Intel�̎�����CPU�ɂ��Č�낤 26
1 �FSocket774�F
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 25
http://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B
�@�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
11���ɂ��b�o�t�������I�H
Intel�̎�����CPU�ɂ��Č�낤 25
http://pc7.2ch.net/test/read.cgi/jisaku/1147545560/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B
�@�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
11���ɂ��b�o�t�������I�H
|
|
|
2 �FSocket774�F2006/08/31(��) 19:24:31 ID:EniP45wc
���ߋ��X��
24 http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 http://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ��ށB�p�[�g2
21 http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
24 http://pc7.2ch.net/test/read.cgi/jisaku/1144400151/
23 http://pc7.2ch.net/test/read.cgi/jisaku/1141882416/
22 ��ށB�p�[�g2
21 http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�Q�Q�Q�Q
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@__,,�^�@�@_, ----�M�R�@�@�F.
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�F.�@�@�^�@_�@�@�@�@�@___�@�@�@��_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/ �^�@�@�@i�@�@�@ �@ �_ �@ �_�_�@�F.
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �F.�@,'./ �@ �@ �@ i�@�@�R:.�@ �@�R:.:..�@�R.�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,'/�@�@�@ / .�n �R�@�R:.:.:.:.�@�R::..�@�R�R�@�F. �ȁc
�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�F. |i .i�@i�@ .i /�@ �R � � �_�:.:.:. ',:.',:.:.l�R} �@�@ �Ȃ�Ȃ�ł����H
�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@|i .i�@l �@:�m�Q, -�T�@�_���T�i:}:.:} �@�@�@�@�@�Ȃ�ł������A�j�̑̂ɂȂ��Ă��ł����H
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�F.|i�� ',�@:{�@,�j��ā@�_�@ �j�~IJ��u�@�F. �@�@�@�Ȃ�ł��̃X��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@ :ҁR.', `oz�y} �@ �@�@ izN��::{ �@�@�@�@�@�@�@�������̂���Ȏp�ŏI����ł����H
�@�@�@�@�@�@�Q�Q �@�@�@�@�@�@ �F|�@ :�S_! �T�@"�ށ@�@�@ ' �@�M� �n.:',�@�F.
�@�@/�L�P �@ �@ �@ `!�@�@�@�@�@�@|�@ :.:_� .:.�R. �@�@(��́@, � :.:.:!:.�R
�@ �b�@ �M�ɂ���'_Ɂ@�@�@�F.�@ / r�� |�@:.:.�R:�_�Q�Q�^..�m .::.:.}�R��R�F.
�@ Ɂ@u �@{�@�@�@�@ �@ �@ �@ �@/ ��l;l�@!�@:.:.:.:/�@�@�@,/ / ::...:..::R.:�_
. /�@l �@�@�b�@�Q�Q �@�^�P�P�M>'�L�P�P .�m' �@�@�@�L |.:.:.::.:.:./�@ }: . �R.�F.
/ |/�@�@ �@ {'�L�@�@�@ �M�R.�@"�P�_ U�@�M�R.�@ �@ __,,.�@-!.:..::.:./u �@�R:.:.�@i '
| /�@�S�..�@ }�@ �@ �@ u'�@�r� �@�@�@}�@�@�@�@`�''�L�@�@�^�L�P �M�R '"�P�_
! :}�@�@)�u` ɁA�@�@�@�@ �m�@l�_"�L_,,�=-�\ <�L�@ �R{�@ �m�i�@�@�@`�A�@�@�b
l�@ �@�_,�^���@`�[��''"�@�@ },�@ � ,�@ '''''""�@ �_ �@ �R �܁S�@ �@ �@ v�@ |
�R�@�@�@�Q �@�@�@�@�@�@�@ / �@ } {. { l �����]���@ �R�^�@``�_ �@ �@ �@ �@�
�@ �M�N�L�@ �@ �M�N�N�N�N�L�P`{ 0 �@�M'^��'���|�S�@ �@ }�A�@u' �@ `�@ --�]r'��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@__,,�^�@�@_, ----�M�R�@�@�F.
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�F.�@�@�^�@_�@�@�@�@�@___�@�@�@��_
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@/ �^�@�@�@i�@�@�@ �@ �_ �@ �_�_�@�F.
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �F.�@,'./ �@ �@ �@ i�@�@�R:.�@ �@�R:.:..�@�R.�R
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,'/�@�@�@ / .�n �R�@�R:.:.:.:.�@�R::..�@�R�R�@�F. �ȁc
�@�@�@�@�@�@�@�@�@�@�@�@�@ �@�F. |i .i�@i�@ .i /�@ �R � � �_�:.:.:. ',:.',:.:.l�R} �@�@ �Ȃ�Ȃ�ł����H
�@�@�@�@�@�@�@�@�@�@�@�@�@ �@ �@|i .i�@l �@:�m�Q, -�T�@�_���T�i:}:.:} �@�@�@�@�@�Ȃ�ł������A�j�̑̂ɂȂ��Ă��ł����H
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�F.|i�� ',�@:{�@,�j��ā@�_�@ �j�~IJ��u�@�F. �@�@�@�Ȃ�ł��̃X��
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@.|�@ :ҁR.', `oz�y} �@ �@�@ izN��::{ �@�@�@�@�@�@�@�������̂���Ȏp�ŏI����ł����H
�@�@�@�@�@�@�Q�Q �@�@�@�@�@�@ �F|�@ :�S_! �T�@"�ށ@�@�@ ' �@�M� �n.:',�@�F.
�@�@/�L�P �@ �@ �@ `!�@�@�@�@�@�@|�@ :.:_� .:.�R. �@�@(��́@, � :.:.:!:.�R
�@ �b�@ �M�ɂ���'_Ɂ@�@�@�F.�@ / r�� |�@:.:.�R:�_�Q�Q�^..�m .::.:.}�R��R�F.
�@ Ɂ@u �@{�@�@�@�@ �@ �@ �@ �@/ ��l;l�@!�@:.:.:.:/�@�@�@,/ / ::...:..::R.:�_
. /�@l �@�@�b�@�Q�Q �@�^�P�P�M>'�L�P�P .�m' �@�@�@�L |.:.:.::.:.:./�@ }: . �R.�F.
/ |/�@�@ �@ {'�L�@�@�@ �M�R.�@"�P�_ U�@�M�R.�@ �@ __,,.�@-!.:..::.:./u �@�R:.:.�@i '
| /�@�S�..�@ }�@ �@ �@ u'�@�r� �@�@�@}�@�@�@�@`�''�L�@�@�^�L�P �M�R '"�P�_
! :}�@�@)�u` ɁA�@�@�@�@ �m�@l�_"�L_,,�=-�\ <�L�@ �R{�@ �m�i�@�@�@`�A�@�@�b
l�@ �@�_,�^���@`�[��''"�@�@ },�@ � ,�@ '''''""�@ �_ �@ �R �܁S�@ �@ �@ v�@ |
�R�@�@�@�Q �@�@�@�@�@�@�@ / �@ } {. { l �����]���@ �R�^�@``�_ �@ �@ �@ �@�
�@ �M�N�L�@ �@ �M�N�N�N�N�L�P`{ 0 �@�M'^��'���|�S�@ �@ }�A�@u' �@ `�@ --�]r'��
4 �FSocket774�F2006/08/31(��) 19:25:40 ID:EniP45wc
20 ttp://pc7.2ch.net/test/read.cgi/jisaku/1134332250/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
19 ttp://pc7.2ch.net/test/read.cgi/jisaku/1131783188/
18 ttp://pc7.2ch.net/test/read.cgi/jisaku/1128543843/
17 ttp://pc7.2ch.net/test/read.cgi/jisaku/1125251094/
16 ttp://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
15 ttp://pc7.2ch.net/test/read.cgi/jisaku/1122463712/
14 ttp://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 ttp://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 ttp://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 ttp://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 ttp://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
09 ttp://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
08 ttp://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
07 ttp://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
06 ttp://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
05 ttp://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
04 ttp://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
03 ttp://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
02 ttp://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
01 ttp://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
��Intel Core Microarchitecture
Intel's Next Generation Microarchitecture Unveiled
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Into the Core: Intel's next-generation microarchitecture
http://arstechnica.com/articles/paedia/cpu/core.ars
�O�X�����
���ĂɂȂ����uCore Microarchitecture�v�̑S�e
http://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
Intel��Core Microarchitecture
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
Intel's Next Generation Microarchitecture Unveiled
http://www.realworldtech.com/page.cfm?ArticleID=RWT030906143144
Into the Core: Intel's next-generation microarchitecture
http://arstechnica.com/articles/paedia/cpu/core.ars
�O�X�����
���ĂɂȂ����uCore Microarchitecture�v�̑S�e
http://pc.watch.impress.co.jp/docs/2006/0311/kaigai249.htm
Intel��Core Microarchitecture
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
6 �FSocket774�F2006/08/31(��) 19:29:00 ID:sQNAHnSX
�v���ɁE�E�E�E�E�E
100MHz�œ��삷�钴���^CPU��
10000���炢���ׂ�CPU���a������B
�ŁA�傫���͍���CPU�Ƒ��ĕς��Ȃ��B
100MHz�œ��삷�钴���^CPU��
10000���炢���ׂ�CPU���a������B
�ŁA�傫���͍���CPU�Ƒ��ĕς��Ȃ��B
�C���e������CPU���[�h�}�b�v
�@�f�X�N http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241_02.pdf
�@���o�C���@�@http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241_03.pdf
�@�f�X�N http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241_02.pdf
�@���o�C���@�@http://pc.watch.impress.co.jp/docs/2006/0209/kaigai241_03.pdf
49 ���O�FSocket774 ���e���F2006/08/31(��) 16:29:23 ID:q/YfOvF8
>>46
�悭Core2�̃G���b�^���Đ���悭�������ǁA����ȂɃN���e�B�J���Ȃ��̂������́H
�ނ���ߔN�o�����̂ł́A�G���b�^�̂Ȃ�CPU�͌����������Ȃ���
53 ���O�FSocket774 ���e���F2006/09/01(��) 15:53:05 ID:8QfEqjED
>>49
�����^�C�~���O�F����ł����B
�e���E���ʁF�\���ł����B
���̂����������Ă����o���o���Ȃ��B
�g���Ă���Ƃ��̂܂ɂ��f�[�^�����Ă�B
>>46
�悭Core2�̃G���b�^���Đ���悭�������ǁA����ȂɃN���e�B�J���Ȃ��̂������́H
�ނ���ߔN�o�����̂ł́A�G���b�^�̂Ȃ�CPU�͌����������Ȃ���
53 ���O�FSocket774 ���e���F2006/09/01(��) 15:53:05 ID:8QfEqjED
>>49
�����^�C�~���O�F����ł����B
�e���E���ʁF�\���ł����B
���̂����������Ă����o���o���Ȃ��B
�g���Ă���Ƃ��̂܂ɂ��f�[�^�����Ă�B
10 �FSocket774�F2006/09/08(��) 12:05:01 ID:rigD/DC3
Core2Duo���߂��ăo���X��������
�^�C�~���O������ł��Ȃ��Ȃ�Ăǂ��ɂ������ĂȂ��B
��̂ɏ��������ł��Ȃ��Ȃ璼���悤���Ȃ��B
�C������Β����肾���A�}�C�N���A�[�L�̎����ɂ�����镔��������
���������ڂ������J���Ȃ������B
��̂ɏ��������ł��Ȃ��Ȃ璼���悤���Ȃ��B
�C������Β����肾���A�}�C�N���A�[�L�̎����ɂ�����镔��������
���������ڂ������J���Ȃ������B
�C�����Ă�����Ȃ���C�����Ȃ��ƁA�Ƃ����ATOK�l������������Ă��܂�
AMD���[�U�͍r�炵���̂��̂���
Core3���l����̂�����Ȃ��̂ŁACore2�̐V�V���[�Y��ϑz����
�L���b�V��4MB
Core 2 Duo X6950 3.33GHz
Core 2 Duo E6850 3.0GHz
Core 2 Duo E6750 2.66GHz
Core 2 Duo E6550 2.33GHz
Core 2 Duo E6500 2.13GHz
�L���b�V��2MB
Core 2 Duo E6450 2GHz
Core 2 Duo E6300 1.86GHz
Core 2 Duo E4200 1.6GHz
45nm
Core 2 Duo X8800 3.66GHz
Core 2 Duo E8700 3.33GHz
Core 2 Duo E8600 3.0GHz
Core 2 Duo E8500 2.66GHz
Core 2 Duo E8400 2.33GHz
�L���b�V��4MB
Core 2 Duo X6950 3.33GHz
Core 2 Duo E6850 3.0GHz
Core 2 Duo E6750 2.66GHz
Core 2 Duo E6550 2.33GHz
Core 2 Duo E6500 2.13GHz
�L���b�V��2MB
Core 2 Duo E6450 2GHz
Core 2 Duo E6300 1.86GHz
Core 2 Duo E4200 1.6GHz
45nm
Core 2 Duo X8800 3.66GHz
Core 2 Duo E8700 3.33GHz
Core 2 Duo E8600 3.0GHz
Core 2 Duo E8500 2.66GHz
Core 2 Duo E8400 2.33GHz
15 �FSocket774�F2006/09/09(�y) 14:52:19 ID:FvO12POG
Core2Duo���߂��ăo���X��������
16 �FSocket774�F2006/09/10(��) 13:54:50 ID:qfMXVNcR
Conroe�͂�������
���ځ[��
���ځ[��
���ځ[��
���ł���ߕ\
Intel's Core 2 Quadro Kentsfield: Four Cores on a Rampage
http://www.tomshardware.co.uk/2006/09/10/four_cores_on_the_rampage_uk/
�@��
http://www.tomshardware.co.uk/2006/09/10/four_cores_on_the_rampage_uk/
�@��
���㓡�O��Weekly�C�O�j���[�X��
2010�N��Intel�A�[�L�e�N�`������������
ttp://pc.watch.impress.co.jp/docs/2006/0912/kaigai300.htm
kentsfield�x���`�̌ゾ���Ƀ}���`�R�A�Ɋ��҂��Ă��܂�������
2010�N��Intel�A�[�L�e�N�`������������
ttp://pc.watch.impress.co.jp/docs/2006/0912/kaigai300.htm
kentsfield�x���`�̌ゾ���Ƀ}���`�R�A�Ɋ��҂��Ă��܂�������
23 �FSocket774�F2006/09/12(��) 12:49:11 ID:75pgtRpS
Core2Duo���߂��ăo���X��������
AMD���f�M�҂͑Ό��X���Ō��
>>22
����ǂ�Ŋm�M�����ARattner�̓y�e���t
����ǂ�Ŋm�M�����ARattner�̓y�e���t
26 �FSocket774�F2006/09/13(��) 12:19:21 ID:C915/1zL
. .: : : : : : : : :: :::: :: :: : :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
�@. . : : :�R�����[�Ńo�O�E�E�E:::::::::::::::::::::::::::::::::::::::::::::::::::::
: ::http://www.theinquirer.net/default.aspx?article=33916
�@�@�@�@�@�@�@ .In�Q�� . . . .: : : ::: : :: ::::::::: :::::::::::::::::::::::::::::
�@�@�@�@�@ �@/:�c�~�J�R;�j�[��@. . .: : : :::::: :::::::::::::::::::::::::::::::::
�@�@�@�@�@ / :::/:: �R�A�R�A ::i . .:: :.: ::: . :::::::::::::::::::::::::::::::::::::::
�@�@ �@�@ / :::/;;: �@ �R�@�R ::���@. :. :. .:: : :: :: :::::::: : ::::::::::::::::::
�P�P�P�i_,�m �P�P�P�R�_�m�P
�����E�E�E�E�E
�@";�S�S ;�S "�@�@" ; ; ; ;�S ;�S"; ::::::::::::::::::::::::::....�@�@�@�@�@�@�@ |.::::::::::.......... . .
;�S ;�S ;;�S ;..�^ ;�S �@;" ;�S ;;�S ;�S"::::::::::::::�R�@�@�@�@�@�@�@�@ /:::::::::............. . .
;;"�S ; ;"�^�^ �@;�S�S ;�S �@"�@�@.....::::..:...:::.....�_�@�@�@�@�@ .�^...::::...... .�@.�@.
; ;" �@; �S �V";�S ;"�@�@�@�@�@�@�@�@�@....�@ �@�@..�@�[ �|:::::::::::. . . .�@.�@.�@.
i�@ l ";�S ;;�S ;;"�@||
l�@i|/"/�.�@�@ "In||�� �@�@�@�@�@���߁A�����ݾ��ŏ��҂ɂȂ���Լ������ł��B
�@|�Jl|/"�@�@�@�i�@ �� �R
|�@|.; �@ �@ �@�@ ���@�B� �Ɂ@�@�@ �@�@�@�@�@�@ AmD�@�@�@�@������킹�Ă����Ȃ����B
�@ | |�@�@�@" �T�T����. �@�@�@�@�@�@�@�@�@�@�i�M�@�@�@�j
�J ::|,|�@�@�@�@�@�@�@�@�@�@�@ �@�@�@ �@.AmD,���@�@�@ �j
������������������������(_ �@ _)�@�b �b �b ��������
�� ;| |, .��. , : i ���@ �@ ���@ �@�@(�Q�Q�j �i�Q_�j__�j.���@ �@ ��
/;i;IMY i/'':;ii;.i.i.'/'�@'' ' ' /�@�@�@''::i;:iii:i:i''' ' ':IiIiI;;Ill;:;'' '/'' '�@'�@/
i IiIii ;,;:,iiii;;ii:i;;:;i:i;;::;�@�@,.,.. ,...... ,.... '',,''',,''.,..'' "ii:;i;i;;;,"' ,,,.,.. ,....
�@. . : : :�R�����[�Ńo�O�E�E�E:::::::::::::::::::::::::::::::::::::::::::::::::::::
: ::http://www.theinquirer.net/default.aspx?article=33916
�@�@�@�@�@�@�@ .In�Q�� . . . .: : : ::: : :: ::::::::: :::::::::::::::::::::::::::::
�@�@�@�@�@ �@/:�c�~�J�R;�j�[��@. . .: : : :::::: :::::::::::::::::::::::::::::::::
�@�@�@�@�@ / :::/:: �R�A�R�A ::i . .:: :.: ::: . :::::::::::::::::::::::::::::::::::::::
�@�@ �@�@ / :::/;;: �@ �R�@�R ::���@. :. :. .:: : :: :: :::::::: : ::::::::::::::::::
�P�P�P�i_,�m �P�P�P�R�_�m�P
�����E�E�E�E�E
�@";�S�S ;�S "�@�@" ; ; ; ;�S ;�S"; ::::::::::::::::::::::::::....�@�@�@�@�@�@�@ |.::::::::::.......... . .
;�S ;�S ;;�S ;..�^ ;�S �@;" ;�S ;;�S ;�S"::::::::::::::�R�@�@�@�@�@�@�@�@ /:::::::::............. . .
;;"�S ; ;"�^�^ �@;�S�S ;�S �@"�@�@.....::::..:...:::.....�_�@�@�@�@�@ .�^...::::...... .�@.�@.
; ;" �@; �S �V";�S ;"�@�@�@�@�@�@�@�@�@....�@ �@�@..�@�[ �|:::::::::::. . . .�@.�@.�@.
i�@ l ";�S ;;�S ;;"�@||
l�@i|/"/�.�@�@ "In||�� �@�@�@�@�@���߁A�����ݾ��ŏ��҂ɂȂ���Լ������ł��B
�@|�Jl|/"�@�@�@�i�@ �� �R
|�@|.; �@ �@ �@�@ ���@�B� �Ɂ@�@�@ �@�@�@�@�@�@ AmD�@�@�@�@������킹�Ă����Ȃ����B
�@ | |�@�@�@" �T�T����. �@�@�@�@�@�@�@�@�@�@�i�M�@�@�@�j
�J ::|,|�@�@�@�@�@�@�@�@�@�@�@ �@�@�@ �@.AmD,���@�@�@ �j
������������������������(_ �@ _)�@�b �b �b ��������
�� ;| |, .��. , : i ���@ �@ ���@ �@�@(�Q�Q�j �i�Q_�j__�j.���@ �@ ��
/;i;IMY i/'':;ii;.i.i.'/'�@'' ' ' /�@�@�@''::i;:iii:i:i''' ' ':IiIiI;;Ill;:;'' '/'' '�@'�@/
i IiIii ;,;:,iiii;;ii:i;;:;i:i;;::;�@�@,.,.. ,...... ,.... '',,''',,''.,..'' "ii:;i;i;;;,"' ,,,.,.. ,....
inq�ɗ����ڂ����������̋L���͓ǂ�łȂ��̂��H
ttp://www.theinquirer.net/default.aspx?article=33942
> First off, this is not a reason to panic or not buy the chips,
> they are fine as is, the errata lists always get overblown by
> the fanboi set, and this one is no exception.
ttp://www.theinquirer.net/default.aspx?article=33942
> First off, this is not a reason to panic or not buy the chips,
> they are fine as is, the errata lists always get overblown by
> the fanboi set, and this one is no exception.
ttp://www.spec.org/jbb2005/results/res2006q3/jbb2005-20060815-00179.html
>BIOS
>Hardware Prefetcher : [Enabled] (Default)
ttp://www.spec.org/jbb2005/results/res2006q3/jbb2005-20060815-00180.html
>BIOS
>Hardware Prefetcher : [Disabled]
>BIOS
>Hardware Prefetcher : [Enabled] (Default)
ttp://www.spec.org/jbb2005/results/res2006q3/jbb2005-20060815-00180.html
>BIOS
>Hardware Prefetcher : [Disabled]
Disabled�̕��������������H
>>28
Tested by: Advanced Micro Devices
Tested by: Advanced Micro Devices
>>28�ɂ��ĕ⑫
JVM Command Line
-XXallocprefetch
-XXallocRedoPrefetch
������Woodcrest�����ł͂Ȃ��A������Hardware Prefetch��Conflict����݂���
�ǂ����Ȃ�H/W Prefetch enable�ŏ�L�̃I�v�V�������g�p���Ȃ������ꍇ�̃f�[�^���~������������
���Ƒ��ЂƔ�ׂ�Ǝ�v�����Â����ǂ����AMD������d���������Ȃ�
��Tulsa�����蓾�Ȃ��ʃc���X
��N���b�N��Netburst�̕Ȃɐ��ӋC����
JVM Command Line
-XXallocprefetch
-XXallocRedoPrefetch
������Woodcrest�����ł͂Ȃ��A������Hardware Prefetch��Conflict����݂���
�ǂ����Ȃ�H/W Prefetch enable�ŏ�L�̃I�v�V�������g�p���Ȃ������ꍇ�̃f�[�^���~������������
���Ƒ��ЂƔ�ׂ�Ǝ�v�����Â����ǂ����AMD������d���������Ȃ�
��Tulsa�����蓾�Ȃ��ʃc���X
��N���b�N��Netburst�̕Ȃɐ��ӋC����
What if Intel Penryn uses Rambus XDR, eh?
http://www.theinquirer.net/default.aspx?article=34383
http://www.theinquirer.net/default.aspx?article=34383
http://news.com.com/Turning+a+corner+with+the+new+Itanium/2008-1010_3-6115388.html?tag=nefd.lede
>"For high-end Itanium severs, you've got the Arches chipset that's going to last through Montvale (Montecito's successor, due in 2007). What comes after that, with Tukwila systems?
>Marcello: We've got Windjammer (successor to the Arches chipset) coming down the road.
>
>How about on the low end?
>Marcello: Yeah, there'll be a follow-on as well. It's something called Corsair."
>"Is Poulson, the Itanium model three generations down the road, going to be a major jump after Tukwila, which is two generations away?
>Marcello: Yeah.
>
>Will that be another doubling of performance?
>Marcello: That would be good.
>
>That's what you're hoping for, or that's what you're betting on?
>Marcello: That's what I'm hoping for. You know, I think it's still four or five years out."
>"For high-end Itanium severs, you've got the Arches chipset that's going to last through Montvale (Montecito's successor, due in 2007). What comes after that, with Tukwila systems?
>Marcello: We've got Windjammer (successor to the Arches chipset) coming down the road.
>
>How about on the low end?
>Marcello: Yeah, there'll be a follow-on as well. It's something called Corsair."
>"Is Poulson, the Itanium model three generations down the road, going to be a major jump after Tukwila, which is two generations away?
>Marcello: Yeah.
>
>Will that be another doubling of performance?
>Marcello: That would be good.
>
>That's what you're hoping for, or that's what you're betting on?
>Marcello: That's what I'm hoping for. You know, I think it's still four or five years out."
���{HP�A�f���A���R�AXeon 7100�ԑ�̐V�^�n�C�G���h�T�[�o��SAS�Ή��e�[�v���u
http://japan.zdnet.com/news/hardware/story/0,2000056184,20233927,00.htm
>ProLiant ML570/DL580 G4�̐V���f���́A7100�ԑ��Xeon��4���ڂł���B
>�x���`�}�[�N�e�X�g�uSAP SD Standard Application Benchmark Results, Two-tier Internet Configuration�v�Ōv�������Ƃ���A�ł������L�^���o�����Ƃ����B
>
>�@��̓I�ɂ́A�x���`�}�[�N���[�U�[����2127���[�U�[�ŁA
http://japan.zdnet.com/news/hardware/story/0,2000056184,20233927,00.htm
>ProLiant ML570/DL580 G4�̐V���f���́A7100�ԑ��Xeon��4���ڂł���B
>�x���`�}�[�N�e�X�g�uSAP SD Standard Application Benchmark Results, Two-tier Internet Configuration�v�Ōv�������Ƃ���A�ł������L�^���o�����Ƃ����B
>
>�@��̓I�ɂ́A�x���`�}�[�N���[�U�[����2127���[�U�[�ŁA
XDR���������
Itanium, the speedy encryptor
http://www.gcn.com/print/25_27/41891-1.html
http://www.gcn.com/print/25_27/41891-1.html
���ځ[��
���ځ[��
���ځ[��
���ځ[��
�Ȃ�ł��O�͂���Ȃɂ݂ɂ������ق炵���\���D��œ\��t����́H
���̕\�\��n�߂��̂��āA����A�z��Core2��2���R�A2�Ƃ����Ӗ����Ƃ������Ĉȗ�����ȁB
��������Ȃ��ƌ����A�z�͂��Ȃ��Ȃ�������A���̕\�\��Ȃ��Ă����Ǝv�����ȁB
��������Ȃ��ƌ����A�z�͂��Ȃ��Ȃ�������A���̕\�\��Ȃ��Ă����Ǝv�����ȁB
���ځ[��
���ځ[��
���ځ[��
���ځ[��
���ځ[��
���ځ[��
������������������߂ė~����
�s���\���͋C�Ⴂ���x���邾������
AA��AA�ȊO�ł͍폜�Ώۂ�����^�c�Ɍ����Ă���̂��m������
2�A3�x�폜�˗����ʂ��ď�����Ă��������\���Ă���悤�Ȃ̂ɑ��Ă̓A�N�ւƂ����ʂ�₷���Ȃ�
2�A3�x�폜�˗����ʂ��ď�����Ă��������\���Ă���悤�Ȃ̂ɑ��Ă̓A�N�ւƂ����ʂ�₷���Ȃ�
�폜�˗��o���Ă�����
Intel makes hybrid silicon laser
ttp://www.theinquirer.net/default.aspx?article=34449
ttp://www.theinquirer.net/default.aspx?article=34449
>>32
���A���Ȃ��Ƃ�DP�ȉ��ɂ�FB-DIMM�͂��������ˁH
���̂Ƃ���A�v���Ă����A�������i�ш��ʁj���K�v�ɂȂ�Ƃ��v���A
�f�����b�g�̕��������Ă�悤�ȁE�E�E
���A���Ȃ��Ƃ�DP�ȉ��ɂ�FB-DIMM�͂��������ˁH
���̂Ƃ���A�v���Ă����A�������i�ш��ʁj���K�v�ɂȂ�Ƃ��v���A
�f�����b�g�̕��������Ă�悤�ȁE�E�E
Microbuffer ���ǂ�������āA���O���炵�ĕ��ʂ� FB-DIMM �̌�p��
FB-DIMM2 ���Ȃ� bufferChip ���Ǝv���킯�����ǂ��B
FB-DIMM2 ���Ȃ� bufferChip ���Ǝv���킯�����ǂ��B
FB-DIMM�̓s������}���e�ʂƐ��\���҂��邩��A���܂�IntelCPU�悩
�������R���g���[��������CPU�Ɍ����Ă�Z�p�ł͂����ˁB
�ł��܂��A��������2�R�A�₻���炶�Ⴡ�����ш�͂������ăl�b�N�ɂȂ�͂��Ȃ��Ƃ����b�����邩��A
����ł͂��܂胁���b�g�̑����Ȃ��Z�p�ł͂���̂�������Ȃ��B
Tom's��KentsField�̃e�X�g������Ă��邪�A2.66GHz��FSB1333��FSB1066�ł��������덷���x�ɂ���
�x���`�̐������ς���̂���ȁB�^�̃}���`�R�A���ǂ��̂Ƃ����̂͂���σ}�[�P�e�B���O��̋Y�ꌾ���B
���Ȃ��Ƃ��f�X�N�g�b�v���[�Y�ł́B
�������R���g���[��������CPU�Ɍ����Ă�Z�p�ł͂����ˁB
�ł��܂��A��������2�R�A�₻���炶�Ⴡ�����ш�͂������ăl�b�N�ɂȂ�͂��Ȃ��Ƃ����b�����邩��A
����ł͂��܂胁���b�g�̑����Ȃ��Z�p�ł͂���̂�������Ȃ��B
Tom's��KentsField�̃e�X�g������Ă��邪�A2.66GHz��FSB1333��FSB1066�ł��������덷���x�ɂ���
�x���`�̐������ς���̂���ȁB�^�̃}���`�R�A���ǂ��̂Ƃ����̂͂���σ}�[�P�e�B���O��̋Y�ꌾ���B
���Ȃ��Ƃ��f�X�N�g�b�v���[�Y�ł́B
����ώ�����CPU���ā[��KentsField�ɂȂ�̂��H
Smithfield����Conroe�͎�����CPU���Ċ�������������
�Ȃ�Conroe��KentsField���ē�������ۂ������B
Smithfield����Conroe�͎�����CPU���Ċ�������������
�Ȃ�Conroe��KentsField���ē�������ۂ������B
Nehalem��������B
intel�������B
http://pc.watch.impress.co.jp/docs/2006/0921/ubiq166.htm
���������uCore�v�Ȃ�Ĉ�ʐl�͒N���m��Ȃ�����ȁB
�����ƃZ���X�������O�t���ė~�����B
http://pc.watch.impress.co.jp/docs/2006/0921/ubiq166.htm
���������uCore�v�Ȃ�Ĉ�ʐl�͒N���m��Ȃ�����ȁB
�����ƃZ���X�������O�t���ė~�����B
�ϑ��C������
����A100W�ȓ��ɗ}���邱�Ƃ��Ӑ}���āA�N���b�N�i�邩�ƃI���^�̂�BPenD�݂����ɂˁB
�ł��Aintel�ɂƂ��Ă͈�x�L������TDP�g���Ă̂́A�������ȂˁB
����PC����CPU�̐��\�𗥑����Ă���̂́A��p���E������Ȃ��B
�ł��Aintel�ɂƂ��Ă͈�x�L������TDP�g���Ă̂́A�������ȂˁB
����PC����CPU�̐��\�𗥑����Ă���̂́A��p���E������Ȃ��B
���C�����X�g���[�������́A�i��K�v���邾�낤����
�[���甄��������������R�X�g�x�O���ȃ}�j�A�����̃v���~�A�́A
�p�t�H�[�}���X�d��������}����K�v�ˁ[���
�[���甄��������������R�X�g�x�O���ȃ}�j�A�����̃v���~�A�́A
�p�t�H�[�}���X�d��������}����K�v�ˁ[���
������ƑO��kentsfield��ES�i���N���b�N2.4GHz��TDP95W���Ƃ����L�����������͂������A
�H���ύX�����̂��ˁB
QX6700��2.66GHz���Ƃ������B
Extreme�Ό��Ȃ�FX���������炢�����A�����ʼn����I�P�A�I�ȁB
�H���ύX�����̂��ˁB
QX6700��2.66GHz���Ƃ������B
Extreme�Ό��Ȃ�FX���������炢�����A�����ʼn����I�P�A�I�ȁB
�܂��AExtreme�ŏo��������A���Ȃ��Ƃ��A
���C���X�g���[���̍ō��O���[�h��E6700�i2.66GHz�j�Ɠ��N���b�N���K�{���C���Ȃ킯���B
�łȂ��ƁAExtreme(2.4GHz�Ƃ��̏ꍇ�j�����C���X�g���[����E6700�i2.66GHz�j�������ꍇ�i�V���O���X���b�h�j��
�o�Ă��鍢�������ԂɊׂ�\��������킯��B
�������A���N���b�N�Ȃ�A�ň��ł������\�i�V���O���X���b�h�j�ōς݁A�}���`�X���b�h�ł͓��R���鎖���o����B
���C���X�g���[���̍ō��O���[�h��E6700�i2.66GHz�j�Ɠ��N���b�N���K�{���C���Ȃ킯���B
�łȂ��ƁAExtreme(2.4GHz�Ƃ��̏ꍇ�j�����C���X�g���[����E6700�i2.66GHz�j�������ꍇ�i�V���O���X���b�h�j��
�o�Ă��鍢�������ԂɊׂ�\��������킯��B
�������A���N���b�N�Ȃ�A�ň��ł������\�i�V���O���X���b�h�j�ōς݁A�}���`�X���b�h�ł͓��R���鎖���o����B
�g�b�v�G���h�i��TDP��130W�ɂȂ������ĕʂɃK�^�K�^�����悤�Ȃ��Ƃ���Ȃ����A
�~�h���`�n�C�G���h�N���X���Ə��X���ɂ͂Ȃ邩���ˁB
�܂�������MCM�Ɏg���_�C��Merom�ɂ��Ă��܂��Ηe�Ղ�95W�ȉ��Ɏ��܂�킯��
����قǐS�z������K�v���Ȃ������B
�~�h���`�n�C�G���h�N���X���Ə��X���ɂ͂Ȃ邩���ˁB
�܂�������MCM�Ɏg���_�C��Merom�ɂ��Ă��܂��Ηe�Ղ�95W�ȉ��Ɏ��܂�킯��
����قǐS�z������K�v���Ȃ������B
�g�b�v�G���h�ƃn�C�G���h���Ăǂ��Ⴄ�H
>>70
�I�C�I�C
�N���X�o�Ȃ��A�f���A���_�C��kentsfield�����ł́AFSB�ɑ���ȕ��S��������B
FSB667��Merom�R�A�ł́A���\���o�Ȃ��\�����ɂ߂č������B
�I�C�I�C
�N���X�o�Ȃ��A�f���A���_�C��kentsfield�����ł́AFSB�ɑ���ȕ��S��������B
FSB667��Merom�R�A�ł́A���\���o�Ȃ��\�����ɂ߂č������B
>>68
���i�o�ג��O��TDP���グ�Ă���A���Ă̂́A���Ȋ������ˁB
��ڽ����v���o���B
>>69
PenD��kentsfield���̃f���A���́AFSB�ւ̕��ׂ��d���Ȃ邩�瓯�N���b�N�ŃV���O���R�A�Ɠ����\�͖����B
�����I�ɂ�2.4G�ɗ}���Ă����\�͕ς��Ȃ��\���������̂����ǁAExtreme�ł���ȏ�AE6700�������
�킯�ɂ䂩�Ȃ�����A2.66GHz 130W�ƂȂ����\���������B�c�Ə�̗��R�ŃN���b�N�����߂��Ă����
����Ȃ��̂��ȁB
���i�o�ג��O��TDP���グ�Ă���A���Ă̂́A���Ȋ������ˁB
��ڽ����v���o���B
>>69
PenD��kentsfield���̃f���A���́AFSB�ւ̕��ׂ��d���Ȃ邩�瓯�N���b�N�ŃV���O���R�A�Ɠ����\�͖����B
�����I�ɂ�2.4G�ɗ}���Ă����\�͕ς��Ȃ��\���������̂����ǁAExtreme�ł���ȏ�AE6700�������
�킯�ɂ䂩�Ȃ�����A2.66GHz 130W�ƂȂ����\���������B�c�Ə�̗��R�ŃN���b�N�����߂��Ă����
����Ȃ��̂��ȁB
>>74
FSB�̕��ׂȂAC2D�Ɠ����Ɍ��܂��Ă邾��BC2D�Ɠ����������Ă�Ȃ�ȁB
C2D�����삵�Ă�̂Ƃ܂������ς��Ȃ��킯������B
���������v�Ȃ���BPenD�����B
FSB�̕��ׂȂAC2D�Ɠ����Ɍ��܂��Ă邾��BC2D�Ɠ����������Ă�Ȃ�ȁB
C2D�����삵�Ă�̂Ƃ܂������ς��Ȃ��킯������B
���������v�Ȃ���BPenD�����B
���Ђ̓R�A�����₹�邪���Ђ͑��₹�Ȃ�
���N��Op��Xeon�݂�������
����͋t������
���N��Op��Xeon�݂�������
����͋t������
Tom's�̃x���`����A���N���b�N��Conroe��Kentsfield���ƃx���`�̒l�͌덷�͈͓��łقړ��������ȁB
4�R�A�����p�ł���x���`���قƂ�ǂȂ��̂��A�قړ����Ȃ̂���������̂���w
4�R�A�����p�ł���x���`���قƂ�ǂȂ��̂��A�قړ����Ȃ̂���������̂���w
>�����I�ɂ�2.4G�ɗ}���Ă����\�͕ς��Ȃ��\���������̂�����
��ެȰ�
��ެȰ�
>>75
�L���b�V���R�q�[�����V����ɂ��čl��������������
�L���b�V���R�q�[�����V����ɂ��čl��������������
>>78
����������������������̂ŁA130W�ɂȂ��Ă�2.66G�ɂ����́B
����������������������̂ŁA130W�ɂȂ��Ă�2.66G�ɂ����́B
�Ȃ��A�Y��90W�̃v���Q��130W�Ƃ����v�Z�ɂȂ����B�@�ŏ�����o�X���L��
�p�C�v���C���̃X�J�X�J�x���A���̃v�ȉ������甭�M�����Ȃ����낤�Ƃ������Ƃ��H
�p�C�v���C���̃X�J�X�J�x���A���̃v�ȉ������甭�M�����Ȃ����낤�Ƃ������Ƃ��H
>>73
FSB�����ς�������BFSB�̃N���b�N���ŕς�����d�͂̓f�X�N�g�b�v���[�Y�ł�
�قƂ�NjC�ɂ��Ȃ��Ă����㕨���B
�z���g�^�̃}���`�R�A�Ƃ��AFSB���{�g���l�b�N�ɂȂ�Ƃ����������}�[�P�e�B���O�p���
�x�炳��Ă�z���đ����̂ȁB
FSB�����ς�������BFSB�̃N���b�N���ŕς�����d�͂̓f�X�N�g�b�v���[�Y�ł�
�قƂ�NjC�ɂ��Ȃ��Ă����㕨���B
�z���g�^�̃}���`�R�A�Ƃ��AFSB���{�g���l�b�N�ɂȂ�Ƃ����������}�[�P�e�B���O�p���
�x�炳��Ă�z���đ����̂ȁB
>>79
����A�V���O���X���b�h�œ������ǂ������Ęb����H
����A�V���O���X���b�h�œ������ǂ������Ęb����H
CPU2006��Core��Montesito�̃X�R�A���o�^����Ă���
���܂����X�R�A��
���܂����X�R�A��
86 �FMAC�I�^��85 �����F2006/09/23(�y) 14:18:43 ID:eMoSoCrg
>>85
���ė������BIntel����r�p��Athlon64 FX-62�̌��ʂ�o�^���Ă���̂����邷�ˁB
�ESPECint2006_base (Windows XP 32-bit)
�@�@PentiumD XE/3.73GHz: 11.7
�@�@Athlon64 FX/2.8GHz: 11.4
�@�@Core2Duo/2.93GHz: 18.5
�ESPECfp2006_base (Windows XP 64-bit)
�@�@PentiumD XE/3.73GHz: 12.7
�@�@Athlon64 FX/2.8GHz: 10.3
�@�@Core2Duo/2.93GHz: 16.8
�ESPECint2006Rates_base (Windows XP 32-bit)
�@�@Athlon64 FX/2.8GHz: 21.8
�@�@Core2Duo/2.93GHz: 31.1
�ESPECfp2006Rates_base (Windows XP 32-bit)
�@�@Athlon64 FX/2.8GHz: 18.8
�@�@Core2Duo/2.93GHz: 26.8
���ė������BIntel����r�p��Athlon64 FX-62�̌��ʂ�o�^���Ă���̂����邷�ˁB
�ESPECint2006_base (Windows XP 32-bit)
�@�@PentiumD XE/3.73GHz: 11.7
�@�@Athlon64 FX/2.8GHz: 11.4
�@�@Core2Duo/2.93GHz: 18.5
�ESPECfp2006_base (Windows XP 64-bit)
�@�@PentiumD XE/3.73GHz: 12.7
�@�@Athlon64 FX/2.8GHz: 10.3
�@�@Core2Duo/2.93GHz: 16.8
�ESPECint2006Rates_base (Windows XP 32-bit)
�@�@Athlon64 FX/2.8GHz: 21.8
�@�@Core2Duo/2.93GHz: 31.1
�ESPECfp2006Rates_base (Windows XP 32-bit)
�@�@Athlon64 FX/2.8GHz: 18.8
�@�@Core2Duo/2.93GHz: 26.8
Dailytech��1/2�\�P�b�g�ł�4�R�AXeon���i��B
http://www.dailytech.com/article.aspx?newsid=4253
�@�EKentsfield (1-socket��)
�@�@X3220�@�@2.40GHz, FSB:1066MHz, L2:8MB�@�@$851-
�@�@X3210�@�@2.13GHz, FSB:1066MHz, L2:8MB�@�@$690-
�@�EClovertown (2-socket��)
�@�@X5355�@�@2.66GHz, FSB:1333MHz, L2:8MB�@�@$1172-
�@�@E5345�@�@2.33GHz, FSB:1333MHz, L2:8MB�@�@$851-
�@�@E5320�@�@1.86GHz, FSB:1066MHz, L2:8MB�@�@$690-
�@�@E5310�@�@1.60GHz, FSB:1066MHz, L2:8MB�@�@$455-
http://www.dailytech.com/article.aspx?newsid=4253
�@�EKentsfield (1-socket��)
�@�@X3220�@�@2.40GHz, FSB:1066MHz, L2:8MB�@�@$851-
�@�@X3210�@�@2.13GHz, FSB:1066MHz, L2:8MB�@�@$690-
�@�EClovertown (2-socket��)
�@�@X5355�@�@2.66GHz, FSB:1333MHz, L2:8MB�@�@$1172-
�@�@E5345�@�@2.33GHz, FSB:1333MHz, L2:8MB�@�@$851-
�@�@E5320�@�@1.86GHz, FSB:1066MHz, L2:8MB�@�@$690-
�@�@E5310�@�@1.60GHz, FSB:1066MHz, L2:8MB�@�@$455-
88 �FMAC�I�^���⑫�F2006/09/23(�y) 14:34:09 ID:eMoSoCrg
Dailytech�̃l�^�ŁC���ɋ����[���̂�2�Z�b�g�Ńv���Z�b�T�������2-socket�ł�
Xeon�̒P���������ɍs���Ă���Ƃ����_���B�ƊE�̉��i�̌n�����S���̕����Ɍ������Ă���
�����ˁB�B�B
�@�@---------------------------
�@�@�EKentsfield (1-socket��)
�@�@�@X3220�@�@2.40GHz, FSB:1066MHz, L2:8MB�@�@$851-
�@�@�EClovertown (2-socket��)
�@�@�@E5345�@�@2.33GHz, FSB:1333MHz, L2:8MB�@�@$851-
�@�@---------------------------
Xeon�̒P���������ɍs���Ă���Ƃ����_���B�ƊE�̉��i�̌n�����S���̕����Ɍ������Ă���
�����ˁB�B�B
�@�@---------------------------
�@�@�EKentsfield (1-socket��)
�@�@�@X3220�@�@2.40GHz, FSB:1066MHz, L2:8MB�@�@$851-
�@�@�EClovertown (2-socket��)
�@�@�@E5345�@�@2.33GHz, FSB:1333MHz, L2:8MB�@�@$851-
�@�@---------------------------
�܂����傤���Ȃ����ƂɃP�`���Ă��
>>89
�܂����傤���Ȃ����ƂɃP�`���Ă��
�܂����傤���Ȃ����ƂɃP�`���Ă��
���낻��CIDF Fall 2006�̈ꕔ�̃v���[��������������悤�ɂȂ��Ă��邷�B
Kentsfield�̊T�v��C����Ȋ����̗l�ŁB�B�B
��Intel Core2 Extreme Quad-Core Processor Features
�@�E2.66Ghz, 1066MHz front side bus, 8MB total L2 cache
�@�EIntel VT, Intel 64
�@�ESupports Viiv technology,
�@�EIntel Intelligent Power Capability
�@�@- Shuts off inactive parts of the core
�@�EEnhanced Halt State
�@�@- Independent idle state per core
�@�EEnhanced Intel SpeedStep Technology
�@�@- Reduces power in active work loads
�@�EExecute Disable Bit
�@�EOverspeed protection removed
�@�E975X chipset
Kentsfield�̊T�v��C����Ȋ����̗l�ŁB�B�B
��Intel Core2 Extreme Quad-Core Processor Features
�@�E2.66Ghz, 1066MHz front side bus, 8MB total L2 cache
�@�EIntel VT, Intel 64
�@�ESupports Viiv technology,
�@�EIntel Intelligent Power Capability
�@�@- Shuts off inactive parts of the core
�@�EEnhanced Halt State
�@�@- Independent idle state per core
�@�EEnhanced Intel SpeedStep Technology
�@�@- Reduces power in active work loads
�@�EExecute Disable Bit
�@�EOverspeed protection removed
�@�E975X chipset
�����Z�p�̕���C
�@�EOOoE�̋���R�A�ɂ��}���`�R�A -> �V���v���R�A�ɂ�郁�j�[�R�A
�@�E�g�����U�N�V����������
�@�EDRAM�_�C�ƃv���Z�b�T�_�C�̃X�^�b�N
�@�E�f�[�^���x�����d���̃x�N�g�����Z��
�@�E�V���R���t�H�g�j�N�X�ɂ����z��
�Ƃ�������Ȃ��ǁC�u���b�N�}�������Ă�Ɩ���CELL BE�Ɏ��Ă�悤�ȁB�B�B
�@�EOOoE�̋���R�A�ɂ��}���`�R�A -> �V���v���R�A�ɂ�郁�j�[�R�A
�@�E�g�����U�N�V����������
�@�EDRAM�_�C�ƃv���Z�b�T�_�C�̃X�^�b�N
�@�E�f�[�^���x�����d���̃x�N�g�����Z��
�@�E�V���R���t�H�g�j�N�X�ɂ����z��
�Ƃ�������Ȃ��ǁC�u���b�N�}�������Ă�Ɩ���CELL BE�Ɏ��Ă�悤�ȁB�B�B
Intel's microcore future shown in pictures
http://uk.theinquirer.net/?article=34623
http://uk.theinquirer.net/?article=34623
Intel's Otellini shows off November quads, benchmarks
http://www.theinquirer.net/default.aspx?article=34641
The first new core on 45 nanometres is Nehalem, basically a beefed up Woodcrest wih CSI.
http://www.theinquirer.net/default.aspx?article=34641
The first new core on 45 nanometres is Nehalem, basically a beefed up Woodcrest wih CSI.
ntel�A�N�A�b�h�R�A�́uCore 2�v����сuXeon�v�V���[�Y�̏o�v������J
http://journal.mycom.co.jp/news/2006/09/27/400.html
Rackable and Intel scratch each other behind AMD's back
http://www.theregister.co.uk/2006/09/26/intel_rackable_amd/
Intel on top of the server world again
http://www.theregister.co.uk/2006/09/26/intel_fourcore_server/
�yIDF Fall 2006�z�u45nm�v���Z�X�C2007�N�̉ғ��ɕύX�Ȃ��v�CIntel�Ђ�15���i���J����
http://itpro.nikkeibp.co.jp/article/COLUMN/20060927/249066/?ST=ep1
�yIDF Fall 2006�z��Intel�̌����J�����傪�ŐV�̐��ʂ��I
http://itpro.nikkeibp.co.jp/article/USNEWS/20060926/249014/
�yIDF Fall 2006�z�u�T�[�o�[�s��̐������Ăсv��Otellini�В�
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249057/
�yIDF Fall 2006�zIntel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
http://journal.mycom.co.jp/news/2006/09/27/400.html
Rackable and Intel scratch each other behind AMD's back
http://www.theregister.co.uk/2006/09/26/intel_rackable_amd/
Intel on top of the server world again
http://www.theregister.co.uk/2006/09/26/intel_fourcore_server/
�yIDF Fall 2006�z�u45nm�v���Z�X�C2007�N�̉ғ��ɕύX�Ȃ��v�CIntel�Ђ�15���i���J����
http://itpro.nikkeibp.co.jp/article/COLUMN/20060927/249066/?ST=ep1
�yIDF Fall 2006�z��Intel�̌����J�����傪�ŐV�̐��ʂ��I
http://itpro.nikkeibp.co.jp/article/USNEWS/20060926/249014/
�yIDF Fall 2006�z�u�T�[�o�[�s��̐������Ăсv��Otellini�В�
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249057/
�yIDF Fall 2006�zIntel��4�R�A�E�v���Z�T��11���ɏo�J�n�C80�R�A��1�e��FLOPS�v���Z�T������
http://itpro.nikkeibp.co.jp/article/USNEWS/20060927/249038/
96 �FSocket774�F2006/09/27(��) 16:52:14 ID:qeEiWpit
FSB�S�{���āE�E�E
>96
���L�o�X��4way������������A�ڂ����Ă��\�ɂȂ�B
�K�R�I�ɂ����Ȃ�㩁B
���L�o�X��4way������������A�ڂ����Ă��\�ɂȂ�B
�K�R�I�ɂ����Ȃ�㩁B
�}���`FSB�͈ȑO����̋K��H������
99 �FSocket774�F2006/09/28(��) 00:21:08 ID:dd1YT+mm
�������܂�A�Ђ�FX�Ȃ̓f���A���R�A�ł����ʂ�120W�I�[�o�[�Ƃ������S�R���Ȃ���ˁH
A�Ђ͕̂��ׂ�����Ə�ʔł�TDP���y�X������݂�������
A�Ђ͕̂��ׂ�����Ə�ʔł�TDP���y�X������݂�������
100 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/28(��) 00:27:56 ID:8MJ8HWw7
> �X�k�[�v�p�P�b�g�ʂ̓m�[�h��N�Ƃ���� (N-1)! �ɔ�Ⴕ�đ傫���Ȃ�
�܂œǂ�
�܂œǂ�
>64MB�̃X�k�[�v�t�B���^�[�L���b�V��
�܂œǂ�
�܂œǂ�
�V�F�A�A�����郊�[�_�[�V�b�v�B
Intel's Kicking Pat opens front side bus to pardners
http://www.theinquirer.net/default.aspx?article=34690
'Get on our bus' �H Intel calls out to partners
http://www.theregister.co.uk/2006/09/27/intel_fsb_pciexpress/
Intel's Kicking Pat opens front side bus to pardners
http://www.theinquirer.net/default.aspx?article=34690
'Get on our bus' �H Intel calls out to partners
http://www.theregister.co.uk/2006/09/27/intel_fsb_pciexpress/
SSE4����(SSSE3�ł͂���܂���)�̐��������ł�
ftp://download.intel.com/technology/architecture/new-instructions-paper.pdf
ftp://download.intel.com/technology/architecture/new-instructions-paper.pdf
���g�i�[�̎���i�͂ǂ��ł�����
�{���̓p�[�����b�^�[�̍u��
�{���̓p�[�����b�^�[�̍u��
http://www.hkepc.com/bbs/itnews.php?tid=675864&starttime=0&endtime=0
YorkField@2007/Q2
FSB1333MHz , 4core�� shared L2$
DDR3-1333/DDR2-800 and dual PCI-Express 2.0 interface
Bearlake X chipset
vs K8L�ǂ����������̂��ȁB
YorkField@2007/Q2
FSB1333MHz , 4core�� shared L2$
DDR3-1333/DDR2-800 and dual PCI-Express 2.0 interface
Bearlake X chipset
vs K8L�ǂ����������̂��ȁB
>>92
>�@�EOOoE�̋���R�A�ɂ��}���`�R�A -> �V���v���R�A�ɂ�郁�j�[�R�A
�������Niagara�݂����Ȋ�����ڎw���Ă���Ă��ƁH
>�@�EOOoE�̋���R�A�ɂ��}���`�R�A -> �V���v���R�A�ɂ�郁�j�[�R�A
�������Niagara�݂����Ȋ�����ڎw���Ă���Ă��ƁH
Nehalem�͔�Ώ̃}���`�R�A����ˁ[�̂��ˁH
Nehalem��4�R�A�ȏ�(8�R�A����?)�̃}���`�R�ACPU�ɂ�����
��{�I��1�R�A�ɂȂ�Ƃ����b��������A
��Ώ̃}���`�R�A�ɂ�������̂́ANehalem�ȊO�̃R�A�A�Ƃ��Ď������邶��Ȃ��ł�����?
Nehalem��CSI�����N�Ō��Ԓ��ɁA�ǂ����ɓ��������R�A��������A�I�ȁB
��{�I��1�R�A�ɂȂ�Ƃ����b��������A
��Ώ̃}���`�R�A�ɂ�������̂́ANehalem�ȊO�̃R�A�A�Ƃ��Ď������邶��Ȃ��ł�����?
Nehalem��CSI�����N�Ō��Ԓ��ɁA�ǂ����ɓ��������R�A��������A�I�ȁB
Intel��IBM��PCI Express�̌�p�d�l�uGeneseo�v���J���CDell�CHP�CSun�Ȃǂ��x��
http://itpro.nikkeibp.co.jp/article/USNEWS/20060928/249223/?ST=?ST=enterprise
�yIDF Fall 2006�z�n�[�h�ƃA�v���P�[�V�����̗Z���ւƐi��Intel
http://itpro.nikkeibp.co.jp/article/USNEWS/20060928/249257/?ST=ep1
http://itpro.nikkeibp.co.jp/article/USNEWS/20060928/249223/?ST=?ST=enterprise
�yIDF Fall 2006�z�n�[�h�ƃA�v���P�[�V�����̗Z���ւƐi��Intel
http://itpro.nikkeibp.co.jp/article/USNEWS/20060928/249257/?ST=ep1
110 �FSocket774�F2006/09/28(��) 23:28:49 ID:JhtWjz0c
�C���e���A�������d�͌^�`�b�v�uSteeley�v��UMPC�̒ቿ�i����ڎw��
http://headlines.yahoo.co.jp/hl?a=20060927-00000003-cnet-sci
http://headlines.yahoo.co.jp/hl?a=20060927-00000003-cnet-sci
���v�����CPU�{�m�[�X�{�O���t�B�b�N�̓����`�b�v���Ă��Ƃ��H
���Ȃ�T�E�X���������傭���ɂ����Ⴆ�����̂ɁB
���Ȃ�T�E�X���������傭���ɂ����Ⴆ�����̂ɁB
112 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/28(��) 23:56:01 ID:8MJ8HWw7
�o�����Č����Ă����ˁB�����`�b�v�Z���g���[�m�I�Ȃ��̂��B
CPU�R�A��Yonah�V���O���Ɠ������ȁB
CPU�R�A��Yonah�V���O���Ɠ������ȁB
IPF�Ƃ���UMPC�Ƃ���Transmeta���ۂ���
�_�C�T�C�Y��1/4�Ƃ������Ă邩��Yonah�Ɠ����x���Ȃ�Ęb����Ȃ��ł���B
115 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/29(��) 00:18:26 ID:0SqSPWug
1�R�A�ɂ��ăL���b�V���������������������͂Ȃ�Ǝv�����ǁB�B�B
Mac mini��p�@�p�̐Ό��܂����ȁB�B�B
Mac mini��p�@�p�̐Ό��܂����ȁB�B�B
116 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/09/29(��) 00:26:32 ID:0SqSPWug
2007�N�㔼���Ă��Ƃ�45nm�v���Z�X�̗����グ����������A�_�C�T�C�Y�͔������炢�ɂȂ�B
�V���O���R�A�ɂ��邾�낤����_�C�T�C�Y�͂��������������t���B
�S���̐V�v�̃R�A�ł͂Ȃ�PenM-Core�̉�������̃V���O���R�A�ƍl�����B
�V���O���R�A�ɂ��邾�낤����_�C�T�C�Y�͂��������������t���B
�S���̐V�v�̃R�A�ł͂Ȃ�PenM-Core�̉�������̃V���O���R�A�ƍl�����B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2840&p=8
���̋L����ǂތ���A��r�Ώۂ�ULV Core Solo������
���݂̏���d�͂�5W
2007�N�ɂ͏���d�́A�_�C�T�C�Y���ɔ����ɂȂ�
2008�N�ɂ͏���d�͂�1/10�Ń_�C�T�C�Y��1/7
�o�ꎞ����1H'07�Ə����Ă��邩��65nm�v���Z�X���낤�B
PenM���n�ł��̃T�C�Y�Ɏ��܂邩�ȁB
�ȑOTom�̃T�C�g��Stealey���o�Ă�������512KB�Ə����Ă���������
�L���b�V�������炵���������Ⴙ������1/2�~�܂肶��ˁB
���̋L����ǂތ���A��r�Ώۂ�ULV Core Solo������
���݂̏���d�͂�5W
2007�N�ɂ͏���d�́A�_�C�T�C�Y���ɔ����ɂȂ�
2008�N�ɂ͏���d�͂�1/10�Ń_�C�T�C�Y��1/7
�o�ꎞ����1H'07�Ə����Ă��邩��65nm�v���Z�X���낤�B
PenM���n�ł��̃T�C�Y�Ɏ��܂邩�ȁB
�ȑOTom�̃T�C�g��Stealey���o�Ă�������512KB�Ə����Ă���������
�L���b�V�������炵���������Ⴙ������1/2�~�܂肶��ˁB
118 �FSocket774�F2006/09/29(��) 05:58:29 ID:6so5cHt6
1TSRAM�ɂ��ķ������ݼ��ʂ�1/6��
�����Intel�ɂ�DRAM���݃v���Z�X�Ɏ���o���C�͂Ȃ����낤
���㓡�O��Weekly�C�O�j���[�X��
�N���ɓ�������A45nm�ŕ��y��ڎw��Intel�̃N�A�b�h�R�A
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai305.htm
�N���ɓ�������A45nm�ŕ��y��ڎw��Intel�̃N�A�b�h�R�A
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai305.htm
>>120
���̒���4Core�̎ʐ^�����āA�Y���v���o���Ă��܂����B
���̒���4Core�̎ʐ^�����āA�Y���v���o���Ă��܂����B
8�R�A���ĂȂ�ēǂނ�
�I�N�e�b�g�R�A�A�I�N�^�v���R�A�H
�I�N�e�b�g�R�A�A�I�N�^�v���R�A�H
�n�`�R�A
Presler�̂ق������Ă��
http://pc.watch.impress.co.jp/docs/2005/1228/tawada_3.jpg
http://pc.watch.impress.co.jp/docs/2005/1228/tawada_4.jpg
http://pc.watch.impress.co.jp/docs/2005/1228/tawada_3.jpg
{kind=link}
http://pc.watch.impress.co.jp/docs/2005/1228/tawada_4.jpg
{kind=link}
�C���e���A���А��`�b�v�Ƃ̐ڑ��ɓ����
http://japan.cnet.com/news/ent/story/0,2000056022,20252188,00.htm
http://japan.cnet.com/news/ent/story/0,2000056022,20252188,00.htm
�yIDF Fall 2006 Vol.3�zCPU�̃R�A�ԁg�ʐM�h�̓��b�V���^�H�����O�^�H ����������ɁH
http://headlines.yahoo.co.jp/hl?a=20060929-00000003-rbb-sci
http://headlines.yahoo.co.jp/hl?a=20060929-00000003-rbb-sci
�yIDF Fall 2006 Vol.1�zQuad-Core�v���Z�b�T�����N11���ɏo�ׂ�
http://www.rbbtoday.com/news/20060927/34392.html
�yIDF Fall 2006 Vol.2�z�u�d�͌�������Ń��[�_�[�V�b�v�����Ă����v-�C���e��
http://www.rbbtoday.com/news/20060928/34413.html
�yIDF Fall 2006 Vol.3�zCPU�̃R�A�ԁg�ʐM�h�̓��b�V���^�H�����O�^�H ����������ɁH
http://www.rbbtoday.com/news/20060929/34453.html
�yIDF Fall 2006 Vol.4�z���̏�ŁuPersonal Supercomputer�v
http://www.rbbtoday.com/news/20060929/34490.html
�yIDF Fall 2006 Vol.5�z���̃N�A�b�h�R�ACPU�̐��\�̓f���A���R�A��70������ɂƂǂ܂�
http://www.rbbtoday.com/news/20060930/34497.html
http://www.rbbtoday.com/news/20060927/34392.html
�yIDF Fall 2006 Vol.2�z�u�d�͌�������Ń��[�_�[�V�b�v�����Ă����v-�C���e��
http://www.rbbtoday.com/news/20060928/34413.html
�yIDF Fall 2006 Vol.3�zCPU�̃R�A�ԁg�ʐM�h�̓��b�V���^�H�����O�^�H ����������ɁH
http://www.rbbtoday.com/news/20060929/34453.html
�yIDF Fall 2006 Vol.4�z���̏�ŁuPersonal Supercomputer�v
http://www.rbbtoday.com/news/20060929/34490.html
�yIDF Fall 2006 Vol.5�z���̃N�A�b�h�R�ACPU�̐��\�̓f���A���R�A��70������ɂƂǂ܂�
http://www.rbbtoday.com/news/20060930/34497.html
128 �FSocket774�F2006/09/30(�y) 15:57:04 ID:3rrcBdJV
http://japan.cnet.com/news/ent/story/0,2000056022,20254608,00.htm
�T���t�����V�X�R��--Intel�́A�R���s���[�^�������̔̔����Ƃ��ĊJ����̂��낤���B
(����)���`�b�v�̍ő�̓����́A�e�R�A���ATSV�iThrough Silicon Vias�j�ƌĂ��Z�p�ɂ���āA
256M�o�C�g�������`�b�v�ɒ��ڐڑ�����Ă���_���B
(����)TSV��80�R�A�v���Z�b�T�����łȂ��A���܂��܂ȃv���Z�b�T�ɂ��g�p�\���B
(����)�������R���g���[���̓v���Z�b�T�ɔ�ד��쑬�x���ɒ[�ɒx���B
���̓_���A�R���s���[�^�̐��\�����}���ő傫�ȏ�Q��1�ƂȂ��Ă����B
�������A�������R���g���[���̑����TSV���g�p����A�f�[�^�]�����x���啝�Ɍ��シ�邾�낤�B
(����)�܂��A���������瑗����f�[�^�́A�ߖ���Ԃ̃|�[�g����ʂ蔲����K�v������B
���̓_TSV�́A�������̃|�[�g���J�����Ƃ��ł���Ƃ����B
(����)�S�ʓI�ɁA80�R�A�`�b�v�̃v���g�^�C�v�ɂ����鑍�������ш��1�e���o�C�g�^�b�A
�܂薈�b1���o�C�g�̃f�[�^�]�����\���B
(����)Rattner���́A�u�܂������i�K�v�Ƃ��Ȃ�����A
�u���������N�Ԃ́A���̋Z�p�̊J���ɐϋɓI�Ɏ��g��ł����v�ƌ�����B
�T���t�����V�X�R��--Intel�́A�R���s���[�^�������̔̔����Ƃ��ĊJ����̂��낤���B
(����)���`�b�v�̍ő�̓����́A�e�R�A���ATSV�iThrough Silicon Vias�j�ƌĂ��Z�p�ɂ���āA
256M�o�C�g�������`�b�v�ɒ��ڐڑ�����Ă���_���B
(����)TSV��80�R�A�v���Z�b�T�����łȂ��A���܂��܂ȃv���Z�b�T�ɂ��g�p�\���B
(����)�������R���g���[���̓v���Z�b�T�ɔ�ד��쑬�x���ɒ[�ɒx���B
���̓_���A�R���s���[�^�̐��\�����}���ő傫�ȏ�Q��1�ƂȂ��Ă����B
�������A�������R���g���[���̑����TSV���g�p����A�f�[�^�]�����x���啝�Ɍ��シ�邾�낤�B
(����)�܂��A���������瑗����f�[�^�́A�ߖ���Ԃ̃|�[�g����ʂ蔲����K�v������B
���̓_TSV�́A�������̃|�[�g���J�����Ƃ��ł���Ƃ����B
(����)�S�ʓI�ɁA80�R�A�`�b�v�̃v���g�^�C�v�ɂ����鑍�������ш��1�e���o�C�g�^�b�A
�܂薈�b1���o�C�g�̃f�[�^�]�����\���B
(����)Rattner���́A�u�܂������i�K�v�Ƃ��Ȃ�����A
�u���������N�Ԃ́A���̋Z�p�̊J���ɐϋɓI�Ɏ��g��ł����v�ƌ�����B
���Ђ���DRAM�x�A�`�b�v���Ă��ĕt����Ƃ���������邯�ǁA
Intel�̐����\�͂�����A�i�̎�����n���Łj���Ђō�邩������Ȃ��B
�ł��ASi�ђʂ�DRAM�������ƁA�\���̏璷���������Ȃ��ȁB�O�t���ɂ��邩�B
�܂������͎��p����Ȃ��ł��傤�BSi�ђʂ̃R�X�g�̖�������B
Intel�̐����\�͂�����A�i�̎�����n���Łj���Ђō�邩������Ȃ��B
�ł��ASi�ђʂ�DRAM�������ƁA�\���̏璷���������Ȃ��ȁB�O�t���ɂ��邩�B
�܂������͎��p����Ȃ��ł��傤�BSi�ђʂ̃R�X�g�̖�������B
���ŏ��̊�u���ŁCOtellini�В��́C���\���Ăяd�v�ɂȂ�ƂԂ��グ�܂������C
���v����ɁCAMD�ɐ��\�ŕ����Ă��鎞�́C���\�������]���ړx�ł͂Ȃ��ƌ����C
��Core 2�v���Z�T�̓o��Ő��\�I�ɏ��ƁC���\���Ăяd�v�ɂȂ����ƌ����Ă��邾���ŁC
���������N��Intel�̌��������v���N�����ƁC�悭������Ƃ��������ł��B
�����\���d�v�ɂȂ����Ƃ������R�́CYouTube�Ȃǂɑ�\�����r�f�I�̃f�R�[�h�Ȃǂ�
���d�������������Ă��邱�Ƃɂ��Əq�ׂĂ��܂����B�������C�d�������Ƃ��ċ�̉����n�߂�
������̂̓r�f�I�f�R�[�h��3D�O���t�B�b�N�X���x�ł���C����炾���Ȃ��p�R�A���������
�������x�^�[�ŁC�ėpCPU������������CATI������AMD�̕��������Ƃ����C�����܂��B
���v����ɁCAMD�ɐ��\�ŕ����Ă��鎞�́C���\�������]���ړx�ł͂Ȃ��ƌ����C
��Core 2�v���Z�T�̓o��Ő��\�I�ɏ��ƁC���\���Ăяd�v�ɂȂ����ƌ����Ă��邾���ŁC
���������N��Intel�̌��������v���N�����ƁC�悭������Ƃ��������ł��B
�����\���d�v�ɂȂ����Ƃ������R�́CYouTube�Ȃǂɑ�\�����r�f�I�̃f�R�[�h�Ȃǂ�
���d�������������Ă��邱�Ƃɂ��Əq�ׂĂ��܂����B�������C�d�������Ƃ��ċ�̉����n�߂�
������̂̓r�f�I�f�R�[�h��3D�O���t�B�b�N�X���x�ł���C����炾���Ȃ��p�R�A���������
�������x�^�[�ŁC�ėpCPU������������CATI������AMD�̕��������Ƃ����C�����܂��B
�������c�q�̕����}���`���f�B�A�����ɏڂ������Ƃ��킩����
youtube�̔@��������CPU�ł�点�邽�߂Ƀp���[���K�v���ƌ����o���̂�
Intel��CPU��������Ƃ��������ł���A�ߋ��Ƀ��f����T�E���h�J�[�h�܂�Pentium��
��点�悤�Ƃ��ēڍ�����NSP�Ɠ������Ƃ��J��Ԃ��Ă���ɉ߂��Ȃ��B
GPU����CPU��������獡�x�͂��ꂱ����youtube�ɍœK�A�ƌ����o�������̂��Ƃ��B
Intel��CPU��������Ƃ��������ł���A�ߋ��Ƀ��f����T�E���h�J�[�h�܂�Pentium��
��点�悤�Ƃ��ēڍ�����NSP�Ɠ������Ƃ��J��Ԃ��Ă���ɉ߂��Ȃ��B
GPU����CPU��������獡�x�͂��ꂱ����youtube�ɍœK�A�ƌ����o�������̂��Ƃ��B
����[���A�����P�Ƀp���[�����������������Ȃ���
������A�Ȃ��B�B�B�B
������A�Ȃ��B�B�B�B
���������Woodcrest��SPEC_int_2000�ō��X�R�A��@���o�����Ƃ���DDR2�̂������Ƃ������Ă�
youtube�Ƃ�CPU�g�p��10���Ȃ̂�CPU�p���[���K�v�ł��Ƃ������͖̂�������߂����낗
youtube�̒�����Ȃ����H
>>136
Core��]�����ň������낵�Ă�̂�SPEC�̂Ƃ�����Ȃ������B
����o���ŏ����Ă��܂�B
�ŁA3���̋L���Ȃ̂ɊԈႢ���炯�Ń����X���ƁB
�P�DIntel��������v���Z�T��Core Microarchitecture�\
http://www.geocities.jp/andosprocinfo/wadai06/20060311.htm
�Q�D�Q�[���A�v����Intel��Conroe��AMD��Athlon�Ɉ���
http://www.geocities.jp/andosprocinfo/wadai06/20060318.htm
>>138
�f�R�[�h���T�[�o�ł�����������p���N����悤�ȁB
Core��]�����ň������낵�Ă�̂�SPEC�̂Ƃ�����Ȃ������B
����o���ŏ����Ă��܂�B
�ŁA3���̋L���Ȃ̂ɊԈႢ���炯�Ń����X���ƁB
�P�DIntel��������v���Z�T��Core Microarchitecture�\
http://www.geocities.jp/andosprocinfo/wadai06/20060311.htm
�Q�D�Q�[���A�v����Intel��Conroe��AMD��Athlon�Ɉ���
http://www.geocities.jp/andosprocinfo/wadai06/20060318.htm
>>138
�f�R�[�h���T�[�o�ł�����������p���N����悤�ȁB
140 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/01(��) 01:04:44 ID:lMj1l+49
�Q�h�[�i�c���ĉ��҃R���H
youtube��FullHD�ɂȂ������̂��ƁA�ł���A�����intel���\�B
�ǂ��ɂǂ̐��\���g�������A����葁���Ȃ�̂͑劽�}�ł��B
�ǂ��ɂǂ̐��\���g�������A����葁���Ȃ�̂͑劽�}�ł��B
142 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/01(��) 01:13:46 ID:lMj1l+49
>>139
CoreMA���������낵�Ă�Ƃ������AIntel�̐�`���������낵�Ă�悤�ȁB
�u�ǂ����w�Ȗ��O��t���Ă邯�ǂ��̎����\����ɂ͂��܂��^�������ɂȂ���v�Ƃ����l���B
�����ő匴���́uCoreMA�̐��\�̓L���b�V���̍������ɂ��̂��傫���̂ł́H�v�Ƃ��������ƌq�����Ă���킯�ł����B
CoreMA���������낵�Ă�Ƃ������AIntel�̐�`���������낵�Ă�悤�ȁB
�u�ǂ����w�Ȗ��O��t���Ă邯�ǂ��̎����\����ɂ͂��܂��^�������ɂȂ���v�Ƃ����l���B
�����ő匴���́uCoreMA�̐��\�̓L���b�V���̍������ɂ��̂��傫���̂ł́H�v�Ƃ��������ƌq�����Ă���킯�ł����B
���ۖ�葬���Ȃ��Ă�Η����Ȃ�ĂȂ�Ƃł���t���Ă�����Ă��܂�Ȃ��킯�ŁB
���[�U�[�T�C�h���炷��ˁB
���[�U�[�T�C�h���炷��ˁB
�{��CPU�̖����������ėp�I�ȏ����̈ꕔ��GPU�������肷��̂ł͂Ȃ����A
������MS�����i�������AIntel�ɂ͂����b����Ȃ��̂͊m���B
������AIntel���ł���GPU�W���������悤�Ƃ��Ă�B
Nvidia����ɓ�������낤���ǁE�E�B
CPU��GPU���Q���Ƃ����̂��A�I���������Ȃ��ėǂ��Ȃ��ˁB
������MS�����i�������AIntel�ɂ͂����b����Ȃ��̂͊m���B
������AIntel���ł���GPU�W���������悤�Ƃ��Ă�B
Nvidia����ɓ�������낤���ǁE�E�B
CPU��GPU���Q���Ƃ����̂��A�I���������Ȃ��ėǂ��Ȃ��ˁB
>>143
>Intel�̐�`���������낵�Ă�
���F���LL2������A���F���@���[�h������A���F�v���t�F�b�`������A
���O������̂�Markitecture���Ă��Ƃł���?
