CPUアーキテクチャについて語れ 16
1 :Socket774:
おいお前らいい加減、無能なAMD房・Intel房・GKに振りまわされず、
エンコ時間がどうとかPIがどうとかPS3がどうとかじゃなく、
CPUコアのアーキテクチャについて語りましょう。
x86/RISC/CISC/スーパースカラ/VLIW/MIMD/SIMD
等について語ってもよし、
各SPUの汎用レジスタ128本のCell B.E.マンセー、
x86なワンチップスパコンのLarrabeeマンセー、
時代はGPGPUだ!、Sunは漢の浪漫!、龍芯(笑)、
昔々8086の時代は(以下略・・・等もよし。
さあ、不毛な争いを止めてCPUアーキテクチャについて語ろう!
前スレ
CPUアーキテクチャについて語れ 15
http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
【過去スレ】
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
エンコ時間がどうとかPIがどうとかPS3がどうとかじゃなく、
CPUコアのアーキテクチャについて語りましょう。
x86/RISC/CISC/スーパースカラ/VLIW/MIMD/SIMD
等について語ってもよし、
各SPUの汎用レジスタ128本のCell B.E.マンセー、
x86なワンチップスパコンのLarrabeeマンセー、
時代はGPGPUだ!、Sunは漢の浪漫!、龍芯(笑)、
昔々8086の時代は(以下略・・・等もよし。
さあ、不毛な争いを止めてCPUアーキテクチャについて語ろう!
前スレ
CPUアーキテクチャについて語れ 15
http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
【過去スレ】
Part 1 http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2 http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
Part 3 http://pc7.2ch.net/test/read.cgi/jisaku/1139046363/
Part 4 http://pc7.2ch.net/test/read.cgi/jisaku/1151732227/
Part 5 http://pc9.2ch.net/test/read.cgi/jisaku/1159238563/
Part 6 http://pc9.2ch.net/test/read.cgi/jisaku/1169393906/
Part 7 http://pc11.2ch.net/test/read.cgi/jisaku/1172923824/
Part 8 http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
part 9 http://pc11.2ch.net/test/read.cgi/jisaku/1186887760/
part10 http://pc11.2ch.net/test/read.cgi/jisaku/1202913839/
part11 http://pc11.2ch.net/test/read.cgi/jisaku/1214999146/
part12 http://pc11.2ch.net/test/read.cgi/jisaku/1219884494/
part13 http://pc11.2ch.net/test/read.cgi/jisaku/1223189876/
part14 http://pc11.2ch.net/test/read.cgi/jisaku/1231064800/
part15 http://pc11.2ch.net/test/read.cgi/jisaku/1235699613/
|
|
|
2 :Socket774:2009/09/21(月) 16:31:32 ID:WEoT1ID/
1乙
3 :,,・´∀`・,,)っ-○○○:2009/09/21(月) 18:29:32 ID:gVZrgLZ/
乙
ウ ゲ こ
ン ハ こ
コ か は
ゲ ら
ハ 押
厨 し
の か
糞 け
ス て
レ 来
で た
す
ン ハ こ
コ か は
ゲ ら
ハ 押
厨 し
の か
糞 け
ス て
レ 来
で た
す
乙
6 :Socket774:2009/09/22(火) 19:19:37 ID:CKLwJRiO
これからはAtom対ARMがメインになるわけですね
否定はしないが、どこでだよ
>>1 乙
乙
10 :Socket774:2009/09/23(水) 01:44:45 ID:harojAw6
1チップで3TFlops弱のプロセッサが出ようとしてるのに
0.1TFLOPS程度のCPUがあーだこーだ語ってる場合かw
0.1TFLOPS程度のCPUがあーだこーだ語ってる場合かw
>>10
君、このスレに向いてないから帰りなよ
君、このスレに向いてないから帰りなよ
12 :Socket774:2009/09/23(水) 07:23:04 ID:kyWtRV7D
>>10
ムーアの法則がIntelに逆襲する
http://pc.watch.impress.co.jp/docs/2008/0418/kaigai436.htm
あながちそうともいえないんじゃないのw?
ムーアの法則がIntelに逆襲する
http://pc.watch.impress.co.jp/docs/2008/0418/kaigai436.htm
あながちそうともいえないんじゃないのw?
13 :Socket774:2009/09/23(水) 12:06:17 ID:F3KoxbZK
Z80が最強
V30
6502
Z1
IBM、DNAとナノテクで作る次世代チップ──さらなる回路の微細化を可能に
http://headlines.yahoo.co.jp/hl?a=20090818-00000003-cwj-sci
マルチコア化にこだわらなくても、まだまだ進歩していける余地があるのだな。
CPUアーキアクチャーを構成する材料はまだまだ改良する余地はあるわけだし。
http://headlines.yahoo.co.jp/hl?a=20090818-00000003-cwj-sci
マルチコア化にこだわらなくても、まだまだ進歩していける余地があるのだな。
CPUアーキアクチャーを構成する材料はまだまだ改良する余地はあるわけだし。
>>17
量産するのにどんだけ時間かかるんだよそれ
量産するのにどんだけ時間かかるんだよそれ
>>18
数十年前にはシリコンウエハだってこんな量産できると思われてなかったろ
数十年前にはシリコンウエハだってこんな量産できると思われてなかったろ
トランジスタの発明からわずか10年で量産のためのシリコン集積回路が発案されてるがね
拡張命令が糞の元凶、なんだよSSEってwww
22 :,,・´∀`・,,)っ-○○○:2009/09/26(土) 10:22:05 ID:FqUneIa2
と、ID: MMXが嫉妬しております
MMXの嫉妬
>>22
うまいね、どうも
うまいね、どうも
【レポート】Hot Chips 21 - Sunの16コア256スレッドプロセサ「Rainbow Falls」
http://journal.mycom.co.jp/articles/2009/09/28/hot_chips21_rainbowfalls/index.html
http://journal.mycom.co.jp/articles/2009/09/28/hot_chips21_rainbowfalls/index.html
いっそ富士通もマルチスレッド・マルチコアの製品作って「Kegon Falls」とか名付けてくれればなぁ
華厳は最近水量が少なくなっていると聞くが
ARMやMIPS、PowerPCがもてはやされている今、
SPARCアーキテクチャっておちぶれた芸能人みたいだね
SPARCアーキテクチャっておちぶれた芸能人みたいだね
富士通なめんな
中森章ってNの人なの?
普段何してる人?
普段何してる人?
33 :Socket774:2009/10/02(金) 12:20:16 ID:0tDHmNrv
クタさんは本当にコンピュータの未来を半導体の面からも予言してて凄いわ
時代が追いついてきたよクタさん
時代が追いついてきたよクタさん
俺のアーキテクチャもちょっとしたもんだよ。
>>33
pgr
pgr
クタは数千億円をドブに捨てた(米国に貢いだ)だけのアホ
>>31
そういや龍芯はx86互換にする話もあったが、これも権利絡みで消えたのかな?
そういや龍芯はx86互換にする話もあったが、これも権利絡みで消えたのかな?
共産圏がまともに権利関係に従うわけなかろう
有事の際は全権利&工場&スタッフ全部押さえられるんだから
何で自由主義経済圏と同じに考えられるのかねえ。平和ボケすぎる。
有事の際は全権利&工場&スタッフ全部押さえられるんだから
何で自由主義経済圏と同じに考えられるのかねえ。平和ボケすぎる。
後進共産国なんぞに海外拠点を移した企業は後でバカを見るという訳だな
だから米国の基幹企業はそのまま中国というのが少ない。
進出はたぶん米軍勢力範囲内に収まってる。
進出はたぶん米軍勢力範囲内に収まってる。
ttp://pc.watch.impress.co.jp/img/pcw/docs/319/968/html/297.jpg.html
ttp://pc.watch.impress.co.jp/docs/news/event/20091007_319968.html
{kind=link}
ttp://pc.watch.impress.co.jp/docs/news/event/20091007_319968.html
44 :,,・´∀`・,,)っ-○○○:2009/10/07(水) 00:37:19 ID:AhzexVqQ
2012年以降・・・
4GHzのHaswellで256bit FMAを2命令発行できたら4倍速なわけで
それでなくとも来年には量産されるSandy Bridgeには負ける。
いつプレスリリースってハッタリ言う場になったのかね
4GHzのHaswellで256bit FMAを2命令発行できたら4倍速なわけで
それでなくとも来年には量産されるSandy Bridgeには負ける。
いつプレスリリースってハッタリ言う場になったのかね
さすがに2012年はないわ…
TSMC maintains 18-inch wafer tape-out in 2012
http://blog.livedoor.jp/amd646464/archives/51423975.html
http://blog.livedoor.jp/amd646464/archives/51423975.html
頼んで宣伝してもらってんだろ、察してやれよ
48 :Socket774:2009/10/10(土) 17:41:01 ID:q8bIQjO5
Sparcが今までにintelの脅威になったことなんてある?
49 :Socket774:2009/10/10(土) 20:22:20 ID:x6vMfceg
あるよ。エンタープライズサーバー市場ではずっと脅威のまま。今でも。
はやくIA-64なんて捨てればいいのにね。
はやくIA-64なんて捨てればいいのにね。
51 :Socket774:2009/10/10(土) 21:14:16 ID:q8bIQjO5
52 :,,・´∀`・,,)っ-○○○:2009/10/10(土) 22:18:59 ID:4pELrNs/
演算毎にパリティチェックが必要なようなクリティカル用途じゃ
ニッチながらも生きながらえる必要がある。
ニッチながらも生きながらえる必要がある。
航空宇宙分野か?
海洋研究開発機構のような導入事例もあるけど
大半は金融・証券
大半は金融・証券
55 :,,・´∀`・,,)っ-○○○:2009/10/11(日) 04:15:16 ID:X3Uk0g//
あと電力とかも
何年か前にJR東日本もIA64で主要システム統合化して雑誌に載ってたな
>>56
EM64TじゃなくてIA64なの?
EM64TじゃなくてIA64なの?
メインフレーム代替用途だと、日本ではItaniumが結構採用されているよ。
日本で採用されてなかったら、Itaniumの売上もっと悲惨なことになってるだろうし。
日本で採用されてなかったら、Itaniumの売上もっと悲惨なことになってるだろうし。
なんで日本でだけあんな採用されてたのかねぇ
>>59
Win-NTも日本が一番採用されたらしい。なんでもその昔PC-Wave(今は亡きラッセル社
出版のPC/AT系雑誌)によると日本はUNIXを使用してる企業が少ないのでNTが売れたとの
こと。多分日本でitaium採用が多いのも日本企業にunix資産が少ないからじゃ
ないの?
Win-NTも日本が一番採用されたらしい。なんでもその昔PC-Wave(今は亡きラッセル社
出版のPC/AT系雑誌)によると日本はUNIXを使用してる企業が少ないのでNTが売れたとの
こと。多分日本でitaium採用が多いのも日本企業にunix資産が少ないからじゃ
ないの?
インテルの犬ころが多いだけだろ
∧_∧
( ´∀`) オマエガナー
( )
| | |
(__)_)
( ´∀`) オマエガナー
( )
| | |
(__)_)
もうすぐ秋葉の中古サーバー屋さんとこに原価償却した中古itaniumマシンが出回るという訳か
mP6ってまだ生きていたんだなぁ
http://akiba-pc.watch.impress.co.jp/hotline/20091010/ni_cebox.html
どんな進化を遂げているんだろう?
ちなみに>>25のIDがmP6
http://akiba-pc.watch.impress.co.jp/hotline/20091010/ni_cebox.html
どんな進化を遂げているんだろう?
ちなみに>>25のIDがmP6
{kind=link}
>>65
FPUが退化しているらしい。SXだけに。
FPUが退化しているらしい。SXだけに。
ARM社のデュアルコアCortex-A9、低消費電力版でも性能はAtomを上回る
http://www.eetimes.jp/news/3380
http://www.eetimes.jp/news/3380
70 :Socket774:2009/10/20(火) 10:30:53 ID:Egg9/Om3
age
Power.org、「Power Architecture Conference 2009」レポート
〜PowerPCを通じて考えるCPUの未来像
http://pc.watch.impress.co.jp/docs/news/event/20091020_322898.html
〜PowerPCを通じて考えるCPUの未来像
http://pc.watch.impress.co.jp/docs/news/event/20091020_322898.html
おもいっきり恐ろしいこと書いてあるんですけど
Big Brother potentially exists right now in our PCs, compliments of Intel's vPro
http://www.tgdaily.com/content/view/39455/128/
技術者によるvPro機能紹介ビデオ
http://www.youtube.com/watch?v=wlj7u3tOQ9s
カスパースキーさんもこんなことを
Kris Kaspersky- Remote Code Execution Through Intel CPU Bugs
http://tinyurl.com/remote-code-exec-intel-cpu-bug
マーケティングの裏返しともいえるし、ここでいっても仕方がないでしょうけど
Big Brother potentially exists right now in our PCs, compliments of Intel's vPro
http://www.tgdaily.com/content/view/39455/128/
技術者によるvPro機能紹介ビデオ
http://www.youtube.com/watch?v=wlj7u3tOQ9s
カスパースキーさんもこんなことを
Kris Kaspersky- Remote Code Execution Through Intel CPU Bugs
http://tinyurl.com/remote-code-exec-intel-cpu-bug
マーケティングの裏返しともいえるし、ここでいっても仕方がないでしょうけど
>Kris Kaspersky
またオマエか
ちなみにアナリスト達はAMDがシェアを失う原因はNehalem-EPのパフォーマンスよりも仮想化やvProのような管理機能の遅れにある指摘している
またオマエか
ちなみにアナリスト達はAMDがシェアを失う原因はNehalem-EPのパフォーマンスよりも仮想化やvProのような管理機能の遅れにある指摘している
>>72
ついに奴等が本気を出してきた。陰謀論的にも非常におもしろい。
「MSのWindowsアップデート、IntelのvPro、EFIにはどんな情報を取られても構いません。」
って態度になるのが普通だからな・・
Dr, Mihcio Kaku talks about his book" "Visions"
http://www.youtube.com/watch?v=9H74dqU-ybw
自作とはちょっと逸れるけどコンピュータ関連の話もある。(英語)
21世紀はこうなってるらしい。あたってるのがすごい。
ついに奴等が本気を出してきた。陰謀論的にも非常におもしろい。
「MSのWindowsアップデート、IntelのvPro、EFIにはどんな情報を取られても構いません。」
って態度になるのが普通だからな・・
Dr, Mihcio Kaku talks about his book" "Visions"
http://www.youtube.com/watch?v=9H74dqU-ybw
自作とはちょっと逸れるけどコンピュータ関連の話もある。(英語)
21世紀はこうなってるらしい。あたってるのがすごい。
>>74
司会者ウザすぎw田原みたいなハゲだな
司会者ウザすぎw田原みたいなハゲだな
76 :Socket774:2009/10/28(水) 10:54:35 ID:GhxwAL4Y
GRAPE-DRって失敗だったの?
元から用途限定だったんだよね、たしか
そうやって性能稼いでたと
そうやって性能稼いでたと
VIA、Isaiahアーキテクチャを踏襲した「Nano 3000」
http://pc.watch.impress.co.jp/docs/news/20091104_326254.html
http://pc.watch.impress.co.jp/docs/news/20091104_326254.html
>>78
元来は重力多重体問題の演算用に設計された。
元来は重力多重体問題の演算用に設計された。
ぐらびてぃぱいぷだよね。
で、DRで汎用的な処理もこなせる、というふれこみだったけど失敗なの?
で、DRで汎用的な処理もこなせる、というふれこみだったけど失敗なの?
作ってる先生がWebで「作ったばっかで実効性能出ないなー」ぐらいのことは書いてた気がする
もともとアホみたいに演算力の要るN体問題を安く計算するための専用機を汎用化したものだし
今の世代もFPGAでつくってるんで専用設計にはかなわないし、予算の問題から必要な量と速度のメモリも採用できないらしい
足らぬ足らぬは予算が足らぬ
もともとアホみたいに演算力の要るN体問題を安く計算するための専用機を汎用化したものだし
今の世代もFPGAでつくってるんで専用設計にはかなわないし、予算の問題から必要な量と速度のメモリも採用できないらしい
足らぬ足らぬは予算が足らぬ
DRはASICだろ?
今月のtop500で新しいが数字出るらしいよ
green500ではトップ狙ってるらしいがはてさて
今月のtop500で新しいが数字出るらしいよ
green500ではトップ狙ってるらしいがはてさて
×新しいが数字
○新しい数字が
○新しい数字が
>83
ごみん、うろ覚えで書いたらまちがってた
DRでFPGAなのはPCIex x8とかのインタフェースだた
ごみん、うろ覚えで書いたらまちがってた
DRでFPGAなのはPCIex x8とかのインタフェースだた
そこがネックとは書いていだけどな
NECが開発したDRPだと、処理実行中でも回路の再構成が可能。
ttp://journal.mycom.co.jp/news/2002/10/24/17.html
マルチコア化に変わるプロセッサーの新機軸になりそうだな。
ttp://journal.mycom.co.jp/news/2002/10/24/17.html
マルチコア化に変わるプロセッサーの新機軸になりそうだな。
動的再構成のFPGAなら昔からあるけど、流行った覚えはないな
キャッシュロジックTMってやつ
キャッシュロジックTMってやつ
89 :,,・´∀`・,,)っ-○○○:2009/11/09(月) 22:10:57 ID:Q5DSOVTc
DAPDNAもKilocoreも会社ごと逝ってしまいました
>>88
機能固定で高速演算!低消費電力!!がハードロジックの売りみたいに言われる訳で。
それを再構成しても演算能力が極端に上がったりする事はマレだし。
ビット数で多数決とかビットを数えるとかみたいなハードウェア実装すればぜんぜん違う!なんてのもあるけど
演算機の数こそが力!みたいなのにはね〜。
消えちゃう事を利用した機密保持に特化した応用も有るけど。
機能固定で高速演算!低消費電力!!がハードロジックの売りみたいに言われる訳で。
それを再構成しても演算能力が極端に上がったりする事はマレだし。
ビット数で多数決とかビットを数えるとかみたいなハードウェア実装すればぜんぜん違う!なんてのもあるけど
演算機の数こそが力!みたいなのにはね〜。
消えちゃう事を利用した機密保持に特化した応用も有るけど。
92 :Socket774:2009/11/13(金) 19:31:49 ID:AuONsbsb
スパコンは友愛されました…
【事業仕分け】スパコン開発予算、大幅に削減へ…「1位でなければ駄目なのか」など疑問相次ぐ [09/11/13]
ttp://www.chunichi.co.jp/s/article/2009111301000164.html
【事業仕分け】スパコン開発予算、大幅に削減へ…「1位でなければ駄目なのか」など疑問相次ぐ [09/11/13]
ttp://www.chunichi.co.jp/s/article/2009111301000164.html
>「1位でなければ駄目なのか」
もうダメだな この国
順位の問題じゃなくて開発力維持の為の目標なんだが >スパコン一位
もうダメだな この国
順位の問題じゃなくて開発力維持の為の目標なんだが >スパコン一位
案の定自民の頃より酷いことになってるなwww
アフガンに毎年1000億円捨てに行くような狂った政権を選択したおまえらが友愛されろ
開発力とかも1位じゃなくて構わないだろ
そもそも欧米に勝てるレベルでもないし
人がたくさんいるような国の方が向いているし
もっと足元を見た福祉とかに回すべき
そもそも欧米に勝てるレベルでもないし
人がたくさんいるような国の方が向いているし
もっと足元を見た福祉とかに回すべき
いや足元は見るなよ。
別にF1レースじゃなくてもラリーとか開発力磨く場はあるだろ
F1以前に自動車は既に…
スパコン以前にコンピュータは既に…w
スパコン以前にコンピュータは既に…w
>開発力維持の為の目標なんだが
既存のシステムを超える性能を設定して開発すれば
結果的に出来た物が「完成時に」一位になるわけだからな。
>そもそも欧米に勝てるレベルでもないし
米はともかくEU圏はそもそもスパコン開発しとらんがな。
ハコ自体はアメリカか日本製。
つかスパコンと福祉がなぜ同列なんだか。
既存のシステムを超える性能を設定して開発すれば
結果的に出来た物が「完成時に」一位になるわけだからな。
>そもそも欧米に勝てるレベルでもないし
米はともかくEU圏はそもそもスパコン開発しとらんがな。
ハコ自体はアメリカか日本製。
つかスパコンと福祉がなぜ同列なんだか。
何をするかが重要であってベンチで1位とるのが目的じゃ困るわ
米ってPCや組み込みに大量にCPU売り裁いて、その収益やフィードバックを
大規模サーバやスパコンに活用できるからね。それだけでもすごい優位だよ。
大規模サーバやスパコンに活用できるからね。それだけでもすごい優位だよ。
税金と人材を浪費する「ITゼネコン」
http://ascii.jp/elem/000/000/134/134297/
http://ascii.jp/elem/000/000/134/134297/
その逆を唱えて常に失敗し続けている日本。
重要な技術というならばお金になるはずなのに、
産業として成り立たせられずになぜいつもゼネコンみたいに税金にすがるのかね。
対象がスパコンかどうかが問題ではなく、何をやってもヘタレな電気ゼネコンの力不足が真相では。
GFLOPSが一位かどうかなんてお飾りのお題目にしか見えない
重要な技術というならばお金になるはずなのに、
産業として成り立たせられずになぜいつもゼネコンみたいに税金にすがるのかね。
対象がスパコンかどうかが問題ではなく、何をやってもヘタレな電気ゼネコンの力不足が真相では。
GFLOPSが一位かどうかなんてお飾りのお題目にしか見えない
アメリカは軍の予算が大きいからなぁ
戦闘機開発とか核兵器の賞味期限をシミュレーションしたり
戦闘機開発とか核兵器の賞味期限をシミュレーションしたり
108 :,,・´∀`・,,)っ-○○○:2009/11/14(土) 14:54:49 ID:8rfW0ww8
日本のコンピュータ産業育ててるのは自動車と電子ゲーム産業だと思うのです
後者は政府が任天堂に支援したことなんて一度も無い
国がやったのはせいぜいCEROだとか変な天下り団体を作ったくらいだ
後者は政府が任天堂に支援したことなんて一度も無い
国がやったのはせいぜいCEROだとか変な天下り団体を作ったくらいだ
>>106
そうそう
ちゃんとスパコンの需要があるからな すごい大規模な。
需要が無いのに供給だけってのは商売としては厳しい。
逆を言えばだからこそ官でやらないと
灯が消えてしまう。
32チャン2048ビットのデータバス引き回しなんて
今のところ日本でしかやれん
(京速プロジェクトの光コネ研究はこれの代替技術)。
Linpack番長のスカラ型じゃ効率悪くて話にならんネタも
世の中にはたくさんあるんでな。
そうそう
ちゃんとスパコンの需要があるからな すごい大規模な。
需要が無いのに供給だけってのは商売としては厳しい。
逆を言えばだからこそ官でやらないと
灯が消えてしまう。
32チャン2048ビットのデータバス引き回しなんて
今のところ日本でしかやれん
(京速プロジェクトの光コネ研究はこれの代替技術)。
Linpack番長のスカラ型じゃ効率悪くて話にならんネタも
世の中にはたくさんあるんでな。
団子屋さんはソフト屋さんだからな
CPUなんて何でもいいんだろ
CPUなんて何でもいいんだろ
112 :,,・´∀`・,,)っ-○○○:2009/11/14(土) 16:52:37 ID:8rfW0ww8
それを言ったらどっかの京速に使われる予定だった不治痛のSPARCだって元々はSunだが?
あとカーナビはSH4使ってるぜ
3Dモーションセンサーはニッチ製品でアホみたいに高かったけど、
Wiiでの採用で単価が落ちていろんな製品で使えるデバイスになり得た。
ついでに言うとソニーのプレステ事業の生き血をIBMがすすって出来たのがRoadRunner
やっぱゲーム機で採用されることのスケールメリットは大きいと思うのです。
携帯電話は日本は独自進化過ぎて駄目っぽいし
あとカーナビはSH4使ってるぜ
3Dモーションセンサーはニッチ製品でアホみたいに高かったけど、
Wiiでの採用で単価が落ちていろんな製品で使えるデバイスになり得た。
ついでに言うとソニーのプレステ事業の生き血をIBMがすすって出来たのがRoadRunner
やっぱゲーム機で採用されることのスケールメリットは大きいと思うのです。
携帯電話は日本は独自進化過ぎて駄目っぽいし
今後はARMの天下ってことか
箱○とPS3でPowerは一杯作られた、いまこそPowerアーキテクチャ復権のとき!!!111 なわけないね
次期箱も箱○の設計そのまんまで行くみたいだけどCPUはどうするんだろ
Powerで3コア3.2GHzって現状から何をどうやったら性能向上できるのか
次期箱も箱○の設計そのまんまで行くみたいだけどCPUはどうするんだろ
Powerで3コア3.2GHzって現状から何をどうやったら性能向上できるのか
ゲームでマルチコアはどのくらい有効なんかね
cellを使い切れてないってのはとりあえず置いといても、PC向けでさえいまだに
高クロックデュアルがほしい、可能ならシングルでさらに上って感じのが多いみたいだし
まあ、次期ゲーム機CPUは無難にクロック上げ&コアちょっと増える程度じゃね?
値段高い時期にWiiに独走された経験からして、発売時の定価も6万どころか4万切るあたりが上限だろうし
あとはGPU強化&メモリとHDD増量ってとこで
cellを使い切れてないってのはとりあえず置いといても、PC向けでさえいまだに
高クロックデュアルがほしい、可能ならシングルでさらに上って感じのが多いみたいだし
まあ、次期ゲーム機CPUは無難にクロック上げ&コアちょっと増える程度じゃね?
値段高い時期にWiiに独走された経験からして、発売時の定価も6万どころか4万切るあたりが上限だろうし
あとはGPU強化&メモリとHDD増量ってとこで
116 :,,・´∀`・,,)っ-○○○:2009/11/14(土) 18:05:12 ID:8rfW0ww8
箱○のはCellのPPEと同一マイクロアーキテクチャのカスタム版なんだよな
HD対応だったのが次期ゲーム機では必須になるのかね。
PS4にララビー採用の噂あったけどブルドーザー+ララビーとかだったら笑う。
PS4にララビー採用の噂あったけどブルドーザー+ララビーとかだったら笑う。
その前に家庭用ゲーム機が携帯型ゲーム機に喰わr
ゲーム容量的に、DVD何枚組とかなゲームは当分携帯できないだろう
ま、大画面が据え置き型最後のメリットだろうな
ま、大画面が据え置き型最後のメリットだろうな
ゲーム機も今までの公式が崩れちゃったからなー
ARM Forum 2009レポート【CPUコア編】
〜マルチコア拡張の普及版「Cortex-A5」の凄さ
http://pc.watch.impress.co.jp/docs/news/event/20091116_329293.html
〜マルチコア拡張の普及版「Cortex-A5」の凄さ
http://pc.watch.impress.co.jp/docs/news/event/20091116_329293.html
IntelとNEC、スパコン技術の共同開発に合意
http://pc.watch.impress.co.jp/docs/news/20091117_329468.html
http://pc.watch.impress.co.jp/docs/news/20091117_329468.html
やっぱNECはこういう展開を考えてたのね。
相手がIntelとは思わなかったが。
相手がIntelとは思わなかったが。
昔あんな目にあったのに学習力無さ過ぎわろた
もうすぐ、インテルのお許しがないとスーパーコンピュータ作れなくなるのか
大丈夫か日電
大丈夫か日電
なぜこんなネタをPC watchが取り上げるのか謎
Intelネタを取り上げた記者には、毎回CPUが一個送付されるとか、何か隠れたインセンティブが有るんジャネ?
132 :,,・´∀`・,,)っ-○○○:2009/11/20(金) 01:24:29 ID:OfG4YBQO
A8/A9はごく限られたケースだけAtomより電力効率良いとか言ってるけど
データバス帯域が狭いからSIMD使ってストリーミングとかやるとズタボロ。
外部アクセラレータに頼らなくて良い程度にはSIMD演算性能持ってるのは
Atomの強み。
データバス帯域が狭いからSIMD使ってストリーミングとかやるとズタボロ。
外部アクセラレータに頼らなくて良い程度にはSIMD演算性能持ってるのは
Atomの強み。
133 :,,・´∀`・,,)っ-○○○:2009/11/20(金) 01:28:52 ID:OfG4YBQO
というかAtomはP4バス使ってるんだよな。
FreescaleのPPC G4系アーキなんていまだにFSB166MHzとかだぜ
FreescaleのPPC G4系アーキなんていまだにFSB166MHzとかだぜ
基板の問題もあるからな…
その辺PCは恵まれてる
その辺PCは恵まれてる
団子って日本の競争力低下喜んでそうだが
IBMはCELL止めるんだとか
ロードランナーに入ってるやつの後継チップ
ロードランナーに入ってるやつの後継チップ
137 :,,・´∀`・,,)っ-○○○:2009/11/22(日) 19:54:14 ID:Htnio03U
富士通のSPARC64を使うことが競争のためだとは思わんが?w
>>136
ドイツ語
ttp://www.heise.de/newsticker/meldung/SC09-IBM-laesst-Cell-Prozessor-auslaufen-864497.html
↓
英語
ttp://www.playstationuniversity.com/ibm-cancels-cell-processor-development-1295/
↓
日本語
ttp://pocketnews.cocolog-nifty.com/pkns/2009/11/cellibmcell-7a1.html
現行CellのPowerXCell 8iの後継PowerXCell 32ivは開発中止
Cellのヘテロジニアス的アプローチは続ける
Sonyが金出せばPS4にCell後継乗るかも
ドイツ語
ttp://www.heise.de/newsticker/meldung/SC09-IBM-laesst-Cell-Prozessor-auslaufen-864497.html
↓
英語
ttp://www.playstationuniversity.com/ibm-cancels-cell-processor-development-1295/
↓
日本語
ttp://pocketnews.cocolog-nifty.com/pkns/2009/11/cellibmcell-7a1.html
現行CellのPowerXCell 8iの後継PowerXCell 32ivは開発中止
Cellのヘテロジニアス的アプローチは続ける
Sonyが金出せばPS4にCell後継乗るかも
やっぱり今後はARMの天下ってことか
クライアント側ではじわじわとARMが勢力拡大していくと思う。
そしてx86は高級機に追いやられ…
いつか来た道
そしてx86は高級機に追いやられ…
いつか来た道
141 :,,・´∀`・,,)っ-○○○:2009/11/22(日) 23:48:03 ID:Htnio03U
ARMの「パソコン」作ったのは結局SHARPくらいでしたけどね。
Atomネットブックですら先進国では買い増し需要でしかない。
Atomネットブックですら先進国では買い増し需要でしかない。
142 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 00:14:00 ID:nT9DryEJ
アクセラレータを含むARMのハードウェア共通規格策定
↓
ソフトウェアの共通規格策定
↓
各社ともプラットフォーム共通化
↓
Windows/x86エミュレーション技術の確立
これができんことにはARMのPC化は無理だろ。
結局各ベンダーの垂直統合モデルに都合が良い独自製品向けの汎用コントローラだからこそ
IP売上げトップなわけで。
たとえばAppleがiPhoneでGoogle Androidサポートするとか言うか?
あり得ない。
↓
ソフトウェアの共通規格策定
↓
各社ともプラットフォーム共通化
↓
Windows/x86エミュレーション技術の確立
これができんことにはARMのPC化は無理だろ。
結局各ベンダーの垂直統合モデルに都合が良い独自製品向けの汎用コントローラだからこそ
IP売上げトップなわけで。
たとえばAppleがiPhoneでGoogle Androidサポートするとか言うか?
あり得ない。
>>141
NetWalkerはパソコンじゃないし
>>142
前時代的だねー
wintelって時代がいつまで続くか分からない気配がどんどん強くなってるのに
OSSは止められんよ
団子さんはARMが勢力拡大すると不都合でもあるん?
なんか生温い視線じゃなくて、ARMに対する敵意を感じるんだけど。
消費電力の壁が律速要因として存在するなら電力効率に優れたCPUが伸びるって思わへんの?
NetWalkerはパソコンじゃないし
>>142
前時代的だねー
wintelって時代がいつまで続くか分からない気配がどんどん強くなってるのに
OSSは止められんよ
団子さんはARMが勢力拡大すると不都合でもあるん?
なんか生温い視線じゃなくて、ARMに対する敵意を感じるんだけど。
消費電力の壁が律速要因として存在するなら電力効率に優れたCPUが伸びるって思わへんの?
ARMのPC進出を妨げるのはARM社自身がCPUを作ってないこと
つまりライセンスを受けた他の会社が作ることになるわけだが、
競争の激しいPC市場に参入できるほどの余裕のある企業が無い
まあ参入の可能性があるとすれば新興企業じゃね
つまりライセンスを受けた他の会社が作ることになるわけだが、
競争の激しいPC市場に参入できるほどの余裕のある企業が無い
まあ参入の可能性があるとすれば新興企業じゃね
>>143
ARMの糞性能でどうにかなると思ってるなら相当アレ
ARMの糞性能でどうにかなると思ってるなら相当アレ
たいていの人が携帯電話で足りてるわけだし、性能なんてそんなにいらんだろ
意外とMIPSが行けるんじゃないかね。
今後、人口がバカデカい中国で龍芯MIPSノートとか流通するようになるなら、そのおこぼれが先進国にも波及する可能性がある。
逆にARMが勝つ要素はスマートフォンとの兼ね合いだな。
今後、人口がバカデカい中国で龍芯MIPSノートとか流通するようになるなら、そのおこぼれが先進国にも波及する可能性がある。
逆にARMが勝つ要素はスマートフォンとの兼ね合いだな。
armの年間生産量は既にx86抜いてんじゃないの大幅に
ps4、次期箱○、wiiで採用されたらいよいよ天下取るかもね
期待してるよ pc?用はキャッシュ大幅に増やして10wでも許すw
ps4、次期箱○、wiiで採用されたらいよいよ天下取るかもね
期待してるよ pc?用はキャッシュ大幅に増やして10wでも許すw
箱は互換路線だから次もPower
用途も単価もダイサイズもまるっきり違うものの生産量比べてもねぇ…
用途も単価もダイサイズもまるっきり違うものの生産量比べてもねぇ…
151 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 02:43:33 ID:nT9DryEJ
OSSの力(笑)
だからハードの共通規格作れよ。
垂直統合モデルで分断しまくりの現状じゃどうしようもない。
だからハードの共通規格作れよ。
垂直統合モデルで分断しまくりの現状じゃどうしようもない。
152 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 02:58:13 ID:nT9DryEJ
ARM搭載端末って、結局ハードウェア(プラットフォーム)がオープンじゃないからな。
SHARPみたいなガジェット作ってくれるメーカーがいっぱいいて
ソフト開発プラットフォームとして解放してくれない限りは
オープンソース以前の問題。
SHARPみたいなガジェット作ってくれるメーカーがいっぱいいて
ソフト開発プラットフォームとして解放してくれない限りは
オープンソース以前の問題。
153 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 03:00:46 ID:nT9DryEJ
この話のオチが「冷蔵庫に80186が載ってました」というオチだったら素晴らしいな。
今日日の冷蔵庫はもっと高性能なの乗せてるだろうが。
今日日の冷蔵庫はもっと高性能なの乗せてるだろうが。
>>150
arm系ならatomと同じ値段でもっとハイパフォーマンスのプロセッサー作りそう
内ゲバ防止のしばりもないし、同じ消費電力でいいなら楽かもね、進化のスピード早いし
糞x86はいい加減死なないかなw windowsも肥大化しすぎてるし
arm系ならatomと同じ値段でもっとハイパフォーマンスのプロセッサー作りそう
内ゲバ防止のしばりもないし、同じ消費電力でいいなら楽かもね、進化のスピード早いし
糞x86はいい加減死なないかなw windowsも肥大化しすぎてるし
156 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 03:28:19 ID:nT9DryEJ
限られたケースで性能良かろうが結局そういうのは流行らない
>進化のスピード早いし
ぷぷぷぷぷぷぷぷぷぷ
ちなみに今デモされてる40nmプロセスのARMが実際の製品に使われるのは2,3年後で
その時にはAtomはもっと電力効率は上がってるオチな。
マクロだけ先に完成→パートナー契約結んだ企業がSoC製造→ベンダーが製品開発、と
製品化までのスパンが長いのよ。組み込みの宿命だな。
ハードウェアプラットフォームが共通化されててチップ完成後即製品になるx86とはえらい違いですよ。
プンプン
>進化のスピード早いし
ぷぷぷぷぷぷぷぷぷぷ
ちなみに今デモされてる40nmプロセスのARMが実際の製品に使われるのは2,3年後で
その時にはAtomはもっと電力効率は上がってるオチな。
マクロだけ先に完成→パートナー契約結んだ企業がSoC製造→ベンダーが製品開発、と
製品化までのスパンが長いのよ。組み込みの宿命だな。
ハードウェアプラットフォームが共通化されててチップ完成後即製品になるx86とはえらい違いですよ。
プンプン
157 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 03:44:42 ID:nT9DryEJ
製品レベルではハイエンド(笑)のARMを搭載したNetWalkerの実際のとこの性能って
おおよそ10年前のPentium III水準なんだよね
SIMD性能もPentium III程度でもあればいいほうくらい
ネタにはなるがネタでしかない代物だ
おおよそ10年前のPentium III水準なんだよね
SIMD性能もPentium III程度でもあればいいほうくらい
ネタにはなるがネタでしかない代物だ
>>138
互換維持するために普通にCELLだと思うよ
GPUはNVIDIAでもATIでも構わないようになってるけどCELLは丸裸 らしい
それにしても4コア(拡張版?)+32コアも必要なのか次世代ともなると想像つかんな
CELLをGPUにしたいように見える
互換維持するために普通にCELLだと思うよ
GPUはNVIDIAでもATIでも構わないようになってるけどCELLは丸裸 らしい
それにしても4コア(拡張版?)+32コアも必要なのか次世代ともなると想像つかんな
CELLをGPUにしたいように見える
>>151
goldfishとか
でも別に共通規格作る必要ないんじゃね?
決め打ちにしなくてもいいんだから
>>157
Pen3程度の能力があればクライアントには充分と思いますが。
win98相当がそうストレスなく動く、これでいいんじゃないの?
多分団子さんは多くを望みすぎなんだよ
なーんかな、団子さんは…
goldfishとか
でも別に共通規格作る必要ないんじゃね?
決め打ちにしなくてもいいんだから
>>157
Pen3程度の能力があればクライアントには充分と思いますが。
win98相当がそうストレスなく動く、これでいいんじゃないの?
多分団子さんは多くを望みすぎなんだよ
なーんかな、団子さんは…
>Pen3程度の能力があればクライアントには充分と思いますが。
じゃあ今使ってるPCを窓から投げ捨ててPen3マシンに替えろよwww
ほぼ確実に発狂できるから
じゃあ今使ってるPCを窓から投げ捨ててPen3マシンに替えろよwww
ほぼ確実に発狂できるから
>>160
馬鹿?あまりにお粗末なので死んでくれないか。
メインマシンでLinuxのパッケージ自ビルドしてる俺が性能低いのに乗り換えとか、嫌よ。
将来性能の高いARMが出たら乗り換えるかも。
端末専用機ならARMにしてもいいと思うけどね。
馬鹿?あまりにお粗末なので死んでくれないか。
メインマシンでLinuxのパッケージ自ビルドしてる俺が性能低いのに乗り換えとか、嫌よ。
将来性能の高いARMが出たら乗り換えるかも。
端末専用機ならARMにしてもいいと思うけどね。
支離滅裂
とりあえず団子にケチつけたいだけの阿呆という認識でOKか
ARMがメインユースに耐えるほど高性能化したら売りであるはずの電力性能は駄々下がりじゃぼけ
ARMがメインユースに耐えるほど高性能化したら売りであるはずの電力性能は駄々下がりじゃぼけ
>>162
「開発機で現状のARMはありえん。高性能のx86がいい。」
「端末機ならARMでいいかもー」
これのどこが支離滅裂だよ。
もうちょい言うと、開発機としてのコンピュータを必要としてる層なんか少数だぞ。
加えて、FullHD動画再生程度ならARMプラットフォームで出来るようになってる。
「現行のバイナリオブジェクトをそのままARMで利用する」という枷が無いのなら、
いいプラットフォームだと思うんだが、ARMは。
>>163
>ARMがメインユースに耐えるほど高性能化したら売りであるはずの電力性能は駄々下がりじゃぼけ
これ、実際の所どうなんだろうねー、とは思う。
究極的にはISAの出来不出来が問題になると思うんだけど。
そういう所からARMの駄目さを論じるんなら歓迎よ。
「開発機で現状のARMはありえん。高性能のx86がいい。」
「端末機ならARMでいいかもー」
これのどこが支離滅裂だよ。
もうちょい言うと、開発機としてのコンピュータを必要としてる層なんか少数だぞ。
加えて、FullHD動画再生程度ならARMプラットフォームで出来るようになってる。
「現行のバイナリオブジェクトをそのままARMで利用する」という枷が無いのなら、
いいプラットフォームだと思うんだが、ARMは。
>>163
>ARMがメインユースに耐えるほど高性能化したら売りであるはずの電力性能は駄々下がりじゃぼけ
これ、実際の所どうなんだろうねー、とは思う。
究極的にはISAの出来不出来が問題になると思うんだけど。
そういう所からARMの駄目さを論じるんなら歓迎よ。
>>156
来年には32nmのCortex-A9搭載製品が出るって話だぞ
来年には32nmのCortex-A9搭載製品が出るって話だぞ
CPUでもsamsungが覇権握ったらバロス
>>157
消費電力が数十分の一だろ
しかも全盛期のp3の10分の1以下の面積と値段は3分の1くらいか
面積、消費電力、値段同じにすればatom軽く超えるだろ
atomもintel信者御用達のπなら1M 90秒位なんだしw P3とかわらんだろw
armも新規格立ち上げるんじゃね?自由度それなりに残しながら
wm6xやchoromeやanndroido走ればいいんだし
消費電力が数十分の一だろ
しかも全盛期のp3の10分の1以下の面積と値段は3分の1くらいか
面積、消費電力、値段同じにすればatom軽く超えるだろ
atomもintel信者御用達のπなら1M 90秒位なんだしw P3とかわらんだろw
armも新規格立ち上げるんじゃね?自由度それなりに残しながら
wm6xやchoromeやanndroido走ればいいんだし
とりあえず、現在Pentium3と大差ないG4のノートでネットやってるが
困ることといえば動画の再生くらいだな。
動画の再生はGPUその他の補助がちゃんとある最近の機種ではなんとかなってるみたいだし
3DCG作るとか、ゲーム機ではできないほどクソ重いゲームとかでもないかぎり
このくらいで足りる気がする
SHARPのアレは、店頭でちょっとさわった。遅いって感じはしなかったが画面狭いなw
携帯電話に慣れた連中は違うんだろうか
困ることといえば動画の再生くらいだな。
動画の再生はGPUその他の補助がちゃんとある最近の機種ではなんとかなってるみたいだし
3DCG作るとか、ゲーム機ではできないほどクソ重いゲームとかでもないかぎり
このくらいで足りる気がする
SHARPのアレは、店頭でちょっとさわった。遅いって感じはしなかったが画面狭いなw
携帯電話に慣れた連中は違うんだろうか
169 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 10:37:16 ID:nT9DryEJ
170 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 10:40:23 ID:nT9DryEJ
製品ってのはチップレベルの製品だろう。
携帯電話メーカーはそのチップが出来上がってから開発が始まるんだ
携帯電話メーカーはそのチップが出来上がってから開発が始まるんだ
171 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 10:42:12 ID:nT9DryEJ
>>169
多分元ネタのFudzilla
http://www.fudzilla.com/content/view/16500/70/
ARMの大本営まんまだしFudzillaだし"might be coming"だし、そこまでアテになる情報じゃないかな…
まぁ1年間生温い目で見てればいいと思うよ。
http://techon.nikkeibp.co.jp/article/NEWS/20091027/176991/
こんなのもあるけど、現在どうなってるのか不明
googleが出すとかだったら笑う
多分元ネタのFudzilla
http://www.fudzilla.com/content/view/16500/70/
ARMの大本営まんまだしFudzillaだし"might be coming"だし、そこまでアテになる情報じゃないかな…
まぁ1年間生温い目で見てればいいと思うよ。
http://techon.nikkeibp.co.jp/article/NEWS/20091027/176991/
こんなのもあるけど、現在どうなってるのか不明
googleが出すとかだったら笑う
173 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 11:09:55 ID:nT9DryEJ
Atomのネットブックの立ち位置って5年前ならXScaleのWindows CE/Linux搭載機、俗にハンドヘルドPC市場
だと思ってるが、あの市場って壊滅したろ?
Windows CEじゃなくてフルスペックのWindowsが動いて、好きなアプリが起動できる
x86マシンに駆逐されたも同然だよ。
今更ARMが取り戻せる市場ではない。
だと思ってるが、あの市場って壊滅したろ?
Windows CEじゃなくてフルスペックのWindowsが動いて、好きなアプリが起動できる
x86マシンに駆逐されたも同然だよ。
今更ARMが取り戻せる市場ではない。
>>173
おぬし頑固よのう
平行線にしかする気ナッシングですか
まぁ5年もすれば市場が結果を見せてくれるでしょ
俺はARMの勢力拡大・x86一部切り崩し成功に賭ける
団子さんはx86一択にしてればいいよ
おぬし頑固よのう
平行線にしかする気ナッシングですか
まぁ5年もすれば市場が結果を見せてくれるでしょ
俺はARMの勢力拡大・x86一部切り崩し成功に賭ける
団子さんはx86一択にしてればいいよ
175 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 11:19:19 ID:nT9DryEJ
>>172
32nmはhigh-k使えないってよ。
AndroidだかChromeOSだかってのは結局、Googleに情報を管理されるわけで
情報統制って意味では、アクティベーションやってるMSはグレーだが
Googleは真っ黒だな。
客商売には使えない。ISO認証やプライバシーマークすら通らない。
家庭用もしかりだが、デジカメで撮ってきた画像を加工して年賀状を印刷したりするもんだ
そういうきめ細かいサービスがクラウドにできるかな?
Google docsって縦書き文書すら作れないぜ?
いまさらワープロ専用機やプリントごっこ(笑)に戻れというわけでもあるまい?
32nmはhigh-k使えないってよ。
AndroidだかChromeOSだかってのは結局、Googleに情報を管理されるわけで
情報統制って意味では、アクティベーションやってるMSはグレーだが
Googleは真っ黒だな。
客商売には使えない。ISO認証やプライバシーマークすら通らない。
家庭用もしかりだが、デジカメで撮ってきた画像を加工して年賀状を印刷したりするもんだ
そういうきめ細かいサービスがクラウドにできるかな?
Google docsって縦書き文書すら作れないぜ?
いまさらワープロ専用機やプリントごっこ(笑)に戻れというわけでもあるまい?
IBM陣営はBulkもHigh-kだぞ
ところで何でそんなにARMを敵対視するのかわからん
Google批判まで始める始末だし
ところで何でそんなにARMを敵対視するのかわからん
Google批判まで始める始末だし
企業向けの低価格端末が出ない限りはx86の優位は当面揺るがないだろ…
昔、Hがパソコン止めると宣言した時、SH端末でも全社的に使うんだろうか?と期待したんだけど…
徐々にARM等の機能を絞った端末が増えていくとは思うけど。
昔、Hがパソコン止めると宣言した時、SH端末でも全社的に使うんだろうか?と期待したんだけど…
徐々にARM等の機能を絞った端末が増えていくとは思うけど。
178 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 11:34:29 ID:nT9DryEJ
「まぁ5年もすれば市場が結果を見せてくれるでしょ」
=21世紀になったら車が宙に浮いてる
=21世紀になったら車が宙に浮いてる
でも、Pen3機はまだ使ってるw
けど、CPU自体は不足してないけど、メモリが載らないとか
インターフェイス周りの弱さが目立つのでメイン機には使えないんだな。
せめて2G載ればねぇ…。
けど、CPU自体は不足してないけど、メモリが載らないとか
インターフェイス周りの弱さが目立つのでメイン機には使えないんだな。
せめて2G載ればねぇ…。
180 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 11:37:39 ID:nT9DryEJ
181 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 11:44:07 ID:nT9DryEJ
>>177
AtomネットトップがCPUの省電力メリットが殺されてる現状では
バイナリ互換などデメリットのほうが多いARMが置き換えることはないと思うのだ。
HDDやUSB 2.0機器を複数繋げる用途に耐えうるI/Oハブ用意したら
それだけでそれこそARM本体よりも消費電力大きくなっちゃう。
液晶だって15インチクラスは最低限欲しいだろ仕事で使うなら。
性能で訴えるしかない。
というかハードの時代なんて終わってるんだが。
今はソフトが無ければただの箱。
ARMには実用に耐えうるビジネスアプリがないのが現状。
AtomネットトップがCPUの省電力メリットが殺されてる現状では
バイナリ互換などデメリットのほうが多いARMが置き換えることはないと思うのだ。
HDDやUSB 2.0機器を複数繋げる用途に耐えうるI/Oハブ用意したら
それだけでそれこそARM本体よりも消費電力大きくなっちゃう。
液晶だって15インチクラスは最低限欲しいだろ仕事で使うなら。
性能で訴えるしかない。
というかハードの時代なんて終わってるんだが。
今はソフトが無ければただの箱。
ARMには実用に耐えうるビジネスアプリがないのが現状。
ARM厨を一行でまとめると
俺が使うのはヤだけどお前らはARMクライアントで十分
でok?
俺は宣伝だけしてやるからお前らが素晴らしいものを作れ
だとTRON厨になるな...
俺が使うのはヤだけどお前らはARMクライアントで十分
でok?
俺は宣伝だけしてやるからお前らが素晴らしいものを作れ
だとTRON厨になるな...
183 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 12:17:00 ID:nT9DryEJ
Cellの性能がPentium 4の○倍とか言ってホルホルしてたどっかのゲートキーピング屋さんと同レベルの妄想は辞めようよ。
Wintelの抱えるソフト資産規模はARMとは比べものにならん。
秀丸がNetWalkerで動くような時代になればまた別だが
Linuxブームの時ですら無視してたからなタキシード山本仮面様は
Wintelの抱えるソフト資産規模はARMとは比べものにならん。
秀丸がNetWalkerで動くような時代になればまた別だが
Linuxブームの時ですら無視してたからなタキシード山本仮面様は
>>181
新規案件でのシステム一括納入なら話は違うけどね。
Win機からMacへいれかえる見たいなもんだし。
ただ、ARMやSH、MIPS機にはVisualなんとか見たいな開発環境がないとかハードル高すぎw
>HDDやUSB 2.0機器を複数繋げる用途に耐えうるI/Oハブ用意したら
確かに実際に製品として供給されるARMチップだと省電力に的を絞った物が多くて
キャッシュ少ないはメモリMax512Mとかで載らない、USBは…と不満が多い。
>今はソフトが無ければただの箱。
それはクラウドで解消しそうだが…
もっとも、クライアント側に求められる性能ってのが
OSS連中が言うほど軽くないってのは重要な問題だが…。
新規案件でのシステム一括納入なら話は違うけどね。
Win機からMacへいれかえる見たいなもんだし。
ただ、ARMやSH、MIPS機にはVisualなんとか見たいな開発環境がないとかハードル高すぎw
>HDDやUSB 2.0機器を複数繋げる用途に耐えうるI/Oハブ用意したら
確かに実際に製品として供給されるARMチップだと省電力に的を絞った物が多くて
キャッシュ少ないはメモリMax512Mとかで載らない、USBは…と不満が多い。
>今はソフトが無ければただの箱。
それはクラウドで解消しそうだが…
もっとも、クライアント側に求められる性能ってのが
OSS連中が言うほど軽くないってのは重要な問題だが…。
186 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 12:30:34 ID:nT9DryEJ
ARMにはウィルスがないから安全!(棒
ソフトが重くなって何が悪いんだ
そんなに死んだ世界がお望みか
そんなに死んだ世界がお望みか
Wintelでソフトが重いというか
ARMじゃ性能が足りなくて
重くできない
だけ
ARMじゃ性能が足りなくて
重くできない
だけ
191 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 14:06:03 ID:nT9DryEJ
普及すれば必然的にウィルス対策が必要になる。
逆にウィルス対策ソフト程度も動かせないんじゃ共通プラットフォームとしての普及は許されないだろう
垂直統合モデルで分断された世界がある意味理想ともいえる。
ARMの市場は「ニッチクライアント」で十分なのよ。
逆にウィルス対策ソフト程度も動かせないんじゃ共通プラットフォームとしての普及は許されないだろう
垂直統合モデルで分断された世界がある意味理想ともいえる。
ARMの市場は「ニッチクライアント」で十分なのよ。
192 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 14:09:11 ID:nT9DryEJ
ARMの性能が足りないだって?
混載されたSuperHコアの出番だな!
混載されたSuperHコアの出番だな!
iPhone様がARMと仰っているのでね、もう勝負はついてるんだよw
195 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 16:29:36 ID:nT9DryEJ
iPhone様(笑)
まだNintendo DSとか言った方が笑いだけはとれたのに。
まだNintendo DSとか言った方が笑いだけはとれたのに。
196 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 16:32:51 ID:nT9DryEJ
日本じゃソフトバンクという3番手キャリアの1機種という扱いだし
ワールドワイドじゃそれこそノキアやエリクソンを幅を利かせる世界で
世界ウン百万台程度じゃ成功とは言いがたい。
マカーが持ち上げてるだけで。
ワールドワイドじゃそれこそノキアやエリクソンを幅を利かせる世界で
世界ウン百万台程度じゃ成功とは言いがたい。
マカーが持ち上げてるだけで。
198 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 16:55:36 ID:nT9DryEJ
うん、だから言ってるだろ。垂直統合モデルだって。
CPUのコードが共通でもSoCの構成要素の一つに過ぎず、プラットフォーム間の互換性は持たない。
Wintelプラットフォーム下での各PCベンダーのような平行分散を嫌うからだ。
たとえばNintendo DSのソフトがiPhoneで動いても任天堂にはメリットがないわけだぜ。
単に複数の「独自プラットフォーム」を構成する共通要素としてARMが存在しているだけ。
仕様が共通化され同じソフトウェアが動くx86のようなスケールメリットは生じない。
CPUのコードが共通でもSoCの構成要素の一つに過ぎず、プラットフォーム間の互換性は持たない。
Wintelプラットフォーム下での各PCベンダーのような平行分散を嫌うからだ。
たとえばNintendo DSのソフトがiPhoneで動いても任天堂にはメリットがないわけだぜ。
単に複数の「独自プラットフォーム」を構成する共通要素としてARMが存在しているだけ。
仕様が共通化され同じソフトウェアが動くx86のようなスケールメリットは生じない。
アームのIP商売の収益ってたいしたことないよ。
逆に言うと格安でライセンスしてるから顧客は多い。
>2006年にARMコアは24億個出荷され、そのおよそ3分の2が携帯電話機向けだった。
>16億個前後のARMコアが携帯電話機に搭載されたことになる。この物凄い数値
>からすると、ARMの売上高はさぞかし巨大な金額かと思いきや、実際はそうでもない。
>ARMの2006年の売上高は4億8,360万米ドル、日本円で約500億円である。
>売上高が500億円とは、いささか少なすぎるようにみえる。Intelの2006年
>年間売上高は354億米ドルであるから、日本円で4兆円近くもある。
>ARMの売上高は、Intelの売上高の1.3%に過ぎない。
>アーム株式会社の代表取締役社長を務める西嶋貴史氏は、「ARMコアを内蔵した
>“半導体チップ”の売上高は総額で2兆円〜3兆円に達すると推定しています。
>ですが、ARMコアが半導体チップのトータルコストに占める割合はわずかです。
>このため企業としてのARMの事業規模は、Intelと違って比較的小さな金額にとどまっています」
逆に言うと格安でライセンスしてるから顧客は多い。
>2006年にARMコアは24億個出荷され、そのおよそ3分の2が携帯電話機向けだった。
>16億個前後のARMコアが携帯電話機に搭載されたことになる。この物凄い数値
>からすると、ARMの売上高はさぞかし巨大な金額かと思いきや、実際はそうでもない。
>ARMの2006年の売上高は4億8,360万米ドル、日本円で約500億円である。
>売上高が500億円とは、いささか少なすぎるようにみえる。Intelの2006年
>年間売上高は354億米ドルであるから、日本円で4兆円近くもある。
>ARMの売上高は、Intelの売上高の1.3%に過ぎない。
>アーム株式会社の代表取締役社長を務める西嶋貴史氏は、「ARMコアを内蔵した
>“半導体チップ”の売上高は総額で2兆円〜3兆円に達すると推定しています。
>ですが、ARMコアが半導体チップのトータルコストに占める割合はわずかです。
>このため企業としてのARMの事業規模は、Intelと違って比較的小さな金額にとどまっています」
200 :,,・´∀`・,,)っ-○○○:2009/11/23(月) 17:15:34 ID:nT9DryEJ
所詮部品のそのまた構成要素にすぎん。
「DDR2-DRAMチップはCore 2 Duoより売れている」
って言うようなもんで野暮
「DDR2-DRAMチップはCore 2 Duoより売れている」
って言うようなもんで野暮
垂直統合と対になるのは水平分業
NECがスパコンでIntelを選んだ理由
http://pc.watch.impress.co.jp/docs/column/hot/20091124_330515.html
http://pc.watch.impress.co.jp/docs/column/hot/20091124_330515.html
>価格競争力を度外視して、国家プロジェクトで世界一性能の高いスーパーコンピュータを開発しても、それは一時的な国威発揚にしかならない。
光インターコネクトとか45nmプロセスとかそういう要素技術が残ると思うのだが。
それをPCなり家電なりに活かせるのか、即転用はできないにしても先鞭になるのかという議論はまた必要かもしれない。
>総事業費約1,150億円という予算は、それに見合っているのか、ということを仕分け人は問うているのだと思う。
Intelは年間6000億以上R&Dに投資しているんですよ?5年で3兆円。
1150億円しか支援しないのだから先の見通しが微妙になるのはそらー当たり前でしょう。
スパコン開発の意義もわからなかった仕分け人には大金に思えるのかも知れないがなwww
だからアメリカ見習ってフェーズを幾つかに分けて一社に絞ってどかんと予算落とす方が良かったんだよ。
ただでさえ少なすぎる予算なのだから。
光インターコネクトとか45nmプロセスとかそういう要素技術が残ると思うのだが。
それをPCなり家電なりに活かせるのか、即転用はできないにしても先鞭になるのかという議論はまた必要かもしれない。
>総事業費約1,150億円という予算は、それに見合っているのか、ということを仕分け人は問うているのだと思う。
Intelは年間6000億以上R&Dに投資しているんですよ?5年で3兆円。
1150億円しか支援しないのだから先の見通しが微妙になるのはそらー当たり前でしょう。
スパコン開発の意義もわからなかった仕分け人には大金に思えるのかも知れないがなwww
だからアメリカ見習ってフェーズを幾つかに分けて一社に絞ってどかんと予算落とす方が良かったんだよ。
ただでさえ少なすぎる予算なのだから。
204 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 00:34:17 ID:hPX1Nh9Y
富士通という私企業の予算を国に組ませないといけない時点でおかしいだろボケ
それともIntelは米の国営企業か?
それともIntelは米の国営企業か?
206 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:00:05 ID:hPX1Nh9Y
で、あと何年おんぶにだっこさせればIntelみたいに自立してお金落ちるようになるの?
任天堂なんて国に技術開発支援受けたことは一度もないのに世界に誇るグローバル企業だぞ。
それは兎も角、先端プロセスを手がける半導体企業は露光技術でニコンやらの日本企業と協力関係にあるわけで
無理してまでIntelと同じ土俵で競争する必要なんてないんだよ。
任天堂なんて国に技術開発支援受けたことは一度もないのに世界に誇るグローバル企業だぞ。
それは兎も角、先端プロセスを手がける半導体企業は露光技術でニコンやらの日本企業と協力関係にあるわけで
無理してまでIntelと同じ土俵で競争する必要なんてないんだよ。
207 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:10:56 ID:hPX1Nh9Y
Intelはリソースの米国内調達に拘ってないんだよね。
モバイルチームはイスラエル人を雇ってるし、最先端プロセス用の露光装置は日本から買ってるわけだよな。
なんで日本は外部調達じゃなしに全部国産でやらんといかんのですか?
