x86�̎�����CPU�ɂ��đ����I�Ɍ�낤
1 �FSocket774�F
x86�̎�����CPU�ɂ��đ����I�Ɍ�낤�B
�W�X��
Intel�̎�����CPU�ɂ��Č�낤 21
http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
AMD�̎�����CPU�ɂ��Č�낤 �Q������
http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
�W�X��
Intel�̎�����CPU�ɂ��Č�낤 21
http://pc7.2ch.net/test/read.cgi/jisaku/1136822334/
AMD�̎�����CPU�ɂ��Č�낤 �Q������
http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/
|
|
|
>>1
�ǂ��l�����Ǝv����ŁC�撣���ė~�������B
�ǂ��l�����Ǝv����ŁC�撣���ė~�������B
>>1
�X�����ĉ��Ȃ̂ŁC�撣���ė~�������B
�X�����ĉ��Ȃ̂ŁC�撣���ė~�������B
4 �FSocket774�F2006/02/05(��) 16:53:51 ID:So5PVPgs
�����X�^�[�̃r�����E�h���E�S������ɕ����Ă݂��炢���Ǝv���܂�
�ECPU Power Consumption (Burn)
ttp://www.xbitlabs.com/images/cpu/athlon64-fx60/cons.png
110.4W : Athlon64 FX-60�@(2.6GHz dual, L2 1MB�~2, 90nm) TDP 110W
ttp://www.xbitlabs.com/images/cpu/pentiumm-780/charts/cons-1.png
27.0W : Pentium M 780 (2.26GHz, L2 2MB, 90nm) TDP : 27W
ttp://www.xbitlabs.com/images/cpu/athlon64-fx60/cons.png
{kind=link}
110.4W : Athlon64 FX-60�@(2.6GHz dual, L2 1MB�~2, 90nm) TDP 110W
ttp://www.xbitlabs.com/images/cpu/pentiumm-780/charts/cons-1.png
{kind=link}
27.0W : Pentium M 780 (2.26GHz, L2 2MB, 90nm) TDP : 27W
������̘b������肢���܂��B
7 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 17:24:31 ID:R0hFAHW0
�������������ŃC�C�ł����H
�ix86���߃f�R�[�h�ɑΉ������j��OPs�����s����RISC�v���Z�b�T�ɂ��đ����I�Ɍ�낤
9 �FSocket774�F2006/02/05(��) 19:41:43 ID:OzYcyiNu
>>8
���̃�OPs�ڎ��s�ł���Ȃ�RISC�ƔF�߂Ă���Ă��������ǂˁB
���̃�OPs�ڎ��s�ł���Ȃ�RISC�ƔF�߂Ă���Ă��������ǂˁB
Transmeta�͊��S�ɏI����Ă��܂����̂��낤���B
13 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 19:53:24 ID:R0hFAHW0
>>9
Pentium 4���āA�����g���[�X�L���b�V���ɒ��ڃ�OP�]�������ł���A���ڎ��s�ł���������ˁH
Pentium 4���āA�����g���[�X�L���b�V���ɒ��ڃ�OP�]�������ł���A���ڎ��s�ł���������ˁH
�����IPC
http://www.ne.jp/asahi/comp/tarusan/main81.htm
���N���b�N����x86���߂̕���
http://www.ne.jp/asahi/comp/tarusan/main89.htm
CMS�R����atom��x86�R����atom�̕��s����
http://www.ne.jp/asahi/comp/tarusan/main101.htm
x86���߂̕��𐔂Ǝ��s���j�b�g�̔䗦
http://www.ne.jp/asahi/comp/tarusan/main105.htm
CPU�̃��X�g��
http://www.ne.jp/asahi/comp/tarusan/main113.htm
ILP���x���ƃf�R�[�_�[�̃o�����X���
http://www.ne.jp/asahi/comp/tarusan/main124.htm
http://www.ne.jp/asahi/comp/tarusan/main81.htm
���N���b�N����x86���߂̕���
http://www.ne.jp/asahi/comp/tarusan/main89.htm
CMS�R����atom��x86�R����atom�̕��s����
http://www.ne.jp/asahi/comp/tarusan/main101.htm
x86���߂̕��𐔂Ǝ��s���j�b�g�̔䗦
http://www.ne.jp/asahi/comp/tarusan/main105.htm
CPU�̃��X�g��
http://www.ne.jp/asahi/comp/tarusan/main113.htm
ILP���x���ƃf�R�[�_�[�̃o�����X���
http://www.ne.jp/asahi/comp/tarusan/main124.htm
�܂肱�̃X�������ꂾ��A
�C���e���Ƃ`�l�c�̋c�_���Ă��ꂾ��
ttp://www.uploda.org/uporg305087.mp3.html
���[�[�[�[�[�[���Ƃ��̋c�_����Ă邾���݂����Ȃ�
�C���e���Ƃ`�l�c�̋c�_���Ă��ꂾ��
ttp://www.uploda.org/uporg305087.mp3.html
���[�[�[�[�[�[���Ƃ��̋c�_����Ă邾���݂����Ȃ�
�딚����Ȃ�
>>17
�Ⴄ�Ǝv���B
x86�nCPU�̍ő�̃E���́A�ߋ��̃\�t�g���Y���������邱�ƁB
�������Ȃ�čŏ�����킩���Ă邱�Ƃ����ǁA���ꂾ���͊O���Ȃ��B
�܂��A���Ƀ�OP�������Ƃ��Ă�NetBurst�ł��������Ȃ��R�[�h�ɉ��̈Ӗ�������H
�t�Ɏ�����CPU�ł�����悤�ɂł����Ƃ��Ă��A���ꂪ�V���ȑ������ɂȂ邾���B
�Ⴄ�Ǝv���B
x86�nCPU�̍ő�̃E���́A�ߋ��̃\�t�g���Y���������邱�ƁB
�������Ȃ�čŏ�����킩���Ă邱�Ƃ����ǁA���ꂾ���͊O���Ȃ��B
�܂��A���Ƀ�OP�������Ƃ��Ă�NetBurst�ł��������Ȃ��R�[�h�ɉ��̈Ӗ�������H
�t�Ɏ�����CPU�ł�����悤�ɂł����Ƃ��Ă��A���ꂪ�V���ȑ������ɂȂ邾���B
19 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 00:15:39 ID:WwONqoe8
Pentium III�܂ł̍œK����@�{����Pentium M�x�[�X�̃A�[�L�e�N�`�����c�������Ƃ�
Pentium 4�̍œK���m�E�n�E�i�lj����߂͂Ƃ������j���Č��ǖ��ʂɂȂ����Ǝv���B
Pentium 4�̍œK���m�E�n�E�i�lj����߂͂Ƃ������j���Č��ǖ��ʂɂȂ����Ǝv���B
�ǂ�����merom�̃A�[�L�e�N�`���͂܂������J�B
Merom�\�z�̓r���o��
http://www.ne.jp/asahi/comp/tarusan/main122.htm
http://www.ne.jp/asahi/comp/tarusan/main122.htm
���̌l�̃T�C�g���ĂɂȂ��
>>19
���������AX11�̘b�͔@���������H���Ȃ����H
���������AX11�̘b�͔@���������H���Ȃ����H
24 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 02:18:13 ID:WwONqoe8
���ɂ܂Ƃ��t�����Ƃ��������������H
�O�X���̖��ߊ������܂����B
AMD�̎�����CPU�ɂ��Č�낤 �Q������
http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/1000
1000 ���O�FSocket774[] ���e���F2006/02/06(��) 08:50:19 ID:s6E10/wH
1000�Ȃ甐���F�b�ƃZ�b�N�X�ł���B
1000�Ȃ狣�j�����p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ烁�C�h����̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�鏑�X�[�c�p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�u���}�[�p�̍��̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�X�N�[�������p�̍��̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�t��̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�o�j�[�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�n�C���O���I�^�[�h�p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�DOA�̃e�B�i�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�~�X�A�����J�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�Z�[�����̃R�X�v�����������̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ炯���������ʂ̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�~�j�X�J�|���X�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�X�`�����[�f�X�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�L���e�B�[�n�j�[�̃R�X�v�����������̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ烂���K���̃R�X�v�������������F�b���A�i���Z�b�N�X�����Ă����B
1000�Ȃ�s�m�Ε��̃R�X�v�������������F�b�����̓����M��Ȃ���t�F�����Ă����B
1000�Ȃ�Z�[���[��m�̃R�X�v������ʂ肵�������F�b���f�B�[�v�L�X�����Ȃ����R�L���Ă����B
1000�Ȃ�R�M�����p�̔����F�b�����̃A�i�����r�߁A������h�����Ȃ��烍�[�V�����t���Ŏ�R�L���Ă����B
1000�Ȃ�U�k�@�����̑���f�q�̃R�X�v�������������F�b�������������Ȃ��牴�̑O�Ńo�C�u�I�i�j�[���Ă����B
1000�Ȃ瓧�������s�b�`���������u���E�X�Ƀ^�C�g�~�j�̏����t���b�N�̔����F�b���������S���ː������Ă����B
1000�Ȃ甐���F�b���������Ă��Ă���āA�l�Z�����A����ȃZ�b�N�X�ʼn��l�Ɍ��d���Ă����B
�����ĉ��l�̈�`�q�Ŕ����F�b���s��ł����I
AMD�̎�����CPU�ɂ��Č�낤 �Q������
http://pc7.2ch.net/test/read.cgi/jisaku/1133374045/1000
1000 ���O�FSocket774[] ���e���F2006/02/06(��) 08:50:19 ID:s6E10/wH
1000�Ȃ甐���F�b�ƃZ�b�N�X�ł���B
1000�Ȃ狣�j�����p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ烁�C�h����̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�鏑�X�[�c�p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�u���}�[�p�̍��̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�X�N�[�������p�̍��̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�t��̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�o�j�[�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�n�C���O���I�^�[�h�p�̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�DOA�̃e�B�i�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�~�X�A�����J�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�Z�[�����̃R�X�v�����������̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ炯���������ʂ̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�~�j�X�J�|���X�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�X�`�����[�f�X�̃R�X�v�������������F�b�ƃZ�b�N�X�ł���B
1000�Ȃ�L���e�B�[�n�j�[�̃R�X�v�����������̔����F�b�ƃZ�b�N�X�ł���B
1000�Ȃ烂���K���̃R�X�v�������������F�b���A�i���Z�b�N�X�����Ă����B
1000�Ȃ�s�m�Ε��̃R�X�v�������������F�b�����̓����M��Ȃ���t�F�����Ă����B
1000�Ȃ�Z�[���[��m�̃R�X�v������ʂ肵�������F�b���f�B�[�v�L�X�����Ȃ����R�L���Ă����B
1000�Ȃ�R�M�����p�̔����F�b�����̃A�i�����r�߁A������h�����Ȃ��烍�[�V�����t���Ŏ�R�L���Ă����B
1000�Ȃ�U�k�@�����̑���f�q�̃R�X�v�������������F�b�������������Ȃ��牴�̑O�Ńo�C�u�I�i�j�[���Ă����B
1000�Ȃ瓧�������s�b�`���������u���E�X�Ƀ^�C�g�~�j�̏����t���b�N�̔����F�b���������S���ː������Ă����B
1000�Ȃ甐���F�b���������Ă��Ă���āA�l�Z�����A����ȃZ�b�N�X�ʼn��l�Ɍ��d���Ă����B
�����ĉ��l�̈�`�q�Ŕ����F�b���s��ł����I
�g����g�����W�X�^������������A�܂���x87��SSE���Z���j�b�g�̋������낤��
����SSE���j�b�g�́AIntel��AMD��64�r�b�g���������Z�ł��Ȃ��s���S�ȃ��m����
Merom/Conroe��128�r�b�g����C�ɉ��Z���镂�������_SSE���Z���j�b�g�������ăz���g�H
����SSE���j�b�g�́AIntel��AMD��64�r�b�g���������Z�ł��Ȃ��s���S�ȃ��m����
Merom/Conroe��128�r�b�g����C�ɉ��Z���镂�������_SSE���Z���j�b�g�������ăz���g�H
x87�Ɋւ��Ă͂�����̂Ă���
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/dwamd_Porting_Win_DD_to_AMD64_Sept24.pdf
��Microsoft Windows for AMD64 will not context switch x87, 3DNow!, MMX for 64-bit native threads
http://www.amd.com/us-en/assets/content_type/DownloadableAssets/dwamd_Porting_Win_DD_to_AMD64_Sept24.pdf
��Microsoft Windows for AMD64 will not context switch x87, 3DNow!, MMX for 64-bit native threads
64�r�b�gOS��32-bit�X���b�h�ł�x87��3DNow!���T�|�[�g���邯�ǁA64-bit�X���b�h�ł͂��Ȃ����낤�B
64�r�b�g�ւ̈ڐA���l�����x87��3DNow!���g���̂�߂�SSE��SSE2�����ŏ����Ƃ��Ƃ�����B
���Ď�|�̂��Ƃ��AAMD�̍œK���K�C�h�ɂ������Ă������B�X�}�\�B
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
64�r�b�g�ւ̈ڐA���l�����x87��3DNow!���g���̂�߂�SSE��SSE2�����ŏ����Ƃ��Ƃ�����B
���Ď�|�̂��Ƃ��AAMD�̍œK���K�C�h�ɂ������Ă������B�X�}�\�B
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
30 �FSocket774�F2006/02/06(��) 19:37:05 ID:Neiwo04r
��䍂����H
31 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 23:36:18 ID:WwONqoe8
�����ɂ�80bit(1bit+15bit+64bit)���x��������������s����x64�ł�x87�͗��p�\�������肷��B
�ł�x87/MMX�̐؎̂Ă��������Ȃ���SIMD���j�b�g��128bit����XMM���W�X�^�łS�{���x���������̎���
�Ƃ�������ɂ��܂ł����Ȃ��W�����}�B
128�~1���64�~2�̂ق������������ł�����̂��������ˁB�R���������Ɨ����悩�{���悩�̘b�ɂȂ��Ă��܂����ǁB
SSE�����A��128bit������A�V�t�g���Z�␅�����Z����ł��������ƃ��b�`�Ȗ��߂̎�����
�\�ɂȂ�Ǝv���̂ł��BAltiVec��vperm�̈ڐA�͖������낤���ǂˁB
�����ɂ�64bit�̈ڍs������������A�uMMX�g�������Z�������ɓ����������v���Ď��v���k�����Ă��������
128bit�~1�ɂ悤�₭�Ȃ邩�ƁB
�������u128bit�~2��MMX(3DNOW!)���p���͉��ʂ̂݃}�X�N����64bit�~2�Ƃ��ė��p�v�Ƃ���
�H���ɂȂ�\��������B
�������A�����܂ł���SIMD����������́A���j�B�R�A�̂��߂�x86��ISA����������Ȃ����b�`��
SIMD��p�R�A�̕W������i�߂�̂ł́A�Ƃ����\�z���ł���B
�ł�x87/MMX�̐؎̂Ă��������Ȃ���SIMD���j�b�g��128bit����XMM���W�X�^�łS�{���x���������̎���
�Ƃ�������ɂ��܂ł����Ȃ��W�����}�B
128�~1���64�~2�̂ق������������ł�����̂��������ˁB�R���������Ɨ����悩�{���悩�̘b�ɂȂ��Ă��܂����ǁB
SSE�����A��128bit������A�V�t�g���Z�␅�����Z����ł��������ƃ��b�`�Ȗ��߂̎�����
�\�ɂȂ�Ǝv���̂ł��BAltiVec��vperm�̈ڐA�͖������낤���ǂˁB
�����ɂ�64bit�̈ڍs������������A�uMMX�g�������Z�������ɓ����������v���Ď��v���k�����Ă��������
128bit�~1�ɂ悤�₭�Ȃ邩�ƁB
�������u128bit�~2��MMX(3DNOW!)���p���͉��ʂ̂݃}�X�N����64bit�~2�Ƃ��ė��p�v�Ƃ���
�H���ɂȂ�\��������B
�������A�����܂ł���SIMD����������́A���j�B�R�A�̂��߂�x86��ISA����������Ȃ����b�`��
SIMD��p�R�A�̕W������i�߂�̂ł́A�Ƃ����\�z���ł���B
32 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 23:38:21 ID:WwONqoe8
�����ƁA���b�`�ȃR�A�̓w�e���Ɍ����Ȃ��ȁB
�R�I�y�����h�Ń��W�X�^�����A�C���I�[�_�Ƃ���Cell��SPE�I�Ȃ��̂�\�z���Ă���B
�R�I�y�����h�Ń��W�X�^�����A�C���I�[�_�Ƃ���Cell��SPE�I�Ȃ��̂�\�z���Ă���B
���Ljꎞ�̃N���b�N�����ł�����10GHz�ɂ����B���邼�A���Ă��������
���S�ɂȂ��Ȃ����̂��ȁH
���S�ɂȂ��Ȃ����̂��ȁH
>>31
���A��128bit���������ǁA64bit*2�Ƃ�����ŗ����Ȃ����ȁB
128bit�ɂ���ƍ��Â炢�悤�Ɏv�����ASSE�͖��ߑ̌n���̂�64bit�L�����邩��B
���A��128bit���������ǁA64bit*2�Ƃ�����ŗ����Ȃ����ȁB
128bit�ɂ���ƍ��Â炢�悤�Ɏv�����ASSE�͖��ߑ̌n���̂�64bit�L�����邩��B
�X�J���{���x�ƃp�b�N�h�{���x�̖��߂��������C�e���V�ɂȂ�����
����������������v���O�����������Ȃ��H
K10�ł�SSE���Z���j�b�g��128�r�b�g���̉\������݂�������
����������������v���O�����������Ȃ��H
K10�ł�SSE���Z���j�b�g��128�r�b�g���̉\������݂�������
37 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/08(��) 00:38:19 ID:o61rCDDP
>>35
4�{���x��128bit���K�{���ƁB
�p�b�N�h��������ѕ������������ǁA64�~2�Ŏ������Ă邢�܂̕������ƁA
�iYonah�݂����ȏ�肢���@���g���Ă�Ȃ�Ƃ������j�f�R�[�_�̕��S���傫����ɁA
���ߑш��2�{�����̂ŒP���Ƀ��j�b�g�����ɂ��X���[�v�b�g�̌��オ�}��ɂ����̂ł́B
�������Z�Ɋւ��Ă�64bit���쎞�̔ėpALU��SIMD�������j�b�g�Ƃ̃X���[�v�b�g���t�]���Ă���
�ςĂ��Ă��Ă��H���Ȃ����ƁB
�������8bit, 16bit, 32bit�P�ʂ̃p�b�N�h���Z���ł���ɂ���A����܂�ėp�I�Ɏg�������̂���Ȃ��B
������128bit��������Ƃ��P����Ȃ��Ƃ��\���Ӗ��͂���B
3issue�ōő�128+64+64=256bit�������������_��\�ɁB
4�{���x��128bit���K�{���ƁB
�p�b�N�h��������ѕ������������ǁA64�~2�Ŏ������Ă邢�܂̕������ƁA
�iYonah�݂����ȏ�肢���@���g���Ă�Ȃ�Ƃ������j�f�R�[�_�̕��S���傫����ɁA
���ߑш��2�{�����̂ŒP���Ƀ��j�b�g�����ɂ��X���[�v�b�g�̌��オ�}��ɂ����̂ł́B
�������Z�Ɋւ��Ă�64bit���쎞�̔ėpALU��SIMD�������j�b�g�Ƃ̃X���[�v�b�g���t�]���Ă���
�ςĂ��Ă��Ă��H���Ȃ����ƁB
�������8bit, 16bit, 32bit�P�ʂ̃p�b�N�h���Z���ł���ɂ���A����܂�ėp�I�Ɏg�������̂���Ȃ��B
