����
�����E�E�E
�uK7�n�i�Ƃ�������ł����́H�j�̓v���f�R�[�h�ς݂̖��߂�L1I�ɓ����Ă�v
�Ă��Ƃ𖢂��ɋL���ł��Ȃ��̂�
�`���V�̗���100���Ȃ�Ȃ�Ȃ肵�ĂƂ��ƂƑS���o�����
>>552
�Е��̃X���b�h���A�C�h�����Ă�P�[�X(���邢��POWER7�̂悤�ɋx�������郂�[�h������)�Ȃ��
4���ߐ�L�ł��Ċ�������������Ȃ��B�ł��f�R�[�_���牺��
1�R�A�����蕽��2���ߔ��s�O��̃��\�[�X�z���̂悤������A��͂薳�Ӗ����B
>>555
4���ߓ������s�f�R�[�_�~1�́A
2���ߓ������s�f�R�[�_�~2���A�͂邩�ɑ傫���Ȃ�B
�Е��̃X���b�h���A�C�h�����Ă�P�[�X(���邢��POWER7�̂悤�ɋx�������郂�[�h������)�Ȃ��
4���ߐ�L�ł��Ċ�������������Ȃ��B�ł��f�R�[�_���牺��
1�R�A�����蕽��2���ߔ��s�O��̃��\�[�X�z���̂悤������A��͂薳�Ӗ����B
>>555
4���ߓ������s�f�R�[�_�~1�́A
2���ߓ������s�f�R�[�_�~2���A�͂邩�ɑ傫���Ȃ�B
>>556
�R�AA�ɂ�2���ߔ��s�̃f�R�[�_�[A
�R�AB�ɂ�2���ߔ��s�̃f�R�[�_�[B
���W���[���Ƃ��Ă�2���ߔ��s�f�R�[�_�~2��4���ĈӖ���
�R�AA�ɂ�2���ߔ��s�̃f�R�[�_�[A
�R�AB�ɂ�2���ߔ��s�̃f�R�[�_�[B
���W���[���Ƃ��Ă�2���ߔ��s�f�R�[�_�~2��4���ĈӖ���
�u4����f�R�[�h�����݂ɃX���b�h���蓖�āv��
�u��{2*2�ŏɉ����Ċ�����ς���v�̂ǂ��炪���G�ŋK�͂��f�J���Ȃ邩�͔���Ȃ�
���������܂Ńx�N�^�f�R�[�_1�i1/3�j�������̂�
�����Ȃ�4�i4/4�j�͑����߂���
�����܂Œ����߂������̂�
�ł�2*2�@�i2/2�j�Ȃ�܂�����
�Ă�����Complex Decoder*4���܂��\�̈�Ȃ킯������
�ǂ����ɂ��Ă��v���f�R�[�h�ς݂̌�������Ȃ��z�ɂ�
�uIntel�ɖ����iCotre2�̃��[�v��p�L���b�V���̂݁j�Z�p�Ɏ��i���v�Ƃ������t�|����ȊO�������
�u��{2*2�ŏɉ����Ċ�����ς���v�̂ǂ��炪���G�ŋK�͂��f�J���Ȃ邩�͔���Ȃ�
���������܂Ńx�N�^�f�R�[�_1�i1/3�j�������̂�
�����Ȃ�4�i4/4�j�͑����߂���
�����܂Œ����߂������̂�
�ł�2*2�@�i2/2�j�Ȃ�܂�����
�Ă�����Complex Decoder*4���܂��\�̈�Ȃ킯������
�ǂ����ɂ��Ă��v���f�R�[�h�ς݂̌�������Ȃ��z�ɂ�
�uIntel�ɖ����iCotre2�̃��[�v��p�L���b�V���̂݁j�Z�p�Ɏ��i���v�Ƃ������t�|����ȊO�������
2���߂Ȃ�alu,agu�͊e1�ŏ\���ł́H
560 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 17:32:37 ID:sNWFFdis
�Б���2�`3���߁AFPU��2���ߕ��i���������W�X�^��movaps�̃��_�N�V�����\�Ȃ̂Ŏ�������ȏ�j���ĂƂ��납
1�X���b�h������4���߂̑ш�g���Ă��\�����ނ肪����
1�X���b�h������4���߂̑ш�g���Ă��\�����ނ肪����
>>546
�˂����܂��Ă��炤��
>>516��
�R�A1/�R�A2�ւ̖��ߔ��s�̐U�蕪����1�F3�A2�F2�A3�F1���x��
�Е��̃R�A�ɑ�4�̖��߂����s�͑z�肵�Ă��Ȃ���Ȃ���
���ăR���ɂ��O��
>>518��
�o�b�N�G���h�ׂ̍��l������̒��x�ŏ\�����Ǝv����B
���ĐU�蕪���ɂ����ӂ��Ă����
����͊��Ⴂ���R�������Ă��Ƃ�
>>546�̕s�\���Ă̂����O�̈ӌ��Ƃ������ƊE�̏펯���Ă��Ƃł����ȁH
�f�R�[�_�[�̍\������ȋC�����邯�ǂ�
�X���b�h�ӂ�2���߁A2�F2�ŐU�蕪���邱�Ƃ�O��Ƀf�R�[�_�[����āA
3���߂�4���ߓ����Ă����ꍇ�́A�X���b�h�̃f�R�[�h���������Ƃ����������Ȃ�����
3���߂�4���߂��p�o����ꍇ�͒ᐫ�\�ɂȂ邯�ǁA����͂悭���邱�ƂȂ̂���
�����̃A�v���P�[�V�����╪��ł������狳���Ă���
�˂����܂��Ă��炤��
>>516��
�R�A1/�R�A2�ւ̖��ߔ��s�̐U�蕪����1�F3�A2�F2�A3�F1���x��
�Е��̃R�A�ɑ�4�̖��߂����s�͑z�肵�Ă��Ȃ���Ȃ���
���ăR���ɂ��O��
>>518��
�o�b�N�G���h�ׂ̍��l������̒��x�ŏ\�����Ǝv����B
���ĐU�蕪���ɂ����ӂ��Ă����
����͊��Ⴂ���R�������Ă��Ƃ�
>>546�̕s�\���Ă̂����O�̈ӌ��Ƃ������ƊE�̏펯���Ă��Ƃł����ȁH
�f�R�[�_�[�̍\������ȋC�����邯�ǂ�
�X���b�h�ӂ�2���߁A2�F2�ŐU�蕪���邱�Ƃ�O��Ƀf�R�[�_�[����āA
3���߂�4���ߓ����Ă����ꍇ�́A�X���b�h�̃f�R�[�h���������Ƃ����������Ȃ�����
3���߂�4���߂��p�o����ꍇ�͒ᐫ�\�ɂȂ邯�ǁA����͂悭���邱�ƂȂ̂���
�����̃A�v���P�[�V�����╪��ł������狳���Ă���
>>556
> 4���ߓ������s�f�R�[�_�~1�́A
> 2���ߓ������s�f�R�[�_�~2���A�͂邩�ɑ傫���Ȃ�B
�������ԈႢ
�{���̋c�_��2�X���b�h�����ɂ����āA
K10��3����*2�ƁABull��4����*1�̂ǂ��炪�傫������
�c�q�����O��������������ǂ�
> 4���ߓ������s�f�R�[�_�~1�́A
> 2���ߓ������s�f�R�[�_�~2���A�͂邩�ɑ傫���Ȃ�B
�������ԈႢ
�{���̋c�_��2�X���b�h�����ɂ����āA
K10��3����*2�ƁABull��4����*1�̂ǂ��炪�傫������
�c�q�����O��������������ǂ�
���߂�ˁ@���ꂿ���^�P�V�������������̂��킩��Ȃ��Ă��߂��
564 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 17:49:53 ID:sNWFFdis
������͊��Ⴂ���R�������Ă��Ƃ�
���͑���̒m�����m���߂邽�߂Ɋ��Ⴂ���킴�ƌ��������Ƃ�����B
�m��Ȃ��Ȃ犚�݂��Ă��Ӗ��Ȃ�����B
���Ȃ݂�
3����/clk�̃t�����g�G���h��1����/clk�A�Ƃ�����Ώ̂ȃt�����g�G���h��������
�N���b�N�T�C�N�����ɒʂ��X���b�g�����ւ��邱�Ƃ��ł���A
�Ƃ��Ȃ犄�Əo����C�������B
���Ȃ݂ɂ�����CoolSpeed�i�j�ɂ��Ă��킴�ƍ��������錾�������Ă���B
���ꂪ�Ȃ��ȓd�͋Z�p�Ȃ̂��͊��ƒP���ȗ��R�ʼn��̓h���s�V���ȓ����͒m���ĂĊ����Č����ĂȂ��B
���͑���̒m�����m���߂邽�߂Ɋ��Ⴂ���킴�ƌ��������Ƃ�����B
�m��Ȃ��Ȃ犚�݂��Ă��Ӗ��Ȃ�����B
���Ȃ݂�
3����/clk�̃t�����g�G���h��1����/clk�A�Ƃ�����Ώ̂ȃt�����g�G���h��������
�N���b�N�T�C�N�����ɒʂ��X���b�g�����ւ��邱�Ƃ��ł���A
�Ƃ��Ȃ犄�Əo����C�������B
���Ȃ݂ɂ�����CoolSpeed�i�j�ɂ��Ă��킴�ƍ��������錾�������Ă���B
���ꂪ�Ȃ��ȓd�͋Z�p�Ȃ̂��͊��ƒP���ȗ��R�ʼn��̓h���s�V���ȓ����͒m���ĂĊ����Č����ĂȂ��B
���ł����Ȃ�G���̐^���H
>>564
����Ȃǂ��ł��������Ƃւ̃��X�̓z���g�ǂ��ł�������
�R���Ă��߂�Ȃ����̈ꌾ�ōςޘb
>3����/clk�̃t�����g�G���h��1����/clk�A�Ƃ�����Ώ̂ȃt�����g�G���h��������
����ȉ����ɂ����݂��Ȃ����m�̘b�Ȃǂ��ł�������
>CoolSpeed�i�j�ɂ��Ă��킴�ƍ��������錾�������Ă���B
�����ǂ��납�N���C�ɂ����ĂȂ����Ƃ����O���n���������Ă邾���B
���傢���Ȃ炻��𗹏����č̗p�������T�[�o�[���[�J�[�Ɍ�����B
�ŁA
K10��3����*2�ƁABull��4����*1�̂ǂ��炪�傫�����A
�X���b�h�ӂ��3���߂�4���߂̕p�x��A����炪�p������悤�ȃ\�t�g�╪��
�X���b�h�ӂ�2���ߌ��ߑł��ŁA2�X���b�h�����f�R�[�h�o���邩�ǂ���
�ɂ��ě������͂Ȃ��̂��H
����Ȃǂ��ł��������Ƃւ̃��X�̓z���g�ǂ��ł�������
�R���Ă��߂�Ȃ����̈ꌾ�ōςޘb
>3����/clk�̃t�����g�G���h��1����/clk�A�Ƃ�����Ώ̂ȃt�����g�G���h��������
����ȉ����ɂ����݂��Ȃ����m�̘b�Ȃǂ��ł�������
>CoolSpeed�i�j�ɂ��Ă��킴�ƍ��������錾�������Ă���B
�����ǂ��납�N���C�ɂ����ĂȂ����Ƃ����O���n���������Ă邾���B
���傢���Ȃ炻��𗹏����č̗p�������T�[�o�[���[�J�[�Ɍ�����B
�ŁA
K10��3����*2�ƁABull��4����*1�̂ǂ��炪�傫�����A
�X���b�h�ӂ��3���߂�4���߂̕p�x��A����炪�p������悤�ȃ\�t�g�╪��
�X���b�h�ӂ�2���ߌ��ߑł��ŁA2�X���b�h�����f�R�[�h�o���邩�ǂ���
�ɂ��ě������͂Ȃ��̂��H
���͑���̒m�����m���߂邽�߂Ɋ��Ⴂ���킴�ƌ��������Ƃ�����B
�����͏��Ƃ�����
�����͏��Ƃ�����
568 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:19:07 ID:sNWFFdis
�ނ���p�C�v���C���̍\���v�f���ăf�R�[�_��������Ȃ����
Decoder�����ɍS���Ă��Ӗ����Ȃ��Ǝv�����ǂˁB
���\�Ȍ�����������e�[�u���Q�Ƃ��đΉ�����Opcode�ɒu�������邾���̏����Ȃ��
���̌���������ɂ���Ă��S�R�{������Ȃ��B�Ƃ����B
�f�R�[�h���̂��̂���1���߃X�g���[������f�R�[�_�̐����̖��߂��o�������̂ق�������ۂǃR�X�g�����B
�����������Ă�Pick�X�e�[�W�̎����R�X�g�Ȃ�ăf�R�[�_��������ۂǏd�v����B
���ƁA��ʓI�ȃA�E�g�I�u�I�[�_�R�A��Decoder�̂����キ�炢�̃X�e�[�W�ɂ���Renamer�̘b������ƁA
���̋K�͂̓p�C�v���C���̕���x��2��ɔ�Ⴕ�đ傫���Ȃ�ˁB
3^2 * 2 �� 4^2 ���ƑO�҂̕����͂��ɑ傫�����炢���B
����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
Decoder�����ɍS���Ă��Ӗ����Ȃ��Ǝv�����ǂˁB
���\�Ȍ�����������e�[�u���Q�Ƃ��đΉ�����Opcode�ɒu�������邾���̏����Ȃ��
���̌���������ɂ���Ă��S�R�{������Ȃ��B�Ƃ����B
�f�R�[�h���̂��̂���1���߃X�g���[������f�R�[�_�̐����̖��߂��o�������̂ق�������ۂǃR�X�g�����B
�����������Ă�Pick�X�e�[�W�̎����R�X�g�Ȃ�ăf�R�[�_��������ۂǏd�v����B
���ƁA��ʓI�ȃA�E�g�I�u�I�[�_�R�A��Decoder�̂����キ�炢�̃X�e�[�W�ɂ���Renamer�̘b������ƁA
���̋K�͂̓p�C�v���C���̕���x��2��ɔ�Ⴕ�đ傫���Ȃ�ˁB
3^2 * 2 �� 4^2 ���ƑO�҂̕����͂��ɑ傫�����炢���B
����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
569 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:21:11 ID:sNWFFdis
> �����ǂ��납�N���C�ɂ����ĂȂ����Ƃ����O���n���������Ă邾���B
�����̖ړI���S�������ĂȂ�����C�ɂ��Ȃ��悤�ɂ��Ă邾�����낗����
�f���ɂȂ�悗��
�����̖ړI���S�������ĂȂ�����C�ɂ��Ȃ��悤�ɂ��Ă邾�����낗����
�f���ɂȂ�悗��
570 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:26:10 ID:sNWFFdis
�N�[���[���̏Ⴕ���Ƃ���P-State�������I�ɉ�����̂��ȓd�͋Z�p�Ƃ͌���Ȃ���
������������Ȃ��Ƃ�ړI�Ƃ��ĂȂ�
���X�����ǁAAMD�̃T�C�g�ɏ����Ă���p����ǂ߂Ȃ��z�炾�炯�Ȃ̂��H
���͂��O�牴����AMD�����Ȃ�Ȃ��̂��H
������������Ȃ��Ƃ�ړI�Ƃ��ĂȂ�
���X�����ǁAAMD�̃T�C�g�ɏ����Ă���p����ǂ߂Ȃ��z�炾�炯�Ȃ̂��H
���͂��O�牴����AMD�����Ȃ�Ȃ��̂��H
572 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:32:22 ID:sNWFFdis
�ŁA���̃W�����P���̉�����ɏo�����̂͒N����
���܂�ɂ��n���Ȓ��������o�Ă��Ȃ����玩���Ń~�X���[�h���Ď����Ńl�^�炵�����킯����
���܂�ɂ��n���Ȓ��������o�Ă��Ȃ����玩���Ń~�X���[�h���Ď����Ńl�^�炵�����킯����
L1I���Ŋ��Ƀv���f�R�[�h�ς�
�_�C�T�C�Y���̖��ʂ��C�ɂ��Ȃ�����f�R�[�_�̐��𑝂₹�鋰�낵��AMD
�ł�Intel�ł��g���[�X�L���b�V���ł����萦���̂���Ă����
�p�C�v���C���̓L���b�V������n�܂邩��f�R�[�h�W�S�Ă�����
�ł�Pen4�̓f�R�[�_��1�i���j�Ȃ̂�
���̍ŏ��̃g���[�X�L���b�V���ɖ��߂����܂�̂��x��
���i����x���̂ɏ������X�ɒx���Ȃ��Ă��܂�
�Ƃ����̂��u��������v�Ȃ̂ł͂Ȃ��낤��
�t��AMD�̓v���f�R�[�h��f�����ς܂�����̂ŃL�r�L�r
�Ȃ�Ă��Ƃ͂Ȃ����낤��
���E���R�͂��낻�뉽���o�������H12<16�͊m�莖��������ȖY���Ȃ�H
�_�C�T�C�Y���̖��ʂ��C�ɂ��Ȃ�����f�R�[�_�̐��𑝂₹�鋰�낵��AMD
�ł�Intel�ł��g���[�X�L���b�V���ł����萦���̂���Ă����
�p�C�v���C���̓L���b�V������n�܂邩��f�R�[�h�W�S�Ă�����
�ł�Pen4�̓f�R�[�_��1�i���j�Ȃ̂�
���̍ŏ��̃g���[�X�L���b�V���ɖ��߂����܂�̂��x��
���i����x���̂ɏ������X�ɒx���Ȃ��Ă��܂�
�Ƃ����̂��u��������v�Ȃ̂ł͂Ȃ��낤��
�t��AMD�̓v���f�R�[�h��f�����ς܂�����̂ŃL�r�L�r
�Ȃ�Ă��Ƃ͂Ȃ����낤��
���E���R�͂��낻�뉽���o�������H12<16�͊m�莖��������ȖY���Ȃ�H
������͂�����������
�p�̏�h��ɋC�t��A�z��
�p�̏�h��ɋC�t��A�z��
575 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:40:46 ID:sNWFFdis
576 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:44:09 ID:sNWFFdis
> 4���ߎ��̓���
> �f�R�[�_�[�F1������
> Pipeline�F2�p�X
>
> 2���ߎ�
> �f�R�[�_�[�F1clk��2�X���b�h��
> Pipeline�F1�p�X
�������Ĕт����܂��Ȃ���������������
> �f�R�[�_�[�F1������
> Pipeline�F2�p�X
>
> 2���ߎ�
> �f�R�[�_�[�F1clk��2�X���b�h��
> Pipeline�F1�p�X
�������Ĕт����܂��Ȃ���������������
L1�ւ̃q�b�g�Ɋ��҂��āA�v���f�R�[�_�����̓s�[�N4���߂ɑΉ��ł��邾����
�����\�͂͂Ȃ��Ă������Ă��ƁH
�����\�͂͂Ȃ��Ă������Ă��ƁH
Decoder�Ő���オ���Ă���̂ł�������f�l�\�z���Ă݂�
������2 thread��decoder�����L����\���Ȃ��Ƃ��l����ƁA
���G��decoder+�ȈՂ�decoder�̑g�ݍ��킹�ɂȂ��Ă���̂ł͂Ȃ����B
���Ƃ���3����/cycle decoder+2����/cycle decoder�̑g�ݍ��킹�̏ꍇ�B
1 thread�̏ꍇ�͏��3����/cycle�̕����g����K10�����̐��\�B
2 thread�̏ꍇ�͌��݂Ɏg����2.5����*2/cycle�����B
Cache miss�ȂǂŕЕ����~�܂�A�����Ă���thread�̕���3����/cycle�Ő�o���ł���̂ŁA
�����I��3����/cycle*2��ɋ߂����\�����҂ł��邩���B
Tr���Ɋւ��ẮA2����/cycle��decoder�Ȃ炩�Ȃ菬�����͂�������A
3����+2���ߍ\���ł�3����decoder 1�Ɣ�ׂ�1.5�{���x�ōςނ�Ȃ�����
����ȍ\���Ȃ�1.5�{�̖ʐς�1.8�{�̐��\�Ƃ���AMD�̐����ɂ����Ɣ[���ł���B
�ϑz��>>�I��
������2 thread��decoder�����L����\���Ȃ��Ƃ��l����ƁA
���G��decoder+�ȈՂ�decoder�̑g�ݍ��킹�ɂȂ��Ă���̂ł͂Ȃ����B
���Ƃ���3����/cycle decoder+2����/cycle decoder�̑g�ݍ��킹�̏ꍇ�B
1 thread�̏ꍇ�͏��3����/cycle�̕����g����K10�����̐��\�B
2 thread�̏ꍇ�͌��݂Ɏg����2.5����*2/cycle�����B
Cache miss�ȂǂŕЕ����~�܂�A�����Ă���thread�̕���3����/cycle�Ő�o���ł���̂ŁA
�����I��3����/cycle*2��ɋ߂����\�����҂ł��邩���B
Tr���Ɋւ��ẮA2����/cycle��decoder�Ȃ炩�Ȃ菬�����͂�������A
3����+2���ߍ\���ł�3����decoder 1�Ɣ�ׂ�1.5�{���x�ōςނ�Ȃ�����
����ȍ\���Ȃ�1.5�{�̖ʐς�1.8�{�̐��\�Ƃ���AMD�̐����ɂ����Ɣ[���ł���B
�ϑz��>>�I��
581 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 18:59:13 ID:sNWFFdis
>>578
�\����Ȃ����A�f�R�[�_�̃X���[�v�b�g�̓��W���[���S�̂�4����/clk���Č������\�����ɏo�Ă��
�\����Ȃ����A�f�R�[�_�̃X���[�v�b�g�̓��W���[���S�̂�4����/clk���Č������\�����ɏo�Ă��
�D�������c�q�B����Ȃ������g���Ȃ��Ă����ȁI
>>580
�p�C�v���C���̘A�����������Ƃ����̂�
���i���߁j���������̃��\�[�X�ɗ����Ă����Ȃ���Ȃ�Ȃ�����A�����Ă���
�ł��L���b�V��������Β��߂���
�p�C�v���C�����ł̃��\�[�X�P�ʂł̔\�͂̉ߕs���͂��̂܂܃p�C�v���C���S�̂̔\�͂Ɍq���邯��
�L���b�V���Ƃ��f�R�[�_���L���͂��̃f�R�{�R���Ȃ炷��ڂɂȂ��Ă���
�v���f�R�[�_���f�R�[�_�̔\�͂ƒ݂荇���Ă���̂��]�܂�������
��L�̂悤�ɂ��܂�ׂ������߂��Ȃ��Ă�����
����\���~�X�Ńp�C�v���C���X�g�[�����Ă��v���f�R�[�_�����ɂ͊W�����A�͂�
�p�C�v���C���̘A�����������Ƃ����̂�
���i���߁j���������̃��\�[�X�ɗ����Ă����Ȃ���Ȃ�Ȃ�����A�����Ă���
�ł��L���b�V��������Β��߂���
�p�C�v���C�����ł̃��\�[�X�P�ʂł̔\�͂̉ߕs���͂��̂܂܃p�C�v���C���S�̂̔\�͂Ɍq���邯��
�L���b�V���Ƃ��f�R�[�_���L���͂��̃f�R�{�R���Ȃ炷��ڂɂȂ��Ă���
�v���f�R�[�_���f�R�[�_�̔\�͂ƒ݂荇���Ă���̂��]�܂�������
��L�̂悤�ɂ��܂�ׂ������߂��Ȃ��Ă�����
����\���~�X�Ńp�C�v���C���X�g�[�����Ă��v���f�R�[�_�����ɂ͊W�����A�͂�
�ߕs���͂��̂܂܃p�C�v���C���S�̂̔\�͂Ɍq����
��
�ߏ�͖��ʂɏI��邵�s���͑S�̂̔\�͂�������
��
�ߏ�͖��ʂɏI��邵�s���͑S�̂̔\�͂�������
>>583
�p�C�v���C���Ԃł̃f�R�{�R���Ȃ炷��ڂƂ����̂͌��\�I���˂Ă�Ǝv��
Intel�̓f�R�[�_��ɂ���LSD��RAT��[��ROB�Ȃǂ̃o�b�t�@���f�R�[�_���̃f�R�{�R���z�����Ă����̂ɑ��āA
AMD�̐v�ł́A�ɐp�b�N�o�b�t�@�ƁA���[���ʂŃG���g���������Ȃ�ROB�ERS�����Ȃ��āA�ƂĂ��z���ł��Ȃ�
������A�f�R�[�h�̕��ϑш���m�ۂ������Intel�ƁA�Œ�ш���m�ۂ��Ȃ��Ƃ����Ȃ�AMD�A�Ƃ����̂��A
�f�R�[�_�̐v�̈Ⴂ�Ɍ���Ă�Ǝv��
�p�C�v���C���Ԃł̃f�R�{�R���Ȃ炷��ڂƂ����̂͌��\�I���˂Ă�Ǝv��
Intel�̓f�R�[�_��ɂ���LSD��RAT��[��ROB�Ȃǂ̃o�b�t�@���f�R�[�_���̃f�R�{�R���z�����Ă����̂ɑ��āA
AMD�̐v�ł́A�ɐp�b�N�o�b�t�@�ƁA���[���ʂŃG���g���������Ȃ�ROB�ERS�����Ȃ��āA�ƂĂ��z���ł��Ȃ�
������A�f�R�[�h�̕��ϑш���m�ۂ������Intel�ƁA�Œ�ш���m�ۂ��Ȃ��Ƃ����Ȃ�AMD�A�Ƃ����̂��A
�f�R�[�_�̐v�̈Ⴂ�Ɍ���Ă�Ǝv��
>>570
�����x�ŃN���b�N������Ȃ�ċ@�\�A�t�F�C���Z�[�t�ȊO�̉��҂ł�����������Ęb����ˁH
���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
�܂Ƃ��ȗ�p�����č������ł����x��Ⴍ�������Ă���N���b�N�_�E���͂��Ȃ����Ă��Ƃ���
�ȓd�͂��Đ����͈Ӗ��s�������ǁA�܂��ǂ��ł�������z���g
�����x�ŃN���b�N������Ȃ�ċ@�\�A�t�F�C���Z�[�t�ȊO�̉��҂ł�����������Ęb����ˁH
���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
�܂Ƃ��ȗ�p�����č������ł����x��Ⴍ�������Ă���N���b�N�_�E���͂��Ȃ����Ă��Ƃ���
�ȓd�͂��Đ����͈Ӗ��s�������ǁA�܂��ǂ��ł�������z���g
>>568
> �f�R�[�h���̂��̂���1���߃X�g���[������f�R�[�_�̐����̖��߂��o�������̂ق�������ۂǃR�X�g�����B
> �����������Ă�Pick�X�e�[�W�̎����R�X�g�Ȃ�ăf�R�[�_��������ۂǏd�v����B
�f�R�[�_�[���ɉe�����邩��A��������邽�߂Ƀf�R�[�_�[�����L�ɂ��Ă��
>>575
�f�l�ɂƂ��ẮA���p��Ƃ��ōׂ��������������A�㓡��
�ux86 ���ߊ��Z��2���ߒ��x����������s�ł��Ȃ��P�[�X�����Ȃ��Ȃ��B
uOP�ɍӂ��Ď��s����ꍇ�ł������ŁA3�`4 x86���߂̕�����s�ш�́A
�����܂ł��s�[�N�ł���A���ς͂����肩�Ȃ菭�Ȃ��Ƃ����̂��펯���Ƃ����B�v
�Ƃ����悤�ȁA���������Ȃ����A�ǂ̒��x�����Ă��������܂��Ȑ����ŏ\���Ȃ�B
>>576
���������X�˂����܂�Ă��ȁc
���i�ǂ��s�������O�̔т���
> �f�R�[�h���̂��̂���1���߃X�g���[������f�R�[�_�̐����̖��߂��o�������̂ق�������ۂǃR�X�g�����B
> �����������Ă�Pick�X�e�[�W�̎����R�X�g�Ȃ�ăf�R�[�_��������ۂǏd�v����B
�f�R�[�_�[���ɉe�����邩��A��������邽�߂Ƀf�R�[�_�[�����L�ɂ��Ă��
>>575
�f�l�ɂƂ��ẮA���p��Ƃ��ōׂ��������������A�㓡��
�ux86 ���ߊ��Z��2���ߒ��x����������s�ł��Ȃ��P�[�X�����Ȃ��Ȃ��B
uOP�ɍӂ��Ď��s����ꍇ�ł������ŁA3�`4 x86���߂̕�����s�ш�́A
�����܂ł��s�[�N�ł���A���ς͂����肩�Ȃ菭�Ȃ��Ƃ����̂��펯���Ƃ����B�v
�Ƃ����悤�ȁA���������Ȃ����A�ǂ̒��x�����Ă��������܂��Ȑ����ŏ\���Ȃ�B
>>576
���������X�˂����܂�Ă��ȁc
���i�ǂ��s�������O�̔т���
588 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 19:53:03 ID:sNWFFdis
> �����x�ŃN���b�N������Ȃ�ċ@�\�A�t�F�C���Z�[�t�ȊO�̉��҂ł�����������Ęb����ˁH
> ���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
�v����ɖ����ɂ킩���ĂȂ����Ă��Ƃł��ˁB
���ŏȓd�͋Z�p�Ȃ̂����͔[�����Ă��i�ȓd�͉���������Z�p�Ƃ������ق����������ȁj
> ���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
�v����ɖ����ɂ킩���ĂȂ����Ă��Ƃł��ˁB
���ŏȓd�͋Z�p�Ȃ̂����͔[�����Ă��i�ȓd�͉���������Z�p�Ƃ������ق����������ȁj
���������ڂ�ڂ��
>>585
����݂̖��������ȗp����X�ɗ���ŏ�����Ă�������ƁiLSD�͔��邪�j
�����A�A�E�g�I�u�I�[�_�͖��ߒ��߂Ă����Ȃ��Əo���Ȃ���
�X���b�h�Ԃ̃f�R�[�h�U�蕪����2�R�A�̖��߂̒��܂�����Ă���킯�������
���������̃��\�[�X�ɗ����Ă����Ȃ���Ȃ�Ȃ�
�͌����Ɍ����Ƃǂ����낤
���߂Ă镔���Ŗ{���̓p�C�v���C��������ׂ��H
����݂̖��������ȗp����X�ɗ���ŏ�����Ă�������ƁiLSD�͔��邪�j
�����A�A�E�g�I�u�I�[�_�͖��ߒ��߂Ă����Ȃ��Əo���Ȃ���
�X���b�h�Ԃ̃f�R�[�h�U�蕪����2�R�A�̖��߂̒��܂�����Ă���킯�������
���������̃��\�[�X�ɗ����Ă����Ȃ���Ȃ�Ȃ�
�͌����Ɍ����Ƃǂ����낤
���߂Ă镔���Ŗ{���̓p�C�v���C��������ׂ��H
Westmere���Magny Cours�̂��u��v�ȓd�͂Ȃ̂ɂ܂��c�q�͊��ݕt���Ă���悤��
>>568
> 3^2 * 2 �� 4^2 ���ƑO�҂̕����͂��ɑ傫�����炢���B
> ����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
> K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
���������b������������
�͂����ǂ̒��x���m��A�K�͂��������o������Ă��Ƃ����
XOP��lj����Ă������邩������Ȃ����Ă��ƂŁAK10�̂܂�XOP�ɑΉ�������̓}�V���Ă��Ƃ����
���ɒc�q��Bulldozer�̃f�R�[�_�[��K10���K�͂��������Ȃ���ĔF�߂���
��͉��L2�����A�ǂ�Ȑ������Ă����̂���
1�E�X���b�h�ӂ��3���߂�4���߂̕p�x��A����炪�p������悤�ȃ\�t�g�╪��
2�E�X���b�h�ӂ�2���ߌ��ߑł��ŁA2�X���b�h�����f�R�[�h�o���邩�ǂ���
2�E�ɂ��Ă͏o�����炢���ȁ[���x�̊�]������A�o���Ȃ�������͐�������o�J�ɂ��Ȃ��Ă�����
> 3^2 * 2 �� 4^2 ���ƑO�҂̕����͂��ɑ傫�����炢���B
> ����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
> K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
���������b������������
�͂����ǂ̒��x���m��A�K�͂��������o������Ă��Ƃ����
XOP��lj����Ă������邩������Ȃ����Ă��ƂŁAK10�̂܂�XOP�ɑΉ�������̓}�V���Ă��Ƃ����
���ɒc�q��Bulldozer�̃f�R�[�_�[��K10���K�͂��������Ȃ���ĔF�߂���
��͉��L2�����A�ǂ�Ȑ������Ă����̂���
1�E�X���b�h�ӂ��3���߂�4���߂̕p�x��A����炪�p������悤�ȃ\�t�g�╪��
2�E�X���b�h�ӂ�2���ߌ��ߑł��ŁA2�X���b�h�����f�R�[�h�o���邩�ǂ���
2�E�ɂ��Ă͏o�����炢���ȁ[���x�̊�]������A�o���Ȃ�������͐�������o�J�ɂ��Ȃ��Ă�����
>>588
> �����x�ŃN���b�N������Ȃ�ċ@�\�A�t�F�C���Z�[�t�ȊO�̉��҂ł�����������Ęb����ˁH
> > ���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
>
> �v����ɖ����ɂ킩���ĂȂ����Ă��Ƃł��ˁB
>
> ���ŏȓd�͋Z�p�Ȃ̂����͔[�����Ă��i�ȓd�͉���������Z�p�Ƃ������ق����������ȁj
�������˂��O��w
�ȓd�͂ł��t�F�C���Z�[�t�ł��ǂ����ł�������A�����
�}�j�N�[���Ȃ������Ƃ��g�����Ƃ��������낤�����
�����ȃx���_�[���[�����č̗p���Ă���Ȃ炻��ł��������Ęb
> �����x�ŃN���b�N������Ȃ�ċ@�\�A�t�F�C���Z�[�t�ȊO�̉��҂ł�����������Ęb����ˁH
> > ���x�㏸�Ō̏��ُ��~���邱�Ƃ��뜜���Ă��邾������
>
> �v����ɖ����ɂ킩���ĂȂ����Ă��Ƃł��ˁB
>
> ���ŏȓd�͋Z�p�Ȃ̂����͔[�����Ă��i�ȓd�͉���������Z�p�Ƃ������ق����������ȁj
�������˂��O��w
�ȓd�͂ł��t�F�C���Z�[�t�ł��ǂ����ł�������A�����
�}�j�N�[���Ȃ������Ƃ��g�����Ƃ��������낤�����
�����ȃx���_�[���[�����č̗p���Ă���Ȃ炻��ł��������Ęb
��ɃA�b�`�b�`��cool��speed�������܂���H
>>592
���s���j�b�g���ɊW����̂́u�Ō�̃f�R�[�h�v������u�X�P�W���[���v��
�u�f�R�[�_�v���̂͊W���������Ɏv�����ǂ�
�����S�R�ڂ����Ȃ����ǃE���R�̔����͂܂��o�O���Ă邩��
K7�n�f�R�[�_�̓����O�i���K�́H�j��3�Ńx�N�^�i��K�́H�j��1�i�炵���j
Bull��Comp��4�Ȃ烍���O���x�N�^��4����
���̏�ł�1�R�A�Ŕ�ׂĒ��x�{
���s���j�b�g���ɊW����̂́u�Ō�̃f�R�[�h�v������u�X�P�W���[���v��
�u�f�R�[�_�v���̂͊W���������Ɏv�����ǂ�
�����S�R�ڂ����Ȃ����ǃE���R�̔����͂܂��o�O���Ă邩��
K7�n�f�R�[�_�̓����O�i���K�́H�j��3�Ńx�N�^�i��K�́H�j��1�i�炵���j
Bull��Comp��4�Ȃ烍���O���x�N�^��4����
���̏�ł�1�R�A�Ŕ�ׂĒ��x�{
�ԈႦ��
1�R�A��1���W���Ŕ�ׂ�
1�R�A��1���W���Ŕ�ׂ�
3�A���X�̓z�����ۂ��Č�������
�Ƃ肠�����X�P�W���[���̒��g������悤�Ȑ}��\��
ttp://pc.watch.impress.co.jp/img/pcw/docs/336/298/html/03.jpg.html
�Ƃ肠�����X�P�W���[���̒��g������悤�Ȑ}��\��
ttp://pc.watch.impress.co.jp/img/pcw/docs/336/298/html/03.jpg.html
{kind=link}
>>590
���܂�ARAT�̓��W�X�^�E�G�C���A�X�E�e�[�u���AROB�̓��I�[�_�E�o�b�t�@�ARS�̓��U�x�[�V�����E�X�e�[�V����
Intel�͕��G��RAT�@�\���g���ĐϋɓI�Ɍ��ʓI�ȃ��W�X�^�E���l�[�����Ă�̂ɑ��āA
AMD�̃��W�X�^�E���l�[�~���O�͒P����RISC�����l�[���@�\�̈ڐA��ROB�̃G���g���������Ȃ�
�ėp���W�X�^��8�����Ȃ�x86�ł�Intel�̂����������ȂƎv��
AMD��K7��K8�Ńp�b�N�o�b�t�@��݂��ċĂ�p�C�v���C�����[�U���₷���������ǁA
Bulldozer�ł͋Ă�p�C�v���C�����Ȃ���A�ʂ̃X���b�h(�R�A)�ɗ�����悤�ɂ��āA
����ɏ[�U�������߂�v�ɂ��Ă�Ǝv��
���܂�ARAT�̓��W�X�^�E�G�C���A�X�E�e�[�u���AROB�̓��I�[�_�E�o�b�t�@�ARS�̓��U�x�[�V�����E�X�e�[�V����
Intel�͕��G��RAT�@�\���g���ĐϋɓI�Ɍ��ʓI�ȃ��W�X�^�E���l�[�����Ă�̂ɑ��āA
AMD�̃��W�X�^�E���l�[�~���O�͒P����RISC�����l�[���@�\�̈ڐA��ROB�̃G���g���������Ȃ�
�ėp���W�X�^��8�����Ȃ�x86�ł�Intel�̂����������ȂƎv��
AMD��K7��K8�Ńp�b�N�o�b�t�@��݂��ċĂ�p�C�v���C�����[�U���₷���������ǁA
Bulldozer�ł͋Ă�p�C�v���C�����Ȃ���A�ʂ̃X���b�h(�R�A)�ɗ�����悤�ɂ��āA
����ɏ[�U�������߂�v�ɂ��Ă�Ǝv��
> Bulldozer�ł͋Ă�p�C�v���C�����Ȃ���A�ʂ̃X���b�h(�R�A)�ɗ�����悤�ɂ��āA
����͌����I�ȃR�X�g�ł͖���
����͌����I�ȃR�X�g�ł͖���
>>599
�u�ʂ̃R�A�ɗ�����悤�ɂ��āv�͌���������\��������
�u�ʂ̃X���b�h�̃f�R�[�h�����āv�̂���ŏ�����
Bulldozer�̎��s���j�b�g�́A�R�A�ԂŃo�C�p�X�@�\���Ȃ��炵������K���X���b�h�͕ʂɂȂ�
�u�ʂ̃R�A�ɗ�����悤�ɂ��āv�͌���������\��������
�u�ʂ̃X���b�h�̃f�R�[�h�����āv�̂���ŏ�����
Bulldozer�̎��s���j�b�g�́A�R�A�ԂŃo�C�p�X�@�\���Ȃ��炵������K���X���b�h�͕ʂɂȂ�
�����������O�Őv�����Ȃ�o�b�N�G���h����������SMT�ɂ������������I�Ȃ�
>>601
Andy Glew�̕قł͈�̏��e��L1D$��2�X���b�h����荇�����Ƃɂ�鐫�\�ቺ���傫���炵��
�܂��AIntel��SMT���ɂ�ROB���Ďg���Ă邩��A�o�b�N�G���h��������x������Ă���킯����
Intel��ROB��җ�ɋ������Ă���̂́Ax86-64�Ŕėp���W�X�^�����������SMT���ɂ�ROB�������ɂȂ���
���W�X�^�E���[�h�E�X�g�[������������\�������܂邩�炾�Ɖ��͎v���Ă�
���Ԃ�ASandy Bridge�ł�ROB�G���g�����͑��₵�Ă��邺
Andy Glew�̕قł͈�̏��e��L1D$��2�X���b�h����荇�����Ƃɂ�鐫�\�ቺ���傫���炵��
�܂��AIntel��SMT���ɂ�ROB���Ďg���Ă邩��A�o�b�N�G���h��������x������Ă���킯����
Intel��ROB��җ�ɋ������Ă���̂́Ax86-64�Ŕėp���W�X�^�����������SMT���ɂ�ROB�������ɂȂ���
���W�X�^�E���[�h�E�X�g�[������������\�������܂邩�炾�Ɖ��͎v���Ă�
���Ԃ�ASandy Bridge�ł�ROB�G���g�����͑��₵�Ă��邺
603 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 21:15:05 ID:sNWFFdis
�u�V���O���X���b�h���\�őË����Ȃ��v���߂�
�x�N�^���L�f�R�[�_���L�Ŏg���郊�\�[�X���₵�Ă邯��
��{�I�ɂ̓x�N�^�]���Ń}���`�X���b�h�ł̐����X�J�����\�d��������˂�
�X�P�W���[���̔�傪���s���j�b�g��2��ɔ�Ⴗ���Ȃ�
ALU2*2�ŏȃX�y�[�X�ȗ��������ɓK��
�u�����ALU�Ȃ�2�ŏ[���v�ƌ�������ɂ�
�L���b�V���n�\�͂�Intel�ɗ��Ƃ��Ă�
�o�b�t�@�[�����Ŏ��s�p�C�v�[�U�ɗ͂�����Ǝv�����ǂ�
>602
>601�́u�ɂɂȂ����瑼�X���b�h�f�R�[�h�������x�v�Ȍ��������Ă�ł���
�x�N�^���L�f�R�[�_���L�Ŏg���郊�\�[�X���₵�Ă邯��
��{�I�ɂ̓x�N�^�]���Ń}���`�X���b�h�ł̐����X�J�����\�d��������˂�
�X�P�W���[���̔�傪���s���j�b�g��2��ɔ�Ⴗ���Ȃ�
ALU2*2�ŏȃX�y�[�X�ȗ��������ɓK��
�u�����ALU�Ȃ�2�ŏ[���v�ƌ�������ɂ�
�L���b�V���n�\�͂�Intel�ɗ��Ƃ��Ă�
�o�b�t�@�[�����Ŏ��s�p�C�v�[�U�ɗ͂�����Ǝv�����ǂ�
>602
>601�́u�ɂɂȂ����瑼�X���b�h�f�R�[�h�������x�v�Ȍ��������Ă�ł���
605 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 21:32:09 ID:sNWFFdis
>>592
> > ����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
> > K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
> ���������b������������
> �͂����ǂ̒��x���m��A�K�͂��������o������Ă��Ƃ����
> XOP��lj����Ă������邩������Ȃ����Ă��ƂŁAK10�̂܂�XOP�ɑΉ�������̓}�V���Ă��Ƃ����
�����Renamer�̘b��Decoder�̘b�ł͂Ȃ��B
Intel�v���Z�b�T�ł�Renamer��Decoder�̂�����̃X�e�[�W���B
Renamar��Decoder�ł͂Ȃ��B
���x���B���h���Ă�̂Ɂ�����Ȋ��Ⴂ�R�Ƃ���Ă̂���B
> ���ɒc�q��Bulldozer�̃f�R�[�_�[��K10���K�͂��������Ȃ���ĔF�߂���
�{���ɔn������
���A���łɌ�����SSSE3, SSE4, AVX�̃f�R�[�h���W�b�N���n�[�h���C���[�h�Őς߂�
K10�ɔ�ׂ��1�f�R�[�_������̋K�͂͊i�i�ɂł����Ȃ�͖̂��炩�����ǂȁB
Opcode�}�b�v�����ł�SSE3�܂ł̖�2�{�̋�Ԃ��T�|�[�g���Ȃ��Ƃ����Ȃ��Ȃ�B
> > ����̏ꍇBulldozer��XOP��3�\�[�X�I�y�����h���߂Ȃ��lj�����Ă�̂�
> > K10��2�R�A���Bulldozer��1���W���[���̎����R�X�g���オ��v���͂���B
> ���������b������������
> �͂����ǂ̒��x���m��A�K�͂��������o������Ă��Ƃ����
> XOP��lj����Ă������邩������Ȃ����Ă��ƂŁAK10�̂܂�XOP�ɑΉ�������̓}�V���Ă��Ƃ����
�����Renamer�̘b��Decoder�̘b�ł͂Ȃ��B
Intel�v���Z�b�T�ł�Renamer��Decoder�̂�����̃X�e�[�W���B
Renamar��Decoder�ł͂Ȃ��B
���x���B���h���Ă�̂Ɂ�����Ȋ��Ⴂ�R�Ƃ���Ă̂���B
> ���ɒc�q��Bulldozer�̃f�R�[�_�[��K10���K�͂��������Ȃ���ĔF�߂���
�{���ɔn������
���A���łɌ�����SSSE3, SSE4, AVX�̃f�R�[�h���W�b�N���n�[�h���C���[�h�Őς߂�
K10�ɔ�ׂ��1�f�R�[�_������̋K�͂͊i�i�ɂł����Ȃ�͖̂��炩�����ǂȁB
Opcode�}�b�v�����ł�SSE3�܂ł̖�2�{�̋�Ԃ��T�|�[�g���Ȃ��Ƃ����Ȃ��Ȃ�B
606 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 21:32:57 ID:sNWFFdis
��Renamer
>>604
�ɂɂȂ�����������A�f�R�[�_��2�X���b�h�ŋ��L���Ă鎞�_�Ń��\�[�X�̋����ɂȂ邱�Ƃɕς��͂Ȃ�
�ɂɂȂ�����������A�f�R�[�_��2�X���b�h�ŋ��L���Ă鎞�_�Ń��\�[�X�̋����ɂȂ邱�Ƃɕς��͂Ȃ�
608 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 21:41:07 ID:sNWFFdis
>>602
> Andy Glew�̕قł͈�̏��e��L1D$��2�X���b�h����荇�����Ƃɂ�鐫�\�ቺ���傫���炵��
> �܂��AIntel��SMT���ɂ�ROB���Ďg���Ă邩��A�o�b�N�G���h��������x������Ă���킯����
�܂����̏��e��L1D���Ă̂�NetBurst��8KB�`16KB�̂��Ƃł�����
�Ԉ���Ă�32KB���L���16KB�~2�̂ق������\�������ƌ����Ă�킯����Ȃ����ǂ�
> Andy Glew�̕قł͈�̏��e��L1D$��2�X���b�h����荇�����Ƃɂ�鐫�\�ቺ���傫���炵��
> �܂��AIntel��SMT���ɂ�ROB���Ďg���Ă邩��A�o�b�N�G���h��������x������Ă���킯����
�܂����̏��e��L1D���Ă̂�NetBurst��8KB�`16KB�̂��Ƃł�����
�Ԉ���Ă�32KB���L���16KB�~2�̂ق������\�������ƌ����Ă�킯����Ȃ����ǂ�
nano��complex decoder x3�Ȃ�
>>607
�u�f�R�[�_�Ɂv�ȏł͋����ɂ͂Ȃ�Ȃ�
�X�P�W���[���ӂ�Ŏ��s���ߒ��߉߂�����
����ȏ�f�R�[�h���Ă��ی������������߂Ȃ����낤��
���ς�LSD���[�v��p�g���[�X�L���b�V����
�f�R�[�_���x�܂��ď���d�͉����邽�߂̂��̂ł�����͂�����
�Ƃɂ����ɂȏ͏o����
�ɂȂ狣���ɂȂ�Ȃ�
�]�T�o���邱�Ƃ��܂������̂̓L���b�V�����炢��
�u�f�R�[�_�Ɂv�ȏł͋����ɂ͂Ȃ�Ȃ�
�X�P�W���[���ӂ�Ŏ��s���ߒ��߉߂�����
����ȏ�f�R�[�h���Ă��ی������������߂Ȃ����낤��
���ς�LSD���[�v��p�g���[�X�L���b�V����
�f�R�[�_���x�܂��ď���d�͉����邽�߂̂��̂ł�����͂�����
�Ƃɂ����ɂȏ͏o����
�ɂȂ狣���ɂȂ�Ȃ�
�]�T�o���邱�Ƃ��܂������̂̓L���b�V�����炢��
612 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 21:58:06 ID:sNWFFdis
>>609
����ŃV���O���R�A�Ȃ̂ɑ�ы�炢�Ȃ�
Nano L2100 1.8GHz
1MB L2
TDP 25W
65nm�v���Z�X
Core 2 Duo L7700 1.80 GHz
4MB L2
TDP 17W
65nm�v���Z�X
����ŃV���O���R�A�Ȃ̂ɑ�ы�炢�Ȃ�
Nano L2100 1.8GHz
1MB L2
TDP 25W
65nm�v���Z�X
Core 2 Duo L7700 1.80 GHz
4MB L2
TDP 17W
65nm�v���Z�X
Nano����SOI��HKMG���g���ĂȂ���Ȃ���
>>605
> �����Renamer�̘b��Decoder�̘b�ł͂Ȃ��B
> Intel�v���Z�b�T�ł�Renamer��Decoder�̂�����̃X�e�[�W���B
> Renamar��Decoder�ł͂Ȃ��B
> ���x���B���h���Ă�̂Ɂ�����Ȋ��Ⴂ�R�Ƃ���Ă̂���B
���͕ʂɃv���ł����Ƃł������ꎩ��er������p��̈Ӗ��Ȃ悭���Ⴂ�������
Renamer�̃R�X�g�����鎖�͂킩����
�ŁA�f�R�[�_�[�͂ǂ��Ȃ́H���Ęb��
������A����A�����A���Ȃ�A������Ȃ��Ƃ��̕�����₷�����t�Ő������Ă���
�����A�ォ��R�����Ƃ��A�f�R�[�_�[�̘b����Ȃ����Ă̂͊��ق�
> �{���ɔn������
����ɓ����Ȃ��ł������Ă̘b�����邨�O���n�������ǂ�
> ���A���łɌ�����SSSE3, SSE4, AVX�̃f�R�[�h���W�b�N���n�[�h���C���[�h�Őς߂�
> K10�ɔ�ׂ��1�f�R�[�_������̋K�͂͊i�i�ɂł����Ȃ�͖̂��炩�����ǂȁB
> Opcode�}�b�v�����ł�SSE3�܂ł̖�2�{�̋�Ԃ��T�|�[�g���Ȃ��Ƃ����Ȃ��Ȃ�B
Bulldozer���n�[�h���C���[�h���Ęb�Ȃ��������Ȃ�����
>>609
Bulldozer�̓X���b�h�ӂ�Complex Decoder��X2����
> �����Renamer�̘b��Decoder�̘b�ł͂Ȃ��B
> Intel�v���Z�b�T�ł�Renamer��Decoder�̂�����̃X�e�[�W���B
> Renamar��Decoder�ł͂Ȃ��B
> ���x���B���h���Ă�̂Ɂ�����Ȋ��Ⴂ�R�Ƃ���Ă̂���B
���͕ʂɃv���ł����Ƃł������ꎩ��er������p��̈Ӗ��Ȃ悭���Ⴂ�������
Renamer�̃R�X�g�����鎖�͂킩����
�ŁA�f�R�[�_�[�͂ǂ��Ȃ́H���Ęb��
������A����A�����A���Ȃ�A������Ȃ��Ƃ��̕�����₷�����t�Ő������Ă���
�����A�ォ��R�����Ƃ��A�f�R�[�_�[�̘b����Ȃ����Ă̂͊��ق�
> �{���ɔn������
����ɓ����Ȃ��ł������Ă̘b�����邨�O���n�������ǂ�
> ���A���łɌ�����SSSE3, SSE4, AVX�̃f�R�[�h���W�b�N���n�[�h���C���[�h�Őς߂�
> K10�ɔ�ׂ��1�f�R�[�_������̋K�͂͊i�i�ɂł����Ȃ�͖̂��炩�����ǂȁB
> Opcode�}�b�v�����ł�SSE3�܂ł̖�2�{�̋�Ԃ��T�|�[�g���Ȃ��Ƃ����Ȃ��Ȃ�B
Bulldozer���n�[�h���C���[�h���Ęb�Ȃ��������Ȃ�����
>>609
Bulldozer�̓X���b�h�ӂ�Complex Decoder��X2����
615 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 22:09:20 ID:sNWFFdis
�܂��A65nm���_�ł�Core 2��HKMG�͎g���ĂȂ����ǂ�
616 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 22:11:39 ID:sNWFFdis
> Bulldozer���n�[�h���C���[�h���Ęb�Ȃ��������Ȃ�����
���[����͑ʖڂ��b�ɂȂ�˂�
���[����͑ʖڂ��b�ɂȂ�˂�
617 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 22:13:30 ID:sNWFFdis
�����ŎT�������
>>611
����������>601�Ƃǂ��q�����Ă�̂������̂�����
�Ƃ肠�����A�o�b�t�@�Ƃ��ɖ��߂̒��~�����邤����
�}���ł��̃X���b�h�̃f�R�[�h������K�v�͖���
���������]�T�������ق���u���Ƃ��ď��Ȃ��ق��̃X���b�h�œ���
����̓f�R�[�h�\�͂���荇���Ă͂��Ȃ�
�X���b�h�ɂ�CPU�S�R�g��Ȃ����̂�������
�����������܂��Ɂ��u�ɂɂȂ����瑼�X���b�h�f�R�[�h�������x�v
�����ɂȂ�u�Ԃ��S�������킯�ł͂Ȃ����ǁE�E�E
�Ă����X���������b�����[����Ȃ������������H
����������>601�Ƃǂ��q�����Ă�̂������̂�����
�Ƃ肠�����A�o�b�t�@�Ƃ��ɖ��߂̒��~�����邤����
�}���ł��̃X���b�h�̃f�R�[�h������K�v�͖���
���������]�T�������ق���u���Ƃ��ď��Ȃ��ق��̃X���b�h�œ���
����̓f�R�[�h�\�͂���荇���Ă͂��Ȃ�
�X���b�h�ɂ�CPU�S�R�g��Ȃ����̂�������
�����������܂��Ɂ��u�ɂɂȂ����瑼�X���b�h�f�R�[�h�������x�v
�����ɂȂ�u�Ԃ��S�������킯�ł͂Ȃ����ǁE�E�E
�Ă����X���������b�����[����Ȃ������������H
621 �F,,�E�L�́M�E,,�j��-�������F2010/05/09(��) 22:19:01 ID:sNWFFdis
�n�[�h���C���[�h���W�b�N�����ꂽ�f�R�[�_���Ă̂̓f�R�[�h�Ƀ}�C�N���R�[�h��p���Ȃ����Ă��Ƃ���
���Ȃ킿Simple Decoder�iAMD�ł���DirectPath�j�̂��ƁB
���Ȃ킿Simple Decoder�iAMD�ł���DirectPath�j�̂��ƁB
�G���e�w�c�q�͂���ȂɃC���e������D���Ȃ�C���e��������X���ɍs����
�R���_���S��Intel�X���ł��S�~����������c�B
���c�q�̌Ñ��͂����c
C2D�EC2Q�Ei7�͂���ς�������肾���� Part70
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/l50
���c�q�̌Ñ��͂����c
C2D�EC2Q�Ei7�͂���ς�������肾���� Part70
http://pc11.2ch.net/test/read.cgi/jisaku/1262094066/l50
>>621
�����A���܂܂�ASIMD�̃f�R�[�_�[�̂��ƂˁB
256bit�ŐV���߂������剻���Ďז����Ă��Ƃ�2�R�A���L�����A�[���珟���ɂȂ�Ƃ͎v���ĂȂ�
SSSE3��4���܂߂Č݊����m�ۂ̂��߂ɍ̗p���邾�����낤������҂����ĂȂ����ǂ��ł�������B
Bulldozer�̍\�����܂Ƃ߂��
�f�R�[�_�[��4���ߑΉ�������L
�X�P�W���[���[��pipeline�Ƃ���2���ߎ��s
(�t�����邢���ȋ@�\��K10���ォ��͍���Ă邾�낤)
AVX��2�R�A���L
SSE��SSSE3/4�ɑΉ�
��������͌��\�������Ȃ��Ă����ŁA
SIMD���肪�ǂ̒��x��剻���Ă邩���ĂƂ��낾��
����AVX�����y���܂�������A���L����Ȃ��R�A�P�ʂŎ��悤�ɂȂ�Ƃ͎v�����ǁA
�Ƃ肠�������y���邩������Ȃ�����ŋ��L���ĘH���͐������Ǝv��
�����A���܂܂�ASIMD�̃f�R�[�_�[�̂��ƂˁB
256bit�ŐV���߂������剻���Ďז����Ă��Ƃ�2�R�A���L�����A�[���珟���ɂȂ�Ƃ͎v���ĂȂ�
SSSE3��4���܂߂Č݊����m�ۂ̂��߂ɍ̗p���邾�����낤������҂����ĂȂ����ǂ��ł�������B
Bulldozer�̍\�����܂Ƃ߂��
�f�R�[�_�[��4���ߑΉ�������L
�X�P�W���[���[��pipeline�Ƃ���2���ߎ��s
(�t�����邢���ȋ@�\��K10���ォ��͍���Ă邾�낤)
AVX��2�R�A���L
SSE��SSSE3/4�ɑΉ�
��������͌��\�������Ȃ��Ă����ŁA
SIMD���肪�ǂ̒��x��剻���Ă邩���ĂƂ��낾��
����AVX�����y���܂�������A���L����Ȃ��R�A�P�ʂŎ��悤�ɂȂ�Ƃ͎v�����ǁA
�Ƃ肠�������y���邩������Ȃ�����ŋ��L���ĘH���͐������Ǝv��
>>625
> (�t�����邢���ȋ@�\��K10���ォ��͍���Ă邾�낤)
�˂����܂��O�ɒ������Ƃ���
�@�\���̂̍팸����Ȃ��A�@�\�̐��\��K�͂̂��Ƃł�
> (�t�����邢���ȋ@�\��K10���ォ��͍���Ă邾�낤)
�˂����܂��O�ɒ������Ƃ���
�@�\���̂̍팸����Ȃ��A�@�\�̐��\��K�͂̂��Ƃł�
���܂Ńe�w�c�q�Ƀ}�W���X������́H������߂�悗
�������Z�@���g�킸��SIMD���j�b�g�������������鏈�����Ėw�ǖ�����Ȃ���
�������Z�킪���L����Ă��Ȃ��Ȃ�ASIMD���j�b�g�����L�����Ƃ���ő債�Đ��\�����Ȃ���Ȃ�
�������Z�킪���L����Ă��Ȃ��Ȃ�ASIMD���j�b�g�����L�����Ƃ���ő債�Đ��\�����Ȃ���Ȃ�
109���f���̃m�[�g�Ɏ�����AMD CPU���̗p�����
http://blog.livedoor.jp/amd646464/archives/51686260.html#comments
> AMD CPU���ڃm�[�g������Ȃɒ��ڂ��W�߂�̂͏��߂�
http://blog.livedoor.jp/amd646464/archives/51686260.html#comments
> AMD CPU���ڃm�[�g������Ȃɒ��ڂ��W�߂�̂͏��߂�
���łɌ����ƃX���~�X���ĂˁH
632 �F,,�E�L�́M�E,,�j��-�������F2010/05/10(��) 05:33:15 ID:u3WIg2Mq
���͂悤�̫��
> �����A���܂܂�ASIMD�̃f�R�[�_�[�̂��ƂˁB
> 256bit�ŐV���߂������剻���Ďז����Ă��Ƃ�2�R�A���L�����A�[���珟���ɂȂ�Ƃ͎v���ĂȂ�
SIMD���낤���������낤���f�R�[�_�͓��������B
�o�b�N�G���h�̃n�[�h�E�F�A��������Ȃ��ăf�R�[�h���W�b�N�̕��S���l�����Ȃ���Ȃ�Ȃ��B
�������x�����͕ʂɂ���SSSE3/SSE4��AVX�����s�o����L���p������A�f�R�[�_�͖��߂�
�f�R�[�h�ł��Ȃ��Ƃ����Ȃ����A���̃��W�b�N��ς�ł镪�����f�R�[�_�͔�剻�����B
�X���b�h���ɕ�����Ă邩���L���Ă邩�̓f�R�[�_��ʂ�����̘b�B
�P����Sandy Bridge�Ɣ�r���Ă�XOP���̃T�|�[�g�������f�R�[�_�͋���ɂȂ�B
> SSSE3��4���܂߂Č݊����m�ۂ̂��߂ɍ̗p���邾�����낤������҂����ĂȂ����ǂ��ł�������B
���҂ǂ��납���̂������n�����ȁB�i�K�I�ɒlj�����������Ȃ��ăE���S���߂���C�ɒlj�����킯������
���ݓI�ȕs��͌v��m��Ȃ��B
���܂����ǂ��ł��ǂ��Ă�AMD�ɂƂ��Ă͏d��Ȗ�肾�ȁB
> �����A���܂܂�ASIMD�̃f�R�[�_�[�̂��ƂˁB
> 256bit�ŐV���߂������剻���Ďז����Ă��Ƃ�2�R�A���L�����A�[���珟���ɂȂ�Ƃ͎v���ĂȂ�
SIMD���낤���������낤���f�R�[�_�͓��������B
�o�b�N�G���h�̃n�[�h�E�F�A��������Ȃ��ăf�R�[�h���W�b�N�̕��S���l�����Ȃ���Ȃ�Ȃ��B
�������x�����͕ʂɂ���SSSE3/SSE4��AVX�����s�o����L���p������A�f�R�[�_�͖��߂�
�f�R�[�h�ł��Ȃ��Ƃ����Ȃ����A���̃��W�b�N��ς�ł镪�����f�R�[�_�͔�剻�����B
�X���b�h���ɕ�����Ă邩���L���Ă邩�̓f�R�[�_��ʂ�����̘b�B
�P����Sandy Bridge�Ɣ�r���Ă�XOP���̃T�|�[�g�������f�R�[�_�͋���ɂȂ�B
> SSSE3��4���܂߂Č݊����m�ۂ̂��߂ɍ̗p���邾�����낤������҂����ĂȂ����ǂ��ł�������B
���҂ǂ��납���̂������n�����ȁB�i�K�I�ɒlj�����������Ȃ��ăE���S���߂���C�ɒlj�����킯������
���ݓI�ȕs��͌v��m��Ȃ��B
���܂����ǂ��ł��ǂ��Ă�AMD�ɂƂ��Ă͏d��Ȗ�肾�ȁB
>>628
�p�C�v�����{��A�E�g�I�u�I�[�_�̃o�b�t�@(?)�̓f�[�^���[�h�҂����̖��߂𑝂₷���߂ɂ���
���������L����ǂ�����������邱�ƂɂȂ���Ă̂�����
��SIMD���j�b�g�������������鏈��
���Ă͖̂����Ă�SIMD���j�b�g�����p�x�œ������i�������ȁj�}���`���f�B�A�n������
SIMD���j�b�g�̑������傫������̂͐��\�̑傫�Ȓቺ�ɂȂ��ł͂Ȃ���
�܂����̕ӂ͂����Ƃ����\�[�X�ł������Ƃ�
�p�C�v�����{��A�E�g�I�u�I�[�_�̃o�b�t�@(?)�̓f�[�^���[�h�҂����̖��߂𑝂₷���߂ɂ���
���������L����ǂ�����������邱�ƂɂȂ���Ă̂�����
��SIMD���j�b�g�������������鏈��
���Ă͖̂����Ă�SIMD���j�b�g�����p�x�œ������i�������ȁj�}���`���f�B�A�n������
SIMD���j�b�g�̑������傫������̂͐��\�̑傫�Ȓቺ�ɂȂ��ł͂Ȃ���
�܂����̕ӂ͂����Ƃ����\�[�X�ł������Ƃ�
�ЂƂ�ł悭���܂��_���_���Ǝ��⎩���ƌ��������Ȕᔻ���ł���ȁB
�����Ɂ������Ă݂邩
�����Ɂ������Ă݂邩
635 �F,,�E�L�́M�E,,�j��-�������F2010/05/10(��) 06:45:40 ID:u3WIg2Mq
���Ȃ�Ďh���ĂȂ��B�c�O�ł�������
�ߌ����������sonet��������ocn�������肵���������ǂȂ�
637 �F,,�E�L�́M�E,,�j��-������@z152186.ppp.asahi-net.or.jp�F2010/05/10(��) 06:58:55 ID:u3WIg2Mq
>>628
> �������Z�@���g�킸��SIMD���j�b�g�������������鏈�����Ėw�ǖ�����Ȃ���
�ܘ_�Ȃ���B
�A�h���X���v�Z���Ȃ��Ⴂ���Ȃ�����C�e���[�V�������ɔėp���W�X�^�̒l�̉��Z�E���Z���x�ɂ�
�������Z�͕K�v�ɂȂ�ˁB
> �������Z�킪���L����Ă��Ȃ��Ȃ�ASIMD���j�b�g�����L�����Ƃ���ő債�Đ��\�����Ȃ���Ȃ�
2����Ȃ�SIMD���j�b�g�Ń��\�[�X�����������Ă��A�������j�b�g�ł͉��������ł��Ȃ���B
> �������Z�@���g�킸��SIMD���j�b�g�������������鏈�����Ėw�ǖ�����Ȃ���
�ܘ_�Ȃ���B
�A�h���X���v�Z���Ȃ��Ⴂ���Ȃ�����C�e���[�V�������ɔėp���W�X�^�̒l�̉��Z�E���Z���x�ɂ�
�������Z�͕K�v�ɂȂ�ˁB
> �������Z�킪���L����Ă��Ȃ��Ȃ�ASIMD���j�b�g�����L�����Ƃ���ő債�Đ��\�����Ȃ���Ȃ�
2����Ȃ�SIMD���j�b�g�Ń��\�[�X�����������Ă��A�������j�b�g�ł͉��������ł��Ȃ���B
>Core 2 Duo L7700 1.80 GHz
>4MB L2
>TDP 17W
>65nm�v���Z�X
�Ȃɂ��̒��I�ʕi
>4MB L2
>TDP 17W
>65nm�v���Z�X
�Ȃɂ��̒��I�ʕi
639 �F,,�E�L�́M�E,,�j��-�������F2010/05/10(��) 07:33:20 ID:u3WIg2Mq
>>638
L2100���f���A���R�A��������TDP�����炭�炢�ɂȂ邾�낤�ȁH
Core 2 Duo T7000�V���[�Y�@�`2.4GHz TDP 35W
Nano L2100 1.8GHz TDP 25W
�Ă������ANano L2100��VID 1.2V�邩��L�V���[�Y�Ƃ̔�r���Ó����Ǝv������(T�V���[�Y��1.3V)
L2100���f���A���R�A��������TDP�����炭�炢�ɂȂ邾�낤�ȁH
Core 2 Duo T7000�V���[�Y�@�`2.4GHz TDP 35W
Nano L2100 1.8GHz TDP 25W
�Ă������ANano L2100��VID 1.2V�邩��L�V���[�Y�Ƃ̔�r���Ó����Ǝv������(T�V���[�Y��1.3V)
>>637
�uGeForece��SIMD���j�b�g���炯�ŃX�J���Ȃ�Ė�����x86�Ȃ�SSE��r���ŃX�J���ɕ����o����v
�Ȃ�Ďv����̂̓E���R100%�o�[�x�L���[�̂��O����
>628�͒P�Ɂu�ǂ�ȏ����ł��������Z�����x�N�^���Z�䗦������邱�Ƃ͖����v�݂����Ȃ��ƌ����Ă邾������
�uGeForece��SIMD���j�b�g���炯�ŃX�J���Ȃ�Ė�����x86�Ȃ�SSE��r���ŃX�J���ɕ����o����v
�Ȃ�Ďv����̂̓E���R100%�o�[�x�L���[�̂��O����
>628�͒P�Ɂu�ǂ�ȏ����ł��������Z�����x�N�^���Z�䗦������邱�Ƃ͖����v�݂����Ȃ��ƌ����Ă邾������
641 �F,,�E�L�́M�E,,�j��-�������F2010/05/10(��) 08:23:30 ID:u3WIg2Mq
> �uGeForece��SIMD���j�b�g���炯�ŃX�J���Ȃ�Ė�����x86�Ȃ�SSE��r���ŃX�J���ɕ����o����v
�Ȃɂ��̒����B���߂ĕ�������B
�܂�128�r�b�gSSE��64�r�b�gSIMD���j�b�g�~2�ŏ����o������x�ɂ͕����\���낤���ǂ�
> �u�ǂ�ȏ����ł��������Z�����x�N�^���Z�䗦������邱�Ƃ͖����v
�ǂ��A�z�Ȃ��Ă���
���Ƃ��s��ς⑽�̉��Z��SIMD�����ꂽ�R�[�h�̓������[�v�ɂ����ăX�J���������Z���߂̏o���p�x�Ȃ�Đ���1�����Ȃ��B
http://grape.mtk.nao.ac.jp/~nitadori/phantom/
��Limited accuracy version for BH-tree code
gravity.c�݂Ă݁H
�Ȃɂ��̒����B���߂ĕ�������B
�܂�128�r�b�gSSE��64�r�b�gSIMD���j�b�g�~2�ŏ����o������x�ɂ͕����\���낤���ǂ�
> �u�ǂ�ȏ����ł��������Z�����x�N�^���Z�䗦������邱�Ƃ͖����v
�ǂ��A�z�Ȃ��Ă���
���Ƃ��s��ς⑽�̉��Z��SIMD�����ꂽ�R�[�h�̓������[�v�ɂ����ăX�J���������Z���߂̏o���p�x�Ȃ�Đ���1�����Ȃ��B
http://grape.mtk.nao.ac.jp/~nitadori/phantom/
��Limited accuracy version for BH-tree code
gravity.c�݂Ă݁H
>>637
���������Ƃ��͒��߂邵���Ȃ����ǁASIMD���j�b�g�̎g�p�p�x���Ⴂ�p�x����������ȂȂ��̂��Ă��Ƃ�
�P���ɍl����ƁASIMD���j�b�g�g�p�p�x��1/���Ȃ�SIMD���j�b�g�����̕p�x��(1/n^2)�~n��1/n
���ƁA���j�b�g�ɗ������ރ^�C�~���O�͂���Ă��ǒ����ł����Ȃ��̂���
���������Ƃ��͒��߂邵���Ȃ����ǁASIMD���j�b�g�̎g�p�p�x���Ⴂ�p�x����������ȂȂ��̂��Ă��Ƃ�
�P���ɍl����ƁASIMD���j�b�g�g�p�p�x��1/���Ȃ�SIMD���j�b�g�����̕p�x��(1/n^2)�~n��1/n
���ƁA���j�b�g�ɗ������ރ^�C�~���O�͂���Ă��ǒ����ł����Ȃ��̂���
>>641
������f�[�^���^�X�N����Ȃ��O�����̐����ƌ����Ă���
�u���܂�Pentium 4�ɂ�L1D�������v���ĐM���Ă�̂����O����
������f�[�^���^�X�N����Ȃ��O�����̐����ƌ����Ă���
�u���܂�Pentium 4�ɂ�L1D�������v���ĐM���Ă�̂����O����
>>641
���͒c�q�̌����Ă邱�Ƃ͊Ԉ���ĂȂ��Ǝv�����A���ɓK�ȃR�[�h����o���Ă����Ǝv��
�������̃R�[�h�Ŗ��ߐ��𐔂��Ă݂�ƁA�������j�b�g���ɍs�����߂�1���z���Ă�C�����邼
���͒c�q�̌����Ă邱�Ƃ͊Ԉ���ĂȂ��Ǝv�����A���ɓK�ȃR�[�h����o���Ă����Ǝv��
�������̃R�[�h�Ŗ��ߐ��𐔂��Ă݂�ƁA�������j�b�g���ɍs�����߂�1���z���Ă�C�����邼
CPU�ȂɃo�O�Ȃ�Ă���킯�Ȃ�����
�v���O�������d���܂�Ă���킯�ł�����܂���
�v���O�������d���܂�Ă���킯�ł�����܂���
�V���O���Ȃ̂ɑ�ы�炢����
celeron 420 tdp:35w
celeron 420 tdp:35w
>>632
> ���҂ǂ��납���̂������n�����ȁB�i�K�I�ɒlj�����������Ȃ��ăE���S���߂���C�ɒlj�����킯������
> ���ݓI�ȕs��͌v��m��Ȃ��B
> ���܂����ǂ��ł��ǂ��Ă�AMD�ɂƂ��Ă͏d��Ȗ�肾�ȁB
�������X�Ȃ��Ƃ������Ă��
SSE/2/3�g���̓x�ɐ��\�`100�߂��lj������Ă��Ă��邵�AAVX�ɂ��Ă����N�����đΉ����Ă��邩��A
�傫�ȕs����o��قǐق������Ȃ��Ȃ�����B
��������Bulldozer�̓T�[�o�[��HPC�����ɊJ�����Ă��āA�x���_�[�̐V�@�\�ɑ���`�F�b�N�����������낤���A
�v���I�ȕs���������܂s��ɓ������邭�炢�Ȃ甭�\�������������I�Ԃ���B
Phenom��TLB�G���b�^��������w��ł��̕ӂ͐T�d�ɑΉ�����Ǝv�����B
>>644
�x�N�g�����ߐ����������ߐ��������邩�ǂ����̋c�_�ŁA
1���������Ƃ����ӌ��ɁA1���͒�����Ȃ�Č����Ă����ǒ����Ă��Ȃ��킯�����炠�܂�Ӗ��͖����̂ł́B
> ���҂ǂ��납���̂������n�����ȁB�i�K�I�ɒlj�����������Ȃ��ăE���S���߂���C�ɒlj�����킯������
> ���ݓI�ȕs��͌v��m��Ȃ��B
> ���܂����ǂ��ł��ǂ��Ă�AMD�ɂƂ��Ă͏d��Ȗ�肾�ȁB
�������X�Ȃ��Ƃ������Ă��
SSE/2/3�g���̓x�ɐ��\�`100�߂��lj������Ă��Ă��邵�AAVX�ɂ��Ă����N�����đΉ����Ă��邩��A
�傫�ȕs����o��قǐق������Ȃ��Ȃ�����B
��������Bulldozer�̓T�[�o�[��HPC�����ɊJ�����Ă��āA�x���_�[�̐V�@�\�ɑ���`�F�b�N�����������낤���A
�v���I�ȕs���������܂s��ɓ������邭�炢�Ȃ甭�\�������������I�Ԃ���B
Phenom��TLB�G���b�^��������w��ł��̕ӂ͐T�d�ɑΉ�����Ǝv�����B
>>644
�x�N�g�����ߐ����������ߐ��������邩�ǂ����̋c�_�ŁA
1���������Ƃ����ӌ��ɁA1���͒�����Ȃ�Č����Ă����ǒ����Ă��Ȃ��킯�����炠�܂�Ӗ��͖����̂ł́B
HPC�͑_���Ă�̂��Ȃ�
Bull�P�̂ł̍\���ł͑債�ďd�v����Ȃ��Ƃ��Ď̂Ă��Ă�C������
������ւ��APU�ŃJ�o�[����ׂ����삾�Ǝv����
Bull�P�̂ł̍\���ł͑債�ďd�v����Ȃ��Ƃ��Ď̂Ă��Ă�C������
������ւ��APU�ŃJ�o�[����ׂ����삾�Ǝv����
GPU�ɂ��v�Z������䂤�Ă͂�����
���łɂ��̑卑����������������
���łɂ��̑卑����������������
���܂ł̔����̂̃p�^�[���ł����ABulldozer�͎��Y����Ȃ����Ȃ��A�Ǝv���Ă���B
AMD���g����O�҂��N�����W���[���\���̃����b�g���ɐ����ł��Ă��Ȃ��A�Ƃ����̂������B
AMD���g����O�҂��N�����W���[���\���̃����b�g���ɐ����ł��Ă��Ȃ��A�Ƃ����̂������B
�ق��ĂĂ�Intel��AVX�A�v������点�邾�낤���A���ꂪ�����Ȃ��͉̂����ƋX�����������낤
�D��x�͕ʂɂ��āA�����I�ɂ�AVX��GPGPU��OpenGL��DirectX���A���ł��Ή�����̂�AMD�̃X�^���X
�D��x�͕ʂɂ��āA�����I�ɂ�AVX��GPGPU��OpenGL��DirectX���A���ł��Ή�����̂�AMD�̃X�^���X
���W���[���P�ʂō\������̂͂����ǂ����������������x���̘b����Ȃ��Ǝv����
Sandy�ɂ��Ă�Llano�ɂ��Ă����W���[���\��������
Bulldozer�Ń��W���[�����̒P�ʂ��ς�����Ƃ������ƂɊւ��ĂȂ�
150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
Sandy�ɂ��Ă�Llano�ɂ��Ă����W���[���\��������
Bulldozer�Ń��W���[�����̒P�ʂ��ς�����Ƃ������ƂɊւ��ĂȂ�
150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
>>650
���������Ă���O�́H
�]�T�Ńq�b�g���i�ɂȂ��
45nm SOI�̃}�j�N�[����130W��12�R�A2.3GHz������A
32nm SOI HK/MG��Bulldozer 16�R�A�Ȃ�3GHz�͍s����B
�}���`�X���b�h���\�� 2.3x12=27.6G�ƁA3.0*16=48G�ŁA7���߂����\�A�b�v�ɂȂ邵�A
�������Z��H�̏k���Ƃ��ő�����������Ă�5���ȏ�͌��シ�邱�ƂɂȂ�B
5�������シ��Ή��������匾��Ȃ����̗p��������Ǝv�����ˁB
���������Ă���O�́H
�]�T�Ńq�b�g���i�ɂȂ��
45nm SOI�̃}�j�N�[����130W��12�R�A2.3GHz������A
32nm SOI HK/MG��Bulldozer 16�R�A�Ȃ�3GHz�͍s����B
�}���`�X���b�h���\�� 2.3x12=27.6G�ƁA3.0*16=48G�ŁA7���߂����\�A�b�v�ɂȂ邵�A
�������Z��H�̏k���Ƃ��ő�����������Ă�5���ȏ�͌��シ�邱�ƂɂȂ�B
5�������シ��Ή��������匾��Ȃ����̗p��������Ǝv�����ˁB
>>652
> 150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
������������Ȃ��Ƃ������Ă���
�V�������N�Ń_�C�T�C�Y��6�����x�ɂȂ鎖���l������ƁA
�_�C�T�C�Y�͌����葽���������Ȃ��āA���\�͖�{���Ă��ƂɂȂ�ˁB
(150%*0.6�{=0.9�{�ŏ����k���A190%�͔{�ƌ����Ă������낤)
�P���ɍl����ƁA45nm 4�R�A 250mm2��32nm 8�R�A 230mm2(0.9�{)�ɂȂ��
�A���R�A�����ǂ��Ȃ邩���m�������ǁADeneb�Ɩʐϔ�͓����ʂ��낤���Ă��ƂŌv�Z
> 150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
������������Ȃ��Ƃ������Ă���
�V�������N�Ń_�C�T�C�Y��6�����x�ɂȂ鎖���l������ƁA
�_�C�T�C�Y�͌����葽���������Ȃ��āA���\�͖�{���Ă��ƂɂȂ�ˁB
(150%*0.6�{=0.9�{�ŏ����k���A190%�͔{�ƌ����Ă������낤)
�P���ɍl����ƁA45nm 4�R�A 250mm2��32nm 8�R�A 230mm2(0.9�{)�ɂȂ��
�A���R�A�����ǂ��Ȃ邩���m�������ǁADeneb�Ɩʐϔ�͓����ʂ��낤���Ă��ƂŌv�Z
655 �F,,�E�L�́M�E,,�j��-�������F2010/05/11(��) 03:02:39 ID:51kWPjlr
>>644
�������SIMD��load�imovaps)�Ȃ͐����N���X�^�ɂԂ牺�����Ă�Load Unit�ŏ�������邪
�}�k�P�ɂ��X�J�����Z���Č����Ă�̂ł킴�Ɛ�����O������
���Ȃ݂ɂ��̎�̖���Load�̔䗦��32�r�b�g��64�r�b�g�ł��ς��i32�r�b�g���ƃ��W�X�^�����s���j��
�ꕔ�Ϙa�Z���g�����Ƃ�SIMD���߂��팸�Ȃ̂ŁA���������Ӗ��ł̓X�J���N���X�^��
�����I�y���[�V�����̔䗦�͕ς��B
>>647
> SSE/2/3�g���̓x�ɐ��\�`100�߂��lj������Ă��Ă��邵�A
SSE2�̔{���xSIMD�T�|�[�g�͂Ƃ����������͑唼��MMX��2�{���ł�P���x�̃X�J���łȂ�
�����I�y���[�V�����̕��ύX�ł��唼������A�قƂ�ǃg�����W�X�^�̊g���͕K�v�Ȃ����낤�B
�n�[�h�I�ɂ�66, F2, F3�̃v���t�B�N�X�ɓ���ȈӖ�����������悤�ɂ������炢�����傫�Ȋg���͂���ĂȂ��B
> AVX�ɂ��Ă����N�����đΉ����Ă��邩��
���N�������̂�Intel�������낗����
���Ȃ݂�Intel��Sandy Bridge(�J��������Gesher)��4�N������ō���Ă�B
AMD�̒��̐l��binutils��ML��SSE5�̍폜�p�b�`�𑗂����̂�2009�N5�����炢���ȁB
����܂ł�SSE5��O��Ƃ����\�t�g�𑱁X�o���Ă����B
�������Ă��Đv��1�N�����x���B����Ȃ�ēˊэH���H
����VEX�v���t�B�N�X�����܂ł�x86�̃t�H�[�}�b�g�̍��{����ς�邱�Ƃ��B
���Ȃ킿�f�R�[�h�n�[�h�E�F�A�����{����Đv���Ȃ��Ƃ����Ȃ����A�ꍇ�ɂ���Ă͓���ops�̍\�����̂��ς��B
�������SIMD��load�imovaps)�Ȃ͐����N���X�^�ɂԂ牺�����Ă�Load Unit�ŏ�������邪
�}�k�P�ɂ��X�J�����Z���Č����Ă�̂ł킴�Ɛ�����O������
���Ȃ݂ɂ��̎�̖���Load�̔䗦��32�r�b�g��64�r�b�g�ł��ς��i32�r�b�g���ƃ��W�X�^�����s���j��
�ꕔ�Ϙa�Z���g�����Ƃ�SIMD���߂��팸�Ȃ̂ŁA���������Ӗ��ł̓X�J���N���X�^��
�����I�y���[�V�����̔䗦�͕ς��B
>>647
> SSE/2/3�g���̓x�ɐ��\�`100�߂��lj������Ă��Ă��邵�A
SSE2�̔{���xSIMD�T�|�[�g�͂Ƃ����������͑唼��MMX��2�{���ł�P���x�̃X�J���łȂ�
�����I�y���[�V�����̕��ύX�ł��唼������A�قƂ�ǃg�����W�X�^�̊g���͕K�v�Ȃ����낤�B
�n�[�h�I�ɂ�66, F2, F3�̃v���t�B�N�X�ɓ���ȈӖ�����������悤�ɂ������炢�����傫�Ȋg���͂���ĂȂ��B
> AVX�ɂ��Ă����N�����đΉ����Ă��邩��
���N�������̂�Intel�������낗����
���Ȃ݂�Intel��Sandy Bridge(�J��������Gesher)��4�N������ō���Ă�B
AMD�̒��̐l��binutils��ML��SSE5�̍폜�p�b�`�𑗂����̂�2009�N5�����炢���ȁB
����܂ł�SSE5��O��Ƃ����\�t�g�𑱁X�o���Ă����B
�������Ă��Đv��1�N�����x���B����Ȃ�ēˊэH���H
����VEX�v���t�B�N�X�����܂ł�x86�̃t�H�[�}�b�g�̍��{����ς�邱�Ƃ��B
���Ȃ킿�f�R�[�h�n�[�h�E�F�A�����{����Đv���Ȃ��Ƃ����Ȃ����A�ꍇ�ɂ���Ă͓���ops�̍\�����̂��ς��B
�t���[���C�h�͂�����AMD�̐헪�Ȃ���
�{�i�I�ɕ��y����܂ł͚j�Ă��Ă܂��ˁA���x�ł�������Ȃ���?
���\�Ŏc�O�Ȃ��Ƃ͔ۂ߂Ȃ����ǂ�
�M�Ҕ]�I�ɂ͐V���ߏ����ɂ����āA�œK���J�b�R����!�I�Ȑ���̕��ւƂ��Ȃ�
�{�i�I�ɕ��y����܂ł͚j�Ă��Ă܂��ˁA���x�ł�������Ȃ���?
���\�Ŏc�O�Ȃ��Ƃ͔ۂ߂Ȃ����ǂ�
�M�Ҕ]�I�ɂ͐V���ߏ����ɂ����āA�œK���J�b�R����!�I�Ȑ���̕��ւƂ��Ȃ�
>>652
>150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
�����B�����邽�߂ɁA�Ȃ�2�R�A��1���W���[���ɂ���A�v���[�`���Ƃ����̂���
���m�łȂ��B
>150%�̃_�C�T�C�Y��190%�̐��\�Ƃ������ƂŖ������Ǝv����
�����B�����邽�߂ɁA�Ȃ�2�R�A��1���W���[���ɂ���A�v���[�`���Ƃ����̂���
���m�łȂ��B
�E�f�R�[�_���L�ŕ�����s�����̃����_���������\�Ɉ����e����^����̂��ɘa
�ESSE���j�b�g���炵�����L���ŃV���O���X���b�h���̕���x�ێ�
���̕ӂ͉��x�J��Ԃ��Ęb��ɂ�������H
�ESSE���j�b�g���炵�����L���ŃV���O���X���b�h���̕���x�ێ�
���̕ӂ͉��x�J��Ԃ��Ęb��ɂ�������H
>>657
���{�I�ɍl�������Ⴄ
2�R�A��1���W���[���ɉ������̂ł͂Ȃ�
1���W���[����2�X���b�h���s�\�ɂ����̂�Bulldozer��
�l�����I�ɂ̓n�C�p�[�X���b�f�B���O�̉�������ɂ���
���{�I�ɍl�������Ⴄ
2�R�A��1���W���[���ɉ������̂ł͂Ȃ�
1���W���[����2�X���b�h���s�\�ɂ����̂�Bulldozer��
�l�����I�ɂ̓n�C�p�[�X���b�f�B���O�̉�������ɂ���
��`�͂��ꂼ��F�X���邾�낤���ǂ�
HTT
�l���Ȃ��ɕ����܂����ĈĂ̒�]�������\�[�X��L�����p���邽�߂̋@�\
Bull
1�R�A�ɍX�ɐ������s�p�C�v�����݂̂�1�Z�b�g�lj�����
�}���`�X���b�h���̐����X�J�����\���ŗD��
�R�ł͂��邯�ǐ��͕ʂ��Ǝv��
HTT
�l���Ȃ��ɕ����܂����ĈĂ̒�]�������\�[�X��L�����p���邽�߂̋@�\
Bull
1�R�A�ɍX�ɐ������s�p�C�v�����݂̂�1�Z�b�g�lj�����
�}���`�X���b�h���̐����X�J�����\���ŗD��
�R�ł͂��邯�ǐ��͕ʂ��Ǝv��
>>658
>�E�f�R�[�_���L�ŕ�����s�����̃����_���������\�Ɉ����e����^����̂��ɘa
�����͋��L���Ċ������Ƃ��낶��Ȃ��A�Ƃ����b������x���J��Ԃ���Ă����ˁB
FPU�͎g�p�p�x�Ƀ��������邩�狤�L����Ӗ������邪�A
�f�R�[�_��(��e�ʃg���[�X�L���b�V���ł��ς܂Ȃ������)��Ƀr�W�[�ŁA
����n�{�̃X���[�v�b�g��̂�n^2�{�̃g�����W�X�^������Ă��܂��B
�����p�C�v���C�����R�A�Ԃŋ��L���Č������グ��Ȃ���̑O�i�����L����
�͎̂��ɓ��������A�p�C�v���C���͕������Ƃ����B�킯���킩��Ȃ��B
>�E�f�R�[�_���L�ŕ�����s�����̃����_���������\�Ɉ����e����^����̂��ɘa
�����͋��L���Ċ������Ƃ��낶��Ȃ��A�Ƃ����b������x���J��Ԃ���Ă����ˁB
FPU�͎g�p�p�x�Ƀ��������邩�狤�L����Ӗ������邪�A
�f�R�[�_��(��e�ʃg���[�X�L���b�V���ł��ς܂Ȃ������)��Ƀr�W�[�ŁA
����n�{�̃X���[�v�b�g��̂�n^2�{�̃g�����W�X�^������Ă��܂��B
�����p�C�v���C�����R�A�Ԃŋ��L���Č������グ��Ȃ���̑O�i�����L����
�͎̂��ɓ��������A�p�C�v���C���͕������Ƃ����B�킯���킩��Ȃ��B
�܂��A�����킩��Ȃ��̂͂����B
AMD Fanboy�ȊO�ł����̃��W�b�N���ɐ����ł���l�Ԃ������ɒN�����Ȃ��̂�
���ɂ��Ă���B�������Ƃ���Ȃ狳���ė~�����B
AMD Fanboy�ȊO�ł����̃��W�b�N���ɐ����ł���l�Ԃ������ɒN�����Ȃ��̂�
���ɂ��Ă���B�������Ƃ���Ȃ狳���ė~�����B
�@�x�N�^�[���j�b�g���L�ɂ�郍�X���ŏ������邽�߁A���Ȃ��H
����\���Ńf�R�[�_�̔\�͂Ɖ��Z���j�b�g�̔\�͂��݂荇���Ă���Ƃ���
�����Ńf�R�[�_��10�{�ɂ��ĂȂ����f�R�[�_����ɓ����Ă���Ƃ����
�f�R�[�_�͊��Ƀf�R�[�h�������߂����x�����x���J��Ԃ��f�R�[�h���Ă邱�ƂɂȂ�
����Ȕn���Ȃ��Ƃ͂��ႦIntel�ł�99%���Ȃ�
�Ƃ������㓡���u�L���[�����܂��ĂȂ��ق��̎��s�p�C�v�i�X�P�W���[���H�j�Ƀf�R�[�h��U�蕪����v�ƌ����Ă��邵
���Ƃ����b������x���J��Ԃ���Ă���
�Ȃ�đ��H�t���̉����ꂭ�炢�ł����������Ƃ�����
�����Ńf�R�[�_��10�{�ɂ��ĂȂ����f�R�[�_����ɓ����Ă���Ƃ����
�f�R�[�_�͊��Ƀf�R�[�h�������߂����x�����x���J��Ԃ��f�R�[�h���Ă邱�ƂɂȂ�
����Ȕn���Ȃ��Ƃ͂��ႦIntel�ł�99%���Ȃ�
�Ƃ������㓡���u�L���[�����܂��ĂȂ��ق��̎��s�p�C�v�i�X�P�W���[���H�j�Ƀf�R�[�h��U�蕪����v�ƌ����Ă��邵
���Ƃ����b������x���J��Ԃ���Ă���
�Ȃ�đ��H�t���̉����ꂭ�炢�ł����������Ƃ�����
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091217_336298.html
���X�T���ė�����Ă̂��A�������ǁA���ꂾ��
�ʂ́i�����́j�b������
�����T�C�N���Ƀf�R�[�h�����x86���߂́A�����L���b�V�����C�������o����邽�߁A������������X���b�h�ɑ����邱�ƂɂȂ�
�Ă��Ƃ�2�X���b�h*2����f�R�[�h�Ƃ��͖����킯��
L1I�Ńv���f�R�[�h�ς݂�AMD������ʂɂ��̕ӂ͂ǂ��ł���������
���X�T���ė�����Ă̂��A�������ǁA���ꂾ��
�ʂ́i�����́j�b������
�����T�C�N���Ƀf�R�[�h�����x86���߂́A�����L���b�V�����C�������o����邽�߁A������������X���b�h�ɑ����邱�ƂɂȂ�
�Ă��Ƃ�2�X���b�h*2����f�R�[�h�Ƃ��͖����킯��
L1I�Ńv���f�R�[�h�ς݂�AMD������ʂɂ��̕ӂ͂ǂ��ł���������
>>663
�_�C�T�C�Y���k��������
SIMD���j�b�g�͗��p�p�x���Ⴂ���猸�炵����
2�̃R�A�ŋ��L�����悤
���łɑ��̋��L�ł��镔�������L�����悤
�����Ŕ��ɕ���Ղ��Ǝv����
�_�C�T�C�Y���k��������
SIMD���j�b�g�͗��p�p�x���Ⴂ���猸�炵����
2�̃R�A�ŋ��L�����悤
���łɑ��̋��L�ł��镔�������L�����悤
�����Ŕ��ɕ���Ղ��Ǝv����
SIMD�̎g�p�p�x���Ⴍ��
�_�C���������������Ȃ�
Fusion�Ȃ�Ď��߂�Ηǂ��̂�
�_�C���������������Ȃ�
Fusion�Ȃ�Ď��߂�Ηǂ��̂�
Fusion�O���炱������FPU�̖��������炵�Ă�������
Bulldozer�̘b���ĂāA����ǂ�łȂ��z���邩�H
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/587-600
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/587-600
��Fusion�O���炱������FPU�̖��������炵�Ă�������
�i�j
�i�j
AMD�̑_���́A�݊����ێ��̂���SSE��AVX�ɂ͑Ή����邯�ǐ��\��������C�͂Ȃ��A
���C���͐����N���X�^(���W���[����)�ƃV�F�[�_�[�N���X�^(MIMD?)�̑g�����ŋƊE�̔e����_���A����
���C���͐����N���X�^(���W���[����)�ƃV�F�[�_�[�N���X�^(MIMD?)�̑g�����ŋƊE�̔e����_���A����
����ȓƎ��K�i
���ꂪ�g����
���ꂪ�g����
GPU����Y�ꂽ�z��
>>673
AVX�͓Ǝ��K�i�Ƃ͂���Intel����v�b�V�����邩�猋�\�g�����
AVX�͓Ǝ��K�i�Ƃ͂���Intel����v�b�V�����邩�猋�\�g�����
�݊����̂Ȃ�
shader cluster�Ƃ��̕�����
shader cluster�Ƃ��̕�����
AVX�ڂ��ĂȂ��ƃL�c�C�ƌ�����悤�ɂȂ�͉̂��N�ギ�炢���낤���c�c
678 �F,,�E�L�́M�E,,�j��-�������F2010/05/11(��) 21:38:02 ID:51kWPjlr
>>670
����O��Řb���Ă�Ǝv���Ă��B
����>>653
���ɐ��\�\�z�������Ă���
http://www.ospn.jp/osc2009-shimane/amd.pdf
�O���t����ǂݎ��鐔���͑�̂���Ȃ���
Istanbul 17
Magny-Cours 26
Interagos 33
K10 1�R�A��K11 2�R�A�ł̃X���[�v�b�g��1.8�{���x�Ɖ��肵�ċt�Z�����
Interagos�̓���N���b�N�͂����Ƃ�2.5GHz�O��
����O��Řb���Ă�Ǝv���Ă��B
����>>653
���ɐ��\�\�z�������Ă���
http://www.ospn.jp/osc2009-shimane/amd.pdf
�O���t����ǂݎ��鐔���͑�̂���Ȃ���
Istanbul 17
Magny-Cours 26
Interagos 33
K10 1�R�A��K11 2�R�A�ł̃X���[�v�b�g��1.8�{���x�Ɖ��肵�ċt�Z�����
Interagos�̓���N���b�N�͂����Ƃ�2.5GHz�O��
�����O�ɂ���������
�L���S���̒N�����Ă��Ƃ��ɍ����
Opteron��Istanbul������Ɉ���ꂽ��Ȃǂ��Ă邻������ăz�����^���Ɍ���Ă�}�Ƃ����̂�
�����K10@6�R�A��K10@6�R�A*2��int��froat�̊���������Ă邪
�uOpteron��Istanbul�v�͖����Ȃ��Ă��
�L���S���̒N�����Ă��Ƃ��ɍ����
Opteron��Istanbul������Ɉ���ꂽ��Ȃǂ��Ă邻������ăz�����^���Ɍ���Ă�}�Ƃ����̂�
�����K10@6�R�A��K10@6�R�A*2��int��froat�̊���������Ă邪
�uOpteron��Istanbul�v�͖����Ȃ��Ă��
���ꂪ�A�ǂ�����Ďg����
����ȃ}�C�i�[�Ǝ��K�i��
Intel�Ƃ̌݊����Ȃ���
����ȃ}�C�i�[�Ǝ��K�i��
Intel�Ƃ̌݊����Ȃ���
�Ƃ����OpenCL���ăx���`�ȊO��
���Ɏg���Ă�H
���Ɏg���Ă�H
�w�e���W�j�A�X�͋K��H���ł��B
Intel��AMD�͂��܂����߂��܂��`��B
VIA��NV�͂ǂ��Ȃ��ł��傤���A�m�肽��������܂��B
Intel��AMD�͂��܂����߂��܂��`��B
VIA��NV�͂ǂ��Ȃ��ł��傤���A�m�肽��������܂��B
>>678
���̂����l�����ăR�A�̐�������L���Ă݂�
2007 4C 8 (Barcelona/Agena)
2008 4C 10 (Shanghai/Deneb)
2009 6C 17 (Istanbul/Thuban)
2010 12 26 (Magni-Cours)
2011 16 33 (Interlagos)
������ăN���b�N������̐��\��r����ˁH
Athlon64(1C)��1�Ƃ������̂ˁB
�E�N���b�N�ƃR�A�������l�����ꍇ
Athlon64 1C 1GHz=1
Istanbul 6C 2.6GHz=16(17)
�łقڃO���t�ʂ�̍��ɂȂ��Ă���B
IPC����܂߂���17�ǂ��낶��Ȃ����ɂȂ肻�������ǂˁB
Agena(8) vs Deneb(10)
Deneb(10) vs Istanbul(17)
�͍ō��N���b�N���m���Ƃ��肦�Ȃ����ʂ���
Magni-Cours(26) vs Interlagos(33)�̓R�A�������x
33/26=1.27�A16/12=1.33
Magni-Cours�����R�A�����藎���Ă��闝�R�͕����B
12/6=2�A26/17=1.5
�������������\��Ȃ̂��ȁH
���̂����l�����ăR�A�̐�������L���Ă݂�
2007 4C 8 (Barcelona/Agena)
2008 4C 10 (Shanghai/Deneb)
2009 6C 17 (Istanbul/Thuban)
2010 12 26 (Magni-Cours)
2011 16 33 (Interlagos)
������ăN���b�N������̐��\��r����ˁH
Athlon64(1C)��1�Ƃ������̂ˁB
�E�N���b�N�ƃR�A�������l�����ꍇ
Athlon64 1C 1GHz=1
Istanbul 6C 2.6GHz=16(17)
�łقڃO���t�ʂ�̍��ɂȂ��Ă���B
IPC����܂߂���17�ǂ��낶��Ȃ����ɂȂ肻�������ǂˁB
Agena(8) vs Deneb(10)
Deneb(10) vs Istanbul(17)
�͍ō��N���b�N���m���Ƃ��肦�Ȃ����ʂ���
Magni-Cours(26) vs Interlagos(33)�̓R�A�������x
33/26=1.27�A16/12=1.33
Magni-Cours�����R�A�����藎���Ă��闝�R�͕����B
12/6=2�A26/17=1.5
�������������\��Ȃ̂��ȁH
>>681
���O�̓��̈����ɂ͂т����肾ww
�V�F�[�_�[���o�C�i�����\�[�X�ڎ��s����킯����Ȃ�
API�ɂ̓h���C�o�őΉ����邩��A�x���_�[��CPU�̒��g�ȂC�ɂ��Ȃ���
DX��OGL�AOCL�AC++�Ƃ��D���Ȍ���ŊJ�����������B
�œK����������Ⴗ����������ŁA���̎���AMD��������T�|�[�g���Ă����
���O�̓��̈����ɂ͂т����肾ww
�V�F�[�_�[���o�C�i�����\�[�X�ڎ��s����킯����Ȃ�
API�ɂ̓h���C�o�őΉ����邩��A�x���_�[��CPU�̒��g�ȂC�ɂ��Ȃ���
DX��OGL�AOCL�AC++�Ƃ��D���Ȍ���ŊJ�����������B
�œK����������Ⴗ����������ŁA���̎���AMD��������T�|�[�g���Ă����
AMD��������T�|�[�g���Ă������Ăǂ����Ԕ��Ȃ�
OpenCL�͊e�f�o�C�X���Ƃ̃o�C�i�������s����d�l�����A
���gCPU�ȏ�ɈႤGPU�̈Ⴂ�����ăR�[�h�����Ă����\�ȂłȂ����낤�B
���̌���g���ɂ���A�^�[�Q�b�g�Ƃ���GPU���ƂɍœK�����邱�Ƃ͕K�{����Ȃ��́H
���gCPU�ȏ�ɈႤGPU�̈Ⴂ�����ăR�[�h�����Ă����\�ȂłȂ����낤�B
���̌���g���ɂ���A�^�[�Q�b�g�Ƃ���GPU���ƂɍœK�����邱�Ƃ͕K�{����Ȃ��́H
GPU���ƂɍœK���Ȃ�Ėʓ|���������Ƃ��Ă��邤���͕��y�Ȃ��Ȃ��Ǝv��
.NET�����肪���ɂȂ��Ȃ�����
.NET�����肪���ɂȂ��Ȃ�����
>>670
Andy Glew��dresdenboy���A�f�R�[�_���L�̓����ɂ��Ă͓��ɐ[���͌��y���ĂȂ���Ȃ����B
�f�R�[�_���L�ɁAFPU���L�̂��₷���Ƃ��̃����b�g�͂���ɂ��Ă��A
3���ߓ������s�Ƃ���x86�̃x�X�g�v���N�e�B�X���̂Ă�قǂ̉��l�͂���̂��A
���邢�́A����2���߂ł����Ȃ�A4���ߓ������s�~1���2���ߓ������s�~2�̕����V���v���ŏȃg�����W�X�^�E�ȓd�͂Ȃ�Ȃ����B
Andy Glew��dresdenboy���A�f�R�[�_���L�̓����ɂ��Ă͓��ɐ[���͌��y���ĂȂ���Ȃ����B
�f�R�[�_���L�ɁAFPU���L�̂��₷���Ƃ��̃����b�g�͂���ɂ��Ă��A
3���ߓ������s�Ƃ���x86�̃x�X�g�v���N�e�B�X���̂Ă�قǂ̉��l�͂���̂��A
���邢�́A����2���߂ł����Ȃ�A4���ߓ������s�~1���2���ߓ������s�~2�̕����V���v���ŏȃg�����W�X�^�E�ȓd�͂Ȃ�Ȃ����B
�O���ߔ��s���g�����W�X�^�����I�Ƀx�X�g����Ȃ��Ɣ��f�����������Ǝv����
�g�����W�X�^�����Ƀt�H�[�J�X����Ȃ�2���ߔ��s�~2�̓Ɨ��f�R�[�_���x�X�g���낤�B
4���ߔ��s�͓������(=�d�͂ƃg�����W�X�^����)�ŁA
