AMD�̎�����CPU�ɂ��Č�낤 ��32����
�Q�Q�Q_
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��31����
http://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
�_.�Q�@ | �r�炵�E����E�~�[�͕��u����ԁB
�^|�Q|�@| �ނ�ꂸ�ɃX���[���܂��傤�B
|�Q�^�_! sage�i�s�Ń}�^�[�������܂��傤�B
���O�X��
AMD�̎�����CPU�ɂ��Č�낤 ��31����
http://pc11.2ch.net/test/read.cgi/jisaku/1258895864/
�����AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
Intel�̎�����CPU�ɂ��Č�낤 42
http://pc11.2ch.net/test/read.cgi/jisaku/1262241441/
CPU�A�[�L�e�N�`���ɂ��Č�� 16
http://pc11.2ch.net/test/read.cgi/jisaku/1253517890/
|
|
|
���ߋ��X���ꗗ
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
30 ttp://pc11.2ch.net/test/read.cgi/jisaku/1252750795/
29 ttp://pc11.2ch.net/test/read.cgi/jisaku/1247396388/
28 ttp://pc11.2ch.net/test/read.cgi/jisaku/1240713914/
27 ttp://pc11.2ch.net/test/read.cgi/jisaku/1236773340/
26 ttp://pc11.2ch.net/test/read.cgi/jisaku/1231688064/
25 ttp://pc11.2ch.net/test/read.cgi/jisaku/1228783643/
24 ttp://pc11.2ch.net/test/read.cgi/jisaku/1226628399/
23 ttp://pc11.2ch.net/test/read.cgi/jisaku/1219751351/
22 ttp://pc11.2ch.net/test/read.cgi/jisaku/1214276833/
21 ttp://pc11.2ch.net/test/read.cgi/jisaku/1209908499/
20 ttp://pc11.2ch.net/test/read.cgi/jisaku/1203947286/
19 ttp://pc11.2ch.net/test/read.cgi/jisaku/1199338832/
18 ttp://pc11.2ch.net/test/read.cgi/jisaku/1197562571/
17 ttp://pc11.2ch.net/test/read.cgi/jisaku/1195270082/
16 ttp://pc11.2ch.net/test/read.cgi/jisaku/1192923006/
15 ttp://pc11.2ch.net/test/read.cgi/jisaku/1190954072/
14 ttp://pc11.2ch.net/test/read.cgi/jisaku/1189440665/
13 ttp://pc11.2ch.net/test/read.cgi/jisaku/1187934610/
12 ttp://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
11 ttp://pc11.2ch.net/test/read.cgi/jisaku/1181563841/
10 ttp://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
09 ttp://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
08 ttp://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
07 ttp://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
06 ttp://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
05 ttp://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
04 ttp://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
03 ttp://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
02 ttp://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
01 ttp://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�X�����ďI���B�e���v�����Z���̂͊y�ł������ǁA
���ɉߋ��X������������ȁc�ǂ���Ƃ���Ƃ�����ˁB
���ɉߋ��X������������ȁc�ǂ���Ƃ���Ƃ�����ˁB
�ŁASSE3�Œ��炭�~�܂��Ă���B
���s�\�P��AVX�Ή��̂͏o��̂��H
���s�\�P��AVX�Ή��̂͏o��̂��H
>>4
AM3r2�̓\�P�b�g�`��͈ꏏ������AMD�̌������\�ł́A
"AM2"����"AM2+"�̎��Ɠ����Ŕ̐���ɂ���Đ���Ǝv���c�����A
�uC State Performance Boost "�͌����Ȃ����Ǔ�����I�v
����ȑΉ�����͌��\�o�����ȗ\���B�ǂ��Ƃ͌���Ǖϑԃ��[�J�[�Ƃ��B
AM3r2�̓\�P�b�g�`��͈ꏏ������AMD�̌������\�ł́A
"AM2"����"AM2+"�̎��Ɠ����Ŕ̐���ɂ���Đ���Ǝv���c�����A
�uC State Performance Boost "�͌����Ȃ����Ǔ�����I�v
����ȑΉ�����͌��\�o�����ȗ\���B�ǂ��Ƃ͌���Ǖϑԃ��[�J�[�Ƃ��B
AMD�͌݊������������
90nm��X2��V���i�Ƃ��Ĕ����Ă����̔Ȃ̂ɁABIOS�A�b�v�f�[�g��45nm��Phenom�T�|����邵
���������ւ�������Intel�Ƃ͑�Ⴂ��
90nm��X2��V���i�Ƃ��Ĕ����Ă����̔Ȃ̂ɁABIOS�A�b�v�f�[�g��45nm��Phenom�T�|����邵
���������ւ�������Intel�Ƃ͑�Ⴂ��
7 �FSocket774�F2010/01/13(��) 17:21:34 ID:nSBi8VQo
�g����̂Ȃ��̕ӂ̎��Ӌ@��n��������B
���܂�CPU�ƃ`�b�v�Z�b�g�ƃ������͂قڃZ�b�g
����er�͖�����440BX�{PC100�������̎���̌��z�ɔ���ꂷ�����Ǝv���B
��́u���������v�Ƃ������Ă����Ă��O�牽��CPU��������̂��ƁB
����������낤���A�������̓I�Ȍ��ʂ����҂���Ȃ�
�ŏ��̓v���b�g�t�H�[���ʼn��ʂ��Ă����āA
�v���b�g�t�H�[���̖����������Ă��������
�ŏ�ʂɌ������邭�炢�̂��肶��Ȃ��Ɛ����Ӗ��Ȃ�����B
�����v���b�g�t�H�[����ł�CPU�̐i���Ȃ�������1.5�{�Ȃ���B
�ŏ�������͂ꂽ�v���b�g�t�H�[���̏�ʂőg�ނ���Ȃ�
����ŏI����Ă��\�������A�ǂ���AMD�X���ɂ���悤�ȓz�炾���B
�Ƃ������A���X�Ǝg����440BX��PC100SDRAM�̎���̂ق���
����PC�̗��j�̒��ł͖��炩�Ɉٗ�Ȏ��ゾ������ȁB
�A��������Intel�̗\��ł�Coppermine�o��Ɠ�����820��RDRAM���i��
�{����PC100SDRAM�Ȃ�đ��U�ŋ�����̈╨�ɂȂ��Ă�͂�����������
���j��܂�Ɍ���Intel�̑厸�s�����A���R�̍K���Ȏ���B
�ł����̍��̎���Ɏ��삪�L�����y�����̂�������
���ł����[�U�[�̓v���b�g�t�H�[���̎����Ɋ��҂��߂��Ă�Ǝv���B
���܂�CPU�ƃ`�b�v�Z�b�g�ƃ������͂قڃZ�b�g
����er�͖�����440BX�{PC100�������̎���̌��z�ɔ���ꂷ�����Ǝv���B
��́u���������v�Ƃ������Ă����Ă��O�牽��CPU��������̂��ƁB
����������낤���A�������̓I�Ȍ��ʂ����҂���Ȃ�
�ŏ��̓v���b�g�t�H�[���ʼn��ʂ��Ă����āA
�v���b�g�t�H�[���̖����������Ă��������
�ŏ�ʂɌ������邭�炢�̂��肶��Ȃ��Ɛ����Ӗ��Ȃ�����B
�����v���b�g�t�H�[����ł�CPU�̐i���Ȃ�������1.5�{�Ȃ���B
�ŏ�������͂ꂽ�v���b�g�t�H�[���̏�ʂőg�ނ���Ȃ�
����ŏI����Ă��\�������A�ǂ���AMD�X���ɂ���悤�ȓz�炾���B
�Ƃ������A���X�Ǝg����440BX��PC100SDRAM�̎���̂ق���
����PC�̗��j�̒��ł͖��炩�Ɉٗ�Ȏ��ゾ������ȁB
�A��������Intel�̗\��ł�Coppermine�o��Ɠ�����820��RDRAM���i��
�{����PC100SDRAM�Ȃ�đ��U�ŋ�����̈╨�ɂȂ��Ă�͂�����������
���j��܂�Ɍ���Intel�̑厸�s�����A���R�̍K���Ȏ���B
�ł����̍��̎���Ɏ��삪�L�����y�����̂�������
���ł����[�U�[�̓v���b�g�t�H�[���̎����Ɋ��҂��߂��Ă�Ǝv���B
�͓���440BX�Ƃ��ǂ��̘̂b����w
���~�͂��ƂȂ����������̂Ȃ��{�b�^�N��i3/i5�ł������Ă��
���~�͂��ƂȂ����������̂Ȃ��{�b�^�N��i3/i5�ł������Ă��
9 �FSocket774�F2010/01/13(��) 18:30:36 ID:/3Tv9ZZk
���[�U�[���猩����݊����͍������������Ɍ��܂��Ă邾��
���Ƃ������̃f�����b�g���������Ƃ��Ă��A�����b�g�̕����傫��
���悤�Șb�����ᖳ����
���Ƃ������̃f�����b�g���������Ƃ��Ă��A�����b�g�̕����傫��
���悤�Șb�����ᖳ����
�O���t�B�b�N�����Ń}���`�\�P�b�g��ް
>1
��
>1
��
2011�N�̐VCPU�R�A�uBulldozer�v�uBobcat�v�̎p
http://ascii.jp/elem/000/000/489/489200/
���Ƃ��낪�A����Ɋւ��Ă͓��{AMD�o�R�ŕ�AMD���A���m��
���u�X���b�h������ALU��2�AAGU��2�̍��v4�ł���v�Ƃ������A���Ă����B
���ꂪ�{���Ȃ�IPC�͉����邯�ǁA���Ђ̐��i���C���i�b�v�������ōl����Ƃ��������Ȃ���
�iK10�R�A�́jLlano���V���O���X���b�h�����Ƃ�����A�n�C�G���h�̗̈��C������Ƃ͎v���Ȃ�
����d�͂�}���邽�߂Ƀg�����W�X�^������Nj�����Ƃ������j�͐^�����ł͂��邯���
�V���O���X���b�h���̂Ăă}���`�X���b�h�ɑ������Ƃ���őΓ��E�ΊO�I�ɋ����͂��Ȃ����i�ɂȂ�
�ł��⊮����A�v���[�`�Ƃ����Ă��N���b�N�グ�邮�炢�������Ɏv������̂�ˁE�E�E
http://ascii.jp/elem/000/000/489/489200/
���Ƃ��낪�A����Ɋւ��Ă͓��{AMD�o�R�ŕ�AMD���A���m��
���u�X���b�h������ALU��2�AAGU��2�̍��v4�ł���v�Ƃ������A���Ă����B
���ꂪ�{���Ȃ�IPC�͉����邯�ǁA���Ђ̐��i���C���i�b�v�������ōl����Ƃ��������Ȃ���
�iK10�R�A�́jLlano���V���O���X���b�h�����Ƃ�����A�n�C�G���h�̗̈��C������Ƃ͎v���Ȃ�
����d�͂�}���邽�߂Ƀg�����W�X�^������Nj�����Ƃ������j�͐^�����ł͂��邯���
�V���O���X���b�h���̂Ăă}���`�X���b�h�ɑ������Ƃ���őΓ��E�ΊO�I�ɋ����͂��Ȃ����i�ɂȂ�
�ł��⊮����A�v���[�`�Ƃ����Ă��N���b�N�グ�邮�炢�������Ɏv������̂�ˁE�E�E
�V���O���X���b�h��2�N���X�^�ŏ������ł��邱�Ƃ����Y��Ȃ�
����2*(2ALU+2AGU)������A3ALU+3AGU��K10��Nehalem���IPC�͏�
�f�R�[�h��4Complex+4Simple�ŁANehalem�i1Comlex+3Simple�j�̔{
����2*(2ALU+2AGU)������A3ALU+3AGU��K10��Nehalem���IPC�͏�
�f�R�[�h��4Complex+4Simple�ŁANehalem�i1Comlex+3Simple�j�̔{
���V���O���X���b�h��2�N���X�^
�����i�Ƃ������s�\�j
�������Z�͊��S�ɓƗ����Ă�
�����i�Ƃ������s�\�j
�������Z�͊��S�ɓƗ����Ă�
>>11
���̃y�[�W�������ēǂ����I
>�P����ALU���߂������ꍇ�́A���R�Ȃ���IPC��2����/�T�C�N���ɗ��܂�킯�ŁA
>���̂���������Ă����(���R�A�v���P�[�V�����ɂ�邪)��Ȃ��瓯����g����
>����̐��\�́AK10�����艺����̂ł͂Ȃ����Ƒz�������B
�����A���̃y�[�W�̍Ō�ɂ���Ȏ��������Ă��邪�A
�P����ALU���߂������ꍇ���Ăǂ�ȂƂ�����H
����ȏꍇ���ăx���`�ȊO�ł��蓾��̂��H
���̃y�[�W�������ēǂ����I
>�P����ALU���߂������ꍇ�́A���R�Ȃ���IPC��2����/�T�C�N���ɗ��܂�킯�ŁA
>���̂���������Ă����(���R�A�v���P�[�V�����ɂ�邪)��Ȃ��瓯����g����
>����̐��\�́AK10�����艺����̂ł͂Ȃ����Ƒz�������B
�����A���̃y�[�W�̍Ō�ɂ���Ȏ��������Ă��邪�A
�P����ALU���߂������ꍇ���Ăǂ�ȂƂ�����H
����ȏꍇ���ăx���`�ȊO�ł��蓾��̂��H
�Ɨ����ĂȂ�����u�N���X�^�v�����Ȃ�ł���
���W�X�^�t�@�C���͋���
���W�X�^�t�@�C���͋���
AMD�̏�̕����u�V���O���X���b�h�̐��\�͉����Ȃ��v�ƌ����Ă�������A
�V���O���X���b�h�����̏ꍇ��1�N���X�^��1��CPU�Ƃ��Ĉ����\���͂����ȁB
�V���O���X���b�h�����̏ꍇ��1�N���X�^��1��CPU�Ƃ��Ĉ����\���͂����ȁB
>>7
�����̔����ȃR�s�y�N��
�����̔����ȃR�s�y�N��
Bulldozer�̃N���b�N������̐������\�͑��������邾�낤���ǁA
�����₦��قǂ̃N���b�N�㏸�ƒ����d�͂ɂȂ��Ă��āA
���b�g�p�t�H�[�}���X�͏オ���Ă���낤�B
�����₦��قǂ̃N���b�N�㏸�ƒ����d�͂ɂȂ��Ă��āA
���b�g�p�t�H�[�}���X�͏オ���Ă���낤�B
>>18
�ے肳��Ă��������H
�ے肳��Ă��������H
<meta name="generator" content="notepad.exe">
�ے肳��ĂȂ��ǂ��납�A1�X���b�h��2��INTEGER UNIT��Dispatch�ł��邩�炱��
US20090172359�݂����ȓ���������킯��
US20090172359�݂����ȓ���������킯��
�X�P�W���[���ǂ����H
24 �FSocket774�F2010/01/13(��) 23:30:09 ID:z/HAKvkO
���쎩���r�炵�ŕK���Ƃ��B�ǂ���x���c�B
http://blogs.amd.com/work/2009/12/11/aiming-for-the-sweet-spot-in-2010-and-beyond/
#9 by Rerri - December 12th, 2009 at 11:31
�@Modeule is not two cores but single core.
�@Two int cores can be used to execute 1 thread (its speculative multithreading design).
�@Module will be seen to OS as a single core.
#10 by John Fruehe - December 14th, 2009 at 09:44
�@Incorrect. The module has 2 integer cores.
�@The two cores will execute 2 threads, not one.
�@The OS will not ever see the module, the OS will only see the cores.
#11 by Rerri - December 14th, 2009 at 21:07
�@Look at Bulldozer patent: 20090172362(026).
�@Processor dispath module can be configured to execute only a single
thread and dispath integer instructions associated with the thread to
both integer cores so OS will see one module as one core.
#12 by John Fruehe - December 16th, 2009 at 18:41
�@Patents are for protection of intellectual property, there is not always
a 1-1 relationship with final shipping products.
���������ł͂�����ӂ̂��Ƃ肪�߂�����
#9 by Rerri - December 12th, 2009 at 11:31
�@Modeule is not two cores but single core.
�@Two int cores can be used to execute 1 thread (its speculative multithreading design).
�@Module will be seen to OS as a single core.
#10 by John Fruehe - December 14th, 2009 at 09:44
�@Incorrect. The module has 2 integer cores.
�@The two cores will execute 2 threads, not one.
�@The OS will not ever see the module, the OS will only see the cores.
#11 by Rerri - December 14th, 2009 at 21:07
�@Look at Bulldozer patent: 20090172362(026).
�@Processor dispath module can be configured to execute only a single
thread and dispath integer instructions associated with the thread to
both integer cores so OS will see one module as one core.
#12 by John Fruehe - December 16th, 2009 at 18:41
�@Patents are for protection of intellectual property, there is not always
a 1-1 relationship with final shipping products.
���������ł͂�����ӂ̂��Ƃ肪�߂�����
>>26
�����ςȂŁu1�X���b�h��2�R�A�g����Ł[�v���Č����Ă���ȁB
�����ςȂŁu1�X���b�h��2�R�A�g����Ł[�v���Č����Ă���ȁB
Rerri�i�O��j�̔�����John Fruehe(AMD)���ے肵�Ă���悤�Ɍ������
�}�[�P�e�B���O�����E�E�E���{�ł������Ă̌Z�M�Ɠ����ʒu
�v����ɁA����Ȃ�ɓ������͓����闧�ꂾ�����F�Z�p�҂ł͂Ȃ�
�E���x�������ĂȂ��i���蕶�傾���m���Ă�����j����̐l
�v����ɁA����Ȃ�ɓ������͓����闧�ꂾ�����F�Z�p�҂ł͂Ȃ�
�E���x�������ĂȂ��i���蕶�傾���m���Ă�����j����̐l
�ʂ肷���肾���ǁA
�A���~���Ĕn������w
�悭����ȊԈ�����������葱������Ȃ��B
�S���w�K�\�͂̌��Ђ������Ȃ��B
�A���~���Ĕn������w
�悭����ȊԈ�����������葱������Ȃ��B
�S���w�K�\�͂̌��Ђ������Ȃ��B
>>29
����͋Z�p�I�Ș_�_����Y�����b��
�Ó����ǂ����Ƃ����c�_�ʼn���Ӗ��������Ȃ�
AnalystDay�ł�����x���̍\�����o�Ă���
����ł����������߂̎d���͏����h
�v�͂��̍����ƂȂ�ޗ������Ȃ����邩��
�N������Ȃ��Ƃ�����Ȃ��Ȃ���
����͋Z�p�I�Ș_�_����Y�����b��
�Ó����ǂ����Ƃ����c�_�ʼn���Ӗ��������Ȃ�
AnalystDay�ł�����x���̍\�����o�Ă���
����ł����������߂̎d���͏����h
�v�͂��̍����ƂȂ�ޗ������Ȃ����邩��
�N������Ȃ��Ƃ�����Ȃ��Ȃ���
���Ȃ肷��
�u�����I��1�X���b�h��2�����R�A�Ŏ��s����v�̂ƁuOS���牽�R�A�Ɍ����邩�v�͖��W
�����������ǁ[�ł��낤��OS�����2�R�A�Ɍ�����
�Ɠ���Ⴂ���̂�
R:�����݂Ă�A1�X���b�h��2�����R�A�Ŏ��s���Ă邶��Ȃ����IOS�����1���W���[��1�R�A����I
F:�����Ɛ��i�̎����������Ƃ͌���Ȃ�
�Ȃ�āu�����Ƃ��炵�������͖��W�Șb�v�Ō떂�����Ă�̂͗������ĂȂ��؋�
�����������ǁ[�ł��낤��OS�����2�R�A�Ɍ�����
�Ɠ���Ⴂ���̂�
R:�����݂Ă�A1�X���b�h��2�����R�A�Ŏ��s���Ă邶��Ȃ����IOS�����1���W���[��1�R�A����I
F:�����Ɛ��i�̎����������Ƃ͌���Ȃ�
�Ȃ�āu�����Ƃ��炵�������͖��W�Șb�v�Ō떂�����Ă�̂͗������ĂȂ��؋�
>>30
�܂��N�����̂��B�����͑���ɂ���Ȃ��āB
�ѐ~���B���̕��R�e�r�炵���o�J�Ȃ̂́A
�����̗��E������������炩�Șb�B
�����čr�炵�ɔ�������z���r�炵���B�����͑�l�ɂȂ�B
�܂��N�����̂��B�����͑���ɂ���Ȃ��āB
�ѐ~���B���̕��R�e�r�炵���o�J�Ȃ̂́A
�����̗��E������������炩�Șb�B
�����čr�炵�ɔ�������z���r�炵���B�����͑�l�ɂȂ�B
�G����������ƌ����āA�g���b�L�[�Ȃ��Ƃ�����K�v�͂Ȃ��Ǝv�����ǂ˂��E�E�E
http://d.hatena.ne.jp/hagex/20100105
http://d.hatena.ne.jp/hagex/20100105
�ŏ���1�X���b�h��2�R�A�ɐU�蕪�������ō��n�߂āA
������������Ǝv����B
����Ă��������ɁA����ϖ��������A�Ƃ������Ƃŕ������āA
���̌`�ɂȂ�����Ȃ����ȁB
�����łȂ��ƁA�킴�킴�N���X�^�����闝�R���A
2�N�x��Ȃ̂ɏo�Ă������̂����܂�p�b�Ƃ��Ȃ����R���v�����Ȃ��B
�������u�ق�Ƃ��͂�����Bulldozer�v��ϑz����̂����R�B
����͎��������炩�ɂȂ��ĂȂ��������o���Ȃ�����ˁB
������������Ǝv����B
����Ă��������ɁA����ϖ��������A�Ƃ������Ƃŕ������āA
���̌`�ɂȂ�����Ȃ����ȁB
�����łȂ��ƁA�킴�킴�N���X�^�����闝�R���A
2�N�x��Ȃ̂ɏo�Ă������̂����܂�p�b�Ƃ��Ȃ����R���v�����Ȃ��B
�������u�ق�Ƃ��͂�����Bulldozer�v��ϑz����̂����R�B
����͎��������炩�ɂȂ��ĂȂ��������o���Ȃ�����ˁB
2�R�A��1�X���b�h���ĉ����܂ň��������Ă��
�P�Ȃ�K�Z�l�^�Ō�����������
Bulldozer�͌����̂悢�}���`�X���b�h�����̂��߂ɃN���X�^�����Ă邾��
�V���O���X���b�h����͂����A�C�f�A���Ȃ�����ۗ����đË����Ă��邾������
�v�̓V���O���X���b�h���l������AMD�����j�[�R�A�Ƃ����Ƃ��낾�낤�B
�P�Ȃ�K�Z�l�^�Ō�����������
Bulldozer�͌����̂悢�}���`�X���b�h�����̂��߂ɃN���X�^�����Ă邾��
�V���O���X���b�h����͂����A�C�f�A���Ȃ�����ۗ����đË����Ă��邾������
�v�̓V���O���X���b�h���l������AMD�����j�[�R�A�Ƃ����Ƃ��낾�낤�B
ID:7gg7ahUm�����������ȏЉ�ƕ����āB
�o�J�������I�^�̖ϑz�Ƃ͈����28�����������Ȃ悤�łȂɂ��
Global Foundries 28nm wafer spotted�iSemiAccurate�j
28-nm GlobalFoundries wafer spotted�iThe Tech Report�j
Global Foundries 28nm wafer spotted�iSemiAccurate�j
28-nm GlobalFoundries wafer spotted�iThe Tech Report�j
http://www.semiaccurate.com/2010/01/09/global-foundries-28nm-wafer-spotted/
http://techreport.com/discussions.x/18282
�Y�����
http://techreport.com/discussions.x/18282
�Y�����
>>39
�A���~���{�l�l�H
�A���~���{�l�l�H
43 �FMAC�I�^��40 �����F2010/01/14(��) 08:13:36 ID:k6CkydoL
>>40
�@�@----------------
�@�@�o�J�������I�^�̖ϑz�Ƃ͈����28����������
�@�@----------------
���ɑa�����疢���ɃA����������Ă���Ƃ������Ƃ��ǂ�����J�L�R�~�ł���(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1258895864/946
�@�@=================
�@�@946 ���O�FMAC�I�^ ���e���F2010/01/11(��) 22:16:27 ID:sd9ZhS4B
�@�@�@�@"FUD"zilla��M���Ă�q�g�������c���Ă����肵�āA�������ς�炸�I���V�����ł���(��)
�@�@�@�@CES��GF��28nm�̎���E�F�n���I�����Ƃ̂��ƁB
�@�@�@�@http://www.semiaccurate.com/2010/01/09/global-foundries-28nm-wafer-spotted/
�@�@=================
�@�@----------------
�@�@�o�J�������I�^�̖ϑz�Ƃ͈����28����������
�@�@----------------
���ɑa�����疢���ɃA����������Ă���Ƃ������Ƃ��ǂ�����J�L�R�~�ł���(��)
http://pc11.2ch.net/test/read.cgi/jisaku/1258895864/946
�@�@=================
�@�@946 ���O�FMAC�I�^ ���e���F2010/01/11(��) 22:16:27 ID:sd9ZhS4B
�@�@�@�@"FUD"zilla��M���Ă�q�g�������c���Ă����肵�āA�������ς�炸�I���V�����ł���(��)
�@�@�@�@CES��GF��28nm�̎���E�F�n���I�����Ƃ̂��ƁB
�@�@�@�@http://www.semiaccurate.com/2010/01/09/global-foundries-28nm-wafer-spotted/
�@�@=================
Fudzilla��GT300�ł��Ԃ�����������ȁB
�܂�MAC�I�^���n���Ƃ����_�ɂ͓��ӂ����B
�܂�MAC�I�^���n���Ƃ����_�ɂ͓��ӂ����B
Fudzilla
12���ɂł��
1���ɂ͂ł��
2���ɂ͂ł�ł���[
3���ɂł���Ă�@��������
12���ɂł��
1���ɂ͂ł��
2���ɂ͂ł�ł���[
3���ɂł���Ă�@��������
MAC�I�^�͔n������Ȃ���
�����Ɖ�
�����Ɖ�
>46
����܂�a�l�M��̂��A�����Ƃ͎v����w
����܂�a�l�M��̂��A�����Ƃ͎v����w
>>38
OS����݂���_���E�����R�A���ƁACPU�̓����\���ɒ��ڂ̊W�͂Ȃ�
�ɘ_�����1RISC�R�A�ŁA50�̕����R�A�E100�̘_���R�A������x86CPU�Ɍ��������Ă�������
100RISC�R�A��1�̕����R�A�E�_���R�A������x86CPU�Ɍ����Ă����܂�Ȃ�
���FRISC-Core���x86CPU�G�~�����[�^�������Ă邾��
OS����݂���_���E�����R�A���ƁACPU�̓����\���ɒ��ڂ̊W�͂Ȃ�
�ɘ_�����1RISC�R�A�ŁA50�̕����R�A�E100�̘_���R�A������x86CPU�Ɍ��������Ă�������
100RISC�R�A��1�̕����R�A�E�_���R�A������x86CPU�Ɍ����Ă����܂�Ȃ�
���FRISC-Core���x86CPU�G�~�����[�^�������Ă邾��
"Fudzilla"�͒N���M���Ă��Ȃ�����H
�������͓ǎ҂��L�����y���ރT�C�g���B
�����Ă����Ɗy���܂��Ă���Ă���B
�������͓ǎ҂��L�����y���ރT�C�g���B
�����Ă����Ɗy���܂��Ă���Ă���B
�����ă��x�������킹�Ă�A����ɉ�����
�u���x86�G�~�����[�^�����s�ł���SingleCoreRISC-CPU�v����CMP
SingleCoreRISC-CPU��œ��x86�G�~�����[�^���ғ�->HyperThreading(SMT)
DualCoreRISC-CPU��œ��x86�G�~�����[�^���ғ���Bulldozer CMT
�Ƃł������Ȃ��Ɨ����ł��Ȃ�����
�u���x86�G�~�����[�^�����s�ł���SingleCoreRISC-CPU�v����CMP
SingleCoreRISC-CPU��œ��x86�G�~�����[�^���ғ�->HyperThreading(SMT)
DualCoreRISC-CPU��œ��x86�G�~�����[�^���ғ���Bulldozer CMT
�Ƃł������Ȃ��Ɨ����ł��Ȃ�����
������ɂ���2INT�R�A��1�X���b�h���n���h���ł���Ȃ��
�����_�ł͉��獪���������̂Ŋ���̋�_�ɉ߂����
���Ɨ����Ɍ�����x86�G�~���Ƃ������Ă鎞�_�ŃA�z
�����_�ł͉��獪���������̂Ŋ���̋�_�ɉ߂����
���Ɨ����Ɍ�����x86�G�~���Ƃ������Ă鎞�_�ŃA�z
"Bulldozer"���̂����܂��o�Ă��Ȃ��̂ŁA
�F�X�ϑz����̂��ʔ�����Ȃ��́H
�u������CPU�v�X���Ȃ��炻��ł��������B
�F�X�ϑz����̂��ʔ�����Ȃ��́H
�u������CPU�v�X���Ȃ��炻��ł��������B
Bulldozer�̃V���O���X���b�h���\�́H
1.������
�@ALU��AGU�������Ă���瓖�R
�@�����͔��ł���
2.��{�I�ɉ����邪����قǂł��Ȃ�
�@ALU/AGU�͌����Ă邪���ɂ��Ȃ�����Ŏ��s�������オ���Ă��邽��
3.��{�I�ɓ����`���傢��
�@AGU���Ȉ�ALU�I�Ɏg���邩��
�@�ł�AGU�𑽗p����Ɖ����邩��
4.����Ȃ��ɏオ��
�@������CPU��������CPU�ɕ�����킯�Ȃ������
�@2 integer cores�ŃV���O���X���b�h���s�ł��邵
�@����ALU�͔{���쓮
�݂Ȃ���̗\�z�͉��ԁH
1.������
�@ALU��AGU�������Ă���瓖�R
�@�����͔��ł���
2.��{�I�ɉ����邪����قǂł��Ȃ�
�@ALU/AGU�͌����Ă邪���ɂ��Ȃ�����Ŏ��s�������オ���Ă��邽��
3.��{�I�ɓ����`���傢��
�@AGU���Ȉ�ALU�I�Ɏg���邩��
�@�ł�AGU�𑽗p����Ɖ����邩��
4.����Ȃ��ɏオ��
�@������CPU��������CPU�ɕ�����킯�Ȃ������
�@2 integer cores�ŃV���O���X���b�h���s�ł��邵
�@����ALU�͔{���쓮
�݂Ȃ���̗\�z�͉��ԁH
�n���M�҈ȊO��1��2��3��I��
IPC�̂��Ƃ������Ă�낤����
�N���b�N��������V���O���X���b�h�\�͉͂����?
����荂��]��_���Ă�Ƃ����b�͂���������?
�N���b�N��������V���O���X���b�h�\�͉͂����?
����荂��]��_���Ă�Ƃ����b�͂���������?
>>55
���₢��c�Ȃ�ł����܂ŐF�X�b���o�邩�Ƃ����ƁA
�M�҂Ƃ�����Ȃ��āA�v��C����`���b�N�E���[�A���g��
�u�V���O���X���b�h���Ë����Ȃ��v�ƌ����Ă����B
������F�X���ʂ���Ȃ��b���o����Ă���́B
�����ĐF�X�b���Ċy����ł���́B
�u�n���M�ҁv�Ƃ������O�ɏ����͏����d����Ȃ����B
���₢��c�Ȃ�ł����܂ŐF�X�b���o�邩�Ƃ����ƁA
�M�҂Ƃ�����Ȃ��āA�v��C����`���b�N�E���[�A���g��
�u�V���O���X���b�h���Ë����Ȃ��v�ƌ����Ă����B
������F�X���ʂ���Ȃ��b���o����Ă���́B
�����ĐF�X�b���Ċy����ł���́B
�u�n���M�ҁv�Ƃ������O�ɏ����͏����d����Ȃ����B
���\�[�X�������Ă�̂����܂��J�o�[����ɂ͂�͂�
intel��turbo boost�I�ȉ������ǂ��\�����[�V���������?
����̐���G���W���̏o���@���ł܂��^�X���Ń��b�T���L�r�L�r��
�I���Ȃ��킢���J��L������\����
intel��turbo boost�I�ȉ������ǂ��\�����[�V���������?
����̐���G���W���̏o���@���ł܂��^�X���Ń��b�T���L�r�L�r��
�I���Ȃ��킢���J��L������\����
�G�~����ے肷��ق����A�z���Ǝv����
ttp://www.faqs.org/patents/app/20080301364
���o����2int core��1thread���s�ɂ͍���������������
ttp://www.faqs.org/patents/app/20090164758
ttp://www.faqs.org/patents/app/20090172362
ttp://www.faqs.org/patents/app/20090172359
�ނ���ے�h�̍������F��
ttp://www.faqs.org/patents/app/20080301364
���o����2int core��1thread���s�ɂ͍���������������
ttp://www.faqs.org/patents/app/20090164758
ttp://www.faqs.org/patents/app/20090172362
ttp://www.faqs.org/patents/app/20090172359
�ނ���ے�h�̍������F��
intel�I�ɂ�AMD�I�ɂ�����I�ɂ�4�͂������낢�W�J
�O�ɏo�Ă�AntiHT�݂����̂���������Ă邾�낤�ˁB
BIOS���炩OS�ォ�炩����Ȃ�����ON-OFF�o����悤�ɂȂ�Ǝv���B
�܂��A�����Ȃ�Ȃ�g���[�X�L���b�V���ł��t���Ȃ��ƃf�R�[�_�[�����
���낤���B
BIOS���炩OS�ォ�炩����Ȃ�����ON-OFF�o����悤�ɂȂ�Ǝv���B
�܂��A�����Ȃ�Ȃ�g���[�X�L���b�V���ł��t���Ȃ��ƃf�R�[�_�[�����
���낤���B
�G���I�ɂ̓f�[�^���^�X�N������Ȃ�
�\�����킩��Ȃ�������CPU��ϑz���Ċy���ރX���Ȃ̂ɁA
�Ȃ�ŕK���ɂȂ��Ĕے肵�Ă���z������H
���������������Ƃɖϑz���O�ꂽ���x�̎��ŁA
�S�̎���Ƃ����悤�ɖ\�ꂻ���Ȃ̂��|���B
�Ȃ�ŕK���ɂȂ��Ĕے肵�Ă���z������H
���������������Ƃɖϑz���O�ꂽ���x�̎��ŁA
�S�̎���Ƃ����悤�ɖ\�ꂻ���Ȃ̂��|���B
�ϑz���Ċy���ރX�����Ǝv���Ă���̂͂��O����������
�������Ċy���ނ̂͂����Ă�
�ϑz���Ė\��Ċy����ł�͎̂G���A���i�Ƃ�j�����ł���
�ϑz���Ė\��Ċy����ł�͎̂G���A���i�Ƃ�j�����ł���
>>64
���ۂ̏��i���o��܂ŁA�ϑz���\�z���債�ĕς����B
���ۂ̏��i���o��܂ŁA�ϑz���\�z���債�ĕς����B
>>59
���O�̓p�e���g������炻��������[�X���鐻�i��
��Ɏ�������Ƃł��v���Ă�̂��H�]�����Ԕ�������
�ŋ߂�x86CPU�͓���RISC���C�N�i��Ops�j�Ȃ�����
������G�~���ƌĂԂ̂͊��S�Ɍ��
���O�̓p�e���g������炻��������[�X���鐻�i��
��Ɏ�������Ƃł��v���Ă�̂��H�]�����Ԕ�������
�ŋ߂�x86CPU�͓���RISC���C�N�i��Ops�j�Ȃ�����
������G�~���ƌĂԂ̂͊��S�Ɍ��
��������1�X���b�h/2�R�A���s�o���Ȃ��Ǝv���́H
�O�X���Řb��ɂȂ����A��AMD�L��w�Z�M�x�̃N�r�ɂȂ�����̎��
���̕Ԃ����Ղ���Ȃ��Ȃ����܂������B�X�Ȃ����Ȏ�����
Intel�̓Ƌ֖@�ᔽ�i�ׂ̎������疾�炩�ɂȂ����l�ł��B
Hector Ruiz����ɃA���������܂��������{�l, Henri Richard ��
2004�N�̎Г����[��������B
http://www.ftc.gov/os/adjpro/d9341/091231respanswertocmplt.pdf
(p. 3 �Q��)
�@�@--------------------
�@�@I certainly would never buy AMD for a personal system if I wasn't
�@�@working here.
�@�@[����]
�@�@"we're cheap, less reliable, lower quality consumer type product."
�@�@---------------------
����ȓz�����x����ē��M����������A��������B����(��)
���̕Ԃ����Ղ���Ȃ��Ȃ����܂������B�X�Ȃ����Ȏ�����
Intel�̓Ƌ֖@�ᔽ�i�ׂ̎������疾�炩�ɂȂ����l�ł��B
Hector Ruiz����ɃA���������܂��������{�l, Henri Richard ��
2004�N�̎Г����[��������B
http://www.ftc.gov/os/adjpro/d9341/091231respanswertocmplt.pdf
(p. 3 �Q��)
�@�@--------------------
�@�@I certainly would never buy AMD for a personal system if I wasn't
�@�@working here.
�@�@[����]
�@�@"we're cheap, less reliable, lower quality consumer type product."
�@�@---------------------
����ȓz�����x����ē��M����������A��������B����(��)
�����l�^���J��Ԃ��Ă邯�ǖO���Ȃ��̂���?
ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/211-217
ttp://pc11.2ch.net/test/read.cgi/jisaku/1258895864/211-217
71 �FMAC�I�^��66 �����F2010/01/14(��) 22:23:32 ID:Qfwj0uW3
>>66
��ʂɔ̔������悤�Ȑ��i���\������Z�p�͊��m�̂��̂ɉ߂��܂���B
�����玖������ł��Ă���l�B�ɂƂ��Ă͖ϑz�Ɨ\�z�͋�ʂł��܂��B
���Ȃ������Č���l�ł�����w�l�Ԃ����ɍs���x���Ƃ͉\�ŁA�A�w�i�v�@��
����������x�Ƃ��w���ԗ��s������x�Ƃ��͖ϑz���Ƃ�����ʂ������Ǝv��
�܂����A�������ł��傤���H
��ʂɔ̔������悤�Ȑ��i���\������Z�p�͊��m�̂��̂ɉ߂��܂���B
�����玖������ł��Ă���l�B�ɂƂ��Ă͖ϑz�Ɨ\�z�͋�ʂł��܂��B
���Ȃ������Č���l�ł�����w�l�Ԃ����ɍs���x���Ƃ͉\�ŁA�A�w�i�v�@��
����������x�Ƃ��w���ԗ��s������x�Ƃ��͖ϑz���Ƃ�����ʂ������Ǝv��
�܂����A�������ł��傤���H
���ɍs�����Ƃ��\�Ƃ��������
�s���ĂȂ����
�s���ĂȂ����
���h��Ŋ̐S�ȕ�������Ȃ��̂Ɍ��t�̗g����������肷��J�X�͎��˂����̂ɂ��Ďv�����B
�����̓��ɔ�߂��M�O���O���̐V�����������ۂ��Ă��܂��̂͂悭���邱��
�C���e�����AMD��CPU���g�����W�X�^�������������_�C���傫��
�͎̂����Ȃ�ŁA���̂ւ��Bulldozer�łǂ����ǂ��Ă��邩��������
�v���Ă邯�ǂˁBHKMG�����ɓ������邩�H�Ƃ��B
�͎̂����Ȃ�ŁA���̂ւ��Bulldozer�łǂ����ǂ��Ă��邩��������
�v���Ă邯�ǂˁBHKMG�����ɓ������邩�H�Ƃ��B
>>75
�����Ȃ́H
�����Ȃ́H
MAC���^���܂܂łǂ����Ă���
�������ŏ�������ł��̂��H
�������ŏ�������ł��̂��H
�[���V���O���X���b�h���ăL���b�V�����\�̕���������Ȃ��́H
�d�͂͐H�����������
�d�͂͐H�����������
Bobcat�x�[�X��FUSION�̕����C�ɂȂ�����
Cedar������Ƒg�ݍ��킹��LIano���ギ�炢�ɏo�Ă��Ă���Ȃ�����
Cedar������Ƒg�ݍ��킹��LIano���ギ�炢�ɏo�Ă��Ă���Ȃ�����
MAC�I�^�����������Ă��Ƌ֖@�ᔽ�Ő^������Intel���AMD�̂ق����y���Ƀ}�V�Ȃ͕̂ς��Ȃ�
81 �FSocket774�F2010/01/15(��) 00:07:29 ID:Za5vZswb
�Q�[���G���W�����}���`�R�A�Ή����Ă�̂ɁA����ȂɋC�ɂȂ�H
���͂��̖���Ɋւ���^�ɋ����[���l�^��m���Ă��邪�A
�A���~�̑ԓx���C�ɓ���Ȃ��̂ł����ɋL�����Ƃ͂��Ȃ�
���ق��Ƃ��Ă��A���~��������Mac�I�^�����̓���������ǁ[��
�A���~�̑ԓx���C�ɓ���Ȃ��̂ł����ɋL�����Ƃ͂��Ȃ�
���ق��Ƃ��Ă��A���~��������Mac�I�^�����̓���������ǁ[��
MAC�I�^����Intel�M�҂Ȃ̂ɂ킴�킴AMD�X���ɗ���̂�
�Ȃ��l����C�ɂȂ��Ďd���Ȃ���
�ǂ������Ă�l�q�͋q�ϓI�Ɍ��đ����}�k�P������
�Ȃ��l����C�ɂȂ��Ďd���Ȃ���
�ǂ������Ă�l�q�͋q�ϓI�Ɍ��đ����}�k�P������
2�R�A��1�X���b�h�����s���Đ��\���シ��Ȃ�
2�R�A���̃��\�[�X���g���ăV���O���R�A��
��������Ȃ��́H
2�R�A���̃��\�[�X���g���ăV���O���R�A��
��������Ȃ��́H
���̘H���͉ߋ��ɒʂ��Ă������Ȃ�
>>85
�Ȃ�Ń}���`�R�A�H���ɂȂ����̂���������x�����Ă��܂��傤�B
�Ȃ�Ń}���`�R�A�H���ɂȂ����̂���������x�����Ă��܂��傤�B
2�R�A��1�X���b�h�����s���邽�߂ɁA�R�A�Ԃœ���ȓ����@�\���������̂�
�]���̃}���`�R�A�Ɠ��l�ɍl���Ă����̂���
�]���̃}���`�R�A�Ɠ��l�ɍl���Ă����̂���
�ˑ��W�ɂ��閽�߂����ԕς��Ď��s����킯�ɂ����Ȃ�����
���ǁA���@���s�Ń��������C�e���V�̉B����
�ˑ��W�̂Ȃ��Ǐ��I�ȃ��[�v�̓W�J��
���鎖��intel�Ǝ��Ă����Ȃ���?
AMD���������v�����܂���ł���!�I���Z������Ȃ瑁�����Ă݂���
���ǁA���@���s�Ń��������C�e���V�̉B����
�ˑ��W�̂Ȃ��Ǐ��I�ȃ��[�v�̓W�J��
���鎖��intel�Ǝ��Ă����Ȃ���?
AMD���������v�����܂���ł���!�I���Z������Ȃ瑁�����Ă݂���
�Q�R�A�P�X�����Q�R�A�Q�X�����͂܂��m����Ȃ���ˁB
2�R�A2�X���͊m�肵�Ă�ł���c
�W��������TSMC 40nm�̕����܂�̘b
http://megalodon.jp/2010-0115-0348-54/digitimes.com/news/a20100113PD201.html
(DigiTimes�͎��Ԃ����ƌ����Ȃ��Ȃ�̂ŋ���)
�����łӂƎʐ^������ƒ��̃_�C�Ɍ��o�����c�c
http://www.amd.com/45nm/presskit
�ǂ����Ă�Shanghai�ł��{���ɂ��肪�Ƃ��������܂���
�ŁA40nm(TSMC?)��Shanghai����Ă�́H
�Ƃ��v�������ǂǂ��l���Ă��ԈႢ���蔲������ȁc
�ǂ�����ʐ^�����Ă����̂��Ȃ�
�W��������TSMC 40nm�̕����܂�̘b
http://megalodon.jp/2010-0115-0348-54/digitimes.com/news/a20100113PD201.html
(DigiTimes�͎��Ԃ����ƌ����Ȃ��Ȃ�̂ŋ���)
�����łӂƎʐ^������ƒ��̃_�C�Ɍ��o�����c�c
http://www.amd.com/45nm/presskit
�ǂ����Ă�Shanghai�ł��{���ɂ��肪�Ƃ��������܂���
�ŁA40nm(TSMC?)��Shanghai����Ă�́H
�Ƃ��v�������ǂǂ��l���Ă��ԈႢ���蔲������ȁc
�ǂ�����ʐ^�����Ă����̂��Ȃ�
NV��1�x�N�^���������̃X���b�h�ɕ��������@������Ă���
�x�N�^����Ȃ�����́��������Ɠ�����낤���ǂ�����X���b�h���邱�Ƃ͉\�ƍl������
�������f�[�^���^�X�N����Ȃ炻��ȑO�̖�肾����
2�R�A2�X�����m�肵�Ă��܂��킯��
�x�N�^����Ȃ�����́��������Ɠ�����낤���ǂ�����X���b�h���邱�Ƃ͉\�ƍl������
�������f�[�^���^�X�N����Ȃ炻��ȑO�̖�肾����
2�R�A2�X�����m�肵�Ă��܂��킯��
���ɐV���̂���b��ł͂���܂��AGF��Chartered�̍��������Ƃ̂��ƁB
http://www.globalfoundries.com/newsroom/2010/20100113.aspx
�@�@---------------
�@�@GLOBALFOUNDRIES today announced it has officially integrated operations
�@�@with Chartered Semiconductor Manufacturing started functioning as one company
�@�@under the GLOBALFOUNDRIES brand.
�@�@---------------
IBM�͌�������{�b�^�N��鑊�肪��Ќ����đ呹�c��(��)
http://www.globalfoundries.com/newsroom/2010/20100113.aspx
�@�@---------------
�@�@GLOBALFOUNDRIES today announced it has officially integrated operations
�@�@with Chartered Semiconductor Manufacturing started functioning as one company
�@�@under the GLOBALFOUNDRIES brand.