>�����ő匴���́uCoreMA�̐��\�̓L���b�V���̍������ɂ��̂��傫���̂ł́H�v�Ƃ�������
http://www.yusuke-ohara.com/weblog2/archive/2006/09/post_46.html
���łɌ����Ɨ�̑S���ʃx���`�}�[�N��Intel Smart Memory Access�̕]�����܂܂�ĂȂ��̂őS�R�S���ʂ��Ⴀ��܂���
http://download.intel.com/technology/architecture/sma.pdf
>Intel�̐�`���������낵�Ă�
���F���LL2������A���F���@���[�h������A���F�v���t�F�b�`������A
���O������̂�Markitecture���Ă��Ƃł���?
>�����ő匴���́uCoreMA�̐��\�̓L���b�V���̍������ɂ��̂��傫���̂ł́H�v�Ƃ�������
http://www.yusuke-ohara.com/weblog2/archive/2006/09/post_46.html
���łɌ����Ɨ�̑S���ʃx���`�}�[�N��Intel Smart Memory Access�̕]�����܂܂�ĂȂ��̂őS�R�S���ʂ��Ⴀ��܂���
http://download.intel.com/technology/architecture/sma.pdf
>>120
>�u45nm�v���Z�X�ł́A���Ȃ��Ƃ�15��(CPU���i��)�v�����ݐi�߂��Ă���B
>���̂����A�p�t�H�[�}���X�I���G���e�b�h�Ȑv�̂قƂ�ǂ́A�N�A�b�h�R�A��O���ɒu���Ă���v��Smith���͐�������B
>�u���m���V�b�N�ȃN�A�b�h�R�A�v�́A45nm�����\�z���Ă���v��Smith���͌��B
�V�R�A��Nehalem����ł͂Ȃ��APenryn�ł��łɃ��m���V�b�N�E�N�A�b�h�R�A�ł�
����������Ă��Ƃ���ȁH
Penryn��2008Q1�����\��BAMD��Deerhound��2007Q3�����\�肾����
���m���V�b�N���ł�AMD�ɔ��N�x��邾�����B
>�u45nm�v���Z�X�ł́A���Ȃ��Ƃ�15��(CPU���i��)�v�����ݐi�߂��Ă���B
>���̂����A�p�t�H�[�}���X�I���G���e�b�h�Ȑv�̂قƂ�ǂ́A�N�A�b�h�R�A��O���ɒu���Ă���v��Smith���͐�������B
>�u���m���V�b�N�ȃN�A�b�h�R�A�v�́A45nm�����\�z���Ă���v��Smith���͌��B
�V�R�A��Nehalem����ł͂Ȃ��APenryn�ł��łɃ��m���V�b�N�E�N�A�b�h�R�A�ł�
����������Ă��Ƃ���ȁH
Penryn��2008Q1�����\��BAMD��Deerhound��2007Q3�����\�肾����
���m���V�b�N���ł�AMD�ɔ��N�x��邾�����B
�F�X�Ԉ���Ă�
�c�q����ando�����m���̂��B�Ђ傦�[�B�������ǁB
> ���F���LL2������A���F���@���[�h������A���F�v���t�F�b�`������A
> ���O������̂�Markitecture���Ă��Ƃł���?
�����������Ƃł���B
�V�����Z�p�ɐV�������O������Ȃ炻��͐��������Ƃ����ǁA�̂�����
����Z�p�ɕʂ̖��O�����āAIntel���L�̋Z�p�̂悤�ɐ�`����̂́A
�Z�p���Ƃ��Ă͕ςȊ���������͓̂�����O�ł́H
�������}�[�P�e�B���O����������A����Ȃ̏펯���Č������낤���ǂˁB
���ƁA�u���F���@���[�h������v�Ƃ͌����ĂȂ��B�u���F OoO ���[�h������v
�Ƃ�(�Â�)�����Ă邯�ǁB�܂��u���F�v���t�F�b�`������v�Ƃ������ĂȂ��B
�u���FConstant Stride������v�Ƃ͌����Ă邯�ǁB
> ���O������̂�Markitecture���Ă��Ƃł���?
�����������Ƃł���B
�V�����Z�p�ɐV�������O������Ȃ炻��͐��������Ƃ����ǁA�̂�����
����Z�p�ɕʂ̖��O�����āAIntel���L�̋Z�p�̂悤�ɐ�`����̂́A
�Z�p���Ƃ��Ă͕ςȊ���������͓̂�����O�ł́H
�������}�[�P�e�B���O����������A����Ȃ̏펯���Č������낤���ǂˁB
���ƁA�u���F���@���[�h������v�Ƃ͌����ĂȂ��B�u���F OoO ���[�h������v
�Ƃ�(�Â�)�����Ă邯�ǁB�܂��u���F�v���t�F�b�`������v�Ƃ������ĂȂ��B
�u���FConstant Stride������v�Ƃ͌����Ă邯�ǁB
>>128
> (����)���`�b�v�̍ő�̓����́A�e�R�A���ATSV�iThrough Silicon Vias�j�ƌĂ��Z�p�ɂ���āA
> 256M�o�C�g�������`�b�v�ɒ��ڐڑ�����Ă���_���B
��������256KB�B
> (����)���`�b�v�̍ő�̓����́A�e�R�A���ATSV�iThrough Silicon Vias�j�ƌĂ��Z�p�ɂ���āA
> 256M�o�C�g�������`�b�v�ɒ��ڐڑ�����Ă���_���B
��������256KB�B
152 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/01(��) 15:26:52 ID:lMj1l+49
>>149
Windows��CPU���ׂ��v�������Ƃ���Ȃ��̂ɉ����őʕ��������l
���Ƃ������Ƃ͂悭�킩�����B
�����Ƃ��ACPU�̓t���ғ������Ȃ���d�͌����������Ȃ�Ă��Ƃ͖����킯������
����̃f�R�[�h�]�X�������炸�Ƃ������炸���B
Windows��CPU���ׂ��v�������Ƃ���Ȃ��̂ɉ����őʕ��������l
���Ƃ������Ƃ͂悭�킩�����B
�����Ƃ��ACPU�̓t���ғ������Ȃ���d�͌����������Ȃ�Ă��Ƃ͖����킯������
����̃f�R�[�h�]�X�������炸�Ƃ������炸���B
�d�͌������ŏd������Ȃ�ACPU����Ȃ��Đ�p�n�[�h�ɂ�点��
���������͓̂��R�ł��傤�B
���������͓̂��R�ł��傤�B
>>150
>�V�����Z�p�ɐV�������O������Ȃ炻��͐��������Ƃ����ǁA�̂�����
>����Z�p�ɕʂ̖��O�����āAIntel���L�̋Z�p�̂悤�ɐ�`����̂́A
>�Z�p���Ƃ��Ă͕ςȊ���������͓̂�����O�ł́H
�Z�p�����������̈Ⴂ�Ƃ���ɂ�鐫�\���P�̋�Ŕ�]���ׂ��Ȃ�Ȃ��ł���?
�����N�O�̘_������ɊJ�������v���Z�b�T�ɐV�����Z�p�Ȃ�Ė����ł���B
Intel64��Itanium��HTT�͋^��Ɏv�������A��������̂���͂���Intel�ᔻ�����������ɂ��������܂���B
AMD��Direct Connect Architecture���ɑ���ᔻ�͈�ؖ����݂�������(�m
>�V�����Z�p�ɐV�������O������Ȃ炻��͐��������Ƃ����ǁA�̂�����
>����Z�p�ɕʂ̖��O�����āAIntel���L�̋Z�p�̂悤�ɐ�`����̂́A
>�Z�p���Ƃ��Ă͕ςȊ���������͓̂�����O�ł́H
�Z�p�����������̈Ⴂ�Ƃ���ɂ�鐫�\���P�̋�Ŕ�]���ׂ��Ȃ�Ȃ��ł���?
�����N�O�̘_������ɊJ�������v���Z�b�T�ɐV�����Z�p�Ȃ�Ė����ł���B
Intel64��Itanium��HTT�͋^��Ɏv�������A��������̂���͂���Intel�ᔻ�����������ɂ��������܂���B
AMD��Direct Connect Architecture���ɑ���ᔻ�͈�ؖ����݂�������(�m
�������Ȃ��B
���LL2 ���Č������������̘b�� Advanced Smart Cache ���ČĂԂ̂��āA
�Z�p���̐���Ȋ������Ƃ͎v���Ȃ��B
2ch �ł����A���LL2�ƌ����z�͂��Ă� Advanced Smart Cache ���ČĂ�ł�
�z�Ȃ�Ă��Ȃ��ł���H ���Ȃ��Ƃ������ CPU �n�̃X���ł́B
���LL2 ���Č������������̘b�� Advanced Smart Cache ���ČĂԂ̂��āA
�Z�p���̐���Ȋ������Ƃ͎v���Ȃ��B
2ch �ł����A���LL2�ƌ����z�͂��Ă� Advanced Smart Cache ���ČĂ�ł�
�z�Ȃ�Ă��Ȃ��ł���H ���Ȃ��Ƃ������ CPU �n�̃X���ł́B
�}�[�L�e�N�`���̉��������̂������ς�킩���
����ʂ� ando ������܂߂āA�����Ƃ͒N�������ĂȂ��ł���B
�}�[�P�e�B���O�I�Ɍ�������Ɛ������s�ׂȂ낤���B
�P�ɋZ�p�����猩�āA�����������̃}�[�P�e�B���O�p��͊�����
�Z�p�̉����Ӗ����Ă���̂�(���邢�́A�{���ɐV�Z�p�Ȃ̂�)�A
�p���ƌ��ŕ�����Ȃ��̂Ŗʓ|��������A�C�������������肷�邾���B
�}�[�P�e�B���O�I�Ɍ�������Ɛ������s�ׂȂ낤���B
�P�ɋZ�p�����猩�āA�����������̃}�[�P�e�B���O�p��͊�����
�Z�p�̉����Ӗ����Ă���̂�(���邢�́A�{���ɐV�Z�p�Ȃ̂�)�A
�p���ƌ��ŕ�����Ȃ��̂Ŗʓ|��������A�C�������������肷�邾���B
>>155
>2ch �ł����A���LL2�ƌ����z�͂��Ă� Advanced Smart Cache ���ČĂ�ł�
?�z�Ȃ�Ă��Ȃ��ł���H ���Ȃ��Ƃ������ CPU �n�̃X���ł́B
�������̕��������₷������ł���B�������i��Shared�`��狤�L�`����Advanced Smart Cache�Ȃ�ď������Ƃ͖ő��ɖ����ȁB
��Markitecture�ƒf����ɑ����������ǂ�����_���Ă�̂ł����āA�X�����O���炯��2ch�͕]���̊�ɂ͂Ȃ�Ȃ��Ǝv�����B
>2ch �ł����A���LL2�ƌ����z�͂��Ă� Advanced Smart Cache ���ČĂ�ł�
?�z�Ȃ�Ă��Ȃ��ł���H ���Ȃ��Ƃ������ CPU �n�̃X���ł́B
�������̕��������₷������ł���B�������i��Shared�`��狤�L�`����Advanced Smart Cache�Ȃ�ď������Ƃ͖ő��ɖ����ȁB
��Markitecture�ƒf����ɑ����������ǂ�����_���Ă�̂ł����āA�X�����O���炯��2ch�͕]���̊�ɂ͂Ȃ�Ȃ��Ǝv�����B
�Ȃ悭�킩���ĂȂ��z�������ȁB
�wAdvanced Smart Cache�x�Ƃ����̂̓}�[�P�`���O�p��B
�ʂ�Intel�̊J���҂��������̂���Ȃ�����B���g�̂킩���Ă���Z�p���ł���Ȃ炱���C�Ɏ~�߂��X���[���ׂ��|�C���g�B
Intel�̃A�[�L�e�N�g�����ċZ�p�_���ŁAshared L2 cache�̂��Ƃ�"Smart Cache"�Ȃ�Ēp���������ď̂œǂ肵�܂���B
HyperThreading������������B
������ƕςȂ��Ƃ������ǗႦ��CRT�ŁA�_�C�������h�g�����Ƃ��g���j�g�����Ƃ����̂��Z�p�I�{���f���Ă��邩
�Ȃ�ċC�ɂ��Ĕᔻ�Ƃ������肷�邩?
����Ȃ������C�ɂ��Ă��獡�̎��{��`�̐��̒������Ă����܂���B
��������Intel�Ɋ��݂Ă��݂����������낤�ɁB
�wAdvanced Smart Cache�x�Ƃ����̂̓}�[�P�`���O�p��B
�ʂ�Intel�̊J���҂��������̂���Ȃ�����B���g�̂킩���Ă���Z�p���ł���Ȃ炱���C�Ɏ~�߂��X���[���ׂ��|�C���g�B
Intel�̃A�[�L�e�N�g�����ċZ�p�_���ŁAshared L2 cache�̂��Ƃ�"Smart Cache"�Ȃ�Ēp���������ď̂œǂ肵�܂���B
HyperThreading������������B
������ƕςȂ��Ƃ������ǗႦ��CRT�ŁA�_�C�������h�g�����Ƃ��g���j�g�����Ƃ����̂��Z�p�I�{���f���Ă��邩
�Ȃ�ċC�ɂ��Ĕᔻ�Ƃ������肷�邩?
����Ȃ������C�ɂ��Ă��獡�̎��{��`�̐��̒������Ă����܂���B
��������Intel�Ɋ��݂Ă��݂����������낤�ɁB
160 �FMAC�I�^��159 �����F2006/10/01(��) 18:18:37 ID:8vISBPSa
>>159
SMT��Hyper Threading�ƌĂႤ�q�g��C�����悤�ȋC�����邷(��)
SMT��Hyper Threading�ƌĂႤ�q�g��C�����悤�ȋC�����邷(��)
> �ʂ�Intel�̊J���҂��������̂���Ȃ�����B
�������}�[�P�̐l�ԂƑ��k���Č��߂Ă�Ɍ��܂��Ă�ł���B
> ��������Intel�Ɋ��݂Ă��݂����������낤�ɁB
���ꂪIntel�̋Z�p�w�Ɋ��݂��Ă���悤�Ɍ�������Ă̂��A
�Ȃς��Ǝv�����ǂȂ��B
�u����͗�ɂ����Intel�̃}�[�P�e�B���O�p��ł���v����
������Ă邾���ł���B
���Ȃ́A�{���ɐV�Z�p�Ȃ̂��A����Ƃ������̋Z�p�ɐV����
���O�������̂���ʂ����̂ŏd�Ă���ǁB
�������}�[�P�̐l�ԂƑ��k���Č��߂Ă�Ɍ��܂��Ă�ł���B
> ��������Intel�Ɋ��݂Ă��݂����������낤�ɁB
���ꂪIntel�̋Z�p�w�Ɋ��݂��Ă���悤�Ɍ�������Ă̂��A
�Ȃς��Ǝv�����ǂȂ��B
�u����͗�ɂ����Intel�̃}�[�P�e�B���O�p��ł���v����
������Ă邾���ł���B
���Ȃ́A�{���ɐV�Z�p�Ȃ̂��A����Ƃ������̋Z�p�ɐV����
���O�������̂���ʂ����̂ŏd�Ă���ǁB
������Ɖ������ƁA��������� Itanium �T�[�o���i���o���Ă镔���
�̂��l�Ȃ̂ŁAIntel �Ɋ��݂��闧�ꂶ��Ȃ��ł��BIntel �ɑ���
�{�����������Ƃ͂��邩������Ȃ����B(w
�Ƃ����킯�ŁA�����Intel�ᔻ���Ǝv���l�́A�����ł��C�Â��ĂȂ�����
����Ȃ����M�ғ����Ă�Ǝv���ȁB
�̂��l�Ȃ̂ŁAIntel �Ɋ��݂��闧�ꂶ��Ȃ��ł��BIntel �ɑ���
�{�����������Ƃ͂��邩������Ȃ����B(w
�Ƃ����킯�ŁA�����Intel�ᔻ���Ǝv���l�́A�����ł��C�Â��ĂȂ�����
����Ȃ����M�ғ����Ă�Ǝv���ȁB
>>159
�Ă��A����ando����̕����ǂ�ł�H
�Ă��A����ando����̕����ǂ�ł�H
>>162
���Ⴀ�ő�̏��ǂ����
1.3
>���̂悤�Ȃ�蒼������������P�[�X�͔�r�I���Ȃ��C���W�̃��[�h�𑁂����s���邱�Ƃɂ�鐫�\����̕����傫���̂ŗL�p�ȕ��@�ł��邪�C�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
1.4
>��������P�Ȃ̂ł����C���ɑ��Ђ̃v���Z�T�ł���Ă���Z�p�ŁC�����Advanced������̂�Markitecture�ł��B
���Ⴀ�ő�̏��ǂ����
1.3
>���̂悤�Ȃ�蒼������������P�[�X�͔�r�I���Ȃ��C���W�̃��[�h�𑁂����s���邱�Ƃɂ�鐫�\����̕����傫���̂ŗL�p�ȕ��@�ł��邪�C�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
1.4
>��������P�Ȃ̂ł����C���ɑ��Ђ̃v���Z�T�ł���Ă���Z�p�ŁC�����Advanced������̂�Markitecture�ł��B
OoO load �Ȃ�āA�T�[�o�nCPU�ł͐̂��������Ă�b����˂��B
RISC �n�Ȃ烍�[�G���h�̃T�[�o�ɂ������Ă�@�\�����B
�ł��ʂ� ando ����� Intel ���������ĈӐ}�͂Ȃ��Ǝv�����ǂȂ��B
RISC �n�Ȃ烍�[�G���h�̃T�[�o�ɂ������Ă�@�\�����B
�ł��ʂ� ando ����� Intel ���������ĈӐ}�͂Ȃ��Ǝv�����ǂȂ��B
���ɂł�Advanced�ƕt����̂�Intel�̕Ȃ��ƁB�ނ���A�����J�̉�Ђł͂ǂ��ł��������ȁB
�����Ƃ�Advanced�Ƃ����炢������A�����Ă��̏ꍇ�͑��Ђ̓��l�̋@�\�����ǂ������Ă͂���i���̑����͕ʂƂ��āj
������ƑO�܂ł�IntelCPU��HyperThreading�͂��Ȃ킿SMT���������ǁA���܂͂�������Ȃ���˂��B
�����Ƃ�Advanced�Ƃ����炢������A�����Ă��̏ꍇ�͑��Ђ̓��l�̋@�\�����ǂ������Ă͂���i���̑����͕ʂƂ��āj
������ƑO�܂ł�IntelCPU��HyperThreading�͂��Ȃ킿SMT���������ǁA���܂͂�������Ȃ���˂��B
Physical Experimentation with Prefetching Helper Threadson Intel�fs Hyper-Threaded Processors
http://www.cgo.org/cgo2004/papers/02_80_Kim_D_REVISED.pdf#search=%22Simultaneous%20Multithreading%20intel%20.pdf%22
>With the advent of Intel PentiumR 4 processor with Hyper-Threading Technology [9, 13], a commercially available multithreaded
>processor supporting two logical processors simultaneously, it is possible to evaluate the helper threading idea on a physical
>SMT machine.
Pentium 4�ɂ�����HyperThreading�́ASMT�ł��邱�Ƃ�Intel���g�݂Ƃ߂Ă���B
Montecito�ɂ�����CGMT���}�[�P�`���O�p��Ƃ��Ă͓����HyperThreading�ł���B
�{���I�ɗ��҂͈قȂ���̂����A���g�̂킩���Ă���l�Ԃ��킴�킴���݂��قǐ_�o���ɂȂ�K�v�͂Ȃ��B
���F�́A�}�[�P�`���O�p��B���m�ȃ��[�U�̐S���L���b�`�ł�������OK�B
�������̃T�C�g�������Ɠǂ�ł�AIntel�Ɋ��݂��������������Ă̂킩��ł���B
�{�l�����o�Ǐ��Ȃ���?
Intel��l�����͂₾�Ƃ��A��l������Intel�ɂ͑����[�J�[�̂�����݂������ƈ��������g�ߋ��ɂ����Ă��邵�B
http://www.cgo.org/cgo2004/papers/02_80_Kim_D_REVISED.pdf#search=%22Simultaneous%20Multithreading%20intel%20.pdf%22
>With the advent of Intel PentiumR 4 processor with Hyper-Threading Technology [9, 13], a commercially available multithreaded
>processor supporting two logical processors simultaneously, it is possible to evaluate the helper threading idea on a physical
>SMT machine.
Pentium 4�ɂ�����HyperThreading�́ASMT�ł��邱�Ƃ�Intel���g�݂Ƃ߂Ă���B
Montecito�ɂ�����CGMT���}�[�P�`���O�p��Ƃ��Ă͓����HyperThreading�ł���B
�{���I�ɗ��҂͈قȂ���̂����A���g�̂킩���Ă���l�Ԃ��킴�킴���݂��قǐ_�o���ɂȂ�K�v�͂Ȃ��B
���F�́A�}�[�P�`���O�p��B���m�ȃ��[�U�̐S���L���b�`�ł�������OK�B
�������̃T�C�g�������Ɠǂ�ł�AIntel�Ɋ��݂��������������Ă̂킩��ł���B
�{�l�����o�Ǐ��Ȃ���?
Intel��l�����͂₾�Ƃ��A��l������Intel�ɂ͑����[�J�[�̂�����݂������ƈ��������g�ߋ��ɂ����Ă��邵�B
Itanium �� CGMT �Ȃ̂� HyperThreading ���ČĂ�ł邩��˂��B
�����AThreading �Z�p�ɂ��ẮA���Ђ����Ȃ蕴��킵���悤�ȁB
���� Xbox360 CPU ���āASMT �Ȃ́H FGMT �Ȃ́H
�����AThreading �Z�p�ɂ��ẮA���Ђ����Ȃ蕴��킵���悤�ȁB
���� Xbox360 CPU ���āASMT �Ȃ́H FGMT �Ȃ́H
>>167
��������{��̓lj�͂ɖ�肪�L��Ǝv�����B
��������{��̓lj�͂ɖ�肪�L��Ǝv�����B
> �{���I�ɗ��҂͈قȂ���̂����A���g�̂킩���Ă���l�Ԃ��킴�킴���݂�
> ���قǐ_�o���ɂȂ�K�v�͂Ȃ��B
���[�A����͉��͖��_�o���Ǝv���ȁB(w
�Z�p���Ȃ�A���R�A���ꂮ�炢�͋�ʂ��ׂ��ł���B
�}�[�P�e�B���O���Ȃ�A�������A��ʂ��Ȃ��Ă�낵���B
����̈Ⴂ�B
> �������̃T�C�g�������Ɠǂ�ł�AIntel�Ɋ��݂��������������Ă̂�
> ����ł���B
���͂��̈ӌ��ɂ͎^�����Ȃ��ȁB
�{�����Ă�Ȃ����Ďv�������Ƃ͂��邯�ǁA���݂��Ă�Ȃ��Ǝv�������Ƃ͂Ȃ��B
�Ђ���Ƃ��ĐM�ғ����ĂȂ��H
> ���قǐ_�o���ɂȂ�K�v�͂Ȃ��B
���[�A����͉��͖��_�o���Ǝv���ȁB(w
�Z�p���Ȃ�A���R�A���ꂮ�炢�͋�ʂ��ׂ��ł���B
�}�[�P�e�B���O���Ȃ�A�������A��ʂ��Ȃ��Ă�낵���B
����̈Ⴂ�B
> �������̃T�C�g�������Ɠǂ�ł�AIntel�Ɋ��݂��������������Ă̂�
> ����ł���B
���͂��̈ӌ��ɂ͎^�����Ȃ��ȁB
�{�����Ă�Ȃ����Ďv�������Ƃ͂��邯�ǁA���݂��Ă�Ȃ��Ǝv�������Ƃ͂Ȃ��B
�Ђ���Ƃ��ĐM�ғ����ĂȂ��H
��ς̍���_���Ă����Ӗ�
RISC���̐M�҂��̓��{��̓lj�͂��̍P��̐��蕶�傪��яo���Ă��܂����B
>>170
�_�o�����_�o�̘b�Ƃ��Ă�
�ׂ������Ƃ��C�ɂ��遁�g�������ŃE�_�E�_����オ��ׂ̃I�^�N�I�Ȋ���
�ׂ������Ƃ��C�ɂ��Ȃ����ڋq�Ƃ̑Ή��ƌ���̍�Ƃ̈Ⴂ���킫�܂��Ă�
�_�o�����_�o�̘b�Ƃ��Ă�
�ׂ������Ƃ��C�ɂ��遁�g�������ŃE�_�E�_����オ��ׂ̃I�^�N�I�Ȋ���
�ׂ������Ƃ��C�ɂ��Ȃ����ڋq�Ƃ̑Ή��ƌ���̍�Ƃ̈Ⴂ���킫�܂��Ă�
���̃y�[�W�́A�ڋq�Ή��y�[�W����Ȃ��āAando ����� CPU �Ɋւ���
�I�^�N�I�S(���܂��ܖ{�Ƃ̈ꕔ�ł����邪)��f�I�����y�[�W������
�˂��B�ׂ������Ƃ��C�ɂ���͓̂��R���Ǝv����B
�ڋq�Ή��Ȃ��Ђ̃y�[�W�ł������킯�ŁB
�I�^�N�I�S(���܂��ܖ{�Ƃ̈ꕔ�ł����邪)��f�I�����y�[�W������
�˂��B�ׂ������Ƃ��C�ɂ���͓̂��R���Ǝv����B
�ڋq�Ή��Ȃ��Ђ̃y�[�W�ł������킯�ŁB
175 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/01(��) 19:04:25 ID:lMj1l+49
>>166
�킩�����B�^�Ђ́u�l�c�v�ƌĂׂΗǂ���
�킩�����B�^�Ђ́u�l�c�v�ƌĂׂΗǂ���
>>174
�����炱���}�[�P�e�B���O�̕���̘b�ɃP�`��t���鎖�̖��Ӗ������ӎ����Ȃ���
�Z�p�̘b�����Ă����ʂŃ}�[�P�e�B���O�p��̘b���������_�Łh������킫�܂��ĂȂ��h
�����炱���}�[�P�e�B���O�̕���̘b�ɃP�`��t���鎖�̖��Ӗ������ӎ����Ȃ���
�Z�p�̘b�����Ă����ʂŃ}�[�P�e�B���O�p��̘b���������_�Łh������킫�܂��ĂȂ��h
>>175
�����^
�����^
>>175
�ƊE�ŗD�ʂɂ���Ԃ���A���_������Ƃ��B
��������������against��A�ɑ}���ւ��B
IDF��IMF�ɉ��̂���Έꌏ���������?
����Ƀf�x���b�p�������x�邩��w�p�I���ʂɌ��o��������B
�ƊE�ŗD�ʂɂ���Ԃ���A���_������Ƃ��B
��������������against��A�ɑ}���ւ��B
IDF��IMF�ɉ��̂���Έꌏ���������?
����Ƀf�x���b�p�������x�邩��w�p�I���ʂɌ��o��������B
> �����炱���}�[�P�e�B���O�̕���̘b�ɃP�`��t���鎖�̖��Ӗ������ӎ����Ȃ���
�}�[�P�e�B���O�ɃP�`�����Ă��Ȃ��āAIntel ���g���Ă���p���
���āA�ǂꂪ�}�[�P�e�B���O�p�ꂩ������Ă��ł���B
�������Ȃ��ƁA�}�[�P�e�B���O�p�ꂶ��Ȃ��V�Z�p�ƕʒf���Ȃ�����B
������Ȃ��Ă��}�[�P�e�B���O�p�ꂾ�ƕ�����l�Ԃɂ͂������s�v�Șb�����ǁA
���ɂ͕K�v�ȉ�����ȁB
�}�[�P�e�B���O�ɃP�`�����Ă��Ȃ��āAIntel ���g���Ă���p���
���āA�ǂꂪ�}�[�P�e�B���O�p�ꂩ������Ă��ł���B
�������Ȃ��ƁA�}�[�P�e�B���O�p�ꂶ��Ȃ��V�Z�p�ƕʒf���Ȃ�����B
������Ȃ��Ă��}�[�P�e�B���O�p�ꂾ�ƕ�����l�Ԃɂ͂������s�v�Șb�����ǁA
���ɂ͕K�v�ȉ�����ȁB
> �ʒf���Ȃ�����B
�u���f���Ȃ�����v
�ԈႦ���B
�u���f���Ȃ�����v
�ԈႦ���B
>>166
NEC�̉t��SA-SFT�����������BSuper Advanced Super Fine TFT���B
TFT�ȊO���������Ă��Ȃ��ɓ������B�N���~�߂�z�͂��Ȃ������̂��B
NEC�̉t��SA-SFT�����������BSuper Advanced Super Fine TFT���B
TFT�ȊO���������Ă��Ȃ��ɓ������B�N���~�߂�z�͂��Ȃ������̂��B
SSE3
SSSE3
SSSSE3
SSSSSE3
SSSE3
SSSSE3
SSSSSE3
>>179
�������́A�P�`�������������܂�A���m�ȏ��ׂ��ɏ���ȑz���Ō������������邱�Ƃ�����̂Œ��ӂ��K�v���B
>���̂悤�Ȃ�蒼������������P�[�X�͔�r�I���Ȃ��C���W�̃��[�h�𑁂����s���邱�Ƃɂ�鐫�\����̕����傫���̂ŗL�p�ȕ��@�ł��邪�C
>�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
>Constant Stride������Ă���Ǝv���܂��B��������P�Ȃ̂ł����C���ɑ��Ђ̃v���Z�T�ł���Ă���Z�p�ŁC
>�����Advanced������̂�Markitecture�ł��B
>���ʃL���b�V�����ɂ��C�����̖�肪��������Əq�ׂĂ��܂����C���X���蔲���ŁC����ē��R�Ƃ��������ŁC
>�����Markitecute�ł��B
���[�h�̐�s���s�́AIntel�͈ȑO�������āACore 2�ł́A�\�����܂߂������ƕ��G�ȓ��@���[�h������Ă��邱�Ƃ����̌㔭�o�B
�v���t�F�b�`�ɂ��Ă��AIntel���A�s�[�����Ă���̂́A2�R�A�ō��v8�̃v���t�F�b�`�������Ă��āA
�Ⴆ�AL1�ւ����Ȃ�v���t�F�b�`���\�ɂȂ��Ă��邱�ƂȂǂŎw�E�̃s���g������Ă���B
���L�L���b�V���ɂ��Ă��APPC970MP, Athlon64 X2/Opteron, UltraSPARC IV+�̑��݂����Ă���ē��R�Ƃ̕]���B
������Intel��Markitecture�ɂ����蔲����Ƃ��Ĕ�r�̓y��ɂ��オ��Ȃ��̂�?POWER4/5��Niagara�ȊO�L������������Ă�̂�?
>�������CIBM�ł�40�N�ȏ�O��System 360�������炱��Fused���ꂽ���߂��������Ă���̂ł�����C�������X�Ƃ����C�����܂��B
�ƁAMicro Fusion�ɂ��Ă��������X�Ɣᔻ�B
�ŁAIntel Core Markitecture��SPEC�x���`�̌��ʌ��J�����ƁA
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=1&v=1&if=0&ncf=1&nct=256&cpcf=1&cpct=4&mf=200&mt=3800&o=0&o=1
>����SPECint�ʼn��́C���̂悤�ȍ������\���o��̂������ł��܂��C���ٓI�ł��邱�Ƃ͊m���ł��B
�ƕ]������]�B
������Intel��SPEC�x���`�œK���è�Ƃ͂����A����Ȃɓˏo�����Ƃ���Markitecture���Ƃ��Ȃ�Ƃ������Ă����Đ����͂Ȃ�㩁B
�Ⴆ���ƂƂ����ǂ��A�ŐV�̃v���Z�b�T�̗����Ɨ\���͓���ˁB
�������́A�P�`�������������܂�A���m�ȏ��ׂ��ɏ���ȑz���Ō������������邱�Ƃ�����̂Œ��ӂ��K�v���B
>���̂悤�Ȃ�蒼������������P�[�X�͔�r�I���Ȃ��C���W�̃��[�h�𑁂����s���邱�Ƃɂ�鐫�\����̕����傫���̂ŗL�p�ȕ��@�ł��邪�C
>�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
>Constant Stride������Ă���Ǝv���܂��B��������P�Ȃ̂ł����C���ɑ��Ђ̃v���Z�T�ł���Ă���Z�p�ŁC
>�����Advanced������̂�Markitecture�ł��B
>���ʃL���b�V�����ɂ��C�����̖�肪��������Əq�ׂĂ��܂����C���X���蔲���ŁC����ē��R�Ƃ��������ŁC
>�����Markitecute�ł��B
���[�h�̐�s���s�́AIntel�͈ȑO�������āACore 2�ł́A�\�����܂߂������ƕ��G�ȓ��@���[�h������Ă��邱�Ƃ����̌㔭�o�B
�v���t�F�b�`�ɂ��Ă��AIntel���A�s�[�����Ă���̂́A2�R�A�ō��v8�̃v���t�F�b�`�������Ă��āA
�Ⴆ�AL1�ւ����Ȃ�v���t�F�b�`���\�ɂȂ��Ă��邱�ƂȂǂŎw�E�̃s���g������Ă���B
���L�L���b�V���ɂ��Ă��APPC970MP, Athlon64 X2/Opteron, UltraSPARC IV+�̑��݂����Ă���ē��R�Ƃ̕]���B
������Intel��Markitecture�ɂ����蔲����Ƃ��Ĕ�r�̓y��ɂ��オ��Ȃ��̂�?POWER4/5��Niagara�ȊO�L������������Ă�̂�?
>�������CIBM�ł�40�N�ȏ�O��System 360�������炱��Fused���ꂽ���߂��������Ă���̂ł�����C�������X�Ƃ����C�����܂��B
�ƁAMicro Fusion�ɂ��Ă��������X�Ɣᔻ�B
�ŁAIntel Core Markitecture��SPEC�x���`�̌��ʌ��J�����ƁA
http://www.aceshardware.com/SPECmine/index.jsp?b=0&s=1&v=1&if=0&ncf=1&nct=256&cpcf=1&cpct=4&mf=200&mt=3800&o=0&o=1
>����SPECint�ʼn��́C���̂悤�ȍ������\���o��̂������ł��܂��C���ٓI�ł��邱�Ƃ͊m���ł��B
�ƕ]������]�B
������Intel��SPEC�x���`�œK���è�Ƃ͂����A����Ȃɓˏo�����Ƃ���Markitecture���Ƃ��Ȃ�Ƃ������Ă����Đ����͂Ȃ�㩁B
�Ⴆ���ƂƂ����ǂ��A�ŐV�̃v���Z�b�T�̗����Ɨ\���͓���ˁB
���ʐl��葽�����闧��Ȃ̂ɂ��Ȃ��̓I�ɂȂ��Ă����O���̎��_�ł���ł́u��ȕt�����������v�Ƃ����Ă��d��������
���������炦�Ȃ�����v���̃��C�^�[�Ƃ��ď����K�v�͂Ȃ����A�v���̋Z�p�҂Ƃ��Ă̎��o�Ƃ��v���C�h(ry
���������炦�Ȃ�����v���̃��C�^�[�Ƃ��ď����K�v�͂Ȃ����A�v���̋Z�p�҂Ƃ��Ă̎��o�Ƃ��v���C�h(ry
> ���[�h�̐�s���s�́AIntel�͈ȑO�������āACore 2�ł́A�\�����܂߂�����
> �ƕ��G�ȓ��@���[�h������Ă��邱�Ƃ����̌㔭�o�B
���́A�����ƕ��G�ȃ��[�h�A���Ȃ킿 OoO load �́A�ʂ� Intel �ɓ��L��
�Z�p����Ȃ��āA���̃v���Z�b�T�ł��̂��炠�����Z�p�����Ă�������ł���B
�ǂ����Ԉ���ĂȂ��Ǝv�����ǁA�ǂ����Ⴄ�́H
> ���L�L���b�V���ɂ��Ă��APPC970MP, Athlon64 X2/Opteron, UltraSPARC
> IV+�̑��݂����Ă���ē��R�Ƃ̕]���B
> ������Intel��Markitecture�ɂ����蔲����Ƃ��Ĕ�r�̓y��ɂ��オ
> ��Ȃ��̂�?POWER4/5��Niagara�ȊO�L������������Ă�̂�?
Opteron, UltraSPARC, Itanium �̂悤�ȃT�[�o�v���Z�b�T�ł́A���L�L���b
�V���ƕ����L���b�V���̂ǂ��炪�ǂ����́A�T�[�o�̃��[�N���[�h�ɂ�肯��
����B�W�Ȃ��^�X�N�ɃL���b�V�������������댯���Ȃ��̂ŁA�����L���b
�V���̕����A�g�[�^���X���[�v�b�g�Ƃ��Ă͗D��Ă���ꍇ������B
(SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA����
���ʂ��o�ɂ������A���^�p���ł͏o��B)
1�X���b�h���������ĂȂ����Ƃ��������[�U�����v���Z�b�T�ł͎���Ⴂ�A
1�X���b�h�őS�L���b�V���e�ʂ��g���鋤�L�L���b�V���̕����A�V���O��
�X���b�h���\�̓_�ŗL���B������A�l���[�X����{�� Merom �� Conroe �ł�
���L�L���b�V���́A����ē��R�Ƃ����b�ł���B
����ɁA���̂���ē��R�̋��L L1 �ɂ킴�킴�ʂ̖��O�����邩��A
����̓}�[�P�e�B���O�p�ꂾ����ĉ�������킯�ŁB
> �ƁAMicro Fusion�ɂ��Ă��������X�Ɣᔻ�B
����ɂ��Ă��A�V�����p����ł��������Ă邱�Ƃɂ��Č����Ă��ł���B
��B�̎d���ɂ����ƌ��y���Ă�� (����͊w�p�_���ł́A���R�̏K���B����
���AIntel �ɂ��������K���ɏ]���`���͂Ȃ�����)�A�����͏����ĂȂ��ł���B
> �Ⴆ���ƂƂ����ǂ��A�ŐV�̃v���Z�b�T�̗����Ɨ\���͓���ˁB
�����͓����B
> �ƕ��G�ȓ��@���[�h������Ă��邱�Ƃ����̌㔭�o�B
���́A�����ƕ��G�ȃ��[�h�A���Ȃ킿 OoO load �́A�ʂ� Intel �ɓ��L��
�Z�p����Ȃ��āA���̃v���Z�b�T�ł��̂��炠�����Z�p�����Ă�������ł���B
�ǂ����Ԉ���ĂȂ��Ǝv�����ǁA�ǂ����Ⴄ�́H
> ���L�L���b�V���ɂ��Ă��APPC970MP, Athlon64 X2/Opteron, UltraSPARC
> IV+�̑��݂����Ă���ē��R�Ƃ̕]���B
> ������Intel��Markitecture�ɂ����蔲����Ƃ��Ĕ�r�̓y��ɂ��オ
> ��Ȃ��̂�?POWER4/5��Niagara�ȊO�L������������Ă�̂�?
Opteron, UltraSPARC, Itanium �̂悤�ȃT�[�o�v���Z�b�T�ł́A���L�L���b
�V���ƕ����L���b�V���̂ǂ��炪�ǂ����́A�T�[�o�̃��[�N���[�h�ɂ�肯��
����B�W�Ȃ��^�X�N�ɃL���b�V�������������댯���Ȃ��̂ŁA�����L���b
�V���̕����A�g�[�^���X���[�v�b�g�Ƃ��Ă͗D��Ă���ꍇ������B
(SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA����
���ʂ��o�ɂ������A���^�p���ł͏o��B)
1�X���b�h���������ĂȂ����Ƃ��������[�U�����v���Z�b�T�ł͎���Ⴂ�A
1�X���b�h�őS�L���b�V���e�ʂ��g���鋤�L�L���b�V���̕����A�V���O��
�X���b�h���\�̓_�ŗL���B������A�l���[�X����{�� Merom �� Conroe �ł�
���L�L���b�V���́A����ē��R�Ƃ����b�ł���B
����ɁA���̂���ē��R�̋��L L1 �ɂ킴�킴�ʂ̖��O�����邩��A
����̓}�[�P�e�B���O�p�ꂾ����ĉ�������킯�ŁB
> �ƁAMicro Fusion�ɂ��Ă��������X�Ɣᔻ�B
����ɂ��Ă��A�V�����p����ł��������Ă邱�Ƃɂ��Č����Ă��ł���B
��B�̎d���ɂ����ƌ��y���Ă�� (����͊w�p�_���ł́A���R�̏K���B����
���AIntel �ɂ��������K���ɏ]���`���͂Ȃ�����)�A�����͏����ĂȂ��ł���B
> �Ⴆ���ƂƂ����ǂ��A�ŐV�̃v���Z�b�T�̗����Ɨ\���͓���ˁB
�����͓����B
>>185
>��v�������̂�����Ƃ��̃��[�h���߂Ƃ���ȍ~�̖��߂̎��s�𒆒f���C�X�g�A���߂����s����Ă��烍�[�h����
>�Ƃ���ȍ~�̖��߂̎��s����蒼���Ƃ������@���p�����܂��B
>�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
���܂ł�����Ă����̂��悭���ׂ��ɍ��܂ł͂���ĂȂ������́`�Ɣ������Ă���_��
�\�������āA��蒼������������P�[�X���ŏ����ɂ��悤�Ƃ����w�͂����Ă���Ƃ������Ƃ������Ă���B
�������̉�����悭�ǂނƁA�㑱�̃��[�h�ƈˑ����Ȃ����Ƃ�O��ɃX�g�A�����ɐ�s���s����̂�
=Memory Disambiguation�Ɛ����Ă��邱�Ƃ��ǂݎ���ł���B���Ƃ���ł�MYCOM�̋L���ł͉��P����Ă邯�ǁB
�������̍l���ɂ��Ęb�����Ă���̂ɁA�L���b�V���Ɋւ��āA�����Ȃ�>>185�l�̍l��������Ă�����B
>�������AIBM��2001�N�ɔ��\����POWER4�v���Z�T�ł͊���2�R�A�Ԃŋ��L����L���b�V���𓋍ڂ��Ă���A
>2006�N�ɂȂ��ċ��L�L���b�V������i�I�Ō����Ƃ����͉̂�c�����̐�`����Ƃ��Ă������߂��ł��낤�Ǝv���B
�Ƃ������Ƃ�MYCOM�̋L���ł����Ă��āA>>185�̍l���Ƃ͊W�Ȃ��Ɉ������̔�r�̑Ώۂ̓T�[�o�������܂܂�Ă���B
(���Ƃ��ƃT�[�o�n�̐l�Ȃ̂łނ��낻�����Ɣ�r���Ă���ƍl����������ʂ��Ǝv����)
>��v�������̂�����Ƃ��̃��[�h���߂Ƃ���ȍ~�̖��߂̎��s�𒆒f���C�X�g�A���߂����s����Ă��烍�[�h����
>�Ƃ���ȍ~�̖��߂̎��s����蒼���Ƃ������@���p�����܂��B
>�G�`�`�C���܂ł͂���ĂȂ������́`�`�Ƃ��������ŁC���ꂪ�ڋʂ̐V�@�\�ƌ�����ƈ�a��������܂��B
���܂ł�����Ă����̂��悭���ׂ��ɍ��܂ł͂���ĂȂ������́`�Ɣ������Ă���_��
�\�������āA��蒼������������P�[�X���ŏ����ɂ��悤�Ƃ����w�͂����Ă���Ƃ������Ƃ������Ă���B
�������̉�����悭�ǂނƁA�㑱�̃��[�h�ƈˑ����Ȃ����Ƃ�O��ɃX�g�A�����ɐ�s���s����̂�
=Memory Disambiguation�Ɛ����Ă��邱�Ƃ��ǂݎ���ł���B���Ƃ���ł�MYCOM�̋L���ł͉��P����Ă邯�ǁB
�������̍l���ɂ��Ęb�����Ă���̂ɁA�L���b�V���Ɋւ��āA�����Ȃ�>>185�l�̍l��������Ă�����B
>�������AIBM��2001�N�ɔ��\����POWER4�v���Z�T�ł͊���2�R�A�Ԃŋ��L����L���b�V���𓋍ڂ��Ă���A
>2006�N�ɂȂ��ċ��L�L���b�V������i�I�Ō����Ƃ����͉̂�c�����̐�`����Ƃ��Ă������߂��ł��낤�Ǝv���B
�Ƃ������Ƃ�MYCOM�̋L���ł����Ă��āA>>185�̍l���Ƃ͊W�Ȃ��Ɉ������̔�r�̑Ώۂ̓T�[�o�������܂܂�Ă���B
(���Ƃ��ƃT�[�o�n�̐l�Ȃ̂łނ��낻�����Ɣ�r���Ă���ƍl����������ʂ��Ǝv����)
>���́A�����ƕ��G�ȃ��[�h�A���Ȃ킿 OoO load �́A�ʂ� Intel �ɓ��L��
>�Z�p����Ȃ��āA���̃v���Z�b�T�ł��̂��炠�����Z�p�����Ă�������ł���B
�����Z�p�ł����Ђ��D��Ă�����ǂ���͏d�v�ł͂Ȃ��킯�H
Intel���ȑO����̗p���Ă��Z�p�Ȃ̂Ɂu�܂�����ĂȂ������́H�v�Ƃ������Ă錏�́H
>Opteron, UltraSPARC, Itanium �̂悤�ȃT�[�o�v���Z�b�T�ł́A���L�L���b
>�V���ƕ����L���b�V���̂ǂ��炪�ǂ����́A�T�[�o�̃��[�N���[�h�ɂ�肯��
>����B�W�Ȃ��^�X�N�ɃL���b�V�������������댯���Ȃ��̂ŁA�����L���b
>�V���̕����A�g�[�^���X���[�v�b�g�Ƃ��Ă͗D��Ă���ꍇ������B
PowerPC970MP�̃A�[�L�e�N�g���{���͋��L�L���b�V���ɂ������������NJJ�����Ԃ̊W�Łc�I�Ȕ��������Ă錏
��������Last Level Cache�݂̂����L�ɂ���ΐH�������ɂ���Q�͑����y���ł��邵
�Ǐ����╉�ׂ��ϓ��Ŗ������Ƃ̕��������̂ɕ����Ƃ��A�t�H
>SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA
�L�L���b�V���̎�_���I�悵�܂���
>����ɁA���̂���ē��R�̋��L L1 �ɂ킴�킴�ʂ̖��O�����邩��A
>����̓}�[�P�e�B���O�p�ꂾ����ĉ�������킯�ŁB
����ē��R�̋Z�p�ł������̍������Ȃ��Ȃ��ł��Ȃ����Ƃ�����
SMT��CGMT�֘A���T�[�o�[�v���Z�b�T�Ȃ����ē��R�̋Z�p�ł���H
�N���e�B�J���T�[�o�[�����Ȃ�G���[������b�N�X�e�b�v���K�v����
Opteron8xxx�͂ǂ������or�n�ゾ���
��̂ˁA�������Ђ���Ă���猖�`���邱�ƂɃP�`�t���������͖���
>����ɂ��Ă��A�V�����p����ł��������Ă邱�Ƃɂ��Č����Ă��ł���B
>��B�̎d���ɂ����ƌ��y���Ă�� (����͊w�p�_���ł́A���R�̏K���B����
>���AIntel �ɂ��������K���ɏ]���`���͂Ȃ�����)�A�����͏����ĂȂ��ł���B
http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
>�Z�p����Ȃ��āA���̃v���Z�b�T�ł��̂��炠�����Z�p�����Ă�������ł���B
�����Z�p�ł����Ђ��D��Ă�����ǂ���͏d�v�ł͂Ȃ��킯�H
Intel���ȑO����̗p���Ă��Z�p�Ȃ̂Ɂu�܂�����ĂȂ������́H�v�Ƃ������Ă錏�́H
>Opteron, UltraSPARC, Itanium �̂悤�ȃT�[�o�v���Z�b�T�ł́A���L�L���b
>�V���ƕ����L���b�V���̂ǂ��炪�ǂ����́A�T�[�o�̃��[�N���[�h�ɂ�肯��
>����B�W�Ȃ��^�X�N�ɃL���b�V�������������댯���Ȃ��̂ŁA�����L���b
>�V���̕����A�g�[�^���X���[�v�b�g�Ƃ��Ă͗D��Ă���ꍇ������B
PowerPC970MP�̃A�[�L�e�N�g���{���͋��L�L���b�V���ɂ������������NJJ�����Ԃ̊W�Łc�I�Ȕ��������Ă錏
��������Last Level Cache�݂̂����L�ɂ���ΐH�������ɂ���Q�͑����y���ł��邵
�Ǐ����╉�ׂ��ϓ��Ŗ������Ƃ̕��������̂ɕ����Ƃ��A�t�H
>SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA
�L�L���b�V���̎�_���I�悵�܂���
>����ɁA���̂���ē��R�̋��L L1 �ɂ킴�킴�ʂ̖��O�����邩��A
>����̓}�[�P�e�B���O�p�ꂾ����ĉ�������킯�ŁB
����ē��R�̋Z�p�ł������̍������Ȃ��Ȃ��ł��Ȃ����Ƃ�����
SMT��CGMT�֘A���T�[�o�[�v���Z�b�T�Ȃ����ē��R�̋Z�p�ł���H
�N���e�B�J���T�[�o�[�����Ȃ�G���[������b�N�X�e�b�v���K�v����
Opteron8xxx�͂ǂ������or�n�ゾ���
��̂ˁA�������Ђ���Ă���猖�`���邱�ƂɃP�`�t���������͖���
>����ɂ��Ă��A�V�����p����ł��������Ă邱�Ƃɂ��Č����Ă��ł���B
>��B�̎d���ɂ����ƌ��y���Ă�� (����͊w�p�_���ł́A���R�̏K���B����
>���AIntel �ɂ��������K���ɏ]���`���͂Ȃ�����)�A�����͏����ĂȂ��ł���B
http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
>�㑱�̃��[�h�ƈˑ����Ȃ����Ƃ�O��ɃX�g�A�����ɐ�s���s�����
���[�h�ƃX�g�A���t�corz
���[�h�ƃX�g�A���t�corz
����
> �������̉�����悭�ǂނƁA�㑱�̃��[�h�ƈˑ����Ȃ����Ƃ�O��ɃX�g�A��
> �������ɐ�s���s����̂�=Memory Disambiguation�Ɛ����Ă��邱�Ƃ��ǂݎ�
> ���ł���B���Ƃ���ł�MYCOM�̋L���ł͉��P����Ă邯�ǁB
�ڍׂɂ��ẮA�}�[�P�e�B���O�p�ꂵ���o�ĂȂ��i�K�ŁA��������Ă邩
�z�����Ă����A���傤���Ȃ���Ȃ����Ȃ��B
������ Intel �Ƀ}�[�P�e�B���O�p�ꂶ��Ȃ��āA�����̃e�N�j�J���^�[����
�g���K��������A�V�������t���g���Ă��遨�{���ɐV�����Z�p���܂�ł���
�Ƒz���ł���킯�����ǁA����� Intel �̏K������A���f�ł��Ȃ��Ă����傤��
�Ȃ��ł���B
> ��������Last Level Cache�݂̂����L�ɂ���ΐH�������ɂ���Q�͑����y
> ���ł��邵
�H�������ɂ���Q���y���ł���̂́ALast Level Cache ����r�I���傾����
�ł���B�܂�A���܂��� ���[�L���O�Z�b�g�� Last Level Cache �ɓ�����
���邩��ŁB
��������v���Z�X�ɁALast Level Cache �ɓ���Ȃ����[�L���O�Z�b�g������
�v���Z�X������A�Ȃ肽���Ȃ����B
> >SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA
> �L�L���b�V���̎�_���I�悵�܂���
�{�g���l�b�N�ƂȂ��Ă��镔���̃R�[�h�Ƃ��A���L�L���b�V���̕����L���ł́H
> ��̂ˁA�������Ђ���Ă���猖�`���邱�ƂɃP�`�t���������͖���
��`���邱�Ƃɂ͂������٘_�͂Ȃ����ǁA���LL2 �̂��߂ɁA�V�����p���
����̂͋Z�p�I�ɂ͕ς��Ǝv�����ǂȂ��B
> http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
����̂ǂ����w���ĉ������������́H
> �������ɐ�s���s����̂�=Memory Disambiguation�Ɛ����Ă��邱�Ƃ��ǂݎ�
> ���ł���B���Ƃ���ł�MYCOM�̋L���ł͉��P����Ă邯�ǁB
�ڍׂɂ��ẮA�}�[�P�e�B���O�p�ꂵ���o�ĂȂ��i�K�ŁA��������Ă邩
�z�����Ă����A���傤���Ȃ���Ȃ����Ȃ��B
������ Intel �Ƀ}�[�P�e�B���O�p�ꂶ��Ȃ��āA�����̃e�N�j�J���^�[����
�g���K��������A�V�������t���g���Ă��遨�{���ɐV�����Z�p���܂�ł���
�Ƒz���ł���킯�����ǁA����� Intel �̏K������A���f�ł��Ȃ��Ă����傤��
�Ȃ��ł���B
> ��������Last Level Cache�݂̂����L�ɂ���ΐH�������ɂ���Q�͑����y
> ���ł��邵
�H�������ɂ���Q���y���ł���̂́ALast Level Cache ����r�I���傾����
�ł���B�܂�A���܂��� ���[�L���O�Z�b�g�� Last Level Cache �ɓ�����
���邩��ŁB
��������v���Z�X�ɁALast Level Cache �ɓ���Ȃ����[�L���O�Z�b�g������
�v���Z�X������A�Ȃ肽���Ȃ����B
> >SPECrate �ł́A�P��̃A�v�������[�C�h���œ����ɕ������点��̂ŁA
> �L�L���b�V���̎�_���I�悵�܂���
�{�g���l�b�N�ƂȂ��Ă��镔���̃R�[�h�Ƃ��A���L�L���b�V���̕����L���ł́H
> ��̂ˁA�������Ђ���Ă���猖�`���邱�ƂɃP�`�t���������͖���
��`���邱�Ƃɂ͂������٘_�͂Ȃ����ǁA���LL2 �̂��߂ɁA�V�����p���
����̂͋Z�p�I�ɂ͕ς��Ǝv�����ǂȂ��B
> http://www.geocities.jp/andosprocinfo/wadai06/20060701.htm
����̂ǂ����w���ĉ������������́H
Advanced Smart Cache�́E�E�E
Yonah�̎��_�ł͒P��Smart Cache�Ƃ̌ď̂������悤�Ɏv�����A
�A���͒P�ɋ��L�ɂ��܂����A���Ă�������Ȃ��Ă��낢��ƍH�v���Â炳��Ă��ˁB
Smart Cache�ȂǂƖ�������قǂ̖ڐV�������̂��ǂ����͕ʂƂ��āB
�ŁAMerom�ɂȂ��Ă܂����ǂ�����������AAdvanced Smart Cache�ƁB
����܂�Advanced�Ƃ���قǂ̉��ǂ��ǂ����͕ʖ�肾�B
Yonah�̎��_�ł͒P��Smart Cache�Ƃ̌ď̂������悤�Ɏv�����A
�A���͒P�ɋ��L�ɂ��܂����A���Ă�������Ȃ��Ă��낢��ƍH�v���Â炳��Ă��ˁB
Smart Cache�ȂǂƖ�������قǂ̖ڐV�������̂��ǂ����͕ʂƂ��āB
�ŁAMerom�ɂȂ��Ă܂����ǂ�����������AAdvanced Smart Cache�ƁB
����܂�Advanced�Ƃ���قǂ̉��ǂ��ǂ����͕ʖ�肾�B
>>���LL2 �̂��߂ɁA�V�����p�������̂͋Z�p�I�ɂ͕�
�܂��O�_�O�_�Ӗ��������ƌ����Ă�̂�
�}�[�P�e�B���O�p����Ď��͗v�͏��i���݂����Ȃ���
����o�����̎�i�ł����ċZ�p�Ƃ��Ɩ����̂���
�u���̑f�v�Ɩ��Â������w��������o������
�O���^�~���_�i�g���E�����Čď̂�����̂Ɂu���̑f�v�Ȃ��
���O������͉̂��w�I�ɂ͕ς��Č����Ă�̂ƕς���
�}�[�P�e�B���O�p��ɑ��ċZ�p�I�ɂǂ��������Ď��_�œ�����������
http://pc.watch.impress.co.jp/docs/2006/0223/mobile326.htm
�{�c���́u�T�����o�C���ʐM�v�@��326�� Viiv�̓`�b�`�L�`�[
�܂��O�_�O�_�Ӗ��������ƌ����Ă�̂�
�}�[�P�e�B���O�p����Ď��͗v�͏��i���݂����Ȃ���
����o�����̎�i�ł����ċZ�p�Ƃ��Ɩ����̂���
�u���̑f�v�Ɩ��Â������w��������o������
�O���^�~���_�i�g���E�����Čď̂�����̂Ɂu���̑f�v�Ȃ��
���O������͉̂��w�I�ɂ͕ς��Č����Ă�̂ƕς���
�}�[�P�e�B���O�p��ɑ��ċZ�p�I�ɂǂ��������Ď��_�œ�����������
http://pc.watch.impress.co.jp/docs/2006/0223/mobile326.htm
�{�c���́u�T�����o�C���ʐM�v�@��326�� Viiv�̓`�b�`�L�`�[
193 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/02(��) 02:47:53 ID:8sT24f1b
�L���^�s���[
�z�b�`�L�X
���Ă��āB�B�B
�z�b�`�L�X
���Ă��āB�B�B
���W���}�[�P�e�B���O�p��Ȃ̂��H
�}�[�P�e�B���O�p��i��������j�A�}�[�P�b�g�ɍׂ����Z�p�I�Șb���Ă������āc
�M�ғ����Ă�Ƃ����l�Ɍ����Ă�ꍇ����Ȃ��C������l������ȁB
���g�Ȃ̂��������w
���g�Ȃ̂��������w
http://journal.mycom.co.jp/articles/2006/10/02/idf1/002.html
�́uTERAFLOP OF PERFORMANCE�v�̎ʐ^�����Ďv�����B
�ʐ^�E����R�A�̌`�� L �����ɓ|���������ɂȂ��Ă邯�ǁA
�ʐ^��������ƃ_�C�̒[���Ⴛ�̃R�A�̐^�����ł��傤�ǐ�Ă��˂��B
�́uTERAFLOP OF PERFORMANCE�v�̎ʐ^�����Ďv�����B
�ʐ^�E����R�A�̌`�� L �����ɓ|���������ɂȂ��Ă邯�ǁA
�ʐ^��������ƃ_�C�̒[���Ⴛ�̃R�A�̐^�����ł��傤�ǐ�Ă��˂��B
>>197
���̕��́A�u�摜�̓C���[�W�ł��v�Ȃ̂łȂ����B
���̕��́A�u�摜�̓C���[�W�ł��v�Ȃ̂łȂ����B
�@�\�I�ɂ͓������̂ł��A�������@���قȂ�Ȃ���ʂȖ��O��t�������Ȃ���̂��B
���L�L���b�V���Ƃ͌����Ă��\�t�g�E�F�A���Ƃɗe�ʂ̔z����ς������Ȃ��������B
���L�L���b�V���Ƃ͌����Ă��\�t�g�E�F�A���Ƃɗe�ʂ̔z����ς������Ȃ��������B
>>197
��ĂȂ��B������40�R�A�ƉE���R�A�Ő��Ώ̂ɂȂ��Ă邾���B
��ĂȂ��B������40�R�A�ƉE���R�A�Ő��Ώ̂ɂȂ��Ă邾���B
>>200
ʧ�H
ʧ�H
����(http://pc.watch.impress.co.jp/docs/2006/1002/ati.htm)
1 �{���x�x��
2 PCI-Express x16���{�g���l�b�N
3 ���[�J�����������Ȃ�
����(GPU��CPU�ɓ���?)
1 �������ш悪����Ȃ�
2 �_�C�T�C�Y��傫���o���Ȃ�
���I����
1 GPU�����͏ȓd�͈ʂ����Ӗ�������
(�֑�:�ߋ���Intel��ULV��PentiumM��GMCH����Ƀp�b�P�[�W���O�����������삵�Ă���)
2 �Q�[���Ȃǂ̖{���̗p�r�ł́A�g���o�X���l�b�N�ɂȂ�Ȃ��̂Ō��݂̕��������\�̖ʂŗL��
3 �ėp�v���Z�b�T�̐��\���オ�s���l�����킯�ł͂Ȃ��̂Ɉ��Ղɂ��̗��_���̂Ă�̂͑��v
Folding@Home�Ȃ��40�{�����낤��1���{�����낤���ǂ��ł�����
H264�G���R��10�{���ɂ���
H264�G���R��10�{���ɂ���
204 �FSocket774�F2006/10/03(��) 18:22:17 ID:jifZAbX7
Intel uses Imagination for CPU graphics cores
Plunges millions into graphics firm
http://www.theinquirer.net/default.aspx?article=34822
Intel��CPU-GPU�̂��߂ɉpImagination��GPU���g�p����B
Intel�͉pImagination�Ђ�2.9%���̊�������5.2 million(��1,160-1,150���~)�Ŏ擾�B
�pImagination��Intel�ƁA�O���t�B�N�X��r�f�I�֘A�ŋ��͂��邱�Ƃ�B
Plunges millions into graphics firm
http://www.theinquirer.net/default.aspx?article=34822
Intel��CPU-GPU�̂��߂ɉpImagination��GPU���g�p����B
Intel�͉pImagination�Ђ�2.9%���̊�������5.2 million(��1,160-1,150���~)�Ŏ擾�B
�pImagination��Intel�ƁA�O���t�B�N�X��r�f�I�֘A�ŋ��͂��邱�Ƃ�B
Imagination��PowerVR�APC�����ł͉ߋ�Kyro1/2�Œm����O���t�B�N�X���[�J�[�B
Intel Invests in PowerVR Graphics
http://www.extremetech.com/article2/0,1558,2022947,00.asp?kc=ETRSS02129TX1K0000532
AMD/ATi vs Intel + PowerVR
http://www.extremetech.com/article2/0,1558,2022947,00.asp?kc=ETRSS02129TX1K0000532
AMD/ATi vs Intel + PowerVR
GPU�����̗���͂��͂�K�R���B
�����APwoerVR��Shader��
�ǂ̒��x�̃p�t�H�[�}���X�����̂��s���ł���
���ꂩ��A�����J�����H
>>202
�ȓd�͂ɂ͒��ڊW�Ȃ��B
GPU�������Ă��O�t��GPU�������Ȃ��ł͂Ȃ��B
���Ղɔėp�R�A���₷�������R�A�𑫂��������悢
�i���ݔėp�R�A�Ō��ʂ̂���p�r���A��͂�h��������h�ł���䂦�E�E�E�j
AMD�̏ꍇCPU���@�\�u���b�N���ƂɃ��W���[��������
�J���̍�����y�����悤��Ƃ��Ă���
GPU�͂��̃��W���[����1�ɂ����Ȃ��B
�����APwoerVR��Shader��
�ǂ̒��x�̃p�t�H�[�}���X�����̂��s���ł���
���ꂩ��A�����J�����H
>>202
�ȓd�͂ɂ͒��ڊW�Ȃ��B
GPU�������Ă��O�t��GPU�������Ȃ��ł͂Ȃ��B
���Ղɔėp�R�A���₷�������R�A�𑫂��������悢
�i���ݔėp�R�A�Ō��ʂ̂���p�r���A��͂�h��������h�ł���䂦�E�E�E�j
AMD�̏ꍇCPU���@�\�u���b�N���ƂɃ��W���[��������
�J���̍�����y�����悤��Ƃ��Ă���
GPU�͂��̃��W���[����1�ɂ����Ȃ��B
�����āA�Ȃ���������̂�GPU�Ȃ̂����l����Ɨǂ��B
���ځ[��
>GPU�������Ă��O�t��GPU�������Ȃ��ł͂Ȃ��B
����GPU�͖Ӓ��ł����H
>���Ղɔėp�R�A���₷�������R�A�𑫂��������悢
�َ퍬����ے肵�Ă���킯�ł͂Ȃ�
>AMD�̏ꍇCPU���@�\�u���b�N���ƂɃ��W���[��������
>�J���̍�����y�����悤��Ƃ��Ă���
Intel�ɂ�AMD��10�{�ȏ�̊J�����\�[�X�����邩��s�v�Ȃ���
(����ł�������x�͂���Ă�͂��A����������蒼���͔̂��������)
���Џ@�̑�D����RadeonX1950XT�̃������ш悪GDDR4 1GHz��64GB/s�������Ǝv����
2008�N�Ƀ��C���������������荂��������Ǝv���Ă�́H
�P��DLP�̍���(�}���`���f�B�A)���������Ȃ�CELL�݂����ȕ������������
�{���x���x���̂��s���A�ł�GPU�ɖ{���K�v�̖����{���x������������ăA�z�炵���Ȃ��H
>�����āA�Ȃ���������̂�GPU�Ȃ̂����l����Ɨǂ��B
�搶�I�킩��܂���I
����GPU�͖Ӓ��ł����H
>���Ղɔėp�R�A���₷�������R�A�𑫂��������悢
�َ퍬����ے肵�Ă���킯�ł͂Ȃ�
>AMD�̏ꍇCPU���@�\�u���b�N���ƂɃ��W���[��������
>�J���̍�����y�����悤��Ƃ��Ă���
Intel�ɂ�AMD��10�{�ȏ�̊J�����\�[�X�����邩��s�v�Ȃ���
(����ł�������x�͂���Ă�͂��A����������蒼���͔̂��������)
���Џ@�̑�D����RadeonX1950XT�̃������ш悪GDDR4 1GHz��64GB/s�������Ǝv����
2008�N�Ƀ��C���������������荂��������Ǝv���Ă�́H
�P��DLP�̍���(�}���`���f�B�A)���������Ȃ�CELL�݂����ȕ������������
�{���x���x���̂��s���A�ł�GPU�ɖ{���K�v�̖����{���x������������ăA�z�炵���Ȃ��H
>�����āA�Ȃ���������̂�GPU�Ȃ̂����l����Ɨǂ��B
�搶�I�킩��܂���I
���������̂̓~�h�������W�N���X
Shader�͑����Ă�32����x
����́A�M���̌����ʂ胁�����ш�̌��E�䂦�B
�O�t��GPU��ڑ����Ă�����GPU�͖��ʂɂȂ��ł͂Ȃ��B
2008�N�ȍ~�̓o��Ǝv���邱���̓���CPU��
DirectX10.1����Ɨ\������A�O���t�B�b�N�X�`�b�v��
�O���t�B�b�N�X�������̉��z�����Ȃ����B
�{���x�Ɋւ���ATI�͌������Ă���͗l�B
ttp://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
�ȒP�Ɍ����AGPU�͍ł���ʓI�ȃx�N�^�v���Z�b�T�ł��邩�瓝�������B
Shader�͑����Ă�32����x
����́A�M���̌����ʂ胁�����ш�̌��E�䂦�B
�O�t��GPU��ڑ����Ă�����GPU�͖��ʂɂȂ��ł͂Ȃ��B
2008�N�ȍ~�̓o��Ǝv���邱���̓���CPU��
DirectX10.1����Ɨ\������A�O���t�B�b�N�X�`�b�v��
�O���t�B�b�N�X�������̉��z�����Ȃ����B
�{���x�Ɋւ���ATI�͌������Ă���͗l�B
ttp://pc.watch.impress.co.jp/docs/2006/0725/kaigai290.htm
�ȒP�Ɍ����AGPU�͍ł���ʓI�ȃx�N�^�v���Z�b�T�ł��邩�瓝�������B
212 �FMAC�I�^���Џ@ �����F2006/10/03(��) 21:01:50 ID:91nymxuU
>>211
�@�@------------------
�@�@����́A�M���̌����ʂ胁�����ш�̌��E�䂦�B
�@�@------------------
������CIntel��X�^�b�N�h�E�_�C��TB/s�̃������ш����������f��������Ă��������ǁB�B�B
�@�@------------------
�@�@����́A�M���̌����ʂ胁�����ш�̌��E�䂦�B
�@�@------------------
������CIntel��X�^�b�N�h�E�_�C��TB/s�̃������ш����������f��������Ă��������ǁB�B�B
>>212
������̂ɁA�����炩����́H
������̂ɁA�����炩����́H
PowerVR�c
�h���L���X���I
�h���L���X���I
>>211
>�O�t��GPU��ڑ����Ă�����GPU�͖��ʂɂȂ��ł͂Ȃ��B
>2008�N�ȍ~�̓o��Ǝv���邱���̓���CPU��
>DirectX10.1����Ɨ\������A�O���t�B�b�N�X�`�b�v��
>�O���t�B�b�N�X�������̉��z�����Ȃ����B
������AGPU�̃��\�[�X��SMP�I�ɊǗ������(���z�����Ă��������Ӗ�����ˁH)���S�ɖ��ʂɂȂ�Ƃ������Ƃ͖�����������Ȃ�
�ł��ȉ��̓_�ɂ��Ă͉��̔��_�ɂ��Ȃ��Ă��Ȃ�
>2 �Q�[���Ȃǂ̖{���̗p�r�ł́A�g���o�X���l�b�N�ɂȂ�Ȃ��̂Ō��݂̕��������\�̖ʂŗL��
>3 �ėp�v���Z�b�T�̐��\���オ�s���l�����킯�ł͂Ȃ��̂Ɉ��Ղɂ��̗��_���̂Ă�̂͑��v
>�P��DLP�̍���(�}���`���f�B�A)���������Ȃ�CELL�݂����ȕ������������
>�{���x���x���̂��s���A�ł�GPU�ɖ{���K�v�̖����{���x������������ăA�z�炵���Ȃ��H
�Ƃǂ̋l�܂�A�x�N�g�����Z�������邽�߂�GPU������Ƃ����l�����̑s��ȉ�蓹
>�O�t��GPU��ڑ����Ă�����GPU�͖��ʂɂȂ��ł͂Ȃ��B
>2008�N�ȍ~�̓o��Ǝv���邱���̓���CPU��
>DirectX10.1����Ɨ\������A�O���t�B�b�N�X�`�b�v��
>�O���t�B�b�N�X�������̉��z�����Ȃ����B
������AGPU�̃��\�[�X��SMP�I�ɊǗ������(���z�����Ă��������Ӗ�����ˁH)���S�ɖ��ʂɂȂ�Ƃ������Ƃ͖�����������Ȃ�
�ł��ȉ��̓_�ɂ��Ă͉��̔��_�ɂ��Ȃ��Ă��Ȃ�
>2 �Q�[���Ȃǂ̖{���̗p�r�ł́A�g���o�X���l�b�N�ɂȂ�Ȃ��̂Ō��݂̕��������\�̖ʂŗL��
>3 �ėp�v���Z�b�T�̐��\���オ�s���l�����킯�ł͂Ȃ��̂Ɉ��Ղɂ��̗��_���̂Ă�̂͑��v
>�P��DLP�̍���(�}���`���f�B�A)���������Ȃ�CELL�݂����ȕ������������
>�{���x���x���̂��s���A�ł�GPU�ɖ{���K�v�̖����{���x������������ăA�z�炵���Ȃ��H
�Ƃǂ̋l�܂�A�x�N�g�����Z�������邽�߂�GPU������Ƃ����l�����̑s��ȉ�蓹
�����烍�[�G���h������Ă����ެȰ�
�f�B�X�N���[�g�ɏ��ĂȂ�����Ӗ������Ƃ��A�z�������̂͒r���̋ɂ݁B
������Intel��GPU�����o�����ɂ̓}���Z�[���Ă�낤�Ȃ��B
�f�B�X�N���[�g�ɏ��ĂȂ�����Ӗ������Ƃ��A�z�������̂͒r���̋ɂ݁B
������Intel��GPU�����o�����ɂ̓}���Z�[���Ă�낤�Ȃ��B
�㓡�X���ł������͂悩��GPU�����ɂ������Ă�����t�������Ȃ��c
�����������ł͂Ȃ��A�v�z�I��GPU�����Ńx�N�g�����Z���\���グ����Ă͔̂������Ȃ���ȁB
MMX��SSE�̂悤��CPU�ɖ��Ȍ`�ł̎����ł͂Ȃ�������̂��H
MMX��SSE�̂悤��CPU�ɖ��Ȍ`�ł̎����ł͂Ȃ�������̂��H
����Ȃ�CELL�ł�������
>>219
�v���O���}�̕��S������Ⴄ��
�v���O���}�̕��S������Ⴄ��
>>216
>������Intel��GPU�����o�����ɂ̓}���Z�[���Ă�낤�Ȃ��B
���Ȃ���AIntel�͍D�������M�҂ł͂Ȃ��̂ł�
����TraceCache, HTT�̉��ق�CSI�̒x���ɕs��������Ă���
>>220
CELL���o�J�݂����ɕ��G�Ȃ��������
>������Intel��GPU�����o�����ɂ̓}���Z�[���Ă�낤�Ȃ��B
���Ȃ���AIntel�͍D�������M�҂ł͂Ȃ��̂ł�
����TraceCache, HTT�̉��ق�CSI�̒x���ɕs��������Ă���
>>220
CELL���o�J�݂����ɕ��G�Ȃ��������
PS3���Ȃ�
>>215
�����A�ėp�R�A�̐i���͍s�l���Ă͂��Ȃ��Ǝv�����݉����ė����Ƃ͎v���B
GPU��DX10�ŃS�[���Ƃ����킯�ł͂Ȃ����{���x�̖���
ATI�͊��Ɍ������Ƃ̂��Ƃ����iAMD�̂���݂��瓖�R���낤���ǁE�E�E�j
������́A�������邾�낤�Ɗy�ρB
>>218
�Ǝ��̃x�N�^�v���Z�b�T���o����
���ꂪ�\�t�g�ŃT�|�[�g�����܂łɂ͎��Ԃ�������߂��邩��ł́H
�ň��A�ǂ����\�t�g���o���Ă���Ȃ��\��������B
GPU�̏ꍇ�ň��ł��`��Ɏg���邵
����CPU���o�ꂷ��܂łɏo��DX10�����
GPGPU�ȃ\�t�g�i�ǂꂾ���o��E�E�E�H�j�͎g���鎖�ɂȂ�B
�S���V�K�̃x�N�^�v���Z�b�T�̓��X�N���傫���B
�����ADirectX����Ďg�p���镪�ɂ�DX10����GPU��
�@�\�I�ȍ��ق͂Ȃ��͂������i�p�t�H�[�}���X�̍��͂���E�E�E�j
�����Ƀx�N�^�v���Z�b�T�Ƃ��Ďg�����Ƃ����DirectX�̓I�[�o�[�w�b�h�ɐ��肤�邵
GPU���Ƃ�ISA�Ⴄ�̂Ŗ�肪����B
ATI�J�����Ă����DPVM�̂悤�ȉ��z�}�V����{����Microsoft�����ׂ������B
�����A�ėp�R�A�̐i���͍s�l���Ă͂��Ȃ��Ǝv�����݉����ė����Ƃ͎v���B
GPU��DX10�ŃS�[���Ƃ����킯�ł͂Ȃ����{���x�̖���
ATI�͊��Ɍ������Ƃ̂��Ƃ����iAMD�̂���݂��瓖�R���낤���ǁE�E�E�j
������́A�������邾�낤�Ɗy�ρB
>>218
�Ǝ��̃x�N�^�v���Z�b�T���o����
���ꂪ�\�t�g�ŃT�|�[�g�����܂łɂ͎��Ԃ�������߂��邩��ł́H
�ň��A�ǂ����\�t�g���o���Ă���Ȃ��\��������B
GPU�̏ꍇ�ň��ł��`��Ɏg���邵
����CPU���o�ꂷ��܂łɏo��DX10�����
GPGPU�ȃ\�t�g�i�ǂꂾ���o��E�E�E�H�j�͎g���鎖�ɂȂ�B
�S���V�K�̃x�N�^�v���Z�b�T�̓��X�N���傫���B
�����ADirectX����Ďg�p���镪�ɂ�DX10����GPU��
�@�\�I�ȍ��ق͂Ȃ��͂������i�p�t�H�[�}���X�̍��͂���E�E�E�j
�����Ƀx�N�^�v���Z�b�T�Ƃ��Ďg�����Ƃ����DirectX�̓I�[�o�[�w�b�h�ɐ��肤�邵
GPU���Ƃ�ISA�Ⴄ�̂Ŗ�肪����B
ATI�J�����Ă����DPVM�̂悤�ȉ��z�}�V����{����Microsoft�����ׂ������B
7. SSE �̌��E(2005/12/23)
http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note008.html
http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note008.html
>7. SSE �̌��E(2005/12/23)
>http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note008.html
>���̂悤�Ȃ킯�ŁA SIMD ���߂̓n�[�h�E�F�A���ɂ߂ĊȒP�ł��ށA�Ƃ����� ���b�g�͂�����̂́A
>���p�I�ȃv���O�����Ő��\���ł�悤�ɂ��悤�Ƃ���� �ǂ�ǂG�ɂȂ�A�Ƃ������ƂɂȂ�܂��B
>���ہA SSE3 �ɂȂ��ă��[�h/ �X�g�A���߂̃o���G�[�V�����������Ă���̂͂����������Ƃł��B
>
>���ǁA�A SIMD ���߂��g���₷������ɂ̓x�N�g���v�Z�@���̋��͂ȃ������A �N�Z�X�@�\�����Ȃ��Ƃ����Ȃ��A�Ƃ������ƂɂȂ��āA���܂肠�肪������ ���킯�ł��B
>SIMD �Ȃ牉�Z������ɑ��₹�����Ȃ̂ɁA�����Ȃ��Ă� �Ȃ��̂͂��̕ӂɗ��R������܂��B
10. ���̉\���́H --- II. GPGPU (2005/12/29)
http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note011.html
>�s�[�N���\�������l����ƁA GPGPU �ł���Ȃɂ������Ƃ����邩�H�Ƃ����� �͌��\�^��ł��B
>(��������̂ň��p�͏ȗ�)
>�Ƃ����킯�ŁA�l�I�ɂ� GPGPU �ɂ��܂���҂��Ȃ��ق��������̂ł́A�A�A �Ǝv���Ă��܂��B
�ǂ��z
�L���b�V�����ʂ�SSE&�������ш�̊g���}���Z�[(Intel�����܂Ōp�����Ă���Ă�������)
��Memory Wall�����������Ȃ�
>http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note008.html
>���̂悤�Ȃ킯�ŁA SIMD ���߂̓n�[�h�E�F�A���ɂ߂ĊȒP�ł��ށA�Ƃ����� ���b�g�͂�����̂́A
>���p�I�ȃv���O�����Ő��\���ł�悤�ɂ��悤�Ƃ���� �ǂ�ǂG�ɂȂ�A�Ƃ������ƂɂȂ�܂��B
>���ہA SSE3 �ɂȂ��ă��[�h/ �X�g�A���߂̃o���G�[�V�����������Ă���̂͂����������Ƃł��B
>
>���ǁA�A SIMD ���߂��g���₷������ɂ̓x�N�g���v�Z�@���̋��͂ȃ������A �N�Z�X�@�\�����Ȃ��Ƃ����Ȃ��A�Ƃ������ƂɂȂ��āA���܂肠�肪������ ���킯�ł��B
>SIMD �Ȃ牉�Z������ɑ��₹�����Ȃ̂ɁA�����Ȃ��Ă� �Ȃ��̂͂��̕ӂɗ��R������܂��B
10. ���̉\���́H --- II. GPGPU (2005/12/29)
http://grape.astron.s.u-tokyo.ac.jp/~makino/articles/future_sc/note011.html
>�s�[�N���\�������l����ƁA GPGPU �ł���Ȃɂ������Ƃ����邩�H�Ƃ����� �͌��\�^��ł��B
>(��������̂ň��p�͏ȗ�)
>�Ƃ����킯�ŁA�l�I�ɂ� GPGPU �ɂ��܂���҂��Ȃ��ق��������̂ł́A�A�A �Ǝv���Ă��܂��B
�ǂ��z
�L���b�V�����ʂ�SSE&�������ш�̊g���}���Z�[(Intel�����܂Ōp�����Ă���Ă�������)
��Memory Wall�����������Ȃ�
���x�ł��������ACELL�̓V�X�e���S�̂łP�̎d�������邽�߂�
�v���BPC�݂����Ȕėp�����ɂ͂܂������s�����B
SPE���g�����߂ɂ����������[�J���������ɃR�[�h�ƃf�[�^��]��
���Ȃ���Ȃ��̂����B
�v���BPC�݂����Ȕėp�����ɂ͂܂������s�����B
SPE���g�����߂ɂ����������[�J���������ɃR�[�h�ƃf�[�^��]��
���Ȃ���Ȃ��̂����B
228 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/04(��) 00:18:49 ID:SNLCLFpr
���̂���4�o�C�gopcode�Ƃ������o�����B
���߃Z�b�g�g�����������ɂ���B
���A����������PNAND/NANDPS/NANDPD���ߎ������Ă���
�iPNOR/NORPS/NORPD���j
���߃Z�b�g�g�����������ɂ���B
���A����������PNAND/NANDPS/NANDPD���ߎ������Ă���
�iPNOR/NORPS/NORPD���j
Intel�X����IDF����Ȃ̂�AMD�̘b�������̂�
SSE4���߂ƃA�N�Z�����[�^���猩����Intel CPU�̕�����
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
���܂�MNI��SSE3�������Ȃ�Ēm���������c
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
���܂�MNI��SSE3�������Ȃ�Ēm���������c
232 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/04(��) 01:44:16 ID:SNLCLFpr
����IDF�ŁuSSE4�v���X�I�ɔ��\�����̂��āA
Penryn New Instructions����Prescott�`�Ɠ�����PNI�ɂȂ邩�炾�Ǝv������
Penryn New Instructions����Prescott�`�Ɠ�����PNI�ɂȂ邩�炾�Ǝv������
Cell�n�A�[�L�e�N�`���̂悤�ȃx�N�^�v���Z�T�����ʼn��Z���\���グ�悤�Ƃ����͎̂������\�Ƃ��Ă͋^�₪�c��܂��B
http://homepage1.nifty.com/bee/diary/20068.html#d20060818
http://homepage1.nifty.com/bee/diary/20068.html#d20060818
>>230
>Penryn�́ACore MA��45nm�v���Z�X�ɔ������邾���łȂ��A���߃Z�b�g�̊g���ƁA
>���m���V�b�N�ȃN�A�b�h�R�A�ł��܂ނ��ƂɂȂ�B
��͂胂�m���V�b�N�E�N�A�b�h�R�A��Penryn���炩�BAMD�̔���̃��m���V�b�N�E�N�A�b�h�R�A��
AMD����킸�����N�x��A�f�X�N�g�b�v�łɂ������Ă͉��肷��2008Q1��AMD�Ɠ�����
���ĉ\�����炠��ȁB
>Penryn�́ACore MA��45nm�v���Z�X�ɔ������邾���łȂ��A���߃Z�b�g�̊g���ƁA
>���m���V�b�N�ȃN�A�b�h�R�A�ł��܂ނ��ƂɂȂ�B
��͂胂�m���V�b�N�E�N�A�b�h�R�A��Penryn���炩�BAMD�̔���̃��m���V�b�N�E�N�A�b�h�R�A��
AMD����킸�����N�x��A�f�X�N�g�b�v�łɂ������Ă͉��肷��2008Q1��AMD�Ɠ�����
���ĉ\�����炠��ȁB
>>235
Yorkfield�Ɠ�����(07Q3?)��AM2+���Ă����̂��f�X�N�g�b�v�łł���?