�����ς����2���߂ɗ�����Ƃ����A�N��������̂��킩��Ȃ��A�v���[�`���B
�s�[�N���ǂ��炩�̃R�A�ɕ�Ȃ�Ӗ������邪�A�f�R�[�_�͂������������͔������A
��i(�X�P�W���[��)�ŃL���[�C���O����Ƃ������Ƃ́A��͂Ȃ炳��ĕ��ω������Ƃ������Ƃ��B
4���ߔ��s�͓������(=�d�͂ƃg�����W�X�^����)�ŁA
�����ς����2���߂ɗ�����Ƃ����A�N��������̂��킩��Ȃ��A�v���[�`���B
�s�[�N���ǂ��炩�̃R�A�ɕ�Ȃ�Ӗ������邪�A�f�R�[�_�͂������������͔������A
��i(�X�P�W���[��)�ŃL���[�C���O����Ƃ������Ƃ́A��͂Ȃ炳��ĕ��ω������Ƃ������Ƃ��B
�������̕����������ǂ��Ƃ����V�~�����[�g���ʂ��o����
�����o�Ă��画�f���邵���˂����낤��������ւ��
�����o�Ă��画�f���邵���˂����낤��������ւ��
3���߃f�R�[�_x2����L1I��2�{�����Ȃ��́H
���邢�̓}���`�|�[�g���Ƃ�
���邢�̓}���`�|�[�g���Ƃ�
�f�R�[�_�b�̃��[�v�X�g���[���ɉ�����
Core2��4���߂ɂ܂Ŗϑz�������ޓz�܂ŏo�ė���Ƃ͂�
Core2��4���߂ɂ܂Ŗϑz�������ޓz�܂ŏo�ė���Ƃ͂�
>685
API�o�R�̂����x�����̂�
���ꂪ�D���D��Ŏg����
�Ƃ����AMD��SSE4a��
���Ŏg���Ă���̂�
API�o�R�̂����x�����̂�
���ꂪ�D���D��Ŏg����
�Ƃ����AMD��SSE4a��
���Ŏg���Ă���̂�
Llano��Ontario�̃T���v�����o�ׂ���Ă�炵������
Ontario��CPU������Bulldozer��1/2���W���[���Ȃ́H
Ontario��CPU������Bulldozer��1/2���W���[���Ȃ́H
�ӂƎv�����̂���Windows2000Pro����Bulldozer��FPU�͈�����g���Ȃ��̂��낤���B
�c�c�ǂ��ł������ȁB
�c�c�ǂ��ł������ȁB
>>697
FP�X�P�W���[���̎���2�{�̃p�C�v��Bull��1���W�����L��Bob��1�R�A�����L
����FPU�̍\�����Đ����p�C�v�̃��j�b�g�Ɣ�ׂĂ킯�����f���͏o����
ttp://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:AMD_A64_Opteron_arch.svg
K10�͂���Ȃ��ƂɂȂ��Ă邵
FP�X�P�W���[���̎���2�{�̃p�C�v��Bull��1���W�����L��Bob��1�R�A�����L
����FPU�̍\�����Đ����p�C�v�̃��j�b�g�Ɣ�ׂĂ킯�����f���͏o����
ttp://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A1%E3%82%A4%E3%83%AB:AMD_A64_Opteron_arch.svg
{kind=link}
K10�͂���Ȃ��ƂɂȂ��Ă邵
700 �F,,�E�L�́M�E,,�j��-�������F2010/05/12(��) 08:41:05 ID:8+RU6ZtX
>>684
> ������ăN���b�N������̐��\��r����ˁH
> Athlon64(1C)��1�Ƃ������̂ˁB
���₻�ꂠ�肦�Ȃ����炗
����K8�ŃN���b�N�����オ���ĂȂ�2003-2004�̔����ȐL�т͂ǂ������������Ă���������
1.8GHz��2.4GHz���炢�ɐL�т����������H
��������Opteron���ď����Ă��������Athlon64����Ȃ���Opteron(SledgeHammer)����B
������SPECint_rate�̒l�Ɣ�Ⴕ�Ă���
FP�̂ق��̓R�A���\���������i�������ш�j�̐��\�ɂ����Ƃ��낪�傫���Ǝv�����B
����2009-2010�͒P���Ƀ�����ch�����̕�����FP���\���L�тĂ���㩁B
�i���ΓI��Integer�̓N���b�N���������L�єY��ł���j
Interagos��FPU�͋��L�Ƃ͂���FMA���g�����Ƃł̃X���[�v�b�g��K10�̍ő�2�{������A
���p�^�C�~���O�����d�����Ȃ���R�A������̐��\�������グ�邱�Ƃ͂ł���B
> ������ăN���b�N������̐��\��r����ˁH
> Athlon64(1C)��1�Ƃ������̂ˁB
���₻�ꂠ�肦�Ȃ����炗
����K8�ŃN���b�N�����オ���ĂȂ�2003-2004�̔����ȐL�т͂ǂ������������Ă���������
1.8GHz��2.4GHz���炢�ɐL�т����������H
��������Opteron���ď����Ă��������Athlon64����Ȃ���Opteron(SledgeHammer)����B
������SPECint_rate�̒l�Ɣ�Ⴕ�Ă���
FP�̂ق��̓R�A���\���������i�������ш�j�̐��\�ɂ����Ƃ��낪�傫���Ǝv�����B
����2009-2010�͒P���Ƀ�����ch�����̕�����FP���\���L�тĂ���㩁B
�i���ΓI��Integer�̓N���b�N���������L�єY��ł���j
Interagos��FPU�͋��L�Ƃ͂���FMA���g�����Ƃł̃X���[�v�b�g��K10�̍ő�2�{������A
���p�^�C�~���O�����d�����Ȃ���R�A������̐��\�������グ�邱�Ƃ͂ł���B
701 �F,,�E�L�́M�E,,�j��-�������F2010/05/12(��) 09:10:41 ID:8+RU6ZtX
���Ȃ݂�
> Deneb(10) vs Istanbul(17)
> �͍ō��N���b�N���m���Ƃ��肦�Ȃ����ʂ���
2008�N�ō����\��Opteron�� 2386 SE�iBarcelona 2.8GHz�~4�j
2009�N�� Istanbul 2.9GHz�~6
�Ƃ������ƂŐ����͊T�˃N���b�N�~�R�A���Ȃ݁B
> Deneb(10) vs Istanbul(17)
> �͍ō��N���b�N���m���Ƃ��肦�Ȃ����ʂ���
2008�N�ō����\��Opteron�� 2386 SE�iBarcelona 2.8GHz�~4�j
2009�N�� Istanbul 2.9GHz�~6
�Ƃ������ƂŐ����͊T�˃N���b�N�~�R�A���Ȃ݁B
702 �F,,�E�L�́M�E,,�j��-�������F2010/05/12(��) 09:15:35 ID:8+RU6ZtX
�~2009�N�� Istanbul 2.9GHz�~6
��2009�N��2439 SE 2.8GHz�~6(Istanbul)
��2009�N��2439 SE 2.8GHz�~6(Istanbul)
>>670
MAC�I�^�͈Ӓn�����ȁE�E�E
MAC�I�^�͈Ӓn�����ȁE�E�E
�A�E�g�I�u�I�[�_���X�[�p�[�X�J���i>541�j�Ȃ�����
�ȑOOpteron�i�u�����h�j��Istanbul�i�R�[�h�j�̖����ꏏ�ɕ���ł��悤��
���������ȍL���ɐl����q����V���^�z��55�i����j
�ȑOOpteron�i�u�����h�j��Istanbul�i�R�[�h�j�̖����ꏏ�ɕ���ł��悤��
���������ȍL���ɐl����q����V���^�z��55�i����j
>>697
�ʕ��B
�ʕ��B
�A�E�g�I�u�I�[�_�Ƃ�����
�A�[�L�e�N�`���X����MAD�I�^�R�s�y�ŁuFP�X�P�W���[���̓A�E�g�I�u�I�[�_�ł͂Ȃ��v�Ƃ��������ǂق�Ƃ��ˁH
����Ȃ狤�L������ΒP�Ȃ�C���I�[�_����SMT���t����Atom�݂����ɂȂ邩�炢����
�����Bull��FP�����̂��ƂȂ̂�
�u���W���[���̓N���X�^�ŊF�Ђ�����Ԃ��ČĂ�łĂ���炩���v�Ƃ悭����Ȃ����Ƃ������Ă�z�̔�������������Ƃ����ق��������̂�
�ǂ��Ȃ�
�A�[�L�e�N�`���X����MAD�I�^�R�s�y�ŁuFP�X�P�W���[���̓A�E�g�I�u�I�[�_�ł͂Ȃ��v�Ƃ��������ǂق�Ƃ��ˁH
����Ȃ狤�L������ΒP�Ȃ�C���I�[�_����SMT���t����Atom�݂����ɂȂ邩�炢����
�����Bull��FP�����̂��ƂȂ̂�
�u���W���[���̓N���X�^�ŊF�Ђ�����Ԃ��ČĂ�łĂ���炩���v�Ƃ悭����Ȃ����Ƃ������Ă�z�̔�������������Ƃ����ق��������̂�
�ǂ��Ȃ�
���㓡�O��Weekly�C�O�j���[�X��
�R���s���[�e�B���O�s��̋K�͂�5�N��6�����Intel���\��
http://pc.watch.impress.co.jp/docs/column/kaigai/20100512_366386.html
Intel�͍����Investor Meeting�ŁA2013�N�́uHaswell(�n�X�E�F��)�v�ɂ��Ă��A�������y���Ȃ������B
Haswell�́ANehalem��S�������ăI���S���B�̊J���Z���^�[�ŊJ�����Ă���CPU���B2013�N�ɓo�ꂷ��\��ŁA���łɈꕔ�ڋq�ɑ��Ă͐������J�n���Ă���B
�@2013�N�̎��X���}�C�N���A�[�L�e�N�`��CPU��Intel�I���S�����J�����Ă��邱�Ƃ́A���łɖ�������Ă���B
���N(2010�N)2���ɕăX�^���t�H�[�h��w�̌��J�u�`EE380�ŁAIntel�̃A�[�L�e�N�gGlenn J. Hinton��(Intel Fellow, Intel Architecture Group, Director, IA-32 Microarchitecture Development, Intel)
���s�Ȃ����u���uKey Nehalem Choices�v�ŁA�I���S����2013�N��CPU���J�����Ă��邱�Ƃ��������ꂽ�B
Hinton���̓I���S���v�Z���^�[�̃A�[�L�e�N�g�̃��[�_�[�ŁA Haswell���S�����Ă���ƌ�����BHaswell�ɂ��ẮASandy Bridge���o��O�Ƃ����āA����������������Ă���Ɛ��肳���B
�R���s���[�e�B���O�s��̋K�͂�5�N��6�����Intel���\��
http://pc.watch.impress.co.jp/docs/column/kaigai/20100512_366386.html
Intel�͍����Investor Meeting�ŁA2013�N�́uHaswell(�n�X�E�F��)�v�ɂ��Ă��A�������y���Ȃ������B
Haswell�́ANehalem��S�������ăI���S���B�̊J���Z���^�[�ŊJ�����Ă���CPU���B2013�N�ɓo�ꂷ��\��ŁA���łɈꕔ�ڋq�ɑ��Ă͐������J�n���Ă���B
�@2013�N�̎��X���}�C�N���A�[�L�e�N�`��CPU��Intel�I���S�����J�����Ă��邱�Ƃ́A���łɖ�������Ă���B
���N(2010�N)2���ɕăX�^���t�H�[�h��w�̌��J�u�`EE380�ŁAIntel�̃A�[�L�e�N�gGlenn J. Hinton��(Intel Fellow, Intel Architecture Group, Director, IA-32 Microarchitecture Development, Intel)
���s�Ȃ����u���uKey Nehalem Choices�v�ŁA�I���S����2013�N��CPU���J�����Ă��邱�Ƃ��������ꂽ�B
Hinton���̓I���S���v�Z���^�[�̃A�[�L�e�N�g�̃��[�_�[�ŁA Haswell���S�����Ă���ƌ�����BHaswell�ɂ��ẮASandy Bridge���o��O�Ƃ����āA����������������Ă���Ɛ��肳���B
������ǂ������Ƃ��������悤���Ȃ�
����Ȃ�܂�Larrabee�ɂ��Č��y���Ă��镔���̕����ʔ����Ǝv����
����Ȃ�܂�Larrabee�ɂ��Č��y���Ă��镔���̕����ʔ����Ǝv����
���X�����Haswell��Intel��
�������Bulldozer�̉��������Ȃ�AMD
���Ȃ��Ƃ��A���������Ă���Orochi�̍��N�㔼�̐��Y�J�n�͂Ȃ��ȁB
�������Bulldozer�̉��������Ȃ�AMD
���Ȃ��Ƃ��A���������Ă���Orochi�̍��N�㔼�̐��Y�J�n�͂Ȃ��ȁB
710 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 02:30:09 ID:K0i0hle1
>>700-702�ɕ⑫
���̎��_��2009�N�ȍ~�̐����͂����܂ŗ\�z�l�ł����Ȃ����
Istanbul 6�R�A��2009�N����3.0GHz�o���\�肾�����Ɖ��肷��ΐ����̒��K����̍����B
�y2008-2009�z
�O���t�䗦�F�@17/10 = 1.7
�R�A�~�N���b�N���䗦�F(3.0 * 6) / (2.8 * 4) �� 1.6 �i+ HT Assist + DDR3 + etc = 1.7�H�j
�y2009-2010�z
�O���t�䗦�F�@26/17 �� 1.56
�R�A�~�N���b�N���䗦�F(2.3 * 12) / (3.0 * 6) �� 1.56
2011�N��Interagos��3GHz�ʼn��Ƃ����炻��͂���ŃN���b�N������̃X���[�v�b�g�͒Ⴂ�ł���
���Ă��ƂɂȂ�킯�ŁA����ȏ�̗v�f�͖����Ǝv�����ǂȁB
���̎��_��2009�N�ȍ~�̐����͂����܂ŗ\�z�l�ł����Ȃ����
Istanbul 6�R�A��2009�N����3.0GHz�o���\�肾�����Ɖ��肷��ΐ����̒��K����̍����B
�y2008-2009�z
�O���t�䗦�F�@17/10 = 1.7
�R�A�~�N���b�N���䗦�F(3.0 * 6) / (2.8 * 4) �� 1.6 �i+ HT Assist + DDR3 + etc = 1.7�H�j
�y2009-2010�z
�O���t�䗦�F�@26/17 �� 1.56
�R�A�~�N���b�N���䗦�F(2.3 * 12) / (3.0 * 6) �� 1.56
2011�N��Interagos��3GHz�ʼn��Ƃ����炻��͂���ŃN���b�N������̃X���[�v�b�g�͒Ⴂ�ł���
���Ă��ƂɂȂ�킯�ŁA����ȏ�̗v�f�͖����Ǝv�����ǂȁB
Intel�ł��I���S���`�[���͂ς��Ƃ��Ȃ�����Haswell���ǂ��Ȃ邱�Ƃ��B
�܂��I���S�����ǂ��Ƃ������Ă�z�����w
713 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 07:30:12 ID:K0i0hle1
�ς��Ƃ��Ȃ��`�[���������Nehalem�ɖ��c�ɂ��s���D��ꂽOpteron���ĉ��Ȃ́H
�{���ɒc�q��intel�������Ă���ȁB
Haswell�ɂ��I���S���������̂���...
�m�[�gPC�ł��G���̖@����������
�I���S���`�[���͎s���D������Ȃ��I�G���̒m�\��D�����I
���_�̂���ŃY����������������y����
����Ȃ̂�Haswell�ւ̕s���������邩����
����Ȃ̂�Haswell�ւ̕s���������邩����
�T���^�N�����`�[�����č����Itanium�ێ�`�[���ł��葱����낤��
Nehalem-EX�̓T���^�N��������������ǁAWestmere-EX�̓o���K���[���炵�����A
RAS�@�\��������Ƃ��ɏo�����Ă��邭�炢�Ȃ̂��낤���B
RAS�@�\��������Ƃ��ɏo�����Ă��邭�炢�Ȃ̂��낤���B
721 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 18:12:02 ID:K0i0hle1
>>718
�A���^���s���Ȃ����ɂ��������B
���s���̃��X�N�w�b�W�̂��߂�Tick-Tock���f���Ȃ킯�ŁA
* Bridge�̑����ł͂Ȃ��}�C�N���A�[�L�e�N�`���̍��V�Ƃ������[�h�}�b�v�ɕύX���Ȃ�������
�\���Ƃ����Ă�����Ȃ��́H
FMA���߂̒lj��ōX��1�R�A�������FP�̗��_�X���[�v�b�g��Sandy Bridge�̍X��2�{�ɂ��邱�Ƃ�
�ł���ƌ����Ă��邪�A���̌v��ɕύX���Ȃ������ł���̎��B
�ނ���2008�N���_�Ő�̕��܂ŏ����o�������������A����ȏ�̊��҂����悤���Ȃ��B
�ނ���AMD�̐S�z���Ă���
��Haswell���ĈӖ��ł�Bulldozer�̎�����i22nm? 25nm?)�̂ق����s���v�f�����Ȃ����H
�eFMA��256�r�b�g������ΐ��\�I�ɂ�Haswell�ɒǏ]�\�����A
���邢��GPU�̃V�F�[�_�N���X�^�Ƃ̋��p���������߂Ă��邩�ˁH
�A���^���s���Ȃ����ɂ��������B
���s���̃��X�N�w�b�W�̂��߂�Tick-Tock���f���Ȃ킯�ŁA
* Bridge�̑����ł͂Ȃ��}�C�N���A�[�L�e�N�`���̍��V�Ƃ������[�h�}�b�v�ɕύX���Ȃ�������
�\���Ƃ����Ă�����Ȃ��́H
FMA���߂̒lj��ōX��1�R�A�������FP�̗��_�X���[�v�b�g��Sandy Bridge�̍X��2�{�ɂ��邱�Ƃ�
�ł���ƌ����Ă��邪�A���̌v��ɕύX���Ȃ������ł���̎��B
�ނ���2008�N���_�Ő�̕��܂ŏ����o�������������A����ȏ�̊��҂����悤���Ȃ��B
�ނ���AMD�̐S�z���Ă���
��Haswell���ĈӖ��ł�Bulldozer�̎�����i22nm? 25nm?)�̂ق����s���v�f�����Ȃ����H
�eFMA��256�r�b�g������ΐ��\�I�ɂ�Haswell�ɒǏ]�\�����A
���邢��GPU�̃V�F�[�_�N���X�^�Ƃ̋��p���������߂Ă��邩�ˁH
x86�x�N�^�̋�����GPU��1/100����2/100�ɁI�I�I
723 �FSocket774�F2010/05/13(��) 18:40:07 ID:Ojsonk68
���Fusion��2015�N�炵��
724 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 19:39:04 ID:K0i0hle1
Linpack������Ȃ�Sandy Bridge 6�R�A�Ŏ���140GFLOPS(�{���x)���x�͏o�����
> x86�x�N�^�̋�����GPU��1/100����2/100�ɁI�I�I
�ւ�70TFLOPS���o�����GPU��
> x86�x�N�^�̋�����GPU��1/100����2/100�ɁI�I�I
�ւ�70TFLOPS���o�����GPU��
>>724
|�֥)���،v�Z���C���� 140GFLOPS / (2/100) = 7TFLOPS
|�֥)���،v�Z���C���� 140GFLOPS / (2/100) = 7TFLOPS
726 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:00:54 ID:K0i0hle1
������A���p���̂Ȃ�����GPU��0.2�|�����炢���Ó������炱��ł���
radeon�͂��ł����̒l����
NVIDIA�̃T�C�g�Ŋm�F����ƁC�m���ɃV�F�[�_�N���b�N��1.15GHz�ɂȂ��Ă���C
�{���x���������_���Z�̃s�[�N���\��515GFlops�ɂȂ��Ă��܂��B
Intel��8�R�A��X7560��72.5GFlops��130W�ł�����C
�܂��C�s�[�NFlops/W�ł�4�{���x�̃A�h�o���e�[�W������̂ł����C
���N���ɏo��Ƃ݂��Ă���Sandy Bridge�ł̓T�C�N���������Flops��
�{������ƍl������̂ł��Ȃ荷���k�܂茵�����Ƃ���ł�
�{���x���������_���Z�̃s�[�N���\��515GFlops�ɂȂ��Ă��܂��B
Intel��8�R�A��X7560��72.5GFlops��130W�ł�����C
�܂��C�s�[�NFlops/W�ł�4�{���x�̃A�h�o���e�[�W������̂ł����C
���N���ɏo��Ƃ݂��Ă���Sandy Bridge�ł̓T�C�N���������Flops��
�{������ƍl������̂ł��Ȃ荷���k�܂茵�����Ƃ���ł�
�|���Z���o���Ȃ����[��
12<16�͊o�����̂��z��
12<16�͊o�����̂��z��
>>729
CPU��GPU��1/100�Ƃ�2/100���Ă̂͂ǂ����痈���H
CPU��GPU��1/100�Ƃ�2/100���Ă̂͂ǂ����痈���H
>>730
GPU 100�{�@�ŃO�O���������
GPU 100�{�@�ŃO�O���������
732 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:30:29 ID:K0i0hle1
>>730
CPU�͍œK����ؖ���1�X���b�h
GPU�iCUDA�j�͉��������o���ăJ���J���Ƀ`���[��
��w����o�Ă��郌�|�[�g�Ȃ�Ă���Ȃ����������
���ꂷ��Radeon�Ȃ�Ė��������ǂ�
CPU�͍œK����ؖ���1�X���b�h
GPU�iCUDA�j�͉��������o���ăJ���J���Ƀ`���[��
��w����o�Ă��郌�|�[�g�Ȃ�Ă���Ȃ����������
���ꂷ��Radeon�Ȃ�Ė��������ǂ�
1+1��2����Ȃ��@200���I�@10�{����10�{�I
734 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:34:36 ID:K0i0hle1
��H�^GPU�͔{���x�i���_�l�j�͒P���x�i���_�l�j��0.2�|������Ȃ������̂��H
�Ȃ�Ńe�w�͑��l�ɐ��肷�܂��Ă܂Ńt�@�r�����Ă����?
��D����Intel�����\��AMD�ɂ��܂��ܕ������̂�����Ȃɉ�������w
��D����Intel�����\��AMD�ɂ��܂��ܕ������̂�����Ȃɉ�������w
736 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:38:30 ID:K0i0hle1
���₵��������
���₵����������������������
�킩�������炳�����ƃN�\���ĐQ��
���₵����������������������
�킩�������炳�����ƃN�\���ĐQ��
>>731
�f�o�t�̃R�A(�ƌĂԃx���_�[������A�b�o�t�̉��Z��ɑ���)�Ƃb�o�t�̃R�A�̐����r����
100�{�����Ƃ������Ă镳�L�����o�Ă�����
�f�o�t�̃R�A(�ƌĂԃx���_�[������A�b�o�t�̉��Z��ɑ���)�Ƃb�o�t�̃R�A�̐����r����
100�{�����Ƃ������Ă镳�L�����o�Ă�����
>>733
tp://beye2.com/item_7464.html
�����Ƃ����ɒ�������Ă�
����͌����ԈႢ���Ă���낤��
�����ĊԈႤ�̂ƃ��x�����Ⴄ���Ă�����
����ς�12<16����܂�����Ȃ��z���͒m�\0�Ȃ��
tp://beye2.com/item_7464.html
�����Ƃ����ɒ�������Ă�
����͌����ԈႢ���Ă���낤��
�����ĊԈႤ�̂ƃ��x�����Ⴄ���Ă�����
����ς�12<16����܂�����Ȃ��z���͒m�\0�Ȃ��
>>736
�Ȃ�Ńe�w�̘b��Ƀ_���S���t����w
�Ȃ�Ńe�w�̘b��Ƀ_���S���t����w
740 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:45:15 ID:K0i0hle1
>>737
�n�R�������͉Ȍ����Ȃ���NVIDIA�����t�������Ȃ��Ƃ���Ă��Ȃ��A�Ǝv������܂��o�Ă����B
�v�Z�@�Ȋw�̌��ؐ���c�߂�N�\���Ȃ����ėǂ��B�����z�[�̓S�Ɗ�]�B
�n�R�������͉Ȍ����Ȃ���NVIDIA�����t�������Ȃ��Ƃ���Ă��Ȃ��A�Ǝv������܂��o�Ă����B
�v�Z�@�Ȋw�̌��ؐ���c�߂�N�\���Ȃ����ėǂ��B�����z�[�̓S�Ɗ�]�B
741 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 20:46:07 ID:K0i0hle1
>>739
���Ȃ��炸����F�肷�铪�̈����q���������邩�炾��
���Ȃ��炸����F�肷�铪�̈����q���������邩�炾��
�z���Ă�肳��Ă�����
>>742
�z���͎G���̎�
12<16�̌���>420�֘A��ǂ߂Δ���
�u��������̘J���҂�������ăv�����X���[�i�l�ԁj�ƎG���i�m�\�̖��������j���ꏏ�ɂ���Ȃ�v
������������������
�z���͎G���̎�
12<16�̌���>420�֘A��ǂ߂Δ���
�u��������̘J���҂�������ăv�����X���[�i�l�ԁj�ƎG���i�m�\�̖��������j���ꏏ�ɂ���Ȃ�v
������������������
>>713
> �ς��Ƃ��Ȃ��`�[���������Nehalem�ɖ��c�ɂ��s���D��ꂽOpteron���ĉ��Ȃ́H
Intel�ŋ��̃C�X���G���̌���ł���Core2�Ƀ����R����L3�𑫂����̂�Nehalem������ȁA
�]���̃{���N������Ȃ�����D�G�ȃR�A�ɂȂ�̂͊m�肵�Ă�����B
> �ς��Ƃ��Ȃ��`�[���������Nehalem�ɖ��c�ɂ��s���D��ꂽOpteron���ĉ��Ȃ́H
Intel�ŋ��̃C�X���G���̌���ł���Core2�Ƀ����R����L3�𑫂����̂�Nehalem������ȁA
�]���̃{���N������Ȃ�����D�G�ȃR�A�ɂȂ�̂͊m�肵�Ă�����B
745 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:00:32 ID:K0i0hle1
�܂�������ɂ��Ă�
Broadcast�{��Z�{���Z�{����1�T�C�N���ɓ������s�o����O��Őv���ꂽFLOPS����
��ɑS���̖��߃X���b�g��Ϙa�Z�Ɋ���U��Ȃ��Ɣ����ł��Ȃ��펯�I�ɂ��蓾�Ȃ����p�V�[���ł�FLOPS����P����r���Ă�
�S���Ӗ����Ȃ����ǂ�
Broadcast�{��Z�{���Z�{����1�T�C�N���ɓ������s�o����O��Őv���ꂽFLOPS����
��ɑS���̖��߃X���b�g��Ϙa�Z�Ɋ���U��Ȃ��Ɣ����ł��Ȃ��펯�I�ɂ��蓾�Ȃ����p�V�[���ł�FLOPS����P����r���Ă�
�S���Ӗ����Ȃ����ǂ�
�����̒c�q�͐����������ȁB�����ǂ����ł��������̂��B
747 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:05:04 ID:K0i0hle1
>>744
����Pentium Pro����
����͂Ƃ�����
���̗D�G�ȃC�X���G���`�[����4�N�Ԃ�̃��W���[�A�b�v�f�[�g�Ƃ��ĕ���Sandy Bridge��FPU��
�X��FMA�ɑւ�������Haswell����B
�]���̃{���N������Ȃ�����D�G�ȃR�A�ɂȂ�̂͊m�肶��Ȃ��́H
����Pentium Pro����
����͂Ƃ�����
���̗D�G�ȃC�X���G���`�[����4�N�Ԃ�̃��W���[�A�b�v�f�[�g�Ƃ��ĕ���Sandy Bridge��FPU��
�X��FMA�ɑւ�������Haswell����B
�]���̃{���N������Ȃ�����D�G�ȃR�A�ɂȂ�̂͊m�肶��Ȃ��́H
GPU�ɂ�点���ق����N�\�����Ƃ���GPU��
CPU�ɂ�点ry
�Ă̂��w�e���̍s��������
CPU�ɂ�点ry
�Ă̂��w�e���̍s��������
�܂Ƃ������ȃT�C�g��100�{���Č�������ɂ͂�����������������낤��
ttp://www.brightsideofnews.com/Data/2010_3_16/ATI-Radeon-HD-5970-king-of-iPhone-Wi-Fi-password-cracking/ElcomSoft_GPU_Performance_6.jpg
�ʂɂ��ꂭ�炢�ł��[�������
�܂�uIntel��x86�x�N�^���̂Ă���AMDCPU�Ɍ��ܐ���������ȊO�ɖ]�݂������v�Ƃ�������
SSE����pSIMD�g���Ƃ��Č����������ĂႠ
CPU�ɂ͂���FPU�g����3DNow!�����ł�����Ȃ����H
�ɂ�������炸AVX�@LNI�Ǝ��ł̓������ł���Intel
�����ꂠ�����
ttp://www.brightsideofnews.com/Data/2010_3_16/ATI-Radeon-HD-5970-king-of-iPhone-Wi-Fi-password-cracking/ElcomSoft_GPU_Performance_6.jpg
{kind=link}
�ʂɂ��ꂭ�炢�ł��[�������
�܂�uIntel��x86�x�N�^���̂Ă���AMDCPU�Ɍ��ܐ���������ȊO�ɖ]�݂������v�Ƃ�������
SSE����pSIMD�g���Ƃ��Č����������ĂႠ
CPU�ɂ͂���FPU�g����3DNow!�����ł�����Ȃ����H
�ɂ�������炸AVX�@LNI�Ǝ��ł̓������ł���Intel
�����ꂠ�����
750 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:18:26 ID:K0i0hle1
�f�[�^����x�����������̃X���[�v�b�g�����������ő����킯����Ȃ�
�Ԃɚg����Ȃ�
�X�|�[�c�J�[�̃g�����N�������g�����N����4�g���g���b�N�̕��������̉ו����^�ׂ邯��
���������ו��͂��Ԃ̂������Ԃ̖�������Ȃ����Ă���������
�Ԃɚg����Ȃ�
�X�|�[�c�J�[�̃g�����N�������g�����N����4�g���g���b�N�̕��������̉ו����^�ׂ邯��
���������ו��͂��Ԃ̂������Ԃ̖�������Ȃ����Ă���������
25.75�{��
flops���ȏ�̍��A���₱�����Ȃ��ǂ��ȁE�E�E
flops���ȏ�̍��A���₱�����Ȃ��ǂ��ȁE�E�E
PPU(58gflops)=9600GT(208gflops)�Ƃ�
x4 955(102.4gflops) > HD4870(1200gflops)�Ƃ�
���ĂɂȂ��
x4 955(102.4gflops) > HD4870(1200gflops)�Ƃ�
���ĂɂȂ��
���ɂ�������炸AVX�@LNI�Ǝ��ł̓������ł���Intel
��������AVX�Ή��Ȃ�Ă��Ȃ���SSE5�ł悩�����̂Ɂi�_�j
��������AVX�Ή��Ȃ�Ă��Ȃ���SSE5�ł悩�����̂Ɂi�_�j
754 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:27:04 ID:K0i0hle1
����A�G���h���[�U�[�����炷��܂��������p�����Ȃ�����
���Ƃ���AES�݂����ȃu���b�N�Í��Ȃ�ECB�Ȃ�N���b�N�i�j�Ɠ��������Ńu���b�N�����������\������
��ʓI�ɂ�CBC��CFB�Ŏg�����Ƃ�����������ł��Ȃ��B
���Ƃ���AES�݂����ȃu���b�N�Í��Ȃ�ECB�Ȃ�N���b�N�i�j�Ɠ��������Ńu���b�N�����������\������
��ʓI�ɂ�CBC��CFB�Ŏg�����Ƃ�����������ł��Ȃ��B
>>721