�@�@---------------
IBM�͌�������{�b�^�N��鑊�肪��Ќ����đ呹�c��(��)
����3.8 �ł�ALU�̔{���쓮�����͐�ɖ����Ǝv����
Bulldozer�͍�������ڎw���Ă��CPU 3.5GHz��7GHz�쓮�Ƃ�
���������Ⴂ�߂���C������
���z�͐��������炵�����ǂ˂��E�E�E
Bulldozer�͍�������ڎw���Ă��CPU 3.5GHz��7GHz�쓮�Ƃ�
���������Ⴂ�߂���C������
���z�͐��������炵�����ǂ˂��E�E�E
IBM�ׂ͖����Ă邩��e�����Ȃ����ȁ[
���x��IBM�͍�悷�鑤�����悳��鑤�ɂȂ�̂��c
�l�g�o�ł����ĂH
���炩�ɂ����肭������
IBM�ɕ������C�Z���X���͎��ƋK�͂ɉ����Č��߂ĂāA
��������������Ĕ����ɂȂ�����͂��Ȃ���Ȃ��̂��˂��B
��������������Ĕ����ɂȂ�����͂��Ȃ���Ȃ��̂��˂��B
101 �FSocket774�F2010/01/16(�y) 02:18:32 ID:juBdPJPA
>>95
ALU���Дx��s�̎��́A�f�R�[�_�[��ALU�̔����ł������肵�Ȃ��H
����Ȃ�A�Дx��s���ɗႦ��ALU��150���ɃN���b�N�A�b�v�����ꍇ�́A
�f�R�[�_�[�͂��̋t��150/2��75���܂ŃN���b�N�_�E�����Ă���
�d�C��H���̂̓f�R�[�_�炵�����A�d�͓I�ɂ͂���ő��E����Ȃ�����
ALU���Дx��s�̎��́A�f�R�[�_�[��ALU�̔����ł������肵�Ȃ��H
����Ȃ�A�Дx��s���ɗႦ��ALU��150���ɃN���b�N�A�b�v�����ꍇ�́A
�f�R�[�_�[�͂��̋t��150/2��75���܂ŃN���b�N�_�E�����Ă���
�d�C��H���̂̓f�R�[�_�炵�����A�d�͓I�ɂ͂���ő��E����Ȃ�����
Llano����480SP�����ǁA
����5600�V���[�Y(400sp)��萫�\�����̂��ȁH
����5600�V���[�Y(400sp)��萫�\�����̂��ȁH
Llano���o�鍠�ɂ�HD6000�V���[�Y���o�鍠�����A
HD5600��荂���\���͂��肻���B
HD5600��荂���\���͂��肻���B
���܂�딚����
>>101
�����m��Ȃ����ǁA�����������G�Ȏd�g�݂��
CPU�S�̂ŏ����ł����������悤�ɂ���C������B
����ɂ�����������1�X���b�h/2�R�A���s�I���Ďv��������3.8
�����m��Ȃ����ǁA�����������G�Ȏd�g�݂��
CPU�S�̂ŏ����ł����������悤�ɂ���C������B
����ɂ�����������1�X���b�h/2�R�A���s�I���Ďv��������3.8
�L�������x�ǂ�ł��ǂ�������Ȃ����
�V���O���X���b�h��CPU���ւ��Ȃ���4���߁^�T�C�N���œ����Â���́H
�V���O���X���b�h��CPU���ւ��Ȃ���4���߁^�T�C�N���œ����Â���́H
>>103
GPU�̃���������ɍH���{����ĂȂ����5600�ɕ�����
GPU�̃���������ɍH���{����ĂȂ����5600�ɕ�����
CPU��GPU�Ԃ̑ш悪���I�ɉ��P����
�邾�낤���A���Z���\���̂�20~40%����
���炢�ɂȂ肻��������A4670�ɂ͏��Ă��
����ˁB
�������ш悪�{�߂��ႤGT240��GDDR5/GD
DR3���f���̐��\�����A��������10~25%���Ă�
���ŁA���I�ȈႢ���������B
http://www.anandtech.com/video/showdoc.aspx?i=3709&p=6
���Ȃ݂Ƀm�[�g���ƁAGDDR3��Mobility Radeon
HD5830��GDDR5���g��Mobility Radeon
HD4770/4750����ʃ��f������
�邾�낤���A���Z���\���̂�20~40%����
���炢�ɂȂ肻��������A4670�ɂ͏��Ă��
����ˁB
�������ш悪�{�߂��ႤGT240��GDDR5/GD
DR3���f���̐��\�����A��������10~25%���Ă�
���ŁA���I�ȈႢ���������B
http://www.anandtech.com/video/showdoc.aspx?i=3709&p=6
���Ȃ݂Ƀm�[�g���ƁAGDDR3��Mobility Radeon
HD5830��GDDR5���g��Mobility Radeon
HD4770/4750����ʃ��f������
4�R�A�{4670�������Ď��́ATDP125W�œ������Ă���̂��ȁH
>>110
�m�[�g����������ő�45W���낤�B
������������SFF PC������65W���f�����L�邩������ǁB
45nm SOI �� 32nm SOI H/MG�ł��Ȃ����d�͂����P����邩��A���肷��፡�̔����ʂɂȂ�B
65W���f���FCPU/3GHz�AGPU/700MHz
45W���f���FCPU/2.5�`2.8GHz�AGPU/500MHz
25W���f���FCPU/2GHz�AGPU/300�`500MHz
�݂����ɂȂ��Ȃ�����
�m�[�g����������ő�45W���낤�B
������������SFF PC������65W���f�����L�邩������ǁB
45nm SOI �� 32nm SOI H/MG�ł��Ȃ����d�͂����P����邩��A���肷��፡�̔����ʂɂȂ�B
65W���f���FCPU/3GHz�AGPU/700MHz
45W���f���FCPU/2.5�`2.8GHz�AGPU/500MHz
25W���f���FCPU/2GHz�AGPU/300�`500MHz
�݂����ɂȂ��Ȃ�����
�����A"32nm�v���Z�X"�ł�3GHz�ȏ�œ��삵�A
����d�͂�2.5�`25W�Ƃ������b�����邵�ǁ[�Ȃ�̂��B
����d�͂�2.5�`25W�Ƃ������b�����邵�ǁ[�Ȃ�̂��B
����܂���҂������Ă��O�ꂽ�Ƃ��ɃK�b�J�����邩��A
�T���߂ɗ\�z���Ƃ����������_�q���ɂ͂����B
�T���߂ɗ\�z���Ƃ����������_�q���ɂ͂����B
Radeon�v��Ȃ��Ȃ�SandyBridge�ł������A
Radeon�D���Ȃ�SandyBridge+Mobility Radeon��I�ԂƎv�����B
Radeon�D���Ȃ�SandyBridge+Mobility Radeon��I�ԂƎv�����B
Llano+�O��GPU�ɂ����Ƃ�CrossFire�I�Ȃ��Ƃ͉\�H
���C�e���V������������o���Ă�����Ȃɍ��������Ȃ������B
�f���A��CPU�Ȃ�o���邩������Ȃ��B
�f���A��CPU�Ȃ�o���邩������Ȃ��B
>>116
Llano�̓m�[�g�p������O��GPU�Ƃ̑g�ݍ��킹�͂��肦�Ȃ��B
Llano�̓m�[�g�p������O��GPU�Ƃ̑g�ݍ��킹�͂��肦�Ȃ��B
Sandy��2�R�A�łł�150mm2�ʂ��邩�獡��i5�Ɠ����x�̒l�i�ň����͂Ȃ����낤�B
AthlonIIX2/4+785G����2�N�͋��炭�R�X�g�p�t�H�[�}���X�ŋ��B
�悭�l������ABulldozer8�R�A��Llano4�R�A�������ጄ�Ԃ��炯�Ƃ������A���C���i�b�v������Ȃ��ȁB
���N�͌��݂̃R�A�̃V�������N������Ƒz�肵�ė\�z���Ă݂�
�n�C�G���h�F
Bulldozer 8�R�A/6�R�A(2�R�A�E��)
250mm2��
�~�h���F
32nm Propus 6��8�R�A
150�`200mm2
�G���g���[�F
32nm Propus
(����Llano����GPU���������R�A)
100mm2��
���[�G���h
45nm Regor ���s
�m�[�g�F
Llano 4�R�A (160mm2��)
��2�R�A(�����ʐv��100mm2��)
�l�b�g�u�b�N(pine����������)�F
Ontario (1�R�A+80SP�ʂ�GPU��50m2�ȉ�)
AthlonIIX2/4+785G����2�N�͋��炭�R�X�g�p�t�H�[�}���X�ŋ��B
�悭�l������ABulldozer8�R�A��Llano4�R�A�������ጄ�Ԃ��炯�Ƃ������A���C���i�b�v������Ȃ��ȁB
���N�͌��݂̃R�A�̃V�������N������Ƒz�肵�ė\�z���Ă݂�
�n�C�G���h�F
Bulldozer 8�R�A/6�R�A(2�R�A�E��)
250mm2��
�~�h���F
32nm Propus 6��8�R�A
150�`200mm2
�G���g���[�F
32nm Propus
(����Llano����GPU���������R�A)
100mm2��
���[�G���h
45nm Regor ���s
�m�[�g�F
Llano 4�R�A (160mm2��)
��2�R�A(�����ʐv��100mm2��)
�l�b�g�u�b�N(pine����������)�F
Ontario (1�R�A+80SP�ʂ�GPU��50m2�ȉ�)
Llano�̓f�X�N�g�b�v�ɂ���������܂���
�������[�h�}�b�v����
�������[�h�}�b�v����
�l�\�z�����A�n�C�G���h��Bulldozer�ȊO��L3�ς܂Ȃ����낤�B
L3�Ȃ��Ă������ő��v�Ȃ̂�Propus vs Clark�Ŏ��ł������A
�����ɐςނ��炢�Ȃ�R�A�𑽂��ς�����قǍ����\���낤�B
PC������32nm��Propus 4�R�A��8�R�A�̃_�C������āA
GPU��785G/890G�ƁA����45nm �� 40nm�ō����@DX11 �Ή��̃`�b�v�Z�b�g����GPU�ŁA
2011�N���߂����B(���� Cedar�R�A���̂��̂��h���R�A)
�}���Ƃ��Ă�
Rager��Propus +785G vs Clark i3 or PenG
32nm Propus4�R�A + 890G vs Sandy 2�R�A
32nm Propus8�R�A + 890GorDX11�R�A vs Sandy4�R�A
Bulldozer 8�R�A�� Propus 8�R�A�ǂ������傫���낤�H
����L3�܂߂Ă������������ʂŁA������������12�R�A��300mm2�ʂŏo���Ă��邩���B
���������R�A����Bulldozer�̕����傫��������Ӗ��Ȃ�����ȁB
�Ƃ������ƂŁA����Bulldozer 12�R�A vs Sandy 8�R�A������300mm2�ʂŃn�C�G���h�Ό����ۂ��C������B
L3�Ȃ��Ă������ő��v�Ȃ̂�Propus vs Clark�Ŏ��ł������A
�����ɐςނ��炢�Ȃ�R�A�𑽂��ς�����قǍ����\���낤�B
PC������32nm��Propus 4�R�A��8�R�A�̃_�C������āA
GPU��785G/890G�ƁA����45nm �� 40nm�ō����@DX11 �Ή��̃`�b�v�Z�b�g����GPU�ŁA
2011�N���߂����B(���� Cedar�R�A���̂��̂��h���R�A)
�}���Ƃ��Ă�
Rager��Propus +785G vs Clark i3 or PenG
32nm Propus4�R�A + 890G vs Sandy 2�R�A
32nm Propus8�R�A + 890GorDX11�R�A vs Sandy4�R�A
Bulldozer 8�R�A�� Propus 8�R�A�ǂ������傫���낤�H
����L3�܂߂Ă������������ʂŁA������������12�R�A��300mm2�ʂŏo���Ă��邩���B
���������R�A����Bulldozer�̕����傫��������Ӗ��Ȃ�����ȁB
�Ƃ������ƂŁA����Bulldozer 12�R�A vs Sandy 8�R�A������300mm2�ʂŃn�C�G���h�Ό����ۂ��C������B
>>120
��������Ă��\�P�b�g�݊����Ȃ�����V�\�P�b�g�o��ɂȂ�͂��B
�f�X�N�g�b�v�ƌ����Ă����炭���[�J�[�̏ȃX�y�[�X�����p�ŁA
�}�U�[���t���Ƃ�����GPU���l������AM4�Ƃ����낤�B
����GPU�E����AM3�ɑ}����悤�ɂ��Ă��A�R�X�g�������������ĈӖ����Ȃ��B
���\���̂�Propus�Ɠ����x���낤���ˁB(�V�������N���������N���b�N����o���邩��)
����Ȃ�A100mm2�ʂ�32nm Propus�������������قnj����������B
����GPU���l�������\�P�b�g�����炭2011�N�㔼��2012�N���ɏo��Ƃ������B
����AM4�Ƃ��āA32nm�ł�CPU�R�A���s���������ς��đΉ���������ALlano��AM4�Ή��ł��o��B
�����ċ��炭Bulldozer + HD6xxx��Fusion���e�����̃\�P�b�g�ɑΉ�����Ǝv���B
�܂��A32nm����T�C�Y��J�����ԓI�ɖ�������������A22nm��2012/13�N���ɏo��C������B
��������Ă��\�P�b�g�݊����Ȃ�����V�\�P�b�g�o��ɂȂ�͂��B
�f�X�N�g�b�v�ƌ����Ă����炭���[�J�[�̏ȃX�y�[�X�����p�ŁA
�}�U�[���t���Ƃ�����GPU���l������AM4�Ƃ����낤�B
����GPU�E����AM3�ɑ}����悤�ɂ��Ă��A�R�X�g�������������ĈӖ����Ȃ��B
���\���̂�Propus�Ɠ����x���낤���ˁB(�V�������N���������N���b�N����o���邩��)
����Ȃ�A100mm2�ʂ�32nm Propus�������������قnj����������B
����GPU���l�������\�P�b�g�����炭2011�N�㔼��2012�N���ɏo��Ƃ������B
����AM4�Ƃ��āA32nm�ł�CPU�R�A���s���������ς��đΉ���������ALlano��AM4�Ή��ł��o��B
�����ċ��炭Bulldozer + HD6xxx��Fusion���e�����̃\�P�b�g�ɑΉ�����Ǝv���B
�܂��A32nm����T�C�Y��J�����ԓI�ɖ�������������A22nm��2012/13�N���ɏo��C������B
�������ɂ��Ԕ��ƌ��킴��Ȃ��B
Analyst Day�ł̃��[�h�}�b�v��ɂ̓T�[�o�[�E�f�X�N�g�b�v�E�m�[�g���킹�Ă�
Zambezi�iBulldozer 8/6/4�R�A�j
Llano�iK10 4�R�A+APU�j
Ontarino�iBobcat 2�R�A+APU�j
�����Ȃ��B
���C���i�b�v�I�ɒlj������Ƃ��Ă�Llano 2�R�A���x���낤�B
Analyst Day�ł̃��[�h�}�b�v��ɂ̓T�[�o�[�E�f�X�N�g�b�v�E�m�[�g���킹�Ă�
Zambezi�iBulldozer 8/6/4�R�A�j
Llano�iK10 4�R�A+APU�j
Ontarino�iBobcat 2�R�A+APU�j
�����Ȃ��B
���C���i�b�v�I�ɒlj������Ƃ��Ă�Llano 2�R�A���x���낤�B
����intel���R�A�����ς�ł悤�₭�����Ƃ�
����Ȃ̃x���`�ȊO�̈�ʗp�r���ᕉ�����肶��Ȃ����E�E
����Ȃ̃x���`�ȊO�̈�ʗp�r���ᕉ�����肶��Ȃ����E�E
8��12���炢�̘b�Ȃ炻��قǂł��Ȃ����ȁ[
�R�A������̃I�[�o�[�N���b�N�ϐ��@���ł�
TurboBoost�I���ʔ����Ȃ肻���ł͂Ȃ���
TurboBoost�I���ʔ����Ȃ肻���ł͂Ȃ���
TurboBoost��AMD����������Ƃ��Ă��ABulldozer����2�R�A�P�ʂɂȂ�Ȃ��H
�������Z������2���邯�ǁA���͋��L�Ȃ��B
�������Z������2���邯�ǁA���͋��L�Ȃ��B
>>121-122
�������݂Ɋ��o����������������́u�l���l����CPU�ϑz�v���l�܂��Ă��Ċy�����ȁc�B
"Propus"��8�R�A�Ƃ��B"Bulldozer"��12�R�A�Ƃ���
������AMD�ɂ�"Propus"��8�R�A�Ȃ�Čv��ɂȂ����A"Bulldozer"��12�R�A��������
�܂�"Bulldozer"�̍ŏ��ɓ��������"Zambezi"�͊���8�R�A���Ă킩���Ă�����H
���Ԃ�͌��s��"Opteron"�Ȃǂ̎I�p�����v���[�X���邽�߂�CPU���낤���ǁA
����ȏ�̃R�A�͂��܂Ɠ����ŁAMCM����16�R�A�E12�R�A�ƂȂ邾�낤�ˁB
"Zambezi"�ȏ�̃R�A�͏o�邩������Ȃ����ǁA����͂��̎��̃v���Z�X����B
�����Ĉ��PC�����ɂ́A���ł�"Bulldozer"��4�R�A�ȏ�Ƃ����v�悪�����Əo����Ă���B
�����������X"Propus"�Ƃ�����"K10�R�A"��"Llano"�ȊO�ɊJ�����Ă���Ƃ��B
AMD�̊J���\�͂̉ߑ�]�����ˁ[���낗
����Llano����p�\�P�b�g�ɂȂ�͓̂��ӂ��ȁB���m�ɂ͕ς������������Ǝv���B
Core i3/i5�͈ꉞVGA�o�͖��Ή���LGA1156�ɑ}��������H
��������Ă������̂��낤���ǁA����Ȃ̂͑債�����_�ł͂Ȃ����A�����Ȃ����Ă������낤���B
�܂��B�m���Ɏ�����CPU���l����X��������A���̖ϑz�͊y�����������ǁA
���o�̏�炸�ꂽ�ϑz�͂���Ȃ���B
>>124
>intel���R�A�����ς�ł悤�₭����
���̈Ӗ����킩���B"SandyBridge"���ő�8�R�A�����c�B
������8/6�R�A�͂ǂ���Opteron�p����B
��ʌ����ɏo��Ƃ�����6/4����B
�����ăx���`�ɂ��������̂�Intel CPU�̐ꔄ�����c�B
�������݂Ɋ��o����������������́u�l���l����CPU�ϑz�v���l�܂��Ă��Ċy�����ȁc�B
"Propus"��8�R�A�Ƃ��B"Bulldozer"��12�R�A�Ƃ���
������AMD�ɂ�"Propus"��8�R�A�Ȃ�Čv��ɂȂ����A"Bulldozer"��12�R�A��������
�܂�"Bulldozer"�̍ŏ��ɓ��������"Zambezi"�͊���8�R�A���Ă킩���Ă�����H
���Ԃ�͌��s��"Opteron"�Ȃǂ̎I�p�����v���[�X���邽�߂�CPU���낤���ǁA
����ȏ�̃R�A�͂��܂Ɠ����ŁAMCM����16�R�A�E12�R�A�ƂȂ邾�낤�ˁB
"Zambezi"�ȏ�̃R�A�͏o�邩������Ȃ����ǁA����͂��̎��̃v���Z�X����B
�����Ĉ��PC�����ɂ́A���ł�"Bulldozer"��4�R�A�ȏ�Ƃ����v�悪�����Əo����Ă���B
�����������X"Propus"�Ƃ�����"K10�R�A"��"Llano"�ȊO�ɊJ�����Ă���Ƃ��B
AMD�̊J���\�͂̉ߑ�]�����ˁ[���낗
����Llano����p�\�P�b�g�ɂȂ�͓̂��ӂ��ȁB���m�ɂ͕ς������������Ǝv���B
Core i3/i5�͈ꉞVGA�o�͖��Ή���LGA1156�ɑ}��������H
��������Ă������̂��낤���ǁA����Ȃ̂͑債�����_�ł͂Ȃ����A�����Ȃ����Ă������낤���B
�܂��B�m���Ɏ�����CPU���l����X��������A���̖ϑz�͊y�����������ǁA
���o�̏�炸�ꂽ�ϑz�͂���Ȃ���B
>>124
>intel���R�A�����ς�ł悤�₭����
���̈Ӗ����킩���B"SandyBridge"���ő�8�R�A�����c�B
������8/6�R�A�͂ǂ���Opteron�p����B
��ʌ����ɏo��Ƃ�����6/4����B
�����ăx���`�ɂ��������̂�Intel CPU�̐ꔄ�����c�B
4/8��Zambezi�̓f�X�N�g�b�v������PhenomII�̌�p�AOpteron�n�Ƃ͕ʁB
Opteron�n��12/16��Interlagos�Ƃ�6/8��Valencia�B
Analyst Day�̔��\����ς���Ă�̂Ȃ���o���Ƃ��������Ă���B
Opteron�n��12/16��Interlagos�Ƃ�6/8��Valencia�B
Analyst Day�̔��\����ς���Ă�̂Ȃ���o���Ƃ��������Ă���B
���B�������BOpteron�n��"Valencia"����������c�B
���Ď��͈�ʌ����ɂ�8�R�A�������B
"Sandy Bridge"�Ƃ͕����R�A��{�Ř_���������̐킢���B
���Ď��͈�ʌ����ɂ�8�R�A�������B
"Sandy Bridge"�Ƃ͕����R�A��{�Ř_���������̐킢���B
SandyBridge��LGA1366��p��8�R�A�A6�R�A�Ȃ̂�
��ʂ͕����R�A�����Ř_���R�A�{�̊W�ɂȂ�B
��ʂ͕����R�A�����Ř_���R�A�{�̊W�ɂȂ�B
Interlagos�uOpteron6xxx�v�F12�`16�R�A�i�UӼޭ�ف`8Ӽޭ�فj
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
SandyBridge�@�@Interlagos
�����F8�R�A�@�@�@�����F16�R�A
�_���F16�R�A�@�@�@�_���F8�R�A�i8Ӽޭ�فH�j
�{
GPU�R�A����
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
SandyBridge�@�@Interlagos
�����F8�R�A�@�@�@�����F16�R�A
�_���F16�R�A�@�@�@�_���F8�R�A�i8Ӽޭ�فH�j
�{
GPU�R�A����
>>133
SandyBridge��LGA1366��p��GPU�Ȃ��炵����B
�����Interlagos�Ɠ��i��XeonMP������ASandyBridge�����XeonMP��2011�N���ɂ͏o�Ă��Ȃ����낤�B
2011�N��Westmere����MP�̕���12�R�A�_��24�R�A�܂ł����Ȃ��͂��B
SandyBridge��LGA1366��p��GPU�Ȃ��炵����B
�����Interlagos�Ɠ��i��XeonMP������ASandyBridge�����XeonMP��2011�N���ɂ͏o�Ă��Ȃ����낤�B
2011�N��Westmere����MP�̕���12�R�A�_��24�R�A�܂ł����Ȃ��͂��B
135 �FSocket774�F2010/01/17(��) 11:45:57 ID:KovAHKTa
����ȏ��ł͂Ȃ����ȁH�Ɩϑz���Ă݂�B
�o�����[�P�`�Q �FSandy Bridge�@H2�@2C 2T�@VS�@Llano�@2C
�o�����[�Q�`�R �FSandy Bridge�@H2�@2C 4T VS�@Llano�@4C
�G�b�Z���V���� �FSandy Bridge�@H2�@4C 4T VS Bulldozer�@4C 2���W���[��
���C���X�g���[���P�`�R�FSandy Bridge�@H2�@4C 8T VS�@Bulldozer�@6C 3���W���[��
�p�t�H�[�}���X �FSandy Bridge�@H2�@6C 12T VS�@Bulldozer�@8C 4���W���[��
�p�t�H�[�}���X �FSandy Bridge�@B2�@6C 12T VS�@Bulldozer�@8C 4���W���[��
�G�N�X�g���[�� �FSandy Bridge�@B2�@8C 16T VS�@Bulldozer�@12C 3���W���[��MCM
�o�����[�P�`�Q �FSandy Bridge�@H2�@2C 2T�@VS�@Llano�@2C
�o�����[�Q�`�R �FSandy Bridge�@H2�@2C 4T VS�@Llano�@4C
�G�b�Z���V���� �FSandy Bridge�@H2�@4C 4T VS Bulldozer�@4C 2���W���[��
���C���X�g���[���P�`�R�FSandy Bridge�@H2�@4C 8T VS�@Bulldozer�@6C 3���W���[��
�p�t�H�[�}���X �FSandy Bridge�@H2�@6C 12T VS�@Bulldozer�@8C 4���W���[��
�p�t�H�[�}���X �FSandy Bridge�@B2�@6C 12T VS�@Bulldozer�@8C 4���W���[��
�G�N�X�g���[�� �FSandy Bridge�@B2�@8C 16T VS�@Bulldozer�@12C 3���W���[��MCM
Llano��Congo Platform�Ɠ����ŁA���ԑ_���Ȃ�ˁB
���ʂ��璧��ł����@�͖�������A���͂�GPU+4�R�A
���i���Œ݂����ȁB
���ƁA�e���[�J�[�̗̍p�́AHP,DELL�Ƃ��ɗ�
�����f���݂̂�����A���͂�GPU���v���X���邱�ƂŁA��
�ʃ��f���ւ̗̍p��_���邩������Ȃ����B
���ʂ��璧��ł����@�͖�������A���͂�GPU+4�R�A
���i���Œ݂����ȁB
���ƁA�e���[�J�[�̗̍p�́AHP,DELL�Ƃ��ɗ�
�����f���݂̂�����A���͂�GPU���v���X���邱�ƂŁA��
�ʃ��f���ւ̗̍p��_���邩������Ȃ����B
Interlagos�uOpteron6xxx�v�F12�`16�R�A�i�UӼޭ�ف`8Ӽޭ�فj
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
--------------------------------------------------------------------------------------------
SandyBridge�iLGA1155�j�@�@SandyBridge�iLGA1366�j�@�@�@�@Zambezi
�����F4�R�A�@�@�@�@�@�@�@�@�@�����F8�R�A�@�@�@�@�@�@�@�@�@�@�@�����F8�R�A
�_���F8�R�A�@�@�@�@�@�@�@�@�@�_���F16�R�A�@�@�@�@�@�@�@�@�@�@�_���F4�R�A�i4Ӽޭ�فH�j
�@�{
GPU����
---------------------------------------------------------------------------------------------
Westmere-EX�@�@�@�@�@�@�@SandyBridge-EX�iLGA????�j�@�@�@Interlagos
�����F12�R�A�@�@�@�@�@�@�@�@�����F----�@�@�@�@�@�@�@�@�@�@�@�@�����F16�R�A
�_���F24�R�A�@�@�@�@�@�@�@�@�_���F----�@�@�@�@�@�@�@�@�@�@�@�@�_���F8�R�A�i8Ӽޭ�فH�j
---------------------------------------------------------------------------------------------
�R�A���͂����Ƃ��āA�X���b�h���I��AMD�������Ȃ���
SandyBridge����Nehalem����傫���ς��Ȃ��炵���̂ŁA�����܂�Bulldozer�A�[�L�ŃA�h�o���e�[�W��z���邩��������
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
--------------------------------------------------------------------------------------------
SandyBridge�iLGA1155�j�@�@SandyBridge�iLGA1366�j�@�@�@�@Zambezi
�����F4�R�A�@�@�@�@�@�@�@�@�@�����F8�R�A�@�@�@�@�@�@�@�@�@�@�@�����F8�R�A
�_���F8�R�A�@�@�@�@�@�@�@�@�@�_���F16�R�A�@�@�@�@�@�@�@�@�@�@�_���F4�R�A�i4Ӽޭ�فH�j
�@�{
GPU����
---------------------------------------------------------------------------------------------
Westmere-EX�@�@�@�@�@�@�@SandyBridge-EX�iLGA????�j�@�@�@Interlagos
�����F12�R�A�@�@�@�@�@�@�@�@�����F----�@�@�@�@�@�@�@�@�@�@�@�@�����F16�R�A
�_���F24�R�A�@�@�@�@�@�@�@�@�_���F----�@�@�@�@�@�@�@�@�@�@�@�@�_���F8�R�A�i8Ӽޭ�فH�j
---------------------------------------------------------------------------------------------
�R�A���͂����Ƃ��āA�X���b�h���I��AMD�������Ȃ���
SandyBridge����Nehalem����傫���ς��Ȃ��炵���̂ŁA�����܂�Bulldozer�A�[�L�ŃA�h�o���e�[�W��z���邩��������
�V���O���x���Ȃ�v����
�X���b�h���͂�����x����Ζ�薳������
��͂�d�͌����ɐs����
���ꂪ�s������TDP�̊W��R�A�����N���b�N���グ���Ȃ�
intel��荂���Ă��ǂ��Ȃ烁�C���X�g���[���ł͉��Ƃ��Ȃ邾�낤����
�n�C�G���h�Ő�]�I�ȏɂȂ��Ă��܂�
��͂�d�͌����ɐs����
���ꂪ�s������TDP�̊W��R�A�����N���b�N���グ���Ȃ�
intel��荂���Ă��ǂ��Ȃ烁�C���X�g���[���ł͉��Ƃ��Ȃ邾�낤����
�n�C�G���h�Ő�]�I�ȏɂȂ��Ă��܂�
>>138
ttp://blogs.amd.com/work/2009/12/11/aiming-for-the-sweet-spot-in-2010-and-beyond/
US20090172359
ttp://blogs.amd.com/work/2009/12/11/aiming-for-the-sweet-spot-in-2010-and-beyond/
US20090172359
dual�ł�������IPC�ƃN���b�N�グ�Ă����
���Ř_���R�A���炵�Ă�̂�
1���W���[����2�X���b�h�����o���邱�Ƃ͊m�肵�Ă�̂�
1���W���[����2�X���b�h�����o���邱�Ƃ͊m�肵�Ă�̂�
clarkdale������قǂ̂����̂��ɂȂ�������
Liano�̐��\���ǂ�قǂ��y���݂��ȁB
Liano�̐��\���ǂ�قǂ��y���݂��ȁB
>>142
Interlagos�uOpteron6xxx�v�F12�`16�R�A�i�UӼޭ�ف`8Ӽޭ�فj
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
--------------------------------------------------------------------------------------------
SandyBridge�iLGA1155�j�@�@SandyBridge�iLGA1366�j�@�@�@�@Zambezi
�����F4�R�A�@�@�@�@�@�@�@�@�@�����F8�R�A�@�@�@�@�@�@�@�@�@�@�@�����F8�R�A
�_���F8�R�A�@�@�@�@�@�@�@�@�@�_���F16�R�A�@�@�@�@�@�@�@�@�@�@�_���F8�R�A�i4Ӽޭ�فj
�@�{
GPU����
---------------------------------------------------------------------------------------------
Westmere-EX�@�@�@�@�@�@�@SandyBridge-EX�iLGA????�j�@�@�@Interlagos
�����F12�R�A�@�@�@�@�@�@�@�@�����F----�@�@�@�@�@�@�@�@�@�@�@�@�����F16�R�A
�_���F24�R�A�@�@�@�@�@�@�@�@�_���F----�@�@�@�@�@�@�@�@�@�@�@�@�_���F16�R�A�i8Ӽޭ�فj
---------------------------------------------------------------------------------------------
������
Interlagos�uOpteron6xxx�v�F12�`16�R�A�i�UӼޭ�ف`8Ӽޭ�فj
Valencia�uOpteron4xxx�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
Zambezi�uCS�pCPU�v�F4�`8�R�A�i2Ӽޭ�ف`4Ӽޭ�فj
--------------------------------------------------------------------------------------------
SandyBridge�iLGA1155�j�@�@SandyBridge�iLGA1366�j�@�@�@�@Zambezi
�����F4�R�A�@�@�@�@�@�@�@�@�@�����F8�R�A�@�@�@�@�@�@�@�@�@�@�@�����F8�R�A
�_���F8�R�A�@�@�@�@�@�@�@�@�@�_���F16�R�A�@�@�@�@�@�@�@�@�@�@�_���F8�R�A�i4Ӽޭ�فj
�@�{
GPU����
---------------------------------------------------------------------------------------------
Westmere-EX�@�@�@�@�@�@�@SandyBridge-EX�iLGA????�j�@�@�@Interlagos
�����F12�R�A�@�@�@�@�@�@�@�@�����F----�@�@�@�@�@�@�@�@�@�@�@�@�����F16�R�A
�_���F24�R�A�@�@�@�@�@�@�@�@�_���F----�@�@�@�@�@�@�@�@�@�@�@�@�_���F16�R�A�i8Ӽޭ�فj
---------------------------------------------------------------------------------------------
������
>>142
���X���b�h�ł������o���܂���
���X���b�h�ł������o���܂���
>>128
����A����Zambezi��8�R�A�Ȃ̂͒m���Ă���
�����Apropus8�R�A���ł����ƈӖ����Ȃ��ȁ[�Ǝv������
�V���O���X���b�h���\�͉����邩�������炢�炵�������
��������A�������R�A�ɂȂ�K�v�����邵�A���̏ꍇ������������12�R�A���炢�撣��ΐς߂�̂��ȂƎv������B
���Ȃ݂ɑS���̐V�R�A�ŐV�v���Z�X�ɂȂ邾�낤Bulldozar�́A�x�ꂽ��ň����s����\�����L�邩��A
���P��Ƃ��āA�����߂ł�������R�A�̃V�������N�𖧂��ɗp�ӂ��Ă��Ȃ����Ƃ��v�����B
���̏ꍇ�ALlano�R�A���猩��4�R�A��100mm2�ʂɂł�������Propus�R�A�̓V�������N�̉��l������Ǝv���B
���������8�R�A�ł�200mm2�ɂȂ�ASandybridge����ł��\���킦�����ȂقNj��͂Ɍ�����B
�ϑz�Ƃ����Ζϑz�����ǁAPropus��4�R�A��8�R�A�̃V�������N���L��ABulldozer���x��Ă����Ȃ��C������B
����A����Zambezi��8�R�A�Ȃ̂͒m���Ă���
�����Apropus8�R�A���ł����ƈӖ����Ȃ��ȁ[�Ǝv������
�V���O���X���b�h���\�͉����邩�������炢�炵�������
��������A�������R�A�ɂȂ�K�v�����邵�A���̏ꍇ������������12�R�A���炢�撣��ΐς߂�̂��ȂƎv������B
���Ȃ݂ɑS���̐V�R�A�ŐV�v���Z�X�ɂȂ邾�낤Bulldozar�́A�x�ꂽ��ň����s����\�����L�邩��A
���P��Ƃ��āA�����߂ł�������R�A�̃V�������N�𖧂��ɗp�ӂ��Ă��Ȃ����Ƃ��v�����B
���̏ꍇ�ALlano�R�A���猩��4�R�A��100mm2�ʂɂł�������Propus�R�A�̓V�������N�̉��l������Ǝv���B
���������8�R�A�ł�200mm2�ɂȂ�ASandybridge����ł��\���킦�����ȂقNj��͂Ɍ�����B
�ϑz�Ƃ����Ζϑz�����ǁAPropus��4�R�A��8�R�A�̃V�������N���L��ABulldozer���x��Ă����Ȃ��C������B
>>146
���V���O���X���b�h���\�͉����邩�������炢
ttp://blogs.amd.com/work/2009/12/11/aiming-for-the-sweet-spot-in-2010-and-beyond/
����US20090172359
���̏��͉�����Ȃ���Ȃ�����
���V���O���X���b�h���\�͉����邩�������炢
ttp://blogs.amd.com/work/2009/12/11/aiming-for-the-sweet-spot-in-2010-and-beyond/
����US20090172359
���̏��͉�����Ȃ���Ȃ�����
�N���C�A���g�p������L3����Ă������̂ł����āA�I�p�ɑ�e��L3�Ȃ��͌��������낤�B
�}���`�v���Z�b�T���̐��\�_�E�����ɘa����ProbFilter���g���Ȃ��Ȃ�B
8�R�A�ƂȂ�ƃN���X�o�[������Istanbul�̂Ƃ�����剻���邵�B
�}���`�v���Z�b�T���̐��\�_�E�����ɘa����ProbFilter���g���Ȃ��Ȃ�B
8�R�A�ƂȂ�ƃN���X�o�[������Istanbul�̂Ƃ�����剻���邵�B
149 �FSocket774�F2010/01/17(��) 14:47:29 ID:KovAHKTa
�悭�l������R�X�g�I�ɂ��肦�����������̂Ŗϑz�����B
�o�����[�Q�@�@�@�@ �FSandy Bridge�@H2�@2C 2T�@VS�@Llano�@2C
�o�����[�R �FSandy Bridge�@H2�@2C 4T VS�@Llano�@4C
�G�b�Z���V���� �FSandy Bridge�@H2�@4C 4T VS Bulldozer�@4C 2���W���[��
���C���X�g���[���P�`�R �FSandy Bridge�@H2�@4C 8T VS�@Bulldozer�@6C 3���W���[��
���C���X�g���[���R�A�p�t�H�[�}���X �FSandy Bridge�@H2�H6C 12T VS�@Bulldozer�@8C 4���W���[��
���C���X�g���[���R�A�p�t�H�[�}���X �FSandy Bridge�@B2�@6C 12T VS�@Bulldozer�@8C 4���W���[���@
�G�N�X�g���[�� �FSandy Bridge�@B2�@8C 16T VS�@Bulldozer�@12C 3���W���[��MCM�H
�@
�o�����[�Q�@�@�@�@ �FSandy Bridge�@H2�@2C 2T�@VS�@Llano�@2C
�o�����[�R �FSandy Bridge�@H2�@2C 4T VS�@Llano�@4C
�G�b�Z���V���� �FSandy Bridge�@H2�@4C 4T VS Bulldozer�@4C 2���W���[��
���C���X�g���[���P�`�R �FSandy Bridge�@H2�@4C 8T VS�@Bulldozer�@6C 3���W���[��
���C���X�g���[���R�A�p�t�H�[�}���X �FSandy Bridge�@H2�H6C 12T VS�@Bulldozer�@8C 4���W���[��
���C���X�g���[���R�A�p�t�H�[�}���X �FSandy Bridge�@B2�@6C 12T VS�@Bulldozer�@8C 4���W���[���@
�G�N�X�g���[�� �FSandy Bridge�@B2�@8C 16T VS�@Bulldozer�@12C 3���W���[��MCM�H
�@
�������N��ɍ������C�̂���K10�n�R�A�~8��CPU�͂����
����Ȃ̂ɉ��\�[�X�����邮�炢�Ȃ獡��̂��Ƃ��l����Bulldozer�ɒ��͂��ׂ��Ƃ���
GPU�ƃZ�b�g�ŗ����E�m�[�g������Llano���������Ă���̂͐�����
����Ȃ̂ɉ��\�[�X�����邮�炢�Ȃ獡��̂��Ƃ��l����Bulldozer�ɒ��͂��ׂ��Ƃ���
GPU�ƃZ�b�g�ŗ����E�m�[�g������Llano���������Ă���̂͐�����
�m�[�g�Ȃ��C�̂���K10�ł����c�c�Ƃ����̂��Ԉ���Ă�悤�ȁB
�ŏ��̃v�����ʂ�AGPU������Bulldozer�x�[�X�ōs���ׂ��Ƃ���ł͂Ȃ����ƁB
�܂������ł��Ȃ��������̂͂킩����ǁA
K10�R�A�ŒN��������? �Ƃ����B
�ŏ��̃v�����ʂ�AGPU������Bulldozer�x�[�X�ōs���ׂ��Ƃ���ł͂Ȃ����ƁB
�܂������ł��Ȃ��������̂͂킩����ǁA
K10�R�A�ŒN��������? �Ƃ����B
>>149
>Bulldozer�@12C 3���W���[��MCM�H
�n�C�G���h�����ʂ̃\�P�b�g���Ă͍̂l���ɂ����Ȃ��H
>>151
Agena��Deneb/Propus��Thuban��Llano���ăA�[�L�e�N�`���I��3����}�C�i�[�`�F���W���Ă邵�A
���[�G���h�����i���o�b�N�A�b�v�v�����H�j�ł͈����Ȃ��Ǝv��
������ނ���Llano��2010�N����Sandy Bridge����ɏo����Ȃ��E�E�E�Ǝv��
>Bulldozer�@12C 3���W���[��MCM�H
�n�C�G���h�����ʂ̃\�P�b�g���Ă͍̂l���ɂ����Ȃ��H
>>151
Agena��Deneb/Propus��Thuban��Llano���ăA�[�L�e�N�`���I��3����}�C�i�[�`�F���W���Ă邵�A
���[�G���h�����i���o�b�N�A�b�v�v�����H�j�ł͈����Ȃ��Ǝv��
������ނ���Llano��2010�N����Sandy Bridge����ɏo����Ȃ��E�E�E�Ǝv��
>>151
�}�[�P�e�B���O���悾�Ǝv���܂�
�}�[�P�e�B���O���悾�Ǝv���܂�
Bulldozer 4C�ł�������2010�ɏo���Ă���B
���ǁA���zOS���R�������T�[�o�[�ɍœK�����₪�����̂�
��Ƃ̃f�X�N�g�b�v�݂͂�ȃ��[�G���h�H�������A�܂��������̂��ˁB
��Ƃ̃f�X�N�g�b�v�݂͂�ȃ��[�G���h�H�������A�܂��������̂��ˁB
���̔���͂��̕ӂ�
���{�̓Z�����������ł�����B
�Ƃ������I�H���ŏ��ĂȂ���
���ǂ̂Ƃ���10�N�O�̂ǂ����悤���Ȃ��ɖ߂邵���Ȃ�
�܂�Bulldozer�łق�Ƃɏ��Ă邩�ǂ��������������ǂ�
���ǂ̂Ƃ���10�N�O�̂ǂ����悤���Ȃ��ɖ߂邵���Ȃ�
�܂�Bulldozer�łق�Ƃɏ��Ă邩�ǂ��������������ǂ�
RADEON�̂悤�Ƀ��[�`�~�h���𐧂������
>>153
AMD�̐��E�ł̓}�[�P�e�B���O=�_���s���O�Ȃ̂����c�c
AMD�̐��E�ł̓}�[�P�e�B���O=�_���s���O�Ȃ̂����c�c
���܂�̔\�V�C���Ղ�ɁA���̃J�L�R�~�������n�߂���ł����ǑÓ��Ȍ��_��
�c�_��������������܂��ˁB
����A����ł� istanbul �� nehalem �̃V���O���\�P�b�g���f���ł� SPEC2006
�ł̔�r�ł����A1.5�{�̃R�A���ł��琫�\�Œǂ������Ƃ����ڂ��Ȃ��n���B
�R�A�̃��\�[�X���P�`���� bulldozer �� sandy bridge �̔�r���z������������
���m�͂���܂��B
�@(base/peak)�@�@�@�@�@�@�@int�@�@�@�@�@�@�@fp�@�@�@�@�@�@�@int-rate�@�@�@�@fp-rate
Opteron 2435/2.6GHz�@�@18.0 / 21.1�@�@22.0 / 23.9�@�@82.0 / 104�@�@65.1 / 72.0
Xeon E5540/2.53GHz�@�@26.5 / 29.4�@�@31.8 / 33.8�@�@104 / 111�@�@84.8 / 87.6
[�Q�l]
�� Opteron 2435/2.6GHz (HP ProLiant DL165 G6)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07830.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07831.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07510.html
�� Xeon E5540/2.53GHz (Bull R440 E2)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07141.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07139.html
(��L��CINT2006, CFP2006�̓f���A���\�P�b�g���f���̌��ʂ����A���x���`��
�V���O���v���Z�X�̃x���`�}�[�N�ł���B)
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08785.html
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08784.html
�c�_��������������܂��ˁB
����A����ł� istanbul �� nehalem �̃V���O���\�P�b�g���f���ł� SPEC2006
�ł̔�r�ł����A1.5�{�̃R�A���ł��琫�\�Œǂ������Ƃ����ڂ��Ȃ��n���B
�R�A�̃��\�[�X���P�`���� bulldozer �� sandy bridge �̔�r���z������������
���m�͂���܂��B
�@(base/peak)�@�@�@�@�@�@�@int�@�@�@�@�@�@�@fp�@�@�@�@�@�@�@int-rate�@�@�@�@fp-rate
Opteron 2435/2.6GHz�@�@18.0 / 21.1�@�@22.0 / 23.9�@�@82.0 / 104�@�@65.1 / 72.0
Xeon E5540/2.53GHz�@�@26.5 / 29.4�@�@31.8 / 33.8�@�@104 / 111�@�@84.8 / 87.6
[�Q�l]
�� Opteron 2435/2.6GHz (HP ProLiant DL165 G6)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07830.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07831.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07505.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090525-07510.html
�� Xeon E5540/2.53GHz (Bull R440 E2)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07141.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090424-07139.html
(��L��CINT2006, CFP2006�̓f���A���\�P�b�g���f���̌��ʂ����A���x���`��
�V���O���v���Z�X�̃x���`�}�[�N�ł���B)
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08785.html
http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091005-08784.html
Llano�̓m�[�g������Congo��Tigris�N���X��u���������Ȃ����Ɩϑz
���������6�`10�����炢�Œ���邩�琫�\�ɑ��ĕs���Ɉ�����������Ȃ��ł���
���������6�`10�����炢�Œ���邩�琫�\�ɑ��ĕs���Ɉ�����������Ȃ��ł���
>>109
GPU/CPU�Ԃ̑ш���Đ��\�ɂ���Ȃɉe�����邩�Ȃ��H
�ܘ_�����̃`�v�Z�g����GPU�̎����̓}�V�ɂȂ邾�낤���ǁA���̑���780�ȍ~��
�`�v�Z�g����LFB���ڂ����ʂ�����A���ꂪ���C���������ɂȂ�f�����b�g�ő��E����
�����Ȉ������B
>>122
GPU����CPU�̃\�P�b�g�����Video�o�͂��āA�����AMD�Ǝ��ɂȂ�̂��ˁH
�����W���I�ȏo�̓C���^�[�t�F�[�X���L��Ηǂ��̂ɁA�ƃI���^�B
GPU/CPU�Ԃ̑ш���Đ��\�ɂ���Ȃɉe�����邩�Ȃ��H
�ܘ_�����̃`�v�Z�g����GPU�̎����̓}�V�ɂȂ邾�낤���ǁA���̑���780�ȍ~��
�`�v�Z�g����LFB���ڂ����ʂ�����A���ꂪ���C���������ɂȂ�f�����b�g�ő��E����
�����Ȉ������B
>>122
GPU����CPU�̃\�P�b�g�����Video�o�͂��āA�����AMD�Ǝ��ɂȂ�̂��ˁH
�����W���I�ȏo�̓C���^�[�t�F�[�X���L��Ηǂ��̂ɁA�ƃI���^�B
���\�ɑ��ĕs���Ɉ������炢�ł���
�G���͒m�\�̉��P�̒���������ꂸ���炩��
�ނ���`�����x���̒m�\�ێ�
���C�g�o�b�N�L���b�V���ɂ��Č�荇��Ȃ����H
21GB/s�̑ш�łǂ�������ẮE�E
170 �FMAC�I�^��168 �����F2010/01/17(��) 18:06:16 ID:RiQ1mYyb
>>168
�n���Ɏv���邩������܂��A����\���ɂ��Č�荇�����ق����ǂ����Ǝv���܂���B
http://www.realworldtech.com/page.cfm?ArticleID=RWT102808015436
���傤�Lj������̍ŋ߂̍u�����A���̕��ʂ̘b�������Ă܂����B
http://journal.mycom.co.jp/column/architecture/167/index.html
�n���Ɏv���邩������܂��A����\���ɂ��Č�荇�����ق����ǂ����Ǝv���܂���B
http://www.realworldtech.com/page.cfm?ArticleID=RWT102808015436
���傤�Lj������̍ŋ߂̍u�����A���̕��ʂ̘b�������Ă܂����B
http://journal.mycom.co.jp/column/architecture/167/index.html
APU�̓m�[�g�Ƃ����[�R�X�g�f�X�N�g�b�v�p����ȁB
���������\��������̂��킩�肫���Ăăp�t�H�[�}���X
�Ȃo����킯���Ȃ��B
���������\��������̂��킩�肫���Ăăp�t�H�[�}���X
�Ȃo����킯���Ȃ��B
WriteCoalescingCache
TransientTransactionCache
TransientTransactionCache
����ς�}�C�R�~�͂܂�HD5670�̃��r���[�Ȃ��ȁ[
�s���̈������̂̓x���`�Ԓ���
���s���j�b�g������������ׂĂ��A�ˑ��W�̂����ŗL�����p�ł��ĂȂ�
���ł����ʂ��炯�Ȃ�ŁA�C���e����HT�������ėL�����p��}�������ǁA
5���̉�H�lj���30�����炢�������\�オ��Ȃ��B
���ꂾ������ׂ����s���j�b�g����ׂ������}�V�ƌ����Ă�킯�ˁB
12%�̉�H�lj���80���オ��܂�����Ă��B
�m���ɉ��zOS�g���Ȃ�AHT��肱�����̂����������ȁB
�W�T�J�[�I�ɂ́A�}���`�R�A�Ή��\�t�g���ǂ̂��炢�����Ȃ邩���ȁB
���ł����ʂ��炯�Ȃ�ŁA�C���e����HT�������ėL�����p��}�������ǁA
5���̉�H�lj���30�����炢�������\�オ��Ȃ��B
���ꂾ������ׂ����s���j�b�g����ׂ������}�V�ƌ����Ă�킯�ˁB
12%�̉�H�lj���80���オ��܂�����Ă��B
�m���ɉ��zOS�g���Ȃ�AHT��肱�����̂����������ȁB
�W�T�J�[�I�ɂ́A�}���`�R�A�Ή��\�t�g���ǂ̂��炢�����Ȃ邩���ȁB
�R�A�����₵�Ă����Ă���ʗp�r�Ƃ̘������i�ނ���
4�R�A8�X���b�h��Intel�̕��������������Ă邯�ǂ�
HyperThreading�̓^�C�~���O�n�A�v���ŕs��N�������Ƃ�
���邩�牴�͔ے�I�B
���邩�牴�͔ے�I�B
�O��50%�̃��\�[�X����80%�̃X���[�v�b�g�A�b�v�������̂��A
12%����80%���Ă��Ȃ萔�����ς���Ă���ˁB
���\�[�X�����̌v�Z�̎d���ς����̂��낤���B
12%����80%���Ă��Ȃ萔�����ς���Ă���ˁB
���\�[�X�����̌v�Z�̎d���ς����̂��낤���B
�������j�b�g�̐��Ƃ��ǂ��ł���������
���[�h�E�X�g�A�̐��\�グ�ė~����
x86 Memory disambiguition test
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=73407&threadid=73407&roomid=2
Phenom
ttp://pc10.2ch.net/test/read.cgi/tech/1168399966/551
> Test 1 -- Loading before unknown load address:
> Loading before unknown load address:�@10 cycles
> Loading before known load address:�@�@ 10 cycles
> Loading before unknown load address:�@Yes!
> Test 2 -- Loading before unknown store address:
> Loading before unknown store address:�@20 cycles
> Loading before known store address:�@ �@10 cycles
> Loading before unknown store address:�@No!
> Test 3 -- Storeing before unknown load address:
> Storeing before unknown load address:�@25 cycles
> Storeing before known load address:�@ �@12 cycles
> Storeing before unknown load address:�@No!
> Test 4 -- Storeing before unknown store address:
> Storeing before unknown store address:�@25 cycles
> Storeing before known store address:�@�@ 10 cycles
> Storeing before unknown store address:�@No!
���[�h�E�X�g�A�̐��\�グ�ė~����
x86 Memory disambiguition test
ttp://www.realworldtech.com/forums/index.cfm?action=detail&id=73407&threadid=73407&roomid=2
Phenom
ttp://pc10.2ch.net/test/read.cgi/tech/1168399966/551
> Test 1 -- Loading before unknown load address:
> Loading before unknown load address:�@10 cycles
> Loading before known load address:�@�@ 10 cycles
> Loading before unknown load address:�@Yes!
> Test 2 -- Loading before unknown store address:
> Loading before unknown store address:�@20 cycles
> Loading before known store address:�@ �@10 cycles
> Loading before unknown store address:�@No!
> Test 3 -- Storeing before unknown load address:
> Storeing before unknown load address:�@25 cycles
> Storeing before known load address:�@ �@12 cycles
> Storeing before unknown load address:�@No!
> Test 4 -- Storeing before unknown store address:
> Storeing before unknown store address:�@25 cycles
> Storeing before known store address:�@�@ 10 cycles
> Storeing before unknown store address:�@No!
core i5 6xx�V���[�Y�͒n�ɑ��̒������Ǖi
�ˑ��W�̂��ƍl����Ɓu2�R�A��1�X���v�����܂����x�̂��̂�
�V���O���X���b�h�ł͂�͂�N���b�N�グ��̂���ԂȂ��
�V���O���X���b�h�ł͂�͂�N���b�N�グ��̂���ԂȂ��
i5 6xx�ɂ��邮�炢�Ȃ�750�̂ق����K���B
�r�f�I�J�[�h�͓Ɨ��œ��ڂ�����B
�r�f�I�J�[�h�͓Ɨ��œ��ڂ�����B
�X���`
���������H
���X2.66GHz��4core���3.47GHz��2core�̕����x���`�ȊO������K���Ǝv�����H
���X2.66GHz��4core���3.47GHz��2core�̕����x���`�ȊO������K���Ǝv�����H
Bulldozer�͐V�R�A�V�v���Z�X�Ń��X�N�ł�������H
���P��Ŋ����R�A�̃V�������N�ł͕K�v�B
�����\�[�X�͊W�Ȃ��A��ƂƂ��ē��R�̐헪
Llano��15���~�ȏ�̍����\�m�[�g����
5���`10���̃����W��AthlonII+785G�Ƃ��̍ɏ������낤
5���ȉ��̃l�b�g�u�b�N�N���X�̓V���O���R�A��Ontario
Llano��10���ȉ��͂��蓾�Ȃ��ȁA�����Ă�99800�Ƃ����낤�B
(�I�ʗ�����2�R�A�łƂ���)
���P��Ŋ����R�A�̃V�������N�ł͕K�v�B
�����\�[�X�͊W�Ȃ��A��ƂƂ��ē��R�̐헪
Llano��15���~�ȏ�̍����\�m�[�g����
5���`10���̃����W��AthlonII+785G�Ƃ��̍ɏ������낤
5���ȉ��̃l�b�g�u�b�N�N���X�̓V���O���R�A��Ontario
Llano��10���ȉ��͂��蓾�Ȃ��ȁA�����Ă�99800�Ƃ����낤�B
(�I�ʗ�����2�R�A�łƂ���)
Llano�����݃��C���̃V�������N�R�A�ł������������Ȃ��ė]�T�̂ł�������GPU�ɉĂ邾��
���̃��C����CPU�R�A�~2��Ontario�����邾��
���̃��C����CPU�R�A�~2��Ontario�����邾��
Clarkdale��CPU��84mm2�Ń����R���Ƃ���������100mm2�ʂ��낤�B
Llano����GPU�������A100mm2�ʂɂȂ�B
�܂�A32nm�v���Z�X��K10.5 4�R�A��Nehalem 2�R�A4�X���b�h�������T�C�Y�ɂȂ�B
���\���͂��܂�o�Ȃ��̂�AthlonII vs i3/i5�̐F��ȃx���`���ؖ����Ă���B
������llano�̓^�[�{�u�[�X�g���ۂ��@�\��������ƕ���
�ő�AMD��Intel�̍���CPU�ɂ͑��݂����A����GPU�̍��ɂȂ��Ȃ����ȁB
Llano����GPU�������A100mm2�ʂɂȂ�B
�܂�A32nm�v���Z�X��K10.5 4�R�A��Nehalem 2�R�A4�X���b�h�������T�C�Y�ɂȂ�B
���\���͂��܂�o�Ȃ��̂�AthlonII vs i3/i5�̐F��ȃx���`���ؖ����Ă���B
������llano�̓^�[�{�u�[�X�g���ۂ��@�\��������ƕ���
�ő�AMD��Intel�̍���CPU�ɂ͑��݂����A����GPU�̍��ɂȂ��Ȃ����ȁB
Llano�͂��Ԃ�m�[�g�S�ʂ��Ǝv����B
�܂��̗p����邱�Ƃ��O����A
���i�͈��߂ɐݒ肳��Ă���͂��B
���Ƃ͏���d�͂����P����Ă���c�̘b�����B
�܂��̗p����邱�Ƃ��O����A
���i�͈��߂ɐݒ肳��Ă���͂��B
���Ƃ͏���d�͂����P����Ă���c�̘b�����B
191 �FMAC�I�^��175 �����F2010/01/17(��) 19:44:43 ID:RiQ1mYyb
>>175
�@�@----------------------
�@�@�N��>>161�̃V�X�e�����i�̈Ⴂ��˂�����ł���Ȃ����ȁB
�@�@----------------------
�v���Z�b�T���i�Ȃ�ȒP�ɒ��ׂ��܂���B
Opteron 2435: 112,590 �~ http://www.1-s.jp/products/list/1?mode=search&name=Opteron%202435
Xeon E5540: 82,620 �~ http://www.1-s.jp/products/list/3?mode=search&name=Xeon E5540
�@�@----------------------
�@�@�N��>>161�̃V�X�e�����i�̈Ⴂ��˂�����ł���Ȃ����ȁB
�@�@----------------------
�v���Z�b�T���i�Ȃ�ȒP�ɒ��ׂ��܂���B
Opteron 2435: 112,590 �~ http://www.1-s.jp/products/list/1?mode=search&name=Opteron%202435
Xeon E5540: 82,620 �~ http://www.1-s.jp/products/list/3?mode=search&name=Xeon E5540
2 core��4 core�Ńx���`�̍����Ȃ����Ă̂�
4 core�ɂƂ��Ĕ߂������Ƃ���
4 core�ɂƂ��Ĕ߂������Ƃ���
�l���Ă݂��turbo boost����nano�̋t�I�[�o�[�N���b�N�Ɠ����Ȃ�
Tukwila��PLL����ڂ�C7�Ɠ���
centaur��������
Tukwila��PLL����ڂ�C7�Ɠ���
centaur��������
Adaptive PowerSaver�̎����I�[�o�[�N���b�N���čs��
Yet another feature provides automatic overclocking if the die
temperature is low. Another feature allows the processor to automatically maintain the die
temperature at a user-specified temperature.
Yet another feature provides automatic overclocking if the die
temperature is low. Another feature allows the processor to automatically maintain the die
temperature at a user-specified temperature.