MP�Ή�����Hyper Transport3.0�Ȃ̂�08Q1?�ŁA
MP�Ή���Hyper Transport2.0(SocketF)��07Q2�B
Yorkfield�Ɠ�����(07Q3?)��AM2+���Ă����̂��f�X�N�g�b�v�łł���?
MP�Ή�����Hyper Transport3.0�Ȃ̂�08Q1?�ŁA
MP�Ή���Hyper Transport2.0(SocketF)��07Q2�B
>>237
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267_04l.gif
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
AMD��2�i�K�ŃN�A�b�h�R�ACPU�̓������v�悵�Ă���B��1�w��2007�N���ՂŁA�܂�
�T�[�o�[CPU�uOpteron�v�n�ŃN�A�b�h�R�A�uDeerhound(�f�B�A�n�E���h)�v�𓊓��A
2008�N�ɂ̓L���b�V���\���Ȃǂ�����ɉ��ǂ����N�A�b�h�R�AOpteron�uZamora(�T����)�v������B
�܂��A2008�N�ɂ̓f�X�N�g�b�v�����̃N�A�b�h�R�A�uGreyhound(�O���C�n�E���h=Athlon 64 X4?)�v��
�������錩���݂��B
Rev. G��Opteron�́AMP(Multi-Processor)�Ή���800�V���[�Y��DP(Dual-Processor)�Ή���
200�V���[�Y���A�܂��N�A�b�h�R�A�Ɉڍs����B�R�[�h�l�[����Deerhound�ŁA
2007�N��3�l�������̓o�ꂾ�ƌ�����B
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267_04l.gif
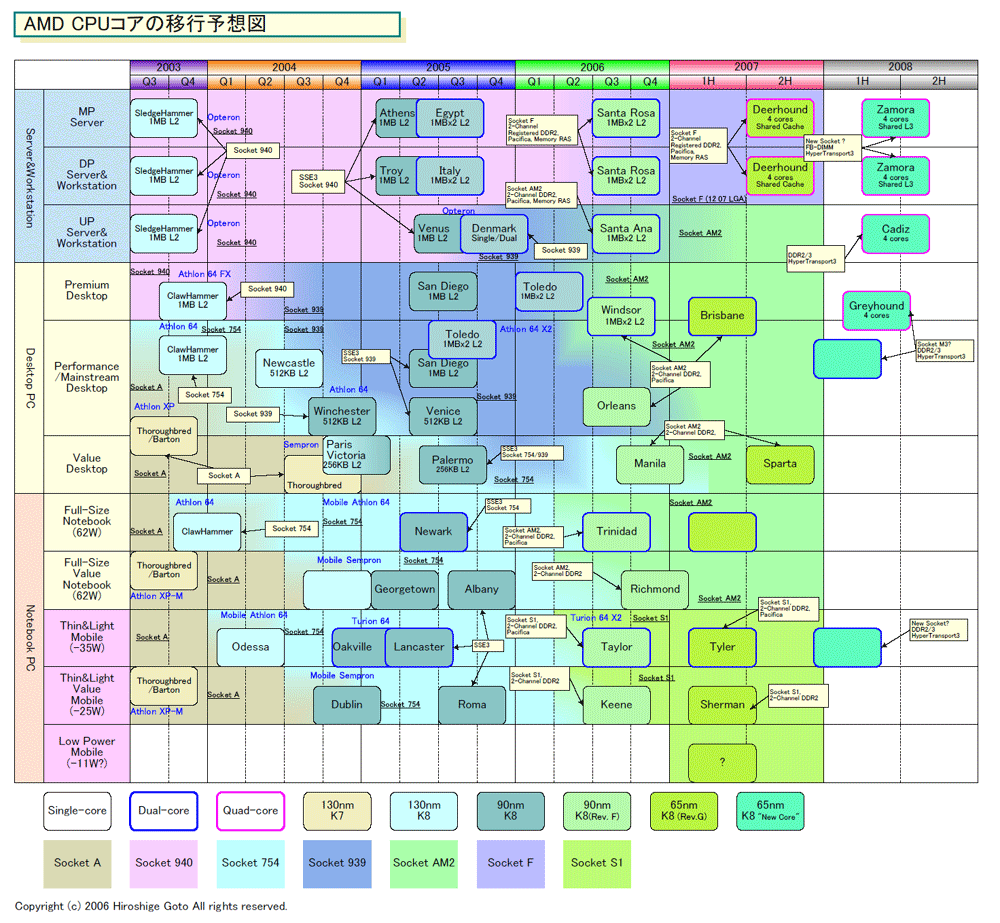{kind=link}
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
AMD��2�i�K�ŃN�A�b�h�R�ACPU�̓������v�悵�Ă���B��1�w��2007�N���ՂŁA�܂�
�T�[�o�[CPU�uOpteron�v�n�ŃN�A�b�h�R�A�uDeerhound(�f�B�A�n�E���h)�v�𓊓��A
2008�N�ɂ̓L���b�V���\���Ȃǂ�����ɉ��ǂ����N�A�b�h�R�AOpteron�uZamora(�T����)�v������B
�܂��A2008�N�ɂ̓f�X�N�g�b�v�����̃N�A�b�h�R�A�uGreyhound(�O���C�n�E���h=Athlon 64 X4?)�v��
�������錩���݂��B
Rev. G��Opteron�́AMP(Multi-Processor)�Ή���800�V���[�Y��DP(Dual-Processor)�Ή���
200�V���[�Y���A�܂��N�A�b�h�R�A�Ɉڍs����B�R�[�h�l�[����Deerhound�ŁA
2007�N��3�l�������̓o�ꂾ�ƌ�����B
http://pc.watch.impress.co.jp/docs/2006/1004/config126.htm
���O����A��ʂ̃R���V���[�}���[�U�[�ɂƂ��āA�f�X�N�g�b�v�p�\�R���Ŏg����
�y�^�X�P�[���R���s���[�e�B���O�́A���������ǂ�ȈӖ�������̂��ƕ������
�����ɋ�����ȂǏ���U����ʂ��������B
���O����A��ʂ̃R���V���[�}���[�U�[�ɂƂ��āA�f�X�N�g�b�v�p�\�R���Ŏg����
�y�^�X�P�[���R���s���[�e�B���O�́A���������ǂ�ȈӖ�������̂��ƕ������
�����ɋ�����ȂǏ���U����ʂ��������B
>>237 >>240
�������܂�AK8L��2008Q1����2007Q3�ɑO�|�����ꂽ�ȁB
�����ł����x�ꂪ����AMD�̃��[�h�}�b�v�����N���O�|�����B
�M���Ă������̂��E�E�E
�������܂�AK8L��2008Q1����2007Q3�ɑO�|�����ꂽ�ȁB
�����ł����x�ꂪ����AMD�̃��[�h�}�b�v�����N���O�|�����B
�M���Ă������̂��E�E�E
�܂Ƃ߂�Ƃ����������Ƃ��B
�@�@�@�@�@�@Intel�@�@�@�@�@�@�@�@�@�@�@AMD
2006Q4�@Kentsfield(65nm,x2x2)
2007Q1
2007Q2
2007Q3�@Yorkfield(65nm,x4)�@�@�@Altair(65nm,x4)
2007Q4�@Penryn(45nm,x4)
2008Q4�@Nehalem(45nm,x4)
Intel�̃N�A�b�h���ւ̎��O�͂����܂����ȁB���̕�����
�T�N��ɂ̓��m���V�b�N�łP�U�R�A�܂ōs�����Ⴄ�ȁB
�@�@�@�@�@�@Intel�@�@�@�@�@�@�@�@�@�@�@AMD
2006Q4�@Kentsfield(65nm,x2x2)
2007Q1
2007Q2
2007Q3�@Yorkfield(65nm,x4)�@�@�@Altair(65nm,x4)
2007Q4�@Penryn(45nm,x4)
2008Q4�@Nehalem(45nm,x4)
Intel�̃N�A�b�h���ւ̎��O�͂����܂����ȁB���̕�����
�T�N��ɂ̓��m���V�b�N�łP�U�R�A�܂ōs�����Ⴄ�ȁB
>>242
Intel��4�R�A�ȏ����̃��[�h�}�b�v�͂����B
45nm����Core 2�̑��� Penryn
45nm����Core 3�̑��� Nehalem
(�����_�ł�Merom�ɂ�����R�[�h�l�[��)
07Q3
45nm�f�X�N�g�b�v���� Yorkfield
45nm XeonDP Harpertown
65nm XeonMP Tigerton
08H1�ȍ~�ŔʃC���^�[�R�l�N�g
45nm XeonMP Dunnington
�����܂ł�Core 2�B
08H1�ȍ~�ŋ��ʃC���^�[�R�l�N�g
65nm Itanium2 Tukwila
45nm �f�X�N�g�b�v���� Bloomfield
45nm XeonMP Whitefield
Intel��4�R�A�ȏ����̃��[�h�}�b�v�͂����B
45nm����Core 2�̑��� Penryn
45nm����Core 3�̑��� Nehalem
(�����_�ł�Merom�ɂ�����R�[�h�l�[��)
07Q3
45nm�f�X�N�g�b�v���� Yorkfield
45nm XeonDP Harpertown
65nm XeonMP Tigerton
08H1�ȍ~�ŔʃC���^�[�R�l�N�g
45nm XeonMP Dunnington
�����܂ł�Core 2�B
08H1�ȍ~�ŋ��ʃC���^�[�R�l�N�g
65nm Itanium2 Tukwila
45nm �f�X�N�g�b�v���� Bloomfield
45nm XeonMP Whitefield
�T�[�o�p�͈�i�Â��v���Z�X�g����Ȃ��B
�R�X�g�I�ɂ��������ėL���ɂȂ����������̂��낤���B
�R�X�g�I�ɂ��������ėL���ɂȂ����������̂��낤���B
����̘͐̂b
>>243
Penryn��2007�N���Ȃ̂�Yorkfield��45nm��2007Q3���Ă��肦��
Penryn��2007�N���Ȃ̂�Yorkfield��45nm��2007Q3���Ă��肦��
���o�C���Ɗ��Ⴂ���Ă܂���
>>241
�O�|�����ĂȂ�
AMD�̃N�A�b�h�R�A���������́u�\�z�v�́A07Q2����1�N�̕���������
���ǁA�S�Ă̗\�z�������������킯
�܂�f�X�N�g�b�v�ł���HT3.0�ł��̂����X�Ƀ����[�X�����̂��A
���ꂪ���̃N�A�b�h�R�A�����ɂȂ�Ə���Ɋ��Ⴂ���Ă���
�O�|�����ĂȂ�
AMD�̃N�A�b�h�R�A���������́u�\�z�v�́A07Q2����1�N�̕���������
���ǁA�S�Ă̗\�z�������������킯
�܂�f�X�N�g�b�v�ł���HT3.0�ł��̂����X�Ƀ����[�X�����̂��A
���ꂪ���̃N�A�b�h�R�A�����ɂȂ�Ə���Ɋ��Ⴂ���Ă���
AMD�̌������Ƃ�M���ĂȂ������Ƃ������Ƃ��
AMD�͑O����Mid'07���Č����Ă����B
AMD�͑O����Mid'07���Č����Ă����B
>>248-249
>>235�́uAMD�̔���̃��m���V�b�N�E�N�A�b�h�R�A��AMD����킸�����N�x��v�ƌ����Ă܂���
��ԑ���SocketF��K8L��2007�N�̑O���ł��邱�Ƃ͒N���ے肵�Ă��Ȃ��ł���
�_�c�̑ΏۂɂȂ��Ă����̂�SocketAM3�̎����ł���
����2007�N�̑�4�l�����ƌ���ꂽAM3�������ɂȂ���AM2+������đ������̂ł���
���ꂪ��3�l�����ɂȂ����̂Ŏ�����̑O�|���ł���
>>235�́uAMD�̔���̃��m���V�b�N�E�N�A�b�h�R�A��AMD����킸�����N�x��v�ƌ����Ă܂���
��ԑ���SocketF��K8L��2007�N�̑O���ł��邱�Ƃ͒N���ے肵�Ă��Ȃ��ł���
�_�c�̑ΏۂɂȂ��Ă����̂�SocketAM3�̎����ł���
����2007�N�̑�4�l�����ƌ���ꂽAM3�������ɂȂ���AM2+������đ������̂ł���
���ꂪ��3�l�����ɂȂ����̂Ŏ�����̑O�|���ł���
�@�@�@�@�@�@�@�^ �@ �@ �^�@���@�@�@�@�@�@�@�@�@�� �@ �R. �@ �@ �_
.�@�@�@�@�@�@�q�@ �@ | / ,. �@-'�[�]'�[�]'�[�]'�[-�@ __�@�@�@�_�@�@ �@�_
�@�@�@�@�@�@�@�_�@ |�^�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@�_�@�@�@�M�R|�@�@ �
�@�@�@�@ �@ �@ �@ >'�@�@ �@ �@ �@ �@ �@ �@ ��@�@�@�@�@�@�M�R.�� }���@�C
�@�@�@�@�@�@�@�@/ ,�@�@ /�@ �^ �@ �@ �@ /�n�@�@�@�@�R�@�@�@�R ���p�@ |
�@�@�@�@�@�@�@ ;' / �@ / �^�@ �@ �^�@ //�@ �_�@�@�@ l|�@�@�@ | }���@ �I
�@ �@ �@ �@ �@ | | �@ / /�\- �^/�@�^/�@�@�@__�������@ �@ | ���p �@ |
�@ �@ �@ �@ �@ | |�@ | ��r�]���^)< //�@� '"�@�@ �Q_ |�@�@�@/ }���@�@�I�@�^������Ȃł����I
�@ �@ �@ �@ �@ �R�R |͢ �_�Q�� �^�@�@ ���@"�L�@ �^/�@�@ /�@���p�@�@ |
�@�@�@�@�@ �@ �@ /�_�ȁ@�@�@�@�@�@�@�@�@�@�M�[ '�@�� ��@/�� }|�@ ! �I
.�@ �@ �@ �@ �@ /�@ā@���@�@�@�@�@�@�@�@�@ �@ �@ �@ �^�@��@�@ ���p�@ i�@ ��
�@�@ �@ �@ �@ /�@ �n �@| ���@�@�R �� Ɓ�)�@�@�� �� |{�@�@�@}l�@�@���@�I
�@�@�@�@�@�@/�@ /�@�ol�@�gy/ �@�� �@ �Q,.�@�@�� �@ �@ �o�� .��. ���p �@ ���@�b
. �@ �@�@�@/�@ / �@ ��{�@ V/�@�@�@�@�@�@�@�@ �@ �@ �@ �@ ��{�@�@�@}ā@�@ ���@�I
�@ �@ �@ /�@ /�@�@�o�n�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o�� �@ �@���p� �@ !
�@ �@ �^�@ /�@ �^��{�@�R���A�@�@�@�@�@�@�@�@�@�@�@ �@ �@ ��{ .���@}�� �ȁ@ ��
�@�^�@�@ /�@ �b �o�� ���r �_�@�@�@�@�@�@�@�@�@ (�܁R �o�� �@ �@���p�@�ȁ@� �A
�@�@�@�@/�@/���@��{�@�@�q���@�_�@�@�@�@�@�@�@�@ �M�'�@��{ �@ �@ }���@�@ �_�@�_
.�@�@�@�@�@�@�q�@ �@ | / ,. �@-'�[�]'�[�]'�[�]'�[-�@ __�@�@�@�_�@�@ �@�_
�@�@�@�@�@�@�@�_�@ |�^�@�@�@�@�@�@�@�@�@�@ |�@�@�@�@�_�@�@�@�M�R|�@�@ �
�@�@�@�@ �@ �@ �@ >'�@�@ �@ �@ �@ �@ �@ �@ ��@�@�@�@�@�@�M�R.�� }���@�C
�@�@�@�@�@�@�@�@/ ,�@�@ /�@ �^ �@ �@ �@ /�n�@�@�@�@�R�@�@�@�R ���p�@ |
�@�@�@�@�@�@�@ ;' / �@ / �^�@ �@ �^�@ //�@ �_�@�@�@ l|�@�@�@ | }���@ �I
�@ �@ �@ �@ �@ | | �@ / /�\- �^/�@�^/�@�@�@__�������@ �@ | ���p �@ |
�@ �@ �@ �@ �@ | |�@ | ��r�]���^)< //�@� '"�@�@ �Q_ |�@�@�@/ }���@�@�I�@�^������Ȃł����I
�@ �@ �@ �@ �@ �R�R |͢ �_�Q�� �^�@�@ ���@"�L�@ �^/�@�@ /�@���p�@�@ |
�@�@�@�@�@ �@ �@ /�_�ȁ@�@�@�@�@�@�@�@�@�@�M�[ '�@�� ��@/�� }|�@ ! �I
.�@ �@ �@ �@ �@ /�@ā@���@�@�@�@�@�@�@�@�@ �@ �@ �@ �^�@��@�@ ���p�@ i�@ ��
�@�@ �@ �@ �@ /�@ �n �@| ���@�@�R �� Ɓ�)�@�@�� �� |{�@�@�@}l�@�@���@�I
�@�@�@�@�@�@/�@ /�@�ol�@�gy/ �@�� �@ �Q,.�@�@�� �@ �@ �o�� .��. ���p �@ ���@�b
. �@ �@�@�@/�@ / �@ ��{�@ V/�@�@�@�@�@�@�@�@ �@ �@ �@ �@ ��{�@�@�@}ā@�@ ���@�I
�@ �@ �@ /�@ /�@�@�o�n�@|�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�o�� �@ �@���p� �@ !
�@ �@ �^�@ /�@ �^��{�@�R���A�@�@�@�@�@�@�@�@�@�@�@ �@ �@ ��{ .���@}�� �ȁ@ ��
�@�^�@�@ /�@ �b �o�� ���r �_�@�@�@�@�@�@�@�@�@ (�܁R �o�� �@ �@���p�@�ȁ@� �A
�@�@�@�@/�@/���@��{�@�@�q���@�_�@�@�@�@�@�@�@�@ �M�'�@��{ �@ �@ }���@�@ �_�@�_
�߂�����Intel��CPU�͂���Ȃ�Ȃ��Ă������ȁB
2010Q4 Purpletown�@(MP�T�[�o�[����)
32nm, ���N���b�N4GHz
1�_�C������4�R�A��4�_�C��1�`�b�v�ɂ���16�R�ACPU
SSE5, 256bit SIMD(doublex4)
1�R�A������SIMD���Z��x2+��Z��x2�������s�[�N���\��4���Z/clock
���������s�[�N���\���o��̂�rep�v���t�B�b�N�X�t���Ϙa���߁E���ϖ��߂�
�@�������A�N�Z�X��L1�Ɏ��܂�ꍇ�̂�w
�g���[�X�L���b�V������
�f�[�^L1�F16KB(�R�A��)
L2�F4MB(�R�A��)
�����C�e���V�͒x���Ȃ邪����_�C�̑��R�A��L2�ɂ��A�N�Z�X�\
������P�U�悹���}�V���𐔏\��Ńl�b�g���[�N��g�ނ�w
2010Q4 Purpletown�@(MP�T�[�o�[����)
32nm, ���N���b�N4GHz
1�_�C������4�R�A��4�_�C��1�`�b�v�ɂ���16�R�ACPU
SSE5, 256bit SIMD(doublex4)
1�R�A������SIMD���Z��x2+��Z��x2�������s�[�N���\��4���Z/clock
���������s�[�N���\���o��̂�rep�v���t�B�b�N�X�t���Ϙa���߁E���ϖ��߂�
�@�������A�N�Z�X��L1�Ɏ��܂�ꍇ�̂�w
�g���[�X�L���b�V������
�f�[�^L1�F16KB(�R�A��)
L2�F4MB(�R�A��)
�����C�e���V�͒x���Ȃ邪����_�C�̑��R�A��L2�ɂ��A�N�Z�X�\
������P�U�悹���}�V���𐔏\��Ńl�b�g���[�N��g�ނ�w
AMD�̊�{�A�[�L�e�N�`���Ȃ�AHT�Ń_�_�Ȃ����邾���łȂ�ڂł��R�A�͋l�߂�����
Nvidia shares surge amid takeover speculation
http://today.reuters.com/news/articlenews.aspx?type=technologyNews&storyid=2006-10-04T192407Z_01_N04413247_RTRUKOC_0_US-NVIDIA-STOCKS.xml
Intel�����̐��j��(���n4��)�ˑRnVidia����S�̂�8%�܂Ŕ������������B
���̂��ߎs��ɂ�Intel��nVidia�����l���Ă���̂ł͂Ȃ���
�Ƃ������������ł���B
http://today.reuters.com/news/articlenews.aspx?type=technologyNews&storyid=2006-10-04T192407Z_01_N04413247_RTRUKOC_0_US-NVIDIA-STOCKS.xml
Intel�����̐��j��(���n4��)�ˑRnVidia����S�̂�8%�܂Ŕ������������B
���̂��ߎs��ɂ�Intel��nVidia�����l���Ă���̂ł͂Ȃ���
�Ƃ������������ł���B
�}���`�R�A�̔\�͂𑶕��Ɉ����o����̂�VISTA�̎��ł����H
>����2007�N�̑�4�l�����ƌ���ꂽAM3�������ɂȂ���AM2+������đ������̂ł���
>���ꂪ��3�l�����ɂȂ����̂Ŏ�����̑O�|���ł���
�������ȉ�����
�����܂ł��đO�|�����Ď��ɂ��������R�ł�����̂���
>���ꂪ��3�l�����ɂȂ����̂Ŏ�����̑O�|���ł���
�������ȉ�����
�����܂ł��đO�|�����Ď��ɂ��������R�ł�����̂���
Intel Compiler�̎��������������邽�߂ɖ��ߊg��������ĕ��j��
NUMA���嗬�����ʐM�̃I�[�o�[�w�b�h�傫����������SMP�ł͐��\�����o���Ȃ����낤���Ǒ��R�A�Ȃ猋�\�ǂ���������Ȃ���
MPI�̔ώG�������Ƃ����Ă���Ȃ����ȁ[�Ɩ��R�Ǝv���Ă�����OpenMP�̊g��������Ă�悤�Łc
NUMA���嗬�����ʐM�̃I�[�o�[�w�b�h�傫����������SMP�ł͐��\�����o���Ȃ����낤���Ǒ��R�A�Ȃ猋�\�ǂ���������Ȃ���
MPI�̔ώG�������Ƃ����Ă���Ȃ����ȁ[�Ɩ��R�Ǝv���Ă�����OpenMP�̊g��������Ă�悤�Łc
Celeron��40�h���ցA100�h���ȏ�̓f���A���R�A��
�`Intel�f�X�N�g�b�vCPU���[�h�}�b�v�l�@
http://pc.watch.impress.co.jp/docs/2006/1006/kaigai308.htm
����̓N���b�N�͐��u�ŃR�A�{���ւƐi�ނ킯���ȁB
�Q�N���Ƀv���Z�X���P����i��ŃR�A���͂Q�{�ɂȂ�͂�������
�����������ڂɂȂ�B
�Z�O�����g�@�@�@�@�@2006���Ձ@2007���Ձ@2008���Ձ@2009����
�p�t�H�[�}���X�@�@�@ Dual�@�@�@�@Quad�@�@�@Quad�@�@�@�@Octet
���C���X�g���[���@�@�@Dual�@�@�@�@Dual�@�@�@ Quad�@�@�@�@Quad
�o�����[�@�@�@�@�@�@�@Single�@�@�@Single�@�@�@Dual�@�@�@�@�@Dual
�`Intel�f�X�N�g�b�vCPU���[�h�}�b�v�l�@
http://pc.watch.impress.co.jp/docs/2006/1006/kaigai308.htm
����̓N���b�N�͐��u�ŃR�A�{���ւƐi�ނ킯���ȁB
�Q�N���Ƀv���Z�X���P����i��ŃR�A���͂Q�{�ɂȂ�͂�������
�����������ڂɂȂ�B
�Z�O�����g�@�@�@�@�@2006���Ձ@2007���Ձ@2008���Ձ@2009����
�p�t�H�[�}���X�@�@�@ Dual�@�@�@�@Quad�@�@�@Quad�@�@�@�@Octet
���C���X�g���[���@�@�@Dual�@�@�@�@Dual�@�@�@ Quad�@�@�@�@Quad
�o�����[�@�@�@�@�@�@�@Single�@�@�@Single�@�@�@Dual�@�@�@�@�@Dual
�����I�ɂ͐����u�������������A���\���ێ�&���シ�邽�߂̃N���b�N��
�A�[�L�e�B�N�`�����ƂɈقȂ���̂�����A
Nehalem�ōX�ɉ�����悤�Ȃ�����Ɩʔ����Ȃ��Ȃ��ł����ˁB
�A�[�L�e�B�N�`�����ƂɈقȂ���̂�����A
Nehalem�ōX�ɉ�����悤�Ȃ�����Ɩʔ����Ȃ��Ȃ��ł����ˁB
>>259
�L���ƑS���W�Ȃ��A�z�ϑz�ꏏ�ɓ\���˂���o�J
�L���ƑS���W�Ȃ��A�z�ϑz�ꏏ�ɓ\���˂���o�J
IDF Fall 2006�F�u80�R�A�v�̌���Ɛ^��
http://plusd.itmedia.co.jp/pcuser/articles/0610/06/news034.html
http://plusd.itmedia.co.jp/pcuser/articles/0610/06/news034.html
> IDF Fall 2006�F�u80�R�A�v�̌���Ɛ^��
�͂��H��������ʼn����^���ȂH
�U�X���̋L���Ŋ��o�̎�������ŁA
�����V�������͏����ĂȂ����ǁB
�͂��H��������ʼn����^���ȂH
�U�X���̋L���Ŋ��o�̎�������ŁA
�����V�������͏����ĂȂ����ǁB
>>259
�ĊO����Core�\���x�[�X��Celeron����������Ȃ�
���悢��AMD��Duron������̈Í�����ɋt�߂��
�ڋq�I�ɂ͏��i�I�т��y�ɂȂ��đ劽�}�Ȃ̂���
�ĊO����Core�\���x�[�X��Celeron����������Ȃ�
���悢��AMD��Duron������̈Í�����ɋt�߂��
�ڋq�I�ɂ͏��i�I�т��y�ɂȂ��đ劽�}�Ȃ̂���
>>264
�Ӗ��s���B
>Pentium�u�����hConroe-L��L2�L���b�V����1MB��FSB 800MHz��1.4�`1.8GHz�A
>Celeron�u�����hConroe-L��512KB��FSB�͖���(533MHz?)���B
������CoreMA�ł������܂ʼn������ጻ�s�Z���v��64�ɂ��珟�Ă��B
���x�̎��Ȃ���Intel�̃o�����[�]�[���͐��������̕��B
�Ӗ��s���B
>Pentium�u�����hConroe-L��L2�L���b�V����1MB��FSB 800MHz��1.4�`1.8GHz�A
>Celeron�u�����hConroe-L��512KB��FSB�͖���(533MHz?)���B
������CoreMA�ł������܂ʼn������ጻ�s�Z���v��64�ɂ��珟�Ă��B
���x�̎��Ȃ���Intel�̃o�����[�]�[���͐��������̕��B
Intel�̃o�����[�]�[���ł������������̂͘m�Z���ʁH
267 �F�E�́E�j��-�������V���I�_���S���I�� ��DanGorION6 �F2006/10/06(��) 20:13:04 ID:OMcVxfEw
����Z���@�y�X450MHz���߂�������
�����Z���@�f���A��CPU���߂�������
�^���Z���@�L���b�V��256k���߂�������
�m�Z�����ĒL�Z����萫�\�Ⴉ���������
�����Z���@�f���A��CPU���߂�������
�^���Z���@�L���b�V��256k���߂�������
�m�Z�����ĒL�Z����萫�\�Ⴉ���������
������������
��ΐ��\��2003�N��Pentium4���݂̐VPentium
>>265
��ΐ��\�ǂ��������l�g�o�Ŗ����Ȃ���Ď����傫���Ǝv��
�l�g�o�ł̕��]�ŃC���e�������ɂȂ����w���Ăі߂��ɂ͏\���߂���v�f
���M�����d�̖͂ʂł�L2�����Ȃ������m���ɗL���Ȃ̂���
�ނ���Geode NX�Ƃ��ō\��Ȃ��Ɗ��������ΐ��\���C�ɂ��Ȃ��w�̕���
�����œ��萫�̗ǂ�CPU�Ƃ��Ċ��}�����\�����\���ɗL�蓾��
��ΐ��\�ǂ��������l�g�o�Ŗ����Ȃ���Ď����傫���Ǝv��
�l�g�o�ł̕��]�ŃC���e�������ɂȂ����w���Ăі߂��ɂ͏\���߂���v�f
���M�����d�̖͂ʂł�L2�����Ȃ������m���ɗL���Ȃ̂���
�ނ���Geode NX�Ƃ��ō\��Ȃ��Ɗ��������ΐ��\���C�ɂ��Ȃ��w�̕���
�����œ��萫�̗ǂ�CPU�Ƃ��Ċ��}�����\�����\���ɗL�蓾��
80�R�A�̂���ď���d�͉͂����b�g�H
Performance per watt is 10Gflpos
PentiumL��������Ə���d�͍��߂̃Z������M
PentiumE��������
>>265
Celeron D�̌�p��Pentium�u�����hConroe-L(L2=1MB)�B
Celeron�u�����hConroe-L(L2=512KB)�̕��͂��̂���ɉ��ɐV�݂���钴�����i�т�����
���sSempron�ɏ��K�v�Ȃ�ĂȂ��B���荇����Ώ\���B
Sempron�Ȃ��L2��128KB/256KB�����B
Celeron D�̌�p��Pentium�u�����hConroe-L(L2=1MB)�B
Celeron�u�����hConroe-L(L2=512KB)�̕��͂��̂���ɉ��ɐV�݂���钴�����i�т�����
���sSempron�ɏ��K�v�Ȃ�ĂȂ��B���荇����Ώ\���B
Sempron�Ȃ��L2��128KB/256KB�����B
�������AGPU�̂悤�ɐ��\�����t����������
GPU�̓��[�G���h������Ȃ�ɏオ���Ă������ǁA
Celeron��Pentium�͈ˑR�A���N�O�̃��[�G���h���\�̃��[�G���hCPU�ɂȂ肻����
�ςȗႦ�����A�u
���܂�GeForceFX 5200���Ă��܂������ANV30�A�[�L�e�N�`���̓A���Ȃ̂ŁA��p���i�Ƃ���G70�A�[�L�e�N�`���̃��[�G���h�i��lj����܂��I�v
�݂����Ȋ���
GeForceFX 5200(�l�g�oCeleron D)
GeForce7050 GS(�R�ACeleron D) 1�p�C�v
���i�͈ꏏ
�܂��A4�p�C�v���Z�b�g�iGF6100�����j������A1�p�C�v�̐��i�͕ʂɍ��Ȃ�����Ȃ�Ȃ������@���Ƃ��b�Ȃ̂�
GPU�̓��[�G���h������Ȃ�ɏオ���Ă������ǁA
Celeron��Pentium�͈ˑR�A���N�O�̃��[�G���h���\�̃��[�G���hCPU�ɂȂ肻����
�ςȗႦ�����A�u
���܂�GeForceFX 5200���Ă��܂������ANV30�A�[�L�e�N�`���̓A���Ȃ̂ŁA��p���i�Ƃ���G70�A�[�L�e�N�`���̃��[�G���h�i��lj����܂��I�v
�݂����Ȋ���
GeForceFX 5200(�l�g�oCeleron D)
GeForce7050 GS(�R�ACeleron D) 1�p�C�v
���i�͈ꏏ
�܂��A4�p�C�v���Z�b�g�iGF6100�����j������A1�p�C�v�̐��i�͕ʂɍ��Ȃ�����Ȃ�Ȃ������@���Ƃ��b�Ȃ̂�
>>277
���[�G���h�̓��[�G���h�炵�������Ȑ��\����
���̂͂������Đ���Ō��S�ȌX���ʼn��̖����������ǁH
����̏ꍇ�����C�o���Ƃ̐��\���̏k���ɂ����Ӗ�������킯�ŁB
�ނ��냍�[�G���h���ᐫ�\�Ȃ܂܂̕������[�G���h���ł̃V�F�A��
�����ł��Ȃ����W���[�ȃ\�t�g�E�F�A�̕K�v�X�y�b�N�̗}���Ɍq������
�~�h���N���XCPU�ł̉��K�x�̌㉟���ɂȂ�Ƌt�ɍl����B
���[�G���h�̓��[�G���h�炵�������Ȑ��\����
���̂͂������Đ���Ō��S�ȌX���ʼn��̖����������ǁH
����̏ꍇ�����C�o���Ƃ̐��\���̏k���ɂ����Ӗ�������킯�ŁB
�ނ��냍�[�G���h���ᐫ�\�Ȃ܂܂̕������[�G���h���ł̃V�F�A��
�����ł��Ȃ����W���[�ȃ\�t�g�E�F�A�̕K�v�X�y�b�N�̗}���Ɍq������
�~�h���N���XCPU�ł̉��K�x�̌㉟���ɂȂ�Ƌt�ɍl����B
>>256
AM2+��AM3�݊����������Ęb�ۂ�����A�卷�Ȃ����ƁB�Q�N��̘b���낤����
AM2+��AM3�݊����������Ęb�ۂ�����A�卷�Ȃ����ƁB�Q�N��̘b���낤����
>>259
Core 2 Duo��Conroe-L�̊Ԃ�Pentium D�������c��͕̂s���R���ȁB
���������ɂ�$90�`$160�̉��i�т�Core 2 Duo�����āAPentium D�ƕ����Ƃ���
�`�ɂȂ��Ȃ����B
2.13GHz,L2=4MB��E6500�𓊓�����6400,6300�����ɃX���C�h������Ƃ��A
1.6GHz��E6200�𓊓�����Ƃ��ACore 2 Quad��Core 2 Duo�̉��i���������Ƃ���Ƃ��A
���悤�͂�����ł�����B
Core 2 Duo��Conroe-L�̊Ԃ�Pentium D�������c��͕̂s���R���ȁB
���������ɂ�$90�`$160�̉��i�т�Core 2 Duo�����āAPentium D�ƕ����Ƃ���
�`�ɂȂ��Ȃ����B
2.13GHz,L2=4MB��E6500�𓊓�����6400,6300�����ɃX���C�h������Ƃ��A
1.6GHz��E6200�𓊓�����Ƃ��ACore 2 Quad��Core 2 Duo�̉��i���������Ƃ���Ƃ��A
���悤�͂�����ł�����B
�ɂ��ςݏオ���Ă�ˁ[�́B
����ɂ��Ă�������Ă���Ӗ��q����Ȃ��B
���肷��V�F�A�͎��Ă�ASP�啝�����Ȃ�Ă��ƂɁB
2002�N�݂����ɂ܂��������i�ɂȂ�ȁB
����ɂ��Ă�������Ă���Ӗ��q����Ȃ��B
���肷��V�F�A�͎��Ă�ASP�啝�����Ȃ�Ă��ƂɁB
2002�N�݂����ɂ܂��������i�ɂȂ�ȁB
>>280
Q2�ł��l�g�o4���Ȃ���S�R�s���R����Ȃ�����
�Ƃ����������i�тɓ����f���A������������D�����B
Conroe-L�̃N���b�N���₽��Ⴗ����̂�D���Ȃ����߂��낤�B
Q2�ł��l�g�o4���Ȃ���S�R�s���R����Ȃ�����
�Ƃ����������i�тɓ����f���A������������D�����B
Conroe-L�̃N���b�N���₽��Ⴗ����̂�D���Ȃ����߂��낤�B
���������L���b�V�����ʂɐς�ł��̉��i�ŏo����C2D����
�����ɐM�����Ȃ����Ǒ��������Ȃ�Ȃ��́H
�����ɐM�����Ȃ����Ǒ��������Ȃ�Ȃ��́H
���Ⴂ���Ă�N���A�z�Ȃ���
Intel Core�܂ł͗ǂ��������ǁA2 Duo E6x00�ƕt����������_������
Core 2 Duo E6x00
Pentium D 9xx
Pentium E1xxx
Celeron D 4xx
�ȑO�ƕς��Ȃ��Ƃ������A���G�ɂȂ���������
Core 2 Duo E6x00
Pentium D 9xx
Pentium E1xxx
Celeron D 4xx
�ȑO�ƕς��Ȃ��Ƃ������A���G�ɂȂ���������
�X���̃C���e���̃v�����[�V�����r�f�I��A�e���rCM�̃C���g�l�[�V�������o���ɂ���
�i���[�^�[�u�C���e�����R�A���f���I���v���Z�b�T�[���v
�i���[�^�[�u�C���e�����R�A���f���I���v���Z�b�T�[���v
�����Y�ꂽ�B�A�J�L�X�}��
�i���[�^�[�u�C���e�����R�A���c�[���f���I���v���Z�b�T�[���v
�i���[�^�[�u�C���e�����R�A���c�[���f���I���v���Z�b�T�[���v
Wading Into Stream Computing
http://www.hpcwire.com/hpc/960279.html
http://www.hpcwire.com/hpc/960279.html
>>283
���F�͒Y���_�C�T�C�Y���������i����R�X�g�j�ł���
���F�͒Y���_�C�T�C�Y���������i����R�X�g�j�ł���
>>283
�S�R��������Ȃ���B
core2�ł͑����v�ƌ����������P�p����A���[�J�[���猩��Β��B���i���啝�ɏオ���Ă���B
��胁�[�J�[����core2�̗p�@�����Ɍ���I�Ȃ̂́A���ꂪ�����B
���̂�����A�`���l���������e�[�����i�������Ă���Ɨ������ɂ����̂����B
�S�R��������Ȃ���B
core2�ł͑����v�ƌ����������P�p����A���[�J�[���猩��Β��B���i���啝�ɏオ���Ă���B
��胁�[�J�[����core2�̗p�@�����Ɍ���I�Ȃ̂́A���ꂪ�����B
���̂�����A�`���l���������e�[�����i�������Ă���Ɨ������ɂ����̂����B
�������������L���b�V���������Ƃ����̂��Ԉ���Ă�
�Ƃ������L���b�V����"�ς�"�Ƃ����\�����̂�����̌��B
�����I�ɂ͌���ꂽ�g�����W�X�^�̓��ǂꂾ���L���b�V���Ɋ��蓖�Ă邩���Ă����̘b�����ˁB
�����I�ɂ͌���ꂽ�g�����W�X�^�̓��ǂꂾ���L���b�V���Ɋ��蓖�Ă邩���Ă����̘b�����ˁB
>>292
���m�ɂ͌���ꂽ�_�C�ʐς̒��ŁA���ˁB
�����g�����W�X�^���ł����W�b�N�������SRAM�����̕����ʐς͋����čςނ���B
SRAM�����̓��W�b�N�ɔ�ׂď���d�͂����Ȃ�����A>>271��
>���M�����d�̖͂ʂł�L2�����Ȃ������m���ɗL���Ȃ̂���
������ԈႢ�B
�����\�Ȃ�L2�L���b�V���𑝂₵�ăN���b�N�𗎂Ƃ����������M�����d�͂ł͗L���B
������m�[�g����CPU�̓f�X�N�g�b�v�������L2�����߂ɂȂ��Ă邾��B
���m�ɂ͌���ꂽ�_�C�ʐς̒��ŁA���ˁB
�����g�����W�X�^���ł����W�b�N�������SRAM�����̕����ʐς͋����čςނ���B
SRAM�����̓��W�b�N�ɔ�ׂď���d�͂����Ȃ�����A>>271��
>���M�����d�̖͂ʂł�L2�����Ȃ������m���ɗL���Ȃ̂���
������ԈႢ�B
�����\�Ȃ�L2�L���b�V���𑝂₵�ăN���b�N�𗎂Ƃ����������M�����d�͂ł͗L���B
������m�[�g����CPU�̓f�X�N�g�b�v�������L2�����߂ɂȂ��Ă邾��B
�䗦�Ɛ�ΐ����������ċc�_����Ă��Ȃ��B
�_�C�T�C�Y���Œ肵�āA�L���b�V�����ǂꂾ����邩�A
���ċc�_�Ȃ�292�͑Ó������A�A
�������̃��W�b�N���ɑ��A�L���b�V���̐�Ηʂ𑝂₹��
����d�͂������A���Ă����̂��^�B
�܂��A������̐��\���Ғl�ɑ��A���W�b�N�ƃL���b�V����
�䗦���ǂ����ׂ����A�Ƃ����Ȃ�293��������x�������̂��낤�B
�����A��ʘ_�ł́A�L���b�V���͑�e�ʂɂȂ�Ȃ�ق�
�e�ʂ�����̐��\����͌������邵�A�����Ɏ��Ԃ�������
�̂�����A�K�������L���b�V���䗦�̑�����������d�͖ʂ�
�L���Ƃ͌����Ȃ��Ǝv���B
�܂��A�e�l�̋c�_�̑O��Ɣ�r�Ώۂ��Ⴄ����A
�[���犚�ݍ����͂��̂Ȃ��c�_�Ȃ낤���ǁB
�_�C�T�C�Y���Œ肵�āA�L���b�V�����ǂꂾ����邩�A
���ċc�_�Ȃ�292�͑Ó������A�A
�������̃��W�b�N���ɑ��A�L���b�V���̐�Ηʂ𑝂₹��
����d�͂������A���Ă����̂��^�B
�܂��A������̐��\���Ғl�ɑ��A���W�b�N�ƃL���b�V����
�䗦���ǂ����ׂ����A�Ƃ����Ȃ�293��������x�������̂��낤�B
�����A��ʘ_�ł́A�L���b�V���͑�e�ʂɂȂ�Ȃ�ق�
�e�ʂ�����̐��\����͌������邵�A�����Ɏ��Ԃ�������
�̂�����A�K�������L���b�V���䗦�̑�����������d�͖ʂ�
�L���Ƃ͌����Ȃ��Ǝv���B
�܂��A�e�l�̋c�_�̑O��Ɣ�r�Ώۂ��Ⴄ����A
�[���犚�ݍ����͂��̂Ȃ��c�_�Ȃ낤���ǁB
>>294
Conroe-L��L2=1MB�����\/����d�͔�ŕs���Ȃ͖̂��炩���낤�B
���Ƃ���4MB�Őv����Ă�̂�1/4�ł́B
�܂��Ă킸��512KB��Conroe�Z���́B
Conroe-L��L2=1MB�����\/����d�͔�ŕs���Ȃ͖̂��炩���낤�B
���Ƃ���4MB�Őv����Ă�̂�1/4�ł́B
�܂��Ă킸��512KB��Conroe�Z���́B
>>293�̗�ɋ������Ă�>>271�̏������݂Ɋւ��Ă�
Conroe-L�̎�蕿�ɂȂ�̂͐�ΓI�ȏ���d�͂��炢���Ď��s�l�^��
�d�͌����Ƃ����\�Ƃ̃o�����X�Ƃ��[���Ӗ��͊F���ȋC�����邗��
Conroe-L�̎�蕿�ɂȂ�̂͐�ΓI�ȏ���d�͂��炢���Ď��s�l�^��
�d�͌����Ƃ����\�Ƃ̃o�����X�Ƃ��[���Ӗ��͊F���ȋC�����邗��
intel���Ă���64bit������́H
>>295
>Conroe-L��L2=1MB�����\/����d�͔�ŕs��
L2�̃q�b�g���͕��ς���40%�قǒቺ����킯�����ǁA�P���ɃV���O���R�A������s�[�N���̏���d�͔͂����ɂȂ邩���킩��B
�o�Ă݂Ȃ��ƂȂ�Ƃ������Ȃ��B
>���Ƃ���4MB�Őv����Ă�̂�1/4�ł́B
���[�G���h�Ȃ�Ă��Ƃ�肻��Ȃ���ł���B
>Conroe-L��L2=1MB�����\/����d�͔�ŕs��
L2�̃q�b�g���͕��ς���40%�قǒቺ����킯�����ǁA�P���ɃV���O���R�A������s�[�N���̏���d�͔͂����ɂȂ邩���킩��B
�o�Ă݂Ȃ��ƂȂ�Ƃ������Ȃ��B
>���Ƃ���4MB�Őv����Ă�̂�1/4�ł́B
���[�G���h�Ȃ�Ă��Ƃ�肻��Ȃ���ł���B
�K�v�ȏ�ɁA���\�����ɍL���Ă�C������
Core2 1.6/1.86GHz���������ł����Ԋy�ɂȂ�C�͂��邪�A�オ�オ��킯�ł��Ȃ��̂ŃA�������B
Core2 1.6/1.86GHz���������ł����Ԋy�ɂȂ�C�͂��邪�A�オ�オ��킯�ł��Ȃ��̂ŃA�������B
>>299
���ɍL���Ȃ���OEM���̗p�ł��Ȃ��ď�̍����Ȃ��̂�����Ȃ��Ȃ�B
2G�ȉ��Ȃ�����܂�ς��낤����Intel�̎�����l�����
�����Ȃ��ǁB
���ɍL���Ȃ���OEM���̗p�ł��Ȃ��ď�̍����Ȃ��̂�����Ȃ��Ȃ�B
2G�ȉ��Ȃ�����܂�ς��낤����Intel�̎�����l�����
�����Ȃ��ǁB
�������R�A�ɑ傫���L���b�V���ݾ�
�C�X���G����Special Sizing Techniques�ݾ�
�펯���z�����啝��CPU�R�A�̏k��������Timna��
http://pc.watch.impress.co.jp/docs/article/20000825/kaigai03.htm
Dothan����@�\�g�����Ȃ���g�����W�X�^�������点��Yonah��
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai02l.gif
�C�X���G����Special Sizing Techniques�ݾ�
�펯���z�����啝��CPU�R�A�̏k��������Timna��
http://pc.watch.impress.co.jp/docs/article/20000825/kaigai03.htm
Dothan����@�\�g�����Ȃ���g�����W�X�^�������点��Yonah��
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai02l.gif
{kind=link}
>>302
Yonah��151.6M�g�����W�X�^�ł�����120M��L2(2MB)�̕��B
Conroe��291M�g�����W�X�^��L2(4MB)������L2�E���W�b�N���Ƃ��ɔ{�����Ă�킯���B
����ł�143����mm�ōς�ł�̂�65nm�̂������B
���W�b�N���͂��͂���Ȃɏ������Ȃ��B�inetburst�͂��̍ۘ_�O�j
Yonah��151.6M�g�����W�X�^�ł�����120M��L2(2MB)�̕��B
Conroe��291M�g�����W�X�^��L2(4MB)������L2�E���W�b�N���Ƃ��ɔ{�����Ă�킯���B
����ł�143����mm�ōς�ł�̂�65nm�̂������B
���W�b�N���͂��͂���Ȃɏ������Ȃ��B�inetburst�͂��̍ۘ_�O�j
>>303
�^��Ȃ��ǁA�u�ςӂ��[�܂ρ[����Ɓv���d������Ȃ�AYonah��Merom��
�啝�Ɋg����������AYonah4�R�A�̂ق����ǂ�������Ȃ��́H
http://pc.watch.impress.co.jp/docs/2006/0822/kaigai04l.gif
http://pc.watch.impress.co.jp/docs/2006/0822/kaigai06l.gif
�^��Ȃ��ǁA�u�ςӂ��[�܂ρ[����Ɓv���d������Ȃ�AYonah��Merom��
�啝�Ɋg����������AYonah4�R�A�̂ق����ǂ�������Ȃ��́H
http://pc.watch.impress.co.jp/docs/2006/0822/kaigai04l.gif
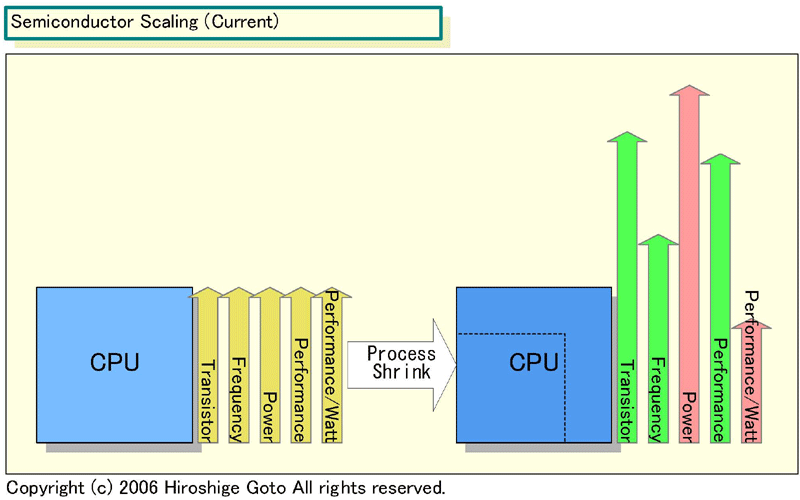{kind=link}
http://pc.watch.impress.co.jp/docs/2006/0822/kaigai06l.gif
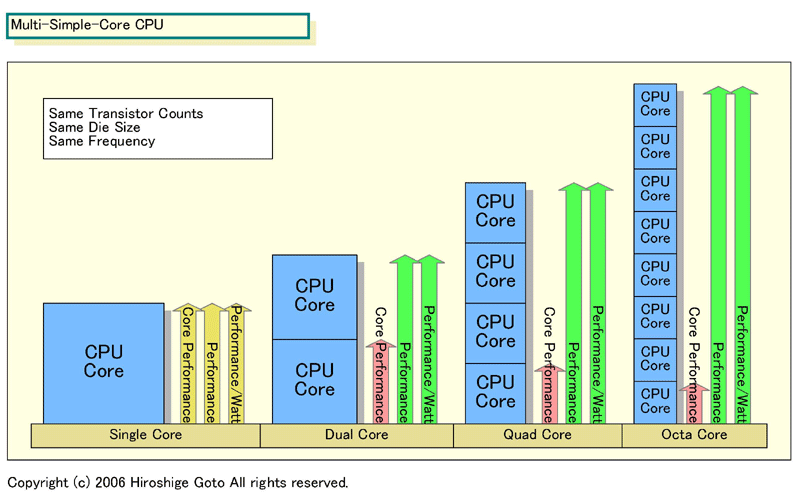{kind=link}
�m�[�gPC���G���R�@��Web�I�Ɏg���悤�Ȑl�ɂƂ��Ă͗ǂ����������Ȃ���
>>304
Yonah��Merom�Ń��W�b�N���͂Q�{��ɑ����Ă邯�Ǐ���d�͂����̂܂�
�����Ă�킯����Ȃ����炻���Ƃ������Ȃ��̂ł́B
SIMD���Z��̔\�̓A�b�v�Ȃ̓g�����W�X�^�������قǐH�킸�Ƀs�[�N���\��
��C�ɂ�����B�i���̂����A�v�����̑Ή����K�v�����j
������ɂ��挻��łS�R�A���f�X�N�g�b�v�̎�͑w��m�[�g�Ɏ����Ă���͖̂����B
�A�v�����̑Ή����܂������ǂ����ĂȂ��B���z�̓V���v���ȃ��j�C�R�A�ł�
����ł̓V���O���X���b�h���\���d������������Ȃ��B
Yonah��Merom�Ń��W�b�N���͂Q�{��ɑ����Ă邯�Ǐ���d�͂����̂܂�
�����Ă�킯����Ȃ����炻���Ƃ������Ȃ��̂ł́B
SIMD���Z��̔\�̓A�b�v�Ȃ̓g�����W�X�^�������قǐH�킸�Ƀs�[�N���\��
��C�ɂ�����B�i���̂����A�v�����̑Ή����K�v�����j
������ɂ��挻��łS�R�A���f�X�N�g�b�v�̎�͑w��m�[�g�Ɏ����Ă���͖̂����B
�A�v�����̑Ή����܂������ǂ����ĂȂ��B���z�̓V���v���ȃ��j�C�R�A�ł�
����ł̓V���O���X���b�h���\���d������������Ȃ��B
>>305
�t�ɃT�[�o�p�Ƃ��Ă�Yonah�x�[�X�łW�R�A�Ƃ����l���������肾���������ȁB
���C���������̑ш�s�����������������B
�t�ɃT�[�o�p�Ƃ��Ă�Yonah�x�[�X�łW�R�A�Ƃ����l���������肾���������ȁB
���C���������̑ш�s�����������������B
�������ш���Č�������Bensley��FB-DIMM�Ȃ̂�4ch���ăP�`�肷�����Ǝv���B
>>307
Yonah����Intel 64(��EM64T)���Ȃ�����I�ɂ͔���ɂ�������
Yonah����Intel 64(��EM64T)���Ȃ�����I�ɂ͔���ɂ�������
�������������x�u���[�h�T�[�o�p�r�ł͂���ȂɃ������ς܂Ȃ�����B
HDD��̃f�[�^�Ƀ������}�b�s���O����悤�Ȏg��������Ȃ�40bit�̃A�h���b�V���O��Ԃ�
���ɂ͂���
HDD��̃f�[�^�Ƀ������}�b�s���O����悤�Ȏg��������Ȃ�40bit�̃A�h���b�V���O��Ԃ�
���ɂ͂���
Core 2 Quad Q6xxx (Kentsfield/�WMB) �c�c K8L�N�A�b�h�R�A�R
Core 2 Duo E6xxx/E4xxx (Conroe/2MB,4MB) �c�c Athlon64�f���A���R�A�R
Pentium E1xxx(Conroe-L/1MB) �c�c Athlon64�V���O���R�A�R
�VCeleron 4xx(Conroe-L/512kB) �c�c Sempron�R
����������K8L���o�鍠�ɂ͑R��Yorkfield�ɂȂ��Ă��������B
Core 2 Duo E6xxx/E4xxx (Conroe/2MB,4MB) �c�c Athlon64�f���A���R�A�R
Pentium E1xxx(Conroe-L/1MB) �c�c Athlon64�V���O���R�A�R
�VCeleron 4xx(Conroe-L/512kB) �c�c Sempron�R
����������K8L���o�鍠�ɂ͑R��Yorkfield�ɂȂ��Ă��������B
http://pc.watch.impress.co.jp/docs/2006/1006/kaigai03l.gif
��
http://pc.watch.impress.co.jp/docs/2006/1010/kaigai309_02l.gif
�N�A�b�h��Penryn���폜����Ă�ȁB�X�y�b�N���ǂ߂Ȃ��̂ŏ��������B
���Ԃ�L2��12MB�Ń_�C�T�C�Y��200����mm�O�ゾ�낤�B
���̑O��65nm��4core 1die�iL2��8MB�j���o��ƌ����B
{kind=link}
��
http://pc.watch.impress.co.jp/docs/2006/1010/kaigai309_02l.gif
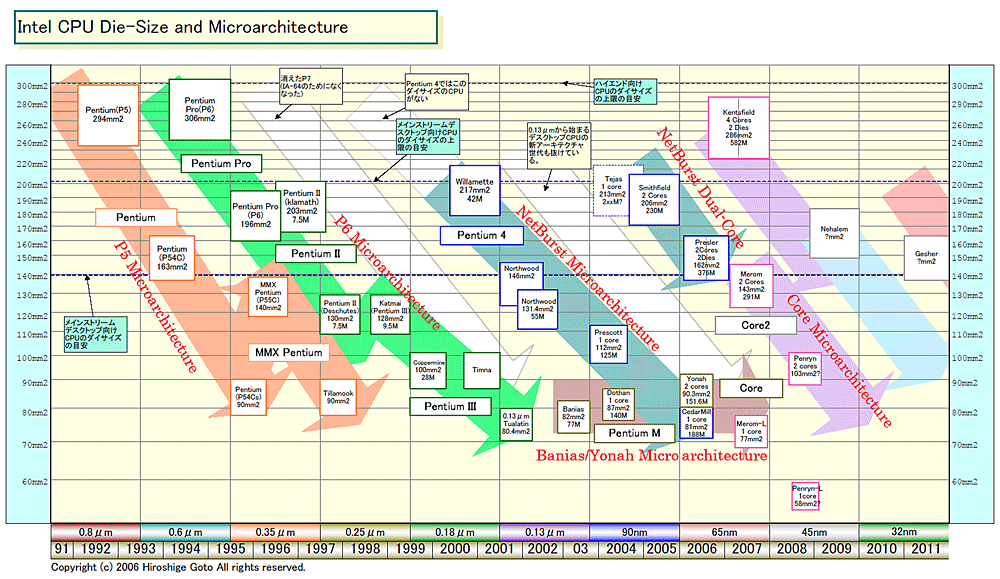{kind=link}
�N�A�b�h��Penryn���폜����Ă�ȁB�X�y�b�N���ǂ߂Ȃ��̂ŏ��������B
���Ԃ�L2��12MB�Ń_�C�T�C�Y��200����mm�O�ゾ�낤�B
���̑O��65nm��4core 1die�iL2��8MB�j���o��ƌ����B
Yorkfield�����̗\��ʂ�Ȃ�2�_�CPenryn�N�A�b�h�̏o�開�͖������������B
>>313
Penryn�̃N�A�b�h��1die����B�ǂ�����2die�Ȃ�[�b���B
�ŋߏo������Yorkfield��Penryn���̂��́B���͂��̏��͐M���ĂȂ����ǁB
Penryn�̃N�A�b�h��1die����B�ǂ�����2die�Ȃ�[�b���B
�ŋߏo������Yorkfield��Penryn���̂��́B���͂��̏��͐M���ĂȂ����ǁB
315 �FMAC�I�^��314 �����F2006/10/10(��) 00:55:27 ID:TWRRozcF
>>314
�@�@------------------
�@�@Penryn�̃N�A�b�h��1die����B�ǂ�����2die�Ȃ�[�b���B
�@�@------------------
���N��TomsHardware�̋L�����͂��߂Ƃ��āCPenryn��f���A���R�A�Ƃ����b�̕����L�͂���
�v���邷�B�ŋ߂̋L���ł��C����Ȃ�Ƃ��B�B�B
http://news.com.com/2100-1006_3-6071046.html
�@�@==================
�@�@But Penryn is a dual-core 45-nanometer chip specifically designed for notebooks,
�@�@sources said. Wolfdale is the name of the dual-core 45nm chip that will be slated for
�@�@desktops in that time frame. Penryn is essentially a smaller version of Merom, which
�@�@is due in August, while Wolfdale is a smaller version of Conroe, scheduled for a July launch.
�@�@==================
�@�@------------------
�@�@Penryn�̃N�A�b�h��1die����B�ǂ�����2die�Ȃ�[�b���B
�@�@------------------
���N��TomsHardware�̋L�����͂��߂Ƃ��āCPenryn��f���A���R�A�Ƃ����b�̕����L�͂���
�v���邷�B�ŋ߂̋L���ł��C����Ȃ�Ƃ��B�B�B
http://news.com.com/2100-1006_3-6071046.html
�@�@==================
�@�@But Penryn is a dual-core 45-nanometer chip specifically designed for notebooks,
�@�@sources said. Wolfdale is the name of the dual-core 45nm chip that will be slated for
�@�@desktops in that time frame. Penryn is essentially a smaller version of Merom, which
�@�@is due in August, while Wolfdale is a smaller version of Conroe, scheduled for a July launch.
�@�@==================
>>315
��ȌÂ�����Ă����Ă��B
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
Penryn�́ACore MA��45nm�v���Z�X�ɔ������邾���łȂ��A���߃Z�b�g�̊g���ƁA
���m���V�b�N�ȃN�A�b�h�R�A�ł��܂ނ��ƂɂȂ�B
�������Ă邵�B
��ȌÂ�����Ă����Ă��B
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
Penryn�́ACore MA��45nm�v���Z�X�ɔ������邾���łȂ��A���߃Z�b�g�̊g���ƁA
���m���V�b�N�ȃN�A�b�h�R�A�ł��܂ނ��ƂɂȂ�B
�������Ă邵�B
317 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 01:02:19 ID:mz+N63ZY
Penryn��Merom��p�̃��o�C���p�̃R�A�����炻���N�A�b�h�͂Ȃ�����
319 �FMAC�I�^��316 �����F2006/10/10(��) 01:05:34 ID:TWRRozcF
320 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 01:06:15 ID:mz+N63ZY
>>320
Kentsfield�̓��m���V�b�N����Ȃ����B
Conroe��Conroe-L�����R�A�Ȃ̂Ɠ�����
Penryn�N�A�b�h(�R�[�h�l�[���̓f�X�N�g�b�v�p������Ⴄ�낤����)��
Penryn�f���A����,Penryn�V���O���͓��R�A���B
Kentsfield�̓��m���V�b�N����Ȃ����B
Conroe��Conroe-L�����R�A�Ȃ̂Ɠ�����
Penryn�N�A�b�h(�R�[�h�l�[���̓f�X�N�g�b�v�p������Ⴄ�낤����)��
Penryn�f���A����,Penryn�V���O���͓��R�A���B
322 �FMAC�I�^��321 �����F2006/10/10(��) 01:13:30 ID:TWRRozcF
>>322
�g�������͂�������B
�v��Intel��45nm����̍ŏ��̃f�X�N�g�b�v����CPU�̓��m���V�b�N�ȃN�A�b�h�R�A
�i�ނ��f���A���R�A�ł����邾�낤�������Conroe-L�̂悤�ɃN�A�b�h�ł̃T�u�Z�b�g���j
���Ă��Ƃ��B
�g�������͂�������B
�v��Intel��45nm����̍ŏ��̃f�X�N�g�b�v����CPU�̓��m���V�b�N�ȃN�A�b�h�R�A
�i�ނ��f���A���R�A�ł����邾�낤�������Conroe-L�̂悤�ɃN�A�b�h�ł̃T�u�Z�b�g���j
���Ă��Ƃ��B
324 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 01:26:20 ID:mz+N63ZY
�L���b�V���e�ʂ�12MB�����琄��_�C�T�C�Y��200mm^2�O�ゾ�ˁB
�V���O���E�f���A���R�A�p�ƃN�A�b�h�R�A�p�ŕʃ}�X�N�ɂȂ�Ɨ\�z�B
�V���O���E�f���A���R�A�p�ƃN�A�b�h�R�A�p�ŕʃ}�X�N�ɂȂ�Ɨ\�z�B
>>324
�N�A�b�h12�l�a(��200����mm??)