��x�厸�s���Ĉ������߂��v�����̏Ă������A
�������������n�[�h�ł͂Ȃ��\�t�g���̏o���̈��������������Ȃ̂ɂ悭����Ȏ��M����C�ɘb����ȁB
>>�eFMA��256�r�b�g������ΐ��\�I�ɂ�Haswell�ɒǏ]�\�����A
AVX��128bit*2�̍\���ɂ������_�ŁA�݊��͂Ƃ邯�Ǐ��C�͑S���Ȃ��̂͌��Ď���Ǝv�����H
>>���邢��GPU�̃V�F�[�_�N���X�^�Ƃ̋��p���������߂Ă��邩�ˁH
AVX�ɂ��Ή������V�F�[�_�[����邩�AAVX/LNI < GPGPU�L�����y�[���ł����đΉ��\�t�g���₷���̂ǂ���������ˁH
AMD��SIMD��Intel�ɒǏ]���AGPGPU�Ƃ����Ǝ��H�������邩�猋�\���������ʒu�ɂ����ȁB
ALU/FPU/SSE/AVX/GPU(OpenGL/OpenCL/DX11)
Intel�݊����܂߂ċƊE�W���ƌ�����API�̑S����CPU��őΉ��o����悤�ɂȂ�B
�������ǂ���Ƃ��Ă�����Ȃ�ɍ����\���o����Ƃ���A�̗p�������Ǝv���Ƃ���͌��\����Ƃ�������B
�ǂ��炩�Ƃ�����AVX�����Intel�̕��������͂���Ǝv�����B
�Ȃɂ�AVX���s������I��肾����ˁB��փv������SSE�̌p���ȊO�Ȃ�����H
��x�厸�s���Ĉ������߂��v�����̏Ă������A
�������������n�[�h�ł͂Ȃ��\�t�g���̏o���̈��������������Ȃ̂ɂ悭����Ȏ��M����C�ɘb����ȁB
>>�eFMA��256�r�b�g������ΐ��\�I�ɂ�Haswell�ɒǏ]�\�����A
AVX��128bit*2�̍\���ɂ������_�ŁA�݊��͂Ƃ邯�Ǐ��C�͑S���Ȃ��̂͌��Ď���Ǝv�����H
>>���邢��GPU�̃V�F�[�_�N���X�^�Ƃ̋��p���������߂Ă��邩�ˁH
AVX�ɂ��Ή������V�F�[�_�[����邩�AAVX/LNI < GPGPU�L�����y�[���ł����đΉ��\�t�g���₷���̂ǂ���������ˁH
AMD��SIMD��Intel�ɒǏ]���AGPGPU�Ƃ����Ǝ��H�������邩�猋�\���������ʒu�ɂ����ȁB
ALU/FPU/SSE/AVX/GPU(OpenGL/OpenCL/DX11)
Intel�݊����܂߂ċƊE�W���ƌ�����API�̑S����CPU��őΉ��o����悤�ɂȂ�B
�������ǂ���Ƃ��Ă�����Ȃ�ɍ����\���o����Ƃ���A�̗p�������Ǝv���Ƃ���͌��\����Ƃ�������B
�ǂ��炩�Ƃ�����AVX�����Intel�̕��������͂���Ǝv�����B
�Ȃɂ�AVX���s������I��肾����ˁB��փv������SSE�̌p���ȊO�Ȃ�����H
756 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:35:01 ID:K0i0hle1
�����̂���16�o�C�g�ƕʂ�16�o�C�g�̕����̃r�b�g�p�^�[���������ꍇ�A�Í����������ӏ��������r�b�g�p�^�[���ɂȂ�̂�ECB�B
���ꂱ���N���b�N�i�j�Ɏキ�Ȃ�̂ŒN���g��Ȃ��B
> ��x�厸�s���Ĉ������߂��v�����̏Ă������A
> �������������n�[�h�ł͂Ȃ��\�t�g���̏o���̈��������������Ȃ̂ɂ悭����Ȏ��M����C�ɘb����ȁB
�H�H�H�H�H�H
Larrabee�̂��ƂȂ�S���̌����Ⴂ����
���C���R�A��Sandy Bridge�̊g���Ńx�N�^����256�r�b�g�ɗ���
GPU�R�A����Larrabee�x�[�X�o�͂Ȃ�GMA�̏Ă������ƌ����Ă邭�炢���B
���ꂱ���N���b�N�i�j�Ɏキ�Ȃ�̂ŒN���g��Ȃ��B
> ��x�厸�s���Ĉ������߂��v�����̏Ă������A
> �������������n�[�h�ł͂Ȃ��\�t�g���̏o���̈��������������Ȃ̂ɂ悭����Ȏ��M����C�ɘb����ȁB
�H�H�H�H�H�H
Larrabee�̂��ƂȂ�S���̌����Ⴂ����
���C���R�A��Sandy Bridge�̊g���Ńx�N�^����256�r�b�g�ɗ���
GPU�R�A����Larrabee�x�[�X�o�͂Ȃ�GMA�̏Ă������ƌ����Ă邭�炢���B
>>734
0,2�{������540G�����A������190W(HD5870)�B
72.5G/130W��X7560�̖�5�{�ɂȂ�B
���������ɂȂ��Ă�2�{�ȏ�̐��\�����ȁB
�R�X�g�����l����Ƃ��������ƂɂȂ邼�B
0,2�{������540G�����A������190W(HD5870)�B
72.5G/130W��X7560�̖�5�{�ɂȂ�B
���������ɂȂ��Ă�2�{�ȏ�̐��\�����ȁB
�R�X�g�����l����Ƃ��������ƂɂȂ邼�B
758 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:36:32 ID:K0i0hle1
> �Ȃɂ�AVX���s������I��肾����ˁB��փv������SSE�̌p���ȊO�Ȃ�����H
MS���S�ʎx���AAMD��SSE5���L�����Z������AVX�ɒǏ]�̎��_��
��ւ��ǂ��Ƃ��n��������������
MS���S�ʎx���AAMD��SSE5���L�����Z������AVX�ɒǏ]�̎��_��
��ւ��ǂ��Ƃ��n��������������
759 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:38:04 ID:K0i0hle1
>>757
�n�����ȁB
��p�v��2�{�Ƃ������������R�B10�`100�{���ڈ��B
RISC�Ȃ�Ĕėp��x86�̐��{����������10�N�O����Â���������ł����������B
�n�����ȁB
��p�v��2�{�Ƃ������������R�B10�`100�{���ڈ��B
RISC�Ȃ�Ĕėp��x86�̐��{����������10�N�O����Â���������ł����������B
�����ŃX�p�R�������o������
762 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:42:41 ID:K0i0hle1
�܂���Haswell��Larrabee�x�[�X�ɂȂ�Ǝv���Ă�̂�������
�㓡�ł��牽�������O�ɒ������Ă�̂ɂ���
������Rockwell��GPU�R�A�ɂ���Larrabee�ڂ�Ȃ��Ȃ�ĉ\�܂�3���ɂ͕��サ�Ă��
�㓡�ł��牽�������O�ɒ������Ă�̂ɂ���
������Rockwell��GPU�R�A�ɂ���Larrabee�ڂ�Ȃ��Ȃ�ĉ\�܂�3���ɂ͕��サ�Ă��
���\�c�[���Ƃ�����̂�
���\�������Ⴊ����
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@by �ёq��
���\�������Ⴊ����
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@by �ёq��
GPGPU = ��p����p�n�R
�ėp = �V�X�e���A�����n�A�v������
�ėp = �V�X�e���A�����n�A�v������
765 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:49:09 ID:K0i0hle1
������u�ėp�@�v���S�R�ėp����Ȃ�������Ƃ���
�ėp�v���Z�b�T�̔ėp�Ƃ�
�V�X�e���A�����n�A�v������
�Ƃ������Ƃł���B
�V�X�e���A�����n�A�v������
�Ƃ������Ƃł���B
���������uFP�X�P�W���[���͑S�ăC���I�[�_�Ȃ̂��H�v�̘b���I����ĂȂ���������
�A�E�g�I�u�I�[�_���X�[�p�[�X�J���ŗ����i��������j����̒呀�_���Ă�C���������V���^�z���̂�����
����ȕ��͋C����S���Ȃ��Ȃ��Ă��
12<16���o����܂ʼn����ꂩ��o�ė���Ȃ�
�A�E�g�I�u�I�[�_���X�[�p�[�X�J���ŗ����i��������j����̒呀�_���Ă�C���������V���^�z���̂�����
����ȕ��͋C����S���Ȃ��Ȃ��Ă��
12<16���o����܂ʼn����ꂩ��o�ė���Ȃ�
Bulldozer�̓��W���[���ȂǂƂ���ɂӂ���8�R�A�Ƃ��Ă����Ă���ˁB
Intel��8�R�A�Ɣ�r���ăX���[�v�b�g�ɂ������Ƃ���������������Ȃ��̂ɁB
Intel��8�R�A�Ɣ�r���ăX���[�v�b�g�ɂ������Ƃ���������������Ȃ��̂ɁB
>>762
�㓡����d���ꂽ����R�������̕������������悤�Ɍ����}
�㓡����d���ꂽ����R�������̕������������悤�Ɍ����}
770 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 21:55:23 ID:K0i0hle1
>>761
�X�p�R���قǃn�[�h�ɍœK�����Ă����p�r�͂Ȃ���
�X�p�R���قǃn�[�h�ɍœK�����Ă����p�r�͂Ȃ���
>>745
�P���x�ɂ��Ă͌��������̏��m��VLIW�ɂ��Ă��邩��d���Ȃ�
�{���x�Ɋւ�����SFU������4���g���Ă��邩��P���x�قnj����͈����Ȃ�Ȃ����ǂ�
�܂��A�v�Z�̎�ނɉ�����SSE/AVX�ƃV�F�[�_�[���g�������������������
>>747
���̐����Ƃ���Sandybridge��westmere�Ɣ�ׂĂǂ̒��x���\���オ���Ă�́H
�V���O���X���b�h���\�A�N���b�N�̏������������Ƃ��ˁB
����������LNI�����炵�����ǁAAMD���Ή��������ȋC������ȁA�݊����ێ��̂��߂ɂˁB
AVX�ɂ��Ή���������ALNI�͔�Ή��͂Ȃ��Ǝv���B
�X�ɋK�͂��傫���Ȃ邩�狤�L�̂܂܂��낤���ǂˁB
AMD��LNI�Ή�������c�q�͂ǂ�����̂��ȁH�����́H
�P���x�ɂ��Ă͌��������̏��m��VLIW�ɂ��Ă��邩��d���Ȃ�
�{���x�Ɋւ�����SFU������4���g���Ă��邩��P���x�قnj����͈����Ȃ�Ȃ����ǂ�
�܂��A�v�Z�̎�ނɉ�����SSE/AVX�ƃV�F�[�_�[���g�������������������
>>747
���̐����Ƃ���Sandybridge��westmere�Ɣ�ׂĂǂ̒��x���\���オ���Ă�́H
�V���O���X���b�h���\�A�N���b�N�̏������������Ƃ��ˁB
����������LNI�����炵�����ǁAAMD���Ή��������ȋC������ȁA�݊����ێ��̂��߂ɂˁB
AVX�ɂ��Ή���������ALNI�͔�Ή��͂Ȃ��Ǝv���B
�X�ɋK�͂��傫���Ȃ邩�狤�L�̂܂܂��낤���ǂˁB
AMD��LNI�Ή�������c�q�͂ǂ�����̂��ȁH�����́H
LNI���� ���̋@�\���₵��
�����@��剻
�����@��剻
Haswell=Nehalem���ǃR�A+�I���{��GPU+Larrabee��512BitSIMD����Ȃ����������H
�R�A��GPU�Ƃ�����Ƒ債�ĕς���S���������Ă�����
�R�A��GPU�Ƃ�����Ƒ債�ĕς���S���������Ă�����
GPU���e�[�v�A�E�g���Ă���X���Ŕ������Ƃ��ł���܂ł̊��Ԃ���CPU�̂Ƃ������Z�������H
Southern Islands�͍��N���ɂ݂͂���̂���
Southern Islands�͍��N���ɂ݂͂���̂���
��AVX�ɂ��Ή������V�F�[�_�[����邩
���[�Ɏg�����ɂȂ�Ȃ��ėp���Ŕ�剻�ł���
���[�Ɏg�����ɂȂ�Ȃ��ėp���Ŕ�剻�ł���
776 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 22:18:08 ID:K0i0hle1
���Ȃ��Ƃ�GMA�x�[�X�̒ᐫ�\IGP�{AVX�ɂ��\�t�g�E�F�AVertex Shader�Ő��\�⊮�Ƃ�����{�H����
������ɂ킽���Čp������\�肾������S����B
LNI�E�E�EIntel��AMD�Ƀ��C�Z���X���Ă邩�ǂ������s�����ȁB
�����Larrabee��p��OS�ƃZ�b�g�̃��m�����疽�߃Z�b�g���������Ă����Ӗ�
������ɂ���AVX�̃t��256�r�b�g�����炳��ĂȂ��i�K��512�r�b�g�Ȃ�Ă̂͂Ȃ�
������ɂ킽���Čp������\�肾������S����B
LNI�E�E�EIntel��AMD�Ƀ��C�Z���X���Ă邩�ǂ������s�����ȁB
�����Larrabee��p��OS�ƃZ�b�g�̃��m�����疽�߃Z�b�g���������Ă����Ӗ�
������ɂ���AVX�̃t��256�r�b�g�����炳��ĂȂ��i�K��512�r�b�g�Ȃ�Ă̂͂Ȃ�
DirectX+GPU�ɂ����ׂ��ꂻ����AVX&LNI�Ȃ�Ăǂ��ł�������
�m�\0���C���������V���^�z�����E������
Bull�̃p�C�v���C���\�z�Ƃ��ł���肽����
�m�\0���C���������V���^�z�����E������
Bull�̃p�C�v���C���\�z�Ƃ��ł���肽����
�����ȃ����r���k��
Rockwell�ł��瓝������Ȃ��̂��Ƃ����2015�N��
��DirectX+GPU
DXCS��PS�̑��pass�ł����Ȃ�
DXCS��PS�̑��pass�ł����Ȃ�
�����Ȃ��Ƃ�GMA�x�[�X�̒ᐫ�\IGP�{AVX�ɂ��\�t�g�E�F�AVertex Shader�Ő��\�⊮�Ƃ�����{�H����
VS�ȊO������Ă������ȋC�����Ȃ��ł��Ȃ�
VS�ȊO������Ă������ȋC�����Ȃ��ł��Ȃ�
782 �F,,�E�L�́M�E,,�j��-�������F2010/05/13(��) 22:31:30 ID:K0i0hle1
LNI��AVX�݂����ȃv���t�B�b�N�X���Œ�̖��߃Z�b�g�ɂȂ邪
AVX�̃G���R�[�h�X�L�[���Ǝ��Ĕ�Ȃ郂�m��
�����_�ł�AVX2�Ƃ�AVX3�Ƃ��̊g���v��̉������ɂȂ�
�ʕ�
Itanium�݊��v���Z�b�T��AMD�����Ȃ��̂Ɠ������x����
Intel��p���߃Z�b�g�ɂȂ�\�������
AVX�̃G���R�[�h�X�L�[���Ǝ��Ĕ�Ȃ郂�m��
�����_�ł�AVX2�Ƃ�AVX3�Ƃ��̊g���v��̉������ɂȂ�
�ʕ�
Itanium�݊��v���Z�b�T��AMD�����Ȃ��̂Ɠ������x����
Intel��p���߃Z�b�g�ɂȂ�\�������
GeForce��RADEON�ɍœK���͂킩�邪GMA�ɍœK���͒N����肽����Ȃ�������
4gamer�̋L�҂��Ō�܂ł悭�撣������
4gamer�̋L�҂��Ō�܂ł悭�撣������
����Œǂ�����Ă��
���b�˂�����
���b�˂�����
�Z�����o���Ȃ��z(ID)�ƍ��ꂪ�o���Ȃ��z��2�{����
�N�����Ƃ�����
�N�����Ƃ�����
>>782
> Itanium�݊��v���Z�b�T��AMD�����Ȃ��̂Ɠ������x����
> Intel��p���߃Z�b�g�ɂȂ�\�������
Itanium(IA64)�͕��y���Ȃ��Ɣ��f��������x86-64�����肵����
�t�ɍl�����LNI�����y����Ɣ��f�����瓋�ڂ��Ă���Ǝv����
SSE��AVX�𓋍ڂ����̂����y���������炾�����
SSE�Ƃ͕ʕ���AVX�ɑΉ���������A�܂��ʂ�LNI�ɑΉ����Ă��s�v�c����Ȃ��Ǝv����
LNI�̋K�i���̂͐��N�O�ɂł��Ă邵�AAMD�ƕ����ȃN���X���C�Z���X������A
���Ɍv�悪�i��łĂ����������͂Ȃ���
>������ɂ���AVX�̃t��256�r�b�g�����炳��ĂȂ��i�K��512�r�b�g�Ȃ�Ă̂͂Ȃ�
128bit SSE�̐��\��D�悵����A�����B
256Bit AVX���j�b�g��128Bit SSE*2������������������y��������Ȃ����ȁB
�܂��A128it SSE5�̗��p���Ă������낤���ǁB
> Itanium�݊��v���Z�b�T��AMD�����Ȃ��̂Ɠ������x����
> Intel��p���߃Z�b�g�ɂȂ�\�������
Itanium(IA64)�͕��y���Ȃ��Ɣ��f��������x86-64�����肵����
�t�ɍl�����LNI�����y����Ɣ��f�����瓋�ڂ��Ă���Ǝv����
SSE��AVX�𓋍ڂ����̂����y���������炾�����
SSE�Ƃ͕ʕ���AVX�ɑΉ���������A�܂��ʂ�LNI�ɑΉ����Ă��s�v�c����Ȃ��Ǝv����
LNI�̋K�i���̂͐��N�O�ɂł��Ă邵�AAMD�ƕ����ȃN���X���C�Z���X������A
���Ɍv�悪�i��łĂ����������͂Ȃ���
>������ɂ���AVX�̃t��256�r�b�g�����炳��ĂȂ��i�K��512�r�b�g�Ȃ�Ă̂͂Ȃ�
128bit SSE�̐��\��D�悵����A�����B
256Bit AVX���j�b�g��128Bit SSE*2������������������y��������Ȃ����ȁB
�܂��A128it SSE5�̗��p���Ă������낤���ǁB
Larrabee���ǂ�Ȃ��̂Ȃ̂������������ĂȂ������Ǝv����
�Ƃ肠����45nm��48�R�A�A2+16�̉��Z���600m�u�Ƃ���
48*18��864��HD4870���x�ł���HD5870�̔����ł���
HD5870��40nm��334m�u�Ȃ̂����E�E�E
��������GPU�̓X�J�����j�b�g�ς�ł���̂ɑ����ނ̂̓x�N�^���j�b�g
�x�N�^�ESIMD�̂ق����X�y�[�X�ߖ�o������Ă̂�1/3�`1/4�����Ȃ����Ăǂ��������Ƃ�H
SIMD�̓X�[�p�[�X�J���ł͂Ȃ����瓯�����߂������s�o���Ȃ�
���[�v�╪��ɑΉ������Ƃ������Ă������͕ς��Ȃ����낤
��̫��8�X�J�����j�b�g��1�O���[�v
��ނ�5VLIW�X�J�����j�b�g��1�O���[�v
���ނ�16�x�N�^�i+2�X�J���j
16�ƒ��������Ƀx�N�^
������PenD�����Intel�����\���ςȂ�ł���
�ςł����\�o��u�V�ˁI�v���ĕ]���ɂȂ����
���\�ǂ��납���m����o�ė��Ȃ�����
���������ꂩ�����������
�Ƃ肠����45nm��48�R�A�A2+16�̉��Z���600m�u�Ƃ���
48*18��864��HD4870���x�ł���HD5870�̔����ł���
HD5870��40nm��334m�u�Ȃ̂����E�E�E
��������GPU�̓X�J�����j�b�g�ς�ł���̂ɑ����ނ̂̓x�N�^���j�b�g
�x�N�^�ESIMD�̂ق����X�y�[�X�ߖ�o������Ă̂�1/3�`1/4�����Ȃ����Ăǂ��������Ƃ�H
SIMD�̓X�[�p�[�X�J���ł͂Ȃ����瓯�����߂������s�o���Ȃ�
���[�v�╪��ɑΉ������Ƃ������Ă������͕ς��Ȃ����낤
��̫��8�X�J�����j�b�g��1�O���[�v
��ނ�5VLIW�X�J�����j�b�g��1�O���[�v
���ނ�16�x�N�^�i+2�X�J���j
16�ƒ��������Ƀx�N�^
������PenD�����Intel�����\���ςȂ�ł���
�ςł����\�o��u�V�ˁI�v���ĕ]���ɂȂ����
���\�ǂ��납���m����o�ė��Ȃ�����
���������ꂩ�����������
788 �F,,�E�L�́M�E,,�j��-�������F2010/05/14(��) 06:50:20 ID:SD3ubyu3
>>786
�����Ɋ��Ⴂ���Ă�悤������
Larrabee�����y���邩�ǂ����ƁAIntel��AMD�Ƀ��C�Z���X���邩�ǂ�����
�܂����������ĕʖ��Ȃ̂Ő藣���čl���ĉ�����������
�㓡�͊��Ⴂ���Ă邪AVX��LNI�́iHPC�p�r�͕ʂƂ��āj�S���ΏۂƂ���A�v���P�[�V�������Ⴄ�B
Windows��Linux�œ����R�[�h��SSE��3DNow!�����̂Ɠ������x���ōl���Ă������B
AVX���Ƃ��͍��܂Œʂ�CPU�̖��߂Ƃ��ă_�C���N�g�ɃR�[�f�B���O�ł��邯��
Larrabee�̃R�[�h�̓z�X�g�Ɨ���Intel�ސ��̐�pOS�œ�����ł���B
OS�̃��C�Z���X�܂�Intel����w������́H
�����Ɋ��Ⴂ���Ă�悤������
Larrabee�����y���邩�ǂ����ƁAIntel��AMD�Ƀ��C�Z���X���邩�ǂ�����
�܂����������ĕʖ��Ȃ̂Ő藣���čl���ĉ�����������
�㓡�͊��Ⴂ���Ă邪AVX��LNI�́iHPC�p�r�͕ʂƂ��āj�S���ΏۂƂ���A�v���P�[�V�������Ⴄ�B
Windows��Linux�œ����R�[�h��SSE��3DNow!�����̂Ɠ������x���ōl���Ă������B
AVX���Ƃ��͍��܂Œʂ�CPU�̖��߂Ƃ��ă_�C���N�g�ɃR�[�f�B���O�ł��邯��
Larrabee�̃R�[�h�̓z�X�g�Ɨ���Intel�ސ��̐�pOS�œ�����ł���B
OS�̃��C�Z���X�܂�Intel����w������́H
�n���Ȃ́H
791 �F,,�E�L�́M�E,,�j��-�������F2010/05/14(��) 07:05:21 ID:SD3ubyu3
AMD��Itanium�����Ȃ��̂�
��������Itanium��AMD�Ƀ��C�Z���X���ĂȂ�����Ȃ�ł���B
AMD��x86�݊��v���Z�b�T������̂�Intel�����C�Z���X���Ă��邩�炾���Ă��ƖY��Ȃ��ł���
�����Ɋւ���{������Intel���������Ă邩��AMD��Intel�ƌ_������Ȃ���
�������邱�Ƃ��ł��Ȃ��B
Larrabee��x86��{�����Ƃ͕ʂɁA�����\���Ɋւ��d�v�ȕ����̓����������Ă���
������������Larrabee�݊��v���Z�b�T�����̂͊�{�I�ɖ����B
�������Ɍ݊��v���Z�b�T������肵����AMD��100%�s�i�ł��B
��������Itanium��AMD�Ƀ��C�Z���X���ĂȂ�����Ȃ�ł���B
AMD��x86�݊��v���Z�b�T������̂�Intel�����C�Z���X���Ă��邩�炾���Ă��ƖY��Ȃ��ł���
�����Ɋւ���{������Intel���������Ă邩��AMD��Intel�ƌ_������Ȃ���
�������邱�Ƃ��ł��Ȃ��B
Larrabee��x86��{�����Ƃ͕ʂɁA�����\���Ɋւ��d�v�ȕ����̓����������Ă���
������������Larrabee�݊��v���Z�b�T�����̂͊�{�I�ɖ����B
�������Ɍ݊��v���Z�b�T������肵����AMD��100%�s�i�ł��B
����̫��8�X�J�����j�b�g��1�O���[�v
SIMD�ł��i�j
AMD�ȊO��SIMD�ł�
SIMD�ł��i�j
AMD�ȊO��SIMD�ł�
AMD��AVX���ꂽ�͕̂ی�
��������x86�Ȃ�ĉߋ��Ƃ̌݊��������ɂ�����S�~���R�Ȃ�ł���B
x86���ɏo����������Ă������ƖY��Ȃ��ł���
�܂��\���x��������Bull��Comp�f�R�[�_*4����Ă邩������[��
�x�N�^�v���Z�b�T�ɂ܂�x86�Ή�����Ȃ�Ĕn���n�������Ăł��Ȃ��B
Larrabee�������炭
�������������Đ��ɏo���̂͊�{�I�ɖ����B
�������ɏ؋����މ�₂Ȃ�Ă�����100%�s�i�ł��B
��������x86�Ȃ�ĉߋ��Ƃ̌݊��������ɂ�����S�~���R�Ȃ�ł���B
x86���ɏo����������Ă������ƖY��Ȃ��ł���
�܂��\���x��������Bull��Comp�f�R�[�_*4����Ă邩������[��
�x�N�^�v���Z�b�T�ɂ܂�x86�Ή�����Ȃ�Ĕn���n�������Ăł��Ȃ��B
Larrabee�������炭
�������������Đ��ɏo���̂͊�{�I�ɖ����B
�������ɏ؋����މ�₂Ȃ�Ă�����100%�s�i�ł��B
794 �F,,�E�L�́M�E,,�j��-�������F2010/05/14(��) 07:49:59 ID:SD3ubyu3
Larrabee�Ɋւ��Ă͐Ϙa���j�b�g�Ȃ��Load/Store Unit�̂ق��������R�X�g�傫���C�������
Fermi�́uCUDA Core�v�́A512�r�b�gSIMD���σ��j�b�g��2�ɑ���512bit����LSU��1��
Larrabee��Load���j�b�g1��{Store���j�b�g1��Ȃ�ŁA�P���ɍl����FLOPS�������
L1�ш��Fermi��4�{�͂��邱�ƂɂȂ�B
�^�ϊ��Ƃ��u���[�h�L���X�g�Ȃ��g�ݍ��܂�Ă�ƍl����Ƒ����傫���Ǝv���ˁB
�܂�����z�u����Ȃ��Ē���z�u�Ȃ�łǂ��܂ł�LSU�łǂ��܂ł�FPU���Ȃ�čl����͖̂�邾���ǂ��B
����łȂ��Ƃ�256KB/core�Ƃ���GPU�Ƃ��Ă͔j�i�̑�e�ʂ�L2�L���b�V����
���킸�����ȁB
�ǂ��ł��������X�J���i��Vector Mask�j���j�b�g��1�R�A������1��
Fermi�́uCUDA Core�v�́A512�r�b�gSIMD���σ��j�b�g��2�ɑ���512bit����LSU��1��
Larrabee��Load���j�b�g1��{Store���j�b�g1��Ȃ�ŁA�P���ɍl����FLOPS�������
L1�ш��Fermi��4�{�͂��邱�ƂɂȂ�B
�^�ϊ��Ƃ��u���[�h�L���X�g�Ȃ��g�ݍ��܂�Ă�ƍl����Ƒ����傫���Ǝv���ˁB
�܂�����z�u����Ȃ��Ē���z�u�Ȃ�łǂ��܂ł�LSU�łǂ��܂ł�FPU���Ȃ�čl����͖̂�邾���ǂ��B
����łȂ��Ƃ�256KB/core�Ƃ���GPU�Ƃ��Ă͔j�i�̑�e�ʂ�L2�L���b�V����
���킸�����ȁB
�ǂ��ł��������X�J���i��Vector Mask�j���j�b�g��1�R�A������1��
795 �F,,�E�L�́M�E,,�j��-�������F2010/05/14(��) 07:51:13 ID:SD3ubyu3
�~���σ��j�b�g
���Ϙa���j�b�g
���Ϙa���j�b�g
�ǂ������A�Ƃ����Ă�����͐�����ł̘b
http://www.youtube.com/watch?v=_l2e0mf3CcA
�̂悤�ɂ��ŗL���ȏ���Phenom�ł����̍�
http://www.youtube.com/watch?v=_l2e0mf3CcA
�̂悤�ɂ��ŗL���ȏ���Phenom�ł����̍�
������
�N����胆�[�U�[���l������Ӗ���������
�N����胆�[�U�[���l������Ӗ���������
>>798
�����Ɉڍs��i�߂Ă�IA64�̃h�b�y���Q���K�[�������邾��
x86�ɂƂ�����C�n����ɂ��܂��ł����t���ė���DirectX�̂悤��
��x86��GPU��x86�ɂ����t���Ă������ł���
�����Ɉڍs��i�߂Ă�IA64�̃h�b�y���Q���K�[�������邾��
x86�ɂƂ�����C�n����ɂ��܂��ł����t���ė���DirectX�̂悤��
��x86��GPU��x86�ɂ����t���Ă������ł���
>>798
�����
http://ux.getuploader.com/mosa/download/33/athlon2-i5.wmv
��������ȍ�������Ƃ͎v���ĂȂ�������������܂�����
�����
http://ux.getuploader.com/mosa/download/33/athlon2-i5.wmv
��������ȍ�������Ƃ͎v���ĂȂ�������������܂�����
����
�掿���Ⴂ�������
�掿���Ⴂ�������
�E�̕��͉掿���Ƃ��Ă��������������Ƃ�̂�
���������Ӗ�����ˁ[��
AMDer���Ӑ}�I�ɃC���e���̂ق��ɍH���Ă邾�낱�ꂗ
AMDer���Ӑ}�I�ɃC���e���̂ق��ɍH���Ă邾�낱�ꂗ
���A�E�͐ݒ藎�Ƃ��Ă��������肵�Ă܂��x���`���x����Ȃ��ł��Ă������悶��Ȃ���
youtube�̓���E����
�����t��������
�Z�b�e�B���O���͂�������s��
��قljɂȂ���ȁA����Ȃ̍���
�����t��������
�Z�b�e�B���O���͂�������s��
��قljɂȂ���ȁA����Ȃ̍���
�Q�[�����������GPU������Ă��Ƃ��ĔF���������铮��ł����܂�
�}�W���X����ƍ��ƉE�Ƃł͉�ʃL���v�`���`����G���R�[�h�ɗp�����\�t�g���������ˁB
�E�̓��X�L�[�g�m�C�Y���˂ɂłĂ��邵�A�𑜓x���ڂ��Ă���B�����̌����������ł̓u���b�N�m�C�Y
������ɂłĂ�ˁB�F���ω����Ă���B
���Ƃ���GPU�ł͍��̂łȂ��t�H���g���܂߂Ă�����₢����B
���������̂ɂ��܂����l�͂������������̔F���ɐT�d�ɂȂ����ق���������B
�E�̓��X�L�[�g�m�C�Y���˂ɂłĂ��邵�A�𑜓x���ڂ��Ă���B�����̌����������ł̓u���b�N�m�C�Y
������ɂłĂ�ˁB�F���ω����Ă���B
���Ƃ���GPU�ł͍��̂łȂ��t�H���g���܂߂Ă�����₢����B
���������̂ɂ��܂����l�͂������������̔F���ɐT�d�ɂȂ����ق���������B
�悩��������ˁ[���A�����GMA�Ɋ�]�⌶�z�������͋��Ȃ��Ȃ���
�܂��ɒ����オ�����ɂ����l�^���ȁB
http://www.digitimes.com/news/a20100513PD208.html
> AMD said to use bulk 40nm at TSMC for Fusion chips
GF����Chartered��40nm���C�������Ă�͂��Ȃ��A�Ȃ���B
> AMD said to use bulk 40nm at TSMC for Fusion chips
GF����Chartered��40nm���C�������Ă�͂��Ȃ��A�Ȃ���B
GF�V���{�߂��Ă����Ȃ�
�ȏ�
�ȏ�
>>788
> AVX���Ƃ��͍��܂Œʂ�CPU�̖��߂Ƃ��ă_�C���N�g�ɃR�[�f�B���O�ł��邯��
> Larrabee�̃R�[�h�̓z�X�g�Ɨ���Intel�ސ��̐�pOS�œ�����ł���B
> OS�̃��C�Z���X�܂�Intel����w������́H
�܂�Windows��Linux�AUnix���ᓮ���Ȃ����Ă��Ƃ��H
����Ȃ��y�ȑO�̖�肾��H�N���g���H
> AVX���Ƃ��͍��܂Œʂ�CPU�̖��߂Ƃ��ă_�C���N�g�ɃR�[�f�B���O�ł��邯��
> Larrabee�̃R�[�h�̓z�X�g�Ɨ���Intel�ސ��̐�pOS�œ�����ł���B
> OS�̃��C�Z���X�܂�Intel����w������́H
�܂�Windows��Linux�AUnix���ᓮ���Ȃ����Ă��Ƃ��H
����Ȃ��y�ȑO�̖�肾��H�N���g���H
GF���g�̃��C�������ɃL���p�����ς����A
TSMC�ɗ�����������or�����\�Ȃ��̂�����A���Ă��Ƃ��ˁB
���O�ł������̂���������]�T������Ȃ�A�]���ɂ͗��܂Ȃ���ȁB
TSMC�ɗ�����������or�����\�Ȃ��̂�����A���Ă��Ƃ��ˁB
