AMD�̎�����CPU�ɂ��Č�낤 ��11����
���ߋ��X��
10 http://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
9 http://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
8 http://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
7 http://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
6 http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
5 http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�������AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
CPU�A�[�L�e�N�`���ɂ��Č�� �W
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Intel�̎�����CPU�ɂ��Č�낤 29
http://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
10 http://pc11.2ch.net/test/read.cgi/jisaku/1177368830/
9 http://pc11.2ch.net/test/read.cgi/jisaku/1172183431/
8 http://pc9.2ch.net/test/read.cgi/jisaku/1167003467/
7 http://pc7.2ch.net/test/read.cgi/jisaku/1161618220/
6 http://pc7.2ch.net/test/read.cgi/jisaku/1157327883/
5 http://pc7.2ch.net/test/read.cgi/jisaku/1150393478/
4 http://pc7.2ch.net/test/read.cgi/jisaku/1145187468/
3 http://pc7.2ch.net/test/read.cgi/jisaku/1138983969/
2 http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
1 http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�������AMD�n�X���b�h�ߋ����O�ۑ��T�C�g�l
http://amd.jisakuita.net/
���֘A�X��
CPU�A�[�L�e�N�`���ɂ��Č�� �W
http://pc11.2ch.net/test/read.cgi/jisaku/1178140550/
Intel�̎�����CPU�ɂ��Č�낤 29
http://pc11.2ch.net/test/read.cgi/jisaku/1180753939/
|
|
|
�������[�h�}�b�v�̓����N����Ă����̂œP���B
����̃y�[�W�͌�����Ȃ������B
�܂��B�ǂ������炭�l�^���Ȃ����c�������B
����̃y�[�W�͌�����Ȃ������B
�܂��B�ǂ������炭�l�^���Ȃ����c�������B
�e���v��
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�t�@���̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�t�@���̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
�e���v��
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�B>>3��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
>>3��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������>>3�̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�B>>3��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���t�@���ɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
>>3��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������>>3�̂����g�����h�B�ƊE�̃g�����h�ƍ������Ă͂����Ȃ��j
�����ƍL�����E�ɖڂ�������ׂ����Ǝv����
>>4
���̋ƊE�̃g�����h�̓t���[�W��������ˁi�j
���̋ƊE�̃g�����h�̓t���[�W��������ˁi�j
6 �FMAC�I�^�F2007/06/12(��) 00:12:14 ID:MDfzQR8J
���������Ő\���������ǁAAnandtech��Computex�ł�Barcelona�W�̏����܂Ƃ߂Ă邷�B
http://www.anandtech.com/tradeshows/showdoc.aspx?i=3006
�����J��������f�A����Ƃ��ڂɂ�������������1.4GHz��1.6GHz(��҂탊�r�W����B01
�������Ƃ̂���)�������������Ƃ��A�}�U�[�{�[�h�x���_�ɂ��̃��r�W�����������̂����捠�ŁA
�S�RBIOS���o���ĂȂ����ߌ����_��HT�����������r�f�I�J�[�h���܂Ƃ��ɓ����Ȃ���Ԃ�
�Ƃ��ABarcelona��9���ɂȂ�Ƃ��T�Șb���肷�B
�l�K�e�B�u�ȕ��������p����Ƃ��肪�����̂ŁA�Ō�̂܂Ƃ߂���ꕶ�������B
�@�@-----------------------
�@�@The biggest story in all of this is that AMD is just not ready yet, the chips are not
�@�@scaling well, and today it's looking like Intel may eat their lunch the rest of this year.
�@�@AMD seems very optimistic with internal roadmaps showing 2.9GHz cores by Q1 2008,
�@�@but everything we've seen or heard today makes this seem unlikely.
�@�@-----------------------
http://www.anandtech.com/tradeshows/showdoc.aspx?i=3006
�����J��������f�A����Ƃ��ڂɂ�������������1.4GHz��1.6GHz(��҂탊�r�W����B01
�������Ƃ̂���)�������������Ƃ��A�}�U�[�{�[�h�x���_�ɂ��̃��r�W�����������̂����捠�ŁA
�S�RBIOS���o���ĂȂ����ߌ����_��HT�����������r�f�I�J�[�h���܂Ƃ��ɓ����Ȃ���Ԃ�
�Ƃ��ABarcelona��9���ɂȂ�Ƃ��T�Șb���肷�B
�l�K�e�B�u�ȕ��������p����Ƃ��肪�����̂ŁA�Ō�̂܂Ƃ߂���ꕶ�������B
�@�@-----------------------
�@�@The biggest story in all of this is that AMD is just not ready yet, the chips are not
�@�@scaling well, and today it's looking like Intel may eat their lunch the rest of this year.
�@�@AMD seems very optimistic with internal roadmaps showing 2.9GHz cores by Q1 2008,
�@�@but everything we've seen or heard today makes this seem unlikely.
�@�@-----------------------
>747 �FSocket774 �F2007/06/06(��) 17:39:28 ID:AnU2ejnf
>�}���`�R�A�̈Ă��o�����̂���AMD�ł���H
>�����Ƃ邱�Ƃ��ďo���Ȃ������̂��ȁE�E�E�B
�u���E���̃N�A�b�h�R�ACPU�v�ł���Barcelona�̔������������ꂻ��������A�^�����Ă�Ƃ��납�������������ł͂Ȃ����H
�N�A�b�h�R�APOWER5+��Core 2 Quad�����肩��B
�ǂ����������ς݂����ǂ�
>�}���`�R�A�̈Ă��o�����̂���AMD�ł���H
>�����Ƃ邱�Ƃ��ďo���Ȃ������̂��ȁE�E�E�B
�u���E���̃N�A�b�h�R�ACPU�v�ł���Barcelona�̔������������ꂻ��������A�^�����Ă�Ƃ��납�������������ł͂Ȃ����H
�N�A�b�h�R�APOWER5+��Core 2 Quad�����肩��B
�ǂ����������ς݂����ǂ�
�O�X���̂ӂ₯���l�^�Œނ�̂͂�߂Ă������������B
AMD�͖��ʂ�Quad Core�ɂ�����肷���B
���ʃj�b�`��Quad�ɗ͓���Ă��Ȃ��E�E�E
�Ƃ肠����Phenom X2���o����B
���̕����A��Δ���邩��B
���ʃj�b�`��Quad�ɗ͓���Ă��Ȃ��E�E�E
�Ƃ肠����Phenom X2���o����B
���̕����A��Δ���邩��B
>>9
Barcelona-1.6G�̃X�R�A���������K10 X4�͓��N���b�N��Kentsfield�Ƃقړ����B
���Ƃ����K10 X2(Kuma)�����N���b�N��Conroe�Ƃقړ������낤�B
7/22��2.66G��$183�ɂȂ�Conroe��2G�o�邩���₵��Kuma�łǂ�����ė����������̂��B
�����Ɛ��������肵��2.8G���炢�܂ŃN���b�N�L�т�܂ł͂ǂ��ɂ��Ȃ���B
Barcelona-1.6G�̃X�R�A���������K10 X4�͓��N���b�N��Kentsfield�Ƃقړ����B
���Ƃ����K10 X2(Kuma)�����N���b�N��Conroe�Ƃقړ������낤�B
7/22��2.66G��$183�ɂȂ�Conroe��2G�o�邩���₵��Kuma�łǂ�����ė����������̂��B
�����Ɛ��������肵��2.8G���炢�܂ŃN���b�N�L�т�܂ł͂ǂ��ɂ��Ȃ���B
���̂���ɂ̓C���e���͂����Ɛ�s���Ă邾�낤����
�`�l�c�����I���^
�`�l�c�����I���^
�Ƃ����Kuma���ċ��LL3��2MB����ȁB
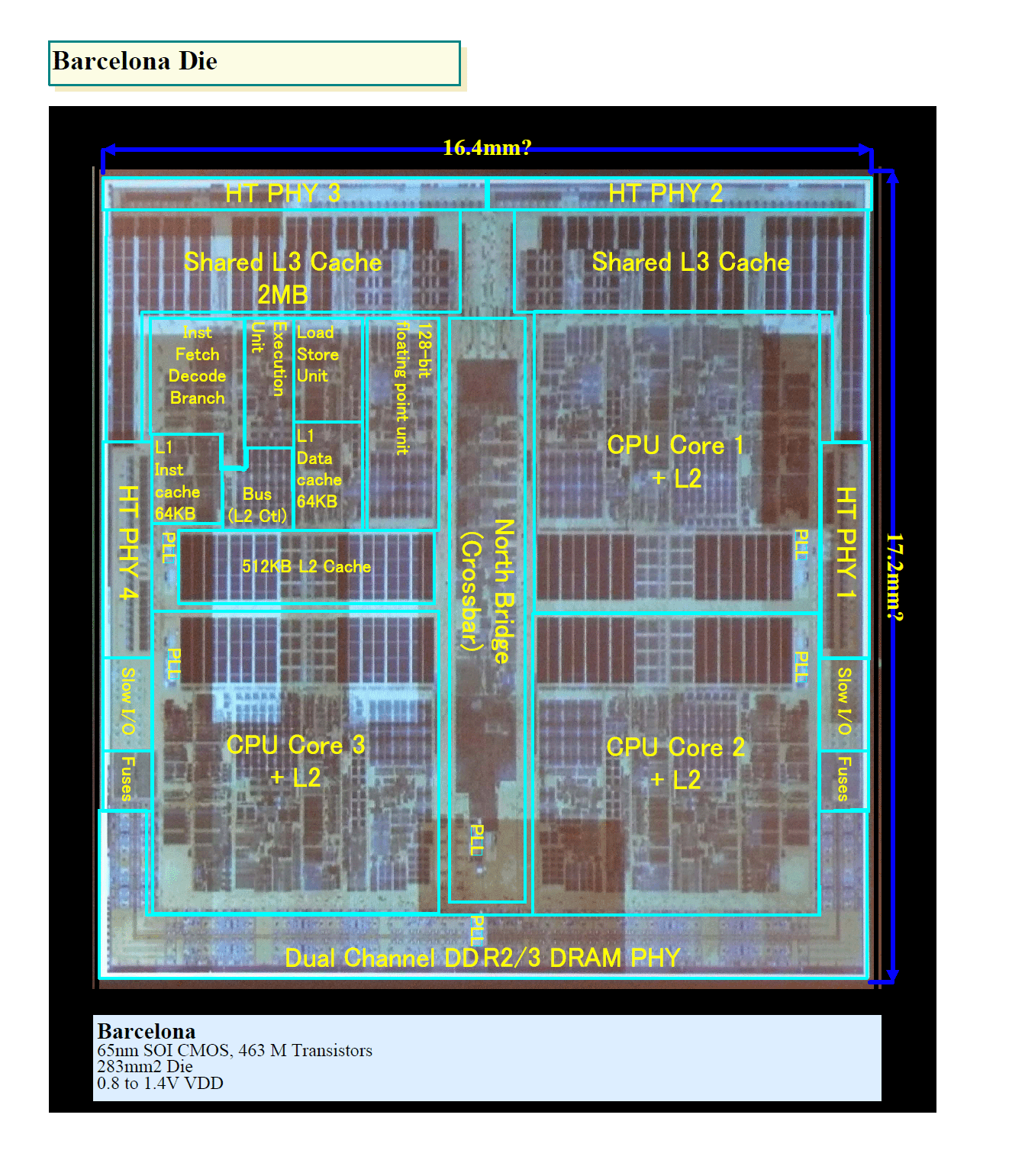
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_01l.gif
���LL3��2MB�ŃR�A�����Q�ɂ���̂��Ċ��S�ɐv���Ȃ����Ȃ��Ɩ������������B
1MB�����Ȃ獶�E�ɂԂ�������������������B
������Kuma��X4�_�C�̃R�A���P���z�Ƃ����g���̂��ˁB
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_01l.gif
{kind=link}
���LL3��2MB�ŃR�A�����Q�ɂ���̂��Ċ��S�ɐv���Ȃ����Ȃ��Ɩ������������B
1MB�����Ȃ獶�E�ɂԂ�������������������B
������Kuma��X4�_�C�̃R�A���P���z�Ƃ����g���̂��ˁB
�[���ǂ���Kuma�p�ɐv���Ȃ����Ȃ��pL2��߂ċ��LL2 2MB�ɂ�������
�_�C���������ςނ����\��512KBx2+2MB�Ȃ�ĕϑԐv��肢���Ƃ��������E�E�E
�_�C���������ςނ����\��512KBx2+2MB�Ȃ�ĕϑԐv��肢���Ƃ��������E�E�E
DDR2-1066�Ή����ĈӖ�������̂��˂��B
Phenom���o�鍠�ɂ�DDR3-1066�̕��������Ȃ��Ă�Ǝv�����B
Phenom���o�鍠�ɂ�DDR3-1066�̕��������Ȃ��Ă�Ǝv�����B
DDR3��DDR2�̉��i�����H
���ƂT�����łЂ�����Ԃ�H
�����A�����Ȃ[�A�Ӂ[��E�E�E(�L��֥�M)
���ƂT�����łЂ�����Ԃ�H
�����A�����Ȃ[�A�Ӂ[��E�E�E(�L��֥�M)
>>15
DDR2-1066�̌��݂̉��i�m���Ă�H
DDR2-1066�̌��݂̉��i�m���Ă�H
>>9
�f�X�N�g�b�vPC����ɋC������Ă邩�炻���������Ⴂ������̂�
�f�X�N�g�b�vPC����ɋC������Ă邩�炻���������Ⴂ������̂�
Single -> Dual�ŃN���b�N�����������悤��
Dual -> Quad�ł��N���b�N��������B
�_�C�T�C�Y���傫���Ȃ�Γ��R�N���b�N�グ��͓̂���B
�����I��K10 Dual core�ł�
���Ƃ��܂�ς��Ȃ��N���b�N���\�Ȃ͂��Ȃ̂�B
Athlon64 -> Athlon64 X2�ڍs���ɂ́AIntel��P4�ŃN���b�N���グ�Ȃ�������������
AMD���N���b�N���グ��K�v���Ȃ������̂ŁASingle core�ł��N���b�N���Ⴉ�����B
�iDual���Ɍ����ăM���b�v���傫���Ȃ�Ȃ��悤�ɃN���b�N��}�����Ƃ�����j
���̂܂�Dual�Ɉڍs�����̂ŁA�����N���b�N�͕ς��Ȃ��悤�ɕ\�ʏ�͎v��ꂽ�B
Dual��Single������N���b�N�ɂȂ�ƌ����Ă����ɂ�������炸�ˁB
kentsfield��2�_�C�ł��邽�߁AQuad�ł��_�C�T�C�Y�]�X�͂��܂�W�Ȃ��B
����Dual Core x2������ˁB
���Ƃ�Quad Core�������ɂ������Ƃ��Ă�
��ʎs��ɂ̓j�b�`�ł��邽�߁A����Ȃɔ����͂��������B
������Ƃ肠����Dual core�Ńp�t�H�[�}���X���P���s��
Core2Duo�ɑ��ċ����͂���������ׂ��������B
�N���b�N�̏グ�h���l�C�e�B�uQuad core�́E�E�E
Dual -> Quad�ł��N���b�N��������B
�_�C�T�C�Y���傫���Ȃ�Γ��R�N���b�N�グ��͓̂���B
�����I��K10 Dual core�ł�
���Ƃ��܂�ς��Ȃ��N���b�N���\�Ȃ͂��Ȃ̂�B
Athlon64 -> Athlon64 X2�ڍs���ɂ́AIntel��P4�ŃN���b�N���グ�Ȃ�������������
AMD���N���b�N���グ��K�v���Ȃ������̂ŁASingle core�ł��N���b�N���Ⴉ�����B
�iDual���Ɍ����ăM���b�v���傫���Ȃ�Ȃ��悤�ɃN���b�N��}�����Ƃ�����j
���̂܂�Dual�Ɉڍs�����̂ŁA�����N���b�N�͕ς��Ȃ��悤�ɕ\�ʏ�͎v��ꂽ�B
Dual��Single������N���b�N�ɂȂ�ƌ����Ă����ɂ�������炸�ˁB
kentsfield��2�_�C�ł��邽�߁AQuad�ł��_�C�T�C�Y�]�X�͂��܂�W�Ȃ��B
����Dual Core x2������ˁB
���Ƃ�Quad Core�������ɂ������Ƃ��Ă�
��ʎs��ɂ̓j�b�`�ł��邽�߁A����Ȃɔ����͂��������B
������Ƃ肠����Dual core�Ńp�t�H�[�}���X���P���s��
Core2Duo�ɑ��ċ����͂���������ׂ��������B
�N���b�N�̏グ�h���l�C�e�B�uQuad core�́E�E�E
>>10
���F��SSE4�������ĂȂ���ȁH
SSE4�������チ�f�B�A�֘A�̒lj����߂Ƃ����ċL�����ȑO�������ǁA
����Intel�̌��s��͕i�̋C���������܂ł̓������Ղ�����Ă�ƁA
SSE4�̗L���ő������\�����o���Ȃ����A�Ǝv���Ă��܂��B
�܁A���F�͑f�l�l���Ȃ�ŁA��[�������Ű��
���F��SSE4�������ĂȂ���ȁH
SSE4�������チ�f�B�A�֘A�̒lj����߂Ƃ����ċL�����ȑO�������ǁA
����Intel�̌��s��͕i�̋C���������܂ł̓������Ղ�����Ă�ƁA
SSE4�̗L���ő������\�����o���Ȃ����A�Ǝv���Ă��܂��B
�܁A���F�͑f�l�l���Ȃ�ŁA��[�������Ű��
>>18
ASP���������������ł���2P�I�����̒e���~�����̂ɁADualCore�ɂ��ׂ��������Ȃ��
������������B
���ƁA�M�������ŃN���b�N�グ���Ȃ��Ȃ�Ƃ������A2GHz���l�ꔪ�ꂵ�Ă�Ƃ����̂́A
�M�ȊO�̌����ŏオ���ĂȂ��\���������B
���̏�DualCore���ƁA2GHz�����Ƃ����I�����ł��_�������Ƃ����ߌ��ɂȂ�\�����B
>>19
http://crystalmark.info/bbs/c-board.cgi?cmd=one;no=1057;id=report#1057
Barcelona���������Ă���̂�SSE4a�B
�ŁASSE4�Ɩ��W�炵���B
�܂�ASSE4a�ɂ��ʓr�Ή����Ă����Ȃ��ƁASSE4�ɑΉ����������̃A�v���ł�Barcelona�Ő��\�オ��Ȃ����ƂɂȂ�B
ASP���������������ł���2P�I�����̒e���~�����̂ɁADualCore�ɂ��ׂ��������Ȃ��
������������B
���ƁA�M�������ŃN���b�N�グ���Ȃ��Ȃ�Ƃ������A2GHz���l�ꔪ�ꂵ�Ă�Ƃ����̂́A
�M�ȊO�̌����ŏオ���ĂȂ��\���������B
���̏�DualCore���ƁA2GHz�����Ƃ����I�����ł��_�������Ƃ����ߌ��ɂȂ�\�����B
>>19
http://crystalmark.info/bbs/c-board.cgi?cmd=one;no=1057;id=report#1057
Barcelona���������Ă���̂�SSE4a�B
�ŁASSE4�Ɩ��W�炵���B
�܂�ASSE4a�ɂ��ʓr�Ή����Ă����Ȃ��ƁASSE4�ɑΉ����������̃A�v���ł�Barcelona�Ő��\�オ��Ȃ����ƂɂȂ�B
>>19
Conroe�c�cSSSE3
Penryn�c�cSSSE3�ASSE4
K10�c�cSSE4a(4���߂̂݁ASSE4��SSSE3���܂܂�)
�A�v����SSE4a�Ή��͐�]�I������ASSS3�ASSE4�ւ̑Ή����i�ނ�
K10�͂���ɕs���ɂȂ�ˁB
Conroe�c�cSSSE3
Penryn�c�cSSSE3�ASSE4
K10�c�cSSE4a(4���߂̂݁ASSE4��SSSE3���܂܂�)
�A�v����SSE4a�Ή��͐�]�I������ASSS3�ASSE4�ւ̑Ή����i�ނ�
K10�͂���ɕs���ɂȂ�ˁB
���F������CPU
�����I���Ƃ��Ă̓N�}�҂��ŗ��N�Ƃ��A���G�l�[���āE�E�E
�H�ʂɑg�ݑւ����������ȁE�E
�H�ʂɑg�ݑւ����������ȁE�E
K10�_���Ȃ̂��H
AMD�������܂ł���
AMD�������܂ł���
���܂�AMD�ɂ́AQuad Core���܂Ƃ��ɓ����܂ő҂Ƃ��A����ȗ]�T�͖����B
ATI���������ɂ��A�����I�Ȏ����s���Ɋׂ��Ă���B
�����A����Ȃ��Ƃɓ��ʎ������ɂȂ肻���ȕ���ATI�ɂ����Ȃ��̂������B
�i2600,2400�̃��[�J�[PC�ւ̓��ڂ����\�Ȑ��ɂȂ����B�j
Native Quad Core�ňꔭ�t�]�_���Ă�낤��
���ꂪ�o����̂́A��Ђɂ����Ƒ̗͂��������ꍇ�B
�ւ������kentsfield�ɋy�Ȃ��\�����炠��킯�����B
��肠����Dual�̉��ǂ�Core2Duo�ɑ������͂̂�����̂��o��
�n���ɉ҂��ɂႢ�������B
ATI���������ɂ��A�����I�Ȏ����s���Ɋׂ��Ă���B
�����A����Ȃ��Ƃɓ��ʎ������ɂȂ肻���ȕ���ATI�ɂ����Ȃ��̂������B
�i2600,2400�̃��[�J�[PC�ւ̓��ڂ����\�Ȑ��ɂȂ����B�j
Native Quad Core�ňꔭ�t�]�_���Ă�낤��
���ꂪ�o����̂́A��Ђɂ����Ƒ̗͂��������ꍇ�B
�ւ������kentsfield�ɋy�Ȃ��\�����炠��킯�����B
��肠����Dual�̉��ǂ�Core2Duo�ɑ������͂̂�����̂��o��
�n���ɉ҂��ɂႢ�������B
������Athlon64 X2 3.4GHz/512KB/TDP150W����
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233.htm
�̊g����K8�H���Ă���Ă���̂������炭Barcelona���낤����AK8�Ɠ�����
Opteron��4�R�A����������I����Ő��\�A�s�[�����ė\�肾�����낤�ȁB
Barcelona�v�����́Aintel��Netburst�ŁA���̎���Nehalem�����N���b�N�H������������A
Core2��AMD�̑z��͈̔͊O�������낤�B
Core2�o�Ă���ABarcelona��DualCore�ɐv�������]�T���Ȃ����낤���A�����Ƀj�R�C�`�p�b�P�[�W��
�J�����������낤����A����Ӗ��ACore2��ł��������͂������܂��Ă����̂�������Ȃ��B
NVIDIA��G80�������V�F�[�_�Ɨ\�z�O����āA���̌�A���\���P�̂��߉������d�ˁA
���������ɂȂ�����R600�Ǝ��Ă���B
�̊g����K8�H���Ă���Ă���̂������炭Barcelona���낤����AK8�Ɠ�����
Opteron��4�R�A����������I����Ő��\�A�s�[�����ė\�肾�����낤�ȁB
Barcelona�v�����́Aintel��Netburst�ŁA���̎���Nehalem�����N���b�N�H������������A
Core2��AMD�̑z��͈̔͊O�������낤�B
Core2�o�Ă���ABarcelona��DualCore�ɐv�������]�T���Ȃ����낤���A�����Ƀj�R�C�`�p�b�P�[�W��
�J�����������낤����A����Ӗ��ACore2��ł��������͂������܂��Ă����̂�������Ȃ��B
NVIDIA��G80�������V�F�[�_�Ɨ\�z�O����āA���̌�A���\���P�̂��߉������d�ˁA
���������ɂȂ�����R600�Ǝ��Ă���B
G80�͒P�ɌŒ�@�\�̐��ŏ��邾���B
����Shader�]�X�͂قƂ�NJW�Ȃ��B
����Shader�]�X�͂قƂ�NJW�Ȃ��B
���Ⴀ�A�P����ATI�`���̊J���x���ł������������������B
>>28
AMD�͐����ʂ�Intel�ɑ啝�ɐ������Ă邩��A�v�������Ȃ�
�����Z�p�ō���������B������O�̘b�B
MCM�Z�p���Ȃ���Ƀv���Z�X�ł��P�N�߂��x��Ă����B
AMD�͐����ʂ�Intel�ɑ啝�ɐ������Ă邩��A�v�������Ȃ�
�����Z�p�ō���������B������O�̘b�B
MCM�Z�p���Ȃ���Ƀv���Z�X�ł��P�N�߂��x��Ă����B
�X���Ⴂ�Ȃ�ł��̌�͍T���邪
�O���ォ��R600�Œ��ڃp�t�H�[�}���X��
���т��悤�ȑ������Ă͎̂������܂薳���B
Shader��ALU�P�ʂŐ����Ă��邽�ߑ��������邪
���ۂ͂���Ȃɑ����ĂȂ��B
�Œ�@�\�Ɋւ��Ă��A�����m�̂悤�ɐ��͑O����Ɠ����B
�������ꂽ�̂�
Command Processor
Ultra-Threaded Dispatch Processor
Memory Read/Write Cache
Render-to-texture
���A�\�ɂ͌������̂������B
����Command Processor���ɂ͎�Ԃ��������炵���B
�܂�AGPU���̂̐���n�����������ADriver���ׂ��y����
�}���`GPU���Ō��ʂ��o�₷���悤�ɂ����킯���B
���炭����ȃn�C�G���h��R600�ōŌ�ɐ��邾�낤�B
�P��`�b�v�ł�512bit���B
�����DX10.1��������z���Ă̂��ƂȂ̂���
�͂����āA����܂�AMD�������ǂ�������肾�B
�O���ォ��R600�Œ��ڃp�t�H�[�}���X��
���т��悤�ȑ������Ă͎̂������܂薳���B
Shader��ALU�P�ʂŐ����Ă��邽�ߑ��������邪
���ۂ͂���Ȃɑ����ĂȂ��B
�Œ�@�\�Ɋւ��Ă��A�����m�̂悤�ɐ��͑O����Ɠ����B
�������ꂽ�̂�
Command Processor
Ultra-Threaded Dispatch Processor
Memory Read/Write Cache
Render-to-texture
���A�\�ɂ͌������̂������B
����Command Processor���ɂ͎�Ԃ��������炵���B
�܂�AGPU���̂̐���n�����������ADriver���ׂ��y����
�}���`GPU���Ō��ʂ��o�₷���悤�ɂ����킯���B
���炭����ȃn�C�G���h��R600�ōŌ�ɐ��邾�낤�B
�P��`�b�v�ł�512bit���B
�����DX10.1��������z���Ă̂��ƂȂ̂���
�͂����āA����܂�AMD�������ǂ�������肾�B
>>32
���̎��͊m���ǂ����Ŏw�E����Ă����ȁB
�h���C�o�����n���Ă����A���̐^���������������Ď����B
AMD�Ƌ�ATI�ƂŃh���C�o�̐��n�c�B�ꖕ�̕s����������̂͂Ȃ����H
���̎��͊m���ǂ����Ŏw�E����Ă����ȁB
�h���C�o�����n���Ă����A���̐^���������������Ď����B
AMD�Ƌ�ATI�ƂŃh���C�o�̐��n�c�B�ꖕ�̕s����������̂͂Ȃ����H
�h���C�o�̐��n�Ő��\�E�v���锤�Ȍ��́A�m���S�g�[���̋L���ɂ������Ǝv���B
�u�Ƭ�ׂ̐��n�Ő��\�E�v�v
���S�t���O
���S�t���O
36 �FSocket774�F2007/06/12(��) 23:00:20 ID:AM5GeeLU
>>34
G80������������AMD�����������Ă�킯����(�L�E�́E�M)
G80������������AMD�����������Ă�킯����(�L�E�́E�M)
>>36
�����̎������ID
�����̎������ID
38 �FSocket774�F2007/06/12(��) 23:43:42 ID:x8u/RoCQ
�V���O���R�A�ő����̏o���ė~����
�x���Ē����d�͂Ȃ̏o���ė~����
���Ȃ������\���ꂽ9W��sempron�Ƃ�����������
�\�P�b�gS1�Ƃ����삶�Ⴀ��܂�Ӗ��Ȃ���
20W�ȉ���AM2�Ńf���A���R�A�Ȃ�������
���Ȃ������\���ꂽ9W��sempron�Ƃ�����������
�\�P�b�gS1�Ƃ����삶�Ⴀ��܂�Ӗ��Ȃ���
20W�ȉ���AM2�Ńf���A���R�A�Ȃ�������
>>39
9W��Sempron�̓��C�o�����������ď����ɂȂ�Ȃ����낤����A��������20W��̗~������
9W��Sempron�̓��C�o�����������ď����ɂȂ�Ȃ����낤����A��������20W��̗~������
>>26
AMD��MCM�̋Z�p���Ȃ��ȏ�A�N�A�b�h�R�A�ł���ɂ�Ȃ��͕̂K�R�B
����ɃT�[�o�[�ŋ��߂��Ă�̂̓f���A���ł͂Ȃ��A�N�A�b�h�ŁA������
�f�X�N�g�b�v�Ƃ͗����₪��r�ɂȂ�Ȃ��̂ŗD�揇�ʂ̓T�[�o�[����B
����ɃN�A�b�h���ɍ���ăf���A������������h��������̂͊ȒP�����t�͐V�v�ɂȂ�B
��q����̂̓R�A���̂��̂̐v�ƍœK���ł�����
�ʂɃf���A���R�A�ŊJ�������甭�������܂����肵�����Ƃ����Ƃ���Ȃ����[�����B
AMD��MCM�̋Z�p���Ȃ��ȏ�A�N�A�b�h�R�A�ł���ɂ�Ȃ��͕̂K�R�B
����ɃT�[�o�[�ŋ��߂��Ă�̂̓f���A���ł͂Ȃ��A�N�A�b�h�ŁA������
�f�X�N�g�b�v�Ƃ͗����₪��r�ɂȂ�Ȃ��̂ŗD�揇�ʂ̓T�[�o�[����B
����ɃN�A�b�h���ɍ���ăf���A������������h��������̂͊ȒP�����t�͐V�v�ɂȂ�B
��q����̂̓R�A���̂��̂̐v�ƍœK���ł�����
�ʂɃf���A���R�A�ŊJ�������甭�������܂����肵�����Ƃ����Ƃ���Ȃ����[�����B
>>32
R600��Shader�̏����n����
Stream Processors inc�̂�Ɏ��Ă��ˁB
ttp://www.altimanet.com/solutions/spi/index.html
ttp://journal.mycom.co.jp/articles/2007/03/04/isscc2/
R600��Shader�̏����n����
Stream Processors inc�̂�Ɏ��Ă��ˁB
ttp://www.altimanet.com/solutions/spi/index.html
ttp://journal.mycom.co.jp/articles/2007/03/04/isscc2/
AMD�����̃`�b�v�Z�b�g���ďo�Ȃ��́H
CPU���̂��������ǃ`�b�v�Z�b�g���ꏏ�ɍ���Ăق���
CPU���̂��������ǃ`�b�v�Z�b�g���ꏏ�ɍ���Ăق���
���O�����̏����Ȃ�āE�E�E
���`�s�h�̃`�b�v�Z�b�g�Ȃ��
�����ǂ��Ƃ���Ȃ���������܂���
���`�s�h�̃`�b�v�Z�b�g�Ȃ��
�����ǂ��Ƃ���Ȃ���������܂���
46 �FSocket774�F2007/06/13(��) 13:49:55 ID:X8bP4YVx
��Ђ���������������Ƃ��Ƃ�AMD�̋Z�p�҂��`�b�v�Z�b�g�AGPU�J���ɗ���Ă邾�낤�����S�ȍ�
�삪�łĂ���̂͗��N�ȍ~�ɂȂ��Ȃ��B�t���[
�W�����ȊO�ɂ����낢��J���͂��Ă邾�낤�����͍��̂Ƃ���Ȃ��H
�삪�łĂ���̂͗��N�ȍ~�ɂȂ��Ȃ��B�t���[
�W�����ȊO�ɂ����낢��J���͂��Ă邾�낤�����͍��̂Ƃ���Ȃ��H
�ނ���J���҂̓C���e����NVIDIA�ɗ���Ă����ۂ��E�E�E
Barcelona�̃N���b�N���オ��Ȃ��̂̓��W�����[���̂��߂����ĒN������Ȃ��ˁB
���W�����[���̘b���o���Ƃ��͐��\�オ��Ȃ�����Č����܂����Ă����ǁB
���W�����[���̘b���o���Ƃ��͐��\�オ��Ȃ�����Č����܂����Ă����ǁB
�@�����ɂ��i�삵�悤�ɂ����W���[�����Ƃ����b�肻�̂��̂̔R�����Ȃ�����
�݂�Ȃb�o�t�̐v�Ȃ�Ă������Ɩ������A��r�ޗ����Ȃ�����
�ǂ̒��x�e������̂��킩��i�X�B
�݂�Ȃb�o�t�̐v�Ȃ�Ă������Ɩ������A��r�ޗ����Ȃ�����
�ǂ̒��x�e������̂��킩��i�X�B
�N���b�N���オ��Ȃ��Ȃ�ă��x���̘b����Ȃ�����BOS�N������悤�ɂȂ����̂�
�����ŋ߂��Ęb�����炱��̓N���b�N�ǂ������ł͂Ȃ��J�����߂��߂��ɒx��Ă���
�i�Ƃ�����AMD�̌��\�����X�P�W���[�����ُ�Ɋy�ϓI�j�Ȃ����B
�����ŋ߂��Ęb�����炱��̓N���b�N�ǂ������ł͂Ȃ��J�����߂��߂��ɒx��Ă���
�i�Ƃ�����AMD�̌��\�����X�P�W���[�����ُ�Ɋy�ϓI�j�Ȃ����B
�o���Z���i�ǂ��납�A�W�l�ڂ̃_���V���ɋ�킵�Ă���Ƃ��낾�B
�i�[�C���E�E�E�E�G�[�C�g�E�E�E�E�Z�u�[���E�E�E�E�E�V�b�t�@�C�t�H�X���c���[�� ��������������!
GAME OVER
�i�[�C���E�E�E�E�G�[�C�g�E�E�E�E�Z�u�[���E�E�E�E�E�V�b�t�@�C�t�H�X���c���[�� ��������������!
GAME OVER
>>50
�N���b�N���グ���OS���N�����Ȃ�(OC�����OS���N�����Ȃ��悤�Ȃ���)������
�Ⴂ�N���b�N�Ȃ�OS�͂����ƋN������B
���N�̎��_�Ńf�����s���Ă邵�B
�N���b�N���グ���OS���N�����Ȃ�(OC�����OS���N�����Ȃ��悤�Ȃ���)������
�Ⴂ�N���b�N�Ȃ�OS�͂����ƋN������B
���N�̎��_�Ńf�����s���Ă邵�B
>>52
����Ȃ�K8 65nm 3.5GHz+�̕����}�V
�N�A�b�h�R�AK10 1.6GHz�ƃf���A���R�AK8 3.5GHz������̏��������Ă݂��������B
����Pentium4��(�v���X�R�o�ꎞ����)������������A
Tejas 5GHz VS X2 4800+�Ȃnj���ꂽ��������Ȃ�
�܂������I�Ȑ��\�ł͌�҂̏������낤���ǂ�
����Ȃ�K8 65nm 3.5GHz+�̕����}�V
�N�A�b�h�R�AK10 1.6GHz�ƃf���A���R�AK8 3.5GHz������̏��������Ă݂��������B
����Pentium4��(�v���X�R�o�ꎞ����)������������A
Tejas 5GHz VS X2 4800+�Ȃnj���ꂽ��������Ȃ�
�܂������I�Ȑ��\�ł͌�҂̏������낤���ǂ�
�����A�ǂ̒��x���W���[���ł킯�Ă�̂��A�S����Ȃ�����킩������˂��B
�p�C�v���C�������镔����L1���Đ藣���Ȃ��Ƃ��A��J����ύX�����
�S�̂ɉe�����A�Ƃ��悭�����Ă�킯�ŁA���R���Z�Ɋւ��郌�W�X�^��A
�t�F�b�`�Ɋւ��镔������̂ɂȂ��Ă�킯�ł���A���ʁB
����ƁA���������AL2�AL3�A�R�A�AI/O�A�����R���Ōʃ��W���[���ɂȂ��Ă���x����Ȃ��́H
AMD�̐����ł��A�s��̃j�[�Y�ɐv���ɓ����邽�߃o���G�[�V������
���ݏo���₷���Ƃ����Ƃ����Đ������������ˁB
�o���G�[�V�����ƌ����Ă��Ⴄ�̂��ăL���b�V���e�ʁE�������C���^�t�F�[�X�E�R�A�����炢�ł���H
�p�C�v���C�������镔����L1���Đ藣���Ȃ��Ƃ��A��J����ύX�����
�S�̂ɉe�����A�Ƃ��悭�����Ă�킯�ŁA���R���Z�Ɋւ��郌�W�X�^��A
�t�F�b�`�Ɋւ��镔������̂ɂȂ��Ă�킯�ł���A���ʁB
����ƁA���������AL2�AL3�A�R�A�AI/O�A�����R���Ōʃ��W���[���ɂȂ��Ă���x����Ȃ��́H
AMD�̐����ł��A�s��̃j�[�Y�ɐv���ɓ����邽�߃o���G�[�V������
���ݏo���₷���Ƃ����Ƃ����Đ������������ˁB
�o���G�[�V�����ƌ����Ă��Ⴄ�̂��ăL���b�V���e�ʁE�������C���^�t�F�[�X�E�R�A�����炢�ł���H
�ނ���o���G�[�V�����吙����
���������ʐ��i������
��ʂ�����
���������ʐ��i������
��ʂ�����
�uAMD�v:CPU�R�A�̓l�C�e�B�u�ɑ��₹�Α��₷�قǐ��\�E�v�����I
�uIntel�v:�p�C�v���C���͑��₹�Α��₷�قǍ��N���b�N���o���Đ��\�E�v�����I
�Ȃx���R�A�̔ߎS�ȏ�Ԃ́A�f�W���u�����Ă�C�ɂȂ��Ă�����B
�uIntel�v:�p�C�v���C���͑��₹�Α��₷�قǍ��N���b�N���o���Đ��\�E�v�����I
�Ȃx���R�A�̔ߎS�ȏ�Ԃ́A�f�W���u�����Ă�C�ɂȂ��Ă�����B
�p�C�v���C���������Ă����N���b�N���o����Ώ������x���オ��̂͊ԈႢ����Ȃ����H
03�N�܂ł�AMD�����p�C�v���C�����N���b�N�A�[�L�e�N�`����\�肵�Ă����ȁB
�P�ɔM�ł��ꂪ�o���Ȃ��Ȃ����������B
���Ɖ������Ⴂ���Ă�悤����AMD�̏ꍇ�l�C�e�B�u�ɃR�A�����₷���Ƃɖ�N�ɂȂ��Ă��
�������A�Ƃ������l�C�e�B�u�ɑ��₷�����Ȃ���B���[�R�X�g��MCM����Z�p��Ղ��Ȃ�����B
���̂����R�A����Intel�̂���s���Ă���B
�Z�p�I�ɂ��s��I�ɂ����ɑI�����i������j�ȂȂ��B
03�N�܂ł�AMD�����p�C�v���C�����N���b�N�A�[�L�e�N�`����\�肵�Ă����ȁB
�P�ɔM�ł��ꂪ�o���Ȃ��Ȃ����������B
���Ɖ������Ⴂ���Ă�悤����AMD�̏ꍇ�l�C�e�B�u�ɃR�A�����₷���Ƃɖ�N�ɂȂ��Ă��
�������A�Ƃ������l�C�e�B�u�ɑ��₷�����Ȃ���B���[�R�X�g��MCM����Z�p��Ղ��Ȃ�����B
���̂����R�A����Intel�̂���s���Ă���B
�Z�p�I�ɂ��s��I�ɂ����ɑI�����i������j�ȂȂ��B
>>57
�x�X�g�ȓ����ǂ����͂Ƃ������A�T�[�o�s��͎̂Ăăl�C�e�B�u�f���A���R�A�̂܂�
���\���グ�Ă����Ƃ����I�����͂�������B
�T�[�o�s��̂Ă�Ȃ�Ăƌ������낤���ǁAK10�̐v�̓f���A���R�A�܂�f�X�N�g�b�v/���o�C���s��
�̑唼���̂ĂĂ�悤�Ȃ��̂���B�f���A���R�A��p�ɍl�����炠����b�`��L2/L3�\���ɂ�
��ɂ��Ȃ��B
�x�X�g�ȓ����ǂ����͂Ƃ������A�T�[�o�s��͎̂Ăăl�C�e�B�u�f���A���R�A�̂܂�
���\���グ�Ă����Ƃ����I�����͂�������B
�T�[�o�s��̂Ă�Ȃ�Ăƌ������낤���ǁAK10�̐v�̓f���A���R�A�܂�f�X�N�g�b�v/���o�C���s��
�̑唼���̂ĂĂ�悤�Ȃ��̂���B�f���A���R�A��p�ɍl�����炠����b�`��L2/L3�\���ɂ�
��ɂ��Ȃ��B
�e�n�X����1�R�A��4�X���b�h����������������H
>>58
�������o��̂�Kuma�ȏ�ɂ킩��Ȃ��Ȃ���L3�Ȃ���Rana����2�R�A�p��K10����̂��������A
�ʂɃf�X�N�g�b�v/���o�C�����̂Ă�����AMD���Ȃ����낤�B
Barcelona�Ŗ�肪�N���܂����Ă���̂ŁARana��Barcelona�̕������͏�������������Ȃ����A
�N���b�N���オ��Ȃ������ɂ���ẮA2�R�A�ŃN���b�N�オ��Ȃ��Ƃ����I�����ɂ�����Ȃ��ߌ��̉\����
�������킯�ŁB
>>59
Tejas��HTT��4�X���b�h�ɂȂ�炵�������ˁB
�\���x������IA-64�ɂ��Ή��\�肾�����Ƃ��B�ŁA1�R�A��TDP150W�Ƃ������낵���㕨�������炵���B
�������o��̂�Kuma�ȏ�ɂ킩��Ȃ��Ȃ���L3�Ȃ���Rana����2�R�A�p��K10����̂��������A
�ʂɃf�X�N�g�b�v/���o�C�����̂Ă�����AMD���Ȃ����낤�B
Barcelona�Ŗ�肪�N���܂����Ă���̂ŁARana��Barcelona�̕������͏�������������Ȃ����A
�N���b�N���オ��Ȃ������ɂ���ẮA2�R�A�ŃN���b�N�オ��Ȃ��Ƃ����I�����ɂ�����Ȃ��ߌ��̉\����
�������킯�ŁB
>>59
Tejas��HTT��4�X���b�h�ɂȂ�炵�������ˁB
�\���x������IA-64�ɂ��Ή��\�肾�����Ƃ��B�ŁA1�R�A��TDP150W�Ƃ������낵���㕨�������炵���B
�����@Wolfdale�ɑR�@
>>57
CPU�R�A���l�C�e�B�u�ɑ��₹�ΐ��\�E�v����̂��A�ԈႢ����Ȃ���ˁB
CPU�R�A���l�C�e�B�u�ɑ��₹�ΐ��\�E�v����̂��A�ԈႢ����Ȃ���ˁB
�Ƃ����
http://techreport.com/onearticle.x/12650�@�Ƃ�
http://www.xbitlabs.com/news/cpu/display/20070612143452.html�@�Ƃ�
http://www.infoworld.com/article/07/06/06/Barcelona-delay-could-hurt-AMD-earnings_1.html
�̓X���[�������H
http://techreport.com/onearticle.x/12650�@�Ƃ�
http://www.xbitlabs.com/news/cpu/display/20070612143452.html�@�Ƃ�
http://www.infoworld.com/article/07/06/06/Barcelona-delay-could-hurt-AMD-earnings_1.html
�̓X���[�������H
2�R�A�̏ꍇ�ɂǂꂭ�炢���LL3�����\�ɉe�����邩�킩��Ȃ��̂ŁAWolfdale�ɑR�ł��Ȃ��Ƃ�
����Ȃ��Ⴀ�H
Barcelona�̃x���`���炷��ƁA��������Kuma��Wolfdale�ɑR�ł��Ȃ��\���������������c�B
����Ȃ��Ⴀ�H
Barcelona�̃x���`���炷��ƁA��������Kuma��Wolfdale�ɑR�ł��Ȃ��\���������������c�B
���̑O�ɁAPhenom X2��Athlon64 X2���z���邩�ǂ���
>>65
���L6MB��512KBx2�����ׂ�̂��n���炵����ł����E�E�E
���L6MB��512KBx2�����ׂ�̂��n���炵����ł����E�E�E
68 �FSocket774�F2007/06/14(��) 21:06:25 ID:HPsLOTjs
Phenom X2 2.2GH����Athlon64 6000+�����肪���i�������ƁA�����B
>>68
Athlon64 X2�u�܂������Ă��܂����i�j�v
Athlon64 X2�u�܂������Ă��܂����i�j�v
>405 ���O�FSocket774 ���e���F2007/05/17(��) 20:03:19 ID:53gABQib
>Barcelona��9�����Ƃ���Ɠo�ꎞ���\�z�͂���Ȋ����B
>
>07 . 9���@Barcelona
>07 10���@Phenom FX
>07 11���@Phenom X4
>07 12���@Yorkfield�AWolfdale�AHarpertown�AWolfdale-DP
>08 . 1���@Phenom X2(Kuma)
>08 . 2��
>08 . 3���@Phenom X2(Rana)
�ŐV������ɗ\�z�C��
07 10���@Barcelona�AHarpertown
07 11���@
07 12���@Phenom FX�APhenom X4�AYorkfield
08 . 1���@Wolfdale�AWolfdale-DP
08 . 2���@Phenom X2(Kuma)
08 . 3��
08 . 4���@Phenom X2(Rana)
>Barcelona��9�����Ƃ���Ɠo�ꎞ���\�z�͂���Ȋ����B
>
>07 . 9���@Barcelona
>07 10���@Phenom FX
>07 11���@Phenom X4
>07 12���@Yorkfield�AWolfdale�AHarpertown�AWolfdale-DP
>08 . 1���@Phenom X2(Kuma)
>08 . 2��
>08 . 3���@Phenom X2(Rana)
�ŐV������ɗ\�z�C��
07 10���@Barcelona�AHarpertown
07 11���@
07 12���@Phenom FX�APhenom X4�AYorkfield
08 . 1���@Wolfdale�AWolfdale-DP
08 . 2���@Phenom X2(Kuma)
08 . 3��
08 . 4���@Phenom X2(Rana)
>>69
����������Rev.G����L���b�V�������L3�̃`�F�b�N������������
L3������Rana��Rev.G�݂�����Latency�ɐ����ȁc
����������Rev.G����L���b�V�������L3�̃`�F�b�N������������
L3������Rana��Rev.G�݂�����Latency�ɐ����ȁc
�Ƃ肠�����Ⴄ�A�[�L�e�N�`���Ȃ̂�L2�̗ʂŐ��\���ׂ�悤�Ȕ����͂�߂�B
NetBurst��CoreMA�ŃN���b�N������ׂĐ��\������Ă��炨����������H
NetBurst��CoreMA�ŃN���b�N������ׂĐ��\������Ă��炨����������H
�����Ă��܂����S�Ƃ��߂��悤�ȃl�^���Ȃ�����AMD���Ă�
����ω���AMD�̎В��ɂȂ邵���Ȃ��悤���ȁI
>>72
���ႠK10��256KB�ł�����
���ႠK10��256KB�ł�����
AMD pushes out Phenom SKUs once more
http://www.theinquirer.net/default.aspx?article=40347
AMD numbers the Phenoms of the ordinary beast
http://www.theinquirer.net/default.aspx?article=40348
7xxx: 4 Core
6xxx: 2 Core
G: high end/B: middle/L: low end
P: 89W/S: 65W/E: 45W
2007 Q4: GP-7000/7100 GS-6550
2008 Q1: GP-6800, GS-6650, GE-6600/6500/6400
71xx: 2.2-2.4GHz
70xx: 2.0-2.2GHz
http://www.theinquirer.net/default.aspx?article=40347
AMD numbers the Phenoms of the ordinary beast
http://www.theinquirer.net/default.aspx?article=40348
7xxx: 4 Core
6xxx: 2 Core
G: high end/B: middle/L: low end
P: 89W/S: 65W/E: 45W
2007 Q4: GP-7000/7100 GS-6550
2008 Q1: GP-6800, GS-6650, GE-6600/6500/6400
71xx: 2.2-2.4GHz
70xx: 2.0-2.2GHz
�ł����N���b�N���Ɍ��ς����
2.4G 7100
2.3G 7050
2.2G 7000
2.8G 6800
2.7G 6750
2.6G 6700
2.5G 6650
2.4G 6600
2.3G 6550
2.2G 6500
2.1G 6450
2.0G 6400
2.4G 7100
2.3G 7050
2.2G 7000
2.8G 6800
2.7G 6750
2.6G 6700
2.5G 6650
2.4G 6600
2.3G 6550
2.2G 6500
2.1G 6450
2.0G 6400
>>76
2007 Q4: FX80(2.2-2.4G)
2008 Q1: FX90(2.2-2.4G)�AFX91(2.4-2.6G)
�N����Quad�̍ō��N���b�N��2.4GHz���B
�ł����N���b�N���̌��ς��肩�X�P�W���[�����x��Ȃ���A�����B
2007 Q4: FX80(2.2-2.4G)
2008 Q1: FX90(2.2-2.4G)�AFX91(2.4-2.6G)
�N����Quad�̍ō��N���b�N��2.4GHz���B
�ł����N���b�N���̌��ς��肩�X�P�W���[�����x��Ȃ���A�����B
AMD�̂����y�ϓI�ȃV�i���I�͒B�����ꂽ�o�����Ȃ�
81 �FSocket774�F2007/06/15(��) 11:00:59 ID:Cpl6UmKP
intel��{�C�ɂ������܂ł͗ǂ��������A���̌オ����
K10�̐��\��AMD�̗\���̒ʂ肾�Ƃ��āAPenom X4-2.4G��QX6850(3.00G)�ɑ���
�������Z�ł͎��蕂�������_���Z�ł͂��Ȃ����BSSSE3���Ȃ����Ƃ����������Ă�
�����ނ˓����ƌ����邾�낤�B
Yorkfield�Ƃ͑���ɂȂ�Ȃ����AKentsfield�ƌ݊p�Ȃ猻��ێ����ĂƂ����B
�������Z�ł͎��蕂�������_���Z�ł͂��Ȃ����BSSSE3���Ȃ����Ƃ����������Ă�
�����ނ˓����ƌ����邾�낤�B
Yorkfield�Ƃ͑���ɂȂ�Ȃ����AKentsfield�ƌ݊p�Ȃ猻��ێ����ĂƂ����B
�o��ȁc�{����orz
�����u�����́v�o�邾��B
�ł������炭��x��
Intel���낵��
AMD�͊��S�Ɉꐢ��u���Ă��ꂽ��orz
AMD�͊��S�Ɉꐢ��u���Ă��ꂽ��orz
>>86
�����čs����Ă͂Ȃ��B��������ǂ������ꂽ�����B
�������S���}�[�N���Ă��Ȃ����������ɁB
�v���Z�X���[���ł͈ꐢ��u���Ă���Ă��邯�ǂȁB
�����čs����Ă͂Ȃ��B��������ǂ������ꂽ�����B
�������S���}�[�N���Ă��Ȃ����������ɁB
�v���Z�X���[���ł͈ꐢ��u���Ă���Ă��邯�ǂȁB
>>82
AMD�����������_���Z��50%�ȏ����Ǝ咣���Ă���̂́A2P�\����Xeon�ɑ���
��SPECfp2006rate�̒l�̖͗l�B
intel��1P����2P��2�{�ɂȂ�Ȃ��̂ɑ��āAOpteron�ł̓v���Z�b�T�������邲�ƂɃ��j�A�ɐ��l���オ���Ă���B
Barcelona�������X���������ꍇ�́ASPEC2006fprate�Őh������2.4GHz��PhenomX4��QX6850�ɏ��Ă�
�A�v���P�[�V�����x���`�}�[�N�ł͑�����\���̕��������B
2.6GHz���o����A�݊p�ȏ�ɐ킦�����Ȃ��B
AMD�����������_���Z��50%�ȏ����Ǝ咣���Ă���̂́A2P�\����Xeon�ɑ���
��SPECfp2006rate�̒l�̖͗l�B
intel��1P����2P��2�{�ɂȂ�Ȃ��̂ɑ��āAOpteron�ł̓v���Z�b�T�������邲�ƂɃ��j�A�ɐ��l���オ���Ă���B
Barcelona�������X���������ꍇ�́ASPEC2006fprate�Őh������2.4GHz��PhenomX4��QX6850�ɏ��Ă�
�A�v���P�[�V�����x���`�}�[�N�ł͑�����\���̕��������B
2.6GHz���o����A�݊p�ȏ�ɐ킦�����Ȃ��B
�v���Z�X���[���ɂ��Ă͐̂��炢�����������ȁB��������Intel�̂P�N�x��B
����͔����̋ƊE�̐������炷���AMD���x���ƌ������AIntel���ٗl�ɑ����Ƃ����ׂ��B
����͔����̋ƊE�̐������炷���AMD���x���ƌ������AIntel���ٗl�ɑ����Ƃ����ׂ��B
90 �FSocket774�F2007/06/15(��) 13:58:11 ID:JGB67k8s
>>2
2P Barcelona��Core2�ɑ����N���b�N��SPEC int��120���@������150���̐��\�����Ƃ����b�ł��傤�B
�����A1P���ƕς���Ă��邾�낤���A��������Intel�ŐV�R���p�C�����ƁAint��104���܂Őڋ߂��Ă邵�ˁB
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_13223,00.html?redir=CPBM01
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070528-01177.html
X5365�i3GH���j��Barcelona2.6GHz�̃X�R�A���t�]���Ă���B
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070528-01175.html
2P Barcelona��Core2�ɑ����N���b�N��SPEC int��120���@������150���̐��\�����Ƃ����b�ł��傤�B
�����A1P���ƕς���Ă��邾�낤���A��������Intel�ŐV�R���p�C�����ƁAint��104���܂Őڋ߂��Ă邵�ˁB
http://www.amd.com/us-en/Processors/ProductInformation/0,,30_118_13223,00.html?redir=CPBM01
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070528-01177.html
X5365�i3GH���j��Barcelona2.6GHz�̃X�R�A���t�]���Ă���B
http://www.spec.org/cpu2006/results/res2007q2/cpu2006-20070528-01175.html
Intel�@: ���ʍ��̃A�����J
AMD�@�@: ���_�͂̓��{
���ĂƂ��납�ȁH
AMD�@�@: ���_�͂̓��{
���ĂƂ��납�ȁH
92 �FSocket774�F2007/06/15(��) 14:17:12 ID:mVAYayVG
AMD�@�@: ���悾���̊؍�
AMD�I���^�����t������������
ATI��nvidia�ɑ傫�������ꂿ�������
���̂܂܂��ƃ}�W�Ń��o�C
�����AMD
ATI��nvidia�ɑ傫�������ꂿ�������
���̂܂܂��ƃ}�W�Ń��o�C
�����AMD
���А��i�ɍœK�������R���p�C�����o�������ł��Ȃ芪���Ԃ���Ǝv�����Ȃ��c
�ȒP�ɏo�����Ȃ炻��Ⴛ�̂Ƃ���ł��傤���ǂˁc�c�o����Ǝv���܂�?
# Intel�R���p�C���̗��j���Ȃ߂��炠���B
# Intel�R���p�C���̗��j���Ȃ߂��炠���B
�\�t�g�E�F�A�܂ŊJ���������܂���ĂȂ���Ȃ����Ȃ��B
���А��i�����̃R���p�C���͐̂��猾���Ă��邯�ǁA�S�R�������B
Intel�̎����͂�CPU�J�������ł͂Ȃ��āA
�\�t�g�E�F�A�J���͂ɂ��͂𒍂��ł��邩�狭���B
���А��i�����̃R���p�C���͐̂��猾���Ă��邯�ǁA�S�R�������B
Intel�̎����͂�CPU�J�������ł͂Ȃ��āA
�\�t�g�E�F�A�J���͂ɂ��͂𒍂��ł��邩�狭���B
�[���A�\�t�g�E�F�A����Ɉ�ԃ}���p���[�𒍂�����ł��邶��Ȃ����������H
IA-64�ɂقƂ�Njz������Ă��
>>87
���ꂾ��
intel:���܂ŊԈ���������ɕ⋭���Ă����ǁA����ƎO�ԃ^�C�v�̃o�b�^�[���W�߂܂��������l
AMD:������Ƃ̊Ԃɒ��_�ɗ����Ă��������œV��ɂȂ��đ債�ăr�W�����𗧂Ă��Ȃ�������_
���ꂾ��
intel:���܂ŊԈ���������ɕ⋭���Ă����ǁA����ƎO�ԃ^�C�v�̃o�b�^�[���W�߂܂��������l
AMD:������Ƃ̊Ԃɒ��_�ɗ����Ă��������œV��ɂȂ��đ債�ăr�W�����𗧂Ă��Ȃ�������_
���낻��}���`�v���Z�b�T�Ή���3D�Q�[���Ƃ��o�Ȃ�����
�N�����痈�N�����ɂ�4�R�ACPU���]���]���o�ė���̂ɁE�E�E
�N�����痈�N�����ɂ�4�R�ACPU���]���]���o�ė���̂ɁE�E�E
>>100
�Ⴄ��B
Intel�F��͌̏�Ő�����O�ɁA�T�������唲�F�ő劈��B
AMD�F���N�I������Ɏ��͂������Ɍł߂Ă�����A���N�I��̏�ő�Q�āB
�݂����ȁB
>>102
���낻��o���Ȃ��H
�Ⴄ��B
Intel�F��͌̏�Ő�����O�ɁA�T�������唲�F�ő劈��B
AMD�F���N�I������Ɏ��͂������Ɍł߂Ă�����A���N�I��̏�ő�Q�āB
�݂����ȁB
>>102
���낻��o���Ȃ��H
����CPU����p���ăr�f�I�J�[�h�ɍi�낤���B
�{�C�ɂ������̂͂ǂ��l���Ă����[�N�Ƃ����������ۂ̂悤�ȋC��������A
������AMD�̎d���ɂ��Ă����������ۂ����܂�낤�ȁc
������AMD�̎d���ɂ��Ă����������ۂ����܂�낤�ȁc
�܂��C�C�g�R���܂Ŏ����Ă������͎̂���������
�Ԃ��J���Ȃ��Łu���̎�v���~���������Ȃ��E�E�B
���������_���Z��50%�ȏ����A��
AMD���咣���Ă�o�׃X�P�W���[����
�����ɃC�}�C�`�����Ă��Ȃ�CPU��
�A�e�ɂ��Ă����傤���Ȃ����ǁB
�Ԃ��J���Ȃ��Łu���̎�v���~���������Ȃ��E�E�B
���������_���Z��50%�ȏ����A��
AMD���咣���Ă�o�׃X�P�W���[����
�����ɃC�}�C�`�����Ă��Ȃ�CPU��
�A�e�ɂ��Ă����傤���Ȃ����ǁB
>>106
���[�N�d������肾�����Ȃ�APrescott�̌㔼���݂�킩��悤�ɁA
TDP�͂����ԗ������āA����܂ł̃l�g�o�n�Ɣ�ׂĂ����e�͈͂ɓ����Ă���B
���̒��x�Ȃ���܂ł�Intel�̃}�[�P�e�B���O�Ɛ�����
�ʂɂ��̂܂�Tejas�ֈڍs���Ă��S�����Ȃ������͂��B
�o�ׂ����傢�ƒx�点��������A�ǂ������{�l�Ƃ��́A
�uIntel inside�v�Ƃł��\���Ă����Ή����l���Ȃ��Ŕ��������낤���B
�������Ȃ������̂͂Ȃ����c���āAIntel��AMD���ڂ̏�̂��Ԃ���������
�F�߂Ă��锭�������Ă�������܂����c�B
���[�N�d������肾�����Ȃ�APrescott�̌㔼���݂�킩��悤�ɁA
TDP�͂����ԗ������āA����܂ł̃l�g�o�n�Ɣ�ׂĂ����e�͈͂ɓ����Ă���B
���̒��x�Ȃ���܂ł�Intel�̃}�[�P�e�B���O�Ɛ�����
�ʂɂ��̂܂�Tejas�ֈڍs���Ă��S�����Ȃ������͂��B
�o�ׂ����傢�ƒx�点��������A�ǂ������{�l�Ƃ��́A
�uIntel inside�v�Ƃł��\���Ă����Ή����l���Ȃ��Ŕ��������낤���B
�������Ȃ������̂͂Ȃ����c���āAIntel��AMD���ڂ̏�̂��Ԃ���������
�F�߂Ă��锭�������Ă�������܂����c�B
http://www.theinquirer.net/default.aspx?article=40363
45nm��K10(K10.5�H)�͗��N�㔼�B
�O���ɏo��Ƃ������ĂȂ��������H�@�܂��N���M�����Ⴂ�Ȃ��������낤���B
45nm��K10(K10.5�H)�͗��N�㔼�B
�O���ɏo��Ƃ������ĂȂ��������H�@�܂��N���M�����Ⴂ�Ȃ��������낤���B
�h�V���E�g�Ȉӌ����U�X�T�o�������Ƃ��������ǁA
ʲ�߰�گ�ިݸނ��Ă����Z�p�͂ǂ��Ȃ�����!?
C2D��ʲ�߰�گ�ިݸޓ��ڂōŋ��݂����Ȃ��Ƃɂ͂Ȃ�Ȃ���?
�ڂ����l�������
ʲ�߰�گ�ިݸނ��Ă����Z�p�͂ǂ��Ȃ�����!?
C2D��ʲ�߰�گ�ިݸޓ��ڂōŋ��݂����Ȃ��Ƃɂ͂Ȃ�Ȃ���?
�ڂ����l�������
>>111
HyperThreading�𐄐i����Netburst�J���`�[����Nehalem������Ă�B
Nehalem�ɂ�HyperThreading�I�Ȃ��́i���̂܂܂ł͂Ȃ��炵���j���ڂ�B
Core2��Banias�n�̊J���`�[��������Ă��āAHyperThreading�͌�����������
Core2�n�A�[�L�e�N�`���ɂ��܍ڂ���͓̂d�͌����������Ƃ������Ƃōڂ��Ȃ������B
HyperThreading�𐄐i����Netburst�J���`�[����Nehalem������Ă�B
Nehalem�ɂ�HyperThreading�I�Ȃ��́i���̂܂܂ł͂Ȃ��炵���j���ڂ�B
Core2��Banias�n�̊J���`�[��������Ă��āAHyperThreading�͌�����������
Core2�n�A�[�L�e�N�`���ɂ��܍ڂ���͓̂d�͌����������Ƃ������Ƃōڂ��Ȃ������B
�n�C�p�[�X���b�f�B���O�͗V��ł镔���̑���
�����̈���CPU����Ȃ��Ƃ���܂�Ӗ����Ȃ���ˁH
�����̈���CPU����Ȃ��Ƃ���܂�Ӗ����Ȃ���ˁH
K10�̒x��ǂ������ȑO��AMD��65nm�v���Z�X���厸�s��������Ȃ��낤���B
���܂��ɋ��N������65nm�ŏo�ׂ��Ă�͂��Ȃ̂ɔ��N���������܂ł�65nm��X2��
2.6GHz�~�܂�B�V�������N�Ń_�C�T�C�Y���������͂��Ȃ̂ɂȂ���65nm��X2��L2=1MB�̂݁B
X2���i�i�Ƀg�����W�X�^���̑���Kuma��2.6GHz��������̂��ˁE�E�E
���܂��ɋ��N������65nm�ŏo�ׂ��Ă�͂��Ȃ̂ɔ��N���������܂ł�65nm��X2��
2.6GHz�~�܂�B�V�������N�Ń_�C�T�C�Y���������͂��Ȃ̂ɂȂ���65nm��X2��L2=1MB�̂݁B
X2���i�i�Ƀg�����W�X�^���̑���Kuma��2.6GHz��������̂��ˁE�E�E
>�n�C�p�[�X���b�f�B���O�͗V��ł镔���̑���
>�����̈���CPU����Ȃ��Ƃ���܂�Ӗ����Ȃ���ˁH
������̕������L���ł͂��邪�A�Ӗ��������킯����Ȃ��B
�{���̖ړI�̓��������C�e���V�̉B���ł��邩��B
���̌��ʎ��s���j�b�g�������ǂ��g���Ă���ɂ����Ȃ��B
>�����̈���CPU����Ȃ��Ƃ���܂�Ӗ����Ȃ���ˁH
������̕������L���ł͂��邪�A�Ӗ��������킯����Ȃ��B
�{���̖ړI�̓��������C�e���V�̉B���ł��邩��B
���̌��ʎ��s���j�b�g�������ǂ��g���Ă���ɂ����Ȃ��B
>>113-115
�Ӗ����Ȃ����Ƃ͂Ȃ����A�}���`�R�ACPU�ɂ����HyperThreading��lj����Ă�
�\�t�g�������Ȃ�}���`�X���b�h����i�߂Ă��Ȃ��ƌ��ʂ��Ȃ��B
�Ⴆ��Nehalem�̓l�C�e�B�u�N�A�b�h�R�A�Ŋe�R�A�ɂQ�X���b�h����̂ōő�W�X���b�h����A
����̃j�R�C�`�ł��o��Ɨ\�z�����̂ł����͍ő�P�U�X���b�h���B
���ꂾ���̃X���b�h��H�킹��\�t�g���ǂꂾ�����邩���Ęb�B
�Ӗ����Ȃ����Ƃ͂Ȃ����A�}���`�R�ACPU�ɂ����HyperThreading��lj����Ă�
�\�t�g�������Ȃ�}���`�X���b�h����i�߂Ă��Ȃ��ƌ��ʂ��Ȃ��B
�Ⴆ��Nehalem�̓l�C�e�B�u�N�A�b�h�R�A�Ŋe�R�A�ɂQ�X���b�h����̂ōő�W�X���b�h����A
����̃j�R�C�`�ł��o��Ɨ\�z�����̂ł����͍ő�P�U�X���b�h���B
���ꂾ���̃X���b�h��H�킹��\�t�g���ǂꂾ�����邩���Ęb�B
>>109
45nm���i�̏o�ׂ�2008�N���Ƃ͌����Ă����B
45nm���i�̏o�ׂ�2008�N���Ƃ͌����Ă����B
128SSE��Core2Duo�Ƃ̌���I�ȍ�������
����������Core2Duo�Ɛ킦���Ȃ����H
����������Core2Duo�Ɛ킦���Ȃ����H
>>113
SMT�̓l�g�o�������̂����̂ł��̗p����Ă邼
SMT�̓l�g�o�������̂����̂ł��̗p����Ă邼
K10�͋tNetburst�A�[�L�e�N�`���Ɩ����
�����_��OS���N������T���v����1.6GHz���āE�E�E
�����_��OS���N������T���v����1.6GHz���āE�E�E
122 �FMAC�I�^��118 �����F2007/06/16(�y) 08:58:22 ID:qcd6RBae
>>118
�@�@-------------------
�@�@128SSE��Core2Duo�Ƃ̌���I�ȍ�������
�@�@-------------------
����Core2Duo�ɂ�����ς݂��B
http://www.intel.com/technology/architecture/coremicro/
�@�@=====================
�@�@Intel Advanced Digital Media Boost
�@�@[����]
�@�@Intel Advanced Digital Media Boost feature enables these 128-bit instructions to be
�@�@completely executed at a throughput rate of one per clock cycle, effectively doubling,
�@�@on a per clock basis, the speed of execution for these instructions as compared to
�@�@previous generations.
�@�@=====================
�@�@-------------------
�@�@128SSE��Core2Duo�Ƃ̌���I�ȍ�������
�@�@-------------------
����Core2Duo�ɂ�����ς݂��B
http://www.intel.com/technology/architecture/coremicro/
�@�@=====================
�@�@Intel Advanced Digital Media Boost
�@�@[����]
�@�@Intel Advanced Digital Media Boost feature enables these 128-bit instructions to be
�@�@completely executed at a throughput rate of one per clock cycle, effectively doubling,
�@�@on a per clock basis, the speed of execution for these instructions as compared to
�@�@previous generations.
