後藤弘茂を応援するスレ Part15
コアなCPU/GPU解説とSF・ゲーム・アニメなどで我々をうならせる
後藤弘茂一家を応援するスレです。
ただしゲームのネタは荒れ気味なので程々に。
後藤弘茂のWeekly海外ニュース(バックナンバー)
http://pc.watch.impress.co.jp/docs/article/backno/kaigai.htm
<前スレ>
後藤弘茂を応援するスレ Part14
http://pc11.2ch.net/test/read.cgi/jisaku/1166398064/
後藤弘茂一家を応援するスレです。
ただしゲームのネタは荒れ気味なので程々に。
後藤弘茂のWeekly海外ニュース(バックナンバー)
http://pc.watch.impress.co.jp/docs/article/backno/kaigai.htm
<前スレ>
後藤弘茂を応援するスレ Part14
http://pc11.2ch.net/test/read.cgi/jisaku/1166398064/
|
|
|
2 :Socket774:2007/03/31(土) 09:12:59 ID:7Gl+0dYy
/ \
/ / ̄⌒ ̄\
/ / ⌒ ⌒ | | ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
| / (・) (・) | | てめーなんだよこの糞スレは!!
/⌒ (6 つ | | てめーは精神障害でもあんのか?
( | / ___ | < 何とか言えよゴルァァァァァァ!
− \ \_/ / \__________________
// ,,r'´⌒ヽ___/ ,ィ
/ ヽ ri/ 彡
/ i ト、 __,,,丿)/ ζ
| ! )`Y'''" ヽ,,/ / ̄ ̄ ̄ ̄\
! l | く,, ,,,ィ'" /. \
ヽヽ ゝ ! ̄!~〜、 / |
ヽ / ̄""'''⌒ ̄"^'''''ー--、 :::|||||||||||||||||||||||||||||||||
Y'´ / """''''〜--、|||||||||||||||||)
( 丿 ,,;;'' ....::::::::::: ::::r''''"" ̄""ヽ |
ゝ ー--、,,,,,___ ::: ::,,,,,ー`''''''⌒''ーイ ./
ヽ \  ̄""'''"" ̄ \____/-、
ヽ ヽ :::::::::::::::::::: / `ヽ
ヽ 丿 ) / ノ ゝ ヽ ,〉
ゝ ! / ∀
! | / 人 ヽ ヽ
| ,;;} !ー-、/ ヽ _,,,-ー'''''--ヘ
|ノ | | / Y ヽ
{ | | j ) >>1 ヽ
/ / ̄⌒ ̄\
/ / ⌒ ⌒ | | ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
| / (・) (・) | | てめーなんだよこの糞スレは!!
/⌒ (6 つ | | てめーは精神障害でもあんのか?
( | / ___ | < 何とか言えよゴルァァァァァァ!
− \ \_/ / \__________________
// ,,r'´⌒ヽ___/ ,ィ
/ ヽ ri/ 彡
/ i ト、 __,,,丿)/ ζ
| ! )`Y'''" ヽ,,/ / ̄ ̄ ̄ ̄\
! l | く,, ,,,ィ'" /. \
ヽヽ ゝ ! ̄!~〜、 / |
ヽ / ̄""'''⌒ ̄"^'''''ー--、 :::|||||||||||||||||||||||||||||||||
Y'´ / """''''〜--、|||||||||||||||||)
( 丿 ,,;;'' ....::::::::::: ::::r''''"" ̄""ヽ |
ゝ ー--、,,,,,___ ::: ::,,,,,ー`''''''⌒''ーイ ./
ヽ \  ̄""'''"" ̄ \____/-、
ヽ ヽ :::::::::::::::::::: / `ヽ
ヽ 丿 ) / ノ ゝ ヽ ,〉
ゝ ! / ∀
! | / 人 ヽ ヽ
| ,;;} !ー-、/ ヽ _,,,-ー'''''--ヘ
|ノ | | / Y ヽ
{ | | j ) >>1 ヽ
____)__
,. ´ ` ` 、
./ _ _ \
/ _  ̄ _ ヽ
/イィィ,,.,.,.,.,.,  ̄ ̄ !
f/ノノノノノノノ ヘ.__ j jノ__ノ
|/////// _ (__ ゚_>` __( ゚_イ
.!|.|i/_^ヽ|_'___r⌒ y' ヽ^)|
!|| fニ> :::::: `ー'゙ (_`___)ノ
ヽ.ニ` : /_ノ/川! / 煽ったね・・・・・・
__ノ 、 / ヾ---'´ ノ
__ノ \l ` ____,/
\ ノ リ.|`ー--
\ .//
/ , , , , , , __ ___` 、
,//////ィ ヽ.
ノノノノノノノl /\ , -、 !
///////l ",二ヽ.二_ヽ. l lノ_へノ!
//////ノ (_jリ ゙T`’ノ / (rリ`y゙
ソ´,-、\| -` ー--‐ " __{ ー-'{ サザエにも
| ,f^ソ |____/ ゙̄ヾ"´ \^ヽ. |
| に( l j ,.. ヽ |.| 煽られたことないのにっ!!
\` ' j `ー-‐' イ_ ` ノ'" i
゙‐-' /,. ‐-、/TTT|| ノ
_} / |----二ニフ ノ
人\ ヽ. ! r'二ヽ / /
_「 \\ ` 、 ` ̄ ̄/
\\ Ti"
\\ ノ | |\
,. ´ ` ` 、
./ _ _ \
/ _  ̄ _ ヽ
/イィィ,,.,.,.,.,.,  ̄ ̄ !
f/ノノノノノノノ ヘ.__ j jノ__ノ
|/////// _ (__ ゚_>` __( ゚_イ
.!|.|i/_^ヽ|_'___r⌒ y' ヽ^)|
!|| fニ> :::::: `ー'゙ (_`___)ノ
ヽ.ニ` : /_ノ/川! / 煽ったね・・・・・・
__ノ 、 / ヾ---'´ ノ
__ノ \l ` ____,/
\ ノ リ.|`ー--
\ .//
/ , , , , , , __ ___` 、
,//////ィ ヽ.
ノノノノノノノl /\ , -、 !
///////l ",二ヽ.二_ヽ. l lノ_へノ!
//////ノ (_jリ ゙T`’ノ / (rリ`y゙
ソ´,-、\| -` ー--‐ " __{ ー-'{ サザエにも
| ,f^ソ |____/ ゙̄ヾ"´ \^ヽ. |
| に( l j ,.. ヽ |.| 煽られたことないのにっ!!
\` ' j `ー-‐' イ_ ` ノ'" i
゙‐-' /,. ‐-、/TTT|| ノ
_} / |----二ニフ ノ
人\ ヽ. ! r'二ヽ / /
_「 \\ ` 、 ` ̄ ̄/
\\ Ti"
\\ ノ | |\
オクタコアが最初マジでオタクコアに見えてしまった…orz
6 :Socket774:2007/03/31(土) 18:22:31 ID:jXuDwEaX
7 :Socket774:2007/03/31(土) 18:23:28 ID:jXuDwEaX
このhは弱いけどちゃんと発音すると思う>前スレ996
9 :Socket774:2007/03/31(土) 19:43:52 ID:jXuDwEaX
イソテノレもヲタ市場の重要性にやっと気づきはじめたってことだな
>>8
http://www.geocities.jp/andosprocinfo/wadai07/20070331.htm
>Nehalemの発音ですが,筆者には「ネヘーレム」で「へ」にアクセントがある感じ
>に聞こえます。
発音しまくりらしいぞ。
http://www.geocities.jp/andosprocinfo/wadai07/20070331.htm
>Nehalemの発音ですが,筆者には「ネヘーレム」で「へ」にアクセントがある感じ
>に聞こえます。
発音しまくりらしいぞ。
エイプリルフールktkr
イモか…
メモリインターフェース統合でまたもAMDの後追いか。
GPU統合はどちらが先に出るかわからんが。
PentiumIII〜Banias〜Meromの流れを全く汲まない、
ひさびさの完全新アーキテクチャだね。
コアの性能はmeromより向上?あまり変わらなさそうな気がするが…
GPU統合はどちらが先に出るかわからんが。
PentiumIII〜Banias〜Meromの流れを全く汲まない、
ひさびさの完全新アーキテクチャだね。
コアの性能はmeromより向上?あまり変わらなさそうな気がするが…
メモリインターフェイスとGPUの統合はTimnaで既にやってるじゃん
Rambusのせいでキャンセルされたけど
Rambusのせいでキャンセルされたけど
Timna VS MediaGXとか書くとなんかショボく感じてしまう・・・
後藤の記事でも出てるけど、CSIとFB-DIMMI/Fの共通化は止めたのかな。
まぁ、FB-DIMMの先行き自体不透明だけど。
IDFで新情報が出る(そして大原あたりがレポートする)ことを期待するか。
まぁ、FB-DIMMの先行き自体不透明だけど。
IDFで新情報が出る(そして大原あたりがレポートする)ことを期待するか。
くそもらし
ウンコー●●●
21 :Socket774:2007/04/04(水) 01:44:04 ID:/kANN+PG
GPUコアを統合する次世代CPU「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0404/kaigai349.htm
http://pc.watch.impress.co.jp/docs/2007/0404/kaigai349.htm
CPU内GPUとチップセット内GPUでSLI、メモリはGPAカードで、とかいうお遊びが出来るといいな
23 :Socket774:2007/04/04(水) 07:28:39 ID:KsR7JRVg
まともに翻訳する能力がないのなら、
助詞以外は全部カタカナにしたらどうよ>後藤
読みにくくて仕方ない。
×DirectX 10フィーチャを
○DirectX 10機能を
×性能レンジはどうなるのだろう
○どのような性能を持つのだろう
×セントラルリーダーシップポジションを取る性能だ
○中心的な存在となり、市場を牽引する役割を果たす性能だ
×それは完全に異なるセグメントとなる
○それは完全に異なる領域になる
×ディスクリートGPUの性能
○非統合型GPUの性能
×スタンダードなDDR2/3
○標準的なDDR2/3
×GPUのプロセッシング性能に見合ったメモリ帯域が確保されなければ性能を発揮できないからだ
○充分なメモリ帯域がなければ、GPUの処理能力が高くても性能は頭打ちになるからだ。
×コスト、消費電力、フォームファクタのトレードオフがある
○コスト、消費電力、製品サイズの制約がある
×GPUコアをスタンダードなフィーチャにしようという意図
○GPUコアの機能を標準装備させようという意図
つーか、毎度のことながら編集者はよく通すよな。
こんな不自由な日本語で。
助詞以外は全部カタカナにしたらどうよ>後藤
読みにくくて仕方ない。
×DirectX 10フィーチャを
○DirectX 10機能を
×性能レンジはどうなるのだろう
○どのような性能を持つのだろう
×セントラルリーダーシップポジションを取る性能だ
○中心的な存在となり、市場を牽引する役割を果たす性能だ
×それは完全に異なるセグメントとなる
○それは完全に異なる領域になる
×ディスクリートGPUの性能
○非統合型GPUの性能
×スタンダードなDDR2/3
○標準的なDDR2/3
×GPUのプロセッシング性能に見合ったメモリ帯域が確保されなければ性能を発揮できないからだ
○充分なメモリ帯域がなければ、GPUの処理能力が高くても性能は頭打ちになるからだ。
×コスト、消費電力、フォームファクタのトレードオフがある
○コスト、消費電力、製品サイズの制約がある
×GPUコアをスタンダードなフィーチャにしようという意図
○GPUコアの機能を標準装備させようという意図
つーか、毎度のことながら編集者はよく通すよな。
こんな不自由な日本語で。
ほら、いるじゃん、バラエティ番組で使われてる芸能界用語を使いたがるやつ、あれのヲタ版。
スタパとちょっと方向性と表現方法が違うだけでスキームは同じ、と考えることも出来るし。
スタパとちょっと方向性と表現方法が違うだけでスキームは同じ、と考えることも出来るし。
グダグダ言うなら
コテハンつけて、それ以上の記事書けよ
後藤さんからすれば汎用多コア、キャッシュ増量なんて方が
よほど、お花畑なんだろ
コテハンつけて、それ以上の記事書けよ
後藤さんからすれば汎用多コア、キャッシュ増量なんて方が
よほど、お花畑なんだろ
編集者のチェックなんてないんじゃないか?
だいたい、編集が見てたら毎回毎回同じことしか書いてねぇと差し戻すだろ
だいたい、編集が見てたら毎回毎回同じことしか書いてねぇと差し戻すだろ
>>27
ゴトウ本人はそうしたいけど、編集の意向でカタカナにしてる、と予想
ゴトウ本人はそうしたいけど、編集の意向でカタカナにしてる、と予想
戦時中の野球かw
アホくさい
アホくさい
後藤氏は誤魔化したいときにカタカナを多用するって感じだよな。
真面目に読むと、後藤自身が完全に否定している「高性能なGPUの統合」(統合GPUは制約が多過ぎるから高性能に成りえない)を、
AMDを擁護する立場から「実現可能」だとする言い回しに無理がある為誤魔化す方向で意味不明な言い回しにしている。
と受け取るのが自然だ。
Intelの技術者の解説や言い分は自然であり納得出来るもの、それを「方向性が明確ではない」という表現で貶しつつ、
AMDの技術者のいい加減で場当たり的な発言である「GPUの並列処理をCPU的に活用」を支持。
しかし並列処理に特化すれば、きめ細かいフロー制御は不能となり広範囲な用途に適用することは不可能。
それを誤魔化す為に、ここ最近ジオメトリ演算がプログラマブル化し専用回路からレンダリング処理にも使用可能な汎用的回路に変化
している例をあげるという姑息なやり方・・・・
ハードワイヤーをやめたことによる処理効率の大幅な低下を隠しつつ、「プログラマブル化」というキーワードを使ってあたかも自在なフロー制御
がそこで成されているかのような錯覚を読者に与えつつ、高度な並列高速演算と高度なフロー制御の両立が可能であるかのような結論へ・・・
もう詐欺というか無茶というか滑稽というか・・・・そこまでしてAMD擁護を何故する?
真面目に読むと、後藤自身が完全に否定している「高性能なGPUの統合」(統合GPUは制約が多過ぎるから高性能に成りえない)を、
AMDを擁護する立場から「実現可能」だとする言い回しに無理がある為誤魔化す方向で意味不明な言い回しにしている。
と受け取るのが自然だ。
Intelの技術者の解説や言い分は自然であり納得出来るもの、それを「方向性が明確ではない」という表現で貶しつつ、
AMDの技術者のいい加減で場当たり的な発言である「GPUの並列処理をCPU的に活用」を支持。
しかし並列処理に特化すれば、きめ細かいフロー制御は不能となり広範囲な用途に適用することは不可能。
それを誤魔化す為に、ここ最近ジオメトリ演算がプログラマブル化し専用回路からレンダリング処理にも使用可能な汎用的回路に変化
している例をあげるという姑息なやり方・・・・
ハードワイヤーをやめたことによる処理効率の大幅な低下を隠しつつ、「プログラマブル化」というキーワードを使ってあたかも自在なフロー制御
がそこで成されているかのような錯覚を読者に与えつつ、高度な並列高速演算と高度なフロー制御の両立が可能であるかのような結論へ・・・
もう詐欺というか無茶というか滑稽というか・・・・そこまでしてAMD擁護を何故する?
さあいつもの人が湧きましたよ
昔は淫厨呼ばわりされてたのに
今度はAMD擁護呼ばわりかw
大変だねぇライターって・・・
今度はAMD擁護呼ばわりかw
大変だねぇライターって・・・
お金になる方を選んだ結果ってことで良いんじゃねぇの?
Intelは広告費削減の方向だろうし、大々的な広告をするにしても姑息な手段はもう必要じゃねぇ状況だしな。
逆にAMDは・・・・・やっぱ草の根だろうしなw
Intelは広告費削減の方向だろうし、大々的な広告をするにしても姑息な手段はもう必要じゃねぇ状況だしな。
逆にAMDは・・・・・やっぱ草の根だろうしなw
ここで後藤をこき下ろしているいつもの奴より
後藤の方が情報持っているんだよな
どちらが脳内妄想を叫んでいるかは明白
ただ、変にカタカナが多いのは同意するw
後藤の方が情報持っているんだよな
どちらが脳内妄想を叫んでいるかは明白
ただ、変にカタカナが多いのは同意するw
> 後藤の方が情報持っているんだよな
持ってると思うぞ、そして持っているからこそ腹立たしい。
商売のためとはいえ嘘を吹聴するその姿勢こそ腹立たしい。
そして、騙し続けることが難しくなるとほんの少し言い訳を書き込む。
そんな奴が技術系ライターをやっていると思うと反吐がでる。
持ってると思うぞ、そして持っているからこそ腹立たしい。
商売のためとはいえ嘘を吹聴するその姿勢こそ腹立たしい。
そして、騙し続けることが難しくなるとほんの少し言い訳を書き込む。
そんな奴が技術系ライターをやっていると思うと反吐がでる。
どっちかというと情報を得ることの方が主の仕事なんじゃないのか。
ぶっちゃけ、これから(今も)のネットの時代ユーザが求めているのは、
できるだけ正確で速い情報だけだよ。
ジャーナリストやコラムニストのような記事の味付けは素人の一般人のページでも十分だから。
だから、持っているから叩かれると書いた。
できるだけ正確で速い情報だけだよ。
ジャーナリストやコラムニストのような記事の味付けは素人の一般人のページでも十分だから。
だから、持っているから叩かれると書いた。
応援スレなのに…
うんうん、応援しよう(棒読み)
このスレでクダ巻いてるだけで、外に出ていけないような人間じゃあ、
後藤氏なみの情報なんて得られないでしょw
後藤氏なみの情報なんて得られないでしょw
>>23
ゴトゥに何期待してるんだよw
ゴトゥに何期待してるんだよw
>>23
後藤の記事じゃないが、インプレスの記事のRadix-16 dividerの翻訳が酷い
http://pc.watch.impress.co.jp/docs/2007/0329/intel.htm
>「Radix 16」によりディバイダー速度を高め、命令の実行速度を向上させる
まともな翻訳
http://plusd.itmedia.co.jp/pcuser/articles/0704/02/news067.html
>基数を16にした除算器(Radix-16 divider)による高速な除算
後藤の記事じゃないが、インプレスの記事のRadix-16 dividerの翻訳が酷い
http://pc.watch.impress.co.jp/docs/2007/0329/intel.htm
>「Radix 16」によりディバイダー速度を高め、命令の実行速度を向上させる
まともな翻訳
http://plusd.itmedia.co.jp/pcuser/articles/0704/02/news067.html
>基数を16にした除算器(Radix-16 divider)による高速な除算
>>23
どこの小学生だよw
どこの小学生だよw
いや>23はかなりできておる。
セグメントとフォームファクタはそのままでも良いと思うけどネ!
セグメントとフォームファクタはそのままでも良いと思うけどネ!
>>45
つか別にそこまで糞丁寧に訳さなくても分かるじゃん・・・
つか別にそこまで糞丁寧に訳さなくても分かるじゃん・・・
まあなんだかんだ言って後藤が気になるからこのスレにいるんだしな
別に後藤は嘘を書いてるわけじゃないのにね。
GPUのfoldingが一番パフォーマンス高いってのも明らかになったしな
CTMすら、使わないで
ようは、使い方しだい
むいてる使い方をすれば良い。
まぁ、それもGPUしだいか?
CTMすら、使わないで
ようは、使い方しだい
むいてる使い方をすれば良い。
まぁ、それもGPUしだいか?
「後藤がAMDを擁護してる」という先入観で目が曇ってるんだからしょうがないよ
使い方次第なのにGPUが統合されるのは自然な流れであるかのように書き連ねるのは不自然な気が
全ては、文章や図をい〜っぱいかくことができる
お花畑テクノロジーをネタに、原稿料を稼ぐため。
だからその都度、特定の企業を擁護しているように
感じてしまう時もあるが、それはあくまでも演出の一環。
お花畑テクノロジーをネタに、原稿料を稼ぐため。
だからその都度、特定の企業を擁護しているように
感じてしまう時もあるが、それはあくまでも演出の一環。
>>51
実際自然な流れだから。
ビデオカード販売数は年々減少しチップセット統合VGAのみ増えてるという現実。
プロセス更新ごとに倍々で増やせるトランジスタ数、
その全てをホモマルチに費やすなど非効率すぎ。
ホモマルチのまま行けると思ってる奴なんているのか?
実際自然な流れだから。
ビデオカード販売数は年々減少しチップセット統合VGAのみ増えてるという現実。
プロセス更新ごとに倍々で増やせるトランジスタ数、
その全てをホモマルチに費やすなど非効率すぎ。
ホモマルチのまま行けると思ってる奴なんているのか?
命令レベルでの統合前提で話してるのかと思ってたのだけど…
Intelは当面GMCHで稼ぐ
GPUがCPUソケット側に来てもMCMで旧世代プロセス
まずもって工場の効率運用が第一
GPUがCPUソケット側に来てもMCMで旧世代プロセス
まずもって工場の効率運用が第一
>>55
その流れ+GPGPUで解るだろ、一々言われんと想像も出来んのか。
その流れ+GPGPUで解るだろ、一々言われんと想像も出来んのか。
GPGPU妄想はかつてのメニーコア妄想、ネットバースト妄想を彷彿とさせる
>>58
無い知恵絞ってGPGPUを越える代替案を示してください。
無い知恵絞ってGPGPUを越える代替案を示してください。
http://www.geocities.jp/andosprocinfo/wadai07/20070331.htm
>メモリインタフェースは,サーバ用の4ソケット構成ではFB-DIMM,
>2ソケット構成ではDDR3,そして一般的なプロセサでは
>メモリコントローラは内蔵ではなく,現状と同様な外付けになる
>メモリインタフェースは,サーバ用の4ソケット構成ではFB-DIMM,
>2ソケット構成ではDDR3,そして一般的なプロセサでは
>メモリコントローラは内蔵ではなく,現状と同様な外付けになる
>>55
技術の実現可能性や製品について短期と中長期の区別はついてる?
中長期的に命令の統合やら演算コア化がどこまでうまくいくかは分からん。
しかし短期的にはダイの空きを埋めるためにビデオコアを突っ込むのは自然な流れ。
前者がうまく行かなかったとしても、後者の需要もコスト面でのメリットもあるから
ホモジニアスマルチコアに戻ることはない。
技術の実現可能性や製品について短期と中長期の区別はついてる?
中長期的に命令の統合やら演算コア化がどこまでうまくいくかは分からん。
しかし短期的にはダイの空きを埋めるためにビデオコアを突っ込むのは自然な流れ。
前者がうまく行かなかったとしても、後者の需要もコスト面でのメリットもあるから
ホモジニアスマルチコアに戻ることはない。
SoC・SiPの流れに巻き込まれるのか
良くも悪くもPCが小型化・家電化・コモデティ化してきた結果か
良くも悪くもPCが小型化・家電化・コモデティ化してきた結果か
>>62
長期計画でも無理だしw
長期計画でも無理だしw
AMDがやるといったらIntelもやるのです。
そういう会社。
そういう会社。
http://pc.watch.impress.co.jp/docs/2007/0122/kaigai330.htm
一方、クライアントCPUは45nm世代になると、バリューCPU向けのダイ(半導体本体)でも
4個以上の汎用CPUコアを搭載できるようになる。しかし、バリューやモバイル向けCPUを
クアッドコアにしても、消費電力効率を考えると利点は薄い。
そこで、GPUコアを統合することが、半導体技術的にも合理的となる。
おまえら後藤の文章を鵜呑みにしすぎ。45nmプロセスで後藤の言うように
バリューやモバイル向けCPUでGPU統合が必要なほどダイサイズに余裕があるか
http://pc.watch.impress.co.jp/docs/2007/0206/kaigai_3.jpg
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_02l.gif
よく見てみろや。
一方、クライアントCPUは45nm世代になると、バリューCPU向けのダイ(半導体本体)でも
4個以上の汎用CPUコアを搭載できるようになる。しかし、バリューやモバイル向けCPUを
クアッドコアにしても、消費電力効率を考えると利点は薄い。
そこで、GPUコアを統合することが、半導体技術的にも合理的となる。
おまえら後藤の文章を鵜呑みにしすぎ。45nmプロセスで後藤の言うように
バリューやモバイル向けCPUでGPU統合が必要なほどダイサイズに余裕があるか
http://pc.watch.impress.co.jp/docs/2007/0206/kaigai_3.jpg
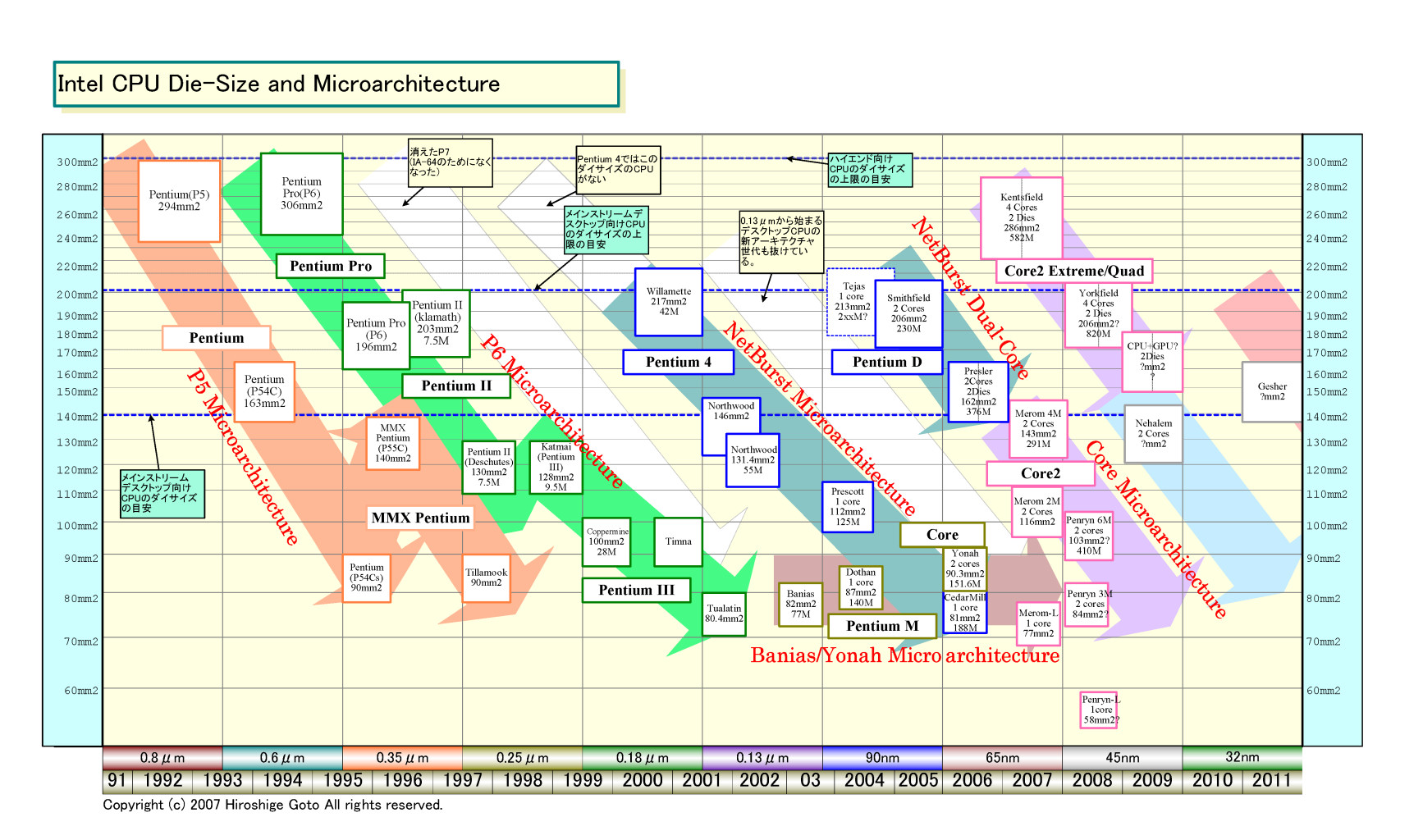{kind=link}
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai_02l.gif
{kind=link}
よく見てみろや。
やると言っても出来ない、というか論理的に矛盾してるからどんなに頑張っても不可能。
CPUがCPUである為にステップレベルのフロー制御を可能とした論理構造が採用されている。
これにより汎用性は最大化されている。
しかしその結果、並列処理を優先した構造にはなっていないというか出来ない。
GPUがGPUである為に、並列処理で最高のパフォーマンスになる構造を採用している。
並列度は必要な解像度(ポリゴン/オブジェクト数含む、効果演算含む)により変化するので、
その時代のトレンドに応じた解像度を処理出来るように設計される。
しかし並列処理を優先した構造であることからフロー制御は細かくすることが出来ない。
例えば、最も細かなフロー制御はステップ単位である・・・
1命令毎にフロー制御が可能ということは1サイクル単位で並列処理の各パイプへの命令供給とデータ供給が行える構造である必要があり、
しかも各命令やデータ間の依存関係を全て理解したうえで配置する強力なスケジューラを必要とする。
とするとこのスケジューラが最も高速な動作速度を要求されていることになるから、スケジューラの性能でパイプ数と最大実クロックが決まる。
パイプ数を増やせば、増やすほど実クロックは低下し、パイプ数を減らせば減らすほど実クロックは高速へと変化、1パイプのときに最高となる。
つまり、ステップ単位にフロー制御を行う構造にしてしまうと並列化数の上限は実クロックとのトレードオフとなり、並列度を上げれば上げるほど
実クロックは下がってしまう。
GPUに求められる性能はステップ単位にフロー制御を行う構造下で実現することは不可能。(性能が低過ぎるから)
そこでフロー制御の粒度をグンと上げ、並列演算に適した命令群やデータのみを扱うことを前提に設計することになる。
そうすることで、スケジューラを簡素化し命令やデータも並列処理を前提としたアクセスに特化することで全体としての処理速度を上げ、
並列処理時の処理性能を高めている。
CPUがCPUである為にステップレベルのフロー制御を可能とした論理構造が採用されている。
これにより汎用性は最大化されている。
しかしその結果、並列処理を優先した構造にはなっていないというか出来ない。
GPUがGPUである為に、並列処理で最高のパフォーマンスになる構造を採用している。
並列度は必要な解像度(ポリゴン/オブジェクト数含む、効果演算含む)により変化するので、
その時代のトレンドに応じた解像度を処理出来るように設計される。
しかし並列処理を優先した構造であることからフロー制御は細かくすることが出来ない。
例えば、最も細かなフロー制御はステップ単位である・・・
1命令毎にフロー制御が可能ということは1サイクル単位で並列処理の各パイプへの命令供給とデータ供給が行える構造である必要があり、
しかも各命令やデータ間の依存関係を全て理解したうえで配置する強力なスケジューラを必要とする。
とするとこのスケジューラが最も高速な動作速度を要求されていることになるから、スケジューラの性能でパイプ数と最大実クロックが決まる。
パイプ数を増やせば、増やすほど実クロックは低下し、パイプ数を減らせば減らすほど実クロックは高速へと変化、1パイプのときに最高となる。
つまり、ステップ単位にフロー制御を行う構造にしてしまうと並列化数の上限は実クロックとのトレードオフとなり、並列度を上げれば上げるほど
実クロックは下がってしまう。
GPUに求められる性能はステップ単位にフロー制御を行う構造下で実現することは不可能。(性能が低過ぎるから)
そこでフロー制御の粒度をグンと上げ、並列演算に適した命令群やデータのみを扱うことを前提に設計することになる。
そうすることで、スケジューラを簡素化し命令やデータも並列処理を前提としたアクセスに特化することで全体としての処理速度を上げ、
並列処理時の処理性能を高めている。
>>60
単純にGPUをCPUの近くに持っていくだけではコストダウンにならんからね。
メモコンもCPU側に持つとして、それ以外のMCHの機能をICH側に統合しなくてはいけない。
CPUが45nm、ICHを65nmで作るとして、余った90nmの工場、どうする?
単純にGPUをCPUの近くに持っていくだけではコストダウンにならんからね。
メモコンもCPU側に持つとして、それ以外のMCHの機能をICH側に統合しなくてはいけない。
CPUが45nm、ICHを65nmで作るとして、余った90nmの工場、どうする?
おんなじパッケージつかウェハー内にCPUとGPU入れたとして、
クロックの差はどうすんだろ
45nmはコア毎にクロック変更出来るみたいだけどその応用で出来る?
クロックの差はどうすんだろ
45nmはコア毎にクロック変更出来るみたいだけどその応用で出来る?
できるだろ。
PLLを複数配置すればいいだけだし。
実際Barcelonaはコア毎にクロックを動的に変更できるし、コア部とノース+L3部は動作クロックが違う。
PLLを複数配置すればいいだけだし。
実際Barcelonaはコア毎にクロックを動的に変更できるし、コア部とノース+L3部は動作クロックが違う。
Pentium4の倍速ALUを忘れたのか?
nVIDIAのG80もshaderはクロック違う。
上の方では何でもかんでもGPUにやらす
みたいな事いうし。
特定用途向けだってのに・・・
現状のR580程度の粒度でもFolding@Homeで
それなりのパフォーマンス出してるんだから・・・
nVIDIAのG80もshaderはクロック違う。
上の方では何でもかんでもGPUにやらす
みたいな事いうし。
特定用途向けだってのに・・・
現状のR580程度の粒度でもFolding@Homeで
それなりのパフォーマンス出してるんだから・・・
>>69
MCHの機能なんてメモコン、FSB、PCIEだけだから、PCIEをICHをもっていくことになるな。
そのころの90nmの工場は次の世代へ転換されていくと思うよ。
>>70
クロックドメインを分けるのはたやすいがVcoreは共用になるのんじゃないかな・・・
Intelもバリュー向けといってるからコスト高なDualVRMはやらないでしょう。
>>72
たぶん>>68は方向を間違えていると思うね・・・
ちょっと曲がるだけなのに90度曲がってる感じ。
というか、後藤&AMDのCPUとGPUの密な統合の妄想に付き合ってるだけ?
>>67
Penryn3Mだと84平方mmだし、ダイ写真をみてもちょっと余裕がある感じだから、
RADEON9600クラスなら乗っけられるんじゃないか?
まぁ、実際に統合するのははUnifiedShaderだろうが。
CSIに移行したとき、メモコンをノースに内蔵するとICHかCPUにGPUをくっつけないといけないわけだから、
それを考えるとCPU側が有利なのは間違いない。
ダイサイズに余裕(まぁ余裕だが)、というよりどっちかに統合するならCPUのほうがいいという程度かと。
MCHの機能なんてメモコン、FSB、PCIEだけだから、PCIEをICHをもっていくことになるな。
そのころの90nmの工場は次の世代へ転換されていくと思うよ。
>>70
クロックドメインを分けるのはたやすいがVcoreは共用になるのんじゃないかな・・・
Intelもバリュー向けといってるからコスト高なDualVRMはやらないでしょう。
>>72
たぶん>>68は方向を間違えていると思うね・・・
ちょっと曲がるだけなのに90度曲がってる感じ。
というか、後藤&AMDのCPUとGPUの密な統合の妄想に付き合ってるだけ?
>>67
Penryn3Mだと84平方mmだし、ダイ写真をみてもちょっと余裕がある感じだから、
RADEON9600クラスなら乗っけられるんじゃないか?
まぁ、実際に統合するのははUnifiedShaderだろうが。
CSIに移行したとき、メモコンをノースに内蔵するとICHかCPUにGPUをくっつけないといけないわけだから、
それを考えるとCPU側が有利なのは間違いない。
ダイサイズに余裕(まぁ余裕だが)、というよりどっちかに統合するならCPUのほうがいいという程度かと。
CPU+GPUについては両方が作るといってるならもう現物勝負だな
AMDにある商品がIntelに無いというのはIntelの社風から考えるとあってはならないことだから
AMDがGPU統合するよといったらIntelもとりあえず作るだろ
失敗してもIntelにとっては大した傷にならないし
AMDの場合は致命傷になりかねないのが悩ましいw
AMDがGPU統合するよといったらIntelもとりあえず作るだろ
失敗してもIntelにとっては大した傷にならないし
AMDの場合は致命傷になりかねないのが悩ましいw
DOS/V PowerReportだかを立ち読みしていてんだが(記事はもちろん我らがgoto)
CPUとGPUは今後急速に違いが無くなっていって、10年後にはGPUはCPUの構成要素その1に埋没するって
断定口調で書いてあったぞ。
CPUとGPUは今後急速に違いが無くなっていって、10年後にはGPUはCPUの構成要素その1に埋没するって
断定口調で書いてあったぞ。
>>62 >>76
> 中長期的に命令の統合やら演算コア化
> GPUはCPUの構成要素その1に埋没する
これを別の視点で見ると
「SSEを強化拡張してグラフィック処理できるようにする」
そう考えると実にバカらしい話
> 中長期的に命令の統合やら演算コア化
> GPUはCPUの構成要素その1に埋没する
これを別の視点で見ると
「SSEを強化拡張してグラフィック処理できるようにする」
そう考えると実にバカらしい話
>>66
それは真理だな。つかそれでこそIntelだし。
それは真理だな。つかそれでこそIntelだし。
SSEとGPGPUは別物だってAMD自身が言ってます。
教祖と占い師とスピリチュアルカウンセラーと電波ライターの言うことは絶対です
リアルタイムで高度なレイトレができるようになるまでのつなぎだし。
82 :Socket774:2007/04/06(金) 02:44:01 ID:GCY83iHF
ゴトウに限らず、GPU統合と、64bit命令との関連あるいは競合について書いてる記事ってある?
>82 「64bit」の言葉は出てきていないが
http://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
【GPU命令のx86体系への統合】
Hester@AMD「x86のユーザーモード命令セットフォーマットには、
まだ十分なオペコードポイントが残されている。
エクステンションで、命令を加えることが可能だ。
また、命令デコーダは現状でもすでに複雑だ。だから、
さらに複雑性を加えても、比較的小さい変化でしかない。(後略)」
(チラシの裏)
AMD64が「プレフィクス+新規のまともな命令体系」だったらなぁ…
http://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
【GPU命令のx86体系への統合】
Hester@AMD「x86のユーザーモード命令セットフォーマットには、
まだ十分なオペコードポイントが残されている。
エクステンションで、命令を加えることが可能だ。
また、命令デコーダは現状でもすでに複雑だ。だから、
さらに複雑性を加えても、比較的小さい変化でしかない。(後略)」
(チラシの裏)
AMD64が「プレフィクス+新規のまともな命令体系」だったらなぁ…
> というか、後藤&AMDのCPUとGPUの密な統合の妄想に付き合ってるだけ?
あい、妄想に付き合ってるだけです。
究極の妄想というか、両者の特徴を殺し腐ったCPUを開発することが目標らしいので笑えるのだけども、
後藤の巧みな言い回しに騙されそれが実現可能だと思い込んでいる奴が哀れなので少し書いてみた。
77さんが書いているように、後藤&AMDの妄想の終点は「SSEを強化拡張してグラフィック処理できるようにする」に行き着く。
SSEユニットを拡張し1サイクルで数百の同時演算を行えるようにする気なんじゃないかな?
1命令で数百のデータを予めその命令が処理可能な固有配列構造として読み込み一気に演算する。
1つの演算回路では実現不能だろうから演算回路は並列化し数十回路を内包する感じだろう。
しかし、そのようなものは実際のところ実現不可能。
そもそも、「その命令が処理可能な固有配列構造」であることからして汎用性を失っており、尚且つそれほどに大きなデータを
1サイクルで供給する等は不可能、効率的にメモリから読み込むにしてもメモリ側のチューニングも必要だろうし、
そのチューニングは必ず代償を伴う。
結局全てがバラ色の回路など存在しない、特徴を殺せば殺すほど特徴を活かしたものより性能は劣化する。
CPUとしても遅く、GPUとしても遅い品物にしかならねぇ。
あい、妄想に付き合ってるだけです。
究極の妄想というか、両者の特徴を殺し腐ったCPUを開発することが目標らしいので笑えるのだけども、
後藤の巧みな言い回しに騙されそれが実現可能だと思い込んでいる奴が哀れなので少し書いてみた。
77さんが書いているように、後藤&AMDの妄想の終点は「SSEを強化拡張してグラフィック処理できるようにする」に行き着く。
SSEユニットを拡張し1サイクルで数百の同時演算を行えるようにする気なんじゃないかな?
1命令で数百のデータを予めその命令が処理可能な固有配列構造として読み込み一気に演算する。
1つの演算回路では実現不能だろうから演算回路は並列化し数十回路を内包する感じだろう。
しかし、そのようなものは実際のところ実現不可能。
そもそも、「その命令が処理可能な固有配列構造」であることからして汎用性を失っており、尚且つそれほどに大きなデータを
1サイクルで供給する等は不可能、効率的にメモリから読み込むにしてもメモリ側のチューニングも必要だろうし、
そのチューニングは必ず代償を伴う。
結局全てがバラ色の回路など存在しない、特徴を殺せば殺すほど特徴を活かしたものより性能は劣化する。
CPUとしても遅く、GPUとしても遅い品物にしかならねぇ。
85 :Socket774:2007/04/06(金) 08:04:39 ID:TWsOekFp
はいはい、流石その通り
国内プログラマには、元々無縁
オイテケボリ
国内プログラマには、元々無縁
オイテケボリ
ベクトル演算機をCPUに統合するGPUの替わりにも使えるなる
…という程度の話じゃないの?
実装面積や部品点数減らしたいモバイルノートPCやローエンドPC
普段はディスプレイつなげないブレード(ラック)サーバーにはいいと思う
…という程度の話じゃないの?
実装面積や部品点数減らしたいモバイルノートPCやローエンドPC
普段はディスプレイつなげないブレード(ラック)サーバーにはいいと思う
そもそも代償を伴わない拡張など存在しないのだが、何でこんなに必死なの?
>77さんが書いているように、後藤&AMDの妄想の終点は「SSEを強化拡張してグラフィック処理できるようにする」に行き着く。
行き着きません。
終了〜
行き着きません。
終了〜
>>86
一行目の意味がよくわからんのでkwsk
一行目の意味がよくわからんのでkwsk
後藤はAMDのセールストークに利用されてるだけ。
>66
>78
AMD側が主張するメリットを全て無にする似て非なる非互換製品をばらまいて
AMDがやることをスタンダードにされることは絶対に阻止するでしょう。
将来的なビジョンなんかなくったっていいんです。
x86-64で失敗したから今回はわりと早く手を打ってきてるように思う。
>78
AMD側が主張するメリットを全て無にする似て非なる非互換製品をばらまいて
AMDがやることをスタンダードにされることは絶対に阻止するでしょう。
将来的なビジョンなんかなくったっていいんです。
x86-64で失敗したから今回はわりと早く手を打ってきてるように思う。
>>83
AMD64の仕様を知ったときの大原の嘆きを思い出す。
AMD64の仕様を知ったときの大原の嘆きを思い出す。
チューニングの結果として従来型の仕事が遅くなったとしても
従来型CPUコアを2個ばかり突っ込んどいて既存の処理はそっちにやらせればいいんでは?
従来型の仕事でもっと性能が必要でマルチコアが効かないなんてものがあれば別だが。
既存のGPU的処理を高速にやりたいなら従来型GPUを拡張スロットに差せ。
従来型CPUコアを2個ばかり突っ込んどいて既存の処理はそっちにやらせればいいんでは?
従来型の仕事でもっと性能が必要でマルチコアが効かないなんてものがあれば別だが。
既存のGPU的処理を高速にやりたいなら従来型GPUを拡張スロットに差せ。
われらがカーマック元帥も「既存のハイエンドGPUで十分。これ以上速いものは必要ない」
みたいなことを言っているから、別に大丈夫じゃね>FusionのGPUの性能
みたいなことを言っているから、別に大丈夫じゃね>FusionのGPUの性能
Radeonを物理演算器として使うデモとかやってたから、
Fusionのやつはそれに使って廃スペック外付けGPUは別に買えばいいんじゃね。
Fusionのやつはそれに使って廃スペック外付けGPUは別に買えばいいんじゃね。
>>67
Brisbaneの256KB×2版を作ると110平方mm台。
これをシュリンクすればオンボードクラスのビデオコアを入れても
バリューセグメントのダイサイズ(100平方mm以下)に収まるだろ。
Brisbaneの256KB×2版を作ると110平方mm台。
これをシュリンクすればオンボードクラスのビデオコアを入れても
バリューセグメントのダイサイズ(100平方mm以下)に収まるだろ。
ID:mM0sM3VR
お前以前L3搭載するとL3無しより性能低下するって言ってたアホだろww
お前以前L3搭載するとL3無しより性能低下するって言ってたアホだろww
偶然にもたった今帰宅。
>>99
読んだ。ってかその記事は当然知ってる。
で、どこに将来的にSSEがグラフィック機能をカバーする、あるいはGPUコアがSSEをカバーすると書いてあるんだ?
普通に考えれば、GPUが統合されても現状のSSEとGPUコアは並列に存在するだろ。
>>99
読んだ。ってかその記事は当然知ってる。
で、どこに将来的にSSEがグラフィック機能をカバーする、あるいはGPUコアがSSEをカバーすると書いてあるんだ?
普通に考えれば、GPUが統合されても現状のSSEとGPUコアは並列に存在するだろ。
実際DX8以降はそれぞれの前世代に対して
トランジスタあたりのパフォーマンス効率は悪くなってるのよ。
理由はShader搭載のため。
ならなんでShaderなんか載せてるんだって言えば
固定機能でDX9までの表現やDX10以降の表現させる機能をのせてしまったら
更に効率が悪いからだ。
(っていうか無理だろうな。どんな表現にするかはプログラマしだいだから)
前世代に対してトランジスタあたりのパフォーマンス効率が悪くなるのは
今後も同じだ。
いわゆるFPSが量的指標なら表現の複雑さは質的な指標と言える。
そのバランスをどう取るかはGPUメーカーしだい。
トランジスタあたりのパフォーマンス効率は悪くなってるのよ。
理由はShader搭載のため。
ならなんでShaderなんか載せてるんだって言えば
固定機能でDX9までの表現やDX10以降の表現させる機能をのせてしまったら
更に効率が悪いからだ。
(っていうか無理だろうな。どんな表現にするかはプログラマしだいだから)
前世代に対してトランジスタあたりのパフォーマンス効率が悪くなるのは
今後も同じだ。
いわゆるFPSが量的指標なら表現の複雑さは質的な指標と言える。
そのバランスをどう取るかはGPUメーカーしだい。
>>101
お前全然理解してねぇな。
解説編だ、読め。
ttp://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
> AMDは、どうせGPU命令セットを露出させるなら、x86のベースフォーマットの中に、
> ユーザーモードの拡張命令として組み込もうというビジョンを持っているようだ。
> 「GPU機能を統合するなら、人々は(GPUコアに)もっとスタンダードな方法でアクセスしたいと考えるだろう。
> そこで、GPU機能を、ユーザーモード命令セットとして、適切にビジブルにすることができると思う。
> ビジブルなGPU命令を一貫性を持って将来にも提供する。それによって、x86アーキテクチャを、
> 32-bitから64-bitへの前進の時と同じような方法で、前進させることができると私は信じている」(Hester氏)
これから見ても後藤とAMDの妄想は、GPU回路をCPUの内部ユニットとして密結合する思想を持つ。
言わばAMD風SSE回路拡張強化版だ。
お前全然理解してねぇな。
解説編だ、読め。
ttp://pc.watch.impress.co.jp/docs/2007/0228/kaigai341.htm
> AMDは、どうせGPU命令セットを露出させるなら、x86のベースフォーマットの中に、
> ユーザーモードの拡張命令として組み込もうというビジョンを持っているようだ。
> 「GPU機能を統合するなら、人々は(GPUコアに)もっとスタンダードな方法でアクセスしたいと考えるだろう。
> そこで、GPU機能を、ユーザーモード命令セットとして、適切にビジブルにすることができると思う。
> ビジブルなGPU命令を一貫性を持って将来にも提供する。それによって、x86アーキテクチャを、
> 32-bitから64-bitへの前進の時と同じような方法で、前進させることができると私は信じている」(Hester氏)
これから見ても後藤とAMDの妄想は、GPU回路をCPUの内部ユニットとして密結合する思想を持つ。
言わばAMD風SSE回路拡張強化版だ。
>>103
AMDのマイクロアーキはCoreMAと違ってALUとFPUでパイプラインが分かれてる。
統合されたGPUも、デコード段は共用だけどパイプラインはFPUなんかとは別になるでしょ。
もっともデータキャッシュの方はどうなるかわからんけど。
密結合ってのがどの程度を想像してるのかわからんけど、既存のユニットの性格が変わら
ないなら、性格の異なるユニットが統合されても問題ないでしょ。
GPUの方はトランジスタ効率は落ちてくるかもしれないけどね。
でもそれは>>102の言うように汎用性を求めるためには受け入れざるを得ないトレードオフ。
AMDのマイクロアーキはCoreMAと違ってALUとFPUでパイプラインが分かれてる。
統合されたGPUも、デコード段は共用だけどパイプラインはFPUなんかとは別になるでしょ。
もっともデータキャッシュの方はどうなるかわからんけど。
密結合ってのがどの程度を想像してるのかわからんけど、既存のユニットの性格が変わら
ないなら、性格の異なるユニットが統合されても問題ないでしょ。
GPUの方はトランジスタ効率は落ちてくるかもしれないけどね。
でもそれは>>102の言うように汎用性を求めるためには受け入れざるを得ないトレードオフ。
>>104
> でもそれは>>102の言うように汎用性を求めるためには受け入れざるを得ないトレードオフ。
だからそこがそもそも間違っているんだよ。
そこをトレードオフとするなら行き着く先は>84、全然使い物にならねぇ代物だぜ。
そしてAMDや後藤が騙していることはそれ、あたかも小さな犠牲で大きな成果があるような論調だ。
しかしそれは物理的に無理、汎用性を犠牲にしフロー制御を犠牲にすることで並列動作を可能としその結果の高速性能なんだよ。
そもそも、GPUが超並列で高速化出来るのも多くの頂点が存在し、それぞれの演算式が同じでデータのみが異なる性質を持つからだし、
物理演算に付いてもGPUのそれは、無数にあるオブジェクトの物理動作を並行で演算しているに過ぎず、それもまた演算式は同じで、
データのみが異なる性質だからこそだ。
このように超並列化での高速化は最初から(同じ構造のものを複数)という制約が伴う訳で汎用性等は元からない。
それをさも両立出来るかの如く素人を誤魔化すのは見ていて腹立たしい。
> でもそれは>>102の言うように汎用性を求めるためには受け入れざるを得ないトレードオフ。
だからそこがそもそも間違っているんだよ。
そこをトレードオフとするなら行き着く先は>84、全然使い物にならねぇ代物だぜ。
そしてAMDや後藤が騙していることはそれ、あたかも小さな犠牲で大きな成果があるような論調だ。
しかしそれは物理的に無理、汎用性を犠牲にしフロー制御を犠牲にすることで並列動作を可能としその結果の高速性能なんだよ。
そもそも、GPUが超並列で高速化出来るのも多くの頂点が存在し、それぞれの演算式が同じでデータのみが異なる性質を持つからだし、
物理演算に付いてもGPUのそれは、無数にあるオブジェクトの物理動作を並行で演算しているに過ぎず、それもまた演算式は同じで、
データのみが異なる性質だからこそだ。
このように超並列化での高速化は最初から(同じ構造のものを複数)という制約が伴う訳で汎用性等は元からない。
それをさも両立出来るかの如く素人を誤魔化すのは見ていて腹立たしい。
汎用性とのトレードオフってのはもちろんGPUに対してのみ言ったこと。
そしてGPUでの汎用性って言っても別にSSE並の汎用性を求めてるわけじゃないぞ。
まあ現状のGPGPUと大きくは違わないだろう。
汎用性という言葉を勘違いしてるだけじゃないか?
そしてGPUでの汎用性って言っても別にSSE並の汎用性を求めてるわけじゃないぞ。
まあ現状のGPGPUと大きくは違わないだろう。
汎用性という言葉を勘違いしてるだけじゃないか?
ちなみに後藤も
http://pc.watch.impress.co.jp/docs/2007/0326/kaigai346.htm
> 「フィロソフィとしては、我々は比較的シンプルなコードをより速く走らせ、その一方で、
> より複雑なコードについては、やや非効率でもいいと判断した。
> (略)」
>
> つまり、GPUは動的に分岐が多発するような複雑なコードは、やや非効率で構わない。
> 犠牲を払ってそこを速くするよりも、シンプルなコードが速く走るように最適化した方がい
> いと判断しているわけだ。GPUは、あくまでも、多くのデータに同一の処理を行なうことに
> 最適化した、データパラレルプロセッサの枠にある。
とちゃんと書いてる。
http://pc.watch.impress.co.jp/docs/2007/0326/kaigai346.htm
> 「フィロソフィとしては、我々は比較的シンプルなコードをより速く走らせ、その一方で、
> より複雑なコードについては、やや非効率でもいいと判断した。
> (略)」
>
> つまり、GPUは動的に分岐が多発するような複雑なコードは、やや非効率で構わない。
> 犠牲を払ってそこを速くするよりも、シンプルなコードが速く走るように最適化した方がい
> いと判断しているわけだ。GPUは、あくまでも、多くのデータに同一の処理を行なうことに
> 最適化した、データパラレルプロセッサの枠にある。
とちゃんと書いてる。
Cellで浮名を馳せた電波芸者誤荅の信者が集うスレはここですね
ちょっと古い話になるけど、
バーテックスシェーダ非内蔵型GMCHでCPU側がソフトウェア処理する場合って、
どれくらいの並列度の演算をどの程度の負荷で行ってたの?
バーテックスシェーダ非内蔵型GMCHでCPU側がソフトウェア処理する場合って、
どれくらいの並列度の演算をどの程度の負荷で行ってたの?
>>106-107
だから矛盾しているんだよ。
あからさまに、妄想を書き連ねると騙せなくなるから、所々で注意や言い訳を書いてある。
その上で103を書くと錯覚し騙される。
そして騙されたアム信徒は自作板で騒ぎ出す > 迷惑なことだ。
で、結論から言えば後藤やAMDが言ってるのは殆ど妄想の世界、現実には汎用性は殆ど得られない。
これは宿命というか常識、半端に信用しちゃダメってことです。
だから矛盾しているんだよ。
あからさまに、妄想を書き連ねると騙せなくなるから、所々で注意や言い訳を書いてある。
その上で103を書くと錯覚し騙される。
そして騙されたアム信徒は自作板で騒ぎ出す > 迷惑なことだ。
で、結論から言えば後藤やAMDが言ってるのは殆ど妄想の世界、現実には汎用性は殆ど得られない。
これは宿命というか常識、半端に信用しちゃダメってことです。
結局満足な反論もできないのかよw
ID:mM0sM3VRは自分の読解力の無さを棚に上げて、勝手に妄想を膨らまして喚いてるだけw
いい迷惑だよまったく
ID:mM0sM3VRは自分の読解力の無さを棚に上げて、勝手に妄想を膨らまして喚いてるだけw
いい迷惑だよまったく
> 結局満足な反論もできないのかよw
論理矛盾を起こしているのは後藤でありAMDw
これ常識。
論理矛盾を起こしているのは後藤でありAMDw
これ常識。
>>112
どうあってもその結論じゃなくちゃいけないから、満足な反論もできずに知ってる単語並べるだけの淫厨がmM0sM3VRってこと?
どうあってもその結論じゃなくちゃいけないから、満足な反論もできずに知ってる単語並べるだけの淫厨がmM0sM3VRってこと?
ID:mM0sM3VRの言いたいことはわかるから、落ち着け
なぜそこまで必死なのだろうか?
売れてないライターさんか
それとも世界の流れから取り残されている日本製3Dゲー関連の人かな?
売れてないライターさんか
それとも世界の流れから取り残されている日本製3Dゲー関連の人かな?
よくわからないんだけど
>現実には汎用性は殆ど得られない。
これ前例が既にあるってことだよね?
>現実には汎用性は殆ど得られない。
これ前例が既にあるってことだよね?
>>117
数学的に証明済みだよ。
数学的に証明済みだよ。
>>118
数学的wwww
数学的wwww
http://pc.watch.impress.co.jp/docs/2004/1115/kaigai134.htm
【Q】 GPUを汎用コンピューティングに使おうという動きがある。
汎用GPUと呼ばれている動きで、今年前半はこの話題が大きく盛り上がった。
IntelはCPUメーカーとして、こうした動きをどう見ているのか。
【Gelsinger】 確かに、グラフィックスパイプラインは、非常に高パフォーマン
スな浮動小数点ユニットを備えている。だから、人々がそれを利用することに
関心を寄せるのは不思議ではない。しかし、こうしたパイプラインをプログラム
することは非常に難しい。なぜなら、割り込みやメモリアクセスの汎用的な
モデルを持っていないからだ。興味深い研究は行なわれているものの、実際
にグラフィックスプロセッサを使うアプリケーションは非常に少ないと思う。
一般的に言って、GPUをもっと汎用にする、つまりGPUの中にCPUを作り
出すようなこともできないだろう。なぜなら、CPUは高度にプログラマブルで、
優れたコンパイラのサポートがあり、長期にわたって(プログラム性を)チューン
されてきた。NVIDIAなどが語る汎用コンピューティングへのビジョンは楽し
いが、しかし、幅広いアプリケーションが対応するとは考えていない。また、
我々も、マルチコア、メニーコア(Many-Core)に向かいパフォーマンスを高める。
そして、CPUはずっとプログラム効率がよい。
【Q】 GPUを汎用コンピューティングに使おうという動きがある。
汎用GPUと呼ばれている動きで、今年前半はこの話題が大きく盛り上がった。
IntelはCPUメーカーとして、こうした動きをどう見ているのか。
【Gelsinger】 確かに、グラフィックスパイプラインは、非常に高パフォーマン
スな浮動小数点ユニットを備えている。だから、人々がそれを利用することに
関心を寄せるのは不思議ではない。しかし、こうしたパイプラインをプログラム
することは非常に難しい。なぜなら、割り込みやメモリアクセスの汎用的な
モデルを持っていないからだ。興味深い研究は行なわれているものの、実際
にグラフィックスプロセッサを使うアプリケーションは非常に少ないと思う。
一般的に言って、GPUをもっと汎用にする、つまりGPUの中にCPUを作り
出すようなこともできないだろう。なぜなら、CPUは高度にプログラマブルで、
優れたコンパイラのサポートがあり、長期にわたって(プログラム性を)チューン
されてきた。NVIDIAなどが語る汎用コンピューティングへのビジョンは楽し
いが、しかし、幅広いアプリケーションが対応するとは考えていない。また、
我々も、マルチコア、メニーコア(Many-Core)に向かいパフォーマンスを高める。
そして、CPUはずっとプログラム効率がよい。
122 :Socket774:2007/04/06(金) 21:59:49 ID:LZStKVY7
CPUなんてもう古臭いよw
GPUなんてもうとっくに7億トランジスタ越えw
メモリバンド幅もミドルエンドでもCPUの倍以上、ハイエンドはR600でとうとう180GB/secまで逝ったw
ダイの半分以上をカスSRAM(笑)で埋めてるCPUなんぞに未来はないよw
GPUなんてもうとっくに7億トランジスタ越えw
メモリバンド幅もミドルエンドでもCPUの倍以上、ハイエンドはR600でとうとう180GB/secまで逝ったw
ダイの半分以上をカスSRAM(笑)で埋めてるCPUなんぞに未来はないよw
124 :Socket774:2007/04/06(金) 22:10:54 ID:gzfmJ3go
くそもらし
ウンコー●●●
>>122
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=197006580
IBM 「今日、メモリはMPUの3/4の領域を占めますが、2010年までには9割を占めるようになるでしょう。」
http://www.eetimes.com/news/latest/showArticle.jhtml?articleID=197006580
IBM 「今日、メモリはMPUの3/4の領域を占めますが、2010年までには9割を占めるようになるでしょう。」
> MSがGPGPUに利点を見出せば
心配するな、ありえねぇからw
心配するな、ありえねぇからw
MSはGPGPUに利点を見出てるだろ。
ふつーにやる気あるしVistaでは早速使ってるし。
ありえねぇのはCPUとGPUのx86命令レベルでの統合だろ…
ふつーにやる気あるしVistaでは早速使ってるし。
ありえねぇのはCPUとGPUのx86命令レベルでの統合だろ…
質問に質問で返し
前提条件の仮定をまず否定する
相手にするなよ
前提条件の仮定をまず否定する
相手にするなよ
> MSはGPGPUに利点を見出てるだろ。
> ふつーにやる気あるしVistaでは早速使ってるし。
こけGPGPUじゃねぇし、単にGPUの仮想化だしさ。
> ありえねぇのはCPUとGPUのx86命令レベルでの統合だろ…
うん、そこを俺も否定している。
> ふつーにやる気あるしVistaでは早速使ってるし。
こけGPGPUじゃねぇし、単にGPUの仮想化だしさ。
> ありえねぇのはCPUとGPUのx86命令レベルでの統合だろ…
うん、そこを俺も否定している。
x86命令での統合と言っても、要はGPUがCPUの中にある姿が自然になれば命令
レベルでの統合もおかしくないってことだろ。
デコード段だけはCPUとGPUで共通にして、その先はCPUとGPUで完全に分かれる。
そういうレベルの統合はありえなくはないでしょ。
L1キャッシュの完全共用とかはCPUの方にも負担を強いるから無理な気がするが。
速くなるソフトがあればGPUを使えばいいし、速くならないソフトがあってもグラフィック
処理をさせておけば無駄にはならない。
そういう考えでしょ。
レベルでの統合もおかしくないってことだろ。
デコード段だけはCPUとGPUで共通にして、その先はCPUとGPUで完全に分かれる。
そういうレベルの統合はありえなくはないでしょ。
L1キャッシュの完全共用とかはCPUの方にも負担を強いるから無理な気がするが。
速くなるソフトがあればGPUを使えばいいし、速くならないソフトがあってもグラフィック
処理をさせておけば無駄にはならない。
そういう考えでしょ。
>>134
統合は徐々に進むから、問題が起きれば解決するなりよけるなり
そこでやめるなりすればいいんだよね。
最近吠えてる香具師はいきなり完全な統合を妄想して
ありえないと切り捨てて賢い気分になってるようだ。
統合は徐々に進むから、問題が起きれば解決するなりよけるなり
そこでやめるなりすればいいんだよね。
最近吠えてる香具師はいきなり完全な統合を妄想して
ありえないと切り捨てて賢い気分になってるようだ。
未だx86互換を維持しつづけるCPU。
10年前に発売したVC6でも充分現役のソフトが書ける。
Cudaで書いたコードは、10年後のGPUで動くのだろうか。
長期の互換性という「縛り」を受け入れる余裕やメリットが
GPU側にあるとは思えないが…。
10年前に発売したVC6でも充分現役のソフトが書ける。
Cudaで書いたコードは、10年後のGPUで動くのだろうか。
長期の互換性という「縛り」を受け入れる余裕やメリットが
GPU側にあるとは思えないが…。
DirectX10の仕様を満たそうとするならVSとPSを敢えて分ける必要は
ないわな。
ないわな。
GPUにもx86使いそうなのはどっちかつうとIntelだわな
(メニーコア云々言ってるあたりマジでやりそうで恐いが)
つうか、GPUに関しては完全にMicrosoftが主導なわけだが
ATIやnVIDIAがDirectXの仕様を満たそうと四苦八苦してるのが現状だ。
ちなみにMicrosoftからも.netからGPGPUをやらせるための
ライブラリは公開されてたりする。
ttp://research.microsoft.com/research/downloads/Details/50ee362a-c4d7-4fe6-9018-1b7f9c1dd5dc/Details.aspx
(メニーコア云々言ってるあたりマジでやりそうで恐いが)
つうか、GPUに関しては完全にMicrosoftが主導なわけだが
ATIやnVIDIAがDirectXの仕様を満たそうと四苦八苦してるのが現状だ。
ちなみにMicrosoftからも.netからGPGPUをやらせるための
ライブラリは公開されてたりする。
ttp://research.microsoft.com/research/downloads/Details/50ee362a-c4d7-4fe6-9018-1b7f9c1dd5dc/Details.aspx
それ古いURL
こっち
ttp://research.microsoft.com/research/downloads/Details/25e1bea3-142e-4694-bde5-f0d44f9d8709/Details.aspx
こっち
ttp://research.microsoft.com/research/downloads/Details/25e1bea3-142e-4694-bde5-f0d44f9d8709/Details.aspx
一見正しいけど微妙に違うような。
キャッシュってデータの局所性を前提にしてるんじゃ?
ランダムだと意味無い気がする。
キャッシュってデータの局所性を前提にしてるんじゃ?
ランダムだと意味無い気がする。
データの局所性とアクセスのランダム性は別に相反しないのでは
それもそうか。
何かもっと大きなランダム性を思い浮かべてたけど、規則性がなけりゃ何でもランダムだな。
何かもっと大きなランダム性を思い浮かべてたけど、規則性がなけりゃ何でもランダムだな。
後藤弘茂の記事に右往左往するスレはここですか
>>136
プロセス技術は進歩し続けるから、例えば5年前に更新が停止された命令セット用に
5年前と同じ速度で処理が出来る回路(当然小さくなってる)や
5年前と同じ速度で処理が出来るエミュレータ(当然軽くなってる)を用意するってのは
充分可能だと思うよ。
当面のターゲットがオンボードビデオなら尚更。
プロセス技術は進歩し続けるから、例えば5年前に更新が停止された命令セット用に
5年前と同じ速度で処理が出来る回路(当然小さくなってる)や
5年前と同じ速度で処理が出来るエミュレータ(当然軽くなってる)を用意するってのは
充分可能だと思うよ。
当面のターゲットがオンボードビデオなら尚更。
GPUの場合ISAが固まるのは当分先の話だ
未だに急速な進歩をMicrosoftに迫られるわけだし
最低でもDX11世代(倍精度までは固まらんと思う。
Fusionも当分GPUのシーケンサの変わりに
汎用CPUコアが使われるような統合は先の話だ
ttp://www.watch.impress.co.jp/game/docs/20070311/dx11.htm
未だに急速な進歩をMicrosoftに迫られるわけだし
最低でもDX11世代(倍精度までは固まらんと思う。
Fusionも当分GPUのシーケンサの変わりに
汎用CPUコアが使われるような統合は先の話だ
ttp://www.watch.impress.co.jp/game/docs/20070311/dx11.htm
おまえらそういう厨の会話してるとオタの人が湧いてきますよ
>>134
誤答もこの程度の考えで書いてるんだろうなあ。
誤答もこの程度の考えで書いてるんだろうなあ。
後藤は、できるかどうかなんて本当はどうでもいいんだよ。
飯が食えれば。
飯が食えれば。
ションナコトイッタラサビシイヨ!
コモディティ化しつつあって価格競争だけになった世界って
もちろんメーカー側は苦しいだろうけどパワーユーザーもつまんないかと
(おいしいのは単なる道具として使う≒中身なんて知りたくもない人達だけ)
そうなるとどうしても斜めに見ちゃうPCライターの中でもナチュラルに何事も大きく書ける後藤って貴重種なのかもよ
コモディティ化しつつあって価格競争だけになった世界って
もちろんメーカー側は苦しいだろうけどパワーユーザーもつまんないかと
(おいしいのは単なる道具として使う≒中身なんて知りたくもない人達だけ)
そうなるとどうしても斜めに見ちゃうPCライターの中でもナチュラルに何事も大きく書ける後藤って貴重種なのかもよ
このスレを見ている人はこんなスレも見ています。(ver 0.20)
Cell 85 [ハード・業界]
ユー!Cellプログラミングしちゃいなよ [プログラム]
君のぞらじお 第32回 [ラジオ番組]
レズ声優 Part28 [声優総合]
x86命令の所要クロック計測スレPart3 [プログラム]
Cell 85 [ハード・業界]
ユー!Cellプログラミングしちゃいなよ [プログラム]
君のぞらじお 第32回 [ラジオ番組]
レズ声優 Part28 [声優総合]
x86命令の所要クロック計測スレPart3 [プログラム]
変態スレばかりですね
154 :Socket774:2007/04/08(日) 20:28:03 ID:ayPfxmk/
なんで多和田スレがないの?
奴の方が神過ぎるわけでして
奴の方が神過ぎるわけでして
なんちゃってCPU研究家が多いスレですね
んで、そのうち何割がコード書ける人間なんだ?
んで、そのうち何割がコード書ける人間なんだ?
>>155
コード書けるけどCPU研究家じゃないよ
コード書けるけどCPU研究家じゃないよ
CPU研究家ってもうかりますか?
CAST IN THE NAME OF GOD, YE NOT GUILTY.
どうせマルチコア化でソフトウェアにまで変革を迫るなら、
ボトルネックがDRAMが速くならないことにあるのは明らかなんだからさ、
ここをガッと高速化する路線をつきつめないもんかね。
DRAMより容量は小さくなってもレイテンシは早いメモリをメインメモリに。
メインメモリは1GBytes程度で動かす。
メインメモリ以外にDRAMを大量につみ、大容量データ領域が必要な
ソフトウェアは明示的にDRAMを使う、とかね。
DRAMでさえ標準1GBしか積んでない現行のシステムじゃまだ無理だが。
DRAMレイテンシが速くならんのにCPUだけ速くなって、結果キャッシュ
ばかり肥大化して、それでもRAMに足引っ張られてるのは馬鹿らしい。
ボトルネックがDRAMが速くならないことにあるのは明らかなんだからさ、
ここをガッと高速化する路線をつきつめないもんかね。
DRAMより容量は小さくなってもレイテンシは早いメモリをメインメモリに。
メインメモリは1GBytes程度で動かす。
メインメモリ以外にDRAMを大量につみ、大容量データ領域が必要な
ソフトウェアは明示的にDRAMを使う、とかね。
DRAMでさえ標準1GBしか積んでない現行のシステムじゃまだ無理だが。
DRAMレイテンシが速くならんのにCPUだけ速くなって、結果キャッシュ
ばかり肥大化して、それでもRAMに足引っ張られてるのは馬鹿らしい。
まずDRAMより高速で1GBも積める夢のメモリを開発してから妄想してくれ
ショウターイム!!
レイテンシ隠蔽の効果も狙ってのマルチスレッド化じゃないの?
容量・レイテンシ・帯域・・・すべてを満たすのはかなりコストの点で無理だよなあ。
159の言ってるのは「3次キャッシュを1GB積めば画期的に高速化できる」
ってのと同義だからな。
そりゃそうだw
ってのと同義だからな。
そりゃそうだw
いやいや、今では2次キャッシュで8MBだの16MBだの載せるんだよ
Windows3.1なら動くのではないだか
超高速Windowsの夢、実現して良かったな
Windows3.1なら動くのではないだか
超高速Windowsの夢、実現して良かったな
キャッシュじゃなくて、明示的に速いアドレスを指定したいということじゃない?
キャッシュは非保証じゃない。
ヒットすりゃいいけど、しないと速度ガタ落ち。
しかもこのままではCPUの面積が大部分キャッシュになってしまう。
CPUの製造はキャッシュを製造してるようなもの、
CPUを買うのはキャッシュを買ってるようなもの、
性能もメモリアクセスで大概決まる、
あまり本質的じゃないなあ、と思う。
解決方法はなんでもいいんだけど、
今のアプローチはキャッシュでなんとかしようの一点張りなのがね。
ヒットすりゃいいけど、しないと速度ガタ落ち。
しかもこのままではCPUの面積が大部分キャッシュになってしまう。
CPUの製造はキャッシュを製造してるようなもの、
CPUを買うのはキャッシュを買ってるようなもの、
性能もメモリアクセスで大概決まる、
あまり本質的じゃないなあ、と思う。
解決方法はなんでもいいんだけど、
今のアプローチはキャッシュでなんとかしようの一点張りなのがね。
>>167
>160
>160
Windows3.1のころはメインメモリ16MB、HDD300MBくらいだったから、
今のPCで動かせば、(全部キャッシュにのるので)メインメモリが超高速、ということになる。
演算が十分速くなったから、メモリアクセスが律速要因になるのは仕方が無い。
でも、1GBものメモリを高速化するのは非効率。
さらに、CELLのSPUのLSのやりくりみたいなのはプログラマに不評だから、
キャッシュで楽させるようになってるんでしょ。
マルチコアも持て余し気味だし、他にトランジスタの使い道は
分岐予測の精度向上か、データの自動プリフェッチくらいしか思いつかない。
今のPCで動かせば、(全部キャッシュにのるので)メインメモリが超高速、ということになる。
演算が十分速くなったから、メモリアクセスが律速要因になるのは仕方が無い。
でも、1GBものメモリを高速化するのは非効率。
さらに、CELLのSPUのLSのやりくりみたいなのはプログラマに不評だから、
キャッシュで楽させるようになってるんでしょ。
マルチコアも持て余し気味だし、他にトランジスタの使い道は
分岐予測の精度向上か、データの自動プリフェッチくらいしか思いつかない。
170 :Socket774:2007/04/11(水) 16:00:47 ID:OW8ENJDH
ていうか、なんでもかんでもプログラマブルになるGPUがどんどん
進化すると、将来汎用目的のCPUなんて必要あるの?
少なくともゲーム機がゲーム機として「のみ」使われるなら、イランような
気がトーシロにはする。
進化すると、将来汎用目的のCPUなんて必要あるの?
少なくともゲーム機がゲーム機として「のみ」使われるなら、イランような
気がトーシロにはする。
・ゲームにはグラフィック(とか、GPGPUの対象になるような演算)は重要だが全てではない
・餅は餅屋
ってことだ。
・餅は餅屋
ってことだ。
オンボードビデオクラスのGPUを統合しようとする直近の動きに限っては、
単にCPU1コでの性能向上に限界が見えたからマルチコア化する、そして
ついでに画面描画していない時は遊んでるGPUにも少し働いてもらおう、ぐらいの感じ
単にCPU1コでの性能向上に限界が見えたからマルチコア化する、そして
ついでに画面描画していない時は遊んでるGPUにも少し働いてもらおう、ぐらいの感じ
>169
>演算が十分速くなったから、メモリアクセスが律速要因になるのは仕方が無い。
メモリセルが速くならないのを「仕方ない」で済ませてしまうのはどんなもんか。
演算機と同じペースで高速化しろというのも暴論だが、
いつまでも変わらなくていいというのも暴論では。
もはやCPU屋はメモリ屋に全く期待してないし今後も進歩を見込んでいない。
DRAMなんて昔のマシンにおけるHDDと同じ存在。
キャッシュが昔でいうところのメインメモリ。そこだけは俺らCPU屋が責任持ってなんとかする。
という割り切りなのか。
>演算が十分速くなったから、メモリアクセスが律速要因になるのは仕方が無い。
メモリセルが速くならないのを「仕方ない」で済ませてしまうのはどんなもんか。
演算機と同じペースで高速化しろというのも暴論だが、
いつまでも変わらなくていいというのも暴論では。
もはやCPU屋はメモリ屋に全く期待してないし今後も進歩を見込んでいない。
DRAMなんて昔のマシンにおけるHDDと同じ存在。
キャッシュが昔でいうところのメインメモリ。そこだけは俺らCPU屋が責任持ってなんとかする。
という割り切りなのか。
もうメモリ全部SRAMで良いんじゃ?
メモリも1チップあたり130WくらいのTDPにすれば、もっと速くなるんじゃ?
いや、知らんけど
いや、知らんけど
>>173
メモリコントローラのCPUへの内蔵とか、出来そうなことはやってるでしょ。
レイテンシ1/10、価格10倍、のメインメモリが有ったら、買うのかい?
いや、価格10倍ですめば、スパコン用に売れるかな。
メモリコントローラのCPUへの内蔵とか、出来そうなことはやってるでしょ。
レイテンシ1/10、価格10倍、のメインメモリが有ったら、買うのかい?
いや、価格10倍ですめば、スパコン用に売れるかな。
>>172
例えばどういうアプリで?
例えばどういうアプリで?
45nmだろうが1GBなんて到底無理
ダイサイズってどのぐらい違うものなんだろ?
6倍で済むなら・・・まあ出る数が違うからコスト最優先のメインメモリにはなれないか
6倍で済むなら・・・まあ出る数が違うからコスト最優先のメインメモリにはなれないか
くそもらし
まだメガとギガの違いが分かってない馬鹿がいる
ソフトウェアが年々大量のメモリを必要とするように肥大化していく限り
メモリを速度優先で進化させる余地はなさげ。
Vistaだってメモリは大量に要求するようになったけど、CPU速度は
それほど求めてない。
ソフトウェアを進化させるのに嬉しいのは、実際のところ
CPU性能向上 < メモリアクセス速度向上 < メモリ増量
といったところか。
CPUはメモリ以上に急速に進化しても意味ないな。用途にもよるけど。
メモリを速度優先で進化させる余地はなさげ。
Vistaだってメモリは大量に要求するようになったけど、CPU速度は
それほど求めてない。
ソフトウェアを進化させるのに嬉しいのは、実際のところ
CPU性能向上 < メモリアクセス速度向上 < メモリ増量
といったところか。
CPUはメモリ以上に急速に進化しても意味ないな。用途にもよるけど。
なんでもかんでも肥大化言うなと
>>184
今のL2が1〜4MBだから、1GBのSRAMは現行CPUの256倍とかのダイサイズが必要だわな
今のL2が1〜4MBだから、1GBのSRAMは現行CPUの256倍とかのダイサイズが必要だわな
SRAM SRAM言ってる奴らがいるけどSRAMっていったって外付けしたらそんなに速いもんじゃないよ。
くそもらし
>>188
だよな。オンダイで演算コアと広域直結してるからこそ速いわけで。
かといってMCMで大容量L3-DRAMをオンパッケージでつけてなんか意味あるか
ってーと微妙。DRAMなら頑張れば1GBぐらいオンパッケージで載せられそうではあるが。
だよな。オンダイで演算コアと広域直結してるからこそ速いわけで。
かといってMCMで大容量L3-DRAMをオンパッケージでつけてなんか意味あるか
ってーと微妙。DRAMなら頑張れば1GBぐらいオンパッケージで載せられそうではあるが。
>190
CPU 1コア+DRAM512MBをワンパッケージにしてメモリアクセス最速化。
そのCPUを4個並べて4コア2GBのマシンを作れば、用途によってはバカっ速の予感。
MCMといっても今なら256MB程度が現実的かな。
今から開発初めて数年後登場なら1GBだろうけど。
CPU 1コア+DRAM512MBをワンパッケージにしてメモリアクセス最速化。
そのCPUを4個並べて4コア2GBのマシンを作れば、用途によってはバカっ速の予感。
MCMといっても今なら256MB程度が現実的かな。
今から開発初めて数年後登場なら1GBだろうけど。
>>191
それは32nmでも無理だって。DRAMと演算コアを混載してパフォーマンス出すのは無理。
4コアのCPU(共有L2-32MB)と同程度のダイサイズのDRAMをMCMで広域接続で1GB
ぐらいが3年後ぐらいのレベルでしょ。
それは32nmでも無理だって。DRAMと演算コアを混載してパフォーマンス出すのは無理。
4コアのCPU(共有L2-32MB)と同程度のダイサイズのDRAMをMCMで広域接続で1GB
ぐらいが3年後ぐらいのレベルでしょ。
ttp://www.beyond3d.com/content/articles/31/2
Intel presentation reveals the future of the CPU-GPU war
Intel presentation reveals the future of the CPU-GPU war
>>191
eDRAMってむずかしいんだよ。
DRAM向きのプロセスはCの大きいプロセス→小さいセルで一定容量が確保できる
ロジック向けのプロセスはCの小さいプロセス→高速動作
eDRAMの場合、これらを適当に折り合いをつけたプロセスで作るんだけど、
まぁ結局どっちつかずになる。
IBMとかがんばってるけど、最先端ロジック用プロセスにeDRAMのせるのは無理なわけ。
eDRAMってむずかしいんだよ。
DRAM向きのプロセスはCの大きいプロセス→小さいセルで一定容量が確保できる
ロジック向けのプロセスはCの小さいプロセス→高速動作
eDRAMの場合、これらを適当に折り合いをつけたプロセスで作るんだけど、
まぁ結局どっちつかずになる。
IBMとかがんばってるけど、最先端ロジック用プロセスにeDRAMのせるのは無理なわけ。
AMDがやりたいのは (PS3+Xbox360+AppleTV)を足して3で割ったものをWiiより安く
提供する――すなわち脱PCではないだろうか。
提供する――すなわち脱PCではないだろうか。
18 :14 [] :2007/04/12(木) 12:22:57 ID:9Ay6E5zR
いまやって試してみたが、
文字が見やすくなってるよ。
プレステ3より文字が見やすくなってる。
ただスクロールが相変わらずやりにくいが、
検索に関してはプレステ3よりはるかによくなった。
あとはキーボードでできたらいいね。
20 :14 [] :2007/04/12(木) 12:27:31 ID:9Ay6E5zR
>>19
よくわからないが、おきにいりのところに
i-フィルターてのがある。
文字は本当に見やすくなったよ。
プレステ3より苦なく読めるてのが
なんとも皮肉。オペラブラウザも完全にWii仕様て感じ。
50 :名刺は切らしておりまして [sage] :2007/04/12(木) 23:27:01 ID:TUMkV7zI
>>20
なんか動作もPS3ブラウザよりキビキビしてる感じだね。
特に←戻る・進む→ あたりの処理が
ハードの性能差考えるとPS3ブラウザ作った奴は万死に値するな
んでもようつべてかはPS3のが快適だけど
いまやって試してみたが、
文字が見やすくなってるよ。
プレステ3より文字が見やすくなってる。
ただスクロールが相変わらずやりにくいが、
検索に関してはプレステ3よりはるかによくなった。
あとはキーボードでできたらいいね。
20 :14 [] :2007/04/12(木) 12:27:31 ID:9Ay6E5zR
>>19
よくわからないが、おきにいりのところに
i-フィルターてのがある。
文字は本当に見やすくなったよ。
プレステ3より苦なく読めるてのが
なんとも皮肉。オペラブラウザも完全にWii仕様て感じ。
50 :名刺は切らしておりまして [sage] :2007/04/12(木) 23:27:01 ID:TUMkV7zI
>>20
なんか動作もPS3ブラウザよりキビキビしてる感じだね。
特に←戻る・進む→ あたりの処理が
ハードの性能差考えるとPS3ブラウザ作った奴は万死に値するな
んでもようつべてかはPS3のが快適だけど
>>194
諦めたらそこで試合終了ですよ
諦めたらそこで試合終了ですよ
>192,194,198
>190,191はeDRAMでなくMCMの話では。
MCMじゃどれだけ効果出せるのか?って疑問ならそうだろうけど。
>190,191はeDRAMでなくMCMの話では。
MCMじゃどれだけ効果出せるのか?って疑問ならそうだろうけど。
そうですか。
早い話がレジスタの中で全ての処理が終了するソフト作ればいいんですよ。
そのソフトに何の意味があるのでつか?
メモリが遅いという問題を根本から解決できます。
>MCMの話をしているつもりは全く無い。
そうか。でもeDRAMが無理なのはわかってるわけで。
速いRAMが欲しければMCMがもっとも早道じゃないかな。
貫通電極で広帯域にCPUとメモリを直結するとか。
intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
明確なソースはないけど。
そうか。でもeDRAMが無理なのはわかってるわけで。
速いRAMが欲しければMCMがもっとも早道じゃないかな。
貫通電極で広帯域にCPUとメモリを直結するとか。
intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
明確なソースはないけど。
>>205
> 速いRAMが欲しければMCMがもっとも早道じゃないかな。
MCMは「速くない」ので速いRAMがほしいという要求は満たせない。って話。
で、不可能なものはあきらめて、現状の階層キャッシュでがんばるしかないよなという立場。
速いRAM(=メインメモリ)をどばーっと確保するなんて無理。
#もともとの>188は>173とかの「速いメモリ(=SRAMとか)があればマンセーじゃーん」
#とか言っている頭ゆるい人への反論だったり。
> intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
メインメモリをどばっと取り込むなんてことはしないと思うけど。
もしキャッシュのことを言ってるとしても何でそんなことをする必要があるのかと。
SRAMキャッシュのMCMでつけるぐらいだったら、今までと同じオンダイSRAMキャッシュを
使い続けると思うし。
#80コアダイ+キャッシュのMCMより 40コアダイ/大容量キャッシュ×2のMCMの方が
#パフォーマンス出ると思うよ。同じサイズでも。
DRAMでキャッシュを作るって言うなら...Intelが積極的にそんな研究やってますって話は
聞かないな。せっかく小さなセルのSRAMマクロ持ってるのに。わざわざそれ捨てるかな。
> 速いRAMが欲しければMCMがもっとも早道じゃないかな。
MCMは「速くない」ので速いRAMがほしいという要求は満たせない。って話。
で、不可能なものはあきらめて、現状の階層キャッシュでがんばるしかないよなという立場。
速いRAM(=メインメモリ)をどばーっと確保するなんて無理。
#もともとの>188は>173とかの「速いメモリ(=SRAMとか)があればマンセーじゃーん」
#とか言っている頭ゆるい人への反論だったり。
> intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
メインメモリをどばっと取り込むなんてことはしないと思うけど。
もしキャッシュのことを言ってるとしても何でそんなことをする必要があるのかと。
SRAMキャッシュのMCMでつけるぐらいだったら、今までと同じオンダイSRAMキャッシュを
使い続けると思うし。
#80コアダイ+キャッシュのMCMより 40コアダイ/大容量キャッシュ×2のMCMの方が
#パフォーマンス出ると思うよ。同じサイズでも。
DRAMでキャッシュを作るって言うなら...Intelが積極的にそんな研究やってますって話は
聞かないな。せっかく小さなセルのSRAMマクロ持ってるのに。わざわざそれ捨てるかな。
>MCMは「速くない」ので速いRAMがほしいという要求は満たせない。って話。
MCMというか貫通電極でロジックとメモリの接続を多ピン化して高速データ伝送してるのは
http://www.necel.com/pkg/ja/pk02_smafti.html
こんなのとか。
>> intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
>
>メインメモリをどばっと取り込むなんてことはしないと思うけど。
どばっとでもなくて、CELLのLS程度なんじゃない?
今の80コアはローカルな記憶領域が殆どないし、外部メモリへのアクセスは他のコアを
いくつも経由しないといけないからかなり遠い。
MCMというか貫通電極でロジックとメモリの接続を多ピン化して高速データ伝送してるのは
http://www.necel.com/pkg/ja/pk02_smafti.html
こんなのとか。
>> intelが80コアプロセッサで次にやろうとしてるのはそういうことじゃない?
>
>メインメモリをどばっと取り込むなんてことはしないと思うけど。
どばっとでもなくて、CELLのLS程度なんじゃない?
今の80コアはローカルな記憶領域が殆どないし、外部メモリへのアクセスは他のコアを
いくつも経由しないといけないからかなり遠い。
>>207
> >メインメモリをどばっと取り込むなんてことはしないと思うけど。
> どばっとでもなくて、CELLのLS程度なんじゃない?
少ないならMCMにする必要が無いんじゃない?
> 今の80コアはローカルな記憶領域が殆どないし、外部メモリへのアクセスは他のコアを
> いくつも経由しないといけないからかなり遠い。
さっきの素敵MCMでも80コア全部に対してローカルなメモリをMCMで接続するのは無理だと思うよ。
どれだけの数のピンを結ばないといけなくなるか分かってる?
#というかパッドの面積が...いくら素敵技術で小さく出来るからっていってもなぁ。
現実的にはコアを減らしてその分オンダイローカルメモリを乗せる。
コアが足りないのであればMCMでその分のせる。って所だと思うけど。
チップとメモリを結線するにはちょっとなぁ。
> >メインメモリをどばっと取り込むなんてことはしないと思うけど。
> どばっとでもなくて、CELLのLS程度なんじゃない?
少ないならMCMにする必要が無いんじゃない?
> 今の80コアはローカルな記憶領域が殆どないし、外部メモリへのアクセスは他のコアを
> いくつも経由しないといけないからかなり遠い。
さっきの素敵MCMでも80コア全部に対してローカルなメモリをMCMで接続するのは無理だと思うよ。
どれだけの数のピンを結ばないといけなくなるか分かってる?
#というかパッドの面積が...いくら素敵技術で小さく出来るからっていってもなぁ。
現実的にはコアを減らしてその分オンダイローカルメモリを乗せる。
コアが足りないのであればMCMでその分のせる。って所だと思うけど。
チップとメモリを結線するにはちょっとなぁ。
メモリバスはシリアルがオンダイになってるのが前提?
その昔、ウエハースケールインテグレーションというものがあってのう。
IBMも意欲的だね > 3Dスタッキング
http://journal.mycom.co.jp/news/2007/04/13/013/index.html
これに賭けてるわけでなく、可能性があるものは何でも手をつけてるし、
メモリを混載するためだけでもないけど。
http://journal.mycom.co.jp/news/2007/04/13/013/index.html
これに賭けてるわけでなく、可能性があるものは何でも手をつけてるし、
メモリを混載するためだけでもないけど。
>>200
微妙とは書いたが意味がないとは言ってないぞ。
>>206
>MCMは「速くない」ので速いRAMがほしいという要求は満たせない。って話。
CPUソケットとメモリソケットを介在するのに比べたら断然速い。
仮にクロックが同程度だとしても配船数を段違いに多く取れるからな。
>>208
なんでそう極論でMCMをムキになって否定するんだ?
MCMでCPUにメインメモリをオンパッケージで直結することがもし可能なら
現状のメインメモリDRAMに比べたら現実的なコストでより高速にできるのは自明だ。
現実的にはメインメモリとしての必要量(3年後なら4〜16GBぐらいか)を
オンパッケージにするのは無理だから512MB〜1GB程度のL3(L4)になるだろう。
どっちにしろSRAMのL2(L3)は必須だしSRAMとDRAMは二択ではない。
微妙とは書いたが意味がないとは言ってないぞ。
>>206
>MCMは「速くない」ので速いRAMがほしいという要求は満たせない。って話。
CPUソケットとメモリソケットを介在するのに比べたら断然速い。
仮にクロックが同程度だとしても配船数を段違いに多く取れるからな。
>>208
なんでそう極論でMCMをムキになって否定するんだ?
MCMでCPUにメインメモリをオンパッケージで直結することがもし可能なら
現状のメインメモリDRAMに比べたら現実的なコストでより高速にできるのは自明だ。
現実的にはメインメモリとしての必要量(3年後なら4〜16GBぐらいか)を
オンパッケージにするのは無理だから512MB〜1GB程度のL3(L4)になるだろう。
どっちにしろSRAMのL2(L3)は必須だしSRAMとDRAMは二択ではない。
{kind=link}
http://journal.mycom.co.jp/news/2006/07/26/342.html
> p5 590/595のプロセッサコアは、マルチチップモジュール(MCM)と呼ばれる
> プロセッサモジュール単位に分解される。MCMには8つのチップが搭載されており、
> 中央の4つのチップがデュアルコアのPower5+プロセッサ、周囲の4つのチップが
> それぞれ36MBのL3キャッシュとなっている。Power5+プロセッサ内部には8MBの
> L2キャッシュとメモリコントローラが内蔵され、MCM1つで合計8つのプロセッサ
> コア(8-way)構成となっている。
> p5 590/595のプロセッサコアは、マルチチップモジュール(MCM)と呼ばれる
> プロセッサモジュール単位に分解される。MCMには8つのチップが搭載されており、
> 中央の4つのチップがデュアルコアのPower5+プロセッサ、周囲の4つのチップが
> それぞれ36MBのL3キャッシュとなっている。Power5+プロセッサ内部には8MBの
> L2キャッシュとメモリコントローラが内蔵され、MCM1つで合計8つのプロセッサ
> コア(8-way)構成となっている。
もともとはCPUとメモリのメモリギャップはもはや永遠にうまんねー。プギャー。
だったんだがw
>212も「MCMによる高速メモリはキャッシュに」って考えてるみたいだし。
>>212
#まぁMCMそのものを否定なんてしてない訳だが。
でも、メモリとCPUのスピードギャップをうめるほどは速くないよね。
MCMによるオンチップメモリは、オンダイメモリほど速くもなく、外づけメモリほど容量も確保できず中途半端。
CPUとメモリとを 高 速 に接続する手段としては不適切だと思うよ。
今はメモリをMCMしているのは高速化のためでなくて実装面積を減らすためのものがほとんど。
既に書いているようにメモリとCPUはオンダイで高速に結合し、CPU間をMCMで接続する方が
絶対賢いって。
あるいはロジック(CPU)とメモリ(DRAMやフラッシュ)を違うプロセスで作るために
は有効かもしれないけどこれは必ずしも高速化を指向してはいない。
#PXA27xなんかはこっち。
だったんだがw
>212も「MCMによる高速メモリはキャッシュに」って考えてるみたいだし。
>>212
#まぁMCMそのものを否定なんてしてない訳だが。
でも、メモリとCPUのスピードギャップをうめるほどは速くないよね。
MCMによるオンチップメモリは、オンダイメモリほど速くもなく、外づけメモリほど容量も確保できず中途半端。
CPUとメモリとを 高 速 に接続する手段としては不適切だと思うよ。
今はメモリをMCMしているのは高速化のためでなくて実装面積を減らすためのものがほとんど。
既に書いているようにメモリとCPUはオンダイで高速に結合し、CPU間をMCMで接続する方が
絶対賢いって。
あるいはロジック(CPU)とメモリ(DRAMやフラッシュ)を違うプロセスで作るために
は有効かもしれないけどこれは必ずしも高速化を指向してはいない。
#PXA27xなんかはこっち。
メインメモリの大半はディスクキャッシュ的に使われてるから
MCMでL3-DRAMを256MBも積めば大半の用途でかなりの高速化が見込めるだろうな。
256MBも積めるか知らんけど。
高価なDDR3なんか使うよりDDR2でディスクキャッシュwを大量に積んで
L3-DRAMという構成の方がよっぽどコストパフォーマンス良さそう。
まあIntelはDRAM作れないから無理だろうけど。
MCMでL3-DRAMを256MBも積めば大半の用途でかなりの高速化が見込めるだろうな。
256MBも積めるか知らんけど。
高価なDDR3なんか使うよりDDR2でディスクキャッシュwを大量に積んで
L3-DRAMという構成の方がよっぽどコストパフォーマンス良さそう。
まあIntelはDRAM作れないから無理だろうけど。
「『System-in-Silicon(SiS)』の特徴と応用例」あたり
「VLSI 技術により、できるようになった」 研究は、ヤバい。
http://www.arch.cs.titech.ac.jp/event/fit2006/fit2006_goshima.pdf
http://www.arch.cs.titech.ac.jp/event/fit2006/fit2006_goshima.pdf
ずいぶん古いネタを持ってきたな。
■後藤弘茂のWeekly海外ニュース■
スケーラブルに展開するNVIDIAのG80アーキテクチャ
ttp://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
久々の更新
スケーラブルに展開するNVIDIAのG80アーキテクチャ
ttp://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
久々の更新
馬鹿には判らない
なんでGPUの解説記事にCell B.E.が出てくんの
ここらへんがCELLと似てるんだろう。
> NVIDIAが推奨するモデルでは GPUの外部メモリ上のデータを、
> まずShared Memoryにフィットするサブセットに分割する。
> そのサブセットをShared Memoryにロードし、…
GPGPUの難易度はCELL並み?
> NVIDIAが推奨するモデルでは GPUの外部メモリ上のデータを、
> まずShared Memoryにフィットするサブセットに分割する。
> そのサブセットをShared Memoryにロードし、…
GPGPUの難易度はCELL並み?
Shared Memoryはその名のとおり、Streaming Processor間で
共有するわけでしょ(後藤の記事が正しいとすれば)。
でもCellのLSはSPE毎に完全に分離された空間だよな。
・・・全然似てないんじゃね?
共有するわけでしょ(後藤の記事が正しいとすれば)。
でもCellのLSはSPE毎に完全に分離された空間だよな。
・・・全然似てないんじゃね?
「キャッシュと違い、分割して明示的にロード」って点 だけ は似てるから、
そこ だけ 抜き書きしたんだけど
そこ だけ 抜き書きしたんだけど
そんなどうでもいい類似点より、なんで汎用プロセッサのCell B.E.を
3Dグラフィック専用プロッセッサの記事で引き合いに出すのか意味不明だよ
3Dグラフィック専用プロッセッサの記事で引き合いに出すのか意味不明だよ
もともとCellでグラフィックをやる予定だったからだろ。
最近は一部の処理もRSX使うよりCell使う方が速いことが分かったとか。
最近は一部の処理もRSX使うよりCell使う方が速いことが分かったとか。
それより、そのちょっと上
> Super Function Unitは、RCP/RSQ/LG2/EX2/SIN/COSといった複雑な演算を
> 行なうユニットだ。4個のStreaming Processorの間で、共有される…(中略)
> 4クロック毎に 1命令を発行できる。実際には、
> 1クロック毎に1スレッドの命令を発行していると考えられる。
↑↑↑
これが理解不能。全体でも4クロック毎じゃないの?
ユニット自体が1クロック毎に結果を出せるならば、「1クロック毎」って宣伝するのでは?
1つのスレッドしか命令を出さなくても、4クロック毎にしか受け付けてもらえない、ってこと?
> Super Function Unitは、RCP/RSQ/LG2/EX2/SIN/COSといった複雑な演算を
> 行なうユニットだ。4個のStreaming Processorの間で、共有される…(中略)
> 4クロック毎に 1命令を発行できる。実際には、
> 1クロック毎に1スレッドの命令を発行していると考えられる。
↑↑↑
これが理解不能。全体でも4クロック毎じゃないの?
ユニット自体が1クロック毎に結果を出せるならば、「1クロック毎」って宣伝するのでは?
1つのスレッドしか命令を出さなくても、4クロック毎にしか受け付けてもらえない、ってこと?
確かにちょっとぎこちないね。
でも、ようやくソフト屋向けの文章も読むようになったのは良し。
でも、ようやくソフト屋向けの文章も読むようになったのは良し。
頂点シェーダーはCellにやらせた方がRSX使うより何倍も速いと言ってるメーカーあるね
■後藤弘茂のWeekly海外ニュース■
Intelがアクセラレータ向けI/F「Geneseo」を公開
ttp://pc.watch.impress.co.jp/docs/2007/0417/kaigai351.htm
Intelがアクセラレータ向けI/F「Geneseo」を公開
ttp://pc.watch.impress.co.jp/docs/2007/0417/kaigai351.htm
ttp://arstechnica.com/news.ars/post/20070416-intel-officially-owns-up-to-gpu-plans-with-larrabee.html
Intel officially owns up to GPU plans with Larrabee
The major thing to note about the quote above
is that Larrabee will in fact use the x86 ISA.
IntelのGPU(Larrabee)はやっぱりx86 ISAだと。
演算も出来るGPUってよりは、
描画も出来るGPU(CPU寄り)って感じか?
Intelもコプロ、やる気満々じゃん。
Intel officially owns up to GPU plans with Larrabee
The major thing to note about the quote above
is that Larrabee will in fact use the x86 ISA.
IntelのGPU(Larrabee)はやっぱりx86 ISAだと。
演算も出来るGPUってよりは、
描画も出来るGPU(CPU寄り)って感じか?
Intelもコプロ、やる気満々じゃん。
>>231
> 1つのスレッドしか命令を出さなくても、4クロック毎にしか受け付けてもらえない、ってこと?
自分はそういう意味だと思った。
「ラウンドロビン(かそれに類するスケジューリング)でやってるのだろう」っていう意味じゃないかと。
> 1つのスレッドしか命令を出さなくても、4クロック毎にしか受け付けてもらえない、ってこと?
自分はそういう意味だと思った。
「ラウンドロビン(かそれに類するスケジューリング)でやってるのだろう」っていう意味じゃないかと。
くそもらし
>236
LarrabeeはGPUとは発表してないのでは?
x86 ISAによるストリームプロセッサだと紹介しただけで。
記事ではGPUと比較してるけど。
LarrabeeはGPUとは発表してないのでは?
x86 ISAによるストリームプロセッサだと紹介しただけで。
記事ではGPUと比較してるけど。
>>236
ttp://www.4gamer.net/news/history/2007.04/20070417154239detail.html
中国IDFで発表されたIntelの新アーキテクチャ「Larrabee」の謎
>通常,「IA」といえば,IA-32またはIA-64を指す。
>となると,Pentium互換ないしItanium互換のコードが実行できるという意味に取らざるをえないのだが,
>単体GPUでそのような無駄の多い処理を行うとは考えにくい。
>CPU統合型グラフィックスコアであれば意味は通るのだが,
>それなりにハイエンドな製品と仮定すると,予想されるダイサイズや消費電力から考えて,
>そこまで特異な製品を作るメリットというのはほとんど見出せない。
>実際のところ,今回の発表ではLarrabeeはGPUであると明言されているわけではなく,
>素直に読めば,高並列の浮動小数点演算機能(SSEの強化版?)を
>搭載したCPUアーキテクチャの開発発表である。
ttp://www.beyond3d.com/content/articles/31/2
実際のところは4Gamerでも言ってる通りCPUにちかいもので
コプロとしての役割の方を期待した物っぽい。
ISAがx86なのもソフト面での広まりを期待しての物もだろう。
GPUのかたちをとるとすれば、その方が一般にも広まりやすいからだろうな。
AGEIA PhysXのように専用ものだと、広まりにくい上に
相手にしてもらえない可能性の方が大きいし。
>>236の捕らえ方
描画も出来るCPUっての、あってるかもね。
近々後藤氏のLarrabee絡みの記事が出るんじゃないかな?
ttp://www.4gamer.net/news/history/2007.04/20070417154239detail.html
中国IDFで発表されたIntelの新アーキテクチャ「Larrabee」の謎
>通常,「IA」といえば,IA-32またはIA-64を指す。
>となると,Pentium互換ないしItanium互換のコードが実行できるという意味に取らざるをえないのだが,
>単体GPUでそのような無駄の多い処理を行うとは考えにくい。
>CPU統合型グラフィックスコアであれば意味は通るのだが,
>それなりにハイエンドな製品と仮定すると,予想されるダイサイズや消費電力から考えて,
>そこまで特異な製品を作るメリットというのはほとんど見出せない。
>実際のところ,今回の発表ではLarrabeeはGPUであると明言されているわけではなく,
>素直に読めば,高並列の浮動小数点演算機能(SSEの強化版?)を
>搭載したCPUアーキテクチャの開発発表である。
ttp://www.beyond3d.com/content/articles/31/2
実際のところは4Gamerでも言ってる通りCPUにちかいもので
コプロとしての役割の方を期待した物っぽい。
ISAがx86なのもソフト面での広まりを期待しての物もだろう。
GPUのかたちをとるとすれば、その方が一般にも広まりやすいからだろうな。
AGEIA PhysXのように専用ものだと、広まりにくい上に
相手にしてもらえない可能性の方が大きいし。
>>236の捕らえ方
描画も出来るCPUっての、あってるかもね。
近々後藤氏のLarrabee絡みの記事が出るんじゃないかな?
http://www.theinquirer.net/default.aspx?article=37548
最初にGPU言い出したのはこのルーマー
そしてその情報が他のルーマー間を一人歩き
IntelがオフィシャルでLarrabeeについて書いたのは
間違って広まった情報を正したかったのかも
最初にGPU言い出したのはこのルーマー
そしてその情報が他のルーマー間を一人歩き
IntelがオフィシャルでLarrabeeについて書いたのは
間違って広まった情報を正したかったのかも
プランとしてはあるものの論理設計も何もない状態で、
適当な情報をルーマーにリークして、
観測気球してたっつーのが俺の見解。
適当な情報をルーマーにリークして、
観測気球してたっつーのが俺の見解。
お前の見解はどうでもいい
スマン
こっちこそスマン
よし、お前らはこれで貸し借りナシな。
仲良くやれよ!!
仲良くやれよ!!
珍しく爽やかな展開だな
ソフトウェアRAID-5を専用チップ並の性能に引き上げるのが目的か。
高並列の浮動小数点演算は要らんけどな。
ま、SSEなら整数演算にも役立つけど。
x86版Niagara…というわけでもなさそうか。
ま、SSEなら整数演算にも役立つけど。
x86版Niagara…というわけでもなさそうか。
NVIDIAがDirectX 10世代GPUの第2弾「G84」と「G86」を発表
http://pc.watch.impress.co.jp/docs/2007/0418/kaigai352.htm
http://pc.watch.impress.co.jp/docs/2007/0418/kaigai352.htm
SLIかデュアルコアGPUに話が続きそうな終わり方だな
Larrabeeはかなり本気で開発している模様
> またRattner CTOが基調講演で触れたIAコアによるテラフロップCPUに関し、
> もう少し細かい話も出てきた。デモで紹介された80コアの試作チップはIAコアでは
> なく、もっとシンプルなものだったが、IAコアを搭載するものを同社は開発中で、
> コードネームは「Larrabee」であることがGelsinger氏から明らかにされた。
>
> 実際のコア数がどのくらいになるのかは不明だが、命令セットが拡張された
> IAコアを搭載することになるようだ。これは製品化を前提にした開発のようで、
> 「来年にもデモが披露できる予定」とGelsinger氏。
そしてGPGPU終了のお知らせ
> 最後にMicrosoft ResearchのDavid Williams氏の「Intelのこのアプローチは、
> GPGPUコンピューティングに関するディベートを終わらせることになる」という
> コメントを引用し、Larrabeeに対する自信を見せた。
http://journal.mycom.co.jp/articles/2007/04/18/idf06/index.html
> またRattner CTOが基調講演で触れたIAコアによるテラフロップCPUに関し、
> もう少し細かい話も出てきた。デモで紹介された80コアの試作チップはIAコアでは
> なく、もっとシンプルなものだったが、IAコアを搭載するものを同社は開発中で、
> コードネームは「Larrabee」であることがGelsinger氏から明らかにされた。
>
> 実際のコア数がどのくらいになるのかは不明だが、命令セットが拡張された
> IAコアを搭載することになるようだ。これは製品化を前提にした開発のようで、
> 「来年にもデモが披露できる予定」とGelsinger氏。
そしてGPGPU終了のお知らせ
> 最後にMicrosoft ResearchのDavid Williams氏の「Intelのこのアプローチは、
> GPGPUコンピューティングに関するディベートを終わらせることになる」という
> コメントを引用し、Larrabeeに対する自信を見せた。
http://journal.mycom.co.jp/articles/2007/04/18/idf06/index.html
AMDのやろうとしてる新しいことはほとんど外れないから最初から本気出してもオッケー
みたいなノリなのかわからんが、最近はAMDのアイディアをパクる際も本気でやるようになってきたね
みたいなノリなのかわからんが、最近はAMDのアイディアをパクる際も本気でやるようになってきたね
AMDのアイデアをパクることLarrabeeに何の関係が?
所詮Media GX VS Timnaなんだよね。時代は巡る,巡る因果は糸車。
ゴミ vs タコ
129 :Socket774 :2007/04/19(木) 01:39:01 ID:H9HpQLsK
Fusionは全然融合していない設計
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
130 :Socket774 :2007/04/19(木) 01:41:21 ID:hJW7H+yL
Fusionたいしたことなさそうだ
オンボVGAがただのるだけで期待はずれな予感
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
Fusionは全然融合していない設計
http://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/Hammer-Info.html
130 :Socket774 :2007/04/19(木) 01:41:21 ID:hJW7H+yL
Fusionたいしたことなさそうだ
オンボVGAがただのるだけで期待はずれな予感
http://www.dailytech.com/AMD+Talks+Multichip+Modules+for+Fusion/article6928.htm
夢を見ていられなくなった後藤たんが書く記事や如何に
Fusionの世代で「オンボVGAがただのるだけ」以上の何を妄想してたんだろ?
GPGPU詐欺
>>259
ソフトウェアがもっとダイレクトにアクセスできるように道が整えられることじゃね?
ソフトウェアがもっとダイレクトにアクセスできるように道が整えられることじゃね?
最初から6億トランジスタのハイエンドGPUと同性能のものがFusionすると思ってたやつが3割は居そうだな
FUSIONを待たずしてAMDは潰れるからもうどうでもいい
結局チップ数も減らないし、メモリ帯域やレイテンシ問題も上手く解決できないし、良いことなしのFusion
やっぱり後藤は騙されていたのか・・・
AMDのインチキ株価対策の片棒を担いだ誤答
AMDはCPUとGPUがクロスバー経由で接続されるってプレゼンをしてた。
後藤ですら3世代ぐらいかけて段階的に統合が進むと控えめに解説してるのに
いきなりGPUがまるまる乗ると夢想してたアホなんているのか
いきなりGPUがまるまる乗ると夢想してたアホなんているのか
後藤逝ってよし
糞もらし
>>270
ま た お ま え か !
ま た お ま え か !
もうケータイにメモリとCPUとGPU統合したやつがあるんだが。
組み込み屋はスレ違い
(・∀・)チンポー!
実現不可能とかいってる知恵遅れが驚くかと思って。
>>257のリンク先にもあるようにAMDの資料には初めからMCMのFusionも載ってるのだが
数年前からSoCやSiPが広まってきていることくらい
みんなわかってるからいちいち書かんでよろしい
みんなわかってるからいちいち書かんでよろしい
いや、知恵遅れは判ってないからw
それぞれの目的は
SoC→省実装面積
SiP→+納期(設計期間)短縮
メインボードにDRAMソケットは別に用意されていて
最新プロセスルールシリコンをどんどん投入する競争激しい
パソコンやサーバーではプライオリティの低い要素、あまり関係ない
SoC→省実装面積
SiP→+納期(設計期間)短縮
メインボードにDRAMソケットは別に用意されていて
最新プロセスルールシリコンをどんどん投入する競争激しい
パソコンやサーバーではプライオリティの低い要素、あまり関係ない
モバイルノートの為に実装面積減らすのは結構だけど
それで熱密度上げたら元も子もないと思うのよね
それで熱密度上げたら元も子もないと思うのよね
>>257
single-dieよりもMCMのほうが柔軟性が高いとして、その例として、
DX10統合チップ作製後にDX11にしようとしたら完全に再設計になってしまうが、
MCMならばGPU側だけ取り換えれば済むとした。
数年後予想 ↓
single-dieよりもMCMのほうが柔軟性が高いとして、その例として、
DX11統合チップ作製後にDX12にしようとしたら完全に再設計になってしまうが、
MCMならばGPU側だけ取り換えれば済むとした。
single-dieよりもMCMのほうが柔軟性が高いとして、その例として、
DX10統合チップ作製後にDX11にしようとしたら完全に再設計になってしまうが、
MCMならばGPU側だけ取り換えれば済むとした。
数年後予想 ↓
single-dieよりもMCMのほうが柔軟性が高いとして、その例として、
DX11統合チップ作製後にDX12にしようとしたら完全に再設計になってしまうが、
MCMならばGPU側だけ取り換えれば済むとした。
そんなことしたらいつまでたっても命令レベルで統合できないじゃないか!
統合するメリット殆どないし、逆にデメリットばっかだし・・・・
まともな思考の人なら統合とか言わんでしょ?
ここ最近のAMDはまともじゃないかも。
まともな思考の人なら統合とか言わんでしょ?
ここ最近のAMDはまともじゃないかも。
アレ?インテルも統合するって言ってなかったっけ?
DX11→DX12の違いならドライバで吸収できるんじゃね。
>>276
香具師はなまじな知識はあるからそれでは驚かんだろ
ワンチップ化できるかどうかではなく、GPUを描画以外にも使うコアとして
CPUに取り込めるかどうかが論点なんだから
AMDとしてもどこまで可能かは完全には分かってない段階だと思われ
相対的に劣る研究開発リソースを無駄遣いするわけはないから
実現不可能と決まってるんじゃないだろうけど
香具師はなまじな知識はあるからそれでは驚かんだろ
ワンチップ化できるかどうかではなく、GPUを描画以外にも使うコアとして
CPUに取り込めるかどうかが論点なんだから
AMDとしてもどこまで可能かは完全には分かってない段階だと思われ
相対的に劣る研究開発リソースを無駄遣いするわけはないから
実現不可能と決まってるんじゃないだろうけど
GPUとCPUの完全な統合なんてのは、まだまだ先だ。
GPU自体がまだ発展途上で、激しく変化中。
同じメーカーでもISAは、まだまだ固まらない。
とりあえず、倍精度に成るかもしれないDX11までは。
DXの世代交代は単にパフォーマンス面だけでなく
演算の内容にまで係わる拡張がなされるため
単にShaderの増設やドライバで対応できるもんじゃない
ttp://forums.vr-zone.com/showthread.php?t=140444
とりあえず今世代でR600ベースのSocket GPUが出るかもしれないが。
GPU自体がまだ発展途上で、激しく変化中。
同じメーカーでもISAは、まだまだ固まらない。
とりあえず、倍精度に成るかもしれないDX11までは。
DXの世代交代は単にパフォーマンス面だけでなく
演算の内容にまで係わる拡張がなされるため
単にShaderの増設やドライバで対応できるもんじゃない
ttp://forums.vr-zone.com/showthread.php?t=140444
とりあえず今世代でR600ベースのSocket GPUが出るかもしれないが。
>>264
ビデオコアがCPUに移ればチップセットはワンチップで済むから(M690は2チップ)
チップは3個から2個に減る
>>281
統合チップセットをアクティブに冷却しなきゃならん状態よりは
CPUにまとまってたほうが冷却は楽だろ
総熱量が増えるわけじゃないし
ビデオコアがCPUに移ればチップセットはワンチップで済むから(M690は2チップ)
チップは3個から2個に減る
>>281
統合チップセットをアクティブに冷却しなきゃならん状態よりは
CPUにまとまってたほうが冷却は楽だろ
総熱量が増えるわけじゃないし
全面改良ではなく、部分改良に留まったPenryn
http://pc.watch.impress.co.jp/docs/2007/0420/kaigai353.htm
http://pc.watch.impress.co.jp/docs/2007/0420/kaigai353.htm
DX11で倍精度?そりゃまたGPUには無駄な機能だな。
HDコンテンツでは必要になってくるか。
HDコンテンツでは必要になってくるか。
>HDコンテンツでは必要になってくるか。
必要じゃねえよ馬鹿。
必要じゃねえよ馬鹿。
>>290
総熱量変わらずに熱密度が上がると、Tcaseは下がっちゃうんでないか?
それでConroeはあまりケースを小さく出来ないって話があったと思うけど、
モバイルノート向けなのにそうなるときびしいんじゃないかなと
総熱量変わらずに熱密度が上がると、Tcaseは下がっちゃうんでないか?
それでConroeはあまりケースを小さく出来ないって話があったと思うけど、
モバイルノート向けなのにそうなるときびしいんじゃないかなと
VAIO Uみたいな極小PCだったら、clock下げてでもチップ減らしに行くかも。
しかし、もしGPUを統合して、汎用で使える演算器が増えても、
一般人には使い道が無いんじゃないか。ビデオのエンコード/デコードくらいしか。
しかし、もしGPUを統合して、汎用で使える演算器が増えても、
一般人には使い道が無いんじゃないか。ビデオのエンコード/デコードくらいしか。
【PS3】「PowerDVD7 PS3」発売、PS3でHD DVDビデオ再生可能に
http://news21.2ch.net/test/read.cgi/news7/1171991823/
> サイバーリンク トランスデジタル株式会社は、プレイステーション3にて
>Blu-ray Disc(BD)ビデオやHD DVDビデオ、DVDビデオ再生に対応するプレーヤーソフト
>「PowerDVD 7 PS3 ハイビジョンシアター」を6月5日より順次発売する。
>(中略)
>に解像度を高めるトゥルーアップコンバートなど本体機能との差別化を図っているという。
>なお、対応するHD DVDドライブは未定となっている。
360の外付けドライブ対応まだ?
http://news21.2ch.net/test/read.cgi/news7/1171991823/
> サイバーリンク トランスデジタル株式会社は、プレイステーション3にて
>Blu-ray Disc(BD)ビデオやHD DVDビデオ、DVDビデオ再生に対応するプレーヤーソフト
>「PowerDVD 7 PS3 ハイビジョンシアター」を6月5日より順次発売する。
>(中略)
>に解像度を高めるトゥルーアップコンバートなど本体機能との差別化を図っているという。
>なお、対応するHD DVDドライブは未定となっている。
360の外付けドライブ対応まだ?
私のニュース、ねぇ…
>>298
そのヒートパイプの限界熱流束は無限大なのか?
そのヒートパイプの限界熱流束は無限大なのか?
今のピートパイプでも十分余裕がある
…何でそんな極端に考えが行くんだろ?
…何でそんな極端に考えが行くんだろ?
>>298
ああ、元々チップセットとCPU同時冷却してるのね
ああ、元々チップセットとCPU同時冷却してるのね
>>301
PCによってはチップセットやGPUがヒートシンクだけでは足りないらしい
PCによってはチップセットやGPUがヒートシンクだけでは足りないらしい
なんで怒ってるの?
なんとかなるもんだ
http://www.blogsmithmedia.com/www.engadget.com/media/2007/01/1-26-07-via_epia_mobo.jpg
http://journal.mycom.co.jp/articles/2007/03/17/cebit08/images/005l.jpg
http://pc.watch.impress.co.jp/docs/2007/0420/via_03.jpg
http://www.blogsmithmedia.com/www.engadget.com/media/2007/01/1-26-07-via_epia_mobo.jpg
{kind=link}
http://journal.mycom.co.jp/articles/2007/03/17/cebit08/images/005l.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2007/0420/via_03.jpg
{kind=link}
消耗戦になるよ
需要は作りだすものです。
2000年以降すっかり投資家が魅力をなくしてしまった業界
それが半導体産業
それが半導体産業
>>310
MicrosoftとAppleの仕事だな(*´∀`)
MicrosoftとAppleの仕事だな(*´∀`)
IntelはIntelで頑張ってるだろ。自前のチップセット売るために
セントリノとか意味不明なこと言い出したり。
それで需要を掘り起こすわけです。
セントリノとか意味不明なこと言い出したり。
それで需要を掘り起こすわけです。
YAMATOはもう沈没したんじゃないのか?w
>>315
大和事業所はまだ健在です><
大和事業所はまだ健在です><
■後藤弘茂のWeekly海外ニュース■
モバイル向けの省電力機能を強化したPenryn
ttp://pc.watch.impress.co.jp/docs/2007/0423/kaigai354.htm
モバイル向けの省電力機能を強化したPenryn
ttp://pc.watch.impress.co.jp/docs/2007/0423/kaigai354.htm
>イスラエルとサンタクララの共同開発
サンタクララもx86に出戻りか。
とうとうItaniumは見放したか?(笑)
当然、建前上はItaniumもサンタクララで続けます、だろうけど。
力の注ぎ具合いは歴然か。
サンタクララもx86に出戻りか。
とうとうItaniumは見放したか?(笑)
当然、建前上はItaniumもサンタクララで続けます、だろうけど。
力の注ぎ具合いは歴然か。
そう言えばMontecitoって出たんだっけ?
そう言えば今回のIDFではIA64の話題が皆無だったな。
ItaniumはFort Collinsでやってるんじゃないの?
Intel64とIA-64のフュージョンしないか。
■後藤弘茂のWeekly海外ニュース■
もう1つの超低消費電力CPU「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0425/kaigai355.htm
もう1つの超低消費電力CPU「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0425/kaigai355.htm
思いきり笠原とネタかぶってるな。
「これは何を意味するのか、次回は、…」なんて二回に分けずに、
そっちのネタ書けばいいのに。
「これは何を意味するのか、次回は、…」なんて二回に分けずに、
そっちのネタ書けばいいのに。
笠原の方が面白かった
後藤はSilverthorneに的を絞って、
笠原は総合的で、一応住み分けてるじゃん。
結局のところ笠原のここがポイントだと思うけど…
>CPUが0.5Wまで下がるのに、チップセットが2.5Wも食っているというのはシステムとしてはアンバランスであると言わざるを得ない。
CPUだけ省電力になってもねえ。
笠原は総合的で、一応住み分けてるじゃん。
結局のところ笠原のここがポイントだと思うけど…
>CPUが0.5Wまで下がるのに、チップセットが2.5Wも食っているというのはシステムとしてはアンバランスであると言わざるを得ない。
CPUだけ省電力になってもねえ。
笠原はMCM実装のSoCとか言ってるけど、これって矛盾してね?
SoCなら1ダイだし2ダイ以上ならMCMかSiPでしょ。
まあIntelがSoCって言ってるんだからMCMもSoCになるのかもしれんけど。
SoCなら1ダイだし2ダイ以上ならMCMかSiPでしょ。
まあIntelがSoCって言ってるんだからMCMもSoCになるのかもしれんけど。
■後藤弘茂のWeekly海外ニュース■
超低消費電力を達成するSilverthorneの秘密
http://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
超低消費電力を達成するSilverthorneの秘密
http://pc.watch.impress.co.jp/docs/2007/0426/kaigai356.htm
まだ続くのか。
規模に比例した消費電力ってだけで、文章にワクワク感が感じられないんだが。
>>329
笠原の書き方は混乱しているけど、チャンドラシーカの発言部分は
「まずはMCMで出すけど、要望が有ればワンチップのも作る」ってなってるよ。
規模に比例した消費電力ってだけで、文章にワクワク感が感じられないんだが。
>>329
笠原の書き方は混乱しているけど、チャンドラシーカの発言部分は
「まずはMCMで出すけど、要望が有ればワンチップのも作る」ってなってるよ。
楽しみにしてたのにすごいオチが待っていた
ポラックの法則をネタにポラックの法則を解説する記事で
全然Silverthorneの秘密に迫っていないじゃん
ポラックの法則をネタにポラックの法則を解説する記事で
全然Silverthorneの秘密に迫っていないじゃん
65nmと比較すればもっと強調出来たのになぁ
続くて
クタタン名誉会長おめ
336 :Socket774:2007/04/27(金) 13:56:18 ID:rSyXH7DK
はい、wikipediaに後藤弘茂つくった。あとはおまえらヨロ。
http://ja.wikipedia.org/wiki/%E5%BE%8C%E8%97%A4%E5%BC%98%E8%8C%82
http://ja.wikipedia.org/wiki/%E5%BE%8C%E8%97%A4%E5%BC%98%E8%8C%82
↓以後ゲハ厨書き込み禁止
そんなにVIAが嫌いか
既に勢いがないだろう>VIA
長男、次男、長女の順に3人の子供がおり、ゲーム機の記事などに登場する。
×impress.com→○Impress Watch(項目あるよ)
×impress.com→○Impress Watch(項目あるよ)
クタラギ引退記事だせよw
>341
それ来週の火曜に出すでしょ。
あれだけ散々ネタにした(原稿料稼いだ)んだから
本田雅一より先に出すのが筋だったと思うが。
それ来週の火曜に出すでしょ。
あれだけ散々ネタにした(原稿料稼いだ)んだから
本田雅一より先に出すのが筋だったと思うが。
> 5月6日(日)まで更新をお休みさせていただきます。
> 次回の更新は5月7日(月)です。
> 次回の更新は5月7日(月)です。
Silverthorneネタで引っ張るのかよ。
いいからさっさと出せよ。
この前のは無意味な回だったんだから。
いいからさっさと出せよ。
この前のは無意味な回だったんだから。
お前がここに書けば皆が添削してくれると思う
今年のWINHECは中旬か
久夛良木が追放されたニュースは木曜の夜。
後藤が翌午前中に入稿してれば、金曜の夕方に
クタ追悼記事は出せたんだけど。
後藤が翌午前中に入稿してれば、金曜の夕方に
クタ追悼記事は出せたんだけど。
昨年(2006年)12月人事からの既定路線。
ソニーの経営立て直しに関連して、ストリンガー会長があまりに技術に傾倒しすぎて
足下の経営を見ずSCE内部でも浮いていた久夛良木氏を切ったのだ。
負け規格のPS3もこれでオシマイ。
負担の大きい負けゲーム規格を整理する第一ステップ。
まずは象徴的な存在である久夛良木氏に詰め腹を切らせた
ソニーの経営立て直しに関連して、ストリンガー会長があまりに技術に傾倒しすぎて
足下の経営を見ずSCE内部でも浮いていた久夛良木氏を切ったのだ。
負け規格のPS3もこれでオシマイ。
負担の大きい負けゲーム規格を整理する第一ステップ。
まずは象徴的な存在である久夛良木氏に詰め腹を切らせた
ソニーという企業にクターを泳がせておくだけの余裕が無くなったってことだろ
そういう意味では、なんとなく寂しいが
そういう意味では、なんとなく寂しいが
ゲハの連中は今までネタを提供してくれたクターに感謝しないとなw
>>352
内部の人間でもないのに内情語るなよ。
内部の人間でもないのに内情語るなよ。
>>352
ソニー社内の技術評価の場で、突っ込んで画質や音質、製品のビジョンや将来の発展性、
応用分野などについて、数多く質問し、的確な指摘を語る役員は、
近年において久夛良木氏だけだったという。
http://pc.watch.impress.co.jp/docs/2007/0427/mobile374.htm
って書いてあるが、技術者出身の中鉢社長も質問&指摘はしてないってことなんだろうか
この「ある商品開発者」が中鉢氏の社長就任後もプレゼンしてたかは分からんけどさ
エンジニアの立場と士気を上げるためにこの人を社長にしたんだから
そうだとは思いたくないけど……
ソニー社内の技術評価の場で、突っ込んで画質や音質、製品のビジョンや将来の発展性、
応用分野などについて、数多く質問し、的確な指摘を語る役員は、
近年において久夛良木氏だけだったという。
http://pc.watch.impress.co.jp/docs/2007/0427/mobile374.htm
って書いてあるが、技術者出身の中鉢社長も質問&指摘はしてないってことなんだろうか
この「ある商品開発者」が中鉢氏の社長就任後もプレゼンしてたかは分からんけどさ
エンジニアの立場と士気を上げるためにこの人を社長にしたんだから
そうだとは思いたくないけど……
出井を社長にしたときから物作り部門の切り捨ては始まっていたから
ソニーの金融部門を拡大しまくっている裏で
中堅技術者や工場の相次いだ閉鎖も行っていた
またクタが副社長になったのはどうにもならない位PSとPS2の実績あったからだし
PS3の大幅な開発遅れと開発費増大の責任取らされるのもまた道理
本田の言っているところでクタが更迭されたと市場に取られると
PS3の完全な失敗というイメージが確定させてしまうというのも理解できる
ソニーの金融部門を拡大しまくっている裏で
中堅技術者や工場の相次いだ閉鎖も行っていた
またクタが副社長になったのはどうにもならない位PSとPS2の実績あったからだし
PS3の大幅な開発遅れと開発費増大の責任取らされるのもまた道理
本田の言っているところでクタが更迭されたと市場に取られると
PS3の完全な失敗というイメージが確定させてしまうというのも理解できる
PS3が生産面とコストでつまづいたのはBlurayの責任も大きいし、
Bluray推進はSONYの戦略でもあるから必ずしもクタのせいでもないけどな。
ソフトウェアのラインナップと人気の面でもうまくいってない、
独占タイトルにも逃げられた(独占でなくなった)、
Xbox360に大きく水をあけられたのは発売の遅れが大きいし、
BlurayがなくてもCELLのせいでやっぱり遅れてたろうな…
全てひっくるめて誰かが責任とらないといけないし、クタ以外に責任取れる
のはいないでしょ。
Bluray推進はSONYの戦略でもあるから必ずしもクタのせいでもないけどな。
ソフトウェアのラインナップと人気の面でもうまくいってない、
独占タイトルにも逃げられた(独占でなくなった)、
Xbox360に大きく水をあけられたのは発売の遅れが大きいし、
BlurayがなくてもCELLのせいでやっぱり遅れてたろうな…
全てひっくるめて誰かが責任とらないといけないし、クタ以外に責任取れる
のはいないでしょ。
>>355
90年代後半から2000年頃の好調と賞賛(WEGA、VAIO、PS、ついでにAIBO)は
出井以前の蓄積で食ってたってことか
5年遅れで表面化すると考えれば2000年代半ばまでの低迷も説明つくな
90年代後半から2000年頃の好調と賞賛(WEGA、VAIO、PS、ついでにAIBO)は
出井以前の蓄積で食ってたってことか
5年遅れで表面化すると考えれば2000年代半ばまでの低迷も説明つくな
>>358
出井の唯一の実績はCDプレイヤーのディレクターだった事
当たり前だけど当然技術系の事は一切分からず
しかしながらプロダクトマネージャーとしては優秀だった
尻の叩き方がうまいんだよね
出井が社長として決めたこと
ファイナンスへの進出→黒字化して現在の稼ぎ頭が、まだトータルだと大して稼いでない
技術者の大量解雇→開発ラインが縮小し、製品の多様性がなくなった。
またトラブった時の対応ができなくなり、開発遅延
以上のため市場での売れ筋を外したときにどうにもならなくなり赤字転落
いわゆるソニーショック
国内工場閉鎖→品質低下、ソニータイマー強化
サムスンと手を組まざるを得なくなった
しかし液晶に関しては低コストでパネルを調達できなおかつ技術流出よりも流入が多かったw
これ以外ないぞw
出井の唯一の実績はCDプレイヤーのディレクターだった事
当たり前だけど当然技術系の事は一切分からず
しかしながらプロダクトマネージャーとしては優秀だった
尻の叩き方がうまいんだよね
出井が社長として決めたこと
ファイナンスへの進出→黒字化して現在の稼ぎ頭が、まだトータルだと大して稼いでない
技術者の大量解雇→開発ラインが縮小し、製品の多様性がなくなった。
またトラブった時の対応ができなくなり、開発遅延
以上のため市場での売れ筋を外したときにどうにもならなくなり赤字転落
いわゆるソニーショック
国内工場閉鎖→品質低下、ソニータイマー強化
サムスンと手を組まざるを得なくなった
しかし液晶に関しては低コストでパネルを調達できなおかつ技術流出よりも流入が多かったw
これ以外ないぞw
くそもらし
>>342
後藤の予定としては
火曜はSilverthorneの続きを出す予定だったの。
当然クタ追放ネタは記事にはするが
自分に火の粉がかからない文章にするのに
時間が掛かってる、来週中には拝めるから待ってなさい。
後藤の予定としては
火曜はSilverthorneの続きを出す予定だったの。
当然クタ追放ネタは記事にはするが
自分に火の粉がかからない文章にするのに
時間が掛かってる、来週中には拝めるから待ってなさい。
>>361 乙です。
くそもらし
今日さパチンコで侍ジャイアンツ(始めて)打ったのよ 打つ気無かったけどめっちゃ良い台有ったから
なんか古い漫画が原作らしいんだけど 後藤タンはこんなのも好き?
打った感想は有る意味SFっぽい ピッチャーとバッターが二人で回転してるとこは笑った あれはすごい 原作見てみたい
で確変のまま閉店になったんけど これってどうなるんだろ…
なんか古い漫画が原作らしいんだけど 後藤タンはこんなのも好き?
打った感想は有る意味SFっぽい ピッチャーとバッターが二人で回転してるとこは笑った あれはすごい 原作見てみたい
で確変のまま閉店になったんけど これってどうなるんだろ…
超汚染人乙
366 :Socket774:2007/05/07(月) 13:57:07 ID:8OJWIjQi
age
367 :Socket774:2007/05/10(木) 00:12:38 ID:S/LsBOI9
■後藤弘茂のWeekly海外ニュース■
デスクトップCPUと同じ仕様を載せた「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
デスクトップCPUと同じ仕様を載せた「Silverthorne」
http://pc.watch.impress.co.jp/docs/2007/0510/kaigai357.htm
なんだこの中身の無い記事は
後藤はGW中何をやってたんだ
後藤はGW中何をやってたんだ
家族で海外旅行でもしてたんじゃないか?
なるほど、それじゃあ仕方ないね。
積ゲーを片っ端から処理してたのかと思ってた
アニメは順調に消化してるみたいで感心だ。
今期は切ろうと思えば切れる物が多いからな
つかロケットガールとらきすたとおお振りしか残ってねえぞ、もう
全部切ることにした。
半年分の番組が全部飛んだよヽ(`Д´)ノウワァァン
芝機のクソが
東芝RD「録画状態に問題があり・・・」ERR-02
http://hobby9.2ch.net/test/read.cgi/av/1156520458/
半年分の番組が全部飛んだよヽ(`Д´)ノウワァァン
芝機のクソが
東芝RD「録画状態に問題があり・・・」ERR-02
http://hobby9.2ch.net/test/read.cgi/av/1156520458/
クターのインタビュー読みたいな
多和田がもう少し経験積んだら
あと後藤は要らんな
あと後藤は要らんな
だから言ったじゃないか
>>327
うむ
うむ
後藤たんはパチンコの侍ジャイアンツを一生懸命打ってたんだよ きっと…
ここで余計な書き込みをする奴がいるから…
まぁ 多分勝ってるよ CRはコンピュータでの抽選だから 後藤たんには朝飯前
ここで余計な書き込みをする奴がいるから…
まぁ 多分勝ってるよ CRはコンピュータでの抽選だから 後藤たんには朝飯前
382 :Socket774:2007/05/11(金) 04:56:07 ID:j08w228d
くそもらし
CR機のTDPにでも憂慮してるとするか。
確かにアニメの数が多すぎてGW中はずっと消化してそうな気もするが、
後藤たん好みなのはあんまなくね?
後藤たん好みなのはあんまなくね?
若手が育ってないと嘆いてたけど,今の20代はすべて携帯で済ませて
しまうようだし,この仕事に先はないな。
しまうようだし,この仕事に先はないな。
ここ1,2年 書く内容はどんどんレベルが落ちていったが
最近は目に余る酷さ
やる気が無いならもう辞めちまえって 後藤弘茂
最近は目に余る酷さ
やる気が無いならもう辞めちまえって 後藤弘茂
むしろパソコン自体が成熟して面白みがなくなってきたんだよ。
389 :MACオタ>387 さん:2007/05/13(日) 22:41:29 ID:GHYfJOuG
>>387
-----------------
ここ1,2年 書く内容はどんどんレベルが落ちていったが
-----------------
単に時代が変わったすよ。技術的に先進的な話題わ、富士通の安藤氏のような本物のプロセッサ
アーキテクトの記事が読めるようになり、後藤氏が得意だった業界ネタわ、HKEPC.comとかで
現物のプレゼンが見られるようになったす。
もう素人の怪しげな講釈つきの情報を待ち焦がれることが、不要になったというだけす。
-----------------
ここ1,2年 書く内容はどんどんレベルが落ちていったが
-----------------
単に時代が変わったすよ。技術的に先進的な話題わ、富士通の安藤氏のような本物のプロセッサ
アーキテクトの記事が読めるようになり、後藤氏が得意だった業界ネタわ、HKEPC.comとかで
現物のプレゼンが見られるようになったす。
もう素人の怪しげな講釈つきの情報を待ち焦がれることが、不要になったというだけす。
安藤氏のリンク先が後藤がだったりする
391 :Socket774:2007/05/14(月) 18:02:59 ID:jMGx8n8z
くそもらし
■後藤弘茂のWeekly海外ニュース■
ラディカルなAMDの「Radeon HD 2000」アーキテクチャ
ttp://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
ラディカルなAMDの「Radeon HD 2000」アーキテクチャ
ttp://pc.watch.impress.co.jp/docs/2007/0515/kaigai358.htm
なんか奥歯に物が挟まったような提灯記事だな。
以下、>>393による「正しい」技術的解説↓
>>394
何がしたいのコイツ?
何がしたいのコイツ?
NVIDIA GeForce 8800に続き、Radeon HD 2900・・・・
糞みたいなGPUが増えたな、全くと言ってよいほど売れないGPU・・・
それがGeForce 8800であり、HD 2900
もうバカとしか言い様がねぇっすw
糞みたいなGPUが増えたな、全くと言ってよいほど売れないGPU・・・
それがGeForce 8800であり、HD 2900
もうバカとしか言い様がねぇっすw
一個のVLIWシーケンサで16個ものシェーダーユニットを同時制御してるんだなー。
つまり、1つ命令スロットに穴が開くと、一気に16個ものALUが遊ぶ事に・・・
トロいわけだわ。
命令に依存性がある限り、いくらコンパイラを改良しても命令スロットを100%埋めるのは不可能。
平均で6割も埋まればいい方だろう。
まーだX86命令との融合とか寝言言ってるし、アホだな後藤。
つまり、1つ命令スロットに穴が開くと、一気に16個ものALUが遊ぶ事に・・・
トロいわけだわ。
命令に依存性がある限り、いくらコンパイラを改良しても命令スロットを100%埋めるのは不可能。
平均で6割も埋まればいい方だろう。
まーだX86命令との融合とか寝言言ってるし、アホだな後藤。
398 :Socket774:2007/05/15(火) 21:02:56 ID:iKpCqp+k
___ ━┓
/ ―\ ┏┛
/ノ (●)\ ・
. | (●) ⌒)\
. | (__ノ ̄ |
\ /
\ _ノ
/´ `\
| |
| |
___ ━┓
/ ― \ ┏┛
/ (●) \ヽ ・
/ (⌒ (●) /
/  ̄ヽ__) /
. /´ ___/
| \
| |
/ ―\ ┏┛
/ノ (●)\ ・
. | (●) ⌒)\
. | (__ノ ̄ |
\ /
\ _ノ
/´ `\
| |
| |
___ ━┓
/ ― \ ┏┛
/ (●) \ヽ ・
/ (⌒ (●) /
/  ̄ヽ__) /
. /´ ___/
| \
| |
やる必要の無いチキンレースでドツボにハマっていく
融合をいってるのはAMDなんだが池沼には判らんのですよ。
真に受ける奴もアホ
つまり書く方もアホ
403 :Socket774:2007/05/16(水) 11:55:48 ID:PBerGWxo
融合をいってるのはAMDなんだが池沼には判らんのですよ。
404 :Socket774:2007/05/16(水) 16:38:04 ID:Mux7E266
くそもらし
405 :Socket774:2007/05/16(水) 21:57:27 ID:62ljByyN
クタラギみたいなスペック馬鹿をプッシュした責任は?ww
PSシリーズを失敗と言えるとは。
どんな商品を作りましたかあなたはw
どんな商品を作りましたかあなたはw
これがGK脳ってやつですか?
>>405
「責任」って、あんたは資本家で、後藤は経営アドバイザかよ。
保守的技術の順当勝ちより革新が旋風を起こすほうが、ネタとしては面白いから、
ライターは新しいモノ寄りで、読者はそれを割り引いて読めばいいんでは?
不利な事実を無視して記事を書くのは困るが。
「責任」って、あんたは資本家で、後藤は経営アドバイザかよ。
保守的技術の順当勝ちより革新が旋風を起こすほうが、ネタとしては面白いから、
ライターは新しいモノ寄りで、読者はそれを割り引いて読めばいいんでは?
不利な事実を無視して記事を書くのは困るが。
ところでファウンドリにケチつけてたヤツは
大原みたいに翻訳あきらめてあらゆる単語を英語のまま記事にして欲しいのかね。
大原みたいに翻訳あきらめてあらゆる単語を英語のまま記事にして欲しいのかね。
後藤WinHEC行ってるんだろ
さっさと記事書けよ
さっさと記事書けよ
>>409
ファウンドリ云々に関してケチつけたことないけど、その方が1000000000000000000000000倍くらいマシ。
ファウンドリ云々に関してケチつけたことないけど、その方が1000000000000000000000000倍くらいマシ。
>>411
本気でいってんの?w
本気でいってんの?w
>>412
俺も411に賛成
俺も411に賛成
いくらなんでもファブとファウンドリを同一視するのは無理があり過ぎるだろw
>>415-417
ゆとり乙
ゆとり乙
中二病患者乙
ファーブにはもう少し頑張ってもらいたい
誤答はソニーやATiから金貰ってるのかな。
今度はVLIWネタでATI提灯か
日本語文中に英単語入れていいのは技術書だけだ、って俺様規則だろ。
もう全部英語でいいよ。
この辺の対象読者には全然問題ないだろうし。
一回やってみてよ。
この辺の対象読者には全然問題ないだろうし。
一回やってみてよ。
今更なネタのくせに遅筆
最悪だ
最悪だ
>>424
いいかげんロジャースに道を譲れよおっさん
いいかげんロジャースに道を譲れよおっさん
スロでパトレイバー打ってるんじゃない? 気をつけろ!
固有名詞はアルファベットでつづってくれてもかまわないが、他は
日本語(訳語がなければカタカナ)で書いてほしいよ。
日本語文書なんだから。
日本語(訳語がなければカタカナ)で書いてほしいよ。
日本語文書なんだから。
固有名詞も公式な日本語読みが有るなら書いて欲しい
「エヌだ、いや本社が〜だからヌと読むべきだ」とか不毛なスレは見たくない
「エヌだ、いや本社が〜だからヌと読むべきだ」とか不毛なスレは見たくない
ならなおのことアルファベットのままがいいじゃん。
>>436の知能の低さ。
ヘボン法でいいじゃん
とか思ったが発音記号で書いときゃ間違い無いな
とか思ったが発音記号で書いときゃ間違い無いな
さてそろそろPOWER6くるか
POWER6はこないよ
AMDがRadeon HD 2000で倍速シェーダを採らなかった理由
http://pc.watch.impress.co.jp/docs/2007/0523/kaigai360.htm
http://pc.watch.impress.co.jp/docs/2007/0523/kaigai360.htm
誤答はやたらめったら「効率アップ」を連呼しているが・・・・・
その結果はこれだもんなあ
全て1920*1200
Half-Life 2: Episode One
8800GTX 134
HD2900XT 91
Battlefield 2142
8800GTX 114
HD2900XT 94
FEAR
8800GTX 70
HD2900XT 54
Splinter Cell - Chaos Theory
8800GTX 93
HD2900XT 68
ノイズ
8800GTX 50.7dB
HD2900XT 62.3dB
消費電力
8800GTX 348W
HD2900XT 384W
http://www.hwupgrade.it/articoli/skvideo/1725/ati-radeon-hd-2900-xt-e-il-momento-di-r600_index.html
その結果はこれだもんなあ
全て1920*1200
Half-Life 2: Episode One
8800GTX 134
HD2900XT 91
Battlefield 2142
8800GTX 114
HD2900XT 94
FEAR
8800GTX 70
HD2900XT 54
Splinter Cell - Chaos Theory
8800GTX 93
HD2900XT 68
ノイズ
8800GTX 50.7dB
HD2900XT 62.3dB
消費電力
8800GTX 348W
HD2900XT 384W
http://www.hwupgrade.it/articoli/skvideo/1725/ati-radeon-hd-2900-xt-e-il-momento-di-r600_index.html
まあぶっちゃけ利用してるEDAの癖がでてるだけなんだけどね。NVIDIAはSのEDAツールをメインで使ってたはずだけど。
ATIのfoldingの性能見る限りじゃ効率はかなりよさそうだけどな。
GPUとしての効率は犠牲になってるが。
GPUとしての効率は犠牲になってるが。
開発環境整わんことには…
AMDの言い訳・嘘を無批判に垂れ流し
手始めにFinal CutやEdiusでアクセラレータとして使えるようにならんかねぇ
後藤が批判してるの見たことないんだけど、何について批判してますか?
出来ればその記事のURLも教えてください。
出来ればその記事のURLも教えてください。
>>448
この手法が有効ならMac Proがそのうち積むんじゃないかと・・・
この手法が有効ならMac Proがそのうち積むんじゃないかと・・・
449は誰に対して発言してるんだ?
446 :Socket774:2007/05/23(水) 05:19:11 ID:bEbH0WUf
AMDの言い訳・嘘を無批判に垂れ流し
AMDの言い訳・嘘を無批判に垂れ流し
>> 「プロデューサ−コンシューマロカリティ(Producer-Consumer Locality)」の活用と「Local Working-set Update」が可能になり、
確かにこりゃ酷いなぁ。
ただ単にカタカナで書いただけかよ。Locality をロカリティとカナ表記するのもわけ分からん。
それ以前に何でカナ表記するしないを統一しないんだろ。
確かにこりゃ酷いなぁ。
ただ単にカタカナで書いただけかよ。Locality をロカリティとカナ表記するのもわけ分からん。
それ以前に何でカナ表記するしないを統一しないんだろ。
>VLIW命令は、SIMDアレイ内の
の後で
>VLIW(Very Long Instruction Word)タイプであるため
と既出の略語の説明をしてるのも何だか不恰好だなぁ、
と思った。
の後で
>VLIW(Very Long Instruction Word)タイプであるため
と既出の略語の説明をしてるのも何だか不恰好だなぁ、
と思った。
実は最近弘茂の代わりに息子が書いてるんじゃね?
それだったら息子は(年齢の割には)相当な英語力だな…まだ中学生だろ?
後藤はその昔nVIDIAの新GPUが出る度に、
ダイサイズが大きいのが駄目だと決まったように批判してたな。
ダイサイズが大きいのが駄目だと決まったように批判してたな。
後藤はダメだとは言わないんだよね
「Socket423は短命で、Intelが考えるNetBurstの本命はSocket478ですよ」とか
「nVidiaの新GPUは凄い消費電力&発熱で、冷却の為に2スロット使う設計ですよ」
とかは書く。(この辺がIntelから「必要悪」と言われる理由らしい)
でも、
「だから買わずに様子を見た方が良いですよ」とか
「ライバル製品買った方が良いですよ」とか書いてるのは見たことがない。
「Socket423は短命で、Intelが考えるNetBurstの本命はSocket478ですよ」とか
「nVidiaの新GPUは凄い消費電力&発熱で、冷却の為に2スロット使う設計ですよ」
とかは書く。(この辺がIntelから「必要悪」と言われる理由らしい)
でも、
「だから買わずに様子を見た方が良いですよ」とか
「ライバル製品買った方が良いですよ」とか書いてるのは見たことがない。
まあアンチの頭のおかしさが良く分る話でした。
ttp://pc.watch.impress.co.jp/docs/2002/1218/kaigai01.htm
製造コストが非常に高い? GeForce FXの勝算
→ttp://pc.watch.impress.co.jp/docs/2003/0210/kaigai01.htm
なぜGeForce FX 5800 Ultraはこんなに安いのか
ttp://pc.watch.impress.co.jp/docs/2004/0421/kaigai085.htm
NVIDIA GeForce 6800(NV40)のウイークポイント
ATiの場合はなぜか「トレードオフとしては悪くない」と擁護
ttp://pc.watch.impress.co.jp/docs/2006/0127/kaigai236.htm
製造コストが非常に高い? GeForce FXの勝算
→ttp://pc.watch.impress.co.jp/docs/2003/0210/kaigai01.htm
なぜGeForce FX 5800 Ultraはこんなに安いのか
ttp://pc.watch.impress.co.jp/docs/2004/0421/kaigai085.htm
NVIDIA GeForce 6800(NV40)のウイークポイント
ATiの場合はなぜか「トレードオフとしては悪くない」と擁護
ttp://pc.watch.impress.co.jp/docs/2006/0127/kaigai236.htm
あほ?
20%のトランジスタ数増加で
100%の演算能力アップが悪くないとでも?
20%のトランジスタ数増加で
100%の演算能力アップが悪くないとでも?
20%のトランジスタ数アップはコストにどれだけ響くでしょう?
■後藤弘茂のWeekly海外ニュース■
AMD初のモバイル専用CPU「Griffin」の正体
ttp://pc.watch.impress.co.jp/docs/2007/0524/kaigai361.htm
AMD初のモバイル専用CPU「Griffin」の正体
ttp://pc.watch.impress.co.jp/docs/2007/0524/kaigai361.htm
100%の演算能力アップは、どれだけ演算能力が上がるでしょう
>>450
MacにRadeonは載らんでしょ。
MacにRadeonは載らんでしょ。
>Rev. Gとほぼ同じGPUコアに、
CPUコアの間違い?
CPUコアの間違い?
>>467
そのまま返すよw
そのまま返すよw
しかし、性能より面白いのは、その戦略だ。同社は、一世代先の製造技術に合わせてチップを設計しているのだという。
nVIDIAの戦略マーケティングのディレクタ、マイケル・W・ハラ氏によると
「RIVA 128は350万トランジスタで約72平方mmのダイサイズで30ドル以下で提供する。
これが'98年には0.25ミクロンが使えるようになり、ダイサイズは36平方mmになる。
すると、現在S3やCirrus Logicが提供している20ドル以下の価格帯で販売できるようになる。
その時になれば、当社はさらに700万トランジスタを使う次世代チップを開発する。
RIVA 128を引きずらずに、ゼロからもう一度再設計するので性能はスケールアップする。おそらく2倍の性能にできるだろう。
その新チップが0.18ミクロンが使えるようになる'99年には、20ドル以下の価格帯に降りてくる」という。
しかし、ホントウにそれだけの性能の3Dグラフィックスが必要とされる時代が来るのだろうか。
↑性能アップを批判w。
こいつRIVA128の頃からnVIDIA嫌いだったんだな。
ある意味一貫性が通っているw
nVIDIAの戦略マーケティングのディレクタ、マイケル・W・ハラ氏によると
「RIVA 128は350万トランジスタで約72平方mmのダイサイズで30ドル以下で提供する。
これが'98年には0.25ミクロンが使えるようになり、ダイサイズは36平方mmになる。
すると、現在S3やCirrus Logicが提供している20ドル以下の価格帯で販売できるようになる。
その時になれば、当社はさらに700万トランジスタを使う次世代チップを開発する。
RIVA 128を引きずらずに、ゼロからもう一度再設計するので性能はスケールアップする。おそらく2倍の性能にできるだろう。
その新チップが0.18ミクロンが使えるようになる'99年には、20ドル以下の価格帯に降りてくる」という。
しかし、ホントウにそれだけの性能の3Dグラフィックスが必要とされる時代が来るのだろうか。
↑性能アップを批判w。
こいつRIVA128の頃からnVIDIA嫌いだったんだな。
ある意味一貫性が通っているw
>>469
コストと性能を比べなくては「トレードオフとしては悪くない」かどうかを判断できるないのに、
単純にトランジスタ数と性能で比べている>462は頭が悪い。って話なんだが。
まぁ
> 100%の演算能力アップは、どれだけ演算能力が上がるでしょう
なんて書いて喜んでいるぐらいだから相当頭悪いんだろうな。
コストと性能を比べなくては「トレードオフとしては悪くない」かどうかを判断できるないのに、
単純にトランジスタ数と性能で比べている>462は頭が悪い。って話なんだが。
まぁ
> 100%の演算能力アップは、どれだけ演算能力が上がるでしょう
なんて書いて喜んでいるぐらいだから相当頭悪いんだろうな。
トレードオフって必ずしもコストを含める必要はないんだが。
今回はトランジスタ数と性能との比較をしてるわけで。
まあダイサイズが2割増えたくらいでは製造コストも2倍にならんので十分。
今回はトランジスタ数と性能との比較をしてるわけで。
まあダイサイズが2割増えたくらいでは製造コストも2倍にならんので十分。
ID:5zDP/r+Xは池沼
>>462
面積はスクエアで性能はリニアだから悪くないよ
面積はスクエアで性能はリニアだから悪くないよ
>ドキュメンテーションとベリファイに
>文書化とベリファイを
ドキュメンテーション=文書化だよね?
日本語訳、カタカナ、英語のまま、のどれにするかの問題はまあ
置いておいても、同じ語句は統一しないとやっぱり不恰好だよなあ。
>文書化とベリファイを
ドキュメンテーション=文書化だよね?
日本語訳、カタカナ、英語のまま、のどれにするかの問題はまあ
置いておいても、同じ語句は統一しないとやっぱり不恰好だよなあ。
>>472
トランジスタ数=ダイサイズでもないってことに注意した方がよいかと思う。
それから「ダイサイズ」が二割増えるとしても、うっかりするとコストは倍以上になる。
サイズが大きくなると加速度的に歩留まりが悪くなるからね。
トランジスタ数=ダイサイズでもないってことに注意した方がよいかと思う。
それから「ダイサイズ」が二割増えるとしても、うっかりするとコストは倍以上になる。
サイズが大きくなると加速度的に歩留まりが悪くなるからね。
300平方mm→超巨大なダイサイズ
→様々な問題が発生する
→ホットなNV40が問題に
→疑問が残る高コスト体質
→レギュレーションを無視して排気量の巨大なエンジンを積んでレースに出るようなもの
→それによって得られる効果のバランスが取れていないように見える
350平方mm→トレードオフとしては悪くない
>>475
> >ドキュメンテーションとベリファイに
普通ドキュメンテーションに並べるならベリフィケーションになるよなぁ。
> >文書化とベリファイを
文書化と検証でいいと思うよ。
> フルチップのパーツとしての環境でベリファイするのではなく、コンポーネントレベルでベリフィケーションすることで標準化している。
こっちだとベリフィケーションなんだけど。
チップ全体を検証するのではなく、チップ内部の部品単位で検証を行い標準化している。
ぐらいでいいと思うんだけど。
検証って言葉が思い浮かばなかったんだろうか。
> >ドキュメンテーションとベリファイに
普通ドキュメンテーションに並べるならベリフィケーションになるよなぁ。
> >文書化とベリファイを
文書化と検証でいいと思うよ。
> フルチップのパーツとしての環境でベリファイするのではなく、コンポーネントレベルでベリフィケーションすることで標準化している。
こっちだとベリフィケーションなんだけど。
チップ全体を検証するのではなく、チップ内部の部品単位で検証を行い標準化している。
ぐらいでいいと思うんだけど。
検証って言葉が思い浮かばなかったんだろうか。
>>476
そんなことは分かってるけど同じロジック部を拡張してるんだから比例に近くなるでしょ。
それに元がこれくらいのダイサイズじゃまだコスト2倍にはならんよ。
よっぽど壊滅的な歩留まりなら別だけど。
そんなことは分かってるけど同じロジック部を拡張してるんだから比例に近くなるでしょ。
それに元がこれくらいのダイサイズじゃまだコスト2倍にはならんよ。
よっぽど壊滅的な歩留まりなら別だけど。
確かにNV40を狂ったように貶してるな。
NV40を批判するなら、R520やR600なんかは糞味噌に批判しないとダメだろう。
NV40を批判するなら、R520やR600なんかは糞味噌に批判しないとダメだろう。
>>480
むしろハイエンドGPUでダイ面積を語る無意味さを悟ったのだろう。
NもAももはや商業的にはありえないレベル。
CPUのIntelやAMDのように面積維持で性能Upってのを念頭においていたから
昔の記事は批判的なんじゃね?
ところがGF5900/RADE9800ぐらい以降はどんどん肥大化がエスカレートしてて
CPUとは違うということに気づいたんだよ、たぶん。
むしろハイエンドGPUでダイ面積を語る無意味さを悟ったのだろう。
NもAももはや商業的にはありえないレベル。
CPUのIntelやAMDのように面積維持で性能Upってのを念頭においていたから
昔の記事は批判的なんじゃね?
ところがGF5900/RADE9800ぐらい以降はどんどん肥大化がエスカレートしてて
CPUとは違うということに気づいたんだよ、たぶん。
>>477
GPUは年々肥大化を繰り返してきたんだから
サイズの絶対値に対する評価なんて数年も経てば変わるのが当たり前だろ。
N厨の被害妄想はホント酷いな。
Nvidia賞賛以外は全て批判にみえるとは韓国人なみの病気。
GPUは年々肥大化を繰り返してきたんだから
サイズの絶対値に対する評価なんて数年も経てば変わるのが当たり前だろ。
N厨の被害妄想はホント酷いな。
Nvidia賞賛以外は全て批判にみえるとは韓国人なみの病気。
後藤信者の盲目擁護っぷりが凄いな。
結局ズレた事を書いてたんだから、
記事への批評があっても仕方無いだろう。
結局ズレた事を書いてたんだから、
記事への批評があっても仕方無いだろう。
しかし、結局ATI記事でTDPに触れなかったんだな。
どこが批判なのが具体的に出せよ池沼w
100%の演算能力アップのトレードオフとして悪くなるのは、コストが100%を超えた場合。
同一アーキテクチャのトランジスタ20%増しは≒ダイサイズ20%増しと考えられる。
一般に製造コストはダイサイズに比例、あるいはダイサイズの二乗に比例するといわれている。
(書き手によって、さまざまな考え方があるようだ)
二乗のケースを考えてもコストは1.2^2=1.44倍、44%にしかならない。
つまり、20%のトランジスタ増で、100%の演算能力アップは
トレードオフとして、悪くないといえるだろう。
同一アーキテクチャのトランジスタ20%増しは≒ダイサイズ20%増しと考えられる。
一般に製造コストはダイサイズに比例、あるいはダイサイズの二乗に比例するといわれている。
(書き手によって、さまざまな考え方があるようだ)
二乗のケースを考えてもコストは1.2^2=1.44倍、44%にしかならない。
つまり、20%のトランジスタ増で、100%の演算能力アップは
トレードオフとして、悪くないといえるだろう。
でもNV40の場合は悪いと。
シェーダ性能はNV38の2倍〜9倍アップだそうだが。
シェーダ性能はNV38の2倍〜9倍アップだそうだが。
誤答はそんなんだから、
nVIDIAはUnified Shaderを採用しないなんていう嘘にコロっと騙されて、
ダメ記事書いちゃうんだよw
nVIDIAはUnified Shaderを採用しないなんていう嘘にコロっと騙されて、
ダメ記事書いちゃうんだよw
単に昔と今と考え方が変わっただけじゃないのか?
G80はダメ、R600はイイ、とは書いてないように思うが?
ベンチマークの差を苦しい言い訳で無かったことにしてる、とかならば問題だが、
「悪くない」に文句言うなんて過敏過ぎ。悪いと思う人は買わなければいいだけ。
G80はダメ、R600はイイ、とは書いてないように思うが?
ベンチマークの差を苦しい言い訳で無かったことにしてる、とかならば問題だが、
「悪くない」に文句言うなんて過敏過ぎ。悪いと思う人は買わなければいいだけ。
好意的に見すぎだろ。
ATiもでっかくなっちゃったから、持論を引っ込めざるおえなくなったんだよコイツは。
ATiもでっかくなっちゃったから、持論を引っ込めざるおえなくなったんだよコイツは。
( ^ω^)おっおっ
こんなことでちまちま文句言ってないで後藤にメールすればいいのに・・・
イソプレスはミスリード誤答をさっさと切れ
>>487
だってシェーダだろぉ〜?
だってシェーダだろぉ〜?
こんなところにもゲフォ厨が沸いてスレ荒らしてるな。
お前らここで引きこもってろよw
NVIDIA厨 vs AMDATi厨 Intel厨 S3厨 Part 42
http://pc11.2ch.net/test/read.cgi/jisaku/1178252658/
お前らここで引きこもってろよw
NVIDIA厨 vs AMDATi厨 Intel厨 S3厨 Part 42
http://pc11.2ch.net/test/read.cgi/jisaku/1178252658/
むしろそれだけのトランジスタを搭載していながら未だリアルタイム・レイトレーシング
が不可能な現実。
が不可能な現実。
まあ後藤がアレってのは周知の事実だし・・
出たな、叩きの十八番、根拠のないレッテル貼り
というか、我らがGotoに匹敵するレビューを書ける人は他にいるの?
500 :MACオタ>499 さん:2007/05/25(金) 01:57:34 ID:6ojiKhut
>>499
以前から書いているすけど、経歴(職歴)がしっかりしてる分だけ大原氏の方が良いす。
以前から書いているすけど、経歴(職歴)がしっかりしてる分だけ大原氏の方が良いす。
大原は知ったかだからなあ
どっちも業界アナリストの書いた文だと思って読めば問題ないさ。
100%正しい情報も100%正しい判断も、情報がない部外者にはできないんだよ。
100%正しい情報も100%正しい判断も、情報がない部外者にはできないんだよ。
503 :MACオタ>502 さん:2007/05/25(金) 02:36:53 ID:6ojiKhut
>>502
真偽までわ行かなくて怪しいかどうかが読み取れないのわ、読者に電子工学の素養が無いからだと
思うす。所謂「アナリスト」も同様の手法で読者を騙すす。
結局騙されるのわ、知ったかぶりの素人さんかと。。。
真偽までわ行かなくて怪しいかどうかが読み取れないのわ、読者に電子工学の素養が無いからだと
思うす。所謂「アナリスト」も同様の手法で読者を騙すす。
結局騙されるのわ、知ったかぶりの素人さんかと。。。
おっしゃるとおりw
おぜぜを出すのは「素人さん」だから
「最終的にはPS3がシェアトップ」みたいなアナリストの騙し記事はあったが、
後藤はそういうの書いてないだろ。
開発環境が整っていない等、PS3が出だしでコケる危険性も指摘していたし。
後藤の期待か何かを勝手に予言だと思い込んで、後で「騙された」と感じるだけでは?
FUSIONだってAMDの発表以上のことは(ほとんど)書いてないし。
後藤はそういうの書いてないだろ。
開発環境が整っていない等、PS3が出だしでコケる危険性も指摘していたし。
後藤の期待か何かを勝手に予言だと思い込んで、後で「騙された」と感じるだけでは?
FUSIONだってAMDの発表以上のことは(ほとんど)書いてないし。
>経歴(職歴)がしっかりしてる
大原はこれがなかったらもうとっくに切られてるw
大原はこれがなかったらもうとっくに切られてるw
掲示板作りが上手な事で知られる自称“永遠の19歳”西村博之さん(30)、横文字多用に苦言。
http://news21.2ch.net/test/read.cgi/mnewsplus/1180150801/l50
http://news21.2ch.net/test/read.cgi/mnewsplus/1180150801/l50
O原は指数関数グラフにするとか確信犯でやるからなぁ…気持ちは解るが信用出来ない
510 :MACオタ>509 さん:2007/05/27(日) 16:04:46 ID:s6ZjjMlj
>>509
------------------
O原は指数関数グラフにするとか
------------------
具体的なソースを提示しないと、中傷の類かと思うす。
例えば、リーク電流の微細化に対するスケーリングなんかを図にするにわ指数表示が当たり前だし。。。
------------------
O原は指数関数グラフにするとか
------------------
具体的なソースを提示しないと、中傷の類かと思うす。
例えば、リーク電流の微細化に対するスケーリングなんかを図にするにわ指数表示が当たり前だし。。。
そもそもデータを持っているからグラフ化もできるす。
実験もせず、自分で集めたデータも持たないライターさんを「指数関数グラフを使わない」という
理由で持ち上げるのわ、本末転倒な気がするすけど。。。
実験もせず、自分で集めたデータも持たないライターさんを「指数関数グラフを使わない」という
理由で持ち上げるのわ、本末転倒な気がするすけど。。。
信用ってのは増減するからね。
大原はまず信用増やすところからやらないとw
大原はまず信用増やすところからやらないとw
なんだかんだ言っても大原は技術的な事をキチンと書ける数少ないまともなライターだからなあ。
抽象的な与太記事しか書けない後藤とはレベルが違うよ。
後藤は、一般マスコミで言えばタブロイド誌の記者レベル。
まあ芸能界のゴシップ記事好きなおばさんレベルの人には、
後藤の記事の方が面白いのかもしれないが。
抽象的な与太記事しか書けない後藤とはレベルが違うよ。
後藤は、一般マスコミで言えばタブロイド誌の記者レベル。
まあ芸能界のゴシップ記事好きなおばさんレベルの人には、
後藤の記事の方が面白いのかもしれないが。
しょうがないじゃない
後藤の方が面白いんだから
後藤の方が面白いんだから
技術的なことをキチンと書いたであろうつまらない記事より、
面白い与太話を読みたいなあ。
面白い与太話を読みたいなあ。
516 :MACオタ>515 さん:2007/05/27(日) 23:24:45 ID:s6ZjjMlj
>>515
別に構わないすけど、本当だと信じ込んで掲示板で自慢げに吹聴するのわ勘弁して欲しいす(笑)
別に構わないすけど、本当だと信じ込んで掲示板で自慢げに吹聴するのわ勘弁して欲しいす(笑)
518 :MACオタ>517 さん:2007/05/27(日) 23:37:26 ID:s6ZjjMlj
大原の大長編コラム「バスのアーキテクチャ」は面白かった。
>>519
アレは本にして欲しい
アレは本にして欲しい
AMD幹部の暴走
524 :MACオタ>522 さん:2007/05/28(月) 01:11:15 ID:o+9DaRUl
後藤が嫌いなことはわかったから、もう応援スレに顔出すなよ
>>524
大量にあるGPU用の演算器の一部をFPU用に使い回してやろうって考えはそんなおかしくないと
思うけどね。その場合ISAは全く変化しないだろう。
FPUを回しているときは少しGPUのパワーが落ちるがそれほど気にはならんだろ。
それよりもx87とSSEでバラバラに演算器を持ってる現状をどうにかしろとも思うが。
大量にあるGPU用の演算器の一部をFPU用に使い回してやろうって考えはそんなおかしくないと
思うけどね。その場合ISAは全く変化しないだろう。
FPUを回しているときは少しGPUのパワーが落ちるがそれほど気にはならんだろ。
それよりもx87とSSEでバラバラに演算器を持ってる現状をどうにかしろとも思うが。
>>527
PentiumDやOpteronもバラバラだった気がしたのだが、とりあえず
C5のフロアプランしかみつからんかった。
http://pc.watch.impress.co.jp/docs/2004/0519/epf06.jpg
ひょっとしたら勘違いかもしれん。
PentiumDやOpteronもバラバラだった気がしたのだが、とりあえず
C5のフロアプランしかみつからんかった。
http://pc.watch.impress.co.jp/docs/2004/0519/epf06.jpg
{kind=link}
ひょっとしたら勘違いかもしれん。
Opteronはこれかな。これは分離してない…ように見えるが。
http://journal.mycom.co.jp/photo/column/sopinion/095/images/photo01l.jpg
http://journal.mycom.co.jp/photo/column/sopinion/095/images/photo01l.jpg
{kind=link}
そのフロアプランはおおざっぱにしか解説が無くてな。
もう少し細かい奴があった気がするのだが。
もう少し細かい奴があった気がするのだが。
531 :MACオタ>528 さん:2007/05/28(月) 02:02:40 ID:o+9DaRUl
>>528
http://www.watch.impress.co.jp/PC/DOCS/ARTICLE/20011017/mpf02.htm
---------------------
FPUは、MMX、3DNow!テクノロジ、ストリーミングSIMD拡張命令(SSE)、ストリーミングSIMD
拡張命令2(SSE2)が処理できるようになっており、SSE2が実行できるようになった点がAthlon
からの強化点といえる。
---------------------
http://www.watch.impress.co.jp/PC/DOCS/ARTICLE/20011017/mpf02.htm
---------------------
FPUは、MMX、3DNow!テクノロジ、ストリーミングSIMD拡張命令(SSE)、ストリーミングSIMD
拡張命令2(SSE2)が処理できるようになっており、SSE2が実行できるようになった点がAthlon
からの強化点といえる。
---------------------
MACオタってそういう些末な点にしか答えないから嫌なんだよなぁ。
533 :MACオタ>532 さん:2007/05/28(月) 02:21:55 ID:o+9DaRUl
>>528
> PentiumDやOpteronもバラバラだった気がした
もしかしてこれかな?
Fall Processor Forum 2004 - Centaur、CN Architectureを発表
http://journal.mycom.co.jp/articles/2004/10/07/fpf1/
> AMDやIntelの場合、FPUとSSEユニットは完全に独立しているので、
> どうしても回路の肥大化に繋がる訳だが
Pentium 4の資料は見つかった
インテル Pentium 4 プロセッサの マイクロアーキテクチャ (p.12)
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf
> Pentium 4 プロセッサのFP 加算器は、1 クロック・サイクルに1 回の拡張
> 精度(EP) 加算、1 回の倍精度(DP) 加算、または2回の単精度(SP) 加算の
> いずれかを実行できます。
> FP 乗算器は2 クロックで1 回のEP 乗算、あるいは1 クロック・サイクルで
> 1 回のDP 乗算または2 回のSP 乗算を実行できます。
> PentiumDやOpteronもバラバラだった気がした
もしかしてこれかな?
Fall Processor Forum 2004 - Centaur、CN Architectureを発表
http://journal.mycom.co.jp/articles/2004/10/07/fpf1/
> AMDやIntelの場合、FPUとSSEユニットは完全に独立しているので、
> どうしても回路の肥大化に繋がる訳だが
Pentium 4の資料は見つかった
インテル Pentium 4 プロセッサの マイクロアーキテクチャ (p.12)
http://download.intel.com/jp/developer/jpdoc/2001q1_art02_j.pdf
> Pentium 4 プロセッサのFP 加算器は、1 クロック・サイクルに1 回の拡張
> 精度(EP) 加算、1 回の倍精度(DP) 加算、または2回の単精度(SP) 加算の
> いずれかを実行できます。
> FP 乗算器は2 クロックで1 回のEP 乗算、あるいは1 クロック・サイクルで
> 1 回のDP 乗算または2 回のSP 乗算を実行できます。
応援する気ねーならこなきゃーのに・・・
537 :MACオタ>525, 536 さん:2007/05/28(月) 03:07:00 ID:o+9DaRUl
>>525 >>536
-----------------
応援する気ねーならこなきゃーのに・・・
-----------------
むしろ意見が違うヒトを見るのがイヤなら、自分で掲示板をつくって独り言を書き込み続けるのが
良いと思うすけど。。。
百歩譲って他のヒトの書き込みも読みたいと言う我侭を認めたとしても、2ちゃんねるにそれを
求めるのわ、お門違いじゃないすかね?
-----------------
応援する気ねーならこなきゃーのに・・・
-----------------
むしろ意見が違うヒトを見るのがイヤなら、自分で掲示板をつくって独り言を書き込み続けるのが
良いと思うすけど。。。
百歩譲って他のヒトの書き込みも読みたいと言う我侭を認めたとしても、2ちゃんねるにそれを
求めるのわ、お門違いじゃないすかね?
あぼーん連発で「こなきゃいいのに」か。
この連投具合はダンゴかMACオタあたりだろうな。
ほんと粘着好きだな。
この連投具合はダンゴかMACオタあたりだろうな。
ほんと粘着好きだな。
棲み分けが出来る仕組み(スレッド)があるのにそれを無視する奴は単なる荒らし。
そんなに批判したけりゃスレ立ててろや。
そんなに批判したけりゃスレ立ててろや。
MACオタの書き込みだけを読みたくないだけなんだが。
基地害は透明あぼんがいいよ。無視が一番だお
ところでSanday Bridgeってほんとに綴り合ってんのか?
>>542
Googleではコードネーム"Sandy Bridge"と表記している文章が多いが、
"Sanday"という地名があって橋もあるから、どちらか分からない。
Intelのサイトにはどちらも見つからなかった。
Googleではコードネーム"Sandy Bridge"と表記している文章が多いが、
"Sanday"という地名があって橋もあるから、どちらか分からない。
Intelのサイトにはどちらも見つからなかった。
>>541
だな
だな
AMDとIntelの携帯機器向けCPU戦略を妄想
http://pc.watch.impress.co.jp/docs/2007/0529/kaigai363.htm
http://pc.watch.impress.co.jp/docs/2007/0529/kaigai363.htm
PC Watchのリンクミス直ったか
さっきまで /0529/kaigai362.htm になってた
さっきまで /0529/kaigai362.htm になってた
その前は0528だった
> Microsoftなどが提供する、膨大な量のコードをリンクすることもできる。
(by Hester@AMD) とあるが、PC用のコードをリンクして携帯機器で動くのか?
IntelやAMDが言うほど、組込用x86に利点が有るとは思えないのだが。
(by Hester@AMD) とあるが、PC用のコードをリンクして携帯機器で動くのか?
IntelやAMDが言うほど、組込用x86に利点が有るとは思えないのだが。
>>545
ちょw
ちょw
家電や携帯が強い日本とは違って、アメリカだとPCマンセーなんじゃなかったっけ。
全てがアメリカンサイズですから
人類は早く86のISAを捨てたほうがいいと思うんだが
557 :MACオタ>556 さん:2007/05/29(火) 20:26:17 ID:Pb70WNRO
>>556
--------------------
ソフトウェア作る労力のほうが問題
--------------------
別にこの意見を否定しないすけど、あなたわx86に「組込や携帯機器向けのソフトウェア資産」
なるものがあると信じてるすか?
--------------------
ソフトウェア作る労力のほうが問題
--------------------
別にこの意見を否定しないすけど、あなたわx86に「組込や携帯機器向けのソフトウェア資産」
なるものがあると信じてるすか?
スーパーロボット大戦COMPACTシリーズは組み込みのソフトウェア資産になりませんか、なりませんよね
本当にx86乗換えのほうが開発が楽ならば結構なことだが、
結局、開発の手間は大して変わらなくて、Intel&AMDが得するだけな気がする。
ARM/PPC/SHがもっと開発環境を整備すればいいんだが。
結局、開発の手間は大して変わらなくて、Intel&AMDが得するだけな気がする。
ARM/PPC/SHがもっと開発環境を整備すればいいんだが。
>>559
Windowsがそのまま動くってだけで、価値が数十倍跳ね上がるんじゃないの。
Windowsがそのまま動くってだけで、価値が数十倍跳ね上がるんじゃないの。
数万倍になるんじゃね。
CPUもIBMですらスケールメリットを必要としてるわけで。
CPUもIBMですらスケールメリットを必要としてるわけで。
>>557
ネットワーク端末としての携帯(やセットアップボックスだのなんだの)に関しては、
直接x86(というよりはWindows。だが)で書かれたブラウザなどの
プラグインがそのまま食えるといいよね。という話があるが。
まぁほかの用途ならx86である必要はないが、逆に言うとx86以外である必要もない。
とはいうものの
>>560
組み込みでWindowsがそのまま動くと言うことはあり得ないんじゃないかなぁ。
Windowsの資産の一部がそのまま食える。程度が関の山ではないかと。
プロセッサはIntelががんばって小さくなったとしても、メモリだの何だのの周辺に対する
要求が大きすぎると思うよ<Windows
#そのへんMicrosoftががんばるって話は聞こえてこないのだよね。
x86が組み込みに浸透→Windowsプログラマがそのまま組み込みプログラマに!
なんて夢のような話は成立しないだろうしねぇ。
結局のところ、組み込みの場合だと「単に選択肢が増えた」以上にはならんと思う。
積極的にx86を利用する理由もないけど、かといって積極的に利用を避ける理由もない。
ネットワーク端末としての携帯(やセットアップボックスだのなんだの)に関しては、
直接x86(というよりはWindows。だが)で書かれたブラウザなどの
プラグインがそのまま食えるといいよね。という話があるが。
まぁほかの用途ならx86である必要はないが、逆に言うとx86以外である必要もない。
とはいうものの
>>560
組み込みでWindowsがそのまま動くと言うことはあり得ないんじゃないかなぁ。
Windowsの資産の一部がそのまま食える。程度が関の山ではないかと。
プロセッサはIntelががんばって小さくなったとしても、メモリだの何だのの周辺に対する
要求が大きすぎると思うよ<Windows
#そのへんMicrosoftががんばるって話は聞こえてこないのだよね。
x86が組み込みに浸透→Windowsプログラマがそのまま組み込みプログラマに!
なんて夢のような話は成立しないだろうしねぇ。
結局のところ、組み込みの場合だと「単に選択肢が増えた」以上にはならんと思う。
積極的にx86を利用する理由もないけど、かといって積極的に利用を避ける理由もない。
既存のソフトウェア資産のことはおれはどうでもいい。
別にx86でなくてもいいけど、世の中のCPUが単一のアーキテクチャになれば
(PCからケータイから家電までアーキテクチャが統一されれば)
組み込みの開発作業自体が圧倒的に楽になるし、
PC向けから家電まで視野に入れた開発作業もずっと効率的になるし、
それが狙えるのはx86だけだわ。
別にx86でなくてもいいけど、世の中のCPUが単一のアーキテクチャになれば
(PCからケータイから家電までアーキテクチャが統一されれば)
組み込みの開発作業自体が圧倒的に楽になるし、
PC向けから家電まで視野に入れた開発作業もずっと効率的になるし、
それが狙えるのはx86だけだわ。
サーバ向けは、PCサーバはともかく基幹サーバ的なマシンは
どうせ将来も専用に開発したソフトを動かすのだろうからどうでもいいや。
どうせ将来も専用に開発したソフトを動かすのだろうからどうでもいいや。
>>557
発想が逆だろ。PCの資産をほぼそのまま持ち込もうという(無茶(というか無謀)な)計画なわけで。
発想が逆だろ。PCの資産をほぼそのまま持ち込もうという(無茶(というか無謀)な)計画なわけで。
無茶で無謀と笑われようと
既存のソフトウェア資産が問題なんじゃなくて
86のデコードでパイプライン5段は無駄にしてることとか
コンパイラーの出力が面倒臭いこととか
メモリー帯域を無駄に消費することとか
そっちのほうが問題だと思う
86のデコードでパイプライン5段は無駄にしてることとか
コンパイラーの出力が面倒臭いこととか
メモリー帯域を無駄に消費することとか
そっちのほうが問題だと思う
Windowsの組み込みといえばXbox360
x86じゃないけどな
えっ、x86だろ、CPUはPentiumのキャッシュ128kバージョンだし
失礼、XBOX無印と勘違いしてたorz
Microsoftが対応してくれればx86資産は不要、とまでは言えないが、
CPUがx86になっても、PC用のソフトがそのまま動くわけではないし。
CPUがx86になっても、PC用のソフトがそのまま動くわけではないし。
>>554
淫「オレもそう思ってたんだが、どこかの互換メーカーが空気の読めない真似をしやがるから」
淫「オレもそう思ってたんだが、どこかの互換メーカーが空気の読めない真似をしやがるから」
っと、言いつつ裏でYamhillを用意していた淫であった。。。
色んなCPUをアセンブラで使った経験で言うと、
ARMのアーキテクチャが1番好きだ。
MIPSやPowerも悪くは無いが、ちと面白みに欠ける。
でもARMの全部の演算命令に条件実行とレジスタシフトを付けられるのは、
クロック高速化の足を引っ張ってそうだな・・・
ARMのアーキテクチャが1番好きだ。
MIPSやPowerも悪くは無いが、ちと面白みに欠ける。
でもARMの全部の演算命令に条件実行とレジスタシフトを付けられるのは、
クロック高速化の足を引っ張ってそうだな・・・
>>576
> ARMのアーキテクチャが1番好きだ。
えーあの変態アーキのどこがと思ったが、
> MIPSやPowerも悪くは無いが、ちと面白みに欠ける。
「面白い」という評価軸が含まれてるならまぁそんなもんか?
もって手を広げて8bitマイコンの変態さを味わっていただくとよいかと。
> ARMのアーキテクチャが1番好きだ。
えーあの変態アーキのどこがと思ったが、
> MIPSやPowerも悪くは無いが、ちと面白みに欠ける。
「面白い」という評価軸が含まれてるならまぁそんなもんか?
もって手を広げて8bitマイコンの変態さを味わっていただくとよいかと。
面白さという点では、m88kもなかなか良かった。
なんつーか、RISCになりきれずに未練たらたらのところとか。
なんつーか、RISCになりきれずに未練たらたらのところとか。
変態といったらx86の右に出るものは無いだろw
>>579
x86は無節操。変態にすらなれていない。
x86は無節操。変態にすらなれていない。
そもそもしょっぱなの576からしてスレ違いだし更に続けるのもなんな気がするが...
>>581
> 68000と大差ない性能らしいから狙いは悪くないっぽいけど
同じクロック同じメモリ速度であるのならば68000は8086の2倍速い。
と当時からいわれていましたけど。
>>581
> 68000と大差ない性能らしいから狙いは悪くないっぽいけど
同じクロック同じメモリ速度であるのならば68000は8086の2倍速い。
と当時からいわれていましたけど。
なんだこの雑談スレ
後藤、仕事しろ
今日もコネー
とうとう700か
下がったもんやね
Larrabee来たage
なんかアレだな。AMDとIntelで住み分けしちゃいそうなくらいな勢いだな
intel純正GPUってまさかコレじゃないよな
592 :MACオタ>588 さん:2007/06/11(月) 07:15:47 ID:3acacnku
>>588
普通の読者が読んだらLarrabeeとPolarisの区別がついてないと思うす。
しかし
-------------------
長らくディスクリートGPUと見られていたLarrabeeは、実際にはGPUではない。
-------------------
と書きながら、
-------------------
競合するAMDやNVIDIAはどう出るのだろう。
-------------------
で締めるのわ、何故すかね?噂のNVIDIAのCPU開発の話でも始めるすか。。。
LarrabeeがCPUだとすれば、時期的にも明らかにCELL BEに対抗して開発された訳すけど、
それに関する言及も無いすね。単に「SONYのちょうちん持ち」と馬鹿にされるのがイヤだった
んだとすると、プライド無さ過ぎす。
普通の読者が読んだらLarrabeeとPolarisの区別がついてないと思うす。
しかし
-------------------
長らくディスクリートGPUと見られていたLarrabeeは、実際にはGPUではない。
-------------------
と書きながら、
-------------------
競合するAMDやNVIDIAはどう出るのだろう。
-------------------
で締めるのわ、何故すかね?噂のNVIDIAのCPU開発の話でも始めるすか。。。
LarrabeeがCPUだとすれば、時期的にも明らかにCELL BEに対抗して開発された訳すけど、
それに関する言及も無いすね。単に「SONYのちょうちん持ち」と馬鹿にされるのがイヤだった
んだとすると、プライド無さ過ぎす。
突っ込むべきところはこっちだろ。
>システムまたはチップの中に、ヘテロジニアスなコアが混在しても、命令セットはできる限り
>ホモジニアスに保ち、アプリケーションからは可能な限り隠蔽する。それがIntelのポリシーのようだ。
違うっての。NehalemとLarrabeeが混在してたとして、それを意識せずにプログラムなんて
できっこない。そんな代物をIntelは目指してるわけじゃない。
x86-ISAにこだわるのはコンパイラが使えるから。
>システムまたはチップの中に、ヘテロジニアスなコアが混在しても、命令セットはできる限り
>ホモジニアスに保ち、アプリケーションからは可能な限り隠蔽する。それがIntelのポリシーのようだ。
違うっての。NehalemとLarrabeeが混在してたとして、それを意識せずにプログラムなんて
できっこない。そんな代物をIntelは目指してるわけじゃない。
x86-ISAにこだわるのはコンパイラが使えるから。
594 :MACオタ>593 さん:2007/06/11(月) 07:36:44 ID:3acacnku
>>593
-----------------
x86-ISAにこだわるのはコンパイラが使えるから。
-----------------
パーサーが流用できても、スケジューリング/最適化部分が別なら「使える」と言えるかどうか。。。
-----------------
x86-ISAにこだわるのはコンパイラが使えるから。
-----------------
パーサーが流用できても、スケジューリング/最適化部分が別なら「使える」と言えるかどうか。。。
>>594
コンパイラのプログラムは人間が書くんだよ
コンパイラのプログラムは人間が書くんだよ
596 :MACオタ>595 さん:2007/06/11(月) 07:42:47 ID:3acacnku
x86-ISAの採用は、ソフト資産を活かせそうという思わせるイメージ戦略でしょ。
そんなことより、キャッシュコーヒーレンシーとかコア間接続を書けよ。>後藤
そんなことより、キャッシュコーヒーレンシーとかコア間接続を書けよ。>後藤
お前ら文句しかいわねーのな
真につっこむべきところはここだ。
> Jim Held氏は...次のように語っている。
> 「プログラマは対称型アーキテクチャのシンプルさを好んでいる。
おまえが言うか。
> Jim Held氏は...次のように語っている。
> 「プログラマは対称型アーキテクチャのシンプルさを好んでいる。
おまえが言うか。
>>599
あ、出遅れた。そこでちょっと吹いた。
あ、出遅れた。そこでちょっと吹いた。
GPGPUと競合してるってことでは苦しい?
ISAに拘ったのは特許がウゼーからじゃw
古いソフトをこいつで動かして省電力を売りにするって手もあるか。
古いソフトをこいつで動かして省電力を売りにするって手もあるか。
肝心のFP命令が違うのに互換も何も無いもんだ。
またx86か
IA64をメインに持ってこれなかった責任はでかいな
IA64をメインに持ってこれなかった責任はでかいな
何言ってんだよ
IA64なんて糞だろ
IA64なんて糞だろ
iAPX432があるじゃない
このスレを見ている人はこんなスレも見ています。(ver 0.20)
インターネットラジオステーション<音泉> 5鯖目 [声優総合]
レズ声優 Part30 [声優総合]
「ウォッチ!声優板」をウォッチするスレ Part17 [声優総合]
君のぞらじお 第31回 [ラジオ番組]
CR侍ジャイアンツ2 [パチンコ機種等]
典型的なキモイ集団だなwww
インターネットラジオステーション<音泉> 5鯖目 [声優総合]
レズ声優 Part30 [声優総合]
「ウォッチ!声優板」をウォッチするスレ Part17 [声優総合]
君のぞらじお 第31回 [ラジオ番組]
CR侍ジャイアンツ2 [パチンコ機種等]
典型的なキモイ集団だなwww
おまえもな。
そして誰もいなくなった
さくせん:いのちだいじに
めいれいさせろ、じゃなくて大丈夫か?w
IntelのLarrabeeに対抗するAMDとNVIDIA
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
やっぱり>>604のいうようにGPGPUについてのことだったね。
っていうかGPGPU以外考えようも無かったが。
それにしても変な時間にupされたな。
深夜にupし忘れたのかな。
http://pc.watch.impress.co.jp/docs/2007/0618/kaigai365.htm
やっぱり>>604のいうようにGPGPUについてのことだったね。
っていうかGPGPU以外考えようも無かったが。
それにしても変な時間にupされたな。
深夜にupし忘れたのかな。
俺様が予言しよう
3社とも失敗する
3社とも失敗する
>>615
だろうなぁ・・・
だろうなぁ・・・
単なるVGA統合型ノースブリッジのCPU統合と
これはGPUですからって逃げ道の有る二社は気が楽かな?
これはGPUですからって逃げ道の有る二社は気が楽かな?
Intelはどうやって普及させるつもりなんだろう・・・。
ゲームのグラフィックとビデオのデコードならば、
ユーザー層が重なって、兼用するのも意味が有りそうだけど、
ゲームにも学術計算にも使える、という汎用性が有っても、どういうメリットが有るのだろう。
ユーザー層が重なって、兼用するのも意味が有りそうだけど、
ゲームにも学術計算にも使える、という汎用性が有っても、どういうメリットが有るのだろう。
1TFLOPS×24Hを100円くらいで時間貸しするサービスでも始めるんじゃない?
>>620
Intelが狙ってるのはHPCとかもっと大規模なとこでしょ。
個人がわざわざCPU,GPUとは別にLarrabeeを買うとは思えん。
グラフィックがそこそこ出来るなら別だけど。
でAMD,NVIDIAの場合、個人でもGPUは買うので量産効果でLarrabeeに対して有利。
そしてその量産効果でもってHPCにも進出したいんじゃないかと。
NVIDIAは「レンダリングサーバーがやりたい」って昔から言ってるし。
ただ、上に進出する前にそこでIntelが地歩を固められると二社は大変。
Intelが狙ってるのはHPCとかもっと大規模なとこでしょ。
個人がわざわざCPU,GPUとは別にLarrabeeを買うとは思えん。
グラフィックがそこそこ出来るなら別だけど。
でAMD,NVIDIAの場合、個人でもGPUは買うので量産効果でLarrabeeに対して有利。
そしてその量産効果でもってHPCにも進出したいんじゃないかと。
NVIDIAは「レンダリングサーバーがやりたい」って昔から言ってるし。
ただ、上に進出する前にそこでIntelが地歩を固められると二社は大変。
Larrabee+GPUボードで良いじゃん、後藤は決め付きすぎw
>>615
万一他の一社が成功すると困るんですよ。
万一他の一社が成功すると困るんですよ。
お前らたまには応援しろよ
>Intelが狙ってるのはHPCとかもっと大規模なとこでしょ。
>個人がわざわざCPU,GPUとは別にLarrabeeを買うとは思えん。
Intelが狙うにはニッチ過ぎると思うがなあ。
最初はHPCからにしても、狙いは一般企業・個人なのでは。
一般人向けのキラーアプリは出てくるかね。
動画エンコ程度しか思いつかないが。
ゲームも普及のキラーになるほどの需要はなさそうだし。
>個人がわざわざCPU,GPUとは別にLarrabeeを買うとは思えん。
Intelが狙うにはニッチ過ぎると思うがなあ。
最初はHPCからにしても、狙いは一般企業・個人なのでは。
一般人向けのキラーアプリは出てくるかね。
動画エンコ程度しか思いつかないが。
ゲームも普及のキラーになるほどの需要はなさそうだし。
> Intelが狙うにはニッチ過ぎると思うがなあ。
ニッチで良いんじゃないの?
別にLarrabeeをメインストリームに据える必要全然ないし、
GPGPU騒ぎをLarrabeeで沈静化しておけばOKだろ。
後はマルチコアの使い方の方向性としてランタイム(CPU内臓)による自動並列化処理の楔を打つって感じて十分。
ニッチで良いんじゃないの?
別にLarrabeeをメインストリームに据える必要全然ないし、
GPGPU騒ぎをLarrabeeで沈静化しておけばOKだろ。
後はマルチコアの使い方の方向性としてランタイム(CPU内臓)による自動並列化処理の楔を打つって感じて十分。
お前等って本当に素人丸出しだな
>>623
多分そうは成らん
何れにせよ3社3規格の並存期間があるだろうが
出来ることが同じならもっとも普及しづらい物から消えていく。
3規格それぞれにソフトを開発するの面倒
すでに広まっており、最低でもDX経由での
GPGPUが可能であるGPUが消えることは考えずらい。
GPUでは無いと主張するIntelを信じれば、Larrabeeはニッチで消えていく。
またGPUであるとしても、異メーカーのマルチGPUは考えづらい。
実際は当面を考え、NVIDIAに配慮しGPUと言わないだけで
準備が出来れば・・・なんて気もするが。
多分そうは成らん
何れにせよ3社3規格の並存期間があるだろうが
出来ることが同じならもっとも普及しづらい物から消えていく。
3規格それぞれにソフトを開発するの面倒
すでに広まっており、最低でもDX経由での
GPGPUが可能であるGPUが消えることは考えずらい。
GPUでは無いと主張するIntelを信じれば、Larrabeeはニッチで消えていく。
またGPUであるとしても、異メーカーのマルチGPUは考えづらい。
実際は当面を考え、NVIDIAに配慮しGPUと言わないだけで
準備が出来れば・・・なんて気もするが。
>>632が毎度お馴染みのアホです。
>IntelのLarrabeeは、(略)ランタイム層で制御を行なう可能性はある。
>AMDのFUSIONは、(略)ランタイムでラップもする。
>NVIDIA GPUは、(略)ランタイム層でラップする。
ハッタリ3バカはどうしよーもねーな。
そんな簡単にランタイムでネイティブ命令セットを隠蔽できたら誰も苦労しねーっつーの。
>AMDのFUSIONは、(略)ランタイムでラップもする。
>NVIDIA GPUは、(略)ランタイム層でラップする。
ハッタリ3バカはどうしよーもねーな。
そんな簡単にランタイムでネイティブ命令セットを隠蔽できたら誰も苦労しねーっつーの。
それはNVIDIAだけちゃうのん
>>634
隠蔽はできるんじゃないの?
性能はあまり出ないだろうけど
それと一行目のIntelに関しては「CPUへも統合するかもしれない」という妄想文脈の中での記述だよ
Larrabeeは急伸しているx86ベースのHPCクラスタ市場を狙うにはいい選択
Larrabeeのライバルをしいて挙げるならNehalemやGesher(Sandy Bridge)
隠蔽はできるんじゃないの?
性能はあまり出ないだろうけど
それと一行目のIntelに関しては「CPUへも統合するかもしれない」という妄想文脈の中での記述だよ
Larrabeeは急伸しているx86ベースのHPCクラスタ市場を狙うにはいい選択
Larrabeeのライバルをしいて挙げるならNehalemやGesher(Sandy Bridge)
.net frameworkは・・
>>636
GRAPE-DR・・・
GRAPE-DR・・・
http://it.nikkei.co.jp/business/news/release.aspx?i=162405
システム価格の安いx86サーバーのクラスターシステムへの需要シフトが継続するとIDCではみています。
2006年におけるx86サーバーは前年比40.6%増で、4年連続で前年比プラス成長となりました。
国内HPC市場におけるx86サーバーの出荷金額構成比は、過去最高の36.6%に達しました。
RISCサーバーからx86サーバーに民間企業のHPC需要がシフトしたとみられ、民間企業向けの大規模クラスターシステムが好調でした。
システム価格の安いx86サーバーのクラスターシステムへの需要シフトが継続するとIDCではみています。
2006年におけるx86サーバーは前年比40.6%増で、4年連続で前年比プラス成長となりました。
国内HPC市場におけるx86サーバーの出荷金額構成比は、過去最高の36.6%に達しました。
RISCサーバーからx86サーバーに民間企業のHPC需要がシフトしたとみられ、民間企業向けの大規模クラスターシステムが好調でした。
>>629
お前はパーツ組み立て作業員に何を期待しているのかと
お前はパーツ組み立て作業員に何を期待しているのかと
なんかIBMも出張ってきそうだね
IBM to unveil stream computing system
http://news.com.com/IBM+to+unveil+stream+computing+system/2100-1010_3-6191819.html
IBM to unveil stream computing system
http://news.com.com/IBM+to+unveil+stream+computing+system/2100-1010_3-6191819.html
GPUライクな構造が想定されるIntelの「Larrabee」
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
http://pc.watch.impress.co.jp/docs/2007/0620/kaigai366.htm
Transmeta Efficeon and Crusoe コケた,
AGEIA PhysX PPU コケた,
PS3 Cell コケた,
・・・とくれば,IntelもAMDもNVIDIAも間違いなくね,だめでしょ。
AGEIA PhysX PPU コケた,
PS3 Cell コケた,
・・・とくれば,IntelもAMDもNVIDIAも間違いなくね,だめでしょ。
コストパフォーマンスに優れる
フリーランチの提供
最低条件としてこの2つを兼ね備えていたとしても市場性が最大の敵
フリーランチの提供
最低条件としてこの2つを兼ね備えていたとしても市場性が最大の敵
フリーランチという言葉を見て無料の昼飯を思い浮かべた俺は勉強すればいいと思います。
え?タダ飯のことじゃないの?
いやタダ飯であってるだろ
開発者にとって高級レストランなんだよPS3は
開発者にとって高級レストランなんだよPS3は
651 :MACオタ>642 さん:2007/06/20(水) 08:13:23 ID:OgFpxvHt
>>642
System Sわソフトウェアす。つまりDLPに特化したハードウェアの用途を見つけてくれた。。。という
ことす。もちろんプラットフォームわ自社ハードウェアであるCELLブレードやBlue Geneとのことす。
http://www.eweek.com/article2/0,1895,2148140,00.asp
------------------------
"It's a unique software architecture for managing data in systems," the IBM spokesperson
said of System S. "It can use any type of hardware or processors it needs to get a job done.
Whether it's IBM blades combined with the Cell processor or it could even be run on
Blue Gene."
------------------------
ソフト・ハード一体で「生産性の高いスーパーコンピューティング」の開発を目指した米国国防省の
プロジェクト"HPCS"の成果が出つつあると見るべきなんすかね。。。
http://techon.nikkeibp.co.jp/article/NEWS/20061123/124281/
System Sわソフトウェアす。つまりDLPに特化したハードウェアの用途を見つけてくれた。。。という
ことす。もちろんプラットフォームわ自社ハードウェアであるCELLブレードやBlue Geneとのことす。
http://www.eweek.com/article2/0,1895,2148140,00.asp
------------------------
"It's a unique software architecture for managing data in systems," the IBM spokesperson
said of System S. "It can use any type of hardware or processors it needs to get a job done.
Whether it's IBM blades combined with the Cell processor or it could even be run on
Blue Gene."
------------------------
ソフト・ハード一体で「生産性の高いスーパーコンピューティング」の開発を目指した米国国防省の
プロジェクト"HPCS"の成果が出つつあると見るべきなんすかね。。。
http://techon.nikkeibp.co.jp/article/NEWS/20061123/124281/
日本の諺で言うと、ただより高いものはない、てとこか
でも無料の昼飯で合ってるような
フリーランチを否定するハードウェアはそのうち消えてなくなるから心配するな。
「銀の弾丸」と似たようなもんか
>>659
お前のセンスにはある意味脱帽する
お前のセンスにはある意味脱帽する
あれー
「フリーランチなんてない」と「銀の弾丸なんてない」って似てない?
だめかぁ
「フリーランチなんてない」と「銀の弾丸なんてない」って似てない?
だめかぁ
>>662
いやBrooksの"No Silver Bullet"っしょ?似てるんじゃない?経験則的なところが違うというか、
NFLTは完全な汎用最適化が「理論上不可能」なことを立証してるけど。
フリーランチを要求し続けられるx86エコシステムの開発者は恵まれてるよなぁ…XtensaのConfigで頭悩まさなくて良いなんて…
いやBrooksの"No Silver Bullet"っしょ?似てるんじゃない?経験則的なところが違うというか、
NFLTは完全な汎用最適化が「理論上不可能」なことを立証してるけど。
フリーランチを要求し続けられるx86エコシステムの開発者は恵まれてるよなぁ…XtensaのConfigで頭悩まさなくて良いなんて…
ttp://www.dailytech.com/article.aspx?newsid=7772
NVIDIA Announces Tesla General Purpose Processor Platform
ttp://pc.watch.impress.co.jp/docs/2007/0621/nvidia.htm
NVIDIA、G80ベースのHPC向けGPU「Tesla」
〜PCI Expressカードタイプから1Uラックまで
>Teslaのソフトウェアプラットフォームは同社の汎用プログラミングモデル
>「CUDA (Compute Unified Device Architecture)」を利用。
>CUDAにはGPU用のCコンパイラが含まれており、
>Cプログラムに若干の修正を加えるだけで、
>CUDAコンパイラが処理をCPUとGPUに振り分けられる。
NVIDIA Announces Tesla General Purpose Processor Platform
ttp://pc.watch.impress.co.jp/docs/2007/0621/nvidia.htm
NVIDIA、G80ベースのHPC向けGPU「Tesla」
〜PCI Expressカードタイプから1Uラックまで
>Teslaのソフトウェアプラットフォームは同社の汎用プログラミングモデル
>「CUDA (Compute Unified Device Architecture)」を利用。
>CUDAにはGPU用のCコンパイラが含まれており、
>Cプログラムに若干の修正を加えるだけで、
>CUDAコンパイラが処理をCPUとGPUに振り分けられる。
http://pc.watch.impress.co.jp/docs/2007/0621/nvidia_3.jpg
とはいえ、値段が安くなると、相対的に電力コストが上がってきます。消費電力が
どれくらいで、それがどれくらいのコストになるかをちょっと見積もってみましょう。
東京電力で普通の家庭用だと、1kWh 20円 くらいです。8800GTX のフル動作時の
消費電力は 200W を超えるようで、1時間当り4円、1年間フルに動かすと 35000 円、
5年使うと 17万5千円です。この 200W は変換損失等を考慮していないので、実際
の数字はもうちょっと高くなります。さらに、空調のコストも入れると 1.3-1.5 倍にな
ります。もちろん、業務用電力はこの半分程度なので、GPU だけでは年 2万円程度
ですが、色々考えると業務用でも年 4万円程度、2年も使うと電気代のほうが高い
という代物であることは要注意です。 8800GTX の現在の価格は 8万円程度なので。
つまり、スーパーコンピューティング用、ということを考えると、現在の GPU はコスト
の大半を電力コストが占めかねなくなっています。ここまでハードウェアの値段が
下がると、電気代のほうが大きくなるわけです。
{kind=link}
とはいえ、値段が安くなると、相対的に電力コストが上がってきます。消費電力が
どれくらいで、それがどれくらいのコストになるかをちょっと見積もってみましょう。
東京電力で普通の家庭用だと、1kWh 20円 くらいです。8800GTX のフル動作時の
消費電力は 200W を超えるようで、1時間当り4円、1年間フルに動かすと 35000 円、
5年使うと 17万5千円です。この 200W は変換損失等を考慮していないので、実際
の数字はもうちょっと高くなります。さらに、空調のコストも入れると 1.3-1.5 倍にな
ります。もちろん、業務用電力はこの半分程度なので、GPU だけでは年 2万円程度
ですが、色々考えると業務用でも年 4万円程度、2年も使うと電気代のほうが高い
という代物であることは要注意です。 8800GTX の現在の価格は 8万円程度なので。
つまり、スーパーコンピューティング用、ということを考えると、現在の GPU はコスト
の大半を電力コストが占めかねなくなっています。ここまでハードウェアの値段が
下がると、電気代のほうが大きくなるわけです。
演算器余ってるからHPCででも使ってよ、みたいなテキトーさを感じる。
プログラマ楽させるための機能を実装するほどHPCって有望な市場なのか?
ソフトが出ればハードも売れる、という好循環もゲーム機ほど期待できないし。
プログラマ楽させるための機能を実装するほどHPCって有望な市場なのか?
ソフトが出ればハードも売れる、という好循環もゲーム機ほど期待できないし。
■後藤弘茂のWeekly海外ニュース■
AMDの省電力CPUコア「Bobcat」とFUSION構想
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
AMDの省電力CPUコア「Bobcat」とFUSION構想
http://pc.watch.impress.co.jp/docs/2007/0621/kaigai367.htm
スパコンいらねって意見>>667は久しぶりに見たなw
はいはい極論極論
>>668
デジタル家電用のCPUにGPU入れてどうすんだよAMDは・・・
デジタル家電用のCPUにGPU入れてどうすんだよAMDは・・・
インターフェース革命だな
国内のシステムLSI厨には出来ない真似だ
国内のシステムLSI厨には出来ない真似だ
ATIは元から家電用の製品も作っているわけだが。
UVDの正体は家電用のXilleonをGPUに統合した物だし。
UVDの正体は家電用のXilleonをGPUに統合した物だし。
CPU/GPUの統合プロセッサ「Fusion」正式発表
http://journal.mycom.co.jp/news/2006/10/26/101.html
米AMDは「Fusion」というコードネームで、CPUとGPUを
シリコンレベルで設計統合する新たなx86プロセッサを
開発する。ATIの買収完了発表の中で明らかにした。
http://journal.mycom.co.jp/news/2006/10/26/101.html
米AMDは「Fusion」というコードネームで、CPUとGPUを
シリコンレベルで設計統合する新たなx86プロセッサを
開発する。ATIの買収完了発表の中で明らかにした。
携帯向けにもImageonがある
これらとCPUを統合すれば
各々分野別の製品が出来るわけだ。
これらとCPUを統合すれば
各々分野別の製品が出来るわけだ。
Hesterの顔写真貼るの好きなんだな
まあそんなことはどうでもいいから、IBMは早く3GHzのPPCを出せよ
つ[XENON]
最近のPCのトレンドは、
ヘテロかホモか
スカラかベクタか
それだけで簡単に整理できてしまうぞ。
ややこしい分析し過ぎな後藤の記事より、
その要素だけで整理したほうがスッキリするぞ。
ヘテロかホモか
スカラかベクタか
それだけで簡単に整理できてしまうぞ。
ややこしい分析し過ぎな後藤の記事より、
その要素だけで整理したほうがスッキリするぞ。
(´・∀・`)ヘー
>>678
そんなもの作っても誰も使わないから意味がないだろ。
そんなもの作っても誰も使わないから意味がないだろ。
つまりNECハジマタってこと?
ところで、俺はちょい入院してたんで、読んでない回があるんだが、
K8Lはホラ情報だったっていう訂正文か謝罪文は掲載されたか?
それとK10はキャンセルになったっていう当初の情報は、
対Intelの情報戦術だったのかな?
K8Lはホラ情報だったっていう訂正文か謝罪文は掲載されたか?
それとK10はキャンセルになったっていう当初の情報は、
対Intelの情報戦術だったのかな?
てめーの態度が気に入らない
>>684
ニート乙www
ニート乙www
688 :MACオタ>687 さん:2007/06/26(火) 00:05:13 ID:E+b+TZBO
>>687
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
---------------------
Intelの「Tejas(テハス)」と「Nehalem(ネハーレン)」、AMDの「K9」と「K10」。x86系の両CPU
メーカーは、過去数年で相次いで次世代CPUマイクロアーキテクチャのプランをキャンセル
または見直し/延期した。両CPUメーカーの、CPUアーキテクチャの方向性の転換を、
これほど如実に物語るものはない。
---------------------
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
---------------------
Intelの「Tejas(テハス)」と「Nehalem(ネハーレン)」、AMDの「K9」と「K10」。x86系の両CPU
メーカーは、過去数年で相次いで次世代CPUマイクロアーキテクチャのプランをキャンセル
または見直し/延期した。両CPUメーカーの、CPUアーキテクチャの方向性の転換を、
これほど如実に物語るものはない。
---------------------
または見直し/延期した
NehalemもK10も当初の予定とはまったく別のものとしてコードネームだけ復活した。
そんだけの話。
そんだけの話。
>>684
K8L=Rev.H=Barcelonaファミリ
ホラ情報じゃない
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai336.htm
K10に関する最新の後藤ニュースはこれ
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
糞コテはまた明らかに間違ったレスを書いては返り討ちにあってるな
どうしてこんなに馬鹿なんだろう
K8L=Rev.H=Barcelonaファミリ
ホラ情報じゃない
http://pc.watch.impress.co.jp/docs/2007/0214/kaigai336.htm
K10に関する最新の後藤ニュースはこれ
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
糞コテはまた明らかに間違ったレスを書いては返り討ちにあってるな
どうしてこんなに馬鹿なんだろう
693 :MACオタ>692 さん:2007/06/27(水) 00:48:10 ID:pjHcr4eL
>>692
----------------
糞コテはまた明らかに間違ったレスを書いて
----------------
何か信者さんの心の琴線に触れるようなこと書いたすか(笑)
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
現行"K10"の正体がK8Lってのわ、この後藤記事が執筆された段階で既に通説化しているす。
K8Lの名前が最初に出たのわ、2005年11月のこの記事す。
http://www.theinquirer.net/default.aspx?article=27421
==================
Either way, if you were expecting the K10 in 2007, don't, and maybe not in 2008 either.
To make up for it, there is a new chip called K8L to slot in the middle, but little is known
about that, as yet.
==================
----------------
糞コテはまた明らかに間違ったレスを書いて
----------------
何か信者さんの心の琴線に触れるようなこと書いたすか(笑)
http://pc.watch.impress.co.jp/docs/2006/0821/kaigai296.htm
現行"K10"の正体がK8Lってのわ、この後藤記事が執筆された段階で既に通説化しているす。
K8Lの名前が最初に出たのわ、2005年11月のこの記事す。
http://www.theinquirer.net/default.aspx?article=27421
==================
Either way, if you were expecting the K10 in 2007, don't, and maybe not in 2008 either.
To make up for it, there is a new chip called K8L to slot in the middle, but little is known
about that, as yet.
==================
とりあえず、まともな日本語の文章を打てるようになってから御託を並べろ糞コテ
MACなんとかとダンゴはまとめてあぼーんするのがこの板での常識
まともな日本語が使えない奴は本国へ帰れってことだな。
K8L=Turion
■後藤弘茂のWeekly海外ニュース■
AMDの製品戦略全体の再構築となるFUSION
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
AMDの製品戦略全体の再構築となるFUSION
http://pc.watch.impress.co.jp/docs/2007/0628/kaigai368.htm
281 :名無しさん必死だな :2007/01/21(日) 19:40:32 ID:YdbEZ84w
AMDのfusionはSoC
半年前なんとなくこう書いたけど、やっぱり狙ってる市場はそっちだったか。
AMDのfusionはSoC
半年前なんとなくこう書いたけど、やっぱり狙ってる市場はそっちだったか。
コードネームゴクウとコードネームベジータを組み合わせてAMD最強に
>>699
Intelもそっち方面ねらってるけど、家電・携帯市場に
食い込んでいくのは実際のところ難しいだろうね。
全体で数が出る市場ではあるから、IntelもAMD
とりあえず布石は打っておこう、という感じがする。
Intelもそっち方面ねらってるけど、家電・携帯市場に
食い込んでいくのは実際のところ難しいだろうね。
全体で数が出る市場ではあるから、IntelもAMD
とりあえず布石は打っておこう、という感じがする。
全く後藤はわかってないな。
だいたいAMDが思いこみで仕様策定したASSPライクなSoCなんて
デジタル家電メーカーや携帯端末メーカーが採用するわけ無い。
彼らが望んでいるのはASIC手法のSoC。
本気でSoC市場に参入するなら、AMDもx86コアとGPUをIP化して
セットメーカから仕様書受けでASICを開発するくらいのことをしないとダメだな。
だいたいAMDが思いこみで仕様策定したASSPライクなSoCなんて
デジタル家電メーカーや携帯端末メーカーが採用するわけ無い。
彼らが望んでいるのはASIC手法のSoC。
本気でSoC市場に参入するなら、AMDもx86コアとGPUをIP化して
セットメーカから仕様書受けでASICを開発するくらいのことをしないとダメだな。
Hester貼り自重
というかAMDはIntelに対して白旗を上げたって感じなんだよな。
ノートPCの低価格市場でもう少し頑張るのかと思ったが・・・・あんなこと言ってるようではダメっぽいな・・・・
ノートPCの低価格市場でもう少し頑張るのかと思ったが・・・・あんなこと言ってるようではダメっぽいな・・・・
「x86の開発環境」とか「x86のコード資産」とかいつも出てくるけど、
その本山(?)であるMicrosoftが、Xbox360で Pentium→PPC と乗り換えたくらいだから、
大したメリット無い気がする。
その本山(?)であるMicrosoftが、Xbox360で Pentium→PPC と乗り換えたくらいだから、
大したメリット無い気がする。
まったくだ
LarrabeeのISAがx86であるのなんて滑稽すぎますね
LarrabeeのISAがx86であるのなんて滑稽すぎますね
>>706
x86を生かしても儲かるのはCPUメーカーだけだということです。
x86を生かしても儲かるのはCPUメーカーだけだということです。
>>693
688にあるK10はキャンセルされた旧K10だと主張するのか。
旧K10だとは688のレスのどこにも言及されてないが、まあいいや。
で、「この後藤記事が執筆された段階で」新K10=K8Lが通説化しているというソースは?
その頃にそう解説した記事をせめてひとつは挙げてくれよ。
688にあるK10はキャンセルされた旧K10だと主張するのか。
旧K10だとは688のレスのどこにも言及されてないが、まあいいや。
で、「この後藤記事が執筆された段階で」新K10=K8Lが通説化しているというソースは?
その頃にそう解説した記事をせめてひとつは挙げてくれよ。
>>705
あたまだいじょうぶですか
あたまだいじょうぶですか
>>709
相手すんな
相手すんな
>>709
わざわざ餌を蒔いて、アレを延々と定住させるのが趣味ですか
わざわざ餌を蒔いて、アレを延々と定住させるのが趣味ですか
>>709
まぁアレ自体はレス番が飛ぶだけだからどうでもいいが、お前自体がうっとおしい。
まぁアレ自体はレス番が飛ぶだけだからどうでもいいが、お前自体がうっとおしい。
714 :MACオタ>709 さん:2007/06/28(木) 20:17:34 ID:B7qBBFTo
>>709
--------------------
で、「この後藤記事が執筆された段階で」新K10=K8Lが通説化しているというソースは?
--------------------
これらの記事で"K8L"と呼ばれているプロセッサわ何すかね(笑)
DailyTech (06/06/01) http://www.dailytech.com/article.aspx?newsid=2637
=====================
Each K8L core will have 64KB of dedicated L1 cache, followed by 512KB of dedicated L2
cache. The base models of K8L will have 2MB of shared L3 cache,
=====================
TG Daily (06/07/20) http://www.tgdaily.com/index.php/content/view/27659
=====================
Meyer also reiterated that AMD is working on a new processor core, which will debut as
a native quad-core. Code-named K8L, the chip will launch by mid-2007 or more than half
a year after Intel's Kentsfield and Clovertown quad-core processors.
=====================
--------------------
で、「この後藤記事が執筆された段階で」新K10=K8Lが通説化しているというソースは?
--------------------
これらの記事で"K8L"と呼ばれているプロセッサわ何すかね(笑)
DailyTech (06/06/01) http://www.dailytech.com/article.aspx?newsid=2637
=====================
Each K8L core will have 64KB of dedicated L1 cache, followed by 512KB of dedicated L2
cache. The base models of K8L will have 2MB of shared L3 cache,
=====================
TG Daily (06/07/20) http://www.tgdaily.com/index.php/content/view/27659
=====================
Meyer also reiterated that AMD is working on a new processor core, which will debut as
a native quad-core. Code-named K8L, the chip will launch by mid-2007 or more than half
a year after Intel's Kentsfield and Clovertown quad-core processors.
=====================
ほらまた日本語に不自由な三国人が召還された
家電までINTELが押し寄せてきたら日本はPCから家電まで奴隷かよ
家電組み込みでは日本のカスタムLSI・ASICは強いよ
強いというか、主要部品やソフトの内製ができないと、単なるアセンブリベンダ化するというか
ぶっちゃけ価格勝負でアジア勢に負ける訳でなぁ…
ぶっちゃけ価格勝負でアジア勢に負ける訳でなぁ…
糞コテはどうしようもないな。答えになってない。
少なくとも「K10が2007年に出る」というその時期の記事を示さなければ
K10=K8Lという通説のソースにならないのに。
読解力のない馬鹿か、真面目に答える気のない厨房のどちらかだな。
少なくとも「K10が2007年に出る」というその時期の記事を示さなければ
K10=K8Lという通説のソースにならないのに。
読解力のない馬鹿か、真面目に答える気のない厨房のどちらかだな。
だからばっちいウンコをつつくなよ。手が汚れるぞ。
>>706
初代Xboxは、ゲーム機(PS2)が家庭内の多機能エンターテインメントデバイス
(映像配信含む)になり、ソニーがWintelに代わってそこを押さえる可能性があるから
MSが対抗しようって側面があったんでは
ハードもソフトもPCの流用なのは開発期間短縮だけでなく自社の支配を維持するため
でも何年経ってもそんなクタラギ的未来は来なかったから、
360はゲーム機としての性能向上とコストダウンのしやすいPPC系カスタムになったんでは?
初代Xboxは、ゲーム機(PS2)が家庭内の多機能エンターテインメントデバイス
(映像配信含む)になり、ソニーがWintelに代わってそこを押さえる可能性があるから
MSが対抗しようって側面があったんでは
ハードもソフトもPCの流用なのは開発期間短縮だけでなく自社の支配を維持するため
でも何年経ってもそんなクタラギ的未来は来なかったから、
360はゲーム機としての性能向上とコストダウンのしやすいPPC系カスタムになったんでは?
722 :MACオタ>719 さん:2007/06/29(金) 18:43:02 ID:hM78bIG1
>>719
------------------
少なくとも「K10が2007年に出る」というその時期の記事
------------------
>>714で引用した部分だけでも"mid-2007"という記述があるすけど。。。
英語読めないなら読めないと正直に告白することをお勧めするす(笑)
------------------
少なくとも「K10が2007年に出る」というその時期の記事
------------------
>>714で引用した部分だけでも"mid-2007"という記述があるすけど。。。
英語読めないなら読めないと正直に告白することをお勧めするす(笑)
724 :MACオタ>723 さん:2007/06/29(金) 20:47:03 ID:hM78bIG1
>>723
----------------
K10とはかつてK8Lと呼ばれていたもの、とAMDが発表した記事がない限り、
----------------
AMDの公式見解わ、「K8Lなるものは存在しない」というモノなんすけど(笑)
----------------
K10とはかつてK8Lと呼ばれていたもの、とAMDが発表した記事がない限り、
----------------
AMDの公式見解わ、「K8Lなるものは存在しない」というモノなんすけど(笑)
うわあ、すごい方向に話持ってったwwwww
>>723
いや別にAMDの公式発表でなくてもいいんだよ(開発中の製品に関してはあまり明かされないんだし)
後藤氏みたいなライターが情報を掴んできて
「(新)K10はK8Lのことだ」
または
「2007年に(新)K10が出る」
っていう文章を書いてれば(2007年にK8Lが出るって記事は既にあるから)
>現行"K10"の正体がK8Lってのわ、この後藤記事が執筆された段階で既に通説化しているす。
という主張のある程度の証拠になるんだが、
DailyTech (06/06/01)にもTG Daily (06/07/20)にもK10とは一言も書いてない
つまりこのふたつは前記の主張の証明にまったくなっていない
既知害が真面目に答えていない(つまりソースを持っていない)というのは同意
いや別にAMDの公式発表でなくてもいいんだよ(開発中の製品に関してはあまり明かされないんだし)
後藤氏みたいなライターが情報を掴んできて
「(新)K10はK8Lのことだ」
または
「2007年に(新)K10が出る」
っていう文章を書いてれば(2007年にK8Lが出るって記事は既にあるから)
>現行"K10"の正体がK8Lってのわ、この後藤記事が執筆された段階で既に通説化しているす。
という主張のある程度の証拠になるんだが、
DailyTech (06/06/01)にもTG Daily (06/07/20)にもK10とは一言も書いてない
つまりこのふたつは前記の主張の証明にまったくなっていない
既知害が真面目に答えていない(つまりソースを持っていない)というのは同意
727 :MACオタ>726 さん:2007/06/29(金) 21:33:48 ID:hM78bIG1
>>726
---------------
「(新)K10はK8Lのことだ」
---------------
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
===============
AMDは、ネイティブクアッドコアCPU「Barcelona(バルセロナ)」の詳細を明らかにした。これは、
「K8 Revision H(Rev. H)」または「K8L」と呼ばれていたCPUコアをベースにしたクアッドコアCPU
で、「Deerhound(ディアハウンド)」と呼ばれいていたクアッドコアと同じものだ。AMDのコード
ネームやリビジョン名はしばしば変わる。
===============
AMDがBarcelonaのコアをK10と呼ぶことにしたのわ周知の通りす。
しかしこの引用部分の最後って。。。流石の後藤氏も恥ずかしかったすね(笑)
---------------
「(新)K10はK8Lのことだ」
---------------
http://pc.watch.impress.co.jp/docs/2006/1013/kaigai311.htm
===============
AMDは、ネイティブクアッドコアCPU「Barcelona(バルセロナ)」の詳細を明らかにした。これは、
「K8 Revision H(Rev. H)」または「K8L」と呼ばれていたCPUコアをベースにしたクアッドコアCPU
で、「Deerhound(ディアハウンド)」と呼ばれいていたクアッドコアと同じものだ。AMDのコード
ネームやリビジョン名はしばしば変わる。
===============
AMDがBarcelonaのコアをK10と呼ぶことにしたのわ周知の通りす。
しかしこの引用部分の最後って。。。流石の後藤氏も恥ずかしかったすね(笑)
今ではBarcelona=K10というのが明らかだが、
2006年の時点でそう指摘してるソースを用意していない。再提出。
>>703
素人考えだけど、必要に応じて専用回路のモジュールをFUSIONに突っ込めば?
全部カスタムで作るよりは安いはず
デジタル家電なら消費電力の要求は相対的に緩いから
必要な性能・機能があれば出来合いの(量産効果で)安いFUSIONチップでいいような
チップのハードウェアではアセンブリベンダ化するけど、独自開発してもそれより安くなるとは限らないし
独自機能に独自のハードウェアが必要になるとは限らないし
2006年の時点でそう指摘してるソースを用意していない。再提出。
>>703
素人考えだけど、必要に応じて専用回路のモジュールをFUSIONに突っ込めば?
全部カスタムで作るよりは安いはず
デジタル家電なら消費電力の要求は相対的に緩いから
必要な性能・機能があれば出来合いの(量産効果で)安いFUSIONチップでいいような
チップのハードウェアではアセンブリベンダ化するけど、独自開発してもそれより安くなるとは限らないし
独自機能に独自のハードウェアが必要になるとは限らないし
だからウンコ弄るなって何度言えば分かるんだ?
>>728
正直、FUSIONの値段次第じゃないかなぁ…
東芝のポータブルWMPに使われたARM11コア(FreeScale i.MX31だったと思うけど)なら今だって\3000以下だし…
そういう商売をAMDが望んでいるとはとても思えないんだけど…
正直、FUSIONの値段次第じゃないかなぁ…
東芝のポータブルWMPに使われたARM11コア(FreeScale i.MX31だったと思うけど)なら今だって\3000以下だし…
そういう商売をAMDが望んでいるとはとても思えないんだけど…
レスするだけゴミが散らかるのがオタ
釣り針いっぱい仕込んでいるのでツッコミレスしたくなるだろうから
あぼーんしておくのが正解
釣り針いっぱい仕込んでいるのでツッコミレスしたくなるだろうから
あぼーんしておくのが正解
一度会話の成り立たない相手だと悟ればあぼーん必至。
733 :Socket774:2007/06/30(土) 13:09:36 ID:JIydrBjo
ID:AzE2nags
情報家電&携帯電話用FUSIONはGPU(そのうちDSP兼用)その他と
x86コアの抱き合わせのような気がしてくる
もちろん前者がメインで、FUSIONは便利だからついでにx86に乗り換えてね〜と
x86コアの抱き合わせのような気がしてくる
もちろん前者がメインで、FUSIONは便利だからついでにx86に乗り換えてね〜と
無理
x86をそんなに安売りするのはAMDには無理。
Sempronクラスでも家電用に比べたらあほほど利益大きい
Sempronクラスでも家電用に比べたらあほほど利益大きい
コンシューマ機器の組込ソフトの人海戦術デスマーチソフトウェア開発モデルが
破綻しかかっているから、x86系へ移行する可能性は高いんじゃないかな。
直接見聞きする範囲でもアレッと思うような話がある。
有象無象のweb屋さんを奴隷仕事に投入できるのはメリットが大きいし。
破綻しかかっているから、x86系へ移行する可能性は高いんじゃないかな。
直接見聞きする範囲でもアレッと思うような話がある。
有象無象のweb屋さんを奴隷仕事に投入できるのはメリットが大きいし。
携帯電話一台でもプログラムのソースコードが1000万行以上らしいしな。
大学の組み込みシステムの講義で、先生が開発者に直接聞いた話として語ってくれた
大学の組み込みシステムの講義で、先生が開発者に直接聞いた話として語ってくれた
x86にしても500万行に減るわけじゃない
デスマーチなのはいっしょ
デスマーチなのはいっしょ
そう言えばiPhoneはどの位のコードなんだろね?
携帯だけにコードレスーなんつって
誰がうまいこと言えと(ry
なんかネコミミがどうとか書いてたな、今月
まあ、ちゃんと作れば10分の1くらいのソースコードに出来ると思われ。
伝説のプログラマ、まあちゃん
10分の1にする頃には時代遅れってオチか
インタビューで2GHzのTNT2なんて話題があったな
インタビューで2GHzのTNT2なんて話題があったな
まあちゃんが作り直せばOSも効率は10倍くらいに。
互換性はナシに。
互換性はナシに。
>>750
なにも知らないバカはお前だろ。
じゃあ、なぜそこまで長くしなきゃならんのか言ってみろ。
まさかダイアログ一個作るにも「描画命令からアセンブラでフルスクラッチ」して作るつもりか?
それなら1000万でも1億でも行くだろうが、無駄な長さだろーが。
組み込み機器だとメモリーやプログラム記録メディアの制限で
フルアセンブラで作ることが多かったが最近は携帯でも
フル実装のX68000やFM-TOWNSより豊富なメモリに高速なCPU積んでる。
そこまでゼロから作ってプログラムをシェイプするメリットは殆ど無い。
画像系はアクセラレータもついてるうえ、ケータイでもJAVAが走る時代だっつーのに
そこまでやるか。
メディア系のデコードや、通信のドライバまで全部自前のコードで持つだろうから
その分長くなるのを考慮してもひとつの会社で一回書いたらフツーライブラリ化するだろ。
なにも知らないバカはお前だろ。
じゃあ、なぜそこまで長くしなきゃならんのか言ってみろ。
まさかダイアログ一個作るにも「描画命令からアセンブラでフルスクラッチ」して作るつもりか?
それなら1000万でも1億でも行くだろうが、無駄な長さだろーが。
組み込み機器だとメモリーやプログラム記録メディアの制限で
フルアセンブラで作ることが多かったが最近は携帯でも
フル実装のX68000やFM-TOWNSより豊富なメモリに高速なCPU積んでる。
そこまでゼロから作ってプログラムをシェイプするメリットは殆ど無い。
画像系はアクセラレータもついてるうえ、ケータイでもJAVAが走る時代だっつーのに
そこまでやるか。
メディア系のデコードや、通信のドライバまで全部自前のコードで持つだろうから
その分長くなるのを考慮してもひとつの会社で一回書いたらフツーライブラリ化するだろ。
「ケータイ一台」と言われてもピンキリだしなぁ。
W-Zero3だって簡単ケータイだって同じケータイだしw
W-Zero3だって簡単ケータイだって同じケータイだしw
いい加減「フルスクラッチ」はやめないか?
後藤が間違えて使ったのが広まったんだろうが正確には「フロムスクラッチ」だ。
後藤が間違えて使ったのが広まったんだろうが正確には「フロムスクラッチ」だ。
まあちゃんが作れば1/10になるくらい、無駄がいっぱいなんだろ。
似たような処理でも毎回コードをコピーして微修正とか。
それがx86になったら改善されるの?
Intelがライブラリ提供してくれるの? Windows XP Embedded で携帯電話つくるの?
似たような処理でも毎回コードをコピーして微修正とか。
それがx86になったら改善されるの?
Intelがライブラリ提供してくれるの? Windows XP Embedded で携帯電話つくるの?
いや、「ゼロから・最初から」を意味するのが「from scratch」だというのは確かだ。
だが、フルスクラッチというのが和製英語化しちゃってるのも事実。
日本の常識に即してない英語の知識というよくあるパターン。
だが、フルスクラッチというのが和製英語化しちゃってるのも事実。
日本の常識に即してない英語の知識というよくあるパターン。
まぁ いまさら 「バイク?そりゃ自転車って意味だ」 とか言われても困るよなぁ。
いちいちモーターサイクルとか言ってるほうが、めんどくさい上に なにかっこつけてんのと言われそうだしw
いちいちモーターサイクルとか言ってるほうが、めんどくさい上に なにかっこつけてんのと言われそうだしw
普通に「一から」って日本語を使えばいいじゃねえか
後藤のカタカナ脳に汚染されてんじゃねえよ
後藤のカタカナ脳に汚染されてんじゃねえよ
>>751
小さくなるっていうならお前が1/10のサイズで携帯電話のファームを書いてみろよw
> まさかダイアログ一個作るにも「描画命令からアセンブラでフルスクラッチ」して作るつもりか?
まず最初に出てくる部品が「ダイアログ」ってあたり組み込みがさっぱりわかってない感が
プンプンしますねーw
> 画像系はアクセラレータもついてるうえ、ケータイでもJAVAが走る時代だっつーのに
> そこまでやるか。
はいはい。そのJAVA VMのコードサイズはどのくらいなんでしょーねー。
全部で1000万ステップのコードにはそういうライブラリからなにからぜーんぶ含まれているんですよ?
小さくなるっていうならお前が1/10のサイズで携帯電話のファームを書いてみろよw
> まさかダイアログ一個作るにも「描画命令からアセンブラでフルスクラッチ」して作るつもりか?
まず最初に出てくる部品が「ダイアログ」ってあたり組み込みがさっぱりわかってない感が
プンプンしますねーw
> 画像系はアクセラレータもついてるうえ、ケータイでもJAVAが走る時代だっつーのに
> そこまでやるか。
はいはい。そのJAVA VMのコードサイズはどのくらいなんでしょーねー。
全部で1000万ステップのコードにはそういうライブラリからなにからぜーんぶ含まれているんですよ?
本当にどうでもいいこと気にしてる奴いるなぁ。バカじゃねえの?
>>757 が勝手にそう思いこんでるだけで模型関係から流れてきた言葉だろ。
交友関係が狭いからって勝手に妄想膨らませられても・・
友達の友達の友達の友達に模型やフィギュア関係の人間がいるっつーだけでも伝染してくるよw
ググってみろ、どれくらい使われてる単語かわかるから。
>>757 が勝手にそう思いこんでるだけで模型関係から流れてきた言葉だろ。
交友関係が狭いからって勝手に妄想膨らませられても・・
友達の友達の友達の友達に模型やフィギュア関係の人間がいるっつーだけでも伝染してくるよw
ググってみろ、どれくらい使われてる単語かわかるから。
ちょっと前に編むvs淫スレで、CPUの設計の素人は、とか大上段から構えて喋ってたイタイ奴がいたのを思い出した。
自作板って761みたいにやたら専門家ヅラしてるやつに限って全くその専門知識の片鱗も見えないレスが多いのはなんなんだろうな。
組み込みどころかプログラムのイロハを知らなくても言えるようなことばっかに見える。
自作板って761みたいにやたら専門家ヅラしてるやつに限って全くその専門知識の片鱗も見えないレスが多いのはなんなんだろうな。
組み込みどころかプログラムのイロハを知らなくても言えるようなことばっかに見える。
ただのド素人がド素人をド素人呼ばわりするのが2ch
つか、自分がソース持ってるもんならまだしもライブラリ化されてるコードの行数まで開発したプログラム行数に含めるのか?w
仕事楽でしょうがないな
つか、自分がソース持ってるもんならまだしもライブラリ化されてるコードの行数まで開発したプログラム行数に含めるのか?w
仕事楽でしょうがないな
だいたい>>752が言ってるように一口に
ケータイと言ったってピンキリだろ。
せいぜい写メールの送受信しか
出来ないようなのと、音楽聞けてワンセグ見れて
ブラウザ載っけてナビまで搭載してるケータイでは
規模が数十倍違うのはバカでもわかる。
あの程度のシステム呼ばわりした奴も
組み込み知ってますヅラした奴も、どれくらいのケータイを指してるか
全く語らずにソースの行数だけ
語ってる時点で両方ド素人か池沼。
ケータイと言ったってピンキリだろ。
せいぜい写メールの送受信しか
出来ないようなのと、音楽聞けてワンセグ見れて
ブラウザ載っけてナビまで搭載してるケータイでは
規模が数十倍違うのはバカでもわかる。
あの程度のシステム呼ばわりした奴も
組み込み知ってますヅラした奴も、どれくらいのケータイを指してるか
全く語らずにソースの行数だけ
語ってる時点で両方ド素人か池沼。
>>764
> つか、自分がソース持ってるもんならまだしもライブラリ化されてるコードの行数まで開発したプログラム行数に含めるのか?w
っていってるあたりで全然わかってねーな。
まともな製品なら、ソースがないコードなんか組み込む訳ねーだろ。
> 仕事楽でしょうがないな
ふつーOSやミドルウェアもコード付きで提供されるんだぞ。
> つか、自分がソース持ってるもんならまだしもライブラリ化されてるコードの行数まで開発したプログラム行数に含めるのか?w
っていってるあたりで全然わかってねーな。
まともな製品なら、ソースがないコードなんか組み込む訳ねーだろ。
> 仕事楽でしょうがないな
ふつーOSやミドルウェアもコード付きで提供されるんだぞ。
>>762
プログラムを一から開発することは、大昔から"From Scratch"と言われてきたから、
「フロム・スクラッチ」と言え、という話であって、
「フル・スクラッチ」がフィギュア発祥かどうかにこだわってるのは、
あんたと >>755 だけだ。
プログラムを一から開発することは、大昔から"From Scratch"と言われてきたから、
「フロム・スクラッチ」と言え、という話であって、
「フル・スクラッチ」がフィギュア発祥かどうかにこだわってるのは、
あんたと >>755 だけだ。
プログラムを一から開発するのは当たり前の話だからフルスクラッチだのフロムスクラッチだの
昔は言わんよ。すくなくとも日本では。
昔は言わんよ。すくなくとも日本では。
なんでこのスレって言葉の使い方の議論にいつも必死なの?
>>770
ただ難癖つけたいだけだから。
ただ難癖つけたいだけだから。
フロムスクラッチなんて聞いたことねーよ。
フロムAやフロムソフトウェアなら知ってるけどフロムスクラッチなんて言わないよ
http://pc.watch.impress.co.jp/docs/2005/0822/kaigai204.htm
>フロムスクラッチで作り上げた
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
>フロムスクラッチ(ゼロからの設計)で開発された
フロムファイブなら知ってるけど
■後藤弘茂のWeekly海外ニュース■
GPUサーバーの時代を開くNVIDIAの「Tesla」
http://pc.watch.impress.co.jp/docs/2007/0702/kaigai369.htm
GPUサーバーの時代を開くNVIDIAの「Tesla」
http://pc.watch.impress.co.jp/docs/2007/0702/kaigai369.htm
Nの妄想垂れ流し
GPGPUはグラフィックカードの余技であって、
HPC用ならば、GPUチップの使い廻しより専用チップの方がいいと思う。
GRAPE-DR
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
> 2006年度中には、同プロセッサ4チップ(計2T FLOPS)を1枚のボードに搭載したアクセラレータを製造するという。
> また、1枚当たり1T FLOPSを超えるアクセラレータボードを100万円を切る価格で出したいとした。
Tesla
http://pc.watch.impress.co.jp/docs/2007/0621/nvidia.htm
> ラインナップは、PCI Expressカード型の「Tesla GPU (C870)」、
> このカードを2枚内蔵した外付けボックス型の「Tesla GPU Deskside Supercomputer (D870)」、
> カードを4枚内蔵した1Uラックマウント型の「Tesla GPU Server (S870)」の3モデル。
> 価格は順に1,499ドル、7,500ドル、12,000ドル。
> C870のハードウェアはGeForce 8800 GTXとほぼ同じで、
(中略)
> ピーク性能は518GFLOPSに達するという。
HPC用ならば、GPUチップの使い廻しより専用チップの方がいいと思う。
GRAPE-DR
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
> 2006年度中には、同プロセッサ4チップ(計2T FLOPS)を1枚のボードに搭載したアクセラレータを製造するという。
> また、1枚当たり1T FLOPSを超えるアクセラレータボードを100万円を切る価格で出したいとした。
Tesla
http://pc.watch.impress.co.jp/docs/2007/0621/nvidia.htm
> ラインナップは、PCI Expressカード型の「Tesla GPU (C870)」、
> このカードを2枚内蔵した外付けボックス型の「Tesla GPU Deskside Supercomputer (D870)」、
> カードを4枚内蔵した1Uラックマウント型の「Tesla GPU Server (S870)」の3モデル。
> 価格は順に1,499ドル、7,500ドル、12,000ドル。
> C870のハードウェアはGeForce 8800 GTXとほぼ同じで、
(中略)
> ピーク性能は518GFLOPSに達するという。
約100万のモデルで1TFLOPSなんだし
使いまわしでも結構勝負になるもんだね
G90世代になれば価格そのままでスライドしてくれる期待が持てるので
それなら1チップ1TFLOPSで20万円以下で
2チップ100万のモデルなら2TFLOPSか
使いまわしでも結構勝負になるもんだね
G90世代になれば価格そのままでスライドしてくれる期待が持てるので
それなら1チップ1TFLOPSで20万円以下で
2チップ100万のモデルなら2TFLOPSか
>>779
GRAPEはずっとニッチな専用計算パイプライン装置でしょ。
元々は天文学での重力多体問題専用のアクセラレータだし、最近はFPGA上に
組んだりしてプログラマビリティを増してきているとはいえ、GPUでのシェーダー
記述のような汎用性は持っていない。
MDみたいにGRAPEが適用できる問題にはGRAPEを使うのがコスト効果高いと思うけど、
そうはいかない分野で、いわゆるBeowulf型PCクラスタのように使うというのがTesla
ということではないかな?動大規模データのマイニングとか、バイオだと配列解析がらみ
とかね。Teslaの詳細がわからないから妄想レベルだけど、ミニBlueGene/Lみたいな
マシンを数ラックで組めるなら、欲しいという研究所結構あるかもしれないよ。
GRAPEはずっとニッチな専用計算パイプライン装置でしょ。
元々は天文学での重力多体問題専用のアクセラレータだし、最近はFPGA上に
組んだりしてプログラマビリティを増してきているとはいえ、GPUでのシェーダー
記述のような汎用性は持っていない。
MDみたいにGRAPEが適用できる問題にはGRAPEを使うのがコスト効果高いと思うけど、
そうはいかない分野で、いわゆるBeowulf型PCクラスタのように使うというのがTesla
ということではないかな?動大規模データのマイニングとか、バイオだと配列解析がらみ
とかね。Teslaの詳細がわからないから妄想レベルだけど、ミニBlueGene/Lみたいな
マシンを数ラックで組めるなら、欲しいという研究所結構あるかもしれないよ。
>>775
プログラムの話じゃねーじゃねーか。
プログラムの話じゃねーじゃねーか。
785 :Socket774:2007/07/02(月) 22:36:01 ID:VxuoV4wc
>>777 の魚拓有ったよ。
http://megalodon.jp/?url=http://pc.watch.impress.co.jp/docs/2007/0702/kaigai369.htm&date=20070702144124
http://megalodon.jp/?url=http://pc.watch.impress.co.jp/docs/2007/0702/kaigai369.htm&date=20070702144124
> ピーク性能は518GFLOPSに達するという。
倍精度にすると、どこまで落ちるんですか
倍精度にすると、どこまで落ちるんですか
性能はGrape向けの演算でGrape-DR=Geforce8800GTXだとGrape開発責任者が書いてたろ。
完全に万歳だよ。
完全に万歳だよ。
ちょっと違う気もするが、これのことか?
http://jun.artcompsci.org/articles/future_sc/note048.html
http://jun.artcompsci.org/articles/future_sc/note048.html
どうせIEEE754とか準拠してないんだろ。
それでかまわない用途もあるにはあるだろうけどさ。
それでかまわない用途もあるにはあるだろうけどさ。
>>790
単精度だからそれ以前の問題だろ
単精度だからそれ以前の問題だろ
単精度でも間に合う用途に使えばそれでいいのでは?
>>789によればGRAPE-3はそれ以下の精度しか持たないにもかかわらず問題なかったみたいだし。
>>789によればGRAPE-3はそれ以下の精度しか持たないにもかかわらず問題なかったみたいだし。
GRAPE-3が作られた1991年ってこんな時代。
http://www.eonet.ne.jp/~building-pc/pc/pc1991.htm
いまどき単精度で科学計算はねーべ。レンダリングサーバとか用途はもちろんあるだろうけど。
http://www.eonet.ne.jp/~building-pc/pc/pc1991.htm
いまどき単精度で科学計算はねーべ。レンダリングサーバとか用途はもちろんあるだろうけど。
精度が必要かどうかは昔かいまどきかではなくて用途によるのだってどうしてわかんないのかなぁこの人は。
車輪の再計算?
整数演算機でも小数計算できるんだよザコ
掛け算、割り算の命令がなかったZ80でも四則演算できるんだぜ
x86イラネ
NECエレ、2倍の周波数性能で消費電力を同等に抑えた携帯電話向けLSI
http://pc.watch.impress.co.jp/docs/2007/0704/necel.htm
ARMの最高経営責任者、「iPhone」を語る
http://japan.cnet.com/interview/story/0,2000055954,20352144,00.htm
NECエレ、2倍の周波数性能で消費電力を同等に抑えた携帯電話向けLSI
http://pc.watch.impress.co.jp/docs/2007/0704/necel.htm
ARMの最高経営責任者、「iPhone」を語る
http://japan.cnet.com/interview/story/0,2000055954,20352144,00.htm
↓ハイエンドGPU競争から脱落するAMD
MACオタがARMマンセーになるのか
いやiPhoneオタじゃないから、それはないか
いやiPhoneオタじゃないから、それはないか
■後藤弘茂のWeekly海外ニュース■
AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
お、丸一日レス付かなかった
いくら仮想化しても、機能面での差が無くなるだけで性能差がなくなるわけじゃない
つまり8600GTのような低性能GPUは
いくら仮想化でマルチGPUにしても
ウンコって事ですね。
いくら仮想化でマルチGPUにしても
ウンコって事ですね。
だんごやさんのこれ2づおデスクトップマシンは8600GT搭載だよ(・∀・)
AeroGlass程度なら余裕。
Vista x64だからどのみちまともにゲームできんしサブマシンとしては十分だよ。
AeroGlass程度なら余裕。
Vista x64だからどのみちまともにゲームできんしサブマシンとしては十分だよ。
AeroGlassなんかノートのおんぼVGAでも余裕だよ
だからキチガイにかまうなよ。
810 :Socket774:2007/07/07(土) 17:58:18 ID:K6uGJcy/
くそもらし
後藤のまとめ力は向こうにも一目置かれてるんだろうか
812 :MACオタ>811 さん:2007/07/08(日) 11:11:31 ID:ChmlG/hc
>>811
日本人が"FUD"zillaをソースにするのと同じす(笑)
日本人が"FUD"zillaをソースにするのと同じす(笑)
■天才MACオタのWeekly海外ニュース■
AMDの次世代GPUは55nmプロセスがターゲット
↓
AMDの次世代GPUは55nmプロセスがターゲット
↓
FUDの意味わかってんのか…?
ウンコは>>728の宿題が終わるまで出てくるな
>>812
MACオタ馬鹿すぎ
MACオタ馬鹿すぎ
だからいちいちウンコつついて喜ぶなよおまいらは。
幼稚園児かよ。
幼稚園児かよ。
818 :MACオタ>816 さん:2007/07/09(月) 00:36:10 ID:8D+ovYso
>>816
後藤氏の記事がFUDだと主張するつもりわ、更々無いす。
しかしFUDの定義を読めば判るように"FUD"zillaわ文字通りのサイトす。
http://www.yamdas.org/column/technique/fuddefj.html
こんな記事とか(笑)
http://www.fudzilla.com/index.php?option=com_content&task=view&id=874&Itemid=35
http://northwood.blog60.fc2.com/blog-entry-819.html (国内腐れルーマーサイトによる紹介)
---------------
K10 B0 stepping does miracles
Tuesday, 08 May 2007 07:31
- Pushing Barcelona / Agena to 3 GHz -
---------------
後藤氏の記事がFUDだと主張するつもりわ、更々無いす。
しかしFUDの定義を読めば判るように"FUD"zillaわ文字通りのサイトす。
http://www.yamdas.org/column/technique/fuddefj.html
こんな記事とか(笑)
http://www.fudzilla.com/index.php?option=com_content&task=view&id=874&Itemid=35
http://northwood.blog60.fc2.com/blog-entry-819.html (国内腐れルーマーサイトによる紹介)
---------------
K10 B0 stepping does miracles
Tuesday, 08 May 2007 07:31
- Pushing Barcelona / Agena to 3 GHz -
---------------
いいか、ウンコはつつくなよ。
対象スレ: 後藤弘茂を応援するスレ Part15
キーワード: ウンコ
720 :Socket774 [sage] :2007/06/29(金) 17:02:52 ID:grAtza3m
だからばっちいウンコをつつくなよ。手が汚れるぞ。
729 :Socket774 [sage] :2007/06/29(金) 23:25:02 ID:c8YLP3AV
だからウンコ弄るなって何度言えば分かるんだ?
805 :Socket774 [sage] :2007/07/06(金) 22:45:00 ID:pNzQ2xZA
つまり8600GTのような低性能GPUは
いくら仮想化でマルチGPUにしても
ウンコって事ですね。
815 :Socket774 [sage] :2007/07/08(日) 13:31:57 ID:r41koaOu
ウンコは>>728の宿題が終わるまで出てくるな
817 :Socket774 [sage] :2007/07/08(日) 23:16:09 ID:PAN5RW8a
だからいちいちウンコつついて喜ぶなよおまいらは。
幼稚園児かよ。
819 :Socket774 [sage] :2007/07/09(月) 01:01:36 ID:ESmfQLr+
いいか、ウンコはつつくなよ。
抽出レス数:6
キーワード: くそもらし
19 :Socket774 [sage] :2007/04/03(火) 19:22:02 ID:5gioYmf6
くそもらし
124 :Socket774 [] :2007/04/06(金) 22:10:54 ID:gzfmJ3go
くそもらし
183 :Socket774 [sage] :2007/04/12(木) 01:06:42 ID:ZdSWfp6u
くそもらし
189 :Socket774 [sage] :2007/04/12(木) 19:38:24 ID:ZdSWfp6u
くそもらし
238 :Socket774 [sage] :2007/04/17(火) 19:59:18 ID:40ecHx9u
くそもらし
360 :Socket774 [sage] :2007/05/02(水) 05:22:52 ID:6Kz2E6oI
くそもらし
363 :Socket774 [sage] :2007/05/05(土) 18:10:37 ID:3fjs6jSI
くそもらし
382 :Socket774 [] :2007/05/11(金) 04:56:07 ID:j08w228d
くそもらし
391 :Socket774 [] :2007/05/14(月) 18:02:59 ID:jMGx8n8z
くそもらし
404 :Socket774 [] :2007/05/16(水) 16:38:04 ID:Mux7E266
くそもらし
810 :Socket774 [] :2007/07/07(土) 17:58:18 ID:K6uGJcy/
くそもらし
抽出レス数:11
キーワード: ウンコ
720 :Socket774 [sage] :2007/06/29(金) 17:02:52 ID:grAtza3m
だからばっちいウンコをつつくなよ。手が汚れるぞ。
729 :Socket774 [sage] :2007/06/29(金) 23:25:02 ID:c8YLP3AV
だからウンコ弄るなって何度言えば分かるんだ?
805 :Socket774 [sage] :2007/07/06(金) 22:45:00 ID:pNzQ2xZA
つまり8600GTのような低性能GPUは
いくら仮想化でマルチGPUにしても
ウンコって事ですね。
815 :Socket774 [sage] :2007/07/08(日) 13:31:57 ID:r41koaOu
ウンコは>>728の宿題が終わるまで出てくるな
817 :Socket774 [sage] :2007/07/08(日) 23:16:09 ID:PAN5RW8a
だからいちいちウンコつついて喜ぶなよおまいらは。
幼稚園児かよ。
819 :Socket774 [sage] :2007/07/09(月) 01:01:36 ID:ESmfQLr+
いいか、ウンコはつつくなよ。
抽出レス数:6
キーワード: くそもらし
19 :Socket774 [sage] :2007/04/03(火) 19:22:02 ID:5gioYmf6
くそもらし
124 :Socket774 [] :2007/04/06(金) 22:10:54 ID:gzfmJ3go
くそもらし
183 :Socket774 [sage] :2007/04/12(木) 01:06:42 ID:ZdSWfp6u
くそもらし
189 :Socket774 [sage] :2007/04/12(木) 19:38:24 ID:ZdSWfp6u
くそもらし
238 :Socket774 [sage] :2007/04/17(火) 19:59:18 ID:40ecHx9u
くそもらし
360 :Socket774 [sage] :2007/05/02(水) 05:22:52 ID:6Kz2E6oI
くそもらし
363 :Socket774 [sage] :2007/05/05(土) 18:10:37 ID:3fjs6jSI
くそもらし
382 :Socket774 [] :2007/05/11(金) 04:56:07 ID:j08w228d
くそもらし
391 :Socket774 [] :2007/05/14(月) 18:02:59 ID:jMGx8n8z
くそもらし
404 :Socket774 [] :2007/05/16(水) 16:38:04 ID:Mux7E266
くそもらし
810 :Socket774 [] :2007/07/07(土) 17:58:18 ID:K6uGJcy/
くそもらし
抽出レス数:11
AMDが次期GPU「R700」を巨大にできない理由
http://pc.watch.impress.co.jp/docs/2007/0709/kaigai371.htm
http://pc.watch.impress.co.jp/docs/2007/0709/kaigai371.htm
後藤氏の文章にも昔のようなキレがなくなったなぁ
テクニカルな記事を紹介してくれるのはとてもありがたいんだけど
字数稼ぎのためか、回りくどい言い回しが多くて半分くらいで読むのが面倒になる
まぁ全体的な文章量はそれほど多くないんだから、これくらい読めやって言われたらそうなんだけど
「ひよこの親はにわとりである」、「にわとりの子はひよこである」みたいな記述を繰り返されると萎えるんだよね
後藤氏も年食ったんだなぁ…
テクニカルな記事を紹介してくれるのはとてもありがたいんだけど
字数稼ぎのためか、回りくどい言い回しが多くて半分くらいで読むのが面倒になる
まぁ全体的な文章量はそれほど多くないんだから、これくらい読めやって言われたらそうなんだけど
「ひよこの親はにわとりである」、「にわとりの子はひよこである」みたいな記述を繰り返されると萎えるんだよね
後藤氏も年食ったんだなぁ…
しかも次の記事でも「ひよこの親は実はにわとりであった」」、「にわとりの子はひよこであった」って続くんだもんな。
やってらんねーよ。
やってらんねーよ。
やらなくていいよ
まとまってて読みやすいのが良けりゃ雑誌に載ってる解説記事を読みな
本人がコラムで説明してたように媒体によって書き方を変えてるから
本人がコラムで説明してたように媒体によって書き方を変えてるから
今後GPUが向かう方向みたいなつまらない記事書く暇があったら、
またいつものように、
家族の誰がどんなゲームを何時間遊んでるとかいう、
どうでもいい個人情報記事をだらだら垂れ流せや。
またいつものように、
家族の誰がどんなゲームを何時間遊んでるとかいう、
どうでもいい個人情報記事をだらだら垂れ流せや。
それよりも後藤はスクールデイズTV版についてどう考えているのか。
アレを思い出した
17 名前: Ψ [sage] 投稿日: 2007/07/10(火) 11:46:14 ID:tpQ/3eeZ0
アメリカはマジで情報漏えいを危惧しておるっす。
ステルス技術が流出してしまうと、ステルス弾道ミサイルという
最悪のシナリオへ一直線です。 ですので、日本へ
F22を輸出する事は不可能であるっす。
日本がステルスを所有する唯一の道は一つ、それは
国産ステルス戦闘機の開発っす。 ですが、これも
情報の流出のリスクが大きいので止めた方がいいっす。
17 名前: Ψ [sage] 投稿日: 2007/07/10(火) 11:46:14 ID:tpQ/3eeZ0
アメリカはマジで情報漏えいを危惧しておるっす。
ステルス技術が流出してしまうと、ステルス弾道ミサイルという
最悪のシナリオへ一直線です。 ですので、日本へ
F22を輸出する事は不可能であるっす。
日本がステルスを所有する唯一の道は一つ、それは
国産ステルス戦闘機の開発っす。 ですが、これも
情報の流出のリスクが大きいので止めた方がいいっす。
MACヲタの甥か?
アメリカ「わ」って書いてないから違うんじゃない?
>>827
後藤弘茂タンとごとうじゅんじ特別顧問は親戚でつか
後藤弘茂タンとごとうじゅんじ特別顧問は親戚でつか
誰も書かないから今更書くが、今月のパワレポ。
後藤タンの最近のお気に入りの曲はアニメ『月詠』のBGMだそうである。
ネコミミモード→目の前にネコミミの人が歩いてるけどここはアキバじゃないよ、サンノゼだよ
→なぜならアニメのカンファレンスがあったからだよ→アメリカ人ってカンファレンス好きだよね
とまぁそういう流れでした。
後藤タンの最近のお気に入りの曲はアニメ『月詠』のBGMだそうである。
ネコミミモード→目の前にネコミミの人が歩いてるけどここはアキバじゃないよ、サンノゼだよ
→なぜならアニメのカンファレンスがあったからだよ→アメリカ人ってカンファレンス好きだよね
とまぁそういう流れでした。
それが本当だったらすごいぶっちゃけぶりだな
あの一件以来隠そうともしてないってことか
あの一件以来隠そうともしてないってことか
パワレポのコラムはときどきアニメネタあるよ
というか今はPCネタ非限定の文章って不定期の買い物山脈とこれだけでね?
というか今はPCネタ非限定の文章って不定期の買い物山脈とこれだけでね?
くそもらし
最近の記事で頻繁にインタビューが出ていた元ATI CEOのデーブ・オートン氏が退社www
http://pc.watch.impress.co.jp/docs/2007/0711/amd.htm
http://pc.watch.impress.co.jp/docs/2007/0711/amd.htm
浦島乙
>>838
>日本以外の市場では快進撃を続けていたXbox 360も、PLAYSTATION 3(PS3)とWii登場以降は急進撃にブレーキがかかりつつあるという。
この文以降の文脈では華麗にヌル〜されているPS3を、この文で引き合いに出すのが精一杯なのか?
…どうした、Goto!
×日本以外の市場では快進撃を続けていたXbox 360も、PLAYSTATION 3(PS3)とWii登場以降は急進撃にブレーキがかかりつつあるという。
○日本以外の市場では快進撃を続けていたXbox 360も、Wii登場以降は急進撃にブレーキがかかりつつあるという。
それはともかく、製造コストは…
プロセスがどうこうよりも、一人勝ち状態になって、もっとシェアとれないと
初期投資の回収も出来ないし再設計費用も捻出できない訳でな…
>日本以外の市場では快進撃を続けていたXbox 360も、PLAYSTATION 3(PS3)とWii登場以降は急進撃にブレーキがかかりつつあるという。
この文以降の文脈では華麗にヌル〜されているPS3を、この文で引き合いに出すのが精一杯なのか?
…どうした、Goto!
×日本以外の市場では快進撃を続けていたXbox 360も、PLAYSTATION 3(PS3)とWii登場以降は急進撃にブレーキがかかりつつあるという。
○日本以外の市場では快進撃を続けていたXbox 360も、Wii登場以降は急進撃にブレーキがかかりつつあるという。
それはともかく、製造コストは…
プロセスがどうこうよりも、一人勝ち状態になって、もっとシェアとれないと
初期投資の回収も出来ないし再設計費用も捻出できない訳でな…
どちらかといえばPS3はもう眼中になし?
くそもらし
くそもらし
仕切り直しに入ったPLAYSTATION 3戦略の今後
ttp://pc.watch.impress.co.jp/docs/2007/0718/kaigai373.htm
ttp://pc.watch.impress.co.jp/docs/2007/0718/kaigai373.htm
PS3の記事も随分と久しぶりだな
848 :Socket774:2007/07/18(水) 17:44:12 ID:ZRzMfzQ6
環境が全く揃ってない只のゲーム機にエコシステムも糞もねえべ
そこがまず間違ってると、何故書かないかね
そこがまず間違ってると、何故書かないかね
849 :Socket774:2007/07/18(水) 18:29:46 ID:r8MfiqyA
ゲハでやれ
850 :hkd8-p27.flets.hi-ho.ne.jp:2007/07/18(水) 18:31:56 ID:tUbJLv8+
CellのCPUパワー配分機能とかいろいろあったじゃない。
クタラギのエゴシステム
K氏放逐に殉じてPS3ネタは封印すると思ってたから意外だ
『Wii Fit』で見えてきたWiiの次のステップ
http://pc.watch.impress.co.jp/docs/2007/0725/kaigai374.htm
http://pc.watch.impress.co.jp/docs/2007/0725/kaigai374.htm
857 :Socket774:2007/07/25(水) 00:20:21 ID:tV9BwJ94
>それは開発リソースの厚みであり、おそらく、それのためにWii Fitに
>象徴されるWii新戦略の展開は、かなりスローペースだ
開発リソースが厚くて新規展開が遅くなるという論旨が俺には理解不能なんだが、
誰か翻訳を頼む。
>象徴されるWii新戦略の展開は、かなりスローペースだ
開発リソースが厚くて新規展開が遅くなるという論旨が俺には理解不能なんだが、
誰か翻訳を頼む。
それは開発リソースの厚み(が足りないこと)であり
と書きたかったんだろう
と書きたかったんだろう
これくらい読み取れない方がおかしいだろ。
日常生活に支障を来すレベル。
日常生活に支障を来すレベル。
Wii版ビリーズブートキャンプの発売も近そうだなw
>857
普通だったら開発リソースの問題とか不足と書きたいところだけど
企業経営者のインタビュー記事を垂れ流す御用ライターの後藤にとっては
ネガティブな言葉は使って干されると困るから曖昧な言葉を使って
ごまかしたと言うくらい気づいてやれよww
普通だったら開発リソースの問題とか不足と書きたいところだけど
企業経営者のインタビュー記事を垂れ流す御用ライターの後藤にとっては
ネガティブな言葉は使って干されると困るから曖昧な言葉を使って
ごまかしたと言うくらい気づいてやれよww
任天堂信者はどうしても認めたくないんです
まー任天堂は顧客の期待に比べると開発は遅いよね
バーチャルコンソールももっとザクザク追加されるかと思ったがそうでもなかった
バーチャルコンソールももっとザクザク追加されるかと思ったがそうでもなかった
ゴトウが使う提灯は、この手法が多いよね
ゴトウは英語でもこういう表現が出来るんだろうか?嫁に相談するのかな?
ゴトウは英語でもこういう表現が出来るんだろうか?嫁に相談するのかな?
任天堂の開発の場合、宮本茂が一人しかいないというのが辛いところ
アイデア重視なソフトの完成度は単純にリソースを注ぎ込めば上がるというわけではないしな
アイデア重視なソフトの完成度は単純にリソースを注ぎ込めば上がるというわけではないしな
「インターフェイス」の登場回数34回*8文字=272
総文字数=5773(タイトル含まず)
34*8/5773=0.0471*100=4.71%
文章を8文字ずつ読んだ場合、20回に一度は「インターフェイス」の文字がでることになる。
1行に80文字表示させた場合、4行に一度のペース。ざっくり計算して3行に1度は出る計算になる。
3行とは1文節以内にまとまるケースがほとんどであるため、
1文節に1度以上、「インターフェイス」の文字が躍ることになる。
総文字数=5773(タイトル含まず)
34*8/5773=0.0471*100=4.71%
文章を8文字ずつ読んだ場合、20回に一度は「インターフェイス」の文字がでることになる。
1行に80文字表示させた場合、4行に一度のペース。ざっくり計算して3行に1度は出る計算になる。
3行とは1文節以内にまとまるケースがほとんどであるため、
1文節に1度以上、「インターフェイス」の文字が躍ることになる。
文節の意味を調べてみようね
1段落の間違いだろうけど多いか
マンマシンインターフェイスっていろいろ定義はあるだろうが
この場合、コントローラって言えばいいだけじゃないの
マンマシンインターフェイスっていろいろ定義はあるだろうが
この場合、コントローラって言えばいいだけじゃないの
871 :Socket774:2007/07/26(木) 09:55:29 ID:9tMudYBI
平井氏とのパイプは本田が握るのか
リィィッジレイサァァァァア
Wiiの死角はソフトウェア開発リソース
http://pc.watch.impress.co.jp/docs/2007/0727/kaigai375.htm
http://pc.watch.impress.co.jp/docs/2007/0727/kaigai375.htm
「(ネットワークの)帯域が広がり、サーバーサイドに持てるコンピューティング
パワーが広がると、より大それたことがシンクライアントで出来るわけです。
実際、AJAXを使ったページがブラウザの上で動いていますから」
http://ja.wikipedia.org/wiki/%E3%82%B7%E3%83%B3%E3%82%AF%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%B3%E3%83%88
AjaxやFlashはリッチクライアントの範疇
・・・・と、揚げ足をとってもしょうがないか。
まあ、そういう方向を目指すのは間違っていないだろう。
http://satoshi.blogs.com/life/2005/11/post_2.html
パワーが広がると、より大それたことがシンクライアントで出来るわけです。
実際、AJAXを使ったページがブラウザの上で動いていますから」
http://ja.wikipedia.org/wiki/%E3%82%B7%E3%83%B3%E3%82%AF%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%B3%E3%83%88
AjaxやFlashはリッチクライアントの範疇
・・・・と、揚げ足をとってもしょうがないか。
まあ、そういう方向を目指すのは間違っていないだろう。
http://satoshi.blogs.com/life/2005/11/post_2.html
間違えた、>>874だ
>>871は本田の記事じゃね?
ぶっちゃけ、今一番hotなのはwiiだし、PS3もXBOX360も言うべきことは
「さっさとプロセス縮めてコスト下げて値下げしろ」だけだし、そんな事は
他のライターが腐るほど書いてるわけで・・・
後藤氏的にはwiiの懸案事項とか書いた方がメリットデカイだけだと思われ
ぶっちゃけ、今一番hotなのはwiiだし、PS3もXBOX360も言うべきことは
「さっさとプロセス縮めてコスト下げて値下げしろ」だけだし、そんな事は
他のライターが腐るほど書いてるわけで・・・
後藤氏的にはwiiの懸案事項とか書いた方がメリットデカイだけだと思われ
「有限のリソース」という当たり前の事象について書くなら
それこそPS3、Cellのクッタリビジョン全開の時にやってくれよっつー話だ。
それこそPS3、Cellのクッタリビジョン全開の時にやってくれよっつー話だ。
そもそもクタ公の脳内リソースが足りません><
http://pc.watch.impress.co.jp/docs/2006/0608/kaigai277.htm
クタ 「(ソフトウェア開発の)ガンマンっているじゃない。彼らがやってくれるかもしれない。」
http://pc.watch.impress.co.jp/docs/2006/0608/kaigai277.htm
クタ 「(ソフトウェア開発の)ガンマンっているじゃない。彼らがやってくれるかもしれない。」
>>879
本格的なHD画質ゲームは、数GByteの容量が当たり前であり、現在の
インターネットインフラではダウンロード販売は、コンシューマでは手軽
に行える物ではないし、その為のHDD容量も決して十分ではないとか、
双方の問題点を指摘するとらしくなるんだけどね
本格的なHD画質ゲームは、数GByteの容量が当たり前であり、現在の
インターネットインフラではダウンロード販売は、コンシューマでは手軽
に行える物ではないし、その為のHDD容量も決して十分ではないとか、
双方の問題点を指摘するとらしくなるんだけどね
確かにNANDフラッシュの管理は面倒だけど…
普通は管理込みの…ウェアレベリングとか色々やってくれるJFFS2とかの既製ファイルシステム使ってるんじゃ?
Wiiは自前なのかなぁ…
普通は管理込みの…ウェアレベリングとか色々やってくれるJFFS2とかの既製ファイルシステム使ってるんじゃ?
Wiiは自前なのかなぁ…
>チャンネルを1つ立ち上げようとすればゲームが遅れ、ゲームに中核要員を
>割けば開発サポートが手薄になるといった状況かもしれない。任天堂にとっては、
>新旧どちらのユーザーも、開発者も大切なので、リソースの配分は難しい。
誤答もちょっとは成長したみたいだな。
クッタリ教に染まってたおまえいらも成長したか?
370 :Socket774 [sage] :2006/08/23(水) 07:11:34 ID:YK6ysv9a
後藤はハードウェアサイドの都合ばっかり書く。
ダイコスト、プロセッサ開発コスト・・・etc
それは立場上しょうがないにしても、問題なのは
「低脳プログラマ乙」「使いこなせない奴がアホ」
を連呼するような厨を量産してしまったこと。
限られたリソースの中で最大限のコストエフェクティブ
を得るということは、どの業界でも重要な要素なのだ。
371 :Socket774 [sage] :2006/08/23(水) 07:35:22 ID:MHnrbSyq
同じハードウェアに対してより高い性能をだせるアプリを制作できる方に
仕事が回るのは当然のこと。限られたリソース云々言ってて下に甘んじれば
それなりの仕事だけになるのも当然のこと。お仲間みんなで談合して非対応で
いけるように頑張れば?
384 :Socket774 [sage] :2006/08/23(水) 23:16:03 ID:wJhLdWxh
>>371
その書き方からするとリソース(人 物 金)が無尽蔵に使える会社に勤めているみたいだな
ちょっと紹介してくれないか?
386 :Socket774 [sage] :2006/08/24(木) 00:52:35 ID:0SMsGeM1
>>384
使えないヤツはどこに行っても使えないヤツだから無駄。
>割けば開発サポートが手薄になるといった状況かもしれない。任天堂にとっては、
>新旧どちらのユーザーも、開発者も大切なので、リソースの配分は難しい。
誤答もちょっとは成長したみたいだな。
クッタリ教に染まってたおまえいらも成長したか?
370 :Socket774 [sage] :2006/08/23(水) 07:11:34 ID:YK6ysv9a
後藤はハードウェアサイドの都合ばっかり書く。
ダイコスト、プロセッサ開発コスト・・・etc
それは立場上しょうがないにしても、問題なのは
「低脳プログラマ乙」「使いこなせない奴がアホ」
を連呼するような厨を量産してしまったこと。
限られたリソースの中で最大限のコストエフェクティブ
を得るということは、どの業界でも重要な要素なのだ。
371 :Socket774 [sage] :2006/08/23(水) 07:35:22 ID:MHnrbSyq
同じハードウェアに対してより高い性能をだせるアプリを制作できる方に
仕事が回るのは当然のこと。限られたリソース云々言ってて下に甘んじれば
それなりの仕事だけになるのも当然のこと。お仲間みんなで談合して非対応で
いけるように頑張れば?
384 :Socket774 [sage] :2006/08/23(水) 23:16:03 ID:wJhLdWxh
>>371
その書き方からするとリソース(人 物 金)が無尽蔵に使える会社に勤めているみたいだな
ちょっと紹介してくれないか?
386 :Socket774 [sage] :2006/08/24(木) 00:52:35 ID:0SMsGeM1
>>384
使えないヤツはどこに行っても使えないヤツだから無駄。
フラッシュ問題はSDカードを同梱すればいいだけじゃなかろか。
それで本体内フラッシュ間でコピーとかムーブとかさせるのか?
じゃあコピーは9回まで、孫は不可なwww
>>886
いや、写真チャンネルですでに使ってるのだが。
いや、写真チャンネルですでに使ってるのだが。
wiiのコンセプトからすると、「全員に」SDを使わせるのはハードルが高くなるから没
>>875
揚げ足取りとは言わないだろ。
AJAXって、ようするにクライアントサイドのJavaScriptを使ってサーバーから
非同期にデータを持ってきて、再読み込み無しに表示するってことなんだし。
当然、シンクライアントとは間逆のリッチクライアント。
http://www.atmarkit.co.jp/ad/fujitsu/interstage0706/01.html
それなのに
>より大それたことがシンクライアントで出来るわけです。
>実際、AJAXを使ったページがブラウザの上で動いていますから
はおかしいだろ。従来サーバーでやっていた処理をクライアントに持ってきて、
レスポンスを上げているんだから。
揚げ足取りとは言わないだろ。
AJAXって、ようするにクライアントサイドのJavaScriptを使ってサーバーから
非同期にデータを持ってきて、再読み込み無しに表示するってことなんだし。
当然、シンクライアントとは間逆のリッチクライアント。
http://www.atmarkit.co.jp/ad/fujitsu/interstage0706/01.html
それなのに
>より大それたことがシンクライアントで出来るわけです。
>実際、AJAXを使ったページがブラウザの上で動いていますから
はおかしいだろ。従来サーバーでやっていた処理をクライアントに持ってきて、
レスポンスを上げているんだから。
AJAXのキモは非同期の部分だと思うんだが
シンクライアントの真逆ってのは言いすぎじゃないか?
シンクライアントの真逆ってのは言いすぎじゃないか?
どうでもいいよ
こんなとこでネチネチ言ってること自体が揚げ足取り
こんなとこでネチネチ言ってること自体が揚げ足取り
それを言っちゃあお終い
AMDが2009年のCPUコアと統合CPUの概要を発表
http://pc.watch.impress.co.jp/docs/2007/0727/kaigai376.htm
http://pc.watch.impress.co.jp/docs/2007/0727/kaigai376.htm
後藤さんは、もうゲームの記事を書かないで欲しいよ
ここ1年ほど、ほんとゲーハー板の変な厨が大量に流れ込んできて
以前のように、まったり技術話ができる雰囲気が完全に無くなってしまった
ここ1年ほど、ほんとゲーハー板の変な厨が大量に流れ込んできて
以前のように、まったり技術話ができる雰囲気が完全に無くなってしまった
ブルドーザーね
>>897 6400W!
次スレからは、「後藤弘茂のPC記事を応援するスレ」とでもして、
ゲーム関係記事は、別の板でやってもらおう。
>>896が言うように、自分が持ってるオモチャの自慢をしたいお子様は、
どこかよその板で思う存分やってほしい。
ゲーム関係記事は、別の板でやってもらおう。
>>896が言うように、自分が持ってるオモチャの自慢をしたいお子様は、
どこかよその板で思う存分やってほしい。
901 :MACオタ>900 さん:2007/07/27(金) 22:02:30 ID:bWzOiuF4
>>900
------------------------
ゲーム関係記事は、別の板でやってもらおう。
------------------------
教育のない後藤氏にとって唯一の専門性って「ゲーマーとして純粋培養した家族」だけ
なんじゃないすか(笑)
------------------------
ゲーム関係記事は、別の板でやってもらおう。
------------------------
教育のない後藤氏にとって唯一の専門性って「ゲーマーとして純粋培養した家族」だけ
なんじゃないすか(笑)
>>900
おまえが去る方が無難だと思われ。
おまえが去る方が無難だと思われ。
「教育のない」って何処の国の言葉だろ
>>901
お前も、頼むから日本語教育を小学1年からやりなおしてくれ。
お前も、頼むから日本語教育を小学1年からやりなおしてくれ。
> 「教育のない」って何処の国の言葉だろ
いや極普通に使われる言葉だが・・・
http://www.google.co.jp/search?hl=ja&q=%E6%95%99%E8%82%B2%E3%81%AE%E3%81%AA%E3%81%84&lr=
例
教育のない人
教育のないXX氏
いや極普通に使われる言葉だが・・・
http://www.google.co.jp/search?hl=ja&q=%E6%95%99%E8%82%B2%E3%81%AE%E3%81%AA%E3%81%84&lr=
例
教育のない人
教育のないXX氏
ごく普通ってことはないだろ
いや極普通だぞ
教養の無い人や教育のない人、意味は違えど良く使われる言葉な。
教養の無い人や教育のない人、意味は違えど良く使われる言葉な。
学がない、って言うことの方が多い気がするがまあええことよ。
教養のない人とは言うけど、教育のない人とは言わないなあ
まあどうでもいいけど
まあどうでもいいけど
近頃の若者は活字離れというか小説とか読まないのな?
「教育のない人とは言わないなあ」というような発言を恥ずかしげもなくするのは無知な証拠か・・・
「教育のない人とは言わないなあ」というような発言を恥ずかしげもなくするのは無知な証拠か・・・
>>905
文体変えて火消しか?
検索エンジンに出てきた結果数が「普通に使われる」ってことの証左になると、
本気で思ってんのか?
お前のやってることのマヌケさの一端を示してやるよ
http://www.google.co.jp/search?num=100&hl=ja&q=%22%E9%A2%A8%E3%81%AE%E5%99%82%22&lr=
http://www.google.co.jp/search?num=100&hl=ja&q=%22%E6%B1%9A%E5%90%8D%E6%8C%BD%E5%9B%9E%22&lr=
セコイ真似してんんじゃねえよカス
文体変えて火消しか?
検索エンジンに出てきた結果数が「普通に使われる」ってことの証左になると、
本気で思ってんのか?
お前のやってることのマヌケさの一端を示してやるよ
http://www.google.co.jp/search?num=100&hl=ja&q=%22%E9%A2%A8%E3%81%AE%E5%99%82%22&lr=
http://www.google.co.jp/search?num=100&hl=ja&q=%22%E6%B1%9A%E5%90%8D%E6%8C%BD%E5%9B%9E%22&lr=
セコイ真似してんんじゃねえよカス
> 近頃の若者は活字離れというか小説とか読まないのな?
> 「教育のない人とは言わないなあ」というような発言を恥ずかしげもなくするのは無知な証拠か・・・
この時点で「普通」の範囲がデカすぎると思われ
日常ではあまり耳にすることのない表現だと思う>教育のない人
> 「教育のない人とは言わないなあ」というような発言を恥ずかしげもなくするのは無知な証拠か・・・
この時点で「普通」の範囲がデカすぎると思われ
日常ではあまり耳にすることのない表現だと思う>教育のない人
小説とか堅苦しい文章でしか使わないってことだよねぇ
「極普通」って感覚がずれてると思うよ
「極普通」って感覚がずれてると思うよ
あ、「教育のない人」を普通と思えないのは「教育のない人」なのかな?
火消しも大変だな
まあ、もうすぐ日付変わるから、それまで火消しに邁進して
何事もないフリして現れるのも慣れてるんだろけどな( ´,_ゝ`)
まあ、もうすぐ日付変わるから、それまで火消しに邁進して
何事もないフリして現れるのも慣れてるんだろけどな( ´,_ゝ`)
森鴎外 かのように
ttp://www.aozora.gr.jp/cards/000129/files/678_22884.html
そんな事は不可能である。そうして見ると、教育のない人の信仰が遺伝して、微(かす)かに残っているとでも思わなくてはなるまい。
ttp://www.aozora.gr.jp/cards/000129/files/678_22884.html
そんな事は不可能である。そうして見ると、教育のない人の信仰が遺伝して、微(かす)かに残っているとでも思わなくてはなるまい。
で、その森鴎外の使う言葉が日本人にとっての普通に使われる言葉だということかね?
脚気は伝染病とかも信じなくちゃだわ
というか教養のない人達ばかりなのか?
「教育のない」なんて普通に理解しろよというか>>905で使われ方ぐらい覚えておけ。
「教育のない」なんて普通に理解しろよというか>>905で使われ方ぐらい覚えておけ。
言葉ってのは人が作ってるものだからw
正しい言葉とかいってる池沼はうせろ。
正しい言葉とかいってる池沼はうせろ。
教養で思考停止を強要しなくても良いよw
火消しが1名しか出現しないのはなぜなの?
火消しなの?
しまった、日付変わったら終了だったのか…
ゲハ厨を相手にするべからず
日本語として正しかったとしても、
小説の中でしか使われなくなったような言葉で日常で使うと
なんだこいつって思われるだろう。
「教育がない」がそこまでのレベルかどうかは知らないけどね。
小説の中でしか使われなくなったような言葉で日常で使うと
なんだこいつって思われるだろう。
「教育がない」がそこまでのレベルかどうかは知らないけどね。
あの…もう終わりみたいよ?
元々は
教育がない → そんな使い方無いよ
って流れだったわけだ。
で、
そんな使い方無いよ → あるよ
となってるのでもうこの話題は終了してます。
普段の日本語がどうとか必死すぎます。
教育がない → そんな使い方無いよ
って流れだったわけだ。
で、
そんな使い方無いよ → あるよ
となってるのでもうこの話題は終了してます。
普段の日本語がどうとか必死すぎます。
お、まだやるんだw
まぁ、なんだ、お前ら人間なんだから、その程度の寛容ぐらいもてよ。
どこぞのコンパイラじゃあるまいし。
どこぞのコンパイラじゃあるまいし。
IDがAWKw
つうか、此処は後藤氏の記事の
そういう国語の添削してる所だろ。
他人の記事にケチつけるなら・・・
そういう国語の添削してる所だろ。
他人の記事にケチつけるなら・・・
936 :Socket774:2007/07/28(土) 06:45:18 ID:m6w1howB
身内のMACオタには優しいんだろw
批判するなら、それ以上の内容が求められるのは当然だが。
批判するなら、それ以上の内容が求められるのは当然だが。
MACがAMDを採用するべきだったってことですね
>元々は「K8 Revision H(Rev. H)」または「K8L」と名付けられていた。K8コアのパフォーマンス拡張版で、
>フロムスクラッチ(ゼロから)作られていたオリジナルプランのK10とは異なる。
フルスクラッチ って書くのやめたんだ。
あぁそうか、フロム〜のほうが1文字多く稼げるもんな。
>フロムスクラッチ(ゼロから)作られていたオリジナルプランのK10とは異なる。
フルスクラッチ って書くのやめたんだ。
あぁそうか、フロム〜のほうが1文字多く稼げるもんな。
http://pc.watch.impress.co.jp/docs/2007/0727/kaigai376.htm
AMDが2009年のCPUコアと統合CPUの概要を発表
AMDが2009年のCPUコアと統合CPUの概要を発表
942 :名無しさん@そうだ選挙に行こう:2007/07/29(日) 01:22:56 ID:fRW9LJbf
くそもらし
943 :Socket774:2007/07/30(月) 02:09:22 ID:31FXNDbP
日本人はどうしてバカしかいないだろう?
日帝滅ぶのが世界の屑ではないですかね?
日帝滅ぶのが世界の屑ではないですかね?
944 : ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄|/ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄:2007/07/30(月) 07:51:16 ID:NeTZYhcw
,, --―-
.,/ ゙l. ゙゙̄ヾ,,
/ _,,,,,,,,l ゙ヽ
,ミ .,,,wll'゙゙″ .゙゙ミ .゙ミ
l ,,rl'゙ ミ ミ
l、 /l/,,,,,、 ,,,,iiiiiiiiii,, ミ, ,,l|
'ly ll!!!!!llllll_,llll!llllliiillllllrー-f゙/-.,
.゙l-(゙ ''-",l゙^゙l, _ ''"ノ ゙llll゙::::|
'll゙ー─,/″lii,, ̄ . ...:: .il.r.,/
゙! ,il,_、 ,,,,).、 ::::: .l._,!
. ゙l、/゙,..-v- 、.\ ,j
. ヽ.゙゙'=ニニ-. ,/、 .,/l、
. ヽゞー-‐" .,,,.ィ´″ |ヽ
/ ー--''゙” / \
ノリミツ・オオニシ[NORIMITSU ONISHI]
(1969〜 朝鮮系 千葉→カナダ)
.,/ ゙l. ゙゙̄ヾ,,
/ _,,,,,,,,l ゙ヽ
,ミ .,,,wll'゙゙″ .゙゙ミ .゙ミ
l ,,rl'゙ ミ ミ
l、 /l/,,,,,、 ,,,,iiiiiiiiii,, ミ, ,,l|
'ly ll!!!!!llllll_,llll!llllliiillllllrー-f゙/-.,
.゙l-(゙ ''-",l゙^゙l, _ ''"ノ ゙llll゙::::|
'll゙ー─,/″lii,, ̄ . ...:: .il.r.,/
゙! ,il,_、 ,,,,).、 ::::: .l._,!
. ゙l、/゙,..-v- 、.\ ,j
. ヽ.゙゙'=ニニ-. ,/、 .,/l、
. ヽゞー-‐" .,,,.ィ´″ |ヽ
/ ー--''゙” / \
ノリミツ・オオニシ[NORIMITSU ONISHI]
(1969〜 朝鮮系 千葉→カナダ)
揺れる2009年のAMDデスクトッププラットフォーム
http://pc.watch.impress.co.jp/docs/2007/0801/kaigai377.htm
http://pc.watch.impress.co.jp/docs/2007/0801/kaigai377.htm
ようするに、何も決まってないと
947 :MACオタ>945 さん:2007/08/01(水) 01:09:41 ID:S3G4hAVz
>>945
------------------------
また、Sandtigerに搭載される次世代CPUコア「Bulldozer(ブルドーザ)」コアが、それほど
大きなCPUコアでないことも推測できる。少なくとも、現行のK8/K10系のCPUコアより、
大きく肥大化させるつもりはなさそうだ。
------------------------
ゆっくり原稿書いてた割りにAnalyst Dayの当日掲載されたCNETのニュースと同じ話すか。。。
パクりと言われても仕方が無い品質すね。。。
http://itpro.nikkeibp.co.jp/article/MAG/20070727/278473/?L=top5
=========================
チップの大きさを尋ねたところ,AMDの最高技術責任者(CTO),Phil Hester氏は笑顔を
見せ,ダイサイズについては明言を避けたものの,「コスト的に魅力的」なものになること
を約束した。チップが大きければ大きいほど,1枚のシリコンウエハから切り出せるチップ
の数が減るため,プロセッサの表面積は製造と利益にとって非常に大きな要因となる。
In-StatのアナリストJim McGregor氏は,同世代より根本的に新しい(そして小さい)コア
デザインをAMDは用意する可能性が高いことを示唆した。
=========================
------------------------
また、Sandtigerに搭載される次世代CPUコア「Bulldozer(ブルドーザ)」コアが、それほど
大きなCPUコアでないことも推測できる。少なくとも、現行のK8/K10系のCPUコアより、
大きく肥大化させるつもりはなさそうだ。
------------------------
ゆっくり原稿書いてた割りにAnalyst Dayの当日掲載されたCNETのニュースと同じ話すか。。。
パクりと言われても仕方が無い品質すね。。。
http://itpro.nikkeibp.co.jp/article/MAG/20070727/278473/?L=top5
=========================
チップの大きさを尋ねたところ,AMDの最高技術責任者(CTO),Phil Hester氏は笑顔を
見せ,ダイサイズについては明言を避けたものの,「コスト的に魅力的」なものになること
を約束した。チップが大きければ大きいほど,1枚のシリコンウエハから切り出せるチップ
の数が減るため,プロセッサの表面積は製造と利益にとって非常に大きな要因となる。
In-StatのアナリストJim McGregor氏は,同世代より根本的に新しい(そして小さい)コア
デザインをAMDは用意する可能性が高いことを示唆した。
=========================
ゼンゼン違う内容になるわけないだろ。アホか。
949 :MACオタ>948 さん:2007/08/01(水) 02:36:58 ID:S3G4hAVz
■天才MACオタのWeekly海外ニュース■
揺れる2009年のAMDデスクトッププラットフォーム
↓
揺れる2009年のAMDデスクトッププラットフォーム
↓
ダイを小さくしてIPCアップ…R-HTくるのか?
批判のための批判はいらない
>>949
実際自分で考えたのでは?
実際自分で考えたのでは?
くそもらし
オクタルコアになってしまったんじゃ
もうオタクコアネタは使えないのか・・・残念だw
もうオタクコアネタは使えないのか・・・残念だw
久しぶりにたるさんの所見にいったら件の先生とまだコスト論争してて和んだ
「たるさんのしょけん」って何だろうって一瞬考えた
きのこる先生みたいなもんか
この先ナマトマだこって何だか旨そうって一瞬考えた
{kind=link}
ワンダ、ワンダ、ワンダ、ワンダ、ワンダ
>>961
トランスフォームしそうだな
トランスフォームしそうだな
3.2Gbpsを狙う次々世代メモリ「DDR4」
http://pc.watch.impress.co.jp/docs/2007/0806/kaigai378.htm
http://pc.watch.impress.co.jp/docs/2007/0806/kaigai378.htm
>>964
--------------------
だが、XDR DRAMも、PLAYSTATION 3(PS3)以外の有力な顧客をつかんだようだ。
--------------------
これだけ書いて具体的な記述が一切無いのわ、伏線張って次回へ客を引っ張るテレビドラマ的
手法を取り入れたつもりすか(笑)
そのうち毎回最初の十行わ、前回のをそのまま繰り返すという文体になったりして。。。
--------------------
だが、XDR DRAMも、PLAYSTATION 3(PS3)以外の有力な顧客をつかんだようだ。
--------------------
これだけ書いて具体的な記述が一切無いのわ、伏線張って次回へ客を引っ張るテレビドラマ的
手法を取り入れたつもりすか(笑)
そのうち毎回最初の十行わ、前回のをそのまま繰り返すという文体になったりして。。。
みんな、ウンコ踏まないように気をつけろよ
>>966
AMDを踏まなければ安牌だな
AMDを踏まなければ安牌だな
966も運固の仲間
>>728での宿題をほっぽっておきながらウンコテはよく出てこられるな
説得力のあるレスをする気が元からないオナニーなんだろうけど
説得力のあるレスをする気が元からないオナニーなんだろうけど
ウンコテはあぼーんしろよ。