���O�ł������̂���������]�T������Ȃ�A�]���ɂ͗��܂Ȃ���ȁB
>�܂�Windows��Linux�AUnix���ᓮ���Ȃ����Ă��Ƃ��H
>����Ȃ��y�ȑO�̖�肾��H�N���g���H
driver���OS������
���قƂ�ǂ�GPU�ł́A�l�C�e�B�u���߃Z�b�g�ւ̃R���p�C�������߁A�唼�̃\�t�g�E�F�A�������z�X�gCPU���ōs�Ȃ��B
������ɑ��āALarrabee�ł́ALarrabee���̂̏�Ń}�C�N��OS�������Ă���A
���]��GPU�Ȃ�z�X�gCPU��̃h���C�o�ōs�Ȃ��Ă����悤�ȏ������ALarrabee��ōs�Ȃ��B
>����Ȃ��y�ȑO�̖�肾��H�N���g���H
driver���OS������
���قƂ�ǂ�GPU�ł́A�l�C�e�B�u���߃Z�b�g�ւ̃R���p�C�������߁A�唼�̃\�t�g�E�F�A�������z�X�gCPU���ōs�Ȃ��B
������ɑ��āALarrabee�ł́ALarrabee���̂̏�Ń}�C�N��OS�������Ă���A
���]��GPU�Ȃ�z�X�gCPU��̃h���C�o�ōs�Ȃ��Ă����悤�ȏ������ALarrabee��ōs�Ȃ��B
AMD�ɂƂ��Ă͎g�������Ƃ̖���GF��40nm���A
���f�Ŏg�����ꂽTSMC��40nm�̕����J�����₷���������Ă������낤�B
������������GPU�����f��������o���ƃm�E�n�E�����̂܂ܐ������邩�烊�X�N�����Ȃ�Ⴂ�B
���f�Ŏg�����ꂽTSMC��40nm�̕����J�����₷���������Ă������낤�B
������������GPU�����f��������o���ƃm�E�n�E�����̂܂ܐ������邩�烊�X�N�����Ȃ�Ⴂ�B
>>817
�v�̓h���C�o�[���Ă������g�����X���^��CMS�݂����Ȃ���
�_�������A�h���C�o�֘A�̎��s�t���O���x���Ă�C���ςނ�Intel�́c
��������Haswell��Rockwell�o��\���2014�N�ӂ��Win8��DX12���o�ꂵ�Ă����������A
Intel���܂Ƃ��ɑΉ��o����Ƃ͎v����B
���������DX11�Q�[�������y���Ă��鍠���낤���ǁADx11�Ή��h���C�o����̂���
OpenCL��OpenGL�������ǁB
�v�̓h���C�o�[���Ă������g�����X���^��CMS�݂����Ȃ���
�_�������A�h���C�o�֘A�̎��s�t���O���x���Ă�C���ςނ�Intel�́c
��������Haswell��Rockwell�o��\���2014�N�ӂ��Win8��DX12���o�ꂵ�Ă����������A
Intel���܂Ƃ��ɑΉ��o����Ƃ͎v����B
���������DX11�Q�[�������y���Ă��鍠���낤���ǁADx11�Ή��h���C�o����̂���
OpenCL��OpenGL�������ǁB
�n������
���O��
���O��
�����Z�|���Z�܂�őʖ�
�o�O����R�s�y����点����
���E��I���E��I���E�O�I
���E�E����
�o�O����R�s�y����点����
���E��I���E��I���E�O�I
���E�E����
822 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 07:33:09 ID:O1FPzVWB
>>817, 819
�h���C�o�ɍڂ�H�Ⴄ��
��������Ԃ̓Ɨ��������Ȋ��������}�V�������݂���ƍl��������B
������u�h���C�o�v�̓z�X�g-Larrabee�f�o�C�X�Ԃ𒇉�邽�߂̍Œ���̋@�\�݂̂Ŏ��������B
�f�[�^�̂��Ƃ�͍���������Ă�Shared Virtual Memory���g���邩���ˁB
�܂��A�ÓT�I��Message Passing�������_�ł͑Ó����낤���ǂˁB
�����b�g���킩��H
�z�X�g�Ɨ���OS�œ����A�v���P�[�V�������Ă��Ƃ́A�z�X�g��Linux�ł�Mac�ł�����
�R�[�h�������Ƃ���������O�̗�������B
> �܂�Windows��Linux�AUnix���ᓮ���Ȃ����Ă��Ƃ��H
> ����Ȃ��y�ȑO�̖�肾��H�N���g���H
�Ⴄ�AIntel�ɂƂ��ĕ��y�ȑO�ɁyAMD�Ɏg�킹��K�v�z���Ȃ�������
�z�X�gOS���̃R�[�h��Larrabee�f�o�C�X�ƒʐM���邽�߂̍Œ���̃R�[�h�����������ł����B
�z�X�g��API/ABI�ɍ��E����Ȃ��Ƃ����Ӗ��ň��|�I�Ɋy�ȊJ�����f������B
�h���C�o�ɍڂ�H�Ⴄ��
��������Ԃ̓Ɨ��������Ȋ��������}�V�������݂���ƍl��������B
������u�h���C�o�v�̓z�X�g-Larrabee�f�o�C�X�Ԃ𒇉�邽�߂̍Œ���̋@�\�݂̂Ŏ��������B
�f�[�^�̂��Ƃ�͍���������Ă�Shared Virtual Memory���g���邩���ˁB
�܂��A�ÓT�I��Message Passing�������_�ł͑Ó����낤���ǂˁB
�����b�g���킩��H
�z�X�g�Ɨ���OS�œ����A�v���P�[�V�������Ă��Ƃ́A�z�X�g��Linux�ł�Mac�ł�����
�R�[�h�������Ƃ���������O�̗�������B
> �܂�Windows��Linux�AUnix���ᓮ���Ȃ����Ă��Ƃ��H
> ����Ȃ��y�ȑO�̖�肾��H�N���g���H
�Ⴄ�AIntel�ɂƂ��ĕ��y�ȑO�ɁyAMD�Ɏg�킹��K�v�z���Ȃ�������
�z�X�gOS���̃R�[�h��Larrabee�f�o�C�X�ƒʐM���邽�߂̍Œ���̃R�[�h�����������ł����B
�z�X�g��API/ABI�ɍ��E����Ȃ��Ƃ����Ӗ��ň��|�I�Ɋy�ȊJ�����f������B
>>813
GF��40nm�̐��Y���C���͑����܂��{�i�ғ����Ė������i�N���ɉғ��j�A���C���������d�͌����̃��C������
CPU��GPU�p�Ŏg���郉�C���Ƃ͕�
���̃��C���͊O������������̂̐����ɏ[�Ă���
GF��40nm�̐��Y���C���͑����܂��{�i�ғ����Ė������i�N���ɉғ��j�A���C���������d�͌����̃��C������
CPU��GPU�p�Ŏg���郉�C���Ƃ͕�
���̃��C���͊O������������̂̐����ɏ[�Ă���
�ŋ������Larrabee
�Ȃ�ł��ꂪ�ڍ������I���̒��Ԉ���Ă�
�Ȃ�ł��ꂪ�ڍ������I���̒��Ԉ���Ă�
�ėp���Ə���d�͔͂���Ⴞ�����
�n����
���A���A���A����
���A��Ƒ��`��
���A��Ƒ��`��
�ėp��(x86�Ƃ�������)�ƈ��������ɐ��\�ƊJ����Փx(�ȈՐ�)���]���ɂ��鉻����Larrabee
ttp://pc.watch.impress.co.jp/docs/2009/0305/kaigai493.htm
ttp://pc.watch.impress.co.jp/docs/2009/0305/kaigai493.htm
>>825
�Q�t�H�������Fermi���ǂ��Ⴞ
�Q�t�H�������Fermi���ǂ��Ⴞ
�����~�͔ėp���������Ă邯�ǂ߂��Ⴍ����d�C�H���ł���
�h���C�o�ʼn��z�������Ȃ�
���̃n�[�h�E�F�A��x86�ł���K�v���S���Ȃ��Ǝv����
���̃n�[�h�E�F�A��x86�ł���K�v���S���Ȃ��Ǝv����
832 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 10:51:05 ID:O1FPzVWB
> �h���C�o�ʼn��z�������Ȃ�
�t���A�u�h���C�o�v�Ƃ����T�O���̂��̂����z�������B
�h���C�o�����̏����̑唼�̓f�o�C�X���MicroOS��Ŏ������g�ŏ��������B
�z�X�g�̓R�}���h�ƃf�[�^�𑗂邾���B
> ���̃n�[�h�E�F�A��x86�ł���K�v���S���Ȃ��Ǝv����
����́A��x86�̃n�[�h�E�F�A��
# ./configure
# make
# make install
��3�R�}���h��POSIX�A�v���̃R�[�h���r���h������ł��Ă͂��߂Ă������̂��B
�œK���͌�ɂ��Ă������Ɂu�������v���Ƃɏo���鑦��������Larrabee�̋��݂��B
Fermi�̔ėp���Ȃ�ď��FGT200�ɖт��������悤�Ȃ����ACell SPE�̈�ɂ��B���ĂȂ�
�t���A�u�h���C�o�v�Ƃ����T�O���̂��̂����z�������B
�h���C�o�����̏����̑唼�̓f�o�C�X���MicroOS��Ŏ������g�ŏ��������B
�z�X�g�̓R�}���h�ƃf�[�^�𑗂邾���B
> ���̃n�[�h�E�F�A��x86�ł���K�v���S���Ȃ��Ǝv����
����́A��x86�̃n�[�h�E�F�A��
# ./configure
# make
# make install
��3�R�}���h��POSIX�A�v���̃R�[�h���r���h������ł��Ă͂��߂Ă������̂��B
�œK���͌�ɂ��Ă������Ɂu�������v���Ƃɏo���鑦��������Larrabee�̋��݂��B
Fermi�̔ėp���Ȃ�ď��FGT200�ɖт��������悤�Ȃ����ACell SPE�̈�ɂ��B���ĂȂ�
5�N��̘b�����Ă��d���Ȃ�
������̘b�ɔ�ׂ�Ζ����̘b���炢���ł��Ȃ�
�g����Intel���S���ʓ|����Ȃ�t���X�y�b�N��x86�ł���K�v�͑S���������
�܂�Larrabee�͂ǂ��ł��������c�c
�܂�Larrabee�͂ǂ��ł��������c�c
5�N�ザ��Ȃ���50�N��Ȃ��ǂ�
837 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 13:10:20 ID:O1FPzVWB
>>835
> �g����Intel���S���ʓ|����Ȃ�t���X�y�b�N��x86�ł���K�v�͑S���������
�S����ʓ|�����Ȃ�����P54C�x�[�X�{�Œ���̊g���Ȃ��ǂˁB
�E����OS���x���̃R�[�h���Y������
�E�n�[�h�E�F�A��IP���C�Z���X���w�����Ă���K�v���Ȃ�
�E�n�[�h�Z�p�E�\�t�g�Z�p�Ƃ��ɂ��Ȃ�Ă���
�܂��A���ꂪIntel����Ȃ���IBM�Ȃ�PPC�x�[�X�ɂȂ��Ă���������Ȃ��ˁB
������_���Ȕėpx86�Ƃ��ăt���X�y�b�N�ł���K�v�͂Ȃ��B
�����ɓ����K�v���Ȃ����߂͓������ǃ}�C�N���R�[�h�f�R�[�h�Ƃ��ASun�̂悤��MicroOS���g���b�v����
��������Ƃ��ł��݊����͊m�ۂł���B
Larrabee�A�v���P�[�V����������ŕK�{�łȂ����W�b�N�͏k���E���邢�͏Ȃ��Ă����B
����łȂ��Ƃ�����������Ώ�2-issue�̃p�C�v���C��������f�R�[�h���W�b�N���啝�Ɋȗ����ł��������ˁB
>>836
�p���_�C���V�t�g��50�N�N���Ȃ���ȁB
���\���ǂ��Ƃ��h���C�o�̐��n���ǂ��Ƃ����Ă̂͂����܂ŕ��ւł����āA�K�v�Ȃ�o�����낤��
�K�v�ɔ����Ȃ���Ήi�v�ɏo�����ɏI���Ǝv����B
> �g����Intel���S���ʓ|����Ȃ�t���X�y�b�N��x86�ł���K�v�͑S���������
�S����ʓ|�����Ȃ�����P54C�x�[�X�{�Œ���̊g���Ȃ��ǂˁB
�E����OS���x���̃R�[�h���Y������
�E�n�[�h�E�F�A��IP���C�Z���X���w�����Ă���K�v���Ȃ�
�E�n�[�h�Z�p�E�\�t�g�Z�p�Ƃ��ɂ��Ȃ�Ă���
�܂��A���ꂪIntel����Ȃ���IBM�Ȃ�PPC�x�[�X�ɂȂ��Ă���������Ȃ��ˁB
������_���Ȕėpx86�Ƃ��ăt���X�y�b�N�ł���K�v�͂Ȃ��B
�����ɓ����K�v���Ȃ����߂͓������ǃ}�C�N���R�[�h�f�R�[�h�Ƃ��ASun�̂悤��MicroOS���g���b�v����
��������Ƃ��ł��݊����͊m�ۂł���B
Larrabee�A�v���P�[�V����������ŕK�{�łȂ����W�b�N�͏k���E���邢�͏Ȃ��Ă����B
����łȂ��Ƃ�����������Ώ�2-issue�̃p�C�v���C��������f�R�[�h���W�b�N���啝�Ɋȗ����ł��������ˁB
>>836
�p���_�C���V�t�g��50�N�N���Ȃ���ȁB
���\���ǂ��Ƃ��h���C�o�̐��n���ǂ��Ƃ����Ă̂͂����܂ŕ��ւł����āA�K�v�Ȃ�o�����낤��
�K�v�ɔ����Ȃ���Ήi�v�ɏo�����ɏI���Ǝv����B
Larrabee��10�N�키��
839 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 14:06:05 ID:O1FPzVWB
����ɂ��Ă�GPGPU�i��_�҂̘_�����Đ��N�O��PS3�t�@���{�[�C�ƌ\���S�����Ȃ��Ǝv���B
�������Ƃ��܂�ŕς��Ȃ��B
�܂��AIntel��AMD�����������ʂ��Ă�̂́ACPU�ɂ�����SIMD�g���̓V���O���X���b�h�̐��\�������グ�邽�߂�
�u�������v�̕����1�ł���Ƃ������ƁB1�̃g�����U�N�V������@���ɍ������ł��邩�ɂ���B
���Ƃ���3D���Z�ł悭�g����P���x4�~4�s�m�̐ς́A64��̏�Z��48��̉��Z���K�v����
SSE���g����16��̏�Z���߂�12��̉��Z���߂ŏ����ł���BAVX�Ȃ炻�̔����B
�X��16�����FMA���j�b�g�������1��̏�Z��3��̐Ϙa�Z�ŏ����o����B
����ȏ�͂����Ă�1�s��ɑ��鉉�Z�����������邱�Ƃ͂ł��Ȃ��B
���̈Ӗ�Haswell��256�r�b�gFMA�~2�Ƃ�Larrabee��512�r�b�gFMA�́uCPU�v1�R�A��SIMD�g���Ƃ��Ă͍ŏ�������ˁB
���ꂪGPU���ƁA������4x4�s���ᑬ�E��������̉��Z���j�b�g�܂Ƃ߂ď�������Ƃ��̃��x���ɂȂ�B
������ꂾ�������̈ˑ��W�̂Ȃ��f�[�^����ʂɂ������ł��������A�p�r�͍i�����ˁB
�k��5���̏ꏊ�ɂ��闠�ʂ�̃R���r�j�ŃA���p����1�����Ă���̂Ɏ��]�ԂȂ��葬�������ł��邩������Ȃ����A
��^�g���b�N���Ƃ������Ď��Ԃ������邩������Ȃ��̂Ɠ������x���B
�������Ƃ��܂�ŕς��Ȃ��B
�܂��AIntel��AMD�����������ʂ��Ă�̂́ACPU�ɂ�����SIMD�g���̓V���O���X���b�h�̐��\�������グ�邽�߂�
�u�������v�̕����1�ł���Ƃ������ƁB1�̃g�����U�N�V������@���ɍ������ł��邩�ɂ���B
���Ƃ���3D���Z�ł悭�g����P���x4�~4�s�m�̐ς́A64��̏�Z��48��̉��Z���K�v����
SSE���g����16��̏�Z���߂�12��̉��Z���߂ŏ����ł���BAVX�Ȃ炻�̔����B
�X��16�����FMA���j�b�g�������1��̏�Z��3��̐Ϙa�Z�ŏ����o����B
����ȏ�͂����Ă�1�s��ɑ��鉉�Z�����������邱�Ƃ͂ł��Ȃ��B
���̈Ӗ�Haswell��256�r�b�gFMA�~2�Ƃ�Larrabee��512�r�b�gFMA�́uCPU�v1�R�A��SIMD�g���Ƃ��Ă͍ŏ�������ˁB
���ꂪGPU���ƁA������4x4�s���ᑬ�E��������̉��Z���j�b�g�܂Ƃ߂ď�������Ƃ��̃��x���ɂȂ�B
������ꂾ�������̈ˑ��W�̂Ȃ��f�[�^����ʂɂ������ł��������A�p�r�͍i�����ˁB
�k��5���̏ꏊ�ɂ��闠�ʂ�̃R���r�j�ŃA���p����1�����Ă���̂Ɏ��]�ԂȂ��葬�������ł��邩������Ȃ����A
��^�g���b�N���Ƃ������Ď��Ԃ������邩������Ȃ��̂Ɠ������x���B
���@�͂ǂ��ɂ��Ȃ���B
Larrabee�����ė�O�ł͂Ȃ��B
Larrabee�����ė�O�ł͂Ȃ��B
���́u�p�r�����肳�ꂽ��^�g���b�N�v���A
���܂ł�(�����o�Ȃ����߂�)�ŐV�̔����̋Z�p�ō�ꂸ�A
�ėp��CPU�ɂ͑����ł��ł��Ȃ������̂ɑ��A
GPU�̎��v�ɕ֏悵��CPU�Ɠ����y�U�ō���悤�ɂȂ����A
�Ƃ����Ƃ��낪�~�\�Ȃ�ł��B
���܂ł�(�����o�Ȃ����߂�)�ŐV�̔����̋Z�p�ō�ꂸ�A
�ėp��CPU�ɂ͑����ł��ł��Ȃ������̂ɑ��A
GPU�̎��v�ɕ֏悵��CPU�Ɠ����y�U�ō���悤�ɂȂ����A
�Ƃ����Ƃ��낪�~�\�Ȃ�ł��B
���������Ƃ��܂�ŕς��Ȃ��B
�A�E�g�I�u�I�[�_���X�[�p�[�X�J���@�Ƃ�
�t�F�b�`���v���t�F�b�`�@�Ƃ�
���Pentium4�ɂ�L1D������@�Ƃ�
�m���ɂ����������Ƃ����܂肫���Ă���
�A�E�g�I�u�I�[�_���X�[�p�[�X�J���@�Ƃ�
�t�F�b�`���v���t�F�b�`�@�Ƃ�
���Pentium4�ɂ�L1D������@�Ƃ�
�m���ɂ����������Ƃ����܂肫���Ă���
>>839
> ���̈Ӗ�Haswell��256�r�b�gFMA�~2�Ƃ�
�X���Ⴂ�̘b�肾���A����͊m�莖���Ȃ̂��H
�h���������Ȃ��Ώ̂�256bit FMA + 256bit FP-Add
������ɂ��Ă���悤�ȋC�������
> ���̈Ӗ�Haswell��256�r�b�gFMA�~2�Ƃ�
�X���Ⴂ�̘b�肾���A����͊m�莖���Ȃ̂��H
�h���������Ȃ��Ώ̂�256bit FMA + 256bit FP-Add
������ɂ��Ă���悤�ȋC�������
844 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 15:47:13 ID:O1FPzVWB
���͏o�Ă������ꕔ�̉Ȋw�Z�p���Z�ȊO�A�\�t�g���̎��v�����N�ł��ĂȂ��̂����X�ˁB
COBOL�̐E�ƃv���O���}�l���͐��E300���l�Ƃ����Ă邪�ACUDA�l���͂������̖�6���iNVIDIA���ׁj���B
SDK�������Ƀ_�E�����[�h���Ă݂������̐l���܂߂��v���낤��������l���͐����Ēm��ׂ��B
COBOL�̐E�ƃv���O���}�l���͐��E300���l�Ƃ����Ă邪�ACUDA�l���͂������̖�6���iNVIDIA���ׁj���B
SDK�������Ƀ_�E�����[�h���Ă݂������̐l���܂߂��v���낤��������l���͐����Ēm��ׂ��B
AVX�g����Dirt2��120FPS�Ńv���C�\�I�I
���O���t�B�b�N�X�J�[�h��}�����ꍇ
���O���t�B�b�N�X�J�[�h��}�����ꍇ
�~�R�e�̃��X�͊ԈႢ�T��
���R�e�̃��X�͌��鉿�l�����̂ŃR�e��NG�o�^
���R�e�̃��X�͌��鉿�l�����̂ŃR�e��NG�o�^
>>844
�Ȃ���r�Ώۂ�COBOL�B
�Ȃ���r�Ώۂ�COBOL�B
849 �F,,�E�L�́M�E,,�j��-�������F2010/05/15(�y) 16:26:55 ID:O1FPzVWB
>>843
���ꂾ�Ə�Z�̃X���[�v�b�g�l�b�N�ōs��ςȂ̐��\�͊�{�I�ɏオ��Ȃ�����FMA�̈Ӗ����̂قƂ�ǂȂ��ˁB
�uFMA�ōő�4�{�v���Ė������Ă邩��256bit FMA�~2���Đ��͗L�́B
�Ƃ͂���Haswell�̐��\�ɂ��Ă͂��낢��^�₪�����
���肵��16SP/clk�̃X���[�v�b�g��ɂ́Avbroadcastss + vmulps + vaddps ��
���ߒ������v16�o�C�g�ȓ��ɗ}����K�v������B
vmulps, vaddps��4�o�C�g�Ɉ��k�ł��邩��vbroadcastss��8�o�C�g�܂łɗ}����Ώ\���ł���B
������FMA�T�|�[�g�ōX��2�{�̐��\��ɂ�vbroadcastss�~2 + vfmadd231ps�~2���ɔ��s���Ȃ�������Ȃ��B
��������16byte/clk�̖��߃t�F�b�`�ш悾�Ɗm���ɑ���Ȃ��āALoop Stream Detector�Ɏ��܂�悤��
�v���O������g�܂Ȃ��Ƃ����Ȃ��B
�t�ɍl�����256bit FMA�~2�̎����������Ƃ��ɂ͖��߃t�F�b�`�ш�̊g���͊m���ɓ���Ƃ������ƁB
���ꂾ�Ə�Z�̃X���[�v�b�g�l�b�N�ōs��ςȂ̐��\�͊�{�I�ɏオ��Ȃ�����FMA�̈Ӗ����̂قƂ�ǂȂ��ˁB
�uFMA�ōő�4�{�v���Ė������Ă邩��256bit FMA�~2���Đ��͗L�́B
�Ƃ͂���Haswell�̐��\�ɂ��Ă͂��낢��^�₪�����
���肵��16SP/clk�̃X���[�v�b�g��ɂ́Avbroadcastss + vmulps + vaddps ��
���ߒ������v16�o�C�g�ȓ��ɗ}����K�v������B
vmulps, vaddps��4�o�C�g�Ɉ��k�ł��邩��vbroadcastss��8�o�C�g�܂łɗ}����Ώ\���ł���B
������FMA�T�|�[�g�ōX��2�{�̐��\��ɂ�vbroadcastss�~2 + vfmadd231ps�~2���ɔ��s���Ȃ�������Ȃ��B
��������16byte/clk�̖��߃t�F�b�`�ш悾�Ɗm���ɑ���Ȃ��āALoop Stream Detector�Ɏ��܂�悤��
�v���O������g�܂Ȃ��Ƃ����Ȃ��B
�t�ɍl�����256bit FMA�~2�̎����������Ƃ��ɂ͖��߃t�F�b�`�ш�̊g���͊m���ɓ���Ƃ������ƁB
>>841
���H��̘_�����Ă��
��^�g���b�N�̉ב�ɉו��i�f�[�^�j�����Ԗ����L�b�`���ς߂��Ƃ�
�n���ɂȂ�Ȃ��{�g���l�b�N�ŗp�r�̌���̂���������[�Ȃ����ǂȁB
CPU�Ɠ����y�U���Ă̂͂ǂ������ȁB
���H��̘_�����Ă��
��^�g���b�N�̉ב�ɉו��i�f�[�^�j�����Ԗ����L�b�`���ς߂��Ƃ�
�n���ɂȂ�Ȃ��{�g���l�b�N�ŗp�r�̌���̂���������[�Ȃ����ǂȁB
CPU�Ɠ����y�U���Ă̂͂ǂ������ȁB
�Ƃ肠�����AIntel�ŃN���[�\�[��Larrabee���ė����ł����̂���
�������͔�x86�R�A��X86�������ăR���Z�v�g���������ǁA
��������x86�R�A�Ŕ�X86�����Ƃ������ƂɂȂ�̂��ȁB
��̓I�ɉ���z�肵�Ă���̂��͕s�������ǁADirectX��openCL�ӂ��Win��Linux����Ȃ��ŁA
�z�X�gOS��Ŏ��s�����Ⴈ�����Ă��Ƃ��H
�z�X�gOS�ɂ��LNI�����[�U�[����͒��ڌ����Ȃ����Ă��ƂɂȂ�݂���������A
�m����AMD���T�|�[�g����K�v�͂Ȃ��ȁB
���������z�X�gOS�͉����G�~�����[�V�������Ă���H
x86�Ȃ�A����x86������z�X�gOS�Ȃ�Ă���Ȃ����ALNI�͉B��Ă��邩��Ax86��LNI�ȊO�Ȃ낤���ǁB
�������͔�x86�R�A��X86�������ăR���Z�v�g���������ǁA
��������x86�R�A�Ŕ�X86�����Ƃ������ƂɂȂ�̂��ȁB
��̓I�ɉ���z�肵�Ă���̂��͕s�������ǁADirectX��openCL�ӂ��Win��Linux����Ȃ��ŁA
�z�X�gOS��Ŏ��s�����Ⴈ�����Ă��Ƃ��H
�z�X�gOS�ɂ��LNI�����[�U�[����͒��ڌ����Ȃ����Ă��ƂɂȂ�݂���������A
�m����AMD���T�|�[�g����K�v�͂Ȃ��ȁB
���������z�X�gOS�͉����G�~�����[�V�������Ă���H
x86�Ȃ�A����x86������z�X�gOS�Ȃ�Ă���Ȃ����ALNI�͉B��Ă��邩��Ax86��LNI�ȊO�Ȃ낤���ǁB
>>829
Fermi�̏ꍇ�͕����v�~�X����
�Ԃ����{�ԂŗʎY���n�߂�TMSC�̖��Ɍ����Ɉ����������Ă��܂���
ATi��47**�ň�i�K�͂���ł���5***�̐v����������TMSC��㩂�����ł���
nVidia�͌�o�������Ȃ���ATi�����Đv���Ȃ��������߂�Ηǂ������̂�
TMSC���������ǂ��̑Ή��Ŗ��Â��o����
Fermi�̏ꍇ�͕����v�~�X����
�Ԃ����{�ԂŗʎY���n�߂�TMSC�̖��Ɍ����Ɉ����������Ă��܂���
ATi��47**�ň�i�K�͂���ł���5***�̐v����������TMSC��㩂�����ł���
nVidia�͌�o�������Ȃ���ATi�����Đv���Ȃ��������߂�Ηǂ������̂�
TMSC���������ǂ��̑Ή��Ŗ��Â��o����
>>852
Nvidia���ꉞGT21x�ŗ\�K�������ǁAAMD�݂����ɓ��̃N���A�ɒ��킵�Ȃ��������玸�s���������B
���킵�����Ǐo���Ȃ��������������H
�܂��A�������łǂ�����Ή����ł��邩��AMD�������Ă��ꂽ���獡�x�͑��v���낤�B
>>841
�ŋ߂�3D�Q�[����HD�𑜓x(1920x1200)��AA��AF�Ƃ��̏�����������āA�c��ȗʂ̌v�Z���K�v����B
�Ⴆ��Ȃ�A��ʂ̍�ƈ�����������ŁA�����A���p��1���z�B���Ă��炤�K�v�������v�ŁA
���]�Ԃ�10�`20�������Ă�������A�_���v�łP���܂Ƃ߂Ď����Ă��������������ȒP���낤���Ă��Ƃ���Ȃ����ȁB
����͎͂��]�Ԃ��Ă��傫���Ȃ��č��܂ł̔{�ȏ㎝���Ă����悤�ɂȂ邯�ǁA
����̋K�͂��傫��(3D�\���A�}���`���)�Ȃ��Ă��Ă��āA�_���v�J�[�̓��ڗʂ⑬�x���ǂ��Ȃ��Ă��Ă邩��A
���ΓI�ȍ��͈ˑR�Ƃ��đ傫���܂܂��ĂƂ��납�ƁB
Nvidia���ꉞGT21x�ŗ\�K�������ǁAAMD�݂����ɓ��̃N���A�ɒ��킵�Ȃ��������玸�s���������B
���킵�����Ǐo���Ȃ��������������H
�܂��A�������łǂ�����Ή����ł��邩��AMD�������Ă��ꂽ���獡�x�͑��v���낤�B
>>841
�ŋ߂�3D�Q�[����HD�𑜓x(1920x1200)��AA��AF�Ƃ��̏�����������āA�c��ȗʂ̌v�Z���K�v����B
�Ⴆ��Ȃ�A��ʂ̍�ƈ�����������ŁA�����A���p��1���z�B���Ă��炤�K�v�������v�ŁA
���]�Ԃ�10�`20�������Ă�������A�_���v�łP���܂Ƃ߂Ď����Ă��������������ȒP���낤���Ă��Ƃ���Ȃ����ȁB
����͎͂��]�Ԃ��Ă��傫���Ȃ��č��܂ł̔{�ȏ㎝���Ă����悤�ɂȂ邯�ǁA
����̋K�͂��傫��(3D�\���A�}���`���)�Ȃ��Ă��Ă��āA�_���v�J�[�̓��ڗʂ⑬�x���ǂ��Ȃ��Ă��Ă邩��A
���ΓI�ȍ��͈ˑR�Ƃ��đ傫���܂܂��ĂƂ��납�ƁB
Larraee�̃L�����Z���ɂ���
ttp://www.4gamer.net/games/049/G004963/20091212001/
����Larrabee�́C���̏���d�͂┭�M�ʂ̑����ɑ��ď������\���\���Ƃ͌������C
�u���Z�������\�ł��ꐢ��O�̃n�C�G���h�O���t�B�b�N�X���i�ɋy�Ȃ���Ԃ������v
�܂� 45nm Larrabee < 55nm GT200b �� RV790
�ő�̖��́C�O���t�B�b�N�X�J�[�h�Ƃ��Ďs�������ɂ́CDirectX�̃T�|�[�g�ȂǁC
�\�t�g�E�F�A���̖�肪�R�ς��Ă����_�ɂ���Ƃ̂��ƁB
�Ƃ���Q�[���f�x���b�p�W�҂ɂ��CLarrabee�́C
DirectX 10�ւ̍œK������C�\���Ƃ͂����Ȃ���Ԃ������悤���B
�z�X�gOS�̖��Ȃ̂��A�h���C�o�̖��Ȃ̂��A���邢�͗����̖��Ȃ̂��B
ttp://www.4gamer.net/games/049/G004963/20091212001/
����Larrabee�́C���̏���d�͂┭�M�ʂ̑����ɑ��ď������\���\���Ƃ͌������C
�u���Z�������\�ł��ꐢ��O�̃n�C�G���h�O���t�B�b�N�X���i�ɋy�Ȃ���Ԃ������v
�܂� 45nm Larrabee < 55nm GT200b �� RV790
�ő�̖��́C�O���t�B�b�N�X�J�[�h�Ƃ��Ďs�������ɂ́CDirectX�̃T�|�[�g�ȂǁC
�\�t�g�E�F�A���̖�肪�R�ς��Ă����_�ɂ���Ƃ̂��ƁB
�Ƃ���Q�[���f�x���b�p�W�҂ɂ��CLarrabee�́C
DirectX 10�ւ̍œK������C�\���Ƃ͂����Ȃ���Ԃ������悤���B
�z�X�gOS�̖��Ȃ̂��A�h���C�o�̖��Ȃ̂��A���邢�͗����̖��Ȃ̂��B
�����m�ƃT���f�[�͂ǂ����������̂�
CPU���SandyBridge>>Llano
GPU���Llano>>SandyBridge
�ʓrGPU��ςނȂ�Sandy�D�ʁA�ς܂Ȃ��Ȃ�Llano�D��
GPU���Llano>>SandyBridge
�ʓrGPU��ςނȂ�Sandy�D�ʁA�ς܂Ȃ��Ȃ�Llano�D��
CPU�̓L���b�V�����炯������Intel�L��
GPU�ɂ̓L���b�V����������Intel�Y�^�{��
Larrabee�ɂ��L���b�V�����邯�Ǎ\�z���̂��E���R�߂��Ĕ҉�o���Ȃ�
GPU�ɂ̓L���b�V����������Intel�Y�^�{��
Larrabee�ɂ��L���b�V�����邯�Ǎ\�z���̂��E���R�߂��Ĕ҉�o���Ȃ�
�A�z
>AA��AF�Ƃ��̏�����������āA�c��ȗʂ̌v�Z���K�v����B
�P�Ȃ�Œ�@�\��������
���_���v�J�[
�����]��
�_���v�J�[�͗ǂ����낤���A���]�Ԃ͕s�K������
�ȂN���b�N��3-4�{����킯������
�X�|�[�c�J�[���ĂƂ��낾��200-300�̃p���Ƃ����߂�
�P�Ȃ�Œ�@�\��������
���_���v�J�[
�����]��
�_���v�J�[�͗ǂ����낤���A���]�Ԃ͕s�K������
�ȂN���b�N��3-4�{����킯������
�X�|�[�c�J�[���ĂƂ��낾��200-300�̃p���Ƃ����߂�
860 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 08:52:01 ID:ZpwaxppR
>>859
���͏����̗����₷��������ʂɑ��s���̑��x�͘_���ĂȂ��B
���͏����̗����₷��������ʂɑ��s���̑��x�͘_���ĂȂ��B
1/25.75�X�s�[�h��CPU���X�|�[�c�J�[
���Ⴄ���Ⴄ�A>>853�̒P�ɑ�ʗA���̂��b�ɑ��Č����Ă�킯
�����Ƃ��A�Ŋ�̃R���r�j�ɃA���p�������ɂ����Ⴆ�ɂ�����
��ʗA����������o���Ă�́A�ǂ��Ȃ��Ă��b
�����Ƃ��A�Ŋ�̃R���r�j�ɃA���p�������ɂ����Ⴆ�ɂ�����
��ʗA����������o���Ă�́A�ǂ��Ȃ��Ă��b
863 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 09:12:04 ID:ZpwaxppR