得意でもない分野まで。
食料自給率うpみたいな生産性のあることならまだわかるが。
Intelが22nmを手がけて旧くなった露光装置は中古で外部ファウンドリに流してるような2012年という時期に
独自に45nm作ったところで何が国益になるんですか?
45nmなんてルネサスは2008年に量産してるんですぜ?
君の主張は日本を鎖国して後進国にさせたいように見えてならんよ。
モバイルチームはイスラエル人を雇ってるし、最先端プロセス用の露光装置は日本から買ってるわけだよな。
なんで日本は外部調達じゃなしに全部国産でやらんといかんのですか?
得意でもない分野まで。
食料自給率うpみたいな生産性のあることならまだわかるが。
Intelが22nmを手がけて旧くなった露光装置は中古で外部ファウンドリに流してるような2012年という時期に
独自に45nm作ったところで何が国益になるんですか?
45nmなんてルネサスは2008年に量産してるんですぜ?
君の主張は日本を鎖国して後進国にさせたいように見えてならんよ。
話が分散しすぎていると思うが。
光インターコネクトとか要素技術の話だろう?
光インターコネクトとか要素技術の話だろう?
>>206
>で、あと何年おんぶにだっこさせればIntelみたいに自立してお金落ちるようになるの?
だから今の状態じゃおんぶにもだっこにもなってないんだよw
>任天堂なんて国に技術開発支援受けたことは一度もないのに世界に誇るグローバル企業だぞ。
任天堂に何の関係があるのか
団子は国がスパコン開発支援しないで現状を打開できると思ってるの?
>それは兎も角、先端プロセスを手がける半導体企業は露光技術でニコンやらの日本企業と協力関係にあるわけで
>無理してまでIntelと同じ土俵で競争する必要なんてないんだよ。
競争が激し過ぎるところを避けるのはわからないでもない
でもIntelと競合するリスクや見込める利益なんかの議論は尽くされていないと思う
>で、あと何年おんぶにだっこさせればIntelみたいに自立してお金落ちるようになるの?
だから今の状態じゃおんぶにもだっこにもなってないんだよw
>任天堂なんて国に技術開発支援受けたことは一度もないのに世界に誇るグローバル企業だぞ。
任天堂に何の関係があるのか
団子は国がスパコン開発支援しないで現状を打開できると思ってるの?
>それは兎も角、先端プロセスを手がける半導体企業は露光技術でニコンやらの日本企業と協力関係にあるわけで
>無理してまでIntelと同じ土俵で競争する必要なんてないんだよ。
競争が激し過ぎるところを避けるのはわからないでもない
でもIntelと競合するリスクや見込める利益なんかの議論は尽くされていないと思う
210 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:20:08 ID:hPX1Nh9Y
消費者向けの光伝送インターフェイスならそれもIntelがやってると思うのだが。
不治痛の手掛けたMOは流行らなかったぞ?
不治痛の手掛けたMOは流行らなかったぞ?
211 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:22:45 ID:hPX1Nh9Y
>団子は国がスパコン開発支援しないで現状を打開できると思ってるの?
国の金で国産CPU作る必要があるかといえば、否だな
ITゼネコンに金ばらまくって意味なら全く意味がないな
そもそもなんで民主党政権になってから言うわけだ?
日本が国営半導体企業を作らないといけないようなことを
自民がやってたわけでもあるまい?
国の金で国産CPU作る必要があるかといえば、否だな
ITゼネコンに金ばらまくって意味なら全く意味がないな
そもそもなんで民主党政権になってから言うわけだ?
日本が国営半導体企業を作らないといけないようなことを
自民がやってたわけでもあるまい?
212 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:27:14 ID:hPX1Nh9Y
それとも、Xeonでスパコン作って研究したら成果がどっかの企業にもってかれるんですか?
国の施策が不満ならそれこそ経団連構成企業で金出し合ってどっかの大学にスパコンでも作ればいい。
国立大への寄付の場合、国に税金もってかれない特権がある。
国の施策が不満ならそれこそ経団連構成企業で金出し合ってどっかの大学にスパコンでも作ればいい。
国立大への寄付の場合、国に税金もってかれない特権がある。
213 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 01:34:46 ID:hPX1Nh9Y
俺はコンピュータに必要なのは後にも先にもソフトだと思う
任天堂って電通の総バックアップ受けてなかったっけ
国じゃないにしろ真っ当な企業じゃねーだろな
それにウィンテルの構図だって米国政府が望んだ形だろうに
たぶん一企業の技術とがんばりだけってのはどこも無理。
国じゃないにしろ真っ当な企業じゃねーだろな
それにウィンテルの構図だって米国政府が望んだ形だろうに
たぶん一企業の技術とがんばりだけってのはどこも無理。
外人に金もたせ荒らさせ、トロン潰しなんてのも痕跡あるしな。
日本のソフト屋はゲームも何もかもその収益性から博打ヤクザが経営してるようなもんで、
ものづくり的な会社に育つはずもなし。
日本のソフト屋はゲームも何もかもその収益性から博打ヤクザが経営してるようなもんで、
ものづくり的な会社に育つはずもなし。
216 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 02:05:08 ID:hPX1Nh9Y
シアトルマリナーズのスポンサー企業でもある
217 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 02:09:31 ID:hPX1Nh9Y
http://blog.livedoor.jp/newskorea/archives/627525.html
自民政権でもろくなことになってない気がするんだが。
自民政権でもろくなことになってない気がするんだが。
元IBMの中の人でさえこんな意見だっつーのに団子ときたら
>●この事業仕分け手法はアメリカ人には話せない 投稿日: 2009/11/13
>(中略)
>・もし法的にオーソライズされていない質問者が多数決でプロジェクトに致命的とも言える
> 金額レベルの削減を1時間で決め、そのまままかり通るという手法が通ったとします。
> まさにアメリカのみならず世界の科学技術界の物笑いで、日本の大型科学技術プロジェクト
> 遂行への信用は大きく失墜するでしょう。(アメリカ人から聞かれてもうまく説明できないし、
> 話したくもないですね。来週がSC09ですから、日本の主な出展者にとってはワーストタイミング
> になってしまったに違いありません。)
>
>・ふたを開けてみたら、次世代スーパーコンピューター競争の最大の敵は20PetaFLOPSを
> 目指すIBMではなく実は自国政府でした、というのではしゃれにもなりません。個人的には、
> 最後まで関係者のねばりを見せて欲しいところです。
>
>・もう少し言うと、国の科学技術戦略を担当してきたオーソリティ(総合科学技術会議か)は
> こうした状況に対して当然ながら、きちんとなんらかの意思表示をする義務があると思います。
> と書いて総合科学技術会議のメンバーを調べたらトップが鳩山首相でした。
>
>●Blue Waters用POWER7 投稿日: 2009/11/18
>(中略)
>スーパーコンピュータのトップレベルでは、こんな激しい技術競争をしているわけですから、
>これがわかっていれば、2位でもいいなどという甘い発想はとても出てきません。
>●この事業仕分け手法はアメリカ人には話せない 投稿日: 2009/11/13
>(中略)
>・もし法的にオーソライズされていない質問者が多数決でプロジェクトに致命的とも言える
> 金額レベルの削減を1時間で決め、そのまままかり通るという手法が通ったとします。
> まさにアメリカのみならず世界の科学技術界の物笑いで、日本の大型科学技術プロジェクト
> 遂行への信用は大きく失墜するでしょう。(アメリカ人から聞かれてもうまく説明できないし、
> 話したくもないですね。来週がSC09ですから、日本の主な出展者にとってはワーストタイミング
> になってしまったに違いありません。)
>
>・ふたを開けてみたら、次世代スーパーコンピューター競争の最大の敵は20PetaFLOPSを
> 目指すIBMではなく実は自国政府でした、というのではしゃれにもなりません。個人的には、
> 最後まで関係者のねばりを見せて欲しいところです。
>
>・もう少し言うと、国の科学技術戦略を担当してきたオーソリティ(総合科学技術会議か)は
> こうした状況に対して当然ながら、きちんとなんらかの意思表示をする義務があると思います。
> と書いて総合科学技術会議のメンバーを調べたらトップが鳩山首相でした。
>
>●Blue Waters用POWER7 投稿日: 2009/11/18
>(中略)
>スーパーコンピュータのトップレベルでは、こんな激しい技術競争をしているわけですから、
>これがわかっていれば、2位でもいいなどという甘い発想はとても出てきません。
219 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 03:53:25 ID:hPX1Nh9Y
2位じゃ駄目か。わかってるじゃないか。
なら、海外で売れるような競争力も無いSPARC64(笑)だけで組むとか尚更駄目だな。
Sandy BridgeとLarrabeeで仕切りなおしするとかのほうがまだ生産的だ。
なら、海外で売れるような競争力も無いSPARC64(笑)だけで組むとか尚更駄目だな。
Sandy BridgeとLarrabeeで仕切りなおしするとかのほうがまだ生産的だ。
221 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 04:10:18 ID:hPX1Nh9Y
民主党がやろうとしてんのは前時代的な革命だね
形になってるものまで鬼の首とったかのように壊してる
支持もその茶番劇によるものだろう
形になってるものまで鬼の首とったかのように壊してる
支持もその茶番劇によるものだろう
元IBMといっても脳沢みたいなのもいるからなぁw
>>210
なぜそこでMOが?
なぜそこでMOが?
一般消費者はもはや求めてないのにお役所が生きながらえさせてるメディアの代表格ではある。
>>207
超スレチだけどアメリカからイスラエルへの投資や寄付の免税措置は病的だ。
超スレチだけどアメリカからイスラエルへの投資や寄付の免税措置は病的だ。
227 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 22:20:49 ID:hPX1Nh9Y
>>218の引用元ググったら出てきたけどこの人も相当キてるよな
経団連に期待しろって言ったのは撤回する。
自社の雇用すら守らないお便所さんが景気対策のために税金投じてくれ云々言うから笑えるわ。
安定雇用を破壊して国内消費を鈍らせてるのは何処の誰だよ。
かつて経済一流と言われた日本だが、今はその程度の自浄作用すら期待できない。
経団連に期待しろって言ったのは撤回する。
自社の雇用すら守らないお便所さんが景気対策のために税金投じてくれ云々言うから笑えるわ。
安定雇用を破壊して国内消費を鈍らせてるのは何処の誰だよ。
かつて経済一流と言われた日本だが、今はその程度の自浄作用すら期待できない。
No future!
229 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 23:08:31 ID:hPX1Nh9Y
杉林は適度に伐採してやんないと
花粉症が増えたりして経済にマイナスなのです
樹脂も豊富で良質な燃料にもなる。
まずは日本の林業を救うところから始めようか。
だんご粉自給率100%は二の次
花粉症が増えたりして経済にマイナスなのです
樹脂も豊富で良質な燃料にもなる。
まずは日本の林業を救うところから始めようか。
だんご粉自給率100%は二の次
団子の口から自給率とか聞くとは思わなかった
もっとグローバリゼーションマンセーな錬金術師のイメージだったよ
それとも何かを炙り出すためポーズで言ってんの?
もっとグローバリゼーションマンセーな錬金術師のイメージだったよ
それとも何かを炙り出すためポーズで言ってんの?
231 :,,・´∀`・,,)っ-○○○:2009/11/24(火) 23:46:06 ID:hPX1Nh9Y
砂糖をバイオ燃料にするよりは余ってる木を燃やす方が生産的だろう。
有機物は無駄に腐らせてはいけない。
有機物は無駄に腐らせてはいけない。
【ET2009レポート】XilinxとARM、合同記者発表会を開催
http://pc.watch.impress.co.jp/docs/news/event/20091125_331110.html
http://pc.watch.impress.co.jp/docs/news/event/20091125_331110.html
農産物からアルコールってのは詭弁だしな
大輸出国アメリカが自国で食う分まで燃料にしても、アメリカの2ヶ月分の燃料にしかならない
大輸出国アメリカが自国で食う分まで燃料にしても、アメリカの2ヶ月分の燃料にしかならない
ARM7/9を既に実装してるトコロは、上位機としてARM11を望むけど
ARMとしてはCortex-A使って欲しくて揉めがちである、と。
ARM11コア製品がロードマップに前々から載ってるけど出てこないって会社、確かにあるなw
ARMとしてはCortex-A使って欲しくて揉めがちである、と。
ARM11コア製品がロードマップに前々から載ってるけど出てこないって会社、確かにあるなw
モータ制御をAtomで代替するのは非現実的
http://journal.mycom.co.jp/articles/2009/11/25/et2009_intel/002.html
http://journal.mycom.co.jp/articles/2009/11/25/et2009_intel/002.html
237 :,,・´∀`・,,)っ-○○○:2009/11/25(水) 23:15:05 ID:XnXiDy9n
モータの制御なんてGHzなんてマスクROM内蔵の数十MHzの世界だな
今までの常識ならば。
どこまで打ち破れるか興味は尽きない
今までの常識ならば。
どこまで打ち破れるか興味は尽きない
Intelは、まだ8051改良型のMCS251や
8096系のMCS296とか作ってるんだから
そっち使え!って事だろ…
8096系のMCS296とか作ってるんだから
そっち使え!って事だろ…
239 :,,・´∀`・,,)っ-○○○:2009/11/25(水) 23:43:31 ID:XnXiDy9n
仮想敵は元ローラ、TI、ルネサスあたりか。。。
一体いくらで売る気だ
チャレンジャーにも程がある
一体いくらで売る気だ
チャレンジャーにも程がある
240 :,,・´∀`・,,)っ-○○○:2009/11/25(水) 23:44:48 ID:XnXiDy9n
モトローラってよりはフリスケか
MCS251/MCS296は既にディスコンで保守品種ですが
まだ一応手に入ります。えぇ。
っていうか、その代わりがAtom?無茶すぐる…
まだ一応手に入ります。えぇ。
っていうか、その代わりがAtom?無茶すぐる…
242 :,,・´∀`・,,)っ-○○○:2009/11/25(水) 23:52:30 ID:XnXiDy9n
Cortex A9のクアッドコアでMini-ITXのボードあるから買って遊んでみようと思ったら
60マンとかふざけてるのかと
それはそうとiPhoneに感染するウィルスも出てきたし「MacOSは絶対にウィルスに感染しない」なんて
基地外マカーが少しは減るんだろうか
60マンとかふざけてるのかと
それはそうとiPhoneに感染するウィルスも出てきたし「MacOSは絶対にウィルスに感染しない」なんて
基地外マカーが少しは減るんだろうか
244 :,,・´∀`・,,)っ-○○○:2009/11/26(木) 00:02:16 ID:XnXiDy9n
デュアルコアCortex-A9のAndroidケータイの白ロム何個か繋いでクラスタリングみたいな
とてつもなくアホなことがやりたくなった
とてつもなくアホなことがやりたくなった
基地外マカーと言えば団子ちゃんと仲良しのあの方を最近見ないんだが
ザイリンクスって読むのかw
?
スパコン開発は世界一を目指さなければ意味がない - 東大・平木教授
http://journal.mycom.co.jp/articles/2009/11/27/hiraki/index.html
http://journal.mycom.co.jp/articles/2009/11/27/hiraki/index.html
249 :,,・´∀`・,,)っ-○○○:2009/11/28(土) 01:42:42 ID:q4aoUrmv
GRAPE関係はなんでこうもキてる人ばかりなのか
幕末の武士のように
もう自分たちが要らないんだって認めたくないんで
必死なんじゃない
もう自分たちが要らないんだって認めたくないんで
必死なんじゃない
CPUあーきてくちゃ、を語る人も同じに見えてるぞ。
武士道を語る町民がいたっていいじゃんw
ニュー速とか見てるとスカラプロセッサは安い、
ベクトルプロセッサは高いという議論になったりしてんのな
安いスカラプロセッサなんてx86だけだというのに
これを理由にNECディスって富士通マンセーしたり
SPARCの富士通が日本勢だったりPS3にしろだのもう滅茶苦茶w
ベクトルプロセッサは高いという議論になったりしてんのな
安いスカラプロセッサなんてx86だけだというのに
これを理由にNECディスって富士通マンセーしたり
SPARCの富士通が日本勢だったりPS3にしろだのもう滅茶苦茶w
254 :,,・´∀`・,,)っ-○○○:2009/11/28(土) 15:31:07 ID:q4aoUrmv
たしかにひどい
255 :,,・´∀`・,,)っ-○○○:2009/11/28(土) 15:34:27 ID:q4aoUrmv
世界的にCO2排出量削減の流れになればベクトルは復権とはいかないまでも
アクセラレータとしては一定の支持を取り戻すことはできると思うよ。
いつになるかは知らんが。
まあ、汎用性は低いが安いベクトル型プロセッサ(GPU)も台頭してきたことだし
いろいろ面白いことになりそうですな
アクセラレータとしては一定の支持を取り戻すことはできると思うよ。
いつになるかは知らんが。
まあ、汎用性は低いが安いベクトル型プロセッサ(GPU)も台頭してきたことだし
いろいろ面白いことになりそうですな
>>255
米中もやる気ないし自国の経済を悪くする政策に世界が乗り気になるわけない。
「アホの日本が罠にかかりおった。
排出権相場を釣り上げて日本にある金を搾り取ってやる。ウヘヘ」
ってのが地球温暖化詐欺だろうに。
米中もやる気ないし自国の経済を悪くする政策に世界が乗り気になるわけない。
「アホの日本が罠にかかりおった。
排出権相場を釣り上げて日本にある金を搾り取ってやる。ウヘヘ」
ってのが地球温暖化詐欺だろうに。
ま、CO2は25%減らさなきゃってのは科学的に要求される最低レベルの対策ってことはおいといて
日本のアレは中国とかもやるなら削減って話だから、実行に移されるなら米中も削減するよ
日本のアレは中国とかもやるなら削減って話だから、実行に移されるなら米中も削減するよ
258 :OOO-⊂(´∀`旦⊂☆諫碕:2009/11/28(土) 23:54:45 ID:6zYEyD45
>>253
LRBスレにもちょっと前に書いたが、
スカラvsベクトルっていう世界観で未だに分析しているくせがあるのが悪い。
スパコンは
・どれだけ汎用品のものを流用するか
・どれだけ専用のものを新規に設計するか
という部分が重要で、アーキテクチャとか技術論というよりは
経済面でのメリット・デメリット論の世界なんだよ。
純粋に技術的にいえばHPCで自分がよく走らせるコードを神が分析して
それ用に神が最適化して設計したプロセッサのアーキテクチャが一番効率がいい。
つまり専用プロセッサの方が有利。
しかし、新規部分の多い開発にはコストがかかる。
結局のところ彼らの議論は、経済面の話なの。それがわかってないHPCオタが多い。
LRBスレにもちょっと前に書いたが、
スカラvsベクトルっていう世界観で未だに分析しているくせがあるのが悪い。
スパコンは
・どれだけ汎用品のものを流用するか
・どれだけ専用のものを新規に設計するか
という部分が重要で、アーキテクチャとか技術論というよりは
経済面でのメリット・デメリット論の世界なんだよ。
純粋に技術的にいえばHPCで自分がよく走らせるコードを神が分析して
それ用に神が最適化して設計したプロセッサのアーキテクチャが一番効率がいい。
つまり専用プロセッサの方が有利。
しかし、新規部分の多い開発にはコストがかかる。
結局のところ彼らの議論は、経済面の話なの。それがわかってないHPCオタが多い。
259 :OOO-⊂(´∀`旦⊂☆諫碕:2009/11/28(土) 23:57:21 ID:6zYEyD45
まあ一部プロセッサと書いてしまったけど、当然プロセッサだけじゃないよね。
経済面の話だってのは納得
でも、ものを安く作れるってのも「技術」じゃないのかな
経済面を全く無視した技術ってのは成り立ちうるんだろうか
でも、ものを安く作れるってのも「技術」じゃないのかな
経済面を全く無視した技術ってのは成り立ちうるんだろうか
261 :OOO-⊂(´∀`旦⊂☆諫碕:2009/11/29(日) 00:21:44 ID:5LUz4v7U
>>260
おれがいってるのはそこまで完璧に経済面を排除した首尾一貫した理屈じゃない罠。
少なくともGPGPUはベクトルプロセッサと似ているからベクトルプロセッサの様な末路を迎えるとか、
スパコン用にスカラプロセッサさえ頑張って開発して沢山つなげば、世界一になれるとか、
無理のある論理は排除できるだろ。
HPCオタは殆ど経済面の理屈で合理的に理解できる議論をしているのにもかかわらず、
自分達は科学・技術の話をしていると思いこんでいるところ。
だから技術面と経済面が合致しない部分で永遠に矛盾を抱えたまま綺麗な結論が出せないでいる。
おれがいってるのはそこまで完璧に経済面を排除した首尾一貫した理屈じゃない罠。
少なくともGPGPUはベクトルプロセッサと似ているからベクトルプロセッサの様な末路を迎えるとか、
スパコン用にスカラプロセッサさえ頑張って開発して沢山つなげば、世界一になれるとか、
無理のある論理は排除できるだろ。
HPCオタは殆ど経済面の理屈で合理的に理解できる議論をしているのにもかかわらず、
自分達は科学・技術の話をしていると思いこんでいるところ。
だから技術面と経済面が合致しない部分で永遠に矛盾を抱えたまま綺麗な結論が出せないでいる。
なるほど、了解
263 :OOO-⊂(´∀`旦⊂☆諫碕:2009/11/29(日) 00:29:15 ID:5LUz4v7U
まあ蛇足であるが、用途が科学技術計算というジャンルで専門家の顔もよくでる話だから、
HPCオタは特にそういう傾向が強いんだと思う。技術に経済面の話を導入すると純粋な技術論が汚れるみたいな。
その点、コンシューマの雑多な話が多いおれらの方は技術と経済面とは自然にミックス
された状態の話題になれているからな。自作板の勝利ってことで。
HPCオタは特にそういう傾向が強いんだと思う。技術に経済面の話を導入すると純粋な技術論が汚れるみたいな。
その点、コンシューマの雑多な話が多いおれらの方は技術と経済面とは自然にミックス
された状態の話題になれているからな。自作板の勝利ってことで。
安全保障とかそういう政治的な話を持ち出す輩にはどう対応すればいいすかね?
265 :MACオタ>264 さん:2009/11/29(日) 01:13:21 ID:pL7dE78L
>>264
--------------------
安全保障とかそういう政治的な話を持ち出す輩にはどう対応すればいいすかね?
--------------------
海千山千の悪党国家であるギリスもフランスもドイツも自国製スーパーコンピュータ用プロセッサなんて
開発していない…というのが、最も判り易い回答では?
--------------------
安全保障とかそういう政治的な話を持ち出す輩にはどう対応すればいいすかね?
--------------------
海千山千の悪党国家であるギリスもフランスもドイツも自国製スーパーコンピュータ用プロセッサなんて
開発していない…というのが、最も判り易い回答では?
うお 久々に見た
MACオタさん生きてたんだ…
せっかくだからオタさんに質問
- IBMがHPCでのCellの使用をやめるらしい件
- PS4のCPUにPOWER7コアが使われるという噂
について、何かコメントください
- IBMがHPCでのCellの使用をやめるらしい件
- PS4のCPUにPOWER7コアが使われるという噂
について、何かコメントください
The RegisterのT.P.Morgan記者がSC09で展示されていたBlue Waters向けPOWER7ノード
について結構詳しい記事を書いています。
http://www.theregister.co.uk/2009/11/27/ibm_power7_hpc_server/
4chip (=32core) MCMの写真なども興味深いですが、マザーボードについて面白い記述が…
--------------------
There are two monster motherboards underpinning the processors and their
memory and the hub/switch and its interconnects. These mobos are
manufactured by Japanese server maker Hitachi and Brenner said that these
were the largest motherboards ever made.
--------------------
京速から遁走した日立はBlue Watersノード向けマザーボードの製造を担当していた
とか(笑) 国が技術振興のためにやるべきことは『何』なのか、考えさせられますね。
について結構詳しい記事を書いています。
http://www.theregister.co.uk/2009/11/27/ibm_power7_hpc_server/
4chip (=32core) MCMの写真なども興味深いですが、マザーボードについて面白い記述が…
--------------------
There are two monster motherboards underpinning the processors and their
memory and the hub/switch and its interconnects. These mobos are
manufactured by Japanese server maker Hitachi and Brenner said that these
were the largest motherboards ever made.
--------------------
京速から遁走した日立はBlue Watersノード向けマザーボードの製造を担当していた
とか(笑) 国が技術振興のためにやるべきことは『何』なのか、考えさせられますね。
ということが判明した訳ですが、技術振興のために国がやるべきことって『何』という
ことのヒントが隠されているような…
ことのヒントが隠されているような…
271 :MACオタ>268 さん:2009/11/29(日) 02:01:02 ID:pL7dE78L
>>268
最初の話ですが、IBMの米国特許をちょっと調べてみるだけでもCELL/B.E.への開発
投資が続いていそうなのは推察できますよ。
http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=0&p=1&f=S&l=50&Query=AN%2F%22International+Business+Machines%22+and+%22Broadband+Engine%22&d=PTXT
2番目の話ですが、上の記事でPOWER7 MCMの消費電力とパッケージサイズについて
の記述を読んでから真偽を考えてみてはいかがでしょうか?
-----------------------
Both chip packages have the same pin count at 5,336 pins (92 pins by 58 pins),
according to Alan Brenner, a senior technical staff member of the server and
network architecture team within IBM's Systems and Technology Group:
…
At 800 watts, the package is not cool by any means, but the Power7 IH MCM is
delivering performance at 1.28 gigaflops per watt at the package level.
-----------------------
最初の話ですが、IBMの米国特許をちょっと調べてみるだけでもCELL/B.E.への開発
投資が続いていそうなのは推察できますよ。
http://patft.uspto.gov/netacgi/nph-Parser?Sect1=PTO2&Sect2=HITOFF&u=%2Fnetahtml%2FPTO%2Fsearch-adv.htm&r=0&p=1&f=S&l=50&Query=AN%2F%22International+Business+Machines%22+and+%22Broadband+Engine%22&d=PTXT
2番目の話ですが、上の記事でPOWER7 MCMの消費電力とパッケージサイズについて
の記述を読んでから真偽を考えてみてはいかがでしょうか?
-----------------------
Both chip packages have the same pin count at 5,336 pins (92 pins by 58 pins),
according to Alan Brenner, a senior technical staff member of the server and
network architecture team within IBM's Systems and Technology Group:
…
At 800 watts, the package is not cool by any means, but the Power7 IH MCM is
delivering performance at 1.28 gigaflops per watt at the package level.
-----------------------
日立は京速では要素技術担当だったから(と思う)
IBMの下請けは何ら不思議ではないが
日立もPOWER売ってるしな
IBMの下請けは何ら不思議ではないが
日立もPOWER売ってるしな
>>229
植林の売り文句は「伐採した木材を販売すれば儲けも出ますよ」だったが
輸入木材などで国産木材価格が暴落→放置
落葉広葉樹が一掃されて山も川も痩せて護岸工事の弊害もあって土砂崩れに鉄砲水。
森も山も川も海も壊滅状態。
日本の林業を救う方針は研修生という名の奴隷待遇の外国人労働力の使い捨て
日本人は石油化学や金属製品を加工する機械と紙屑紙幣を引きかえに
竹籠や藁細工を作る技術すらほぼ失ったのである。
植林の売り文句は「伐採した木材を販売すれば儲けも出ますよ」だったが
輸入木材などで国産木材価格が暴落→放置
落葉広葉樹が一掃されて山も川も痩せて護岸工事の弊害もあって土砂崩れに鉄砲水。
森も山も川も海も壊滅状態。
日本の林業を救う方針は研修生という名の奴隷待遇の外国人労働力の使い捨て
日本人は石油化学や金属製品を加工する機械と紙屑紙幣を引きかえに
竹籠や藁細工を作る技術すらほぼ失ったのである。
上のBlue Waters向けPOWER7ノードの件、Cheer HPCブログも良い写真を載せているので
紹介しておきます。
http://cheerhpc.wordpress.com/2009/11/18/%E2%97%8Fblue-waters%E7%94%A8power7/
・ノード内部
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_1647abf0-a4da-402e-9386-3cd693db8676.jpeg
・POWER7 MCM
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_5b4d0a30-3132-405d-ad38-739e917dff71.jpeg
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_d32d1653-c8d6-4178-bc13-628e2f5d5d1e.jpeg
・インタコネクトモジュール
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_ccfeb776-2cc2-4cf1-9b3d-81e3383f2856.jpeg
紹介しておきます。
http://cheerhpc.wordpress.com/2009/11/18/%E2%97%8Fblue-waters%E7%94%A8power7/
・ノード内部
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_1647abf0-a4da-402e-9386-3cd693db8676.jpeg
{kind=link}
・POWER7 MCM
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_5b4d0a30-3132-405d-ad38-739e917dff71.jpeg
{kind=link}
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_d32d1653-c8d6-4178-bc13-628e2f5d5d1e.jpeg
{kind=link}
・インタコネクトモジュール
http://cheerhpc.files.wordpress.com/2009/11/p_2048_1536_ccfeb776-2cc2-4cf1-9b3d-81e3383f2856.jpeg
{kind=link}
ID変わってるけど275です
一応元ネタ(?)貼っときます
Cell is no longer HPC material
http://www.theinquirer.net/inquirer/news/1563659/cell-hpc-material
Sony chooses IBM POWER 7 CPU for PlayStation 4
http://www.gamekicker.com/Gaming-News/Sony-chooses-IBM-POWER-7-CPU-for-PlayStation-4
一応元ネタ(?)貼っときます
Cell is no longer HPC material
http://www.theinquirer.net/inquirer/news/1563659/cell-hpc-material
Sony chooses IBM POWER 7 CPU for PlayStation 4
http://www.gamekicker.com/Gaming-News/Sony-chooses-IBM-POWER-7-CPU-for-PlayStation-4
京速を大艦巨砲主義と批判する人がいるが
アメリカだって巨大戦艦を作っているということだな<800W
アメリカだって巨大戦艦を作っているということだな<800W
>>277
RadeonHD5750なら100W切ってますよ(棒
RadeonHD5750なら100W切ってますよ(棒
カタログスペックは結構です
281 :,,・´∀`・,,)っ-○○○:2009/11/29(日) 14:30:45 ID:1kopwAVM
>>277
Larrabeeのこないだのは単精度だぞ。
倍精度ならこないだのデモ機なら半分の500GFLOPS程度がピークだろうね。
(ただ同時処理できる演算数が減るので実効性能比は改善されると思われる)
Larrabeeのこないだのは単精度だぞ。
倍精度ならこないだのデモ機なら半分の500GFLOPS程度がピークだろうね。
(ただ同時処理できる演算数が減るので実効性能比は改善されると思われる)
すれっどすとっぱー
>>278
それ池田とかいう池沼だろwww
それ池田とかいう池沼だろwww
いや、ノビーの影響なのか何なのか
結構言ってる人いるよ
結構言ってる人いるよ
あのおっさんはただの芸能人だから指さして笑ってやるのが優しさってもん
自称アルファブロガーは総じてキチガイ
SH-Mobileは、もうARMなんだな
ルネサス、1GHz CPU搭載の「SH-Mobile Appliation Engine 4」
http://k-tai.impress.co.jp/docs/news/20091130_332387.html
ルネサス、1GHz CPU搭載の「SH-Mobile Appliation Engine 4」
http://k-tai.impress.co.jp/docs/news/20091130_332387.html
>>288
WindowsCEがSHサポート止めるからね…
WindowsCEがSHサポート止めるからね…
あら、そうなの
他社製OS使ってると怖いよな……
>>288
http://ja.wikipedia.org/wiki/SuperH#SH-Mobile_G.E3.82.B7.E3.83.AA.E3.83.BC.E3.82.BA
要はGシリーズの流れなんじゃないの?
GPGPUに対応するようになるらしいし、SuperHがいらない子になるような……
http://ja.wikipedia.org/wiki/SuperH#SH-Mobile_G.E3.82.B7.E3.83.AA.E3.83.BC.E3.82.BA
要はGシリーズの流れなんじゃないの?
GPGPUに対応するようになるらしいし、SuperHがいらない子になるような……
そこでRXでつよ。
294 :,,・´∀`・,,)っ-○○○:2009/12/01(火) 22:46:47 ID:ekg7DMWw
1個3000円か・・・
評価ボードとか1台ウン万円なんだろうな
評価ボードとか1台ウン万円なんだろうな
http://ednjapan.rbi-j.com/news/2009/12/5754
Hypercoreだそうな
Hypercoreだそうな
296 :,,・´∀`・,,)っ-○○○:2009/12/05(土) 16:36:51 ID:KKTvEirv
なにこの超イケメン
キャー
キャー
団子ちゃんってその気があったの?
298 :,,・´∀`・,,)っ-○○○:2009/12/06(日) 01:32:15 ID:nTu8nNRJ
ねーよwwww
ちょっとだけお塩先生に似てるな
ちょっとだけお塩先生に似てるな
訳:ちょっとだけその気があった
300 :,,・´∀`・,,)っ-○○○:2009/12/07(月) 23:55:37 ID:3pFyeiTC
お塩先生はだんごやさんの心の師
緑赤青w
303 :,,・´∀`・,,)っ-○○○:2009/12/12(土) 16:24:55 ID:LfwDXAhP
クラウドは 逆から読めば 道楽だ
-○○○
-○○○
オレ何色?
黄色
306 :,,・´∀`・,,)っ-○○○:2009/12/13(日) 03:19:24 ID:Gw3F5ZKy
ああVIAのマザボの基盤の色か
いや、まじでs3は黄色
ページ見てみりゃわかる黄色と黒は勇気の標
あとepia,vbやらのボードは青
そういや、黄色のボードってsocket7時代のficとasus位しか
うちにないな
あと、ati/amdって何色?
ページ見てみりゃわかる黄色と黒は勇気の標
あとepia,vbやらのボードは青
そういや、黄色のボードってsocket7時代のficとasus位しか
うちにないな
あと、ati/amdって何色?
308 :,,・´∀`・,,)っ-○○○:2009/12/13(日) 12:43:46 ID:Gw3F5ZKy
クリスマスカラーだよな
クリスマベクトル
310 :Socket774:2009/12/13(日) 18:03:13 ID:QmFAYWWh
あげ
POWER7でやっとOoO復活したのがうれしいね
インテルが失敗したインオーダーの深パイプライン設計を踏襲したりとしばらく迷走してたからなあ…
インテルが失敗したインオーダーの深パイプライン設計を踏襲したりとしばらく迷走してたからなあ…
来年のISSCCでPOWER7の詳細が複数の論文で公開されることは周知の通りです。
http://www.isscc.org/isscc/2010/ISSCCAP2010.pdf
------------------------
5.4 The Implementation of POWER7): A Highly Parallel and Scalable
Multi-Core High-End Server Processor
5.5 A Wire-Speed Power Processor: 2.3GHz 45nm SOI with 16 Cores and 64 Threads
(MACオタ注: おそらくPOWER6 - Z10の関係に対応するメインフレームプロセッサ)
9.3 POWER7 Local Clocking and Clocked Storage Elements
19.1 A 45nm SOI Embedded DRAM Macro for POWER7 32MB On-Chip L3 Cache
19.2 A 32kB 2R/1W L1 Data Cache in 45nm SOI Technology for the POWER7 Processor
------------------------
今年のまとめとして、Hot Chips 21以来公開された資料からPOWER7についての技術情報を
書いてみます。
http://www.isscc.org/isscc/2010/ISSCCAP2010.pdf
------------------------
5.4 The Implementation of POWER7): A Highly Parallel and Scalable
Multi-Core High-End Server Processor
5.5 A Wire-Speed Power Processor: 2.3GHz 45nm SOI with 16 Cores and 64 Threads
(MACオタ注: おそらくPOWER6 - Z10の関係に対応するメインフレームプロセッサ)
9.3 POWER7 Local Clocking and Clocked Storage Elements
19.1 A 45nm SOI Embedded DRAM Macro for POWER7 32MB On-Chip L3 Cache
19.2 A 32kB 2R/1W L1 Data Cache in 45nm SOI Technology for the POWER7 Processor
------------------------
今年のまとめとして、Hot Chips 21以来公開された資料からPOWER7についての技術情報を
書いてみます。
Hot Chipのプレゼン自体はまだ公開されていませんが、Power.orgが公開している
このプレゼンがKalla氏の講演とほぼ同じものであるようです。
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_POWER7.pdf
・1.2 Billion transistors
・45nm, Cu-SOI, ダイサイズ: 567mm2
・2 FXU, 2 LSU, 4 FPU, 1Vector Unit, 1 Branch Unit, 1 Condition Register Unit,
1 Decimal FPU
・6-wide dispatch / 8-wide issue
・ 1, 2, 4-way SMT
・OoOE
・32KB L1-I, 32KB L1-D, 256KB L2 per core
・ 8-core + 32MB shared eDRAM L3
・up to 32-socket
・コア性能向上
- パイプライン改良
- L1レイテンシ低減
- L2とコアを緊密化
・チップ性能向上
- 2-core (POWER6) -> 8-core (POWER7)
- コア間インタコネクト高性能化
- off-die eDRAM L3 (POWER6) -> on-die eDRAM L3 (POWER7)
- Dual DDR3対応メモリコントローラ
・省電力機能
- Power Gating 採用
- Dose - Nap - Sleep
- DVFS (Dynamic Voltage and Frequency Slewing)
- Turbo-Mode (up to 10% frequency boost)
最終ページのプロセッサモジュールの写真は、明らかに>>274あたりのBlue Waters向けの
モノとは異なっているようですから、一般サーバー向けの開発もすすんでいるようです。
このプレゼンがKalla氏の講演とほぼ同じものであるようです。
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_POWER7.pdf
・1.2 Billion transistors
・45nm, Cu-SOI, ダイサイズ: 567mm2
・2 FXU, 2 LSU, 4 FPU, 1Vector Unit, 1 Branch Unit, 1 Condition Register Unit,
1 Decimal FPU
・6-wide dispatch / 8-wide issue
・ 1, 2, 4-way SMT
・OoOE
・32KB L1-I, 32KB L1-D, 256KB L2 per core
・ 8-core + 32MB shared eDRAM L3
・up to 32-socket
・コア性能向上
- パイプライン改良
- L1レイテンシ低減
- L2とコアを緊密化
・チップ性能向上
- 2-core (POWER6) -> 8-core (POWER7)
- コア間インタコネクト高性能化
- off-die eDRAM L3 (POWER6) -> on-die eDRAM L3 (POWER7)
- Dual DDR3対応メモリコントローラ
・省電力機能
- Power Gating 採用
- Dose - Nap - Sleep
- DVFS (Dynamic Voltage and Frequency Slewing)
- Turbo-Mode (up to 10% frequency boost)
最終ページのプロセッサモジュールの写真は、明らかに>>274あたりのBlue Waters向けの
モノとは異なっているようですから、一般サーバー向けの開発もすすんでいるようです。
Power.orgが公開している別の資料にも興味深い記述があります。
http://www.power.org/news/newsletter/Power.org_Q3_2009_Newsletter_final.pdf
(p.11)
----------------------
The new POWER7 Core has a total of 18 execution units, including two
fixed point pipelines bit aligned to the two LSU pipes.
----------------------
資料ごとにPOWER7の実行ユニット数の表記は異なっているのですが、>>313でも書いたような
12個という表記が多く、"two fixed point pipelines bit aligned to the two LSU pipes"というのは
FXUのことではなく、LSUにx86のAGU相当のアドレス演算用整数演算ユニットが追加されたもの
と思われます。
その他の追加情報は下記の通り
・11 levels of metal layer
・L3はコヒーレンシトラフィック低減のためのディレクトリとしても機能する
http://www.power.org/news/newsletter/Power.org_Q3_2009_Newsletter_final.pdf
(p.11)
----------------------
The new POWER7 Core has a total of 18 execution units, including two
fixed point pipelines bit aligned to the two LSU pipes.
----------------------
資料ごとにPOWER7の実行ユニット数の表記は異なっているのですが、>>313でも書いたような
12個という表記が多く、"two fixed point pipelines bit aligned to the two LSU pipes"というのは
FXUのことではなく、LSUにx86のAGU相当のアドレス演算用整数演算ユニットが追加されたもの
と思われます。
その他の追加情報は下記の通り
・11 levels of metal layer
・L3はコヒーレンシトラフィック低減のためのディレクトリとしても機能する
315 :,,・´∀`・,,)っ-○○○:2009/12/23(水) 12:40:58 ID:P04lSfD3
>x86のAGU相当のアドレス演算用整数演算ユニット
別モノだよ。
そもそもx86相当のアドレッシングモード自体がないのでAGUのような仕組みは原理的に無理。
ModRM以降の可変長フィールドを解決するものだが、あれは形式にもとづいてアドレス生成専用に
カスタマイズされている。
一方POWER ISAはアドレス演算も通常の整数演算も同じ命令で区別がない。
依存関係を走査すればできなくもないけど、コストがかかりすぎる。
Load/Store + アドレスインクリメントの複合命令ならあるがそれを分解せずに実行するのが一番コストかからんでしょ
逆にx86のアドレッシングモードはポインタをインクリメントしない。
「ARM相当」の間違いでしょ。
別モノだよ。
そもそもx86相当のアドレッシングモード自体がないのでAGUのような仕組みは原理的に無理。
ModRM以降の可変長フィールドを解決するものだが、あれは形式にもとづいてアドレス生成専用に
カスタマイズされている。
一方POWER ISAはアドレス演算も通常の整数演算も同じ命令で区別がない。
依存関係を走査すればできなくもないけど、コストがかかりすぎる。
Load/Store + アドレスインクリメントの複合命令ならあるがそれを分解せずに実行するのが一番コストかからんでしょ
逆にx86のアドレッシングモードはポインタをインクリメントしない。
「ARM相当」の間違いでしょ。
316 :MACオタ@ここまで:2009/12/23(水) 12:54:13 ID:FLB/nvDP
IBMがセミナー資料として公開しているJ. M. Tendler氏のプレゼンのいくつかのバージョン
がネット上で見つかりますが、POWER7のキャッシュ/メモリ階層と、コヒーレンシ維持機構
について詳細に記されています。
http://www.ibm.com/developerworks/wikis/download/attachments/104533325/POWER7+-+The+Beat+Goes+On+v3+(Presented+to+Philadelphia+Users+Group,+2009-11-17).pdf
・メモリ
- デュアル・メモリコントローラ
- メモリコントローラとDIMMの間には"Advanced Buffer Chip"を挟む
(POWER4以来の"SMI"チップと同じ)
- メモリコントローラとバッファ間は8-chの高速リンク
差動インターフェース採用、6.4GHz, 28-byte (total?)
- DDR3、800, 1066, 1333, 1600MHz サポート
・eDRAM L3 (32MB)
- ローカル接続メモリの1/3のレイテンシ
- 単一スレッドが全領域を占有する設定も可能
・"Fast Local" L3
- L3の一部 (up to 4MB)を低レイテンシの高速領域として利用可能
- 通常L3の1/5のレイテンシ
・L2 "Turbo" キャッシュ
- L2はコアと緊密に結合
- 上記の『ローカル』L3の1/3のレイテンシ
・キャッシュ階層
L1: write-through, L2: write-back, Local L3: partial-victim, Shared L3: adaptive
・メモリコヒーレンシ
- Global Coherence Throughput: 32GB/s (POWER6) -> 450GB/s (POWER7)
- 『投機的』コヒーレンシ通信
- 複雑な共有状態を表現する13レベルの共有ステータス
書き忘れましたが、統合eDRAMに関してSOIを利用したFBC (Floating Body Cell)との
観測もありましたが、トレンチ構造とのこと。
http://journal.mycom.co.jp/articles/2009/09/16/hot_chips21_power7/002.html
----------------------
このDRAMはDeep Trenchキャパシタを使用するタイプのものであり、SOIのBox
(Buried Oxide)層を取り除いてその下のシリコンバルクに深い溝を掘り、その溝の
側面に情報記憶用のキャパシタを作る。
----------------------
がネット上で見つかりますが、POWER7のキャッシュ/メモリ階層と、コヒーレンシ維持機構
について詳細に記されています。
http://www.ibm.com/developerworks/wikis/download/attachments/104533325/POWER7+-+The+Beat+Goes+On+v3+(Presented+to+Philadelphia+Users+Group,+2009-11-17).pdf
・メモリ
- デュアル・メモリコントローラ
- メモリコントローラとDIMMの間には"Advanced Buffer Chip"を挟む
(POWER4以来の"SMI"チップと同じ)
- メモリコントローラとバッファ間は8-chの高速リンク
差動インターフェース採用、6.4GHz, 28-byte (total?)
- DDR3、800, 1066, 1333, 1600MHz サポート
・eDRAM L3 (32MB)
- ローカル接続メモリの1/3のレイテンシ
- 単一スレッドが全領域を占有する設定も可能
・"Fast Local" L3
- L3の一部 (up to 4MB)を低レイテンシの高速領域として利用可能
- 通常L3の1/5のレイテンシ
・L2 "Turbo" キャッシュ
- L2はコアと緊密に結合
- 上記の『ローカル』L3の1/3のレイテンシ
・キャッシュ階層
L1: write-through, L2: write-back, Local L3: partial-victim, Shared L3: adaptive
・メモリコヒーレンシ
- Global Coherence Throughput: 32GB/s (POWER6) -> 450GB/s (POWER7)
- 『投機的』コヒーレンシ通信
- 複雑な共有状態を表現する13レベルの共有ステータス
書き忘れましたが、統合eDRAMに関してSOIを利用したFBC (Floating Body Cell)との
観測もありましたが、トレンチ構造とのこと。
http://journal.mycom.co.jp/articles/2009/09/16/hot_chips21_power7/002.html
----------------------
このDRAMはDeep Trenchキャパシタを使用するタイプのものであり、SOIのBox
(Buried Oxide)層を取り除いてその下のシリコンバルクに深い溝を掘り、その溝の
側面に情報記憶用のキャパシタを作る。
----------------------
317 :MACオタ>団子 さん:2009/12/23(水) 13:34:48 ID:FLB/nvDP
>>315
----------------
Load/Store + アドレスインクリメントの複合命令ならあるが
----------------
"update"オプションのつくlwzu/stwuのような命令以外にも、FXUリソースを必要とする
命令はある様なのです。
gccの最適化ファイルが実行ユニットの内部構造の推測にどの程度役に立つかは謎ですが、
下記は power4 の最適化設定ファイルです。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/power4.md?revision=152732&view=markup
単純ロード (power4-load) 以外は、整数演算リソース (iuX_power4) を必要とするのが
判るかと…
----------------
Load/Store + アドレスインクリメントの複合命令ならあるが
----------------
"update"オプションのつくlwzu/stwuのような命令以外にも、FXUリソースを必要とする
命令はある様なのです。
gccの最適化ファイルが実行ユニットの内部構造の推測にどの程度役に立つかは謎ですが、
下記は power4 の最適化設定ファイルです。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/power4.md?revision=152732&view=markup
単純ロード (power4-load) 以外は、整数演算リソース (iuX_power4) を必要とするのが
判るかと…
>>312
5.5って "Power Processor" って書いてあるけどz11のことなの?
5.5って "Power Processor" って書いてあるけどz11のことなの?
319 :,,・´∀`・,,)っ-○○○:2009/12/23(水) 15:59:33 ID:P04lSfD3
>>318 さん
-------------------
5.5って "Power Processor" って書いてあるけどz11のことなの?
-------------------
言われてみると、Z10も実行ユニットの構成はPOWER6と同じでもISAはPOWERじゃないですね。
勘違いだったかも。
でも他にこのプロセッサの使い道って何なんでしょう?
>>319 団子 さん
そのプレゼンのダイ写真は、>>313や>>316に含まれている写真とどこか違いますか?
資料を読まずに脊髄反射で書き込む癖はヤメた方が良いかと…
-------------------
5.5って "Power Processor" って書いてあるけどz11のことなの?
-------------------
言われてみると、Z10も実行ユニットの構成はPOWER6と同じでもISAはPOWERじゃないですね。
勘違いだったかも。
でも他にこのプロセッサの使い道って何なんでしょう?
>>319 団子 さん
そのプレゼンのダイ写真は、>>313や>>316に含まれている写真とどこか違いますか?
資料を読まずに脊髄反射で書き込む癖はヤメた方が良いかと…
323 :MACオタ>322 さん:2009/12/23(水) 20:48:45 ID:AbeI9a02
>>322
----------------
ネットワークプロセッサ
----------------
それってボッタくりIBMが最新45nm SOIプロセスで製造した、ダイサイズ400mm2超の
チップが売れる市場なんでしょうか?
FreescaleのG4クラスの製品が強い分野だったような…
----------------
ネットワークプロセッサ
----------------
それってボッタくりIBMが最新45nm SOIプロセスで製造した、ダイサイズ400mm2超の
チップが売れる市場なんでしょうか?
FreescaleのG4クラスの製品が強い分野だったような…
うーん、確かに
謎だね
謎だね
あとはメインフレームのI/Oプロセッサかな
それなら、ある程度値が張っても大丈夫じゃないか?
POWER7よりダイが小さいのにコア数が倍になってるから
メインフレームのCPUってことはないと思う
それなら、ある程度値が張っても大丈夫じゃないか?
POWER7よりダイが小さいのにコア数が倍になってるから
メインフレームのCPUってことはないと思う
326 :MACオタ>325 さん:2009/12/23(水) 23:52:01 ID:AbeI9a02
>>325
--------------------
POWER7よりダイが小さいのにコア数が倍になってるから
--------------------
この辺はPOWER7に限らず、近年のハイエンドプロセッサはアンコア部の面積が大きいので
証拠とは言えないかと。コア自体もメインフレーム向けはVSXが削除されている可能性が
あります。
--------------------
POWER7よりダイが小さいのにコア数が倍になってるから
--------------------
この辺はPOWER7に限らず、近年のハイエンドプロセッサはアンコア部の面積が大きいので
証拠とは言えないかと。コア自体もメインフレーム向けはVSXが削除されている可能性が
あります。
>>323
クロック控えめでスレッド数も多いし、100GbE用のネットワークプロセッサじゃないの
クロック控えめでスレッド数も多いし、100GbE用のネットワークプロセッサじゃないの
IOP纏めてあるサイトってない?
ネットワークプロセッサーの意見に賛成.
16core 64Threds 2+ GHz ってスペックが
いかにもCaviumのOcteonや旧RMIのNetLogicのXLPの豪華版という感じだ…
# Octeon CN5860が 16core,XLP832 が 8core 32Threds.共に MIPS64
MACオタの言う「ボッタくりIBMがチップ売れる市場」と言えるか謎だけど
ハイエンドの Octeon だと$500〜$1000 ぐらい.
http://www.en-genius.net/site/zones/networkZONE/product_reviews/netp_101606
あるいはSun Niagara的な特定用途に強いサーバー用プロセッサーとか?
16core 64Threds 2+ GHz ってスペックが
いかにもCaviumのOcteonや旧RMIのNetLogicのXLPの豪華版という感じだ…
# Octeon CN5860が 16core,XLP832 が 8core 32Threds.共に MIPS64
MACオタの言う「ボッタくりIBMがチップ売れる市場」と言えるか謎だけど
ハイエンドの Octeon だと$500〜$1000 ぐらい.
http://www.en-genius.net/site/zones/networkZONE/product_reviews/netp_101606
あるいはSun Niagara的な特定用途に強いサーバー用プロセッサーとか?
x86のμOpsで直接プログラムが書ければいいのに
メモリウォールに自分で激突するのがお好き?
332 :,,・´∀`・,,)っ-○○○:2009/12/28(月) 00:46:38 ID:TJ8Uq2yz
>>330
VIAと契約すれば?
VIAと契約すれば?
333 :,,・´∀`・,,)っ-○○○:2009/12/28(月) 00:48:53 ID:TJ8Uq2yz
最近はx86命令セットは高級言語だと思うようにしている。
確かにw
安藤氏の年頭のコラムが出ています。
http://journal.mycom.co.jp/articles/2010/01/02/next_generation_supercomputer/index.html
-------------------
安いからという理由で米国製のスパコンを買うことは、まんまと米国の策略に載るものである。
-------------------
一見もっともらしい言い分ですが、スパコンを開発することとプロセッサを開発することを意図的に
混同して誤魔化してますね。
ここの皆さんは周知のように、昨年下期のTop500でトップを取ったCrayにしてもプロセッサは他社
製なわけで…
http://journal.mycom.co.jp/articles/2010/01/02/next_generation_supercomputer/index.html
-------------------
安いからという理由で米国製のスパコンを買うことは、まんまと米国の策略に載るものである。
-------------------
一見もっともらしい言い分ですが、スパコンを開発することとプロセッサを開発することを意図的に
混同して誤魔化してますね。
ここの皆さんは周知のように、昨年下期のTop500でトップを取ったCrayにしてもプロセッサは他社
製なわけで…
スパコン利権とは全然関係なく、『日本出身』アーキテクチャであるCELL/B.E.はHPC市場で
活躍を続けています。今回紹介するのは、HPCにおける電力効率ランキング"Green500"で
上位を独占するヨーロッパ開発のCELLベース・スパコンQPACEの話。
今年のGreen500ランキングはこちら
http://www.green500.org/lists/2009/11/top/list.php
ご覧の通り同成績で1位にランクされている3システムは全て QPACE SFB TR Cluster です。
http://www.fz-juelich.de/jsc/datapool/cell/eQPACE/pleiter-eqpace-20090209.pdf
このプレゼンは今年初めのものでやや古いですが、アーキテクチャの概要を述べてあります。
QPACEの1ノードは、p.9のブロック図のようにシングルプロセッサのPowerXCell 8iとFPGA製の
ネットワークチップで構成されます。
Roadrunnerとは違ってプロセッサはCELLのみで構成されているのが興味深いかと。
ネットワークは京速と同じく3Dトーラス。
秋のSC09 (Top500でのお披露目)以降の資料はこちら。
http://www.fz-juelich.de/jsc/files/docs/vortraege/jak-2009/jak-2009-qpace.pdf
http://www.desy.de/dvsem/WS0910/pleiter_talk.pdf
性能評価や、FPGAの構成などが述べられています。
活躍を続けています。今回紹介するのは、HPCにおける電力効率ランキング"Green500"で
上位を独占するヨーロッパ開発のCELLベース・スパコンQPACEの話。
今年のGreen500ランキングはこちら
http://www.green500.org/lists/2009/11/top/list.php
ご覧の通り同成績で1位にランクされている3システムは全て QPACE SFB TR Cluster です。
http://www.fz-juelich.de/jsc/datapool/cell/eQPACE/pleiter-eqpace-20090209.pdf
このプレゼンは今年初めのものでやや古いですが、アーキテクチャの概要を述べてあります。
QPACEの1ノードは、p.9のブロック図のようにシングルプロセッサのPowerXCell 8iとFPGA製の
ネットワークチップで構成されます。
Roadrunnerとは違ってプロセッサはCELLのみで構成されているのが興味深いかと。
ネットワークは京速と同じく3Dトーラス。
秋のSC09 (Top500でのお披露目)以降の資料はこちら。
http://www.fz-juelich.de/jsc/files/docs/vortraege/jak-2009/jak-2009-qpace.pdf
http://www.desy.de/dvsem/WS0910/pleiter_talk.pdf
性能評価や、FPGAの構成などが述べられています。
QPACEは間違いなく『ヨーロッパ製スパコン』と言えるかと思うのですが、プロセッサ
は日本+米国の製品であることは注目に値するかと思います。米国だってRoadrunner
にCELL/B.E.の技術を使うことに躊躇はありません。
HPC方面ではとっくにコア性能の争いよりマルチプロセッサでのスケーラビリティやら
インタコネクトやらが主戦場になっています。
>>335でも触れたように、Crayが一般向けx86プロセッサをコアに使って世界一のスパ
コンを製造し、果てにはあっさり次世代ではAMDからIntelに乗り換えるというのも、そう
した流れの上にあります。
http://japan.internet.com/webtech/20080502/11.html
--------------------
なお今回の提携は、Cray の『Cascade』プラットフォームから Intel が技術製品を
提供するというものだ。Cascade は医学や物理学などの複雑な問題を解くために
用いられる。
--------------------
そういう意味で、『スパコン開発=ハイエンドプロセッサ開発』というすりかえをやっている
輩は信用できないことが良く判るかと…
そうは言っても、日本発のプロセッサであるCELL/B.E.を評価したのは欧米であって、
日本国内では叩きに余念が無いヒトが未だにいるというのも、ある種興味深い現象で
あったりするわけです(笑)
は日本+米国の製品であることは注目に値するかと思います。米国だってRoadrunner
にCELL/B.E.の技術を使うことに躊躇はありません。
HPC方面ではとっくにコア性能の争いよりマルチプロセッサでのスケーラビリティやら
インタコネクトやらが主戦場になっています。
>>335でも触れたように、Crayが一般向けx86プロセッサをコアに使って世界一のスパ
コンを製造し、果てにはあっさり次世代ではAMDからIntelに乗り換えるというのも、そう
した流れの上にあります。
http://japan.internet.com/webtech/20080502/11.html
--------------------
なお今回の提携は、Cray の『Cascade』プラットフォームから Intel が技術製品を
提供するというものだ。Cascade は医学や物理学などの複雑な問題を解くために
用いられる。
--------------------
そういう意味で、『スパコン開発=ハイエンドプロセッサ開発』というすりかえをやっている
輩は信用できないことが良く判るかと…
そうは言っても、日本発のプロセッサであるCELL/B.E.を評価したのは欧米であって、
日本国内では叩きに余念が無いヒトが未だにいるというのも、ある種興味深い現象で
あったりするわけです(笑)
日本で叩いてるのは勉強したくない技術者。
スパコンからハンディ機まで(電力)性能向上にマルチコアはどう考えても不可避なのに
どうしてもそのパラダイムから抜け出せないがゆえに叩いてクライアントの目から隠す。
団子は競争相手が追いついて来ないように叩きネタを日本語でばら撒いて煙に巻いてる変り種。
欧米のエンジニアは立派な大学出てて職の心配する必要ない、
あるいは競争の足止めたら食っていけないの判ってるからニューパラダイム受け入れるに易い。
スパコンからハンディ機まで(電力)性能向上にマルチコアはどう考えても不可避なのに
どうしてもそのパラダイムから抜け出せないがゆえに叩いてクライアントの目から隠す。
団子は競争相手が追いついて来ないように叩きネタを日本語でばら撒いて煙に巻いてる変り種。
欧米のエンジニアは立派な大学出てて職の心配する必要ない、
あるいは競争の足止めたら食っていけないの判ってるからニューパラダイム受け入れるに易い。
340 :,,・´∀`・,,)っ-○○○:2010/01/03(日) 15:40:14 ID:os5qML5t
そこまでご立派なものじゃないよ。
というか、「今使える」ものを選ぶのは理に適った判断だろう。
というか、「今使える」ものを選ぶのは理に適った判断だろう。
Cellで片付く問題なんてGPUより間口が広いだけでニッチにゃ変わりない
それを不勉強だとか罵ってるんだからただの精神論、最早オカルト
バカは放っとけばよい
それを不勉強だとか罵ってるんだからただの精神論、最早オカルト
バカは放っとけばよい
>HPC方面ではとっくにコア性能の争いよりマルチプロセッサでのスケーラビリティやら
>インタコネクトやらが主戦場になっています。
って流れなのに>>341-342みたいな攻撃的弁護がでてくるあたり、
もう日本だめじゃね?Cell叩きがマルチコア叩きにまで発展しててさ。
数々のネガキャンが奏功したってところか。
>インタコネクトやらが主戦場になっています。
って流れなのに>>341-342みたいな攻撃的弁護がでてくるあたり、
もう日本だめじゃね?Cell叩きがマルチコア叩きにまで発展しててさ。
数々のネガキャンが奏功したってところか。
>>343
>HPC方面ではとっくにコア性能の争いよりマルチプロセッサでのスケーラビリティやら
>インタコネクトやらが主戦場になっています。
その流れでもMACキチは平気でCell擁護しちゃうから笑っちゃうよな
普通の人なら逆説的に「Cellである必要性なんて大して無いんだな」というごくありきたりな答えに辿り着くと思うよ
>HPC方面ではとっくにコア性能の争いよりマルチプロセッサでのスケーラビリティやら
>インタコネクトやらが主戦場になっています。
その流れでもMACキチは平気でCell擁護しちゃうから笑っちゃうよな
普通の人なら逆説的に「Cellである必要性なんて大して無いんだな」というごくありきたりな答えに辿り着くと思うよ
現状Cellが丁度いいって話だろ現物あるし
しかしどーなってんだろこの働きたくないでござるな脳みそ
MACオタもMACオタならアンチもアンチだよ
しかしどーなってんだろこの働きたくないでござるな脳みそ
MACオタもMACオタならアンチもアンチだよ
手軽に速くできるなら、コアも速いに越したことはないしな
速いCPUなら、同じ性能なら使う数減らせる→そのぶん性能も出しやすいし接続も楽
また、同じ数使うなら当然性能は上がる。
速いCPUなら、同じ性能なら使う数減らせる→そのぶん性能も出しやすいし接続も楽
また、同じ数使うなら当然性能は上がる。
POWER無敵
日経BPが今回の事業仕分けに参加した金田教授のインタビューを掲載しています。
http://itpro.nikkeibp.co.jp/article/COLUMN/20091225/342666/
--------------------
世界最大のスパコンの国際会議「Supercomputing2009(SC09)」でもIBMの
POWER7ベースと富士通のSPARC64 VIIIfxベースの基板が展示されていた
ようだが、技術が分かる人が見れば富士通劣勢は明らかであると分かったはずだ。
--------------------
これって安藤氏がMYCOMに投稿したBlue Watersと京速の比較記事に対する痛烈な
皮肉になっているような気が…
http://journal.mycom.co.jp/articles/2010/01/03/supercomputer2010/index.html
====================
POWER7はチップあたり200Wで256GFlopsであるが、富士通は58Wで128GFlops
であり、富士通の方が約1.7倍、電力効率が良い。
====================
Green500の結果あたりが楽しみですね。
http://itpro.nikkeibp.co.jp/article/COLUMN/20091225/342666/
--------------------
世界最大のスパコンの国際会議「Supercomputing2009(SC09)」でもIBMの
POWER7ベースと富士通のSPARC64 VIIIfxベースの基板が展示されていた
ようだが、技術が分かる人が見れば富士通劣勢は明らかであると分かったはずだ。
--------------------
これって安藤氏がMYCOMに投稿したBlue Watersと京速の比較記事に対する痛烈な
皮肉になっているような気が…
http://journal.mycom.co.jp/articles/2010/01/03/supercomputer2010/index.html
====================
POWER7はチップあたり200Wで256GFlopsであるが、富士通は58Wで128GFlops
であり、富士通の方が約1.7倍、電力効率が良い。
====================
Green500の結果あたりが楽しみですね。
スパコンというよりコンピューター研究予算であの程度あってもいいよ。
副産物の方が重要だからなこの場合。税金でなく企業が金出したケースがSCEだが、
案の定国内の足並み総崩れだしね。評価したのは欧米。
久多良木も日本では総スカンされるのわかっててIBMと手を組むのにやぶさかでなかったのだろう。
米国なら官民問わず研究予算はものすごい額になってるだろう。
副産物の方が重要だからなこの場合。税金でなく企業が金出したケースがSCEだが、
案の定国内の足並み総崩れだしね。評価したのは欧米。
久多良木も日本では総スカンされるのわかっててIBMと手を組むのにやぶさかでなかったのだろう。
米国なら官民問わず研究予算はものすごい額になってるだろう。
ちなみに上の記事、金田教授のこの指摘は興味深いかと。
----------------
恐れるべきは、マスコミがよく比較するかつて地球シミュレータの計算速度を
抜いたIBM製「BlueGene」の後継機である20ペタFLOPS級の最新鋭機ではなく、
POWER7を搭載したIBMが真に本腰を入れて開発する汎用性の高い最新鋭機
なのである。
----------------
POWER7は米国防総省のプロジェクトHPCS (High Productivity Computing Systems)
において、5社 (Cray, HP, IBM, SGI, Sun) -> 3社 (Cray, IBM, Sun) -> 2社 (Cray, IBM)
と3段階の競争試作で勝ち残ったシステムです。
http://www.darpa.mil/ipto/programs/hpcs/hpcs_plan.asp
HPCSの目標設定には『economically viable』の条件がつけられており、フェーズ間の
中間評価でも商業応用を強く意識して実験的なアーキテクチャは排除されたという
話も伝えられています。
偶然なのか真似たのかは判りませんが、京速プロジェクトの方もHPC専用というよりは
そのままSUN互換サーバーに使えそうなSPARC64 VIIIfxをプロセッサとして選択して、
やはり商用サーバーへの採用も狙っているようです。
IBMと正面からぶつかって勝つ算段があるのか、はたまた富士通一社のプロセッサ開
発を助成しただけなのかも見守るべきなのかもしれません。
----------------
恐れるべきは、マスコミがよく比較するかつて地球シミュレータの計算速度を
抜いたIBM製「BlueGene」の後継機である20ペタFLOPS級の最新鋭機ではなく、
POWER7を搭載したIBMが真に本腰を入れて開発する汎用性の高い最新鋭機
なのである。
----------------
POWER7は米国防総省のプロジェクトHPCS (High Productivity Computing Systems)
において、5社 (Cray, HP, IBM, SGI, Sun) -> 3社 (Cray, IBM, Sun) -> 2社 (Cray, IBM)
と3段階の競争試作で勝ち残ったシステムです。
http://www.darpa.mil/ipto/programs/hpcs/hpcs_plan.asp
HPCSの目標設定には『economically viable』の条件がつけられており、フェーズ間の
中間評価でも商業応用を強く意識して実験的なアーキテクチャは排除されたという
話も伝えられています。
偶然なのか真似たのかは判りませんが、京速プロジェクトの方もHPC専用というよりは
そのままSUN互換サーバーに使えそうなSPARC64 VIIIfxをプロセッサとして選択して、
やはり商用サーバーへの採用も狙っているようです。
IBMと正面からぶつかって勝つ算段があるのか、はたまた富士通一社のプロセッサ開
発を助成しただけなのかも見守るべきなのかもしれません。
というわけで自説の為に公開処刑狙ってるだけな気がする仕分け人には反対。
処刑した後、類似予算も立ち上げにくくなる。そこまで考えてないだろうな。
原資はどうあれもうちょっと研究関連職潤ってもいいと思うんだ。
日本がここまで消極的なのは貧乏性が故かもしれないし。上の無理解はどこだって変わらないよ。
処刑した後、類似予算も立ち上げにくくなる。そこまで考えてないだろうな。
原資はどうあれもうちょっと研究関連職潤ってもいいと思うんだ。
日本がここまで消極的なのは貧乏性が故かもしれないし。上の無理解はどこだって変わらないよ。
352 :MACオタ>レトリック さん:2010/01/06(水) 03:27:04 ID:6srrhf1b
353 :MACオタ>351 さん:2010/01/06(水) 03:30:37 ID:6srrhf1b
>>351
-----------------
研究関連職潤ってもいいと思うんだ。
-----------------
総枠は増えませんから、京速に投入された予算の分だけ他の研究が割を食う
というのが世の道理なんですが?