������128bit��������Ƃ��P����Ȃ��Ƃ��\���Ӗ��͂���B
3issue�ōő�128+64+64=256bit�������������_��\�ɁB
�˂��A�Ȃ�Ń��i�@�̓p�C�Ă��������́H
�ڂ����l�����[��
�ڂ����l�����[��
���i�[���āA�p�C�Ă��������i�[�B
�p�C�Y�����������Ȃ��B
>>38
L2�L���b�V���̗e�ʂ�2MB�����炾�Ƒ��X���Ō����Ă��B
2MB����ƁA�p�C�̏ꍇ�̓q�b�g�����ɒ[�ɗǂ��Ȃ邻�����B
�c�Ƃ������Ƃ́A�_�u���p�C����Yonah�ł��x���̂��ȁH
L2�L���b�V���̗e�ʂ�2MB�����炾�Ƒ��X���Ō����Ă��B
2MB����ƁA�p�C�̏ꍇ�̓q�b�g�����ɒ[�ɗǂ��Ȃ邻�����B
�c�Ƃ������Ƃ́A�_�u���p�C����Yonah�ł��x���̂��ȁH
>>41
�ꉞ�⑫�B
Yonah��L2�L���b�V����2�R�A���L��2MB�B
�V���O������2MB���قڃt���Ɏg���邪�A
�_�u�����Ɩ��ɂȂ�͂��Ƃ����b�B
PentiumD��Athlon64X2��L2�L���b�V�����Ɨ��Ȃ̂ŁA
�_�u���ł����܂萫�\�͕ς��Ȃ��B
�ꉞ�⑫�B
Yonah��L2�L���b�V����2�R�A���L��2MB�B
�V���O������2MB���قڃt���Ɏg���邪�A
�_�u�����Ɩ��ɂȂ�͂��Ƃ����b�B
PentiumD��Athlon64X2��L2�L���b�V�����Ɨ��Ȃ̂ŁA
�_�u���ł����܂萫�\�͕ς��Ȃ��B
Yonah�ł̓V���O�����_�u�����x���̂͂��̒ʂ肾���A
��ʓI�ȃN���C�A���gPC�ł͂��̂悤�Ȑ����̕����I�m�B
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
PentiumD��Athlon64X2��L2�L���b�V�����Ɨ���1MB�~2�B
�_�u������2MB���t���Ɏg���邪�A
�V���O�����Ɣ����i1�R�A���j�����g���Ȃ��B
Yonah�ł�L2�L���b�V�������L�Ȃ̂ŁA
�V���O���ł��_�u���ł�2MB��L2��
�t���Ɏg�����p�t�H�[�}���X�邱�Ƃ��ł���B
��ʓI�ȃN���C�A���gPC�ł͂��̂悤�Ȑ����̕����I�m�B
�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|�|
PentiumD��Athlon64X2��L2�L���b�V�����Ɨ���1MB�~2�B
�_�u������2MB���t���Ɏg���邪�A
�V���O�����Ɣ����i1�R�A���j�����g���Ȃ��B
Yonah�ł�L2�L���b�V�������L�Ȃ̂ŁA
�V���O���ł��_�u���ł�2MB��L2��
�t���Ɏg�����p�t�H�[�}���X�邱�Ƃ��ł���B
>>41
���̐������ƁAPentiumM��葬�����R�ɂȂ��ĂȂ��B
L2�L���b�V���̗e�ʂ������Ń��C�e���V��Yonah�̕��������B
����Yonah�������̂�L2�ш�̌���̂������Ǝv���B
>>37
�S�{���x���Ė{���ɂ������������̂��H
����ɁAMerom����op�t���[�W��������������Ă��邩��
���ߑш�̕��ׂ͏������͂��B
���A��128bit���Z������̂͑�ς��Ǝv�����ǂȂ��B
���̐������ƁAPentiumM��葬�����R�ɂȂ��ĂȂ��B
L2�L���b�V���̗e�ʂ������Ń��C�e���V��Yonah�̕��������B
����Yonah�������̂�L2�ш�̌���̂������Ǝv���B
>>37
�S�{���x���Ė{���ɂ������������̂��H
����ɁAMerom����op�t���[�W��������������Ă��邩��
���ߑш�̕��ׂ͏������͂��B
���A��128bit���Z������̂͑�ς��Ǝv�����ǂȂ��B
PenD��Pen4��2M�L���b�V�������ȁ[
Merom�̓�OP���t���[�W�����ł��������AAMD�̏ꍇ�̓A�[�L�����{����Đv����K�v�����邩��ȁB
128bit���̂ق����e�Ղ��낤�B
32bit�A�v���P�[�V�����̑��������̓��A��128bit���͓�����ȋC���X�B
128bit���̂ق����e�Ղ��낤�B
32bit�A�v���P�[�V�����̑��������̓��A��128bit���͓�����ȋC���X�B
>>46
32bit�A�v���P�[�V�����Ƃ͊W�Ȃ�����c
32bit�A�v���P�[�V�����Ƃ͊W�Ȃ�����c
32bit��MMX�֎~�Ƃ�����ĂȂ�����ȁB
����SIMD�I�ȃR�[�h�������ĂȂ��Ƃ����Ȃ����W�X�^���҂����߂�MMX���g���Ă������Ȃ��Ȃ��B
64bit�����Z���T�|�[�g���Ă邩��ȈՓI�ɂ�64bit�������W�X�^�Ƃ��Ă��g����B
�����128bit������MMX�͉��ʂ��}�X�N���ė��p�Ƃ������ƂɂȂ�Ɠ��R�Ȃ���MMX���\�͔����ɗ�����B
����SIMD�I�ȃR�[�h�������ĂȂ��Ƃ����Ȃ����W�X�^���҂����߂�MMX���g���Ă������Ȃ��Ȃ��B
64bit�����Z���T�|�[�g���Ă邩��ȈՓI�ɂ�64bit�������W�X�^�Ƃ��Ă��g����B
�����128bit������MMX�͉��ʂ��}�X�N���ė��p�Ƃ������ƂɂȂ�Ɠ��R�Ȃ���MMX���\�͔����ɗ�����B
Merom��64bitALU��4�ڂ��Ă���Ƃ����b������A
SSE�����Ɋւ��Ă�64bit*4�i128bit����2��1clk���s�j�Ƃ��ł���̂����B
SSE�����Ɋւ��Ă�64bit*4�i128bit����2��1clk���s�j�Ƃ��ł���̂����B
Athlon63��63bit�̎�����
�����[�c�{�ɃL�^��
63bit CPU��
63bit CPU��
>>48
���Z���j�b�g128�r�b�g���Ő��\�������闝�R���܂��悭������Ȃ��̂ł���
���������Č��ݏ��64�r�b�g�Ɖ���64�r�b�g�͈ˑ������I�ɏ�������Ă���̂ł��傤���H
>>49
����SIMD��FP���Z���j�b�g�ł���Ă�MMX/SSE���Z��ALU�ɂ�点����Ă��ƁH
����͂Ȃ��̂ł�
���Z���j�b�g128�r�b�g���Ő��\�������闝�R���܂��悭������Ȃ��̂ł���
���������Č��ݏ��64�r�b�g�Ɖ���64�r�b�g�͈ˑ������I�ɏ�������Ă���̂ł��傤���H
>>49
����SIMD��FP���Z���j�b�g�ł���Ă�MMX/SSE���Z��ALU�ɂ�点����Ă��ƁH
����͂Ȃ��̂ł�
>>52
2���64bitSIMD���j�b�g��128bit�~1��ɂ��Ă��܂��ƁA�u2��SIMD���Z���j�b�g�v�Ƃ��Ă͎g���Ȃ��Ȃ邶���B
2��64bit SIMD���j�b�g�Ŗ������1��128bit SIMD���j�b�g���G�~�����[�g���Ă�̂����̏�ԁB
�iPentium4�͐�����64bit��2��ʂ��A����������128bit�Ŕ��������������ȁH�悭����ˁj
Intel�̓�OPs Fusion�Ŏb�������悤�����AAMD�Ȃł�65nm�ł̓f���A���R�A���k������̂�
����t���낤����A128bit SIMD���j�b�g�~2�͓�����ɂȂ��łˁH
2���64bitSIMD���j�b�g��128bit�~1��ɂ��Ă��܂��ƁA�u2��SIMD���Z���j�b�g�v�Ƃ��Ă͎g���Ȃ��Ȃ邶���B
2��64bit SIMD���j�b�g�Ŗ������1��128bit SIMD���j�b�g���G�~�����[�g���Ă�̂����̏�ԁB
�iPentium4�͐�����64bit��2��ʂ��A����������128bit�Ŕ��������������ȁH�悭����ˁj
Intel�̓�OPs Fusion�Ŏb�������悤�����AAMD�Ȃł�65nm�ł̓f���A���R�A���k������̂�
����t���낤����A128bit SIMD���j�b�g�~2�͓�����ɂȂ��łˁH
Intel Core with Altivec
����ʼn���
����ʼn���
���߃Z�b�g���Ⴂ�������ŋ����s�\�B
�������j�B�R�A����������ۂ�SIMD��p�R�A�Ƃ��Ď�������̂������H�����ȁi�܂��SPE���j
�������j�B�R�A����������ۂ�SIMD��p�R�A�Ƃ��Ď�������̂������H�����ȁi�܂��SPE���j
>>53
����x86CPU�ɂ͓����������ł���SIMD���Z���j�b�g��2����̂ł����H
���Ȃ��Ƃ�Pen4��Ath64�ł͊e��FP/SIMD���j�b�g��������Ǝv���Ă܂���
����x86CPU�ɂ͓����������ł���SIMD���Z���j�b�g��2����̂ł����H
���Ȃ��Ƃ�Pen4��Ath64�ł͊e��FP/SIMD���j�b�g��������Ǝv���Ă܂���
ALU�Ɛ���SIMD�̎��s���j�b�g�����ʂɂ���ɂ�
���W�X�^�t�@�C���̖�肪����
���W�X�^�t�@�C���̖�肪����
>>57
MMX�p�b�N�h�������j�b�g��2��A���[�h�E�X�g�A��Pen4��128bit�Ŗ������ʁX�Ȃ̈ȊO��
��T�̎����͑o����64bit�~2��B���A�A�[�L�e�N�`���}�j���A������B
MMX�p�b�N�h�������j�b�g��2��A���[�h�E�X�g�A��Pen4��128bit�Ŗ������ʁX�Ȃ̈ȊO��
��T�̎����͑o����64bit�~2��B���A�A�[�L�e�N�`���}�j���A������B
PentiumM�ł́AALU*2�ASSE����64bit*2�AFP_ADD*1�AFP_MUL*1�ɂȂ��Ă�B
�ŁAALU��SSE������FP�́A���s�|�[�g�����L���Ă���B
ALU��SSE���������Z���W�b�N�����L���Ă��邩�ǂ����͒m��Ȃ����A
Merom��ALU*4�ƕ����ƁA�P���ɂ�����{�ɂ����Ƃ��l������B
���̏ꍇSSE������64bit*4�ɂȂ�B
���ۂǂ����낤�ˁB�{���ɔ{�ɂȂ��ĂĂ��ꂽ����������ǁB
�ŁAALU��SSE������FP�́A���s�|�[�g�����L���Ă���B
ALU��SSE���������Z���W�b�N�����L���Ă��邩�ǂ����͒m��Ȃ����A
Merom��ALU*4�ƕ����ƁA�P���ɂ�����{�ɂ����Ƃ��l������B
���̏ꍇSSE������64bit*4�ɂȂ�B
���ۂǂ����낤�ˁB�{���ɔ{�ɂȂ��ĂĂ��ꂽ����������ǁB
>>59
�u��̊��S��FP/SSE���s���j�b�g�̑���ɁAFP/SSE moves��FP/SSE store��
�f�[�^�v���~�e�B���ɍs���P���ȓ�Ԗڂ̃|�[�g�ŃR�X�g�E�p�t�H�[�}���X���œK�������v
�Ƃ����Ӗ��̓��e��10�y�[�W�ɂ���܂��B���������Ď��A���̂��������Ⴂ���Ă܂��H
ttp://download.intel.com/technology/itj/q12001/pdf/art_2.pdf
>>60
Pentium �V�ł�ALU��SSE�����͕ʂ̎��s���j�b�g�������Ǝv���܂�
Pentium M�ł��ʂȂ̂ł́H
ttp://www.hardwaresecrets.com/article/270/6
�u��̊��S��FP/SSE���s���j�b�g�̑���ɁAFP/SSE moves��FP/SSE store��
�f�[�^�v���~�e�B���ɍs���P���ȓ�Ԗڂ̃|�[�g�ŃR�X�g�E�p�t�H�[�}���X���œK�������v
�Ƃ����Ӗ��̓��e��10�y�[�W�ɂ���܂��B���������Ď��A���̂��������Ⴂ���Ă܂��H
ttp://download.intel.com/technology/itj/q12001/pdf/art_2.pdf
>>60
Pentium �V�ł�ALU��SSE�����͕ʂ̎��s���j�b�g�������Ǝv���܂�
Pentium M�ł��ʂȂ̂ł́H
ttp://www.hardwaresecrets.com/article/270/6
���Z��Ȃ��2bit�ŏ[���Ȃ�I
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
�����A���͂⎞���2bit
http://japan.renesas.com/fmwk.jsp?cnt=press_release20060209.htm&fp=/company_info/news_and_events/press_releases
�����A���͂⎞���2bit
�o�^�t���C���Z�������ɏ��������̂͂����ȁB�p�C�Ă��������Ȃ肻���B
���āAx86����Ȃ������I�I
���āAx86����Ȃ������I�I
>>61��
���̋L�q�́ASIMD���Z�̎��s�|�[�g���P�����Ȃ��Ƃ����Ӗ��B
�ł��A128bit���߂̓X���[�v�b�g��2clk�ȏゾ����A���N���b�N���߂s�����
2������s���j�b�g����������B
�|�[�g�P�ɂ͂����ς����j�b�g�������āA���̃|�[�g�ł������s�ł��Ȃ����߂𑱂��Ă��A
���Ȃ������s�ł���B
Pen4��SIMD���j�b�g�͔���64bit*2�Ǝv���܂��B
128bitSIMD�ŏ�ʂƉ��ʂɈˑ������Ȃ��Ƃ����̂�PenM�ł�Pen4�ł��g���Ă���B
���A��128bit���ɂ��ẮAAltivec�̂����ŃN���b�N�グ�ɂ����Ƃ������̂łǂ����Ǝv�����B
64bit�ł��A�t���[�W�������Ă��ΐ��\�ʂł̃f�����b�g�͂قƂ�ǂȂ����A
SSE3�̐������Z��ꕔ�̃A���p�b�N�Ȃǂ�64bit�̕����������i�����₷���j�Ǝv���B
FP�Ɋւ��Ă��Ax64�ł�FPU�̑����SISD���g������64bit�Ō��𑝂₵�����������B
������128bit���x��FP���߂͗~�������ǃi�[�B
>>61��
���́A�u���s�|�[�g�v�������Ə������B�m���Ɏ��s���j�b�g�͈Ⴄ�݂����ˁB
���̋L�q�́ASIMD���Z�̎��s�|�[�g���P�����Ȃ��Ƃ����Ӗ��B
�ł��A128bit���߂̓X���[�v�b�g��2clk�ȏゾ����A���N���b�N���߂s�����
2������s���j�b�g����������B
�|�[�g�P�ɂ͂����ς����j�b�g�������āA���̃|�[�g�ł������s�ł��Ȃ����߂𑱂��Ă��A
���Ȃ������s�ł���B
Pen4��SIMD���j�b�g�͔���64bit*2�Ǝv���܂��B
128bitSIMD�ŏ�ʂƉ��ʂɈˑ������Ȃ��Ƃ����̂�PenM�ł�Pen4�ł��g���Ă���B
���A��128bit���ɂ��ẮAAltivec�̂����ŃN���b�N�グ�ɂ����Ƃ������̂łǂ����Ǝv�����B
64bit�ł��A�t���[�W�������Ă��ΐ��\�ʂł̃f�����b�g�͂قƂ�ǂȂ����A
SSE3�̐������Z��ꕔ�̃A���p�b�N�Ȃǂ�64bit�̕����������i�����₷���j�Ǝv���B
FP�Ɋւ��Ă��Ax64�ł�FPU�̑����SISD���g������64bit�Ō��𑝂₵�����������B
������128bit���x��FP���߂͗~�������ǃi�[�B
>>61��
���́A�u���s�|�[�g�v�������Ə������B�m���Ɏ��s���j�b�g�͈Ⴄ�݂����ˁB
ttp://www.agner.org/assem/pentopt.pdf
�ナ���N��86�ł�Pen4��MMX��FP�́A��̔���64�r�b�g���s���j�b�g������ƌ��_����Ă܂���
128�r�b�g���߂̓��64�r�b�g���߂Ƃ��ẴA�E�g�I�u�I�[�_���s�͂ł��Ȃ��Ƃ������Ă܂�
���́A64�r�b�g���߂�2���C�e���V/1�X���[�v�b�g�i128�r�b�g��4/2�j�Ȃ̂ň�̃��j�b�g����i��
�p�C�v���C�������Ď��s���Ă���̂��Ǝv���Ă܂���
�ナ���N��86�ł�Pen4��MMX��FP�́A��̔���64�r�b�g���s���j�b�g������ƌ��_����Ă܂���
128�r�b�g���߂̓��64�r�b�g���߂Ƃ��ẴA�E�g�I�u�I�[�_���s�͂ł��Ȃ��Ƃ������Ă܂�
���́A64�r�b�g���߂�2���C�e���V/1�X���[�v�b�g�i128�r�b�g��4/2�j�Ȃ̂ň�̃��j�b�g����i��
�p�C�v���C�������Ď��s���Ă���̂��Ǝv���Ă܂���
>>65
Pen4�̃^�C�~���O�͂����łȂ����ȁB
�œK���}�j���A���̋L�q�A���̎������ɂ����Ȃ��Ă���B
������64bit��2/1�A128bit��2/2�B
FP��64bit��4/2�A128bit��4/2�i��ʂƉ��ʂ������s���邽�߁j�B
���ƁA64bit��2/1�̃��j�b�g�P��������A128bit��4/2�łȂ�3/2�ɂȂ�͂��B
Pen4�̃^�C�~���O�͂����łȂ����ȁB
�œK���}�j���A���̋L�q�A���̎������ɂ����Ȃ��Ă���B
������64bit��2/1�A128bit��2/2�B
FP��64bit��4/2�A128bit��4/2�i��ʂƉ��ʂ������s���邽�߁j�B
���ƁA64bit��2/1�̃��j�b�g�P��������A128bit��4/2�łȂ�3/2�ɂȂ�͂��B
addps xmm0,xmm0 / andps xmm0,xmm0 ���J��Ԃ��ƁA
Pen4�ł�8clk�ʼn��B�^�C�~���O�͗����A����4/2�����炻�̒ʂ�̌��ʁB
�������Aandps��pand�i2/2�j�ɕς��Ă����ʂ͓����B
����andps��pand�͓��삪�����Ȃ̂Ń^�C�~���O�������Ǝv����B
�ł͂Ȃ�addps(4/2)��pand(2/2)��8clk������̂��B
addps�͎��́i4/2�j*2=�i6/2�j�̖��߂Ȃ̂��i�Ǝv���j�B
�ł����ʂ�addps�𑱂���Ə�ʂƉ��ʂŃ��C�e���V���B�������4/2�Ɍ�����B
���ꂪand���肾�ƉB���ł��Ȃ��B
>>65���A�E�g�I�u�I�[�_���s�͂ł��Ȃ�
�Ƃ����̂͑������̂��ƂŁA�Ⴄ��ނ̑���ɂ܂ł̓X�P�W���[�����Ή����Ă��Ȃ��悤���B
PenM�ł͂��̏ꍇ��64bit��������s�ł���B
Pen4�ł�8clk�ʼn��B�^�C�~���O�͗����A����4/2�����炻�̒ʂ�̌��ʁB
�������Aandps��pand�i2/2�j�ɕς��Ă����ʂ͓����B
����andps��pand�͓��삪�����Ȃ̂Ń^�C�~���O�������Ǝv����B
�ł͂Ȃ�addps(4/2)��pand(2/2)��8clk������̂��B
addps�͎��́i4/2�j*2=�i6/2�j�̖��߂Ȃ̂��i�Ǝv���j�B
�ł����ʂ�addps�𑱂���Ə�ʂƉ��ʂŃ��C�e���V���B�������4/2�Ɍ�����B
���ꂪand���肾�ƉB���ł��Ȃ��B
>>65���A�E�g�I�u�I�[�_���s�͂ł��Ȃ�
�Ƃ����̂͑������̂��ƂŁA�Ⴄ��ނ̑���ɂ܂ł̓X�P�W���[�����Ή����Ă��Ȃ��悤���B
PenM�ł͂��̏ꍇ��64bit��������s�ł���B
>>66
���߂�Ȃ����B4/2�ł͂Ȃ�2/2�ł����B
> ���ƁA64bit��2/1�̃��j�b�g�P��������A128bit��4/2�łȂ�3/2�ɂȂ�͂��B
���C�e���V�̒�`���A���閽�߂��n�߂Ă��瓯�����j�b�g�Ŏ��̈ˑ����߂��n�߂���܂�
�Ƃ���ƁA��i�p�C�v�̉����128�r�b�gSSE��3/2�łȂ�2/2�Ƃ��Ă��R�łȂ��C�����܂��B
Ath64�ł�128�r�b�g���߂́AFMUL��FADD�̓�̃p�C�v�ɕ�������ꍇ�ɃX���[�v�b�g1
�Е��̃p�C�v�ł����s���Ȃ��ꍇ�̓X���[�v�b�g1/2�ł��B
Pen4��128�r�b�g���߂̃X���[�v�b�g��64�r�b�g���߂̔����Ƃ������Ƃ́A
��͂���s�p�C�v�͓�{�łȂ���{�Ƃ������Ƃł͂Ȃ��ł��傤���H
���߂�Ȃ����B4/2�ł͂Ȃ�2/2�ł����B
> ���ƁA64bit��2/1�̃��j�b�g�P��������A128bit��4/2�łȂ�3/2�ɂȂ�͂��B
���C�e���V�̒�`���A���閽�߂��n�߂Ă��瓯�����j�b�g�Ŏ��̈ˑ����߂��n�߂���܂�
�Ƃ���ƁA��i�p�C�v�̉����128�r�b�gSSE��3/2�łȂ�2/2�Ƃ��Ă��R�łȂ��C�����܂��B
Ath64�ł�128�r�b�g���߂́AFMUL��FADD�̓�̃p�C�v�ɕ�������ꍇ�ɃX���[�v�b�g1
�Е��̃p�C�v�ł����s���Ȃ��ꍇ�̓X���[�v�b�g1/2�ł��B
Pen4��128�r�b�g���߂̃X���[�v�b�g��64�r�b�g���߂̔����Ƃ������Ƃ́A
��͂���s�p�C�v�͓�{�łȂ���{�Ƃ������Ƃł͂Ȃ��ł��傤���H
>>68
�m����3/2�Ƃ�2/2�Ƃ������܂��ˁB
Intel�̍œK���}�j���A���̐����ł́APenM��3/2�ɂȂ鏑�����APen4��2/2�ɂȂ鏑������
���ꂼ�ꂵ�Ă���BPen4��3/2�ɂȂ����Ⴄ�ꍇ������̂�>>67�݂����Ȃ��Ƃ�����B
���̕ӂ͕\�L�̖�肩�ȁB
�ŁA64bit(2/1)*1��64bit(2/2)*2�̋�ʂ��ē����ˁB
68����́A64bit(2/1)*1���ƌ��������̂��낤���ǁA���ǂǂ�����قړ�������ɂȂ�B
Athlon�Ɠ������Ƃ����̂͏؋��ł����Ȃ��B
����ɁA��������64bit�ł�����j�b�g�����ł��A128bit�̃X���[�v�b�g�͔����ɗ�����B
���Ⴀ�ǂ��炩�킩��Ȃ��̂��Ƃ����ƁAPen4�̓����ł͔{���œ��삷�镔����
�����œ��삷�镔��������̂ŁASIMD���������Ǝv���A�����́i2/2�j��
��������Ȃ����Ȃ��Ƃ����킯�B
�m����3/2�Ƃ�2/2�Ƃ������܂��ˁB
Intel�̍œK���}�j���A���̐����ł́APenM��3/2�ɂȂ鏑�����APen4��2/2�ɂȂ鏑������
���ꂼ�ꂵ�Ă���BPen4��3/2�ɂȂ����Ⴄ�ꍇ������̂�>>67�݂����Ȃ��Ƃ�����B
���̕ӂ͕\�L�̖�肩�ȁB
�ŁA64bit(2/1)*1��64bit(2/2)*2�̋�ʂ��ē����ˁB
68����́A64bit(2/1)*1���ƌ��������̂��낤���ǁA���ǂǂ�����قړ�������ɂȂ�B
Athlon�Ɠ������Ƃ����̂͏؋��ł����Ȃ��B
����ɁA��������64bit�ł�����j�b�g�����ł��A128bit�̃X���[�v�b�g�͔����ɗ�����B
���Ⴀ�ǂ��炩�킩��Ȃ��̂��Ƃ����ƁAPen4�̓����ł͔{���œ��삷�镔����
�����œ��삷�镔��������̂ŁASIMD���������Ǝv���A�����́i2/2�j��
��������Ȃ����Ȃ��Ƃ����킯�B
x87�̃X���[�v�b�g��1�Ȃ�
SSE�Ǝ��s���j�b�g���Ⴄ�̂�?