�f���A��6MB/3MB(103����mm?)
�V���O��2MB(58����mm?)
��3�}�X�N�ɂȂ�͗l�B
�N�A�b�h12�l�a(��200����mm??)
�f���A��6MB/3MB(103����mm?)
�V���O��2MB(58����mm?)
��3�}�X�N�ɂȂ�͗l�B
ID:HRpnwGgz
327 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 02:44:36 ID:mz+N63ZY
���̃V���O���R�A��p�}�X�N����ULV��p�r����ˁH
>>327
���ʂ�Merom-L�̌�p�Ǝv����B
>�V���O���R�A��Penryn-L�͂���ɏ������A60����mm���ƌ�����B
>�܂��ATDP��Merom��34/35W��艺����A30W���ƌ����Ă���B
���ʂ�Merom-L�̌�p�Ǝv����B
>�V���O���R�A��Penryn-L�͂���ɏ������A60����mm���ƌ�����B
>�܂��ATDP��Merom��34/35W��艺����A30W���ƌ����Ă���B
Nehalem�A�[�L�̓��o�C���ɂ͍~��Ă��Ȃ��Ɨ\�z
�ʂ����Ė{���Ƀ��m���V�b�N�Ȃ̂��˂��B
Yorkfield�ɂ͐F��ȏ����Ă邯�ǁB
ttp://www.hkepc.com/bbs/itnews.php?tid=675864
ttp://www.vr-zone.com/?i=4109
Yorkfield�ɂ͐F��ȏ����Ă邯�ǁB
ttp://www.hkepc.com/bbs/itnews.php?tid=675864
ttp://www.vr-zone.com/?i=4109
���m���V�b�N�̈Ӗ����킩��Ȃ��Ȃ炻�����������̂�
���m������ȕ�����������Ⴂ�܂���
>>330
hkepc��Yorkfield��2007�N�㔼�ŁA���m���V�b�N�E�N�A�b�h�R�A���Ƃ��������Ȃ�
���ꂪPenryn�N�A�b�h(�f�X�N�g�b�v��)���Ƒf���ɐM��������B
vr-zone��Penryn�x�[�X�œ���������2007�NQ3�Ƃ����͓̂���M�����Ȃ���
L2��6MBx2�Ƃ����̂��Ӗ��s�����B
hkepc��Yorkfield��2007�N�㔼�ŁA���m���V�b�N�E�N�A�b�h�R�A���Ƃ��������Ȃ�
���ꂪPenryn�N�A�b�h(�f�X�N�g�b�v��)���Ƒf���ɐM��������B
vr-zone��Penryn�x�[�X�œ���������2007�NQ3�Ƃ����͓̂���M�����Ȃ���
L2��6MBx2�Ƃ����̂��Ӗ��s�����B
>>333
>second half of 2007
>such that it can increase the cache hit and lower the loading of FSB.
vr-zone�̃l�^��ے肷�鍪���Ƃ��Ă͎ア�Ǝv���c(�ނ����ڂȂm�肷�鍪�����蓾��)
���Ă�[���A�|�X�gKenstfield��4�R�A��L2�����L���ăl�^�Avr-zone�ł�5�����Ɏ��グ���Ă����
���ꂪIDF�̌�ɂ����Ȃ���
�Ӗ��[�ł���
>second half of 2007
>such that it can increase the cache hit and lower the loading of FSB.
vr-zone�̃l�^��ے肷�鍪���Ƃ��Ă͎ア�Ǝv���c(�ނ����ڂȂm�肷�鍪�����蓾��)
���Ă�[���A�|�X�gKenstfield��4�R�A��L2�����L���ăl�^�Avr-zone�ł�5�����Ɏ��グ���Ă����
���ꂪIDF�̌�ɂ����Ȃ���
�Ӗ��[�ł���
>>333
> ����������2007�NQ3�Ƃ����͓̂���M�����Ȃ���
HKEPC�ł�Q3�����Ƃ������͂����B
ttp://www.hkepc.com/bbs/itnews.php?tid=678736
> L2��6MBx2�Ƃ����̂��Ӗ��s�����B
Conroe x2 = Kentsfield
Penryn x2 = Yorkfield
�Ƃ�����������������ł���B
> ����������2007�NQ3�Ƃ����͓̂���M�����Ȃ���
HKEPC�ł�Q3�����Ƃ������͂����B
ttp://www.hkepc.com/bbs/itnews.php?tid=678736
> L2��6MBx2�Ƃ����̂��Ӗ��s�����B
Conroe x2 = Kentsfield
Penryn x2 = Yorkfield
�Ƃ�����������������ł���B
>>335
http://www.hkepc.com/bbs/itnews.php?tid=675864
�����������肾�ƁA�S�R�A�œ���L2�L���b�V�������L���Ă���̂ł́B
http://www.hkepc.com/bbs/itnews.php?tid=675864
�����������肾�ƁA�S�R�A�œ���L2�L���b�V�������L���Ă���̂ł́B
������HKEPC�͋��LL2�����Avr-zone�̓j�R�C�`�B
����Yorkfield�ł������Ă鎖���Ⴄ���Ă��Ƃ�B
>>330�ŐF��ȏ����Č������̂͂���B
����Yorkfield�ł������Ă鎖���Ⴄ���Ă��Ƃ�B
>>330�ŐF��ȏ����Č������̂͂���B
�Ɨ��L���b�V�����R�A�Ԃ������C���^�[�R�l�N�g�Ō������Ă�Ȃ�ʂ�Paxville����Ȃ��Ă�64X2�Ȃł���������
PowerVR SGX supports unified Shaders
http://www.theinquirer.net/default.aspx?article=34966
GeForce 8800 launch details revealed
http://www.theinquirer.net/default.aspx?article=34963
http://www.theinquirer.net/default.aspx?article=34966
GeForce 8800 launch details revealed
http://www.theinquirer.net/default.aspx?article=34963
>>338
���m���V�b�N�Ȃ̂�2�R�A����L2�������ĈӖ��s������B
1�R�A���ɐ�pL2�Ȃ�킩�邪�B
vr-zone�̋L����Yorkfield�̓j�R�C�`�ƍl����̂��f���ȓlj����Ǝv�����B
���m���V�b�N�Ȃ̂�2�R�A����L2�������ĈӖ��s������B
1�R�A���ɐ�pL2�Ȃ�킩�邪�B
vr-zone�̋L����Yorkfield�̓j�R�C�`�ƍl����̂��f���ȓlj����Ǝv�����B
>>343
�ŁA�킴�킴�����܂�̉����郂�m���V�b�N�ɂ���Ӗ��́H
�ŁA�킴�킴�����܂�̉����郂�m���V�b�N�ɂ���Ӗ��́H
345 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 22:35:45 ID:mz+N63ZY
1�R�A��12MB
346 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/10(��) 22:36:36 ID:mz+N63ZY
���̃X���b�h���x��ł�Ƃ���
>>344
�L���b�V���R�q�[�����X�̊ɘa��FSB�̍������̂��߁B
�L���b�V���R�q�[�����X�̊ɘa��FSB�̍������̂��߁B
>>338,340
Paxville������MP�������ƒm���ĂČ����Ă�Ȃ�債������
Paxville������MP�������ƒm���ĂČ����Ă�Ȃ�債������
����MP�����Ƃ͂���DP�����ɂ��̔����ꂽ�킯�ŁA�˂��B
>>342
>���m���V�b�N�Ȃ̂�2�R�A����L2�������ĈӖ��s������B
�J���ɕK�v�ȏ��X�̃R�X�g�B
>>343���T�����ƐG��Ă邪������g��3.73GHz���Ă̂��傫�ȃq���g�B
>>348
L2�L���j�R�C�`
�������Ă��������܂������H
>���m���V�b�N�Ȃ̂�2�R�A����L2�������ĈӖ��s������B
�J���ɕK�v�ȏ��X�̃R�X�g�B
>>343���T�����ƐG��Ă邪������g��3.73GHz���Ă̂��傫�ȃq���g�B
>>348
L2�L���j�R�C�`
�������Ă��������܂������H
MCM�̈�Ԃ̃����b�g�͎s����𑁂��ł���Ƃ������ƁB
�t�Ɍ������m���V�b�N�ɂ���ɂ͎��Ԃ�������B
Penryn����o��o���邩�����������ɁA����������������m���V�b�N��CPU���o�Ă���킯�������̂������B
�����āAMP�����ł�FSB�̊W����ǂ����Ă��������������ǁADesktop�ł͂��ł�MCM���m�����Ă���B
������g��Ȃ���͖�����B
�l�I�ɂ�Yorkfield������Tigerton�̃f�X�N�g�b�v�ł������Ƃ����\���Ȃ�A�������Ƃ͎v���Ă邯�ǁB
�t�Ɍ������m���V�b�N�ɂ���ɂ͎��Ԃ�������B
Penryn����o��o���邩�����������ɁA����������������m���V�b�N��CPU���o�Ă���킯�������̂������B
�����āAMP�����ł�FSB�̊W����ǂ����Ă��������������ǁADesktop�ł͂��ł�MCM���m�����Ă���B
������g��Ȃ���͖�����B
�l�I�ɂ�Yorkfield������Tigerton�̃f�X�N�g�b�v�ł������Ƃ����\���Ȃ�A�������Ƃ͎v���Ă邯�ǁB
Tigerton = Clovertown = Kentsfield
http://ascii24.com/news/i/topi/article/2006/04/06/images/images804633.jpg
���O�X��>>915�ӂ�ŎU�X����Ă�ȁc
http://ascii24.com/news/i/topi/article/2006/04/06/images/images804633.jpg
{kind=link}
���O�X��>>915�ӂ�ŎU�X����Ă�ȁc
����Ⴗ�܂����B
���̔c�����Ă���Â������ȁB
���̔c�����Ă���Â������ȁB
Yorkfield��Penryn�x�[�X�Ƃ����̂͌�Ɨ\�z�B
2007/Q3
Yorkfield�@�@�@Kentsfield�̌�p�Ń��m���V�b�N�E�N�A�b�h��
65nm
1die 4�R�A
���LL2=8MB
��250����mm
�Ή��`�b�v�Z�b�g�FIntel 975X
2007/Q4
Penryn�f�X�N�g�b�v��
45nm
1die 4�R�A
���LL2=12MB
��200����mm
SSE4����
�Ή��`�b�v�Z�b�g�FBearlake-X
���������͂����Ȃ�ƌ����B
���̗\�z����Yorkfield�͂킸��1�l�����Ńn�C�G���hCPU�̍�����
�]�������邪�A�p���m�C�AIntel�Ȃ�K8L Altair�R�̂��߂�����
���̂��炢�͂�邗
2007/Q3
Yorkfield�@�@�@Kentsfield�̌�p�Ń��m���V�b�N�E�N�A�b�h��
65nm
1die 4�R�A
���LL2=8MB
��250����mm
�Ή��`�b�v�Z�b�g�FIntel 975X
2007/Q4
Penryn�f�X�N�g�b�v��
45nm
1die 4�R�A
���LL2=12MB
��200����mm
SSE4����
�Ή��`�b�v�Z�b�g�FBearlake-X
���������͂����Ȃ�ƌ����B
���̗\�z����Yorkfield�͂킸��1�l�����Ńn�C�G���hCPU�̍�����
�]�������邪�A�p���m�C�AIntel�Ȃ�K8L Altair�R�̂��߂�����
���̂��炢�͂�邗
>>355
���\�I�ɂ͏��Ă邾�낤����45nm��Q3�ɂ͊Ԃɍ����ł���
���\�I�ɂ͏��Ă邾�낤����45nm��Q3�ɂ͊Ԃɍ����ł���
�F�̏O
�C���e���l�̒�`���郂�m���V�b�N�d�A���R�A�ɒY���܂܂�Ă���̂����Y�ꂩ
Yorkfield��Penryn�̃j�R�C�`�_�C�łƗ\�z
�C���e���l�̒�`���郂�m���V�b�N�d�A���R�A�ɒY���܂܂�Ă���̂����Y�ꂩ
Yorkfield��Penryn�̃j�R�C�`�_�C�łƗ\�z
�藣���ĂȂ������̃f���A���_�C���Ă��Ƃ�
�܂�������MCM���͔z�����y������
�܂�������MCM���͔z�����y������
ttp://www.vr-zone.com/?i=4140
Yorkfield�̃N���b�N�������ɉ��������\���ɂȂ��Ă�悤�ȁB
���ƁA45nm��DualCore�V���B
Wolfdale(Penryn��Desktop��)�� 3.5-4.0GHz ���Ƃ��B
������TDP��57W�B
���[�ށA���̃N���b�N��TDP�̗����͉�ɂ͐M�����������c�B
������POWER6���N���b�N2�{�ŏ���d�͂��̂܂܂��Ƃ����b�����Ȃ��B
Penryn�͒P�Ȃ�V�������N���Ƃ͎v���̂����c�B
���ނނށc�B
vr-zone�ȊO���瑱�����ȁB
Yorkfield�̃N���b�N�������ɉ��������\���ɂȂ��Ă�悤�ȁB
���ƁA45nm��DualCore�V���B
Wolfdale(Penryn��Desktop��)�� 3.5-4.0GHz ���Ƃ��B
������TDP��57W�B
���[�ށA���̃N���b�N��TDP�̗����͉�ɂ͐M�����������c�B
������POWER6���N���b�N2�{�ŏ���d�͂��̂܂܂��Ƃ����b�����Ȃ��B
Penryn�͒P�Ȃ�V�������N���Ƃ͎v���̂����c�B
���ނނށc�B
vr-zone�ȊO���瑱�����ȁB
>>359
�P�N��Conroe 1.86GHz�������i�ŋ�����ȏ�APentium��Celeron�̂��߂ɁACore2�́i���ɉ����j���\�͏オ���ė~�������
Pentium��1.8GHz�ŗ��N���l�����o��炵�����c
POWER6�̓N���b�N2�{��TDP�ێ������A����������������ǂ���Ă邼
�P�N��Conroe 1.86GHz�������i�ŋ�����ȏ�APentium��Celeron�̂��߂ɁACore2�́i���ɉ����j���\�͏オ���ė~�������
Pentium��1.8GHz�ŗ��N���l�����o��炵�����c
POWER6�̓N���b�N2�{��TDP�ێ������A����������������ǂ���Ă邼
>>359
����ȑO��45nm��Q3�Ƃ����̂��S���M������
����ȑO��45nm��Q3�Ƃ����̂��S���M������
�t�@�[�X�g�V���R���͂����Ƃ�Ă�̂��ȁH
57W���Ă����L������������̓I�Ȑ����͋C�ɂȂ�
57W���Ă����L������������̓I�Ȑ����͋C�ɂȂ�
>>362
http://pc.watch.impress.co.jp/docs/2006/1002/kaigai306.htm
>Gelsinger���́A45nm����CPU�Ɏ��������A50���߂ɋy�ԑ啝�Ȗ��߃Z�b�g�g���gSSE4�h��
>�T�v�\�B����ɃX�s�[�`�̍Ō�ɂ́u�����Fab����o�Ă��������㐻�i�����c�c�v��
>�v�킹�Ԃ�ɃV���R���E�F�n�����o�����B
���ꂪPenryn���낤�B�������_�łƂ�ĂȂ���Q3�Ȃ�Ė����B
http://pc.watch.impress.co.jp/docs/2006/1002/kaigai306.htm
>Gelsinger���́A45nm����CPU�Ɏ��������A50���߂ɋy�ԑ啝�Ȗ��߃Z�b�g�g���gSSE4�h��
>�T�v�\�B����ɃX�s�[�`�̍Ō�ɂ́u�����Fab����o�Ă��������㐻�i�����c�c�v��
>�v�킹�Ԃ�ɃV���R���E�F�n�����o�����B
���ꂪPenryn���낤�B�������_�łƂ�ĂȂ���Q3�Ȃ�Ė����B
45nm����̃e�[�v�A�E�g�����l�����Ƃ����b����������Ȃ��B
�����i�łȂ��͓̂��R�Ƃ��āA���̃N���b�N�̓��{�œ����������ʂ��R�ꂽ�Ƃ��H
���i���̂����͂����Ə������Ȃ��Ă�Ƃ����\���͂��肻���ȋC������B
�����i�łȂ��͓̂��R�Ƃ��āA���̃N���b�N�̓��{�œ����������ʂ��R�ꂽ�Ƃ��H
���i���̂����͂����Ə������Ȃ��Ă�Ƃ����\���͂��肻���ȋC������B
�C���e���͂����܂����ȁB
�Y�Ŋj�Z���Ƃ��n���ɂ���Ă������납��C�X���G���`�[�����撣���Ă��낤�ȁB
�Y�Ŋj�Z���Ƃ��n���ɂ���Ă������납��C�X���G���`�[�����撣���Ă��낤�ȁB
>>359
����͂������A�܂��N���b�N�����̍ĔR���I�H
���ATDP�͂ނ��뉺�����Ă邵������
�V���O���X���b�h�̐��\��5�N�œ�{���炢�����オ��Ȃ���Ȃ������̂���
����͂������A�܂��N���b�N�����̍ĔR���I�H
���ATDP�͂ނ��뉺�����Ă邵������
�V���O���X���b�h�̐��\��5�N�œ�{���炢�����オ��Ȃ���Ȃ������̂���
>>359
���ꂪ�z���g�Ȃ����F�͂�������N�Œ�������킯���E�E�E
����ɂ��Ă�Source: VR-Zone�Ă̂́A
���ʂ������������đ�pM/B���[�J�[�Ƃ��O���ɂȂ��Ȃ��̂��B
���ꂪ�z���g�Ȃ����F�͂�������N�Œ�������킯���E�E�E
����ɂ��Ă�Source: VR-Zone�Ă̂́A
���ʂ������������đ�pM/B���[�J�[�Ƃ��O���ɂȂ��Ȃ��̂��B
http://pc.watch.impress.co.jp/docs/2006/0929/kaigai305.htm
�ʉَq�َq�A�����������肾��2007�N����Kents��conroe�̂܂܂̂悤�ȁE�E�E�B
�����{���Ȃ낤�ˁB
�ʉَq�َq�A�����������肾��2007�N����Kents��conroe�̂܂܂̂悤�ȁE�E�E�B
�����{���Ȃ낤�ˁB
SATA Port Multiplier in ICH9
http://www.hkepc.com/bbs/itnews.php?tid=682354&starttime=0&endtime=0
http://www.hkepc.com/bbs/itnews.php?tid=682354&starttime=0&endtime=0
�������匴�B
�����Ă܂ōs�����b�オ����ȁB
��������҂��Ă܂��B
����ɂ��Ă��ʐ^�̗ʂ������c�B
��q�ɂ�������炵�����B
�����Ă܂ōs�����b�オ����ȁB
��������҂��Ă܂��B
����ɂ��Ă��ʐ^�̗ʂ������c�B
��q�ɂ�������炵�����B
�Ԍ����L�����A�ǂ݉��������Ղ�
��ԊS�̂���Speculative Multithreading�ɂ��Ă͈����������������̂ł��ˁB
Usage Model ����2-6
���̃y�[�W����Ԗʔ��������B
Photo66�Ȃ����ɂł����H���ė~�����B
���̃y�[�W����Ԗʔ��������B
Photo66�Ȃ����ɂł����H���ė~�����B
AMD�����ꂩ��̓L���b�V���̊K�w���厖���Č����Ă邵�ȁB
K8L�͂��̑����݂��������B
K8L�͂��̑����݂��������B
��180��Core MicroArchitecture������������(4)
http://journal.mycom.co.jp/column/sopinion/180/
http://journal.mycom.co.jp/column/sopinion/180/
377 �FSocket774�F2006/10/16(��) 04:01:57 ID:lq+7EA5j
>>377
Dog year�Ƃ�Rat year�̋ƊE�ɂ���ƁA���ł�����ł�
�����Ɂu�����v���Ă��܂��̂ŁA��X�Ɏ��グ�Ċ�����
�g�����Ƃ͊m���ɂȂ����A�ʂɒ������P��ł͂Ȃ����낤�B
Dog year�Ƃ�Rat year�̋ƊE�ɂ���ƁA���ł�����ł�
�����Ɂu�����v���Ă��܂��̂ŁA��X�Ɏ��グ�Ċ�����
�g�����Ƃ͊m���ɂȂ����A�ʂɒ������P��ł͂Ȃ����낤�B
>>377
�������ɁA�p�ɂɎg���悤�ȒP��ł��Ȃ��Ǝv�����A�g��������ƌ����Ĉ�a�����o����قǂł��Ȃ�
�������ɁA�p�ɂɎg���悤�ȒP��ł��Ȃ��Ǝv�����A�g��������ƌ����Ĉ�a�����o����قǂł��Ȃ�
>>380
So point totals don't necessarily reflect the relative folding power of the Radeon X1900 XTX.
The GPU client may be doing between 20 and 40 times more work,
but the points Stanford awards don't reflect that.
So point totals don't necessarily reflect the relative folding power of the Radeon X1900 XTX.
The GPU client may be doing between 20 and 40 times more work,
but the points Stanford awards don't reflect that.
382 �FSocket774�F2006/10/17(��) 04:21:05 ID:MZS6129e
������Ȃ�Ă܂�����Ȃ�����Core2Duo�̃G���b�^�C���ŏo���Ă�A�C���e����
�܂Ƃ߂Ă݂��B
process�@core�@�@cache�@�@�@�@�@�@�@�@�@�@�@die-size�@�@�@�@�@�@clock�@�@�@SSE�@�@�@loanch�@�@CPU
90nm�@�@�@dual�@. 2MB(1MBx2) �@�@�@�@�@199����mm.�@�@�`2.80GHz.�@�@SSE3 . �@05'Q2.�@�@AMD Toredo
65nm�@�@..quad�@. 4MB(512kBx4+2MB)�@300����mm??�@�`2.90GHz.�@�@SSE3 . �@07'Q3.�@�@AMD Altair(Barcelona)
65nm�@�@�@dual�@. 3MB(512kBx2+2MB)�@�@??�@�@�@�@�@.�@�@�`2.90GHz.�@�@SSE3 . �@07'Q3.�@�@AMD Antares
65nm�@�@�@dual�@. 1MB(512kBx2)�@�@�@�@ �@??�@�@�@�@�@.�@�@�`2.30GHz.�@�@SSE3 . �@07'Q4.�@�@AMD Arcturus
65nm�@ . single�@�@??�@�@�@�@�@�@�@�@�@�@�@ �@??�@�@�@�@�@�@�@�@�@�@?? �@ �@�@�@SSE3 . �@07'Q4.�@�@AMD Spica
65nm�@�@..quad�@. 8MB(4MBx2) �@�@�@�@�@286����mm.�@�@�`2.66GHz.�@�@S.SSE3�@06'Q4.�@�@Intel Kentsfield
65nm�@�@�@dual�@. 4MB �@�@�@�@�@�@�@�@�@�@143����mm.�@�@�`2.93GHz.�@�@S.SSE3�@06'Q3.�@�@Intel Conroe
65nm�@ . single�@. 1MB �@�@�@�@�@�@�@�@�@�@. 77����mm.�@�@�`1.80GHz.�@�@S.SSE3�@07'Q2.�@�@Intel Conroe-L
45nm�@�@..quad�@12MB(6MBx2) �@�@�@�@�@200����mm??�@�`3.73GHz??�@SSE4 . �@07'Q3??�@Intel Yorkfield
45nm�@�@�@dual�@. 6MB �@�@�@�@�@�@�@�@�@�@103����mm??�@�`4.00GHz??�@SSE4 . �@07'Q4.�@�@Intel Wolfdale
45nm�@ . single�@. 2MB �@�@�@�@�@�@�@�@�@�@. 58����mm??�@�@�@?? �@�@�@�@�@SSE4 . �@�@?? �@�@�@Intel Wolfdale-L
process�@core�@�@cache�@�@�@�@�@�@�@�@�@�@�@die-size�@�@�@�@�@�@clock�@�@�@SSE�@�@�@loanch�@�@CPU
90nm�@�@�@dual�@. 2MB(1MBx2) �@�@�@�@�@199����mm.�@�@�`2.80GHz.�@�@SSE3 . �@05'Q2.�@�@AMD Toredo
65nm�@�@..quad�@. 4MB(512kBx4+2MB)�@300����mm??�@�`2.90GHz.�@�@SSE3 . �@07'Q3.�@�@AMD Altair(Barcelona)
65nm�@�@�@dual�@. 3MB(512kBx2+2MB)�@�@??�@�@�@�@�@.�@�@�`2.90GHz.�@�@SSE3 . �@07'Q3.�@�@AMD Antares
65nm�@�@�@dual�@. 1MB(512kBx2)�@�@�@�@ �@??�@�@�@�@�@.�@�@�`2.30GHz.�@�@SSE3 . �@07'Q4.�@�@AMD Arcturus
65nm�@ . single�@�@??�@�@�@�@�@�@�@�@�@�@�@ �@??�@�@�@�@�@�@�@�@�@�@?? �@ �@�@�@SSE3 . �@07'Q4.�@�@AMD Spica
65nm�@�@..quad�@. 8MB(4MBx2) �@�@�@�@�@286����mm.�@�@�`2.66GHz.�@�@S.SSE3�@06'Q4.�@�@Intel Kentsfield
65nm�@�@�@dual�@. 4MB �@�@�@�@�@�@�@�@�@�@143����mm.�@�@�`2.93GHz.�@�@S.SSE3�@06'Q3.�@�@Intel Conroe
65nm�@ . single�@. 1MB �@�@�@�@�@�@�@�@�@�@. 77����mm.�@�@�`1.80GHz.�@�@S.SSE3�@07'Q2.�@�@Intel Conroe-L
45nm�@�@..quad�@12MB(6MBx2) �@�@�@�@�@200����mm??�@�`3.73GHz??�@SSE4 . �@07'Q3??�@Intel Yorkfield
45nm�@�@�@dual�@. 6MB �@�@�@�@�@�@�@�@�@�@103����mm??�@�`4.00GHz??�@SSE4 . �@07'Q4.�@�@Intel Wolfdale
45nm�@ . single�@. 2MB �@�@�@�@�@�@�@�@�@�@. 58����mm??�@�@�@?? �@�@�@�@�@SSE4 . �@�@?? �@�@�@Intel Wolfdale-L
384 �FSocket774�F2006/10/17(��) 06:12:55 ID:VctWK8J8
45nm�ł��V�f���A��������
Yorkfield��4GHz�ɒB����
Wolfdale�ł͂���ɏ�ɂȂ��Ȃ��́H
Wolfdale�ł͂���ɏ�ɂȂ��Ȃ��́H
4G�����Ȃ��\��
4GHz�Ƃ�����Nehalem�̏��Ƃ�������ɂȂ��Ă���̂ł͂Ȃ����ƌl�I�Ɏv���E�E�E�B
Nehalem��10GHz���낗����������
Nehalem��CoreMA�{�w�e���W�j�A�X�}���`�R�A
4G�͂�����Ȃ�ł������W���}�C�J
�w�e���ȏꍇ�A�V���O���X���b�h���\���K�v�ȏ����ƁA�}���`�X���b�h������
������OS�ɒm�点�ā^���邢��OS�������I�Ɍ������āA���ꂼ��̏�����K��
�R�A�ɃX�P�W���[�����O���Ă��K�v������킯�����ǁAVista �ɂ́A��������
�@�\�̃T�|�[�g�͂Ȃ���˂��B
�Ƃ������Ƃ́AVista �̎��� Windows �ɂȂ�킯�ŁA����Microsoft�̊J���y�[�X
���ƁA2010�N�`2012�N���A�Ƃ������Ƃ́ANehalem �͂��肦�Ȃ��āAGesher ���A
�Ђ���Ƃ���Ƃ��̎����炢�ł́H
������OS�ɒm�点�ā^���邢��OS�������I�Ɍ������āA���ꂼ��̏�����K��
�R�A�ɃX�P�W���[�����O���Ă��K�v������킯�����ǁAVista �ɂ́A��������
�@�\�̃T�|�[�g�͂Ȃ���˂��B
�Ƃ������Ƃ́AVista �̎��� Windows �ɂȂ�킯�ŁA����Microsoft�̊J���y�[�X
���ƁA2010�N�`2012�N���A�Ƃ������Ƃ́ANehalem �͂��肦�Ȃ��āAGesher ���A
�Ђ���Ƃ���Ƃ��̎����炢�ł́H
�V���v���Ȑ�p�R�A�Ɗg������
2030�N�܂ő҂��Ƃ�
394 �FSocket774�F2006/10/17(��) 22:57:20 ID:OOT4ZckY
Nehalem�́A���s�g���[�X�L���b�V���A�n�C�p�[�X���b�f�B���O�ƁA�l�b�g�o�[�X�g�̋Z�p����������낤�ˁB
�{�����R�������Ȃ��s���邾�낤�B
CoreMA���A����Ȃɏ_��ȃ}�C�N���A�[�L�e�N�`���Ƃ͎v���Ȃ��̂ŁA�܂������̐V�K�v���Ɨ\�z���Ă��邪�B
�{�����R�������Ȃ��s���邾�낤�B
CoreMA���A����Ȃɏ_��ȃ}�C�N���A�[�L�e�N�`���Ƃ͎v���Ȃ��̂ŁA�܂������̐V�K�v���Ɨ\�z���Ă��邪�B
394�̃A�z���ɒE�X
����ۂ��Ă�����Ȃ���
�g���[�X�L���b�V���͈̂��l�����������Ă��͂��B
Nehalem���ǂ����͒m��A�V�A�[�L�e�B�N�`���ōs���Ȃ瓋�ڂ͂��肦����?
�d�͌������X�ɍ��߂�ɂ͗ǂ���i���ƁB
HyperThreading�ɂ��ẮA�]����intel�ISMT�������̖̂��̂͂Ƃ肠������߂āA
���@�I�}���`�X���b�f�B���O�Z�p�������ď̂������ȗ\��������B
�����������Nehalem�ɂȂ邩�͒m��ANetBurst�X�����R�A�ɂ͉B��Ď����A
���enable�݂����ȓW�J���ʔ������B
Nehalem���ǂ����͒m��A�V�A�[�L�e�B�N�`���ōs���Ȃ瓋�ڂ͂��肦����?
�d�͌������X�ɍ��߂�ɂ͗ǂ���i���ƁB
HyperThreading�ɂ��ẮA�]����intel�ISMT�������̖̂��̂͂Ƃ肠������߂āA
���@�I�}���`�X���b�f�B���O�Z�p�������ď̂������ȗ\��������B
�����������Nehalem�ɂȂ邩�͒m��ANetBurst�X�����R�A�ɂ͉B��Ď����A
���enable�݂����ȓW�J���ʔ������B
Nehalem��CoreMA+CSI�Ƃ����\���嗬����ˁH
Core MA�����ǁ{CSI
2008�N�Ƃ����������l����ƃ��X�N���傫�����邱�Ƃ͂���
2008�N�Ƃ����������l����ƃ��X�N���傫�����邱�Ƃ͂���
Core 3 Quad
�X��Core 2 Oct��
�����AIntel��ł�Oct��Double Quad������
�X��Core 2 Oct��
�����AIntel��ł�Oct��Double Quad������
Core 3 Oct orz
�܂��A�ǂ��������邩�������
�܂��A�ǂ��������邩�������
�܂��J������̂̓C�X���G���`�[��
Gesher�̂��ƁH
Pentium5�ŗǂ�������Ȃ����Ǝv��
���������v��
>>359
90nm�v���Z�X�Z�p�ɔ�ׁA65nm�v���Z�X�Z�p�̓g�����W�X�^���\��20���A�b�v���Ȃ���A
�X�C�b�`���O�d�͂�30����������B2007�N�ɂ�45nm�v���Z�X�Z�p�̎��p����ڎw���Ă���B�����65nm�v���Z�X�Z�p�����A����Ƀg�����W�X�^���\��20���A�b�v���A�X�C�b�`���O�d�͂�30���ጸ���邱�Ƃ��ł���B
http://enterprise.watch.impress.co.jp/cda/topic/2006/04/07/7574.html
���g�����W�X�^���̏ꍇ
C2E X6800 2.93Ghz TDP 75W
wolfdale x1.2= 3.5Ghz x0.7= 52W
C2E X6900 3.2Ghz TDP 80W �������~�H
wolfdale x1.2= 3.84Ghz x0.7= 56W
����Ȋ�����
90nm�v���Z�X�Z�p�ɔ�ׁA65nm�v���Z�X�Z�p�̓g�����W�X�^���\��20���A�b�v���Ȃ���A
�X�C�b�`���O�d�͂�30����������B2007�N�ɂ�45nm�v���Z�X�Z�p�̎��p����ڎw���Ă���B�����65nm�v���Z�X�Z�p�����A����Ƀg�����W�X�^���\��20���A�b�v���A�X�C�b�`���O�d�͂�30���ጸ���邱�Ƃ��ł���B
http://enterprise.watch.impress.co.jp/cda/topic/2006/04/07/7574.html
���g�����W�X�^���̏ꍇ
C2E X6800 2.93Ghz TDP 75W
wolfdale x1.2= 3.5Ghz x0.7= 52W
C2E X6900 3.2Ghz TDP 80W �������~�H
wolfdale x1.2= 3.84Ghz x0.7= 56W
����Ȋ�����
Next-Generation Intel DP Workstation Platform Unveiled
http://www.dailytech.com/article.aspx?newsid=4590
http://www.dailytech.com/article.aspx?newsid=4590
IDF : Intel Excited About Penryn
http://www.vr-zone.com/?i=4159
>Mooly Eden also drop hints about an integrated memory controller in the next processor architecture
>which is none other than Nehalem.
http://www.vr-zone.com/?i=4159
>Mooly Eden also drop hints about an integrated memory controller in the next processor architecture
>which is none other than Nehalem.
http://www.dailytech.com/article.aspx?newsid=4589
FSB1333MHz��Conroe@2007
3GHz��E6850�AFSB1066MHz�̂܂܂�2.93GHz��E6800�A
2.66GHz��E6750�A2.33GHz��E6650
Bearlake�`�b�v�Z�b�g�t�@�~���[�ƈꏏ�ɓo��H
FSB1333MHz��Conroe@2007
3GHz��E6850�AFSB1066MHz�̂܂܂�2.93GHz��E6800�A
2.66GHz��E6750�A2.33GHz��E6650
Bearlake�`�b�v�Z�b�g�t�@�~���[�ƈꏏ�ɓo��H
Inq�ɂ���ȋL�����B
Intel QuickData laid bare
http://www.theinquirer.net/default.aspx?article=35154
I/OAT
http://www.intel.com/technology/ioacceleration/306484.pdf
http://www.intel.com/technology/ioacceleration/306517.pdf
http://www.intel.com/technology/ioacceleration/media/demo.html
VT�Ƃ�EM64T�̉e�ł��܂�b��ɂȂ�Ȃ�I/OAT�����nj��݂�*Ts�̒��ł͍ō����삾�Ǝv���B
*Ts�Ƃ����Η��N��AMT2, TXT, VT-d����������͓I�B
vPro��Viiv�ƈ���đ���Centrino�ɂȂ鈫���B
Intel QuickData laid bare
http://www.theinquirer.net/default.aspx?article=35154
I/OAT
http://www.intel.com/technology/ioacceleration/306484.pdf
http://www.intel.com/technology/ioacceleration/306517.pdf
http://www.intel.com/technology/ioacceleration/media/demo.html
VT�Ƃ�EM64T�̉e�ł��܂�b��ɂȂ�Ȃ�I/OAT�����nj��݂�*Ts�̒��ł͍ō����삾�Ǝv���B
*Ts�Ƃ����Η��N��AMT2, TXT, VT-d����������͓I�B
vPro��Viiv�ƈ���đ���Centrino�ɂȂ鈫���B
Nehalem�́A394�̂悤�Ȋ���(+CSI)���Ⴀ�Ȃ��́H�ł��p�C�v���C���͒Z����
���邾�낤�ȁB�Ƃɂ����ȓd�͂�O��ɍ��B
�ł��A����CoreMA+CSI�Ƃ����������ɏo�Ă�b��������A�{�����Ƃ���ƁE�E�A
�܂����Ă�Nehalem�͎��s���āA�������Ȃ��I���S����Penryn����Ă��āA
CSI�����������Ƃ����Ă�B�R�[�h�l�[�����������u���B�Ƃ������ɂȂ�Ȃ����H
Penryn�o�����悳�����Ȃ̂ŁA���肦�Ȃ��b���Ⴀ�Ȃ��B
���邾�낤�ȁB�Ƃɂ����ȓd�͂�O��ɍ��B
�ł��A����CoreMA+CSI�Ƃ����������ɏo�Ă�b��������A�{�����Ƃ���ƁE�E�A
�܂����Ă�Nehalem�͎��s���āA�������Ȃ��I���S����Penryn����Ă��āA
CSI�����������Ƃ����Ă�B�R�[�h�l�[�����������u���B�Ƃ������ɂȂ�Ȃ����H
Penryn�o�����悳�����Ȃ̂ŁA���肦�Ȃ��b���Ⴀ�Ȃ��B
��Nehalem���c���Ă��Ȃ�����
����Nehalem���Ⴀ�Ȃ��āA�A�Q���Nehalem��HTT���ڂ��Ƃ������b��
�O����o�Ă���B���Ȃ����匴�����������Ă����A�܂�Inq������ǂ��
�����Ă邾�����낤���ǁB
�O����o�Ă���B���Ȃ����匴�����������Ă����A�܂�Inq������ǂ��
�����Ă邾�����낤���ǁB
Intel to Include 1GB NAND Chipset on New Notebooks
http://www.dailytech.com/article.aspx?newsid=4605
IDF Fall 2006 - PCI Express Update
http://journal.mycom.co.jp/articles/2006/10/18/idf1/
http://www.dailytech.com/article.aspx?newsid=4605
IDF Fall 2006 - PCI Express Update
http://journal.mycom.co.jp/articles/2006/10/18/idf1/
SocketB�̓����R��������Nehalem�p�ŁASocketH�̓����R���������Nehalem�p�H
�Ȃ�ł���Ȃ��Ƃ�����낤�B
���o�C���������ȁB
CPU���ɓ��ڂ���ƃ������A�N�Z�X������x��CPU���������Ȃ���Ȃ��̂ŏ���d�̖͂ʂł͕s���ł͂��邪�B
�Ȃ�ł���Ȃ��Ƃ�����낤�B
���o�C���������ȁB
CPU���ɓ��ڂ���ƃ������A�N�Z�X������x��CPU���������Ȃ���Ȃ��̂ŏ���d�̖͂ʂł͕s���ł͂��邪�B
���o�C�����Ƃ�����A�t��200pin�ȏ㑝���Ă�킯������A
���̕���IMC�̕��A�ƍl�����ق������R����ȁB
���̕���IMC�̕��A�ƍl�����ق������R����ȁB
�����R��������DP�ȏ�ŁAUP��GMCH�Ƀ������q����Ȃ�?
IDF Taiwan: 45nm Penryn design project to be completed in 1Q, Robson to become pervasive in 2-3 years
http://www.digitimes.com/NewsShow/NewsSearch.asp?DocID=VL000000000000000000000000000282&query=PENRYN
Intel is on track to complete its first 45nm design in the first quarter of 2007, and the company aims to launch related
products in the second half of next year, Intel confirmed at the ongoing Intel Developer Forum (IDF) conference in Taipei.
The company also revealed it expects Robson cache technology to become pervasive in notebooks in 2-3 years.
Intel����pIDF��H2 2007��45nm���i�̃��[���`�������Ă��邲�l�q�i�E�́E�j
http://www.digitimes.com/NewsShow/NewsSearch.asp?DocID=VL000000000000000000000000000282&query=PENRYN
Intel is on track to complete its first 45nm design in the first quarter of 2007, and the company aims to launch related
products in the second half of next year, Intel confirmed at the ongoing Intel Developer Forum (IDF) conference in Taipei.
The company also revealed it expects Robson cache technology to become pervasive in notebooks in 2-3 years.
Intel����pIDF��H2 2007��45nm���i�̃��[���`�������Ă��邲�l�q�i�E�́E�j
Tigerton (4�R�A Xeon MP)��CSI�̔�I���B
http://news.com.com/2100-1006_3-6128125.html
���X�̎ʐ^��C������B
http://news.com.com/2300-1006_3-6128108.html
�@�@-----------------------
�@�@In addition, servers based on Tigerton will use the Clarksboro chipset. Clarksboro eliminates
�@�@the dual-independent bus structure used on current Tulsa-class servers and replaces it with
�@�@a dedicated link between each quad-core chip and the chipset.
�@�@-----------------------
�����[�X������C���炩�ɂ���Ȃ������݂��������ǁC���̕��ł퉓�������������B
http://news.com.com/2100-1006_3-6128125.html
���X�̎ʐ^��C������B
http://news.com.com/2300-1006_3-6128108.html
�@�@-----------------------
�@�@In addition, servers based on Tigerton will use the Clarksboro chipset. Clarksboro eliminates
�@�@the dual-independent bus structure used on current Tulsa-class servers and replaces it with
�@�@a dedicated link between each quad-core chip and the chipset.
�@�@-----------------------
�����[�X������C���炩�ɂ���Ȃ������݂��������ǁC���̕��ł퉓�������������B
421 �FMAC�I�^���⑫�F2006/10/21(�y) 15:16:47 ID:AaJ6b2ox
���ɋ����悤�Șb�ł����������ǁCTigerton��MCM���B
http://news.com.com/2300-1006_3-6128108-3.html
�@�@-------------------------
�@�@A Tigerton processor package up close. Each package contains two dual-core chips
�@�@for a total of four processing cores per package.
�@�@-------------------------
�m�[�X�u���b�W�̃q�[�g�V���N����ۓI���B
http://news.com.com/2300-1006_3-6128108-6.html
�@�@-------------------------
�@�@The north bridge is part of the "Clarksboro" chipset used in the "Caneland" platform
�@�@for servers using Tigerton processors and their successors, "Dunnington."
�@�@-------------------------
http://news.com.com/2300-1006_3-6128108-3.html
�@�@-------------------------
�@�@A Tigerton processor package up close. Each package contains two dual-core chips
�@�@for a total of four processing cores per package.
�@�@-------------------------
�m�[�X�u���b�W�̃q�[�g�V���N����ۓI���B
http://news.com.com/2300-1006_3-6128108-6.html
�@�@-------------------------
�@�@The north bridge is part of the "Clarksboro" chipset used in the "Caneland" platform
�@�@for servers using Tigerton processors and their successors, "Dunnington."
�@�@-------------------------
CSI����Ȃ��BHigh Speed Interconnect�B
�����[�X�����͐����IDF�ɂ���Q3�B
�����[�X�����͐����IDF�ɂ���Q3�B
423 �FMAC�I�^��422 �����F2006/10/21(�y) 15:40:03 ID:AaJ6b2ox
>>422
�@�@-----------------
�@�@CSI����Ȃ��BHigh Speed Interconnect�B
�@�@-----------------
�������ӂ��邷�BCSI����Ȃ��Ƃ���ƁC"High Speed Interconnect"�Ƃ����̂�]���^FSB�Ȃ��H
�������̃T�C�g�ł�C���������ϑ��݂��������ǁB�B�B
�@�@-----------------
�@�@CSI����Ȃ��BHigh Speed Interconnect�B
�@�@-----------------
�������ӂ��邷�BCSI����Ȃ��Ƃ���ƁC"High Speed Interconnect"�Ƃ����̂�]���^FSB�Ȃ��H
�������̃T�C�g�ł�C���������ϑ��݂��������ǁB�B�B
>>423
TheInquirer���ʂ���4 x FSB�Ƃ����b���o�Ă��邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=120068917&forumid=1
�@�@------------------------
�@�@Yeah, it is 4x FSB, but they are trying like hell to make it seem otherwise. My concerns
�@�@here are pin count and power, which brings secondary effects into play like board cost
�@�@and layers, PSU size etc etc.
�@�@It is basically two Blackfords welded together, so I have high hopes for performance. :)
�@�@------------------------
two Blackfords�Ƃ�������Ă��邷���ǁC�܂����m�[�X�u���b�W��MCM�����H
TheInquirer���ʂ���4 x FSB�Ƃ����b���o�Ă��邷�B
http://www.aceshardware.com/forums/read_post.jsp?id=120068917&forumid=1
�@�@------------------------
�@�@Yeah, it is 4x FSB, but they are trying like hell to make it seem otherwise. My concerns
�@�@here are pin count and power, which brings secondary effects into play like board cost
�@�@and layers, PSU size etc etc.
�@�@It is basically two Blackfords welded together, so I have high hopes for performance. :)
�@�@------------------------
two Blackfords�Ƃ�������Ă��邷���ǁC�܂����m�[�X�u���b�W��MCM�����H
MCM�Ȃ�FB-DIMM��6ch�ł͂Ȃ�8ch�ɂȂ�Ǝv���B
����ɃX�k�[�v�t�B���^��������Ȃ��ăf�B���N�g�����K�v�ɂȂ�B
�����Č�����MCM�ł͂Ȃ��A�������āA�X�̃��C�e���V�Ƀt�H�[�J�X(NUMA)�����ق����s�[�N���\�͍����͂��B
1Chip���Ǝv���܂��B
����ɃX�k�[�v�t�B���^��������Ȃ��ăf�B���N�g�����K�v�ɂȂ�B
�����Č�����MCM�ł͂Ȃ��A�������āA�X�̃��C�e���V�Ƀt�H�[�J�X(NUMA)�����ق����s�[�N���\�͍����͂��B
1Chip���Ǝv���܂��B
��H CNET �ɂ� Tigerton �� third quarter of 2007 ���Ă��邯�ǁH
ttp://news.com.com/Intel+shows+off+sweet+16+server/2100-1006_3-6128125.html
AMD �Ƃ��ẮA���b�L�[���˂��B
> 1Chip���Ǝv���܂��B
����͊�]����Ȃ��āA�Ȃ���������́H �|�C���^���ڂ�B
ttp://news.com.com/Intel+shows+off+sweet+16+server/2100-1006_3-6128125.html
AMD �Ƃ��ẮA���b�L�[���˂��B
> 1Chip���Ǝv���܂��B
����͊�]����Ȃ��āA�Ȃ���������́H �|�C���^���ڂ�B
����Ȏ����>>426��A���傢�ƕ����Ă����B�X���Ƃ���܊W�Ȃ����ǂ��B
���̂������A�ߏ��̎�����X���s������ł��B������X���B
��������Ȃ�MAC�I�^�̏������݂��߂��Ⴍ���Ⴂ���ς��œǂ݂���Ȃ���ł��B
�ŁA�悭������Ȃ��ꖋ�������ĂāATigerton�A�Ƃ������Ă����ł��B
�����ˁA�A�z���ƁB�n�����ƁB
���O��ȁATigerton�@���ŕ��i���ĂȂ�������X���ɗ��Ă�ˁ[��A�{�P���B
Tigerton����ATigerton�B
�Ȃe�q�A��Ƃ������邵�B��ƂS�l�Ŏ�����X�����B���߂łā[�ȁB
��[���p�p�㓡�L���ᔻ�������Ⴄ���[�A�Ƃ������Ă�́B�������Ă��Ȃ��B
���O��ȁAPaxvillMP��邩��폜�˗��o���Ƃ��ƁB
������X�����Ă̂͂ȁA�����ƎE���Ƃ��Ă�ׂ��Ȃ�B
�����Ƀ��X�����z�Ƃ����܂��n�܂��Ă����������Ȃ��A
�h�����h����邩�A����ȕ��͋C��������ˁ[���B���q���́A��������ł�B
�ŁA����ƍ��ꂽ���Ǝv������A�ׂ̓z���A�|�C���^���ڂ�A�Ƃ������Ă��ł��B
�����ł܂��Ԃ���ł���B
���̂ȁA�|�C���^�Ȃ�Ă��傤�ї��s��ˁ[��B�{�P���B
���ӂ��Ȋ炵�ĉ����A�|�C���^���ڂ�A���B
���O�͖{���Ƀ|�C���^�~�����̂��Ɩ₢�����B�₢�l�߂����B���P���Ԗ₢�l�߂����B
���O�A�|�C���^���Č��������������Ⴄ�ƁB
Intel�ʂ̉����猾�킹�Ă��炦���AIntel�ʂ̊Ԃł̍ŐV���s�͂���ς�A
Caneland�A���ꂾ�ˁB
�吷��FSB �ϑz�B���ꂪ�ʂ̏������݁B
Caneland���Ă̂�FSB�����߂ɓ����Ă�B�������ׂ������Ȃ߁B����B
�ŁA����ɑ吷��ϑz�B����ŋ��B
����������𗊂ނƎ�����Z���Ƀ}�[�N�����Ƃ����댯�������A���n�̌��B
�f�l�ɂ͂��E�ߏo���Ȃ��B
�܂����O�A>>426�́AClovertown�ł������ĂȂ������Ă������B
���̂������A�ߏ��̎�����X���s������ł��B������X���B
��������Ȃ�MAC�I�^�̏������݂��߂��Ⴍ���Ⴂ���ς��œǂ݂���Ȃ���ł��B
�ŁA�悭������Ȃ��ꖋ�������ĂāATigerton�A�Ƃ������Ă����ł��B
�����ˁA�A�z���ƁB�n�����ƁB
���O��ȁATigerton�@���ŕ��i���ĂȂ�������X���ɗ��Ă�ˁ[��A�{�P���B
Tigerton����ATigerton�B
�Ȃe�q�A��Ƃ������邵�B��ƂS�l�Ŏ�����X�����B���߂łā[�ȁB
��[���p�p�㓡�L���ᔻ�������Ⴄ���[�A�Ƃ������Ă�́B�������Ă��Ȃ��B
���O��ȁAPaxvillMP��邩��폜�˗��o���Ƃ��ƁB
������X�����Ă̂͂ȁA�����ƎE���Ƃ��Ă�ׂ��Ȃ�B
�����Ƀ��X�����z�Ƃ����܂��n�܂��Ă����������Ȃ��A
�h�����h����邩�A����ȕ��͋C��������ˁ[���B���q���́A��������ł�B
�ŁA����ƍ��ꂽ���Ǝv������A�ׂ̓z���A�|�C���^���ڂ�A�Ƃ������Ă��ł��B
�����ł܂��Ԃ���ł���B
���̂ȁA�|�C���^�Ȃ�Ă��傤�ї��s��ˁ[��B�{�P���B
���ӂ��Ȋ炵�ĉ����A�|�C���^���ڂ�A���B
���O�͖{���Ƀ|�C���^�~�����̂��Ɩ₢�����B�₢�l�߂����B���P���Ԗ₢�l�߂����B
���O�A�|�C���^���Č��������������Ⴄ�ƁB
Intel�ʂ̉����猾�킹�Ă��炦���AIntel�ʂ̊Ԃł̍ŐV���s�͂���ς�A
Caneland�A���ꂾ�ˁB
�吷��FSB �ϑz�B���ꂪ�ʂ̏������݁B
Caneland���Ă̂�FSB�����߂ɓ����Ă�B�������ׂ������Ȃ߁B����B
�ŁA����ɑ吷��ϑz�B����ŋ��B
����������𗊂ނƎ�����Z���Ƀ}�[�N�����Ƃ����댯�������A���n�̌��B
�f�l�ɂ͂��E�ߏo���Ȃ��B
�܂����O�A>>426�́AClovertown�ł������ĂȂ������Ă������B
http://www.techpowerup.com/?18887
Intel Corp., the world's largest maker of x86 central processing units,
said that the first 45nm microprocessor's design will be
completed this quarter and the commercial shipments
of such chips will begin in the second half of next year.
�͂����������������I�I�I�I�I�I
Intel Corp., the world's largest maker of x86 central processing units,
said that the first 45nm microprocessor's design will be
completed this quarter and the commercial shipments
of such chips will begin in the second half of next year.
�͂����������������I�I�I�I�I�I
429 �FMAC�I�^��428 �����F2006/10/21(�y) 20:42:24 ID:AaJ6b2ox
>>428
����C�O�����Ȃ��ǁB�B�B
�@Intel�̎l�����̃����[�X http://www.intel.com/intel/finance/earnings/IntelQ32006EarningsRelease.pdf
-> X-bit Labs http://www.xbitlabs.com/news/cpu/display/20061019222838.html
-> techPowerUp!
���Ȃ݂Ɉꎟ����C����ȃ������B
�@�@---------------------------
�@�@Intel announced that the first of 15 45nm processor designs is scheduled to be completed
�@�@by the end of the year, with Intel's next-genertion 45nm process technology on track for
�@�@production in the second half of 2007.
�@�@---------------------------
����C�O�����Ȃ��ǁB�B�B
�@Intel�̎l�����̃����[�X http://www.intel.com/intel/finance/earnings/IntelQ32006EarningsRelease.pdf
-> X-bit Labs http://www.xbitlabs.com/news/cpu/display/20061019222838.html
-> techPowerUp!
���Ȃ݂Ɉꎟ����C����ȃ������B
�@�@---------------------------
�@�@Intel announced that the first of 15 45nm processor designs is scheduled to be completed
�@�@by the end of the year, with Intel's next-genertion 45nm process technology on track for
�@�@production in the second half of 2007.
�@�@---------------------------
������ƕ���������ł����B�B
http://journal.mycom.co.jp/articles/2006/10/21/fpf2/
���̋L���ɂ���悤��SPARC64VI��Conroe�̗l��
2�̃R�A��L2�����L���Ă��āASPARC64VII��4�̃R�A
��L2�����L���Ă��܂��B
KentsField��Conroe�̃_�C�����ׂ��\���ŁA���̎���
Nehalem���V���O���_�C�ɂ͂Ȃ���̂́ADualCore����
���ׂ����ɋ߂��ł���ˁH
SPARCVII�̗l��4�R�A�ň��L2�����L�Ƃ����͓̂��
�̂ł����ˁH
http://journal.mycom.co.jp/articles/2006/10/21/fpf2/
���̋L���ɂ���悤��SPARC64VI��Conroe�̗l��
2�̃R�A��L2�����L���Ă��āASPARC64VII��4�̃R�A
��L2�����L���Ă��܂��B
KentsField��Conroe�̃_�C�����ׂ��\���ŁA���̎���
Nehalem���V���O���_�C�ɂ͂Ȃ���̂́ADualCore����
���ׂ����ɋ߂��ł���ˁH
SPARCVII�̗l��4�R�A�ň��L2�����L�Ƃ����͓̂��
�̂ł����ˁH
>>430
>KentsField��Conroe�̃_�C�����ׂ��\���ŁA���̎���
>Nehalem���V���O���_�C�ɂ͂Ȃ���̂́ADualCore����
>���ׂ����ɋ߂��ł���ˁH
Kentsfield�̎���Yorkfield�iPenryn�n�f�X�N�g�b�v�ŃN�A�b�h�j�B�S�R�A�Ȃ̂͊m������
�ǂ������\���ɂȂ邩�͂܂��s���B
Nehalem��Penryn�̂���Ɏ��B
>KentsField��Conroe�̃_�C�����ׂ��\���ŁA���̎���
>Nehalem���V���O���_�C�ɂ͂Ȃ���̂́ADualCore����
>���ׂ����ɋ߂��ł���ˁH
Kentsfield�̎���Yorkfield�iPenryn�n�f�X�N�g�b�v�ŃN�A�b�h�j�B�S�R�A�Ȃ̂͊m������
�ǂ������\���ɂȂ邩�͂܂��s���B
Nehalem��Penryn�̂���Ɏ��B
433 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/10/22(��) 00:50:18 ID:9hdXmUzn
�搶�I�����ł��H
Core1 Core2 �@Core3 Core 4
�@�@|�@�@�@|�@�@�@�@�@�@|�@�@�@|
���LL2(2MB)�@���LL2(2MB)
�@�@�@�b�@�@�@�@�@�@�@ �b
�@���@�L�@L�@3�@(8�`16MB)
Core1 Core2 �@Core3 Core 4
�@�@|�@�@�@|�@�@�@�@�@�@|�@�@�@|
���LL2(2MB)�@���LL2(2MB)
�@�@�@�b�@�@�@�@�@�@�@ �b
�@���@�L�@L�@3�@(8�`16MB)
434 �FMAC�I�^���c�q �����F2006/10/22(��) 01:11:49 ID:omApUt1I
>>433
�p���m�C�A��Intel��L1-L1�Ƃ�L2-L2��direct intervention���Ȃ��͂��������Ǝv�����B
����Ȋ������ƁB�B�B
�@�@Core1 Core2 �@Core3 Core 4
�@�@�@�@|�@�@�@|�@�@�@�@ �@�@|�@�@�@|
�@�@���LL2(2MB) <-> ���LL2(2MB)
�@�@ �@�@�@�b�@�@�@ �@�@�@�@ �b
�@�@�@ ���@�L�@L�@3�@(8�`16MB)
�p���m�C�A��Intel��L1-L1�Ƃ�L2-L2��direct intervention���Ȃ��͂��������Ǝv�����B
����Ȋ������ƁB�B�B
�@�@Core1 Core2 �@Core3 Core 4
�@�@�@�@|�@�@�@|�@�@�@�@ �@�@|�@�@�@|
�@�@���LL2(2MB) <-> ���LL2(2MB)
�@�@ �@�@�@�b�@�@�@ �@�@�@�@ �b
�@�@�@ ���@�L�@L�@3�@(8�`16MB)
�@�@�@�@�@�@�@����ͱشŽ
�@�@Core1�@�@Core2 �@ Core3 �@ Core 4
�@ �@�^�_�@�@ �^�_�@�@�@�^�_�@�@ �^�_
�@1M�@�@L2 1M�@�@L2 1M�@�@L2 1M�@�@L2
�@�@�@�@�@�@�b�@ �@ �@ �b�@ �@ �@ �b�@ �@ �@ �b
�@�@�@�@�@�@�@L�@3�@(8�`16MB)
�@�@Core1�@�@Core2 �@ Core3 �@ Core 4
�@ �@�^�_�@�@ �^�_�@�@�@�^�_�@�@ �^�_
�@1M�@�@L2 1M�@�@L2 1M�@�@L2 1M�@�@L2
�@�@�@�@�@�@�b�@ �@ �@ �b�@ �@ �@ �b�@ �@ �@ �b
�@�@�@�@�@�@�@L�@3�@(8�`16MB)
436 �FDunnington�F2006/10/22(��) 01:14:47 ID:3bTeMige
>>433-434
�ĂHL2�̗e�ʂ��Ⴄ���ǁB
�ĂHL2�̗e�ʂ��Ⴄ���ǁB
>>431-432
�������K�w���ǂ����炢���Ă��悤�ȋC����������ς��̂����ȁB
��̋��勤�L�L���b�V����肠����x�������ė}�����ق����A
���X�̃L���b�V���\�́i�ш��C�e���V�Ƃ��j���P���₷�����낤����A���ʓI�ɂƂ����邩���ȁB�܂��A�m��ǁB
�������K�w���ǂ����炢���Ă��悤�ȋC����������ς��̂����ȁB
��̋��勤�L�L���b�V����肠����x�������ė}�����ق����A
���X�̃L���b�V���\�́i�ш��C�e���V�Ƃ��j���P���₷�����낤����A���ʓI�ɂƂ����邩���ȁB�܂��A�m��ǁB
http://plusd.itmedia.co.jp/pcuser/articles/0610/23/news011.html
�R�[�h�l�[�����^�K��
�R�[�h�l�[�����^�K��
��Intel�W�����\��CIO�������ACIO�����͂��ׂ��̈�ƕ]�����@���Љ�
http://enterprise.watch.impress.co.jp/cda/topic/2006/10/23/8896.html
http://enterprise.watch.impress.co.jp/cda/topic/2006/10/23/8896.html
�b�Ƃ��Ă�C>>420-424�̑��������ǁCTechReport��Tigerton�̃f���̋L�����f�ڂ��Ă��邷�B
http://www.techreport.com/onearticle.x/11099
�������C�o�X��FSB����Ȃ��Ƃ����l���̗l��
�@�@---------------------
�@�@Notice the four CPU coolers grouped together across the length of the case. Such a l
�@�@ayout would likely be impossible without Caneland's point-to-point connection between
�@�@the chipset and the CPU.
�@�@---------------------
�v���Z�b�T�ƃ`�b�v�Z�b�g�̈ʒu�W����C�����z�����K�v�ȃo�X�ł햳���Ƃ������Ƃ̂悤�����ǁB�B�B
http://www.techreport.com/onearticle.x/11099
�������C�o�X��FSB����Ȃ��Ƃ����l���̗l��
�@�@---------------------
�@�@Notice the four CPU coolers grouped together across the length of the case. Such a l
�@�@ayout would likely be impossible without Caneland's point-to-point connection between
�@�@the chipset and the CPU.
�@�@---------------------
�v���Z�b�T�ƃ`�b�v�Z�b�g�̈ʒu�W����C�����z�����K�v�ȃo�X�ł햳���Ƃ������Ƃ̂悤�����ǁB�B�B
443 �FSocket774�F2006/10/26(��) 19:51:56 ID:uOROfs85
http://sg.vr-zone.com/?i=4208
2007Q4
�EWolfdale-M
3MB L2$
FSB 1066MHz
3.4�`3.7GHz
dual core
TDP 57W
�EWolfdale-L
1MB L2$
FSB 800MHz
2.4�`3.0 GHz
single core
TDP 35W
2007Q4
�EWolfdale-M
3MB L2$
FSB 1066MHz
3.4�`3.7GHz
dual core
TDP 57W
�EWolfdale-L
1MB L2$
FSB 800MHz
2.4�`3.0 GHz
single core
TDP 35W
���x���Ă�3.4�`3.7GHz���Ă̂��M���
�ق�Ƃɂ����Ȃ�������������ǂ�
�ق�Ƃɂ����Ȃ�������������ǂ�
FSB 1333����Ȃ��̂���
http://sg.vr-zone.com/?i=4184
Wolfdale
(45nm, 2C/2T, 1333FSB, 6MB L2)
3.5-4.0GHz
wolfdale-M��wolfdale�������āAwolfdale-M�̂ق���FSB1066
wolfdale�̂ق���FSB1333�炵���B
M�͒�R�X�g�ł��낤��
Wolfdale
(45nm, 2C/2T, 1333FSB, 6MB L2)
3.5-4.0GHz
wolfdale-M��wolfdale�������āAwolfdale-M�̂ق���FSB1066
wolfdale�̂ق���FSB1333�炵���B
M�͒�R�X�g�ł��낤��
Wolfdale��Wolfdale-M�̊W��Conroe��Allendale�̊W�Ɠ����B
�f���A���R�A�̃x�[�V�b�N��
��
�L���b�V�������̃f���A���R�A������
��
����ɃL���b�V����������V���O���R�ACeleron
�f���A���R�A�̃x�[�V�b�N��
��
�L���b�V�������̃f���A���R�A������
��
����ɃL���b�V����������V���O���R�ACeleron
2cpu.com��Tigerton�ʐ^�W���B
http://www.2cpu.com/gallery/tigerton_caneland_beta
Conroe/Woodcrest�̎��Ɠ��l�ɁC�����@�����f�B�A�̃q�g�����R�ɐG���悤�ȓ�����
���J���Ă���͗l���B
Core2/2.66GHz x 16-way�����B�B�B
http://www.2cpu.com/gallery/tigerton_caneland_beta
Conroe/Woodcrest�̎��Ɠ��l�ɁC�����@�����f�B�A�̃q�g�����R�ɐG���悤�ȓ�����
���J���Ă���͗l���B
Core2/2.66GHz x 16-way�����B�B�B
2P�ł͑�������������������FB-DIMM���ǂꂾ�����͂��o����̂���������Ƃ��낾�B
�������o��͗��NQ3����H
����Ƃ��O�|�������̂��ˁB
����Ƃ��O�|�������̂��ˁB
>>449
MP�ȏ��UMA����FB-DIMM�����I���������������B
�������̃o���h��1.5�{�Ń��[�X�g�P�[�X�̕��ׂ�1.6�{�����A
Clovertown�̃X�R�A�����̂܂ܔ{�ɂȂ���x����Ȃ��B
����ł�RAS�����邵�ȓd�͂�����Intel�I�ɂ͏\���Ȃ낤���ǁA
Tulsa�݂����ɉؗ�ɋt�]�Ƃ͂����Ȃ��C������B
Dunnington�ł܂�L3�ς�ŋt�]�������CSI�ɓ˓�����Ɨ\�z�B
>>442
Tukwila�̒x���ɂ��āB
MP�ȏ��UMA����FB-DIMM�����I���������������B
�������̃o���h��1.5�{�Ń��[�X�g�P�[�X�̕��ׂ�1.6�{�����A
Clovertown�̃X�R�A�����̂܂ܔ{�ɂȂ���x����Ȃ��B
����ł�RAS�����邵�ȓd�͂�����Intel�I�ɂ͏\���Ȃ낤���ǁA
Tulsa�݂����ɉؗ�ɋt�]�Ƃ͂����Ȃ��C������B
Dunnington�ł܂�L3�ς�ŋt�]�������CSI�ɓ˓�����Ɨ\�z�B
>>442
Tukwila�̒x���ɂ��āB
452 �FMAC�I�^��451 �����F2006/10/27(��) 21:39:53 ID:M0bvFzkf
>>451
�@�@---------------
�@�@Tukwila�̒x���ɂ��āB
�@�@---------------
CSI�̂��߂ɊJ�������C���^�R�l�N�g�Z�p�̈ꕔ��FSB�Ɏ�荞�܂�Ă���\����C�L�蓾��
���Ǝv�����BIBM��Wave-Pipelined Interface��POWER4����xbox360�܂ł��܂��܂ȃo�X�̕����w
�Ƃ��Ďg�p���Ă��邷����B
�@�@---------------
�@�@Tukwila�̒x���ɂ��āB
�@�@---------------
CSI�̂��߂ɊJ�������C���^�R�l�N�g�Z�p�̈ꕔ��FSB�Ɏ�荞�܂�Ă���\����C�L�蓾��
���Ǝv�����BIBM��Wave-Pipelined Interface��POWER4����xbox360�܂ł��܂��܂ȃo�X�̕����w
�Ƃ��Ďg�p���Ă��邷����B
453 �FSocket774�F2006/10/27(��) 21:57:40 ID:sHceHHTn
���\���O�CIntel���N�A�b�h�R�ACPU�̊T�v�����炩��
ttp://www.4gamer.net/news/history/2006.10/20061027163151detail.html
ttp://www.4gamer.net/news/history/2006.10/20061027163151detail.html
�C���e���A�N�A�b�h�R�A��Santa Rosa�̓W�J���j�����
http://pc.watch.impress.co.jp/docs/2006/1027/intel.htm
�{�����[���]�[���ɂ�Core 2 Duo������܂œ��l�ɒ���邪�A2007�N�̉Ăɂ�
�N�A�b�h�R�A���傫�������Ă��邱�ƂɂȂ�Ƃ����B���̗��R�Ƃ��āA���Ђ����[�h�}�b�v�Ɖ��i��
���ʂ��烁�j�C�R�A�Ɍ����Ĉڍs���A�O���b�V�u�ɐi�߂Ă��邱�ƂƁA�Y�ƊE�ƃR���V���[�}��
���ʂ���HD�R���e���c�ւ̗v�������܂肪�N�A�b�h�R�A�ւ̃��`�x�[�V�����ƂȂ��Ă��邱�Ƃ��������B
http://pc.watch.impress.co.jp/docs/2006/1006/kaigai01l.gif
����܂ł�Intel�I�t�B�V�����̃A�i�E���X�ł�2007Q1��Q6600�AQ4��Penryn�n�N�A�b�hCPU����
�ƂȂ��Ă��ĉĂɂ͐V���i�����ǂ��납�l�����̗\�肷��Ȃ��̂����A�Ȃɂ�������Ă��Ƃ��ˁB
�\��Yorkfield���{����Q3�ɓo�ꂩ�A����Ƃ�Q6400�������B
������ɂ��旈�Ăɂ͂S���~�O��̉��i�тɃN�A�b�hCPU���~��Ă���킯���B
http://pc.watch.impress.co.jp/docs/2006/1027/intel.htm
�{�����[���]�[���ɂ�Core 2 Duo������܂œ��l�ɒ���邪�A2007�N�̉Ăɂ�
�N�A�b�h�R�A���傫�������Ă��邱�ƂɂȂ�Ƃ����B���̗��R�Ƃ��āA���Ђ����[�h�}�b�v�Ɖ��i��
���ʂ��烁�j�C�R�A�Ɍ����Ĉڍs���A�O���b�V�u�ɐi�߂Ă��邱�ƂƁA�Y�ƊE�ƃR���V���[�}��
���ʂ���HD�R���e���c�ւ̗v�������܂肪�N�A�b�h�R�A�ւ̃��`�x�[�V�����ƂȂ��Ă��邱�Ƃ��������B
http://pc.watch.impress.co.jp/docs/2006/1006/kaigai01l.gif
{kind=link}
����܂ł�Intel�I�t�B�V�����̃A�i�E���X�ł�2007Q1��Q6600�AQ4��Penryn�n�N�A�b�hCPU����
�ƂȂ��Ă��ĉĂɂ͐V���i�����ǂ��납�l�����̗\�肷��Ȃ��̂����A�Ȃɂ�������Ă��Ƃ��ˁB
�\��Yorkfield���{����Q3�ɓo�ꂩ�A����Ƃ�Q6400�������B
������ɂ��旈�Ăɂ͂S���~�O��̉��i�тɃN�A�b�hCPU���~��Ă���킯���B
TheInquirer��Tigerton�̂���I�ڂɏ����ꂽ�͗l���B
http://www.theinquirer.net/default.aspx?article=35383
�������FSB x4�Ƃ̎咣����C12�w��̒������ȃ}�U�[�{�[�h�ɂȂ�Ɣ�����Ă��邷�B
�@�@---------------------
�@�@A visual inspection of the edge of the board showed it is pretty damn thick, I would say
�@�@easily 10 layers, maybe 12. Tigertown will sell into a very cost insensitive market, four ways
�@�@are not cheap, but if it performs as I think it will, this becomes much less of a problem.
�@�@---------------------
�u���̌����Ƃ���C���ۃ}�U�{�̊�͂߂��Ⴍ������������B�B�B�v�Ƃ������Ă邷����C
�{����������Ȃ����B
http://www.theinquirer.net/default.aspx?article=35383
�������FSB x4�Ƃ̎咣����C12�w��̒������ȃ}�U�[�{�[�h�ɂȂ�Ɣ�����Ă��邷�B
�@�@---------------------
�@�@A visual inspection of the edge of the board showed it is pretty damn thick, I would say
�@�@easily 10 layers, maybe 12. Tigertown will sell into a very cost insensitive market, four ways
�@�@are not cheap, but if it performs as I think it will, this becomes much less of a problem.
�@�@---------------------
�u���̌����Ƃ���C���ۃ}�U�{�̊�͂߂��Ⴍ������������B�B�B�v�Ƃ������Ă邷����C
�{����������Ȃ����B
456 �FMAC�I�^���⑫�F2006/10/28(�y) 09:30:18 ID:sPoboL/5
�Ƃ���ŁC����Ȃɍ����ȑ��w����g���K�v������Ȃ�v���Z�b�T�ƃm�[�X�u���b�W�ߕӂ�����
�g�p���āC�T�E�X��I/O�p�͕ʊ�ɂ��Ȃ������ˁH����FB-DIMM�탉�C�U�[�J�[�h�����B�B�B
����������PCI-Express�����������Ȃ����Ǝv�����B
�g�p���āC�T�E�X��I/O�p�͕ʊ�ɂ��Ȃ������ˁH����FB-DIMM�탉�C�U�[�J�[�h�����B�B�B
����������PCI-Express�����������Ȃ����Ǝv�����B
���{�ł����ɃA�j���I�^�N��BS�f�W�^�����f��
�A�v�R�������L��HD�R���e���c��PC�ň����Ă�悗
�A�v�R�������L��HD�R���e���c��PC�ň����Ă�悗
�Ă�����HDV�Ƃ����邶���B
�J���R�[�_�ŎB����������A���ʂ̓R���e���c�ƌĂ�B
461 �F+++�F2006/11/01(��) 22:58:50 ID:Qcs4RDeK
Intel carries on crafting Tukwila
http://www.theinquirer.net/default.aspx?article=35440
�e�[�v�A�E�g��early 2008����Ȃ������āA�x��Ă�ȁE�E�B
������Ȃ�ł���J�������B�uTanglewood�v�Ƃ����R�[�h�l�[���������������B
�utangled tale�v�Ƃ�������Ă邯�ǁB
http://www.theinquirer.net/default.aspx?article=35440
�e�[�v�A�E�g��early 2008����Ȃ������āA�x��Ă�ȁE�E�B
������Ȃ�ł���J�������B�uTanglewood�v�Ƃ����R�[�h�l�[���������������B
�utangled tale�v�Ƃ�������Ă邯�ǁB
Anandtech��Kentsfield���r���[�����ǁC������4-core�g���A�v���ł�Performance per Watt��
�����Ɍ��サ�Ă��邱�Ƃ�������Ă��邷�B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2866&p=5
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2866&p=6
�P���Ɂu2�{�̐��\���オ��������_���v�I�ȕ]����C���삪�����ᖳ�������ˁB�B�B
http://journal.mycom.co.jp/articles/2006/11/02/qx6700/003.html
�@�@-------------------------
�@�@�m����Multi CPU Rendering�ł͂���Ȃ�ɃX�R�A���オ���Ă��邩�烁���b�g����������
�@�@�����Ȃ����������A����ł����\��5�������x�B�Ȃɂ�肻�̑��̃e�X�g(Cinema 4D���g����
�@�@Shading���܂�)�܂őS�ł��Ă��邠����A��͂�ő��Ȏ��ł͐��\�������o���Ȃ����Ƃ�����
�@�@����B
�@�@-------------------------
�����Ɍ��サ�Ă��邱�Ƃ�������Ă��邷�B
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2866&p=5
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2866&p=6
�P���Ɂu2�{�̐��\���オ��������_���v�I�ȕ]����C���삪�����ᖳ�������ˁB�B�B
http://journal.mycom.co.jp/articles/2006/11/02/qx6700/003.html
�@�@-------------------------
�@�@�m����Multi CPU Rendering�ł͂���Ȃ�ɃX�R�A���オ���Ă��邩�烁���b�g����������
�@�@�����Ȃ����������A����ł����\��5�������x�B�Ȃɂ�肻�̑��̃e�X�g(Cinema 4D���g����
�@�@Shading���܂�)�܂őS�ł��Ă��邠����A��͂�ő��Ȏ��ł͐��\�������o���Ȃ����Ƃ�����
�@�@����B
�@�@-------------------------
�f�[�^���x���̕�����������ł͌��サ�ē�����O�B
�������������A�v�����Ȃ�������A���������s��ɏo����B
�������������A�v�����Ȃ�������A���������s��ɏo����B
�f�X�N�g�b�v���[�X���Ƌ��LL2�̕����V���O���X���b�h���u�[�X�g�����ꍇ�����邩��ǂ��̂��낤���ǁB
4core���LL2�ɂ���Ƒш�{�K�{�Ȃ킯�����
Yonah(2core���j��L2�ш�{��Merom�ł����L2�ш�{��4core���ł���ɂ����L2�ш�{
�܂��A�i���m�V���b�N�o��������j����I�ɗ��V�ɂ�肻���ȋC�����邯�ǁE�E�E
4core���LL2�ɂ���Ƒш�{�K�{�Ȃ킯�����
Yonah(2core���j��L2�ш�{��Merom�ł����L2�ш�{��4core���ł���ɂ����L2�ш�{
�܂��A�i���m�V���b�N�o��������j����I�ɗ��V�ɂ�肻���ȋC�����邯�ǁE�E�E
�ʂɑ匴���́A�{�ɂȂ�Ȃ�����_�����Č����Ă��Ȃ��āASandra��
�s�[�N���\�Ŕ{�߂���������A���ۂ̃A�v���Ő��\�o���͓̂���A
�܂��́A����ł͐��\�������o����A�v�������܂�Ȃ����Ă��Ƃ��������������ł���B
���̌�̃x���`�ł̃R�����g���A���\�������o���Ȃ��A4�R�A���g����ĂȂ�����
�����Ă邵�B
�s�[�N���\�Ŕ{�߂���������A���ۂ̃A�v���Ő��\�o���͓̂���A
�܂��́A����ł͐��\�������o����A�v�������܂�Ȃ����Ă��Ƃ��������������ł���B
���̌�̃x���`�ł̃R�����g���A���\�������o���Ȃ��A4�R�A���g����ĂȂ�����
�����Ă邵�B
���ݕt��������������B
�����Performance per Watt�͌��サ�Ă�ƌ������A���̏���d�͂��ăV�X�e���S�̂̒l�����B
4-core�ɂȂ������ăV�X�e���S�̂̏���d�͂���{�ɂȂ�킯�������炠�܂�Ӗ��̂����r�ł͂Ȃ��B
�����Performance per Watt�͌��サ�Ă�ƌ������A���̏���d�͂��ăV�X�e���S�̂̒l�����B
4-core�ɂȂ������ăV�X�e���S�̂̏���d�͂���{�ɂȂ�킯�������炠�܂�Ӗ��̂����r�ł͂Ȃ��B
�P���Ȃ��Ƃ��B
�ʏ�p�r��PC��
�E�X�[�o�[�R���s���[�^�ł͂Ȃ�
�EHPC�N���X�^�ł͂Ȃ�
�E���C���t���[���ł͂Ȃ�
�E�T�[�o�[�ł͂Ȃ�
�E���[�N�X�e�[�V�����ł͂Ȃ�
�Ƃ������Ƃ��A���߂ĕ�������ɂ����������B
�ʏ�p�r��PC��
�E�X�[�o�[�R���s���[�^�ł͂Ȃ�
�EHPC�N���X�^�ł͂Ȃ�
�E���C���t���[���ł͂Ȃ�
�E�T�[�o�[�ł͂Ȃ�
�E���[�N�X�e�[�V�����ł͂Ȃ�
�Ƃ������Ƃ��A���߂ĕ�������ɂ����������B
�ƌ������R���V���[�}����̍ŏ��ɏo���N�A�b�h�Ƀ\�t�g���Ή����ĂȂ��̂͂���Ӗ����R�Ȃ킯�ŁB
��o���ł���ς�^�ł͈Ⴄ�˂Ȃ�ċ������Ѓ��[�U�[�������Ȃ�Ă��Ƃ��B
��o���ł���ς�^�ł͈Ⴄ�˂Ȃ�ċ������Ѓ��[�U�[�������Ȃ�Ă��Ƃ��B
�Q�[���\�t�g��Ђ̓N�A�b�h�Ή��ɑO�����̂悤��
http://www.hothardware.com/viewarticle.aspx?page=14&articleid=897
�����u�Ή��v�Ɓu�\�͂������o���v�Ƃ̊Ԃɂ͑傫�ȕǂ����邩��A���ۏo�Ă�����A�����Ă��ƂɁB
http://www.hothardware.com/viewarticle.aspx?page=14&articleid=897
�����u�Ή��v�Ɓu�\�͂������o���v�Ƃ̊Ԃɂ͑傫�ȕǂ����邩��A���ۏo�Ă�����A�����Ă��ƂɁB
�h���h�ėp�@�ɂȂ��Ă�����ł��傤�A���ꂩ���PC
������I���[�J�[�Ƃ����C���t���[�����[�J�[�Ƃ��K�������Ď����Ƃ��̗D�ʐ����A�s�[�����Ă���
������I���[�J�[�Ƃ����C���t���[�����[�J�[�Ƃ��K�������Ď����Ƃ��̗D�ʐ����A�s�[�����Ă���
>��o���ł���ς�^�ł͈Ⴄ�˂Ȃ�ċ������Ѓ��[�U�[�������Ȃ�Ă��Ƃ��B
����͂��������ł���B
HyperThreading��TLP���d������R�[�h���ǂ���A���Ċ撣�����̂�intel������
���̌�̉��b��Free Ride�Ȗ^�Ђ͏�ɖW�Q����Ă���ċ��Ԕ\�͂����͈�l�O�B
����Ȏp������ΐ^���ȃ��[�U�[�قǃR�����Ɛ������˂Ȃ��B
�R�A���^���Ƃ��U���Ƃ��ɂ�����邠����A
���̋ɂ̓G���C�����k�D�z����^����p�͔F�m���Ă�̂��t�Ɉ�ۈ����B
SMT���U�R�A�Ɣl�鈢��������ɂ͂�����������Ȃ�?
����͂��������ł���B
HyperThreading��TLP���d������R�[�h���ǂ���A���Ċ撣�����̂�intel������
���̌�̉��b��Free Ride�Ȗ^�Ђ͏�ɖW�Q����Ă���ċ��Ԕ\�͂����͈�l�O�B
����Ȏp������ΐ^���ȃ��[�U�[�قǃR�����Ɛ������˂Ȃ��B
�R�A���^���Ƃ��U���Ƃ��ɂ�����邠����A
���̋ɂ̓G���C�����k�D�z����^����p�͔F�m���Ă�̂��t�Ɉ�ۈ����B
SMT���U�R�A�Ɣl�鈢��������ɂ͂�����������Ȃ�?
�ʂɂǂ��ł������
intel���^���Ƃ��咣���Ă�����ʂ���
intel���^���Ƃ��咣���Ă�����ʂ���
MCM�Ő��\�I�ɉ��̖����Ȃ�������AIntel��MCM�ł����o����B
���̕��������܂�I�ɂ͗L���Ȃ��B
Intel�ł��A�����ł��\��ɂ���̂́A���������Ӗ��B
�����2�R�A�����̎��݂����ɑ啝��AMD�ɒx����Ƃ邱�Ƃ͂Ȃ����B
AMD��K8L�Ŏ�Ԏ��AIntel�̕��������o��\�������Ă���B
���̕��������܂�I�ɂ͗L���Ȃ��B
Intel�ł��A�����ł��\��ɂ���̂́A���������Ӗ��B
�����2�R�A�����̎��݂����ɑ啝��AMD�ɒx����Ƃ邱�Ƃ͂Ȃ����B
AMD��K8L�Ŏ�Ԏ��AIntel�̕��������o��\�������Ă���B
SingleDie�ɂ��Ă����ꎩ�̂ɐ��\�I�ȗ��_�͖����B+�����K�v�B
+������...Smithfield
+���قƂ�ǖ���...Paxvill
+���L��...Tulsa
Penryn��Prescott�Ɠ���������ȉ��̊g���������Ȃ����ۂ���Plesler�����ŏ\�����Ǝv���B
L2-6MB*2�Ȃ�DieSize��Plesler��83mm^2*2�Ɠ����x�ɂȂ肻�������A
�����Ȃ��DieSize��300mm^2�߂�K8L��K�ڂɉ��i�U���ɏo����B
Dempsey�Ȃ�2���~���Ă邵�ˁB
����Ƃ�Stoakley��FSB�̓]�����[�g��1600MT/s�Ɉ����グ��\�肪����Ƃ��H
+������...Smithfield
+���قƂ�ǖ���...Paxvill
+���L��...Tulsa
Penryn��Prescott�Ɠ���������ȉ��̊g���������Ȃ����ۂ���Plesler�����ŏ\�����Ǝv���B
L2-6MB*2�Ȃ�DieSize��Plesler��83mm^2*2�Ɠ����x�ɂȂ肻�������A
�����Ȃ��DieSize��300mm^2�߂�K8L��K�ڂɉ��i�U���ɏo����B
Dempsey�Ȃ�2���~���Ă邵�ˁB
����Ƃ�Stoakley��FSB�̓]�����[�g��1600MT/s�Ɉ����グ��\�肪����Ƃ��H
SingleDie�ɂ���[���́A���R4Core�ɍœK������[���ɂȂ�ȁB
>>475
�� �m�Y�n�i��������SingleDie�����ǂ������ĂȂ������j
�� �m�Y�n�i��������SingleDie�����ǂ������ĂȂ������j
����̓p�b�P�[�W���O�Ɏ��Ԃ��Ȃ���������ȁB
�����獡��́A�ŏ�����MCM����B
�Y�����͕����܂肪�������邾���Ńf�����b�g�����Ȃ���ˁB
�����獡��́A�ŏ�����MCM����B
�Y�����͕����܂肪�������邾���Ńf�����b�g�����Ȃ���ˁB
���������͍ő��Ƃ��������b�g������
�����܂�������������x���_���̉v�ɉ߂��Ȃ�����
�ǂ��炪�D��Ă��邩�����[�U�[���_���Ă��s��
�����܂�������������x���_���̉v�ɉ߂��Ȃ�����
�ǂ��炪�D��Ă��邩�����[�U�[���_���Ă��s��
479 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/10(��) 06:38:09 ID:dD4ykxwC
L2�L���b�V����4�R�A�ŋ��L�Ȃ�Ă�����ш悪�E�E�E�B
�܂��펯�I��2�R�A���Ńf�[�^���L���ăN���X�o�[�ŃX�k�[�v����Ώ\��
�܂��펯�I��2�R�A���Ńf�[�^���L���ăN���X�o�[�ŃX�k�[�v����Ώ\��
480 �FMAC�I�^���c�q �����F2006/11/10(��) 21:49:22 ID:t8jfOheK
>>479
�@�@----------------
�@�@�܂��펯�I��2�R�A���Ńf�[�^���L���ăN���X�o�[�ŃX�k�[�v����Ώ\��
�@�@----------------
��������̃m�[�h�ԂɃX�k�[�v��p�̔z����lj����邾���Ȃ�C�N���X�o�[�Ȃ�ĕs�v�����ǁB�B�B
�@�@----------------
�@�@�܂��펯�I��2�R�A���Ńf�[�^���L���ăN���X�o�[�ŃX�k�[�v����Ώ\��
�@�@----------------
��������̃m�[�h�ԂɃX�k�[�v��p�̔z����lj����邾���Ȃ�C�N���X�o�[�Ȃ�ĕs�v�����ǁB�B�B
�@�@�@�@�@�@�@�@�@�@�@_,,..-�]--�[-- � _
�@�@�@�@�@�@�@�@, -'"�@�@�@�c�@�@�@�~�@ �MށR�
�@�@�@�@�@�@�^�@�@ �^�@�@�@�@�@�@�@�@�R�@�@�@�_
�@�@�@�@�@/�@ �@ :/�@�@�@�@�@�@�@�@�@�@�@}�@ �R �@�R
�@�@�@�@/ :::/::// �@ / /�@�@�@�@Ɂ@/ i�@Ĥ �@ �R�@� � �@
�@�@�@ / .:/:::::/: �@/../�@�@..::�^,�:� .� ,��i::: i i�R�R�R
�@�@�@ i .::i:::::/�@�@i:::�m ...::::::::�^ .��C :/_}___i:::.��: �� � ���ޤ
�@�@�@ | ::i:::::i::.�@�@�, -'" �^ �^ /Ƀm ,Ɂ@ }��: }: } l::. }�@}
�@�@�@ ! ::i:::::i:: �@�@ڼ�׃~<"�^�^�@���;��::,� l:: � �m
�@�@�@ | ::i ::ri:::..::..|'�@l::;;� '}�@ �@ �@ �@ l:;;�;:} �:/i:�::/
�@�@�@�b::l:::{�::::::::�� ��U:;;'� �@ �@ �@�@ �U;� /��:�/
�@�@ �@ V�:}::�R�U;::� �M"::::::::.�@�Q_' �@:::: �m,�:} �' �@�@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@ �@//::�:/�::l::āU��@�@ �@�R__�m�@ �@,.�;}::� �@�@�@�@���@����5G��OC����wolfdale�ł��������Q�[����肽�`��
�@�@ �m/::/:/::�::k�. . . ށR��@_�Q_ , �B/::��:� �@�@�@�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q_
�@�^/�:/:�^���::::�u�PƁR�_/�@ r�'^�R���
�@�^�:::::�, �� �@�x<�@�@�@ ��rr �R {�x/i�@�@�M}�_
�@�@/::r/'"�@ �@�M/:�@�_ �m�m�@!�n }.�_ L{ _,�.�@ �_
�@�@�@�@�@�@�@�@, -'"�@�@�@�c�@�@�@�~�@ �MށR�
�@�@�@�@�@�@�^�@�@ �^�@�@�@�@�@�@�@�@�R�@�@�@�_
�@�@�@�@�@/�@ �@ :/�@�@�@�@�@�@�@�@�@�@�@}�@ �R �@�R
�@�@�@�@/ :::/::// �@ / /�@�@�@�@Ɂ@/ i�@Ĥ �@ �R�@� � �@
�@�@�@ / .:/:::::/: �@/../�@�@..::�^,�:� .� ,��i::: i i�R�R�R
�@�@�@ i .::i:::::/�@�@i:::�m ...::::::::�^ .��C :/_}___i:::.��: �� � ���ޤ
�@�@�@ | ::i:::::i::.�@�@�, -'" �^ �^ /Ƀm ,Ɂ@ }��: }: } l::. }�@}
�@�@�@ ! ::i:::::i:: �@�@ڼ�׃~<"�^�^�@���;��::,� l:: � �m
�@�@�@ | ::i ::ri:::..::..|'�@l::;;� '}�@ �@ �@ �@ l:;;�;:} �:/i:�::/
�@�@�@�b::l:::{�::::::::�� ��U:;;'� �@ �@ �@�@ �U;� /��:�/
�@�@ �@ V�:}::�R�U;::� �M"::::::::.�@�Q_' �@:::: �m,�:} �' �@�@�@�@�^�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@ �@//::�:/�::l::āU��@�@ �@�R__�m�@ �@,.�;}::� �@�@�@�@���@����5G��OC����wolfdale�ł��������Q�[����肽�`��
�@�@ �m/::/:/::�::k�. . . ށR��@_�Q_ , �B/::��:� �@�@�@�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q_
�@�^/�:/:�^���::::�u�PƁR�_/�@ r�'^�R���
�@�^�:::::�, �� �@�x<�@�@�@ ��rr �R {�x/i�@�@�M}�_
�@�@/::r/'"�@ �@�M/:�@�_ �m�m�@!�n }.�_ L{ _,�.�@ �_
>>469
HT�Ƃ�2�R�A���o�Ă��炭�o���Ǎŋ߂̃Q�[�����đ����̓}���`�X���b�h�ɑΉ����Ă�́H
HT�Ƃ�2�R�A���o�Ă��炭�o���Ǎŋ߂̃Q�[�����đ����̓}���`�X���b�h�ɑΉ����Ă�́H
E6400��E6600�ł͂ǂ̒��x���\�̍����o��̂ł��傤���H
�����ς̎�����ł͂Ȃ�CPU�ɂ��Ă̘b��͑��̓K�ȃX���b�h�ւǂ����B
Intel eyes nanotubes for future chip designs
http://news.com.com/Intel+eyes+nanotubes+for+future+chip+designs/2100-1008-6134437.html?part=dtx&tag=nl.e433
http://news.com.com/Intel+eyes+nanotubes+for+future+chip+designs/2100-1008-6134437.html?part=dtx&tag=nl.e433
487 �FSocket774�F2006/11/12(��) 15:44:41 ID:Ni8A9/bL
http://sg.vr-zone.com/?i=4295
We have previously reported on two new sockets for Nehalem CPUs in 2008 and
this time round we will take comparative look at both new sockets offerings
from Intel and AMD. Socket B will LGA1366 due to the integrated memory
controller and AM3 is most likely still be Socket 940. The first CPU offering
from Intel to be on Socket B will be Bloomfield from the Nehalem family while
the first 45nm processors from AMD will be based on Socket AM3 somewhere in mid 2008.
Both Socket B and AM3 will support DDR3 1066/1333/1600 memories and interconnection
technology will be CSI (Common Serial Interconnect) and Hypertransport 3.0 respectively.
We have previously reported on two new sockets for Nehalem CPUs in 2008 and
this time round we will take comparative look at both new sockets offerings
from Intel and AMD. Socket B will LGA1366 due to the integrated memory
controller and AM3 is most likely still be Socket 940. The first CPU offering
from Intel to be on Socket B will be Bloomfield from the Nehalem family while
the first 45nm processors from AMD will be based on Socket AM3 somewhere in mid 2008.
Both Socket B and AM3 will support DDR3 1066/1333/1600 memories and interconnection
technology will be CSI (Common Serial Interconnect) and Hypertransport 3.0 respectively.
http://news.com.com/Intel+eyes+nanotubes+for+future+chip+designs/2100-1008-6134437.html?part=dtx&tag=nl.e433
�@�`�b�v���[�J�[�ɂƂ��Ă̑�����������菜���Ă����ł��낤�X�C�b�`�Ƃ���
�C���e���͔����̂̓����̓����̂��߂̑�̑f�ނƂ��ăJ�[�{���i�m�`���[�u�ɒ��ڂ��Ă��܂�
�@���l�`�b�v���[�J�[�i�C���e���j�͂ǂ��ɂ����ăv���g�^�C�v��������B
�����ăg�����W�X�^�[�ɐڑ�����`�b�v�̓����̔����I�ȃ��^���b�N�E���C���[��
�J�[�{���i�m�`���[�u�̊O�\�ʂő��ݐڑ����A���̑��ݐڑ��̃p�t�H�[�}���X�𑪒肵���B
�����́A�J�[�{���i�m�`���[�u�̓����ɂ��Ă̐��������m���ǂ����e�X�g������@�ł��B
�@MikeMayberry(�C���e���̃I���S���̌������ł̃R���|�[�l���g�����̊Ǘ���)�́A
�T���t�����V�X�R�ŁA�Đ^��w��i�H�j�̍��ۃV���|�W�E���ŗ��T�����ɂ��ċc�_����B
�C���e���́A�v���W�F�N�g��̃J���t�H���j�A�H�ȑ�w�A�R�����r�A��w�A
�C���m�C��w�A�[�o�i�E�V�����y���Z����у|�[�g�����h�B����w�Ƌ��͂��܂����B
�@�`�b�v�̑��ݘA���̓`�b�v���[�J�[�ɂڂ���ƌ����铪�ɂɂȂ�܂����B
���[�A�̖@���̉��ł́A�`�b�v���[�J�[�́A2�N���Ƃɔ����̂̓����̃R���|�[�l���g���k�߂܂��B
���������ݐڑ��`�b�v�̏k���i�_�C�T�C�Y�k���H�j�͓d�C��R�������p�t�H�[�}���X������������B
�`�b�v���[�J�[�́A���̖��̉����̂���1990�N�㖖�ɃA���~�j�E�����瓺�z���܂ŕς��܂����B
�s�^�ɂ��A�C���e���y�ё��Ђ͍��㐔�N�ԂɁA��菬���ȓ��z���ׂ̈ɓd�C��R������
�d�v�Ȗ��ɂȂ�n�߂�ł��傤�B
�@�u�����ł́A���ݐڑ��`�b�v�̒��a���k������̂ŁA��R�͏㏸���܂��v
�f�C�u�E���}�[�X( VLSI���� �A�����̕��͉�Ђ̊Ǘ���)�͌����܂����B
�u�d�q�͋������q����Ԃ����Ă͂˕Ԃ�܂��B����̓X�s�[�h��x������ł��傤�B�v
���}�[�X�́A�ŏ��Ƀ`�b�v�E�C���T�C�_�[�AVLSI�̃j���[�X���^�[�̒���
���ݐڑ��`�b�v�̎����ɂ��ď������B
�@�`�b�v���[�J�[�ɂƂ��Ă̑�����������菜���Ă����ł��낤�X�C�b�`�Ƃ���
�C���e���͔����̂̓����̓����̂��߂̑�̑f�ނƂ��ăJ�[�{���i�m�`���[�u�ɒ��ڂ��Ă��܂�
�@���l�`�b�v���[�J�[�i�C���e���j�͂ǂ��ɂ����ăv���g�^�C�v��������B
�����ăg�����W�X�^�[�ɐڑ�����`�b�v�̓����̔����I�ȃ��^���b�N�E���C���[��
�J�[�{���i�m�`���[�u�̊O�\�ʂő��ݐڑ����A���̑��ݐڑ��̃p�t�H�[�}���X�𑪒肵���B
�����́A�J�[�{���i�m�`���[�u�̓����ɂ��Ă̐��������m���ǂ����e�X�g������@�ł��B
�@MikeMayberry(�C���e���̃I���S���̌������ł̃R���|�[�l���g�����̊Ǘ���)�́A
�T���t�����V�X�R�ŁA�Đ^��w��i�H�j�̍��ۃV���|�W�E���ŗ��T�����ɂ��ċc�_����B
�C���e���́A�v���W�F�N�g��̃J���t�H���j�A�H�ȑ�w�A�R�����r�A��w�A
�C���m�C��w�A�[�o�i�E�V�����y���Z����у|�[�g�����h�B����w�Ƌ��͂��܂����B
�@�`�b�v�̑��ݘA���̓`�b�v���[�J�[�ɂڂ���ƌ����铪�ɂɂȂ�܂����B
���[�A�̖@���̉��ł́A�`�b�v���[�J�[�́A2�N���Ƃɔ����̂̓����̃R���|�[�l���g���k�߂܂��B
���������ݐڑ��`�b�v�̏k���i�_�C�T�C�Y�k���H�j�͓d�C��R�������p�t�H�[�}���X������������B
�`�b�v���[�J�[�́A���̖��̉����̂���1990�N�㖖�ɃA���~�j�E�����瓺�z���܂ŕς��܂����B
�s�^�ɂ��A�C���e���y�ё��Ђ͍��㐔�N�ԂɁA��菬���ȓ��z���ׂ̈ɓd�C��R������
�d�v�Ȗ��ɂȂ�n�߂�ł��傤�B
�@�u�����ł́A���ݐڑ��`�b�v�̒��a���k������̂ŁA��R�͏㏸���܂��v
�f�C�u�E���}�[�X( VLSI���� �A�����̕��͉�Ђ̊Ǘ���)�͌����܂����B
�u�d�q�͋������q����Ԃ����Ă͂˕Ԃ�܂��B����̓X�s�[�h��x������ł��傤�B�v
���}�[�X�́A�ŏ��Ƀ`�b�v�E�C���T�C�_�[�AVLSI�̃j���[�X���^�[�̒���
���ݐڑ��`�b�v�̎����ɂ��ď������B
�@�J�[�{���i�m�`���[�u( �i�m�e�N�m���W�[�E�̉����ɂ��閼��)�͋������
�͂邩�Ɍ����ǂ��d�C���܂��B
���ہA�i�m�`���[�u�́A�e���̓`���� (�d�q����Q�ɂ����
�U�݂��Ȃ����W�Q����Ȃ����Ƃ��Ӗ�����)�ƌĂ����̂������B
�i�m�`���[�u�A10������1���[�^�[�̔����ł���ɋ����̑��ݘA�����͂邩�ɔ�������Ă���B
���ݓI�ɁA����́A�k���Ɋւ�������������܂��B
IBM�⑼�Ђ̓J�[�{���i�m�`���[�u�Ńg�����W�X�^�[�����܂����B
�@���̎����ł́A�C���e���́A�d��ɂ��i�m�`���[�u�̃o���h�����āA
�K���ȕW���I�ݔ��Ŕނ�̕p�x���r���܂����B
�@�J�[�{���i�m�`���[�u�͑��ɂ͖����L�v�ȓ����������܂����A��ʐ��Y����̂�����B
�������̃i�m�`���[�u�́A�����̂ł���B�܂�d�q�̓`�B���R���g���[���ł���B
�������������͌��q�z�u�Ɉˑ����鏃�`���̂ł���B
������̂͂͒���������̂͒Z���B�����o�b�`�̒��Ő��Y���ꂽ�i�m�`���[�u�́A
�����̂߂܂����������Ȕz����܂ނ��낤�B
�@���ꂼ��̃`�b�v��������̃i�m�`���[�u��v������̂ŁA�����҂͈��̂��̂��ʐ��Y���邩
���邢�͑����k����悢���̂��i�@�B�I�Ɂj��������@���l���o���Ȃ���Ȃ�Ȃ��Ȃ�ł��傤�B
�@���̂��߁A�J�[�{���i�m�`���[�u�͑����Ă����N�Ԃ͏��p�`�b�v�ɂ͌���Ȃ����낤
�@�J�[�{���i�m�`���[�u���`�b�v�ɂȂ낤�ƂȂ�Ȃ��낤�ƁA�����̂̓����̊�{�\������эޗ���
����20�N�Ԃɍ��{�I�ɕς�邾�낤�B
2010�N���邢��2012�N����A�����҂́A�����Ȃ���Ȃ�Ȃ��ύX���i�荞�ݎn�߂邾�낤�B
���ɁA���V�����i�m�v�f������������V���R���v�f�����炭�n�܂�`�b�v�́A
���̏\�N�Ԃ̒����̕��ɋN���낤�Ƃ��Ă��܂��B
2020�N��ɁA�V���R���`�b�v���k�߂�\�͂́A���ɈقȂ�ޗ��ւ̕ύX��K�v�Ƃ��邾�낤�B
�͂邩�Ɍ����ǂ��d�C���܂��B
���ہA�i�m�`���[�u�́A�e���̓`���� (�d�q����Q�ɂ����
�U�݂��Ȃ����W�Q����Ȃ����Ƃ��Ӗ�����)�ƌĂ����̂������B
�i�m�`���[�u�A10������1���[�^�[�̔����ł���ɋ����̑��ݘA�����͂邩�ɔ�������Ă���B
���ݓI�ɁA����́A�k���Ɋւ�������������܂��B
IBM�⑼�Ђ̓J�[�{���i�m�`���[�u�Ńg�����W�X�^�[�����܂����B
�@���̎����ł́A�C���e���́A�d��ɂ��i�m�`���[�u�̃o���h�����āA
�K���ȕW���I�ݔ��Ŕނ�̕p�x���r���܂����B
�@�J�[�{���i�m�`���[�u�͑��ɂ͖����L�v�ȓ����������܂����A��ʐ��Y����̂�����B
�������̃i�m�`���[�u�́A�����̂ł���B�܂�d�q�̓`�B���R���g���[���ł���B
�������������͌��q�z�u�Ɉˑ����鏃�`���̂ł���B
������̂͂͒���������̂͒Z���B�����o�b�`�̒��Ő��Y���ꂽ�i�m�`���[�u�́A
�����̂߂܂����������Ȕz����܂ނ��낤�B
�@���ꂼ��̃`�b�v��������̃i�m�`���[�u��v������̂ŁA�����҂͈��̂��̂��ʐ��Y���邩
���邢�͑����k����悢���̂��i�@�B�I�Ɂj��������@���l���o���Ȃ���Ȃ�Ȃ��Ȃ�ł��傤�B
�@���̂��߁A�J�[�{���i�m�`���[�u�͑����Ă����N�Ԃ͏��p�`�b�v�ɂ͌���Ȃ����낤
�@�J�[�{���i�m�`���[�u���`�b�v�ɂȂ낤�ƂȂ�Ȃ��낤�ƁA�����̂̓����̊�{�\������эޗ���
����20�N�Ԃɍ��{�I�ɕς�邾�낤�B
2010�N���邢��2012�N����A�����҂́A�����Ȃ���Ȃ�Ȃ��ύX���i�荞�ݎn�߂邾�낤�B
���ɁA���V�����i�m�v�f������������V���R���v�f�����炭�n�܂�`�b�v�́A
���̏\�N�Ԃ̒����̕��ɋN���낤�Ƃ��Ă��܂��B
2020�N��ɁA�V���R���`�b�v���k�߂�\�͂́A���ɈقȂ�ޗ��ւ̕ύX��K�v�Ƃ��邾�낤�B
>>473
MCM���̂ɃR�X�g���|���邩��
�����܂肪�����Ȃ��Ă��鐻���v���Z�X���͂ꂽ������_�C�T�C�Y���������ꍇ�ɂ�
�R�X�g�I�ɂP�_�C�ɂ��������L��
MCM���̂ɃR�X�g���|���邩��
�����܂肪�����Ȃ��Ă��鐻���v���Z�X���͂ꂽ������_�C�T�C�Y���������ꍇ�ɂ�
�R�X�g�I�ɂP�_�C�ɂ��������L��
491 �FSocket774�F2006/11/14(��) 13:39:22 ID:r8r2uuf1
����Ȃ̂ł���
�f���A���R�A �C���e�� Xeon 2.80GHz�@(Paxville)�@BOX
\135,800 \143,687 Xeon(Socket604)�@2.8GHz�@2048KB�@800MHz�@
Xeon 5150�@BOX
\87,800 \96,741 Xeon(LGA771)�@2.66GHz�@4096KB�@1330MHz�@
6�������i�������邯�ǂǂ����̕������\�����̂ł��傤���H���Ȃ�Ⴄ���̂ł��傤��?
�f���A���R�A �C���e�� Xeon 2.80GHz�@(Paxville)�@BOX
\135,800 \143,687 Xeon(Socket604)�@2.8GHz�@2048KB�@800MHz�@
Xeon 5150�@BOX
\87,800 \96,741 Xeon(LGA771)�@2.66GHz�@4096KB�@1330MHz�@
6�������i�������邯�ǂǂ����̕������\�����̂ł��傤���H���Ȃ�Ⴄ���̂ł��傤��?
>>491
���̕������|�I�ɂ����B��̂͋�����B
���̕������|�I�ɂ����B��̂͋�����B
Clovertown��MCM��FSB 1333MT/s��B�������ˁB
HKEPC�������Ƃ��͔��M���^�������B
Intel�̒�͂ɋ��Q���A�������Ă���B
Stoakley&Harpertown�ł�FSB�̋����͊m�肵���ƌ��ėǂ��ł��傤�B
http://www.theinquirer.net/default.aspx?article=35723
>Woodcrest was supposed to come out on a 1066FSB but due to one engineering miracle or another, it pulled off 1333.
>This gave it a decent performance boost.
>The problem is that with Clovertown, it didn't raise the FSB, so it is probably leaving a bunch of performance on the table.
>If Intel could pull off a 1600 or 2132FSB you know it would, and the gains would be tangible.
HKEPC�������Ƃ��͔��M���^�������B
Intel�̒�͂ɋ��Q���A�������Ă���B
Stoakley&Harpertown�ł�FSB�̋����͊m�肵���ƌ��ėǂ��ł��傤�B
http://www.theinquirer.net/default.aspx?article=35723
>Woodcrest was supposed to come out on a 1066FSB but due to one engineering miracle or another, it pulled off 1333.
>This gave it a decent performance boost.
>The problem is that with Clovertown, it didn't raise the FSB, so it is probably leaving a bunch of performance on the table.
>If Intel could pull off a 1600 or 2132FSB you know it would, and the gains would be tangible.
�C���e�����e���X�P�[���E�R���s���[�e�B���O�A���j�[�R�A�Ȃǂ����
http://journal.mycom.co.jp/articles/2006/11/17/intel/001.html
�Ȃ����N�b�^���݂����ɂȂ��Ă���
http://journal.mycom.co.jp/articles/2006/11/17/intel/001.html
�Ȃ����N�b�^���݂����ɂȂ��Ă���
495 �FSocket774�F2006/11/17(��) 20:01:01 ID:tAaBDZgU
>>494
�ʂɃN�b�^��(�n�b�^��)����Ȃ�����
���傪�����悤�ɋ@�\���i���ď��^������CPU��512�R�A���ڂ���GRAPE-DR
����90nm�v���Z�X�Ń_�C�T�C�Y��GeForce8800GTX��500m�u�ɑ���GRAPE-DR��289m�u��
GeForce8800GTX��1350MH����518GFLOPS�Ȃ̂�GRAPE-DR��500MH����512GFLOPS��
GeForce8800GTX��200W�߂��d�͂������̂�GRAPE-DR�͍ő�60W�ƒ����d��
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
GeForce8800GTX�͔{���x
����������Ă��Ďv������
AMD�݂�����GPU��CPU�ɓ������
Intel�݂����ɋ@�\���i���ď��^������CPU����������������������悳�����ɂ݂���
�ʂɃN�b�^��(�n�b�^��)����Ȃ�����
���傪�����悤�ɋ@�\���i���ď��^������CPU��512�R�A���ڂ���GRAPE-DR
����90nm�v���Z�X�Ń_�C�T�C�Y��GeForce8800GTX��500m�u�ɑ���GRAPE-DR��289m�u��
GeForce8800GTX��1350MH����518GFLOPS�Ȃ̂�GRAPE-DR��500MH����512GFLOPS��
GeForce8800GTX��200W�߂��d�͂������̂�GRAPE-DR�͍ő�60W�ƒ����d��
http://pc.watch.impress.co.jp/docs/2006/1106/tokyou.htm
GeForce8800GTX�͔{���x
����������Ă��Ďv������
AMD�݂�����GPU��CPU�ɓ������
Intel�݂����ɋ@�\���i���ď��^������CPU����������������������悳�����ɂ݂���
http://pc.watch.impress.co.jp/docs/2004/1130/kaigai136.htm
�� 5�N��i2009�N�j�ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤
�������̂�
http://journal.mycom.co.jp/articles/2006/11/17/intel/002.html
�� ����5�N�`10�N��ɂ́A���\�`���S�̃R�A���_�C�ɓ��ڂ����悤�ɂȂ�
�����̂悤�Ɍ�������g���A�h�C�c��Tera-Scale Computing��
�������܂ō���Ă�������Ƃ����̂ɁB
�n�b�^���x��2001�N�̎��A2007�N��20GHz�A�Ƃ������Ă����Ɠ������B
�� 5�N��i2009�N�j�ɂ́A�����A100�R�A�ȏオ����ɓ����Ă��邾�낤
�������̂�
http://journal.mycom.co.jp/articles/2006/11/17/intel/002.html
�� ����5�N�`10�N��ɂ́A���\�`���S�̃R�A���_�C�ɓ��ڂ����悤�ɂȂ�
�����̂悤�Ɍ�������g���A�h�C�c��Tera-Scale Computing��
�������܂ō���Ă�������Ƃ����̂ɁB
�n�b�^���x��2001�N�̎��A2007�N��20GHz�A�Ƃ������Ă����Ɠ������B
>>495
GK��
GK��
>>496
"����ɓ����Ă��邾�낤"������2009�N�̎��_��100�R�A���ڂ���K�v�Ȃ��̂ł́H
Keifer�Ȃ����R�A�̖ʐς����������ǂ���ł�32�R�A�B
����������_�C�T�C�Y��400mm^2���x�B
32nm��100�R�A�͖���������B
"����ɓ����Ă��邾�낤"������2009�N�̎��_��100�R�A���ڂ���K�v�Ȃ��̂ł́H
Keifer�Ȃ����R�A�̖ʐς����������ǂ���ł�32�R�A�B
����������_�C�T�C�Y��400mm^2���x�B
32nm��100�R�A�͖���������B
>>496
���g�i�[�g��Intel�̃v�����[�V�����`�[���݂����Ȃ���
�W�T�J�[�I�ɂ̓C�X���G���ƃI���S����ǂ������Ă��������ۂ���
���g�i�[�g��Intel�̃v�����[�V�����`�[���݂����Ȃ���
�W�T�J�[�I�ɂ̓C�X���G���ƃI���S����ǂ������Ă��������ۂ���
>>495
Intel��AMD�������H���ōs�����ʂ̘H���̕����ʔ����Ȃ��ėǂ���B
�o����V���O���R�A�����H�����c���ė~�����B
Intel��AMD�������H���ōs�����ʂ̘H���̕����ʔ����Ȃ��ėǂ���B
�o����V���O���R�A�����H�����c���ė~�����B
�����Ăˁ[��
�u80�R�A�̃v���g�^�C�v�����삵���v�Ƃ����j���[�X�͂����Ă�
���炩�̃\�t�g�E�F�A���u�������v�Ƃ����L���͌������Ƃ��Ȃ��Ȃ�
����͂��̎�̔��\�Ɠ����x���̂���ł���
http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
���炩�̃\�t�g�E�F�A���u�������v�Ƃ����L���͌������Ƃ��Ȃ��Ȃ�
����͂��̎�̔��\�Ɠ����x���̂���ł���
http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
GRAPE�̒��̐l���l�^�ɂ��Ă�
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2006-11.html#7
�� Intel �̃����[�X���݂Ă��A���ꂪ�����ĂȂ��ɗ��v�Z���ł����A�Ƃ͏����ĂȂ�
�� �Ƃ����ȑO�� develops �Č��`�ł���Ƃ������Ƃ͂܂������ĂȂ��A���Ă��ƂȂ킯�ŁA
ttp://grape.astron.s.u-tokyo.ac.jp/~makino/journal/journal-2006-11.html#7
�� Intel �̃����[�X���݂Ă��A���ꂪ�����ĂȂ��ɗ��v�Z���ł����A�Ƃ͏����ĂȂ�
�� �Ƃ����ȑO�� develops �Č��`�ł���Ƃ������Ƃ͂܂������ĂȂ��A���Ă��ƂȂ킯�ŁA
>>503 ����
�@�@------------------------
�@�@����͂��̎�̔��\�Ɠ����x���̂���ł���
�@�@http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
�@�@------------------------
�����Z�p�̘b��Ǝ��ۂ̃`�b�v�̎����̘b�̋�ʂ����Ȃ��̂�A�C�^�����Ǝv�����B
>>504 ����
�@�@------------------------
�@�@develops �Č��`�ł���Ƃ������Ƃ͂܂������ĂȂ��A���Ă��ƂȂ킯��
�@�@------------------------
�`�b�v�̎����܂Ői��ł���Ƃ������Ƃ�A�V�~�����[�^��FPGA�̏�ŃA�[�L�e�N�`����
�����푊���i��ł���\�����������B
�����Ƃ�����̎����A�A�[�L�e�N�`���̊m�F�Ƃ��������������`�b�v�Ƃ̃X�^�b�L���O
�Z�p�̃e�X�g�̗v�f���傫���������ǁB�B�B
�@�@------------------------
�@�@����͂��̎�̔��\�Ɠ����x���̂���ł���
�@�@http://ascii24.com/news/i/tech/article/2001/06/12/626899-000.html
�@�@------------------------
�����Z�p�̘b��Ǝ��ۂ̃`�b�v�̎����̘b�̋�ʂ����Ȃ��̂�A�C�^�����Ǝv�����B
>>504 ����
�@�@------------------------
�@�@develops �Č��`�ł���Ƃ������Ƃ͂܂������ĂȂ��A���Ă��ƂȂ킯��
�@�@------------------------
�`�b�v�̎����܂Ői��ł���Ƃ������Ƃ�A�V�~�����[�^��FPGA�̏�ŃA�[�L�e�N�`����
�����푊���i��ł���\�����������B
�����Ƃ�����̎����A�A�[�L�e�N�`���̊m�F�Ƃ��������������`�b�v�Ƃ̃X�^�b�L���O
�Z�p�̃e�X�g�̗v�f���傫���������ǁB�B�B
>>505
���t������Ȃ������B
�����x�����[�̂̓z��������̂��ƂˁB
>������g��10GHz�̃v���Z�b�T�[������5�`10�N�ȓ��ɊJ������
>�\��Ƃ��Ă���A����͎���������̓I�Ȃ��̂ɂȂ��Ă���B
���t������Ȃ������B
�����x�����[�̂̓z��������̂��ƂˁB
>������g��10GHz�̃v���Z�b�T�[������5�`10�N�ȓ��ɊJ������
>�\��Ƃ��Ă���A����͎���������̓I�Ȃ��̂ɂȂ��Ă���B
�����Ă邩�����ĂȂ��̂��Ƃ����Γ����Ă�낤�B
���Ⴀ�����Ɏs��ɓ����ł���̂��ƌ����m�[�B
��ڂɂ��čő�̗��R�͂����炭�R�A��IA����Ȃ�����B
IA��80�R�A�ƂȂ��22nm�v���Z�X�ł��Ȃ��Ȃ��ۂǂ��C������B
Niagara�݂����ɃA�O���b�V�u�ɃR�A�����ʂ���Θb�͕ʂ����B
��ڂ̗��R�̓R�A�̃o���f�[�V�������o���ĂȂ�����B
IA����߂ėႦ��GRAPE-DR�R�ŏo���Ƃ��Ă�1�N�͎��Ԃ�������̂ł͂Ȃ����B
�O�ڂ̗��R�̓V���R���t�H�g�j�N�X�ƃ_�C�X�^�b�L���O�������n�ȋZ�p�ł��邱�ƁB
�M�̖���R�X�g�̖��A�������邱�Ƃ��������ĉ��N������̂����������Ȃ��B
Intel��5�N�ł��Ƃ����Ă邵�A���̃X���ɋ���ȏ���҂��Ă͂��邪�������s��ɓ����ł���㕨�ł͂Ȃ����Ƃ͊m�����B
���Ⴀ�����Ɏs��ɓ����ł���̂��ƌ����m�[�B
��ڂɂ��čő�̗��R�͂����炭�R�A��IA����Ȃ�����B
IA��80�R�A�ƂȂ��22nm�v���Z�X�ł��Ȃ��Ȃ��ۂǂ��C������B
Niagara�݂����ɃA�O���b�V�u�ɃR�A�����ʂ���Θb�͕ʂ����B
��ڂ̗��R�̓R�A�̃o���f�[�V�������o���ĂȂ�����B
IA����߂ėႦ��GRAPE-DR�R�ŏo���Ƃ��Ă�1�N�͎��Ԃ�������̂ł͂Ȃ����B
�O�ڂ̗��R�̓V���R���t�H�g�j�N�X�ƃ_�C�X�^�b�L���O�������n�ȋZ�p�ł��邱�ƁB
�M�̖���R�X�g�̖��A�������邱�Ƃ��������ĉ��N������̂����������Ȃ��B
Intel��5�N�ł��Ƃ����Ă邵�A���̃X���ɋ���ȏ���҂��Ă͂��邪�������s��ɓ����ł���㕨�ł͂Ȃ����Ƃ͊m�����B
>>506
���̂�����̋L���̓A���~�̐S�̎x������
core2�o��O�����̂�����̑�̂̋L���T���o���Ă��āA�Ƃ��������C�ɓ���ɂł�����Ă�̂�
�K���Ɂucore2�͂ǂ������s��v�Ɗ����Ă������
���̂�����̋L���̓A���~�̐S�̎x������
core2�o��O�����̂�����̑�̂̋L���T���o���Ă��āA�Ƃ��������C�ɓ���ɂł�����Ă�̂�
�K���Ɂucore2�͂ǂ������s��v�Ɗ����Ă������
���g�i�[������Ă�̂͊�b�����A�v�f�Z�p�����̒i�K�B
�h�C�c��100�l�K�͂̃��{����Č������Ă邯�ǃ��m�ɂȂ�̂͑�����̖����B
http://pc.watch.impress.co.jp/docs/2006/0721/hot438.htm
�t�v�\�[�X�ŐM�ߐ��͂��ꂾ���A��Intel���Ńv���Z�b�T��
�}�C�N���A�[�L�e�N�`���S�ʂɊւ��錈�茠�����ƌ����Ă���̂�
�p�[�����b�^�[�BTimna�APentium M�ACore Duo�ACore 2 Duo���J�������l���B
���̐l�ƕ����̃��[���[�C�[�f���̍ŋ߂̔������炷��ƁA
�R�A�𑝂₷���Ƃ��A�L���b�V�����������A��ops fusion�ASSE�Ȃǂ�
���ǂɐG��Ă��āA�ǂ��炩�Ƃ�����ILP�d���̎p���B
�����ăp�[�����b�^�[�ƁACentrino�𐬌��ɓ������`�����h���V�[�J��
���{�C�Ŏ��g��ł���̂�UMPC�����̃v���Z�b�T�B
����A�Q���V���K�[������G���v���O���[�v�́A�A�[�L�e�N�`���̏ڍׂ͕s������
Nehalem�ł��悢��҂��ɑ҂���CSI����������ƌ����Ă���B
���̃X���I�ɂ́A�Z�����X�p���Ō��ʂ��邱�����̃l�^�Ő���オ���Ăق����B
�h�C�c��100�l�K�͂̃��{����Č������Ă邯�ǃ��m�ɂȂ�̂͑�����̖����B
http://pc.watch.impress.co.jp/docs/2006/0721/hot438.htm
�t�v�\�[�X�ŐM�ߐ��͂��ꂾ���A��Intel���Ńv���Z�b�T��
�}�C�N���A�[�L�e�N�`���S�ʂɊւ��錈�茠�����ƌ����Ă���̂�
�p�[�����b�^�[�BTimna�APentium M�ACore Duo�ACore 2 Duo���J�������l���B
���̐l�ƕ����̃��[���[�C�[�f���̍ŋ߂̔������炷��ƁA
�R�A�𑝂₷���Ƃ��A�L���b�V�����������A��ops fusion�ASSE�Ȃǂ�
���ǂɐG��Ă��āA�ǂ��炩�Ƃ�����ILP�d���̎p���B
�����ăp�[�����b�^�[�ƁACentrino�𐬌��ɓ������`�����h���V�[�J��
���{�C�Ŏ��g��ł���̂�UMPC�����̃v���Z�b�T�B
����A�Q���V���K�[������G���v���O���[�v�́A�A�[�L�e�N�`���̏ڍׂ͕s������
Nehalem�ł��悢��҂��ɑ҂���CSI����������ƌ����Ă���B
���̃X���I�ɂ́A�Z�����X�p���Ō��ʂ��邱�����̃l�^�Ő���オ���Ăق����B
>>499
���̔F���͂Ȃ��Ȃ��I���˂Ă�B�������10�N20�N�X�p���Ō����
���g�i�[�̌����͑傫�ȈӖ��������Ă���Ǝv�����B
�Q�l�F���N�̃p�[�����b�^�[�ƃC�[�f���̔���
http://news.com.com/2008-1006_3-6047173.html
�uYonah�ł́A���p�������̃R�A���A�R�A�̃L���b�V���̂��ׂĂ𗘗p�ł�
�邩��ł��B�L���b�V����1MB����2MB�ɂȂ�A�v���Z�b�T�̏������\��
10������15�����x�A�ȒP�Ɍ��サ�܂��B �f���A���R�A�H�������肵������
�s���������̂́A�}���`�^�X�N��}���`�X���b�h���ł͍����������\��
�����ł��Ă��A�V���O���X���b�h���ł́A�����̃\�t�g�E�F�A�J���҂��u�O��
�V�X�e���̕����悩�����v�Ɗ�����̂ł͂Ȃ����Ƃ������Ƃł����B�L���b�V��
�̂��ׂĂ𗘗p�ł���悤�ɂȂ�A����͔��ɑ傫�ȋ��݂ƂȂ�܂��B �v
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
�u���[�U�[�̐l�B�ɂ͎��g���̐��E����R�A���̐��E�ւƈڍs���Ăق����B
�������A���ɃN���C���g��Ԃł͑����̃R�A��ςݏグ�邱�Ƃɒ��ӂ��A����
�����̂��������Ȃ���Ȃ�܂���B����"2"��good�ȃR�A���ł����
�M���Ă��܂��B"4"��high-end�ł������낢�R�A���ł��B�N���C���g���[�X��
������2�N���8�R�A�������Ă��邩�H �����N���I������̂Ȃ�A�v����
���Ƃ͉\�ł��B�������A����market needs���ǂ�قǂ���̂��͋^��ł��B�v
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
�u�Ƃ͂����A�V���O���X���b�h�A�v���P�[�V�����̐��\���p�����Č���
�����悤�Ƃ��Ă���B���̂��߂ɁA�������ނ̃e�N�j�b�N��p����B�v
http://journal.mycom.co.jp/articles/2006/10/19/wpc1/003.html
�����Ƀ��o�C���ŃN�A�b�h�R�A����������邱�Ƃ͂Ȃ��A�u�������N�̓f���A���R�A�v�Ɠ������B
���̔F���͂Ȃ��Ȃ��I���˂Ă�B�������10�N20�N�X�p���Ō����
���g�i�[�̌����͑傫�ȈӖ��������Ă���Ǝv�����B
�Q�l�F���N�̃p�[�����b�^�[�ƃC�[�f���̔���
http://news.com.com/2008-1006_3-6047173.html
�uYonah�ł́A���p�������̃R�A���A�R�A�̃L���b�V���̂��ׂĂ𗘗p�ł�
�邩��ł��B�L���b�V����1MB����2MB�ɂȂ�A�v���Z�b�T�̏������\��
10������15�����x�A�ȒP�Ɍ��サ�܂��B �f���A���R�A�H�������肵������
�s���������̂́A�}���`�^�X�N��}���`�X���b�h���ł͍����������\��
�����ł��Ă��A�V���O���X���b�h���ł́A�����̃\�t�g�E�F�A�J���҂��u�O��
�V�X�e���̕����悩�����v�Ɗ�����̂ł͂Ȃ����Ƃ������Ƃł����B�L���b�V��
�̂��ׂĂ𗘗p�ł���悤�ɂȂ�A����͔��ɑ傫�ȋ��݂ƂȂ�܂��B �v
http://www.tgdaily.com/2006/07/27/tgdaily_interviews_david_perlmutter/
�u���[�U�[�̐l�B�ɂ͎��g���̐��E����R�A���̐��E�ւƈڍs���Ăق����B
�������A���ɃN���C���g��Ԃł͑����̃R�A��ςݏグ�邱�Ƃɒ��ӂ��A����
�����̂��������Ȃ���Ȃ�܂���B����"2"��good�ȃR�A���ł����
�M���Ă��܂��B"4"��high-end�ł������낢�R�A���ł��B�N���C���g���[�X��
������2�N���8�R�A�������Ă��邩�H �����N���I������̂Ȃ�A�v����
���Ƃ͉\�ł��B�������A����market needs���ǂ�قǂ���̂��͋^��ł��B�v
http://pc.watch.impress.co.jp/docs/2006/1004/kaigai307.htm
�u�Ƃ͂����A�V���O���X���b�h�A�v���P�[�V�����̐��\���p�����Č���
�����悤�Ƃ��Ă���B���̂��߂ɁA�������ނ̃e�N�j�b�N��p����B�v
http://journal.mycom.co.jp/articles/2006/10/19/wpc1/003.html
�����Ƀ��o�C���ŃN�A�b�h�R�A����������邱�Ƃ͂Ȃ��A�u�������N�̓f���A���R�A�v�Ɠ������B
4�R�A�ȏ�Ȃ�č��̂Ƃ���G���R�[�h���炢�ɂ����g������������ȁB
���ɂ��L���[�A�v���������o�Ă��Ȃ���8�R�A�ȏ�ɂ͐i�݂Â炢�B
���ɂ��L���[�A�v���������o�Ă��Ȃ���8�R�A�ȏ�ɂ͐i�݂Â炢�B
�G���R�[�h���炢�Ƃ͊ȒP�Ɍ������A
���\��~���镔���ŗL���Ȃ̂͂������ƃW���}�C�J�B
�����_�����O�ɂ��L���Ȃ��A
���A���^�C�����C�g���[�V���O���ł���悤�ɂȂ�Ȃ��̂��Ƃ��炵���B
���̕��ʂ�AMD���A�^�}�Ƃ�A
���ꂱ���e�̋w���A�S�̎�ł��Ƃ������̂悤�ɐ�`����Ǝv����?
���\��~���镔���ŗL���Ȃ̂͂������ƃW���}�C�J�B
�����_�����O�ɂ��L���Ȃ��A
���A���^�C�����C�g���[�V���O���ł���悤�ɂȂ�Ȃ��̂��Ƃ��炵���B
���̕��ʂ�AMD���A�^�}�Ƃ�A
���ꂱ���e�̋w���A�S�̎�ł��Ƃ������̂悤�ɐ�`����Ǝv����?
IDF�l�^�͑匴���ڂ��������Ă�
http://journal.mycom.co.jp/articles/2006/10/12/idf1/
�� �t�Ɍ����Ό����_�ł܂����̒��x�Ƃ������Ƃ́A����������ۂ̐��i
�� �ւ̓��̂�͂܂������������̂Ǝv����B���̂�����𗝉������ɁA
�� �u����80�R�A��Many Core�̃v���g�^�C�v�������v�Ȃǂƌ������ƁA
�� ����Trial�̈Ӌ`���������������B
http://journal.mycom.co.jp/articles/2006/10/12/idf1/
�� �t�Ɍ����Ό����_�ł܂����̒��x�Ƃ������Ƃ́A����������ۂ̐��i
�� �ւ̓��̂�͂܂������������̂Ǝv����B���̂�����𗝉������ɁA
�� �u����80�R�A��Many Core�̃v���g�^�C�v�������v�Ȃǂƌ������ƁA
�� ����Trial�̈Ӌ`���������������B
>>495
����[���AGRAPE-DR���āA�ȋZ���Z�̂��߂�accelerator������A�ʂ���ˁH
�܂��Aintel�ɂ��Ă��Ƃ肠�����L�������ȓ���p�r������accelerator�Ƃ��Ďg������[�I��������̂����m��E�E�E�B
����[���AGRAPE-DR���āA�ȋZ���Z�̂��߂�accelerator������A�ʂ���ˁH
�܂��Aintel�ɂ��Ă��Ƃ肠�����L�������ȓ���p�r������accelerator�Ƃ��Ďg������[�I��������̂����m��E�E�E�B
�T�[�o�pCPU��PC�pCPU�̃R�A����������ˁB�܂�IA64�n�͈Ⴄ���ǁB
��ŁA�T�[�o�p�Ƃ��Ă͑��X���b�h���s�ւ̎��v�������B
�}���`�R�A�̊J���͕K�R����B���̂ւ����ĂȂ��l���邯�ǁB
�N���C�A���g�p�r�Ɏ����Ă���̂͂��̎��X�̃j�[�Y�ɔC����������A
�����l�͔�����B
��ŁA�T�[�o�p�Ƃ��Ă͑��X���b�h���s�ւ̎��v�������B
�}���`�R�A�̊J���͕K�R����B���̂ւ����ĂȂ��l���邯�ǁB
�N���C�A���g�p�r�Ɏ����Ă���̂͂��̎��X�̃j�[�Y�ɔC����������A
�����l�͔�����B
Tick Tock���Ƃ��̕ӂŃo�����X���Ƃ�̂����
Itanium��XeonMP�ɑ����ʈ��������\�ɂȂ�������c
�Ƃ肠����Sam Naffiziger�͎��˂�
Itanium��XeonMP�ɑ����ʈ��������\�ɂȂ�������c
�Ƃ肠����Sam Naffiziger�͎��˂�
�}���`�R�A��CPU���s��ɍL�܂�Ȃ���}���`�R�A�����A�v���Ȃ�ďo�Ȃ��B
�t����Ȃ��B��Ƀn�[�h����A�\�t�g�͌�B
�j�[�Y���Ȃ��낤��Intel�͂�邵���Ȃ��́B
�t����Ȃ��B��Ƀn�[�h����A�\�t�g�͌�B
�j�[�Y���Ȃ��낤��Intel�͂�邵���Ȃ��́B
519 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/18(�y) 21:46:43 ID:1rwpm1lR
�����ƋZ�p�Ҏx��������Ă邵�ˁB
������pthread�͋C���������ȁBWin32 Thread�̂ق���������₷���B
������pthread�͋C���������ȁBWin32 Thread�̂ق���������₷���B
TLP�ӎ����Ȃ��Ă��������Ljӎ�����Ƃ����Ƒ������Ă̂����z�B
��Ώ�HTT�Ƃ��ǂ��Ȃ��Ă�낤�B
Nehalem��1S/4C/16T�ʂɂȂ�낤���H
��Ώ�HTT�Ƃ��ǂ��Ȃ��Ă�낤�B
Nehalem��1S/4C/16T�ʂɂȂ�낤���H
�����R�A�𑝂₷����͂������
AMD�̓R�v���헪��GPU����
Intel��SSE�g��
����������Cell��Niagara�Ƃ����O��̂�����
AMD�̓R�v���헪��GPU����
Intel��SSE�g��
����������Cell��Niagara�Ƃ����O��̂�����
80�R�A�̂����20MB��SRAM���������ƊeCPU�R�A��1��1�ڑ����Ă�ȁB
�Ƃ������Ƃ�1�R�A������256KB�B
�c�cPentiumPRO�Ɠ�����
�Ƃ������Ƃ�1�R�A������256KB�B
�c�cPentiumPRO�Ɠ�����
���o�C�������ɊJ�����ꂽ�A�[�L�e�N�`����Xeon�ɂ��g���̂�
�l�g�o�L�����Z����̋߂郏���|�C���g�����[�t�B
Nehalem�A�[�L�����Ȍ�́A���ۂ͂��낢�날�邾�낤���P���ɂ킯��
�G���^�[�v���C�Y/�I���S�� �� ���o�C��/�C�X���G��
�Ŗ��m�ɂ킩��邩��T�[�o������͐S�z����ł����ł���B
�l�g�o�L�����Z����̋߂郏���|�C���g�����[�t�B
Nehalem�A�[�L�����Ȍ�́A���ۂ͂��낢�날�邾�낤���P���ɂ킯��
�G���^�[�v���C�Y/�I���S�� �� ���o�C��/�C�X���G��
�Ŗ��m�ɂ킩��邩��T�[�o������͐S�z����ł����ł���B
525 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/18(�y) 23:14:17 ID:1rwpm1lR
�Ȃ�ƂȂ�Penryn�x�[�X�Ń}�C�i�[�`�F���W�����ł��̂������ȋC������B
Nehalem��Core�R�A�����p�����Ă̂��ŗL�͂Ȃ�Ȃ��́H
>>526
����̓I���S���ƃC�X���G���Q�ӏ��ŊJ�����Ă�Ӗ����Ȃ��Ȃ�B
���`�[���̐v�̉����ŊJ�����Ă���J���y�[�X�������ƒx���Ȃ�B
���ꂾ������C�X���G���őS����������������B
����̓I���S���ƃC�X���G���Q�ӏ��ŊJ�����Ă�Ӗ����Ȃ��Ȃ�B
���`�[���̐v�̉����ŊJ�����Ă���J���y�[�X�������ƒx���Ȃ�B
���ꂾ������C�X���G���őS����������������B
�p�r�ɂ���Ắi�Q�[�������m��Ȃ����ǁj�R�A�������Ă����ʂ����Ȃ����Ă��Ƃ�����
�����䂤�̂��č���͑Ή����ăR�A�������قǑ����Ȃ�悤�ɏo����́H
����Ƃ����g���̌���ȊO�͂ǂ�����Ă����ʂ������́H
�����䂤�̂��č���͑Ή����ăR�A�������قǑ����Ȃ�悤�ɏo����́H
����Ƃ����g���̌���ȊO�͂ǂ�����Ă����ʂ������́H
2007�N�ȍ~�̓Q�[���������Ȃ��
http://www.driverheaven.net/articles/Valve_Editor's_Day_1106/
http://techreport.com/etc/2006q4/source-multicore/index.x?pg=2
http://www.driverheaven.net/articles/Valve_Editor's_Day_1106/
http://techreport.com/etc/2006q4/source-multicore/index.x?pg=2
>>497
�u�N�b�^���v���Č��t���������܂��Ǝ�����������X�N���v�g���H
>>494-495��Intel�̘b�Ȃ̂�
�ǂ������ǂ�������
�u�N�b�^���v���Č��t���������܂��Ǝ�����������X�N���v�g���H
>>494-495��Intel�̘b�Ȃ̂�
�ǂ������ǂ�������
�y�Ɠd�zPC�̔��̗������ݐ[���@�u�r�X�^�̔��O�̔����T�����������R�ł͂Ȃ��B���v���g�тȂǂɃV�t�g���Ă���v
http://news19.2ch.net/test/read.cgi/newsplus/1163956911/
�p�\�R�����
http://news19.2ch.net/test/read.cgi/newsplus/1163956911/
�p�\�R�����
532 �FSocket774�F2006/11/20(��) 10:05:05 ID:NKyjtNUg
http://www.vr-zone.com/?i=4322
Bloomfield Is Quad Core & Octo Threads
Bloomfield Is Quad Core & Octo Threads
>>531
���ł�PC�����Ă��ʂ̐l�͔����ւ���قǐ��\�ɕs��������킯����Ȃ����낤����
���ł�PC�����Ă��ʂ̐l�͔����ւ���قǐ��\�ɕs��������킯����Ȃ����낤����
�p�\�R���Ɍ��炸�A�ԂƂ�
������x���z�ȍH�Ɛ��i�̗������݂����{�S�̂Ō����邵��
�D���Ȃ͔̂��^�e���r���炢��
������x���z�ȍH�Ɛ��i�̗������݂����{�S�̂Ō����邵��
�D���Ȃ͔̂��^�e���r���炢��
http://www.vr-zone.com/?i=4322
Nehalem�A�[�L�e�N�`���Ɋ�Â��C���e���̎�����v���Z�b�T�[��
VR-ZONE�����������ʂ肿���Ƒ��݂���B
�����I��45nm��penryn�A�[�L�e�N�`���Ɋ�Â�4�R�A��yorkfield�ɑ�����
Bloomfield��45nm��Nehalem�A�[�L�e�N�`���̃n�C�G���h�Ƃ���2008�N���ՂɈʒu���Ă��邱�Ƃ��낤�B
Bloomfiled��4�R�A�������AHTT�Ɏ��Ă邪��蔭�W�����Z�p�ɂ��W�X���b�h���\�ɂ���B
Bloomfiled��socketB�ƌĂ��LGA1366�̐V�����\�P�b�g��K�v�Ƃ���
�����������R���g���[���[���܂ނ��낤
Nehalem�A�[�L�e�N�`���Ɋ�Â��C���e���̎�����v���Z�b�T�[��
VR-ZONE�����������ʂ肿���Ƒ��݂���B
�����I��45nm��penryn�A�[�L�e�N�`���Ɋ�Â�4�R�A��yorkfield�ɑ�����
Bloomfield��45nm��Nehalem�A�[�L�e�N�`���̃n�C�G���h�Ƃ���2008�N���ՂɈʒu���Ă��邱�Ƃ��낤�B
Bloomfiled��4�R�A�������AHTT�Ɏ��Ă邪��蔭�W�����Z�p�ɂ��W�X���b�h���\�ɂ���B
Bloomfiled��socketB�ƌĂ��LGA1366�̐V�����\�P�b�g��K�v�Ƃ���
�����������R���g���[���[���܂ނ��낤
[Intel Desktop CPU Roadmap Updated]
http://www.vr-zone.com/index.php?i=4309
http://www.vr-zone.com/index.php?i=4309
VR-Zone�͑��ς�炸�\�[�X�����̖ϑz���ꗬ����
����C2D�Ή��̃}�U�[�ŗ��N�̏H�ɏo��炵���N�A�b�h�R�A��CPU���Ďg���܂����H
�ǂȂ��������ĉ�����m(_ _)m
�ǂȂ��������ĉ�����m(_ _)m
>>538
Nehalem�̓������R���g���[�����������炻��ȑO��M/B�͈�؎g���Ȃ���
Nehalem�̓������R���g���[�����������炻��ȑO��M/B�͈�؎g���Ȃ���
>>539
�킩��܂����A�ǂ������肪�Ƃ��������܂��B
�킩��܂����A�ǂ������肪�Ƃ��������܂��B
���[�N����ˁH
�ǂ���ɂ���`�b�v�Z�b�g�ς�邾�낤�ˁB
�ǂ���ɂ���`�b�v�Z�b�g�ς�邾�낤�ˁB
�}���`�R�A���͂�����������A�f���A���R�A�̃N���b�N���グ�Ă���B
�ǂ���4�R�A�ɂȂ��Ă��g�����Ȃ��˂���B
�ǂ���4�R�A�ɂȂ��Ă��g�����Ȃ��˂���B
DLP�����邩�ǂ����A�܂�c��ȃf�[�^���������邩�ۂ��B
PC�p�rWS�p�r�ł����A�G���R�[�h�ADTP�ADTV�ADTM�ADAW�A�����_�����O�������邩�S�����Ȃ����B
�ŁA���̃j�[�Y�͂܂������قȂ�B
������Intel��UMPC��Tera-Scale�Ƃ������ɂ��J�Ă����B
���͂��̋��ԂŒ��r���[�Ȏ���B
PC�p�rWS�p�r�ł����A�G���R�[�h�ADTP�ADTV�ADTM�ADAW�A�����_�����O�������邩�S�����Ȃ����B
�ŁA���̃j�[�Y�͂܂������قȂ�B
������Intel��UMPC��Tera-Scale�Ƃ������ɂ��J�Ă����B
���͂��̋��ԂŒ��r���[�Ȏ���B
Intel and Nvidia in marriage of inconvenience
http://www.theinquirer.net/default.aspx?article=35862
http://www.theinquirer.net/default.aspx?article=35862
�鍑�̐V�^�͉�������?!
Intel Xeon X5355
SPECint_rate_base2000 = 200
http://www.spec.org/cpu2000/results/res2006q4/cpu2000-20061030-07837.html
AMD Opteron 8220SE
SPECint_rate_base2000 = 160
http://www.spec.org/cpu2000/results/res2006q4/cpu2000-20060918-07377.html
Intel Xeon X5355
SPECint_rate_base2000 = 200
http://www.spec.org/cpu2000/results/res2006q4/cpu2000-20061030-07837.html
AMD Opteron 8220SE
SPECint_rate_base2000 = 160
http://www.spec.org/cpu2000/results/res2006q4/cpu2000-20060918-07377.html
�܂�Itanium�͈ꌅ�Ⴄ���ǂ�(�l�i���Ⴄ��)
Intel�A3���̃T���t�����V�X�R�ł�IDF���}篃L�����Z��
�`4���ɖk���ŊJ��
ttp://pc.watch.impress.co.jp/docs/2006/1122/intel.htm
�`4���ɖk���ŊJ��
ttp://pc.watch.impress.co.jp/docs/2006/1122/intel.htm
Intel to take AMD approach to future chips
http://www.theinquirer.net/default.aspx?article=35892
Bloomfield�́A�E�ENeharem�n����Ȃ������̂��ȁH
������Ƃ悭������Ȃ��B
Bloomfield/Gilo/Gainestown�œ��n����Ă��ƂɂȂ��Ă�B
��A mobile variant of Bloomfield will be named Gilo,
��while the server parts are codenamed Gainestown.
�ȑO�A�㓡�L���ł́AGilo��Gesher�̊ԈႢ�������AGesher��
�C�X���G���`�[��������Ă�ƌ����Ă����ǁB
����͊ԈႢ�ŁABloomfield/Gilo/Gainestown�����Ȃ킿Neharem�n���
�������ƂŁAGesher�͕ʂɃC�X���G���ō���Ă�A�Ƃ������Ƃ��ȁB
http://www.theinquirer.net/default.aspx?article=35892
Bloomfield�́A�E�ENeharem�n����Ȃ������̂��ȁH
������Ƃ悭������Ȃ��B
Bloomfield/Gilo/Gainestown�œ��n����Ă��ƂɂȂ��Ă�B
��A mobile variant of Bloomfield will be named Gilo,
��while the server parts are codenamed Gainestown.
�ȑO�A�㓡�L���ł́AGilo��Gesher�̊ԈႢ�������AGesher��
�C�X���G���`�[��������Ă�ƌ����Ă����ǁB
����͊ԈႢ�ŁABloomfield/Gilo/Gainestown�����Ȃ킿Neharem�n���
�������ƂŁAGesher�͕ʂɃC�X���G���ō���Ă�A�Ƃ������Ƃ��ȁB
>>549
�����I�т����肵���B
>Bloomfield integrates memory controller, supports HT
�Ȃ��memory controller�Ɠ���ɏ����Ă��邩��
HT=Hyper Transport
�Ɠǂ�ł��܂����B
�����I�т����肵���B
>Bloomfield integrates memory controller, supports HT
�Ȃ��memory controller�Ɠ���ɏ����Ă��邩��
HT=Hyper Transport
�Ɠǂ�ł��܂����B
���C���X�g���[�����f����2Core+HT�Ȃ̂��ȁH
�^���̓�N�O�̗\�z�ʂ�H
�^���̓�N�O�̗\�z�ʂ�H
�^�����ĒN��H
553 �FSocket774�F2006/11/24(��) 13:35:21 ID:3IyvhaeT
Power6�Ǝ���Itanium���Ăǂ����������́H
����ł���ق���������
555 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/24(��) 22:08:59 ID:O+5Ar/Cq
Xeon MP�Ɠ����v���b�g�t�H�[���ɂȂ�ƌ����b������ˁB
�\�P�b�g��������肩�ȁH
�\�P�b�g��������肩�ȁH
http://www.theinquirer.net/default.aspx?article=35892
�@�C���e����CPU�A�[�L�e�N�`���̏����̕������������܂����悤���B
������CPU�̊�{�v�̗D�ʐ����C���e����18�����O�܂�
�ŏI�����x�点�邱�Ƃ������Ă������A�����������ƌ��肳�ꂽ�悤��
�@��2�N�O�䂪�Ђ̋L��EvaGlass��Bloomfield�̋L�����������A
�����Ƃ����̓����͂��Ȃ�s�m���ȏ��
�@���ꂩ�狎�N��6��Charlie Demerjian ��intel���҂̐������܂����ƍŏ��̋L����������
Kentsfield�̎��Ƀ��m���V�b�N�_�C�̂S�R�Ayorkfield�����āA
Bloomfield�͂���Yorkfield�̎���CPU�ɂȂ�B
Kentsfield�Ƃ�Conroe�����������ɂ����Ȃ����̂ł���AConroe�́A�A�����m�̒ʂ�B
�@���̃f�X�N�g�b�vCPU��AMD��Q3'07.�ɏo�����҂̐��i�ɑR����ۂɏd�v�Ȗ������ʂ���
���̂Ƃ���2008�N�㔼�o��\���Bloomfield��AMD��Fusion�ɑR����d�v���i�ł���B
Bloomfield�̃��o�C���ł�Glio�ƃR�[�h�l�[�������t�����A�T�[�o�[�p��Gainestown�B
�@�R�[�h�l�[�������������Ƃ���ŁA���͂���炪���ۂǂ��������̂����炩�ɂ��悤
�܂��\�P�b�g775�ƃ��o�C���œo��\��̃\�P�b�gP�͖Y��Ă���A
�V�����\�P�b�g�̓\�P�b�gB��LGA��1366�{����B
LGA775��2�{�߂����v������Ă�̂�Bloomfield�͂S�R�A��800.1066.1333.1600MH��
�i���������ۂ̃N���b�N��400.533.667.800�j��DDR3�������[��
�T�|�[�g���铝���������R���g���[���[���������V���O���_�C�̍����\��45nmCPU������ł���B
Nehalem�A�[�L�e�N�`���ɂ����ă������R���g���[���[�͏d�v�Ȗ������ʂ����̂ŃC���e����
�S���V�����n�C�p�[�X���b�f�B���O�e�N�m���W�[������B
�V����HTT�͋����̂����y���ɐi�����Ă��Ď��ۂ̃X�s�[�h�A�b�v��
Cinema 4D��Lightwave 3D���̃\�t�g���������̃A�v���ő̌��ł��邾�낤
�@�V���Ȋg����FPU���j�b�g��SSE���߃Z�b�g�̓������V���܂ށA
�������܂������̕ύX�ɂ��ē`����̂͑����B
�@2008�N�ɃC���e����FSB���h�[�h�[���̂��Ƃ���ł̓���H�邾�낤���đO�ɉ�X�͌���Ȃ����������H
�@�C���e����CPU�A�[�L�e�N�`���̏����̕������������܂����悤���B
������CPU�̊�{�v�̗D�ʐ����C���e����18�����O�܂�
�ŏI�����x�点�邱�Ƃ������Ă������A�����������ƌ��肳�ꂽ�悤��
�@��2�N�O�䂪�Ђ̋L��EvaGlass��Bloomfield�̋L�����������A
�����Ƃ����̓����͂��Ȃ�s�m���ȏ��
�@���ꂩ�狎�N��6��Charlie Demerjian ��intel���҂̐������܂����ƍŏ��̋L����������
Kentsfield�̎��Ƀ��m���V�b�N�_�C�̂S�R�Ayorkfield�����āA
Bloomfield�͂���Yorkfield�̎���CPU�ɂȂ�B
Kentsfield�Ƃ�Conroe�����������ɂ����Ȃ����̂ł���AConroe�́A�A�����m�̒ʂ�B
�@���̃f�X�N�g�b�vCPU��AMD��Q3'07.�ɏo�����҂̐��i�ɑR����ۂɏd�v�Ȗ������ʂ���
���̂Ƃ���2008�N�㔼�o��\���Bloomfield��AMD��Fusion�ɑR����d�v���i�ł���B
Bloomfield�̃��o�C���ł�Glio�ƃR�[�h�l�[�������t�����A�T�[�o�[�p��Gainestown�B
�@�R�[�h�l�[�������������Ƃ���ŁA���͂���炪���ۂǂ��������̂����炩�ɂ��悤
�܂��\�P�b�g775�ƃ��o�C���œo��\��̃\�P�b�gP�͖Y��Ă���A
�V�����\�P�b�g�̓\�P�b�gB��LGA��1366�{����B
LGA775��2�{�߂����v������Ă�̂�Bloomfield�͂S�R�A��800.1066.1333.1600MH��
�i���������ۂ̃N���b�N��400.533.667.800�j��DDR3�������[��
�T�|�[�g���铝���������R���g���[���[���������V���O���_�C�̍����\��45nmCPU������ł���B
Nehalem�A�[�L�e�N�`���ɂ����ă������R���g���[���[�͏d�v�Ȗ������ʂ����̂ŃC���e����
�S���V�����n�C�p�[�X���b�f�B���O�e�N�m���W�[������B
�V����HTT�͋����̂����y���ɐi�����Ă��Ď��ۂ̃X�s�[�h�A�b�v��
Cinema 4D��Lightwave 3D���̃\�t�g���������̃A�v���ő̌��ł��邾�낤
�@�V���Ȋg����FPU���j�b�g��SSE���߃Z�b�g�̓������V���܂ށA
�������܂������̕ύX�ɂ��ē`����̂͑����B
�@2008�N�ɃC���e����FSB���h�[�h�[���̂��Ƃ���ł̓���H�邾�낤���đO�ɉ�X�͌���Ȃ����������H
DDR3-800,1066,1333,1600�̎��N���b�N����
100,133,166,200�̊ԈႢ����Ȃ���
100,133,166,200�̊ԈႢ����Ȃ���
����������Ȃ�
200,266,333,400�̊ԈႢ����Ȃ���
200,266,333,400�̊ԈႢ����Ȃ���
����A�����Ԉ���Ă܂����c
�s���������ʂĂ��Ȃ�
561 �FSocket774�F2006/11/24(��) 23:56:28 ID:Q8NdX/s1
>>553
POWER6�̃X�y�b�N�͂ǂ����M�����Ȃ���
POWER6�̃X�y�b�N�͂ǂ����M�����Ȃ���
>>561
�o�Ă���l���悤����Ȃ����B
�܁A���ۃf���A���R�A��2001�N�ɏo���Ă�킯�����APOWER5�ł�SMT�c�ƁA
�C���e���̍���̐��i��POWER��H���Ă���悤�ɂ��݂���B�����܂Ō����
POWER6��ǂ�������Ƃ�����ATDP���̂܂܂�Core3��7-8GHz+(POWER6��65nm��5GHz�Ȃ̂�)�����Ă��ƂɂȂ邩�H
Core3�̓����R��������悤�����APOWER�n�ɂ̓����R�������̂��̂����łɂ���i�ƊE�S�̂ł͒������Ȃ��j����
���̓_�ł����Ă�̂�����
���ɂ�PCI-E�����A�O���t�B�b�N�����Ȃǂ��낢�날�邪�AIA-32�������R�A��g�ݍ���ł��������قǁA�����ɋ߂��Ȃ��Ă����C������
�o�Ă���l���悤����Ȃ����B
�܁A���ۃf���A���R�A��2001�N�ɏo���Ă�킯�����APOWER5�ł�SMT�c�ƁA
�C���e���̍���̐��i��POWER��H���Ă���悤�ɂ��݂���B�����܂Ō����
POWER6��ǂ�������Ƃ�����ATDP���̂܂܂�Core3��7-8GHz+(POWER6��65nm��5GHz�Ȃ̂�)�����Ă��ƂɂȂ邩�H
Core3�̓����R��������悤�����APOWER�n�ɂ̓����R�������̂��̂����łɂ���i�ƊE�S�̂ł͒������Ȃ��j����
���̓_�ł����Ă�̂�����
���ɂ�PCI-E�����A�O���t�B�b�N�����Ȃǂ��낢�날�邪�AIA-32�������R�A��g�ݍ���ł��������قǁA�����ɋ߂��Ȃ��Ă����C������
���\�I�ȕ��U���L��������SMP�̓C���l
Socket H(LGA715)��Xeon�p�ł���܂��悤��
Socket H(LGA715)��Xeon�p�ł���܂��悤��
>>557
�����g����`�g���m��ǂ��������Ӗ��̎��N���b�N�Ȃ炻�����낤�ˁB
�����g����`�g���m��ǂ��������Ӗ��̎��N���b�N�Ȃ炻�����낤�ˁB
>>564
��͂肻�����B�ݸ�
��͂肻�����B�ݸ�
566 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/25(�y) 01:12:28 ID:ZlwuLiR3
715��2�R�A�p�Ȋ�K�X
567 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/25(�y) 01:15:23 ID:ZlwuLiR3
���������d�������͌���Œǂ����͂������A�M�����̓V���A�����Ŗ{�����点�邩��
775��715�͐����i���̔��Ȃ̂ł�
1366�͋����E������悤�ȂƂĂ��Ȃ��f�J�C���̂ł��ڂ���̂��Ǝv���Ă��܂���
775��715�͐����i���̔��Ȃ̂ł�
1366�͋����E������悤�ȂƂĂ��Ȃ��f�J�C���̂ł��ڂ���̂��Ǝv���Ă��܂���
�����R�����͂ǂ�������
569 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/25(�y) 10:26:36 ID:ZlwuLiR3
�V���A�������ꂽ�������C���^�t�F�C�X�܂߂Ă��M���������悤�ȁE�E�E
���������������W���������ɉe�����Ȃ����߂ɍ��܂�
�p�������������C���^�[�t�F�C�X���ډ�����Ă�����Ȃ����������B
�����������A1366��DDR3�p�������C���^�[�t�F�C�X�Ƃ̃f���A�����ڂ�
���������������W���������ɉe�����Ȃ����߂ɍ��܂�
�p�������������C���^�[�t�F�C�X���ډ�����Ă�����Ȃ����������B
�����������A1366��DDR3�p�������C���^�[�t�F�C�X�Ƃ̃f���A�����ڂ�
ttp://journal.mycom.co.jp/column/sopinion/184/
>�M�҂̉��߂Ō����AK8��Core Microarchitecture��
>��̓����x�̎��s���j�b�g�̐��\�����ƍl���Ă���B
ttp://journal.mycom.co.jp/column/sopinion/185/
>��G�c�Ɍ�����Athlon 64 X2��7290MIPS/GHz���x�A
>Core 2��9270MIPS/GHz�Ƃ������Ƃ���ł���B���\���Ō�����1.27�{
�N���b�N������̐��\���D��Ă��āA���N���b�N���[���}�[�W��������A
����d�͂����|�I�ɒႢ�̂ɁA
�I�n�hK8�͑f���炵����Core�͑債�����Ȃ��h
�Ƃ����_���Řb���i��ł�͉̂��̂��ˁB
�Ȃ�ƂȂ����̂ɂقЂ�����E�E�E
>�M�҂̉��߂Ō����AK8��Core Microarchitecture��
>��̓����x�̎��s���j�b�g�̐��\�����ƍl���Ă���B
ttp://journal.mycom.co.jp/column/sopinion/185/
>��G�c�Ɍ�����Athlon 64 X2��7290MIPS/GHz���x�A
>Core 2��9270MIPS/GHz�Ƃ������Ƃ���ł���B���\���Ō�����1.27�{
�N���b�N������̐��\���D��Ă��āA���N���b�N���[���}�[�W��������A
����d�͂����|�I�ɒႢ�̂ɁA
�I�n�hK8�͑f���炵����Core�͑債�����Ȃ��h
�Ƃ����_���Řb���i��ł�͉̂��̂��ˁB
�Ȃ�ƂȂ����̂ɂقЂ�����E�E�E
���|�I��3�{�ȏ�̊J�����Ȃ��Ǝg�����Ⴂ���Ȃ���
�R�����݂����ɂ����Ƃ��̃R�A���p�Ɉꂩ��v����4�R�ACPU�͂�����
�ł��
�ł��
3�{�������o��x���`�e�X�g�Ȃ�Č������ƂȂ�
�匴���̍l�����ƁAALU�̐���A�[�L�̑S�̂̃o�����X�Ƃ��āACoreMA�Ŗڎw���Ă���̂�3IPC�ŁA
ALU3��Load/Store���t���ɓ���4IPC�̓}�[�P�e�B���O��̐������A���Č���������������Ȃ��́H
http://www.yusuke-ohara.com/weblog2/archive/2006/09/post_46.html
�������̋L�q���O��ɂ��邱�Ƃ��l����ƁA�ނ���AAMD�͂܂��߂Ɏ������Ă邪���ʂ������A
intel�͌����I�Ȏ��������Ă�����ēǂ߂�B
�Ȃ�ɂ���AK8�̎��s���j�b�g��3���邩��ƌ����āA����3IPC�Ȃ킯�Ȃ��̂ŁA
CoreMA���s�[�N��4IPC�͂����ł�悤�Ȑv�ł͂Ȃ����ē�����O�Ȍ��_�ɂȂ邾���ȋC������B
ALU3��Load/Store���t���ɓ���4IPC�̓}�[�P�e�B���O��̐������A���Č���������������Ȃ��́H
http://www.yusuke-ohara.com/weblog2/archive/2006/09/post_46.html
�������̋L�q���O��ɂ��邱�Ƃ��l����ƁA�ނ���AAMD�͂܂��߂Ɏ������Ă邪���ʂ������A
intel�͌����I�Ȏ��������Ă�����ēǂ߂�B
�Ȃ�ɂ���AK8�̎��s���j�b�g��3���邩��ƌ����āA����3IPC�Ȃ킯�Ȃ��̂ŁA
CoreMA���s�[�N��4IPC�͂����ł�悤�Ȑv�ł͂Ȃ����ē�����O�Ȍ��_�ɂȂ邾���ȋC������B
575 �FSocket774�F2006/11/25(�y) 20:25:00 ID:U9MqrtJn
��������SSE���\�������Əグ��
����64bit���\�������Əグ��
����64bit���\�������Əグ��
576 �FSocket774�F2006/11/25(�y) 21:36:43 ID:SqM1Lulr
>>575 CPU����GPU�ɔ�ׂ�Ɛi���x��������̃j�[�Y�ɑ��Đ��\/�R�X�g�����������ˁB
10���~�ȏ�̍ō��O���[�h�ł���Ɖ䖝�ł��邩�ǂ������Ă������\�����E�E�E
���[�h�}�b�v�I�ɂ�8Ghz�Ƃ��o�Ă�͂��Ȃ�Intel�͂ǂ��Ȃ��Ă���낤���B
���[�A�̖@���j������܂�1���l���X�g���ł��̂�B
10���~�ȏ�̍ō��O���[�h�ł���Ɖ䖝�ł��邩�ǂ������Ă������\�����E�E�E
���[�h�}�b�v�I�ɂ�8Ghz�Ƃ��o�Ă�͂��Ȃ�Intel�͂ǂ��Ȃ��Ă���낤���B
���[�A�̖@���j������܂�1���l���X�g���ł��̂�B
����ɂP���l�}�[�P�e�B���O��������X�g������̂�
�����ȁA�c�ƃ}���Ȃv��Ȃ��ŋ��̊�Ƃ���
�����ȁA�c�ƃ}���Ȃv��Ȃ��ŋ��̊�Ƃ���
>>576
�P���ɍl����GPU�̏ꍇ�A���Z���j�b�g���₵��
�����\�͍��߂Ă�����ɔ�Ⴕ�ăp�t�H�[�}���X���オ���Ă���
������A�v���Z�X�̐i���Ƌ��Ƀp�t�H�[�}���X�͂����邱�ƂɂȂ�B
1280*1024�̉𑜓x�Ȃ�1310720�̕������ׂ��d��������̂�����B
CPU�Ƃ́A���Ƃ��ƕ����i�Ⴂ�Ȃ�ŒP���ɂ͔�ׂ��Ȃ��B
��ʗp�r�ł͕��̖R����CPU�̏ꍇ
�i�グ����Ȃ�j�N���b�N�����������p�t�H�[�}���X�͂�����₷���B
����2�{�ɂ��Ă��ˑ��W���őf����2�{�ɂȂ�Ȃ�
�N���b�N2�{�Ȃ�ˑ����͊W�Ȃ��B
����ŁAIntel��AMD���l�ɃR�v�����E�E�E
�P���ɍl����GPU�̏ꍇ�A���Z���j�b�g���₵��
�����\�͍��߂Ă�����ɔ�Ⴕ�ăp�t�H�[�}���X���オ���Ă���
������A�v���Z�X�̐i���Ƌ��Ƀp�t�H�[�}���X�͂����邱�ƂɂȂ�B
1280*1024�̉𑜓x�Ȃ�1310720�̕������ׂ��d��������̂�����B
CPU�Ƃ́A���Ƃ��ƕ����i�Ⴂ�Ȃ�ŒP���ɂ͔�ׂ��Ȃ��B
��ʗp�r�ł͕��̖R����CPU�̏ꍇ
�i�グ����Ȃ�j�N���b�N�����������p�t�H�[�}���X�͂�����₷���B
����2�{�ɂ��Ă��ˑ��W���őf����2�{�ɂȂ�Ȃ�
�N���b�N2�{�Ȃ�ˑ����͊W�Ȃ��B
����ŁAIntel��AMD���l�ɃR�v�����E�E�E
579 �FSocket774�F2006/11/25(�y) 22:21:27 ID:SqM1Lulr
�Ȃ�[�̂��Ȃ��Ⴆ��Pentium4(��ڽ�)�����Ă��Ƃ���
���ʂ̃\�t�g�œ��N���b�N�������\����C2D�ɔ����ւ�����ϋɓI�ȗ��R���������
�������w�ǂ�Prescott��4.5Ghz�ȏ�œ��삵�Ă��܂��B
�P���Ɍ����ċ��^�ɕ�����(���\����)�Ȃ����H
Intel�Ђ�I����C2D��6Ghz�ł̃����[�X��v���������܂��B
Vista�ł��ꂩ��n���p�������삪�d���Ȃ�B����ł�����邩�ǂ��������ł������
���ʂ̃\�t�g�œ��N���b�N�������\����C2D�ɔ����ւ�����ϋɓI�ȗ��R���������
�������w�ǂ�Prescott��4.5Ghz�ȏ�œ��삵�Ă��܂��B
�P���Ɍ����ċ��^�ɕ�����(���\����)�Ȃ����H
Intel�Ђ�I����C2D��6Ghz�ł̃����[�X��v���������܂��B
Vista�ł��ꂩ��n���p�������삪�d���Ȃ�B����ł�����邩�ǂ��������ł������
580 �FSocket774�F2006/11/25(�y) 22:25:46 ID:U9MqrtJn
>>578
�P���ɍl����CPU�̏ꍇ�A����ō����x����CPU�ł���ɗ]��d�����Ă����̂́A
����̃G���R�[�h�Ƃ��f�[�^�}�C�j���O�Ƃ��g���b�v�����Ƃ��A���Ȃ�����Ă��
��ˁB�ŁA�����̎d���̑啔���́A���Ȃ���𒊏o�ł���B
�\�t�g�E�F�A�ƃn�[�h�E�F�A�������ݑ����Đi�����Ă����Ȃ��A�Ǝv���B
�P���ɍl����CPU�̏ꍇ�A����ō����x����CPU�ł���ɗ]��d�����Ă����̂́A
����̃G���R�[�h�Ƃ��f�[�^�}�C�j���O�Ƃ��g���b�v�����Ƃ��A���Ȃ�����Ă��
��ˁB�ŁA�����̎d���̑啔���́A���Ȃ���𒊏o�ł���B
�\�t�g�E�F�A�ƃn�[�h�E�F�A�������ݑ����Đi�����Ă����Ȃ��A�Ǝv���B
581 �FSocket774�F2006/11/25(�y) 22:28:16 ID:SqM1Lulr
OS���x���Ń}���`�R�A����(����Ȃ�X���b�h���ɃR�A�����蓖�Ă邾���ł�����)
���Ă����̂�VISTA�̍Œ���x�̎g�����Ǝv�����B
���ꂪ�ǂ�������ĂȂ��炵�����VISTA��ME�݂����ɏ�������Ă�����������������
����ł��Œ�2�N�͐i�����x��A���̊��Ԃ͂��̂܂܃}���`�R�A���������Ȃ����ԂƂȂ�B
���̊Ԃ߂鍂�N���b�N�œ���CPU�����Ƃ��o���Ȃ��Ƒ�ςȂ��ƂɂȂ肻���ȋC����������
�܂�Intel�����������킯����Ȃ����Ď��Ȃ��ǂ�
���Ă����̂�VISTA�̍Œ���x�̎g�����Ǝv�����B
���ꂪ�ǂ�������ĂȂ��炵�����VISTA��ME�݂����ɏ�������Ă�����������������
����ł��Œ�2�N�͐i�����x��A���̊��Ԃ͂��̂܂܃}���`�R�A���������Ȃ����ԂƂȂ�B
���̊Ԃ߂鍂�N���b�N�œ���CPU�����Ƃ��o���Ȃ��Ƒ�ςȂ��ƂɂȂ肻���ȋC����������
�܂�Intel�����������킯����Ȃ����Ď��Ȃ��ǂ�
�g���b�v�����i�j
583 �FSocket774�F2006/11/25(�y) 22:35:43 ID:SqM1Lulr
>>580�@�Q�[���Ȃ̐l�����\����ĂȂ����ۂ���ˁB
�G���R�Ƃ��̌������̂��߂ɏ����𑽏��O�コ������o����o�b�`�����I�Ȃ��̂�
���ʼn��Ƃ��o����Ƃ��Ă�(OS�������Ƃ���̂��Œ����)
�Q�[���Ƃ����̏u�ԏu�Ԃŏ������Ȃ��Ƃ����Ȃ��W�������ˁB
���������͂�͂�����\�����m��������B
CPU��10�����Ă��������ǂ��ꂱ�����̃N���b�N�Ɛ��\���ۂ����܂�
8Ghz���炢�s���ĂĖ��Ȃ��Ƃ��Ă����̂͂��邩�ȁB
�G���R�Ƃ��̌������̂��߂ɏ����𑽏��O�コ������o����o�b�`�����I�Ȃ��̂�
���ʼn��Ƃ��o����Ƃ��Ă�(OS�������Ƃ���̂��Œ����)
�Q�[���Ƃ����̏u�ԏu�Ԃŏ������Ȃ��Ƃ����Ȃ��W�������ˁB
���������͂�͂�����\�����m��������B
CPU��10�����Ă��������ǂ��ꂱ�����̃N���b�N�Ɛ��\���ۂ����܂�
8Ghz���炢�s���ĂĖ��Ȃ��Ƃ��Ă����̂͂��邩�ȁB
�uOS���x���Ő������v�Ƃ��uOS�������Ƃ���v�̈Ӗ����悭�킩���
�Q�[���Ȃ̒P�̂ŏd���A�v���𑬂��������̂ɂn�r�̑Ή��͊W�Ȃ���
581�͂Ȃɂ����Ⴂ���Ă��܂���
581�͂Ȃɂ����Ⴂ���Ă��܂���
586 �FSocket774�F2006/11/25(�y) 22:46:18 ID:SqM1Lulr
�R�A���Ɍ����I�ɃX���b�h���蓖�Ă�X�P�W���[�����O����
OS������Ă���Ȃ��ƃ}���`�R�A�V����͗��Ȃ���Ȃ����낤���B
���ꂩOS���猩���1�R�A��CPU�ɂȂ��Ăē����I��n�R�A�Ƀn�[�h�E�G�A�I��
�X�P�W���[�����O���Ă���邩�ǂ���������B
�Ƃɂ����A���̎d�g�݂̉��z����i�������������Ă���Ȃ���
�ėp���̖����v���O���������萶�ݏo���đ�ϖ��ʂɂȂ����Ⴄ�B
�S�R�A�p�̃v���O�������P�U�R�A�ɂȂ����Ƃ��ɂ���Ȃ�ɑ��������Ȃ���
����ς茙�ł��傤�H���݂����ɐVCPU������Ȃ��Ƃ�Intel�I�ɂ��悭�Ȃ���
�v�����B�����l�����炱��͐�Γ��ڂ��ׂ����B
OS������Ă���Ȃ��ƃ}���`�R�A�V����͗��Ȃ���Ȃ����낤���B
���ꂩOS���猩���1�R�A��CPU�ɂȂ��Ăē����I��n�R�A�Ƀn�[�h�E�G�A�I��
�X�P�W���[�����O���Ă���邩�ǂ���������B
�Ƃɂ����A���̎d�g�݂̉��z����i�������������Ă���Ȃ���
�ėp���̖����v���O���������萶�ݏo���đ�ϖ��ʂɂȂ����Ⴄ�B
�S�R�A�p�̃v���O�������P�U�R�A�ɂȂ����Ƃ��ɂ���Ȃ�ɑ��������Ȃ���
����ς茙�ł��傤�H���݂����ɐVCPU������Ȃ��Ƃ�Intel�I�ɂ��悭�Ȃ���
�v�����B�����l�����炱��͐�Γ��ڂ��ׂ����B
�܁AIntel�l�Ɋ��҂��܂��傤��
http://www.hpc.co.jp/hit/support/multicore.html
>>586
OS�����Ĉ�\�t�g�E�F�A
�Ȃ�ł����ʂ���u�_�l�v����Ȃ���
http://www.hpc.co.jp/hit/support/multicore.html
>>586
OS�����Ĉ�\�t�g�E�F�A
�Ȃ�ł����ʂ���u�_�l�v����Ȃ���
���S�R�A�p�̃v���O�������P�U�R�A�ɂȂ����Ƃ��ɂ���Ȃ�ɑ��������Ȃ���
������ς茙�ł��傤�H
�Ȃ������{�I�Ɋ��Ⴂ���Ă�Ƃ���
������ς茙�ł��傤�H
�Ȃ������{�I�Ɋ��Ⴂ���Ă�Ƃ���
�@���@�}���`�X���b�f�B���O
Geisher�iCore4?)�EK11?�����肩������\��炵���B
Geisher�iCore4?)�EK11?�����肩������\��炵���B
590 �FSocket774�F2006/11/25(�y) 22:52:10 ID:SqM1Lulr
>>588�@���̂��Ƃ����l���Ė����Ƃ��̓����ł����Ă��B
591 �FSocket774�F2006/11/25(�y) 22:54:35 ID:iN/8fvcf
�p�\�R���w��������������
http://search.goo.ne.jp/web.jsp?MT=do+%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B5%E3%82%AF%E3%83%88&STYPE=web&IE=UTF-8&from=gootop
http://search.goo.ne.jp/web.jsp?MT=do+%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B5%E3%82%AF%E3%83%88&STYPE=web&IE=UTF-8&from=gootop
������������Ƃ苳��̐��ʂ��A����Ƃ�
ILP�ɂ����āA���߃��x���̕��𒊏o����R�X�g�i�g�����W�X�^�A����d�́j���偁�|���b�N�̖@��
����ɂ��ATLP�ɂ�����X���b�h�X�P�W���[�����O�̃R�X�g�i��ɐl�ԁj���ߏ��]������^�W���[�i���X�g�̉e�����B
ILP�ɂ����āA���߃��x���̕��𒊏o����R�X�g�i�g�����W�X�^�A����d�́j���偁�|���b�N�̖@��
����ɂ��ATLP�ɂ�����X���b�h�X�P�W���[�����O�̃R�X�g�i��ɐl�ԁj���ߏ��]������^�W���[�i���X�g�̉e�����B
�}���`�^�X�N�ł����K�ɂȂ�܂�����Ă����ŁA�ЂƂ̃A�v���P�[�V�����ɑ��鐫�\�͂���܂�オ�肻���ɂȂ�
�����I
595 �FSocket774�F2006/11/25(�y) 23:08:47 ID:SqM1Lulr
�������߂��Ă���̂͒����|�I�Ɍ�҂�����Ȃ��B
�������������̃A�v�����Ȃ����s�������Ȃ�\������CPU��
7����1���炢�̒l�i��CPU��PC2��g�����������������R�}�������������
���[�U�[�ɂƂ��Ẵ����b�g���킩�肸�炢���ȁB
�������������̃A�v�����Ȃ����s�������Ȃ�\������CPU��
7����1���炢�̒l�i��CPU��PC2��g�����������������R�}�������������
���[�U�[�ɂƂ��Ẵ����b�g���킩�肸�炢���ȁB
�d���ł悭�g�����t�A
���[�N�t���[�E�^�X�N�t���[�E�t���[�`���[�g�B
�t���[�Ƃ͗���B�܂菇�����Ăčs��Ȃ��Ƃ����Ȃ��B
����𑁂���������ɂ͂Ƃɂ�����]�����グ�邵���Ȃ��B
���[�N�t���[�E�^�X�N�t���[�E�t���[�`���[�g�B
�t���[�Ƃ͗���B�܂菇�����Ăčs��Ȃ��Ƃ����Ȃ��B
����𑁂���������ɂ͂Ƃɂ�����]�����グ�邵���Ȃ��B
�����͂���Ȋ����ŏo�Ă�Ǝv���̂�
(���N���b�N��orDie)+�V�A�[�L�e�B�N�`���ŌӎU�L��x���A�b�v�Ƃ��c
�����Ȃ��낤��CPU�����Ƃ̖{���͍������Ȃ��B
���N�����胍�[�h�}�b�v�������Ă��������̂��ǁ[��Əo�Ă���Ƃ͎v����B
VISTA(�����l����̂�?)�ō������l�����̂����������ŕ��匾���n�߂����������
�V�����̔������̂ɃX�Q�[�x���Ƃ���������������
(���N���b�N��orDie)+�V�A�[�L�e�B�N�`���ŌӎU�L��x���A�b�v�Ƃ��c
�����Ȃ��낤��CPU�����Ƃ̖{���͍������Ȃ��B
���N�����胍�[�h�}�b�v�������Ă��������̂��ǁ[��Əo�Ă���Ƃ͎v����B
VISTA(�����l����̂�?)�ō������l�����̂����������ŕ��匾���n�߂����������
�V�����̔������̂ɃX�Q�[�x���Ƃ���������������
��b���������Ă˂���
599 �FSocket774�F2006/11/25(�y) 23:29:41 ID:U9MqrtJn
>>597
���{��ł���
���{��ł���
600 �F�܂���^���X�ɂ͂���ŏ\���F2006/11/25(�y) 23:31:54 ID:SqM1Lulr
>>599 ���N�l����
���̎����CPU�n�̃X���ɏW�܂�l�́A
���s�A�[�L�e�N�`���̗����͂���Ȃ�ɐZ�����Ă��邩��A
ID:SqM1Lulr�̂悤�ȊԈႢ���炯�̔F���̐��ꗬ��������Ă���b���������Ȃ��ˁB
���s�A�[�L�e�N�`���̗����͂���Ȃ�ɐZ�����Ă��邩��A
ID:SqM1Lulr�̂悤�ȊԈႢ���炯�̔F���̐��ꗬ��������Ă���b���������Ȃ��ˁB
602 �FSocket774�F2006/11/25(�y) 23:36:02 ID:SqM1Lulr
�悵���႟���O�̏o�Ԃ��B
����ł͑S�R����Ȃ�CPU�̐��\���グ��ɂ͂ǂ������炢���H
����ł͑S�R����Ȃ�CPU�̐��\���グ��ɂ͂ǂ������炢���H
�R���ID:SqM1Lulr�Ɠ������ߏ�ȃ}���`�R�A�ɂ͉��^�h�Ȃ��ǁA
(1) �N���b�N���グ��
(2) ���߃��x������UP
(3) �}���`�X���b�f�B���O��}���`�R�A�ɂ��TLP���\��UP
(4) ����p�rHW�ASIMD�A�x�N�g���v���Z�b�T��
�Ƒ傫���킯��4��ނ̍������������āA(1)(2)���d�͖��œ���Ȃ��Ă��Ă��邩��A
(3)(4)�̕����Ɍ����Ă��B
�ŁA(3)��(4)����������ACPU=�}�C�N���v���Z�b�T���Ă������i�W���������A
���͂������Ȃ��ēW�J���܂��Ă���킯���B
�������A�R�ꂪ�˂����݂����̂͂����ł͂Ȃ��AID:SqM1Lulr�́ACPU�̐��\�ɑ���l�����S�̓I�ɂ��������B
Prescott��Core 2�������N���b�N�œ����\���Ɩ{�C�Ŏv���Ă��?
(1) �N���b�N���グ��
(2) ���߃��x������UP
(3) �}���`�X���b�f�B���O��}���`�R�A�ɂ��TLP���\��UP
(4) ����p�rHW�ASIMD�A�x�N�g���v���Z�b�T��
�Ƒ傫���킯��4��ނ̍������������āA(1)(2)���d�͖��œ���Ȃ��Ă��Ă��邩��A
(3)(4)�̕����Ɍ����Ă��B
�ŁA(3)��(4)����������ACPU=�}�C�N���v���Z�b�T���Ă������i�W���������A
���͂������Ȃ��ēW�J���܂��Ă���킯���B
�������A�R�ꂪ�˂����݂����̂͂����ł͂Ȃ��AID:SqM1Lulr�́ACPU�̐��\�ɑ���l�����S�̓I�ɂ��������B
Prescott��Core 2�������N���b�N�œ����\���Ɩ{�C�Ŏv���Ă��?
���͂������Ȃ��ēW�J���܂��Ă���킯���B
��
���͂������Ȃ���PC�s��S�̂����ނ���Ƃ��������W�J���܂��Ă���킯���B
��
���͂������Ȃ���PC�s��S�̂����ނ���Ƃ��������W�J���܂��Ă���킯���B
�������ނō\������Ă���PC���̂́i��ɃP�~�J�����i�́j�����������Ē���I�����ւ������҂ł���B
�ł��V���R�������ŐH���Ă���͂����B
CMOS�E���z���̌��E���v���Z�b�T���̌��E�B
���Ă��ƂɂȂ�Ȃ����߂ɂ́A���Ȃ�f�ނ̊J����r�W�l�X���f���̓]�����K�v�B
�ł��V���R�������ŐH���Ă���͂����B
CMOS�E���z���̌��E���v���Z�b�T���̌��E�B
���Ă��ƂɂȂ�Ȃ����߂ɂ́A���Ȃ�f�ނ̊J����r�W�l�X���f���̓]�����K�v�B
����ő���Ȃ��̂�CPU�̐��\�ł͂Ȃ��B
���j�C�R�A�⒴����SIMD�������߂̃v���O�����Z�p��
���C���������̑ш悾��
���j�C�R�A�⒴����SIMD�������߂̃v���O�����Z�p��
���C���������̑ш悾��
�\�t�g�E�F�A�I�Ȗ������\�傫����Ȃ����ȁH
��PC�Ŏ嗬�̌���iC/C++/Java/C#)�n�͂ǂ��
�X���b�h�̑Ή������܂�ɂ��ώG�߂��邵�A
�T�|�[�g���e���A�ƂĂ����ꃌ�x���ō���������Ή����Ă�Ƃ͌����Ȃ���ˁE�E�E
��PC�Ŏ嗬�̌���iC/C++/Java/C#)�n�͂ǂ��
�X���b�h�̑Ή������܂�ɂ��ώG�߂��邵�A
�T�|�[�g���e���A�ƂĂ����ꃌ�x���ō���������Ή����Ă�Ƃ͌����Ȃ���ˁE�E�E
�܂���LISP�Ƃ�����Ȃ����
ID:SqM1Lulr�̃��X��ް??? �тɂ������ɑ҂��Ă�����̂Ɂc�B
�}���`�X���b�h/�}���`�R�A�̕��y�ɂ�����\�t�g���̍ő�̖��́A
���̒��̖w�ǂ̃v���O�����ɂ����āA����3�̍��ڂ̒��ŁA
�D�悳���̂����|�I��(3)����(1)(2)�ł���A(3)��D�悷���(1)(2)���]���ɂȂ��Ă��܂����Ƃł���B
(1) �o�O�炸�ɓ��삷�邱��
(2) ���x�̒Ⴂ�v���O���}�ł��e�ՂɃR�[�f�B���O�ł��A�J�����Ԃ��Z������
(3) ��荂���œ��삷�邱��
�}���`�X���b�h�v���O���~���O�̐��E�ł͓��ɂ��ꂪ�����B
(1)(2)���D�悳��闝�R
������X���[�Y�ɓ��삵�ĂĂ��p�ɂɃt���[�Y����A�v���Ȃ�ĒN���g��������Ȃ�������Ȃ��B
����J�����Ԃ��������������������A���ʂ�����Ȃ�A
�܂Ƃ��ȃv���W�F�N�g���[�_�[�Ȃ�킴�킴���s���x�̂��߂Ƀ}���`�X���b�h�֓��U���悤�ȂǂƎv��Ȃ��̂����������̖��B
�܂��A�X�N���v�g�v���O���}�݂����Ƀv���O���~���O�ňꉞ�т͐H���Ă���悤�����A
�v�Z�@�̒��g�͓��ꗝ���ł��Ă���Ƃ͎v���Ȃ��A�Ȃ���ăR���s���[�^���̂Ȑl�������Ă��Ă��邲�����ŁA
�}���`�X���b�h�ō��������K���K���ł���l�ނ͂ق�̈ꈬ�肵�����Ȃ��Ƃ����l�Ԃ̐��\�̖�������ɂ���B
�ŁA���̂��Ƃ̋c�_�͎������͂ǂ��܂ʼn\���Ƃ������ɂȂ�A
���̂��Ƃɂ́A���\��PC�n�A�v���͌����ɂǂ��܂Ŏ��v������̂��Ƃ��������T���Ă���B
�Ƃ����킯�ŁA�}���`�X���b�h/�}���`�R�A�̓n�[�h�E�G�A�̖�肾������Ȃ����R�ς݁B
�}���`�X���b�h/�}���`�R�A�̕��y�ɂ�����\�t�g���̍ő�̖��́A
���̒��̖w�ǂ̃v���O�����ɂ����āA����3�̍��ڂ̒��ŁA
�D�悳���̂����|�I��(3)����(1)(2)�ł���A(3)��D�悷���(1)(2)���]���ɂȂ��Ă��܂����Ƃł���B
(1) �o�O�炸�ɓ��삷�邱��
(2) ���x�̒Ⴂ�v���O���}�ł��e�ՂɃR�[�f�B���O�ł��A�J�����Ԃ��Z������
(3) ��荂���œ��삷�邱��
�}���`�X���b�h�v���O���~���O�̐��E�ł͓��ɂ��ꂪ�����B
(1)(2)���D�悳��闝�R
������X���[�Y�ɓ��삵�ĂĂ��p�ɂɃt���[�Y����A�v���Ȃ�ĒN���g��������Ȃ�������Ȃ��B
����J�����Ԃ��������������������A���ʂ�����Ȃ�A
�܂Ƃ��ȃv���W�F�N�g���[�_�[�Ȃ�킴�킴���s���x�̂��߂Ƀ}���`�X���b�h�֓��U���悤�ȂǂƎv��Ȃ��̂����������̖��B
�܂��A�X�N���v�g�v���O���}�݂����Ƀv���O���~���O�ňꉞ�т͐H���Ă���悤�����A
�v�Z�@�̒��g�͓��ꗝ���ł��Ă���Ƃ͎v���Ȃ��A�Ȃ���ăR���s���[�^���̂Ȑl�������Ă��Ă��邲�����ŁA
�}���`�X���b�h�ō��������K���K���ł���l�ނ͂ق�̈ꈬ�肵�����Ȃ��Ƃ����l�Ԃ̐��\�̖�������ɂ���B
�ŁA���̂��Ƃ̋c�_�͎������͂ǂ��܂ʼn\���Ƃ������ɂȂ�A
���̂��Ƃɂ́A���\��PC�n�A�v���͌����ɂǂ��܂Ŏ��v������̂��Ƃ��������T���Ă���B
�Ƃ����킯�ŁA�}���`�X���b�h/�}���`�R�A�̓n�[�h�E�G�A�̖�肾������Ȃ����R�ς݁B
����A�悯���ȕҏW���Ă��炮���Ⴎ����ɂȂ����ȕ��͂��B
612 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 01:31:05 ID:zqjEHEea
�O��̉��Z�Ɉˑ��������Ȃ��������ł�����x�グ�����B
���́A����ȉ��Z���ǂ��܂ł��邩�H
������S�����@���s���Đ����p�X�����R�~�b�g����Ƃ��H
���́A����ȉ��Z���ǂ��܂ł��邩�H
������S�����@���s���Đ����p�X�����R�~�b�g����Ƃ��H
>>610
Intel�l�͂���Ȃ��Ƃ͕S�����m�B�v���O���}�ɂ��l�̓}���`�X���b�h���Ȃ��
�n�i������҂��ĂȂ��B����Ȃ̂��ł��镪��͂����}���`�X���b�h�ɑΉ����Ă�B
�R���p�C������s���ɕ��������ɒ��o���邩�A���̌��������ܕK�������Ă���Ă�B
Intel�l�͂���Ȃ��Ƃ͕S�����m�B�v���O���}�ɂ��l�̓}���`�X���b�h���Ȃ��
�n�i������҂��ĂȂ��B����Ȃ̂��ł��镪��͂����}���`�X���b�h�ɑΉ����Ă�B
�R���p�C������s���ɕ��������ɒ��o���邩�A���̌��������ܕK�������Ă���Ă�B
>>612
����ȉ��Z�͕����I�ɂ͈�t����̂����A���̕������P�O�O�{����������Ă�
�{�g���l�b�N���P�ӏ�����ΑS�̂̑��x�͂Q�{�ɂ���Ȃ��Ƃ���
����ȉ��Z�͕����I�ɂ͈�t����̂����A���̕������P�O�O�{����������Ă�
�{�g���l�b�N���P�ӏ�����ΑS�̂̑��x�͂Q�{�ɂ���Ȃ��Ƃ���
Intel�����m���ĂĂ��A�\�t�g���̖��͂��̕ӂ̉���L���ł͂悭��������ɂ���Ă�ł���B
�ŁA���������ꂽ�A�v�����ANehalem�̂Ƃ��܂łɂǂꂭ�炢�łĂ���Ɓc�B
Penryn�Œlj������ASSE4�Ɏ������R���p�C���p�̖��߂��F�X�lj�����Ă�Ƃ���Ȃ͖ʔ����B
Penryn�`Nehalem�ŁA���A�v���y�����āA���̌�̃}���`�R�A�H�����X�ɉ�������������Ȃ낤���ǁA
�ǂ��܂ł��܂��������́c�B
�ŁA���������ꂽ�A�v�����ANehalem�̂Ƃ��܂łɂǂꂭ�炢�łĂ���Ɓc�B
Penryn�Œlj������ASSE4�Ɏ������R���p�C���p�̖��߂��F�X�lj�����Ă�Ƃ���Ȃ͖ʔ����B
Penryn�`Nehalem�ŁA���A�v���y�����āA���̌�̃}���`�R�A�H�����X�ɉ�������������Ȃ낤���ǁA
�ǂ��܂ł��܂��������́c�B
intel�̌����Ƃ��ẮA�g�����U�N�V���i�����������ʔ������Ȃ��ǁA
�܂����ɂȂ���́A�ǂ��Ȃ낤�B���ꑤ�̎x�����K�v�Ȃ낤�Ȃ��B
���������n�[�h�E�F�A���̎d�g�݂������ƁA�}���`�R�A�����Â炢�B
�܂����ɂȂ���́A�ǂ��Ȃ낤�B���ꑤ�̎x�����K�v�Ȃ낤�Ȃ��B
���������n�[�h�E�F�A���̎d�g�݂������ƁA�}���`�R�A�����Â炢�B
>>615
>Intel�����m���ĂĂ��A�\�t�g���̖��͂��̕ӂ̉���L���ł͂悭��������ɂ���Ă�ł���B
����㓡�^�����n���Ȃ������Ǝv��������́c�c
>Intel�����m���ĂĂ��A�\�t�g���̖��͂��̕ӂ̉���L���ł͂悭��������ɂ���Ă�ł���B
����㓡�^�����n���Ȃ������Ǝv��������́c�c
618 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 01:57:05 ID:zqjEHEea
>>615
> SSE4�Ɏ������R���p�C���p�̖��߂��F�X�lj�����Ă�Ƃ���Ȃ͖ʔ����B
��������Ȃ��āA�V���߂�����邱�Ƃ�
���Ƃ���
for_each( i in 0...1000 ) dest[i] = UINT_MAX(a[i], b[i])
�������������̑傫�������Ƃ閽�߂�pmaxub�����Ȃ������̂�
�x�N�g���C�Y�̑j�Q�v���ɂȂ��Ă��i�{���͂ł�����ǁj�B
SSE4�ł͕����L��E��������������������₷���Ȃ�킯�B
> SSE4�Ɏ������R���p�C���p�̖��߂��F�X�lj�����Ă�Ƃ���Ȃ͖ʔ����B
��������Ȃ��āA�V���߂�����邱�Ƃ�
���Ƃ���
for_each( i in 0...1000 ) dest[i] = UINT_MAX(a[i], b[i])
�������������̑傫�������Ƃ閽�߂�pmaxub�����Ȃ������̂�
�x�N�g���C�Y�̑j�Q�v���ɂȂ��Ă��i�{���͂ł�����ǁj�B
SSE4�ł͕����L��E��������������������₷���Ȃ�킯�B
>>616
�[���������C����������Intel�����ЊJ�����₪��
�[���������C����������Intel�����ЊJ�����₪��
���̂Ă����������܂����W�J��
������܂��悵����
������܂��悵����
�s��������������ާ?(�E�́E )��ɼ���܁�����
623 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 02:07:04 ID:zqjEHEea
UINT_MAX��C�ł����̍ő�l�̒萔�̂��Ƃ������ȁB�B�B�B
624 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 02:10:30 ID:zqjEHEea
>>622
��������Ȃ��Ă��̎�̊g�����߂͕��R���p�C���ň������ȒP������
���킴�킴��ŃA�Z���u�����������肷���Ԃ�ς킹���ɍ������ɍv�����܂���
�I�Ȃ��́B��������I�ɗ��p���Ă��\�����ʂ���Ǝv���B
��������Ȃ��Ă��̎�̊g�����߂͕��R���p�C���ň������ȒP������
���킴�킴��ŃA�Z���u�����������肷���Ԃ�ς킹���ɍ������ɍv�����܂���
�I�Ȃ��́B��������I�ɗ��p���Ă��\�����ʂ���Ǝv���B
>>624
�Ƃǂ̂܂�Intel�����R���p�C����Z�����������n�̖��߂��Ă킯�ł���B
�Ȃɂ�ے肵�����̂��킩���c�B
�܂�c�q�͎����̃R�[�h�b����������������B
�Ƃǂ̂܂�Intel�����R���p�C����Z�����������n�̖��߂��Ă킯�ł���B
�Ȃɂ�ے肵�����̂��킩���c�B
�܂�c�q�͎����̃R�[�h�b����������������B
BLENDPS, BLENDPD, BLENDVPS, BLENDVPD, PBLENDVB, PBLENDDW
�ɂ��ĉ����]
�ɂ��ĉ����]
���A����A���c�q�̂����Ă��邱�Ƃ��悭�킩�����B
�}���`�X���b�h�͊W�Ȃ��ˁB
�}���`�X���b�h�͊W�Ȃ��ˁB
628 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 02:31:32 ID:zqjEHEea
SSE2�ŕ�������DWORD�l�̑傫�������Ƃ�ɂ͂ǂ�����H
0x80000000�𗼑���������Ă���PMAXSD�A���ʂ�0x80000000�������邱�ƂɂȂ�Ǝv������
���ꂪPMAXUD���g����1���߂ŁA�����炭�P��OP�Ŏ����ł���B
���߂��R���p�C���̎������ɍv�������Ȃ��āA�R���p�C�����V���߂��T�|�[�g����
���x�̈Ӗ��ł����Ȃ����Ă��ƁB
���̈Ӗ��ł����ƁASSE3, SSSE3�̐������Z�Ȃ͎������̌�������������
����ɑ��Č����Ă��ł��傤�B
0x80000000�𗼑���������Ă���PMAXSD�A���ʂ�0x80000000�������邱�ƂɂȂ�Ǝv������
���ꂪPMAXUD���g����1���߂ŁA�����炭�P��OP�Ŏ����ł���B
���߂��R���p�C���̎������ɍv�������Ȃ��āA�R���p�C�����V���߂��T�|�[�g����
���x�̈Ӗ��ł����Ȃ����Ă��ƁB
���̈Ӗ��ł����ƁASSE3, SSSE3�̐������Z�Ȃ͎������̌�������������
����ɑ��Č����Ă��ł��傤�B
629 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 02:34:36 ID:zqjEHEea
BLENDPS, BLENDPD,
BLENDVPS, BLENDVPD,
PBLENDVB, PBLENDDW
Broadly useful for automated compiler vectorization
of data processing written in high level languages
(like C and Fortran), and applications such as image
processing, video processing, multimedia, and gaming.
�������R���p�C��(C&Fortran)�̃x�N�g�������Ă�B
BLENDVPS, BLENDVPD,
PBLENDVB, PBLENDDW
Broadly useful for automated compiler vectorization
of data processing written in high level languages
(like C and Fortran), and applications such as image
processing, video processing, multimedia, and gaming.
�������R���p�C��(C&Fortran)�̃x�N�g�������Ă�B
SSE4 adds several new compiler vectorization primitives (fundamental
operations from which more complex operations can be constructed)
that extend the capabilities of Intel architecture by enabling performanceoptimized
and lower power code generation. Compilers making use
of these improved compiler vectorization primitives will be able to
deliver these benefits to a broad range of applications, including
media and high performance computing (HPC) server applications.
exxite�|��:
Intel�́ASSE4�Ŏ����x�N�g�����ŁA�R���p�C����SIMD���߂��y�ɐ����ł���悤�ɁA
�v���~�e�B�u�̃o���G�[�V�����𑝂₵�܂����B���̊g���ɂ���ăp�t�H�[�}���X�I�v�e�B�}�C�Y�h
�ŁA���[�p���[�ȃR�[�h�������\�ɂȂ�܂��B(�œK�������[�p���[�̎��ォ��!)
operations from which more complex operations can be constructed)
that extend the capabilities of Intel architecture by enabling performanceoptimized
and lower power code generation. Compilers making use
of these improved compiler vectorization primitives will be able to
deliver these benefits to a broad range of applications, including
media and high performance computing (HPC) server applications.
exxite�|��:
Intel�́ASSE4�Ŏ����x�N�g�����ŁA�R���p�C����SIMD���߂��y�ɐ����ł���悤�ɁA
�v���~�e�B�u�̃o���G�[�V�����𑝂₵�܂����B���̊g���ɂ���ăp�t�H�[�}���X�I�v�e�B�}�C�Y�h
�ŁA���[�p���[�ȃR�[�h�������\�ɂȂ�܂��B(�œK�������[�p���[�̎��ォ��!)
���_:
FB-DIMM(XDR DRAM��)��Intel�R���p�C����������Ή����v��Ȃ�
FB-DIMM(XDR DRAM��)��Intel�R���p�C����������Ή����v��Ȃ�
633 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 03:08:03 ID:zqjEHEea
Dest = ( (A * alpha) + (B * (256-alpha)) ) / 256 ;
SSE���g���Ȃ�}�X�N�����炩���ߐ������Ă�����
movaps xmm0, [A]
movaps xmm0, [B]
mulps xmm0, [psAlpha]
mulps xmm1, [psAlphaC]
addps xmm0, xmm1
psubd xmm0, [psDiv256]
movaps [Dest], xmm0
�����i�p�b�N�h�o�C�g�j�ł��ƁApunpck{h,l}bw�ň��������Ă��烿�l�������A
256�Ŋ�����packsswd�Ńp�b�N���������ƂɂȂ邩�炩�Ȃ蕉�S���傫��
�����R���p�C���̕��S���d����Ζ��ߐ��������Ȃ���
�������A�{����imm8�Ŏw�肾�Ƃ���A�܂Ƃ��Ɋ��p���悤�Ǝv������
���ȏ��������R�[�h�����̂���ς��Ǝv������B
SSE���g���Ȃ�}�X�N�����炩���ߐ������Ă�����
movaps xmm0, [A]
movaps xmm0, [B]
mulps xmm0, [psAlpha]
mulps xmm1, [psAlphaC]
addps xmm0, xmm1
psubd xmm0, [psDiv256]
movaps [Dest], xmm0
�����i�p�b�N�h�o�C�g�j�ł��ƁApunpck{h,l}bw�ň��������Ă��烿�l�������A
256�Ŋ�����packsswd�Ńp�b�N���������ƂɂȂ邩�炩�Ȃ蕉�S���傫��
�����R���p�C���̕��S���d����Ζ��ߐ��������Ȃ���
�������A�{����imm8�Ŏw�肾�Ƃ���A�܂Ƃ��Ɋ��p���悤�Ǝv������
���ȏ��������R�[�h�����̂���ς��Ǝv������B
Blending conditionally copies one field in the
source onto the same field in the destination.
exxite�|��:
�u�����f�B���O�����t�R�s�[�́A�\�[�X����1�̃t�B�[���h��
�f�B�X�e�B�l�[�V�����̓����̈�ɃR�s�[���܂��B
source onto the same field in the destination.
exxite�|��:
�u�����f�B���O�����t�R�s�[�́A�\�[�X����1�̃t�B�[���h��
�f�B�X�e�B�l�[�V�����̓����̈�ɃR�s�[���܂��B
635 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 03:11:05 ID:zqjEHEea
�����߂̗\��
�u�����f�B���O�̓\�[�X����1�̃t�B�[���h��
�f�B�X�e�B�l�[�V�����̓����t�B�[���h�ɏ����t�ŃR�s�[���܂��B
�����������ăC���[�W���O�A�r�f�I�A3D�Q�[���ł悭����̂�?
�܂��A�܂��ʖ|������悭�킩��ǂȁB
�f�B�X�e�B�l�[�V�����̓����t�B�[���h�ɏ����t�ŃR�s�[���܂��B
�����������ăC���[�W���O�A�r�f�I�A3D�Q�[���ł悭����̂�?
�܂��A�܂��ʖ|������悭�킩��ǂȁB
byte ���@byte �̃��u�����h�Ȃ�ăe�[�u�����Z�ł��ׂ��Ȃ̂ł���B
���̂ق������x�ȏ����������ׂłł���B
���u�����h���Ȃ���R���g���X�g�ς�����Z�s�A�G�t�F�N�g�|������Ƃ��ˁB
������K�v�Ȃ̂�>>633�݂����ȗp�r�̌��肳�ꂽ���Z�ł͂Ȃ�
�e�[�u�������̂ɕ֗��Ȗ��߂��B
���̂ق������x�ȏ����������ׂłł���B
���u�����h���Ȃ���R���g���X�g�ς�����Z�s�A�G�t�F�N�g�|������Ƃ��ˁB
������K�v�Ȃ̂�>>633�݂����ȗp�r�̌��肳�ꂽ���Z�ł͂Ȃ�
�e�[�u�������̂ɕ֗��Ȗ��߂��B
638 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/26(��) 03:27:14 ID:zqjEHEea
pinsrb���߁B
�Ȃɂ��ɂ悭�g���Ǝv���܂����B
�܂��A�C�y�ɕ��i�g���̖��߂��Ă��ƂŁB
�Ȃɂ��ɂ悭�g���Ǝv���܂����B
�܂��A�C�y�ɕ��i�g���̖��߂��Ă��ƂŁB
�m�[�X���烁���R����������
�`�l�c�̃n�C�p�[�g�����X�|�[�g�����̋@�\�ƃ����R���ƁA�����r�f�I�`�b�v�̋@�\
������ă`�b�v�Z�b�g�R�߂Ƃ��Đ��i��������ǂ����낤���H
�`�l�c�̃n�C�p�[�g�����X�|�[�g�����̋@�\�ƃ����R���ƁA�����r�f�I�`�b�v�̋@�\
������ă`�b�v�Z�b�g�R�߂Ƃ��Đ��i��������ǂ����낤���H
�C���e���A�v���Z�b�T�ԒʐM�Z�p��AMD�ɑR��
http://japan.cnet.com/news/ent/story/0,2000056022,20229987,00.htm
2�����O�̌Â��L������Nehalem�œ����\���Common System Interface(CSI)�ɂ��ĉ�����Ă�B
http://japan.cnet.com/news/ent/story/0,2000056022,20229987,00.htm
2�����O�̌Â��L������Nehalem�œ����\���Common System Interface(CSI)�ɂ��ĉ�����Ă�B
�t�c�[�̉ƒ납�� �p�\�R�����������
http://news.livedoor.com/webapp/journal/cid__2422869/detail
�p�\�R�����
http://news.livedoor.com/webapp/journal/cid__2422869/detail
�p�\�R�����
�g�ѓd�b�̂ق������͂��₷���Ƃ����肦�Ȃ�����A�펯�I�ɍl���āE�E�E�B
�g�ѓd�b��300type/min�ȏ�łĂ�Ȃ炢�����ǁB
���łɌ�������{�̲���ȯ͌g�ѓd�b���嗬�炵��
�g�ѓd�b��300type/min�ȏ�łĂ�Ȃ炢�����ǁB
���łɌ�������{�̲���ȯ͌g�ѓd�b���嗬�炵��
�u���C���h�^�b�`���ł��Ȃ��q�Ȃ�A�g�ѓ��͂̕�����������
�܂��O���t�B�b�N�Ƃ��A�}�V���p���[��K�v�ȍ�Ƃ������Ă�
�g�тɋ����̂́A���Ԃ̖�肾�Ǝv��
�܂��O���t�B�b�N�Ƃ��A�}�V���p���[��K�v�ȍ�Ƃ������Ă�
�g�тɋ����̂́A���Ԃ̖�肾�Ǝv��
Intel�͑���65nm�v���Z�X��PXA(����ǂ�29X�V���[�Y����)������
�ł���Œ�667MHz�`�ő�1GHz�ł��肢���܂�
W-ZERO3�ɓ��ڂ���Ă���PXA270�ɂ��Ắ�
http://www.intel.co.jp/jp/developer/design/pca/prodbref/253820.htm
�ł���Œ�667MHz�`�ő�1GHz�ł��肢���܂�
W-ZERO3�ɓ��ڂ���Ă���PXA270�ɂ��Ắ�
http://www.intel.co.jp/jp/developer/design/pca/prodbref/253820.htm
�g�тȂ�Ēʘb�����g���ĂȂ����炽�܂�Ұقŕ����ł̂����Ԃ������邯��
�ŋ߂̎Ⴂ�݂͒������őłĂ�̂��E�E�E��������('A`)
�ŋ߂̎Ⴂ�݂͒������őłĂ�̂��E�E�E��������('A`)
�g�тŒ������őłĂ�̂ł͂Ȃ�
�L�[�{�[�h�Œ��ᑬ�ł����łĂȂ���
�L�[�{�[�h�Œ��ᑬ�ł����łĂȂ���
���������A�ŋ߂̌g�ѓd�b�̓A�C���[�h�Ƃ����̂ŃC���^�[�l�b�g���ł�������ȁB
�֗��Ȑ��̒��ɂȂ������̂��B
�֗��Ȑ��̒��ɂȂ������̂��B
>>644
����Marvell�ɔ����ς���ĂȂ�����������
����Marvell�ɔ����ς���ĂȂ�����������
http://wince.goo.ne.jp/snap/cnBoard.asp?PID=2046
����z���g���m��Ȃ�������
����z���g���m��Ȃ�������
650 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/11/27(��) 22:24:57 ID:z3pBkiF2
�g�т��烁�[���ł̂����q�����Ȃ݂ɑ����ϑԂ����܂���
http://www.xbitlabs.com/news/cpu/display/20061127154338.html
Intel Samples 45nm �gPenryn�h Microprocessors.
Intel Creates Working 45nm Central Processors
��������������
Intel Samples 45nm �gPenryn�h Microprocessors.
Intel Creates Working 45nm Central Processors
��������������
�܂�K8L�����T�����ɂ͑����Ǝv���̂����A
���ꂪ�ŋ߂�intel�̗]�T�Ȃ낤���B
���ꂪ�ŋ߂�intel�̗]�T�Ȃ낤���B
�]�T�Ƃ͋t�̂��̂���Ȃ��́H
>>651
> Intel��45nm�̎���Core:Penyn�̃T���v�����Y���s���Ă���B
> 2007�N�̑��(�Ă��H��)��Penryn�����CPU���ڋq�̌��֓͂��B
> Penyn�ł�SSE4���߂��lj��A�X�Ȃ�N���b�N�A�b�v�A���ڃL���b�V���̑啝�ȑ����A����d�͌���
> �����R�X�g�팸�����҂���Ă���B
> Bloomfield, Yorkfied������Wolfdale��45nm�v���Z�X���g�p����15�̃v���Z�b�T�Ɋ܂܂��B
�\��ʂ藈�N���ɂ�45nm�v���Z�X�Ɉڍs����������Core���o�ꂷ��͗l�B
> Intel��45nm�̎���Core:Penyn�̃T���v�����Y���s���Ă���B
> 2007�N�̑��(�Ă��H��)��Penryn�����CPU���ڋq�̌��֓͂��B
> Penyn�ł�SSE4���߂��lj��A�X�Ȃ�N���b�N�A�b�v�A���ڃL���b�V���̑啝�ȑ����A����d�͌���
> �����R�X�g�팸�����҂���Ă���B
> Bloomfield, Yorkfied������Wolfdale��45nm�v���Z�X���g�p����15�̃v���Z�b�T�Ɋ܂܂��B
�\��ʂ藈�N���ɂ�45nm�v���Z�X�Ɉڍs����������Core���o�ꂷ��͗l�B
We are processing the first samples of the Penryn design.
These samples will go back to the design team to determine
if design is working as expected,
first sample�����B�\�z�ƍ����Ă��邩���f���邽�߁Adesign team�ɑ�����B
According to the
director of Intel, the company is on-track to produce
Penryn in volumes and ship them to customers in the second
half of 2007.
�o�ׂ͗��N�㔼�i�V������12���j�̗\��
These samples will go back to the design team to determine
if design is working as expected,
first sample�����B�\�z�ƍ����Ă��邩���f���邽�߁Adesign team�ɑ�����B
According to the
director of Intel, the company is on-track to produce
Penryn in volumes and ship them to customers in the second
half of 2007.
�o�ׂ͗��N�㔼�i�V������12���j�̗\��
656 �FSocket774�F2006/11/28(��) 18:54:27 ID:8mLMRYbh
45nm����TDP�͂ǂꂮ�炢�ɂȂ�܂����H
Kentsfield��100���b�g��܂����H
Kentsfield��100���b�g��܂����H
657 �FSocket774�F2006/11/28(��) 19:12:08 ID:5Y6reYrV
�p�\�R��������\��̕�������
http://search.goo.ne.jp/web.jsp?MT=do+%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B5%E3%82%AF%E3%83%88&STYPE=web&IE=UTF-8&from=gootop
http://search.goo.ne.jp/web.jsp?MT=do+%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B5%E3%82%AF%E3%83%88&STYPE=web&IE=UTF-8&from=gootop
http://www.vr-zone.com/index.php?i=4309
wolfdale-M�i2�R�A�AFSB1066�AL2�L���b�V��3MB�A3,4-3,7GHz�j��TDP57W
�������琄�������
wolfdale-H�i2�R�A�AFSB1333�AL2�L���b�V��6MB�A3,5-4,0GHz�j��TDP65W���炢�H
yorkfield�i4�R�A�AFSB1333�AL2�L���b�V��6MB�~2�A3,4-3,73GHz�j��TDP�́A�A�A�A�킩���
4�������m���V�b�N������邵���\���ʂ͂���Ǝv�����ǁA�A�A�B
wolfdale-M�i2�R�A�AFSB1066�AL2�L���b�V��3MB�A3,4-3,7GHz�j��TDP57W
�������琄�������
wolfdale-H�i2�R�A�AFSB1333�AL2�L���b�V��6MB�A3,5-4,0GHz�j��TDP65W���炢�H
yorkfield�i4�R�A�AFSB1333�AL2�L���b�V��6MB�~2�A3,4-3,73GHz�j��TDP�́A�A�A�A�킩���
4�������m���V�b�N������邵���\���ʂ͂���Ǝv�����ǁA�A�A�B
���������A45nm����High-k�g�������H
�R�A�ɂ���Ă܂��܂�������
����N���b�N������TDP�����炢�㏸���邩��Ȃ�
yorkfield�̃|�e���V�����͂ǂ�Ȃ��̂����C�ɂȂ邪�A�͂�����
����N���b�N������TDP�����炢�㏸���邩��Ȃ�
yorkfield�̃|�e���V�����͂ǂ�Ȃ��̂����C�ɂȂ邪�A�͂�����
http://www.theinquirer.net/default.aspx?article=36010
�ɁA
��The Yorktown rumours that were flying around at IDF were and are wrong,
�� there is no converged quad core parts until Nehalem.
�Ƃ�����ǁB�����Yorkfield����ˁB
�ɁA
��The Yorktown rumours that were flying around at IDF were and are wrong,
�� there is no converged quad core parts until Nehalem.
�Ƃ�����ǁB�����Yorkfield����ˁB
��Փx�I�ɂ�Clovertown��FSB1333 = Yorkfield��FSB1600
���Ȃ����R������́H
���Ȃ����R������́H
http://www.theinquirer.net/default.aspx?article=36010
�i�@�j���͉��̕⑫��B
�@���C�^�[�ʐM�ɂ��ƃC���e����penryn�̐v�̍ŏI�i�K���I���āi�T���v���܂ł̒i�K���I���āj
�����J�n���n�߂��ƕ����B�����45nm�̃`�b�v��merom�t�@�~���[�̏k���łł���B
1�N���O�ɂ��`���������̎��Ƃ����債�ĕς���ĂȂ��B
�@�������͂���Ă���̂̊�{�I�ɂ͓���core2duo�̃R�A�̂܂܂ł���B
�傫�ȕύX�̓L���b�V����4MB��6MB�ɑ��ʂ���Ă���A���̕ύX�̓N���b�N���ł���B
�ő�N���b�N���ł͂Ȃ��A�N���b�N�����@�\�ł���B
�iyorkfield�́j3,46-3,73GHz����N���b�N�����@�\�����Ă݂��
���܂ł�333MHz���Ƃ̃X�e�b�v�ł͂Ȃ�166MHz���Ƃ̃X�e�b�v�ƂȂ�B
�iyorkfield��3,46�D3,60�D3,73���H���ꂾ��166MH������Ȃ�133MHz���Ƃ̕����̂悤�����A�A�A�j
�@����core2duo�̎���1,6-3,0GH���܂ł������̂��s�v�c��������Ȃ����A�s��̗v���ɂ��
5�i�K�̃N���b�N�����K�v���������炾�B�����ăN���b�N�����@�\���Ȃ����
�܂�2,66��3,33���Ƃ̃N���b�N�ɂȂ��Ă��܂����A��������͉ߋ��̘b���B
(conroe��1,86�A2,12�A2,40�A2,66�A2,90��5�i�K���������Ƃ������Ă�)
�@�`�b�v��45nm�v���Z�X�ɂȂ菇���ɐi��ł�A�C���e���̓��C���X�g���[����CPU��TDP��
65w����50w�ɉ����Ă����A����������1�N���邱�Ƃ����ύX�����邩������Ȃ�
�����Ƃ�65nm�̎����͒Ⴍ�Ȃ邾�낤
�i�@�j���͉��̕⑫��B
�@���C�^�[�ʐM�ɂ��ƃC���e����penryn�̐v�̍ŏI�i�K���I���āi�T���v���܂ł̒i�K���I���āj
�����J�n���n�߂��ƕ����B�����45nm�̃`�b�v��merom�t�@�~���[�̏k���łł���B
1�N���O�ɂ��`���������̎��Ƃ����債�ĕς���ĂȂ��B
�@�������͂���Ă���̂̊�{�I�ɂ͓���core2duo�̃R�A�̂܂܂ł���B
�傫�ȕύX�̓L���b�V����4MB��6MB�ɑ��ʂ���Ă���A���̕ύX�̓N���b�N���ł���B
�ő�N���b�N���ł͂Ȃ��A�N���b�N�����@�\�ł���B
�iyorkfield�́j3,46-3,73GHz����N���b�N�����@�\�����Ă݂��
���܂ł�333MHz���Ƃ̃X�e�b�v�ł͂Ȃ�166MHz���Ƃ̃X�e�b�v�ƂȂ�B
�iyorkfield��3,46�D3,60�D3,73���H���ꂾ��166MH������Ȃ�133MHz���Ƃ̕����̂悤�����A�A�A�j
�@����core2duo�̎���1,6-3,0GH���܂ł������̂��s�v�c��������Ȃ����A�s��̗v���ɂ��
5�i�K�̃N���b�N�����K�v���������炾�B�����ăN���b�N�����@�\���Ȃ����
�܂�2,66��3,33���Ƃ̃N���b�N�ɂȂ��Ă��܂����A��������͉ߋ��̘b���B
(conroe��1,86�A2,12�A2,40�A2,66�A2,90��5�i�K���������Ƃ������Ă�)
�@�`�b�v��45nm�v���Z�X�ɂȂ菇���ɐi��ł�A�C���e���̓��C���X�g���[����CPU��TDP��
65w����50w�ɉ����Ă����A����������1�N���邱�Ƃ����ύX�����邩������Ȃ�
�����Ƃ�65nm�̎����͒Ⴍ�Ȃ邾�낤
�@���̃`�b�v��core2duo�̂Ƃ���菭���ǂ��Ȃ��Ă���A���������I�ɂȂ��āA�G���b�^��������
�C�����Ă���B�n�C�p�[�X���b�f�B���O�e�N�m���W�[���������̃��[�h�}�b�v�ɏo�Ă��邪
���Ăقǖ��͓I�ł͂Ȃ����낤�B
�@����Ȃ������̂͐^�̃N�A�b�h�R�A��1600MHz��FSB���B
IDF�J�ÈȑO��J�Ò���yorkfield�Ɋւ���\�͊Ԉ���Ă����B�W�������S�R�A��Nehalem�܂Ō���Ȃ�
�i�u�W������4�R�A�v���Ӗ��s�������A���m���V�b�N�����R�Ȃ̂��A
����Ƃ�K8L�Ɣ�ׂ��Ɛ^�̃N�A�b�h�R�A�ƌĂׂȂ��Ƃ����Ӗ��Ȃ̂���������͕s���j
FSB��1600MHz����Nehalem��CSI�ɉ�����肪�����邩�A
����Ƃ�AMD����̃v���b�V���[������ɂȂ�Ȃ�����s���Ȃ����낤
�@�`�b�v�͏������������ł��Ă�悤�������Y�������Ƃ͍l���Ȃ������ǂ��B
Q4/07�Y�O�̍ŏI���������BQ1/08�����ۂ̐��Y�J�n�B�ƍl���������ǂ��B
�C���e���͑����̃X�P�W���[����2006�N���Ɏ����Ă�����
�������Y�̊��҂�����ɂ͐����H���╔�i��������������i�ʂ������đ�ρj�悤��
�C�����Ă���B�n�C�p�[�X���b�f�B���O�e�N�m���W�[���������̃��[�h�}�b�v�ɏo�Ă��邪
���Ăقǖ��͓I�ł͂Ȃ����낤�B
�@����Ȃ������̂͐^�̃N�A�b�h�R�A��1600MHz��FSB���B
IDF�J�ÈȑO��J�Ò���yorkfield�Ɋւ���\�͊Ԉ���Ă����B�W�������S�R�A��Nehalem�܂Ō���Ȃ�
�i�u�W������4�R�A�v���Ӗ��s�������A���m���V�b�N�����R�Ȃ̂��A
����Ƃ�K8L�Ɣ�ׂ��Ɛ^�̃N�A�b�h�R�A�ƌĂׂȂ��Ƃ����Ӗ��Ȃ̂���������͕s���j
FSB��1600MHz����Nehalem��CSI�ɉ�����肪�����邩�A
����Ƃ�AMD����̃v���b�V���[������ɂȂ�Ȃ�����s���Ȃ����낤
�@�`�b�v�͏������������ł��Ă�悤�������Y�������Ƃ͍l���Ȃ������ǂ��B
Q4/07�Y�O�̍ŏI���������BQ1/08�����ۂ̐��Y�J�n�B�ƍl���������ǂ��B
�C���e���͑����̃X�P�W���[����2006�N���Ɏ����Ă�����
�������Y�̊��҂�����ɂ͐����H���╔�i��������������i�ʂ������đ�ρj�悤��
Intel already sampling 45nm chips
http://techreport.com/onearticle.x/11328
clock speeds going up to 4.0GHz and cache sizes as large as 12MB
Penryn�����1�R�A�ӂ�4.0GHz, �L���b�V��12MB��
http://techreport.com/onearticle.x/11328
clock speeds going up to 4.0GHz and cache sizes as large as 12MB
Penryn�����1�R�A�ӂ�4.0GHz, �L���b�V��12MB��
TechReport��Inq�ƈ����Penryn��Q3/07�f�r���[��`���Ă��
Inq�̋L����Inq�̓Ǝ����͂���
http://techreport.com/onearticle.x/11328
�@�\��AMD�̐؉H�l����65nm�f�X�N�g�b�vCPU�̃����[�X��\�z�����
���x�̓��C�^�[�ʐM���C���e��������45nm�v���Z�X�̏������o�����Ɠ`�����B
�@���C�^�[�̓C���e��������45nm��CPU�̌����n�߂��Ɠ`����
���̃`�b�v��core�A�[�L�e�N�`���̏k���łł��鎟����CPU��Penryn�R�A�ł���B
�C���e���̃v���Z�X�A�[�L�e�N�`���̐ӔC��MarkBohr�́A2,3�����O��IDF�œ`�����Ƃ���
Penryn�`�b�v�͗��N����f�r���[�Ɍ����Ē��X�Ə������ł���ƌ������B
�@���̌�o�Ă����\�ǂ���APenryn�`�b�v��Q3/07�Ƀf���A���R�A�ƃN�A�b�h�R�A��
�N���b�N��4GHz�A�L���b�V���͍ő�12MB�܂Őς�œo�ꂷ�邾�낤
Inq�̋L����Inq�̓Ǝ����͂���
http://techreport.com/onearticle.x/11328
�@�\��AMD�̐؉H�l����65nm�f�X�N�g�b�vCPU�̃����[�X��\�z�����
���x�̓��C�^�[�ʐM���C���e��������45nm�v���Z�X�̏������o�����Ɠ`�����B
�@���C�^�[�̓C���e��������45nm��CPU�̌����n�߂��Ɠ`����
���̃`�b�v��core�A�[�L�e�N�`���̏k���łł��鎟����CPU��Penryn�R�A�ł���B
�C���e���̃v���Z�X�A�[�L�e�N�`���̐ӔC��MarkBohr�́A2,3�����O��IDF�œ`�����Ƃ���
Penryn�`�b�v�͗��N����f�r���[�Ɍ����Ē��X�Ə������ł���ƌ������B
�@���̌�o�Ă����\�ǂ���APenryn�`�b�v��Q3/07�Ƀf���A���R�A�ƃN�A�b�h�R�A��
�N���b�N��4GHz�A�L���b�V���͍ő�12MB�܂Őς�œo�ꂷ�邾�낤
4���̑�pIDF�ł̌������
MCM����FSB�̑��x�����悻30%�ቺ����
(Woodcrest FSB1333 �� Dempsey FSB1066)
64bit��FSB��1600MHz�����E
(Itanium2��144bit�̌��E�͕s������800MHz�܂ł�Montecito�ŗ\�肳��Ă����BFoxton�̗��݂ŗ��ꂽ���B)
9����IDF�ł̌������
45nm�͓d�͐����u����20%�̃N���b�N�A�b�v���N���b�N�����u����80%�̃��[�N�팸
2007H2��45nm
45nm��QuadCore��SingleDie
2006Q4�ɏ���45nm���i���e�[�v�A�E�g
INQ��Yorktown�́A�����炭�AYorkfield + Harpertown�A�܂莟��Core 2 QX�Ǝ���XeonDP�̃f�U�C�������ʂ��ƌ����Ă���B
�܂�����͑Ó����낤�B
FSB��QuadCore�̍s�͐����Ӗ����킩��Ȃ��B
Yorktown��MCM�Ȃ�FSB��Clovertown�Ɠ�����1333�����E�B
������AMD�̈��͂������Ă�FSB1600�ł͏o���Ȃ��킯�B
IDF�J�Ò���Yorkfield�̉\���ԈႢ�Ƃ��������������Ă��邪�A���̉\�Ƃ����̂�HKEPC��Yorkfield��4�R�A��L2�����L����Ƃ�����̂��Ƃ��H
K8L��L3��4�̃R�A�ŋ��L���邩�炻��Ɣ�r����Ƃ�����SingleDie�ł�Yorkfield�͑ʖڂŁANehalem�܂ł܂Ƃ���QuadCore�͂łȂ��A�Ƃ����Ӗ��Ȃ�[���������B
#MCM��FSB1333����SingleDie�̕��������o���邵�A45nm�Ȃ�_�C�T�C�Y���������Ȃ邩��Intel�I�ɂ͈Ӗ�������B
#XeonUP�ł�FSB1333���\�肳��Ă邵�B
#L2�����[�ȑ����������Ă�̂́ASPECfp_2000_base�ŃR�X�g�Ƃ̃g���[�h�I�t���l�����L2-6MB�����x�ǂ��Ƃ��������H
#���Ȃ݂�SPECint_2000_base��4MB�ŏ\���B
4GHz�͋L�҂̖ϑz�����Ă邾��BWoodcrest�̎��݂����ɃN���b�N����i�K�オ�����Ƃ��Ă�3GHz�㔼�������Ƃ���B
MCM����FSB�̑��x�����悻30%�ቺ����
(Woodcrest FSB1333 �� Dempsey FSB1066)
64bit��FSB��1600MHz�����E
(Itanium2��144bit�̌��E�͕s������800MHz�܂ł�Montecito�ŗ\�肳��Ă����BFoxton�̗��݂ŗ��ꂽ���B)
9����IDF�ł̌������
45nm�͓d�͐����u����20%�̃N���b�N�A�b�v���N���b�N�����u����80%�̃��[�N�팸
2007H2��45nm
45nm��QuadCore��SingleDie
2006Q4�ɏ���45nm���i���e�[�v�A�E�g
INQ��Yorktown�́A�����炭�AYorkfield + Harpertown�A�܂莟��Core 2 QX�Ǝ���XeonDP�̃f�U�C�������ʂ��ƌ����Ă���B
�܂�����͑Ó����낤�B
FSB��QuadCore�̍s�͐����Ӗ����킩��Ȃ��B
Yorktown��MCM�Ȃ�FSB��Clovertown�Ɠ�����1333�����E�B
������AMD�̈��͂������Ă�FSB1600�ł͏o���Ȃ��킯�B
IDF�J�Ò���Yorkfield�̉\���ԈႢ�Ƃ��������������Ă��邪�A���̉\�Ƃ����̂�HKEPC��Yorkfield��4�R�A��L2�����L����Ƃ�����̂��Ƃ��H
K8L��L3��4�̃R�A�ŋ��L���邩�炻��Ɣ�r����Ƃ�����SingleDie�ł�Yorkfield�͑ʖڂŁANehalem�܂ł܂Ƃ���QuadCore�͂łȂ��A�Ƃ����Ӗ��Ȃ�[���������B
#MCM��FSB1333����SingleDie�̕��������o���邵�A45nm�Ȃ�_�C�T�C�Y���������Ȃ邩��Intel�I�ɂ͈Ӗ�������B
#XeonUP�ł�FSB1333���\�肳��Ă邵�B
#L2�����[�ȑ����������Ă�̂́ASPECfp_2000_base�ŃR�X�g�Ƃ̃g���[�h�I�t���l�����L2-6MB�����x�ǂ��Ƃ��������H
#���Ȃ݂�SPECint_2000_base��4MB�ŏ\���B
4GHz�͋L�҂̖ϑz�����Ă邾��BWoodcrest�̎��݂����ɃN���b�N����i�K�オ�����Ƃ��Ă�3GHz�㔼�������Ƃ���B
Mobo makers: CPU wars to enter new level with 45nm Penryn in 2007
http://www.digitimes.com/mobos/a20061129PD206.html
45nm Penryn���ォ��CPU�푈�͐V���ȃ��x���ցB
�}�U�[���[�J��Penryn�ł�3GHz�ȏ��Core2 Duo�����C���i�b�v����Ă���Ǝw�E�B
65nm����45nm�v���Z�X�ւ̈ڍs��2007�N�㔼����Penryn�ɂ��}�����悤�Ƃ��Ă���B
http://www.digitimes.com/mobos/a20061129PD206.html
45nm Penryn���ォ��CPU�푈�͐V���ȃ��x���ցB
�}�U�[���[�J��Penryn�ł�3GHz�ȏ��Core2 Duo�����C���i�b�v����Ă���Ǝw�E�B
65nm����45nm�v���Z�X�ւ̈ڍs��2007�N�㔼����Penryn�ɂ��}�����悤�Ƃ��Ă���B
>>669
����σV���O���_�C�ɂ͂Ȃ���
�u4�R�A��L2���L�v���ԈႢ�������A���ĂȂ番���邵�B
4GHz��Yorkfield�ł͂Ȃ�Wolfdale�̂��Ƃ��Ǝv��
>>670
�������̋L���ł�Penryn��Q3/07�Ƀf�r���[�\����ď����Ă����
����σV���O���_�C�ɂ͂Ȃ���
�u4�R�A��L2���L�v���ԈႢ�������A���ĂȂ番���邵�B
4GHz��Yorkfield�ł͂Ȃ�Wolfdale�̂��Ƃ��Ǝv��
>>670
�������̋L���ł�Penryn��Q3/07�Ƀf�r���[�\����ď����Ă����
Wolfdale�ł�4G�͖������Ǝv���A3.73G���ĂƂ�����˂���
Yorkfield��3.46G�ƌ���
Yorkfield��3.46G�ƌ���
FSB1333MHz�E�{��0.5�{���݂ɂ̂悤������
Wolfdale��3.66GHz�E3.83GHz�E4.0GHz�A
Yorkfield��3.33GHz�E3.50GHz���ĂƂ�����Ȃ����ȁB
Wolfdale��3.66GHz�E3.83GHz�E4.0GHz�A
Yorkfield��3.33GHz�E3.50GHz���ĂƂ�����Ȃ����ȁB
�ǂ��l���Ă�����ȃN���b�N��������ȁB
���̒��O��6x50�Ƃ������ȃ��C���i�b�v�lj����邵�B
���̒��O��6x50�Ƃ������ȃ��C���i�b�v�lj����邵�B
Wolfdale��3.33GHz�A
Yorkfield��3.00GHz���ĂƂ����B
Yorkfield��3.00GHz���ĂƂ����B
>>675
�܂����̃N���b�N�͖�����������Ȃ����A6X50�����͂���܊W�Ȃ��Ǝv��
Woodcrest����1�����O���炢�ɂ��l�b�g�o�[�X�g�n�̐VXeon�𓊓�������
���ꂩ��Pentium4��D-0�ɂȂ���TDP65W�ɂ��邵
�C���e���͂���ł������悤�ȒZ����CPU�����ǂ����蓊�������肷�邩��
�܂����̃N���b�N�͖�����������Ȃ����A6X50�����͂���܊W�Ȃ��Ǝv��
Woodcrest����1�����O���炢�ɂ��l�b�g�o�[�X�g�n�̐VXeon�𓊓�������
���ꂩ��Pentium4��D-0�ɂȂ���TDP65W�ɂ��邵
�C���e���͂���ł������悤�ȒZ����CPU�����ǂ����蓊�������肷�邩��
�o�Ă�Wolfdale��3.5GHz���炢����Ȃ����B
TDP��������̂ɃN���b�N��1.3�{�ɂȂ�Ƃ��l���Â炢�B
����ɁA4.0GHz�Ƃ��o����0.5�{���݂ɂ�����5�����N���̐��i�ł�3.2GHz���炢�ɂȂ��Ċ��S��65nm�̏�ɏo�Ă��܂��B
���܂ł̐��i�헪���炵�āA���������͊������i�{2�����N���炢�ȋC������B
TDP��������̂ɃN���b�N��1.3�{�ɂȂ�Ƃ��l���Â炢�B
����ɁA4.0GHz�Ƃ��o����0.5�{���݂ɂ�����5�����N���̐��i�ł�3.2GHz���炢�ɂȂ��Ċ��S��65nm�̏�ɏo�Ă��܂��B
���܂ł̐��i�헪���炵�āA���������͊������i�{2�����N���炢�ȋC������B
E6850��3GHz������X6950?��3.33GHz
�����Ă���Santa Rosa�̑S�e�`�V���O���R�A���쎞�ɃN���b�N�A�b�v����@�\��lj�
ttp://pc.watch.impress.co.jp/docs/2006/1130/ubiq169.htm
> IDA�̎d�g�݂͂������B2����CPU�R�A�̂����A1��C3�X�e�[�g������ȉ��̃X�e�[�g�Ɉڍs��
> (�܂�X���[�v��Ԃɓ������Ƃ�)�A����OS�Ȃ����̓A�v���P�[�V�������V���O���X���b�h�̓���Ȃǂ�
> 1�̃R�A�����Ŏ��s����̂ɓK������Ԃɂ��鎞�ɁA�v���Z�b�T��IDA���[�h�ֈڍs����B
> IDA���[�h���L���ɂȂ�ƁA���Ƃ��Ƃ̍ō����g������1��̍ō����g���œ��삳�����邱�ƂɂȂ�B
ttp://pc.watch.impress.co.jp/docs/2006/1130/ubiq169.htm
> IDA�̎d�g�݂͂������B2����CPU�R�A�̂����A1��C3�X�e�[�g������ȉ��̃X�e�[�g�Ɉڍs��
> (�܂�X���[�v��Ԃɓ������Ƃ�)�A����OS�Ȃ����̓A�v���P�[�V�������V���O���X���b�h�̓���Ȃǂ�
> 1�̃R�A�����Ŏ��s����̂ɓK������Ԃɂ��鎞�ɁA�v���Z�b�T��IDA���[�h�ֈڍs����B
> IDA���[�h���L���ɂȂ�ƁA���Ƃ��Ƃ̍ō����g������1��̍ō����g���œ��삳�����邱�ƂɂȂ�B
4Ghz�]�X�̉\�ƊW���Ă�̂��ˁB
>>681
���O�V�˂���ˁH
���O�V�˂���ˁH
�QAMD�r�Ōv�搋�s���Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j
l�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�@�@((
l�@�i �E�́E�j�����Z���v�����@�E�@�j�@�@�E�@�@�E �@�@�E�E�@�@�@�@�@�@�F
l�@�iCore2 �j�U�@�@�@�@�@�@�@�@�E�E ��FX_���E �@�F�@�@�@��X2���E�@�E�@�@�@
l__�b �b�@| �_ _________________�i�B�@�B�E�j�E_____�@�@__(�@:�;�Do:)�E_____________________________________
l�@�i_�Q�j�Q�j�@�@�@�@�@�@�@�@�@�@�i�E�@�G�@*�j�� �@�@�i�E�@�G�@*�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�܁j�i�܁j�@�@�@�@ �i�܁j�i�܁j�@�@ �@�@�@�@�@�@
�@�@�@�@�Q�Q_ �@�@�@�@�@�@�@ �Q�Q_ �@�@�@�@�@�@�@�Q�Q_ �@�@�@�@
�@ �@�@/Intel�� �@�@�@�@�@�@/Intel�� �@�@�@ �@�@/Intel�ہ@�@�@�@
�@�@ ��=====���@�j))==)) ��=====���@�j))==)) ��=====���@�j))=)�@�@
�@�@�@�iCore�@�@�m�@ �@�@�@�iPentium�m�@ �@�@�@�iCeleron�m
�@�@�@�b �b�@|�@�@�@�@�@�@�@�b �b�@|�@�@�@�@�@�@ �b �b�@|�@
�@�@�@�i�Q�i�Q_�j�Q__ �@�@�@ �i�Q�i�Q_�j�Q__ �@�@ �i�Q�i�Q_�j�Q__
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
Core2�Ɋ��s�@Quad FX�@Athlon 64 FX-74/3.0GHz
http://www.4gamer.net/review/quad_fx/quad_fx.shtml
Intel Core2��������
http://plusd.itmedia.co.jp/pcuser/articles/0607/14/news062.html
�D�ꂽ�p�t�H�[�}���X/�d�͂�����Core 2�V���[�Y
http://pc.watch.impress.co.jp/docs/2006/0714/tawada79.htm
X6800 VS FX-62
http://www.hkepc.com/hwdb/x6800vsfx62-10.htm
Half-Life2�EFarcry�EDoom3�EQuake4�EUT2004
http://journal.mycom.co.jp/special/2006/conroe/014.html
CoreDuo PenD PenM Pen4��r
http://journal.mycom.co.jp/articles/2006/02/22/coreduo/002.html
Conroe�Ƃ��낢���r�ł���x���`
http://www23.tomshardware.com/cpu.html?modelx=33&model1=433&model2=465&chart=177
l�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�j
l�@ �ȁ@�ȁ@�@�@�@�@�@�@�@�@�@�@�@((
l�@�i �E�́E�j�����Z���v�����@�E�@�j�@�@�E�@�@�E �@�@�E�E�@�@�@�@�@�@�F
l�@�iCore2 �j�U�@�@�@�@�@�@�@�@�E�E ��FX_���E �@�F�@�@�@��X2���E�@�E�@�@�@
l__�b �b�@| �_ _________________�i�B�@�B�E�j�E_____�@�@__(�@:�;�Do:)�E_____________________________________
l�@�i_�Q�j�Q�j�@�@�@�@�@�@�@�@�@�@�i�E�@�G�@*�j�� �@�@�i�E�@�G�@*�j�@�@�@
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �i�܁j�i�܁j�@�@�@�@ �i�܁j�i�܁j�@�@ �@�@�@�@�@�@
�@�@�@�@�Q�Q_ �@�@�@�@�@�@�@ �Q�Q_ �@�@�@�@�@�@�@�Q�Q_ �@�@�@�@
�@ �@�@/Intel�� �@�@�@�@�@�@/Intel�� �@�@�@ �@�@/Intel�ہ@�@�@�@
�@�@ ��=====���@�j))==)) ��=====���@�j))==)) ��=====���@�j))=)�@�@
�@�@�@�iCore�@�@�m�@ �@�@�@�iPentium�m�@ �@�@�@�iCeleron�m
�@�@�@�b �b�@|�@�@�@�@�@�@�@�b �b�@|�@�@�@�@�@�@ �b �b�@|�@
�@�@�@�i�Q�i�Q_�j�Q__ �@�@�@ �i�Q�i�Q_�j�Q__ �@�@ �i�Q�i�Q_�j�Q__
Conroe�Ɣ�r���Ȃ����Ƃ�������AM2���r���[�L�b�g��݂��o��AMD
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2762&p=12
���n�ɗ������ꂽAMD�̋ꂵ���������\��
http://pc.watch.impress.co.jp/docs/2006/0524/amd.htm
Core2�Ɋ��s�@Quad FX�@Athlon 64 FX-74/3.0GHz
http://www.4gamer.net/review/quad_fx/quad_fx.shtml
Intel Core2��������
http://plusd.itmedia.co.jp/pcuser/articles/0607/14/news062.html
�D�ꂽ�p�t�H�[�}���X/�d�͂�����Core 2�V���[�Y
http://pc.watch.impress.co.jp/docs/2006/0714/tawada79.htm
X6800 VS FX-62
http://www.hkepc.com/hwdb/x6800vsfx62-10.htm
Half-Life2�EFarcry�EDoom3�EQuake4�EUT2004
http://journal.mycom.co.jp/special/2006/conroe/014.html
CoreDuo PenD PenM Pen4��r
http://journal.mycom.co.jp/articles/2006/02/22/coreduo/002.html
Conroe�Ƃ��낢���r�ł���x���`
http://www23.tomshardware.com/cpu.html?modelx=33&model1=433&model2=465&chart=177
[Penryn Prototypes Out]
http://www.vr-zone.com/index.php?i=4344
3GHz�ȏ�ɂȂ邾�낤�Ƃ̌��ʂ��A���Ƃ�
4G���炾���ԗ��������������ɂȂ�����
http://www.vr-zone.com/index.php?i=4344
3GHz�ȏ�ɂȂ邾�낤�Ƃ̌��ʂ��A���Ƃ�
4G���炾���ԗ��������������ɂȂ�����
MCM�ł�FSB1333MHz�������ł��邲�����ɂ킴�킴3.73GHz�ȂǂƁiFSB1066MHz�������jNetburst�̃g�b�v�G���h�Ɛ��������킹�Ă�������˂��B
�N���b�N������Ȃ�ɑ傫���L�т邱�Ƃ͎������낤���A���܂ŏo�Ă��������̂̓��^�L���̗ނ��낤�Ǝv���B
�N���b�N������Ȃ�ɑ傫���L�т邱�Ƃ͎������낤���A���܂ŏo�Ă��������̂̓��^�L���̗ނ��낤�Ǝv���B
>>681�������Ă邯�Ǎ����IDA���݂���4GHz�`���]�T�Ȃ�ȂƏ���C�������B
��Xeon 5080 3.73GHz TDP130w
�f�X�N�g�b�v�ւ̎�����Merom����Ȃ���Nehalem�ɂȂ邩���m��B
��Xeon 5080 3.73GHz TDP130w
�f�X�N�g�b�v�ւ̎�����Merom����Ȃ���Nehalem�ɂȂ邩���m��B
687 �FSocket774�F2006/12/01(��) 15:00:12 ID:FqzRBdD+
������������Ăǂꂪ�{���̎�����CPU�̖��O���킩��Ȃ���
������ƌ����̂Ȃ犮�S��Nehalem�ł��傤�B
��ԋ߂�"��"�Ƃ����̂Ȃ�Penryn�R�A����B
��ԋ߂�"��"�Ƃ����̂Ȃ�Penryn�R�A����B
45nm Core Micro Architetcture�F4�R�A��Yorkfield�@2�R�A��Wolfdale�@Mobile2�R�A��Penryn
45nm Nehalem�F4�R�A�i�H�j��Bloomfield
45nm Nehalem�F4�R�A�i�H�j��Bloomfield
��Nehalem��2008�N�����̗\�肾�����H
�\��ł͂�
692 �FSocket774�F2006/12/02(�y) 12:28:44 ID:u4Tt0vcM
http://www.xbitlabs.com/news/cpu/display/20061130230506.html
Intel Starts 45nm Transition, Crossover of 45nm and 65nm Shipments in mid-2008.
Intel Starts 45nm Transition, Crossover of 45nm and 65nm Shipments in mid-2008.
693 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/02(�y) 12:30:39 ID:RV3tWDMA
�l����ނ܂ł�65nm���i�p������̂�
�ŋ߁A����CPU�킩��Ȃ��Ȃ�����
�A�[�L�̕ύX��2�N�u���Ȃ�e�v���Z�b�T�̐��Y�I����2�N�u���ɂȂ�B
�ȒP�Șb�B
�ȒP�Șb�B
http://northwood.blog60.fc2.com/blog-entry-386.html
Intel��2007�N��������45nm CPU�̃��[���`��\�肵�Ă��邪�A���̌�A2008�N��65nm����45nm�ւ̃N���X�I�[�o�[
�i�܂�45nm�v���Z�X�̏o�חʂ�65nm�����邱�Ɓj��\�肵�Ă����Intel��Technology Analyst�ł���
Rob Willoner���͌�����BRob Willoner����45nm�v���Z�X�̃`�b�v�̓I���S����D1D Fab�Ő������J�n���Ă���Ɛ��������B
�����āA���̃I���S����D1D Fab��45nm CPU��Intel�ł͍ŏ��ɑ�ʐ��Y���邱�ƂɂȂ邾�낤�ƌ�����B
Rob Willoner���ɂ���Intel�ʏ�ACPU�̃v���Z�X�̃N���X�I�[�o�[��2�N�����ɍs���B
90nm����65nm�ւ̃N���X�I�[�o�[�͍��N�����ɍs��ꂽ�B
Intel�̍ŏ���45nm Dual-Core�ł���Penryn�͊��ɃV���R���̃f�o�b�O�ɓ����Ă���A
���������̃T���v��������Ă���BPenryn�ɂ̓T�[�o�[�A�f�X�N�g�b�v�A���o�C����
�e�o���G�[�V����������A�V�����d�͐���@�\��SSE4�ƌĂ��48��SIMD���߂�lj����Ă���B
����SSE4�̓}���`���f�B�A�⍂���\��v������A�v���P�[�V�����ňЗ͂�����Ƃ���Ă���B
����ɁA���݂�CoreMicroArchitecture��Dual-Core CPU�Ɣ�r�����Penryn�͂�荂�����g���ƂȂ�A
�����Ă�葽���̃L���b�V���𓋍ڂ���BPenryn�̎��g���͂����炭3GHz����Ɨ\�z����Ă���B
Intel��2007�N��������45nm CPU�̃��[���`��\�肵�Ă��邪�A���̌�A2008�N��65nm����45nm�ւ̃N���X�I�[�o�[
�i�܂�45nm�v���Z�X�̏o�חʂ�65nm�����邱�Ɓj��\�肵�Ă����Intel��Technology Analyst�ł���
Rob Willoner���͌�����BRob Willoner����45nm�v���Z�X�̃`�b�v�̓I���S����D1D Fab�Ő������J�n���Ă���Ɛ��������B
�����āA���̃I���S����D1D Fab��45nm CPU��Intel�ł͍ŏ��ɑ�ʐ��Y���邱�ƂɂȂ邾�낤�ƌ�����B
Rob Willoner���ɂ���Intel�ʏ�ACPU�̃v���Z�X�̃N���X�I�[�o�[��2�N�����ɍs���B
90nm����65nm�ւ̃N���X�I�[�o�[�͍��N�����ɍs��ꂽ�B
Intel�̍ŏ���45nm Dual-Core�ł���Penryn�͊��ɃV���R���̃f�o�b�O�ɓ����Ă���A
���������̃T���v��������Ă���BPenryn�ɂ̓T�[�o�[�A�f�X�N�g�b�v�A���o�C����
�e�o���G�[�V����������A�V�����d�͐���@�\��SSE4�ƌĂ��48��SIMD���߂�lj����Ă���B
����SSE4�̓}���`���f�B�A�⍂���\��v������A�v���P�[�V�����ňЗ͂�����Ƃ���Ă���B
����ɁA���݂�CoreMicroArchitecture��Dual-Core CPU�Ɣ�r�����Penryn�͂�荂�����g���ƂȂ�A
�����Ă�葽���̃L���b�V���𓋍ڂ���BPenryn�̎��g���͂����炭3GHz����Ɨ\�z����Ă���B
> �e�o���G�[�V����������A�V�����d�͐���@�\��SSE4�ƌĂ��48��SIMD���߂�lj����Ă���B
SSE4��50���߂̂͂������BApplication Targeted Accelerators(CRC32��POPCNT)��
�T�|�[�g���Ȃ��Ƃ����Ӗ��Ȃ̂��낤���H
SSE4��50���߂̂͂������BApplication Targeted Accelerators(CRC32��POPCNT)��
�T�|�[�g���Ȃ��Ƃ����Ӗ��Ȃ̂��낤���H
698 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/02(�y) 15:03:14 ID:RV3tWDMA
����2���߂�SIMD���߂���Ȃ�����
���l��PNI��fisttp��x87�g�����߂ł�����SIMD���߂ł͂Ȃ�
���l��PNI��fisttp��x87�g�����߂ł�����SIMD���߂ł͂Ȃ�
IDF�Ŕ��\���ꂽ�̂�50��SSE4���߂�
2��Application Targeted Accelerators�ł�
�����������̂�
IDF�Ŕ��\���ꂽ���߂͑S����50���߂��Ǝv���Ă����B
-> ��̖��߂��T�|�[�g����Ȃ��ƒm����
�@-> 48���߂Ə�����
�Ƃ��������ł�
50��SSE4���߂̂����T�|�[�g����Ȃ����߂�
�����Ƃ���A�����Ɨ\�z����܂����H
2��Application Targeted Accelerators�ł�
�����������̂�
IDF�Ŕ��\���ꂽ���߂͑S����50���߂��Ǝv���Ă����B
-> ��̖��߂��T�|�[�g����Ȃ��ƒm����
�@-> 48���߂Ə�����
�Ƃ��������ł�
50��SSE4���߂̂����T�|�[�g����Ȃ����߂�
�����Ƃ���A�����Ɨ\�z����܂����H
700 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/02(�y) 15:32:17 ID:RV3tWDMA
SSE4�ŃO�O�����牴���̏������d�g�L�����q�b�g����orz
����Google�L���b�V������폜�v�������Ƃ�������
http://en.wikipedia.org/wiki/SSE4
�����炭CRC32��POPCNT�����50���߂��Ǝv���B����SIMD���߂̒lj���48���߁B
����Google�L���b�V������폜�v�������Ƃ�������
http://en.wikipedia.org/wiki/SSE4
�����炭CRC32��POPCNT�����50���߂��Ǝv���B����SIMD���߂̒lj���48���߁B
http://www.intel.com/technology/architecture/new_instructions.htm
���̎��������Ď��ۂɐ�������SSE4��50������(SSE��PEXTRW�͏��O)�B
�܂��A���ۂɑ��݂��Ȃ����߂������Ă���\��������܂���
���̎��������Ď��ۂɐ�������SSE4��50������(SSE��PEXTRW�͏��O)�B
�܂��A���ۂɑ��݂��Ȃ����߂������Ă���\��������܂���
�܂��N���b�N���ɏグ��ꂽ�ق����������Ď��ł��ˁB
intel�͕��R�A���������I�ɓ��삵�ĂȂ����͖����I�ɃI�[�o�[�N���b�N����炵���ȁB
TDP���e�ł���͈͂ŁB
����ȗ]�T������ӂ�A�N���b�N�Ɋւ��Ă�intel�ɕ������肻���B
TDP���e�ł���͈͂ŁB
����ȗ]�T������ӂ�A�N���b�N�Ɋւ��Ă�intel�ɕ������肻���B
���ʂɗ]�T����ˁH�A����d�͂�AMD���Ⴂ����B
���������ETDP�ŏ�������Ȃ�A�R�A�ӂ�̏���d�͂��Ⴂ�����N���b�N����������铹���B
�A�C�f�B�A�̂��Ƃ�]�T�Ƃ����Ă�킯����Ȃ��B
>TDP���e�ł���͈�
��
���ꂪ�]�T�B
���������ETDP�ŏ�������Ȃ�A�R�A�ӂ�̏���d�͂��Ⴂ�����N���b�N����������铹���B
�A�C�f�B�A�̂��Ƃ�]�T�Ƃ����Ă�킯����Ȃ��B
>TDP���e�ł���͈�
��
���ꂪ�]�T�B
����AIntel�̏���d�͂����������Ƃ͊W�Ȃ�����B
��i��TDP�͈̔͂ŃI�[�o�[�N���b�N����킯������B
>>703�̌������e�ł���TDP�Ƃ͋����E�̂��Ƃł͂Ȃ�
��i��65W�̂��Ƃ��낤�B
AthlonX2�ł��������Ƃ͋Z�p�I�ɉ\�Ȃ͂��B
�ނ���AL2�L���b�V�������L���Ă��Ȃ����A
�Дx����̏���d�͂�傫������\��������B
��i��TDP�͈̔͂ŃI�[�o�[�N���b�N����킯������B
>>703�̌������e�ł���TDP�Ƃ͋����E�̂��Ƃł͂Ȃ�
��i��65W�̂��Ƃ��낤�B
AthlonX2�ł��������Ƃ͋Z�p�I�ɉ\�Ȃ͂��B
�ނ���AL2�L���b�V�������L���Ă��Ȃ����A
�Дx����̏���d�͂�傫������\��������B
�����B������������������>706�������Ă�悤�Ȃ��ƁB
�f���A���R�A��TDP�͂Q�R�A���t���X�s�[�h�œ��삵�������l�����Ă邩��
�P�R�A�x��ł鎞��TDP�ɂ͗]�T������B���̃}�[�W���𗘗p�����̂�
�P�R�A���쎞��OC���낤�B�܂�A�C�f�B�A�I�ȋZ�p�ł�����
TDP���Ⴂ����\�ɂȂ����Ƃ������̂ł͂Ȃ��B
TDP�����ōl����Ȃ�Intel�EAMD�W�Ȃ��i�f���A���ȏ�̃R�A�Ȃ�ǂ��̉�Ђł��j�o����\��������B
�f���A���R�A��TDP�͂Q�R�A���t���X�s�[�h�œ��삵�������l�����Ă邩��
�P�R�A�x��ł鎞��TDP�ɂ͗]�T������B���̃}�[�W���𗘗p�����̂�
�P�R�A���쎞��OC���낤�B�܂�A�C�f�B�A�I�ȋZ�p�ł�����
TDP���Ⴂ����\�ɂȂ����Ƃ������̂ł͂Ȃ��B
TDP�����ōl����Ȃ�Intel�EAMD�W�Ȃ��i�f���A���ȏ�̃R�A�Ȃ�ǂ��̉�Ђł��j�o����\��������B
core��penryn�̃N���b�N���i�I�[�o�[�N���b�N�ϐ����j��K8��ō����̂�
�l�b�g�o�[�X�g�̌o������������Ă�ȁH
�l�b�g�o�[�X�g�̌o������������Ă�ȁH
TDP��������N���b�N�グ����Ƃ����̂���O��
�ǂ���p�������Ă������ăN���b�N�オ��Ƃ����Ă���
�ǂ���p�������Ă������ăN���b�N�オ��Ƃ����Ă���
�� TDP��������N���b�N�グ����Ƃ����̂���O��
�m���ɁB������
�ŏ�ʃ`�b�v�̃N���b�N�������ǂ������グ����x�����͂����ĕς���
�m���ɁB������
�ŏ�ʃ`�b�v�̃N���b�N�������ǂ������グ����x�����͂����ĕς���
703�������Ă�̂���Montecito(Itanium2)�ɍڂ�\�肾����Foxton��
�����悤�ȋZ�p���Ă��Ƃł����H
�����悤�ȋZ�p���Ă��Ƃł����H
�ŋ߃N���b�N�̐L�т��݉����Ă�̂�
����d�͂�������Ȃ��Ȃ��Ă������炾��H
�܂�TDP�����Ȃ炩�Ȃ�N���b�N���グ��]�T��
�����Ȃ��̂��ȁB
�Ă�����>>703�̌����Ă�̂���>>680�ˁB
����d�͂�������Ȃ��Ȃ��Ă������炾��H
�܂�TDP�����Ȃ炩�Ȃ�N���b�N���グ��]�T��
�����Ȃ��̂��ȁB
�Ă�����>>703�̌����Ă�̂���>>680�ˁB
>>711
>Montecito(Itanium2)�ɍڂ�\�肾����Foxton�Ɠ����悤�ȋZ�p���Ă��Ƃł����H
�N���b�N���オ��_�͎��Ă邯�nj����ɂ͈Ⴄ�B
Foxton�̓A�v���ɂ���ēd���m�C�Y�̓x�������Ⴄ���Ƃɒ��ڂ����Z�p�B
Itanium2��int��������Power���U�����邽�߂̋Z�p�������B
>Montecito(Itanium2)�ɍڂ�\�肾����Foxton�Ɠ����悤�ȋZ�p���Ă��Ƃł����H
�N���b�N���オ��_�͎��Ă邯�nj����ɂ͈Ⴄ�B
Foxton�̓A�v���ɂ���ēd���m�C�Y�̓x�������Ⴄ���Ƃɒ��ڂ����Z�p�B
Itanium2��int��������Power���U�����邽�߂̋Z�p�������B
�����Y��B���R�A�Е��̃R�A���E���Ƃ�������ĂȂ��B
715 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/04(��) 23:24:41 ID:cgr3UZfy
���Ƃ���2�R�A�ŃN���b�N�A�b�v����\�肾�������NJg��TDP 42W�����I�����������ł���B
�V���O���X���b�h�ł��f���A���X���b�h�ł����\�������o���邢���Ƃ����A�[�L�e�N�`���Ƃ������Ƃ�
��������
�V���O���X���b�h�ł��f���A���X���b�h�ł����\�������o���邢���Ƃ����A�[�L�e�N�`���Ƃ������Ƃ�
��������
>�ނ���AL2�L���b�V�������L���Ă��Ȃ����A
>�Дx����̏���d�͂�傫������\��������B
���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
�L���b�V�����d�͍��Ȃ��킯������I�[�o�[�N���b�N�ł������d�͓I�ȃ}�[�W���͌���킯�ł����A
�L���b�V�������������ʂƁA�L���b�V�����E�����Ԃ�̏���d�͂ŃI�[�o�[�N���b�N�������ʂ���
�ǂ��炪�D�ʂȂ낤?
>�Дx����̏���d�͂�傫������\��������B
���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
�L���b�V�����d�͍��Ȃ��킯������I�[�o�[�N���b�N�ł������d�͓I�ȃ}�[�W���͌���킯�ł����A
�L���b�V�������������ʂƁA�L���b�V�����E�����Ԃ�̏���d�͂ŃI�[�o�[�N���b�N�������ʂ���
�ǂ��炪�D�ʂȂ낤?
����Ȃ킫��˂��[����B
>>680��IDA�̌��ʂɂ��Ę_���Ă����A
���R�V���O���X���b�h�����̏ꍇ�̘b�����H
���R�V���O���X���b�h�����̏ꍇ�̘b�����H
> >�ނ���AL2�L���b�V�������L���Ă��Ȃ����A
> >�Дx����̏���d�͂�傫������\��������B
>
>���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
>�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
�ǂ������^����
���������u����d�͂�����v���Ęb��
�u�����\�̓A�b�v�����ҏo���܂���v���Ĕ��_���Ă�
�b�����ݍ����Ă˂������B
> >�Дx����̏���d�͂�傫������\��������B
>
>���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
>�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
�ǂ������^����
���������u����d�͂�����v���Ęb��
�u�����\�̓A�b�v�����ҏo���܂���v���Ĕ��_���Ă�
�b�����ݍ����Ă˂������B
>>720
�ЃR�A�E�����Ƃł̐��\�A�b�v���ǂ̂��炢���̘b������A
>���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
>�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
����͐^�ł͂Ȃ��B
���ł��L���b�V����S���g���邩��E���Ă��A�b�v���Ȃ��B
�܂��A����d�͂�����Ƃ����̂́A���̕��N���b�N���グ����
�Ƃ������Ƃ�����A�����\�͂��A�b�v�ł���Ƃ����Ӗ��B
�����珈���\�̖͂ʂł̔��_�͂����Ɗ��ݍ����Ă���B
�ЃR�A�E�����Ƃł̐��\�A�b�v���ǂ̂��炢���̘b������A
>���L���Ă�ꍇ�́A�ЃR�A�E�����ɂ����
>�L���b�V���{���ɂ�鏈���\�̓A�b�v�����҂ł��܂���?
����͐^�ł͂Ȃ��B
���ł��L���b�V����S���g���邩��E���Ă��A�b�v���Ȃ��B
�܂��A����d�͂�����Ƃ����̂́A���̕��N���b�N���グ����
�Ƃ������Ƃ�����A�����\�͂��A�b�v�ł���Ƃ����Ӗ��B
�����珈���\�̖͂ʂł̔��_�͂����Ɗ��ݍ����Ă���B
>>719
�܂�Е��̃R�A����~���Ă���ȁH
�܂�Е��̃R�A����~���Ă���ȁH
�[���L���b�V���̏���d�͂Ȃ����������Ƃˁ[����
15���g�����W�X�^����27MB�ς�ł�Montecito�ł��炽������5.2w����
15���g�����W�X�^����27MB�ς�ł�Montecito�ł��炽������5.2w����
�悭�悭���ׂ��猻��ł����R�Ɏg���L���b�V���T�C�Y�͌��߂����A
�g��Ȃ��L���b�V���̓d�͂̓I�t�ł���悤�ł��ˁB
���L�Ȃ�A�L���b�V���{��������ʂ����邵�A
����d�͂��������ւ��V�t�g�ł���2�x�|���Ƃ���������
�L�̏ꍇ�L���b�V�����̓d�͍���A�Ƃ����͓̂��ɋ��L�ł͖����Ƃ����킯�ł��Ȃ������B
���܂ł̋c�_�Ӗ�Ż�
�g��Ȃ��L���b�V���̓d�͂̓I�t�ł���悤�ł��ˁB
���L�Ȃ�A�L���b�V���{��������ʂ����邵�A
����d�͂��������ւ��V�t�g�ł���2�x�|���Ƃ���������
�L�̏ꍇ�L���b�V�����̓d�͍���A�Ƃ����͓̂��ɋ��L�ł͖����Ƃ����킯�ł��Ȃ������B
���܂ł̋c�_�Ӗ�Ż�
�������Ǝv�������A1�R�A����ł̓L���b�V���S���I�t�ɂ��Ă��̕��N���b�N�グ�������ˁH
>>724
�����R�A���0.3V���d�����Ƃ��Ĕ������Montecito�����炾��B
SPARC64 VI����L2�L���b�V���̏���d�͂��T�^���쎞��TDP�̔����߂��B
�����R�A���0.3V���d�����Ƃ��Ĕ������Montecito�����炾��B
SPARC64 VI����L2�L���b�V���̏���d�͂��T�^���쎞��TDP�̔����߂��B
���������悩�����̂��H
�~�[���L���b�V���̏���d�͂Ȃ����������Ƃˁ[����
���[��Intel�̃L���b�V���̏���d�͂Ȃ����������Ƃˁ[����
��watt������Ƃ���ŔL$�őË����邱�Ƃƃy�C����قǃN���b�N���グ����̂��^����ĈӖ��ŏ�������(�ȉ�>>725
�~�[���L���b�V���̏���d�͂Ȃ����������Ƃˁ[����
���[��Intel�̃L���b�V���̏���d�͂Ȃ����������Ƃˁ[����
��watt������Ƃ���ŔL$�őË����邱�Ƃƃy�C����قǃN���b�N���グ����̂��^����ĈӖ��ŏ�������(�ȉ�>>725
���L���b�V���͋v�X�ɂ킭�킭�����Z�p���������Ȃ��Ȃ�PC�����ɉ���Ă��Ȃ��ˁB
��e��L3�����ʂɂ�����ɂȂ�Ȃ��ƃ_�����B
��e��L3�����ʂɂ�����ɂȂ�Ȃ��ƃ_�����B
>>731
��ȁA���قȁB�Q�l���S�l���L���b�V�����ڂ��Ă�̂ɂ��H
�R�A�̕��G�����M/�p�t�H�[�}���X�����̈��� �ɋꂵ���
�R�A��P���������̂Ԃ�R�A���l�ߍ��ޗ���ɂȂ����̂�
���̂o�b�p�b�o�t�ƊE���낤�B
���ۂɂ͑������G�����Ă邪�A�悹����g�����W�X�^�����炷���
PentiumIII��Pentium4�̂����舳�|�I�Ƀ��W�b�N�̊g�����͌����Ă�B
�܁[�ł��܂�Intel�̓{�`�{�`���W�b�N���₻���Ƃ��Ă�݂��������ǁB
��ȁA���قȁB�Q�l���S�l���L���b�V�����ڂ��Ă�̂ɂ��H
�R�A�̕��G�����M/�p�t�H�[�}���X�����̈��� �ɋꂵ���
�R�A��P���������̂Ԃ�R�A���l�ߍ��ޗ���ɂȂ����̂�
���̂o�b�p�b�o�t�ƊE���낤�B
���ۂɂ͑������G�����Ă邪�A�悹����g�����W�X�^�����炷���
PentiumIII��Pentium4�̂����舳�|�I�Ƀ��W�b�N�̊g�����͌����Ă�B
�܁[�ł��܂�Intel�̓{�`�{�`���W�b�N���₻���Ƃ��Ă�݂��������ǁB
�����͂���AEM64T�����ꂳ����ꂽ���݂�Y��ĂȂ�����ˁB
�{�Ƃ̈Ӓn�Ŗ��߃Z�b�g���M�邳�B
�{�Ƃ̈Ӓn�Ŗ��߃Z�b�g���M�邳�B
734 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/06(��) 02:59:33 ID:At82ZlrU
Intel 64 = EM64T + LAHF/SAHF + SSSE3
���݂��Č������A���ʂ�Intel64�Ƃ������o���ӂ肩��
���\�ł��{�Ƃ��z�����M�̕\��ł͂Ǝv���Ă���B
���\�ł��{�Ƃ��z�����M�̕\��ł͂Ǝv���Ă���B
�����z���Ă邶���
65nm�E45nm�E�E�E�����Ă��̐�`32nm�v���Z�X�̂��b
http://northwood.blog60.fc2.com/blog-entry-402.html
http://northwood.blog60.fc2.com/blog-entry-402.html
intel�Ƃ����A�̂���p���m�C�A�ƕ]����Ă����Ђ���B
�����J�͖Y��Ȃ��B
�����J�͖Y��Ȃ��B
Intel��32nm��EUV�͂ˁ[�悗����FB-DIMM�̋L���Ƃ����k�X�͒m���������Ȃ�
22nm�ŃM���M���ǂ��Ȃ邩���ȁB
Intel�C�u�����ܗ��t�Z��22nm����ɂ��Ԃɍ���Ȃ��v
http://techon.nikkeibp.co.jp/article/NEWS/20061206/125094/
����̋L���B
�����ܗ��t�Z�͊��҂��Ă����ǁAIntel�̗̍p�͂Ȃ������ƁB���ۓ�����B
32nm�ł��h���C�̉����̉\���������Ă����ǁA����͂������ɏ����Ă�B
Intel�I�ɂ͓�d�I���ɌX���Ă�悤�����ǁB
�����́u2009�N��32nm����́C�t�Z�̃_�u���E�p�^�[�j���O���v�悵�Ă���v
�ƕʋL�������ǁAIntel��32nm�ł���͂��Ȃ��B
http://techon.nikkeibp.co.jp/article/NEWS/20061206/125094/
����̋L���B
�����ܗ��t�Z�͊��҂��Ă����ǁAIntel�̗̍p�͂Ȃ������ƁB���ۓ�����B
32nm�ł��h���C�̉����̉\���������Ă����ǁA����͂������ɏ����Ă�B
Intel�I�ɂ͓�d�I���ɌX���Ă�悤�����ǁB
�����́u2009�N��32nm����́C�t�Z�̃_�u���E�p�^�[�j���O���v�悵�Ă���v
�ƕʋL�������ǁAIntel��32nm�ł���͂��Ȃ��B
�ł�EM64T���g���Ă��邩����͂��̍��݂͂����Ȃ������B
vista��64bit�ł��ŏ��̍�����MS���̑��������Ȃ��݂�������
64bit�����C���ɂȂ�͎̂���OS���炩�˂�
64bit�����C���ɂȂ�͎̂���OS���炩�˂�
744 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/08(��) 00:10:39 ID:XG7+HwtJ
���������I���W�i���ɍS��قǃv���C�h����������
�i���p�͂������̂́jARM�݊����[�J�[�Ȃ�Ă��Ȃ���
AMD64�́u�e�N�j�J�����������v��SSE/SSE2�ɂ�����̂�
MS�̌��т���B���݂����Ȃ�����B
�i���p�͂������̂́jARM�݊����[�J�[�Ȃ�Ă��Ȃ���
AMD64�́u�e�N�j�J�����������v��SSE/SSE2�ɂ�����̂�
MS�̌��т���B���݂����Ȃ�����B
ttp://news.com.com/Ancient+calculator+was+1,000+years+ahead+of+its+time/2100-11397_3-6139636.html?tag=cd.top
���������}����������ȁc
���������}����������ȁc
Electronic News����F
Intel�ЁA45nm�v���Z�X�Z�p�̊J���͏���
http://www.ednjapan.com/content/l_news/2006/12/l_news061207_0301.html
Intel�ЁA45nm�v���Z�X�Z�p�̊J���͏���
http://www.ednjapan.com/content/l_news/2006/12/l_news061207_0301.html
>>746
�Ȃ̎����悤�Ȏ��������Ȃ���x�ꂽ���i����C������E�E�E
�Ȃ̎����悤�Ȏ��������Ȃ���x�ꂽ���i����C������E�E�E
FSB�̍������ƃv���Z�X�̔�������������ɂ���Ă��ȁ[
�R�N�O��Intel�\��ł͗��N�P�OGHz�B���ł����ȁ[
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
���̍��͉����f���ɂ����Ȃ���̂��ƐM���Ă�����w
http://pc.watch.impress.co.jp/docs/2003/0227/kaigai01.htm
���̍��͉����f���ɂ����Ȃ���̂��ƐM���Ă�����w
>>749
�uPrescott��5GHz�ACedarMill��8GHz�ANehalem��10GHz�v
����͂���Ŗʔ����������ǂȁB
����Nehalem�ōĂэ��N���b�N�H���ɁE�E�E�Ȃ�Ȃ���ȁE�E�E�B
�uPrescott��5GHz�ACedarMill��8GHz�ANehalem��10GHz�v
����͂���Ŗʔ����������ǂȁB
����Nehalem�ōĂэ��N���b�N�H���ɁE�E�E�Ȃ�Ȃ���ȁE�E�E�B
751 �FSocket774�F2006/12/10(��) 13:28:37 ID:D2eH7h7s
������Pentium4 10GHz���ˑR�����J�n�I
���R�A�A�}���`�X���b�h���i�ނƃf�X�N�g�b�vCPU�ł�
�v���f�B�P�[�V�����^�̕���ɂȂ�̂��ȁH
1�̃v���O�����ł��������̉\��������
����܂ł������ԓI�ɂ͑����Ȃ�H
�������R���g���[�������������悤�����E�E�E
�ш悪�S�z�H
�v���f�B�P�[�V�����^�̕���ɂȂ�̂��ȁH
1�̃v���O�����ł��������̉\��������
����܂ł������ԓI�ɂ͑����Ȃ�H
�������R���g���[�������������悤�����E�E�E
�ш悪�S�z�H
Prescott
http://members.jcom.home.ne.jp/3233730401/67017s.jpg
CedarMill
http://img227.imageshack.us/img227/8282/pi661tt9.jpg
7GHz�ݾ�
���͖ق��Ē����Ԓ�
http://members.jcom.home.ne.jp/3233730401/67017s.jpg
{kind=link}
CedarMill
http://img227.imageshack.us/img227/8282/pi661tt9.jpg
{kind=link}
7GHz�ݾ�
���͖ق��Ē����Ԓ�
�� IDF�ł́AIntel��Justin Rattner�����A2010�N�ɂ�15�`20GHz�ɂȂ�ƌ����\�����������B
���ł� ���ƁA���݂����Ȃ�\�����ȁE�E
���ł� ���ƁA���݂����Ȃ�\�����ȁE�E
�� ����5�N�`10�N��ɂ́A���\�`���S�̃R�A���_�C�ɓ��ڂ����悤�ɂȂ�Ƃ����B
���̑O�̂���v���o�����B
���̑O�̂���v���o�����B
�Ƃ肠�����傫���ڕW���s���Ă�����OK�݂�����
���C�ɂĂ͑�ƂȂ炸
�A�[�L�e�N�g���͎������Ȃ�
�A�[�L�e�N�g���͎������Ȃ�
758 �FSocket774�F2006/12/10(��) 23:13:58 ID:SRcma8gB
�R�A���Ȃ�ă��[�U�[����݂���ǂ������Ă����B
�ނ��낻��ȋY������Ȃ��Ă����B
�R�A���Ȃ��OS����݂���ǂ������Ă����B
�ނ���P�R�A�Ƃ��ĉB������A�����I�ɑ��R�A�����Ă��������B
�����͂ʂ�߂����������E�E�E
���݂��݈��߂@���݂��݂ƁE�E�E
�ނ��낻��ȋY������Ȃ��Ă����B
�R�A���Ȃ��OS����݂���ǂ������Ă����B
�ނ���P�R�A�Ƃ��ĉB������A�����I�ɑ��R�A�����Ă��������B
�����͂ʂ�߂����������E�E�E
���݂��݈��߂@���݂��݂ƁE�E�E
Pentium5���ďo�Ȃ���ł��H
>>750�@���N���b�N�H���ւ̕��A�͂ǂ���ɂ��Ă��}���E�K�{�ł�����
���͍��N���b�N�œ������Ă����v�ȕ�����͍����Ă��Ȃ����ȁB
���ł�C2D���SGhz�œ������ƃQ�[���Ȃ����\�܂Ƃ��ɓ����B
���ꂱ���Q�[���@���݂ɂˁB
���N�������\�I�ɍ��N�Ƒ卷�Ȃ���܂����N�̓�̕�(�P���l��)�B
�N���b�N��L2���e�ʉ��Ȃ�Ă��Ă�ꍇ����Ȃ���"��"���ǂ�ǂ�o���Ȃ��ƂˁB
���NVISTA�͒N������Ȃ����낤���炢���Ȃ�OS�ɐH���镪��
�A�v���ő����Ɏg����N�ɂȂ肻�������C���e�������̑������������D�̃`�����X����ˁB
���͍��N���b�N�œ������Ă����v�ȕ�����͍����Ă��Ȃ����ȁB
���ł�C2D���SGhz�œ������ƃQ�[���Ȃ����\�܂Ƃ��ɓ����B
���ꂱ���Q�[���@���݂ɂˁB
���N�������\�I�ɍ��N�Ƒ卷�Ȃ���܂����N�̓�̕�(�P���l��)�B
�N���b�N��L2���e�ʉ��Ȃ�Ă��Ă�ꍇ����Ȃ���"��"���ǂ�ǂ�o���Ȃ��ƂˁB
���NVISTA�͒N������Ȃ����낤���炢���Ȃ�OS�ɐH���镪��
�A�v���ő����Ɏg����N�ɂȂ肻�������C���e�������̑������������D�̃`�����X����ˁB
>>759
���ɂ��ɂ���������
���ɂ��ɂ���������
>>759
�y�����zPentium5�ɂ��Č�낤�y���G�z
http://pc.2ch.net/jisaku/kako/1021/10217/1021721319.html
�uPentium�T�v�͂j�W�A�[�L�e�N�`���ŏo�܂��B
http://pc7.2ch.net/test/read.cgi/jisaku/1106063563/
�y�����zPentium5�ɂ��Č�낤�y���G�z
http://pc.2ch.net/jisaku/kako/1021/10217/1021721319.html
�uPentium�T�v�͂j�W�A�[�L�e�N�`���ŏo�܂��B
http://pc7.2ch.net/test/read.cgi/jisaku/1106063563/
���̂�PentiumPenta�Ȃ͎̂^�����ȁB���킢��
>>748
�v���Z�X�̔������x�ꂽ��ˁE�E�E
�v���Z�X�̔������x�ꂽ��ˁE�E�E
90nm���̃��[�N�݂����ɗ\�z�O�̎��Ԃ��N����Ȃ�����A
�啝�ɒx�����Ď��͂Ȃ���Ȃ����B
�啝�ɒx�����Ď��͂Ȃ���Ȃ����B
Penryn�͏���d�͂�Smithfield�����傫���Ȃ�̂�FMB���ύX����A�܂��AFSB��2132MHz�ɒB���錩���݂�
�����ł����H�킩��܂���I�I
�����ł����H�킩��܂���I�I
���ō���FSB(1333MHz�ȏ�Ƃ�)�グ�Ă���݂̔z���x���Ƃ����v�Ȃ́H
�̂�6�w��݂ł������������l�ȁc
�̂�6�w��݂ł������������l�ȁc
PPC970�̃o�X�Ȃ�32bit�P����x2������64bit�o������Intel FSB�Ƃ͔�r�ɂȂ��B
770 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/12(��) 00:30:08 ID:qhFpMFYp
771 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/12(��) 00:30:42 ID:qhFpMFYp
�딚���}�X�^������������
AMD��SOI�x�[�X��eDRAM�Z�p�ł���ZRAM�����C�Z���X�����̂���m�̘b�����ǁA
���N��IEDM��Intel����������eDRAM "Floating Body (Memory) Cell"�ɂ��Ĕ��\
���s���Ƃ����b���B
http://www.theinquirer.net/default.aspx?article=36285
���N��IEDM��Intel����������eDRAM "Floating Body (Memory) Cell"�ɂ��Ĕ��\
���s���Ƃ����b���B
http://www.theinquirer.net/default.aspx?article=36285
�����͐i�ނ����g���オ��Ȃ�����
�]�����ʐςŃ}���`�R�A
�Ȃ��Ȃ��A�K���
�]�����ʐςŃ}���`�R�A
�Ȃ��Ȃ��A�K���
>>772
eDRAM����˂�����
eDRAM����˂�����
���t���b�V�����삪�K�v�Ȃ�DRAM�ł���H
RDRAM��Rambus�������������Ń���������̓����͋�J���������ȁB
AMD��ZRAM��������Ȃ��Ė��J���Z�p���D��I�ɂ����郉�C�Z���X����ł��ȁB
AMD��ZRAM��������Ȃ��Ė��J���Z�p���D��I�ɂ����郉�C�Z���X����ł��ȁB
777 �FSocket774�F2006/12/13(��) 23:35:59 ID:nDS+V2Vh
Intel��Windows�����S�ɉ��z���ɑΉ��������x86���̂ĂĐV�����A�[�L�e�N�`���Ɉڍs�����肷��낤���H
IA-32������������ꂽ��
i432��IA-64�̗l�Ȃ��Ă��̎��R�ɍ����
�ł�����肵��
i432��IA-64�̗l�Ȃ��Ă��̎��R�ɍ����
�ł�����肵��
AMD64�Ƃ��͏����̂ɂȂ肻������
�}���`�R�A���ő����������d�͂�}�����邽�߂�
�P�̂̎��g����}������A���R�P�̐��\��������
���Ȑ��̒��ɂȂ����Ȃ�
�P�̂̎��g����}������A���R�P�̐��\��������
���Ȑ��̒��ɂȂ����Ȃ�
>>779
�U�߂��A�ނ�܂������H
�U�߂��A�ނ�܂������H
�yIEDM�zIntel�C�v���Z�T���ڑ_���t�B��FET�^SOI�������[���J��
http://techon.nikkeibp.co.jp/article/NEWS/20061214/125404/
>���S��R�^SOI�isilicon on insulator�j�ɂ��������������[���J�������B
http://techon.nikkeibp.co.jp/article/NEWS/20061214/125404/
>���S��R�^SOI�isilicon on insulator�j�ɂ��������������[���J�������B
784 �FSocket774 ��TriPwOTA.E �F2006/12/14(��) 19:50:47 ID:dJVx85o6
�܂�i860���Y����Ă�c
i960�������H
>>787
�g�ݍ������Ɏ嗬����O��ď����Ă����������
�g�ݍ������Ɏ嗬����O��ď����Ă����������
Intel Extends Embedded Offerings With Intel Core2 Duo Processors
Intel Core Microarchitecture Sets New Standard for Low Power, Scalability in the Embedded Market
http://www.intel.com/pressroom/archive/releases/20060926comp_b.htm
Intel Core Microarchitecture Sets New Standard for Low Power, Scalability in the Embedded Market
http://www.intel.com/pressroom/archive/releases/20060926comp_b.htm
mac�̃X���ɂȂ��Ȃ��h���I�ȋL�����\���Ă������B
P.Gelsinger�H���A�uAMD��45nm�v���Z�X�̊J����Intel�Ƃ̍����k�߂�ƐM���Ă鍁��t��fanboy�v
P.Gelsinger�H���A�uAMD��45nm�v���Z�X�̊J����Intel�Ƃ̍����k�߂�ƐM���Ă鍁��t��fanboy�v
792 �FSocket774�F2006/12/17(��) 10:24:29 ID:53BX9zTB
fanboy���Ēm��Ȃ��P��Ȃ��lj�?
�M�҂�?
�M�҂�?
fanboy
�y���z �}�j�A�̏��N�o���傤�˂�p�A���������}�j�A���E�����ł́A���̌�͂����Όy�̓I�B
�Q�[���ASF�A�A�j���A����A���y�A�t�@���^�W�[�̂悤�Ȍ������痣�ꂽ�����̃t�@���ŁA
�}�j�A�b�N�Ȓm���E���������ҁB���̃}�j�A����������ɂ͑Ώۂ̐l�E���E��i�̖���O�u �B
��ATolkien fanboy, XBox fanboy, Gundam fanboy
�y���z �}�j�A�̏��N�o���傤�˂�p�A���������}�j�A���E�����ł́A���̌�͂����Όy�̓I�B
�Q�[���ASF�A�A�j���A����A���y�A�t�@���^�W�[�̂悤�Ȍ������痣�ꂽ�����̃t�@���ŁA
�}�j�A�b�N�Ȓm���E���������ҁB���̃}�j�A����������ɂ͑Ώۂ̐l�E���E��i�̖���O�u �B
��ATolkien fanboy, XBox fanboy, Gundam fanboy
>>791
����\������
����\������
Gelsinger�݂͂肪��肢�̂�
>>796
���肪�ƁA�}�J�[�͂₽��ڂ����z�瑽����
���肪�ƁA�}�J�[�͂₽��ڂ����z�瑽����
798 �FMAC�I�^��792 �����F2006/12/17(��) 22:50:21 ID:rbd1iWOa
>>792
�@�@�A���~ = AMD fanboy
�Ǝv���Ă����ΊԈႢ�������B�~�[�̌ꌹ�����V�ł��邱�Ƃ��l����ƁC���ē����Ӗ��Ƃ������Ƃ�
�[�����������邩�Ǝv�����B
�@�@�A���~ = AMD fanboy
�Ǝv���Ă����ΊԈႢ�������B�~�[�̌ꌹ�����V�ł��邱�Ƃ��l����ƁC���ē����Ӗ��Ƃ������Ƃ�
�[�����������邩�Ǝv�����B
AMD fanboy�uAMD��45nm��2008�N�̑��l����������90nm����͐��i�Ƃ���2009�N�܂ō�葱���܂��v
http://blog.livedoor.jp/amd646464/archives/50756163.html
http://blog.livedoor.jp/amd646464/archives/50756163.html
800 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2006/12/17(��) 23:03:43 ID:ro0kalBe
�܂�GPU��90nm���낤��
ATI schedules 45nm production at TSMC for 2008
http://www.futura-sciences.com/newsrss-ati-schedules-45nm-production-at-tsmc-for-2008_321208.php
http://www.futura-sciences.com/newsrss-ati-schedules-45nm-production-at-tsmc-for-2008_321208.php
802 �FSocket774�F2006/12/18(��) 00:38:03 ID:HToRYGvo
>>780�@����d�͉]�X���ē������[�h����Ȃ��B
�݂�Ȑ��\�͂����Ƃ����Ɨ~�������ʂɏ���d�͉͂����Ȃ��Ă��������Č����Ă�̂�
����d�͂�ɂ��܂����Ȃ�Č����Ă��w���ӗ~���S�R�킩�Ȃ��B
�q�[�g�X�v���b�_�������A���~�_�C�L���X�g�ȋ���q�[�g�V���N�ɂȂ��Ă�Ƃ�
�܂��܂���͂���Ǝv����ˁB�q�[�g�X�v���b�_�ƃq�[�g�V���N���ʂɂȂ��Ă�i�K��
�M�`�����͂��Ȃ舫���Ȃ��Ă�Ǝv���B�ǂ�Ȃɂ����O���X�g���Ă��ˁB
�݂�Ȑ��\�͂����Ƃ����Ɨ~�������ʂɏ���d�͉͂����Ȃ��Ă��������Č����Ă�̂�
����d�͂�ɂ��܂����Ȃ�Č����Ă��w���ӗ~���S�R�킩�Ȃ��B
�q�[�g�X�v���b�_�������A���~�_�C�L���X�g�ȋ���q�[�g�V���N�ɂȂ��Ă�Ƃ�
�܂��܂���͂���Ǝv����ˁB�q�[�g�X�v���b�_�ƃq�[�g�V���N���ʂɂȂ��Ă�i�K��
�M�`�����͂��Ȃ舫���Ȃ��Ă�Ǝv���B�ǂ�Ȃɂ����O���X�g���Ă��ˁB
803 �FSocket774�F2006/12/18(��) 00:45:43 ID:HToRYGvo
�N���b�N����������グ��ׂ̃u���C�N�X���[�������Ȃ�L2�L���b�V��1GB�Ƃ��ȁB
�ꎞPentium��10GHz�s���Ȃ�Č����Ă����̂͂Ȃ����낤���B
��N�܂�Core���{�̐��\���オ�����߂邩���������CPU�͒x���Ă������B
�����l�������B
4Ghz��CPU��4�ڂ����16Ghz���݂ɐ��\���o��B
�����l���Ă�����������܂����B
���ʂ�4Ghz�̃X�s�[�h��4�̃A�v��������Ƃ������e���Ȃ��́B
�ꎞPentium��10GHz�s���Ȃ�Č����Ă����̂͂Ȃ����낤���B
��N�܂�Core���{�̐��\���オ�����߂邩���������CPU�͒x���Ă������B
�����l�������B
4Ghz��CPU��4�ڂ����16Ghz���݂ɐ��\���o��B
�����l���Ă�����������܂����B
���ʂ�4Ghz�̃X�s�[�h��4�̃A�v��������Ƃ������e���Ȃ��́B
��AMD��45nm��2008�N�̑��l����������90nm����͐��i�Ƃ���2009�N�܂ō�葱���܂�
�E�E�E�H
���L���ɂ���Ȃ��Ə����Ă��������H
�E�E�E�H
���L���ɂ���Ȃ��Ə����Ă��������H
>>802
�q�[�g�X�v���b�_���A���~����V���R���ƔM�c�������Ⴂ
�����ă_���ł��B���̕����̋@�B�I�ȃg���u���͌��\������B
�q�[�g�X�v���b�_���A���~����V���R���ƔM�c�������Ⴂ
�����ă_���ł��B���̕����̋@�B�I�ȃg���u���͌��\������B
>>803
��4Ghz��CPU��4�ڂ����16Ghz���݂ɐ��\���o��B
�������l���Ă�����������܂����B
����������k����
�����{���ɂ����l���Ă����Ȃ�A�ߋ����̎�̖ϑz���J��Ԃ��Ă��H
�p�C�v���C���X�e�[�W��{�ɂ���i����
�t�F�b�`�ш��{�ɂ���i��
�f�R�[�_����{�Ɂi����
���Z���j�b�g��{�悹��i����
���[�h�X�g�A���j�b�g���i��
��4Ghz��CPU��4�ڂ����16Ghz���݂ɐ��\���o��B
�������l���Ă�����������܂����B
����������k����
�����{���ɂ����l���Ă����Ȃ�A�ߋ����̎�̖ϑz���J��Ԃ��Ă��H
�p�C�v���C���X�e�[�W��{�ɂ���i����
�t�F�b�`�ш��{�ɂ���i��
�f�R�[�_����{�Ɂi����
���Z���j�b�g��{�悹��i����
���[�h�X�g�A���j�b�g���i��
����A����d�͉͂����ė~�������낤�B
core�𑝂₹�c�Ă̂͂������̂Ƃَ͈�����
����������͌J��Ԃ�
�c�ƂɂƂ��Ƃ��Ɛ����̖������[�v
����������ꂽ��
����������͌J��Ԃ�
�c�ƂɂƂ��Ƃ��Ɛ����̖������[�v
����������ꂽ��
>���ʂ�4Ghz�̃X�s�[�h��4�̃A�v��������Ƃ������e���Ȃ��́B
���₱�ꂪ�����ł���Ȃ�\������������
���₱�ꂪ�����ł���Ȃ�\������������
>>809
���ꂵ���ł��Ȃ��̂����Ȃ�
4GHz�̃X�s�[�h��4�̃A�v���𑖂点��@�̂�
4GHz��4�{�̃X�s�[�h�łP�̃A�v���𑖂点��@�I�������Ȃ��A�O�҂̂�
���ꂾ�����ꂽAthlon64 X2 3800+�ł����A�قƂ�ǂ�3D�Q�[����3�N�O�̐��\�����
CPU���鑤�̓}�[�P�e�B���O�ŃZ�[���X�|�C���g���A�s�[������͓̂�����O�����ǁA������Ǝ₵���ȁA���Ęb�Ȃ�
���ꂵ���ł��Ȃ��̂����Ȃ�
4GHz�̃X�s�[�h��4�̃A�v���𑖂点��@�̂�
4GHz��4�{�̃X�s�[�h�łP�̃A�v���𑖂点��@�I�������Ȃ��A�O�҂̂�
���ꂾ�����ꂽAthlon64 X2 3800+�ł����A�قƂ�ǂ�3D�Q�[����3�N�O�̐��\�����
CPU���鑤�̓}�[�P�e�B���O�ŃZ�[���X�|�C���g���A�s�[������͓̂�����O�����ǁA������Ǝ₵���ȁA���Ęb�Ȃ�
���������ɂЂɂ��͂��悤���Ȃ������I�R�}���h�H
�y775�zPC�̒��Ƀ}���`�X���b�h��Ή��̃A�v�������܂�
Q:���̈��p���Ă��邨�G�����\�t�g�̂��Ƃł��B
����7�`8�N�A�b�v�f�[�g������܂���B
�ȑO����A�ō����\�̃v���Z�b�T�ł���QX6700�ɑ��āA�ЂƂ̃R�A�����s�߂�Ƃ����c�t�Ȍ����点�������肵�Ă��܂������A
�ŋ߂͂��ꂪ�G�X�J���[�g���Ă���܂��B
Intel:�@�܂����Ƃ͎v���܂����A���́u�}���`�X���b�h��Ή��̃A�v���v�Ƃ́A���Ȃ��̑z����̑��݂ɂ����Ȃ��̂ł�
�Ȃ��ł��傤���B�����������Ƃ���A���Ȃ����g�����������ǂł��邱�Ƃ�
�قڊԈႢ�Ȃ��Ǝv���܂��B
�@���邢�́A�u�}���`�X���b�h��Ή��̃A�v���v�͎��݂��āA�����������ɏ�����Ă���悤�Ȉُ�Ȏ��Ԃɂ�
�S���ׂ��Ă��炸�A���ׂĂ͂��Ȃ��̖ϑz�Ƃ����\�����ǂݎ��܂��B
���̏ꍇ���A���Ȃ����g�����������ǂł��邱�ƂɂقڊԈႢ�Ȃ��Ƃ������ƂɂȂ�܂��B
Q:���̈��p���Ă��邨�G�����\�t�g�̂��Ƃł��B
����7�`8�N�A�b�v�f�[�g������܂���B
�ȑO����A�ō����\�̃v���Z�b�T�ł���QX6700�ɑ��āA�ЂƂ̃R�A�����s�߂�Ƃ����c�t�Ȍ����点�������肵�Ă��܂������A
�ŋ߂͂��ꂪ�G�X�J���[�g���Ă���܂��B
Intel:�@�܂����Ƃ͎v���܂����A���́u�}���`�X���b�h��Ή��̃A�v���v�Ƃ́A���Ȃ��̑z����̑��݂ɂ����Ȃ��̂ł�
�Ȃ��ł��傤���B�����������Ƃ���A���Ȃ����g�����������ǂł��邱�Ƃ�
�قڊԈႢ�Ȃ��Ǝv���܂��B
�@���邢�́A�u�}���`�X���b�h��Ή��̃A�v���v�͎��݂��āA�����������ɏ�����Ă���悤�Ȉُ�Ȏ��Ԃɂ�
�S���ׂ��Ă��炸�A���ׂĂ͂��Ȃ��̖ϑz�Ƃ����\�����ǂݎ��܂��B
���̏ꍇ���A���Ȃ����g�����������ǂł��邱�ƂɂقڊԈႢ�Ȃ��Ƃ������ƂɂȂ�܂��B
�ᐫ�\�Ȉ�R�A�I�����[�ɂ���ΏȃG�l�ň����Ă݂�Ȃ��͂��͂Ȃ�ˁB
OS�܂߂��S�ẴA�v���̕��ׂ�100����1�ɂ���A�v����������
>>802
����ȏ����d�͖����œ˂�����܂���ƍŏI�I�ɂ́u������Ē����c�Ƃ���ׂĂǂ��ȂH�v�Ƃ�����ꂩ�˂Ȃ�����
����ȏ����d�͖����œ˂�����܂���ƍŏI�I�ɂ́u������Ē����c�Ƃ���ׂĂǂ��ȂH�v�Ƃ�����ꂩ�˂Ȃ�����
AMD��QuadFX���Q�t�H4�@�������A��Ē����c�̐擪�𑖂��Ă���܂�
817 �FSocket774�F2006/12/19(��) 15:29:40 ID:0PJeceF0
http://www.hkepc.com/bbs/news.php?tid=714527&starttime=0&endtime=0
YorkField 4core 6MB shared L2$ 1333MHzFSB?
YorkField 4core 6MB shared L2$ 1333MHzFSB?
L2 Shader Cache�ł���
>>807
���\�������Ă܂ŏ���d�͂���������̂�����������X�ɁB
��d���ŁA����d���ł݂����ɍ��d���ŁA�����d���ł�����ė~�����B
>>810
�l�p�r�ł�������4�A�v�����x�͎g�����瑬�x�ቺ���N���Ȃ��̂͗ǂ���B
�ł��A100�R�A�ȏ�܂ő��₳��Ă��g�����������̂ʼn��Ƃ��ė~�����B
100�R�A�ȏオ���ʂɂȂ鍠�ɂ̓A�v�����Ή����ăR�A��������قǑ����Ȃ�Ηǂ����ǁB
���\�������Ă܂ŏ���d�͂���������̂�����������X�ɁB
��d���ŁA����d���ł݂����ɍ��d���ŁA�����d���ł�����ė~�����B
>>810
�l�p�r�ł�������4�A�v�����x�͎g�����瑬�x�ቺ���N���Ȃ��̂͗ǂ���B
�ł��A100�R�A�ȏ�܂ő��₳��Ă��g�����������̂ʼn��Ƃ��ė~�����B
100�R�A�ȏオ���ʂɂȂ鍠�ɂ̓A�v�����Ή����ăR�A��������قǑ����Ȃ�Ηǂ����ǁB
���l�p�r�ł�������4�A�v�����x�͎g��
�����郁�K�^�X�L���O���Ă�ł���
�����郁�K�^�X�L���O���Ă�ł���
�^�恕����G���R�[�h�p�ɐ�pPC��
������g���Ă��̂����ɂ܂Ƃ߂��肶��ˁH
�ŋ߂̒n��g�A�j�����f�{���ُ͈�
������g���Ă��̂����ɂ܂Ƃ߂��肶��ˁH
�ŋ߂̒n��g�A�j�����f�{���ُ͈�
�l�Ԃ̎�̖{���Ƃ�����������Ƃ��������[�h�}�b�v���Č��J����Ă������H
824 �FSocket774�F2006/12/20(��) 16:42:05 ID:d3byOUX9
���̓���Core2Duo��g�ݍ���ł�������
�l�Ԃ̎v�l�̕��͎������ŋ[���}���`�^�X�N�̂܂܊撣�邵���Ȃ���
�ɒ[�Ɏ��Ԃ��������^�������ɂ��Ȃ����ɂ��x���x�����\������
�ɒ[�Ɏ��Ԃ��������^�������ɂ��Ȃ����ɂ��x���x�����\������
���������Ȃ������Ɏ����I�ɍœK�����i�ނ���A�Ⴂ�����͊撣��
�N������炾�߂���`���Ȃ����Ԃ�����
�N������炾�߂���`���Ȃ����Ԃ�����
�l�Ԃ̔]�͉E�ƍ��ɕ����ꂽ�f���A���R�A����
����͂ǂ����낤�H
���m�ɂ͑O���t�A�㓪�t�A�����t�A�����t�A���]�A�]��
���ꂼ��ɓ������ꂽ6�R�A����Ȃ�����
���m�ɂ͑O���t�A�㓪�t�A�����t�A�����t�A���]�A�]��
���ꂼ��ɓ������ꂽ6�R�A����Ȃ�����
���E�]�͔]�����Ԃ�����ƁA���S�ɓƗ����삷�邱�Ƃ�
�̂̂Ă҂̎�p�Ŋm�F����Ă邪
�O���t�Ƃ������t�͂Ԃ���������v�l�����Ƃ��Ă͋@�\����B
�L���̒������̂��C�n�⑤���t�ɂ��邩�炻�����Ȃ�������
�ǂ��Ȃ���ȁB���]�̓^�C�~���O���L������
���W���[�����K������������ł邾���Ȃ̂ł��ꂾ�����Ǝ������͂Ȃ��B
�܂��A�ł������G�ȃw�e���W�j�A�X�R�A�Ƃ����Ȃ����Ȃ����B
�̂̂Ă҂̎�p�Ŋm�F����Ă邪
�O���t�Ƃ������t�͂Ԃ���������v�l�����Ƃ��Ă͋@�\����B
�L���̒������̂��C�n�⑤���t�ɂ��邩�炻�����Ȃ�������
�ǂ��Ȃ���ȁB���]�̓^�C�~���O���L������
���W���[�����K������������ł邾���Ȃ̂ł��ꂾ�����Ǝ������͂Ȃ��B
�܂��A�ł������G�ȃw�e���W�j�A�X�R�A�Ƃ����Ȃ����Ȃ����B
�v���ʂ�ɂȂ�Ȃ��ď���ɖu�N���鉴�̃`�\�R�͊��S�Ɨ����삾��
�����A����E�C���X�ɏ������Ă邩�烁�C������������O�ɐ؏���������������
��x�ꂾ
[�I]�����ăC���X�g�[�����Ă��������B
Intel�͂���Ȍ������n�߂��̂�
Core2 Duo���Ăǂꂭ�炢�Ⴄ�́H
�ƕ����ꂽ��ł����A����CPU�Ȃǂ��܂߂Ėڈ��ɂȂ�
��r�摜����T�C�g�̃����N�������m�̕������Ă��炦�܂��`
�����������L���͂����ł����u�b�N�}�[�N���Ă��Ȃ������̂ŁB
�ƕ����ꂽ��ł����A����CPU�Ȃǂ��܂߂Ėڈ��ɂȂ�
��r�摜����T�C�g�̃����N�������m�̕������Ă��炦�܂��`
�����������L���͂����ł����u�b�N�}�[�N���Ă��Ȃ������̂ŁB
�����O����iTune�̌��ʈȊO�����Ŋm�F���ĂȂ�����B�܁A��������w
16S/32C/64T��Windows�Ɣ�r����64S/128C/256T��5�{�߂��X�R�A��B���B
http://www.sap.com/solutions/benchmark/pdf/cert8906.pdf
http://www.sap.com/solutions/benchmark/pdf/cert9006.pdf
�����\��(rx6600)�Ŕ�r�����1.4�{�̐��\����B
http://www.sap.com/solutions/benchmark/pdf/cert8306.pdf
http://www.sap.com/solutions/benchmark/pdf/cert7006.pdf
HP-UX 11iV3�̈З͋���ׂ��B�B�B
http://www.sap.com/solutions/benchmark/pdf/cert8906.pdf
http://www.sap.com/solutions/benchmark/pdf/cert9006.pdf
�����\��(rx6600)�Ŕ�r�����1.4�{�̐��\����B
http://www.sap.com/solutions/benchmark/pdf/cert8306.pdf
http://www.sap.com/solutions/benchmark/pdf/cert7006.pdf
HP-UX 11iV3�̈З͋���ׂ��B�B�B
DB�ƃ`���[�j���O�̍��Ɍ����邪�E�E�E
HP�AHP-UX�����ǒ�--�Z�L�����e�B�Ɖ��z���ʼn��P
http://japan.zdnet.com/news/os/story/0,2000056192,20337308,00.htm
>�V�R���p�C���̂������ŁA�T�[�o�\�t�g�E�F�A�̓o�[�W����3�̕����S�ʓI��25�`35�������ɓ��삵�A
>Java�v���O�����ł͂���Ȃ鍂��������������ƁAvan der Zweep���͌���Ă���B
http://japan.zdnet.com/news/os/story/0,2000056192,20337308,00.htm
>�V�R���p�C���̂������ŁA�T�[�o�\�t�g�E�F�A�̓o�[�W����3�̕����S�ʓI��25�`35�������ɓ��삵�A
>Java�v���O�����ł͂���Ȃ鍂��������������ƁAvan der Zweep���͌���Ă���B
�u�R�s�[�����X�������_�v�ɕ�������C���e���̐헪
http://plusd.itmedia.co.jp/lifestyle/articles/0612/25/news012.html
http://plusd.itmedia.co.jp/lifestyle/articles/0612/25/news012.html
>�ł�����Intel�N�A�b�h�́Apen4�~2�̂悤��penD����Ȃ�����
>C2D�~2�̂悤�Ȍ`�ɂȂ�Ǝv���B
>pen4��C2D���Ⴀ�A��ו��ɂȂ�Ȃ��킯�ŁE�E�E
C2D�f���A���_�C��Quad�Ȃ�����o�Ă�ł���BTDP��130W�B
����Intel�̃N���b�h���f���A���_�C�����m�V���b�N���͕s���B
>>954
Yorkfield�����m�V���b�N�Ȃ̂��f���A���_�C�Ȃ̂��AL2��4�R�A���L�Ȃ̂�2�R�A���L�Ȃ̂�
���������ĂĔc���ł��ĂȂ���Ȃ����������B
>C2D�~2�̂悤�Ȍ`�ɂȂ�Ǝv���B
>pen4��C2D���Ⴀ�A��ו��ɂȂ�Ȃ��킯�ŁE�E�E
C2D�f���A���_�C��Quad�Ȃ�����o�Ă�ł���BTDP��130W�B
����Intel�̃N���b�h���f���A���_�C�����m�V���b�N���͕s���B
>>954
Yorkfield�����m�V���b�N�Ȃ̂��f���A���_�C�Ȃ̂��AL2��4�R�A���L�Ȃ̂�2�R�A���L�Ȃ̂�
���������ĂĔc���ł��ĂȂ���Ȃ����������B
�딚�����i�L�E�ցE�M)
>>843
���܂܂Ŏ蔲�����Ă���
�Ǝ~�߂�ꂩ�˂Ȃ���`���Ƃ������悤���Ȃ���
�ǂ��܂ł����\���C���t���[�V��������悤�Ȍ��z��^�����`
�z���g�n���݂���
���܂܂Ŏ蔲�����Ă���
�Ǝ~�߂�ꂩ�˂Ȃ���`���Ƃ������悤���Ȃ���
�ǂ��܂ł����\���C���t���[�V��������悤�Ȍ��z��^�����`
�z���g�n���݂���
EPIC��2001�N���琔���ĔN��ǂ����Ƃɐ��\���オ���Ă�킯�����c
http://iwatam-server.dyndns.org/software/devintro/deathmarch/deathmarch/x49.html
>�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂����A�M�����͏\���Ɋ��Ԃ������ăe�X�g�����邱 �ƂŌ��炷���Ƃ��ł��܂��B
>
>�܂�A�\�t�g�Ƃ����͎̂��Ԃ��������������ł��ǂ��Ȃ�Ƃ������Ƃ� ���B
http://iwatam-server.dyndns.org/software/devintro/deathmarch/deathmarch/x49.html
>�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂����A�M�����͏\���Ɋ��Ԃ������ăe�X�g�����邱 �ƂŌ��炷���Ƃ��ł��܂��B
>
>�܂�A�\�t�g�Ƃ����͎̂��Ԃ��������������ł��ǂ��Ȃ�Ƃ������Ƃ� ���B
�����N��ǂ����Ƃɐ�ΐ��\�����������ς�����Ȃ��B
�u�V�R���p�C���̂������Łv
���������Ă��̃X�����ӂ̌Q��H
���������Ă��̃X�����ӂ̌Q��H
���R���p�C�����S�ʓI��25�`35���x�����������Ƃ����ǂ߂Ȃ�
���ĈӖ���������
����Ȃɐ��\����]�n���c�����R���p�C��
���܂Ŕ����Ă����̂����
25�`35���͂��܂�ɂ��傫�������
���ĈӖ���������
����Ȃɐ��\����]�n���c�����R���p�C��
���܂Ŕ����Ă����̂����
25�`35���͂��܂�ɂ��傫�������
�J���V�E��������Ȃ��̂��ȁH>>850
���̕ӂɓ]�����Ă���x���`�\�t�g��executable���s���Ă݂邾��
�ł͂Ȃ������Ńn�[�h��\�t�g�̐��\���͂ł��郄�V
���̃X���ɁA���₱�̔ɉ��l���炢����낤
�����{���Ɉꈬ��Ȃ낤�ȁc
�ł͂Ȃ������Ńn�[�h��\�t�g�̐��\���͂ł��郄�V
���̃X���ɁA���₱�̔ɉ��l���炢����낤
�����{���Ɉꈬ��Ȃ낤�ȁc
EPIC��
�Ƃ����A�f�l���}�X���f�B�A�̕���������̕��`��
�g�������Ƃ��Ȃ�������
�Ƃ����A�f�l���}�X���f�B�A�̕���������̕��`��
�g�������Ƃ��Ȃ�������
�œK���̎�@(�A�C�f�B�A)�͈����Ȃ����A�܂��Ă�A�������������R���p�C���̊J���͂����ŏI���Ƃ����킯�ł��Ȃ�
>http://iwatam-server.dyndns.org/software/devintro/deathmarch/deathmarch/x49.html
>>�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂����A�M�����͏\���Ɋ��Ԃ������ăe�X�g�����邱 �ƂŌ��炷���Ƃ��ł��܂��B
>>
>>�܂�A�\�t�g�Ƃ����͎̂��Ԃ��������������ł��ǂ��Ȃ�Ƃ������Ƃ� ���B
�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂�
>http://japan.zdnet.com/news/os/story/0,2000056192,20337308,00.htm
>�V�R���p�C���̂������ŁA�T�[�o�\�t�g�E�F�A�̓o�[�W����3�̕����S�ʓI��25�`35�������ɓ��삵�A
>Java�v���O�����ł͂���Ȃ鍂��������������ƁAvan der Zweep���͌���Ă���B
Java�v���O�����ł͂���Ȃ鍂��������������
>http://iwatam-server.dyndns.org/software/devintro/deathmarch/deathmarch/x49.html
>>�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂����A�M�����͏\���Ɋ��Ԃ������ăe�X�g�����邱 �ƂŌ��炷���Ƃ��ł��܂��B
>>
>>�܂�A�\�t�g�Ƃ����͎̂��Ԃ��������������ł��ǂ��Ȃ�Ƃ������Ƃ� ���B
�u�@�\�̑����v�Ƃ����̂͗ʂ̖��ł��̂ŁA�J�����Ԃ���������� ��ł����₷���Ƃ��ł��܂�
>http://japan.zdnet.com/news/os/story/0,2000056192,20337308,00.htm
>�V�R���p�C���̂������ŁA�T�[�o�\�t�g�E�F�A�̓o�[�W����3�̕����S�ʓI��25�`35�������ɓ��삵�A
>Java�v���O�����ł͂���Ȃ鍂��������������ƁAvan der Zweep���͌���Ă���B
Java�v���O�����ł͂���Ȃ鍂��������������
>>855
�}�W���X����ƍ����̃R���p�C���̍œK���͂����܂�����
���n������
����̃}�C�i�[�ȃA�[�L�e�N�`���[�͂��̌���ł͂Ȃ��̂���
�}�W���X����ƍ����̃R���p�C���̍œK���͂����܂�����
���n������
����̃}�C�i�[�ȃA�[�L�e�N�`���[�͂��̌���ł͂Ȃ��̂���
�����������̂͂b�AC++,Fortran�̘b
Java�͐��\�I�ɂ܂����n���Č��_�H
�u�l�̐��\���c
Java�͐��\�I�ɂ܂����n���Č��_�H
�u�l�̐��\���c
>>856-857
zdnet�̋L�������ۓI�߂��ē˂������Ƃ͌����Ȃ��̂����c
�Ƃ肠�����A�R���p�C���ɐ��n�Ƃ��A�����Ȃ�Č��t�͂Ȃ��Ǝv��
SX�V���[�Y�݂����Ƀn�[�h�̎d�l��ڋq�̐��i�����������Ɍł߂Ă��܂��Θb�͕ʂ�������Ȃ�����
zdnet�̋L�������ۓI�߂��ē˂������Ƃ͌����Ȃ��̂����c
�Ƃ肠�����A�R���p�C���ɐ��n�Ƃ��A�����Ȃ�Č��t�͂Ȃ��Ǝv��
SX�V���[�Y�݂����Ƀn�[�h�̎d�l��ڋq�̐��i�����������Ɍł߂Ă��܂��Θb�͕ʂ�������Ȃ�����
����25�`35�����|���|�����\���オ��R���p�C�������݂�����
����͑O�̃o�[�W�������]���w�{��������
���邢�̓��g���b�N�����Č����Ă�́B
���̎�̃��g���b�N�퓅��i�Ȃ��炳
����͑O�̃o�[�W�������]���w�{��������
���邢�̓��g���b�N�����Č����Ă�́B
���̎�̃��g���b�N�퓅��i�Ȃ��炳
zdnet�̋L�������ۓI�߂��ē˂������Ƃ͌����Ȃ����Č����Ă邶���
�����Montecito��Madison�͂��Ȃ�ѐF������Ă��邵�A��������Č��ߕt����Ӗ����킩����
�����Montecito��Madison�͂��Ȃ�ѐF������Ă��邵�A��������Č��ߕt����Ӗ����킩����
���ǂ������Ɍ����邩��g���Ă݂���������������B
�����ƃg���b�N�̍����o�[�W�����Ȃ�
rhetoric
�y���z���g���b�N�A���t�����A���t�̂���A�����A�٘_�A�C���w�A�������A�֒�
�y���z���g���b�N�A���t�����A���t�̂���A�����A�٘_�A�C���w�A�������A�֒�
>>859�̕����ł����Ɓh�֒��h���ȁB
>>����͑O�̃o�[�W�������]���w�{��������
>>���邢�́h�֒��h�����Č����Ă�́B
>>���̎�́h�֒��h(��)�퓅��i�Ȃ��炳
>>����͑O�̃o�[�W�������]���w�{��������
>>���邢�́h�֒��h�����Č����Ă�́B
>>���̎�́h�֒��h(��)�퓅��i�Ȃ��炳
�}���p���[�₨�����̂悤�ɒ�������ō���Ă����R���p�C�����w�{�Ă��
���̐��ɂ܂Ƃ��ȃR���p�C���Ȃ�đ��݂��Ȃ����ƂɂȂ�Ȃ�
���̐��ɂ܂Ƃ��ȃR���p�C���Ȃ�đ��݂��Ȃ����ƂɂȂ�Ȃ�
�g���b�N�ƃ��g���b�N���ԈႤ�l������Ȃ�āB
�C���^�[�l�b�g�̎���ɂȂ��Ă��܂��܂����E�͍L���B
�v���Ԃ�Ɋ������܂�����B
�C���^�[�l�b�g�̎���ɂȂ��Ă��܂��܂����E�͍L���B
�v���Ԃ�Ɋ������܂�����B
�ǂ��ɊԈ�����l������H ���O������Ɋ��Ⴂ���Ă��邾���ł́H
>>855�̃T�C�g�̉���͖\�_�B
���̓n�[�h�������ǃ\�t�g�̊J�������č��x�ȗ��_���v������ċZ�p���Ƃ��Ĉꗬ�łȂ���ΐ������Ȃ��̈��
���݂��邾��B���x�̒Ⴂ�A�v���P�[�V�����̊J��������������ƂȂ�����Ȃ������̐l�c�B
�t�Ƀn�[�h��@�B�n�����Ď��Ԃ���������Α�T�̂��Ƃ͕��݂̋Z�p�҂ł��ł���B
���̓n�[�h�������ǃ\�t�g�̊J�������č��x�ȗ��_���v������ċZ�p���Ƃ��Ĉꗬ�łȂ���ΐ������Ȃ��̈��
���݂��邾��B���x�̒Ⴂ�A�v���P�[�V�����̊J��������������ƂȂ�����Ȃ������̐l�c�B
�t�Ƀn�[�h��@�B�n�����Ď��Ԃ���������Α�T�̂��Ƃ͕��݂̋Z�p�҂ł��ł���B
>>870
���݂��Ȃ��Ƃ͌����ĂȂ�����H
���ݍӂ��Ă����ƁA���̕���͔��ɋ������E�ł����Ȃ��œ_�����Ă�Ӗ��������ƌ����Ă�B
�����āA�����͊J������(�Ƃ͂����ꂩ��S�ĕ����܂��Ƃ����̂͏��O����Ă���Ǝv����)�Ɛ��\(���̏ꍇ�͏������x)�̈Ⴂ�ނ킯�����A
�������x�̑����͐i������n�[�h�ŋz�������וt�����l�ރP�[�X�͂����Ə��Ȃ��ƌ����Ă���B
��������Ǝc���ꂽ���̂͊J�����Ԃ̈Ⴂ�ł����Ȃ��B
�����܂ł͂��̃T�C�g�̘_�͐������B
���͂��̌ゾ�A�J�����Ԃ̈Ⴂ�͊J���R�X�g�̍��ƂȂ�͓̂�����O���B
�����āA���̃T�C�g�ł͔������J���R�X�g�ɂ�茈�肷�邩�̂悤�Ș_����������Ă��Č����ɑ����Ă��Ȃ��B
�������A�J���`�[�����ɋZ�p�̗D���݂��邩��J���R�X�g�͂��ꂼ��̃`�[���ňقȂ�B
�������A�����Ƃ������̂͋������ЂƂ̔�r�ɂ�錈�肳���̂���A�J���R�X�g�̑��ǂŌ��܂���̂���Ȃ��B
�������A���ς���̎w�W���Đl���P�����g�����A����͒P����1�l��������̐��Y�������ЂƂ̋����̒��Ő��܂ꂽ����̋����͂�L����l�ł����Ȃ��B
���̐��l�͊J���R�X�g�ƈ�v���Ȃ�����v����K�v���͂ǂ��ɂ��Ȃ��B
���݂��Ȃ��Ƃ͌����ĂȂ�����H
���ݍӂ��Ă����ƁA���̕���͔��ɋ������E�ł����Ȃ��œ_�����Ă�Ӗ��������ƌ����Ă�B
�����āA�����͊J������(�Ƃ͂����ꂩ��S�ĕ����܂��Ƃ����̂͏��O����Ă���Ǝv����)�Ɛ��\(���̏ꍇ�͏������x)�̈Ⴂ�ނ킯�����A
�������x�̑����͐i������n�[�h�ŋz�������וt�����l�ރP�[�X�͂����Ə��Ȃ��ƌ����Ă���B
��������Ǝc���ꂽ���̂͊J�����Ԃ̈Ⴂ�ł����Ȃ��B
�����܂ł͂��̃T�C�g�̘_�͐������B
���͂��̌ゾ�A�J�����Ԃ̈Ⴂ�͊J���R�X�g�̍��ƂȂ�͓̂�����O���B
�����āA���̃T�C�g�ł͔������J���R�X�g�ɂ�茈�肷�邩�̂悤�Ș_����������Ă��Č����ɑ����Ă��Ȃ��B
�������A�J���`�[�����ɋZ�p�̗D���݂��邩��J���R�X�g�͂��ꂼ��̃`�[���ňقȂ�B
�������A�����Ƃ������̂͋������ЂƂ̔�r�ɂ�錈�肳���̂���A�J���R�X�g�̑��ǂŌ��܂���̂���Ȃ��B
�������A���ς���̎w�W���Đl���P�����g�����A����͒P����1�l��������̐��Y�������ЂƂ̋����̒��Ő��܂ꂽ����̋����͂�L����l�ł����Ȃ��B
���̐��l�͊J���R�X�g�ƈ�v���Ȃ�����v����K�v���͂ǂ��ɂ��Ȃ��B
�Ă䂤���AEPIC �����̍œK�������ꂾ��������Ă��Ƃł���B
OoO �Ȃ�n�[�h�E�F�A���撣���Ă����̂ŁA�R���p�C�����w�{���Ă�
EPIC �قǂ͍����łȂ��B
> ����25�`35�����|���|�����\���オ��R���p�C�������݂�����
> ����͑O�̃o�[�W�������]���w�{��������
> ���邢�̓��g���b�N�����Č����Ă�́B
���������AOoO �� x86 �����̃R���p�C���ł����A���ꂭ�炢�̐��\����
������O�ɂ������肷�邼�B���Ƃ��A
ttp://www-bl20.spring8.or.jp/xct/soft/bench.html
�� Backprojection(SEC) �Ȃ�āAIntel C++ 6.0 ���� 7.0 �ŁA
21% ���サ�Ă���B(P4 1.7GHz, RedHat 7.1 �� 1-5.4/6.8=0.21)
OoO �Ȃ�n�[�h�E�F�A���撣���Ă����̂ŁA�R���p�C�����w�{���Ă�
EPIC �قǂ͍����łȂ��B
> ����25�`35�����|���|�����\���オ��R���p�C�������݂�����
> ����͑O�̃o�[�W�������]���w�{��������
> ���邢�̓��g���b�N�����Č����Ă�́B
���������AOoO �� x86 �����̃R���p�C���ł����A���ꂭ�炢�̐��\����
������O�ɂ������肷�邼�B���Ƃ��A
ttp://www-bl20.spring8.or.jp/xct/soft/bench.html
�� Backprojection(SEC) �Ȃ�āAIntel C++ 6.0 ���� 7.0 �ŁA
21% ���サ�Ă���B(P4 1.7GHz, RedHat 7.1 �� 1-5.4/6.8=0.21)
�����A�\�t�g�����J���������Ƃ̂Ȃ���̓n�[�h�v�Ȃǂ���Ȃ�����A
���������Ό����o�Ă���낤�ˁB
�n�[�h�v�����đ啔���́A�悭���镔�i��g�ݍ��킹����A����i�̃f�o�b�N�A�]����
�������Ƃ����t�����l�̐��ݏo���ɂ�����Ƃ�����Ȃ�B
�������A�g���Ă���̂�CAD�⌾��c�[���Ȃ̂ŁA�\�t�g�J���ƍ��͑卷�Ȃ���B
�\�t�g�Ƃ̈Ⴂ�͕��i�R�X�g���������邩���炢�̍��ق��������Ȃ��B
���������Ό����o�Ă���낤�ˁB
�n�[�h�v�����đ啔���́A�悭���镔�i��g�ݍ��킹����A����i�̃f�o�b�N�A�]����
�������Ƃ����t�����l�̐��ݏo���ɂ�����Ƃ�����Ȃ�B
�������A�g���Ă���̂�CAD�⌾��c�[���Ȃ̂ŁA�\�t�g�J���ƍ��͑卷�Ȃ���B
�\�t�g�Ƃ̈Ⴂ�͕��i�R�X�g���������邩���炢�̍��ق��������Ȃ��B
> �\�t�g�̊J�������č��x�ȗ��_���v������ċZ�p���Ƃ��Ĉꗬ�łȂ����
> �������Ȃ��̈�͑��݂��邾��B
����͑S�����������ǁAItanium �n�̃R���p�C������́A�R���p�C�����Ƃ��ẮA
���ꗬ����B������A>>855 �ւ̔��_�ɂ͂Ȃ��ĂȂ����A>>855 �̌����Ă邱��
�͊Ԉ���ĂȂ��B
Java �Ŏg���Ă� JIT �n�̋Z�p�A���ɓ��I�v���t�@�C�����g�����œK���́A�܂�
���W�r��Ȃ̂ŁA�܂��܂����\�͏オ��Ǝv���BEPIC �͍œK���̉e��������
�����ł�A�[�L�e�N�`�������B
> �������Ȃ��̈�͑��݂��邾��B
����͑S�����������ǁAItanium �n�̃R���p�C������́A�R���p�C�����Ƃ��ẮA
���ꗬ����B������A>>855 �ւ̔��_�ɂ͂Ȃ��ĂȂ����A>>855 �̌����Ă邱��
�͊Ԉ���ĂȂ��B
Java �Ŏg���Ă� JIT �n�̋Z�p�A���ɓ��I�v���t�@�C�����g�����œK���́A�܂�
���W�r��Ȃ̂ŁA�܂��܂����\�͏オ��Ǝv���BEPIC �͍œK���̉e��������
�����ł�A�[�L�e�N�`�������B
>>874
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
>>874
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
>>874
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����ƁA�R���p�C���̍œK���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
>>874
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����HT�ɍœK������ƁA�R���p�C���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����HT�ɍœK������ƁA�R���p�C���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
>>874
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͋����Ȃ���������ȁB
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����HT�ɍœK������ƁA�R���p�C���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͋����Ȃ���������ȁB
Montecito�́AHyperThreading�p�ɖ��߂��lj�����Ă��ˁB
��������܂����p����HT�ɍœK������ƁA�R���p�C���Ő��\�p�[�����肤��Ǝv���B
icc�̘b������HP�̂͂���ǁA���ł��v���t�F�b�`�p�X���b�h�����͂���Ă��邭�炢������ȁB
�܁A���̓����N��̓��e���C�ɂȂ���������Itanium�Ƃ�EPIC�̘b��ɂ͋C�ɂ��Ȃ��ĂȂ��ǂˁB
Montecito�ł́AHT�ƃ}���`�X���b�h�̂��߂̖��߂�������ƒlj����ꂽ����A
���܂��g���ΐ��\�p�[�����邩���Ǝv�������炢�Bicc�ł��}���`�X���b�h�̃v���t�F�b�`�Ƃ��ʼn҂��ł邩��ȁB
Montecito�ł́AHT�ƃ}���`�X���b�h�̂��߂̖��߂�������ƒlj����ꂽ����A
���܂��g���ΐ��\�p�[�����邩���Ǝv�������炢�Bicc�ł��}���`�X���b�h�̃v���t�F�b�`�Ƃ��ʼn҂��ł邩��ȁB
���͂������������N��̓��e���C�ɂȂ���������Itanium�Ƃ�EPIC�̘b��ɂ͑債�ċC�ɂ��Ȃ��ĂȂ���������B
Montecito�ł́AHT�ƃ}���`�X���b�h�̂��߂̖��߂�������ƒlj����ꂽ����A
���܂��g���ΐ��\�p�[�����邩���ƍ��L���ǂ�Ŏv�������炢�Bicc�ł��}���`�X���b�h�̃v���t�F�b�`�Ƃ��ʼn҂��ł邩��ȁB
Montecito�ł́AHT�ƃ}���`�X���b�h�̂��߂̖��߂�������ƒlj����ꂽ����A
���܂��g���ΐ��\�p�[�����邩���ƍ��L���ǂ�Ŏv�������炢�Bicc�ł��}���`�X���b�h�̃v���t�F�b�`�Ƃ��ʼn҂��ł邩��ȁB
���݂܂���B����Ă��܂��܂����B�폜�ȗ��o���Ă���B
��������
>Java �Ŏg���Ă� JIT �n�̋Z�p�A���ɓ��I�v���t�@�C�����g�����œK���́A�܂�
>���W�r��Ȃ̂ŁA�܂��܂����\�͏オ��Ǝv���B
BEA JRocket�͍ŋ߂̂�p���Ăő啝�ɐ��\�����サ�Ă邯�ǁA�O��ver���ւډ߂��������Ȃ̂ŖJ�߂Ă͂����܂���B
http://www.spec.org/jbb2005/results/res2006q4/jbb2005-20061107-00211.html
http://www.spec.org/jbb2005/results/res2006q4/jbb2005-20060929-00197.html
�ƃ^�C�����[�ɕ֏悵�Ă݂�B
>���W�r��Ȃ̂ŁA�܂��܂����\�͏オ��Ǝv���B
BEA JRocket�͍ŋ߂̂�p���Ăő啝�ɐ��\�����サ�Ă邯�ǁA�O��ver���ւډ߂��������Ȃ̂ŖJ�߂Ă͂����܂���B
http://www.spec.org/jbb2005/results/res2006q4/jbb2005-20061107-00211.html
http://www.spec.org/jbb2005/results/res2006q4/jbb2005-20060929-00197.html
�ƃ^�C�����[�ɕ֏悵�Ă݂�B
�Ȃɂ��̃o�O��������
�Ϲ�����炦�`
1.12 SEC, 7.1 SEC, pentium 4 2000, win 2k, Intel C++ 7.1, -O
1.12 SEC, 7.1 SEC, pentium 4 2000, win 2k, Intel C++ 7.1, -O
�� -O ����Ȃ��� -O3 ������ orz
������ -O3 �͉��Z�̗D�揇�ʂ����ĕ���ł邩�������������
������ -O3 �͉��Z�̗D�揇�ʂ����ĕ���ł邩�������������
>>886
http://www.physics.ohio-state.edu/doco/intel/compiler60/docs/C++ReleaseNotes.htm
http://www.physics.ohio-state.edu/doco/intel/compiler70/docs/C++ReleaseNotes.htm
>>855�̌����u�@�\�̑����v����
http://www.physics.ohio-state.edu/doco/intel/compiler60/docs/C++ReleaseNotes.htm
http://www.physics.ohio-state.edu/doco/intel/compiler70/docs/C++ReleaseNotes.htm
>>855�̌����u�@�\�̑����v����
-O3�͊W�Ȃ�����
6��SSE2�o��O��version
���Ă����I�`����Ȃ���ȁH
���Ă����I�`����Ȃ���ȁH
> ���̓����N��̓��e���C�ɂȂ��������ŁAEPIC�Ƃ�Itanium�̘b�ɂ͎Q�����ĂȂ��B
�����A�Ȃ�قǂ��������Ӗ����B
�m���ɉ��L�̕����͕ς��ȁB
>> �ł�����A�\�t�g�J���ł͔\�͂ɂ�鍷�ʉ������ɂ����̂ł��B�u�����
>> ���ɂ͂ł��Ȃ��v�Ƃ͌����܂���B�Ȃ��Ȃ玞�Ԃ���������ǂ�ȃ\�t�g
>> �ł��J���ł��邩��ł��B
�ꗬ�̐l�Ԃ�����Ă��r�I�`�������W���O�Ȏd���ɂ��ẮA�O���̐l�ނ���
���Ȃ��Ƃ��낾�ƁA�����玞�Ԃ������Ă������Ċ����ɂ����������Ȃ����낤�ˁB
�Ă䂤���A�\�t�g�̏ꍇ�A�O���`����ȉ��̂�����̃��x�����ꖳ��������Ȃ��B
�܂������Ă��̉�Ђ́A�ꗬ�`�̐l�ނ����̊����ł��āA�����ʼn���Ă�
���ǁB���܂ɎO���ȉ������A�T�C������Ȃ��v���W�F�N�g������ƁA�����
��ςȂ��ƂɁc
HP-UX�݂����ȁA���������g���Ă���ėpOS�����R���p�C���̏ꍇ�A�J���w��
�ꗬ�̐l�ނ����ȏア�邱�Ƃ́A�قڊm�肾���ǂˁB�����łȂ��ƃo�O�̊�����
�����āA��������OS�������Ȃ��̂ŁB
�g�ݍ��ݗp�r�̃}�C�i�[�ȃv���Z�b�T�����R���p�C�����ƁA���܁`�ɂƂ�ł��Ȃ�
�̂��������肷�邯�ǁB
�����A�Ȃ�قǂ��������Ӗ����B
�m���ɉ��L�̕����͕ς��ȁB
>> �ł�����A�\�t�g�J���ł͔\�͂ɂ�鍷�ʉ������ɂ����̂ł��B�u�����
>> ���ɂ͂ł��Ȃ��v�Ƃ͌����܂���B�Ȃ��Ȃ玞�Ԃ���������ǂ�ȃ\�t�g
>> �ł��J���ł��邩��ł��B
�ꗬ�̐l�Ԃ�����Ă��r�I�`�������W���O�Ȏd���ɂ��ẮA�O���̐l�ނ���
���Ȃ��Ƃ��낾�ƁA�����玞�Ԃ������Ă������Ċ����ɂ����������Ȃ����낤�ˁB
�Ă䂤���A�\�t�g�̏ꍇ�A�O���`����ȉ��̂�����̃��x�����ꖳ��������Ȃ��B
�܂������Ă��̉�Ђ́A�ꗬ�`�̐l�ނ����̊����ł��āA�����ʼn���Ă�
���ǁB���܂ɎO���ȉ������A�T�C������Ȃ��v���W�F�N�g������ƁA�����
��ςȂ��ƂɁc
HP-UX�݂����ȁA���������g���Ă���ėpOS�����R���p�C���̏ꍇ�A�J���w��
�ꗬ�̐l�ނ����ȏア�邱�Ƃ́A�قڊm�肾���ǂˁB�����łȂ��ƃo�O�̊�����
�����āA��������OS�������Ȃ��̂ŁB
�g�ݍ��ݗp�r�̃}�C�i�[�ȃv���Z�b�T�����R���p�C�����ƁA���܁`�ɂƂ�ł��Ȃ�
�̂��������肷�邯�ǁB
���X�Ԏw��ł��Ȃ��O���͏����Ăق����Ǝv���͉̂�������
>>893 ���Ԃւ̃��X�H
��낽��
897 �FID:KAOo9MV/�F2006/12/30(�y) 01:02:29 ID:MYjShne4
�@�@(�@_, ,_)�@�@�@�@�@�E�E�E�E�E
�Q(__��/�P�P�P/�Q�@
�@�@�_/�@�@�@�@/
�@�@�@�@�@�@�@�@ �^�_
�@�@�@ �@ �@ ..�^�@ .�^|
�@�@�@�@�@ ���_�^.�^
�@�@ �@ _, ,_߁� |�^
�@�@ (�߄D�)� �@�@�@
�@�@/�@�@/
�P�P�P�P�P�P
�Q(__��/�P�P�P/�Q�@
�@�@�_/�@�@�@�@/
�@�@�@�@�@�@�@�@ �^�_
�@�@�@ �@ �@ ..�^�@ .�^|
�@�@�@�@�@ ���_�^.�^
�@�@ �@ _, ,_߁� |�^
�@�@ (�߄D�)� �@�@�@
�@�@/�@�@/
�P�P�P�P�P�P
898 �F�G���ƌĂ�Ă��邪�F2006/12/30(�y) 18:36:31 ID:0PtbOpFF
���̓��e��>>871�����ł�
���ɔS�����X�g�[�J�[�����̐l�B���Ėϑz�Ȃ����邩��|����Ȃ��B
���ɔS�����X�g�[�J�[�����̐l�B���Ėϑz�Ȃ����邩��|����Ȃ��B
�����Ƃ����S�R�A�͂��H
Goto�AHKEPC�@���@Penryn quad�@native��
Inq�AVR�@�@�@ �@���@Penryn quad�@��native��
Inq�AVR�@�@�@ �@���@Penryn quad�@��native��
901 �FSocket774�F2006/12/30(�y) 20:58:31 ID:J4dpAmK8
HKEPC
http://www.hkepc.com/bbs/itnews.php?tid=675864&starttime=0&endtime=0
VR
http://www.vr-zone.com/?i=4109
VR�̍ŐV���[�h�}�b�v
http://sg.vr-zone.com/index.php?i=4309
http://www.hkepc.com/bbs/itnews.php?tid=675864&starttime=0&endtime=0
VR
http://www.vr-zone.com/?i=4109
VR�̍ŐV���[�h�}�b�v
http://sg.vr-zone.com/index.php?i=4309
�������̎��ɓ�����q���āA�d���݂���ˁH
903 �FSocket774�F2006/12/31(��) 01:04:54 ID:YYeHsa9D
�����ł��Ȃ�
Intel�͔{�R�A����i�K�N���b�N���Ƃ��ďo���Ă��邩��
�ǂ������ō����\���͗p�r�Ƃ��\�t�g�̐����ɂ��
�Ƃ���������͗]�T�����Woodcrest�o�����ɂ���Clovertown�̗\����������낤����
�ǂ����Ȃ�Woodcrest��3GHz�܂ň����ς�Ȃ�
�ǂ������ō����\���͗p�r�Ƃ��\�t�g�̐����ɂ��
�Ƃ���������͗]�T�����Woodcrest�o�����ɂ���Clovertown�̗\����������낤����
�ǂ����Ȃ�Woodcrest��3GHz�܂ň����ς�Ȃ�
906 �FSocket774�F2006/12/31(��) 16:27:27 ID:klk9asgB
>>905
���͂P�i���Ƃ��Ă邯�ǁAIntel���{�������Quad��ɂ���������
Dual�Ɠ��N���b�N�ŏo���悤�ɂȂ�B
����������Dual��Quad��荂�N���b�N�i���o����킯����������
Quad�̍ō��N���b�N��Dual��}�����ށBIntel�̂���܂ł̔̔��헪���炵��
�K����������B
���͂P�i���Ƃ��Ă邯�ǁAIntel���{�������Quad��ɂ���������
Dual�Ɠ��N���b�N�ŏo���悤�ɂȂ�B
����������Dual��Quad��荂�N���b�N�i���o����킯����������
Quad�̍ō��N���b�N��Dual��}�����ށBIntel�̂���܂ł̔̔��헪���炵��
�K����������B
�Q�[���̘b�����AR6 Vegas�ŁAdual core�Aquad core�ɑΉ����Ă��āA�V���O���ɔ�ׂđ啝��fps���オ��悤���B
�Q�[���ړI��quad core���Ӗ����o�Ă���̂ŁA���̃Q�[��������
�Q�[���ړI��quad core���Ӗ����o�Ă���̂ŁA���̃Q�[��������
908 �FSocket774�F2007/01/02(��) 12:40:36 ID:wNLLlAwp
�V�N����
909 �FSocket774�F2007/01/05(��) 23:41:04 ID:3Di8PjuN
http://www.hkepc.com/bbs/itnews.php?tid=723070&starttime=0&endtime=0
Wolfdale��end of this year
Wolfdale��end of this year
The 45nm Core 2 Duo, codenamed Wolfdale, is releasing in the end of this year,
however, though it should be more power save, Intel decided to keep its TDP also at 65W.
Such decision is made between a balance of performance and market value.
It is stating that 65W TDP is already low enough for mainstream market,
a lower TDP couldn�ft give more significant effect to the market. Besides,
combining the advantages of 45nm manufacturing process and a acceptable TDP level,
it helps to increase the yield for high clock speed product on the mean while lowering the cost.
wolfdale��conroe�����ȓd�͂ɂȂ邪TDP��65W�ɐ����u���B�i���̂Ԃ�N���b�N���グ�ăL���b�V���𑝂₷�j
For the quad-core Intel Core 2 Quad Q6600 releasing in Jan 7, its TDP is 105W.
Thus, a motherboard has to support FMB 05B power consumption specification to support this model.
However, Desktop Quad-Core products would stepped into G Stepping some time in Q2 and Q3,
and supports 05A FMB power consumption specification at 95W TDP. Starting from G Stepping,
all Quad Core except Extreme edition would set at 95W TDP including the existing Kentsfield and upcoming 45nm Yorkfield.
07Q3�ȍ~��G�X�e�b�s���O��Kentsfield��45nm��Yorkfield��ExtremeEditon�ȊO��TDP95W
however, though it should be more power save, Intel decided to keep its TDP also at 65W.
Such decision is made between a balance of performance and market value.
It is stating that 65W TDP is already low enough for mainstream market,
a lower TDP couldn�ft give more significant effect to the market. Besides,
combining the advantages of 45nm manufacturing process and a acceptable TDP level,
it helps to increase the yield for high clock speed product on the mean while lowering the cost.
wolfdale��conroe�����ȓd�͂ɂȂ邪TDP��65W�ɐ����u���B�i���̂Ԃ�N���b�N���グ�ăL���b�V���𑝂₷�j
For the quad-core Intel Core 2 Quad Q6600 releasing in Jan 7, its TDP is 105W.
Thus, a motherboard has to support FMB 05B power consumption specification to support this model.
However, Desktop Quad-Core products would stepped into G Stepping some time in Q2 and Q3,
and supports 05A FMB power consumption specification at 95W TDP. Starting from G Stepping,
all Quad Core except Extreme edition would set at 95W TDP including the existing Kentsfield and upcoming 45nm Yorkfield.
07Q3�ȍ~��G�X�e�b�s���O��Kentsfield��45nm��Yorkfield��ExtremeEditon�ȊO��TDP95W
yorkfield�͕����ɂ͎����͖�������ĂȂ������[�h�}�b�v�̐}���画�f�����
Q3���O���������ʒu�ɂȂ��Ă��̂�9�����H
Q3���O���������ʒu�ɂȂ��Ă��̂�9�����H
��������̑O�ɔ�ׂ�CPU�̈Ⴂ��������ɂ����Ȃ����ȁB
�w���c�\�L�̕����ǂ�������BPEN4����M���D���A�����HT�L���Ƃ��B
���N���삩�痣��Ă�ƒ��ׂ�̂���ς��B
�w���c�\�L�̕����ǂ�������BPEN4����M���D���A�����HT�L���Ƃ��B
���N���삩�痣��Ă�ƒ��ׂ�̂���ς��B
>>912
����netburst��core�����݂���ߓn��������킩��ɂ�����
core�n��������N���b�N�E�R�A���E�L���b�V���̍������B
�R�A�������ʂ�Dual�����l�����������ȒP����BQuad�n��Dual�n�Ń��f���i���o�[��
�����ƃN���b�N�̑Ή�������������킩��₷�����B
core2/Quad(4MB)�c�cQX6700,Q6600
core2/Dual(4MB)�c�cX6800,E6700,E6600,E6420,E6320
core2/Dual(2MB)�c�cE6400,E6300,E4400,E4300
����netburst��core�����݂���ߓn��������킩��ɂ�����
core�n��������N���b�N�E�R�A���E�L���b�V���̍������B
�R�A�������ʂ�Dual�����l�����������ȒP����BQuad�n��Dual�n�Ń��f���i���o�[��
�����ƃN���b�N�̑Ή�������������킩��₷�����B
core2/Quad(4MB)�c�cQX6700,Q6600
core2/Dual(4MB)�c�cX6800,E6700,E6600,E6420,E6320
core2/Dual(2MB)�c�cE6400,E6300,E4400,E4300
Pen4/D�̃��f��No��������ԕ�����ɂ����č��������B
>>910��Ă���A���ƒ����B
�i�~�jwolfdale��conroe�����ȓd�͂ɂȂ邪TDP��65W�ɐ����u��
��wolfdale��TDP��65W�ɐ����u���B
�i45nm�ɂȂ��ďȓd�͉��ł����������}�[�P�e�B���O��̗��R��
����ȏ㉺���Ă��C���p�N�g�������̂�
TDP�����u���ŃN���b�N�A�b�v������]�T������̂�TDP��65W�̂܂܁j
�i�~�jwolfdale��conroe�����ȓd�͂ɂȂ邪TDP��65W�ɐ����u��
��wolfdale��TDP��65W�ɐ����u���B
�i45nm�ɂȂ��ďȓd�͉��ł����������}�[�P�e�B���O��̗��R��
����ȏ㉺���Ă��C���p�N�g�������̂�
TDP�����u���ŃN���b�N�A�b�v������]�T������̂�TDP��65W�̂܂܁j
���N�܂ł̋ꋫ�����������̂��Ǝv����قǂ̏���������w
���ԂBIntel�̊J�����D���Ȃ�Ȃ���AMD���ǂڂɂ͂܂��Ă邾���Ȃ�B
�����Ƃ������A�����Ƃ������B
core2�ւ̈ڍs���S�R�i��łȂ��ȁ[
core2�ւ̈ڍs���S�R�i��łȂ��ȁ[
core2�ւ̈ڍs�͂��܂����ĂȂ��قǏ����ɐi��ł邪���������Ă����
P4�n�̓C���e�����������Ǝ~�߂������낤�����
�������ƃZ�������̍ŗ�����core�ɂ��Ă��炢��������
����������ɂ͂����Ă���
�������ƃZ�������̍ŗ�����core�ɂ��Ă��炢��������
����������ɂ͂����Ă���
922 �FSocket774�F2007/01/06(�y) 22:05:39 ID:tahSwHZm
>>921
http://www.hkepc.com/bbs/news.php?tid=723002&starttime=0&endtime=0
TDP 35W�ɂȂ�炵��>Celeron(CoreMA)
http://www.hkepc.com/bbs/news.php?tid=723002&starttime=0&endtime=0
TDP 35W�ɂȂ�炵��>Celeron(CoreMA)
�����v���Z�X�Ȃ�netburst�n���core2�̕����_�C�T�C�Y���������ł��Đ��\�͏オ�����ȁB
netburst�̐V���f���Ȃ�čɏ���������C���̌������p�ł����Ȃ����āB
netburst�̐V���f���Ȃ�čɏ���������C���̌������p�ł����Ȃ����āB
924 �FSocket774�F2007/01/07(��) 00:24:06 ID:qHFSFzsi
>>913
����₷�����H
Quad��QX��Q�Ȃ�Dual��DX��DE�ADual��X��E�Ȃ�Quad��DX��DE�ɂȂ�Ǝv���B
����Ƀf���I�Ƃ��\���Ƃ������O�ŃR�A����\���Ă���Ȃ�Q�Ƃ����v��Ȃ��Ǝv���B
4MB��2MB�̖����Ƃ��N���b�N���̖���������ɂ����B
����₷�����H
Quad��QX��Q�Ȃ�Dual��DX��DE�ADual��X��E�Ȃ�Quad��DX��DE�ɂȂ�Ǝv���B
����Ƀf���I�Ƃ��\���Ƃ������O�ŃR�A����\���Ă���Ȃ�Q�Ƃ����v��Ȃ��Ǝv���B
4MB��2MB�̖����Ƃ��N���b�N���̖���������ɂ����B
E��X��TDP�̖ڈ��Ȃ���ACore2DuoX6800�����TDP�̂�ɁA
QX6700��Q6600������̂́A�ʂɕςł��Ȃ����낤�B
�����AQ�Ȃ�Ă���܂������ĂȂ������@��������ANehalem�ł܂��d�蒼���������B
QX6700��Q6600������̂́A�ʂɕςł��Ȃ����낤�B
�����AQ�Ȃ�Ă���܂������ĂȂ������@��������ANehalem�ł܂��d�蒼���������B
����ς�N���b�N�\�L��������ȁ[
���ꂾ�A�Ԃ݂����ɃN���b�N�̓p���[�ɑ�������Ƃ���
�g���N�\�L�݂����Ȃ̂�\�����������
�Ⴆ�E�E�E��
�g���N�\�L�݂����Ȃ̂�\�����������
�Ⴆ�E�E�E��
�ő�̗��R��Pentium4 3.8GHz��Pentium D 3.2GHz���낤
930 �FSocket774�F2007/01/07(��) 01:12:01 ID:JJld/f14
�������̂��ƃx���`�}�[�N�̃X�R�A�ɂ��Ă݂Ă͂ǂ����낤
931 �FSocket774�F2007/01/07(��) 01:15:29 ID:L9h3H/iG
���������L���b�V���Ȃ�Ȃ���
�S���ꎟ�L���b�V���ɂ����
���̕�������
�S���ꎟ�L���b�V���ɂ����
���̕�������
932 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/07(��) 01:22:58 ID:Pk14geMm
���C�e���V���i����
AMD�����������̂́A�ǂ������Ă�intel�̃N���b�N�\�L��ڈ��Ƃ������������������
Model Number���͕̂ʂɈ����A�C�f�B�A�ł͂Ȃ��Ǝv���B
�^��AMD�~�قǔے肷�邯�ǂ��B
AMD�̒��̐l�����ė�����Ƃ��}�W�Ŏv���Ă˂��ׁB
Model Number���͕̂ʂɈ����A�C�f�B�A�ł͂Ȃ��Ǝv���B
�^��AMD�~�قǔے肷�邯�ǂ��B
AMD�̒��̐l�����ė�����Ƃ��}�W�Ŏv���Ă˂��ׁB
934 �FSocket774�F2007/01/07(��) 01:40:58 ID:L9h3H/iG
�ǂ̓��C���e���̃��f���i���o�[�̖��������̓E���R����
�����I�ȈႢ��\���\�L�@+�@���\��\���\�L�@�ɂ���Ηǂ��̂�
�����I�ȈႢ��\���\�L�@+�@���\��\���\�L�@�ɂ���Ηǂ��̂�
935 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/07(��) 01:45:02 ID:Pk14geMm
ZGMF-�w�Ȃ�� �Ƃ�����Ă�����
�g�����W�X�^���F�N���b�N
�́H
�́H
937 �FSocket774�F2007/01/07(��) 02:20:17 ID:L9h3H/iG
���̖����������Ⴀ�A�A�[�L�e�N�`�����ς��x�ɁA
��CPU�̂ǂ̃��f���ƐVCPU�̂ǂ̃��f���łǂ������ォ������Ȃ��Ȃ��
�������ē��ꐢ�㓯�m�ł���A���o�C���p�̃v���Z�b�T�̕��ɂ͍������l�g���Ă邾��
�����Ԃ�3�i���o�[��5�i���o�[�̍����炢�ɂ����l���Ė�����
�܂��O���[�h���������āA���̃O���[�h���ŏ����Ă邾��
�����烂�f���i���o�[�̍��͐��\����\�������̂ł���Ȃ�
�������C���e����ܻނƂ���Ȑ^������Ă�
P4�ŃN���b�N�����\������߶���ނ�@����Ĕ��Ȃ����U������Ȃ���A
���͂܂��ϼ������l���Ă�
���߂�����pen3��1GHz�̐��\��1000�Ƃł����āA�������Ƀ��f���i���o�[�U��Ηǂ���
���ꂪP4�̔��蕶��Ō�����������f���U�炩���Ă����C���e�����A
����҂ɑ��Ď��ׂ��Œ���x�̌����ȑԓx���Ă���
��CPU�̂ǂ̃��f���ƐVCPU�̂ǂ̃��f���łǂ������ォ������Ȃ��Ȃ��
�������ē��ꐢ�㓯�m�ł���A���o�C���p�̃v���Z�b�T�̕��ɂ͍������l�g���Ă邾��
�����Ԃ�3�i���o�[��5�i���o�[�̍����炢�ɂ����l���Ė�����
�܂��O���[�h���������āA���̃O���[�h���ŏ����Ă邾��
�����烂�f���i���o�[�̍��͐��\����\�������̂ł���Ȃ�
�������C���e����ܻނƂ���Ȑ^������Ă�
P4�ŃN���b�N�����\������߶���ނ�@����Ĕ��Ȃ����U������Ȃ���A
���͂܂��ϼ������l���Ă�
���߂�����pen3��1GHz�̐��\��1000�Ƃł����āA�������Ƀ��f���i���o�[�U��Ηǂ���
���ꂪP4�̔��蕶��Ō�����������f���U�炩���Ă����C���e�����A
����҂ɑ��Ď��ׂ��Œ���x�̌����ȑԓx���Ă���
intel�̓s���ɂ�閽���ɑΉ�����ȗ��ȕ\���ꖇ�����
�ςނƎv����
�ςނƎv����
���\ + �t�����l = MN �Ȃ���Merom��Montecito�̂��ꂪ�傫���Ȃ�͕̂���
���\�ł�������Ȃ��l��Intel�̃v���b�g�t�H�[���헪�𗝉����Ă��Ȃ�
���\�ł�������Ȃ��l��Intel�̃v���b�g�t�H�[���헪�𗝉����Ă��Ȃ�
4800+�Ƃ�5200+�Ƃ��A���͂≽����̐��l�Ȃ̂��S���Ӗ��s����
���r���[�ȃ��f���i���o�[�ɂȂ��肩�͂܂�����
���r���[�ȃ��f���i���o�[�ɂȂ��肩�͂܂�����
>>930
���܂�AMD�����̕��������BQuad/Dual�A�L���b�V��4MB/2MB�Ŏ��N���b�N��
���f���i���o�[�̊W���������Ă킯�킩��Ȃ��Ȃ邼�B
AMD��Quad�����Ɠ����ɂ��܂̃��f���i���o�[�̌n�͂�߂邻�����B�܂����R���ȁB
���܂�AMD�����̕��������BQuad/Dual�A�L���b�V��4MB/2MB�Ŏ��N���b�N��
���f���i���o�[�̊W���������Ă킯�킩��Ȃ��Ȃ邼�B
AMD��Quad�����Ɠ����ɂ��܂̃��f���i���o�[�̌n�͂�߂邻�����B�܂����R���ȁB
�������܂����_���G���̖@��
>>937
�N���b�N�������Ńv���Z�T�̐��\��\���͖̂��������f���i���o�[�����Ńv���Z�T�̐��\��\���͖̂���
�N���b�N�������Ńv���Z�T�̐��\��\���͖̂��������f���i���o�[�����Ńv���Z�T�̐��\��\���͖̂���
�N�ɂł�������₷�����O�t���邵���Ȃ���Ȃ��H
�u2ch�ƃG���Q�������Ȃ����^�N����CPU 2007�v�Ƃ��uOffice�����g��Ȃ��̂�Vista���� 2007�v�Ƃ�
�u2ch�ƃG���Q�������Ȃ����^�N����CPU 2007�v�Ƃ��uOffice�����g��Ȃ��̂�Vista���� 2007�v�Ƃ�
>>938
���݂�core2�f�X�N�g�b�v�̖������[��
���̉p���P�`�Q����
QX:Quad(Extreme)
Q:Quad(Extreme�ȊO)
X:Dual(Extreme)
E:Dual/Single(Extreme�ȊO)
��̌�
6:Extreme/Mainstream
4:Middle
1:Value
�S�̌�
���N���b�N�̑��Βl����������
����
00:�Ő攭�i
20:00�̂��̂��Q���L���b�V�����傫��
50:00�̂��̂��FSB������
�c�c�������łɊȗ��ƌ����������B
���݂�core2�f�X�N�g�b�v�̖������[��
���̉p���P�`�Q����
QX:Quad(Extreme)
Q:Quad(Extreme�ȊO)
X:Dual(Extreme)
E:Dual/Single(Extreme�ȊO)
��̌�
6:Extreme/Mainstream
4:Middle
1:Value
�S�̌�
���N���b�N�̑��Βl����������
����
00:�Ő攭�i
20:00�̂��̂��Q���L���b�V�����傫��
50:00�̂��̂��FSB������
�c�c�������łɊȗ��ƌ����������B
����
Core 2 �l�d�t
Core 2 ���m���o
Xeon ���A��
�������߉�2
��܌��f 4
��܌��f ���o����
������������
Core 2 �l�d�t
Core 2 ���m���o
Xeon ���A��
�������߉�2
��܌��f 4
��܌��f ���o����
������������
����ɃL���b�V���e�ʂ�FSB�܂Ń��f���i���o�[�ɓ��ꂿ�Ⴄ����킯�킩��Ȃ��Ȃ�ȁB
���[�J�[��PC�̃��[�U�[�w�����ɂ͎��N���b�N�ɑΔ䂷�鐔���ƃR�A�������������u�i���v
�����ł����B
����w�ɂ͎��N���b�N�A�L���b�V���e�ʁAFSB�L���Ĕ�������B
���[�J�[��PC�̃��[�U�[�w�����ɂ͎��N���b�N�ɑΔ䂷�鐔���ƃR�A�������������u�i���v
�����ł����B
����w�ɂ͎��N���b�N�A�L���b�V���e�ʁAFSB�L���Ĕ�������B
Core 2 Duo 1.66GHz/1.8GHz/1.83GHz/2GHz/2.13GHz/2.16GHz/2.2GHz/2.33GHz/2.4GHz/2.66GHz/2.93GHz/3GHz
0.5�{���݂ŁA����ɃN���b�N���オ�����艺�������肷��ƁA�����Ƒ������
0.5�{���݂ŁA����ɃN���b�N���オ�����艺�������肷��ƁA�����Ƒ������
�ǂ��ł��������A����1.86GHz�Y��Ă�
1.83-2.4GHz�͖�킩��Ȃ��Ȃ�
1.83-2.4GHz�͖�킩��Ȃ��Ȃ�
>>937
���[�J�[�����ӓI�Ȑ�����t���Ă悱�����
����N���b�N�ƃL���b�V���e�ʂ������������ƕ\�L����
���Ƃ͎g���z���D���ɔ��f����A�ł�����ˁ@�{���́B
���[�J�[�����ӓI�Ȑ�����t���Ă悱�����
����N���b�N�ƃL���b�V���e�ʂ������������ƕ\�L����
���Ƃ͎g���z���D���ɔ��f����A�ł�����ˁ@�{���́B
intel�̓��f���i���o�[�̉��ɃN���b�N�ƃL���b�V���e�ʂ��킩��₷���\�L���Ă��邪�A
ttp://www.watch.impress.co.jp/akiba/hotline/20060729/image/ncex2.jpg
AMD���ă��f���i���o�[�����ŁA�N���b�N���L���b�V�����B�����Ă�̂Ȃ�
���ʂƂ��ɋC�t����Ȃ��悤�ɂ������菑���Ă�����H
ttp://www.watch.impress.co.jp/akiba/hotline/20061028/image/ioa64x24.jpg
ttp://www.watch.impress.co.jp/akiba/hotline/20060729/image/ncex2.jpg
{kind=link}
AMD���ă��f���i���o�[�����ŁA�N���b�N���L���b�V�����B�����Ă�̂Ȃ�
���ʂƂ��ɋC�t����Ȃ��悤�ɂ������菑���Ă�����H
ttp://www.watch.impress.co.jp/akiba/hotline/20061028/image/ioa64x24.jpg
{kind=link}
952 �FSocket774�F2007/01/07(��) 17:13:37 ID:t9fCDfjh
Q6600�̔����͂��H
5�M�K���炢�ɂȂ����甃����
>>950
Netburst�����S�ɏ�����������A������������ɂȂ邩���ȁB
Netburst�����S�ɏ�����������A������������ɂȂ邩���ȁB
>>952
����
����
956 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/07(��) 21:48:33 ID:Pk14geMm
>>950
���ɃA�|�[�����[����Ă�
���ɃA�|�[�����[����Ă�
>>951
>intel�̓��f���i���o�[�̉��ɃN���b�N�ƃL���b�V���e�ʂ�
>�킩��₷���\�L���Ă��邪�A
�����̃��f���i���o�[�́A�������낻��K�v��������
�Ƃ����b�����Ă���B
�N���b�N�ƃL���b�V���e�ʂ����Ȃ�
�����Ƃ킩��₷���\�L�ɂȂ�Ǝv��H
45nm�v���Z�X�������ɗ����オ������
����Ȃ�����͖����Ȃ�Ƃ͎v�����B
>intel�̓��f���i���o�[�̉��ɃN���b�N�ƃL���b�V���e�ʂ�
>�킩��₷���\�L���Ă��邪�A
�����̃��f���i���o�[�́A�������낻��K�v��������
�Ƃ����b�����Ă���B
�N���b�N�ƃL���b�V���e�ʂ����Ȃ�
�����Ƃ킩��₷���\�L�ɂȂ�Ǝv��H
45nm�v���Z�X�������ɗ����オ������
����Ȃ�����͖����Ȃ�Ƃ͎v�����B
���f���i���o�[�Ȃ�Ă����̏��i�����Ǝv����
�ʂɂ����Ă��ז��ɂ͂Ȃ��
�ʂɂ����Ă��ז��ɂ͂Ȃ��
959 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/07(��) 23:21:35 ID:Pk14geMm
���f���i���o�[��AMD�́A�[�����͖S��Cyrix�̂��o�������K��
�ǂ����ɂ��Ă��A�^�ԁi���i���j�����ŏ��i�����Ă�z�Ȃ�Ă��Ȃ�������B
�ʂ�CPU�Ɍ��炸�A���ׂĂ̏��i�ł����鎖�����E�E�E
���ʁA�����̔������i�̃X�y�b�N(���e�j���炢���ׂĔ���������B
���[�J����PC�ɂ������āA�^�Ԃ��������ڂ��ĂȂ��Ȃ�Ď��͂Ȃ��Ǝv�����ǁB
�ʂ�CPU�Ɍ��炸�A���ׂĂ̏��i�ł����鎖�����E�E�E
���ʁA�����̔������i�̃X�y�b�N(���e�j���炢���ׂĔ���������B
���[�J����PC�ɂ������āA�^�Ԃ��������ڂ��ĂȂ��Ȃ�Ď��͂Ȃ��Ǝv�����ǁB
961 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/07(��) 23:25:53 ID:Pk14geMm
AMD���痦�悵��GHz�\�L�ɖ߂�
����}�j�A�ȊO��2���L���b�V���A�N���b�N���g���܂Ń`�F�b�N���Ă�͂����������
�Ƃ������L���b�V���Ƃ������t����m��Ȃ��B
�������f�J�����ǂ��Ǝv���Ă��
��ŁA���������A����PC�l���̒��ň�ԑ���
�Ƃ������L���b�V���Ƃ������t����m��Ȃ��B
�������f�J�����ǂ��Ǝv���Ă��
��ŁA���������A����PC�l���̒��ň�ԑ���
�܂��A���ʂ̐l�́A�ǂ��̃��[�J�[�ŁA�ǂ�Ȏ����o���āA��炩�A���炢�����C�ɂ��Ȃ����낤��
���f���i���o�[�͎���er�ɂƂ��Ă͕�����ɂ����Ăǂ��ł��������낤���ǁA��ʐl�ɂƂ��Ă͈ꉞ�w�W�ɂ͂Ȃ邩�炠���Ă������Ǝv�����ǂȁB
���g����L���b�V���A�A�[�L�e�N�`���܂Ń`�F�b�N���Ă�͎̂���er���炢�Ȃ��̂���Ȃ��̂��B
���g����L���b�V���A�A�[�L�e�N�`���܂Ń`�F�b�N���Ă�͎̂���er���炢�Ȃ��̂���Ȃ��̂��B
>>960
���[�J�[�T�C�g�ł����N���b�N�͂������Q���L���b�V���e�ʂ�FSB�̓X�y�b�N�\�ɍڂ��Ă��B
���
http://www.fmworld.net/product/hard/pcpm0608/deskpower/ek/method/index.html
���[�J�[�T�C�g�ł����N���b�N�͂������Q���L���b�V���e�ʂ�FSB�̓X�y�b�N�\�ɍڂ��Ă��B
���
http://www.fmworld.net/product/hard/pcpm0608/deskpower/ek/method/index.html
�v���Ԃ�ɒc�q���������ł��̎��̎ʐ^�v���o���Đ�����������
967 �F�E�́E�j��-�������n���̃_���S���I�� ��DanGorION6 �F2007/01/08(��) 00:25:03 ID:UK32QivF
�Ă��ǂ��̃��[�J�[�ł����������\�L���Ă�����Ă�
VALUESTAR S���Ĕp�~�ɂȂ��ĂȂ������ȁB��Yonah�R�A���B
http://121ware.com/product/pc/0609/valuestar/vss/spec/index.html
VALUESTAR S���Ĕp�~�ɂȂ��ĂȂ������ȁB��Yonah�R�A���B
http://121ware.com/product/pc/0609/valuestar/vss/spec/index.html
��ʐl�́ACPU�̂��ƂȂ�ċC�ɂ��Ă�̂��Ȃ��B
�V���b�v�̓X�������ǁA����Ⴀ�C�ɂ����
����
CPU�E�������EHDD�Ewindows
����4���ڂ��炢���ˁA���Ƃ��܂�VGA�̐��\�Ƃ��C�ɂ���l�����邭�炢
NEC�ƕx�m�ʂ�P4/D���f�����l�C�������āAC2D���f���͂����[���甄��Ȃ���
����
CPU�E�������EHDD�Ewindows
����4���ڂ��炢���ˁA���Ƃ��܂�VGA�̐��\�Ƃ��C�ɂ���l�����邭�炢
NEC�ƕx�m�ʂ�P4/D���f�����l�C�������āAC2D���f���͂����[���甄��Ȃ���
�ȃX�y�[�X�̃J�R�C�C�f�U�C���i➑́j �� ��������������
��
���o�C���v���b�g�t�H�[��
��
Yonah�@�� �ł��邾���P�`��
��
���o�C���v���b�g�t�H�[��
��
Yonah�@�� �ł��邾���P�`��
�P�`��Ƃ��������M�����Ȃ�����ł́H
Conroe�̏ȓd�͔ł܂��o�ĂȂ�����B
Conroe�̏ȓd�͔ł܂��o�ĂȂ�����B
Conroe-L(Single,TDP35W)���o���炱�̂�����̏ȃX�y�[�X�f�X�N�g�b�v��
Celeron-M��u��������낤�ˁB
Celeron-M��u��������낤�ˁB
>>972
prescott�Ɣ�ׂ�A65W��merom�͖��̂悤�Ȓᔭ�M�v���Z�b�T�����ǁB
prescott�Ɣ�ׂ�A65W��merom�͖��̂悤�Ȓᔭ�M�v���Z�b�T�����ǁB
���i�Z����PenD���Ăǂ����̕��������\���낤
����ς�N���b�N�����{�ȏ゠��PenD��?
����ς�N���b�N�����{�ȏ゠��PenD��?
>>975
���i�Z����2GHz�܂ł���B2GHz�łȂ�3.4GHz�Ɠ����ȏザ��Ȃ����ˁB�������Pentium4�ˁAD����Ȃ���
�f�X�N�g�b�v�̘b�ɂȂ邪�A
Pentium E���V���O���R�A�Œ�N���b�N��������AConroe�x�[�X��Celeron�ł̓l�g�oCeleron D 3.6GHz�ɂ͏��ĂȂ������낤
���i�Z����2GHz�܂ł���B2GHz�łȂ�3.4GHz�Ɠ����ȏザ��Ȃ����ˁB�������Pentium4�ˁAD����Ȃ���
�f�X�N�g�b�v�̘b�ɂȂ邪�A
Pentium E���V���O���R�A�Œ�N���b�N��������AConroe�x�[�X��Celeron�ł̓l�g�oCeleron D 3.6GHz�ɂ͏��ĂȂ������낤
�]�T�ŏ��Ă�B2�R�A�����B
Pentium E��Conroe�x�[�X��Celeron�ł͂Ȃ��B
Conroe�x�[�X��Celeron��Conroe-L�A�V���O���B
Conroe�x�[�X��Celeron��Conroe-L�A�V���O���B
>>978
����APentium E1000�V���[�Y�̂܂܂�������A�����������Celeron 400�͂���ɐ��\�����Ńl�g�o�ƕς��Ȃ����낤�A���Ęb��
������Pentium E1000�V���[�Y��1.4/1.6/18GHz,FSB800,�L���b�V��1MB�̃V���O���R�A���������
Celeron 400��FSB533,�L���b�V��512KB�ŁAPentium�̉��ƂȂ�ƃN���b�N�͍ō��ł�1.6GHz���x���낤
>>976��
Conroe-L 1.6GHz�i���j/533/0.5MB��Celeron D 3.6GHz�ɏ��Ă邩�H
�Ƃ����Ӗ��B
���̌v��ł�Pentium���f���A���R�A�i�N���b�N������j�ɂȂ�����������Celeron��FSB800�ɕ��サ�ĉ��Ƃ��Ȃ��
����APentium E1000�V���[�Y�̂܂܂�������A�����������Celeron 400�͂���ɐ��\�����Ńl�g�o�ƕς��Ȃ����낤�A���Ęb��
������Pentium E1000�V���[�Y��1.4/1.6/18GHz,FSB800,�L���b�V��1MB�̃V���O���R�A���������
Celeron 400��FSB533,�L���b�V��512KB�ŁAPentium�̉��ƂȂ�ƃN���b�N�͍ō��ł�1.6GHz���x���낤
>>976��
Conroe-L 1.6GHz�i���j/533/0.5MB��Celeron D 3.6GHz�ɏ��Ă邩�H
�Ƃ����Ӗ��B
���̌v��ł�Pentium���f���A���R�A�i�N���b�N������j�ɂȂ�����������Celeron��FSB800�ɕ��サ�ĉ��Ƃ��Ȃ��
�Ə����Ă݂����A���Ă邩������Ȃ��B
���A��ΐ��\�ł͕ς���ȁB
Athlon64 3200+���x���̐��\��ۂ������Ă�Sempron�⌻�sCeleron D�Ɠ�����
�l�i�����łɉ������Ă邵
���A��ΐ��\�ł͕ς���ȁB
Athlon64 3200+���x���̐��\��ۂ������Ă�Sempron�⌻�sCeleron D�Ɠ�����
�l�i�����łɉ������Ă邵
>>979
PentiumE�̓f���A���AConroe-L�̓V���O���B
Celeron�̐��i���炵�ăN���b�N�����͍���2G���炢�܂Ń��C���i�b�v���Ă�
�s�v�c�͂Ȃ����B
PentiumE�̓f���A���AConroe-L�̓V���O���B
Celeron�̐��i���炵�ăN���b�N�����͍���2G���炢�܂Ń��C���i�b�v���Ă�
�s�v�c�͂Ȃ����B
>>981
>PentiumE�̓f���A���AConroe-L�̓V���O���B
>>979�ł��\�L�������ǁA
Pentium E1000�i�v�悳��Ă������_�ł̃��f���i���o�[�j���V���O���APentium E2000���f���A����
>PentiumE�̓f���A���AConroe-L�̓V���O���B
>>979�ł��\�L�������ǁA
Pentium E1000�i�v�悳��Ă������_�ł̃��f���i���o�[�j���V���O���APentium E2000���f���A����
Celeron 400����ƂĂ��Ȃ��I�[�o�[�N���b�N�����I�I�[�����o�Ă��
������Ă���������300@450�̍ė�����ˁH
������Ă���������300@450�̍ė�����ˁH
>>979
���܂ʁA�����Ɠǂ�łȂ������B
���܂ʁA�����Ɠǂ�łȂ������B
>>983
���傹��V���O�������Ȃ��B����3G�܂�OC�ł����Ƃ��Ă��t�[���ŏI��肶��Ȃ��́B
E4300�������OC������������������B
���傹��V���O�������Ȃ��B����3G�܂�OC�ł����Ƃ��Ă��t�[���ŏI��肶��Ȃ��́B
E4300�������OC������������������B
3G��������Ӂ[��ŏI��肩������Ȃ���4G��p�o�����疳���o���Ȃ����݂ɂȂ�Ǝv����
�V���O���X���b�h�A�v���ɂ͑O�҂�������
�Q���L���b�V���e�ʂ��S�{�Ⴄ����V���O���X���b�h�A�v���ł����܂�ς���
COOL�ȕ����g��
MICRO39 - ���\�_���Ɍ���Intel�̌�������
ttp://journal.mycom.co.jp/articles/2007/01/08/micro2/
ttp://journal.mycom.co.jp/articles/2007/01/08/micro2/
>>969
Core2������������sage�Ƃ��ǂ����Ō����悤�Ȋ�K�X
Core2������������sage�Ƃ��ǂ����Ō����悤�Ȋ�K�X
^
^
t
t
p
^
1000 �F���q�D�q ��en0rG2J.f6 �F2007/01/09(��) 06:59:27 ID:15uE3gtc
1000�Ȃ�W���[�X�ł����ނ�
1001 �F�P�O�O�P�F
1��̃}�V�����g�ݏオ��܂����B�B�B
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/
�V����➑̂�p�ӂ��Ă��������ł��B�B�B�B
�@�@�@�@�@�@�@�@�@����PC��2ch http://pc7.2ch.net/jisaku/