-----------------
研究関連職潤ってもいいと思うんだ。
-----------------
総枠は増えませんから、京速に投入された予算の分だけ他の研究が割を食う
というのが世の道理なんですが?
総枠は増えません(キリッ
賢しい…
賢しい…
ロケット予算も日米比べた場合むこうは国際戦略上の予算だから仕方ないが
確かNASAと比べ日本は人的、資金的にも1/20程度と聞いた事がある。
官だの民だの拘ってる場合じゃないっていう。
確かNASAと比べ日本は人的、資金的にも1/20程度と聞いた事がある。
官だの民だの拘ってる場合じゃないっていう。
MACヲタはPowerPCになるとハッスルハッスルするなw
ほんとIBM大好きなんだから
IBMオタに改名するベキダ
これがDSに載るの?
スマートフォン市場ではSnapdragonとの戦いに勝てそうにないな
363 :Socket774:2010/01/09(土) 16:59:57 ID:Tp8xxeNS
保守age
本当の意味で集積回路だからな>モバイル
何となく気になったので聞いてみるけどGPUでよく聞くFMADと
Bulldozerのブロック図で見たFMACってのはまったく違うもの?
Bulldozerのブロック図で見たFMACってのはまったく違うもの?
NvidiaのFermi、なんとか量産に漕ぎ着けたようで…
http://journal.mycom.co.jp/articles/2010/01/11/ces05/002.html
-----------------
この日のイベントはTegraが主役だったが、最後にHuang氏は「NVIDIAのイベントは
GeForce抜きでは終われない」と、"Fermi"アーキテクチャを採用した「GF100」につ
いて語り始めた。
現在、量産段階に入っており急ピッチで生産が進められているという。
-----------------
http://journal.mycom.co.jp/articles/2010/01/11/ces05/002.html
-----------------
この日のイベントはTegraが主役だったが、最後にHuang氏は「NVIDIAのイベントは
GeForce抜きでは終われない」と、"Fermi"アーキテクチャを採用した「GF100」につ
いて語り始めた。
現在、量産段階に入っており急ピッチで生産が進められているという。
-----------------
http://www.4gamer.net/games/099/G009929/20100108053/SS/003.jpg
同システムは,ご覧のとおりの液冷仕様だが,近づくとものすごい熱を放っていたのが印象的。
PCケースベンダーやOEM関係者が,「NVIDIAの次世代GPUでは,冷却が最大の問題になる」
と口を揃えていた理由がたいへんよく分かるシステムでもあった。
{kind=link}
同システムは,ご覧のとおりの液冷仕様だが,近づくとものすごい熱を放っていたのが印象的。
PCケースベンダーやOEM関係者が,「NVIDIAの次世代GPUでは,冷却が最大の問題になる」
と口を揃えていた理由がたいへんよく分かるシステムでもあった。
キャッシュ搭載でようやくまともにshaderが使い物になるな
{kind=link}
だがx86ではない
いいことです
と思っているのは馬鹿だけです
Tegra2ってスマートフォン向けとは誰も言ってないよね
タブレット型デバイス向けみたいな事は言われてるけど
タブレット型デバイス向けみたいな事は言われてるけど
スマートフォンだったらHDムービーの再生は、やるとしても間引き映像だろうしな
昔話題になったNC辺りか
次世代Blue Geneである"Sequoia" (BG/Q)の情報が少し出てきたような…
>>376
どんな感じですか?
どんな感じですか?
378 :MACオタ>377 さん:2010/01/14(木) 21:57:43 ID:Qfwj0uW3
>>378
野心的な目標値に思えるのでいったいどんな物が出てくるか興味深いです。
野心的な目標値に思えるのでいったいどんな物が出てくるか興味深いです。
Digitimesがグラフィックカードベンダ筋から拾ってきたFermiの状況です。
発表は3月だが、4月までは入手難らしいとのこと。
http://www.digitimes.com/news/a20100114PD202.html
----------------------
Nvidia may see drop in global discrete graphics chip market share in 1Q10
Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 14 January 2010]
Nvidia is expected to see its share of the global discrete graphics chip market
drop from 65% in 2009 to 60% or even lower due to strong competition from AMD,
according to sources from graphics card makers.
Nvidia has refuted the claims saying it expects to see strong demand.
Although Nvidia plans to launch its 40nm Fermi-GF100 graphics chip in March
2010, mass shipments are unlikely to start until April, the sources noted. Nvidia
responded saying its launch schedule remains unchanged.
On the other hand, AMD has already launched its DirectX 11-supporting 40nm
ATI Radeon HD 5970, 5870, 5850 and 5750 GPUs and will launch HD 5670, 5570
and 5450 shortly. The company recently claimed to have shipped a total of two
million DirectX 11-capable GPUs.
----------------------
発表は3月だが、4月までは入手難らしいとのこと。
http://www.digitimes.com/news/a20100114PD202.html
----------------------
Nvidia may see drop in global discrete graphics chip market share in 1Q10
Monica Chen, Taipei; Joseph Tsai, DIGITIMES [Thursday 14 January 2010]
Nvidia is expected to see its share of the global discrete graphics chip market
drop from 65% in 2009 to 60% or even lower due to strong competition from AMD,
according to sources from graphics card makers.
Nvidia has refuted the claims saying it expects to see strong demand.
Although Nvidia plans to launch its 40nm Fermi-GF100 graphics chip in March
2010, mass shipments are unlikely to start until April, the sources noted. Nvidia
responded saying its launch schedule remains unchanged.
On the other hand, AMD has already launched its DirectX 11-supporting 40nm
ATI Radeon HD 5970, 5870, 5850 and 5750 GPUs and will launch HD 5670, 5570
and 5450 shortly. The company recently claimed to have shipped a total of two
million DirectX 11-capable GPUs.
----------------------
上記に関連して、TSMCの40nmプロセスの歩留まりが上がらないという記事を
同じくDigitimesが数日前に掲載しています。
魚拓のリンクはAMD次世代スレッドのこちら。
http://pc11.2ch.net/test/read.cgi/jisaku/1263352294/91
-----------------
Foundry chipmakers, including Taiwan Semiconductor Manufacturing Company
(TSMC), have been struggling to increase their yields on 40nm to over 70%,
according to industry sources. The unsatisfactory yield rate has caused
production for next-generation graphics processors and FPGA (field-
programmable gate array) chips to run tight.
-----------------
同じくDigitimesが数日前に掲載しています。
魚拓のリンクはAMD次世代スレッドのこちら。
http://pc11.2ch.net/test/read.cgi/jisaku/1263352294/91
-----------------
Foundry chipmakers, including Taiwan Semiconductor Manufacturing Company
(TSMC), have been struggling to increase their yields on 40nm to over 70%,
according to industry sources. The unsatisfactory yield rate has caused
production for next-generation graphics processors and FPGA (field-
programmable gate array) chips to run tight.
-----------------
Fermiの歩留まりですが、もう少し詳しい情報が台湾HKEPCより。
http://www.hkepc.com/4465
----------------------
但近日外間據消息指出,目前 Fermi 繪圖核心的實際良率僅有約 20 %
----------------------
・Fermiの歩留まりはおよそ20%程度
・このため、3月に発表されても供給状態がまともになるのは4月
・一方、AMDのHD5000シリーズの歩留まりは60-80%程度
http://www.hkepc.com/4465
----------------------
但近日外間據消息指出,目前 Fermi 繪圖核心的實際良率僅有約 20 %
----------------------
・Fermiの歩留まりはおよそ20%程度
・このため、3月に発表されても供給状態がまともになるのは4月
・一方、AMDのHD5000シリーズの歩留まりは60-80%程度
富士通/SUNより発売されたばかりのSPARC Enterprise M3000
(Quad-Core SPARC64 VII/2.75GHz x 1)のSPEC2006が登録され
ています。
http://www.spec.org/cpu2006/results/res2010q1/
似たような動作周波数のx86シングルソケットシステムとの比較は下記の通り。
(base/peak) int fp int-rate fp-rate
SPARC64 VII/2.75GHz 13.6 / 14.8 15.2 / 15.9 45.4 / 49.1 38.1 / 40.4
Xeon W3520/2.6tGHz 27.4 / 30.7 32.5 / 33.8 94.1 / 101 74.4 / 77.8
Opteron2384/2.7GHz 17.4 / 21.0 19.5 / 21.5 56.9 / 67.7 53.2 / 59.7
クロックだけはx86並になっても性能はも一つの様で…
(Quad-Core SPARC64 VII/2.75GHz x 1)のSPEC2006が登録され
ています。
http://www.spec.org/cpu2006/results/res2010q1/
似たような動作周波数のx86シングルソケットシステムとの比較は下記の通り。
(base/peak) int fp int-rate fp-rate
SPARC64 VII/2.75GHz 13.6 / 14.8 15.2 / 15.9 45.4 / 49.1 38.1 / 40.4
Xeon W3520/2.6tGHz 27.4 / 30.7 32.5 / 33.8 94.1 / 101 74.4 / 77.8
Opteron2384/2.7GHz 17.4 / 21.0 19.5 / 21.5 56.9 / 67.7 53.2 / 59.7
クロックだけはx86並になっても性能はも一つの様で…
上のカキコミの参考リンクです。
■ SPARC64 VII/2.75MHz (富士通 SPARC Enterprise M3000)
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091217-09277.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091217-09278.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091218-09281.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091218-09282.html
■ Xeon W3520/2.67GHz (富士通 CELSIUS M470)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07317.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07318.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07319.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07320.html
■ Opteron 2384/2.7GHz (HP ProLiant DL165 G5p)
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06413.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06416.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06420.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06423.html
■ SPARC64 VII/2.75MHz (富士通 SPARC Enterprise M3000)
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091217-09277.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091217-09278.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091218-09281.html
http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091218-09282.html
■ Xeon W3520/2.67GHz (富士通 CELSIUS M470)
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07317.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07318.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07319.html
http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090511-07320.html
■ Opteron 2384/2.7GHz (HP ProLiant DL165 G5p)
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06413.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06416.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06420.html
http://www.spec.org/cpu2006/results/res2009q1/cpu2006-20090116-06423.html
SPARC64 VII/2.75MHz→2.75GHzだね
SunとFujitsuは同じ物?
SunとFujitsuは同じ物?
Xeon(Nehalem-EP)とOpteron(Istanbul)で
組んだので簡単な性能測定結果。評判のNehaってこんなもの?
これならXeon E5540とOp 2431で似たようなモノで、Opのが安い。
Sandra 2009 SP3 Benchmark Result on WinXP-Pro SP3
======================================================
CPU XEON E5540 OPTERON 2435 C2Q Q6600
Core 2x 4core+HTT 2x 6core 1x 4core
TDP 2x 80W 2x 75W 1x 105W
Clock 2x 2.53GHz 2x 2.60GHz 1x 2.40GHz
Memory 6xDDR3-1066R 4xDDR2-800R 4xDDR2-800
M/B Super X8DT3 Tyan S2927E Dell 755
ChipSet Intel 5520 NFP3600 Intel Q35
------------------------------------------------------
Int. 132GIPS 106GIPS 37GIPS
F.P. 119GFLOPS 102GFLOPS 29GFLOPS
1'Cashe 419GB/s 485GB/s 201GB/s
2'Cache 258GB/s 307GB/s 33GB/s
3'Cache 91GB/s 81GB/s (Non)
Memory 13.9GB/s 20.0GB/s 4.7GB/s
FP*Mem 1654 2040 174
------------------------------------------------------
MM-Int 239MPix/s 284MPix/s 80MPix/s
MM-FP 192MPix/s 134MPix/s 50MPix/s
MM-Dbl 100MPix/s 73MPix/s 25MPix/s
Cording 761MB/s 1000MB/s 364MB/s
------------------------------------------------------
FileSystem NTSC by LSI_MegaRAID-SAS_RAID5 (4xSATA)
・R.Read 66MB/s 62MB/s ----
・R.Write 32MB/s 60MB/s ----
・S.Read 123MB/s 340MB/s ----
・S.Write 48MB/s 270MB/s ----
======================================================
組んだので簡単な性能測定結果。評判のNehaってこんなもの?
これならXeon E5540とOp 2431で似たようなモノで、Opのが安い。
Sandra 2009 SP3 Benchmark Result on WinXP-Pro SP3
======================================================
CPU XEON E5540 OPTERON 2435 C2Q Q6600
Core 2x 4core+HTT 2x 6core 1x 4core
TDP 2x 80W 2x 75W 1x 105W
Clock 2x 2.53GHz 2x 2.60GHz 1x 2.40GHz
Memory 6xDDR3-1066R 4xDDR2-800R 4xDDR2-800
M/B Super X8DT3 Tyan S2927E Dell 755
ChipSet Intel 5520 NFP3600 Intel Q35
------------------------------------------------------
Int. 132GIPS 106GIPS 37GIPS
F.P. 119GFLOPS 102GFLOPS 29GFLOPS
1'Cashe 419GB/s 485GB/s 201GB/s
2'Cache 258GB/s 307GB/s 33GB/s
3'Cache 91GB/s 81GB/s (Non)
Memory 13.9GB/s 20.0GB/s 4.7GB/s
FP*Mem 1654 2040 174
------------------------------------------------------
MM-Int 239MPix/s 284MPix/s 80MPix/s
MM-FP 192MPix/s 134MPix/s 50MPix/s
MM-Dbl 100MPix/s 73MPix/s 25MPix/s
Cording 761MB/s 1000MB/s 364MB/s
------------------------------------------------------
FileSystem NTSC by LSI_MegaRAID-SAS_RAID5 (4xSATA)
・R.Read 66MB/s 62MB/s ----
・R.Write 32MB/s 60MB/s ----
・S.Read 123MB/s 340MB/s ----
・S.Write 48MB/s 270MB/s ----
======================================================
NehalemはInt.とF.P.は速くて、キャッシュは少し遅いだけだから、
キャッシュ内で完了する処理なら「速い」とは言えるし、MultiMedia
のF.P.と倍精度は3割も速い(逆にCording/暗号化は遅い)。
でもメモリーが絡むとガックリ遅くなる。DDR3-1066MHz×3chで
理屈の上ではOpteronのDDR2-800MHz×2chより速い筈なのに。
これなら今回組んだOp.2435(2.6GHz)の下のOp.2431(2.4GHz)で
メモリーが絡む大半の処理では、ほぼ同等性能になると読める。
そんな記事見たことないから質問してみた次第。
Super X8DT3の設定でも狂っているのかな?
これが設定ミスでないなら、OpteronのIstanbuleはNehalemに
負けてないって事になる。・・・・・詳しい人、教えて下され!
キャッシュ内で完了する処理なら「速い」とは言えるし、MultiMedia
のF.P.と倍精度は3割も速い(逆にCording/暗号化は遅い)。
でもメモリーが絡むとガックリ遅くなる。DDR3-1066MHz×3chで
理屈の上ではOpteronのDDR2-800MHz×2chより速い筈なのに。
これなら今回組んだOp.2435(2.6GHz)の下のOp.2431(2.4GHz)で
メモリーが絡む大半の処理では、ほぼ同等性能になると読める。
そんな記事見たことないから質問してみた次第。
Super X8DT3の設定でも狂っているのかな?
これが設定ミスでないなら、OpteronのIstanbuleはNehalemに
負けてないって事になる。・・・・・詳しい人、教えて下され!
528 名前:Socket774[sage] 投稿日:2010/01/01(金) 12:22:44 ID:lEhCwdPM
TOP500だとNehalem-EPとBarcelonaでコア辺りのクロック性能同じ位だね。
参考になるのかどうか判らないが。
でも実質Intel専用ベンチのSandraで差が付かないってのは凄いな。
TOP500だとNehalem-EPとBarcelonaでコア辺りのクロック性能同じ位だね。
参考になるのかどうか判らないが。
でも実質Intel専用ベンチのSandraで差が付かないってのは凄いな。
389 :,,・´∀`・,,)っ-○○○:2010/01/19(火) 02:40:36 ID:V4ouHagw
LINPACKってFP演算ユニットの並列度×クロック数が素直に現れるぞ
390 :MACオタ>386-388 さん:2010/01/19(火) 02:52:40 ID:Xfz8gXKr
>>386-388
コピペなのは存じ上げていますが、検索してみるとあちこちに貼られているようですので
回答しておきます。
---------------------
でもメモリーが絡むとガックリ遅くなる。
[中略]
そんな記事見たことないから質問してみた次第。
---------------------
流石にSandraは有名ベンチマークですから同種の記事は検索すれば簡単に見つかります。
http://www.bit-tech.net/hardware/cpus/2009/03/30/intel-xeon-w5580-nehalem-ep-review/5
こちらの"unbuffered memory test"は、その一例ですね。それでも注目すべきなのは
メモリレイテンシでOpteronを圧倒している点です。たしかアム虫さんってPentium4は帯域番長
とかで、AMD製品はメモリレイテンシが優秀だから速いって主張していたのでは?
実はメモリ帯域の方も測定法で大きく異なる様で、同じbit-tech.comのistanbulベンチでは
こういう結果が(笑)
http://www.bit-tech.net/hardware/2009/07/07/amd-opteron-2434-review/3
bit-techの言い訳はこちら。
--------------------
We started by retesting the Xeon W5580, as a new version of Sandra, which supports
Intel's implementation of NUMA, has been released since our original review. These
new results show that the Xeon W5580 system has significantly more memory bandwidth
and lower latency than either Opteron system - an important consideration if you're
running lots of apps together such as a server used to power multiple virtual machines.
---------------------
まあ結果を推敲せずに、脳内妄想に一致するとコピペしまくるアム虫さんの習性ががGoogleの
検索結果に晒されただけ…というのが結論ですか。
コピペなのは存じ上げていますが、検索してみるとあちこちに貼られているようですので
回答しておきます。
---------------------
でもメモリーが絡むとガックリ遅くなる。
[中略]
そんな記事見たことないから質問してみた次第。
---------------------
流石にSandraは有名ベンチマークですから同種の記事は検索すれば簡単に見つかります。
http://www.bit-tech.net/hardware/cpus/2009/03/30/intel-xeon-w5580-nehalem-ep-review/5
こちらの"unbuffered memory test"は、その一例ですね。それでも注目すべきなのは
メモリレイテンシでOpteronを圧倒している点です。たしかアム虫さんってPentium4は帯域番長
とかで、AMD製品はメモリレイテンシが優秀だから速いって主張していたのでは?
実はメモリ帯域の方も測定法で大きく異なる様で、同じbit-tech.comのistanbulベンチでは
こういう結果が(笑)
http://www.bit-tech.net/hardware/2009/07/07/amd-opteron-2434-review/3
bit-techの言い訳はこちら。
--------------------
We started by retesting the Xeon W5580, as a new version of Sandra, which supports
Intel's implementation of NUMA, has been released since our original review. These
new results show that the Xeon W5580 system has significantly more memory bandwidth
and lower latency than either Opteron system - an important consideration if you're
running lots of apps together such as a server used to power multiple virtual machines.
---------------------
まあ結果を推敲せずに、脳内妄想に一致するとコピペしまくるアム虫さんの習性ががGoogleの
検索結果に晒されただけ…というのが結論ですか。
WinXPってNehalemのNUMAに対応してたっけ?
今日はTheRegisterより目ぼしいニュースが二つ。
まず、IBMの2009Q4業績の電話会議でIBMのCFO, Mark Loughridge より POWER7
のリリース時期が示されたとのこと。
http://www.theregister.co.uk/2010/01/20/ibm_power7_q1_launch/
-----------------------
"Later [in Q1], we'll introduce the next generation Power Systems, which will
deliver two to three times the performance, in the same energy envelope,"
Loughridge told the assembled Wall Street multitudes on Tuesday.
-----------------------
・今四半期中にPOWER7製品が発表される
・45nm CPUプロセスの立ち上がりは順調で、65nm世代より5ヶ月は短かった。
・今年中にPOWERサーバーはPOWER7世代に更新される
まず、IBMの2009Q4業績の電話会議でIBMのCFO, Mark Loughridge より POWER7
のリリース時期が示されたとのこと。
http://www.theregister.co.uk/2010/01/20/ibm_power7_q1_launch/
-----------------------
"Later [in Q1], we'll introduce the next generation Power Systems, which will
deliver two to three times the performance, in the same energy envelope,"
Loughridge told the assembled Wall Street multitudes on Tuesday.
-----------------------
・今四半期中にPOWER7製品が発表される
・45nm CPUプロセスの立ち上がりは順調で、65nm世代より5ヶ月は短かった。
・今年中にPOWERサーバーはPOWER7世代に更新される
もう一つは龍芯3号を使った中共の国産スーパーコンピュータ 『曙光 6000』が
今年完成予定とのこと。
http://www.theregister.co.uk/2010/01/20/china_ict_dawning_super/
---------------------
Weiwu Hu, chief architect of the Loongson processors developed by ICT, told
Technology Review that the future Dawning 6000 super, presumably based on
the quad-core Loogson-3 MIPS-style processor, would be finished by the middle
of this year and operational by the end of 2010.
---------------------
元ネタは MIT Technology Review のこちらの記事。
http://www.technologyreview.com/computing/24374/
概要は次の通り。
・昨年登場予定が今年に遅れた
・量産版マスクのテープアウトは昨年12月末。STMicro にて量産開始予定。
・遅延した分、65nm世代で8-16コアバージョンが出てくるかもしれない
噂のx86エミュレーション機能に関しては、TheRegs の Morgan 記者によると、IEEE Micro
に掲載された論文、
http://www.computer.org/portal/web/csdl/doi/10.1109/MM.2009.30
には、x86エミュレーション支援命令の追加によりネイティブコードの70%程度性能で
x86コードが実行できるという記述があるとのこと。
今年完成予定とのこと。
http://www.theregister.co.uk/2010/01/20/china_ict_dawning_super/
---------------------
Weiwu Hu, chief architect of the Loongson processors developed by ICT, told
Technology Review that the future Dawning 6000 super, presumably based on
the quad-core Loogson-3 MIPS-style processor, would be finished by the middle
of this year and operational by the end of 2010.
---------------------
元ネタは MIT Technology Review のこちらの記事。
http://www.technologyreview.com/computing/24374/
概要は次の通り。
・昨年登場予定が今年に遅れた
・量産版マスクのテープアウトは昨年12月末。STMicro にて量産開始予定。
・遅延した分、65nm世代で8-16コアバージョンが出てくるかもしれない
噂のx86エミュレーション機能に関しては、TheRegs の Morgan 記者によると、IEEE Micro
に掲載された論文、
http://www.computer.org/portal/web/csdl/doi/10.1109/MM.2009.30
には、x86エミュレーション支援命令の追加によりネイティブコードの70%程度性能で
x86コードが実行できるという記述があるとのこと。
IBMの昨年第4四半期の業績ですが、CELL/B.E. と Xbox360 CPU の設計サービスで
がっつり稼いだ2006年以来、長期低落が続いていた Microelectronics 部門がちょっと
上向いたとのこと。
http://www.theregister.co.uk/2010/01/20/ibm_q42009_numbers/page2.html
---------------------
On the Microelectronics front, chip sales were up 2 per cent in the quarter,
and Loughridge said that the 300mm wafer baker in East Fishkill, New York
was nearing full utilization and that 45 nanometer output was sold out again
this quarter. No doubt some of that wafer baking capacity is being pressed
into action to crank out Power7 chips and probably the z11 mainframe engines
too. ?
---------------------
最後の一節は Morgan 記者の推測に過ぎませんが、45nm ラインもフル操業体制に
なっているとか。
がっつり稼いだ2006年以来、長期低落が続いていた Microelectronics 部門がちょっと
上向いたとのこと。
http://www.theregister.co.uk/2010/01/20/ibm_q42009_numbers/page2.html
---------------------
On the Microelectronics front, chip sales were up 2 per cent in the quarter,
and Loughridge said that the 300mm wafer baker in East Fishkill, New York
was nearing full utilization and that 45 nanometer output was sold out again
this quarter. No doubt some of that wafer baking capacity is being pressed
into action to crank out Power7 chips and probably the z11 mainframe engines
too. ?
---------------------
最後の一節は Morgan 記者の推測に過ぎませんが、45nm ラインもフル操業体制に
なっているとか。
牧野教授の『スーパーコンピューティングの将来』が今月は怒涛の更新ですね。
最新はコレですが、スーパーコンピュータ関係のスレッドでまた怒り狂うネトウヨ
さんが現れそうな…
http://www.artcompsci.org/~makino/articles/future_sc/note083.html
--------------------
そういう見積もりをもってくるのは、そういうので買ってくれる人がいるからですから、
買うほうに問題がある、ということではあります。国立大学の計算機センターや、
理研の次世代にしても結局は同じ問題、というところもあります。ハードウェアの思想
が15年遅れ、というだけではなくて、計算機を買う側の意識が、計算機というのは大変
高価なものであるという 30年くらい前の意識のままである、ということです。
--------------------
最新はコレですが、スーパーコンピュータ関係のスレッドでまた怒り狂うネトウヨ
さんが現れそうな…
http://www.artcompsci.org/~makino/articles/future_sc/note083.html
--------------------
そういう見積もりをもってくるのは、そういうので買ってくれる人がいるからですから、
買うほうに問題がある、ということではあります。国立大学の計算機センターや、
理研の次世代にしても結局は同じ問題、というところもあります。ハードウェアの思想
が15年遅れ、というだけではなくて、計算機を買う側の意識が、計算機というのは大変
高価なものであるという 30年くらい前の意識のままである、ということです。
--------------------
ここのところしばらくカキコミしていなかった間の POWER/PowerPC 関係の大きな
ニュースは IBM の新組込コア "PowerPC 476FP" です。
http://www-03.ibm.com/press/us/en/pressrelease/28399.wss
- LSI との共同開発
- 1.6GHz @ 45nm SOI
- 1.6W, 3.6mm^2
- 256k - 1MB L2 support
- PLB6 local bus, support 1 - 16 core
順当に考えると、これにHPC専用 Book-E 規格 APU を組み合わせたモノが
"Sequoia" (BG/Q) のプロセッサになりそうです。
実は今週もこのPPC476、ちょっとニュースに顔をだしていました。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301670
-------------------
LSI announced in September it helped IBM Corp. developed the multicore PowerPC
476FP. A four-core version running at up to 1.6 GHz is now available from LSI in
TSMC's 40nm process.
-------------------
共同開発の権利なのかどうかは不明ですが、TSMCでも製造できるようです。同時に
LSIは 500MHz eDRAM を顧客の設計に提供するというアナウンスもしてます。
ところで私にはハイエンドネットワークプロセッサと言えば、この辺のコアを使用した
SoC 製品になるような気がするのですが、>>312の "Wire-Speed Power Processor"
の正体が何なのかは、来る ISSCC の発表が楽しみです。
ニュースは IBM の新組込コア "PowerPC 476FP" です。
http://www-03.ibm.com/press/us/en/pressrelease/28399.wss
- LSI との共同開発
- 1.6GHz @ 45nm SOI
- 1.6W, 3.6mm^2
- 256k - 1MB L2 support
- PLB6 local bus, support 1 - 16 core
順当に考えると、これにHPC専用 Book-E 規格 APU を組み合わせたモノが
"Sequoia" (BG/Q) のプロセッサになりそうです。
実は今週もこのPPC476、ちょっとニュースに顔をだしていました。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222301670
-------------------
LSI announced in September it helped IBM Corp. developed the multicore PowerPC
476FP. A four-core version running at up to 1.6 GHz is now available from LSI in
TSMC's 40nm process.
-------------------
共同開発の権利なのかどうかは不明ですが、TSMCでも製造できるようです。同時に
LSIは 500MHz eDRAM を顧客の設計に提供するというアナウンスもしてます。
ところで私にはハイエンドネットワークプロセッサと言えば、この辺のコアを使用した
SoC 製品になるような気がするのですが、>>312の "Wire-Speed Power Processor"
の正体が何なのかは、来る ISSCC の発表が楽しみです。
また自分を棚にあげて牧野はしょうもないこと書いてるな
銀ピカの棚?
>>393の龍芯3号ですが、一昨年のHot Chips 20のプレゼン資料が公開されて
います。
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.621.pdf
個人的には今までの報道を勘違いしていた部分がありました。
- 龍芯3は MIPS64 の "GS464" コアと SIMD プロセッサの "GStera" コア
のヘテロジニアス構成
- 報道中で出ていた『コア数』は上記の2種類のコアの合計
います。
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.621.pdf
個人的には今までの報道を勘違いしていた部分がありました。
- 龍芯3は MIPS64 の "GS464" コアと SIMD プロセッサの "GStera" コア
のヘテロジニアス構成
- 報道中で出ていた『コア数』は上記の2種類のコアの合計
そういう訳で、今年のTOP500で5位に輝いたGPGPUクラスタ天河1号も
含めて、中共のスーパーコンピュータ・プロジェクトはヘテロジニアス
路線に専念していると言えそうです。
含めて、中共のスーパーコンピュータ・プロジェクトはヘテロジニアス
路線に専念していると言えそうです。
ちょっと古いニュースですが、>>382-383あたりで書いたTSMC 40nm プロセス
の歩留まり、現状で解決されているというニュースが流れています。
ソースは Digitimes ですが、すぐ読めなくなるので DailyTech の記事を
引用しておきます。
http://www.dailytech.com/TSMC+Says+40nm+Problems+Resolved+Preparing+28nm+Fab+Production+/article17355c.htm
-----------------------
DailyTech spoke with a TSMC spokesperson yesterday, who stated
that TSMC's 40nm yields are now "approximately at the same level"
as the more mature 65nm process. Semiconductors are made in
lithography chambers, and the process can be comprised of several
hundred steps. Usually a new manufacturing process is developed
and refined in a test fab and then transferred to production
lines in a process called Chamber Matching. This theoretically
ensures standard conformity and higher yields. There were several
problems with chamber matching on TSMC's 40nm lines, leading to
yield problems despite using the same process and recipes.
-----------------------
の歩留まり、現状で解決されているというニュースが流れています。
ソースは Digitimes ですが、すぐ読めなくなるので DailyTech の記事を
引用しておきます。
http://www.dailytech.com/TSMC+Says+40nm+Problems+Resolved+Preparing+28nm+Fab+Production+/article17355c.htm
-----------------------
DailyTech spoke with a TSMC spokesperson yesterday, who stated
that TSMC's 40nm yields are now "approximately at the same level"
as the more mature 65nm process. Semiconductors are made in
lithography chambers, and the process can be comprised of several
hundred steps. Usually a new manufacturing process is developed
and refined in a test fab and then transferred to production
lines in a process called Chamber Matching. This theoretically
ensures standard conformity and higher yields. There were several
problems with chamber matching on TSMC's 40nm lines, leading to
yield problems despite using the same process and recipes.
-----------------------
>>396に書いた PowerPC 476, もう少し調べてみました。
まずこちらのプレゼン資料は概要を判りやすく書いてあります。
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_PowerPC476FP.pdf
HPC向け SoC に使用される筈の Book-E APU (演算器やレジスタの内部拡張仕様)に
関しては、この資料の P.6 に次のような記述があります。
------------------------
・ High performance out-of-order auxiliary processor pipeline interface
- Support the floating point unit
- Support for future accelerator extensions such as VMX
------------------------
ますますもって、Sequoia のベースとなる公算は大きいかと。
更に 32nm 世代までは予定に入っているようで、こちらのプレゼンの P.7 にロードマップ図
が掲載されています。
http://www.cn.power.org/resources/power/pdf/06.PPC%20Embedded%20PowerPC%20Architecture.pdf
- 476FP 12S: 45nm世代, 1.6GHz, 3.5mm^2 / 1.6W
- 476FP 13S: 32nm世代, 2.1GHz, 2.5mm^2 / 1.3W
その他、P.34にはチップ内バスの PLB6 の帯域幅が 102.4GB/s であること、P.35 には
PPC440 直系である PPC464FP と比較して 7段パイプラインから 9段パイプラインにした分
ステージあたりのロジックは 37FO4 から 26FO4 に減少し、動作クロック向上に寄与している
ことが記されています。
積極的なロードマップから見ても、どうやら IBM の今後の組込向けコアはこの系列で決定の
ようで、現世代のゲーム機に使用された PPE / PX コアはお払い箱になったようです。
次世代 CELL/B.E. があるとすれば、制御用 POWER ISA コアも PPC470 系列の設計になる
のではないでしょうか。
まずこちらのプレゼン資料は概要を判りやすく書いてあります。
http://www.power.org/events/powercon09/taiwan09/IBM_Overview_PowerPC476FP.pdf
HPC向け SoC に使用される筈の Book-E APU (演算器やレジスタの内部拡張仕様)に
関しては、この資料の P.6 に次のような記述があります。
------------------------
・ High performance out-of-order auxiliary processor pipeline interface
- Support the floating point unit
- Support for future accelerator extensions such as VMX
------------------------
ますますもって、Sequoia のベースとなる公算は大きいかと。
更に 32nm 世代までは予定に入っているようで、こちらのプレゼンの P.7 にロードマップ図
が掲載されています。
http://www.cn.power.org/resources/power/pdf/06.PPC%20Embedded%20PowerPC%20Architecture.pdf
- 476FP 12S: 45nm世代, 1.6GHz, 3.5mm^2 / 1.6W
- 476FP 13S: 32nm世代, 2.1GHz, 2.5mm^2 / 1.3W
その他、P.34にはチップ内バスの PLB6 の帯域幅が 102.4GB/s であること、P.35 には
PPC440 直系である PPC464FP と比較して 7段パイプラインから 9段パイプラインにした分
ステージあたりのロジックは 37FO4 から 26FO4 に減少し、動作クロック向上に寄与している
ことが記されています。
積極的なロードマップから見ても、どうやら IBM の今後の組込向けコアはこの系列で決定の
ようで、現世代のゲーム機に使用された PPE / PX コアはお払い箱になったようです。
次世代 CELL/B.E. があるとすれば、制御用 POWER ISA コアも PPC470 系列の設計になる
のではないでしょうか。
404 :MACオタ>402 さん:2010/01/24(日) 03:13:00 ID:Q/AWDBGf
>>402
----------------
オタさんとあろうものが勘違いですか
----------------
てっきり GS464 も GStera も同じ MIPS64 コアで、GStera の方には Altivec や SSE のような
かたちで SIMD ユニットが追加されているモノと解釈してました。
----------------
オタさんとあろうものが勘違いですか
----------------
てっきり GS464 も GStera も同じ MIPS64 コアで、GStera の方には Altivec や SSE のような
かたちで SIMD ユニットが追加されているモノと解釈してました。
龍芯情報、少し追加。
http://blogmag.ascii.jp/china/2010/01/003384.html
-----------------------
これが今までの龍芯のように「創ったという結果を残して終了」ではなく、スパコン
「曙光」のロードマップでは、曙光6000に8000超の龍芯3号を載せるとしているし、
また上海のお隣、江蘇省政府は15万台の龍芯3号搭載PCを購入することを約束し
ている。後者は額にして、2009年年末に5000万元(約6億8000万円)、今年と来年で
それぞれ1億5000万元(20億円強)を支払うのだそうだ。15万台を50億円弱で購入す
るのなら、平均して1台あたり3万円強となる。
-----------------------
山谷氏は過去記事で龍芯を散々ネタ扱いしてきましたが、今回は好評価のようで…
http://blogmag.ascii.jp/china/2010/01/003384.html
-----------------------
これが今までの龍芯のように「創ったという結果を残して終了」ではなく、スパコン
「曙光」のロードマップでは、曙光6000に8000超の龍芯3号を載せるとしているし、
また上海のお隣、江蘇省政府は15万台の龍芯3号搭載PCを購入することを約束し
ている。後者は額にして、2009年年末に5000万元(約6億8000万円)、今年と来年で
それぞれ1億5000万元(20億円強)を支払うのだそうだ。15万台を50億円弱で購入す
るのなら、平均して1台あたり3万円強となる。
-----------------------
山谷氏は過去記事で龍芯を散々ネタ扱いしてきましたが、今回は好評価のようで…
>>404
たしか↓の記事だったかな?
Hot Chips: the third Dragon CPU
http://www.h-online.com/newsticker/news/item/Hot-Chips-the-third-Dragon-CPU-737069.html
たしか↓の記事だったかな?
Hot Chips: the third Dragon CPU
http://www.h-online.com/newsticker/news/item/Hot-Chips-the-third-Dragon-CPU-737069.html
407 :MACオタ>406 さん:2010/01/24(日) 11:33:04 ID:bsqgJCTe
>>406
ご紹介ありがとうございました。
それにしても>>336-337 に書いた、
『CELL/B.E. を叩くのに懸命な日本…
一方、欧米ではスーパーコンピュータ用コアとしておいしくいただいた。』
という構図も興味深いですが、中共のヘテロジニアスへの傾倒も,
『Intelを持ち上げて、成功した自国開発のヘテロジニアスチップ CELL/B.E. を
引きずりおろすのに必死な日本。一方、中国はヘテロジニアスコアにx86
エミュレータを実装していた。』
という対比でみると、なかなか(笑)
ご紹介ありがとうございました。
それにしても>>336-337 に書いた、
『CELL/B.E. を叩くのに懸命な日本…
一方、欧米ではスーパーコンピュータ用コアとしておいしくいただいた。』
という構図も興味深いですが、中共のヘテロジニアスへの傾倒も,
『Intelを持ち上げて、成功した自国開発のヘテロジニアスチップ CELL/B.E. を
引きずりおろすのに必死な日本。一方、中国はヘテロジニアスコアにx86
エミュレータを実装していた。』
という対比でみると、なかなか(笑)
ヲタさんもういいんだよ、cellは終わったんだよ・・・
>>396, >>403 で紹介した PPC476FP に関して GCC ML に情報が出ているようです。
http://gcc.gnu.org/ml/gcc-patches/2009-10/msg00499.html
- 推測通り FPU は APU インターフェース接続で、FPU 無しの PPC476 もありえる。
- 命令レイテンシ
単純整数演算(加減算、論理演算、等): 1
複雑整数演算(整数乗算、SPRアクセス、等): 4
整数除算: 11, non-pipelined
ロード/ストア: 4 (アップデート付きアドレシングのペナルティなし)
浮動小数点演算: 6
浮動小数点除算: 19 (単精度), 33 (倍精度), 共に non-pipelined
ところで>>403 で書いたこれですが、大きな勘違いで PPE と違って 32bit コアのPPC47x
では無理でした。
-----------------
次世代 CELL/B.E. があるとすれば、制御用 POWER ISA コアも PPC470 系列の設計になる
のではないでしょうか。
-----------------
http://gcc.gnu.org/ml/gcc-patches/2009-10/msg00499.html
- 推測通り FPU は APU インターフェース接続で、FPU 無しの PPC476 もありえる。
- 命令レイテンシ
単純整数演算(加減算、論理演算、等): 1
複雑整数演算(整数乗算、SPRアクセス、等): 4
整数除算: 11, non-pipelined
ロード/ストア: 4 (アップデート付きアドレシングのペナルティなし)
浮動小数点演算: 6
浮動小数点除算: 19 (単精度), 33 (倍精度), 共に non-pipelined
ところで>>403 で書いたこれですが、大きな勘違いで PPE と違って 32bit コアのPPC47x
では無理でした。
-----------------
次世代 CELL/B.E. があるとすれば、制御用 POWER ISA コアも PPC470 系列の設計になる
のではないでしょうか。
-----------------
>>409
ブルドーザの目指してるところってこれじゃないのか
ブルドーザの目指してるところってこれじゃないのか
それでは 64-bit 組込コアのロードマップはどうなっているかというと、"PowerPC A2"
という情報が世間では飛び交っているようです。
これもちゃんと根拠があったようで、GCC に設定が追加されていました。
http://gcc.gnu.org/ml/gcc-patches/2009-09/msg01764.html
- こちらはちゃんと PPC64。
- 組込向けコアなのは間違いないらしく、APU 接続演算リソースの定義がある。
- in-order コアの様に見える
- 乗除算専用パイプラインがあるらしい (DSP?)
- MT は止めた?
- 命令レイテンシ
整数乗算: 1 (32bit), 6 (64bit)
整数除算: 32 (32bit), 65 (64bit), 共に non-pipelined
ロード: 5 (整数), 6 (fp)
ストア: 1 (整数), 2 (fp)
浮動小数点演算: 6
浮動小数点比較: 5
浮動小数点除算: 59 (単精度), 72 (倍精度), non-pipelined
平方根: 65 (単精度), 69 (倍精度), non-pipelined
PPE直系の設計の様に見えます。文中に"SPE"なる記述も…
という情報が世間では飛び交っているようです。
これもちゃんと根拠があったようで、GCC に設定が追加されていました。
http://gcc.gnu.org/ml/gcc-patches/2009-09/msg01764.html
- こちらはちゃんと PPC64。
- 組込向けコアなのは間違いないらしく、APU 接続演算リソースの定義がある。
- in-order コアの様に見える
- 乗除算専用パイプラインがあるらしい (DSP?)
- MT は止めた?
- 命令レイテンシ
整数乗算: 1 (32bit), 6 (64bit)
整数除算: 32 (32bit), 65 (64bit), 共に non-pipelined
ロード: 5 (整数), 6 (fp)
ストア: 1 (整数), 2 (fp)
浮動小数点演算: 6
浮動小数点比較: 5
浮動小数点除算: 59 (単精度), 72 (倍精度), non-pipelined
平方根: 65 (単精度), 69 (倍精度), non-pipelined
PPE直系の設計の様に見えます。文中に"SPE"なる記述も…
>>411
次のCELLにはこれが付くのか
次のCELLにはこれが付くのか
>>411 はちょっと訂正。
------------------
- MT は止めた?
------------------
a2.md に記されたレイテンシ記述と、rs6000.c に記されたものが、ほぼ
2:1 の比率になっているようですから、2-way FGMT で間違い無さそうです。
------------------
- MT は止めた?
------------------
a2.md に記されたレイテンシ記述と、rs6000.c に記されたものが、ほぼ
2:1 の比率になっているようですから、2-way FGMT で間違い無さそうです。
414 :MACオタ>412 さん:2010/01/24(日) 21:06:48 ID:oeZiwZQt
>>412
----------------
次のCELLにはこれが付くのか
----------------
むしろ次期 XCPU かと。
参考までに PPU の記述と比較してみました。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/cell.md?view=log
a2.md の中で演算リソースの割付が"nothing"のモノは、枠組だけ用意して
数値は適当な値を入れてあるだけっぽいので、もっともらしい値だけ比較します。
64bit整数乗算: 9 cycles (PPU) -> 6 cycles (A2)
32bit整数除算: 32 cycles (PPU) -> 32 cycles (A2)
64bit整数除算: 64 cycles (PPU) -> 65 cycles (A2)
浮動小数点演算: 10 cycles (PPU) -> 6 cycles (A2)
浮動小数点ロード: 7 cycles (PPU) -> 6 cycles (A2)
浮動小数点ストア: 13 cycles (PPU) -> 2 cycles (A2)
浮動小数点比較: 6 cycles (PPU) -> 5 cycles (A2)
単精度fp除算: 74 cycles (PPU) -> 59 cycles (A2)
倍精度fp除算: 74 cycles (PPU) -> 72 cycles (A2)
単精度fp平方根: 84 cycles (PPU) -> 65 cycles (A2)
倍精度fp平方根: 84 cycles (PPU) -> 69 cycles (A2)
・整数DSP用のパイプラインが新設されて、一般の処理を行う一般整数パイプラインの負荷が
軽くなった
・全体にパイプラインが短くなった
というのが改善点なのでしょうか?
----------------
次のCELLにはこれが付くのか
----------------
むしろ次期 XCPU かと。
参考までに PPU の記述と比較してみました。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/cell.md?view=log
a2.md の中で演算リソースの割付が"nothing"のモノは、枠組だけ用意して
数値は適当な値を入れてあるだけっぽいので、もっともらしい値だけ比較します。
64bit整数乗算: 9 cycles (PPU) -> 6 cycles (A2)
32bit整数除算: 32 cycles (PPU) -> 32 cycles (A2)
64bit整数除算: 64 cycles (PPU) -> 65 cycles (A2)
浮動小数点演算: 10 cycles (PPU) -> 6 cycles (A2)
浮動小数点ロード: 7 cycles (PPU) -> 6 cycles (A2)
浮動小数点ストア: 13 cycles (PPU) -> 2 cycles (A2)
浮動小数点比較: 6 cycles (PPU) -> 5 cycles (A2)
単精度fp除算: 74 cycles (PPU) -> 59 cycles (A2)
倍精度fp除算: 74 cycles (PPU) -> 72 cycles (A2)
単精度fp平方根: 84 cycles (PPU) -> 65 cycles (A2)
倍精度fp平方根: 84 cycles (PPU) -> 69 cycles (A2)
・整数DSP用のパイプラインが新設されて、一般の処理を行う一般整数パイプラインの負荷が
軽くなった
・全体にパイプラインが短くなった
というのが改善点なのでしょうか?
>>411 でキャッシュに関する記述を書き忘れたので、追記しておきます。
- 64-byte キャッシュライン
- 16KB L1
- 2MB L2
- 16本の自動プリフェッチストリーム
キャッシュラインのサイズを半分にして、多少は利用率を上げた一方で、L1 は PPU より半減
ですか…
- 64-byte キャッシュライン
- 16KB L1
- 2MB L2
- 16本の自動プリフェッチストリーム
キャッシュラインのサイズを半分にして、多少は利用率を上げた一方で、L1 は PPU より半減
ですか…
こちらも昨年秋のニュースですが、AMCC の Titan コアを搭載した製品が発表されています。
Titan の発表ってもう2年以上前だったりするのですが…
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/392
http://pc.watch.impress.co.jp/docs/2007/0531/mpf07.htm
AMCC のリリースはこちら。
http://investor.appliedmicro.com/phoenix.zhtml?c=78121&p=irol-newsArticle&ID=1342823&highlight=
-----------------------
The APM 83290 includes a processor subsystem that integrates two Titan cores
based on Power Architecture technology, delivering frequencies of 1.5 GHz per core.
The Titan core is a superscalar, dual-issue, out-of-order core designed to achieve
industry leading single thread performance on a per clock basis. Along with high
performance, innovative circuit design techniques enable the APM 83290 to deliver
speeds of 1.5 GHz in 90nm bulk CMOS while comparable designs require 45nm SOI
process technology to achieve similar operating speeds.
-----------------------
今となってはあらゆる点で PPC476 に劣る訳ですが、リリースにあるように 90nm バルクプロセス
で同レベルのクロックを実現しているのは立派と言えるのかも。
量産は今年Q1なので、476より早く登場するのも確かです。
Titan の発表ってもう2年以上前だったりするのですが…
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/392
http://pc.watch.impress.co.jp/docs/2007/0531/mpf07.htm
AMCC のリリースはこちら。
http://investor.appliedmicro.com/phoenix.zhtml?c=78121&p=irol-newsArticle&ID=1342823&highlight=
-----------------------
The APM 83290 includes a processor subsystem that integrates two Titan cores
based on Power Architecture technology, delivering frequencies of 1.5 GHz per core.
The Titan core is a superscalar, dual-issue, out-of-order core designed to achieve
industry leading single thread performance on a per clock basis. Along with high
performance, innovative circuit design techniques enable the APM 83290 to deliver
speeds of 1.5 GHz in 90nm bulk CMOS while comparable designs require 45nm SOI
process technology to achieve similar operating speeds.
-----------------------
今となってはあらゆる点で PPC476 に劣る訳ですが、リリースにあるように 90nm バルクプロセス
で同レベルのクロックを実現しているのは立派と言えるのかも。
量産は今年Q1なので、476より早く登場するのも確かです。
>>414
なぜXCPU、CELLとは考えないの?
なぜXCPU、CELLとは考えないの?
418 :MACオタ>417 さん:2010/01/24(日) 21:54:55 ID:oeZiwZQt
>>417
PPUの開発リソースをMSに横流しされた恨みをそう簡単に忘れるとも思えませんが…
PPUの開発リソースをMSに横流しされた恨みをそう簡単に忘れるとも思えませんが…
>>418
それが根拠なの、根拠が弱いと思う
それが根拠なの、根拠が弱いと思う
420 :MACオタ>419 さん:2010/01/24(日) 22:08:46 ID:oeZiwZQt
>>419
--------------
根拠が弱いと思う
--------------
では言い換えましょう。チップ開発能力が殆ど無いMSのために、半導体開発の研究所を
持つSONYが開発費を共同で負担してあげる必要があるでしょうか?
--------------
根拠が弱いと思う
--------------
では言い換えましょう。チップ開発能力が殆ど無いMSのために、半導体開発の研究所を
持つSONYが開発費を共同で負担してあげる必要があるでしょうか?
>>419
真偽はともかく、こういう報道もありました。
http://pc.watch.impress.co.jp/docs/2008/0929/kaigai469.htm
--------------------
ちなみに、Cell B.E.の開発をSCE(ソニー)、IBM、東芝の3社のエンジニアで行なった
米オースティンのSTI Design Centerには、現在、SCEのアーキテクトチームはほと
んど残っていないと言われる。
--------------------
現時点で未発表の"A2"ですから、昨年初頭の段階はちょうどアーキテクチャ設計の最中
だった筈。その時点でSCEの技術者が手を引いていたすれば…
真偽はともかく、こういう報道もありました。
http://pc.watch.impress.co.jp/docs/2008/0929/kaigai469.htm
--------------------
ちなみに、Cell B.E.の開発をSCE(ソニー)、IBM、東芝の3社のエンジニアで行なった
米オースティンのSTI Design Centerには、現在、SCEのアーキテクトチームはほと
んど残っていないと言われる。
--------------------
現時点で未発表の"A2"ですから、昨年初頭の段階はちょうどアーキテクチャ設計の最中
だった筈。その時点でSCEの技術者が手を引いていたすれば…
423 :MACオタ>422 さん:2010/01/24(日) 23:06:10 ID:oeZiwZQt
>>422
IBMは商売に関しては悪の権化のような会社です。客から開発費をふんだくった上、
開発した製品の販売権も手に入れるという所業を繰り返しています。
今回話題にしている PPE, PPC476 も全て例外ではありません。
・PPE: SONYの資金で開発 -> MSに派生製品をライセンス
・PPC476: LSI Corp. の資金で開発 (>>396参照) -> コアはIBMブランドで販売
https://www-01.ibm.com/chips/techlib/techlib.nsf/products/PowerPC_476FP_Embedded_Core
さて、A2の開発費を出した客は誰でしょうか?誰が A2 を必要としているかで判るかと。
IBMは商売に関しては悪の権化のような会社です。客から開発費をふんだくった上、
開発した製品の販売権も手に入れるという所業を繰り返しています。
今回話題にしている PPE, PPC476 も全て例外ではありません。
・PPE: SONYの資金で開発 -> MSに派生製品をライセンス
・PPC476: LSI Corp. の資金で開発 (>>396参照) -> コアはIBMブランドで販売
https://www-01.ibm.com/chips/techlib/techlib.nsf/products/PowerPC_476FP_Embedded_Core
さて、A2の開発費を出した客は誰でしょうか?誰が A2 を必要としているかで判るかと。
ちょっと CELL/B.E. 開発の現状を整理してみましょう。
龍芯3号と同じ Hot Chips 20 で東芝は SpursEngine を発表しています。資料はこちら。
http://www.hotchips.org/archives/hc20/2_Mon/HC20.25.211.pdf
p.17を見れば判りますが、SPEは単にバルクSiで製造しているだけでなく、完全にレイアウト
設計をやり直しています。SpursEngine が PPE を持たないのも周知の通りです。
一方で IBM が HPC 向けに設計した PowerXCell のレイアウトはこんな具合。
http://www.power.org/resources/devcorner/cellcorner/hpcspe.pdf (P.18参照)
倍精度ユニットは正に『ポン付け』としか言い様がありません。最新の CELL/B.E. のユーザー
ズマニュアルを読めば書いてますが、PowerXCellで新たにサポートされたDDRメモリの
インターフェースも、XDRメモリコントローラの先にコンバータが『ポン付け』…
IBMの設計がダメとは言いませんが、地道な設計の最適化を行うような人的リソースが
無いのは明らかです。そんなIBMに改良設計を頼むような顧客って誰でしょうか?
龍芯3号と同じ Hot Chips 20 で東芝は SpursEngine を発表しています。資料はこちら。
http://www.hotchips.org/archives/hc20/2_Mon/HC20.25.211.pdf
p.17を見れば判りますが、SPEは単にバルクSiで製造しているだけでなく、完全にレイアウト
設計をやり直しています。SpursEngine が PPE を持たないのも周知の通りです。
一方で IBM が HPC 向けに設計した PowerXCell のレイアウトはこんな具合。
http://www.power.org/resources/devcorner/cellcorner/hpcspe.pdf (P.18参照)
倍精度ユニットは正に『ポン付け』としか言い様がありません。最新の CELL/B.E. のユーザー
ズマニュアルを読めば書いてますが、PowerXCellで新たにサポートされたDDRメモリの
インターフェースも、XDRメモリコントローラの先にコンバータが『ポン付け』…
IBMの設計がダメとは言いませんが、地道な設計の最適化を行うような人的リソースが
無いのは明らかです。そんなIBMに改良設計を頼むような顧客って誰でしょうか?