SSE�Ǝ��s���j�b�g���Ⴄ�̂�?
>>70
�������B��̓�B�s���ł��B
80bit���x�����烆�j�b�g�Ⴄ�̂��ȁ`�Ƃ��v���Ă���B
�������v���X�R��SSE���C�e���V���(;�L�D�M)
�������B��̓�B�s���ł��B
80bit���x�����烆�j�b�g�Ⴄ�̂��ȁ`�Ƃ��v���Ă���B
�������v���X�R��SSE���C�e���V���(;�L�D�M)
�v���X�q��SSE���j�b�g�ɂ͔����̂��̂ƁA2.5����1���̂�����
�����Ȃ킯�Ȃ���
�����Ȃ킯�Ȃ���
����܂Ŕ������݂ʼnĂ�SIMD���������_�̓�̃p�C�v�̒���
����or��i�ł��������Ȃ��X�e�[�W��Prescott�ł͂ł����Ƃ�
�S��4/1�̂Q���4/2���������̂�5/1�̂Q���5/2�ɂȂ����Ƃ��H�H�H
����or��i�ł��������Ȃ��X�e�[�W��Prescott�ł͂ł����Ƃ�
�S��4/1�̂Q���4/2���������̂�5/1�̂Q���5/2�ɂȂ����Ƃ��H�H�H
���ō����́Ax86���߂̏��v�N���b�N�v���X���̑����H
75 �FAMD������X���Q����F2006/02/14(��) 01:15:17 ID:Tdy07aTi
���X�������������Ƃ̎G�k�B�e���v�����ǂ������̘b�ɂāB
982 ���O�FSocket774 �F2006/02/04(�y) 22:48:48 ID:pQKfehTx
���Ƃ���Intel�̎�����CPU�X����AMD�̘b������X���Ⴂ�Ȑl�B��
�u�����邽�߂ɏo�����u���X���Ȃ̂ŁA�X�������݂��邾���ʼn��l����B
�^�ʖڂɃe���v���ɕ��匾�����肵�Ă�̂͂�����Ə����Ⴄ�B
986 ���O�FSocket774 �F2006/02/05(��) 00:41:11 ID:JUjr/4Y3
>>982
�ǂ����ł������悤�Șb���o�邯�ǁB
��r�ΏۂƂ��Ă͓��R�̘b�����B
987 ���O�FSocket774 �F2006/02/05(��) 02:31:26 ID:siRO18eK
���႟�A�ux86�̎�����CPU�ɂ��Č�낤�v�X�����������炢�������B
�Ǝv�������A�ǂ����o���̃A���`�~���œK�������萫���Ŕl�荇����
�Ό��X��������̂��ւ̎R�Ȃ낤�ȁB
���낻�떄�߂Ă��悭�ˁH
988 ���O�FSocket774 �F2006/02/05(��) 05:40:24 ID:8muxG8Y4
�o���̎������X���́A�����ł����Ό��X��������̂�
������Ȃ�ă\�[�X�Ɩϑz�łǂ��ɂł��]�Ԙb�����������A�������ɂȂ肻���B
�E�E�E������ƌ��Ă݂����C�����邪��
989 ���O�FSocket774 �F2006/02/05(��) 16:40:19 ID:D3J/cLfs
���Ă܂����B
x86�̎�����CPU�ɂ��đ����I�Ɍ�낤
http://pc7.2ch.net/test/read.cgi/jisaku/1139125138/
����������>1
982 ���O�FSocket774 �F2006/02/04(�y) 22:48:48 ID:pQKfehTx
���Ƃ���Intel�̎�����CPU�X����AMD�̘b������X���Ⴂ�Ȑl�B��
�u�����邽�߂ɏo�����u���X���Ȃ̂ŁA�X�������݂��邾���ʼn��l����B
�^�ʖڂɃe���v���ɕ��匾�����肵�Ă�̂͂�����Ə����Ⴄ�B
986 ���O�FSocket774 �F2006/02/05(��) 00:41:11 ID:JUjr/4Y3
>>982
�ǂ����ł������悤�Șb���o�邯�ǁB
��r�ΏۂƂ��Ă͓��R�̘b�����B
987 ���O�FSocket774 �F2006/02/05(��) 02:31:26 ID:siRO18eK
���႟�A�ux86�̎�����CPU�ɂ��Č�낤�v�X�����������炢�������B
�Ǝv�������A�ǂ����o���̃A���`�~���œK�������萫���Ŕl�荇����
�Ό��X��������̂��ւ̎R�Ȃ낤�ȁB
���낻�떄�߂Ă��悭�ˁH
988 ���O�FSocket774 �F2006/02/05(��) 05:40:24 ID:8muxG8Y4
�o���̎������X���́A�����ł����Ό��X��������̂�
������Ȃ�ă\�[�X�Ɩϑz�łǂ��ɂł��]�Ԙb�����������A�������ɂȂ肻���B
�E�E�E������ƌ��Ă݂����C�����邪��
989 ���O�FSocket774 �F2006/02/05(��) 16:40:19 ID:D3J/cLfs
���Ă܂����B
x86�̎�����CPU�ɂ��đ����I�Ɍ�낤
http://pc7.2ch.net/test/read.cgi/jisaku/1139125138/
����������>1
>>27�����肩��SSE���Z���j�b�g��128�r�b�g�������邩�ɂ��Ă̘b�肾�����̂�
�r������x86���߂̏��v�N���b�N�v���X���i���j�̘A���i����j���������Ă���
�ǂ�ǂ�b������Ă������A�����イ�������ȁB
ttp://www.digit-life.com/articles2/cpu/intel-yonah.html
> Thus we can assume (it's confirmed by some sources) that Merom/Conroe processors
> will have 128-bit full-frequency floating point SSE arithmetic for all operand types.
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/H-I_roadmap.html
> 2007�N�ȍ~�̘b�Ƃ��āA�^���Ɍ�������Ă��邱�Ƃ͊ԈႢ�Ȃ�����ǂ��A�����A�������@�Ƃ��ɂ͂����肵�Ȃ��B
> �e�R�A����SIMD unit��128-bit���@�@�@�@�@20%
���ȉ��������Ȃ��������̂悤�Ɏ�����ϑz�Ό��X���s
�r������x86���߂̏��v�N���b�N�v���X���i���j�̘A���i����j���������Ă���
�ǂ�ǂ�b������Ă������A�����イ�������ȁB
ttp://www.digit-life.com/articles2/cpu/intel-yonah.html
> Thus we can assume (it's confirmed by some sources) that Merom/Conroe processors
> will have 128-bit full-frequency floating point SSE arithmetic for all operand types.
ttp://mypage.odn.ne.jp/www/k/8/k8_hammer_trans/files/H-I_roadmap.html
> 2007�N�ȍ~�̘b�Ƃ��āA�^���Ɍ�������Ă��邱�Ƃ͊ԈႢ�Ȃ�����ǂ��A�����A�������@�Ƃ��ɂ͂����肵�Ȃ��B
> �e�R�A����SIMD unit��128-bit���@�@�@�@�@20%
���ȉ��������Ȃ��������̂悤�Ɏ�����ϑz�Ό��X���s
77 �FSocket774�F2006/02/14(��) 08:29:27 ID:gDV2HX7L
�����I�ɂ͂ǂ��Ȃ��H
IPC�������A�d�͏���l��������x�̎��s���j�b�g�ɂȂ�E�E�E�Ȃ̂��ȁH
�h�o�b�͂S�����E�H�܂����������H
IPC�������A�d�͏���l��������x�̎��s���j�b�g�ɂȂ�E�E�E�Ȃ̂��ȁH
�h�o�b�͂S�����E�H�܂����������H
>>77
IPC�����̘b����Ȃ��Ȃ��Ă��Ă邩��BIPC����ɔ����p�t�H�[�}���X�̌����
�g�����W�X�^����R�X�g��������Ȃ����Ęb�ɂȂ��Ă銴�����B
�����悭�_�C���g���Ȃ�A����ȏ�V���O���X���b�h�̐��\�グ����
�}���`�X���b�h�̕����g�[�^���ł͂�����ł́H���Ęb����ˁB
Intel�͋}���ȃ}���`�R�A�h�AAMD�͂��T�d�B
�A���_�[���̖@�������邯�ǁA�ǂ��]�Ԃ��E�E�E�B
�ނ���v���O�������鑤�ɑ傫�ȕϊv�����߂��邩��
������ǂ����z���Ă������B
IPC�����̘b����Ȃ��Ȃ��Ă��Ă邩��BIPC����ɔ����p�t�H�[�}���X�̌����
�g�����W�X�^����R�X�g��������Ȃ����Ęb�ɂȂ��Ă銴�����B
�����悭�_�C���g���Ȃ�A����ȏ�V���O���X���b�h�̐��\�グ����
�}���`�X���b�h�̕����g�[�^���ł͂�����ł́H���Ęb����ˁB
Intel�͋}���ȃ}���`�R�A�h�AAMD�͂��T�d�B
�A���_�[���̖@�������邯�ǁA�ǂ��]�Ԃ��E�E�E�B
�ނ���v���O�������鑤�ɑ傫�ȕϊv�����߂��邩��
������ǂ����z���Ă������B
4Issue�ɂȂ���������āA���ۂ�4�߂�����IPC����������͓̂���ˁH
x86-64�Ń��W�X�^������������A�R���p�C�����ˑ��W�̂Ȃ��R�[�h��f���₷���Ȃ���
������A4IPC��_�����Ƃɂ�����Ȃ�����
������A4IPC��_�����Ƃɂ�����Ȃ�����
���̏ꍇ�A�ʂ�4IPC�ɂȂ�Ȃ��Ă��A
�O�����3Issue���A����IPC���グ����ΈӖ������Ȃ��́B
�O�����3Issue���A����IPC���グ����ΈӖ������Ȃ��́B
4IPC�Ȃs�[�N�ł������ł���B
64�����Ēʏ킾��2���s���Ȃ����炢�炵�����B
64�����Ēʏ킾��2���s���Ȃ����炢�炵�����B
83 �FSocket774�F2006/02/14(��) 13:52:37 ID:6GBIWH88
>>80
���W�X�^���̑����͂���ȂɊW�Ȃ��B
�i�E��CPU�ł�push/pop��mov*�����W�X�^���l�[�~���O�̃q���g�Ɏg�����肵��
������s�Ő��\���҂��ł�B
�ш�E���j�b�g�����������瑝�����Ń��[�h���߂̓��@���s�Ƃ��Ɏg����B
�܂��AYonah�̐��\��30�����������҂���Ȃ�ԈႢ���낤�ȁB
���W�X�^���̑����͂���ȂɊW�Ȃ��B
�i�E��CPU�ł�push/pop��mov*�����W�X�^���l�[�~���O�̃q���g�Ɏg�����肵��
������s�Ő��\���҂��ł�B
�ш�E���j�b�g�����������瑝�����Ń��[�h���߂̓��@���s�Ƃ��Ɏg����B
�܂��AYonah�̐��\��30�����������҂���Ȃ�ԈႢ���낤�ȁB
�������A�N�Z�X�������ł�����Ώ\������ˁH
�f���A���R�A�ł����ł����������Ă��
���R���p�C�������Ȃ�10%���x�����Ȃ邾���ł����X������
�L���b�V�����Ȃ�����̃��W�X�^�̐��̍��͂���͂���͂��炵�����ʂł�����
�f���A���R�A�ł����ł����������Ă��
���R���p�C�������Ȃ�10%���x�����Ȃ邾���ł����X������
�L���b�V�����Ȃ�����̃��W�X�^�̐��̍��͂���͂���͂��炵�����ʂł�����
>>83
���W�X�^���l�[����x86�̃��W�X�^�������ɂ���Ďg���Ă�����̂ł����āA
�R���p�C�����猩����W�X�^���������ق����n�U�[�h�����炵�₷���Ȃ�̂͂������Ƃł́H
�������̂ق����p�C�v���C����IPC�̒��߂����₷���������B
�܂�x86-64�̃��W�X�^�����Ȃ��ق������獡�܂łƂ���܂�ς��B
���W�X�^���l�[����x86�̃��W�X�^�������ɂ���Ďg���Ă�����̂ł����āA
�R���p�C�����猩����W�X�^���������ق����n�U�[�h�����炵�₷���Ȃ�̂͂������Ƃł́H
�������̂ق����p�C�v���C����IPC�̒��߂����₷���������B
�܂�x86-64�̃��W�X�^�����Ȃ��ق������獡�܂łƂ���܂�ς��B
�ЃX�����Ȃ��i�b�肪�Ȃ��Ȃ������玟�X���Ȃ��Ƃ��������j�̂ł�����܂�
Transmeta�ACulturecom�ւ�Crusoe���p�𒆎~
http://pc.watch.impress.co.jp/docs/2006/0213/transmeta.htm
Transmeta�ACulturecom�ւ�Crusoe���p�𒆎~
http://pc.watch.impress.co.jp/docs/2006/0213/transmeta.htm
>>86
IA-64�i�_�����W�X�^�F����128�{�{��������128�{�j�ł����W�X�^���l�[�~���O�����
�����ă��W�X�^���l�[�~���O�͋U�I�y�����h�ˑ��������̂��߂�����
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%A6%E3%83%88%E3%83%BB%E3%82%AA%E3%83%96%E3%83%BB%E3%82%AA%E3%83%BC%E3%83%80%E3%83%BC%E5%AE%9F%E8%A1%8C
IA-64�i�_�����W�X�^�F����128�{�{��������128�{�j�ł����W�X�^���l�[�~���O�����
�����ă��W�X�^���l�[�~���O�͋U�I�y�����h�ˑ��������̂��߂�����
http://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%A6%E3%83%88%E3%83%BB%E3%82%AA%E3%83%96%E3%83%BB%E3%82%AA%E3%83%BC%E3%83%80%E3%83%BC%E5%AE%9F%E8%A1%8C
>>88
�~IA-64
��Itanium
���W�X�^���l�[�~���O�Ȃ�IA-64���������Ԃ�s�\����Ȃ��
�i����Ȃ��o�J�Ȃ������邱�Ɖi���ɂȂ����낤���ǂ��j
�~IA-64
��Itanium
���W�X�^���l�[�~���O�Ȃ�IA-64���������Ԃ�s�\����Ȃ��
�i����Ȃ��o�J�Ȃ������邱�Ɖi���ɂȂ����낤���ǂ��j
��ϖ��߃Z�b�g�̌݊����d�������܂ܐ��\��������̂�OOOOOOO���K�v�Ȃ̂��B
>>81-82
���̓_�APenM��IPC�������Ȃ��悤�Ȑv�ɂȂ��Ă�̂͂����Ǝv����ˁB
Athlon64��IPC�������グ��悤�Ȑv�ɂȂ��Ă�݂��������ǁB
>>82
Pen4��1�Ƃ���ƁAAthlon64�V���O���R�A����1.5�`1.7���炢�����ˁB�i���f���i���o�[����l����Ɓj
>>90
IA-64�̓R�P�������R�ł��������H��
���ǁA�ߋ��Ƃ̌݊������d�v�Ȃ̂�B�Â��\�t�g��IA-32�ŏ����ꂷ��������B
�Â��G���Q�Ƃ��Â��G���Q�Ƃ��Â��G���Q�������Ȃ��ƍ��邵��������
���̓_�APenM��IPC�������Ȃ��悤�Ȑv�ɂȂ��Ă�̂͂����Ǝv����ˁB
Athlon64��IPC�������グ��悤�Ȑv�ɂȂ��Ă�݂��������ǁB
>>82
Pen4��1�Ƃ���ƁAAthlon64�V���O���R�A����1.5�`1.7���炢�����ˁB�i���f���i���o�[����l����Ɓj
>>90
IA-64�̓R�P�������R�ł��������H��
���ǁA�ߋ��Ƃ̌݊������d�v�Ȃ̂�B�Â��\�t�g��IA-32�ŏ����ꂷ��������B
�Â��G���Q�Ƃ��Â��G���Q�Ƃ��Â��G���Q�������Ȃ��ƍ��邵��������
>>82
�P����Dhrystone MIPS�l���猩��ƁAAth64��4.5 MIPS/MHz�A
PenM��4.0 MIPS/MHz�APen4��2.9 MIPS/MHz���炢�͂���悤���B
x86��VAX��薽�ߐ������Ȃ��Ȃ�̂�IPC�̐�Βl�͕�����B
�P����Dhrystone MIPS�l���猩��ƁAAth64��4.5 MIPS/MHz�A
PenM��4.0 MIPS/MHz�APen4��2.9 MIPS/MHz���炢�͂���悤���B
x86��VAX��薽�ߐ������Ȃ��Ȃ�̂�IPC�̐�Βl�͕�����B
>>93
�\�t�g�ɂ���Ă͎�ς�邪���o�I�ɂ͂���Ȃ��ˁB
ALU��AGU���y�A�Ŋe�R���Ԃ�A�ő�X���[�v�b�g��Athlon64�̂ق���������Ȃ�B
�i�u��v�Ƃ������̂̓f�R�[�h�E���^�C�������g�X�e�[�W���{�g���l�b�N�ɂȂ邩��j
�����APenM��MMX/SSE2���܂߂Đ������Z�̃��C�e���V���Z���Ԃ�肪��������A
PenM��Athlon64�ɂȂ邱�Ƃ��BL2�L���b�V���̗e�ʁE�ш�E���C�e���V��PenM�D�����ˁB
�\�t�g�ɂ���Ă͎�ς�邪���o�I�ɂ͂���Ȃ��ˁB
ALU��AGU���y�A�Ŋe�R���Ԃ�A�ő�X���[�v�b�g��Athlon64�̂ق���������Ȃ�B
�i�u��v�Ƃ������̂̓f�R�[�h�E���^�C�������g�X�e�[�W���{�g���l�b�N�ɂȂ邩��j
�����APenM��MMX/SSE2���܂߂Đ������Z�̃��C�e���V���Z���Ԃ�肪��������A
PenM��Athlon64�ɂȂ邱�Ƃ��BL2�L���b�V���̗e�ʁE�ш�E���C�e���V��PenM�D�����ˁB
K6 vs Pen2���������������ǁAIPC��K6�̕��������������APen2�̓o�b�N�T�C�h�L���b�V����������
���ǂ�Pen2�L���Ȍ��ʂ��ł�v���O��������������
���ǂ�Pen2�L���Ȍ��ʂ��ł�v���O��������������
L2�L���b�V���e�ʂ�����PenM�ƁA���Z�킪����Ath64���݊p�̌����ɂȂ��Ă��ł��ˁB
�x���`�ɂ���Ă̓������ш���傫�������Ă���悤�ł����B
�x���`�ɂ���Ă̓������ш���傫�������Ă���悤�ł����B
>>94
�ł��APen�V��PenM��L2�L���b�V���̃��C�e���V�͑����Ă邯�ǂ�
�ł��APen�V��PenM��L2�L���b�V���̃��C�e���V�͑����Ă邯�ǂ�
�N���b�N���オ���Ă邯��?
���C�e���V���N���b�N���Ő����邩���ԂŌv�邩�B
�N���b�N���Ő�����ƃN���b�N�オ����C�e���V���傫���Ȃ��ȁB
�N���b�N���Ő�����ƃN���b�N�オ����C�e���V���傫���Ȃ��ȁB
���N���b�N��Pen3��PenM�ő̊����x�܂������Ⴄ����Ȃ�
�q���g�F���������x
DDR400��DualChannnel�ł�10�{�߂��Ⴄ�B
DDR400��DualChannnel�ł�10�{�߂��Ⴄ�B
PC133�͗��_��1GB/s���炢���B
DDR�Ŏ������x���悯���ɏo��悤�Ȏd�g�݂ł��Ȃ�����P�O�{�͌�������Ȃ����H
DDR400��Dual�͗��_�ł�6.4GB/s�Ȃ킯�����B
�ł������Ă݂�P�O�{�͂��łɎ肪�͂��͈͂��ȁB�N���Ƃ�킯���c�corz
DDR�Ŏ������x���悯���ɏo��悤�Ȏd�g�݂ł��Ȃ�����P�O�{�͌�������Ȃ����H
DDR400��Dual�͗��_�ł�6.4GB/s�Ȃ킯�����B
�ł������Ă݂�P�O�{�͂��łɎ肪�͂��͈͂��ȁB�N���Ƃ�킯���c�corz
>>98
Dothan(10�T�C�N��)��Yonah(14�T�C�N��)�ł�L2�L���b�V�����C�e���V�͑����Ă�
�����A���ꂪ�����Ő��т��傫���������x���`�͍��̂Ƃ��댩������Ȃ�
Hammer(12�T�C�N��)�������C�e���V�����A����Œv���I�ɂȂ邱�Ƃ͂Ȃ��炵��
Yonah�͑�e�ʂ̓���L2�L���b�V���̂��߁AHammer�͑�e��L1�L���b�V���Ƃ̔r������̂���
�Ɨ��R�͈Ⴄ���AL2�L���b�V�����C�e���V���傫���̂̓g�����h�炵��
Dothan(10�T�C�N��)��Yonah(14�T�C�N��)�ł�L2�L���b�V�����C�e���V�͑����Ă�
�����A���ꂪ�����Ő��т��傫���������x���`�͍��̂Ƃ��댩������Ȃ�
Hammer(12�T�C�N��)�������C�e���V�����A����Œv���I�ɂȂ邱�Ƃ͂Ȃ��炵��
Yonah�͑�e�ʂ̓���L2�L���b�V���̂��߁AHammer�͑�e��L1�L���b�V���Ƃ̔r������̂���
�Ɨ��R�͈Ⴄ���AL2�L���b�V�����C�e���V���傫���̂̓g�����h�炵��
>>98
���C�e���V�͑����Ă��A�N���b�N�������L2���\��P3�����オ���Ă����B
PenM��P3��葬���̂̓L���b�V�����C���T�C�Y������������i���ɂ��������邩���j�B
Yonah��L2�������̂́A�ш悪����������Ǝv���B
���C�e���V�͑����Ă��A�N���b�N�������L2���\��P3�����オ���Ă����B
PenM��P3��葬���̂̓L���b�V�����C���T�C�Y������������i���ɂ��������邩���j�B
Yonah��L2�������̂́A�ш悪����������Ǝv���B
�n�[�h�E�F�A�v���t�F�b�`�̐i��
Banias�ȍ~�f���炵��
Banias�ȍ~�f���炵��
107 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/19(��) 01:14:29 ID:ul9c5iiD
�e�[�u���Q�Ƃ͎����ɂ��斾���I�ɂ���v���t�F�b�`���g���ɂ�����
���Ƃ����������̂͂ǂ����悤���Ȃ��B
http://www.dawgsdk.org/tripmona/index.php/optimization
�e�[�u���S�̂����[�h���Ă����ɂ�L1�̃T�C�Y�����肸�A�Ȃ����A
�e�[�u���Q�Ƃ̒��O�܂ŔԒn���m�肵�Ȃ��B
���������̂́AL2�ɂ͎��܂�Ώ�����L2�̃��[�h���C�e���V����ёш�Ɉˑ�����̂���
���C�e���V��������ƂȂ�A���Z�����˂đ��ΓI�Ƀ��C�e���V���B�����邵���Ȃ��B
����x86�̏��Ȃ��_�����W�X�^��������E�������Ă�B
���͂�L1�Ɏ��܂�͈͓��̃e�[�u���Ɏ��߂邵���Ȃ��낤�ȁB
���m�h�����̒��ł��ȁB
�ނ��A���m�ɂ���Ă�
�uL2�̑�e�ʉ��ł��傫�ȃe�[�u�����X�b�|�����܂�悤�ɂȂ����B�}���Z�[�v
�Ƃ����������邩������́B
Core�v���Z�b�T��ULV�������Ί��S�Ƀf���A���R�A��p�}�X�N�ɂȂ�悤�ł��ȁB
���Ƃ����������̂͂ǂ����悤���Ȃ��B
http://www.dawgsdk.org/tripmona/index.php/optimization
�e�[�u���S�̂����[�h���Ă����ɂ�L1�̃T�C�Y�����肸�A�Ȃ����A
�e�[�u���Q�Ƃ̒��O�܂ŔԒn���m�肵�Ȃ��B
���������̂́AL2�ɂ͎��܂�Ώ�����L2�̃��[�h���C�e���V����ёш�Ɉˑ�����̂���
���C�e���V��������ƂȂ�A���Z�����˂đ��ΓI�Ƀ��C�e���V���B�����邵���Ȃ��B
����x86�̏��Ȃ��_�����W�X�^��������E�������Ă�B
���͂�L1�Ɏ��܂�͈͓��̃e�[�u���Ɏ��߂邵���Ȃ��낤�ȁB
���m�h�����̒��ł��ȁB
�ނ��A���m�ɂ���Ă�
�uL2�̑�e�ʉ��ł��傫�ȃe�[�u�����X�b�|�����܂�悤�ɂȂ����B�}���Z�[�v
�Ƃ����������邩������́B
Core�v���Z�b�T��ULV�������Ί��S�Ƀf���A���R�A��p�}�X�N�ɂȂ�悤�ł��ȁB
>>107
�}���`�X���b�h�A�v���Ȃ�AHT�ɂ��x�����B���c
�Ƃ����̂��̃C���e���������Ă��V�i���I�������낤���A
Pen4�̎��s�ɂ������Ă��܂����B
HT���g���ƃL���b�V���̃q�b�g���������邩��A
Pen4�̂悤�ȃp�C�v���C��������CPU����
�L���b�V���~�X���v���I�Ȃ̂Œx���Ȃ��Ă��B
�ł��A���݂�PentiumM��IntelCore�̂悤��CPU��
HT�������犄�Ƃ����̂ł͂Ȃ����Ǝv���B
�Ƃ͂����A2�{���x��HT�ł͂Ȃ�4�{�ȏ��HT�ł��Ȃ��ƌ��ʂ͔��������B
�������A���s���j�b�g�̐��͑����̂��̂ɂ���K�v������(4�{�Ƃ͌���Ȃ��܂ł�)�B
�}���`�X���b�h�A�v���Ȃ�AHT�ɂ��x�����B���c
�Ƃ����̂��̃C���e���������Ă��V�i���I�������낤���A
Pen4�̎��s�ɂ������Ă��܂����B
HT���g���ƃL���b�V���̃q�b�g���������邩��A
Pen4�̂悤�ȃp�C�v���C��������CPU����
�L���b�V���~�X���v���I�Ȃ̂Œx���Ȃ��Ă��B
�ł��A���݂�PentiumM��IntelCore�̂悤��CPU��
HT�������犄�Ƃ����̂ł͂Ȃ����Ǝv���B
�Ƃ͂����A2�{���x��HT�ł͂Ȃ�4�{�ȏ��HT�ł��Ȃ��ƌ��ʂ͔��������B
�������A���s���j�b�g�̐��͑����̂��̂ɂ���K�v������(4�{�Ƃ͌���Ȃ��܂ł�)�B
ȯ��ް�Ă͂Ƃ���ǂ���Ɍ��錴���i�������������j������Ă��̂�
���ݽ�̈����ȂǂŎ��b�������O�ȱ��ø���Ƃ������Ƃ�(�E�́E)��??
���ݽ�̈����ȂǂŎ��b�������O�ȱ��ø���Ƃ������Ƃ�(�E�́E)��??
�ǂ�ȃA�[�L�e�N�`���ł�����͌�������ǂˁB
���ǂ̓o�����X���ǂ���邩�ŕ]���͌��܂�B
���ǂ̓o�����X���ǂ���邩�ŕ]���͌��܂�B
>>107�̃R�A�E���[�v���s�ɗv����N���b�N���̕��ϒl
Pentium III(Coppermine)74��
Celeron(Coppermine)198��
���̍��̌����͂Ȃ낤�B
L2�̃��C�e���V?
Pentium III(Tualatin)77��
Celeron(Tualatin)78��
Pentium III(Coppermine)74��
Celeron(Coppermine)198��
���̍��̌����͂Ȃ낤�B
L2�̃��C�e���V?
Pentium III(Tualatin)77��
Celeron(Tualatin)78��
L2 chache���낤�B
128k�ɂ͎��܂�Ȃ����A256k�Ɏ��܂郋�[�v�Ȃ낤�ȁB
128k�ɂ͎��܂�Ȃ����A256k�Ɏ��܂郋�[�v�Ȃ낤�ȁB
(��ͥ)�����!!
�܂�A�����������Ƃł���
ttp://pc7.2ch.net/test/read.cgi/jisaku/1138610260/127
ttp://pc7.2ch.net/test/read.cgi/jisaku/1138610260/127
��҂͂ǂ����I�I�I
AMD��L2�L���b�V���e�ʂ��Ȃ��Ȃ��オ��Ȃ��̂͂Ȃ��H
L1�L���b�V����AMD�̂ق����͂邩�ɑ傫���̂�
L1�L���b�V����AMD�̂ق����͂邩�ɑ傫���̂�
���Ɣ�r���āH
1MB�܂ŏo�Ă邶��Ȃ��ł���
1MB�܂ŏo�Ă邶��Ȃ��ł���
�C���e���̐��i��90nm��1MB����2MB�ɑ����A���N����4MB���o�邻����
�ł�AMD��Athlon 64�͓o�ꎞ��1MB�̂܂܂ŁARev.F�ł�1�R�A1MB���ő�
�ł�AMD��Athlon 64�͓o�ꎞ��1MB�̂܂܂ŁARev.F�ł�1�R�A1MB���ő�
�P���Ƀv���Z�X��intel�ɔ�ׂĒx��Ă���Ă̂����
���o�����߂Ƀ_�C�G���A����炴��Ȃ����Ă̂����
�Ƃɂ����A��K��L2���������\�[�X��AMD�ɂ͖����B���Ȃ��Ƃ��~�h���G���h�܂ł͂ˁB
���o�����߂Ƀ_�C�G���A����炴��Ȃ����Ă̂����
�Ƃɂ����A��K��L2���������\�[�X��AMD�ɂ͖����B���Ȃ��Ƃ��~�h���G���h�܂ł͂ˁB
�~�h���G���h
�G���h�~���Ȃ�m���Ă�B
�}�W���X����Ɓu�~�h�������W�v����������ȁB
�G���h�͒[�����B
�u�n�C�G���h�v�Ƃ��u���[�G���h�v�͒[���������ǁA�u�~�h���G���h�v�͌`�e�����B
�G���h�͒[�����B
�u�n�C�G���h�v�Ƃ��u���[�G���h�v�͒[���������ǁA�u�~�h���G���h�v�͌`�e�����B
�G���h�~�����Ƶ��
������G���h�~���ɂ��đ����I�Ɍ�낤
�˂˂ˁA�Q�ڂ��Ă���ł���[
�����ヌ�~�I�������ɂ��Ă��Ȃ����䂫������
>>116
�o�X�ɂ܂��]�T�����邩��B
intel��quad core�Ńo�X�ш悪�s������̂����z����
������2nd cache�̑��ʂɌ������Ă���B
�o�X�ɂ܂��]�T�����邩��B
intel��quad core�Ńo�X�ш悪�s������̂����z����
������2nd cache�̑��ʂɌ������Ă���B
�ǂ�����K8���m(A64vsSemp)�̃x���`�������ǁAP4vsCele���ɐ��\�ቺ���ĂȂ������Ȃ��B
���̂Ƃ���1MB����Ώ\���Ȃ�Ȃ��H �����]���v�ɂȂ��Ă�Ƃ��B
���̂Ƃ���1MB����Ώ\���Ȃ�Ȃ��H �����]���v�ɂȂ��Ă�Ƃ��B
A64�F�r���@�\���������������Ă��܂�L�тȂ�
Semp�F�r���̂������ŗe�ʂ̏��Ȃ��̊���ɃL���b�V���̃q�b�g������
�Ă��ACeleron�̓o�X�ш�Ƃ�HT�L���Ƃ��ł����ʉ�����Ă邩��B
Semp�F�r���̂������ŗe�ʂ̏��Ȃ��̊���ɃL���b�V���̃q�b�g������
�Ă��ACeleron�̓o�X�ш�Ƃ�HT�L���Ƃ��ł����ʉ�����Ă邩��B
130 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/23(��) 21:31:40 ID:ul8Y+VJV
>>116
L1���傫���̂̓g���[�h�I�t������BAMD��L1�͗e�ʂ��傫�ڂ̑����
�A�\�V�G�C�e�B�r�e�B��2�E�F�C�����Ȃ��B
�ǂ��������Ƃ��Ƃ����ƁA�Ԓn�̉��ʕ���������̃L���b�V�����C����
�Q�܂ł������݂ł��Ȃ��B
��ɂ��ꂪ�{�g���l�b�N�ɂȂ�B
Intel��AMD�̂��L1�e�ʂ�����������Ƀ��C�e���V�̒Z���ƃA�\�V�G�C�e�B�r�e�B���d���B
�����L2�̍L�ш�ƒ�C�e���V�i�ŋ߂͍L�ш�Ƒ�e�ʁA�n�[�h�E�F�A�v���t�F�b�`�j�ł����ĕ₢�A
���\���҂��`�B
L1���傫���̂̓g���[�h�I�t������BAMD��L1�͗e�ʂ��傫�ڂ̑����
�A�\�V�G�C�e�B�r�e�B��2�E�F�C�����Ȃ��B
�ǂ��������Ƃ��Ƃ����ƁA�Ԓn�̉��ʕ���������̃L���b�V�����C����
�Q�܂ł������݂ł��Ȃ��B
��ɂ��ꂪ�{�g���l�b�N�ɂȂ�B
Intel��AMD�̂��L1�e�ʂ�����������Ƀ��C�e���V�̒Z���ƃA�\�V�G�C�e�B�r�e�B���d���B
�����L2�̍L�ш�ƒ�C�e���V�i�ŋ߂͍L�ш�Ƒ�e�ʁA�n�[�h�E�F�A�v���t�F�b�`�j�ł����ĕ₢�A
���\���҂��`�B
>>130
���������Aintel��AMD��ϲ�ۺ��ނ��đ傫���ꏏ�Ȃ̂��ȁH
���������Aintel��AMD��ϲ�ۺ��ނ��đ傫���ꏏ�Ȃ̂��ȁH
Intel��L2�Ɋ����Ă���g�����W�X�^��Athlon�͕ʂ̂��ƂɎg���Ă��邾��
�Ƃ����C������B
�Ƃ����C������B
136 �FSocket774�F2006/02/24(��) 22:10:41 ID:pI1ogD8I
�ǁ[��intel�̃L���V���́A���x�A�d�́A���x�Ȃ�
������_�ŗD��Ă�L�K�X��
�\�����I��
������_�ŗD��Ă�L�K�X��
�\�����I��
137 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/24(��) 22:15:38 ID:lD5La1di
����������̃o�����X���▭���Ǝv���B
PenM�͐_���x�������ǁA�ł�NetBurst��Prescott�Ŋ��S����̊�K�X�B
PenM�͐_���x�������ǁA�ł�NetBurst��Prescott�Ŋ��S����̊�K�X�B
�Ȃ�ł���������AMD��65nm�ɂȂ�����r���L���b�V���p�~���ā`�p�~�`
����Sempron�ł�256K����Ȃ���512K�ł��������B
���̐�̎��l����Ƃǂ��l���Ă��K������B
����Sempron�ł�256K����Ȃ���512K�ł��������B
���̐�̎��l����Ƃǂ��l���Ă��K������B
PenM���āA����Ȃɂ������H
�g�������G�́A�������ʂ��Ċ�������
�g�������G�́A�������ʂ��Ċ�������
>>135
1�R�A������Ə����Ă���ł���BL2�L���b�V�����R�A�ʂȂ̂Ƌ��L�Ȃ̂ł͗��������S�R�Ⴄ
>>137
Prescott�ł́A�{�g���l�b�N���ʂ̂Ƃ��ɂ�����L2�L���b�V�������Ă��Ӗ��Ȃ��ꍇ��������
PenM�n��Hammer���ƁA���Z��̌������ǂ����āA�������A�N�Z�X�Ƀ{�g���l�b�N�������Ⴄ
���̂Ƃ���A�����R��������Hammer����e��L2�L���b�V����PenM�̂ق��������Ă銴������
1�R�A������Ə����Ă���ł���BL2�L���b�V�����R�A�ʂȂ̂Ƌ��L�Ȃ̂ł͗��������S�R�Ⴄ
>>137
Prescott�ł́A�{�g���l�b�N���ʂ̂Ƃ��ɂ�����L2�L���b�V�������Ă��Ӗ��Ȃ��ꍇ��������
PenM�n��Hammer���ƁA���Z��̌������ǂ����āA�������A�N�Z�X�Ƀ{�g���l�b�N�������Ⴄ
���̂Ƃ���A�����R��������Hammer����e��L2�L���b�V����PenM�̂ق��������Ă銴������
143 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/02/25(�y) 02:08:12 ID:7ufFaaSH
L1���₷��
���C�e���V�����u���Ȃ�L���b�V�����C���̃T�C�Y���{�����Ȃ��Ƃ����Ȃ�
�L���b�V�����C���T�C�Y�𐘂��u���ɂ���Ȃ�T����[�����Ȃ��Ƃ����Ȃ��̂Ń��C�e���V����
��������Way���팸�Ń_�C���N�g�}�b�s���O���i�ň��E�E�E�j
���xCell��SPE�̃��[�J���X�g�A���_�C���N�g�}�b�s���O�݂����Ȍ`���B
�Ă�SPE�Ń_�C���N�g�Ɉ����郁���������̒�����������L���b�V���������Ȃ��킯�����B
���C�e���V�����u���Ȃ�L���b�V�����C���̃T�C�Y���{�����Ȃ��Ƃ����Ȃ�
�L���b�V�����C���T�C�Y�𐘂��u���ɂ���Ȃ�T����[�����Ȃ��Ƃ����Ȃ��̂Ń��C�e���V����
��������Way���팸�Ń_�C���N�g�}�b�s���O���i�ň��E�E�E�j
���xCell��SPE�̃��[�J���X�g�A���_�C���N�g�}�b�s���O�݂����Ȍ`���B
�Ă�SPE�Ń_�C���N�g�Ɉ����郁���������̒�����������L���b�V���������Ȃ��킯�����B
AMD�́ABarton�̎���L2��512KB�ɔ{�����Ėk�X�Ɛ�������A
����͑�e��L3�L���b�V����Intel�ɑR����炵����
����͑�e��L3�L���b�V����Intel�ɑR����炵����
����K8�ő�e��L3�L���b�V���Ȃ�đ債�ĈӖ������Ǝv�����ǂȂ��c
����L2�̗e�ʂ͂����������邵�A�_�C���N�g�R�l�N�g�̂������Ń��������Ⴂ���C�e���V�ň�����B
�L���b�V���e�ʂŏo�鐫�\���Ȃ�ċ͂��Ȃ���B
�c����������L3�̓_�C���N�g�R�l�N�g��߂�z�Ƃ��H
���Ƃ����猙���Ȃ��c
����L2�̗e�ʂ͂����������邵�A�_�C���N�g�R�l�N�g�̂������Ń��������Ⴂ���C�e���V�ň�����B
�L���b�V���e�ʂŏo�鐫�\���Ȃ�ċ͂��Ȃ���B
�c����������L3�̓_�C���N�g�R�l�N�g��߂�z�Ƃ��H
���Ƃ����猙���Ȃ��c
DEC Alpha���Ă��������Ȃ�
�T�[�o�[�����ł͓Ɨ�L2�L���b�V���͑�����ӌ�������L3�L���b�V���͕K�{�B
32�\�P�b�g�܂ŃT�|�[�g������Č����Ă邵�ˁB
32�\�P�b�g�܂ŃT�|�[�g������Č����Ă邵�ˁB
�_�C���N�g�R�l�N�g����߂����͂Ȃ����낤���ǁA�������
RAM�K�i���ǂ��]�Ԃ�������Ȃ�����A�ꎞ�I�ɂ�߂����
���Ȃ��������Ċ����Ȃ�ł���B
RAM�K�i���ǂ��]�Ԃ�������Ȃ�����A�ꎞ�I�ɂ�߂����
���Ȃ��������Ċ����Ȃ�ł���B
����XDR�ł������c�Ǝv���Ă��܂��B
Intel�ɃV���u�Ђ��ɂ��ꂽJEDEC�悩Rambus�̕����p�[�g�i�[�Ƃ��ĐM���o�����������B
Intel�ɃV���u�Ђ��ɂ��ꂽJEDEC�悩Rambus�̕����p�[�g�i�[�Ƃ��ĐM���o�����������B
���������Ă̂̓p�\�R���̃��C�������������Ŏg���Ă�킯����Ȃ�����
�ȒP�ɂ͂�����̂�
�ȒP�ɂ͂�����̂�
�ȒP�Ɍ����Ă�B
����A�ȒP����Ȃ��Ă���������\�����炢���悤��B
�u����v�ōς܂��Ă���܂�ȁ[��
����PC��DDR1+DDR2
�g�ݍ��n��SDRAM��DDR1�ւ̈ڍs��
VGA��GDDR3�S��
�Q�[���@�ɂ����Ă�
Xbox360:GDDR3
PS2:DRDRAM
PSP:DDR1
(PS3:XDR+GDDR3)
PC�ɂ��g����ėp�i���g���Ă�̂͂��̂��炢�H
DDR1��AMD��DDR2�ڍs�ɂ�荡��k��������A�g�ݍ��ݗp�Ɉ��̎��v���ێ��B
GDDR3��DDR2�̓������ƊE�̐�̓W�]���ǂ߂Ȃ����߁A������x�̊��Ԏ嗬�ɂȂ�Ǝv����B
�ꕔGDDR4�̎g�p���n�܂��Ă��邪�A�܂��j�b�`�B
GDDR4�̕��y�����AGDDR3�̎��v���Q�[���p�Ɋm�ۂ���Ă���̂ŁA
���W���[�����[�J�[��GDDR3��GDDR4�ւ̈ڍs���a��Ǝv����B
�܂��AGDDR4�̎��v���̂����n�C�G���h�ȊO����܂������B����đ����j�b�`�̂܂܁B
�l�I�ɂ�nVIDIA��XDR��PC�p�ɍ̗p��ATI+JEDEC��������Ɨ\�����Ă���c
JEDEC�͎�l�܂�Ȋ�������B�����Rambus�ɕ������ˁH
����A�ȒP����Ȃ��Ă���������\�����炢���悤��B
�u����v�ōς܂��Ă���܂�ȁ[��
����PC��DDR1+DDR2
�g�ݍ��n��SDRAM��DDR1�ւ̈ڍs��
VGA��GDDR3�S��
�Q�[���@�ɂ����Ă�
Xbox360:GDDR3
PS2:DRDRAM
PSP:DDR1
(PS3:XDR+GDDR3)
PC�ɂ��g����ėp�i���g���Ă�̂͂��̂��炢�H
DDR1��AMD��DDR2�ڍs�ɂ�荡��k��������A�g�ݍ��ݗp�Ɉ��̎��v���ێ��B
GDDR3��DDR2�̓������ƊE�̐�̓W�]���ǂ߂Ȃ����߁A������x�̊��Ԏ嗬�ɂȂ�Ǝv����B
�ꕔGDDR4�̎g�p���n�܂��Ă��邪�A�܂��j�b�`�B
GDDR4�̕��y�����AGDDR3�̎��v���Q�[���p�Ɋm�ۂ���Ă���̂ŁA