>>191
�p�[�c����Opteron/Xeon�����l�͂��Ȃ�����A�����͔��f����ĂȂ���Ȃ����Ȃ��B
HP ProLiant DL165 G6
AMD Opteron 2435 2.6GHz*2 8GB RAM ��434,700�~
http://h10010.www1.hp.com/wwpc/jp/ja/sm/WF25a/15351-15351-3328412-3328421-3328421-3955644.html
������HP ProLiant DL160 G6
Intel Xeon X5550 2.66GHz*2 8GB RAM ��510,300�~
�V�X�e�����i�Ō���A���\���Ɍ����������i���͂��肻����? (�܂����R������)
�p�[�c����Opteron/Xeon�����l�͂��Ȃ�����A�����͔��f����ĂȂ���Ȃ����Ȃ��B
HP ProLiant DL165 G6
AMD Opteron 2435 2.6GHz*2 8GB RAM ��434,700�~
http://h10010.www1.hp.com/wwpc/jp/ja/sm/WF25a/15351-15351-3328412-3328421-3328421-3955644.html
������HP ProLiant DL160 G6
Intel Xeon X5550 2.66GHz*2 8GB RAM ��510,300�~
�V�X�e�����i�Ō���A���\���Ɍ����������i���͂��肻����? (�܂����R������)
�ł܂��A�̂Ȃ�uOpteron�̕���amd64�o�C�i���ŗL���v�Ƃ������āA
���i�ȊO�ɂ�AMD��I�ԗ��R�����������ǁA���͓��ɂȂ���ˁB
���߂�AES�A�N�Z�����[�V�������炢���肷������Ǝv�����ˁB
VIA�����ɂ���Ă��邱�Ƃ����B
���i�ȊO�ɂ�AMD��I�ԗ��R�����������ǁA���͓��ɂȂ���ˁB
���߂�AES�A�N�Z�����[�V�������炢���肷������Ǝv�����ˁB
VIA�����ɂ���Ă��邱�Ƃ����B
15���ȏ���Ă��͂�Q�[�~���O���f�������
���ꂩ�������ɃI�v�V�������܂��������f����
AION�Ȃǂ̃��W���[��MMO�Ƃ������ݒ�ȉ��ʼn��K�ɓ��������̂�10���O�オ����ϑÓ�����
���ꂩ�������ɃI�v�V�������܂��������f����
AION�Ȃǂ̃��W���[��MMO�Ƃ������ݒ�ȉ��ʼn��K�ɓ��������̂�10���O�オ����ϑÓ�����
>>192
> 2 core��4 core�Ńx���`�̍����Ȃ����Ă̂�
> 4 core�ɂƂ��Ĕ߂������Ƃ���
2�R�A��4�R�A�ɃT�C�Y�̍������܂�Ȃ�����C�ɂ��邱�Ƃ��Ȃ��������B
�������R�A(K10)4�� �� �傫�ȃR�A(Corei)2��
> 2 core��4 core�Ńx���`�̍����Ȃ����Ă̂�
> 4 core�ɂƂ��Ĕ߂������Ƃ���
2�R�A��4�R�A�ɃT�C�Y�̍������܂�Ȃ�����C�ɂ��邱�Ƃ��Ȃ��������B
�������R�A(K10)4�� �� �傫�ȃR�A(Corei)2��
�g�����W�X�^���ƃ_�C�T�C�Y�Ɋւ��Č��������Ȃ��Ă����ł����c
http://techreport.com/articles.x/17005
�@- Istanbul: 904 million transistors, and its six-core die is 346 mm2
�@- Nehalem: 751 million transistors in a 263 mm2 die
�����Đ��\����>>161�A���i����>>191�ɂ���ʂ�B
http://techreport.com/articles.x/17005
�@- Istanbul: 904 million transistors, and its six-core die is 346 mm2
�@- Nehalem: 751 million transistors in a 263 mm2 die
�����Đ��\����>>161�A���i����>>191�ɂ���ʂ�B
�g�����W�X�^����Shanghai�Ɠ������ƍl����ƁANehalem�̃g�����W�X�^�ΐ��\���
�������ł��ȁB
�������ł��ȁB
>>182
�W�T�b�J�[���猩������Ă邯�ǂȂ�
�W�T�b�J�[���猩������Ă邯�ǂȂ�
������MAC�I�^���ABulldozer�̂Ђ݂ɂ��Ă�
�܂�����������ۂ��l�^��͂�łȂ��̂��ˁB
Rock���l�A��������(�����~�̃R���{)�ł������Ȃ����B
CMT�ł͂�����Ƃ�������Ȃ����낤�B
CMT�łȂ��Ƃ����ɂ́A�܂��p�Y���̃s�[�X�������Ă���B
�܂�����������ۂ��l�^��͂�łȂ��̂��ˁB
Rock���l�A��������(�����~�̃R���{)�ł������Ȃ����B
CMT�ł͂�����Ƃ�������Ȃ����낤�B
CMT�łȂ��Ƃ����ɂ́A�܂��p�Y���̃s�[�X�������Ă���B
SPEC�݂����Ȓł������\���Ȃ��̂�
�͂��H
��������炸�A���~�̓A�z�ł��ȁ`
> 2 core��4 core�Ńx���`�̍����Ȃ����Ă̂�
> 4 core�ɂƂ��Ĕ߂������Ƃ���
�V���O���ň��|�I�ɗ����Ă�
�V���O���̒x��4core�̓x���`�ł����g���Ȃ�
�ł��N���C�A���g��atom 100�R�A�Ƃ���������
������������ȁA�����̘A��
> 4 core�ɂƂ��Ĕ߂������Ƃ���
�V���O���ň��|�I�ɗ����Ă�
�V���O���̒x��4core�̓x���`�ł����g���Ȃ�
�ł��N���C�A���g��atom 100�R�A�Ƃ���������
������������ȁA�����̘A��
�ō��ȒL�����ǂ߂�悤�ɂȂ����ŗǂ��ł�
���m�̉��S����Ƃ����������Z�p�̒�����A���b�g�p�t�H�[�}���X�̗ǂ����̂��E���o���������͍����
�O��I�Ƀu���b�V���A�b�v�����̂�Core2�Ƃ��̎q��
�܂��A���b�g�p�t�H�[�}���X���g�����W�X�^���������炻������D�G
Bulldozer���A�[�L�e�N�`���̐ߖڂȂ��炻�̕ӂ�̎��͓��R����Ă��邾��
�O��I�Ƀu���b�V���A�b�v�����̂�Core2�Ƃ��̎q��
�܂��A���b�g�p�t�H�[�}���X���g�����W�X�^���������炻������D�G
Bulldozer���A�[�L�e�N�`���̐ߖڂȂ��炻�̕ӂ�̎��͓��R����Ă��邾��
Op�X�����XEON E5540��OPTERON 2435��r
http://pc11.2ch.net/test/read.cgi/jisaku/1239850967/515-
http://pc11.2ch.net/test/read.cgi/jisaku/1239850967/515-
Intel�œK�����܂�����Ă�z������Ƃ�
>>206
���������c���̒��͑��v���H
���������c���̒��͑��v���H
528 ���O�FSocket774[sage] ���e���F2010/01/01(��) 12:22:44 ID:lEhCwdPM
TOP500����Nehalem-EP��Barcelona�ŃR�A�ӂ�̃N���b�N���\�����ʂ��ˁB
�Q�l�ɂȂ�̂��ǂ�������Ȃ����B
�ł�����Intel��p�x���`��Sandra�ō����t���Ȃ����Ă̂͐����ȁB
TOP500����Nehalem-EP��Barcelona�ŃR�A�ӂ�̃N���b�N���\�����ʂ��ˁB
�Q�l�ɂȂ�̂��ǂ�������Ȃ����B
�ł�����Intel��p�x���`��Sandra�ō����t���Ȃ����Ă̂͐����ȁB
>>211
�t�@�C��IO�Ɍ��炸�������Ȃ��s���ɒx��
�t�@�C��IO�Ɍ��炸�������Ȃ��s���ɒx��
����Ȃ��Ƃ��Bobcat�̘b���悤���I
���������Ă�̂́u�J�X�^����H���g��Ȃ��v�u���x�ȕ���\���E���@���s�͔����Ȃ��v
����p�C�v���C����߂ŁA��r�I����g���Ȃ��Ƃ��炢�H
�V���O���X���b�h�̐������Z���\���̂ĂĂȂ��V���v���R�A���āA�����Ȃ��������낤�������
���������Ă�̂́u�J�X�^����H���g��Ȃ��v�u���x�ȕ���\���E���@���s�͔����Ȃ��v
����p�C�v���C����߂ŁA��r�I����g���Ȃ��Ƃ��炢�H
�V���O���X���b�h�̐������Z���\���̂ĂĂȂ��V���v���R�A���āA�����Ȃ��������낤�������
Bobcat���ăX�}�[�g�ł������������
������ӂ̎������炳�ꂽ�ƔL�Ƃ͂ЂƖ��Ⴄ��
������ӂ̎������炳�ꂽ�ƔL�Ƃ͂ЂƖ��Ⴄ��
���̓����O���Z�~�����O���D������
�I�Z���b�g�̉����̓K�`
>>218
���̃����[�h�̓��{�����[�V���������I�I�I�I�I�I
���̃����[�h�̓��{�����[�V���������I�I�I�I�I�I
>>216
��������������������
��������������������
�t�@�C���I���炢�Ȃ�Core2�̒�N���b�N�i�Ƃ��ŏ\���Ȃ��
�\�t�g�E�F�ARAID6�̃����_�����C�g��1GB/s�o��ʂɑ����Ȃ�Ȃ����ˁB
SAS��16�䂭�炢���ׂĂ݂���ǂ����낤
���ꂾ���̃A���C��ڑ��ł����Ȃ����Ă݂���Ċ�������
�s�s���̃R�[�h�l�[���͎~�߁H
2010�NCES�@3D�f���́A�u���������l�v������
http://cybergarden.cocolog-nifty.com/blog/2010/01/2010ces3d-6c69.html
CES����2010�N��O����W�]����`���������J�^�`���
http://cybergarden.cocolog-nifty.com/blog/2010/01/ces2010-0e72.html
http://cybergarden.cocolog-nifty.com/blog/2010/01/2010ces3d-6c69.html
CES����2010�N��O����W�]����`���������J�^�`���
http://cybergarden.cocolog-nifty.com/blog/2010/01/ces2010-0e72.html
229 �FSocket774�F2010/01/19(��) 14:22:18 ID:jf7EPGQ2
������u�ŖG�����C�A�E�g�~�߂���Ȃ�
>>7
������g�����������̂�Super 7�B
Pentium 75MHz����K-6II+550MHz�܂ŁA�ŒႩ��ō��܂ł̎��g���̕��������Ƃ��L���A
�C���e������AMD�A�T�C���b�N�X���烉�C�Y�܂ŁA�����Ƃ����Ђ�CPU���ڂ����B
������g�����������̂�Super 7�B
Pentium 75MHz����K-6II+550MHz�܂ŁA�ŒႩ��ō��܂ł̎��g���̕��������Ƃ��L���A
�C���e������AMD�A�T�C���b�N�X���烉�C�Y�܂ŁA�����Ƃ����Ђ�CPU���ڂ����B
����m��ǃN�h���킢����
���K�I�ɔ����Ȃ��������Ƀ��[�A���O���ȔY�E�ʐ^���E�E�E
���K�I�ɔ����Ȃ��������Ƀ��[�A���O���ȔY�E�ʐ^���E�E�E
����͍����딚
>>231
����������
����������
http://www.sc.isc.tohoku.ac.jp/~funaya/index.php?plugin=attach&refer=Files&openfile=soturon_funa.pdf
���k��̊w������̑��_�Ȃ��ǁA���ꂪBULLDOZER�̌��l�^���Ȃ����Ƃ�
�������Z�R�@���[�h�X�g�A�Q��CPU�V�~�����[�^�[�ŁA����IPC��1.5�ɂ��͂��Ȃ��̂��B
�����Ă�CPU�͂����ƍH�v���Â炳��Ă�낤���ǁA
IPC=3�ȏ��ڎw���Ċ撣��͖̂���������̂�������Ȃ��ȁB
��͉�邩�ǂ������Ȃ�
���k��̊w������̑��_�Ȃ��ǁA���ꂪBULLDOZER�̌��l�^���Ȃ����Ƃ�
�������Z�R�@���[�h�X�g�A�Q��CPU�V�~�����[�^�[�ŁA����IPC��1.5�ɂ��͂��Ȃ��̂��B
�����Ă�CPU�͂����ƍH�v���Â炳��Ă�낤���ǁA
IPC=3�ȏ��ڎw���Ċ撣��͖̂���������̂�������Ȃ��ȁB
��͉�邩�ǂ������Ȃ�
>>230
���̒��x�̘_���H�ƌĂׂ邩�ǂ�������Ȃ��㕨�����l�^�������������
CPU�̉�Б�R�o���Ă��B���e�I�ɑ匴�̋L���̕����܂��܂�����B
���̒��x�̘_���H�ƌĂׂ邩�ǂ�������Ȃ��㕨�����l�^�������������
CPU�̉�Б�R�o���Ă��B���e�I�ɑ匴�̋L���̕����܂��܂�����B
���[�A���J�[�ԈႦ��235���ĂˁE�E
>>238
����ȃ}�W���X���Ȃ��Ă�
����ȃ}�W���X���Ȃ��Ă�
>>237-238
�l�^�Ƀ}�W���X�i�D�������x��������
�l�^�Ƀ}�W���X�i�D�������x��������
>>239-240
���܂�ȁB
>�������Z�R�@���[�h�X�g�A�Q��CPU�V�~�����[�^�[�ŁA����IPC��1.5�ɂ��͂��Ȃ��̂��B
�Ƃ������Ă邩��}�W�œ����A���ȓz���Ǝv����������B
���܂�ȁB
>�������Z�R�@���[�h�X�g�A�Q��CPU�V�~�����[�^�[�ŁA����IPC��1.5�ɂ��͂��Ȃ��̂��B
�Ƃ������Ă邩��}�W�œ����A���ȓz���Ǝv����������B
242 �F,,�E�L�́M�E,,�j��-�������F2010/01/20(��) 02:08:04 ID:3l1MxLJm
�����l�Ȃ�Ă���Ȃ��B
244 �F,,�E�L�́M�E,,�j��-�������F2010/01/20(��) 07:03:25 ID:3l1MxLJm
����IPC=3�Ȃ�Ė��߁E�f�[�^�Ƃ����S��L1�L���b�V���Ƀq�b�g���ĂȂ�����
�I�y���[�V�����Ɉˑ��W�������ꍇ�ɏ��߂Ăł�����B
�I�y���[�V�����Ɉˑ��W�������ꍇ�ɏ��߂Ăł�����B
IPC=9��CPU���ł�܂ŐQ���
>>245
�Ⓚ���������߁B
�Ⓚ���������߁B
���̑匴��AMD�͕���IPC3���Ɠ��킹��悤�ȋL�������ăt���{�b�R�������悤��
�����Ăˁ[��
>>247
�Â��ȁc�m��K10���܂�K8L�ƌĂ�Ă������ゾ�����H
�Â��ȁc�m��K10���܂�K8L�ƌĂ�Ă������ゾ�����H
Itanium�������㎀��ŁAILP�ɓ��������v���Z�b�T�Ȃ��Ȃ����������
�d�͌��������낤�Ƃ��A�V���O���X���b�h���\�݂̂�Nj����镪����ĂȂ��̂���
�d�͌��������낤�Ƃ��A�V���O���X���b�h���\�݂̂�Nj����镪����ĂȂ��̂���
251 �FSocket774�F2010/01/20(��) 20:55:03 ID:v2BmrT8w
�v���U���2��������ǁAAMD���Ă܂��������̂�
GF�̐e��ЂŃA�u�_�r��ATIC���؍��̔����̋ƊE�Ǝ��g�ނƂ̂��ƁB
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301428
�@�@--------------------
�@�@The agreement is broad-ranging covering development collaboration, commercial,
�@�@public-private and educational cooperation. The possibility of ATIC investing in
�@�@Hynix, a memory chip vendor from which a number of banks are seeking to
�@�@disengage, was not discussed in a statement issued by ATIC, but nor was it excluded.
�@�@--------------------
�܂��A���̒��x�ŃA��������̐M�S�͗h�炪�Ȃ��̂ł��傤���A����� Intel �����{�ւ�
��������������Ȃ�ăj���[�X���c
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301514
�@�@====================
�@�@The story quotes Akimichi Degawa, a Tokyo-based strategic investment manager
�@�@at Intel Capital saying the firm plans to invest "aggressively" in Japan and is
�@�@looking at opportunities in both publicly traded companies and private firms.
�@�@====================
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301428
�@�@--------------------
�@�@The agreement is broad-ranging covering development collaboration, commercial,
�@�@public-private and educational cooperation. The possibility of ATIC investing in
�@�@Hynix, a memory chip vendor from which a number of banks are seeking to
�@�@disengage, was not discussed in a statement issued by ATIC, but nor was it excluded.
�@�@--------------------
�܂��A���̒��x�ŃA��������̐M�S�͗h�炪�Ȃ��̂ł��傤���A����� Intel �����{�ւ�
��������������Ȃ�ăj���[�X���c
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301514
�@�@====================
�@�@The story quotes Akimichi Degawa, a Tokyo-based strategic investment manager
�@�@at Intel Capital saying the firm plans to invest "aggressively" in Japan and is
�@�@looking at opportunities in both publicly traded companies and private firms.
�@�@====================
890FX+Thuban��ް
>>252
�؍��͍��␢�E�̃G���N�g���j�N�X�H��ɂȂ��Ă���̂�
���m�̎������Ǝv�����A�����܂������Ƃł�����̂��H
�ǂ����ǂ��Ƒg�������ǂ��ł������b���낤�B
�؍��͍��␢�E�̃G���N�g���j�N�X�H��ɂȂ��Ă���̂�
���m�̎������Ǝv�����A�����܂������Ƃł�����̂��H
�ǂ����ǂ��Ƒg�������ǂ��ł������b���낤�B
����Șb�͂�������イ�o�Ă邪��x�������Ȃ������͂Ȃ��B
���ꂩ��������Ȃ�Ȃ����낤�B
���ꂩ��������Ȃ�Ȃ����낤�B
�؍��p�[�c�ǂ�����PC���h�L�g���Ă�}�J���؍���ے肵���Ⴂ���낗
�Ƃ������APC�n���Ċ�{������������
�����̃����L���O�ɂ͂����Ă���{��Ƃ͓��ł����������H
>>252
����Ȃ��ƌ����Ă���d�q�@��Ȃǂ������@�n����
����Ȃ��ƌ����Ă���d�q�@��Ȃǂ������@�n����
>>259
���l�T�X�́H
���l�T�X�́H
ATIC�����̍��Ɏ���o������H
���̍��̖@���ɏ]���Ď������肪�������A
GF�ɂ܂ʼne�����o�Ȃ����S�z���B
���̍��̖@���ɏ]���Ď������肪�������A
GF�ɂ܂ʼne�����o�Ȃ����S�z���B
����Ȃ��Ƃ�胉�C�g�o�b�N�L���b�V���ɂ��Č�낤��
GPU�����߂Ă�
GPU�����߂Ă�
264 �F,,�E�L�́M�E,,�j��-�������F2010/01/21(��) 00:42:27 ID:bARPtRXi
���܂ǂ���CPU�Ń��C�g�o�b�N����Ȃ��L���b�V�����Ăǂ�����́H
Netburst��L1��L2�̓��C�g�X���[��������
Netburst��L1��L2�̓��C�g�X���[��������
GT300�̃L���b�V���̓��C�g�o�b�N�L���b�V������Ȃ���
���C�^�u���i���C�g�X���[�j�L���b�V������Ȃ��́H
���C�^�u���i���C�g�X���[�j�L���b�V������Ȃ��́H
>>228
�RD�f���Ȃ��web2.0�ƈꏏ�ŁA�ׂ��l�^���~�����ƊE�������ɑ����ł邾������ȁB
�RD�f���Ȃ��web2.0�ƈꏏ�ŁA�ׂ��l�^���~�����ƊE�������ɑ����ł邾������ȁB
267 �FSocket774�F2010/01/21(��) 02:29:43 ID:GsWx9FvL
3D�̓R�P��C������
����{�l�͐V�������̂ɔے�I������`��Ƃ�����Ȃ��ĕ��ʂɐ��E�K�͂ŃR�P����
����{�l�͐V�������̂ɔے�I������`��Ƃ�����Ȃ��ĕ��ʂɐ��E�K�͂ŃR�P����
�f��͍L�����Ă邵
���s���Ă܂�5,6�N��ɍĔR���邩��������
���s���Ă܂�5,6�N��ɍĔR���邩��������
���ށc
�ዾ�̂���Ȃ�3D���K�v
�f��ق�2���Ԓ��x�Ȃ�����̌o���Ƃ��Ē�R�͂Ȃ���
�Ƃ̒���TV������̂ɂ킴�킴�ዾ�͖�����
���v�������Ă��{�C�Ńz�[���V�A�^�[�g��ł�l���炢�ł���
�f��ق�2���Ԓ��x�Ȃ�����̌o���Ƃ��Ē�R�͂Ȃ���
�Ƃ̒���TV������̂ɂ킴�킴�ዾ�͖�����
���v�������Ă��{�C�Ńz�[���V�A�^�[�g��ł�l���炢�ł���
�����3D�ŏ����~�N���݂���Ȃ�킴�킴�ዾ�������Ⴂ�܂���?
RealWorldTech�f���̓��e�Ŕ������܂������AOPEN64�̃��|�W�g����
bulldozer�̃L���b�V���\���Ǝv������c
RWT�f����
http://www.realworldtech.com/forums/index.cfm?action=detail&id=106752&threadid=106752&roomid=2
���̃\�[�X
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/com/x8664/config_cache_targ.cxx
�� L1
case TARGET_orochi:
L[0] = MHD_LEVEL(MHD_TYPE_CACHE, // Type
16*1024, // Size
64, // Line Size
18, // Clean Miss Penalty
18, // Dirty Miss Penalty
4, // Associativity
32, // TLB Entries
4*1024, // Page Size
50, // TLB Clean Miss Penalty ?
50, // TLB Dirty Miss Penalty ?
6.0, // Typical Outstanding Loads ?
0.8, // Load_OP_Overlap_1 ?
0.4, // Load_OP_Overlap_2 ?
50); // Pct_Excess_Writes_Nonhidable ?
break;
bulldozer�̃L���b�V���\���Ǝv������c
RWT�f����
http://www.realworldtech.com/forums/index.cfm?action=detail&id=106752&threadid=106752&roomid=2
���̃\�[�X
http://svn.open64.net/filedetails.php?repname=Open64&path=/trunk/osprey/common/com/x8664/config_cache_targ.cxx
�� L1
case TARGET_orochi:
L[0] = MHD_LEVEL(MHD_TYPE_CACHE, // Type
16*1024, // Size
64, // Line Size
18, // Clean Miss Penalty
18, // Dirty Miss Penalty
4, // Associativity
32, // TLB Entries
4*1024, // Page Size
50, // TLB Clean Miss Penalty ?
50, // TLB Dirty Miss Penalty ?
6.0, // Typical Outstanding Loads ?
0.8, // Load_OP_Overlap_1 ?
0.4, // Load_OP_Overlap_2 ?
50); // Pct_Excess_Writes_Nonhidable ?
break;
273 �FMAC�I�^�������F2010/01/21(��) 08:40:12 ID:of8CGWIO
�� L2
�@case TARGET_barcelona:
�@�@�@�@// TODO: this might be too generous: in multiple processor situations,
�@�@�@�@// there is a cost to loading the shared bus/memory.
�@�@�@�@L[1] = MHD_LEVEL(MHD_TYPE_CACHE,
�@�@�@�@�@�@�@�@1*512*1024,
�@�@�@�@�@�@�@�@64,
�@�@�@�@�@�@�@�@150,
�@�@�@�@�@�@�@�@200, // ?
�@�@�@�@�@�@�@�@16,
�@�@�@�@�@�@�@�@512,
�@�@�@�@�@�@�@�@4*1024,
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 1.8: 1.0, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.7 : 0.1, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.3 : 0.05, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 25 : 50); // ?
�@break;
�@case TARGET_barcelona:
�@�@�@�@// TODO: this might be too generous: in multiple processor situations,
�@�@�@�@// there is a cost to loading the shared bus/memory.
�@�@�@�@L[1] = MHD_LEVEL(MHD_TYPE_CACHE,
�@�@�@�@�@�@�@�@1*512*1024,
�@�@�@�@�@�@�@�@64,
�@�@�@�@�@�@�@�@150,
�@�@�@�@�@�@�@�@200, // ?
�@�@�@�@�@�@�@�@16,
�@�@�@�@�@�@�@�@512,
�@�@�@�@�@�@�@�@4*1024,
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 1.8: 1.0, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.7 : 0.1, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.3 : 0.05, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 25 : 50); // ?
�@break;
����σX�J���[����ڂ�������
275 �FMAC�I�^�������F2010/01/21(��) 08:42:46 ID:of8CGWIO
>>273 �͌��Ă̒ʂ� Barcelona �̋L�q�ł����B�����炪 bulldozer
�@case TARGET_orochi:
�@�@�@�@// TODO: this might be too generous: in multiple processor situations,
�@�@�@�@// there is a cost to loading the shared bus/memory.
�@�@�@�@L[1] = MHD_LEVEL(MHD_TYPE_CACHE,
�@�@�@�@�@�@�@�@2*1024*1024,
�@�@�@�@�@�@�@�@64,
�@�@�@�@�@�@�@�@150,
�@�@�@�@�@�@�@�@200, // ?
�@�@�@�@�@�@�@�@16,
�@�@�@�@�@�@�@�@512,
�@�@�@�@�@�@�@�@4*1024,
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 1.8: 1.0, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.7 : 0.1, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.3 : 0.05, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 25 : 50); // ?
�@break;
�@case TARGET_orochi:
�@�@�@�@// TODO: this might be too generous: in multiple processor situations,
�@�@�@�@// there is a cost to loading the shared bus/memory.
�@�@�@�@L[1] = MHD_LEVEL(MHD_TYPE_CACHE,
�@�@�@�@�@�@�@�@2*1024*1024,
�@�@�@�@�@�@�@�@64,
�@�@�@�@�@�@�@�@150,
�@�@�@�@�@�@�@�@200, // ?
�@�@�@�@�@�@�@�@16,
�@�@�@�@�@�@�@�@512,
�@�@�@�@�@�@�@�@4*1024,
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@50, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 1.8: 1.0, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.7 : 0.1, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 0.3 : 0.05, // ?
�@�@�@�@�@�@�@�@LNO_Run_Prefetch ? 25 : 50); // ?
�@break;
L1D: 16KB
���LL2: 2MB
���̗e�ʍ�����Inclusive��?
���LL2: 2MB
���̗e�ʍ�����Inclusive��?
�g���[�X�L���b�V����������
�Ӂ[��B���̃L���b�V���ʂ��{�����Ƃ���ƁA
�{���ɐV�A�[�L�e�B�N�`���ȂȂ��c�B
�{���ɐV�A�[�L�e�B�N�`���ȂȂ��c�B
�܂�L2���Ȃ��̂�
1���W���[���������L2��2MB�Ȃ�Ȃ��́H
���W���[���Ԃŋ��L����L3�����邵�B
���W���[���Ԃŋ��L����L3�����邵�B
>>279
L2�͑傫������B
L2�͑傫������B
L2�����ꂾ�������L3�͗e�ʍ��I��Victim��
����Ƃ�T-RAM�̗p�ő�e�ʉ�����Inclusive��
����Ƃ�T-RAM�̗p�ő�e�ʉ�����Inclusive��
��������L3����̂��^��
>>283
����c���̔����͗��Ɂc�B
����c���̔����͗��Ɂc�B
�`����������
�����Ƃ��Ă�
ttp://journal.mycom.co.jp/photo/articles/2009/11/13/amd/images/Photo11l.jpg
�����Ƃ��Ă�
ttp://journal.mycom.co.jp/photo/articles/2009/11/13/amd/images/Photo11l.jpg
{kind=link}
L2��Latency�傫���ˁH
L1�͔�������way�����{��
�܂��B���ۂɂ͑S����CPU�̕��������肵�Ă�
>>288
�����ˁB�ł��ABulldozer��2�R�A�œ���L2�L���b�V����
���L�������A��r���^�ŏ��e��L1�Ƒ�e��L2�Ƃ����̂�
���ɂ͂��Ȃ��Ă��Ȃ��H
���������A�ǂ�����CPU�݂����ȍ\�����Ȃ�
�����ˁB�ł��ABulldozer��2�R�A�œ���L2�L���b�V����
���L�������A��r���^�ŏ��e��L1�Ƒ�e��L2�Ƃ����̂�
���ɂ͂��Ȃ��Ă��Ȃ��H
���������A�ǂ�����CPU�݂����ȍ\�����Ȃ�
�܂��Pen4������d�͎u���̌����d����
���܂�ς�点���݂�������
���܂�ς�点���݂�������
Pen4�݂�����CPU�ɂ���Ƃ͒n���꒼������܂���
�����Intel�̂悤�ɒL�����������Ȃ���
�����Intel�̂悤�ɒL�����������Ȃ���
�A���~���܂���
(Pentium4 - 1�R�A2�X�b�h��) + 2�R�A1�X�b�h�� + HKMG + 32nm + AMD��TB = Bulldozer
�������I�@��Y���
Some instruction latency numbers of Bulldozer?
http://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
���߃��C�e���V���o�Ă�݂�����
http://citavia.blog.de/2010/01/21/some-instruction-latency-numbers-of-bulldozer-7850137/
���߃��C�e���V���o�Ă�݂�����
ttp://svn.open64.net/filedetails.php?repname=Open64&path=%2Ftrunk%2Fosprey%2Fcommon%2Ftarg_info%2Fproc%2Fx8664%2Forochi_si.cxx&rev=2722
Any_Result_Available_Time()�����C�e���V
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
Any_Result_Available_Time()�����C�e���V
fp-load 2 -> 5
fadd/fmul 4 -> 6
fmadd 6
fdiv32 18 -> 27
fdiv64 20 -> 30
�ӂ��n����
�e�\�����ς��߂��Ăċ�����Ƃ̔�r�Ő��\���\���ł��Ȃ���
300 �F,,�E�L�́M�E,,�j��-�������F2010/01/22(��) 18:21:52 ID:F0MHD1R9
���Ƀs�[�L�[�Ȑv���B
>>300
�s�L�s�L�b�Ɨ���z��
�s�L�s�L�b�Ɨ���z��
���ȗ\�������Ă���
���N���N����
���N���N����
�s�[�L�[�߂��Ă��O�ɂᖳ������
���邳
�n�b�n�b�A�~�������ȁA���O���f�J�C�̂Ԃ�ǂ�ȁI
���������B�ߓd�ݒ�ł��A���g����3.8GHz��艺�����Ⴂ���Ȃ��ȁB
>>300
�������
�������
11000MHz�܂ł�������B
�Q���W���[���S�R�A�̍��N���b�N�i���_���ڂȂ̂��ȁH
Pentium4��IPC��1���炢�������炵�����ǁA
IPC2������N���b�N�ɐU�����������������肵�ĂȁB
�X�P�W���[����H�̃��X�g���œd�͉�����Ƃ���
4GHz��120W�Ȃ�E�E�E
Pentium4��IPC��1���炢�������炵�����ǁA
IPC2������N���b�N�ɐU�����������������肵�ĂȁB
�X�P�W���[����H�̃��X�g���œd�͉�����Ƃ���
4GHz��120W�Ȃ�E�E�E
�܂�����������d�͂ƔM���l����
�s�[�N�����A�x���[�W�d���v��
�g���g�����W�X�^��ߖ�
���Ƃ̓N���b�N�ʼn҂��E�E�E�̂���
���N�̌��Ď���������L1/L2��
�悤�₭�肪�������Ȃ�N��
�s�[�N�����A�x���[�W�d���v��
�g���g�����W�X�^��ߖ�
���Ƃ̓N���b�N�ʼn҂��E�E�E�̂���
���N�̌��Ď���������L1/L2��
�悤�₭�肪�������Ȃ�N��
>>307
>290-293�ł����̂悤�ɈӖ��s���ɑ����ł邩�炻�̐�����
>290-293�ł����̂悤�ɈӖ��s���ɑ����ł邩�炻�̐�����
�ʏ�c�Ƃ���
�������I�₷���I
�ł���
�ł���
�V���O���X���b�h�����Ƃ��ϑz���Ă��n���������Ȃ���
�X���[�v�b�g�d���̎I���ƕ��ʂɍl����킩����
�X���[�v�b�g�d���̎I���ƕ��ʂɍl����킩����
����A�܂���
6GHz�ł܂킹�A���邢�́E�E
6GHz�ł܂킹�A���邢�́E�E
Intel�Ƃ̍��̓L���b�V�����\�ɖw�Ljˑ����Ă��邩��ȁA�������ǂ��܂ʼn��P���Ă��邩�ɂ�邾�낤�B
���O�ɂ��߰���߂��Ė�������
ALU�{���쓮�ɂ���
�����ƃ|�W�e�B�u�ɍs������E�E�E
1�̃f�R�[�_�[�ŁA1�T�C�N�����ƂɃf�R�[�h����X���b�h��
��ւ��Ď��s�������A�x���Ȃ�͎̂d���Ȃ��łȂ��́B
����ύl�����Ƃ��ẮA�f���A���R�A��4�X���b�h�����s����̂�
�قړ����̐��\���V���O���R�A(50%�̃��\�[�X��)�Ŏ����ł��܂����B��
�l�����(�g�[�^���ł�)�����ߊς���قǂ̕��ł��Ȃ�
1�̃f�R�[�_�[�ŁA1�T�C�N�����ƂɃf�R�[�h����X���b�h��
��ւ��Ď��s�������A�x���Ȃ�͎̂d���Ȃ��łȂ��́B
����ύl�����Ƃ��ẮA�f���A���R�A��4�X���b�h�����s����̂�
�قړ����̐��\���V���O���R�A(50%�̃��\�[�X��)�Ŏ����ł��܂����B��
�l�����(�g�[�^���ł�)�����ߊς���قǂ̕��ł��Ȃ�
�N���ߊς��Ă�́H
�������Z�̃s�[�N�l���~���������ߊς��Ă�B
FPU�̓X���[�v�b�g�d���ł������ǁA
ALU�͒�C�e���V�d���ɂ��悤��c
FPU�̓X���[�v�b�g�d���ł������ǁA
ALU�͒�C�e���V�d���ɂ��悤��c
�s�[�N�p���[�����~�����đ����X���[�v�b�g�͒Ⴍ�Ă����Ȃ��Pen4����
���ۂ̃N���b�N���悾���nj��i�K���ƃ^�[�Q�b�g��web�T�[�o�ɍi���Ă�̂��ȂƎv���B
web�Ƃ��������Z�Ƃ����܂�flops�����܂�W�Ȃ��T�[�o�B
�ǂ��CPU�ɂȂ�̂��z������
���ށB���z�͕�����͂����ȁB
�s�[�N���]���ɂ��ăX���[�v�b�g���߂�̂�web�T�[�o�ɂ͌����Ă�B
�ł��A�s�[�N�����߂��ɃX���[�v�b�g�d�����Ă���肾�ƁA
�߂�����ARM�nMicro Slice�T�[�o�ƏՓ˂���̂�ˁc�����B
�����āAx86���Ƃ��̃R���Z�v�g�ł͂قڊm����ARM�ɏ��ĂȂ��B
64bit(�A�h���X��48bit������)�̉��b�����邤���͗L���Ɏ����^�ׂ邾�낤���ǂˁB
�s�[�N���]���ɂ��ăX���[�v�b�g���߂�̂�web�T�[�o�ɂ͌����Ă�B
�ł��A�s�[�N�����߂��ɃX���[�v�b�g�d�����Ă���肾�ƁA
�߂�����ARM�nMicro Slice�T�[�o�ƏՓ˂���̂�ˁc�����B
�����āAx86���Ƃ��̃R���Z�v�g�ł͂قڊm����ARM�ɏ��ĂȂ��B
64bit(�A�h���X��48bit������)�̉��b�����邤���͗L���Ɏ����^�ׂ邾�낤���ǂˁB
����ARM���䓪���Ă���̂͋߂��������ĉ��N��H
>>295�̖��߃��C�e���V�ł�
�����_�̓{���{��������
����ȊO�̂�
packed insert
dynamic tls call
load8_16/32/64�������������炢�ő��͌���ێ����Ă�
�isqrt�`�͕������̂��ƂȂ珬���_�W�����j
AMD��CPU����FPU�͎̂Ă������Ă邩�炱�̕ӂ͗\��ʂ�
���FPU��L1D�̃��C�e���V�Ȃǂ������������肪�ǂ��ɏo�邩
���̕ӂ��y���݂��i�����N���b�N���낤���ǁj
�����_�̓{���{��������
����ȊO�̂�
packed insert
dynamic tls call
load8_16/32/64�������������炢�ő��͌���ێ����Ă�
�isqrt�`�͕������̂��ƂȂ珬���_�W�����j
AMD��CPU����FPU�͎̂Ă������Ă邩�炱�̕ӂ͗\��ʂ�
���FPU��L1D�̃��C�e���V�Ȃǂ������������肪�ǂ��ɏo�邩
���̕ӂ��y���݂��i�����N���b�N���낤���ǁj
http://www.ne.jp/asahi/comp/tarusan/main90.htm
�������ɖ����Ɏ��s���j�b�g���������Ɖ��肵���ꍇ�ł���A
�ˑ��W�ɂ�����1.7���x�ɂ����Ȃ�Ȃ����������ɂ�蕪�����Ă���B
�Ƃ������炵�����ǁA�ǂ��ł����ˁB
��IPC�H����K9�ō��܂�����Ȃ��̂��ȁB
���X����x�̍����v���O������������A�}���`�X���b�h�ɂ�������������B
�����v�Z�݂����Ȃ̂̓V���O���ł�邵���Ȃ����ǁAIPC�͏オ��Ȃ��ƁB
�������ɖ����Ɏ��s���j�b�g���������Ɖ��肵���ꍇ�ł���A
�ˑ��W�ɂ�����1.7���x�ɂ����Ȃ�Ȃ����������ɂ�蕪�����Ă���B
�Ƃ������炵�����ǁA�ǂ��ł����ˁB
��IPC�H����K9�ō��܂�����Ȃ��̂��ȁB
���X����x�̍����v���O������������A�}���`�X���b�h�ɂ�������������B
�����v�Z�݂����Ȃ̂̓V���O���ł�邵���Ȃ����ǁAIPC�͏オ��Ȃ��ƁB
�ŏI�I��GPU������̂ł��낤����A
FLOPS��Ⴍ���Ă���̂�AMD�I�ɗ��ɂ��Ȃ��Ă��邪�A
���ꂪ�{���Ȃ�Ȃ���������CPU�\�����ȁB
���X�N���b�N�d������Ƃ͎v���Ȃ����A
��������̉B�������܂�����̂��H
���邢�͂܂������ʂ�CPU���ăI�`���H
FLOPS��Ⴍ���Ă���̂�AMD�I�ɗ��ɂ��Ȃ��Ă��邪�A
���ꂪ�{���Ȃ�Ȃ���������CPU�\�����ȁB
���X�N���b�N�d������Ƃ͎v���Ȃ����A
��������̉B�������܂�����̂��H
���邢�͂܂������ʂ�CPU���ăI�`���H
�X���[�v�b�g�d���������B
Barcelona��Bulldozer���r����̂́A
US-IV��US-T1���r����悤�Ȃ��̂��B
���҂͖ڎw���Ă�����̂��قȂ�B
�ʂɋ����悤�Ȏ������Ȃ����A�Y�ނ��Ƃ͂Ȃ��B
US-IV��US-T1���r����悤�Ȃ��̂��B
���҂͖ڎw���Ă�����̂��قȂ�B
�ʂɋ����悤�Ȏ������Ȃ����A�Y�ނ��Ƃ͂Ȃ��B
PC���[�U�I�ɂ́ABarcelona������ǂ��g������Ă����𒆐S�Ƀt�H���[���Ă����ׂ��Ȃ��?
Bulldozer�͂����AMD���i������I�ȃT�u�X�g�[���[���B
Intel��Core 2�n���x�[�X�ɏ������g�����Ă����Ă��܂������Ă邾��B
AMD�͂��ꂪK10�n�����Ă������B
Bulldozer�͂����AMD���i������I�ȃT�u�X�g�[���[���B
Intel��Core 2�n���x�[�X�ɏ������g�����Ă����Ă��܂������Ă邾��B
AMD�͂��ꂪK10�n�����Ă������B
�X���[�v�b�g�������\�́@�d���Ȃ͓̂�����O���낤
Intel��Pen4�Ƃ��s�[�L�[�i�S�����g���[�X�L���b�V���ɍڂ��ĕ����������I���ݔ\�͂͐����I�Ƃ��j�Ȃ̂C�ō�����肷�邪
Intel��Pen4�Ƃ��s�[�L�[�i�S�����g���[�X�L���b�V���ɍڂ��ĕ����������I���ݔ\�͂͐����I�Ƃ��j�Ȃ̂C�ō�����肷�邪
�V���O�����x����Ӗ���������
��ʃN���C�A���g��
��ʃN���C�A���g��
>>332
GPU�������Ă���FPU���̂Ă�̂��B
�ǂ����\�t�g�E�F�A���̑Ή��̓n�[�h�������Ă���10�N������B
�����̖ڏ����痧���ĂȂ��Ƃ����i�K�œ����O���FLOPS�̂Ă�o�J�͂��Ȃ��B
GPU�������Ă���FPU���̂Ă�̂��B
�ǂ����\�t�g�E�F�A���̑Ή��̓n�[�h�������Ă���10�N������B
�����̖ڏ����痧���ĂȂ��Ƃ����i�K�œ����O���FLOPS�̂Ă�o�J�͂��Ȃ��B
�� Liano
���ALiano�������������ʂ̓o�b�N�A�b�v���Ă��邩��ȁB
�ނ���Liano������Ƃ������ƂŁA�����K10�n���g������v�����������Ɗ��҂�������킯�ŁB
Bulldozer�̓W���������Ⴄ�̂ł͂����肢���Ē��ڊ��ł͂Ȃ��B
�A�[�L�e�N�`�����V�����Ƃ��������Ŋ��҂��鎞��͂��킽�B
���ALiano�������������ʂ̓o�b�N�A�b�v���Ă��邩��ȁB
�ނ���Liano������Ƃ������ƂŁA�����K10�n���g������v�����������Ɗ��҂�������킯�ŁB
Bulldozer�̓W���������Ⴄ�̂ł͂����肢���Ē��ڊ��ł͂Ȃ��B
�A�[�L�e�N�`�����V�����Ƃ��������Ŋ��҂��鎞��͂��킽�B
Liano��AVX���Ԃɍ����ĂȂ������Ȃ̂�Intel�ւ̑R�n�Ƃ��Ă͒ɂ��ȁB
Liano�̌�p���ǂ��Ȃ邩������Ԃ̒��ڂǂ���ł��B
Bulldozer�̕������̃X���̃l�^�I�ɂ͐���オ��낤���ǁA
Liano���Y��Ȃ��łˁB
Liano�̌�p���ǂ��Ȃ邩������Ԃ̒��ڂǂ���ł��B
Bulldozer�̕������̃X���̃l�^�I�ɂ͐���オ��낤���ǁA
Liano���Y��Ȃ��łˁB
>>338
�����̖ڏ��cFUSION�J�����̂�"Llano"�ł悤�₭���i�������A
�J�����̂͐̂������Ă��邵�A�m�E�n�E�͒~�ς���Ă��邾��B
�ł�FPU�����炷�̂͊m���Ɂu���������v�Ȋ����͂ʂ�������Ȃ���ˁB
�����̖ڏ��cFUSION�J�����̂�"Llano"�ł悤�₭���i�������A
�J�����̂͐̂������Ă��邵�A�m�E�n�E�͒~�ς���Ă��邾��B
�ł�FPU�����炷�̂͊m���Ɂu���������v�Ȋ����͂ʂ�������Ȃ���ˁB
Llano��p��bulldozer+RV9xx�Ȃ�Ȃ��́H
�����ALiano�̌�p��Bulldozer���ƍl���Ă���l��Bulldozer�ɒ��ڂ��Ă��āA
Liano�̌�p��K10�n�x�[�X���ƍl���Ă���l��Bulldozer�ɉ��^�I�Ȃ낤�ȁB
���̎���A�V�����A�[�L�e�N�`�����ł�����Ƃ����āA�S�Ă�u�������邩�͂킩���킯�ŁA
���[�G���h�̓��[�G���h��Bobcat���J�o�[�BAMD�I�ɂ͍ŏ����番�S�H�������ɂ͂����Ă�̂�����B
Liano�̌�p��K10�n�x�[�X���ƍl���Ă���l��Bulldozer�ɉ��^�I�Ȃ낤�ȁB
���̎���A�V�����A�[�L�e�N�`�����ł�����Ƃ����āA�S�Ă�u�������邩�͂킩���킯�ŁA
���[�G���h�̓��[�G���h��Bobcat���J�o�[�BAMD�I�ɂ͍ŏ����番�S�H�������ɂ͂����Ă�̂�����B
Llano��GPU��R800����ʼn��Z�Ɋ��҂ł���悤�ȑ㕨����Ȃ�
>>343
���ꂾ�ƊJ�����\�[�X�̏��Ȃ�AMD�͕s������ˁH>Bulldozer,Hound+,bobcat����
�uCPU�p���[�Ȃ�Ă����\��������Hound+�̃N���b�N�A�b�v�����ŏ\���B
�N���C�A���g������GPU�����ɒ��͂���v�Ȃ�Ă����̂����肩������Ȃ����ǁB
���ꂾ�ƊJ�����\�[�X�̏��Ȃ�AMD�͕s������ˁH>Bulldozer,Hound+,bobcat����
�uCPU�p���[�Ȃ�Ă����\��������Hound+�̃N���b�N�A�b�v�����ŏ\���B
�N���C�A���g������GPU�����ɒ��͂���v�Ȃ�Ă����̂����肩������Ȃ����ǁB
Llano�͐F�X�����Ēx�ꂽFusion������łƂ肢�����̊Ԃɍ��킹�B
�̂�Llano�̌�p�����ڂȂBAMD����w������قǏ����\�z�̍��Ȃ炢���m�炸�A
PC�s���Bulldozer��Intel�Ɩ{�C�œ�����������Ƃ͎v���ĂȂ��͂����B
�ނ��낻�̉Ƃ��Ă��Ƃ���p�ӂ��ꂽ�̂�Llano�Ȃ�Ȃ����ƁB
�̂�Llano�̌�p�����ڂȂBAMD����w������قǏ����\�z�̍��Ȃ炢���m�炸�A
PC�s���Bulldozer��Intel�Ɩ{�C�œ�����������Ƃ͎v���ĂȂ��͂����B
�ނ��낻�̉Ƃ��Ă��Ƃ���p�ӂ��ꂽ�̂�Llano�Ȃ�Ȃ����ƁB
���i�ȑO�ɁA�����A�[�L�e�B�N�`�����̂�AMD�͖����J���ł��Ă��Ȃ��B
�ϑz�Ƀg�`�����đ喇�͂�����ATi�������������O�A�����Ɠ������邷�錾���Ă邾���ŁA
GPU������FPU�̑�ւȂǖ��̂܂����B
�ϑz�Ƀg�`�����đ喇�͂�����ATi�������������O�A�����Ɠ������邷�錾���Ă邾���ŁA
GPU������FPU�̑�ւȂǖ��̂܂����B
>>343
�������Ɍ�p��"Bulldozer"���Ǝv���Ă��邾��B
���ۂ�"Bulldozer"�̃��[�h�}�b�v�ɂ�APU���ď����Ă��邵�B
������>>344���������Ƃ����R800����Ȃ̂������B
"Llano"�͍��N�o��ׂ����i��������B
�����ē�������Ȃ�Έ�V�����Ƃ���R900���ゾ������B
�������Ɍ�p��"Bulldozer"���Ǝv���Ă��邾��B
���ۂ�"Bulldozer"�̃��[�h�}�b�v�ɂ�APU���ď����Ă��邵�B
������>>344���������Ƃ����R800����Ȃ̂������B
"Llano"�͍��N�o��ׂ����i��������B
�����ē�������Ȃ�Έ�V�����Ƃ���R900���ゾ������B
�܂�>>346�͖ϑz�Ƃ��Ă��A
Bulldozer���{�C�ŕ��y���邱�Ƃƍl���Ă��A�n�C�G���hPC����
���X�Ƀ��[�G���h�֊g�傷�邱�ƂɂȂ邩��A���̐틵��Llano�n�œ������A
Bulldozer��{�C�Ō�p�ɂ���̂����f���邱�ƂɂȂ�Ǝv���ˁB
���̃��[�h�}�b�v�̓��C���X�g���[���ȉ��̃}�[�P�b�g��Bulldozer�͂Ȃ�����A
�����Ȃ�Bulldozer�ɒu����������邱�Ƃ͏��Ȃ��Ƃ��Ȃ����A
�o�����Ă���L�����Z���o����Ǝv���B
Bulldozer���{�C�ŕ��y���邱�Ƃƍl���Ă��A�n�C�G���hPC����
���X�Ƀ��[�G���h�֊g�傷�邱�ƂɂȂ邩��A���̐틵��Llano�n�œ������A
Bulldozer��{�C�Ō�p�ɂ���̂����f���邱�ƂɂȂ�Ǝv���ˁB
���̃��[�h�}�b�v�̓��C���X�g���[���ȉ��̃}�[�P�b�g��Bulldozer�͂Ȃ�����A
�����Ȃ�Bulldozer�ɒu����������邱�Ƃ͏��Ȃ��Ƃ��Ȃ����A
�o�����Ă���L�����Z���o����Ǝv���B
>>348
�T�[�o�ł̌�p��Bulldozer�ł�����Ȃ���?
������Bulldozer��K10�̌�p�Ƃ����Ă��R����Ȃ��ȁB
APU��AMD�̊J���͂ɋ^��͂��邪�A�T�[�o�����̊g����������Ȃ��B
�T�[�o�ł̌�p��Bulldozer�ł�����Ȃ���?
������Bulldozer��K10�̌�p�Ƃ����Ă��R����Ȃ��ȁB
APU��AMD�̊J���͂ɋ^��͂��邪�A�T�[�o�����̊g����������Ȃ��B
>>346
"Llano"�͂��Ƃ��Ɓu�����͌���I�v���ĂȂ��Ă��邩��A
���N������"Swift"���ǔłȂ̂͊m�����낤�ȁB
>>350
>APU��AMD�̊J���͂ɋ^��͂��邪�A�T�[�o�����̊g����������Ȃ��B
�c���[�BAPU�ɔے�I����"Llano"���̂��S�ے�ɂȁi����
"Llano"�͂��Ƃ��Ɓu�����͌���I�v���ĂȂ��Ă��邩��A
���N������"Swift"���ǔłȂ̂͊m�����낤�ȁB
>>350
>APU��AMD�̊J���͂ɋ^��͂��邪�A�T�[�o�����̊g����������Ȃ��B
�c���[�BAPU�ɔے�I����"Llano"���̂��S�ے�ɂȁi����
���͍����Open64�̎��������āAAMD�̓V���O���X���b�h���\�����Ƃ���
���ɍ�������N���b�N����������ƌ��܂���B
�ʏ퉉�Z�p�C�v���C���ɂ����āA�����ɍ�������N���b�N�ł�ALU�͈�i��
�p�C�v���C���ōό��܂��B(�ȉ���POWER6�̗�)
http://pc.watch.impress.co.jp/docs/2007/0215/isscc04_1.jpg
���������̑O�i�̓p�C�v���C����[������K�v���o�Ă��܂��B
Netburst �ɑ�\����鍂�N���b�N�H���͏���d�͂Ɣ��M�̕ǂɑj�܂�đސw
����H�ڂɂȂ�܂������A����ł�
�@�E���쒆�Ƀ_�C�i�~�b�N�ɓ�����g���Ɠd���d���𐧌䂷�� (DVFS)
�@�E�K�v�ȏꍇ�͒�i�ȏ�̓���N���b�N�œ��삷��
�Ƃ�����@�ŕ���������܂��B
�܂��ă��W���[���ԂŖ��ߐ�������L����bulldozer�̏ꍇ�A�V���O���X���b�h��
�M���Ȃ�����Б����x�܂��ėׂ̃��W���[�����A�N�e�B�u�ɂ���w���W���[���E
�z�b�s���O�x���l���Ă���̂�������܂���B
������� Intel ���ȑO�������Ă��� "core hopping" ����A�C�f�A��q����
�����ł����c
http://www.computerworld.jp/news/plf/91649.html
�@�@-----------------
�@�@���̂ق��A�ߏ�ɔ��M�����R�A�̉ғ����~���A�ʂ̃R�A�փV�[�����X��
�@�@������p��������R�A�Ԃł̃z�b�s���O�@�\��A�������E�o�X�̍�������
�@�@��������`�b�v�̐ϑw�Z�p�Ȃǂ��ABorkar���ɂ���ďЉ�ꂽ�B
�@�@-----------------
���ɍ�������N���b�N����������ƌ��܂���B
�ʏ퉉�Z�p�C�v���C���ɂ����āA�����ɍ�������N���b�N�ł�ALU�͈�i��
�p�C�v���C���ōό��܂��B(�ȉ���POWER6�̗�)
http://pc.watch.impress.co.jp/docs/2007/0215/isscc04_1.jpg
{kind=link}
���������̑O�i�̓p�C�v���C����[������K�v���o�Ă��܂��B
Netburst �ɑ�\����鍂�N���b�N�H���͏���d�͂Ɣ��M�̕ǂɑj�܂�đސw
����H�ڂɂȂ�܂������A����ł�
�@�E���쒆�Ƀ_�C�i�~�b�N�ɓ�����g���Ɠd���d���𐧌䂷�� (DVFS)
�@�E�K�v�ȏꍇ�͒�i�ȏ�̓���N���b�N�œ��삷��
�Ƃ�����@�ŕ���������܂��B
�܂��ă��W���[���ԂŖ��ߐ�������L����bulldozer�̏ꍇ�A�V���O���X���b�h��
�M���Ȃ�����Б����x�܂��ėׂ̃��W���[�����A�N�e�B�u�ɂ���w���W���[���E
�z�b�s���O�x���l���Ă���̂�������܂���B
������� Intel ���ȑO�������Ă��� "core hopping" ����A�C�f�A��q����
�����ł����c
http://www.computerworld.jp/news/plf/91649.html
�@�@-----------------
�@�@���̂ق��A�ߏ�ɔ��M�����R�A�̉ғ����~���A�ʂ̃R�A�փV�[�����X��
�@�@������p��������R�A�Ԃł̃z�b�s���O�@�\��A�������E�o�X�̍�������
�@�@��������`�b�v�̐ϑw�Z�p�Ȃǂ��ABorkar���ɂ���ďЉ�ꂽ�B
�@�@-----------------
APU�̈Ӗ��킩���Ă�̂�?
�A�v���P�[�V���������A�N�Z�����[�^�������ł����āA
GPU�Ƃ͂������̂���B�T�[�o�����Ȃ�ŋ߂̃g�����h�ɂ̂���
�Í��������Ƃ��AHPC�����̃A�N�Z�����[�^���������B
AMD�̊J���͂ɋ^��͂��邪�APC������Llano�Ɠ����Ƃ͌���Ȃ��ƌ������Ƃ��B
�A�v���P�[�V���������A�N�Z�����[�^�������ł����āA
GPU�Ƃ͂������̂���B�T�[�o�����Ȃ�ŋ߂̃g�����h�ɂ̂���
�Í��������Ƃ��AHPC�����̃A�N�Z�����[�^���������B
AMD�̊J���͂ɋ^��͂��邪�APC������Llano�Ɠ����Ƃ͌���Ȃ��ƌ������Ƃ��B
FPU�ƃL���b�V���̃��C�e���V�l������
���N���b�N�ɂȂ�Ƃ����P���ȃh���X�f���\�z�͊O���ł��낤�B
���N���b�N�ɂȂ�Ƃ����P���ȃh���X�f���\�z�͊O���ł��낤�B
>>352
POWER7�ō��N���b�N�����߂Ă܂�IPC���ɐU���Ă�������
POWER7�ō��N���b�N�����߂Ă܂�IPC���ɐU���Ă�������
APU���ĒN���g����
����AMD��4Q, 2009�̌��Z����݂Ōo�c��Ԃɂ������j���[�X���o����Ă��܂��B
���ɐV�������Ȃ��ł����A�������߂Ă����܂��B
�܂�2009�N�ʊ��̋Ɛ�
http://phx.corporate-ir.net/External.File?item=UGFyZW50SUQ9MjcyODB8Q2hpbGRJRD0tMXxUeXBlPTM=&t=1
�@- CPU����: ���� $4,131M ($4,559M @2008), ���v $127M ( -$461M @2008)
�@- GPU����: ���� $1.206M ($1,165M @2008), ���v $50M ( $12M @2008)
�Ƃ������ƂŁA�����CPU�̐Ԏ��̔���Ԃ���E���܂����B
Intel���番�߂���$1,242M��������Ύ����Ԏ��������Ƃ͌����A�����J�� ($1,721M)���A
�����������X�g������Ȃ�Ƃ������c�ꂻ���ł��B
����ŁAATIC �͊��S�� AMD ����t�@�u�����Ƃ����j���[�X������Ă��܂��B
http://www.eweek.com/c/a/IT-Infrastructure/ATIC-Looking-for-Full-Control-of-Globalfoundries-186526/
�@�@--------------------
�@�@Advanced Technology Investment Co. reportedly is looking to take full control
�@�@of Globalfoundries, the processor manufacturing venture created in 2009 with
�@�@chip maker Advanced Micro Devices.
�@�@--------------------
VIA�̗l�ɐ����c��Ƃ������ƂɂȂ�̂ł��傤���H
���ɐV�������Ȃ��ł����A�������߂Ă����܂��B
�܂�2009�N�ʊ��̋Ɛ�
http://phx.corporate-ir.net/External.File?item=UGFyZW50SUQ9MjcyODB8Q2hpbGRJRD0tMXxUeXBlPTM=&t=1
�@- CPU����: ���� $4,131M ($4,559M @2008), ���v $127M ( -$461M @2008)
�@- GPU����: ���� $1.206M ($1,165M @2008), ���v $50M ( $12M @2008)
�Ƃ������ƂŁA�����CPU�̐Ԏ��̔���Ԃ���E���܂����B
Intel���番�߂���$1,242M��������Ύ����Ԏ��������Ƃ͌����A�����J�� ($1,721M)���A
�����������X�g������Ȃ�Ƃ������c�ꂻ���ł��B
����ŁAATIC �͊��S�� AMD ����t�@�u�����Ƃ����j���[�X������Ă��܂��B
http://www.eweek.com/c/a/IT-Infrastructure/ATIC-Looking-for-Full-Control-of-Globalfoundries-186526/
�@�@--------------------
�@�@Advanced Technology Investment Co. reportedly is looking to take full control
�@�@of Globalfoundries, the processor manufacturing venture created in 2009 with
�@�@chip maker Advanced Micro Devices.
�@�@--------------------
VIA�̗l�ɐ����c��Ƃ������ƂɂȂ�̂ł��傤���H
�ɂ��Ă��A�Ƃ肠�����\�t�g�E�G�A���ŁA�A�N�Z�����[�V������API�K�i����(DirectX��AOpenGL�̂悤��)������āA
�n�[�h�������Ă��A�ᑬ�ł��Œ�������悤�ȃ\�t�g�E�F�A���C���[������Ă���
�n�[�h�E�F�A�̃A�N�Z�����[�^�[��t�����Ă��������̂ɂȁB
��������Ȃ���v���O���}�̑唼����˂����āB���܂���MMX�����Ďg��Ȃ��\�t�g����܂قǂ���B
�����������̋@�\�����݂��Ă邩�ǂ������`�F�b�N���āA���݂��Ă�Ƃ��ƁA�Ȃ��Ƃ��̗����̏����������Ȃ��Ƃ����Ȃ�����ȁB
�܂�����ŁA�C���e���EAMD�����ꂼ��o���o���ȃA�N�Z�����[�^��CPU�ɓ������āA
���y���f�t�@�N�g�X�^���_�[�h�����܂�܂ŁA�uCPU�ɂ͏���Ă�̂ɖw�ǎg���Ȃ��v���ʂȎ��オ�A
�Y�[�[�[�[���Ƒ����킯�ł����E�E�E
�n�[�h�������Ă��A�ᑬ�ł��Œ�������悤�ȃ\�t�g�E�F�A���C���[������Ă���
�n�[�h�E�F�A�̃A�N�Z�����[�^�[��t�����Ă��������̂ɂȁB
��������Ȃ���v���O���}�̑唼����˂����āB���܂���MMX�����Ďg��Ȃ��\�t�g����܂قǂ���B
�����������̋@�\�����݂��Ă邩�ǂ������`�F�b�N���āA���݂��Ă�Ƃ��ƁA�Ȃ��Ƃ��̗����̏����������Ȃ��Ƃ����Ȃ�����ȁB
�܂�����ŁA�C���e���EAMD�����ꂼ��o���o���ȃA�N�Z�����[�^��CPU�ɓ������āA
���y���f�t�@�N�g�X�^���_�[�h�����܂�܂ŁA�uCPU�ɂ͏���Ă�̂ɖw�ǎg���Ȃ��v���ʂȎ��オ�A
�Y�[�[�[�[���Ƒ����킯�ł����E�E�E
359 �FMAC�I�^��355 �����F2010/01/23(�y) 15:27:59 ID:F/R2HRG8
>>355
POWER7�ɂ� Power Gating �ƃ^�[�{���[�h�͍̗p����Ă�����Ă����m�ł����H
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_POWER7.pdf
(p.10)
�@�@-----------------
�@�@�E -50% to +10% frequency slew independent per core
�@�@-----------------
POWER7�ɂ� Power Gating �ƃ^�[�{���[�h�͍̗p����Ă�����Ă����m�ł����H
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_POWER7.pdf
(p.10)
�@�@-----------------
�@�@�E -50% to +10% frequency slew independent per core
�@�@-----------------
OC�̃I�[�g����Nano����APLL2�ڂ���C7����
>>355
4GHz�Ńu������\������B
�����N
�����I�ɃV�������N�����X�Ȃ鍂�N���b�N�ŏo����ƌ����Ă������B
�iBlue Waters�̐��\�X�V�p�j
4GHz�Ńu������\������B
�����N
�����I�ɃV�������N�����X�Ȃ鍂�N���b�N�ŏo����ƌ����Ă������B
�iBlue Waters�̐��\�X�V�p�j
362 �FMAC�I�^��360 �����F2010/01/23(�y) 15:45:24 ID:ebeYPP2S
>>360
�@�@--------------
�@�@PLL2�ڂ���C7����
�@�@--------------
��̂�PowerPC G3�Ɏ�������Ă����Z�p���ƁB
http://spg.ict.ac.cn/paper/cassetDownload.action?cassetId=80551
C7��2005�N�ł��������H
http://ascii.jp/elem/000/000/437/437005/index-2.html
�@�@--------------
�@�@PLL2�ڂ���C7����
�@�@--------------
��̂�PowerPC G3�Ɏ�������Ă����Z�p���ƁB
http://spg.ict.ac.cn/paper/cassetDownload.action?cassetId=80551
C7��2005�N�ł��������H
http://ascii.jp/elem/000/000/437/437005/index-2.html
Bulldozer�̓��\�[�X�ߖ�����Ȃ̂Ń��[�N�d���I�ɂ͗L��
�����Ǎ��N���b�N�ʼnȂ�Vth�̏������g�����W�X�^���g�����炻�̗L�������������ł��ނ肪����C��
�����Ǎ��N���b�N�ʼnȂ�Vth�̏������g�����W�X�^���g�����炻�̗L�������������ł��ނ肪����C��
APU=�w�e���v���Z�b�T=CPU+GPGPU+��(�F��ȃA�N�Z�����[�^)
APU�̑��e=Llano=K10+RV830?
��2�i=Bulldozer+RV9xx
Bulldozer�͐������Z�̕����ɓ��������v���Z�b�T�[
���̕ӂ܂ł͊m�肵���H�����낤
�����Bulldozer�̐v�v�z��\������A
�V���O���X���b�h���\�͍T���߁A
FPU/SSE/AVX�͑Ή����Ă��邾���̂��܂����x�ɂ����l�����ĂȂ��Ǝv���B
����AVX�̓x���`�}�[�N�ŏ��C���S���Ȃ��蔲���\���Ƃ�����B
RADEON�̏������Ƃ������ڕW��FPU�̑�ւ��낤�B
���̂��߂ɂǂ�ȉ��ǂ�A�[�L�e�N�`���ύX������̂��͕s�������A
CPU�݂�����L1/L2���ځAMIMD�������肪�Ó��ȂƂ��납�ȁB
2011�N�̃��C���A�b�v����l���āAAMD�̒��ł́A
CPU�`�[���͐������Z�����̃��j�[�R�A�J���@(Bulldozer�n�Ȃǂ̍ŐVCPU�R�A)
GPU�`�[���͍ŐVDX�ւ̍œK���ƃX���[�v�b�g�d����GPGPU�R�A�J���@(RADEON�̍ŐVGPU�R�A)
APU�`�[���͑O�����CPU+GPGPU�̓����R�A�J���@(Llano�Ȃǂ�Fusion�R�A)
APU���x�[�X�ɂ������^���ɂ�郂�o�C���R�A�J�� (Bobcat��Ontario)
�ɑ�ʂ���ĊJ�����i��ł����Ȃ����ȁB
APU�̑��e=Llano=K10+RV830?
��2�i=Bulldozer+RV9xx
Bulldozer�͐������Z�̕����ɓ��������v���Z�b�T�[
���̕ӂ܂ł͊m�肵���H�����낤
�����Bulldozer�̐v�v�z��\������A
�V���O���X���b�h���\�͍T���߁A
FPU/SSE/AVX�͑Ή����Ă��邾���̂��܂����x�ɂ����l�����ĂȂ��Ǝv���B
����AVX�̓x���`�}�[�N�ŏ��C���S���Ȃ��蔲���\���Ƃ�����B
RADEON�̏������Ƃ������ڕW��FPU�̑�ւ��낤�B
���̂��߂ɂǂ�ȉ��ǂ�A�[�L�e�N�`���ύX������̂��͕s�������A
CPU�݂�����L1/L2���ځAMIMD�������肪�Ó��ȂƂ��납�ȁB
2011�N�̃��C���A�b�v����l���āAAMD�̒��ł́A
CPU�`�[���͐������Z�����̃��j�[�R�A�J���@(Bulldozer�n�Ȃǂ̍ŐVCPU�R�A)
GPU�`�[���͍ŐVDX�ւ̍œK���ƃX���[�v�b�g�d����GPGPU�R�A�J���@(RADEON�̍ŐVGPU�R�A)
APU�`�[���͑O�����CPU+GPGPU�̓����R�A�J���@(Llano�Ȃǂ�Fusion�R�A)
APU���x�[�X�ɂ������^���ɂ�郂�o�C���R�A�J�� (Bobcat��Ontario)
�ɑ�ʂ���ĊJ�����i��ł����Ȃ����ȁB
����362
���A���イ
���A���イ
��RADEON�̏������Ƃ������ڕW��FPU�̑�ւ��낤�B
������A�ǂ�����Ďg����ł���
������A�ǂ�����Ďg����ł���
�Q�[�}�[���ʂ̓��f
�Ɩ��p�̓Q�t�H
���f��GPGPU�ɗ͓���Ă��ꂽ��ō��Ȃ���
�Ɩ��p�̓Q�t�H
���f��GPGPU�ɗ͓���Ă��ꂽ��ō��Ȃ���
GPGPU�ɗ͂����Ȃ��悤�ɂȂ�������RV7x0�ȍ~�̐l�C�Ȃ�ł���
95%�ȏ�̃��[�U���g��Ȃ��悤�ȂƂ����
�_�C�T�C�Y�Ə���d�͂��ʂɂ����ޕK�v�͂Ȃ�
���Ă������AGPGPU�ɗ͂���ꂽ���ʂ�R600����̕s�l�C�������킯����
95%�ȏ�̃��[�U���g��Ȃ��悤�ȂƂ����
�_�C�T�C�Y�Ə���d�͂��ʂɂ����ޕK�v�͂Ȃ�
���Ă������AGPGPU�ɗ͂���ꂽ���ʂ�R600����̕s�l�C�������킯����
HD6xxx�͂ǂ������
R600�̕������H
R600�̕������H
>>357
> �����J�� ($1,721M)���A�����������X�g������Ȃ�Ƃ������c�ꂻ���ł��B
������������߂�
> ����ŁAATIC �͊��S�� AMD ����t�@�u�����Ƃ����j���[�X������Ă��܂��B
������GF�ɔ����Ȃ��Ȃ�AMD�Ɉ���I�ɗL���Șb�̂悤�ȁB
����������?
> �����J�� ($1,721M)���A�����������X�g������Ȃ�Ƃ������c�ꂻ���ł��B
������������߂�
> ����ŁAATIC �͊��S�� AMD ����t�@�u�����Ƃ����j���[�X������Ă��܂��B
������GF�ɔ����Ȃ��Ȃ�AMD�Ɉ���I�ɗL���Șb�̂悤�ȁB
����������?
PCI�����t���^����ނ̍\���͕`���������͕ς���
GPGP�p�ƕ��s���郊�\�[�X�������Ȃ�Ƃ�����
GPGP�p�ƕ��s���郊�\�[�X�������Ȃ�Ƃ�����
>>364
>����AVX�̓x���`�}�[�N�ŏ��C���S���Ȃ��蔲���\���Ƃ�����B
�蔲���Ƃ������B�قڐv�������Ă����ł��낤"Bulldozer"��
AVX�̗p�̂��߂Ɉ�N�������ċ����ɓ��ڂ����킯�����A
�蔲���Ƃ������B��N�Ŋ撣�������Ăق߂Ă�ꂗ
>����AVX�̓x���`�}�[�N�ŏ��C���S���Ȃ��蔲���\���Ƃ�����B
�蔲���Ƃ������B�قڐv�������Ă����ł��낤"Bulldozer"��
AVX�̗p�̂��߂Ɉ�N�������ċ����ɓ��ڂ����킯�����A
�蔲���Ƃ������B��N�Ŋ撣�������Ăق߂Ă�ꂗ
>>370
ATIC��GF�����S�ɔ������̂ł͂Ȃ����Ƃ����b��Intel�Ƃ̘a��ɂ��o�Ă����B
GF�ɔ����Ȃ��Ȃ�ƌ����Ă����ɂǂ���AMD��CPU������A�Ƃ��������ł͂��邪�B
�ǂ����ɂ��掟����AMD�̌��Z���\�ɂ�GF�̕��͊܂܂�Ȃ��Ȃ�̂ŕ��ʂɍ���������\���͍����B
ATIC��GF�����S�ɔ������̂ł͂Ȃ����Ƃ����b��Intel�Ƃ̘a��ɂ��o�Ă����B
GF�ɔ����Ȃ��Ȃ�ƌ����Ă����ɂǂ���AMD��CPU������A�Ƃ��������ł͂��邪�B
�ǂ����ɂ��掟����AMD�̌��Z���\�ɂ�GF�̕��͊܂܂�Ȃ��Ȃ�̂ŕ��ʂɍ���������\���͍����B
AVX�Ō����H���ɕύX
GPU��CPU��FP�̌����Ȃ�Ă��Ԕ��͎����
GPU�͂�����GPU
GPU��CPU��FP�̌����Ȃ�Ă��Ԕ��͎����
GPU�͂�����GPU
>>372
�P���ŃX�p���̒Z��GPU��
�킴�킴���������ǂ���K�v�͖���
������ނ�VLIW�Ńx�N�^�Ɍ���Ȃ�������v���Z�b�T�ɂȂ��Ă��邪
GPGP�Ƃ��Ĕėp�����������悤�Ƃ���NV�̂悤�ɂ���ƃ_�C������������������
�����NV�̋Z�p�������̂ł͂Ȃ�
CPU�������Ȃ�NV��1�̃A�[�L��GPGP���`����������Ȃ����Ƃ������j�̂���
�P���ŃX�p���̒Z��GPU��
�킴�킴���������ǂ���K�v�͖���
������ނ�VLIW�Ńx�N�^�Ɍ���Ȃ�������v���Z�b�T�ɂȂ��Ă��邪
GPGP�Ƃ��Ĕėp�����������悤�Ƃ���NV�̂悤�ɂ���ƃ_�C������������������
�����NV�̋Z�p�������̂ł͂Ȃ�
CPU�������Ȃ�NV��1�̃A�[�L��GPGP���`����������Ȃ����Ƃ������j�̂���
AMD�ȊO��VLIW���ᖳ�����ǂ�
Intel��GMA�܂߂�
Intel��GMA�܂߂�
NVIDIA�͂Ȃ��AGPGPU�ɓ����A�Q�[���ɓ����œ��ލ��Ηǂ�������Ȃ����Ǝv�����
�Q�[��������VLIW���L�����Č����Ȃ�
GPGPU�Ȃ�ĊW�̂Ȃ�Intel��S3���Ȃ�VLIW����Ȃ��̂��s�v�c
GPGPU�Ȃ�ĊW�̂Ȃ�Intel��S3���Ȃ�VLIW����Ȃ��̂��s�v�c
�v�Z�����̃`�b�v��GPU�̂ق��ɂ�DSP�Ȃǂ��낢�날�邪�A
�ėp�i(CPU)�ɔ�ׂă{�����[�����o�Ȃ��̂ŁA�����v���Z�X��K�͂ŕs�����B
GPU���v�̃{�����[���ɑ���肷��͔̂��ɏd�v�ŁAGPGPU�̋��݂̖{���ƌ����ėǂ��B
�ėp�i(CPU)�ɔ�ׂă{�����[�����o�Ȃ��̂ŁA�����v���Z�X��K�͂ŕs�����B
GPU���v�̃{�����[���ɑ���肷��͔̂��ɏd�v�ŁAGPGPU�̋��݂̖{���ƌ����ėǂ��B
NVIDIA�͖@�l����
ATI�̓R���V���[�}����
�ł�AMD�͌��X�@�l�I�����C���ڋq����������A�����ȁc
�ǂ���ɂ���NVIDIA��
GPGPU���i������CG�v���_�N�V������GPU���荞�ނ����Ȃ�����
��ʂɓ�������Ǝv����
ATI�̓R���V���[�}����
�ł�AMD�͌��X�@�l�I�����C���ڋq����������A�����ȁc
�ǂ���ɂ���NVIDIA��
GPGPU���i������CG�v���_�N�V������GPU���荞�ނ����Ȃ�����
��ʂɓ�������Ǝv����
�킯�̂킩���̂��o�Ă������猾���Ƃ���
�ʂɉ����uVLIW�����͑f���炵���v�Ƃ������Ă�킯����Ȃ�
������ނ͕��̂��߂̃X�P�W���[�����O�����O�łȂ�CPU�ɔC���Ă��邽��
���̕��X�y�[�X���Ȃ��T�C�Y�ʂ̌������ǂ�
������CPU�͂���Ȃ��Ƃ̂��߂ɐv���ꂽ�킯����Ȃ��̂�
CPU�ɂƂ��Ă��S�̂Ō��Ă������͈���
������GPU�ɂƂ��Ă͌������ǂ�
�厖�Ȃ��ƂȂ̂łQ���܂���
�ł��ǂ��ł���������MIMD��IntelIGP�ł���Ȃ��Ƃ�����n���ۏo������Ȃ����H
�ʂɉ����uVLIW�����͑f���炵���v�Ƃ������Ă�킯����Ȃ�
������ނ͕��̂��߂̃X�P�W���[�����O�����O�łȂ�CPU�ɔC���Ă��邽��
���̕��X�y�[�X���Ȃ��T�C�Y�ʂ̌������ǂ�
������CPU�͂���Ȃ��Ƃ̂��߂ɐv���ꂽ�킯����Ȃ��̂�
CPU�ɂƂ��Ă��S�̂Ō��Ă������͈���
������GPU�ɂƂ��Ă͌������ǂ�
�厖�Ȃ��ƂȂ̂łQ���܂���
�ł��ǂ��ł���������MIMD��IntelIGP�ł���Ȃ��Ƃ�����n���ۏo������Ȃ����H
���Ƃ����Quadro�̕i�������C�}�C�`
Fire��������
Fire��������
386 �FSocket774�F2010/01/23(�y) 18:57:19 ID:BXRXj6ZG
�@��AMD��1��21���A2009�N��4�l�����̋Ɛт������]�������Ɣ��\�����B13�l�����Ԃ�̍����ƂȂ�B
�@���l�����̔��㍂��16��4600���h���ƁA�O�N��������42�����������B�����v��11��7800���h���i1��������1.52�h���j�B
�O�N������14��3600���h���̐Ԏ��������B���Intel���������Ƌ֖@�i�ׂ̘a����12��5000���h�����Ɛт�
�v�������Ƃ��Ă���B
�@2009�N�ʊ��ł́A���㍂��54��300���h���ŁA�O�N��58��800���h�����猸�������B���v�ʂ͉��P���Ă���A�O�N��
31��2900���h���̐Ԏ��������̂ɑ��A3��400���h���̏����v���v�サ�Ă���B
�@2010�N��1�l�����̔��㍂�́A�G�ߓI�v���ɂ��A�O�l���������������錩�ʂ����Ƃ��Ă���B
http://www.itmedia.co.jp/news/articles/1001/22/news022.html
CPU�̐��\�ŕ����Ă邩��V�F�A�Ƃ�Ȃ������Ȃ̂��������Ă��������Ȃ����H
��������i7�ȏ�̐��\�̕����o����������
�@���l�����̔��㍂��16��4600���h���ƁA�O�N��������42�����������B�����v��11��7800���h���i1��������1.52�h���j�B
�O�N������14��3600���h���̐Ԏ��������B���Intel���������Ƌ֖@�i�ׂ̘a����12��5000���h�����Ɛт�
�v�������Ƃ��Ă���B
�@2009�N�ʊ��ł́A���㍂��54��300���h���ŁA�O�N��58��800���h�����猸�������B���v�ʂ͉��P���Ă���A�O�N��
31��2900���h���̐Ԏ��������̂ɑ��A3��400���h���̏����v���v�サ�Ă���B
�@2010�N��1�l�����̔��㍂�́A�G�ߓI�v���ɂ��A�O�l���������������錩�ʂ����Ƃ��Ă���B
http://www.itmedia.co.jp/news/articles/1001/22/news022.html
CPU�̐��\�ŕ����Ă邩��V�F�A�Ƃ�Ȃ������Ȃ̂��������Ă��������Ȃ����H
��������i7�ȏ�̐��\�̕����o����������
�딚���܂���('A`)
GPU�ɂƂ��Č����������̂Ȃ牽��AMD������VLIW�Ȃ́H
>>388
�lj�͂ƌ����͂��������炢�͐g�ɕt���Ă������Ǝv�����E�E�E
�Ƃ肠�������ꂾ���\���Ƃ�
ttp://pc.watch.impress.co.jp/docs/2008/0707/kaigai_02l.gif
�lj�͂ƌ����͂��������炢�͐g�ɕt���Ă������Ǝv�����E�E�E
�Ƃ肠�������ꂾ���\���Ƃ�
ttp://pc.watch.impress.co.jp/docs/2008/0707/kaigai_02l.gif
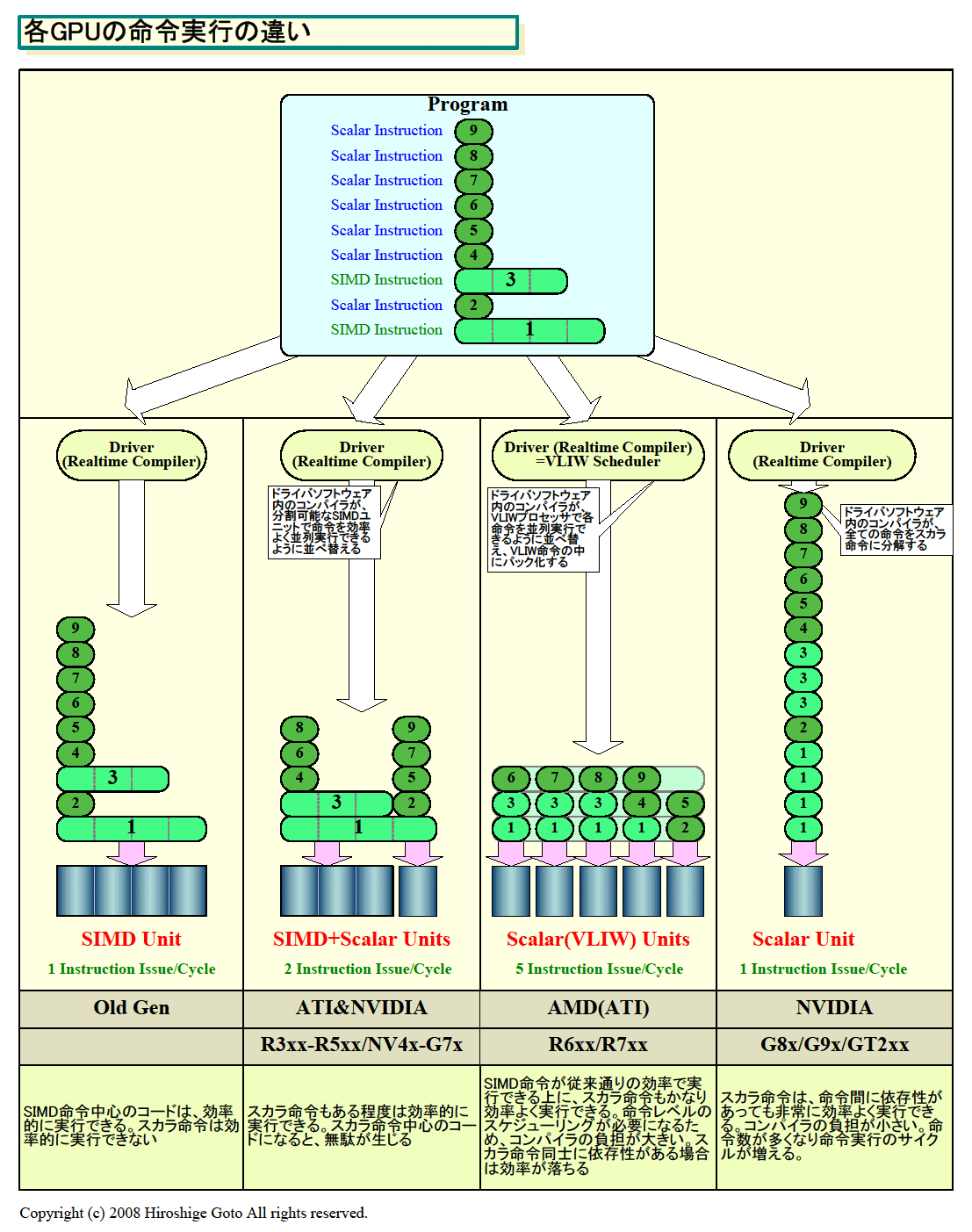{kind=link}
������Ȃ�ő��Ђ�vliw����Ȃ���
�����������
���R�͂킩����ۃQ�[���Ń_�C�ʐς���������d�͂�����̐��\�̌����͗ǂ��Ǝv����
NV�̕����i���߂�S�ăo���o���ɂ���j��
AMD�iATi�j�̕����i���߂������Ɉ��ɂ���j�������o����Ƃ�����
�����炭����́u�f�[�^���^�X�N����v�ȋ��g���̐��E�̏o��������
AMD�iATi�j�̕����i���߂������Ɉ��ɂ���j�������o����Ƃ�����
�����炭����́u�f�[�^���^�X�N����v�ȋ��g���̐��E�̏o��������
nv�̏ꍇ�A���߂�S�ăo���o���ɂȂ�Ă��ĂȂ���
�����vliw���悭��3/5���x�̌���
�����vliw���悭��3/5���x�̌���
3/5�̃\�[�X�́H
�������_���pixel�̖w�ǂ�3�v�f������
2�����ɗ��Ƃ����܂ꂽ������Ɖ����邯��
2�����ɗ��Ƃ����܂ꂽ������Ɖ����邯��
�ϑz�Ȃ�ϑz�����Č����Ă��������̂�
http://www.cgo.org/cgo2008/presentations/CGO-rubin.pdf
Bioshock: 2290 ps 4.222533
Call of Juarez: 594 ps 3.922494
Crysis: 284 ps 3.800968
LostPlanet: 83 ps 3.383631
�s�[�N���\���80%�O��A�ɒ[�ɒႢ���X�v���ł�68%�̎������\
http://www.cgo.org/cgo2008/presentations/CGO-rubin.pdf
Bioshock: 2290 ps 4.222533
Call of Juarez: 594 ps 3.922494
Crysis: 284 ps 3.800968
LostPlanet: 83 ps 3.383631
�s�[�N���\���80%�O��A�ɒ[�ɒႢ���X�v���ł�68%�̎������\
�����VLIW�͍ō����l
403 �FMAC�I�^��402 �����F2010/01/23(�y) 21:13:43 ID:Mz/BEPLA
>>402
����������Ȃ�A������Intel���J�߂Ȃ���(��)
Elbrus ���� Transmeta �Ɏ���܂ŁAVLIW �̎�v������ Intel �̌���
�W�܂��Ă��܂���B
����ɂ��Ă� Tukwila �́c
2008�N�� Hot Chips �̃v���[���́A���ǂނƗܖ����ɂ͂����܂���B
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.911.pdf
����������Ȃ�A������Intel���J�߂Ȃ���(��)
Elbrus ���� Transmeta �Ɏ���܂ŁAVLIW �̎�v������ Intel �̌���
�W�܂��Ă��܂���B
����ɂ��Ă� Tukwila �́c
2008�N�� Hot Chips �̃v���[���́A���ǂނƗܖ����ɂ͂����܂���B
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.911.pdf
Itanium���Ă�ƃA�[�L�e�N�`���Ȃ����Ȗ��Ō��ǂ͎�K����ȂƂ킩��
��K����Ȃ��ăQ�C�c�\�t�g�ɃV�J�g���ꂽ���炾��
����ł������������ʂ��Ȃ������킯�ł��Ȃ���
�\��ʂ肾���Ă�˂�
�\��ʂ肾���Ă�˂�
570mm^2��
�������c�c�傫���ł��c�c�c
�������c�c�傫���ł��c�c�c
24mm * 24mm�@���炢��
��������
��������
������Intel�ɂ��C���������̂�Montecito�L�����Z������Chivano�Ń��l�[�����\����܂�
�v�����Madison�o����2003�N���Ō�
���N��Itanium���\��7�N�ڂŃn�[�h�E�F�A���炷��X����������
�v�����Madison�o����2003�N���Ō�
���N��Itanium���\��7�N�ڂŃn�[�h�E�F�A���炷��X����������
x86�ȊO�̓}�C�P���\�t�g�Ɏ���ĉ��l������
x86-64�̎�����{�C���X�g���N�V�������ʂɂ��������A�Ⴂ������̂�
FPU�̂����ꕔ�̂�
���̍���CPU��Linux�����[�J����Unix���炢�����g���Ȃ�
x86-64�̎�����{�C���X�g���N�V�������ʂɂ��������A�Ⴂ������̂�
FPU�̂����ꕔ�̂�
���̍���CPU��Linux�����[�J����Unix���炢�����g���Ȃ�
�}�C�P���\�t�g����
�\�t�g�̐��\�����[���E�H�[�N�ł�����̂���
�\�t�g�̐��\�����[���E�H�[�N�ł�����̂���
APU�̓��[�R�X�gPC������SoC�ł���Bi3�Ƃ�i5�Ɠ����H������B
���͂��������邩���m������͂����ł͂Ȃ��̂ł�
�����Ƃ������A�ߋ��ɂ̓��[�R�X�g�����łȂ����Ƃ��������B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~113741,00.html
> AMD plans to create a new class of x86 processor that integrates the
> central processing unit (CPU) and graphics processing unit (GPU) at
> the silicon level with a broad set of design initiatives collectively
> codenamed �gFusion.�h
> Fusion processors are expected in late 2008/early 2009, and the
> company expects to use them within all of the company�fs priority
> computing categories, including laptops, desktops, workstations
> and servers
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~113741,00.html
> AMD plans to create a new class of x86 processor that integrates the
> central processing unit (CPU) and graphics processing unit (GPU) at
> the silicon level with a broad set of design initiatives collectively
> codenamed �gFusion.�h
> Fusion processors are expected in late 2008/early 2009, and the
> company expects to use them within all of the company�fs priority
> computing categories, including laptops, desktops, workstations
> and servers
��������Ȃ�800SP 1.2Tflops��GPU���
32SP 35.2gflops��GPU�̕��������ł����肻����
Radeon HD4870 VS Chrome540GTX Shader performance
ttp://www.youtube.com/watch?v=jXvSnOWDuX8
32SP 35.2gflops��GPU�̕��������ł����肻����
Radeon HD4870 VS Chrome540GTX Shader performance
ttp://www.youtube.com/watch?v=jXvSnOWDuX8
Chrome�ŃQ�[���͂ł��Ȃ���
�����A�ȓd�͂ōׂ��o�X�ł��������܂Ȃ����������ł���
>>414
�̂������ς���Ă��Ȃ�����B���[�R�X�g�ł���s���������ŁB
�̂������ς���Ă��Ȃ�����B���[�R�X�g�ł���s���������ŁB
���̂�86CPU���ۂ��Ȃ��Ă���NV��GPU��
GPU�̎�@�i�����X���b�h�Ń��C�e���V�B���j�������ꂽ��������Ȃ�Bull
���������ׂƂ��Ă��܂���
GPU�̎�@�i�����X���b�h�Ń��C�e���V�B���j�������ꂽ��������Ȃ�Bull
���������ׂƂ��Ă��܂���
Bulldozer��SMT�Ƃ����b���łĂ��ĂȂ��Ǝv�����A�ȂɂŃ��C�e���V�B���������?
�uHT�Ń��������C�e���V�B���v�Ȃ�Ă̂�1�R�A�ŕ����X���b�h��S�����Ȃ���Ȃ�Ȃ��������̘b��
���́u���R�A���邯��1�X���b�h���\�͂ǂ��Ȃ�H�v�ɂ͖��W
ttp://pc.watch.impress.co.jp/docs/2002/0624/kaigai01.htm
GPU�ƃX���b�h�̊W�͂悭�͒m��Ȃ�����
�������̏����Ƃ������ƂŃK���K���ɃX���b�h���Ď��s���Ă���Ƃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091105_326442.html
Bull��1�X���b�h������ɕ�����tHT��t����̂����m��Ȃ��Ƃ�������
�����������̕���x���l����Ƒ債�Č��ʖ������낤���ǂˁE�E�E
���́u���R�A���邯��1�X���b�h���\�͂ǂ��Ȃ�H�v�ɂ͖��W
ttp://pc.watch.impress.co.jp/docs/2002/0624/kaigai01.htm
GPU�ƃX���b�h�̊W�͂悭�͒m��Ȃ�����
�������̏����Ƃ������ƂŃK���K���ɃX���b�h���Ď��s���Ă���Ƃ���
ttp://pc.watch.impress.co.jp/docs/column/kaigai/20091105_326442.html
Bull��1�X���b�h������ɕ�����tHT��t����̂����m��Ȃ��Ƃ�������
�����������̕���x���l����Ƒ債�Č��ʖ������낤���ǂˁE�E�E
GPU�͌��X�X���b�h���������邩����Ă����ŁACPU�Ƃ͏��Ⴄ�B
�tHT���ē������Ă��A�������߂̂Ƃ���2���j�b�g�g�������ڂ��Ă邾���ŁA
������1�X���b�h2�X���b�h�ɕ�������Ƃ����b����Ȃ����B
�tHT���ē������Ă��A�������߂̂Ƃ���2���j�b�g�g�������ڂ��Ă邾���ŁA
������1�X���b�h2�X���b�h�ɕ�������Ƃ����b����Ȃ����B
>>421
�H
���@���s�́u���R�A�L�邯��1�X���b�h���\�͂ǂ��Ȃ�H�v�ɊW���邾�낤�B�Ă����������ɂ��ꂶ��ˁB
�����̃R�A�������Ă��A�ǂ����Ă����X���b�h�ɕ��U�����ł��Ȃ��V���O���X���b�h�����ł�
���̃R�A�̃p���[���g���Ă̍��������ł��Ȃ��̂������_��CPU�B
���������@���s�́A�����X���b�h�����s���̏������ǂނł��낤��������
���̃X���b�h�ɓǂ܂��Đ�ɃL���b�V�������Ă��܂����ƂŃ��������C�e���V���B������Z�p�B
�����I�ɂ�Hyper-Threading����̃e�N����Ȃ�����A���ʂ̃}���`�R�A�ł��g����B
����������A�������ш����ɘQ���̂ŁA�C���e����RDRAM���W�^�̍�����������
���p������u�Ȃ�v�����肾�����Z�p�ł����āA���ꂪ�|�V���b�^���݂ł͂���
�����������ƂɂȂ��Ă邯�ǂȁB
�H
���@���s�́u���R�A�L�邯��1�X���b�h���\�͂ǂ��Ȃ�H�v�ɊW���邾�낤�B�Ă����������ɂ��ꂶ��ˁB
�����̃R�A�������Ă��A�ǂ����Ă����X���b�h�ɕ��U�����ł��Ȃ��V���O���X���b�h�����ł�
���̃R�A�̃p���[���g���Ă̍��������ł��Ȃ��̂������_��CPU�B
���������@���s�́A�����X���b�h�����s���̏������ǂނł��낤��������
���̃X���b�h�ɓǂ܂��Đ�ɃL���b�V�������Ă��܂����ƂŃ��������C�e���V���B������Z�p�B
�����I�ɂ�Hyper-Threading����̃e�N����Ȃ�����A���ʂ̃}���`�R�A�ł��g����B
����������A�������ш����ɘQ���̂ŁA�C���e����RDRAM���W�^�̍�����������
���p������u�Ȃ�v�����肾�����Z�p�ł����āA���ꂪ�|�V���b�^���݂ł͂���
�����������ƂɂȂ��Ă邯�ǂȁB
>>424
�b�����[�v������Ȃ�B
����Hyper-Threading�Ń��������C�e���V�̉B�����Č����̂��A
���@���s�Ȃ��ĂB
�ʂ�Hyper-Threading����̋Z�p�ł��Ȃ��̂ŁA
�u1�R�A�ŕ����X���b�h��S�����Ȃ���Ȃ�Ȃ��������v "����"�̋Z�p��
�����킯�ł��Ȃ��A�Ƃ䂤�Ă邾���B
���̋C�ɂȂ��Bulldozer�ɂ����ėL������
��ŏq�ׂ��悤�Ƀ������ш�̘b������ł���̂�
���݂̃������ł͉\�����������Ƃ��������B
�b�����[�v������Ȃ�B
����Hyper-Threading�Ń��������C�e���V�̉B�����Č����̂��A
���@���s�Ȃ��ĂB
�ʂ�Hyper-Threading����̋Z�p�ł��Ȃ��̂ŁA
�u1�R�A�ŕ����X���b�h��S�����Ȃ���Ȃ�Ȃ��������v "����"�̋Z�p��
�����킯�ł��Ȃ��A�Ƃ䂤�Ă邾���B
���̋C�ɂȂ��Bulldozer�ɂ����ėL������
��ŏq�ׂ��悤�Ƀ������ш�̘b������ł���̂�
���݂̃������ł͉\�����������Ƃ��������B
�F�X���炪���Ă�
HT+���@���܂��̂͂��Ȃ̂�
HT�ɂ��łɓ��@���s�̋@�\���g�ݍ��܂�Ă邱�ƂɂȂ��Ă���Ƃ����E�E�E
HT�ɂ��łɓ��@���s�̋@�\���g�ݍ��܂�Ă邱�ƂɂȂ��Ă���Ƃ����E�E�E
���A�t���ȁH
>423,425�̏���������
�u���@���s�̋Z�p�E�@�\�̒���HT���܂܂��v�̂ق���
>423,425�̏���������
�u���@���s�̋Z�p�E�@�\�̒���HT���܂܂��v�̂ق���
������ƃu���h�[�U�[�Ő��n�����ق���������
���n��EXEcute������Rock�������o������
>>427
���₢�₢��A����Ȃ��ƂЂƂ�����������Ă܂ւȁB
�u���@���s��HT����̋Z�p����Ȃ��v�A���ĉ��x�������Ă邾��H���B
�܂�uHT�Ƃ͊W�Ȃ��g����Z�p�v�����Č������Ƃ���ȁA���ʂɓǂ�B
�ł��A�N�́uHyper-Threading�̂Ȃ��ɓ��@���s�v���Ƃ��A
�u���@���s�̒���HT�v�@���ƁA�܂�����萳���̈Ӗ�����ȁH
HT����Ƃɂ��������B
���A����>>420�Ƃ͕ʐl�����A���B���������������������ƂƂ͌q�����ĂȂ���
�ȒP�ȃc�b�R�~���ꂽ�����Ȃ��ȁB
���₢�₢��A����Ȃ��ƂЂƂ�����������Ă܂ւȁB
�u���@���s��HT����̋Z�p����Ȃ��v�A���ĉ��x�������Ă邾��H���B
�܂�uHT�Ƃ͊W�Ȃ��g����Z�p�v�����Č������Ƃ���ȁA���ʂɓǂ�B
�ł��A�N�́uHyper-Threading�̂Ȃ��ɓ��@���s�v���Ƃ��A
�u���@���s�̒���HT�v�@���ƁA�܂�����萳���̈Ӗ�����ȁH
HT����Ƃɂ��������B
���A����>>420�Ƃ͕ʐl�����A���B���������������������ƂƂ͌q�����ĂȂ���
�ȒP�ȃc�b�R�~���ꂽ�����Ȃ��ȁB
�uHT�Ƃ͊W�Ȃ��g����Z�p�v����
��Hyper-Threading�Ń��������C�e���V�̉B�����Č����̂��A
�����@���s
���ʂɓǂނƂ����킯�킩��܂���
�ǂ����������E�̂��Ƃ���Ȃ�����ǂ��ł���������
��Hyper-Threading�Ń��������C�e���V�̉B�����Č����̂��A
�����@���s
���ʂɓǂނƂ����킯�킩��܂���
�ǂ����������E�̂��Ƃ���Ȃ�����ǂ��ł���������
GPU�I�ȃ}���`�X���b�f�B���O�ɂ�郌�C�e���V�B����
Speculative Multithreading�ɂ�郌�C�e���V�B�����������Ă�̂ł�
�O�҂̓f�[�^�̃��[�h���ɑ��̃X���b�h���s���Ƃ��܂��傤���ċZ�p
���s����Ă�X���b�h���炷����C�e���V�͉B������Ă���ƌ�����
���A���[�U�[���猩���1�X���b�h������̏������Ԃ͒Z���Ȃ��ĂȂ�
��҂͓��@�X���b�h�𑖂点�ă��C���X���b�h���K�v�Ƃ���f�[�^��
�\�ߑ����Ă������Ƃ����Z�p
���܂��U���1�X���b�h������̏������Ԃ͒Z���Ȃ�
����Hyper-threading�̌��ʂ͑O�҂̂�
http://www.watch.impress.co.jp/pc/docs/2002/0624/kaigai01.htm
Speculative Multithreading�ɂ�郌�C�e���V�B�����������Ă�̂ł�
�O�҂̓f�[�^�̃��[�h���ɑ��̃X���b�h���s���Ƃ��܂��傤���ċZ�p
���s����Ă�X���b�h���炷����C�e���V�͉B������Ă���ƌ�����
���A���[�U�[���猩���1�X���b�h������̏������Ԃ͒Z���Ȃ��ĂȂ�
��҂͓��@�X���b�h�𑖂点�ă��C���X���b�h���K�v�Ƃ���f�[�^��
�\�ߑ����Ă������Ƃ����Z�p
���܂��U���1�X���b�h������̏������Ԃ͒Z���Ȃ�
����Hyper-threading�̌��ʂ͑O�҂̂�
http://www.watch.impress.co.jp/pc/docs/2002/0624/kaigai01.htm
>>432
���[�ށE�E���ʂɓǂ�ł��ē��@���s�������Ă�Ȃ�A�ނ���A�킩��Ȃ������Ӗ��s���Ȃ��B
����Ȃ����������������Ă邩�Ȃ��H�ӎv�̑a�ʂ��Ăނ����������B
�������������킩��Ȃ��̂��킩��Ȃ��B�����ǂ��ł�������w
���������āA�u���݂́vHT�Ɍ��肵�čl���Ă�̂��BHT�ł����@���s���\�Ȃ̂͒m���Ă邾��H�i����HT�A����Ȃ����j
�����I�ɂ�HT�łȂ��}���`�R�A�ł����@���s�̌��ʂ͓�������āu�����v�̘b�B�u���ꂾ���v�̘b�BHT�͏��O����B
>>433
�����A�����������ƁB��҂̘b�B�O�҂́A���@���s�ƊW�Ȃ��}���`�X���b�h�Ȃ瓾������p�����B
���[�ށE�E���ʂɓǂ�ł��ē��@���s�������Ă�Ȃ�A�ނ���A�킩��Ȃ������Ӗ��s���Ȃ��B
����Ȃ����������������Ă邩�Ȃ��H�ӎv�̑a�ʂ��Ăނ����������B
�������������킩��Ȃ��̂��킩��Ȃ��B�����ǂ��ł�������w
���������āA�u���݂́vHT�Ɍ��肵�čl���Ă�̂��BHT�ł����@���s���\�Ȃ̂͒m���Ă邾��H�i����HT�A����Ȃ����j
�����I�ɂ�HT�łȂ��}���`�R�A�ł����@���s�̌��ʂ͓�������āu�����v�̘b�B�u���ꂾ���v�̘b�BHT�͏��O����B
>>433
�����A�����������ƁB��҂̘b�B�O�҂́A���@���s�ƊW�Ȃ��}���`�X���b�h�Ȃ瓾������p�����B
�uHT�̓V���O���X���b�h���\�ɖ��W�B���ɑ��R�A�ȍ��ł́v��
�u�W���邾�듊�@���s�Ȃ���v�Ɗ��ݕt����
���̌�O�`���O�`����ID:XxdXHRhO�̎咣��N���܂Ƃ߂Ă���Ȃ���
�u�W���邾�듊�@���s�Ȃ���v�Ɗ��ݕt����
���̌�O�`���O�`����ID:XxdXHRhO�̎咣��N���܂Ƃ߂Ă���Ȃ���
�ȒP�ȃc�b�R�~�Ȃ̂ɂ����Ⴎ����ǂ�ǂ�ɒE�����Ă�̂��O����[���Iw
�킩��Ȃ��ƌ�������A��������Ȃ���?�ƕ�������A�܂��ߏ�s�����X���Ԃ��Ă��邵�B�B
�O���433���ȒP�ɗ������Ă�̂ɁB
������Ȃ�ł�ID:Xlar/xuY������Ɠ���������B
�킩��Ȃ��ƌ�������A��������Ȃ���?�ƕ�������A�܂��ߏ�s�����X���Ԃ��Ă��邵�B�B
�O���433���ȒP�ɗ������Ă�̂ɁB
������Ȃ�ł�ID:Xlar/xuY������Ɠ���������B
�����AID:Xlar/xuY�͕����I�Ƀ}���`�R�A�ɂȂ��Ă��邩��A
���̒��x���Ⴂ�A�v���������Ȍ���ł́A
����������Ă���HTT�ł̃��������C�e���V�̉B���̌��ʂ͏�������˂��Č����Ă邾���Ȃ̂ł́H
�ŁA����>>421�Ō㓡�L����URL�\���Č������������̂́A
�uHyper-Threading�Ń��������C�e���V���B���v�̍��ڂ����Ȃ�Ȃ��́H
���ꂪ�A���̉��ɓ��@�}���`�X���b�f�B���O�ɂ��Ẳ��������������A
ID:XxdXHRhO�����Ⴂ���ē��@���s�ɘb�����点����Ȃ��́H
���̒��x���Ⴂ�A�v���������Ȍ���ł́A
����������Ă���HTT�ł̃��������C�e���V�̉B���̌��ʂ͏�������˂��Č����Ă邾���Ȃ̂ł́H
�ŁA����>>421�Ō㓡�L����URL�\���Č������������̂́A
�uHyper-Threading�Ń��������C�e���V���B���v�̍��ڂ����Ȃ�Ȃ��́H
���ꂪ�A���̉��ɓ��@�}���`�X���b�f�B���O�ɂ��Ẳ��������������A
ID:XxdXHRhO�����Ⴂ���ē��@���s�ɘb�����点����Ȃ��́H
>>437
�Ă�����>424�ł����ƌ����Ă邵�˂��E�E�E
>421�ł����@�̕����͏o����HT�Ə����Ă邵�ԈႦ�悤���Ȃ��悤��
�u�o�����\�[�X�Ɏ֑����������v�Ƃ�����ȒP���Ȍ����ł͂Ȃ�����
�Ă�����>424�ł����ƌ����Ă邵�˂��E�E�E
>421�ł����@�̕����͏o����HT�Ə����Ă邵�ԈႦ�悤���Ȃ��悤��
�u�o�����\�[�X�Ɏ֑����������v�Ƃ�����ȒP���Ȍ����ł͂Ȃ�����
�Ă������A���݂��ǂ��ł��������ƂȂ���A����������ˁB�B
�L���ē������Ƃ��������͍̂ς܂Ȃ��������B
�L���ē������Ƃ��������͍̂ς܂Ȃ��������B
SMT�̖ړI�̓��������C�e���V�̉B���ƈ̂��l���������Ă邩��
>�uHT�Ń��������C�e���V�B���v�Ȃ�Ă̂�1�R�A�ŕ����X���b�h��S�����Ȃ���Ȃ�Ȃ��������̘b
�Ƃ������̂����������]��
�A�[�L�e�N�g��������ӂ�悗
>�uHT�Ń��������C�e���V�B���v�Ȃ�Ă̂�1�R�A�ŕ����X���b�h��S�����Ȃ���Ȃ�Ȃ��������̘b
�Ƃ������̂����������]��
�A�[�L�e�N�g��������ӂ�悗
Xlar/xuY��XxdXHRhO���Ԉ�����v�����݂ŏ����Ă邩��
�c�_�̌����n�Y�����Ղ肪���܂����ȁB
���������L�`�K�C�W�J��������̂�AMD�X���̑�햡�B
�c�_�̌����n�Y�����Ղ肪���܂����ȁB
���������L�`�K�C�W�J��������̂�AMD�X���̑�햡�B
�ŁA�n���Ȏ��ɋ����Ă��������B
Bulldozer���Ă�͑����X�S�C��ł����H
����Phenom�Ƃ���3�{�Ƃ������Ȃ����肷���ł����H
Bulldozer���Ă�͑����X�S�C��ł����H
����Phenom�Ƃ���3�{�Ƃ������Ȃ����肷���ł����H
�����J����Ă�����ł͂܂������킩��Ȃ��B
�V���O���X���b�h�����������Ȃ�v�f�͂قƂ�ǂȂ�(���炩�ɂ���Ă��Ȃ�)�B
�R�A���������āA�}���`�X���b�h�A�v���P�[�V�����͑����Ȃ邩������Ȃ��B
�V���O���X���b�h�����������Ȃ�v�f�͂قƂ�ǂȂ�(���炩�ɂ���Ă��Ȃ�)�B
�R�A���������āA�}���`�X���b�h�A�v���P�[�V�����͑����Ȃ邩������Ȃ��B
���������C�e���V�̉B���͒P�Ȃ�}���`�X���b�h�̂��Ƃ�
HT�Ɍ������b�ł͂Ȃ��B
HT���ڎw�����Ƃ����1�R�A�̃��\�[�X��2�R�A�Ɍ�����
���Ƃŏ��Ȃ������ő����̃����b�g���������ƂƁA���s
����CPU���\�[�X�̋����炵�Ď��s���������߂邱�ƁB
���A���f���A���R�A���1.2�`1.5�{�̐��\�����łȂ�����
����A�f���A���R�A����ʉ����ď������Ǝv�����畜���B
HT�Ɍ������b�ł͂Ȃ��B
HT���ڎw�����Ƃ����1�R�A�̃��\�[�X��2�R�A�Ɍ�����
���Ƃŏ��Ȃ������ő����̃����b�g���������ƂƁA���s
����CPU���\�[�X�̋����炵�Ď��s���������߂邱�ƁB
���A���f���A���R�A���1.2�`1.5�{�̐��\�����łȂ�����
����A�f���A���R�A����ʉ����ď������Ǝv�����畜���B
>>441
���������B
ID:zefH5VM�̂悤�ȁA�����Ȃ����������͐������Ǝv������ł�
�����S����債���o�J�������̂������B
�}�N�I�^�Ƃ��G���Ƃ�����������w
���������B
ID:zefH5VM�̂悤�ȁA�����Ȃ����������͐������Ǝv������ł�
�����S����債���o�J�������̂������B
�}�N�I�^�Ƃ��G���Ƃ�����������w
�������Ď���ł̓Q�n�~�����v�ȑ����𑱂��Ă���
�@�@�@�@�@�@�@�@ �@ �@ �@ .�@-�\-�@.�@�@�@�@�@�@������b�I�I�@������>>440�I
�@�@�@�@�@�@ �@ �@ �@ �^�@�@�@�@�@�@ �R
�@�@�@�@�@�@�@�@�@�@//�@�@�@�@�@�@�@�@ ',�@�@�@�@�@�@�̂��l�̌�����
�@�@�@�@�@ �@ �@ �@ | { �Q�Q�Q�Q�Q �@|�@�@�@�@�@�@�@�@�ꌾ�����o�����Ȃ��b�I
�@�@�@�@�@ �@ (�܁R7�L�@�@�@�@�@�@�@ �M`�qƁN�R
�@�@�@�@�@�@�@ �R�..��������. -r�]''���@�@�@�@�@�����ɃV�r���I
�@�@�@�@�@�@�@�@/�L �r'"����,,.�B��N'�@{.�@ �R�@ �@�@ �Q�@�Q�@�@�@�@�@�@��������驁I
�@�@�@�@�@�@ �@ `r�|�@�._(9,)�x�L_(9_l�� )�@ �i�@ , -'���@�M�N�N�L�P�M�R�A
�@�@�@�@�@�@�@�@ {�i,|�@`'''�V�,. � �܁@�@|/Ƃx�@{�@�@ �@ �@ �@ �@ �@ �@�_
�@�@�@�@ �@ �@ �@ �S|�@�@�@^'^ ��-��@,�r')���@ ,�T���M�\�\-'- ��,_�@ �
�@�@�@�@�@�@�@�@ �@ | �@ �������|�@'"|�B'�i�@�i,�,r'ނ�.�P�P,��Ƥ�}��
�@�@�@�@, �w��]- � l �@�b /�O''��|�@�@| |�@,�T )�,>�i_9,`!i!}i!�_9,�j�@|�l
�@ -�]�m .�w�[�]-� �R �@!�]}_�Q,..Ɂ@ �b| /-�]�R| �@ -�C,__,.>�]�@�@ʁ@}
�@''"/�^�R�� �@ɁR�ȁ@`���'�L�@�^�@|���@��!�@�@, -===- ��@�@}���- ..._
�@ /�^�O�_ �@�S-� :| � �@�P�@�^�@Ɂ@|.�@�@{ {�. �@�u'��'��\�@ �| |�@�@�@�M�R
,�m �@ �R,_�@�R�m�R_)�:l�@'����.�@�@/ �@|.�@�@�R�R�R._ �M��N�L�@�^�m �
/�@ �@ <�O_,.� `r�]'� :::�R �@�_�@�M��� �@|�A �@�@�_�_'�--�]''"�^�^
�_�Q�Q_,�^|�@ !�@�@::::::l�A�@�@�_�@�@�_| �_�@�@�@�_�R �@�@/ �m
�@�@�@�@�@�@ �@ �@ �@ �^�@�@�@�@�@�@ �R
�@�@�@�@�@�@�@�@�@�@//�@�@�@�@�@�@�@�@ ',�@�@�@�@�@�@�̂��l�̌�����
�@�@�@�@�@ �@ �@ �@ | { �Q�Q�Q�Q�Q �@|�@�@�@�@�@�@�@�@�ꌾ�����o�����Ȃ��b�I
�@�@�@�@�@ �@ (�܁R7�L�@�@�@�@�@�@�@ �M`�qƁN�R
�@�@�@�@�@�@�@ �R�..��������. -r�]''���@�@�@�@�@�����ɃV�r���I
�@�@�@�@�@�@�@�@/�L �r'"����,,.�B��N'�@{.�@ �R�@ �@�@ �Q�@�Q�@�@�@�@�@�@��������驁I
�@�@�@�@�@�@ �@ `r�|�@�._(9,)�x�L_(9_l�� )�@ �i�@ , -'���@�M�N�N�L�P�M�R�A
�@�@�@�@�@�@�@�@ {�i,|�@`'''�V�,. � �܁@�@|/Ƃx�@{�@�@ �@ �@ �@ �@ �@ �@�_
�@�@�@�@ �@ �@ �@ �S|�@�@�@^'^ ��-��@,�r')���@ ,�T���M�\�\-'- ��,_�@ �
�@�@�@�@�@�@�@�@ �@ | �@ �������|�@'"|�B'�i�@�i,�,r'ނ�.�P�P,��Ƥ�}��
�@�@�@�@, �w��]- � l �@�b /�O''��|�@�@| |�@,�T )�,>�i_9,`!i!}i!�_9,�j�@|�l
�@ -�]�m .�w�[�]-� �R �@!�]}_�Q,..Ɂ@ �b| /-�]�R| �@ -�C,__,.>�]�@�@ʁ@}
�@''"/�^�R�� �@ɁR�ȁ@`���'�L�@�^�@|���@��!�@�@, -===- ��@�@}���- ..._
�@ /�^�O�_ �@�S-� :| � �@�P�@�^�@Ɂ@|.�@�@{ {�. �@�u'��'��\�@ �| |�@�@�@�M�R
,�m �@ �R,_�@�R�m�R_)�:l�@'����.�@�@/ �@|.�@�@�R�R�R._ �M��N�L�@�^�m �
/�@ �@ <�O_,.� `r�]'� :::�R �@�_�@�M��� �@|�A �@�@�_�_'�--�]''"�^�^
�_�Q�Q_,�^|�@ !�@�@::::::l�A�@�@�_�@�@�_| �_�@�@�@�_�R �@�@/ �m
>>444
���������C�e���V�̉B���ɂ��ẮAout-of-order�̎�����
���Ɏ��p������Ă���B
out-of-order�@�\���������ƁAHT�����̃R�X�g������قǍ����Ȃ��̂�
�[��Dual-CPU�Ƃ��Ăg�s�����������B
�����A�g�s�����̋[��Dual-CPU�͖{����Dual-CPU�ɐ��\���y�Ȃ��A
�V���O���X���b�h���\�ɂ����e�����y�Ԃ��Ƃ�������c
�Ȃ�Ă��Ƃ��Ǝv���B
��HT�Ŏ��������[��Dual-CPU�́A�{����Dual-CPU�������\%���\�������邱�Ƃ�����
���������C�e���V�̉B���ɂ��ẮAout-of-order�̎�����
���Ɏ��p������Ă���B
out-of-order�@�\���������ƁAHT�����̃R�X�g������قǍ����Ȃ��̂�
�[��Dual-CPU�Ƃ��Ăg�s�����������B
�����A�g�s�����̋[��Dual-CPU�͖{����Dual-CPU�ɐ��\���y�Ȃ��A
�V���O���X���b�h���\�ɂ����e�����y�Ԃ��Ƃ�������c
�Ȃ�Ă��Ƃ��Ǝv���B
��HT�Ŏ��������[��Dual-CPU�́A�{����Dual-CPU�������\%���\�������邱�Ƃ�����
���@���s���āA��������Ȃǂ����鎞�ɁA���ʂ��ǂ����ɍs�����킩��Ȃ�����
�p�C�v���C����V���Ă����̂͂��������Ȃ��̂Ŋm���̍������̕�����Ƃ肠�����p�C�v���C���ɗ������ƂȂ̂����E�E�E
�Ȃ��}���`�X���b�h�̃L���b�V���ǂݍ��݂Ƃ��̘b�ɂȂ��ĂH
�p�C�v���C����V���Ă����̂͂��������Ȃ��̂Ŋm���̍������̕�����Ƃ肠�����p�C�v���C���ɗ������ƂȂ̂����E�E�E
�Ȃ��}���`�X���b�h�̃L���b�V���ǂݍ��݂Ƃ��̘b�ɂȂ��ĂH
>>449
�������̕��͕��������Ƃ��������ǁA���p������Ă���́H
��������łȂ��āA���Z�ƃ����������̉��Z�ߒ��̈ˑ��W�ɂ���
���W�X�^�𑽂߂ɂ�����Ńp���Ɏ��s���Ď����Ǝv������
�������̕��͕��������Ƃ��������ǁA���p������Ă���́H
��������łȂ��āA���Z�ƃ����������̉��Z�ߒ��̈ˑ��W�ɂ���
���W�X�^�𑽂߂ɂ�����Ńp���Ɏ��s���Ď����Ǝv������
PentiunPro�̃E���͕���\���Ɠ��@���s�ł����A�Ȃɂ��H
>���p������Ă���́H
�Ƃ����̐̂�
�Ƃ����̐̂�
���@�I�}���`�X���b�f�B���O�͂܂��ǂ����������Ă��Ȃ���B
����\���̓��@���s�Ƃ͕ʕ������B
����\���̓��@���s�Ƃ͕ʕ������B
�ꕔ�ǂ݊ԈႦ���Ă��̂ŏC��
����\���F�����ς�
���@�I�}���`�X���b�f�B���O�i����̑o���ɑ����s���e���p�C�v�ɓ����j
�@�@�@�@�@�@�F�������тȂ�
���@�I���s�F�@����\���Ŏ��o�������߂̗���ɑ��A��s���s�ł���ӏ��𒊏o����
�@�@�@�@�@�@�@�@�@�p���ɏ�������i�f�[�^���[�h���܂ށj
�Ƃ����̂����̒m�����e�B
�ԈႢ�����邩������Ȃ����B
����\���F�����ς�
���@�I�}���`�X���b�f�B���O�i����̑o���ɑ����s���e���p�C�v�ɓ����j
�@�@�@�@�@�@�F�������тȂ�
���@�I���s�F�@����\���Ŏ��o�������߂̗���ɑ��A��s���s�ł���ӏ��𒊏o����
�@�@�@�@�@�@�@�@�@�p���ɏ�������i�f�[�^���[�h���܂ށj
�Ƃ����̂����̒m�����e�B
�ԈႢ�����邩������Ȃ����B
>>454
���@�I�}���`�X���b�f�B���O�ŃV���O���X���b�h�̃��������C�e���V�̉B���Ƃ����̂́A
http://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
�ʼn������Ă���A�w���p�[�X���b�h�Œl�\�����āA���C���X���b�h�Ƀf�[�^���[�h�҂������Ȃ����Ęb�B
���@�I�}���`�X���b�f�B���O�ŃV���O���X���b�h�̃��������C�e���V�̉B���Ƃ����̂́A
http://pc.watch.impress.co.jp/docs/2003/0222/kaigai01.htm
�ʼn������Ă���A�w���p�[�X���b�h�Œl�\�����āA���C���X���b�h�Ƀf�[�^���[�h�҂������Ȃ����Ęb�B
>>455
���\�����シ��̂͊ȒP�ɗ\�����s�����A�L�����m���Ă���B
�����A�܂���������ĂȂ������Ǝv����ˁB
�����������C�e���V�Ƃ������́A��蒼���T�C�N����Z���o������Ă��ƂƎv��
���������A��X�I�ɍL������C�����邵�B
���@CORE�ɂ��Ắc�}�C�N���t���[�W�����̌��ʂ������C������B
�@�܂��A�����͂���ĂȂ��c�Ǝv��
���\�����シ��̂͊ȒP�ɗ\�����s�����A�L�����m���Ă���B
�����A�܂���������ĂȂ������Ǝv����ˁB
�����������C�e���V�Ƃ������́A��蒼���T�C�N����Z���o������Ă��ƂƎv��
���������A��X�I�ɍL������C�����邵�B
���@CORE�ɂ��Ắc�}�C�N���t���[�W�����̌��ʂ������C������B
�@�܂��A�����͂���ĂȂ��c�Ǝv��
>>455
������A���@�I�}���`�X���b�f�B���O�͎�������ĂȂ���B
��œ��@���s���ǂ��̌����o�����l�Ԃ͌��ݎ�������Ă��Ȃ��Z�p�̘b�����Ă���B
������A���@�I�}���`�X���b�f�B���O�͎�������ĂȂ���B
��œ��@���s���ǂ��̌����o�����l�Ԃ͌��ݎ�������Ă��Ȃ��Z�p�̘b�����Ă���B
����̂��߂ł͂Ȃ��������A�N�Z�X�̂��߂̐�ǂ݂���
�e�[�v�A�E�g�܂ł��� Rock �������㎸�s���Ă��邩��˂��B
���@���s�N�͂��l��l�|���Ă����̂�����A
���@���s�Ƃ������t���Ԉ���Ďg���Ă��܂����ƎӍ߂���̂��悶��Ȃ����ȁB
���@���s�Ƃ������t���Ԉ���Ďg���Ă��܂����ƎӍ߂���̂��悶��Ȃ����ȁB
�f�[�^�̐�ǂ݂Ɍ��ʂ�����Z�p
�@�v���t�F�b�`
�@Out-of-Order
�@Memory Disambiguation(Out-of-Order Load) - ���@�I
�@Speculative Multithreading - ���@�I
�@�v���t�F�b�`
�@Out-of-Order
�@Memory Disambiguation(Out-of-Order Load) - ���@�I
�@Speculative Multithreading - ���@�I
�Ӎ߂Ȃ�Ď�������v��������̂���Ȃ���B���̂Ƃ��ƍ߂ő��肪����I�ɉ��Q�҂Ȃ�Ƃ������B
�܂��܂�
�����͂ЂƂ��ɖƂ���
�u���@���s��Hyper-Threading�Ń��������C�e���V�̉B���v
��F�߂Ă���Ă���悤����Ȃ���
�����͂ЂƂ��ɖƂ���
�u���@���s��Hyper-Threading�Ń��������C�e���V�̉B���v
��F�߂Ă���Ă���悤����Ȃ���
�����ƌ��������A�܂Ƃ��Ȏ������Ă����Ȃ̂�ID:lGDJaw7L���炢���ȁB
���Ƃ͂₽��A��������ĂȂ��z�Ă�肵�Ă�A�������ĂȂ��z�������B
���Ł[
���Ƃ͂₽��A��������ĂȂ��z�Ă�肵�Ă�A�������ĂȂ��z�������B
���Ł[
�X���b�h���Ă����̂��ǂ����ˁB
OS���x���̘b�ɂȂ����Ⴄ���B
�⏕�X���b�h���R�A�œ����ɓ����悤�ɃX�P�W���[�����O����悤OS�ɉ��C���K�v�Ȃ�B
�v���t�F�b�`���߂�K�X����Ń������R���g���[�������ŃL���b�V���ɂ��ߍ��ނ̂Ƃǂꂾ�������ɍ����o�邩�B
�⏕�X���b�h������R�X�g�ƃv���t�F�b�`���߂s����R�X�g���r����ƈ��|�I�Ƀv���t�F�b�`���߂̕���������ȁB
OS���x���̘b�ɂȂ����Ⴄ���B
�⏕�X���b�h���R�A�œ����ɓ����悤�ɃX�P�W���[�����O����悤OS�ɉ��C���K�v�Ȃ�B
�v���t�F�b�`���߂�K�X����Ń������R���g���[�������ŃL���b�V���ɂ��ߍ��ނ̂Ƃǂꂾ�������ɍ����o�邩�B
�⏕�X���b�h������R�X�g�ƃv���t�F�b�`���߂s����R�X�g���r����ƈ��|�I�Ƀv���t�F�b�`���߂̕���������ȁB
>>454
���@���s�̈Ӗ����ԈႢ�B
���ꂶ��P�Ȃ�out of order���s����B
����������Ȃ��\�������邯�ǎ��s�����Ă��܂��̂��u���@�v���s�B
���@���s�̈Ӗ����ԈႢ�B
���ꂶ��P�Ȃ�out of order���s����B
����������Ȃ��\�������邯�ǎ��s�����Ă��܂��̂��u���@�v���s�B
�T�O�I�Ɏ��Ă镨��������ȁB���ƃv���t�F�b�`�Ƃ����ǂ��Ⴄ�̂������݁B
�ق�ƕ��G�ȏ������Ă��CPU�B
�ق�ƕ��G�ȏ������Ă��CPU�B
�����ȈႢ����ʂ��čו������Ă��邾������B
���߂̐�̃f�[�^���[�h���܂߂Ď��s���Ă���i�{���ɕK�v��������Ȃ��j���Ă̂�
���@�I���s�B
���������A���@�I���s���g�A����\�����閳���Ɋւ�炸�A���߂̐�ɂ���
��U�p�C�v���C���ɓ˂�����ł������Ƃ��Ǝv����ˁB
�i����\���F�ÓI���낤���A���I���낤���F���O���p�C�v���C���ɓ��ꂽ���g��p���j
out-of-order�͕��߂��܂܂Ȃ����ȂŁA�f�[�^�̏����ˑ��������Đ�ɏ����ł��鏊��
�������Ă��܂������B
�����P�[�X�ɂȂ�Ƃ߂�ǂ��Ȃ��B�@�F�X�A�ו������Ė��O�t���Ă邩������Ȃ�����
���߂̐�̃f�[�^���[�h���܂߂Ď��s���Ă���i�{���ɕK�v��������Ȃ��j���Ă̂�
���@�I���s�B
���������A���@�I���s���g�A����\�����閳���Ɋւ�炸�A���߂̐�ɂ���
��U�p�C�v���C���ɓ˂�����ł������Ƃ��Ǝv����ˁB
�i����\���F�ÓI���낤���A���I���낤���F���O���p�C�v���C���ɓ��ꂽ���g��p���j
out-of-order�͕��߂��܂܂Ȃ����ȂŁA�f�[�^�̏����ˑ��������Đ�ɏ����ł��鏊��
�������Ă��܂������B
�����P�[�X�ɂȂ�Ƃ߂�ǂ��Ȃ��B�@�F�X�A�ו������Ė��O�t���Ă邩������Ȃ�����
Bulldozer��Power6��Niagara�𑫂��ē�Ŋ�����������
>>469
���s�\�ȂƂ�����s�b�N�A�b�v���āA�ƌ������t���獪�{�I�ɓ��@���s�̈Ӗ��𗝉����Ă��Ȃ��Ɣ��f�����B
���s�\�ȂƂ�����s�b�N�A�b�v���āA�ƌ������t���獪�{�I�ɓ��@���s�̈Ӗ��𗝉����Ă��Ȃ��Ɣ��f�����B
���@���s�́A����ɂ�������������true��false�̗�����
�����Ɏ��s�J�n���āA���ʂ������������_�ł͂��ꂽ��
���̂Ă邱�Ƃ���Ȃ��́H
�����Ɏ��s�J�n���āA���ʂ������������_�ł͂��ꂽ��
���̂Ă邱�Ƃ���Ȃ��́H
�����قǓ��@�Ȃ�Ĕ��M�@�\
>>472
���������������̂��Ǝv���Ă������Ⴄ�̂��ˁB
�Ă������A�������ĂȂ��A�Ԉ���Ă�A�Ƃ��������̓z��
��������C���A��������\�͂̂ǂ������������Ă�Ȃ�A
�]���s�������ƂȂ���ROM���Ăė~�������B
��b�ɂ��Q�l�ɂ��Ȃ��B
���������������̂��Ǝv���Ă������Ⴄ�̂��ˁB
�Ă������A�������ĂȂ��A�Ԉ���Ă�A�Ƃ��������̓z��
��������C���A��������\�͂̂ǂ������������Ă�Ȃ�A
�]���s�������ƂȂ���ROM���Ăė~�������B
��b�ɂ��Q�l�ɂ��Ȃ��B
http://journal.mycom.co.jp/column/architecture/167/index.html
���傤�Ǎŋ߂̘A�ڂ�����\���ɂ��Ẳ���Ȃ̂ŎQ�l�ɁB
���傤�Ǎŋ߂̘A�ڂ�����\���ɂ��Ẳ���Ȃ̂ŎQ�l�ɁB
ID:lGDJaw7L��>>450�œ��@���s�̂��Ƃ�m��Ȃ��ƌ����Ă����Ȃ���A���̌�̃��X�ł͂����ŏ�����m���Ă��镗�����Ƃ��Ă���̂͂Ȃ��H
�ʂɒm��Ȃ��������Ƃ��p�ł����ł��Ȃ��̂����A�m��Ȃ��ƌ����Ă����Ȃ���m���Ă��ƌ����̂͒p����������B
�ʂɒm��Ȃ��������Ƃ��p�ł����ł��Ȃ��̂����A�m��Ȃ��ƌ����Ă����Ȃ���m���Ă��ƌ����̂͒p����������B
�Ӂ[�ށA����Ȋ������H
���ǂ����ɕ��邩�\�����āA���������Ǝv�����ق��ɕ���@���@����\��
���Ƃ肠�����A�\�������ق������s����i�\�����O�ꂽ�疳�ʁj�@ �@���@���@�I���s�@�i������v���t�F�b�`�H�j
���ЂƂ̃v���O�������A�{���̏����ʂ�Ɏ��s����̂łȂ��A
���s�ł�����̂���ǂ�ǂ���s���Ă��܂� �@ �@ �@ �@ �@ �@ �@ �@���@�A�E�g�I�u�I�[�_�[
��"���@�X���b�h"�ƌĂ��T�u�X���b�h�ŁA���C���X���b�h����
�u����������f�[�^��ǂݏo�����߁v�Ɓu����Ɉˑ����閽�߁v
�������o���A�{�X���b�h�ƕ��s���đ��铊�@�X���b�h�ŁA
��Ɏ��s���Ă��܂��B
�������邱�ƂŖ{���̃X���b�h�����[�h���߂����s���鎞�ɂ́A
�K�v�f�[�^��L1�L���b�V���Ƀ��[�h����Ă��邱�ƂɂȂ�B�@�@ �@ �� ���@�I�}���`�X���b�f�B���O�́A���@�I�v���R���s���e�[�V����
�i���@�}���`�X���b�f�B���O�ł�邱�Ƃ��ĕ���\�������@���s�ł��o�������ȋC���B�B�H�j
���ǂ����ɕ��邩�\�����āA���������Ǝv�����ق��ɕ���@���@����\��
���Ƃ肠�����A�\�������ق������s����i�\�����O�ꂽ�疳�ʁj�@ �@���@���@�I���s�@�i������v���t�F�b�`�H�j
���ЂƂ̃v���O�������A�{���̏����ʂ�Ɏ��s����̂łȂ��A
���s�ł�����̂���ǂ�ǂ���s���Ă��܂� �@ �@ �@ �@ �@ �@ �@ �@���@�A�E�g�I�u�I�[�_�[
��"���@�X���b�h"�ƌĂ��T�u�X���b�h�ŁA���C���X���b�h����
�u����������f�[�^��ǂݏo�����߁v�Ɓu����Ɉˑ����閽�߁v
�������o���A�{�X���b�h�ƕ��s���đ��铊�@�X���b�h�ŁA
��Ɏ��s���Ă��܂��B
�������邱�ƂŖ{���̃X���b�h�����[�h���߂����s���鎞�ɂ́A
�K�v�f�[�^��L1�L���b�V���Ƀ��[�h����Ă��邱�ƂɂȂ�B�@�@ �@ �� ���@�I�}���`�X���b�f�B���O�́A���@�I�v���R���s���e�[�V����
�i���@�}���`�X���b�f�B���O�ł�邱�Ƃ��ĕ���\�������@���s�ł��o�������ȋC���B�B�H�j
>>478
����\���͈��̃A���S���Y���ɉ����Ċm���̍���
�����i�̃A�h���X�j�����O�ɐ������Ă����āA�����
�����̒ʂ肾�����琶���ς݂̃A�h���X�ɔ�����Ƃ�
�A�h���X�����̃^�C�����O�����炷�@�\���Ǝv�����B
������炲�w�E���B
���Ȃ݂ɕ����A�h���X���X�g��ێ�����̂�BTB�B
���@���s�͂��łɏ��������ǁu�\���v�ȂǓ���Ȃ��B
��������true��false�̗��������s���āA�ǂ���̕���
�����������_�ŊO�ꂽ�����̂Ă�B
�A�E�g�I�u�I�[�_�[�̓v���O�����Ƃ��X���b�h���x���̘b
�ł͂Ȃ��āA�A�Z���u���R�[�h���x���ňˑ��W�̂Ȃ�
�I�y�R�[�h�𒊏o���āA���߂̕��я������Ď��s����
���ƁB�u�v���O�����v�Ȃ�ă}�N���ȒP�ʂ̘b�ł͂Ȃ��B
���@�I�}���`�X���b�f�B���O�͂��ł�CPU���x���̘b����
�Ȃ��āA�v���O���~���O���x���̘b������X���Ⴂ�ł́H
�Ȃm�������Ԃ肪�K���ɒm���Ă�ӂ肵�Ď������Ă�
�����݂������ȁB
����\���͈��̃A���S���Y���ɉ����Ċm���̍���
�����i�̃A�h���X�j�����O�ɐ������Ă����āA�����
�����̒ʂ肾�����琶���ς݂̃A�h���X�ɔ�����Ƃ�
�A�h���X�����̃^�C�����O�����炷�@�\���Ǝv�����B
������炲�w�E���B
���Ȃ݂ɕ����A�h���X���X�g��ێ�����̂�BTB�B
���@���s�͂��łɏ��������ǁu�\���v�ȂǓ���Ȃ��B
��������true��false�̗��������s���āA�ǂ���̕���
�����������_�ŊO�ꂽ�����̂Ă�B
�A�E�g�I�u�I�[�_�[�̓v���O�����Ƃ��X���b�h���x���̘b
�ł͂Ȃ��āA�A�Z���u���R�[�h���x���ňˑ��W�̂Ȃ�
�I�y�R�[�h�𒊏o���āA���߂̕��я������Ď��s����
���ƁB�u�v���O�����v�Ȃ�ă}�N���ȒP�ʂ̘b�ł͂Ȃ��B
���@�I�}���`�X���b�f�B���O�͂��ł�CPU���x���̘b����
�Ȃ��āA�v���O���~���O���x���̘b������X���Ⴂ�ł́H
�Ȃm�������Ԃ肪�K���ɒm���Ă�ӂ肵�Ď������Ă�
�����݂������ȁB
> ���@���s�͂��łɏ��������ǁu�\���v�ȂǓ���Ȃ��B
> ��������true��false�̗��������s���āA�ǂ���̕���
> �����������_�ŊO�ꂽ�����̂Ă�B
����͉���>>475�@�w�������Ǝv���Ă��x�Ə��������ǂ���ς�Ⴄ�炵���B
���ꂩ�炠�������ǂ�ł݂���A����\���ɂ���ĕЕ��������s���邱�Ƃ�
���@�I���s�ƁA2�J���قǂœǂB
�l���Ă݂�Ɨ������s����Ȃ番��\���@�\�A�������Ă���Ȃ��悤�ȁB
> ��������true��false�̗��������s���āA�ǂ���̕���
> �����������_�ŊO�ꂽ�����̂Ă�B
����͉���>>475�@�w�������Ǝv���Ă��x�Ə��������ǂ���ς�Ⴄ�炵���B
���ꂩ�炠�������ǂ�ł݂���A����\���ɂ���ĕЕ��������s���邱�Ƃ�
���@�I���s�ƁA2�J���قǂœǂB
�l���Ă݂�Ɨ������s����Ȃ番��\���@�\�A�������Ă���Ȃ��悤�ȁB
>>479
�����牴�͒m���Ă�ӂ�Ȃ��Ă˂���B�ŏ�����u�����L�{���v���ď����Ă邵�A
�u����Ȋ������H�v���đO��ŕ����Ă邾�낪��B
�ق��ēǂ�ł��A�Ă߂��������l����B
�����牴�͒m���Ă�ӂ�Ȃ��Ă˂���B�ŏ�����u�����L�{���v���ď����Ă邵�A
�u����Ȋ������H�v���đO��ŕ����Ă邾�낪��B
�ق��ēǂ�ł��A�Ă߂��������l����B
86��POWER���Ƃ���ƁA����ω��B�p�ɂ�4.7GHz�H
���҂����Ⴄ��
���҂����Ⴄ��
�R�A���������Ȃ�ƃz�b�s���O�Ƃ��R�A������̃I�[�o�[�N���b�N�ϐ����厖�ɂȂ邩��Ȃ�
�ʏ�͍��Ɠ������炢�ʼnĂ�����
�V���O���X���b�h�͂��Ȃ�v����悤�Ȋ����ɂȂ�̂ł�?
Nehalem��SandyBridg���N���b�N�̃w�b�h���[���𑽂߂Ɏ���Ă�Ƃ�����
intel��TurboBoost��bin���P�`�P�`����Ă鎞�ɁAAMD�͂�����ɂł���Ƃ�������
�ʏ�͍��Ɠ������炢�ʼnĂ�����
�V���O���X���b�h�͂��Ȃ�v����悤�Ȋ����ɂȂ�̂ł�?
Nehalem��SandyBridg���N���b�N�̃w�b�h���[���𑽂߂Ɏ���Ă�Ƃ�����
intel��TurboBoost��bin���P�`�P�`����Ă鎞�ɁAAMD�͂�����ɂł���Ƃ�������
C State Performance Boost�ŃV���O���X���b�h���o�b�`��
�Ȃ�Ă��ƂɂȂ�Ȃ����Ȃ��B�B
C State Performance Boost�͏ڍׂ��o�ĂȂ��Ȃ�����
Intel��TurboBoost���ĉ������_�Ƃ������ł����H
�Ȃ�Ă��ƂɂȂ�Ȃ����Ȃ��B�B
C State Performance Boost�͏ڍׂ��o�ĂȂ��Ȃ�����
Intel��TurboBoost���ĉ������_�Ƃ������ł����H
���@�N���������ɂ���肷������
�ǂ��܂Œp�̏�h�肷�邫�Ȃ�
�ǂ��܂Œp�̏�h�肷�邫�Ȃ�
HT�i���g�j�ʼnB���H�삷�邱�Ƃł����H
>>272 �Ƃ��̃��X�g�̌�����������Ȃ�����
L1���߃L���b�V���̗e�ʂƂ����C�e���V�݂����Ȃ̂��Đ����ł��܂����H
L1���߃L���b�V���̗e�ʂƂ����C�e���V�݂����Ȃ̂��Đ����ł��܂����H
�������炩�H�������点�߂����Ȃ��Ƃ��߂��H
�[�����炨�Ȃ������܂�
�T�N��ɂ́A�V�f�g���P�Q�R�A���f�t�H�ɂȂ��Ă�\��������
���ꂩ��̓n�C�r�W��������̎��ゾ����
�y���݂���
���̂���A�����ŋߔ������c�c�q�Q-800�̗��ꂪ�ǂ��Ȃ�̂��������C�ɂȂ邪
���ꂩ��̓n�C�r�W��������̎��ゾ����
�y���݂���
���̂���A�����ŋߔ������c�c�q�Q-800�̗��ꂪ�ǂ��Ȃ�̂��������C�ɂȂ邪
�Ȃ��Ȃ��B
�gThuban�h�̃��C���i�b�v����\�gThuban�h��5���ɓo�ꂷ��
ttp://northwood.blog60.fc2.com/blog-entry-3465.html
ttp://northwood.blog60.fc2.com/blog-entry-3465.html
�F�X�Ɛ��������Ă��邯�ǂ���Ȃ��낤�A�B���Ӗ������܂芴�����Ȃ�
1095T�@2.80GHz�@TDP140W
1075T�@2.60GHz�@TDP125W
1055T�@2.40GHz�@TDP95/125W
1035T�@2.20GHz�@TDP95W
1095T�@2.80GHz�@TDP140W
1075T�@2.60GHz�@TDP125W
1055T�@2.40GHz�@TDP95/125W
1035T�@2.20GHz�@TDP95W
����˂���
�v���Z�X�ς�炸�R�A�������₵��TDP�g���Ɏ��߂����
�����Ȃ�͓̂�����O���ȁB�D���҈ȊO�ɗp�͂Ȃ��������ˁB
�����Ȃ�͓̂�����O���ȁB�D���҈ȊO�ɗp�͂Ȃ��������ˁB
OCW���V���K�|�[���ŕW�҂�AMD�����J�������[�h�}�b�v���f�ڂ��Ă��܂��B
http://www.ocworkbench.com/2010/AMD/AMD-Regional-Press-Briefing-2010/p3.htm
�n�C�G���h�m�[�g�pFusion�v���Z�b�T�ɂ�"GigaFLOPS-class compute DX11 GPU"��
��������ƌ����Ă܂��ˁB
���ꂩ��4Q2009��2009�N�ʔN��x86�v���Z�b�T�̃V�F�A��IDG�����\���Ă��܂��B
http://news.cnet.com/8301-13924_3-10441017-64.html
��������ʁH��AMD�͔����ł����A�T�[�o�[�����͉����~�܂炸�B
http://www.ocworkbench.com/2010/AMD/AMD-Regional-Press-Briefing-2010/p3.htm
�n�C�G���h�m�[�g�pFusion�v���Z�b�T�ɂ�"GigaFLOPS-class compute DX11 GPU"��
��������ƌ����Ă܂��ˁB
���ꂩ��4Q2009��2009�N�ʔN��x86�v���Z�b�T�̃V�F�A��IDG�����\���Ă��܂��B
http://news.cnet.com/8301-13924_3-10441017-64.html
��������ʁH��AMD�͔����ł����A�T�[�o�[�����͉����~�܂炸�B
>>493
��������2.2�܂ł����945�̕�����������
��������2.2�܂ł����945�̕�����������
���[�J�[��Opteron���f����ϋɓI�ɔ����ĂȂ���ȁB
�Ȃ�����l���Ȃ��Ƃ��߂��낤�B
�Ȃ�����l���Ȃ��Ƃ��߂��낤�B
Intel�͂o�b���[�J�[�ɂ�����
���������Ă�̂��ȁH
�`�l�c�̃p�t�H�[�}���X���C���e���̓z�Ƃ��܂�ς��Ȃ��W�����H
���������Ă�̂��ȁH
�`�l�c�̃p�t�H�[�}���X���C���e���̓z�Ƃ��܂�ς��Ȃ��W�����H
����
������N��AMD��������
������N��AMD��������
>>499
��ʍw���͈����̂��펯�B�`�b�v�Z�b�g���Z�b�g���Ƃ���Ɉ����ɁI
��ʍw���͈����̂��펯�B�`�b�v�Z�b�g���Z�b�g���Ƃ���Ɉ����ɁI
>499
�働�b�g���郁�[�J�[�����[�i���i��
�A�L�o�E�G�̎�������̉��i�Ɠ������Ǝv���Ă�قǃo�J����Ȃ����
�働�b�g���郁�[�J�[�����[�i���i��
�A�L�o�E�G�̎�������̉��i�Ɠ������Ǝv���Ă�قǃo�J����Ȃ����
�f���A���R�A���m�ł̏���d�͔�r�̓{����������H
���\�I�ɂ͂������������B
���\�I�ɂ͂������������B
�Ȃ�Ƃ�����ӂ̑����c�c
�₷���I
�������I
�������I
�x������������Ȃ��Ɣ���Ȃ�
�Ă�4core��2core�Ɣ�r����Ă鎞�_��
���b�ɂȂ�Ȃ���
���b�ɂȂ�Ȃ���
�m�I��Q�ҍė�
�����ꂪ32nm�̎��͂�
>>509
�����i�ѓ��m�Ŕ�r���ď����Ă���Ęb�Ȃ���
�Q���������A�S���������͗��Ђ̃A�v���[�`�̈Ⴂ�ł����ă��[�U�[�͈ӎ�����K�v�͂Ȃ�
�����ӎ������Ƃ��Ă��قƂ�ǂ̏ꍇ�S�����������L��
���_�S���������͂Ȃ���ĂȂ�ŕ����S���������ɂ͏��ĂȂ�
�����i�ѓ��m�Ŕ�r���ď����Ă���Ęb�Ȃ���
�Q���������A�S���������͗��Ђ̃A�v���[�`�̈Ⴂ�ł����ă��[�U�[�͈ӎ�����K�v�͂Ȃ�
�����ӎ������Ƃ��Ă��قƂ�ǂ̏ꍇ�S�����������L��
���_�S���������͂Ȃ���ĂȂ�ŕ����S���������ɂ͏��ĂȂ�
clark�������Q8xxx�ԑ䔃����
���܂���Core2�͂Ȃ�����
��܂�X2��555��TDP��80W�Ȃ��������ēd�͏���I�ɂ�AMD���i�̒��ł����ƍ����������A�d���Ȃ��ƌ����Ύd���Ȃ��B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3726&p=7
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3726&p=7
ttp://www.phoronix.com/data/img/results/intel_lynnfield/13.png
Linux�Ȃ�Intel�͂��肦��B
Linux�Ȃ�Intel�̔ڋ��ȃR���p�C���̉e�����Ȃ��̂ŁA���̌��ʂȂ̂��������ȁB
�����Ƀv���Z�b�T�̐��\���r����Ȃ�ALinux��ł̃x���`�}�[�N���K�v���ȁB
{kind=link}
Linux�Ȃ�Intel�͂��肦��B
Linux�Ȃ�Intel�̔ڋ��ȃR���p�C���̉e�����Ȃ��̂ŁA���̌��ʂȂ̂��������ȁB
�����Ƀv���Z�b�T�̐��\���r����Ȃ�ALinux��ł̃x���`�}�[�N���K�v���ȁB
>>517
AMD�₦�₦�@�������Ă�Clarkdale�@��6950�̒�i�ƂقƂ�Ǖς�炸�i14.6������21.6���ɂ����j
G6950�͂��������牷�x��2�D5�{�Ɂi20������51���ɔ��M���j
http://www.tomshardware.com/reviews/phenom-ii-x2-555,2540-8.html
AMD�₦�₦�@�������Ă�Clarkdale�@��6950�̒�i�ƂقƂ�Ǖς�炸�i14.6������21.6���ɂ����j
G6950�͂��������牷�x��2�D5�{�Ɂi20������51���ɔ��M���j
http://www.tomshardware.com/reviews/phenom-ii-x2-555,2540-8.html
�Ȃ��A���~�̓O���t��������摜�Œ���̂�
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield&num=9
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield&num=9
GPU�̓��ӕ���ŏ������Ȃ���Intel�͈В���Ȃ����Ƃ𖾂�݂ɏo���Ă��܂���
AMD�̔��W�͂܂��܂������܂���B
���M�̕�
�������A�N�Z�X�̕�
IPC�̕ǁ@�@�@�@�@�@�@�@�@�@�@��������
�}���`�X���b�h�̕�
�l�b�g���[�N���x�̕�
�����v���Z�X�̕�
���[�U�[�p�r�̕�
�l�[�~���O�Z���X�̕�
���M�̕�
�������A�N�Z�X�̕�
IPC�̕ǁ@�@�@�@�@�@�@�@�@�@�@��������
�}���`�X���b�h�̕�
�l�b�g���[�N���x�̕�
�����v���Z�X�̕�
���[�U�[�p�r�̕�
�l�[�~���O�Z���X�̕�
Phenom�U�ATurion�U�AAthlon�U�AAthlon�ASempron����������̂�
�������ɂ�肷���� > �m�[�g�p
Intel�Ȃ�āA������ł�Core����{�ŁA���������f���p��Celeron����
�����Ȃ̂ɁB
�������ɂ�肷���� > �m�[�g�p
Intel�Ȃ�āA������ł�Core����{�ŁA���������f���p��Celeron����
�����Ȃ̂ɁB
�m�[�g��Phenom�Ȃ�Ă����������H
���͂Ȃ����A�o���v��͂���悤���E�E�E
http://www.hardware-infos.com/news.php?news=3350
http://www.hardware-infos.com/news.php?news=3350
>>520
�c����B����Ȃ����������悩������Ȃ����H
�c����B����Ȃ����������悩������Ȃ����H
���̎ア�q�����炵�傤���Ȃ�
�p��悭�������ڍ׃`�F�b�N���ĂȂ����A
�Ȃ�ŁAx3���r�ΏƂɂ����낤���H
i5�͊m��4�R�A�����������H�H�@�cpcwatch��CPU�\����ƁA�R�A�����Ȃ̂ˁB�@������ɂ����Ȃ��B
�Ȃ�ŁAx3���r�ΏƂɂ����낤���H
i5�͊m��4�R�A�����������H�H�@�cpcwatch��CPU�\����ƁA�R�A�����Ȃ̂ˁB�@������ɂ����Ȃ��B
>>520
920/870��750���x���̂��C�ɂȂ�BHT������������^�C�v�̃x���`�Ȃ̂��H
710���R�A���̊���ɑ����̂͐�L�L���b�V����N���b�N������t���Ă�H
920/870��750���x���̂��C�ɂȂ�BHT������������^�C�v�̃x���`�Ȃ̂��H
710���R�A���̊���ɑ����̂͐�L�L���b�V����N���b�N������t���Ă�H
�S�̓I�������Ƃ݂����A3D�̃��C�g���[�V���O�n��
NAS�ւ̃A�N�Z�X�֘A��Stream�x���`���x���ȊO�́A
X3 710�̕����������݊p���炢�݂����ˁB
NAS��Strem���x���̂̓������A�N�Z�X���x������H
NAS�ւ̃A�N�Z�X�֘A��Stream�x���`���x���ȊO�́A
X3 710�̕����������݊p���炢�݂����ˁB
NAS��Strem���x���̂̓������A�N�Z�X���x������H
PhenomII X3 710�@����r�ΏۂƂ��Ď��グ��ꂽ�̂�
�茳�ɂ���������A�݂������ˁB
�茳�ɂ���������A�݂������ˁB
920�͕������750��870���x���̂�BIOS�ɖ�肪����������炵���ˁB
TurboBoost��L���ɂ���Ƒ����Ȃ�Ȃ����ꕔ�̃x���`�ł͒x���Ȃ�̂Ő�܂����A���Ă��邵�B
Windows�ł̃��r���[�Ɣ�ׂĂ��ςȌ��ʂȂ̂ŃV�X�e����ς��Ă������e�X�g���܂���ƌ����āA
Intel����@�ނ�݂��Ă�����čăe�X�g�����̂�����炵���B
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield_add&num=1
TurboBoost���ɂ����ꍇ�ł��X�R�A�͑傫�����サ�Ă�̂�DP55KG�̏���BIOS�������Ă��ƌ������ƂȂ̂��ȁB
TurboBoost��L���ɂ���Ƒ����Ȃ�Ȃ����ꕔ�̃x���`�ł͒x���Ȃ�̂Ő�܂����A���Ă��邵�B
Windows�ł̃��r���[�Ɣ�ׂĂ��ςȌ��ʂȂ̂ŃV�X�e����ς��Ă������e�X�g���܂���ƌ����āA
Intel����@�ނ�݂��Ă�����čăe�X�g�����̂�����炵���B
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield_add&num=1
TurboBoost���ɂ����ꍇ�ł��X�R�A�͑傫�����サ�Ă�̂�DP55KG�̏���BIOS�������Ă��ƌ������ƂȂ̂��ȁB
206 ���O�FSocket774[sage] ���e���F2010/01/30(�y) 23:58:55 ID:OCKk1ry5
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield&num=9
207 ���O�FSocket774[sage] ���e���F2010/01/31(��) 00:11:24 ID:aWaMkb8x
the AMD Phenom II X3 710 had a number of strong finishes especially considering its only a triple-core processor and costs just over $100 USD.
Even the Core i5 750 will cost more than the AMD Phenom II X3 710.
What is important to keep in mind though is that Intel Turbo Boost Technology was disabled on the processors during testing,
since this functionality had not worked under Linux for increasing the clock frequency but instead appeared to cause some sporadic performance problems.
turbo boost�͂������������ł͓��삹���A���X���������������Ȃ�悤��
http://www.phoronix.com/scan.php?page=article&item=intel_lynnfield&num=9
207 ���O�FSocket774[sage] ���e���F2010/01/31(��) 00:11:24 ID:aWaMkb8x
the AMD Phenom II X3 710 had a number of strong finishes especially considering its only a triple-core processor and costs just over $100 USD.
Even the Core i5 750 will cost more than the AMD Phenom II X3 710.
What is important to keep in mind though is that Intel Turbo Boost Technology was disabled on the processors during testing,
since this functionality had not worked under Linux for increasing the clock frequency but instead appeared to cause some sporadic performance problems.
turbo boost�͂������������ł͓��삹���A���X���������������Ȃ�悤��
�����̒m�I��Q��
���_���猾����
2�R�A�ŏ\���ł��A�͂�
2�R�A�ŏ\���ł��A�͂�
>>517
i3 530�̈ٗl�ȏȓd�͐U��ɂ��������A555BE��X2 255�ł����Ԃ�Ⴄ�̂ɂ������ȁB
�L���b�V����100MHz�̈Ⴂ��18W������Ă���̂��B
i3 530�̈ٗl�ȏȓd�͐U��ɂ��������A555BE��X2 255�ł����Ԃ�Ⴄ�̂ɂ������ȁB
�L���b�V����100MHz�̈Ⴂ��18W������Ă���̂��B
>>532
DP55KG���Č^�Ԃ��炷��Ə������H
��肪�����ĉ��P�����Ȃ�悩�����킗
�܂����茳�ɂ�����������3�R�A�ɁA
8�R�A��炪�S�s�C�����Ă̂͟����ɂȂ��B
�����ǁc�����������܂�A�����ȁc�B
DP55KG���Č^�Ԃ��炷��Ə������H
��肪�����ĉ��P�����Ȃ�悩�����킗
�܂����茳�ɂ�����������3�R�A�ɁA
8�R�A��炪�S�s�C�����Ă̂͟����ɂȂ��B
�����ǁc�����������܂�A�����ȁc�B
>>529
SQL�n�ł�HT�I�t��̂�HT���������ꂽ�C�j�V�G����̏펯�ł��B
���̃x���`�}�[�N�̃e�X�^�[�̓A�t�H���Ǝv���B
http://japan.cnet.com/news/ent/story/0,2000056022,20091397,00.htm
�[���A���Ƀ|�X�O���͎������A���ȋC�����Ȃ��ł��Ȃ��B
http://d.hatena.ne.jp/moto0215/20060630/1151653430
SQL�n�ł�HT�I�t��̂�HT���������ꂽ�C�j�V�G����̏펯�ł��B
���̃x���`�}�[�N�̃e�X�^�[�̓A�t�H���Ǝv���B
http://japan.cnet.com/news/ent/story/0,2000056022,20091397,00.htm
�[���A���Ƀ|�X�O���͎������A���ȋC�����Ȃ��ł��Ȃ��B
http://d.hatena.ne.jp/moto0215/20060630/1151653430
>>538
���������@���@�V���[�Y�͂������������ł͑�������
���������@���@�V���[�Y�͂������������ł͑�������
>>539
�܂��A�������낤�ˁB
�V�����@�\��A�[�L�ւ̑Ή����x���̂�linux�ł͂������A
�ʂ�core i�Ɍ������b�ł͂Ȃ����ƁB
�܂��A�������낤�ˁB
�V�����@�\��A�[�L�ւ̑Ή����x���̂�linux�ł͂������A
�ʂ�core i�Ɍ������b�ł͂Ȃ����ƁB
http://www.phoronix.com/scan.php?page=article&item=intel_corei3_530&num=9
����Linux��̃e�X�g��Phenom II X3 710��Core i3 530�ɕ��ʂɕ����Ă�����A
���̎��M�͂��������ǂ����痈��̂�?
����Linux��̃e�X�g��Phenom II X3 710��Core i3 530�ɕ��ʂɕ����Ă�����A
���̎��M�͂��������ǂ����痈��̂�?
>>541
�V�A�[�L�e�N�`���ɎアLinux��ł̃e�X�g�Ȃ�ē��ĂɂȂ�Ȃ��ӂ����ӂ���
�V�A�[�L�e�N�`���ɎアLinux��ł̃e�X�g�Ȃ�ē��ĂɂȂ�Ȃ��ӂ����ӂ���
>>541
533�ɂ������������̌��_
533�ɂ������������̌��_
�r�p�k�ł̊����Ăr�p�k�����������Ȃ��ł����Ȃ́H
�����ȋ@�\�����Ƃ�����A�r�p�k���s�������g�s��Ƃ��������ۂ��Ǝv�����B
�����ȋ@�\�����Ƃ�����A�r�p�k���s�������g�s��Ƃ��������ۂ��Ǝv�����B
SQL�x���`���K�v�Ȃقǂ̃g�����U�N�V�������ׂ���������
�Ɩ��ŁA���ł�����ł����ɋl�ߍ���SIer�������Ƃ�����
�^���̃o�J���ȁBjk
�Ɩ��ŁA���ł�����ł����ɋl�ߍ���SIer�������Ƃ�����
�^���̃o�J���ȁBjk
AMD�X���ŃC���e���������������̃o�J�����ǂ�
�������w�E���Ă��邾���Ȃ̂����A�C���e�������Ă���悤�Ɍ�����̂��H
�@�����ȁB
�@�����ȁB
�n���ǂ��̒��ł܂Ƃ��Ȏ��������Ă�����
���ǂ������c
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@�@ �i�E�L��`�E�j
�@�@�@�@�@�@,,,
(�@߄t�)��
�@�@�@ �i�E�L��`�E�j
>>547
�w�E������m����肨�O�ɕK�v�Ȃ̂̓X���[����펯���B
�w�E������m����肨�O�ɕK�v�Ȃ̂̓X���[����펯���B
>>550
�܂�s�s���ȏ������݂͎����ł��낤�ƃX���[����̂�"�펯"�ŁA
���AMD�}���Z�[���Ȃ��Ă͂����Ȃ��̂����̃X���Ȃ�ł��ˁB
����ς�@����������B
�܂�s�s���ȏ������݂͎����ł��낤�ƃX���[����̂�"�펯"�ŁA
���AMD�}���Z�[���Ȃ��Ă͂����Ȃ��̂����̃X���Ȃ�ł��ˁB
����ς�@����������B
���g�ʼnB���H�삷��̂����@���s�ł����H
DDR5��ް
��
�u�t�F�b�`���v���t�F�b�`�v�u�f�[�^���^�X�N����v�uHyper-Threading�Ń��������C�e���V�̉B�������@���s�v
�Ȃ�Ă��Ƃ��������������Ə�Ɋ����Ă邩���
�u�t�F�b�`���v���t�F�b�`�v�u�f�[�^���^�X�N����v�uHyper-Threading�Ń��������C�e���V�̉B�������@���s�v
�Ȃ�Ă��Ƃ��������������Ə�Ɋ����Ă邩���
���O��S���X���^�C�݂�
ID:OCKk1ry5��Intel�X���ɂ��\�������炱�̌��ʂɂȂ��Ă�
PC-343B�ē��ׂ̗\�肪�P�[�X�}�j�A�b�N�ɂłĂ��
�A���~�����^��
�A���~�͏��F���R�e�B�������͓̂�����O�B
����ɂ�������ԈႦ�B
����ɂ�������ԈႦ�B
�A�����ė�������ARM�ȋC�����Ă��傤���Ȃ�
���ł̓A���h
ID�Œǂ��Ă݂�ƃA���A�������Ă����S���P���Ȍ��B
�ƒP�����\���Ă���܂�
�G���ɂ�������������
http://citavia.blog.de/2010/01/31/globalfoundries-flyer-about-hkmg-7909891/
�o�R��pdf
http://www.globalfoundries.com/pdf/GF_HKMG_TrifoldBrochure.pdf
Proof #5
Customer Product Introductions in Q1 2010:
GLOBALFOUNDRIES�f customers will begin to
announce HKMG product results in early 2010 - not
test chips, not 64M SRAMS, not IP shuttle results,
but full products. As with the 45/40nm ramp, this
will be far ahead of any other pure play foundry.
�v�͍��N������GF�Ђ̌ڋq��40/45nm��HKMG���̗p�������i�\���܂�����Ă�����
AMD��Fab�������Shared Transistor Technology������Ă��炵������AHKMG�m���
32nm�̑O��45nm�ł�HKMG���̗p���Ă����Ȃ����Ǝv���Ă�����������ттĂ���
�o�R��pdf
http://www.globalfoundries.com/pdf/GF_HKMG_TrifoldBrochure.pdf
Proof #5
Customer Product Introductions in Q1 2010:
GLOBALFOUNDRIES�f customers will begin to
announce HKMG product results in early 2010 - not
test chips, not 64M SRAMS, not IP shuttle results,
but full products. As with the 45/40nm ramp, this
will be far ahead of any other pure play foundry.
�v�͍��N������GF�Ђ̌ڋq��40/45nm��HKMG���̗p�������i�\���܂�����Ă�����
AMD��Fab�������Shared Transistor Technology������Ă��炵������AHKMG�m���
32nm�̑O��45nm�ł�HKMG���̗p���Ă����Ȃ����Ǝv���Ă�����������ттĂ���
����ڂ�
AMD�̌����I�ɂ�HKMG��32nm������Ęb�����ǁA32nm�̃e�X�g
�Ƃ���45nm�ɓ������ăZ���͂��邩���ˁB
�Ƃ���45nm�ɓ������ăZ���͂��邩���ˁB
HKMG��32/28nm����A������Q1��45/40nm��HKMG�̗p�̐��i���o��Ƃ����B
> �gIf you can�ft explain it simply,
> you don�ft understand it well
> enough.�h
> - Albert Einstein
�Ƃ��`���Ő��銄�ɁA�Ȃ��悭�킩���ȁB
> �gIf you can�ft explain it simply,
> you don�ft understand it well
> enough.�h
> - Albert Einstein
�Ƃ��`���Ő��銄�ɁA�Ȃ��悭�킩���ȁB
K10 Rev.E�Ɖ\��Thuban��HKMG�̉\���������Ǝv����
955BE�g���Ă邩�甃���C�����������ǔ��������悤���Ȃ�
955BE�g���Ă邩�甃���C�����������ǔ��������悤���Ȃ�
572 �FSocket774�F2010/02/01(��) 09:34:05 ID:JEVKREv7
�Ȃɂ��ɃX�S�C���
����Ȃ�thuban��2.8GHz�ȏ���Ă̂����肦�邩��
����Ȃ�thuban��2.8GHz�ȏ���Ă̂����肦�邩��
�ȏ�ƌ��������̂����߂ƌ��������̂�
574 �FSocket774�F2010/02/01(��) 12:07:27 ID:JEVKREv7
�����܂ł��g�ȏ�h�ł��B���ǁA3.2GHz�����͓����
����6�R�AOp2.8GH�������Ă邼
GPU�ɂ��LuxRender�̃����_�����O�f������
http://blender.jp/modules/news/article.php?storyid=2771
http://blender.jp/modules/news/article.php?storyid=2771
>>575
����6�R�AOpteron�̉��ǔłȎ��͊m���B
����6�R�AOpteron�̉��ǔłȎ��͊m���B
4�R�A32nm��CPU�͂ǂ��炪��ɏo���̂���
intel�͖��炩�Ɏ��������ȁA��ɋ����Ȃ���
HKMG�Ȃ̂�140W���Ă��Ƃ͂��ꂾ���N���b�N��������! ������!
�ƃ|�W�e�B�u�ɍl���Ȃ���AMD Fanboy�͂���Ă��B
�ƃ|�W�e�B�u�ɍl���Ȃ���AMD Fanboy�͂���Ă��B
�q�[�����̂ɃG���b�^�{���ǂ��납�����Ă�ˁ[���悗�����Ƃ�
GF�͑��̃t�@�E���h���̔��������Ă邩��A�������̌ڋq�̐��i�Ă��Ƃ����邩����
http://citavia.blog.de/2010/01/31/globalfoundries-flyer-about-hkmg-7909891/
http://www.globalfoundries.com/pdf/GF_HKMG_TrifoldBrochure.pdf
Proof #5
Customer Product Introductions in Q1 2010:
GLOBALFOUNDRIES�f customers will begin to
announce HKMG product results in early 2010 - not
test chips, not 64M SRAMS, not IP shuttle results,
but full products. As with the 45/40nm ramp, this
will be far ahead of any other pure play foundry.
GPU�ȋC�����邯��
http://www.globalfoundries.com/pdf/GF_HKMG_TrifoldBrochure.pdf
Proof #5
Customer Product Introductions in Q1 2010:
GLOBALFOUNDRIES�f customers will begin to
announce HKMG product results in early 2010 - not
test chips, not 64M SRAMS, not IP shuttle results,
but full products. As with the 45/40nm ramp, this
will be far ahead of any other pure play foundry.
GPU�ȋC�����邯��
586 �F,,�E�L�́M�E,,�j��-�������F2010/02/03(��) 00:12:15 ID:5WuOqVYL
>>202
�T���X������Bulldozer��FP�X�P�W���[���͌��\�ʔ����M�~�b�N�������
Open64�̃t�H�[�����ɂ�����
�@�@���W�X�^��movaps���[���R�X�g
���Ă̂͂ǂ������Ӗ������Ă����ƁA���Ƃ���
xmm0.f32[0..3] = xmm1.f32[0..3] + xmm2.f32[0..3]
����������̂�SSE�ł�
movaps xmm0, xmm1
addps xmm0, xmm2
����2���߂ɂ�����ǁA
Bulldozer��movaps���n���h�����O���āA�����I��3�I�y�����h�ɓW�J����B
���ʂƂ���movaps�̃�OP���팸�����Ƃ����킯�B
����Ӗ��ł�AVX��
vaddps xmm0, xmm1, xmm2
�����̃I�y���[�V�����ւ̕ϊ����A�ăR���p�C���Ȃ��ɓ��I�ɂ�邱�Ƃ��ł���B
���Ȃ݂�Intel��AVX�ւ̈ڍs�𑣂����߂ɏ]��SSE�̍������͂�����x���߂Ă���i�x������킯�ł͂Ȃ��j��
AMD�͏]��SSE�̃X���[�v�b�g������ڎw���Ă���B
�����Ƃ����X���uSSE5�v�����̃o�b�N�G���h�v������ˁB�t�Ɍ�����AVX�����ɍœK���͂���ĂȂ��B
�E�E�E�ƌ��������݂�
�T���X������Bulldozer��FP�X�P�W���[���͌��\�ʔ����M�~�b�N�������
Open64�̃t�H�[�����ɂ�����
�@�@���W�X�^��movaps���[���R�X�g
���Ă̂͂ǂ������Ӗ������Ă����ƁA���Ƃ���
xmm0.f32[0..3] = xmm1.f32[0..3] + xmm2.f32[0..3]
����������̂�SSE�ł�
movaps xmm0, xmm1
addps xmm0, xmm2
����2���߂ɂ�����ǁA
Bulldozer��movaps���n���h�����O���āA�����I��3�I�y�����h�ɓW�J����B
���ʂƂ���movaps�̃�OP���팸�����Ƃ����킯�B
����Ӗ��ł�AVX��
vaddps xmm0, xmm1, xmm2
�����̃I�y���[�V�����ւ̕ϊ����A�ăR���p�C���Ȃ��ɓ��I�ɂ�邱�Ƃ��ł���B
���Ȃ݂�Intel��AVX�ւ̈ڍs�𑣂����߂ɏ]��SSE�̍������͂�����x���߂Ă���i�x������킯�ł͂Ȃ��j��
AMD�͏]��SSE�̃X���[�v�b�g������ڎw���Ă���B
�����Ƃ����X���uSSE5�v�����̃o�b�N�G���h�v������ˁB�t�Ɍ�����AVX�����ɍœK���͂���ĂȂ��B
�E�E�E�ƌ��������݂�
���s�������ƂȂ���
�A
�@���h
����Ȃ���?
�A
�@���h
����Ȃ���?
�N�ɃC���g�l�[�V�����ă}�W�H
���ႠmCdonald���H
���ႠmCdonald���H
�l�^�Ƀ}�W���X����Ɓu���[���ނł��[�v����
MS���u�܂��v�Ƃ͔������Ȃ���
NEC���u�ˁ[���v�Ƃ������o�J�͂��Ȃ��̂Ɠ����B
�u���ނǁv�Ɣ�������͔̂]�������z�ȕ��̂݁B
MS���u�܂��v�Ƃ͔������Ȃ���
NEC���u�ˁ[���v�Ƃ������o�J�͂��Ȃ��̂Ɠ����B
�u���ނǁv�Ɣ�������͔̂]�������z�ȕ��̂݁B
MAC�I�^���猩��ƁA�h�U�[���h�U�[�g���Ă���߷ެ�!�@���Ċ����Ȃ낤��
"�˂���"�͎g���l������c
���Ⴀ�l�b�V�[��
ISSCC�Ŕ��\�����̂�Llano�Ȃ́H
>>352�́u���W���[���z�b�s���O�v�āA
��Ԃ̃z�b�g�X�|�b�g�̃f�R�[�_���z�b�v�ł��Ȃ�����Ӗ��Ȃ��Ǝv���Ă�����
�{��ALU�Ƒg�ݍ��킹������ʂ��邩
�X�P�W���[���Ɋւ��Č����A
SMT��4 issue�߂邱�Ƃ�ڎw���A�v���[�`(Inetl)��
�V���O���X���b�h���͑��ΓI�Ɋȑf��(IPC 3��2)���ꂽ2�i�ڂ̃f�R�[�_��{���œ������A�v���[�`(AMD�H)
�ŁAInteger Core�Ԃ̃X�e�[�g�̋��L�Ƃ��A�N���b�N�h���C���̍X�Ȃ镪���Ɠ����ɂ�鐧���H�̕��G���Ƃ�
�l����ƌ����I�ɂ͂ǂ��Ȃ̂�H
�����������\�łȂ��H�����ăG�����l
��Ԃ̃z�b�g�X�|�b�g�̃f�R�[�_���z�b�v�ł��Ȃ�����Ӗ��Ȃ��Ǝv���Ă�����
�{��ALU�Ƒg�ݍ��킹������ʂ��邩
�X�P�W���[���Ɋւ��Č����A
SMT��4 issue�߂邱�Ƃ�ڎw���A�v���[�`(Inetl)��
�V���O���X���b�h���͑��ΓI�Ɋȑf��(IPC 3��2)���ꂽ2�i�ڂ̃f�R�[�_��{���œ������A�v���[�`(AMD�H)
�ŁAInteger Core�Ԃ̃X�e�[�g�̋��L�Ƃ��A�N���b�N�h���C���̍X�Ȃ镪���Ɠ����ɂ�鐧���H�̕��G���Ƃ�
�l����ƌ����I�ɂ͂ǂ��Ȃ̂�H
�����������\�łȂ��H�����ăG�����l
RD800����ICH10R��葬�����ȁB
�������Z�p�t�H�[�}���X���]���ɂ��Č��������AMD�́uBulldozer�v
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20100205_346902.html
ILP�̐��\��������͎̂��łւ̓��Ǝv�����ˁc
x86�̗����̓��[�R�X�g��ILP���グ�鎖�ɓ��������̂�����t�����Ǝv�����B
���ƁANehalem�ȍ~��CPU��Intel��Bulldozer���j�b�g�ގ��̕����g���Ă���\���͏[������Ǝv���B
���������ABulldozer���j�b�g���Ă͉̂ғ����Ă郌�W�X�^�̗L�����𑝂₵����������ꂽ���̂���Ȃ��ˁH
���ɂ͂��������A�v���[�`�̉��ɍ��ꂽ���̂Ɍ�����B
�����Ă���͕ʂɓ˔�Ȕ��z�ł��Ȃ����AIntel��������HyperThreading����Ȃ��āA
Bulldozer���C�N�ȃ��j�b�g�ɂ��Ă���\����������Ȃ����낤���B
�u���̓p�C�v���C����l�߂Ă�ILP�������ł��v
�Ƃ�����Ȃ�����ABulldozer�̓p�X���Ȃ��c
�N���b�N�̍���Thuban�œ����������c
���邢�͂��ꂪx86�̏I�̏Z���ɂȂ邩�ȁc
x86�̗����̓��[�R�X�g��ILP���グ�鎖�ɓ��������̂�����t�����Ǝv�����B
���ƁANehalem�ȍ~��CPU��Intel��Bulldozer���j�b�g�ގ��̕����g���Ă���\���͏[������Ǝv���B
���������ABulldozer���j�b�g���Ă͉̂ғ����Ă郌�W�X�^�̗L�����𑝂₵����������ꂽ���̂���Ȃ��ˁH
���ɂ͂��������A�v���[�`�̉��ɍ��ꂽ���̂Ɍ�����B
�����Ă���͕ʂɓ˔�Ȕ��z�ł��Ȃ����AIntel��������HyperThreading����Ȃ��āA
Bulldozer���C�N�ȃ��j�b�g�ɂ��Ă���\����������Ȃ����낤���B
�u���̓p�C�v���C����l�߂Ă�ILP�������ł��v
�Ƃ�����Ȃ�����ABulldozer�̓p�X���Ȃ��c
�N���b�N�̍���Thuban�œ����������c
���邢�͂��ꂪx86�̏I�̏Z���ɂȂ邩�ȁc
�u�V���O���X���b�h�A�v���P�[�V����������ǂꂾ�������c�邩�v�ɂ����̂ł́H
�����AMD���̂́u3���߂��ߏ�v�Ƃ������f���牺�����킯�����B
�悭�悭�l����ƁAWindows�n���Ǝ��ЃR���p�C���������Ȃ�AMD�ł́A
���̃R�A�ɍœK�������v���O������ł��Ȃ�����A
�u���_�l�v�Ȃ�ĂقƂ�Ǐo���Ă��Ȃ���Ȃ��́H
�����ŃR���p�C���ł���Linux�n���ƃR���p�C������Ƃ��ɁA
CPU�P�Ƃɓ�����������������̘b�Ȃ����ŁA
���̏ꍇ�́u�}���`�X���b�h�v�ɔ�d��u�����������̘b�����B
�u�m���ɓ���̃V���O���X���b�h�����x���`�ł́A������ƍ��������ǁA
�@�V���O���X���b�h�d���ł͂Ȃ��l�ɂ͑S���W�Ȃ��b���������I�v
�Ȃ�ăI�`�ɂ��Ȃ肻�������B
�����AMD���̂́u3���߂��ߏ�v�Ƃ������f���牺�����킯�����B
�悭�悭�l����ƁAWindows�n���Ǝ��ЃR���p�C���������Ȃ�AMD�ł́A
���̃R�A�ɍœK�������v���O������ł��Ȃ�����A
�u���_�l�v�Ȃ�ĂقƂ�Ǐo���Ă��Ȃ���Ȃ��́H
�����ŃR���p�C���ł���Linux�n���ƃR���p�C������Ƃ��ɁA
CPU�P�Ƃɓ�����������������̘b�Ȃ����ŁA
���̏ꍇ�́u�}���`�X���b�h�v�ɔ�d��u�����������̘b�����B
�u�m���ɓ���̃V���O���X���b�h�����x���`�ł́A������ƍ��������ǁA
�@�V���O���X���b�h�d���ł͂Ȃ��l�ɂ͑S���W�Ȃ��b���������I�v
�Ȃ�ăI�`�ɂ��Ȃ肻�������B
>�܂�A���Z&���[�h/�X�g�A�̃y�A��2�g�����Ă���ƌ�����B
�O��ɂ��Ă邱�ꂪ�Ԉ���Ă邩���
�O��ɂ��Ă邱�ꂪ�Ԉ���Ă邩���
�������˂�������
�V���O���X���b�h�A�v�����}���`���Ȃ�ł�����
�̍����i�߂�Intel
�V���O���X���b�h�A�v���̓C�}�C�`�����ǃ}���`��Intel�Ə��Ȃ��Ƃ����F�Ȃ���
�̒ቿ�i�߂�AMD
���Ăȕ��ɏZ�ݕ����ɂȂ�H
���Ɠ����d
�̍����i�߂�Intel
�V���O���X���b�h�A�v���̓C�}�C�`�����ǃ}���`��Intel�Ə��Ȃ��Ƃ����F�Ȃ���
�̒ቿ�i�߂�AMD
���Ăȕ��ɏZ�ݕ����ɂȂ�H
���Ɠ����d
�������Z�̃V���O���X���b�h���\���w�lj�����Ȃ��Ǝv�����ǂˁB
Bulldozer��Bobcat��K10��K6�ɋt�s����悤�ɏ�����Ă邯�ǁA�����̃��[�U�[�Ȃ�m���Ă�ʂ�
K6-3��Athlon�̐������Z���\��K6-3����Ȃ��炢K6�n�̐������\�͍�������
L2��L3�ƃN���b�N���ɂ����ꍇ�̐������\���́AK6��1�Ƃ����ꍇ
K6(1)=K7(1)=<K8(1.1)=<K10(1.2)=K10.5(1.2)
�ʂ��Ǝv���B
�P�Ȃ�V�������N��������Ȃ��A�ŐV�̋Z�p���g����K6������K10.5�Ɩw�Ǔ������炢�ɂȂ肻���B
�Ƃ������ABulldozer�̐��̂����͂ȕ����������\�������3GHz���œ��삷��}���`�R�AK6-3�ƍl����ƁA
wktk�������ĕ@���o�����Ȃ��B
Bulldozer��Bobcat��K10��K6�ɋt�s����悤�ɏ�����Ă邯�ǁA�����̃��[�U�[�Ȃ�m���Ă�ʂ�
K6-3��Athlon�̐������Z���\��K6-3����Ȃ��炢K6�n�̐������\�͍�������
L2��L3�ƃN���b�N���ɂ����ꍇ�̐������\���́AK6��1�Ƃ����ꍇ
K6(1)=K7(1)=<K8(1.1)=<K10(1.2)=K10.5(1.2)
�ʂ��Ǝv���B
�P�Ȃ�V�������N��������Ȃ��A�ŐV�̋Z�p���g����K6������K10.5�Ɩw�Ǔ������炢�ɂȂ肻���B
�Ƃ������ABulldozer�̐��̂����͂ȕ����������\�������3GHz���œ��삷��}���`�R�AK6-3�ƍl����ƁA
wktk�������ĕ@���o�����Ȃ��B
�̐S�̃X���[�v�b�g�ł͏��Ă��
Intel�͔����i��ł邩��_��CPU���ł͏�ɏ�������ꂻ��
�����ŏ��Ă�T�[�o�ł͂܂����͐L����������
Intel�͔����i��ł邩��_��CPU���ł͏�ɏ�������ꂻ��
�����ŏ��Ă�T�[�o�ł͂܂����͐L����������
���͔n���ł�
�܂œǂ�
�܂œǂ�
1���W���[��4�g�̃p�C�v�̂����A2�g��2�X���b�h�ŋ��L���āA
1�X���b�h���s�[�N3�g�E����2�g�g����悤�ɂ���̂�
Bulldozer�̓����̖ژ_���������Ƃ�����A���̍\���͂��Ɣ[�����ȁB
1�X���b�h���s�[�N3�g�E����2�g�g����悤�ɂ���̂�
Bulldozer�̓����̖ژ_���������Ƃ�����A���̍\���͂��Ɣ[�����ȁB
ILPILP���邹�[�z���܂����̃X���ɏo�Ă����ȂƂ��v������
�㓡�܂Ō����Ă�̂��E�E�E
ttp://ja.wikipedia.org/wiki/%E5%91%BD%E4%BB%A4%E3%83%AC%E3%83%99%E3%83%AB%E3%81%AE%E4%B8%A6%E5%88%97%E6%80%A7
�㓡�܂Ō����Ă�̂��E�E�E
ttp://ja.wikipedia.org/wiki/%E5%91%BD%E4%BB%A4%E3%83%AC%E3%83%99%E3%83%AB%E3%81%AE%E4%B8%A6%E5%88%97%E6%80%A7
�A���~�͔S��˂���
Bulldozer���V���A���R�[�h������������K10�S���u�������邾�낊��
�ł����[�h�}�b�v�͂����Ȃ��ĂȂ�
�����������Ƃ�
Bulldozer���V���A���R�[�h������������K10�S���u�������邾�낊��
�ł����[�h�}�b�v�͂����Ȃ��ĂȂ�
�����������Ƃ�
�u�����̃R�e���p�X���[�h�Ŏ��s�v�Ƃ����ς�炸�̋C��������
6GHz�ŁE�E
>>612
���[�h�}�b�v�ł͍ŏI�I�ɑS���u�������Ă邶���B
���[�h�}�b�v�ł͍ŏI�I�ɑS���u�������Ă邶���B
�u���ƃ{�u�����ł�2�n����CPU�ɂȂ�
�X��K10�܂ő��������郊�\�[�X�Ȃ��AMD�ɂ͖������낤
���ƁA�V���O��/�}���`�X���b�h�ɂ����ă��b�g�p�t�H�[�}���X�����ǂ����ILP�͂ǂ��ł��������Ƃ�
�m���ɉߋ��iP4����j�ɂ����Ă�ILP�̍��������b�g�p�t�H�[�}���X�ł��������A���ЂƂ����͂��̒i�K�͑��Ƃ��Ă���
���܂���ILP�ɍS��Ӗ��͖������낤
�X��K10�܂ő��������郊�\�[�X�Ȃ��AMD�ɂ͖������낤
���ƁA�V���O��/�}���`�X���b�h�ɂ����ă��b�g�p�t�H�[�}���X�����ǂ����ILP�͂ǂ��ł��������Ƃ�
�m���ɉߋ��iP4����j�ɂ����Ă�ILP�̍��������b�g�p�t�H�[�}���X�ł��������A���ЂƂ����͂��̒i�K�͑��Ƃ��Ă���
���܂���ILP�ɍS��Ӗ��͖������낤
�V�A�[�L�e�N�`���ɂ�B�Ă��K�v������
����̃R�A�̔��W�`���l���Ă�����
����̃R�A�̔��W�`���l���Ă�����
618 �FSocket774�F2010/02/05(��) 11:53:26 ID:1nKJCBij
>>612
Fusion��V�R�A�ł�郊�X�N�����������������B�i�ƌ������Fusion���m���ɏo�����������B���ȁj
�ł��ǂ��l�����AVX �Ή����Ăǂ�����Ă����H
Intel�����J���Ă����𗊂�ɐv����̂��ȁB
Fusion��V�R�A�ł�郊�X�N�����������������B�i�ƌ������Fusion���m���ɏo�����������B���ȁj
�ł��ǂ��l�����AVX �Ή����Ăǂ�����Ă����H
Intel�����J���Ă����𗊂�ɐv����̂��ȁB
����Ⴀ�A��������ċZ�p�ҌĂ��
���ڂɘA�����Ȃ���v���Ă�Ɍ��܂��Ă��B
���ڂɘA�����Ȃ���v���Ă�Ɍ��܂��Ă��B
�N���X���C�Z���X�Ō݂��Ɋg�����߂��g���邯�ǁA���J���ꂽ���������ƂɁA
�݂��ɏ���Ɏ������Ă�͂��B
Intel�AAMD�Ԃŏ����̊g�����߂ɂ��ċ��������Ƃ����S���Ȃ����B
�݂��ɏ���Ɏ������Ă�͂��B
Intel�AAMD�Ԃŏ����̊g�����߂ɂ��ċ��������Ƃ����S���Ȃ����B
>>617
����ȏ�K8�R�A�ɉ�����点�悤�Ɓc�B
����ȏ�K8�R�A�ɉ�����点�悤�Ɓc�B
�V���A���R�[�h���Ăǂ��̑���ł����B
>>603
>�����ŃR���p�C���ł���Linux�n���ƃR���p�C������Ƃ��ɁA
>CPU�P�Ƃɓ�����������������̘b�Ȃ����ŁA
>���̏ꍇ�́u�}���`�X���b�h�v�ɔ�d��u�����������̘b�����B
�}���`�X���b�h�Ή��̓v���O�����̐v���̕ς����̂�
�R���p�C���͒��ڊW������
*nix�͕ێ�I������
�n�[�h�E�F�A���ʼnߋ��̐؎̂Ă��N�����
Windows�������ɂȂ�₷����
>�����ŃR���p�C���ł���Linux�n���ƃR���p�C������Ƃ��ɁA
>CPU�P�Ƃɓ�����������������̘b�Ȃ����ŁA
>���̏ꍇ�́u�}���`�X���b�h�v�ɔ�d��u�����������̘b�����B
�}���`�X���b�h�Ή��̓v���O�����̐v���̕ς����̂�
�R���p�C���͒��ڊW������
*nix�͕ێ�I������
�n�[�h�E�F�A���ʼnߋ��̐؎̂Ă��N�����
Windows�������ɂȂ�₷����
�V���A���R�[�h���ĘA���������ݖ��߂̂��Ƃ��낗
���V��̗p��Ɗ��Ⴂ�����Ⴂ���Ȃ���
���V��̗p��Ɗ��Ⴂ�����Ⴂ���Ȃ���
>>625
���A�ق�Ƃ�
�����Ă��̘b��ӂ��ɖu�ˑ���������̃v���O�����v�ɂȂ�̂��Ǝv����
�ł�>612���܂Ƃ��ȕ��ɂ���ɂ�
�V���A���R�[�h���V���O���X���b�h�@�Ƃł����Ȃ��ᖳ�������
���A�ق�Ƃ�
�����Ă��̘b��ӂ��ɖu�ˑ���������̃v���O�����v�ɂȂ�̂��Ǝv����
�ł�>612���܂Ƃ��ȕ��ɂ���ɂ�
�V���A���R�[�h���V���O���X���b�h�@�Ƃł����Ȃ��ᖳ�������
���\�Ɍ����Δ������߂ɋ߂����̂����V���O���X���b�h�Ɉˑ��K�{�̎荇���̂��̂���Ȃ��̂͊m�������B
>>612�͕��݂̃G�X�p�[�����͕s������
>>612�͕��݂̃G�X�p�[�����͕s������
�P�ɐ���ɗ��Ă���z�ɒm���Ȃ�ċ��߂�Ƃ��B
���܂���A����ɂ������ăn�[�h���グ�Ă��Ȃ�
���܂���A����ɂ������ăn�[�h���グ�Ă��Ȃ�
����A�ɂԂ��ޗ��ŗV��ł邾������
630 �F,,�E�L�́M�E,,�j��-�������F2010/02/06(�y) 09:51:39 ID:kCi1iHQ2
>>621
SIMD���j�b�g��256�r�b�g������������K8�Ƃ��E�E�E
SIMD���j�b�g��256�r�b�g������������K8�Ƃ��E�E�E
631 �F,,�E�L�́M�E,,�j��-�������F2010/02/06(�y) 09:53:57 ID:kCi1iHQ2
�����Ȃ�N���Ă��Ăǂ������c�q
���O���H�����قǂ̃l�^����Ȃ�����K8��AVX�Ȃ�
���O���H�����قǂ̃l�^����Ȃ�����K8��AVX�Ȃ�
���O�𗬂�������
634 �F,,�E�L�́M�E,,�j��-�������F2010/02/06(�y) 16:04:57 ID:kCi1iHQ2
���܂ɂ͗N���Ȃ���
��
��
>>607
K6-3�̐������Z�����������͓̂����Q���L���b�V�����D�G���������A�ł́H
���̂����ŕ����܂肪�オ�炸�����Ȃ�Ȃ��������B������Athlon�ł�
���Ȃ��āA���\���������܂�ɐU�����݂��������B
>>620
x86-64�̎��݂����ɁAMS�������ƒ������Ă����ł��B
K6-3�̐������Z�����������͓̂����Q���L���b�V�����D�G���������A�ł́H
���̂����ŕ����܂肪�オ�炸�����Ȃ�Ȃ��������B������Athlon�ł�
���Ȃ��āA���\���������܂�ɐU�����݂��������B
>>620
x86-64�̎��݂����ɁAMS�������ƒ������Ă����ł��B
636 �FSocket774�F2010/02/06(�y) 20:31:31 ID:010JeSSI
�܁[���AK�P�O��V���O���X���b�h���\���Q/�R�ɂȂ���Ċm�肵���킯�ł�
�Ȃ��ł���B
�s�[�N���\��K�P�O�����R�A���N���b�N��́A�W�O�����x���m�肾���ǁB
�Ȃ��ł���B
�s�[�N���\��K�P�O�����R�A���N���b�N��́A�W�O�����x���m�肾���ǁB
2/3����66%�����
Turbo Boost�݂����ȋZ�p���K�{�ɂȂ��Ă��邾�낤����
���N���b�N�����₷���v�ɂȂ��Ă����Ȃ�����
�V���O���X���b�h���\�͍��N���b�N���ŕ₤������
���N���b�N�����₷���v�ɂȂ��Ă����Ȃ�����
�V���O���X���b�h���\�͍��N���b�N���ŕ₤������
2/3�����Ƃ����Ď���
�V���O�����\�Ō��s���������ɂ���Ȃ�
�Œ�ł�4.8Ghz���x�K�v
�����Corei7�ȏ�Ɠ����ɂ���Ȃ�
6.0Ghz�`7.0Ghz�ȏ�K�v�����ǂ���Ȃ�
���N���b�N���\�Ȃ̂��ˁH
�V���O�����\�Ō��s���������ɂ���Ȃ�
�Œ�ł�4.8Ghz���x�K�v
�����Corei7�ȏ�Ɠ����ɂ���Ȃ�
6.0Ghz�`7.0Ghz�ȏ�K�v�����ǂ���Ȃ�
���N���b�N���\�Ȃ̂��ˁH
������p�C�v���C������������s�[�N���K��2/3�ɂȂ�Ȃ�
�킴�킴�{�����炷�����Ă�
�킴�킴�{�����炷�����Ă�
�r���L���b�V����߂�Α����Ȃ��ˁB
>>641
K8�ɂȂ����Ƃ����
1.3�{���x�����ɂȂ�Ȃ��ƒނ荇�������ˁH
��������ƃV���O�����\�L�����Ƃ���ƁA��͂�
���s��x�[�X��4.8Ghz�ȏオ�K�v
����ȂɃN���b�N���ėe�Ղɏオ��̂��ˁH
K8�ɂȂ����Ƃ����
1.3�{���x�����ɂȂ�Ȃ��ƒނ荇�������ˁH
��������ƃV���O�����\�L�����Ƃ���ƁA��͂�
���s��x�[�X��4.8Ghz�ȏオ�K�v
����ȂɃN���b�N���ėe�Ղɏオ��̂��ˁH
�����p�C�v�̖{�������ς��Ȃ��Ǝv���Ă���炨�߂ł���
����������K5�ȍ~�v���Ԃ�̎��Аv�J�����H�H�
K6 NexGen���疬�X�Ƒ����O���̐v�����v���Z�b�T�������C������
K6 NexGen���疬�X�Ƒ����O���̐v�����v���Z�b�T�������C������
�捞�ł���
����A�u����IBM�̐l�ނ��Ăэ���ŊJ�����Ă�
K6�FNexGen��K7�`K10�FAlpha����Power
K6�FNexGen��K7�`K10�FAlpha����Power
>642
���g���������Ȃ�Ƌ}���Ƀ��[�N���傷�邩��
�e�Ղɏグ��͖̂����B
Intel���SG��O�Œ�i�ł��~�߂ɂ��Ă�̂͂��̂����B
���g���������Ȃ�Ƌ}���Ƀ��[�N���傷�邩��
�e�Ղɏグ��͖̂����B
Intel���SG��O�Œ�i�ł��~�߂ɂ��Ă�̂͂��̂����B
>>643
���ۖ��AMD�����̍œK��������Ăăs�[�N���\�o�Ă�\�t�g�ȂقƂ�ǂȂ����炢����B
�œK���ł͗L���Ȃ͂���intel�ł���3�p�C�v������������ĂȂ�����SMT�������Ă���B
���ۖ��AMD�����̍œK��������Ăăs�[�N���\�o�Ă�\�t�g�ȂقƂ�ǂȂ����炢����B
�œK���ł͗L���Ȃ͂���intel�ł���3�p�C�v������������ĂȂ�����SMT�������Ă���B
>>648
32nm�Ń��[�N�d���̖��͂���ɐ[��������̂ł́H
��i��3GHz�͗]�T��������Ȃ����N���b�N�A�b�v���Ă�3.6�`3.8���炢�܂ł����オ��Ȃ��Ɛ����B
32nm�Ń��[�N�d���̖��͂���ɐ[��������̂ł́H
��i��3GHz�͗]�T��������Ȃ����N���b�N�A�b�v���Ă�3.6�`3.8���炢�܂ł����オ��Ȃ��Ɛ����B
�����p�C�v3�{����g����悤�ȋɌ���ꂽ�������Ő��\��2/3�ɗ����邱�Ƃ�������x����B
���ꃂ�W���[������2�R�A�g���ăp�C�v���C����3�{��4�{�g���悤�Ȃ��Ƃ��o����̂�������Ȃ��B
���4�{�g���悤�ȏ���������Ƃ͎v���Ȃ����A�Z���Ԃ�2�R�A�̋�������Ȃ�S�̂̐��\�ɂ��܂�e���o�Ȃ��Ǝv���B
�ƍl���Ă݂����ǁA�X�P�W���[���[���ʂ����疳���������B
���ꃂ�W���[������2�R�A�g���ăp�C�v���C����3�{��4�{�g���悤�Ȃ��Ƃ��o����̂�������Ȃ��B
���4�{�g���悤�ȏ���������Ƃ͎v���Ȃ����A�Z���Ԃ�2�R�A�̋�������Ȃ�S�̂̐��\�ɂ��܂�e���o�Ȃ��Ǝv���B
�ƍl���Ă݂����ǁA�X�P�W���[���[���ʂ����疳���������B
OS�̃X�P�W���[���[�Ƃ���
����ȕ��G�ȓ���ɂ����ɑΉ��ł���킯���Ȃ�
�œK���������ł���܂ŕ��x���Ǝv���̂�����
����ȕ��G�ȓ���ɂ����ɑΉ��ł���킯���Ȃ�
�œK���������ł���܂ŕ��x���Ǝv���̂�����
�Ȃ��OS�̃X�P�W���[���[���o�Ă������
Core2���IPC������ł�����Ă��邯��
AMD�ɂ͍��Ȃ��̂��ȁH
�u���h�[�U�[��IPC������݂��������ǁB
���v�H
AMD�ɂ͍��Ȃ��̂��ȁH
�u���h�[�U�[��IPC������݂��������ǁB
���v�H
�ꉞ�˂�����ł�����
IPC��ILP�͕ʃ�������
IPC��ILP�͕ʃ�������
>>655
�u�������Ȃ����v�Ɨ\�z����Ă��邾���ŁA
AMD���g�́u�������Z�̃X���[�v�b�g��K10�v
�ƌ����Ă邩��A�����������Ă����Z�R�A�^�[�{?
�݂����Ȃ̂ŕ₤��ˁB
�u�������Ȃ����v�Ɨ\�z����Ă��邾���ŁA
AMD���g�́u�������Z�̃X���[�v�b�g��K10�v
�ƌ����Ă邩��A�����������Ă����Z�R�A�^�[�{?
�݂����Ȃ̂ŕ₤��ˁB
"C-state performance boost"��"Bulldozer"�Ɏ������邾�낤����A
���N���b�N�Ŕ�r�����ꍇ�ɂ͊m���ɐ��\��������̂�������Ȃ����A
�V���O���X���b�h�������œ��N���b�N�œ������Ƃ����݂��Ȃ����痎���Ȃ��B
���ăI�`���l������B
���N���b�N�Ŕ�r�����ꍇ�ɂ͊m���ɐ��\��������̂�������Ȃ����A
�V���O���X���b�h�������œ��N���b�N�œ������Ƃ����݂��Ȃ����痎���Ȃ��B
���ăI�`���l������B
����Bulldozer+�w�J�g���P�C���ŗ��������낤��
�������Z���������Ȃ�N���b�N8G�ł��]�T�ł���
�f�R�[�_�[�E�L���b�V���EFPU�ESIMD�G���W���Ȃ��������Ă�Ɠ�����낤����
�f�R�[�_�[�E�L���b�V���EFPU�ESIMD�G���W���Ȃ��������Ă�Ɠ�����낤����
�ʂ����ĂV�W�T�f�Ƀu���h�[�U�[�͏��̂��낤���E�E�E�E�E
�ڂ��邾���Ȃ�690G�ł��\���낤
���̓}�U�[��BIOS�őΉ����邩�ǂ�������
���̓}�U�[��BIOS�őΉ����邩�ǂ�������
>>662
�������E�E�E�E�E
���̂P�N�ԓK���Ȃ̂ł��̂��Ł@�R�Q�����U�R�A���ڂ��������E�E�E
�}�U�[�{�[�h�͗��p�ł���̂Ȃ炻�������Ȃ̂��Ƃ�������
�Ή����Ȃ�������}�U�[�{�[�h�����߂̂ɂ��Ƃ��������Ȃ�
�������E�E�E�E�E
���̂P�N�ԓK���Ȃ̂ł��̂��Ł@�R�Q�����U�R�A���ڂ��������E�E�E
�}�U�[�{�[�h�͗��p�ł���̂Ȃ炻�������Ȃ̂��Ƃ�������
�Ή����Ȃ�������}�U�[�{�[�h�����߂̂ɂ��Ƃ��������Ȃ�
�܂������ĂȂ��̂��H
3�����������ɏo��890GX�Ƃ��͑Ή��ł���ƕ�������
3�����������ɏo��890GX�Ƃ��͑Ή��ł���ƕ�������
>>663
600��700�Ԍn�͏�����Ƃ��Ă��uC-state performance boost���g���Ȃ��v�͊m�����ȁB
�܂������Ă��Ȃ��Ȃ�A800�Ԍn�܂ő҂̂�����B
600��700�Ԍn�͏�����Ƃ��Ă��uC-state performance boost���g���Ȃ��v�͊m�����ȁB
�܂������Ă��Ȃ��Ȃ�A800�Ԍn�܂ő҂̂�����B
����GX����Ȃ���FX�̂ق����ɏo���Ăق����B
���������A�������Z���j�b�g��K8����������Ƃ�����
�������x��������Ƃ͌���Ȃ�����
�������Z���j�b�g�����Ő��\�����肳���Ȃ�
����قNJy�Ȃ��Ƃ͂Ȃ�����
�������x��������Ƃ͌���Ȃ�����
�������Z���j�b�g�����Ő��\�����肳���Ȃ�
����قNJy�Ȃ��Ƃ͂Ȃ�����
�@�L���b�V������Ƃ��ˁB
���̂܂�K8�����ɏオ�����́H
PenD����ėV��ł�ɂ̂���Intel�Ȃ�
������10�����CPU���̂������Ǝv����
������10�����CPU���̂������Ǝv����
>>671
>PenD����ėV��ł�ɂ̂���Intel�Ȃ�
>����10�����CPU���̂������Ǝv����
���������u���h��Intel�M�ҁv���Ă��܂��ɑ��݂���ȁB
AMD�n�̃X���ł݂�u�^���v���Ăق�Ƃ��Ɂu�^���v�Ȃ̂��H
>PenD����ėV��ł�ɂ̂���Intel�Ȃ�
>����10�����CPU���̂������Ǝv����
���������u���h��Intel�M�ҁv���Ă��܂��ɑ��݂���ȁB
AMD�n�̃X���ł݂�u�^���v���Ăق�Ƃ��Ɂu�^���v�Ȃ̂��H
��ɉΕa��Ƃ����ĂȂ���
��������邭�炢�̗]�T�͗~�����Ƃ���
��������邭�炢�̗]�T�͗~�����Ƃ���
���m�������Ă���̂ɋC�t���Ă��Ȃ��Ƃ��c�B
�����Ō�邱�Ƃ����Ă��Ƃ��炢����悗
PentiumD�ŗV��Ă��܂���Ђɂ͂���Ȃ�̐킢���������ł���
����点�č��܂ŗ����������苣����肽���Ă���Ă�킯����Ȃ���
�������Ƃ��Ă�(�Z���I��)���肪��������
����点�č��܂ŗ����������苣����肽���Ă���Ă�킯����Ȃ���
�������Ƃ��Ă�(�Z���I��)���肪��������
>>675
�ǂ�ɑ��Č����Ă�̂������
>671��>652�ӂ�̗���Ő���ɁA�����Ė����Ɍ���Ă�
�u�����p�C�v�̖{���i�̊����j�����\�i�̊����j�v
�ɑ��Č����Ă邩��ʂɖ�薳�����
�ǂ�ɑ��Č����Ă�̂������
>671��>652�ӂ�̗���Ő���ɁA�����Ė����Ɍ���Ă�
�u�����p�C�v�̖{���i�̊����j�����\�i�̊����j�v
�ɑ��Č����Ă邩��ʂɖ�薳�����
>>677
�ق�Ƃ��ɁuPenD����ėV��ł�ɂ̂���Intel�v���Ďv���Ă���킯�H�@�������m�肽�����B
�ق�Ƃ��ɁuPenD����ėV��ł�ɂ̂���Intel�v���Ďv���Ă���킯�H�@�������m�肽�����B
�u���A���I�X��
���B��͐��g�ł�
���B��͐��g�ł�
>>678
�uK8�͊��Ƀf���A���R�A�ł���悤�ȍ\���ɂȂ��Ă��܂��I�v
��AMD�̔��\�����ɂ��āu���������āI�v�Ɣ��M�j�R�C�`�����o��
�x���`�ő�s���ĒE��������o�c�I�ɂ͓��ɉ�����薳���Ƃ����n��
��ЂƂ��Č���Ζ��炩�ɗV��ł��
�K���Ȃ�PenM��DT�Ɏ����Ă�����j�R�C�`�ɂ������Ă悩��������
�uK8�͊��Ƀf���A���R�A�ł���悤�ȍ\���ɂȂ��Ă��܂��I�v
��AMD�̔��\�����ɂ��āu���������āI�v�Ɣ��M�j�R�C�`�����o��
�x���`�ő�s���ĒE��������o�c�I�ɂ͓��ɉ�����薳���Ƃ����n��
��ЂƂ��Č���Ζ��炩�ɗV��ł��
�K���Ȃ�PenM��DT�Ɏ����Ă�����j�R�C�`�ɂ������Ă悩��������
���A����������PenM����TDP����������ꍇ�N���b�N�ǂ̂��炢�オ������H
>>680
�ȂcIntel�������܂Łu�n���ɂł���v�̂͑債�����̂��Ǝv���B
�ȂcIntel�������܂Łu�n���ɂł���v�̂͑債�����̂��Ǝv���B
���ꂪ�V�тɌ�����̂�
�T�^�I�ȑ��ƕa������
�T�^�I�ȑ��ƕa������
���[�h�}�b�v��y�d��ŃL�����Z�����邱�ƂɂȂ�����A
����Ȃ��̏ꂵ�̂���CPU���o������Ȃ����Ă��Ƃ��낤�B
���̏ꂵ�̂��𗬗p����Core2Quad������A�J�������Z�p�͖��ʂɂ��Ȃ��������������邯�ǁB
����Ȃ��̏ꂵ�̂���CPU���o������Ȃ����Ă��Ƃ��낤�B
���̏ꂵ�̂��𗬗p����Core2Quad������A�J�������Z�p�͖��ʂɂ��Ȃ��������������邯�ǁB
�m����C2Q�͋Z�p�I��"Smithfield"�̓A��������"Presler"����̗��ꂾ�낤�ˁB
CPU�̊J���͑S���l�X�ȊW���������Ă���Ă���B
�u�V�тŁ`�v�Ƃ��������́AIntel�̊J���\�͂�n���ɂ������B
CPU�̊J���͑S���l�X�ȊW���������Ă���Ă���B
�u�V�тŁ`�v�Ƃ��������́AIntel�̊J���\�͂�n���ɂ������B
686 �FSocket774�F2010/02/07(��) 13:23:30 ID:iIxlGRIt
�悭�l������L1���߃L���b�V����2�R�A���L����x86�ł͏��߂ĂȂ�Ȃ����H
�����CPU������Ώ��߂Ă��ȁB
�u�V�сv���Č������͓K����Ȃ��ȁB
�ǂ�ȂɃ��C�o���ɐ��\�A���M�Ŋ��s
������CPU���o�����S�R�]�T������
�ł���BAMD�͂���ő�Ԏ��ɂȂ���
�킯�����B
�ǂ�ȂɃ��C�o���ɐ��\�A���M�Ŋ��s
������CPU���o�����S�R�]�T������
�ł���BAMD�͂���ő�Ԏ��ɂȂ���
�킯�����B
�܂����z���Ă����
�ǂ�Ȃɐ��\�ŕ����ĂĂ���ʎs��͏��Ă���Ă��Ƃł���
�ǂ�Ȃɐ��\�ŕ����ĂĂ���ʎs��͏��Ă���Ă��Ƃł���
>>688
�ʂɗ]�T����Ȃ�����"��Ȃ�"�ŁuPentiumD�v���o�����킯�����H
���̎�Intel�̂������肩�����Ƃ���͖����ɉ��i��������킯�ł��Ȃ��A
�W�X�Ɛ��i�Q�𓊓����Ă����Ƃ����u�u�����h�헪�v����B
���\������Ă����Ƃ��Ă��A"Pentium4"�Ƃقړ����i�œ������A
�����炩�ɖ����Ȓl�����̔��͂��Ă��Ȃ��B���ۂɂ͒P���ɍl�����
������"Pentium 4"�̓�{�̃R�X�g�̂͂����������ǂ˂�
�m���ɂ��ꂾ���̗̑͂Ǝ��{�͂����������炱���́u�]�T�v�Ƃ������邪�B
�u�V�сv�ł��u�]�T�v�ł��Ȃ��BIntel�͊J���͂�����A��������肢�������B
�Ȃ�Ő�����Intel���Ȃ߂�����c���̗��R���킩���B
�ʂɗ]�T����Ȃ�����"��Ȃ�"�ŁuPentiumD�v���o�����킯�����H
���̎�Intel�̂������肩�����Ƃ���͖����ɉ��i��������킯�ł��Ȃ��A
�W�X�Ɛ��i�Q�𓊓����Ă����Ƃ����u�u�����h�헪�v����B
���\������Ă����Ƃ��Ă��A"Pentium4"�Ƃقړ����i�œ������A
�����炩�ɖ����Ȓl�����̔��͂��Ă��Ȃ��B���ۂɂ͒P���ɍl�����
������"Pentium 4"�̓�{�̃R�X�g�̂͂����������ǂ˂�
�m���ɂ��ꂾ���̗̑͂Ǝ��{�͂����������炱���́u�]�T�v�Ƃ������邪�B
�u�V�сv�ł��u�]�T�v�ł��Ȃ��BIntel�͊J���͂�����A��������肢�������B
�Ȃ�Ő�����Intel���Ȃ߂�����c���̗��R���킩���B
����intel��AMD�݂����t�@�u�ƊJ���ŕ���������Aintel�𖼏��̂̓t�@�u��������Ȃ��ȁB
>>691
�u�J���́v��u�������v���u�]�T�v�Ƃ����̂͂�����������H
�u�J���́v��u�������v���u�]�T�v�Ƃ����̂͂�����������H
>>692
���̏ꍇ�͊J�����傪Rambus������ł�ww
���̏ꍇ�͊J�����傪Rambus������ł�ww
>>693
���|�I�ȊJ���͂ŁA�Ԃɍ��킹�ł�
�����ɐ��i���o���邵�A�Ԃɍ��킹�i
�����N�����������C�o�������|����
���i���o�ׁB
����ǂ��납�A�������������\�͂��S�R
�Ⴄ����A���\�A�d�͌����ŗD��Ă���
�͂��̋������S���H�����߂Ȃ��BAMD��
��Intel�̑�ւɂȂ肦�Ȃ��B
����AAMD�͉��N���Ԏ��ŁAK10��
�x��ɒx��Đ��\�s���BAthlon64 X2
���烉�C���i�b�v����V�ł����̂͂Ȃ��
���N���BAMD�͐��\�A�d�͌�����
��鐻�i�������肷�邵���Ȃ��B
�Ƃ������A���\���ꌅ����Ă��V�F�A��
���ĂȂ������B
�����]�T�̈Ⴂ�Ƃ��킸�ɂȂ�Ƃ����̂��B
���|�I�ȊJ���͂ŁA�Ԃɍ��킹�ł�
�����ɐ��i���o���邵�A�Ԃɍ��킹�i
�����N�����������C�o�������|����
���i���o�ׁB
����ǂ��납�A�������������\�͂��S�R
�Ⴄ����A���\�A�d�͌����ŗD��Ă���
�͂��̋������S���H�����߂Ȃ��BAMD��
��Intel�̑�ւɂȂ肦�Ȃ��B
����AAMD�͉��N���Ԏ��ŁAK10��
�x��ɒx��Đ��\�s���BAthlon64 X2
���烉�C���i�b�v����V�ł����̂͂Ȃ��
���N���BAMD�͐��\�A�d�͌�����
��鐻�i�������肷�邵���Ȃ��B
�Ƃ������A���\���ꌅ����Ă��V�F�A��
���ĂȂ������B
�����]�T�̈Ⴂ�Ƃ��킸�ɂȂ�Ƃ����̂��B
>>695
���̕ӂ������o���Ƃ��肪�Ȃ��ˁH
�}�[�P�b�g�ł悭������
�u���\��10�{�ɂȂ�����v
�u���i�������ɂȂ�����v
�Ƃ����̂������ł�����A�m���Ɉ��̃V�F�A�͎��邾�낤��
�ׂ��邽�߂ɃV�F�A����肽���Ȃ�
��K�͂ȃL���b�V���i�l�ށE�ݔ����܂߁j���Ȃ��Ǝ����o���Ȃ������
�Z�p���u���[�N�X���[�ɂȂ�Ȃ�����Ȃ���
���̕ӂ������o���Ƃ��肪�Ȃ��ˁH
�}�[�P�b�g�ł悭������
�u���\��10�{�ɂȂ�����v
�u���i�������ɂȂ�����v
�Ƃ����̂������ł�����A�m���Ɉ��̃V�F�A�͎��邾�낤��
�ׂ��邽�߂ɃV�F�A����肽���Ȃ�
��K�͂ȃL���b�V���i�l�ށE�ݔ����܂߁j���Ȃ��Ǝ����o���Ȃ������
�Z�p���u���[�N�X���[�ɂȂ�Ȃ�����Ȃ���
�p�C�v���C���̒��g��������CPU�ƑS�������Ƃ͎v���Ȃ����
�����̐��\�͏o�Ă���̂��y���݂��ȁB
������������̏d�x���`���Ɛ��\�͗����邾�낤�ˁB
�����̐��\�͏o�Ă���̂��y���݂��ȁB
������������̏d�x���`���Ɛ��\�͗����邾�낤�ˁB
>>665
�������E�E�E�@�O�g���Ă��p�\�R�����U�N�̎g�p���Ԃ��o�ĂԂ�������
�����̎g���Ă邩��Ȃ�炩�̂킴��Ȃ��Ȃ��
�U�R�A�y���݂�������@������Q�N�Ԃ͂Ƃ肠�����A�X�����ƈ��߂̃}�U�{�ŏ��邩�E�E�E�E�E
�T���N�X
�������E�E�E�@�O�g���Ă��p�\�R�����U�N�̎g�p���Ԃ��o�ĂԂ�������
�����̎g���Ă邩��Ȃ�炩�̂킴��Ȃ��Ȃ��
�U�R�A�y���݂�������@������Q�N�Ԃ͂Ƃ肠�����A�X�����ƈ��߂̃}�U�{�ŏ��邩�E�E�E�E�E
�T���N�X
���������_�͍���VGA��SIMD����邩�炢���A���Ă��Ƃ��낤
���Ԕ����قǂقǂ�
���N�ɂ͂����m�[�g��[�J�[��PC������CPU�ɂ���Ȃ�GPU���t���Ă���悤�ɂȂ�
�\�t�g���[�J�[��VGA��SIMD���g��Ȃ��ᐶ���c��Ȃ�����
�\�t�g���[�J�[��VGA��SIMD���g��Ȃ��ᐶ���c��Ȃ�����
�͂��H
IntelIGP��MIMD�炵����
��ނ��̫���X�J�����j�b�g�ς��
�ǂ�ǂ�SIMD�炵���Ȃ��Ȃ��Ă�炵�����ǂ�
��ނ��̫���X�J�����j�b�g�ς��
�ǂ�ǂ�SIMD�炵���Ȃ��Ȃ��Ă�炵�����ǂ�
�Ȃ�ŃX�J�����j�b�g�ςނ�SIMD�ɂȂ��
�ǂ���MS�哱�ɂȂ����
���������u������v�ɂȂ�̂͐��������ǂȁB
�����MS�哱�Œi�K�I�Ɂux86�̂Ă��Ⴆ��I�v�Ƃ��v���B
�����MS�哱�Œi�K�I�Ɂux86�̂Ă��Ⴆ��I�v�Ƃ��v���B
X86���Ă���windows������Ȃ��Ȃ邶��˂���
>>707
���₻���ł��Ȃ��BMS�����ĈȑO��x86�ȊO��Windows����Ă����ȁB
x86����E�p���悤�Ɩ͍��������j���炢���łɂ���B
���ǁA����ł͑ʖڂ��ƂȂ������炱���Ax86�ɂ�������Ă���킯�����B
���₻���ł��Ȃ��BMS�����ĈȑO��x86�ȊO��Windows����Ă����ȁB
x86����E�p���悤�Ɩ͍��������j���炢���łɂ���B
���ǁA����ł͑ʖڂ��ƂȂ������炱���Ax86�ɂ�������Ă���킯�����B
��̫��CPU�I��������悤�ɂȂ�̂���
710 �FSocket774�F2010/02/07(��) 18:41:16 ID:avKC9r35
>>708
�}�C�N���\�t�g���ăC���e��cpu���m�J���`���[�ŗL������Ȃ����������H
�ŋ߂ł������낢��ȃv���b�g�t�H�[���ł���Ă邯��
�}�C�N���\�t�g���ăC���e��cpu���m�J���`���[�ŗL������Ȃ����������H
�ŋ߂ł������낢��ȃv���b�g�t�H�[���ł���Ă邯��
CPU���[�J�[���ɂ��Ă���������GPU��SIMD���j�b�g�Ƃ��Ďg�킴��Ȃ��Ȃ�
�����v���Z�X���i���������ق�CPU�R�A�͏������Ȃ�
�ł��`�b�v�̑傫���ɂ͉��������邵�A���Ƃ����Ĉ�ʓI�ȗp�r�ł�CPU�R�A���𑝂₵�܂����Ă��L�肪�����Ȃ�
�ƂȂ���X�y�[�X�߂�̂�GPU���L���b�V�������Ȃ��A�_�C�ɐ�߂�GPU�̊����͑���������
Intel���g�����W�X�^�ƌ����R�X�g����u�������
�����v���Z�X���i���������ق�CPU�R�A�͏������Ȃ�
�ł��`�b�v�̑傫���ɂ͉��������邵�A���Ƃ����Ĉ�ʓI�ȗp�r�ł�CPU�R�A���𑝂₵�܂����Ă��L�肪�����Ȃ�
�ƂȂ���X�y�[�X�߂�̂�GPU���L���b�V�������Ȃ��A�_�C�ɐ�߂�GPU�̊����͑���������
Intel���g�����W�X�^�ƌ����R�X�g����u�������
�������ƁA���Ԃ������܂�
����Xbox���Ċm��Win2k�̃J�X�^��OS����Ȃ������H
���܂͒m��ǁB������PowerPC�n������ƌ�������B
���܂͒m��ǁB������PowerPC�n������ƌ�������B
x86 CPU��Mac��Linux/Solaris�T�[�o�Ƃ�����x86���Y�����Ȃ��Ƃ���ł��g���Ă���悤��
x86���Y�����O���Ă�CPU�Ƃ��Ă���Ȃ�ɋ����͂����邯��
��x86 Windows������������������悤��x86���Y�������Ă�����Windows�Ȃ̂�
x86 CPU���[�J�[�ȏ��MS��x86�ɔ����Ă�Ǝv����
�܁AWindows�̏ꍇ��Linux���͂��߂Ƃ���Unix�n��0�~�`�Ƃ������������Ȃ킯��
Windows�̃f�L�������̂������Ƃ��ł͂Ȃ����낤���ǂ�
x86���Y�����O���Ă�CPU�Ƃ��Ă���Ȃ�ɋ����͂����邯��
��x86 Windows������������������悤��x86���Y�������Ă�����Windows�Ȃ̂�
x86 CPU���[�J�[�ȏ��MS��x86�ɔ����Ă�Ǝv����
�܁AWindows�̏ꍇ��Linux���͂��߂Ƃ���Unix�n��0�~�`�Ƃ������������Ȃ킯��
Windows�̃f�L�������̂������Ƃ��ł͂Ȃ����낤���ǂ�
>>717
����Xbox��PentiumIII�x�[�X����
���O�܂�Athlon�x�[�X�ƌ����Ă����̂ɉ��i�����ŕ�����
�ŁAXbox360��PPC
OS�̗���Ƃ��Ă�Windows 2000(x86)���x�[�X�ɏ���Xbox(x86) OS���J������
����ɏ���Xbox(x86) OS���x�[�X��Xbox360(PPC) OS���J�����ꂽ
ttp://pc.watch.impress.co.jp/docs/2005/0602/kaigai184.htm
���������A������Xbox��Bulldozer��Bobcat���Ԃɍ����悤�����lj\���͂���̂���
GPU�Ƃ��킹�č̗p���Ă��炦��Ȃ�AMD�Ƃ��Ă�
���肵���������Ƃ��Ċ��҂ł�����������
����Xbox��PentiumIII�x�[�X����
���O�܂�Athlon�x�[�X�ƌ����Ă����̂ɉ��i�����ŕ�����
�ŁAXbox360��PPC
OS�̗���Ƃ��Ă�Windows 2000(x86)���x�[�X�ɏ���Xbox(x86) OS���J������
����ɏ���Xbox(x86) OS���x�[�X��Xbox360(PPC) OS���J�����ꂽ
ttp://pc.watch.impress.co.jp/docs/2005/0602/kaigai184.htm
���������A������Xbox��Bulldozer��Bobcat���Ԃɍ����悤�����lj\���͂���̂���
GPU�Ƃ��킹�č̗p���Ă��炦��Ȃ�AMD�Ƃ��Ă�
���肵���������Ƃ��Ċ��҂ł�����������
AMD Focusing on Integrating GPUs into Servers in 2012
http://www.hardocp.com/news/2010/02/06/amd_focusing_on_integrating_gpus_into_servers_in_2012
AMD aims for GPUs in mainstream servers starting 2012
http://www.computerworld.com.au/article/335351/amd_aims_gpus_mainstream_servers_starting_2012/
http://www.hardocp.com/news/2010/02/06/amd_focusing_on_integrating_gpus_into_servers_in_2012
AMD aims for GPUs in mainstream servers starting 2012
http://www.computerworld.com.au/article/335351/amd_aims_gpus_mainstream_servers_starting_2012/
Xenon��TDP�ł����\�J���̂ɓ�V���Ă��邩��Ȃ�
CISC�ł���u����Bobcat�������ɂȂ�̂����̕����
CISC�ł���u����Bobcat�������ɂȂ�̂����̕����
>>719
���̂��߂ɂ́A�����Ɖ��i���l�b�N�ɂȂ邩���
GPU�n���̗p����Ă����̂́A�O��Fab�ő��Y�ł��邽���炾����
����������AMD�̋����\�͂͐M������ĂȂ��̂��c
���̂��߂ɂ́A�����Ɖ��i���l�b�N�ɂȂ邩���
GPU�n���̗p����Ă����̂́A�O��Fab�ő��Y�ł��邽���炾����
����������AMD�̋����\�͂͐M������ĂȂ��̂��c
���{��50���䂾�����H���ʓI�ɂ����ǐ����\�͂������悤�Ȑ����ł͂Ȃ��ȥ��
>>722
�����̃`�b�v����Ă�Chartered����ATIC�������������ǁH
�����̃`�b�v����Ă�Chartered����ATIC�������������ǁH
�Ă�����XBOX360��MHF�ł���悤�ɂȂ�Ȃ�
������wii���܂߂āiAMD�j�O���̂���Ȃ������������H
�M������ĂȂ��̂͋����\�́i��������j���Ď�����
�M������ĂȂ��̂͋����\�́i��������j���Ď�����
���������Ă�Chartered�������Ă���GF�ɂȂ��Ă�
>>726
�c�BAMD�̓t�@���_�����O�Ȃ�Ă���Ă��܂���ł������H
�c�BAMD�̓t�@���_�����O�Ȃ�Ă���Ă��܂���ł������H
SIMD��SIMM�ƌ����Ă̂���Ҏ҂͂ǂ������I
�L�`�K�C�����������
MAC�I�^���R�e���ď�������ł���Ȃ��Ď₵��
�u���h�[�U�[���āA���O���炵�Ă߂��Ⴍ���Ⴄ�邳���������ǎ��ۂǂ��Ȃ́H
�����͑���܂���
����ް�ނȂ����ɊJ������Ŋ���
�m���ɃR���p�C���̕���r���h�ɂ͖𗧂�������
>���O�܂�Athlon�x�[�X�ƌ����Ă����̂ɉ��i�����ŕ�����
���̎��͍���������
���̎��͍���������
�V���O���X���b�h���\���R���p�C����̃����N���ɗv�������̂�
Bulldozer�͂����炭�s�K�Ƃ����]���ɂȂ邩�ƁB
Bulldozer�͂����炭�s�K�Ƃ����]���ɂȂ邩�ƁB
���ǂ��̌���̓����J���������ǂˁB
�R���p�C���F�P�O��
�����N�F�P�O�b
�Ƃ�����Ȋ����Ȃ��ǁH
�ǂ��n���ł������W���[���������N����C�Ȃ��H
�����N�F�P�O�b
�Ƃ�����Ȋ����Ȃ��ǁH
�ǂ��n���ł������W���[���������N����C�Ȃ��H
ttp://pc.watch.impress.co.jp/docs/news/event/20100208_347728.html
> AMD��x86�A�[�L�e�N�`���̎�����}�C�N���v���Z�b�T�pCPU�R�A�Z�p�ɂ��ču������(�u���ԍ�5.6)�B
> 32nm�̃v���Z�X�Z�p�Ő�������R�A�̃V���R���ʐς�9.69����mm(2���L���b�V���͊܂܂Ȃ�)�B
> AMD��x86�A�[�L�e�N�`���̎�����}�C�N���v���Z�b�T�pCPU�R�A�Z�p�ɂ��ču������(�u���ԍ�5.6)�B
> 32nm�̃v���Z�X�Z�p�Ő�������R�A�̃V���R���ʐς�9.69����mm(2���L���b�V���͊܂܂Ȃ�)�B
�ڐV�������ł��Ȃ�
742 �F,,�E�L�́M�E,,�j��-�������F2010/02/08(��) 01:48:48 ID:MFMKHMlE
������K7�܂ł͊O���L���b�V������������ˁB
�����H
�����H
L2�͊O�t������
�ꉞ�Ȃɂ��@�����H�@�Ȃ̂��������Ăق���
>>710
Linux�ׂ�FUD��M������ł�l���ċ���ȁB
Linux�ׂ�FUD��M������ł�l���ċ���ȁB
��K6-III��2���L���b�V�����_�C��Ɏ����������ƂŐ��\�����サ�����A�_�C�T�C�Y���傫���Ȃ������Ƃ�������܂肪�������Ă��܂��A�]�T�̖�������AMD�̐����\�͂�����ɕN�������Ă��܂����ƂɂȂ����B
���܂�CPU�R�A�̓�����g���Ɠ������g���œ��삷��B��������Pentium II��Pentium III��2���L���b�V����512K�o�C�g�ł�������CPU�R�A�̓�����g���̔����ł���A�܂�Celeron�̓R�A�Ɠ����ł͂�������128K�o�C�g�������B
��2���L���b�V���̎����ɂ��A�]���̃}�U�[�{�[�h��̃L���b�V����3���L���b�V���Ƃ��ė��p�ł���B�iK6-�V�j
��2���L���b�V���������͓������� Pentium III �Ɠ�����CPU�R�A�̊O���ɐڑ����ꂽ512K�o�C�g�ŁACPU�R�A�N���b�N�̔����̎��g���œ��삵���B
������͓����̔����̐����Z�p���x���ł́A2���L���b�V������������邱�Ƃ�CPU�̕����܂肪�ቺ���A���̌��ʁA���i���i���オ�邱�Ƃ����������߂ł���B�iK7����j
���܂�CPU�R�A�̓�����g���Ɠ������g���œ��삷��B��������Pentium II��Pentium III��2���L���b�V����512K�o�C�g�ł�������CPU�R�A�̓�����g���̔����ł���A�܂�Celeron�̓R�A�Ɠ����ł͂�������128K�o�C�g�������B
��2���L���b�V���̎����ɂ��A�]���̃}�U�[�{�[�h��̃L���b�V����3���L���b�V���Ƃ��ė��p�ł���B�iK6-�V�j
��2���L���b�V���������͓������� Pentium III �Ɠ�����CPU�R�A�̊O���ɐڑ����ꂽ512K�o�C�g�ŁACPU�R�A�N���b�N�̔����̎��g���œ��삵���B
������͓����̔����̐����Z�p���x���ł́A2���L���b�V������������邱�Ƃ�CPU�̕����܂肪�ቺ���A���̌��ʁA���i���i���オ�邱�Ƃ����������߂ł���B�iK7����j
> 744 ���O�FSocket774[sage] ���e���F2010/02/08(��) 06:20:02 ID:hA059AvQ
> L2�͊O�t������
>
> 745 ���O�FSocket774[sage] ���e���F2010/02/08(��) 08:09:09 ID:b8h9zitL
> �ꉞ�Ȃɂ��@�����H�@�Ȃ̂��������Ăق���
K6-�V�͂Ȃ��������ƂɂȂ��Ă�̂��H��
> L2�͊O�t������
>
> 745 ���O�FSocket774[sage] ���e���F2010/02/08(��) 08:09:09 ID:b8h9zitL
> �ꉞ�Ȃɂ��@�����H�@�Ȃ̂��������Ăق���
K6-�V�͂Ȃ��������ƂɂȂ��Ă�̂��H��
>>740
�V���R���ʐς́A����AthlonII x2���݂��Ď��Ȃ̂���
intel���݂�L2�L���b�V������āA���̕�L3 6M�ɂ�����Ď��������c
�V���R���ʐς́A����AthlonII x2���݂��Ď��Ȃ̂���
intel���݂�L2�L���b�V������āA���̕�L3 6M�ɂ�����Ď��������c
�r�����M����������c
>>750
>>740
> 32nm�̃v���Z�X�Z�p�Ő�������R�A�̃V���R���ʐς�9.69����mm(2���L���b�V���͊܂܂Ȃ�)�B
���Ă��邯�ǁH�@L2��邩�ǂ����͕ʂ̘b����B
>>750
>>740
> 32nm�̃v���Z�X�Z�p�Ő�������R�A�̃V���R���ʐς�9.69����mm(2���L���b�V���͊܂܂Ȃ�)�B
���Ă��邯�ǁH�@L2��邩�ǂ����͕ʂ̘b����B
Llano�̎ʐ^����\�z�����R�A�̖ʐςƂقڈ�v���Ă��
>>751
�������ĂH>>744-745�Ȃ��K6�ǂ��납����ȊO�̘b���炵�ĂȂ��P���N���낪��
���O�̃G�X�p�[�����̐l�ɒʂ���Ǝv���Ă�Ƃ��a�C�߂���B
>>743�͒c�q��
������K7�܂ł͊O���L���b�V������������ˁB
�@�@�@�@~~~~~~~~~
�Ɍ������Č����Ă��[�̂�
�܂����ꂪK7�A�[�L����Ō����Ă�Ƃ��Ă��c�q�̓��{�ꂪ���������������낤��
�D�ӓI�ɉ��߂��āA����K7�̂ݓL���b�V���͊O�����Ă��Ƃɂ��Ăق����̂��H
�ǂ����ɂ��Ă����{�ꂪ�s���R�����Ă��߂���
�������ĂH>>744-745�Ȃ��K6�ǂ��납����ȊO�̘b���炵�ĂȂ��P���N���낪��
���O�̃G�X�p�[�����̐l�ɒʂ���Ǝv���Ă�Ƃ��a�C�߂���B
>>743�͒c�q��
������K7�܂ł͊O���L���b�V������������ˁB
�@�@�@�@~~~~~~~~~
�Ɍ������Č����Ă��[�̂�
�܂����ꂪK7�A�[�L����Ō����Ă�Ƃ��Ă��c�q�̓��{�ꂪ���������������낤��
�D�ӓI�ɉ��߂��āA����K7�̂ݓL���b�V���͊O�����Ă��Ƃɂ��Ăق����̂��H
�ǂ����ɂ��Ă����{�ꂪ�s���R�����Ă��߂���
�����ȂF�X�K������
756 �FSocket774�F2010/02/08(��) 17:47:00 ID:NfFm0s5n
http://northwood.blog60.fc2.com/blog-entry-3504.html
�@ �@ �@�@�@�Q�Q�Q_
�@ �@�@�@�^�@AMD�@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@��邱�ƂȂ����T�[�o�[��GPU�ł��������邨�c
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|�@�@
�@ �_�@�@ �@ �M �܁L �@ �@ �^
�@�@�@�@�@�@�@�Q�Q
�@�@�@�@�@ �^GF�@�_
�@�@�@�@�^�(�@_�m�@�@�_ �@
�@�@�@�@|�@��(�i ���j�i���j �@�@�@�@
�@�@�@�@.|�@�@�@�@ �i__�l__�j�@/��l
�@�@�@ �@|�@�@�@�@�@�M �܁LɁ@|`'''|�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q
�@�@�@�@�^ �܁R�@�@�@�@ }�@ |�@ |�@�@�@�@�@�@�@�@�@�@�@�^ AMD�@�_ �@�@
�@�^�@�^�@|�@�@�@�@�@ �m �@ �m�@�@�@�@�@�@�@�@�@�@ �^���j�j�@�@�i�i���_ . �f,�@� �@�@
( _ �m�@�@�@ |�@�@�@�@�@ �_�L�@�@�@�@�@�@ �Q�@ �@�^�@�@�@ �i__�l__�j�f,���_ ,�@ �f�@
�@�@�@�@�@ �@|�@�@�@�@�@�@�@�_�Q,, -�] ''"�@ �P�P�''?---��'�L�P�M�R/�@�@>�@�ā@
�@�@�@�@�@�@ .|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q �m�@�^�@ �i
�@�@�@�@�@�@�@�R�@�@�@�@�@�@�@�@�@�@�@�Q,, -�] ''"�P�R��P�@`�['�L�@ �^ �@��'"�P
�@�@�@�@�@�@�@�@ �_�@�@�@�@�@�@�@, '�L�@�@�@�@�@�@�@�@�@ /�@�@�@�@ �@ .|�@
�@�@�@�@�@�@�@�@�@�@�_�@�@�@�@�@(�@�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@�@�@|
�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@�@�_�@�@�@�@�@�@�@�@/�@�@ �@�@�@�@�@
�@ �@ �@�@�@�Q�Q�Q_
�@ �@�@�@�^�@AMD�@�_
�@�@�@�^�@ _�m �@�R�_�@ �_
�@ �^ �@o߁܁@�@�@���o�@ �_ �@��邱�ƂȂ����T�[�o�[��GPU�ł��������邨�c
�@ |�@�@�@�@ �i__�l__�j�@�@�@�@|�@�@
�@ �_�@�@ �@ �M �܁L �@ �@ �^
�@�@�@�@�@�@�@�Q�Q
�@�@�@�@�@ �^GF�@�_
�@�@�@�@�^�(�@_�m�@�@�_ �@
�@�@�@�@|�@��(�i ���j�i���j �@�@�@�@
�@�@�@�@.|�@�@�@�@ �i__�l__�j�@/��l
�@�@�@ �@|�@�@�@�@�@�M �܁LɁ@|`'''|�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q
�@�@�@�@�^ �܁R�@�@�@�@ }�@ |�@ |�@�@�@�@�@�@�@�@�@�@�@�^ AMD�@�_ �@�@
�@�^�@�^�@|�@�@�@�@�@ �m �@ �m�@�@�@�@�@�@�@�@�@�@ �^���j�j�@�@�i�i���_ . �f,�@� �@�@
( _ �m�@�@�@ |�@�@�@�@�@ �_�L�@�@�@�@�@�@ �Q�@ �@�^�@�@�@ �i__�l__�j�f,���_ ,�@ �f�@
�@�@�@�@�@ �@|�@�@�@�@�@�@�@�_�Q,, -�] ''"�@ �P�P�''?---��'�L�P�M�R/�@�@>�@�ā@
�@�@�@�@�@�@ .|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q �m�@�^�@ �i
�@�@�@�@�@�@�@�R�@�@�@�@�@�@�@�@�@�@�@�Q,, -�] ''"�P�R��P�@`�['�L�@ �^ �@��'"�P
�@�@�@�@�@�@�@�@ �_�@�@�@�@�@�@�@, '�L�@�@�@�@�@�@�@�@�@ /�@�@�@�@ �@ .|�@
�@�@�@�@�@�@�@�@�@�@�_�@�@�@�@�@(�@�@�@�@�@�@�@�@�@�@ /�@�@�@�@�@�@�@|
�@�@�@�@�@�@�@�@�@�@�@ �_�@�@�@�@�_�@�@�@�@�@�@�@�@/�@�@ �@�@�@�@�@
758 �F�o�A���̗l�Ȏ� ��TAVZkIPhug �F2010/02/08(��) 18:32:56 ID:aTdwNiy5
80286���x��80386
80386����Z���x��80486
80386����Z���x��80486
�͓̂����L���b�V����1���ŁAM/B�ɑ}���̂�2���������ˁc
760 �F,,�E�L�́M�E,,�j��-�������F2010/02/08(��) 20:04:20 ID:MFMKHMlE
K7�͏���܂ł́A�̂ق����悩�����ˁB
761 �F,,�E�L�́M�E,,�j��-�������F2010/02/08(��) 20:08:43 ID:MFMKHMlE
����FP�X�P�W���[���Ŏg���Ă����3 operand���������p�C�v���C���ł��L���Ȃ�A
���W�X�^��MOV�I�y���[�V�����̍팸����������IPC�����シ��̂ŁA����ALU2�{�ł����\�͐L�т�\���͂���
���W�X�^��MOV�I�y���[�V�����̍팸����������IPC�����シ��̂ŁA����ALU2�{�ł����\�͐L�т�\���͂���
762 �F,,�E�L�́M�E,,�j��-�������F2010/02/08(��) 20:15:04 ID:MFMKHMlE
���������{��́A�V���O���X���b�h���\�]�X����Ȃ������́H
L2�L���b�V�������]�X�Ȃ��10�N���O�̘b�Ȃ̂ɂ����ɍS���Ăǂ������
���t�K�����𑨂��Ęb�����炵�Ă�����͕ς���B
L2�L���b�V�������]�X�Ȃ��10�N���O�̘b�Ȃ̂ɂ����ɍS���Ăǂ������
���t�K�����𑨂��Ęb�����炵�Ă�����͕ς���B
L2���\���V���O���X���b�h���\�ɉe�������邱�Ƃ��画��Ȃ���
�������
�������
L1D 16KB������
���b�͂���ŏI���
���b�͂���ŏI���
3��2 issue�Ŋȑf������邵�AIBM�̃A�[�L�e�N�g���Ă���Č������A
Bulldozer��POWER6�I�Ȏ��g������͂قڊm���ɓ����Ă邾�낤����
PG�{TB�ŃV���O���X���b�h���̔M�I����͑��ΓI�Ɍy�����Ă邵�A
ttp://pc.watch.impress.co.jp/docs/2006/0831/kaigai299.htm
��Performance vs Watt�̐}�ō�(IPC)���ɐU�����X�C�[�g�X�|�b�g����A
���߂����N���ĉE(�N���b�N)���Ɋ���Ă�͍l�����Ȃ��H
�V���O���X���b�h���\�オ�邯�Ǔd�͌��������邩�疳�����E�E�E
Bulldozer��POWER6�I�Ȏ��g������͂قڊm���ɓ����Ă邾�낤����
PG�{TB�ŃV���O���X���b�h���̔M�I����͑��ΓI�Ɍy�����Ă邵�A
ttp://pc.watch.impress.co.jp/docs/2006/0831/kaigai299.htm
��Performance vs Watt�̐}�ō�(IPC)���ɐU�����X�C�[�g�X�|�b�g����A
���߂����N���ĉE(�N���b�N)���Ɋ���Ă�͍l�����Ȃ��H
�V���O���X���b�h���\�オ�邯�Ǔd�͌��������邩�疳�����E�E�E
�N���b�N�A�b�v��_���Ă̍\���ύX����Ȃ��Ǝv�����ǂˁB
�͂��炸��Intel���f�X�N�g�b�vCPU�̃N���b�N���E���ؖ�
���Ă��܂������A����������Ƃ�4GHz�~�܂肾�낤�B
�͂��炸��Intel���f�X�N�g�b�vCPU�̃N���b�N���E���ؖ�
���Ă��܂������A����������Ƃ�4GHz�~�܂肾�낤�B
POWER6+��5GHz�ʼn���Ă�킯����
�R���V���[�}���������T�[�o�[����CPU�Ȃ���C�ɂ��Ȃ�
�������ȁH�@K8�R�A�قǁu�T�[�o�[�����v�ɂ͊����Ȃ����c�B
K8����HT���ڐV����������
K6����
����HT���ő�̃T�[�o�����|�C���g�Ȃ�Ȃ���
�R�A��K7�̃}�C�i�[�`�F���W
>>773
K6��NexGen�ł���
K6��NexGen�ł���
777 �FSocket774�F2010/02/08(��) 21:26:55 ID:NfFm0s5n
�@�@�@�@�@�@�@ �Q�Q�Q_�@
�@ �@ �@ �@ �^�@ AMD �_�@
�@�@�@�@ �^�@ �@�܁@�@�� �_�@ ����σQ�[������Ȃ�NVIDIA�Ɍ��邨
�@�@�@�^�@ �@ �i�܁j �@�i�܁j �_
�@ �@ |�@ �@�"�@�)�i__�l__�j"�@.�j|�@�@�@_�Q�Q�Q�Q�Q�Q�Q�Q�Q_
�@�@�@�_�@ �@ �@ ��M ���:j�L�@,�^�@ �@ | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
�Q�Q�^�@�@�@�@�@�@�@�@�@�@�_�@�@ || | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| |�@/ �@�@ ,�@�@|�P�P�P�P�P|�_n|| | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| | /�@�@ /�@�@ �R����i ���j| |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| | |�@�� �[n����.�R�Q�Q�Q/�@ (���|_|_�Q�Q�Q�Q_�Q�Q�Q�Q_|
�P �_�Q_�("��j�@�������P������@ �Q|_|�Q_|�Q
�@�@�@�@�@�@�Q�@�m�P�P�M�R�A�\�j ��@�@
�@�@�@ �@�^�@�^�@�L�M�R _�@ �O,:�O�[��
�@�@�@�^�@�m�R--/�P ,�@�@�@ �M�P�P�P
�@ �^�@�@}�@�@...|�@ /!�@�@�@�@�@ �A�u�_�r
�@|�@�@�@_}�M�[�]��'�TL _
�@�_�@�@_,:͂�--�]�]'�L}�@�@�@ ;�[------
�@�^�@�@�m�M�S:::-�]'�[���]'"����-
����AA�������남��������������������������������������
�@ �@ �@ �@ �^�@ AMD �_�@
�@�@�@�@ �^�@ �@�܁@�@�� �_�@ ����σQ�[������Ȃ�NVIDIA�Ɍ��邨
�@�@�@�^�@ �@ �i�܁j �@�i�܁j �_
�@ �@ |�@ �@�"�@�)�i__�l__�j"�@.�j|�@�@�@_�Q�Q�Q�Q�Q�Q�Q�Q�Q_
�@�@�@�_�@ �@ �@ ��M ���:j�L�@,�^�@ �@ | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
�Q�Q�^�@�@�@�@�@�@�@�@�@�@�_�@�@ || | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| |�@/ �@�@ ,�@�@|�P�P�P�P�P|�_n|| | |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| | /�@�@ /�@�@ �R����i ���j| |�@�@�@�@�@�@�@�@�@�@�@�@�@|
| | |�@�� �[n����.�R�Q�Q�Q/�@ (���|_|_�Q�Q�Q�Q_�Q�Q�Q�Q_|
�P �_�Q_�("��j�@�������P������@ �Q|_|�Q_|�Q
�@�@�@�@�@�@�Q�@�m�P�P�M�R�A�\�j ��@�@
�@�@�@ �@�^�@�^�@�L�M�R _�@ �O,:�O�[��
�@�@�@�^�@�m�R--/�P ,�@�@�@ �M�P�P�P
�@ �^�@�@}�@�@...|�@ /!�@�@�@�@�@ �A�u�_�r
�@|�@�@�@_}�M�[�]��'�TL _
�@�_�@�@_,:͂�--�]�]'�L}�@�@�@ ;�[------
�@�^�@�@�m�M�S:::-�]'�[���]'"����-
����AA�������남��������������������������������������
778 �FSocket774�F2010/02/08(��) 21:29:19 ID:NfFm0s5n
�߂��Ⴍ����ʔ����ˁH��
�������H
�������H
779 �FSocket774�F2010/02/08(��) 21:38:01 ID:NfFm0s5n
�ԁ[��ԁ[��
>>772
�܂���c�Ԃ�̓g�����h�ł͂��邵��
�܂���c�Ԃ�̓g�����h�ł͂��邵��
2012�N���Ă������炷�łɗ��Ћ���Fusion�������Ă��炭�o���낶���
����Ȃ̂���������̂������T�[�o�[�Ȃ�ė\�z�ł����ł���
����Ȃ̂���������̂������T�[�o�[�Ȃ�ė\�z�ł����ł���
Bulldozer��IBM����
Power6�ׂ����肾�Ɛ��\�ʂ�
�����߂���Intel�Ƌ����ɂȂ�Ȃ��Ȃ����H
�����߂���Intel�Ƌ����ɂȂ�Ȃ��Ȃ����H
x86��Power6���̂��̂��Č�����킯����Ȃ�����B
�������̓C���I�[�_�[����
1���W���[������2�R�A�������Ă���Ď������ǁA�V���O���X���b�h�̂Ƃ��͎g��Ȃ����̃R�A�̃N���b�N�͗��Ƃ���̂���
����ς�8�R�A32�X���b�h�ɂ���
Power7�Ƌ���Ȃ��ƈӖ����Ȃ��Ȃ����H
Power7�Ƌ���Ȃ��ƈӖ����Ȃ��Ȃ����H
POWER7�Ƃ̓Z�O�����g���Ⴄ�Ǝv����
��������Itanium�ɂł��܂����Ă����������
��������Itanium�ɂł��܂����Ă����������
789 �FSocket774�F2010/02/09(��) 01:42:43 ID:vRvsRzzT
2�R�A1�X���N�͂ǂ��s�����́H
���̑��q��2�R�A1�ƁI
�������������ł���
�ǂ�����Ȃ����ǁA�u���h�[�U�[����
���i�g���iOffice�n�@�u���E�W���O�@�e�L�g�[�ȉ�ЃA�v���j��
�x���`�}�[�J�[�@�G���R�t�@�Q�[�}�[���̍��g�h�ŕ]���̏o��\���H
�������I�Ȋ����H
���i�g���iOffice�n�@�u���E�W���O�@�e�L�g�[�ȉ�ЃA�v���j��
�x���`�}�[�J�[�@�G���R�t�@�Q�[�}�[���̍��g�h�ŕ]���̏o��\���H
�������I�Ȋ����H
793 �FSocket774�F2010/02/09(��) 04:28:24 ID:vRvsRzzT
���́A���g�̓��e���Ăǂ���S�����삪�Ⴄ���ǁE�E�E�B
���o�Ɛ��j�ƃT�b�J�[�S���ŋ��҂���v�����Ă��Ȃ��ł��傗�B
���o�Ɛ��j�ƃT�b�J�[�S���ŋ��҂���v�����Ă��Ȃ��ł��傗�B
ISSCC�ł�Llano�̔��\�̃��|�[�g�����Ă܂��B
http://www.theinquirer.net/inquirer/news/1590961/amd-talks-fusion-chip
�@�@--------------------
�@�@The upcoming 'Llano' Accelerated Processing Unit (APU) will see the joining
�@�@of a 32nm silicon-on-insulator (SoI) Phenom II quad core CPU with a DirectX 11
�@�@capable GPU on the same die. This is a more sophisticated approach than Intel's
�@�@at present, in which it simply adds a GPU chip to the processor package and
�@�@calls that 'integrated'.
�@�@--------------------
���\�̕��́A��Ƃ��Ă�����x86�R�A�̒����d�͉���}�邩�Ƃ������e�Ƃ̂��ƁB
�@- Power Gating �̗̍p
�@- �N���b�N�z���̍œK��
�Ȃǂ����ꂽ�悤�ł��B
Llano��2010�O���ɃT���v�����O�J�n�A���N������OEM�����̏o�ׂ��n�܂�Ƃ��B
http://www.theinquirer.net/inquirer/news/1590961/amd-talks-fusion-chip
�@�@--------------------
�@�@The upcoming 'Llano' Accelerated Processing Unit (APU) will see the joining
�@�@of a 32nm silicon-on-insulator (SoI) Phenom II quad core CPU with a DirectX 11
�@�@capable GPU on the same die. This is a more sophisticated approach than Intel's
�@�@at present, in which it simply adds a GPU chip to the processor package and
�@�@calls that 'integrated'.
�@�@--------------------
���\�̕��́A��Ƃ��Ă�����x86�R�A�̒����d�͉���}�邩�Ƃ������e�Ƃ̂��ƁB
�@- Power Gating �̗̍p
�@- �N���b�N�z���̍œK��
�Ȃǂ����ꂽ�悤�ł��B
Llano��2010�O���ɃT���v�����O�J�n�A���N������OEM�����̏o�ׂ��n�܂�Ƃ��B
�܂��^�̓����Ƃ������o���̂���
EETimes�̃��|�[�g�ł��B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700324
�R�A�̏ڍׂ͂قƂ�nj��ꂸ�A���C�����e�Ƃ̕]���ł����A�V���͂���Ȋ���
�@�@--------------------
�@�@AMD revealed the x86 core in Llano measures 9.69mm2 and uses 35 million
�@�@transistors, excluding a Mbyte L2 cache block. It will run at up to 3 GHz and
�@�@operates across a 0.8 to 1.2 V range while dissipating up to 25W. It is made
�@�@in a 32nm silicon-on-insulator process.
�@�@--------------------
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700324
�R�A�̏ڍׂ͂قƂ�nj��ꂸ�A���C�����e�Ƃ̕]���ł����A�V���͂���Ȋ���
�@�@--------------------
�@�@AMD revealed the x86 core in Llano measures 9.69mm2 and uses 35 million
�@�@transistors, excluding a Mbyte L2 cache block. It will run at up to 3 GHz and
�@�@operates across a 0.8 to 1.2 V range while dissipating up to 25W. It is made
�@�@in a 32nm silicon-on-insulator process.
�@�@--------------------
�ŏI�I��250mm2��9���A280mm2��10���g�����W�X�^���炢�ɂȂ�v�Z��
AnandTech�̃��|�[�g�ł��B�X���C�h�����B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3736
Power Gating�Ɋւ��Ă�GND���ŃX�C�b�`����ƌ����̂��w����x�̂悤�Łc
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=3736
Power Gating�Ɋւ��Ă�GND���ŃX�C�b�`����ƌ����̂��w����x�̂悤�Łc
EETimes�̕ʂ̃��|�[�g�B
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700375
Llano�R�A��Bobcat�ł͖����Ƃ̂��ƁB
�@�@--------------------
�@�@Their design innovations are significant considering that Llano is not actually
�@�@a new architecture for AMD like the upcoming Bulldozer or Bobcat. Instead,
�@�@AMD uses a legacy X86 core to minimize the risk of moving to a new process
�@�@technology ' la Intel's tick-tock approach.
�@�@--------------------
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700375
Llano�R�A��Bobcat�ł͖����Ƃ̂��ƁB
�@�@--------------------
�@�@Their design innovations are significant considering that Llano is not actually
�@�@a new architecture for AMD like the upcoming Bulldozer or Bobcat. Instead,
�@�@AMD uses a legacy X86 core to minimize the risk of moving to a new process
�@�@technology ' la Intel's tick-tock approach.
�@�@--------------------
��
>>796
> It will run at up to 3 GHz and
> �@�@operates across a 0.8 to 1.2 V range while dissipating up to 25W. It is made
> �@�@in a 32nm silicon-on-insulator process.
> �@�@--------------------
3GHz��25W�Ƃ��_�����郏�b�g�p�t�H�[�}���X����w
>>797
> �ŏI�I��250mm2��9���A280mm2��10���g�����W�X�^���炢�ɂȂ�v�Z��
150mm2�O��̖�10���g�����W�X�^�Ŋm�肵�Ă����
>>799
> Llano�R�A��Bobcat�ł͖����Ƃ̂��ƁB
�����ƑO����Stars�R�A�ƌ��\���Ă������獡�X����
> It will run at up to 3 GHz and
> �@�@operates across a 0.8 to 1.2 V range while dissipating up to 25W. It is made
> �@�@in a 32nm silicon-on-insulator process.
> �@�@--------------------
3GHz��25W�Ƃ��_�����郏�b�g�p�t�H�[�}���X����w
>>797
> �ŏI�I��250mm2��9���A280mm2��10���g�����W�X�^���炢�ɂȂ�v�Z��
150mm2�O��̖�10���g�����W�X�^�Ŋm�肵�Ă����
>>799
> Llano�R�A��Bobcat�ł͖����Ƃ̂��ƁB
�����ƑO����Stars�R�A�ƌ��\���Ă������獡�X����
Intel�ȊO�ɂ̓P�`��t����̂�MAC�I�^�̎d���������
����������iPad�̃`�b�v����GF�ō���Ă�������
>>802
4�R�A��100W�ł���B
4�R�A��100W�ł���B
����I�ڂ��Ă��炦�Ȃ�����Bulldozer����S�z�ł��B
anandtech�̃X���C�h���銴�����ƁA3GHz��25W����Ȃ��āA
����d�͈͂̔͂�2.5�`25W�ŁA�N���b�N��3GHz�ȏ�
�Ȃ̂ŁA25W�̂Ƃ��̃N���b�N����GHz����
�܂��s���Ȃ�Ȃ����ȁB
����d�͈͂̔͂�2.5�`25W�ŁA�N���b�N��3GHz�ȏ�
�Ȃ̂ŁA25W�̂Ƃ��̃N���b�N����GHz����
�܂��s���Ȃ�Ȃ����ȁB
���Ⴀ2.5W��3GH������Ȃ����E�E�E
�ʼn����H
�ʼn����H
ttp://images.anandtech.com/reviews/cpu/amd/llano/ISSCCdisclosure/core.jpg
�Ȃ�2.5-25W��0.8-1.3V�ŃZ�b�g��
���Ⴀ�A�C�h������
{kind=link}
�Ȃ�2.5-25W��0.8-1.3V�ŃZ�b�g��
���Ⴀ�A�C�h������
�ȓd��PC��m�[�gPC�����C�����ۂ�����
TDP65W/45W/25W�Ƃ������C���i�b�v����
65W�F3.0GHz(TB��3.4G��)
45W�F2.5GHz(TB��3.0G��)
25W�F2.0GHz(TB��2.5G��)
GPU���\��HD5450�`HD5570��
���łɒ�d�͗p��2�R�A�ł�������
45W�F3.0GHz
25W�F2.5GHz
�ʂȂ�撣��ΒB���o�������B
TDP65W/45W/25W�Ƃ������C���i�b�v����
65W�F3.0GHz(TB��3.4G��)
45W�F2.5GHz(TB��3.0G��)
25W�F2.0GHz(TB��2.5G��)
GPU���\��HD5450�`HD5570��
���łɒ�d�͗p��2�R�A�ł�������
45W�F3.0GHz
25W�F2.5GHz
�ʂȂ�撣��ΒB���o�������B
>>811
����ȂƂ��낾�ȁB
����ȂƂ��낾�ȁB
Bulldozer�̓g�����W�X�^��12��
eDRAM��64MB���炢���ڂ��Ȃ���Intel�ɏ��Ă錩���݂Ȃ��Ȃ����H
eDRAM��64MB���炢���ڂ��Ȃ���Intel�ɏ��Ă錩���݂Ȃ��Ȃ����H
Bulldozer�̃g�����W�X�^�����炷��ƁA�V���O���X���b�h���\�̂��߂ɃL���b�V���R������ĉ\��������㩁B
2�R�A1���W���[����1�R�A�ƃJ�E���g�����ꍇ�AL2���R�A������1MB����V���O���X���b�h���\�̗������݂͂��Ȃ�}�����邾�낤��
L3������K10.5��6MB����12MB���炢�ɑ����Ă���A������قǂɐ��\���������ނ��Ƃ͂Ȃ��Ǝv�����ǁB
2�R�A1���W���[����1�R�A�ƃJ�E���g�����ꍇ�AL2���R�A������1MB����V���O���X���b�h���\�̗������݂͂��Ȃ�}�����邾�낤��
L3������K10.5��6MB����12MB���炢�ɑ����Ă���A������قǂɐ��\���������ނ��Ƃ͂Ȃ��Ǝv�����ǁB
>>813
������������^��
������������^��
�L���b�V���͂��܂�l�݂����ɂȂ��C������
�Ƃ������A��e�ʃL���b�V���ɂ�����R�A��W���[���𑝂₵���������\����ɉe�����₷�����B
L1��64kB�AL2�͋��L512k/1M�AL3�͋��L10M(�R�A�ӂ�1�`2M)�ʂ�
�p�C�v���C�������������L1���������o���AL2���������o����B
L1/l2�͗e�ʂ������C�e���V�⑬�x�D��̐ݒ�ɂ��āA���̕�L3���e�ʂɂ���Ƃ��B
�Ƃ������A��e�ʃL���b�V���ɂ�����R�A��W���[���𑝂₵���������\����ɉe�����₷�����B
L1��64kB�AL2�͋��L512k/1M�AL3�͋��L10M(�R�A�ӂ�1�`2M)�ʂ�
�p�C�v���C�������������L1���������o���AL2���������o����B
L1/l2�͗e�ʂ������C�e���V�⑬�x�D��̐ݒ�ɂ��āA���̕�L3���e�ʂɂ���Ƃ��B
>>816
�O���ƌ㔼�Ŏx���ŗ��^
�O���ƌ㔼�Ŏx���ŗ��^
�L���b�V���̃T�C�Y�͐������o�Ă��Ă�킯����
>>272-276
Fudzilla���ł͂��邪Zambezi��L3��8MB�Ƃ����b������
Deneb��L2/L3���킹��8MB������AL3-8MB�̓A��
POWER7�Ɠ����悤��eDRAM���g���Ƃ���A�_�C�T�C�Y�I�ɂ���3�{�܂ł͋��e�͈͂���
>>272-276
Fudzilla���ł͂��邪Zambezi��L3��8MB�Ƃ����b������
Deneb��L2/L3���킹��8MB������AL3-8MB�̓A��
POWER7�Ɠ����悤��eDRAM���g���Ƃ���A�_�C�T�C�Y�I�ɂ���3�{�܂ł͋��e�͈͂���
eDRAM64MB���炢�ς܂Ȃ���
���ĂȂ��ł���
���ĂȂ��ł���
��ɔn��
���ׂĂ����������ł������f�ł��Ȃ��Q�n�]�B
�����Ƃ͑厖����
�������G���Ƃ����펞��]��
�u���ɂ��Ă̏����Ȃ̂��܂�Ŕ����Ă��Ȃ��v�ȂǂƂƂɂ����n���Ȃ̂�
�����ŏE���Ă����������������Ă������ׂ邱�Ƃ����ɏI�n����
�������G���Ƃ����펞��]��
�u���ɂ��Ă̏����Ȃ̂��܂�Ŕ����Ă��Ȃ��v�ȂǂƂƂɂ����n���Ȃ̂�
�����ŏE���Ă����������������Ă������ׂ邱�Ƃ����ɏI�n����
2�R�A1�X���N�������̂���
��Ȃ��ƂȂ̂œ�x�����܂���
E3200���Q�R�A�ŏ\����eDRAM
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����܂���
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�����܂���
�ނ���AMD��L3�L���b�V���͐��\�ւ̊�^�����Ȃ��Ƃ�������̂͂������B
�R�A�𑝂₵�_�C�T�C�Y����邽�߂�
�킴�킴�j�R�C�`�̐V�A�[�L�e�B�N�`�����X�N���b�`�������Ă�̂ɁA
��e�ʃL���b�V���Ő��\����Ƃ��Ӗ��s��������B
�R�A�𑝂₵�_�C�T�C�Y����邽�߂�
�킴�킴�j�R�C�`�̐V�A�[�L�e�B�N�`�����X�N���b�`�������Ă�̂ɁA
��e�ʃL���b�V���Ő��\����Ƃ��Ӗ��s��������B
>>826
K10.5�́AL1�������Ȃ�������
L2�EL3�����ΓI�ɒx�����邩���
�I�p�r�Ƃ��Đv����Ă�����K�̓L���b�V���̉��b��
�x���Ȃ�ɂ����Ǝv���Ă��ق����悳��
K10.5�́AL1�������Ȃ�������
L2�EL3�����ΓI�ɒx�����邩���
�I�p�r�Ƃ��Đv����Ă�����K�̓L���b�V���̉��b��
�x���Ȃ�ɂ����Ǝv���Ă��ق����悳��
Propus�̊������L3�ȗ��ɂ́u������Ȃ���ǂ��Ƃ������Ƃ͂Ȃ��v�ɂ�����AMD�̊��C���������B
���Z�팸�炵�Ƃ��ăL���b�V���͑��₷�݂����Ȗ����͒j�炵���Ȃ��B
��͒��߂�����A�����낤�����낤�œV�������ׂ��B
���Z�팸�炵�Ƃ��ăL���b�V���͑��₷�݂����Ȗ����͒j�炵���Ȃ��B
��͒��߂�����A�����낤�����낤�œV�������ׂ��B
�ז��Ȕn���͂Ƃ�����
AMD�̃L���b�V����Intel�̂�萫�\�����̂�
�L���b�V�����Ȗڂ̃o�����X�����ׂ�
�f�R�[�_��L2�����W���[���ŋ��L
L3���_�C�i��86�R�A�H�j�ŋ��L
���̑��F�X�Ɩ����Ȃ����ʂ��Ȃ��H�v����
���ꂪ�N���b�N�㏸�ɂȂ��邩�Ƃ��ɋ���������
�������Z�̊�{�ł���ˑ��L��̏����̓N���b�N��������
AMD�̃L���b�V����Intel�̂�萫�\�����̂�
�L���b�V�����Ȗڂ̃o�����X�����ׂ�
�f�R�[�_��L2�����W���[���ŋ��L
L3���_�C�i��86�R�A�H�j�ŋ��L
���̑��F�X�Ɩ����Ȃ����ʂ��Ȃ��H�v����
���ꂪ�N���b�N�㏸�ɂȂ��邩�Ƃ��ɋ���������
�������Z�̊�{�ł���ˑ��L��̏����̓N���b�N��������
�t���X�N���b�`���ꂽCPU�̃L���b�V���ɂ��āA
�ϑz�ȊO�̉����������邩�킩��ǂˁB
�ϑz�ȊO�̉����������邩�킩��ǂˁB
�œK��CPU���x�X�g�ł͂Ȃ��Ƃ���������E�B
http://www.ne.jp/asahi/comp/tarusan/main222.htm
L3�L���b�V���ɂ��Ă�������Ă饥��K�ޓK���Ƃ������Ƃł����͂ЂƂ�
http://www.ne.jp/asahi/comp/tarusan/main222.htm
L3�L���b�V���ɂ��Ă�������Ă饥��K�ޓK���Ƃ������Ƃł����͂ЂƂ�
ttp://www.chip-architect.com/news/2007_02_19_Various_Images.html
�L���b�V���ɂ��Ă�
L3 / L2 Cache Sram
Brisbane 18.5 mm2 / MB
Barcelona�@11.2 - 12.1 mm2 / MB�iL2��12.1���Ă��Ƃ���ȁH�j
��K8����K10�Ŗ��x���オ��
�uAMD��邶���v�Ǝv�킹�邪
L1�ɔ�ׂĂ��Ȃ萫�\�����������Ƃ���Ȃ�
���̂悤�ɊԂ��l�߂�������������Ȃ�
�t��K8��L2�́u�r�������nj��\���C�e���V�Ⴂ�v�ƌ����邱�Ƃ����邪
���̂悤�ɋ�ԑ啝�ɋĂ̌��ʂ���
�܂�AMD�Z�p�w��Intel�̃L���b�V���̓~���N�����ƌ����Ă���悤����
AMD�̃L���b�V����Intel�����Ǝv���Ă����Ǝv��
�L���b�V���ɂ��Ă�
L3 / L2 Cache Sram
Brisbane 18.5 mm2 / MB
Barcelona�@11.2 - 12.1 mm2 / MB�iL2��12.1���Ă��Ƃ���ȁH�j
��K8����K10�Ŗ��x���オ��
�uAMD��邶���v�Ǝv�킹�邪
L1�ɔ�ׂĂ��Ȃ萫�\�����������Ƃ���Ȃ�
���̂悤�ɊԂ��l�߂�������������Ȃ�
�t��K8��L2�́u�r�������nj��\���C�e���V�Ⴂ�v�ƌ����邱�Ƃ����邪
���̂悤�ɋ�ԑ啝�ɋĂ̌��ʂ���
�܂�AMD�Z�p�w��Intel�̃L���b�V���̓~���N�����ƌ����Ă���悤����
AMD�̃L���b�V����Intel�����Ǝv���Ă����Ǝv��
���t��K8��L2�́u�r�������nj��\���C�e���V�Ⴂ�v�ƌ����邱�Ƃ����邪
�����̂悤�ɋ�ԑ啝�ɋĂ̌��ʂ���
���܂�AMD�Z�p�w��Intel�̃L���b�V���̓~���N�����ƌ����Ă���悤����
��AMD�̃L���b�V����Intel�����Ǝv���Ă����Ǝv��
�a�@�r
�����̂悤�ɋ�ԑ啝�ɋĂ̌��ʂ���
���܂�AMD�Z�p�w��Intel�̃L���b�V���̓~���N�����ƌ����Ă���悤����
��AMD�̃L���b�V����Intel�����Ǝv���Ă����Ǝv��
�a�@�r
>>538
>Over time there could be tighter integration, and AMD could de-emphasize CPU cores
> if heterogeneous computing using GPUs takes off, Longoria said.
AMD��GPU���T�[�o�ɓW�J����Ƃ��������ƁA
�������d������CPU�R�A�͏d�����Ȃ������̂悤���ˁB
>Over time there could be tighter integration, and AMD could de-emphasize CPU cores
> if heterogeneous computing using GPUs takes off, Longoria said.
AMD��GPU���T�[�o�ɓW�J����Ƃ��������ƁA
�������d������CPU�R�A�͏d�����Ȃ������̂悤���ˁB
�yISSCC�zAMD�́gLlano�h��32nm�v���Z�X�Ɋւ���u��
http://northwood.blog60.fc2.com/blog-entry-3508.html
AMD��Llano��TB���C�N�ȋ@�\��PG���C�N�Ȃ��̂�����B
�ӂ���Llano�Ɋ��҂��܂��B
Bulldozer�~���S�̗\���B
http://northwood.blog60.fc2.com/blog-entry-3508.html
AMD��Llano��TB���C�N�ȋ@�\��PG���C�N�Ȃ��̂�����B
�ӂ���Llano�Ɋ��҂��܂��B
Bulldozer�~���S�̗\���B
�Ƃ����킯��>>353�͖ϑz�ɂ���肻���Ȃ킯�����A
��͂�AMD�Ƃ��Ă̓T�[�o�p�̓T�[�o�p�̃A�N�Z�����[�^�R�A���������Ƃ���A
�J���͂��܂��Ȃ������Ƃ����̂ƁABulldozer�̍\�z�i�K�Ń}���`�X���b�h�ȃR�[�h�̕��y�\����
�Â��l���Ă��܂��āA�X���[�v�b�g�ɐ��\��U���Ă��܂�������
�܂�GPU�����ĉ��Ƃ����낤�Ƃ��������Ɍ�����ȁB
��͂�AMD�Ƃ��Ă̓T�[�o�p�̓T�[�o�p�̃A�N�Z�����[�^�R�A���������Ƃ���A
�J���͂��܂��Ȃ������Ƃ����̂ƁABulldozer�̍\�z�i�K�Ń}���`�X���b�h�ȃR�[�h�̕��y�\����
�Â��l���Ă��܂��āA�X���[�v�b�g�ɐ��\��U���Ă��܂�������
�܂�GPU�����ĉ��Ƃ����낤�Ƃ��������Ɍ�����ȁB
���œˑR�\��o���Ă�
���̂܂܂�Bulldozer�ɒ��ڂ��āA�U�X���ׂČ�����̂ɍŏI�I�ɂ�PC�p���l������8���ȏ��
���ʂȋc�_�ł�����Ă��܂���������낤�B
������͑��̉\������ɍl���Ă��Ȃ���Ȃ�Ȃ��̂��B
���ʂȋc�_�ł�����Ă��܂���������낤�B
������͑��̉\������ɍl���Ă��Ȃ���Ȃ�Ȃ��̂��B
Llano�̌�p�`�b�v��CPU�R�A�̕����ɂ�Bulldozer�n�̂���邼
>>839
�\�[�X����B�������T�[�o�p����Ȃ���PC�p�̌�p�`�b�v�����B
�܁[�l�I�ɂ͌��s�̃��[�h�}�b�v���ǂ����낤��Bulldozer��PC�ɂ�
���ǂ̂Ƃ��땁�y���Ȃ��Ǝv���Ă��邪�ȁB
�\�[�X����B�������T�[�o�p����Ȃ���PC�p�̌�p�`�b�v�����B
�܁[�l�I�ɂ͌��s�̃��[�h�}�b�v���ǂ����낤��Bulldozer��PC�ɂ�
���ǂ̂Ƃ��땁�y���Ȃ��Ǝv���Ă��邪�ȁB
���ꂪ�ނ̖]��
��������������>823���H
�����قǂ̒�]���C���������G���Ȃ�
���ꂪ���炭�b��ɏo�Ȃ��Ƃ��������ő�������̂͏[���L�蓾�邱�Ƃ���
2�R�A1�X���ɂ��Ă̓����������H
���ꂪ���@�X���b�h�̂��Ƃ��Ƃ���
���@�X���b�h���Ă��܂���p�I����Ȃ��X���b�h����đш������������Ă��Ƃ炵������
����̓V���O���X���b�h������ɂȂ�낤��
���@�œ����f�[�^�̓��W���[�����L��L2�ɍڂ�
���@�������Ă��V���O���X���b�h���ɂ̓��W���[������L2�ƃ_�C����L3�͑S�Ďg����킯������
��L�L���b�V�����肾����K8�ƑΏƓI�Ŗʔ���
IntelCPU�̂������肪�A�[�L���̂̂��̂Ȃ̂����L�L���b�V���̂����Ȃ̂��ߏ�ȏȓd�͋@�\�̂����Ȃ̂�
�u���L�L���b�V���̂����Ȃ̂��v�̕�����Bull�ɂ���Ă��Ȃ�T��邾�낤��
�����قǂ̒�]���C���������G���Ȃ�
���ꂪ���炭�b��ɏo�Ȃ��Ƃ��������ő�������̂͏[���L�蓾�邱�Ƃ���
2�R�A1�X���ɂ��Ă̓����������H
���ꂪ���@�X���b�h�̂��Ƃ��Ƃ���
���@�X���b�h���Ă��܂���p�I����Ȃ��X���b�h����đш������������Ă��Ƃ炵������
����̓V���O���X���b�h������ɂȂ�낤��
���@�œ����f�[�^�̓��W���[�����L��L2�ɍڂ�
���@�������Ă��V���O���X���b�h���ɂ̓��W���[������L2�ƃ_�C����L3�͑S�Ďg����킯������
��L�L���b�V�����肾����K8�ƑΏƓI�Ŗʔ���
IntelCPU�̂������肪�A�[�L���̂̂��̂Ȃ̂����L�L���b�V���̂����Ȃ̂��ߏ�ȏȓd�͋@�\�̂����Ȃ̂�
�u���L�L���b�V���̂����Ȃ̂��v�̕�����Bull�ɂ���Ă��Ȃ�T��邾�낤��
������]���͂����Ă����ȁB
Llano�̌�p��CPU��������AWin�̔����݂��Ȃ��A���܂܂ł��ܗ������Ȃ������Q�[����
�J�N�J�N���n�߂��肵���炾�ꂾ���Ĉނ��邾��B
�������^���̉e���͂͂����[�ȁB
Bulldozer��������Ɣے肷��Ƙ^���n�����������Ă܂Ƃ��ȋc�_���Ԃ��Ԃ���
�X���̒Ꮏ���ɕK���ɂȂ�悤���B
Llano�̌�p��CPU��������AWin�̔����݂��Ȃ��A���܂܂ł��ܗ������Ȃ������Q�[����
�J�N�J�N���n�߂��肵���炾�ꂾ���Ĉނ��邾��B
�������^���̉e���͂͂����[�ȁB
Bulldozer��������Ɣے肷��Ƙ^���n�����������Ă܂Ƃ��ȋc�_���Ԃ��Ԃ���
�X���̒Ꮏ���ɕK���ɂȂ�悤���B
������l���Ă鎞�̋C�������Ăǂ�Ȋ����Ȃ낤
�ӂӂӁA�悭�����^�����ƌ��������ȁB
�ق߂Ă�낤�B
�ق߂Ă�낤�B
>>840
���܂���Ƃ������������������\�[�X�͖�������
�����̎v�����݂������悤��
�Ƃ͍s���Ă����b�g�p�t�H�[�}���X�E�R�X�g�p�t�H�[�}���X�̒ႢK10�n�ŔS��̂͂������낤
AVX�ւ̑Ή����L�邵
����ɐ��i�̐��i�Ƃ��āA��ʓI��PC�p�r�Ȃ�K�v�Ƃ����̂̓��b�g�p�t�H�[�}���X�E�R�X�g�p�t�H�[�}���X���낤
����Ȃ�Bulldozer�R�A�̕����K���Ă邾�낤
���܂���Ƃ������������������\�[�X�͖�������
�����̎v�����݂������悤��
�Ƃ͍s���Ă����b�g�p�t�H�[�}���X�E�R�X�g�p�t�H�[�}���X�̒ႢK10�n�ŔS��̂͂������낤
AVX�ւ̑Ή����L�邵
����ɐ��i�̐��i�Ƃ��āA��ʓI��PC�p�r�Ȃ�K�v�Ƃ����̂̓��b�g�p�t�H�[�}���X�E�R�X�g�p�t�H�[�}���X���낤
����Ȃ�Bulldozer�R�A�̕����K���Ă邾�낤
�ց[�^���Ȃ[
CPU�R�A�̍�����������Ă��邨�����ŁA
�V�A�[�L�e�N�`�������̉��l�͈ȑO���������Ă���̂��B
�̂Ȃ�A�V�����}�C�N���A�[�L�e�N�`���������Ȃ�A��C�ɔj�łւƓ]���������̂����A
���Ȃ�Â��R�A�����t�@�C�����Ĕ��葱���Ă�������x�킦��B
���ƐV�v���Z�X�Ŏ��鉶�b���̂��ւ��Ă��邩��ȁB
�����Ēǂ����ɂ͐킢�₷���B�B��ȓd�͋Z�p�������̂����ꂵ���B
��������Sandy Bridge�͓d�͂���������Ȃɐ����Ȃ����������B
�V�A�[�L�e�N�`�������̉��l�͈ȑO���������Ă���̂��B
�̂Ȃ�A�V�����}�C�N���A�[�L�e�N�`���������Ȃ�A��C�ɔj�łւƓ]���������̂����A
���Ȃ�Â��R�A�����t�@�C�����Ĕ��葱���Ă�������x�킦��B
���ƐV�v���Z�X�Ŏ��鉶�b���̂��ւ��Ă��邩��ȁB
�����Ēǂ����ɂ͐킢�₷���B�B��ȓd�͋Z�p�������̂����ꂵ���B
��������Sandy Bridge�͓d�͂���������Ȃɐ����Ȃ����������B
�[���A��������������Intel���̂��g���n(���Ă��F�X�g�����Ă邪)�B
>>846
Zambezi
Zambezi
���Ƃ͊J�����\�[�X�ƃR�X�g����
Bulldozer�����i������鍠�ɂ͂��̎�����̃R�A�̊J�����n�߂Ȃ��Ⴂ���Ȃ�
����ɂ�K10�`�[���������Ȃ����낤
���ƁA�T�[�o�[��p�`�b�v�͍���Ă����v�ɂȂ�Ȃ�
Opteron��Xeon�iTesla�������j���������v���o��̂�PC�p�Ƃقړ����`�b�v������
Bulldozer���T�[�o�[��p�ɂ����ꍇ���i�����ˏオ���āAXeon�Ȃǂ̈�����PC�R���̃`�b�v�Ɛ킦�Ȃ�
Bulldozer�����i������鍠�ɂ͂��̎�����̃R�A�̊J�����n�߂Ȃ��Ⴂ���Ȃ�
����ɂ�K10�`�[���������Ȃ����낤
���ƁA�T�[�o�[��p�`�b�v�͍���Ă����v�ɂȂ�Ȃ�
Opteron��Xeon�iTesla�������j���������v���o��̂�PC�p�Ƃقړ����`�b�v������
Bulldozer���T�[�o�[��p�ɂ����ꍇ���i�����ˏオ���āAXeon�Ȃǂ̈�����PC�R���̃`�b�v�Ɛ킦�Ȃ�
�܂��F���̈Ⴂ���낤�ˁB
Bulldozer�ɃA�[�L�e�N�`���ꂷ�邱�Ƃ́A
�n�C�G���h�̃v���Z�b�T�R�A�̊J����������E������Sun�Ɠ��n���̓W�J�ł����āA
�ň��̃V�i���I�Ȃ킯�����A�Ȃ���������AMD�t�@���͂���ł�Bulldozer�������Ǝv���Ă���炵���B
#����AMD�͍��܂��ɂǂ����ɂ��ׂ������f���Ă���Ƃ��납������Ȃ�
Bulldozer�ɃA�[�L�e�N�`���ꂷ�邱�Ƃ́A
�n�C�G���h�̃v���Z�b�T�R�A�̊J����������E������Sun�Ɠ��n���̓W�J�ł����āA
�ň��̃V�i���I�Ȃ킯�����A�Ȃ���������AMD�t�@���͂���ł�Bulldozer�������Ǝv���Ă���炵���B
#����AMD�͍��܂��ɂǂ����ɂ��ׂ������f���Ă���Ƃ��납������Ȃ�
�[��
����IPC1.5���炢�炵������Ő����p�C�v1�{���炵�Đ��\��������Ƃ�
���肩����܂����Ă������ɐM���Ă�z�Ȃ܂Ƃ��ɑ��肵�Ȃ��Ă�������
����IPC1.5���炢�炵������Ő����p�C�v1�{���炵�Đ��\��������Ƃ�
���肩����܂����Ă������ɐM���Ă�z�Ȃ܂Ƃ��ɑ��肵�Ȃ��Ă�������
>Over time there could be tighter integration, and AMD could de-emphasize CPU cores
> if heterogeneous computing using GPUs takes off, Longoria said.
AMD��Bulldozer�ł����A�[�L�e�N�`����{�C�Œu���������Ă���ƍl���Ă���Ȃ�A
����͊J����������E�����܂����錾�ɕ������邼�B
> if heterogeneous computing using GPUs takes off, Longoria said.
AMD��Bulldozer�ł����A�[�L�e�N�`����{�C�Œu���������Ă���ƍl���Ă���Ȃ�A
����͊J����������E�����܂����錾�ɕ������邼�B
>>852
K10��Bulldozer�̂����AK10�������c����ĉ\�����L��Ƃ͎v���Ă��
���̂Ƃ���Bulldozer���̂Ă��Ȃ�����
�����P�ɕ����̌n�������̂�AMD�ɂ͂������낤���Ďv��������
K10��Bulldozer�̂����AK10�������c����ĉ\�����L��Ƃ͎v���Ă��
���̂Ƃ���Bulldozer���̂Ă��Ȃ�����
�����P�ɕ����̌n�������̂�AMD�ɂ͂������낤���Ďv��������
�N���b�N������̐��\�����Ƃ����������Ƃ��Ă�
���b�g������̐��\���オ���Ă���A�[�L�e�N�`���[�Ƃ��Ă͐�������
�ǂ��l���Ă�����d�͂̐������ő�̓G����
���b�g������̐��\���オ���Ă���A�[�L�e�N�`���[�Ƃ��Ă͐�������
�ǂ��l���Ă�����d�͂̐������ő�̓G����
��86�R�A�ŕ���ƈˑ�
GPU�Ńp���[�̗v�����
���̖������S�𐄂��i�߂�AMD�������c�邩
��86�Ńx�N�^������蓾������
�����悤�ȃv���Z�b�T�������Ă�Intel�������c�邩
�������ꂾ��
GPU�Ńp���[�̗v�����
���̖������S�𐄂��i�߂�AMD�������c�邩
��86�Ńx�N�^������蓾������
�����悤�ȃv���Z�b�T�������Ă�Intel�������c�邩
�������ꂾ��
�܂��͂����肢���Ă��܂���Bulldozer�͐��N�Ƀt�F�[�h�A�E�g����^���ɂ���Ƃ������Ƃ��ȁB
�����Ȃ�͂����Ƃ܂ł͌���Ȃ����A�����̒��ł͉\�����ł������̂��t�F�[�h�A�E�g�B
�r��邩�獡�܂ł͂����菑���ĂȂ������킯�ŁB
�����Ȃ�͂����Ƃ܂ł͌���Ȃ����A�����̒��ł͉\�����ł������̂��t�F�[�h�A�E�g�B
�r��邩�獡�܂ł͂����菑���ĂȂ������킯�ŁB
>>854�̕���
�u�����i�ނɂ�ē����͂ǂ�ǂڂɂȂ�
������GPU�������������ق�CPU�̉e�͔����Ȃ�v
�݂����Ȋ����ɂȂ邩�Ǝv������
�����AMD�̎v�f�ʂ�
�������u�p���[���鏈���͂�86�R�A��SIMD�g���ȊO�ɓ��͖�����I�v
�Ƃ��ϐM���Ă�ƒE���Ƃ��Ƃ�Ă��܂��낤��
����Ƃ������ƕʂȒm�I��Q����
�u�����i�ނɂ�ē����͂ǂ�ǂڂɂȂ�
������GPU�������������ق�CPU�̉e�͔����Ȃ�v
�݂����Ȋ����ɂȂ邩�Ǝv������
�����AMD�̎v�f�ʂ�
�������u�p���[���鏈���͂�86�R�A��SIMD�g���ȊO�ɓ��͖�����I�v
�Ƃ��ϐM���Ă�ƒE���Ƃ��Ƃ�Ă��܂��낤��
����Ƃ������ƕʂȒm�I��Q����
�����̒��ł͂�����
Llano�̌�p������Bulldozer�ɂȂ�Ȃ�������A
���̃X������ِ~�͑S�͂ŎӍ߂��Ă����낤�ȁB
������y���݂��ˁB
�������AK10�����h�����Ȃ��ɂ͋������ȁB
���̃X������ِ~�͑S�͂ŎӍ߂��Ă����낤�ȁB
������y���݂��ˁB
�������AK10�����h�����Ȃ��ɂ͋������ȁB
K10�͂͂����茾���ĖO����
�����Ȃ�R�e�n���t���Č��ꂽ���唭�����܂����Ă�z�Ƀ��N�Ȃ̂͋��Ȃ�
�G���ɉ������Ă�����
�Ȃ�قǁA������
"�A���~"
���Ȃ��n���ɂ���Ă��邩�������ł����C�����܂��B
"�A���~"
���Ȃ��n���ɂ���Ă��邩�������ł����C�����܂��B
��������̂�10�N�x��
LIano�̃R�A����K10.75�Ƃ��ɂȂ�̂���
K11��Bulldozer���낤��
K11��Bulldozer���낤��
���킵�܂����f�ŖY��Ă�
>859������ƒ���
�~SIMD
��SIMM
>859������ƒ���
�~SIMD
��SIMM
��������Bulldozer������ISSCC�Ŕ��\�ł��邮�炢�Ȃ�
K10��Fusion�Ȃ�Čv�悷�郏�P������
K10��Fusion�Ȃ�Čv�悷�郏�P������
Llano��p��Fusion��Bulldozer�R�A+�w�J�g���P�C���ɂȂ��H���ǂ�
GeForce�̑��V�X������̓]��
208 �FSocket774�F2010/02/10(��) 20:54:05 ID:EnY0aMN0
������ƁA�Z�����̂ƁA�����������̂Ŗ|��Ƃ��v��Ƃ����Ă�]�T���������k�ł����c
�\��Llano���e�[�v�A�E�g�炵���ł��B
ttp://www.brightsideofnews.com/news/2010/2/9/amd-llano-fusion-taped-out2c-32nm-soi-cpu-2b-gpu.aspx
ttp://www.xbitlabs.com/news/cpu/display/20100209114243_AMD_Discloses_Peculiarities_of_32nm_Llano_Microprocessors.html
����GPU�R�A�̐��\�����ڂł����A����d�͒ጸ�ɂ��Ă��F�X�Ɖ��ǂ�����悤�ł��ˁB
AMD�I�ɂ́A��͂�Llano�ɂ͂��܂�Fusion����肭�����Ȃ�AOptimus�����������ł��傤���H
�l�^�I�ɂ��X���Ⴂ�I�ł͂���܂����A����I�Ɉꉞ�������Ă����܂��ˁB
�������v������悤�ł�����A�v��ł̖|�炢�́A���Ԃ̂���Ƃ��ɂł��Ǝv���܂����A
�܂��A�傫�ȃl�^�Ȃ̂ŁA���̂��������̏��T�C�g�ɖ|���ł��傤���A�㓡��������
�������Ƃ����L�������������ȓ��e������A�o�開���Ȃ��ł��傤�ˁB��
208 �FSocket774�F2010/02/10(��) 20:54:05 ID:EnY0aMN0
������ƁA�Z�����̂ƁA�����������̂Ŗ|��Ƃ��v��Ƃ����Ă�]�T���������k�ł����c
�\��Llano���e�[�v�A�E�g�炵���ł��B
ttp://www.brightsideofnews.com/news/2010/2/9/amd-llano-fusion-taped-out2c-32nm-soi-cpu-2b-gpu.aspx
ttp://www.xbitlabs.com/news/cpu/display/20100209114243_AMD_Discloses_Peculiarities_of_32nm_Llano_Microprocessors.html
����GPU�R�A�̐��\�����ڂł����A����d�͒ጸ�ɂ��Ă��F�X�Ɖ��ǂ�����悤�ł��ˁB
AMD�I�ɂ́A��͂�Llano�ɂ͂��܂�Fusion����肭�����Ȃ�AOptimus�����������ł��傤���H
�l�^�I�ɂ��X���Ⴂ�I�ł͂���܂����A����I�Ɉꉞ�������Ă����܂��ˁB
�������v������悤�ł�����A�v��ł̖|�炢�́A���Ԃ̂���Ƃ��ɂł��Ǝv���܂����A
�܂��A�傫�ȃl�^�Ȃ̂ŁA���̂��������̏��T�C�g�ɖ|���ł��傤���A�㓡��������
�������Ƃ����L�������������ȓ��e������A�o�開���Ȃ��ł��傤�ˁB��
K10��Bulldozer�ɏ���_���ĉ����낤
874 �FMAC�I�^��872 �����F2010/02/10(��) 21:30:48 ID:ioIW7ln4
>>873
�_�C�̏�����
�_�C�̏�����
>>868
Llano��Shrink��̂�K10.5�ɂȂ邾������Ȃ��́H
Pine Trail Atom���i3/i5�̃|�W�V�����_���̂悤�ȋC���������
AMD�̃m�[�g������g�ݍ��������ĉ��C�ɌÂ��v���Z�X�𗘗p���Ă�����
Fab1��32nm��s�v���Z�X�m�����ĈӖ�����������̂���
Llano��Shrink��̂�K10.5�ɂȂ邾������Ȃ��́H
Pine Trail Atom���i3/i5�̃|�W�V�����_���̂悤�ȋC���������
AMD�̃m�[�g������g�ݍ��������ĉ��C�ɌÂ��v���Z�X�𗘗p���Ă�����
Fab1��32nm��s�v���Z�X�m�����ĈӖ�����������̂���
�\�z�ʂ�߂��Ă�낽
MAC�I�^�A�w�E�ǁ[��
MAC�I�^�A�w�E�ǁ[��
>>875
K10�̕��������������Ă��Ƃ��ȁH
K10�̕��������������Ă��Ƃ��ȁH
����B�ł��n���ɂ����킯����Ȃ���
�C�ɏ�����炲�߂��
�C�ɏ�����炲�߂��
Bulldozer����K6-III������H
K6�Ȃł܂Ƃ��ɋ����͐��܂�Ȃ���
eDRAM�Ƃ��K�c�[���Ɠ��ڂ��Ȃ��Ɩ{����
�I����Ă��܂���
����Ƀf�X�N�g�b�v������CPU�Ȃ��
�Ԏ��ɂ����Ȃ�Ȃ�����~�߂�����������
K6�Ȃł܂Ƃ��ɋ����͐��܂�Ȃ���
eDRAM�Ƃ��K�c�[���Ɠ��ڂ��Ȃ��Ɩ{����
�I����Ă��܂���
����Ƀf�X�N�g�b�v������CPU�Ȃ��
�Ԏ��ɂ����Ȃ�Ȃ�����~�߂�����������
Bulldozer�̃X�N���[���V���b�g��_�C�̃T�C�Y�͍��̂Ƃ��뉞�F���Ȃ�
�܂�K10(phenomII?) < Bulldozer���ǂ����͋Ɍ���ꂽAMD�̒��̈ꕔ�̐l�����m��Ȃ��͂�
�p�C�v���C������ăf�R�[�_�[���y�ʉ����邩�瓯���R�A����L���b�V���̃T�C�Y����Bulldozer���������Ǝv��
Bulldozer�̐v�v�z����剻�����R�A�̌y�ʉ��ƁA��葽���̃R�A�̓��ڂȂ͖̂��炩�������
�܂�K10(phenomII?) < Bulldozer���ǂ����͋Ɍ���ꂽAMD�̒��̈ꕔ�̐l�����m��Ȃ��͂�
�p�C�v���C������ăf�R�[�_�[���y�ʉ����邩�瓯���R�A����L���b�V���̃T�C�Y����Bulldozer���������Ǝv��
Bulldozer�̐v�v�z����剻�����R�A�̌y�ʉ��ƁA��葽���̃R�A�̓��ڂȂ͖̂��炩�������
eDRAM�͂킩������������Q�Ȃ����O�O
��EDO-DRAM�Ƃ����̂������Ă��ȁE�E�E�B
>>880
�ϑz�f���Ȃ�A ID:k+EliWVE���Ɋ撣���B
�ϑz�f���Ȃ�A ID:k+EliWVE���Ɋ撣���B
886 �FSocket774�F2010/02/10(��) 23:18:54 ID:RVwlh5OV
�����V�[���܂��H
>>885
2ch�Ɂu���F�v���u����F�v�����邩��
2ch�Ɂu���F�v���u����F�v�����邩��
sandybridge��4core��TDP65w�Ƃ��A�O���t�B�b�N�R�A��W����2���ڂ���Ƃ��A
����Ă���\�����т�amd�͂ǂ��Ȃ�̂��S�z�ɂȂ�B
�u���h�[�U�[�͂��߂Č��si7�ɏ��Ă邭�炢�ɂ͂Ȃ�̂��ȁH
�������̂��o�Ă��ė~������B
����Ă���\�����т�amd�͂ǂ��Ȃ�̂��S�z�ɂȂ�B
�u���h�[�U�[�͂��߂Č��si7�ɏ��Ă邭�炢�ɂ͂Ȃ�̂��ȁH
�������̂��o�Ă��ė~������B
GPU2���ڂ�2�{UP�炵����(Clarkdale���)
>>858
>Bulldozer�͐��N�Ƀt�F�[�h�A�E�g����^��
�P�A�[�L�̎����Ȃ�Ăӂ��ɐ��N���낤���B
�n�C�G���h����Intel�ƒ��ڂԂ���Ȃ��H����������
�ʂɃt�F�[�h�A�E�g�����闝�R�������킯�����B
>Bulldozer�͐��N�Ƀt�F�[�h�A�E�g����^��
�P�A�[�L�̎����Ȃ�Ăӂ��ɐ��N���낤���B
�n�C�G���h����Intel�ƒ��ڂԂ���Ȃ��H����������
�ʂɃt�F�[�h�A�E�g�����闝�R�������킯�����B
���A���\��m���Ă��̔@�������Ȃ�Đ_�ł���
�A�ׂ͖ϑz�Ő����Ă��邩��ȁB
���ƕ��y�ł�GPU 2�Ƃ����肦�˂�����B
Llano��CPU������K10.5�̏Ă������ɉ߂��炠��܂���҂͏o����
���m���ȕ����̑���Bulldozer�ɐF��ȈӖ��Œ��ڂ��W�܂�͓̂��R�����
>>888
���GPU��������������ďȓd�͉����i�Ƃ��Ă�
32nm�v���Z�X��4�R�A+AVX+�f���A��GPU��Sandybridge��TDP65W���Ă̂�
�₩�ɂ͐M������������Ȃ����
�����v���Z�X�ō��ꂽClarkdale��TDP73W�Ȃ�����
���m���ȕ����̑���Bulldozer�ɐF��ȈӖ��Œ��ڂ��W�܂�͓̂��R�����
>>888
���GPU��������������ďȓd�͉����i�Ƃ��Ă�
32nm�v���Z�X��4�R�A+AVX+�f���A��GPU��Sandybridge��TDP65W���Ă̂�
�₩�ɂ͐M������������Ȃ����
�����v���Z�X�ō��ꂽClarkdale��TDP73W�Ȃ�����
>>891
���̐��N�Ƃ������Ӗ������I�ɂ́AK7��1999�N�ɂłāA
���̌�AK8�Ŋ�{�I�ȃ}�C�N���A�[�L�e�N�`���P���Ȃ��Ƃ����Ӗ�����B
�����琔�N�Ńt�F�[�h�A�E�g�ȂB
���̐��N�Ƃ������Ӗ������I�ɂ́AK7��1999�N�ɂłāA
���̌�AK8�Ŋ�{�I�ȃ}�C�N���A�[�L�e�N�`���P���Ȃ��Ƃ����Ӗ�����B
�����琔�N�Ńt�F�[�h�A�E�g�ȂB
Clark��2�{�ɂȂ����Ƃ����HD5570�������������Llano�̓G����Ȃ�����
�������ASandybrige��Llano�ɂ�Bulldozer�ɂ��S�s�Z����������Ĉ����͕K����������
�B�ꏟ�Ă����Ȃ̂��p�C�Ă������ɂȂ肻���Ȃ̂����ꂷ����
�������ASandybrige��Llano�ɂ�Bulldozer�ɂ��S�s�Z����������Ĉ����͕K����������
�B�ꏟ�Ă����Ȃ̂��p�C�Ă������ɂȂ肻���Ȃ̂����ꂷ����
>>897
���̍����́H�@�܂����uLlano��K10�R�A������v�����H
���̍����́H�@�܂����uLlano��K10�R�A������v�����H
ttp://northwood.blog60.fc2.com/blog-entry-3514.html
�ɂ��ƁA95W�ł�����悤������A65W�ł͒�d���ł��낤�ȁB
GPU���\���̂�GPU�����̓v���Z�X�V�������N�������A
�ʂ�1�ł�2�{���炢�ɂȂ肻�������ǁA2�g���Ă��h���C�o������������A
GPU2�g���Ă�1�̔{�ɂ͂Ȃ�Ȃ����낤�B
�ɂ��ƁA95W�ł�����悤������A65W�ł͒�d���ł��낤�ȁB
GPU���\���̂�GPU�����̓v���Z�X�V�������N�������A
�ʂ�1�ł�2�{���炢�ɂȂ肻�������ǁA2�g���Ă��h���C�o������������A
GPU2�g���Ă�1�̔{�ɂ͂Ȃ�Ȃ����낤�B
���N���Č��������ᕝ�������ĉ��߂��ɂ�������
6�N���炢�Ȃ�m������
6�N���炢�Ȃ�m������
>>898
Intel�̊J���͂Ȃ߂�ȁB���ƁA�Ԃ����Ⴏ�����ƁA
��ꐢ��"Bulldozer"�͍��N�o�Ă����͂�������A
Nehalem�R�̂͂��Ȃ�B
AVX�lj����邱�Ƃł���Ȃ�ɒlj����ǂ͂���邾�낤���ǁA
"SandyBrige"�̂ł�����ł͂ǂ��Ȃ邩�킩���B
����AVX���݂̃x���`�ł͔s�k�m�肵�Ă���̂ŁA
�ǂ�ȂɃf�L���悭�Ă��u�x���`���ʁv�ł͓��R�����͊m�肵�Ă���B
Intel�̊J���͂Ȃ߂�ȁB���ƁA�Ԃ����Ⴏ�����ƁA
��ꐢ��"Bulldozer"�͍��N�o�Ă����͂�������A
Nehalem�R�̂͂��Ȃ�B
AVX�lj����邱�Ƃł���Ȃ�ɒlj����ǂ͂���邾�낤���ǁA
"SandyBrige"�̂ł�����ł͂ǂ��Ȃ邩�킩���B
����AVX���݂̃x���`�ł͔s�k�m�肵�Ă���̂ŁA
�ǂ�ȂɃf�L���悭�Ă��u�x���`���ʁv�ł͓��R�����͊m�肵�Ă���B
�Ԃ����ႯIntel��GPU�R�A���ǂ��ɂ����Ȃ��Ƃ����Ȃ��̂�
���\���������Ƒ��̖ʂ��Ǝv����
���\���������Ƒ��̖ʂ��Ǝv����
Clark��2�{�Ƃ��R���Ă���z�͂Ȃ�ȂH
�J���ł̃R�A��2�{�A�ŏI���i�ł�4�{�ȏ�
�����ɂȂ��
�J���ł̃R�A��2�{�A�ŏI���i�ł�4�{�ȏ�
�����ɂȂ��
>>899
Llano��K10�R�A�ŁASandy Bridge��Sandy Bridge�����炾�˂��B
�܂������̃u���~�́ABulldozer�����N���b�N�Ȃ�Ȃ����Ƃ��A
���Ȋ��҂̎d�������Ă���悤������A���ꂾ���ł͔[���ł��Ȃ��낤�ȁB
����Bulldozer��PC�ɂ��L�͂ɕ��y�������ŊJ�������̂Ȃ�A
�v���Z�b�T�̊J���ɂ͉��N��������悤������A�����ǂ݂�����������Ȃ�Ȃ����ˁB
�ǂ݂�������ƌ����ACell�����̍ł����ł��邪�A����̒��x���y���ł݂����ȁB
Llano��K10�R�A�ŁASandy Bridge��Sandy Bridge�����炾�˂��B
�܂������̃u���~�́ABulldozer�����N���b�N�Ȃ�Ȃ����Ƃ��A
���Ȋ��҂̎d�������Ă���悤������A���ꂾ���ł͔[���ł��Ȃ��낤�ȁB
����Bulldozer��PC�ɂ��L�͂ɕ��y�������ŊJ�������̂Ȃ�A
�v���Z�b�T�̊J���ɂ͉��N��������悤������A�����ǂ݂�����������Ȃ�Ȃ����ˁB
�ǂ݂�������ƌ����ACell�����̍ł����ł��邪�A����̒��x���y���ł݂����ȁB
>>898
���[�G���h�N���X��GPU�͂قڑS�ł��邾�낤����(Nvidia�Ƃ�Nvidia�Ƃ�Nvidia�Ƃ�)
�S�s�Z���͌��������AFermi�������ɏo�Ă��Ȃ��̂ɏ����錾����y���ɒɂ���
���[�G���h�N���X��GPU�͂قڑS�ł��邾�낤����(Nvidia�Ƃ�Nvidia�Ƃ�Nvidia�Ƃ�)
�S�s�Z���͌��������AFermi�������ɏo�Ă��Ȃ��̂ɏ����錾����y���ɒɂ���
Bulldozer�͂ǂ��������Power6�̗ł�
���Ȃ�Ȃ��BeDRAM�ς�Ŋ撣���
���Ȃ�Ȃ��BeDRAM�ς�Ŋ撣���
908 �FSocket774�F2010/02/10(��) 23:53:41 ID:RVwlh5OV
���l�̉��z���\�ɂጵ�����Ď����̂���ɂ͑�ÂŃX�o���V�C
>>905
�o�����̍����������ς�킩��Ȃ���A
�u�ǂ݂�������v�̍����������ς�킩���Ȃ�
���t����ׂ邾���Łu�������Ȃ��v�Ȃ�ǂ��������ȁB
���t����ׂ邾���Łu���O�̗���͂��Ȃ��v�Ƃ����Ȃ�A
��l�������Ԕ��Ŏ�����肵�Ă��ȁB
�o�����̍����������ς�킩��Ȃ���A
�u�ǂ݂�������v�̍����������ς�킩���Ȃ�
���t����ׂ邾���Łu�������Ȃ��v�Ȃ�ǂ��������ȁB
���t����ׂ邾���Łu���O�̗���͂��Ȃ��v�Ƃ����Ȃ�A
��l�������Ԕ��Ŏ�����肵�Ă��ȁB
Clarkdale��GPU�͈ꕔ�̃x���`���\�ł͊���785G�������Ă邩��˂�
AMD������܂��r�߂��^���͂��Ă��Ȃ����Ȃ����
AMD������܂��r�߂��^���͂��Ă��Ȃ����Ȃ����
>>895
Clarkdale���j�R�C�`���ĂS�R�A�Q�f�o�t�Ƃ���
Clarkdale���j�R�C�`���ĂS�R�A�Q�f�o�t�Ƃ���
>>909
�����̃u���~�̍������S�����t����ׂĂ��邾����
���x����������ĂȂ�����B
�v�͌�����Bulldozer���L�����y���邩�ǂ����Ȃ�B
����łǂ����������邩�͌��܂�ˁB
�O�ꂽ����ŏ����Ă����悤�B
�����̃u���~�̍������S�����t����ׂĂ��邾����
���x����������ĂȂ�����B
�v�͌�����Bulldozer���L�����y���邩�ǂ����Ȃ�B
����łǂ����������邩�͌��܂�ˁB
�O�ꂽ����ŏ����Ă����悤�B
Intel��2011�N�I�Ղɂ�Radeon5850���z����
GPU��CPU�ɓ��ڂ��Ă��邵
Radeon�Ȃ�Đ��\�U���������Ƃ�����
GPU��CPU�ɓ��ڂ��Ă��邵
Radeon�Ȃ�Đ��\�U���������Ƃ�����
�܁A�o�Ă݂�܂Ő��\�͂킩�����
���S�ɖ��ӔC�ȗ\�z����
CPU���\��SandyBridge�AGPU���\��LIano��������
���������ǂ������ɂȂ��Ă���邱�Ƃ����҂��Ă�
���S�ɖ��ӔC�ȗ\�z����
CPU���\��SandyBridge�AGPU���\��LIano��������
���������ǂ������ɂȂ��Ă���邱�Ƃ����҂��Ă�
�����PhenomII��i7��i5�ɐ�ΐ��\�őR�o���Ă�Ƃ������A�����ł͂Ȃ�����˂�
K10.5�ɖт����������x�ł�������Llano�}���Z�[����܂��Ă�����܂�����
K10.5�ɖт����������x�ł�������Llano�}���Z�[����܂��Ă�����܂�����
���\�U�����Ăǂ����낤�˂�
Llano�Ȃ�ĊJ�����������ō�������ǂ�
Radeon��5xxx�V���[�Y�Ő��\�Ƃ܂��Ă��܂�������
�������CPU�Ɍ��������ė��v�o������
���Ă��邾������w
Intel�̂悤�ɖ{���̋Z�p�Ő��i�����Ȃ��̂͒ɂ�����
Radeon��5xxx�V���[�Y�Ő��\�Ƃ܂��Ă��܂�������
�������CPU�Ɍ��������ė��v�o������
���Ă��邾������w
Intel�̂悤�ɖ{���̋Z�p�Ő��i�����Ȃ��̂͒ɂ�����
Intel��GPU�͂Ȃ��A�ߋ��̎��т��炵�Ă��@��
��Intel��2011�N�I�Ղɂ�Radeon5850���z����
��`���o���Ă����܂�������
��`���o���Ă����܂�������
�{���̋Z�p
���ς�炸�V�����T�O�������Ċy����
���ς�炸�V�����T�O�������Ċy����
�Ă��A�u�Ȃ�Llano��"Bulldozer"�R�A�ł͂Ȃ��̂��v�̓����͊ȒP�Ȃ�B
--------------------
���N�̂����Ɋ������Ă���͂�������"Bulldoze"�R�A��AVX�Ή��̂��߁A
��N�����ɂȂ����̂ŁA"Swift"���猤���𑱂��Ă���K10�R�A�œ����B
--------------------
���Ă�������B�u"Bulldozer"�R�A���_�������瓝�����Ă��Ȃ��v�̂ł͂Ȃ��āA
"Bulldozer"�R�A���Ԃɍ���Ȃ��������瓝���ł��Ȃ����������Ȃ낤�ˁB
--------------------
���N�̂����Ɋ������Ă���͂�������"Bulldoze"�R�A��AVX�Ή��̂��߁A
��N�����ɂȂ����̂ŁA"Swift"���猤���𑱂��Ă���K10�R�A�œ����B
--------------------
���Ă�������B�u"Bulldozer"�R�A���_�������瓝�����Ă��Ȃ��v�̂ł͂Ȃ��āA
"Bulldozer"�R�A���Ԃɍ���Ȃ��������瓝���ł��Ȃ����������Ȃ낤�ˁB
�܂��������j�b�g���������ĉ]�X�̕����O�����b�����A
�p���[�Q�[�e�B���O�ƃ^�[�{�[�u�[�X�g���������ēd�͂ɂ₽��C���������A
�ƌ������������Ă��ꂽ�������̎������ۂǐV�v���Z�b�T�Ƃ��Đ����͂������B
�ڋq�̗v���ɉ�����̂�AMD�̓��ӂ̃}�[�P�e�B���O�헪����Ȃ������̂��ƁB
���āABull����͂ǂ��Ȃ邩�˂��B
�p���[�Q�[�e�B���O�ƃ^�[�{�[�u�[�X�g���������ēd�͂ɂ₽��C���������A
�ƌ������������Ă��ꂽ�������̎������ۂǐV�v���Z�b�T�Ƃ��Đ����͂������B
�ڋq�̗v���ɉ�����̂�AMD�̓��ӂ̃}�[�P�e�B���O�헪����Ȃ������̂��ƁB
���āABull����͂ǂ��Ȃ邩�˂��B
��N���RadeonHD5850�����Ă��Ȃ��B
���Ȃ݂ɓ�N�O��RadeonHD 3xxx�̎���ŁA
�����AMD�̈ꐢ��O�̓����`�b�v�Z�b�g��GPU�Ɏg��ꂽ���́B
���Ȃ݂ɓ�N�O��RadeonHD 3xxx�̎���ŁA
�����AMD�̈ꐢ��O�̓����`�b�v�Z�b�g��GPU�Ɏg��ꂽ���́B
�{���̋Z�p�Ȃ�DB(�I���N���AMSSQL�APostgres��)�ŕs��o���܂���Ȃ��
�ʂ�Bulldozer���L�܂�Ȃ��Ă�K10�͏����Ă��Ǝv�����ǂ�
�Ȃ��Ȃ�AMD���̂��̂�(ry
�Ȃ��Ȃ�AMD���̂��̂�(ry
Bulldozer�́A�y�[�p�[�����`�݂̂������
���ۏo��Ƃ��Ă�2013�N��2015�N�������Ƃ�����
���ۏo��Ƃ��Ă�2013�N��2015�N�������Ƃ�����
���ۃA���u�n�̘B���p�t�ɗx�炳���
�������Ȃ��A�J�����炳��Ă��Ȃ�"Bulldozer"���Ă����̂�
�L���������W�߂Ă��邾������
�������Ȃ��A�J�����炳��Ă��Ȃ�"Bulldozer"���Ă����̂�
�L���������W�߂Ă��邾������
>>910
Clarkdale��GPU�̂S�`�T�{�ł����HD5570�`HD5670��������B
Intel�Ƃ��ẮA�܂������܂ł̐��\�͂���Ȃ��낤���ǁB
�����A�Œ�ł�DX10.1�ɑΉ����Ȃ����Ⴂ���Ȃ���
OpenCL��DX11�ɑΉ����l���Ȃ��Ƃ����Ȃ����������猋�\��ρB
Clarkdale��GPU�̂S�`�T�{�ł����HD5570�`HD5670��������B
Intel�Ƃ��ẮA�܂������܂ł̐��\�͂���Ȃ��낤���ǁB
�����A�Œ�ł�DX10.1�ɑΉ����Ȃ����Ⴂ���Ȃ���
OpenCL��DX11�ɑΉ����l���Ȃ��Ƃ����Ȃ����������猋�\��ρB
���������AAMD��GF��ATIC�̊W�͂�������c�����悤��
GF���݂œ��̈���AA���������������
>>928
�������ASandybridge�����DX10.1��11�ɑΉ�����ۏ͖���������
�������[�J�[��PC�Ƃ��������債���Ɏ�ɂ͂Ȃ�Ȃ��C������
�������ASandybridge�����DX10.1��11�ɑΉ�����ۏ͖���������
�������[�J�[��PC�Ƃ��������債���Ɏ�ɂ͂Ȃ�Ȃ��C������
�Ȃ���AMD��Intel�̃��C�o�����[�J�[�����ȂȁB
�K����FUD���ςĂ���ƂȂAAMD�h���A
Intel�h�̕���AMD�ɑ��Ėϑz���Ă������ŕ|����
�K����FUD���ςĂ���ƂȂAAMD�h���A
Intel�h�̕���AMD�ɑ��Ėϑz���Ă������ŕ|����
�ϑz�ǂ��납���o�܂Ō����o���Ă�̂����邼���ݏZ�̎���PC�̗L���l�B
���ۃo�O���i�Ɖˋi�̐�`����
�ł��Ȃ����BAMD�͍ŏ����狣�����肶��Ȃ����낤
�ł��Ȃ����BAMD�͍ŏ����狣�����肶��Ȃ����낤
�������̂��Ƃ�
AMD�Ȃ�ă����R���Ƀo�O����
TDP����
�s���Ȉ��͂ɂ��Nvida�ׂ�
DDR3�֘A�o�O���E�L�^�X�V��
�����_������
TDP����
�s���Ȉ��͂ɂ��Nvida�ׂ�
DDR3�֘A�o�O���E�L�^�X�V��
�����_������
>AMD�Ȃ�ă����R���Ƀo�O����
i7�̃o�O�͒������́H�����A�d�l���Ď��ɂ��������B
i3�̃����R���Ă���̂��d�l���Ď��ɂ���́H
>TDP����
i7�A����160w��������ȁB�m�[�g�ɐς܂�Ă�̂��M�����Đ��\�S�R�o�Ȃ��炵���ˁB
>�s���Ȉ��͂ɂ��Nvida�ׂ�
NV�ɕs���Ȉ��͂����ăo�X���C�Z���X�o���Ȃ������̂ǂ��������H
>DDR3�֘A�o�O���E�L�^�X�V��
�L�^�X�V����ɂ͔{�ȏ�o�O����Intel�����Ȃ��ƂȁB
i7�̃o�O�͒������́H�����A�d�l���Ď��ɂ��������B
i3�̃����R���Ă���̂��d�l���Ď��ɂ���́H
>TDP����
i7�A����160w��������ȁB�m�[�g�ɐς܂�Ă�̂��M�����Đ��\�S�R�o�Ȃ��炵���ˁB
>�s���Ȉ��͂ɂ��Nvida�ׂ�
NV�ɕs���Ȉ��͂����ăo�X���C�Z���X�o���Ȃ������̂ǂ��������H
>DDR3�֘A�o�O���E�L�^�X�V��
�L�^�X�V����ɂ͔{�ȏ�o�O����Intel�����Ȃ��ƂȁB
ID:QYG5E9oE
�n���߂��ŕ����ā[��
�o����������
�n���߂��ŕ����ā[��
�o����������
�܂�Intel�̕��������ƌ����Ă�z��
������m��Ȃ����������肾��
��������Ă��Ӗ����Ȃ���w
������m��Ȃ����������肾��
��������Ă��Ӗ����Ȃ���w
>>940
���̊��ɃV�F�A���Ƃ��Ă��ˁB
����Ɣ����̂̓Z����Atom������i5/i7�͑S�R�炵�����ǁA���O�̗��_�Ō�����
�Z���ȊO�͂����Ď��ł����̂��ȁH
���̊��ɃV�F�A���Ƃ��Ă��ˁB
����Ɣ����̂̓Z����Atom������i5/i7�͑S�R�炵�����ǁA���O�̗��_�Ō�����
�Z���ȊO�͂����Ď��ł����̂��ȁH
http://pc.watch.impress.co.jp/img/pcw/docs/346/902/html/03.jpg.html
�����Bulldozer�̐}���������A�V���O���X���b�h��Integer Core2���g��Ȃ��ꍇ�̓f�R�[�_�[�p���[�������]��
������g����ɂ�Integer Core1��{���œ������Ƃ��傤�ǂ���
Integer Core1�̏���d�͂Ȃ�Ĕ��X�������Ȃ���{���쓮�������ȋC������
{kind=link}
�����Bulldozer�̐}���������A�V���O���X���b�h��Integer Core2���g��Ȃ��ꍇ�̓f�R�[�_�[�p���[�������]��
������g����ɂ�Integer Core1��{���œ������Ƃ��傤�ǂ���
Integer Core1�̏���d�͂Ȃ�Ĕ��X�������Ȃ���{���쓮�������ȋC������
����AntiHT���t���Ǝv���B
952�̔{���쓮���Ă̂�Integer Core�̕Е����g��Ȃ��Ƃ���
AMD��Llano�Ńu���b�N���Ƃ̃N���b�N���䂪�o������Ă��Ƃ�����
Bulldozer�ł��o�����Ȃ�����
AMD��Llano�Ńu���b�N���Ƃ̃N���b�N���䂪�o������Ă��Ƃ�����
Bulldozer�ł��o�����Ȃ�����
>>942
�������A�[�L�e�N�`�����Ȃ��{��
�������A�[�L�e�N�`�����Ȃ��{��
ID���ς�����r�[�Ɍ|���`�F���W�A�z���g�킩��₷���Ȃ�
>>943
��������邩������Ȃ����ǁA942�̐}�i�L�҂̑z�������琫�i�ł͂Ȃ��j�ł�
Core1��Core2��L1�L���b�V���������N���ĂȂ�
�f�[�^�̐����������̂�L2���Ȃ���s���Ȃ������H
�t�ɁAL1���m�������N���Ă�ꍇ��L1���̂̃��C�e���V���傫���Ȃ肻�������
��������邩������Ȃ����ǁA942�̐}�i�L�҂̑z�������琫�i�ł͂Ȃ��j�ł�
Core1��Core2��L1�L���b�V���������N���ĂȂ�
�f�[�^�̐����������̂�L2���Ȃ���s���Ȃ������H
�t�ɁAL1���m�������N���Ă�ꍇ��L1���̂̃��C�e���V���傫���Ȃ肻�������
AntiHT���͔{��ALU�̕����܂����肻��
>>947
�R�A����Ȃ�����f�[�^�̐���������荇������͂��Ȃ��Ǝv�����H
���߂̕��т╪�ߗ\���̓X�P�W���[���[������Ă���邵�B
�R�A����Ȃ�����f�[�^�̐���������荇������͂��Ȃ��Ǝv�����H
���߂̕��т╪�ߗ\���̓X�P�W���[���[������Ă���邵�B
�����L�тĂ����
Bulldozer����ԍŏ��ɔ��\���ꂽ�Ƃ���Falcon(Bulldozer�R�A+GPU)�Ȃ�Ă̂���������
Bulldozer����ԍŏ��ɔ��\���ꂽ�Ƃ���Falcon(Bulldozer�R�A+GPU)�Ȃ�Ă̂���������
ID:QYG5E9oE�����̎G��
952 �FSocket774�F2010/02/11(��) 02:01:53 ID:WzrgCtgF
�J�����ԂɂȂ��ŁA6�N�������Ă邩��A�o���͂����Ɨǂ��ł��傤�B
Sandy 2�R�A��llano�Ƀt���{�b�R
Sandy 4�R�A��Zambezi 6�R�A�Ƀt���{�b�R�m�肾����K������
���Ȃ݂�Intel�̊J���͂̒�ȂƂ����Ɋ���Ă��
�ELarrabee�͐��\�s���ȏ�ɕ��h���C�o�Ŗ�������
�ECPU�R�A��Core2���ǂ�Nehalem�n��Haswell�܂Ōp�����m�肵�Ă���
�܂�CPU�̐��\�͍��㐔�N�̓N���b�N���ȏ�̃��m�ɂ͂Ȃ�Ȃ��B
���������V�������N�ɂ��ȓd�͂�������x�B
�v�͗��N��AVX(256it)�A22nm�̌㔼�ȍ~��LNI(512/1024it)�ւ�Ő��\���シ�邾���B
���̌��pentium�R�A�g�������j�[�R�A�H�����Z���B
Sandy 4�R�A��Zambezi 6�R�A�Ƀt���{�b�R�m�肾����K������
���Ȃ݂�Intel�̊J���͂̒�ȂƂ����Ɋ���Ă��
�ELarrabee�͐��\�s���ȏ�ɕ��h���C�o�Ŗ�������
�ECPU�R�A��Core2���ǂ�Nehalem�n��Haswell�܂Ōp�����m�肵�Ă���
�܂�CPU�̐��\�͍��㐔�N�̓N���b�N���ȏ�̃��m�ɂ͂Ȃ�Ȃ��B
���������V�������N�ɂ��ȓd�͂�������x�B
�v�͗��N��AVX(256it)�A22nm�̌㔼�ȍ~��LNI(512/1024it)�ւ�Ő��\���シ�邾���B
���̌��pentium�R�A�g�������j�[�R�A�H�����Z���B
�����̔ނ�9600GT�����X���ɒ���t�����ςȂ��̂悤���ȁB
�Ȃɂ�肾�B
�Ȃɂ�肾�B
Llano����GPU�I���_�C�����ȂH
������������㗝�X�����{�@�l�����Ă��w
Bulldozer��ALU�팸�ł̐������Z���\�ւ̉e�����đ債�Ė��Ȃ̂��ˁH
P6�A�[�L�e�N�`����Pentium3��ALU/AGU 2�y�A�ł�Athlon�ƌ݊p�ɐ킦�Ă�����A
���ۂقƂ�lje���Ȃ���Ȃ����Ǝv�����B
�ǂ������Ƃ����ƃf�R�[�_���ǂ��Ȃ邩�̕����C�ɂȂ�ȁE�E�E
����ς�K7����p����ComplexDecoder�݂̂̃V�����g���\���̂܂�4���߃f�R�[�h�Ɋg�������̂��ˁH
ALU/AGU�y�A���������ȏ�A���ł������̃f�R�[�_�͕s�v���낤����Complex/Simple�y�A��2��4���߂��炢�ŏ\���ȋC��������B
P6�A�[�L�e�N�`����Pentium3��ALU/AGU 2�y�A�ł�Athlon�ƌ݊p�ɐ킦�Ă�����A
���ۂقƂ�lje���Ȃ���Ȃ����Ǝv�����B
�ǂ������Ƃ����ƃf�R�[�_���ǂ��Ȃ邩�̕����C�ɂȂ�ȁE�E�E
����ς�K7����p����ComplexDecoder�݂̂̃V�����g���\���̂܂�4���߃f�R�[�h�Ɋg�������̂��ˁH
ALU/AGU�y�A���������ȏ�A���ł������̃f�R�[�_�͕s�v���낤����Complex/Simple�y�A��2��4���߂��炢�ŏ\���ȋC��������B
959 �FSocket774�F2010/02/11(��) 06:21:12 ID:jTKM68w7
>K7����p����ComplexDecoder�݂̂̃V�����g���\��
DirectPath(Simple
DirectPath(Simple
>K7����p����ComplexDecoder�݂̂̃V�����g���\��
K7�̃f�R�[�_
DirectPath(SimpleDecoder�ɑ����j x3
VectorPath(���G�Ȗ��ߐ�p) x1
�Ȃ̂ŁAK7�ɂ͒P���Ȗ��߂��畡�G�Ȗ��߂܂őΉ�����
ComplexDecoder�ɑ�������f�R�[�_�͂Ȃ�
K7�̃f�R�[�_
DirectPath(SimpleDecoder�ɑ����j x3
VectorPath(���G�Ȗ��ߐ�p) x1
�Ȃ̂ŁAK7�ɂ͒P���Ȗ��߂��畡�G�Ȗ��߂܂őΉ�����
ComplexDecoder�ɑ�������f�R�[�_�͂Ȃ�
>>889
�����_���_��������w
�����_���_��������w
�P�������N�͓��Ⴂ���Ȃ����Ă����Ⴊ�i����
>>932
>�������[�J�[��PC�Ƃ��������債���Ɏ�ɂ͂Ȃ�Ȃ��C������
����ጻ��ł��炿����7����������ȁB
Aero�̍Œᓮ��v����DX9�ȏ�
�Ƃɂ������삷������Ƃ����Ȃ�
DX10.1��11�̑Ή��Ȃ�Ăǂ��ł������B
>�������[�J�[��PC�Ƃ��������債���Ɏ�ɂ͂Ȃ�Ȃ��C������
����ጻ��ł��炿����7����������ȁB
Aero�̍Œᓮ��v����DX9�ȏ�
�Ƃɂ������삷������Ƃ����Ȃ�
DX10.1��11�̑Ή��Ȃ�Ăǂ��ł������B
LIano���āA����Athlon II X4��GPU����������邾���H
�EBulldozer��HPC�ȊO�Ō����̗ǂ����ł���
�E���ႠHPC�͂ǂ�����̂��H�ƂȂ��Fusion(Llano�̌�p��Bulldozer+�w�J�g���P�C���Ɩϑz)
�ł����H
�E���ႠHPC�͂ǂ�����̂��H�ƂȂ��Fusion(Llano�̌�p��Bulldozer+�w�J�g���P�C���Ɩϑz)
�ł����H
Bulldozer��Atom�̑R�n�ł���HPC�Ƃ͖��W
HPC�͍��܂ł�Opteron��2015�N�܂Ŗ�����ʂ�
���ꂪ���̃V�i���I�B�������������J��������͖̂����Ȃ�
Intel�ɏ�芷������������
HPC�͍��܂ł�Opteron��2015�N�܂Ŗ�����ʂ�
���ꂪ���̃V�i���I�B�������������J��������͖̂����Ȃ�
Intel�ɏ�芷������������
��Bulldozer��Atom�̑R�n�ł���HPC�Ƃ͖��W
����������Bobcat��Y�����
��HPC�͍��܂ł�Opteron��2015�N�܂Ŗ�����ʂ�
�ł��傤�ˁA���g���ς���ĂĂ�Opteron�Ƃ������O�Ƃ������u�����h�͕ς��Ȃ����낤��
�����ꂪ���̃V�i���I�B�������������J��������͖̂����Ȃ�
ATIC�̂��@���Ȃ���Α��v����Ȃ��H
��Intel�ɏ�芷������������
���ł�intel�g���Ă܂���`�A������܂�����Ȃ��������`
����������Bobcat��Y�����
��HPC�͍��܂ł�Opteron��2015�N�܂Ŗ�����ʂ�
�ł��傤�ˁA���g���ς���ĂĂ�Opteron�Ƃ������O�Ƃ������u�����h�͕ς��Ȃ����낤��
�����ꂪ���̃V�i���I�B�������������J��������͖̂����Ȃ�
ATIC�̂��@���Ȃ���Α��v����Ȃ��H
��Intel�ɏ�芷������������
���ł�intel�g���Ă܂���`�A������܂�����Ȃ��������`
>967
���O�A���O�����w
�e�������������̂��H
���O�A���O�����w
�e�������������̂��H
970 �FSocket774�F2010/02/11(��) 09:49:57 ID:Bs2TbaxZ
�ߋ��Ɏ��������l�^��������ƊԂ�u���Α��v�Ǝv����̂��X�S�C
�e��SIMM�ł���
>>965
"Llano"��"Propus"�R�A�ł͂Ȃ��āA
���x�o��"Thuban"�R�A�̔��W�n���ȁH
L3�͂Ȃ����ǁB
�܁BK10�iK8�j�A�[�L�̔��W�n�ɂ͈Ⴂ�Ȃ��B
"Llano"��"Propus"�R�A�ł͂Ȃ��āA
���x�o��"Thuban"�R�A�̔��W�n���ȁH
L3�͂Ȃ����ǁB
�܁BK10�iK8�j�A�[�L�̔��W�n�ɂ͈Ⴂ�Ȃ��B
Bulldozer��Bobcat���J������K10�R�A���u���W�v������p���[��
AMD�ɂ͂Ȃ��낤�B�P�Ȃ�V�������N�ł́B
AMD�ɂ͂Ȃ��낤�B�P�Ȃ�V�������N�ł́B
�L���b�V����1M�ɂȂ��Ă���班�Ȃ��Ƃ��P���V�������N�ł͂Ȃ�����
eDRAM���ڂ��Ȃ��Ə��ĂȂ��̂�
�����l���Ă���̂���w
�����l���Ă���̂���w
>>974
�����v�������Ȃ炻��ł�����Ȃ��H
�����v�������Ȃ炻��ł�����Ȃ��H
>>975
Propus�́uL2 1M�v����B
Propus�́uL2 1M�v����B
>>978
Regor�R�A�Ɗ��Ⴂ���ĂȂ��H
Regor�R�A�Ɗ��Ⴂ���ĂȂ��H
Propus�̓R�A����512KB�ł���
Llano�̓R�A����1MB�̂�\��炵���ł���
Llano�̓R�A����1MB�̂�\��炵���ł���
981 �FSocket774�F2010/02/11(��) 12:24:38 ID:D4vURzRj
ID:QYG5E9oE
�݂��Ƃ��Ȃ�AMD�Ȃ�đ���ɂ����
�݂��Ƃ��Ȃ�AMD�Ȃ�đ���ɂ����
���邦����Ă̂�LL�T�C�Y�̂��Ƃ�
�̃~���I�l�A�ƌĂ�
�u��������������̂͐����~�j������ȁI�~�j�I�l�A�Ɩ���邱�Ƃɂ��悤�I�v
�ƗL���V�ɂȂ��Ă������
�������E�̉��l�ςł̓A�����������̂͒p�������Ƃ������ƂɋC�t������
���悤�₭�������Ă���Ƃ��Ȃ킯��
�̃~���I�l�A�ƌĂ�
�u��������������̂͐����~�j������ȁI�~�j�I�l�A�Ɩ���邱�Ƃɂ��悤�I�v
�ƗL���V�ɂȂ��Ă������
�������E�̉��l�ςł̓A�����������̂͒p�������Ƃ������ƂɋC�t������
���悤�₭�������Ă���Ƃ��Ȃ킯��
>>981
�{�l���B
�{�l���B
����V�������N�������A�L���b�V���T�C�Y���炢�͎�����邾�낤�B
�ł�2way��4way�ɂȂ�����͂��Ȃ����낤�BAVX���ڂ�Ȃ��B
�ł�2way��4way�ɂȂ�����͂��Ȃ����낤�BAVX���ڂ�Ȃ��B
>>984
�ǂ̃��X�ɑ��郌�X�ȂH
�ǂ̃��X�ɑ��郌�X�ȂH
>LIano
Athlon II ���V�������N����L2���₵��L3�̂�����GPU���悹��ƁB
GPU��HD4xxx�H5xxx�H
GPU��邩��V�\�P�b�g�ɂȂ�̂��ȁH
Athlon II ���V�������N����L2���₵��L3�̂�����GPU���悹��ƁB
GPU��HD4xxx�H5xxx�H
GPU��邩��V�\�P�b�g�ɂȂ�̂��ȁH
>>987
�Ă��A�����u������CPU�X���v�Ȃ��ǁc�B
��{�I�Ȓm�����x�����Ŏd����Ă�����B
�Ă������B�ߋ��X���ŁB
����ɗ��Ă���z�̕������O���m�������ĂE�E�E�B
�Ă��A�����u������CPU�X���v�Ȃ��ǁc�B
��{�I�Ȓm�����x�����Ŏd����Ă�����B
�Ă������B�ߋ��X���ŁB
����ɗ��Ă���z�̕������O���m�������ĂE�E�E�B
�ǂ��݂Ă�Power7�̋Z�p���������
���p�ł��Ȃ������O�YCPU�ɂ����Ȃ���
�����Ahypertransport���p�N���Ă݂��͂�����
���\�ƌ��т��Ȃ�������
���p�ł��Ȃ������O�YCPU�ɂ����Ȃ���
�����Ahypertransport���p�N���Ă݂��͂�����
���\�ƌ��т��Ȃ�������
�ǂ��ł�������LIano����Ȃ���Llano����Ȃ��̂��H
Liano���������炵��
5890���ڂ������...
�����U��ɂ����X�ɂ�
�����U��ɂ����X�ɂ�
Llano����Ȃ��́H
�匴��Liano����Llano�ɒ������Ă����B
�匴��Liano����Llano�ɒ������Ă����B
996 �FSocket774�F2010/02/11(��) 14:47:11 ID:/c0G9iQo
AMD�̎�����CPU�ɂ��Č�낤 ��33����
http://pc11.2ch.net/test/read.cgi/jisaku/1265866982/l50
980�߂��Đ��肠������Ȃ点�߂Ď��X���𗧂ĂĂ���ɔ�
http://pc11.2ch.net/test/read.cgi/jisaku/1265866982/l50
980�߂��Đ��肠������Ȃ点�߂Ď��X���𗧂ĂĂ���ɔ�
Llano��Propus�� (L2 1M) + Redwood�� (SP480)�ŁA
�����قNjZ�p�I�ɗD�ꂽ���̂ł͂Ȃ�
AMD�Ƃ��Ă͎g�����ꂽ�R�A���������ǂ��Ă������������̑㕨
�����A32nm SOI HK/MG�v���Z�X�ō�����琢�E�ŋ��������Ƃ�������
�����قNjZ�p�I�ɗD�ꂽ���̂ł͂Ȃ�
AMD�Ƃ��Ă͎g�����ꂽ�R�A���������ǂ��Ă������������̑㕨
�����A32nm SOI HK/MG�v���Z�X�ō�����琢�E�ŋ��������Ƃ�������
999��1000�Ȃ�ID:QYG5E9oE�͂��̐����祥�
1000 �FSocket774�F2010/02/11(��) 15:00:42 ID:Bs2TbaxZ
�����Ė����Ȃ�
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc11.2ch.net/jisaku/