もう少し大胆に予測してみましょう。
まず、PPC476。 2-issue の PPC440 シリーズから一気に 5-issue OoOE に高性能化を
図りました。共同開発した LSI Corp. はネットワークプロセッサへの応用を考えているでしょう
が、これって仕様としては明らかに PPC750 (PowerPC G3) シリーズの後継に当たります。
おそらく IBM が狙う顧客は任天堂でしょう。
APU インターフェースには小変更した VSX ユニットを搭載して、従来の倍精度FPUレジスタ
応用の単精度2並列SIMD命令をサポートすると共に、Altivec でSIMD幅2倍の性能向上も
図るものと思われます。
PPC-A2については、SONYとMS以外にはさっぱり売れなかったPPEをあえて改良したという
ことは、どちらかの会社が開発を依頼したことが間違いありません。しかし、それに留まらず
IBMの狙いは両方に売って大儲けすることです。
>>424 に書いたように、より開発依頼をする動機があるのはMS。しかし舶来信仰の日本企業
も引き続きパートナーシップを継続しようとする可能性はあります。
ここで注目すべきは、CELL開発中止のリーク。
http://www.itmedia.co.jp/news/articles/0911/25/news030.html
これもIBMのいつものやり方で、過去にはAppleのIntel移行の際にもPowerPCの極秘ロード
マップが半ば意図的にIBMのホームページに置いてあったことがありました。
メディアを利用したFUDはIBMのいつもの手口です。CELLがネタになっていることから、ター
ゲットはSONYでしょう。SONYは疑惑の2社のうち、積極的じゃ無い方ということになります。
従って A2 の顧客は MS でしょう。
SONYがIBMのFUDに掛かったか、否か、は現段階では不明ですが PS4 が一番先行不明
ということになりそうですね。
当たるか外れるかは数年後のお楽しみ。
まず、PPC476。 2-issue の PPC440 シリーズから一気に 5-issue OoOE に高性能化を
図りました。共同開発した LSI Corp. はネットワークプロセッサへの応用を考えているでしょう
が、これって仕様としては明らかに PPC750 (PowerPC G3) シリーズの後継に当たります。
おそらく IBM が狙う顧客は任天堂でしょう。
APU インターフェースには小変更した VSX ユニットを搭載して、従来の倍精度FPUレジスタ
応用の単精度2並列SIMD命令をサポートすると共に、Altivec でSIMD幅2倍の性能向上も
図るものと思われます。
PPC-A2については、SONYとMS以外にはさっぱり売れなかったPPEをあえて改良したという
ことは、どちらかの会社が開発を依頼したことが間違いありません。しかし、それに留まらず
IBMの狙いは両方に売って大儲けすることです。
>>424 に書いたように、より開発依頼をする動機があるのはMS。しかし舶来信仰の日本企業
も引き続きパートナーシップを継続しようとする可能性はあります。
ここで注目すべきは、CELL開発中止のリーク。
http://www.itmedia.co.jp/news/articles/0911/25/news030.html
これもIBMのいつものやり方で、過去にはAppleのIntel移行の際にもPowerPCの極秘ロード
マップが半ば意図的にIBMのホームページに置いてあったことがありました。
メディアを利用したFUDはIBMのいつもの手口です。CELLがネタになっていることから、ター
ゲットはSONYでしょう。SONYは疑惑の2社のうち、積極的じゃ無い方ということになります。
従って A2 の顧客は MS でしょう。
SONYがIBMのFUDに掛かったか、否か、は現段階では不明ですが PS4 が一番先行不明
ということになりそうですね。
当たるか外れるかは数年後のお楽しみ。
ポン付けワロタw 正しくモジュール志向な設計方法取ってんなw
なんかSONY信者さんが狂ってますね
半導体開発の研究所を持つSONYさんがなぜIBMに開発を委託してるんでしょ?
単にMSと同じでCPUのような大規模プロセッサの開発能力がないからでしょ?
半導体開発の研究所を持つSONYさんがなぜIBMに開発を委託してるんでしょ?
単にMSと同じでCPUのような大規模プロセッサの開発能力がないからでしょ?
428 :MACオタ>427 さん:2010/01/25(月) 00:27:37 ID:EtwJE1f0
>>427
------------------
CPUのような大規模プロセッサの開発能力がないからでしょ?
------------------
外人様に開発していただいたプロセッサを、最適化しつつシュリンクする術に長けている
ことはPS2用チップで証明済みかと?
------------------
CPUのような大規模プロセッサの開発能力がないからでしょ?
------------------
外人様に開発していただいたプロセッサを、最適化しつつシュリンクする術に長けている
ことはPS2用チップで証明済みかと?
>>428
うん だから開発する能力はないんでしょ?
うん だから開発する能力はないんでしょ?
MSはAMDに依頼する可能性も高いから
どうなるかはわからんな。CPUもGPUも
同一会社開発、製造の方が何かと楽で安心だろうし。
どうなるかはわからんな。CPUもGPUも
同一会社開発、製造の方が何かと楽で安心だろうし。
これでSONY信者と読み取ってしまう思考能力はある意味跳躍してるな。
つかSONYはPPE'なりA2なり使うしかないじゃん。
x86プロセッサーをSPEの頭になんか無理なんだし。
つかSONYはPPE'なりA2なり使うしかないじゃん。
x86プロセッサーをSPEの頭になんか無理なんだし。
434 :MACオタ>433 さん:2010/01/25(月) 01:13:48 ID:EtwJE1f0
>>433
----------------
2010年にPowerXCell 32ivってロードマップはまだ現存してそうなの?
----------------
もう今年は2010年ですから消えたのでは?
ただし、"A2"により PPE' 相当のコアが現存したことが確認された訳です。
----------------
2010年にPowerXCell 32ivってロードマップはまだ現存してそうなの?
----------------
もう今年は2010年ですから消えたのでは?
ただし、"A2"により PPE' 相当のコアが現存したことが確認された訳です。
コンソールの世代間の性能差となるとやっぱ一桁くらいは欲しいから、
まだちょっと早いんじゃないかなあ。
まだちょっと早いんじゃないかなあ。
436 :MACオタ>435 さん:2010/01/25(月) 01:18:52 ID:EtwJE1f0
まあチップじゃなくてコアだからあってもいいのかもね。
32SPEのチップとか言う話だと今年大量に使われることはまずないけど。
32SPEのチップとか言う話だと今年大量に使われることはまずないけど。
そういやPS2のEEってかなり速いらしいね
ゲーム使用に限定するなら世代の違うPPEと比べても遜色ない性能だとか
ゲーム使用に限定するなら世代の違うPPEと比べても遜色ない性能だとか
ゲーム用CPUは暫し休憩だよ。
MSは現行チップを45nmに移行させ、かつ、省電力にしないと次の6 or 8コアに
取り組めない。SCEはチップ面積的に45nm世代は無理。いずれも32nm世代以降
だが、両社爆熱での品質不良や高価格でWiiに完敗した経験から、32nm世代で
は無理せず、その次の22nm移行前後位しか次のゲーム機は出しづらい。
しかし、CPU設計のコア部分はもう大幅変更する力は両社とも残っていない
から、現行コアの改良だけなら急いで研究開発してその技術を他社に横流し
されたら涙目だし。
ゲーム機の三国志状態は続くし、ソフトメーカーのマルチ化は続くから、
移植の容易さを確保する必要があるので、極端に変わるとは思えないしね。
MSは現行チップを45nmに移行させ、かつ、省電力にしないと次の6 or 8コアに
取り組めない。SCEはチップ面積的に45nm世代は無理。いずれも32nm世代以降
だが、両社爆熱での品質不良や高価格でWiiに完敗した経験から、32nm世代で
は無理せず、その次の22nm移行前後位しか次のゲーム機は出しづらい。
しかし、CPU設計のコア部分はもう大幅変更する力は両社とも残っていない
から、現行コアの改良だけなら急いで研究開発してその技術を他社に横流し
されたら涙目だし。
ゲーム機の三国志状態は続くし、ソフトメーカーのマルチ化は続くから、
移植の容易さを確保する必要があるので、極端に変わるとは思えないしね。
ゲーム機自体は、携帯機が主戦場になっちゃってるからねぇ…。
省電力コアとか機能の取捨選択という部分では面白いし
組み込み系チップのハイパフォーマンス化を先導するのだけど
スパコンとかそういうレベルの話では無いからね。
省電力コアとか機能の取捨選択という部分では面白いし
組み込み系チップのハイパフォーマンス化を先導するのだけど
スパコンとかそういうレベルの話では無いからね。
それにしても、22nmとそれ以降って、まともに微細化がすすむのかねえ。
EUVになるのかEBになるのか。いずれにしてもすごいコストだ。
ゲーム用ならスループットの高いEUVが必要だろう。
代わりの3DLSIのロードマップもあっちこっちで出ているが、こないだの学会じゃ大手はみんな及び腰。
2015年に密結合の3DLSIとか書かれているが、3年5年遅れても驚かんぞ。
EUVになるのかEBになるのか。いずれにしてもすごいコストだ。
ゲーム用ならスループットの高いEUVが必要だろう。
代わりの3DLSIのロードマップもあっちこっちで出ているが、こないだの学会じゃ大手はみんな及び腰。
2015年に密結合の3DLSIとか書かれているが、3年5年遅れても驚かんぞ。
台湾が新しいリソグラフィ技術を考案しましたよ
http://journal.mycom.co.jp/articles/2010/01/25/iedm2009_sram/index.html
とは言えこういうのがすぐに物になるとも思えんが
http://journal.mycom.co.jp/articles/2010/01/25/iedm2009_sram/index.html
とは言えこういうのがすぐに物になるとも思えんが
>442
これはただのEBの変種だからな。
EBの最大の問題はスループット。
この問題を解決する方法は、マルチビームとか昔から研究されているが
まともな形になったものはまだない。
少量な試作に使うくらいなら何とかならんこともないだろうが。
これはただのEBの変種だからな。
EBの最大の問題はスループット。
この問題を解決する方法は、マルチビームとか昔から研究されているが
まともな形になったものはまだない。
少量な試作に使うくらいなら何とかならんこともないだろうが。
ま、確かに
現行の方式と比べて二桁ほど足りないんだっけか
装置価格との兼ね合いもあるけどまだ話にならんね
現行の方式と比べて二桁ほど足りないんだっけか
装置価格との兼ね合いもあるけどまだ話にならんね
どうやら PPC A2 は思ったより大物な気がしてきました。
命令セットの一覧が Binutils ML に投稿されています。
http://sourceware.org/ml/binutils/2009-09/msg00495.html
POWER5までの 64bit POWER サーバーの命令の全てと、POWER7 命令の一部を
サポートする上、多くの新命令が追加されています。
----------------------
* ppc-opc.c (powerpc_opcodes): Add eratilx, eratsx, eratsx.,
eratre, wchkall, eratwe, ldawx., mdfcrx., mfdcr. mtdcrx., icswx,
icswx., mtdcr., dci, wclrone, wclrall, wclr, erativax, tlbsrx.,
ici mnemonics. Update other mnemonics where required.
[略]
+ { "ppca2", (PPC_OPCODE_PPC | PPC_OPCODE_CLASSIC | PPC_OPCODE_ISEL
+ | PPC_OPCODE_POWER4 | PPC_OPCODE_POWER5 | PPC_OPCODE_CACHELCK
+ | PPC_OPCODE_64 | PPC_OPCODE_PPCA2),
+ 0 },
[略]
+{"bpermd", X(31,252), X_MASK, POWER7|PPCA2, PPCNONE, {RA, RS, RB}},
-----------------------
といった感じ。同時に、Freescale e500 の命令の多くもサポートしているようです。
例えば、こんな風。
-----------------------
+{"dcbtstep", XRT(31,255,0), X_MASK, E500MC|PPCA2, PPCNONE, {RT, RA, RB}},
-----------------------
仕様はてんこ盛りな訳ですが用途は何なんでしょう…というか、結局これが今年のISSCCで
発表される"A Wire-Speed Power Processor" (>>312参照)なのでは?
命令セットの一覧が Binutils ML に投稿されています。
http://sourceware.org/ml/binutils/2009-09/msg00495.html
POWER5までの 64bit POWER サーバーの命令の全てと、POWER7 命令の一部を
サポートする上、多くの新命令が追加されています。
----------------------
* ppc-opc.c (powerpc_opcodes): Add eratilx, eratsx, eratsx.,
eratre, wchkall, eratwe, ldawx., mdfcrx., mfdcr. mtdcrx., icswx,
icswx., mtdcr., dci, wclrone, wclrall, wclr, erativax, tlbsrx.,
ici mnemonics. Update other mnemonics where required.
[略]
+ { "ppca2", (PPC_OPCODE_PPC | PPC_OPCODE_CLASSIC | PPC_OPCODE_ISEL
+ | PPC_OPCODE_POWER4 | PPC_OPCODE_POWER5 | PPC_OPCODE_CACHELCK
+ | PPC_OPCODE_64 | PPC_OPCODE_PPCA2),
+ 0 },
[略]
+{"bpermd", X(31,252), X_MASK, POWER7|PPCA2, PPCNONE, {RA, RS, RB}},
-----------------------
といった感じ。同時に、Freescale e500 の命令の多くもサポートしているようです。
例えば、こんな風。
-----------------------
+{"dcbtstep", XRT(31,255,0), X_MASK, E500MC|PPCA2, PPCNONE, {RT, RA, RB}},
-----------------------
仕様はてんこ盛りな訳ですが用途は何なんでしょう…というか、結局これが今年のISSCCで
発表される"A Wire-Speed Power Processor" (>>312参照)なのでは?
自分のカキコミを読み直して、単なる腐れルーマーの類だと思っていた
『PS4にPOWER7が搭載される』というネタの大元は、IBMが"A2"コアを
SONYに売り込んだという話が元になっているのではなかろうかという
気がしてきました。
http://gaming.hexus.net/content/item.php?item=21348
ちなみに binutils のリポジトリを掘っていくと、"e500mc64" なる名前が登場します。
http://sourceware.org/cgi-bin/cvsweb.cgi/src/opcodes/ppc-dis.c?rev=1.44&content-type=text/x-cvsweb-markup&cvsroot=src
----------------------
{ "e500mc64", (PPC_OPCODE_PPC | PPC_OPCODE_BOOKE | PPC_OPCODE_ISEL
| PPC_OPCODE_PMR | PPC_OPCODE_CACHELCK | PPC_OPCODE_RFMCI
| PPC_OPCODE_64 | PPC_OPCODE_POWER5 | PPC_OPCODE_POWER6
| PPC_OPCODE_POWER7),
0 },
----------------------
どう見ても、Freescale QorIQ の 64bit 版な訳ですが、POWER7 命令もサポートしているよう
に見えます。
果たしてサマセット研時代のようなPOWER陣営大連合が果たされるのかどうか…
『PS4にPOWER7が搭載される』というネタの大元は、IBMが"A2"コアを
SONYに売り込んだという話が元になっているのではなかろうかという
気がしてきました。
http://gaming.hexus.net/content/item.php?item=21348
ちなみに binutils のリポジトリを掘っていくと、"e500mc64" なる名前が登場します。
http://sourceware.org/cgi-bin/cvsweb.cgi/src/opcodes/ppc-dis.c?rev=1.44&content-type=text/x-cvsweb-markup&cvsroot=src
----------------------
{ "e500mc64", (PPC_OPCODE_PPC | PPC_OPCODE_BOOKE | PPC_OPCODE_ISEL
| PPC_OPCODE_PMR | PPC_OPCODE_CACHELCK | PPC_OPCODE_RFMCI
| PPC_OPCODE_64 | PPC_OPCODE_POWER5 | PPC_OPCODE_POWER6
| PPC_OPCODE_POWER7),
0 },
----------------------
どう見ても、Freescale QorIQ の 64bit 版な訳ですが、POWER7 命令もサポートしているよう
に見えます。
果たしてサマセット研時代のようなPOWER陣営大連合が果たされるのかどうか…
PPC A2のお披露目に期待age
POWER7ですが、ISSCCでの論文発表と同時に製品も発表されると言うことになりそうで。
http://www.itjungle.com/tfh/tfh012510-story07.html
------------------------
Power your planet.
In February, IBM will introduce the next generation Power Systems--the first of a
family of systems and storage designed to meet the demands of a smarter planet.
From the chip and virtualization capabilities all the way through to the operating
system, middleware and energy management, Power Systems from IBM are integrated
to help support the complex workloads and dynamic computing models of a new
kind of world.
Power Systems--the future of Unix servers. They're coming. Smarter systems for a
Smarter Planet.
ibm.com/poweryourplanet
------------------------
ソースは Wallstreet Journal に掲載された新聞広告だそうですが、確かに…
http://www-03.ibm.com/systems/info/power/poweryourplanet/
http://www.itjungle.com/tfh/tfh012510-story07.html
------------------------
Power your planet.
In February, IBM will introduce the next generation Power Systems--the first of a
family of systems and storage designed to meet the demands of a smarter planet.
From the chip and virtualization capabilities all the way through to the operating
system, middleware and energy management, Power Systems from IBM are integrated
to help support the complex workloads and dynamic computing models of a new
kind of world.
Power Systems--the future of Unix servers. They're coming. Smarter systems for a
Smarter Planet.
ibm.com/poweryourplanet
------------------------
ソースは Wallstreet Journal に掲載された新聞広告だそうですが、確かに…
http://www-03.ibm.com/systems/info/power/poweryourplanet/
MACオタさん洞察すばらしいですね。
某社ではこのA2のことで話題が持ちきりでしたw
某社ではこのA2のことで話題が持ちきりでしたw
各地でMACオタさんの株が上昇しています↑
PPC A2 が ISSCC で発表される "Wire-Speed Power Processor" だとすると、
アブストラクトには、こうあります。
https://submissions.miracd.com/ISSCC2010/WebAP/PDF/AP_Session5.pdf
--------------------
A 64-thread simultaneous multi-threaded processor uses architecture
and implementation techniques to achieve high throughput at low power.
Included are static VDD scaling, multi-voltage design,
clock gating, multiple VT devices, dynamic thermal control,
eDRAM and low-voltage circuit design. Power is reduced by >50% in a
428mm2 chip. Worst-case power is 65W at 2.0GHz, 0.85V.
--------------------
PPUより大規模そうな仕様にしては、16-core のチップ全体で 65W@2GHzは
現実的な数字に見えます。
それでも 4 Flops/Cycle 程度の APU を搭載したとして、2GHz でおよそ 2GFlops/W。
チップ単体でこれでは、システム全体で3GFlops/W を狙うと言われる Sequoia 用の
プロセッサでは無さそうに見えますが、さて。
アブストラクトには、こうあります。
https://submissions.miracd.com/ISSCC2010/WebAP/PDF/AP_Session5.pdf
--------------------
A 64-thread simultaneous multi-threaded processor uses architecture
and implementation techniques to achieve high throughput at low power.
Included are static VDD scaling, multi-voltage design,
clock gating, multiple VT devices, dynamic thermal control,
eDRAM and low-voltage circuit design. Power is reduced by >50% in a
428mm2 chip. Worst-case power is 65W at 2.0GHz, 0.85V.
--------------------
PPUより大規模そうな仕様にしては、16-core のチップ全体で 65W@2GHzは
現実的な数字に見えます。
それでも 4 Flops/Cycle 程度の APU を搭載したとして、2GHz でおよそ 2GFlops/W。
チップ単体でこれでは、システム全体で3GFlops/W を狙うと言われる Sequoia 用の
プロセッサでは無さそうに見えますが、さて。
A2 = Wire-Speed Power 説ですが、RealWorldTech 掲示板で Wes Felter 氏が思わせぶり
なカキコミをしていますね。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=106880&threadid=106859&roomid=2
------------------------
>Is there any primary source about the A2, or hard evidence of it at all, besides
>this file in GCC?
Be patient. (But not too patient.)
------------------------
ちなみに Felter 氏はこんなヒト。
http://felter.org/wesley/
なカキコミをしていますね。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=106880&threadid=106859&roomid=2
------------------------
>Is there any primary source about the A2, or hard evidence of it at all, besides
>this file in GCC?
Be patient. (But not too patient.)
------------------------
ちなみに Felter 氏はこんなヒト。
http://felter.org/wesley/
Freescale の 64bit Book-E プロセッサ, e500mc64 の方ですが、GCC の
リポジトリに Machine Description が置いてありました。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/e500mc64.md?revision=156013&view=markup
-----------------
;; e500mc64 64-bit SU(2), LSU, FPU, BPU
;; Max issue 3 insns/clock cycle (includes 1 branch)
-----------------
パイプライン構造、レイテンシ共に e500mc (QorIQ) と変わらない様ですから、
上限 2GHz 程度の普通の上位組込コアの様です。
Freescale は e500 コアで Altivec をサポートするつもりは無い様ですから、興味深い
応用は無さそうですね。
リポジトリに Machine Description が置いてありました。
http://gcc.gnu.org/viewcvs/branches/ibm/power7-meissner/gcc/config/rs6000/e500mc64.md?revision=156013&view=markup
-----------------
;; e500mc64 64-bit SU(2), LSU, FPU, BPU
;; Max issue 3 insns/clock cycle (includes 1 branch)
-----------------
パイプライン構造、レイテンシ共に e500mc (QorIQ) と変わらない様ですから、
上限 2GHz 程度の普通の上位組込コアの様です。
Freescale は e500 コアで Altivec をサポートするつもりは無い様ですから、興味深い
応用は無さそうですね。
>>453
XBOX用って言っていたのは何だったのか?勘違い?
XBOX用って言っていたのは何だったのか?勘違い?
やっぱりIBMオタに改名するベキダ
456 :MACオタ>454 さん:2010/01/26(火) 22:40:38 ID:bF9XPRSO
>>454
-----------------
XBOX用って言っていたのは何だったのか?勘違い?
-----------------
命令セットの増強を見ると、単純な PPU/PX 改良版では無かったようです。
もっともBMが客も決まっていないプロセッサを開発する訳がありませんから、A2 に関
しては XCPU 後継として使われる可能性があります。しかし、その場合は VMX128 後継
となる APU を別途開発する必要がありますから、もう少し先の話では?
実現するとすればバリア同期やコア単位の電力管理に役に立つ "Wait" カテゴリの命令
が大きく増強されているようですから、8コア以上のマルチコアとして実装されそうですね。
-----------------
XBOX用って言っていたのは何だったのか?勘違い?
-----------------
命令セットの増強を見ると、単純な PPU/PX 改良版では無かったようです。
もっともBMが客も決まっていないプロセッサを開発する訳がありませんから、A2 に関
しては XCPU 後継として使われる可能性があります。しかし、その場合は VMX128 後継
となる APU を別途開発する必要がありますから、もう少し先の話では?
実現するとすればバリア同期やコア単位の電力管理に役に立つ "Wait" カテゴリの命令
が大きく増強されているようですから、8コア以上のマルチコアとして実装されそうですね。
新聞報道されていた京速の機密文書が公開されたようです。
http://www.mext.go.jp/b_menu/houdou/22/01/__icsFiles/afieldfile/2010/01/26/1289511_1.pdf
作業部会での悲惨な評価はp.13からの資料にあります。
-------------------
・ スカラ部による性能目標達成のためには、ベクトルは完成が遅れてもやむを得ない。
・ 現状では、世界一奪取に対する貢献度が見えない。
・ 統合アプリはない、統合Linpack はやらない、ということなので、ベクトル部を継続する意義
はほとんど無い。
・ ベクトルで3ペタ達成可能であるならば、作る意味はある。3ペタが達成されないならば意義
は低い。
・ メモリーのクロックが遅くなったベクトル計算機では、既存プロクラムの継続利用以外のメリ
ットが無くなりつつあり、1ノード毎にばらばらに使うのでなければ、システム構成として見
直すべき時期に来ている。
・ 現在のベクトル部詳細設計では、メモリバンド幅・演算速度比がベクトル計算機として
効率的に動作するには小さすぎる。また、電力が世界の状況と比較して過大である。し
たがって、製作を行うことには、地球シミュレータ以来のソフトウェア資産を継承する
以外の意義は少なく、仮に中止したとしてもその影響は限定的である。
-------------------
NECって自主的撤退と言うよりは、切られたのでは?
http://www.mext.go.jp/b_menu/houdou/22/01/__icsFiles/afieldfile/2010/01/26/1289511_1.pdf
作業部会での悲惨な評価はp.13からの資料にあります。
-------------------
・ スカラ部による性能目標達成のためには、ベクトルは完成が遅れてもやむを得ない。
・ 現状では、世界一奪取に対する貢献度が見えない。
・ 統合アプリはない、統合Linpack はやらない、ということなので、ベクトル部を継続する意義
はほとんど無い。
・ ベクトルで3ペタ達成可能であるならば、作る意味はある。3ペタが達成されないならば意義
は低い。
・ メモリーのクロックが遅くなったベクトル計算機では、既存プロクラムの継続利用以外のメリ
ットが無くなりつつあり、1ノード毎にばらばらに使うのでなければ、システム構成として見
直すべき時期に来ている。
・ 現在のベクトル部詳細設計では、メモリバンド幅・演算速度比がベクトル計算機として
効率的に動作するには小さすぎる。また、電力が世界の状況と比較して過大である。し
たがって、製作を行うことには、地球シミュレータ以来のソフトウェア資産を継承する
以外の意義は少なく、仮に中止したとしてもその影響は限定的である。
-------------------
NECって自主的撤退と言うよりは、切られたのでは?
携帯型コンピュータのプロセッサ、「2013年にはARMがx86を超える」
http://www.eetimes.jp/news/3634
http://www.eetimes.jp/news/3634
2004年にはItaniumがx86を超える(キリッ
すでに8086くらいは超えてるな
>>461
志村ーッ、2004だってばw
志村ーッ、2004だってばw
Apple A4のベースになってるARMって何なのか分かる人いる?
資料が見つからない…
資料が見つからない…
なんで、出来合いのチップを調達せずに、わざわざ自前で用意しようと思ったんだろうな?
3G → 90nm / ARM11 412MHz / PowerVR MBX-Lite
3G S → 65nm / ARM Cortex A8 600MHz / PowerVR SGX
どちらも既存のものをベースにちょいカスタムしたSamsung製SoCを採用。
自前でもなんでもなく順当にiPadもこの系統だと思うが。
IPは他社のものだからどうしようもないけど、SoC設計をApple買い取ったってことなのかもね。
3G S → 65nm / ARM Cortex A8 600MHz / PowerVR SGX
どちらも既存のものをベースにちょいカスタムしたSamsung製SoCを採用。
自前でもなんでもなく順当にiPadもこの系統だと思うが。
IPは他社のものだからどうしようもないけど、SoC設計をApple買い取ったってことなのかもね。
A1→68k
A2→PowerPC
A3→x86(-64)
A4→ARM
A3はいつまで続くのかなぁーっと
A2→PowerPC
A3→x86(-64)
A4→ARM
A3はいつまで続くのかなぁーっと
468 :MACオタ>467 さん:2010/01/29(金) 01:54:39 ID:nDBbxlWP
>>467
Apple ][ が抜けているのは、ちょっと歴史認識が間違っている気が…
Apple ][ が抜けているのは、ちょっと歴史認識が間違っている気が…
TomsHardware の SpursEngine レビュー。
http://www.tomshardware.com/reviews/leadtek-winfast-pxvc1100,2523.html
複数のIntel/AMDのホストプロセッサでの比較を行っていますが、
- 消費電力据置きで、エンコード時間は半分以下で済む。
- 画質はソフトウェアエンコーディングに匹敵
- アドオンカードにしては値段も安い
ということで、好意的なレビュー結果でした。
http://www.tomshardware.com/reviews/leadtek-winfast-pxvc1100,2523.html
複数のIntel/AMDのホストプロセッサでの比較を行っていますが、
- 消費電力据置きで、エンコード時間は半分以下で済む。
- 画質はソフトウェアエンコーディングに匹敵
- アドオンカードにしては値段も安い
ということで、好意的なレビュー結果でした。
TheRegs の ISSCC プレビューですが、Morgan 記者は "Wire-Speed Power" を
試作品と見ている様で…
http://www.theregister.co.uk/2010/01/28/isscc_chip_preview/page2.html
--------------------
IBM's chip designers will be showing off another experimental Power7 derivative,
an unnamed 2.3 GHz "wire-speed Power processor" that sports 16 cores and 64 threads.
--------------------
試作品と見ている様で…
http://www.theregister.co.uk/2010/01/28/isscc_chip_preview/page2.html
--------------------
IBM's chip designers will be showing off another experimental Power7 derivative,
an unnamed 2.3 GHz "wire-speed Power processor" that sports 16 cores and 64 threads.
--------------------
理研とNVIDIAが主催した"Accelerated Computing"研究会で、
https://reg-nvidia.jp/public/seminar/view/3
牧野教授が次世代GRAPE-DR の開発状況を語ったようです。
http://www.artcompsci.org/~makino/talks/roppongi201001xx.pdf (P.56)
------------------------
GRAPEs with eASIC
・Completed an experimental design of a
programmable processor for quadruple-precision
arithmetic. 6PEs in nominal 2.5Mgates.
・Started designing low-accuracy GRAPE hardware
with 7.4Mgates chip.
Summary of planned specs:
・around 8-bit relative precision
・support for quadrupole moment in hardware
・100-200 pipelines, 300MHz, 2-4Tflops/chip
・small power consumption: single PCIe card can
house 4 chips (10 Tflops, 50W in total)
------------------------
300MHz の HPC 向けプロセッサとはあまりに貧乏路線過ぎる気もしますが、電力効率
勝負になっている現在のトレンドには合致しているのかもしれません。
でも電力管理に(設計)リソースを振り向けられなくて、それほど効率も上がらないかも…
https://reg-nvidia.jp/public/seminar/view/3
牧野教授が次世代GRAPE-DR の開発状況を語ったようです。
http://www.artcompsci.org/~makino/talks/roppongi201001xx.pdf (P.56)
------------------------
GRAPEs with eASIC
・Completed an experimental design of a
programmable processor for quadruple-precision
arithmetic. 6PEs in nominal 2.5Mgates.
・Started designing low-accuracy GRAPE hardware
with 7.4Mgates chip.
Summary of planned specs:
・around 8-bit relative precision
・support for quadrupole moment in hardware
・100-200 pipelines, 300MHz, 2-4Tflops/chip
・small power consumption: single PCIe card can
house 4 chips (10 Tflops, 50W in total)
------------------------
300MHz の HPC 向けプロセッサとはあまりに貧乏路線過ぎる気もしますが、電力効率
勝負になっている現在のトレンドには合致しているのかもしれません。
でも電力管理に(設計)リソースを振り向けられなくて、それほど効率も上がらないかも…
armがmsと共通規格策定できれば凄いことになりそう
2年後くらいかな
1年後のandroid共通規格でもいいけど
2年後くらいかな
1年後のandroid共通規格でもいいけど
PPC "A2" の開発に LSI が参加していることについて MAC ヲタが>>425で↓と書いているが
> 共同開発した LSI Corp. はネットワークプロセッサへの応用を考えているでしょう
個人的にはネットワークプロセッサーよりも IO プロセッサーへの応用を期待してみる.
intel は IOP がディスコンしまくりだし,AMCC は 3ware を手放したみたいだが
マルチコアにスケールしやすいプロセッサーはIOプロセッサーとしてどうなのだろう?
# RAIDだとパリティ演算とかマルチコアで性能出し易そうに思えるのだが…触ったこと無いから解らん…
LSI のネットワークプロセッサーはハイエンドではない ARM だし,どうなのかね?
> 共同開発した LSI Corp. はネットワークプロセッサへの応用を考えているでしょう
個人的にはネットワークプロセッサーよりも IO プロセッサーへの応用を期待してみる.
intel は IOP がディスコンしまくりだし,AMCC は 3ware を手放したみたいだが
マルチコアにスケールしやすいプロセッサーはIOプロセッサーとしてどうなのだろう?
# RAIDだとパリティ演算とかマルチコアで性能出し易そうに思えるのだが…触ったこと無いから解らん…
LSI のネットワークプロセッサーはハイエンドではない ARM だし,どうなのかね?
475 :MACオタ>474 さん:2010/01/30(土) 03:26:18 ID:9on66SoV
>>474
------------------
> 共同開発した LSI Corp. はネットワークプロセッサへの応用を考えている
------------------
カキコミが分散して誤解させてしまったことは申し訳ありませんが、それA2じゃなくて
PPC476の話です(>>396参照)。
------------------
> 共同開発した LSI Corp. はネットワークプロセッサへの応用を考えている
------------------
カキコミが分散して誤解させてしまったことは申し訳ありませんが、それA2じゃなくて
PPC476の話です(>>396参照)。
安藤氏の今日の更新ですが、
http://www.geocities.jp/andosprocinfo/wadai10/20100130.htm
----------------
今の計画では,富士通は当初計画通り2012年3月末に10PFlopsを作り,
NECのベクトル部が無くなったのに,予算は変わらないというのは理解
できません。
----------------
マスメディアでの記事まで含めて、散々事業仕分けを批判した挙句に
他人事のようにこれは無いのではないでしょうか?
文責とかそういうものって、いったい何所に…
http://www.geocities.jp/andosprocinfo/wadai10/20100130.htm
----------------
今の計画では,富士通は当初計画通り2012年3月末に10PFlopsを作り,
NECのベクトル部が無くなったのに,予算は変わらないというのは理解
できません。
----------------
マスメディアでの記事まで含めて、散々事業仕分けを批判した挙句に
他人事のようにこれは無いのではないでしょうか?
文責とかそういうものって、いったい何所に…
翻って事業仕分けはスバラシイとか言い始めたわけじゃないんだから別に矛盾して無いでしょ。
事業仕分けに批判的な人でも京速計算機に問題が無いなんて考えてる人はほぼ皆無だと思う。
オタさんはこの問題に関して「スパコン利権vs事業仕分け」みたいな二極思考のようだけど。
事業仕分けに批判的な人でも京速計算機に問題が無いなんて考えてる人はほぼ皆無だと思う。
オタさんはこの問題に関して「スパコン利権vs事業仕分け」みたいな二極思考のようだけど。
馬鹿だから仕方ない
479 :MACオタ>477 さん:2010/01/30(土) 22:28:24 ID:9on66SoV
>>477
-------------
翻って事業仕分けはスバラシイとか言い始めたわけじゃない
-------------
いわゆる『文系』の世界と違って、自説の前提が間違っていることが明らか
になった場合は、そういう主張を行っても我々の世界では非難はされません。
むしろ過去の自説に偏執するほうが馬鹿にされます。
過去の安藤氏の主張に関しては、例えばこの記事を通読下さい。
http://journal.mycom.co.jp/articles/2010/01/02/next_generation_supercomputer/index.html
仕分け側の金田教授や、計画見直し論に京速サイドに立って批判を加えて
いるのが判るかと思います。
-------------
翻って事業仕分けはスバラシイとか言い始めたわけじゃない
-------------
いわゆる『文系』の世界と違って、自説の前提が間違っていることが明らか
になった場合は、そういう主張を行っても我々の世界では非難はされません。
むしろ過去の自説に偏執するほうが馬鹿にされます。
過去の安藤氏の主張に関しては、例えばこの記事を通読下さい。
http://journal.mycom.co.jp/articles/2010/01/02/next_generation_supercomputer/index.html
仕分け側の金田教授や、計画見直し論に京速サイドに立って批判を加えて
いるのが判るかと思います。
命令キューとリオーダバッファの区別のついていないMACオタが何を言うか(笑)
ちと話は変わりますが、>>336で紹介した CELL を採用した欧州のスーパー
コンピュータQPACEの開発スケジュールが最後のリンクにあります。
もう一度貼り直しておきますが、
http://www.desy.de/dvsem/WS0910/pleiter_talk.pdf (P.32)
----------------
・ 01/08 Official Project Start
[中略]
・ 08/09 Deployment of 4 racks at JSC and
4 racks at U Wuppertal complete
-----------------
TOP500でのお披露目まで入れても、余裕で2年以下ですね。
汎用プロセッサを選択するだけでも、これだけの開発速度を実現できるという
のは、頭においておいて良いかと思うのですが…
コンピュータQPACEの開発スケジュールが最後のリンクにあります。
もう一度貼り直しておきますが、
http://www.desy.de/dvsem/WS0910/pleiter_talk.pdf (P.32)
----------------
・ 01/08 Official Project Start
[中略]
・ 08/09 Deployment of 4 racks at JSC and
4 racks at U Wuppertal complete
-----------------
TOP500でのお披露目まで入れても、余裕で2年以下ですね。
汎用プロセッサを選択するだけでも、これだけの開発速度を実現できるという
のは、頭においておいて良いかと思うのですが…
>>479
>仕分け側の金田教授や、計画見直し論に京速サイドに立って批判を加えて
いるのが判るかと思います。
そういうのが二極思考だと言っているんです。
京速サイド、事業仕分けサイドどっちの味方とかそういう視点でしか見ていない。
>今の計画では,富士通は当初計画通り2012年3月末に10PFlopsを作り,
NECのベクトル部が無くなったのに,予算は変わらないというのは理解
できません。
この主張に矛盾するような箇所は見つけられませんでした。
>仕分け側の金田教授や、計画見直し論に京速サイドに立って批判を加えて
いるのが判るかと思います。
そういうのが二極思考だと言っているんです。
京速サイド、事業仕分けサイドどっちの味方とかそういう視点でしか見ていない。
>今の計画では,富士通は当初計画通り2012年3月末に10PFlopsを作り,
NECのベクトル部が無くなったのに,予算は変わらないというのは理解
できません。
この主張に矛盾するような箇所は見つけられませんでした。
>>482
馬の耳に念仏だよ
馬の耳に念仏だよ
484 :MACオタ>482 さん:2010/01/30(土) 23:06:20 ID:9on66SoV
>>482
-------------------
そういうのが二極思考だと言っているんです。
-------------------
当該記事から安藤氏独自の『極』なる提案を読み取ることができると主張
されるのでしたら、その内容をお書き下さい。
-------------------
そういうのが二極思考だと言っているんです。
-------------------
当該記事から安藤氏独自の『極』なる提案を読み取ることができると主張
されるのでしたら、その内容をお書き下さい。
きもい
落ち着け
Power.org が Power ISA 2.06 (サーバー仕様) の特徴について白書を公開しています。
ISA 2.06 Server Environment というのは POWER7 のための規格のようなモノですから、
POWER7 の改良点そのものかと。
http://www.power.org/resources/downloads/Power.org_White_Paper_What_is_New_in_Server_Environment_of_Power_ISA_v2.06.pdf
・ VSX (Vector-Scalar Extension)
・ Processor Compatibility Register
ISA 2.05用の仮想マシンとISA 2.06用の仮想マシンの切替に役に立つそうで。
・ Authority Mask Override Register と User Authority Mask Override Register
・ 複数ページサイズの同時サポート
・ DCBT/DCBTST 命令によるプリフェッチの拡張
昔から使われているテクニックですが、より現代的な仕様を追加しました。
- Transient (一時的使用) 指定
- Stride-N プリフェッチ: 疎行列アクセス用
・ メモリアクセス順序の強制
PowerPC ISA は『緩い』メモリオーダリングを持つ命令セットですが、SPARCやx86の
エミュレーション用にこの機能が役に立つそうで。
・ DFP (Decimal Floating Point)
ISA 2.06 Server Environment というのは POWER7 のための規格のようなモノですから、
POWER7 の改良点そのものかと。
http://www.power.org/resources/downloads/Power.org_White_Paper_What_is_New_in_Server_Environment_of_Power_ISA_v2.06.pdf
・ VSX (Vector-Scalar Extension)
・ Processor Compatibility Register
ISA 2.05用の仮想マシンとISA 2.06用の仮想マシンの切替に役に立つそうで。
・ Authority Mask Override Register と User Authority Mask Override Register
・ 複数ページサイズの同時サポート
・ DCBT/DCBTST 命令によるプリフェッチの拡張
昔から使われているテクニックですが、より現代的な仕様を追加しました。
- Transient (一時的使用) 指定
- Stride-N プリフェッチ: 疎行列アクセス用
・ メモリアクセス順序の強制
PowerPC ISA は『緩い』メモリオーダリングを持つ命令セットですが、SPARCやx86の
エミュレーション用にこの機能が役に立つそうで。
・ DFP (Decimal Floating Point)
オタさんファビョっちゃった
一瞬POWER7版PowerPCかと思ったw
MACオタの口から文系批判が出るとは思わんかったw
492 :MACオタ>491 さん:2010/01/31(日) 18:21:54 ID:1yjeuoJz
>>491
特に批判しているつもりはありませんよ。昔、かの世界は伝統芸能の様に
説が『存在する』ということに意味があるので、現実世界の動向にかかわらず
間違いを認めると変節漢として非難されると聞いたのですが…
特に批判しているつもりはありませんよ。昔、かの世界は伝統芸能の様に
説が『存在する』ということに意味があるので、現実世界の動向にかかわらず
間違いを認めると変節漢として非難されると聞いたのですが…
認めなきゃ!間違いを!<オタへ
>いわゆる『文系』の世界と違って、自説の前提が間違っていることが明らか
>になった場合は、そういう主張を行っても我々の世界では非難はされません。
>むしろ過去の自説に偏執するほうが馬鹿にされます。
ゲハ厨風情が「我々の世界」とか言い出すようになってるとはワナビー病も根が深い
>になった場合は、そういう主張を行っても我々の世界では非難はされません。
>むしろ過去の自説に偏執するほうが馬鹿にされます。
ゲハ厨風情が「我々の世界」とか言い出すようになってるとはワナビー病も根が深い
495 :MACオタ>494 さん:2010/01/31(日) 21:56:21 ID:1yjeuoJz
>>494
特に自慢になるような話でもありませんが、ゲハ板より私の方が古いんですよ。
古いカキコミを検索してみると、この位は辿れますね…
http://mimizun.com/2chlog/mac/piza.2ch.net/log/mac/kako/943/943041662.html
-------------------
6 名前:MACオタ :1999/11/25(木) 07:48
ドルさん,解説どうも。
サポートをMac OS 8以上に限定すれば,httpはiCabの様にHTTP Access
機能をAppleScriptで呼び出すだけで使えるす。遅いけど。
どなたかREALBasicあたりで頑張ってみてわいかがすかね?
-------------------
特に自慢になるような話でもありませんが、ゲハ板より私の方が古いんですよ。
古いカキコミを検索してみると、この位は辿れますね…
http://mimizun.com/2chlog/mac/piza.2ch.net/log/mac/kako/943/943041662.html
-------------------
6 名前:MACオタ :1999/11/25(木) 07:48
ドルさん,解説どうも。
サポートをMac OS 8以上に限定すれば,httpはiCabの様にHTTP Access
機能をAppleScriptで呼び出すだけで使えるす。遅いけど。
どなたかREALBasicあたりで頑張ってみてわいかがすかね?
-------------------
「> ゲハ板より私の方が古い」ことがどう>>494 と繋がるのかさっぱり分からん。
いきなり自分語りしだして何考えてるんだコイツ。
いきなり自分語りしだして何考えてるんだコイツ。
しーっ、見ちゃいけません
ふと懐かしくなって自作板の過去ログを探していましたが、最古のスレッドも
残っているのですね。
http://mentai.2ch.net/jisaku/kako/945/
私の最初のカキコミはこれっぽいです。
http://mentai.2ch.net/jisaku/kako/945/945651630.html
-------------------
10 名前: MACオタ 投稿日: 1999/12/20(月) 21:57
登録シールを見ると92年8月から使ってるApple Keyboard II (US)。
当然キートップの刻印はほとんど消えてるす。
-------------------
残っているのですね。
http://mentai.2ch.net/jisaku/kako/945/
私の最初のカキコミはこれっぽいです。
http://mentai.2ch.net/jisaku/kako/945/945651630.html
-------------------
10 名前: MACオタ 投稿日: 1999/12/20(月) 21:57
登録シールを見ると92年8月から使ってるApple Keyboard II (US)。
当然キートップの刻印はほとんど消えてるす。
-------------------
反転、MACオタさんの株が下落しています↓
こんなMACオタには減滅した・・・かまってちゃん全開でひくわ
団子が消えてオタが残った
MOTO製G5の話題あたりから懐メロ入って来たとかw
>>476辺りでバランスを崩し始め、復旧を試みるもそのまま負のスパイラルへ
FYIや情報交換ではなく自我を保つために書き込みするタイプがたびたび陥る罠です
FYIや情報交換ではなく自我を保つために書き込みするタイプがたびたび陥る罠です
>>393 で言及されている龍芯3号の論文見つけました。
http://ams.ict.ac.cn/onchipmem/papers/ICT-Godson-3%20--%20A%20Scalable%20Multicore%20RISC%20Processor%20with%20x86%20Emulation.pdf
それから>>392でこういうニュースがありましたが、
----------------
・今年中にPOWERサーバーはPOWER7世代に更新される
----------------
IBMが POWER7 搭載ブレードサーバー (POWER6 搭載の JS23/JS43 の後継機)の研修会
を3月に予定しているとのこと。
http://www.redbooks.ibm.com/residents.nsf/residencies/PW-0105-R01?Open
Q2あたりに製品がでるのでしょうか?
http://ams.ict.ac.cn/onchipmem/papers/ICT-Godson-3%20--%20A%20Scalable%20Multicore%20RISC%20Processor%20with%20x86%20Emulation.pdf
それから>>392でこういうニュースがありましたが、
----------------
・今年中にPOWERサーバーはPOWER7世代に更新される
----------------
IBMが POWER7 搭載ブレードサーバー (POWER6 搭載の JS23/JS43 の後継機)の研修会
を3月に予定しているとのこと。
http://www.redbooks.ibm.com/residents.nsf/residencies/PW-0105-R01?Open
Q2あたりに製品がでるのでしょうか?
上のIBMのリンクって研修会の案内じゃなくて、該当機種の Redbook の編集バイト
の募集ですね…
の募集ですね…
2/8のISSCCのプロセッサセッションでのPOWER7講演(>>312参照)と共に、製品発表も行われるようです。
http://www.theregister.co.uk/2010/02/01/ibm_power7_launch/
-------------------------
It looks like IBM's initial Power7-based servers are going to be launched in
New York on February 8. Big Blue sent out the invitations today.
-------------------------
http://www.theregister.co.uk/2010/02/01/ibm_power7_launch/
-------------------------
It looks like IBM's initial Power7-based servers are going to be launched in
New York on February 8. Big Blue sent out the invitations today.
-------------------------
507 :,,・´∀`・,,)っ-○○○:2010/02/02(火) 23:45:50 ID:hSNfD5Gf
2chより面白いサイトがあってね
もう団子食べ飽きた、イラネ
なんと2/8にはTukwilaも発表になるんだとか。
http://www.theregister.co.uk/2010/02/02/intel_server_chip_launches/
--------------------
High-end server chip rivals Intel and IBM have picked the same day
- next Monday, February 8 - to launch their respective quad-core
"Tukwila" Itanium and eight-core Power7 processors.
--------------------
すでに顧客には出荷が始まっているとのことで、Intel の新製品発表の通例
として、搭載製品も同時に公開されるのでしょう。
http://www.theregister.co.uk/2010/02/02/intel_server_chip_launches/
--------------------
High-end server chip rivals Intel and IBM have picked the same day
- next Monday, February 8 - to launch their respective quad-core
"Tukwila" Itanium and eight-core Power7 processors.
--------------------
すでに顧客には出荷が始まっているとのことで、Intel の新製品発表の通例
として、搭載製品も同時に公開されるのでしょう。
参考までに一昨年の Hot Chips 20 で発表された Tukwila のプレゼン資料を
貼っておきます。
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.911.pdf
ここからメモリコントローラの変更が行われたことは発表されている訳ですが…
貼っておきます。
http://www.hotchips.org/archives/hc20/3_Tues/HC20.26.911.pdf
ここからメモリコントローラの変更が行われたことは発表されている訳ですが…
ARM系で一本
Cortex A、R、Mそれぞれに後継のロードマップとな
ARM Preps 2-GHz, Multicore Chips for Smartphones
http://www.pcmag.com/article2/0,2817,2358752,00.asp
Cortex-Aに関して言えば、今後は鯖にも使われていくんだろうけど、
そうなると気になるメモリの心許なさ
アドレス空間拡張の予定はあるんじゃろうか…
Cortex A、R、Mそれぞれに後継のロードマップとな
ARM Preps 2-GHz, Multicore Chips for Smartphones
http://www.pcmag.com/article2/0,2817,2358752,00.asp
Cortex-Aに関して言えば、今後は鯖にも使われていくんだろうけど、
そうなると気になるメモリの心許なさ
アドレス空間拡張の予定はあるんじゃろうか…
512 :,,・´∀`・,,)っ-○○○:2010/02/06(土) 09:31:36 ID:kCi1iHQ2
サーバねぇ
組み込み向けサーバとかあんの?
ARMとか鯖にならんかと妄想したこともあるが、
よくよく考えると棲み分けできる場所が無い。
高性能なヤツは何個CPU積んでも無理っぽいし、
中小企業のちっさいヤツはどうせWindowsだしAtomで十分だし。
よくよく考えると棲み分けできる場所が無い。
高性能なヤツは何個CPU積んでも無理っぽいし、
中小企業のちっさいヤツはどうせWindowsだしAtomで十分だし。
515 :,,・´∀`・,,)っ-○○○:2010/02/06(土) 16:14:37 ID:kCi1iHQ2
ARMは割と好きだけど流石に・・・ねぇ
団子ちゃんは無理せず今までのようにARM(笑)って言ってればいいと思うよ。
その方が自然です。
これまでもARMをサーバに出来ないかって話は結構出てたんだけどね。
http://www.eetimes.com/222601123
とりあえず、PASemiとCiscoはアップを始めたっぽい。
その方が自然です。
これまでもARMをサーバに出来ないかって話は結構出てたんだけどね。
http://www.eetimes.com/222601123
とりあえず、PASemiとCiscoはアップを始めたっぽい。
Atomがあんだけ安く出ちゃうと、ARMの出番は無いな。
Intelが殿様商売でボッタクリCPUのみ売ってた頃ならともかく。
Intelが殿様商売でボッタクリCPUのみ売ってた頃ならともかく。
その意味ではVIAに頑張ってもらわんと。
ARMが鯖になれるならSuperHもなんとか頼む!
>>516
PASemiってPowerPCやってたんじゃなかったっけ?
PASemiってPowerPCやってたんじゃなかったっけ?
>>520
Apple傘下でARM作らされてるよ。
Apple傘下でARM作らされてるよ。
うん、それは知ってる
いよいよx86が終わると思うと胸が熱くなるな
10年後もx86が残っているに1票
MSが他のプロセッサへの移行を本格的に始めたらx86も終わりそうな
気がするけど、MS自身がハードウェアの商売でも始めない限り、Winを
別の環境に移行させる意味はないからな。
気がするけど、MS自身がハードウェアの商売でも始めない限り、Winを
別の環境に移行させる意味はないからな。
>>396 で紹介した LSI Corp がIP売りするPPC476FPコアについて、
LSIのサイトに資料がありました。
http://www.lsi.com/DistributionSystem/AssetDocument/PPC476FP-PB-v7.pdf
将来的には TSMC の 28nm プロセスでも製造可能にして、1.6-1.8GHz で動作予定
とのこと。
アプリケーションの例として、同時発表した eDRAM を混載したブロック図も掲載され
ています。
LSIのサイトに資料がありました。
http://www.lsi.com/DistributionSystem/AssetDocument/PPC476FP-PB-v7.pdf
将来的には TSMC の 28nm プロセスでも製造可能にして、1.6-1.8GHz で動作予定
とのこと。
アプリケーションの例として、同時発表した eDRAM を混載したブロック図も掲載され
ています。
528 :MACオタ>520-522 さん:2010/02/08(月) 07:51:38 ID:kCnuu4MY
>>520-522
少なからぬ旧 P.A Semi の社員が Apple を退社済みとのこと。
Ahlee Vance 氏の記事なので信用できると思いますよ。
http://www.nytimes.com/2010/02/02/technology/business-computing/02chip.html?ref=technology
------------------------
Some of the chip engineers Apple gained in its purchase of PA Semi appear
to have already left the company. According to partial records on the job
networking site LinkedIn, at least half a dozen former PA Semi engineers
have left Apple and turned up at a start-up called Agnilux, based in San
Jose. The company was co-founded by one of PA’s leading system architects,
Mark Hayter.
Neither Mr. Hayter nor other onetime PA workers who left Apple for Agnilux were
willing to discuss either company’s plans. According to two people with knowledge
of the two companies, who were unwilling to be named because the matter is delicate,
some PA engineers left Apple a few months after the acquisition because they
were given grants of Apple stock at an unattractive price.
------------------------
少なからぬ旧 P.A Semi の社員が Apple を退社済みとのこと。
Ahlee Vance 氏の記事なので信用できると思いますよ。
http://www.nytimes.com/2010/02/02/technology/business-computing/02chip.html?ref=technology
------------------------
Some of the chip engineers Apple gained in its purchase of PA Semi appear
to have already left the company. According to partial records on the job
networking site LinkedIn, at least half a dozen former PA Semi engineers
have left Apple and turned up at a start-up called Agnilux, based in San
Jose. The company was co-founded by one of PA’s leading system architects,
Mark Hayter.
Neither Mr. Hayter nor other onetime PA workers who left Apple for Agnilux were
willing to discuss either company’s plans. According to two people with knowledge
of the two companies, who were unwilling to be named because the matter is delicate,
some PA engineers left Apple a few months after the acquisition because they
were given grants of Apple stock at an unattractive price.
------------------------
http://www.yusuke-ohara.com/weblog2/archive/2010/01/second_opi.html
>iPadにP.A.Semiの技術が...という論調を目にするけれど、私が知る限りにおいてP.A.Semiの部隊は四散してしまった筈。
>iPadにP.A.Semiの技術が...という論調を目にするけれど、私が知る限りにおいてP.A.Semiの部隊は四散してしまった筈。
ISSCCを前に、色々情報が出てきています。
まず、発表を目前に控えたPOWER7搭載サーバーの話題。
http://www.theregister.co.uk/2010/02/08/ibm_power7_systems_launch/
http://www.theregister.co.uk/2010/02/08/ibm_power7_chip_launch/page2.html
- Power 750 (Power 550 後継)
- Power 755 (HPC向け)
- Power 770, 780
- 3 GHz, 3.3 GHz, 3.5 GHz, 3.55 GHz, 3.8 GHz, and 4.1 GHz。最高 4.5GHz?
- 4.1GHz は Power 780 の "TurboCore" モード (4-coreのみ有効でOC)
まず、発表を目前に控えたPOWER7搭載サーバーの話題。
http://www.theregister.co.uk/2010/02/08/ibm_power7_systems_launch/
http://www.theregister.co.uk/2010/02/08/ibm_power7_chip_launch/page2.html
- Power 750 (Power 550 後継)
- Power 755 (HPC向け)
- Power 770, 780
- 3 GHz, 3.3 GHz, 3.5 GHz, 3.55 GHz, 3.8 GHz, and 4.1 GHz。最高 4.5GHz?
- 4.1GHz は Power 780 の "TurboCore" モード (4-coreのみ有効でOC)
RealWorldTech の David Kanter 氏が掲示板に POWER7 講演の詳細を投稿していました。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=107204&threadid=107204&roomid=2
- L1D のレイテンシは 2-cycle (POWER6は4-cycle)
- L1のSRAMセルは、0.426um^2。6T構造
- "Fast Local L3" の load-to-use レイテンシは 25-cycle。SRAM を採用した場合より
3-cycle 程度のペナルティはある。(>>316参照)
- L3 の動作クロックはコアの1/2
- L2のレイテンシは 8〜9-cylcle
- L3 全体のレイテンシは 75-cycle 程度
- 2つの整数および4つ?の浮動小数点パイプラインごとに独立したレジスタファイルを持つ
http://www.realworldtech.com/forums/index.cfm?action=detail&id=107204&threadid=107204&roomid=2
- L1D のレイテンシは 2-cycle (POWER6は4-cycle)
- L1のSRAMセルは、0.426um^2。6T構造
- "Fast Local L3" の load-to-use レイテンシは 25-cycle。SRAM を採用した場合より
3-cycle 程度のペナルティはある。(>>316参照)
- L3 の動作クロックはコアの1/2
- L2のレイテンシは 8〜9-cylcle
- L3 全体のレイテンシは 75-cycle 程度
- 2つの整数および4つ?の浮動小数点パイプラインごとに独立したレジスタファイルを持つ
上の話ですが、講演はまだ始まっていないので、予稿集の情報だと思われます。
Fast Local L3、コヒーレンシ取らない占有領域として使うんですかLSみたいに
534 :MACオタ>533 さん:2010/02/08(月) 21:31:26 ID:i2j+4fL+
>>533
>>316のプレゼン資料を見れば判りますが、コヒーレンシは維持されます。
---------------------
- Automatically clones shared data to multiple private regions.
---------------------
>>316のプレゼン資料を見れば判りますが、コヒーレンシは維持されます。
---------------------
- Automatically clones shared data to multiple private regions.
---------------------
Power7の最大の売りは何ですか?
先週のニュースらしいですが、POWER7で浮かれるIBMの East Fishkill 工場で
飲料水に大量の鉛が含まれていることがバレたそうで…
http://www.poughkeepsiejournal.com/apps/pbcs.dll/article?AID=2010100202008
----------------------
WICCOPEE ― Too-high levels of lead have been found in drinking water at
IBM Corp.’s East Fishkill complex, prompting the company to provide alternate
sources of water.
----------------------
流石、工場労働者なんて人とも思わない守銭奴IBMらしい所業ですね。
飲料水に大量の鉛が含まれていることがバレたそうで…
http://www.poughkeepsiejournal.com/apps/pbcs.dll/article?AID=2010100202008
----------------------
WICCOPEE ― Too-high levels of lead have been found in drinking water at
IBM Corp.’s East Fishkill complex, prompting the company to provide alternate
sources of water.
----------------------
流石、工場労働者なんて人とも思わない守銭奴IBMらしい所業ですね。
>>536
Power7の最大の売りは何か答えてよ?
Power7の最大の売りは何か答えてよ?
538 :MACオタ>537 さん:2010/02/08(月) 22:25:42 ID:i2j+4fL+
>>538
さんざんコピペしてるくせに、答えられないのかよ
さんざんコピペしてるくせに、答えられないのかよ
POWER7のベンチマーク結果も出てきました。
まずは SAP SD (Standard) http://www.sap.com/solutions/benchmark/sd2tier.epx
- SPARC64 VII/2.88GHz (32-chip/128-core): 17,430 [users]
- POWER7/3.55GHz (4-chip/32-core): 15,600 [users]
- POWER6/4.2GHz (16-chip/32-core): 14,432 [users]
- Itanium2/1.6GHz (32-chip/64-core): 12,500 [users]
- Tigerton Xeon/2.93GHz (16-chip/64-core): 10,600 [users]
- Istanbul Opteron/2.6GHz (8-chip/48-core): 10,000 [users]
まずは SAP SD (Standard) http://www.sap.com/solutions/benchmark/sd2tier.epx
- SPARC64 VII/2.88GHz (32-chip/128-core): 17,430 [users]
- POWER7/3.55GHz (4-chip/32-core): 15,600 [users]
- POWER6/4.2GHz (16-chip/32-core): 14,432 [users]
- Itanium2/1.6GHz (32-chip/64-core): 12,500 [users]
- Tigerton Xeon/2.93GHz (16-chip/64-core): 10,600 [users]
- Istanbul Opteron/2.6GHz (8-chip/48-core): 10,000 [users]
性能ぶっ千切りだな
お値段の方もブッチギリです
IBMのプレスリリース来ました。>>535さんご希望の『売り文句』も書いてありますよ。
http://www-03.ibm.com/press/us/en/pressrelease/29315.wss
FUDの元祖IBMとは思えないほど発表から販売開始までの時間は短く、一部機種は
2月半ばに販売するとのこと。
- Power 750 Express, Power 755: 2/19
- Power 770, Power 780: 3/16
ベンチマークをまとめたSystems Performance Report はこちら。
http://www-03.ibm.com/systems/power/hardware/reports/system_perf.html
SPEC2006_rate, SPECjbb, 前述の SAP SD 2-Tiers, Oracle eBS Benchmark,
LINPACK HPC, STREAM, NAMD, SPEC OMP2001 の結果があります。
http://www-03.ibm.com/press/us/en/pressrelease/29315.wss
FUDの元祖IBMとは思えないほど発表から販売開始までの時間は短く、一部機種は
2月半ばに販売するとのこと。
- Power 750 Express, Power 755: 2/19
- Power 770, Power 780: 3/16
ベンチマークをまとめたSystems Performance Report はこちら。
http://www-03.ibm.com/systems/power/hardware/reports/system_perf.html
SPEC2006_rate, SPECjbb, 前述の SAP SD 2-Tiers, Oracle eBS Benchmark,
LINPACK HPC, STREAM, NAMD, SPEC OMP2001 の結果があります。
IntelのTukwila発表も来ました。Itenium 9300シリーズとのこと。
http://www.intel.com/pressroom/archive/releases/2010/20100208comp.htm
----------------
The Intel Itanium processor 9300 series ranges in price from $946 to $3,838 in
quantities of 1,000. OEM systems are expected to ship within 90 days.