���W���[�����[�J�[��GDDR3��GDDR4�ւ̈ڍs���a��Ǝv����B
�܂��AGDDR4�̎��v���̂����n�C�G���h�ȊO����܂������B����đ����j�b�`�̂܂܁B
�l�I�ɂ�nVIDIA��XDR��PC�p�ɍ̗p��ATI+JEDEC��������Ɨ\�����Ă���c
JEDEC�͎�l�܂�Ȋ�������B�����Rambus�ɕ������ˁH
������������������Ȃ��ă������R���g���[�����ł����C�Z���X�������邩��
�������R���g���[�����삪���ʂȑg�ݍ��n�ł͑��肾��H
�������R���g���[�����삪���ʂȑg�ݍ��n�ł͑��肾��H
�g�ݍ��݂͕ʂɖ�����XDR�Ɉڍs���Ȃ��Ă�������Ȃ��́H
������������K�v���������A���܂Œʂ�PC��1�e���|2�e���|�x���
SDRAM��DDR1��DDR2�ł������ڍs���Ă�����낵�����ƁB
������������K�v���������A���܂Œʂ�PC��1�e���|2�e���|�x���
SDRAM��DDR1��DDR2�ł������ڍs���Ă�����낵�����ƁB
���̐�H���̐�̎��Ȃm���B
�g�ݍ��n��DDR2�����y����܂ł���5�N���炢�����邾�낤���A
���̂��炢�ɂȂ����玟�̓W�J�������Ă���ł���B
�g�ݍ��n��DDR2�����y����܂ł���5�N���炢�����邾�낤���A
���̂��炢�ɂȂ����玟�̓W�J�������Ă���ł���B
XDR�ɍs�����炢�Ȃ�GDDR�ɂł��ڍs���Ƃ����Ƃ������B
���������}�}�����t���ɂ���ƌ����̂�
�Ƃɂ���
FB-DIMM��Rambus�����Ɉ����������Ď��S�H
DDR3��DDR2-800�̖{�̗p�ŋ}���ɂ���Ȃ��q��
�ȏŎ�����CPU�ƑɂȂ鎟���チ������T�������A�Ƃ������ł��您�O���B
FB-DIMM��Rambus�����Ɉ����������Ď��S�H
DDR3��DDR2-800�̖{�̗p�ŋ}���ɂ���Ȃ��q��
�ȏŎ�����CPU�ƑɂȂ鎟���チ������T�������A�Ƃ������ł��您�O���B
��DDR3��DDR2-800�̖{�̗p�ŋ}���ɂ���Ȃ��q��
�uDDR2��DDR1-400�̖{�̗p�ŋ}���ɂ���Ȃ��q���v�ƌ����Ă�����
Intel���ڍs�����s�������ʍ��Ă�AM2��PC�Ɋւ��Ă͂قڈڍs���I��������B
�[�킯�Ō��ǂ̂Ƃ���DDR3��Intel���ڍs�����s���邩�ɂ��Ǝv���B
�uDDR2��DDR1-400�̖{�̗p�ŋ}���ɂ���Ȃ��q���v�ƌ����Ă�����
Intel���ڍs�����s�������ʍ��Ă�AM2��PC�Ɋւ��Ă͂قڈڍs���I��������B
�[�킯�Ō��ǂ̂Ƃ���DDR3��Intel���ڍs�����s���邩�ɂ��Ǝv���B
�ŁA���ŃL���b�V���̘b���烁�����̘b�ɐ����Ă�́H
>>149
Rambus�͑匙�������ǁARambus�ɑi����ꂽ�肵�ĝ��߂���͎��g�ق������������ˁB
XDR���̗p���邩�ǂ����͕ʂƂ��ĂˁB
>>155
GDDR�����������W���[���ɂł���Ǝv���Ă�̂��H
Rambus�͑匙�������ǁARambus�ɑi����ꂽ�肵�ĝ��߂���͎��g�ق������������ˁB
XDR���̗p���邩�ǂ����͕ʂƂ��ĂˁB
>>155
GDDR�����������W���[���ɂł���Ǝv���Ă�̂��H
�܂��������R���g���[�������������Ă��Ă��ŊW���Ȃ��Ƃ�������Ȃ������
>>158
DDR2�̎��Ƃ͎���Ⴄ�B
DDR3�����̂܂�܍̗p�����1�`���l��������DIMM1�{�Ƃ����V���{�C���ԂɂȂ�\���傾����ȁB
DDR3�ō̗p����̂Ȃ�DDR2-800x2�ł������������\�E�e�ʓI�Ɉ��|�I�Ƀo�����X�������B
�܂�DDR3���̗p���鎞�ɂ̓������̍X�Ȃ鑽�`�����l������}��Ƃ����������͂��肾���A
�f���A���R�A�ł�DDR2-800x2�őш摫�肿�Ⴄ���낤���ADDR3�̓��C�e���V��������B
������DDR1��DDR2�̎��ƈ���ă��C�e���V�����₤�Z�p������킯����Ȃ��B
���\���l����Ƃ���܂肢���肶��Ȃ��Ǝv�������B
�Ƃɂ���DDR1��DDR2�Ɠ������x���ōl���Ă�̂̓S�~����
�Ȃ��DDR3���x���Ă����ł����Ƃ��i�܂�̂����[�ƍl����
>>159
�܂�X�Ԃ��Ȃ���
�g�ݍ��ݎs��͍��̐ݔ������̂܂ܗ��p���Q���œ��ɖ�薳���ƕ��������炳�����Ǝ�����PC�������ɂ��čl�����B
>>160
���₳�A�����Ă��AAMD�ɂƂ��Ă͂��̂����[���d�v�Șb�����AIntel��PARROT�ł̓_�C���N�g�R�l�N�g�g���Ƃ������Ă��B
�_�C�̗��p�@���l�����Ń������̓������l������͔̂��ɏd�v�Ȏ����Ǝv���܂��ł��B
�܂�Intel����̏ꍇ�́u���邹�[�Ƃɂ�����e�ʃL���b�V���v�Ƃ��������Ȏ�@���g�����ł����c
���߂�A�݂�ȁB
AMD�̓��������܂�ɂ̂��������炵�т��炵�������Ȃc
DDR2�̎��Ƃ͎���Ⴄ�B
DDR3�����̂܂�܍̗p�����1�`���l��������DIMM1�{�Ƃ����V���{�C���ԂɂȂ�\���傾����ȁB
DDR3�ō̗p����̂Ȃ�DDR2-800x2�ł������������\�E�e�ʓI�Ɉ��|�I�Ƀo�����X�������B
�܂�DDR3���̗p���鎞�ɂ̓������̍X�Ȃ鑽�`�����l������}��Ƃ����������͂��肾���A
�f���A���R�A�ł�DDR2-800x2�őш摫�肿�Ⴄ���낤���ADDR3�̓��C�e���V��������B
������DDR1��DDR2�̎��ƈ���ă��C�e���V�����₤�Z�p������킯����Ȃ��B
���\���l����Ƃ���܂肢���肶��Ȃ��Ǝv�������B
�Ƃɂ���DDR1��DDR2�Ɠ������x���ōl���Ă�̂̓S�~����
�Ȃ��DDR3���x���Ă����ł����Ƃ��i�܂�̂����[�ƍl����
>>159
�܂�X�Ԃ��Ȃ���
�g�ݍ��ݎs��͍��̐ݔ������̂܂ܗ��p���Q���œ��ɖ�薳���ƕ��������炳�����Ǝ�����PC�������ɂ��čl�����B
>>160
���₳�A�����Ă��AAMD�ɂƂ��Ă͂��̂����[���d�v�Șb�����AIntel��PARROT�ł̓_�C���N�g�R�l�N�g�g���Ƃ������Ă��B
�_�C�̗��p�@���l�����Ń������̓������l������͔̂��ɏd�v�Ȏ����Ǝv���܂��ł��B
�܂�Intel����̏ꍇ�́u���邹�[�Ƃɂ�����e�ʃL���b�V���v�Ƃ��������Ȏ�@���g�����ł����c
���߂�A�݂�ȁB
AMD�̓��������܂�ɂ̂��������炵�т��炵�������Ȃc
��������� �����鏑��
http://www.teu.ac.jp/kougi/tukamoto/ipsj/9909/ie9909.html
��SDRAM��RDRAM�̂悤�ȁA�A���A�h���X�Q�Ƃ����������������ł͕s��
PC�C���^�[�t�F�C�X�̃V���A�����Ɉӗ~�I��Intel
http://pc.watch.impress.co.jp/docs/article/20010831/hot162.htm
���p�������C���^�[�t�F�C�X���������������ƊE
DRAM�̑O�ɗ����͂�����ő�̕ǃO���j�������e�B
http://pc.watch.impress.co.jp/docs/article/20011130/kaigai01.htm
��PC�����Ȃ�ARDRAM���������\�����[�V����
�������C���^�[�t�F�C�X���V���A���ɁBIntel�̃V���A���������\�z
http://pc.watch.impress.co.jp/docs/article/20011207/kaigai01.htm
Rambus�㋉���В�Steve Tobak���C���^�r���[
http://pc.watch.impress.co.jp/docs/2002/0715/kaigai01.htm
��DDR�͏X��(ugly)�\�����[�V�������Ǝv���B
2006�N�ɂ�DIMM�X���b�g�͂�����1�X���b�g/�`���l����?
http://pc.watch.impress.co.jp/docs/2003/0711/kaigai002.htm
RDRAM�����₳��AFB-DIMM�������ꂽ���R
http://pc.watch.impress.co.jp/docs/2004/0911/hot337.htm
FB-DIMM�Ɍ�����Intel�Ƃ��̐�
http://pcweb.mycom.co.jp/articles/2004/09/12/idf5/002.html
��DDR4�ɂ�����K�i�������オ�����
Intel CPU�̓V���A��FSB�ւƌ�����
http://pc.watch.impress.co.jp/docs/2004/1117/kaigai135.htm
���u�V���A��DRAM�v�ɂȂ�A����Ƀ��C�e���V�[�͏������Ȃ�B
������DDR2 667�AFB-DIMM�̔��M���ɂ���
http://pcweb.mycom.co.jp/articles/2005/03/04/idf1/
�w�j�̕������DDR3
http://pcweb.mycom.co.jp/articles/2005/09/07/idf1/002.html
Intel�̃��[�h�}�b�v�ɉe�����y�ڂ�FB-DIMM���
http://pc.watch.impress.co.jp/docs/2005/1114/kaigai224.htm
��Intel�����Ȃ��Ȃ玩������(ADT�Q��DRAM�x���_�[)��AMD�Ƒg��ł���čs��
IBM�Ƃ̋����J���ŕς��AMD��CPU
http://pc.watch.impress.co.jp/docs/2006/0206/kaigai239.htm
��DDR3�ɂ��ẮAAMD�͖��m�ɐ��i
http://www.teu.ac.jp/kougi/tukamoto/ipsj/9909/ie9909.html
��SDRAM��RDRAM�̂悤�ȁA�A���A�h���X�Q�Ƃ����������������ł͕s��
PC�C���^�[�t�F�C�X�̃V���A�����Ɉӗ~�I��Intel
http://pc.watch.impress.co.jp/docs/article/20010831/hot162.htm
���p�������C���^�[�t�F�C�X���������������ƊE
DRAM�̑O�ɗ����͂�����ő�̕ǃO���j�������e�B
http://pc.watch.impress.co.jp/docs/article/20011130/kaigai01.htm
��PC�����Ȃ�ARDRAM���������\�����[�V����
�������C���^�[�t�F�C�X���V���A���ɁBIntel�̃V���A���������\�z
http://pc.watch.impress.co.jp/docs/article/20011207/kaigai01.htm
Rambus�㋉���В�Steve Tobak���C���^�r���[
http://pc.watch.impress.co.jp/docs/2002/0715/kaigai01.htm
��DDR�͏X��(ugly)�\�����[�V�������Ǝv���B
2006�N�ɂ�DIMM�X���b�g�͂�����1�X���b�g/�`���l����?
http://pc.watch.impress.co.jp/docs/2003/0711/kaigai002.htm
RDRAM�����₳��AFB-DIMM�������ꂽ���R
http://pc.watch.impress.co.jp/docs/2004/0911/hot337.htm
FB-DIMM�Ɍ�����Intel�Ƃ��̐�
http://pcweb.mycom.co.jp/articles/2004/09/12/idf5/002.html
��DDR4�ɂ�����K�i�������オ�����
Intel CPU�̓V���A��FSB�ւƌ�����
http://pc.watch.impress.co.jp/docs/2004/1117/kaigai135.htm
���u�V���A��DRAM�v�ɂȂ�A����Ƀ��C�e���V�[�͏������Ȃ�B
������DDR2 667�AFB-DIMM�̔��M���ɂ���
http://pcweb.mycom.co.jp/articles/2005/03/04/idf1/
�w�j�̕������DDR3
http://pcweb.mycom.co.jp/articles/2005/09/07/idf1/002.html
Intel�̃��[�h�}�b�v�ɉe�����y�ڂ�FB-DIMM���
http://pc.watch.impress.co.jp/docs/2005/1114/kaigai224.htm
��Intel�����Ȃ��Ȃ玩������(ADT�Q��DRAM�x���_�[)��AMD�Ƒg��ł���čs��
IBM�Ƃ̋����J���ŕς��AMD��CPU
http://pc.watch.impress.co.jp/docs/2006/0206/kaigai239.htm
��DDR3�ɂ��ẮAAMD�͖��m�ɐ��i
>>165
��
��
������CPU�̘b�Ȃ�AIntel��Conroe/Merom�͐����_�����Z�����������悤�����ǁA
AMD��K8L�̃T�[�o�������i�́A���������_���Z�����������Ƃ����b������܂��B
����PenM��K8�ł́A�����n���p�x���`�ł̓������A�N�Z�X���{�g���l�b�N�ɂȂ�̂ɑ��A
���������_�n�x���`�ł͉��Z��X���[�v�b�g���{�g���l�b�N�ɂȂ邱�Ƃ������Ǝv���܂��B
�����R�X�g���Ⴄ�Ǝv���܂����A�ǂ����̉��Z���j�b�g�����������ʑ�Ȃ̂ł��傤���B
AMD��K8L�̃T�[�o�������i�́A���������_���Z�����������Ƃ����b������܂��B
����PenM��K8�ł́A�����n���p�x���`�ł̓������A�N�Z�X���{�g���l�b�N�ɂȂ�̂ɑ��A
���������_�n�x���`�ł͉��Z��X���[�v�b�g���{�g���l�b�N�ɂȂ邱�Ƃ������Ǝv���܂��B
�����R�X�g���Ⴄ�Ǝv���܂����A�ǂ����̉��Z���j�b�g�����������ʑ�Ȃ̂ł��傤���B
AMD�̓������̂������Ȃ�Ă����̎�����
Hammer�Ȃ�ĉ��N�x�ꂽ�楥�
Hammer�Ȃ�ĉ��N�x�ꂽ�楥�
>������HT����
����A��Ȃɔے聕����w�������ˁB
PentiumM�n�̓p�C�v���C���Z������X�g�[�����Ă����Q���Ȃ����A�����K�v�Ȃ�"
����A��Ȃɔے聕����w�������ˁB
PentiumM�n�̓p�C�v���C���Z������X�g�[�����Ă����Q���Ȃ����A�����K�v�Ȃ�"
���߁A�r�����M���Ă��܂��܂����B
�����K�v�Ȃ��h�A��
�}���`�R�A���������AHTT�̂悤�Ȓ��r���[�ȃ}���`�X���b�f�B���O�Z�p�͋Z�p�Ƃ��ĕK�v�Ȃ��h�B
������킯�����ǁB
���������C�e���V�̉B�����A�w���p�[�X���b�h���A�܂��g�����͏\�Ɏc����Ă���Ǝv����B(�Ƃ����������炪�{��)
�N���b�N�����Ă̂悤�ɂ������Ȃ��Ȃ����ȏ�A�����������ʂ̋@�\�ō��ʉ�����̂ɂ�
����\���������B
�����K�v�Ȃ��h�A��
�}���`�R�A���������AHTT�̂悤�Ȓ��r���[�ȃ}���`�X���b�f�B���O�Z�p�͋Z�p�Ƃ��ĕK�v�Ȃ��h�B
������킯�����ǁB
���������C�e���V�̉B�����A�w���p�[�X���b�h���A�܂��g�����͏\�Ɏc����Ă���Ǝv����B(�Ƃ����������炪�{��)
�N���b�N�����Ă̂悤�ɂ������Ȃ��Ȃ����ȏ�A�����������ʂ̋@�\�ō��ʉ�����̂ɂ�
����\���������B
PARROT�ŃX�P�W���[�����O�����シ�邱�Ƃ����z���Ă�4 issue��
�����^��64bit������Ƒ��ΓIL2�L���b�V���T�C�Y���������邩��A
���������C�e���V�̖���Intel�̂ق����[������
���������C�e���V�̖���Intel�̂ق����[������
>>170
HT�݂����ɖ��ڂɕ������Ă�گ�ނ��Í�������Ă��ڲ�ݼ�ϓ����琄���ł���������Ƃ�
���݂����ɉ������邩�킩��Ȃ���
���ڲ�ݼ�B�������ړI�̓����ɂ͕������Ȃ�*MT���������c��Ȃ���Ȃ��H
HT�݂����ɖ��ڂɕ������Ă�گ�ނ��Í�������Ă��ڲ�ݼ�ϓ����琄���ł���������Ƃ�
���݂����ɉ������邩�킩��Ȃ���
���ڲ�ݼ�B�������ړI�̓����ɂ͕������Ȃ�*MT���������c��Ȃ���Ȃ��H
�����̖��Ȃ̂��AOS�̖��Ȃ̂��킩��Ȃ�����
�����Ȃ�Ȃ����炾��AHT����Ă�
RISC�`�b�v�ł́ASMT��FGMT�ł݂�ȑ����Ȃ��Ă��
�����Ȃ�Ȃ����炾��AHT����Ă�
RISC�`�b�v�ł́ASMT��FGMT�ł݂�ȑ����Ȃ��Ă��
x86�͖��ߐ�����������ARISC�ɔ�ׂăX�s�����b�N����������Ȃ��́H
RISC�̎��͂悤�m���
RISC�̎��͂悤�m���
Conroe/Merom��4issue���́A�C�X���G���`�[���J����PARROT�����邽�߂̑����̂悤�ł��ˁB
4issue���̌��ʂ��o�Ă���̂́A���X����Ńg���[�X�L���b�V���Ɠ��I�œK������������Ă���ł����B
ttp://www.cgo.org/cgo2004/papers/11_57_ROSNER_RONI.pdf
K8L���{����FP���Z���{������Ȃ�A128�r�b�gSSE2���߂̃X���[�v�b�g������1/2����1�ɂȂ�A
�X�J�����1�T�C�N�����������p�b�N�h�̃��C�e���V���A�X�J���Ɠ����ɂȂ�ł��傤�ˁB
�������A�X�J���̃X���[�v�b�g�͔{���ł��A�p�b�N�h��Double�f�R�[�h�̂����Ŏ���1.5�{�����B
4issue���̌��ʂ��o�Ă���̂́A���X����Ńg���[�X�L���b�V���Ɠ��I�œK������������Ă���ł����B
ttp://www.cgo.org/cgo2004/papers/11_57_ROSNER_RONI.pdf
K8L���{����FP���Z���{������Ȃ�A128�r�b�gSSE2���߂̃X���[�v�b�g������1/2����1�ɂȂ�A
�X�J�����1�T�C�N�����������p�b�N�h�̃��C�e���V���A�X�J���Ɠ����ɂȂ�ł��傤�ˁB
�������A�X�J���̃X���[�v�b�g�͔{���ł��A�p�b�N�h��Double�f�R�[�h�̂����Ŏ���1.5�{�����B
���X���Ō����b�Ȃ��APen4��NOP���߂��g���[�X�L���b�V���ɃL���b�V������Ȃ����Ė{���H
Transmeta�̃R�[�h���[�t�B���O��NOP�������Ęb�͕�����
Transmeta�̃R�[�h���[�t�B���O��NOP�������Ęb�͕�����
�����A�b�v�ŏȃG�l�H(���s���j�b�g�̋��p)
http://www.ne.jp/asahi/comp/tarusan/main136.htm
http://www.ne.jp/asahi/comp/tarusan/main136.htm
���s���j�b�g�̋��L�Ȃ�Ăǂ��̃��[�J�[�ł��ŏ��Ɍ�������Ă邾��
�����������s���j�b�g���̂̓l�b�N�ɂ͂Ȃ��ĂȂ��Ǝv������
�z�b�g�X�|�b�g�����P����ړI�Ŏg���Ȃ烌�X�|���X�����Ȃ舫������������
�����������s���j�b�g���̂̓l�b�N�ɂ͂Ȃ��ĂȂ��Ǝv������
�z�b�g�X�|�b�g�����P����ړI�Ŏg���Ȃ烌�X�|���X�����Ȃ舫������������
181 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/03/01(��) 16:59:13 ID:TWLTmB/g
>>178 �d���Ŏg���Ă�}�V���ŃR�\�[�����������B�ǂ��݂Ă��T�{��ł��B�{���ɂ��肪�Ƃ��������܂����B
�y���z
�}�V���F��640, WinXP Pro
�R���p�C���FVC2003
�v���O�����\�[�X�Fhttp://up2.viploader.net/mini/src/viploader14287.zip.html
�y���s���ʁz
256��93.824clock
1024��357.656clock
4096�� 1477.22clock
16384��16817.8clock
65536�� 66816.8clock
�y�l�@�z
NOP�̌���������ɂ����N���b�N����������B
�܂��A���[�v����NOP���g���[�X�L���b�V���̗e��12K��OPs������ɂȂ��
�}���ɑ��x�������Ă���B
�I���L���b�V���̏ꍇ1/3+���{�A�L���b�V���~�X�����1�{���{�̃N���b�N����v���Ă�B
�ǂ����NOP���g���[�X�L���b�V���ɓ���炵���B
�L���b�V���ɍڂ��Ă�ꍇ���ߑш悪�A�L���b�V���~�X�̏ꍇ�f�R�[�_�{���i1��j��
�l�b�N�ɂȂ��Ă�B�Ȃ��A���̕�����OS�̃I�[�o�[�w�b�h�ƍl������B
�y���_�z
�������܂����B���Ⴂ�B
�����Ahttp://pc7.2ch.net/test/read.cgi/jisaku/1139114170/
�́������炩�ɊԈႢ�B���傤�т�CPU�̃p�C�v���C����1issue�Ȃ킯�Ȃ�����B����3�{����Ƃقڐ������B
944 ���O�F 933 [sage] ���e���F 2006/02/28(��) 21:18:11 ID:k9AttTYF
�ŋ߂̃��J�C�z���āANOP���ׂĂق��痝�_���\xxMIPS!!���Ēʂ��Ȃ��ȁc
Pen4 670�Ȃ��b�Ԃ�38�����NOP���Z���\�Ȃ��BPenD950�Ȃ�68�����B
FX-57�̕b��28����APenM780��22��6�疜��ɂ���ׂ��爳�|�I����Ȃ����B
�y���z
�}�V���F��640, WinXP Pro
�R���p�C���FVC2003
�v���O�����\�[�X�Fhttp://up2.viploader.net/mini/src/viploader14287.zip.html
�y���s���ʁz
256��93.824clock
1024��357.656clock
4096�� 1477.22clock
16384��16817.8clock
65536�� 66816.8clock
�y�l�@�z
NOP�̌���������ɂ����N���b�N����������B
�܂��A���[�v����NOP���g���[�X�L���b�V���̗e��12K��OPs������ɂȂ��
�}���ɑ��x�������Ă���B
�I���L���b�V���̏ꍇ1/3+���{�A�L���b�V���~�X�����1�{���{�̃N���b�N����v���Ă�B
�ǂ����NOP���g���[�X�L���b�V���ɓ���炵���B
�L���b�V���ɍڂ��Ă�ꍇ���ߑш悪�A�L���b�V���~�X�̏ꍇ�f�R�[�_�{���i1��j��
�l�b�N�ɂȂ��Ă�B�Ȃ��A���̕�����OS�̃I�[�o�[�w�b�h�ƍl������B
�y���_�z
�������܂����B���Ⴂ�B
�����Ahttp://pc7.2ch.net/test/read.cgi/jisaku/1139114170/
�́������炩�ɊԈႢ�B���傤�т�CPU�̃p�C�v���C����1issue�Ȃ킯�Ȃ�����B����3�{����Ƃقڐ������B
944 ���O�F 933 [sage] ���e���F 2006/02/28(��) 21:18:11 ID:k9AttTYF
�ŋ߂̃��J�C�z���āANOP���ׂĂق��痝�_���\xxMIPS!!���Ēʂ��Ȃ��ȁc
Pen4 670�Ȃ��b�Ԃ�38�����NOP���Z���\�Ȃ��BPenD950�Ȃ�68�����B
FX-57�̕b��28����APenM780��22��6�疜��ɂ���ׂ��爳�|�I����Ȃ����B
>>175
HT�����Ȃ�A���s���j�b�g�̐�������Ɍ����������̂ɂ��邱�Ƃ��K�v�B
Pentium4�̓p�C�v���C�����X�J�X�J�����炱��HT�������ł���(�ʂ̖��͂��邪)�B
�����猻��̂܂܂̎��s���j�b�g����HT�����̂̓i���Z���X�����A
�������������Ƃ��l���Ď�������Ό��ʂ͊��҂ł���Ǝv���B
HT��Pentium4�ł����Ԉ�ۂ������Ȃ��Ă��܂������AHT���̂����ł͂Ȃ��Ǝv���B
HT���g���ƃL���b�V���̃q�b�g����������̂ŁAPentium4�̂悤�ȃp�C�v���C��������CPU�ł�
�L���b�V���~�X���̃y�i���e�B���傫�����߂��Ȃ�x���Ȃ�̂��Ɛ�������B
>>181
MIPS�l���c
�̂�CPU���[�J�[�����C�ł����������Ƃ���Ă�����˂��B
HT�����Ȃ�A���s���j�b�g�̐�������Ɍ����������̂ɂ��邱�Ƃ��K�v�B
Pentium4�̓p�C�v���C�����X�J�X�J�����炱��HT�������ł���(�ʂ̖��͂��邪)�B
�����猻��̂܂܂̎��s���j�b�g����HT�����̂̓i���Z���X�����A
�������������Ƃ��l���Ď�������Ό��ʂ͊��҂ł���Ǝv���B
HT��Pentium4�ł����Ԉ�ۂ������Ȃ��Ă��܂������AHT���̂����ł͂Ȃ��Ǝv���B
HT���g���ƃL���b�V���̃q�b�g����������̂ŁAPentium4�̂悤�ȃp�C�v���C��������CPU�ł�
�L���b�V���~�X���̃y�i���e�B���傫�����߂��Ȃ�x���Ȃ�̂��Ɛ�������B
>>181
MIPS�l���c
�̂�CPU���[�J�[�����C�ł����������Ƃ���Ă�����˂��B
�̂Ƃ��������ł�����
>Pentium4�̂悤�ȃp�C�v���C��������CPU�ł� �L���b�V���~�X���̃y�i���e�B���傫������
���̃y�i���e�B�̉B���̂��߂�HTT�������킯�����B
���s���j�b�g���ғ����Ԃ��A�Ă��鎞�Ԃ̕��������킯��
���̌������P��HTT�̗ǂ������������͂��B
���̃y�i���e�B�̉B���̂��߂�HTT�������킯�����B
���s���j�b�g���ғ����Ԃ��A�Ă��鎞�Ԃ̕��������킯��
���̌������P��HTT�̗ǂ������������͂��B
����CPU��SMT�Ƃ����ƃ��C�e���V�B���̌��ʂłĂ邯��
pentium4��HT�̏ꍇ�A�G���R�[�h�Ƃ����C�e���V�̉e�����قƂ��
�Ȃ������ł��������Ȃ��ĂȂ�
L1�L���b�V���e�ʂ����Ȃ�����̂������Ȃ낤����
pentium4��HT�̏ꍇ�A�G���R�[�h�Ƃ����C�e���V�̉e�����قƂ��
�Ȃ������ł��������Ȃ��ĂȂ�
L1�L���b�V���e�ʂ����Ȃ�����̂������Ȃ낤����
>>184
�L���b�V���~�X�ɂ���ċ����s���j�b�g�߂���ʂ͊m���ɂ��邪�A
����ł����߂��ꂸ�A�X�J�X�J�������̂�Pentium4�̖��B
�L���b�V���~�X�ɂ���ċ����s���j�b�g�߂���ʂ͊m���ɂ��邪�A
����ł����߂��ꂸ�A�X�J�X�J�������̂�Pentium4�̖��B
������肠��ق����ǂ����ɂ͕ς��Ȃ������ł���?
���Ƃ������A���Ƃ��ƍ��N���b�N��SMT��O��ɂ��Ă�������
�p�C�v���C���̓X�J�X�J�ł����܂�Ȃ��A�Ƃ����A�[�L�e�N�`���B
�p�C�v���C���̓X�J�X�J�ł����܂�Ȃ��A�Ƃ����A�[�L�e�N�`���B
���������A�p�C�v���C���������ƃL���b�V���~�X���̃y�i���e�B���傫���Ƃ����̂�
�Ӗ��s���B
�Ӗ��s���B
���[
>>190
�҂đ҂đ҂�
�҂đ҂đ҂�
193 �FSocket774�F2006/03/06(��) 23:13:27 ID:/DAgNfVo
190 Socket774 (sage) 2006/03/06(��) 10:48 ID:7CXRFsp+
���������A�p�C�v���C���������ƃL���b�V���~�X���̃y�i���e�B���傫���Ƃ����̂�
�Ӗ��s���B
���������A�p�C�v���C���������ƃL���b�V���~�X���̃y�i���e�B���傫���Ƃ����̂�
�Ӗ��s���B
��������
Pen4��L1�L���b�V���~�X������ƃ��g���C����������̂Ŋm���Ƀy�i���e�B�͑傫���B
���g���C����������d�l�Ȃ̂́AL1���C�e���V��Z�����邽�߁B
�����܂ł���L1���C�e���V��Z���������̂́A�p�C�v���C�����ו�������Ă��邩��
���ʂɍ���L1���C�e���V�����߂ɂȂ��Ă��܂����߁B
���������Ӗ��ł́A�p�C�v���C������������ԐړI�ɃL���b�V���~�X�̃y�i���e�B��
�傫���Ȃ����ƌ����邪�A��ʓI�ɂ͊W�Ȃ��B
�Ȃ̂�>>190�̂悤�ȃ��X�������̂����A�Ԉ���Ă������̓I�Ɏw�E�Ղ�[���B
���g���C����������d�l�Ȃ̂́AL1���C�e���V��Z�����邽�߁B
�����܂ł���L1���C�e���V��Z���������̂́A�p�C�v���C�����ו�������Ă��邩��
���ʂɍ���L1���C�e���V�����߂ɂȂ��Ă��܂����߁B
���������Ӗ��ł́A�p�C�v���C������������ԐړI�ɃL���b�V���~�X�̃y�i���e�B��
�傫���Ȃ����ƌ����邪�A��ʓI�ɂ͊W�Ȃ��B
�Ȃ̂�>>190�̂悤�ȃ��X�������̂����A�Ԉ���Ă������̓I�Ɏw�E�Ղ�[���B
�m���ɁA�L���b�V���~�X���ɋ͂��̎��s���\�[�X�����v���C�Ɏg���ĂāA
SMT�Ő��\���オ��Ȃ��APentium 4�͈Ӗ��s�������
SMT�Ő��\���オ��Ȃ��APentium 4�͈Ӗ��s�������
����͂܂�A�p�C�v���C���ď[�U�̎��Ԃ�
�L���b�V���~�X�ɂ��y�i���e�B�ɂ͊܂܂�Ȃ��A�Ƃ����l������?
�L���b�V���~�X�ɂ��y�i���e�B�ɂ͊܂܂�Ȃ��A�Ƃ����l������?
����\���̎��s
>>182�������Ă���L���b�V���Ƃ����̂̓g���[�X�L���b�V���̂��ƁB
182���f�[�^�L���b�V���̂���ŏ������Ȃ�182���ԈႢ�B
>>184�̌����Ă���y�i���e�B�̉B���Ƃ����̂̓f�[�^�L���b�V���̂��ƁB
>>190�́A182����̃L���b�V���b���f�[�^�L���b�V���ɂ��Ă̘b���Ƃ���
�O��Łi�v������Łj�b���Ă���B
182���f�[�^�L���b�V���̂���ŏ������Ȃ�182���ԈႢ�B
>>184�̌����Ă���y�i���e�B�̉B���Ƃ����̂̓f�[�^�L���b�V���̂��ƁB
>>190�́A182����̃L���b�V���b���f�[�^�L���b�V���ɂ��Ă̘b���Ƃ���
�O��Łi�v������Łj�b���Ă���B
Intel�̎�����CPU�A�[�L�e�N�`���uCore Microarchitecture�v
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
http://pc.watch.impress.co.jp/docs/2006/0309/kaigai248.htm
202 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/03/10(��) 00:15:32 ID:bvuIoG8k
�킴�ƃ��[�v��傫�����ăg���[�X�L���b�V���~�X������R�[�h�����Ă݂����Ƃ��邯�ǁA
�f�R�[�h�l�b�N��1����/clk�����o�Ȃ��B�Ă�>>181�ɏ����Ă�ʂ�̊����B
HT�g���Ă������I�ɂ�1��CPU�Ȃ̂ŁA�܂�HT�Ȃ�Ă����̏���ł��B
�ˑ��W�̃`�F�C���̒����R�[�h�������s����̂ɂ͗L�����Ǝv���܂��B
�\�t�g�ɂ���ẮAHT�g�����瑬�x��������Ƃ�����Ȍ��ۂ�����܂��Ȃ�
�i2�X���b�h�������ɂ��N������ɂ�HT�����ق��������Ƃ����s�v�c�Ȏ��ԁj
�f�R�[�h�l�b�N��1����/clk�����o�Ȃ��B�Ă�>>181�ɏ����Ă�ʂ�̊����B
HT�g���Ă������I�ɂ�1��CPU�Ȃ̂ŁA�܂�HT�Ȃ�Ă����̏���ł��B
�ˑ��W�̃`�F�C���̒����R�[�h�������s����̂ɂ͗L�����Ǝv���܂��B
�\�t�g�ɂ���ẮAHT�g�����瑬�x��������Ƃ�����Ȍ��ۂ�����܂��Ȃ�
�i2�X���b�h�������ɂ��N������ɂ�HT�����ق��������Ƃ����s�v�c�Ȏ��ԁj
�����̏���ł��p�t�H�[�}���X�A�b�v���邱�Ƃ��������ʔ������www
intel��SMT�Z�p���n�����邽�߂ɂ͕K�v�Ȏ����������̂�����?
�����I�Ɍ�����B
�����Speculative MultiThreading��������̂��͒m��Ȃ����ǁB
intel��SMT�Z�p���n�����邽�߂ɂ͕K�v�Ȏ����������̂�����?
�����I�Ɍ�����B
�����Speculative MultiThreading��������̂��͒m��Ȃ����ǁB
�V�A�[�L��IDF�Ŗ������ꂽ�����{�ϑz���A�x���`�����̂Ȃ������ɏ������܂��Ă��������B
�\��Macro-Fusion�̓X�L�������s�b�N�i�K�ł�2��x86���߂̗Z���i��r�{����Ȃǁj�B
����̘A�����߂��ꊇ�s�b�N���āA��ops�ϊ��O��"Instruction Queue"�֑���炵���B
���̃t�F�b�`���́u�U���߁v�Ƃ�����������A16�o�C�g���B
Reservation Station�̕�����"Schedulers"�Ƃ����\���Ȃ̂́AALU�AAGU�AFPU�ւ̖��߂�
�X�P�W���[�����ʂ�Pen4�����v�킹�邪�AALU��AGU�ւ̖��߂͗Z������Ă��邵�A
���[�����Ƃɕʂ̃X�P�W���[��������Ă���K8���Ȃ̂��낤���H
�u4 issue wide�v��ALU���ł͂Ȃ��A�f�R�[�h���甭�s�܂�4����Ń�ops���Ǘ��ł���A
�Ƃ����Ӗ��̂悤�ŁA3�������[���{FP/SIMD���[����K8�Ǝ����\���H
PenM����ALU��MMX/SSE���P�������A"FPmove"���R����i�R�͋@�\���Ⴄ�H�j�B
MOVMSKPS�Ȃǂ�WIRE�A�V���b�t���Ȃǂ�PFSHUF�̋@�\�́AFPmove�ɂ���Ɨ\�z�����B
���s�|�[�g���p�͕ς�炸�APenM�ɂ�����Store Data��p�|�[�g���Ȃ��Ȃ��āA
Pen4����AGU��p�|�[�g*2(Load/Store Address)+���p�|�[�g*3�̍\���ɂȂ����݂����B
SIMD FP���Z���FMul(x87���p)�{FAdd�̍\����ς�����128bit���i�X���[�v�b�g1�j�B
128bit���[�h/�X�g�A�����ŏ�������悤�ɂȂ����B
�\��Macro-Fusion�̓X�L�������s�b�N�i�K�ł�2��x86���߂̗Z���i��r�{����Ȃǁj�B
����̘A�����߂��ꊇ�s�b�N���āA��ops�ϊ��O��"Instruction Queue"�֑���炵���B
���̃t�F�b�`���́u�U���߁v�Ƃ�����������A16�o�C�g���B
Reservation Station�̕�����"Schedulers"�Ƃ����\���Ȃ̂́AALU�AAGU�AFPU�ւ̖��߂�
�X�P�W���[�����ʂ�Pen4�����v�킹�邪�AALU��AGU�ւ̖��߂͗Z������Ă��邵�A
���[�����Ƃɕʂ̃X�P�W���[��������Ă���K8���Ȃ̂��낤���H
�u4 issue wide�v��ALU���ł͂Ȃ��A�f�R�[�h���甭�s�܂�4����Ń�ops���Ǘ��ł���A
�Ƃ����Ӗ��̂悤�ŁA3�������[���{FP/SIMD���[����K8�Ǝ����\���H
PenM����ALU��MMX/SSE���P�������A"FPmove"���R����i�R�͋@�\���Ⴄ�H�j�B
MOVMSKPS�Ȃǂ�WIRE�A�V���b�t���Ȃǂ�PFSHUF�̋@�\�́AFPmove�ɂ���Ɨ\�z�����B
���s�|�[�g���p�͕ς�炸�APenM�ɂ�����Store Data��p�|�[�g���Ȃ��Ȃ��āA
Pen4����AGU��p�|�[�g*2(Load/Store Address)+���p�|�[�g*3�̍\���ɂȂ����݂����B
SIMD FP���Z���FMul(x87���p)�{FAdd�̍\����ς�����128bit���i�X���[�v�b�g1�j�B
128bit���[�h/�X�g�A�����ŏ�������悤�ɂȂ����B
�ƁA�㓡�������ĂȂ��������H
�������s�v�c�Ȃ��Ƃ�����
yonah�Ƃ�conroe�Ƃ����ꂾ���̐��\�ŁA
���[�h�X�g�A���j�b�g���A���[�h1�A�X�g�A�P�����Ȃ����ē_
athlon�Ƃ��A���N���X��RISC�`�b�v��
���[�h�X�g�A���j�b�g���A�����ƃ��b�`�Ȃ̂�
yonah�Ƃ�conroe�Ƃ����ꂾ���̐��\�ŁA
���[�h�X�g�A���j�b�g���A���[�h1�A�X�g�A�P�����Ȃ����ē_
athlon�Ƃ��A���N���X��RISC�`�b�v��
���[�h�X�g�A���j�b�g���A�����ƃ��b�`�Ȃ̂�
Athlon��2Load/clk�����A�������ꂾ���̂��Ƃ��B
CPU�̑��������߂�v���͑��ɎR�قǂ���B
�P�ɐv�v�z�̈Ⴂ�B
Yonah�ɂ��Č����AL2�L���b�V����Athlon��舳�|�I�ɑ����B
Conroe�͂����炭1Load��128bit��2Load*64bit��Athlon�Ƒш�͓����B
����ł�2Load�ł��������������A���j�b�g�̍\����X�P�W���[���̓_��
Intel��1Load��I�̂��낤�i2����������������ǁj�B
��������ăg�����W�X�^��ߖ�Α��̂����Əd�v�ȋ@�\�̋������ł���B
CPU�̑��������߂�v���͑��ɎR�قǂ���B
�P�ɐv�v�z�̈Ⴂ�B
Yonah�ɂ��Č����AL2�L���b�V����Athlon��舳�|�I�ɑ����B
Conroe�͂����炭1Load��128bit��2Load*64bit��Athlon�Ƒш�͓����B
����ł�2Load�ł��������������A���j�b�g�̍\����X�P�W���[���̓_��
Intel��1Load��I�̂��낤�i2����������������ǁj�B
��������ăg�����W�X�^��ߖ�Α��̂����Əd�v�ȋ@�\�̋������ł���B
128bit���[�h���Đ̂ǂ�����CPU�Ō����悤�ȋC�����邪�c�C�̏��ׂ�
210 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/03/11(�y) 00:26:33 ID:ka24fMcF
>>208
Athlon��Load/Store���p�~�Q����B
>>209
NetBurst������
Merom/Conroe��4issue������1�N���b�N��Load��Store�s����
����2���߂͔��s�ł���B�iNetBurst��3-2=1����)
���ꂪ���|�I�ȃp���[�̔閧�ł́B
���ꂾ���̃��[�h�X�g�A���\�������XMM���W�X�^��8�{�����Ȃ��Ă��\�������B
Athlon��Load/Store���p�~�Q����B
>>209
NetBurst������
Merom/Conroe��4issue������1�N���b�N��Load��Store�s����
����2���߂͔��s�ł���B�iNetBurst��3-2=1����)
���ꂪ���|�I�ȃp���[�̔閧�ł́B
���ꂾ���̃��[�h�X�g�A���\�������XMM���W�X�^��8�{�����Ȃ��Ă��\�������B
>>210
�����w�E����Ă���̂��悭�킩��Ȃ����ǁA
����������Ȃ�Load/Store/ALU���p*3�i���j�b�g���j�ł́H
����ɃX�g�A��1clk��1��܂ł̂͂��B
�����w�E����Ă���̂��悭�킩��Ȃ����ǁA
����������Ȃ�Load/Store/ALU���p*3�i���j�b�g���j�ł́H
����ɃX�g�A��1clk��1��܂ł̂͂��B
212 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/03/11(�y) 00:37:21 ID:ka24fMcF
���߂�AAMD�̍œK�����t�@�����X�ǂ�ł���B
���ꂾ�Ƃ����܂�MMX/3DNOW!�̂��p�t�H�[�}���X�o��̂ˁB
K8L����x87/3DNOW!���ǂ�����̂����Ė����ɓ䂶��ˁH
x87��3D NOW!��1�N���b�N2���ߔ��s�ł���悤�ɂ��邩
����Ƃ��A128bit�p�b�N�h����������1��OPs�ň�����悤�ɂ��邩
���ꂾ�Ƃ����܂�MMX/3DNOW!�̂��p�t�H�[�}���X�o��̂ˁB
K8L����x87/3DNOW!���ǂ�����̂����Ė����ɓ䂶��ˁH
x87��3D NOW!��1�N���b�N2���ߔ��s�ł���悤�ɂ��邩
����Ƃ��A128bit�p�b�N�h����������1��OPs�ň�����悤�ɂ��邩
3D Now!�́A���낻���̂ĂĂ�������K�X�B�B
�������\��x���`�]�����l������64bit���\���ɂ��Ăł�128bit��
����ׂ����낤�ˁi���Ȃ��Ƃ�FP�́BMMX�͂ǂ����낤�j�B
�����A�ꕔ��3D Now!�t�@���𗠐�̂��S�ꂵ�����B
���������AMerom�ł�MMX���\�͂ǂ��Ȃ낤�ˁB
�������\��x���`�]�����l������64bit���\���ɂ��Ăł�128bit��
����ׂ����낤�ˁi���Ȃ��Ƃ�FP�́BMMX�͂ǂ����낤�j�B
�����A�ꕔ��3D Now!�t�@���𗠐�̂��S�ꂵ�����B
���������AMerom�ł�MMX���\�͂ǂ��Ȃ낤�ˁB
K7
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/22007.pdf
AppendixB: Pipeline and Execution Unit Resources Overview
�@Execution Unit Resources
�@�@Load/Store Pipeline Operations
�� Two 64-bit loads per cycle or
�� One 64-bit load and one 64-bit store per cycle or
�� Two 32-bit stores per cycle
K8
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
Appendix A Microarchitecture for AMD Athlon. 64 and AMD Opteron. Processors
�@A.15 Load-Store Unit
The 12-entry queue can request a maximum of two L1 cache operations (and mix
of loads and stores) per cycle.