�@�@=====================
>>113
CPU�����̌������ǂ��Ă��A���C���������ւ̃A�N�Z�X�ő҂������͔̂������Ȃ�����A
�������ɘA���ł͂Ȃ��ă����_���ɃA�N�Z�X����l�ȃA�v���i�X���b�h�j����������l��
�V�`���G�[�V�����������Ȃ�A���ɗ����B
�Ⴆ��SIMD���߂𑽐��g���āA���C���������A�N�Z�X���啔���ȃX���b�h���肾��
�S�ẴX���b�h���������A�N�Z�X�ő҂�����邩��A�������������B
����ƃ}���`�R�A��CPU�̏ꍇ�A�R�A���ɃX���b�h������U���������������ǂ����A
>>116 �̒ʂ�ŁA�����܂ł���̂͏��Ȃ��Ƃ�����̃N���C�A���g�p�ł͈Ӗ���
�����B
>>114
Athlon x2 ��TDP45W�i�������̃��C���ɂ����Ă��悤�Ƃ��Ă�H�݂���������A
�v���Z�X�̎��s���Ęb�ł͖����C���B
K6-2+/III+�̎��ɁA0.18��m�v���Z�X�ł��قǍ��N���b�N���o���Ȃ������̂�
�����ŁA�v���Z�X�����f�U�C���̌������傫�������C���B
CPU�����̌������ǂ��Ă��A���C���������ւ̃A�N�Z�X�ő҂������͔̂������Ȃ�����A
�������ɘA���ł͂Ȃ��ă����_���ɃA�N�Z�X����l�ȃA�v���i�X���b�h�j����������l��
�V�`���G�[�V�����������Ȃ�A���ɗ����B
�Ⴆ��SIMD���߂𑽐��g���āA���C���������A�N�Z�X���啔���ȃX���b�h���肾��
�S�ẴX���b�h���������A�N�Z�X�ő҂�����邩��A�������������B
����ƃ}���`�R�A��CPU�̏ꍇ�A�R�A���ɃX���b�h������U���������������ǂ����A
>>116 �̒ʂ�ŁA�����܂ł���̂͏��Ȃ��Ƃ�����̃N���C�A���g�p�ł͈Ӗ���
�����B
>>114
Athlon x2 ��TDP45W�i�������̃��C���ɂ����Ă��悤�Ƃ��Ă�H�݂���������A
�v���Z�X�̎��s���Ęb�ł͖����C���B
K6-2+/III+�̎��ɁA0.18��m�v���Z�X�ł��قǍ��N���b�N���o���Ȃ������̂�
�����ŁA�v���Z�X�����f�U�C���̌������傫�������C���B
���C�e���V�B�����ړI�ŁA�f�R�[�h�Ƀl�b�N��������Ă̂��ق�ƂȂ�
SMT�܂Ŋ撣��Ȃ��Ă�VMT�������Ƃ��Ώ\���ȋC�����邯��
�������̂��ȁH
SMT�܂Ŋ撣��Ȃ��Ă�VMT�������Ƃ��Ώ\���ȋC�����邯��
�������̂��ȁH
����������ւ�̓_�C�R�X�g�Ƃ̌��ˍ�������Ȃ����ȁH
�����HTT��SMT�Ɋ���Ă���Ă̂��傫������
�����HTT��SMT�Ɋ���Ă���Ă̂��傫������
SMT�̕����R�X�g�͍������낤�B
����Ă�Ƃ�����ĂȂ��Ƃ��͊W�Ȃ��Ǝv�����ǁB
�Z�p�I�ɂ�SMT�̕�������������B
����Ă�Ƃ�����ĂȂ��Ƃ��͊W�Ȃ��Ǝv�����ǁB
�Z�p�I�ɂ�SMT�̕�������������B
�܂��AMAC�I�^�́u�����ȊO�S���o�J�v�̐l������d���Ȃ���
�����A�����ځ[�Ă邩��128�����O�o���Ȃ���A�z�����邱�Ƃɂ���C�t���Ȃ������̂ɁE�E�E
�����Ԃ�ƃi�C�[�u�Ȃ�
����A�ɂ��������ȁA�Ǝv���āB
�N���b�N�����̍��͂ǂ����痈��̂��ȁH
128SSE�R���Ȃ�
K10�ł���Ώ\���킦��Ǝv����
����ȊO�Ȃ炵��˂���
128SSE�R���Ȃ�
K10�ł���Ώ\���킦��Ǝv����
����ȊO�Ȃ炵��˂���
>>115
�����炱���������ш悪�����Ȃ̂ɁADualCore��}���`�R�A�������\����
��i�ɂȂ��ˁB
���������{���ɃA�b�v�A�b�v�Ȃ�ADual Socket ��}���`�\�P�b�g��MB
�ɂ��������ǂ����B
�ܘ_�A�������Ȃ��̂͂n�r�̃��C�Z���X���̖�肪��ԑ傫�����ǁB
�����炱���������ш悪�����Ȃ̂ɁADualCore��}���`�R�A�������\����
��i�ɂȂ��ˁB
���������{���ɃA�b�v�A�b�v�Ȃ�ADual Socket ��}���`�\�P�b�g��MB
�ɂ��������ǂ����B
�ܘ_�A�������Ȃ��̂͂n�r�̃��C�Z���X���̖�肪��ԑ傫�����ǁB
AcesHardware�f������E���Ă����b���B����ŋߌ��J���ꂽItanium�̃��[�h�}�b�v�̘b
�Ɋւ���X���b�h�Ȃ��ǁA�_�C�T�C�Y�ƃv���Z�b�T�̃����[�X�����Ƃ̊W�ɂ��Ėʔ���
�R�����g���t���Ă邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=120083317&forumid=1
�@�@---------------------
�@�@At TI we always shipped the smallest die chips to be manufactured on a new node
�@�@many quarters before the larger ones mostly due to the time it took to work out
�@�@the production kinks as the node matured and we could produce shippable quantities
�@�@of the larger dies.
�@�@---------------------
���������v���Z�X�ɂ����Ă�A�_�C�T�C�Y���傫���Ƃ��������̗��R�Ő��l�����o�ׂ��x���̂�
���ʂ��B�B�B�Ƃ����b���B
65nm�v���Z�X��512KB L2��K8�ł��܂�����������ƌ����āA����ȃl�C�e�B�u4�R�A�̃`�b�v��
�������X���[�Y�ɐi�ނƂ����̂�A�y�ϓI�߂�����Ȃ������ˁB�B�B
�Ɋւ���X���b�h�Ȃ��ǁA�_�C�T�C�Y�ƃv���Z�b�T�̃����[�X�����Ƃ̊W�ɂ��Ėʔ���
�R�����g���t���Ă邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=120083317&forumid=1
�@�@---------------------
�@�@At TI we always shipped the smallest die chips to be manufactured on a new node
�@�@many quarters before the larger ones mostly due to the time it took to work out
�@�@the production kinks as the node matured and we could produce shippable quantities
�@�@of the larger dies.
�@�@---------------------
���������v���Z�X�ɂ����Ă�A�_�C�T�C�Y���傫���Ƃ��������̗��R�Ő��l�����o�ׂ��x���̂�
���ʂ��B�B�B�Ƃ����b���B
65nm�v���Z�X��512KB L2��K8�ł��܂�����������ƌ����āA����ȃl�C�e�B�u4�R�A�̃`�b�v��
�������X���[�Y�ɐi�ނƂ����̂�A�y�ϓI�߂�����Ȃ������ˁB�B�B
>>123
>Athlon x2 ��TDP45W�i�������̃��C���ɂ����Ă��悤�Ƃ��Ă�H�݂���������A
>�v���Z�X�̎��s���Ęb�ł͖����C���B
�����̑傫���͂���6000+����65nm�łŐ�������Ȃ��͖̂��炩�ɂ�����������B
�ӂ��Ȃ�V�������N�v���Z�X�ł�L2�͔{�ɂȂ�̂ɁA�t��90nm�łł�1MB��2MB�������̂�
65nm�łł�1MB�����B�v���Z�X�ɂȂ�炩�̖�������Ă��邩�AAMD�̐헪������������
�ǂ����ɂ��남�������B
>Athlon x2 ��TDP45W�i�������̃��C���ɂ����Ă��悤�Ƃ��Ă�H�݂���������A
>�v���Z�X�̎��s���Ęb�ł͖����C���B
�����̑傫���͂���6000+����65nm�łŐ�������Ȃ��͖̂��炩�ɂ�����������B
�ӂ��Ȃ�V�������N�v���Z�X�ł�L2�͔{�ɂȂ�̂ɁA�t��90nm�łł�1MB��2MB�������̂�
65nm�łł�1MB�����B�v���Z�X�ɂȂ�炩�̖�������Ă��邩�AAMD�̐헪������������
�ǂ����ɂ��남�������B
VLSI�V���|�W�E���ł�IBM�A���̎�����SOI�v���Z�X�ɂ��Ă̔��\���B
http://techon.nikkeibp.co.jp/article/NEWS/20070615/134344/
45nm����̎����v���Z�X��SOI+High-K�Q�[�g�≏��+�����Q�[�g�ɂȂ�Ƃ̂��Ƃ��B
Electronic News�̋L���ɂ��ƁA���̃v���Z�X�Ń��[�N�d���̑啝�ጸ�Ƌ���20%�̐��\���オ
������Ƃ̂��Ƃ��BIBM�ł허�N��Power�v���Z�b�T����̗p���J�n���A�����J���̃p�[�g�i�[��
���̌㏇���̗p���錩���݂Ƃ̂��ƁB
�Ȃ����ȑg�D���ɂ��G�A�M���b�v�≏��32nm�ȍ~�ɍ̗p�\��Ƃ̂��Ƃ��B
http://www.edn.com/article/CA6452010.html?nid=2019&rid=1697220362
http://techon.nikkeibp.co.jp/article/NEWS/20070615/134344/
45nm����̎����v���Z�X��SOI+High-K�Q�[�g�≏��+�����Q�[�g�ɂȂ�Ƃ̂��Ƃ��B
Electronic News�̋L���ɂ��ƁA���̃v���Z�X�Ń��[�N�d���̑啝�ጸ�Ƌ���20%�̐��\���オ
������Ƃ̂��Ƃ��BIBM�ł허�N��Power�v���Z�b�T����̗p���J�n���A�����J���̃p�[�g�i�[��
���̌㏇���̗p���錩���݂Ƃ̂��ƁB
�Ȃ����ȑg�D���ɂ��G�A�M���b�v�≏��32nm�ȍ~�ɍ̗p�\��Ƃ̂��Ƃ��B
http://www.edn.com/article/CA6452010.html?nid=2019&rid=1697220362
AMD�̃t���b�O�V�b�vCPU�̕ϑJ(���t��Akiba PC Hotline! CPU�ň��l���̏��o���)
2001/06/02 Athlon 1.4GHz(256KB)
2001/10/06 Athlon XP 1800+(1.53GHz,256KB)
2001/11/10 Athlon XP 1900+(1.60GHz,256KB)
2001/12/28 Athlon XP 2000+(1.67GHz,256KB)
2002/03/16 Athlon XP 2100+(1.73GHz,256KB)
2002/06/22 Athlon XP 2200+(1.80GHz,256KB)
2002/10/19 Athlon XP 2400+(2.00GHz,256KB)
2002/11/09 Athlon XP 2700+(2.17GHz,256KB)
2003/02/15 Athlon XP 2800+(2.08GHz,512KB)
2003/02/22 Athlon XP 3000+(2.17GHz,512KB)
2003/05/17 Athlon XP 3200+(2.20GHz,512KB)
2003/09/27 Athlon 64 FX-51(2.20GHz,1MB)
2004/03/27 Athlon 64 FX-53(2.40GHz,1MB)
2004/10/23 Athlon 64 FX-55(2.60GHz,1MB)
2005/06/25 Athlon 64 X2 4600+(2.40GHz,512KBx2)
2005/08/06 Athlon 64 X2 4800+(2.40GHz,1MBx2)
2006/01/14 Athlon 64 FX-60(2.60GHz,1MBx2)
2006/06/10 Athlon 64 FX-62(2.80GHz,1MBx2)
2007/02/03 Athlon 64 FX-74(3.00GHz,1MBx2)
2001/06/02 Athlon 1.4GHz(256KB)
2001/10/06 Athlon XP 1800+(1.53GHz,256KB)
2001/11/10 Athlon XP 1900+(1.60GHz,256KB)
2001/12/28 Athlon XP 2000+(1.67GHz,256KB)
2002/03/16 Athlon XP 2100+(1.73GHz,256KB)
2002/06/22 Athlon XP 2200+(1.80GHz,256KB)
2002/10/19 Athlon XP 2400+(2.00GHz,256KB)
2002/11/09 Athlon XP 2700+(2.17GHz,256KB)
2003/02/15 Athlon XP 2800+(2.08GHz,512KB)
2003/02/22 Athlon XP 3000+(2.17GHz,512KB)
2003/05/17 Athlon XP 3200+(2.20GHz,512KB)
2003/09/27 Athlon 64 FX-51(2.20GHz,1MB)
2004/03/27 Athlon 64 FX-53(2.40GHz,1MB)
2004/10/23 Athlon 64 FX-55(2.60GHz,1MB)
2005/06/25 Athlon 64 X2 4600+(2.40GHz,512KBx2)
2005/08/06 Athlon 64 X2 4800+(2.40GHz,1MBx2)
2006/01/14 Athlon 64 FX-60(2.60GHz,1MBx2)
2006/06/10 Athlon 64 FX-62(2.80GHz,1MBx2)
2007/02/03 Athlon 64 FX-74(3.00GHz,1MBx2)
�ŏ��̃f���A���R�A��2.4GHz�œo�ꂵ�āA�P�N��������3GHz�܂ł����オ��Ȃ������ȁB
Phenom X4���o�ꎞ��2.4GHz�ɂȂ肻�����B
�c�c3GHz�ł��o��̂�2009�N6�����B
Phenom X4���o�ꎞ��2.4GHz�ɂȂ肻�����B
�c�c3GHz�ł��o��̂�2009�N6�����B
>>139
2.4����FX-60�͏o�����ǁA5000+(512KB)�����\���ꂽ�̂��P�N��A�������㔭���O�ɒl�����A�o��
2.4����FX-60�͏o�����ǁA5000+(512KB)�����\���ꂽ�̂��P�N��A�������㔭���O�ɒl�����A�o��
�������ɂ���͂Ȃ����낤���A�w�^���Ă�ȁ`�B
�ŏ���Hammer���o�鎞�͓�Y�ŁASOI�v���Z�X������œ���Ă��Č����Ă�����
�v���Z�X�Ŏ肱����Ȃ��Ă��������߂��̂ɐF�D���j���[�X���������Ă��Ȃ��̂͂�������A�Ƃ����E�E
�܂��A���̎��݂����ɉ��x����������������������Ȃ����ǁB
�E�E�܂��B
�ŏ���Hammer���o�鎞�͓�Y�ŁASOI�v���Z�X������œ���Ă��Č����Ă�����
�v���Z�X�Ŏ肱����Ȃ��Ă��������߂��̂ɐF�D���j���[�X���������Ă��Ȃ��̂͂�������A�Ƃ����E�E
�܂��A���̎��݂����ɉ��x����������������������Ȃ����ǁB
�E�E�܂��B
�オ45nm�Ɉڍs����͍̂ė��N�O��������H
Core3�͂��łɂ�����݂ɂȂ��Ă鍠����
Core3�͂��łɂ�����݂ɂȂ��Ă鍠����
����nehalem�̃l�g�o���Ɋ��҂��邵���E�E�E
145 �FSocket774�F2007/06/17(��) 00:37:41 ID:EqyNNCa3
AMD��45nm�͗��N�㔼(�O��������Ɍ�ނ��Ă��邪�j�����A���ۂ̂Ƃ����Nehalem�Ɠ������炢�����ȁB
45nm�Ŏ��̂�2008Q3���낤���ǁA�t���O�V�b�v��45nm�ł�2008Q4��Nehalem�Ɠ������A
���肷���2009Q1���Ǝv��
���肷���2009Q1���Ǝv��
>>145
>>146�̌����ʂ�ŁA���ł����Ȃ�5000+(2.6GHz)��65nm�̃g�b�v�B
���N�̎��_��5000+�̈ʒu�Â��̂�Core3����킦�Ȃ����낤
5000+���甼�N�ԑS���X�V����Ȃ��̂́A90nm�̃��r�W����E��莞�Ԃ������Ă��
>>146�̌����ʂ�ŁA���ł����Ȃ�5000+(2.6GHz)��65nm�̃g�b�v�B
���N�̎��_��5000+�̈ʒu�Â��̂�Core3����킦�Ȃ����낤
5000+���甼�N�ԑS���X�V����Ȃ��̂́A90nm�̃��r�W����E��莞�Ԃ������Ă��
�����{���̗\��Ȃ�2007Q2����K10�̐����ɓ����Ă��͂�������E�E�E
ATI�������~�b�h�E�F�[�C�킾������
150 �FSocket774�F2007/06/17(��) 03:19:49 ID:bZkRZXBy
151 �FSocket774�F2007/06/17(��) 03:40:24 ID:pWK4jIvJ
���m�� �u�}���`�R�ACPU�v
�}���`�X���b�h�\�����R�A���Ǝv���Ă�A�z�����邪�A�����ł͂Ȃ��B
�S�R�A��������4�X���b�h�܂ŁA�ł͂Ȃ��B
���̃R�A���ǂꂾ���̏����@�\������Ă��邩�ŕς��̂ŁA
4�R�A��64�X���b�h�����ł�����̂����݂���B
�����Ⴊ�A�T���E�}�C�N���V�X�e���Y��SPARC��
�����1�R�A��8�X���b�h�����ł��邽�߁A���ۂ̐��i�ł���8�R�ASPARC�ł�
8x8��1CPU������64�X���b�h�������ł���̂ł���B
�}���`�X���b�h�\�����R�A���Ǝv���Ă�A�z�����邪�A�����ł͂Ȃ��B
�S�R�A��������4�X���b�h�܂ŁA�ł͂Ȃ��B
���̃R�A���ǂꂾ���̏����@�\������Ă��邩�ŕς��̂ŁA
4�R�A��64�X���b�h�����ł�����̂����݂���B
�����Ⴊ�A�T���E�}�C�N���V�X�e���Y��SPARC��
�����1�R�A��8�X���b�h�����ł��邽�߁A���ۂ̐��i�ł���8�R�ASPARC�ł�
8x8��1CPU������64�X���b�h�������ł���̂ł���B
����A�������ˁ[
���g������K7�i�M�j�{WinXP��
�^�X�N�}�l�[�W���ǂ݂�
�@45�v���Z�X
�@470�X���b�h
����������
���g������K7�i�M�j�{WinXP��
�^�X�N�}�l�[�W���ǂ݂�
�@45�v���Z�X
�@470�X���b�h
����������
153 �FSocket774�F2007/06/17(��) 04:05:56 ID:OS1u0+Ju
����̓��C�u�X���b�h/�v���Z�X�ł����ăI���v���Z�V���O�ł͂Ȃ�
���C�u�X���b�h�A���C�u�v���Z�X�Ƃ͏��������̂�҂��Ă����
���C�u�X���b�h�A���C�u�v���Z�X�Ƃ͏��������̂�҂��Ă����
�^�C���X���C�X
AMD�̐��i��SMT���̗p�������i�͂Ȃ�=���E��SMT�������������i�͖����͂�
�ӂ��������Ə����Ă���AID��68K�Ȃ̂ɋC�Â���
2.4Ghz�Ń��o�ɂ͏\�����Ă�����
�N���b�N�グ�͂Ȃ������낤�ˁB
���Ă��C���e��Core2Duo�o��Ő��\�グ����
�ׂ�Ȃ����x��AMD�͂���Ȃ���ł�����Ȃ��H
�C���e�������������̏o���Ƃ���ɂ������̂őR����ƌ������Ƃ�
�N���b�N�グ�͂Ȃ������낤�ˁB
���Ă��C���e��Core2Duo�o��Ő��\�グ����
�ׂ�Ȃ����x��AMD�͂���Ȃ���ł�����Ȃ��H
�C���e�������������̏o���Ƃ���ɂ������̂őR����ƌ������Ƃ�
�S�[���h�}���E�T�b�N�X�̃A�i���X�g���uAMD�������̍H��蕥���ăt�@�u���X��Ɖ�
����v�Ƃ̃��|�[�g���o���āu�����v�Ɣ��f���Ă邻�������ǁA���̃��|�[�g�Ŋ����퉺�����Ă邻�����B
http://www.theinquirer.net/default.aspx?article=40377
�@�@------------------
�@�@Goldmine reckons that AMD stands to suffer because it will have to outsource its
�@�@production while Intel doesn't need to take that route.
�@�@------------------
����v�Ƃ̃��|�[�g���o���āu�����v�Ɣ��f���Ă邻�������ǁA���̃��|�[�g�Ŋ����퉺�����Ă邻�����B
http://www.theinquirer.net/default.aspx?article=40377
�@�@------------------
�@�@Goldmine reckons that AMD stands to suffer because it will have to outsource its
�@�@production while Intel doesn't need to take that route.
�@�@------------------
C2D�͒P�Ȃ�m�[�g����CPU������悠���ŁA
���C���X�g���[���ɓ˂����܂�鎖�ɂȂ�������������Ȃ��B
������l����ƁA�C�X���G���`�[������������c�B
�ȓd�͐��\�͌��X�����ē�����O�����A���\���������܂ŏo��Ƃ́c�B
���C���X�g���[���ɓ˂����܂�鎖�ɂȂ�������������Ȃ��B
������l����ƁA�C�X���G���`�[������������c�B
�ȓd�͐��\�͌��X�����ē�����O�����A���\���������܂ŏo��Ƃ́c�B
Conroe-L 1GHz��Tualatin 1GHz�łǂꂮ�炢���\������̂����Ă݂���
>>160
Tualatin-1.4G��Celeron 420(1.6G)�Ŕ�ׂĂ݂�Ⴂ���B
Tualatin-1.4G��Celeron 420(1.6G)�Ŕ�ׂĂ݂�Ⴂ���B
162 �F�s���ȃf�o�C�X�����F2007/06/17(��) 10:50:39 ID:OutmIOZj
>>159 �C�X�����`�[�����D�G�Ȃ̂ł͂Ȃ��I���S���`�[���H���������������B
AMD��SOI���̂Ă��INTEL�ɋ߂Â���ƌ��Ă���B
AMD��SOI���̂Ă��INTEL�ɋ߂Â���ƌ��Ă���B
AMD��
����d��170W
�R�A��16
�Q�����L������8MB
�R�����L������32MB
���ꂮ�炢���Ȃ��Ə��Ă����ɂȂ���
����d��170W
�R�A��16
�Q�����L������8MB
�R�����L������32MB
���ꂮ�炢���Ȃ��Ə��Ă����ɂȂ���
���Ƃ���PentiumIII�̍��� ����x86�b�o�t�͕��G���������āA����ȏ�IPC��������͓̂���A
�g�����W�X�^���g���đ傫���g�����Ă�����Ɍ����������̃o�b�N���Ȃ��A�ƌ����Ă�����ȁB
������Intel��AMD����x�̓N���b�N����H���ɑǂ�����킯�ŁB
�Ƃ��낪�A�C�X���G���`�[���͂�����Ђ����肩�������܂����B
PentiumIII���炠�ꂾ�����I��IPC���オ��Ƃ͒N���\�z���ĂȂ������B
�L���b�V���̑��ʂ�512K���z��������ʂ������ƌ����Ă����ˁB
Intel�̊���������͗\�z�O�������낤�ȁB�����܂�x86�̃g�b�v�`�[���̓I���S���J���`�[���ŁA
�C�X���G���J���`�[���͂����܂ōT���A�݂����Ȉ�����������ȁB
�č��{���̃`�[���ƌ������Ƃ������Ă����C���A�[�L�����̂̓I���S���œ��R�A�݂�����
��C���������B
�����ǂ��̍��̃j���[�X��ǂނ����F���e�[�v�A�E�g���������肩��intel������
�����ɂ������Ɉ������݂�݂�ς���Ă����̂��ڂɌ�����w
�g�����W�X�^���g���đ傫���g�����Ă�����Ɍ����������̃o�b�N���Ȃ��A�ƌ����Ă�����ȁB
������Intel��AMD����x�̓N���b�N����H���ɑǂ�����킯�ŁB
�Ƃ��낪�A�C�X���G���`�[���͂�����Ђ����肩�������܂����B
PentiumIII���炠�ꂾ�����I��IPC���オ��Ƃ͒N���\�z���ĂȂ������B
�L���b�V���̑��ʂ�512K���z��������ʂ������ƌ����Ă����ˁB
Intel�̊���������͗\�z�O�������낤�ȁB�����܂�x86�̃g�b�v�`�[���̓I���S���J���`�[���ŁA
�C�X���G���J���`�[���͂����܂ōT���A�݂����Ȉ�����������ȁB
�č��{���̃`�[���ƌ������Ƃ������Ă����C���A�[�L�����̂̓I���S���œ��R�A�݂�����
��C���������B
�����ǂ��̍��̃j���[�X��ǂނ����F���e�[�v�A�E�g���������肩��intel������
�����ɂ������Ɉ������݂�݂�ς���Ă����̂��ڂɌ�����w
>>162
���XSOI�̂ĂĔM�X�ł����H
�Ă��A���XSOI���̂Ă�Ӗ����킩���B
>>163
���₾����A�V�X�e���S�̂�170W�������炢�����ǁA
�m����̃��C����150W��������ƁA
���i������l������舵���Ȃ��A
�d�ł��d���𓋍ڂ��Ȃ��Ƃ����Ȃ��Ȃ邩��A
��ʂɔ̔�����͖̂����Ȃ��āc�B�Ȃ��Intel���c�B
���XSOI�̂ĂĔM�X�ł����H
�Ă��A���XSOI���̂Ă�Ӗ����킩���B
>>163
���₾����A�V�X�e���S�̂�170W�������炢�����ǁA
�m����̃��C����150W��������ƁA
���i������l������舵���Ȃ��A
�d�ł��d���𓋍ڂ��Ȃ��Ƃ����Ȃ��Ȃ邩��A
��ʂɔ̔�����͖̂����Ȃ��āc�B�Ȃ��Intel���c�B
>>164
�I���S�������Ȃ�AMD�́E�E�E
X2�o�Ă���IPC���N���b�N���オ���ĂȂ����� >>138
Phenom�o��܂łQ�N����AMD�͂�������������Ă���
�I���S�������Ȃ�AMD�́E�E�E
X2�o�Ă���IPC���N���b�N���オ���ĂȂ����� >>138
Phenom�o��܂łQ�N����AMD�͂�������������Ă���
>>166
�u�N���b�N���グ�鎖���A���\�㏸�ł͂Ȃ��v
������������̂�Hammer�n��������������B
�����A�����悭�N���b�N���グ����Ȃ�A
����ɂ����������Ȃ����Ă̂��������̂��A
�C�X���G���`�[����C2D�B
�u�N���b�N���グ�鎖���A���\�㏸�ł͂Ȃ��v
������������̂�Hammer�n��������������B
�����A�����悭�N���b�N���グ����Ȃ�A
����ɂ����������Ȃ����Ă̂��������̂��A
�C�X���G���`�[����C2D�B
>>158
���̃����N��̕��͂��ƁA���������������o���Ȃ����NjC�̂����ȁH
�S�[���h�}���̕��͂ł́A�ϑ��Ȃ��ł̓`�b�v�������o���Ȃ����A�h���X�f���ɂ͗D�G��
�l�ނ����āA�v�Ɋւ��Ă���ɑ�����̂͋��Ȃ����낤�B�ƌ���ł���悤�ȋC������B
�ݔ����p�Ɋւ��邱�Ƃ��ď����Ă���H
���̃����N��̕��͂��ƁA���������������o���Ȃ����NjC�̂����ȁH
�S�[���h�}���̕��͂ł́A�ϑ��Ȃ��ł̓`�b�v�������o���Ȃ����A�h���X�f���ɂ͗D�G��
�l�ނ����āA�v�Ɋւ��Ă���ɑ�����̂͋��Ȃ����낤�B�ƌ���ł���悤�ȋC������B
�ݔ����p�Ɋւ��邱�Ƃ��ď����Ă���H
170 �FMAC�I�^��159 �����F2007/06/17(��) 11:55:29 ID:Kp8SxLEQ
>>159
�@�@-----------------
�@�@�ȓd�͐��\�͌��X�����ē�����O�����A���\���������܂ŏo��Ƃ́c�B
�@�@-----------------
���ʂ̃q�g��A���̒i�K�łƂ����ɋC�t���Ă��������ǁB�B�B
http://pc5.2ch.net/test/read.cgi?bbs=jisaku&key=1101223278
�@�@=================
�@�@217 ���O�FMAC�I�^��206 ���� ���e���F04/11/27 13:04:25 ID:P/k4P/t9
�@�@�@�@>>206
�@�@�@�@�������Z�ōςނȂ�Pentium M��Athlon 64�Ȃ��y���ɍ������B1MB L2��Opteron�Ɣ�r���Ă���
�@�@�@�@����ȃ������B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@SPECint(base/peak)
�@�@�@�@�@Pentium M 755/2GHz�@�@1528/1541�@�@�@��PC2700�V���O���`�����l���̃m�[�gPC
�@�@�@�@�@Opteron 150/2.4GHz�@�@�@1369/1487�@�@�@��PC3200�f���A���`�����l��
�@�@=================
�@�@-----------------
�@�@�ȓd�͐��\�͌��X�����ē�����O�����A���\���������܂ŏo��Ƃ́c�B
�@�@-----------------
���ʂ̃q�g��A���̒i�K�łƂ����ɋC�t���Ă��������ǁB�B�B
http://pc5.2ch.net/test/read.cgi?bbs=jisaku&key=1101223278
�@�@=================
�@�@217 ���O�FMAC�I�^��206 ���� ���e���F04/11/27 13:04:25 ID:P/k4P/t9
�@�@�@�@>>206
�@�@�@�@�������Z�ōςނȂ�Pentium M��Athlon 64�Ȃ��y���ɍ������B1MB L2��Opteron�Ɣ�r���Ă���
�@�@�@�@����ȃ������B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@SPECint(base/peak)
�@�@�@�@�@Pentium M 755/2GHz�@�@1528/1541�@�@�@��PC2700�V���O���`�����l���̃m�[�gPC
�@�@�@�@�@Opteron 150/2.4GHz�@�@�@1369/1487�@�@�@��PC3200�f���A���`�����l��
�@�@=================
171 �FMAC�I�^��169 �����F2007/06/17(��) 11:57:34 ID:Kp8SxLEQ
>>169
�@�@-----------------
�@�@�h���X�f���ɂ͗D�G�Ȑl�ނ����āA�B�B�B
�@�@-----------------
����������TheInquirer�̉�����B
�@�@-----------------
�@�@�h���X�f���ɂ͗D�G�Ȑl�ނ����āA�B�B�B
�@�@-----------------
����������TheInquirer�̉�����B
�Ă�����Core2�Ɋւ��Ă͑S�R���gPentiumu�����Ȃ��Ȃ��Ă˂����H
��������Pentium3�̓I���S���ŊJ������Ă邵�A�T���Ƃ��Ă�Pentium-M�����������̂�
���������Ȃ����ȋC�����邪�B
�v���Z�X�ƘA�����������I�Ȑv���܂߁A�I���S���͈��|�I�ɗD�G�Ȃ͍̂����̂��ς��Ȃ��Ǝv���B
Pentium4�̏ꍇ�A���̍\���ł��̃N���b�N�œ����������̑��̃`�[���ł̓X�P�W���[���ʂ�ɂ͖����ł́B
��������Pentium3�̓I���S���ŊJ������Ă邵�A�T���Ƃ��Ă�Pentium-M�����������̂�
���������Ȃ����ȋC�����邪�B
�v���Z�X�ƘA�����������I�Ȑv���܂߁A�I���S���͈��|�I�ɗD�G�Ȃ͍̂����̂��ς��Ȃ��Ǝv���B
Pentium4�̏ꍇ�A���̍\���ł��̃N���b�N�œ����������̑��̃`�[���ł̓X�P�W���[���ʂ�ɂ͖����ł́B
�C�X���G�����D�G������I���S���͕����Ă̂͂Ȃ�[��
�u�A�����\���x������V���[�}�b�n�̓w�^���v���炢�̈�a���������
�u�A�����\���x������V���[�}�b�n�̓w�^���v���炢�̈�a���������
>>168
C2D�A�[�L�ƃC�X���G���`�[�����������A�Ƃ������
�P�ɁAC2D�̓o�ꎞ�����A����܂�Intel���������Ă����Ő�[�v���Z�X�Z�p��
�i�c�݃V���R���A8�w�̓��z���C���^�[�R�l�N�g�Alow-k�≏�ޗ��j
�������鎞���Ƃ��傤�Ǎ��v�������߂ł�B
���̃v���Z�X�Z�p�̐����ƁA���F�̗\�z�O�̐��\���オIntel�ɂƂ��Ă͑�����ʂɂȂ����B
�C�X���G���͂����_���Ď������A�Ƃ�����蕡���̗v�f�������I�ɗǂ������Ɍ����Č��ʓI�ɂ����Ȃ����B
�l�g�o���]���Ă��Ȃ���A���F�͂����܂Œ����d�͂̃��o�C���b�o�t�Ƃ��Ă�������
�g���Ȃ������\�������Ă������B���F�̊J���X�^�[�g����
�l�g�o�͂܂��]���ĂȂ���������C�X���G���`�[���������܂ő_���Ă��킯���Ⴀ��܂��B
C2D�A�[�L�ƃC�X���G���`�[�����������A�Ƃ������
�P�ɁAC2D�̓o�ꎞ�����A����܂�Intel���������Ă����Ő�[�v���Z�X�Z�p��
�i�c�݃V���R���A8�w�̓��z���C���^�[�R�l�N�g�Alow-k�≏�ޗ��j
�������鎞���Ƃ��傤�Ǎ��v�������߂ł�B
���̃v���Z�X�Z�p�̐����ƁA���F�̗\�z�O�̐��\���オIntel�ɂƂ��Ă͑�����ʂɂȂ����B
�C�X���G���͂����_���Ď������A�Ƃ�����蕡���̗v�f�������I�ɗǂ������Ɍ����Č��ʓI�ɂ����Ȃ����B
�l�g�o���]���Ă��Ȃ���A���F�͂����܂Œ����d�͂̃��o�C���b�o�t�Ƃ��Ă�������
�g���Ȃ������\�������Ă������B���F�̊J���X�^�[�g����
�l�g�o�͂܂��]���ĂȂ���������C�X���G���`�[���������܂ő_���Ă��킯���Ⴀ��܂��B
>>171
�����OK�ł��B
���S�ɃA�E�g�\�[�X����A�ł͂Ȃ��āA
�A�E�g�\�[�V���O�̉\���͊��S�ɕ�����ł��邪�A�Ƃ������Ƃ��Ǝv���Ȃ��B
�S�[���h�}���̕��͎��̂́A�C���e���̓A�E�g�\�[�X����K�v���Ȃ����AAMD�͈ϑ����邩��
�ꂵ���Ȃ��Ă������낤�ƕ��͂��Ă��āA����ȏ�̂��Ƃɂ����ł͌��y���Ȃ���B
��������ǂݎ���̂��āA�S�[���h�}���̕��͂ł�AMD�Ɣ�r����intel�������ł���Ƃ������Ƃ���
��������C�ɉ������ċ���ƌ������ƂƁA�ϑ����Y�Ƃ����̂������Ă��邱�Ƃ�CPU�ɋ������Ȃ��f�C�g���[�_�[
�ɏЉ�Ă���ƌ������Ƃ��炢���ȂƁB
�ł��،���Ђ̕��݂͂����Ɉ�Ԓx�����ނ̃}�X�R�~���ɂȂ镨�������������Ƃ������n�߂Ă���Ƃ������Ƃ�
������ʓI�Ȑl�����̔F���Ƃ��ĐZ�����Ă��܂����Ƃ������ƂɂȂ邩���B
�����OK�ł��B
���S�ɃA�E�g�\�[�X����A�ł͂Ȃ��āA
�A�E�g�\�[�V���O�̉\���͊��S�ɕ�����ł��邪�A�Ƃ������Ƃ��Ǝv���Ȃ��B
�S�[���h�}���̕��͎��̂́A�C���e���̓A�E�g�\�[�X����K�v���Ȃ����AAMD�͈ϑ����邩��
�ꂵ���Ȃ��Ă������낤�ƕ��͂��Ă��āA����ȏ�̂��Ƃɂ����ł͌��y���Ȃ���B
��������ǂݎ���̂��āA�S�[���h�}���̕��͂ł�AMD�Ɣ�r����intel�������ł���Ƃ������Ƃ���
��������C�ɉ������ċ���ƌ������ƂƁA�ϑ����Y�Ƃ����̂������Ă��邱�Ƃ�CPU�ɋ������Ȃ��f�C�g���[�_�[
�ɏЉ�Ă���ƌ������Ƃ��炢���ȂƁB
�ł��،���Ђ̕��݂͂����Ɉ�Ԓx�����ނ̃}�X�R�~���ɂȂ镨�������������Ƃ������n�߂Ă���Ƃ������Ƃ�
������ʓI�Ȑl�����̔F���Ƃ��ĐZ�����Ă��܂����Ƃ������ƂɂȂ邩���B
>>175
Inq�͈ϑ����Y�Ȃ�ĉ��ւȘb�ł͂Ȃ�Intel��IBM�ɐg�����邮�炢������ĝ������Ă銴��
Inq�͈ϑ����Y�Ȃ�ĉ��ւȘb�ł͂Ȃ�Intel��IBM�ɐg�����邮�炢������ĝ������Ă銴��
177 �FMAC�I�^��175 �����F2007/06/17(��) 12:13:02 ID:Kp8SxLEQ
>>175
�@�@----------------
�@�@�S�[���h�}���̕��͎��̂́A�C���e���̓A�E�g�\�[�X����K�v���Ȃ����AAMD�͈ϑ����邩��
�@�@�ꂵ���Ȃ��Ă������낤
�@�@----------------
�S�[���h�}�����̂�AMD��"buy"�Ɋi�グ�����Ə����Ă��邷����A�ϑ��ŃR�X�g���팸���Čo�c�I
�ɗǂ��Ȃ�ƕ��͂��Ă���͗l���B
�@�@----------------
�@�@�S�[���h�}���̕��͎��̂́A�C���e���̓A�E�g�\�[�X����K�v���Ȃ����AAMD�͈ϑ����邩��
�@�@�ꂵ���Ȃ��Ă������낤
�@�@----------------
�S�[���h�}�����̂�AMD��"buy"�Ɋi�グ�����Ə����Ă��邷����A�ϑ��ŃR�X�g���팸���Čo�c�I
�ɗǂ��Ȃ�ƕ��͂��Ă���͗l���B
inq�Őg�����o�����Ď���AMD�̂Ƃ�������7�������炢��
�����������獡������N���X�ɂ͋z��������IBM�̊֘A�q��Љ�������
�����������獡������N���X�ɂ͋z��������IBM�̊֘A�q��Љ�������
>>174
>���F�̊J���X�^�[�g���̓l�g�o�͂܂��]���ĂȂ���������
�]���Ă���B�Ƃ�����Banias�o�ꎞ�_��
�E����͂���Banias�n���f�X�N�g�b�v�ɓ������邵���Ȃ�
�E���₢��I���S���ɂ��ʎq�����邵�N���b�N�����`�̃}�[�P�e�B���O�I�ɖ���������
�Ƌc�_�ɂȂ��Ă����B
>���F�̊J���X�^�[�g���̓l�g�o�͂܂��]���ĂȂ���������
�]���Ă���B�Ƃ�����Banias�o�ꎞ�_��
�E����͂���Banias�n���f�X�N�g�b�v�ɓ������邵���Ȃ�
�E���₢��I���S���ɂ��ʎq�����邵�N���b�N�����`�̃}�[�P�e�B���O�I�ɖ���������
�Ƌc�_�ɂȂ��Ă����B
>>177
buy�A����intel�̂ق��̕]�����Ǝv�������LjႤ�̂��ȁB
�Ƃ�����S�[���h�}�����ʂ��ߊϓI�ȏ��Ƃ��Ă͈����Ă͋��Ȃ��Ƃ������B
�H��p�Ƃ����̂͂�������Ђ��ςĂ��Ă��Ȃ���ł���H�ǂ��B�m�肽���B
>>176
����͎����ɋ@�B�|��ɂ����Ă��o�Ă��Ȃ������悗
buy�A����intel�̂ق��̕]�����Ǝv�������LjႤ�̂��ȁB
�Ƃ�����S�[���h�}�����ʂ��ߊϓI�ȏ��Ƃ��Ă͈����Ă͋��Ȃ��Ƃ������B
�H��p�Ƃ����̂͂�������Ђ��ςĂ��Ă��Ȃ���ł���H�ǂ��B�m�肽���B
>>176
����͎����ɋ@�B�|��ɂ����Ă��o�Ă��Ȃ������悗
>>174
�����̌v��ł́A�l�g�o�n���K���K���N���b�N���グ�ăf�X�N�g�b�v�n�B
Core�n�̓m�[�g�ŏȓd�͌n�B�Ő�[�v���Z�X���Ԃ������R�����ꂾ���ˁB
�[���c�l�g�o�n���������܂œ]�|����Ƃ́AIntel��w�����v���ĂȂ��������낤���A
AMD�n��CPU���������܂Ő��\���o���Ƃ��v���ĂȂ������낤�ȁB
�����̌v��ł́A�l�g�o�n���K���K���N���b�N���グ�ăf�X�N�g�b�v�n�B
Core�n�̓m�[�g�ŏȓd�͌n�B�Ő�[�v���Z�X���Ԃ������R�����ꂾ���ˁB
�[���c�l�g�o�n���������܂œ]�|����Ƃ́AIntel��w�����v���ĂȂ��������낤���A
AMD�n��CPU���������܂Ő��\���o���Ƃ��v���ĂȂ������낤�ȁB
>>179
����͂��̔�AMD�M�҂̓����̘_���ł́B
�����}�[�P�e�B���O�I�ɂ͉ߋ��ō��v�ŁA���S���Ă���G���g���[�N���X�𒆐S��
AMD�ɃV�F�A���L����ꂽ�Ƃ����̂͂���������ƌ�B
���̂Ƃ��ɂ͂��łɃm�[�g�p�\�R����PenM��������O�������̂ŁA�A�����ĂȂ��B
�ނ���A���ɂȂ��Ďv�����ꂾ�����\�̒Ⴉ�����Z���������������Ȃ��A�����J�l�ł���
�{�C�ł��₪���������ƂƂ��BAMD�̐��\�����������Ƃ������f�X�N�g�b�v������Pen4��
���\���Ⴗ�������čl����ׂ����ƁB
����͂��̔�AMD�M�҂̓����̘_���ł́B
�����}�[�P�e�B���O�I�ɂ͉ߋ��ō��v�ŁA���S���Ă���G���g���[�N���X�𒆐S��
AMD�ɃV�F�A���L����ꂽ�Ƃ����̂͂���������ƌ�B
���̂Ƃ��ɂ͂��łɃm�[�g�p�\�R����PenM��������O�������̂ŁA�A�����ĂȂ��B
�ނ���A���ɂȂ��Ďv�����ꂾ�����\�̒Ⴉ�����Z���������������Ȃ��A�����J�l�ł���
�{�C�ł��₪���������ƂƂ��BAMD�̐��\�����������Ƃ������f�X�N�g�b�v������Pen4��
���\���Ⴗ�������čl����ׂ����ƁB
Banias�o��͖k�X��HTT�����ڂ��ꂽ�̂Ɠ�����������A
Tejas���L�����Z������ĂȂ������B�l�g�o���������Ƃ͌����Ȃ���Ȃ���!?
�܂�PenM�������\���������烁�C���ł��s�����Ȃ����Ƃ͌����Ă�����
Tejas���L�����Z������ĂȂ������B�l�g�o���������Ƃ͌����Ȃ���Ȃ���!?
�܂�PenM�������\���������烁�C���ł��s�����Ȃ����Ƃ͌����Ă�����
>>180
>����͎����ɋ@�B�|��ɂ����Ă��o�Ă��Ȃ������悗
The possibility of AMD entirely outsourcing its manufacturing has been floated.
But AMD has a very high skilled set of engineers and designers in Dresden.
Who could fab the X86 designs for them? IBM? Intel? ��
�����@�B�|�ᝈ���͂킩��낤�B
�uAMD�̓h���X�f���ɔ��ɗD�G�ȃG���W�j�A�ƃf�U�C�i�[������Ă���B�ނ��x86�v��
�N�����Y�ł���H�@IBM�H�@Intel�H�v
����IBM�͂Ƃ�����Intel���o�Ă���������������g����𝈝����Ă���Ă��Ƃ���B
>����͎����ɋ@�B�|��ɂ����Ă��o�Ă��Ȃ������悗
The possibility of AMD entirely outsourcing its manufacturing has been floated.
But AMD has a very high skilled set of engineers and designers in Dresden.
Who could fab the X86 designs for them? IBM? Intel? ��
�����@�B�|�ᝈ���͂킩��낤�B
�uAMD�̓h���X�f���ɔ��ɗD�G�ȃG���W�j�A�ƃf�U�C�i�[������Ă���B�ނ��x86�v��
�N�����Y�ł���H�@IBM�H�@Intel�H�v
����IBM�͂Ƃ�����Intel���o�Ă���������������g����𝈝����Ă���Ă��Ƃ���B
>>179
�H�H
Banias�o��Ƃ����Ƃ܂��A�l�g�o�ł��烂�o�C���ł������Ă��炢��
�f�X�N�g�b�v�ł͎�����b�o�t�ł���Prescott�͂TGHz��˔j�o����œK�����s���Ă���A�Ɣ��\����
��͂͂����܂Ńl�g�o�ł���A�l�g�o���S�R�_���A�Ȃ�ċ�C�͂ǂ��ɂ��Ȃ������B
Banias�o��iPentium-M�j�����́A�܂��g�����X���^�̑R�Ƃ����F�����������āA
���ꂩ���Intel�̓��o�C���ƕʃA�[�L�ōs���A�Ƃ������j�\��������̍���
�����Intel�����o�C���ɖڂ��������b�o�t���o���C�ɂȂ����Ƃ������x���B
�l�g�o������I�Ɉ������n����邫�������ɂȂ����̂́A�v���X�R�ŁA
�d���K�i�����x���ύX�����������ɁA����ł��K�i���Ɏ��܂�Ȃ��A������������
���P�̗\����Ȃ��A�ƂȂ��Ă��悢��A�Ƃ����i�ɂȂ��Ă��B
�H�H
Banias�o��Ƃ����Ƃ܂��A�l�g�o�ł��烂�o�C���ł������Ă��炢��
�f�X�N�g�b�v�ł͎�����b�o�t�ł���Prescott�͂TGHz��˔j�o����œK�����s���Ă���A�Ɣ��\����
��͂͂����܂Ńl�g�o�ł���A�l�g�o���S�R�_���A�Ȃ�ċ�C�͂ǂ��ɂ��Ȃ������B
Banias�o��iPentium-M�j�����́A�܂��g�����X���^�̑R�Ƃ����F�����������āA
���ꂩ���Intel�̓��o�C���ƕʃA�[�L�ōs���A�Ƃ������j�\��������̍���
�����Intel�����o�C���ɖڂ��������b�o�t���o���C�ɂȂ����Ƃ������x���B
�l�g�o������I�Ɉ������n����邫�������ɂȂ����̂́A�v���X�R�ŁA
�d���K�i�����x���ύX�����������ɁA����ł��K�i���Ɏ��܂�Ȃ��A������������
���P�̗\����Ȃ��A�ƂȂ��Ă��悢��A�Ƃ����i�ɂȂ��Ă��B
�ł��A����v���X�R�͂���Ȃ��TDP���ቺ���Ă������A
�ŐV�v���Z�X��@�����߂���Ȃ�ɐ킦�Ă����C������B
�g�����X���^�c���܂͉������������������c�B
�ŐV�v���Z�X��@�����߂���Ȃ�ɐ킦�Ă����C������B
�g�����X���^�c���܂͉������������������c�B
>>184
�H�H�H���߂�B�N�̖킩��Ȃ��B
�H�H�H���߂�B�N�̖킩��Ȃ��B
>>186
�E�EPentiumM�o�����03�N����H���o�C���͋C�Ȃ�ĂȂ��������āE�E
Intel�����͔E�ъ��90nm�v���Z�X�̑�ʃ��[�N�d���̋��|��S�R�F�����ĂȂ����y�ώ����Ă�������
�i�ނ�ꃌ�x���ł͂ǂ�������j�B
�l�g�o�̉X�����\��\���������̂����̍��B07�N�ɂ�10GHz���z����Ȃ�Ĕ��\�����Ă���B
���[�U�[���x���ł��d�͐H�����ǁA�b�o�t�ƊE�͂��̂܂܍s���낤�ȁA�Ƃ݂�Ȏv���Ă��B
PentiumM�͓d�C�H��Ȃ��̂ŁA�É��}�j�A�̂������ł͐l�C���������ǃ}�U�{���Ȃ�������
�N���b�N���L�тȂ����낤�Ǝv���Ă��B���̍��̃��O�T���Ă݁B
>>187
�l�g�o�ōs���ƂȂ�ƂQ�`�R�N���炢�̓t���b�O�V�b�v�������Ȃ��Ȃ����Ⴄ�ɒǂ��߂�ꂽ����˂��B
�T�[�o�[���ł��ԁ[�ԁ[����ꂽ���A�T���t�����V�X�R�̑��d���������B
�ł��l�g�o������65nm�v���Z�X�g���āA�ȓd�͋@�\����܂���A
���Ȃ�100W�łT�`�UGHZ���炢�s�������ȋC�����邯�ǂˁB
45nm�ł͌��I�ɓd�͉������Ă�炵���̂ł����܂Ŏg���z���g��120W���Ȃ��Ȃ�P�O�M�K�s�������m��Ȃ��B
���܂���~�����Ƃ��v��ǁE�E
�E�EPentiumM�o�����03�N����H���o�C���͋C�Ȃ�ĂȂ��������āE�E
Intel�����͔E�ъ��90nm�v���Z�X�̑�ʃ��[�N�d���̋��|��S�R�F�����ĂȂ����y�ώ����Ă�������
�i�ނ�ꃌ�x���ł͂ǂ�������j�B
�l�g�o�̉X�����\��\���������̂����̍��B07�N�ɂ�10GHz���z����Ȃ�Ĕ��\�����Ă���B
���[�U�[���x���ł��d�͐H�����ǁA�b�o�t�ƊE�͂��̂܂܍s���낤�ȁA�Ƃ݂�Ȏv���Ă��B
PentiumM�͓d�C�H��Ȃ��̂ŁA�É��}�j�A�̂������ł͐l�C���������ǃ}�U�{���Ȃ�������
�N���b�N���L�тȂ����낤�Ǝv���Ă��B���̍��̃��O�T���Ă݁B
>>187
�l�g�o�ōs���ƂȂ�ƂQ�`�R�N���炢�̓t���b�O�V�b�v�������Ȃ��Ȃ����Ⴄ�ɒǂ��߂�ꂽ����˂��B
�T�[�o�[���ł��ԁ[�ԁ[����ꂽ���A�T���t�����V�X�R�̑��d���������B
�ł��l�g�o������65nm�v���Z�X�g���āA�ȓd�͋@�\����܂���A
���Ȃ�100W�łT�`�UGHZ���炢�s�������ȋC�����邯�ǂˁB
45nm�ł͌��I�ɓd�͉������Ă�炵���̂ł����܂Ŏg���z���g��120W���Ȃ��Ȃ�P�O�M�K�s�������m��Ȃ��B
���܂���~�����Ƃ��v��ǁE�E
���Ɖߋ��X�������Ă݂����ABanias���o�Ă�����ƌ�APrescotto���o��O�̎��_�ł̋L��
http://journal.mycom.co.jp/news/2003/09/19/17.html
http://journal.mycom.co.jp/news/2003/09/19/17.html
����������X���Ȃ̂ɂ�����
>>190
Nehalem���������̂�03��04�N���������H
Nehalem���������̂�03��04�N���������H
>>191
Prescott�o��ԋ߂ɂȂ�����A�������o�C��C�͂�������B
�d�͂�������Ȃ��Ń}�U�[�{�[�h���[�J�[�����x���ʒm���ύX�ɂȂ����A������Intel����Ȃ��A���������A�Ƃ����L�����o�n�߂Ă鍠�B
�Ȃɂ���ABanias�̓o�ꂪ03�N�̏t�Ńl�g�o�̋��C�̃X�P�W���[�������̍��A
�Ƃ��낪�A�l�g�o�̔p�~�����\���ꂽ�̂�04�N�̔��Ȃ���A
�Ђƌ��P�ʂŏ��傫�������Ă���ĂB
Prescott�o��ԋ߂ɂȂ�����A�������o�C��C�͂�������B
�d�͂�������Ȃ��Ń}�U�[�{�[�h���[�J�[�����x���ʒm���ύX�ɂȂ����A������Intel����Ȃ��A���������A�Ƃ����L�����o�n�߂Ă鍠�B
�Ȃɂ���ABanias�̓o�ꂪ03�N�̏t�Ńl�g�o�̋��C�̃X�P�W���[�������̍��A
�Ƃ��낪�A�l�g�o�̔p�~�����\���ꂽ�̂�04�N�̔��Ȃ���A
�Ђƌ��P�ʂŏ��傫�������Ă���ĂB
>>193
04�N���ƌ������̂ŁA�ꉞ�m�F��������04�N�̂T���̔��\�L��������ˁB
http://www.itmedia.co.jp/news/articles/0405/07/news020.html
04�N���ƌ������̂ŁA�ꉞ�m�F��������04�N�̂T���̔��\�L��������ˁB
http://www.itmedia.co.jp/news/articles/0405/07/news020.html
����ς�ߋ��̎���������\�͂������q�g��AMD�������グ�Ă��邷�ˁB�B�B
Dothan�̔��\ (2002/9/11)
http://www.intel.co.jp/jp/intel/pr/press2002/020911b.htm
�e���w���c�g�����W�X�^�v��̔��\ (2002/9/19)
http://www.intel.co.jp/jp/intel/pr/press2002/020919c.htm
Dothan�̔��\ (2002/9/11)
http://www.intel.co.jp/jp/intel/pr/press2002/020911b.htm
�e���w���c�g�����W�X�^�v��̔��\ (2002/9/19)
http://www.intel.co.jp/jp/intel/pr/press2002/020919c.htm
197 �FMAC�I�^�������F2007/06/17(��) 13:01:36 ID:Kp8SxLEQ
Banias�̔��\�̊ԈႢ���B
>>194
�����͌����Ă�Merom�̊J���J�n���͑O����B
�����2003IDF�t�̒i�K�ŔM��������Ęb�͏o�Ă��B
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
�����͌����Ă�Merom�̊J���J�n���͑O����B
�����2003IDF�t�̒i�K�ŔM��������Ęb�͏o�Ă��B
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
>>198
�M�Ń��o�C�Ƃ����͔̂����̋ƊE�S�̘̂b�������B
���Ȃ��Ƃ�Intel�����͔M�̓n�[�h�������AIntel�ɂ͂���������o����Z�p������A��
�v���Ă��낤�B������Intel�̃v���Z�X�Z�p�͋ƊE�P�ƌ����Ă������̂�
�����̋ƊE�̈�ʓI�Ȋ�ł͍l���Ă��Ȃ������Ǝv����B
���̋L�����ɂ����邾��H�uIntel��2007�N�܂ł�10GHz�Ɩ��m�ɐ������Ă���B�v
�M�Ń��o�C�Ƃ����͔̂����̋ƊE�S�̘̂b�������B
���Ȃ��Ƃ�Intel�����͔M�̓n�[�h�������AIntel�ɂ͂���������o����Z�p������A��
�v���Ă��낤�B������Intel�̃v���Z�X�Z�p�͋ƊE�P�ƌ����Ă������̂�
�����̋ƊE�̈�ʓI�Ȋ�ł͍l���Ă��Ȃ������Ǝv����B
���̋L�����ɂ����邾��H�uIntel��2007�N�܂ł�10GHz�Ɩ��m�ɐ������Ă���B�v
>>198
���łɂ��̍�����Core�n�ւ̃X�C�b�`���n�܂��Ă����ƌ���̂������B
�M���v���Z�b�T=���l���Ⴂ�Ƃ����F���̉������͂��̍�����n�܂��Ă����ƌ�����B
����Pen4�͎��s�����ƌ������A�N���b�N���g���ɗ���Ȃ��Ă����\�����I�ɂ̂������
��邱�Ƃɂ����������Ǝv����B
P6���l�g�o���I���S���ō�������̂����A�I���S���Ƃ��Ă͂������̗ǂ������Ƃ�邾���̏_�������B
AMD�͖ڐ�̐����Ƃ��A����̕����]���̌��Ԃ�{���̎��͂��Ɗ��Ⴂ���Ă��܂����B
���茠�̂��鐔�l���{�C�Ŋ��Ⴂ�����B���̑��̐l�Ԃ͒N�������v���ĂȂ������ɂ���ˁB
�g�D�Ƃ��ĕ����Ă�B
���łɂ��̍�����Core�n�ւ̃X�C�b�`���n�܂��Ă����ƌ���̂������B
�M���v���Z�b�T=���l���Ⴂ�Ƃ����F���̉������͂��̍�����n�܂��Ă����ƌ�����B
����Pen4�͎��s�����ƌ������A�N���b�N���g���ɗ���Ȃ��Ă����\�����I�ɂ̂������
��邱�Ƃɂ����������Ǝv����B
P6���l�g�o���I���S���ō�������̂����A�I���S���Ƃ��Ă͂������̗ǂ������Ƃ�邾���̏_�������B
AMD�͖ڐ�̐����Ƃ��A����̕����]���̌��Ԃ�{���̎��͂��Ɗ��Ⴂ���Ă��܂����B
���茠�̂��鐔�l���{�C�Ŋ��Ⴂ�����B���̑��̐l�Ԃ͒N�������v���ĂȂ������ɂ���ˁB
�g�D�Ƃ��ĕ����Ă�B
����A��������������Ď��������Ă݂�ƁA
�����������F�̊J���J�n�����́A�l�g�o�]���Ă邩�������ȁB
�l���Ă݂��Banias�����F�̂���������Banias�ADothan�AYonah�AMerom�Ƒ����Ă����ȁE�E
���b�o�t�̊J�������͂R�N�A���Č������ōl���Ă������ǁB
����͉��̂ق����l���Ⴂ���������A���܂�B
�ł�Banias�o�ꎞ���Ƀl�g�o�]���Ă������Č����͈̂Ⴄ�Ǝv�����B
�����������F�̊J���J�n�����́A�l�g�o�]���Ă邩�������ȁB
�l���Ă݂��Banias�����F�̂���������Banias�ADothan�AYonah�AMerom�Ƒ����Ă����ȁE�E
���b�o�t�̊J�������͂R�N�A���Č������ōl���Ă������ǁB
����͉��̂ق����l���Ⴂ���������A���܂�B
�ł�Banias�o�ꎞ���Ƀl�g�o�]���Ă������Č����͈̂Ⴄ�Ǝv�����B
http://www.itmedia.co.jp/news/articles/0405/07/news020.html
2004/05/07 11:55 �X�V
Intel��2005�N���邢��2006�N�ɁA�f�X�N�g�b�vPC�v���Z�b�T�����sPentium 4��NetBurst�A�[�L�e�N�`������A
Pentium M�̊�ՂƂȂ��Ă���d�͌����̗ǂ�Banias�A�[�L�e�N�`���Ɉڍs����B�iIDG�j
Intel�͌�����2�`3�N�̂����ɁA�f�X�N�g�b�vPC�v���Z�b�T�̃A�[�L�e�N�`�����A���sPentium 4�ō̗p����Ă������d�͂̑����v����A
Pentium M�̐����܂����d�͌����̍����v�Ɉڍs����B���Ђ̌v��ɏڂ��������T���炩�ɂ����B
Yonah�́AIntel���̃m�[�gPC�����f���A���R�A�v���Z�b�T�ɂȂ�\�肾�B���̂Ƃ���A
Intel��Yonah��Merom�Ƀf�X�N�g�b�v���i���C�����V�t�g����̂��ǂ����͂͂����肵�Ă��Ȃ����A
������Intel�̃f�X�N�g�b�vPC�v���Z�b�T�́A�����2�̃v���Z�b�T�Ŏg����Pentium M�A�[�L�e�N�`������ՂƂȂ�B
2004/05/07 11:55 �X�V
Intel��2005�N���邢��2006�N�ɁA�f�X�N�g�b�vPC�v���Z�b�T�����sPentium 4��NetBurst�A�[�L�e�N�`������A
Pentium M�̊�ՂƂȂ��Ă���d�͌����̗ǂ�Banias�A�[�L�e�N�`���Ɉڍs����B�iIDG�j
Intel�͌�����2�`3�N�̂����ɁA�f�X�N�g�b�vPC�v���Z�b�T�̃A�[�L�e�N�`�����A���sPentium 4�ō̗p����Ă������d�͂̑����v����A
Pentium M�̐����܂����d�͌����̍����v�Ɉڍs����B���Ђ̌v��ɏڂ��������T���炩�ɂ����B
Yonah�́AIntel���̃m�[�gPC�����f���A���R�A�v���Z�b�T�ɂȂ�\�肾�B���̂Ƃ���A
Intel��Yonah��Merom�Ƀf�X�N�g�b�v���i���C�����V�t�g����̂��ǂ����͂͂����肵�Ă��Ȃ����A
������Intel�̃f�X�N�g�b�vPC�v���Z�b�T�́A�����2�̃v���Z�b�T�Ŏg����Pentium M�A�[�L�e�N�`������ՂƂȂ�B
��������ł����炱��Ȃ�łĂ�����
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233_01l.gif
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233_01l.gif
{kind=link}
>>203
����������ĂȂ��ȁB
����������ĂȂ��ȁB
�����A�������BIntel�̃l�g�o�R�̃A�[�L���u�`�グ�����낾����B
�P�N�����Ȃ��ŕ��j�ύX�����͂�w
�P�N�����Ȃ��ŕ��j�ύX�����͂�w
Intel�̘b�͂������炳�BX2���o�Ă���K10�܂ł̋��ԁA
AMD�͂������������Ă��́H
AMD�͂������������Ă��́H
>>206
�{����Hammer�̂��Ƃ�K9�AK10�Ƃ����A�[�L�e�N�`�������S���V�������m���o��\�肾�����炵������
�{����K9�AK10���|�V���b�^�݂���������˂��B
Barcelona��X2���e�[�v�A�E�g�������ƂŁA�J���͂��߂����̂����E�E
Barcelona��K10���Ă����̂���t�������ˁB
�{����Hammer�̂��Ƃ�K9�AK10�Ƃ����A�[�L�e�N�`�������S���V�������m���o��\�肾�����炵������
�{����K9�AK10���|�V���b�^�݂���������˂��B
Barcelona��X2���e�[�v�A�E�g�������ƂŁA�J���͂��߂����̂����E�E
Barcelona��K10���Ă����̂���t�������ˁB
�Ƃ������{����K8���ڍ�����K7�̏��X�̊g����K8�Ɩ�����Ă킯�����B
K6������J���Ɏ��s����NexGen���Ɣ������ȁc����������
>>209
�g�����������͂Ȃ�̖��ɂ������Ă��Ȃ����ǂ˂�
�g�����������͂Ȃ�̖��ɂ������Ă��Ȃ����ǂ˂�
212 �FMAC�I�^��206 �����F2007/06/17(��) 13:55:33 ID:Kp8SxLEQ
>>206
�@�@----------------
�@�@X2���o�Ă���K10�܂ł̋��ԁA
�@�@----------------
���x�������Ă��邷���ǁAX2�ǂ��납2001�N��Hammer�̔��\�ȗ��A�[�L�e�N�`���I�ɉ����i���
���Ȃ��炵���B�B�B�Ƃ����̂���肷�B
http://www.watch.impress.co.jp/pc/docs/article/20011109/kaigai01.htm
�@�@----------------
�@�@X2���o�Ă���K10�܂ł̋��ԁA
�@�@----------------
���x�������Ă��邷���ǁAX2�ǂ��납2001�N��Hammer�̔��\�ȗ��A�[�L�e�N�`���I�ɉ����i���
���Ȃ��炵���B�B�B�Ƃ����̂���肷�B
http://www.watch.impress.co.jp/pc/docs/article/20011109/kaigai01.htm
>>207
�I�[�P�[�BK10���x���͎̂d���Ȃ��Ƃ��悤�B
����Ȃ��Ƃ�AMD�Г��ł͂����ƑO����킩���Ă����͂�����ȁB
���Ⴀ�x�ꂽ���߂�͂���65nm��X2�̏�ʔł��܂������o�Ă��Ȃ��̂�
�Ȃ��Ȃ��B65nm�ō��N���b�N���o�Ȃ��ɂ��Ă�L2=1MBx2�ł��J�����炵�ĂȂ��̂�
�����������邾�낤�B
�����K10���v�Œx���Ȃ�X2��65nm�Ō��w�V�������N���ăI���_�C�łQ�悹���̂�
�������Əo����������Ȃ��B�u����Ȃ���A��������v��H
���≴�����̎d�l������������o���Ă�Ǝv�����ǁB
http://www.watch.impress.co.jp/akiba/hotline/20070616/etc_intelvsamd.html
�I�[�P�[�BK10���x���͎̂d���Ȃ��Ƃ��悤�B
����Ȃ��Ƃ�AMD�Г��ł͂����ƑO����킩���Ă����͂�����ȁB
���Ⴀ�x�ꂽ���߂�͂���65nm��X2�̏�ʔł��܂������o�Ă��Ȃ��̂�
�Ȃ��Ȃ��B65nm�ō��N���b�N���o�Ȃ��ɂ��Ă�L2=1MBx2�ł��J�����炵�ĂȂ��̂�
�����������邾�낤�B
�����K10���v�Œx���Ȃ�X2��65nm�Ō��w�V�������N���ăI���_�C�łQ�悹���̂�
�������Əo����������Ȃ��B�u����Ȃ���A��������v��H
���≴�����̎d�l������������o���Ă�Ǝv�����ǁB
http://www.watch.impress.co.jp/akiba/hotline/20070616/etc_intelvsamd.html
214 �FSocket774�F2007/06/17(��) 14:10:11 ID:J2Z2Ne21
Core Duo�͑債�����Ɩ�����������
����Core 2 Duo��P4��ׂ��X2�ɂ�����
P4���S�~�̂悤���Ȃ�
����ȉ���PenPro����II�ɂ�����K7�AK8�Ɨ���
C2D�ɓ������^�̏��҂ɂ��Ċ�����}�ˁi���ʐl�j
�ǂ����悤���Ȃ��G���́AK6�AK6II�Ɨ���Cle��
������P4���g���A���̉��ꂩ�g�������̗L��z��
�����鉿�l���Ȃ���̂Ȃ��n����ww
����Core 2 Duo��P4��ׂ��X2�ɂ�����
P4���S�~�̂悤���Ȃ�
����ȉ���PenPro����II�ɂ�����K7�AK8�Ɨ���
C2D�ɓ������^�̏��҂ɂ��Ċ�����}�ˁi���ʐl�j
�ǂ����悤���Ȃ��G���́AK6�AK6II�Ɨ���Cle��
������P4���g���A���̉��ꂩ�g�������̗L��z��
�����鉿�l���Ȃ���̂Ȃ��n����ww
215 �FMAC�I�^��213 �����F2007/06/17(��) 14:11:05 ID:Kp8SxLEQ
{kind=link}
>>213
K8��65nm�ł�CoreMA�ɏ��ĂȂ��i�������l�i�Ŕ��邱�Ƃ��ł��Ȃ��j���Ƃ�
�������Ă���ȏ�AL2=512KBx2�����ɂ��Đ����R�X�g��}�����̂�
�������Ƃ����v��Ȃ����B
MCM�Ɋւ��Ắu��������v���Ă�1�N���x�łł�����ĈӖ�����B
�m��Smithfield�̊J�����Ԃ�10����������ȁB
K8��65nm�ł�CoreMA�ɏ��ĂȂ��i�������l�i�Ŕ��邱�Ƃ��ł��Ȃ��j���Ƃ�
�������Ă���ȏ�AL2=512KBx2�����ɂ��Đ����R�X�g��}�����̂�
�������Ƃ����v��Ȃ����B
MCM�Ɋւ��Ắu��������v���Ă�1�N���x�łł�����ĈӖ�����B
�m��Smithfield�̊J�����Ԃ�10����������ȁB
218 �FMAC�I�^��216 �����F2007/06/17(��) 14:25:00 ID:Kp8SxLEQ
>>216
>>135�̍Ō��2�s��ǂ�ł���R�����g�����ق����ǂ�������Ȃ������ˁH
���Ȃ݂�>>213��
�@�@--------------------
�@�@65nm�Ō��w�V�������N���āw�I���_�C�łQ�x�悹����
�@�@--------------------
�Ƃ����\����MCM�Ƃ����Ӗ��ɓǂݎ�邱�Ƃ�s�\���B
>>135�̍Ō��2�s��ǂ�ł���R�����g�����ق����ǂ�������Ȃ������ˁH
���Ȃ݂�>>213��
�@�@--------------------
�@�@65nm�Ō��w�V�������N���āw�I���_�C�łQ�x�悹����
�@�@--------------------
�Ƃ����\����MCM�Ƃ����Ӗ��ɓǂݎ�邱�Ƃ�s�\���B
���������Əo����������Ȃ��B�u����Ȃ���A��������v��H
��������������ł���A����
��������������ł���A����
�Ă��A�o�j����B����������͌��X�m�[�g�����A
����������P�Ƀf�X�N�g�b�v�n�Ɏ����Ă����B
���̑O�����ۂ蔲���Ă���l������H
������l�g�o�n���܂��撣���Ă��Ă��A
�o�j�������������������R�̔����ꂽ�͂������H
����������>>203�̕\�Ŏv���o�������A
K9�̓l�g�o�n�݂����ȃN���b�N�d���v�����������H
����������P�Ƀf�X�N�g�b�v�n�Ɏ����Ă����B
���̑O�����ۂ蔲���Ă���l������H
������l�g�o�n���܂��撣���Ă��Ă��A
�o�j�������������������R�̔����ꂽ�͂������H
����������>>203�̕\�Ŏv���o�������A
K9�̓l�g�o�n�݂����ȃN���b�N�d���v�����������H
>>218
���[��Brisbane�̃I���_�C�j�R�C�`�ł�K10���͎�_�C�T�C�Y�������Ȃ邾��
>>217
AMD�ɂ�MCM�Z�p���Ȃ��̂Ŋ��Ԃɗ]�T�̂Ȃ����̏�MCM�͖�����������B
������Ȃ�ł�������P�N�O��K10�̃��[���`��2007Q2�ɊԂɍ���Ȃ����Ƃ��炢
AMD�Г��ł͂킩���Ă��͂����낤�H
���[��Brisbane�̃I���_�C�j�R�C�`�ł�K10���͎�_�C�T�C�Y�������Ȃ邾��
>>217
AMD�ɂ�MCM�Z�p���Ȃ��̂Ŋ��Ԃɗ]�T�̂Ȃ����̏�MCM�͖�����������B
������Ȃ�ł�������P�N�O��K10�̃��[���`��2007Q2�ɊԂɍ���Ȃ����Ƃ��炢
AMD�Г��ł͂킩���Ă��͂����낤�H
222 �FMAC�I�^��221 �����F2007/06/17(��) 14:33:03 ID:Kp8SxLEQ
>>221
�@�@-----------------
�@�@K10���͎�_�C�T�C�Y�������Ȃ邾��
�@�@-----------------
L2 512KB->1MB�̃`�b�v���X��2���ڂ��邱�Ƃ�2�{�ȏ�_�C�T�C�Y���傫���Ȃ�̂�
��肶��Ȃ��āA�w��x�_�C�T�C�Y���傫���Ȃ�Ƒ�����Ē����_��A�ǂ�����o�Ă���
�����ˁB�B�B
�@�@-----------------
�@�@K10���͎�_�C�T�C�Y�������Ȃ邾��
�@�@-----------------
L2 512KB->1MB�̃`�b�v���X��2���ڂ��邱�Ƃ�2�{�ȏ�_�C�T�C�Y���傫���Ȃ�̂�
��肶��Ȃ��āA�w��x�_�C�T�C�Y���傫���Ȃ�Ƒ�����Ē����_��A�ǂ�����o�Ă���
�����ˁB�B�B
>>221
������̖�肪1�N�O�ɂ킩��킯�Ȃ����B
������̖�肪1�N�O�ɂ킩��킯�Ȃ����B
>>222
������r�Ώۂ����������B
K10��2007Q4�`2008Q1�ɂ����Ԃɍ���Ȃ��̂ł����2007Q2��X2�j�R�C�`���o����悤�J����
�i�߂Ă����ׂ��������Ƃ����b�����Ă���̂ł����āA
�Ȃ��X2��X2�j�R�C�`�̐��Y�����r����B
������r�Ώۂ����������B
K10��2007Q4�`2008Q1�ɂ����Ԃɍ���Ȃ��̂ł����2007Q2��X2�j�R�C�`���o����悤�J����
�i�߂Ă����ׂ��������Ƃ����b�����Ă���̂ł����āA
�Ȃ��X2��X2�j�R�C�`�̐��Y�����r����B
225 �FMAC�I�^��224 �����F2007/06/17(��) 14:39:04 ID:Kp8SxLEQ
>>224
�@�@---------------------
�@�@�Ȃ��X2��X2�j�R�C�`�̐��Y�����r����B
�@�@---------------------
>>135�ɏ������ʂ�Ȃ��ǁB�B�B
�@�@=====================
�@�@���������v���Z�X�ɂ����Ă�A�_�C�T�C�Y���傫���Ƃ����w�����x�̗��R�Ő��l�����o�ׂ�
�@�@�x���̂����ʂ��B�B�B�Ƃ����b���B
�@�@=====================
�@�@---------------------
�@�@�Ȃ��X2��X2�j�R�C�`�̐��Y�����r����B
�@�@---------------------
>>135�ɏ������ʂ�Ȃ��ǁB�B�B
�@�@=====================
�@�@���������v���Z�X�ɂ����Ă�A�_�C�T�C�Y���傫���Ƃ����w�����x�̗��R�Ő��l�����o�ׂ�
�@�@�x���̂����ʂ��B�B�B�Ƃ����b���B
�@�@=====================
�܂�AMD����������MCM�Z�p�Ă����ׂ��������Ƃ����_�ɂ͓��ӂ����B
>>225
�����炻�̐��̂Ƃ���Ȃ�K10��X2�j�R�C�`��肳��ɂ����ƒx��邩�瓯�������Ă�
�����炻�̐��̂Ƃ���Ȃ�K10��X2�j�R�C�`��肳��ɂ����ƒx��邩�瓯�������Ă�
>>227
�����猻���ɒx��ɒx��Ă���ɒx���\�肾��
�����猻���ɒx��ɒx��Ă���ɒx���\�肾��
229 �FMAC�I�^��226 �����F2007/06/17(��) 14:44:45 ID:Kp8SxLEQ
>>226
AMD��(�����Z�p��������)�w�Z�p�ɂ�����������x�Ƃ������z����������B�ߋ������Ă��V�Z�p��
�S�Ĕ����W�߂Ă������m���BK8�ɂ��Ă�>>212�ɏ������悤�ɁA2001�N�̒i�K��X2�����܂�
�A�[�L�e�N�`���v�튮�����āA�������牽�������ɕ��u���Ă������B
�ׂ�������S�āA
�@�E�M�҂���邽�߂̍ٔ����}�[�P�e�B���O��p
�@�E���ЋZ�p�̔���
�@�E�H�ꌚ��
�ɂ�����ł������B
AMD��(�����Z�p��������)�w�Z�p�ɂ�����������x�Ƃ������z����������B�ߋ������Ă��V�Z�p��
�S�Ĕ����W�߂Ă������m���BK8�ɂ��Ă�>>212�ɏ������悤�ɁA2001�N�̒i�K��X2�����܂�
�A�[�L�e�N�`���v�튮�����āA�������牽�������ɕ��u���Ă������B
�ׂ�������S�āA
�@�E�M�҂���邽�߂̍ٔ����}�[�P�e�B���O��p
�@�E���ЋZ�p�̔���
�@�E�H�ꌚ��
�ɂ�����ł������B
>>228
������Ƒ҂āB2008�N3���ɂ͂�����Ȃ�ł��H�t���Ŕ����邾��Hw
������Ƒ҂āB2008�N3���ɂ͂�����Ȃ�ł��H�t���Ŕ����邾��Hw
���f�l�Ȃ�ł悭�킩��Ȃ����ǂ��B
AMD�̃o�X���ă|�C���g�E�c�[�E�|�C���g�ڑ�������A
Intel���MCM�ɂ���n�[�h�����č�����Ȃ��́H
AMD�̃o�X���ă|�C���g�E�c�[�E�|�C���g�ڑ�������A
Intel���MCM�ɂ���n�[�h�����č�����Ȃ��́H
��{�I�ɁAAMD�M�҂̎���
intel=���������Z�p���Ȃ��̂ɁA�}�[�P�e�B���O�����ŁA�s��������g���āA�Ȃ�̓w�͂��Ȃ��ɁA���������ӂ���B
�Ƃ����C���[�W�͂��ׂČ�����AMD����B
���肫�����g�D�ƁA���ЂƑ��А��i���g�����[�U�[�A���܂��ɂ�̔��X���������悤�ȓ��{�@�l�c�ƁB
�J���͎���10�N�P�ʂłق��ۂ炩���B
�ٔ���D���B
�ݔ������͂��邯�ǁA�������镨���ߋ��̐��i�B
��L�̃C���[�W�Ƀv���X���Ă��������������Z�b�g�̊�Ƃ��BK8�̎��݂����ɃC���[�W�����ŃX�^�[�g�_�b�V��
����悤�Ȏ�͍���ʗp���Ȃ��Ǝv���B
intel=���������Z�p���Ȃ��̂ɁA�}�[�P�e�B���O�����ŁA�s��������g���āA�Ȃ�̓w�͂��Ȃ��ɁA���������ӂ���B
�Ƃ����C���[�W�͂��ׂČ�����AMD����B
���肫�����g�D�ƁA���ЂƑ��А��i���g�����[�U�[�A���܂��ɂ�̔��X���������悤�ȓ��{�@�l�c�ƁB
�J���͎���10�N�P�ʂłق��ۂ炩���B
�ٔ���D���B
�ݔ������͂��邯�ǁA�������镨���ߋ��̐��i�B
��L�̃C���[�W�Ƀv���X���Ă��������������Z�b�g�̊�Ƃ��BK8�̎��݂����ɃC���[�W�����ŃX�^�[�g�_�b�V��
����悤�Ȏ�͍���ʗp���Ȃ��Ǝv���B
>>231
����{�I��MCM�͐v���y�ɂ���i���Ƃɂ��g����j��
�����I�ɂ͍��x�ȋZ�p����B�Ƃ��ɍ��N���b�N�ŃR�X�g���d�������ł́B
����{�I��MCM�͐v���y�ɂ���i���Ƃɂ��g����j��
�����I�ɂ͍��x�ȋZ�p����B�Ƃ��ɍ��N���b�N�ŃR�X�g���d�������ł́B
>>232
�g�̏�ȏ�̋Z�p���������Ă��Ă��A���g�������肫��Ȃ��B
��b�I�ȕ����̕��K�ɒǂ��Ē��g�����������ɂ͋����i�B
���ʂƂ��ĐV�K�J�������S�Ɏ~�܂�B
�������ʼn�Ђ��Ƃ����Ȃ�Ƃ����펯�����AAMD�͋Z�p�n�̑�^��Ƃł�������������B
K7���J�����Ă������̃C���[�W���Y����Ȃ���ɁA���Ԃ��K�܂ŏE����������Ƃ������Ƃ��B
�g�̏�ȏ�̋Z�p���������Ă��Ă��A���g�������肫��Ȃ��B
��b�I�ȕ����̕��K�ɒǂ��Ē��g�����������ɂ͋����i�B
���ʂƂ��ĐV�K�J�������S�Ɏ~�܂�B
�������ʼn�Ђ��Ƃ����Ȃ�Ƃ����펯�����AAMD�͋Z�p�n�̑�^��Ƃł�������������B
K7���J�����Ă������̃C���[�W���Y����Ȃ���ɁA���Ԃ��K�܂ŏE����������Ƃ������Ƃ��B
236 �FMAC�I�^��231 �����F2007/06/17(��) 14:53:53 ID:Kp8SxLEQ
>>231
�@�@-------------------
�@�@Intel���MCM�ɂ���n�[�h�����č�����Ȃ��́H
�@�@-------------------
�z�������Ȃ��čςޕ��A�ނ���Ⴂ���B
�@�@-------------------
�@�@Intel���MCM�ɂ���n�[�h�����č�����Ȃ��́H
�@�@-------------------
�z�������Ȃ��čςޕ��A�ނ���Ⴂ���B
�C�X���G���EPenM�n�l�^���n��܂Ƃ�
���[���[�E�G�f�����R�����g
http://www.itmedia.co.jp/news/articles/0501/20/news039.html
Pentium M�ƂȂ锼���̐v��1990�N�㖖�ɏ������Ă���
�u2000�N���O�ɁA�����͓d�̖͂ʂŕǂɂԂ����Ă��܂����Ƃ��������Ă����v
�㓡����
http://pc.watch.impress.co.jp/docs/article/20010810/kaigai01.htm
Timna��{�I�Ȑv��'99�N���ɂقڏI����Ă������ƂɂȂ�킯�ŁA�����炭
�ŏ㗬�̃A�[�L�e�N�`���̌�����'99�N����������Ă����\���������B�����āA
Intel�����o�C����p�����𐳎��ɔ����������̂�2000�N�̏t�B
2003�N2����IDF��90nm���[�N�d���̃��o������킹��
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
Prescott�ł͔p�M�͍ŏd�v�̉ۑ�ƂȂ肻�����B�܂����̓q�[�g�V���N�ŁA
�Z��CPU��Nocona�̏ꍇ�̓q�[�g�V���N�̏d�ʂ�900g�ɂȂ�Ɨ\������Ă���B
���ۃ��o������
http://pc.watch.impress.co.jp/docs/2003/0722/kaigai005.htm
http://pc.watch.impress.co.jp/docs/2003/1010/kaigai031.htm
Intel�A90nm�v���Z�XCPU�S�i�x��
2004�N3�����_��Conroe�v��͂�����
http://pc.watch.impress.co.jp/docs/2004/0312/kaigai073.htm
Intel��2006�N�̃��o�C��CPU�uMerom�v���x�[�X�ɂ����f�X�N�g�b�vCPU���A���N�ɓ�������
2004�N5�����_�Ńl�g�o�L�����Z���͌��肳��Ă���
http://pc.watch.impress.co.jp/docs/2004/0509/kaigai088.htm
http://pc.watch.impress.co.jp/docs/2004/0512/kaigai089.htm
�Q�����˂��2002�N����Banias�ɒ��ڂ��Ă���
http://pc3.2ch.net/test/read.cgi/jisaku/1031896895/
�����p�}�}���{Dothan���o�āi����d�͂��C�ɂ���ꕔ�́j�Q�[�}�[����т�
http://www.x86-secret.com/articles/cm/dfi855/dfi855-10.htm
http://www.gamepc.com/labs/view_content.asp?id=770ct479&page=8
�Q�l�F�J���T�C�N���}�i�㓡����j
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268_03l.gif
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233_02l.gif
���[���[�E�G�f�����R�����g
http://www.itmedia.co.jp/news/articles/0501/20/news039.html
Pentium M�ƂȂ锼���̐v��1990�N�㖖�ɏ������Ă���
�u2000�N���O�ɁA�����͓d�̖͂ʂŕǂɂԂ����Ă��܂����Ƃ��������Ă����v
�㓡����
http://pc.watch.impress.co.jp/docs/article/20010810/kaigai01.htm
Timna��{�I�Ȑv��'99�N���ɂقڏI����Ă������ƂɂȂ�킯�ŁA�����炭
�ŏ㗬�̃A�[�L�e�N�`���̌�����'99�N����������Ă����\���������B�����āA
Intel�����o�C����p�����𐳎��ɔ����������̂�2000�N�̏t�B
2003�N2����IDF��90nm���[�N�d���̃��o������킹��
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
Prescott�ł͔p�M�͍ŏd�v�̉ۑ�ƂȂ肻�����B�܂����̓q�[�g�V���N�ŁA
�Z��CPU��Nocona�̏ꍇ�̓q�[�g�V���N�̏d�ʂ�900g�ɂȂ�Ɨ\������Ă���B
���ۃ��o������
http://pc.watch.impress.co.jp/docs/2003/0722/kaigai005.htm
http://pc.watch.impress.co.jp/docs/2003/1010/kaigai031.htm
Intel�A90nm�v���Z�XCPU�S�i�x��
2004�N3�����_��Conroe�v��͂�����
http://pc.watch.impress.co.jp/docs/2004/0312/kaigai073.htm
Intel��2006�N�̃��o�C��CPU�uMerom�v���x�[�X�ɂ����f�X�N�g�b�vCPU���A���N�ɓ�������
2004�N5�����_�Ńl�g�o�L�����Z���͌��肳��Ă���
http://pc.watch.impress.co.jp/docs/2004/0509/kaigai088.htm
http://pc.watch.impress.co.jp/docs/2004/0512/kaigai089.htm
�Q�����˂��2002�N����Banias�ɒ��ڂ��Ă���
http://pc3.2ch.net/test/read.cgi/jisaku/1031896895/
�����p�}�}���{Dothan���o�āi����d�͂��C�ɂ���ꕔ�́j�Q�[�}�[����т�
http://www.x86-secret.com/articles/cm/dfi855/dfi855-10.htm
http://www.gamepc.com/labs/view_content.asp?id=770ct479&page=8
�Q�l�F�J���T�C�N���}�i�㓡����j
http://pc.watch.impress.co.jp/docs/2006/0509/kaigai268_03l.gif
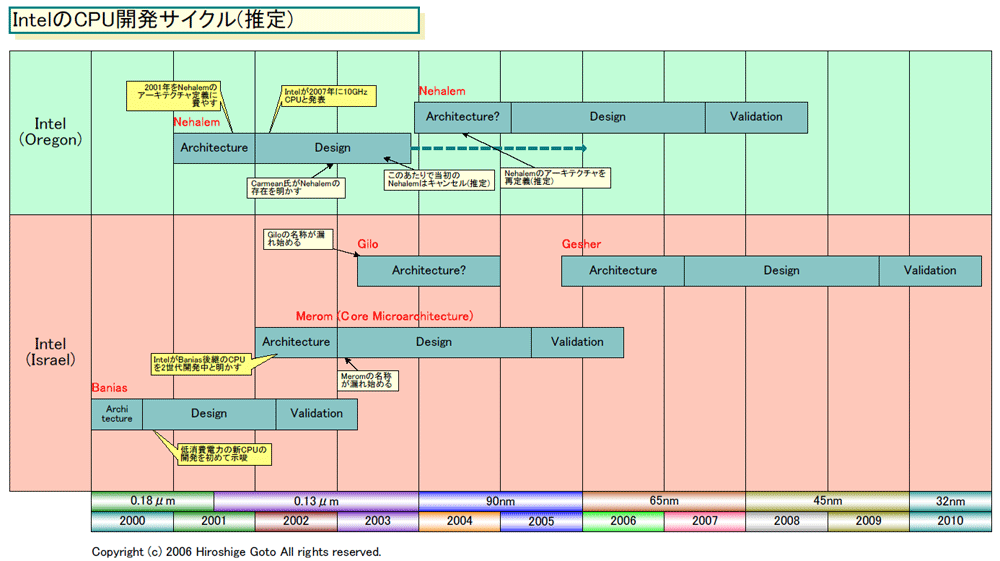{kind=link}
http://pc.watch.impress.co.jp/docs/2006/0119/kaigai233_02l.gif
{kind=link}
>>237
���悭�n���ɂ���邯�nj㓡�̏����Đ��m�����
���悭�n���ɂ���邯�nj㓡�̏����Đ��m�����
>>213
�� �������Əo����������Ȃ��B�u����Ȃ���A��������v��H
�H�H
����Ȏ����Ɍ����Ă��B
�N��ɘ_�����Ă邩�m��Ȃ����ǁA������Ȏ������ĂȂ����B
������ID���Ĕ������Ă�H
�� �������Əo����������Ȃ��B�u����Ȃ���A��������v��H
�H�H
����Ȏ����Ɍ����Ă��B
�N��ɘ_�����Ă邩�m��Ȃ����ǁA������Ȏ������ĂȂ����B
������ID���Ĕ������Ă�H
K9���|�V���������Ă̂͒m���Ă�̂ɁAHammer���\�ȗ��������ĂȂ����Č�����͉̂��z������ȁB
��������Barcelona�����ĐV�A�[�L�����B
��������Barcelona�����ĐV�A�[�L�����B
�܂�Hammer�ȗ��C����Ȃ��Ȍ|���@���Ă�������ȁD
����
����l�M�ł����ʂ��Ȃ�
����l�M�ł����ʂ��Ȃ�
>>237 ����
����90�N�㖖�ɜa���̂��Ƃ����ꂽ�̂�Transmeta���������Ƃ�Y��Ă�_�����B
http://pc.watch.impress.co.jp/docs/article/991119/kaigai01.htm
>>238 ����
CPU�x���_��A��v�ڋq��}�U�[�{�[�h�x���_�ɏ����̐��i�ɂ��ĐF�X�������Ă��邷�B
���ł������E���̃��[�}�[�T�C�g��ʂ��āA���̃I���W�i���̎��������邱�Ƃ��ł��邷���ǁA
������㓡���̂悤�ȃW���[�i���X�g�̎肪�K�v���������B
�����������A�����܂ʼnߋ��̘b���B
>>240 ����
�@�@--------------------
�@�@Barcelona�����ĐV�A�[�L�����B
�@�@--------------------
�ނ�Ȃ̂����f������B�B�B
����90�N�㖖�ɜa���̂��Ƃ����ꂽ�̂�Transmeta���������Ƃ�Y��Ă�_�����B
http://pc.watch.impress.co.jp/docs/article/991119/kaigai01.htm
>>238 ����
CPU�x���_��A��v�ڋq��}�U�[�{�[�h�x���_�ɏ����̐��i�ɂ��ĐF�X�������Ă��邷�B
���ł������E���̃��[�}�[�T�C�g��ʂ��āA���̃I���W�i���̎��������邱�Ƃ��ł��邷���ǁA
������㓡���̂悤�ȃW���[�i���X�g�̎肪�K�v���������B
�����������A�����܂ʼnߋ��̘b���B
>>240 ����
�@�@--------------------
�@�@Barcelona�����ĐV�A�[�L�����B
�@�@--------------------
�ނ�Ȃ̂����f������B�B�B
244 �Fpowered by google�F2007/06/17(��) 15:19:41 ID:tL8JVCey
http://d.hatena.ne.jp/keyword/%B6�H�H%A6�H
��D.C.�`�_�E�J�[�|�`�̗�
�����S�����������ޗ��́AD.C.WhiteSeason�ȍ~�̍�i�ɂ͊ւ���Ă��Ȃ��B
�A���L���f�X�̂킷�����(��s�Ŏ��^)
D.C.�`�_�E�J�[�|�` CD-ROM ��������
D.C.�`�_�E�J�[�|�` DVD-ROM ��������
D.C.�`�_�E�J�[�|�` �}�E�X�p�b�h�tCD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` �}�E�X�p�b�h�tDVD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` CD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` DVD-ROM �ʏ��
D.C.WhiteSeason �N���X�}�X�����
D.C.WhiteSeason CD-ROM �ʏ��
D.C.WhiteSeason DVD-ROM �ʏ��
D.C.WhiteSeason ���j���[�A���p�b�P�[�W�� DVD-ROM
D.C.�`�_�E�J�[�|�` ���ӂς��� CD-ROM�� (�ȗ�����܂����E�E�S�Ă�ǂނɂ͂��z�{���Ă�������)
��D.C.�`�_�E�J�[�|�`�̗�
�����S�����������ޗ��́AD.C.WhiteSeason�ȍ~�̍�i�ɂ͊ւ���Ă��Ȃ��B
�A���L���f�X�̂킷�����(��s�Ŏ��^)
D.C.�`�_�E�J�[�|�` CD-ROM ��������
D.C.�`�_�E�J�[�|�` DVD-ROM ��������
D.C.�`�_�E�J�[�|�` �}�E�X�p�b�h�tCD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` �}�E�X�p�b�h�tDVD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` CD-ROM �ʏ��
D.C.�`�_�E�J�[�|�` DVD-ROM �ʏ��
D.C.WhiteSeason �N���X�}�X�����
D.C.WhiteSeason CD-ROM �ʏ��
D.C.WhiteSeason DVD-ROM �ʏ��
D.C.WhiteSeason ���j���[�A���p�b�P�[�W�� DVD-ROM
D.C.�`�_�E�J�[�|�` ���ӂς��� CD-ROM�� (�ȗ�����܂����E�E�S�Ă�ǂނɂ͂��z�{���Ă�������)
>>185 >>186 >>190 >>194
90nm�̃t�@�[�X�g�V���R�������Ă����ł��낤2002�NQ3�`Q4�ɂ�
���̐l�͋C�t���Ă����Ǝv����A���̂܂܂��Ⴂ���Ȃ����āB
���������ɂ͕����]���ł��Ȃ�����A�\�����ɂ̓l�b�g�o�[�X�g�̐���
���A�s�[�����܂����Ă����B
���X�N���w�b�W���邽�߂ɃC�X���G���̃��o�C���A�[�L�e�N�`���ɒ���
����͓̂��R�ŁA���̏�����2003�N�ɂ͎n�߂Ă����ł��傤�B
2004�N�ɂȂ��ăf�X�N�g�b�v�Ń������ƃl�g�o�L�����Z���������[�N����
�̂́A��w�����x���Ŋ��S�ɕ������ł܂�������ȂƎv���B
90nm�̃t�@�[�X�g�V���R�������Ă����ł��낤2002�NQ3�`Q4�ɂ�
���̐l�͋C�t���Ă����Ǝv����A���̂܂܂��Ⴂ���Ȃ����āB
���������ɂ͕����]���ł��Ȃ�����A�\�����ɂ̓l�b�g�o�[�X�g�̐���
���A�s�[�����܂����Ă����B
���X�N���w�b�W���邽�߂ɃC�X���G���̃��o�C���A�[�L�e�N�`���ɒ���
����͓̂��R�ŁA���̏�����2003�N�ɂ͎n�߂Ă����ł��傤�B
2004�N�ɂȂ��ăf�X�N�g�b�v�Ń������ƃl�g�o�L�����Z���������[�N����
�̂́A��w�����x���Ŋ��S�ɕ������ł܂�������ȂƎv���B
>>245
�u���̐l���ǂ��v���Ă��v���Ƃ��u�\�����͂��������Ă����ǂ����Ƃ����v���Ă��v�Ƃ������n�߂���
�i���������u���̐l�v���[�����ĂЂƂ肶�Ⴀ��܂��B�����牴���u���ꃌ�x���ł͂ǂ�������v�ƌ������킯�Łj
����ޗ����������ł̒��ŁA�����ⓚ�ɂ����Ȃ�Ȃ�����
����̂���肽���Ȃ牴�̓p�X�B
�u���̐l���ǂ��v���Ă��v���Ƃ��u�\�����͂��������Ă����ǂ����Ƃ����v���Ă��v�Ƃ������n�߂���
�i���������u���̐l�v���[�����ĂЂƂ肶�Ⴀ��܂��B�����牴���u���ꃌ�x���ł͂ǂ�������v�ƌ������킯�Łj
����ޗ����������ł̒��ŁA�����ⓚ�ɂ����Ȃ�Ȃ�����
����̂���肽���Ȃ牴�̓p�X�B
�܂������ʎq�̐��E�͖ʔ����B
�{���s���悤���Ȃ��͂��̏ꏊ�Ƀ|�e���V���������݂���
���ہA�≏���ŕ����Ă���͂��Ȃ̂ɓd�q����яo��
�g���l������
����͂�܂������ʔ���
�{���s���悤���Ȃ��͂��̏ꏊ�Ƀ|�e���V���������݂���
���ہA�≏���ŕ����Ă���͂��Ȃ̂ɓd�q����яo��
�g���l������
����͂�܂������ʔ���
>>243
�ȂI�^�������R��������f�R�[�_�������݂����ɖڂɌ����ĕ�����₷���ω��������ƐV�A�[�L�ƔF�߂Ȃ��h�Ȃ̂��B
�ȂI�^�������R��������f�R�[�_�������݂����ɖڂɌ����ĕ�����₷���ω��������ƐV�A�[�L�ƔF�߂Ȃ��h�Ȃ̂��B
>>246
����܂��A�ǂ���Ă���Ȃ���n�߂�܂Ŏ��Ԃ������邱�̋ƊE�B
������t�Z�Ő������Ă݂���`�A�Ƃ��������ł��B�n�C�B
�������^�����ǂ����Ȃ�āA�����ł̒��ł��B
����܂��A�ǂ���Ă���Ȃ���n�߂�܂Ŏ��Ԃ������邱�̋ƊE�B
������t�Z�Ő������Ă݂���`�A�Ƃ��������ł��B�n�C�B
�������^�����ǂ����Ȃ�āA�����ł̒��ł��B
250 �FMAC�I�^��248 �����F2007/06/17(��) 16:14:27 ID:Kp8SxLEQ
>>248
�ʏ�A���ߎ��s�̗��ꂪ�ς�邱�Ƃ�V�A�[�L�e�N�`���ƌĂԂ��B
�]���āA
�@�E(����OoOE��)FPU��x�N�g�����̐�p���Z�p�C�v���C���́w���݁x��A�V�A�[�L�e�N�`����
�@�@��������Ƃ�����
�@�E�f�R�[�h���A���ߏ����n�̕ύX��A�V�A�[�L�e�N�`��
�@�EISA�̕ύX��A���R�V�A�[�L�e�N�`��
�@�E�L���b�V���̕ύX��A�X�P�W���[�����O�ɉe������̂ŐV�A�[�L�e�N�`���ƌĂ�ł�
�@�@�ǂ��ꍇ������
�@�E�I���_�C�E�������R���g���[����P�Ɏ��Ӄ`�b�v��������邾���Ȃ̂ŁA�V�A�[�L�e�N�`���Ƃ�
�@�@��������Ƃ������B(�H�ɖ��߂̃X�P�W���[�����O�ɉe������قǖ���������ꍇ���A��)
�Ƃ����悤�Ȋ���Ǝv�����B
�ʏ�A���ߎ��s�̗��ꂪ�ς�邱�Ƃ�V�A�[�L�e�N�`���ƌĂԂ��B
�]���āA
�@�E(����OoOE��)FPU��x�N�g�����̐�p���Z�p�C�v���C���́w���݁x��A�V�A�[�L�e�N�`����
�@�@��������Ƃ�����
�@�E�f�R�[�h���A���ߏ����n�̕ύX��A�V�A�[�L�e�N�`��
�@�EISA�̕ύX��A���R�V�A�[�L�e�N�`��
�@�E�L���b�V���̕ύX��A�X�P�W���[�����O�ɉe������̂ŐV�A�[�L�e�N�`���ƌĂ�ł�
�@�@�ǂ��ꍇ������
�@�E�I���_�C�E�������R���g���[����P�Ɏ��Ӄ`�b�v��������邾���Ȃ̂ŁA�V�A�[�L�e�N�`���Ƃ�
�@�@��������Ƃ������B(�H�ɖ��߂̃X�P�W���[�����O�ɉe������قǖ���������ꍇ���A��)
�Ƃ����悤�Ȋ���Ǝv�����B
251 �FSocket774�F2007/06/17(��) 16:14:45 ID:XtqgdWPk
�������A���u�A�[�L�v����
�A�[�L�e�N�`�����A�[�L�����z�́A�����Ă����N�Ȃ���Ȃ�
�A�[�L�e�N�`�����A�[�L�����z�́A�����Ă����N�Ȃ���Ȃ�
252 �FMAC�I�^�������F2007/06/17(��) 16:15:51 ID:Kp8SxLEQ
�ŁABarcelona��V�A�[�L�e�N�`���Ǝ咣���闝�R�픖�ォ�Ǝv�����B
253 �FSocket774�F2007/06/17(��) 16:16:01 ID:XtqgdWPk
�Ă������c�q�Ȃɂ���Ƃ�
���イ�Ă��ARISC��CISC�ʼn����Ⴄ���Ƃ�����
���g���܂����������Ŗ��߂��ς�邾��
�f�R�[�_���ς�邭�炢�ŁB
���g���܂����������Ŗ��߂��ς�邾��
�f�R�[�_���ς�邭�炢�ŁB
Barcelona�̎��s�́E�E�E�E�����Ǝ���
Barcelona�̍���́A�����[�X�����Ă̖����ȃX�P�[�W���[���̗��ĂɋN������̂ł͂܂����H
Barcelona�̍���́A�����[�X�����Ă̖����ȃX�P�[�W���[���̗��ĂɋN������̂ł͂܂����H
256 �FMAC�I�^��253 �����F2007/06/17(��) 16:25:15 ID:Kp8SxLEQ
>>256
�o���X�������������{���ɖ\��Ă邗
�o���X�������������{���ɖ\��Ă邗
258 �FMAC�I�^��257 �����F2007/06/17(��) 16:31:39 ID:Kp8SxLEQ
>>257
����퓪�����������q�g������̂悤������A�����̂悤�ɑ���̊ԈႢ���l�^�ɂ���
�l�i�G���������Ȃ��Ǝv�����B�ߑa�X���b�h�Ȃ�Ŕ��������Ȃ��Ǝv���̂ŁA���܂�
������Ȃ������ˁB�B�B
����퓪�����������q�g������̂悤������A�����̂悤�ɑ���̊ԈႢ���l�^�ɂ���
�l�i�G���������Ȃ��Ǝv�����B�ߑa�X���b�h�Ȃ�Ŕ��������Ȃ��Ǝv���̂ŁA���܂�
������Ȃ������ˁB�B�B
>>256
�c�q���}�g���Ɍ�����
�c�q���}�g���Ɍ�����
>>250
���̊�Ɋ�Â��Ȃ���Ǔ_�̈��͐V�A�[�L�ƌĂԂɂ͔����ȃ��C����������Ȃ����ǁA
���̉��ǂ�CPU�̑S�̂ɋy��ł邩�猋�ʓI�ɐV�A�[�L�ƌĂׂ郌�x���ɂ͂Ȃ��Ă�Ǝv�����ǂˁB
���g�т������̓I�ɏq�ׂ��Ȃ����ǁB
���̊�Ɋ�Â��Ȃ���Ǔ_�̈��͐V�A�[�L�ƌĂԂɂ͔����ȃ��C����������Ȃ����ǁA
���̉��ǂ�CPU�̑S�̂ɋy��ł邩�猋�ʓI�ɐV�A�[�L�ƌĂׂ郌�x���ɂ͂Ȃ��Ă�Ǝv�����ǂˁB
���g�т������̓I�ɏq�ׂ��Ȃ����ǁB
262 �FSocket774�F2007/06/17(��) 16:59:50 ID:XtqgdWPk
����������
CELL��SSE�������������������
���������ACell��eax��xmm0�Ԃ̃��C�e���V���Ď����ł���̂����イ�^��͂����ȁB
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
�����Ƃ����͎������ʂ��邯��
����������������������
CELL��SSE�������������������
���������ACell��eax��xmm0�Ԃ̃��C�e���V���Ď����ł���̂����イ�^��͂����ȁB
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
�����Ƃ����͎������ʂ��邯��
����������������������
263 �FSocket774�F2007/06/17(��) 17:01:04 ID:XtqgdWPk
CELL��SSE�g���Ȃ�
��
�����XMM0���W�X�^���Ȃ�
��
�ł��c�q�u���������v
���ɋ����[��
��
�����XMM0���W�X�^���Ȃ�
��
�ł��c�q�u���������v
���ɋ����[��
Core MicroArchitecture��P3�̏Ă������Ɣl��M�҂�����ȏ�A
�����̖͂����͔ۂ߂Ȃ��ȁB
AMD�Ɍ�����������Ǝv�����̂́A�������Ђ̃R���p�C���̓���ɃP�`����������B
����^������A�ƁB
AMD���R���p�C���ŏo���オ�������̓����
�^�А�CPU���̈ӂɒx������̂Ȃ�܂����̓{��������ł�����B
��Ƒ̗͂̍�������낤���ǁA�^�Ђ�AMD�ł͋Z�p�I�Ɍ��Ă�悪�Ⴄ�̂��ȁB
���������C�e���V�ւ̑��AMD�͒Z���I�Ɍ��ʂ̍������@��
�^�Ђ̓C���`�L�Ă�肳���قǂ̑s��Ȍv�悾�������ˁB
�����̖͂����͔ۂ߂Ȃ��ȁB
AMD�Ɍ�����������Ǝv�����̂́A�������Ђ̃R���p�C���̓���ɃP�`����������B
����^������A�ƁB
AMD���R���p�C���ŏo���オ�������̓����
�^�А�CPU���̈ӂɒx������̂Ȃ�܂����̓{��������ł�����B
��Ƒ̗͂̍�������낤���ǁA�^�Ђ�AMD�ł͋Z�p�I�Ɍ��Ă�悪�Ⴄ�̂��ȁB
���������C�e���V�ւ̑��AMD�͒Z���I�Ɍ��ʂ̍������@��
�^�Ђ̓C���`�L�Ă�肳���قǂ̑s��Ȍv�悾�������ˁB
265 �FSocket774�F2007/06/17(��) 17:04:32 ID:XtqgdWPk
�c�q�s���`�I
�c�q�s���`�I
�e�e�e�b�e�e�e�b�e�[�e�[�e�[(SOS!!)
�e�e�e�b�e�e�e�b�e�[�e�[�e�[(SOS!!)
���Ђ�Ђ�Ђ�Ђ�Ђ႗����������������
Cell�̃��C�e���V�̘b���Ă�����
882 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 17:02:20
�[���A�uCell�Łv�Ȃ�Ĉꌾ�������ĂȂ�����
����������������������������������������
�v���O��������m��Ȃ��`�������o���Ă����܂Ō��ꂵ���������������������������������
�c�q�s���`�I
�e�e�e�b�e�e�e�b�e�[�e�[�e�[(SOS!!)
�e�e�e�b�e�e�e�b�e�[�e�[�e�[(SOS!!)
���Ђ�Ђ�Ђ�Ђ�Ђ႗����������������
Cell�̃��C�e���V�̘b���Ă�����
882 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 17:02:20
�[���A�uCell�Łv�Ȃ�Ĉꌾ�������ĂȂ�����
����������������������������������������
�v���O��������m��Ȃ��`�������o���Ă����܂Ō��ꂵ���������������������������������
266 �FMAC�I�^��262 �����F2007/06/17(��) 17:07:12 ID:Kp8SxLEQ
>>262-263
�_�j����ē����o�����ᖳ����A���Z��Ő��X���X�Ƌc�_���ׂ����Ǝv�����B
���Ȃ݂ɒc�q����̎����f�[�^��A���ꂾ�Ǝv�����B
http://tripper.kousaku.in/?date=200703
SSE�̌���uSSE�ł̃��C�e���V�̑���@�v��������Ă������������A��̈�������ׂ����B
�_�j����ē����o�����ᖳ����A���Z��Ő��X���X�Ƌc�_���ׂ����Ǝv�����B
���Ȃ݂ɒc�q����̎����f�[�^��A���ꂾ�Ǝv�����B
http://tripper.kousaku.in/?date=200703
SSE�̌���uSSE�ł̃��C�e���V�̑���@�v��������Ă������������A��̈�������ׂ����B
267 �FSocket774�F2007/06/17(��) 17:09:59 ID:XtqgdWPk
���O�c�q��
268 �FSocket774�F2007/06/17(��) 17:17:39 ID:XtqgdWPk
�c�q�����������̂ŁA�J�}�������猩����������
���炵���B
��������CELL��SSE����
�c�q�����܂ł킩���悤�ɂȂ������`
���̊C�͔߂����F��ˁB
���炵���B
��������CELL��SSE����
�c�q�����܂ł킩���悤�ɂȂ������`
���̊C�͔߂����F��ˁB
�����ł��ȁB���̃X���b�h�ł͊F�Q�[����CPU�ȂȂ�̋������Ȃ��B����ȂƂ���ɓ����Ă��Ȃ��ł���B
270 �F�E�́E�j��-�������F2007/06/17(��) 17:23:54 ID:tanIEtWU
�J�}���ė~�����q�Ȃ�ő��肵�Ă����Ă�������
271 �FMAC�I�^���c�q �����F2007/06/17(��) 17:25:48 ID:Kp8SxLEQ
>>270
�_�j����ē����o�����ᖳ����A���Z��Ő��X���X�Ƌc�_���Ăė~�������B
�_�j����ē����o�����ᖳ����A���Z��Ő��X���X�Ƌc�_���Ăė~�������B
272 �FSocket774�F2007/06/17(��) 17:27:58 ID:XtqgdWPk
�_�j���ꂽ���������������Ƃ���Ȃ����B
���������ACell��eax��xmm0�Ԃ̃��C�e���V���Ď����ł���̂����イ�^��͂����ȁB
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
�����Ƃ����͎������ʂ��邯��
����������������������
���������ACell��eax��xmm0�Ԃ̃��C�e���V���Ď����ł���̂����イ�^��͂����ȁB
864 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 16:22:27
�����Ƃ����͎������ʂ��邯��
����������������������
273 �FSocket774�F2007/06/17(��) 17:28:47 ID:XtqgdWPk
�ŁA�����Ȃ��������B
���Ђ�Ђ�Ђ�Ђ�Ђ႗����������������
Cell�̃��C�e���V�̘b���Ă�����
882 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 17:02:20
�[���A�uCell�Łv�Ȃ�Ĉꌾ�������ĂȂ�����
����������������������������������������
�v���O��������m��Ȃ��`�������o���Ă����܂Ō��ꂵ���������������������������������
���Ђ�Ђ�Ђ�Ђ�Ђ႗����������������
Cell�̃��C�e���V�̘b���Ă�����
882 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 17:02:20
�[���A�uCell�Łv�Ȃ�Ĉꌾ�������ĂȂ�����
����������������������������������������
�v���O��������m��Ȃ��`�������o���Ă����܂Ō��ꂵ���������������������������������
>>273
�悭�킩��Ȃ��ł����ǁA���Ȃ������������Ȃ��Ƃ����͂悭�킩��܂����B
�悭�킩��Ȃ��ł����ǁA���Ȃ������������Ȃ��Ƃ����͂悭�킩��܂����B
��n�O�����ɗU������Ȃ�
276 �FSocket774�F2007/06/17(��) 17:54:20 ID:XtqgdWPk
ID��������
277 �FSocket774�F2007/06/17(��) 17:56:09 ID:XtqgdWPk
�c�q�A�C���e���D���Ȃ̂ɂȂ�ŃC���e���������\�[�X�o����H
����������������������������������
�N���グ����������������
Core2�N�\�x��������������������
795 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 13:21:06
http://www.pcstats.com/articleview.cfm?articleid=2095&page=8
Core 2 Duo E6600(2.4GHz) 7328 FPU / 10785 SSE2
Athlon64 FX-60(2.6GHz) 8899 FPU / 11522 SSE2
��ʃ��f���ł�Core 2�̂ق����L���ł��˂�����
����������������������������������
�N���グ����������������
Core2�N�\�x��������������������
795 ���O�F �E�́E�j��-������ [sage] ���e���F 2007/06/17(��) 13:21:06
http://www.pcstats.com/articleview.cfm?articleid=2095&page=8
Core 2 Duo E6600(2.4GHz) 7328 FPU / 10785 SSE2
Athlon64 FX-60(2.6GHz) 8899 FPU / 11522 SSE2
��ʃ��f���ł�Core 2�̂ق����L���ł��˂�����
278 �F�E�́E�j��-�������F2007/06/17(��) 17:57:43 ID:tanIEtWU
���͌Ăo���Ȃ���
�A���`�̂�����PS3�͎��s�ɏI������ǂ����Ă����
�Ƃ������Ă��Q�n�̒ɂ��q�Ȃ̂͂킩�邪
���������l�b�g�H���SONY���N�����
�A���`�̂�����PS3�͎��s�ɏI������ǂ����Ă����
�Ƃ������Ă��Q�n�̒ɂ��q�Ȃ̂͂킩�邪
���������l�b�g�H���SONY���N�����
>>233
>���肫�����g�D�ƁA���ЂƑ��А��i���g�����[�U�[�A���܂��ɂ�̔��X���������悤�ȓ��{�@�l�c�ƁB
>�J���͎���10�N�P�ʂłق��ۂ炩���B
>�ٔ���D���B
>�ݔ������͂��邯�ǁA�������镨���ߋ��̐��i�B
���̂ւ�̃\�[�X�L�{���B�ڂ����m�肽���B
�܂����\�[�X���Ȃ��ɖϑz������킯����Ȃ���ȁH
>���肫�����g�D�ƁA���ЂƑ��А��i���g�����[�U�[�A���܂��ɂ�̔��X���������悤�ȓ��{�@�l�c�ƁB
>�J���͎���10�N�P�ʂłق��ۂ炩���B
>�ٔ���D���B
>�ݔ������͂��邯�ǁA�������镨���ߋ��̐��i�B
���̂ւ�̃\�[�X�L�{���B�ڂ����m�肽���B
�܂����\�[�X���Ȃ��ɖϑz������킯����Ȃ���ȁH
�J���v�悪�������肵�Ă����Ђ̗�
http://journal.mycom.co.jp/articles/2007/06/02/intel/images/013.jpg
����̃A�i���X�g�~�[�e�B���O�Ō��J���ꂽ������̋����[�����́A
Perlmutter���̍u���̒��Ŏ����ꂽ�AIntel�̃v���Z�T�J���v��̎��{��
�ւ�����P����������̃X���C�h�ł���B2001�N��Willamette�̈ȍ~��
�v���Z�T�̊J���ɂ��āA�����̌v��̏o�����Ǝ��ۂ̏o������
�Ⴂ���܂Ƃ߂����̂ŁA(Banias���O�Ƃ���)2004�N�܂ł�5�����ȏ��
�x������ʓI�ł��������A2004�N�ȍ~�͌v��ʂ�A���邢��Tulsa��Cl
overtown�̂悤��3�����ȏ���ڕW��葁���o�ׂƂ������̂��o�Ă��Ă���B
���̂悤�ȉ��P�́A�P�ɃG���W�j�A�̐K��@�������ł͎��������A�J��
�v���Z�X���̂ɑ傫�ȉ��P���s��ꂽ���̂Ɛ��������B���R�͂Ƃ������A
�v��ʂ�ɊJ������������ΗʎY�̏������X���[�Y�ɍs���A�܂��A����
�Ƃ����_�ł��L���ɂȂ�̂ŁA�o�c�I�ɂ͑傫�ȃ����b�g�ł���A�A�i���X�g
�ւ̃A�s�[���x�̍����X���C�h�ł���B
http://journal.mycom.co.jp/articles/2007/06/02/intel/images/013.jpg
{kind=link}
����̃A�i���X�g�~�[�e�B���O�Ō��J���ꂽ������̋����[�����́A
Perlmutter���̍u���̒��Ŏ����ꂽ�AIntel�̃v���Z�T�J���v��̎��{��
�ւ�����P����������̃X���C�h�ł���B2001�N��Willamette�̈ȍ~��
�v���Z�T�̊J���ɂ��āA�����̌v��̏o�����Ǝ��ۂ̏o������
�Ⴂ���܂Ƃ߂����̂ŁA(Banias���O�Ƃ���)2004�N�܂ł�5�����ȏ��
�x������ʓI�ł��������A2004�N�ȍ~�͌v��ʂ�A���邢��Tulsa��Cl
overtown�̂悤��3�����ȏ���ڕW��葁���o�ׂƂ������̂��o�Ă��Ă���B
���̂悤�ȉ��P�́A�P�ɃG���W�j�A�̐K��@�������ł͎��������A�J��
�v���Z�X���̂ɑ傫�ȉ��P���s��ꂽ���̂Ɛ��������B���R�͂Ƃ������A
�v��ʂ�ɊJ������������ΗʎY�̏������X���[�Y�ɍs���A�܂��A����
�Ƃ����_�ł��L���ɂȂ�̂ŁA�o�c�I�ɂ͑傫�ȃ����b�g�ł���A�A�i���X�g
�ւ̃A�s�[���x�̍����X���C�h�ł���B
281 �FMAC�I�^��279 �����F2007/06/17(��) 18:24:32 ID:Kp8SxLEQ
>>279
2�Ԗڂ�4�Ԗڂɂ��Ă�A>>229�ɏ������ʂ肩�Ǝv�����B10�N���U���Ǝv�������ǁA
Griffin�̔��\�����̃��[�h�}�b�v���画�f����ɁA2008-2009�N�܂Ō��s�R�A����̑傫��
�ύX�햳����Ȃ������ˁH
�ׂ����Ă��������ɂ����ƊJ�����Ă��Ȃ��������ʂƂ��āA�喇�����Č��݂����V�H���
�@�@-------------------
�@�@�������镨���ߋ��̐��i�B
�@�@-------------------
�ƌ�����H�ڂɂȂ邷�B
2�Ԗڂ�4�Ԗڂɂ��Ă�A>>229�ɏ������ʂ肩�Ǝv�����B10�N���U���Ǝv�������ǁA
Griffin�̔��\�����̃��[�h�}�b�v���画�f����ɁA2008-2009�N�܂Ō��s�R�A����̑傫��
�ύX�햳����Ȃ������ˁH
�ׂ����Ă��������ɂ����ƊJ�����Ă��Ȃ��������ʂƂ��āA�喇�����Č��݂����V�H���
�@�@-------------------
�@�@�������镨���ߋ��̐��i�B
�@�@-------------------
�ƌ�����H�ڂɂȂ邷�B
>>264
P3����Ȃ���P6�A�[�N�e�N�`������@
�Ȃ�ŃA�[�L�e�N�`���̘b��Pentium III���o�Ă��悗
�t�@�~���[��6�ɖ߂�������P6�t�@�~���Ƃ����Ă��d���ˁ[����
P3����Ȃ���P6�A�[�N�e�N�`������@
�Ȃ�ŃA�[�L�e�N�`���̘b��Pentium III���o�Ă��悗
�t�@�~���[��6�ɖ߂�������P6�t�@�~���Ƃ����Ă��d���ˁ[����
283 �F�E�́E�j��-�������F2007/06/17(��) 18:34:00 ID:tanIEtWU
����������Ȃ�AMD��
K5 = K6 = 5
K7 = 6
K8 = 15
�Ȃ�
K5 = K6 = 5
K7 = 6
K8 = 15
�Ȃ�
���̘_����PenM�̎���������
����ɂ���Ă��낢��
457 �FMAC�I�^��456 ���� �F2006/03/12(��) 17:37:51 ID:wXE3ifwK0
>>456
CNET�̃C���^�r���[�ŁC�S�Ă�m�肦�闧��ɂ���Mooly Eden�������Ă��邷�B
http://news.com.com/2008-1006_3-6047173-2.html
[MAC�I�^��] ������O�̘b�����ǁC�O����̃`�b�v��������p��������������C
�V�K�ɓ������ꂽ�A�C�f�A��������Ă��Ƃ���B�m����Pentium III�ƃA�[�L�e�N�`��
�I�ɗǂ����Ă��镔���͂��邯�ǁC�����I�ɂ͑S�R����Ă���Ƃ�������X�������
���Ƃ��B
��������������̃A�[�L�e�N�`���̂܂܂ŁC�ǂꂾ�����\���グ����Ǝv���H
Pentium III�̃A�[�L�e�N�`�����p�����Ă��镔�������邩�ƕ������C�������
�C�G�X���BDothan����Yonah���J������ߒ��ŐV���ɕt��������ꂽ�����͑S��
���猩��Ώ����ȕω������CYonah����Merom�ł̒lj��������悤�ɑS�ʓI�ȍ��V
���Ėᖳ���B�ł�Banias���uP6�A�[�L�e�N�`���̂܂܂��v���Č����̂́C�J����
�g��������S�l�̃X�^�b�t�ɑ��Ď�����Ă��̂���Ȃ����ȁB
462 �Finteler �F2006/03/12(��) 22:00:08 ID:xA2UIw9L0
The PentiumR II/III Processor �gCompiler on a Chip Compiler on a Chip�h
Ronny Ronen, Senior Principal Engineer Director of Architecture
Research Intel Labs --Haifa
ttp://www.cs.tau.ac.il/~afek/p6tx050111.pdf
>Most significant, major improvement over P6 architecture ever
������PenM=P6�x�[�X�ł����ʷ�ؔF�߂Ă���͗l�i�m
����ɂ���Ă��낢��
457 �FMAC�I�^��456 ���� �F2006/03/12(��) 17:37:51 ID:wXE3ifwK0
>>456
CNET�̃C���^�r���[�ŁC�S�Ă�m�肦�闧��ɂ���Mooly Eden�������Ă��邷�B
http://news.com.com/2008-1006_3-6047173-2.html
[MAC�I�^��] ������O�̘b�����ǁC�O����̃`�b�v��������p��������������C
�V�K�ɓ������ꂽ�A�C�f�A��������Ă��Ƃ���B�m����Pentium III�ƃA�[�L�e�N�`��
�I�ɗǂ����Ă��镔���͂��邯�ǁC�����I�ɂ͑S�R����Ă���Ƃ�������X�������
���Ƃ��B
��������������̃A�[�L�e�N�`���̂܂܂ŁC�ǂꂾ�����\���グ����Ǝv���H
Pentium III�̃A�[�L�e�N�`�����p�����Ă��镔�������邩�ƕ������C�������
�C�G�X���BDothan����Yonah���J������ߒ��ŐV���ɕt��������ꂽ�����͑S��
���猩��Ώ����ȕω������CYonah����Merom�ł̒lj��������悤�ɑS�ʓI�ȍ��V
���Ėᖳ���B�ł�Banias���uP6�A�[�L�e�N�`���̂܂܂��v���Č����̂́C�J����
�g��������S�l�̃X�^�b�t�ɑ��Ď�����Ă��̂���Ȃ����ȁB
462 �Finteler �F2006/03/12(��) 22:00:08 ID:xA2UIw9L0
The PentiumR II/III Processor �gCompiler on a Chip Compiler on a Chip�h
Ronny Ronen, Senior Principal Engineer Director of Architecture
Research Intel Labs --Haifa
ttp://www.cs.tau.ac.il/~afek/p6tx050111.pdf
>Most significant, major improvement over P6 architecture ever
������PenM=P6�x�[�X�ł����ʷ�ؔF�߂Ă���͗l�i�m
Athlon 64 X2 �� Rana �̕ω���� Yonah �� Merom �̕ω��̕����傫�����
��(�r)���r�߂����̂���l�Ɏ���B
�r�߂Ă��鎞�̏��̕\��͂ǂ��������H
�b�������y�̂̊፷�����������������������������B
�r�߂Ă��鎞�̏��̕\��͂ǂ��������H
�b�������y�̂̊፷�����������������������������B
288 �FMAC�I�^��284 �����F2007/06/17(��) 18:43:49 ID:Kp8SxLEQ
>>284
�@�@-----------------
�@�@>Most significant, major improvement over P6 architecture ever
�@�@-----------------
���ɂ�A�R���uP6�A�[�L�e�N�`���ȗ��A�ő�̐i���ƂȂ郂�m[�V�A�[�L�e�N�`��]�ł���v
�Ɠǂ߂邷����(��)
�@�@-----------------
�@�@>Most significant, major improvement over P6 architecture ever
�@�@-----------------
���ɂ�A�R���uP6�A�[�L�e�N�`���ȗ��A�ő�̐i���ƂȂ郂�m[�V�A�[�L�e�N�`��]�ł���v
�Ɠǂ߂邷����(��)
���cnet�C���^�r���[�ƃj���A���X���Ⴄ�C�����邪
Yonah���o��O�̃��[���[����
http://www.itmedia.co.jp/news/articles/0508/29/news008_2.html
>�uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i�����Ă���Ƃ���ƁA
>Dothan����Yonah�ւ̐i���͂��̐��{���̑傫�ȍ�������܂��B
>Yonah����Merom�̐i���������ď������͂���܂��ADothan����Yonah�ւ̕ω�
>�قǑ傫�Ȃ��̂ł͂���܂���v
>>288
���̂܂܃R�s�y�������ǁA�|��ɂ��Ă͐������Ȃ������B���܂�B
Yonah���o��O�̃��[���[����
http://www.itmedia.co.jp/news/articles/0508/29/news008_2.html
>�uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i�����Ă���Ƃ���ƁA
>Dothan����Yonah�ւ̐i���͂��̐��{���̑傫�ȍ�������܂��B
>Yonah����Merom�̐i���������ď������͂���܂��ADothan����Yonah�ւ̕ω�
>�قǑ傫�Ȃ��̂ł͂���܂���v
>>288
���̂܂܃R�s�y�������ǁA�|��ɂ��Ă͐������Ȃ������B���܂�B
291 �FMAC�I�^��289 �����F2007/06/17(��) 18:49:51 ID:Kp8SxLEQ
>>289
���LL2�̐v�ɂ푊���̊J�����\�[�X���K�v������A���̔������̂�[�����������B
���LL2�̐v�ɂ푊���̊J�����\�[�X���K�v������A���̔������̂�[�����������B
>>291
�Ȃ�ق�
�Ȃ�ق�
293 �FMAC�I�^��290 �����F2007/06/17(��) 18:52:14 ID:Kp8SxLEQ
>>290
Andy Glew�̂悤�ɁAIntel�Г��ł�P4��ޕ����ƍl���Ă���q�g������̂펖�����B
Andy Glew�̂悤�ɁAIntel�Г��ł�P4��ޕ����ƍl���Ă���q�g������̂펖�����B
>>293
����|�C���g�͂�������Ȃ���improvement�ɑ���over���ȗ��Ɖ��߂���̂͂�����������
����|�C���g�͂�������Ȃ���improvement�ɑ���over���ȗ��Ɖ��߂���̂͂�����������
295 �FMAC�I�^��294 �����F2007/06/17(��) 19:04:42 ID:Kp8SxLEQ
>>294
�@�@----------------
�@�@improvement�ɑ���over���ȗ��Ɖ��߂���̂͂�����������
�@�@----------------
�������������H�����������Ƃ��Ǝv�����B
�@�@P6 ���@Banias [�V�A�[�L�e�N�`��]
�@�@�@�@���啝�ȉ���
�u���̃e�[�}��"Compiler on a Chip Compiler on a Chip"������CRISC�Z�p�ɂ��ĂƂ������Ƃ�
P5�ȗ��̃v���Z�b�T��S�Ċ܂܂�邷�B
�@�@----------------
�@�@improvement�ɑ���over���ȗ��Ɖ��߂���̂͂�����������
�@�@----------------
�������������H�����������Ƃ��Ǝv�����B
�@�@P6 ���@Banias [�V�A�[�L�e�N�`��]
�@�@�@�@���啝�ȉ���
�u���̃e�[�}��"Compiler on a Chip Compiler on a Chip"������CRISC�Z�p�ɂ��ĂƂ������Ƃ�
P5�ȗ��̃v���Z�b�T��S�Ċ܂܂�邷�B
Banias�����ʂƂ���(P6�A�[�L�e�N�`���̉������)�ō��̓��B�_���Ƃ����Ӗ��ł����āA
Tualatin �� Banias �̕ω����@Intel�j������Ƃ��傫�ȕω����Ă��肦�Ȃ����|��Ƃ��Ă����������B
Tualatin �� Banias �̕ω����@Intel�j������Ƃ��傫�ȕω����Ă��肦�Ȃ����|��Ƃ��Ă����������B
>>295
�����Ƃ��ڗ��������ڂƂ��ẮAp6�A�[�L�e�N�`���S�̂��Ђ�����߂āA�傫�Ȑi���������B
�Ɩ̂��������ƁB
�����A��ops��ς��Ă�����o�X��ς�����ƁAp6���x�[�X�ɃL�[�t�B�[�`���[������������ւ�������
p6.8���炢��CPU�ɂȂ��Ă�Ǝv����ˁB
Core2�Ɋւ��ẮA�S���ʕ����Ǝv���Bp6�n�̓�ops�̈�������������I�����邵�B
�����Ƃ��ڗ��������ڂƂ��ẮAp6�A�[�L�e�N�`���S�̂��Ђ�����߂āA�傫�Ȑi���������B
�Ɩ̂��������ƁB
�����A��ops��ς��Ă�����o�X��ς�����ƁAp6���x�[�X�ɃL�[�t�B�[�`���[������������ւ�������
p6.8���炢��CPU�ɂȂ��Ă�Ǝv����ˁB
Core2�Ɋւ��ẮA�S���ʕ����Ǝv���Bp6�n�̓�ops�̈�������������I�����邵�B
Intel�n�ōő����IA64�Ƃ��l�g�o�n�Ƃ�����˂��́H
�[���B�d�g�Ɖ�b���Ă���̂��H�@���܂���B
�[���B�d�g�Ɖ�b���Ă���̂��H�@���܂���B
�x�[�X�����V�I�����ċc�_���̎��̂���b����Ȃ��Ǝv�����E�E�E�E
����pdf�́APen4�ƕ��ĕʂ̃A�[�L�e�N�`�������݂��邱�Ƃ𓊎��Ƃɑ�X�I�ɒm�点�����Ȃ�
�����ops�̃��W�b�N���̂�ύX���Ă�̂ɁAp6�Ƃ��Ă킴�킴����pdf�ɗ�L���Ă�Ƃ������߂��o����B
Pen4���t�F�[�h�A�E�g���Ă�������Core���o���Ƃ��A����̏����ǂ�V�A�[�L�e�N�`���ƌ����Ă��܂�
�z�ȂƎv����B�}�[�P�e�B���O�I�ɂ͕ʕ��ł��J���`�[���ɂ͓������̕��݂����Ȃ��̂��ƁB
����Core2�͑S���̕ʕ��ƈ������Ƃ͏o���邯�ǁA����ȑO�͎�͐��i�̏��i�͂����Ȃ���}�[�P�e�B���O�̋�ł��낱��ƌ������Ƃ�
�����ɕς�����֗��ȕi���Ƃ��Ĉ����Ă����ƌ������Ƃł́B
�����ops�̃��W�b�N���̂�ύX���Ă�̂ɁAp6�Ƃ��Ă킴�킴����pdf�ɗ�L���Ă�Ƃ������߂��o����B
Pen4���t�F�[�h�A�E�g���Ă�������Core���o���Ƃ��A����̏����ǂ�V�A�[�L�e�N�`���ƌ����Ă��܂�
�z�ȂƎv����B�}�[�P�e�B���O�I�ɂ͕ʕ��ł��J���`�[���ɂ͓������̕��݂����Ȃ��̂��ƁB
����Core2�͑S���̕ʕ��ƈ������Ƃ͏o���邯�ǁA����ȑO�͎�͐��i�̏��i�͂����Ȃ���}�[�P�e�B���O�̋�ł��낱��ƌ������Ƃ�
�����ɕς�����֗��ȕi���Ƃ��Ĉ����Ă����ƌ������Ƃł́B
301 �FMAC�I�^��299 �����F2007/06/17(��) 19:36:09 ID:Kp8SxLEQ
����Barcelona���v�V�I���ǂ����ł͂Ȃ��AX2�ɑ��Ăǂꂾ�����\���グ���邩�A����H
303 �F�E�́E�j��-�������F2007/06/17(��) 19:38:31 ID:tanIEtWU
�Ȃ܂�Marced��7��^���Ă��܂�������8��t�����Ȃ������Ȋ�K�X�B
305 �FSocket774�F2007/06/17(��) 19:44:42 ID:rSjf3cqS
�݂Ȃ���Intel�̘b�Ŏ�������ł��ȁB
ּּ�i�L�́M �j
ּּ�i�L�́M �j
��x�ł������猩�Ă݂����AP6�������ǂ��������̐�K10���{����������Ƃ���B
�̖��C�ł��B�ǂ������肪�Ƃ��������܂����B
�̖��C�ł��B�ǂ������肪�Ƃ��������܂����B
>>306
���������{�I�ɂ�P6��K7�̐킢�Ȃ�ȁc�B
���������{�I�ɂ�P6��K7�̐킢�Ȃ�ȁc�B
�H�H
Core����̍��̓l�g�o�Ƃ̐킢����������Ȃ���
Core����̍��̓l�g�o�Ƃ̐킢����������Ȃ���
>>309
���A�������B�f�X�N�g�b�v�p�̃��e�[���͂Ȃ��������B
���[�J�[���͑�^�m�[�g�����ꂾ����A����Pen4�͂��łɑޖ��݂����ȕ��������L��������
���ǎv�����݂�������Ȃ��B
�Ƃ������Ƃ́A���ۂɂ͑�K�͂�P6��K7�̐킢�͖��������Ƃ����邩���B
�f�X�N�m�[�g�s��ł�Sempron�͘b�ɂȗ��p�t�H�[�}���X�Ȃ̂ŁB
���A�������B�f�X�N�g�b�v�p�̃��e�[���͂Ȃ��������B
���[�J�[���͑�^�m�[�g�����ꂾ����A����Pen4�͂��łɑޖ��݂����ȕ��������L��������
���ǎv�����݂�������Ȃ��B
�Ƃ������Ƃ́A���ۂɂ͑�K�͂�P6��K7�̐킢�͖��������Ƃ����邩���B
�f�X�N�m�[�g�s��ł�Sempron�͘b�ɂȗ��p�t�H�[�}���X�Ȃ̂ŁB
�ׂɃ����T�C�h���Č�����ق�Core 2 Duo��X2�ɍ�������Ƃ͎v��B
Core 2 Quad�ɑR�ł�����̂��܂������Ȃ����ĈӖ��ł̓����T�C�h�����ǁB
Core 2 Quad�ɑR�ł�����̂��܂������Ȃ����ĈӖ��ł̓����T�C�h�����ǁB
SSE��L2�L���b�V���̍�������Pentium4�̎��ォ�烏���T�C�h�������悤�Ɏv��
>>311
���i���肪�����Ă���ǂ����i�тł̑R�͂����m�����Ǝv����B
����܂ł̓V�F�A�قǂ̃����T�C�h�ł͂Ȃ������Ǝv�����ǂˁB
Quad�Ɋւ��ẮA�ǂ������u�Ԃ����Ƃ����ԂɃI�N�^���o�����ȋC������B
�Ȃ���AMD����i���ɒǂ����Ȃ��X�p�C��������o��ꂻ���ɂȂ��B
���i���肪�����Ă���ǂ����i�тł̑R�͂����m�����Ǝv����B
����܂ł̓V�F�A�قǂ̃����T�C�h�ł͂Ȃ������Ǝv�����ǂˁB
Quad�Ɋւ��ẮA�ǂ������u�Ԃ����Ƃ����ԂɃI�N�^���o�����ȋC������B
�Ȃ���AMD����i���ɒǂ����Ȃ��X�p�C��������o��ꂻ���ɂȂ��B
>>312
SSE���g��Ȃ��Ă��������Z�̒T����������Ɣ߂������炢�����o��B
SSE���g��Ȃ��Ă��������Z�̒T����������Ɣ߂������炢�����o��B
>>313
�u�ԓI�ɂ��ǂ�����ł���BK10��Kentsfield�ɂ��ǂ�����Ǝv���Ȃ�����������
Harpertown/Yorkfield�����������BK10.5���ǂ���Nehalem�Ɠ����ł���B
���̂��Ƃ�Intel�͂R�Q�R�A�ȏ�̃s�[�N���\�����͂߂��Ⴍ����Ȏ���ɓ˓����邵�B
�u�ԓI�ɂ��ǂ�����ł���BK10��Kentsfield�ɂ��ǂ�����Ǝv���Ȃ�����������
Harpertown/Yorkfield�����������BK10.5���ǂ���Nehalem�Ɠ����ł���B
���̂��Ƃ�Intel�͂R�Q�R�A�ȏ�̃s�[�N���\�����͂߂��Ⴍ����Ȏ���ɓ˓����邵�B
���Ă������p���m�C�A���Intel�ɍō����\�Œ��ޕK�v�Ȃ�Ă���̂��H
���C���X�g���[����C/P�̍������̍������ł��������B
���C���X�g���[����C/P�̍������̍������ł��������B
>>315
�o�Ă݂Ȃ��Ƃ킩��A����Ă݂Ȃ��Ƃ킩��H
K10���{����"���������T���v��������"���čň��̏�������A
K11���Ӗ��s���Ȃقǐ��\���o���\�������邵�B
�܂����K10�͉\��������ˁB
�o�Ă݂Ȃ��Ƃ킩��A����Ă݂Ȃ��Ƃ킩��H
K10���{����"���������T���v��������"���čň��̏�������A
K11���Ӗ��s���Ȃقǐ��\���o���\�������邵�B
�܂����K10�͉\��������ˁB
�������������\�ŃA�h�o���e�[�W���Ȃ���Βl�����ɂ��邸����������Ă��ځ[��
>>318
�����Z�p�ɗ��AMD���_�C�T�C�Y������ɂȂ�l�C�e�B�u�N�A�b�h�ɂ������Ӗ���
�������̂��˂��B
�f���A�������Ń��[�G���h�܂Ńf���A���ōs���Ƃ��A�ȓd�͐��ŏ�������Ƃ��A
���͂��낢�날��킯�ŁB
�����Z�p�ɗ��AMD���_�C�T�C�Y������ɂȂ�l�C�e�B�u�N�A�b�h�ɂ������Ӗ���
�������̂��˂��B
�f���A�������Ń��[�G���h�܂Ńf���A���ōs���Ƃ��A�ȓd�͐��ŏ�������Ƃ��A
���͂��낢�날��킯�ŁB
�t�@�u��ATi�ɃA���������˂������A�ő̗͖������ȁB
���܂���ATi��ATi��Nvidia�ɖw�lj����Ԃ��ꂩ���Ă邵�c
ttp://www.4gamer.net/news/image/2007.06/20070613100000_41big.html
����Ȋ����ōŌ�̉��܂ŕ����ꂽ
���܂���ATi��ATi��Nvidia�ɖw�lj����Ԃ��ꂩ���Ă邵�c
ttp://www.4gamer.net/news/image/2007.06/20070613100000_41big.html
����Ȋ����ōŌ�̉��܂ŕ����ꂽ
�^�̈��@������Kuma���o�������낤��
Kuma�Ɋւ���\�z
1)X4�Ƌ��ʃ_�C�ŃR�A���ɔł��g���ꍇ
�E2008�N3���o��
�E�ō��N���b�N��2.6G
�E���i�͍ʼn��ʃN���b�N��6000+�̂P�����N��
2)��p�_�C���g���ꍇ
�E2008�N6���o��
�E�ō��N���b�N��2.8G
�E���i�͍ʼn��ʃN���b�N��5000+�̂P�����N��
3)�L�����Z��
1)X4�Ƌ��ʃ_�C�ŃR�A���ɔł��g���ꍇ
�E2008�N3���o��
�E�ō��N���b�N��2.6G
�E���i�͍ʼn��ʃN���b�N��6000+�̂P�����N��
2)��p�_�C���g���ꍇ
�E2008�N6���o��
�E�ō��N���b�N��2.8G
�E���i�͍ʼn��ʃN���b�N��5000+�̂P�����N��
3)�L�����Z��
>>322
����B�������ɐ�p�_�C���낤�B
4�R�A�_�C���ʂɐ��Y�ł���قǁA
AMD�̐��Y�͂��˂���B
3�����c3�͂Ȃ��c45nm�����̌シ���������炠�蓾�����ǂȂ��B
����B�������ɐ�p�_�C���낤�B
4�R�A�_�C���ʂɐ��Y�ł���قǁA
AMD�̐��Y�͂��˂���B
3�����c3�͂Ȃ��c45nm�����̌シ���������炠�蓾�����ǂȂ��B
324 �FMAC�I�^��323 �����F2007/06/17(��) 23:21:40 ID:Kp8SxLEQ
>>323
�S�R�A�����Ȃ��s�ǃ`�b�v��p�������ɂ������Ȃ�������A���Ȃ��Ƃ������܂肪�オ��Ȃ�
�����̂�����A�f���A���R�A���N�A�h�R�A�������_�C���Ǝv�����B
�S�R�A�����Ȃ��s�ǃ`�b�v��p�������ɂ������Ȃ�������A���Ȃ��Ƃ������܂肪�オ��Ȃ�
�����̂�����A�f���A���R�A���N�A�h�R�A�������_�C���Ǝv�����B
>>323
����1)+3)���Ǝv���B���ʂ��v���~�A���i�ŏo�ׂ��āA�ʎY��Rana�Ƀo�g���^�b�`�B
Kuma�̎d�l����283����mm��X4�قǂł͂Ȃ��ɂ��Ă�200����mm�O���
���Ȃ�傫�ȃ_�C�T�C�Y�ɂȂ��Ă��܂��B
����1)+3)���Ǝv���B���ʂ��v���~�A���i�ŏo�ׂ��āA�ʎY��Rana�Ƀo�g���^�b�`�B
Kuma�̎d�l����283����mm��X4�قǂł͂Ȃ��ɂ��Ă�200����mm�O���
���Ȃ�傫�ȃ_�C�T�C�Y�ɂȂ��Ă��܂��B
>>325
�������Ɂu1�v�͂Ȃ����낤�E�E�B
�������Ɂu1�v�͂Ȃ����낤�E�E�B
Barcelona�����ꂾ���x��Ă��܂���Kuma���p�_�C�Őv���Ă�]�T������̂�
���Ęb
���Ęb
HKEPC�ɍŏ��͋��ʃ_�C���ċL��������������URL�Y�ꂿ�����
���ʃ_�C����Ȃ���X4�Ɠ����ɏo����킯�Ȃ����ȁB
�ƂȂ�ƃN���b�N�͂��Ԃ��BSKU�� >>76 >>79
X4 2.6G FX-91
X4 2.5G
X4 2.4G 7100�AFX-90�AFX-80
X4 2.3G 7050
X4 2.2G 7000
X2 2.6G 6800
X2 2.5G 6750
X2 2.4G 6700
X2 2.3G 6650
X2 2.2G 6600
X2 2.1G 6550
X2 2.0G 6500
X2 1.9G 6450
X2 1.8G 6400
�c�c65nm�ł�2.6GHz�����E���B
�ƂȂ�ƃN���b�N�͂��Ԃ��BSKU�� >>76 >>79
X4 2.6G FX-91
X4 2.5G
X4 2.4G 7100�AFX-90�AFX-80
X4 2.3G 7050
X4 2.2G 7000
X2 2.6G 6800
X2 2.5G 6750
X2 2.4G 6700
X2 2.3G 6650
X2 2.2G 6600
X2 2.1G 6550
X2 2.0G 6500
X2 1.9G 6450
X2 1.8G 6400
�c�c65nm�ł�2.6GHz�����E���B
331 �F�E�́E�j��-�������F2007/06/18(��) 04:06:14 ID:QfAjJyNa
���i�́H
�܂����J����ĂȂ��Ȃ�AIntel�̊�F�f���Ă�̂��H
�����Ȃ�p�pG33�ł������g�Ⴄ���[
�܂����J����ĂȂ��Ȃ�AIntel�̊�F�f���Ă�̂��H
�����Ȃ�p�pG33�ł������g�Ⴄ���[
2.6GHz�o�邩�ǂ�����������
Brisbane��3GHz���炢�o���Ă���Ȃ���
Brisbane��3GHz���炢�o���Ă���Ȃ���
>>331
���N�ȏ����̘b�Ȃ���c���i�̑O�ɕ������ƁB
>>332
������2.6GHz�ł��̂���3GHz���ł��ˁH
3GHz���łȂ��Ȃ�A�����̃N���b�N�͂����Ɖ����낤�B
���N�ȏ����̘b�Ȃ���c���i�̑O�ɕ������ƁB
>>332
������2.6GHz�ł��̂���3GHz���ł��ˁH
3GHz���łȂ��Ȃ�A�����̃N���b�N�͂����Ɖ����낤�B
ttp://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
Intel��Larrabee�ɑR����AMD��NVIDIA
�Ȃ��ŁAAMD����Ԍ����ȓ��i��ł�ȁB
Larrabee���������GPU�ɂ��Ċ������B
�����܂�CPU���Ď咣��CPU���Ƃ��Ă�Intel�̃v���C�h���낤���B
�T�[�o�[��[�N�X�e�[�V�����͂Ƃ�����
��ʌ����ɂ�GPU�̌`���Ƃ�ɂᕁ�y������́B
NVIDIA�́E�E�E
Intel��Larrabee�ɑR����AMD��NVIDIA
�Ȃ��ŁAAMD����Ԍ����ȓ��i��ł�ȁB
Larrabee���������GPU�ɂ��Ċ������B
�����܂�CPU���Ď咣��CPU���Ƃ��Ă�Intel�̃v���C�h���낤���B
�T�[�o�[��[�N�X�e�[�V�����͂Ƃ�����
��ʌ����ɂ�GPU�̌`���Ƃ�ɂᕁ�y������́B
NVIDIA�́E�E�E
>>334
�㓡�̃��^�b���܂��^�ɎĂ�̂�������
GPU�{���̗p�r�̐����i���n��DirectX10.1�ł����s���s���������Ă̂�
�\�t�g�E�F�A�x���_����̗v�]���g�ݓ���ėp�ӎ����ɕ��y�����Ă����Ă�
����K�i�ł�������͗L�����p����h���Ȃ��Ă��B�܂��Ă�G�ɂ��`�����ɂ���݂���E�E�E
�㓡�̃��^�b���܂��^�ɎĂ�̂�������
GPU�{���̗p�r�̐����i���n��DirectX10.1�ł����s���s���������Ă̂�
�\�t�g�E�F�A�x���_����̗v�]���g�ݓ���ėp�ӎ����ɕ��y�����Ă����Ă�
����K�i�ł�������͗L�����p����h���Ȃ��Ă��B�܂��Ă�G�ɂ��`�����ɂ���݂���E�E�E
�㓡�͗^���b�Ȃ�Ă������Ɩ����ł���B
�㓡�͒P�ɁA�Z�p�҂�[�J�[�̐l�Ԃɘb���āA
�u�h�ނ炪�h �ڕW�Ƃ��Ă��邱�Ɓv��������Ă��邾����
�����Ȃ��ė~�����Ƃ��A�����Ȃ�ɈႢ�Ȃ��A�ƌ������Ƃ�����ɏ����Ă�킯�ł͂Ȃ��B
�i�ނ��A�������邩�ǂ����͕ʖ��ŁA�������������̍���ɂ��G��ĉ�����Ă���j
�����炭PS3�̋L�������Ƃł����������Ƃ��������c���������Ǝv�����A
����ɂ��Ă��u�v���ǖ��ڕW�Ƃ��Ă��邱�Ɓv��ނ̖ڕW�����������ꍇ�ɂȂɂ��\�Ȃ̂��A��
����������Ƃ��A�㓡���ϑz�����b���Ɖ��߂��Ă�A�lj�͂̂Ȃ�
�i�܂��͓ǂ܂Ȃ��ŒN���������������ɂ����Ă��Ƃ������肾�����Ă�j
������������
�㓡�͒P�ɁA�Z�p�҂�[�J�[�̐l�Ԃɘb���āA
�u�h�ނ炪�h �ڕW�Ƃ��Ă��邱�Ɓv��������Ă��邾����
�����Ȃ��ė~�����Ƃ��A�����Ȃ�ɈႢ�Ȃ��A�ƌ������Ƃ�����ɏ����Ă�킯�ł͂Ȃ��B
�i�ނ��A�������邩�ǂ����͕ʖ��ŁA�������������̍���ɂ��G��ĉ�����Ă���j
�����炭PS3�̋L�������Ƃł����������Ƃ��������c���������Ǝv�����A
����ɂ��Ă��u�v���ǖ��ڕW�Ƃ��Ă��邱�Ɓv��ނ̖ڕW�����������ꍇ�ɂȂɂ��\�Ȃ̂��A��
����������Ƃ��A�㓡���ϑz�����b���Ɖ��߂��Ă�A�lj�͂̂Ȃ�
�i�܂��͓ǂ܂Ȃ��ŒN���������������ɂ����Ă��Ƃ������肾�����Ă�j
������������
�܂�A���[�J�[�̐l�Ԃ��^���b�����Ă���Ƃ������Ƃ�
�܂��A�Ԃ����Ⴏ��Ƃ������ȁB
�v���ǖ͂��������^�C�v�������炵�����E�E�^���Ƃ������ڕW���s�傷�����Ƃ������E�E
�v���ǖ͂��������^�C�v�������炵�����E�E�^���Ƃ������ڕW���s�傷�����Ƃ������E�E
�܂��Z�p�҂���X�Ɠ����x���ł͍���킯�ŁA
�ނ�̘b����X�������ł��Ȃ���������̂������͂ł���B
�܂��Đl�ÂĂȂ�]�v�ɂ����Ȃ�\���������킯�ŁB
�ނ�̘b����X�������ł��Ȃ���������̂������͂ł���B
�܂��Đl�ÂĂȂ�]�v�ɂ����Ȃ�\���������킯�ŁB
�� �܂��Z�p�҂���X�Ɠ����x���ł͍���킯��
����Ⴛ������w
�܂��Ď�����Z�p����낤���ēz���u����Ȃ̖����Ɍ��܂��Ă�[��v����
�ߊϘ_�҂��肶��b�ɂȂ����
����Ⴛ������w
�܂��Ď�����Z�p����낤���ēz���u����Ȃ̖����Ɍ��܂��Ă�[��v����
�ߊϘ_�҂��肶��b�ɂȂ����
>>338
����㓡�̂���܂ł̎��͒m����
����GPGPU�֘A�̌㓡�̋L���Ɋւ��Ă͖��炩�Ƀ��^��
����̋L���̏��������ł���Ƃ�������b����啝�ɒE������
��Ƃ̎v�f��n�삵�ă~�X���[�f�B���O��U���Ă��镔��������
����㓡�̂���܂ł̎��͒m����
����GPGPU�֘A�̌㓡�̋L���Ɋւ��Ă͖��炩�Ƀ��^��
����̋L���̏��������ł���Ƃ�������b����啝�ɒE������
��Ƃ̎v�f��n�삵�ă~�X���[�f�B���O��U���Ă��镔��������
�����A���������b����ʐl�����Ɋ��ݍӂ��]���������L���������̂��W���[�i���X�g�̎d���ł͂���̂���
>>341
��̓I�ɋ����Ă݂�
��̓I�ɋ����Ă݂�
��̓I�ɂǂ����H
����̋L���Ȃ�ĂR�Ђ̃C���^�r���[�̓��e���܂�܉�����Ă�̂��X�����炢���Ǝv�����B
����̋L���Ȃ�ĂR�Ђ̃C���^�r���[�̓��e���܂�܉�����Ă�̂��X�����炢���Ǝv�����B
Larrabee�����̃}�U�[��ATI��NVIDIA�̃O���t�B�b�N���ڂ����Ȃ��Ƃ����Ȃ�Ƃ������c
�s����x�z�ł��Ȃ��Ƃ���intel�̈̂��l�̗���Ȃ�킩�邪
���[�U�[�Ɍ����Đ������Ă����傤���Ȃ���K�X�B
�s����x�z�ł��Ȃ��Ƃ���intel�̈̂��l�̗���Ȃ�킩�邪
���[�U�[�Ɍ����Đ������Ă����傤���Ȃ���K�X�B
>>345
�킴�킴Nehalem�AFUSION�������Ȃ��Ƃ����Ȃ��̂��H
�킴�킴Nehalem�AFUSION�������Ȃ��Ƃ����Ȃ��̂��H
�f�B�X�N���[�gGPU�̎s�ꂪ���܂��NVIDIA�Ƃ��Ă͐����Ă����̂�����B
������GPGPU�ɒ��͂��Ďs��͈̔͂������ƍL���Ă��H
�ǂ����ϑz�ȂH
������GPGPU�ɒ��͂��Ďs��͈̔͂������ƍL���Ă��H
�ǂ����ϑz�ȂH
CPUGPU�����Ȃ�Ă��肫���肶��Ȃ����B
���o�C�����������Ԃ�ȕ����������낤�B
�������̕��ʂ�Intel���͂�����ƂȂ�ƁA
AMD��NVIDIA�ɂƂ��Ă͈�Ԃ̋��Ђ��낤�B
���ۂ�Intel�͏��^�f�o�C�X�̕��ʂɗ͂����Ă��Ă��邵�ˁB
�����������݂̗���Ō��Ă��A�ǂ��Ƀ��^�b���g�ݍ��܂�Ă��邩�䂾�B
���o�C�����������Ԃ�ȕ����������낤�B
�������̕��ʂ�Intel���͂�����ƂȂ�ƁA
AMD��NVIDIA�ɂƂ��Ă͈�Ԃ̋��Ђ��낤�B
���ۂ�Intel�͏��^�f�o�C�X�̕��ʂɗ͂����Ă��Ă��邵�ˁB
�����������݂̗���Ō��Ă��A�ǂ��Ƀ��^�b���g�ݍ��܂�Ă��邩�䂾�B
>>348
����� �u�傫�ȋ��ЂƂȂ�\���������v �u���ЂƂȂ闝�R��v���Ă���̂ł����āA
NVIDIA�͂������Ă���A�Ə����Ă�킯�ł͂Ȃ��Ǝv�����B
�Č��������ʂɂ����ǂ߂镶�͂��낤�B
���Z�������̋L������Ȃ������B
PC�����Ƃ��Ă����Ȃ荂�x�i�}�j�A�b�N�j�ȓ��e�Ȃ��B
����Ȃ�̕��͈Ӑ}��ǂ݉����͂��v�������͓̂��R���낤�B
����� �u�傫�ȋ��ЂƂȂ�\���������v �u���ЂƂȂ闝�R��v���Ă���̂ł����āA
NVIDIA�͂������Ă���A�Ə����Ă�킯�ł͂Ȃ��Ǝv�����B
�Č��������ʂɂ����ǂ߂镶�͂��낤�B
���Z�������̋L������Ȃ������B
PC�����Ƃ��Ă����Ȃ荂�x�i�}�j�A�b�N�j�ȓ��e�Ȃ��B
����Ȃ�̕��͈Ӑ}��ǂ݉����͂��v�������͓̂��R���낤�B
353 �FMAC�I�^��336 �����F2007/06/18(��) 19:45:41 ID:VPyccqp7
>>336
�@�@-----------------------
�@�@�u�h�ނ炪�h �ڕW�Ƃ��Ă��邱�Ɓv��������Ă��邾����
�@�@-----------------------
�c�O�Ȃ���㓡���ɂ��̑f�{�햳�����B
���l����������o���Ă��A�u���[���I�l���𗊂��Ă���t�V�����邷���nj��ǂ���
�q�g�̗͗ʂ̕]�����o���Ȃ����߂ɈӖ��������Ȃ��Ă��邷�B
�@�@-----------------------
�@�@�u�h�ނ炪�h �ڕW�Ƃ��Ă��邱�Ɓv��������Ă��邾����
�@�@-----------------------
�c�O�Ȃ���㓡���ɂ��̑f�{�햳�����B
���l����������o���Ă��A�u���[���I�l���𗊂��Ă���t�V�����邷���nj��ǂ���
�q�g�̗͗ʂ̕]�����o���Ȃ����߂ɈӖ��������Ȃ��Ă��邷�B
354 �FSocket774�F2007/06/18(��) 19:51:43 ID:4lBrCoNn
�V��MAC�I�^��Weekly�C�O�j���[�X
Intel��Larrabee�ɑR����AMD��NVIDIA
��
Intel��Larrabee�ɑR����AMD��NVIDIA
��
592 ���O�FMAC�I�^��588 ����[sage] ���e���F2007/06/11(��) 07:15:47 ID:3acacnku
>>588
���ʂ̓ǎ҂��ǂ�Larrabee��Polaris�̋�ʂ����ĂȂ��Ǝv�����B
������
�@�@-------------------
�@�@���炭�f�B�X�N���[�gGPU�ƌ����Ă���Larrabee�́A���ۂɂ�GPU�ł͂Ȃ��B
�@�@-------------------
�Ə����Ȃ���A
�@�@-------------------
�@�@��������AMD��NVIDIA�͂ǂ��o��̂��낤�B
�@�@-------------------
�Œ��߂�̂�A���̂����ˁH�\��NVIDIA��CPU�J���̘b�ł��n�߂邷���B�B�B
Larrabee��CPU���Ƃ���A�����I�ɂ����炩��CELL BE�ɑR���ĊJ�����ꂽ���ǁA
����Ɋւ��錾�y���������ˁB�P�ɁuSONY�̂��傤�����v�Ɣn���ɂ����̂��C��������
�Ƃ���ƁA�v���C�h�����߂����B
604 ���O�FSocket774[sage] ���e���F2007/06/11(��) 17:01:20 ID:kCyXQBgF
>>592
�R����̂�GPGPU�ɑ��Ă���o�J�W���l�[�m
���x�̗g������艳�B
�����������X�͖��������Ȃ�
>>588
���ʂ̓ǎ҂��ǂ�Larrabee��Polaris�̋�ʂ����ĂȂ��Ǝv�����B
������
�@�@-------------------
�@�@���炭�f�B�X�N���[�gGPU�ƌ����Ă���Larrabee�́A���ۂɂ�GPU�ł͂Ȃ��B
�@�@-------------------
�Ə����Ȃ���A
�@�@-------------------
�@�@��������AMD��NVIDIA�͂ǂ��o��̂��낤�B
�@�@-------------------
�Œ��߂�̂�A���̂����ˁH�\��NVIDIA��CPU�J���̘b�ł��n�߂邷���B�B�B
Larrabee��CPU���Ƃ���A�����I�ɂ����炩��CELL BE�ɑR���ĊJ�����ꂽ���ǁA
����Ɋւ��錾�y���������ˁB�P�ɁuSONY�̂��傤�����v�Ɣn���ɂ����̂��C��������
�Ƃ���ƁA�v���C�h�����߂����B
604 ���O�FSocket774[sage] ���e���F2007/06/11(��) 17:01:20 ID:kCyXQBgF
>>592
�R����̂�GPGPU�ɑ��Ă���o�J�W���l�[�m
���x�̗g������艳�B
�����������X�͖��������Ȃ�
>>334�̌�ǂɒނ���Ȃ�B
����̋L���ł͌㓡������܂ł̘_�������炽�߂�
�uIntel��Larrabee��GPU�]�p�͍l���Ă��Ȃ��v�Ƃ�������ŋL���������Ă邶���B
����̋L���ł͌㓡������܂ł̘_�������炽�߂�
�uIntel��Larrabee��GPU�]�p�͍l���Ă��Ȃ��v�Ƃ�������ŋL���������Ă邶���B
GPU�Ƃ��Ĉ�ʂɕ��y���镨����Ȃ���
x86�ł��邽�ߕ���f�[�^���s�Ɍ��������m�ɂ��Ȃ�Ȃ�
�Ȃ�Larrabee���āE�E�E
AMD��R600���������ASPI��Storm-1�Ɏ������ɂȂ肻�������B
x86�ł��邽�ߕ���f�[�^���s�Ɍ��������m�ɂ��Ȃ�Ȃ�
�Ȃ�Larrabee���āE�E�E
AMD��R600���������ASPI��Storm-1�Ɏ������ɂȂ肻�������B
����Opteron����l�C��x86�x�[�XHPC�N���X�^�E�V�X�e���S�ے�ł���
359 �FMAC�I�^��358 �����F2007/06/18(��) 22:48:30 ID:VPyccqp7
>>358
�@�@----------------
�@�@x86�x�[�XHPC�N���X�^�E�V�X�e���S�ے�ł���
�@�@----------------
���߃Z�b�g���������Ȃ�A�v���O���~���O�p���_�C�����ς��Ȃ��Ƃ����ϑz��
�ǂ�����o�Ă��邷���ˁB�B�B
Blue Gene��Power Mac�̃\�t�g�������Ƃ��l���Ă�������(��)
�@�@----------------
�@�@x86�x�[�XHPC�N���X�^�E�V�X�e���S�ے�ł���
�@�@----------------
���߃Z�b�g���������Ȃ�A�v���O���~���O�p���_�C�����ς��Ȃ��Ƃ����ϑz��
�ǂ�����o�Ă��邷���ˁB�B�B
Blue Gene��Power Mac�̃\�t�g�������Ƃ��l���Ă�������(��)
GPGPU������������������
�������Ⴂ�����Ă���Ȃ�
���������ꂩ��X�[�p�[�X�J����番��\������������Ƃ���
CPU���H�����s�o�ς̓���Ǐ]���Ă���
�������Ⴂ�����Ă���Ȃ�
���������ꂩ��X�[�p�[�X�J����番��\������������Ƃ���
CPU���H�����s�o�ς̓���Ǐ]���Ă���
>>359
�����łȂ��Blue Gene��Power Mac���ɏo���̂��Ӗ��킩���B
�C�ɂȂ�Ƃ���́AOpteron��Xeon��HPC�N���X�^��
Larrabee��HPC�N���X�^�ŁA�����\�t�g���������ǂ�������B
�����łȂ��Blue Gene��Power Mac���ɏo���̂��Ӗ��킩���B
�C�ɂȂ�Ƃ���́AOpteron��Xeon��HPC�N���X�^��
Larrabee��HPC�N���X�^�ŁA�����\�t�g���������ǂ�������B
�����(x86�v���Z�b�T�ƃf�[�^����v���Z�b�T)�������v���ł��邩�A�ƌ����A����͂������ł���B
�������A���s�������l����ƁA�����I���ɂ͂Ȃ�Ȃ��B
x86���߃Z�b�g�̃v���Z�b�T�͔ėp�����ɂ͂������A����f�[�^���s�Ɍ������}�V���ɂ͂Ȃ�Ȃ����炾�B
�����Ă��̂悤�ɐv�͂���Ă��Ȃ��B
by Phil Hester
�������A���s�������l����ƁA�����I���ɂ͂Ȃ�Ȃ��B
x86���߃Z�b�g�̃v���Z�b�T�͔ėp�����ɂ͂������A����f�[�^���s�Ɍ������}�V���ɂ͂Ȃ�Ȃ����炾�B
�����Ă��̂悤�ɐv�͂���Ă��Ȃ��B
by Phil Hester
http://pc.watch.impress.co.jp/docs/2004/1115/kaigai134.htm
CPU�͍��x�Ƀv���O���}�u���ŁA�D�ꂽ�R���p�C���̃T�|�[�g������A�����ɂ킽����
(�v���O��������)�`���[������Ă����BNVIDIA�Ȃǂ����ėp�R���s���[�e�B���O�ւ�
�r�W�����͊y�������A�������A���L���A�v���P�[�V�������Ή�����Ƃ͍l���Ă��Ȃ��B
�܂��A��X���A�}���`�R�A�A���j�[�R�A(Many-Core)�Ɍ������p�t�H�[�}���X�����߂�B
�����āACPU�͂����ƃv���O�����������悢�B
http://www.ednjapan.com/content/l_news/2007/04/l_news070427_0401.html
Gelsinger���́A�uGPGPU�ɂ��Ă̋c�_�����邪�A(GPU�̖��߃Z�b�g�Ń\�t�g�E�G�A
���J����������A�]�����炠��IA�̖��߃Z�b�g��p�����ق���)�\�t�g�E�G�A�̊J����
�e�Ղō����M������������B�]���āALarrabee���Ȋw�Z�p���Z�Ȃǂ�S���̂�
�Ó��ł���BLarrabee�ɂ���āAGPGPU�̋c�_�͏I�����邾�낤�v�Əq�ׂ��B
CPU�͍��x�Ƀv���O���}�u���ŁA�D�ꂽ�R���p�C���̃T�|�[�g������A�����ɂ킽����
(�v���O��������)�`���[������Ă����BNVIDIA�Ȃǂ����ėp�R���s���[�e�B���O�ւ�
�r�W�����͊y�������A�������A���L���A�v���P�[�V�������Ή�����Ƃ͍l���Ă��Ȃ��B
�܂��A��X���A�}���`�R�A�A���j�[�R�A(Many-Core)�Ɍ������p�t�H�[�}���X�����߂�B
�����āACPU�͂����ƃv���O�����������悢�B
http://www.ednjapan.com/content/l_news/2007/04/l_news070427_0401.html
Gelsinger���́A�uGPGPU�ɂ��Ă̋c�_�����邪�A(GPU�̖��߃Z�b�g�Ń\�t�g�E�G�A
���J����������A�]�����炠��IA�̖��߃Z�b�g��p�����ق���)�\�t�g�E�G�A�̊J����
�e�Ղō����M������������B�]���āALarrabee���Ȋw�Z�p���Z�Ȃǂ�S���̂�
�Ó��ł���BLarrabee�ɂ���āAGPGPU�̋c�_�͏I�����邾�낤�v�Əq�ׂ��B
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
�@�����āA������Larrabee�𓊓�����Intel���A2�Ђ͋����x�����Ă���B
����GPU�W�҂́uLarrabee�����ő�̋��Ёv�Ƃ����B����́AGPU��
��J������V�s�����C�ɂ������\�������邩�炾�B
�@AMD�ɂƂ��Č���AIntel�����̎s��ŃX�^���_�[�h��ł����āA
Intel�̃v���O���~���O���f�����ƊE�W���Ƃ���Ă��܂��ƁA�Ă�x86��
��̕��ɂȂ��Ă��܂��B�v���O���~���O�R�~���j�e�B�����炷��A
�ł���Έ��ނ̃��f�����]�܂����B���̂��߁A���ґ�����Intel
�ɓƐ肳��Ă��܂��\��������BIntel��x86�̊g�����߃Z�b�g��
Larrabee��I�������ő�̗��R�͂����ɂ���B
�@�����āA������Larrabee�𓊓�����Intel���A2�Ђ͋����x�����Ă���B
����GPU�W�҂́uLarrabee�����ő�̋��Ёv�Ƃ����B����́AGPU��
��J������V�s�����C�ɂ������\�������邩�炾�B
�@AMD�ɂƂ��Č���AIntel�����̎s��ŃX�^���_�[�h��ł����āA
Intel�̃v���O���~���O���f�����ƊE�W���Ƃ���Ă��܂��ƁA�Ă�x86��
��̕��ɂȂ��Ă��܂��B�v���O���~���O�R�~���j�e�B�����炷��A
�ł���Έ��ނ̃��f�����]�܂����B���̂��߁A���ґ�����Intel
�ɓƐ肳��Ă��܂��\��������BIntel��x86�̊g�����߃Z�b�g��
Larrabee��I�������ő�̗��R�͂����ɂ���B
�ŁAGPU�ȏ�ɕ��y���錩���݂�����́H
http://pc.watch.impress.co.jp/docs/2007/0611/kaigai364.htm
�uLarrabee���o�ꂵ����A�n�C�p�t�H�[�}���X�R���s���[�e�B���O�̃x���`�}�[�N��
���Ȃ߂ɂ���\��������v�Ƃ���ƊE�W�҂͊��҂����B
�uIA���߃Z�b�g�Ƃ̌݊����͔��ɏd�v���B�Ȃ��Ȃ�A�\�t�g�E�F�A�c�[���A���C�u�����ȂǁA
�����̑S�Ă̎��Y�����������Ƃ��ł��邩�炾�v��Gelsinger���͋�������B
�uLarrabee���o�ꂵ����A�n�C�p�t�H�[�}���X�R���s���[�e�B���O�̃x���`�}�[�N��
���Ȃ߂ɂ���\��������v�Ƃ���ƊE�W�҂͊��҂����B
�uIA���߃Z�b�g�Ƃ̌݊����͔��ɏd�v���B�Ȃ��Ȃ�A�\�t�g�E�F�A�c�[���A���C�u�����ȂǁA
�����̑S�Ă̎��Y�����������Ƃ��ł��邩�炾�v��Gelsinger���͋�������B
�����̎��Y��32core���e�ՂɎg����̂��H
369 �FSocket774�F2007/06/19(��) 01:29:44 ID:yc5e5ZSV
http://pc11.2ch.net/test/read.cgi/tech/1158559031/l50
�������Ƃ����Ă炠
���݂̍j��Core2��Athlon�ɑ�s���ċC���G�ꂽ�킯���悗
�������Ƃ����Ă炠
���݂̍j��Core2��Athlon�ɑ�s���ċC���G�ꂽ�킯���悗
�܂����O���B
371 �F�E�́E�j��-�������F2007/06/19(��) 02:50:25 ID:8N3k0BjT
Cell�p��128bit��Vista���o��x86���S�Ƃ������Ă��n���Ȃ�łق��Ƃ��܂��傤
��������x86�������āACore2��Athlon�Ƃ�S�ł������ӕs���ӕ���������
Larrabee�������̎��Y�Ƃ��ł܂Ƃ��Ɏg����Ƃ��v��ǂ�
�P�Ȃ�q�悹�ł���Ax86�ɂ����̂́B
Larrabee�������̎��Y�Ƃ��ł܂Ƃ��Ɏg����Ƃ��v��ǂ�
�P�Ȃ�q�悹�ł���Ax86�ɂ����̂́B
>>366
OpenMP��MKL��IPP�Ƃ�����Intel�̕����C�u�������g���Ă鐻�i�͂�������Ή������������
Adobe Premiere, Maya, LightWave etc...
OpenMP��MKL��IPP�Ƃ�����Intel�̕����C�u�������g���Ă鐻�i�͂�������Ή������������
Adobe Premiere, Maya, LightWave etc...
>>360
�Ȃ�Ȃ��B
���̂Ȃ�GPU�͔ėp�v���Z�b�T�ł͖����B
�����܂�Stream Processor�Ƃ��Ă̐i�����Ă����B
������s���ɂ��Ă�R600�ł̓V�[�P���T���ōs��
Shader���̂ł͕��G�ȕ���͍s��Ȃ��B
�܂��AGPU�Ɍ����Ȃ����G�ȏ�����CPU�ōs���悢�B
�Ȃ�Ȃ��B
���̂Ȃ�GPU�͔ėp�v���Z�b�T�ł͖����B
�����܂�Stream Processor�Ƃ��Ă̐i�����Ă����B
������s���ɂ��Ă�R600�ł̓V�[�P���T���ōs��
Shader���̂ł͕��G�ȕ���͍s��Ȃ��B
�܂��AGPU�Ɍ����Ȃ����G�ȏ�����CPU�ōs���悢�B
�����̎��Y�Ȃ�ĐV�������߂��o�������ł����b���Ȃ�����
���ꂭ�炢�V�X�e���\�����X�e�b�v�A�b�v�������ɉ��b����킯�Ȃ��̂����R�Ƃ������E�E�B
�X�g���[����p�v���Z�b�T�������I�ɖڎw���̈�́A
���̃A�v���i�I�t�B�X���A�Q�[���j���������Ă���x����������̈�ł͂Ȃ�
�����Ƃ����Ƃ����ƍ��������Ȃ��ƕs�\�Ȍ��I�ȏ������K�v�ȗ̈悾�낤�B
�Ⴆ�Ό��݂P���Ԃ�����G���R�[�h�𐔕b�ŏI��点����
���S�ɕ����V���~���[�V�������ꂽ���z��Ԃ��R���s���[�^�[���ɍČ�������
�Ƃ������A���݂̉�������ō��������Ă��s�\�ȗ̈�B
���ꂭ�炢�V�X�e���\�����X�e�b�v�A�b�v�������ɉ��b����킯�Ȃ��̂����R�Ƃ������E�E�B
�X�g���[����p�v���Z�b�T�������I�ɖڎw���̈�́A
���̃A�v���i�I�t�B�X���A�Q�[���j���������Ă���x����������̈�ł͂Ȃ�
�����Ƃ����Ƃ����ƍ��������Ȃ��ƕs�\�Ȍ��I�ȏ������K�v�ȗ̈悾�낤�B
�Ⴆ�Ό��݂P���Ԃ�����G���R�[�h�𐔕b�ŏI��点����
���S�ɕ����V���~���[�V�������ꂽ���z��Ԃ��R���s���[�^�[���ɍČ�������
�Ƃ������A���݂̉�������ō��������Ă��s�\�ȗ̈�B
>>233�݂����ȓ��e�̃��X���đO���Ȃ����������H
�m��AMD�̉c�Ƃ��ǂ��̂��Ęb��ŁAAMD�͑g�D���N�\�݂����ȓ��e�̂�B
�ŁA�\�[�X�́H���ĕ�����Ă��\�[�X�o���Ȃ�������B
>>233�ł��\�[�X�o���ĂȂ����A����l�����H
�m��AMD�̉c�Ƃ��ǂ��̂��Ęb��ŁAAMD�͑g�D���N�\�݂����ȓ��e�̂�B
�ŁA�\�[�X�́H���ĕ�����Ă��\�[�X�o���Ȃ�������B
>>233�ł��\�[�X�o���ĂȂ����A����l�����H
>>376
�m��Ȃ����ǁAAMD�̃}�[�P�e�B���O�̓A�����낗
�m��Ȃ����ǁAAMD�̃}�[�P�e�B���O�̓A�����낗
����Intel��Larrabee���Ă̂́ASUN��UltraSPARC T1��x86�ł݂����Ȃ���B
������A���ꂪ�������邩�ǂ����̓\�t�g�E�G�A�̃}���`�X���b�h���A����
�N���C�A���g�p�\�t�g�������Ȃ邩�ǂ����ɂ������Ă�C������B
���X�摜�����W��GPU�����������}���`�X���b�h���O����A�摜������
�D�悷�鎞�͑����̃R�A������Ɋ���U���āA�����łȂ��ꍇ�̓A�v���Ɋ���
�U����Ċ����ŁA�}���`�ȃR�A��GPU�p�Ɣėp�̂ǂ���ւ��g����l�ɂ����
�L�����p�o����̂����B
��������Α����ALarrabee��GPU�p�r�Ɏg���ꍇ�ɔ�����ł��A�g�[�^���ł�
�����A�b�v�o���锤�����B
������A���ꂪ�������邩�ǂ����̓\�t�g�E�G�A�̃}���`�X���b�h���A����
�N���C�A���g�p�\�t�g�������Ȃ邩�ǂ����ɂ������Ă�C������B
���X�摜�����W��GPU�����������}���`�X���b�h���O����A�摜������
�D�悷�鎞�͑����̃R�A������Ɋ���U���āA�����łȂ��ꍇ�̓A�v���Ɋ���
�U����Ċ����ŁA�}���`�ȃR�A��GPU�p�Ɣėp�̂ǂ���ւ��g����l�ɂ����
�L�����p�o����̂����B
��������Α����ALarrabee��GPU�p�r�Ɏg���ꍇ�ɔ�����ł��A�g�[�^���ł�
�����A�b�v�o���锤�����B
����������ł��A�˂��c
>>378
UltraSPARC T1(niagara)�͍ŏ�����Web�I�i�Ɨ��Ȃ���قǏd���Ȃ��X���b�h��������ł������Ă���j
�_�������炿����ƈႤ�悤��
UltraSPARC T1(niagara)�͍ŏ�����Web�I�i�Ɨ��Ȃ���قǏd���Ȃ��X���b�h��������ł������Ă���j
�_�������炿����ƈႤ�悤��
>>380
����A���̃R�A�̏����\�͂͒Ⴂ�܂܁A���ĂƂ���ƁA�}���`�X���b�h
���O��ȂƂ��낪���Ă���Ęb�B
�܂�Larrabee��niagara�Ɠ��l�ɁAweb�I�p�ɂ��l���Ă�̂ł́H���Đ����ł�
���邪�B��������Ηp�r�������Đ��Y�ʂ��m�ۂ��Ղ��Ȃ�A�R�X�g�_�E���ɂ�
��^����f�\�B
����A���̃R�A�̏����\�͂͒Ⴂ�܂܁A���ĂƂ���ƁA�}���`�X���b�h
���O��ȂƂ��낪���Ă���Ęb�B
�܂�Larrabee��niagara�Ɠ��l�ɁAweb�I�p�ɂ��l���Ă�̂ł́H���Đ����ł�
���邪�B��������Ηp�r�������Đ��Y�ʂ��m�ۂ��Ղ��Ȃ�A�R�X�g�_�E���ɂ�
��^����f�\�B
Larrabee��GPU�p�r�Ɏg���Ȃ��Intel���g���^��������ے肵�Ă邱�Ƃ�
�d�g�����܂��Ă�
�d�g�����܂��Ă�
384 �FMAC�I�^��382 �����F2007/06/19(��) 19:10:34 ID:x7aI0GJL
>>382
�@�@------------------
�@�@�p�r�⊈�p�m�E�n�E���m�肵�Ă镪������̎茘�����i�Ȃ̂���
�@�@------------------
���������̂����邷�ˁB
http://journal.mycom.co.jp/articles/2005/11/01/fpf/index.html
�@�@------------------
�@�@�p�r�⊈�p�m�E�n�E���m�肵�Ă镪������̎茘�����i�Ȃ̂���
�@�@------------------
���������̂����邷�ˁB
http://journal.mycom.co.jp/articles/2005/11/01/fpf/index.html
>>365
�g�ѓd�b���ĂقƂ�ǂ�CPU+GPU�������Ǝv�������H
�g�ѓd�b���ĂقƂ�ǂ�CPU+GPU�������Ǝv�������H
�V�e�B�O���[�v��AMD��t�@�u���X�ɂȂ�Ƃ������|�[�g���o�����Ƃ̂��Ƃ��B
"AMD moves closer to fabless design "
http://www.theinquirer.net/default.aspx?article=40419
�@�@------------------
�@�@Which may contribute to the report from Gleny Yeung, Citigroup analyst, who tells readers
�@�@that AMD has confirmed that it is looking to scale back its in-house manufacturing.
�@�@This will result, Yeung reckons, in a selling off of manufacturing capacity in Dresden and
�@�@New York and more outsourcing to TSMC and Chartered.
�@�@------------------
"AMD moves closer to fabless design "
http://www.theinquirer.net/default.aspx?article=40419
�@�@------------------
�@�@Which may contribute to the report from Gleny Yeung, Citigroup analyst, who tells readers
�@�@that AMD has confirmed that it is looking to scale back its in-house manufacturing.
�@�@This will result, Yeung reckons, in a selling off of manufacturing capacity in Dresden and
�@�@New York and more outsourcing to TSMC and Chartered.
�@�@------------------
>>387
�S������
�ǂ����̓d�g��������~���_�� �����M�҂͂��������ӌ�������A��
���Ɏ����Ă��������˂��������Ă����Ă��˂��B
�u�m��ˁ[��A���������������ɒ��ڃL�`���C���m��荇����v �ƌ��������B
�N�Ɠ����Ă�̂��m��Ȃ����݂�Ȓ����Řb���Ă��Ă����������Ȃ茾���n�߂邵�B
���}�g��œ��ق��Ă邶��Ȃ�����A���m��ʐ~�[���Q������
�����������Ƃ�S���ӔC���Ă邩�A�z�炵���E�E
�S������
�ǂ����̓d�g��������~���_�� �����M�҂͂��������ӌ�������A��
���Ɏ����Ă��������˂��������Ă����Ă��˂��B
�u�m��ˁ[��A���������������ɒ��ڃL�`���C���m��荇����v �ƌ��������B
�N�Ɠ����Ă�̂��m��Ȃ����݂�Ȓ����Řb���Ă��Ă����������Ȃ茾���n�߂邵�B
���}�g��œ��ق��Ă邶��Ȃ�����A���m��ʐ~�[���Q������
�����������Ƃ�S���ӔC���Ă邩�A�z�炵���E�E
�ނ��낻�̊��m�O�O���M���Ă���̂�>>386�������Ƌ^���ȁB
Intel/AMD�̍ő�̖��́A�����x86�A�[�L�e�N�`���ȊO�Ɋ��H�����o���Ȃ����Ƃɂ���B
x86-64�ɂ���A���̉�������B
�ŁA���̗]���Ă���I��x86���p���ɂ���GPU�̃p���A�[�L�e�N�`����x86�x�[�X�Ŏ�������ƌ����Ă݂���A
A�͔�Ώ̌n�Ő���͂��W�U�AGPU�͐�p�ƌ����Ă݂��肵�Ă��邾���B
x86-64�ɂ���A���̉�������B
�ŁA���̗]���Ă���I��x86���p���ɂ���GPU�̃p���A�[�L�e�N�`����x86�x�[�X�Ŏ�������ƌ����Ă݂���A
A�͔�Ώ̌n�Ő���͂��W�U�AGPU�͐�p�ƌ����Ă݂��肵�Ă��邾���B
�u�}���`�R�A�̃A�C�f�B�A���o�����̂�AMD�Ƃ������Ă��z�v�݂����ɔ��������{�l�����肵�ĂȂ���邯�ǂȁB
�X���̑��ӂƂ��Ă��܂��猾��������A������ �݂����Ȏ�������Ɍ����n�߂��Ă���
�X���̑��ӂƂ��Ă��܂��猾��������A������ �݂����Ȏ�������Ɍ����n�߂��Ă���
GPU���C�N�ȍ\�����z�肳���Intel�́uLarrabee�v
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
�_�C�T�C�Y(�����̖{�̖̂ʐ�)������̃p�t�H�[�}���X�Ƃ����_�Ō���ƁA�Ⴄ���ʂ������Ă���B
Intel�́A��N(2006�N)��Intel Developer Forum(IDF)�ŁA�C���I�[�_�^�̏��^CPU�R�A�ł́A
�`���I�ȃA�E�g�I�u�I�[�_CPU�R�A�����_�C�ʐϓ�����̉��Z�p�t�H�[�}���X��4�{�ɂȂ�Ƃ������Z���ʂ��o�����B
����Ȃ�A65nm�v���Z�X��4GHz���ɁA�`���ICPU�R�A�Ɠ��ʐς�100GFLOPS�ȏ��B�����邱�Ƃ��ł���B
Larrabee�̗��_�́ACPU�Ɠ��l�Ƀt���J�X�^���ʼn�H�v����`���[�����邱�ƂŁA
������g����CPU���ɏグ�邱�Ƃ��ł���_���B���� CPU�ƊE�W�҂́A
�uGPU��ASIC�ł��邽�߁A�ǂ��܂ōs���Ă�CPU�ɂ͎��g���ŗ������v�ƌ��B
���������_���Z�ɓ�������Larrabee�ł́APentium 4�����W�̓�����g���ɂȂ�Ɨ\�z�����B
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
�_�C�T�C�Y(�����̖{�̖̂ʐ�)������̃p�t�H�[�}���X�Ƃ����_�Ō���ƁA�Ⴄ���ʂ������Ă���B
Intel�́A��N(2006�N)��Intel Developer Forum(IDF)�ŁA�C���I�[�_�^�̏��^CPU�R�A�ł́A
�`���I�ȃA�E�g�I�u�I�[�_CPU�R�A�����_�C�ʐϓ�����̉��Z�p�t�H�[�}���X��4�{�ɂȂ�Ƃ������Z���ʂ��o�����B
����Ȃ�A65nm�v���Z�X��4GHz���ɁA�`���ICPU�R�A�Ɠ��ʐς�100GFLOPS�ȏ��B�����邱�Ƃ��ł���B
Larrabee�̗��_�́ACPU�Ɠ��l�Ƀt���J�X�^���ʼn�H�v����`���[�����邱�ƂŁA
������g����CPU���ɏグ�邱�Ƃ��ł���_���B���� CPU�ƊE�W�҂́A
�uGPU��ASIC�ł��邽�߁A�ǂ��܂ōs���Ă�CPU�ɂ͎��g���ŗ������v�ƌ��B
���������_���Z�ɓ�������Larrabee�ł́APentium 4�����W�̓�����g���ɂȂ�Ɨ\�z�����B
395 �FSocket774�F2007/06/20(��) 01:08:04 ID:dz1Qk++0
>>391
�܂����Ƃ���x86��Intel+M$ Windows�ɁA�����\�E�ቿ�i�ŋ��l�̋r����������
�т�H���Ă���AMD������d���Ȃ���
�r���������Ӗ��������Ȃ��Ă����̂Ȃ� Mips �Ƃ� Power �A�[�L�e�N�`���ɘH���ύX���Ă�
�����낤���ǁAx86�ƂƂ��ɍ�����L���т�H�������Ȃ��Ƃ����Ȃ��^���͕ς��Ȃ����낤�Ȃ�
�܂����Ƃ���x86��Intel+M$ Windows�ɁA�����\�E�ቿ�i�ŋ��l�̋r����������
�т�H���Ă���AMD������d���Ȃ���
�r���������Ӗ��������Ȃ��Ă����̂Ȃ� Mips �Ƃ� Power �A�[�L�e�N�`���ɘH���ύX���Ă�
�����낤���ǁAx86�ƂƂ��ɍ�����L���т�H�������Ȃ��Ƃ����Ȃ��^���͕ς��Ȃ����낤�Ȃ�
396 �FMAC�I�^��395 �����F2007/06/20(��) 01:15:34 ID:OgFpxvHt
>>395
�@�@------------------
�@�@�܂����Ƃ���x86��Intel+M$ Windows�ɁA�����\�E�ቿ�i�ŋ��l�̋r����������
�@�@------------------
Microsoft�̐K��A�r�߂܂����Ă�悤�ȋC�����邷���ǁB�B�B
�@�@------------------
�@�@�܂����Ƃ���x86��Intel+M$ Windows�ɁA�����\�E�ቿ�i�ŋ��l�̋r����������
�@�@------------------
Microsoft�̐K��A�r�߂܂����Ă�悤�ȋC�����邷���ǁB�B�B
>>395
MIPS/POWER�͋������āAAMD���Q�����Ă�����ɂȂ��
MIPS/POWER�͋������āAAMD���Q�����Ă�����ɂȂ��
398 �FMAC�I�^��397 �����F2007/06/20(��) 01:36:16 ID:OgFpxvHt
�m�E�n�E�������Ă�Ƃ�������邵���Ȃ�
x86�Ƃ������g���O���āAAMD�Ђ̔��f�������l�����ꍇ�A
intel�Ə�����������L���ȓy�U�͑��ɂ����肻���Ȃ��̂����A
���샆�[�U�[�Ƃ��ẮAAMD���ǂ����ɍs���Ă��܂��̂͐S���ɂށB
intel�Ə�����������L���ȓy�U�͑��ɂ����肻���Ȃ��̂����A
���샆�[�U�[�Ƃ��ẮAAMD���ǂ����ɍs���Ă��܂��̂͐S���ɂށB
��ЋK�͂��Ⴂ������B������Ƃ����Ă������ɂȂ��Ƃ͌�����Ȃ����A
����Ȏ��������Ă�����A���߂Ēׂ��ƌ����Ă���悤�Ȃ����ȁB
��������Ђ����炱���ACPU������肪�����悤��CPU�����j�b�g���Ƃ�
�g�ݑւ��ł���悤�ɂ���̂��낤���AATI�����ĐF�X�ȕ����
���W���Ă������������_���Ă���̂��낤�B�������邩�ǂ�������B
�ł��A�u��x��v�Ƃ����ĉ������Ȃ��̂ł���A�������Ɣ��p�����Ⴄ������������ȁB
�c�u��������Ёv�ƌ����Ă�Intel�ȂǂƔ�ׂĂ����c�B
����Ȏ��������Ă�����A���߂Ēׂ��ƌ����Ă���悤�Ȃ����ȁB
��������Ђ����炱���ACPU������肪�����悤��CPU�����j�b�g���Ƃ�
�g�ݑւ��ł���悤�ɂ���̂��낤���AATI�����ĐF�X�ȕ����
���W���Ă������������_���Ă���̂��낤�B�������邩�ǂ�������B
�ł��A�u��x��v�Ƃ����ĉ������Ȃ��̂ł���A�������Ɣ��p�����Ⴄ������������ȁB
�c�u��������Ёv�ƌ����Ă�Intel�ȂǂƔ�ׂĂ����c�B
>>394
�bLarrabee�̗��_�́ACPU�Ɠ��l�Ƀt���J�X�^���ʼn�H�v����`���[�����邱�ƂŁA
�b������g����CPU���ɏグ�邱�Ƃ��ł���_���B���� CPU�ƊE�W�҂́A
�b�uGPU��ASIC�ł��邽�߁A�ǂ��܂ōs���Ă�CPU�ɂ͎��g���ŗ������v�ƌ��B
�ǂ�������AIntel�̓`�b�v�Z�b�g������GPU������Ă邪�A�����ASIC��
����Ă���Ď����ȁH
����Fab���ʂɎ����Ă�̂�����A�t�@�u���X�Ő����˗����Ȃ���Ȃ�Ȃ�
ATi��nVidia�݂�����ASIC�ō쐬����K�v���Ӗ��������������B
�����CPU�Ɠ��l�Ƀt���J�X�^���ō���Ă�Ȃ�A���Ȃ��Ƃ�ATi��nVidia��
�`�b�v�Z�b�g������GPU�������N���b�N�œ���\������A����������ȏ�
�̐��\�ɂȂ锤�����AG35/G33������Ȃɍ����\�Șb�͓ǂo�����Ȃ����B
����G35/G33 ���t���J�X�^���ō���Ă��Ȃ���A���̑̂��炭���Ƃ�����A
�����Ȃ��Ƃ����̌��ɂ��Ă�Larrabee�̗��_�̂��͂Ȃ�Ȃ��C�����邪�A
�ǂ��Ȃ낤�H
�bLarrabee�̗��_�́ACPU�Ɠ��l�Ƀt���J�X�^���ʼn�H�v����`���[�����邱�ƂŁA
�b������g����CPU���ɏグ�邱�Ƃ��ł���_���B���� CPU�ƊE�W�҂́A
�b�uGPU��ASIC�ł��邽�߁A�ǂ��܂ōs���Ă�CPU�ɂ͎��g���ŗ������v�ƌ��B
�ǂ�������AIntel�̓`�b�v�Z�b�g������GPU������Ă邪�A�����ASIC��
����Ă���Ď����ȁH
����Fab���ʂɎ����Ă�̂�����A�t�@�u���X�Ő����˗����Ȃ���Ȃ�Ȃ�
ATi��nVidia�݂�����ASIC�ō쐬����K�v���Ӗ��������������B
�����CPU�Ɠ��l�Ƀt���J�X�^���ō���Ă�Ȃ�A���Ȃ��Ƃ�ATi��nVidia��
�`�b�v�Z�b�g������GPU�������N���b�N�œ���\������A����������ȏ�
�̐��\�ɂȂ锤�����AG35/G33������Ȃɍ����\�Șb�͓ǂo�����Ȃ����B
����G35/G33 ���t���J�X�^���ō���Ă��Ȃ���A���̑̂��炭���Ƃ�����A
�����Ȃ��Ƃ����̌��ɂ��Ă�Larrabee�̗��_�̂��͂Ȃ�Ȃ��C�����邪�A
�ǂ��Ȃ낤�H
���с[���Ă̂͑O��INTEL�������100�R�ACPU��X86
�ł݂����ȕ��ɂȂ��ˁH
�ėp�����ł�Ȃ��H
�ł݂����ȕ��ɂȂ��ˁH
�ėp�����ł�Ȃ��H
>>404
MAC�I�^����ł����H
MAC�I�^����ł����H
ttp://news.mydrivers.com/1/85/85550.htm
K10 Barcelona�͑�3�l�����ɔ��\���܂�
K10 Barcelona�͑�3�l�����ɔ��\���܂�
����̓����r�[
>404
>394 �������Ă�A�R�A��x86���ē_���Ⴄ��������Ȃ��A�R�A��
�ǂ��q���邩�A���쐧����ǂ����邩�A���\�Ⴄ���̂Ȃ�Ȃ�����
����
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
NoC
http://pc.watch.impress.co.jp/docs/2007/0221/kaigai339.htm
>394 �������Ă�A�R�A��x86���ē_���Ⴄ��������Ȃ��A�R�A��
�ǂ��q���邩�A���쐧����ǂ����邩�A���\�Ⴄ���̂Ȃ�Ȃ�����
����
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
NoC
http://pc.watch.impress.co.jp/docs/2007/0221/kaigai339.htm
>>330 >>332
AMD Preps 65nm Athlon 64 X2 5200+ Processor.
http://www.xbitlabs.com/news/cpu/display/20070619121402.html
Brisbane-2.7GHz�o��ˁB
AMD Preps 65nm Athlon 64 X2 5200+ Processor.
http://www.xbitlabs.com/news/cpu/display/20070619121402.html
Brisbane-2.7GHz�o��ˁB
Pen4���̎��g���Ƃ����̂��C�ɂȂ��
�V�[�_�~���ǂ��܂ł������ȁH
�R�����̂���3.8Ghz�ɗ}����ꂽ��
�V�[�_�~���ǂ��܂ł������ȁH
�R�����̂���3.8Ghz�ɗ}����ꂽ��
2007�N�̔����̐ݔ������z�A
1�����̗\����16�Ђ�10���ăh����
http://www.eetimes.jp/contents/200706/20769_1_20070620224457.cfm
1�����̗\����16�Ђ�10���ăh����
http://www.eetimes.jp/contents/200706/20769_1_20070620224457.cfm
Intel��AMD�A�N�A�b�h�R�A�Őڋߓ��������̃A�s�[������
Intel�̓}�l�[�W���[�o��AAMD��Intel�Ɂu����Ȃ���v����
���_���}�����uAMD�����100���o�ׁv
�ŏ��̃X�e�[�W�Z�b�V�����Ƃ��ă_�C���N�g�}�[�P�e�B���O���̊������u�����܂��o�ꂵ�A
������ Intel��CPU�̗��j��Core 2�V���[�Y�̓������Љ����AAMD�̃N�A�b�h�R�A��Intel�̃N�A�b�h�R�A���r���Ȃ���A
�A�[�L�e�N�`���Ƃ��Ă͈꒷��Z������̂́A�S�̂̃o�����X�Ƃ��Ă�Intel���D�G�ł��邱�ƁA
���ł�AMD�Ƃ�10�{�̍���t���ăN�A�b�h�R�A��ʎY�o�ׂ��Ă���_�ŗD�ʂł���Ƃ����B
��AMD�́u����Ȃ���A��������v
�������A�����[�g����̃h�X�p���H�t���{�X�ł́A��T���l��AMD���C�x���g���s���Ă����B
Intel�̃X�e�[�W���I���ƁAIntel�̃��S�t�����j�t�H�[���𒅂�Intel�W�҂����X��AMD�̃C�x���g�Ɋϋq�Ƃ��ĎQ�����A
����������i����̍������������uIntel�̊W�ҕ�����������Ⴂ�܂����v�Ƃ��������B
�����ăN�A�b�h�R�A�ɂ��Č��n�߂�ƁA�u�g�Z�M�h�iAMD�y�������Y���j�H���A
Phenom�͋ƊE��k����������́B�����߂��ɁiIntel ���j�����łǂ����悤���ȂƎv���܂����ǁA
�iIntel�̃C�x���g���Ɍ������āj�{���̃N�A�b�h�R�A�o���܁[���B���܂ł́iIntel�́j�N�A�b�h�R�A�́g�Ȃ���ăN�A�b�h�R�A�h�ł��B
�������ŔF�߂Ă���̂ł܂������̂��ȂƁB�{���̃N�A�b�h�R�A�Ɋւ��Ă�AMD���悾�Ǝv���܂��B
�g�_�l�h �iIntel�V��L�F���j�͂Ȃ���ă^�C�v�͂����ɍ���ƌ����Ă܂������ǁA�����ł��ȒP�ɍ����ł��A����Ȃ���B�v
�Ƌ���ɔ����A�߂��s����Ƃ���FASN8�̃f���Ɋ��҂���悤�ϋq�ɋ��߂��B
�킸�������[�g���̋����œ�����AMD��Intel�̃C�x���g���s���A
�قړ������ɑ��Ђ��������Ȃ���݂��ɃN�A�b�h�R�ACPU���A�s�[������Ƃ����A���ĂȂ����C�o���ӎ��ނ��o���̐ڋߐ�ƂȂ����B
���́g�Ȃ���ăN�A�b�h�R�A�h�Ɓg�^�̃N�A�b�h�R�A�h�̑Ό��́A�s��ł̎荇�킹�O�Ƀq�[�g�A�b�v���������B
http://www.watch.impress.co.jp/akiba/hotline/20070616/etc_intelvsamd.html
Intel�̓}�l�[�W���[�o��AAMD��Intel�Ɂu����Ȃ���v����
���_���}�����uAMD�����100���o�ׁv
�ŏ��̃X�e�[�W�Z�b�V�����Ƃ��ă_�C���N�g�}�[�P�e�B���O���̊������u�����܂��o�ꂵ�A
������ Intel��CPU�̗��j��Core 2�V���[�Y�̓������Љ����AAMD�̃N�A�b�h�R�A��Intel�̃N�A�b�h�R�A���r���Ȃ���A
�A�[�L�e�N�`���Ƃ��Ă͈꒷��Z������̂́A�S�̂̃o�����X�Ƃ��Ă�Intel���D�G�ł��邱�ƁA
���ł�AMD�Ƃ�10�{�̍���t���ăN�A�b�h�R�A��ʎY�o�ׂ��Ă���_�ŗD�ʂł���Ƃ����B
��AMD�́u����Ȃ���A��������v
�������A�����[�g����̃h�X�p���H�t���{�X�ł́A��T���l��AMD���C�x���g���s���Ă����B
Intel�̃X�e�[�W���I���ƁAIntel�̃��S�t�����j�t�H�[���𒅂�Intel�W�҂����X��AMD�̃C�x���g�Ɋϋq�Ƃ��ĎQ�����A
����������i����̍������������uIntel�̊W�ҕ�����������Ⴂ�܂����v�Ƃ��������B
�����ăN�A�b�h�R�A�ɂ��Č��n�߂�ƁA�u�g�Z�M�h�iAMD�y�������Y���j�H���A
Phenom�͋ƊE��k����������́B�����߂��ɁiIntel ���j�����łǂ����悤���ȂƎv���܂����ǁA
�iIntel�̃C�x���g���Ɍ������āj�{���̃N�A�b�h�R�A�o���܁[���B���܂ł́iIntel�́j�N�A�b�h�R�A�́g�Ȃ���ăN�A�b�h�R�A�h�ł��B
�������ŔF�߂Ă���̂ł܂������̂��ȂƁB�{���̃N�A�b�h�R�A�Ɋւ��Ă�AMD���悾�Ǝv���܂��B
�g�_�l�h �iIntel�V��L�F���j�͂Ȃ���ă^�C�v�͂����ɍ���ƌ����Ă܂������ǁA�����ł��ȒP�ɍ����ł��A����Ȃ���B�v
�Ƌ���ɔ����A�߂��s����Ƃ���FASN8�̃f���Ɋ��҂���悤�ϋq�ɋ��߂��B
�킸�������[�g���̋����œ�����AMD��Intel�̃C�x���g���s���A
�قړ������ɑ��Ђ��������Ȃ���݂��ɃN�A�b�h�R�ACPU���A�s�[������Ƃ����A���ĂȂ����C�o���ӎ��ނ��o���̐ڋߐ�ƂȂ����B
���́g�Ȃ���ăN�A�b�h�R�A�h�Ɓg�^�̃N�A�b�h�R�A�h�̑Ό��́A�s��ł̎荇�킹�O�Ƀq�[�g�A�b�v���������B
http://www.watch.impress.co.jp/akiba/hotline/20070616/etc_intelvsamd.html
AMD�̒��̐l�͊�n�O���o���D���Ȃ̂�?
����������Ɨ��������������B
����������Ɨ��������������B
>>413�݂����ȃf���͎q���̌��܂��B�����݂��Ƃ��Ȃ��B
�����f������ɂ��Ă��]���ł�4000+��BE-2350�̔�r�ł������
BE-2350�̏ȓd�͐��̃A�s�[���ł�����Ⴂ���̂ɁB���̂ق�������ۂǃ}�V�B
�����f������ɂ��Ă��]���ł�4000+��BE-2350�̔�r�ł������
BE-2350�̏ȓd�͐��̃A�s�[���ł�����Ⴂ���̂ɁB���̂ق�������ۂǃ}�V�B
�t���O�V�b�v�̂b�o�t������Ă�̂ƍ���ĂȂ��̂ɂ�
�傫�ȍ��������ł���A��`���Ċp�x����݂��
�ł��A�ƊE��k�������鐫�\���Ă̂͗ǂ��Ӗ��Ȃ�ʔ�����
�����Ӗ��Ȃ�I���ȁB
�傫�ȍ��������ł���A��`���Ċp�x����݂��
�ł��A�ƊE��k�������鐫�\���Ă̂͗ǂ��Ӗ��Ȃ�ʔ�����
�����Ӗ��Ȃ�I���ȁB
�����ł������{�ł͔�r�L����������Ȃ����Ă̂�
���i����������Ȃ������͂����狭�C�Ȕ��������Ă����������ĕ�����Ȃ��̂���
������A�����J��ƂƂ͂����A�q�͓��{�l�Ȃ��炻�̕ӂ̊���𗝉����Ȃ��ƍL��Ƃ��Ė��܂�Ȃ����낤��
���N�}���K�ň�������̑�l�ɂ́A���C�o����F�߂A���������������Ă͂��܂����A�Ƃ����p���̕����D��ۂ��Ǝv��
���ɂ�AMD��Intel���W�Ȃ��g��������ė��Ă邾�낤��
���i����������Ȃ������͂����狭�C�Ȕ��������Ă����������ĕ�����Ȃ��̂���
������A�����J��ƂƂ͂����A�q�͓��{�l�Ȃ��炻�̕ӂ̊���𗝉����Ȃ��ƍL��Ƃ��Ė��܂�Ȃ����낤��
���N�}���K�ň�������̑�l�ɂ́A���C�o����F�߂A���������������Ă͂��܂����A�Ƃ����p���̕����D��ۂ��Ǝv��
���ɂ�AMD��Intel���W�Ȃ��g��������ė��Ă邾�낤��
418 �FSocket774�F2007/06/21(��) 16:59:56 ID:1HOAHy7w
AMD�����ʂ�INTEL�͂܂����������Ȃ��̂����C������B
419 �FSocket774�F2007/06/21(��) 17:29:55 ID:4MTLAWwR
VIP�łЂ�䂫�ނꂽ����������
�܂��x�����VIP�ɗ����킯�����E�E�E�E�E�E�E�E�E�E
http://wwwww.2ch.net/test/read.cgi/news4vip/1182352006/6
�� 6 �F�Ђ�䂫���ǂ����Ǘ��l �� �F2007/06/21(��) 00:08:45.01 ID:????
�� �X���ꗗ���痈�܂�����B�B�B
�܂��x�����VIP�ɗ����킯�����E�E�E�E�E�E�E�E�E�E
http://wwwww.2ch.net/test/read.cgi/news4vip/1182352006/6
�� 6 �F�Ђ�䂫���ǂ����Ǘ��l �� �F2007/06/21(��) 00:08:45.01 ID:????
�� �X���ꗗ���痈�܂�����B�B�B
420 �FSocket774�F2007/06/21(��) 18:05:54 ID:6HnBOhoJ
�A�s�[�������肾��ȃR�������Ȃ�ăG���R�[�h��OC�p�r�ȊO�́AAMD�ɏ��Ă�v�f���Ȃ��̂�
��i�d�l�Ȃ�AMD�̕���M/B�͈�������A���ɃQ�[���p�r�Ȃ�CPU��M/B������ăO���{�ɂ�����������������
��i�d�l�Ȃ�AMD�̕���M/B�͈�������A���ɃQ�[���p�r�Ȃ�CPU��M/B������ăO���{�ɂ�����������������
���̉Εa�Ԃ�͂����Ă����邗
���͖{����VS�X���ł������l�^���B
�킴�킴AMD�X���܂Ŏ����Ă��邩��ȁB
���̉Εa�Ԃ�́A�SIntel�g���������ȁB�}�W�ŁB
�킴�킴AMD�X���܂Ŏ����Ă��邩��ȁB
���̉Εa�Ԃ�́A�SIntel�g���������ȁB�}�W�ŁB
���̊Ԃɂ��uFUSION�v���A�������蒆�g�̖���
�ȃu�����h�l�[���^�}�[�P�e�B���O�p��ɂȂ��Ă��܂����B
http://techon.nikkeibp.co.jp/article/NEWS/20061026/122718/
��Advanced Micro Devices�CInc.�iAMD�Ёj�̓O���t�B�b�N�X�`���H��CPU�R�A��
1�`�b�v��ɏW�ς���86�n�}�C�N���v���Z�T�uFusion�v�i�J���R�[�h���j��2008�N���`
2009�N���߂����h�ɊJ������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
�uFUSION�́A�A�N�Z�����[�g�^�R���s���[�e�B���O�ɂ��Ă̑S�Ă��J�o�[����B
������A�V�X�e���I���`�b�v(SoC)�̃����`�b�v�\���Ɍ��炸�A�����`�b�v�ɂ��
�V�X�e�����x���ł̃w�e���W�j�A�X�\����FUSION�Ɋ܂�ł���B�܂��A�g�ѓd�b
�r�W�l�X�����̂��܂��܂ȋ@�\�v�f�̓���(���i)����APC�����̃n�C�p�t�H�[�}
���X�̃N���C�A���gCPU�܂ŁA�S�Ă�FUSION�ɒ�`���Ă���v
�ȃu�����h�l�[���^�}�[�P�e�B���O�p��ɂȂ��Ă��܂����B
http://techon.nikkeibp.co.jp/article/NEWS/20061026/122718/
��Advanced Micro Devices�CInc.�iAMD�Ёj�̓O���t�B�b�N�X�`���H��CPU�R�A��
1�`�b�v��ɏW�ς���86�n�}�C�N���v���Z�T�uFusion�v�i�J���R�[�h���j��2008�N���`
2009�N���߂����h�ɊJ������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@��
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
�uFUSION�́A�A�N�Z�����[�g�^�R���s���[�e�B���O�ɂ��Ă̑S�Ă��J�o�[����B
������A�V�X�e���I���`�b�v(SoC)�̃����`�b�v�\���Ɍ��炸�A�����`�b�v�ɂ��
�V�X�e�����x���ł̃w�e���W�j�A�X�\����FUSION�Ɋ܂�ł���B�܂��A�g�ѓd�b
�r�W�l�X�����̂��܂��܂ȋ@�\�v�f�̓���(���i)����APC�����̃n�C�p�t�H�[�}
���X�̃N���C�A���gCPU�܂ŁA�S�Ă�FUSION�ɒ�`���Ă���v
>>423
AMD�͏��X�Ɏ����̐g�̏���킩���Ă�����
910 �FMAC�I�^ �F2007/04/20(��) 00:17:58 ID:7fCHblND
���ɌĂq�g���������Ǝv�������ǁA����Fusion��CPU��GPU��MCM�������Ƃ����I�`������
�݂������B
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
�@�@--------------------
�@�@In the press session about AMDs K10 architecture Guiseppe Amato also gave some
�@�@additional info on the AMD Fusion project. He explained that it is very possible, that
�@�@Fusion products might come in the form of multi-chip modules, also known as MCMs.
�@�@--------------------
�j�R�C�`�����̃A��������̊��z��@��������(��)
595 �FMAC�I�^ �F2007/05/28(��) 01:09:22 ID:o+9DaRUl
�㓡���������̂��Ƃ��Ӗ����킩�炸Fusion�̉���L���������Ă��邷�B
http://pc.watch.impress.co.jp/docs/2007/0528/kaigai362.htm
�@�@-------------------
�@�@GPU�^�̃f�[�^����R�A���Ax87���������_���Z�R�v���Z�b�T�̂悤��CPU�̕W���I�ȋ@�\
�@�@�Ƃ��Ď�荞�ރC���[�W���B
�@�@-------------------
�ق�̐��N�O��x86�ւ�64-bit�g���̂��Ƃ��v���o���Ζ��炩�Șb�����ǁA���S�ȐV�T�O��
ISA�Ɏ�荞�ނƂ����̂�ƂĂ����Ԃ������邷�B
AMD��x86-64�̔��\��A1999�N�H�B
http://pc.watch.impress.co.jp/docs/article/991006/mpf2.htm
�ŏ��̎����ł���Opteron�̔��\��2003�N�t
http://pc.watch.impress.co.jp/docs/2003/0423/amd.htm
���O�̏�����3�N�ȏォ���Ă��邷�B2009�N�Ƃ����^�C���t���[�����l�����ꍇ�A�Ƃ����Ɏd�l��
���\���Ă��ē��R�Ȗ�ŁA������
�@�u��`���傾���ŁA�����l���Ă��Ȃ��v
�Ƃ����̂��������BAMD�̏d��w��5�N��܂ʼn�Ў��̎c���Ă��Ȃ��Ǝv���ēK���Ȃ��ƌ����܂���
�Ă���Z���炠�邷�B
AMD�͏��X�Ɏ����̐g�̏���킩���Ă�����
910 �FMAC�I�^ �F2007/04/20(��) 00:17:58 ID:7fCHblND
���ɌĂq�g���������Ǝv�������ǁA����Fusion��CPU��GPU��MCM�������Ƃ����I�`������
�݂������B
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
�@�@--------------------
�@�@In the press session about AMDs K10 architecture Guiseppe Amato also gave some
�@�@additional info on the AMD Fusion project. He explained that it is very possible, that
�@�@Fusion products might come in the form of multi-chip modules, also known as MCMs.
�@�@--------------------
�j�R�C�`�����̃A��������̊��z��@��������(��)
595 �FMAC�I�^ �F2007/05/28(��) 01:09:22 ID:o+9DaRUl
�㓡���������̂��Ƃ��Ӗ����킩�炸Fusion�̉���L���������Ă��邷�B
http://pc.watch.impress.co.jp/docs/2007/0528/kaigai362.htm
�@�@-------------------
�@�@GPU�^�̃f�[�^����R�A���Ax87���������_���Z�R�v���Z�b�T�̂悤��CPU�̕W���I�ȋ@�\
�@�@�Ƃ��Ď�荞�ރC���[�W���B
�@�@-------------------
�ق�̐��N�O��x86�ւ�64-bit�g���̂��Ƃ��v���o���Ζ��炩�Șb�����ǁA���S�ȐV�T�O��
ISA�Ɏ�荞�ނƂ����̂�ƂĂ����Ԃ������邷�B
AMD��x86-64�̔��\��A1999�N�H�B
http://pc.watch.impress.co.jp/docs/article/991006/mpf2.htm
�ŏ��̎����ł���Opteron�̔��\��2003�N�t
http://pc.watch.impress.co.jp/docs/2003/0423/amd.htm
���O�̏�����3�N�ȏォ���Ă��邷�B2009�N�Ƃ����^�C���t���[�����l�����ꍇ�A�Ƃ����Ɏd�l��
���\���Ă��ē��R�Ȗ�ŁA������
�@�u��`���傾���ŁA�����l���Ă��Ȃ��v
�Ƃ����̂��������BAMD�̏d��w��5�N��܂ʼn�Ў��̎c���Ă��Ȃ��Ǝv���ēK���Ȃ��ƌ����܂���
�Ă���Z���炠�邷�B
�A�t�HMac���^������
������>>3�̃e���v���Ŋ������Ă��܂��X������
>>424
����Fusion��CPU��GPU��MCM�������Ƃ����I�`�������݂������B
�܂��A�l���悤�ɂ���Ă͂�����������A�w�e���ł̃j�R�C�`�ƃz��
�̃j�R�C�`���ׂ��Ă�̂������B�B�B
����Fusion��CPU��GPU��MCM�������Ƃ����I�`�������݂������B
�܂��A�l���悤�ɂ���Ă͂�����������A�w�e���ł̃j�R�C�`�ƃz��
�̃j�R�C�`���ׂ��Ă�̂������B�B�B
>>424
>�j�R�C�`�����̃A��������̊��z��@��������(��)
�j�R�C�`�ƌ����Ă��ACPU�R�A���m�ł͖�����CPU�R�A��GPU�R�A�Ȃ̂����B
���҂̉e���͈Ⴂ��������B
�ǂ����Ă�MAC���^��mislead�ł��B
�{���ɂ��肪�Ƃ��������܂����B
>�j�R�C�`�����̃A��������̊��z��@��������(��)
�j�R�C�`�ƌ����Ă��ACPU�R�A���m�ł͖�����CPU�R�A��GPU�R�A�Ȃ̂����B
���҂̉e���͈Ⴂ��������B
�ǂ����Ă�MAC���^��mislead�ł��B
�{���ɂ��肪�Ƃ��������܂����B
�Ȃ��BGPU��CPU���I���_�C�ɂ܂Ƃ߂�ő�̗��R���ăv���Z�X�k���ɂ���ă_�C�T�C�Y��������
�Ȃ肷���ăf���A���R�A�ł͖��߂���Ȃ�����]�����X�y�[�X��GPU���悹�܂��傤���Ęb��������ȁB
K10��65nm�Ń_�C�T�C�Y283����mm�������Đ����ɂƂ�ł��Ȃ���J���Ă���悤�����A
���ꂪ45nm�ɂȂ����Ƃ���Ńf���A���R�A�{GPU���悹�邱�ƂȂ��AMD�ɏo����̂��H
�Ȃ肷���ăf���A���R�A�ł͖��߂���Ȃ�����]�����X�y�[�X��GPU���悹�܂��傤���Ęb��������ȁB
K10��65nm�Ń_�C�T�C�Y283����mm�������Đ����ɂƂ�ł��Ȃ���J���Ă���悤�����A
���ꂪ45nm�ɂȂ����Ƃ���Ńf���A���R�A�{GPU���悹�邱�ƂȂ��AMD�ɏo����̂��H
AMD��CPU���ďo�n�߂͖���ɋ߂��傫������B
>>431
����AMD�j�ォ�Ȃ�ł�����
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_02l.gif
283����mm�Ƃ���܂łɂȂ��r�b�O�T�C�Y��Barcelona
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai336.htm
����AMD�j�ォ�Ȃ�ł�����
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_02l.gif
283����mm�Ƃ���܂łɂȂ��r�b�O�T�C�Y��Barcelona
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai336.htm
>>430
283mm2��Quad-Core�̏ꍇ�̐���������ȁE�E�E�B
45nm��Dual-Core�{�~�h�������W�N���X��GPU�Ȃ牽�Ƃ��Ȃ��Ȃ����ȁB
283mm2��Quad-Core�̏ꍇ�̐���������ȁE�E�E�B
45nm��Dual-Core�{�~�h�������W�N���X��GPU�Ȃ牽�Ƃ��Ȃ��Ȃ����ȁB
>>432
����B���̕\�ɂ��łɓ������o�Ă���C���c�B
�Ⴆ��DualCore K8 rev.F��220����mm�B
�V�������N���Rev.G��126����mm�ŁA��60%�������Ȃ��Ă���B
���������l���Ȃ��Ōv�Z����ƁAQuad Core K10�͏�����283����mm������A
45nm�ɂȂ�ƁA��170����mm�ɂȂ�B����ɂ���́uQuad Core�v������A
�Ⴆ��Dual Core���ƒ��P���ɍl����Α傫���͂���ɔ����ɂȂ�B85����mm���炢���H
�Ⴆ��FUSION��Dual Core CPU+GPU�ƍl����c
���[�I�@�����[�I�@�߂�ǂ������I�@���Ԃ�]�T���낤��B
����B���̕\�ɂ��łɓ������o�Ă���C���c�B
�Ⴆ��DualCore K8 rev.F��220����mm�B
�V�������N���Rev.G��126����mm�ŁA��60%�������Ȃ��Ă���B
���������l���Ȃ��Ōv�Z����ƁAQuad Core K10�͏�����283����mm������A
45nm�ɂȂ�ƁA��170����mm�ɂȂ�B����ɂ���́uQuad Core�v������A
�Ⴆ��Dual Core���ƒ��P���ɍl����Α傫���͂���ɔ����ɂȂ�B85����mm���炢���H
�Ⴆ��FUSION��Dual Core CPU+GPU�ƍl����c
���[�I�@�����[�I�@�߂�ǂ������I�@���Ԃ�]�T���낤��B
�]���Ă��傤���Ȃ�����f�o�t�ł��悹�邩�A�Ƃ����b��
�u�Ȃ�Ƃ��Ȃ�v�Ƃ������x���ɂ��肩����Ă�
�u�Ȃ�Ƃ��Ȃ�v�Ƃ������x���ɂ��肩����Ă�
�]�T���ȁA�������
>>434
>�Ⴆ��DualCore K8 rev.F��220����mm�B
>�V�������N���Rev.G��126����mm�ŁA��60%�������Ȃ��Ă���B
90nm:183����mm��65nm:126����mm�����B
90nm:220����mm��L2 1MBx2�ł�65nm�ł͍���ĂȂ��B
>�Ⴆ��DualCore K8 rev.F��220����mm�B
>�V�������N���Rev.G��126����mm�ŁA��60%�������Ȃ��Ă���B
90nm:183����mm��65nm:126����mm�����B
90nm:220����mm��L2 1MBx2�ł�65nm�ł͍���ĂȂ��B
>>437
�ށB���܂����B�{�����B512kb�R�A�Ōv�Z����Ɩ�70%���B
�Ă��ˁc����B���Ԃ̈Ӗ��s���Ȃقǂ��̑��v�����Ȃ����v�Z�ɁA
���قLjӖ��͑��݂��Ȃ��C������́B
283����mm��198����mm��99����mm�����ǁA
Quad Core�̕����Ɂu6MB L3�v���v�悳��Ă���Ƃ��������ƁA
45nm�ւ̃V�������N�͂����Ƒ傫�����������Ȃ�C������B
���ƁA�Ⴆ��FUSION��L3�����Ȃ��B�܂���L3�̖ʐς�����������ƍl����ƁA
�_�C�T�C�Y�͂����Ə������Ȃ�Ǝv���B
�Ă��A�����������̐F�X�ȗv����S�ĂԂ��������v�Z�ɈӖ����iqw���������������������G�F���v�u
�ށB���܂����B�{�����B512kb�R�A�Ōv�Z����Ɩ�70%���B
�Ă��ˁc����B���Ԃ̈Ӗ��s���Ȃقǂ��̑��v�����Ȃ����v�Z�ɁA
���قLjӖ��͑��݂��Ȃ��C������́B
283����mm��198����mm��99����mm�����ǁA
Quad Core�̕����Ɂu6MB L3�v���v�悳��Ă���Ƃ��������ƁA
45nm�ւ̃V�������N�͂����Ƒ傫�����������Ȃ�C������B
���ƁA�Ⴆ��FUSION��L3�����Ȃ��B�܂���L3�̖ʐς�����������ƍl����ƁA
�_�C�T�C�Y�͂����Ə������Ȃ�Ǝv���B
�Ă��A�����������̐F�X�ȗv����S�ĂԂ��������v�Z�ɈӖ����iqw���������������������G�F���v�u
�����̃u���O�͍��܂łɂ����X�̗\�z���O���Ă������ҁB
���������\�z���ă��x������Ȃ����ǂȁB
���������\�z���ă��x������Ȃ����ǂȁB
�ϑz���Ď����B
>>439
����L������Ȃ��Čl�̃A�z�u���O�B
����L������Ȃ��Čl�̃A�z�u���O�B
GPU������̂̓R�X�g�_�E���̂��߂���Ȃ��́H
�`�b�v�Z�b�g����GPU����������i�߂����̂��Ǝv���Ă����B
�`�b�v�Z�b�g����GPU����������i�߂����̂��Ǝv���Ă����B
http://news22.2ch.net/test/read.cgi/newsplus/1182515967/58
58 �F�������������N�F2007/06/22(��) 21:54:38 ID:s6aHNYKaO
�}�b�N���^�ܖڂ�������������������������������������������������������������������������������
58 �F�������������N�F2007/06/22(��) 21:54:38 ID:s6aHNYKaO
�}�b�N���^�ܖڂ�������������������������������������������������������������������������������
Fusion=Timna
�R�A���̂̊����x�͍������Ď������]�n�͂قƂ�ǂȂ�����ȁB
Larrabee���ē�������v�Z�ɂނ��Ȃ��悤�Ȍv�Z�ł��L����
�\�͔����ł���́H
�Í��������Ƃ����\����������s�ł��Ȃ����Ƃ�������
���ł��X�g�[���������[���ǂ��ق�ƂɗL�p�Ȃ낤���H
�\�͔����ł���́H
�Í��������Ƃ����\����������s�ł��Ȃ����Ƃ�������
���ł��X�g�[���������[���ǂ��ق�ƂɗL�p�Ȃ낤���H
449 �F�E�́E�j��-�������F2007/06/23(�y) 16:11:14 ID:dKNl7abl
�Í��ŕ���v�Z�A�ǂ��݂Ă��N���b�N�ł��B�{���ɂ��肪�Ƃ��������܂����B
���������������Č����Ă邩�琮���S�ʂ͊��҂��Ȃ��ق��������Ǝv�����ǂȁB
���������������Č����Ă邩�琮���S�ʂ͊��҂��Ȃ��ق��������Ǝv�����ǂȁB
�����������Z�̕���ꡂ��ɏd�v�Ȃ͂������A���̒��I�Ɏg�������Ȃ����������_����
�t�B�[�`���[�����̂͂Ȃ�łȂH
�t�B�[�`���[�����̂͂Ȃ�łȂH
10�i�����̂܂��s�ł��郆�j�b�g�Ƃ��������Ă�̂��H
���������Ȃ�ĉȊw�����炢�����g�����Ȃ����炢���B
�f�[�^�̉�͂�^���������J����̂ɂ͐������Z���\�Ȍ���
�������������������
���������Ȃ�ĉȊw�����炢�����g�����Ȃ����炢���B
�f�[�^�̉�͂�^���������J����̂ɂ͐������Z���\�Ȍ���
�������������������
���������_����Ȃ����������������A�t�H�߂��邗������
��̓I�ɉ��Ɏg���킯�H�Q�[���H
�摜�����ł����������ł����C�g���ł��G���R�ł���{�͕s�������_���Z�Ȃ�
�ނ��됮�����Z�ȂɂɎg���̂�
�ނ��됮�����Z�ȂɂɎg���̂�
���[�`���B
����珈�������������_�œ����Ă��Ȃ�����B
�摜�������̉����������͎̂��Ӄ`�b�v��DSP���̂��Ă邵�A�ނ���CPU��
�������������Ȃ����ނ̂��̂���Ȃ������ʁB
���C�g���Ȃ�Ă��Ȃ����B
�I���I�ɂ�CAD�ł����g��Ȃ��B
����珈�������������_�œ����Ă��Ȃ�����B
�摜�������̉����������͎̂��Ӄ`�b�v��DSP���̂��Ă邵�A�ނ���CPU��
�������������Ȃ����ނ̂��̂���Ȃ������ʁB
���C�g���Ȃ�Ă��Ȃ����B
�I���I�ɂ�CAD�ł����g��Ȃ��B
�摜�����≹�����������ӂ�DSP����
�ǂ��̃X�[�p�[�t�@�~�R������E�E�E
�ǂ��̃X�[�p�[�t�@�~�R������E�E�E
VGA���T�E���h�`�b�v���̂��ĂȂ��̂��I�}�G��PC�ɂ́B
iDCT�͐������Z�g�����Ƒ�����
IE��JPEG�W�J���������Z����Ȃ����������H
HPC���K�v�Ȋ�ƁE�����ҁA������f���������N���G�[�^�[�E�ҏW��
����Ȃ���Ε��������_���Z�̏d�v���͑��ΓI�ɒႢ
IE��JPEG�W�J���������Z����Ȃ����������H
HPC���K�v�Ȋ�ƁE�����ҁA������f���������N���G�[�^�[�E�ҏW��
����Ȃ���Ε��������_���Z�̏d�v���͑��ΓI�ɒႢ
>>458
�ŁA�N�A�b�hCPU��SSE�ł��������d���������Z���K�v�Ȑl�Ԃ��āH
�ŁA�N�A�b�hCPU��SSE�ł��������d���������Z���K�v�Ȑl�Ԃ��āH
���ׂĂ݂Ă݂�ƁA���܂ł���Ă���H
���Ă����E�Ƃ̐l���������肾�ˁA�K�v�Ȃ̂́B
���Ă����E�Ƃ̐l���������肾�ˁA�K�v�Ȃ̂́B
�o��16bit�����̉��������ł���������Z��double���K�{�Ȃ��ǂ�
�������������̂��
�������������̂��
���ׂČ���ƍ��g���Ă鉹�y�Đ��\�t�g��MP3�f�R�[�h�v���O�C���͐������Z������
���������K�v���������Ȃ��Ƃ����ӌ����A�]���ŋ����I��
�K�v�Ȃ��A�����Ȃ�ꍇ�ɂ��K�v�ƌ��킹�Ȃ��B�ƕϊ����Ă��܂��y�Ɖ�b�͐��藧���Ȃ��Ǝv���B
�����̃e�����X�g���炢�b���S�����ݍ���Ȃ��B
���������A������v���O�������������Z��œ����Ă�̂ɁA�v���O������ŕK�v�Ȑ��l��
�v�Z���邽�߂́A���l�I���������鉉�Z�킾���ł��ׂĂ������Ǝv���Ă�l�Ɖ�b�͐��藧���Ȃ��B
�ɒ[�Șb�A�d���c++�������Ǝv���Ă邽�����̌�����B
�K�v�Ȃ��A�����Ȃ�ꍇ�ɂ��K�v�ƌ��킹�Ȃ��B�ƕϊ����Ă��܂��y�Ɖ�b�͐��藧���Ȃ��Ǝv���B
�����̃e�����X�g���炢�b���S�����ݍ���Ȃ��B
���������A������v���O�������������Z��œ����Ă�̂ɁA�v���O������ŕK�v�Ȑ��l��
�v�Z���邽�߂́A���l�I���������鉉�Z�킾���ł��ׂĂ������Ǝv���Ă�l�Ɖ�b�͐��藧���Ȃ��B
�ɒ[�Șb�A�d���c++�������Ǝv���Ă邽�����̌�����B
>>464
����
����
�������Z�@��
�����̐��l���v�Z���邽�߂̕��A�����_������Ȃ��d�삩�����Ɗ��Ⴂ���Ă邩��b���ςȂA�ƁB
�����̐��l���v�Z���邽�߂̕��A�����_������Ȃ��d�삩�����Ɗ��Ⴂ���Ă邩��b���ςȂA�ƁB
�K�v����=����Ȃ��@�͓T�^�I�ȃ��^�v�l
�̂�CPU�͕��������_���Z���s���̂ɃR�v���Z�b�T���K�v�������肵�����
���ł����������Ă��邪�p�r�͌��\����I��
���ł����������Ă��邪�p�r�͌��\����I��
���_����x����������^
�����Ƃ�SFC��9801�̃A�Z���u���������Ă��v���O���}�����Ă�
�A���S���Y�����x�����玩���ō�炸�ɐl�̂������v���O�����������Ă邩��
���l���Z�̊�{���������Z�Ȃ�ĂƂ�Ȋ��o�ɂȂ��
�����Ƃ�SFC��9801�̃A�Z���u���������Ă��v���O���}�����Ă�
�A���S���Y�����x�����玩���ō�炸�ɐl�̂������v���O�����������Ă邩��
���l���Z�̊�{���������Z�Ȃ�ĂƂ�Ȋ��o�ɂȂ��
��x���v���O���}�̌������ɐM�p�Ȃ�Ēu����܂���
471 �FSocket774�F2007/06/24(��) 11:41:22 ID:pxzfSop6
ID:bsHSQPpg
ID��pg�����ɒ�x�������ď���B
���܂���PC�̒��ł͂قƂ�ǂ̌v�Z��
���������ł���Ă�̂��ƁB
���܂���PC�̒��ł͂قƂ�ǂ̌v�Z��
���������ł���Ă�̂��ƁB
>>469�͂ǁ[�݂Ă��ނ肾��
�����ꂽ�I�b�T���ł���Ƃ������Ƃ͂킩����
�u�A�Z���u���������Ă��v�����͂���ĂȂ����[�g�����Ď��ł��ȁB
���������_���Z�Ɋւ��āA���v���ߏ��]�����Ă�l��������
���l���Z�v���Z�b�T�ł����Ė��߂̎��s���j�b�g�ł͂Ȃ��Ƃ������Ƃ��킩���ĂȂ��A
�g�������悭�킩���ĂȂ��̂ɕK�v����͐�����l�̕��������B
�g�������悭�킩���ĂȂ��̂ɕK�v����͐�����l�̕��������B
��AKIBA PC Hotline! ���������ω��i�̕ϑJ
�@�@�@�@�@�@. PC133. PC133.PC2100.PC2700.PC3200.PC3200.PC2-42.PC2-64
�@�@�@�@�@�@. 256MB. 512MB. 512MB. 512MB. 512MB�@�@1GB�@�@1GB�@�@1GB
01/04/07�@10,337�@37,380�@78,000�@�@�@�@�@
01/07/07�@. 4,014�@. 8,215�@40,460�@�@�@�@�@
01/10/06�@. 2,602�@. 5,153�@. 9,190�@�@�@�@�@
02/01/12�@. 7,110�@13,596�@17,198�@27,114�@�@�@�@
02/04/06�@. 7,630�@13,947�@16,199�@19,866�@�@�@�@
02/07/06�@. 4,941�@. 9,345�@. 9,886�@12,130�@�@�@�@
02/10/05�@. 3,345�@. 5,412�@12,979�@13,377�@�@�@�@
03/01/11�@. 4,281�@. 6,421�@11,427�@12,261�@�@�@�@
03/04/05�@. 4,594�@. 7,310�@. 6,227�@. 6,583�@10,114�@�@�@
03/07/05�@. 4,574�@. 6,812�@. 7,301�@. 7,904�@10,135�@�@�@
03/10/04�@. 5,409�@. 7,980�@. 9,189�@. 9,517�@10,910�@49,999�@�@
04/01/10�@. 6,085�@. 9,872�@. 7,646�@. 7,680�@. 8,715�@33,467�@�@
04/04/03�@. 7,127�@11,092�@. 9,673�@10,267�@10,757�@30,725�@�@
04/07/03�@. 7,579�@11,273�@. 9,952�@10,235�@10,654�@33,527�@67,050�@
04/10/02�@. 7,167�@11,047�@10,178�@10,161�@10,053�@28,156�@40,495�@
05/01/08�@. 7,113�@10,302�@. 9,243�@. 9,056�@. 9,042�@23,617�@31,111�@
05/04/02�@�@ �@ �@�@�@ �@ �@�@. 7,154�@. 6,702�@. 6,466�@17,690�@20,906�@
05/07/02�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,511�@. 5,463�@11,429�@13,305�@
05/10/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 6,228�@. 5,847�@12,522�@11,810�@
06/01/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,510�@. 5,187�@10,756�@. 9,700�@
06/04/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,072�@. 4,835�@10,144�@11,037�@
06/07/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,664�@. 5,075�@10,091�@. 9,967�@14,402
06/10/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 7,300�@13,781�@13,718�@16,715
07/01/13�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 6,340�@12,292�@12,829�@15,174
07/04/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 4,968�@. 9,852�@. 8,445�@. 9,932
�@�@�@�@�@�@. PC133. PC133.PC2100.PC2700.PC3200.PC3200.PC2-42.PC2-64
�@�@�@�@�@�@. 256MB. 512MB. 512MB. 512MB. 512MB�@�@1GB�@�@1GB�@�@1GB
01/04/07�@10,337�@37,380�@78,000�@�@�@�@�@
01/07/07�@. 4,014�@. 8,215�@40,460�@�@�@�@�@
01/10/06�@. 2,602�@. 5,153�@. 9,190�@�@�@�@�@
02/01/12�@. 7,110�@13,596�@17,198�@27,114�@�@�@�@
02/04/06�@. 7,630�@13,947�@16,199�@19,866�@�@�@�@
02/07/06�@. 4,941�@. 9,345�@. 9,886�@12,130�@�@�@�@
02/10/05�@. 3,345�@. 5,412�@12,979�@13,377�@�@�@�@
03/01/11�@. 4,281�@. 6,421�@11,427�@12,261�@�@�@�@
03/04/05�@. 4,594�@. 7,310�@. 6,227�@. 6,583�@10,114�@�@�@
03/07/05�@. 4,574�@. 6,812�@. 7,301�@. 7,904�@10,135�@�@�@
03/10/04�@. 5,409�@. 7,980�@. 9,189�@. 9,517�@10,910�@49,999�@�@
04/01/10�@. 6,085�@. 9,872�@. 7,646�@. 7,680�@. 8,715�@33,467�@�@
04/04/03�@. 7,127�@11,092�@. 9,673�@10,267�@10,757�@30,725�@�@
04/07/03�@. 7,579�@11,273�@. 9,952�@10,235�@10,654�@33,527�@67,050�@
04/10/02�@. 7,167�@11,047�@10,178�@10,161�@10,053�@28,156�@40,495�@
05/01/08�@. 7,113�@10,302�@. 9,243�@. 9,056�@. 9,042�@23,617�@31,111�@
05/04/02�@�@ �@ �@�@�@ �@ �@�@. 7,154�@. 6,702�@. 6,466�@17,690�@20,906�@
05/07/02�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,511�@. 5,463�@11,429�@13,305�@
05/10/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 6,228�@. 5,847�@12,522�@11,810�@
06/01/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,510�@. 5,187�@10,756�@. 9,700�@
06/04/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,072�@. 4,835�@10,144�@11,037�@
06/07/01�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 5,664�@. 5,075�@10,091�@. 9,967�@14,402
06/10/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 7,300�@13,781�@13,718�@16,715
07/01/13�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 6,340�@12,292�@12,829�@15,174
07/04/07�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@�@ �@ �@�@. 4,968�@. 9,852�@. 8,445�@. 9,932
>>478
DDR3��DDR2�̂��傤�ǂR�N�x�ꂾ�ȁB�Ƃ������Ƃ͂P�N��ɂ�DDR2��DDR3�̉��i����
�Q�`�R�����x�A�p�t�H�[�}���X�Z�O�����g�ł͖��ɂȂ�Ȃ��Ȃ��Ă���ƍl������B
AM3��2009�N�ɂ��ꂱ�ނ悤�Ȃ��ƂɂȂ�Ƃ���ˁB
DDR3��DDR2�̂��傤�ǂR�N�x�ꂾ�ȁB�Ƃ������Ƃ͂P�N��ɂ�DDR2��DDR3�̉��i����
�Q�`�R�����x�A�p�t�H�[�}���X�Z�O�����g�ł͖��ɂȂ�Ȃ��Ȃ��Ă���ƍl������B
AM3��2009�N�ɂ��ꂱ�ނ悤�Ȃ��ƂɂȂ�Ƃ���ˁB
AMD��45nm CPU�Q�`�o���2008�N������
AMD��45nm�v���Z�X��SocketAM3�Ή��ƂȂ�CPU�Q�̃��[���`��2008�N�������ɗ\�肵�Ă���B
������CPU��HyperTransport 3.0���T�|�[�g���ADDR2 / DDR3���Ή��̃������R���g���[���𓋍ڂ���B
�k�X���ł��
AMD��45nm�v���Z�X��SocketAM3�Ή��ƂȂ�CPU�Q�̃��[���`��2008�N�������ɗ\�肵�Ă���B
������CPU��HyperTransport 3.0���T�|�[�g���ADDR2 / DDR3���Ή��̃������R���g���[���𓋍ڂ���B
�k�X���ł��
����ɂ����A�����]�݂�4�̎��ォ�E�E�E�������̂���
3D�Q�[�������낻��]�݂��S�ɑΉ����Ă���
���܂���Dual�ɑΉ����Ă�����̂��������̂Ɂc�ł����H
�����炱����ʂɑΉ����ė~������
���̔]�݂������݂ł����炢���̂ɁE�E�E
���݂���Ȃ��Č����ɂȂ�Ǝv�����c
����A���������
ttp://northwood.blog60.fc2.com/blog-entry-964.html
9���ɏo��Semp��TDP45W���Ă���Ȃ̔����킯�Ȃ���Ȃ��c
25W���炢�ɂȂ�����
9���ɏo��Semp��TDP45W���Ă���Ȃ̔����킯�Ȃ���Ȃ��c
25W���炢�ɂȂ�����
�x���Ĉ���DRAM��40GB���炢���ڂ����V���R���f�B�X�N���ق����B
�������[�d�r�̃o�b�N�A�b�v���ŁB
�������[�d�r�̃o�b�N�A�b�v���ŁB
Sempron 2GHz(512KB/TDP25W) \12,000
Athlon64 3500+ \8,000
Athlon64 3500+ \8,000
>>489
SCSI10000rpmRAID������O�̍����I�p�s��Ȃ�ĂƂ����ɐ������ĂĂ����������Ȃ����ǂ�
�̂�DRAM�������P�����₽�獂����������̋L���������Ȃ��̂��ȁH
SCSI10000rpmRAID������O�̍����I�p�s��Ȃ�ĂƂ����ɐ������ĂĂ����������Ȃ����ǂ�
�̂�DRAM�������P�����₽�獂����������̋L���������Ȃ��̂��ȁH
DRAM�̓R���f�B�e�B������������Ȃ����ADDR2���g���̂�����������Ȃ�Ǝv�����ǁB
40GB���ς�A2�C30���ōς܂Ȃ��Ǝv�����B
40GB���ς�A2�C30���ōς܂Ȃ��Ǝv�����B
1���ԓ��e�ێ�����̂ɉ��{�̒P�O���d�r���K�v�ɂȂ�낤�H
>489
���������v�]�i�ꗝ���邵�A����Ȃ�̐l�����瓯�ӂ���j��
���̎�������邯�ǁA�ǂ����Ă��T���E�������甲���o����
�́A�x���ă��t���b�V���̕K�v��DRAM�Ȃ��Ȃ��ŗe��1/4��
�Ȃ��Ă����܂��SRAM���嗬�ɂ��Ă���Ǝv���Ă��������������B
���������v�]�i�ꗝ���邵�A����Ȃ�̐l�����瓯�ӂ���j��
���̎�������邯�ǁA�ǂ����Ă��T���E�������甲���o����
�́A�x���ă��t���b�V���̕K�v��DRAM�Ȃ��Ȃ��ŗe��1/4��
�Ȃ��Ă����܂��SRAM���嗬�ɂ��Ă���Ǝv���Ă��������������B
>>494
���̗v�]�͖����ɏ����Ă͋��Ȃ�����B
1T-SRAM�Ƃ��A���̋Z�p���D�ꂽ�I�[�p�[�c�͂������������B
�Ñ㕶���̏��������������x�Z�p�݂������B
���̗v�]�͖����ɏ����Ă͋��Ȃ�����B
1T-SRAM�Ƃ��A���̋Z�p���D�ꂽ�I�[�p�[�c�͂������������B
�Ñ㕶���̏��������������x�Z�p�݂������B
�k����Ax86CPU�̊֘A�Z�p�ړ]�ɖڏ� - AMD�ƒ������{�Ԃ̈ړ]�v��ɐ���
http://journal.mycom.co.jp/news/2007/06/27/046/index.html
http://journal.mycom.co.jp/news/2007/06/27/046/index.html
AMD�̐��i�헪�S�̂̍č\�z�ƂȂ�FUSION
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
�c�c�^�C�g���́u��������AMD�v�̕����Ó����Ǝv����
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
�c�c�^�C�g���́u��������AMD�v�̕����Ó����Ǝv����
>>497
>FUSION�t�@�~�����APC�����łȂ��A�Ɠd�E�g�ѓd�b�A�R���o�[�W�F���X�f�o�C�X�A�o�����[PC�EUMPC�Ȃǂ̃G�}�[�W���O�s��Ƃ��������L���s��ɓW�J���悤�Ƃ��Ă���B
AMD�����݂ł���̂�x86�̂��������Ǝv�����c
�uPC�����łȂ��i�����v�Ƃ������Ă邯�ǁAPC���������琶���Ă��Ȃ����HAMD�́B
���̎s��o���烉�C�o�����������邾��
>FUSION�t�@�~�����APC�����łȂ��A�Ɠd�E�g�ѓd�b�A�R���o�[�W�F���X�f�o�C�X�A�o�����[PC�EUMPC�Ȃǂ̃G�}�[�W���O�s��Ƃ��������L���s��ɓW�J���悤�Ƃ��Ă���B
AMD�����݂ł���̂�x86�̂��������Ǝv�����c
�uPC�����łȂ��i�����v�Ƃ������Ă邯�ǁAPC���������琶���Ă��Ȃ����HAMD�́B
���̎s��o���烉�C�o�����������邾��
>>498
���{�I�Ɋ��Ⴂ���Ă܂���B
���{�I�Ɋ��Ⴂ���Ă܂���B
>>499
������肢������
������肢������
AMD���Ă����̂͗ǂ���������INTEL�l��IBM�l�̎�̂Ђ�ł���
����Ă����Ȃ���B
����Ă����Ȃ���B
>>500
> �߂������ɂ͉Ɠd�@��ł��A��葽���̋@�\���������邱�Ƃ��d�v�ƂȂ�A
> ���̌��ʁA���G�ȃ\�t�g�E�F�A�w���K�v�ƂȂ�B����ƁAx86�A�[�L�e�N�`�����A�Ɠd�ł����l�������n�߂�B
�i�����j
> �f�o�C�X��x86�v���Z�b�T�����������̂��A���ɂ��Ȃ��悤�ɂȂ�ƐM���Ă���B
������K�v���Ȃ�āA���g�ق�Ƃɓǂ́H
> �߂������ɂ͉Ɠd�@��ł��A��葽���̋@�\���������邱�Ƃ��d�v�ƂȂ�A
> ���̌��ʁA���G�ȃ\�t�g�E�F�A�w���K�v�ƂȂ�B����ƁAx86�A�[�L�e�N�`�����A�Ɠd�ł����l�������n�߂�B
�i�����j
> �f�o�C�X��x86�v���Z�b�T�����������̂��A���ɂ��Ȃ��悤�ɂȂ�ƐM���Ă���B
������K�v���Ȃ�āA���g�ق�Ƃɓǂ́H
>>502
�ǂ��ǁAAMD�̐l�Ԃ̌��t����ȁB
�܂�x86���͂������Ă���\���͒Ⴍ�Ȃ�����A>>498�̈�s�ڂ͎��������B
2,3�s�ڂ͎������Ȃ�
�ǂ��ǁAAMD�̐l�Ԃ̌��t����ȁB
�܂�x86���͂������Ă���\���͒Ⴍ�Ȃ�����A>>498�̈�s�ڂ͎��������B
2,3�s�ڂ͎������Ȃ�
��ATI�̐��i�͖����ł����A�����ł����B
AMD������������Ƃ̋Z�p�́A�ړ��Ă̋Z�p��������
�������u�v���[�̌�����Ƒ��ꂪ���܂��Ă܂���
�������u�v���[�̌�����Ƒ��ꂪ���܂��Ă܂���
�Ɠd�ɂ���g�тɂ���̂Ɣ�ׂ���@�\�����Ă��邪
���[�U�[�����p����@�\�E�T�[�r�X�͌Œ�I���B
x86�������͂����Ă��ʂ�������Ƒz���ł��Ȃ��B
���[�U�[�����p����@�\�E�T�[�r�X�͌Œ�I���B
x86�������͂����Ă��ʂ�������Ƒz���ł��Ȃ��B
>>505
> AMD������������Ƃ̋Z�p�́A�ړ��Ă̋Z�p��������
���̖ړ��Ă̋Z�p����荞�̂�FUSION���Ɨ������Ă������A�Ⴄ�̂��H
> AMD������������Ƃ̋Z�p�́A�ړ��Ă̋Z�p��������
���̖ړ��Ă̋Z�p����荞�̂�FUSION���Ɨ������Ă������A�Ⴄ�̂��H
>>506
�������l����Η\�z�ł������Ȃ��Ǝv�����ȁA�g�тł݂Ă�
�l�b�g�A���[���A�A�v�����A�g�тɂg�c���t��������߂��B
�o�b�ɋ߂Â��Ă��遁�ėp�������߂��遁��86�������Ă���
�������l����Η\�z�ł������Ȃ��Ǝv�����ȁA�g�тł݂Ă�
�l�b�g�A���[���A�A�v�����A�g�тɂg�c���t��������߂��B
�o�b�ɋ߂Â��Ă��遁�ėp�������߂��遁��86�������Ă���
509 �FSocket774�F2007/06/28(��) 03:38:33 ID:Muk3IYrN
�l�b�g�A���[���A�A�v���͂��łɓ����Ă��邵�E�E�E
hdd�̂�����Acpu��������́H
hdd�̂�����Acpu��������́H
FUSION��1��2�O�̃~�h�����悹��炵�����猋�\�����\����GPU��
�g�тɔėp���Ȃ����
�O���f�B�X�v���C�ł��Ȃ���
�O���f�B�X�v���C�ł��Ȃ���
DDR3��1�N���1GB6��ɂȂ�ƁH(��)
>>510
�g�т̓d�r���������
�g�т̓d�r���������
�m�[�g�����d�����玝�����������Ȃ�
110���@�R���������@���������@�ł�86�A�v��8���ԑ���g�ї~����
����Ȏ��オ���N�カ����
�m904���̂�86�o�[�W�����������ȃC���[�W
�R���d�r�K�{
110���@�R���������@���������@�ł�86�A�v��8���ԑ���g�ї~����
����Ȏ��オ���N�カ����
�m904���̂�86�o�[�W�����������ȃC���[�W
�R���d�r�K�{
�Œ�@�\��Shader�ő�ւ��鎖�ɂ��
3D�p�C�v���C���̃X�e�[�W�����팸��
����d�͂�������B
�g�т̂悤�Ȓ�𑜓x�ł����
����ɂ��p�t�H�[�}���X�ቺ�͖��ł͂Ȃ��B
3D�p�C�v���C���̃X�e�[�W�����팸��
����d�͂�������B
�g�т̂悤�Ȓ�𑜓x�ł����
����ɂ��p�t�H�[�}���X�ቺ�͖��ł͂Ȃ��B
�g�ѓd�b��3DMark��^���p�N����͂��s���d�g���E����AMD
�g�тł͂��������������Ȃ��A�X�}�[�g�t�H���K�v�Ȃ������������Ǝx�z�I�ŁA
�X�}�[�g�t�H����K�v�Ƃ���Ƃ������g�����Ȃ��銄���͂����Ə��Ȃ��ȁB
�X�}�[�g�t�H����K�v�Ƃ���Ƃ������g�����Ȃ��銄���͂����Ə��Ȃ��ȁB
518 �FSocket774�F2007/06/28(��) 08:06:58 ID:GM1xBPlZ
�g�т̓d�b�@�\��������Ȃ���
>>518
���Ⴀ�A�͂����ƁA�f�W�J���ƁANintendoDS��
�������������ł͂���܂��H��
�Ȃ�ĂȁB����PDA�������Ă��������ǂ��܂�g�����Ȃ���
�t���@�\�o�b�������������ق��������Ǝv�����B
�ړ����Ƃ��͂�����ƍ��邪�A�����Ƃo�b��肩�܂�������
���Ⴀ�A�͂����ƁA�f�W�J���ƁANintendoDS��
�������������ł͂���܂��H��
�Ȃ�ĂȁB����PDA�������Ă��������ǂ��܂�g�����Ȃ���
�t���@�\�o�b�������������ق��������Ǝv�����B
�ړ����Ƃ��͂�����ƍ��邪�A�����Ƃo�b��肩�܂�������
�����^PC�ɂ���X�}�[�g�t�H���ɂ���A��ʋ�������uPC�Ɠ����A�v���P�[�V�����v�͎�����g���Ȃ���
�J���֘A�̃����b�g�i���邩�ǂ����m��Ȃ����ǁj�����Ȃ��Ǝv����
����ȂɃ����b�g�������Ȃ̂��H
WINDOWS�g������PC�݂����ɐ��i�T�C�N����MS���݂ɂȂ��Ă��܂���
����܂��Ɠd�Ƃ��ɂ͂����Ƃ͎v���Ȃ���
�J���֘A�̃����b�g�i���邩�ǂ����m��Ȃ����ǁj�����Ȃ��Ǝv����
����ȂɃ����b�g�������Ȃ̂��H
WINDOWS�g������PC�݂����ɐ��i�T�C�N����MS���݂ɂȂ��Ă��܂���
����܂��Ɠd�Ƃ��ɂ͂����Ƃ͎v���Ȃ���
�X�}�[�g�t�H���ɍ̗p�����悤�ȑg�ݍ�����CPU�͏���d�͂����SmW�N���X������A
Fusion���̗p�����Ƃ��Ă��A�܂��܂���̘b���낤�B
Fusion���̗p�����Ƃ��Ă��A�܂��܂���̘b���낤�B
PDA�����ǒ��������Ȃ��̂�
�g���ɂ������炾�낤��
�g���ɂ������炾�낤��
>>516
�d�g���Ǝv���H�@�����Ɍg�т�3D�Q�[���������Ă���̂ɁH
�d�g���Ǝv���H�@�����Ɍg�т�3D�Q�[���������Ă���̂ɁH
CELL�������u�Ɠd�ɓ��ڂ���Đ��\���啝�Ɂ`�v�Ƃ������l�Ȃ��ƌ����Ă����A
�u����ȓd�͑���ڂ��邩�I�I�v�ƌ��Ǔ���sony�����炷��n�u���Ă�
Fusion�Ȃ�ē��ڂ�����A�R���d�r�ł���d�͎��Ƃ͎v����̂���
�u����ȓd�͑���ڂ��邩�I�I�v�ƌ��Ǔ���sony�����炷��n�u���Ă�
Fusion�Ȃ�ē��ڂ�����A�R���d�r�ł���d�͎��Ƃ͎v����̂���
>>524
�Ȃ�ŊW�Ȃ�CELL�̘b���o�Ă����́H
�Ȃ�ŊW�Ȃ�CELL�̘b���o�Ă����́H
FUSION = Cell�Ƃł��v���Ă����Ȃ��H
cell�ɂ���Fusion�ɂ���A�Ɠd�Ƃ��Ɍ������g�ݍ��ނƂ͍l���ĂȂ��ł���
�����Ƃ��A�v���Z�X�Ƃ����P���ꂽ��g�ݍ��n�̐������P�����킯������
�����Ƃ��A�v���Z�X�Ƃ����P���ꂽ��g�ݍ��n�̐������P�����킯������
>>527
������Ȃ��CELL������́H
������Ȃ��CELL������́H
>>527
�g�уf�o�C�X�̋@�\�����ꂩ�烊�b�`�ɂȂ�ł��낤�B
���b�`�ɂȂ����@�\����������ɂ́A�����\�ȃ`�b�v���K�v�ł���B
����āAIntel��AMD��NVIDIA�����̎s���_���Ă���B
�g�т�g���Ɠd�̋@�\������ȏ��剻�����A
����ێ��B���邢�͋t�Ƀv�A�[�ɂȂ��Ă����̂ł���A
x86�n�`�b�v�̏o�Ԃ͂Ȃ��B
�ŁA�Ȃ��CELL��FUSION����ׂĂ�́H�@�����s�v�c�ł��܂��B
�g�уf�o�C�X�̋@�\�����ꂩ�烊�b�`�ɂȂ�ł��낤�B
���b�`�ɂȂ����@�\����������ɂ́A�����\�ȃ`�b�v���K�v�ł���B
����āAIntel��AMD��NVIDIA�����̎s���_���Ă���B
�g�т�g���Ɠd�̋@�\������ȏ��剻�����A
����ێ��B���邢�͋t�Ƀv�A�[�ɂȂ��Ă����̂ł���A
x86�n�`�b�v�̏o�Ԃ͂Ȃ��B
�ŁA�Ȃ��CELL��FUSION����ׂĂ�́H�@�����s�v�c�ł��܂��B
�g�уf�o�C�X�Ƀv���W�F�N�^�[�@�\���t������L����ʂŎg����悤�ɂȂ�
>>526��>>528�͂ǂ��lj�͂������̂��ނ�Ȃ̂��E�E�E
>>497�����FUSION���Ɠd�E�g�ѓd�b�ɂƂ�������Ȃ���
�Ɠd�����Ɍv�悪�������ʂ�CPU�̘b���o�Ă��Ă������s�v�c����Ȃ�����
>>497�����FUSION���Ɠd�E�g�ѓd�b�ɂƂ�������Ȃ���
�Ɠd�����Ɍv�悪�������ʂ�CPU�̘b���o�Ă��Ă������s�v�c����Ȃ�����
>>531
Cell���Ɠd�����Ɏg���́H�@������ĂȂ��_������́H
FUSION�̂悤��CPU+GPU�����A���^������v��ł�����̂��H
����Ƃ�Cell = �w�e���W�j�A�X�}���`�R�A���ĈӖ��Ŏg���Ă��̂��H
�����������Ƃ�����A�m���ɊԈႦ�������B
Cell���Ɠd�����Ɏg���́H�@������ĂȂ��_������́H
FUSION�̂悤��CPU+GPU�����A���^������v��ł�����̂��H
����Ƃ�Cell = �w�e���W�j�A�X�}���`�R�A���ĈӖ��Ŏg���Ă��̂��H
�����������Ƃ�����A�m���ɊԈႦ�������B
>>531
�lj�͂��������m�̑��� �撣��
�lj�͂��������m�̑��� �撣��
����Z�p�I�Ȓ��g�Ƃ��lj�͂Ƃ��ȑO��
�ǂꂪ�N�̔������Ƃ��������ĂȂ�2ch���S�҂̓V�R����ȋC�����Ă���������
�ǂꂪ�N�̔������Ƃ��������ĂȂ�2ch���S�҂̓V�R����ȋC�����Ă���������
>>534
����B�������ȁB����B�撣��B
����B�������ȁB����B�撣��B
>>532
���ʂ�HDTV�̓������R�[�_�[�Ƃ����ׂ̂������Ƃ�����@��ɗD�擋�ځA
��X�͑��̉Ɠd��CELL����pCPU��ς�ʼnƒ���l�b�g�Ōq���A���U�^�R���s���[�^�ɂ���Ƃ����Ƃ��Ƃ��̍\�z��������
���ł�SED�e���r��CELL�ς�ŐF�X��낤�Ƃ��Ă���A����06�N�̒i�K�ł̓j���[�X�ɂȂ��Ă���
�ł��A���݂͊��S�ɒ�~��ԁB�R�X�g��������������d�͂����������ŁA����
�u�Ɠd�ɂ͉Ɠd������CPU�ςق�������v
���Ęb�ɂȂ��Ă�B
�ėpCPU�Ȃ�Ė��ʂɍ��Ȃ��̐ς瑼�̐��i�Ƌ����o����̂�B
������Fusion�łǂ��˂����ނ�H�ėpCPU���̂������ĂȂ��A���Ęb�Ȃ̂�GPU�v���X���܂���A�ƌ����Ă��c
���ʂ�HDTV�̓������R�[�_�[�Ƃ����ׂ̂������Ƃ�����@��ɗD�擋�ځA
��X�͑��̉Ɠd��CELL����pCPU��ς�ʼnƒ���l�b�g�Ōq���A���U�^�R���s���[�^�ɂ���Ƃ����Ƃ��Ƃ��̍\�z��������
���ł�SED�e���r��CELL�ς�ŐF�X��낤�Ƃ��Ă���A����06�N�̒i�K�ł̓j���[�X�ɂȂ��Ă���
�ł��A���݂͊��S�ɒ�~��ԁB�R�X�g��������������d�͂����������ŁA����
�u�Ɠd�ɂ͉Ɠd������CPU�ςق�������v
���Ęb�ɂȂ��Ă�B
�ėpCPU�Ȃ�Ė��ʂɍ��Ȃ��̐ς瑼�̐��i�Ƌ����o����̂�B
������Fusion�łǂ��˂����ނ�H�ėpCPU���̂������ĂȂ��A���Ęb�Ȃ̂�GPU�v���X���܂���A�ƌ����Ă��c
>>536
z
z
>>536
AMD��Fusion�̈Ӗ����w�e���W�j�A�X�}���`�R�A�𗘗p���Ă�����Ē��x�̃u�����h�����炢��
�g���Ă邩��ACPU�{GPU�Ƃ͌���Ȃ���ˁB�A�Ɠd�����ɂ́A�ʂ̂Ȃɂ�����������\�������邵�A
Bobcat����CPU�̐��\�����邾�낤����AGPU��H264�f�R�[�h�Ɏg�����ĉ\�������邵�B
Cell��SPE��L�����p�����v���O�������̂��ʓ|�������Ƃ����̂�A�Ɠd������SPE�̌���
��������̂����������o�Ă��Ȃ��̂ŁACell���Ɠd�Ő������Ă��Ȃ���Fusion���������Ȃ��Ƃ�
�Ȃ�Ȃ����낤�B
�Ƃ͂����Ax86������i�i�ɗL�����Ă��Ƃ��Ȃ����낤����A���̑g�ݍ�����CPU�Ɣ�r�A������
���炳��邾���ŁAAMD�������悤�ȍ��@�\�ȉƓd�Ȃ�Fusion���L���Ƃ͂Ȃ肻���ɂȂ��C���B
AMD��Fusion�̈Ӗ����w�e���W�j�A�X�}���`�R�A�𗘗p���Ă�����Ē��x�̃u�����h�����炢��
�g���Ă邩��ACPU�{GPU�Ƃ͌���Ȃ���ˁB�A�Ɠd�����ɂ́A�ʂ̂Ȃɂ�����������\�������邵�A
Bobcat����CPU�̐��\�����邾�낤����AGPU��H264�f�R�[�h�Ɏg�����ĉ\�������邵�B
Cell��SPE��L�����p�����v���O�������̂��ʓ|�������Ƃ����̂�A�Ɠd������SPE�̌���
��������̂����������o�Ă��Ȃ��̂ŁACell���Ɠd�Ő������Ă��Ȃ���Fusion���������Ȃ��Ƃ�
�Ȃ�Ȃ����낤�B
�Ƃ͂����Ax86������i�i�ɗL�����Ă��Ƃ��Ȃ����낤����A���̑g�ݍ�����CPU�Ɣ�r�A������
���炳��邾���ŁAAMD�������悤�ȍ��@�\�ȉƓd�Ȃ�Fusion���L���Ƃ͂Ȃ肻���ɂȂ��C���B
GeodeGX����FUSION�𖼏�点���FUSION���Ă��ƂɂȂ�̂�
FUSION���Đ��i���ł͂Ȃ��ăR�[�h�l�[���ł́H
541 �FSocket774�F2007/06/28(��) 16:56:56 ID:LFh1O4C7
�ł���ڲ��ں��ް����Pen4 3G ������2GB�Ƃ��̂��Ă�Ȃ�����
>>536
Cell���Ɠd�Ɏg����\�肾�����̂͗L���Șb�B
�����ǁA�̂ƍ���Ō���Ă����傤���Ȃ����B
2-3�N�O�ɂ���Ȃ��Ǝv��ꂽ���\���A2-3�N��ɂ���Ȃ��Ƃ͌���Ȃ���
���ƁAAMD��Intel��"x86�n�̔ėpCPU"���Ɠd�Ɏ����Ă������̂́A
�v���O���~���O��x86�n�̖��߃Z�b�g���g���Ăł��邩��B
���܂ł̂悤�Ɋe�Ђ��Ǝ��̊J������Power�n��CPU����A
x86�n��CPU�Ɉڍs����A���̕����ЂɗL���ȊJ�������Y�܂��B
���̕��V����x86 CPU��K�v�Ƃ���s�ꂪ���܂�A���Ђɗ��v�������炷�����ł���B
�m����FUSION�̂悤�ȓ����`�b�v�́A�ȓd�͖ʂȂǂŏ����I�ɂ��s���͑��݂���B
�����A>>497�̋L����ǂ߂킩�邪�AAMD��FUSION�����܂ł̈Ӗ��ł͂Ȃ��āA
AMD���J������CPU+GPU�Ƃ����w�e���R�A�̑��̓I�Ȏg�����ɂ��Ă���B
�悤�́A���܂ł�FUSION�������ACPU+GPU�Ƌ敪�����ł͂Ȃ��āA
x86�nCPU����菬���Ȍ`�ɂ܂Ƃ߂�CPU+GPU�A���ȓd�͂̃`�b�v���w���Ă���̂ł́H
�ėpCPU�������Ă��Ȃ����ǂ����͍���̑��҂Ƃ̌��ˍ�����A�삯�����B
x86�n�̔ėpCPU���ǂ��܂ŏ���d�͂������A���\���o�����ɂ��������Ă��邾�낤�B
�ŁACell�͊m���ɂ��낢��ׂ��ɐ�o���Ďg�p����v������������ǁA
�m����Cell�̐��\�͍������A����ȊO�ɂ��낢��`�b�v��ς܂Ȃ�������Ȃ��B
���̓_�ł���ɏȓd�͂̓_�ł͕s���ɂȂ�B�C���l�Ƃ�����B
���̂��Ƃ���AFUSION��Cell�ł͍��{�I�ɖڎw���ꏊ���Ⴄ�Ǝv�����ǁH
Cell���Ɠd�Ɏg����\�肾�����̂͗L���Șb�B
�����ǁA�̂ƍ���Ō���Ă����傤���Ȃ����B
2-3�N�O�ɂ���Ȃ��Ǝv��ꂽ���\���A2-3�N��ɂ���Ȃ��Ƃ͌���Ȃ���
���ƁAAMD��Intel��"x86�n�̔ėpCPU"���Ɠd�Ɏ����Ă������̂́A
�v���O���~���O��x86�n�̖��߃Z�b�g���g���Ăł��邩��B
���܂ł̂悤�Ɋe�Ђ��Ǝ��̊J������Power�n��CPU����A
x86�n��CPU�Ɉڍs����A���̕����ЂɗL���ȊJ�������Y�܂��B
���̕��V����x86 CPU��K�v�Ƃ���s�ꂪ���܂�A���Ђɗ��v�������炷�����ł���B
�m����FUSION�̂悤�ȓ����`�b�v�́A�ȓd�͖ʂȂǂŏ����I�ɂ��s���͑��݂���B
�����A>>497�̋L����ǂ߂킩�邪�AAMD��FUSION�����܂ł̈Ӗ��ł͂Ȃ��āA
AMD���J������CPU+GPU�Ƃ����w�e���R�A�̑��̓I�Ȏg�����ɂ��Ă���B
�悤�́A���܂ł�FUSION�������ACPU+GPU�Ƌ敪�����ł͂Ȃ��āA
x86�nCPU����菬���Ȍ`�ɂ܂Ƃ߂�CPU+GPU�A���ȓd�͂̃`�b�v���w���Ă���̂ł́H
�ėpCPU�������Ă��Ȃ����ǂ����͍���̑��҂Ƃ̌��ˍ�����A�삯�����B
x86�n�̔ėpCPU���ǂ��܂ŏ���d�͂������A���\���o�����ɂ��������Ă��邾�낤�B
�ŁACell�͊m���ɂ��낢��ׂ��ɐ�o���Ďg�p����v������������ǁA
�m����Cell�̐��\�͍������A����ȊO�ɂ��낢��`�b�v��ς܂Ȃ�������Ȃ��B
���̓_�ł���ɏȓd�͂̓_�ł͕s���ɂȂ�B�C���l�Ƃ�����B
���̂��Ƃ���AFUSION��Cell�ł͍��{�I�ɖڎw���ꏊ���Ⴄ�Ǝv�����ǁH
>>541
�����B�L���ȏ��l�^�������ˁB�����{�C�Ŕ����ă^��������Ȃ��B
�W�Ȃ����ǁA���܃p�`���R���X���b�g�����̂̊�Ղɂ��A
NVIDIA�̃`�b�v�Ƃ�����Ă���炵�����H
�����B�L���ȏ��l�^�������ˁB�����{�C�Ŕ����ă^��������Ȃ��B
�W�Ȃ����ǁA���܃p�`���R���X���b�g�����̂̊�Ղɂ��A
NVIDIA�̃`�b�v�Ƃ�����Ă���炵�����H
>>540
���̏������͕s���m�����ǁAFUSION�͓����CPU�̃R�[�h�l�[���ł͂Ȃ��Ƃ̂��ƁB
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
��FUSION�\�z�̒���1�p�[�c�ƂȂ�Bobcat���Ēi���ŁA�ǂ������̂�AMD��FUSION�Ɋ܂ނ������Ă邪�A
�u�w�e���W�j�A�X�^�̃R���s���[�e�B���O�X�^�C���v�̂��̂�FUSION�ɑS���܂ނ炵���B
AMD��GeodeGX�����ꂩ����ǂ�ǂ���肪����Ȃ�AFUSION�̈���ɂȂ邩������Ȃ����ǁA
���\�I�ɂ�����ƌ�������Ȃ����ȁB
>>541
HD DVD�v���C���[�ƃ��R�[�_��Pen4-M���ˁB
���ł̏ꍇ�́APC���傪intel��CPU���ʂɔ����Ă��邩��A�����������\�����Ȃ��ɂ������炸�����ǁB
���̏������͕s���m�����ǁAFUSION�͓����CPU�̃R�[�h�l�[���ł͂Ȃ��Ƃ̂��ƁB
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
��FUSION�\�z�̒���1�p�[�c�ƂȂ�Bobcat���Ēi���ŁA�ǂ������̂�AMD��FUSION�Ɋ܂ނ������Ă邪�A
�u�w�e���W�j�A�X�^�̃R���s���[�e�B���O�X�^�C���v�̂��̂�FUSION�ɑS���܂ނ炵���B
AMD��GeodeGX�����ꂩ����ǂ�ǂ���肪����Ȃ�AFUSION�̈���ɂȂ邩������Ȃ����ǁA
���\�I�ɂ�����ƌ�������Ȃ����ȁB
>>541
HD DVD�v���C���[�ƃ��R�[�_��Pen4-M���ˁB
���ł̏ꍇ�́APC���傪intel��CPU���ʂɔ����Ă��邩��A�����������\�����Ȃ��ɂ������炸�����ǁB
�ŏ�����cell�͏���d�͂��l�b�N�ɂȂ�����Fusion�͂����Ȃ�Ȃ����낤
���Ďv���Ă�Ȃ炻�������ςޘb�Ȃ̂ɉ����S���Ĉ����������
���Ďv���Ă�Ȃ炻�������ςޘb�Ȃ̂ɉ����S���Ĉ����������
>>545
�ɂ���������B
�ɂ���������B
Fusion�Ȃ�ĂȂ�̎��̂��Ȃ��}�[�P�e�B���O�p��Ȃ���
�p��ɒނ�ꂸ���ꂼ��̕����AMD�ɏ����ڂ�����̂��l���Ȃ���ʖڂ���B
�c�c����Ȃ��Ƃ���Ԋ̐S�̃f�X�N�g�b�v/���o�C�������̃f���A���R�ACPU�̐��\��
Intel�Ƀ{�������̏��ǁ[����̂��ˁB
�p��ɒނ�ꂸ���ꂼ��̕����AMD�ɏ����ڂ�����̂��l���Ȃ���ʖڂ���B
�c�c����Ȃ��Ƃ���Ԋ̐S�̃f�X�N�g�b�v/���o�C�������̃f���A���R�ACPU�̐��\��
Intel�Ƀ{�������̏��ǁ[����̂��ˁB
>>547
>����Ȃ��Ƃ���Ԋ̐S�̃f�X�N�g�b�v/���o�C��������
>�f���A���R�ACPU�̐��\��
>Intel�Ƀ{�������̏��ǁ[����̂��ˁB
�E�E�E������
�̗͂����Ⴂ�̑���ɐ^�����������
�R���N���̕ǂɐ����Ԃ���悤�Ȑ^���͎~�߂�
����͔�PC����x86�v���Z�b�T�iFUSION�j�Ɏ����ڂ�
�Ƃ���������A���܂��ɂ͕������̂��H
>����Ȃ��Ƃ���Ԋ̐S�̃f�X�N�g�b�v/���o�C��������
>�f���A���R�ACPU�̐��\��
>Intel�Ƀ{�������̏��ǁ[����̂��ˁB
�E�E�E������
�̗͂����Ⴂ�̑���ɐ^�����������
�R���N���̕ǂɐ����Ԃ���悤�Ȑ^���͎~�߂�
����͔�PC����x86�v���Z�b�T�iFUSION�j�Ɏ����ڂ�
�Ƃ���������A���܂��ɂ͕������̂��H
>>550
�����Ȃ�S�������o���Ăǂ����悗
����ɐ^���������͂ނ���T�[�o����Quad����B
Dual�̂����$150�ȉ��̗̈�Ȃ獡��AMD�ł��\�������ɂȂ�B
AMD�͐̂��炻�̗̈�ŏ������Ă����B
���̃r�W�������܂����������Ă��Ȃ��̂͂Ȃ�Ȃ̂��ˁA���Ęb�B
�����Ȃ�S�������o���Ăǂ����悗
����ɐ^���������͂ނ���T�[�o����Quad����B
Dual�̂����$150�ȉ��̗̈�Ȃ獡��AMD�ł��\�������ɂȂ�B
AMD�͐̂��炻�̗̈�ŏ������Ă����B
���̃r�W�������܂����������Ă��Ȃ��̂͂Ȃ�Ȃ̂��ˁA���Ęb�B
>>550
��PC�n�ƂȂ�ƁA�����̑g�ݍ�����CPU�Ƌ������Ȃ��Ƃ����Ȃ���Ax86�n�Ƃ��Ă�
intel��LPIA�̖{����2008�N�ɓ�������̂ŁA��PC�n�ł�intel�ƂԂ���B
PC�s���intel�ƂԂ�����y�Ƃ͈�T�Ɍ����Ȃ����������B
��PC�n�ƂȂ�ƁA�����̑g�ݍ�����CPU�Ƌ������Ȃ��Ƃ����Ȃ���Ax86�n�Ƃ��Ă�
intel��LPIA�̖{����2008�N�ɓ�������̂ŁA��PC�n�ł�intel�ƂԂ���B
PC�s���intel�ƂԂ�����y�Ƃ͈�T�Ɍ����Ȃ����������B
>>549
�m��c�Ƃ������āA���ʂ�Phenom�̂��悩������ȁB
�m��c�Ƃ������āA���ʂ�Phenom�̂��悩������ȁB
>>539
Geode�V���[�Y�͏���d�͂����Ⴂ�ɂł�������g�����̂ɂȂ��
���āA�����_��Phenom X2��3����4���Ƃ�����o�Ă�킯�����A���̕�����3���܂łɉ������2�炢�ł������ȁc
Geode�V���[�Y�͏���d�͂����Ⴂ�ɂł�������g�����̂ɂȂ��
���āA�����_��Phenom X2��3����4���Ƃ�����o�Ă�킯�����A���̕�����3���܂łɉ������2�炢�ł������ȁc
>>554
���ʏo�ׂŁu�o�����I�v�ƌ������邩�������B
���ʏo�ׂŁu�o�����I�v�ƌ������邩�������B
�Ⴆ�v���Z�X��1�`2���㗣�����Ƃ��Ă�
ARM XScale MIPS PowerPC�̉�������͓̂��
ARM XScale MIPS PowerPC�̉�������͓̂��
>>555
�j�R�C�`�Łu�f���A���R�A�P�Ԃ̂�ł��I�v�݂����Ȃ��ȁB
�j�R�C�`�Łu�f���A���R�A�P�Ԃ̂�ł��I�v�݂����Ȃ��ȁB
>>557
�͂��͂�2001�N2001�N
�͂��͂�2001�N2001�N
Kuma�͉������A���\���킩���������^�̈��@�������Ǝv�����B
���̗\�z���ƁA���Ȃ蓾��s���肪���邪�����ނ�6000+�ƌ݊p�Ȃ̂�Kuma-2.6GHz�B
���̗\�z���ƁA���Ȃ蓾��s���肪���邪�����ނ�6000+�ƌ݊p�Ȃ̂�Kuma-2.6GHz�B
���ꂶ�Ⴀ�Ӗ��Ȃ������
>>560
����s���肪���邩��A���ӂȂƂ��낾���������
����s���肪���邩��A���ӂȂƂ��낾���������
6000+����3GHz���������B
L3��ʂɏ�����Ă邵6000+�Ɠ������Ă��Ƃ�
�Ȃ��Ǝv�����ǁB
L3��ʂɏ�����Ă邵6000+�Ɠ������Ă��Ƃ�
�Ȃ��Ǝv�����ǁB
>>562
6000+�̓L���b�V�����e��2MB
Kuma�̓L���b�V�����e��3MB
L3��L2��背�C�e���V�x���Ȃ�͂������炻��Ȃɕς���Ǝv����B
6000+�̓L���b�V�����e��2MB
Kuma�̓L���b�V�����e��3MB
L3��L2��背�C�e���V�x���Ȃ�͂������炻��Ȃɕς���Ǝv����B
�ς��Ȃ��Ȃ�킴�킴�v�ύX�����肵�Ȃ����낤
�ׂ�Dual�̂��߂�L3�\������Ă�킯����Ȃ�����B
Quad�̂��߂�L3�\���ŁAKuma��Agena�̃R�A���ɔł��g���܂킷���߂�
�����\���ɂȂ��Ă邾���B
Quad�̂��߂�L3�\���ŁAKuma��Agena�̃R�A���ɔł��g���܂킷���߂�
�����\���ɂȂ��Ă邾���B
>>550
�m���ɐ^���������������FUSION���J�����Ă�ɈႢ�Ȃ���
�`�l�c��intel�����ȏ�̐��\�̂b�o�t�͋��̂����銄��ɗ��v
�����Ȃ����Ďv���Ă�B�Ǝv��
�v�͂o�b�p�b�o�t�͗���Ƃ��܂ŗ��Ă���Ă������H
�V�����s���T���Ă�̂͂ǂ����ꏏ���ȁB
�m���ɐ^���������������FUSION���J�����Ă�ɈႢ�Ȃ���
�`�l�c��intel�����ȏ�̐��\�̂b�o�t�͋��̂����銄��ɗ��v
�����Ȃ����Ďv���Ă�B�Ǝv��
�v�͂o�b�p�b�o�t�͗���Ƃ��܂ŗ��Ă���Ă������H
�V�����s���T���Ă�̂͂ǂ����ꏏ���ȁB
567 �FSocket774�F2007/06/29(��) 01:24:27 ID:ULzfYajh
L2�AL3�̑��v��3MB�A2MBL2��6000+���͑������A�ہX3MB�ɂȂ�킯����Ȃ��B
http://pc.watch.impress.co.jp/docs/2006/1016/kaigai312.htm
����ƁA�����Ă���悤��L3�̃��C�e���V�[��L2���傫�����낤�B
���Ԃ�L���b�V�����ʂ̌��ʂ͂�����Ȃ��Ƃ݂�B
http://pc.watch.impress.co.jp/docs/2006/1016/kaigai312.htm
����ƁA�����Ă���悤��L3�̃��C�e���V�[��L2���傫�����낤�B
���Ԃ�L���b�V�����ʂ̌��ʂ͂�����Ȃ��Ƃ݂�B
Pentium4EE�ł������\���ʂ���������A������������Ǝv�����ǁB
�L���b�V���̗ʂ��ׂ����ɃR�A�̐��\���C�ɂ���B
�������̕����ł�������B
�������̕����ł�������B
������L���b�V�����x���Ă����C�����������͐��i�������낤�B
571 �FSocket774�F2007/06/29(��) 03:56:36 ID:N1L9crsN
�L���b�V���������瑁���Ă����傹��M���낤
DDR2�ADDR3�̓��C�e���V����������L���b�V������͐��\�ɒ������邾��B
�����̂܂ɂ��L���b�V���ݾ��ɂȂ��Ă��
��̑O��K8�̓����R���ς�ł邩��L���b�V�����₵�Ă����܂�Ӗ��Ȃ����ĊF�����Ă��̂�
���O��CMA�Ɋ������ꂷ������ˁH
K10��K8�̊g���łȂ���A�L���b�V���ς��Ă����܂Ō��ʂ��o��Ƃ͎v���Ȃ���
���A�l���[�U�[�����ɂ͑���K10��CMA�ɂ͏��ĂȂ��Ǝv��
K10�̐v�v�z�������A���Ȃ�T�[�o�[�������ӎ��������̂���
��̑O��K8�̓����R���ς�ł邩��L���b�V�����₵�Ă����܂�Ӗ��Ȃ����ĊF�����Ă��̂�
���O��CMA�Ɋ������ꂷ������ˁH
K10��K8�̊g���łȂ���A�L���b�V���ς��Ă����܂Ō��ʂ��o��Ƃ͎v���Ȃ���
���A�l���[�U�[�����ɂ͑���K10��CMA�ɂ͏��ĂȂ��Ǝv��
K10�̐v�v�z�������A���Ȃ�T�[�o�[�������ӎ��������̂���
>>573
DDR1�̓��C�e���V2��3��1T��Pen4(�m�[�X�o�R��CPU���A�N�Z�X)��
��ׂ����e�ʃL���b�V���͕K�v�ł͂Ȃ������B
���͂܂������������Ⴄ�BIntel�������R���������邵�L���b�V���͋���A
AMD���������[�̃��C�e���V�̓K���K�������邵�L���b�V���͐�����
�R�X�g�̌��ˍ�����������Ȃ����\�ʂł��s���ɂȂ��Ă�B
DDR1�̓��C�e���V2��3��1T��Pen4(�m�[�X�o�R��CPU���A�N�Z�X)��
��ׂ����e�ʃL���b�V���͕K�v�ł͂Ȃ������B
���͂܂������������Ⴄ�BIntel�������R���������邵�L���b�V���͋���A
AMD���������[�̃��C�e���V�̓K���K�������邵�L���b�V���͐�����
�R�X�g�̌��ˍ�����������Ȃ����\�ʂł��s���ɂȂ��Ă�B
DDR2��DDR3�́A�������o�X�̃N���b�N�����������Ă镪���C�e���V�������Ă���悤�Ɍ����邪�A
���ۂ�DDR1�Ɣ�ׂĂ���ȑ����Ă���킯����Ȃ����ADDR3��DDR2�ɔ�ׂČ����Ă������
�L�������������ȁB
�����ACPU�̃N���b�N�����IPC����ŁA�����҂����Ԃ�CPU���ł���͂������������ʂ͑����Ă��邾�낤����A
���̕��L���b�V���̏d�v���͈ȑO��葝���Ă邾�낤�B
���ۂ�DDR1�Ɣ�ׂĂ���ȑ����Ă���킯����Ȃ����ADDR3��DDR2�ɔ�ׂČ����Ă������
�L�������������ȁB
�����ACPU�̃N���b�N�����IPC����ŁA�����҂����Ԃ�CPU���ł���͂������������ʂ͑����Ă��邾�낤����A
���̕��L���b�V���̏d�v���͈ȑO��葝���Ă邾�낤�B
�S�R�Ⴄ�A�����ȃL���b�V���͌�����d�v�B
AMD�Ђ��_�C�T�C�Y�̊W�{������e�ʃL���b�V�������Z�p�͕s�����떂�����ׂɁA
�u�����R�����ڂ�AMD�ɃL���b�V���͂��܂�d�v�ł͂Ȃ��v���̉R�������Ă������B
�����R�����ڂŃ��������C�e���V�����Ȃ��Ƃ͂����L���b�V���̑��x�Ɣ�ׂ�Έ��|�I�ɒx���B
AMD�Ђ��_�C�T�C�Y�̊W�{������e�ʃL���b�V�������Z�p�͕s�����떂�����ׂɁA
�u�����R�����ڂ�AMD�ɃL���b�V���͂��܂�d�v�ł͂Ȃ��v���̉R�������Ă������B
�����R�����ڂŃ��������C�e���V�����Ȃ��Ƃ͂����L���b�V���̑��x�Ɣ�ׂ�Έ��|�I�ɒx���B
����S�R�R���ᖳ������B
�����܂��R�X�g�̌��ˍ����� �Z�p�I�ȑË��͕K�v�B
���܂�̂�Ȃ��悤�Ȃ��̐��Y�o����B
�����܂��R�X�g�̌��ˍ����� �Z�p�I�ȑË��͕K�v�B
���܂�̂�Ȃ��悤�Ȃ��̐��Y�o����B
�Ë��ƉR��臒l�̖����Ă��B
>�����R�����ڂ�AMD�ɃL���b�V���͂��܂�d�v�ł͂Ȃ�
�ł�����͖��炩�Ƀ��[�U�[�x���ɂ����������Ȃ��������B
�d�v�ł͂Ȃ��A�Ƃ����j���A���X���ǂ��~�߂邩���M�҂�����ȊO���̓��݊G�ɂȂ��Ă��K�X
>�����R�����ڂ�AMD�ɃL���b�V���͂��܂�d�v�ł͂Ȃ�
�ł�����͖��炩�Ƀ��[�U�[�x���ɂ����������Ȃ��������B
�d�v�ł͂Ȃ��A�Ƃ����j���A���X���ǂ��~�߂邩���M�҂�����ȊO���̓��݊G�ɂȂ��Ă��K�X
����܂��A���������̂����[�U�[�x���Ƃ������o���̂��������̐M�ҏL�����邪�ˁB
�̂���AMD�̂b�o�t�̓L���b�V���̗e�ʂɂ�鐫�\�������Ȃ������͎̂��������B
�i�L���b�V���̌��ʂ����Ȃ��̂��A�L���b�V�������炵�Ă����\�������Ȃ��̂��A�ǂ��炩�A���邢�͗����Ȃ̂��͂킩��Ȃ����j
�[���A�����K7�̍����炻������Ȃ��������H
L1���傫�߂�������r���L���b�V���Ȃ���������̂����m��Ȃ����B
�̂���AMD�̂b�o�t�̓L���b�V���̗e�ʂɂ�鐫�\�������Ȃ������͎̂��������B
�i�L���b�V���̌��ʂ����Ȃ��̂��A�L���b�V�������炵�Ă����\�������Ȃ��̂��A�ǂ��炩�A���邢�͗����Ȃ̂��͂킩��Ȃ����j
�[���A�����K7�̍����炻������Ȃ��������H
L1���傫�߂�������r���L���b�V���Ȃ���������̂����m��Ȃ����B
>>579
C2D���o�Đ��\�������i�ɓ]�ł���K�v�������_�C�T�C�Y������������ׂ�AMD�������o�������ƂȂ�B
C2D���o�Đ��\�������i�ɓ]�ł���K�v�������_�C�T�C�Y������������ׂ�AMD�������o�������ƂȂ�B
>>580
�ł��A�������Ƃ���Ɓ�n�ŃL���b�V���������Ȃ����R���킩���ȁB
�I�n�Ȃ�ΕʂɃL���b�V���𑝂₵���Ƃ���ŁA
���̃R�X�g���オ����̕��l�i�ɔ��f�ł���B
����Ƀf�X�N�g�b�v�n�ɔ�ׂĐ��Y�ʂ͂��قǖ��ɂȂ�Ȃ����낤���B
�܂��A�ߋ���CPU�x���`������ƁA512kb�ł�1MB�łƂł́A
�債�����\�����o�ĂȂ��������������B
�����1MB��2MB�ɂ���c����B2MB��4MB�ɂ���ΈႤ���Ă����̂́A
�Ȃi���Z���X���Ă������B�܂��c�撣��Ƃ����B
�ł��A�������Ƃ���Ɓ�n�ŃL���b�V���������Ȃ����R���킩���ȁB
�I�n�Ȃ�ΕʂɃL���b�V���𑝂₵���Ƃ���ŁA
���̃R�X�g���オ����̕��l�i�ɔ��f�ł���B
����Ƀf�X�N�g�b�v�n�ɔ�ׂĐ��Y�ʂ͂��قǖ��ɂȂ�Ȃ����낤���B
�܂��A�ߋ���CPU�x���`������ƁA512kb�ł�1MB�łƂł́A
�債�����\�����o�ĂȂ��������������B
�����1MB��2MB�ɂ���c����B2MB��4MB�ɂ���ΈႤ���Ă����̂́A
�Ȃi���Z���X���Ă������B�܂��c�撣��Ƃ����B
���ۂ��������A�[�L�e�N�`���Ȃ��� ��Ō���������
�R���Ă����킯���ᖳ����B
�����C2D���o�邸���ƑO����Pen4�̃A�[�L�e�N�`�����ׂ�
���������b�͉��x�����Ă邾��B
�v�����݂ő����ł邾���B
�R���Ă����킯���ᖳ����B
�����C2D���o�邸���ƑO����Pen4�̃A�[�L�e�N�`�����ׂ�
���������b�͉��x�����Ă邾��B
�v�����݂ő����ł邾���B
>>580
���̎�̋ꂵ����͐��\���s���̎��ɁA�c�b�R�~�������Ƃǂ��̃��[�J�[�����Č����i�č����[�J�[�͂Ƃ��Ɂj����E�E
�����炢���猾���Ă��ǂ��ƌ������Ƃɂ��Ȃ�B
�J�����̘b�ŁA�t�H�[�T�[�Y�Ƃ����K�i������̂����A���ꂪ���̃f�W�^�������
�����߂�CCD���g���K�i�Ȃ̂����A���̋K�i�𐄐i�����I�����p�X�E�R�_�b�N��
�u�J�����̏��^���Ɖ掿�̃o�����X����邽�߂ɂ́`�����`���̃T�C�Y���œK�v�ĂȎ��������Ă���
���ۂɏo���オ�����J������APS-C�̃J�����̃T�C�Y�ƑS����������̃T�C�Y��
�]���ɂȂ����͉̂掿������������E�E
�g�����X���^�������͂��Ȃ�ꂵ�����Ƃ����Ă���ȁB
��{�A���[�J�[���ĕs���ȂƂ���͍m�肵�Ȃ�����B
���̎�̋ꂵ����͐��\���s���̎��ɁA�c�b�R�~�������Ƃǂ��̃��[�J�[�����Č����i�č����[�J�[�͂Ƃ��Ɂj����E�E
�����炢���猾���Ă��ǂ��ƌ������Ƃɂ��Ȃ�B
�J�����̘b�ŁA�t�H�[�T�[�Y�Ƃ����K�i������̂����A���ꂪ���̃f�W�^�������
�����߂�CCD���g���K�i�Ȃ̂����A���̋K�i�𐄐i�����I�����p�X�E�R�_�b�N��
�u�J�����̏��^���Ɖ掿�̃o�����X����邽�߂ɂ́`�����`���̃T�C�Y���œK�v�ĂȎ��������Ă���
���ۂɏo���オ�����J������APS-C�̃J�����̃T�C�Y�ƑS����������̃T�C�Y��
�]���ɂȂ����͉̂掿������������E�E
�g�����X���^�������͂��Ȃ�ꂵ�����Ƃ����Ă���ȁB
��{�A���[�J�[���ĕs���ȂƂ���͍m�肵�Ȃ�����B
>>582
�Ⴄ�Ⴄ�B���႟�B�Ȃ�ŃR�X�g�ʂł��قǖ��̏o�Ȃ��ł��낤�A
��n�ŃL���b�V�����ʔł��o�Ȃ��̂�����ȂB
�����L���p�ɉe�����ł�قǁ�n������ɔ��ꂷ���Ă����̂��H
�Ⴆ�AS940����Socket F�ɕύX�����Ƃ��Ȃ�āA
�L���b�V���𑝂₷��D�@��Ǝv���B�ꎞ�I�ɃL���b�V���𑝂₵�Ă��A
C2D�n�w�������ɑR�ł�����ꂾ���Ō�̎��������͂��B��������ł��Ȃ������H
>C2D���o�Đ��\�������i�ɓ]�ł���K�v�������_�C�T�C�Y������������ׂ�AMD�������o��������
�Ⴆ����́AC2D�̃L���b�V���ʂ��݂āA�s�ꂩ��ł��uL2�L���b�V�����ʂ��Ȃ��̂��H�v�Ƃ̋^��ɁA
AMD���uHammer�n��L2�L���b�V�����₵�Ă��Ӗ��˂����_��v���ē������������������B
���̎��ɐ��\��������������A�u�����B���i���������邽�߂̌����ȁv���Ďv�������������m��B
�Ⴄ�Ⴄ�B���႟�B�Ȃ�ŃR�X�g�ʂł��قǖ��̏o�Ȃ��ł��낤�A
��n�ŃL���b�V�����ʔł��o�Ȃ��̂�����ȂB
�����L���p�ɉe�����ł�قǁ�n������ɔ��ꂷ���Ă����̂��H
�Ⴆ�AS940����Socket F�ɕύX�����Ƃ��Ȃ�āA
�L���b�V���𑝂₷��D�@��Ǝv���B�ꎞ�I�ɃL���b�V���𑝂₵�Ă��A
C2D�n�w�������ɑR�ł�����ꂾ���Ō�̎��������͂��B��������ł��Ȃ������H
>C2D���o�Đ��\�������i�ɓ]�ł���K�v�������_�C�T�C�Y������������ׂ�AMD�������o��������
�Ⴆ����́AC2D�̃L���b�V���ʂ��݂āA�s�ꂩ��ł��uL2�L���b�V�����ʂ��Ȃ��̂��H�v�Ƃ̋^��ɁA
AMD���uHammer�n��L2�L���b�V�����₵�Ă��Ӗ��˂����_��v���ē������������������B
���̎��ɐ��\��������������A�u�����B���i���������邽�߂̌����ȁv���Ďv�������������m��B
���ꂾ�Ƒ�|����ɐV�����f�U�C���������Ȃ��Ƒʖڂ���B
�����AMD�͍H�ꂪ1�Ȃ��琶�Y����INTEL���
�����Ɛ����������B
�o�c�I�ɂ��L���b�V���𐧌��ł���A�[�L�e�N�`����
���Ă�Ƃ������ƁB���ʂ��Ă邾��B
�����AMD�͍H�ꂪ1�Ȃ��琶�Y����INTEL���
�����Ɛ����������B
�o�c�I�ɂ��L���b�V���𐧌��ł���A�[�L�e�N�`����
���Ă�Ƃ������ƁB���ʂ��Ă邾��B
�ǂ��ł��������ǁAOpteron����ƕ\������́A���N�Ԃ肩�Ō�����B���������B
IntelMac���o��ȑO�AMAC�I�^��Opteron�X����
�X���Z�l�ƒ��ǂ��b���Ă������ȗ����ȁA�݂��́E�E
IntelMac���o��ȑO�AMAC�I�^��Opteron�X����
�X���Z�l�ƒ��ǂ��b���Ă������ȗ����ȁA�݂��́E�E
> �Ⴆ����́AC2D�̃L���b�V���ʂ��݂āA�s�ꂩ��ł��uL2�L���b�V�����ʂ��Ȃ��̂��H�v�Ƃ̋^��ɁA
> AMD���uHammer�n��L2�L���b�V�����₵�Ă��Ӗ��˂����_��v���ē������������������B
����͂��܂�ɂ���������A������K10�ł̓L���b�V���e�ʑ��₵�܂���w
> AMD���uHammer�n��L2�L���b�V�����₵�Ă��Ӗ��˂����_��v���ē������������������B
����͂��܂�ɂ���������A������K10�ł̓L���b�V���e�ʑ��₵�܂���w
K8�́AL2�L���b�V���̃��C�e���V�ł����������ш拷�����炠�܂�L���b�V���̌��ʖ���������łȂ��́B
K10��L2�Ƃ̃o�X�����{�ɂȂ��Ă邵���C�e���V���팸���Ă邻��������L���b�V���̌��ʗL��A�ƌ��đ��₵���E�E���ǂ�����K10�o�Ă݂Ȃ��Ƃ킩��ǂ�
K10��L2�Ƃ̃o�X�����{�ɂȂ��Ă邵���C�e���V���팸���Ă邻��������L���b�V���̌��ʗL��A�ƌ��đ��₵���E�E���ǂ�����K10�o�Ă݂Ȃ��Ƃ킩��ǂ�
�P��1M��512K�Ő[���ȉe���͂Ȃ����Ĕ��f����
Core 2 Duo�͂���ς�������肾���� Part22
http://pc11.2ch.net/test/read.cgi/jisaku/1181829644/
787 ���O�F�G���{�� pd3fde3.osaknt01.ap.so-net.ne.jp ���e���F2007/06/29(��) 12:23:34 ID:jDpIom0M
����{�ƂȂ�ł����Ă�w
788 ���O�F�G���{�� ��ugc/ULAIhY ���e���F2007/06/29(��) 12:24:13 ID:jDpIom0M
�g���b�v�t���Ƃ�����w
791 ���O�F�G���{�� ��ugc/ULAIhY ���e���F2007/06/29(��) 12:26:55 ID:mhRRtQ4z
�����ă��_�ɍU�������̌������烊���z�ύXw
http://pc11.2ch.net/test/read.cgi/jisaku/1181829644/
787 ���O�F�G���{�� pd3fde3.osaknt01.ap.so-net.ne.jp ���e���F2007/06/29(��) 12:23:34 ID:jDpIom0M
����{�ƂȂ�ł����Ă�w
788 ���O�F�G���{�� ��ugc/ULAIhY ���e���F2007/06/29(��) 12:24:13 ID:jDpIom0M
�g���b�v�t���Ƃ�����w
791 ���O�F�G���{�� ��ugc/ULAIhY ���e���F2007/06/29(��) 12:26:55 ID:mhRRtQ4z
�����ă��_�ɍU�������̌������烊���z�ύXw
����MS-DOS����Ȃ�OS�̃�������ԑS���L���b�V���ɏ��̂ɂ�
X68000��Expert��XVI���炢�̃�������ԂȂ�AE4400�ł��S���L���b�V���ɏ���Ă��܂��Ƃ́E�E���낵��
X68000��Expert��XVI���炢�̃�������ԂȂ�AE4400�ł��S���L���b�V���ɏ���Ă��܂��Ƃ́E�E���낵��
>>585
������A�����L���p��t��t�ɂȂ�قǂłĂ����āc�B
Xeon��ɃV�F�A�𗎂Ƃ��Ă���A�����ł����ʂ��Đ��\���҂��������������낤�B
�܂��B�o�Ȃ��������̐��\�ɑ��Ă������������Ă����傤���Ȃ����ǂ��B
�[���B65nm�Ɉڍs������AL2�̃��e���V�[���������i�K�ŁA
���L���b�V����AM2�ł������悩�����̂ɂȁB
�Ă��AK10�x�����̌v���L2���ʔł��ĂȂ����������H
>>587
K10�ő�������L���b�V����L3�L���b�V���ȁB
�����悤�ňႤ���Ǔ����B����L3������45nm�܂Ō��z���Ă���Ȃ��̂��ȁH
������A�����L���p��t��t�ɂȂ�قǂłĂ����āc�B
Xeon��ɃV�F�A�𗎂Ƃ��Ă���A�����ł����ʂ��Đ��\���҂��������������낤�B
�܂��B�o�Ȃ��������̐��\�ɑ��Ă������������Ă����傤���Ȃ����ǂ��B
�[���B65nm�Ɉڍs������AL2�̃��e���V�[���������i�K�ŁA
���L���b�V����AM2�ł������悩�����̂ɂȁB
�Ă��AK10�x�����̌v���L2���ʔł��ĂȂ����������H
>>587
K10�ő�������L���b�V����L3�L���b�V���ȁB
�����悤�ňႤ���Ǔ����B����L3������45nm�܂Ō��z���Ă���Ȃ��̂��ȁH
K10�ȍ~�ŃL���b�V���������Č����Ă�̂�L3���ˁB
���ǂ��ł��������ǁAOpteron����ƕ\������́A���N�Ԃ肩�Ō�����B���������B
������
������
>>592
�����Ă��킩��Ȃ��݂��������R�A�̃f�U�C������Ƃ������Ƃ�
�������C������Ƃ������ƁB�_�C���傫���Ȃ�ƕ����܂�������邵
�L���b�V���e�ʂ͂����Ȍ��ˍ����Ō��߂��Ă�B
����ȊȒP�Ȃ��Ƃ���Ȃ���B
�����Ă��킩��Ȃ��݂��������R�A�̃f�U�C������Ƃ������Ƃ�
�������C������Ƃ������ƁB�_�C���傫���Ȃ�ƕ����܂�������邵
�L���b�V���e�ʂ͂����Ȍ��ˍ����Ō��߂��Ă�B
����ȊȒP�Ȃ��Ƃ���Ȃ���B
�ŋ߂̏������݂�ǂތ���A����Ƃ��̃X�����������ł��镁�ʂ̃q�g�������Ă������ˁB
�A�����ƌĂꂽ�A�����o�čs���Ă��ꂽ�̂팋�\�Șb���B
����Barcelona���ڗ\���SUN��"Constellation System"�̃j���[�X����m�̂��ƂƎv�����B
http://japan.cnet.com/news/ent/story/0,2000056022,20351637,00.htm
TACC (Texas Advanced Computing Center)�̃T�C�g�Ŏd�l�̏ڍׂ�ǂނƁA
http://www.tacc.utexas.edu/resources/hpcsystems/#ranger
�@�E13,152�v���Z�b�T
�@�E�N�A�h�R�A�A�b�v�O���[�h�łŗ\�z�s�[�N���\: 421TFlops
���ꂩ�瓮��N���b�N���v�Z����ƁABarcelona��R�A������4-flops������A
�@420 x 10^3 [GFlops] / ( 13,152 [processors] x 4 [core] * 4 [flops/core] ) �` 2.0 [GHz]
�ƂȂ邷�B
���N�����ς���A�ŏd�v�ڋq���ł���ł���̂�2GHz�Ƃ������Ƃ����邷�B
�A�����ƌĂꂽ�A�����o�čs���Ă��ꂽ�̂팋�\�Șb���B
����Barcelona���ڗ\���SUN��"Constellation System"�̃j���[�X����m�̂��ƂƎv�����B
http://japan.cnet.com/news/ent/story/0,2000056022,20351637,00.htm
TACC (Texas Advanced Computing Center)�̃T�C�g�Ŏd�l�̏ڍׂ�ǂނƁA
http://www.tacc.utexas.edu/resources/hpcsystems/#ranger
�@�E13,152�v���Z�b�T
�@�E�N�A�h�R�A�A�b�v�O���[�h�łŗ\�z�s�[�N���\: 421TFlops
���ꂩ�瓮��N���b�N���v�Z����ƁABarcelona��R�A������4-flops������A
�@420 x 10^3 [GFlops] / ( 13,152 [processors] x 4 [core] * 4 [flops/core] ) �` 2.0 [GHz]
�ƂȂ邷�B
���N�����ς���A�ŏd�v�ڋq���ł���ł���̂�2GHz�Ƃ������Ƃ����邷�B
6000+��65nm�����܂�����ė~�����ł��ˁB
�딚
>>596
���ƁA�A������������Ȃ��Ă��Ȃ�������Ȃ���ł����ǁH
���ƁA�A������������Ȃ��Ă��Ȃ�������Ȃ���ł����ǁH
����o�������A�L���b�V���ɂ��p�t�H�[�}���X�A�b�v����
y=log x�@�݂����Ȋ�������B�����������͗e�ʑ��ɂ����p�������傾��
������x�傫���Ȃ�ƁA�{�������Ă����X������ʁB
y=log x�@�݂����Ȋ�������B�����������͗e�ʑ��ɂ����p�������傾��
������x�傫���Ȃ�ƁA�{�������Ă����X������ʁB
�Q�n�ɓ]�������Ǝv���Ă���@�A���ė��Ȃ��Ă����̂�
>>600
���̂�����͍��N���b�N���ɂ�鐫�\�E�v�����Ă��ȁB
�ǂ�������F�̓��C���������̑��x���A���{�I�l�b�N�ɂȂ��Ă�_�����������B
���̂�����͍��N���b�N���ɂ�鐫�\�E�v�����Ă��ȁB
�ǂ�������F�̓��C���������̑��x���A���{�I�l�b�N�ɂȂ��Ă�_�����������B
603 �FMAC�I�^��586 �����F2007/06/29(��) 20:39:47 ID:hM78bIG1
>>586
�@�@------------------
�@�@IntelMac���o��ȑO�AMAC�I�^��Opteron�X����
�@�@�X���Z�l�ƒ��ǂ��b���Ă������ȗ����ȁA�݂��́E�E
�@�@------------------
Intel Mac�̔��\��2�N�O�̘b�����ǁA�A�����Ǝ��̈�����A���������ȑO����̃��m��(��)
http://pc3.2ch.net/test/read.cgi/jisaku/1033611085/
�@�@==================
�@�@892 ���O�F�L�I�^ ���e���F02/11/25 23:43 ID:qcG8fW2C
�@�@�@�@MAC�I�^�ɂ͈�ڒu���Ă������ǂ������肾�ɂ�B
�@�@�@�@�e���͂���ȉ�Ђ���Ȃ��ɂ�B�V�J�g�ł��Ȃ��Ȃ����̂�
�@�@�@�@���[�U�[�̐�����Ȃ��ăg�����X���^���̃j�b�`��_�����C�o�����ɂ�B
�@�@�@�@10%�̐��\���オ�K�v�Ȃ̂̓C���e���ŁA���[�U�[����Ȃ��ɂ�B
�@�@�@�@���C�o����10%����t���邽�ߓ���2�{�i��ɐ��]��ł����j�A
�@�@�@�@������3�{�̉��i�Ŕ���̂��e�����ɂ�B
�@�@�@�@�����T�C�g�ɖ߂�ɂ�B
�@�@902 ���O�FSocket774 ���e���F02/11/26 00:54 ID:TlOUJMDo
�@�@�@�@���߂������Bcrusoe�������l��intel���̑�łȂ��ƋC�����܂Ȃ��݂������ȁB
�@�@�@�@�b���鉿�l�����B
�@�@903 ���O�FSocket774 ���e���F02/11/26 01:00 ID:oEBv+0WS
�@�@�@�@�e���I�^�ɖ��O�ς�����B
�@�@==================
���̘A�������]������߂Ă�̂��ǂ����S�z���B
�@�@------------------
�@�@IntelMac���o��ȑO�AMAC�I�^��Opteron�X����
�@�@�X���Z�l�ƒ��ǂ��b���Ă������ȗ����ȁA�݂��́E�E
�@�@------------------
Intel Mac�̔��\��2�N�O�̘b�����ǁA�A�����Ǝ��̈�����A���������ȑO����̃��m��(��)
http://pc3.2ch.net/test/read.cgi/jisaku/1033611085/
�@�@==================
�@�@892 ���O�F�L�I�^ ���e���F02/11/25 23:43 ID:qcG8fW2C
�@�@�@�@MAC�I�^�ɂ͈�ڒu���Ă������ǂ������肾�ɂ�B
�@�@�@�@�e���͂���ȉ�Ђ���Ȃ��ɂ�B�V�J�g�ł��Ȃ��Ȃ����̂�
�@�@�@�@���[�U�[�̐�����Ȃ��ăg�����X���^���̃j�b�`��_�����C�o�����ɂ�B
�@�@�@�@10%�̐��\���オ�K�v�Ȃ̂̓C���e���ŁA���[�U�[����Ȃ��ɂ�B
�@�@�@�@���C�o����10%����t���邽�ߓ���2�{�i��ɐ��]��ł����j�A
�@�@�@�@������3�{�̉��i�Ŕ���̂��e�����ɂ�B
�@�@�@�@�����T�C�g�ɖ߂�ɂ�B
�@�@902 ���O�FSocket774 ���e���F02/11/26 00:54 ID:TlOUJMDo
�@�@�@�@���߂������Bcrusoe�������l��intel���̑�łȂ��ƋC�����܂Ȃ��݂������ȁB
�@�@�@�@�b���鉿�l�����B
�@�@903 ���O�FSocket774 ���e���F02/11/26 01:00 ID:oEBv+0WS
�@�@�@�@�e���I�^�ɖ��O�ς�����B
�@�@==================
���̘A�������]������߂Ă�̂��ǂ����S�z���B
���]����Ă�킯�ł��Ȃ��f�ʼn��N������Ȍ`�ő��݃A�s�[�����Ă�l�̂������ƐS�z��
�������ɂȂ�Ȃ��̂ɂ퉽������w�Ȏg���ł����邩��Ȃ��H��
�A�����o�łƂ�����
�������ɂȂ�Ȃ��̂ɂ퉽������w�Ȏg���ł����邩��Ȃ��H��
�A�����o�łƂ�����
605 �FMAC�I�^��604 �����F2007/06/29(��) 21:49:00 ID:hM78bIG1
>>604
�@�@----------------
�@�@�������ɂȂ�Ȃ��̂ɂ퉽������w�Ȏg��
�@�@----------------
>>603������Δ���悤�ɁA5�N��ɂ��n���������N���̂ɂ�֗���(��)
�@�@----------------
�@�@�������ɂȂ�Ȃ��̂ɂ퉽������w�Ȏg��
�@�@----------------
>>603������Δ���悤�ɁA5�N��ɂ��n���������N���̂ɂ�֗���(��)
AMD��Barcelona���������\�������B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~118193,00.html
���}�����Ă��������ǁA�R�����g���ŁB�B�B
http://www.amd.com/us-en/Corporate/VirtualPressRoom/0,,51_104_543~118193,00.html
���}�����Ă��������ǁA�R�����g���ŁB�B�B
607 �FMAC�I�^�F2007/06/29(��) 22:28:06 ID:hM78bIG1
�ꉞ�Aage�Ƃ����B
���ς�炸���������Ă���̂̓A���`AMD�ł���MAC�I�^������
���̃X���̍\�}�͖ʔ����킗
���̃X���̍\�}�͖ʔ����킗
�����ė\��ʂ肾��
���X�E�E�E
���X�E�E�E
��[���A���߂łƂ�
611 �FMAC�I�^�F2007/06/29(��) 23:06:58 ID:hM78bIG1
>>606��AMD�̃����[�X��TheInquirer�̉���ǂ��B
http://www.theinquirer.net/default.aspx?article=40680
AMD�̃����[�X�ɂ��������邷���ǁA
�@�@-------------------
�@�@Designed to operate within the same thermal envelopes as current generation
�@�@AMD Opteron processors, AMD estimates that the new processors can provide
�@�@a performance increase up to 70 percent on certain database applications and
�@�@up to 40 percent on certain floating point applications, with subsequent higher
�@�@frequency processors expected to significantly add to this performance advantage.
�@�@-------------------
�v����ɁA���sOpteron�Ɓu����TDP�Łv��r����ƁA40-70%�̐��\���オ����ƌ����Ă邾��
���B���X�u����TDP��2�R�A����4�R�A�Ɂv���Ă̂����肾����������A���̐��\����ɂ�
�R�A��2�{�ɑ��������ʂŁA�R�A������̐��\�����͂��B�B�B���Ă��Ƃ̂悤�ŁB
�N���܂ł�A�ō��̃O���[�h��2GHz������Ƃ��Ƃ������Ƃ�����A�F�X�ȈӖ��Ő��ꂵ�������B
http://www.theinquirer.net/default.aspx?article=40680
AMD�̃����[�X�ɂ��������邷���ǁA
�@�@-------------------
�@�@Designed to operate within the same thermal envelopes as current generation
�@�@AMD Opteron processors, AMD estimates that the new processors can provide
�@�@a performance increase up to 70 percent on certain database applications and
�@�@up to 40 percent on certain floating point applications, with subsequent higher
�@�@frequency processors expected to significantly add to this performance advantage.
�@�@-------------------
�v����ɁA���sOpteron�Ɓu����TDP�Łv��r����ƁA40-70%�̐��\���オ����ƌ����Ă邾��
���B���X�u����TDP��2�R�A����4�R�A�Ɂv���Ă̂����肾����������A���̐��\����ɂ�
�R�A��2�{�ɑ��������ʂŁA�R�A������̐��\�����͂��B�B�B���Ă��Ƃ̂悤�ŁB
�N���܂ł�A�ō��̃O���[�h��2GHz������Ƃ��Ƃ������Ƃ�����A�F�X�ȈӖ��Ő��ꂵ�������B
�Ȃ���Ăɕ����������Ȃ�
��������
��������
4�R�A�ɂȂ������̌���ȊO�����Ȃ��݂��������B
������2�R�C�`�ɂ����l�C�e�B�u�R�A��K��������
�J�����������B���낻��Nvidia�ɔ������������߂���
������2�R�C�`�ɂ����l�C�e�B�u�R�A��K��������
�J�����������B���낻��Nvidia�ɔ������������߂���
�j�R�C�`�ɂ����A���Ă̂��ԈႢ�B
Kentsfield�����\�������̂̓j�R�C�`������B
�j�R�C�`������Conroe�̂��Ƃ����ɔ����ł���G-STEPPING��TDP���ǂ��o�����B
�j�R�C�`����������܂肪�����̂ō��N���b�N�ł������ɒł���B
Kentsfield�����\�������̂̓j�R�C�`������B
�j�R�C�`������Conroe�̂��Ƃ����ɔ����ł���G-STEPPING��TDP���ǂ��o�����B
�j�R�C�`����������܂肪�����̂ō��N���b�N�ł������ɒł���B
>>614
�Ƃ������Ƃ�2�C�`�̂ق����������Ă��Ƃ���ȁH
�Z�p�I�ȉ��l�Ȃǒu���Ă��������ʂŌ����ꍇ�\����
�ǂ����\��������̂̓j�R�C�`���Ă��Ƃ���H
�Ƃ������Ƃ�2�C�`�̂ق����������Ă��Ƃ���ȁH
�Z�p�I�ȉ��l�Ȃǒu���Ă��������ʂŌ����ꍇ�\����
�ǂ����\��������̂̓j�R�C�`���Ă��Ƃ���H
>>615
Intel��MCM�Z�p�̃R�X�g�p�t�H�[�}���X�����ꂾ�������i�ǂ��Ȃ����j�Ƃ������Ƃ�
AMD�������ɐ^���ł�����̂ł͂Ȃ����ǂˁB
Intel��MCM�Z�p�̃R�X�g�p�t�H�[�}���X�����ꂾ�������i�ǂ��Ȃ����j�Ƃ������Ƃ�
AMD�������ɐ^���ł�����̂ł͂Ȃ����ǂˁB
�^������O�ɋz�������Ȃ����
618 �FMAC�I�^�F2007/06/29(��) 23:40:31 ID:hM78bIG1
eWeek�̋L����AMD�̏d����>>611�Ɠ����R�����g���Ă��邷�B
http://www.eweek.com/article2/0,1895,2152593,00.asp
�@�@---------------------
�@�@In addition to the 2.0GHz clock speed, Shaw said that the quad-core Opteron
�@�@processor will work within the same thermal envelope as the company's dual-core
�@�@chips.
�@�@[����]
�@�@The result, Shaw said, is not only better performance but also better performance
�@�@per watt.
�@�@"With typical servers workloads, we will be able to show a 40 to 50 percent increase
�@�@in performance, and in some cases, as much as a 70 percent improvement," Shaw said.
�@�@---------------------
�ǂ����{���ɐ�ΐ��\���オ�錩���݂햳���������B
http://www.eweek.com/article2/0,1895,2152593,00.asp
�@�@---------------------
�@�@In addition to the 2.0GHz clock speed, Shaw said that the quad-core Opteron
�@�@processor will work within the same thermal envelope as the company's dual-core
�@�@chips.
�@�@[����]
�@�@The result, Shaw said, is not only better performance but also better performance
�@�@per watt.
�@�@"With typical servers workloads, we will be able to show a 40 to 50 percent increase
�@�@in performance, and in some cases, as much as a 70 percent improvement," Shaw said.
�@�@---------------------
�ǂ����{���ɐ�ΐ��\���オ�錩���݂햳���������B
����TDP��AMD�̗\���قlj������ĂȂ��Ƃ����������������̂�
����ȉ����Ȑ���͂���܈Ӗ��Ȃ��B
�ǂ������������x���`�o�邩�炨�ƂȂ����҂āB
����ȉ����Ȑ���͂���܈Ӗ��Ȃ��B
�ǂ������������x���`�o�邩�炨�ƂȂ����҂āB
620 �FMAC�I�^��619 �����F2007/06/29(��) 23:53:41 ID:hM78bIG1
>>619
�@�@----------------
�@�@�ǂ������������x���`�o�邩�炨�ƂȂ����҂āB
�@�@----------------
����̃����[�X����ɏ������o���ĂȂ���ԂŊ�����ŏo�����Ǝv���邷�B
�@�@================
�@�@, with systems from AMD platform partners beginning to ship in September 2007.
�@�@================
�Ƃ������Ƃ�����ANDA��������9���܂ŏ��o�Ȃ������B
�@�@----------------
�@�@�ǂ������������x���`�o�邩�炨�ƂȂ����҂āB
�@�@----------------
����̃����[�X����ɏ������o���ĂȂ���ԂŊ�����ŏo�����Ǝv���邷�B
�@�@================
�@�@, with systems from AMD platform partners beginning to ship in September 2007.
�@�@================
�Ƃ������Ƃ�����ANDA��������9���܂ŏ��o�Ȃ������B
����x���`�o���Ȃ��ł��傤�B
�S�s�K�{�����甭�\���Ȍ�ɂ����x���`�łȂ����B
�I���͍����Y�ǂ��ӂ�킯�邩�����[�����Ă邼
�S�s�K�{�����甭�\���Ȍ�ɂ����x���`�łȂ����B
�I���͍����Y�ǂ��ӂ�킯�邩�����[�����Ă邼
9��10�������Ȃ̂�9���܂Ńx���`�o�Ȃ��Ƃ�������Ȃ�ł����肦�Ȃ�����B
����ȃK�[�h�ł��Ȃ�Comptex�̔����ł��x���`�L���Ȃ�ďo�Ȃ���B
����ȃK�[�h�ł��Ȃ�Comptex�̔����ł��x���`�L���Ȃ�ďo�Ȃ���B
INQ�̓K���v�Z���炷��ƁABarcelona�̃R�A�ӂ�̐��\��K8�ɑ��āA
���10%�O��A���������_���C������20%���炢���҂ł�����Ă��炢���B
�ȑO����o�Ă�SPEC�̃V�~�����[�V�����l�ƌ��sOpteron�̐��l����̗\���Ǝ����悤��
�Ƃ���ɗ��������Ă���悤���B
Barcelona��Agena��4�R�A�ɂȂ����Ƃ������_�����邩��܂������A
2.6GHz���炢�ł�Kuma��6000+�ɂ����ĂȂ��x���`�����\���������B
���10%�O��A���������_���C������20%���炢���҂ł�����Ă��炢���B
�ȑO����o�Ă�SPEC�̃V�~�����[�V�����l�ƌ��sOpteron�̐��l����̗\���Ǝ����悤��
�Ƃ���ɗ��������Ă���悤���B
Barcelona��Agena��4�R�A�ɂȂ����Ƃ������_�����邩��܂������A
2.6GHz���炢�ł�Kuma��6000+�ɂ����ĂȂ��x���`�����\���������B
6000+�ɏ��ĂȂ��Ƃ������Ƃ́c
625 �FSocket774�F2007/06/30(�y) 00:06:43 ID:bGvDMeci
>>623
�݂����Ȑ������肾��
�A�[�L�e�N�`������_���I�ɐ������Ă�z�����Ȃ�
���OC2D�̉������D��Ă�̂��������Ȃ�����H
�݂����Ȑ������肾��
�A�[�L�e�N�`������_���I�ɐ������Ă�z�����Ȃ�
���OC2D�̉������D��Ă�̂��������Ȃ�����H
Kuma�̍ō��N���b�N��2008Q1��2.7G������ASSE�g���A�v���Ȃ�6000+�ɂ�
�����ނˏ��Ă������B
3�����܂łɏH�t���ɏo��邩�͂Ƃ������Ƃ��āB
�����ނˏ��Ă������B
3�����܂łɏH�t���ɏo��邩�͂Ƃ������Ƃ��āB
����
Q6600��$200���Ă邺�B
Q6600��$200���Ă邺�B
631 �FMAC�I�^��625 �����F2007/06/30(�y) 00:19:37 ID:SDr9HmSf
>>625
�@�@----------------
�@�@�A�[�L�e�N�`������_���I�ɐ������Ă�z�����Ȃ�
�@�@----------------
Core2�̑傫�ȉ��P�_�̈�햽�ߏ����n�̑O�i���ɂ����������ǁAAMD���Č��X
Load�Ɗ֘A���鉉�Z���߂��t���[�W����������Ԃ�OoO�̃C�V���[�E�L���[(x86�p��I�ɂ�
ROB�����H)�Ɋi�[���Ă�������A�����悤�ȉ��P���Ă�K8����傫�Ȍ���햳������
���Ƃ픻���Ă������B
�@�@----------------
�@�@�A�[�L�e�N�`������_���I�ɐ������Ă�z�����Ȃ�
�@�@----------------
Core2�̑傫�ȉ��P�_�̈�햽�ߏ����n�̑O�i���ɂ����������ǁAAMD���Č��X
Load�Ɗ֘A���鉉�Z���߂��t���[�W����������Ԃ�OoO�̃C�V���[�E�L���[(x86�p��I�ɂ�
ROB�����H)�Ɋi�[���Ă�������A�����悤�ȉ��P���Ă�K8����傫�Ȍ���햳������
���Ƃ픻���Ă������B
632 �FSocket774�F2007/06/30(�y) 00:23:10 ID:bGvDMeci
633 �FMAC�I�^��632 �����F2007/06/30(�y) 00:27:23 ID:SDr9HmSf
����\���ƃv���t�F�b�`�̋����AOoO Load�B
������ӂ͐������Z�ł����ʂ����肻�������ǂȁB
���ƁA����TDP�Ő��\���R�A���������オ��Ȃ����Ă������ǁA����TDP�Ȃ�N���b�N�������ł́H
����σx���`�o��܂ł͂�����Ƃ͂킩���ˁB
������ӂ͐������Z�ł����ʂ����肻�������ǂȁB
���ƁA����TDP�Ő��\���R�A���������オ��Ȃ����Ă������ǁA����TDP�Ȃ�N���b�N�������ł́H
����σx���`�o��܂ł͂�����Ƃ͂킩���ˁB
>>551
>�����Ȃ�S�������o���Ăǂ����悗
�ŋߐ����Fab���p�̘b���o�Ă���ӂ�
�ӊO�Ɛ̂�MIPS�⍡��ARM�݂�����
�v��剮�Ƃ��Ă���Ă����̂�AMD�̗��z���������B
���������Ӗ��Łh�S�������o���h�Ƃ����V�i���I�͗L��ł���B
>�����Ȃ�S�������o���Ăǂ����悗
�ŋߐ����Fab���p�̘b���o�Ă���ӂ�
�ӊO�Ɛ̂�MIPS�⍡��ARM�݂�����
�v��剮�Ƃ��Ă���Ă����̂�AMD�̗��z���������B
���������Ӗ��Łh�S�������o���h�Ƃ����V�i���I�͗L��ł���B
636 �FMAC�I�^��635 �����F2007/06/30(�y) 00:39:10 ID:SDr9HmSf
>>635
�@�@----------------
�@�@�v��剮�Ƃ��Ă���Ă����̂�AMD�̗��z���������B
�@�@----------------
AMD��CEO, Hector Ruiz��A����Motorola��"Asset Light"�̂���ڂ��f���Ĕ�����
�����Œ��ꒃ�ɂ������{�l���BAMD�ł������������邷���H
�@�@----------------
�@�@�v��剮�Ƃ��Ă���Ă����̂�AMD�̗��z���������B
�@�@----------------
AMD��CEO, Hector Ruiz��A����Motorola��"Asset Light"�̂���ڂ��f���Ĕ�����
�����Œ��ꒃ�ɂ������{�l���BAMD�ł������������邷���H
>>625
C2D��L1�ш�͑������|���镨���L��
���\����̖w�ǂ͂��̍L�ш�Ɉˑ����Ă���
http://journal.mycom.co.jp/special/2006/conroe/008.html
�܂��A���h�Ȏ�����
Barcelona�ł�L1�̑ш�͍L����炵��
���ۂǂꂭ�炢�ߊ���̂��m��Ȃ���
���ɓ����ш�ɂȂ�Ζʔ������ɂȂ��
C2D��L1�ш�͑������|���镨���L��
���\����̖w�ǂ͂��̍L�ш�Ɉˑ����Ă���
http://journal.mycom.co.jp/special/2006/conroe/008.html
�܂��A���h�Ȏ�����
Barcelona�ł�L1�̑ш�͍L����炵��
���ۂǂꂭ�炢�ߊ���̂��m��Ȃ���
���ɓ����ш�ɂȂ�Ζʔ������ɂȂ��
>>638
�I�}�G�z���g��C2D���`�[�g���Ǝv���Ă�Ƃ�����o�J����B
���ߎ��s�����炩�ɑ������B
�t�ɂ�������Ƃ����������̂̕����������Ǝv�����B
�ĊO�m�[�g�p�\�R����X���ł�����Ă�������ƌ����Ă�l�����������ȋC������B
HDD���x����Ɏ~�܂��Ă�A���́B
�I�}�G�z���g��C2D���`�[�g���Ǝv���Ă�Ƃ�����o�J����B
���ߎ��s�����炩�ɑ������B
�t�ɂ�������Ƃ����������̂̕����������Ǝv�����B
�ĊO�m�[�g�p�\�R����X���ł�����Ă�������ƌ����Ă�l�����������ȋC������B
HDD���x����Ɏ~�܂��Ă�A���́B
Nehalem�̃L���b�V���̗ʂ����Ȃ�������A�ǂ����Ă����낤�Ȃ�
>>639
�E���C���������̃��C�e���V��X2���傫���B����FSB�ɕ��ׂ����鎞�͌���
�E���Ӌ@�푬�x�����ׂ��オ��ɂꉺ��������傫��
�E���ߗ\���̓�OP�t���[�W�����ւ�ł�������O���ƃy�i���e�B���傫��
�E���̕ӂ���R���p�C���ŃJ�o�[
�_�C�i�~�b�N�g�����U�N�V�����A�����_�����O�A�G���R�[�h�A���̑�����������L2���g����
�ꍇ�͑����A��������Ȃ��ꍇ��X2���x���B���̕ӂ̃f�[�^�̓Z�������̕��܂Ԃ��܂�����
�G���̓x���`�T�C�g���珜�O����B�ǂ����Ă��`�[�g����B
�E���C���������̃��C�e���V��X2���傫���B����FSB�ɕ��ׂ����鎞�͌���
�E���Ӌ@�푬�x�����ׂ��オ��ɂꉺ��������傫��
�E���ߗ\���̓�OP�t���[�W�����ւ�ł�������O���ƃy�i���e�B���傫��
�E���̕ӂ���R���p�C���ŃJ�o�[
�_�C�i�~�b�N�g�����U�N�V�����A�����_�����O�A�G���R�[�h�A���̑�����������L2���g����
�ꍇ�͑����A��������Ȃ��ꍇ��X2���x���B���̕ӂ̃f�[�^�̓Z�������̕��܂Ԃ��܂�����
�G���̓x���`�T�C�g���珜�O����B�ǂ����Ă��`�[�g����B
�R�A�������ꂩ����㏸����̂ɏ��Ȃ����闝�R���c
���Ȃ�����(���₹�Ȃ�)�ւ̗��R���炢�͍l���Ă��邩������Ȃ����ǁB
�����ė�̑匴�L������B
���Ȃ�����(���₹�Ȃ�)�ւ̗��R���炢�͍l���Ă��邩������Ȃ����ǁB
�����ė�̑匴�L������B
"�G����"����Ȃ���"�G����"���E�E�뎚�����E�E
�܁A�x���`�Ĉ���J���Ă鍁��t��́u�{�N������Core2�ō�!�I�I�I�P�P�P�v
xti�Č����Ă������ˁH�ł��܂��A�����̃X���ł���ė~�����������ȁB
�܁A�x���`�Ĉ���J���Ă鍁��t��́u�{�N������Core2�ō�!�I�I�I�P�P�P�v
xti�Č����Ă������ˁH�ł��܂��A�����̃X���ł���ė~�����������ȁB
>>642
Nehalem�͂S�R�A�ł�L2 8MB��Yorkfield L2=12MB��茸�邾�낤�ȁB
Nehalem�͂S�R�A�ł�L2 8MB��Yorkfield L2=12MB��茸�邾�낤�ȁB
�\�t�g�̎����͔F�߂Ȃ��悤�Ȕ����͂ǂ����ƁB
>>641
���C���������̃��C�e���V�ɗD���̂ɒx���B
���Ӌ@��̖��͂قƂ�NJW�Ȃ��B�ނ���ATI�Ƃ�nVidia�̂ق����o���������B
���ߕ���\�����O��ăy�i���e�B���傫���Ƃ��Ă��A���̃p�t�H�[�}���X�ɏ��ĂȂ��B
�R���p�C����GCC�Ȃł�X2��葬���B
�����I�ɒx���B�������������ł��Ȃ��̂ɂȂ�ł���Ȃɓ��ꍞ��łH
���C���������̃��C�e���V�ɗD���̂ɒx���B
���Ӌ@��̖��͂قƂ�NJW�Ȃ��B�ނ���ATI�Ƃ�nVidia�̂ق����o���������B
���ߕ���\�����O��ăy�i���e�B���傫���Ƃ��Ă��A���̃p�t�H�[�}���X�ɏ��ĂȂ��B
�R���p�C����GCC�Ȃł�X2��葬���B
�����I�ɒx���B�������������ł��Ȃ��̂ɂȂ�ł���Ȃɓ��ꍞ��łH
��AMD�A�N�A�b�h�R�AOpteron "Barcelona"��8���Ƀ����[�X��
http://journal.mycom.co.jp/news/2007/06/29/058/index.html
�ׂɖڐV�����Ƃ���͂Ȃ������{��L��
http://journal.mycom.co.jp/news/2007/06/29/058/index.html
�ׂɖڐV�����Ƃ���͂Ȃ������{��L��
>�R���p�C����GCC�Ȃł�X2��葬��
GCC�̂ǂ̃o�[�W�����g������X2��葬���Ȃ�́H���Ȃ��Ƃ����ݎ嗬��4.1.1or4.1.2����
X2�̕����قڑS�Ă̏���������ˁH --march=nocona�ōœK�����邵���o���Ȃ����B
���̑��̃c�b�R�~�́A�܂��E�E���@���ׂĎ��ێg���Ă݂���H�Ƃ����E�Ew
GCC�̂ǂ̃o�[�W�����g������X2��葬���Ȃ�́H���Ȃ��Ƃ����ݎ嗬��4.1.1or4.1.2����
X2�̕����قڑS�Ă̏���������ˁH --march=nocona�ōœK�����邵���o���Ȃ����B
���̑��̃c�b�R�~�́A�܂��E�E���@���ׂĎ��ێg���Ă݂���H�Ƃ����E�Ew
>>646
���������ɂ���ȃf�^���������Ă�̂�����s�\�����E�E�E
�I��������Ă邱�ƂƂ͂����ԖѐF���Ⴄ���ǁA�����ŊȒP�Ɍ����邶��Ȃ����B
http://lucille.atso-net.jp/blog/?p=239
�����Ƃ��B
���ꂪ�����B�Ȃ�ŃI�}�G�̓��̒���X2��C2D��葬���̂��悭�킩���B
��ÂɂȂ낤�ȁB
���������ɂ���ȃf�^���������Ă�̂�����s�\�����E�E�E
�I��������Ă邱�ƂƂ͂����ԖѐF���Ⴄ���ǁA�����ŊȒP�Ɍ����邶��Ȃ����B
http://lucille.atso-net.jp/blog/?p=239
�����Ƃ��B
���ꂪ�����B�Ȃ�ŃI�}�G�̓��̒���X2��C2D��葬���̂��悭�킩���B
��ÂɂȂ낤�ȁB
�����X�H
>>650
���̕��悭�ǂ�ł���ł������`�[�g���Č������Ӗ�����Ȃ��Ȃ�A�������X����ȁB
���̕��悭�ǂ�ł���ł������`�[�g���Č������Ӗ�����Ȃ��Ȃ�A�������X����ȁB
>>649�ւ̂ꂷ�������B�A���J�[�~�X�B
�����Ȃ���AMAC�I�^���B
������ Barcelona �Ɋ���w
������ Barcelona �Ɋ���w
��Core 2 Duo�̉���X2�̉����ׂĂ��B
���N���b�N��r�Ȃ̂��A�����i��r�Ȃ̂��A�ō��N���b�N�ł̔�r�Ȃ̂�
���N���b�N��r�Ȃ̂��A�����i��r�Ȃ̂��A�ō��N���b�N�ł̔�r�Ȃ̂�
>>652
�`�[�g�ł͂Ȃ��ł���B
�����{���ɕ��������_�Ő��m�Ȑ��l���o���Ȃ��Ƃ�����ABOINC�Ȃō̗p����Ȃ�����B
�������������O���藧���Ȃ��Ǝv���Ă鎞�_�ł����������āB
�����intel���g���ƍ\���v�Z���o���Ȃ����Ă��ƂɂȂ邼�H
�������l�o�ē�����O������ˁB
�˔��q���Ȃ����ƌ����Ă�T�C�g��M������ł邾������B�������������d���������ǂ����B
�`�[�g�ł͂Ȃ��ł���B
�����{���ɕ��������_�Ő��m�Ȑ��l���o���Ȃ��Ƃ�����ABOINC�Ȃō̗p����Ȃ�����B
�������������O���藧���Ȃ��Ǝv���Ă鎞�_�ł����������āB
�����intel���g���ƍ\���v�Z���o���Ȃ����Ă��ƂɂȂ邼�H
�������l�o�ē�����O������ˁB
�˔��q���Ȃ����ƌ����Ă�T�C�g��M������ł邾������B�������������d���������ǂ����B
> �_�C�i�~�b�N�g�����U�N�V�����A�����_�����O�A�G���R�[�h�A���̑�����������L2���g����
> �ꍇ�͑����A��������Ȃ��ꍇ��X2���x���B���̕ӂ̃f�[�^�̓Z�������̕��܂Ԃ��܂�����
> �G���̓x���`�T�C�g���珜�O����B�ǂ����Ă��`�[�g����B
�������̓I�ȃ\�t�g���グ�Ă����@> 10�P���x�͊y�ɏ�������?
�Ƃ�����������m�낤��A�ϑz�����\�t�g�Ȃ�ĒN���M���Ȃ���B
> �ꍇ�͑����A��������Ȃ��ꍇ��X2���x���B���̕ӂ̃f�[�^�̓Z�������̕��܂Ԃ��܂�����
> �G���̓x���`�T�C�g���珜�O����B�ǂ����Ă��`�[�g����B
�������̓I�ȃ\�t�g���グ�Ă����@> 10�P���x�͊y�ɏ�������?
�Ƃ�����������m�낤��A�ϑz�����\�t�g�Ȃ�ĒN���M���Ȃ���B
>>641
�\�[�X��?
�\�[�X��?
660 �FMAC�I�^��637 �����F2007/06/30(�y) 01:40:30 ID:SDr9HmSf
>>657
�@�@----------------
�@�@�����intel���g���ƍ\���v�Z���o���Ȃ����Ă��ƂɂȂ邼�H
�@�@----------------
�����������ƂɋC�t���Ȃ�����A�����ɂȂ�Ƃ����������ƁB�B�B
�u�������͂�点�v�ƐM���Ă�q�g�Ɠ��킩�Ǝv����(��)
�@�@----------------
�@�@�����intel���g���ƍ\���v�Z���o���Ȃ����Ă��ƂɂȂ邼�H
�@�@----------------
�����������ƂɋC�t���Ȃ�����A�����ɂȂ�Ƃ����������ƁB�B�B
�u�������͂�点�v�ƐM���Ă�q�g�Ɠ��킩�Ǝv����(��)
�������z�����炩�܂��̂͂�߂Ă����Ă��������c
����Ȃɗ������������̋v���Ԃ肾��B
����Ȃɗ������������̋v���Ԃ肾��B
���G���R�[�h��L2�W�Ȃ������l
�x���`�T�C�g���Ă�E21x0��E4x00�œ��N���b�N�łقƂ�Ǎ����Ȃ��킯����
�x���`�T�C�g���Ă�E21x0��E4x00�œ��N���b�N�łقƂ�Ǎ����Ȃ��킯����
>>660
�Ȃ���l�����ۂ���ˁB
���̂܂����������_���Z��𖽗ߎ��s���j�b�g���Ƃ������Ė\��Ă����c�ƁB
���݂��킩���ĂȂ��߂����邯�ǂ��B
�Ȃ���l�����ۂ���ˁB
���̂܂����������_���Z��𖽗ߎ��s���j�b�g���Ƃ������Ė\��Ă����c�ƁB
���݂��킩���ĂȂ��߂����邯�ǂ��B
>>614
�f�^�����������܂ł����Ƃ������������ȁB
�f�^�����������܂ł����Ƃ������������ȁB
���������_���Z�����l���Z�̊�{�ƌ������͉̂������炻��͕ʐl����
����Intel�h����
����Intel�h����
>>668
OC��ɂ���Ă�
OC��ɂ���Ă�
WeBjNo8F�̎咣
�R���p�C����R�[�f�B���O���w�^���ł����x���o�Ȃ��ƃ`�[�g
����
�f�t�@�N�g�X�^���_�[�h�ȃA�v���ł́u�R���p�C����R�[�f�B���O���w�^���v�Ȃ��Ƃ͂܂��Ȃ�
���_
���̌�������
�R���p�C����R�[�f�B���O���w�^���ł����x���o�Ȃ��ƃ`�[�g
����
�f�t�@�N�g�X�^���_�[�h�ȃA�v���ł́u�R���p�C����R�[�f�B���O���w�^���v�Ȃ��Ƃ͂܂��Ȃ�
���_
���̌�������
>>663
> ���[���������������c�͂₾�B
> �I�[�v���\�[�X�̃`�F�X�v���O�����Ƃ������Ă݂�H1�����炢������B
�����烌�X�ԈႤ����?
���O�������Ă�u1�����炢������v�͂ǂ�����? C2D or X2
���m�Ȕ��������Ȃ��ƃ��X�ԊԈႦ���Ƃ��������ƂɂȂ��
>>669
> OC��ɂ���Ă�
OC�ϐ������鍂���̂�����d���Ȃ�������AX2���s�b�㖳���̂ŃN���b�N�グ����Ԃ�C2D���Ă̂��ق�Ƃ̂Ƃ���
> ���[���������������c�͂₾�B
> �I�[�v���\�[�X�̃`�F�X�v���O�����Ƃ������Ă݂�H1�����炢������B
�����烌�X�ԈႤ����?
���O�������Ă�u1�����炢������v�͂ǂ�����? C2D or X2
���m�Ȕ��������Ȃ��ƃ��X�ԊԈႦ���Ƃ��������ƂɂȂ��
>>669
> OC��ɂ���Ă�
OC�ϐ������鍂���̂�����d���Ȃ�������AX2���s�b�㖳���̂ŃN���b�N�グ����Ԃ�C2D���Ă̂��ق�Ƃ̂Ƃ���
�ނ���A�x���`�Ƃ�Ȃ瓯���o�C�i���Ōv�����Ȃ��ƈӖ����������B
AMD�fs FASN8 May Be Delayed to Next Year ? Sources.
AMD�fs New Dual-Chip Enthusiast FASN8 Platform Slips to 2008
http://www.xbitlabs.com/news/cpu/display/20070628163848.html
������Ղ������
AMD�fs New Dual-Chip Enthusiast FASN8 Platform Slips to 2008
http://www.xbitlabs.com/news/cpu/display/20070628163848.html
������Ղ������
�����������ׂ��
>>674
�����܂ő����ƃl�^�ł���Ă��Ȃ����Ƃ�
�����܂ő����ƃl�^�ł���Ă��Ȃ����Ƃ�
>>646
������945�g���Ă邯��
>���Ӌ@��̖��͂قƂ�NJW�Ȃ��B�ނ���ATI�Ƃ�nVidia�̂ق����o���������B
����͉R����Ȃ����HASUS�����Ȃ̂�������Ȃ����ǁAVIA��舫�����B
���Ӌ@��g���ĂȂ�������ӯ���Ȃ����ȁ[(�E�́E)
������945�g���Ă邯��
>���Ӌ@��̖��͂قƂ�NJW�Ȃ��B�ނ���ATI�Ƃ�nVidia�̂ق����o���������B
����͉R����Ȃ����HASUS�����Ȃ̂�������Ȃ����ǁAVIA��舫�����B
���Ӌ@��g���ĂȂ�������ӯ���Ȃ����ȁ[(�E�́E)
>>678
�m�F��������
>678 ���O�FSocket774[sage] ���e���F2007/06/30(�y) 02:08:24 ID:WeBjNo8F
>>>673
>�ʂɊԈ���ĂȂ��Ǝv�����E�E�E�B
>�ސ��G���W������������ĂȂ��l�Ȃ̂��ȁE�E�E
�����
>672 ���O�FSocket774[sage] ���e���F2007/06/30(�y) 01:55:25 ID:BqEdiUeM
>>>663
>> ���[���������������c�͂₾�B
>> �I�[�v���\�[�X�̃`�F�X�v���O�����Ƃ������Ă݂�H1�����炢������B
>�����烌�X�ԈႤ����?
�ւ̃��X���H
�m�F��������
>678 ���O�FSocket774[sage] ���e���F2007/06/30(�y) 02:08:24 ID:WeBjNo8F
>>>673
>�ʂɊԈ���ĂȂ��Ǝv�����E�E�E�B
>�ސ��G���W������������ĂȂ��l�Ȃ̂��ȁE�E�E
�����
>672 ���O�FSocket774[sage] ���e���F2007/06/30(�y) 01:55:25 ID:BqEdiUeM
>>>663
>> ���[���������������c�͂₾�B
>> �I�[�v���\�[�X�̃`�F�X�v���O�����Ƃ������Ă݂�H1�����炢������B
>�����烌�X�ԈႤ����?
�ւ̃��X���H
�����烌�X���Ĉ������A��̓I�Ȃ��Ƃ������ł���B
���Ƃ͌�������B���ꂾ���B
�[���Ӗ��Ȃ����X�ɈӖ����������悤�Ƃ���Ȃ��āB�҂ޒ��݂��������B
���Ƃ͌�������B���ꂾ���B
�[���Ӗ��Ȃ����X�ɈӖ����������悤�Ƃ���Ȃ��āB�҂ޒ��݂��������B
>>678
�R���p�C��(or Version)�ɂ���ẮA�قȂ����R�[�h������ꍇ�����邾��B
�܂��A��������ׂƂ��邩�ǂ����͂��̃R�[�h����Ȃ��B
�R���p�C��(or Version)�ɂ���ẮA�قȂ����R�[�h������ꍇ�����邾��B
�܂��A��������ׂƂ��邩�ǂ����͂��̃R�[�h����Ȃ��B
�딚�����B
>>682�͖Y��Ă���B
>>682�͖Y��Ă���B
AMD to Launch "Barcelona" Slow this August
http://www.dailytech.com/AMD+to+Launch+Barcelona+Slow+this+August/article7890.htm
To add insult to injury, when DailyTech benchmarked the pre-production 1.6 GHz Barcelona,
the CPU did not match Intel's 65nm quad-core offering clock-for-clock.
AMD engineers stress to DailyTech that this benchmark was premature,
and that final silicon and software will allow for SSE optimizations and better performance.
Comptex�Ŕ�I�����V���R����SSE���{���̐��\�œ����ĂȂ�����AMD����Ȃ�̏�k�ł��������
8���ɏo�ׂł���́H�@�ق�Ƃ�
http://www.dailytech.com/AMD+to+Launch+Barcelona+Slow+this+August/article7890.htm
To add insult to injury, when DailyTech benchmarked the pre-production 1.6 GHz Barcelona,
the CPU did not match Intel's 65nm quad-core offering clock-for-clock.
AMD engineers stress to DailyTech that this benchmark was premature,
and that final silicon and software will allow for SSE optimizations and better performance.
Comptex�Ŕ�I�����V���R����SSE���{���̐��\�œ����ĂȂ�����AMD����Ȃ�̏�k�ł��������
8���ɏo�ׂł���́H�@�ق�Ƃ�
�G���Q������o�Ă��Ȃ��ł�����B
�������̃��x���͂��܂��ɂ��傤�ǂ����B
�������̃��x���͂��܂��ɂ��傤�ǂ����B
�����܂œǂ�łȂ�
�ǂ�ID��NG��������������Ă���
�ǂ�ID��NG��������������Ă���
�悭AMD��T�[�o�[�p�v���Z�b�T�ʼn҂���B�B�B�Ƃ����ӌ���ǂނ����ǁA���Ȃ��Ƃ������
AMD�̎������̑唼��f�X�N�g�b�v�ł��邱�Ƃ�o���Ă����������ǂ��Ǝv�����B
http://www.beyond3d.com/content/articles/32/2
�@�@--------------------
�@�@This implies that about 65% of AMD's CPUs unit sales are still single-core; more importantly,
�@�@this is most likely for the client and server spaces combined so you'd expect 70% of their
�@�@sales in desktops and laptops to be single-core products because servers are more frequently
�@�@dual-core than clients.
�@�@--------------------
��U���Ȑ�`�̊��ɁA���[�G���h�����v���Z�b�T�̃x���_�Ƃ����ʒu�ɂ�A���܂�ω��������Ƃ���
������A�m���Ă������ق����ǂ����B
AMD�̎������̑唼��f�X�N�g�b�v�ł��邱�Ƃ�o���Ă����������ǂ��Ǝv�����B
http://www.beyond3d.com/content/articles/32/2
�@�@--------------------
�@�@This implies that about 65% of AMD's CPUs unit sales are still single-core; more importantly,
�@�@this is most likely for the client and server spaces combined so you'd expect 70% of their
�@�@sales in desktops and laptops to be single-core products because servers are more frequently
�@�@dual-core than clients.
�@�@--------------------
��U���Ȑ�`�̊��ɁA���[�G���h�����v���Z�b�T�̃x���_�Ƃ����ʒu�ɂ�A���܂�ω��������Ƃ���
������A�m���Ă������ق����ǂ����B
�M�K�o�C�q�ƂȂ��Ȃ����݂�������
�N�������������
�N�������������
�u�`�Ƃ������Ă�l�����邯�� �m���Ă������ق��������v �Ƃ����i���猾���Ă邯��
�I�^������ɊW�����L�������Ă����Ƃ��́A�I�^���g�����̋L�������Ēm����������w
�I�^������ɊW�����L�������Ă����Ƃ��́A�I�^���g�����̋L�������Ēm����������w
691 �FMAC�I�^��689 �����F2007/06/30(�y) 10:21:24 ID:SDr9HmSf
>>689
�@�@-------------------
�@�@�I�^������ɊW����
�@�@-------------------
���>>581�ɃR�����g���悤�Ǝv���ĒT���Ă�����ABarcelona�̔��\�ŗ��ꂪ�ς����������������B
�ł��A
�@�@-------------------
�@�@�I�^���g�����̋L�������Ēm����������w
�@�@-------------------
�����ے肵�Ȃ����B
�@�@-------------------
�@�@�I�^������ɊW����
�@�@-------------------
���>>581�ɃR�����g���悤�Ǝv���ĒT���Ă�����ABarcelona�̔��\�ŗ��ꂪ�ς����������������B
�ł��A
�@�@-------------------
�@�@�I�^���g�����̋L�������Ēm����������w
�@�@-------------------
�����ے肵�Ȃ����B
�z���g�ɂł�ȁ�Barcelona
2008Q1�ł������L�c�C����
2008Q1�ł������L�c�C����
�Ƃ���ŁAK8���o�鎞�͂ǂ���������
>>688
�}�X�R�b�g�L�����Ƃ��Ă̍���D��ꂽ�̂��H
�}�X�R�b�g�L�����Ƃ��Ă̍���D��ꂽ�̂��H
>>694
���{����P�ނ��邩��o�C�q���̂Ă��邼
���{����P�ނ��邩��o�C�q���̂Ă��邼
>Comptex�Ŕ�I�����V���R����SSE���{���̐��\�œ����ĂȂ�
�����������Ƃɂ��Ă����������Ă�������˂��́H
���\�I�ɂ���ڂ������Ƃ��̌�����Ƃ���
�����������Ƃɂ��Ă����������Ă�������˂��́H
���\�I�ɂ���ڂ������Ƃ��̌�����Ƃ���
K8���o�����̂��Ђǂ������BSOI�v���Z�X���n�̌����݂�����܂���A
�x��ɒx�ꔭ�\�����\����R�炢���������Ȃ��������H�m���������\�����\�肩��
�P�N�ȏ�x��Ă�͂��B
K8���x��Ă���̂�AthlonXP�ł��̂��Ȃ�������Ȃ��Ȃ�����Thoroughbred-a��
�v���Z�X�����������̂ɃN���b�N�͏オ��Ȃ���A�d�͂������ĂȂ����
�������o�C�̉��́B���̂����AIntel��Northwood�ŃN���b�N������オ����
�d�͂�������A�ŁA�L���b�V������悹���Ă��ăx���`�ł̓{�������B
���̎���AMD�̏I�����͍��̔䂶��Ȃ�������w
���̎������E���`���O�ł���K8�̓N���b�N���オ��Ȃ��Ƃ���
��N���b�N������o�Ă����ȁB
�ǂ���AMD�͐V�����R�A�̍œK���i�Ƃ������N���e�B�J���p�X�ׂ����H�j�m�E�n�E��
Intel�ɔ�ׂĒx��Ă�݂������ȁB
�x��ɒx�ꔭ�\�����\����R�炢���������Ȃ��������H�m���������\�����\�肩��
�P�N�ȏ�x��Ă�͂��B
K8���x��Ă���̂�AthlonXP�ł��̂��Ȃ�������Ȃ��Ȃ�����Thoroughbred-a��
�v���Z�X�����������̂ɃN���b�N�͏オ��Ȃ���A�d�͂������ĂȂ����
�������o�C�̉��́B���̂����AIntel��Northwood�ŃN���b�N������オ����
�d�͂�������A�ŁA�L���b�V������悹���Ă��ăx���`�ł̓{�������B
���̎���AMD�̏I�����͍��̔䂶��Ȃ�������w
���̎������E���`���O�ł���K8�̓N���b�N���オ��Ȃ��Ƃ���
��N���b�N������o�Ă����ȁB
�ǂ���AMD�͐V�����R�A�̍œK���i�Ƃ������N���e�B�J���p�X�ׂ����H�j�m�E�n�E��
Intel�ɔ�ׂĒx��Ă�݂������ȁB
> K8���x��Ă���̂�AthlonXP�ł��̂��Ȃ�������Ȃ��Ȃ�����Thoroughbred-a��
> �v���Z�X�����������̂ɃN���b�N�͏オ��Ȃ���A�d�͂������ĂȂ����
> �������o�C�̉��́B���̂����AIntel��Northwood�ŃN���b�N������オ����
> �d�͂�������A�ŁA�L���b�V������悹���Ă��ăx���`�ł̓{�������B
> ���̎���AMD�̏I�����͍��̔䂶��Ȃ�������w
����A�S�R�����ꡂ��Ƀ}�V�A�u�x���`�ł̓{�������v�Ƃ������Ă邪���قǑ傫�ȍ��͖����������A
AthlonXP���������x���`�����\�������B
�����č��̓{���������AOC�ϐ��܂Ŋ܂߂�ƑS������ɂ���Ă��Ȃ��̂�����B
> �v���Z�X�����������̂ɃN���b�N�͏オ��Ȃ���A�d�͂������ĂȂ����
> �������o�C�̉��́B���̂����AIntel��Northwood�ŃN���b�N������オ����
> �d�͂�������A�ŁA�L���b�V������悹���Ă��ăx���`�ł̓{�������B
> ���̎���AMD�̏I�����͍��̔䂶��Ȃ�������w
����A�S�R�����ꡂ��Ƀ}�V�A�u�x���`�ł̓{�������v�Ƃ������Ă邪���قǑ傫�ȍ��͖����������A
AthlonXP���������x���`�����\�������B
�����č��̓{���������AOC�ϐ��܂Ŋ܂߂�ƑS������ɂ���Ă��Ȃ��̂�����B
>>697
K8�͔N�P�ʂő��ꂽ��c�B
>>699
����Ɠ����悤�ɏ�ʂłڂ땉���A
���ʁE���ʂȂ�ʂɖ��Ȃ��̂����c���Ċ����������Ǝv�����H
�����A�ˁB�Ȃ�Hammer�n���ł�I�@���ĉ\�Ő���オ���Ă������A
����ł́c�B����B����オ���ĂȂ�����ˁB
K8�͔N�P�ʂő��ꂽ��c�B
>>699
����Ɠ����悤�ɏ�ʂłڂ땉���A
���ʁE���ʂȂ�ʂɖ��Ȃ��̂����c���Ċ����������Ǝv�����H
�����A�ˁB�Ȃ�Hammer�n���ł�I�@���ĉ\�Ő���オ���Ă������A
����ł́c�B����B����オ���ĂȂ�����ˁB
AMD���������b�o��������
I�������݂������Ȃ�
I�������݂������Ȃ�
>�b�o��������
I>�����݂������Ȃ�
�ϑz�����ł͓��퐶���Ă͂����Ȃ����H
I>�����݂������Ȃ�
�ϑz�����ł͓��퐶���Ă͂����Ȃ����H
>>699
Barton���o�����キ�炢�ɂ�fsb400�̓����������Ă��������������������A
Thoroughbred�o��������Barton�����͂ق�Ƃ炩�������B
���ƁAOC�ϐ��ɂ��Ă�Thoroughbred-a�͖{���ɍ�����
��i��1.8�ŁA2G�ɂ����Ă����ƃ��o�C�A�Ƃ������炢OC�ϐ����������͂��B
�����̋L���ǂ�Ń~�\
�m���Ƀx���`�ŏ����Ă���̂�����A�Ƃ����̂��u�������i�̐��i�Ȃ�v�Ƃ��������t���������̂�
�����Ă��Ȃ����H���Ɠ����ł��������肾�����B
���ƈ���ė�����̍����T�[�o�[�n�ł̔��グ���S���Ȃ���������
AMD��ASP������܂����ĂĘA���Ԏ��L�^�X�V���̖{���ɃW���n��������B
�ނ���A�Ȃ�Œׂ�Ȃ��́H���Ă��炢�������B
���Ȃ�ĂȂ������Ă��O�������Ƃ͂��������̃j���[�X���o�Ă��Ă邵�A
���̂���̐��N�A���Ԏ��L�^�ɔ�ׂ���S�R�}�V�B
Barton���o�����キ�炢�ɂ�fsb400�̓����������Ă��������������������A
Thoroughbred�o��������Barton�����͂ق�Ƃ炩�������B
���ƁAOC�ϐ��ɂ��Ă�Thoroughbred-a�͖{���ɍ�����
��i��1.8�ŁA2G�ɂ����Ă����ƃ��o�C�A�Ƃ������炢OC�ϐ����������͂��B
�����̋L���ǂ�Ń~�\
�m���Ƀx���`�ŏ����Ă���̂�����A�Ƃ����̂��u�������i�̐��i�Ȃ�v�Ƃ��������t���������̂�
�����Ă��Ȃ����H���Ɠ����ł��������肾�����B
���ƈ���ė�����̍����T�[�o�[�n�ł̔��グ���S���Ȃ���������
AMD��ASP������܂����ĂĘA���Ԏ��L�^�X�V���̖{���ɃW���n��������B
�ނ���A�Ȃ�Œׂ�Ȃ��́H���Ă��炢�������B
���Ȃ�ĂȂ������Ă��O�������Ƃ͂��������̃j���[�X���o�Ă��Ă邵�A
���̂���̐��N�A���Ԏ��L�^�ɔ�ׂ���S�R�}�V�B
IBM����x86�A�[�L����ˁ[����
�����땁�ʂ�
����������86�ɒu����������Ɍg�т��Z������p���_�C���������ς�
�����̃A�v��������g�с@�茳�ł����l�b�g
����������86�ɒu����������Ɍg�т��Z������p���_�C���������ς�
�����̃A�v��������g�с@�茳�ł����l�b�g
�p�\�R�����Ɛ��č����i���ʔ̔��ƒቿ�i��ʔ̔��̓�ɉ���i�߂�IBM��
���X�ǂ���������PC�p�v���Z�b�T�~������Ƃ��v����
���X�ǂ���������PC�p�v���Z�b�T�~������Ƃ��v����
x86=�����̃A�v�����Ă͉̂R����
���ۂ�x86 32bit Windows=�����̃A�v��
���ۂ�x86 32bit Windows=�����̃A�v��
���͂R���������@�r�u�f�`�@110���~
��86�A�v���łȂ��Ƃm�f
���Ԃ��₪�ċC�Â�
��86�A�v���łȂ��Ƃm�f
���Ԃ��₪�ċC�Â�
���̂b�o�t���y���ɑ���
�`�o�o�k�d���₪�Ă͗���H
�`�o�o�k�d���₪�Ă͗���H
>>704
�ʂɂǂ������������ǂ��ł��������ǁA
>>701�݂����Ɂu�o�������ȁv�u�����݂����v�ƁA
�S�����g���Ėϑz����Ă॥�B
���{�ꂪ�s���R�ňӖ�������ł�����ĂȂ�킩���ł��Ȃ����A
����Ȃ�ΐ�Ɂu���͓��{�ꂪ�s���R�ł��v���ď����ė~�����Ƃ��낾�B
�ʂɂǂ������������ǂ��ł��������ǁA
>>701�݂����Ɂu�o�������ȁv�u�����݂����v�ƁA
�S�����g���Ėϑz����Ă॥�B
���{�ꂪ�s���R�ňӖ�������ł�����ĂȂ�킩���ł��Ȃ����A
����Ȃ�ΐ�Ɂu���͓��{�ꂪ�s���R�ł��v���ď����ė~�����Ƃ��낾�B
�I�}�G�̗~��������Ă��ǂ�����
>>706
x86�͂܂����Ⴂ�ɏ���d�͂��傫���Ă�
��������p�I�Ȃ��̂��o���Ƃ��Ă��A���̎��_�œ�����d�͂Ȃ�p���[����̂��̂��o�Ă���
x86�͂܂����Ⴂ�ɏ���d�͂��傫���Ă�
��������p�I�Ȃ��̂��o���Ƃ��Ă��A���̎��_�œ�����d�͂Ȃ�p���[����̂��̂��o�Ă���
714 �F�E�́E�j��-�������F2007/06/30(�y) 14:44:00 ID:tKmdVwOy
���E���ߗ\���̓�OP�t���[�W�����ւ��
�S�R�ʂ̋Z�p�Ȃ��B
�S�R�ʂ̋Z�p�Ȃ��B
>>641��
�����͐������Z���\�ƃ}���`�X���b�h���\�ɂ���
�����Ă��Ȃ����B
�������������Ȃǂ��ł������B��r�I�d����
�������Z���S�̃A�v���������グ�邱�Ƃ�
������ŁA������������@���Ă���悤�ȏ��
�ł̃}���`�^�X�N���\��m�肽���B
�����Ă��Ȃ����B
�������������Ȃǂ��ł������B��r�I�d����
�������Z���S�̃A�v���������グ�邱�Ƃ�
������ŁA������������@���Ă���悤�ȏ��
�ł̃}���`�^�X�N���\��m�肽���B
��������A�o���Z���i��2GHz�œo�ꂷ�邩��A�N�A�b�h�R�AXeon 2GHz�Ƃ̏�������������
�N���b�N���������Ɣ�r���y���݂�
Xeon��TDP50W�����A�܂������͋C�ɂ��Ȃ����Ă��ƂŁA����o�邩������Ȃ�2.5GHz�ł̐��\��������x�킩����
�������N���b�N�������\��������A45nm Core2�n�͂��炭3.33GHz�̂܂܂��낤
�N���b�N���������Ɣ�r���y���݂�
Xeon��TDP50W�����A�܂������͋C�ɂ��Ȃ����Ă��ƂŁA����o�邩������Ȃ�2.5GHz�ł̐��\��������x�킩����
�������N���b�N�������\��������A45nm Core2�n�͂��炭3.33GHz�̂܂܂��낤
>>717
���݁AXeon��TDP����130W��85W��TDP����50W�܂ł�����̂��I
���������������������I�I�I�I�I�I�I�I�I�@������B
���݁AXeon��TDP����130W��85W��TDP����50W�܂ł�����̂��I
���������������������I�I�I�I�I�I�I�I�I�@������B
����̓��[�G���h�m�[�g����CPU�������Ɉ�����邩�ł���
>>714
�A�z�ł�����
�A�z�ł�����
��10��45���ł�����H�@�����R�������₵�g�[�^���ł͂�10��������
�`�b�v�Z�b�g���܂ޏ���d�͂̂��Ƃ�
�S�DAMD��4�R�A Barcelona�\
The Inquirer�́CiPhone Friday�ŁC�Ɨ��L�O���̘A�x�̏T���ɂ͂���O����
���j���̒�9��1���Ƃ����C���̓��̒����ɂ͊Ԃɍ��킸�C�A�x�����ɕ�
����Ă��C�Â��b�Ȃ̂Ńo�b�h�j���[�X�i2GHz�����o�Ȃ��j�����܂�ڗ����Ȃ�
�^�C�~���O�Ŕ��\�����Ƃ������낵�Ă��܂��BThe Register�̘_�����قړ����ŁC
Intel�ɑR����̂ł͂Ȃ��C���Ђ̋����i��������Ă���Ə����Ă��܂��B
��́CAMD�͑O���̖�Ƀj���[�X�����[�X���o���̂���ʓI�ŁC����Ȃ�
�����ɊԂɍ����܂��B�܂��C����̃j���[�X�����[�X�͔��ɒZ���C���܂�C
�C���������Ă���Ƃ��������͂��܂���B
The Inquirer�́CiPhone Friday�ŁC�Ɨ��L�O���̘A�x�̏T���ɂ͂���O����
���j���̒�9��1���Ƃ����C���̓��̒����ɂ͊Ԃɍ��킸�C�A�x�����ɕ�
����Ă��C�Â��b�Ȃ̂Ńo�b�h�j���[�X�i2GHz�����o�Ȃ��j�����܂�ڗ����Ȃ�
�^�C�~���O�Ŕ��\�����Ƃ������낵�Ă��܂��BThe Register�̘_�����قړ����ŁC
Intel�ɑR����̂ł͂Ȃ��C���Ђ̋����i��������Ă���Ə����Ă��܂��B
��́CAMD�͑O���̖�Ƀj���[�X�����[�X���o���̂���ʓI�ŁC����Ȃ�
�����ɊԂɍ����܂��B�܂��C����̃j���[�X�����[�X�͔��ɒZ���C���܂�C
�C���������Ă���Ƃ��������͂��܂���B
>>721
���������Ӗ��킩���B
TDP���肬��܂Ŕ��M����45W�łƂقƂ�ǖ��Ӗ��ȃ����R���͒Ⴂ�g�[�^�����\������Ɉ��������Ă�Ǝv��Ȃ��̂��H
���������Ӗ��킩���B
TDP���肬��܂Ŕ��M����45W�łƂقƂ�ǖ��Ӗ��ȃ����R���͒Ⴂ�g�[�^�����\������Ɉ��������Ă�Ǝv��Ȃ��̂��H
���AAM2+�̔�ɏo�������̂ɂˁB
�Ȃ�����헪���肾��ȁB
�Ȃ�����헪���肾��ȁB
>>725
���������Ă������f����̂������ς蕪����ABIOSTAR����o���
���������Ă������f����̂������ς蕪����ABIOSTAR����o���
����AM2+����ݐ�ɏo�������̂ɂƎv�����B
���߂�Split Power Plane�Ή��́B
��������Ό��CPU�����ڂ��ւ����邩��AM2�������Ɣ��ꂽ�C�����邪�B
AM2��݂�AM2+ CPU�͉������B
���߂�Split Power Plane�Ή��́B
��������Ό��CPU�����ڂ��ւ����邩��AM2�������Ɣ��ꂽ�C�����邪�B
AM2��݂�AM2+ CPU�͉������B
BIOSTAR����o���́AAM2+��CPU��BIOSUpdate�œ����ƃ��[�J�[�������Ă邾���ŁA
�P�Ȃ�AM2��M/B������ȁB
AM2+���\�肵�Ă���@�\�S���Ή��̂́ARD790����ȊO�Ȃ���Ȃ��́H
�P�Ȃ�AM2��M/B������ȁB
AM2+���\�肵�Ă���@�\�S���Ή��̂́ARD790����ȊO�Ȃ���Ȃ��́H
��RD790�͂���2�������炢�����������
�o�ׂł���͂��Ȃ̂���������������Ă��Ȃ��̂��s�v�c
RD790��2�\�P�������o����̐�������Ȃ��Ȃ��Ȃ�
�o�ׂł���͂��Ȃ̂���������������Ă��Ȃ��̂��s�v�c
RD790��2�\�P�������o����̐�������Ȃ��Ȃ��Ȃ�
>>729
2�����O�Ȃ炱��Ȃ���B
2�����O�Ȃ炱��Ȃ���B
�����͂���ς�X�P�[���u���ɐ��\�オ��
���������ł͂����͂����Ȃ�
http://wiredvision.jp/news/200706/2007062923.html
���������ł͂����͂����Ȃ�
http://wiredvision.jp/news/200706/2007062923.html
�N���X�^�g�ނ̂�CPU�̃X�P�[���r���e�B�Ȃ�ĊW����́H
���肷������
�����炏���I��
�����R���Ƃg�s3.0
�����炏���I��
�����R���Ƃg�s3.0
MAC�I�^�Ƃ���Ȃ����炢�������̂������Ă�悤�ŁE�E�E
������[�A�X���[�����l���������@orz
�h�n���\
��8���炻�������v�v�z���
��8���炻�������v�v�z���
InfiniBand�Ō������Ă邵�Ȃ��B�e�m�[�h�̃X�P�[���r���e�B�Ƃ��͂��܂�W�Ȃ����B
HyperTransport to InfiniBand�̃`�b�v���g���Ă�Ȃ烌�C�e���V�͔�r�I�}������낤���ǂˁB
SUN�̂�������́u�����ɂ�SPARC��Xeon����邯�ǁA
Opteron�̕������̎�̌v�Z�@�Ɏg��FP�v�Z�͑����i����A����ł�Opteron���̗p�����j�v���Č����Ă邵�ȁB
HyperTransport to InfiniBand�̃`�b�v���g���Ă�Ȃ烌�C�e���V�͔�r�I�}������낤���ǂˁB
SUN�̂�������́u�����ɂ�SPARC��Xeon����邯�ǁA
Opteron�̕������̎�̌v�Z�@�Ɏg��FP�v�Z�͑����i����A����ł�Opteron���̗p�����j�v���Č����Ă邵�ȁB
���ƂȂ��Ă͉��i�����ߎ肾�낤���ǂ�
>>737
���܂��A�₳������
���܂��A�₳������
���N�㔼Intel�������R������B
������HyperTransport�̗p������ۂ���
������HyperTransport�̗p������ۂ���
����۽
FSB�̓V���A���ɂȂ邯�ǁA��������Hypertransport�͍̗p���Ȃ�w
CSI�̏ڍׂ͂܂����\����ĂȂ����ǁAPCI-Express�Ƌ��ʂ̋Z�p��
�g�������̂ɂȂ��Ȃ����ȁB
CSI�̏ڍׂ͂܂����\����ĂȂ����ǁAPCI-Express�Ƌ��ʂ̋Z�p��
�g�������̂ɂȂ��Ȃ����ȁB
�͂����茾���āA��肽�����Ƃ͓������B
�������Z��ɗ��������B
�ł�AMD�̓}�[�P�e�B���O�̌��悾���̃g�����h�ɗ�����āAintel�̓R�A����荞��ŁA
����Ƀm�[�X�u���b�W�̐������v�����B
�����R���͌��ʂ͋^��ŁA�R�A���̂��̂���荞�������ʂ��傫���B
�����R���Ɉ��|�I�Ȍ��ʂ�����Ƃ����Ă���̂�AMD���g�B
�g�����X���^�����Ă��킩��Ƃ���A���ɉ��ǂ����s�����Ă��Ə��������ł����P���~�������Ă����Ƃ��Ɏ���o���ׂ����́B
�҂ސ~�̒��̐l�����́A�Ȃ�ł���ȂɃ����R���Ƀ~�m�t�X�L�[���q���݂̉��ł��������関���̃e�N�m���W�[
�݂����Ȋ��҂������Ă�낤�B
�킴�킴�����\�ȃm�[�X������āA�̗p���Ȃ����[�J�[������B���̕ӂ��Ȃ�������Ȃ��낤�B
�������Z��ɗ��������B
�ł�AMD�̓}�[�P�e�B���O�̌��悾���̃g�����h�ɗ�����āAintel�̓R�A����荞��ŁA
����Ƀm�[�X�u���b�W�̐������v�����B
�����R���͌��ʂ͋^��ŁA�R�A���̂��̂���荞�������ʂ��傫���B
�����R���Ɉ��|�I�Ȍ��ʂ�����Ƃ����Ă���̂�AMD���g�B
�g�����X���^�����Ă��킩��Ƃ���A���ɉ��ǂ����s�����Ă��Ə��������ł����P���~�������Ă����Ƃ��Ɏ���o���ׂ����́B
�҂ސ~�̒��̐l�����́A�Ȃ�ł���ȂɃ����R���Ƀ~�m�t�X�L�[���q���݂̉��ł��������関���̃e�N�m���W�[
�݂����Ȋ��҂������Ă�낤�B
�킴�킴�����\�ȃm�[�X������āA�̗p���Ȃ����[�J�[������B���̕ӂ��Ȃ�������Ȃ��낤�B
Phenomenal����Ƃ���Phenom���Ė��O�ɂ��Ă�̂ɁACore 2 Duo�ɂ����ĂȂ��Ƃ��Ȃ�����
����Phenom���Ⴀ�˂�����Ċ������ȁE�E
����Phenom���Ⴀ�˂�����Ċ������ȁE�E
���Ă�悪�Ⴄ��ȁB
���������C�e���V�̉B��(�팸�ł��I�P)�́Aintel�AAMD�����̖ڎw���Ƃ��낾���ǁA
AMD�͎����葁���������R���g���[�������Ń��C�e���V���J�o�[�����B
���_���ʂ͑傫���A�M�ҞH�����������̋��菊�ƂȂ�킯�ŁB
���intel�̓������ш�𗘗p���āA
HTT��A���ꂩ����������ł��낤Speculative Multithreading�ɂ�郌�C�e���V�̊��S�B����ڎw�����B
�����͂��ɂȂ�̂��͂킩��Ȃ����ǁB
��Ƒ̗͂̍����낤�ˁB
���������C�e���V�̉B��(�팸�ł��I�P)�́Aintel�AAMD�����̖ڎw���Ƃ��낾���ǁA
AMD�͎����葁���������R���g���[�������Ń��C�e���V���J�o�[�����B
���_���ʂ͑傫���A�M�ҞH�����������̋��菊�ƂȂ�킯�ŁB
���intel�̓������ш�𗘗p���āA
HTT��A���ꂩ����������ł��낤Speculative Multithreading�ɂ�郌�C�e���V�̊��S�B����ڎw�����B
�����͂��ɂȂ�̂��͂킩��Ȃ����ǁB
��Ƒ̗͂̍����낤�ˁB
���lj��̔������Ȃ��I������
��Intel�̌��Ă��̓����R�������Ȃ�ă��x���ł͂Ȃ����C������������CPU������
CoreMA�͂܂����S��4���ߓ������s�ւ̍�荞�݂̓r���B
Penryn�ł��}���ł��Ȃ��͗l�B
intel��SSE4�Ɉ���������Ȃ��悤�A���������_���Z���128bit�������������Phenom��
�o���u�Ԃ����Ƃ����ԂɎ���x��ɂȂ肻���ȗ\���B
Penryn�ł��}���ł��Ȃ��͗l�B
intel��SSE4�Ɉ���������Ȃ��悤�A���������_���Z���128bit�������������Phenom��
�o���u�Ԃ����Ƃ����ԂɎ���x��ɂȂ肻���ȗ\���B
>>747
���ʂ͑傫���Ȃ������Ƃ�������B
�S�̂̃p�t�H�[�}���X��Pentium-M����̃m�[�X���x������B
���ʂ��傫���Ɛ����Ă���̂́A�G���Ў�Â̏��y�[�W�̒��C�^�[���������B
K7�Ɣ�ׂ�ƌ��ʂ͂��邪�AK7�Ƀ����R�������Ă�K8�ɂ͑S���y�Ȃ��A������Ƒ���K7���x��
���ǂł����Ȃ���B
intel���\�肵�Ă���Z�p�́A���Ђ��ǂ�����ł��Ȃ�����͌������Ŋ������ĈȌ���u�v���[�B
����intel�̎s��ł̖{���̓G�͓Ɛ�֎~�@�B�ނ�݂ɋ����͏o���Ȃ����Ă��ƁB
���ʂ͑傫���Ȃ������Ƃ�������B
�S�̂̃p�t�H�[�}���X��Pentium-M����̃m�[�X���x������B
���ʂ��傫���Ɛ����Ă���̂́A�G���Ў�Â̏��y�[�W�̒��C�^�[���������B
K7�Ɣ�ׂ�ƌ��ʂ͂��邪�AK7�Ƀ����R�������Ă�K8�ɂ͑S���y�Ȃ��A������Ƒ���K7���x��
���ǂł����Ȃ���B
intel���\�肵�Ă���Z�p�́A���Ђ��ǂ�����ł��Ȃ�����͌������Ŋ������ĈȌ���u�v���[�B
����intel�̎s��ł̖{���̓G�͓Ɛ�֎~�@�B�ނ�݂ɋ����͏o���Ȃ����Ă��ƁB
�����R�������̌��ʂ������Ȃ�Intel�������R����������킯�Ȃ�����B�A�z���B
>>752
���ȁBWeBjNo8F�͋ɘ_�߂��B
���ȁBWeBjNo8F�͋ɘ_�߂��B
���܂��炪�ɘ_�B
����͂قƂ�ǖ����B�Ƃ������B
���̋��������܂����intel���ڂ���B���̒��x�̕��B
���ی��ɂ��̗���B�{���ɐM�҂ȂȁB�����Z�p�����B
intel��AMD���Ƃ����Ɍ������Ă��镨�����ڂ��邩�Ƃ����헪��AMD�������������B
�ނ��A���̃X���̒����v���Ă���悤�Ȍ��ʂ��Ȃ����Ƃ͐��̒��I�ɂ͏펯�ŁA�}�[�P�e�B���O�I�ɂ��������B
128bit�������Ȗ�͂Ȃ�����B�������Ă��镔���������������Ƃ������Ƃ͕K�R�I��
���̉��ǂ͏��K�́B
Penryn�̉��ǂ����Z���SSE4�������Ƃ��v���Ă��Ȃ��B
����͂قƂ�ǖ����B�Ƃ������B
���̋��������܂����intel���ڂ���B���̒��x�̕��B
���ی��ɂ��̗���B�{���ɐM�҂ȂȁB�����Z�p�����B
intel��AMD���Ƃ����Ɍ������Ă��镨�����ڂ��邩�Ƃ����헪��AMD�������������B
�ނ��A���̃X���̒����v���Ă���悤�Ȍ��ʂ��Ȃ����Ƃ͐��̒��I�ɂ͏펯�ŁA�}�[�P�e�B���O�I�ɂ��������B
128bit�������Ȗ�͂Ȃ�����B�������Ă��镔���������������Ƃ������Ƃ͕K�R�I��
���̉��ǂ͏��K�́B
Penryn�̉��ǂ����Z���SSE4�������Ƃ��v���Ă��Ȃ��B
�قƂ�ǖ����킯����Ȃ��BIntel�ɂ̓����R����������f�����b�g���傫�������̂�
�܂��ڂ��ĂȂ��B�����B
�܂��ڂ��ĂȂ��B�����B
�͂��͂�FUDFUD
�����R�������Ɍ��ʂ������Ƃ����Ȃ�Intel�ȊO�������R���������Ă闝�R�������B
�R�A�̋����Ȃ�ăv���Z�X��������������I���킯�Ȃ�����B
�܂�̓R�A�̋����������R���������ǂ������d�v�B
�ǂ��o�����X����邩�͖ړI�Ƃ���A�v���P�[�V������v�v�z�ɂ��B
�܂��AK8�̓T�[�o�ɏœ_�ĂĂ�����A���̕���ł͌��ʂ������Ƃ������Ƃ͂��邩������B
Intel�������R���������ĂȂ��̂�RDRAM�œ]�����̂��ł����Ǝv���B
��������DRAM�����[�h���Ă������M�������Ȃ����B
�����̃������A�[�L�e�N�`����ǂ݈Ⴆ��ƍň�CPU�܂œ]���邵�B
���Ȃ݂�SSE��128bit���ȊO��Barcelona�̉��ǂ��債�����Ɩ������Č����͕̂��s�����Ǝv���B
Penryn�̉��ǂ�����ۂǑ����B
�R�A�̋����Ȃ�ăv���Z�X��������������I���킯�Ȃ�����B
�܂�̓R�A�̋����������R���������ǂ������d�v�B
�ǂ��o�����X����邩�͖ړI�Ƃ���A�v���P�[�V������v�v�z�ɂ��B
�܂��AK8�̓T�[�o�ɏœ_�ĂĂ�����A���̕���ł͌��ʂ������Ƃ������Ƃ͂��邩������B
Intel�������R���������ĂȂ��̂�RDRAM�œ]�����̂��ł����Ǝv���B
��������DRAM�����[�h���Ă������M�������Ȃ����B
�����̃������A�[�L�e�N�`����ǂ݈Ⴆ��ƍň�CPU�܂œ]���邵�B
���Ȃ݂�SSE��128bit���ȊO��Barcelona�̉��ǂ��債�����Ɩ������Č����͕̂��s�����Ǝv���B
Penryn�̉��ǂ�����ۂǑ����B
�M�҂Ƃ����Ƃ��]�v�Ȃ��̂����Ęb�����ɂ͂����Ȃ�����܂Ƃ��ɑ��肳��Ȃ��낗
�����Ɏ��M����Ȃ�����Ɠ��X�Ƃ��Ă�悗����
�����Ɏ��M����Ȃ�����Ɠ��X�Ƃ��Ă�悗����
�ł�����ڂ�
>>758
�㓡������̍����Ԃ������͂ɓł���Ă�ˁB
�����͂�������Ȃ�����B
Barcelena�Ɋւ��ẮA���̉��ǂł͕s�\���B
Penryn�̓x�[�X�����łɏo���Ă邪�A�����ɂ��瓞�B�ł��Ȃ��B
�����K8�̏����ǂł����Ȃ��B
���ꂪ�킩��Ȃ��Ƃ����̂ł���A���傤���Ȃ��B
>759
�Ӗ��s���B�I���̓I�}�G��ɂ��ĂȂ����B���X�͂�����Ƃ��邪�B
�㓡������̍����Ԃ������͂ɓł���Ă�ˁB
�����͂�������Ȃ�����B
Barcelena�Ɋւ��ẮA���̉��ǂł͕s�\���B
Penryn�̓x�[�X�����łɏo���Ă邪�A�����ɂ��瓞�B�ł��Ȃ��B
�����K8�̏����ǂł����Ȃ��B
���ꂪ�킩��Ȃ��Ƃ����̂ł���A���傤���Ȃ��B
>759
�Ӗ��s���B�I���̓I�}�G��ɂ��ĂȂ����B���X�͂�����Ƃ��邪�B
���ǂ��Ă��f�������X�Ȑ�4�悮�炢�x����
�Ȃ���Ӗ��������B
�Ȃ���Ӗ��������B
����I�ɕςȂ̂��N����
Penryn�������グ�����̂Ȃ�Intel������X���ɍs���Ă��ꂽ�����������
��������Barcelona��l�|��������������Ă����Ǝv����
Penryn�������グ�����̂Ȃ�Intel������X���ɍs���Ă��ꂽ�����������
��������Barcelona��l�|��������������Ă����Ǝv����
http://www.watch.impress.co.jp/akiba/hotline/20070630/etc_exp2k.html
�@3�T�ԑO�ɍs��ꂽRadeon HD 2000�V���[�Y�̓X���f���ł�Phenom��2���ڂ���
8�R�A����PC�uFASN8�iFirst AMD Silicon Next-gen 8-core Platform�j�v���f������Ƃ̗\����
���������A����̃C�x���g�ł���͂Ȃ��A����͕ʂ̃C�x���g�Łu�Ă̏��������Ɂv�s���Ƃ����B
���炢������ˁB�W�������炢���ȁB�B�B
�@3�T�ԑO�ɍs��ꂽRadeon HD 2000�V���[�Y�̓X���f���ł�Phenom��2���ڂ���
8�R�A����PC�uFASN8�iFirst AMD Silicon Next-gen 8-core Platform�j�v���f������Ƃ̗\����
���������A����̃C�x���g�ł���͂Ȃ��A����͕ʂ̃C�x���g�Łu�Ă̏��������Ɂv�s���Ƃ����B
���炢������ˁB�W�������炢���ȁB�B�B
64 ���O�FSocket774[sage] ���e���F2007/06/30(�y) 23:01:16 ID:hRrsLnqO
�ȂA������MSI�̉c�Ƃ����������Ă���B
�u����AMD�͑ʖڂ��Ǝv���܂��E�E�E��AMD���[�U�����猾����������Ǝv����ł��v
�E�E�E����Ȃ�X�̒��ŋq�Ɍ����Ȃ�B
AMD�C�x���g�ŃA���P�[�g�����肢���邢���̓Ő�Z������
����������AMD�����肢���܂��Ɠ��������Ă����B
�ׂ��O�̉�ЂƂ͂���Ȃ���Ȃ낤���A������Ɖ��z�ɂȂ����B
���ǁA�����Ă�邭�炢�����~�����i�͖������A
�c�O�Ȃ��牴���A���̊��������]���Ă���K���҂ł͂Ȃ��̂ŁA
������Ƃ��B
�ȂA������MSI�̉c�Ƃ����������Ă���B
�u����AMD�͑ʖڂ��Ǝv���܂��E�E�E��AMD���[�U�����猾����������Ǝv����ł��v
�E�E�E����Ȃ�X�̒��ŋq�Ɍ����Ȃ�B
AMD�C�x���g�ŃA���P�[�g�����肢���邢���̓Ő�Z������
����������AMD�����肢���܂��Ɠ��������Ă����B
�ׂ��O�̉�ЂƂ͂���Ȃ���Ȃ낤���A������Ɖ��z�ɂȂ����B
���ǁA�����Ă�邭�炢�����~�����i�͖������A
�c�O�Ȃ��牴���A���̊��������]���Ă���K���҂ł͂Ȃ��̂ŁA
������Ƃ��B
>>763
�ɒ[�B����ŕϐl�Ƃ������̓����B
�ɒ[�B����ŕϐl�Ƃ������̓����B
���ȏЉ�H
����ID�ł悭����Ȏ�������Ȃ��E�E�E
�u�Ȃ������Ȃ��v���lj����Ƃ�����H
�u�Ȃ������Ȃ��v���lj����Ƃ�����H
�Ȃ�Ŏ�����X���Ƃ�CPU�A�[�L�X���ɂ͉�̋����ςȐl���W�܂邷���ˁB�B�B
�܂��ނ͗F���ĂԂ��ēz����ˁH
�����ē����f��������������Ď���͒N���m��Ȃ����B
����I�ɕςȉ��߂��邩���X���Ă��B
���肪�s���Ă��邱�Ƃ����ɔے肷�����āA����̕��̂Ƃ��n���h���l�[���Ƃ�
���X�̐��Ƃ�ID�Ƃ��A�����������Ƃɂ����ݓ���郄�c�������B
�Ƃ肠��������̓I�}�G���A�Ə����Ƃ��ˁB
�ő�̓����́A�����̐����Ă邱�Ƃ��Ԉ���Ă��邩��A����̃L�����N�^�[���U������B
���������l�͓��퐶���ł�����Ă�̂ŁB�C�Â��܂��傤�B
����I�ɕςȉ��߂��邩���X���Ă��B
���肪�s���Ă��邱�Ƃ����ɔے肷�����āA����̕��̂Ƃ��n���h���l�[���Ƃ�
���X�̐��Ƃ�ID�Ƃ��A�����������Ƃɂ����ݓ���郄�c�������B
�Ƃ肠��������̓I�}�G���A�Ə����Ƃ��ˁB
�ő�̓����́A�����̐����Ă邱�Ƃ��Ԉ���Ă��邩��A����̃L�����N�^�[���U������B
���������l�͓��퐶���ł�����Ă�̂ŁB�C�Â��܂��傤�B
�Ƃ肠�����܂��A�����̂��܂莋�싷��Ɋׂ��Ă邱�Ƃ͊m���݂��������痎�������Ȃ�������
�����Ă邱�Ƃ��ĉ��ł�����
�����Ă邱�Ƃ��ĉ��ł�����
�I���V���C����WeBjNo8F�͍���̓R�e���Ă���
���[�R�e�͂₾�Ȃ��B�ǂ������ID���邵�B
�O��Ƃ��āA>772�݂����ȃ��c���ĕ��̂Ɛ����Ă邱�Ƃ��S���ꏏ������
�������Ǝv�����ǁA���̑O���������_���嗬�ɂȂ��Đ����Ȃ�č���g��Ȃ���������
���Ɛ����đ�\�ꂵ�Ă���B
�ɍ\���ăL�����w�E���Ă��郄�c���Ă���ȁB
���������_���Z��œ�������Ȃ瓮�����Ă���B
�O��Ƃ��āA>772�݂����ȃ��c���ĕ��̂Ɛ����Ă邱�Ƃ��S���ꏏ������
�������Ǝv�����ǁA���̑O���������_���嗬�ɂȂ��Đ����Ȃ�č���g��Ȃ���������
���Ɛ����đ�\�ꂵ�Ă���B
�ɍ\���ăL�����w�E���Ă��郄�c���Ă���ȁB
���������_���Z��œ�������Ȃ瓮�����Ă���B
�^����
>���̑O���������_���嗬�ɂȂ��Đ����Ȃ�č���g��Ȃ���������
>���Ɛ����đ�\�ꂵ�Ă���B
���ꉴ�Ȃ��ǁB
�ق�Ƃ��܂��I���V���C��
>���Ɛ����đ�\�ꂵ�Ă���B
���ꉴ�Ȃ��ǁB
�ق�Ƃ��܂��I���V���C��
�u�ɍ\���āv���Ĉ�x�����������Ă݂邱�Ƃ������߂����
�w�E���ꂽ���Ƃ���Ȃɕ����������H
�킩�������������悻��ȍׂ������Ɛ�����
�킩�������������悻��ȍׂ������Ɛ�����
>>776
�������Z���j�b�g�łǂ�����ă��[�`�������̂����������������B
�����̃A�j���̂��Z����L�����݂����ȕ��́B
���̌����ŋ����āB
�������Z���j�b�g�łǂ�����ă��[�`�������̂����������������B
�����̃A�j���̂��Z����L�����݂����ȕ��́B
���̌����ŋ����āB
WeBjNo8F�̐l�C�Ɏ��i
>>777
���܂��玫���ʂ肶���
���܂��玫���ʂ肶���
783 �FMAC�I�^���F�����F2007/07/01(��) 00:08:41 ID:v7GwKzCI
���������������A�ォ��ǂ�ł������c�_���ĕ������Ă�̂�����Ȃ����B
�N�������Ă���Ȃ������H
�N�������Ă���Ȃ������H
������������
785 �F�E�́E�j��-�������F2007/07/01(��) 00:09:22 ID:iD8vBFZX
AMD�͐���3Way+FP/SIMD3Way��6Way�p�C�v���C����ڎw���Ă��Ȃ��̂��ˁB
�n���ɒn���ɁA�����p�C�v�ƕ��������p�C�v�̓Ɨ��������߂Ă����Ă�B
���ߑш悪�ǂ����Ȃ��������ǁA�t�F�b�`�ш���������Ă�����
�f�R�[�_���e�p�C�v���Ƃɗp�Ӂi�v6Way�j���Ă�B
���Ƃ̓t�����g�G���h�ƃ��^�C�A������������Έ�C�Ƀs�[�N6IPC�܂ň����グ�\�B
�����A��̂ǂ�ȃv���O�������点����Ă낤��
�n���ɒn���ɁA�����p�C�v�ƕ��������p�C�v�̓Ɨ��������߂Ă����Ă�B
���ߑш悪�ǂ����Ȃ��������ǁA�t�F�b�`�ш���������Ă�����
�f�R�[�_���e�p�C�v���Ƃɗp�Ӂi�v6Way�j���Ă�B
���Ƃ̓t�����g�G���h�ƃ��^�C�A������������Έ�C�Ƀs�[�N6IPC�܂ň����グ�\�B
�����A��̂ǂ�ȃv���O�������点����Ă낤��
>>454 >>456 >>459 >>462 >>469
���̂ւ��̃��X���ȁB
���l���Z�̊�{�͕��������_���Z���ƌ����Ă�̂�
�u�������Z���j�b�g�łǂ�����ă��[�`�������̂��v
������ȁB�l�̃��X�ǂႢ�˂��B
���̂ւ��̃��X���ȁB
���l���Z�̊�{�͕��������_���Z���ƌ����Ă�̂�
�u�������Z���j�b�g�łǂ�����ă��[�`�������̂��v
������ȁB�l�̃��X�ǂႢ�˂��B
�����������AID:WeBjNo8F�ꗬ�̃��[���A�ł��������뎚����Ȃ������Ă�
���܂ȂA�ǂ���������ӂ̃Z���X���܂��܂��݂����ŁE�E�E
���܂ȂA�ǂ���������ӂ̃Z���X���܂��܂��݂����ŁE�E�E
>>783
���҂����Ă���܂���
���҂����Ă���܂���
>>783
���[�Ȃ�̋c�_�ɂ��Ȃ��ĂȂ��ˁB
�P�Ɏ���X2��Core2�ɋy�Ȃ����ď����������Ȃ̂�B
�ł������R�������Ă邩��X2�t�@���Ƃ��ċ����Ȃ��������B
�����R�������Ă��Ȃ����牽���������������Ƃ��Ă��ʖڂ݂����B
�}�W���ȃI���͂����ł͂Ȃ��ƃ��X�������Ă���B���ꂾ���B
���[�Ȃ�̋c�_�ɂ��Ȃ��ĂȂ��ˁB
�P�Ɏ���X2��Core2�ɋy�Ȃ����ď����������Ȃ̂�B
�ł������R�������Ă邩��X2�t�@���Ƃ��ċ����Ȃ��������B
�����R�������Ă��Ȃ����牽���������������Ƃ��Ă��ʖڂ݂����B
�}�W���ȃI���͂����ł͂Ȃ��ƃ��X�������Ă���B���ꂾ���B
791 �FMAC�I�^���c�q �����F2007/07/01(��) 00:13:20 ID:v7GwKzCI
>>785
�@�@----------------
�@�@��C�Ƀs�[�N6IPC�܂ň����グ�\�B
�@�@----------------
4�X���b�h���炢���点�Ȃ��Ɩ��Ӗ����Ǝv�����BAndy Glew�̒u���y�Y�Ȃ��ˁB�B�B
�@�@----------------
�@�@��C�Ƀs�[�N6IPC�܂ň����グ�\�B
�@�@----------------
4�X���b�h���炢���点�Ȃ��Ɩ��Ӗ����Ǝv�����BAndy Glew�̒u���y�Y�Ȃ��ˁB�B�B
�����Ȃ́H>>763�ɂ��Ă̘b���Ǝv���Ă�
793 �FMAC�I�^���⑫�F2007/07/01(��) 00:17:38 ID:v7GwKzCI
Glew����AMD�Œ��Ă����A�[�L�e�N�`���̊T�v��A���g�̃T�C�g�ɋL����Ă��邷�B
http://www.geocities.com/andrew_f_glew/cv-glew.html
�@�@----------------------
�@�@Proposed advanced microarchitecture: multithreaded, multicluster, with multilevel everything:
�@�@multilevel schedulers, multilevel instruction window, multilevel store buffers, multilevel
�@�@register file, and multilevel branch predictors; supporting Implicit Multithreading / Speculative
�@�@Multithreading/Skipahead Multithreading (IMT/SpMT/SkMT) and lightweight user level forking.
�@�@----------------------
http://www.geocities.com/andrew_f_glew/cv-glew.html
�@�@----------------------
�@�@Proposed advanced microarchitecture: multithreaded, multicluster, with multilevel everything:
�@�@multilevel schedulers, multilevel instruction window, multilevel store buffers, multilevel
�@�@register file, and multilevel branch predictors; supporting Implicit Multithreading / Speculative
�@�@Multithreading/Skipahead Multithreading (IMT/SpMT/SkMT) and lightweight user level forking.
�@�@----------------------
> Andy Glew�̒u���y�Y�Ȃ��ˁB�B�B
���������A�������ݐЈȑO����L�邾�낤��
�ǂ���������Ă�
���������A�������ݐЈȑO����L�邾�낤��
�ǂ���������Ă�
>>785
�I���Ƃ��Ă͂����������ꂪ�ԈႢ�̌��ɂȂ肩�˂Ȃ��Ǝv����ˁB
�G�ɕ`�����݂��Ǝv���B�����ɏo����͂����Ȃ��̂Ō����������ł��ׂ�����Ȃ��́H
�I���Ƃ��Ă͂����������ꂪ�ԈႢ�̌��ɂȂ肩�˂Ȃ��Ǝv����ˁB
�G�ɕ`�����݂��Ǝv���B�����ɏo����͂����Ȃ��̂Ō����������ł��ׂ�����Ȃ��́H
796 �FMAC�I�^��794 �����F2007/07/01(��) 00:22:51 ID:v7GwKzCI
797 �FMAC�I�^��795 �����F2007/07/01(��) 00:26:13 ID:v7GwKzCI
>>795
�@�@-----------------
�@�@�G�ɕ`�����݂��Ǝv���B
�@�@-----------------
POWER6��(2�X���b�h��)7IPC�����ǁB�B�B
�@�@-----------------
�@�@�G�ɕ`�����݂��Ǝv���B
�@�@-----------------
POWER6��(2�X���b�h��)7IPC�����ǁB�B�B
��������A�����V�т܂���œ����ĂȂ�
�r���̒u���݂₰�Ƃ͕����ĕ����
���Ĉ��|�I��L1�ш�ʼn��Z�킪�����܂����Intel�Ƃ͑ΏƓI��
�r���̒u���݂₰�Ƃ͕����ĕ����
���Ĉ��|�I��L1�ш�ʼn��Z�킪�����܂����Intel�Ƃ͑ΏƓI��
>>797
��ׂ��Ⴂ����ł��B
����RISC�������Ȃ������獡�͂̂�т�o����͂��Ȃ��ǂˁB
intel��x86�Ƃ���64bit�̗����ʒu�ɑ����ł��Ă���ۂ��悤�ȕ��͋C��������BCore2�ȍ~���ƂȂ�������B
��ׂ��Ⴂ����ł��B
����RISC�������Ȃ������獡�͂̂�т�o����͂��Ȃ��ǂˁB
intel��x86�Ƃ���64bit�̗����ʒu�ɑ����ł��Ă���ۂ��悤�ȕ��͋C��������BCore2�ȍ~���ƂȂ�������B
801 �FMAC�I�^��799 �����F2007/07/01(��) 00:33:15 ID:v7GwKzCI
>>799
�ϑz��A���������ɂ����ق����ǂ��Ǝv�����B
http://journal.mycom.co.jp/column/sopinion/191/index.html
�@�@=====================
�@�@���̂Ƃ���M�҂�"IPC=3"�Ƃ��������ɂ������̂́A������Ɩ���B���Ȃ�Â��b�ŋ��k
�@�@�����A2002�N��2����AMD��Dirk Meyer��(���݂�AMD��COO�����A�����̌�������CPG:
�@�@Computation Products Group��Group Vice President������)����������Press Conference��
�@�@�J�Â��ꂽ�B���̐Ȃ�x86��IPC=3���z����\����q�˂��Ƃ���A���͖��m�ɁuIPC=3�͉z��
�@�@����ƍl���Ă���v�Ɠ������B���ꂪ��ɓ��ɂ��������炱���A�u����IPC=3���z����̂��v��
�@�@�������Ă����킯�����A�ǂ������̉\���͒Z���I�ɂ͂Ȃ��Ȃ����ƌ��ėǂ��������B�����Ȃ��Ƃ�
�@�@���s�̃A�[�L�e�N�`���̉�����IPC=3���z����\����Intel / AMD���ɂȂ����낤(����)�B
�@�@=====================
�ϑz��A���������ɂ����ق����ǂ��Ǝv�����B
http://journal.mycom.co.jp/column/sopinion/191/index.html
�@�@=====================
�@�@���̂Ƃ���M�҂�"IPC=3"�Ƃ��������ɂ������̂́A������Ɩ���B���Ȃ�Â��b�ŋ��k
�@�@�����A2002�N��2����AMD��Dirk Meyer��(���݂�AMD��COO�����A�����̌�������CPG:
�@�@Computation Products Group��Group Vice President������)����������Press Conference��
�@�@�J�Â��ꂽ�B���̐Ȃ�x86��IPC=3���z����\����q�˂��Ƃ���A���͖��m�ɁuIPC=3�͉z��
�@�@����ƍl���Ă���v�Ɠ������B���ꂪ��ɓ��ɂ��������炱���A�u����IPC=3���z����̂��v��
�@�@�������Ă����킯�����A�ǂ������̉\���͒Z���I�ɂ͂Ȃ��Ȃ����ƌ��ėǂ��������B�����Ȃ��Ƃ�
�@�@���s�̃A�[�L�e�N�`���̉�����IPC=3���z����\����Intel / AMD���ɂȂ����낤(����)�B
�@�@=====================
�������Ă��A�������ĂȂ����s�v�c�ȓz����
6IPC�͗��_��Ȃ�A�r���̒u���݂₰�Ŏ����o����Ƃ�����ˁ[�킯
�����o���郍�W�b�N�Ȃ�Ēu���Ă��ĂȂ����낤��
���Z�킪�S�����̉���̘b�Ŏ��ۂ��̂悤�Ȏ����N����킯���Ȃ�
����ĕ��ϓI��3IPC���鎖�͖������낤���Ă�����
6IPC�͗��_��Ȃ�A�r���̒u���݂₰�Ŏ����o����Ƃ�����ˁ[�킯
�����o���郍�W�b�N�Ȃ�Ēu���Ă��ĂȂ����낤��
���Z�킪�S�����̉���̘b�Ŏ��ۂ��̂悤�Ȏ����N����킯���Ȃ�
����ĕ��ϓI��3IPC���鎖�͖������낤���Ă�����
�}���`�R�A����Ɂu�R�A�P�������IPC�v�l����Ӗ��Ȃ�����B
�V���O���X���b�h����IPC�Ȃ�܂��Ӗ����邪�B
�V���O���X���b�h����IPC�Ȃ�܂��Ӗ����邪�B
>>803
�����ė��N���炢�̖����ł��Ǝv�����B
�����ė��N���炢�̖����ł��Ǝv�����B
�}���`�R�A���ゾ�낤�Ƃ����łȂ��낤��
(IPC/core) * Freq
�ŕ������烁�C���X�g���[���s�ꂩ������Ă����܂������
(IPC/core) * Freq
�ŕ������烁�C���X�g���[���s�ꂩ������Ă����܂������
806 �FMAC�I�^��802 �����F2007/07/01(��) 00:53:30 ID:v7GwKzCI
>>802
�@�@-----------------
�@�@���ϓI��3IPC
�@�@-----------------
���ꂪ�ϑz�Ȃ���(��)
���̘_����Table 7����������Ă݂邱�Ƃ������߂��邷�B
http://www.cs.utexas.edu/users/cart/trips/publications/isca00.pdf
���v���O������IPC��2���邱�Ƃ��������Ƃ�����Ǝv�����B
�@�@-----------------
�@�@���ϓI��3IPC
�@�@-----------------
���ꂪ�ϑz�Ȃ���(��)
���̘_����Table 7����������Ă݂邱�Ƃ������߂��邷�B
http://www.cs.utexas.edu/users/cart/trips/publications/isca00.pdf
���v���O������IPC��2���邱�Ƃ��������Ƃ�����Ǝv�����B
>>805
�����ŃR�A���Ŋ���Ӗ����킩���ˁB����Ȃ�X���b�h������B
�����ŃR�A���Ŋ���Ӗ����킩���ˁB����Ȃ�X���b�h������B
�X���b�h���H
���̂���ڂ��V���O���R�A�ł� 44�v���Z�X 472�X���b�h 9230�n���h�� �����Ă܂�����
�_��CPU���ƌ����Ȃ番���邪
���̂���ڂ��V���O���R�A�ł� 44�v���Z�X 472�X���b�h 9230�n���h�� �����Ă܂�����
�_��CPU���ƌ����Ȃ番���邪
�������̈Ӗ��̃X���b�h�Ƌ�ʂ��邽�߃X�g�����h���Č����Ă�̂�Sun������
595 �FSocket774 [sage] �F2006/01/23(��) 00:33:24 ID:3ljonn9J
�V���O���R�A�ł��낤���}���`�R�A�ł��낤���A
�����R�A���Ő키���ƂɂȂ铯��v���Z�X���[������Z�O�����g�ɂ����āA
���C�o���Ƃ̏��������߂�̂͌��ǂ̓X�[�p�[�X�J���̐��\�B
�A�E�g�I�u�I�[�_�[�̐i������߂�AMD�ɖ����Ȃ�
�V���O���R�A�ł��낤���}���`�R�A�ł��낤���A
�����R�A���Ő키���ƂɂȂ铯��v���Z�X���[������Z�O�����g�ɂ����āA
���C�o���Ƃ̏��������߂�̂͌��ǂ̓X�[�p�[�X�J���̐��\�B
�A�E�g�I�u�I�[�_�[�̐i������߂�AMD�ɖ����Ȃ�
�Ȃ�ł������������ŐV���P�O�O�z���Ă��w
�Ǝv������A�ȂςȂ́iID:WeBjNo8F ID:UuWh1MEh �j�����Ă��݂������ȁE�E
�Ǝv������A�ȂςȂ́iID:WeBjNo8F ID:UuWh1MEh �j�����Ă��݂������ȁE�E
�G���K��������
3IPC�A6IPC�ƌ����Ă�x86��uOPs���ŕς���Ă���B
������Ӄn�b�L�������Ȃ��ƈӖ������B
������Ӄn�b�L�������Ȃ��ƈӖ������B
uOPs�Ōv�Z���Ă��Ӗ����Ȃ��Ax86�Ɋ��Z���Čv�Z����̂��펯�B
815 �F�E�́E�j��-�������F2007/07/01(��) 10:29:33 ID:iD8vBFZX
IPC=3�Ȃ�Ă̂�L1�L���b�V���ɏ�Ƀq�b�g���ĂĂ��̏��X�g�[���Ȃ��œ�����
�����ł������Ȃ���ł����B
���C���������A�N�Z�X�Ɉˑ�����悤�Ȃ̂͂��ꂱ��IPC=1������Ⴄ��Ȃ���ł����H
�����炱���L���b�V��������������A�����R���𓋍ڂ��āu�Œ�IPC�v�̈����グ���v��킯�ŁB
>>809
�u�����R���e�N�X�g���s���v�Ƃ��u�_���v���Z�b�T���v�Ƃ������Ƃ�������łȂ��H
CGMT���u�����v���Č����̂����Ƌ^�₾���B
�����ł������Ȃ���ł����B
���C���������A�N�Z�X�Ɉˑ�����悤�Ȃ̂͂��ꂱ��IPC=1������Ⴄ��Ȃ���ł����H
�����炱���L���b�V��������������A�����R���𓋍ڂ��āu�Œ�IPC�v�̈����グ���v��킯�ŁB
>>809
�u�����R���e�N�X�g���s���v�Ƃ��u�_���v���Z�b�T���v�Ƃ������Ƃ�������łȂ��H
CGMT���u�����v���Č����̂����Ƌ^�₾���B
�gFASN8�h�͗��N�ɉ����B
AMD��Single-CPU������Phenom FX-80�݂̂�11����12���Ƃ��Ă���A
�gFASN8�h�����ƂȂ�Phenom FX-91, FX-90��2008�N��1�l�����Ƀ����[�X�ƂȂ��Ă���B
http://northwood.blog60.fc2.com/
AMD��Single-CPU������Phenom FX-80�݂̂�11����12���Ƃ��Ă���A
�gFASN8�h�����ƂȂ�Phenom FX-91, FX-90��2008�N��1�l�����Ƀ����[�X�ƂȂ��Ă���B
http://northwood.blog60.fc2.com/
>>814
���O�͉��������Ă�H
���O�͉��������Ă�H
uOPs�͓���x86�n�ł������̎d���ɂ�葽�������Ȃ����Ȃ邩���r�ΏۂɂȂ�Ȃ��ƌ����Ă�B
IPC@SPECint92�`SPECint2000 (McKinley = 1.25)
ipc@specint cpu
-------------------------
0.09 i386DX
0.19 i486DX4
0.21 R4000
0.21 i486DX2
0.24 i486DX
0.24 Alpha21064
0.25 R3000
0.30 MC68040
0.41 P54CS
0.42 P5
0.42 Alpha21164A
0.44 R8000
0.45 P54CQS
0.45 P54VRT
0.45 P55C
0.45 PA-7000
0.47 P54C
0.50 PPC604
0.54 Deschutes
0.54 Willamette
0.57 Katmai
0.57 Mendocino
0.57 Klamath
0.58 Northwood
0.60 PPC604e
ipc@specint cpu
-------------------------
0.09 i386DX
0.19 i486DX4
0.21 R4000
0.21 i486DX2
0.24 i486DX
0.24 Alpha21064
0.25 R3000
0.30 MC68040
0.41 P54CS
0.42 P5
0.42 Alpha21164A
0.44 R8000
0.45 P54CQS
0.45 P54VRT
0.45 P55C
0.45 PA-7000
0.47 P54C
0.50 PPC604
0.54 Deschutes
0.54 Willamette
0.57 Katmai
0.57 Mendocino
0.57 Klamath
0.58 Northwood
0.60 PPC604e
0.60 NorthwoodHT
0.60 6x86MX
0.61 PPC604e
0.62 P6
0.62 K7
0.66 Merced
0.67 Prescott
0.67 PPC7400
0.69 Coppermine
0.71 Tualatin-S
0.73 Dempsey
0.75 Alpha21264
0.76 PA-7200
0.76 Cedar Mill
0.83 R10000
0.93 PPC970MP
0.96 Italy
0.97 POWER4+
1.00 PA-8200
1.01 Venus
1.03 SanDiego
1.04 Banias
1.07 Alpha21364
1.07 SPARC64 V
1.13 PA-8700+
1.19 POWER5
1.24 Yonah
1.25 McKinley
1.25 Dothan
1.29 R14000
1.53 Madison 9M
1.57 Woodcrest
1.63 Conroe
2.37 Montecito (2006 <-> 2K @Conroe)
0.60 6x86MX
0.61 PPC604e
0.62 P6
0.62 K7
0.66 Merced
0.67 Prescott
0.67 PPC7400
0.69 Coppermine
0.71 Tualatin-S
0.73 Dempsey
0.75 Alpha21264
0.76 PA-7200
0.76 Cedar Mill
0.83 R10000
0.93 PPC970MP
0.96 Italy
0.97 POWER4+
1.00 PA-8200
1.01 Venus
1.03 SanDiego
1.04 Banias
1.07 Alpha21364
1.07 SPARC64 V
1.13 PA-8700+
1.19 POWER5
1.24 Yonah
1.25 McKinley
1.25 Dothan
1.29 R14000
1.53 Madison 9M
1.57 Woodcrest
1.63 Conroe
2.37 Montecito (2006 <-> 2K @Conroe)
Opteron Quad�͗\��ʂ�Ăɏo��炵�����ǂ��Ȃ邩�ȁB
���̂������������ȗ\���B
���̂������������ȗ\���B
�Œ�N���X��7�`8�����炢�H
824 �FSocket774�F2007/07/02(��) 21:15:06 ID:CbwZJr8g
���ۂރI���^�i�L�́M �j
http://northwood.blog60.fc2.com/blog-entry-986.html#comment
http://northwood.blog60.fc2.com/blog-entry-986.html#comment
Mobo makers say AMD Phenom delayed until 1Q08,
but AMD says launch remains set for 2H07 (update)
http://www.digitimes.com/mobos/a20070702PD201.html
but AMD says launch remains set for 2H07 (update)
http://www.digitimes.com/mobos/a20070702PD201.html
2.0GHz�œ��{�~�U�����炢���H
�ӊO�ƍ����͂Ȃ������ˁB
�ӊO�ƍ����͂Ȃ������ˁB
>>824
�I������ǂ��납����ŒN�����N���ɏo��Ȃ�Ďv���Ă˂���B
�I������ǂ��납����ŒN�����N���ɏo��Ȃ�Ďv���Ă˂���B
X2�O�������ȗ��ꂾ�����Ȃ��B
�l�g�o�j�R�C�`�f���A���R�A�����܂�ɔߎS��
���̌�͏�����������ǁB
�܂������Clovertown�������]���o���Ă邩��
�ȑO�̂悤�ɂ͂����Ȃ����낤���A����̓W�J��
�y���݂ł͂���ȁB
�l�g�o�j�R�C�`�f���A���R�A�����܂�ɔߎS��
���̌�͏�����������ǁB
�܂������Clovertown�������]���o���Ă邩��
�ȑO�̂悤�ɂ͂����Ȃ����낤���A����̓W�J��
�y���݂ł͂���ȁB
����܂���҂�������ƕK�����Ƃł������肷�邩���
�����AMD�̐헪�Ȃ̂���
�����AMD�̐헪�Ȃ̂���
�N����]�Ǝv�킹�Ă����ĂP�Q���Q�T���ɔ��\�����
����������
����������
2.4Ghz��Core 2 Duo E4300�ɕ�����x���`���N���X�}�X�ɏo�Ă�����E�E�E
834 �F�E�́E�j��-�������F2007/07/03(��) 00:15:43 ID:fca94uT1
���܂�AE4300�ɕ�����̃\�[�X���ڂ�
X2 2.4G��E4400�Ɠ������炢������E4300�ɕ�����Ƃ����肦���
AMD�hIntel�h�W�Ȃ��A���ۂ̂Ƃ���ǂ̂��炢�̐��\�������o���Ă��邩�\�z�ł�������
�l���Ȃ��H
�l���Ȃ��H
���ƒ���
Q6600 �� Agena-2.4GHz or Agena-2.3GHz
E6600 �� Kuma-2.4GHz or Kuma-2.5GHz
���Ă��ƂˁB
Q6600 �� Agena-2.4GHz or Agena-2.3GHz
E6600 �� Kuma-2.4GHz or Kuma-2.5GHz
���Ă��ƂˁB
���̗\�z����������A6400+�͏o�Ȃ���
�o���Ă�Phenom�̃C���p�N�g���������Ȃ邩���
�C���e���}�b�N�o��O��PPC�}�b�N�݂����Ȃ���
�o���Ă�Phenom�̃C���p�N�g���������Ȃ邩���
�C���e���}�b�N�o��O��PPC�}�b�N�݂����Ȃ���
841 �F�E�́E�j��-�������F2007/07/03(��) 01:08:23 ID:fca94uT1
Mac�͋t����
������DTP�����N���V�b�N���g���Ă�悤�Ȑ��E�����炳
�t�ɔ�����艿�i���l�オ�肵���Ƃ������b�B
AthlonX2��Phenom��鍑Intel�ɑ���A�h�o���e�[�W���ĂȂ�����B
������DTP�����N���V�b�N���g���Ă�悤�Ȑ��E�����炳
�t�ɔ�����艿�i���l�オ�肵���Ƃ������b�B
AthlonX2��Phenom��鍑Intel�ɑ���A�h�o���e�[�W���ĂȂ�����B
>>841
����A�Ō�̃��f���`�F���W�O��MPC7448�Ƃ��A������Ƃ܂Ă�P.A.semi�Ƃ��������̂ɍ̗p���Ȃ���������
���������Ӗ���
Athlon������ȏ㐫�\���グ�Ă��܂��ƁAPhenom�̐��\�������ށA���邢��Athlon���z���鐫�\��B���ł���܂ŏo�ׂ���ł��Ȃ��Ȃ�
�����6400+�͂Ȃ��A�ƁB
����A�Ō�̃��f���`�F���W�O��MPC7448�Ƃ��A������Ƃ܂Ă�P.A.semi�Ƃ��������̂ɍ̗p���Ȃ���������
���������Ӗ���
Athlon������ȏ㐫�\���グ�Ă��܂��ƁAPhenom�̐��\�������ށA���邢��Athlon���z���鐫�\��B���ł���܂ŏo�ׂ���ł��Ȃ��Ȃ�
�����6400+�͂Ȃ��A�ƁB
843 �FSocket774�F2007/07/03(��) 01:24:33 ID:bspsEWoK
����L1�ш悾�A���Z���W�b�N�I�Ɍ���ł�AMD�̕�������
��C2D�ɔ�ׂĈ��|�I�ɗ��L1�ш��K8�͍��ł����\���X�|�C�����Ă�
����͐M�������������m��Ȃ����A������
����AK8��L1�ш�{�������f�ŏ��Ă�ˁH
�Ƃ��낪���ꂪ�ȒP�ɏo���Ȃ�
K6�̎�����AMD�̓L���b�V�����x��Intel�ɒx�����葱���Ă���
��x�����ш�{�������������L�������A�����Ō��ʂ���������i���̎�FPU�͂܂��ォ�����j
���������ɕ����܂�͒���Ɉ����A����͉�Ђ��X����������̉e�����o����
��Ƀ\�P�b�g����X���b�g�ɂȂ�L2�͕������A�N�Z�X���@�ŗL���ɗ���
�\�P�b�g��A�ŃL���b�V���ш�̒x�����葱���A���ꂪ���ł��ς��Ȃ��̂�
K6����̑厸�s����A�����̉��ǂ��ւ���̗l�Ɉ����Ă邩�炾
����C2D�Ŕ{�ȏ�̑ш�Ő��\���҂���Intel�Ƃ̈Ⴂ��
�����Z�p�ɗL��AL1�ш��{������ɂ͒P���Ƀo�X�����g������Ηǂ���
���������Z�p�������ƊȒP�ɂ͏o���Ȃ�
������Phenom�ŁA���Ɏ��t����炵�����E�E�E
���܂ŏo���Ȃ����������A�����܂�������������ɏo����Ǝv�����H
�������o���Ȃ��Ɖ�H�ŏ����Ă��A���\���o�Ȃ�����C2D�̑��݂��ؖ����Ă�
�������A�����Z�p�̃g�s�b�N�X���������Ƃ��Ȃ�AMD�Ɂi�v�ł͂Ȃ��j
C2D�ɔ�����̃L���b�V�����x���o����킯�������A�܂萫�\�͏o���Ȃ�
�t�ɗL�蓾�Ȃ����Ƃ��N����AC2D�ɔ������L1�ш���o�����畁�ʂɏ���
�M���͊�Ղ�M���܂����H
��C2D�ɔ�ׂĈ��|�I�ɗ��L1�ш��K8�͍��ł����\���X�|�C�����Ă�
����͐M�������������m��Ȃ����A������
����AK8��L1�ш�{�������f�ŏ��Ă�ˁH
�Ƃ��낪���ꂪ�ȒP�ɏo���Ȃ�
K6�̎�����AMD�̓L���b�V�����x��Intel�ɒx�����葱���Ă���
��x�����ш�{�������������L�������A�����Ō��ʂ���������i���̎�FPU�͂܂��ォ�����j
���������ɕ����܂�͒���Ɉ����A����͉�Ђ��X����������̉e�����o����
��Ƀ\�P�b�g����X���b�g�ɂȂ�L2�͕������A�N�Z�X���@�ŗL���ɗ���
�\�P�b�g��A�ŃL���b�V���ш�̒x�����葱���A���ꂪ���ł��ς��Ȃ��̂�
K6����̑厸�s����A�����̉��ǂ��ւ���̗l�Ɉ����Ă邩�炾
����C2D�Ŕ{�ȏ�̑ш�Ő��\���҂���Intel�Ƃ̈Ⴂ��
�����Z�p�ɗL��AL1�ш��{������ɂ͒P���Ƀo�X�����g������Ηǂ���
���������Z�p�������ƊȒP�ɂ͏o���Ȃ�
������Phenom�ŁA���Ɏ��t����炵�����E�E�E
���܂ŏo���Ȃ����������A�����܂�������������ɏo����Ǝv�����H
�������o���Ȃ��Ɖ�H�ŏ����Ă��A���\���o�Ȃ�����C2D�̑��݂��ؖ����Ă�
�������A�����Z�p�̃g�s�b�N�X���������Ƃ��Ȃ�AMD�Ɂi�v�ł͂Ȃ��j
C2D�ɔ�����̃L���b�V�����x���o����킯�������A�܂萫�\�͏o���Ȃ�
�t�ɗL�蓾�Ȃ����Ƃ��N����AC2D�ɔ������L1�ш���o�����畁�ʂɏ���
�M���͊�Ղ�M���܂����H
>���Z���W�b�N�I�Ɍ���ł�AMD�̕�������
�ш�Ƃ����C�e���V�ŏ������������̋c�_�ƈꏏ��
�A�E�g�v�b�g�̌��ʂ��ӂ݂Ȃ��Ƃ܂������Ӗ��𐬂��Ȃ��킯�����B
�ш�Ƃ����C�e���V�ŏ������������̋c�_�ƈꏏ��
�A�E�g�v�b�g�̌��ʂ��ӂ݂Ȃ��Ƃ܂������Ӗ��𐬂��Ȃ��킯�����B
amd�͂��Ȃ��Ǝv�����ǂ����������͌��\��������
�����S�Ƃ�����60�������Ƃ��������R�O�O�Ƃ�����2�������H
�`�l�c���o�[�g���R�O�O�O�̕����n�o140���ゾ�Ǝv�����Ǖ���S�R�Ⴄ��
�����S�Ƃ�����60�������Ƃ��������R�O�O�Ƃ�����2�������H
�`�l�c���o�[�g���R�O�O�O�̕����n�o140���ゾ�Ǝv�����Ǖ���S�R�Ⴄ��
��������233��
�o�[�g���R�O�O�O�{�͂`����3000�Ɋ��S�ɕ����Ă���
�ォ��ł��`����2800�ɂ͂��������H�@�A�v���ɂ���낯��
�ǂ����ɂ��Ă��������b�g�����s���҂ɕ����邱�Ƃ͂��Ƃ͕K���������̌�̎��s���Ӗ����Ȃ�
�V�Q�����s�ɗ��̂͂�4�Ƃ�3���炢��
����ł���ΐ��\�ł͂�4���S�R��₯��
�o�[�g���R�O�O�O�{�͂`����3000�Ɋ��S�ɕ����Ă���
�ォ��ł��`����2800�ɂ͂��������H�@�A�v���ɂ���낯��
�ǂ����ɂ��Ă��������b�g�����s���҂ɕ����邱�Ƃ͂��Ƃ͕K���������̌�̎��s���Ӗ����Ȃ�
�V�Q�����s�ɗ��̂͂�4�Ƃ�3���炢��
����ł���ΐ��\�ł͂�4���S�R��₯��
���߂�����@846�̂������͂o�d�m�Q�ł�
�m�͂�3�ɑS�R���ĂȂ��ăv����1.3���Ƃ���3�n�̕���]������
�k�X�őQ���܂Ƃ��ɂȂ�������
�m�͂�3�ɑS�R���ĂȂ��ăv����1.3���Ƃ���3�n�̕���]������
�k�X�őQ���܂Ƃ��ɂȂ�������
�y������3GHz�I�[�o�[�̏Ռ��͑傫���������B
AMD���x�������Ă���̂̓v���Z�X�Z�p�����H
�����v���Z�X�Z�p�������x����������݊p�ȏ�ɐ킦��́H
�����v���Z�X�Z�p�������x����������݊p�ȏ�ɐ킦��́H
>>849
�Ԃ����Ⴏ�Č����Ɛv��Intel�̂P�N�x�ꂾ�Ǝv����B
�����Ɋւ��ẮA�v���Z�X�X�V�������P�N�x��Ȃ����łȂ��A�V�v���Z�X�ւ̃N���X�I�[�o�[�̑����A
��_�C�T�C�Y�⍂�N���b�NMCM�ł̗ʎY�m�E�n�E�A�ʎY���i�ASRAM�P�Z���̑傫���A
Intel������s���Ă镔���͑����B
�Ԃ����Ⴏ�Č����Ɛv��Intel�̂P�N�x�ꂾ�Ǝv����B
�����Ɋւ��ẮA�v���Z�X�X�V�������P�N�x��Ȃ����łȂ��A�V�v���Z�X�ւ̃N���X�I�[�o�[�̑����A
��_�C�T�C�Y�⍂�N���b�NMCM�ł̗ʎY�m�E�n�E�A�ʎY���i�ASRAM�P�Z���̑傫���A
Intel������s���Ă镔���͑����B
http://northwood.blog60.fc2.com/
AMD��Phenom�̃��[���`��2008�N��1�ʎl�����ɒx�点�邩������Ȃ��ƂƂ���}�U�[�{�[�h���[�J�[��������B
Phenom��2007�N�ɓo�ꂵ�Ȃ������ꍇ�A���Ђ̃}�U�[�{�[�h���[�J�[��
SocketAM2+�}�U�[�̏o�ׂ����炵�A�����Intel�����}�U�[�{�[�h�̏o�ׂ������邱�Ƃ��v�悵�Ă���Ƃ����B
AMD��Phenom�̃��[���`��2008�N��1�ʎl�����ɒx�点�邩������Ȃ��ƂƂ���}�U�[�{�[�h���[�J�[��������B
Phenom��2007�N�ɓo�ꂵ�Ȃ������ꍇ�A���Ђ̃}�U�[�{�[�h���[�J�[��
SocketAM2+�}�U�[�̏o�ׂ����炵�A�����Intel�����}�U�[�{�[�h�̏o�ׂ������邱�Ƃ��v�悵�Ă���Ƃ����B
�������R���g���[��������������
>>851
URL�̒�����܂������Ă�B�����B
Phenom�̓o���2007�N��������2008�N��1�l�������H
http://northwood.blog60.fc2.com/blog-entry-986.html
�Ă����� >>824 �Ŋ��o�B
URL�̒�����܂������Ă�B�����B
Phenom�̓o���2007�N��������2008�N��1�l�������H
http://northwood.blog60.fc2.com/blog-entry-986.html
�Ă����� >>824 �Ŋ��o�B
>>852
�������ɂ��̓_�Ɋւ��Ă�AMD�̕�����s���Ă�B����HT���B
�������ɂ��̓_�Ɋւ��Ă�AMD�̕�����s���Ă�B����HT���B
>>837
�������h�Ƃ��W�Ȃ���b�o����l�Ƙb���������Ǔ����˂��B���̔��ƁB
��{�ǂ�������Ƃ������������̐l���A���̌��_���������߂̗�����������Ȃ��̂ŁA
���_�Ƃ����m�\�V�Y���c�_�Ŋy���߂�l���Ȃ���ˁA���̔B
���_�ߒ����ǂ������ɗh��邾���Ŋ��ݕt���l����̂ŋc�_�������Ȃ��B
�v���O�����Ƃ��s�������������̂��B
�b�߂��ƁA���\���Βl�ŗ\�z����͕̂s�\�i�Ƃ�����薳�Ӗ��j�ɋ߂��̂�
�����K8�A�[�L�e�N�`����Core2�ɂ������Ăǂꂭ�炢�̐��\���サ�Ă��邩�A�Ƃ����_�����E�E�B
��͂肱����͂����肳����ɂ͂��������AX2��Core2�Ƃ̐��\��������Â��Ă���v���͂Ȃɂ��H
�Ƃ����_���͂����肳���Ȃ��Ɠ���Ǝv�����A���҂̐��\���ׂ������͂��Ĕ�r����
�݂Ȃ���Phenom���ǂꂭ�炢���\���サ�Ă邩�\�z����Ƃ������肪�Ȃ��Ǝv���B
�b�o�t�̐��\�����肷��v�f���G�c�ɂ킯���
���߂̃t�F�b�`�̑ш�E���C�e���V
���߃f�R�[�h�̑ш�
���ߎ��s�ш�
�f�[�^�̃��[�h�ш�iL1/L2/�������j
�f�[�^�̃X�g�A�ш�iL1/L2/�������j
�f�[�^�̃��[�h���C�e���V�iL1/L2/�������j
�f�[�^�̃X�g�A���C�e���V�iL1/L2/�������j
����ȏ����낤�Ƃ͎v�����E�E�ǂ����v�f�ʂɕ��͂ł���x���`�����T�C�g�������H
�g�[�^���A�v���P�[�V�����x���`���ƃ��[�X�̏��ʌ��ʂ������Ă�悤�Ȃ��̂�����A
�Ԃ̉�����R�[�i�����O�E�u���[�L�E��́E�ō����Ƃ������v�f�ʂ̐��\���킩���̂��
�������h�Ƃ��W�Ȃ���b�o����l�Ƙb���������Ǔ����˂��B���̔��ƁB
��{�ǂ�������Ƃ������������̐l���A���̌��_���������߂̗�����������Ȃ��̂ŁA
���_�Ƃ����m�\�V�Y���c�_�Ŋy���߂�l���Ȃ���ˁA���̔B
���_�ߒ����ǂ������ɗh��邾���Ŋ��ݕt���l����̂ŋc�_�������Ȃ��B
�v���O�����Ƃ��s�������������̂��B
�b�߂��ƁA���\���Βl�ŗ\�z����͕̂s�\�i�Ƃ�����薳�Ӗ��j�ɋ߂��̂�
�����K8�A�[�L�e�N�`����Core2�ɂ������Ăǂꂭ�炢�̐��\���サ�Ă��邩�A�Ƃ����_�����E�E�B
��͂肱����͂����肳����ɂ͂��������AX2��Core2�Ƃ̐��\��������Â��Ă���v���͂Ȃɂ��H
�Ƃ����_���͂����肳���Ȃ��Ɠ���Ǝv�����A���҂̐��\���ׂ������͂��Ĕ�r����
�݂Ȃ���Phenom���ǂꂭ�炢���\���サ�Ă邩�\�z����Ƃ������肪�Ȃ��Ǝv���B
�b�o�t�̐��\�����肷��v�f���G�c�ɂ킯���
���߂̃t�F�b�`�̑ш�E���C�e���V
���߃f�R�[�h�̑ш�
���ߎ��s�ш�
�f�[�^�̃��[�h�ш�iL1/L2/�������j
�f�[�^�̃X�g�A�ш�iL1/L2/�������j
�f�[�^�̃��[�h���C�e���V�iL1/L2/�������j
�f�[�^�̃X�g�A���C�e���V�iL1/L2/�������j
����ȏ����낤�Ƃ͎v�����E�E�ǂ����v�f�ʂɕ��͂ł���x���`�����T�C�g�������H
�g�[�^���A�v���P�[�V�����x���`���ƃ��[�X�̏��ʌ��ʂ������Ă�悤�Ȃ��̂�����A
�Ԃ̉�����R�[�i�����O�E�u���[�L�E��́E�ō����Ƃ������v�f�ʂ̐��\���킩���̂��
>>856
�ŏI���\�͊e�v�f�̑����Z��|���Z�ł͂Ȃ��{�g���l�b�N�ŗ��������B
�o�Ă���CPU�̃{�g���l�b�N��]������̂�����̂Ƀx���`���o�ĂȂ�CPU�̐��\��
���[�J�[���\�X�y�b�N���琄������Ȃ�Ė�������B���[�J�[�͓s���̂������Ƃ���
����Ȃ�����B
�ŏI���\�͊e�v�f�̑����Z��|���Z�ł͂Ȃ��{�g���l�b�N�ŗ��������B
�o�Ă���CPU�̃{�g���l�b�N��]������̂�����̂Ƀx���`���o�ĂȂ�CPU�̐��\��
���[�J�[���\�X�y�b�N���琄������Ȃ�Ė�������B���[�J�[�͓s���̂������Ƃ���
����Ȃ�����B
����ɁA�����ɂ���Ăǂ����{�g���l�b�N�����Ⴄ����
���낢�댾��ꂿ�Ⴂ�邪�A���\�͐ڋ߂��Ă邩�炻�ꂼ��̓��ӕ���ł�
��������|���邱�Ƃ��ł���킯�ŁA���͂��̓��ӕ���̍L����
�����̂�肽�����Ƃ����̓��ӕ���ɓ����Ă邩�ǂ����Ȃ��
���낢�댾��ꂿ�Ⴂ�邪�A���\�͐ڋ߂��Ă邩�炻�ꂼ��̓��ӕ���ł�
��������|���邱�Ƃ��ł���킯�ŁA���͂��̓��ӕ���̍L����
�����̂�肽�����Ƃ����̓��ӕ���ɓ����Ă邩�ǂ����Ȃ��
>>857
������[X2��CORE2��v�f�ʂɕ��͂��āA�ǂ���X2�̃{�g���l�b�N�łǂ���CORE2�̍����\�����肵�Ă�̂�
�킩��� �h������x�h ���������藧����[�B�S�����m�̂b�o�t����Ȃ��āAX2���x�[�X�ɂ��Ċg�����Ă����B
�g�����������ɂ��Ă͂�����x���\���Ă������B
�����Ȃ��Ƃ����X�����x�����A�Ƃ������Ă���m�I�Ȑ������B
>858
������A����̏�������Ȃ��ėv�f���ƂɁA�ƌ����Ă���B
�Ⴆ�t�F�b�`�ƃf�R�[�h�����A���߈���ƂɑS�R�ʂ̐��\���������Ƃ͂قƂ�ǂȂ���B
���ߒ����ς�����肵���Ƃ��ɂ��̂b�o�t�̃f�R�[�h��t�F�b�`�̃{�g���l�b�N��������B
�����疽�ߒ���ς��āA���C�e���V�Ƒш������A���̂b�o�t��
�t�F�b�`�ƃf�R�[�h���\�͂킩��B
������[X2��CORE2��v�f�ʂɕ��͂��āA�ǂ���X2�̃{�g���l�b�N�łǂ���CORE2�̍����\�����肵�Ă�̂�
�킩��� �h������x�h ���������藧����[�B�S�����m�̂b�o�t����Ȃ��āAX2���x�[�X�ɂ��Ċg�����Ă����B
�g�����������ɂ��Ă͂�����x���\���Ă������B
�����Ȃ��Ƃ����X�����x�����A�Ƃ������Ă���m�I�Ȑ������B
>858
������A����̏�������Ȃ��ėv�f���ƂɁA�ƌ����Ă���B
�Ⴆ�t�F�b�`�ƃf�R�[�h�����A���߈���ƂɑS�R�ʂ̐��\���������Ƃ͂قƂ�ǂȂ���B
���ߒ����ς�����肵���Ƃ��ɂ��̂b�o�t�̃f�R�[�h��t�F�b�`�̃{�g���l�b�N��������B
�����疽�ߒ���ς��āA���C�e���V�Ƒш������A���̂b�o�t��
�t�F�b�`�ƃf�R�[�h���\�͂킩��B
�� ID:W9I+B7Kl
���̃X���͂���ȏ�ł͂Ȃ��O���t�̒������ď�Ƃ����Ƃ��ň���J���邾���̃A�z�̃X��
( �L��`)���Űwww
���̃X���͂���ȏ�ł͂Ȃ��O���t�̒������ď�Ƃ����Ƃ��ň���J���邾���̃A�z�̃X��
( �L��`)���Űwww
���b�g������̐��\��ō��N���b�N�͗\�z���悤���Ȃ��Ƃ��������ʂ�����
�P�N���b�N������̐��\�Ȃ�b�̃l�^�ɂ͂Ȃ肻�����ȁB
�N�����܂Ƃ߂Ă������B
�P�N���b�N������̐��\�Ȃ�b�̃l�^�ɂ͂Ȃ肻�����ȁB
�N�����܂Ƃ߂Ă������B
>>859
���Ⴀ���܂��̗\�z��GS-6550(Kuma-2.2GHz)��X2��Conroe�ł�
�ǂ�ɋ߂����\�ɂȂ邩�\�����Ă�B���̗\�z��
GS-6550(2.2GHz/3MB) �� X2 5200+(2.6GHz/2MB)
GS-6550(2.2GHz/3MB) �� E6420(2.13GHz/4MB) �� E4600(2.4GHz/2MB)
�����ޗ��͌��݂܂łɂ킩���Ă���Clovertown��Kentsfield�Ɣ�r�����x���`���ʁB
���Ⴀ���܂��̗\�z��GS-6550(Kuma-2.2GHz)��X2��Conroe�ł�
�ǂ�ɋ߂����\�ɂȂ邩�\�����Ă�B���̗\�z��
GS-6550(2.2GHz/3MB) �� X2 5200+(2.6GHz/2MB)
GS-6550(2.2GHz/3MB) �� E6420(2.13GHz/4MB) �� E4600(2.4GHz/2MB)
�����ޗ��͌��݂܂łɂ킩���Ă���Clovertown��Kentsfield�Ɣ�r�����x���`���ʁB
Core2��X2�ɂ��ẮA
http://journal.mycom.co.jp/special/2006/conroe/index.html
���Ɠ����}�C�R�~�W���[�i���ł̘A�ڂ�
http://journal.mycom.co.jp/column/sopinion/177/index.html
���������ID:W9I+B7Kl����]���Ă���x���`���ڂ��Ă邾�낤�B
�ł��A���̕��́E���_�ɂ��ẮA�ᔻ������B
�匴����blog��Wikipedia��Core2�A�v���O������x86���߂̏��v�N���b�N�v���X���Ȃ������
�X�ɎQ�l�ɂȂ邾�낤���ǁA
����ƁA�����J����Ă���Barcelona�̃A�[�L�g���̏����r���Ă��A
���\�\���͂قƂ�ǖ������Ǝv�����B
http://journal.mycom.co.jp/special/2006/conroe/index.html
���Ɠ����}�C�R�~�W���[�i���ł̘A�ڂ�
http://journal.mycom.co.jp/column/sopinion/177/index.html
���������ID:W9I+B7Kl����]���Ă���x���`���ڂ��Ă邾�낤�B
�ł��A���̕��́E���_�ɂ��ẮA�ᔻ������B
�匴����blog��Wikipedia��Core2�A�v���O������x86���߂̏��v�N���b�N�v���X���Ȃ������
�X�ɎQ�l�ɂȂ邾�낤���ǁA
����ƁA�����J����Ă���Barcelona�̃A�[�L�g���̏����r���Ă��A
���\�\���͂قƂ�ǖ������Ǝv�����B
�����_�̃x���`�Ȃ܂�ł��ĂɂȂ��B�قƂ�ǂ͂��������܂Ƃ��ɓ����ĂȂ�ES�ł̃x���`�炵�����B
�Ƃ������ƂŁA�\��ʂ蔭�������̂��^�₾�B
�����A���̃��f���i���o�[���������ł́E�E����C2D��MN���ӎ����Ă�Ǝv�����
�EPhenom X2 GE-6600(2.3GHz/L2 512KB*2/L3 2MB/HT 3.4GHz/45W/2008�NQ1)
�EPhenom X2 GE-6500(2.1GHz/L2 512KB*2/L3 2MB/HT 3.2GHz/45W/2008�NQ1)
�EPhenom X2 GE-6400(1.9GHz/L2 512KB*2/L3 2MB/HT 3.2GHz/45W/2008�NQ1)
��������C2D��100MHz����Phenom�ɓ���mn�����Ă�Ƃ��납��
���Ԃ�AMD��C2D���킸���ɏ��IPC���Ǝv���Ă�݂����E�E�H
���������Ă��Ȃ����BAMD�������v���Ă��Ȃ������Ď�������B
�Ƃ������ƂŁA�\��ʂ蔭�������̂��^�₾�B
�����A���̃��f���i���o�[���������ł́E�E����C2D��MN���ӎ����Ă�Ǝv�����
�EPhenom X2 GE-6600(2.3GHz/L2 512KB*2/L3 2MB/HT 3.4GHz/45W/2008�NQ1)
�EPhenom X2 GE-6500(2.1GHz/L2 512KB*2/L3 2MB/HT 3.2GHz/45W/2008�NQ1)
�EPhenom X2 GE-6400(1.9GHz/L2 512KB*2/L3 2MB/HT 3.2GHz/45W/2008�NQ1)
��������C2D��100MHz����Phenom�ɓ���mn�����Ă�Ƃ��납��
���Ԃ�AMD��C2D���킸���ɏ��IPC���Ǝv���Ă�݂����E�E�H
���������Ă��Ȃ����BAMD�������v���Ă��Ȃ������Ď�������B
���O�������Ă�낤����
���́AAMD��mn�͂��������u�Ӗ��v����Ȃ����A�Ɨ\�����Ă邾���B
�����g��Phenom�̂���ɈႢ�Ȃ��A�Ƃ��咣����C�͂Ȃ���
�����g��Phenom�̂���ɈႢ�Ȃ��A�Ƃ��咣����C�͂Ȃ���
�Ă�����K10�̂�����Ƃ����x���`�Ȃ�Ă����������B
�ǂ����̃T�C�g�Ńf���}�V��������������~�߂���܂ł̊�
�x���`���点�Ă݂���x�������A�Ƃ�����ȏ���Ȃ��悤��
�ǂ����̃T�C�g�Ńf���}�V��������������~�߂���܂ł̊�
�x���`���点�Ă݂���x�������A�Ƃ�����ȏ���Ȃ��悤��
>>864
AMD�̎v�f�͂��̂Ƃ��肾�낤�ˁB���������̐��\�͓��N���b�N��Conroe(FSB1333/4MB)���
���Ⴍ�Ȃ�Ɖ��͗\�z���Ă���B
��������Kuma���o�鍠��E6xx0�͎���E6550(2.33GHz/4MB)���ʼn��ʂŁA���̉���E4600(2.4GHz/2MB)
�ɂȂ����Ⴄ���炻�����^�[�Q�b�g�ɂ��Ă����łɑ��肪���Ȃ����ǂ˂��B
AMD�̎v�f�͂��̂Ƃ��肾�낤�ˁB���������̐��\�͓��N���b�N��Conroe(FSB1333/4MB)���
���Ⴍ�Ȃ�Ɖ��͗\�z���Ă���B
��������Kuma���o�鍠��E6xx0�͎���E6550(2.33GHz/4MB)���ʼn��ʂŁA���̉���E4600(2.4GHz/2MB)
�ɂȂ����Ⴄ���炻�����^�[�Q�b�g�ɂ��Ă����łɑ��肪���Ȃ����ǂ˂��B
�����I�ȏ��������Ƃ��͂ǂ��ł�������B�g�[�^���Ō�����Intel�������Ȃ͉̂����Ă邵����Ȏ�����Ă����傤���Ȃ��B
���i�̍ō��N���b�N�ɂ��Ă����̎��̏����Intel���ς��Ă��邩��B
���i�̍ō��N���b�N�ɂ��Ă����̎��̏����Intel���ς��Ă��邩��B
�Ȃ�ΐ��\�ŏ��Ă��?
�^�́`���j�R�C�`�ɕ�����Ȃ�Ă��肦�Ȃ��Ƃ��Ⴆ�Ă����z���������낪�¶��
�^�́`���j�R�C�`�ɕ�����Ȃ�Ă��肦�Ȃ��Ƃ��Ⴆ�Ă����z���������낪�¶��
���N���b�N��r�Ȃ珟�Ă邾��
870�݂����Ȃ̂������ނ���b���܂�Ȃ��Ȃ�B
����̂͂b�o�t�̍\���ɂ��Ęb��������Ȃ��āA�ǂ������̃��[�J�[�������ƌ��߂���ł̔l����ݾ������o����B
����̂͂b�o�t�̍\���ɂ��Ęb��������Ȃ��āA�ǂ������̃��[�J�[�������ƌ��߂���ł̔l����ݾ������o����B
183 ���O�FSocket774 ���e���F2006/10/29(��) 22:41:26 ID:fRCIEekB
Altair���}���`�X���b�h�A�v����Conroe�ɕ�����Ȃ�Ă�����Ȃ�ł����肦�Ȃ���
Kentsfield�ɏ��ĂȂ��\���͏\������Ǝv���B
�܂���Yorkfield�ɂ͂܂����������ڂ͂Ȃ����낤�B
�����ꂪ���̓����̉��̃��X�BK10�Ɋւ��鐫�\�\���͂��̍�����قڕς���ĂȂ��B
������ɑ��铖���̃��X�B
185 ���O�FSocket774 ���e���F2006/10/29(��) 22:45:45 ID:ZIRzVhZw
���~���������˂��B���ނ���@�������͑����ł���Ă���B
Altair���}���`�X���b�h�A�v����Conroe�ɕ�����Ȃ�Ă�����Ȃ�ł����肦�Ȃ���
Kentsfield�ɏ��ĂȂ��\���͏\������Ǝv���B
�܂���Yorkfield�ɂ͂܂����������ڂ͂Ȃ����낤�B
�����ꂪ���̓����̉��̃��X�BK10�Ɋւ��鐫�\�\���͂��̍�����قڕς���ĂȂ��B
������ɑ��铖���̃��X�B
185 ���O�FSocket774 ���e���F2006/10/29(��) 22:45:45 ID:ZIRzVhZw
���~���������˂��B���ނ���@�������͑����ł���Ă���B
�N���b�N������̐��\�ł͌݊p�ȏ�ɂ͂Ȃ��Ă�Ǝv�����ˁB
K8��C2D�ɑ傫������Ă�_�̓L���b�V���i�Ƃ��Ƀf�[�^�L���b�V���j�̓]�����x����������B
L1�̃o�X�͂Q�{�Ɋg�����Ă�炵����SIMD���Z���j�b�g�̃r�b�g�����{�Ɋg�����Ă�̂�
conroe�ɗ���Ă镔���͂قږ��߂Ă��Ă�Ǝv���B
�����A�ŏI���\�ł̓N���b�N�ł��Ȃ萅������Ǝv���B�v���Z�X���P����Ⴄ��
Intel�̐V�v���Z�X�͈ٗl�ɒ��q�������݂���������B
K8��C2D�ɑ傫������Ă�_�̓L���b�V���i�Ƃ��Ƀf�[�^�L���b�V���j�̓]�����x����������B
L1�̃o�X�͂Q�{�Ɋg�����Ă�炵����SIMD���Z���j�b�g�̃r�b�g�����{�Ɋg�����Ă�̂�
conroe�ɗ���Ă镔���͂قږ��߂Ă��Ă�Ǝv���B
�����A�ŏI���\�ł̓N���b�N�ł��Ȃ萅������Ǝv���B�v���Z�X���P����Ⴄ��
Intel�̐V�v���Z�X�͈ٗl�ɒ��q�������݂���������B
>>873
�́A�ǂ����̐M�҂������������A�Ƃ������҈ȊO�����Ȃ�����B
�́A�ǂ����̐M�҂������������A�Ƃ������҈ȊO�����Ȃ�����B
>>874
45nm�ȑO��Kentsfield/Conroe�ɂ��N���b�N�œ͂��Ȃ���B
45nm�ȑO��Kentsfield/Conroe�ɂ��N���b�N�œ͂��Ȃ���B
Barcelona�����SSSE3�ɂ���Ή�������ASSSE3�Ή��̃A�v������Merom����Ƃ������������ˁB
�Ⴆ�Ă��A���ɂ͂܂�Ȃ�����Ȃ̂��������ˁB
���Ɛ�����������Δۂ����ł������t�����Ă��܂�������
�ϐ������ėǂ�����Ȃ����B
���Ɛ�����������Δۂ����ł������t�����Ă��܂�������
�ϐ������ėǂ�����Ȃ����B
879 �FSocket774�F2007/07/03(��) 12:53:48 ID:dif8GJn4
>>871,874
���̒ʂ�A��������������
���N���b�N���Ə��邾�낤���ǁE�E�E
����2.4Ghz���x�i������2.0Ghz�ƍX�ɒႢ)�ɑ��ĕ���3.33Ghz��
���̍���1Ghz�ȏ���L��AOC�̗]�͂��܂߂�Ƃ��̍���
�����ƊJ�����낤�A���̍��͂ǂ��l���Ă����߂�����
�܂�A���㌈��i�n�C�G���h�j�ł͂܂������ڂ͖���
���Ԉ�ʓI�ɃC���[�W��AMD�v�M���[m9^�D^)
�Q�[���̃N���C�A���g�ōl���Ă�AMD�v�M���[m9^�D^)
�������A�K�ޓK���������ƕ������Ă�z��
�����d�͗p�r�ł�AMD�ɕ����L�邱�Ƃ��m���Ă邵
SFF������M/B������悤�ȂƂ���ł����߾�Ă�
�\�́iH/W���ށj��Intel�ł�Eagle����ł���b�ɂȂ��
���̕���Ő����c�邵�����͖���
��ʓI�ɂ͂��̕����PC�̕����A�n�C�G���h���������o��
�l�I��WEB���S��PC�����̕���ɓ���A��
�C���[�W��AMD�v�M���[m9^�D^)�ŋ��͕K��
���̒ʂ�A��������������
���N���b�N���Ə��邾�낤���ǁE�E�E
����2.4Ghz���x�i������2.0Ghz�ƍX�ɒႢ)�ɑ��ĕ���3.33Ghz��
���̍���1Ghz�ȏ���L��AOC�̗]�͂��܂߂�Ƃ��̍���
�����ƊJ�����낤�A���̍��͂ǂ��l���Ă����߂�����
�܂�A���㌈��i�n�C�G���h�j�ł͂܂������ڂ͖���
���Ԉ�ʓI�ɃC���[�W��AMD�v�M���[m9^�D^)
�Q�[���̃N���C�A���g�ōl���Ă�AMD�v�M���[m9^�D^)
�������A�K�ޓK���������ƕ������Ă�z��
�����d�͗p�r�ł�AMD�ɕ����L�邱�Ƃ��m���Ă邵
SFF������M/B������悤�ȂƂ���ł����߾�Ă�
�\�́iH/W���ށj��Intel�ł�Eagle����ł���b�ɂȂ��
���̕���Ő����c�邵�����͖���
��ʓI�ɂ͂��̕����PC�̕����A�n�C�G���h���������o��
�l�I��WEB���S��PC�����̕���ɓ���A��
�C���[�W��AMD�v�M���[m9^�D^)�ŋ��͕K��
>>879
>�����d�͗p�r�ł�AMD�ɕ����L�邱�Ƃ��m���Ă邵
���ꎩ��p�r�������ĂȂ����炾��B
Intel�͒����d�͂̓��o�C���ł邩��B��胁�[�J�[���p�\�R���̃��[�G���h��
������Celeron M���g��������B
>�����d�͗p�r�ł�AMD�ɕ����L�邱�Ƃ��m���Ă邵
���ꎩ��p�r�������ĂȂ����炾��B
Intel�͒����d�͂̓��o�C���ł邩��B��胁�[�J�[���p�\�R���̃��[�G���h��
������Celeron M���g��������B
�܂��A�����Ȃ���
���̔́u����PC�v�Ȃ���E�E�E
���̔́u����PC�v�Ȃ���E�E�E
�܂��B��{���\���ǂ��Ă��A>>874�������Ƃ���ɁA
�N���b�N�ō����t���Ă����܂����낤�B
K8�n�̉�������ł���K10�͂��قǃN���b�N���L�тȂ����납��ȁB
���ƁA8���������\���Barcelona�͐����A���\�I�ɐM�p�ł���B
Op�̏��������i�K�Ɠ�������������B
�N���b�N�ō����t���Ă����܂����낤�B
K8�n�̉�������ł���K10�͂��قǃN���b�N���L�тȂ����납��ȁB
���ƁA8���������\���Barcelona�͐����A���\�I�ɐM�p�ł���B
Op�̏��������i�K�Ɠ�������������B
�����d�͔Ńf�X�N�g�b�v�s���Intel�Ɍ�������̂͊m�������ǁA
AMD�ɂ�����D�悵����Ă̂͂ǂ����낤�ˁB�m�[�g�s��ɐH�����ނ��Ƃ̕����厖����Ȃ����ƁB
AMD�ɂ�����D�悵����Ă̂͂ǂ����낤�ˁB�m�[�g�s��ɐH�����ނ��Ƃ̕����厖����Ȃ����ƁB
�D��ł͂Ȃ��āA�����I�ɂ����ɂ���������ꏊ������
���Ęb�ł���
�m�[�g�s��ɓ����ł���u�e�v�́A�܂��܂���ł���H
Griffin�Bobcat�̐��\�͔@���قǂ��z���o���Ȃ���
�T�[�o�[�ƃm�[�g�̎s��̈�p�͎���ė~������
�łȂ��ƃ}�W�ŕ�����E�E�E
���Ęb�ł���
�m�[�g�s��ɓ����ł���u�e�v�́A�܂��܂���ł���H
Griffin�Bobcat�̐��\�͔@���قǂ��z���o���Ȃ���
�T�[�o�[�ƃm�[�g�̎s��̈�p�͎���ė~������
�łȂ��ƃ}�W�ŕ�����E�E�E
AMD�����������A�uBarcelona�ŃT�[�o�����v���Z�b�T�s��̃V�F�A��D�҂���v
ttp://www.computerworld.jp/topics/power/68989.html
Barcelona�́A�P�Ȃ�AMD���̃N�A�b�h�R�A�E�v���Z�b�T�Ƃ��������ł͂Ȃ��B
���Z���j�b�g���������A�A�[�L�e�N�`���̈ꕔ�����{����ύX�����A�V�����v���Z�b�T���B
�Ⴆ�A�L���b�V���A�n�C�p�[�E�g�����X�|�[�g�i������I/O�A�[�L�e�N�`���j�Ȃǂ�
���ׂČ������A���ǂ��Ă���B
����A�f���A���R�A����N�A�b�h�R�A�ւ̈ڍs�ɑ������Ԃ����������̂́A
�N�A�b�h�R�A�ւ̈ڍs��ƂɎ�Ԏ��������ł͂Ȃ��A�R�A���̂̋@�\�������������炾�B
���ł����z���Z�p�Ɠd�͂̌������ɂ́A���Ȃ蒍�͂����B
ttp://www.computerworld.jp/topics/power/68989.html
Barcelona�́A�P�Ȃ�AMD���̃N�A�b�h�R�A�E�v���Z�b�T�Ƃ��������ł͂Ȃ��B
���Z���j�b�g���������A�A�[�L�e�N�`���̈ꕔ�����{����ύX�����A�V�����v���Z�b�T���B
�Ⴆ�A�L���b�V���A�n�C�p�[�E�g�����X�|�[�g�i������I/O�A�[�L�e�N�`���j�Ȃǂ�
���ׂČ������A���ǂ��Ă���B
����A�f���A���R�A����N�A�b�h�R�A�ւ̈ڍs�ɑ������Ԃ����������̂́A
�N�A�b�h�R�A�ւ̈ڍs��ƂɎ�Ԏ��������ł͂Ȃ��A�R�A���̂̋@�\�������������炾�B
���ł����z���Z�p�Ɠd�͂̌������ɂ́A���Ȃ蒍�͂����B
TDP89W��CeleronD���X�����P�[�X�ɓ���Ă�����{���[�J�[���炵����A
�`�b�v�Z�b�g�̍���CoreMA��Celeron�����Œ������Ȃ�Ȃ��́H
�`�b�v�Z�b�g�̍���CoreMA��Celeron�����Œ������Ȃ�Ȃ��́H
>>884
�܂��߂Șb�ABarcelona��Bobcat���S������o���Ăł���������ꍏ������
Rana��ʎY���ׂ����Ǝv�����ǂˉ��́B
�ʎq�ɂ��������Barcelona��Rana�̏��ŊJ�������̂͊��S�ɗ��ڂɏo���BBarcelena������������
�オ�S�����������Ēx��Ă��܂��B
Rana���܂��o���āA���ꂩ�炶�������Barcelona���J������ׂ��������B
�܂��߂Șb�ABarcelona��Bobcat���S������o���Ăł���������ꍏ������
Rana��ʎY���ׂ����Ǝv�����ǂˉ��́B
�ʎq�ɂ��������Barcelona��Rana�̏��ŊJ�������̂͊��S�ɗ��ڂɏo���BBarcelena������������
�オ�S�����������Ēx��Ă��܂��B
Rana���܂��o���āA���ꂩ�炶�������Barcelona���J������ׂ��������B
���v�̒Ⴍ�ĉ��i�̈���Rana���s�����Ăǂ�����B
���v�����v������Barcelona���ĕ����܂肪�オ���Ă���Rana���o���B
���R����B
���v�����v������Barcelona���ĕ����܂肪�オ���Ă���Rana���o���B
���R����B
889 �FSocket774�F2007/07/03(��) 13:37:35 ID:L62A9Fsp
Kuma�𒆎~���āARana��Conroe�ɂԂ���ׂ����낤�ˁB
�_�C�T�C�Y��170mm2���鐨����KUMA���A143����2��Conroe��107mm2��Wolfdale�Ɛ키�̂̓R�X�g�I�Ɍ���������B
�_�C�T�C�Y��170mm2���鐨����KUMA���A143����2��Conroe��107mm2��Wolfdale�Ɛ키�̂̓R�X�g�I�Ɍ���������B
>>889
���Ƃ���Dual��Rana�̎d�l�������̂��A�\��ύX����Dual�ɂ�L3�lj�������ˁB
���͂���͏�����Quad�łŃR�A�����z�镪���ƌ��Ă���B
Kuma��p�_�C��170����mm(����ȏ��������H�@��200��s���Ǝv���Ă邪)�ȏ�ɂȂ�͂��ŁA
��������O��Rana���ɍ��ׂ����Ǝv�����B�B�B
�ǂ���AMD�̂�邱�Ƃ͂悤�킩���B
���Ƃ���Dual��Rana�̎d�l�������̂��A�\��ύX����Dual�ɂ�L3�lj�������ˁB
���͂���͏�����Quad�łŃR�A�����z�镪���ƌ��Ă���B
Kuma��p�_�C��170����mm(����ȏ��������H�@��200��s���Ǝv���Ă邪)�ȏ�ɂȂ�͂��ŁA
��������O��Rana���ɍ��ׂ����Ǝv�����B�B�B
�ǂ���AMD�̂�邱�Ƃ͂悤�킩���B
>���Ƃ���Dual��Rana�̎d�l�������̂��A�\��ύX����Dual�ɂ�L3�lj�������ˁB
�����i�K�ł̓L���b�V���e�ʂƂ��͗����I�Ȃ��̂����ǂ����悤��
��\��ύX������ƌ������\�[�X������́H
�����i�K�ł̓L���b�V���e�ʂƂ��͗����I�Ȃ��̂����ǂ����悤��
��\��ύX������ƌ������\�[�X������́H
>>892
�܁[�ȁ[�c�B�t��Barcelona���o���Ă��܂��A
kuma��Rana�����قNj�J���Ȃ��C�������ȁB
>>891�̒ʂ�ɁAkuma��Quad�ł̃R�A���Ƀo�[�W������A
Rana��L3�����S�o�[�W�����ł�������������Ȃ����B
�悤�́ABarcelona�����ł���ASTARS�̏����i�K�ł�
�����ł��Ȃ�ł��A���ꂱ�����Ƃ��Ȃ肻���B
�t�ɁA�܊pL3������Ő����J�n����STARS����A
L3����苎���ď��^���E�Đv������̂ł���A
���܂ňȏ�ɖ��ʂȎ��Ԃ��Ƃ�ꂻ���B
�����"Rana"��"Sempron"�Ȃ̂�����A�����i�K�ł́A
���s��AM2�V���[�Y��Sempron�l�[���ɒu������������Ă������킯�ŁA
Kuma���J�����~�ɂ��āARana���J�����闘�_���S���������Ȃ��킯�����c�B
�܁[�ȁ[�c�B�t��Barcelona���o���Ă��܂��A
kuma��Rana�����قNj�J���Ȃ��C�������ȁB
>>891�̒ʂ�ɁAkuma��Quad�ł̃R�A���Ƀo�[�W������A
Rana��L3�����S�o�[�W�����ł�������������Ȃ����B
�悤�́ABarcelona�����ł���ASTARS�̏����i�K�ł�
�����ł��Ȃ�ł��A���ꂱ�����Ƃ��Ȃ肻���B
�t�ɁA�܊pL3������Ő����J�n����STARS����A
L3����苎���ď��^���E�Đv������̂ł���A
���܂ňȏ�ɖ��ʂȎ��Ԃ��Ƃ�ꂻ���B
�����"Rana"��"Sempron"�Ȃ̂�����A�����i�K�ł́A
���s��AM2�V���[�Y��Sempron�l�[���ɒu������������Ă������킯�ŁA
Kuma���J�����~�ɂ��āARana���J�����闘�_���S���������Ȃ��킯�����c�B
>>894
Kuma�𒆎~�ɂ����(���~�ɂ��Ȃ��ɂ��Ă�Rana�����Ɠ����Ƀt�F�[�h�A�E�g�������)
Rana��Sempron�ƌĂԕK�v�Ȃ�ĂȂ�����ȁB
Kuma�𒆎~�ɂ����(���~�ɂ��Ȃ��ɂ��Ă�Rana�����Ɠ����Ƀt�F�[�h�A�E�g�������)
Rana��Sempron�ƌĂԕK�v�Ȃ�ĂȂ�����ȁB
���A��������Sempron�̓V���O���łł�����Rana��Sempron�ł͂Ȃ�Phenom X2����B
Kuma�Ƃǂ���ʂ���̂��m��Ȃ����ǁB
Kuma�Ƃǂ���ʂ���̂��m��Ȃ����ǁB
>>895-896
�E�E�E�B���̂ˁB���̎���̏������ɘb���Ă���́H�@�\�[�X����B
�R�[�h�l�[����"Rana"�ɂȂ������_�ł��łɂ���́A
Dual Core��"Sempron"�Ȃ��ǁc�H
kuma�ɂȂ������_�ŁA���ł�L3����Ȃ��ǁH
���������N�O����DualCore��Sempron�̘b�͂łĂ������ǁH
�Ȃ�[���B�_�C�W���E�u���H
�E�E�E�B���̂ˁB���̎���̏������ɘb���Ă���́H�@�\�[�X����B
�R�[�h�l�[����"Rana"�ɂȂ������_�ł��łɂ���́A
Dual Core��"Sempron"�Ȃ��ǁc�H
kuma�ɂȂ������_�ŁA���ł�L3����Ȃ��ǁH
���������N�O����DualCore��Sempron�̘b�͂łĂ������ǁH
�Ȃ�[���B�_�C�W���E�u���H
>>897
http://www.vr-zone.com/?i=5078
���ꂪRana/Spica�Ɋւ��錻���_�ł����Ƃ��M���ł���\�[�X���Ǝv���B
Rana��Sempron���Ęb�����������ǂˁBRana��Spica���\����ăL�����Z�����[�������邵�ˁB
http://www.vr-zone.com/?i=5078
���ꂪRana/Spica�Ɋւ��錻���_�ł����Ƃ��M���ł���\�[�X���Ǝv���B
Rana��Sempron���Ęb�����������ǂˁBRana��Spica���\����ăL�����Z�����[�������邵�ˁB
>>898
���̂��B�\���������ABrisbane�̌�p��"kuma"�ł���A
Orleans��Manila�̌�p��"Rana/Spica"�����B
�Ă��Ƃ́A"Rana/Spica"= Sempron����˂��́H
�Ă��A����"kuma"���t�F�[�h�A�E�g�����闝�R���S���킩���̂����H
����Ƃ��ASTARS�̐��\���悭�āA"Rana/Spica"�ł�
�������ɏo��"Penryn"�ɂ��������Ή��\�Ƃ��ł���̂��H
�܂��A���ł�Balcerona�Ƃ���"L3���ڌ^��CPU"���������O�ɁA
"L3�ڌ^��CPU"��ˊтōĐv���Ă܂Ŕ�������K�v��������̂��H
���Ƃ��ƁAAMD�nCPU��Intel�nCPU�ɔ�ׂă_�C�T�C�Y���傫�������������ȁB
���̂��B�\���������ABrisbane�̌�p��"kuma"�ł���A
Orleans��Manila�̌�p��"Rana/Spica"�����B
�Ă��Ƃ́A"Rana/Spica"= Sempron����˂��́H
�Ă��A����"kuma"���t�F�[�h�A�E�g�����闝�R���S���킩���̂����H
����Ƃ��ASTARS�̐��\���悭�āA"Rana/Spica"�ł�
�������ɏo��"Penryn"�ɂ��������Ή��\�Ƃ��ł���̂��H
�܂��A���ł�Balcerona�Ƃ���"L3���ڌ^��CPU"���������O�ɁA
"L3�ڌ^��CPU"��ˊтōĐv���Ă܂Ŕ�������K�v��������̂��H
���Ƃ��ƁAAMD�nCPU��Intel�nCPU�ɔ�ׂă_�C�T�C�Y���傫�������������ȁB
�R�A�Q����O���̂��ȒP��L3�O���͓̂ˊэH���ōĐv���ĈӖ��킩��Ȃ���B
Barcelona�̃_�C�ʐ^���Ă�Kuma���p�_�C�ō��Ȃ犮�S�ɍĔz�u���K�v�����B
Barcelona�̃_�C�ʐ^���Ă�Kuma���p�_�C�ō��Ȃ犮�S�ɍĔz�u���K�v�����B
ID:AW+i+QgL�̘b�̓X���[�ł����Ǝv���E�E�G���Ƃǂ�ǂ�E�����Ă����E�E
Rana�Ɋւ��Ă�>>58>>60>>61�̂�����Řb�͏I����ĂȂ����H
>>887=>>58��>>889=>>58�Ȃ킯�H
��x�l�^����T�ɂ��Ƃ��ƁB���������B
>>887=>>58��>>889=>>58�Ȃ킯�H
��x�l�^����T�ɂ��Ƃ��ƁB���������B
>>900
�Ă��ABarcelona/Aregna/kuma����������܂��A
���ʂ͌��sAM2��Sempron�l�[���ɂ����Ⴆ�悩��ׁ[��B
���܂̓n�C�G���h�`�~�h�������W�̐��\���AIntel�n�ɔ�ׂĎア�̂����B
�������A�_�C�T�C�Y���ǂ����������Ă��邪�AK7�����R�A��180����mm��B
K8�����R�A��183����mm�ADual K8�i1MB�j��220/190����mm��B
Dual K8�i512kb�j��183����mm������A�_�C�T�C�Y170����mm�Ȃ�ď������B
���邢�͖�肪�Ȃ����x���B
�Ă��A���N�̓���STARS�t�@�~���[�����\���ꂽ���_�ŁA
kuma��L3�t���BRana��L3����Dual�R�A�ɂȂ��Ă���B
>���Ƃ���Dual��Rana�̎d�l�������̂��A�\��ύX����Dual�ɂ�L3�lj�������ˁB
�Ȃ�ēd�g�I�ȏ��͂ǂ�����o�Ă����̂��₢�����B
�Ă��ABarcelona/Aregna/kuma����������܂��A
���ʂ͌��sAM2��Sempron�l�[���ɂ����Ⴆ�悩��ׁ[��B
���܂̓n�C�G���h�`�~�h�������W�̐��\���AIntel�n�ɔ�ׂĎア�̂����B
�������A�_�C�T�C�Y���ǂ����������Ă��邪�AK7�����R�A��180����mm��B
K8�����R�A��183����mm�ADual K8�i1MB�j��220/190����mm��B
Dual K8�i512kb�j��183����mm������A�_�C�T�C�Y170����mm�Ȃ�ď������B
���邢�͖�肪�Ȃ����x���B
�Ă��A���N�̓���STARS�t�@�~���[�����\���ꂽ���_�ŁA
kuma��L3�t���BRana��L3����Dual�R�A�ɂȂ��Ă���B
>���Ƃ���Dual��Rana�̎d�l�������̂��A�\��ύX����Dual�ɂ�L3�lj�������ˁB
�Ȃ�ēd�g�I�ȏ��͂ǂ�����o�Ă����̂��₢�����B
����ł�Barcelona��R�����kuma�����Y���ň����
�ォ�牺�܂Ŗ������Ď��Ȃ�ȁE�E�EKuma�~��������
�ォ�牺�܂Ŗ������Ď��Ȃ�ȁE�E�EKuma�~��������
���܂����B�����]����Barcelona���ꂿ�܂������A
Barcelona�̃_�C�T�C�Y�͊m����280����mm�Œ�����B
>>906
>>891�ŒN���������Ă���Ƃ���ɁA
>���͂���͏�����Quad�łŃR�A�����z�镪���ƌ��Ă���B
���̉\���������ɂ��������c����B���̉\���͏��Ȃ�����Ȃ��B
Barcelona�̃_�C�T�C�Y�͊m����280����mm�Œ�����B
>>906
>>891�ŒN���������Ă���Ƃ���ɁA
>���͂���͏�����Quad�łŃR�A�����z�镪���ƌ��Ă���B
���̉\���������ɂ��������c����B���̉\���͏��Ȃ�����Ȃ��B
��������B
Core 2 Quad �R�c�cPhenom X4(Agena)
Core 2 Duo �R�c�cPhenom X2(Kuma)
Pentium DC �R�c�cAthlon X2(Brisbane��Rana)
Celeron 4x0 �R�c�cSempron(Orleans��Spica)
Core 2 Quad �R�c�cPhenom X4(Agena)
Core 2 Duo �R�c�cPhenom X2(Kuma)
Pentium DC �R�c�cAthlon X2(Brisbane��Rana)
Celeron 4x0 �R�c�cSempron(Orleans��Spica)
http://www.computerworld.jp/news/plf/68970.html
>�܂��AAMD��2007�N��4�l�����ɃN���b�N���x��3GHz�̍����v���Z�b�T�������[�X���邱�Ƃ����炩�ɂ��Ă���B
���̃R�A�����
>�܂��AAMD��2007�N��4�l�����ɃN���b�N���x��3GHz�̍����v���Z�b�T�������[�X���邱�Ƃ����炩�ɂ��Ă���B
���̃R�A�����
>>909
Additional processors will be released in this year's fourth quarter
with faster clock-speed frequencies that eventually will reach 3 GHz, AMD said.
���[���`���ɂ�2GHz�܂ŁA2007Q4�ɂ���ɏ�̃N���b�N���lj�����
�ŏI�I�ɂ�3GHz�ɒB����B
�Ɠǂނ̂ł́B
Additional processors will be released in this year's fourth quarter
with faster clock-speed frequencies that eventually will reach 3 GHz, AMD said.
���[���`���ɂ�2GHz�܂ŁA2007Q4�ɂ���ɏ�̃N���b�N���lj�����
�ŏI�I�ɂ�3GHz�ɒB����B
�Ɠǂނ̂ł́B
>909
�܂�X2�ł͂��łɂRGHz�B�����Ă邩��K10�n��ȊO�͂Ȃ��Ǝv������
Phenom���ė��N����˂��H
�܂�X2�ł͂��łɂRGHz�B�����Ă邩��K10�n��ȊO�͂Ȃ��Ǝv������
Phenom���ė��N����˂��H
���⌴���ǂ�����B�ǂ����Ă�Barcelona 3GHz�ł̂��Ƃ�����
�����ւ̃����N���݂������̂ł����܂ŒT�����Ƃ����C�ɂ��Ȃ��Ȃ�
�Ƃ���ł��AK10�Ȃ�ČĂѕ��̓Z�[���X�}�l�[�W���̓K����
�R���������Ƃ��킩���Ă���� �����g���̎~�߂���H
�R���������Ƃ��킩���Ă���� �����g���̎~�߂���H
>>913
http://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9025948&intsrc=news_ts_head
http://www.computerworld.com/action/article.do?command=viewArticleBasic&articleId=9025948&intsrc=news_ts_head
�ǂ����Ă�>>910�Ő���
����}�[�P�e�B���O�}�l�[�W���������H
>>914
���ႠBarcelona/Agena/Kuma/Rana�̂��ĂȂ�ČĂԂH
���ႠBarcelona/Agena/Kuma/Rana�̂��ĂȂ�ČĂԂH
K10�ł͂Ȃ��̂͊m�������ǂ����Ă����̂��K�v�Ȃ̂��H
�K�v���낤�BSTARS�t�@�~���[�Ƃł��Ăׂ����̂��H
�܂��BK10�ł�����B�Ă��A�R�������̂�K8L����Ȃ��������H
�܂��BK10�ł�����B�Ă��A�R�������̂�K8L����Ȃ��������H
>>920
STARS����45nm�ł��������܂��A���Ԃ�
STARS����45nm�ł��������܂��A���Ԃ�
�܂�Kentsfield/Conroe/Conroe-L/Merom��Core2�ƌĂ�Ă邩��
���̂���Phenom(���邢��Phenom 65nm��)�Œʂ�悤�ɂȂ�낤�ȁB
���̂���Phenom(���邢��Phenom 65nm��)�Œʂ�悤�ɂȂ�낤�ȁB
AMD�����ł�Barcelona��K10�ƌĂ��Ƃ͖����������B
K8L��Barcelona�̂��Ƃ���Ȃ��炵���ȁB
>>921
Barcelona�͢F1���J�Â����s�s��V���[�Y�̖��O�����ȁB
K8L��Barcelona�̂��Ƃ���Ȃ��炵���ȁB
>>921
Barcelona�͢F1���J�Â����s�s��V���[�Y�̖��O�����ȁB
�v�͐��E����K10�Ȃ�ČĂ�ĂȂ��̂ɓ��{�ł���
���܂�K10����A�ƁB
�I�v�e�B�I�����Ⴀ��܂����B
���܂�K10����A�ƁB
�I�v�e�B�I�����Ⴀ��܂����B
intel���Ǝ���45nm��CoreMA��Penryn�ő��̂��Ă��邩��A�P��Barcelona�Ƃ�Barcelona����Ƃ��B
Barcelona�������ɒ����̂���肾���B
Barcelona�������ɒ����̂���肾���B
>>928
5���͂ǂ����������ȁBAMD�ɔے肳��钼�O�����B
5���͂ǂ����������ȁBAMD�ɔے肳��钼�O�����B
�����f�X�N�g�b�v�ł�Phenom���Ă킩�������炻��ȍ~�ɋL����
�����Ă�Barcelona��Phenom�ɂȂ��Ă�K10�͎g����ȁB
�����Ă�Barcelona��Phenom�ɂȂ��Ă�K10�͎g����ȁB
>>930
�܂��A�ے肵���L����\�������Ȃ����H
���႟�BDailyTech���ǂ����B
ttp://www.dailytech.com/AMD+to+Launch+Barcelona+Slow+this+August/article7890.htm
���ƁAWiki�Ƃ��ł��uK10�v�ō��ڂ�����Ȃ��B
�܂��A�ے肵���L����\�������Ȃ����H
���႟�BDailyTech���ǂ����B
ttp://www.dailytech.com/AMD+to+Launch+Barcelona+Slow+this+August/article7890.htm
���ƁAWiki�Ƃ��ł��uK10�v�ō��ڂ�����Ȃ��B
K10���ČĂ�ł�̂�AMD�̍L��ł���B
�O�������ɂ�K10���������̂ł�����Ȃ��́B
�����ł͕ʂ�K10�̃v���W�F�N�g�����������낤����g��Ȃ����������ŁB
�O�������ɂ�K10���������̂ł�����Ȃ��́B
�����ł͕ʂ�K10�̃v���W�F�N�g�����������낤����g��Ȃ����������ŁB
K10�L�����Z�����uK10�Ȃ�Ă��Ƃ��疳���v��Barcelona�����Ɂ��u���������Ă�̂��킩��Ȃ����A�ŏ�����K10�Ƃ��Čv�悳��Ă����̂�Barcelona���v
����ȃ`���`�Ȃ��Ⴀ�f���Ă˂�
K10��3�����ŏ����₷������K10�ł���
937 �FMAC�I�^��918 �����F2007/07/03(��) 19:26:47 ID:vCmERult
>>918
����"Hound"�n��ƌĂԂ̂������Ƃ��K�����Ǝv�����B
����"Hound"�n��ƌĂԂ̂������Ƃ��K�����Ǝv�����B
938 �FMAC�I�^���⑫�F2007/07/03(��) 19:29:37 ID:vCmERult
http://developer.amd.com/articlex.jsp?id=31
�@�@-------------------
�@�@AMD is working on two quad-core processors�\previously code-named Deerhound and
�@�@Greyhound. Get an overview of what's in store for this next phase.
�@�@-------------------
�@�@-------------------
�@�@AMD is working on two quad-core processors�\previously code-named Deerhound and
�@�@Greyhound. Get an overview of what's in store for this next phase.
�@�@-------------------
���Ȃ�����K9�Ȃ�ˁH
Deerhound��Barcelona�ɃR�[�h�l�[�����ς�����̂ŁA�O��Hound�n��Ƃ������Ă��ˁB
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
���{��L���Ȃ�A���̕ӂ������̃R�[�h�l�[���ꗗ�ɂȂ邩�ȁB
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
���{��L���Ȃ�A���̕ӂ������̃R�[�h�l�[���ꗗ�ɂȂ邩�ȁB
http://www.xbitlabs.com/news/cpu/display/20070702235635.html
�����ɍō�2.0GHz�ŏo�J�n����Ɣ��\����CPU�́u2.6GHz���쎞�̐���x���`���ʁv
�\���āB�p�m�炸�߂�����B
�����ɍō�2.0GHz�ŏo�J�n����Ɣ��\����CPU�́u2.6GHz���쎞�̐���x���`���ʁv
�\���āB�p�m�炸�߂�����B
http://www.xbitlabs.com/discussion/4037.html
1. joke, right! [Posted by: Ole Joke | Date: 07/03/07]
1. joke, right! [Posted by: Ole Joke | Date: 07/03/07]
�܂��C���e�����o�����o�����Ƌ���������45nm�͓����łȂ�
�킯�����B���������Ӗ��ł̓v���Z�X�ɂ��Ă�AMD��������
�x��A�L���b�V�����x�͂P����x�ꂭ�炢���ȁB
�C���e�����l�g�o�Ȃ�Ĕn���Ȃ��Ƃ����Ȃ�������͂䂤�䂤
��s������̐��������̂ɁB���s�Ƃ͂������Ȍ����
�������̂��B
�킯�����B���������Ӗ��ł̓v���Z�X�ɂ��Ă�AMD��������
�x��A�L���b�V�����x�͂P����x�ꂭ�炢���ȁB
�C���e�����l�g�o�Ȃ�Ĕn���Ȃ��Ƃ����Ȃ�������͂䂤�䂤
��s������̐��������̂ɁB���s�Ƃ͂������Ȍ����
�������̂��B
AMD Second-Generation "Stars" Plans Unveiled
http://www.dailytech.com/Article.aspx?newsid=7913
http://www.dailytech.com/Article.aspx?newsid=7913
>>944
���̃l�^�͎U�X�o�Ă��邪�A�����ăl�g�o�͈����Ȃ���B
���̃l�^�͎U�X�o�Ă��邪�A�����ăl�g�o�͈����Ȃ���B
���N���b�N������90nm�v���Z�X���\��ʂ�̃��[�N�Ɏ��܂��Ă���A���B
���܂��C���e�����o�����o�����Ƌ���
�Ă͂��Ȃ�
�ȑOvr-zone�����Ⴂ���ĕςȃ��[�h�}�b�v�}�����Ă���
2007�N�㔼���Y�J�n���o�ׂ�2008�N�o��[�̂����������
����H���ł���͍����ς���ĂȂ�
�Ă͂��Ȃ�
�ȑOvr-zone�����Ⴂ���ĕςȃ��[�h�}�b�v�}�����Ă���
2007�N�㔼���Y�J�n���o�ׂ�2008�N�o��[�̂����������
����H���ł���͍����ς���ĂȂ�
>>946
���̃l�^�͎U�X�o�Ă��邪�A��͂�l�g�o�͈�����B
�Ƃ��������̎��ӂ�
�n�C�p�[�p�C�v���C����HTT�͂����Ƃ���
���M�A������MCM�Ƃ̑������ň��c
���ǕǂɂԂ�������A�s���~�܂���CPU�ł�������܂����B
���̃l�^�͎U�X�o�Ă��邪�A��͂�l�g�o�͈�����B
�Ƃ��������̎��ӂ�
�n�C�p�[�p�C�v���C����HTT�͂����Ƃ���
���M�A������MCM�Ƃ̑������ň��c
���ǕǂɂԂ�������A�s���~�܂���CPU�ł�������܂����B
Penryn��ɂ���ɂ�45nm&SSSE3�̎������s����(�ł��낤)Shanghai�܂ő҂��Ȃ���ʖڂ����
���A���̎��ɂ�Intel��Nehalem�ڑO�Ƃ���㩁c
���A���̎��ɂ�Intel��Nehalem�ڑO�Ƃ���㩁c
>>949
�l�g�o�������̂ł͂Ȃ��āA
���[�N�d���̓ǂ݂��Â�����Intel�J���w�̐ӔC�B
���ƁA�����i���\�肾����Tejas��MCM����Ȃ���B
�l�g�o�������̂ł͂Ȃ��āA
���[�N�d���̓ǂ݂��Â�����Intel�J���w�̐ӔC�B
���ƁA�����i���\�肾����Tejas��MCM����Ȃ���B
>>923
���̂���Nu"rburgring�Ƃ��o���������납�c
>>951
���ʓI�ɂ͍��N���b�N�O��̃l�g�o�������������Ď��ɂ͐���悤�ȁc
�S�Ă�1GHz�o�����[�X��AMD�Ƃ��Ă��܂������������Ȃ낤�ȁc
���̂���Nu"rburgring�Ƃ��o���������납�c
>>951
���ʓI�ɂ͍��N���b�N�O��̃l�g�o�������������Ď��ɂ͐���悤�ȁc
�S�Ă�1GHz�o�����[�X��AMD�Ƃ��Ă��܂������������Ȃ낤�ȁc
64bit�Ȃ炩�Ă邩
MP�Ȃ炩�Ă邩
64bitMP�Ȃ炩�Ă邩
MP�Ȃ炩�Ă邩
64bitMP�Ȃ炩�Ă邩
2S��4S�̃V�X�e���Ń��������ʂɐςƂ��̃��b�g�p�t�H�[�}���X�Ȃ珟�ĂȂ����Ƃ͂Ȃ����낤�B
����������̎�p�r�ł���DB�T�[�o�[�ŏd�v��RAS�ŏ��ĂȂ�����Ӗ����������낤
�ނ��Paxville�ł������Ă����̂�����
�ނ��Paxville�ł������Ă����̂�����
AMD Phenom X2 GE-Series Details Unveiled
http://www.dailytech.com/AMD+Phenom+X2+GESeries+Details+Unveiled/article7911.htm
http://www.dailytech.com/AMD+Phenom+X2+GESeries+Details+Unveiled/article7911.htm
>�p�m�炸�߂�����B
�����intel���R���p�C���̓���ɓ�Ȃ����ӂ肩�炨�������������B
��̍ٔ��̓A������ǂ��Ȃ��Ă���̂��ˁB
���B�ӂ肶�ᑊ���������Ă��݂��������ǁB
�����intel���R���p�C���̓���ɓ�Ȃ����ӂ肩�炨�������������B
��̍ٔ��̓A������ǂ��Ȃ��Ă���̂��ˁB
���B�ӂ肶�ᑊ���������Ă��݂��������ǁB
AMD��SOI�E�F�n���B���soitec�Ђ̓����ƌ����̕ɂ��ƁA�u������v�ƌ����̍ɂ�
�R�ς݂ŁA���N�̔����ቺ����v�Ƃ̂��Ƃ��B
http://www.fabtech.org/content/view/3083/
�@�@----------------------
�@�@New products launched by main customers come on stream in the second half of the year
�@�@but given the current uncertainty with regard to the timing of the ramp-up in volume of
�@�@these products, the Group cannot exclude that full year sales may be below the prior year.
�@�@----------------------
�ڋq���ƂɃE�F�n�̎d�l��قȂ邷����A���ꖾ�炩��AMD�̂��Ƃ��B
�R�ς݂ŁA���N�̔����ቺ����v�Ƃ̂��Ƃ��B
http://www.fabtech.org/content/view/3083/
�@�@----------------------
�@�@New products launched by main customers come on stream in the second half of the year
�@�@but given the current uncertainty with regard to the timing of the ramp-up in volume of
�@�@these products, the Group cannot exclude that full year sales may be below the prior year.
�@�@----------------------
�ڋq���ƂɃE�F�n�̎d�l��قȂ邷����A���ꖾ�炩��AMD�̂��Ƃ��B
�܂�����ȏ؋�����ł߂Ȃ��Ă�K10���N���̃{�����[���o�ׂ͐�]�I����
�b�͂����Ԃ�O���疾�炩�ɂ���Ă������BAMD���g���F�߂ĂȂ��������B
�b�͂����Ԃ�O���疾�炩�ɂ���Ă������BAMD���g���F�߂ĂȂ��������B
>>957
�Ƃ肠�������ł��ڋq�Ƃ��Ċl���ł����̂�Intel��
�u�����v���Z�b�T�������ɑ��Ђ͎̂g�p�֎~�ˁv
���Ă��������p�~�������炶��ˁH
�p�~�����̂�AMD���i��������B
Intel�͓��R�i���͔F�߂ĂȂ����ǁA��̓I�ȍs���͋N�������ƁB
�Ƃ肠�������ł��ڋq�Ƃ��Ċl���ł����̂�Intel��
�u�����v���Z�b�T�������ɑ��Ђ͎̂g�p�֎~�ˁv
���Ă��������p�~�������炶��ˁH
�p�~�����̂�AMD���i��������B
Intel�͓��R�i���͔F�߂ĂȂ����ǁA��̓I�ȍs���͋N�������ƁB
Intel���F�߂ĂȂ��̂́u�����v���Z�b�T�������ɑ��Ђ͎̂g�p�֎~�ˁv
�Ƃ�����������B
�Ƃ�����������B
���̓_�ɂ��Ă�AMD�̑i���͑R��ׂ������Ǝv���B
���������Ă�̂́A�l�̋��ō����"����"�̉��b�Ɏ������̂��Ă��Ȃ��Ɠ{��\�}�����������A�ƁB
�ǂ����̔�������Ȃ�����A�v���C�h�͍��������ė~������B
���������Ă�̂́A�l�̋��ō����"����"�̉��b�Ɏ������̂��Ă��Ȃ��Ɠ{��\�}�����������A�ƁB
�ǂ����̔�������Ȃ�����A�v���C�h�͍��������ė~������B
�x���Ȃ�悤�ɍH���Ă�����
�Ȃ�Ɛ�I���ꂩ��̒��ߏo������l�[��
�Ȃ�Ɛ�I���ꂩ��̒��ߏo������l�[��
�H�Ȃ��ˁ[����
Intel CPU�ɂ����œK���������Ȃ��悤�ɂ��邾����
�Ȃ�Ń��C�o����Ђ�CPU�ɂ܂ōœK�����Ă��ɂႢ����̂�
Intel CPU�ɂ����œK���������Ȃ��悤�ɂ��邾����
�Ȃ�Ń��C�o����Ђ�CPU�ɂ܂ōœK�����Ă��ɂႢ����̂�
���₢�▾�炩�ɒx���Ȃ�l�ɂȂ��Ă��炵����
>�Ɛ�I���ꂩ��̒��ߏo������l�[��
intel���R���p�C�������Ȃ��̂Ȃ炻�����낤�ˁB
���ےx���Ȃ����Ƃ��āAAMD�ɂǂ�ȑi���錠��������̂�?�A�Ƃ����b�B
��̓I�Ɍ����A��3�ғI�ȋ@�ւ̊J�������R���p�C����
intel���d�G�ł������āA�̈ӂ�AMD��CPU�ɕs���Ȏd�l�ɂ������Ƃ���B
����Ȃ�AMD���[��������R(`�D�L)ɂƌ����̂͂킩��B
����̂͑S��intel�����g�̋����g���Ď�������CPU�ׂ̈ɂ���Ă鎖�ƂȂ̂���?
����Ȃ��Ƃɓ{�苶���O��AMD���R���p�C�����ׂ��B
���Ɛ���x���`���ʂƂ��}�W��߂ė~�����B
�ǂ����̌Z�M��MCM�ȒP�����Ƃ����AAMD�̓}�]�Ȃ�Ȃ����Ǝv���Ă����B
intel���R���p�C�������Ȃ��̂Ȃ炻�����낤�ˁB
���ےx���Ȃ����Ƃ��āAAMD�ɂǂ�ȑi���錠��������̂�?�A�Ƃ����b�B
��̓I�Ɍ����A��3�ғI�ȋ@�ւ̊J�������R���p�C����
intel���d�G�ł������āA�̈ӂ�AMD��CPU�ɕs���Ȏd�l�ɂ������Ƃ���B
����Ȃ�AMD���[��������R(`�D�L)ɂƌ����̂͂킩��B
����̂͑S��intel�����g�̋����g���Ď�������CPU�ׂ̈ɂ���Ă鎖�ƂȂ̂���?
����Ȃ��Ƃɓ{�苶���O��AMD���R���p�C�����ׂ��B
���Ɛ���x���`���ʂƂ��}�W��߂ė~�����B
�ǂ����̌Z�M��MCM�ȒP�����Ƃ����AAMD�̓}�]�Ȃ�Ȃ����Ǝv���Ă����B
����x���`�ǂ��납�A���@�f�����s�����L�����Ȃ���
���萻�i���H
���萻�i���H
������Č����Ă����ۂ��̃N���b�N�̐��i���o��قړ������Ǝv�����ǂȁB
CPU�v����Ƃ��̓V�~�����[�^�g�����炻�̃V�~�����[�^�Ŋm�F���Ă�ł���B
���ہA��N���b�N�i�Ȃ瓮���Ă�킯�����A��������������͉\�B
�܂����ӔC�ƌ���ꂽ�炻����������E�E�E�B
���߂đ�4�l������2.6GHz���炢�o�邱�Ƃ��F��B
CPU�v����Ƃ��̓V�~�����[�^�g�����炻�̃V�~�����[�^�Ŋm�F���Ă�ł���B
���ہA��N���b�N�i�Ȃ瓮���Ă�킯�����A��������������͉\�B
�܂����ӔC�ƌ���ꂽ�炻����������E�E�E�B
���߂đ�4�l������2.6GHz���炢�o�邱�Ƃ��F��B
969 �FSocket774�F2007/07/04(��) 02:17:00 ID:xwXfggZM
08Q1�I��肱��ɂ�2.6GH�����o��Ɛ��肳���B
>>960
���ʂ��^���������Ă��ꂽ��
���ʂ��^���������Ă��ꂽ��
>>967
���x��������B
���x��������B
���I�ɂ͂Q�\�P�}�U�[���v���X�T��~�ȉ��ŏo���ė~����
�����Ă̓Z���ł�����������
��������K�v�Ȃ��Ă������P�������Ⴄ������ς�������
���������������Ȃ�ƂȂ�����
�ŏ��P�����Ĉ����Ȃ��������1��
�`�l�c�Ƃ��Ă͘J�������ĂP���������
�����ĉ��̖{���͂R�c�Q�[���A�N�Z���[�^�[
�l�ɂ���Ă̓G���R�A�N�Z�����[�^�[
�v���̌v�Z������ɂ͒l�i������ł��낤��������������
�����Q�\�P���p�r�����������헪�������Ă���
�����Ă̓Z���ł�����������
��������K�v�Ȃ��Ă������P�������Ⴄ������ς�������
���������������Ȃ�ƂȂ�����
�ŏ��P�����Ĉ����Ȃ��������1��
�`�l�c�Ƃ��Ă͘J�������ĂP���������
�����ĉ��̖{���͂R�c�Q�[���A�N�Z���[�^�[
�l�ɂ���Ă̓G���R�A�N�Z�����[�^�[
�v���̌v�Z������ɂ͒l�i������ł��낤��������������
�����Q�\�P���p�r�����������헪�������Ă���
�V�F�A�I�ɂ̓C���e���R���p�C���Ȃ��VisualStudio�̂ق���
���|�I���낤����A�e���Ƃ��Ă͂���܂�Ȃ���Ȃ����ȁB
���|�I���낤����A�e���Ƃ��Ă͂���܂�Ȃ���Ȃ����ȁB
>>966
���������A�����AMD����Intel���̈ȑO�ɁA����͍��{�I��966�̍l�������C��������Ă�B
�������A�u���А��̂b�o�t�ɍœK������v�؍����Ȃ͂܂������Ȃ��B���S�ɂȂ��B����ɂ��Ă͓��R�B
�����A�������A���А��b�o�t�ł����u�̈ӂɒx���Ȃ�悤�Ɂv�����̂Ȃ�A��������đR��ׂ��B
����ɋ߂��d�l�i���̉�Ђ̐��i�ɂ����g���Ȃ��Ƃ��j�͂��邯�ǂ��A
�����܂ōs���Ɠ��ݍ��݂����B
�Ⴆ��USB�@���A�f�B�X�v���C�Ȃ��A������������А��i�ł����P�O�O���̐��\���o�Ȃ��悤�Ɍ̈ӂɂȂ��Ă���H
���������̂�S�Ẳ�Ђ�����Ă�����H
����Ȏ������n�߂���}�C�N���\�t�g�����āA�b�o�t���[�J�[�ɂ�����v�����Ă����������ق��̓m�[�E�G�C�g��
��������Ȃ��ق��ɂ͂킴�ƃE�G�C�g������Ƃ�����Ă������ƂɂȂ��ȁB
��Ȏ����ɔF�߂Ă��琢�̒����`���N�`������B
���i�̖{���̐��\��i���Ɋւ��Ȃ��A�������i���Ă����肾�����s���ɗL���ɂȂ�B
����ȋ������j�Q����邵�A����҂͂܂Ƃ��Ɏg���鐻�i�̑I���������`���N�`�����Ȃ��Ȃ�B
���������A�����AMD����Intel���̈ȑO�ɁA����͍��{�I��966�̍l�������C��������Ă�B
�������A�u���А��̂b�o�t�ɍœK������v�؍����Ȃ͂܂������Ȃ��B���S�ɂȂ��B����ɂ��Ă͓��R�B
�����A�������A���А��b�o�t�ł����u�̈ӂɒx���Ȃ�悤�Ɂv�����̂Ȃ�A��������đR��ׂ��B
����ɋ߂��d�l�i���̉�Ђ̐��i�ɂ����g���Ȃ��Ƃ��j�͂��邯�ǂ��A
�����܂ōs���Ɠ��ݍ��݂����B
�Ⴆ��USB�@���A�f�B�X�v���C�Ȃ��A������������А��i�ł����P�O�O���̐��\���o�Ȃ��悤�Ɍ̈ӂɂȂ��Ă���H
���������̂�S�Ẳ�Ђ�����Ă�����H
����Ȏ������n�߂���}�C�N���\�t�g�����āA�b�o�t���[�J�[�ɂ�����v�����Ă����������ق��̓m�[�E�G�C�g��
��������Ȃ��ق��ɂ͂킴�ƃE�G�C�g������Ƃ�����Ă������ƂɂȂ��ȁB
��Ȏ����ɔF�߂Ă��琢�̒����`���N�`������B
���i�̖{���̐��\��i���Ɋւ��Ȃ��A�������i���Ă����肾�����s���ɗL���ɂȂ�B
����ȋ������j�Q����邵�A����҂͂܂Ƃ��Ɏg���鐻�i�̑I���������`���N�`�����Ȃ��Ȃ�B
>>974
���܂���Intel�R���p�C���̂��ƂȂ���킩���Ăˁ[
���܂���Intel�R���p�C���̂��ƂȂ���킩���Ăˁ[
��������Ĉ�����Ŏg���ĂČォ�瑫����Ȃ炢����
>>974
���O�Ȃɂ����Ă�H
���́uIntel�R���p�C���̂��ƂȂ����ĂȂ��v
Intel�R���p�C���̐^�U�ƊW�Ȃ�
�u���А��̐��i�Ȃ�A���А��̐��i�Ƒg�ݍ��킹�����ɒx���Ȃ�H��
���Ă��悤���ǂ����悤������������؍����͂Ȃ��v�Ȃ�Č����l�������̂����������A�ƌ����Ă��
���O�Ȃɂ����Ă�H
���́uIntel�R���p�C���̂��ƂȂ����ĂȂ��v
Intel�R���p�C���̐^�U�ƊW�Ȃ�
�u���А��̐��i�Ȃ�A���А��̐��i�Ƒg�ݍ��킹�����ɒx���Ȃ�H��
���Ă��悤���ǂ����悤������������؍����͂Ȃ��v�Ȃ�Č����l�������̂����������A�ƌ����Ă��
> �����A�������A���А��b�o�t�ł����u�̈ӂɒx���Ȃ�悤�Ɂv�����̂Ȃ�A��������đR��ׂ��B
��̓I�Ɂu�̈ӂɒx���Ȃ�悤�ɂ����v�ӏ����Ăǂ�?
�ϑz�Œ����č���܂���B
��̓I�Ɂu�̈ӂɒx���Ȃ�悤�ɂ����v�ӏ����Ăǂ�?
�ϑz�Œ����č���܂���B
����ĂȂ��ƌ����ӏ����ĉ����H
�ϑz�Ō���Ă�����܂���B
�ϑz�Ō���Ă�����܂���B
>>979
�͂����猩�ĂĂ������ǂ߂Ȃ��ɂ����x�L��
����Ă��Ȃ�Č����ĂȂ��Ǝv����
�����������O�����p���Ă镶�̒��ɂ� �������A���ē����Ă邶���
�͂����猩�ĂĂ������ǂ߂Ȃ��ɂ����x�L��
����Ă��Ȃ�Č����ĂȂ��Ǝv����
�����������O�����p���Ă镶�̒��ɂ� �������A���ē����Ă邶���
�s���̂�����������ȂƂ����Ȃ�Ƃ�����
����̘b���Ă�̂ɋ�̓I�Ɍ������ĉ����c
����̘b���Ă�̂ɋ�̓I�Ɍ������ĉ����c
����̘b�Ȃ�ăA�z�L�߂��܂���A�o�J�ł�?
���̃A�z�L���b���A�������Ǝv���ă��X�����̂͑��O��l
�ϑz���ƌ����Ă�ł͂Ȃ���w
>>946-947
�����Ȃ�45nm�v���Z�X�ŁA5GHz�̃v���X�R������ė~������ˁB
�X��Socket478�ŏo���Ă����A����̗܂ȃ��[�U�[���������낤���B
�����Ȃ�45nm�v���Z�X�ŁA5GHz�̃v���X�R������ė~������ˁB
�X��Socket478�ŏo���Ă����A����̗܂ȃ��[�U�[���������낤���B
8GHz��Tejas�Ƃ����������Ă�����Conroe�Ɠ����ȏゾ�����̂��ˁB
>>986
���������B���̃v���Z�X�Ȃ��10Ghz�͓˔j���ė~�����Ƃ���B
�l�g�o�����v��ł͂��ł�10Ghz�˔j�������͂����B
>>987
�����܂ł���Ȃ��C������̂́c���̂������H
���������B���̃v���Z�X�Ȃ��10Ghz�͓˔j���ė~�����Ƃ���B
�l�g�o�����v��ł͂��ł�10Ghz�˔j�������͂����B
>>987
�����܂ł���Ȃ��C������̂́c���̂������H
���������̂��܂Ƃ��ɓ����Ȃ����炢�̐[���ȃo�O�Ȃ炢�����ǂ�
�A���t�@�x�b�g��S�p�ŏ����z�ɂ܂Ƃ��ȓz�͂��Ȃ�
�Ƃ������Ƃł�낵�����H
�Ƃ������Ƃł�낵�����H
�l�b�g���e���V�[�̏�����m��Ȃ��Ƃ������Ƃł�k
�������ǂ߂Ȃ����[���A�v�l��H�����������h����̘b�h�A
�v�l�����I�ȓW�J���Ă̂��f�t�H�ł͒e���Ă��܂��A�����������̂�
�������̍\�������Ă���l���Ă̂����X����C������B
�v�l�����I�ȓW�J���Ă̂��f�t�H�ł͒e���Ă��܂��A�����������̂�
�������̍\�������Ă���l���Ă̂����X����C������B
�k�ق̃K�C�h���C�����ȁ��O�����������
����
997 �FSocket774�F2007/07/04(��) 23:24:19 ID:6IJdD7Kc
�~
��
�@�@�@�@�@�@�@�@�@,�-�]�ށL^|~~~"''''''Ɂ[-=,�A__
�@�@�@�@ _,�-�]�ށL���-�B�L�܁M)��-���]�R�^]
�@�@�@�@[~~~''''''��-=,�A.._�M/_~�L,,__,,,,.... �^ �@ |,..,,__
�@�@�@_,.-|�@�@�@�@�@�@�@~` ''�--�A.,�B�^�@�@�^�@�^�R
�@ /~"�^~~~''''''��-=,�A..�@�@�@�@ | |�@�@�^�@�^�@�^/
�@�s ./ �_�@�@�@�@�@�@�@ ~` ''�--.,| |.�^�@�^�@�^.�^
�@�_�@ �@ �_�@�@�@�@�@ �^ .�^ _,...�s-�]�^�@�^.�^
�@�@ �_�@�@�@�_�@�@�^ .�^.-'~"�@ �R .�_�^�^�@�@�@�@
.�@�@�@�@�_�@ �@ ��" <-'"~�@�@�@�@�@�R�@|�^
�@�@�@�@�@�@�_,./"�^^�R�@�@�@�@ _,...-'"~"
�@�@�@�@�@�@�@�@�@~'�]=�A,�R_,...-'"~�@�j�j
�@�@�@�@�@�@�@�@�@�@<..,,_'''�]-�A.,�j_�j
�@�@�@�@�@�@�@�@�@�@�@�@ ~"''�]-v/
�@�@�@�@ _,�-�]�ށL���-�B�L�܁M)��-���]�R�^]
�@�@�@�@[~~~''''''��-=,�A.._�M/_~�L,,__,,,,.... �^ �@ |,..,,__
�@�@�@_,.-|�@�@�@�@�@�@�@~` ''�--�A.,�B�^�@�@�^�@�^�R
�@ /~"�^~~~''''''��-=,�A..�@�@�@�@ | |�@�@�^�@�^�@�^/
�@�s ./ �_�@�@�@�@�@�@�@ ~` ''�--.,| |.�^�@�^�@�^.�^
�@�_�@ �@ �_�@�@�@�@�@ �^ .�^ _,...�s-�]�^�@�^.�^
�@�@ �_�@�@�@�_�@�@�^ .�^.-'~"�@ �R .�_�^�^�@�@�@�@
.�@�@�@�@�_�@ �@ ��" <-'"~�@�@�@�@�@�R�@|�^
�@�@�@�@�@�@�_,./"�^^�R�@�@�@�@ _,...-'"~"
�@�@�@�@�@�@�@�@�@~'�]=�A,�R_,...-'"~�@�j�j
�@�@�@�@�@�@�@�@�@�@<..,,_'''�]-�A.,�j_�j
�@�@�@�@�@�@�@�@�@�@�@�@ ~"''�]-v/
AMD�̎�����CPU�ɂ��Č�낤 ��12����
http://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
http://pc11.2ch.net/test/read.cgi/jisaku/1183558273/
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/