----------------
搭載製品の同時発表とはいかなかったようで…
なお、製品ラインは下記の通り。
http://download.intel.com/products/processor/itanium/318691.pdf
9350: 4-core, 1.73GHz, 24MB L3
9340: 4-core, 1.60GHz, 20MB L3
9330: 4-core, 1.46GHz, 20MB L3
9320: 4-core, 1.33GHz, 16MB L3
9310: 2-core, 1.60GHz, 10MB L3
その他、注目点はこんなものでしょうか?
- 既報通り、Neahlem-EPとはプラットフォーム共通化が図られているとのこと。
"share several platform ingredients, including the Intel(R) QuickPath Interconnect,
the Intel Scalable Memory Interconnect, the Intel(R) 7500 Scalable Memory Buffer
(to take advantage of industry standard DDR3 memory), and I/O hub (Intel(R)
7500 chipset). "
- "Foxton" Technology はNehalenと共通のブランド"Intel Turbo Boost Technology"
になった模様。
http://www.intel.com/pressroom/archive/releases/2010/20100208comp.htm
----------------
The Intel Itanium processor 9300 series ranges in price from $946 to $3,838 in
quantities of 1,000. OEM systems are expected to ship within 90 days.
----------------
搭載製品の同時発表とはいかなかったようで…
なお、製品ラインは下記の通り。
http://download.intel.com/products/processor/itanium/318691.pdf
9350: 4-core, 1.73GHz, 24MB L3
9340: 4-core, 1.60GHz, 20MB L3
9330: 4-core, 1.46GHz, 20MB L3
9320: 4-core, 1.33GHz, 16MB L3
9310: 2-core, 1.60GHz, 10MB L3
その他、注目点はこんなものでしょうか?
- 既報通り、Neahlem-EPとはプラットフォーム共通化が図られているとのこと。
"share several platform ingredients, including the Intel(R) QuickPath Interconnect,
the Intel Scalable Memory Interconnect, the Intel(R) 7500 Scalable Memory Buffer
(to take advantage of industry standard DDR3 memory), and I/O hub (Intel(R)
7500 chipset). "
- "Foxton" Technology はNehalenと共通のブランド"Intel Turbo Boost Technology"
になった模様。
>Intel 7500 Scalable Memory Buffer
ここだけ興味がある
他はもうガイシュツネタばっかだろ
ここだけ興味がある
他はもうガイシュツネタばっかだろ
当然のごとく今日も色々。
まず国内でのPOWER7搭載サーバーの発表。
http://www-06.ibm.com/jp/press/2010/02/0901.html
http://enterprise.watch.impress.co.jp/docs/news/20100209_347981.html
個人的な注目はパッケージの写真です。
http://enterprise.watch.impress.co.jp/img/epw/docs/347/981/html/ibm372.jpg.html
今回発表されたミッドレンジサーバーに搭載されているのは、この中で「セラミック・
モジュール」のチップと思われます。真ん中の「オーガニック・モジュール」(要するに
プラスチックパッケージ)のチップはBladeCenter等に使用される筈です。
BladeCenter や IntelliStation POWER がどういった価格帯で登場するかが楽しみかと。
電力効率のスライドも、サーバー製品の消費電力が公開されたという点で興味深いかと
思われます。
http://enterprise.watch.impress.co.jp/img/epw/docs/347/981/html/ibm411.jpg.html
ちなみに POWER System サーバー (旧 pSeries) で用いられる性能指標 rPerf の
解説はこちら。
http://www-03.ibm.com/systems/power/hardware/notices/rperf.html
まず国内でのPOWER7搭載サーバーの発表。
http://www-06.ibm.com/jp/press/2010/02/0901.html
http://enterprise.watch.impress.co.jp/docs/news/20100209_347981.html
個人的な注目はパッケージの写真です。
http://enterprise.watch.impress.co.jp/img/epw/docs/347/981/html/ibm372.jpg.html
{kind=link}
今回発表されたミッドレンジサーバーに搭載されているのは、この中で「セラミック・
モジュール」のチップと思われます。真ん中の「オーガニック・モジュール」(要するに
プラスチックパッケージ)のチップはBladeCenter等に使用される筈です。
BladeCenter や IntelliStation POWER がどういった価格帯で登場するかが楽しみかと。
電力効率のスライドも、サーバー製品の消費電力が公開されたという点で興味深いかと
思われます。
http://enterprise.watch.impress.co.jp/img/epw/docs/347/981/html/ibm411.jpg.html
{kind=link}
ちなみに POWER System サーバー (旧 pSeries) で用いられる性能指標 rPerf の
解説はこちら。
http://www-03.ibm.com/systems/power/hardware/notices/rperf.html
"Wire-Speed POWER" (>>318-329 参照)講演のレポートが EETimesに来てます。
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700420
用途に関しては、色々含みを込めているよう感があります。
--------------------
"It's not a network processor or a server processor but a middle ground, a blurring
of the two worlds," Johnson said.
The chips will be used in a range of standalone systems and PCI Express adapter
cards in servers. It is mainly designed for use in IBM's own systems, however the
company is willing to sell it on a merchant basis as well.
--------------------
正直、『サーバープロセッサと(組込向け)ネットワークプロセッサの中間的存在』って
デスクトッププロセッサのことでは? かつての PowerPC G3/G4 の様な。
含みを持たせていると言えば、記事の最後がこう締めくくられています。
--------------------
Johnson was chief architect of IBM's Power4 processor. He also designed IBM's
portion of the processor in the Microsoft Xbox 3609 [MACオタ注: Xbox 360の誤植
でしょう] videogame console.
--------------------
単に PX/PPE と同じグループが開発したと言いたいのかどうか…
http://www.eetimes.com/news/semi/showArticle.jhtml?articleID=222700420
用途に関しては、色々含みを込めているよう感があります。
--------------------
"It's not a network processor or a server processor but a middle ground, a blurring
of the two worlds," Johnson said.
The chips will be used in a range of standalone systems and PCI Express adapter
cards in servers. It is mainly designed for use in IBM's own systems, however the
company is willing to sell it on a merchant basis as well.
--------------------
正直、『サーバープロセッサと(組込向け)ネットワークプロセッサの中間的存在』って
デスクトッププロセッサのことでは? かつての PowerPC G3/G4 の様な。
含みを持たせていると言えば、記事の最後がこう締めくくられています。
--------------------
Johnson was chief architect of IBM's Power4 processor. He also designed IBM's
portion of the processor in the Microsoft Xbox 3609 [MACオタ注: Xbox 360の誤植
でしょう] videogame console.
--------------------
単に PX/PPE と同じグループが開発したと言いたいのかどうか…
話の順序が逆になりましたが、記事中に含まれる新情報は下記の通り。
- 64-bit
- 16-core, 1.43B Transistors, 428mm^2 (POWER7は 1.2B Transistors, 567mm^2)
- 65W @ 16-core/2.3GHz, 20W @ 4-core/1.4GHz
- 16-core 版は 8MB 内蔵キャッシュサポート
- 10G Ethernet 4ポート内蔵
- XML, 正規表現処理, 暗号化アクセラレータ搭載
- グルーレスでSMP可能
- プロセッサ製品としてを外販予定
- 開発期間は5年
- Linux ハイパーバイザをサポート
- (製品版の?)テープアウトは一週間前。ファーストシリコンは2週間以内に
(既に製作済みの)搭載システムでテスト予定。
- ここでの議論と同様に、アナリストも用途に疑問を呈している。
----------------
"That's a huge chip, bigger than most of the PC and server processor Intel
makes and probably twice the size of many network processors out there,
so cost-wise it will be tough for them to be competitive," Gwennap said.
----------------
- 64-bit
- 16-core, 1.43B Transistors, 428mm^2 (POWER7は 1.2B Transistors, 567mm^2)
- 65W @ 16-core/2.3GHz, 20W @ 4-core/1.4GHz
- 16-core 版は 8MB 内蔵キャッシュサポート
- 10G Ethernet 4ポート内蔵
- XML, 正規表現処理, 暗号化アクセラレータ搭載
- グルーレスでSMP可能
- プロセッサ製品としてを外販予定
- 開発期間は5年
- Linux ハイパーバイザをサポート
- (製品版の?)テープアウトは一週間前。ファーストシリコンは2週間以内に
(既に製作済みの)搭載システムでテスト予定。
- ここでの議論と同様に、アナリストも用途に疑問を呈している。
----------------
"That's a huge chip, bigger than most of the PC and server processor Intel
makes and probably twice the size of many network processors out there,
so cost-wise it will be tough for them to be competitive," Gwennap said.
----------------
> デスクトッププロセッサのことでは?
ないない
ないない
> 『サーバープロセッサと(組込向け)ネットワークプロセッサの中間的存在』
こう↑言われると
旧P.A. SemiのPWRficientを連想してしまったんだが…
# あるいは,SunのNiagaraに近いかな?
こう↑言われると
旧P.A. SemiのPWRficientを連想してしまったんだが…
# あるいは,SunのNiagaraに近いかな?
Azulみたいなアクセラレータ的に使えそうだな
MSと協議して、WindowsにPowerチップを対応してもらうようにすべきだな。
Xbox360にWindows派生のゲームOSが載っているから、
Windows for Power PCをつくるのも難しい話ではない。
Xbox360にWindows派生のゲームOSが載っているから、
Windows for Power PCをつくるのも難しい話ではない。
{kind=link}
以前発表されたRP2の改良型っぽいな。
>>553
おっと、NT4をディスるのはそこまでだ。
おっと、NT4をディスるのはそこまでだ。
一応2000のRCまでAlpha版はあったんだよな。
tp://twitter.com/ali_bin_ibrahim
東京の公共の場所では関西弁は法律で禁止すべきである。関西人はまともな世界では不良外国人。
東京の公共の場所では関西弁は法律で禁止すべきである。関西人はまともな世界では不良外国人。
"Wire-Speed Power Processor" = PowerPC A2 の確定情報来ました。
正確には SOC 製品である Wire-Speed Power Processor の汎用プロセッサコアが
PPC A2 ということになります。
http://www.theregister.co.uk/2010/02/09/ibm_wire_speed_processor/
------------------
The processor's A2 cores are small, 64-bit PowerPC cores based on IBM's
embedded architecture - "a little bit different from our server architecture,"
said Johnson. Full vitualization and hypervisor support is also included, along
with some new instructions that allow for low-latency interaction with the
processors' accelerators.
------------------
その他、新情報は次の通り。
- 2.3GHz は電力効率が良い周波数というだけで、3GHz でも動作する。
- アクティブなコア数で消費電力は 20-65Wの範囲で変化する。平均的には 55W 程度。
正確には SOC 製品である Wire-Speed Power Processor の汎用プロセッサコアが
PPC A2 ということになります。
http://www.theregister.co.uk/2010/02/09/ibm_wire_speed_processor/
------------------
The processor's A2 cores are small, 64-bit PowerPC cores based on IBM's
embedded architecture - "a little bit different from our server architecture,"
said Johnson. Full vitualization and hypervisor support is also included, along
with some new instructions that allow for low-latency interaction with the
processors' accelerators.
------------------
その他、新情報は次の通り。
- 2.3GHz は電力効率が良い周波数というだけで、3GHz でも動作する。
- アクティブなコア数で消費電力は 20-65Wの範囲で変化する。平均的には 55W 程度。
ところで前述の Wes Felter 氏 (>>452 参照)、ArsTechnica 掲示板でも A2 コアに
関して思わせぶりな投稿をしています。
http://episteme.arstechnica.com/eve/forums/a/tpc/f/77909774/m/376004823041?r=332007923041#332007923041
--------------------------
Originally posted by BadAndy:
Whatever it is, not hard to see cross-over from this thing into next-generation
game-console tech
Because games loooove low per-thread performance.
--------------------------
上に書いた3GHzで動作するという話も含めて、PX/PPE と A2 の関係は『何か』ありそうな
感じです。
関して思わせぶりな投稿をしています。
http://episteme.arstechnica.com/eve/forums/a/tpc/f/77909774/m/376004823041?r=332007923041#332007923041
--------------------------
Originally posted by BadAndy:
Whatever it is, not hard to see cross-over from this thing into next-generation
game-console tech
Because games loooove low per-thread performance.
--------------------------
上に書いた3GHzで動作するという話も含めて、PX/PPE と A2 の関係は『何か』ありそうな
感じです。
Sequoia (=Blue Gene/Q)の情報が少しだけ。
http://www.er.doe.gov/ASCR/ASCAC/Meetings/Nov09/Strayer.pdf
P.13 にアルゴンヌ国立研究所の ALCF-2 の後継機 "Mira" について次のような
記述があります。
-----------------
Mira Blue Gene/Q System
・10 Pflop/speak
・~800K cores, 16 per chip
・~70PB disk, ~470 GB/sI/O bandwidth
・Power efficient, water cooled
-----------------
Sequoia のプロセッサに関しては 8-core説と16-core 説がありましたが、16-core で
確定ですね。
SIMDユニットも、3.2GHz/倍精度2並列説と1.6GHz/倍精度4並列 (or 倍精度2並列 x 2)説
がありましたが、16コアともなると1.6GHzで間違いないのではないでしょうか。
PPC470系コアと VSX x 2の"Double Hummer"後継 APU の可能性が高くなったかと。
http://www.er.doe.gov/ASCR/ASCAC/Meetings/Nov09/Strayer.pdf
P.13 にアルゴンヌ国立研究所の ALCF-2 の後継機 "Mira" について次のような
記述があります。
-----------------
Mira Blue Gene/Q System
・10 Pflop/speak
・~800K cores, 16 per chip
・~70PB disk, ~470 GB/sI/O bandwidth
・Power efficient, water cooled
-----------------
Sequoia のプロセッサに関しては 8-core説と16-core 説がありましたが、16-core で
確定ですね。
SIMDユニットも、3.2GHz/倍精度2並列説と1.6GHz/倍精度4並列 (or 倍精度2並列 x 2)説
がありましたが、16コアともなると1.6GHzで間違いないのではないでしょうか。
PPC470系コアと VSX x 2の"Double Hummer"後継 APU の可能性が高くなったかと。
PS4のCPUは普通のマルチコアCPUのプランが浮上してるってことだけど
"A2"を使ったマルチコアなのかな?
去年夏頃にIBMが"A2"を提案
↓
強い関心を持つが態度をはっきりさせないSCE
↓
痺れを切らすIBM、自社販売に旨味がない32ivを開発中止と意図的にリーク
↓
返事を迫られるSCE ←いまここ
"A2"を使ったマルチコアなのかな?
去年夏頃にIBMが"A2"を提案
↓
強い関心を持つが態度をはっきりさせないSCE
↓
痺れを切らすIBM、自社販売に旨味がない32ivを開発中止と意図的にリーク
↓
返事を迫られるSCE ←いまここ
SPE2の試作が行われたのは去年で
しかもFPGAベースのシミュレータを作成したのはSCEIらしいから
依頼してるにしてもPPE部分だけじゃないかね
しかもFPGAベースのシミュレータを作成したのはSCEIらしいから
依頼してるにしてもPPE部分だけじゃないかね
日経BPのISSCCレポートに"Wire-Speed Power"の追加情報がありました。
プロセッサコアのL2キャッシュがeDRAMなんだとか。
http://techon.nikkeibp.co.jp/article/NEWS/20100210/180114/
---------------------
Wire-Speed Power Processorでは,8MバイトのL2キャッシュに混載DRAMを
それぞれ使った。
混載DRAMのセル寸法は,0.067μm2である。Intel社のWestmereのL3キャッシュ
のSRAMのセル寸法は 32nm世代でも0.171μm2であることからも,面積密度が
非常に高いことが分かる。Wire-Speed Power Processorの発表では,SRAMに
比べて面積で2倍,消費電力で5倍以上よいと述べた。
---------------------
プロセッサコアのL2キャッシュがeDRAMなんだとか。
http://techon.nikkeibp.co.jp/article/NEWS/20100210/180114/
---------------------
Wire-Speed Power Processorでは,8MバイトのL2キャッシュに混載DRAMを
それぞれ使った。
混載DRAMのセル寸法は,0.067μm2である。Intel社のWestmereのL3キャッシュ
のSRAMのセル寸法は 32nm世代でも0.171μm2であることからも,面積密度が
非常に高いことが分かる。Wire-Speed Power Processorの発表では,SRAMに
比べて面積で2倍,消費電力で5倍以上よいと述べた。
---------------------
565 :MACオタ>563 さん:2010/02/11(木) 15:00:28 ID:GsEjP4NF
>>563
面白そうな話なので、ソースがあるならよろしくお願いします。
面白そうな話なので、ソースがあるならよろしくお願いします。
性能とか信頼性はどうなんだろうね<eDRAM
スーパーコンピューティングの話題を少しだけ。
Anton というMD専用計算機があります。SC09でゴードンベル特別賞を取ったとのこと。
http://journal.mycom.co.jp/articles/2009/12/01/sc09_gordonbell/index.html
概要は牧野教授のサイトのこちら。
http://www.artcompsci.org/~makino/articles/future_sc/note080.html
技術的な話題は別にして、開発プロジェクトとして興味深い点がいくつか。
・私企業が開発している。
MYCOMの記事にはこうあります。
---------------------
D.E Shaw研究所はAntonと呼ぶ分子動力学(Molecular Dynamics:MD)計算専用
のスパコンを開発し、その最初のシステムでのシミュレーション結果を発表した。
[中略]
D.E.Shaw氏が創立したD.E.Shaw & Coは運用資産2.5兆円の世界最大規模の
ヘッジファンドであるが、現在は、Shaw氏はヘッジファンドの日常のマネジメントに
は携わらず、 D.E.Shaw Researchのチーフサイエンティストとして、MDのアルゴリ
ズムやAntonシステムの開発を行っているという。そして、同研究所の運用費用は
Shaw氏のポケットマネーで賄われていると言われている。
---------------------
・ハードウェア自体は…
一昨年の Hot Chips 20 でも講演が行われています。プレゼンはこちら。
http://www.hotchips.org/archives/hc20/2_Mon/HC20.25.421.pdf
P.30 に演算コアとなる ASIC の写真があります。
チップに記された製造国は… MBxxxというチップ名ですから京速のあの会社でしょうか。
Anton というMD専用計算機があります。SC09でゴードンベル特別賞を取ったとのこと。
http://journal.mycom.co.jp/articles/2009/12/01/sc09_gordonbell/index.html
概要は牧野教授のサイトのこちら。
http://www.artcompsci.org/~makino/articles/future_sc/note080.html
技術的な話題は別にして、開発プロジェクトとして興味深い点がいくつか。
・私企業が開発している。
MYCOMの記事にはこうあります。
---------------------
D.E Shaw研究所はAntonと呼ぶ分子動力学(Molecular Dynamics:MD)計算専用
のスパコンを開発し、その最初のシステムでのシミュレーション結果を発表した。
[中略]
D.E.Shaw氏が創立したD.E.Shaw & Coは運用資産2.5兆円の世界最大規模の
ヘッジファンドであるが、現在は、Shaw氏はヘッジファンドの日常のマネジメントに
は携わらず、 D.E.Shaw Researchのチーフサイエンティストとして、MDのアルゴリ
ズムやAntonシステムの開発を行っているという。そして、同研究所の運用費用は
Shaw氏のポケットマネーで賄われていると言われている。
---------------------
・ハードウェア自体は…
一昨年の Hot Chips 20 でも講演が行われています。プレゼンはこちら。
http://www.hotchips.org/archives/hc20/2_Mon/HC20.25.421.pdf
P.30 に演算コアとなる ASIC の写真があります。
チップに記された製造国は… MBxxxというチップ名ですから京速のあの会社でしょうか。
>>565
ソースは後藤氏のこの記事でしょ。
http://pc.watch.impress.co.jp/docs/column/kaigai/20091224_339258.html
>>562
SCEがPS3との互換性を完全に捨ててでも普通のマルチコアCPUを選択しようと
考えているならPOWERを選ぶ必然性自体がないからなぁ。
他の選択肢も余りないかも知れないけど。
ソースは後藤氏のこの記事でしょ。
http://pc.watch.impress.co.jp/docs/column/kaigai/20091224_339258.html
>>562
SCEがPS3との互換性を完全に捨ててでも普通のマルチコアCPUを選択しようと
考えているならPOWERを選ぶ必然性自体がないからなぁ。
他の選択肢も余りないかも知れないけど。
と思ったら後ろのページにセラミックって書いてた。。。
普通か。
普通か。
>>567
> チップに記された製造国は… MBxxxというチップ名ですから京速のあの会社でしょうか。
p.32に "90 NM CMOS .implemented in Fujitsu CS100HP Process" って書いてあるよ
> チップに記された製造国は… MBxxxというチップ名ですから京速のあの会社でしょうか。
p.32に "90 NM CMOS .implemented in Fujitsu CS100HP Process" って書いてあるよ
>>571 さん
見逃してました… 間違っていた訳でもないので勘弁してください。
教訓としては、こういうことかと。
・欠けているのは予算では無く、知恵ではなかろうか?
・本当に必要なモノなら、投資を集められるのではなかろうか?
・本当に必要で、投資を集めるほど信用されていなくても、自前でできることは
あるのではなかろうか?
・最先端プロセスでプロセッサごと開発しなくても、目的には適うのではあるまいか?
等々
お金の話をすれば、東大一校で集めた個人寄付金は2008年度で50億円近くとのこと。
http://utf.u-tokyo.ac.jp/introduction/index.html
個人寄付金って大半は医学部でしょうか… ガン治療とか看板にすればなんとかなる?
見逃してました… 間違っていた訳でもないので勘弁してください。
教訓としては、こういうことかと。
・欠けているのは予算では無く、知恵ではなかろうか?
・本当に必要なモノなら、投資を集められるのではなかろうか?
・本当に必要で、投資を集めるほど信用されていなくても、自前でできることは
あるのではなかろうか?
・最先端プロセスでプロセッサごと開発しなくても、目的には適うのではあるまいか?
等々
お金の話をすれば、東大一校で集めた個人寄付金は2008年度で50億円近くとのこと。
http://utf.u-tokyo.ac.jp/introduction/index.html
個人寄付金って大半は医学部でしょうか… ガン治療とか看板にすればなんとかなる?
MBっちゃあ、8bitの時代からFがchip名に付けてたぜ。
MB6809とか。
NならμPDか。
MB6809とか。
NならμPDか。
>しかし一方で回路ブロックの設計を根本から改良する機会を失ってはいないだろうか。
>回路ブロックを統合する段階で設計の手直しが発生し、貴重な時間を失ってはいないだろうか。
>あるいは設計内容が陳腐化しているのに気付かず、再利用し続けてはいないだろうか。
何様気取りなんだ、福田
>回路ブロックを統合する段階で設計の手直しが発生し、貴重な時間を失ってはいないだろうか。
>あるいは設計内容が陳腐化しているのに気付かず、再利用し続けてはいないだろうか。
何様気取りなんだ、福田
おれも思った.
本業の人たちが既に検討済みなんだろうとは想像しないのかね?
# その上で,最も「早い・安い・旨い」のが現状なんだろうけど
そもそも某 i や別の某 I 等の少数以外は自社fabすら無くて
TSMCやUMCで製造してるのに独自設計してメリットあるのかね?
個人的には,せっかく動いてる(≒枯れてる,実績ある)ものを
金かけて壊そうとしている中二病患者を見ている気分なんだけど
本業の人たちが既に検討済みなんだろうとは想像しないのかね?
# その上で,最も「早い・安い・旨い」のが現状なんだろうけど
そもそも某 i や別の某 I 等の少数以外は自社fabすら無くて
TSMCやUMCで製造してるのに独自設計してメリットあるのかね?
個人的には,せっかく動いてる(≒枯れてる,実績ある)ものを
金かけて壊そうとしている中二病患者を見ている気分なんだけど
そりゃ本業も検討済みだろ
本業であってもそれが正しいか正しくなかったかは結果論でしか語れんが
本業であってもそれが正しいか正しくなかったかは結果論でしか語れんが
例えば、既存のIPの組み合わせて設計すると、既存IP部の消費電力
はだいたい決まってるのでシステム全体の消費電力の削減にあれ
これ頭を悩ますことになる。
既存のIPを使わずを新規設計した場合、効率を重視した設計をする
ことにより、その部分の消費電力を元から削減出来たりするるので
システム全体の消費電力を削減しやすい。
今回の講演は新規設計のメリットを考えさせられるほど優れた成果だった。
ということでしょ?
はだいたい決まってるのでシステム全体の消費電力の削減にあれ
これ頭を悩ますことになる。
既存のIPを使わずを新規設計した場合、効率を重視した設計をする
ことにより、その部分の消費電力を元から削減出来たりするるので
システム全体の消費電力を削減しやすい。
今回の講演は新規設計のメリットを考えさせられるほど優れた成果だった。
ということでしょ?
必要ならするし不要ならしない
判断ミスはあっても検討しない奴なんてネット番長にしかいない
判断ミスはあっても検討しない奴なんてネット番長にしかいない
http://techon.nikkeibp.co.jp/article/NEWS/20100210/180114/
> SOIプロセスの採用によって,通常のしきい値電圧のNMOSトランジスタを電源スイッチに使えた。
SOIだとNMOSをスイッチに使えるのはなんで?
NMOSがスイッチってことは仮想VssをVdd電圧まで
釣ることになるんだろうけど、通常のCMOSと違って
ソース・ドレインからサブストレートへのリークが少ない
からってことなのかな?
> SOIプロセスの採用によって,通常のしきい値電圧のNMOSトランジスタを電源スイッチに使えた。
SOIだとNMOSをスイッチに使えるのはなんで?
NMOSがスイッチってことは仮想VssをVdd電圧まで
釣ることになるんだろうけど、通常のCMOSと違って
ソース・ドレインからサブストレートへのリークが少ない
からってことなのかな?
NEC to show quad-core Cortex-A9 processor
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=222900146
ARMのクアッドコアだって
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=222900146
ARMのクアッドコアだって
NEC?
なにそれうまいの?
なにそれうまいの?
IPによる設計には色々と光トカゲがある
なまじっかブラックボックス化しようとして中の情報を十分出さないと全体の設計や検証に差し支える。
中の仕様や動作を知らずに全体を作ったり検証できるわけがない。
かといって中の情報を詳しく出していたらな何のためだったのか分からなくなる。
しかも綺麗な理想論を言う人は少なくないので中と外の設計担当間で情報の疎通が…
実際には結構大変でそ
なまじっかブラックボックス化しようとして中の情報を十分出さないと全体の設計や検証に差し支える。
中の仕様や動作を知らずに全体を作ったり検証できるわけがない。
かといって中の情報を詳しく出していたらな何のためだったのか分からなくなる。
しかも綺麗な理想論を言う人は少なくないので中と外の設計担当間で情報の疎通が…
実際には結構大変でそ
光トカゲの鳴き声↓
PPC746FP を共同開発した LSI Corp. が自社でネットワークプロセッサ "Axxia"
をリリースしました。
http://www.lsi.com/news/product_news/2010/2010_02_09b.html
-------------------
Axxia Communication Processors are capable of managing huge volumes of
wireless traffic with low latency and no load on the CPU complex. The first
member of the Axxia Communication Processor family, the ACP3448 processor,
features four powerful PowerPC^(TM) 476FP processor cores with a large 512KB
L2 cache per core, 4 MB of system cache, integrated DDRIII memory controllers,
and a wide array of intelligent offload engines, including industry-proven packet
classification, traffic management, security processing and deep packet inspection.
The on-chip processing elements are tied together using the new LSI Virtual
Pipeline technology.
-------------------
製品ページはこちら。(PDF資料へのリンク有)
http://www.lsi.com/networking_home/networking_products/multicore_comm_processors/axxia/index.html
・4-core, up to 1.8GHz
・512KB L2
・4MB eDRAM システムキャッシュ (アクセラレータを含むSoC全体で共有)
・Dual DDR3 メモリコントローラ
・各種アクセラレータ (パケット処理、セキュリティ、正規表現)
・45nm, SOI
リリースによると
--------------------
The first members of the Axxia family, designed to deliver 20 Gbps performance
for today’s wireless infrastructure requirements, will be available in February of 2010.
--------------------
最初の製品は今月にも販売開始ということと、上記の製造プロセスから IBM で製造するものと
思われます。
をリリースしました。
http://www.lsi.com/news/product_news/2010/2010_02_09b.html
-------------------
Axxia Communication Processors are capable of managing huge volumes of
wireless traffic with low latency and no load on the CPU complex. The first
member of the Axxia Communication Processor family, the ACP3448 processor,
features four powerful PowerPC^(TM) 476FP processor cores with a large 512KB
L2 cache per core, 4 MB of system cache, integrated DDRIII memory controllers,
and a wide array of intelligent offload engines, including industry-proven packet
classification, traffic management, security processing and deep packet inspection.
The on-chip processing elements are tied together using the new LSI Virtual
Pipeline technology.
-------------------
製品ページはこちら。(PDF資料へのリンク有)
http://www.lsi.com/networking_home/networking_products/multicore_comm_processors/axxia/index.html
・4-core, up to 1.8GHz
・512KB L2
・4MB eDRAM システムキャッシュ (アクセラレータを含むSoC全体で共有)
・Dual DDR3 メモリコントローラ
・各種アクセラレータ (パケット処理、セキュリティ、正規表現)
・45nm, SOI
リリースによると
--------------------
The first members of the Axxia family, designed to deliver 20 Gbps performance
for today’s wireless infrastructure requirements, will be available in February of 2010.
--------------------
最初の製品は今月にも販売開始ということと、上記の製造プロセスから IBM で製造するものと
思われます。
既に Freescale を分社している以上、もはやどうでも良い話なのですが、
栄光の Motorola が更に2分割されるんだとか。
http://mediacenter.motorola.com/content/detail.aspx?ReleaseID=12429&NewsAreaID=2
-----------------------
SCHAUMBURG, Ill., February 11, 2010 -- Motorola, Inc. (NYSE: MOT) today
announced the Company is targeting the first quarter of 2011 for its planned
separation. Motorola intends to separate into two independent, publicly traded
companies. One will include the Company’s Mobile Devices and Home businesses,
and the other will include its Enterprise Mobility Solutions and Networks businesses.
-----------------------
栄光の Motorola が更に2分割されるんだとか。
http://mediacenter.motorola.com/content/detail.aspx?ReleaseID=12429&NewsAreaID=2
-----------------------
SCHAUMBURG, Ill., February 11, 2010 -- Motorola, Inc. (NYSE: MOT) today
announced the Company is targeting the first quarter of 2011 for its planned
separation. Motorola intends to separate into two independent, publicly traded
companies. One will include the Company’s Mobile Devices and Home businesses,
and the other will include its Enterprise Mobility Solutions and Networks businesses.
-----------------------
AMDネタの上、11月の Financial Analyst Day の頃の話題なのですが、
プロセッサ・アーキテクチャ的には面白い話題なのでここで取り上げて
おきます。
ネタは当時の comp.arch での "bulldozer details + bobcat"というスレッド
なのですが、業界の人気者 Andy Glew が登場して色々語っています。
http://groups.google.com/group/comp.arch/browse_thread/thread/759bcccbfa0b8b07/73ad8a087e55ed0c
Glew の投稿だけでも拾い読みすると面白いかと。とりあえずここではかい
つまんで興味深いところだけ抽出しておきます。
- AMD's Bulldozer is an MCMT (MultiCluster MultiThreaded)
microarchitecture. That's my baby!
Bulldozer は俺の考えた MCMT (MultiCluster-MultiThread) アーキテクチャの
実装。
- The only bad thing is that some guys I know at AMD say that Bulldozer is
not really all that great a product, but is shipping just because AMD
needs a model refresh. "Sometimes you just gotta ship what you got."
でもなぁ… AMDのツレが言うにはAMDは製品サイクルに切迫して製品化
してくるらしいんだよな。「何でもいいから今出来てるのを出さなきゃいけない
時もあるんだよ」って。
プロセッサ・アーキテクチャ的には面白い話題なのでここで取り上げて
おきます。
ネタは当時の comp.arch での "bulldozer details + bobcat"というスレッド
なのですが、業界の人気者 Andy Glew が登場して色々語っています。
http://groups.google.com/group/comp.arch/browse_thread/thread/759bcccbfa0b8b07/73ad8a087e55ed0c
Glew の投稿だけでも拾い読みすると面白いかと。とりあえずここではかい
つまんで興味深いところだけ抽出しておきます。
- AMD's Bulldozer is an MCMT (MultiCluster MultiThreaded)
microarchitecture. That's my baby!
Bulldozer は俺の考えた MCMT (MultiCluster-MultiThread) アーキテクチャの
実装。
- The only bad thing is that some guys I know at AMD say that Bulldozer is
not really all that great a product, but is shipping just because AMD
needs a model refresh. "Sometimes you just gotta ship what you got."
でもなぁ… AMDのツレが言うにはAMDは製品サイクルに切迫して製品化
してくるらしいんだよな。「何でもいいから今出来てるのを出さなきゃいけない
時もあるんだよ」って。
- came up with MCMT in 1996-2000 while at the University of Wisconsin.
It became public via presentations.
I brought MCMT back to Intel in 2000, and to AMD in 2002.
I was beginning to despair of MCMT ever seeing the light of day. I
thought that when I left AMD in 2004, the MCMT ideas may have left with
me.
元々MCMTはウィスコンシン大にいた1996-2000頃に考えていたんだ。
で、Intelに2000年に戻ったときに提案し、2002年に移ったときにも宣伝
しまくったんだ。でも中々日の目を見なくてAMDを離れた2004年には
すっかりあきらめてたんだよ。
- Of course, AMD has undoubtedly changed and evolved MCMT in many ways
since I first proposed it to them. For example, I called the set of an
integer scheduler, integer execution units, and an L1 data cache a
"cluster", and the whole thing, consisting of shared front end, shared
FP, and 2 or more clusters, a processor core. Apparently AMD is calling
my clusters their cores, and my core their cluster. It has been
suggested that this change of terminology is motivated by marketing, so
that they can say they have twice as many cores.
もちろんAMDは俺のMCMTのコンセプトにに色々手を入れてる。例えばオリジナル
のアイデアでは整数スケジューラ・整数ユニット・L1キャッシュをセットで「クラスタ」
とよび、2組以上のクラスタと共有デコーダ、共有FPUで「コア」を構成するという
ものだった。ところがAMDは俺の「クラスタ」をコアと命名し、「コア」の方をクラスタ
と呼んでる。マーケティングのためにコアが2倍あるように見せかけたいのが丸判り
だよね。
It became public via presentations.
I brought MCMT back to Intel in 2000, and to AMD in 2002.
I was beginning to despair of MCMT ever seeing the light of day. I
thought that when I left AMD in 2004, the MCMT ideas may have left with
me.
元々MCMTはウィスコンシン大にいた1996-2000頃に考えていたんだ。
で、Intelに2000年に戻ったときに提案し、2002年に移ったときにも宣伝
しまくったんだ。でも中々日の目を見なくてAMDを離れた2004年には
すっかりあきらめてたんだよ。
- Of course, AMD has undoubtedly changed and evolved MCMT in many ways
since I first proposed it to them. For example, I called the set of an
integer scheduler, integer execution units, and an L1 data cache a
"cluster", and the whole thing, consisting of shared front end, shared
FP, and 2 or more clusters, a processor core. Apparently AMD is calling
my clusters their cores, and my core their cluster. It has been
suggested that this change of terminology is motivated by marketing, so
that they can say they have twice as many cores.
もちろんAMDは俺のMCMTのコンセプトにに色々手を入れてる。例えばオリジナル
のアイデアでは整数スケジューラ・整数ユニット・L1キャッシュをセットで「クラスタ」
とよび、2組以上のクラスタと共有デコーダ、共有FPUで「コア」を構成するという
ものだった。ところがAMDは俺の「クラスタ」をコアと命名し、「コア」の方をクラスタ
と呼んでる。マーケティングのためにコアが2倍あるように見せかけたいのが丸判り
だよね。
- My original motivation for MCMT was to work around some of the
limitations of Hyperthreading on Willamette. E.g. Willamette had a very
small L0 data cache, 4K in some of the internal proposals, although it
shipped at 8K. Two threads sharing such a tiny L0 data cache thrash.
Indeed, this is one of the reasons why hyperthreading is disabled on
many systems, including many current Nhm based machines with much larger
closest-in caches.
元々 MCMT のアイデアは Willamett で Hyperthreading の性能が上がらない
問題を解決するためのものなんだ。知ってのとおり Willamett の L0 [データ]
キャッシュのサイズはメチャ小さい。初期の設計では 4KB だったし、出荷された
バージョンでは増えたとは言え 8KB だ。
このちっぽけなデータキャッシュを2つのスレッドで共有するとキャッシュスラッシ
ングが多発する。結局のところ、これが多くのシステムで Hyperthreading が
無効に設定された原因だし、当時よりはるかに大きなL1キャッシュを持つ Nehalem
でも状況は変わっていない。
limitations of Hyperthreading on Willamette. E.g. Willamette had a very
small L0 data cache, 4K in some of the internal proposals, although it
shipped at 8K. Two threads sharing such a tiny L0 data cache thrash.
Indeed, this is one of the reasons why hyperthreading is disabled on
many systems, including many current Nhm based machines with much larger
closest-in caches.
元々 MCMT のアイデアは Willamett で Hyperthreading の性能が上がらない
問題を解決するためのものなんだ。知ってのとおり Willamett の L0 [データ]
キャッシュのサイズはメチャ小さい。初期の設計では 4KB だったし、出荷された
バージョンでは増えたとは言え 8KB だ。
このちっぽけなデータキャッシュを2つのスレッドで共有するとキャッシュスラッシ
ングが多発する。結局のところ、これが多くのシステムで Hyperthreading が
無効に設定された原因だし、当時よりはるかに大きなL1キャッシュを持つ Nehalem
でも状況は変わっていない。
- To avoid threads thrashing each other, I wanted to give each thread
their own L0. But, you can't do so, and still keep sharing the
execution units and scheduler - you can't just build a 2X larger array,
or put two arrays side by side, and expect to have the same latency.
Wires. Therefore, I had to replicate the execution units, and enough of
the scheduler so that the "critical loop" of Scheduler->Execution->Data
Cache was all isolated from the other thread/cluster. Hence, the form
of multi-cluster multi-threading you see in Bulldozer.
スラッシングを避けるために、俺はスレッドごとに L0 キャッシュを占有させる
ことを考えた。でもL0独立でALUとスケジューラを共有すると言う構成は無理だ。
単純に2倍のサイズのキャッシュを用意したとしても短いレイテンシを維持できない。
そんな訳で、俺は実行ユニットとスケジューラも独立にした。これで ディスパッチ
→実行→データキャッシュアクセス というクリティカルな部分がスレッドごとに
独立した「クラスタ」ができあがる。。君らが見た Bulldozer の構成図そのものという
ことだね。
their own L0. But, you can't do so, and still keep sharing the
execution units and scheduler - you can't just build a 2X larger array,
or put two arrays side by side, and expect to have the same latency.
Wires. Therefore, I had to replicate the execution units, and enough of
the scheduler so that the "critical loop" of Scheduler->Execution->Data
Cache was all isolated from the other thread/cluster. Hence, the form
of multi-cluster multi-threading you see in Bulldozer.
スラッシングを避けるために、俺はスレッドごとに L0 キャッシュを占有させる
ことを考えた。でもL0独立でALUとスケジューラを共有すると言う構成は無理だ。
単純に2倍のサイズのキャッシュを用意したとしても短いレイテンシを維持できない。
そんな訳で、俺は実行ユニットとスケジューラも独立にした。これで ディスパッチ
→実行→データキャッシュアクセス というクリティカルな部分がスレッドごとに
独立した「クラスタ」ができあがる。。君らが見た Bulldozer の構成図そのものという
ことだね。
- True, there are differences, and I am sure more will become evident as
more Bulldozer information becomes public. For example, although I came
up with MCMT to make Willamette-style threading faster, I have always
wanted to put SpMT, Speculative Multithreading, on such a substrate.
SpMT has potential to speed up a single thread of execution, by
splitting it up into separate threads and running the separate threads
on different clusters, whereas Willamette-style hyperthreading, and
Bulldizer-style MCMT (apparently), only speed up workloads that have
existing independent threads.
Bulldozer に関する情報が増えてくれば明らかになるんだろうけど、俺の
MCMT が Bulldozer そのものって訳じゃないだろうね。例えば、俺は
Willamett の Hyperthreading を高速化するに当たって Speculative Multi-
threading (SpMT) の実装が頭にあった。SpMT は複数スレッドを費やして
シングルスレッドアプリを高速化する手法だ。
- If I received arows in my back for MCMT, I received 10 times as many
arrows for SpMT. And yet still I have hope for it. Unfortunately, I am
not currently working on SpMT. Haitham Akkary, the father of DMT,
continues the work.
もし俺が MCMT の実装にかかわっていたら、SpMT を全力で押してたと
思う。今でもその気持ちに変わりは無いけど、今はそういう立場じゃ無い。
DMT [Dynamic Multithrading] の提案者の Haitham Akkary が今でも
研究している様だね。
more Bulldozer information becomes public. For example, although I came
up with MCMT to make Willamette-style threading faster, I have always
wanted to put SpMT, Speculative Multithreading, on such a substrate.
SpMT has potential to speed up a single thread of execution, by
splitting it up into separate threads and running the separate threads
on different clusters, whereas Willamette-style hyperthreading, and
Bulldizer-style MCMT (apparently), only speed up workloads that have
existing independent threads.
Bulldozer に関する情報が増えてくれば明らかになるんだろうけど、俺の
MCMT が Bulldozer そのものって訳じゃないだろうね。例えば、俺は
Willamett の Hyperthreading を高速化するに当たって Speculative Multi-
threading (SpMT) の実装が頭にあった。SpMT は複数スレッドを費やして
シングルスレッドアプリを高速化する手法だ。
- If I received arows in my back for MCMT, I received 10 times as many
arrows for SpMT. And yet still I have hope for it. Unfortunately, I am
not currently working on SpMT. Haitham Akkary, the father of DMT,
continues the work.
もし俺が MCMT の実装にかかわっていたら、SpMT を全力で押してたと
思う。今でもその気持ちに変わりは無いけど、今はそういう立場じゃ無い。
DMT [Dynamic Multithrading] の提案者の Haitham Akkary が今でも
研究している様だね。
intelがhyperthreadingの効率アップのためにそのテクニックを使わなかった理由も興味があるねぇ
- Perhaps I should say here that my MCMT had a significant difference from
clustering in, say, the Alpha 21264,
http://www.hotchips.org/archives/hc10/2_Mon/HC10.S1/HC10.1.1.pdf
[中略]
Anyway: if it has an L0 or L1 data cache in the cluster, with or
without the scheduler, it's my MCMT. If no cache in the cluster, not
mine (although I have enumerated many such possibilities).
MCMT は Alpha 21264 のクラスタリングの概念とは大きく違うことは強調して
おきたい。
[中略]
要するに、L0なりL1なりの最上位のデータキャッシュがが独立している
クラスタリングは俺の MCMT アーキテクチャということになる。もちろん
そうじゃない構成のクラスタリングは有り得る。
- Motivated by my work to use MCMT to speed up single threads, I often
propose a shared L2 instruction scheduler, to load balance between the
clusters dynamically. Although I admit that I only really figured out
how to do that properly after I left AMD, and before I joined Intel.
How to do this is part of the Multi-star microarchitecture, M*, that is
my next step beyond MCMT.
俺は MCMT でシングルスレッドを高速化するために頑張った。例えばクラスタ
間のロードバランスのための二次スケジューラなんてのも考えた。でも、結局
そのための「正しい方法」ってヤツを思いついたのは AMD を退社した後、ちょうど
Intel に戻る前くらいだった。それが MCMT を越える新しいアーキテクチャ M*
(Multi-star) さ。
clustering in, say, the Alpha 21264,
http://www.hotchips.org/archives/hc10/2_Mon/HC10.S1/HC10.1.1.pdf
[中略]
Anyway: if it has an L0 or L1 data cache in the cluster, with or
without the scheduler, it's my MCMT. If no cache in the cluster, not
mine (although I have enumerated many such possibilities).
MCMT は Alpha 21264 のクラスタリングの概念とは大きく違うことは強調して
おきたい。
[中略]
要するに、L0なりL1なりの最上位のデータキャッシュがが独立している
クラスタリングは俺の MCMT アーキテクチャということになる。もちろん
そうじゃない構成のクラスタリングは有り得る。
- Motivated by my work to use MCMT to speed up single threads, I often
propose a shared L2 instruction scheduler, to load balance between the
clusters dynamically. Although I admit that I only really figured out
how to do that properly after I left AMD, and before I joined Intel.
How to do this is part of the Multi-star microarchitecture, M*, that is
my next step beyond MCMT.
俺は MCMT でシングルスレッドを高速化するために頑張った。例えばクラスタ
間のロードバランスのための二次スケジューラなんてのも考えた。でも、結局
そのための「正しい方法」ってヤツを思いついたのは AMD を退社した後、ちょうど
Intel に戻る前くらいだった。それが MCMT を越える新しいアーキテクチャ M*
(Multi-star) さ。
- Also, although it is natural to have a single (explicit) thread per
cluster in MCMT, I have also proposed allowing two threads per cluster.
Mainly motivated by SpMT: I could fork to a "runt thread" running in
tghe same cluster, and then migrate the run thread to a different
cluster. Intra-cluster forking is faster than inter-cluster forkng, and
does not disturb the parent thread.
But, if you are not doing SpMT, there is much less motivation for
multiple threads per cluster.
そう言えば、SpMT のためにクラスタ内で更に SMT をやるってのも考えた。
スレッドの分割を同じクラスタ内で走るスレッドにやらせて、実行は別クラスタ
でやるんだ。スレッドさえ分かれてしまえば、別々のクラスタで実行する方が
親スレッドに対する干渉は小さいからね。
いずれにせよ SpMT を採用しないなら、クラスタ内 SMT にそれほど意味はない。
cluster in MCMT, I have also proposed allowing two threads per cluster.
Mainly motivated by SpMT: I could fork to a "runt thread" running in
tghe same cluster, and then migrate the run thread to a different
cluster. Intra-cluster forking is faster than inter-cluster forkng, and
does not disturb the parent thread.
But, if you are not doing SpMT, there is much less motivation for
multiple threads per cluster.
そう言えば、SpMT のためにクラスタ内で更に SMT をやるってのも考えた。
スレッドの分割を同じクラスタ内で走るスレッドにやらせて、実行は別クラスタ
でやるんだ。スレッドさえ分かれてしまえば、別々のクラスタで実行する方が
親スレッドに対する干渉は小さいからね。
いずれにせよ SpMT を採用しないなら、クラスタ内 SMT にそれほど意味はない。
- With Willamette as background, I leaned towards a relatively small, L0,
cache in the cluster. Also, such a small L0 can often be pitch-matched
with the cluster execution unit datapath. A big L1, such as Bulldozer
seems to have, nearly always has to lie out of the datapath, and
requires wire turns. Wire turns waste area. I have, from time to time,
proposed putting the alignment muxes and barrel shifters in the wire
turn area. I'm surprised that a large cluster L1 makes sense, but that's
the sort of thing that you can only really tell from layout.
元々 Willamette が頭にあったから、俺はクラスタ内の L0 データキャッシュは
容量が小さいものを考えていた。チップ上のレイアウトで実行ユニットのデータフロー
のサイズに収まるようにL0の容量を決めると良いんだよ。。 Bulldozer の L1 は随分大
きくて配線に無駄な「戻り」部分が必要だと思う。俺は常々配線の戻りのところには
データアライメント用のマルチプレクサとバレルシフタにすれば良いと言ってるん
だけどね。
L1 が大きいからといって良いことは無いと思うんだけど、まぁそれもチップのレイアウト
次第だよね。
cache in the cluster. Also, such a small L0 can often be pitch-matched
with the cluster execution unit datapath. A big L1, such as Bulldozer
seems to have, nearly always has to lie out of the datapath, and
requires wire turns. Wire turns waste area. I have, from time to time,
proposed putting the alignment muxes and barrel shifters in the wire
turn area. I'm surprised that a large cluster L1 makes sense, but that's
the sort of thing that you can only really tell from layout.
元々 Willamette が頭にあったから、俺はクラスタ内の L0 データキャッシュは
容量が小さいものを考えていた。チップ上のレイアウトで実行ユニットのデータフロー
のサイズに収まるようにL0の容量を決めると良いんだよ。。 Bulldozer の L1 は随分大
きくて配線に無駄な「戻り」部分が必要だと思う。俺は常々配線の戻りのところには
データアライメント用のマルチプレクサとバレルシフタにすれば良いと言ってるん
だけどね。
L1 が大きいからといって良いことは無いと思うんだけど、まぁそれもチップのレイアウト
次第だよね。
- Some posters have been surprised by sharing the FP. Of course, AMD's K7
design, with separate clusters for integer and FP, was already half-way
there. They only had to double the integer cluster. It would have been
harder for Intel to go MCMT, since the P6 family had shared integer and
FP. Willamette might have been easier to go MCMT, since it had separate FP.
FPU を共有していることに疑問を持っているヤツもいるよな。もちろん K7 は
[整数パイプと浮動小数点パイプがスケジューラから分離しているという点で]
別々の整数クラスタと浮動小数点クラスタを持っていると言える。後は整数
クラスタをもう一つ追加すれば良いだけの話だよね。
P6は整数パイプと浮動小数点パイプでスケジューラが共通だから MCMT の
実装は難しい。Willamette は浮動小数点パイプラインが分離している分、MCMT
の実装はより楽になっている。
- Anyway... of course, for FP threads you might like to have
thread-private FP. But, in some ways, it is the advent of expensve FP,
like Bulldozer's 2 sets of 128 bit, 4x32 bit, FMAs, that justify integer
MCMT: the FP is so big that the overhead of replicating the integer
cluster, including the OOO logic, is a drop in the bucket.
君らは独立したFPクラスタが必要だって言いたいんだろうけど、Bulldozer の
FPU は128-bit の FMAなんて実行ユニットだけでもでかすぎる。その上、
整数パイプと同じくOOOロジックを備えたスケジューラなんて無理だよ。
design, with separate clusters for integer and FP, was already half-way
there. They only had to double the integer cluster. It would have been
harder for Intel to go MCMT, since the P6 family had shared integer and
FP. Willamette might have been easier to go MCMT, since it had separate FP.
FPU を共有していることに疑問を持っているヤツもいるよな。もちろん K7 は
[整数パイプと浮動小数点パイプがスケジューラから分離しているという点で]
別々の整数クラスタと浮動小数点クラスタを持っていると言える。後は整数
クラスタをもう一つ追加すれば良いだけの話だよね。
P6は整数パイプと浮動小数点パイプでスケジューラが共通だから MCMT の
実装は難しい。Willamette は浮動小数点パイプラインが分離している分、MCMT
の実装はより楽になっている。
- Anyway... of course, for FP threads you might like to have
thread-private FP. But, in some ways, it is the advent of expensve FP,
like Bulldozer's 2 sets of 128 bit, 4x32 bit, FMAs, that justify integer
MCMT: the FP is so big that the overhead of replicating the integer
cluster, including the OOO logic, is a drop in the bucket.
君らは独立したFPクラスタが必要だって言いたいんだろうけど、Bulldozer の
FPU は128-bit の FMAなんて実行ユニットだけでもでかすぎる。その上、
整数パイプと同じくOOOロジックを備えたスケジューラなんて無理だよ。
- You'd like to have per-cluster-thread FP, but such big FP workloads are
often so memory intensive that they thrash the shared-between-clusters
L2 cache: threading may be disabled anyways. As it is, you get good
integer threads via MCMT, and you get 1 integer thread and 1 FP thread.
Two FP threads may have some slowdown, although, again, if memory
intensive they may be blocking on memory, and hence allowing the other
FP thread t use the FP. But two purely computational FP threads will
almost undoubtedly block, unless the schedulers are piss-poor and can't
use all of the FP for a single thread (e.g. by being too small).
じゃあ一つのクラスタの中に FPU も入れろよって言うヤツもいるかもしれない。
でもな、浮動小数点演算ってのはだいたいにおいてメモリの負荷が大きいんだよ。
クラスタで共有している L2 なんて、すぐスラッシングでダメになっちまう。とにかく
二つの整数クラスタでFPUを共有ってのは丁度良いってことになる。
ひとつのFPUを二つのスレッドで共有するっては、ちっとは遅くなるかもしれない
けど、片方のスレッドがメモリで引っかかった時にもう片方が演算が出来るって
意味でうまく動く。ところが独立した二つのFPUなんて、スケジューラがよっぽど
ヘボく無い限りメモリ帯域を喰い合うだけで無意味なのさ。
often so memory intensive that they thrash the shared-between-clusters
L2 cache: threading may be disabled anyways. As it is, you get good
integer threads via MCMT, and you get 1 integer thread and 1 FP thread.
Two FP threads may have some slowdown, although, again, if memory
intensive they may be blocking on memory, and hence allowing the other
FP thread t use the FP. But two purely computational FP threads will
almost undoubtedly block, unless the schedulers are piss-poor and can't
use all of the FP for a single thread (e.g. by being too small).
じゃあ一つのクラスタの中に FPU も入れろよって言うヤツもいるかもしれない。
でもな、浮動小数点演算ってのはだいたいにおいてメモリの負荷が大きいんだよ。
クラスタで共有している L2 なんて、すぐスラッシングでダメになっちまう。とにかく
二つの整数クラスタでFPUを共有ってのは丁度良いってことになる。
ひとつのFPUを二つのスレッドで共有するっては、ちっとは遅くなるかもしれない
けど、片方のスレッドがメモリで引っかかった時にもう片方が演算が出来るって
意味でうまく動く。ところが独立した二つのFPUなんて、スケジューラがよっぽど
ヘボく無い限りメモリ帯域を喰い合うだけで無意味なのさ。
- I don't expect to get any credit for MCMT. In fact, I'm sure I'm going
to get shit for this post. I don't care. I know. The people who were
there, who saw my presentations and read my proposals, know. But, e.g.
Chuck Moore wasn't there at start; he came in later. Even Mike Haertel,
my usual collaborator, wasn't there; he was hired in later, although
before Chuck. Besides, Mike Haertel thinks that MCMT is obvious.
That's cool, although I ask: if MCMT is obvious, then why isn't Intel
doing it? Companies like Intel and AMD need idea generating people like
me about once every 10 years. In between, they don't need new ideas.
They need new incremental improvements of existing ideas.
Anyway... It's cool to see MCMT becoming real. It gives me hope that my
follow-on to MCMT, M* may still, eventually, also become real.
色々書いたけど、俺は MCMT に関する権利を主張しようって訳じゃ無い。
俺は当時誰がAMDで働いていたか知っているし、誰が俺のプレゼンや企画書
を読んでいるか知ってるけど、当時まだ Chuck Moore はいなかったし、俺の
仲間だった Mike Haertel も Chuckよりちょっと前に入社した程度だった。Haertel
は MCMT を買ってくれたけどね。
それにしても俺は思うんだが、 MCMT がうまく機能するとすれば、何故 Intel
は俺の提案を袖にしたんだろうね?結局のところ Intel や AMD みたいな大企業
にとって、新アーキテクチャなんて10年に一度くらいしか必要なくて、既存アーキを
洗練させるのがうまいやり方なんだろうね。
とにかく MCMT が日の目を見たのは良かったと思うよ。願わくば M* も採用される
日が来ればと思うね。
to get shit for this post. I don't care. I know. The people who were
there, who saw my presentations and read my proposals, know. But, e.g.
Chuck Moore wasn't there at start; he came in later. Even Mike Haertel,
my usual collaborator, wasn't there; he was hired in later, although
before Chuck. Besides, Mike Haertel thinks that MCMT is obvious.
That's cool, although I ask: if MCMT is obvious, then why isn't Intel
doing it? Companies like Intel and AMD need idea generating people like
me about once every 10 years. In between, they don't need new ideas.
They need new incremental improvements of existing ideas.
Anyway... It's cool to see MCMT becoming real. It gives me hope that my
follow-on to MCMT, M* may still, eventually, also become real.
色々書いたけど、俺は MCMT に関する権利を主張しようって訳じゃ無い。
俺は当時誰がAMDで働いていたか知っているし、誰が俺のプレゼンや企画書
を読んでいるか知ってるけど、当時まだ Chuck Moore はいなかったし、俺の
仲間だった Mike Haertel も Chuckよりちょっと前に入社した程度だった。Haertel
は MCMT を買ってくれたけどね。
それにしても俺は思うんだが、 MCMT がうまく機能するとすれば、何故 Intel
は俺の提案を袖にしたんだろうね?結局のところ Intel や AMD みたいな大企業
にとって、新アーキテクチャなんて10年に一度くらいしか必要なくて、既存アーキを
洗練させるのがうまいやり方なんだろうね。
とにかく MCMT が日の目を見たのは良かったと思うよ。願わくば M* も採用される
日が来ればと思うね。
- There were several K10s. While I wanted to work on low power when I went
to AMD, I was hired to consult on low power and do high end CPU, since
the low power project was already rolling and did not need a new chef.
The first K10 that I knew at AMD was a low power part. When that was
cancelled I was sent off on my lonesome, then wth Mike Haertel, to work
on a flagship, out-of-order, aggressive processor, while the original
low power team did something else. When that other low-power project was
cancelled, that team came over to the nascent K10 that I was working on.
My K10 was MCMT, plus a few other things. I had actually had to
promise Fred Weber that I would NOT do anything advanced for this K10 -
no SpMT, just MCMT. But when the other guys came on board, I thought
this meant that I could leave the easy stuff for them, while I tried to
figure out how to do SpMT and/or any other way of using MCMT to speed up
single threads.
当時 K10 なるプロジェクトはたくさんあったのさ。そもそも俺がAMDに雇われた時の
仕事は低消費電力プロセッサだったんだけど、これが俺の知る限り最初の「K10」
って名前のプロジェクトだった。
このK10の開発は既に随分進んでいて、俺の仕事は全然なかったんだが、あっさり
キャンセルされて俺は宙ぶらりん状態になった。丁度そのころ Mike Haertel が入社
してきて、一緒にハイエンドの OoOE プロセッサの開発を担当することになった。例の
低消費電力プロセッサのグループは、別のプロジェクトに回され、それとは別の
低消費電力プロジェクトをやっていたチームが我々の K10 の開発を行うことに
なった。この K10 が MCMT の K10 って訳だ。
俺の K10 プロジェクトに関しては、Fred Webner から MCMT の実装だけに専念して
SpMT とか余計なことに手を出さないように約束させられた。しかし (Webner が失脚して)
別の取締役が来たんで、その約束は無かったことにして SpMT を含むあらゆる方法で
MCMT によるシングルスレッドの高速化を実装することにした。
to AMD, I was hired to consult on low power and do high end CPU, since
the low power project was already rolling and did not need a new chef.
The first K10 that I knew at AMD was a low power part. When that was
cancelled I was sent off on my lonesome, then wth Mike Haertel, to work
on a flagship, out-of-order, aggressive processor, while the original
low power team did something else. When that other low-power project was
cancelled, that team came over to the nascent K10 that I was working on.
My K10 was MCMT, plus a few other things. I had actually had to
promise Fred Weber that I would NOT do anything advanced for this K10 -
no SpMT, just MCMT. But when the other guys came on board, I thought
this meant that I could leave the easy stuff for them, while I tried to
figure out how to do SpMT and/or any other way of using MCMT to speed up
single threads.