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/22007.pdf
AppendixB: Pipeline and Execution Unit Resources Overview
�@Execution Unit Resources
�@�@Load/Store Pipeline Operations
�� Two 64-bit loads per cycle or
�� One 64-bit load and one 64-bit store per cycle or
�� Two 32-bit stores per cycle
K8
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/25112.PDF
Appendix A Microarchitecture for AMD Athlon. 64 and AMD Opteron. Processors
�@A.15 Load-Store Unit
The 12-entry queue can request a maximum of two L1 cache operations (and mix
of loads and stores) per cycle.
����A32bit*2�Ȃ�2�X�g�A��OK�I�H
�ׂ̃A�h���X��������32bit+32bit�ł܂Ƃ߂ăX�g�A����Ƃ����ȁB
�X�g�A���Ȃ��炾��2���[�h�ł��Ȃ��̂��m��Ȃ������ȁB
�ׂ̃A�h���X��������32bit+32bit�ł܂Ƃ߂ăX�g�A����Ƃ����ȁB
�X�g�A���Ȃ��炾��2���[�h�ł��Ȃ��̂��m��Ȃ������ȁB
K7�ł� Store �� 32bitx2 ��
K8�ł� 64bitx2�ɂȂ���
ALU����Store��2���s�ł��邯��
FPU����1�������s�ł��Ȃ��̂��낤��?
K8�ł� 64bitx2�ɂȂ���
ALU����Store��2���s�ł��邯��
FPU����1�������s�ł��Ȃ��̂��낤��?
���̒m�����Â������悤���B���߂��210�B
�A�[�L�e�N�`�������ŃK�����Ɛ��\���ς��̂̓C���e���̑Ӗ�����ˁB
����͂����Ƃ��āE�E�E
����������S��256bit�Ƃ�512bit�Ƃ�1024bit�Ƃ��ł���Ă��܂���
�����ƍ����ɂȂ�͂��Ȃ��ǁE�E�E�ǂ��Ȃ낤�B
3�f�ȏ�̃N���b�N�͓���̂ł���A�ǂ�ǂ����Ă���邵���Ȃ�����
����͂����Ƃ��āE�E�E
����������S��256bit�Ƃ�512bit�Ƃ�1024bit�Ƃ��ł���Ă��܂���
�����ƍ����ɂȂ�͂��Ȃ��ǁE�E�E�ǂ��Ȃ낤�B
3�f�ȏ�̃N���b�N�͓���̂ł���A�ǂ�ǂ����Ă���邵���Ȃ�����
>>219
�������������͖̂����邯�ǁA�_�C�T�C�Y�E���M�Ȃǂ��l����ƌ����E�Ȃ̂ł��傤�B
�Ӗ��Ă͍̂����ȁBCPU�J���ɉ��N������Ǝv���Ă�B
Intel��CPU���[�J�[�Ȃ��牴�₨�O��肸����CPU���ɏڂ����͂������B
�������������͖̂����邯�ǁA�_�C�T�C�Y�E���M�Ȃǂ��l����ƌ����E�Ȃ̂ł��傤�B
�Ӗ��Ă͍̂����ȁBCPU�J���ɉ��N������Ǝv���Ă�B
Intel��CPU���[�J�[�Ȃ��牴�₨�O��肸����CPU���ɏڂ����͂������B
>>219
�̫
�̫
222 �F�E�́E�j��-������- ��Pu/ODYSSEY �F2006/03/15(��) 20:57:42 ID:uYotLnS3
>>219
256bitVLIW��8���ߓ������s��Efficeon������Ă��ł���B���ʂ́E�E�E�B
256bitVLIW��8���ߓ������s��Efficeon������Ă��ł���B���ʂ́E�E�E�B
>>219
����256bit�Ƃ��A512bit����SIMD�̂���?
��������A���[�h�X�g�A�Ƃ��������ш悪����Ȃ�����
���Z��g�����Ă������Ȃ�Ȃ���
���Ȃ݂�64bit�Ϙa�Z���A4operation/clock�\��sx-8��
8�v���Z�b�T������A512GB/s�̃������ш�
����256bit�Ƃ��A512bit����SIMD�̂���?
��������A���[�h�X�g�A�Ƃ��������ш悪����Ȃ�����
���Z��g�����Ă������Ȃ�Ȃ���
���Ȃ݂�64bit�Ϙa�Z���A4operation/clock�\��sx-8��
8�v���Z�b�T������A512GB/s�̃������ш�
�����A�[�L�e�N�`�������ŃK�����Ɛ��\���ς��̂̓C���e���̑Ӗ������
�V�R�A�o���đ����Ȃ�͓̂�����O����
�Ȃ�Ȃ��ق�����肾
�V�R�A�o���đ����Ȃ�͓̂�����O����
�Ȃ�Ȃ��ق�����肾
���Ǐ�����(IA-64)���ڐ�̗��v(EM64T)��������ȁB
>>255
K8�Ƃ̋�����A�d���Ȃ�������
K8�Ƃ̋�����A�d���Ȃ�������
>>226
�Ⴄ�BK8�ȑO����IA-64�͌��̂Ă��Ă���
�EIA-32(x86)���i��(���̋ƊE�ł�20�N���x���w��)����
http://pc.watch.impress.co.jp/docs/article/20010829/kaigai02.htm
�Ⴄ�BK8�ȑO����IA-64�͌��̂Ă��Ă���
�EIA-32(x86)���i��(���̋ƊE�ł�20�N���x���w��)����
http://pc.watch.impress.co.jp/docs/article/20010829/kaigai02.htm
>>227
�ł����̎��_�ł́AHPC��T�[�o�[��IA-64�ōs���\�肾�����͂�
�ň��̃V�i���I�ł��A���C���t���[���N���X�ł�
IBM��Power�Ǝs�����Ă�\�肾�����낤��
�G���g���[���x���T�[�o�[�ł��Aitanium���ۂ��ۂ�
�g���͂��������Ǝv��
�ł����̎��_�ł́AHPC��T�[�o�[��IA-64�ōs���\�肾�����͂�
�ň��̃V�i���I�ł��A���C���t���[���N���X�ł�
IBM��Power�Ǝs�����Ă�\�肾�����낤��
�G���g���[���x���T�[�o�[�ł��Aitanium���ۂ��ۂ�
�g���͂��������Ǝv��
�ɂ͍ŏ�����g�����W�X�^����������
�}���`�R�A���Ȃlj����z�肵�ĂȂ������Ƃ����v���Ȃ��B
�}���`�R�A���Ȃlj����z�肵�ĂȂ������Ƃ����v���Ȃ��B
>>229
�M�����̓R�A�����Ȃ珬�����Ȃ��H
�M�����̓R�A�����Ȃ珬�����Ȃ��H
������CISC VS RISC�Ȃ�Ă���č������̗l���ȁc
>>233 ����Ⴛ������A���ɉ������҂��Ă���
�T�[�o�[����͂����炳�܂��ȁB
�V�R�A����ɂ������Ȃ��ƌ�����B
woodcrest���o�Ă�Xeon�u�����h�Ŕ������炵���B
�V�R�A����ɂ������Ȃ��ƌ�����B
woodcrest���o�Ă�Xeon�u�����h�Ŕ������炵���B
xeon�Ƃ��A������u�����h�͂��̂܂܂ł�����
�����������r���[�����A�ǂ����D�����
���܂�Xeon������Ȃ��Ȃ��Ă��܂��ƍ��邩�炾��B
Intel�͋��̖S�҂ȂƂ��낪�ǂ������������Ȃ���A�܂��ŁB
Intel�͋��̖S�҂ȂƂ��낪�ǂ������������Ȃ���A�܂��ŁB
��Ƃł���ȏ���̖S�҂ł��邱�Ƃ͎d���������Ǝv����
240 �FSocket774�F2006/03/18(�y) 13:03:25 ID:LLZTwrmG
�Ɛ�����Ȃ���A�u���̖S�ҁv��Ƃ͐��Ԃ��ׂ��B
�Ɛ�ێ������Ă邩��A�u�S�ҁv�U��͂܂��܂�����B
�Ɛ�ێ������Ă邩��A�u�S�ҁv�U��͂܂��܂�����B
�@�@�@ �@�~� �R�R�R�R���Ƀm�m
�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@.|�@�v�@�@�@�^'�@'�_�@�@|
�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |
�@ �@�@ �� �@�@�@ �R�jƿ�@�@�@l �@�@�@239��������
�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
�@�@�@�@�~�@�@ ,,�,�,�,�,�,�,�� �c
�@�@�@�@ l �@i''" �@�@�@�@�@�@�@i�c
�@�@�@�@.|�@�v�@�@�@�^'�@'�_�@�@|
�@�@�@ ,��-/�@�@ -�=-, �-�=-�@|
�@�@ �@l�@ �@�@ �@ �( �_, )�R�@�@|
�@�@�@�@�' �@�@ �m��Q_!!�Q,.��@ |
�@ �@�@ �� �@�@�@ �R�jƿ�@�@�@l �@�@�@239��������
�@�@ �^�_�R �@ �@�@�@�@�@�@�@ /
�@�^ �@ �@ �R.�@ �M�[--��' �m/�R
���ꂩ��S�R�A�W�R�A���đ����Ă����́H
�R�A���₷�H���̎��ɂ͂ǂ�Ȍv�悪����̂��C�ɂȂ�B
�ȂR�A���₷�̂��߂��Ⴍ����ɃN���b�N�グ��̂��A
�d�͂Ƃ��M�ł������ł��ɂȂ肻��������B
�R�A���₷�H���̎��ɂ͂ǂ�Ȍv�悪����̂��C�ɂȂ�B
�ȂR�A���₷�̂��߂��Ⴍ����ɃN���b�N�グ��̂��A
�d�͂Ƃ��M�ł������ł��ɂȂ肻��������B
>>242
���̂܂ܔ\�͂������R�A�ƁA�ꕔ�̎d��������������͂���Ȃ�̃R�A�̏W����
�ɂȂ��āA�R�قǃR�A���₷�c�����o���Ȃ��ȁA���̏��B
����ł��������Ƃ̓��o�͂ɂ͌��E���邵�A���Â�ǂ����œ��ł����B
���̂܂ܔ\�͂������R�A�ƁA�ꕔ�̎d��������������͂���Ȃ�̃R�A�̏W����
�ɂȂ��āA�R�قǃR�A���₷�c�����o���Ȃ��ȁA���̏��B
����ł��������Ƃ̓��o�͂ɂ͌��E���邵�A���Â�ǂ����œ��ł����B
��������͉����Ȃ��B(���Core Microarchitecture�l)
http://www.ne.jp/asahi/comp/tarusan/main137.htm
http://www.ne.jp/asahi/comp/tarusan/main137.htm
245 �FSocket774�F2006/03/20(��) 21:54:07 ID:+RpGmTfe
��������intel�v���Z�b�T���āA���s���j�b�g���̊���ɐ��\����������
�������[�R���g���[���������ڂ��ĂȂ����ˁB
�^��Ђ̐��i�̓��C�e���V���S�̂悤�ɍ��d�l�Ȃ̂�
��������ǂ�������Ă���琢�b������B
���܂Ō��Ă����̂͌��z�������̂��낤���B
�^��Ђ̐��i�̓��C�e���V���S�̂悤�ɍ��d�l�Ȃ̂�
��������ǂ�������Ă���琢�b������B
���܂Ō��Ă����̂͌��z�������̂��낤���B
>>246
�������R���g���[�����ڂ��ĂĂ��A����Ȃɑ����Ȃ��v���Z�b�T�Ȃ�Ă����������邨
�܂��AK8�͐��\���オ�ړI������A�����Ő킦�鐫�\���K�v�ɂȂ��Ă��邪
�������R���g���[�����ڂ��ĂĂ��A����Ȃɑ����Ȃ��v���Z�b�T�Ȃ�Ă����������邨
�܂��AK8�͐��\���オ�ړI������A�����Ő킦�鐫�\���K�v�ɂȂ��Ă��邪
���������ɃA�N�Z�X����v���O���������Ă݂��
�����R�������̈̑傳�������
�����R�������̈̑傳�������
���̑㏞������Ȃ��傫���킯����
����ȑ㏞���A�������蔲���ꂽw
�y���|�[�g�z Intel��Core Microarchitecture
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
http://pcweb.mycom.co.jp/articles/2006/03/21/intelcore/
�C���e���̎�����`�b�v�ɂ���--�uPentium M�v�J���ӔC�҂ɐu��
http://japan.cnet.com/interview/story/0,2000050154,20098951,00.htm
http://japan.cnet.com/interview/story/0,2000050154,20098951,00.htm
>>250
�L���b�V���������͈͂ł�������v���O�����ł�
4MB��1MB�ł́A�����ɂȂ����
���܂�Ƃ��A�o�Ă�̂͂���ȃv���O�����̃x���`�������낤��
�L���b�V���������͈͂ł�������v���O�����ł�
4MB��1MB�ł́A�����ɂȂ����
���܂�Ƃ��A�o�Ă�̂͂���ȃv���O�����̃x���`�������낤��
�L���b�V�������ɂ����x���`
http://images.anandtech.com/graphs/conroe%20preview%20followup_03090640343/11150.png
http://images.anandtech.com/graphs/conroe%20preview%20followup_03090640343/11152.png
http://images.anandtech.com/graphs/conroe%20preview%20followup_03090640343/11150.png
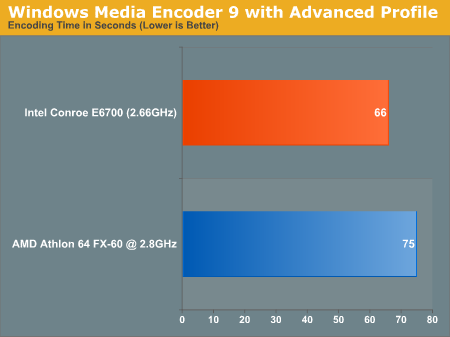{kind=link}
http://images.anandtech.com/graphs/conroe%20preview%20followup_03090640343/11152.png
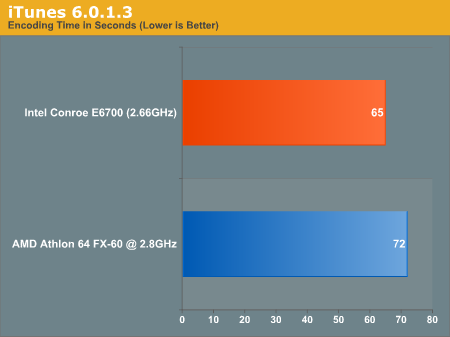{kind=link}
���̂��āA���������ƂȂ���
�x�N�g�����Z���\�Ō��܂���ۂ���ۂ�
�x�N�g�����Z�̓R�������ゾ�낤��������
��o���ł����ŕ�����̂͂��肦��
�x�N�g�����Z���\�Ō��܂���ۂ���ۂ�
�x�N�g�����Z�̓R�������ゾ�낤��������
��o���ł����ŕ�����̂͂��肦��
>>254
iTune�͂���AWMV�G���R��MMX���߂��قƂ�ǂ�SSE�����܂�g��Ȃ��B
Conroe��128bitSSE���j�b�g����������Ȃ���B
iTune�͂���AWMV�G���R��MMX���߂��قƂ�ǂ�SSE�����܂�g��Ȃ��B
Conroe��128bitSSE���j�b�g����������Ȃ���B
��o���ł����ŕ�����̂͂��肦����Ă̂́A
�����ȓd�͂ɂ��Ă��A�������Z�Ȃ�g�[�^�����\�ł������Ă��܂��C���B
�����A��o���ŕ�����̂͂��肦���ȁB
AMD���A��o���̌�o������������܂�
�����̊Ԏ���^�[���̉^���͔�������B
�U�����ւ����͖̂��x�̂��Ƃł͂��邪�A
�����p�b�Ƃ��Ȃ��̂ƁA���������Ă��Ȃ��̂��s���ł͂���B
�����ȓd�͂ɂ��Ă��A�������Z�Ȃ�g�[�^�����\�ł������Ă��܂��C���B
�����A��o���ŕ�����̂͂��肦���ȁB
AMD���A��o���̌�o������������܂�
�����̊Ԏ���^�[���̉^���͔�������B
�U�����ւ����͖̂��x�̂��Ƃł͂��邪�A
�����p�b�Ƃ��Ȃ��̂ƁA���������Ă��Ȃ��̂��s���ł͂���B
��[�킩���
���̂ɃL���b�V���͗����̂��H
���ɗ��������Ɋ�������ǁB
���̂ɃL���b�V���͗����̂��H
���ɗ��������Ɋ�������ǁB
>>259
�G���R�Ɍ�����
���������蓯���������܂Ƃ߂ĕ����悤�Ƃ���
�}�C�N���R�[�h��intel�̂ق���AMD��萔�i�i��ł�
�����疢���ɂ��Ă�
intel=�A���_�[���̖@������J�������̂�
100�܂ŋ}���Ɉڍs���邾�낤
AMD=�A���_�[���̖@���̔����8�R�A���炢����
�ɖ��ɂȂ邾�낤
�ƌ����ɈႢ������
����AMD�̂b�o�t�̓������Ԃ̃��C�e���V�������Ȃ��̂�
�L���b�V���ɂ���܂荶�E����Ȃ����ł͂���
����������͈�ʓI�ȃ\�t�g��
�����悤�ȏ����̘A���ƂȂ�G���R�[�h�͂�͂�
intel�̂b�o�t�ɑ��߂̃L���b�V���̂ق������ӂ��Ƃ�������
�n�͂�intel�Ɖ�����AMD�݂����Ȋ����ł͂Ȃ����낤��
�G���R�Ɍ�����
���������蓯���������܂Ƃ߂ĕ����悤�Ƃ���
�}�C�N���R�[�h��intel�̂ق���AMD��萔�i�i��ł�
�����疢���ɂ��Ă�
intel=�A���_�[���̖@������J�������̂�
100�܂ŋ}���Ɉڍs���邾�낤
AMD=�A���_�[���̖@���̔����8�R�A���炢����
�ɖ��ɂȂ邾�낤
�ƌ����ɈႢ������
����AMD�̂b�o�t�̓������Ԃ̃��C�e���V�������Ȃ��̂�
�L���b�V���ɂ���܂荶�E����Ȃ����ł͂���
����������͈�ʓI�ȃ\�t�g��
�����悤�ȏ����̘A���ƂȂ�G���R�[�h�͂�͂�
intel�̂b�o�t�ɑ��߂̃L���b�V���̂ق������ӂ��Ƃ�������
�n�͂�intel�Ɖ�����AMD�݂����Ȋ����ł͂Ȃ����낤��
>>259
��ʂ̒����f�[�^����������A�قƂ�ǖ��Ӗ��B
Cell�Ƃ��́A�X�g���[�~���O�v���Z�b�T���T�^�B
�����Ƃ₻���Ƒ��₵�Ă��L���b�V�������Ӗ��Ȃ�A
�V���R�����L���b�V���Ɏg��Ȃ��ŁA���̕��̃R�A�����łȂ�Ƃ����悤���_�B
��ʂ̒����f�[�^����������A�قƂ�ǖ��Ӗ��B
Cell�Ƃ��́A�X�g���[�~���O�v���Z�b�T���T�^�B
�����Ƃ₻���Ƒ��₵�Ă��L���b�V�������Ӗ��Ȃ�A
�V���R�����L���b�V���Ɏg��Ȃ��ŁA���̕��̃R�A�����łȂ�Ƃ����悤���_�B
�ǂ�������A�ӌ������
���̂��Ȃ�����A�ǂ��ł���������
���̂��Ȃ�����A�ǂ��ł���������
���G���R�Ȃ�Z������D��OC���Ďg���̂��x�X�g
>>258
Conroe��(Packed��)SSE��1�̃�op�ōςނł���B
Conroe��(Packed��)SSE��1�̃�op�ōςނł���B
���ꂾ���撣���Ă����sAthlon���20%���������Ȃ��B
AMD���肾����20%�͑S�R�Z�C�t�e�B�[���[�h�ɂ͂Ȃ�Ȃ��B
�܂��o�Ă��Ȃ����ǃf�X�N�g�b�v�p�̃z�b�g�o�[�W����CoreDuo��Ȃ�قƂ�nj݊p�Ǝv���B
�v�V�Z�p�𓊓����ĉ���I�Ȑ��\������A�݂����Ȑ�`�p�ɂ�����Ă������Ǘ�ÂɂȂ��Ă݂��..