�A���p��1�̘b�ɚg����Ȃ�_���v�J�[����߂Ă��钓�ԏ�̂ق����R���r�j��肸���Ɖ����I�ȃC���[�W����
���̓Ƃ茾�����C�������߂�
�_���v�J�[��X�|�[�c�J�[�⎩�]�ԂŃp�����^�ԗႦ��
�ǂ�����Ă��������肱�Ȃ����Ƃ��m��
�ǂ�����Ă��������肱�Ȃ����Ƃ��m��
CPU�E�E�E������
GPU�E�E�E�V����
�����̂���CPU
�����ő�GPU
�K�ޓK���Ƃ������Ƃł����͂ЂƂ�
GPU�E�E�E�V����
�����̂���CPU
�����ő�GPU
�K�ޓK���Ƃ������Ƃł����͂ЂƂ�
CPU������Sandy��GPU������Llano��CPU���ق����ł�
868 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 09:49:21 ID:ZpwaxppR
�Ƃ�����GPU��CPU�̕����I�������Z���Ȃ낤�ƃh���C�o�ɐ�����ڍs���鎞�_�ő傫�ȃT�C�N�����X�����邩���
������GPGPU�i�j�����ʂői���Ă��A����ؑւ̕K�v�������f�[�^�ړ����[���R�X�g��SSE�̋@���͂ɂ͋y�Ȃ����݁B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100415_361133.html
>�@Sandy Bridge�ł́ACPU�R�A�Q��GPU�R�A�Q��L3�L���b�V�������L���邽�߁A
���Ȃ݂ɂ���Ƃ͕ʂ�GPU�͓Ɨ�����L1, L2�L���b�V�������݂�����ǂȁB
������GPGPU�i�j�����ʂői���Ă��A����ؑւ̕K�v�������f�[�^�ړ����[���R�X�g��SSE�̋@���͂ɂ͋y�Ȃ����݁B
http://pc.watch.impress.co.jp/docs/column/kaigai/20100415_361133.html
>�@Sandy Bridge�ł́ACPU�R�A�Q��GPU�R�A�Q��L3�L���b�V�������L���邽�߁A
���Ȃ݂ɂ���Ƃ͕ʂ�GPU�͓Ɨ�����L1, L2�L���b�V�������݂�����ǂȁB
���ʂƋ@���͂ɑi����Larrabee�͎��I���̂��I
���Y����������
�{�Ԃ�2015�N�ł���
���̊Ԃ͕z���̊���
���̊Ԃ͕z���̊���
���Y���č��XDirectX�i���̔�x86�j�ׂ��̖�������
�x���Βx���قǕ��s���i��
�x���Βx���قǕ��s���i��
�ׂ�AVX(SSE)��GPU��Shader�Ƃ��Ďg�����ق����ǂ���Ȃ��ł�����
����Ő��\���o�����Ȃ��
�I���{�[�h�Ƃ��Ă͏\��������ł���
�G�`����GPU�ɔC���Ƃ���[������
CPU���Ђ܂��Ă���Ȃ�AAVX��Shader�Ƃ��Ďg���Ă��������낤���ǁA
Intel�ƈ���ē���GPU�̐��\������Ȃ�ɂ��邩��A
���\���オ�邩�ǂ��������ȋC���B
Intel�ƈ���ē���GPU�̐��\������Ȃ�ɂ��邩��A
���\���オ�邩�ǂ��������ȋC���B
Intel�̏ꍇ��GPU�h���C�o�̏o�����s��
���z��]�����āACPU��GPU�̎d���������悤�B
�����������B
SSE�����Ɏg����Ȃ��lj��Ŏg���悭�ˁH
480sp+SSE�Ő��\3�������Ƃ�
���\�̃A���o�����X���Ƌ����̈Ⴂ���ǂ�����Đ��䂷��̂��͍l���Ȃ�
�܂��ACarkdale�̏ꍇ�ł���SSE��ւ�785G���邩�ǂ����̐��\������A
Llano�̏ꍇ�ɑ�ւ��Ă����\�����邵�A�lj��Ŏg���Ă�1�����L�тȂ����낤���ǂȁB
480sp+SSE�Ő��\3�������Ƃ�
���\�̃A���o�����X���Ƌ����̈Ⴂ���ǂ�����Đ��䂷��̂��͍l���Ȃ�
�܂��ACarkdale�̏ꍇ�ł���SSE��ւ�785G���邩�ǂ����̐��\������A
Llano�̏ꍇ�ɑ�ւ��Ă����\�����邵�A�lj��Ŏg���Ă�1�����L�тȂ����낤���ǂȁB
>880
sandybridge�͂����Ȃ邾��
sandybridge�͂����Ȃ邾��
GMA�������Ă�̂ɂ�
���b�g�p�t�H�[�}���X���������邾����
Llano�҂��̓z��GPU��GPGPU�ɂ����҂��Ă邪�A
Sandy�҂��̓z��GPU�Ɋ��҂͂��ĂȂ��A�t�Ɏז��҈���
Sandy�҂��̓z��GPU�Ɋ��҂͂��ĂȂ��A�t�Ɏז��҈���
�����GPGPU�ɂ͊��҂��Ă��Ȃ�
���҂��Ă���l�͑���
CUDA�ׂ̈ɃQ�t�H�����Ă�z�����������
�����A���N�����Ɉ�ʓI�ȃ\�t�g�ŕ��y����Ƃ������͌���Ȃ�����
����ҏW��E�B���X�X�L�����A�Ȋw�Z�p�v�Z�Ȃǐg�߂ȂƂ��납��X�p�R�����x���܂œK�p�͈͂͂��Ȃ�L��
�����܂ŕ����ł͈̔͂��L�������ŁA�V���O���������炯�̌l�����Ɍ�����Ȃ�����Ă��邪��
CUDA�ׂ̈ɃQ�t�H�����Ă�z�����������
�����A���N�����Ɉ�ʓI�ȃ\�t�g�ŕ��y����Ƃ������͌���Ȃ�����
����ҏW��E�B���X�X�L�����A�Ȋw�Z�p�v�Z�Ȃǐg�߂ȂƂ��납��X�p�R�����x���܂œK�p�͈͂͂��Ȃ�L��
�����܂ŕ����ł͈̔͂��L�������ŁA�V���O���������炯�̌l�����Ɍ�����Ȃ�����Ă��邪��
stream���o���̉���������
���������̂��A�͂����āE��
���������̂��A�͂����āE��
���Ȃ����獡����Ȃ��Ƃ����������邾��
���̑召������Ȃ��z�̕Њ��ꂾ��
http://www.brightsideofnews.com/news/2010/5/4/amd-announces-opencl-based-stream-sdk.aspx
http://techreport.com/discussions.x/18851
���悢��Fuison�̂��߂̓������łĂ����A���Ƃ̓n�[�h���ł邾��
http://techreport.com/discussions.x/18851
���悢��Fuison�̂��߂̓������łĂ����A���Ƃ̓n�[�h���ł邾��
�c�O�Ȃ��獡�����������
���ł��g���Ă�l�͎g���Ă�
�g���l�͎g���Ƃ��������̘b
�u�S�Ă̐l���g���悤�ɂȂ�v�Ƃ��u�g���l�͊F���v�ƌ������ɘ_�͖��Ӗ���
�g���l�͎g���Ƃ��������̘b
�u�S�Ă̐l���g���悤�ɂȂ�v�Ƃ��u�g���l�͊F���v�ƌ������ɘ_�͖��Ӗ���
���Ɏg���Ă��
�X�p�R��
AVX��DX11��OpenCL��GL��LNI���ǂ����ʐl�ɂ͉��b�Ȃ�����
���[TENGA��
ttp://www.tenga-love.com/
ttp://www.tenga-love.com/
>>888
AMD�EnVidia�Eintel�܂������W�Ȃ����AGPGPU�ŃE�C���X�X�L��������CPU�g�p�����炷�ȊO�łȂ����b�g����̂��ȁB
�����ō��������邩�Ƃ����ƃf�B�X�N�A�N�Z�X���{�g���l�b�N�ɂȂ��đ����Ȃ�Ȃ��C������B
AMD�EnVidia�Eintel�܂������W�Ȃ����AGPGPU�ŃE�C���X�X�L��������CPU�g�p�����炷�ȊO�łȂ����b�g����̂��ȁB
�����ō��������邩�Ƃ����ƃf�B�X�N�A�N�Z�X���{�g���l�b�N�ɂȂ��đ����Ȃ�Ȃ��C������B
���b�͂���A�C�Â��ĂȂ�����
�܂��A�I�t�B�X�\�t�g��u���E�U�����g��Ȃ��ꍇ�͖����ƌ����邯�ǂ�
�t�ɃN���G�C�e�B�u�Ȏd��������l�ɂ͂��Ȃ艶�b����
�܂��A�I�t�B�X�\�t�g��u���E�U�����g��Ȃ��ꍇ�͖����ƌ����邯�ǂ�
�t�ɃN���G�C�e�B�u�Ȏd��������l�ɂ͂��Ȃ艶�b����
�e���G���R�[�h�Ƃ�
>>899
�͂��ǂ��B�X�g���[�W���l�b�N�ɂȂ�Ǝv���B
>>900
���̃I�t�B�X����PC�͒n���ɍ����ׂ����H
�Z�L�����e�B�����̃\�t�g�����ŕ��������܂����Ă�B
�͂��ǂ��B�X�g���[�W���l�b�N�ɂȂ�Ǝv���B
>>900
���̃I�t�B�X����PC�͒n���ɍ����ׂ����H
�Z�L�����e�B�����̃\�t�g�����ŕ��������܂����Ă�B
904 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 21:11:42 ID:ZpwaxppR
>>890
�ŁAAVIVO���Ăяo�������̃\�t�g�ȊO�ʼn������p���x���̕����o���H
�܂��A����ȊO�̃\�t�g�����Ԃ��o�ĂΏo�Ă�����Č����������ǁA
���蔲���ŁA�������ăr�W�l�X�ɂȂ�Ǝv���H�Ȃ�Ƃ��ĉ��N��H
�܁A�s�ꂪ��������l�ނ��炽�Ȃ��̂��A�l�ނ��炽�Ȃ�����s�ꂪ�����̂��B
������ɂ��Ă��K�v�Ȃ牽�炩�̋��K�I�x�����s���ׂ�����B
NVIDIA�͑�w�Ɏx�����邱�ƂŎs���ւ��悤�Ƃ��Ă�ˁB
�V���R���o���[�̖��������w���̃x���`���[���v�V�������炵�Ă����B
���Ђ̌�ǂ����Ă�����ɗa�����Ƃ������z��A�Ђ�ʖڂɂ����Ǝv���B
�ŁAAVIVO���Ăяo�������̃\�t�g�ȊO�ʼn������p���x���̕����o���H
�܂��A����ȊO�̃\�t�g�����Ԃ��o�ĂΏo�Ă�����Č����������ǁA
���蔲���ŁA�������ăr�W�l�X�ɂȂ�Ǝv���H�Ȃ�Ƃ��ĉ��N��H
�܁A�s�ꂪ��������l�ނ��炽�Ȃ��̂��A�l�ނ��炽�Ȃ�����s�ꂪ�����̂��B
������ɂ��Ă��K�v�Ȃ牽�炩�̋��K�I�x�����s���ׂ�����B
NVIDIA�͑�w�Ɏx�����邱�ƂŎs���ւ��悤�Ƃ��Ă�ˁB
�V���R���o���[�̖��������w���̃x���`���[���v�V�������炵�Ă����B
���Ђ̌�ǂ����Ă�����ɗa�����Ƃ������z��A�Ђ�ʖڂɂ����Ǝv���B
�g���b�v�����\�t�g�����͂ō�����t�������Ă邾���̐l�͗��Ɍ������Ƃ��Ⴄ��
�����������K�I�ɋꂵ���Ȃ��������͂ǁ[�ꂾ
1,Intel�̑��Дr���I�ȏ��K��
2,�w�N�^�[�E���C�Y
3,�_�[�N�E�}�C���[
1,Intel�̑��Дr���I�ȏ��K��
2,�w�N�^�[�E���C�Y
3,�_�[�N�E�}�C���[
K8�ȍ~�܂Ƃ��Ȑ��i�J�����ė��Ȃ��������炶��Ȃ��ł�����
������ATI��GPU�ɂ����ԏ������Ă�悤�ł���
������ATI��GPU�ɂ����ԏ������Ă�悤�ł���
908 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 21:52:37 ID:ZpwaxppR
NVIDIA��GPU�Ƃ��Ă̖{�����̂ĂĂł�GeForce�̔ėp����i�߂Ă�B
�����������Ƃł��Ȃ�������A���ꂾ���̃��X�N��Ȃ��ƃC�m�x�[�V�����͋N�����Ȃ��B
���Ȃ��Ƃ��ێ�I�ȃA�[�L�e�N�`���ɗ��߂Ĉ��S����Ƃ�͎̂s��\�����ς��悤�Ƃ����p���ł͂Ȃ��ˁB
�Ă������炳�܂Ȉ��S����Ƃ��āA�ǂ��̃\�t�g�E�F�A�x���`���[�����X�N���������Ă����̂��B
��̐����Ȃ��Ƃ��������悤���Ȃ��B
�����������Ƃł��Ȃ�������A���ꂾ���̃��X�N��Ȃ��ƃC�m�x�[�V�����͋N�����Ȃ��B
���Ȃ��Ƃ��ێ�I�ȃA�[�L�e�N�`���ɗ��߂Ĉ��S����Ƃ�͎̂s��\�����ς��悤�Ƃ����p���ł͂Ȃ��ˁB
�Ă������炳�܂Ȉ��S����Ƃ��āA�ǂ��̃\�t�g�E�F�A�x���`���[�����X�N���������Ă����̂��B
��̐����Ȃ��Ƃ��������悤���Ȃ��B
909 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 21:56:03 ID:ZpwaxppR
>>906
�i�בΏۂɂȂ��Ă�Intel�̏��K�����]�X�̂Ƃ��͒P��10���I�[�o�[��CPU���f�X�N�g�b�v�s��ɓ�������
��D������������Ȃ��ł����B
�{���ɒ��낪�Ԃ��Ȃ����͎̂��͂ʼn�����o���Ă���ł��傤�B
�i�בΏۂɂȂ��Ă�Intel�̏��K�����]�X�̂Ƃ��͒P��10���I�[�o�[��CPU���f�X�N�g�b�v�s��ɓ�������
��D������������Ȃ��ł����B
�{���ɒ��낪�Ԃ��Ȃ����͎̂��͂ʼn�����o���Ă���ł��傤�B
�C�m�x�[�V�����i�j��
�s��\���̉��v�i�j��
������Ȃ�ł��x�炳�ꂷ���Ă�
�s��\���̉��v�i�j��
������Ȃ�ł��x�炳�ꂷ���Ă�
911 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:05:24 ID:ZpwaxppR
�N���x���Ă���āH
���ɂ��킹���NVIDIA�̑Ή����琶����
�\�t�g���o�Ă���̂́uGPGPU���ׂ���v�̌������\�t�g�ƊE�ɐZ�����ꂽ�Ƃ���
�����\�t�g��I�Ԃ悤�ȃA�[�L�e�N�`������Ă鎞�_�Ŏ���s������߂Ă���킯���B
�܂��A�{���Ƀ\�t�g���ɗD�������ł������悤�Ȕėp�����������v���Z�b�T������Ƃ����
���ꂱ�����c��FLOPS���ʂ���x86��ARM�ƃK�`�������Ȃ��Ƃ����Ȃ��Ȃ邾�����Ǝv�����ǁB
���ɂ��킹���NVIDIA�̑Ή����琶����
�\�t�g���o�Ă���̂́uGPGPU���ׂ���v�̌������\�t�g�ƊE�ɐZ�����ꂽ�Ƃ���
�����\�t�g��I�Ԃ悤�ȃA�[�L�e�N�`������Ă鎞�_�Ŏ���s������߂Ă���킯���B
�܂��A�{���Ƀ\�t�g���ɗD�������ł������悤�Ȕėp�����������v���Z�b�T������Ƃ����
���ꂱ�����c��FLOPS���ʂ���x86��ARM�ƃK�`�������Ȃ��Ƃ����Ȃ��Ȃ邾�����Ǝv�����ǁB
Intel�̏��K�������ɂȂ����̂�K7������̌Â����ォ��̘b�ł���
�u�i�ׂ��N�������̂́AK8���o�Ď��͕t���Ă���������
�S�l���ƌ���ꂸ�ɍςނ���v
�݂����Ȏ���AMD�̐l�����������Ă��C������
�u�i�ׂ��N�������̂́AK8���o�Ď��͕t���Ă���������
�S�l���ƌ���ꂸ�ɍςނ���v
�݂����Ȏ���AMD�̐l�����������Ă��C������
>>907
GPU�ȊO�S���_���̊ԈႢ����Ȃ����H
CPU�����Socket939����ȍ~�ǂ��������p�b���Ƃ��Ȃ����
�Ă������̒u�������Ȃ�Ă��Ă��邩�炱��Ȏ��ɂȂ�E�E�E
GPU�ȊO�S���_���̊ԈႢ����Ȃ����H
CPU�����Socket939����ȍ~�ǂ��������p�b���Ƃ��Ȃ����
�Ă������̒u�������Ȃ�Ă��Ă��邩�炱��Ȏ��ɂȂ�E�E�E
�A�z�߂���
�����Ŏw�E����㩂������r�ɂ�����̂�
�����Ŏw�E����㩂������r�ɂ�����̂�
915 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:21:48 ID:ZpwaxppR
��������Intel�ɂƂ��Ă�GPGPU���ז��ł�������̂�
Larrabee�̓������͖̂{���ł͂Ȃ��Ǝv���
����x86�x�[�X�Ȃ�Xeon�̂ق������|�I�ɖׂ��邩��ȁB
Larrabee�̓������͖̂{���ł͂Ȃ��Ǝv���
����x86�x�[�X�Ȃ�Xeon�̂ق������|�I�ɖׂ��邩��ȁB
Intel�̏��K�������ɂȂ����̂�K6���炶��Ȃ���������
�N�i�ő��ЂɌ����点�A���x�[�g�ő��Дr��
����炪�����č��������
�N�i�ő��ЂɌ����点�A���x�[�g�ő��Дr��
����炪�����č��������
>>907
�܂Ƃ�����Ȃ�X6�ɂ܂Ƃ���i7�����i�������������Ă��
�܂Ƃ�����Ȃ�X6�ɂ܂Ƃ���i7�����i�������������Ă��
MIMD���ɂȂ���ق��̂��̂������
NI��Fermi3�̂Ƃ����܂�������������킯��
NI��Fermi3�̂Ƃ����܂�������������킯��
�����A�C�m�x�[�V�����͉����ւ��
����MS�̃Q�[���@�ɍ̗p�����z�����B Windows�ł́B
921 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:40:22 ID:ZpwaxppR
>>919
�{���������Ƃ�������GPGPU���\�t�g�s��Ő�������Ƃ͑S���v���Ă��Ȃ��̂�B
�����Ă��܂���NVIDIA�̂���Ă邱�Ƃ͖��ʂȑ��~���ɂ�����B
���Ȃ݂�Intel��Larrabee�𓊓����闝�R��GPGPU���������邽�߂Ə����ςȂ���������Ă邩��ȁB
�ׂ��ׂ�GPGPU�\�t�g�s�ꂪ���݂��ĂȂ��i�K�œ�������Ӗ��͂Ȃ���ȁB
����32�R�ACell�̌v������݂��Ȃ����A�g�b�v500�ɐ�߂�Xeon�̃V�F�A�͂ǂ�ǂ�オ���Ă����B
�{���������Ƃ�������GPGPU���\�t�g�s��Ő�������Ƃ͑S���v���Ă��Ȃ��̂�B
�����Ă��܂���NVIDIA�̂���Ă邱�Ƃ͖��ʂȑ��~���ɂ�����B
���Ȃ݂�Intel��Larrabee�𓊓����闝�R��GPGPU���������邽�߂Ə����ςȂ���������Ă邩��ȁB
�ׂ��ׂ�GPGPU�\�t�g�s�ꂪ���݂��ĂȂ��i�K�œ�������Ӗ��͂Ȃ���ȁB
����32�R�ACell�̌v������݂��Ȃ����A�g�b�v500�ɐ�߂�Xeon�̃V�F�A�͂ǂ�ǂ�オ���Ă����B
>>908
> NVIDIA��GPU�Ƃ��Ă̖{�����̂ĂĂł�GeForce�̔ėp����i�߂Ă�B
> �����������Ƃł��Ȃ�������A���ꂾ���̃��X�N��Ȃ��ƃC�m�x�[�V�����͋N�����Ȃ��B
>
> ���Ȃ��Ƃ��ێ�I�ȃA�[�L�e�N�`���ɗ��߂Ĉ��S����Ƃ�͎̂s��\�����ς��悤�Ƃ����p���ł͂Ȃ��ˁB
> �Ă������炳�܂Ȉ��S����Ƃ��āA�ǂ��̃\�t�g�E�F�A�x���`���[�����X�N���������Ă����̂��B
> ��̐����Ȃ��Ƃ��������悤���Ȃ��B
�ǂ�Ȃɔėp����i�߂Ă�Geforce�͏��F�͊O�t���̃A�N�Z�����[�^�[�ł�������
CPU���̂ɂ���Ȃ�̔\�͂�����ΕK�v���͂��Ȃ茸��
�N���������\��GPGPU���������o���Ĕ����킯����Ȃ��A����Ȃ̂͋ɏ���
����CPU�ɂ���Ȃ��GPGPU�����Ă�����w�ǂ̐l�͂���Ŗ��������낤��
���N�͏o�n�߂�����V�F�A�͂����������ƂȂ����ǁA�ė��N�ȍ~�͂قڂ��ׂĂ̐V�K�m�[�gPC��Fusion CPU�ɂȂ�B
�f�X�N�g�b�v�����ė��p����邩�炻��Ȃ�̐��ɂȂ�B
AMD CPU�̃V�F�A��20%�̂܂܂ł��A�S���E�Ő��疜��̋K�͂ɂȂ�AGPU���܂߂��1����ɋ߂��Ȃ�B
���̑S�Ă�DX11�AOpenCL�ɑΉ��o����킯������A�C�m�x�[�V�������N�����ɂ͏\������B
> NVIDIA��GPU�Ƃ��Ă̖{�����̂ĂĂł�GeForce�̔ėp����i�߂Ă�B
> �����������Ƃł��Ȃ�������A���ꂾ���̃��X�N��Ȃ��ƃC�m�x�[�V�����͋N�����Ȃ��B
>
> ���Ȃ��Ƃ��ێ�I�ȃA�[�L�e�N�`���ɗ��߂Ĉ��S����Ƃ�͎̂s��\�����ς��悤�Ƃ����p���ł͂Ȃ��ˁB
> �Ă������炳�܂Ȉ��S����Ƃ��āA�ǂ��̃\�t�g�E�F�A�x���`���[�����X�N���������Ă����̂��B
> ��̐����Ȃ��Ƃ��������悤���Ȃ��B
�ǂ�Ȃɔėp����i�߂Ă�Geforce�͏��F�͊O�t���̃A�N�Z�����[�^�[�ł�������
CPU���̂ɂ���Ȃ�̔\�͂�����ΕK�v���͂��Ȃ茸��
�N���������\��GPGPU���������o���Ĕ����킯����Ȃ��A����Ȃ̂͋ɏ���
����CPU�ɂ���Ȃ��GPGPU�����Ă�����w�ǂ̐l�͂���Ŗ��������낤��
���N�͏o�n�߂�����V�F�A�͂����������ƂȂ����ǁA�ė��N�ȍ~�͂قڂ��ׂĂ̐V�K�m�[�gPC��Fusion CPU�ɂȂ�B
�f�X�N�g�b�v�����ė��p����邩�炻��Ȃ�̐��ɂȂ�B
AMD CPU�̃V�F�A��20%�̂܂܂ł��A�S���E�Ő��疜��̋K�͂ɂȂ�AGPU���܂߂��1����ɋ߂��Ȃ�B
���̑S�Ă�DX11�AOpenCL�ɑΉ��o����킯������A�C�m�x�[�V�������N�����ɂ͏\������B
923 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:42:32 ID:ZpwaxppR
>>920
Tegra�̂��Ƃ�
Tegra�̂��Ƃ�
�Ȃ��Â�AMD�̘H�����m�肵�Ă邪��
�����͐�s������
�����͐�s������
Larrabee����������Ȃ��Ƃ����\��������킯��
926 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:45:12 ID:ZpwaxppR
���{����PC���[�J�[�̉ă��f�����������ł�Intel��F�����ǂ�
AMD���ĐM�p�����ȂƎv������B
AMD���ĐM�p�����ȂƎv������B
�Q�[���@�ƌg�т̋�ʂ܂Ŏ�������
���Ȃ�s�����ۂ���
���Ȃ�s�����ۂ���
928 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:48:37 ID:ZpwaxppR
�X�}�[�g�t�H�����Q�[���v���b�g�t�H�[������
iPhone�̃\�t�g�s��͊���PSP���z���Ă�
iPhone�̃\�t�g�s��͊���PSP���z���Ă�
���͂Ƃ������A���z�x�[�X�ł�
�ꂵ�߂��Ȃ�ˁB���ł�
�����������Ȃ��āA�݂��
�\�[�V�����Q�[���Ɉڂ��Ă�݂��������B
�ꂵ�߂��Ȃ�ˁB���ł�
�����������Ȃ��āA�݂��
�\�[�V�����Q�[���Ɉڂ��Ă�݂��������B
>>922
> ����CPU�ɂ���Ȃ��GPGPU�����Ă�����w�ǂ̐l�͂���Ŗ��������낤��
Ion�ł��ˁB
>>928
iPhone�����Q�[���r�W�l�X�͔��ɋꂵ�������c�c
> ����CPU�ɂ���Ȃ��GPGPU�����Ă�����w�ǂ̐l�͂���Ŗ��������낤��
Ion�ł��ˁB
>>928
iPhone�����Q�[���r�W�l�X�͔��ɋꂵ�������c�c
�܂�����I�߂�����߂�
����ύD���Ȃ̂�
����ύD���Ȃ̂�
932 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 22:54:42 ID:ZpwaxppR
�ߓ������Ō������̂ƁA�ߑa�����R�X�g�Ō������̂Ƃǂ������}�V��
�E�E�E�ǂ������N�\����
�E�E�E�ǂ������N�\����
�Q�[�����[�U�[���������甃���ւ��������Ăǂ��Ȃ�ȁH
934 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 23:16:49 ID:ZpwaxppR
���Ԃ�����Q�[�����@�Ƃ��Ă���Ă������ƍl���Ă�͔̂C�V�����炢�����Ȃ��Ǝv����
���������u���@��Xbox�́u�����p�\�R���v�������͂��Ȃ��Ǝv�����ǂ�
PS3�����ЊJ���̃u���E�U��BD�v���C���[�𓋍ڂ��Ă�
360��IE���ڂ��Ȃ�����
�������ЂƋ������邽�߂Ɏ��А��i�̎s������������悤�Ȗ{���]�|�Ȃ��Ƃ͂��Ȃ��̂�MS��Intel�������B
���������u���@��Xbox�́u�����p�\�R���v�������͂��Ȃ��Ǝv�����ǂ�
PS3�����ЊJ���̃u���E�U��BD�v���C���[�𓋍ڂ��Ă�
360��IE���ڂ��Ȃ�����
�������ЂƋ������邽�߂Ɏ��А��i�̎s������������悤�Ȗ{���]�|�Ȃ��Ƃ͂��Ȃ��̂�MS��Intel�������B
>>926
���ǃ_���S��CPU�I�т͐��\�A�R�X�p���ł͂Ȃ��A�u�݂�Ȃ��g���Ă��邩��v�Ƃ������R���c�B
���ǃ_���S��CPU�I�т͐��\�A�R�X�p���ł͂Ȃ��A�u�݂�Ȃ��g���Ă��邩��v�Ƃ������R���c�B
�v���悗�ł���
�J�������^���Ęb���Ă����̂��Ǝv��������
�Ȃ��ڂ������Ȃ���������Ă��Ă�
�J�������^���Ęb���Ă����̂��Ǝv��������
�Ȃ��ڂ������Ȃ���������Ă��Ă�
937 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 23:38:19 ID:ZpwaxppR
>>935
���������Ȃ�Atom�ŏ\���ȂB���߂�B
���[�J�[�̎��_�ł����Ƃ�������
Core i3/i5/i7�E�E�E���C���X�g���[������p�t�H�[�}���X�����W�܂œ����\�P�b�g�ŃJ�o�[
�@�O���t�B�b�N���\���K�v�Ȃ�f�B�X�N���[�g�J�[�h���h������
Celeron�E�E�E�O�����Core 2�x�[�X��➑̐v�����̂܂g����
�ቿ�i�H���ɓ]����AMD���̗p����邩�ǂ����́A�h�������� IGP�ȏ�f�B�X�N���[�g������
����GPU���\�̂��߂ɕʓr➑̐v�����鉿�l�����邩�ǂ����ɂ������Ă���Ǝv����B
���������i�l�b�g�u�b�N���������j�m�[�gPC�̏���҂�GPU���\��w�ǕK�v�Ƃ��ĂȂ��r�W�l�X���[�U�[��
���Ȃ�̕�����߂Ă���AGPU�����͂ɂȂ�Δ����Ȃ�Ĕ��z�̓t�@���{�[�C1�l������Ă�
�x���_�[�͂����͎v��Ȃ��̂������B
780G/790G�ŃV�F�A�D�ҏo���ĂȂ����Ƃ��ACPU�A�[�L�ς��Ȃ��܂�
CPU�������Ă���{�C�o���Ƃ������Ă������ς���B
���������Ȃ�Atom�ŏ\���ȂB���߂�B
���[�J�[�̎��_�ł����Ƃ�������
Core i3/i5/i7�E�E�E���C���X�g���[������p�t�H�[�}���X�����W�܂œ����\�P�b�g�ŃJ�o�[
�@�O���t�B�b�N���\���K�v�Ȃ�f�B�X�N���[�g�J�[�h���h������
Celeron�E�E�E�O�����Core 2�x�[�X��➑̐v�����̂܂g����
�ቿ�i�H���ɓ]����AMD���̗p����邩�ǂ����́A�h�������� IGP�ȏ�f�B�X�N���[�g������
����GPU���\�̂��߂ɕʓr➑̐v�����鉿�l�����邩�ǂ����ɂ������Ă���Ǝv����B
���������i�l�b�g�u�b�N���������j�m�[�gPC�̏���҂�GPU���\��w�ǕK�v�Ƃ��ĂȂ��r�W�l�X���[�U�[��
���Ȃ�̕�����߂Ă���AGPU�����͂ɂȂ�Δ����Ȃ�Ĕ��z�̓t�@���{�[�C1�l������Ă�
�x���_�[�͂����͎v��Ȃ��̂������B
780G/790G�ŃV�F�A�D�ҏo���ĂȂ����Ƃ��ACPU�A�[�L�ς��Ȃ��܂�
CPU�������Ă���{�C�o���Ƃ������Ă������ς���B
�Q�[���������l�����{���[�J�[��PC���̂��H
�Ȃ���{���[�J�[��Intel��I�Ԃ��
�Ȃ���{���[�J�[��Intel��I�Ԃ��
�c�q�̃Q�[���ƊE��GPU�Ɋւ���R�����g���Ӗ�Ƣintel�̌R��ɍ~��Ȃ��ƊE�Ȃǒׂ�Ă��܂�����Č����Ă邾�������ȁB
�Ⴆ��GPU�Ɋւ��Ă͢GPGPU�Ȃ��CPU�̎d����D���悤�Ȃ��Ƃ͎~�߂�GPU�Ƃ��Ă̎d���������Ă������ƌ�����
������ǁAGPU�Ƃ��Ă̎d���͍���CPU����邩��AGPU�͂������ƂɂȂ��Ă��ꣂ�����ˁB
���̓���d�˂�A���(CPU)�͂��O(GPU)�̎d����D�����ǁA���O(GPU)�͉�(CPU)�̎d����D���Ȃ棂ƌ����Ă邾���B
�Ⴆ��GPU�Ɋւ��Ă͢GPGPU�Ȃ��CPU�̎d����D���悤�Ȃ��Ƃ͎~�߂�GPU�Ƃ��Ă̎d���������Ă������ƌ�����
������ǁAGPU�Ƃ��Ă̎d���͍���CPU����邩��AGPU�͂������ƂɂȂ��Ă��ꣂ�����ˁB
���̓���d�˂�A���(CPU)�͂��O(GPU)�̎d����D�����ǁA���O(GPU)�͉�(CPU)�̎d����D���Ȃ棂ƌ����Ă邾���B
Intel���Q�[���ƊE�ɗn�����߂Ȃ���������@����������ˁH
���{��AMD���̗p����Ȃ��̂͋����ʂɖ�肪���邩�炶��Ȃ���
�ߋ���Intel�̉����������W���Ă邯��
�܂��A�Z�������卑�̓��{����CPU�Ȃ͈�ʐl�ɂ͊W�Ȃ�����
�ߋ���Intel�̉����������W���Ă邯��
�܂��A�Z�������卑�̓��{����CPU�Ȃ͈�ʐl�ɂ͊W�Ȃ�����
942 �F,,�E�L�́M�E,,�j��-�������F2010/05/16(��) 23:53:02 ID:ZpwaxppR
IGP��S�ʂɑł��o�������Ȃ�Sandy Bridge�̃Z�J���h�\�[�X�_��
GMA�̑����Radeon�ڂ��������i�ł�������炢����Ȃ���
CPU�̓r�b�N���}���`���R����Ȃ�����u���܂��v�ړ��Ă̏���҂č��ނ̂͊ԈႢ
GMA�̑����Radeon�ڂ��������i�ł�������炢����Ȃ���
CPU�̓r�b�N���}���`���R����Ȃ�����u���܂��v�ړ��Ă̏���҂č��ނ̂͊ԈႢ
���ꂪ�o����Ȃ����Ă܂�����
Intel�����E�u��҂Ɍ�����Ȃ�Ă���ϕs����
Intel�����E�u��҂Ɍ�����Ȃ�Ă���ϕs����
�����ǂ��ᔻ���ăo�J�ɂ��Ă�����Fusion���m�肷�邵���Ȃ��Ȃ邩���
>>928
�X�}�[�g�t�H���ő������߂�Snapdragon��GPU�R�A��XBox360�݊���Radeon�݊�
���C�Z���X�͏��n���Ă��邯�ǂ�
�A�[�L�e�N�`���ɋ��ʓ_����������A�ڐA���N���X�W�J���ƂĂ����₷��
����ATI�A�[�L�e�N�`�����Q�[���s��̑����h�ł��邱�Ƃ͕ς��Ȃ���
>>930
Ion��Core2�ƈ�@��ō����ׂ�ŗ��N����
Ion2�͒ᐫ�\�O�t���ł��������������ς藈�N����
>>928
�X�}�[�g�t�H���ő������߂�Snapdragon��GPU�R�A��XBox360�݊���Radeon�݊�
���C�Z���X�͏��n���Ă��邯�ǂ�
�A�[�L�e�N�`���ɋ��ʓ_����������A�ڐA���N���X�W�J���ƂĂ����₷��
����ATI�A�[�L�e�N�`�����Q�[���s��̑����h�ł��邱�Ƃ͕ς��Ȃ���
>>930
Ion��Core2�ƈ�@��ō����ׂ�ŗ��N����
Ion2�͒ᐫ�\�O�t���ł��������������ς藈�N����
�c�q��AMD�v���b�g�t�H�[���̗p�̃m�[�gPC�̃��f������50����100�ɔ{�������̂�m��Ȃ��̂�
�m�[�g�x���_�[��90%��DX11 GPU�ɋ���������̂�m��Ȃ��̂�
�m�[�g�x���_�[��90%��DX11 GPU�ɋ���������̂�m��Ȃ��̂�
946 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 00:13:12 ID:3wc/5yYP
>>943
���Ⴀ�t��Radeon��IP�����C�Z���X���ă}�[�W�������I
�E�E�E�ǂ�����������
������Atom������Ɋւ��Ă�TSMC�Ɉϑ����Ă邵�AIon�Ƃ��̓������Ƃ��܂߂��蓾��b����Ȃ�
���Ⴀ�t��Radeon��IP�����C�Z���X���ă}�[�W�������I
�E�E�E�ǂ�����������
������Atom������Ɋւ��Ă�TSMC�Ɉϑ����Ă邵�AIon�Ƃ��̓������Ƃ��܂߂��蓾��b����Ȃ�
>>945
�c���10%�͓��{���[�J�[
�c���10%�͓��{���[�J�[
TSMC�Ɉϑ�����IO�`�b�v�����
>>946
> >>943
> ���Ⴀ�t��Radeon��IP�����C�Z���X���ă}�[�W�������I
> �E�E�E�ǂ�����������
���Ѓn�[�h�ł���낭�Ƀh���C�o�����Ȃ�Intel��VLIW�ł߂�ǂ�����Radeon�͓��ꈵ���Ȃ���
Intel�͂��ƂȂ���Radeon�Ƒg�����Ă�Ⴂ����
> ������Atom������Ɋւ��Ă�TSMC�Ɉϑ����Ă邵�AIon�Ƃ��̓������Ƃ��܂߂��蓾��b����Ȃ�
TSMC��Atom�͈ϑ�����1�N�Ԍڋq�����Ȃ��ēڍ������̂�m��Ȃ��̂��H
> >>943
> ���Ⴀ�t��Radeon��IP�����C�Z���X���ă}�[�W�������I
> �E�E�E�ǂ�����������
���Ѓn�[�h�ł���낭�Ƀh���C�o�����Ȃ�Intel��VLIW�ł߂�ǂ�����Radeon�͓��ꈵ���Ȃ���
Intel�͂��ƂȂ���Radeon�Ƒg�����Ă�Ⴂ����
> ������Atom������Ɋւ��Ă�TSMC�Ɉϑ����Ă邵�AIon�Ƃ��̓������Ƃ��܂߂��蓾��b����Ȃ�
TSMC��Atom�͈ϑ�����1�N�Ԍڋq�����Ȃ��ēڍ������̂�m��Ȃ��̂��H
950 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 00:23:24 ID:3wc/5yYP
> VLIW�ł߂�ǂ�����
GPGPU�Ƃ��Đ������Ȃ��Ǝv���Ă�ő�̗��R��������Ɍ����Ă���Ċ��ӂ���
GPGPU�Ƃ��Đ������Ȃ��Ǝv���Ă�ő�̗��R��������Ɍ����Ă���Ċ��ӂ���
>>934
�ł��C�V������ԃQ�[����p�@���牓����ȁA����Ӗ��B
�ł��C�V������ԃQ�[����p�@���牓����ȁA����Ӗ��B
>>951
���ŁH
���ŁH
953 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 00:37:53 ID:3wc/5yYP
WiiFit�͌��N���Ƃ������Ă�l�ł���
�Ԃ����Ⴏ�A����Ӗ�����͋��ɂ̂�荞�݃Q�[����
�Ԃ����Ⴏ�A����Ӗ�����͋��ɂ̂�荞�݃Q�[����
WiiFit�̑ωd�I�[�o�[��������Ă���l�Ȃ낤��
�Ȃ�������
�Ȃ�������
Fusion���Ă̂�����������ł邩��A�����}�U�{��CPU�ɂ��Ƃ��Ă��ƂŎ���ւ���
���Ă���ꂽ�������Ă�́H
���Ă���ꂽ�������Ă�́H
>>945
�������Intel�̐������ǂ����ĂȂ����炶��Ȃ��́H
�������Intel�̐������ǂ����ĂȂ����炶��Ȃ��́H
>>950
�ő�̗��R�̓}�[�P�e�B���O���ア���Ƃ���
VLIW�͈�������������ő債�����R�ɂ͂Ȃ�Ȃ���
�}�[�P�e�B���O��������X2���PenD������邵�A���l�[��������o�X�팸���\�ł����������
�ő�̗��R�̓}�[�P�e�B���O���ア���Ƃ���
VLIW�͈�������������ő債�����R�ɂ͂Ȃ�Ȃ���
�}�[�P�e�B���O��������X2���PenD������邵�A���l�[��������o�X�팸���\�ł����������
VLIW�͎g�����ɂȂ�Ȃ�������
AMD���؎̂ĘH���W����
MIMID�AMIMD�����ł邪
�܂��߂�MIMD�Ȃ炻�̕��G����larrabee�Ȃ̔䂶��Ȃ�
AMD���؎̂ĘH���W����
MIMID�AMIMD�����ł邪
�܂��߂�MIMD�Ȃ炻�̕��G����larrabee�Ȃ̔䂶��Ȃ�
WiiFit�͗~�������ǃ}���V���������疳����˂�B
>>960
���炩�ɓ��{��ɂȂ��ĂȂ������̌��t���N�V��
�Z���̏o���Ȃ��E���R�Ƃ����R���r��g��ł�ID���Ƃ������Ƃ�җ�ɃA�s�[��
���炩�ɓ��{��ɂȂ��ĂȂ������̌��t���N�V��
�Z���̏o���Ȃ��E���R�Ƃ����R���r��g��ł�ID���Ƃ������Ƃ�җ�ɃA�s�[��
Larrabee�Œc�q�̃g������͂���̂����ł��B
Intel�͕����̍H������[�e�[�V���������A�펞4�H��ȏ�ғ������Ă���
����AMD��1�H��
�}�[�P�e�B���O�������A���̐��Y�\�͂��ች������Ă����Ӗ�
GF�̐V�H��Ɣ����U���Ɋ���
CPU�̐��ŏ��s�����߂�̂͐����̕��ł����ăA�[�L�e�N�`���[�Ȃ�Ă��܂�
����AMD��1�H��
�}�[�P�e�B���O�������A���̐��Y�\�͂��ች������Ă����Ӗ�
GF�̐V�H��Ɣ����U���Ɋ���
CPU�̐��ŏ��s�����߂�̂͐����̕��ł����ăA�[�L�e�N�`���[�Ȃ�Ă��܂�
965 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 08:45:05 ID:3wc/5yYP
>>957
Pentium D�͊��ɓ����\�t�g�����݂��Ă���B�������������ˁH
Radeon�͏\���ȃV�F�A�͊m�����Ă邪GPGPU�Ƃ��Ẵ\�t�g�͂قڊF���B
��ʏ���҂ɂƂ��Ă�VLIW�v���O���~���O���邽�߂ɔ����Ă��Ȃ�����GPGPU�Ƃ��ē��̖ڂ��݂邩�ǂ����ǂ����͑S���̕ʖ��B
�ЂƂ̎����Ƃ��āANVIDIA�́AVLIW�����߂��B
���R�͖����BVLIW�͔ėp�I�ȃR�[�h�̃v���O���~���O�Ɍ����Ȃ����炾�B
Pentium D�͊��ɓ����\�t�g�����݂��Ă���B�������������ˁH
Radeon�͏\���ȃV�F�A�͊m�����Ă邪GPGPU�Ƃ��Ẵ\�t�g�͂قڊF���B
��ʏ���҂ɂƂ��Ă�VLIW�v���O���~���O���邽�߂ɔ����Ă��Ȃ�����GPGPU�Ƃ��ē��̖ڂ��݂邩�ǂ����ǂ����͑S���̕ʖ��B
�ЂƂ̎����Ƃ��āANVIDIA�́AVLIW�����߂��B
���R�͖����BVLIW�͔ėp�I�ȃR�[�h�̃v���O���~���O�Ɍ����Ȃ����炾�B
966 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 08:55:22 ID:3wc/5yYP
>>964
Core 2, Xeon(Woodcrest)�̓o��ȍ~�A�����L���p���]��܂����ĐԎ��ɂȂ����̂�
����Ȃ����i���ʂɍ���Ă��S���ɂȂ邾���ł��傤�H
Core 2, Xeon(Woodcrest)�̓o��ȍ~�A�����L���p���]��܂����ĐԎ��ɂȂ����̂�
����Ȃ����i���ʂɍ���Ă��S���ɂȂ邾���ł��傤�H
�ق�Ƃɖϑz�ƃo�O�����Ȃ���
VLIW���ėp�I�ȃR�[�h�̃v���O���~���O�Ɍ����Ȃ����Ă͎̂����Ȃ낤���ǁA
�ėp���ɐU�肷��������Larrabee�͓d�͌����Ƃ�(���ɂ����R�͂��邾�낤��)�Ŏs��ɏo�Ȃ��������A
���͋ƊE�S�̂Ŕėp���ƌ����𗼗������v���Z�b�T�̃A�[�L�e�N�`���ƃv���O���~���O���f����͍����Ă�i�K�Ȃ�Ȃ��H
�ėp���ɐU�肷��������Larrabee�͓d�͌����Ƃ�(���ɂ����R�͂��邾�낤��)�Ŏs��ɏo�Ȃ��������A
���͋ƊE�S�̂Ŕėp���ƌ����𗼗������v���Z�b�T�̃A�[�L�e�N�`���ƃv���O���~���O���f����͍����Ă�i�K�Ȃ�Ȃ��H
�����������̂��͈̂����̂Œl��������Ƃ����肪����B
�l�������Ĕ����Ȃ�ȁB
�l�������Ĕ����Ȃ�ȁB
>>964
�����_�Ńh���X�f����Fab1�ƃ`���[�^�[�h�����ɂ�蓾��Fab���AFab2�`7�B
NY�̌��ݒ���Fab��Fab8�����ɂȂ�܂��B�����ȉR�����肪�Ƃ��B
���Ȃ݂ɁAFab1��Fab36�y��Fab38�ƌĂ�Ă������m�Ȃ̂ŁA
�����I��2�H�ꕪ�̐��Y�L���p�������Ă���Ƃ����Ă��ߌ��ł͂Ȃ��ł���B
�t�����Y��x86�s��ŃV�F�A50%��_����ƍ��ꂵ�Ă���Fab�����B
�܂��B����Fab36/38��AMD�̌o�c���������Ă������ǂȁI
�����_�Ńh���X�f����Fab1�ƃ`���[�^�[�h�����ɂ�蓾��Fab���AFab2�`7�B
NY�̌��ݒ���Fab��Fab8�����ɂȂ�܂��B�����ȉR�����肪�Ƃ��B
���Ȃ݂ɁAFab1��Fab36�y��Fab38�ƌĂ�Ă������m�Ȃ̂ŁA
�����I��2�H�ꕪ�̐��Y�L���p�������Ă���Ƃ����Ă��ߌ��ł͂Ȃ��ł���B
�t�����Y��x86�s��ŃV�F�A50%��_����ƍ��ꂵ�Ă���Fab�����B
�܂��B����Fab36/38��AMD�̌o�c���������Ă������ǂȁI
���������邽�߂ɉғ������鐢�E�Ƃ����̂��u������v
ATI��������VLIW�𑱂�����đO��Ȃ̂��ʔ���
�X���b�h�͖����ɂ��邯��1�X���b�h���ł͈ˑ���������
�Ƃ����ł�
NV�̃A�[�L�ł̓X���b�h�����X�ƍ���ĉ��Z���]�����g����̂ɑ�
VLIW�ł͕����X���b�h��1���߂Ɏ��߂邱�Ƃ͏o���Ȃ����낤����
1���j�b�g���������Ăđ���4���j�b�g�͉ɂ����ė]���Ă�Ƃ����ɂȂ����������
�������x�N�^�łȂ��Ă�1�X���b�h���łƂɂ�������x�������������̂Ȃ�
VLIW�͔��Ɍ������ǂ�
3D�`�����ނ���̫���{�R���Ă���ʂ�i��̫FX�͉��̂����s�����悤�����ǁj
GPGPU�ł�NV�̂������������̂Ȃ�VLIW������͖̂������낤����
��������16�x�N�^���j�b�g��1��2�̃X�J�����j�b�g�����Ȃ����ނȂ����ƍ�����Ȃ����H
�Ƃ����ł�
NV�̃A�[�L�ł̓X���b�h�����X�ƍ���ĉ��Z���]�����g����̂ɑ�
VLIW�ł͕����X���b�h��1���߂Ɏ��߂邱�Ƃ͏o���Ȃ����낤����
1���j�b�g���������Ăđ���4���j�b�g�͉ɂ����ė]���Ă�Ƃ����ɂȂ����������
�������x�N�^�łȂ��Ă�1�X���b�h���łƂɂ�������x�������������̂Ȃ�
VLIW�͔��Ɍ������ǂ�
3D�`�����ނ���̫���{�R���Ă���ʂ�i��̫FX�͉��̂����s�����悤�����ǁj
GPGPU�ł�NV�̂������������̂Ȃ�VLIW������͖̂������낤����
��������16�x�N�^���j�b�g��1��2�̃X�J�����j�b�g�����Ȃ����ނȂ����ƍ�����Ȃ����H
>>970
���̒���CPU�����p�Ȃ̂�Fab1����
�ł�����Fab1��AMD����Ɍ�������2�H�ꕪ���݂��ꂽ���A�g�����ꂽ2�H��ڂ͌��������Œ��g�͖���
�����݂̓��C��������A�N���ɉғ�
�o���N�p��200�_�E�F�n�p�̍H��Ȃ炢�����L�邪�A���s��CPU�͍��Ȃ�
���̒���CPU�����p�Ȃ̂�Fab1����
�ł�����Fab1��AMD����Ɍ�������2�H�ꕪ���݂��ꂽ���A�g�����ꂽ2�H��ڂ͌��������Œ��g�͖���
�����݂̓��C��������A�N���ɉғ�
�o���N�p��200�_�E�F�n�p�̍H��Ȃ炢�����L�邪�A���s��CPU�͍��Ȃ�
�A�z��
976 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 18:18:21 ID:3wc/5yYP
>>974
�����������Ƃ���H
http://www.itmedia.co.jp/news/articles/0704/10/news020.html
�L���b�V���t���[�������牽���ł��Ȃ����Ă��ƁB
���n���j�[�g�̑���Ȃǂ���C�͍X�X������
http://www.atmarkit.co.jp/fcoding/articles/parallel/03/para03c.html
> T10��SIMT��œ����e�X���b�h�͓Ǝ���architectural state�������Ă��邽�߁A�e�X���b�h���ꂼ�ꂪ
> �Ǝ��̃��[�v���������������s�����Ƃ��\�ł��B�������A���߃f�R�[�_�����L���Ă��邽�߁A
> �e�X���b�h���Ǝ��̏������s�����ꍇ������s�ɂ͂Ȃ�܂���BT10�̐��\�������o�����߂ɂ́A
> ��萔�iT10�ł�32�j�̃X���b�h���������߂����s����K�v������܂��B
NVIDIA�̂����X���b�h�̍l�����ł����Ȃ�Larrabee��1�R�A������16�X���b�h�������ł���i�j
�uSIMT�v�͗v�����SIMD�ɂ�������\�[�X�̊e�v�f���X���b�h�ƌĂ�ł邾���ł̂��̂�
����������̓ǂݏ������Ƀf�[�^���ăp�b�N���ď������Ă��邾���B
�X�ɒ������̂����uarchitectural state�v���Ď��͗v�f�Ɨ��̃v���f�B�P�[�g�r�b�g�}�X�N�ł����Ȃ������肷��B
�f�[�^�̍ăp�b�L���O�Ɨv�f�P�ʂ̃v���f�B�P�[�V�����������SIMD�G���W����SIMT�i�j�ɂȂ肤��B
SSE4�ł����̕ӂ͑啝�ɋ�������Ă�̂ŁA����Ӗ���Core 2 Quad��16�R�A��SIMT�A�[�L�e�N�`���Ƃ������ƂɂȂ�i�j
�i����OpenCL�ł͂�����������U�肪�\�j
�����������Ƃ���H
http://www.itmedia.co.jp/news/articles/0704/10/news020.html
�L���b�V���t���[�������牽���ł��Ȃ����Ă��ƁB
���n���j�[�g�̑���Ȃǂ���C�͍X�X������
http://www.atmarkit.co.jp/fcoding/articles/parallel/03/para03c.html
> T10��SIMT��œ����e�X���b�h�͓Ǝ���architectural state�������Ă��邽�߁A�e�X���b�h���ꂼ�ꂪ
> �Ǝ��̃��[�v���������������s�����Ƃ��\�ł��B�������A���߃f�R�[�_�����L���Ă��邽�߁A
> �e�X���b�h���Ǝ��̏������s�����ꍇ������s�ɂ͂Ȃ�܂���BT10�̐��\�������o�����߂ɂ́A
> ��萔�iT10�ł�32�j�̃X���b�h���������߂����s����K�v������܂��B
NVIDIA�̂����X���b�h�̍l�����ł����Ȃ�Larrabee��1�R�A������16�X���b�h�������ł���i�j
�uSIMT�v�͗v�����SIMD�ɂ�������\�[�X�̊e�v�f���X���b�h�ƌĂ�ł邾���ł̂��̂�
����������̓ǂݏ������Ƀf�[�^���ăp�b�N���ď������Ă��邾���B
�X�ɒ������̂����uarchitectural state�v���Ď��͗v�f�Ɨ��̃v���f�B�P�[�g�r�b�g�}�X�N�ł����Ȃ������肷��B
�f�[�^�̍ăp�b�L���O�Ɨv�f�P�ʂ̃v���f�B�P�[�V�����������SIMD�G���W����SIMT�i�j�ɂȂ肤��B
SSE4�ł����̕ӂ͑啝�ɋ�������Ă�̂ŁA����Ӗ���Core 2 Quad��16�R�A��SIMT�A�[�L�e�N�`���Ƃ������ƂɂȂ�i�j
�i����OpenCL�ł͂�����������U�肪�\�j
NV�A�[�L�Ɠ����l��
�X�J�X�JSIMD���Ƃ�SIMM���j�b�g�̃��������[�h�҂��ɕʃX���b�h�����
�ʂ̖��߂�SIMM�߂邱�Ƃ��o���鐢�E��������
���͗����i��������j����ړ��ĂŃf�[�^���^�X�N����ȃV���^�z���ł���
�X�J�X�JSIMD���Ƃ�SIMM���j�b�g�̃��������[�h�҂��ɕʃX���b�h�����
�ʂ̖��߂�SIMM�߂邱�Ƃ��o���鐢�E��������
���͗����i��������j����ړ��ĂŃf�[�^���^�X�N����ȃV���^�z���ł���
978 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 18:31:17 ID:3wc/5yYP
���m�Ɍ�����Larrabee��4Way�̃n�[�h�E�F�A�}���`�X���b�h�~16Way�̃\�t�g�E�F�A�}���`�X���b�h�i�j��64 thread/core����
���ʂ�CPU�̂悤��1�̃v���O�����t���[�̒��ŕ��Z���\�[�X��S�Ďg���悤�ȃv���O���~���O�X�^�C�����s�����R�x�͗^�����Ă��Ȃ��̂�
GeForce��SIMT�͂ނ���SIMD�̗łƌ��邱�Ƃ��ł���B
���ʂ�CPU�̂悤��1�̃v���O�����t���[�̒��ŕ��Z���\�[�X��S�Ďg���悤�ȃv���O���~���O�X�^�C�����s�����R�x�͗^�����Ă��Ȃ��̂�
GeForce��SIMT�͂ނ���SIMD�̗łƌ��邱�Ƃ��ł���B
979 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 18:35:09 ID:3wc/5yYP
plNa4WAz���j�[�g��������������
�G���������������
�O��㐧���Č����Ă����
982 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 18:43:11 ID:3wc/5yYP
�]����
�����Ŏ����Ă����\�[�X���S���ǂ߂���
1�N�߂��ϑz�R�炵������L���z��
202 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/07/22(��) 06:59:49 ID:3rqpGJeJ
�����ł��ǂ�ł�����
http://www.4gamer.net/games/050/G005004/20080614003/
�i�ȉ����j
���u�C�ӂ̗v�f���̃x�N�g�����Z���CSM�i��IU�j���f�R�[�h�B
���x�z���ƂȂ�8���SP����C�K�v�Ȑ����������p���Ď��s�X���b�h�������C
��SP���]���Ă�����CSP���������A�N�Z�X�����Ă��āC���̌��ʂ��Ԃ��Ă���܂ŃX�g�[�����Ă����肷��̂����m����ƁC
��IU�͎��̖��߂����CSP�����p���ׂ��ʂ̃X���b�h����������v
��SIMD�ł́C�x�N�g�����Z��̓��ӂƂ���x�N�g���l���ɁC�f�[�^��������K�v������B
���Ⴆ��SSE����4�v�f�x�N�g�����Z��ŏ����n����������Ă��邽�߁C
�����ׂẲ��Z�킪���p����āC�ō��̃p�t�H�[�}���X��������̂́C���Z�ΏۂƂȂ�f�[�^��4�v�f�x�N�g���̂Ƃ��Ɍ�����
���i�����邢��2�v�f�x�N�g���~2�Z�b�g�Ȃǁj�B
1�N�߂��ϑz�R�炵������L���z��
202 ���O�F,,�E�L�́M�E,,�j��-������[sage] ���e���F2009/07/22(��) 06:59:49 ID:3rqpGJeJ
�����ł��ǂ�ł�����
http://www.4gamer.net/games/050/G005004/20080614003/
�i�ȉ����j
���u�C�ӂ̗v�f���̃x�N�g�����Z���CSM�i��IU�j���f�R�[�h�B
���x�z���ƂȂ�8���SP����C�K�v�Ȑ����������p���Ď��s�X���b�h�������C
��SP���]���Ă�����CSP���������A�N�Z�X�����Ă��āC���̌��ʂ��Ԃ��Ă���܂ŃX�g�[�����Ă����肷��̂����m����ƁC
��IU�͎��̖��߂����CSP�����p���ׂ��ʂ̃X���b�h����������v
��SIMD�ł́C�x�N�g�����Z��̓��ӂƂ���x�N�g���l���ɁC�f�[�^��������K�v������B
���Ⴆ��SSE����4�v�f�x�N�g�����Z��ŏ����n����������Ă��邽�߁C
�����ׂẲ��Z�킪���p����āC�ō��̃p�t�H�[�}���X��������̂́C���Z�ΏۂƂȂ�f�[�^��4�v�f�x�N�g���̂Ƃ��Ɍ�����
���i�����邢��2�v�f�x�N�g���~2�Z�b�g�Ȃǁj�B
984 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 18:54:51 ID:3wc/5yYP
> �@SIMD�ł́C�x�N�g�����Z��̓��ӂƂ���x�N�g���l���ɁC�f�[�^��������K�v������B
> �Ⴆ��SSE����4�v�f�x�N�g�����Z��ŏ����n����������Ă��邽�߁C���ׂẲ��Z�킪���p����āC
> �ō��̃p�t�H�[�}���X��������̂́C���Z�ΏۂƂȂ�f�[�^��4�v�f�x�N�g���̂Ƃ��Ɍ�����
> �i�����邢��2�v�f�x�N�g���~2�Z�b�g�Ȃǁj�B
GeForce��4�v�f����Ȃ���32�v�f�x�N�g���ɂȂ邾�������ǂȁB
�f�[�^�̍ăp�b�L���O�i���Ƃ���x, y, z, w���ӂ���x����32�Ay����32�E�E�E�j�𒊏ۉ����Ă邾���ɂ����Ȃ��B
Larrabee�ɂ�Gather/Scatter��1���łł��閽�߂��W���Ŕ�����Ă���̂�GeForce�Ɠ������Ƃ��ł���B
�钆���낤�ƕ����������낤�Ƌx�ݖ���2ch�œ����l��
> �Ⴆ��SSE����4�v�f�x�N�g�����Z��ŏ����n����������Ă��邽�߁C���ׂẲ��Z�킪���p����āC
> �ō��̃p�t�H�[�}���X��������̂́C���Z�ΏۂƂȂ�f�[�^��4�v�f�x�N�g���̂Ƃ��Ɍ�����
> �i�����邢��2�v�f�x�N�g���~2�Z�b�g�Ȃǁj�B
GeForce��4�v�f����Ȃ���32�v�f�x�N�g���ɂȂ邾�������ǂȁB
�f�[�^�̍ăp�b�L���O�i���Ƃ���x, y, z, w���ӂ���x����32�Ay����32�E�E�E�j�𒊏ۉ����Ă邾���ɂ����Ȃ��B
Larrabee�ɂ�Gather/Scatter��1���łł��閽�߂��W���Ŕ�����Ă���̂�GeForce�Ɠ������Ƃ��ł���B
�钆���낤�ƕ����������낤�Ƌx�ݖ���2ch�œ����l��
�c�q�������肵��B�n���o�Ă邼�B
>>981
�G����3�l���ĎO���24���ԑԐ��Ȃ̂��Ǝv�����B
�G�����P��l���ł��A�ǂމ��l�����ȃR�e�iNG�ρj��2�����炢���邩��v3�����B
�G����3�l���ĎO���24���ԑԐ��Ȃ̂��Ǝv�����B
�G�����P��l���ł��A�ǂމ��l�����ȃR�e�iNG�ρj��2�����炢���邩��v3�����B
�ߋ��̃E���R�������ė����\�[�Xvs���̃E���R�̖ϑz
���̂͂ǂ�����
���̂͂ǂ�����
988 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 19:21:45 ID:3wc/5yYP
CUDA�̂���warp���]��CPU��Larrabee�ł���thread
CUDA�̂���thread��Larrabee�ł���strand
�܂��A���t�V�т��ȁB
> SP���������A�N�Z�X�����Ă��āC���̌��ʂ��Ԃ��Ă���܂ŃX�g�[�����Ă����肷��̂����m����ƁC
> IU�͎��̖��߂����CSP�����p���ׂ��ʂ̃X���b�h����������v�Ƃ����d�g�݂��̗p����Ă���̂��B
> ���̎d�g�݂ɂ��CSM�͏�ɕ����̎��s�X���b�h�𐿂������C�x�݂Ȃ��g�����h���ƂɂȂ�B
���̃X���b�h�ؑ@�\��warp�P�ʂ̘b�ŁA�����I�ɂ͍L�`��SMT(Intel�ł���HT)�Ɠ����B
���S�ɖ��߃X�g���[���̓Ɨ������u�X���b�h�v���[�ɂԂ牺������SP�ŕʁX�ɏ����ł��邱�Ƃ��Ӗ����Ȃ��B
���̌������Ƃ��������Ă�悤�Ɍ�����̂͗v����ɖ{�����킩���ĂȂ��Ƃ������Ƃ��B
CUDA�̂���thread��Larrabee�ł���strand
�܂��A���t�V�т��ȁB
> SP���������A�N�Z�X�����Ă��āC���̌��ʂ��Ԃ��Ă���܂ŃX�g�[�����Ă����肷��̂����m����ƁC
> IU�͎��̖��߂����CSP�����p���ׂ��ʂ̃X���b�h����������v�Ƃ����d�g�݂��̗p����Ă���̂��B
> ���̎d�g�݂ɂ��CSM�͏�ɕ����̎��s�X���b�h�𐿂������C�x�݂Ȃ��g�����h���ƂɂȂ�B
���̃X���b�h�ؑ@�\��warp�P�ʂ̘b�ŁA�����I�ɂ͍L�`��SMT(Intel�ł���HT)�Ɠ����B
���S�ɖ��߃X�g���[���̓Ɨ������u�X���b�h�v���[�ɂԂ牺������SP�ŕʁX�ɏ����ł��邱�Ƃ��Ӗ����Ȃ��B
���̌������Ƃ��������Ă�悤�Ɍ�����̂͗v����ɖ{�����킩���ĂȂ��Ƃ������Ƃ��B
�c�q�A���̂܂ɂ��������肢���̃e�w�ɖ߂��Ă����w
�u4�T�\�[�X�ɂ���悤��
��̫��SMT�X�[�p�[�X�J���Ɏ����������o����
���ނ����l��SIMM���ŃX�[�p�[�X�J�����o����v
�ȏ�A24���ԉc�Ƃ���ˑR��ԉc�Ƃ݂̂ɂȂ��������ꂩ��̔O�����p�ł���
��̫��SMT�X�[�p�[�X�J���Ɏ����������o����
���ނ����l��SIMM���ŃX�[�p�[�X�J�����o����v
�ȏ�A24���ԉc�Ƃ���ˑR��ԉc�Ƃ݂̂ɂȂ��������ꂩ��̔O�����p�ł���
991 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 19:30:03 ID:3wc/5yYP
992 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 19:42:49 ID:3wc/5yYP
CUDA��SIMT��SIMD���̂��̂Ȃ̂͒��w���x���̉p�ꂷ��ǂ߂Ȃ��l�ȊO�ł͌��R����펯
http://forums.nvidia.com/index.php?showtopic=93655
��������̒��Ȃ�ʃS�~���߂̕����ŕz�c����ăl�b�g�̌�������AMD�X���̃p�g���[�����Ă�l�͈Ⴄ�̂�������Ȃ����ǂ�
http://forums.nvidia.com/index.php?showtopic=93655
��������̒��Ȃ�ʃS�~���߂̕����ŕz�c����ăl�b�g�̌�������AMD�X���̃p�g���[�����Ă�l�͈Ⴄ�̂�������Ȃ����ǂ�
��SMT(Intel�ł���HT)�Ɠ����B
���̂������Ȃ萳������������яo����
�u�����X���b�h�ʼnɂȉ��Z���L�����p����v��
�������E�̃\�[�X�̂ǂ���������Ă邱�Ƃƍ����Ă�
��������������
ttp://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
CPU�ł�����OP�����X���b�h
CPU�̃X���b�h�����[�v�ƌ����Ă���悤������
���̃��[�v�i�X���b�h�j���A�E�g�I�u�I�[�_�i���X�[�p�[�X�J���j�œ��I�Ɉ����炵��
�E���R�̓x�N�^���Z���痝�����ĂȂ��C��������܂������̂��Ƃ�
���̂������Ȃ萳������������яo����
�u�����X���b�h�ʼnɂȉ��Z���L�����p����v��
�������E�̃\�[�X�̂ǂ���������Ă邱�Ƃƍ����Ă�
��������������
ttp://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
CPU�ł�����OP�����X���b�h
CPU�̃X���b�h�����[�v�ƌ����Ă���悤������
���̃��[�v�i�X���b�h�j���A�E�g�I�u�I�[�_�i���X�[�p�[�X�J���j�œ��I�Ɉ����炵��
�E���R�̓x�N�^���Z���痝�����ĂȂ��C��������܂������̂��Ƃ�
AMD��SIMD������SIMD�Ȃ��
16way���ɍX��5way�̉��Z��Ƃ����ɂ߂�ǂ�����
16way���ɍX��5way�̉��Z��Ƃ����ɂ߂�ǂ�����
995 �F,,�E�L�́M�E,,�j��-�������F2010/05/17(��) 19:57:33 ID:3wc/5yYP
��plNa4WAz
�����ǂ����^���Ԃ���������
�悭�撣��������AMD�̃X���̌x���Ȃ�Ă��Ȃ��Ă������玩��̌x���ɖ߂ꂗ����
�����ǂ����^���Ԃ���������
�悭�撣��������AMD�̃X���̌x���Ȃ�Ă��Ȃ��Ă������玩��̌x���ɖ߂ꂗ����
�X���b�h���x��
larrabee 16
cuda 32
stream 320
larrabee 16
cuda 32
stream 320
�Q���V���K�[�̖��͒c�q�̒��ł܂��܂����������Ă���
���x�ǂ��Ƃ���ɁA�ۂ��A�Əo�Ă����������낤���ǁA
Intel�̓Z�J���h�v�����Ƃ���PowerVR�g��������Ƃ����肪���邾�낤�ȁB
������h���C�o��OpenCL�Ή��Ƃ�����ł���H
Intel�̓Z�J���h�v�����Ƃ���PowerVR�g��������Ƃ����肪���邾�낤�ȁB
������h���C�o��OpenCL�Ή��Ƃ�����ł���H
GPU�̍�����PowerVR�ō����
�Œ�@�\���ځA�Œ����EU��GPU�u���b�N�ɂ̂�
�K�v�Ȃ��CPU�̉��Z����g�����Ă̂͂����Ǝv��
�Œ�@�\���ځA�Œ����EU��GPU�u���b�N�ɂ̂�
�K�v�Ȃ��CPU�̉��Z����g�����Ă̂͂����Ǝv��
1000
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/