当時 K10 なるプロジェクトはたくさんあったのさ。そもそも俺がAMDに雇われた時の
仕事は低消費電力プロセッサだったんだけど、これが俺の知る限り最初の「K10」
って名前のプロジェクトだった。
このK10の開発は既に随分進んでいて、俺の仕事は全然なかったんだが、あっさり
キャンセルされて俺は宙ぶらりん状態になった。丁度そのころ Mike Haertel が入社
してきて、一緒にハイエンドの OoOE プロセッサの開発を担当することになった。例の
低消費電力プロセッサのグループは、別のプロジェクトに回され、それとは別の
低消費電力プロジェクトをやっていたチームが我々の K10 の開発を行うことに
なった。この K10 が MCMT の K10 って訳だ。
俺の K10 プロジェクトに関しては、Fred Webner から MCMT の実装だけに専念して
SpMT とか余計なことに手を出さないように約束させられた。しかし (Webner が失脚して)
別の取締役が来たんで、その約束は無かったことにして SpMT を含むあらゆる方法で
MCMT によるシングルスレッドの高速化を実装することにした。
- - indeed, the scheduler structure of queues
feeding an RS arose from the debate between OOO (me) and in-order (Sager
and Upton) -
実際、(Willamette 開発時に) スケジューラの構造で OoO派(俺)とインオーダー派
(Seger と Upton)で議論があった。
- Mitch Alsup was K9.
[K9について尋ねられて]Mitch Alsup が K9 をやってたな。
[MACオタ注: Mitch Alsup は Motorola 88Kや Ross HyperSPARC のアーキテクト]
- Some of us have done a lot of work on dynamic predication. (My resume
includes an OOO Itanium, plus I have been working on VLIW and
predication longer than OOO.) But since such work inside companies will
never see the light of day, do not let that hold you back, since you are
not so constrained by NDAs and trade secrets.
俺の経歴にも書いてあるように、OoO の Itanium やプレディケーションについては色々
研究したけど、Intel 社内では日の目を見なかった。俺はNDA とか色々あって無理だが、
お前さんがやるなら頑張れ。
feeding an RS arose from the debate between OOO (me) and in-order (Sager
and Upton) -
実際、(Willamette 開発時に) スケジューラの構造で OoO派(俺)とインオーダー派
(Seger と Upton)で議論があった。
- Mitch Alsup was K9.
[K9について尋ねられて]Mitch Alsup が K9 をやってたな。
[MACオタ注: Mitch Alsup は Motorola 88Kや Ross HyperSPARC のアーキテクト]
- Some of us have done a lot of work on dynamic predication. (My resume
includes an OOO Itanium, plus I have been working on VLIW and
predication longer than OOO.) But since such work inside companies will
never see the light of day, do not let that hold you back, since you are
not so constrained by NDAs and trade secrets.
俺の経歴にも書いてあるように、OoO の Itanium やプレディケーションについては色々
研究したけど、Intel 社内では日の目を見なかった。俺はNDA とか色々あって無理だが、
お前さんがやるなら頑張れ。
601 :MACオタ@ここまで:2010/02/14(日) 07:10:42 ID:Wj71GeXX
ALU間の配線レイアウトの話について語っているところも面白かったので
書こうかと思いましたが、長いのでヤメておきました。
ところで、この話に関して AMD のサイトで blog を執筆している John Fruehe 氏
(http://blogs.amd.com/work/ 参照)が「Andy Glew なんて知らねーし。そんな怪しい
ヤツの言うことより、俺を信じろ」とか書いて失笑をかっていました。
例のアニキと言い、どうして AMD のマーケティングは間抜けなのやら…
http://www.xtremesystems.org/forums/showpost.php?p=4225217&postcount=206
------------------------
I have no idea who Andy Glew is, but he left the company several years ago.
------------------------
書こうかと思いましたが、長いのでヤメておきました。
ところで、この話に関して AMD のサイトで blog を執筆している John Fruehe 氏
(http://blogs.amd.com/work/ 参照)が「Andy Glew なんて知らねーし。そんな怪しい
ヤツの言うことより、俺を信じろ」とか書いて失笑をかっていました。
例のアニキと言い、どうして AMD のマーケティングは間抜けなのやら…
http://www.xtremesystems.org/forums/showpost.php?p=4225217&postcount=206
------------------------
I have no idea who Andy Glew is, but he left the company several years ago.
------------------------
ワロスw
K9で却下された提案をブルで再び使うのか
ttp://pc.watch.impress.co.jp/docs/2006/0202/kaigai238.htm
提案は、CPUをマルチスレッド&マルチクラスタの構成にし、マイクロアーキテクチャの全レベルでマルチレベル化、
さらにさまざまなマルチスレッディングテクニックを実装するというものだったようだ。
例えば、スケジューラやインストラクションウインドウ、ストアバッファ、レジスタファイル、ブランチプレディクタなどをマルチレベルにする。
加えて、投機マルチスレッディング(SpMT:Speculative Multithreading)、非明示的マルチスレッディング(IMT:Implicit Multithreading)、
スキップアヘッドマルチスレッディング(SkMT:Skipahead Multithreading)といった技法を持ち込む。
ttp://pc.watch.impress.co.jp/docs/2006/0202/kaigai238.htm
提案は、CPUをマルチスレッド&マルチクラスタの構成にし、マイクロアーキテクチャの全レベルでマルチレベル化、
さらにさまざまなマルチスレッディングテクニックを実装するというものだったようだ。
例えば、スケジューラやインストラクションウインドウ、ストアバッファ、レジスタファイル、ブランチプレディクタなどをマルチレベルにする。
加えて、投機マルチスレッディング(SpMT:Speculative Multithreading)、非明示的マルチスレッディング(IMT:Implicit Multithreading)、
スキップアヘッドマルチスレッディング(SkMT:Skipahead Multithreading)といった技法を持ち込む。
604 :MACオタ>603 さん:2010/02/14(日) 08:32:13 ID:Wj71GeXX
K10って書いてた
>Glew氏は、以前、K10のために提案したものの、AMDに拒否されてしまった技術をリストアップしていた。
>Glew氏が提案したのは、かなり尖ったアーキテクチャだった。
>Glew氏は、以前、K10のために提案したものの、AMDに拒否されてしまった技術をリストアップしていた。
>Glew氏が提案したのは、かなり尖ったアーキテクチャだった。
ちなみに2ちゃんねる的には Andy Glew 氏のサイトの職務経歴は2005年半ばの
話題でした。
---------------------
132 名前:MACオタ 投稿日:2005/08/08(月) 06:18:21 ID:9pfRTF4F
P6の主要アーキテクトの一人として知られるAndy Glewが昨年AMDを退社した後,Intelに
戻ってるとのことす。
http://www.geocities.com/andrew_f_glew/cv-glew.html
---------------------
話題でした。
---------------------
132 名前:MACオタ 投稿日:2005/08/08(月) 06:18:21 ID:9pfRTF4F
P6の主要アーキテクトの一人として知られるAndy Glewが昨年AMDを退社した後,Intelに
戻ってるとのことす。
http://www.geocities.com/andrew_f_glew/cv-glew.html
---------------------
どうやら>>580の解釈であってるようでした
609 :MACオタ>608 さん:2010/02/14(日) 21:57:01 ID:Wj71GeXX
>>608
ご当人のブログで発表資料等が紹介されています。
http://andyglew.blogspot.com/2009/12/links-to-mlp-coherent-threading.html
ご当人のブログで発表資料等が紹介されています。
http://andyglew.blogspot.com/2009/12/links-to-mlp-coherent-threading.html
Andy Glewのスライドのほう、新風やハイパースカラじゃないか…
SIMDを使ったプログラムを書いているのだけど、マンデンブロ集合以外に、
プログラミングコストに比較して満足感があるものってなにかないかな。
ゲームは、キャラクターつくったりドット絵かくの大変なのでパス。
プログラミングコストに比較して満足感があるものってなにかないかな。
ゲームは、キャラクターつくったりドット絵かくの大変なのでパス。
つかいま一番つかってみたいのはG4/G5のAltiVecなんですけどね。
613 :,,・´∀`・,,)っ-○○○:2010/02/15(月) 22:38:10 ID:imhVWoSl
別に大したことないぞあれ
俺はMVI,MAX,VIS辺りかな…
IntelのサイトにTukiwilaのTDPが書いてます。
http://www.intel.com/products/processor/itanium/specifications.htm
-9350/1.73GHz (4-core): 185W
-9340/1.60GHz (4-core): 185W
-9339/1.46GHz (4-core): 155W
-9320/1.33GHz (4-core):; 155W
-9310/1.60GHz (2-core): 130W
流石に20億トランジスタは伊達じゃありませんな。
これと比較すると8-core, 4GHzでチップあたり200Wと言われる POWER7 は低消費
電力と言えるのかも…
http://www.intel.com/products/processor/itanium/specifications.htm
-9350/1.73GHz (4-core): 185W
-9340/1.60GHz (4-core): 185W
-9339/1.46GHz (4-core): 155W
-9320/1.33GHz (4-core):; 155W
-9310/1.60GHz (2-core): 130W
流石に20億トランジスタは伊達じゃありませんな。
これと比較すると8-core, 4GHzでチップあたり200Wと言われる POWER7 は低消費
電力と言えるのかも…
ネタの古さと程度の低さにビックリ
最後の行を言いたかっただけでしょw
618 :,,・´∀`・,,)っ-○○○:2010/02/24(水) 16:11:08 ID:QutNOdX2
describe(笑)
ますます描「画」と遠くなったぞ
ますます描「画」と遠くなったぞ
ね…描画
まずは古めのニュースをまとめておきます。
まず、POWER7の製造状況に関するIBM Power Systemsのゼネラルマネージャ、
Ross Mauri のコメント
http://www.itjungle.com/tfh/tfh021510-story03.html
--------------------
"The yields are good on the Power7 chips," Mauri said to me ahead of his
presentation. "And if you are hearing rumors to the contrary, call me up and
I am happy to deny them," he added with a smile.
--------------------
それから、日立と仏Bull SAのPOWER7搭載機の発表。
両者ともPower 75xのOEMの様です。
日立: http://www.hitachi.co.jp/New/cnews/month/2010/02/0210b.html
http://www.hitachi.co.jp/Prod/comp/EP8000/power7.html
Bull SA: http://www.wcm.bull.com/internet/pr/rend.jsp?DocId=539095&lang=en
まず、POWER7の製造状況に関するIBM Power Systemsのゼネラルマネージャ、
Ross Mauri のコメント
http://www.itjungle.com/tfh/tfh021510-story03.html
--------------------
"The yields are good on the Power7 chips," Mauri said to me ahead of his
presentation. "And if you are hearing rumors to the contrary, call me up and
I am happy to deny them," he added with a smile.
--------------------
それから、日立と仏Bull SAのPOWER7搭載機の発表。
両者ともPower 75xのOEMの様です。
日立: http://www.hitachi.co.jp/New/cnews/month/2010/02/0210b.html
http://www.hitachi.co.jp/Prod/comp/EP8000/power7.html
Bull SA: http://www.wcm.bull.com/internet/pr/rend.jsp?DocId=539095&lang=en
IBMオタさんだあ
円周率計算でIntel i7 PCで世界記録を樹立した Fabrice Bellard 氏が件の
実行コード "tpi" を公開しています。Linux版とWindows版。
http://bellard.org/pi/pi2700e9/tpi.html
手近で見つかった結果はこんな感じ。
128Mi (134,217,728)桁, 8-Thread
・Barcelona Opteron/2.3GHz./8-core: 125.018 sec.
・Shanghai Opteron/2.7GHz/8-core: 91.986 sec.
・Harpertown Xeon/2.5GHz/8-core: 89.859 sec.
・Nehalem Xeon/2.66GHz/4-core: 65.080 sec.
マルチスレッドとSSE3に対応した最新の円周率計算コードですので、今後のベンチマークは
この辺に移行すべきかと思うのですが…
実行コード "tpi" を公開しています。Linux版とWindows版。
http://bellard.org/pi/pi2700e9/tpi.html
手近で見つかった結果はこんな感じ。
128Mi (134,217,728)桁, 8-Thread
・Barcelona Opteron/2.3GHz./8-core: 125.018 sec.
・Shanghai Opteron/2.7GHz/8-core: 91.986 sec.
・Harpertown Xeon/2.5GHz/8-core: 89.859 sec.
・Nehalem Xeon/2.66GHz/4-core: 65.080 sec.
マルチスレッドとSSE3に対応した最新の円周率計算コードですので、今後のベンチマークは
この辺に移行すべきかと思うのですが…
上記の結果は全てLinux版によるものでした。
AMDで遅いものなんてアム虫がブーブー言うだけだろ
ちなみに i5 670で2thread
tpi.exe -T 2 -o pi.txt 128M
Using 3.67GiB of RAM
Computation to 128000000 digits, formula=Chudnovsky
Output file=pi.txt, format=txt, binary result size=53.1MB
Binary Splitting
Depth=24, thread_level=1
mem max disk max operation compl lv
545M 545M 0 0 completed 100.0% 0
time = 63.601 s
Compute P, Q
362M 545M 0 0 completed
time = 0.836 s
Division
599M 599M 0 0 completed
time = 5.646 s
Sqrt
528M 599M 0 0 completed
time = 3.793 s
Final multiplication
925M 925M 0 0 completed
time = 2.353 s
Total time (binary result) = 76.247 s
Base conversion
523M 925M 0 0 completed
time = 13.922 s
Total time (base 10 result) = 90.170 s
Writing result to 'pi.txt'
tpi.exe -T 2 -o pi.txt 128M
Using 3.67GiB of RAM
Computation to 128000000 digits, formula=Chudnovsky
Output file=pi.txt, format=txt, binary result size=53.1MB
Binary Splitting
Depth=24, thread_level=1
mem max disk max operation compl lv
545M 545M 0 0 completed 100.0% 0
time = 63.601 s
Compute P, Q
362M 545M 0 0 completed
time = 0.836 s
Division
599M 599M 0 0 completed
time = 5.646 s
Sqrt
528M 599M 0 0 completed
time = 3.793 s
Final multiplication
925M 925M 0 0 completed
time = 2.353 s
Total time (binary result) = 76.247 s
Base conversion
523M 925M 0 0 completed
time = 13.922 s
Total time (base 10 result) = 90.170 s
Writing result to 'pi.txt'
626 :MACオタ>625 さん:2010/02/28(日) 13:51:20 ID:TTBuX29w
あまり変わらんな
tpi.exe -T 2 -o pi.txt 128Mi
Using 3.67GiB of RAM
Computation to 134217728 digits, formula=Chudnovsky
Output file=pi.txt, format=txt, binary result size=55.7MB
Binary Splitting
Depth=24, thread_level=1
mem max disk max operation compl lv
571M 571M 0 0 completed 100.0% 0
time = 66.222 s
Compute P, Q
377M 571M 0 0 completed
time = 0.874 s
Division
623M 623M 0 0 completed
time = 6.115 s
Sqrt
547M 623M 0 0 completed
time = 4.134 s
Final multiplication
966M 966M 0 0 completed
time = 2.699 s
Total time (binary result) = 80.044 s
Base conversion
549M 966M 0 0 completed
time = 14.836 s
Total time (base 10 result) = 94.879 s
Writing result to 'pi.txt'
tpi.exe -T 2 -o pi.txt 128Mi
Using 3.67GiB of RAM
Computation to 134217728 digits, formula=Chudnovsky
Output file=pi.txt, format=txt, binary result size=55.7MB
Binary Splitting
Depth=24, thread_level=1
mem max disk max operation compl lv
571M 571M 0 0 completed 100.0% 0
time = 66.222 s
Compute P, Q
377M 571M 0 0 completed
time = 0.874 s
Division
623M 623M 0 0 completed
time = 6.115 s
Sqrt
547M 623M 0 0 completed
time = 4.134 s
Final multiplication
966M 966M 0 0 completed
time = 2.699 s
Total time (binary result) = 80.044 s
Base conversion
549M 966M 0 0 completed
time = 14.836 s
Total time (base 10 result) = 94.879 s
Writing result to 'pi.txt'
マルチスッドレに対応してるわりには遅い
629 :MACオタ>628 さん:2010/02/28(日) 14:28:21 ID:TTBuX29w
>>628
タスクマネージャで負荷変動でも眺めていれば理由は自明ですよ。
タスクマネージャで負荷変動でも眺めていれば理由は自明ですよ。
>>403でも紹介した中国語版Power.orgにおいてある資料ですが、"64-bit Multi-
threaded"の次世代組込コアについて言及がありました。
http://www.cn.power.org/resources/power/pdf/06.PPC%20Embedded%20PowerPC%20Architecture.pdf
(P.6参照)
今見ると、これが PowerPC A2 コアであることは明らかなのですが、当該スライドの
タイトルが"Power Architecture Cores Available for Licensing"とあるように、A2コア
を外部にライセンスする気満々なのは明らかです。
で、Sequoia 用コアについて再度考え直してみると、>>396, >>403, >>561あたりで書い
たようにPPC 470系であろうと予測している訳ですが、
https://newsline.llnl.gov/_rev02/articles/2009/feb/02.06.09-sequoia.php
- 1.6 PetaBytes of memory
- 98,304 Nodes
ということで、プロセッサカードあたりのメモリは明らかに16GBを想定していることが判
ります。Blue Gene/P からはプロセッサカード内でのSMP動作モードが追加されていま
すので、16GBのメモリを使用するのに32-bitコアのままで問題無いのであろうかという
疑問が出てきます。
PPC470自体がサポートする物理メモリは、ちょうど上のプレゼンに書いてあって、4TB
とのこと。
---------------------
- Real memory support up to 4 terrabytes
---------------------
16コアで16GBを共有するのですから、プロセスあたり4GBの制限があっても何とかなる
のかもしれませんが、PC的な64-bit SMP のようにノード内の全メモリをスレッド間で共有
するようなコードは使えません。
どうせ Blue Gene で動かす以上、PCクラスタからのベタ移植なんて考えないのかもしれ
ませんが、64-bitの A2 コアを選択する可能性も出てきた…ということで。
threaded"の次世代組込コアについて言及がありました。
http://www.cn.power.org/resources/power/pdf/06.PPC%20Embedded%20PowerPC%20Architecture.pdf
(P.6参照)
今見ると、これが PowerPC A2 コアであることは明らかなのですが、当該スライドの
タイトルが"Power Architecture Cores Available for Licensing"とあるように、A2コア
を外部にライセンスする気満々なのは明らかです。
で、Sequoia 用コアについて再度考え直してみると、>>396, >>403, >>561あたりで書い
たようにPPC 470系であろうと予測している訳ですが、
https://newsline.llnl.gov/_rev02/articles/2009/feb/02.06.09-sequoia.php
- 1.6 PetaBytes of memory
- 98,304 Nodes
ということで、プロセッサカードあたりのメモリは明らかに16GBを想定していることが判
ります。Blue Gene/P からはプロセッサカード内でのSMP動作モードが追加されていま
すので、16GBのメモリを使用するのに32-bitコアのままで問題無いのであろうかという
疑問が出てきます。
PPC470自体がサポートする物理メモリは、ちょうど上のプレゼンに書いてあって、4TB
とのこと。
---------------------
- Real memory support up to 4 terrabytes
---------------------
16コアで16GBを共有するのですから、プロセスあたり4GBの制限があっても何とかなる
のかもしれませんが、PC的な64-bit SMP のようにノード内の全メモリをスレッド間で共有
するようなコードは使えません。
どうせ Blue Gene で動かす以上、PCクラスタからのベタ移植なんて考えないのかもしれ
ませんが、64-bitの A2 コアを選択する可能性も出てきた…ということで。
ECのスーパーコンピュータ共同利用プロジェクト PRACE が2009年の技術報告書
を公開しています。
http://www.prace-project.eu/documents/d8-3-2.pdf
この報告書から>>336で述べた QPACE について、目に付いた話題を。
2009年下期のGreen500の上位を独占した QPACE の試作機 eQPACE ですが、
開発目標は下記のように設定されている (P.13)
- QPACE アーキテクチャの QCD 計算以外の分野への応用
- トーラスネットワーク用 FPGA の他分野応用のための改良
- 上記の目的のためのQPACEネットワーク用 MPI ライブラリ等、ソフトウェアの開発
汎用HPCコード応用のため、FPGAインタコネクトは、ハード/ソフト両面から、現在も
開発中 (P.63-66)
現状のインタコネクト性能 (P108, 表24)
・QPACE MPI Latency: 4.7us, BW: 845MB/s
・Altix XE (IB QDR) MPI Lantecy: 1.7us, BW: 2500MB/s
・Altix ICE (4x IB) MPI Latency: 1.9us, BW: 1800MB/s
2009年下期のTop500の登録ではeQPACEの実行効率は77.2%とあまり良好とは言えま
せんが、今後もう少し向上は期待できるのかもしれません。
を公開しています。
http://www.prace-project.eu/documents/d8-3-2.pdf
この報告書から>>336で述べた QPACE について、目に付いた話題を。
2009年下期のGreen500の上位を独占した QPACE の試作機 eQPACE ですが、
開発目標は下記のように設定されている (P.13)
- QPACE アーキテクチャの QCD 計算以外の分野への応用
- トーラスネットワーク用 FPGA の他分野応用のための改良
- 上記の目的のためのQPACEネットワーク用 MPI ライブラリ等、ソフトウェアの開発
汎用HPCコード応用のため、FPGAインタコネクトは、ハード/ソフト両面から、現在も
開発中 (P.63-66)
現状のインタコネクト性能 (P108, 表24)
・QPACE MPI Latency: 4.7us, BW: 845MB/s
・Altix XE (IB QDR) MPI Lantecy: 1.7us, BW: 2500MB/s
・Altix ICE (4x IB) MPI Latency: 1.9us, BW: 1800MB/s
2009年下期のTop500の登録ではeQPACEの実行効率は77.2%とあまり良好とは言えま
せんが、今後もう少し向上は期待できるのかもしれません。
632 :MACオタ>624 さん:2010/02/28(日) 17:24:40 ID:TTBuX29w
>>624
-----------------
AMDで遅いものなんてアム虫がブーブー言うだけだろ
-----------------
ちょっとπスレッドを見てきましたけど、もうAMDで速いコードなんて無くなったみたいですよ。
http://h2np.net/pi/pi_record.html
-----------------
AMDで遅いものなんてアム虫がブーブー言うだけだろ
-----------------
ちょっとπスレッドを見てきましたけど、もうAMDで速いコードなんて無くなったみたいですよ。
http://h2np.net/pi/pi_record.html
蟲にはそれがわからんとです
業界が汎用に走り過ぎている希ガス
とんがったアーキテクチャで差別化しないと共食いになりそう…
とんがったアーキテクチャで差別化しないと共食いになりそう…
>>634
あなたの住んでる世界にはASIC市場がないんですか?
あなたの住んでる世界にはASIC市場がないんですか?
>>622で紹介したTachusPIはWindows版でもコマンドコンソールが必要なので、
バッチファイルを書いてみました。
Bellard氏のサイトからダウンロードして解凍したフォルダに、以下のテキスト
ファイルを "tpi.dat"という名前で保存して、ダブルクリックすると計算できます。
なお、Windows版は64-bit Windows必須。
@ECHO OFF
SET /P NTHREAD="スレッド数: "
SET /P NDIGIT="計算桁数 (例: 1M): "
.\tpi -T %NTHREAD% %NDIGIT%
SET /P ENDOK="終了"
バッチファイルを書いてみました。
Bellard氏のサイトからダウンロードして解凍したフォルダに、以下のテキスト
ファイルを "tpi.dat"という名前で保存して、ダブルクリックすると計算できます。
なお、Windows版は64-bit Windows必須。
@ECHO OFF
SET /P NTHREAD="スレッド数: "
SET /P NDIGIT="計算桁数 (例: 1M): "
.\tpi -T %NTHREAD% %NDIGIT%
SET /P ENDOK="終了"
>>622
πってCPU内蔵キャッシュの性能テストだよな。
πってCPU内蔵キャッシュの性能テストだよな。
完全に同意
amdの報告はまだ?
MACオタのレスくらい読めって
ちゃんと書いてあるよ
ちゃんと書いてあるよ
linuxだろ
あげ
POWER7とTukwilaのSPEC CPU2006の結果がSPECのサイトで公開されています。
どちらもRateのみ。POWER7の値は既にIBMのサイトで公開済みですが、個別の
ベンチマーク結果を確認したい方はどうぞ。
CINT2006_rate
・POWER7 on AIX
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09576.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09577.html
3.1GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09578.html
3.5GHz/48-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09583.html
3.86GHz/16-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
3.86GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09587.html
4.14GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09580.html
・POWER7 on Linux
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09568.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09566.html
・Tukwila on HP-UX
1.73GHz/8-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09616.html
どちらもRateのみ。POWER7の値は既にIBMのサイトで公開済みですが、個別の
ベンチマーク結果を確認したい方はどうぞ。
CINT2006_rate
・POWER7 on AIX
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09576.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09577.html
3.1GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09578.html
3.5GHz/48-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09583.html
3.86GHz/16-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
3.86GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09587.html
4.14GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09580.html
・POWER7 on Linux
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09568.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09566.html
・Tukwila on HP-UX
1.73GHz/8-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09616.html
CINT2006_rate
・POWER7 on AIX
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09573.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09574.html
3.1GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09581.html
3.5GHz/48-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09579.html
3.86GHz/16-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09582.html
3.86GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09584.html
4.14GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09585.html
・POWER7 on Linux
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09569.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09567.html
・Tukwila on HP-UX
1.73GHz/8-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09617.html
・POWER7 on AIX
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09573.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09574.html
3.1GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09581.html
3.5GHz/48-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09579.html
3.86GHz/16-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09582.html
3.86GHz/64-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09584.html
4.14GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09585.html
・POWER7 on Linux
3.3GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09569.html
3.55GHz/32-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100205-09567.html
・Tukwila on HP-UX
1.73GHz/8-core http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09617.html
Tukwila死亡
色々な基準で他のアーキテクチャと比較してみると、こんな感じ
■ 2-socket
processor core CINT(base/peak) CFP(base/peak)
POWER7/3.86GHz 16 586 / 652 531 / 586
Nehalem/3.33GHz 8 255 / 274 204 / 211
Istanbul/2.80GHz 12 168 / 215 133 / 148
Niagara2/1.58GHz 16 171 / 183 124 / 133
Tukwila/1.73GHz 8 128 / 134 132 / 136
■16-core
processor CINT(base/peak) CFP(base/peak)
POWER7/3.86GHz 586 / 652 531 / 586
POWER6/5.0GHz 466 / 542 465 / 544
Nehalem/2.93GHz 466 / 499 361 / 372
POWER6/3.60GHz 289 / 363 226 / 263
Shanghai/3.1GHz 232 / 274 203 / 228
Dunnington/2.4GHz 204 / 221 120 / 128
■ 2-socket
processor core CINT(base/peak) CFP(base/peak)
POWER7/3.86GHz 16 586 / 652 531 / 586
Nehalem/3.33GHz 8 255 / 274 204 / 211
Istanbul/2.80GHz 12 168 / 215 133 / 148
Niagara2/1.58GHz 16 171 / 183 124 / 133
Tukwila/1.73GHz 8 128 / 134 132 / 136
■16-core
processor CINT(base/peak) CFP(base/peak)
POWER7/3.86GHz 586 / 652 531 / 586
POWER6/5.0GHz 466 / 542 465 / 544
Nehalem/2.93GHz 466 / 499 361 / 372
POWER6/3.60GHz 289 / 363 226 / 263
Shanghai/3.1GHz 232 / 274 203 / 228
Dunnington/2.4GHz 204 / 221 120 / 128
POWER7はパッケージにもソケットにも馬鹿みたいに金かけてるから参考にならねえ
プロセッサモジュールの価格も数倍違うだろどうせ
プロセッサモジュールの価格も数倍違うだろどうせ
いやそれは正しい方向なんだよ。
上に上にと逃げて、高く売らなきゃ生き残れない。
立場的に。
上に上にと逃げて、高く売らなきゃ生き残れない。
立場的に。
power4のMCMは家が建つくらいだったが
>>649
不意を突かれたw
不意を突かれたw
>>646
POWER6って性能悪かったんだな…
POWER6って性能悪かったんだな…
レトリック君ってIBMの人だったのか
先週IBMがチップ間光インタコネクトに利用可能なアバランシェ光検出素子を
発表しました。
IBM Researchにまとめた情報が出ていたので、URLを書いておきます。
http://domino.research.ibm.com/comm/research_projects.nsf/pages/photonics.apd.html
IBMによると、今これでダイ上に検出素子、光変調器、光スイッチ、光バッファを集積する
ことが可能になり、光インタコネクトを実装する基礎技術は一通り揃ったとのこと。
発表しました。
IBM Researchにまとめた情報が出ていたので、URLを書いておきます。
http://domino.research.ibm.com/comm/research_projects.nsf/pages/photonics.apd.html
IBMによると、今これでダイ上に検出素子、光変調器、光スイッチ、光バッファを集積する
ことが可能になり、光インタコネクトを実装する基礎技術は一通り揃ったとのこと。
>>41
ゴーストバスターズもPS3リードだけど、超絶劣化したね。
ゴーストバスターズもPS3リードだけど、超絶劣化したね。
MACオタが後藤をネタに語る悪寒
なんでMIPSて落ち目になったの?
WSがPCに喰われほぼ消滅→組み込みに活路を見いだす→ARMとの競争に負ける
というのが消費者側からの見方だが、どうなんかね。
というのが消費者側からの見方だが、どうなんかね。
捲土重来を狙ってるみたいだが。
Androidでビジネス拡大を狙うミップスの新戦略
http://monoist.atmarkit.co.jp/fembedded/31mips/mips01.html
Androidでビジネス拡大を狙うミップスの新戦略
http://monoist.atmarkit.co.jp/fembedded/31mips/mips01.html
POWER7Macを発売してください>MACオタさん
MACオタならできる
MACオタならできる
MACオタ「俺にだって、、できないことくらい、、、ある・・・・」
実際にMIPSがARMに比べて組込向けで劣ってたところって何なんだろうね。
SoC向けのIP展開の遣り方や価格がダメダメだったのかね?
それともPCと対抗するのに力を入れてる間に、ARMが組み込み向けのシェアを
占拠してしまって、出遅れたのが致命傷だったって事なのかな?
SoC向けのIP展開の遣り方や価格がダメダメだったのかね?
それともPCと対抗するのに力を入れてる間に、ARMが組み込み向けのシェアを
占拠してしまって、出遅れたのが致命傷だったって事なのかな?
>>662
高性能に傾斜しすぎていた傾向はあるのでは無いかな。
SHが16bit化コードで先行して、ARMがthumbで続き、MIPS16とかはあまりやる気が…
求められているのは高性能ではなく、ほどほどの性能とローコストだから。
ま、今でもだけど。
なのでARM主流がなかなかARM7TDMIからCortexに移らないww
高性能に傾斜しすぎていた傾向はあるのでは無いかな。
SHが16bit化コードで先行して、ARMがthumbで続き、MIPS16とかはあまりやる気が…
求められているのは高性能ではなく、ほどほどの性能とローコストだから。
ま、今でもだけど。
なのでARM主流がなかなかARM7TDMIからCortexに移らないww
そしてなぜダメだったのかとか議論にもの登らず消えていくSuperH。
MIPSは1995年頃に内紛があったような気がした
R10000はスペックの割に異様に遅かった(速くない)のが印象に残っている。クロックも上がらなかったし
ARMはIPを積極的に売ったので勝ったというのが定評だと思う。
MIPSは命令セットだけ買えるので、独自コアや独自拡張が欲しい人が使っていたかな
ゲーム機とかネットワークプロセッサとか
R10000はスペックの割に異様に遅かった(速くない)のが印象に残っている。クロックも上がらなかったし
ARMはIPを積極的に売ったので勝ったというのが定評だと思う。
MIPSは命令セットだけ買えるので、独自コアや独自拡張が欲しい人が使っていたかな
ゲーム機とかネットワークプロセッサとか
MIPSの内紛はクボタがらみだったと思うが輪をかけて自信なし
個人的な好みで言うと、MIPSは割り込みの扱いが面倒だし、SHはディスプレースメントが短くて不便
個人的な好みで言うと、MIPSは割り込みの扱いが面倒だし、SHはディスプレースメントが短くて不便
すーぱーえっち
みだらなぷっしー
2000年からのXeonのCPUコア数の
変化が解るグラフってどこかにありませんか?
変化が解るグラフってどこかにありませんか?
■福田昭のセミコン業界最前線■
2009年はどんな年だったのか
http://pc.watch.impress.co.jp/docs/column/semicon/20100317_355029.html
2009年はどんな年だったのか
http://pc.watch.impress.co.jp/docs/column/semicon/20100317_355029.html
ロースペの性能比較が面白すぎて困る
[GDC 2010]Larrabee計画の延期が影を落とす,Intelの“グラフィックス最適化”セッション
http://www.4gamer.net/games/107/G010710/20100317030/
> しかし蓋を開けてみれば,その内容は「デュアルコアCore i7・i5・i3プロセッサに搭載された
>『Intel HD Graphics』と,同グラフィックス機能に向けた最適化の話題のみ」という,お寒い内容。
>ただでさえ閑散としたセッション会場を,早々に立ち去る参加者も目立ち,聴講者は筆者を含めて数える程度だった。
http://www.4gamer.net/games/107/G010710/20100317030/
> しかし蓋を開けてみれば,その内容は「デュアルコアCore i7・i5・i3プロセッサに搭載された
>『Intel HD Graphics』と,同グラフィックス機能に向けた最適化の話題のみ」という,お寒い内容。
>ただでさえ閑散としたセッション会場を,早々に立ち去る参加者も目立ち,聴講者は筆者を含めて数える程度だった。
http://www.4gamer.net/games/107/G010710/20100317030/
[GDC 2010]Larrabee計画の延期が影を落とす,Intelの“グラフィックス最適化”セッション
[GDC 2010]Larrabee計画の延期が影を落とす,Intelの“グラフィックス最適化”セッション
Cellといいララビーといい
シンプルコアレンダリングの何が障害なんだろうな
シンプルコアレンダリングの何が障害なんだろうな
>>674
構造がシンプルでも、求められる出力は従来と変わらないんだから、別の何処かが複雑化するだけじゃね?
おまけに新しい構造だからゼロスタートで頑張れとか言われたら、誰も近寄りたくないんじゃないかな。
一方、従来型で構造が複雑なのはプロセスの進化で相殺できるし、使う側もノウハウ流用できる。
構造がシンプルでも、求められる出力は従来と変わらないんだから、別の何処かが複雑化するだけじゃね?
おまけに新しい構造だからゼロスタートで頑張れとか言われたら、誰も近寄りたくないんじゃないかな。
一方、従来型で構造が複雑なのはプロセスの進化で相殺できるし、使う側もノウハウ流用できる。
Larrabeeは多少性能に難があっても製品として出しちゃえば良かったんだよ、否が応でも対応アプリが出てくるだろ
第一期製品で完全版を目指しすぎインテル
第一期製品で完全版を目指しすぎインテル
Mercedみたいになったと思うぞ
Intelと富士通がWestmereのSPEC2006を登録しています。
http://www.spec.org/cpu2006/results/res2010q1/
この話題を語る前に少しばかりおさらいを。
最近のIntelコンパイラは"Auto Parallel"オプションによってCINT/CFPの結果でも
単純なコア当たりの性能が判りにくくなっています。
それでも"base"の結果のみAuto Parallelが無効にされている結果を見つけたという
話がRWT掲示板に投稿されていました。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=107677&threadid=107677&roomid=2
このCore i3-540搭載機のBullの登録(並列化OFF)と富士通の登録(並列化ON)を比較して
みましょう。
■Core i3-540のCINT2006_base & CFP2006_base
CINT_base CFP_base
並列化無 25.6 27.5
並列化有 26.2 29.3
参考:
Bull CINT2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100126-09456.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -opt-prefetch
富士通 CINT2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100118-09374.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -parallel -par-runtime-control -opt-prefetch
Bull CFP2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100126-09454.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -opt-prefetch
富士通 CFP2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100118-09351.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -parallel -opt-prefetch
http://www.spec.org/cpu2006/results/res2010q1/
この話題を語る前に少しばかりおさらいを。
最近のIntelコンパイラは"Auto Parallel"オプションによってCINT/CFPの結果でも
単純なコア当たりの性能が判りにくくなっています。
それでも"base"の結果のみAuto Parallelが無効にされている結果を見つけたという
話がRWT掲示板に投稿されていました。
http://www.realworldtech.com/forums/index.cfm?action=detail&id=107677&threadid=107677&roomid=2
このCore i3-540搭載機のBullの登録(並列化OFF)と富士通の登録(並列化ON)を比較して
みましょう。
■Core i3-540のCINT2006_base & CFP2006_base
CINT_base CFP_base
並列化無 25.6 27.5
並列化有 26.2 29.3
参考:
Bull CINT2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100126-09456.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -opt-prefetch
富士通 CINT2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100118-09374.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -parallel -par-runtime-control -opt-prefetch
Bull CFP2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100126-09454.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -opt-prefetch
富士通 CFP2006 http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100118-09351.html
最適化: -xSSE4.2 -ipo -O3 -no-prec-div -static -parallel -opt-prefetch
CINT/CFP を構成する個別ベンチマークの結果を比較すると、更に興味深い結果が
見て取れます。
■自動並列化の効果
CINT (全12ベンチマーク)
- 462.libquantum: +50.4%
- その他: -3.2〜0%
CFP (全17ベンチマーク)
- 436.cactusADM: +85.7%
- 434.zeusmp: +16.5%
- 410.bwaves: +9.9%
- 482.sphinx3: +9.1%
- 456.GeemsFDTD: +6.6%
- 481.wrf: +3.1%
- 470.lbm: +2.4%
- その他: -2.9〜+1%
つまりCINTで並列化が寄与するベンチはたった一つ。CFPでも顕著に効果があるモノは
5つ程度ということです。
コア単体の性能比較を行いたい場合は、これら並列化の効果が大きなサブベンチマークを
除いた幾何平均を求めればOKということでもあります。先のCore i3-540の結果をこの方式で
計算してみると次のようになりますが、自動並列化の効果がキャンセルできてることが判ります。
■Core i3-540の修正CINT2006_base & 修正CFP2006_baseの比較
CINTは 462 を除く。
CFPは 410, 434, 436, 459, 481, 482 を除く。
CINT_base(Mod) CFP_base(Mod)
並列化無 22.3 26.3
並列化有 22.1 26.2
見て取れます。
■自動並列化の効果
CINT (全12ベンチマーク)
- 462.libquantum: +50.4%
- その他: -3.2〜0%
CFP (全17ベンチマーク)
- 436.cactusADM: +85.7%
- 434.zeusmp: +16.5%
- 410.bwaves: +9.9%
- 482.sphinx3: +9.1%
- 456.GeemsFDTD: +6.6%
- 481.wrf: +3.1%
- 470.lbm: +2.4%
- その他: -2.9〜+1%
つまりCINTで並列化が寄与するベンチはたった一つ。CFPでも顕著に効果があるモノは
5つ程度ということです。
コア単体の性能比較を行いたい場合は、これら並列化の効果が大きなサブベンチマークを
除いた幾何平均を求めればOKということでもあります。先のCore i3-540の結果をこの方式で
計算してみると次のようになりますが、自動並列化の効果がキャンセルできてることが判ります。
■Core i3-540の修正CINT2006_base & 修正CFP2006_baseの比較
CINTは 462 を除く。
CFPは 410, 434, 436, 459, 481, 482 を除く。
CINT_base(Mod) CFP_base(Mod)
並列化無 22.3 26.3
並列化有 22.1 26.2
680 :MACオタ@ここまで:2010/03/20(土) 11:01:14 ID:2FaaqQLO
ここから本題です。Intelと富士通が登録したWestmere-EPの結果を同クロックの
Nehalemと比較してみましょう。
■ i7-980X vs i7-975 on Windows
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
i7-980X/3.33GHz 34.8 28.4 36.9 30.0
i7-975/3.33GHz 31.6 26.5 32.9 27.1
つまりシングルコア性能で見てもCINTで+7%,, CFPで+11%程度の性能向上があります。
ただし、この比較、980Xは64bit Win7 + icc11.1, 975は32bit Vista + icc11.1なので
その点は考慮する必要もあるかもしれません。
■ Xeon X5680 vs Xeon W5590 on 64-bit Linux
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
i7-980X/3.33GHz 39.0 30.2 44.8 33.4
i7-975/3.33GHz 34.2 27.8 40.4 32.0
こちらは両方とも64-bitコードということで、より信頼が置けます。
int でのコア当たりの性能向上は 8.5%, fp では 4.2%ということになります。
まあ Tick-Tock での "Tock" での性能向上としては、こんなモノでしょうか?
Nehalemと比較してみましょう。
■ i7-980X vs i7-975 on Windows
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
i7-980X/3.33GHz 34.8 28.4 36.9 30.0
i7-975/3.33GHz 31.6 26.5 32.9 27.1
つまりシングルコア性能で見てもCINTで+7%,, CFPで+11%程度の性能向上があります。
ただし、この比較、980Xは64bit Win7 + icc11.1, 975は32bit Vista + icc11.1なので
その点は考慮する必要もあるかもしれません。
■ Xeon X5680 vs Xeon W5590 on 64-bit Linux
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
i7-980X/3.33GHz 39.0 30.2 44.8 33.4
i7-975/3.33GHz 34.2 27.8 40.4 32.0
こちらは両方とも64-bitコードということで、より信頼が置けます。
int でのコア当たりの性能向上は 8.5%, fp では 4.2%ということになります。
まあ Tick-Tock での "Tock" での性能向上としては、こんなモノでしょうか?
681 :MACオタ@参考資料:2010/03/20(土) 11:35:40 ID:2FaaqQLO
ソースのリンクを書いておきます。
■Core i7-980X on Win7 64-bit
CINT2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100215-09681.html
CFP2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100215-09682.html
■Core i7-975 on Vista 32-bit
CINT2006: http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07695.html
CFP2006: http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07697.html
■Xeon X5680 on SuSE 10 x86_64
CINT2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09740.html
CFP2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09741.html
■Xeon W5590 on SuSE 10 x86_64
CINT2006: http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090803-08318.html
CFP2006: http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090803-08319.html
■Core i7-980X on Win7 64-bit
CINT2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100215-09681.html
CFP2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100215-09682.html
■Core i7-975 on Vista 32-bit
CINT2006: http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07695.html
CFP2006: http://www.spec.org/cpu2006/results/res2009q2/cpu2006-20090608-07697.html
■Xeon X5680 on SuSE 10 x86_64
CINT2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09740.html
CFP2006: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09741.html
■Xeon W5590 on SuSE 10 x86_64
CINT2006: http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090803-08318.html
CFP2006: http://www.spec.org/cpu2006/results/res2009q3/cpu2006-20090803-08319.html
Modの方は参考にはなるだろうけど
「コア当たりの性能向上」って言い切っちゃうのはどうなの?
「コア当たりの性能向上」って言い切っちゃうのはどうなの?
683 :MACオタ>682 さん:2010/03/20(土) 12:11:34 ID:2FaaqQLO
684 :,,・´∀`・,,)っ-○○○:2010/03/20(土) 13:13:28 ID:lZIalqH7
そもそもWestmereはコアレベルで見るとAES/CLMUL命令の有無を除けばNehalemの単純シュリンクなんで
そんなもんでしょう。
IACAのDLLがNehalem用とWestmere用で全く同じサイズだった時点で素性はわかったようなもの
そんなもんでしょう。
IACAのDLLがNehalem用とWestmere用で全く同じサイズだった時点で素性はわかったようなもの
Macオタさんと団子さんが引っ付いたw
うほっ
TBの上限が同じならL3$が増えた以外にエンハンスあるっけ?ブーストしやすいくらいか?
688 :,,・´∀`・,,)っ-○○○:2010/03/20(土) 22:29:25 ID:lZIalqH7
AES/CLMULの利用で高速化出来るコードってどれくらいあるのかしら
689 :,,・´∀`・,,)っ-○○○:2010/03/20(土) 22:51:13 ID:lZIalqH7
http://www.freeweb.hu/instlatx64/
この辺見るに本当にNehalemと同じだな
L3は確かに容量1.5倍だがレイテンシは14clk→17clkと増大してるし
一概に性能向上に寄与してるとは言い難い気が。
>>687が正解じゃない?
シュリンクでコア当たりの消費電力が落ちてる分TDP枠に余裕ができてるはず
この辺見るに本当にNehalemと同じだな
L3は確かに容量1.5倍だがレイテンシは14clk→17clkと増大してるし
一概に性能向上に寄与してるとは言い難い気が。
>>687が正解じゃない?
シュリンクでコア当たりの消費電力が落ちてる分TDP枠に余裕ができてるはず
>>683
省略した項目が「コアあたりの性能向上」を反映してる可能性はないの?
省略した項目が「コアあたりの性能向上」を反映してる可能性はないの?
LSDが増えるって話はどうなったんだ?
>>684 団子 さん
-------------------
IACAのDLLがNehalem用とWestmere用で全く同じサイズだった時点で素性は
わかったようなもの
------------------
「そんなもの」で頭から決め付けては面白くもなんとも無い訳で、L3の変更やらメモリバッファの増量等の影響がどのように現れるかを問題にしているという
ことになります。命令仕様の改善とマイクロアーキテクチャの改善は区別して考えるべきかと。
http://www.realworldtech.com/page.cfm?ArticleID=RWT031710140138
>>690
上に書いた話とは逆に、Nehalem -> Westmere ではそれほど劇的な変更があったわけでは
ありませんから、個別ベンチマークごとに劇的な性能差が出るとも思えません。
特殊なアクセラレータ命令を使用する場合は話が別ですが、それはまた別の話かと。
-------------------
IACAのDLLがNehalem用とWestmere用で全く同じサイズだった時点で素性は
わかったようなもの
------------------
「そんなもの」で頭から決め付けては面白くもなんとも無い訳で、L3の変更やらメモリバッファの増量等の影響がどのように現れるかを問題にしているという
ことになります。命令仕様の改善とマイクロアーキテクチャの改善は区別して考えるべきかと。
http://www.realworldtech.com/page.cfm?ArticleID=RWT031710140138
>>690
上に書いた話とは逆に、Nehalem -> Westmere ではそれほど劇的な変更があったわけでは
ありませんから、個別ベンチマークごとに劇的な性能差が出るとも思えません。
特殊なアクセラレータ命令を使用する場合は話が別ですが、それはまた別の話かと。
693 :,,・´∀`・,,)っ-○○○:2010/03/21(日) 12:25:23 ID:NRePceAu
だからレイテンシ・スループット一通りデータ取れてるだろ。
データを見る限りでは劇的に変わったものはない
Merom->Penrynでスループットが劇的に改善された命令はあるが
Westmereの特性はNehalemの単純なシュリンクそのものだ
AES/CLMULのために演算ユニットを拡張したと言う情報も特にないし、
むしろAES-NI/CLMULはNehalemに元々実装されていた(が無効にされていた)可能性すらある
> 「そんなもの」で頭から決め付けては面白くもなんとも無い訳で
へえ、Intelはおまいさんを面白がらせるために存在してるのか
見上げたもんだなあ
データを見る限りでは劇的に変わったものはない
Merom->Penrynでスループットが劇的に改善された命令はあるが
Westmereの特性はNehalemの単純なシュリンクそのものだ
AES/CLMULのために演算ユニットを拡張したと言う情報も特にないし、
むしろAES-NI/CLMULはNehalemに元々実装されていた(が無効にされていた)可能性すらある
> 「そんなもの」で頭から決め付けては面白くもなんとも無い訳で
へえ、Intelはおまいさんを面白がらせるために存在してるのか
見上げたもんだなあ
人間性が表れる2レスだなw
ああ、なんか落ち着く
>むしろAES-NI/CLMULはNehalemに元々実装されていた(が無効にされていた)可能性すらある
HTT隠してたオレゴンの事だから、これは可能性でかいよね
隠し玉と呼ぶにはインパクト弱いけど暗号関係のスピードアップは目を見張るものがある
HTT隠してたオレゴンの事だから、これは可能性でかいよね
隠し玉と呼ぶにはインパクト弱いけど暗号関係のスピードアップは目を見張るものがある
「鶏冠にきてけんか腰な物言いしてる方が負けだわ!」
ララァは賢いなぁw
ララァは賢いなぁw
698 :MACオタ>696 さん:2010/03/21(日) 16:57:45 ID:tQ2m2qMB
>>696
------------------
HTT隠してたオレゴンの事だから、これは可能性でかいよね
------------------
物事の前後関係を理解されていない様に思います。
WillametteでHTTが無効にされていた理由は、開発者当人が語っている通り(>>587-600参照)。一方団子さんが書いているように、AES-NI/CLMULに関してハードウェア的な強化は無さそうです。
推理小説じゃ無いんですから、『動機があるから怪しい』という論法は違うかと。
------------------
HTT隠してたオレゴンの事だから、これは可能性でかいよね
------------------
物事の前後関係を理解されていない様に思います。
WillametteでHTTが無効にされていた理由は、開発者当人が語っている通り(>>587-600参照)。一方団子さんが書いているように、AES-NI/CLMULに関してハードウェア的な強化は無さそうです。
推理小説じゃ無いんですから、『動機があるから怪しい』という論法は違うかと。
今回やってみた Westmere vs. Nehalem の比較に関する、個人的なまとめです。
1. Intelはマルチコア化でコア性能を犠牲にするつもりは無さそう。
AMD が Istanbul で 4 → 6 へのコア増強と引き換えにクロックを下げたのとは対照的です。
2. L3レイテンシの低下はL3容量その他の改善によりカバーされている。
3. 次世代以降の性能向上の鍵はダイスタッキング等によるメモリ帯域の改善になる可能性が大きい
今回の比較でもCINTに比べてCFPの改善が小さいという結果になりましたが、これはCFP2006が結果に対するメモリ帯域の依存性が大きいという特性によるものです。
マルチコア化に伴って『コア当たり』のメモリ帯域はますます逼迫する方向に向かうため、メモリ帯域の分野でのブレークスルーがますます重要になりそうです。
1. Intelはマルチコア化でコア性能を犠牲にするつもりは無さそう。
AMD が Istanbul で 4 → 6 へのコア増強と引き換えにクロックを下げたのとは対照的です。
2. L3レイテンシの低下はL3容量その他の改善によりカバーされている。
3. 次世代以降の性能向上の鍵はダイスタッキング等によるメモリ帯域の改善になる可能性が大きい
今回の比較でもCINTに比べてCFPの改善が小さいという結果になりましたが、これはCFP2006が結果に対するメモリ帯域の依存性が大きいという特性によるものです。
マルチコア化に伴って『コア当たり』のメモリ帯域はますます逼迫する方向に向かうため、メモリ帯域の分野でのブレークスルーがますます重要になりそうです。
CellGPUぜひ見たかったw
>>699
コンパイルオプションの違い(-m32と-m64など)がけっこう効いてそうな気がするなぁ
コンパイルオプションの違い(-m32と-m64など)がけっこう効いてそうな気がするなぁ
703 :MACオタ>702 さん:2010/03/21(日) 20:06:52 ID:hb18Li8q
よく読みなおして、>>703は間違っているかもしれませんね。
x86_64 Linux 上の ICC は、-m32 のオプションを明示的につけない限り 64-bit コードでコンパイルします。
W5590でのコンパイルオプションは、
--------------------
C benchmarks: icc
C++ benchmarks: icpc
--------------------
とあるので、64-bit と決め込んでいましたが、"Bortability Flags"の項目を見ると
--------------------
400.perlbench: -DSPEC_CPU_LINUX_IA32
462.libquantum: -DSPEC_CPU_LINUX
483.xalancbmk: -DSPEC_CPU_LINUX
--------------------
とあるので、32-bit 用の互換オプションがつけてあります。
つまり、64-bit Linuxでわざわざ 32-bit 版 ICC でコンパイルしたということですか…
x86_64 Linux 上の ICC は、-m32 のオプションを明示的につけない限り 64-bit コードでコンパイルします。
W5590でのコンパイルオプションは、
--------------------
C benchmarks: icc
C++ benchmarks: icpc
--------------------
とあるので、64-bit と決め込んでいましたが、"Bortability Flags"の項目を見ると
--------------------
400.perlbench: -DSPEC_CPU_LINUX_IA32
462.libquantum: -DSPEC_CPU_LINUX
483.xalancbmk: -DSPEC_CPU_LINUX
--------------------
とあるので、32-bit 用の互換オプションがつけてあります。
つまり、64-bit Linuxでわざわざ 32-bit 版 ICC でコンパイルしたということですか…
CINT2006_base での 32-bit コードと 64-bit コードを比較してみました。
>>680と比べることが可能なW5590のデータはありませんでしたが、X5570だといくつか比較が存在します。
・32-bit: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091209-09268.html
・64-bit: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100202-09553.html
■32-bit ICC on x86_64 Linux の Xeon X5570 CINT2006_base
(Modは462.libquantum を除いた幾何平均)
CINT_base CINT_base(Mod)
64-bit 34.5 27.3
32-bit 32.0 26.1
今回比較に用いたMod指数はちょうど64-bit版が1.5倍ほど有利になる 462.libquantum を除いているため、差が小さくなります。
例によって個別のベンチマークで 32-bit と 64-bit の得失を比較するすると、こうなります。
- 456.hmmer: 約2倍 64-bit 版有利
- 462.libquantum: 49% 64-bit 版有利
- 401.bzip2: 10% 64-bit 版有利
- 473.aster: 10% 64-bit 版有利
- 429.mcf: 16% 32-bit 版有利
- 403.gcc: 11% 32-bit 版有利
- 471.omnetpp: 8% 32-bit 版有利
- 464.h264ref: 7% 32-bit 版有利
32/64で差が大きい 456.hmmer も除外した新指数で幾何平均を求めると、上記の結果は次のようになります。
■32-bit ICC on x86_64 Linux の Xeon X5570 CINT2006_base
(Modは462.libquantum と 456.hmmer を除いた幾何平均)
CINT_base CINT_base(Mod)
64-bit 34.5 26.0
32-bit 32.0 26.4
>>680と比べることが可能なW5590のデータはありませんでしたが、X5570だといくつか比較が存在します。
・32-bit: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20091209-09268.html
・64-bit: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100202-09553.html
■32-bit ICC on x86_64 Linux の Xeon X5570 CINT2006_base
(Modは462.libquantum を除いた幾何平均)
CINT_base CINT_base(Mod)
64-bit 34.5 27.3
32-bit 32.0 26.1
今回比較に用いたMod指数はちょうど64-bit版が1.5倍ほど有利になる 462.libquantum を除いているため、差が小さくなります。
例によって個別のベンチマークで 32-bit と 64-bit の得失を比較するすると、こうなります。
- 456.hmmer: 約2倍 64-bit 版有利
- 462.libquantum: 49% 64-bit 版有利
- 401.bzip2: 10% 64-bit 版有利
- 473.aster: 10% 64-bit 版有利
- 429.mcf: 16% 32-bit 版有利
- 403.gcc: 11% 32-bit 版有利
- 471.omnetpp: 8% 32-bit 版有利
- 464.h264ref: 7% 32-bit 版有利
32/64で差が大きい 456.hmmer も除外した新指数で幾何平均を求めると、上記の結果は次のようになります。
■32-bit ICC on x86_64 Linux の Xeon X5570 CINT2006_base
(Modは462.libquantum と 456.hmmer を除いた幾何平均)
CINT_base CINT_base(Mod)
64-bit 34.5 26.0
32-bit 32.0 26.4
>>705で述べた、462.libquantum と 456.hmmer を除いた改変版 CINT2006_base を用いて Westmere と Nehalem を比較してみましょう。
■ Xeon X5680 vs Xeon W5590 on 64-bit Linux
(Modは462.libquantum と 456.hmmer を除いた幾何平均)
CINT_base CINT_base(Mod)
X5680/3.33GHz 39.0 28.7
W5590/3.33GHz 34.2 28.2
それでも約2%の性能向上ということになります。
コア性能は犠牲にしていないという結論は変わらないと思いますがいかがでしょうか?
■ Xeon X5680 vs Xeon W5590 on 64-bit Linux
(Modは462.libquantum と 456.hmmer を除いた幾何平均)
CINT_base CINT_base(Mod)
X5680/3.33GHz 39.0 28.7
W5590/3.33GHz 34.2 28.2
それでも約2%の性能向上ということになります。
コア性能は犠牲にしていないという結論は変わらないと思いますがいかがでしょうか?
707 :,,・´∀`・,,)っ-○○○:2010/03/22(月) 04:25:28 ID:oQigsKs+
そもそもキャッシュの容量(エントリ数)増やせば必然的にヒットレイテンシは増大するもんなんだが
低下ってなんだ低下って
そのL3自体1コアあたり2MBだし実際のワークロード考えればスレッド当たりのL3容量は決して増えてないしな
ヒットレイテンシの特性見ても8MBが12MBに増えたところで大きくは変わらんでしょう
シュリンクによる消費電力低下とTurbo Boostで説明できてしまうな
低下ってなんだ低下って
そのL3自体1コアあたり2MBだし実際のワークロード考えればスレッド当たりのL3容量は決して増えてないしな
ヒットレイテンシの特性見ても8MBが12MBに増えたところで大きくは変わらんでしょう
シュリンクによる消費電力低下とTurbo Boostで説明できてしまうな
柄の悪い方が出て来た
709 :Socket774:2010/03/22(月) 11:18:14 ID:J9zaGnO2
Cellの基礎技術開発は着々と進んでいるね。
PS3では爆熱をいとわない開発陣と組んだから、高性能だが爆熱の熱処理のため
に高価になって出足くじいたが、PS4では200Wからスタートせずに済みそうだ。
Cellへの東芝の貢献は非常に大きいね。
低電圧LSIを実現するSRAM回路技術の開発
32nmで試作、0.7V動作の不良率1/10000
http://www.semicon.toshiba.co.jp/shared/eye/201002.pdf
PS3では爆熱をいとわない開発陣と組んだから、高性能だが爆熱の熱処理のため
に高価になって出足くじいたが、PS4では200Wからスタートせずに済みそうだ。
Cellへの東芝の貢献は非常に大きいね。
低電圧LSIを実現するSRAM回路技術の開発
32nmで試作、0.7V動作の不良率1/10000
http://www.semicon.toshiba.co.jp/shared/eye/201002.pdf
アーキテクチャにはもう飽きてくちゃった
712 :,,・´∀`・,,)っ-○○○:2010/03/22(月) 12:52:45 ID:oQigsKs+
スカラロード・ストア命令さえあれば多少使い勝手はマシになる
713 :Socket774:2010/03/23(火) 15:05:11 ID:lIIkywfm
>>713
わかったからお前が手本見せろ
わかったからお前が手本見せろ
715 :,,・´∀`・,,)っ-○○○:2010/03/24(水) 00:45:21 ID:CSoVWjfI
SIMD厨の俺ですらあれはかったるい
それは1クロックに命をかけた男達の物語である…
もう伸びしろのないCPUなんか語ったって仕方ないだろ
GPUについて語れ!にスレタイ変更すれば?
GPUについて語れ!にスレタイ変更すれば?
だってGPUの完成形はlarrabeeだもの
TheRegisterのMorgan記者がIBM純正のCELL Blade QSシリーズについて書いてます。
http://www.theregister.co.uk/2010/03/23/ibm_kills_qs21_blade/
QS21は今年の6/25で受注終了、次世代機QS2Zは昨年報じられたように開発中止という話なのですが、最後をこのようにまとめています。
---------------------
The reason why the QS22's days are numbered is simple. IBM, say sources
familiar with the company's plans, is to add specialty processing capabilities
like those embodied in the SPEs in the Cell chip to the future Power chips
beyond the current Power7 generation. Perhaps starting with Power7+ and
definitely in full bloom with the Power8 generation.
---------------------
CELL/B.E.としての開発を止めた理由は、SPEがPOWER8のアーキテクチャに取り込まれるから…という話。
もっとも、IBMはPOWER5の頃から『アクセラレータを搭載する』と言い続けていますが、実際に登場した実装は Altivec, DFP, VSX のように、単なる演算ユニットが増えていくだけでした。
今回も今までと同様に、宣伝文句のみで終わるのか?本当に CELL/B.E .の様ななヘテロコアを投入するのかは注目かもしれません。
VSXが既にSPU ISAの改良版としての要素を取り込んでいますし、今更、Sonyや東芝も権利を持つSPEを使ってまでヘテロコアやコプロ的なアクセラレータに手を出すというのは眉唾なのですが…
http://www.theregister.co.uk/2010/03/23/ibm_kills_qs21_blade/
QS21は今年の6/25で受注終了、次世代機QS2Zは昨年報じられたように開発中止という話なのですが、最後をこのようにまとめています。
---------------------
The reason why the QS22's days are numbered is simple. IBM, say sources
familiar with the company's plans, is to add specialty processing capabilities
like those embodied in the SPEs in the Cell chip to the future Power chips
beyond the current Power7 generation. Perhaps starting with Power7+ and
definitely in full bloom with the Power8 generation.