AMD���肾����20%�͑S�R�Z�C�t�e�B�[���[�h�ɂ͂Ȃ�Ȃ��B
�܂��o�Ă��Ȃ����ǃf�X�N�g�b�v�p�̃z�b�g�o�[�W����CoreDuo��Ȃ�قƂ�nj݊p�Ǝv���B
�v�V�Z�p�𓊓����ĉ���I�Ȑ��\������A�݂����Ȑ�`�p�ɂ�����Ă������Ǘ�ÂɂȂ��Ă݂��..
���Ƃ����Ȃ�������
FX��r�Ȃ̂�ConroeEX�g���ĂȂ������?
FX��r�Ȃ̂�ConroeEX�g���ĂȂ������?
267 �FSocket774�F2006/03/22(��) 15:29:58 ID:N7Jn6igT
���A�G���R�̓��C�e���V����Ȃ��ăX���[�v�b�g�d��������A�����R�����ډ]�X����
�������ш�ƁA��e�ʁE�����ȃL���b�V���ƁA���͂ȉ��Z�p�C�v���C����������B
Gallatin�R�A��P4EE���T�^�����AL3���ڂɂ�胁�������C�e���V�͑��������̂�
Northwood�����i�i�ɃX�R�A�L�тĂ�����B
�����Ƀo�X�������{�g���l�b�N�ɂȂ�̂͂����V���v���ȃu���b�N�]�����炢�����ˁB
���Z�p�C�v���C���̉��P��R�A���𑝂₷�����ł��\�����ʂ͂���B
K8�̃����R���EHT�����̋��݂́A�����̃v���Z�X�������ɓ����p�ɂ�
�R���e�N�X�g�X�C�b�`�̋N����T�[�o�s��ɂ������邾��B
��ʂ�PC�p�ɂ́A�L���b�V���吷��ŏ\���B
�������ш�ƁA��e�ʁE�����ȃL���b�V���ƁA���͂ȉ��Z�p�C�v���C����������B
Gallatin�R�A��P4EE���T�^�����AL3���ڂɂ�胁�������C�e���V�͑��������̂�
Northwood�����i�i�ɃX�R�A�L�тĂ�����B
�����Ƀo�X�������{�g���l�b�N�ɂȂ�̂͂����V���v���ȃu���b�N�]�����炢�����ˁB
���Z�p�C�v���C���̉��P��R�A���𑝂₷�����ł��\�����ʂ͂���B
K8�̃����R���EHT�����̋��݂́A�����̃v���Z�X�������ɓ����p�ɂ�
�R���e�N�X�g�X�C�b�`�̋N����T�[�o�s��ɂ������邾��B
��ʂ�PC�p�ɂ́A�L���b�V���吷��ŏ\���B
>>267
�G���R�Ȃ�ĒP�������Ƃ���Ȃ���
�V�~���n�̃��[�X�Q�[���Ƃ��n�[�h�R�A�t���C�g�V�~���݂����Ȃ̂ł͂ǂ���
���L���Ȃ́H
�G���R�Ȃ�ĒP�������Ƃ���Ȃ���
�V�~���n�̃��[�X�Q�[���Ƃ��n�[�h�R�A�t���C�g�V�~���݂����Ȃ̂ł͂ǂ���
���L���Ȃ́H
�G���R�Ƃ������ADCT��ʎq���̓L���b�V���قƂ�NJW�Ȃ��B
�܂��������ł��Ȃ��z������̂�
�G���R�[�h�ŏd�v�Ȃ̂́A�P���ȃv���Z�b�T�p���[����
���Z�킪�����Ƃ��A�N���b�N���������Ă����`�b�v��
�P���ɑ���
������pentium4�ł����\���ł����A�G���R�ł�
���Z�킪�����Ƃ��A�N���b�N���������Ă����`�b�v��
�P���ɑ���
������pentium4�ł����\���ł����A�G���R�ł�
>�L���b�V���������͈͂ł�������v���O�����ł�
>4MB��1MB�ł́A�����ɂȂ����
����ȏ�̃v���O�����Ȃ�C�G����낤��?
�ǂ��l���Ă��}�Y���������?
�v���O�����T�C�Y�͕ς�邯�ǁA
AMD�̃L���b�V���T�C�Y�������Ȃ����Ƃɂ�
�����ɂȂ�������c
>4MB��1MB�ł́A�����ɂȂ����
����ȏ�̃v���O�����Ȃ�C�G����낤��?
�ǂ��l���Ă��}�Y���������?
�v���O�����T�C�Y�͕ς�邯�ǁA
AMD�̃L���b�V���T�C�Y�������Ȃ����Ƃɂ�
�����ɂȂ�������c
273 �FSocket774�F2006/03/23(��) 11:01:19 ID:L9xfPGAW
�L���b�V�������ő卷���Ȃ�����B�����R���ō������Ȃ��̂Ɠ��l�B
Banias(1MB)��Dothan(��2MB)�Ő��\�卷�Ȃ�������
���ʂɋ��剻���Ă��L���b�V�����̂̃��C�e���V�������Ēx���Ȃ�P�[�X�����肤�邵
���̂ւ�̓o�����X���d�v���Ǝv���B
�Ȃ�ɂ���v���f�R�[�f�B���O�▽�߂̃p�b�L���O�A���������R���Ȃ��œ��N���b�N��K7/K8���݂�
���\���ł��Ă�PenM�͐������Ă��Ƃ��B
Banias(1MB)��Dothan(��2MB)�Ő��\�卷�Ȃ�������
���ʂɋ��剻���Ă��L���b�V�����̂̃��C�e���V�������Ēx���Ȃ�P�[�X�����肤�邵
���̂ւ�̓o�����X���d�v���Ǝv���B
�Ȃ�ɂ���v���f�R�[�f�B���O�▽�߂̃p�b�L���O�A���������R���Ȃ��œ��N���b�N��K7/K8���݂�
���\���ł��Ă�PenM�͐������Ă��Ƃ��B
�v���O�����͋Ǐ��������邩��L���b�V���e�ʂ̌��ʂ͖O�a����B
���ʂ�512�`1M�ŖO�a����B
���C�e���V�Z�k�̌��ʂ͖O�a���Ȃ��B
���ʂ�512�`1M�ŖO�a����B
���C�e���V�Z�k�̌��ʂ͖O�a���Ȃ��B
>>274
�����́i�X���b�h�j�v���Z�X�������T�[�o�[�v���O�����Ȃ�O�a���Ȃ��B
�T�[�o�[�v���O������ >>267 �������Ă���ʂ胁���R�����������ʗL��B
���ǁA��e�ʃL���b�V�����낤�ƒ�C�e���V�����R�����낤�ƌ��ʗL��B
�G���R�̓o�����X���厖�Ƃ��������Ȃ��B
DCT��ʎq�������łȂ��������o���K�v�ŁA�摜�Q�`�R�t���[������
�L���b�V���e�ʂ��Ȃ��Ɠ����f�[�^�����x������������ǂނ��ƂɂȂ�̂�
�K�v�[���̃L���b�V���e�ʂ͕K�v�B
�������A�G���R�̓X�g���[�������Ȃ̂ł���ȏ�͕K�v�Ȃ��B
�X�g���[�������̓���������̃v���t�F�b�`�����₷���̂�
������x�̃��C�e���V�̓J�o�[�ł���B��͑ш�Ɖ��Z��̔n�͎���B
�����́i�X���b�h�j�v���Z�X�������T�[�o�[�v���O�����Ȃ�O�a���Ȃ��B
�T�[�o�[�v���O������ >>267 �������Ă���ʂ胁���R�����������ʗL��B
���ǁA��e�ʃL���b�V�����낤�ƒ�C�e���V�����R�����낤�ƌ��ʗL��B
�G���R�̓o�����X���厖�Ƃ��������Ȃ��B
DCT��ʎq�������łȂ��������o���K�v�ŁA�摜�Q�`�R�t���[������
�L���b�V���e�ʂ��Ȃ��Ɠ����f�[�^�����x������������ǂނ��ƂɂȂ�̂�
�K�v�[���̃L���b�V���e�ʂ͕K�v�B
�������A�G���R�̓X�g���[�������Ȃ̂ł���ȏ�͕K�v�Ȃ��B
�X�g���[�������̓���������̃v���t�F�b�`�����₷���̂�
������x�̃��C�e���V�̓J�o�[�ł���B��͑ш�Ɖ��Z��̔n�͎���B
���ǁA�R�ꂪ255�ɓK���ɏ������̂�
�قڂ�������Ă��ƁH
�قڂ�������Ă��ƁH
�}�J�[��PPC970�ɑ�����itanium�킹��AIA64���嗬�ɐ���Ǝv���B
AMD64/EM64T���ځ[��B
AMD64/EM64T���ځ[��B
>>277
970��݊���64bit�Ae700�����邨�i�@�O�ցO�j
970��݊���64bit�Ae700�����邨�i�@�O�ցO�j
���Ӗ��ȉ����ˁc
Intel CPU�X����Intel�EAMD��r�X��������̂ɁA
Intel CPU�̗D�ʐ���AMD CPU�̌��_��AMD�t�@���̐l�i�ے��
�J��Ԃ��咣����l�B���Ȃ��AMD CPU�X���ɋ���킯�H
Intel CPU�̗D�ʐ���AMD CPU�̌��_��AMD�t�@���̐l�i�ے��
�J��Ԃ��咣����l�B���Ȃ��AMD CPU�X���ɋ���킯�H
>>280
�N�͐^�ʖڂɕ����Đi�w���Ă�������
���܂Ŗڂɂ��鎖���������������m��Ȃ������
���̒��ɂ͐M����Ȃ��悤�Ȕn��������������Ď���
�N�͐^�ʖڂɕ����Đi�w���Ă�������
���܂Ŗڂɂ��鎖���������������m��Ȃ������
���̒��ɂ͐M����Ȃ��悤�Ȕn��������������Ď���
�ނ���AMD CPU�X���͊u���X���Ƃ��Ċ��p����ׂ����ƁB
����AAMD�g�����낤��Intel�g�����낤���AIntelCPU�X���̕����L�p�ł��낤�B
����AAMD�g�����낤��Intel�g�����낤���AIntelCPU�X���̕����L�p�ł��낤�B
���낻��g�[�͂���Ȃ��Ǝv�����E�E�E
�u���X���̂ӂ��͒f�R i �̂ق����Ǝv����
���ɂ���ĈႤ�݂������B
���������́AI�Č�A��X�����u�����ۂ������B
���������́AI�Č�A��X�����u�����ۂ������B
�������́A���O���炵�Ċu�������낗
�s�������˂���
�s�������˂���
�C���e��������24�X��mada-
Intel�X����503�����₪�����E�E�E�ŋ߂͂܂Ƃ��ȗ���ɂȂ��Ă��̂ɂȂ��B
289 �FSocket774�F2006/04/16(��) 18:54:48 ID:FFx3DN74
�@�@�@�@�@�@�@| |::::::::::::::::::::::::::::::::|�P~`l;:;:;:;:;:;:;|
�@�@�@ �@ �@�@ | |::::::::::::::_;;;;;;;;;;;;;;;j . �@ |;:;:;:;:;:;:;|
.�@ �@ �@�@�@�@ | |::::::::::��@�@�@�@�@ �@ �@''�- :;;:|
�@�@�@�@�@,. ::'';:;| |:::::::::::�k. ...----i�@�@. _�@ �@||
�@�@ �@ r'::::::::::;::| |:::::::::::::::::::::;:;:;:;:;|�@�@|;:~`''';:;!
.�@ �@ �@|:::::::::';:';:| |:::::::::::;:;:;:;:;:;:;:;:;j�@.�@��;:;:;:;:;:;:|
.�@ �@ �@ |:::::::::':;:::| |;:;:;:;-�\'; T''"'''��q�,_;:;:;:;:;!
�@�@�@�@�@|:::::::::::';�T'"�@, ,;/l,;�!. �@ �@ };�)�`�R{
�@�@�@�@�@ |:::;:-'" .;' ;'.j'A'-;j-�;�A�@�@j_,!,j,';';�@`i
�@�@�@ �@ �@!"l�@�@l'; l ;j'_,,,.,.,_�@�R�@ __�ɂ� l l�@, !
. �@ �@ �@�@!�@! .!�@i'; ';.jl:;;::j. `�@�@�@i:;:j�Rj�';'�@�� |
�@�@�@�@�@ | ';';, ';�@! ';,'! ~~ �@ �@ �@ `" .!,!'j;' ,.!`!
�@�@�@�@�@ |�@;';; ':,�@!. !'� �@ �@ �@ ' �@ ,�,;',',','Ɂ@�R
. �@ �@�@�@j}�@'; ';, ':,j�S��' �@�@`'''' _,. "; ;'�;'Ɂ@�@�@�@�@�����肷���Ȃ̂�age�܂��ˁ�
�@ �@ �@ ,;'�@!�@':,':,. ! ,;�S�`' �.,,,. '"::::::!'� ��''!
�@ �@ �@'�@�@l':, ._;�m,,,',,_�S:��@��'' ;�@ ;' .;;�A! �� !
�@�@�@�@�@�@ l >=����� �S��=�� ; ';, ';, ','; ��
�@�@�@�@�@�@ j',.:'�@�@�@ `:��S;�;::`!,_:::','; ;,�S,�R!
�@�@�@�@�@�@;';'�@ �@ �@ �@ .�R''i�R::::::`:.�;;'.:';�S,�R,
. �@�@�@ �@ l �@ �@�@�@ �@ ::; `:!}�::::;:-::''�R;.: ';'.;':�S�
�@�@ �@ �@ i�@�@ �@ �@ �@ .;'�@ j;�`"�@_,. -:;`� i:';::';�;�R,
�@�@ �@ �@�q:.�@�@�@�@�@ .::!:�@�@ �R. r':::::::::';:;:;i�.:.i::!,',�@�'
.�@�@ �@ �@ !:..�@�@�@�@.::::l::�@ :. �@ !. !::::::,';:;:;:j.:..;'.:.j j
. �@ �@�@�@�@!:�@�@ �@.:::::}::::�@ ::..�@.} 'i;:;:;:;:;:;��@�;� '"
.�@�@�@�@ �@ {::�@�@ .: :::::|:;::::. ..::::::::��.:|:;:;:;:;/:`��
�@�@�@�@�@�@ }::�@�@�@:::::|:,�R:::::::::::::j:.|;:;:;:;|:::::::::�R,
�@�@�@�@�@�@.}: �@ �@ :::::|;:;i .}-�\''7.:|;:;:;:;|:::::::::::::�R�A
�@�@�@ �@ �@{:�@�@ :�@::::j;:;:j j--::::j:.:.|;:;:;:;:|:::::::::::�@ ::L
290 �FSocket774�F2006/04/23(��) 12:05:38 ID:TbmxXDtB
intel��AMD�������}���`�R�A��j�[�R�A���āA
�����w�e���Z�N�V�����}���`�R�A�ƌĂ����̂̂��ƂȂ�ł��傤���H�ڂ����l�����ĉ������B
�����w�e���Z�N�V�����}���`�R�A�ƌĂ����̂̂��ƂȂ�ł��傤���H�ڂ����l�����ĉ������B
>>290
�N�A�ʔ����ˁB���ƈꏏ�ɋg�{�s���Ȃ��H
�N�A�ʔ����ˁB���ƈꏏ�ɋg�{�s���Ȃ��H
>>290
http://search.impress.co.jp/cgi-bin/namazu.cgi?query=%A5%D8%A5%C6%A5%ED%A5%B8%A5%CB%A5%A2%A5%B9&submit=%B8%A1%BA%F7&whence=0&idxname=pc&max=20&sort=score
http://search.impress.co.jp/cgi-bin/namazu.cgi?query=%83z%83%82%83W%83j%83A%83X&idxname=pc
http://search.impress.co.jp/cgi-bin/namazu.cgi?query=%A5%D8%A5%C6%A5%ED%A5%B8%A5%CB%A5%A2%A5%B9&submit=%B8%A1%BA%F7&whence=0&idxname=pc&max=20&sort=score
http://search.impress.co.jp/cgi-bin/namazu.cgi?query=%83z%83%82%83W%83j%83A%83X&idxname=pc
�����߿�ݍw���\��Ȃ̂ł����A��۰���ł�܂ő҂ĂƂ݂Ȃ���Ɍ����܂��B
�����͂�����o��̂ł��傤���B
�킩�����������Ⴂ�܂������낵�����肢�v���܂�m(__)m
�����͂�����o��̂ł��傤���B
�킩�����������Ⴂ�܂������낵�����肢�v���܂�m(__)m
>>293
��ʂɓ���\�ɂȂ肻���Ȃ̂͑������N�N���B�����A���̎��_�ł�VistaReadyPC
�݂����Ȋ���������Ȃ��BVista���o�āA��v�A�v����Vista�Ή����邭�炢�܂ł�
�҂����Ǝv�����ǁB�������N�t��Vista�Ȃ̂ŁA���N�̏H�ȍ~���炢�B
�܁A���̍��ɂȂ�ƍ��x��4�R�ACPU�H���Č����邾�낤����A�܂��҂����낤���ǂȁB
��ʂɓ���\�ɂȂ肻���Ȃ̂͑������N�N���B�����A���̎��_�ł�VistaReadyPC
�݂����Ȋ���������Ȃ��BVista���o�āA��v�A�v����Vista�Ή����邭�炢�܂ł�
�҂����Ǝv�����ǁB�������N�t��Vista�Ȃ̂ŁA���N�̏H�ȍ~���炢�B
�܁A���̍��ɂȂ�ƍ��x��4�R�ACPU�H���Č����邾�낤����A�܂��҂����낤���ǂȁB
295 �FMAC�I�^��294 �����F2006/05/03(��) 18:34:13 ID:nA89gB59
>>294
�@�@----------------------
�@�@��ʂɓ���\�ɂȂ肻���Ȃ̂͑������N�N���B���̎��_�ł�VistaReadyPC
�@�@�݂����Ȋ���������Ȃ��B
�@�@----------------------
�A������FUD����J�l���BIntel�̏o�v��������Ȋ������B
http://images.dailytech.com/nimage/1136_large_intel.png
�N���ɂ�������Ƃ�����ɋ�������邷�B
�@�@----------------------
�@�@��ʂɓ���\�ɂȂ肻���Ȃ̂͑������N�N���B���̎��_�ł�VistaReadyPC
�@�@�݂����Ȋ���������Ȃ��B
�@�@----------------------
�A������FUD����J�l���BIntel�̏o�v��������Ȋ������B
http://images.dailytech.com/nimage/1136_large_intel.png
{kind=link}
�N���ɂ�������Ƃ�����ɋ�������邷�B
�N���Ă�łȂ����āB
intel������ڂŖZ��������?
intel������ڂŖZ��������?
297 �FMAC�I�^��296 �����F2006/05/03(��) 20:22:09 ID:nA89gB59
>>296
�����̎��̏������݂Ȃ�AMD������X���b�h�̕����ʔ������ƁB�B�B
�����̎��̏������݂Ȃ�AMD������X���b�h�̕����ʔ������ƁB�B�B
298 �F���Ƃ̌o�c�͌������F2006/05/04(��) 15:13:36 ID:UfrlH0H8
299 �FMAC�I�^��298 �����F2006/05/04(��) 16:32:52 ID:C0eJjBUs
>>298
�����������Ƒ��̋ߐ�Ɣ�ׂČ��邱�Ƃ������߂��邷�B
http://money.cnn.com/magazines/fortune/fortune500/snapshots/672.html
�����������Ƒ��̋ߐ�Ɣ�ׂČ��邱�Ƃ������߂��邷�B
http://money.cnn.com/magazines/fortune/fortune500/snapshots/672.html
>>299
�������v�͓�38������13��4700���h��
��������������͂u���i�̗\��j
�N�r�ɂȂ鍁��t�ɂƂ��ẮA����Ń��X�g�����ꂿ�Ⴝ�܂�낤�Ȃ�
�A�����J���͌������Ȃ��������͍D�i�C�����]�E�ł���܁[�����̂�
�������v�͓�38������13��4700���h��
��������������͂u���i�̗\��j
�N�r�ɂȂ鍁��t�ɂƂ��ẮA����Ń��X�g�����ꂿ�Ⴝ�܂�낤�Ȃ�
�A�����J���͌������Ȃ��������͍D�i�C�����]�E�ł���܁[�����̂�
�����Ɛ藘�v�̐��́u�E�B���e���v�́A�u�e���v����j�]���悤�Ƃ��Ă���Ă킯���B
���킩��H��299
���킩��H��299
windows�Ƀ��C�o���Ȃ��Ȃ̂����Ƃ����Ă��ꂗ
�M�Z���ĂȂ낤�A�ƈ�u�v����
�T�[�o�ł́Awin��tel���A���ɂȂ��Ă������ǂˁB
���}�M�Z�ł�
Cell
windows�W�̂��Ȃ̂��Č�������V�i�m�P���V������������B