---------------------
CELL/B.E.としての開発を止めた理由は、SPEがPOWER8のアーキテクチャに取り込まれるから…という話。
もっとも、IBMはPOWER5の頃から『アクセラレータを搭載する』と言い続けていますが、実際に登場した実装は Altivec, DFP, VSX のように、単なる演算ユニットが増えていくだけでした。
今回も今までと同様に、宣伝文句のみで終わるのか?本当に CELL/B.E .の様ななヘテロコアを投入するのかは注目かもしれません。
VSXが既にSPU ISAの改良版としての要素を取り込んでいますし、今更、Sonyや東芝も権利を持つSPEを使ってまでヘテロコアやコプロ的なアクセラレータに手を出すというのは眉唾なのですが…
命令を取り込むだけでしょ?
まさかローカルストアを持つコプロを取り込んだりはしないだろうし。
まさかローカルストアを持つコプロを取り込んだりはしないだろうし。
ローカルストアが最大の肝なのに
32nm版のCellもないのかな?
それとこれとは別
つかPOWERにSPEが付いたらそれCellやん
完全体の?
Cellみたいな共同開発って権利関係はどうなってんの?
>>724
たしかに
たしかに
共同開発元のライバルの案件すらPPE流用しちゃう権利ゴロのIBMさんだから
自社案件にSPE流用することなんて問題にならんだろう
自社案件にSPE流用することなんて問題にならんだろう
なんかデジャブかと思ったらアナハイムだった。
SCEや東芝の権利が入っていようが、POWERに採用したら
金払わないといけないとかそういうのはないから、
大した問題にはならないだろうな。
金払わないといけないとかそういうのはないから、
大した問題にはならないだろうな。
安藤氏の今日の更新は色々と突っ込みどころが多いですね。
http://www.geocities.jp/andosprocinfo/wadai10/20100327.htm
--------------------
1.NVIDIAがFermiベースのGTX480,470を発表
--------------------
流石に真っ当な仕事をしているヒトがネットばかり見ているという訳でも無いでしょうから『情弱』呼ばわりするつもりもありませんが、ルーマーサイトに属する Semiaccurate よりは Anandtech のレビュー位は読んで欲しいような気もします。
GPGPU性能も扱っているという点では、御本人の専門分野にも重なるかと思うのですけれど…
http://www.anandtech.com/video/showdoc.aspx?i=3783&p=6
---------------------
このQS21はTop500 2位のRoadrunnerに使用されているもので,まだ,3年やそこらは
使うでしょうから,その間に必要となる保守部品はストックしておくのでしょうね。
---------------------
PowerXCell 8iを使ったCELL BladeはBladeCenter QS22の方だったりします。
http://www.top500.org/system/9485
http://www.geocities.jp/andosprocinfo/wadai10/20100327.htm
--------------------
1.NVIDIAがFermiベースのGTX480,470を発表
--------------------
流石に真っ当な仕事をしているヒトがネットばかり見ているという訳でも無いでしょうから『情弱』呼ばわりするつもりもありませんが、ルーマーサイトに属する Semiaccurate よりは Anandtech のレビュー位は読んで欲しいような気もします。
GPGPU性能も扱っているという点では、御本人の専門分野にも重なるかと思うのですけれど…
http://www.anandtech.com/video/showdoc.aspx?i=3783&p=6
---------------------
このQS21はTop500 2位のRoadrunnerに使用されているもので,まだ,3年やそこらは
使うでしょうから,その間に必要となる保守部品はストックしておくのでしょうね。
---------------------
PowerXCell 8iを使ったCELL BladeはBladeCenter QS22の方だったりします。
http://www.top500.org/system/9485
なんだ結局Cellは止めちゃうのか
> 安藤氏の今日の更新は色々と突っ込みどころが多いですね。
そう思うなら本人にメールしてあげなよ
きっと喜ぶと思うよ
退職して暇してるかもしれないし
そう思うなら本人にメールしてあげなよ
きっと喜ぶと思うよ
退職して暇してるかもしれないし
>>732
まあ、クターがいなくなっちゃったしね
まあ、クターがいなくなっちゃったしね
QS21に使われているCellって90nm版だけ?
>GPGPU性能も扱っているという点では、御本人の専門分野にも重なるかと思うのですけれど…
退職して唯のライターになったからかんけーないとか
退職して唯のライターになったからかんけーないとか
ttp://images.anandtech.com/graphs/nvidiageforcegtx480launch_032610115215/22215.png
ttp://images.anandtech.com/graphs/nvidiageforcegtx480launch_032610115215/22216.png
というかこの辺はアーキテクチャどうこうよりも
比較対象が遅すぎるだけジャン
285比じゃ物量並では?
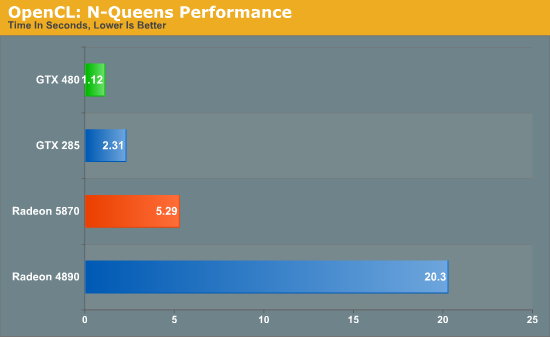{kind=link}
ttp://images.anandtech.com/graphs/nvidiageforcegtx480launch_032610115215/22216.png
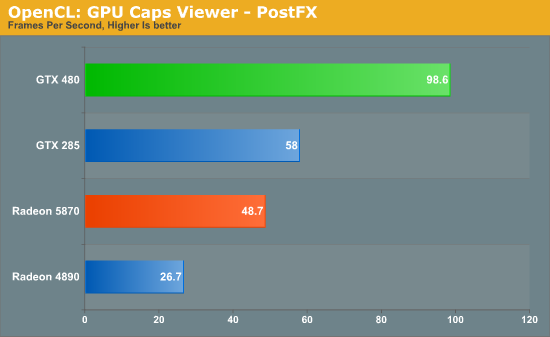{kind=link}
というかこの辺はアーキテクチャどうこうよりも
比較対象が遅すぎるだけジャン
285比じゃ物量並では?
しかしPower8がSPEとのヘテロコアとか面白いな
740 :,,・´∀`・,,)っ-○○○:2010/03/27(土) 23:28:52 ID:pJg4SW1L
SONYが家電のIntelになるとか息巻いてた頃の話だからな
741 :MACオタ>団子 さん:2010/03/28(日) 10:22:38 ID:Xy1m3rTn
>>740
団子さんの方は Anand の GPGPU の結果を見て、ちっとはやる気はでましたか?
http://www.anandtech.com/video/showdoc.aspx?i=3783&p=6
団子さんの方は Anand の GPGPU の結果を見て、ちっとはやる気はでましたか?
http://www.anandtech.com/video/showdoc.aspx?i=3783&p=6
742 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 11:11:23 ID:nvnx7jQ0
得意なのだけ引っ張ってきた感が否めないがそれ以上に前世代が酷すぎた
比較対象の他社もね
744 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 11:13:49 ID:nvnx7jQ0
CPUとの比較がない時点で×だな
ちなみにN-QueenはCell SPEより半速のAtomの方が速かった
ちなみにN-QueenはCell SPEより半速のAtomの方が速かった
745 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 11:14:56 ID:nvnx7jQ0
746 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 11:32:41 ID:nvnx7jQ0
N-Queenは分岐粒度が問われるのでSIMDの並列度が高いのよりも
独立動作するスカラプロセッサ大量のほうが速いよ。
実際問題FermiはGT200に引き続きSIMDをラップしただけのエセスカラからは脱却してないようだから
単純に命令フロントエンドの増分しか性能上がっていない。
予想だと
SCC>>Larrabee>>Fermi
独立動作するスカラプロセッサ大量のほうが速いよ。
実際問題FermiはGT200に引き続きSIMDをラップしただけのエセスカラからは脱却してないようだから
単純に命令フロントエンドの増分しか性能上がっていない。
予想だと
SCC>>Larrabee>>Fermi
だらだらつまんねえレスしてないで、string libraryでも書きなおしたらどうだ?
748 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 11:42:40 ID:nvnx7jQ0
無駄w
>>745
なんかルパンが出てくるんだが
なんかルパンが出てくるんだが
750 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 12:19:30 ID:nvnx7jQ0
イベント終了っぽいから消しといた
ちゃんとベクトル化したか?
探索問題のベクトル化については昔から研究があるぞ
探索問題のベクトル化については昔から研究があるぞ
京大津田研あたりが日本では有名
753 :,,・´∀`・,,)っ-○○○:2010/03/28(日) 19:44:49 ID:nvnx7jQ0
どのみちビットボード使うのが速い
海外BBSでもPower8がSPEとのヘテロみたいに書かれてるけど本当にそうなん?
単にSSEみたいに各コアに簡略化されて搭載されるんじゃないの?
単にSSEみたいに各コアに簡略化されて搭載されるんじゃないの?
オタさんも書いてるけど、VSXが拡張されるだけだと思う
まあ、出て見ないとわからないな
VSXが拡張されてるだけなら現状でもそうなってるわけだし意味わからなくなるw
VSXが拡張されてるだけなら現状でもそうなってるわけだし意味わからなくなるw
Magny-Cours, Nehalem-EX と新製品の発表でSPEC2006の登録も面白いことになっていますが、今回は>>678-681と>>704-706に続いて Westmere vs. Nehalem の比較です。
あれから、同じ4-coreでの Westmere と Nehalem の結果も登録されました。前回の考察がどの程度正しかったのでしょうか。
比較対象は次の二つです。
・Westmere Xeon E5630/2.53GHz
CINT: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09943.html
CFP: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09934.html
・Nehalem Xeon E5540/2.53GHz
CINT: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10044.html
CFP: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10042.html
OSおよびコンパイラは同じ条件で64-bit環境になります。
OS: SuSE Linux Enterprise Server 11 (x86_64), Kernel 2.6.27.19-5-default
Compiler: icc/ifort Version 11.1 Build 20091130
Base Pointe: 64-bit
では結果を見てみましょう。Mod版は>>679の基準で、次の基準で計算しています。
CINTは 462 を除く。
CFPは 410, 434, 436, 459, 481, 482 を除く。
■ Westmere vs. Nehalem (4-core, Linux, 64-bit)
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
E5630/2.53GHz 30.7 24.0 35.6 34.0
E5540/2.53GHz 29.8 23.5 26.6 25.3
+3.2% +1.9% +4.6% +2.7%
コア増加分を抜きにしても2-5%程度の性能向上を果たしています。注目は、シングルスレッド性能のみを評価したMod版での比較より並列化の効果が加味されている公式版の指数の方が差が大きくなっていることで、WestmereとIntelの
最新コンパイラは並列コードへのチューニングが進んでいることが示されているのでしょう。
あれから、同じ4-coreでの Westmere と Nehalem の結果も登録されました。前回の考察がどの程度正しかったのでしょうか。
比較対象は次の二つです。
・Westmere Xeon E5630/2.53GHz
CINT: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09943.html
CFP: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09934.html
・Nehalem Xeon E5540/2.53GHz
CINT: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10044.html
CFP: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10042.html
OSおよびコンパイラは同じ条件で64-bit環境になります。
OS: SuSE Linux Enterprise Server 11 (x86_64), Kernel 2.6.27.19-5-default
Compiler: icc/ifort Version 11.1 Build 20091130
Base Pointe: 64-bit
では結果を見てみましょう。Mod版は>>679の基準で、次の基準で計算しています。
CINTは 462 を除く。
CFPは 410, 434, 436, 459, 481, 482 を除く。
■ Westmere vs. Nehalem (4-core, Linux, 64-bit)
CINT_base CINT_base(Mod) CFP_base CFP_base(Mod)
E5630/2.53GHz 30.7 24.0 35.6 34.0
E5540/2.53GHz 29.8 23.5 26.6 25.3
+3.2% +1.9% +4.6% +2.7%
コア増加分を抜きにしても2-5%程度の性能向上を果たしています。注目は、シングルスレッド性能のみを評価したMod版での比較より並列化の効果が加味されている公式版の指数の方が差が大きくなっていることで、WestmereとIntelの
最新コンパイラは並列コードへのチューニングが進んでいることが示されているのでしょう。
Magny-Cours と Nehalem-EX の方ですが、HP (Magny-Cours), Bull SA, Dell (Nehalem-EX) が rate の結果を登録しています。
Magny-Cours の登録全て2-socket/24-core, Nehalem-EX の方は全て4-socket 構成ということで直接の比較は難しいのですが、同クラスの構成と比較してみた結果を示します。
■各種マルチコア・サーバープロセッサの CINT2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 586 652
Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 466 502
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 355 378
Shanghai/2.6GHz/4-socket/24-core/noSMT 313 400
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 309 398
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 286 302
■各種マルチコア・サーバープロセッサの CFP2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 531 586
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 290 318
Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 272 280
Shanghai/2.6GHz/4-socket/24-core/noSMT 251 276
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 248 257
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 214 222
出揃ってみると、圧勝ですね。POWER7
物量主義だけでなんとかなるのは、CFP2006_rate だけというのも良く判ります。
Magny-Cours の登録全て2-socket/24-core, Nehalem-EX の方は全て4-socket 構成ということで直接の比較は難しいのですが、同クラスの構成と比較してみた結果を示します。
■各種マルチコア・サーバープロセッサの CINT2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 586 652
Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 466 502
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 355 378
Shanghai/2.6GHz/4-socket/24-core/noSMT 313 400
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 309 398
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 286 302
■各種マルチコア・サーバープロセッサの CFP2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 531 586
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 290 318
Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 272 280
Shanghai/2.6GHz/4-socket/24-core/noSMT 251 276
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 248 257
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 214 222
出揃ってみると、圧勝ですね。POWER7
物量主義だけでなんとかなるのは、CFP2006_rate だけというのも良く判ります。
登録データのリンクです。
- POWER7/3.86GHz/2-socket/16-core/4-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
- Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09875.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09878.html
- Magny-Cours/2.3GHz/2-socket/24-core/noSMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10002.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10006.html
- Westmere-EP/3.33GHz/2-socket/12-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09738.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09733.html
- Westmere-EP/3.47GHz/2-socket/8-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09888.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09889.html
- Shanghai/2.6GHz/4-socket/24-core/noSMT
CINT_rate: http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091124-09063.html
CFP_rate: http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091124-09064.html
- POWER7/3.86GHz/2-socket/16-core/4-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100208-09586.html
- Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09875.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09878.html
- Magny-Cours/2.3GHz/2-socket/24-core/noSMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10002.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-10006.html
- Westmere-EP/3.33GHz/2-socket/12-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09738.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100301-09733.html
- Westmere-EP/3.47GHz/2-socket/8-core/2-SMT
CINT_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09888.html
CFP_rate: http://www.spec.org/cpu2006/results/res2010q1/cpu2006-20100315-09889.html
- Shanghai/2.6GHz/4-socket/24-core/noSMT
CINT_rate: http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091124-09063.html
CFP_rate: http://www.spec.org/cpu2006/results/res2009q4/cpu2006-20091124-09064.html
>>758はCFP2006_rateの方に間違いがありました。
誤) Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 272 280
正) Nehalem-EX/1.87GHz/4-socket/16-core/2-SMT 272 280
要するに4-core の E7520 のデータということです。
>>758-759の Nehalem-EX は 1.83GHzのモデルで揃えたつもりでしたが、CINTは6-coreで2.53GHzまでブーストがかかるL7545の結果。CFPは4-coreでターボブースト無しのE7530の結果ということで混じってます。
誤) Nehalem-EX/1.87GHz/4-socket/24-core/2-SMT 272 280
正) Nehalem-EX/1.87GHz/4-socket/16-core/2-SMT 272 280
要するに4-core の E7520 のデータということです。
>>758-759の Nehalem-EX は 1.83GHzのモデルで揃えたつもりでしたが、CINTは6-coreで2.53GHzまでブーストがかかるL7545の結果。CFPは4-coreでターボブースト無しのE7530の結果ということで混じってます。
POWER7の爆熱振りを見ると,どうしてもあれがARMと張り合うような組み込み向けプロセサには見えない。
マイクロソフト、次期Windows ServerではItaniumをサポートせず
http://www.computerworld.jp/topics/mws/178429.html
Itaniumはゆっくり死亡していきそう?
富士通もItaniumサーバ出さないみたいだしね
http://www.computerworld.jp/topics/mws/178429.html
Itaniumはゆっくり死亡していきそう?
富士通もItaniumサーバ出さないみたいだしね
HPどうすんの…
alpha復帰
PA-RISC…
ロシアのiXBTなどで既に言及されていた話ですが、GPU版のGF100は倍精度浮動小数点演算が単精度の1/8に制限されているんだとか…
もう少し判りやすい記事を待っていたのですが、Hexusのレビューを見ると間違い無さそうです。
http://www.hexus.net/content/item.php?item=24000&page=3
-----------------------
Delve a little deeper, handily not mentioned in any briefing, and NVIDIA
is limiting the double-precision speed of the desktop GF100 part to one-
eighth of single-precision throughput, rather than the one-fifth speed of
the Radeon HD 5000-series. We'll have to wait for the Tesla parts before
that's restored to the one-half speed the GF100 is capable of.
-----------------------
安いGPUを買って、文字通りのGPGPUを企んでいた皆さんは残念でした。
PS3のLinuxサポート廃止と言い、貧乏HPCにはイヤな時代になってきました。背景としてはさほど大きいものとは言えないHPCが不況の中で市場として認められきたという事実があるようです。
http://www.theregister.co.uk/2010/03/25/idc_hpc_servers_2009/
=======================
The non-HPC portion of the server market was actually down 20.5 per
cent, to $34.6bn - a decline that was nearly twice as steep as that in
the HPC space.
=======================
唯一の希望は Magny-Cours の投入で自爆的なディスカウントによるサーバー市場での逆襲を狙うAMDプラットフォームくらいでしょうか…
もう少し判りやすい記事を待っていたのですが、Hexusのレビューを見ると間違い無さそうです。
http://www.hexus.net/content/item.php?item=24000&page=3
-----------------------
Delve a little deeper, handily not mentioned in any briefing, and NVIDIA
is limiting the double-precision speed of the desktop GF100 part to one-
eighth of single-precision throughput, rather than the one-fifth speed of
the Radeon HD 5000-series. We'll have to wait for the Tesla parts before
that's restored to the one-half speed the GF100 is capable of.
-----------------------
安いGPUを買って、文字通りのGPGPUを企んでいた皆さんは残念でした。
PS3のLinuxサポート廃止と言い、貧乏HPCにはイヤな時代になってきました。背景としてはさほど大きいものとは言えないHPCが不況の中で市場として認められきたという事実があるようです。
http://www.theregister.co.uk/2010/03/25/idc_hpc_servers_2009/
=======================
The non-HPC portion of the server market was actually down 20.5 per
cent, to $34.6bn - a decline that was nearly twice as steep as that in
the HPC space.
=======================
唯一の希望は Magny-Cours の投入で自爆的なディスカウントによるサーバー市場での逆襲を狙うAMDプラットフォームくらいでしょうか…
AnandTechによると、iPad に搭載された Apple A4 の性能は Nexus One の Snapdragon/1GHz より随分性能が良さそうなんだとか。
http://www.anandtech.com/show/3633/apples-a4-soc-faster-than-snapdragon
いくつか有名どころのサイトの表示時間を比較していますが、m.cnn.com を除いて9-60%高速だとのこと。
SunSpider Javascript Bench の結果も、次の通り。
- iPad (Apple A4): 10475 [ms]
- Nexus One (Snapdragon QSD8250): 14409 [ms]
- iPhone 3GS (Cortex A8): 17360 [ms]
もっともこの結果に関しては、モノが携帯デバイスだけに省電力設定の違いに起因する可能性も大きいと考察しているようです。
http://www.anandtech.com/show/3633/apples-a4-soc-faster-than-snapdragon
いくつか有名どころのサイトの表示時間を比較していますが、m.cnn.com を除いて9-60%高速だとのこと。
SunSpider Javascript Bench の結果も、次の通り。
- iPad (Apple A4): 10475 [ms]
- Nexus One (Snapdragon QSD8250): 14409 [ms]
- iPhone 3GS (Cortex A8): 17360 [ms]
もっともこの結果に関しては、モノが携帯デバイスだけに省電力設定の違いに起因する可能性も大きいと考察しているようです。
RADEONの倍精度解禁によってRADEONに手を出す人も増えるかも
解禁つってもHD4800から倍精度使えてたし中華GPGPUスパコンもそれで組んであるしいまさらだなぁ
どうせならHD5800だけでなく下位モデルでも解禁してくれりゃいいのに
どうせならHD5800だけでなく下位モデルでも解禁してくれりゃいいのに
SunSpiderベンチ Core i5 660&safariでやったら685.4msだった。
速すぎわろた。まあ比べる方が間違いなんだけど・・・
Atomだとどれくらいなのかな?
速すぎわろた。まあ比べる方が間違いなんだけど・・・
Atomだとどれくらいなのかな?
PA-RISCバイナリ互換性を持ったItanumuエミュレーターをamd64版HP-UXで実装予定です
そこで颯爽とPOWER7Macの登場だろ
779 :,,・´∀`・,,)っ-○○○:2010/04/07(水) 20:11:25 ID:4uyD1/UY
債務超過状態で辛うじて儲かるネットワーク部門(PSN)をソニー本体が吸収
有能な社員は辞めていく倒産秒読み状態に入ったそんなSCEにまともなサービスを期待する方が無駄。
有能な社員は辞めていく倒産秒読み状態に入ったそんなSCEにまともなサービスを期待する方が無駄。
うわープログラム齧ってるくせに数字も読めないんだ?
ソニーに承継されるネットワーク事業は2009年3月期売上高15億円、
旧SCEは2009年3月期売上高9851億円、営業利益375億円、債務超過額105億円。
ネットワーク事業以外は新しいSCEに継承。
ソニーに承継されるネットワーク事業は2009年3月期売上高15億円、
旧SCEは2009年3月期売上高9851億円、営業利益375億円、債務超過額105億円。
ネットワーク事業以外は新しいSCEに継承。
サムスン電子の第1四半期業績見通し、連結営業利益は過去最高に
http://jp.reuters.com/article/technologyNews/idJPJAPAN-14679420100406
http://jp.reuters.com/article/technologyNews/idJPJAPAN-14679420100406
Apple製品の分解・修理法を公開しているサイトとして有名な iFixIt が、半導体調査会社の ChipWorks と組んで Apple A4 の断面写真やらダイのX線写真やらを公開しています。
http://www.ifixit.com/Teardown/Apple-A4-Teardown/2204/1
せいぜいインタビューくらいしか一次ソースを持たない日本のメディアと比較して絶望してみてはいかがでしょうか?
http://www.ifixit.com/Teardown/Apple-A4-Teardown/2204/1
せいぜいインタビューくらいしか一次ソースを持たない日本のメディアと比較して絶望してみてはいかがでしょうか?
設計はAppleが握ったけどチップの製造はやっぱりSamsung?
784 :MACオタ>785 さん:2010/04/08(木) 00:10:35 ID:e+L2hcR4
>>783
上の記事ですが、色々面白いことが書いてあります。
A4はTSVでは無いとは言え、プロセッサダイにDRAMダイ2枚を重ねた3層-3Dダイスタッキング構造なのですが、
- DRAMダイは Samsung 製 K4X1G323PE
- プロセッサダイには、従来の iPhoneプロセッサには必ず記されていた Samsung の型番が無い
上の記事ですが、色々面白いことが書いてあります。
A4はTSVでは無いとは言え、プロセッサダイにDRAMダイ2枚を重ねた3層-3Dダイスタッキング構造なのですが、
- DRAMダイは Samsung 製 K4X1G323PE
- プロセッサダイには、従来の iPhoneプロセッサには必ず記されていた Samsung の型番が無い
なんだワイヤボンディングか
そらそうよね
そらそうよね
この手だと、内蔵のグラフィックス・コアが貧弱だったり
有って無きが如しが多いというか…
Imageon積んでたアレとか何故かアクセラレータ無しの
WM標準ドライバで動いてたり、なんて事が珍しく無いけど…
A4はどうなんだろうねぇ…
有って無きが如しが多いというか…
Imageon積んでたアレとか何故かアクセラレータ無しの
WM標準ドライバで動いてたり、なんて事が珍しく無いけど…
A4はどうなんだろうねぇ…
787 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 11:01:02 ID:urB6a2Po
>>780
ああ読む気にもならないね。粉飾まがいなんていくらでも操作しようがある。
そもそも、その「2009年3月期」の営業利益は年じゃなくて四半期単位の数字ってオチだろ。
第2〜第3四半期に莫大な赤字を計上しておいて第4四半期のみ数字をよくするいつもの手だよ。
通年ではどんどん赤字が膨らんでいく。
PSNはゲームのみに収まってるからその程度だがあらゆる家電向けの配信インフラとして拡大した場合の
収益の可能性を考えると、多少見込みあるんじゃね。
あくまで少なくともCell家電だとかPS3搭載家電だとか作るよりは見込みがあるって話であって
俺の感想としてはうまくいきそうにないけどね。
もちろんバージョンアップで元々あった機能を強制的に使えなくするような製品なんて
他のメーカーは見習っちゃいけないしね
ああ読む気にもならないね。粉飾まがいなんていくらでも操作しようがある。
そもそも、その「2009年3月期」の営業利益は年じゃなくて四半期単位の数字ってオチだろ。
第2〜第3四半期に莫大な赤字を計上しておいて第4四半期のみ数字をよくするいつもの手だよ。
通年ではどんどん赤字が膨らんでいく。
PSNはゲームのみに収まってるからその程度だがあらゆる家電向けの配信インフラとして拡大した場合の
収益の可能性を考えると、多少見込みあるんじゃね。
あくまで少なくともCell家電だとかPS3搭載家電だとか作るよりは見込みがあるって話であって
俺の感想としてはうまくいきそうにないけどね。
もちろんバージョンアップで元々あった機能を強制的に使えなくするような製品なんて
他のメーカーは見習っちゃいけないしね
おまえさん住友銀出身の奴かい?
おまいら、テラスケールリサーチ謹製SCC48コアがQ2に出るってのに何やってんの…
>>787
読む気にもならないとか言いつつ粉飾まがいとか恐ろしいこと口走るなよ
つーかパッと見りゃ売上1兆が四半期だとゲーム事業どんだけって話じゃん
ついでに2010年3月期も黒字見込みなんだとよ
で、売上15億のネットワーク部門って読めばこれはインフラベースの事業で
収益ってのは上層のコンテンツプロバイダに乗せるモデルになってんだな、と思うだろうに
事業の再編成は収益ベースでどーのこーのって着眼がそもそもオカシイって言ってんだよ
数字読めないつーかスタンスで頭ん中が固まっちまうのはアホだね
読む気にもならないとか言いつつ粉飾まがいとか恐ろしいこと口走るなよ
つーかパッと見りゃ売上1兆が四半期だとゲーム事業どんだけって話じゃん
ついでに2010年3月期も黒字見込みなんだとよ
で、売上15億のネットワーク部門って読めばこれはインフラベースの事業で
収益ってのは上層のコンテンツプロバイダに乗せるモデルになってんだな、と思うだろうに
事業の再編成は収益ベースでどーのこーのって着眼がそもそもオカシイって言ってんだよ
数字読めないつーかスタンスで頭ん中が固まっちまうのはアホだね
>>786
iPadはサクサク動作
http://d.hatena.ne.jp/silvervine/20100201/1264994671
http://www.nikkei.com/tech/personal/page/p=9694E3EAE3E0E0E2E2EBE0E4E2E6
iPadはサクサク動作
http://d.hatena.ne.jp/silvervine/20100201/1264994671
http://www.nikkei.com/tech/personal/page/p=9694E3EAE3E0E0E2E2EBE0E4E2E6
792 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 21:30:10 ID:urB6a2Po
だからお前の脳内資料はいいから正確なのソース付きで提示してみ。
2008年4月から2009年3月までのQ1からQ4の営業利益全部並べてみ?
Q2で在庫の値下げ分含めて超絶赤字計上してるのにどこでどうやって返してるんですか。
2008年4月から2009年3月までのQ1からQ4の営業利益全部並べてみ?
Q2で在庫の値下げ分含めて超絶赤字計上してるのにどこでどうやって返してるんですか。
793 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 21:38:34 ID:urB6a2Po
そもそもゲーム事業、PS3出して以来通年で黒字出した年一度もないですよ。
http://jp.reuters.com/article/topNews/idJPJAPAN-11635820090924
> 今期のゲーム事業は4年連続の営業赤字になる見込みだが、
> 「黒字化は私の使命」と述べ、積極的なコスト削減や売り上げ増加を狙っ
> て早期の実現を図る考えを示した。
しかも今年度は売上げ台数下方修正してるしね。
それとも逆鞘だから売れないほうが利益になるのか?
http://jp.reuters.com/article/topNews/idJPJAPAN-11635820090924
> 今期のゲーム事業は4年連続の営業赤字になる見込みだが、
> 「黒字化は私の使命」と述べ、積極的なコスト削減や売り上げ増加を狙っ
> て早期の実現を図る考えを示した。
しかも今年度は売上げ台数下方修正してるしね。
それとも逆鞘だから売れないほうが利益になるのか?
AMDが業務用GPUの新型 FirePro V8800 を発表しました。
http://www.amd.com/us/products/workstation/graphics/ati-firepro-3d/v8800/Pages/v8800-specifications.aspx
GPGPU的に見ると、VRAM 2GB, ECC 無しということで新味は無いようです。
現世代ではチップの仕様として、ゲーム向けと大きく差別化することが出来ない様で…
http://www.amd.com/us/products/workstation/graphics/ati-firepro-3d/v8800/Pages/v8800-specifications.aspx
GPGPU的に見ると、VRAM 2GB, ECC 無しということで新味は無いようです。
現世代ではチップの仕様として、ゲーム向けと大きく差別化することが出来ない様で…
>>792
決算の数字は再編のプレスリリースからだよ。
http://ke.kabupro.jp/tsp/20100224/140120100224029598.pdf
最近SCE単独としての子細な決算の数字は本体側に編入されていて出されていなかった。
今回そういう数字を表に出せた事はむしろ経営の健全化に向けた目途が立ったようなもんだろ。
決算の数字は再編のプレスリリースからだよ。
http://ke.kabupro.jp/tsp/20100224/140120100224029598.pdf
最近SCE単独としての子細な決算の数字は本体側に編入されていて出されていなかった。
今回そういう数字を表に出せた事はむしろ経営の健全化に向けた目途が立ったようなもんだろ。
797 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 22:13:23 ID:urB6a2Po
株主向け情報にゲーム事業(≒連結子会社でもあるSCE)の営業利益含めて載ってるから
読んでみたらいいよ。
会計学以前に算数の問題だ
読んでみたらいいよ。
会計学以前に算数の問題だ
798 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 22:18:35 ID:urB6a2Po
> 今回そういう数字を表に出せた事はむしろ経営の健全化に向けた目途が立ったようなもんだろ。
違うな。
在庫を抱えるのはソニー本体(=値下げ時には棚卸資産の評価損で赤字計上)だから
連結での「ゲーム事業」分野でみた方が実情をよく表している。
要するに重要なことからは常に逃げている
違うな。
在庫を抱えるのはソニー本体(=値下げ時には棚卸資産の評価損で赤字計上)だから
連結での「ゲーム事業」分野でみた方が実情をよく表している。
要するに重要なことからは常に逃げている
まあ団子さんはいつものように、『見たいものしか見えない』状態なんで頭が冷えるまで真っ当な議論は無理かと(笑)
PS3に関して言えば、よく話題になるコストは社内のエレクトロニクス部門に貢いでいるだけという構造になています。
例えば、最新のPS3のコスト評価はこれ。(2009/12/11報道)
http://www.isuppli.com/News/Pages/Sony-Gets-One-Step-Closer-to-Breakeven-Point-with-Latest-PlayStation-3-Design.aspx
---------------
Bluray Drive $66.00 x 1
RSX $45.82 x 1
120GB HDD $38.00 x 1
CELL/B.E. $37.73 x 1
Power Supply $20.35 x 1
Cooler Assy. $11.27 x 1
XDR DRAM $9.80 x 4
PCB (6-layer) $8.47 x 1
I/O Bridge Chip $5.59 x 1
Blutooth/WLAN chip $3.92 x 1
Other parts $79.52 x 1
----------------
参考までにBD-ROMの市場価格は http://www.google.com/products?q=BD-ROM+drive&scoring=p
内製品のコストじゃないですよね…
皆さんのお好きな四半期業績資料でも、「ゲーム向けシステムLSI」が売上の大きな要因であることが書いてあります。
http://www.sony.co.jp/SonyInfo/IR/financial/fr/09q3_sonypre.pdf (P.6 参照)
BD-ROMドライブやゲーム機向け半導体が大半を占めると思われる CPD事業部のセグメント間取引による売上は
2009Q4で848.3億円。
http://www.sony.co.jp/SonyInfo/IR/financial/fr/09q3_sony.pdf (P.18 参照)
ちゃんと内製品としての原価で入手できれば、もっと表向きの赤字は縮小するでしょうに…
PS3に関して言えば、よく話題になるコストは社内のエレクトロニクス部門に貢いでいるだけという構造になています。
例えば、最新のPS3のコスト評価はこれ。(2009/12/11報道)
http://www.isuppli.com/News/Pages/Sony-Gets-One-Step-Closer-to-Breakeven-Point-with-Latest-PlayStation-3-Design.aspx
---------------
Bluray Drive $66.00 x 1
RSX $45.82 x 1
120GB HDD $38.00 x 1
CELL/B.E. $37.73 x 1
Power Supply $20.35 x 1
Cooler Assy. $11.27 x 1
XDR DRAM $9.80 x 4
PCB (6-layer) $8.47 x 1
I/O Bridge Chip $5.59 x 1
Blutooth/WLAN chip $3.92 x 1
Other parts $79.52 x 1
----------------
参考までにBD-ROMの市場価格は http://www.google.com/products?q=BD-ROM+drive&scoring=p
内製品のコストじゃないですよね…
皆さんのお好きな四半期業績資料でも、「ゲーム向けシステムLSI」が売上の大きな要因であることが書いてあります。
http://www.sony.co.jp/SonyInfo/IR/financial/fr/09q3_sonypre.pdf (P.6 参照)
BD-ROMドライブやゲーム機向け半導体が大半を占めると思われる CPD事業部のセグメント間取引による売上は
2009Q4で848.3億円。
http://www.sony.co.jp/SonyInfo/IR/financial/fr/09q3_sony.pdf (P.18 参照)
ちゃんと内製品としての原価で入手できれば、もっと表向きの赤字は縮小するでしょうに…
>>797
逆にSCEは黒字で、ゲーム事業単独で営業収支の推移を見た場合でも
ほぼブレイクイーブンまで持ってきたことがわかるじゃん?
だいたい債務超過や在庫の棚卸資産化とかまるでアンチの受け売りじゃん。
売上と純資産の数字を見ればこの程度の債務超過の規模はハッキリ言って大した事がない。
また頻繁な本体モデルチェンジや北米での市場在庫ひっ迫の報など
昨今の情勢で在庫を資産にどうのこうのだからってのも無理がある。
逆にSCEは黒字で、ゲーム事業単独で営業収支の推移を見た場合でも
ほぼブレイクイーブンまで持ってきたことがわかるじゃん?
だいたい債務超過や在庫の棚卸資産化とかまるでアンチの受け売りじゃん。
売上と純資産の数字を見ればこの程度の債務超過の規模はハッキリ言って大した事がない。
また頻繁な本体モデルチェンジや北米での市場在庫ひっ迫の報など
昨今の情勢で在庫を資産にどうのこうのだからってのも無理がある。
>>798
だいたいSCEの決算といった場合に棚卸資産がそちらには反映されないと考える方がおかしい
だいたいSCEの決算といった場合に棚卸資産がそちらには反映されないと考える方がおかしい
PS3と言えば、Geoge Hotz が "OtherOS" 復活版 firmware の開発に成功したようです。
http://geohotps3.blogspot.com/2010/04/otheros-supported-on-321oo.html
http://www.youtube.com/watch?v=1-9wLWQ4-uA
http://geohotps3.blogspot.com/2010/04/otheros-supported-on-321oo.html
http://www.youtube.com/watch?v=1-9wLWQ4-uA
Cellの話するならともかくSCEの赤字額がどうCPUアーキテクチャに関わるのか教えて欲しいもんだ
このクソッタレ共、ゲハか最悪板でやれ
このクソッタレ共、ゲハか最悪板でやれ
804 :MACオタ>803 さん:2010/04/08(木) 23:48:45 ID:e+L2hcR4
>>803
-----------------
どうCPUアーキテクチャに関わるのか
-----------------
業績関係の資料は、製品計画や研究開発投資、契約関係の情報が入っているので、重要なソースになります。嘘書いたら違法ってレベルの信頼度ですから。
-----------------
どうCPUアーキテクチャに関わるのか
-----------------
業績関係の資料は、製品計画や研究開発投資、契約関係の情報が入っているので、重要なソースになります。嘘書いたら違法ってレベルの信頼度ですから。
805 :,,・´∀`・,,)っ-○○○:2010/04/08(木) 23:57:01 ID:urB6a2Po
連結子会社の帳簿なんていくらでも操作出来るぜ。
物理的に移動して無くてもSCE-ソニー本体間で取引したことにできるからな。
重要なのは「ソニーがゲーム事業を存続する価値があるかどうか」であって
赤字がどこの連結子会社あるいは本体が被っていようが連結実績は「大赤字」なのは
4年連続なにも変わってない
倒産しても債務は負いませんという意思すら感じるが
物理的に移動して無くてもSCE-ソニー本体間で取引したことにできるからな。
重要なのは「ソニーがゲーム事業を存続する価値があるかどうか」であって
赤字がどこの連結子会社あるいは本体が被っていようが連結実績は「大赤字」なのは
4年連続なにも変わってない
倒産しても債務は負いませんという意思すら感じるが
また団子病か
PSを捨てるなんて絶対無いよ。
そりゃ赤字だけど数千万台売れるプラットフォームなんて他に無いでしょ。
ウォークマンやソニエリ携帯だけでAppleに対抗なんて不可能だよ。
ゲーム機だけなんだよ可能性があるのは。
そりゃ赤字だけど数千万台売れるプラットフォームなんて他に無いでしょ。
ウォークマンやソニエリ携帯だけでAppleに対抗なんて不可能だよ。
ゲーム機だけなんだよ可能性があるのは。
ゲハでやれ
盛 り 上 が っ て ま い り ま し た !!
Googleは全都市規模の無料無線LAN環境の構築が先だろ
水を得たゲハコテ
ああ屁ルミ キミはどうして屁ルミなんだ
団子はプログラムを語ってればいいのに、「俺は何でも知っている」としゃしゃり出てくるから赤っ恥をかく事になる
たかが掲示板のレス如きで恥を感じるような奴ならとっくの昔にここに来なくなってるだろうよ
817 :,,・´∀`・,,)っ-○○○:2010/04/11(日) 13:45:26 ID:tO9vU4ZA
どっちが恥ずかしいのかの判別もできないからそんな馬鹿なことも言えるんだな
それより最悪板以外でコテ叩きをすることに恥じ入ってもらいたいものだね
興奮すると連続で書き込んでしまう病
820 :,,・´∀`・,,)っ-○○○:2010/04/11(日) 13:56:09 ID:tO9vU4ZA
さしずめお前は見えない敵と戦う病だな
821 :,,・´∀`・,,)っ-○○○:2010/04/11(日) 14:05:49 ID:tO9vU4ZA
PS3 Owner Gets $100 Rebate for Losing Linux
http://www.tomshardware.com/news/PS3-playstation-Linux-Rebate-Amazon,10140.html
EUの消費者法違反だったらしいね。
身勝手な機能削減が結果的に損失うけることを馬鹿共に理解させただけでも小気味いい話だ。
http://www.tomshardware.com/news/PS3-playstation-Linux-Rebate-Amazon,10140.html
EUの消費者法違反だったらしいね。
身勝手な機能削減が結果的に損失うけることを馬鹿共に理解させただけでも小気味いい話だ。
そろそろ春休みはおしまいだっけ?
団子は年中春だからなぁ…
3月半ばにスイスのHPC関係のワークショップの講演のIBMのプレゼンです。
http://www.hpcadvisorycouncil.com/events/switzerland_workshop/pdf/Presentations/Day%203/6_IBM.pdf
p.15 に POWER7 の FPU/VSX 周辺の詳細ブロック図があります。
- VSX レジスタの物理レジスタ数は 344 個
- 2個のVector Unit は機能が異なる。
pipeline0 は スカラFPU VSX, Altivec VPU
pipeline1 は スカラFPU, VSX Altivec VPERM, DFP
- POWER4-POWER6以来、伝統的に高クロック動作のため
にパイプラインごとにレジスタが独立していたが、単一の
VRFを"Bypass"機構経由でアクセスする模様。
見たところ、IBM Journal of R&D の論文用の図と思われますので、近いうちにPOWER7特集号が出るのではないでしょうか?
http://www.hpcadvisorycouncil.com/events/switzerland_workshop/pdf/Presentations/Day%203/6_IBM.pdf
p.15 に POWER7 の FPU/VSX 周辺の詳細ブロック図があります。
- VSX レジスタの物理レジスタ数は 344 個
- 2個のVector Unit は機能が異なる。
pipeline0 は スカラFPU VSX, Altivec VPU
pipeline1 は スカラFPU, VSX Altivec VPERM, DFP
- POWER4-POWER6以来、伝統的に高クロック動作のため
にパイプラインごとにレジスタが独立していたが、単一の
VRFを"Bypass"機構経由でアクセスする模様。
見たところ、IBM Journal of R&D の論文用の図と思われますので、近いうちにPOWER7特集号が出るのではないでしょうか?
>>817
「ゲハでやれ」っていうのが理解できないお前も馬鹿なのは理解出来た
「ゲハでやれ」っていうのが理解できないお前も馬鹿なのは理解出来た
>>773
A4は携帯機器にしては珍しくメモリバスを64bitにして帯域稼いでるそうだから
そこで差が付いてるというのはありそうだ
ただ、画面サイズをあれだけ大きくしておいてiPhone3GSと同じ256MBってのはないわー
A4は携帯機器にしては珍しくメモリバスを64bitにして帯域稼いでるそうだから
そこで差が付いてるというのはありそうだ
ただ、画面サイズをあれだけ大きくしておいてiPhone3GSと同じ256MBってのはないわー
色々紹介する内容が溜まっているのですが、XILINXのプレスリリースから。
http://press.xilinx.com/phoenix.zhtml?c=212763&p=irol-newsArticle&ID=1409753&highlight=
--------------------
Xilinx, Inc. (Nasdaq: XLNX), the world's leading provider of programmable solutions, is applauded for its role in developing QPACE; a bespoke supercomputer developed to unlock the mysteries of Quantum Chromodynamics.
--------------------
ここでも>>336, >>631で紹介した PowerXCell 搭載のスーパーコンピュータ QPACE のインタコネクトチップに Virtex-5 が使用されたという発表です。
なぜこのタイミングなのか?という疑問もありますが…
http://press.xilinx.com/phoenix.zhtml?c=212763&p=irol-newsArticle&ID=1409753&highlight=
--------------------
Xilinx, Inc. (Nasdaq: XLNX), the world's leading provider of programmable solutions, is applauded for its role in developing QPACE; a bespoke supercomputer developed to unlock the mysteries of Quantum Chromodynamics.
--------------------
ここでも>>336, >>631で紹介した PowerXCell 搭載のスーパーコンピュータ QPACE のインタコネクトチップに Virtex-5 が使用されたという発表です。
なぜこのタイミングなのか?という疑問もありますが…
POWER7搭載の Power 780 が 2-socket の TPC-C で新たな記録を打ち立てました。
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?FLTCOL1=tpcc.c_server_procs&FLTCOLOPR1=%3D&FLTCHO1=2&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&sortRowCount=1&DISPRES=100+PERCENT&include_server_cpu=ON
上位に丁度 POWER7, Magny-Cours, Nehalem-EP と 45nm 世代のプロセッサが並んでいます。
IBM POWER7/4.14GHz, 8-core, 32-thread: 1,200,011 [TpmC], 0.69 [US$/TpmC]
HP Op6176SE/2.3GHz, 24-core, 24-thread: 705,652 [TpmC], 0.60 [US$/TpmC]
HP Xeon W5580/3.2GHz, 8-core, 16-thread: 661,475 [TpmC], 1.16 [US$/TpmC]
HP Xeon X5570/2.93GHz, 8-core, 16-thread: 631,766 [TpmC], 1.08 [US$/TpmC]
Magny-Coursの倍近い性能はともかく、AMD並みのコストパフォーマンスというのは驚異です。
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?FLTCOL1=tpcc.c_server_procs&FLTCOLOPR1=%3D&FLTCHO1=2&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&sortRowCount=1&DISPRES=100+PERCENT&include_server_cpu=ON
上位に丁度 POWER7, Magny-Cours, Nehalem-EP と 45nm 世代のプロセッサが並んでいます。
IBM POWER7/4.14GHz, 8-core, 32-thread: 1,200,011 [TpmC], 0.69 [US$/TpmC]
HP Op6176SE/2.3GHz, 24-core, 24-thread: 705,652 [TpmC], 0.60 [US$/TpmC]
HP Xeon W5580/3.2GHz, 8-core, 16-thread: 661,475 [TpmC], 1.16 [US$/TpmC]
HP Xeon X5570/2.93GHz, 8-core, 16-thread: 631,766 [TpmC], 1.08 [US$/TpmC]
Magny-Coursの倍近い性能はともかく、AMD並みのコストパフォーマンスというのは驚異です。
>>758-760の続きですが、Nehalem-EXの真打 X7560/2.26GHz の SPEC CPU2006 の結果が追加しています。
CINT2006_rate と CFP2006_rate の結果の比較を更新しておきます。
■各種マルチコア・サーバープロセッサの CINT2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 586 652
Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT 362 387
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 355 378
Shanghai/2.6GHz/4-socket/24-core/noSMT 313 400
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 309 398
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 286 302
■各種マルチコア・サーバープロセッサの CFP2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 531 586
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 290 318
Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT 274 283
Shanghai/2.6GHz/4-socket/24-core/noSMT 251 276
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 248 257
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 214 222
参照: Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT
CINT2006_rate: http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10292.html
CFP2006_rate: http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10294.html
CINT2006_rate と CFP2006_rate の結果の比較を更新しておきます。
■各種マルチコア・サーバープロセッサの CINT2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 586 652
Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT 362 387
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 355 378
Shanghai/2.6GHz/4-socket/24-core/noSMT 313 400
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 309 398
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 286 302
■各種マルチコア・サーバープロセッサの CFP2006_rate
base peak
POWER7/3.86GHz/2-socket/16-core/4-SMT 531 586
Magny-Cours/2.3GHz/2-socket/24-core/noSMT 290 318
Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT 274 283
Shanghai/2.6GHz/4-socket/24-core/noSMT 251 276
Westmere-EP/3.33GHz/2-socket/12-core/2-SMT 248 257
Westmere-EP/3.47GHz/2-socket/8-core/2-SMT 214 222
参照: Nehalem-EX/2.26GHz/2-socket/16-core/2-SMT
CINT2006_rate: http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10292.html
CFP2006_rate: http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10294.html
IBMは Nehalem-EX の CINT/CFP2006 の結果も登録しています。
自動並列化のためにコア性能を直接比較することはできませんが参考まで。
■ CINT2006 (base/peak)
Xeon X7560/2.26GHz, 4-socket: 29.1 / 32.6
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10287.html
Xeon X7560/2.26Ghz, 2-socket: 28.8 / 32.1
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10291.html
■ CFP2006 (base/peak)
Xeon X7560/2.26GHz, 4-socket: 35.1 / 38.6
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10289.html
Xeon X7560/2.26Ghz, 2-socket: 34.7 / 36.8
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10293.html
自動並列化のためにコア性能を直接比較することはできませんが参考まで。
■ CINT2006 (base/peak)
Xeon X7560/2.26GHz, 4-socket: 29.1 / 32.6
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10287.html
Xeon X7560/2.26Ghz, 2-socket: 28.8 / 32.1
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10291.html
■ CFP2006 (base/peak)
Xeon X7560/2.26GHz, 4-socket: 35.1 / 38.6
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10289.html
Xeon X7560/2.26Ghz, 2-socket: 34.7 / 36.8
http://www.spec.org/cpu2006/results/res2010q2/cpu2006-20100329-10293.html
最後は POWER7 搭載の BladeCenter 発表の話題。
http://www-06.ibm.com/jp/press/2010/04/1501.html
-----------------
[ POWER7搭載ブレード・サーバー ]
(1) BladeCenter PS700
・CPU:動作周波数 3.0 GHz、コア数4コア
・メモリー: 8GB〜64GB
・最小構成価格(税別): 928,100円
・出荷開始日: 6月4日
・保守サポート: 3年保証
(2) BladeCenter PS701
・CPU:動作周波数 3.0 GHz、コア数8コア
・メモリー: 16GB〜128GB
・最小構成価格(税別): 1,264,300円
・出荷開始日: 6月4日
・保守サポート: 3年保証
(3) BladeCenter PS702
・CPU:動作周波数 3.0 GHz、コア数16コア
・メモリー: 32GB〜256GB
・最小構成価格(税別): 2,528,800円
・出荷開始日: 6月4日
・保守サポート: 3年保証
-----------------
シングルソケット, 4-core モデルは100万切ってます。
公開された性能は、この辺をどうぞ。
http://www-03.ibm.com/systems/bladecenter/hardware/servers/ps700series/perfdata.html
システムの構成は Redbook に詳細があります。
http://www.redbooks.ibm.com/Redbooks.nsf/RedpieceAbstracts/redp4655.html?Open
http://www-06.ibm.com/jp/press/2010/04/1501.html
-----------------
[ POWER7搭載ブレード・サーバー ]
(1) BladeCenter PS700
・CPU:動作周波数 3.0 GHz、コア数4コア
・メモリー: 8GB〜64GB
・最小構成価格(税別): 928,100円
・出荷開始日: 6月4日
・保守サポート: 3年保証
(2) BladeCenter PS701
・CPU:動作周波数 3.0 GHz、コア数8コア
・メモリー: 16GB〜128GB
・最小構成価格(税別): 1,264,300円
・出荷開始日: 6月4日
・保守サポート: 3年保証
(3) BladeCenter PS702
・CPU:動作周波数 3.0 GHz、コア数16コア
・メモリー: 32GB〜256GB
・最小構成価格(税別): 2,528,800円
・出荷開始日: 6月4日
・保守サポート: 3年保証
-----------------
シングルソケット, 4-core モデルは100万切ってます。
公開された性能は、この辺をどうぞ。
http://www-03.ibm.com/systems/bladecenter/hardware/servers/ps700series/perfdata.html
システムの構成は Redbook に詳細があります。
http://www.redbooks.ibm.com/Redbooks.nsf/RedpieceAbstracts/redp4655.html?Open
==最速レース===
1.Oracle Database 10G Enterprise Edition 824,164tpmC 8.28 US $(2003/07/30)
2.IBM DB2 UDB 8.1 763,898tpmC 8.31 US $(2003/06/30)
3.Microsoft SQL Server 2000 Enterprise Ed. 64-bit 707,102tpmC 14.96 US $(2003/05/20)
==コストパフォーマンスレース===
1.Microsoft SQL Server 2000 Standard Ed. 20,108tpmC 2.28 US $(2003/07/14)
2.Microsoft SQL Server 2000 19,526tpmC 2.38 US $(2003/05/12)
3.Microsoft SQL Server 2000 Standard Ed. SP3 19,718tpmC 2.44 US $(2003/07/15)
1.Oracle Database 10G Enterprise Edition 824,164tpmC 8.28 US $(2003/07/30)
2.IBM DB2 UDB 8.1 763,898tpmC 8.31 US $(2003/06/30)
3.Microsoft SQL Server 2000 Enterprise Ed. 64-bit 707,102tpmC 14.96 US $(2003/05/20)
==コストパフォーマンスレース===
1.Microsoft SQL Server 2000 Standard Ed. 20,108tpmC 2.28 US $(2003/07/14)
2.Microsoft SQL Server 2000 19,526tpmC 2.38 US $(2003/05/12)
3.Microsoft SQL Server 2000 Standard Ed. SP3 19,718tpmC 2.44 US $(2003/07/15)
AppleInsider が Apple が AMD とプロセッサ採用について話し合いを行っているらしいという話を伝えています。
http://www.appleinsider.com/articles/10/04/16/apple_in_advanced_discussions_to_adopt_amd_chips.html
時々出る噂ですが、今回はちょっと面白いタイミングかと思うので、AMD次世代スレッドに感想を書いています。
http://pc11.2ch.net/test/read.cgi/jisaku/1270329471/173
Apple は各社の秘密のロードマップを元に次世代の採用計画を立てられる立場にありますから、Apple の選択には注目かと。Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
http://www.appleinsider.com/articles/10/04/16/apple_in_advanced_discussions_to_adopt_amd_chips.html
時々出る噂ですが、今回はちょっと面白いタイミングかと思うので、AMD次世代スレッドに感想を書いています。
http://pc11.2ch.net/test/read.cgi/jisaku/1270329471/173
Apple は各社の秘密のロードマップを元に次世代の採用計画を立てられる立場にありますから、Apple の選択には注目かと。Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
>>836
>Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
いやいやいや、その発表する時は既にCore2の話題があったはずだよ。
x86にしろARMにしろ、CPU界への影響がかなり大きな会社になったのは確かだと思うけどね。
>Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
いやいやいや、その発表する時は既にCore2の話題があったはずだよ。
x86にしろARMにしろ、CPU界への影響がかなり大きな会社になったのは確かだと思うけどね。
838 :,,・´∀`・,,)っ-○○○:2010/04/17(土) 14:02:16 ID:w3NivDY2
ノートは「Pentium Mの時代」なんだけどな。
PowerBookのハイエンドが1.5GHzとかじゃとても信者だって騙しきれないよ。
まあPWRficientがもう少し早く出てればまた事情は変わったかもしれん。
PowerBookのハイエンドが1.5GHzとかじゃとても信者だって騙しきれないよ。
まあPWRficientがもう少し早く出てればまた事情は変わったかもしれん。
>>836
> Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
PPCに関してIBMから三行半を突きつけられたから。
単に金の問題。
> Intel 劣勢だった Netburst の時代に PPC -> Intel へのスイッチを発表したことは思い出すべきでしょう。
PPCに関してIBMから三行半を突きつけられたから。
単に金の問題。
841 :,,・´∀`・,,)っ-○○○:2010/04/17(土) 15:58:32 ID:w3NivDY2
そうそうにPPC970ワークステーション撤退してXeonに移行したからな。
PPC980の計画だってあったのにコストメリットを支えてくれるAppleに逃げられて頓挫。
PPC980の計画だってあったのにコストメリットを支えてくれるAppleに逃げられて頓挫。
>>836
ローエンドの利幅を増やす為だけに採用するだけじゃねーの?
供給問題ならAMDの方が心配だし、先日に出たノートのローエンドは、わざわざ新チップセットまで作って製造コストを下げようとしている。
ローエンドの利幅を増やす為だけに採用するだけじゃねーの?
供給問題ならAMDの方が心配だし、先日に出たノートのローエンドは、わざわざ新チップセットまで作って製造コストを下げようとしている。
安藤氏の今日の更新はCool Chips XIII レポート。
http://www.geocities.jp/andosprocinfo/wadai10/20100417.htm
----------------------
Trenchキャパシタは直列抵抗も大きいようで,高速バイパス用に通常のゲート絶縁膜を使うキャパシタも配置しているとのことでした。
----------------------
将来的にはSOIを生かしたFBCに向かう様で…
http://www.geocities.jp/andosprocinfo/wadai10/20100417.htm
----------------------
Trenchキャパシタは直列抵抗も大きいようで,高速バイパス用に通常のゲート絶縁膜を使うキャパシタも配置しているとのことでした。
----------------------
将来的にはSOIを生かしたFBCに向かう様で…
何度か紹介した QPACE と同様に、欧州のスーパーコンピュータ共同利用プロジェクト PRACE の下でスウェーデンの国立計算機センター(SNIC)と王立工科大学(KTH)の共同で Super● の4Pブレードサーバーと Opteron のシステムを試作しています。
この成果をまとめたプレゼンが、結構面白かったので紹介しておきます。
http://www.prace-project.eu/documents/18_amdprototype_lj.pdf
基本的な目標は『汎用パーツで Blue Gene/P 並みの電力効率』ということで、HPCクラスタでは一般的な2Pマザー + 高速x86の組み合わせの代わりに4-socketブレードに ATP 55W の Istanbul/2.1-2.2GHz の Opteron 84xx を使用しています。
・マザーボードは Infiniband QDR 搭載でディスクレス
・7U筐体に10枚のブレード、空冷
・Infiniband スイッチはブレード筐体内蔵
・メモリも Elpida, Hynix, Micron, Samsung で消費電力と性能のベンチマークを収集して Hynix を採用
・1,440 core, 〜28kW (HPL実行時), 12.1 TFlops
・床面積あたりの消費電力で 43.6 kW/m^2 (BG/P はおよそ 45.6 kW/m^2)
・電力効率は 343.91 MFlops/W (BG/P は 357.14 - 371.67 MFlops/W)
・MD (Gromacs) では BG/P の3.9倍の電力効率を達成
Magny-Cours でこの手のシステムは値段コア数2倍になる訳で、我国の国家プロジェクトを含む専用プロセッサによる HPC はいったいどうなることやら…
参考までに Super● から出ている広報資料も書いておきます。
http://www.supermicro.com/CaseStudies/SuperBlade_PRACE.pdf
この成果をまとめたプレゼンが、結構面白かったので紹介しておきます。
http://www.prace-project.eu/documents/18_amdprototype_lj.pdf
基本的な目標は『汎用パーツで Blue Gene/P 並みの電力効率』ということで、HPCクラスタでは一般的な2Pマザー + 高速x86の組み合わせの代わりに4-socketブレードに ATP 55W の Istanbul/2.1-2.2GHz の Opteron 84xx を使用しています。
・マザーボードは Infiniband QDR 搭載でディスクレス
・7U筐体に10枚のブレード、空冷
・Infiniband スイッチはブレード筐体内蔵
・メモリも Elpida, Hynix, Micron, Samsung で消費電力と性能のベンチマークを収集して Hynix を採用
・1,440 core, 〜28kW (HPL実行時), 12.1 TFlops
・床面積あたりの消費電力で 43.6 kW/m^2 (BG/P はおよそ 45.6 kW/m^2)
・電力効率は 343.91 MFlops/W (BG/P は 357.14 - 371.67 MFlops/W)
・MD (Gromacs) では BG/P の3.9倍の電力効率を達成
Magny-Cours でこの手のシステムは値段コア数2倍になる訳で、我国の国家プロジェクトを含む専用プロセッサによる HPC はいったいどうなることやら…
参考までに Super● から出ている広報資料も書いておきます。
http://www.supermicro.com/CaseStudies/SuperBlade_PRACE.pdf
上のカキコミちょっと訂正。
誤) Magny-Cours でこの手のシステムは値段コア数2倍になる訳で、
正) Magny-Cours でこの手のシステムは値段半額コア数2倍になる訳で、
誤) Magny-Cours でこの手のシステムは値段コア数2倍になる訳で、
正) Magny-Cours でこの手のシステムは値段半額コア数2倍になる訳で、
昨年12/10に開催されたPCクラスタコンソシアムの第九回クラスタシンポジウムの資料が公開されていますが、ところどころ面白いところがあります。
http://www.pccluster.org/ja_event/2009/10/pc-1.html
・Intel http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/07_Ikei.pdf
(P. 33)
----------------------
- グラフィックまたはスループット計算の評価用プロセッサとしてLRBも登場予定です
----------------------
・AMD http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/08_Yamano.pdf
(P.56-61) プローブフィルタの詳細
(P.68) HT Assist の効果 4Pシステムの Stream Benchmark で約60%の向上
・日立 http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/10_Shimizu.pdf
(P.16-24) GPGPU の評価
http://www.pccluster.org/ja_event/2009/10/pc-1.html
・Intel http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/07_Ikei.pdf
(P. 33)
----------------------
- グラフィックまたはスループット計算の評価用プロセッサとしてLRBも登場予定です
----------------------
・AMD http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/08_Yamano.pdf
(P.56-61) プローブフィルタの詳細
(P.68) HT Assist の効果 4Pシステムの Stream Benchmark で約60%の向上
・日立 http://www.pccluster.org/mt-static/support/uploads/file/%E7%AC%AC%E4%B9%9D%E5%9B%9E%E3%82%B7%E3%83%B3%E3%83%9D%E7%99%BA%E8%A1%A8%E8%B3%87%E6%96%99/10_Shimizu.pdf
(P.16-24) GPGPU の評価
IBMの2010Q1の業績報告が来ています。
http://www-03.ibm.com/press/us/en/pressrelease/29942.wss
・POWER System と z-series (メインフレーム)は仲良く前年同期比17%減
・Microelectronics (半導体)部門は前年同期比16%増加
今年に入ってIBMに製造委託している半導体ってなにか目立つ話題がありましたっけ?POWER7の量産もあってか East Fishkill の45nmラインはフル操業とのこと。
http://www-03.ibm.com/press/us/en/pressrelease/29942.wss
・POWER System と z-series (メインフレーム)は仲良く前年同期比17%減
・Microelectronics (半導体)部門は前年同期比16%増加
今年に入ってIBMに製造委託している半導体ってなにか目立つ話題がありましたっけ?POWER7の量産もあってか East Fishkill の45nmラインはフル操業とのこと。
価格性能比でも競って欲しいな。
10万円以下で買えるPOWER7マシンがないじゃないか。
10万円以下で買えるPOWER7マシンがないじゃないか。
新型iPhone的な謎物体に関する情報
http://gizmodo.com/5520876/the-next-iphone-dissected
> I couldn't find out if there was an A4 processor?like the iPad's?in this iPhone
http://gizmodo.com/5520876/the-next-iphone-dissected
> I couldn't find out if there was an A4 processor?like the iPad's?in this iPhone
Google が P.A. Semi の残党が起業した Agnilux を買収したとのこと。
http://www.washingtonpost.com/wp-dyn/content/article/2010/04/20/AR2010042004854.html
-------------------
Agnilux was founded by a few ex-Apple employees. More
specifically, it was founded by Apple employees who
came over in the PA Semi acquisition.
-------------------
単なる Apple への嫌がらせということは無いと思われますが、はたして Google まで携帯プロセッサ開発に参入するのでしょうか?いっそ ARM より PowerPC だと面白いかも(笑)
http://www.washingtonpost.com/wp-dyn/content/article/2010/04/20/AR2010042004854.html
-------------------
Agnilux was founded by a few ex-Apple employees. More
specifically, it was founded by Apple employees who
came over in the PA Semi acquisition.
-------------------
単なる Apple への嫌がらせということは無いと思われますが、はたして Google まで携帯プロセッサ開発に参入するのでしょうか?いっそ ARM より PowerPC だと面白いかも(笑)
Googleって検索エンジンじゃないのか??
Nexus One
Googleは検索エンジンとして愛用しているのに、
なぜか検索エンジン以外のところで名前を聞きたくない企業の代表格だな。
なぜ嫌なんだろうか。
なぜか検索エンジン以外のところで名前を聞きたくない企業の代表格だな。
なぜ嫌なんだろうか。
平仮名4文字のコテの気持ちなんて分かるわけもないでしょ
Goプロセッサ開発か
>>850
どうせARM以外ならIntelのAtomと組むとオモロイよな。
どうせARM以外ならIntelのAtomと組むとオモロイよな。
>また、SnapdragonはマルチメディアエンジンのVeNumを内蔵しており、CIFサイズ(352×288ピクセル、30fps)
>程度の動画を録画・再生する場合は、CPUパワーの20%程度しか使用しません。
1GHzのSnapdragonはCIFサイズの動画を再生しただけで20%もパワーをつかうんだね。
Atomどころじゃなくおっせーな。
>程度の動画を録画・再生する場合は、CPUパワーの20%程度しか使用しません。
1GHzのSnapdragonはCIFサイズの動画を再生しただけで20%もパワーをつかうんだね。
Atomどころじゃなくおっせーな。
QualcommのMSMxxxxやSnapdragon
appleが採用してるSamsung製SoCやA4チップ
そんなもん買ってユダ公や半島を儲けさせたくないので
国産半導体を採用してるdocomoのガラケーを買いましょう!
FとSH → ルネサス製SH MOBILE Gシリーズ
P → パナソニック製UniPhierシリーズ
N → NECエレ製Medityシリーズ
appleが採用してるSamsung製SoCやA4チップ
そんなもん買ってユダ公や半島を儲けさせたくないので
国産半導体を採用してるdocomoのガラケーを買いましょう!
FとSH → ルネサス製SH MOBILE Gシリーズ
P → パナソニック製UniPhierシリーズ
N → NECエレ製Medityシリーズ
書き忘れてましたが、安藤氏が Cool Chips の POWER7 の講演のレポートを mycom に掲載しています。
http://journal.mycom.co.jp/articles/2010/04/21/coolchips13_02/index.html
もう少し写真撮影が上手になっていただけると嬉しいのですが…
http://journal.mycom.co.jp/articles/2010/04/21/coolchips13_02/index.html
もう少し写真撮影が上手になっていただけると嬉しいのですが…
> P → パナソニック製UniPhierシリーズ
> N → NECエレ製Medityシリーズ
縦割り&鎖国か…日本のお家芸ですね?
前世代的過ぎて涙出ちゃう
Samsung を採用しろとは言わないが,
製造量とか1/10とか1/100とかなんだろうな.コスト何倍かかってるのやら…
Qualcomm 採用しなくても TI・Broadcom・Marvell・nVIDIA etc でも良いだろ?
> N → NECエレ製Medityシリーズ
縦割り&鎖国か…日本のお家芸ですね?
前世代的過ぎて涙出ちゃう
Samsung を採用しろとは言わないが,
製造量とか1/10とか1/100とかなんだろうな.コスト何倍かかってるのやら…
Qualcomm 採用しなくても TI・Broadcom・Marvell・nVIDIA etc でも良いだろ?
docomoは数年前TI採用機種多かった
やめたのにはそれなりに理由があるんだろ
やめたのにはそれなりに理由があるんだろ
一方、Apple は ARM そのものを買収するという噂が流れています。
http://www.reuters.com/article/idUSTRE63K1KG20100421
----------------------
The Financial Times reported renewed speculation that ARM
could be a takeover target, mentioning Apple as a possible suitor.
----------------------
http://www.reuters.com/article/idUSTRE63K1KG20100421
----------------------
The Financial Times reported renewed speculation that ARM
could be a takeover target, mentioning Apple as a possible suitor.
----------------------
買収されたらARM終わるな
864 :MACオタ>863 さん:2010/04/22(木) 01:04:01 ID:M9CK1M+L
>>863
もともと子会社だったんですが…
http://ja.wikipedia.org/wiki/ARM%E3%83%9B%E3%83%BC%E3%83%AB%E3%83%87%E3%82%A3%E3%83%B3%E3%82%B0%E3%82%B9
---------------------
エイコーン・コンピュータ、アップルコンピュータ、VLSIテクノロジーのジョイントベンチャーとして創業した。
---------------------
もともと子会社だったんですが…
http://ja.wikipedia.org/wiki/ARM%E3%83%9B%E3%83%BC%E3%83%AB%E3%83%87%E3%82%A3%E3%83%B3%E3%82%B0%E3%82%B9
---------------------
エイコーン・コンピュータ、アップルコンピュータ、VLSIテクノロジーのジョイントベンチャーとして創業した。
---------------------
865 :,,・´∀`・,,)っ-○○○:2010/04/22(木) 02:03:04 ID:qtOqQ0Fb
>>857
別にSnapdragonをPCの代わりに使おうって言うんじゃないんだからそこは目くじら立てない
CIFサイズの動画再生のニーズなんてせいぜい携帯電話だぜ
Snapdragonは「mW」だがAtomは「W」なんだぜ
EeePCですら本体重量の半分近くがバッテリなわけで。
別にSnapdragonをPCの代わりに使おうって言うんじゃないんだからそこは目くじら立てない
CIFサイズの動画再生のニーズなんてせいぜい携帯電話だぜ
Snapdragonは「mW」だがAtomは「W」なんだぜ
EeePCですら本体重量の半分近くがバッテリなわけで。
>>864
ライセンスビジネス中止→(Apple以外から)新ARMチップ出ない→終わりでは
ライセンスビジネス中止→(Apple以外から)新ARMチップ出ない→終わりでは
867 :MACオタ>866 さん:2010/04/22(木) 02:38:35 ID:M9CK1M+L
>>866
買収されたら契約を破棄してよいということはありません。
P.A.semiの時すら Apple は最低3年間 PwerEfficient チップの供給を続けることを約束させられています。
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=208808517
----------------------
Apple sent a letter to the DoD saying it will assure production
of the 1.8 GHz PWRficient processor for three to five years,
said one source who saw the letter but asked not to be named.
The letter suggests Apple will explore selling the designs to a
third party after that time.
----------------------
買収されたら契約を破棄してよいということはありません。
P.A.semiの時すら Apple は最低3年間 PwerEfficient チップの供給を続けることを約束させられています。
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=208808517
----------------------
Apple sent a letter to the DoD saying it will assure production
of the 1.8 GHz PWRficient processor for three to five years,
said one source who saw the letter but asked not to be named.
The letter suggests Apple will explore selling the designs to a
third party after that time.
----------------------
>>867
既存契約破棄って話じゃなくて、新規ライセンスは結ばない
新IPも外部へは出さないじゃないかなってこと
iPhone OSを他社へライセンスって噂もあるので、それと
からめてIPやチップ供給を考えてる可能性もあるけど
AppleがARMコアIPライセンスビジネスを継続するメリットが
思いつかない。やるんなら(ARMも含めた)iPhoneのライセンス
既存契約破棄って話じゃなくて、新規ライセンスは結ばない
新IPも外部へは出さないじゃないかなってこと
iPhone OSを他社へライセンスって噂もあるので、それと
からめてIPやチップ供給を考えてる可能性もあるけど
AppleがARMコアIPライセンスビジネスを継続するメリットが
思いつかない。やるんなら(ARMも含めた)iPhoneのライセンス
俺はグーグルシンパみたいなもんだが、気持ちはわかる。
すべてのサービスについて支持できるものではない。今は手広すぎるし。
すべてのサービスについて支持できるものではない。今は手広すぎるし。
実際買収されたら大混乱だな
利があるのはintelか
利があるのはintelか
ARMの歴史が良く解からん
XScaleってIntelだよな…
XScaleってIntelだよな…
むしろ日本こそ各半導体メーカーが協力して
本気でARM互換つくるべきなんだけどな。
本気でARM互換つくるべきなんだけどな。
Cortex-A8 Technical Reference Manual
7.1. About the L1 memory system
The L1 memory system consists of separate instruction and data caches in a Harvard arrangement. The L1 memory system provides the core with:
* fixed line length of 64 bytes
* support for 16KB or 32KB caches
* two 32-entry fully associative ARMv7-A MMU
* data array with parity for error detection
* an instruction cache that is virtually indexed, IVIPT
* a data cache that is physically indexed, PIPT
* 4-way set associative cache structure
* random replacement policy
* nonblocking cache behavior for Advanced SIMD code
* blocking for integer code
* MBIST
* support for hardware reset of the L1 data cache valid RAM, see Hardware RAM array reset.
ランダムリプレースメントポリシー!!
7.1. About the L1 memory system
The L1 memory system consists of separate instruction and data caches in a Harvard arrangement. The L1 memory system provides the core with:
* fixed line length of 64 bytes
* support for 16KB or 32KB caches
* two 32-entry fully associative ARMv7-A MMU
* data array with parity for error detection
* an instruction cache that is virtually indexed, IVIPT
* a data cache that is physically indexed, PIPT
* 4-way set associative cache structure
* random replacement policy
* nonblocking cache behavior for Advanced SIMD code
* blocking for integer code
* MBIST
* support for hardware reset of the L1 data cache valid RAM, see Hardware RAM array reset.
ランダムリプレースメントポリシー!!
Snapdragon 1GHzでDeschutes〜Katmaiあたりの性能かなあ。
ハイエンドスマートフォンのプロセッサコアが11〜12年前くらいのPCプロセッサの性能くらいかな。
ハイエンドスマートフォンのプロセッサコアが11〜12年前くらいのPCプロセッサの性能くらいかな。
マジレスすると、
10〜20年後、アジアメーカーのつくったARMプロセッサを搭載した格安コンピュータが世にあふれている可能性が高い。
日本の半導体メーカーは国内のつまらない競争で自社ISA製品に執着しているあまり、
世界の流れに取り残されて、このままいくと完全にアジアのほかのメーカーに出し抜かれる状況。
正直米国HPCやサーバのハイエンド技術に目を奪われているのやつが多すぎるのか知らないが、
どんどん市場をアジア勢にもっていかれるのに守りが弱すぎるのに気がついているやつが少なすぎる。
20年後になんでこうなってしまったんだ日本の半導体の反省論が例のごとく説かれているだろう。
AppleのARM買収という戦略は露骨そのもので気に食わない。
10〜20年後、アジアメーカーのつくったARMプロセッサを搭載した格安コンピュータが世にあふれている可能性が高い。
日本の半導体メーカーは国内のつまらない競争で自社ISA製品に執着しているあまり、
世界の流れに取り残されて、このままいくと完全にアジアのほかのメーカーに出し抜かれる状況。
正直米国HPCやサーバのハイエンド技術に目を奪われているのやつが多すぎるのか知らないが、
どんどん市場をアジア勢にもっていかれるのに守りが弱すぎるのに気がついているやつが少なすぎる。
20年後になんでこうなってしまったんだ日本の半導体の反省論が例のごとく説かれているだろう。
AppleのARM買収という戦略は露骨そのもので気に食わない。
中国製ARMコア/SoCを大量につかったエクサスケールスパコンに
対抗心を燃やす日本の国産スパコン
とかならないことを祈ってるよ。
本当に世界で通用するスパコンをつくりたいのなら、
スパコンのことなどあとから考えればいい。
対抗心を燃やす日本の国産スパコン
とかならないことを祈ってるよ。
本当に世界で通用するスパコンをつくりたいのなら、
スパコンのことなどあとから考えればいい。
市場関係者の噂なんて碌すっぽ当たらない代物にマジになってどうする
今日では命令セットに知的財産権が認められているので、勝手に互換プロセッサを作ったりはできないよ。
ランダムリプレースメントが珍しいかい?
トランスピュータもそうだったし、時々みかけたよ。擬似LRUけっこう大変だし。
ランダムリプレースメントが珍しいかい?
トランスピュータもそうだったし、時々みかけたよ。擬似LRUけっこう大変だし。
i860もランダムのようだね。
x86(Atom)周辺ではIDFであったようにBIOSライセンスの問題にてこ入れしようとしてるのがでかいね。
AtomもMedfield以降も低消費電力化していく計画だし、ARM vs x86の時代に本格的に突入していくな。
AtomもMedfield以降も低消費電力化していく計画だし、ARM vs x86の時代に本格的に突入していくな。
>日本の半導体メーカーは国内のつまらない競争で自社ISA製品に執着しているあまり、
?????
ひらがな4文字の人は相変わらずトンチンカンだな
Snapdragon, iPhone向けSamsung製SoC, UniPhier 4M, SH-MOBILE Gシリーズ, Medity
これら全て「汎用プロセッサ・コアIPにARMを使ったSoC」です
?????
ひらがな4文字の人は相変わらずトンチンカンだな
Snapdragon, iPhone向けSamsung製SoC, UniPhier 4M, SH-MOBILE Gシリーズ, Medity
これら全て「汎用プロセッサ・コアIPにARMを使ったSoC」です
擬似LRUでは、キャッシュエントリにdirtyビットがついていて、書き込みがあればセット、周期的に全クリアしている。
周期内で書き込みがあったエントリだけdirtyになっているのでリプレースの対象から外すという寸法。
これだけだと簡単そうに見えるが、ハードウェアで実装するとなると
・cleanなエントリから書き込み対象を選ぶ
・dirtyなエントリからリプレース対象を選ぶ
のにプライオリティエンコーダが必要で、しかもプライオリティはランダムに変える必要がある(固定的だと同じエントリばかりが対象になる)ので
実装はかなり面倒くさい。
遅延も許されないし。
ランダムリプレースメントは普通は本当にランダムに選ぶから簡単。
周期内で書き込みがあったエントリだけdirtyになっているのでリプレースの対象から外すという寸法。
これだけだと簡単そうに見えるが、ハードウェアで実装するとなると
・cleanなエントリから書き込み対象を選ぶ
・dirtyなエントリからリプレース対象を選ぶ
のにプライオリティエンコーダが必要で、しかもプライオリティはランダムに変える必要がある(固定的だと同じエントリばかりが対象になる)ので
実装はかなり面倒くさい。
遅延も許されないし。
ランダムリプレースメントは普通は本当にランダムに選ぶから簡単。
> ・dirtyなエントリからリプレース対象を選ぶ
全エントリがdirtyだった場合↑
T9000は256ウェイのランダムリプレースだったかな。
ウェイ数はすごいけど、タグを含めたキャッシュはただの連想メモリになるので出来合いのものが使える。
(アドレッシングがRAMではデコーダのところが連想メモリではコンパレータになる)
全エントリがdirtyだった場合↑
T9000は256ウェイのランダムリプレースだったかな。
ウェイ数はすごいけど、タグを含めたキャッシュはただの連想メモリになるので出来合いのものが使える。
(アドレッシングがRAMではデコーダのところが連想メモリではコンパレータになる)
もしかして、SHにチャンスが・・・
Linux Foundation、携帯機器向けOS「MeeGo」のセミナーを開催
http://k-tai.impress.co.jp/docs/news/20100421_362839.html
LiMo Foundation(Linux Mobile Foundation)と混同しやすい名称だ
http://k-tai.impress.co.jp/docs/news/20100421_362839.html
LiMo Foundation(Linux Mobile Foundation)と混同しやすい名称だ
×MACオタ
●POWERオタ
●POWERオタ
>>887
いちおう広めようとした時もあったんだが、見事に流行らなかったな。
今後アレをどうするつもりなんだろうか。
マルチコアの製品化では先行してるのでSuperHサーバなんかは……ひいき目にみれば。
いちおう広めようとした時もあったんだが、見事に流行らなかったな。
今後アレをどうするつもりなんだろうか。
マルチコアの製品化では先行してるのでSuperHサーバなんかは……ひいき目にみれば。
龍芯3号搭載のブレードサーバーCB-50Aが発表されました
http://tech.sina.com.cn/b/2010-04-23/06301327500.shtml
■龍芯3号 L3A02 プロセッサ
・4-core, 1GHz, max. 15W
・2 x HyperTransport 1.0, 16-bit bus
・DDR2/3 対応メモリコントローラ内蔵
■龍芯ブレード CB-50A
・2-socket Loongson 3A
・8 DDR2 slots, max. 64GB
・2x GbE
・2x 2.5' SATA Drive
・曙光 龍芯BIOS
・紅旗Linuxサポート
・max. 110W
曙光は龍芯ブレードとx86ブレードを混在可能なブレード筐体 TC2600 も発表しています。
http://tech.sina.com.cn/b/2010-04-23/06301327500.shtml
■龍芯3号 L3A02 プロセッサ
・4-core, 1GHz, max. 15W
・2 x HyperTransport 1.0, 16-bit bus
・DDR2/3 対応メモリコントローラ内蔵
■龍芯ブレード CB-50A
・2-socket Loongson 3A
・8 DDR2 slots, max. 64GB
・2x GbE
・2x 2.5' SATA Drive
・曙光 龍芯BIOS
・紅旗Linuxサポート
・max. 110W
曙光は龍芯ブレードとx86ブレードを混在可能なブレード筐体 TC2600 も発表しています。
龍芯3号に関する別の記事です。
http://server.chinabyte.com/69/11229569.shtml
- L3A02 は 65nm, 425 million transistors
- 龍芯3A に続き 3B (8-core), 3C (16-core)も開発中
- 龍芯3B は 3A の8倍の浮動小数点性能 (128GFlops / chip)
- スーパーコンピュータ 『曙光6000』 には龍芯3Bが使用される予定
龍芯3号の詳細は>>399とか。
MIPSコア(GS464)とSIMDコア(GStera)のヘテロ構成ですので、3Aは MIPS x 4 の構成、3B は MIPS x 4 + SIMD x 4 になると考えられます。
http://server.chinabyte.com/69/11229569.shtml
- L3A02 は 65nm, 425 million transistors
- 龍芯3A に続き 3B (8-core), 3C (16-core)も開発中
- 龍芯3B は 3A の8倍の浮動小数点性能 (128GFlops / chip)
- スーパーコンピュータ 『曙光6000』 には龍芯3Bが使用される予定
龍芯3号の詳細は>>399とか。
MIPSコア(GS464)とSIMDコア(GStera)のヘテロ構成ですので、3Aは MIPS x 4 の構成、3B は MIPS x 4 + SIMD x 4 になると考えられます。
地味に手堅い。
IBM版Cell GPUとも言うべき,POWER7 GPUは作らないのか。
その性能ならATiやnVIDIAとも余裕で張り合えるだろうに。
その性能ならATiやnVIDIAとも余裕で張り合えるだろうに。
Cell厨の残党ってまだいたのか
>その性能ならATiやnVIDIAとも余裕で張り合えるだろうに。
む
り
む
り
ムリだろうけど
そういえば HP が PA-RISC でグラボ作ってたよな(Visualizeだっけ)…
あとSunもMAJCとか作ってたっけ…
ところで >>894 って,なんで POWER7 で GPU 作ったら Cell GPU になるのか解らん
# 解っちゃいけないトコかも知れないけど
そういえば HP が PA-RISC でグラボ作ってたよな(Visualizeだっけ)…
あとSunもMAJCとか作ってたっけ…
ところで >>894 って,なんで POWER7 で GPU 作ったら Cell GPU になるのか解らん
# 解っちゃいけないトコかも知れないけど
>>860
アンドロイド利用で開国じゃ!!
アンドロイド利用で開国じゃ!!
携帯電話用ベースバンドI統合アプリケーションプロセッサとしては
SH-Mobile G4が性能/電力面でベストな存在。次点UniPhier 4M。
ちなみに>>880は朝鮮人の皮を被ったアングロサクソン工作員。
SH-Mobile G4が性能/電力面でベストな存在。次点UniPhier 4M。
ちなみに>>880は朝鮮人の皮を被ったアングロサクソン工作員。
3行目間違えた。880じゃなくて>>860ですた。
>>894
「餅は餅屋」とは良く言ったもんで。
「餅は餅屋」とは良く言ったもんで。
Intelと同じ道は歩まず・・・か
おもしろくないな
おもしろくないな
VMX/Altivec改を8個並べたやつの市場実験はもう済んでる
携帯端末、触れずに操作 東大が新技術
http://www.nikkei.com/news/headline/article/g=96958A9C93819696E0E3E290818DE0E3E2E6E0E2E3E2E2E2E2E2E2E2
>高速カメラと画像処理回路を搭載したモバイル機器を試作した。
画像処理回路とCPUとは同じLSIでもどう構造が違うのでしょうか?
画像処理回路というのはCPUよりはGPUに近いものでしょうか?
http://www.nikkei.com/news/headline/article/g=96958A9C93819696E0E3E290818DE0E3E2E6E0E2E3E2E2E2E2E2E2E2
>高速カメラと画像処理回路を搭載したモバイル機器を試作した。
画像処理回路とCPUとは同じLSIでもどう構造が違うのでしょうか?
画像処理回路というのはCPUよりはGPUに近いものでしょうか?
画像処理とFPGAやASICやアプリケーションプロセッサとかを組み合わせてggrks
>>843でちょっと迂闊なことを書きました。
-------------------
将来的にはSOIを生かしたFBCに向かう様で…
-------------------
昨年9月にプレスリリースが出ていたネタですが、32nmのディープ・トレンチ・セルの eDRAM を IEDM 2009 で発表しています。
詳しい紹介記事はこちら。当分IBMの eDRAM はこの路線ということで間違いなかろうかと…
http://www.semiconductor.net/article/354546-IBM_Readies_32_nm_eDRAM_With_Low_Latency.php
======================
The eDRAM is fully compatible with logic transistors,
with no degradation in logic performance. It incorporates
a deep trench capacitor structure, with a high-k dielectric
and metal liner capacitor technology.
======================
そう言えば、Z-RAM の Innovative Silicon も Hynix 向けの Bulk Si 向けの実装の方に力が入っているようです。
http://www.edn.com/article/CA6726490.html?nid=2551
======================
Hynix, Innovative Silicon show floating-body DRAM on bulk silicon
======================
これはこれで FinFET + FBC という意欲的な組み合わせで、先行きが楽しみではあります。
-------------------
将来的にはSOIを生かしたFBCに向かう様で…
-------------------
昨年9月にプレスリリースが出ていたネタですが、32nmのディープ・トレンチ・セルの eDRAM を IEDM 2009 で発表しています。
詳しい紹介記事はこちら。当分IBMの eDRAM はこの路線ということで間違いなかろうかと…
http://www.semiconductor.net/article/354546-IBM_Readies_32_nm_eDRAM_With_Low_Latency.php
======================
The eDRAM is fully compatible with logic transistors,
with no degradation in logic performance. It incorporates
a deep trench capacitor structure, with a high-k dielectric
and metal liner capacitor technology.
======================
そう言えば、Z-RAM の Innovative Silicon も Hynix 向けの Bulk Si 向けの実装の方に力が入っているようです。
http://www.edn.com/article/CA6726490.html?nid=2551
======================
Hynix, Innovative Silicon show floating-body DRAM on bulk silicon
======================
これはこれで FinFET + FBC という意欲的な組み合わせで、先行きが楽しみではあります。
907 :Socket774:2010/04/27(火) 15:29:31 ID:35bcycjE
AMDの6コア「Phenom II X6」はターボモードを備えバーゲン価格で登場
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
http://pc.watch.impress.co.jp/docs/column/kaigai/20100427_364107.html
Turbo Boost と Turbo Coreはどっちが凄いの?
http://pc11.2ch.net/test/read.cgi/jisaku/1272370378/l50
http://pc11.2ch.net/test/read.cgi/jisaku/1272370378/l50
Intrinsity買収をAppleが認めた
ttp://www.nytimes.com/2010/04/28/technology/28apple.html
ttp://www.nytimes.com/2010/04/28/technology/28apple.html
ARMの行く先が不安になってくるな
Appleは買収する会社を間違ってる
世界のPC用プロセッサ市場、第1四半期は前年同期比39%増
http://japan.internet.com/finanews/20100501/12.html
http://japan.internet.com/finanews/20100501/12.html
a
先月半ばにリリースされた GCC 4.5 では、ちょうどこのスレッドに登場した様々なPPCの実装がサポートされています。
http://gcc.gnu.org/gcc-4.5/changes.html
---------------------------
・GCC now supports the Power ISA 2.06, which includes the VSX
instructions that add vector 64-bit floating point support, new
population count instructions, and conversions between floating
point and unsigned types.
・Support for the power7 processor is now available through the
-mcpu=power7 and -mtune=power7.
・GCC will now vectorize loops that contain simple math functions
like copysign when generating code for altivec or VSX targets.
・Support for the A2 processor is now available through the
-mcpu=a2 and -mtune=a2 options.
・Support for the 476 processor is now available through the
-mcpu={476,476fp} and -mtune={476,476fp} options.
・Support for the e500mc64 processor is now available through the
-mcpu=e500mc64 and -mtune=e500mc64 options.
・GCC can now be configured with options --with-cpu-32,
--with-cpu-64, --with-tune-32 and --with-tune-64 to control
the default optimization separately for 32-bit and 64-bit modes.
---------------------------
まだ現物が発表されていないのは Freescale の e500mc64 でしたっけ?今年の FTF で発表されると思われます。
http://www.freescale.com/webapp/sps/site/overview.jsp?nodeId=052577903689DC
http://gcc.gnu.org/gcc-4.5/changes.html
---------------------------
・GCC now supports the Power ISA 2.06, which includes the VSX
instructions that add vector 64-bit floating point support, new
population count instructions, and conversions between floating
point and unsigned types.
・Support for the power7 processor is now available through the
-mcpu=power7 and -mtune=power7.
・GCC will now vectorize loops that contain simple math functions
like copysign when generating code for altivec or VSX targets.
・Support for the A2 processor is now available through the
-mcpu=a2 and -mtune=a2 options.
・Support for the 476 processor is now available through the
-mcpu={476,476fp} and -mtune={476,476fp} options.
・Support for the e500mc64 processor is now available through the
-mcpu=e500mc64 and -mtune=e500mc64 options.
・GCC can now be configured with options --with-cpu-32,
--with-cpu-64, --with-tune-32 and --with-tune-64 to control
the default optimization separately for 32-bit and 64-bit modes.
---------------------------
まだ現物が発表されていないのは Freescale の e500mc64 でしたっけ?今年の FTF で発表されると思われます。
http://www.freescale.com/webapp/sps/site/overview.jsp?nodeId=052577903689DC
power.org がロードマップ図を更新しています。
http://www.power.org/resources/devcorner/roadmap/Power_org_PA_Roadmap_2010_.pdf
AppliedMicro Titan, IBM/LSI PPC476, IBM A2, Freescale QorIQ あたりが次世代を構成すると思われます。
注目すべきはPPC系アクレラレータとして、CELL/B.E. と Blue Gene の Double Hammer は終息の方向で、今年の ISSCC で発表された Wire-Speed POWER のアクセラレータ機構が後継になるとされていることです。
Wire-Speed のアクセラレータ ISAについては、IBM Journal R&D の論文を入手しましたので、そのうち詳しく書きます。
ちなみに上のロードマップで Freescale だけは e500 コアの使いまわしで、とても次世代と言えた代物ではありません。e500mc64 なり e700 なりが登場するのか、PPC はすっぱり諦めて ColdFire や ARM で生きていくことに決めたのか、今後の動向が注目されます。
http://www.power.org/resources/devcorner/roadmap/Power_org_PA_Roadmap_2010_.pdf
AppliedMicro Titan, IBM/LSI PPC476, IBM A2, Freescale QorIQ あたりが次世代を構成すると思われます。
注目すべきはPPC系アクレラレータとして、CELL/B.E. と Blue Gene の Double Hammer は終息の方向で、今年の ISSCC で発表された Wire-Speed POWER のアクセラレータ機構が後継になるとされていることです。
Wire-Speed のアクセラレータ ISAについては、IBM Journal R&D の論文を入手しましたので、そのうち詳しく書きます。
ちなみに上のロードマップで Freescale だけは e500 コアの使いまわしで、とても次世代と言えた代物ではありません。e500mc64 なり e700 なりが登場するのか、PPC はすっぱり諦めて ColdFire や ARM で生きていくことに決めたのか、今後の動向が注目されます。
CELL/B.E. の終息という話題はあくまでヘテロジニアス ISA を諦めたということのようです。
Wire-Speed アクセラレータは大昔のコプロセッサのように、CPU のプログラムの中にアクセラレータ命令を挿入するという手法を選択しており、アクセラレータとしては SPE も利用できるようになっています。
Wire-Speed アクセラレータは大昔のコプロセッサのように、CPU のプログラムの中にアクセラレータ命令を挿入するという手法を選択しており、アクセラレータとしては SPE も利用できるようになっています。
その補足って政治的配慮って事はないの?
SPEの有効性ってどんなもんだ。
SPEの有効性ってどんなもんだ。
919 :MACオタ>918 さん:2010/05/04(火) 21:52:02 ID:PQOz9BHB
>>918
-----------------
その補足って政治的配慮って事はないの?
-----------------
既存のCBEA対応のツールが全てお釈迦になりますから、政治的にはむしろマイナスかと。
SCE特許にあるヘテロコアの"broadband architecture"構想は廃棄ということですね。
いかにもIBMらしいやりかたですが、奇しくも私がメガビで「PowerPCの話」を書いていた
ころの予測通りの構成になっています(笑)
-----------------
その補足って政治的配慮って事はないの?
-----------------
既存のCBEA対応のツールが全てお釈迦になりますから、政治的にはむしろマイナスかと。
SCE特許にあるヘテロコアの"broadband architecture"構想は廃棄ということですね。
いかにもIBMらしいやりかたですが、奇しくも私がメガビで「PowerPCの話」を書いていた
ころの予測通りの構成になっています(笑)
CELL/B.E.終わりって事はPS3でおしまいでPS4は出ないって事?
お友達が待ってるから巣に帰りましょうね。
やだプーンw
923 :,,・´∀`・,,)っ-○○○:2010/05/07(金) 13:03:46 ID:ls/Tt+fy
>>917
> 大昔のコプロセッサのように、CPU のプログラムの中にアクセラレータ命令を挿入するという手法を選択しており、
ARMでは現役だぞ?
まあそのままだとOpcode空間は足りないだろうからステート切替でコプロセッサ命令を発行するする手法は有効だろうな
> 大昔のコプロセッサのように、CPU のプログラムの中にアクセラレータ命令を挿入するという手法を選択しており、
ARMでは現役だぞ?
まあそのままだとOpcode空間は足りないだろうからステート切替でコプロセッサ命令を発行するする手法は有効だろうな
犬板から転載
ARM、サーバで利用した場合のチップアーキテクチャの有効性を検証中
http://japan.cnet.com/news/ent/story/0,2000056022,20413066,00.htm
ARM、サーバで利用した場合のチップアーキテクチャの有効性を検証中
http://japan.cnet.com/news/ent/story/0,2000056022,20413066,00.htm
a
つまりPOWER7 GPUの登場も近いってことか。
>>927
POWER GXTの二の舞に。
POWER GXTの二の舞に。
930 :,,・´∀`・,,)っ-○○○:2010/05/09(日) 09:37:47 ID:sNWFFdis
静的運用のWebサイトなら十分だがDB連携とかやりだすときつい気がする
931 :,,・´∀`・,,)っ-○○○:2010/05/09(日) 10:00:13 ID:sNWFFdis
Wikiのバックエンドと書き換え頻度が知りたいね
「ダメだ! ARMではDB連携の書き換え速度に対応できない!」
「こんなこともあろうかとSupeHコアを混載しておいたのだ!」
役に立ちそうにない。
「こんなこともあろうかとSupeHコアを混載しておいたのだ!」
役に立ちそうにない。
3GHzくらいで動作して6MBくらいのキャッシュ搭載なARMならオケだろ。
単にそんなARMプロセッサが現状で存在してないだけで。
単にそんなARMプロセッサが現状で存在してないだけで。
934 :Socket774:2010/05/09(日) 23:20:30 ID:j4MjQvhL
DB連携って多分RDBMSを念頭に置いているんだよね?
ARMみたいにやや非力で実装面積が少ないプロセッサの場合は
スケールアップはx86に対してディスアドバンテージ、スケールアウトに
関してはアドバンテージが多分あるんじゃないかと思う。
なのでRDBMSは恐らく相性悪そうという気がするけど、KVSとか
だったらどうなんだろう。そういう性能評価もやってるんじゃないかな。
IO性能に何か問題があるからDBには向いてないという話では多分ないよね?
今発表されている中では最高性能のMarvellのArmadaとかだと
最大4コアで動作クロック2GHzなんだけど、3GHzならオケで
2GHzだとアウトとかそういうもんなん?
ARMみたいにやや非力で実装面積が少ないプロセッサの場合は
スケールアップはx86に対してディスアドバンテージ、スケールアウトに
関してはアドバンテージが多分あるんじゃないかと思う。
なのでRDBMSは恐らく相性悪そうという気がするけど、KVSとか
だったらどうなんだろう。そういう性能評価もやってるんじゃないかな。
IO性能に何か問題があるからDBには向いてないという話では多分ないよね?
今発表されている中では最高性能のMarvellのArmadaとかだと
最大4コアで動作クロック2GHzなんだけど、3GHzならオケで
2GHzだとアウトとかそういうもんなん?
よく知らないんだけど、いつまでAtomはいつまでインオーダで
クロック2GHz以下なん?すでにARMはアウトオブオーダになっちゃったし、
クロックもそろそろ抜かれそうなんだけど。
クロック2GHz以下なん?すでにARMはアウトオブオーダになっちゃったし、
クロックもそろそろ抜かれそうなんだけど。
インオーダだろうがアウトオブオーダだろうがクロックがいくつだろうが
そんな違いなどなんの意味も無い。
最終的な性能や消費電力のみが全て。
そんな違いなどなんの意味も無い。
最終的な性能や消費電力のみが全て。
そんな違いなどなんの意味も無い。
最終的な性能や消費電力のみが全て。
このスレでそんなつまらいなこというなよ。
製品スレでやってくれ。
最終的な性能や消費電力のみが全て。
このスレでそんなつまらいなこというなよ。
製品スレでやってくれ。
(´・ω・)OoOだとデコーダが電気喰って熱いし面積もでかくなるからいっそ捨ててまえというのがAtomなのに…
ARMだx86だ言ってトロい世界で争っていて下さい^^
その間にCUDAがぶち抜いていきますんで^^
その間にCUDAがぶち抜いていきますんで^^
ゲームグラフィックスソフトの制作から足を洗えばもっと楽になって
それこそ狂喜乱舞まちがいなしです
人間らしい暮らしが出来ます
それこそ狂喜乱舞まちがいなしです
人間らしい暮らしが出来ます
Cellの何が駄目かって
投入した労力に対してリターンが割合わないという事に尽きる。
投入した労力に対してリターンが割合わないという事に尽きる。
>>942
アンドロイドアプリ(ゲーム)とかに転職すると良いでしょうか?
アンドロイドアプリ(ゲーム)とかに転職すると良いでしょうか?
結局新PPCにもSPEが繋げられるんじゃゲーム開発的には同じことになるだろう
何年も後に出るものが先に出たものより劣っていたら話にならない。
結局辞書通りのあだ花だったという事 >Cell
>>944
割に合う合わないはプログラムがどれだけ普及するかとか大規模に使われるかによるけどな。
割に合う合わないはプログラムがどれだけ普及するかとか大規模に使われるかによるけどな。
>>950
まあでも、個人で使われることはないってことだよな
まあでも、個人で使われることはないってことだよな
同じ8コアで600MHz、2.8WのRP2が消費電力辺り性能なら勝負になるな。
RP2ってSH4ベースでしょ?
600Mz程度でそんな性能でるもんなの?
600Mz程度でそんな性能でるもんなの?
消費電力辺り性能だから勝負になる。
よくわからんけど詳しいデータシートある?
SPEってコア消費電力辺りの性能かなりのもんだよ
ちょっと歪な構造だけど
SPEってコア消費電力辺りの性能かなりのもんだよ
ちょっと歪な構造だけど
どうでもいい
終ったCellの話題禁止
終ったCellの話題禁止
Cellの性能ってどうせ理論ピークFLOPSだろwネタにもならんわ
SPE終わってる説に反論する気はないけど
SH4だって ほぼ 終わってると思うけど…
>>934
> ARMみたいにやや非力で実装面積が少ないプロセッサの場合は
> スケールアップはx86に対してディスアドバンテージ、スケールアウトに
> 関してはアドバンテージが多分あるんじゃないかと思う。
ARMがスケールアウトでアドバンテージがあるなんて意見は初耳だな
プラットフォームが無くて強力な足周りが無い状態でどうやってスケールアウトするのやら
消費電力低いからサーバーの数は増やしやすい場合もあるだろうけど、
そのサーバー群って全く連携しない前提ですよね?
SH4だって ほぼ 終わってると思うけど…
>>934
> ARMみたいにやや非力で実装面積が少ないプロセッサの場合は
> スケールアップはx86に対してディスアドバンテージ、スケールアウトに
> 関してはアドバンテージが多分あるんじゃないかと思う。
ARMがスケールアウトでアドバンテージがあるなんて意見は初耳だな
プラットフォームが無くて強力な足周りが無い状態でどうやってスケールアウトするのやら
消費電力低いからサーバーの数は増やしやすい場合もあるだろうけど、
そのサーバー群って全く連携しない前提ですよね?
> プラットフォームが無くて強力な足周りが無い状態でどうやってスケールアウトするのやら
そのあたりの課題を検証してるっていうのが今回の話ではないでしょうか。
スケールアウトのアドバンテージ云々の話は理屈(もしくは仮定)の上の話であって
(現実の問題は置いておく)、もしそういった理屈の上での何らかのアドバンテージの
見込がなければ検証なんて誰もしないんじゃないの。その理屈が正しいかどうかは
本当に試してみないとわからない。
問題は本当にそれらの問題が解決できるのかどうか、思ったようなパフォーマンス、
消費電力、発熱量になるのか等々ってことじゃないの。将来的にできるものが
今ないことじゃないと思う。
> そのサーバー群って全く連携しない前提ですよね?
検証の結果、そういう答えになることもありうるかと。
そのあたりの課題を検証してるっていうのが今回の話ではないでしょうか。
スケールアウトのアドバンテージ云々の話は理屈(もしくは仮定)の上の話であって
(現実の問題は置いておく)、もしそういった理屈の上での何らかのアドバンテージの
見込がなければ検証なんて誰もしないんじゃないの。その理屈が正しいかどうかは
本当に試してみないとわからない。
問題は本当にそれらの問題が解決できるのかどうか、思ったようなパフォーマンス、
消費電力、発熱量になるのか等々ってことじゃないの。将来的にできるものが
今ないことじゃないと思う。
> そのサーバー群って全く連携しない前提ですよね?
検証の結果、そういう答えになることもありうるかと。
>>952
初代はlinuxインスト可がデフォだったんだから
あれは型番がいくら変わろうが継続するべきだったな
商売的に旨みがなかろうが
あの小物二代目が
PS3はゲーム機以外の何物でもありません!宣言が出た瞬間に
ただの図体がでかいゲーム機と成り下がった
初代はlinuxインスト可がデフォだったんだから
あれは型番がいくら変わろうが継続するべきだったな
商売的に旨みがなかろうが
あの小物二代目が
PS3はゲーム機以外の何物でもありません!宣言が出た瞬間に
ただの図体がでかいゲーム機と成り下がった
>>961(=>>934?)ですか?
何か妄想ばかりで勝手に判断してませんか?
(1) ARM に intel のチップセットのような周辺チップ群 (プラットフォーム) が無いのは常識
(2) I/O 性能はプラットフォーム (SoC の場合は CPU と同シリコン上にある周辺回路群) の性能に依存する
(何を勘違いしているのか>>934はCPUコアの話とI/O性能の話を混同していますが…)
(3) 連携が前提だとスケールアウトするには I/O 性能が高くないと話しにならない
(1)〜(3) を考慮するなら「現状では ARM は intel と比べて大幅にスケールアウトしにくい」ことは
実機で検証する前にデータシート見比べれば解る話で,ARM の実機検証は別の目的と考えるのが妥当です.
勿論,ARMも「何らかの見込み」は持っているでしょうが
>>934>>961の言う「スケールアウト」にアドバンテージが無いのは明らかに思えます
>>961 は自分の妄想でARMの検証の目的を勝手に決めてしまっていませんか?
> 「将来的にできるものが今ないことじゃないと思う。」
それは ARM の意見じゃなくて >>961 の「ぼくがかんがえた さいきょう CPU」の話ですよね?
現に Marvell の SoC で検証しているように,ARM が言っているのは製品レベルの話で妄想じゃない.
何か妄想ばかりで勝手に判断してませんか?
(1) ARM に intel のチップセットのような周辺チップ群 (プラットフォーム) が無いのは常識
(2) I/O 性能はプラットフォーム (SoC の場合は CPU と同シリコン上にある周辺回路群) の性能に依存する
(何を勘違いしているのか>>934はCPUコアの話とI/O性能の話を混同していますが…)
(3) 連携が前提だとスケールアウトするには I/O 性能が高くないと話しにならない
(1)〜(3) を考慮するなら「現状では ARM は intel と比べて大幅にスケールアウトしにくい」ことは
実機で検証する前にデータシート見比べれば解る話で,ARM の実機検証は別の目的と考えるのが妥当です.
勿論,ARMも「何らかの見込み」は持っているでしょうが
>>934>>961の言う「スケールアウト」にアドバンテージが無いのは明らかに思えます
>>961 は自分の妄想でARMの検証の目的を勝手に決めてしまっていませんか?
> 「将来的にできるものが今ないことじゃないと思う。」
それは ARM の意見じゃなくて >>961 の「ぼくがかんがえた さいきょう CPU」の話ですよね?
現に Marvell の SoC で検証しているように,ARM が言っているのは製品レベルの話で妄想じゃない.
>963
報道ではARMの目的はわかんないので、「〜じゃないかな」、「だと思う」という
憶測で勝手なこと言っているわけですが、あーだこーだ言うのが楽しいのでは。
I/O性能云々の話は(1)〜(3)まで相違はないです。現状の話はしてなくて、
SoCなんで最終的には充分な性能のI/Oを同一シリコンに入れてしまえば
OKで、入らなくてもPCI-expressとかその他汎用インターフェイスで
チップの外にI/Oを持てばいいんじゃないの。
ARMのI/O性能が劣ってないと思っているのは特にARMアーキテクチャ上の
制約で高速なI/Oを拡張できないなんてことはないって意見なんですが。
> 現に Marvell の SoC で検証しているように,ARM が言っているのは製品レベルの話で妄想じゃない.
検証するのは現状あるもので試すしかないのは当たり前で、もしそれより
先のことを考えているとしてもそれは変わらない。
逆にARMが製品レベルで考えているっていう根拠はどこなんでしょうか?
どっちにしてもソフトウェアもないので製品化はまだ先、そうなると
今あるチップチップセットで製品化しなければならない必然性は
あんまないと思います(その時には別のチップセットが出ている)。
Marvellのチップセットを使っているのは現状では最もコア性能も
高いこともあるけど、ネットワーク機器に向いている設計でI/Oも他と
比較して充実していることもあると思います。とは言ってもギガイーサ
とかPCI-expressとかSATAとかデスクトップPCレベルのものですけど。
ARMの考える「ぼくのかんがえたさいきょうCPU」に対して実証実験する
価値がある程度には近いとは思います。
報道ではARMの目的はわかんないので、「〜じゃないかな」、「だと思う」という
憶測で勝手なこと言っているわけですが、あーだこーだ言うのが楽しいのでは。
I/O性能云々の話は(1)〜(3)まで相違はないです。現状の話はしてなくて、
SoCなんで最終的には充分な性能のI/Oを同一シリコンに入れてしまえば
OKで、入らなくてもPCI-expressとかその他汎用インターフェイスで
チップの外にI/Oを持てばいいんじゃないの。
ARMのI/O性能が劣ってないと思っているのは特にARMアーキテクチャ上の
制約で高速なI/Oを拡張できないなんてことはないって意見なんですが。
> 現に Marvell の SoC で検証しているように,ARM が言っているのは製品レベルの話で妄想じゃない.
検証するのは現状あるもので試すしかないのは当たり前で、もしそれより
先のことを考えているとしてもそれは変わらない。
逆にARMが製品レベルで考えているっていう根拠はどこなんでしょうか?
どっちにしてもソフトウェアもないので製品化はまだ先、そうなると
今あるチップチップセットで製品化しなければならない必然性は
あんまないと思います(その時には別のチップセットが出ている)。
Marvellのチップセットを使っているのは現状では最もコア性能も
高いこともあるけど、ネットワーク機器に向いている設計でI/Oも他と
比較して充実していることもあると思います。とは言ってもギガイーサ
とかPCI-expressとかSATAとかデスクトップPCレベルのものですけど。
ARMの考える「ぼくのかんがえたさいきょうCPU」に対して実証実験する
価値がある程度には近いとは思います。
http://www.marvell.com/products/processors/embedded/armada_300/armada_310.pdf
Marvellの一番新しいネットワーク装置向けのチップセットはこれみたいです。
これ以上の情報はNDA結ばないとわからない。
Marvellの一番新しいネットワーク装置向けのチップセットはこれみたいです。
これ以上の情報はNDA結ばないとわからない。
米軍怒らせるなよwwwwww
トヨタの二の舞どころじゃないぞ
旧モデルPS3本体の「Install Other OS機能」がアップデートで廃止されたのを発端に米国で複数の
集団訴訟が起こっていますが、クラスタ化した大量のPS3をスーパーコンピューターとして利用していた
米空軍の担当者が、この件を問題視しているようです。
“既に手元にあるシステムは今後も使い続けるつもりですが、この件(ファームウェアアップデート)で
故障した本体を交換するのが難しくなりました。ソニーから修理されて戻ってきた本体には新しいファーム
ウェアがインストールされ、他のOSも利用できなくなるのは、問題があるように思えます。本体にもともと
あったこの機能を取り除いたソニーに対し集団訴訟があるのは我々も認識しております。”
「他のOSのインストール機能」の廃止を巡っては、米国のユーザーらによって三件の集団訴訟が
起こされています。
http://gs.inside-games.jp/news/231/23181.html
トヨタの二の舞どころじゃないぞ
旧モデルPS3本体の「Install Other OS機能」がアップデートで廃止されたのを発端に米国で複数の
集団訴訟が起こっていますが、クラスタ化した大量のPS3をスーパーコンピューターとして利用していた
米空軍の担当者が、この件を問題視しているようです。
“既に手元にあるシステムは今後も使い続けるつもりですが、この件(ファームウェアアップデート)で
故障した本体を交換するのが難しくなりました。ソニーから修理されて戻ってきた本体には新しいファーム
ウェアがインストールされ、他のOSも利用できなくなるのは、問題があるように思えます。本体にもともと
あったこの機能を取り除いたソニーに対し集団訴訟があるのは我々も認識しております。”
「他のOSのインストール機能」の廃止を巡っては、米国のユーザーらによって三件の集団訴訟が
起こされています。
http://gs.inside-games.jp/news/231/23181.html
ここはもうゲハ住人に占拠されてしまったんだな。
Air Force may suffer collateral damage from PS3 firmware update
(空軍はPS3のファームウェアアップデートからの間接被害で苦しむかもしれない)
We checked in with the Air Force Research Laboratory, which noted its disappointment
with the Sonydecision.
(我々は空軍のリサーチラボを調査したが、そこはソニーの決定への失望を示していた)
the lab told Ars, but "this will make it difficult to replace systems
that break or fail.
(しかしラボがArsに語ったところでは「壊れたり、故障したときには復旧するの
が困難だろう。)
We are aware of class-action lawsuits against Sony for taking away this option on
systems that use to have it."
(我々はソニーに対する利用しているシステム上の権利を取り消すためのソニーへの集団訴訟
を承知している」)
(空軍はPS3のファームウェアアップデートからの間接被害で苦しむかもしれない)
We checked in with the Air Force Research Laboratory, which noted its disappointment
with the Sonydecision.
(我々は空軍のリサーチラボを調査したが、そこはソニーの決定への失望を示していた)
the lab told Ars, but "this will make it difficult to replace systems
that break or fail.
(しかしラボがArsに語ったところでは「壊れたり、故障したときには復旧するの
が困難だろう。)
We are aware of class-action lawsuits against Sony for taking away this option on
systems that use to have it."
(我々はソニーに対する利用しているシステム上の権利を取り消すためのソニーへの集団訴訟
を承知している」)
ファームウェア更新しなけりゃいいだろw
>>969
>“既に手元にあるシステムは今後も使い続けるつもりですが、この件(ファームウェアアップデート)で
>故障した本体を交換するのが難しくなりました。ソニーから修理されて戻ってきた本体には新しいファーム
>ウェアがインストールされ、他のOSも利用できなくなるのは、問題があるように思えます。本体にもともと
>あったこの機能を取り除いたソニーに対し集団訴訟があるのは我々も認識しております。”
>“既に手元にあるシステムは今後も使い続けるつもりですが、この件(ファームウェアアップデート)で
>故障した本体を交換するのが難しくなりました。ソニーから修理されて戻ってきた本体には新しいファーム
>ウェアがインストールされ、他のOSも利用できなくなるのは、問題があるように思えます。本体にもともと
>あったこの機能を取り除いたソニーに対し集団訴訟があるのは我々も認識しております。”
米空軍も本当にその辺で売ってるPS3を買ってきてるんだな
もうちょっと違う方法で調達してると思ってた
もうちょっと違う方法で調達してると思ってた
そこまでの予算がついてるプロジェクトでは無い、という事だな…
>>970
保障規定ってどうなってるのかな。LinuxOSをインストールすること事態無保証な気が。
保障規定ってどうなってるのかな。LinuxOSをインストールすること事態無保証な気が。
民生品の軍事転用COTS(Commercial-off-the-Shelf)はずいぶん前からやってるから「またか」程度。
軍隊は昔は何でも専用品だったけど、いまはその辺で買ってきたものを使ってるよ。
イニシャルコストは安く付くけど、そのかわり頻繁なモデルチェンジやディスコンによるコスト増は承知の上
PS3のスパコンはPS3だからニュースになっただけで、川崎のバイクや東芝のノートPCが採用されてもニュースにならん。
そのKLR 650はディーゼルに魔改造されてるけどw
軍隊は昔は何でも専用品だったけど、いまはその辺で買ってきたものを使ってるよ。
イニシャルコストは安く付くけど、そのかわり頻繁なモデルチェンジやディスコンによるコスト増は承知の上
PS3のスパコンはPS3だからニュースになっただけで、川崎のバイクや東芝のノートPCが採用されてもニュースにならん。
そのKLR 650はディーゼルに魔改造されてるけどw
陸自の偵察バイクも川崎だけど普通にオイル漏れてる
もっとも撃たれて穴ぼこだらけになってオイルが抜けても動くから川崎なのかもしれんが
もっとも撃たれて穴ぼこだらけになってオイルが抜けても動くから川崎なのかもしれんが
Kawasakiのバイクは性格上追うバイクじゃなくて追われるバイクだからな
HDDがゲルに包まれてて液晶に強化ガラスなイメージが。。。
>>972
というより米軍も予算縮小でスパコン関係はどんどん苦しくなってるらしい
というより米軍も予算縮小でスパコン関係はどんどん苦しくなってるらしい
979 :,,・´∀`・,,)っ-○○○:2010/05/17(月) 18:45:02 ID:3wc/5yYP
機能を削ることでの社会的リスクも考えられなかったSCEは無能。
SCEにだっていろんなやつがいるだろ
若手がPS3をオープンなものにしようとして、上層部の連中がセキュリティを口実にして押さえつけたと予想。
若手がPS3をオープンなものにしようとして、上層部の連中がセキュリティを口実にして押さえつけたと予想。
逆だと思うな。
ゲーム屋だと思われたくない老人が「Linux入れられるようにしろ!」って言って
ゲームのコピーに使われるようになってようやく”Linux機能いらない派”が勝った。
ゲーム屋だと思われたくない老人が「Linux入れられるようにしろ!」って言って
ゲームのコピーに使われるようになってようやく”Linux機能いらない派”が勝った。
どうしたいのかがさっぱり見えてこないのは・・なあ
PS2の互換捨てたうまみ覚えちゃって、
Cellも一期限りってなりうる
トランジスタ辺りの性能と汎用性、
とあとリアルタイム性能だっけ?
一つはあっても良いプロセッサだとは思うのに
用途はしらん。
PS2の互換捨てたうまみ覚えちゃって、
Cellも一期限りってなりうる
トランジスタ辺りの性能と汎用性、
とあとリアルタイム性能だっけ?
一つはあっても良いプロセッサだとは思うのに
用途はしらん。
983 :,,・´∀`・,,)っ-○○○:2010/05/17(月) 20:21:26 ID:3wc/5yYP
そもそもLinux云々はクタラギさんのトップダウン構想だったような。
PS2のLinux kitも彼の発言が発端のようだし
まあ、Linuxが使えることを期待して購入した消費者を裏切ったのは事実だから
各国の法に従って賠償には応じてしかるべきだな
PS2のLinux kitも彼の発言が発端のようだし
まあ、Linuxが使えることを期待して購入した消費者を裏切ったのは事実だから
各国の法に従って賠償には応じてしかるべきだな
そのへんのGPUみたいに9億とか14億とか投じれば
TDPもすごいことになりそうだが目立つくらいは出来るだろうに
こうなると3GHzでは難しくなるんだっけ?
久々に調べてたらこんなん見つけた
http://www.miyazaki-u.ac.jp/~aoyama_t/IPSJ-MGN500206.pdf
TDPもすごいことになりそうだが目立つくらいは出来るだろうに
こうなると3GHzでは難しくなるんだっけ?
久々に調べてたらこんなん見つけた
http://www.miyazaki-u.ac.jp/~aoyama_t/IPSJ-MGN500206.pdf
>>983
同意だなあ。そういう触れ込みで売ったんだからなあ。
もともとRSXへはアクセス制限されてたんだから、
Cell+やすいGPUのPC作って交換してやればいいのにw
そんなにRSX動作停止させる事って難しいのかなぁ。
Linuxで起動したときはRSXの電力絞られて、
再起動するまでロックされるとか出来ないのか。
同意だなあ。そういう触れ込みで売ったんだからなあ。
もともとRSXへはアクセス制限されてたんだから、
Cell+やすいGPUのPC作って交換してやればいいのにw
そんなにRSX動作停止させる事って難しいのかなぁ。
Linuxで起動したときはRSXの電力絞られて、
再起動するまでロックされるとか出来ないのか。
>>985
そりゃあクタラギ老人だろう。ヤツはかなり前衛的だ。
ソニーはファーム書き換えサービスとかやったらいいんじゃないかね。
有償もしくは実費でファームウェアを旧製品のものに書き換えますよ、と。
ハードウェアの変更があったら終了だけど。
そりゃあクタラギ老人だろう。ヤツはかなり前衛的だ。
ソニーはファーム書き換えサービスとかやったらいいんじゃないかね。
有償もしくは実費でファームウェアを旧製品のものに書き換えますよ、と。
ハードウェアの変更があったら終了だけど。
>>981
20万円でなんでもできるコンピュータとしてハードウェアで利益を出して売るか、
4万円でゲームのロイヤリティで回収するゲーム機として売るかというビジネス
モデルの違いあるいは矛盾を詰めないで、間をとってりゃなんとかなるべと適当に
売り出しちゃったしわ寄せがきただけ。
Cellが家電用として融通が利かなかったり、独自汎用OSの開発の失敗も大きかったけど。
機能は多く開発費もかかり、またソニー本体の製品とかぶることも多いのに、
ハードは赤字で利益はゲームのロイヤリティからしか取れないアンバランス。
ゲームユーザーからすればPS3をコンピューティングだけに使う人間は、ある意味で
PS3の赤字分を自分たちの負担でフリーライドされていた、と言えなくもない。
一方でAppleは今のところはうまいことバランスをとって大成功。けどiPadで間違えそうな気がするんだよなあ。
20万円でなんでもできるコンピュータとしてハードウェアで利益を出して売るか、
4万円でゲームのロイヤリティで回収するゲーム機として売るかというビジネス
モデルの違いあるいは矛盾を詰めないで、間をとってりゃなんとかなるべと適当に
売り出しちゃったしわ寄せがきただけ。
Cellが家電用として融通が利かなかったり、独自汎用OSの開発の失敗も大きかったけど。
機能は多く開発費もかかり、またソニー本体の製品とかぶることも多いのに、
ハードは赤字で利益はゲームのロイヤリティからしか取れないアンバランス。
ゲームユーザーからすればPS3をコンピューティングだけに使う人間は、ある意味で
PS3の赤字分を自分たちの負担でフリーライドされていた、と言えなくもない。
一方でAppleは今のところはうまいことバランスをとって大成功。けどiPadで間違えそうな気がするんだよなあ。
今もHWの採算とれてないのかな?
開発費回収終われば採算とれるようになるでしょ。
開発費回収終われば採算とれるようになるでしょ。
PS3は3月で逆ざやは解消したらしいね
ようやく今年かよw
まあ5年サイクルも崩れたっぽいしガンがレや。
まあ5年サイクルも崩れたっぽいしガンがレや。
負担をソニーの別部門に移しただけという話も…
ところで1チップPS3はまだかね。
とっくにPSPが有るでしょ。
イミフ
>>997
たぶんiPadの方向性っていう意味だと思う
たぶんiPadの方向性っていう意味だと思う
999 :,,・´∀`・,,)っ-○○○:2010/05/18(火) 19:15:36 ID:bwPlRpAo
ARM(Cortex-A9系のSoC)って言ってなかったか?
1000
1001 :1001: