�yCRISC�zCPU�A�[�L�e�N�`���ɂ��Č��yEPIC�z3
�y�V�n���z
���O�炢�������A���\��AMD�[�EIntel�[�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
���O�炢�������A���\��AMD�[�EIntel�[�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�O�X��
Part 1�@http://pc5.2ch.net/test/read.cgi/jisaku/1082357989/
Part 2�@http://pc7.2ch.net/test/read.cgi/jisaku/1101041110/
|
|
|
2 �FSocket774�F2006/02/04(�y) 18:48:52 ID:a8Z41XR/
2het
3 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 18:49:32 ID:/wNwBa14
VC++�̍œK�����ƂĂ��Ȃ����Ȍ�
; Listing generated by Microsoft (R) Optimizing Compiler Version 13.10.3077
; �i�����j
PUBLIC?transpose@@YAXQAD0@Z; transpose
; Function compile flags: /Ogty
; File c:\documents and settings\fusianasan\my documents\hoge.cpp
_TEXTSEGMENT
_a$ = 8; size = 4
_b$ = 12; size = 4
?transpose@@YAXQAD0@Z PROC NEAR; transpose
; 4 : void transpose(char a[8], char b[8]) {
pushebp
movebp, esp
andesp, -8; fffffff8H
; 5 : __m64 m = *((__m64*)a);
moveax, DWORD PTR _a$[ebp]
movqmm0, MMWORD PTR [eax]
; 6 : for (int i = 8; i-- ; ) {
movecx, DWORD PTR _b$[ebp]
moveax, 8
$L948:
; 7 : b[i] = _m_pmovmskb(m);
; 8 : m = _m_paddb(m, m);
movqmm1, mm0
deceax
pmovmskb edx, mm0
paddbmm1, mm0
movBYTE PTR [eax+ecx], dl
movqmm0, mm1
jneSHORT $L948
; 9 : }
; 10 : _m_empty();
emms
; 11 : }
movesp, ebp
popebp
ret0
?transpose@@YAXQAD0@Z ENDP; transpose
_TEXTENDS
END
; Listing generated by Microsoft (R) Optimizing Compiler Version 13.10.3077
; �i�����j
PUBLIC?transpose@@YAXQAD0@Z; transpose
; Function compile flags: /Ogty
; File c:\documents and settings\fusianasan\my documents\hoge.cpp
_TEXTSEGMENT
_a$ = 8; size = 4
_b$ = 12; size = 4
?transpose@@YAXQAD0@Z PROC NEAR; transpose
; 4 : void transpose(char a[8], char b[8]) {
pushebp
movebp, esp
andesp, -8; fffffff8H
; 5 : __m64 m = *((__m64*)a);
moveax, DWORD PTR _a$[ebp]
movqmm0, MMWORD PTR [eax]
; 6 : for (int i = 8; i-- ; ) {
movecx, DWORD PTR _b$[ebp]
moveax, 8
$L948:
; 7 : b[i] = _m_pmovmskb(m);
; 8 : m = _m_paddb(m, m);
movqmm1, mm0
deceax
pmovmskb edx, mm0
paddbmm1, mm0
movBYTE PTR [eax+ecx], dl
movqmm0, mm1
jneSHORT $L948
; 9 : }
; 10 : _m_empty();
emms
; 11 : }
movesp, ebp
popebp
ret0
?transpose@@YAXQAD0@Z ENDP; transpose
_TEXTENDS
END
4 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 19:05:50 ID:/wNwBa14
�����R�[�h��ICC 8.1
; -- Begin ?transpose@@YAXQAD0@Z
; mark_begin;
IF @Version GE 612
.MMX
MMWORD TEXTEQU <QWORD>
ENDIF
IF @Version GE 614
.XMM
XMMWORD TEXTEQU <OWORD>
ENDIF
ALIGN 4
PUBLIC ?transpose@@YAXQAD0@Z
?transpose@@YAXQAD0@ZPROC NEAR
; parameter 1: 8 + ebp
; parameter 2: 12 + ebp
$B1$1: ; Preds $B1$0
push ebp ;4.38
mov ebp, esp ;4.38
and esp, -8 ;4.38
mov edx, DWORD PTR [ebp+8] ;4.6
movq mm0, QWORD PTR [edx] ;5.23
mov eax, DWORD PTR [ebp+12] ;4.6
mov edx, 7 ;6.18
; LOE eax edx ebx esi edi mm0
$B1$2: ; Preds $B1$2 $B1$1
pmovmskb ecx, mm0 ;7.12
mov BYTE PTR [edx+eax], cl ;7.5
paddb mm0, mm0 ;8.9
add edx, -1 ;6.18
cmp edx, -1 ;6.3
jne $B1$2 ; Prob 90% ;6.3
; LOE eax edx ebx esi edi mm0
$B1$3: ; Preds $B1$2
emms ;10.3
; LOE ebx esi edi
$B1$4: ; Preds $B1$3
mov esp, ebp ;11.1
pop ebp ;11.1
ret ;11.1
ALIGN 4
; LOE
; mark_end;
?transpose@@YAXQAD0@Z ENDP
_TEXTENDS
_DATASEGMENT DWORD PUBLIC FLAT 'DATA'
_DATAENDS
; -- End ?transpose@@YAXQAD0@Z
_DATASEGMENT DWORD PUBLIC FLAT 'DATA'
_DATAENDS
END
; -- Begin ?transpose@@YAXQAD0@Z
; mark_begin;
IF @Version GE 612
.MMX
MMWORD TEXTEQU <QWORD>
ENDIF
IF @Version GE 614
.XMM
XMMWORD TEXTEQU <OWORD>
ENDIF
ALIGN 4
PUBLIC ?transpose@@YAXQAD0@Z
?transpose@@YAXQAD0@ZPROC NEAR
; parameter 1: 8 + ebp
; parameter 2: 12 + ebp
$B1$1: ; Preds $B1$0
push ebp ;4.38
mov ebp, esp ;4.38
and esp, -8 ;4.38
mov edx, DWORD PTR [ebp+8] ;4.6
movq mm0, QWORD PTR [edx] ;5.23
mov eax, DWORD PTR [ebp+12] ;4.6
mov edx, 7 ;6.18
; LOE eax edx ebx esi edi mm0
$B1$2: ; Preds $B1$2 $B1$1
pmovmskb ecx, mm0 ;7.12
mov BYTE PTR [edx+eax], cl ;7.5
paddb mm0, mm0 ;8.9
add edx, -1 ;6.18
cmp edx, -1 ;6.3
jne $B1$2 ; Prob 90% ;6.3
; LOE eax edx ebx esi edi mm0
$B1$3: ; Preds $B1$2
emms ;10.3
; LOE ebx esi edi
$B1$4: ; Preds $B1$3
mov esp, ebp ;11.1
pop ebp ;11.1
ret ;11.1
ALIGN 4
; LOE
; mark_end;
?transpose@@YAXQAD0@Z ENDP
_TEXTENDS
_DATASEGMENT DWORD PUBLIC FLAT 'DATA'
_DATAENDS
; -- End ?transpose@@YAXQAD0@Z
_DATASEGMENT DWORD PUBLIC FLAT 'DATA'
_DATAENDS
END
���̗�ł�VC++���ICC�̍œK�����D��Ă��鎖�͂킩�������������������́H
�ߏ��˂�����l�Ԃ̂��鎖�͗����ł���B
�ߏ��˂�����l�Ԃ̂��鎖�͗����ł���B
6 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 19:29:54 ID:/wNwBa14
VC++���A�t�H�Ȃ������ƁB
>>2-6
�Ⴂ�A��B
�Ⴂ�A��B
8 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 20:16:16 ID:/wNwBa14
�����Ƃ��A���̃R�[�h���̂���ܗǂ��Ȃ��B
�A�����[�����Ă��ˑ��W�ŕ��ł���Ƃ��낪���Ȃ����B
����y�i���e�B�̘b�ɂ��Ă�Pentium M�Ȃ烋�[�v��p�̕���\���킪����̂Ŋ��S�m�[�~�X�ł����������Ȃ��i����͗ǂ����Ƃ����ǁj
���̗Ⴞ��_m_psllq(m, 1);�ő�p�\�Ȃ̂ł������A�ǁ[��痼�����ɓ����ϐ�������Ə�ɖ��ʂȃR�[�h��f���炵���B
_m_pxor(m, m);�Ń��W�X�^�N���A����Ƃ��B�܂������_mm_setzero_si64()���g�������̂����A
_m_pcmpeqb(m, m)�Ƃ��A _mm_setone_si64�Ƃ��Ȃ�����A�ǂ����悤���Ȃ�����Ȃ��ł����B
�S�r�b�g���Ă�QWORD�l��ǂݍ��ق��������ł��A�}�W�ŁB�g���܂���B
�܂Ƃ��ɍœK���m�E�n�E�������Ȃ�Intel�������̂��AMS���^�R�Ȃ̂��͒m��Ȃ�����
�����܂ŃR���p�C�����A�t�H�����炱���t�ɁAx86�ł�ASM���������鉿�l�������ł���B
GCC��CW��AltiVec�g����ASM�ŏ��������K�v�Ȃ����炢�܂Ƃ��ȃR�[�h�f���Ă����B
C���x���Ń\�t�g�p�C�v���C�j���O�͗]�T�B�Ƃ��������W�X�^���߂�������Ȃ���C�̂ق������₷���B
�A���S���Y���̃`���[�j���O�ɒ��͂ł���B
Mac�J���҂��ꂩ���ς��ȁBGCC��VC++�Ǝ����悤�ȃ��x����B
�A�����[�����Ă��ˑ��W�ŕ��ł���Ƃ��낪���Ȃ����B
����y�i���e�B�̘b�ɂ��Ă�Pentium M�Ȃ烋�[�v��p�̕���\���킪����̂Ŋ��S�m�[�~�X�ł����������Ȃ��i����͗ǂ����Ƃ����ǁj
���̗Ⴞ��_m_psllq(m, 1);�ő�p�\�Ȃ̂ł������A�ǁ[��痼�����ɓ����ϐ�������Ə�ɖ��ʂȃR�[�h��f���炵���B
_m_pxor(m, m);�Ń��W�X�^�N���A����Ƃ��B�܂������_mm_setzero_si64()���g�������̂����A
_m_pcmpeqb(m, m)�Ƃ��A _mm_setone_si64�Ƃ��Ȃ�����A�ǂ����悤���Ȃ�����Ȃ��ł����B
�S�r�b�g���Ă�QWORD�l��ǂݍ��ق��������ł��A�}�W�ŁB�g���܂���B
�܂Ƃ��ɍœK���m�E�n�E�������Ȃ�Intel�������̂��AMS���^�R�Ȃ̂��͒m��Ȃ�����
�����܂ŃR���p�C�����A�t�H�����炱���t�ɁAx86�ł�ASM���������鉿�l�������ł���B
GCC��CW��AltiVec�g����ASM�ŏ��������K�v�Ȃ����炢�܂Ƃ��ȃR�[�h�f���Ă����B
C���x���Ń\�t�g�p�C�v���C�j���O�͗]�T�B�Ƃ��������W�X�^���߂�������Ȃ���C�̂ق������₷���B
�A���S���Y���̃`���[�j���O�ɒ��͂ł���B
Mac�J���҂��ꂩ���ς��ȁBGCC��VC++�Ǝ����悤�ȃ��x����B
9 �FSocket774�F2006/02/04(�y) 20:23:46 ID:jHMZW75q
Mac�p�ɂ�Intel���R���p�C�������H
10 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 20:33:09 ID:/wNwBa14
Intel��Linux�Œ��x�̂��̂ł��������邩�ǂ����͋^�₾���ǂˁB
�܂��AIntel�ɂ��Ă݂��Objective-C�Ή��̃R���p�C���Ȃ�č���Ă��Ȃ����낤���A
�����Ȃ�ƃR���p�C���̎g���������K�v�ɂȂ�����B�ǂ���ɂ���J���҂͋�J����ˁB
Apple��C/C++�����̃t���[�����[�N�̊J���ĊJ���Ă����Ή��͊��œÂɂ��Đ����B
Cocoa�匙���B
�܂��AIntel�ɂ��Ă݂��Objective-C�Ή��̃R���p�C���Ȃ�č���Ă��Ȃ����낤���A
�����Ȃ�ƃR���p�C���̎g���������K�v�ɂȂ�����B�ǂ���ɂ���J���҂͋�J����ˁB
Apple��C/C++�����̃t���[�����[�N�̊J���ĊJ���Ă����Ή��͊��œÂɂ��Đ����B
Cocoa�匙���B
�ςȔS�����Z�ݒ����Ă��܂��܂�����orz
�ח��x�̃f�[�^�t���[�}�V�������D���H
>>���Œ�
�O�̃X���ł��䖝���Ă���CPU�A�[�e�N�`�������X�����Ƃ��������C�Â��B
�Ƃ������A������肽���̂��Ӗ��s�������犨�ق��Ă���B
���͐��ꗬ�������Ă���悤�ɂ��������Ȃ�����B�`���V�̗��Ɂi����
������ɂ���A���Ȃ�X���Ⴂ�����炳�A���̕ӂ���C�ǂ߂�B
�O�̃X���ł��䖝���Ă���CPU�A�[�e�N�`�������X�����Ƃ��������C�Â��B
�Ƃ������A������肽���̂��Ӗ��s�������犨�ق��Ă���B
���͐��ꗬ�������Ă���悤�ɂ��������Ȃ�����B�`���V�̗��Ɂi����
������ɂ���A���Ȃ�X���Ⴂ�����炳�A���̕ӂ���C�ǂ߂�B
14 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/04(�y) 23:57:24 ID:/wNwBa14
�܂��ȂACPU�A�[�L�e�N�`���̓�����m�炸���ă\�t�g�̍œK�������قNj����ł͂Ȃ�����
��{�I�ɓ˂����܂ꂽ��m���Ă�͈͂Ŗⓚ���悤����B
���Ȃ�Dinamic Binding��Polymorphism�Ȃǂ̃I�u�W�F�N�g�w���I�@�\�������ꂽ
�R�[�h����������̂ɗL���ȊԐڕ���\���̎����ɂ��ď��ꎞ�Ԃł��B
MacOS��Pentium M�x�[�X�̃A�[�L�e�N�`���Ɉڍs���Đ��������킩���ˁB
Java�Ƃ�Objective-C�ł��肪���ȃX�^�b�N�������Ԑڕ���������B
������������ł�����ł��c�_�͐��藧�Ǝv�����ȁB
���_�����ƂĕʔʃX���̓������肽���C�͂Ȃ��̂����A�X�g�[�J�[���ĕ|�����̂��ˁB
��{�I�ɓ˂����܂ꂽ��m���Ă�͈͂Ŗⓚ���悤����B
���Ȃ�Dinamic Binding��Polymorphism�Ȃǂ̃I�u�W�F�N�g�w���I�@�\�������ꂽ
�R�[�h����������̂ɗL���ȊԐڕ���\���̎����ɂ��ď��ꎞ�Ԃł��B
MacOS��Pentium M�x�[�X�̃A�[�L�e�N�`���Ɉڍs���Đ��������킩���ˁB
Java�Ƃ�Objective-C�ł��肪���ȃX�^�b�N�������Ԑڕ���������B
������������ł�����ł��c�_�͐��藧�Ǝv�����ȁB
���_�����ƂĕʔʃX���̓������肽���C�͂Ȃ��̂����A�X�g�[�J�[���ĕ|�����̂��ˁB
IBM�͂����o�b�p�����Q�[���p���ɓK�������̃`�b�v����鎖�ɗ͂���ꂽ�������̂Ă����Ď��Ȃ�ł��傤�ˁA�����Ɓc
�T�[�o�p�}���`�R�A�̏K��Ȃ�Ȃ��́H
17 �FSocket774�F2006/02/05(��) 00:33:50 ID:bVzEMXwj
> �m���Ă�͈�
�����̐������苷���m���Ō���Ă����f�疜�������������ȁB
�����̐������苷���m���Ō���Ă����f�疜�������������ȁB
18 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 00:36:30 ID:R0hFAHW0
����ł�R8C��SH���@�������Ƃ��邪�B����GeForce�̃V�F�[�_���ȁB
���̒��x�̊�b�I�Ȃ��ƂŒm��������Ɗ��Ⴂ���Ă���̂��B
�����������݂̂���苷�����E����O�ɏo���ق����������B
�����������݂̂���苷�����E����O�ɏo���ق����������B
20 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 00:42:27 ID:R0hFAHW0
>>19�͔��w�炵���̂ł�������Ă����̂��낤�Ȃ�����
���O�̌l�X������Ȃ�����A
�������Ɣ��������点�B
�������Ɣ��������点�B
22 �FSocket774�F2006/02/05(��) 02:11:29 ID:Jfoz0fjZ
>>�c�q
VC++�̍œK�����C�ɓ���Ȃ��Ȃ�MS news group��J����blog�Ƃ��ɏ��������B
�ӊO�ɂ܂Ƃ��ɑΉ����Ă���鎖�����邼�B�܂��A���̃R�[�h�̈Ӗ��͓˂����܂�邩��
����ȁE�E�E
gcc�̍œK�����C�ɓ���Ȃ���E�E�E�����E�E�E�����ł����Č����邩������ȁE�E�E
�ǂ���ɂ���Dinamic�Ƃ������Ă���p��͂ł�(ry
�Ƃ����RISC��CISC�̓J�o�[���Ă��邪EPIC�͒@�������Ȃ��̂��H
VC++�̍œK�����C�ɓ���Ȃ��Ȃ�MS news group��J����blog�Ƃ��ɏ��������B
�ӊO�ɂ܂Ƃ��ɑΉ����Ă���鎖�����邼�B�܂��A���̃R�[�h�̈Ӗ��͓˂����܂�邩��
����ȁE�E�E
gcc�̍œK�����C�ɓ���Ȃ���E�E�E�����E�E�E�����ł����Č����邩������ȁE�E�E
�ǂ���ɂ���Dinamic�Ƃ������Ă���p��͂ł�(ry
�Ƃ����RISC��CISC�̓J�o�[���Ă��邪EPIC�͒@�������Ȃ��̂��H
>>20
������Ă��Ă邵���̘A��������Ă��Ă邵�A
����肨�O�ԈႢ�w�E����Ă������ł��Ăˁ[���B
���̂��莆��蔖���v���C�h�ɓD�h���ĉΕa��O�ɂ����������͋C�ǂ߁A�g�O�B
������Ă��Ă邵���̘A��������Ă��Ă邵�A
����肨�O�ԈႢ�w�E����Ă������ł��Ăˁ[���B
���̂��莆��蔖���v���C�h�ɓD�h���ĉΕa��O�ɂ����������͋C�ǂ߁A�g�O�B
�c�q���b�ɎQ�����Ă��������ǁA�c�q�̘b����̂͂�߂ɂ��悤�B
���������̂��悯���������Ȃ�B
PWRfecient�Ƃ����������̘̂b�͂Ȃ��̂��B
���������̂��悯���������Ȃ�B
PWRfecient�Ƃ����������̘̂b�͂Ȃ��̂��B
25 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 03:26:22 ID:R0hFAHW0
>>22
Itanium�͎��@�͒@�������Ƃ͖����������������ʂɖ��߃Z�b�g�̊T�v�͒m���Ă邨�B
�R���p�C�������点�����Ƃ�����B�œK�����Ăǂ�ȓ������邩�͑�̗\�z���B
���[�AIPFsim�Ȃ�Ă̂����������ȁB
���Ƀ��b�`�Ȗ��߃Z�b�g�炵���AIA64�pVC++�ł���r�I�v���ʂ�̃R�[�h��f���炵���B
GCC������������ǁA���W�X�^��������3�I�y�����h�ȏ�i��j��I�j�ȉ��Z����
�܂Ƃ��ȃR�[�h�f���R���p�C�����đ����Ǝv���B
�\�z�Ȃ��ǁAVC++�̃R���p�C���G���W�����Ă��Ƃ��ƌÓT�IRISC�����ɑg�܂�Ă��Ȃ��́H
VC�̓f�����R�[�h����ƋC�Â�����
$L948:
movq�@mm1, mm0
dec�@eax //���Ȃ�ł����Ńt���O�X�V���Ă�́H
pmovmskb edx, mm0
paddb mm1, mm0
mov BYTE PTR [eax+ecx], dl
movq mm0, mm1
jne SHORT $L948//�����W�����v�͂�����
����jump���߂ƃt���O�X�V���߂̊ԂɃt���O���X�V���Ȃ����߁i�����ł�MMX/SSE���߁j����ɉ����A�������邱�Ƃ�
�p�C�v���C���X�g�[�������������Ă̂�RISC�v���Z�b�T�̍œK���̏퓅��i��������K�X�B
��ŁARISC�����̃R���p�C���G���W���ɏ�������x86���L�̍œK����@�������ꂽ�̂�����VC++�ƁB
x86��GCC������Ȋ��������B
�ʂ̃R�[�h�����ǃe�L�X�g�Z�O�����g����剻��������Pentium 4�����̍œK���ł��Ȃ�ɂ��ڂɂ��������Ƃ�����B
Pentium III��M���Ⴝ��������肶��Ȃ��������ǁAPentium 4����L1�L���b�V�������Ȃ菬����
�iNorthwood��HT�L���Ȃ�4kbyte�܂ł����g���Ȃ��j����A1���ŃZ�O�����g����KB�Ƃ��H����
���ꂾ���ŃL���b�V���~�X�̕p�x���オ��̂ˁB
��̃R�[�h��Hacker's Delight�ɍڂ��Ă�Bitwise Tranpose��SSE�œK���łˁB
�I���W�i���Ƃ͂܂������ʂ̕��@���g���Ă邯�ǁB
�͂��͂� PWR / efficient�@PWR / efficient
Itanium�͎��@�͒@�������Ƃ͖����������������ʂɖ��߃Z�b�g�̊T�v�͒m���Ă邨�B
�R���p�C�������点�����Ƃ�����B�œK�����Ăǂ�ȓ������邩�͑�̗\�z���B
���[�AIPFsim�Ȃ�Ă̂����������ȁB
���Ƀ��b�`�Ȗ��߃Z�b�g�炵���AIA64�pVC++�ł���r�I�v���ʂ�̃R�[�h��f���炵���B
GCC������������ǁA���W�X�^��������3�I�y�����h�ȏ�i��j��I�j�ȉ��Z����
�܂Ƃ��ȃR�[�h�f���R���p�C�����đ����Ǝv���B
�\�z�Ȃ��ǁAVC++�̃R���p�C���G���W�����Ă��Ƃ��ƌÓT�IRISC�����ɑg�܂�Ă��Ȃ��́H
VC�̓f�����R�[�h����ƋC�Â�����
$L948:
movq�@mm1, mm0
dec�@eax //���Ȃ�ł����Ńt���O�X�V���Ă�́H
pmovmskb edx, mm0
paddb mm1, mm0
mov BYTE PTR [eax+ecx], dl
movq mm0, mm1
jne SHORT $L948//�����W�����v�͂�����
����jump���߂ƃt���O�X�V���߂̊ԂɃt���O���X�V���Ȃ����߁i�����ł�MMX/SSE���߁j����ɉ����A�������邱�Ƃ�
�p�C�v���C���X�g�[�������������Ă̂�RISC�v���Z�b�T�̍œK���̏퓅��i��������K�X�B
��ŁARISC�����̃R���p�C���G���W���ɏ�������x86���L�̍œK����@�������ꂽ�̂�����VC++�ƁB
x86��GCC������Ȋ��������B
�ʂ̃R�[�h�����ǃe�L�X�g�Z�O�����g����剻��������Pentium 4�����̍œK���ł��Ȃ�ɂ��ڂɂ��������Ƃ�����B
Pentium III��M���Ⴝ��������肶��Ȃ��������ǁAPentium 4����L1�L���b�V�������Ȃ菬����
�iNorthwood��HT�L���Ȃ�4kbyte�܂ł����g���Ȃ��j����A1���ŃZ�O�����g����KB�Ƃ��H����
���ꂾ���ŃL���b�V���~�X�̕p�x���オ��̂ˁB
��̃R�[�h��Hacker's Delight�ɍڂ��Ă�Bitwise Tranpose��SSE�œK���łˁB
�I���W�i���Ƃ͂܂������ʂ̕��@���g���Ă邯�ǁB
�͂��͂� PWR / efficient�@PWR / efficient
�R���p�C�����n���R�[�h�f���č����Ă܂�
�R���g���[�����W�X�^���g��Ȃ��čςސ����L���X�g�p�̖��ߕt���Ă�������
�R���g���[�����W�X�^���g��Ȃ��čςސ����L���X�g�p�̖��ߕt���Ă�������
�������ȁA���������̗ǃX������������C�̕��Œׂ��̂͂��������Ȃ��B
����������AMD��Intel�Ń}���`�R�A�ւ̌������Ⴄ���ǖʔ����ȁB
����������AMD��Intel�Ń}���`�R�A�ւ̌������Ⴄ���ǖʔ����ȁB
RISC���������ʂɃX�P�W���[�����O����Ƃ����Ȃ�
�p�C�v���C�����������ꂽ���_�Ńt���O�ύX���߂ƃt���O��ύX���߂�
����ւ��Ȃ�Ă͕̂��ʂɂ������ȁB
����ւ��Ȃ�Ă͕̂��ʂɂ������ȁB
OS���n�[�h�Ŏ���������Ƃ����Ă���H
�߂�����y�������H
�߂�����y�������H
31 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 13:20:23 ID:R0hFAHW0
>>28 �[�킯��Intel�搶�̍œK��
icl hoge.cpp /FA /Ox /c /G{5,6,7} �Ō���
�E/G5�@Pentium
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
mov BYTE PTR [edx+eax], cl
paddb mm0, mm0
dec edx
cmp edx, -1
jne $B1$2
�E/G6 Pentium III�����B
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
paddb mm0, mm0
mov BYTE PTR [edx+eax], cl
dec edx
cmp edx, -1
jne $B1$2
�E/G7 Pentium 4, Pentium M�����Bdec��add -1�ɒu�������Ă���̂�NetBurst�̓����z�����ƁB
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
mov BYTE PTR [edx+eax], cl
paddb mm0, mm0
add edx, -1
cmp edx, -1
jne $B1$2
OoO�̖�����5����A�[�L�e�N�`���i�����Ƃ�SSE Pentium�Ȃ�ă��m�͑��݂��Ȃ����j�������܂�
�S��jcc�̓t���O�ύX�̒���ɂȂ��Ă�B
�����͔͂Ƃ����VC++�̍œK���̋������Ă���ς��ƌ��킴��Ȃ��B
�����Ă݂�킩�邪���[�v�̒��g�������Ƒ��₵���ꍇ�AVC++�͍ی��Ȃ��t���O����������O�̂ق��Ɏ����Ă���B
VC++�̑z�肵�Ă�A�[�L�e�N�`����
�E�t���O���������͏����W�����v���߂��ł��邾���O�̂ق��Ɏ����Ă����ق�������
�Esrc, dest�����ꃌ�W�X�^�̃I�y���[�V�����̓y�i���e�B������̂ŕʃ��W�X�^�ɒl�R�s�[�����ق�������
�Ȃ܂�IDE�t����Windows�R���p�C�����i�ōő�������x86�ɍœK������Ă�Ǝv��ꂪ������
���̕ӂ̓����������ł�x86�Ƀ`���[�j���O����Ă�Ƃ͌����������B�@
icl hoge.cpp /FA /Ox /c /G{5,6,7} �Ō���
�E/G5�@Pentium
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
mov BYTE PTR [edx+eax], cl
paddb mm0, mm0
dec edx
cmp edx, -1
jne $B1$2
�E/G6 Pentium III�����B
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
paddb mm0, mm0
mov BYTE PTR [edx+eax], cl
dec edx
cmp edx, -1
jne $B1$2
�E/G7 Pentium 4, Pentium M�����Bdec��add -1�ɒu�������Ă���̂�NetBurst�̓����z�����ƁB
mov eax, 7
$B1$2:
pmovmskb ecx, mm0
mov BYTE PTR [edx+eax], cl
paddb mm0, mm0
add edx, -1
cmp edx, -1
jne $B1$2
OoO�̖�����5����A�[�L�e�N�`���i�����Ƃ�SSE Pentium�Ȃ�ă��m�͑��݂��Ȃ����j�������܂�
�S��jcc�̓t���O�ύX�̒���ɂȂ��Ă�B
�����͔͂Ƃ����VC++�̍œK���̋������Ă���ς��ƌ��킴��Ȃ��B
�����Ă݂�킩�邪���[�v�̒��g�������Ƒ��₵���ꍇ�AVC++�͍ی��Ȃ��t���O����������O�̂ق��Ɏ����Ă���B
VC++�̑z�肵�Ă�A�[�L�e�N�`����
�E�t���O���������͏����W�����v���߂��ł��邾���O�̂ق��Ɏ����Ă����ق�������
�Esrc, dest�����ꃌ�W�X�^�̃I�y���[�V�����̓y�i���e�B������̂ŕʃ��W�X�^�ɒl�R�s�[�����ق�������
�Ȃ܂�IDE�t����Windows�R���p�C�����i�ōő�������x86�ɍœK������Ă�Ǝv��ꂪ������
���̕ӂ̓����������ł�x86�Ƀ`���[�j���O����Ă�Ƃ͌����������B�@
32 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/05(��) 13:28:46 ID:R0hFAHW0
�i�[����A�h���X��ecx+eax��������čl���������邩�B
�V�k�S�Ȃ��烋�[�v�� for (int i = 7; i >=0; i--) {} �ɕς��Ă݂���ǂ��Ȃ邩�����Ă݂܂�����B
PUBLIC?transpose@@YAXQAD0@Z; transpose
; Function compile flags: /Ogty
_TEXTSEGMENT
_a$ = 8; size = 4
_b$ = 12; size = 4
?transpose@@YAXQAD0@Z PROC NEAR; transpose
; Line 4
pushebp
movebp, esp
andesp, -8; fffffff8H
; Line 5
moveax, DWORD PTR _a$[ebp]
movqmm0, MMWORD PTR [eax]
; Line 6
movecx, DWORD PTR _b$[ebp]
moveax, 7
$L947:
deceax���Ӓn�ł��t���O�ύX�͂����I
; Line 7
pmovmskb edx, mm0
; Line 8
movqmm1, mm0
movBYTE PTR [eax+ecx+1], dl ��������+1���Ă邠��������K�����ƁB
paddbmm1, mm0
movqmm0, mm1
jnsSHORT $L947
; Line 10
emms
; Line 11
movesp, ebp
popebp
ret0
?transpose@@YAXQAD0@Z ENDP; transpose
_TEXTENDS
END
�V�k�S�Ȃ��烋�[�v�� for (int i = 7; i >=0; i--) {} �ɕς��Ă݂���ǂ��Ȃ邩�����Ă݂܂�����B
PUBLIC?transpose@@YAXQAD0@Z; transpose
; Function compile flags: /Ogty
_TEXTSEGMENT
_a$ = 8; size = 4
_b$ = 12; size = 4
?transpose@@YAXQAD0@Z PROC NEAR; transpose
; Line 4
pushebp
movebp, esp
andesp, -8; fffffff8H
; Line 5
moveax, DWORD PTR _a$[ebp]
movqmm0, MMWORD PTR [eax]
; Line 6
movecx, DWORD PTR _b$[ebp]
moveax, 7
$L947:
deceax���Ӓn�ł��t���O�ύX�͂����I
; Line 7
pmovmskb edx, mm0
; Line 8
movqmm1, mm0
movBYTE PTR [eax+ecx+1], dl ��������+1���Ă邠��������K�����ƁB
paddbmm1, mm0
movqmm0, mm1
jnsSHORT $L947
; Line 10
emms
; Line 11
movesp, ebp
popebp
ret0
?transpose@@YAXQAD0@Z ENDP; transpose
_TEXTENDS
END
>>30
OS��p���߂�n�[�h�E�F�A�Ȃ��������Ă���B
�Ⴆ��MMU���n�[�h�E�F�A��Ǘ��n���߁A�^�X�N��&�}���`�v���Z�b�T�ʐM���ߓ��B
OS��p���߂�n�[�h�E�F�A�Ȃ��������Ă���B
�Ⴆ��MMU���n�[�h�E�F�A��Ǘ��n���߁A�^�X�N��&�}���`�v���Z�b�T�ʐM���ߓ��B
>>25
> Itanium�͎��@�͒@�������Ƃ͖����������������ʂɖ��߃Z�b�g�̊T�v�͒m���Ă邨�B
�m�������Ԃ�\���ł��ˁB
�E�C������܂��ȁB
> Itanium�͎��@�͒@�������Ƃ͖����������������ʂɖ��߃Z�b�g�̊T�v�͒m���Ă邨�B
�m�������Ԃ�\���ł��ˁB
�E�C������܂��ȁB
SYMBOL
36 �FSocket774�F2006/02/05(��) 19:04:17 ID:qQ2o4RPr
�V���{��
>>�c�q
�X���Ⴂ���ĉ��x�������Ă���̂ɉ���VC�̘b��K���ɂȂ��đ����Ă�́H
�X���Ⴂ���ĉ��x�������Ă���̂ɉ���VC�̘b��K���ɂȂ��đ����Ă�́H
38 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 00:24:12 ID:WwONqoe8
�P�ɁuMMX/SSE�̍œK�����o�L�ځv���Ă��ƂŔ]���������Ƃ���B
�����ɂ͕���\���̃A���S���Y���ɂ��Č���l�����Ȃ��Ƃ������Ƃ��킩�����B
�����ɂ͕���\���̃A���S���Y���ɂ��Č���l�����Ȃ��Ƃ������Ƃ��킩�����B
����\���̘b��ȂǏo�����Ƃ��Ȃ��̂���
���Ⴀ������
41 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 01:02:26 ID:WwONqoe8
�m���Ɋ����ďo���Ȃ�������VC���t���O�l���Ȃ�ׂ�jcc�̎��s��葁���X�V���������闝�R���l������
����\���̋@�\�͊O���Ȃ�����B
dec��add�̖��߂̃��C�e���V�͂�������1��2���x�Ȃ̂ŁA�����܂ŕK���Ƀt���O�X�V��jcc��
���s�^�C�~���O�ɊԂ�u�������闝�R�͕���݂̖��ȊO�ɖ����B
Intel�̃R���p�C�������̂͂����܂�Intel�̐Ό����̍œK���Ȃ̂ŁA�݊�CPU�ł̍œK���܂ŕۏႵ�Ȃ��B
���Ƃ���AMD��VIA�̐��ƃ}�C�N���A�[�L�e�N�`���̎�����Intel�Ƃ��炭�Ⴄ�̂��ȁA�Ƃ��B
AMD�̍œK���}�j���A���͂낭�ɓǂ��Ƃ��Ȃ��̂ʼnɂȂƂ��ɖڂ�ʂ����ǁA�k�J�ɏI��邩�������ˁB
����\���̋@�\�͊O���Ȃ�����B
dec��add�̖��߂̃��C�e���V�͂�������1��2���x�Ȃ̂ŁA�����܂ŕK���Ƀt���O�X�V��jcc��
���s�^�C�~���O�ɊԂ�u�������闝�R�͕���݂̖��ȊO�ɖ����B
Intel�̃R���p�C�������̂͂����܂�Intel�̐Ό����̍œK���Ȃ̂ŁA�݊�CPU�ł̍œK���܂ŕۏႵ�Ȃ��B
���Ƃ���AMD��VIA�̐��ƃ}�C�N���A�[�L�e�N�`���̎�����Intel�Ƃ��炭�Ⴄ�̂��ȁA�Ƃ��B
AMD�̍œK���}�j���A���͂낭�ɓǂ��Ƃ��Ȃ��̂ʼnɂȂƂ��ɖڂ�ʂ����ǁA�k�J�ɏI��邩�������ˁB
�����̓R���p�C���������鏊����Ȃ���
����\���̓t�F�b�`���ɂ���n��
44 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 01:21:05 ID:WwONqoe8
>>42
�x�N�g���^�ɂ���X�J���^�ɂ���A�n�[�h�̓��������L���ȍœK����@��m�炸��
�n�[�h�ɂ��Č��邱�ƂȂ�ĂقƂ�ǖ����C�����邯��
>>43
���̒ʂ肾��B
���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
�ł��t�F�b�`�̓C���I�[�_����B
�x�N�g���^�ɂ���X�J���^�ɂ���A�n�[�h�̓��������L���ȍœK����@��m�炸��
�n�[�h�ɂ��Č��邱�ƂȂ�ĂقƂ�ǖ����C�����邯��
>>43
���̒ʂ肾��B
���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
�ł��t�F�b�`�̓C���I�[�_����B
��i�ƖړI������ւ���Ƃ�Ƃ͎v���ł����H
�œK���̓v���O���}�̎菕���ł����āACPU�̍������ł͂Ȃ������i���Ȃ��Ƃ��ŏ��́j
CPU�̖ړI�̓C���X�g���N�V�����̎��s�ł͂Ȃ��A�f�[�^���Z�̂��߂������i���Ȃ��Ƃ��ŏ��́j
�p�\�R���̖ړI�͑������������߂ł͂Ȃ��A�����A�v���������߂������i���Ȃ��Ƃ��ŏ��́j
�œK���̓v���O���}�̎菕���ł����āACPU�̍������ł͂Ȃ������i���Ȃ��Ƃ��ŏ��́j
CPU�̖ړI�̓C���X�g���N�V�����̎��s�ł͂Ȃ��A�f�[�^���Z�̂��߂������i���Ȃ��Ƃ��ŏ��́j
�p�\�R���̖ړI�͑������������߂ł͂Ȃ��A�����A�v���������߂������i���Ȃ��Ƃ��ŏ��́j
> �x�N�g���^�ɂ���X�J���^�ɂ���A�n�[�h�̓��������L���ȍœK����@��m�炸��
> �n�[�h�ɂ��Č��邱�ƂȂ�ĂقƂ�ǖ����C�����邯��
���炩�ɒx���R�[�h�����ăA�[�L�e�N�`������鎖�͖��ʂ��ȁB
�c�q�͂��̃X���ɒr�B
x86���߂̏��v�N���b�N�v���X��Part2
http://pc8.2ch.net/test/read.cgi/tech/1136527588/
> ���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
instruction decoder��symmetric�łȂ��ꍇ�͖�肪����B
> �n�[�h�ɂ��Č��邱�ƂȂ�ĂقƂ�ǖ����C�����邯��
���炩�ɒx���R�[�h�����ăA�[�L�e�N�`������鎖�͖��ʂ��ȁB
�c�q�͂��̃X���ɒr�B
x86���߂̏��v�N���b�N�v���X��Part2
http://pc8.2ch.net/test/read.cgi/tech/1136527588/
> ���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
instruction decoder��symmetric�łȂ��ꍇ�͖�肪����B
47 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 02:28:15 ID:WwONqoe8
���̃X���Ȃ猩�Ă��B�ڂڂ����m���͂Ȃ����珑�����݂͂��Ȃ����ǂˁB
> > ���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
> instruction decoder��symmetric�łȂ��ꍇ�͖�肪����B
�ق炻������Ę_�_�����炷�B���̓t���O�ύX��jcc�̊W�B
> > ���s��x86�݊��A�[�L�͎��s�̓A�E�g�I�u�I�[�_�����疽�߂̕��тȂ�Ă���������肶��Ȃ��B
> instruction decoder��symmetric�łȂ��ꍇ�͖�肪����B
�ق炻������Ę_�_�����炷�B���̓t���O�ύX��jcc�̊W�B
�n�����Ȃ��B
���O�̃I�i�j�[�X���̊ԈႢ���w�E���������B
�ԈႢ���w�E����ĊJ������n������ɋc�_�Ȃ�Ė��Ӗ�����
�c�_���Ă��Ȃ�����_�_�Ȃ�đ��݂��Ȃ��B
���O�̃I�i�j�[�X���̊ԈႢ���w�E���������B
�ԈႢ���w�E����ĊJ������n������ɋc�_�Ȃ�Ė��Ӗ�����
�c�_���Ă��Ȃ�����_�_�Ȃ�đ��݂��Ȃ��B
49 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 03:21:18 ID:WwONqoe8
> instruction decoder��symmetric�łȂ��ꍇ�͖�肪����B
�����b������肵�Č����Ă�͖̂����Ȃ̂ɂ���Ȃ킴�킴�m���Ă�͈͂̂��Ƃӂ���
����Ă�������Ęb��BID�Ⴄ���lj����H�쒆�������̂��ȁB
�u���O�̃X���v���B���Ⴀ���ɏ��L���F�߂��̂ˁB���Ⴀ���̃X���ɏ������܂Ȃ��ł����H
�����b������肵�Č����Ă�͖̂����Ȃ̂ɂ���Ȃ킴�킴�m���Ă�͈͂̂��Ƃӂ���
����Ă�������Ęb��BID�Ⴄ���lj����H�쒆�������̂��ȁB
�u���O�̃X���v���B���Ⴀ���ɏ��L���F�߂��̂ˁB���Ⴀ���̃X���ɏ������܂Ȃ��ł����H
50 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 03:26:22 ID:WwONqoe8
���łɌ������uthread�v�Ɓuresponse�v���ԈႦ���ƌ�����Ȃ�܂��܂��挊�ł���
���̂܂�������Ȃ��b����������ԈႦ��悤�Ȃ̂̓R���s���[�^�Z�p�ɂ��Č��ȑO�̖��Ȃ̂ŁB
���̂܂�������Ȃ��b����������ԈႦ��悤�Ȃ̂̓R���s���[�^�Z�p�ɂ��Č��ȑO�̖��Ȃ̂ŁB
�u�́v�ɂ͏��L�ȊO�̈Ӗ������鎖�͂���Ȃ��̂ł����H
52 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/06(��) 03:32:50 ID:WwONqoe8
�������u�I�i�j�[�X���v�Ƃ��������Ƃ͍m�肵�ꂵ���������܂�����������
��������ŐQ���B���Q�������疰���Ȃ����ǁB
��������ŐQ���B���Q�������疰���Ȃ����ǁB
>>47
>���̓t���O�ύX��jcc�̊W�B
�[��������Ă��AuOp�ɕϊ���ǂ��œK�����Ă�́H���ĕ����Ă�̂Ɠ�������H
����ȂɃf�B�[�v�ȓ�������Intel��AMD�����J���Ȃ�����B���ꂪx86�̎��s�����̃L���ɂ��Ȃ邵�D�D
���n�Ōv�邵��������Ȃ����H
�ꉞ�Cuop�ŃO�O��ƈȉ������������D�ǂ������C�O�j���[�X��(~~;)
K8
http://pc.watch.impress.co.jp/docs/article/20011102/kaigai01.htm
Yonah
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
>���̓t���O�ύX��jcc�̊W�B
�[��������Ă��AuOp�ɕϊ���ǂ��œK�����Ă�́H���ĕ����Ă�̂Ɠ�������H
����ȂɃf�B�[�v�ȓ�������Intel��AMD�����J���Ȃ�����B���ꂪx86�̎��s�����̃L���ɂ��Ȃ邵�D�D
���n�Ōv�邵��������Ȃ����H
�ꉞ�Cuop�ŃO�O��ƈȉ������������D�ǂ������C�O�j���[�X��(~~;)
K8
http://pc.watch.impress.co.jp/docs/article/20011102/kaigai01.htm
Yonah
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
�ǂ��݂Ă��c�q�̗��Ă��c�q�̃I�i�j�[�X���ł��B
�{���ɂ��肪�Ƃ��������܂����B
�{���ɂ��肪�Ƃ��������܂����B
55 �FSocket774�F2006/02/06(��) 05:57:13 ID:6FhlB5zU
�X���̏��L����錾����E���Rwww
�v���O�����ő���ɂ���Ȃ�����������āA
���̗ǐS�I�X���ɒ���t���čr�炵������l���Č����ł�
���̗ǐS�I�X���ɒ���t���čr�炵������l���Č����ł�
MAC���^���̓}�V�����ǂ�
MAC���^�͊ԈႢ��F�߂�̂Œc�q���}�V
���̖��ɂ������ˁ[���ԈႢ�w�E����Ă������ł��Ăˁ[��
�}�W�ōr�炵�ȊO�̉����ł��Ȃ���ȁB���߂ĕ֏��l�^�ł�������Ⴂ���̂ɁB
�}�W�ōr�炵�ȊO�̉����ł��Ȃ���ȁB���߂ĕ֏��l�^�ł�������Ⴂ���̂ɁB
2-60�����ځ[��ʼn�?
>>56
�c�q�͒����ɏ���������t�������т��
�c�q�͒����ɏ���������t�������т��
62 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 00:34:16 ID:T7yiuvqt
MS�̃R���p�C���̓����̓o�O�Ƃ�����Ȃ��ĉ����m�M�������Ă���Ă�悤�Ɍ�������łˁB
x86�Łu�x������v���L�����ǂ����H
MS�̃R���p�C���̗�̓����́A�t���O�𑁊��Ɋm�肳���邱�ƂŃp�C�v���C���n�U�[�h��
�t���O�m�肾����Ɏ����Ă��Ă��A�ǂ̃t���O���g�����A�ǂ��ɃW�����v���邩�̏���JCC�̂ق��ɂ���킯������
�Ӗ��Ȃ��悤�ɂ�������B����Intel�R���p�C���͂���ȓ��������ĂȂ��B
Intel CPU�ȊO�̉����ł͖��ɗ����Ȃ̂�������Ȃ��B
������Intel�R���p�C����VC++��葽�߂ɓf���Ă���̂�test��cmp�Ȃǂ̔�r���߂����A�R���͎��́i�ȉ������j
���̂ւ�̗����͕���\���̎����ɗ���ł���͂��ȂȁB
�܂���ɂ��w�E������悤�ɂ��̂ւ�͊�{�I�Ƀu���b�N�{�b�N�X�Ȃ̂őz���ɗ��邵���Ȃ��Ƃ���͑����Ǝv���B
���̘b��̓��ɒ��x���̋c�_����Ă�X���i�������A�C�X�����Ă�l�̃X������Ȃ���j���������
�������œ����Ă݂��B���͔�䍂��Ă���B
>>55
�܂��ׂɒ�������C�͂Ȃ����u���O�̃X���v���Č�����u���Ⴀ���߂����؍��������ˁv���Đ�Ԃ��̂�
���R�Ǝv���܂����A�����H
�ȉ��߂�ǂ������̂ŗ�
x86�Łu�x������v���L�����ǂ����H
MS�̃R���p�C���̗�̓����́A�t���O�𑁊��Ɋm�肳���邱�ƂŃp�C�v���C���n�U�[�h��
�t���O�m�肾����Ɏ����Ă��Ă��A�ǂ̃t���O���g�����A�ǂ��ɃW�����v���邩�̏���JCC�̂ق��ɂ���킯������
�Ӗ��Ȃ��悤�ɂ�������B����Intel�R���p�C���͂���ȓ��������ĂȂ��B
Intel CPU�ȊO�̉����ł͖��ɗ����Ȃ̂�������Ȃ��B
������Intel�R���p�C����VC++��葽�߂ɓf���Ă���̂�test��cmp�Ȃǂ̔�r���߂����A�R���͎��́i�ȉ������j
���̂ւ�̗����͕���\���̎����ɗ���ł���͂��ȂȁB
�܂���ɂ��w�E������悤�ɂ��̂ւ�͊�{�I�Ƀu���b�N�{�b�N�X�Ȃ̂őz���ɗ��邵���Ȃ��Ƃ���͑����Ǝv���B
���̘b��̓��ɒ��x���̋c�_����Ă�X���i�������A�C�X�����Ă�l�̃X������Ȃ���j���������
�������œ����Ă݂��B���͔�䍂��Ă���B
>>55
�܂��ׂɒ�������C�͂Ȃ����u���O�̃X���v���Č�����u���Ⴀ���߂����؍��������ˁv���Đ�Ԃ��̂�
���R�Ǝv���܂����A�����H
�ȉ��߂�ǂ������̂ŗ�
63 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 00:35:46 ID:T7yiuvqt
-MS�̃R���p�C���̗�̓����́A�t���O�𑁊��Ɋm�肳���邱�ƂŃp�C�v���C���n�U�[�h��
+MS�̃R���p�C���̗�̓����́A�t���O�𑁊��Ɋm�肳���邱�ƂŃp�C�v���C���n�U�[�h�����or�y�����邽�߂̂��̂ł́H
+MS�̃R���p�C���̗�̓����́A�t���O�𑁊��Ɋm�肳���邱�ƂŃp�C�v���C���n�U�[�h�����or�y�����邽�߂̂��̂ł́H
>>62
> MS�̃R���p�C���̓����̓o�O�Ƃ�����Ȃ��ĉ����m�M�������Ă���Ă�悤�Ɍ�������łˁB
�o�O�ł����ʂȏ����ł��Ȃ��A���ʂɃX�P�W���[�����O����Ƃ����Ȃ�(���Ƃ�����)���́B
> x86�Łu�x������v���L�����ǂ����H(�ȉ���)
�S���Ӗ��s��
> ���̂ւ�̗����͕���\���̎����ɗ���ł���͂��ȂȁB
�ǂ����ǂ����ނ̂��A�z���ł��������珑���Ă݂��B
> MS�̃R���p�C���̓����̓o�O�Ƃ�����Ȃ��ĉ����m�M�������Ă���Ă�悤�Ɍ�������łˁB
�o�O�ł����ʂȏ����ł��Ȃ��A���ʂɃX�P�W���[�����O����Ƃ����Ȃ�(���Ƃ�����)���́B
> x86�Łu�x������v���L�����ǂ����H(�ȉ���)
�S���Ӗ��s��
> ���̂ւ�̗����͕���\���̎����ɗ���ł���͂��ȂȁB
�ǂ����ǂ����ނ̂��A�z���ł��������珑���Ă݂��B
65 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 01:12:35 ID:T7yiuvqt
���߂ĕ������ǁA>>32���A���ʂɃX�P�W���[�����O����Ƃ����Ȃ�͈͓��H
���_�́A�uIntel CPU�ɂ͂����܂Ŗ��Ӗ��v�����A�����ʂ̃A�[�L�e�N�`���̕����ł͗L����
�X�P�W���[�����O����Ȃ����Ƃ����b�B
�x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
����攻����ɐ����߁A�ǂ����ɕ��Ă�������p�̖������߂𑱂��邱�Ƃ���
����̃y�i���e�B���������Ƃ�����B
�t���O�X�V��jcc�̊Ԃ̖��ߐ����߂��A���鉽���̃A�[�L�e�N�`���ł́A
�p�C�v���C���X�g�[�����B�����邽�߂Ɏg����̂ł́A�Ƃ��������B
�܂�����͂ނ��땪��\������Ȃ��ĕ���m���̏�����肾���ǂˁB
���_�́A�uIntel CPU�ɂ͂����܂Ŗ��Ӗ��v�����A�����ʂ̃A�[�L�e�N�`���̕����ł͗L����
�X�P�W���[�����O����Ȃ����Ƃ����b�B
�x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
����攻����ɐ����߁A�ǂ����ɕ��Ă�������p�̖������߂𑱂��邱�Ƃ���
����̃y�i���e�B���������Ƃ�����B
�t���O�X�V��jcc�̊Ԃ̖��ߐ����߂��A���鉽���̃A�[�L�e�N�`���ł́A
�p�C�v���C���X�g�[�����B�����邽�߂Ɏg����̂ł́A�Ƃ��������B
�܂�����͂ނ��땪��\������Ȃ��ĕ���m���̏�����肾���ǂˁB
66 �FSocket774�F2006/02/07(��) 01:25:41 ID:1pSEKBge
>>65
> ���߂ĕ������ǁA>>32���A���ʂɃX�P�W���[�����O����Ƃ����Ȃ�͈͓��H
�����Ȃ�͈͓�
> �x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
�x������̓n�[�h�E�F�A�̘b���B
x86�ɒx�����������ꂽ���Ƃ͈�x���Ȃ��B
> �t���O�X�V��jcc�̊Ԃ̖��ߐ����߂��A���鉽���̃A�[�L�e�N�`���ł́A �p�C�v���C���X�g�[�����B�����邽�߂Ɏg����̂ł́A�Ƃ��������B
���̃A�[�L�e�N�`���ł́A��ʓI��(�����R�[�h���܂߂�)�f�[�^�ˑ��W�̂���ꍇ�͂����Ȃ�B
�ǂ��ł��������p�C�v���C���X�g�[�����B���Ƃ����̂͂������Ȍ����������B
> �܂�����͂ނ��땪��\������Ȃ��ĕ���m���̏�����肾���ǂˁB
�����番��\���͑S�R�W�ˁ[�́B
> ���߂ĕ������ǁA>>32���A���ʂɃX�P�W���[�����O����Ƃ����Ȃ�͈͓��H
�����Ȃ�͈͓�
> �x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
�x������̓n�[�h�E�F�A�̘b���B
x86�ɒx�����������ꂽ���Ƃ͈�x���Ȃ��B
> �t���O�X�V��jcc�̊Ԃ̖��ߐ����߂��A���鉽���̃A�[�L�e�N�`���ł́A �p�C�v���C���X�g�[�����B�����邽�߂Ɏg����̂ł́A�Ƃ��������B
���̃A�[�L�e�N�`���ł́A��ʓI��(�����R�[�h���܂߂�)�f�[�^�ˑ��W�̂���ꍇ�͂����Ȃ�B
�ǂ��ł��������p�C�v���C���X�g�[�����B���Ƃ����̂͂������Ȍ����������B
> �܂�����͂ނ��땪��\������Ȃ��ĕ���m���̏�����肾���ǂˁB
�����番��\���͑S�R�W�ˁ[�́B
67 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 01:34:10 ID:T7yiuvqt
�����̃A�[�L�e�N�`���ł́A��ʓI��(�����R�[�h���܂߂�)�f�[�^�ˑ��W�̂���ꍇ�͂����Ȃ�B
�ˑ��W�ˁB�͂��B
��������Ȃ��ƁA��̓I�ɂǂ��ǂ��Ɉˑ��W�̖�肪��������̂ł��傤���H
���ƁAICC�̍œK���ł�jcc�̒��O��cmp��test���߂s���t���O�ύX���Ă܂�������͈�����ł����H
>>66
����\���̓t���O�ύX���Ď����Ă��Ȃ���́H���̉����ɂ͂������ɒ��ڂ͊W�Ȃ����ǁB
�����������R�C�c�H��C�ǂ߂Ȃ��n�����Ė{�C�ŃE�U���ȁB
�N��l�Ƃ��Ďx�����炵�Ă���Ȃ��̂ɂ悭����c���Ȗ����r�������B
�N��l�Ƃ��Ďx�����炵�Ă���Ȃ��̂ɂ悭����c���Ȗ����r�������B
>>67
> ��������Ȃ��ƁA��̓I�ɂǂ��ǂ��Ɉˑ��W�̖�肪��������̂ł��傤���H
��ʓI�ɂ́A�f�[�^�t���[�O���t�D���traverse����ƕ���x�̍����R�[�h���ł���B
��������Ǝ����I��producer��consumer���߂̊Ԃɖ��W�̖��߂�����������肱�ށB
���ۂ̓��\�[�X�̐���������̂ł����ƕ��G�ȃX�P�W���[�����O������Ă�B
> ����\���̓t���O�ύX���Ď����Ă��Ȃ���́H
���ĂȂ��B
�����resolve�ɂ͂������t���O�̒l���K�v�����A�����\�����鎞�̓t���O�͌��Ȃ��B
> ��������Ȃ��ƁA��̓I�ɂǂ��ǂ��Ɉˑ��W�̖�肪��������̂ł��傤���H
��ʓI�ɂ́A�f�[�^�t���[�O���t�D���traverse����ƕ���x�̍����R�[�h���ł���B
��������Ǝ����I��producer��consumer���߂̊Ԃɖ��W�̖��߂�����������肱�ށB
���ۂ̓��\�[�X�̐���������̂ł����ƕ��G�ȃX�P�W���[�����O������Ă�B
> ����\���̓t���O�ύX���Ď����Ă��Ȃ���́H
���ĂȂ��B
�����resolve�ɂ͂������t���O�̒l���K�v�����A�����\�����鎞�̓t���O�͌��Ȃ��B
MIPS�A�}���`�X���b�f�B���O�Ή���32bit�R�A�t�@�~���\
ttp://pc.watch.impress.co.jp/docs/2006/0207/mips.htm
ttp://pc.watch.impress.co.jp/docs/2006/0207/mips.htm
72 �FSocket774�F2006/02/07(��) 02:11:15 ID:DYVyuZtY
> ����\���̓t���O�ύX���Ď����Ă��Ȃ���́H
�i�@߄t߁j�߶��
�i�@߄t߁j�߶��
73 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 02:36:08 ID:T7yiuvqt
����Hjcc���s���̗��������Ŕ��肵�Ă����H
�t���O�l�̕ω����\���ɔ��f����Ă锤�����H
�܂�������B
>>69�̐�������A�ĎO�����Ă�A�ŏI�̃t���O�ύX��jcc�̊Ԃ̕s���R�ȊԊu�̐����ɂȂ��ĂȂ�㩁B
�ˑ��W�Ȃ炽�Ƃ���pmovmskb�����mov [mem], dx�ɂ����Ă���B
[eax+ecx+1]�Ȃ�Ă�����疽�ߒ���������B�����܂ł��Ă��K�v�̂��邱�Ƃ��H
�S�����̗����Ő����\�H
�̈ӂɂ���������Ă�悤����ICC�ɂ��Ă��D�~��낵���B
�X�P�W���[�����O���܂������ʕ��Ȃ̂ł��������������B
�����͂����������낢����בւ��Ă݂ăp�t�H�[�}���X�e�X�g�͍s���Ă��邪�����I�ɐ������Ƃ������_�ɒB�����B
�t���O�l�̕ω����\���ɔ��f����Ă锤�����H
�܂�������B
>>69�̐�������A�ĎO�����Ă�A�ŏI�̃t���O�ύX��jcc�̊Ԃ̕s���R�ȊԊu�̐����ɂȂ��ĂȂ�㩁B
�ˑ��W�Ȃ炽�Ƃ���pmovmskb�����mov [mem], dx�ɂ����Ă���B
[eax+ecx+1]�Ȃ�Ă�����疽�ߒ���������B�����܂ł��Ă��K�v�̂��邱�Ƃ��H
�S�����̗����Ő����\�H
�̈ӂɂ���������Ă�悤����ICC�ɂ��Ă��D�~��낵���B
�X�P�W���[�����O���܂������ʕ��Ȃ̂ł��������������B
�����͂����������낢����בւ��Ă݂ăp�t�H�[�}���X�e�X�g�͍s���Ă��邪�����I�ɐ������Ƃ������_�ɒB�����B
�����y���݂ɂ��̃X����`�����Ă�����Ă���҂ł�
�ŋߒm�������Ԃ���݂�Ȃł����߂鏑�����݂���œǂނ̂����ɂȂ�܂�
�ł�����\���̓t���O�ύX���Ď�����ʂ�Ƃ��������͒v���I�����܂�
�ŋߒm�������Ԃ���݂�Ȃł����߂鏑�����݂���œǂނ̂����ɂȂ�܂�
�ł�����\���̓t���O�ύX���Ď�����ʂ�Ƃ��������͒v���I�����܂�
>>73
> �t���O�l�̕ω����\���ɔ��f����Ă锤�����H
�ǂ����炻�������E�\�m�����B�B�B
����\���͊�{�I�ɂ͕��߂̃A�h���X�ƕ��������g���B
> �ŏI�̃t���O�ύX��jcc�̊Ԃ̕s���R�ȊԊu�̐����ɂȂ��ĂȂ�㩁B
���܂���dec eax����̂ǂ��ɂ���Ύ��R���Ƃ����B
dec eax��jcc�̊Ԃɂ̓��[�v�{�̂����邾�������B
icc���ׂɂ��������͂Ȃ�����B����ȒZ���R�[�h�Ȃ�ǂ����ׂ��Ƃ���ő卷�Ȃ��B
P6�ȏ�Ȃ�dec-cmp-jcc��uops�t���[�W��������Ă邩�������B
> �t���O�l�̕ω����\���ɔ��f����Ă锤�����H
�ǂ����炻�������E�\�m�����B�B�B
����\���͊�{�I�ɂ͕��߂̃A�h���X�ƕ��������g���B
> �ŏI�̃t���O�ύX��jcc�̊Ԃ̕s���R�ȊԊu�̐����ɂȂ��ĂȂ�㩁B
���܂���dec eax����̂ǂ��ɂ���Ύ��R���Ƃ����B
dec eax��jcc�̊Ԃɂ̓��[�v�{�̂����邾�������B
icc���ׂɂ��������͂Ȃ�����B����ȒZ���R�[�h�Ȃ�ǂ����ׂ��Ƃ���ő卷�Ȃ��B
P6�ȏ�Ȃ�dec-cmp-jcc��uops�t���[�W��������Ă邩�������B
76 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 03:02:08 ID:T7yiuvqt
�v���I�Ȃ͕̂�����ǂ��݂Ă����Ⴂ�����Ƃ����v���Ȃ��u�X���v�Ɓu���X�v�̊ԈႢ�ȏ�̂��̂͂Ȃ����ƁB
�������A�ÓT�I�ȕ���\���V�X�e���͕�������E�A�h���X�̗����e�[�u�����g���Ă�̂͏��m�Ȃ��ǂ��A
���[�v���o��̋@�\�̈������ɐ������Ă���Ȃ��H
�������A�ÓT�I�ȕ���\���V�X�e���͕�������E�A�h���X�̗����e�[�u�����g���Ă�̂͏��m�Ȃ��ǂ��A
���[�v���o��̋@�\�̈������ɐ������Ă���Ȃ��H
>>76
> �������A�ÓT�I�ȕ���\���V�X�e���͕�������E�A�h���X�̗����e�[�u�����g���Ă�̂͏��m�Ȃ��ǂ��A
�g���ĂȂ��B
> ���[�v���o��̋@�\�̈������ɐ������Ă���Ȃ��H
���O�̔]���@�\�̐������ł��Ȃ��B
> �������A�ÓT�I�ȕ���\���V�X�e���͕�������E�A�h���X�̗����e�[�u�����g���Ă�̂͏��m�Ȃ��ǂ��A
�g���ĂȂ��B
> ���[�v���o��̋@�\�̈������ɐ������Ă���Ȃ��H
���O�̔]���@�\�̐������ł��Ȃ��B
78 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 03:14:14 ID:T7yiuvqt
>>75
��OP���t���[�W���������߂́u�Č����v���Ǝv���Ă�l������������
> P6�ȏ�Ȃ�dec-cmp-jcc��uops�t���[�W��������Ă邩�������B
�z�[���������́i����
��OP���t���[�W�����Ă̂�
�]��P6�ł̓��W�X�^�E�������ԃI�y���[�V�����́A���������[�h�ƃI�y���[�V�����ɕ������ď������Ă��B
�Q�ȏ�̃�OP�ɕ�������͕̂��G�ȃA���S���Y�����K�v�Ȃ̂ŁA3�̃f�R�[�_�̂�����
�P��ComplexDecorder�p�X�ł����f�R�[�h�ł��Ȃ������B
�iVC++�ł͍��ł�/G6�ł̓������E���W�X�^�ԃI�y���[�V�����̐������Ȃ�ׂ�������j
Pentium M�ł́A�f�R�[�h�X�e�[�W�ŕ��������P�̃�OP�Ƃ��Ĉ����A���̂܂܃X�P�W���[�����O��
���s�O�̃X�e�[�W�ŕ��������s���Č������Ă��烊�^�C���Ƃ����@�\�������́B
����łR���قǓ������������������B
�����Ċ�����x86���߂���������Z�p����Ȃ���B
��OP���t���[�W���������߂́u�Č����v���Ǝv���Ă�l������������
> P6�ȏ�Ȃ�dec-cmp-jcc��uops�t���[�W��������Ă邩�������B
�z�[���������́i����
��OP���t���[�W�����Ă̂�
�]��P6�ł̓��W�X�^�E�������ԃI�y���[�V�����́A���������[�h�ƃI�y���[�V�����ɕ������ď������Ă��B
�Q�ȏ�̃�OP�ɕ�������͕̂��G�ȃA���S���Y�����K�v�Ȃ̂ŁA3�̃f�R�[�_�̂�����
�P��ComplexDecorder�p�X�ł����f�R�[�h�ł��Ȃ������B
�iVC++�ł͍��ł�/G6�ł̓������E���W�X�^�ԃI�y���[�V�����̐������Ȃ�ׂ�������j
Pentium M�ł́A�f�R�[�h�X�e�[�W�ŕ��������P�̃�OP�Ƃ��Ĉ����A���̂܂܃X�P�W���[�����O��
���s�O�̃X�e�[�W�ŕ��������s���Č������Ă��烊�^�C���Ƃ����@�\�������́B
����łR���قǓ������������������B
�����Ċ�����x86���߂���������Z�p����Ȃ���B
79 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 03:31:08 ID:T7yiuvqt
��OPs�t���[�W�����m��Ȃ��Ȃ�PenM�̕���\����̎������m��킯������ȁB
���Ȃ݂Ƀ��[�v���o����Ă̂�Pentium M�ɓ��ڂ��ꂽ�������g���̂ł͂Ȃ��A���[�v�����S�ɃJ�E���g����
���S�ɕ�������ĂĂ��܂����̂Ȃ��ǁA���R�Ȃ��炱���ɂ�BTB�Ȃ�Ďg���ĂȂ��B
Pentium II/III������̎����IA32�œK���}�j���A���ɕ���\���̎����ɂ��ďڍׂɏq�ׂ��Ă��B
�؍��̑�w��FTP�T�C�g�ɂȂ����Â��̂��オ���Ă��肵�������͑��������ȁB
�ŐV�̂͂ǂ���T�v�I�Ȃ��Ƃ����ڂ��ĂȂ�
���Ȃ݂Ƀ��[�v���o����Ă̂�Pentium M�ɓ��ڂ��ꂽ�������g���̂ł͂Ȃ��A���[�v�����S�ɃJ�E���g����
���S�ɕ�������ĂĂ��܂����̂Ȃ��ǁA���R�Ȃ��炱���ɂ�BTB�Ȃ�Ďg���ĂȂ��B
Pentium II/III������̎����IA32�œK���}�j���A���ɕ���\���̎����ɂ��ďڍׂɏq�ׂ��Ă��B
�؍��̑�w��FTP�T�C�g�ɂȂ����Â��̂��オ���Ă��肵�������͑��������ȁB
�ŐV�̂͂ǂ���T�v�I�Ȃ��Ƃ����ڂ��ĂȂ�
���������[�v�͍ŋߐ���̗�������O���[�o���p�^�[���e�[�u���Q�Ƃ̋@�\�ł����邯��
�ł��������[�v�����o����u���[�v���o��v���ǂ�ȃA���S���Y���ɂȂ��Ă邩�͓䂾��
�Ƃ͂����A���Ȃ��Ƃ��t���O�Ď��Ȃ�Ĕ��z�͏o�Ă��Ȃ��Ǝv����
>>BTB�Ȃ�Ďg���ĂȂ��B
BTB�͎g���Ă邾��
�ł��������[�v�����o����u���[�v���o��v���ǂ�ȃA���S���Y���ɂȂ��Ă邩�͓䂾��
�Ƃ͂����A���Ȃ��Ƃ��t���O�Ď��Ȃ�Ĕ��z�͏o�Ă��Ȃ��Ǝv����
>>BTB�Ȃ�Ďg���ĂȂ��B
BTB�͎g���Ă邾��
82 �FSocket774�F2006/02/07(��) 03:47:17 ID:qLVExI4Y
���I�ɂ̓�Ops�t���[�W�������z�[���������Ȃ�A
����\���Ƀt���O�Ď��̓O�����h�X�������A
���X�ƃX���̓V���O���q�b�g��
���ȁB
����\���Ƀt���O�Ď��̓O�����h�X�������A
���X�ƃX���̓V���O���q�b�g��
���ȁB
���́��j��-������- ��Pu/ODYSSEY�́A����ׂ萙
������Web�T�C�g�ł���B
2ch�ł͑��̔����҂d���Ď��d����B
������Web�T�C�g�ł���B
2ch�ł͑��̔����҂d���Ď��d����B
84 �FSocket774�F2006/02/07(��) 04:05:46 ID:qLVExI4Y
85 �F���́��j��-������- ��Pu/ODYSSEY �F2006/02/07(��) 04:19:45 ID:T7yiuvqt
>>80
���������B
���[�v���o��̍쓮�����ׂĂ݂�Ƃ��������ˁB
������for���͌�u�ɓW�J����邯�ǁA���[�v���o�������ĂȂ���Ԃ��ƁABTB�͑O���W�����v�Ŗ��܂��Ă邾�낤����
���[�v����Ƃ��ɕ���~�X����̂͑z���ɓ�Ȃ��B
�ł��AICC�����[�v����cmp/test�����闝�R���Ă̂́i����
> >>BTB�Ȃ�Ďg���ĂȂ��B
> BTB�͎g���Ă邾��
���[�v���o��ň����Ȃ����̂�BTB��p�������I����\����ň����Ƃ����Ӗ��ł͐���������
���[�v���o�펩�̂�BTB�������ĂȂ���B
http://www.intel.co.jp/jp/developer/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm
���������B
���[�v���o��̍쓮�����ׂĂ݂�Ƃ��������ˁB
������for���͌�u�ɓW�J����邯�ǁA���[�v���o�������ĂȂ���Ԃ��ƁABTB�͑O���W�����v�Ŗ��܂��Ă邾�낤����
���[�v����Ƃ��ɕ���~�X����̂͑z���ɓ�Ȃ��B
�ł��AICC�����[�v����cmp/test�����闝�R���Ă̂́i����
> >>BTB�Ȃ�Ďg���ĂȂ��B
> BTB�͎g���Ă邾��
���[�v���o��ň����Ȃ����̂�BTB��p�������I����\����ň����Ƃ����Ӗ��ł͐���������
���[�v���o�펩�̂�BTB�������ĂȂ���B
http://www.intel.co.jp/jp/developer/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm
> ���[�v���o��ň����Ȃ����̂�BTB��p�������I����\����ň���
�������Ⴂ���Ă���悤�����ABTB�̓W�����v�̃^�[�Q�b�g�A�h���X��ێ�����o�b�t�@����
�^�[�Q�b�g�̏����g�킸�ɂǂ�����ĕ���\������H
�܂��A�����e�[�u���Ȃǂ��܂߂ďW���I��BTB�ƌĂԁA�Ə����Ă��邪
�������Ⴂ���Ă���悤�����ABTB�̓W�����v�̃^�[�Q�b�g�A�h���X��ێ�����o�b�t�@����
�^�[�Q�b�g�̏����g�킸�ɂǂ�����ĕ���\������H
�܂��A�����e�[�u���Ȃǂ��܂߂ďW���I��BTB�ƌĂԁA�Ə����Ă��邪
>>78
�������������B
�Z���̑ΏۂɂȂ�̂͒P���x86���߂���ϊ����ꂽuOPs�������Ă��ƁH
compare&branch�ɗZ������[�b�͂Ȃŕ������o����������A
jcxz���߂Ƃ����A����CPU���������APARROT�Ȃ̃��^�b�������������B
�܂�������B����͓����CPU�ɂ͏ڂ����Ȃ��̂�B���ꂩ������ނ�B
�ŁA����PentiumM�̕���\�����VC++��ICC�̃X�P�W���[�����O���ǂ��W����H
>>81
> �ł��������[�v�����o����u���[�v���o��v���ǂ�ȃA���S���Y���ɂȂ��Ă邩�͓䂾��
ttp://www.intel.co.jp/jp/developer/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm
�����̂����ɃJ�E���^�ƃ��~�b�g�Ŕ��肵�Ă�ۂ��ȁB
�������������B
�Z���̑ΏۂɂȂ�̂͒P���x86���߂���ϊ����ꂽuOPs�������Ă��ƁH
compare&branch�ɗZ������[�b�͂Ȃŕ������o����������A
jcxz���߂Ƃ����A����CPU���������APARROT�Ȃ̃��^�b�������������B
�܂�������B����͓����CPU�ɂ͏ڂ����Ȃ��̂�B���ꂩ������ނ�B
�ŁA����PentiumM�̕���\�����VC++��ICC�̃X�P�W���[�����O���ǂ��W����H
>>81
> �ł��������[�v�����o����u���[�v���o��v���ǂ�ȃA���S���Y���ɂȂ��Ă邩�͓䂾��
ttp://www.intel.co.jp/jp/developer/technology/itj/2003/volume07issue02/art03_pentiumm/p05_branch.htm
�����̂����ɃJ�E���^�ƃ��~�b�g�Ŕ��肵�Ă�ۂ��ȁB
����E�ƕ������������Ƃɏڂ����̂����H����Ƃ����H�w�Ȃ̉@������H
�v���O��������ł���Ȃ��Ƃ܂Œm���Ă�́H
�v���O��������ł���Ȃ��Ƃ܂Œm���Ă�́H
>>65
> �x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
���@�J���B�œK����@����l�[���B�v���Z�b�T�f�U�C����̎����̂ЂƂ��B
�m�������́i �E�́E �j�����!
> �x��������Ēm��Ȃ��HRISC�Ƃ��̃R���p�C���ł悭�g��ꂽ�œK����@�����ǁB
���@�J���B�œK����@����l�[���B�v���Z�b�T�f�U�C����̎����̂ЂƂ��B
�m�������́i �E�́E �j�����!
>>84
�^���Ƃ����c�q�Ƃ����Z�[���[���[���Ƃ����A�܂Ƃ��ȋc�_�ł��Ȃ���
���_�����t���Ă���n�����ĂȂ�Ƃ��Ȃ�ˁ[���Ȃ��B
�^���Ƃ����c�q�Ƃ����Z�[���[���[���Ƃ����A�܂Ƃ��ȋc�_�ł��Ȃ���
���_�����t���Ă���n�����ĂȂ�Ƃ��Ȃ�ˁ[���Ȃ��B
�܂Ƃ��ȋc�_�Ƃ��������������������̂��ł��Ȃ��Ȃ��Ă��ȁA
���̂܂܉��x���������Ƃ��J��Ԃ������ɂȂ��ȁB
�������ꂽ�e�[�v���R�[�_���^���ƌĂ�Ă���킯�����B
���̂܂܉��x���������Ƃ��J��Ԃ������ɂȂ��ȁB
�������ꂽ�e�[�v���R�[�_���^���ƌĂ�Ă���킯�����B
�x������͂Ȃ��c�K�v���̗ނ���(w
�C�ɓ���Ȃ��Ȃ�ق��Ƃ��Ⴂ���������A�����Ă�l�����邩��ȁB
���������l�͌��ǂ悵�Ƃ��Ď���Ă���̂��낤�B
�܁A���͕ʂɂ��̎�̘b�͌�������Ȃ�
��Ŏb���͂��܂�ǁB
���������l�͌��ǂ悵�Ƃ��Ď���Ă���̂��낤�B
�܁A���͕ʂɂ��̎�̘b�͌�������Ȃ�
��Ŏb���͂��܂�ǁB
����ȊԈ�������𐂂ꗬ���d�g��Y����u����͕̂S�Q�����Ĉꗘ�Ȃ��B
�u�x������v�Ƃ������t���������Ӗ��Ŏg���ĂȂ����ȁB
�c�q�݂̓w�l�p�^���p�^�w�l�����蒼���Ƃ������ŁB
���[�Ȓm���ŃR���p�C���̍œK���]�X�����z��DPDA�Ƃ�LR(1)��m��Ȃ������肷���Ȃ��B�B�B
>>97
���������A�܂����ʂ̍u�߂��n�܂邼����
���������A�܂����ʂ̍u�߂��n�܂邼����
���ꂶ�Ⴀ�p�p�́ABNF�ōœK���R���p�C������������
���������ق��������ƌ����Ȃ�
�����ŃR���p�C�����������̂ɂˁB
�����ŃR���p�C�����������̂ɂˁB
�u���ꏈ���̐��Ɓv�L�^�H
�̃N���b�N���Ȃ�MPU���������ꂽ�b���������ǂ���ǂ��Ȃ����̂��Ȃ��c�c
�ʂɁA���������A���ʂɔ��v�̃v���Z�b�T���炢�ł����
���\�o�Ȃ�����
���\�o�Ȃ�����
�Ƃ������o�O��肪�����B
IBM�APower��2�{�����ɂ����@���J��
http://www.itmedia.co.jp/news/articles/0602/07/news070.html
http://www.itmedia.co.jp/news/articles/0602/07/news070.html
�c�Ȃ����Ă�H
�≏�w�ŃV���R���w�������Ԃ��Ăǂ������ƌ����Ă邪�B
�Ƃ肠�������̒m���ł͑S�ʍ~���B
���V���R���w�������Ԃ��ƃV���R���̋������ǂ��ς��̂��Ȃ�Ēm���B
�Ƃ肠�������̒m���ł͑S�ʍ~���B
���V���R���w�������Ԃ��ƃV���R���̋������ǂ��ς��̂��Ȃ�Ēm���B
�s���K�q���ĉ����H
�≏�w�ŋ���ē�w�ɂ���Ƃ������������ƁH�H
�≏�w���Ă̂͌������炵�Č��s��PD-SOI����B
�����Ԃ����Ă��Ƃ͈��k���Ă��Ƃ�����cSi���Ă��Ƃ���ˁ[�́B
> �������A���̃v���Z�X�ł̓v���Z�b�T���ߔM����X��������B
���Ă̂�SOI���L��Self-Heating���ۂ��ˁB
�≏�w�������ɒf�M�w�ɂȂ��Ă��܂��M���Ă���₷�����Ă�B
�f�l������m���Ă�P����ׂĂ݂����������ǁB
�����Ԃ����Ă��Ƃ͈��k���Ă��Ƃ�����cSi���Ă��Ƃ���ˁ[�́B
> �������A���̃v���Z�X�ł̓v���Z�b�T���ߔM����X��������B
���Ă̂�SOI���L��Self-Heating���ۂ��ˁB
�≏�w�������ɒf�M�w�ɂȂ��Ă��܂��M���Ă���₷�����Ă�B
�f�l������m���Ă�P����ׂĂ݂����������ǁB
NEC�G���A16bit�}�C�N���R���g���[����
http://pc.watch.impress.co.jp/docs/2006/0214/nec2.htm
http://pc.watch.impress.co.jp/docs/2006/0214/nec2.htm
UltraSPARC Architecture 2005
113 �FSocket774�F2006/02/20(��) 13:27:26 ID:E9Ddttt3
���܂łň�ԃG���K���g�Ȗ��߃Z�b�g�͂ǂꂾ�Ǝv���H
x86
>>114
���
���
MIPS R2000
Z80
4004
MC68000
mips2 ���̂Ă������������͂ЂƂ�
�@�@�@�@�@�@�@�@�@�@6502
�@�@�@�@�@�@�@�@�@�@6502
68000�Ɉ�[
68000�̓A�h���X���W�X�^�ƃf�[�^���W�X�^��������Ă���̂��A���Ȃ�ȁB
V810�Ƃ����Ă݂�̂͂ǂ����낤�H
#V850�Ƃ��ł͂Ȃ��B
V810�Ƃ����Ă݂�̂͂ǂ����낤�H
#V850�Ƃ��ł͂Ȃ��B
V800�n�Ȃ�V83x�B
Super8�ƌ����Č����������ɂ����Samsung8��Ԃ����Ȃ��B
����ς�6502�Ɉ�[���ȁc
Super8�ƌ����Č����������ɂ����Samsung8��Ԃ����Ȃ��B
����ς�6502�Ɉ�[���ȁc
68060
�ӂ[�� Alpha�B
MIPS�������Ȃ����ǁA���[�h�̒x���X���b�g�Ƃ��f�B���C�h�W�����v
�Ƃ��C���l�B
MIPS�������Ȃ����ǁA���[�h�̒x���X���b�g�Ƃ��f�B���C�h�W�����v
�Ƃ��C���l�B
Am29000
TMS9995
6809
6809�͖��߃G���R�[�h����Ώ̂Ȃ̂ŃL���C
Efficeon�Ƃ������Ă݂�B
�c�c�G���K���g���ǂ����Ȃ�Ăǂ��ł�������ȁBCMS�g������B
�c�c�G���K���g���ǂ����Ȃ�Ăǂ��ł�������ȁBCMS�g������B
131 �FSocket774�F2006/02/22(��) 10:23:56 ID:eaTnyYg9
>>130
�������߂��G���K���g���ǂ��������ƂȂ�B
�������߂��G���K���g���ǂ��������ƂȂ�B
68030
����Ӗ��G���K���g�Ȃ낤���A68k�݂����ȃS�V�b�N���̂��L���C
NS32032
������DSP
�r�b�O�G���f�B�A���̂W�r�b�g���ĉ��l���Ă�
137 �FSocket774�F2006/02/23(��) 00:15:23 ID:qHt0mZ5T
Nexgen 6x86
>>135
��̓I��
��̓I��
SH4�͌��\����CPU���Ǝv�����B
���\�������������d�͂őg�ݍ��݂ɂ͂������B
�l�I�ɂ�ARM���D�����ȁB
���\�������������d�͂őg�ݍ��݂ɂ͂������B
�l�I�ɂ�ARM���D�����ȁB
>>139
����Ȋ����̃l�^�ӂ��O����������B
�ł���Âɍl���Ă݂�Ώ���d�͂͑g�ݍ��݂ɂ��Ă͂ł�����Ȃ��H
DDR2�g���邩�炻��ł��ǂ��̂��H
�������A���߃Z�b�g�������Ȃ��Ⴂ���Ȃ��B
���`��c�c�y���e�B�A���o�C�i���H
����Ȋ����̃l�^�ӂ��O����������B
�ł���Âɍl���Ă݂�Ώ���d�͂͑g�ݍ��݂ɂ��Ă͂ł�����Ȃ��H
DDR2�g���邩�炻��ł��ǂ��̂��H
�������A���߃Z�b�g�������Ȃ��Ⴂ���Ȃ��B
���`��c�c�y���e�B�A���o�C�i���H
����ARM�̓T���R�[�h�Ƃ��ϑԖ��߃Z�b�g�������Ȃ����B
���ߒ����������Ƀ��W�X�^���Ȃ����ȁ�ARM
144 �FSocket774�F2006/02/23(��) 15:32:31 ID:R3leZ2BK
SH���āA�x�����
�����Œ����d�͂�ARM�ƁA�n�C�G���h��MIPS�APowerPC�ɋ��܂�Ă��Ċ���
�����Œ����d�͂�ARM�ƁA�n�C�G���h��MIPS�APowerPC�ɋ��܂�Ă��Ċ���
����Ȃɒx���͖����Ǝv�����ǁc
���W�Ƃ��N���b�N������ĈӖ��Ȃ���c���ꂽ�����o�Ă����ǂ�(^^;
���ŋ߁A400MHz��SH4���o�Ă������ǁB
�c�܂���Ђ������ƌ��������Ȃ��c
���������A�������͉����v�b�V�����Ă������ς�����B
��H�n�����ł�H8S��H8SX�̐��\���オ����������SH2�͎����Ȃ̂��Ȃ�?�Ƃ��v�����B
���W�Ƃ��N���b�N������ĈӖ��Ȃ���c���ꂽ�����o�Ă����ǂ�(^^;
���ŋ߁A400MHz��SH4���o�Ă������ǁB
�c�܂���Ђ������ƌ��������Ȃ��c
���������A�������͉����v�b�V�����Ă������ς�����B
��H�n�����ł�H8S��H8SX�̐��\���オ����������SH2�͎����Ȃ̂��Ȃ�?�Ƃ��v�����B
�ŋߏo���̂�600�̂͂��B���\�l�ł�1000MIPS������B
���߃Z�b�g���Ⴄ�̂ł��Ăɂ͏o���Ȃ����ǁB
���\�I�ɂ�SH4������ARM�̔���̓\�t�g�E�F�A���Y�Ȃ�ˁB
LINUX�[���ł��o�Ă����Ȃ��BPOCKETPC�͂��Ăɏo���Ȃ����B
���߃Z�b�g���Ⴄ�̂ł��Ăɂ͏o���Ȃ����ǁB
���\�I�ɂ�SH4������ARM�̔���̓\�t�g�E�F�A���Y�Ȃ�ˁB
LINUX�[���ł��o�Ă����Ȃ��BPOCKETPC�͂��Ăɏo���Ȃ����B
64-way���Ȳ���
>>142
�v���~�e�B�u�A�[�g�݂����Ȃ���
�v���~�e�B�u�A�[�g�݂����Ȃ���
68k�͑s���ISA��ڎw�����͂������A�Ō�ɂȂ��ă��\�[�X�s���ŃA�h���X�E�f�[�^���W�X�^��������
32�r�b�g�I�t�Z�b�g�̃A�h���b�V���O���[�h�������ł��Ȃ������肵�����
6809���A����₱���Ƌl�ߍ������Ƃ��ăI�y�R�[�h����Ȃ��Ȃ�����ˁ[��
32�r�b�g�I�t�Z�b�g�̃A�h���b�V���O���[�h�������ł��Ȃ������肵�����
6809���A����₱���Ƌl�ߍ������Ƃ��ăI�y�R�[�h����Ȃ��Ȃ�����ˁ[��
>>148
�ǂ����G���K���g�Ȃ�
�ǂ����G���K���g�Ȃ�
>>149
���W�X�^��肷���ŃI�y�R�[�h����������RCA��COSMAC�Ƃ�������B
���W�X�^��肷���ŃI�y�R�[�h����������RCA��COSMAC�Ƃ�������B
152 �FSocket774�F2006/02/24(��) 12:45:11 ID:U4Jzovoz
PowerPC ISA�͂��߂ł���
���N�́u����v�̃v���Z�b�T���W�iNo.�j10�A11�x�܂��Ȃ���ǂ��ǁA
�ėp��_�����A�[�L�e�N�`���͖ʔ����̂��Ȃ���Ȃ��c
�^�C���Ƃ����R���t�B�M�����u���Ƃ��͖ʔ������Ǔ���p�r�_���݂��������B
����͂Ƃ������A�E�g�I�u�I�[�_�[�v���Z�b�T��10�N�O��IPC��ۂ��߂�
�ǂꂾ���̃��\�[�X��H���Ă邩�͍l���̊O�Ȃ낤���H�����W�̂܂Ƃߐl
�ėp��_�����A�[�L�e�N�`���͖ʔ����̂��Ȃ���Ȃ��c
�^�C���Ƃ����R���t�B�M�����u���Ƃ��͖ʔ������Ǔ���p�r�_���݂��������B
����͂Ƃ������A�E�g�I�u�I�[�_�[�v���Z�b�T��10�N�O��IPC��ۂ��߂�
�ǂꂾ���̃��\�[�X��H���Ă邩�͍l���̊O�Ȃ낤���H�����W�̂܂Ƃߐl
�iNo.�j10�A11
��
�iNo.10�A11)
��
�iNo.10�A11)
65�n��!
156 �FSocket774�F2006/02/25(�y) 08:21:38 ID:pppxzFHI
�z���x���̂����ŁA���R���t�B�M���A���u���v���Z�b�T�Ƃ�
�Q�[�g�A���C�̓N���b�N��������Ȃ��āA�ėp�v���Z�b�T�ɏ����ɂ������
����IA�����Ȃ��̂���
�Q�[�g�A���C�̓N���b�N��������Ȃ��āA�ėp�v���Z�b�T�ɏ����ɂ������
����IA�����Ȃ��̂���
�A�Z���u�������Ă��l�Ȃ��ǁA�v���Z�b�T�̍\���Ƃ��f�[�^�V�[�g��̘b
�����肵�ĂĖʔ����̂�?
�Ƃ��������܂����B
x86��68000��SH��H8��PIC��8080��Z80�����܂��B
�ǂ������Ă�gcc�ōœK���������ق����͂₢�̂ł����A
gcc��gdb�̎g�������킩���̂Ŏg���܂���(��
�����肵�ĂĖʔ����̂�?
�Ƃ��������܂����B
x86��68000��SH��H8��PIC��8080��Z80�����܂��B
�ǂ������Ă�gcc�ōœK���������ق����͂₢�̂ł����A
gcc��gdb�̎g�������킩���̂Ŏg���܂���(��
�y���ݕ��͐l���ꂼ��B
�A�[�L�e�N�`���I�^���炷��A���^�̂���Ă鎖���āu�����悤��
�v���Z�b�T�ő���h���̂��Ȃ��v���O�����g��ʼn����ʔ����̂��ˁv
�Ǝv���킯��B
>>156
��ɂ��ꂱ��ڂ�悤�ɂȂ��ăv���Z�b�T�̃A�[�L�e�N�`���ȂA
�v���O�����̏����₷���ƊW�Ȃ��Ȃ�������A�����ɐ��\���オ��
���ɂ�IA�ł�����͏o�Ȃ�㩁B
�A�[�L�e�N�`���I�^���炷��A���^�̂���Ă鎖���āu�����悤��
�v���Z�b�T�ő���h���̂��Ȃ��v���O�����g��ʼn����ʔ����̂��ˁv
�Ǝv���킯��B
>>156
��ɂ��ꂱ��ڂ�悤�ɂȂ��ăv���Z�b�T�̃A�[�L�e�N�`���ȂA
�v���O�����̏����₷���ƊW�Ȃ��Ȃ�������A�����ɐ��\���オ��
���ɂ�IA�ł�����͏o�Ȃ�㩁B
�Ȃɂ��Ă���A�o�O�������Ă܂Ƃ��ɓ����Ȃ��v���O�������A������Ɠ����悤�ɂ���
���̍H�����A������c���f���U���Ȃ킯�ł���B
�G���܂���?
���̍H�����A������c���f���U���Ȃ킯�ł���B
�G���܂���?
�S�R
>>159
�Ó�
�Ó�
>>157
����A���܁A���ꂾ���A�Z���u���������āA�Ȃ��gdb�̎g�������������̂���
gdb�����A�ŏ��͂Ƃ����ɂ������A����Ď�ɓ���ނƎ�����Ȃ��Ȃ�A
�^�̃c���f���c�[���B���ꂷ���ăf�o�b�O�R�[�h�ߍ��܂܃����[�X�����肷��B
IMHO, ����ł����Ȃ��o�O��蕪�����Ă����^�̃c���f�����[���Ǝv��
����A���܁A���ꂾ���A�Z���u���������āA�Ȃ��gdb�̎g�������������̂���
gdb�����A�ŏ��͂Ƃ����ɂ������A����Ď�ɓ���ނƎ�����Ȃ��Ȃ�A
�^�̃c���f���c�[���B���ꂷ���ăf�o�b�O�R�[�h�ߍ��܂܃����[�X�����肷��B
IMHO, ����ł����Ȃ��o�O��蕪�����Ă����^�̃c���f�����[���Ǝv��
>>162
�k�n�k
�k�n�k
>>158
������DSP�ŃK���o��
������DSP�ŃK���o��
���W�X�^�E�E�B���h�E�́A�L�����ǂ����ɂ���
�A�v���P�[�V�������삲�Ƃ̓��v���͂��K�v���Ǝv�����ɂ���
>>166
���킵���B
���킵���B
169 �FSocket774�F2006/02/27(��) 16:31:37 ID:iPijvYpL
���W�X�^�E�B���h�E�ő����͂Ȃ邯��
���l�[�~���O�����G�ɂȂ�����A��e�ʃ��W�X�^�ŃN���b�N������������
80�N���R2000��32�{�ŁA90�N���Power��alpha��32�{
���̃\�t�g�͓����̂�背�W�X�^�������������낤����
128�{���W�X�^�X�^�b�N���Ă̂�
���ʂɃ��b�`�ł́H
���l�[�~���O�����G�ɂȂ�����A��e�ʃ��W�X�^�ŃN���b�N������������
80�N���R2000��32�{�ŁA90�N���Power��alpha��32�{
���̃\�t�g�͓����̂�背�W�X�^�������������낤����
128�{���W�X�^�X�^�b�N���Ă̂�
���ʂɃ��b�`�ł́H
>>169
>128�{���W�X�^�X�^�b�N���Ă̂�
>���ʂɃ��b�`�ł́H
�������I �Ȃ�قǁA�킩���Ă��܂����B
���ʂɎv���܂��ˁB
x86���ă��W�X�^�E�B���h�E�g�p���Ė����H
����Ƃ�x86�Ń��W�X�^�E�B���h�E����ƁA
�N���b�N����̖W���ɂȂ邩�炠���č̂����Ȃ��̂��ȁH�H�H
>128�{���W�X�^�X�^�b�N���Ă̂�
>���ʂɃ��b�`�ł́H
�������I �Ȃ�قǁA�킩���Ă��܂����B
���ʂɎv���܂��ˁB
x86���ă��W�X�^�E�B���h�E�g�p���Ė����H
����Ƃ�x86�Ń��W�X�^�E�B���h�E����ƁA
�N���b�N����̖W���ɂȂ邩�炠���č̂����Ȃ��̂��ȁH�H�H
171 �FSocket774�F2006/02/27(��) 20:57:46 ID:MPxn6SHJ
�i�m�e�N���낤�ƂȂ낤�ƁA�����ɓd�C�����Ď��g���ɈӖ��������Ă��Ď��_�łǂ�������B
���x�Ȃ疳�d�͏�E�^��ł̌������̂Ƃ����ԑ����Ƃ����Ă������A����ʉ߁E�Ւf�ɈӖ�����������ő��X�p�R���̏o���オ��B
����𑩂˂ē����ԏ�ňӖ�����������Α��˂�قǂɍ����ɂȂ�B����ނ������Ȃ��B
���x�Ȃ疳�d�͏�E�^��ł̌������̂Ƃ����ԑ����Ƃ����Ă������A����ʉ߁E�Ւf�ɈӖ�����������ő��X�p�R���̏o���オ��B
����𑩂˂ē����ԏ�ňӖ�����������Α��˂�قǂɍ����ɂȂ�B����ނ������Ȃ��B
�����B�X���[���ꂽ�B
>>173
�݊������Ȃ��Ȃ�̂�x86�ɍ�����lj�����͖̂���
�݊������Ȃ��Ȃ�̂�x86�ɍ�����lj�����͖̂���
>>155
���[�ƁB65816�ɂ��Ă͂ǂ��v���܂���?
���[�ƁB65816�ɂ��Ă͂ǂ��v���܂���?
>>175
�G�~����ҋ�����
�G�~����ҋ�����
�@�֎Ԃ̌`���Ɍ��������B
>>178
�R���������Ȃ��ǂ�
�R���������Ȃ��ǂ�
>>180
�킽���̒m���Ă���V35�͒P��V30�Ɏ��ӂ�˂��������̂��̂Ȃ��B
V30�ɂ��Ă�����ȃh���X�e�B�b�N��ISA�̕ύX���Ă����������H
���W�X�^�E�B���h�E�lj��Ƃ�����AMD64�ȏ��ISA�̕ύX�ɂȂ�̂ł��낢�����Ǝv���ˁB
�킽���̒m���Ă���V35�͒P��V30�Ɏ��ӂ�˂��������̂��̂Ȃ��B
V30�ɂ��Ă�����ȃh���X�e�B�b�N��ISA�̕ύX���Ă����������H
���W�X�^�E�B���h�E�lj��Ƃ�����AMD64�ȏ��ISA�̕ύX�ɂȂ�̂ł��낢�����Ǝv���ˁB
182 �FSocket774�F2006/03/01(��) 20:29:35 ID:j9NX1KZ2
�P���ȏ����v�f���������ĉ��Z�p�C�v���C�����\������炵���B
�p�C�v���C���͒Z���Ԃœ��I�ɍč\���\�BFPGA�̏゠����̍ח��x������_���B
���R���t�B�M�����u���A�[�L�e�N�`���ƌ����炵���B�ŋ߂����������̌��������s���Ă�݂������B
http://www.hpcc.jp/sacsis/2004/include/amano-sacsis.pdf
�p�C�v���C���͒Z���Ԃœ��I�ɍč\���\�BFPGA�̏゠����̍ח��x������_���B
���R���t�B�M�����u���A�[�L�e�N�`���ƌ����炵���B�ŋ߂����������̌��������s���Ă�݂������B
http://www.hpcc.jp/sacsis/2004/include/amano-sacsis.pdf
>>183
�������傭�M�������ɂ����g���Ȃ����i
�������傭�M�������ɂ����g���Ȃ����i
���R���t�B�M�����u���A�[�L�e�N�`���Ń��_�N�V�����}�V����g�ނƂ����l�^��
�ǂ����ɂ������Ǝv����ŁA�M�����������ł��Ȃ��悤�ȃL���X�B
��ʂɘI�o���Ă�����Ⴊ�M�������p�r�Ȃ͓̂��ӁB
�ǂ����ɂ������Ǝv����ŁA�M�����������ł��Ȃ��悤�ȃL���X�B
��ʂɘI�o���Ă�����Ⴊ�M�������p�r�Ȃ͓̂��ӁB
���_�N�V�����}�V������Ă�l�A�܂�����̂�orz
����ς荡����Ă�l�͏��Ȃ��̂��B
�ʔ������Ȃ�ŕ����Ă݂悤�Ǝv�����ǁA�{�������̂��Ȃ��B
�f�[�^�t���[�Ƃ����ƃ}�C�i�[�Ȃ�ɖ{���o�Ă邩��A�A�}�`���A�ł�
���₷�����B
�ʔ������Ȃ�ŕ����Ă݂悤�Ǝv�����ǁA�{�������̂��Ȃ��B
�f�[�^�t���[�Ƃ����ƃ}�C�i�[�Ȃ�ɖ{���o�Ă邩��A�A�}�`���A�ł�
���₷�����B
Cell���p�\�R���p�ɉ��ǂ��ďo�Ă��Ȃ����ȁB
>>188
PowerPC750�ŏ\������B
Altivec���g�������Ȃ�7400�V���[�Y��
������Cell�̂悤�Ȃ��̂������Ƃ����Ȃ�APowerPC405�V���[�Y�����������Ă���Ƃ���
PowerPC750�ŏ\������B
Altivec���g�������Ȃ�7400�V���[�Y��
������Cell�̂悤�Ȃ��̂������Ƃ����Ȃ�APowerPC405�V���[�Y�����������Ă���Ƃ���
>>188
GPGPU�ł�����Ȃ����ƁB
GPGPU�ł�����Ȃ����ƁB
191 �FSocket774�F2006/03/04(�y) 20:38:05 ID:QGlKCHEQ
GPGPU�p��API����������āA���ۂɎg�����ɂȂ�̂͂�����ł����H
192 �FSocket774�F2006/03/04(�y) 20:40:10 ID:76jFhW93
�����}�g���b�N�X�̐��E�ɂȂ��ė~�����ł�
>>191
����������o������Cell�͂ǂ��Ȃ̂��Ƃ�
����������o������Cell�͂ǂ��Ȃ̂��Ƃ�
194 �FSocket774�F2006/03/04(�y) 22:18:30 ID:tiF2EG5d
>>193
�u�ꌩ�W���肻���ŊW�Ȃ��b���n�߂�v
�u�ꌩ�W���肻���ŊW�Ȃ��b���n�߂�v
�܂������W�̖����b���n�߂�A���^���܂���
�ł����̂܂�x86��CPU�Ȃ��p�\�R���Œ蒅����������猙�Ȃ�
����Cell���p�\�R�������ɉ��ǂ��ė~�����B
����Cell���p�\�R�������ɉ��ǂ��ė~�����B
>>196
Cell���̂́i�����_�̎������������j�u�ėpCPU+����DSP�v�݂����Ȃ���ŁA�Ấu���f�B�A�v���Z�b�T�t��PC�v��
�債�ĕς��Ȃ��B�u�ėpCPU�v�̕����͌��킸�����ȁA�u����DSP�v�̕������p�r���Ƃ̃��C�u������API���킳��
���낤����A��قǃn�[�h�E�F�A�ɋ߂������Ńv���O���~���O����̂łȂ�����A�v���O���}���猩��p�͑債�č���
PC�ƕς�Ȃ��Ǝv���B
�G�L�]�`�b�N�ȃA�[�L�e�N�`���Ńv���O�������y���݂����Ȃ�ʂ̕��@�����邵�B
�i��y�ȂƂ���ł�GPGPU�Ƃ��B�j
Cell���̂́i�����_�̎������������j�u�ėpCPU+����DSP�v�݂����Ȃ���ŁA�Ấu���f�B�A�v���Z�b�T�t��PC�v��
�債�ĕς��Ȃ��B�u�ėpCPU�v�̕����͌��킸�����ȁA�u����DSP�v�̕������p�r���Ƃ̃��C�u������API���킳��
���낤����A��قǃn�[�h�E�F�A�ɋ߂������Ńv���O���~���O����̂łȂ�����A�v���O���}���猩��p�͑債�č���
PC�ƕς�Ȃ��Ǝv���B
�G�L�]�`�b�N�ȃA�[�L�e�N�`���Ńv���O�������y���݂����Ȃ�ʂ̕��@�����邵�B
�i��y�ȂƂ���ł�GPGPU�Ƃ��B�j
198 �FSocket774�F2006/03/04(�y) 23:35:05 ID:cd9ol5aM
GPGPU�p��API����������āA���ۂɎg�����ɂȂ�̂͂�����ł����H
����Ȏ����͗��Ȃ�����҂������_�B
Cell�̓p�\�R�������ɂ͒x������
>>187
20�N���炢�O�̃A�[�L�e�N�`���̖{�ɂ������ƍڂ��Ă邭�炢
20�N���炢�O�̃A�[�L�e�N�`���̖{�ɂ������ƍڂ��Ă邭�炢
202 �FSocket774�F2006/03/05(��) 04:29:23 ID:6zlI3Qb1
203 �FSocket774�F2006/03/05(��) 07:11:47 ID:6cOqkQ8R
���Ŗϑz����̂͊ȒP�Ȃ�B�����x�[�X�Ɏ����Ă����邾���̌����J����o���Ă���B
���ǁA����邩����Ȃ����Ȃ�˂��E�E�E
����p�r�ɓ������邩�ėp����ɂ��邩�E�E�E
����p�r�ɓ������邩�ėp����ɂ��邩�E�E�E
>>204
�̘̂_���͂���܂�d�q������ĂȂ���
�̘̂_���͂���܂�d�q������ĂȂ���
>>202
PPE�����͂ɂ���SPE�͖����������Ƃ�������
PPE�����͂ɂ���SPE�͖����������Ƃ�������
210 �FSocket774�F2006/03/07(��) 12:11:55 ID:/O/RWaI/
>>207
����A������PowerPC�i970�n�j���낗
����A������PowerPC�i970�n�j���낗
�P�O��SPE���������Ă�PPE���S�Ȃ���ō��H
Conroe�ɂ�cmp/test+jcc��Macro-op fusion�������������悤�B
�x������ɂ��Ă͕s�������B
�x������ɂ��Ă͕s�������B
�f�[�^��肱�ڂ������킢����X���b�h��ւ��p�x�����ɂȂ��Ă��Ă�낤����
���������̂������j�[�R�A�ɐU�肽���Ȃ���
�i���Ȃ݂ɘR��̂Ƃ�����500-5000��/�b���炢�j
�i����X���̃R�s�y�j
969 ���O�FSocket774�F04/11/21 00:39:07 ID:z+YuR4Tk
�N���b�N��GHz�̎���ł��b60����x�̃^�X�N��ւ��̃R�X�g�������܂����H
975 ���O�FSocket774[sage] ���e���F04/11/21 05:38:18 ID:6OkCsAGH
>>969
����͐̂�BSD�̘b����?
Windows�Ȃ�āA���̂��������̃X���b�h��忂��Ă��邩��A���Ȃ�̉���B
�p�t�H�[�}���X���j�^��System��Context Switches/sec�����Ă��������ȁB
���������̂������j�[�R�A�ɐU�肽���Ȃ���
�i���Ȃ݂ɘR��̂Ƃ�����500-5000��/�b���炢�j
�i����X���̃R�s�y�j
969 ���O�FSocket774�F04/11/21 00:39:07 ID:z+YuR4Tk
�N���b�N��GHz�̎���ł��b60����x�̃^�X�N��ւ��̃R�X�g�������܂����H
975 ���O�FSocket774[sage] ���e���F04/11/21 05:38:18 ID:6OkCsAGH
>>969
����͐̂�BSD�̘b����?
Windows�Ȃ�āA���̂��������̃X���b�h��忂��Ă��邩��A���Ȃ�̉���B
�p�t�H�[�}���X���j�^��System��Context Switches/sec�����Ă��������ȁB
�����Ń}���`�X���b�h�A�[�L�e�N�`���ł���B
�n�C�p�[�X���b�h��2�ʑ҂��Ȃ�ĊÂ��Â��B
�n�C�p�[�X���b�h��2�ʑ҂��Ȃ�ĊÂ��Â��B
�}���`�R�A�̓A�[�L�e�N�`���I�H�v���Ȃ��Ă��܂����D���ɂȂ��
�܂��X���b�h�̃X�P�W���[�����O�Ɋւ���b�Ȃ炨�����낢���ǁA
���̂Ƃ��낻�̋@�\��CPU�̊O�i�l�ԁAOS�A�R���p�C���A�����^�C���j�ɂ��邩��ˁB
�R���p�C���̎������́A�قƂ�ǂ̏ꍇ�p�t�H�[�}���X����ɂȂ��炸�A
�܂��v���I�o�O�����މ\��������̂ŁA���ǐl�ԍœK�����Ă���Ƃ�������B
���̂Ƃ��낻�̋@�\��CPU�̊O�i�l�ԁAOS�A�R���p�C���A�����^�C���j�ɂ��邩��ˁB
�R���p�C���̎������́A�قƂ�ǂ̏ꍇ�p�t�H�[�}���X����ɂȂ��炸�A
�܂��v���I�o�O�����މ\��������̂ŁA���ǐl�ԍœK�����Ă���Ƃ�������B
���̃v���O���}�ɕ��S��������������Ă͎̂����ƌ��E������B
�Ⴆ��Ȃ�ILP�i���߃��x���̕��j�ɂ����āA�݂�Ȃ��݂��
�A�Z���u���Ŗ��߂̕��בւ������čœK�����Ȃ��Ⴂ���Ȃ��悤��
�l�ԃA�E�g�I�u�C�I�[�_�[�E�l�ԃX�P�W���[�����O�A
�Ȑ��E���C���[�W����Ƃ��̊��m�����悭�킩��B
�Ⴆ��Ȃ�ILP�i���߃��x���̕��j�ɂ����āA�݂�Ȃ��݂��
�A�Z���u���Ŗ��߂̕��בւ������čœK�����Ȃ��Ⴂ���Ȃ��悤��
�l�ԃA�E�g�I�u�C�I�[�_�[�E�l�ԃX�P�W���[�����O�A
�Ȑ��E���C���[�W����Ƃ��̊��m�����悭�킩��B
���I�X�P�W���[�����O�����@���s�����F�����B
����ς�n�[�h�E�F�A�}���`�X���b�h�ł���B
�ƂԂ₫�ADenelcor HEP��Cray�@MTA2�Ɣs�k�̗��j�����݃��k....orz
����ς�n�[�h�E�F�A�}���`�X���b�h�ł���B
�ƂԂ₫�ADenelcor HEP��Cray�@MTA2�Ɣs�k�̗��j�����݃��k....orz
http://www.watch.impress.co.jp/game/docs/20050316/ps311.jpg
������Č��ǃN�^���L�̖ϑz��������ł���H
{kind=link}
������Č��ǃN�^���L�̖ϑz��������ł���H
>>212
CC�������߂ƕ��߂��Z�b�g�ɂ��ď���������Ă��Ƃ�ALU�ɕ���pRS
�����������悤�ȍ\���ɂȂ���Ă��Ƃ��B1���CC�����ɑ���2��ȏ�
�Q�Ƃ�����ACC�������߂ƕ��߂�����Ă���ꍇ��Marco-op fusion
�ɂȂ�Ȃ��낤���ǁA�ǂ��������ς���Ă���̂��H
�����������1�̑I�������Ƃ͎v�����ǁA���Z���s�ƕ����ʁX�ɂ��
�ꍇ�ɔ�ׂẴ����b�g���킩���B2�̖��߂�1�ɂȂ邱�Ƃ�
���߃X���[�v�b�g�����ǂ��Ȃ�Ƃ͎v�����ǂ������m��Ă��邾��B
Micro-ops�ɕ������Ă��������V���v����RISC�I�������s���Ă���̂�
���G�����Ă������Ƃ�����Ƃ͎v����B
CC�������߂ƕ��߂��Z�b�g�ɂ��ď���������Ă��Ƃ�ALU�ɕ���pRS
�����������悤�ȍ\���ɂȂ���Ă��Ƃ��B1���CC�����ɑ���2��ȏ�
�Q�Ƃ�����ACC�������߂ƕ��߂�����Ă���ꍇ��Marco-op fusion
�ɂȂ�Ȃ��낤���ǁA�ǂ��������ς���Ă���̂��H
�����������1�̑I�������Ƃ͎v�����ǁA���Z���s�ƕ����ʁX�ɂ��
�ꍇ�ɔ�ׂẴ����b�g���킩���B2�̖��߂�1�ɂȂ邱�Ƃ�
���߃X���[�v�b�g�����ǂ��Ȃ�Ƃ͎v�����ǂ������m��Ă��邾��B
Micro-ops�ɕ������Ă��������V���v����RISC�I�������s���Ă���̂�
���G�����Ă������Ƃ�����Ƃ͎v����B
CELL�ɖ��݂Ă�n���������悤�����ACELL��CPU�P�łł���
�^�X�N�P�i�Q�[���j�������I�ɏ������邽�߂̃J�X�^���`�b�v�B
�����^�X�N���R���e�L�X�g�X�C�b�`���Ȃ��珈������ėpPC�ɂ�
�܂����������Ȃ��B
SPE���g��Ȃ��O��Ȃ�A����������Ȃ����A����Ȃ�X86�Ƃ���
�ق�����قǍ����BPPE�̏o�開�͂Ȃ��B
SPE���g���O�ƃR���e�L�X�g�X�C�b�`���O���l�b�N�ɂȂ�B
SPE�̓R���e�L�X�g�X�C�b�`���O���Ȃ��ŏd���^�X�N�������ɏ���
����Ƃ����v�z�Ȃ�ŁA�ėp���W�X�^���P�Q�W�{�Ƃ����낵������
��������B
SPE���g��Ȃ��^�X�N����Ȃ炢�����A���ꂾ��X86�ɋy�Ȃ��B
SPE���g���^�X�N���肾�ƌ���ꂽ���\�[�X�̒D�������ɂȂ�B
�Ȃ��Ȃ�R���e�L�X�g�X�C�b�`���Ȃ��v�v�z������ȁB
�Q�[�����炢�ɂ����g�����B���̂����V���O���^�X�N�Ȃ�
���������ȁB
�^�X�N�P�i�Q�[���j�������I�ɏ������邽�߂̃J�X�^���`�b�v�B
�����^�X�N���R���e�L�X�g�X�C�b�`���Ȃ��珈������ėpPC�ɂ�
�܂����������Ȃ��B
SPE���g��Ȃ��O��Ȃ�A����������Ȃ����A����Ȃ�X86�Ƃ���
�ق�����قǍ����BPPE�̏o�開�͂Ȃ��B
SPE���g���O�ƃR���e�L�X�g�X�C�b�`���O���l�b�N�ɂȂ�B
SPE�̓R���e�L�X�g�X�C�b�`���O���Ȃ��ŏd���^�X�N�������ɏ���
����Ƃ����v�z�Ȃ�ŁA�ėp���W�X�^���P�Q�W�{�Ƃ����낵������
��������B
SPE���g��Ȃ��^�X�N����Ȃ炢�����A���ꂾ��X86�ɋy�Ȃ��B
SPE���g���^�X�N���肾�ƌ���ꂽ���\�[�X�̒D�������ɂȂ�B
�Ȃ��Ȃ�R���e�L�X�g�X�C�b�`���Ȃ��v�v�z������ȁB
�Q�[�����炢�ɂ����g�����B���̂����V���O���^�X�N�Ȃ�
���������ȁB
222 �FMAC�I�^��221 �����F2006/03/11(�y) 15:22:25 ID:W5p9ddCr
>>221
���l�ɐ�������O�ɁC���������������Ă邩�ǂݒ����������ǂ����Ǝv�����B
�@�@-----------------------
�@�@SPE�̓R���e�L�X�g�X�C�b�`���O���Ȃ��ŏd���^�X�N�������ɏ���
�@�@����Ƃ����v�z�Ȃ�ŁA�ėp���W�X�^���P�Q�W�{�Ƃ����낵������
�@�@-----------------------
AltiVec�L���PowerPC�A�[�L�e�N�`����C�����E���������_�E�x�N�g���Ŋe32�{�̃��W�X�^�������Ă��邷�B
96�{��128�{����Ⴂ�B�B�B���Ă̂�C�����s���g�̂��ꂽ�v�����݂���(��)
�X�ɗe�ʂɊ��Z����SPE�̃��W�X�^��2�{�ɂȂ邷���ǁCPPE��}���`�X���b�h�̂��߂Ƀ��W�X�^��2�Z�b�g������
���邷����C���lj����ς��Ȃ����ƂɂȂ邷�B
���l�ɐ�������O�ɁC���������������Ă邩�ǂݒ����������ǂ����Ǝv�����B
�@�@-----------------------
�@�@SPE�̓R���e�L�X�g�X�C�b�`���O���Ȃ��ŏd���^�X�N�������ɏ���
�@�@����Ƃ����v�z�Ȃ�ŁA�ėp���W�X�^���P�Q�W�{�Ƃ����낵������
�@�@-----------------------
AltiVec�L���PowerPC�A�[�L�e�N�`����C�����E���������_�E�x�N�g���Ŋe32�{�̃��W�X�^�������Ă��邷�B
96�{��128�{����Ⴂ�B�B�B���Ă̂�C�����s���g�̂��ꂽ�v�����݂���(��)
�X�ɗe�ʂɊ��Z����SPE�̃��W�X�^��2�{�ɂȂ邷���ǁCPPE��}���`�X���b�h�̂��߂Ƀ��W�X�^��2�Z�b�g������
���邷����C���lj����ς��Ȃ����ƂɂȂ邷�B
>>221
Cell���g�����̂ɂȂ�Ȃ����POWER��PowerPC���g�������̂ŁA�ǂ��ł��ǂ��B
Cell���g�����̂ɂȂ�Ȃ����POWER��PowerPC���g�������̂ŁA�ǂ��ł��ǂ��B
�_�_�����ݍ����ĂȂ�����
> ���̃v���O���}�ɕ��S��������������Ă͎̂����ƌ��E������B
����\�t�g�E�F�A�G���W�j�A�̗��ꂩ�猩�Ă����܂Ńv���O���}��H/W�̐i����
�Â��������Ǝv�����E�E�E
����\�t�g�E�F�A�G���W�j�A�̗��ꂩ�猩�Ă����܂Ńv���O���}��H/W�̐i����
�Â��������Ǝv�����E�E�E
226 �FSocket774�F2006/03/11(�y) 19:39:52 ID:xkZtzpAn
�t���[�����`�̎���͏I������A���Ă�ł����B
�����ėL�������`�̑���͌��ǂ��܂��炪�������ƂɂȂ�
>>222
GPU������O���t�B�b�N��p�v���Z�b�T���牉�Z�����v���Z�b�T�ɂȂ��Ă��Ă邩��
PC�̏ꍇCell��SPE�ɑ������镔���Ƃ��Ă�GPU���g����悤�ɂȂ�\��
GPU������O���t�B�b�N��p�v���Z�b�T���牉�Z�����v���Z�b�T�ɂȂ��Ă��Ă邩��
PC�̏ꍇCell��SPE�ɑ������镔���Ƃ��Ă�GPU���g����悤�ɂȂ�\��
���W�X�^�Ȃ��LS��256KB�̂ق����͂邩�ɂł����킯����
SPE��MMU�Ȃ������C������B
������v���Z�X�X�C�b�`����Ȃ�LS�ۂ��Ə��������Ȃ���܂�����ł́B
�S��PIC�ŃR���p�C�����Ă�Ȃ炬�肬�肿���܂��������ȋC�����Ȃ����Ȃ����B
������v���Z�X�X�C�b�`����Ȃ�LS�ۂ��Ə��������Ȃ���܂�����ł́B
�S��PIC�ŃR���p�C�����Ă�Ȃ炬�肬�肿���܂��������ȋC�����Ȃ����Ȃ����B
231 �FSocket774�F2006/03/12(��) 02:12:24 ID:Bwr4Qhja
>>230
���邯��DMA�p��������ɗ������
���邯��DMA�p��������ɗ������
>>220
�܂����炩�Ɍ��ʂ�����Ƃ��������x���̂��̂ł��Ȃ��������ȁB
�����ACC�̓��l�[�����Ȃ��Ƃ���Ȃ炻���ɗ]�v�Ȓ������������Ă��܂��킯�ŁA
���ꂵ���ǖʂ͂���̂��������B
�܂����炩�Ɍ��ʂ�����Ƃ��������x���̂��̂ł��Ȃ��������ȁB
�����ACC�̓��l�[�����Ȃ��Ƃ���Ȃ炻���ɗ]�v�Ȓ������������Ă��܂��킯�ŁA
���ꂵ���ǖʂ͂���̂��������B
>>222
SPE�͉�����Ǝv���ĂB���̕������Ă݂�o�J�B
SPE�͉�����Ǝv���ĂB���̕������Ă݂�o�J�B
>>233
�o�J������
�o�J������
235 �FMAC�I�^��233 �����F2006/03/12(��) 09:38:49 ID:ksHUgGwY
>>233
�@�@---------------------
�@�@���̕������Ă݂�o�J�B
�@�@---------------------
���W�X�^�̑ޔ���C�eSPE������LS�ɑ��čs���Ηǂ�������C�����낤�ƃ��C�e���V��ꏏ������(��)
�@�@---------------------
�@�@���̕������Ă݂�o�J�B
�@�@---------------------
���W�X�^�̑ޔ���C�eSPE������LS�ɑ��čs���Ηǂ�������C�����낤�ƃ��C�e���V��ꏏ������(��)
SPU�ɂ��Ă͒��ڃA�N�Z�X�ł��郁������256KB�����Ȃ����_�ŁA�ėp�v���Z�b�T��
�����̑��d�^�X�N���������߂�͖̂����Ǝv���B�eorth�݂��������������f���ŋɒ[��
�����ȃ��W���[����g�ݍ��킹�ăV�X�e����g�ނ悤�Ȋ��Ȃ炢���邩���m��ǁB
>>228
����͖����悤�ȁB�f�o�t���[�J�[�Ƃ��Ă̓O���t�B�b�N�����ȊO�ɉ��Z���\�[�X�������
�`�搫�\��������̂͌����낤���A�i���Ƀ��^�����n�C�G���h�@��B�j�C���e���ɂ��Ă�����
�v���Z�b�T�̎d�������ɒD����̂�ق��Ă͌��Ă��Ȃ��Ǝv���B�i���ہA���f�B�A�v���Z�b�T
�ɑ���MMX�őR�����B�j
�������i�X�Ƃ�������Ĕėp�v���Z�b�T�̖���������@�\���j�b�g�ɕ��S�����悤�ɂȂ���
�����ƁA�R�A�����̓V���O���p�C�v�E�C���I�[�_�[�̃V���v���Ȃ��̂ɖ߂��Ă����̂����B
�����̑��d�^�X�N���������߂�͖̂����Ǝv���B�eorth�݂��������������f���ŋɒ[��
�����ȃ��W���[����g�ݍ��킹�ăV�X�e����g�ނ悤�Ȋ��Ȃ炢���邩���m��ǁB
>>228
����͖����悤�ȁB�f�o�t���[�J�[�Ƃ��Ă̓O���t�B�b�N�����ȊO�ɉ��Z���\�[�X�������
�`�搫�\��������̂͌����낤���A�i���Ƀ��^�����n�C�G���h�@��B�j�C���e���ɂ��Ă�����
�v���Z�b�T�̎d�������ɒD����̂�ق��Ă͌��Ă��Ȃ��Ǝv���B�i���ہA���f�B�A�v���Z�b�T
�ɑ���MMX�őR�����B�j
�������i�X�Ƃ�������Ĕėp�v���Z�b�T�̖���������@�\���j�b�g�ɕ��S�����悤�ɂȂ���
�����ƁA�R�A�����̓V���O���p�C�v�E�C���I�[�_�[�̃V���v���Ȃ��̂ɖ߂��Ă����̂����B
237 �FMAC�I�^��236 �����F2006/03/12(��) 11:27:19 ID:ksHUgGwY
>>236
�@�@------------------------
�@�@�eorth�݂��������������f���ŋɒ[�ɏ����ȃ��W���[����g�ݍ��킹�ăV�X�e����g�ނ悤�Ȋ�
�@�@------------------------
���������̂��CCELL�Ή��̃R�[�h�ɗv�������u�V�����v���O���~���O�p���_�C������ă��c���Ǝv���邷�B
���J����Ă���CELL�̐��\���������C���Ԃ���傫����Ȃ������ˁB�B�B
�@�@------------------------
�@�@�eorth�݂��������������f���ŋɒ[�ɏ����ȃ��W���[����g�ݍ��킹�ăV�X�e����g�ނ悤�Ȋ�
�@�@------------------------
���������̂��CCELL�Ή��̃R�[�h�ɗv�������u�V�����v���O���~���O�p���_�C������ă��c���Ǝv���邷�B
���J����Ă���CELL�̐��\���������C���Ԃ���傫����Ȃ������ˁB�B�B
���ɂȂ��Ă���ƁA��L�����̃f�[�^�̈��SPE��LS�A
�Ȃ��Ƃ��X�P�W���[�����O����~�h���E�F�A���o�Ă���Ȃ�Ēx�����B
http://techon.nikkeibp.co.jp/article/NEWS/20060308/114415/
�Ȃ��Ƃ��X�P�W���[�����O����~�h���E�F�A���o�Ă���Ȃ�Ēx�����B
http://techon.nikkeibp.co.jp/article/NEWS/20060308/114415/
CELL�́A�p�\�R���Ŏg���Ȃ�A�O���t�B�b�N�X�A�N�Z�����[�^�ł��傤�B
hp��Visualize fx10�Ƃ����r�f�I�J�[�h�́A�r�f�I�J�[�h����RISC�v���Z�b�T6�ς�ł��肵����B
�p�\�R���Ŏg���ijϰ�Ȃ̂́AXBOX 360�ɐς܂�Ă���CPU���Ǝv���B
3.2GHz��3�R�A6�X���b�h���s�ŁA�������̃o���h��������Ԃ���ԁB
hp��Visualize fx10�Ƃ����r�f�I�J�[�h�́A�r�f�I�J�[�h����RISC�v���Z�b�T6�ς�ł��肵����B
�p�\�R���Ŏg���ijϰ�Ȃ̂́AXBOX 360�ɐς܂�Ă���CPU���Ǝv���B
3.2GHz��3�R�A6�X���b�h���s�ŁA�������̃o���h��������Ԃ���ԁB
240 �FMAC�I�^��239 �����F2006/03/12(��) 12:02:43 ID:ksHUgGwY
>>239
�@�@--------------------
�@�@XBOX 360�ɐς܂�Ă���CPU���Ǝv���B
�@�@--------------------
�g�����߂�������CELL PPE�Ɠ������m���B
2-issue��in-order�̃v���Z�b�T�����ǁC�����Ǝv�������H����̕���Merom�Łu����̗L����
���������Ǝv���Ă��������ǂˁB�B�B
�@�@--------------------
�@�@XBOX 360�ɐς܂�Ă���CPU���Ǝv���B
�@�@--------------------
�g�����߂�������CELL PPE�Ɠ������m���B
2-issue��in-order�̃v���Z�b�T�����ǁC�����Ǝv�������H����̕���Merom�Łu����̗L����
���������Ǝv���Ă��������ǂˁB�B�B
Xenon�̓A�[�r�^���肪�����Ă�̂Ŗ��O
>>239
6���炢�ŋ����ȁB
SGI��Reality Engine2��12��Intel860XP�v���Z�b�T�_�ϊ��̂��߂�
���ڂ��Ă���B�̂�3D�O���t�B�b�N�X�V�X�e���ł�RISC�v���Z�b�T�l��
���ڂ������̂������B
http://www.gisparks.tas.gov.au/sgi/ge10.jpg
6���炢�ŋ����ȁB
SGI��Reality Engine2��12��Intel860XP�v���Z�b�T�_�ϊ��̂��߂�
���ڂ��Ă���B�̂�3D�O���t�B�b�N�X�V�X�e���ł�RISC�v���Z�b�T�l��
���ڂ������̂������B
http://www.gisparks.tas.gov.au/sgi/ge10.jpg
{kind=link}
>>240
2-issue�ł�3�R�A����A�g�[�^����6-issue����B
in-order���Ă��A2�X���b�h�ʼnB������B
�����g�[�^����6-issue�ł��A3-issue��2�R�A�����A�����������Ǝv���B
>>243
i860��SGI�̃����X�^�[���̃}�V���Ŏg��ꂽ���Ƃ�����̂͒m���Ă邯�ǁA
Visualize fx10�́A�������ʂ�OpenGL�̃r�f�I�J�[�h�Ȃ�ł���B
2-issue�ł�3�R�A����A�g�[�^����6-issue����B
in-order���Ă��A2�X���b�h�ʼnB������B
�����g�[�^����6-issue�ł��A3-issue��2�R�A�����A�����������Ǝv���B
>>243
i860��SGI�̃����X�^�[���̃}�V���Ŏg��ꂽ���Ƃ�����̂͒m���Ă邯�ǁA
Visualize fx10�́A�������ʂ�OpenGL�̃r�f�I�J�[�h�Ȃ�ł���B
���ƂŃ��W�X�^�A���P�[�V����������X�P�W���[�����O�����肷��̂��V�����v���O���~���O�p���_�C������
��Ԃ��v���Z�b�T�̊O�ɏo�����[�l������Itanium�������������A
���ꂪ���\�Ɍ��т��Ă���Ƃ͌������Ȃ��B
���ꂪ���\�Ɍ��т��Ă���Ƃ͌������Ȃ��B
247 �FMAC�I�^��245 �����F2006/03/12(��) 22:05:03 ID:ksHUgGwY
>>245
���̕ӂ������ŊȒP�ɂł���悤�ɁCin-order�ɂȂ��Ă�Ǝv�����B
SPE�ł̃^�X�N������C�l�͂ɗ��炴��Ȃ��Ǝv�������ǁB�B�B
���̕ӂ������ŊȒP�ɂł���悤�ɁCin-order�ɂȂ��Ă�Ǝv�����B
SPE�ł̃^�X�N������C�l�͂ɗ��炴��Ȃ��Ǝv�������ǁB�B�B
�n�[�h�Z�p�O�̃\�t�g���̂��킲��
�ECPU�̍��N���b�N���̓v���Z�X�̔����ɂ���Ă݂̂����炳���ׂ��ł���
�E�V���O���R�A�ŃC���I�[�_���s�̃V���O���p�C�v���C���̃v���Z�T���}���`�v���Z�T�Ŏg�p����
�E�x������̗̍p�ɂ�蕪��ɂ��C���^���b�N���s��Ȃ����K�R�I�Ƀp�C�v���C���i���͏��Ȃ����߂�ׂ��ł���
����ȍl�����͂��̂���������x��Ȃ�ł��傤�ˁB
�A�Z���u�����������Ėʔ����͔̂�p�C�v���C����CISC���V���O���p�C�v���C����RISC�Ȃ�ł���ˁB
���W�X�^���l�[�~���O�A�A�E�g�I�u�I�[�_���s�̃X�[�p�[�X�P�[���Ȃ�ăA�[�L�e�N�`��������ƁA���͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
�ECPU�̍��N���b�N���̓v���Z�X�̔����ɂ���Ă݂̂����炳���ׂ��ł���
�E�V���O���R�A�ŃC���I�[�_���s�̃V���O���p�C�v���C���̃v���Z�T���}���`�v���Z�T�Ŏg�p����
�E�x������̗̍p�ɂ�蕪��ɂ��C���^���b�N���s��Ȃ����K�R�I�Ƀp�C�v���C���i���͏��Ȃ����߂�ׂ��ł���
����ȍl�����͂��̂���������x��Ȃ�ł��傤�ˁB
�A�Z���u�����������Ėʔ����͔̂�p�C�v���C����CISC���V���O���p�C�v���C����RISC�Ȃ�ł���ˁB
���W�X�^���l�[�~���O�A�A�E�g�I�u�I�[�_���s�̃X�[�p�[�X�P�[���Ȃ�ăA�[�L�e�N�`��������ƁA���͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
>>246
����������Ȃ�RISC��VLIW���Ǝv���B
Itanium��IPC�Ƃ����ϓ_����͐��\�łĂ�Ǝv����B���ꂾ���s�[�L�[�ȃA�[�L�e�N�`���̊��ɂ́B
����������Ȃ�RISC��VLIW���Ǝv���B
Itanium��IPC�Ƃ����ϓ_����͐��\�łĂ�Ǝv����B���ꂾ���s�[�L�[�ȃA�[�L�e�N�`���̊��ɂ́B
�C���e���̐��ނ�AMD�̔ɉh Part26
http://pc7.2ch.net/test/read.cgi/jisaku/1142021769/373
373 ���O�FSocket774[sage] ���e���F2006/03/12(��) 18:50:45 ID:wbaGuMo1
MAC�I�^���Ē��肸�ɂ܂�����ȁB
���������L���߂����Ė����ɕ������ĂȂ��ȁB�u��v�Ƃ��u�邷�v�Ƃ��}�W�������B
�����ł̓C�P�Ă���Ċ��Ⴂ���Ă�낤�Ȃ�
�f�Ńh�����������ċC�Â��ĂȂ��낤�ȁE�E�E����B
�����A�s�[���������̂��m��A�����ŁuMAC�I�^�v�Ƃ�������Ă�
MAC�Ƃ����u�����h�Ɏ��ȓ��ꎋ����Ȃ��
�����̒ɂ��z�ɂ�������ɂ͌����Ȃ���
��̂����Ȃ�ł��̃X���ɏ�������ł���̂��Ӗ��s���B
�X���^�C���炵��AMD�D���ȓz�ׂ̈ɂ���X���ɂ����ǂ߂Ȃ����ǁH
����Ă鎖�͂��������X���Ⴂ����Intel�X���ɋA��E�E�E�ƌ�������������
������Intel�{�X���ł������Ă邩��A�鋏�ꏊ��������
�L�`�K�C������Intel�D���ȓz�ɂ������Ă��炦����
�d���Ȃ�������AMD�̈��������ăX�g���X���U�Ƃ��ɂ����B
�����A���Ƃ͎�����CPU�X���œ����ɂ��Ă̌������Ђ��炩����
�D�z���ɐZ�邱�Ƃ��Y��Ă̓_������
�܂�Apple��x86�ɏ@�|�Ƒւ������r�[�ɋ����̕��̂悤�ɒǏ]����
���܂ł͉��������́H�Ǝv�킹��قǐߑ�������PPC���̂Ă�
Intel�����`�ɑ���悤�Ȕn���ɂ͉��������Ă����ʂ�m9�i�O�D�O�j�߷ެ�!!
http://pc7.2ch.net/test/read.cgi/jisaku/1142021769/373
373 ���O�FSocket774[sage] ���e���F2006/03/12(��) 18:50:45 ID:wbaGuMo1
MAC�I�^���Ē��肸�ɂ܂�����ȁB
���������L���߂����Ė����ɕ������ĂȂ��ȁB�u��v�Ƃ��u�邷�v�Ƃ��}�W�������B
�����ł̓C�P�Ă���Ċ��Ⴂ���Ă�낤�Ȃ�
�f�Ńh�����������ċC�Â��ĂȂ��낤�ȁE�E�E����B
�����A�s�[���������̂��m��A�����ŁuMAC�I�^�v�Ƃ�������Ă�
MAC�Ƃ����u�����h�Ɏ��ȓ��ꎋ����Ȃ��
�����̒ɂ��z�ɂ�������ɂ͌����Ȃ���
��̂����Ȃ�ł��̃X���ɏ�������ł���̂��Ӗ��s���B
�X���^�C���炵��AMD�D���ȓz�ׂ̈ɂ���X���ɂ����ǂ߂Ȃ����ǁH
����Ă鎖�͂��������X���Ⴂ����Intel�X���ɋA��E�E�E�ƌ�������������
������Intel�{�X���ł������Ă邩��A�鋏�ꏊ��������
�L�`�K�C������Intel�D���ȓz�ɂ������Ă��炦����
�d���Ȃ�������AMD�̈��������ăX�g���X���U�Ƃ��ɂ����B
�����A���Ƃ͎�����CPU�X���œ����ɂ��Ă̌������Ђ��炩����
�D�z���ɐZ�邱�Ƃ��Y��Ă̓_������
�܂�Apple��x86�ɏ@�|�Ƒւ������r�[�ɋ����̕��̂悤�ɒǏ]����
���܂ł͉��������́H�Ǝv�킹��قǐߑ�������PPC���̂Ă�
Intel�����`�ɑ���悤�Ȕn���ɂ͉��������Ă����ʂ�m9�i�O�D�O�j�߷ެ�!!
>>248
����̃v���Z�b�T�v�͂Ȃ�ׂ����Ă����Ȃ��Ă���̂ŁA���������u�ׂ��v�_�̓i���Z���X�B
���߂Đv�ڕW���ɋ����Ă���B�u���͂��������̂��D���v�Ƃ����̂ł͂�����Ǝア�B
����̃v���Z�b�T�v�͂Ȃ�ׂ����Ă����Ȃ��Ă���̂ŁA���������u�ׂ��v�_�̓i���Z���X�B
���߂Đv�ڕW���ɋ����Ă���B�u���͂��������̂��D���v�Ƃ����̂ł͂�����Ǝア�B
>>248�݂����Ƀv�����Ėϑz�������Љ��m��Ȃ����h�͂���������
�匴�Y��܂��V�b�^�J�Ԃ���I���Ă��܂��B
ttp://pcweb.mycom.co.jp/articles/2006/03/11/idf3/
> ���W�X�^�Ԃ̃f�[�^�R�s�[(�ړ������Ȃ�Register Renaming�ōς�)���i���Ă�����̂Ǝv����
> ���߂�Re-order��Retirement��In-order�Ȃ̂͂�����Ƌ����B���ʁA������Out-of-Order�Ŏ��s����
> Retirement��In-order�Ȃ̂́AMemory Access��OOO�Ŏ��s����W�ŁA��xQueueing����K�v�����邩��A�ƍl������B
�����͂Ȃ�̂��߂Ƀ��A�^�C�A�����g���j�b�g������̂��m���̂��B
> ���̃v���t�F�b�`�̃��J�j�Y���͂��낢�날�邪�A���̓A�N�Z�X���������A�h���X����1Line��(�L���b�V����1��Ɋi�[����f�[�^�ʂ̒P��)����荞�ނƂ��������x���ŁA
> �A�N�Z�X�p�^�[���܂ʼn�͂������(�������x���ł͂Ƃ��������p�v���Z�b�T�Ƃ��Ă�)����܂ŕ��������Ƃ��Ȃ��B
�}���R�t�v���t�F�b�`���[�Ȃ�POWER2������Ŏ�������Ƃ�Ǝv�����B
ttp://pcweb.mycom.co.jp/articles/2006/03/11/idf3/
> ���W�X�^�Ԃ̃f�[�^�R�s�[(�ړ������Ȃ�Register Renaming�ōς�)���i���Ă�����̂Ǝv����
> ���߂�Re-order��Retirement��In-order�Ȃ̂͂�����Ƌ����B���ʁA������Out-of-Order�Ŏ��s����
> Retirement��In-order�Ȃ̂́AMemory Access��OOO�Ŏ��s����W�ŁA��xQueueing����K�v�����邩��A�ƍl������B
�����͂Ȃ�̂��߂Ƀ��A�^�C�A�����g���j�b�g������̂��m���̂��B
> ���̃v���t�F�b�`�̃��J�j�Y���͂��낢�날�邪�A���̓A�N�Z�X���������A�h���X����1Line��(�L���b�V����1��Ɋi�[����f�[�^�ʂ̒P��)����荞�ނƂ��������x���ŁA
> �A�N�Z�X�p�^�[���܂ʼn�͂������(�������x���ł͂Ƃ��������p�v���Z�b�T�Ƃ��Ă�)����܂ŕ��������Ƃ��Ȃ��B
�}���R�t�v���t�F�b�`���[�Ȃ�POWER2������Ŏ�������Ƃ�Ǝv�����B
���p�v���Z�b�T��Retirement��Out-of-Order��CPU�͂���܂����H
>>248
>�ECPU�̍��N���b�N���̓v���Z�X�̔����ɂ���Ă݂̂����炳���ׂ��ł���
�ϑz����T�ɁB
>�E�V���O���R�A�ŃC���I�[�_���s�̃V���O���p�C�v���C���̃v���Z�T���}���`�v���Z�T�Ŏg�p����
�V���O���R�A�Ń}���`�v���Z�b�T�H
�`�b�v�̐�(=�p�b�P�[�W�̐�)���ǂ�ǂ₷�킯�H
�}���`�v���Z�b�T�V�X�e�������܂��������̂̓\�t�g�͑�ς�H
�{���Ƀ\�t�g���H
>�E�x������̗̍p�ɂ�蕪��ɂ��C���^���b�N���s��Ȃ����K�R�I�Ƀp�C�v���C���i���͏��Ȃ����߂�ׂ��ł���
�n�[�h�̎����ɂ���ăf�B���C�X���b�g�̐������ɂȂ��ăo�C�i���݊������Ȃ��Ȃ邯�ǁB
MIPS��R4000�̎��_�Ŋ��ɃC���^���b�N����悤�ɂȂ��Ă���̒m���Ă�H
�{���Ƀ\�t�g���H
>����ȍl�����͂��̂���������x��Ȃ�ł��傤�ˁB
�łȂ���o�J�B
>�A�Z���u�����������Ėʔ����͔̂�p�C�v���C����CISC���V���O���p�C�v���C����RISC�Ȃ�ł���ˁB
>���W�X�^���l�[�~���O�A�A�E�g�I�u�I�[�_���s�̃X�[�p�[�X�P�[���Ȃ�ăA�[�L�e�N�`��������ƁA���͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
�{���Ƀ\�t�g���H
>�ECPU�̍��N���b�N���̓v���Z�X�̔����ɂ���Ă݂̂����炳���ׂ��ł���
�ϑz����T�ɁB
>�E�V���O���R�A�ŃC���I�[�_���s�̃V���O���p�C�v���C���̃v���Z�T���}���`�v���Z�T�Ŏg�p����
�V���O���R�A�Ń}���`�v���Z�b�T�H
�`�b�v�̐�(=�p�b�P�[�W�̐�)���ǂ�ǂ₷�킯�H
�}���`�v���Z�b�T�V�X�e�������܂��������̂̓\�t�g�͑�ς�H
�{���Ƀ\�t�g���H
>�E�x������̗̍p�ɂ�蕪��ɂ��C���^���b�N���s��Ȃ����K�R�I�Ƀp�C�v���C���i���͏��Ȃ����߂�ׂ��ł���
�n�[�h�̎����ɂ���ăf�B���C�X���b�g�̐������ɂȂ��ăo�C�i���݊������Ȃ��Ȃ邯�ǁB
MIPS��R4000�̎��_�Ŋ��ɃC���^���b�N����悤�ɂȂ��Ă���̒m���Ă�H
�{���Ƀ\�t�g���H
>����ȍl�����͂��̂���������x��Ȃ�ł��傤�ˁB
�łȂ���o�J�B
>�A�Z���u�����������Ėʔ����͔̂�p�C�v���C����CISC���V���O���p�C�v���C����RISC�Ȃ�ł���ˁB
>���W�X�^���l�[�~���O�A�A�E�g�I�u�I�[�_���s�̃X�[�p�[�X�P�[���Ȃ�ăA�[�L�e�N�`��������ƁA���͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
�{���Ƀ\�t�g���H
256 �FSocket774�F2006/03/13(��) 09:24:19 ID:H2iSGrXX
>>254
360/91
360/91
>>257
>>>248�ʼn���Sun��Niagara�݂����ȓz��z���������B
Niagara�͂܂������z���ł��Ȃ����ǂȂ��B�V���O���R�A���Č����Ă邵�B
�A���̓��j�B�R�A����ˁB
�Ђ���Ƃ��āA�V���v���R�A�Ń}���`�v���Z�b�T�Ƃ������������낤���H
>>>248�ʼn���Sun��Niagara�݂����ȓz��z���������B
Niagara�͂܂������z���ł��Ȃ����ǂȂ��B�V���O���R�A���Č����Ă邵�B
�A���̓��j�B�R�A����ˁB
�Ђ���Ƃ��āA�V���v���R�A�Ń}���`�v���Z�b�T�Ƃ������������낤���H
����Ă������Ďw�E��������z������A�����ƃX���[���Ă����悤��B
���̃\�t�g�E�F�A�v���O���}�Ƃ�������Ń\�t�g���Ə������̂ł���
�Ⴄ�Ӗ��Ɏ��ꂽ�̂ł��傤���B
�\�t�g�E�F�A�����炵��CPU���g�p�������Ƃ��Ȃ��A
CPU�Ɋւ��Ă̓v���t�F�b�V���i���ǂ��납��O���ł��B
�����̐g�Ȃ̂Ŏw�E�A�ᔻ�A�}�A�傢�Ɋ��}�ł��B
�Ⴄ�Ӗ��Ɏ��ꂽ�̂ł��傤���B
�\�t�g�E�F�A�����炵��CPU���g�p�������Ƃ��Ȃ��A
CPU�Ɋւ��Ă̓v���t�F�b�V���i���ǂ��납��O���ł��B
�����̐g�Ȃ̂Ŏw�E�A�ᔻ�A�}�A�傢�Ɋ��}�ł��B
>>255=258=261����A�ԓ����肪�Ƃ��������܂�
���̍l����
�E���݂�CPU�N���b�N�͑������遨500MHz���x�ŏ[��
�E�C���^���b�N�̂Ȃ��x�����p�C�v���C���i���͕ς��Ȃ�
�EUnix�n�̃v���O�������l����ƃ}���`�v���Z�T���͂���قǓ���Ȃ�
���݂̏W�ϓx�Ȃ�p�C�v���C��5�i��500MHz�̎����͉\�Ƃ�������Ȏv�����݂Ɋ�Â��Ă��܂��B
R4000�n�̂悤�Ƀp�C�v���C���i���𑝂₷�ƁA
�o�C�i���݊����̂��߂ɒx���X���b�g�{�C���^���b�N�Ȃ��
MIPS��Microprocessor with interlocked pipeline stages�̗��ł����H
�Ȃ�Ă��ƂɂȂ邩��p�C�v���C���̑����͍D�܂����Ȃ��Ǝv���Ă��܂��B
���̍l����
�E���݂�CPU�N���b�N�͑������遨500MHz���x�ŏ[��
�E�C���^���b�N�̂Ȃ��x�����p�C�v���C���i���͕ς��Ȃ�
�EUnix�n�̃v���O�������l����ƃ}���`�v���Z�T���͂���قǓ���Ȃ�
���݂̏W�ϓx�Ȃ�p�C�v���C��5�i��500MHz�̎����͉\�Ƃ�������Ȏv�����݂Ɋ�Â��Ă��܂��B
R4000�n�̂悤�Ƀp�C�v���C���i���𑝂₷�ƁA
�o�C�i���݊����̂��߂ɒx���X���b�g�{�C���^���b�N�Ȃ��
MIPS��Microprocessor with interlocked pipeline stages�̗��ł����H
�Ȃ�Ă��ƂɂȂ邩��p�C�v���C���̑����͍D�܂����Ȃ��Ǝv���Ă��܂��B
>>260���ϲ
��������ʰ�ނ��Ă��ǂ������Ȃ���g�����ɂȂ�Ȃ����ˁB
���������������K�v�B
248�����͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
��Ȃ����[�Ȃ�
�Ȃ��Ȃ�\����������(C)�Ƃ��̵�ު�Ďw���g��(C++)�͐�ɍ�������Ȃ���Ȃ�����
�ǂ����E�E�E�����l���Ă��������A���˂������܂��ł��B
�Ƃ���Ŏ����گ�ޕ�����߲�>>216�Ȃ�Ƃ��Ȃ��Ă���Ȃ����̂��E�E�E
��������ʰ�ނ��Ă��ǂ������Ȃ���g�����ɂȂ�Ȃ����ˁB
���������������K�v�B
248�����͂�l�Ԃ͍������ꂾ���g�����Ă��ƂȂ�ł��傤���ˁB
��Ȃ����[�Ȃ�
�Ȃ��Ȃ�\����������(C)�Ƃ��̵�ު�Ďw���g��(C++)�͐�ɍ�������Ȃ���Ȃ�����
�ǂ����E�E�E�����l���Ă��������A���˂������܂��ł��B
�Ƃ���Ŏ����گ�ޕ�����߲�>>216�Ȃ�Ƃ��Ȃ��Ă���Ȃ����̂��E�E�E
CELL�͌y���R���g���[�����W�b�N��PPE�ŁA�d�����f�B�A������SPE�łƂ���
���S�\���BPPE��SPE���������āu�P�̃^�X�N���Q�[���v�������B
SPE�̓R�[�h�ƃf�[�^���܂Ƃ߂ă��[�J���̍���RAM�ɓ������ލ\��������
�^�X�N�X�C�b�`�Ȃǂ܂������z�肵�Ă��Ȃ��B�䂦�ɔėp�ɂ͎g���Ȃ��B
360�݂�����PPC���R�R�A�Ƃ��Ȃ�g���Ȃ����Ȃ����A����Ȃ炻��ŃC���e��
��AMD�̂ق����ꖇ�������B
���F�Q�[���pCPU�̓Q�[���p�ł����Ȃ��B
���S�\���BPPE��SPE���������āu�P�̃^�X�N���Q�[���v�������B
SPE�̓R�[�h�ƃf�[�^���܂Ƃ߂ă��[�J���̍���RAM�ɓ������ލ\��������
�^�X�N�X�C�b�`�Ȃǂ܂������z�肵�Ă��Ȃ��B�䂦�ɔėp�ɂ͎g���Ȃ��B
360�݂�����PPC���R�R�A�Ƃ��Ȃ�g���Ȃ����Ȃ����A����Ȃ炻��ŃC���e��
��AMD�̂ق����ꖇ�������B
���F�Q�[���pCPU�̓Q�[���p�ł����Ȃ��B
>>263
CPU���B������v���O���~���O����Ƃ����Ӗ��ō�������Ƃ����������ł��B
�A�Z���u���ł������z�v���Z�T�𑀍삵���肷�邵�B
>>264
IA-64��IA-32�̖��߃Z�b�g�������ł���ˁBVLIW��W�X�^�̑����͂������邯�ǁc
IA-32�̌��������Ă��Ȃ�������̂ɁB
�����̒��Ńv���Z�T�̏��ʕt����
1�ʁ@R3000�nMIPS�F���߃Z�b�g�A�A�[�L�e�N�`���Ƃ��V���v���ōD��
2�ʁ@ARM�F���Ȃ�C�ɓ����Ă��܂������W�X�^�����Ȃ���
3�ʁ@PPC�F������ƕ��G�Ȃ̂��C�ɂȂ�܂����D��ہB�����r�b�O�G���f�B�A���Ȃ̂��Ђ�������
4�ʁ@SPARC�F�G�������ƂȂ����ǂ����G�肽���BPPC�Ɠ������r�b�O�G���f�B�A�����Ђ�������
5�ʁ@MIPS64�F���߃Z�b�g�͍D�������ǃp�C�v���C���i���������C���^���b�N�͂��邵
6�ʁ@SH�F�x���X���b�g������͍̂D�������ǁA���W�X�^2�I�y�����h�A���W�X�^���A���ߌ꒷���~
7�ʁ@IA-16�F�œK�����s���̂��ʔ��������B�ŏ��ɐG����CPU�Ȃ̂ő��߂Ȃ�
-------
IA-32�F���̒��J�l�ł���
�Ȃ�ł���ˁB68K�n��Z80�n��IA-64���ړ_���Ȃ������̂ł悭�m��܂���ł����B
���ꂩ�����r�b�O�G���f�B�A���ɉ��@���Ă��������PPC�ɑ����ł����ǁB
�o�C�G���f�B�A���Ƃ��������g���Ŏg���Ă���̂��������ƂȂ��ł��B
CPU���B������v���O���~���O����Ƃ����Ӗ��ō�������Ƃ����������ł��B
�A�Z���u���ł������z�v���Z�T�𑀍삵���肷�邵�B
>>264
IA-64��IA-32�̖��߃Z�b�g�������ł���ˁBVLIW��W�X�^�̑����͂������邯�ǁc
IA-32�̌��������Ă��Ȃ�������̂ɁB
�����̒��Ńv���Z�T�̏��ʕt����
1�ʁ@R3000�nMIPS�F���߃Z�b�g�A�A�[�L�e�N�`���Ƃ��V���v���ōD��
2�ʁ@ARM�F���Ȃ�C�ɓ����Ă��܂������W�X�^�����Ȃ���
3�ʁ@PPC�F������ƕ��G�Ȃ̂��C�ɂȂ�܂����D��ہB�����r�b�O�G���f�B�A���Ȃ̂��Ђ�������
4�ʁ@SPARC�F�G�������ƂȂ����ǂ����G�肽���BPPC�Ɠ������r�b�O�G���f�B�A�����Ђ�������
5�ʁ@MIPS64�F���߃Z�b�g�͍D�������ǃp�C�v���C���i���������C���^���b�N�͂��邵
6�ʁ@SH�F�x���X���b�g������͍̂D�������ǁA���W�X�^2�I�y�����h�A���W�X�^���A���ߌ꒷���~
7�ʁ@IA-16�F�œK�����s���̂��ʔ��������B�ŏ��ɐG����CPU�Ȃ̂ő��߂Ȃ�
-------
IA-32�F���̒��J�l�ł���
�Ȃ�ł���ˁB68K�n��Z80�n��IA-64���ړ_���Ȃ������̂ł悭�m��܂���ł����B
���ꂩ�����r�b�O�G���f�B�A���ɉ��@���Ă��������PPC�ɑ����ł����ǁB
�o�C�G���f�B�A���Ƃ��������g���Ŏg���Ă���̂��������ƂȂ��ł��B
268 �FSocket774�F2006/03/14(��) 01:27:04 ID:SQXuzcB5
>>267
PPC����ʂɂ��Ă���̂����Ȃ�ӊO�����AAlpha�͂ǂ���B
PPC����ʂɂ��Ă���̂����Ȃ�ӊO�����AAlpha�͂ǂ���B
Intel���{�C��PowerPC�ō��ƍ���CoreDuo���܂����H
>>262
96�R�A�Ő��\2�{�̃R�v���Z�b�T�A�Ċ�Ƃ����\
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
96�R�A�Ő��\2�{�̃R�v���Z�b�T�A�Ċ�Ƃ����\
http://www.itmedia.co.jp/news/articles/0410/07/news039.html
>>267
�ĊOARM��������
�l�I�ɂ͑S���ߏ������s�\�Ȃ̂͌��\�D��������
���̃X���ł͕ϑԖ��߃Z�b�g�Ƃ�����Ȍ����悤������
�ĊOARM��������
�l�I�ɂ͑S���ߏ������s�\�Ȃ̂͌��\�D��������
���̃X���ł͕ϑԖ��߃Z�b�g�Ƃ�����Ȍ����悤������
�Ƃ����IA16����x86��16bit�R�[�h�̂��ƁH
�ǂ��ł��������������g���Ă���̂��Ȃ��B
�ǂ��ł��������������g���Ă���̂��Ȃ��B
>>268=269�@>>272
ARM�͓��_�����������_������2�ʂł��B���I�ł���ˁB
���z�Nj��I�ȋ�MIPS�ƌ����I��ARM���Ċ����ł����B
PPC�͎��_�����Ȃ����_�����Ȃ�3�ʂł��B
PPC�͌��_�炵�����_����������Ȃ��B
R3000�ȊO�̏��ʂ̗��R�͎��̃��x���f���Ă��Ɩ����Ƃ������P���ŁA
�v���O���}�����猩���C���^�t�F�[�X�ł��閽�߃Z�b�g���傫�����m�������Ă܂��B
���Ƃ͔ėp���W�X�^���A���W�X�^�I�y�����h���A�G���f�B�A���B
�n�[�h�E�F�A�͖�O���ł����A�V���v���ȃA�[�L�e�N�`�����D���ł��B
�Ȃ̂ŕ���\�������x���X���b�g���D���B
MIPS64�͂��킢�����܂��Ăɂ���100�{�Ƃ������Ƃ���ł��傤���B
��̓͂��Ƃ����Alpha�͂Ȃ��̂ł�����ƕ�����܂���B
>>271
�a�����̃l�b�g���[�N���U�R���s���[�e�B���O�Ɩ������̃v���Z�T�̒��ԂƂ����������ł����ˁB
���݂̖����o�X���l����ƊɌ����͂��ƌ����I�ȉ��Ȃ�ł��傤���B
>>273
�p�C�v���C��������O��16bitCPU��8086��80286�̂���ŏ����܂����B
�i80286�̓p�C�v���C�������������H�j
ARM�͓��_�����������_������2�ʂł��B���I�ł���ˁB
���z�Nj��I�ȋ�MIPS�ƌ����I��ARM���Ċ����ł����B
PPC�͎��_�����Ȃ����_�����Ȃ�3�ʂł��B
PPC�͌��_�炵�����_����������Ȃ��B
R3000�ȊO�̏��ʂ̗��R�͎��̃��x���f���Ă��Ɩ����Ƃ������P���ŁA
�v���O���}�����猩���C���^�t�F�[�X�ł��閽�߃Z�b�g���傫�����m�������Ă܂��B
���Ƃ͔ėp���W�X�^���A���W�X�^�I�y�����h���A�G���f�B�A���B
�n�[�h�E�F�A�͖�O���ł����A�V���v���ȃA�[�L�e�N�`�����D���ł��B
�Ȃ̂ŕ���\�������x���X���b�g���D���B
MIPS64�͂��킢�����܂��Ăɂ���100�{�Ƃ������Ƃ���ł��傤���B
��̓͂��Ƃ����Alpha�͂Ȃ��̂ł�����ƕ�����܂���B
>>271
�a�����̃l�b�g���[�N���U�R���s���[�e�B���O�Ɩ������̃v���Z�T�̒��ԂƂ����������ł����ˁB
���݂̖����o�X���l����ƊɌ����͂��ƌ����I�ȉ��Ȃ�ł��傤���B
>>273
�p�C�v���C��������O��16bitCPU��8086��80286�̂���ŏ����܂����B
�i80286�̓p�C�v���C�������������H�j
>>268
> >>267
> > IA-64��IA-32�̖��߃Z�b�g�������ł���ˁB
> ���Ȃ�
�⑫
����PentiumII (�ʂ̑��x��IA-32 �� Core)���I�}�P�œ����Ă��邾���D
������CMontecito����Ȃ��Ȃ�݂��������ǁD
> >>267
> > IA-64��IA-32�̖��߃Z�b�g�������ł���ˁB
> ���Ȃ�
�⑫
����PentiumII (�ʂ̑��x��IA-32 �� Core)���I�}�P�œ����Ă��邾���D
������CMontecito����Ȃ��Ȃ�݂��������ǁD
>>275 (=268?)
���̖��m���炭��ڒ����Ȕ����𐳂��Ă��������āA���肪�Ƃ��������܂��B
�Ⴂ�N���b�N�A�Z���p�C�v���C����IA-32�̓I�}�P�ł����B
�ӊO�ƃC�C�z�����B
�H�킸�����Ŏ�������߂�̂͂����܂���ˁB
���Ȃ��܂��B
���̖��m���炭��ڒ����Ȕ����𐳂��Ă��������āA���肪�Ƃ��������܂��B
�Ⴂ�N���b�N�A�Z���p�C�v���C����IA-32�̓I�}�P�ł����B
�ӊO�ƃC�C�z�����B
�H�킸�����Ŏ�������߂�̂͂����܂���ˁB
���Ȃ��܂��B
>>273
IA64���o���Ă���IA32�Ƃ����p�ꂪ���܂�A������IA16�Ƃ������t���g����B
����g���Ȃ����A�g����ɂ͎g����B
�g�p�Ⴊ�������Ȃ炮����H
IA64���o���Ă���IA32�Ƃ����p�ꂪ���܂�A������IA16�Ƃ������t���g����B
����g���Ȃ����A�g����ɂ͎g����B
�g�p�Ⴊ�������Ȃ炮����H
>>275
����͗ǂ������b�Ȃ��ǁA�\�[�X����?
�C���e���̎����ɂ́Ax86���f�R�[�h����IA64�Ɠ������Z���j�b�g�E���W�X�^�Ŏ��s���Ă���悤�ɏ����Ă���B
����PentiumII�̃R�A���ہX�����Ă��āA����ɓ����N���b�N�œ����Ă���̂�̂Ȃ�A
IA-32�̃R�[�h�̎��s���x�́A�����Ƃ����Ƒ����͂��B
����͗ǂ������b�Ȃ��ǁA�\�[�X����?
�C���e���̎����ɂ́Ax86���f�R�[�h����IA64�Ɠ������Z���j�b�g�E���W�X�^�Ŏ��s���Ă���悤�ɏ����Ă���B
����PentiumII�̃R�A���ہX�����Ă��āA����ɓ����N���b�N�œ����Ă���̂�̂Ȃ�A
IA-32�̃R�[�h�̎��s���x�́A�����Ƃ����Ƒ����͂��B
>>278
������m��Ȃ������B
���������O�ɂ�����Ƃ͒��ׂ�A�����\�[�X��
�M�ߐ��]�X�����������₤�ȑO�̘bw
http://www.google.com/search?num=50&hl=ja&q=IA-32+itanium+%E3%82%A8%E3%83%9F%E3%83%A5%E3%83%AC%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3&lr=lang_ja
IA64�͏����̍���IA32�Ƃ̌݊������ێ����邽�ɐ�p�̃f�R�[�h�E���j�b�g���������Ă��B
����IA-32 EL�Ƃ����G�~�����[�V�����B�Ⴆ��Ȃ�Transmeta��CMS�݂����Ȃ́B
������m��Ȃ������B
���������O�ɂ�����Ƃ͒��ׂ�A�����\�[�X��
�M�ߐ��]�X�����������₤�ȑO�̘bw
http://www.google.com/search?num=50&hl=ja&q=IA-32+itanium+%E3%82%A8%E3%83%9F%E3%83%A5%E3%83%AC%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3&lr=lang_ja
IA64�͏����̍���IA32�Ƃ̌݊������ێ����邽�ɐ�p�̃f�R�[�h�E���j�b�g���������Ă��B
����IA-32 EL�Ƃ����G�~�����[�V�����B�Ⴆ��Ȃ�Transmeta��CMS�݂����Ȃ́B
>>277
�ǂ����炻��������ȕ������d����Ă����������������������Ȃ�ŁB
google�����Ă����������Ӗ��Ŏg���Ă��邱�Ƃ͂قƂ�ǂȂ���ˁB
���Ȃ��Ƃ����������ꏊ�Ő����Ȃ��Ɏg���ė������Ă��炦�錾�t����Ȃ��Ǝv����B
�ǂ����炻��������ȕ������d����Ă����������������������Ȃ�ŁB
google�����Ă����������Ӗ��Ŏg���Ă��邱�Ƃ͂قƂ�ǂȂ���ˁB
���Ȃ��Ƃ����������ꏊ�Ő����Ȃ��Ɏg���ė������Ă��炦�錾�t����Ȃ��Ǝv����B
PowerPC��RISC��CISC�������ʂ��Ȃ��ƕ����܂��B
x86��CPU�Ɣ�ׂ�PowerPC�̕����x�����R�͂Ȃ�ł����H
���̋Z�p�ŕ����Ă���Ƃ������ƂȂ̂ł��傤���H
x86��CPU�Ɣ�ׂ�PowerPC�̕����x�����R�͂Ȃ�ł����H
���̋Z�p�ŕ����Ă���Ƃ������ƂȂ̂ł��傤���H
�@..::::::,�_,�::: ::::: ::: :
�@�@/��ށR)-�. :: ::::
���iɄ��R.�����
�@�@/��ށR)-�. :: ::::
���iɄ��R.�����
IA64��32���s�p�R�A�͓����C�C��Ƃ����㕨����������
�}�b�L�����[�̍����������ɂ̓G�~�����[�V�����̕��������Ȃ��Ă��܂���
���ӂȂ��Ȃ邾�낤�ƌ����Ă����ȁc�BIA64���̂��낤�����B
>>281
�@x86��RISC������
�APPC�̕��������ăN���b�N���Ⴂ����
�BPPC�ō����ɓ����悤�ȃR�[�f�B���O�����ĂȂ�����
���̂����̕����̗��R�ɂ��B
�A�ɂ��Ă�PPC�w�c�̈����ȂƂ������C�������s��
�@�\�ɂ���ăN���b�N�̑�����������Ƃ����̂ƁC�t���O�V�b�v
PPC�̎s�ꂪ�ƂĂ������Ƃ����̂������B
�]�k�����C�g��(�Q�[���@��)�Ɣ��Ȃ�PPC��
�ق�Mac��p�ŏ�ɍs����POWER������ׂ�
IBM�ɂ��C���Ȃ��Ƃ����̂�Intel�`�b�v�̗p�̌����Ƃ����B
�}�b�L�����[�̍����������ɂ̓G�~�����[�V�����̕��������Ȃ��Ă��܂���
���ӂȂ��Ȃ邾�낤�ƌ����Ă����ȁc�BIA64���̂��낤�����B
>>281
�@x86��RISC������
�APPC�̕��������ăN���b�N���Ⴂ����
�BPPC�ō����ɓ����悤�ȃR�[�f�B���O�����ĂȂ�����
���̂����̕����̗��R�ɂ��B
�A�ɂ��Ă�PPC�w�c�̈����ȂƂ������C�������s��
�@�\�ɂ���ăN���b�N�̑�����������Ƃ����̂ƁC�t���O�V�b�v
PPC�̎s�ꂪ�ƂĂ������Ƃ����̂������B
�]�k�����C�g��(�Q�[���@��)�Ɣ��Ȃ�PPC��
�ق�Mac��p�ŏ�ɍs����POWER������ׂ�
IBM�ɂ��C���Ȃ��Ƃ����̂�Intel�`�b�v�̗p�̌����Ƃ����B
>>279
�b�̗��ꂩ�疾�L���Ȃ��Ă��킩���Ă��炦��Ǝv���ď����Ȃ������̂����ǁA
> ������CMontecito����Ȃ��Ȃ�݂��������ǁD
�ł͂Ȃ���
> ����PentiumII (�ʂ̑��x��IA-32 �� Core)���I�}�P�œ����Ă��邾���D
�̘b�ɂ��āA�ł��B
�b�̗��ꂩ�疾�L���Ȃ��Ă��킩���Ă��炦��Ǝv���ď����Ȃ������̂����ǁA
> ������CMontecito����Ȃ��Ȃ�݂��������ǁD
�ł͂Ȃ���
> ����PentiumII (�ʂ̑��x��IA-32 �� Core)���I�}�P�œ����Ă��邾���D
�̘b�ɂ��āA�ł��B
����b������Ă��邶��Ȃ��ł����B
�ŏ�����A���������Ă���������B
�т����肵���Ȃ��A�����B
�ŏ�����A���������Ă���������B
�т����肵���Ȃ��A�����B
>>281
����IA-32�ł��Apentium���conroe�̕��������Ƒ�������?
���߃Z�b�g���āA�{���I�ɂ���܊W�Ȃ���
>>283
970�́A2.7Ghz���o�Ă�
K8�Ƒ��F�Ȃ����A�f�X�N�g�b�v�E�T�[�o�[�pCPU�ł�
�N���b�N�ō��̕��ނ�
����IA-32�ł��Apentium���conroe�̕��������Ƒ�������?
���߃Z�b�g���āA�{���I�ɂ���܊W�Ȃ���
>>283
970�́A2.7Ghz���o�Ă�
K8�Ƒ��F�Ȃ����A�f�X�N�g�b�v�E�T�[�o�[�pCPU�ł�
�N���b�N�ō��̕��ނ�
>>278
> ����͗ǂ������b�Ȃ��ǁA�\�[�X����?
> �C���e���̎����ɂ́Ax86���f�R�[�h����IA64�Ɠ������Z���j�b�g�E���W�X�^�Ŏ��s���Ă���悤�ɏ����Ă���B
http://h21007.www2.hp.com/dspp/files/unprotected/itanium2.pdf
�́C29�y�[�W�ɁC
The Itanium 2 processor�fs IA-32 translation hardware engine is an enhanced and in-order version
of the original Itanium�fs IA-32 translation engine. It provides x86 compatibility with Katmai (Pentium 3)
and earlier processors. It will execute IA-32 applications and I/O drivers directly.
An important advance in the Itanium 2 processor that allowed a simplification from an out-of-order to
an in-order IA-32 translation engine was the design of a one-cycle LAGEN unit. The LAGEN unit forms
the address for IA-32 instructions. On the original Itanium processor, this function takes 2 cycles.
The performance of the Itanium 2 processor�fs IA-32 engine is expected to be comparable with
a 300 MHz Pentium Pro.
�Ƃ������Ă���ˁD
ISA �� Pentium3���������C���x��PenPro300MHz ���炢���D
(���܂�C����o���ŏ���������ł�����ƈ����)
���ƁC31�y�[�W�̐}��C32�y�[�W�̎ʐ^�ɂ́CIA-32 Engine �Ƃ��������Ɨ����ď�����Ă���̂ŁC
�ꉞ IA-32 �����̂��̂������Ă���ƌ����Ă����C�C�C�C�C���ȁH
> ����͗ǂ������b�Ȃ��ǁA�\�[�X����?
> �C���e���̎����ɂ́Ax86���f�R�[�h����IA64�Ɠ������Z���j�b�g�E���W�X�^�Ŏ��s���Ă���悤�ɏ����Ă���B
http://h21007.www2.hp.com/dspp/files/unprotected/itanium2.pdf
�́C29�y�[�W�ɁC
The Itanium 2 processor�fs IA-32 translation hardware engine is an enhanced and in-order version
of the original Itanium�fs IA-32 translation engine. It provides x86 compatibility with Katmai (Pentium 3)
and earlier processors. It will execute IA-32 applications and I/O drivers directly.
An important advance in the Itanium 2 processor that allowed a simplification from an out-of-order to
an in-order IA-32 translation engine was the design of a one-cycle LAGEN unit. The LAGEN unit forms
the address for IA-32 instructions. On the original Itanium processor, this function takes 2 cycles.
The performance of the Itanium 2 processor�fs IA-32 engine is expected to be comparable with
a 300 MHz Pentium Pro.
�Ƃ������Ă���ˁD
ISA �� Pentium3���������C���x��PenPro300MHz ���炢���D
(���܂�C����o���ŏ���������ł�����ƈ����)
���ƁC31�y�[�W�̐}��C32�y�[�W�̎ʐ^�ɂ́CIA-32 Engine �Ƃ��������Ɨ����ď�����Ă���̂ŁC
�ꉞ IA-32 �����̂��̂������Ă���ƌ����Ă����C�C�C�C�C���ȁH
31�y�[�W�̐}�̓p�C�v���C���̃X�e�[�W���ɕ`����Ă���̂ŁA
IA-32�̖��߂�IA-64�̖��߂ɕϊ�����Ă邱�Ƃ������Ă���ˁB
�ł�32�y�[�W�̃_�C�̃��C�A�E�g�̐}�ł́AIA-32�̖ʐς��L���āA
IA-32�̃R�A���ۂ��Ɠ��肻���ȋC�������ˁE�E�E�B
IA-32�̖��߂�IA-64�̖��߂ɕϊ�����Ă邱�Ƃ������Ă���ˁB
�ł�32�y�[�W�̃_�C�̃��C�A�E�g�̐}�ł́AIA-32�̖ʐς��L���āA
IA-32�̃R�A���ۂ��Ɠ��肻���ȋC�������ˁE�E�E�B
�����̃\�t�g�E�F�A���Y���d�����Ȃ��p�r�ł�itanium��power���I���B
x86���p���t��������B
x86�ł���K�v�̖����Q�[���@��power���̗p�B
PowerPC��G5�̓X�y�b�N�����̐��\���Ǝv���B
G4�̓��g���[���̋Z�p�͂Ƃ��C�̖����B
�N���b�N��������AIBM�͂��C���X�����������g���[�������Ă������B
������IBM�����[�G���h��G3�A���g���[�����n�C�G���h��G4�S���B
G4��荂�N���b�N��G3�͋����Ȃ��A���ꂪ�A�b�v���̈ӌ���IBM�͂��Ȃ�{���Ă����B
����G3�ł�IBM��G3�͓��z���A���g���[����G3�̓A���~�z���A�Z�p�͂̊i�����͂�����
���Ă��ĎO�p�W�͔����Ȏ��Ԃɓ˓��B
x86���p���t��������B
x86�ł���K�v�̖����Q�[���@��power���̗p�B
PowerPC��G5�̓X�y�b�N�����̐��\���Ǝv���B
G4�̓��g���[���̋Z�p�͂Ƃ��C�̖����B
�N���b�N��������AIBM�͂��C���X�����������g���[�������Ă������B
������IBM�����[�G���h��G3�A���g���[�����n�C�G���h��G4�S���B
G4��荂�N���b�N��G3�͋����Ȃ��A���ꂪ�A�b�v���̈ӌ���IBM�͂��Ȃ�{���Ă����B
����G3�ł�IBM��G3�͓��z���A���g���[����G3�̓A���~�z���A�Z�p�͂̊i�����͂�����
���Ă��ĎO�p�W�͔����Ȏ��Ԃɓ˓��B
>>290
���\����Ȃ��āA�}�[�P�e�B���O�Ƃ��X�P�[���r���q�e�B�[����
�n�C�G���h��power��itanium���g����̂�
�Ȃ��A�n�C�G���h���Ƃ���ʂł̓f�X�N�g�b�v�ȏ��
�\�t�g�E�F�A���Y���d�v
���\����Ȃ��āA�}�[�P�e�B���O�Ƃ��X�P�[���r���q�e�B�[����
�n�C�G���h��power��itanium���g����̂�
�Ȃ��A�n�C�G���h���Ƃ���ʂł̓f�X�N�g�b�v�ȏ��
�\�t�g�E�F�A���Y���d�v
>>290
���B
�����ڂ̃X�y�b�N�\�̂���������Njy���āA
�N���b�N�����߂�W���ɂ��Ă��܂��Ƃ����A
���g���[���̈��Ȃ��o���������끄G4
Altivec�̃��W�X�^���̑����A���@�\����
�N���b�N�㏸��W����K���������B
������ɍ��N���b�N����������A���M�����������ƂɂȂ����B
���g���[����G4���n�C�G���h�p�Ɍ��߂ĂȂ�������A
G4����͂̂���G3�@�����Ă��蓾���̂ɂȁB
���B
�����ڂ̃X�y�b�N�\�̂���������Njy���āA
�N���b�N�����߂�W���ɂ��Ă��܂��Ƃ����A
���g���[���̈��Ȃ��o���������끄G4
Altivec�̃��W�X�^���̑����A���@�\����
�N���b�N�㏸��W����K���������B
������ɍ��N���b�N����������A���M�����������ƂɂȂ����B
���g���[����G4���n�C�G���h�p�Ɍ��߂ĂȂ�������A
G4����͂̂���G3�@�����Ă��蓾���̂ɂȁB
�ȑO�A�G���^�[�v���C�Y�n�́A����T�[�o�\�t�g�̊J��������Ă����Ƃ��A
CPU�̃N���b�N���グ�Ă��A�قƂ�ǃp�t�H�[�}���X���オ��Ȃ�
�Ƃ������Ƃō��������Ƃ�����B
���̃\�t�g�̓R�[�h��99%��CPU���Ԃ�99%���A
�G���[�`�F�b�N�ƃG���[���̑Ώ��ƃG���[�̋L�^
�ɔ�₵�Ă���ƌ����Ă��ߌ��ł͂Ȃ��A
�R�[�h�T�C�Y������Ŗ��߂̃L���b�V���̃q�b�g�����Ⴍ�A
���������� ����╪��\���̂��߂�CPU���̃��\�[�X�͑���Ȃ����ŁA
����͂����ߎS�������B
���������̂��ƁAItanium�̂悤�ȃA�[�L�e�N�`�����ƁA���\���o�����ȋC�������B
CPU�̃N���b�N���グ�Ă��A�قƂ�ǃp�t�H�[�}���X���オ��Ȃ�
�Ƃ������Ƃō��������Ƃ�����B
���̃\�t�g�̓R�[�h��99%��CPU���Ԃ�99%���A
�G���[�`�F�b�N�ƃG���[���̑Ώ��ƃG���[�̋L�^
�ɔ�₵�Ă���ƌ����Ă��ߌ��ł͂Ȃ��A
�R�[�h�T�C�Y������Ŗ��߂̃L���b�V���̃q�b�g�����Ⴍ�A
���������� ����╪��\���̂��߂�CPU���̃��\�[�X�͑���Ȃ����ŁA
����͂����ߎS�������B
���������̂��ƁAItanium�̂悤�ȃA�[�L�e�N�`�����ƁA���\���o�����ȋC�������B
>>293
>���̃\�t�g�̓R�[�h��99%��
�������͂Ƃ�����
>CPU���Ԃ�99%���A
�������͂��肦�Ȃ��̂ł́H
>�G���[�`�F�b�N�ƃG���[���̑Ώ��ƃG���[�̋L�^
>�ɔ�₵�Ă���ƌ����Ă��ߌ��ł͂Ȃ��A
�قƂ�ǎ��Ԃ��ُ�n�̎��s�ɔ�₳��Ă�����Ă����̂�
���������̐v���̂ɏd��Ȍ��ׂ�����Ƃ����v����B
����ȃE���R�\�t�g�Ȃ�A�ǂ�ȃv���Z�b�T�������Ă��Ă��ǂ��ɂ��Ȃ��Ǝv�����B
>���̃\�t�g�̓R�[�h��99%��
�������͂Ƃ�����
>CPU���Ԃ�99%���A
�������͂��肦�Ȃ��̂ł́H
>�G���[�`�F�b�N�ƃG���[���̑Ώ��ƃG���[�̋L�^
>�ɔ�₵�Ă���ƌ����Ă��ߌ��ł͂Ȃ��A
�قƂ�ǎ��Ԃ��ُ�n�̎��s�ɔ�₳��Ă�����Ă����̂�
���������̐v���̂ɏd��Ȍ��ׂ�����Ƃ����v����B
����ȃE���R�\�t�g�Ȃ�A�ǂ�ȃv���Z�b�T�������Ă��Ă��ǂ��ɂ��Ȃ��Ǝv�����B
���������ǁA�n�C�G���h�v���Z�b�T�̂ق�������̃e�[�u���Ƃ�
�L���b�V�����ł�������A�傫�ȃ��[�N���[�h�Ɍ����Ă�͎̂���
�L���b�V�����ł�������A�傫�ȃ��[�N���[�h�Ɍ����Ă�͎̂���
296 �FMAC�I�^��292 �����F2006/03/18(�y) 00:17:55 ID:uXVRKq/u
>>292
�@�@----------------------
�@�@Altivec�̃��W�X�^���̑����A���@�\�����N���b�N�㏸��W����K���������B
�@�@----------------------
�����ɂ��������f�}��M���Ă�q�g���������Ƃ�������B
�����ɓ���4-stage�̃p�C�v���C���\���ł���䂦�ɁC����v���Z�X��7400 G4�����̂�����N���b�N��
75x G3��o�Ȃ��������B���̏�C����AltiVec���̗p����H�ڂɂȂ���G5��C�N���b�N�������J��L����
x86�v���Z�b�T���̓���N���b�N��B�����Ă��邷�B
IBM���ߋ��̌�������āCCELL PPE��Xbox360 PX�ɍ̗p����Ă���g�������W���R�A��AltiVec��
�����ꂽ�Ƃ����̂ɁC����x��̂��n������햢���ɗ^���b��M���Ă�Ƃ����̂�C���Ɋ��m�Șb��(��)
�@�@----------------------
�@�@Altivec�̃��W�X�^���̑����A���@�\�����N���b�N�㏸��W����K���������B
�@�@----------------------
�����ɂ��������f�}��M���Ă�q�g���������Ƃ�������B
�����ɓ���4-stage�̃p�C�v���C���\���ł���䂦�ɁC����v���Z�X��7400 G4�����̂�����N���b�N��
75x G3��o�Ȃ��������B���̏�C����AltiVec���̗p����H�ڂɂȂ���G5��C�N���b�N�������J��L����
x86�v���Z�b�T���̓���N���b�N��B�����Ă��邷�B
IBM���ߋ��̌�������āCCELL PPE��Xbox360 PX�ɍ̗p����Ă���g�������W���R�A��AltiVec��
�����ꂽ�Ƃ����̂ɁC����x��̂��n������햢���ɗ^���b��M���Ă�Ƃ����̂�C���Ɋ��m�Șb��(��)
>>296
�q���g�F ������
�q���g�F ������
�A�b�v������������āAAltivec���̂Ă�Intel���̗p�����悤�ł���
299 �FMAC�I�^��298 �����F2006/03/18(�y) 10:54:22 ID:uXVRKq/u
>>298
PPC�A�[�L�e�N�`�����痣����Ȃ����̂Ƃ��āCApple���r�߂Ă�������IBM��PPE�x�[�X�̃��[�h�}�b�v��
�����CIntel�����Merom����ꂽ�B�B�B�Ƃ����̂��������B
���ƂȂ��Ă�CJobs�̐������펩�����Ǝv�������ǁB�B�B
PPC�A�[�L�e�N�`�����痣����Ȃ����̂Ƃ��āCApple���r�߂Ă�������IBM��PPE�x�[�X�̃��[�h�}�b�v��
�����CIntel�����Merom����ꂽ�B�B�B�Ƃ����̂��������B
���ƂȂ��Ă�CJobs�̐������펩�����Ǝv�������ǁB�B�B
>>299
�W���u�Y�Ƃ������A�b�v���̂�
�W���u�Y�Ƃ������A�b�v���̂�
�܂�Merom/Conroe�����҂ł��鎖���B��̋~���c
�S��IBM�̂����Ȃ�
>>296
>�����ɓ���4-stage�̃p�C�v���C���\���ł���䂦�ɁC����v���Z�X��7400 G4�����̂�����N���b�N��
>75x G3��o�Ȃ��������B
Apple���g���Ă���Ȃ��̂ɂ��̃N���X�̃v���Z�b�T������Ă��Ӗ����Ȃ��̂ō��Ȃ����������B
>�����ɓ���4-stage�̃p�C�v���C���\���ł���䂦�ɁC����v���Z�X��7400 G4�����̂�����N���b�N��
>75x G3��o�Ȃ��������B
Apple���g���Ă���Ȃ��̂ɂ��̃N���X�̃v���Z�b�T������Ă��Ӗ����Ȃ��̂ō��Ȃ����������B
304 �FMAC�I�^��303 �����F2006/03/18(�y) 13:08:45 ID:uXVRKq/u
>>303
�@�@---------------------
�@�@Apple���g���Ă���Ȃ��̂ɂ��̃N���X�̃v���Z�b�T������Ă��Ӗ����Ȃ��̂ō��Ȃ����������B
�@�@---------------------
Intel�ւ̃X�C�b�`������Δ���悤�ɁCApple�퍂���\�v���Z�b�T�ɑI��D�݂킵�Ȃ���(��)
��������G4�o�ꂩ��CG5���\�܂ł�1999-2003�̊ԁCIBM��Motorola����̃v���Z�b�T�w������C�ق�
���X���������Ēm���Ă邷���H
�@�@---------------------
�@�@Apple���g���Ă���Ȃ��̂ɂ��̃N���X�̃v���Z�b�T������Ă��Ӗ����Ȃ��̂ō��Ȃ����������B
�@�@---------------------
Intel�ւ̃X�C�b�`������Δ���悤�ɁCApple�퍂���\�v���Z�b�T�ɑI��D�݂킵�Ȃ���(��)
��������G4�o�ꂩ��CG5���\�܂ł�1999-2003�̊ԁCIBM��Motorola����̃v���Z�b�T�w������C�ق�
���X���������Ēm���Ă邷���H
Intel��PowerPC������Ă��������̂ɁB
>>305
�U�X���o�����A���x�ł����������Ȃ��
�U�X���o�����A���x�ł����������Ȃ��
>>306
�A�b�v���Ƃ��Ă�G4��葬��G3������ƍ�����Ď�����킩���Ă��ȁH
>>307
���́u���N���b�N��750�v�̘b�����Ă���킯�����B
�������Ɓu���̃N���X�́v�ƒf���Ă邾��H
�A�b�v���Ƃ��Ă�G4��葬��G3������ƍ�����Ď�����킩���Ă��ȁH
>>307
���́u���N���b�N��750�v�̘b�����Ă���킯�����B
�������Ɓu���̃N���X�́v�ƒf���Ă邾��H
IBM�̓C���e���ɂ��قǒx��鎖�Ȃ�1GHz��G3�̎���i�\���Ă���B
�s�F�Ȏ���G3�̓��g���[����IBM�̗����ō���Ă��B
���_�����d�l�ł��鎖�����߂�ꂽ�B
�܁AIBM�̓A�b�v���Ɛ�č��x��AMD�ƃ^�b�O�g�ށB
�p�\�R���s��ւ̖�]���܂��������B
�s�F�Ȏ���G3�̓��g���[����IBM�̗����ō���Ă��B
���_�����d�l�ł��鎖�����߂�ꂽ�B
�܁AIBM�̓A�b�v���Ɛ�č��x��AMD�ƃ^�b�O�g�ށB
�p�\�R���s��ւ̖�]���܂��������B
310 �FMAC�I�^��308 �����F2006/03/18(�y) 14:58:48 ID:uXVRKq/u
>>308
�@�@----------------------
�@�@�A�b�v���Ƃ��Ă�G4��葬��G3������ƍ�����Ď�����킩���Ă��ȁH
�@�@----------------------
�܂���������Ȃ��ǂ��납�C�����ɑ��݂�����(��)
�Ⴆ��2001�N�����̃��C���i�b�v
�@�EPower Mac G4 (Digital Audio): PPC7410/466MHz, PPC7410/533MHz
�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
2000�N�Ă�G3��G4�퓯��N���b�N���������B
�@�@----------------------
�@�@�A�b�v���Ƃ��Ă�G4��葬��G3������ƍ�����Ď�����킩���Ă��ȁH
�@�@----------------------
�܂���������Ȃ��ǂ��납�C�����ɑ��݂�����(��)
�Ⴆ��2001�N�����̃��C���i�b�v
�@�EPower Mac G4 (Digital Audio): PPC7410/466MHz, PPC7410/533MHz
�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
2000�N�Ă�G3��G4�퓯��N���b�N���������B
311 �FMAC�I�^��309 �����F2006/03/18(�y) 15:03:22 ID:uXVRKq/u
>>309
�@�@----------------------
�@�@IBM�̓C���e���ɂ��قǒx��鎖�Ȃ�1GHz��G3�̎���i�\���Ă���B
�@�@----------------------
���ꃋ�[�}�[���x����ăf�}��M������ł�݂�������(��)
������IBM��GHz PowerPC�팤���p�̎���i���B
http://www.research.ibm.com/arl/projects/guTS.html
http://www.research.ibm.com/arl/projects/rivina.html
���Ă̒ʂ�64-bit�v���Z�b�T�̎���i��G3�Ƃ퉽�̊W���������B
�@�@----------------------
�@�@IBM�̓C���e���ɂ��قǒx��鎖�Ȃ�1GHz��G3�̎���i�\���Ă���B
�@�@----------------------
���ꃋ�[�}�[���x����ăf�}��M������ł�݂�������(��)
������IBM��GHz PowerPC�팤���p�̎���i���B
http://www.research.ibm.com/arl/projects/guTS.html
http://www.research.ibm.com/arl/projects/rivina.html
���Ă̒ʂ�64-bit�v���Z�b�T�̎���i��G3�Ƃ퉽�̊W���������B
312 �FMAC�I�^���⑫�F2006/03/18(�y) 15:17:49 ID:uXVRKq/u
�n���ɂ��ʂ����Ȃ������݂��������ǁCGuTS�Ɠ�����ISSCC98�Ŏ���G3�����\���ꂽ�Ƃ����̂펖�����B
�������C����ȑ㕨���B
http://bizns.nikkeibp.co.jp/cgi-bin/search/wcs-bun.cgi?ID=44727&FORM=biztechnews
�@�@------------------------
�@�@�Z�p�I�ȓ��e�Ƃ��ẮA��IBM�Ђ�؍�Samsung Electronics�Ђ��ASOI�isilicon-on-insulater�j���̗p����
�@�@�����Z�p���g���ăv���Z�T�̓�����g���������グ�����ʂ\����_���ڐV�����BIBM�́A0.12��m
�@�@�i�����g�����W�X�^���j�Z�p�ɓ��z�������SOI���̗p���āAPowerPC�v���Z�T��580MHz���삵�����Ƃ�A
�@�@1GHz�����PLL�iphase locked loop�j��H�\����B
�@�@------------------------
����SOI�̗p��580MHz�œ������`�b�v���Ă̂�G3���B���̎�����SOI�E�F�A��ʎY�ł���������Ă̂�
�������Ƃ��āCPPC7410 G4�����������ɂ�550-600MHz�i���o�ׂ���Ă������Ƃ��l������ƁC���ɋ����ׂ�
������g���Ƃ팾���Ȃ����Ƃ����锤���B
�������C����ȑ㕨���B
http://bizns.nikkeibp.co.jp/cgi-bin/search/wcs-bun.cgi?ID=44727&FORM=biztechnews
�@�@------------------------
�@�@�Z�p�I�ȓ��e�Ƃ��ẮA��IBM�Ђ�؍�Samsung Electronics�Ђ��ASOI�isilicon-on-insulater�j���̗p����
�@�@�����Z�p���g���ăv���Z�T�̓�����g���������グ�����ʂ\����_���ڐV�����BIBM�́A0.12��m
�@�@�i�����g�����W�X�^���j�Z�p�ɓ��z�������SOI���̗p���āAPowerPC�v���Z�T��580MHz���삵�����Ƃ�A
�@�@1GHz�����PLL�iphase locked loop�j��H�\����B
�@�@------------------------
����SOI�̗p��580MHz�œ������`�b�v���Ă̂�G3���B���̎�����SOI�E�F�A��ʎY�ł���������Ă̂�
�������Ƃ��āCPPC7410 G4�����������ɂ�550-600MHz�i���o�ׂ���Ă������Ƃ��l������ƁC���ɋ����ׂ�
������g���Ƃ팾���Ȃ����Ƃ����锤���B
>>310
>�Ⴆ��2001�N�����̃��C���i�b�v
>�@�EPower Mac G4 (Digital Audio): PPC7410/466MHz, PPC7410/533MHz
2001/01�̎��_��733MHz�����\����Ă���悤�����H
���o�ׂ�2��
>�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
2���ɔ��\���ꂽ���ʂ�500MHz�B
>2000�N�Ă�G3��G4�퓯��N���b�N���������B
2000�N����
iMacDV+��G3/450MHz
PowerMacG4(GigaEthernet)��G4/500MHz
�Ȃ��ǁH
�����Ƃł���߂ɂ��قǂ������łȂ��́H
>�Ⴆ��2001�N�����̃��C���i�b�v
>�@�EPower Mac G4 (Digital Audio): PPC7410/466MHz, PPC7410/533MHz
2001/01�̎��_��733MHz�����\����Ă���悤�����H
���o�ׂ�2��
>�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
2���ɔ��\���ꂽ���ʂ�500MHz�B
>2000�N�Ă�G3��G4�퓯��N���b�N���������B
2000�N����
iMacDV+��G3/450MHz
PowerMacG4(GigaEthernet)��G4/500MHz
�Ȃ��ǁH
�����Ƃł���߂ɂ��قǂ������łȂ��́H
>>313
>>�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
>2���ɔ��\���ꂽ���ʂ�500MHz�B
��ʋ@���600MHz�i�����邯�ǁA�ǂ���ɂ���733MHz�͒����Ȃ��B
>>�@�EiMac (early 2001): PPC750/500MHz, PPC750CXe/600MHz
>2���ɔ��\���ꂽ���ʂ�500MHz�B
��ʋ@���600MHz�i�����邯�ǁA�ǂ���ɂ���733MHz�͒����Ȃ��B
>>313 ����
�@�@-------------------
�@�@2001/01�̎��_��733MHz�����\����Ă���悤�����H
�@�@���o�ׂ�2��
�@�@-------------------
Mac���[�U�[�Ȃ�C7450/733MHz�펖����4-5���܂ŏo�ׂ��ꂸ�C7450/667MHz��o�ׂ��ꂽ������Ȃ���
�\�ɂ����Ȃ������ɏ������̂��o���Ă��邩�Ǝv�����B
>>314 ����
�@�@-------------------
�@�@iMacDV+��G3/450MHz
�@�@-------------------
iMac DV Spesial Edition�������m�����H
�@�@-------------------
�@�@2001/01�̎��_��733MHz�����\����Ă���悤�����H
�@�@���o�ׂ�2��
�@�@-------------------
Mac���[�U�[�Ȃ�C7450/733MHz�펖����4-5���܂ŏo�ׂ��ꂸ�C7450/667MHz��o�ׂ��ꂽ������Ȃ���
�\�ɂ����Ȃ������ɏ������̂��o���Ă��邩�Ǝv�����B
>>314 ����
�@�@-------------------
�@�@iMacDV+��G3/450MHz
�@�@-------------------
iMac DV Spesial Edition�������m�����H
>>315
> Mac���[�U�[�Ȃ�C7450/733MHz�펖����4-5���܂ŏo�ׂ��ꂸ�C7450/667MHz��o�ׂ��ꂽ������Ȃ���
> �\�ɂ����Ȃ������ɏ������̂��o���Ă��邩�Ǝv�����B
����́u�A�b�v���Ƃ��Ă�G4��葬��G3�������č���v�b�̕⋭�ɂ����Ȃ�Ȃ��킯�ł����B
�A�b�v���Ƃ��Ă�G4>G3���ێ��������ł����킯�ł�����B
> iMac DV Spesial Edition�������m�����H
�m���ɂ����500MHz�ł����B
dual��single�łǂ��ɂ����ʉ����v���Ă��������ł����B
���Ȃ��Ƃ��t�]���Ă͍���ƃA�b�v���͍l���Ă����̂ł��傤�B
> Mac���[�U�[�Ȃ�C7450/733MHz�펖����4-5���܂ŏo�ׂ��ꂸ�C7450/667MHz��o�ׂ��ꂽ������Ȃ���
> �\�ɂ����Ȃ������ɏ������̂��o���Ă��邩�Ǝv�����B
����́u�A�b�v���Ƃ��Ă�G4��葬��G3�������č���v�b�̕⋭�ɂ����Ȃ�Ȃ��킯�ł����B
�A�b�v���Ƃ��Ă�G4>G3���ێ��������ł����킯�ł�����B
> iMac DV Spesial Edition�������m�����H
�m���ɂ����500MHz�ł����B
dual��single�łǂ��ɂ����ʉ����v���Ă��������ł����B
���Ȃ��Ƃ��t�]���Ă͍���ƃA�b�v���͍l���Ă����̂ł��傤�B
317 �FMAC�I�^��316�F2006/03/18(�y) 16:07:35 ID:uXVRKq/u
>>316
�@�@---------------------
�@�@���Ȃ��Ƃ��t�]���Ă͍���ƃA�b�v���͍l���Ă����̂ł��傤�B
�@�@---------------------
�������x���ł�G3�̓���N���b�N��600MHz�ɖ����Ȃ��Ƃ���������������Ă��CG3�̓���N���b�N��
�}�[�P�e�B���O�Ō��肳�ꂽ�Ǝ咣���邷���B�B�B
�@�@---------------------
�@�@���Ȃ��Ƃ��t�]���Ă͍���ƃA�b�v���͍l���Ă����̂ł��傤�B
�@�@---------------------
�������x���ł�G3�̓���N���b�N��600MHz�ɖ����Ȃ��Ƃ���������������Ă��CG3�̓���N���b�N��
�}�[�P�e�B���O�Ō��肳�ꂽ�Ǝ咣���邷���B�B�B
>>305
>>306
�C���e����StrongARM�A������XScale���������A
�q���̌��܂ɑ�l���o�Ă��镵�͋C�������ȁB
����MIPS��SH���^�W�^�W�B
�����C���e����PowerPC�������E�E�E
>>306
�C���e����StrongARM�A������XScale���������A
�q���̌��܂ɑ�l���o�Ă��镵�͋C�������ȁB
����MIPS��SH���^�W�^�W�B
�����C���e����PowerPC�������E�E�E
>>318
Xscale��MIPS��SH���ڎw���Ă�s��̕��������Ⴄ����Ȃ��c�B
WindowsCE�n�Ɋւ��Č����Ȃ�ASH�͂�������Pocket/HandheldPC2000��
���f���ɂ����̗p����ĂȂ�(���J�X�ł̑�_���[�W��������?)�B
MIPS��2000���f���ł͊e�@��(OS�ύX���x��)�}�C�i�[�`�F���W���قƂ�ǁB
2000��StrongARM�@���o�Ă��鍠�ɂ́A�Ԃ����Ⴏ
�܂�PDA������Ă�x���_�[�������ǁAPDA�����MIPS/SH�͌������Ă���Ȃ����Ɓc�B
Xscale��MIPS��SH���ڎw���Ă�s��̕��������Ⴄ����Ȃ��c�B
WindowsCE�n�Ɋւ��Č����Ȃ�ASH�͂�������Pocket/HandheldPC2000��
���f���ɂ����̗p����ĂȂ�(���J�X�ł̑�_���[�W��������?)�B
MIPS��2000���f���ł͊e�@��(OS�ύX���x��)�}�C�i�[�`�F���W���قƂ�ǁB
2000��StrongARM�@���o�Ă��鍠�ɂ́A�Ԃ����Ⴏ
�܂�PDA������Ă�x���_�[�������ǁAPDA�����MIPS/SH�͌������Ă���Ȃ����Ɓc�B
SH�n�́ACE�]�X�ȑO�ɁA�����G���x�f�b�h�s�ꂵ�����ĂȂ��ł���B
�J���T�C�h�͂Ƃ������A�c�ƃT�C�h�Ƃ��Ă̘͂b�ˁB
�J���T�C�h�͂Ƃ������A�c�ƃT�C�h�Ƃ��Ă̘͂b�ˁB
>>320
SH�͍ŏ�����g�ݍ��ݎ�̂��Ă����ׂ̈�16bit�����A
���肱�݃f���Ƃ��Ă�CE�@�������Ǝv����B
�ł��A����Ă����Ȃ�CE�@���������낤�Ƃ��v����ŁB
SH�͍ŏ�����g�ݍ��ݎ�̂��Ă����ׂ̈�16bit�����A
���肱�݃f���Ƃ��Ă�CE�@�������Ǝv����B
�ł��A����Ă����Ȃ�CE�@���������낤�Ƃ��v����ŁB
>>321
�܂�SH�̖������Ƃ���邩��ȁB
��ʂ̊J����SuperH�Ђ�
���l�T�X�ƕ������Ă������̍���
�ǂ��������[�h�}�b�v���������B
�܂�SH�̖������Ƃ���邩��ȁB
��ʂ̊J����SuperH�Ђ�
���l�T�X�ƕ������Ă������̍���
�ǂ��������[�h�}�b�v���������B
PDA�n���Ă�[�ƃh���S���{�[�����v���o����
������č��ǂ��Ȃ����́H
������č��ǂ��Ȃ����́H
���g���[����ARM�n�̗p���ăW�E�G���h�łȂ�������
ARM�̂���h���S���{�[���ł͂���
���E�ōł����ꂽARM��GBA�Ƃ�������
328 �FMAC�I�^��326 �����F2006/03/19(��) 10:35:10 ID:FleFeaND
>>326
>>312�ɏ������ʂ肷�B��������ISSCC99�̊ԈႢ������(��)
�ŁC���̔]���ϑz�̃\�[�X�팩�����������H
�@�@-------------------------
�@�@IBM�̓C���e���ɂ��قǒx��鎖�Ȃ�1GHz��G3�̎���i�\���Ă���B
�@�@----------------------
>>312�ɏ������ʂ肷�B��������ISSCC99�̊ԈႢ������(��)
�ŁC���̔]���ϑz�̃\�[�X�팩�����������H
�@�@-------------------------
�@�@IBM�̓C���e���ɂ��قǒx��鎖�Ȃ�1GHz��G3�̎���i�\���Ă���B
�@�@----------------------
326����Ȃ�����
http://72.14.203.104/search?q=cache:bgqw6UWkUukJ:http://too.site.ne.jp/Mac/Macintosh/MacMemo/MacMemo0107_12.html+ibm+powerpc+g3+1GHz&lr=lang_ja&hl=ja&ie=EUC-JP&output=html&client=nttx
G3��1GHz��2001�N10�����ˁB
pentiumIII�����N�����ꂩ�B
����Mac�n�̎G���ő����ł��L��������B
http://72.14.203.104/search?q=cache:bgqw6UWkUukJ:http://too.site.ne.jp/Mac/Macintosh/MacMemo/MacMemo0107_12.html+ibm+powerpc+g3+1GHz&lr=lang_ja&hl=ja&ie=EUC-JP&output=html&client=nttx
G3��1GHz��2001�N10�����ˁB
pentiumIII�����N�����ꂩ�B
����Mac�n�̎G���ő����ł��L��������B
�Ȃv���o���Ă�����B
iMac��1GHz��G3���ڂ�Ǝv���Ă����̂ɗ�����G3��500MHz���炢�ɂȂ��ĂĂ������肵���L�����B
iMac��1GHz��G3���ڂ�Ǝv���Ă����̂ɗ�����G3��500MHz���炢�ɂȂ��ĂĂ������肵���L�����B
>>329
�����N��ǂ�łȂ��Đ\����Ȃ����A
������750FX��2001�N10�����\�ŁA2002�N�O����700����800MHz�o�J�n�A�㔼��1GHz�܂œ��B����Ƃ����b�������B
�܁A�ł�SOI�̗p�ŋ������̂͊o���Ă�
SOI�̗p�v���Z�b�T�̏o�ׂł́A2002�N1����7455 1GHz�̕���������������
�����N��ǂ�łȂ��Đ\����Ȃ����A
������750FX��2001�N10�����\�ŁA2002�N�O����700����800MHz�o�J�n�A�㔼��1GHz�܂œ��B����Ƃ����b�������B
�܁A�ł�SOI�̗p�ŋ������̂͊o���Ă�
SOI�̗p�v���Z�b�T�̏o�ׂł́A2002�N1����7455 1GHz�̕���������������
>>331
����G3 1GHz�̗̍p��͂������́H
����G3 1GHz�̗̍p��͂������́H
333 �FMAC�I�^��329, 331 �����F2006/03/20(��) 00:20:17 ID:s03r4DX7
>>329, >>331
750FX���̂�CMicroprocessor Forum 2001�Ŕ��\����130nm�v���Z�X + SOI + low-k�≏�̂Ɠ����ŐV��
�����Z�p������2002�N������700MHz�œo��C�����I�ɂ�1GHz�ɁB�B�B���ĐG�ꍞ�݂��������B
http://www-306.ibm.com/chips/techlib/techlib.nsf/techdocs/FBEAAB9F7A288ED787256AE200622214
���Ȃ݂ɓ�������G4��180nm�v���Z�X+SOI��1GHz�i��ʎY����2002�N1�����ɐV�^PowerMac�Ƌ���
���\���ꂽ���Bhttp://www.eet.com/story/OEG20020129S0036
750FX�̕���C���̌�low-k�v���Z�X�̑厸�s�ł����ς�N���b�N���オ�炸�C����ȕ��ɝ��������H�ڂɁB�B�B
http://www.theinquirer.net/?article=5927
750FX���̂�CMicroprocessor Forum 2001�Ŕ��\����130nm�v���Z�X + SOI + low-k�≏�̂Ɠ����ŐV��
�����Z�p������2002�N������700MHz�œo��C�����I�ɂ�1GHz�ɁB�B�B���ĐG�ꍞ�݂��������B
http://www-306.ibm.com/chips/techlib/techlib.nsf/techdocs/FBEAAB9F7A288ED787256AE200622214
���Ȃ݂ɓ�������G4��180nm�v���Z�X+SOI��1GHz�i��ʎY����2002�N1�����ɐV�^PowerMac�Ƌ���
���\���ꂽ���Bhttp://www.eet.com/story/OEG20020129S0036
750FX�̕���C���̌�low-k�v���Z�X�̑厸�s�ł����ς�N���b�N���オ�炸�C����ȕ��ɝ��������H�ڂɁB�B�B
http://www.theinquirer.net/?article=5927
����邻���ȕ��͂��ȁB
335 �FSocket774�F2006/03/20(��) 03:18:24 ID:etegJ5Ls
Conroe/Merom�ɑR�ł���v���Z�b�T�͂�����o�Ă���̂�
�����邲�Ƃɏ������uAthlon64 90nm SOI�v��SOI��
>>333��IBM�̋Z�p���������
���ɂ��̗p���Ă���̂�S�������Ȃ��ƃ_�������
�܂�2ch�ŏ����Ă��́A���ЋZ�p���Ǝv������ł�̂�������Ȃ�����
>>333��IBM�̋Z�p���������
���ɂ��̗p���Ă���̂�S�������Ȃ��ƃ_�������
�܂�2ch�ŏ����Ă��́A���ЋZ�p���Ǝv������ł�̂�������Ȃ�����
����͂ǂ����Ă�SPARC64�̍����\�Ԃ肪�C�ɂȂ��Ă��������Ȃ��B
���Ă����O��A�r�炵�ɍ\���z���r�炵���Ă���2ch�̝|��Y�ꂽ���H
���܂ŕ��I�^�������Ă�́B
���܂ŕ��I�^�������Ă�́B
>>338
���O�͉��������Ă���H
���O�͉��������Ă���H
>>290
���̑OPCWatch�Ō㓡���ʔ����L�������Ă�
>�����̃\�t�g�E�F�A���Y���d�����Ȃ��p�r�ł�itanium��power���I���B
�`
>x86�ł���K�v�̖����Q�[���@��power���̗p�B
�Ȋ����ō��܂ŃQ�[���ƊE����Ă����B
�������ŋ߂͊J�����̍��x�������C�u�����̕��G���A��剻�B
�J���҂��n�[�h�Ɂu����Ɓv���Ȃ�Ă��鍠�ɂ�
���łɃ��f���`�F���W�A���̃X�^�C�����p������̂͂��͂△������
�������e�B
����Intel�����ꂾ���J�͕�����x86�ێ����Ă�ɂ�
�����Ɨ��R��������
���̂��A�ŃQ�[���ƊE�̂悤�ȎS��ɂ͂Ȃ��킯���B
���̑OPCWatch�Ō㓡���ʔ����L�������Ă�
>�����̃\�t�g�E�F�A���Y���d�����Ȃ��p�r�ł�itanium��power���I���B
�`
>x86�ł���K�v�̖����Q�[���@��power���̗p�B
�Ȋ����ō��܂ŃQ�[���ƊE����Ă����B
�������ŋ߂͊J�����̍��x�������C�u�����̕��G���A��剻�B
�J���҂��n�[�h�Ɂu����Ɓv���Ȃ�Ă��鍠�ɂ�
���łɃ��f���`�F���W�A���̃X�^�C�����p������̂͂��͂△������
�������e�B
����Intel�����ꂾ���J�͕�����x86�ێ����Ă�ɂ�
�����Ɨ��R��������
���̂��A�ŃQ�[���ƊE�̂悤�ȎS��ɂ͂Ȃ��킯���B
>>340
>����Intel�����ꂾ���J�͕�����x86�ێ����Ă�ɂ�
>�����Ɨ��R��������
>���̂��A�ŃQ�[���ƊE�̂悤�ȎS��ɂ͂Ȃ��킯���B
�O���͑S�����̒ʂ肾���A����̓Q�[���ƊE�̐ӔC
Itanium��POWER���A���X�Ƒ������̂�����
�Ⴆ��PPC970�S�ʔp�~��Cell�݂̂Ɉڍs����A�Ƃ����킯����Ȃ�����H
���ꂱ��440��750��10x�����Ă���킯�ŁB
Cell���̗p����������͍̗̂p���̐ӔC
>����Intel�����ꂾ���J�͕�����x86�ێ����Ă�ɂ�
>�����Ɨ��R��������
>���̂��A�ŃQ�[���ƊE�̂悤�ȎS��ɂ͂Ȃ��킯���B
�O���͑S�����̒ʂ肾���A����̓Q�[���ƊE�̐ӔC
Itanium��POWER���A���X�Ƒ������̂�����
�Ⴆ��PPC970�S�ʔp�~��Cell�݂̂Ɉڍs����A�Ƃ����킯����Ȃ�����H
���ꂱ��440��750��10x�����Ă���킯�ŁB
Cell���̗p����������͍̗̂p���̐ӔC
>>341
���ӂ��Ƃ�
���ӂ��Ƃ�
�낭�ȃ\�t�g�����������Ƃ��Ȃ��z���h���[���S�J�ō�����̂�Cell������ӂ߂�̂͂��킢����
345 �FMAC�I�^��344 �����F2006/03/22(��) 01:03:55 ID:abgVcQI8
>>344
�v���Z�b�T�A�[�L�e�N�g���\�t�g���������m�Ƃ�������C������(��)
�v���Z�b�T�A�[�L�e�N�g���\�t�g���������m�Ƃ�������C������(��)
Andy Glew�͂��Ƃ��ƃv���O���}������
>>345
�N�͂���������ƌ������L�߂��ق���������
�N�͂���������ƌ������L�߂��ق���������
�Ă��A�����炬���ăv���Z�T�A�[�L�e�N�g����Ȃ�����
�m���ɁAMPEG2����48�{�����f�R�[�h�A���s����ł͎茘����肾�ȁB
�܂��ACell�͔ėp�v���Z�T�Ƃ��đn�����̂Ȃ炠�ꂾ���A
�Q�[���@�v���Z�T�Ƃ��đn�����킯������A����͂���ł������
�Q�[���@�v���Z�T�Ƃ��đn�����킯������A����͂���ł������
>>351
���̃Q�[���f�x���b�p�[����s�������Ă���킯����
���̃Q�[���f�x���b�p�[����s�������Ă���킯����
�����܂����䂦�H
�Q�n�~���N���Ă���̂�Cell�����͊��ق��Ă�������
cell���ĕʂɃ��f�B�J������Ȃ�����
3.2Ghz���ăN���b�N�͂�������
3.2Ghz���ăN���b�N�͂�������
>>355
Cell�̓N���b�N�グ�₷���v���Ƃ������Ă��ȁA�������B
�x�[�X��970�Ƃ͈Ⴄ�\����������������Ȃ����ǁB
���Ȃ݂ɁACell��5Ghz���œ����Ă邱�Ƃ����\����Ă���B
Cell�̓N���b�N�グ�₷���v���Ƃ������Ă��ȁA�������B
�x�[�X��970�Ƃ͈Ⴄ�\����������������Ȃ����ǁB
���Ȃ݂ɁACell��5Ghz���œ����Ă邱�Ƃ����\����Ă���B
cell���y����
�Ȃ̂�GK�ƐM�҂���
�Ȃ̂�Goto Kitakore
������ƌÂ����ǁ�������Ăǂ��Ȃ�H
http://www.theregister.co.uk/2006/03/14/sun_rock_deets/
http://www.theregister.co.uk/2006/03/14/sun_rock_deets/
NAP�𐄐i�����Azul�A�����`�b�v��48�R�A�������uVega 2�v���\
http://pcweb.mycom.co.jp/news/2006/03/29/100.html
http://pcweb.mycom.co.jp/news/2006/03/29/100.html
�P�����̋ɖk��
http://www.eforth.com.tw/images/eP32_Core_030305.pdf
http://www.eforth.com.tw/images/eP32_Core_030305.pdf
����P�i...���āAOh!X�̐l���B
�Ȃ������[�ȁ[w
(U)����Ƃ����ȂL�������Ăق�����B
PS3���W���Ƃ��]����1�������ł��������Ă���Ȃ����ȁH
�Ȃ������[�ȁ[w
(U)����Ƃ����ȂL�������Ăق�����B
PS3���W���Ƃ��]����1�������ł��������Ă���Ȃ����ȁH
>>367
���N�̔��\������J�^���O��̃s�[�N���\��
�������\�̘������傫���v���Z�b�T�Ƃ����b�͂���������Ȃ��B
���̃x�N�^���j�b�g���l�ߍ��ނ��߂ɍ�����@�\���ł��������A�ƁB
���N�̔��\������J�^���O��̃s�[�N���\��
�������\�̘������傫���v���Z�b�T�Ƃ����b�͂���������Ȃ��B
���̃x�N�^���j�b�g���l�ߍ��ނ��߂ɍ�����@�\���ł��������A�ƁB
>>370
����A�ł����̃J�^���O�X�y�b�N�����̂܂ܔ����ł���Ǝv������ł�A���̑������ƂƗ�����c
�Q�n��Cell�X���Ƃ�PS3�{�X���`���Ƃ悭�킩���
����A�ł����̃J�^���O�X�y�b�N�����̂܂ܔ����ł���Ǝv������ł�A���̑������ƂƗ�����c
�Q�n��Cell�X���Ƃ�PS3�{�X���`���Ƃ悭�킩���
�P���Ƀr�f�I�̃G���R�[�h��f�R�[�h�A
�Q�[���G���W���╨���~�h���E�F�A���点�镪�ɂ�
������@�̒��ł͔�����o�Ă邩��S�z����ȁB
�Q�[���G���W���╨���~�h���E�F�A���点�镪�ɂ�
������@�̒��ł͔�����o�Ă邩��S�z����ȁB
MPEG�J�[�h�݂�����PCI-Ex������̊�Ղɂ���
�n�[�h�E�F�A�G���R�[�_/�f�R�[�_�ɂ�������
�ǂ��������B
�[���R���V���[�}�Q�[���@�ł̓f�R�[�_�͂Ƃ�����
�G���R�[�_�Ƃ��Ďg�����Ƃ͖�������B
�n�[�h�E�F�A�G���R�[�_/�f�R�[�_�ɂ�������
�ǂ��������B
�[���R���V���[�}�Q�[���@�ł̓f�R�[�_�͂Ƃ�����
�G���R�[�_�Ƃ��Ďg�����Ƃ͖�������B
>>367
>PowerPC 970�͖��ߎ��s�ɃA�E�g�I�u�I�[�_�[(Out-of-Order)����
>�Ή����Ă���A���ߊԂ̈ˑ������Ȃ��ꍇ��
>���s���Ŗ��߂����s����悤�Ȏd�g�݂������Ă��邪
>PPE�ɂ��������@�\�͐��荞�܂�Ă��Ȃ��B
>PowerPC 970�g�݊��h�ł����āg�����h�ł͂Ȃ��̂��B
���Ō��X�������@�\���O�����낤�ˁB
�����̈Ӑ}�������Ȃ��B
���N���b�N��_�����߂̒P�����Ȃ̂��������
������O������ʖڂ���B
>PowerPC 970�͖��ߎ��s�ɃA�E�g�I�u�I�[�_�[(Out-of-Order)����
>�Ή����Ă���A���ߊԂ̈ˑ������Ȃ��ꍇ��
>���s���Ŗ��߂����s����悤�Ȏd�g�݂������Ă��邪
>PPE�ɂ��������@�\�͐��荞�܂�Ă��Ȃ��B
>PowerPC 970�g�݊��h�ł����āg�����h�ł͂Ȃ��̂��B
���Ō��X�������@�\���O�����낤�ˁB
�����̈Ӑ}�������Ȃ��B
���N���b�N��_�����߂̒P�����Ȃ̂��������
������O������ʖڂ���B
>>375
�R�X�g�A����d�́B
�R�X�g�A����d�́B
many core�ł�OoO���O���̂͂悭���鎖
>>376
���`����ς��ꂩ�Ȃ��B
�m���Ƀ��b�`�ȉ�H�\���ɂ���ƍ����Ȃ邵�B
�����v�������h���������B
�Z���߂Ă�Ƃ���ς�u�l�ߍ��݂����v�Ȋ���������ȁB
�t�ɍ���胆�j�b�g�̐����炵�ĒP�̂ł̋@�\���������Ă���
�����������҂ł��������i�@�L�́M�jy-~~
���`����ς��ꂩ�Ȃ��B
�m���Ƀ��b�`�ȉ�H�\���ɂ���ƍ����Ȃ邵�B
�����v�������h���������B
�Z���߂Ă�Ƃ���ς�u�l�ߍ��݂����v�Ȋ���������ȁB
�t�ɍ���胆�j�b�g�̐����炵�ĒP�̂ł̋@�\���������Ă���
�����������҂ł��������i�@�L�́M�jy-~~
>>379
�C�V���u���b�`�Ȃ̂Ȃ炷�łɂ����ς����邩��A������750VX��������g�킹�Ă��炤���@�i�@�O�ցO�j�v
�C�V���u���b�`�Ȃ̂Ȃ炷�łɂ����ς����邩��A������750VX��������g�킹�Ă��炤���@�i�@�O�ցO�j�v
Xbox360CPU�̖��O����"PX"�Ȃ[
>>380
750�n�͒n���ɗD�G����Ȃ�
750�n�͒n���ɗD�G����Ȃ�
>>375
��܃Q�[���@���Ƃ���970�t���Z�b�g�ܑ͖̂˂��A��
IBM����������̂�������Ȃ��B
IBM�I�ɂ̓��C����POWER�V���[�Y��
Cell�Ȃ�ė]���݂����ȃ��������B
��܃Q�[���@���Ƃ���970�t���Z�b�g�ܑ͖̂˂��A��
IBM����������̂�������Ȃ��B
IBM�I�ɂ̓��C����POWER�V���[�Y��
Cell�Ȃ�ė]���݂����ȃ��������B
>>374
PS2���������HDD���R�[�_������������Ȃ��B
PS3���������HDD���R�[�_���o��Ǝv���B
>>375
OoO�Ő��\�������ƌ��シ��̂́A
�Â�CPU�ɍ��킹�čœK�����ꂽ�R�[�h�����s����Ƃ��B
�Q�[���@�̏ꍇ�͓r���ŃR�A��ς�����͂��Ȃ��̂ŁA
�R���p�C�����������ƍœK�������R�[�h���o�͂�������B
PS2���������HDD���R�[�_������������Ȃ��B
PS3���������HDD���R�[�_���o��Ǝv���B
>>375
OoO�Ő��\�������ƌ��シ��̂́A
�Â�CPU�ɍ��킹�čœK�����ꂽ�R�[�h�����s����Ƃ��B
�Q�[���@�̏ꍇ�͓r���ŃR�A��ς�����͂��Ȃ��̂ŁA
�R���p�C�����������ƍœK�������R�[�h���o�͂�������B
>>384
��������邯�ǁAOoO���^��������̂̓������A�N�Z�X�̃��C�e���V�[���\���s�\�ȂƂ�����
��������邯�ǁAOoO���^��������̂̓������A�N�Z�X�̃��C�e���V�[���\���s�\�ȂƂ�����
�L���b�V���Ƀq�b�g���邩�ǂ����܂ŁA�R���p�C���Ɍ��ς��点�邱�Ƃ��ł���悤�ɂȂ�A�Ƃ����ژ_���Ȃ̂�����B
����A�Ⴄ���B
�������A�N�Z�X�̃��C�e���V�́AOoO�ł͂Ȃ��A�}���`�X���b�h�ʼnB������
���Ă��Ƃ��Ǝv���B
�������A�N�Z�X�̃��C�e���V�́AOoO�ł͂Ȃ��A�}���`�X���b�h�ʼnB������
���Ă��Ƃ��Ǝv���B
�l�g�o�Ȃ݂ɐ[���p�C�v���C��������
2�X���b�h���点�Ă��A�p�C�v���C���X�g�[���͂��Ȃ�̂���
cell��PPE�́ASPE�ɃN���b�N�����č��킹���������Ċ���
�f����SPE�̔��N���b�N�ɂ��Ƃ��悩�����̂ł�?�Ǝv��
2�X���b�h���点�Ă��A�p�C�v���C���X�g�[���͂��Ȃ�̂���
cell��PPE�́ASPE�ɃN���b�N�����č��킹���������Ċ���
�f����SPE�̔��N���b�N�ɂ��Ƃ��悩�����̂ł�?�Ǝv��
>�l�g�o�Ȃ݂ɐ[���p�C�v���C��������
�l�g�o���݂���Ȃ��ăl�g�o�ȏ��PPE�̃p�C�v���C���͐[���B
Intel��Prescott���\�z�@�\����������
�e�����ɗ͗}�������A���Ǔ��N���b�N����̖k�X��萫�\���Ƃ��Ă��܂����B
CELL��PPE���x�[�X��970��蕪��\�z����������
�Ȃ�Ęb�͊F��������������\�͔ߎS�Ȏ��ɂȂ��Ă邾��B
�l�g�o���݂���Ȃ��ăl�g�o�ȏ��PPE�̃p�C�v���C���͐[���B
Intel��Prescott���\�z�@�\����������
�e�����ɗ͗}�������A���Ǔ��N���b�N����̖k�X��萫�\���Ƃ��Ă��܂����B
CELL��PPE���x�[�X��970��蕪��\�z����������
�Ȃ�Ęb�͊F��������������\�͔ߎS�Ȏ��ɂȂ��Ă邾��B
Willamet��22�i�APrescott��31�i���������B
�[���Ƃ�35�i�����肩����ȏ�?
�[���Ƃ�35�i�����肩����ȏ�?
7448��7�i�������H
�N���b�N�グ�邽�߂Ƀp�C�v���C����[������̂�
CPU�v�̒������Ȃ��B
ttp://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
�܂����ȁi�H�j�����̂������
�C���e���̎���CPU�͂P�S�X�e�[�W�ɒZ�k���B
���ꂮ�炢��������p�C�v���C���n�U�[�h�N���Ă�
���J�o�����e�Ղ����B
CPU�v�̒������Ȃ��B
ttp://pc.watch.impress.co.jp/docs/2006/0306/kaigai247.htm
�܂����ȁi�H�j�����̂������
�C���e���̎���CPU�͂P�S�X�e�[�W�ɒZ�k���B
���ꂮ�炢��������p�C�v���C���n�U�[�h�N���Ă�
���J�o�����e�Ղ����B
>>392
14�i�i�j�͐Ȃ���
14�i�i�j�͐Ȃ���
���̕����G��IA-64�ł��A����8�i���ȁB
�����x86����Op�ϊ����X�P�W���[�����O�s�����Ȃ����
8�i�ɂ��o�����ȁB
Itanium�́A���̍s�����R���p�C����VLIW�����
����͊��҂����قǏ�肭�����ĂȂ��킯�����B
8�i�ɂ��o�����ȁB
Itanium�́A���̍s�����R���p�C����VLIW�����
����͊��҂����قǏ�肭�����ĂȂ��킯�����B
��x86����10�i�ȉ����������Ȃ��A�Ƃ��������ʂȋC������B
����RISK�ŋ}���ȐL�т݂��Ă��Power�n���������
��RISC
Power6���āAPower5�Ɠ����̃p�C�v���C����
4�`5Ghz��ڎw���\��
�C�J�X
4�`5Ghz��ڎw���\��
�C�J�X
14�i�i�j
GPU�̃p�C�v���C���Ȃ�100�i�N���X������H
20��30�Ȃ�Ă���ڂ�����ڂ�
20��30�Ȃ�Ă���ڂ�����ڂ�
> �����G��IA-64
�H�H�H
�H�H�H
>>402
���Ȃ��킯�ł����B
���Ȃ��킯�ł����B
���Ƃ��l�b�g���[�N�v���Z�b�T�Ȃɂ͔ėp�v���Z�b�T�����͂邩�ɍ����\�Ȃ��̂�����킯����
�}���`�R�A�}���`�X���b�h�Ő��\���҂��̂�
�A�[�L�e�N�g�̔s�k�錾�ƌ����Ă�낵����
�}���`�R�A�}���`�X���b�h�Ő��\���҂��̂�
�A�[�L�e�N�g�̔s�k�錾�ƌ����Ă�낵����
�����Ƃ܂��ȉa�����Ă����B
>>406
��V���O���X���b�h�̐��\�����Ă���
��V���O���X���b�h�̐��\�����Ă���
>>405
����̏����ɓ���������p��H�������͓̂��R���낤�B
�n�[�h�E�F�AMPEG�G���R�[�_�́ACPU�����ȓd�͂ő�����A
�Ȃ�Č����悤�Ȃ��̂ł���B
����̏����ɓ���������p��H�������͓̂��R���낤�B
�n�[�h�E�F�AMPEG�G���R�[�_�́ACPU�����ȓd�͂ő�����A
�Ȃ�Č����悤�Ȃ��̂ł���B
>>408
�����������Ƃ��ȁB
�ח��x�̃��R���t�B�M�����u���}�V�������A�[�L�e�N�g�̔s�k���Ǝv���B
FPGA�Ɖ����Ⴄ�̂����ꎞ�Ԗ₢�l�߂����B
�����������Ƃ��ȁB
�ח��x�̃��R���t�B�M�����u���}�V�������A�[�L�e�N�g�̔s�k���Ǝv���B
FPGA�Ɖ����Ⴄ�̂����ꎞ�Ԗ₢�l�߂����B
>>405�̃l�b�g���[�N�v���Z�b�T�́ANiagara�݂����Ȃ���Ǝv���Ă���
�������ɐ�p��H�����Ƃ邪
�������ɐ�p��H�����Ƃ邪
niagara���ăT���̂��H�i��UltraSPARC T1 �j
�}���`�X���b�h�}���`�R�A�Ő��\���҂��ł�T�^����Ȃ����B
�}���`�X���b�h�}���`�R�A�Ő��\���҂��ł�T�^����Ȃ����B
>>409
TRIPS��
��䂳���2D�g�|���W�[�ł�TRIPS�݂����Ȃ��̂�����Ă����킯����
���߂̃R�~�b�g�̗��x���r���Ȃ�̂͗ǂ������Ȃ̂���
����TRIPS�̓X�g�A�o�b�t�@����f�[�^��ǂނƂ������Ƃ��ł��Ȃ���������
�h�c�{�ɂ͂܂�Ƌ���ɋU�̒��������͂����Ă��܂�
TRIPS��
��䂳���2D�g�|���W�[�ł�TRIPS�݂����Ȃ��̂�����Ă����킯����
���߂̃R�~�b�g�̗��x���r���Ȃ�̂͗ǂ������Ȃ̂���
����TRIPS�̓X�g�A�o�b�t�@����f�[�^��ǂނƂ������Ƃ��ł��Ȃ���������
�h�c�{�ɂ͂܂�Ƌ���ɋU�̒��������͂����Ă��܂�
�����Ƃ����߂̃R�~�b�g�͒ʏ�̃v���Z�b�T�ł����ɂȂ��Ă���̂�
�C���e���Ȃ�P4�x�[�X�̘_�����o���Ă���̂���
(�����Ƃ��C���e���͐��\�]���ɂ�������Ɣ��ɓs���̂����O���������̂ł���܂�M�p�Ȃ��)
�ǂ����ɂ���헪�I�P�ނɂ��������Ȃ��悤�Ȃ��̂��h���̏����Ǝ咣���Ă���悤�ȋC������̂�
>TRIPS
�C���e���Ȃ�P4�x�[�X�̘_�����o���Ă���̂���
(�����Ƃ��C���e���͐��\�]���ɂ�������Ɣ��ɓs���̂����O���������̂ł���܂�M�p�Ȃ��)
�ǂ����ɂ���헪�I�P�ނɂ��������Ȃ��悤�Ȃ��̂��h���̏����Ǝ咣���Ă���悤�ȋC������̂�
>TRIPS
>>416
��
��
�lj�̓[���ň��������ȁi��
�ŁA�������������킯��B
IA�̑���Ɏg���Β����d�͂ō����\���Ă��H
�ŁA�������������킯��B
IA�̑���Ɏg���Β����d�͂ō����\���Ă��H
Niagara�Ȃ�Ă����������Ƃˁ[��A�Ƃ���HP�́�I�Ƃ̔�r�L��
http://h71028.www7.hp.com/ERC/cache/280124-0-0-0-121.html
���̂Ɠ����l�ȍ\���ł̃V�X�e�����i��Sun T2000�̕���1.5�`2�{�������B
anand�ł�T2000 server�̃��|�オ���Ă�
http://www.anandtech.com/it/
�X���[�v�b�g������d�͂�DP Opteron�ɔs��Ă�
http://h71028.www7.hp.com/ERC/cache/280124-0-0-0-121.html
���̂Ɠ����l�ȍ\���ł̃V�X�e�����i��Sun T2000�̕���1.5�`2�{�������B
anand�ł�T2000 server�̃��|�オ���Ă�
http://www.anandtech.com/it/
�X���[�v�b�g������d�͂�DP Opteron�ɔs��Ă�
>>418
����������������
�����A�X�[�p�[�X�J���}�V��(�Ƃ��̑O�g�̃f�[�^�t���[�}�V��)�̑�ڂ�
�v���O�����ɑ��݂���������R�ɒ��o����
�����������
����������������
�����A�X�[�p�[�X�J���}�V��(�Ƃ��̑O�g�̃f�[�^�t���[�}�V��)�̑�ڂ�
�v���O�����ɑ��݂���������R�ɒ��o����
�����������
http://japan.zdnet.com/column/interview/story/0,2000053136,20097277,00.htm
Power6�̒��̐l�̂����t
�u�d�v�Ȃ̂́A�V�X�e���̃X���[�v�b�g���ێ����邱�ƂƁA
�@�V���O���R�A�̃p�t�H�[�}���X���ێ����邱�ƂƂ̃o�����X�ł��B�v
�u�������������ƁiNiagara�j�𐄂��i�߂āA�p�t�H�[�}���X��1��
�@�ʂɓ�����������ƁA���͖��Ȏ��ԂɊׂ�Ƃ������Ƃł��B
�@���̑��̂��Ƃ����ׂĖ����ł���قǁA���̒��͊Â��Ȃ��̂ł��B�v
http://news.com.com/Talkin+about+Intels+next+generation/2008-1006_3-6047173.html?tag=st.num
Core Duo�̒��̐l�̂����t
�u�}���`�^�X�N��}���`�X���b�h���ł͍����������\�������ł��Ă��A
�@�V���O���X���b�h���ł���Ă��������̃\�t�g�E�F�A�J���҂���
�@"�O�̕����ǂ�����"�ƕ���������邾�낤�B�v
Power6�̒��̐l�̂����t
�u�d�v�Ȃ̂́A�V�X�e���̃X���[�v�b�g���ێ����邱�ƂƁA
�@�V���O���R�A�̃p�t�H�[�}���X���ێ����邱�ƂƂ̃o�����X�ł��B�v
�u�������������ƁiNiagara�j�𐄂��i�߂āA�p�t�H�[�}���X��1��
�@�ʂɓ�����������ƁA���͖��Ȏ��ԂɊׂ�Ƃ������Ƃł��B
�@���̑��̂��Ƃ����ׂĖ����ł���قǁA���̒��͊Â��Ȃ��̂ł��B�v
http://news.com.com/Talkin+about+Intels+next+generation/2008-1006_3-6047173.html?tag=st.num
Core Duo�̒��̐l�̂����t
�u�}���`�^�X�N��}���`�X���b�h���ł͍����������\�������ł��Ă��A
�@�V���O���X���b�h���ł���Ă��������̃\�t�g�E�F�A�J���҂���
�@"�O�̕����ǂ�����"�ƕ���������邾�낤�B�v
>>410
FPGA���ƁA�z���x���̂����ŃN���b�N���ނ��Ⴍ����Ⴍ�Ȃ�
���Ȃ��Ƃ��A�v���Z�X���[������������Ă��N���I�N��������Ȃ�
�䂦�Ƀ��R���t�B�M���A���u���v���Z�T�b�T�̓o��炵��
FPGA���ƁA�z���x���̂����ŃN���b�N���ނ��Ⴍ����Ⴍ�Ȃ�
���Ȃ��Ƃ��A�v���Z�X���[������������Ă��N���I�N��������Ȃ�
�䂦�Ƀ��R���t�B�M���A���u���v���Z�T�b�T�̓o��炵��
�܂�sun��ݸ�ٺ����\�����S�ɐ�̂Ă��킯����Ȃ�����
Rock�Ŏ��ЊJ���ɖ߂�or�܂��x�m��SPARC64���́H������
Rock�Ŏ��ЊJ���ɖ߂�or�܂��x�m��SPARC64���́H������
Rock���AUltra SPARC T1�Ǝ����悤�ȃA�[�L�e�B�N�`���炵��
16�̃R�A�������āA4�R�A��L1���L���b�V�������L
�����č����OOO�͂Ȃ�
T1�̐��\������܂悭�Ȃ����A�x�m�ʂ�AMD��CPU��
�C�����ق��������Ǝv��
16�̃R�A�������āA4�R�A��L1���L���b�V�������L
�����č����OOO�͂Ȃ�
T1�̐��\������܂悭�Ȃ����A�x�m�ʂ�AMD��CPU��
�C�����ق��������Ǝv��
�i�L-`�j.�oO�i�x�mSun�a���܂����Ȃ��c�j
���R���t�B�M���A���u�����߂������ɃX�^�e�B�b�N�f�[�^�t���[�ɂȂ邳
���R���t�B�M���A���u���v���Z�b�T��FPGA�̑�ւɂȂ�Ȃ炤�ꂵ���ˁB
���̂Ƃ���́A���R�g�����p�r�ȊO�ł͔�r�ɂȂ��ł���B
���̂Ƃ���́A���R�g�����p�r�ȊO�ł͔�r�ɂȂ��ł���B
429 �FSocket774�F2006/04/03(��) 22:47:11 ID:17/hVORD
�������]����˂��[��
256���ߓ������scpu����Ƃ��ό�^��H
��������������ު�Ȫ�
256���ߓ������scpu����Ƃ��ό�^��H
��������������ު�Ȫ�
cell���ō��ł��B
�m���Ɉ�����͍ō���
>>430
ʲʲ�ACellʽ��
ʲʲ�ACellʽ��
ʲʲ�ACellLight�͂����ƽ��ł��B
���̏����ڂ̓G�ɂ��邭�炢������
CELL���ڂ�PCI Express�J�[�h���o�Ă��������Ǝv����ł����ǂˁB
����̃G���R�[�h��f�R�[�h���A���낢��g�����͂���ł��傤�B
����̃G���R�[�h��f�R�[�h���A���낢��g�����͂���ł��傤�B
���ƃQ�[���̕����v�Z�Ƃ��ɂ��g����B
ClearSpeed��SIMD�ȃv���Z�b�T�����邶��Ȃ����A���ɁB
�ėp��������Γ���p�r�ŔėpCPU���ꌅ�`�͑����Ȃ�̂͂�����܂��B
cell�͔ėp�Ɛ�p�̒��x���Ԃ��B
cell�͔ėp�Ɛ�p�̒��x���Ԃ��B
439 �FSocket774�F2006/04/05(��) 11:50:48 ID:Dmefy6Kn
�������ǂ������1���������2MB�ɂ���Α�����˂��H
���͂����V�˵ڂ�������������������������
���͂����V�˵ڂ�������������������������
�ȂA�ނ�����PA-RISC������Ȑv�������悤�ȁB
�f�[�^512K�A����1M���������B
�t��������?
�t��������?
�Ăh�a�l�A����d��4����1�̐V�^�l�o�t�E�\�͂�10�{
http://www.nikkei.co.jp/news/kaigai/20060405AT2M0500V05042006.html
http://www.nikkei.co.jp/news/kaigai/20060405AT2M0500V05042006.html
443 �FSocket774�F2006/04/05(��) 15:48:39 ID:eaTqXQ3/
�̂̂悤�Ƀ`�b�v�ɐς߂�g�����W�X�^�Ƃ��̐�����Ȃ�ʂ����A���݂��ƃ����b�g�ˁ[��ˁB
���Ƃ��A2MB�̂P���L���b�V����2MB��2���L���b�V�����ƁA���ǁA���C�e���V�⑬�x�������ɂȂ邾��B
���Ƃ��A2MB�̂P���L���b�V����2MB��2���L���b�V�����ƁA���ǁA���C�e���V�⑬�x�������ɂȂ邾��B
����A�Ԃɋ��܂Ȃ����A���C�e���V�͎�L�����E�E�E
>>444
L1�ɍ����ȃg�����W�X�^���H��p�ӂ��邩��L1��L2�ɂ͍����o��(�Ƃ������t����)�B
������H�őg�߂�L1��L2���ꏏ�̑��x�ɂȂ�B
�܂�AL2�~�߂đ�e��L1���Ęb�́A
�e�ʂ����Ȃ��Ȃ邯�Ǎ����ȃ��������ǂ��̂��A����Ƃ������Ƃ낭�Ă���e�ʂ̃��������ǂ��̂����Ă�
�������̂��b�ȖB
L1�ɍ����ȃg�����W�X�^���H��p�ӂ��邩��L1��L2�ɂ͍����o��(�Ƃ������t����)�B
������H�őg�߂�L1��L2���ꏏ�̑��x�ɂȂ�B
�܂�AL2�~�߂đ�e��L1���Ęb�́A
�e�ʂ����Ȃ��Ȃ邯�Ǎ����ȃ��������ǂ��̂��A����Ƃ������Ƃ낭�Ă���e�ʂ̃��������ǂ��̂����Ă�
�������̂��b�ȖB
>>444-445
��2GHz��Ȃ�2MB�̂P��������ɂ�����A���Ԃ�ڲ�ݼ�傫���̂������Ȃ��ė]�T�Ŏ��˂�
��2GHz��Ȃ�2MB�̂P��������ɂ�����A���Ԃ�ڲ�ݼ�傫���̂������Ȃ��ė]�T�Ŏ��˂�
�E�F�f�B���O�s�[�`�ƂȂW����̂�
Alpha��21164�ł����I���`�b�vL2��21264�ŊO�������Ƃ����邵�A���̐扽�����邩�킩����ȁB
�}���`�R������L1�I�����[�ɖ߂����o�Ă��邩�������B
����L1�̕K�v���̓��C�e���V�[�ȊO�ɂ��|�[�g���Ƃ��A�z�x�Ƃ����낢�날��ǃO�w�w�B
Alpha��21164�ł����I���`�b�vL2��21264�ŊO�������Ƃ����邵�A���̐扽�����邩�킩����ȁB
�}���`�R������L1�I�����[�ɖ߂����o�Ă��邩�������B
����L1�̕K�v���̓��C�e���V�[�ȊO�ɂ��|�[�g���Ƃ��A�z�x�Ƃ����낢�날��ǃO�w�w�B
> �}���`�R��
�Ȃe�j�X�I��̖��O�݂�����
�Ȃe�j�X�I��̖��O�݂�����
450 �FSocket774�F2006/04/05(��) 22:24:18 ID:Dmefy6Kn
L1��L2������ݼ��̍\���Ⴄɶ�H
�{�����H
�{�����ȁH
�{���ȂȁH
�{�����H
�{�����ȁH
�{���ȂȁH
L6�L���b�V�����炢�܂ō��A���C������������Ȃ��ˁH
L10�L���b�V�����炢�܂ō��A�n�[�h�f�B�X�N����Ȃ��ˁH
���߂�B
L2���T�C�Y�ƒ����d�͂��d��
L2���T�C�Y�ƒ����d�͂��d��
>>451
�����I�Ɋђʓd�ɂŃ`�b�v�Ƀ��������t������A����ˁ[���
�����I�Ɋђʓd�ɂŃ`�b�v�Ƀ��������t������A����ˁ[���
>>450
SRAM�Z���͊�{�I�ɓ��������A���䕔���S�R�Ⴄ
�|�[�g���Ƃ��Z�b�g�A�\�V�G�e�B�u���Ƃ�
�ɒ[�Ȃ��Ƃ����A�L���b�V�������W�X�^��
����6�g�����W�X�^SRAM
SRAM�Z���͊�{�I�ɓ��������A���䕔���S�R�Ⴄ
�|�[�g���Ƃ��Z�b�g�A�\�V�G�e�B�u���Ƃ�
�ɒ[�Ȃ��Ƃ����A�L���b�V�������W�X�^��
����6�g�����W�X�^SRAM
457 �FSocket774�F2006/04/06(��) 00:22:18 ID:E1qCOOJR
���Ⴀ�S��L1�̍\�������ō\������β��W���}�C�J�I�I�I�I�I�I
���킟�[�I���������ց[�[�[�[�[������
���킟�[�I���������ց[�[�[�[�[������
>>457
���C�e���V�̂ł���L1�ɂȂ邯�ǂȁB��������肩������B
���]�Ԃ��t�����Ɏԗւ��ǂ�ǂ�n���ł���������������������
���nj��݂̃o�����X�ɗ��������Ă��܂����B�������o�����X���̐S�B
���C�e���V�̂ł���L1�ɂȂ邯�ǂȁB��������肩������B
���]�Ԃ��t�����Ɏԗւ��ǂ�ǂ�n���ł���������������������
���nj��݂̃o�����X�ɗ��������Ă��܂����B�������o�����X���̐S�B
L1���������d�C�H����
L1�Ȃ�64bit�Ȃ���64kb�ŏ\���Ȃ�Ȃ��̂��H
Conroe/2.4GHz�̑��B���̂�NIC���_����CPU�܂��肾�����̂��A�Ƃ肠�����O���Č��ʂ�
�܂Ƃ��ɂȂ��Ă����Ƃ��B�B�B
http://vic.expreview.com/read.php?2
�܂Ƃ��ɂȂ��Ă����Ƃ��B�B�B
http://vic.expreview.com/read.php?2
462 �FMAC�I�^�����l���F2006/04/06(��) 08:54:31 ID:cTguVAVL
Intel������X���b�h�ƊԈႦ�����B
RISC�X���ɂ��ꏑ���Ƃ͂킴�ƂȂ猖�ܔ����Ă�Ƃ����v���Ȃ��s�ׂ�
>>463
�u���[�X���^�C�X���^�C
�u���[�X���^�C�X���^�C
�����������Ȃ��J�X�͏�삪�ړI��
Sun��200�l��SPARC�G���W�j�A�����C�I�t
http://www.theregister.co.uk/2006/04/07/sun_jupiter_gone
> Sun��Niagara���x�[�X�ɂ��āCRock�v���Z�T�ɐڑ����C�ʐM�����Ȃǂ�
> �I�t���[�h����Jupitor�Ƃ����v���Z�T���J�����Ă���Ƃ����\�������̂ł����C
> ���̃v���W�F�N�g���L�����Z�����ꂽ�悤�ł��B����ɔ����C���̃v���W�F�N�g
> �Ȃǂɐl���ڂ����肵�����C�ŏI�I�ɂ�200�l�͎�Ƃ������ƂɂȂ����悤�ł��B
> �{��Niagara��Rock�v���Z�T�̊J���H���ɂ͕ύX�͖����Ƃ̂��Ƃł��B
http://www.theregister.co.uk/2006/04/07/sun_jupiter_gone
> Sun��Niagara���x�[�X�ɂ��āCRock�v���Z�T�ɐڑ����C�ʐM�����Ȃǂ�
> �I�t���[�h����Jupitor�Ƃ����v���Z�T���J�����Ă���Ƃ����\�������̂ł����C
> ���̃v���W�F�N�g���L�����Z�����ꂽ�悤�ł��B����ɔ����C���̃v���W�F�N�g
> �Ȃǂɐl���ڂ����肵�����C�ŏI�I�ɂ�200�l�͎�Ƃ������ƂɂȂ����悤�ł��B
> �{��Niagara��Rock�v���Z�T�̊J���H���ɂ͕ύX�͖����Ƃ̂��Ƃł��B
>>467
�x�m�ʂ�����������Ȃ��̂��˂��B
�x�m�ʂ�����������Ȃ��̂��˂��B
�Ђ��Ƃ��
US5���L�����Z���ɂȂ����Ƃ����吨�d�ɂȂ��Ă����Ǝv������
�܂�����ȂɎc���Ă����̂�
�܂�����ȂɎc���Ă����̂�
������L1D�L���b�V���̃��C�e���V
�k�X�F2(cycle)
�v�F3(cycle)
������H��ALL
�k�X�F2(cycle)
�v�F3(cycle)
������H��ALL
���d
�v���X�R��L1�̓��C�e���V4����B
UltraSPARC T2 �e�[�v�A�E�g
http://enterprise.watch.impress.co.jp/cda/foreign/2006/04/13/7616.html
http://pcweb.mycom.co.jp/news/2006/04/13/101.html
http://enterprise.watch.impress.co.jp/cda/foreign/2006/04/13/7616.html
http://pcweb.mycom.co.jp/news/2006/04/13/101.html
���Ȃ݂�CELL�̓��C�e���V8
�x�����ł�
�x�����ł�
476 �FMAC�I�^��474 �����F2006/04/13(��) 22:37:08 ID:8cd737Xj
>>474
�v�����ƃe�[�v�A�E�g��Ⴄ���B
�v�����ƃe�[�v�A�E�g��Ⴄ���B
Sun Microsystems Completes Design Tape-Out for Next-Generation,
Breakthrough UltraSPARC T2 CoolThreads Processor
Breakthrough UltraSPARC T2 CoolThreads Processor
Sun Ray 2/2FS�A�Ȃ����Ȃ�
>>476
���Ƃ������Ă݂��www
���Ƃ������Ă݂��www
>>476
ttp://www.sun.com/smi/Press/sunflash/2006-04/sunflash.20060412.2.xml?cid=155
| Sun Microsystems Completes Design Tape-Out for Next-Generation,
| Breakthrough UltraSPARC T2 CoolThreads Processor
ttp://www.sun.com/smi/Press/sunflash/2006-04/sunflash.20060412.2.xml?cid=155
| Sun Microsystems Completes Design Tape-Out for Next-Generation,
| Breakthrough UltraSPARC T2 CoolThreads Processor
����A�V���R������čŏ��̐��i���o�Ă���͉̂��[�����B
���[���A�E�g������?
���[���A�E�g������?
�t�@�[�X�g�V���R������ˁ[�́B
484 �FMAC�I�^��477-481 �����F2006/04/15(�y) 15:41:05 ID:JAuAcVpr
>>477-481
���L���ǂ܂��Ɏ��炵�����B�������ʏ�v�������Ă̂�A���̈ʂ̒i�K���Ǝv�����B
http://www.designchain.com/coverstory.asp?issue=spring03
�e�[�v�A�E�g���Ă̂�A������p�̃}�X�N�f�[�^�ɂ��āA�H��ɑ����悤�ɂȂ����i�K���B
���L���ǂ܂��Ɏ��炵�����B�������ʏ�v�������Ă̂�A���̈ʂ̒i�K���Ǝv�����B
http://www.designchain.com/coverstory.asp?issue=spring03
�e�[�v�A�E�g���Ă̂�A������p�̃}�X�N�f�[�^�ɂ��āA�H��ɑ����悤�ɂȂ����i�K���B
Cell�̋Z�p���g����CPU���p�\�R���ɓ��鎖�͂��̐���҂ł��܂����H
F1�}�V���������𑖂鎖�͂��̐���҂ł��܂����H
>>485
Cell���J��������Ёi�̂����ꂩ�j�������CPU���p�\�R���ɓ��鎖������Ȃ��
Cell���J��������Ёi�̂����ꂩ�j�������CPU���p�\�R���ɓ��鎖������Ȃ��
> �e�[�v�A�E�g���Ă̂�A������p�̃}�X�N�f�[�^�ɂ��āA�H��ɑ����悤�ɂȂ����i�K���B
�Ⴄ�ł���
�Ⴄ�ł���
�S�[���f���T���v��
�S�ςȂ����t�̘b�ɂȂ邾�������畳�̓X���[����Ƃ���قǁi��
tape out
�@��������LSI�̃��C�A�E�g�f�[�^�����C�e�[�v�ɏ������݁A�g�U�v���Z�X�p�̃}�X�N�̃f�[�^��LSI��������ɏo�ׂ��邱�Ƃ������B���̌�A�g�U�v���Z�X���s�Ȃ��Ď��ۂ̃`�b�v���쐬�����B�܂�e�[�v�A�E�g�́ALSI�̐v�������������Ƃ��Ӗ�����B
�@��������e�[�v�A�E�g�����ƁA�v�Ƀo�O�������Ă��C�������邱�Ƃ��ł��Ȃ��B���̂��߁A������x�e�[�v�A�E�g�����蒼�������Ȃ��B
���ǂ̂Ƃ���ACAD����Fab�Ƀf�[�^�𑗂邱�ƂƂ������Ƃł����̂��H
�@��������LSI�̃��C�A�E�g�f�[�^�����C�e�[�v�ɏ������݁A�g�U�v���Z�X�p�̃}�X�N�̃f�[�^��LSI��������ɏo�ׂ��邱�Ƃ������B���̌�A�g�U�v���Z�X���s�Ȃ��Ď��ۂ̃`�b�v���쐬�����B�܂�e�[�v�A�E�g�́ALSI�̐v�������������Ƃ��Ӗ�����B
�@��������e�[�v�A�E�g�����ƁA�v�Ƀo�O�������Ă��C�������邱�Ƃ��ł��Ȃ��B���̂��߁A������x�e�[�v�A�E�g�����蒼�������Ȃ��B
���ǂ̂Ƃ���ACAD����Fab�Ƀf�[�^�𑗂邱�ƂƂ������Ƃł����̂��H
�܂��A���܂ǂ����C�e�[�v�Ȃł��Ƃ肵�Ȃ����ǂ�
>>493
����Ⴀ�A�������B
����Ⴀ�A�������B
UID�t�������Ǒ��v�Ȃ�H
UID��UserID�ł͂Ȃ�UniqueID�̗����Ǝv����B
�ʔ�������3���Ԃ������ˁ[��(w
�݂�ȓǂނ̂ɖ����Ȃ̂�?
499 �F�����ɃX���Ⴂ�ł������킯�Ȃ������F2006/04/19(��) 17:23:24 ID:feQqY9+y
http://pc.watch.impress.co.jp/docs/2006/0419/kaigai262.htm
�p�C�v���C�����Ƃ��A�N�����킵���������L�{���k
�p�C�v���C�����Ƃ��A�N�����킵���������L�{���k
���̓A�[�L�e�N�g�Ƃ��Ă͕]�����ĂȂ��Ƃ������_���ۂƎv���Ă���
�㐢�̐l�Ԃ����猾���邱�ƁB
�Z���Ԃ�Tr�������ł����ɂ߂��ނ��Ƃ������ꂶ��
����ׂ��A�[�L�e�N�`�����l�����Ȃ��A
���̌P�����ł��Ȃ����Ă̂͂��傤���Ȃ���ł́H
�Z���Ԃ�Tr�������ł����ɂ߂��ނ��Ƃ������ꂶ��
����ׂ��A�[�L�e�N�`�����l�����Ȃ��A
���̌P�����ł��Ȃ����Ă̂͂��傤���Ȃ���ł́H
�����́A��ʓI�ȃA�v���[�`�Ƃ��A���������T�O���Ȃ���������Ȃ����B
�܂��͕K�v�ȋ@�\���A�����ɋl�ߍ��ނ��A�Ƃ������Ƃ��d�v�������킯�ŁB
�܂��͕K�v�ȋ@�\���A�����ɋl�ߍ��ނ��A�Ƃ������Ƃ��d�v�������킯�ŁB
Z80�܂ł̋Ɛт͕]���ł���Ǝv����
����ȍ~���Ȃ��c
����ȍ~���Ȃ��c
���������\�[�X�̐�����ł�肭�肷��͔̂��ɏ�肩�����Ǝv���̂���
�ゾ�������ĎR��o���Ă��銴���ے�ł��Ȃ��C������
�ゾ�������ĎR��o���Ă��銴���ے�ł��Ȃ��C������
506 �FSocket774�F2006/04/29(�y) 06:13:12 ID:Bvy5proX
�ߑa�ߑa���ăn�@�j�B�`age
507 �FSocket774�F2006/04/29(�y) 22:07:50 ID:QB8ey9I0
CELL�������Ƃ�����͑ʖڂ��Ǝv�����B���Ȃ�MIPS�ӂ��16��
L2�L���b�V����2M���炢�ς�Ō떂�����Ă����̂����A����Ȃ班���͔ėp��������
�������B�������A�Q�[����p��TV�g����LSI�Ƃ��Ă݂�Ɩ��͂�����̂�����H
���̓��̐��Ƃ͔@���ł��傤���B
L2�L���b�V����2M���炢�ς�Ō떂�����Ă����̂����A����Ȃ班���͔ėp��������
�������B�������A�Q�[����p��TV�g����LSI�Ƃ��Ă݂�Ɩ��͂�����̂�����H
���̓��̐��Ƃ͔@���ł��傤���B
MIPS��16���ƃV���O���X���b�h���x�������
�Q�[���Ȃ�Xbox360��CPU�̂ق����ǂ����Ƃ����̂������h�����ǂ�
�X�g���[���������Ƃ܂�������Ă��邩���m���
�Q�[���Ȃ�Xbox360��CPU�̂ق����ǂ����Ƃ����̂������h�����ǂ�
�X�g���[���������Ƃ܂�������Ă��邩���m���
�Q�[���̓V���O���X���b�h���x���Ă��\��Ȃ��ł��傤�B
�ėpCPU���ƁA�L���b�V���̐����L���b�V���̓�����
�߂�ǂ���������ACELL�͂��������`�ɂ�����
���������AMIPS�R�A��4waySIMD������A16�R�A������Ȃ�
>>508
xbox360��CPU����Ԗ���Ȋ��������
�߂�ǂ���������ACELL�͂��������`�ɂ�����
���������AMIPS�R�A��4waySIMD������A16�R�A������Ȃ�
>>508
xbox360��CPU����Ԗ���Ȋ��������
�p�r���i��ƁA�L���b�V���݂����Ȕ��I�������Ǘ����
�����I�������Ǘ��̂ق��������ǂ��킯��
cell�̃A�v���[�`�͐�������Ȃ����Ǝv��
�����I�������Ǘ��̂ق��������ǂ��킯��
cell�̃A�v���[�`�͐�������Ȃ����Ǝv��
����������LS���ăL���b�V���ƈ���Ė��炩�ɔ��M���Ă���
http://pc.watch.impress.co.jp/docs/2005/0208/kaigaip051.jpg
�L���b�V�����C���P�ʂ̃A�N�Z�X�ƈ���ăR�[�h�ɂ���Ă͑��Ȃ߂ɂȂ邩�炩?
http://pc.watch.impress.co.jp/docs/2005/0208/kaigaip051.jpg
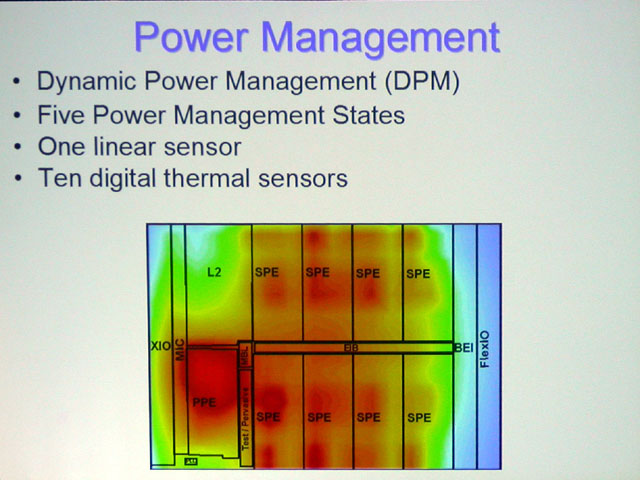{kind=link}
�L���b�V�����C���P�ʂ̃A�N�Z�X�ƈ���ăR�[�h�ɂ���Ă͑��Ȃ߂ɂȂ邩�炩?
����������̂̃Q�[�������V���O���X���b�h���\���厖����B
>>511
���܂��t�B�b�g����A�v���P�[�V�����Ȃ炢���̂���
LS��256KB�Ƃ����T�C�Y�����܂�ɂ������Ȃ̂�
�L���b�V���Ȃ烏�[�N�Z�b�g���I�[�o�[�����Ƃ���ł��₩�ɐ��\���ቺ���Ă䂭��������
���܂��t�B�b�g����A�v���P�[�V�����Ȃ炢���̂���
LS��256KB�Ƃ����T�C�Y�����܂�ɂ������Ȃ̂�
�L���b�V���Ȃ烏�[�N�Z�b�g���I�[�o�[�����Ƃ���ł��₩�ɐ��\���ቺ���Ă䂭��������
>>514
�G���Q�[�̃V�i���I����ˁ[���炳�B
�唼�̃Q�[���ł̏d�������́A�O���t�B�b�N�X�Ȃ킯�ŁA
���������͕̂��U���������₷���ق�����B
�G���Q�[�̃V�i���I����ˁ[���炳�B
�唼�̃Q�[���ł̏d�������́A�O���t�B�b�N�X�Ȃ킯�ŁA
���������͕̂��U���������₷���ق�����B
517 �FSocket774�F2006/04/30(��) 10:31:18 ID:BHwbBXwo
CELL��SIMD��������������v�X�ʂɓ����݂������������A
SIMD�n�̖��߂�����Ƃ��������ł���ˁH
�Q�[������G�`������Ȏd���Ƃ���ƁA�V���O���X���h�]�X��
�����̃Q�[����O��ɂ����b�ňӖ��̂��锭���ł͂Ȃ��悤�Ȃ̂�
����ɋp�������Ă��������܂��B
CELL�̂悤�Ɉَ��CPU���ʌɏ���Ă���̂�
�����x���Ă�������Ԃœ��ꂵ�đ���CPU������Ă���̂�
�ǂ��炪�g���₷���̂ł��傤���H
CELL�݂����ȌǗ��_����Ԃ�CPU�Ō�G�`�������܂����S���Ď��s����̂�
�ʓ|�ł͖������Ǝv���̂ł����H
SIMD�n�̖��߂�����Ƃ��������ł���ˁH
�Q�[������G�`������Ȏd���Ƃ���ƁA�V���O���X���h�]�X��
�����̃Q�[����O��ɂ����b�ňӖ��̂��锭���ł͂Ȃ��悤�Ȃ̂�
����ɋp�������Ă��������܂��B
CELL�̂悤�Ɉَ��CPU���ʌɏ���Ă���̂�
�����x���Ă�������Ԃœ��ꂵ�đ���CPU������Ă���̂�
�ǂ��炪�g���₷���̂ł��傤���H
CELL�݂����ȌǗ��_����Ԃ�CPU�Ō�G�`�������܂����S���Ď��s����̂�
�ʓ|�ł͖������Ǝv���̂ł����H
>>516
���ꂩ�畨���v�Z��AI���d���Ȃ��Ă���킯����
���ꂩ�畨���v�Z��AI���d���Ȃ��Ă���킯����
�����v�Z�̓V���O���X���b�h���\����Ȃ�ł����B
�۽��
��������
��������
521 �FSocket774�F2006/04/30(��) 12:24:18 ID:PWi2s8vj
�R���Z�v�g�͈����Ȃ���256KB�͊m���ɔ����B
�R�A�X�Ȃ�Ė��炩�ɑ����B�قƂ�ǂ̃A�v���ł͂P�^�R���g��ꂸ�ɏI��邾�낤�B
���U����Α����͉̂��ł�������b�ŁA�����l�Ԃ̎�Ŏd�������ĂĂ͑ʖ�
http://2ch.dumper.jp/0001734092/
��Ώ̃}���`�v���Z�b�T�Ƃ����͎̂g�������ǂ���Αf���炵�����\������B
�������A�ȉ��̏����������Ă���K�v������B
1.��������Ԃ̐��Ȃ����ƁB���݂��Ƀ����������L�ł��邱�ƁB
2.��Ώ̃}���`�v���Z�b�T�ɑΉ��������͂ȃf�o�b�K�����邱�ƁB
3.OS�ɂ��Z���X�̗ǂ����ۉ�������ĊȒP�Ɏg���邱��
Cell�͂���3�̂�������������Ă���B
http://hobby8.2ch.net/test/read.cgi/sony/1133737894/
����ɂ�������SPE��DMA�L�b�N�Ƃ��A�S��PPE�ɔC���Ă�킯�ŁA�R�����܂�����
���C�u�������Ȃ���𑁂߂ɒ��Ȃ��ƁAPS2��EE�ƈꏏ�ōŏ��ɃR�P�邼�c�B
���̓v���O���}�ɂƂ��āA�s�v�ȋ�ɂł��ȁB�v���O���}�͖{���̖�����������
�A���S���Y���Ȃǂ̍l�Ăɐ�O���āA���Ƃ�������u���ʁv�ȍ�ƂɎ��Ԃ����������Ȃ�
http://72.14.203.104/search?q=cache:dM7OyiI12e8J:sunset01.bne.jp/blog/index.php
Windows��UNIX�Ń}���`�X���b�h�v���O������g�o���̂�����Ȃ番���邩�Ǝv�����A
���Ɏ�i������̂ł���A�Ȃ�ׂ��}���`�X���b�h���͔����Ēʂ낤�Ƃ��邾�낤�B
�X���b�h�����邾���Ȃ�A���ꔭ�ŊԒP�����A��U����n�߂��X���b�h���Ǘ�
����̂͂Ȃ��Ȃ���ς��BC,C++����i�����łȂ�����̑唼�̌���j�͂��Ƃ���
�����I�ɏ������邱�Ƃ�z�肵�Ă��邽�ߕ���I�ȏ����Ɍ����Ă���Ƃ͂����Ȃ��B
�^�ʖڂɂ������������Ƃ��[������\�z���Ă����ɂ͑����ȓw�͂ƗD�G�Ȑl�ނ��K�{�ƂȂ�A
���`���K�͂ȉ�Ђł͂��܂茻���I�Ƃ͂����Ȃ����낤�B
http://blog.so-net.ne.jp/pcgame/2005-03-28
���U����Α����͉̂��ł�������b�ŁA�����l�Ԃ̎�Ŏd�������ĂĂ͑ʖ�
http://2ch.dumper.jp/0001734092/
��Ώ̃}���`�v���Z�b�T�Ƃ����͎̂g�������ǂ���Αf���炵�����\������B
�������A�ȉ��̏����������Ă���K�v������B
1.��������Ԃ̐��Ȃ����ƁB���݂��Ƀ����������L�ł��邱�ƁB
2.��Ώ̃}���`�v���Z�b�T�ɑΉ��������͂ȃf�o�b�K�����邱�ƁB
3.OS�ɂ��Z���X�̗ǂ����ۉ�������ĊȒP�Ɏg���邱��
Cell�͂���3�̂�������������Ă���B
http://hobby8.2ch.net/test/read.cgi/sony/1133737894/
����ɂ�������SPE��DMA�L�b�N�Ƃ��A�S��PPE�ɔC���Ă�킯�ŁA�R�����܂�����
���C�u�������Ȃ���𑁂߂ɒ��Ȃ��ƁAPS2��EE�ƈꏏ�ōŏ��ɃR�P�邼�c�B
���̓v���O���}�ɂƂ��āA�s�v�ȋ�ɂł��ȁB�v���O���}�͖{���̖�����������
�A���S���Y���Ȃǂ̍l�Ăɐ�O���āA���Ƃ�������u���ʁv�ȍ�ƂɎ��Ԃ����������Ȃ�
http://72.14.203.104/search?q=cache:dM7OyiI12e8J:sunset01.bne.jp/blog/index.php
Windows��UNIX�Ń}���`�X���b�h�v���O������g�o���̂�����Ȃ番���邩�Ǝv�����A
���Ɏ�i������̂ł���A�Ȃ�ׂ��}���`�X���b�h���͔����Ēʂ낤�Ƃ��邾�낤�B
�X���b�h�����邾���Ȃ�A���ꔭ�ŊԒP�����A��U����n�߂��X���b�h���Ǘ�
����̂͂Ȃ��Ȃ���ς��BC,C++����i�����łȂ�����̑唼�̌���j�͂��Ƃ���
�����I�ɏ������邱�Ƃ�z�肵�Ă��邽�ߕ���I�ȏ����Ɍ����Ă���Ƃ͂����Ȃ��B
�^�ʖڂɂ������������Ƃ��[������\�z���Ă����ɂ͑����ȓw�͂ƗD�G�Ȑl�ނ��K�{�ƂȂ�A
���`���K�͂ȉ�Ђł͂��܂茻���I�Ƃ͂����Ȃ����낤�B
http://blog.so-net.ne.jp/pcgame/2005-03-28
�Q�[���̏ꍇ�͒����Ȃǂ̌�H������i�̕i�������߂�B�����ŁA�������x������Ƃ�����
SPE�̊��蓖�Đ���ς��悤���̂Ȃ��ςȍ�蒼���ɂȂ肩�˂Ȃ��B�������K�h���C�u��
�T�^�[�������̂́A���̃n�[�h���\�ɂ킭�킭�ł������炾�B�������邱�Ƃ��ł������炾�B
PS3�ɂ͂��������������Ȃ��B
http://homepage1.nifty.com/bee/diary/20055.html
�}���`�R�A�E�}���`�X���b�h�́A�����͊��Ғʂ�̌��ʂ������邱�Ƃ͂ł��Ȃ��Ƃ��q�ׂĂ���B
�`�揈���͕��̂������{�ƂȂ邪�A�Q�[���v���O�������̂��̂�����邱�Ƃ�
�\�z�ȏ�ɓ�����Ƃł���A���̂��Ƃ�����̃Q�[���J��������ɓ�����Ă������ƂɂȂ邾�낤
http://blog.so-net.ne.jp/pcgame/2005-08-23
�ΉԂ��L�����N�^�[�ɏՓ˂���Ƃ��A���ʂ̔g�̍����ɂ���ăL�����N�^�[�̏���Ă���
�D���h���Ƃ������A�Q�[���V�X�e���ɒ��ډe����^����G�t�F�N�g�͕��ł��Ȃ��B
PhysX���J������AGEIA�ł́A�������ʂ�K������͈͂��̃O���[�v�ɕ��ނ���
��@���Ă��Ă���B�e�O���[�v�͕��̓K���x�ɂ���ĕ��ނ���Ă���A�Q�[�����W�b�N
���̂��̂ւ̊ւ���ƃ��A���^�C�����������Ȃ�قǕ��K���x�͒Ⴍ�Ȃ�B
���ǁACPU�R�A��10�ςƂ��Ă�����ł̓R�A��S�Đ������邱�Ƃ͓��
���̂Ƃ����3,4����Ώ[���������Ǝv����
http://blog.so-net.ne.jp/pcgame/2005-09-15
��荇�����A��ԂƂȂ�f�U�C���p�^�[�����ł܂�Ȃ��ƁA�ԗւ̍Ĕ������n�܂肻��
http://www.igda.jp/modules/newbb/viewtopic.php?topic_id=175&forum=8&post_id=851
���������Q�[�������Ƃ������̂͒����I�ɏ������Ȃ��Ă͂����Ȃ��������������߁A
���U�R���s���[�e�B���O�ɓK���Ȃ��Ƃ������ƁB
http://blog.freelance.ne.jp/mizusawa/archives/200511/14_2017.php
SPE�̊��蓖�Đ���ς��悤���̂Ȃ��ςȍ�蒼���ɂȂ肩�˂Ȃ��B�������K�h���C�u��
�T�^�[�������̂́A���̃n�[�h���\�ɂ킭�킭�ł������炾�B�������邱�Ƃ��ł������炾�B
PS3�ɂ͂��������������Ȃ��B
http://homepage1.nifty.com/bee/diary/20055.html
�}���`�R�A�E�}���`�X���b�h�́A�����͊��Ғʂ�̌��ʂ������邱�Ƃ͂ł��Ȃ��Ƃ��q�ׂĂ���B
�`�揈���͕��̂������{�ƂȂ邪�A�Q�[���v���O�������̂��̂�����邱�Ƃ�
�\�z�ȏ�ɓ�����Ƃł���A���̂��Ƃ�����̃Q�[���J��������ɓ�����Ă������ƂɂȂ邾�낤
http://blog.so-net.ne.jp/pcgame/2005-08-23
�ΉԂ��L�����N�^�[�ɏՓ˂���Ƃ��A���ʂ̔g�̍����ɂ���ăL�����N�^�[�̏���Ă���
�D���h���Ƃ������A�Q�[���V�X�e���ɒ��ډe����^����G�t�F�N�g�͕��ł��Ȃ��B
PhysX���J������AGEIA�ł́A�������ʂ�K������͈͂��̃O���[�v�ɕ��ނ���
��@���Ă��Ă���B�e�O���[�v�͕��̓K���x�ɂ���ĕ��ނ���Ă���A�Q�[�����W�b�N
���̂��̂ւ̊ւ���ƃ��A���^�C�����������Ȃ�قǕ��K���x�͒Ⴍ�Ȃ�B
���ǁACPU�R�A��10�ςƂ��Ă�����ł̓R�A��S�Đ������邱�Ƃ͓��
���̂Ƃ����3,4����Ώ[���������Ǝv����
http://blog.so-net.ne.jp/pcgame/2005-09-15
��荇�����A��ԂƂȂ�f�U�C���p�^�[�����ł܂�Ȃ��ƁA�ԗւ̍Ĕ������n�܂肻��
http://www.igda.jp/modules/newbb/viewtopic.php?topic_id=175&forum=8&post_id=851
���������Q�[�������Ƃ������̂͒����I�ɏ������Ȃ��Ă͂����Ȃ��������������߁A
���U�R���s���[�e�B���O�ɓK���Ȃ��Ƃ������ƁB
http://blog.freelance.ne.jp/mizusawa/archives/200511/14_2017.php
�������̃A�X�L�[�ő匴��Cell���X�ɂ��Ȃ��Ă܂����B
�匴�u���̑O�̃v���Z�b�T�t�H�[�����ł�Cell�̃\�t�g�E�F�A���̘b�������Ԃ�����ł���B
����ƁA����PPE�̏�łǂ��ɂ��������܂���ƁA1��2��SPE���g���Ԃ�ɂ͊��Ɩ��Ȃ��킯�A
�Ƃ��낪�A���������ɂȂ��OS�̃��x���ʼn��ɂ��Ȃ���Ńh���C�o���܂߂āA�S���A�v���P�[�V������
�����Ȃ��Ƃ����Ȃ��A�����S����������悤��OS�Ƃ����b�͂܂�IBM�ł���R���Z�v�g���x���ł���
����Ă��Ȃ��Ƃ��������ƁA�����Ȃ��Ȏ��̂́v
�㓡�u���ł�SPE�̃X�P�W���[�����O�̘b�����Ă����B�����烉�{�̒��ł͂����������Ƃ�����Ă����Ɓv
�匴�u���ǁA���ꂪ���i�̃N�H���e�B�ɂȂ��Ă��邩�Ƃ����ƑS�R�Ⴄ�b�Łv
http://game10.2ch.net/test/read.cgi/ghard/1133854327/
�@PS3�̉��Z�\�͂�XBOX���D��Ă���B�������\�t�g�E�F�A�Z�p���ǂ����Ȃ�����
�@ �����ړI�ɂ�XBOX�ƕς��Ȃ��BHDTV�ŕ\������ƁA720p�ւ̐L���̉e����
�@ XBOX360�����掿�����\���������BMGS4�̂悤��720���ō���Ă����͕ʁB
�A�@�ł̉��Z�\�͕͂��������_�v�Z�ł���AAI�Ȃǂɂ��Ă̓{�g���l�b�N���������邪�A
�@ ����ł�XBOX360�Ɣ�ׂ�����ɓ��������Ƃ͉\�ł���B�������`�b�v�����ߑ��Ȃ̂ŁA
�@ ���������Ɏ�Ԏ��t���[�����[�g���オ��Ȃ��s����������Ă���͗l�B
�BXBOX360�ƈႢ�V�F�[�_�[�͖w�ǎg���Ȃ��B�����PG�̗��x�̖��B
�@ ������Randerware�Ȃ�XBOX�ɏ���Ƃ����Ȃ��N�H���e�B�̍����~�h���E�F�A������̂�
�@ �ς��ƌ��ł͍��͊������Ȃ����낤�B���RHDR���ŏ������̂ĂĂ��邪�A
�@ ������\����̍H�v�œ˔j���镠�Â���ł���B����́A�@�ނ��͂��̂��x�����߁A
�@ ���؊��Ԃ��Z�����ƂɋN������B�����A�����̎Ј���PS3�̂��߂ɓ��Ђ�������
�@ �܂Ƃ��Ɋ��p�ł��Ȃ���Ƃ����o�����B
http://game10.2ch.net/test/read.cgi/ghard/1139634207/
�w���l���J���҂́APS3�̊J������߂����ׁA�����ɓ����o���Ă��܂��܂����B
�@�����́A10�̃v���Z�b�T�[��V�F�[�_�[etc�ɔ��Ɏ���Ă��Ă��āA
�@�Q�[���ɏd�v�ȕ����̓T�b�p��������ł��B�x
http://dona.dip.jp/modules/wordpress1/index.php?p=649
�匴�u���̑O�̃v���Z�b�T�t�H�[�����ł�Cell�̃\�t�g�E�F�A���̘b�������Ԃ�����ł���B
����ƁA����PPE�̏�łǂ��ɂ��������܂���ƁA1��2��SPE���g���Ԃ�ɂ͊��Ɩ��Ȃ��킯�A
�Ƃ��낪�A���������ɂȂ��OS�̃��x���ʼn��ɂ��Ȃ���Ńh���C�o���܂߂āA�S���A�v���P�[�V������
�����Ȃ��Ƃ����Ȃ��A�����S����������悤��OS�Ƃ����b�͂܂�IBM�ł���R���Z�v�g���x���ł���
����Ă��Ȃ��Ƃ��������ƁA�����Ȃ��Ȏ��̂́v
�㓡�u���ł�SPE�̃X�P�W���[�����O�̘b�����Ă����B�����烉�{�̒��ł͂����������Ƃ�����Ă����Ɓv
�匴�u���ǁA���ꂪ���i�̃N�H���e�B�ɂȂ��Ă��邩�Ƃ����ƑS�R�Ⴄ�b�Łv
http://game10.2ch.net/test/read.cgi/ghard/1133854327/
�@PS3�̉��Z�\�͂�XBOX���D��Ă���B�������\�t�g�E�F�A�Z�p���ǂ����Ȃ�����
�@ �����ړI�ɂ�XBOX�ƕς��Ȃ��BHDTV�ŕ\������ƁA720p�ւ̐L���̉e����
�@ XBOX360�����掿�����\���������BMGS4�̂悤��720���ō���Ă����͕ʁB
�A�@�ł̉��Z�\�͕͂��������_�v�Z�ł���AAI�Ȃǂɂ��Ă̓{�g���l�b�N���������邪�A
�@ ����ł�XBOX360�Ɣ�ׂ�����ɓ��������Ƃ͉\�ł���B�������`�b�v�����ߑ��Ȃ̂ŁA
�@ ���������Ɏ�Ԏ��t���[�����[�g���オ��Ȃ��s����������Ă���͗l�B
�BXBOX360�ƈႢ�V�F�[�_�[�͖w�ǎg���Ȃ��B�����PG�̗��x�̖��B
�@ ������Randerware�Ȃ�XBOX�ɏ���Ƃ����Ȃ��N�H���e�B�̍����~�h���E�F�A������̂�
�@ �ς��ƌ��ł͍��͊������Ȃ����낤�B���RHDR���ŏ������̂ĂĂ��邪�A
�@ ������\����̍H�v�œ˔j���镠�Â���ł���B����́A�@�ނ��͂��̂��x�����߁A
�@ ���؊��Ԃ��Z�����ƂɋN������B�����A�����̎Ј���PS3�̂��߂ɓ��Ђ�������
�@ �܂Ƃ��Ɋ��p�ł��Ȃ���Ƃ����o�����B
http://game10.2ch.net/test/read.cgi/ghard/1139634207/
�w���l���J���҂́APS3�̊J������߂����ׁA�����ɓ����o���Ă��܂��܂����B
�@�����́A10�̃v���Z�b�T�[��V�F�[�_�[etc�ɔ��Ɏ���Ă��Ă��āA
�@�Q�[���ɏd�v�ȕ����̓T�b�p��������ł��B�x
http://dona.dip.jp/modules/wordpress1/index.php?p=649
�Ȃ�����
�ƊE�ł�Cell�́u��`���v���ČĂ�Ă�B
Xenon�͘b��ɂ���Ȃ�Ȃ����B
Xenon�͘b��ɂ���Ȃ�Ȃ����B
�ʔ����������ǂ܂��Ă�������B
SCE�͒P����PS2�̋����ł�360������ɏo���Ηǂ������̂ɁE�E�E�B
SCE�͒P����PS2�̋����ł�360������ɏo���Ηǂ������̂ɁE�E�E�B
528 �FSocket774�F2006/04/30(��) 13:39:54 ID:Ue28wLOL
���R�ɃA�N�Z�X�ł���̂�256KB�ŁA��̓��C�e���V�̒����O�����������烍�[�h�c
MS-DOS��640KB�����EMS�݂������ȁB
MS-DOS��640KB�����EMS�݂������ȁB
xbox360��CELL�퓯���g�ݍ��ݗpPowerPC�R�A(P-X, PPE)���g���Ă�̂�CELL��@���q�g������̂��
���̂Ȃ���(��)
�ƊE�̌Ê��Ńn�[�h�E�F�A�I�^�N�Ƃ��Ă��L���ȌÐ쌳MS-J��̃R�����g���B
http://spaces.msn.com/furukawablog/PersonalSpace.aspx?_c11_blogpart_blogpart=blogview&_c=blogpart&partqs=amonth%3d4%26ayear%3d2006
�@�@-----------------------
�@�@���āANAB2006�ł͑f���炵�����m���R�������̂����ǁA�ő�̎��n�łƂɂ��������A�܂�{��
�@�@�͂����قNj������̂�...SONY�a���v���C�x�[�g�W�����ɐݒu���Ă���Cell�R���s���[�e�B���O�ɂ��
�@�@�f���̐��E�ł���܂��B���Ҏ҂݂̂ւ̓W���Ńv���X����J�A�ʐ^�B�e�֎~�Ƃ��������ł���..���S��
�@�@�̕��Ɏ����̊�Ō������Ƃ̓u���O�ɏ����Ă��܂��܂�����ǁA�ǂ��ł��ˁH�Ǝ��O�Ɋm�F�������
�@�@����̂ŁA���t�Ő����������܂��傤�B
�@�@-----------------------
�ڍׂ�������N����ǂ����B
���̂Ȃ���(��)
�ƊE�̌Ê��Ńn�[�h�E�F�A�I�^�N�Ƃ��Ă��L���ȌÐ쌳MS-J��̃R�����g���B
http://spaces.msn.com/furukawablog/PersonalSpace.aspx?_c11_blogpart_blogpart=blogview&_c=blogpart&partqs=amonth%3d4%26ayear%3d2006
�@�@-----------------------
�@�@���āANAB2006�ł͑f���炵�����m���R�������̂����ǁA�ő�̎��n�łƂɂ��������A�܂�{��
�@�@�͂����قNj������̂�...SONY�a���v���C�x�[�g�W�����ɐݒu���Ă���Cell�R���s���[�e�B���O�ɂ��
�@�@�f���̐��E�ł���܂��B���Ҏ҂݂̂ւ̓W���Ńv���X����J�A�ʐ^�B�e�֎~�Ƃ��������ł���..���S��
�@�@�̕��Ɏ����̊�Ō������Ƃ̓u���O�ɏ����Ă��܂��܂�����ǁA�ǂ��ł��ˁH�Ǝ��O�Ɋm�F�������
�@�@����̂ŁA���t�Ő����������܂��傤�B
�@�@-----------------------
�ڍׂ�������N����ǂ����B
���œ����R�A���g���Ă邩��ƌ������R�œ������������˂Ȃ��̂��B
�\�����S�R�Ⴄ����]��������ē��R����B
PowerPC�M�҂ɂ͂킩��Ƃ�������ǁB
�\�����S�R�Ⴄ����]��������ē��R����B
PowerPC�M�҂ɂ͂킩��Ƃ�������ǁB
�}���`�R�A�����������Ƃ������قǃp�t�H�[�}���X�������锠����Xenon�i+GPU�j�͘_�O
http://blogs.dion.ne.jp/arere/archives/1947629.html
http://blogs.dion.ne.jp/arere/archives/1947629.html
>>523
>���������Q�[�������Ƃ������̂͒����I�ɏ������Ȃ��Ă͂����Ȃ��������������߁A
>���U�R���s���[�e�B���O�ɓK���Ȃ��Ƃ������ƁB
(߄D�)ʧ?
>���������Q�[�������Ƃ������̂͒����I�ɏ������Ȃ��Ă͂����Ȃ��������������߁A
>���U�R���s���[�e�B���O�ɓK���Ȃ��Ƃ������ƁB
(߄D�)ʧ?
>>529
�W���u�Y��Cell�@�������B
�W���u�Y��Cell�@�������B
534 �FSocket774�F2006/04/30(��) 14:26:25 ID:oj9trPMz
PS1=R3000(MIPS)+����(SONY)
PS2=R5900(MIPS)+����(SONY)
PS3=PowerPC970(IBM)+GeForce7800(NVIDIA)+����(SONY)
�� SONY�Ǝ��Z�p=����
PS2=R5900(MIPS)+����(SONY)
PS3=PowerPC970(IBM)+GeForce7800(NVIDIA)+����(SONY)
�� SONY�Ǝ��Z�p=����
>>533 ����
CELL�p�̃R�[�h�ɂ���V�����v���O���~���O�p���_�C�����K�v�Ȃ̂Ť�����̃R�[�h�������ɑ��点��K�v��
�������褈ڐA���ȈՂ������肷��K�v������PC�ɂ�s���������炷�B
>>534 ����
CELL��PowerPC�R�A���POWER4/PPC970�Ƃ�ʂ̌n���̃��m���B
CELL�p�̃R�[�h�ɂ���V�����v���O���~���O�p���_�C�����K�v�Ȃ̂Ť�����̃R�[�h�������ɑ��点��K�v��
�������褈ڐA���ȈՂ������肷��K�v������PC�ɂ�s���������炷�B
>>534 ����
CELL��PowerPC�R�A���POWER4/PPC970�Ƃ�ʂ̌n���̃��m���B
>>534
�\�j�[�Ƃ��ł��������ǁA�\�肷�����B
�\�j�[�Ƃ��ł��������ǁA�\�肷�����B
����w�e���ȃ}���`�R�A�ɒ��킵����A�ˊэH���̃}���`�R�A��
�f�b�`�グ�邭�炢�Ȃ�AAthlon64 X2��Core Duo�̃}�C�i�[�`�F���W
�o�[�W�����ł�����Ă�����������ǂ�������Ȃ����Ȃ��B
���{���o�J���ꂷ��Ƃ͎v���Ȃ����ǁA�I����Ă݂��
�̎Z�Ƃꂽ�̂̓��{�����Ƃ����ɂȂ����肵�āB
�f�b�`�グ�邭�炢�Ȃ�AAthlon64 X2��Core Duo�̃}�C�i�[�`�F���W
�o�[�W�����ł�����Ă�����������ǂ�������Ȃ����Ȃ��B
���{���o�J���ꂷ��Ƃ͎v���Ȃ����ǁA�I����Ă݂��
�̎Z�Ƃꂽ�̂̓��{�����Ƃ����ɂȂ����肵�āB
>>537
Athlon64 X2���ᔭ�M�ł�����
Core Duo�������悤�Ȃ���
�g�b�v�X�s�[�h���o���ɂ͔ėp�R�A���ᖳ��������
Athlon64��Core��Cell��Xenon�̗��_�I�ȍō��Ɠ������\���o�����߂ɂ́A�ǂ̂��炢�̃R�X�g�ƃN���b�N����Ǝv���H
Athlon64 X2���ᔭ�M�ł�����
Core Duo�������悤�Ȃ���
�g�b�v�X�s�[�h���o���ɂ͔ėp�R�A���ᖳ��������
Athlon64��Core��Cell��Xenon�̗��_�I�ȍō��Ɠ������\���o�����߂ɂ́A�ǂ̂��炢�̃R�X�g�ƃN���b�N����Ǝv���H
���ł̍H�ꂪ�����Ă���B
���ǃ\�j�[�ɂ̓N�^�^���̃n�b�^�������Ȃ��B
���ǃ\�j�[�ɂ̓N�^�^���̃n�b�^�������Ȃ��B
�b�d�k�k�̘b��ɂȂ�Ƃb�o�t�A�[�L�e�N�`���ɂ��Č���Ȃ�(���Ȃ���)��
>>538
����ᓯ��"���_�l"��B�����悤�Ƃ�����Ƃ�ł��Ȃ����ƂɂȂ邾�낤��B
������@�ŕ]���ł���̂́A�ʊ��Ƀ}���`�R�A�ɒ��킵�����̐S�ӋC�������B
����ᓯ��"���_�l"��B�����悤�Ƃ�����Ƃ�ł��Ȃ����ƂɂȂ邾�낤��B
������@�ŕ]���ł���̂́A�ʊ��Ƀ}���`�R�A�ɒ��킵�����̐S�ӋC�������B
>>541
>������@�ŕ]���ł���̂́A�ʊ��Ƀ}���`�R�A�ɒ��킵�����̐S�ӋC�������B
�����A���ꂪ�����B
��k����Ȃ��āA�e���r�Q�[���Ȃ�ăX�y�b�N���֎����鏟���݂����Ȃ����ȁB
�e���r�Q�[���s�ꂪ�傫���Ȃꂽ�̂��APC�Ƃ͈ꕗ�i�������j��������\�����[�U�[���Ȃ�ƂȂ��~�߂Ă����炾�Ǝv��
�\�t�g�J�������₷���Ȃ����Ƃ��Ă��AAthlon64 X2���݂�CPU�̗p�I����C���p�N�g�Ȃ�����
>������@�ŕ]���ł���̂́A�ʊ��Ƀ}���`�R�A�ɒ��킵�����̐S�ӋC�������B
�����A���ꂪ�����B
��k����Ȃ��āA�e���r�Q�[���Ȃ�ăX�y�b�N���֎����鏟���݂����Ȃ����ȁB
�e���r�Q�[���s�ꂪ�傫���Ȃꂽ�̂��APC�Ƃ͈ꕗ�i�������j��������\�����[�U�[���Ȃ�ƂȂ��~�߂Ă����炾�Ǝv��
�\�t�g�J�������₷���Ȃ����Ƃ��Ă��AAthlon64 X2���݂�CPU�̗p�I����C���p�N�g�Ȃ�����
�C���e�������炩�ɐ��\�̗��y��D���n�b�^���Ō떂�����Ĕ����Ă������
�h�m�s�d�k��`�l�c�̂o�b����4�R�A8�R�A�b�o�t���Ăǂ�ȕ��Ɏg���H
545 �FMAC�I�^��544 �����F2006/04/30(��) 15:19:20 ID:xiRnpVSz
>>544
Intel���撣���ăc�[���z�z���Ă邷�B
http://www.intel.com/cd/software/products/asmo-na/eng/272688.htm
�@�@---------------------
�@�@Platform Support
* Supports Windows*, Linux*, and Mac OS*
* Supports 32-bit applications on IA-32 and Intel? EM64T platforms, and 64-bit applications on
�@�@�@Itanium? 2 and Intel? EM64T platforms
* Supports Intel, Microsoft and GNU compilers
�@�@---------------------
Intel���撣���ăc�[���z�z���Ă邷�B
http://www.intel.com/cd/software/products/asmo-na/eng/272688.htm
�@�@---------------------
�@�@Platform Support
* Supports Windows*, Linux*, and Mac OS*
* Supports 32-bit applications on IA-32 and Intel? EM64T platforms, and 64-bit applications on
�@�@�@Itanium? 2 and Intel? EM64T platforms
* Supports Intel, Microsoft and GNU compilers
�@�@---------------------
>>542
���̃X�y�b�N��PS2�݂�����5�`6�N�ň����o����Ȃ�܂�������B
�i�ł����2�`3�N�ň����o���Ă��炢�������j
����œ`����Ă����ƁAXBOX360�͉��P�̒������Ȃ����A
PS3�͂܂����@�œ������郍���`�^�C�g�������J�ł��Ȃ��B
�ŋ߈�ʎ��ŁA���ʂ������邭�Ȃ�������Q�[���@�ƊE�A
�Ώ̓I�ɍD���Ȍg�уQ�[���A���̂悤�ȋL�����悭��������B
���E�I�}�[�P�b�g�ł͂܂��L�т邩������{���ɑ��v�Ȃ��ȁB
���̃X�y�b�N��PS2�݂�����5�`6�N�ň����o����Ȃ�܂�������B
�i�ł����2�`3�N�ň����o���Ă��炢�������j
����œ`����Ă����ƁAXBOX360�͉��P�̒������Ȃ����A
PS3�͂܂����@�œ������郍���`�^�C�g�������J�ł��Ȃ��B
�ŋ߈�ʎ��ŁA���ʂ������邭�Ȃ�������Q�[���@�ƊE�A
�Ώ̓I�ɍD���Ȍg�уQ�[���A���̂悤�ȋL�����悭��������B
���E�I�}�[�P�b�g�ł͂܂��L�т邩������{���ɑ��v�Ȃ��ȁB
>>547
XeonMP��Onpteron8xx�V���[�Y�ɕ����Ă����Ȃ���
XeonMP��Onpteron8xx�V���[�Y�ɕ����Ă����Ȃ���
�����ς藝���ł��Ȃ����AIntel�̒��̐l�H���uRMS�v
http://www.itmedia.co.jp/news/articles/0402/20/news047.html
http://pc.watch.impress.co.jp/docs/2005/0112/kaigai147.htm
>>548
�l���x���ł���K�̓f�[�^�x�[�X���n�A�v���P�[�V�����◬�̗͊w�v�Z���������Ă��H
http://www.itmedia.co.jp/news/articles/0402/20/news047.html
http://pc.watch.impress.co.jp/docs/2005/0112/kaigai147.htm
>>548
�l���x���ł���K�̓f�[�^�x�[�X���n�A�v���P�[�V�����◬�̗͊w�v�Z���������Ă��H
>>549
Windows�M�҂�Linux(x86��)�~�ł������A�C���e���ɗ������܂܂悗
Windows�M�҂�Linux(x86��)�~�ł������A�C���e���ɗ������܂܂悗
551 �FMAC�I�^��549 �����F2006/04/30(��) 15:46:18 ID:xiRnpVSz
>>549
�@�@----------------
�@�@�l���x���ł���K�̓f�[�^�x�[�X���n�A�v���P�[�V�����◬�̗͊w�v�Z���������Ă��H
�@�@----------------
�Q�[����google�Ť���Ȃ������̎�̃A�v���̉��b�ɂ��������Ă��邩�Ǝv�����B
�@�@----------------
�@�@�l���x���ł���K�̓f�[�^�x�[�X���n�A�v���P�[�V�����◬�̗͊w�v�Z���������Ă��H
�@�@----------------
�Q�[����google�Ť���Ȃ������̎�̃A�v���̉��b�ɂ��������Ă��邩�Ǝv�����B
�~�����Ȃ��Ȃ甃��Ȃ�������̂ł́B
�����v�����R���V���[�}�ƋƖ��n���������Ęb���l��������
�Q�[���@��PC����������b�l������������
�����MAC�I�^�����炵�傤���Ȃ�
�l�ʼn]�X�̘b�ɂȂ����Ⴄ�ƁA���o�Ă�CPU�̂قƂ�ǂ��K�v�Ȃ����̂ɂȂ����Ⴄ��
PC�ő傫�ȃp���[���K�v�ȏ�ʂ�FPS�Q�[���A
����G���R�[�h�E�g�����X�R�[�h��f�W�J���̉摜�������炢�ł���B
WS���܂߂�ƁA�O���t�B�b�N�f�U�C���EDTP�EDAW�E�����_�����O�ECAD�E�R���p�C�������B
Longhorn�œ�������͂��������A�t�@�C���V�X�e���ƃf�[�^�x�[�X�Ǘ��E������
��������WinFS�Ȃ�A�}���`�R�A�E���j�C�R�A�𑶕��ɐ���������̂����B
����G���R�[�h�E�g�����X�R�[�h��f�W�J���̉摜�������炢�ł���B
WS���܂߂�ƁA�O���t�B�b�N�f�U�C���EDTP�EDAW�E�����_�����O�ECAD�E�R���p�C�������B
Longhorn�œ�������͂��������A�t�@�C���V�X�e���ƃf�[�^�x�[�X�Ǘ��E������
��������WinFS�Ȃ�A�}���`�R�A�E���j�C�R�A�𑶕��ɐ���������̂����B
SMP��N���X�^�����O�ŁA�����̎��т͂��ł�
�������Acell�̐��\�������o����悤�ɂȂ�̂����Ԃ̖��
���J������������?���Ă��Ƃł����Ȃ�
������R���s���[�^����Ȃ�����
�J�������ŁA�����`���[�j���O����̂ł��Ȃ��Ȃ�����
�������Acell�̐��\�������o����悤�ɂȂ�̂����Ԃ̖��
���J������������?���Ă��Ƃł����Ȃ�
������R���s���[�^����Ȃ�����
�J�������ŁA�����`���[�j���O����̂ł��Ȃ��Ȃ�����
����MAC�I�^�A�e�[�v�A�E�g�ɂ��Đ������Ă݂��
>>559
SMP�ɔ�ׂĎ��R�x�����Ȃ萧������Ă���̂�Cell�̎�_�Ȃ�
> �J�������ŁA�����`���[�j���O����̂ł��Ȃ��Ȃ�����
�ł��Ȃ��Ȃ��̂Ƃ��łɂł��Ă���̂ɂ͓V�n�̍�����
�܂Ƃ��Ȏ����`���[�i�[���ł���͉̂����Ȃ̂��\�����Ă݂��܂�
SMP�ɔ�ׂĎ��R�x�����Ȃ萧������Ă���̂�Cell�̎�_�Ȃ�
> �J�������ŁA�����`���[�j���O����̂ł��Ȃ��Ȃ�����
�ł��Ȃ��Ȃ��̂Ƃ��łɂł��Ă���̂ɂ͓V�n�̍�����
�܂Ƃ��Ȏ����`���[�i�[���ł���͉̂����Ȃ̂��\�����Ă݂��܂�
562 �FMAC�I�^��560 �����F2006/04/30(��) 17:06:52 ID:xiRnpVSz
>>560
�������������� >>484
�v���Z�b�T�A�[�L�e�N�g�̑�����������̐���
http://v-t.jp/premier/index.php?mode=show&UID=1117037100
�@�@----------------------
�@�@�_���v��1972�N12���Ɏn�߁A���C�A�E�g�v���I�����A�}�X�N����p�̃f�[�^�x�[�X�쐬�ł���
�@�@�e�[�v�A�E�g���I�������̂��A�W������́A1973�N�W���X���ł������B
�@�@----------------------
�������Ƃ������Ă���Ƃ������Ƃ������ł��Ȃ��q�g������Ƃ��v���Ȃ�������(��)
�������������� >>484
�v���Z�b�T�A�[�L�e�N�g�̑�����������̐���
http://v-t.jp/premier/index.php?mode=show&UID=1117037100
�@�@----------------------
�@�@�_���v��1972�N12���Ɏn�߁A���C�A�E�g�v���I�����A�}�X�N����p�̃f�[�^�x�[�X�쐬�ł���
�@�@�e�[�v�A�E�g���I�������̂��A�W������́A1973�N�W���X���ł������B
�@�@----------------------
�������Ƃ������Ă���Ƃ������Ƃ������ł��Ȃ��q�g������Ƃ��v���Ȃ�������(��)
>>535
Cell�̃v���O���~���O�p���_�C�����N�^���̔]���ɂ������݂��Ȃ��̂����ɂȂ��Ă���̂���
MAC�I�^�́A�����̓s���̈����ӌ���ǂ�Ŗ������Ă���̂ł͂Ȃ��āA���������ڂɓ����Ă��Ȃ����ۂ���
�Ƃ肠�����ǂ�ł���Ȃ�e�[�v�A�E�g�̐����������܂�
Cell�̃v���O���~���O�p���_�C�����N�^���̔]���ɂ������݂��Ȃ��̂����ɂȂ��Ă���̂���
MAC�I�^�́A�����̓s���̈����ӌ���ǂ�Ŗ������Ă���̂ł͂Ȃ��āA���������ڂɓ����Ă��Ȃ����ۂ���
�Ƃ肠�����ǂ�ł���Ȃ�e�[�v�A�E�g�̐����������܂�
564 �FMAC�I�^��561 �����F2006/04/30(��) 17:08:31 ID:xiRnpVSz
>>561
�@�@-------------------
�@�@�ł��Ȃ��Ȃ��̂Ƃ��łɂł��Ă���̂ɂ͓V�n�̍�����
�@�@-------------------
SMP�V�X�e���p�ɤ����ȕ֗��Ȃ��̂��u���łɂł��Ă��飂Ƃ����̂평��������(��)
�@�@-------------------
�@�@�ł��Ȃ��Ȃ��̂Ƃ��łɂł��Ă���̂ɂ͓V�n�̍�����
�@�@-------------------
SMP�V�X�e���p�ɤ����ȕ֗��Ȃ��̂��u���łɂł��Ă��飂Ƃ����̂평��������(��)
�q�l�r����܂�INTEL�͂f�o�f�o�t��h�b�d�k�k�{�[�h(�ˋ�)�h��ڎw���Ă�H
����560�A�e�[�v�A�E�g�ɂ��Đ������Ă݂��
>>562�͈̂�̑O�̒�`�ł���
�ǂ������Ƃ����ƍŋ߂́��������̈Ӗ�
http://www.cadence.co.jp/news/h15-11-11.html
> �e�[�v�A�E�g�Ƃ́A�v�҂��^�C�~���O�̌��܂ł��ׂďI�����C
> �v�f�[�^��IC�}�X�N�v�҂ɓn���i�K���w�����̂ŁALSI�̐v��
> �����������Ƃ��Ӗ����܂��B
�}�X�N�f�[�^�̍쐬�͕��ʂ�fab�̑��ł�邩��
�ǂ������Ƃ����ƍŋ߂́��������̈Ӗ�
http://www.cadence.co.jp/news/h15-11-11.html
> �e�[�v�A�E�g�Ƃ́A�v�҂��^�C�~���O�̌��܂ł��ׂďI�����C
> �v�f�[�^��IC�}�X�N�v�҂ɓn���i�K���w�����̂ŁALSI�̐v��
> �����������Ƃ��Ӗ����܂��B
�}�X�N�f�[�^�̍쐬�͕��ʂ�fab�̑��ł�邩��
639 �F����������K������ �F2006/04/29(�y) 02:13:07 ID:Z+wa8V1x
118 ���O�F����������K������ �{���̃��X ���e���F2006/04/29(�y) 01:55:31 3VEZgJYI
�@�� �� �u���O
�@http://spaces.msn.com/furukawablog/blog/cns!156823E649BD3714!3406.entry
�@CELL�̃p���[���̂͐����炵���A�Q�[���@�ɂȂ�ƃo�X�̓]���\�͂Ȃǂ͂����͂����Ȃ���
663 �F����������K������ �F2006/04/29(�y) 09:08:52 ID:cT0pvHhl
Cell���āA�ᑬ�f�o�C�X(XDR)�ɏ����߂��܂łɒ������ŐF�X����Ă��܂������Ĕ��z�Ȃ̂��ȁB
667 �F����������K������ �F2006/04/29(�y) 09:20:34 ID:cT0pvHhl
����ł������v���Z�b�T��ς}�V���͂��邯�ǁA
���݂��ᑬ�o�X�ƃ������Ōq�����Ă�̂݁B���ǖw�ǂ����肵�Ă�B
�ł�Cell�͏��K�͂ł���Ȃ��畡���v���Z�b�T���������o�X�Ōq������
�p�C�v���C����z�������o����킯�ŁA
Pen4��8���ڂ��������ł͓������Ƃ͏o���Ȃ��B
���̂�����ɑ��ɂȂ����l�����o�������o�������B
������PS3�I������E�E�E�E�Borz
118 ���O�F����������K������ �{���̃��X ���e���F2006/04/29(�y) 01:55:31 3VEZgJYI
�@�� �� �u���O
�@http://spaces.msn.com/furukawablog/blog/cns!156823E649BD3714!3406.entry
�@CELL�̃p���[���̂͐����炵���A�Q�[���@�ɂȂ�ƃo�X�̓]���\�͂Ȃǂ͂����͂����Ȃ���
663 �F����������K������ �F2006/04/29(�y) 09:08:52 ID:cT0pvHhl
Cell���āA�ᑬ�f�o�C�X(XDR)�ɏ����߂��܂łɒ������ŐF�X����Ă��܂������Ĕ��z�Ȃ̂��ȁB
667 �F����������K������ �F2006/04/29(�y) 09:20:34 ID:cT0pvHhl
����ł������v���Z�b�T��ς}�V���͂��邯�ǁA
���݂��ᑬ�o�X�ƃ������Ōq�����Ă�̂݁B���ǖw�ǂ����肵�Ă�B
�ł�Cell�͏��K�͂ł���Ȃ��畡���v���Z�b�T���������o�X�Ōq������
�p�C�v���C����z�������o����킯�ŁA
Pen4��8���ڂ��������ł͓������Ƃ͏o���Ȃ��B
���̂�����ɑ��ɂȂ����l�����o�������o�������B
������PS3�I������E�E�E�E�Borz
>>542
�܁A������ԍD����XBOX360�^�C�g����Hexic HD�������肷�����ȁB
�Ԃ����Ⴏ�������I�X�y�b�N������B
BF2�����肮�蓮���Ă�̌���Ƃ܂��}�@�������������ėǂ������Ƃ��v�����ǂˁB
�܁A������ԍD����XBOX360�^�C�g����Hexic HD�������肷�����ȁB
�Ԃ����Ⴏ�������I�X�y�b�N������B
BF2�����肮�蓮���Ă�̌���Ƃ܂��}�@�������������ėǂ������Ƃ��v�����ǂˁB
Cell���A8�R�A��CPU���Ǝv������A�_���Ȃ�ł���B
�V���O���R�A��CPU�ɁA7�̃A�N�Z�����[�^�������o�X�Őڑ���������
�Ƃ����ӂ��ɍl���������ł���B
OS�ɊǗ�������̂�PPE�����ŁA
7�̃A�N�Z�����[�^�Ŏ��s����v���O������f�[�^�́A
OS�ł͂Ȃ��A���[�U�܂�Q�[���v���O�������Ǘ����ׂ����́B
�V���O���R�A��CPU�ɁA7�̃A�N�Z�����[�^�������o�X�Őڑ���������
�Ƃ����ӂ��ɍl���������ł���B
OS�ɊǗ�������̂�PPE�����ŁA
7�̃A�N�Z�����[�^�Ŏ��s����v���O������f�[�^�́A
OS�ł͂Ȃ��A���[�U�܂�Q�[���v���O�������Ǘ����ׂ����́B
573 �FSocket774�F2006/05/01(��) 10:03:03 ID:GMKxQ0gE
>>572
�܂����ꂾ��A
�u����̓f���A���R�A�I�v�ȁ[��Č����Ă���8�R�A�Ɩ������̂��o�Ă��āA�t�@�r���b�^���Ă��ƂȂ�B
�ʂɕ����R�A�Ȃ�Ē��������̂ł�x86�����̂��̂ł��Ȃ��i�ǂ��납�㔭�j�̂ɂˁB
AMD������X���̃e���v���͂��Ƃ��iAMD�ƃC���e���Ɠ���ւ���C���e���p�ɂ��Ȃ�j
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�܂����ꂾ��A
�u����̓f���A���R�A�I�v�ȁ[��Č����Ă���8�R�A�Ɩ������̂��o�Ă��āA�t�@�r���b�^���Ă��ƂȂ�B
�ʂɕ����R�A�Ȃ�Ē��������̂ł�x86�����̂��̂ł��Ȃ��i�ǂ��납�㔭�j�̂ɂˁB
AMD������X���̃e���v���͂��Ƃ��iAMD�ƃC���e���Ɠ���ւ���C���e���p�ɂ��Ȃ�j
A�Ƃ����Z�p���v���Z�b�T�ƊE���ō̗p����n�߂�i�ƊE�̃g�����h�j
�����삪�����̂Œm������Ȃ�
�I�^�uA�Ƃ����Z�p�����ō̗p����Ă邷�BAMD��������̗p�����Ȃ������ˁv
���������B����Ȃ킯�Ȃ�����
�C���e����A�Z�p�̗̍p�\����i�C���e���ׂɂƂ��ăg�����h�j
�����ꂾ����C���e���͂�
AMD��A�Z�p�̗̍p���������n�߂�
�����ꂩ���A�̎��ゾ�I�i������AMD�ׂ̂����g�����h�j
�t���[�����`���߂��Ă���
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2748&p=6
>>575
�������
��Conclusion 2 : The free lunch is back!
�Ȃ�ăz���g�ɏ����Ă���̂˂�
���܂���Č��ǎ����B�̎߂邾���̂��Ƃ̂悤�Ȃ�����
�������
��Conclusion 2 : The free lunch is back!
�Ȃ�ăz���g�ɏ����Ă���̂˂�
���܂���Č��ǎ����B�̎߂邾���̂��Ƃ̂悤�Ȃ�����
�����B���ĒN�̂��Ƃ��H
578 �FSocket774�F2006/05/02(��) 21:26:28 ID:3Glo8CKT
����CPU��SMAP�ł̃A�N�Z�X����ɂ�CELL�̂悤�Ȏ���o�X�͍œK���A
���L�̈�ւ̏������݂�����Ɩ������Ńo�X���������������B
�����L2�L���b�V���ɔC���邱�Ƃ��ł������Ȃ̂ŁA����̂��߂ɋɒ[��
�x���͂Ȃ�Ȃ������⒆�ɂ�Pen4��HT�̂悤�ɕʂ̍�Ƃ��Ă��������낤�B
���̍��̃X�p�R���̐�K�ȏ�Ƃ���CPU�₵�悤�Ƃ����̂ł͂Ȃ��̂�����
�H�v����Α����͒x���Ȃ邪���ɂȂ�قǂł��Ȃ��͂��B
���L�̈�ւ̏������݂�����Ɩ������Ńo�X���������������B
�����L2�L���b�V���ɔC���邱�Ƃ��ł������Ȃ̂ŁA����̂��߂ɋɒ[��
�x���͂Ȃ�Ȃ������⒆�ɂ�Pen4��HT�̂悤�ɕʂ̍�Ƃ��Ă��������낤�B
���̍��̃X�p�R���̐�K�ȏ�Ƃ���CPU�₵�悤�Ƃ����̂ł͂Ȃ��̂�����
�H�v����Α����͒x���Ȃ邪���ɂȂ�قǂł��Ȃ��͂��B
579 �FSocket774�F2006/05/02(��) 21:43:03 ID:A7woAlXj
http://japan.cnet.com/column/apple_onlamp/story/0,2000060061,20104527,00.htm
���Ȃ����A5�N��ɂ�Cell���V�F�A����������Ă��肵�ĂȁAPC CPU�Ƃ��Ă��B
Linux�̕��y�Ƌ��ɁB
���Ȃ����A5�N��ɂ�Cell���V�F�A����������Ă��肵�ĂȁAPC CPU�Ƃ��Ă��B
Linux�̕��y�Ƌ��ɁB
�ϑz�͌v��I��
>>578
�����O�o�X�́A�L���b�V���R�q�[�����V���������y�Ȃ낤��
���C�e���V�������Ȃ肻��
����CPU��L2��10�N���b�N�ȏ�Ȃ̂�
���e�ł��Ȃ����Ȃ���������Ȃ�����
�����O�o�X�́A�L���b�V���R�q�[�����V���������y�Ȃ낤��
���C�e���V�������Ȃ肻��
����CPU��L2��10�N���b�N�ȏ�Ȃ̂�
���e�ł��Ȃ����Ȃ���������Ȃ�����
�s�ǃ����`����
583 �FSocket774�F2006/05/03(��) 01:10:12 ID:tU1PQKrc
����p��PPE��Power�̗ł�����ALinux�̈ڐA�͂������ē���͂Ȃ����ƁB
�����ASPE���g�����Ȃ��̂͑�ς�����A�ł���Ȃ����ʂ�Power���g���������}�V���Ǝv���B
�����ASPE���g�����Ȃ��̂͑�ς�����A�ł���Ȃ����ʂ�Power���g���������}�V���Ǝv���B
584 �FSocket774�F2006/05/03(��) 07:51:15 ID:yKDlLBMH
Cell�������X�^�[CPU�������肵���畳CPU���x��������Ȃ��̂͗ǂ�������B
PS3��������B
PS3��������B
http://spaces.msn.com/furukawablog/blog/cns!156823E649BD3714!3406.entry
�������ɂ����܂ł��ƍ����܂�邾�낤��������
�������ɂ����܂ł��ƍ����܂�邾�낤��������
586 �FSocket774�F2006/05/03(��) 17:01:54 ID:P+Kdq3Vo
���̋Z�p�Ȃ�pen2����2GHz���炢��������H�����8����
��
��
���̎�̂�Ȃ�ނ���Niagara����B
�����R�A��16�R�A�������������B
�����R�A��16�R�A�������������B
HP�̔�r�L������SAP���B
Niagara��DB�܂ő��点�Ăǂ�����B
Web�T�[�o��Application�T�[�o�Ŕ�r���ɂ�B
Niagara��DB�܂ő��点�Ăǂ�����B
Web�T�[�o��Application�T�[�o�Ŕ�r���ɂ�B
AMD�����������C���`�L��`����肷���������Ť
�@�@�uAMD Opteron�ATPC-C�x���`�}�[�N�Ŏ�ʊl��� (����R�A������ő������POWER5���y���ɏ�)
�@�@http://www.itmedia.co.jp/enterprise/articles/0510/08/news016.html
TPC���{���Ĥ���ʂ̕\������ς������B�V�\���`����P(�v���Z�b�T��)/C(�R�A��)/T(�X���b�h��)��
���L�����悤�ɂȂ��Ĥ����Ȋ������B
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?FLTCOL1=tpcc.c_server_procs&FLTCHO1=4&ADDFILTERROW=&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&ADDSORTROW=&sortRowCount=1&include_server_cpu=ON
�@�@�uAMD Opteron�ATPC-C�x���`�}�[�N�Ŏ�ʊl��� (����R�A������ő������POWER5���y���ɏ�)
�@�@http://www.itmedia.co.jp/enterprise/articles/0510/08/news016.html
TPC���{���Ĥ���ʂ̕\������ς������B�V�\���`����P(�v���Z�b�T��)/C(�R�A��)/T(�X���b�h��)��
���L�����悤�ɂȂ��Ĥ����Ȋ������B
http://www.tpc.org/tpcc/results/tpcc_advanced_sort.asp?FLTCOL1=tpcc.c_server_procs&FLTCHO1=4&ADDFILTERROW=&filterRowCount=1&SRTCOL1=tpcc.c_tpmc&SRTDIR1=DESC&ADDSORTROW=&sortRowCount=1&include_server_cpu=ON
>>591
�P�Ƀ}���`�R�A��}���`�X���b�h�Ȃǂ̐V�t�B�[�`���[�ɑΉ����������̂悤�Ɍ����邵�A
��������TPC-C�̓R�A������̐��\�𑪂�x���`����Ȃ�����B
����Ɍ����Ȃ�CPU���[�J�[�̐�`�Ƃ������A�e�x���_�[�̃V�X�e���̐�`�Ƃ��������K�B
> AMD�����������C���`�L��`����肷����������
���X�ŁuAMD��v�Ƃ��u�A������v�Ƃ�����ł邪�A��ntel�̈˗��ɂ��o�C�g���������H
���������Ȃ牴�ɂ�����Љ�Ăق���w
�P�Ƀ}���`�R�A��}���`�X���b�h�Ȃǂ̐V�t�B�[�`���[�ɑΉ����������̂悤�Ɍ����邵�A
��������TPC-C�̓R�A������̐��\�𑪂�x���`����Ȃ�����B
����Ɍ����Ȃ�CPU���[�J�[�̐�`�Ƃ������A�e�x���_�[�̃V�X�e���̐�`�Ƃ��������K�B
> AMD�����������C���`�L��`����肷����������
���X�ŁuAMD��v�Ƃ��u�A������v�Ƃ�����ł邪�A��ntel�̈˗��ɂ��o�C�g���������H
���������Ȃ牴�ɂ�����Љ�Ăق���w
593 �FMAC�I�^��592 �����F2006/05/04(��) 18:25:01 ID:C0eJjBUs
>>592
�@�@--------------------
�@�@CPU���[�J�[�̐�`�Ƃ������A�e�x���_�[�̃V�X�e���̐�`�Ƃ��������K�B
�@�@--------------------
>>591�ň��p�����L���̃^�C�g����AMD�̖��O��L���ĂःV�X�e���x���_�ł���HP������ĂȂ��C��(��)
���Ȃ݂ɤAMD���g�����̃l�^�g���Ă��邷�B
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_13302~102332,00.html
�@�@====================
�@�@�f���A���R�AAMD Op��eron�v���Z�b�T880���f�����̗p����HP ProLiant DL585�T�[�o�́A4 way x86
�@�@�T�[�o�̒��ŗB��TPC-C 200K�g�����U�N�V���� �X�R�A�����T�[�o�ł��B
�@�@====================
���Ɍ��������ʼnR�������Ɩ@�I�Ƀ��o��������"x86�T�[�o"���Ē��߂����Ă��邷�B
�@�@
�@�@--------------------
�@�@CPU���[�J�[�̐�`�Ƃ������A�e�x���_�[�̃V�X�e���̐�`�Ƃ��������K�B
�@�@--------------------
>>591�ň��p�����L���̃^�C�g����AMD�̖��O��L���ĂःV�X�e���x���_�ł���HP������ĂȂ��C��(��)
���Ȃ݂ɤAMD���g�����̃l�^�g���Ă��邷�B
http://www.amd.com/jp-ja/Corporate/VirtualPressRoom/0,,51_104_543_13302~102332,00.html
�@�@====================
�@�@�f���A���R�AAMD Op��eron�v���Z�b�T880���f�����̗p����HP ProLiant DL585�T�[�o�́A4 way x86
�@�@�T�[�o�̒��ŗB��TPC-C 200K�g�����U�N�V���� �X�R�A�����T�[�o�ł��B
�@�@====================
���Ɍ��������ʼnR�������Ɩ@�I�Ƀ��o��������"x86�T�[�o"���Ē��߂����Ă��邷�B
�@�@
>>592
���ځ`�炯�ł悭������A���j��if���͂Ȃ����A
��������Apple��AMD���̗p���Ă�����AMac���^�͕��X��
�uIntel��v�i���풎��������j�Ə����Ă������낤�ˁB����������
���ځ`�炯�ł悭������A���j��if���͂Ȃ����A
��������Apple��AMD���̗p���Ă�����AMac���^�͕��X��
�uIntel��v�i���풎��������j�Ə����Ă������낤�ˁB����������
>>593
> >>591�ň��p�����L���̃^�C�g����AMD�̖��O��L���ĂःV�X�e���x���_�ł���HP������ĂȂ��C��(��)
�s���ɂ���Č�����X���[�����H
> October 7, 2005
> AMD-HP Opteron Tops TPC-C Benchmark
> >>591�ň��p�����L���̃^�C�g����AMD�̖��O��L���ĂःV�X�e���x���_�ł���HP������ĂȂ��C��(��)
�s���ɂ���Č�����X���[�����H
> October 7, 2005
> AMD-HP Opteron Tops TPC-C Benchmark
MAC�I�^���Ȃ�E�U�C����t�B���^���Ă������B
>>595
�p��ǂ߂Ȃ�����d�����Ȃ�
�p��ǂ߂Ȃ�����d�����Ȃ�
>>591
AMD�M�҂ł͂Ȃ����ATPC���{�����ƃf�}�𗬂����͕̂s���Ȃ̂ŁB
http://www.tpc.org/reports/status/BS-2005-05.asp
2005/2�A�}���`�R�A�^�X���b�h���l������CPU���̎�舵������������O���[�v�쐬�B
http://www.tpc.org/reports/status/BS-2005-08.asp
2005/6�A�p��̒�`�A�ύX�̉e���̕]���ȂǁA�O���[�v�̍�Ƃ������B
http://www.tpc.org/reports/status/BS-2005-09.asp
2005/8�ATPC-H 2.3.0�������BProcessors/Cores/Threads���̋L�ڂ��K�v�ɁB
http://www.tpc.org/reports/status/BS-2005-12.asp
2005/10�ATPC-C 5.5�������BProcessors/Cores/Threads���̋L�ڂ��K�v�ɁB
http://www.tpc.org/reports/status/BS-2006-02.asp
2005/12�ATPC-App 1.1.2�ɂ�Processors/Cores/Threads���̋L�ڂ��K�v�ɁB
AMD�M�҂ł͂Ȃ����ATPC���{�����ƃf�}�𗬂����͕̂s���Ȃ̂ŁB
http://www.tpc.org/reports/status/BS-2005-05.asp
2005/2�A�}���`�R�A�^�X���b�h���l������CPU���̎�舵������������O���[�v�쐬�B
http://www.tpc.org/reports/status/BS-2005-08.asp
2005/6�A�p��̒�`�A�ύX�̉e���̕]���ȂǁA�O���[�v�̍�Ƃ������B
http://www.tpc.org/reports/status/BS-2005-09.asp
2005/8�ATPC-H 2.3.0�������BProcessors/Cores/Threads���̋L�ڂ��K�v�ɁB
http://www.tpc.org/reports/status/BS-2005-12.asp
2005/10�ATPC-C 5.5�������BProcessors/Cores/Threads���̋L�ڂ��K�v�ɁB
http://www.tpc.org/reports/status/BS-2006-02.asp
2005/12�ATPC-App 1.1.2�ɂ�Processors/Cores/Threads���̋L�ڂ��K�v�ɁB
CELL�c���悤�Ȃ�c
��`���l�^�֎~
601 �FSocket774�F2006/05/18(��) 15:41:19 ID:V8csdtMq
�����ς��X���C�_�[�I
http://ex14.2ch.net/test/read.cgi/news4vip/1147929857/
http://ex14.2ch.net/test/read.cgi/news4vip/1147929857/
AMD64�Ƃ��ׂ�ڂ��ɑ�������APIC�}�C�R�\�݂����ȑg�ݍ��^1����CPU��
�I���W�i���A�[�L�e�B�N�`���݂����Ȋ����ŃG�~�����[�V��������Ă݂���
���ǁB
��������CPU�̱��è�����ϑz����G�~�����[�^�c�[���Ƃ����ĂȂ��̂��Ȃ��B
����ϻ�ݸ��Ƃ�FPGA�������ȓz�ɂ��܂��܉�H�g��ł����Ă������Ȃ��̂��Ȃ�?
�I���W�i���A�[�L�e�B�N�`���݂����Ȋ����ŃG�~�����[�V��������Ă݂���
���ǁB
��������CPU�̱��è�����ϑz����G�~�����[�^�c�[���Ƃ����ĂȂ��̂��Ȃ��B
����ϻ�ݸ��Ƃ�FPGA�������ȓz�ɂ��܂��܉�H�g��ł����Ă������Ȃ��̂��Ȃ�?
��������Efficeon��Xbox�|�[�^�u���ɓ��ڂ�
http://pc.watch.impress.co.jp/docs/2006/0519/spf04.htm
http://pc.watch.impress.co.jp/docs/2006/0519/spf04.htm
�����Ŏ�����Ă鎑���������[���ȁB
�v���Z�b�T�̃o���c�L��Ƃ��B
�v���Z�b�T�̃o���c�L��Ƃ��B
Efficeon���PowerPC750������̕������\������������d�͂��Ⴂ�C�����邪
�n������C�܂����Ă��܂�
>>610
�N�̐S�̒��ŁA�����Ă����
�N�̐S�̒��ŁA�����Ă����
�Ԃ����ႯEfficeon�̓Q�[����������Ȃ���ȁB
�����ipod�R����v���C���[?
�����ipod�R����v���C���[?
ipod�R����v���C���[��Ver.1��Origami�A
Ver2�����ɏo��B
�����Ȃ̂͂��̎��ɏo�����B
Ver2�����ɏo��B
�����Ȃ̂͂��̎��ɏo�����B
>>598�̓{��ɐG���MAC�I�^��������������
618 �FSocket774�F2006/05/23(��) 00:47:34 ID:4MwbkDUZ
�t���[�X�P�[���͑��@�\�H���˂�����˂�
>>617,619
Pentium��Athlon���ǂ��̂����́A�Ƃ������܂����炢�̘b����Ȃ��cx86�Ȃ�āc
Pentium��Athlon���ǂ��̂����́A�Ƃ������܂����炢�̘b����Ȃ��cx86�Ȃ�āc
�Q�[�n�[������o�̃l�^�����ǤCell�@���ɗ]�O�������F����̂��ӌ���@�������H
http://www.cs.berkeley.edu/%7Esamw/projects/cell/LBL_SCS_march3.pdf
�@�@�@�@�@�@�@�@�@Hammer/2.2GHz��@�@�@IPF/1.4GHz��
�@DGEMM�@�@�@�@�@�@�@12.8x�@�@�@�@�@�@�@�@�@�@�@9.5x
�@SpMV�@�@�@�@�@�@�@�� 8.4x�@�@�@�@�@�@�@�@�@�� 8.4x
�@Stencil�@�@�@�@�@�@�@�@37.0x�@�@�@�@�@�@�@�@�@�@17.7x
�@1D FFT�@�@�@�@�@�@�@ 10.6x�@�@�@�@�@�@�@�@�@�@ 7.6x
�@2D FFT�@�@�@�@�@�@�@ 13.4x�@�@�@�@�@�@�@�@�@�@30.6x
http://www.cs.berkeley.edu/%7Esamw/projects/cell/LBL_SCS_march3.pdf
�@�@�@�@�@�@�@�@�@Hammer/2.2GHz��@�@�@IPF/1.4GHz��
�@DGEMM�@�@�@�@�@�@�@12.8x�@�@�@�@�@�@�@�@�@�@�@9.5x
�@SpMV�@�@�@�@�@�@�@�� 8.4x�@�@�@�@�@�@�@�@�@�� 8.4x
�@Stencil�@�@�@�@�@�@�@�@37.0x�@�@�@�@�@�@�@�@�@�@17.7x
�@1D FFT�@�@�@�@�@�@�@ 10.6x�@�@�@�@�@�@�@�@�@�@ 7.6x
�@2D FFT�@�@�@�@�@�@�@ 13.4x�@�@�@�@�@�@�@�@�@�@30.6x
���T�C�Y�ɂ������ăX�P�[�����Ƃ��
FFT�̓_����傫�����Ă�����Cell�̓M�u�A�b�v���邾��?
�A�[�L�e�N�`�����炿����ƊO��邯�ǁA�p�b�P�[�W�̕��͂ǂ�Ȋ����H
�s�������������Ő������ƂɂȂ�Ȃ����ȁc
�s�������������Ő������ƂɂȂ�Ȃ����ȁc
SPE�͒��ڊO�E�ƌq�����ĂȂ�����A
����ȍ������Ƃɂ͂Ȃ��̂���Ȃ���?
����ȍ������Ƃɂ͂Ȃ��̂���Ȃ���?
������������������̂͋C�̂����ł����H
�C���e���AItanium�̔���5���N���j���p�[�e�B
http://pc.watch.impress.co.jp/docs/2006/0602/intel.htm
�C���e���AItanium�̔���5���N���j���p�[�e�B
http://pc.watch.impress.co.jp/docs/2006/0602/intel.htm
Itanium2�}�V�����o�J�n���ꂽ���߂ɁAItanium�}�V���͂��̏o�J�n���炽����12������ɂ́A�Y�Ɣp�����Ƃ��Ď̂Ă�ꂽ�B
1�N�ŃS�~�ɂȂ�}�V���́A���������Ȃ���ˁB
1�N�ŃS�~�ɂȂ�}�V���́A���������Ȃ���ˁB
{kind=link}
Itanium���������ꂽ����ɂ́A���ł�POWER���f���A���R�A�����Ă�
���܂�̕s�b��Ȃ��Ɉ�x�}�C�N���\�t�g�Ɍ��̂Ă�ꂽ�̂��ɂ�����itanium�B
�}�C�N���\�t�g�P�ނɂ��linux�����B���Ă��܂�itanium2�ɍēx�}�C�N���\�t�g�~�ՁB
�h���h�����ȁB
�}�C�N���\�t�g�P�ނɂ��linux�����B���Ă��܂�itanium2�ɍēx�}�C�N���\�t�g�~�ՁB
�h���h�����ȁB
�s�v�c�ȃ��[�����L��̂��������
����OS�̎d�g�݂Ƃ��ĉ�͍ς݂̃l�C�e�B�u�R�[�h��}�C�N���I�y��HDD�Ƀv���O�������ɃL���b�V�����ĕۑ����Ă����Ȃ��낤�H
�C�q��������ŗL�̈��p�ӂ��Ă���
DEC�̃A���������ςȎ����Ă���
CPU�����f�R�[�h���ʂ�I/O�p�ӂ��Ȃ���n�܂�ǂˁB
����OS�̎d�g�݂Ƃ��ĉ�͍ς݂̃l�C�e�B�u�R�[�h��}�C�N���I�y��HDD�Ƀv���O�������ɃL���b�V�����ĕۑ����Ă����Ȃ��낤�H
�C�q��������ŗL�̈��p�ӂ��Ă���
DEC�̃A���������ςȎ����Ă���
CPU�����f�R�[�h���ʂ�I/O�p�ӂ��Ȃ���n�܂�ǂˁB
>>634
HDD�͒x��+�f�R�[�h���ꂽ�l�C�e�B�u�R�[�h�͌������傫���Ȃ�(���ш��K�v�Ƃ���)�B
�܂�A�����HDD�L���b�V��������A���̏�Ńf�R�[�h�����@�������ɂȂ鎖�������ƍl�����Ă���B
�R�[�h���x��(�L���b�V���\���܂߂�)�������ш�Ƃ̃o�����X�͓���B
ARM��Thumb�Ȃ̓������̐ߖ�Ⴞ�����肷�邯��ǁAThumb�g�����������\�オ�����Ⴄ�����������肷�邮�炢�B
HDD�͒x��+�f�R�[�h���ꂽ�l�C�e�B�u�R�[�h�͌������傫���Ȃ�(���ш��K�v�Ƃ���)�B
�܂�A�����HDD�L���b�V��������A���̏�Ńf�R�[�h�����@�������ɂȂ鎖�������ƍl�����Ă���B
�R�[�h���x��(�L���b�V���\���܂߂�)�������ш�Ƃ̃o�����X�͓���B
ARM��Thumb�Ȃ̓������̐ߖ�Ⴞ�����肷�邯��ǁAThumb�g�����������\�オ�����Ⴄ�����������肷�邮�炢�B
Transmeta�͎����I��AMD�̎P�����B
�Ȃ�قǂ˃������ш悪���ɂȂ�̂�
OS���Ńl�C�e�B�u�R�[�h�Ǘ��ł����Java���͂��߂Ƃ��閳�ʂȒ��ԃR�[�h�Z�p���r���ł���Ǝv�����̂ɁB
�g�ы@��p�r��Java���ēd�͌����ň��Ȃ��
�f�R�[�h���ʂƃI���W�i���R�[�h���Z�O�����g�����X�ɓ���ւ��čs���Ĕ������CPU���Ԃ̏����}���Ă���
�̂��ăX�o���V�C�Ǝv��������
OS���Ńl�C�e�B�u�R�[�h�Ǘ��ł����Java���͂��߂Ƃ��閳�ʂȒ��ԃR�[�h�Z�p���r���ł���Ǝv�����̂ɁB
�g�ы@��p�r��Java���ēd�͌����ň��Ȃ��
�f�R�[�h���ʂƃI���W�i���R�[�h���Z�O�����g�����X�ɓ���ւ��čs���Ĕ������CPU���Ԃ̏����}���Ă���
�̂��ăX�o���V�C�Ǝv��������
�A�[���A�V�t�@�~���[�̑g�ݍ������v���Z�b�T�[�gARM Cortex-R4�h�̐�������J��
http://ascii24.com/news/i/tech/article/2006/06/07/662702-000.html
���]����Thumb���߂ƁA�V����Thumb-2�Ɣ�r����18�`22�������ɂȂ�Ƃ����B
���������疜�`�����g�����W�X�^���̂�������O�̊��o�͉�������Ⴢ��Ă�̂�����
�� 18���`22���Q�[�g
�������Ȃ�̐��\������
http://ascii24.com/news/i/tech/article/2006/06/07/662702-000.html
���]����Thumb���߂ƁA�V����Thumb-2�Ɣ�r����18�`22�������ɂȂ�Ƃ����B
���������疜�`�����g�����W�X�^���̂�������O�̊��o�͉�������Ⴢ��Ă�̂�����
�� 18���`22���Q�[�g
�������Ȃ�̐��\������
>>637
Java��JIT���d���Ƃ������́ACPU�͊W�Ȃ��ȁB
�R�[�h���[�t�B���O����CPU���낤�ƁA�����łȂ��낤�ƁA�d���̂�����B
Java��JIT���d���Ƃ������́ACPU�͊W�Ȃ��ȁB
�R�[�h���[�t�B���O����CPU���낤�ƁA�����łȂ��낤�ƁA�d���̂�����B
���ɂ��A
OS���l�C�e�B�u�R�[�h���Ǘ����ăL���b�V�����čė��p���Ă��A
���ꂪ���܂������̂�OS���Ǘ����Ă���R�[�h�����ł���A
JVM�����I�ɐ�������R�[�h�Ɋւ��Ă̓L���b�V���������Ȃ��B
���܂������悤�ɂ��邽�߂ɂ́AJVM��OS�ɓ������A
OS�Ƃ�������JVM���A
�l�C�e�B�u�R�[�h���Ǘ����ăL���b�V�����Ȃ��Ƃ����Ȃ��B
OS���l�C�e�B�u�R�[�h���Ǘ����ăL���b�V�����čė��p���Ă��A
���ꂪ���܂������̂�OS���Ǘ����Ă���R�[�h�����ł���A
JVM�����I�ɐ�������R�[�h�Ɋւ��Ă̓L���b�V���������Ȃ��B
���܂������悤�ɂ��邽�߂ɂ́AJVM��OS�ɓ������A
OS�Ƃ�������JVM���A
�l�C�e�B�u�R�[�h���Ǘ����ăL���b�V�����Ȃ��Ƃ����Ȃ��B
����ɁA
Java�͓��I�ɃR�[�h�����邱�Ƃ�O��Ƃ����A�[�L�e�N�`���ł���A
���I�ɃR�[�h�����邱�ƂŃp�t�H�[�}���X���o��悤�ɂȂ��Ă��āA
��x���������R�[�h�����������Ƃ����X����킯�ŁE�E�E�E�B
���_�Ƃ��ẮAJava�������Ɏ��s��������A
Efficeon�Ƃ��̃l�C�e�B�u�R�[�h�ڏo�͂���JVM�ƁA
������T�|�[�g����OS�����A�ƁB
Java�͓��I�ɃR�[�h�����邱�Ƃ�O��Ƃ����A�[�L�e�N�`���ł���A
���I�ɃR�[�h�����邱�ƂŃp�t�H�[�}���X���o��悤�ɂȂ��Ă��āA
��x���������R�[�h�����������Ƃ����X����킯�ŁE�E�E�E�B
���_�Ƃ��ẮAJava�������Ɏ��s��������A
Efficeon�Ƃ��̃l�C�e�B�u�R�[�h�ڏo�͂���JVM�ƁA
������T�|�[�g����OS�����A�ƁB
CONFIG_MICROCODE:
If you say Y here and also to "/dev file system support" in the
'File systems' section, you will be able to update the microcode on
Intel processors in the IA32 family, e.g. Pentium Pro, Pentium II,
Pentium III, Pentium 4, Xeon etc. You will obviously need the
actual microcode binary data itself which is not shipped with the
Linux kernel.
����Ȏ�����Ă�Ȃ�����}�C�N���R�[�h���\�Ȃ̂���?
If you say Y here and also to "/dev file system support" in the
'File systems' section, you will be able to update the microcode on
Intel processors in the IA32 family, e.g. Pentium Pro, Pentium II,
Pentium III, Pentium 4, Xeon etc. You will obviously need the
actual microcode binary data itself which is not shipped with the
Linux kernel.
����Ȏ�����Ă�Ȃ�����}�C�N���R�[�h���\�Ȃ̂���?
�o�O�C���������������Ǝv�����ǃi�B
>>644
�u���������ȃX�[�p�[�R���s���[�^�ɋ߂��\�͂����������v
�u1/60�b���ƂɑS�ẴA�N�V�����̃��X�|���X��Ԃ��Ȃ��Ƃ����Ȃ��B������t��HD�̉f���ŁA
���A���^�C���ɑS�č��o���B�v
�ǂ����Ă��R�E��U���E�܂���킵����`����ł��B���肪�Ƃ��������܂����B
�u���������ȃX�[�p�[�R���s���[�^�ɋ߂��\�͂����������v
�u1/60�b���ƂɑS�ẴA�N�V�����̃��X�|���X��Ԃ��Ȃ��Ƃ����Ȃ��B������t��HD�̉f���ŁA
���A���^�C���ɑS�č��o���B�v
�ǂ����Ă��R�E��U���E�܂���킵����`����ł��B���肪�Ƃ��������܂����B
>>645
���܂ł�x86�ɂ������ĂȂ��ŁA�O�̐��E�ɂłĂ݂��
���܂ł�x86�ɂ������ĂȂ��ŁA�O�̐��E�ɂłĂ݂��
>>644
���������ȃX�[�p�[�R���s���[�^��
>�uCell�́A�P���x(32bit)���������_�ł����A
>��É摜������G���^�[�e�C�������g�ɓK���Ă���v
�Ȃ�ĕςȌ�����K�v���������B
�P���x�ʼnȊw���Z����Ă�X�p�R���Ȃ�đ��݂��Ȃ��B
���������ȃX�[�p�[�R���s���[�^��
>�uCell�́A�P���x(32bit)���������_�ł����A
>��É摜������G���^�[�e�C�������g�ɓK���Ă���v
�Ȃ�ĕςȌ�����K�v���������B
�P���x�ʼnȊw���Z����Ă�X�p�R���Ȃ�đ��݂��Ȃ��B
>>637
Java���d���̂́A���Ԍ�����g���Ă邩�炶��Ȃ���
�������Ǘ��Ƃ��Z�L�����e�B�[�Ƃ���
���s���ɂ��Ȃ����Ⴂ���Ȃ��^�X�N���d�����炾��
>>648
�A���S���Y���Ƃ������ɂ���Ă�
�P���x�ł��ςނ��̂��Ă����Ȃ�����?
cell�̃������ш�E���C�e���V��P���x���ē_�Ƃ���
���R�Ȋw�V�~�����[�g�ɂ͕s�����Ȃ̂͊ԈႢ�Ȃ�����
Java���d���̂́A���Ԍ�����g���Ă邩�炶��Ȃ���
�������Ǘ��Ƃ��Z�L�����e�B�[�Ƃ���
���s���ɂ��Ȃ����Ⴂ���Ȃ��^�X�N���d�����炾��
>>648
�A���S���Y���Ƃ������ɂ���Ă�
�P���x�ł��ςނ��̂��Ă����Ȃ�����?
cell�̃������ш�E���C�e���V��P���x���ē_�Ƃ���
���R�Ȋw�V�~�����[�g�ɂ͕s�����Ȃ̂͊ԈႢ�Ȃ�����
>>645
�P���x����Ȃ�A1CPU��CrayX-1��SX-8���
�����ł��鏈���͂�����ł�����Ǝv��
�܂��u�X�p�R�����݁v���Ă̂́A�������Ƃ�����킷
��ʓI�Ȗ����ł͂��邯�ǂ�
�P���x����Ȃ�A1CPU��CrayX-1��SX-8���
�����ł��鏈���͂�����ł�����Ǝv��
�܂��u�X�p�R�����݁v���Ă̂́A�������Ƃ�����킷
��ʓI�Ȗ����ł͂��邯�ǂ�
����A�u�X�p�R�����݁v�ƕ\�L����Ă�R���s���[�^��������A
�N���C�̍ŏ��̓z���x���Ǝv�����Ƃɂ��悤�B
�N���C�̍ŏ��̓z���x���Ǝv�����Ƃɂ��悤�B
90�N�㔼��CrayT90�ŁA2Gflops/�v���Z�b�T�������
�����������X�p�R������
�����������X�p�R������
cell���Ă����[���i�_�ǂ݁j
http://www.watch.impress.co.jp/av/docs/20060609/sce5.jpg
http://www.watch.impress.co.jp/av/docs/20060609/sce5.jpg
{kind=link}
>>653
�Ԃ����ႯAltiVec�̕���SPE���c
�Ԃ����ႯAltiVec�̕���SPE���c
�Ȃɂ��������킯?
�g�߂ȏ��ł�GPU�B
���ƂȂ��Ă͒ᐫ�\��ATI��RadeonX800�ł�12GFlops�B
Nvidia��R600��512GFlops(�\��)
�����x��pentium4��athlon�̌����肵�Ă�̂��e����GPU�B
http://pc.watch.impress.co.jp/docs/2005/0517/ps3.htm
>RSX��Cell�����킹�������������Z���\��2T FLOPS����Ƃ����B
2T FLOPS�Ȃ�ꉞ�X�p�R��������ˁB
>90�N�㔼��CrayT90
��1000�{���B
�\�j�[���v���X�e3��linux���ڂ����̂�2T GFLOPS�̐��\�̓Q�[���ȊO�̗p�r��
����ƍl���Ă��邩��B
�����~�̈�Ë@��̒��Ƀv���X�e3�������Ă��邩������Ȃ��B
�₽���Ë@����������Ă邵��������Ă�̂����ˁB
�g�߂ȏ��ł�GPU�B
���ƂȂ��Ă͒ᐫ�\��ATI��RadeonX800�ł�12GFlops�B
Nvidia��R600��512GFlops(�\��)
�����x��pentium4��athlon�̌����肵�Ă�̂��e����GPU�B
http://pc.watch.impress.co.jp/docs/2005/0517/ps3.htm
>RSX��Cell�����킹�������������Z���\��2T FLOPS����Ƃ����B
2T FLOPS�Ȃ�ꉞ�X�p�R��������ˁB
>90�N�㔼��CrayT90
��1000�{���B
�\�j�[���v���X�e3��linux���ڂ����̂�2T GFLOPS�̐��\�̓Q�[���ȊO�̗p�r��
����ƍl���Ă��邩��B
�����~�̈�Ë@��̒��Ƀv���X�e3�������Ă��邩������Ȃ��B
�₽���Ë@����������Ă邵��������Ă�̂����ˁB
>>655
���{��ł���
���{��ł���
��`���l�^�֎~
>>648
> �P���x�ʼnȊw���Z����Ă�X�p�R���Ȃ�đ��݂��Ȃ��B
��?
���ۂ̌v�Z�ł͂Ȃ��x���`�}�[�N�ŋ��k�����A�P��x���`�͒P���x����B
> �P���x�ʼnȊw���Z����Ă�X�p�R���Ȃ�đ��݂��Ȃ��B
��?
���ۂ̌v�Z�ł͂Ȃ��x���`�}�[�N�ŋ��k�����A�P��x���`�͒P���x����B
>>655
Linux�������Ă���̂�PowerPC�n�̃R�A����B
���ʂɏ������Ȋw���Z�A�v���́ACell�̋��͂ȉ��Z���j�b�g�������g�����Ƃ��ł��Ȃ���B
Linux�������Ă���̂�PowerPC�n�̃R�A����B
���ʂɏ������Ȋw���Z�A�v���́ACell�̋��͂ȉ��Z���j�b�g�������g�����Ƃ��ł��Ȃ���B
�������Ȃ��B
�S��Linux���v���C���X�g�[���ŏo�ׂ���Ƃ������Ă邩��A
�g�ݍ���OS�Ƃ��Ĉʒu�Â���\���������B
�Z�K�̃h���[���L���X�g�ɐς܂ꂽWindowsCE�݂����ɂ��B
����ɂ��Ă�Linux�̐��E���Ă����̂͐�����ł��ˁB
�A�v���������e�l���A������Linux���َ�CPU�̃}���`�v���Z�b�T�ɑΉ�����悤�ɁA�����������ȂB
�����Ȃ牉�Z���j�b�g�Q��Linux�̊Ǘ����ɂ͒u�����ALinux�ɑ��ẮA
���[�U�̃A�v�������Z���j�b�g�Q�ƒʐM�����胁���������L���邽�߂̎d�g�݂���邾���ɗ��߂�Ȃ��B
�܂�A�����̃C���e���W�F���g�Ȋg���{�[�h�̗ނ��Ɠ��������ˁB
�S��Linux���v���C���X�g�[���ŏo�ׂ���Ƃ������Ă邩��A
�g�ݍ���OS�Ƃ��Ĉʒu�Â���\���������B
�Z�K�̃h���[���L���X�g�ɐς܂ꂽWindowsCE�݂����ɂ��B
����ɂ��Ă�Linux�̐��E���Ă����̂͐�����ł��ˁB
�A�v���������e�l���A������Linux���َ�CPU�̃}���`�v���Z�b�T�ɑΉ�����悤�ɁA�����������ȂB
�����Ȃ牉�Z���j�b�g�Q��Linux�̊Ǘ����ɂ͒u�����ALinux�ɑ��ẮA
���[�U�̃A�v�������Z���j�b�g�Q�ƒʐM�����胁���������L���邽�߂̎d�g�݂���邾���ɗ��߂�Ȃ��B
�܂�A�����̃C���e���W�F���g�Ȋg���{�[�h�̗ނ��Ɠ��������ˁB
Cell��ς�PCI Express�J�[�h�Ȃ��o��ƁA�G���R�[�h��g���b�v�����ȂɎg�������Ȃ�ł����A�ǂ��ł��傤���B�B�B
�����A���ƃQ�[���̕����V�~�����[�V�����ɂ��g���邩�ȁB
�����A���ƃQ�[���̕����V�~�����[�V�����ɂ��g���邩�ȁB
�g���b�v�������p�r�Ƃ��ĕ��ʂɏo�Ă���̂����
664 �FSocket774�F2006/06/10(�y) 22:48:56 ID:ItN5UzEq
�u�X�[�p�[�R���s���[�^�[���v���Ă̂̓R���s���[�^�[�ƊE�ł����Ƃ����ȃZ�[���X�g�[�N����B
�Ȋw�Z�p���Z�p�̂�����X�p�R���̓��������\���Ⴂ������B
���ʁA8�o�C�g�̔{���x���������_�f�[�^�Ȃ�2���Z��1��A�N�Z�X�ł���悤�ɁA
4Byte/FLOPS�ʂ̃o���h���̃��������q������ACPU��2TFLOPS�Ȃ�8TB/s�ʂ̃��������K�v�B
����ɑ���PS3��CPU���{����2TFLOPS�ł��A��������25.6GB/s�����Ȃ��B
�Ȋw�Z�p���Z�p�̂�����X�p�R���̓��������\���Ⴂ������B
���ʁA8�o�C�g�̔{���x���������_�f�[�^�Ȃ�2���Z��1��A�N�Z�X�ł���悤�ɁA
4Byte/FLOPS�ʂ̃o���h���̃��������q������ACPU��2TFLOPS�Ȃ�8TB/s�ʂ̃��������K�v�B
����ɑ���PS3��CPU���{����2TFLOPS�ł��A��������25.6GB/s�����Ȃ��B
SONY�͈�Ê���X�p�R����������ƂȂ������ɑ啗�C�~�L����������̂ȁB
�^�C�}�[���������1�N�ʼn����ǂ����̗p���Ȃ��̂��ւ̎R�B
�^�C�}�[���������1�N�ʼn����ǂ����̗p���Ȃ��̂��ւ̎R�B
666 �FSocket774�F2006/06/10(�y) 22:53:30 ID:9X46AeLp
�U�U�U�Ȃ珗�q�����Ƀ��C�v�����
�Í������A�܂�g���b�v�������č��������ȒP�Ȃ��
cell����
cell����
�����ł��Ȃ���
�g���b�v�����͋��Ɏ��ڂ����Ȃ���A��p�̃n�[�h�E�F�A��g��ŁA1�N���b�N��1�L�[�������ł���Ǝv���B
��邱�Ƃ����܂��Ă���̂ŁA���S�i�A����i�Ƃ����p�C�v���C����g��ł��܂������̂�����B
�ȑO�A���E����PC�̋��Ԃ��g���ĈÍ���͂�����Ă݂āA
�Í��̋��x�����ۂɎ����܂��傤�Ƃ����v���W�F�N�g���������̂����ǁA
�c��ȑ䐔�Ǝ��Ԃ��g���ĉ�͂���Ă����̂��A
��p�̃n�[�h�E�F�A��������Ƃ���̎Q���ɂ�萔���ʼn�͂��I������A
�Ƃ����b����������B
CPU�����y���ɑ����X�s�[�h��3DES�����ł���Í����A�N�Z�����[�^�`�b�v�ɂ́A�q�[�g�V���N������Ă��Ȃ��̂�����B
��邱�Ƃ����܂��Ă���̂ŁA���S�i�A����i�Ƃ����p�C�v���C����g��ł��܂������̂�����B
�ȑO�A���E����PC�̋��Ԃ��g���ĈÍ���͂�����Ă݂āA
�Í��̋��x�����ۂɎ����܂��傤�Ƃ����v���W�F�N�g���������̂����ǁA
�c��ȑ䐔�Ǝ��Ԃ��g���ĉ�͂���Ă����̂��A
��p�̃n�[�h�E�F�A��������Ƃ���̎Q���ɂ�萔���ʼn�͂��I������A
�Ƃ����b����������B
CPU�����y���ɑ����X�s�[�h��3DES�����ł���Í����A�N�Z�����[�^�`�b�v�ɂ́A�q�[�g�V���N������Ă��Ȃ��̂�����B
>>669
�g���b�v�����̃A���S���Y���͒m��Ȃ����A�ǂ����_�����Z�ƃV�t�g�ƁA�����Ă��e�[�u�����炢����
FPGA���Ⴞ�߂Ȃ�H
�g���b�v�����̃A���S���Y���͒m��Ȃ����A�ǂ����_�����Z�ƃV�t�g�ƁA�����Ă��e�[�u�����炢����
FPGA���Ⴞ�߂Ȃ�H
671 �FSocket774�F2006/06/11(��) 01:31:38 ID:fouNu/XJ
���ۂ�FPGA�Ɏ������ĘA���g���b�v�̉��l��\��������Լ������
>>661
>�A�v���������e�l���A������Linux���َ�CPU�̃}���`�v���Z�b�T�ɑΉ�����悤�ɁA�����������ȂB
��{�I�ɂ͂����Ȃ�ł��傤�B
�����������Ȃ�ł��B
http://cell.scei.co.jp/pdf/SPU_language_extensions_v21_j.pdf
altavec��sse�����̂Ɠ��l�̑Ή��ɂȂ邩�ƁB
>�A�v���������e�l���A������Linux���َ�CPU�̃}���`�v���Z�b�T�ɑΉ�����悤�ɁA�����������ȂB
��{�I�ɂ͂����Ȃ�ł��傤�B
�����������Ȃ�ł��B
http://cell.scei.co.jp/pdf/SPU_language_extensions_v21_j.pdf
altavec��sse�����̂Ɠ��l�̑Ή��ɂȂ邩�ƁB
>>673
�ėp�����v�Z�@�̃v���Z�T�͂��Г��̊ۃt�@�E���h���Ő������Ăق����B
�ėp�����v�Z�@�̃v���Z�T�͂��Г��̊ۃt�@�E���h���Ő������Ăق����B
675 �FSocket774�F2006/06/13(��) 22:27:43 ID:aitmkBzY
�܂�GK��
678 �FSocket774�F2006/06/13(��) 23:10:05 ID:QJHhx1t+
SIMD�I��@�ƌ����Ă݂�e�X�g
����ɂ��Ă��������C�^�[���r�b�N���ȃO���t�ł���
����ɂ��Ă��������C�^�[���r�b�N���ȃO���t�ł���
16MB/s�͂�������typo���낤���A
4GB/s�ł����イ�Ԃ�x���B
4GB/s�ł����イ�Ԃ�x���B
>>674
>�����̌��ʁA���̂悤�Ȍ��_�āA���Ɖ���f�O���A6�����������ĉ��U���邱�ƂƂȂ����B
>�����̌��ʁA���̂悤�Ȍ��_�āA���Ɖ���f�O���A6�����������ĉ��U���邱�ƂƂȂ����B
�����܂���A�A����Ⴂ��������܂���
���[�A�}�C�N���v���Z�b�T�������Ăǂ�Ȃ��̂ł����H�@
���������Ƃ̓����Ƃ��Ă͂��̌�ǂ̂悤�ȓW�J���\���ł���ł��傤���B
���[�A�}�C�N���v���Z�b�T�������Ăǂ�Ȃ��̂ł����H�@
���������Ƃ̓����Ƃ��Ă͂��̌�ǂ̂悤�ȓW�J���\���ł���ł��傤���B
>>681
moore�}�V����moore����Ȃ��āAforth�ŗL����moore���̓������ȁB
AMD�A�x�m�ʂ��a�����Ă���x�ɂ͋��͂ȕ����Ď����B
moore�}�V����moore����Ȃ��āAforth�ŗL����moore���̓������ȁB
AMD�A�x�m�ʂ��a�����Ă���x�ɂ͋��͂ȕ����Ď����B
>>680
���́A�悭�ǂ�łȂ������c�c
���́A�悭�ǂ�łȂ������c�c
cell�������Ɖ�������̂�����?
��pCPU�Ȃ������p�r�ŔėpCPU�̈ꌅ��͑����Ă�����܂��Ȃ��ǂȁB
conroe���y���ɍ����ɏ����ł��鐔��~��DSP�̑��݂Ƃ��グ����܂��{�肾���̂��낤��w
��pCPU�Ȃ������p�r�ŔėpCPU�̈ꌅ��͑����Ă�����܂��Ȃ��ǂȁB
conroe���y���ɍ����ɏ����ł��鐔��~��DSP�̑��݂Ƃ��グ����܂��{�肾���̂��낤��w
���Ƃ��ẮA����p�r�Ȃ甚�������ėpCPU�Ɠ����悤�Ɏg�����Ƃ���ƃO�_�O�_�Ȃ̂ɁA
���������Ȃ�ɂ����Ă������ł��邩�̂悤�Ɍ��y���������B
���������Ȃ�ɂ����Ă������ł��邩�̂悤�Ɍ��y���������B
����Ȃ�ċv��ǖ،��H
���Ƃ��ẮAIBM PowerPC�̗]���ɂ����Ȃ��̂ɁA�����2�R�A���i���o�ꂵ��x86�M�҂��t�@�r��������A
�Ȃ����ڂ̓G�ɂ��Ē@���y���������B
�Ȃ����ڂ̓G�ɂ��Ē@���y���������B
�����Cell�M�҂��E�U����������B
���j�[���炪676�݂����ȋv��ǂȂ���r�����邩��
�o�����B
������������̖��ߑ̌n�ɓ����������̍�肽�����
�ėpCPU�{FPGA�ł����̒��x�̐��l�͏o��Ǝv�����ȁB
�܂����͂Ƃ�����GK���B
�o�����B
������������̖��ߑ̌n�ɓ����������̍�肽�����
�ėpCPU�{FPGA�ł����̒��x�̐��l�͏o��Ǝv�����ȁB
�܂����͂Ƃ�����GK���B
GRAPE�̌��ɂȂ����z��FPGA(���Ă�����Lattice��CPLD)�ۂ������₤�ȋC�������B
FPGA��CPLD�͏�Z���肾���ǁB
�ŋ߂̓z�͏�Z������v�f(DSP�u���b�N)�������Ă邩��ǂ��Ȃ��Ă邯�ǁB
�ł��܂��A����A���S���Y����p�n�[�h�E�F�A�Ȃ琫�\���o�ē��R�Ǝv���Ă邩��ˁB
�ł��S�̗l�ȑ��x�Ői������ėp�v���Z�b�T���肾�ƁA�Ȃ��Ȃ����������鎖�͓���c
���삵�������Ă̂��˂��c�B
FPGA��CPLD�͏�Z���肾���ǁB
�ŋ߂̓z�͏�Z������v�f(DSP�u���b�N)�������Ă邩��ǂ��Ȃ��Ă邯�ǁB
�ł��܂��A����A���S���Y����p�n�[�h�E�F�A�Ȃ琫�\���o�ē��R�Ǝv���Ă邩��ˁB
�ł��S�̗l�ȑ��x�Ői������ėp�v���Z�b�T���肾�ƁA�Ȃ��Ȃ����������鎖�͓���c
���삵�������Ă̂��˂��c�B
�������Ȃςȃ����O�o�X�݂����Ȃ̎g���Ă邵��
�u�_�C�i�~�b�N���R���t�B�L�����u���v���Ēm���Ă�H
�̂Ȃ̖{�œǂ��ǁA�������ԈႦ���̂�
�O�O���Ă��o�Ă��Ȃ��B
�̂Ȃ̖{�œǂ��ǁA�������ԈႦ���̂�
�O�O���Ă��o�Ă��Ȃ��B
�L����Ȃ��ăM
>>694
�������Ƃ��B�O�O������o�Ă���(*߁��)
�������Ƃ��B�O�O������o�Ă���(*߁��)
�����ʂ��Ă�FPGA�ł͓����M�K�����̘_���g�߂ˁ[���B
���낢��ϑz���������܂����
��[ Virtex4FX ]
��[ DAP/DNA ]
���낢��ϑz���������܂����
��[ Virtex4FX ]
��[ DAP/DNA ]
DRP������ł�
1���~�̃f�W�J���̕���20���̃p�\�R����荂���ɉ摜��������Ă���Ď����B
�p�\�R���I�^�͂��������Ɨ��s�s�������ǁB
�p�\�R���I�^�͂��������Ɨ��s�s�������ǁB
699 �FSocket774�F2006/06/16(��) 10:24:26 ID:FneC5bb8
RISC�̂o�b�s��ɖ����͂��邩
PPCP�̘b�ł����B
PC==IBM PC�ł�����(r
risc���ǂ����͂Ƃ������A��o�����Ȃ̊W��NC��V���N���C�A���g�I�j�[�Y���̂��̂͂��邾�낤���c
���ǃR�X�g���ǁB
CPU���������Ȃ��Ă��ˁc
���ǃR�X�g���ǁB
CPU���������Ȃ��Ă��ˁc
�[������v����V���N���C�A���g�ƂƂ����ɗʎY���܂����PC���ƃR�X�g���S�R�Ⴄ����ˁB
704 �FSocket774�F2006/06/17(�y) 13:34:58 ID:OhKH6ADP
���Ⴀ�����������ȁB
����OS�ƃA�v���̃\�[�X�R�[�h�͂���(=linux)
�R���p�C�������p�ӂ���Ό�͑S�������Ă���B
x86��windows�ɔ����Ȃ��V�����n�[�h�̐�������`�����X�͂���B
�R���p�C�������p�ӂ���Ό�͑S�������Ă���B
x86��windows�ɔ����Ȃ��V�����n�[�h�̐�������`�����X�͂���B
706 �FSocket774�F2006/06/17(�y) 23:28:26 ID:rNGeb5iM
cray��IA-64�����C���ɂ��鎞�ゾ
intel��AMD�������đ����̍��͕̂s�\
intel��AMD�������đ����̍��͕̂s�\
>>705
����ȃ`�����X�͐̂��炠��̂����ǁB
SPARC�n�̃��[�N�X�e�[�V�����Ƃ��A�������ł���B
�ł��Ax86�n�̂ق��������Đ��\�������ł���B
����ȃ`�����X�͐̂��炠��̂����ǁB
SPARC�n�̃��[�N�X�e�[�V�����Ƃ��A�������ł���B
�ł��Ax86�n�̂ق��������Đ��\�������ł���B
�ނ���̂̕������낢�날������
Alpha���ő����������オ���������c
>>706
���������?
x86�n���cell�̕��������ƈ����Ĉꌅ�A�����ł��傤�ɁB
����͖����Ȃ킯?
�ėpCPU��������ɂȂ��̂͂ǂ����Ǝv����B
���������?
x86�n���cell�̕��������ƈ����Ĉꌅ�A�����ł��傤�ɁB
����͖����Ȃ킯?
�ėpCPU��������ɂȂ��̂͂ǂ����Ǝv����B
���������
����p�r��p�Ȃ�DSP�ōςނ��ȁB
>>710
cell����PC�́Ax86����PC�����A������?
cell����PC�́Ax86����PC�����A������?
���̑O�ɁACell�͗����̔�����Ȃ����������B
1�ɂ�2������3���������ɂȂ�Ƃ������L��������킯�����B
1�ɂ�2������3���������ɂȂ�Ƃ������L��������킯�����B
715 �FMAC�I�^��714 �����F2006/06/18(��) 13:26:23 ID:aEfkuQtB
>>714
�@�@-----------------
�@�@���̑O�ɁACell�͗����̔�����Ȃ����������B
�@�@-----------------
IBM, AMD, Sony, ���ł��SOI�v���Z�X�������J�����Ă��Ť���v���Z�X��K8�̒l�i�ƃ_�C�T�C�Y
������Τ�R�X�g�̗\�z��������B
�@Windsor K8 (90nm Dual-Core 1MB L2 x 2): 230 mm^2
�@Cell DD2 (90nm): 235 mm^2
�@�@-----------------
�@�@���̑O�ɁACell�͗����̔�����Ȃ����������B
�@�@-----------------
IBM, AMD, Sony, ���ł��SOI�v���Z�X�������J�����Ă��Ť���v���Z�X��K8�̒l�i�ƃ_�C�T�C�Y
������Τ�R�X�g�̗\�z��������B
�@Windsor K8 (90nm Dual-Core 1MB L2 x 2): 230 mm^2
�@Cell DD2 (90nm): 235 mm^2
�_�C�T�C�Y�͓����ł��A1�N���b�N�ł�������̎d�������Ȃ�������Ȃ����Z��̖ʐς��AK8����Cell�̂ق����A�����ƍL���B
�L���b�V�������Ȃ����������܂�͗ǂ����������ǂ�
718 �FMAC�I�^���⑫�F2006/06/18(��) 14:16:53 ID:aEfkuQtB
�_�C�T�C�Y����R�X�g�����ς���v�Z�@�����������ǂ����B
http://journal.mycom.co.jp/column/architecture/024/
http://journal.mycom.co.jp/column/architecture/024/
�t�Ƃ͌����Ȃ�����B
�_�C�T�C�Y������������ꂾ�������������B
�_�C�T�C�Y������������ꂾ�������������B
721 �FSocket774�F2006/06/18(��) 15:21:20 ID:nSfeMbnq
Cell��MacOSX�����悤�ɏo���Ȃ��́H
722 �FMAC�I�^��721 �����F2006/06/18(��) 15:28:01 ID:aEfkuQtB
>>721
�G���f�B�A���̈Ⴄx86�ɂ���ڐA�ł���������ARM���낤��Itanium���낤���32-bit�ȏ��
�������ɃA�N�Z�X�ł���v���Z�b�T�ɂ�ڐA�\���Ǝv�����B
�G���f�B�A���̈Ⴄx86�ɂ���ڐA�ł���������ARM���낤��Itanium���낤���32-bit�ȏ��
�������ɃA�N�Z�X�ł���v���Z�b�T�ɂ�ڐA�\���Ǝv�����B
>>719
��ʓI�ɃL���b�V���̕����M�`�M�`�ɋl�ߍ��ނ�������܂肪����
�璷�����ď��߂ă��W�b�N���݂̕����܂肪�m�ۂł���킯��
�C���e���Ȃ��L���b�V�������E�����Ƃ��o���Ă�ł���H
��ʓI�ɃL���b�V���̕����M�`�M�`�ɋl�ߍ��ނ�������܂肪����
�璷�����ď��߂ă��W�b�N���݂̕����܂肪�m�ۂł���킯��
�C���e���Ȃ��L���b�V�������E�����Ƃ��o���Ă�ł���H
Cell�v���Z�b�T�Ȃ�AMacBook�̍ő�10�i����
>>723
�������L���b�V���̂́A�����̔��s�Ǖi�̗��p
�ŋ߂̃��W�b�N �́A�N���B�e�B�J���ȉӏ��ł��낢��ς�������Ƃ�
���Ă���̂ŁA�̂� ����ׂĕ����܂茵�����Ȃ��Ă����
�������L���b�V���̂́A�����̔��s�Ǖi�̗��p
�ŋ߂̃��W�b�N �́A�N���B�e�B�J���ȉӏ��ł��낢��ς�������Ƃ�
���Ă���̂ŁA�̂� ����ׂĕ����܂茵�����Ȃ��Ă����
> ���낢��ς��������
�Ȃ�HLowVth�Ƃ��H
�Ȃ�HLowVth�Ƃ��H
�O���t�B�b�N�����ɓ��������V�X�e�����\�z����Ȃ�cell�͔ėpCPU��10�{�`100�{�̐��\�������߂�B
���܂���N�\�x���ėpCPU�ō\�z����̂̓A�z�B
�ėpCPU�Ƃ������M�����[�V�����������������C�������킩�邯��cell�̂悤�ȕ�����������B
cell�̍\���̓I�[�_�[���[�h�ŗe�ՂɃ��j�b�g����芷������Ӑ}������B
�����{�X���x�̕��������_���Z�̒�������������Ƀ��j�b�g����芷���Ēł���B
���܂���N�\�x���ėpCPU�ō\�z����̂̓A�z�B
�ėpCPU�Ƃ������M�����[�V�����������������C�������킩�邯��cell�̂悤�ȕ�����������B
cell�̍\���̓I�[�_�[���[�h�ŗe�ՂɃ��j�b�g����芷������Ӑ}������B
�����{�X���x�̕��������_���Z�̒�������������Ƀ��j�b�g����芷���Ēł���B
�����܂���A�Q�n�̃}���Z�[�X���ɏ����������Ǝv���Č딚���܂����B
731 �FSocket774�F2006/06/19(��) 17:19:13 ID:O2NqL8ye
����cell��PC�ɍ��킹�ăJ�X�^�}�C�Y�����Ƃ�����A
�\��Core2Duo�Ɣ�ׂĉ��{�����ł����H
�\��Core2Duo�Ɣ�ׂĉ��{�����ł����H
10�{�`100�{
������Cell�����ӂȕ������ȁB
�ėpCPU�Ɠ����g���������ꍇ�ǂ̒��x��
���\���o�邩�͎������������ߕs���B
�����Y�^�{���B
�ėpCPU�Ɠ����g���������ꍇ�ǂ̒��x��
���\���o�邩�͎������������ߕs���B
�����Y�^�{���B
>>731
>����cell��PC�ɍ��킹�ăJ�X�^�}�C�Y�����Ƃ�����A
�ǂ�ȕ��ɃJ�X�^�}�C�Y�����ł����H
PPE����������OOOE���\�ɂ�����H
�J�X�^�}�C�Y�Ƃ��̓��e������Ȃ��Ɖ��Ƃ������܂���˂��B
>����cell��PC�ɍ��킹�ăJ�X�^�}�C�Y�����Ƃ�����A
�ǂ�ȕ��ɃJ�X�^�}�C�Y�����ł����H
PPE����������OOOE���\�ɂ�����H
�J�X�^�}�C�Y�Ƃ��̓��e������Ȃ��Ɖ��Ƃ������܂���˂��B
�Ȃ�[���APOWER�̂P�̗���ɂ����Ȃ�Cell�ɉߏ蔽������������ˁH
����`�E�U��
>>731��ǂ�Ŏv�������A��͂�Intel POWER�����ׂ����ȁB
Core2 Duo��x86����Ȃ�������ǂ�Ȃɂ�����
Core2 Duo��x86����Ȃ�������ǂ�Ȃɂ�����
�ėp�����]���ɂ���������ł���Ƃ����D�Ⴞ�ȁB
������A1PFLOPS�̕��q���͊w��p�R���s���[�^���J��
http://pc.watch.impress.co.jp/docs/2006/0619/riken.htm
������A1PFLOPS�̕��q���͊w��p�R���s���[�^���J��
http://pc.watch.impress.co.jp/docs/2006/0619/riken.htm
���̉��Z�Ƃ��͂ڂ�ڂ낾�낤�ȁc
�����炱����HT3.0�Ȃ낤��
>>738
���̃V�X�e���̃L����
>�������J�����������̕��q���͊w�V�~�����[�V������pLSI��4,808����
������ȁB
�����^�p���i�����j���v�����������L�`���ƕ������Ă邩��
�ėp���̖����͖��ɂȂ�Ȃ��B
���̃V�X�e���̃L����
>�������J�����������̕��q���͊w�V�~�����[�V������pLSI��4,808����
������ȁB
�����^�p���i�����j���v�����������L�`���ƕ������Ă邩��
�ėp���̖����͖��ɂȂ�Ȃ��B
GK��`���B
�ߏ蔽���͂������Ȃ����E�U���B
�W���u�X�ɂ��猩�̂Ă�ꂽcell��
�ėpCPU�Ɠ������̂����҂���̂����������ԈႢ�B
�ߏ蔽���͂������Ȃ����E�U���B
�W���u�X�ɂ��猩�̂Ă�ꂽcell��
�ėpCPU�Ɠ������̂����҂���̂����������ԈႢ�B
���́u���q���͊w��p�v�R���s���[�^���Ďv����̗ǂ����f�G�B
�K�i���������Ȃ��Ă��Ȃ�>>HT3
745 �FSocket774�F2006/06/19(��) 23:33:15 ID:RslEzgK4
HT�̃o�X���O�Ɉ����o����PhysX�݂����Ȃ̂���Γ������B
Cell�H�b�ɂȂ���wwwwww
ttp://pc.watch.impress.co.jp/docs/2006/0602/slide117.jpg
Cell�H�b�ɂȂ���wwwwww
ttp://pc.watch.impress.co.jp/docs/2006/0602/slide117.jpg
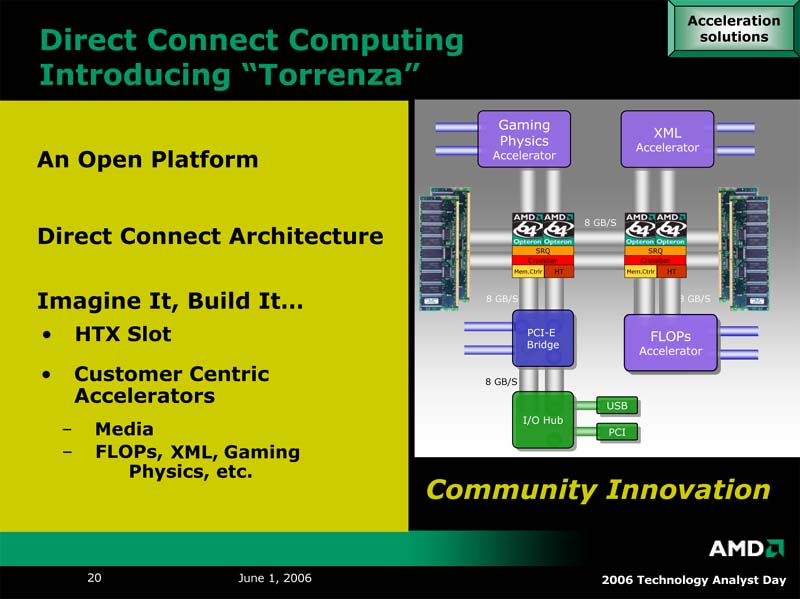{kind=link}
>>738
��pLSI��24�ς{�[�h��201�����B���b�N�ɏc��20������ł��邩��A10�{���B
�܂�A���̎ʐ^�Ɏʂ��Ă���̂őS�Ă��B
> �f���A���R�AXeon��256���ڂ����T�[�o�[��64��
�Ƃ����������͊��ق��Ăق����B4�v���Z�b�T�̃T�[�o��64��ō��v256�v���Z�b�T�̕���V�X�e���B
��pLSI��24�ς{�[�h��201�����B���b�N�ɏc��20������ł��邩��A10�{���B
�܂�A���̎ʐ^�Ɏʂ��Ă���̂őS�Ă��B
> �f���A���R�AXeon��256���ڂ����T�[�o�[��64��
�Ƃ����������͊��ق��Ăق����B4�v���Z�b�T�̃T�[�o��64��ō��v256�v���Z�b�T�̕���V�X�e���B
GK�̔S���͎G����������ȏゾ��
����ł�cell�̂������I�͏o��
�E�E�E����͔��Ƀj�b�`�ł���ihpc.co.jp���j
�I�����ɔ����Ȃ��悤�ȏł��AXeon�����g���Ȃ������肪�A������
���̗p�r�ŁAXeon��Opteron���r������AXeon�̂ق����p�t�H�[�}���X���ǂ������A�Ƃ�����������Ȃ���?
Dempsey�̍ɏ���
�����CPU���ڂ��Ă�I�ȂN�������܂����H
���ʉ��Z�p��SPE�����Ȃ�Ƃ���������p��PPE�ɂ��Ȃ��\������
�SPE�����ł͓��N���b�N��P4��1/5�����p�t�H�[�}���X���łȂ�PPE
�SPE���V��ł��Ă�PPE���Z��������SPE���g���Ȃ��ƌ������Ԃ�����������
��A�E�g�I�u�I�[�_�[���s���o���Ȃ��Ƃ����x�[�X�ƂȂ���PowerPC970�����Ă���PPE~ SPE���̑�
�SPE���Ƃ�DMA�����Ă����d�l(�ʏ��DMA�R���g���[���[��1�ŃL���[������)
����C�e���V���������郊���O�o�X���̗p���������o�X
�SPE�̃X�P�W���[�����O�͂��܂��܂ȗv�����l�����ăv���O���}�����͑g��
��f�[�^+�v���O������256KB�Ɏ��߂Ȃ��Ƃ����Ȃ�SPE
�����\�����Ȃ���Ƀf�[�^�ʂ̐������L��SPE��œ����ƌ����J�[�l���x�[�X�v���O���~���O
������O�o�X+������IO�Ǝ���IO������Ă��邽�߃�������GPU�]����CPU�̓����o�X��ʂ�ƌ�����v
��X�p�R���ƌ������シ����{���x���Z�\��
���ʉ��Z�p��SPE�����Ȃ�Ƃ���������p��PPE�ɂ��Ȃ��\������
�SPE�����ł͓��N���b�N��P4��1/5�����p�t�H�[�}���X���łȂ�PPE
�SPE���V��ł��Ă�PPE���Z��������SPE���g���Ȃ��ƌ������Ԃ�����������
��A�E�g�I�u�I�[�_�[���s���o���Ȃ��Ƃ����x�[�X�ƂȂ���PowerPC970�����Ă���PPE~ SPE���̑�
�SPE���Ƃ�DMA�����Ă����d�l(�ʏ��DMA�R���g���[���[��1�ŃL���[������)
����C�e���V���������郊���O�o�X���̗p���������o�X
�SPE�̃X�P�W���[�����O�͂��܂��܂ȗv�����l�����ăv���O���}�����͑g��
��f�[�^+�v���O������256KB�Ɏ��߂Ȃ��Ƃ����Ȃ�SPE
�����\�����Ȃ���Ƀf�[�^�ʂ̐������L��SPE��œ����ƌ����J�[�l���x�[�X�v���O���~���O
������O�o�X+������IO�Ǝ���IO������Ă��邽�߃�������GPU�]����CPU�̓����o�X��ʂ�ƌ�����v
��X�p�R���ƌ������シ����{���x���Z�\��
>>754
>��X�p�R���ƌ������シ����{���x���Z�\��
>>729�̐l��
>�����{�X���x�̕��������_���Z�̒�������������Ƀ��j�b�g����芷���Ēł���B
�ƌ����Ă��܂�����
�i�{�X���x�c�H�j
>��X�p�R���ƌ������シ����{���x���Z�\��
>>729�̐l��
>�����{�X���x�̕��������_���Z�̒�������������Ƀ��j�b�g����芷���Ēł���B
�ƌ����Ă��܂�����
�i�{�X���x�c�H�j
cell���T�[�o�[�Ɏg���n���͂��Ȃ��ˁB
�摜������p�Ȃ�p�t�H�[�}���X�͕��ʂ�CPU��100�{���炢���肻�����B
��pCPU�͗p�r�����肳��邪����p�r�ł͕��ʂ�CPU���100�{�����B
�摜������p�Ȃ�p�t�H�[�}���X�͕��ʂ�CPU��100�{���炢���肻�����B
��pCPU�͗p�r�����肳��邪����p�r�ł͕��ʂ�CPU���100�{�����B
IBM�ACell�x�[�X�̃u���[�h�T�[�o�[���J��
ttp://pc.watch.impress.co.jp/docs/2006/0209/ibm.htm
ttp://pc.watch.impress.co.jp/docs/2006/0209/ibm.htm
>>758
�l�i�o���Ȃ��A�Ƃ��������i���x���͊��҂���ȂƂ������ƂŁB
> Product Availability
> IBM intends to make the Cell BE-based system available for direct purchase
> beginning in the third quarter of 2006, with availability via special bids
> now.
ttp://www-03.ibm.com/press/us/en/pressrelease/19229.wss
Cell BE�\�����[�V����
ttp://www-06.ibm.com/jp/ibm/apto/cellbe/index.html
�J���A�x���A�g���[�j���O�A�e�X�g�B�ǂ��l���Ă������ł��B
�l�i�o���Ȃ��A�Ƃ��������i���x���͊��҂���ȂƂ������ƂŁB
> Product Availability
> IBM intends to make the Cell BE-based system available for direct purchase
> beginning in the third quarter of 2006, with availability via special bids
> now.
ttp://www-03.ibm.com/press/us/en/pressrelease/19229.wss
Cell BE�\�����[�V����
ttp://www-06.ibm.com/jp/ibm/apto/cellbe/index.html
�J���A�x���A�g���[�j���O�A�e�X�g�B�ǂ��l���Ă������ł��B
�Ɠd�ȊO��1�`�b�v�ɂ��郁���b�g������
Cell��3.2GH���ȊO�F�߂��Ȃ���ł���H
�o���̈���CPU�Ɋւ��āA���Ђ�CPU�Ȃ�2.4GH���̗����łɂ��Ĕ��邱�Ƃ��ł��邯��
Cell�͍��̂Ƃ����K�͂Ȏg�������Ȃ���ˁBIBM�̃T�[�o�[���炢�H
�R�X�g�����낵�����ƂɂȂ肻���B
�o���̈���CPU�Ɋւ��āA���Ђ�CPU�Ȃ�2.4GH���̗����łɂ��Ĕ��邱�Ƃ��ł��邯��
Cell�͍��̂Ƃ����K�͂Ȏg�������Ȃ���ˁBIBM�̃T�[�o�[���炢�H
�R�X�g�����낵�����ƂɂȂ肻���B
>Cell��3.2GH���ȊO�F�߂��Ȃ���ł���H
PS3�̃X�y�b�N�\��3.2G��ǂݕԂ�
PS3�̃X�y�b�N�\��3.2G��ǂݕԂ�
Cell��4.6G����Ȃ������������B
>>755
�{�X���x�͑���128bit������������B
���������j�b�g���ւ�����Ă��A4�{�������W�X�^��
���Z�킪�v��Ǝv�����A��Ԃ���̂�?
>>755
�{�X���x�͑���128bit������������B
���������j�b�g���ւ�����Ă��A4�{�������W�X�^��
���Z�킪�v��Ǝv�����A��Ԃ���̂�?
>>762
http://www.scei.co.jp/corporate/release/pdf/060509a.pdf�i��PDF�j
�Ȃ��ˁB
�ł�360�������ɂ͂��Ȃ��Ǝv�����ǂȂ��B
http://www.scei.co.jp/corporate/release/pdf/060509a.pdf�i��PDF�j
�Ȃ��ˁB
�ł�360�������ɂ͂��Ȃ��Ǝv�����ǂȂ��B
�}�X�R�~�ɃN���b�N���̂������ϔ������PSP�̃N���b�N��333MHz����1�`333MHz�ɏ���������悤�ȉ�Ђ�����ȁB
��������Ă��Ă����������͂Ȃ��B
��������Ă��Ă����������͂Ȃ��B
>>753
�����Ƃ悢�I����������̂Ȃ�A�����ŋ����Ă��炦�܂���?
�����Ƃ悢�I����������̂Ȃ�A�����ŋ����Ă��炦�܂���?
>>763
�����̊g����������A�[�L�e�N�`�����Ƃ������Ƃł����āA
��������������ɗʎY���n�߂܂���A�Ƃ������Ƃł͂Ȃ��Ǝv���B
���Ԃ�ASPE��PPE�̌���ύX����Ƃ��A���̒��g��������ƂȂ�ƁA
����Ȃ�̊J�����Ԃ�������Ǝv���܂���B
�����̊g����������A�[�L�e�N�`�����Ƃ������Ƃł����āA
��������������ɗʎY���n�߂܂���A�Ƃ������Ƃł͂Ȃ��Ǝv���B
���Ԃ�ASPE��PPE�̌���ύX����Ƃ��A���̒��g��������ƂȂ�ƁA
����Ȃ�̊J�����Ԃ�������Ǝv���܂���B
>>766
����Xeon��Opteron�����v�����Ȃ�����
����Xeon��Opteron�����v�����Ȃ�����
769 �FSocket774�F2006/06/20(��) 19:07:16 ID:f8peRyhI
�Z�p�ҁi�j�u����x86�����g��Ȃ�����AXeon��I�B�g���Ȃ���Ȃ����B�g��Ȃ���`�ȂB�v
�V���R���Q���}�j�E���`�b�v��500GHz�̐V�L�^--IBM�ƃW���[�W�A�H�ȑ�A���ቷ����
ttp://japan.cnet.com/news/ent/story/0,2000056022,20145807,00.htm
�ʏ�̎����ł̎����ł́AIBM��GIT�̃`�b�v��350GHz�i���b3500���T�C�N���j��
�L�^�����B���̐����ł��A���s�̈�ʓI��PC�p�v���Z�b�T�̑��x�ł���1.8�`3.8GHz
�ɔ�ׂ�A�͂邩�ɍ������B����SiGe�`�b�v�́A���ቷ�̊����ł���Ȃ�
�p�t�H�[�}���X����������ł���B
ttp://japan.cnet.com/news/ent/story/0,2000056022,20145807,00.htm
�ʏ�̎����ł̎����ł́AIBM��GIT�̃`�b�v��350GHz�i���b3500���T�C�N���j��
�L�^�����B���̐����ł��A���s�̈�ʓI��PC�p�v���Z�b�T�̑��x�ł���1.8�`3.8GHz
�ɔ�ׂ�A�͂邩�ɍ������B����SiGe�`�b�v�́A���ቷ�̊����ł���Ȃ�
�p�t�H�[�}���X����������ł���B
Cell�̓�����g����4GH�����傫���A�ԈႢ�Ȃ��I
http://pc.watch.impress.co.jp/docs/2005/0208/kaigaip006.jpg
http://pc.watch.impress.co.jp/docs/2005/0208/kaigaip006.jpg
{kind=link}
774 �FSocket774�F2006/06/20(��) 20:55:58 ID:DWwuBMoP
�i�ƊE���琔�N�x��Ă��邪�j���ꂩ��̓f���A���R�A�̎��ゾ�I��Cell���\�łӂ��т�[��
4GHz�f�O���c��Cell4GHz���łӂ��т�[��
Cell����PC���ďo��́H���v���Z�b�T���p�\�R���Ƃ�������̋����i�j
Cell���Ď��͂����������ƂȂ��˂���POWER�̂P�ɉ߂��܂��HPowerPC�͔N��x86�̂S���炢���Ⴂ�̏o�חʂł��i�@�O�ցO�j
4GHz�f�O���c��Cell4GHz���łӂ��т�[��
Cell����PC���ďo��́H���v���Z�b�T���p�\�R���Ƃ�������̋����i�j
Cell���Ď��͂����������ƂȂ��˂���POWER�̂P�ɉ߂��܂��HPowerPC�͔N��x86�̂S���炢���Ⴂ�̏o�חʂł��i�@�O�ցO�j
775 �FSocket774�F2006/06/20(��) 20:59:38 ID:DWwuBMoP
�܁A�ӂ����ď����Ă��܂������A���������������Ƃ����ƂȁB
���̐��E�̐��i�Ɏ��i���ăt�@�r����ȁA�t�@�r���邭�炢�Ȃ��˂̒��̃J�G���̂܂܂Œm�炸�ɂ���B
�m���ăt�@�r����ȁAx86�M�҂Ƃ��ē��X�Ƃ��Ă���B
���Ă��Ƃ��B
Cell�̔ėp�����Ⴂ�͍̂ŏ�����킩���Ă������Ƃ����A���O��͏����8�R�A�Ƃ��������ɔ������Ă�����������H����ƃf���A���ɂȂ�������ɏo��������B
���̐��E�̐��i�Ɏ��i���ăt�@�r����ȁA�t�@�r���邭�炢�Ȃ��˂̒��̃J�G���̂܂܂Œm�炸�ɂ���B
�m���ăt�@�r����ȁAx86�M�҂Ƃ��ē��X�Ƃ��Ă���B
���Ă��Ƃ��B
Cell�̔ėp�����Ⴂ�͍̂ŏ�����킩���Ă������Ƃ����A���O��͏����8�R�A�Ƃ��������ɔ������Ă�����������H����ƃf���A���ɂȂ�������ɏo��������B
( ߄t�)�߶��
�L�`�K�C������������X���͂����ł����H
�@�̂́@�R���p�C���Ł@�o���Ă���
I am the bone of my compiler
�@������L3�Ł@�S�͕���@�\
L3cache is my body,and "Speculative load/Predication" is my blood.
�@�т̐����z���ĕs�s
I have exceeded over a thousand benchmark score.
�@������x�̔s���͂Ȃ�
Unaware of loss.
�@������x�̏������Ȃ�
Nor aware of gain.
�@�S����͂����Ɍǂ�B
Withstood pain to create many Records.
�@�g�����W�X�^�̋u�ŃV���R����b��
waiting for one's arrival.
�@�Ȃ�@�@�䂪���U�ɈӖ��͕s�v��
I have no regrets.This is the only path.
�@���͖̑̂����̍œK���I�v�V����(ILP)�ŏo���Ă���
My whole life was "unlimited optimization works"
I am the bone of my compiler
�@������L3�Ł@�S�͕���@�\
L3cache is my body,and "Speculative load/Predication" is my blood.
�@�т̐����z���ĕs�s
I have exceeded over a thousand benchmark score.
�@������x�̔s���͂Ȃ�
Unaware of loss.
�@������x�̏������Ȃ�
Nor aware of gain.
�@�S����͂����Ɍǂ�B
Withstood pain to create many Records.
�@�g�����W�X�^�̋u�ŃV���R����b��
waiting for one's arrival.
�@�Ȃ�@�@�䂪���U�ɈӖ��͕s�v��
I have no regrets.This is the only path.
�@���͖̑̂����̍œK���I�v�V����(ILP)�ŏo���Ă���
My whole life was "unlimited optimization works"
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,.,.,.,.,.,.,.,
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@z��c�c�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ Yk�c�c�~�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i�A,�@�'���~�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@}�L�@�@�uށM�S�;�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M�]�A�m _�^�N�R�A
�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@�@ �Lr'�L-�] ́��R�A
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,.�m�M�R�S�A�@Y�L;: }
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {,;;..:;,:;.:;:;,:,;i�@ �;.;.;i!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i,:;.;,.:;,:;.:;,;;:.�@�@ �r;.;|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �R,:;.:;,:;.;:.�@�@ /.;.;.;.i!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ iށM����'ށ@�^; ; ;/:.!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |; �M�['�L; ; ; ; ;��':':|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i; ; ;�Q�Q�Q/�v':':!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��'�P�Q�Q�Q�Q�':':|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �� '�L�@�@�@�@�@�@ �R:|
�@�@�ui�@�@�@�@�@�@�@�@�@�@�@�@ i���@�@�@�@�@�@�@ i:|�@ �@ �@ �@ �@ �@ �^�^
�@�@�vL�@�@�@�@�@�@�@�@�@�@�@ i|�@ �_�@�@�@�@�@�@ i!�@�@�@�@�@�@�@�^�^
�@�@ ||�@ r!�@�@�ہ@�@�@�@�@�@| i�@�@�@�A�@�@�@�@�@|�@�@�@�@�@ �^�^
�@�@ ||�@ Y�@�@ i!�@�@�@�@�@�@ �',�@�@�@�@�A�@�@�@�@!�@�@�@ �^�^
�@�@ ii�@�@i�@�@ i!�@�@�@�@�@�@/�@ ' ,�@�@�@�@�@�@�@�@|�@ �^�^
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@z��c�c�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ Yk�c�c�~�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i�A,�@�'���~�~�~�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@}�L�@�@�uށM�S�;�
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�M�]�A�m _�^�N�R�A
�@�@�@�@�@�@�@�@�@�@�@ �@ �@ �@�@ �Lr'�L-�] ́��R�A
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@,.�m�M�R�S�A�@Y�L;: }
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ {,;;..:;,:;.:;:;,:,;i�@ �;.;.;i!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i,:;.;,.:;,:;.:;,;;:.�@�@ �r;.;|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �R,:;.:;,:;.;:.�@�@ /.;.;.;.i!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ iށM����'ށ@�^; ; ;/:.!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ |; �M�['�L; ; ; ; ;��':':|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@ i; ; ;�Q�Q�Q/�v':':!
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ ��'�P�Q�Q�Q�Q�':':|
�@�@�@�@�@�@�@�@�@�@�@�@�@�@ �� '�L�@�@�@�@�@�@ �R:|
�@�@�ui�@�@�@�@�@�@�@�@�@�@�@�@ i���@�@�@�@�@�@�@ i:|�@ �@ �@ �@ �@ �@ �^�^
�@�@�vL�@�@�@�@�@�@�@�@�@�@�@ i|�@ �_�@�@�@�@�@�@ i!�@�@�@�@�@�@�@�^�^
�@�@ ||�@ r!�@�@�ہ@�@�@�@�@�@| i�@�@�@�A�@�@�@�@�@|�@�@�@�@�@ �^�^
�@�@ ||�@ Y�@�@ i!�@�@�@�@�@�@ �',�@�@�@�@�A�@�@�@�@!�@�@�@ �^�^
�@�@ ii�@�@i�@�@ i!�@�@�@�@�@�@/�@ ' ,�@�@�@�@�@�@�@�@|�@ �^�^
���~�͉���݂��Ď�݂��Ď��˂�
�Ȃ�Ō��~���Ă킩���
>>774
�۽
�������͂�������������
2001�N�̃f���A���R�A�ɂ͔������Ȃ����������ɁACell�ɂ͔���������
����̏Z�l���āA�悭�킩����ȁ[
�܂����삪��������̂͊ԈႢ�Ȃ�
�۽
�������͂�������������
2001�N�̃f���A���R�A�ɂ͔������Ȃ����������ɁACell�ɂ͔���������
����̏Z�l���āA�悭�킩����ȁ[
�܂����삪��������̂͊ԈႢ�Ȃ�
�ォ��ڐ��ł������m�������Ȃ����킢�����ȓz���N���Ă��Ă�ȁB
���삪�����Ƃ��ȂƂ��Bcell�̘b�������Ȃ�Q�n�ł��H
���삪�����Ƃ��ȂƂ��Bcell�̘b�������Ȃ�Q�n�ł��H
���ꂱ�ꑛ����Ă邪���Ɍ��킹���Cell�̐����Ƃ���̓������C���^�t�F�[�X�̈�_�ɐs����
>>783
��{�I�Ɏ���PC�ɊW�̂���b�����������A
POWER�n�̃f���A���R�A�Ȃ�Ċᒆ�ɖ����ē��R�Ȃ킯�ŁB
����PC�Ƃ������薳����CPU�̃A�[�L�e�N�`���̘b����������A
�ǂ����n�[�h�E�F�A�ł���Ă��������A���Ċ������ȁB
Cell�͎���PC�Ŏg����悤�ɂȂ��?
Cell���ڂ̃r�f�I�J�[�h���o�邭�炢��?
��{�I�Ɏ���PC�ɊW�̂���b�����������A
POWER�n�̃f���A���R�A�Ȃ�Ċᒆ�ɖ����ē��R�Ȃ킯�ŁB
����PC�Ƃ������薳����CPU�̃A�[�L�e�N�`���̘b����������A
�ǂ����n�[�h�E�F�A�ł���Ă��������A���Ċ������ȁB
Cell�͎���PC�Ŏg����悤�ɂȂ��?
Cell���ڂ̃r�f�I�J�[�h���o�邭�炢��?
�ERSX�̃g���C�A���O���Z�b�g�A�b�v�\�͂�2��7500���g���C�A���O��/�b�AXbox360
�@��5���g���C�A���O��/�b�ȏ�ŁARSX�̔{�B
�@���Ȃ킿PS3��360�̔����̐��\���H����A���Ԃ͂����ƈ����B
�E���C���������ɑ��Ă�Cell��25GBps, RSX��15-20GBps�̃o���h��������B
�@����͖��Ȃ��B
�ECell��RSX�̃��[�J��������(VRAM)�Ԃ̃o���h����16Mbps�ł���B(Read��)
�@�M�K�ł͂Ȃ��A���K�B
�@���܂�ɑ傫�ȍ������邽�߁ASONY��PS3�J���҂Ɍ������v���[���e�[�V������
�@�u����͌�A�ł͂Ȃ��v�Ƃ܂ŏ�����Ă���B
�ERSX�̼����߲��ײ݂̏����߂��͖��ɗ����Ȃ��B
�@�iVRAM to Cell �� Read ���������邽�߁j
�@���Ȃ킿�ARSX�ł̏����ͼ���ް�݂̂Ŋ��������Ȃ���Ȃ�Ȃ��B
�E�u����͍ŏI�łł͏C������܂��v�Ƃ����������Ȃ��������߁A
�@����͏C���s�\�Ȗ�肾�Ǝv���
�@��5���g���C�A���O��/�b�ȏ�ŁARSX�̔{�B
�@���Ȃ킿PS3��360�̔����̐��\���H����A���Ԃ͂����ƈ����B
�E���C���������ɑ��Ă�Cell��25GBps, RSX��15-20GBps�̃o���h��������B
�@����͖��Ȃ��B
�ECell��RSX�̃��[�J��������(VRAM)�Ԃ̃o���h����16Mbps�ł���B(Read��)
�@�M�K�ł͂Ȃ��A���K�B
�@���܂�ɑ傫�ȍ������邽�߁ASONY��PS3�J���҂Ɍ������v���[���e�[�V������
�@�u����͌�A�ł͂Ȃ��v�Ƃ܂ŏ�����Ă���B
�ERSX�̼����߲��ײ݂̏����߂��͖��ɗ����Ȃ��B
�@�iVRAM to Cell �� Read ���������邽�߁j
�@���Ȃ킿�ARSX�ł̏����ͼ���ް�݂̂Ŋ��������Ȃ���Ȃ�Ȃ��B
�E�u����͍ŏI�łł͏C������܂��v�Ƃ����������Ȃ��������߁A
�@����͏C���s�\�Ȗ�肾�Ǝv���
AMD��CTO�̈ӌ�
�摜�����ɂ�Cell���f���͌����Ă���Ǝv���܂��B
�������A���ׂĂ̗p�r�ɓK���Ă���킯�ł͂���܂���B
�\�t�g�E�F�A�̊J��������ł��BPLAYSTATION 3�̏����Ă��������B
PLAYSTATION 3�̖��̑����́A�\�t�g�E�F�A�̕��G���ɋN�����Ă���̂ł͂Ȃ��ł��傤���B
����͓���v���O���~���O���f���ł��B�����������ł���A
�傫�ȃ����b�g������܂��B�iAMD���������悤�Ƃ��Ă��郂�f���́A�j�����̂悢
�ėp�v���Z�b�T�ɁA���胏�[�N���[�h�ɓ��������y�ʂ̃R�v���Z�b�T��
�lj����Ă����Ƃ������̂ł��B���݂̃N���C�A���g�܂��̓T�[�o���ł́A
�V�X�e�������̃��[�N���[�h�ɍœK�����悤�Ƃ���ƁA
���̃��[�N���[�h�̐��\�������Ă��܂��܂��B�����̊�ƂɂƂ��āA����͏d��Ȗ��ł��B
�ǂ̃��[�N���[�h�����K�ɏ����ł���悤�ɂ��Ȃ���Ȃ�܂���B
ttp://japan.cnet.com/interview/story/0,2000055954,20139587,00.htm
�摜�����ɂ�Cell���f���͌����Ă���Ǝv���܂��B
�������A���ׂĂ̗p�r�ɓK���Ă���킯�ł͂���܂���B
�\�t�g�E�F�A�̊J��������ł��BPLAYSTATION 3�̏����Ă��������B
PLAYSTATION 3�̖��̑����́A�\�t�g�E�F�A�̕��G���ɋN�����Ă���̂ł͂Ȃ��ł��傤���B
����͓���v���O���~���O���f���ł��B�����������ł���A
�傫�ȃ����b�g������܂��B�iAMD���������悤�Ƃ��Ă��郂�f���́A�j�����̂悢
�ėp�v���Z�b�T�ɁA���胏�[�N���[�h�ɓ��������y�ʂ̃R�v���Z�b�T��
�lj����Ă����Ƃ������̂ł��B���݂̃N���C�A���g�܂��̓T�[�o���ł́A
�V�X�e�������̃��[�N���[�h�ɍœK�����悤�Ƃ���ƁA
���̃��[�N���[�h�̐��\�������Ă��܂��܂��B�����̊�ƂɂƂ��āA����͏d��Ȗ��ł��B
�ǂ̃��[�N���[�h�����K�ɏ����ł���悤�ɂ��Ȃ���Ȃ�܂���B
ttp://japan.cnet.com/interview/story/0,2000055954,20139587,00.htm
�悤��HT3��VL�o�X�H
793 �FSocket774�F2006/06/22(��) 00:02:02 ID:0daS/MQT
�@�@���̏ē��v���[�g��SONY���Ȃ�ł���@ �^
�P�P�P�ɁP�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�ȁ��ȁ@�@�@�@�@�ޭ�
�@ �i�@�E�́E�j�@�@�@ )�@ )�@�@�@�ȁȁ@�@ �^�P�P�P�P�P�P�P�P�P�P
�@ �i ���@�j�@�@ (�@ (�@�@�@(߄D�,,)�@���@�������Η͂���
�@�@|�@�b�@|.�@�������������@�@|�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �i�Q_�j�Q�j ���@Cell�@ �� (�Q�Q)�`
�P�P�P�ɁP�P�P�P�P�P�P�P�P�P�P�P�P�P�P
�@�@�ȁ��ȁ@�@�@�@�@�ޭ�
�@ �i�@�E�́E�j�@�@�@ )�@ )�@�@�@�ȁȁ@�@ �^�P�P�P�P�P�P�P�P�P�P
�@ �i ���@�j�@�@ (�@ (�@�@�@(߄D�,,)�@���@�������Η͂���
�@�@|�@�b�@|.�@�������������@�@|�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �i�Q_�j�Q�j ���@Cell�@ �� (�Q�Q)�`
����Ƃ̒N���������́u�����Ƃ�����CPU�𑬂�����
�ē����܂����v�Ƃ����l�^���v���o�����B
Pen200������̎���ɎG���L���ŃE�Y���̗��Ă��Ă��ȁB
�ē����܂����v�Ƃ����l�^���v���o�����B
Pen200������̎���ɎG���L���ŃE�Y���̗��Ă��Ă��ȁB
>>794
486�c�w4��eyecom���������ȁA���E�Y���̗��Ă��Ă��Ȃ�
486�c�w4��eyecom���������ȁA���E�Y���̗��Ă��Ă��Ȃ�
>>775
>���̐��E�̐��i�Ɏ��i���ăt�@�r����ȁA�t�@�r���邭�炢�Ȃ��˂̒��̃J�G���̂܂܂Œm�炸�ɂ���B
>�m���ăt�@�r����ȁAx86�M�҂Ƃ��ē��X�Ƃ��Ă���B
���X���̃e���v������
>���̐��E�̐��i�Ɏ��i���ăt�@�r����ȁA�t�@�r���邭�炢�Ȃ��˂̒��̃J�G���̂܂܂Œm�炸�ɂ���B
>�m���ăt�@�r����ȁAx86�M�҂Ƃ��ē��X�Ƃ��Ă���B
���X���̃e���v������
���Ȃ�
���A������
�@�@���낻��H�ׂ���ł���@�@�@�@�^
�P�P�P�ɁP�P�P�P�P�P�P�P�P�P
�@�@�ȁ��ȁ@�@�@�@�@���
�@ �i�@�E�́E�j�@�@�@ )�@ )�@�@�@�ȁȁ@�@ �^�P�P�P�P�P�P�P�P�P
�@ �i ���@�j�@�@ (�@ (�@�@�@(߄D�,,)�@���@�^�����ł�����٧!
�@�@|�@�b�@|.�@�������������@�@|�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �i�Q_�j�Q�j ���@Cell�@ �� (�Q�Q)�`
�P�P�P�ɁP�P�P�P�P�P�P�P�P�P
�@�@�ȁ��ȁ@�@�@�@�@���
�@ �i�@�E�́E�j�@�@�@ )�@ )�@�@�@�ȁȁ@�@ �^�P�P�P�P�P�P�P�P�P
�@ �i ���@�j�@�@ (�@ (�@�@�@(߄D�,,)�@���@�^�����ł�����٧!
�@�@|�@�b�@|.�@�������������@�@|�@�@ �_�Q�Q�Q�Q�Q�Q�Q�Q�Q
�@ �i�Q_�j�Q�j ���@Cell�@ �� (�Q�Q)�`
�u���i���Ă�ȁv�̃K�C�h���C��
http://ex13.2ch.net/test/read.cgi/gline/1145447754/
http://ex13.2ch.net/test/read.cgi/gline/1145447754/
>>786
PS3�ɂ�linux���ڂ��Ă��邩�玩��ɖ��W�ł��Ȃ���B
�f�l�ł�PS3����Ƀp�\�R������鎖���ł���B
�p�\�R���ɂȂ��ŃG���R��pbox�ɂ��鎖���ł���B
PS3��ffmpeg���点���琦�܂������\������̂͗e�Ղɑz���ł���B
������Ď��ɑ��Ď��삪���������B
�O���|�}�����������삶��Ȃ��B
PS3�ɂ�linux���ڂ��Ă��邩�玩��ɖ��W�ł��Ȃ���B
�f�l�ł�PS3����Ƀp�\�R������鎖���ł���B
�p�\�R���ɂȂ��ŃG���R��pbox�ɂ��鎖���ł���B
PS3��ffmpeg���点���琦�܂������\������̂͗e�Ղɑz���ł���B
������Ď��ɑ��Ď��삪���������B
�O���|�}�����������삶��Ȃ��B
���C��������256MB�̃p�\�R���ł����B
GK(sony.co.jp)�����Ă��炷�����蕳�X���ɂȂ����܂���
>>802
> �f�l�ł�PS3����Ƀp�\�R������鎖���ł���B
PS3����������̂Ȃ�A���[�J�[���p�\�R���̉����Ɠ����ŁA�n�[�h�E�F�A�ł��ׂ����낤�B
> �p�\�R���ɂȂ��ŃG���R��pbox�ɂ��鎖���ł���B
���̃p�\�R�������[�J�[���ł�����ł��W�Ȃ��A�p�\�R���̎��Ӌ@��Ƃ������Ƃ�����A�n�[�h�E�F�A�ł��ׂ����낤�B
> �f�l�ł�PS3����Ƀp�\�R������鎖���ł���B
PS3����������̂Ȃ�A���[�J�[���p�\�R���̉����Ɠ����ŁA�n�[�h�E�F�A�ł��ׂ����낤�B
> �p�\�R���ɂȂ��ŃG���R��pbox�ɂ��鎖���ł���B
���̃p�\�R�������[�J�[���ł�����ł��W�Ȃ��A�p�\�R���̎��Ӌ@��Ƃ������Ƃ�����A�n�[�h�E�F�A�ł��ׂ����낤�B
�̃p���}�NG5�ł����������ł���ƌ����Ă����l�������悤�ȋC������B
Cell�̉��Z�\�͉]�X���Č��������ĂȁB
CPU��GPU����̉������悤�ȃA�[�L�e�N�`������B
P4�Ƃ�CoreDuo�Ƃ�Athlon64x2�������GeForce7800/7900���RADEONx1900������̃V�F�[�_���j�b�g���킹����A
Cell�̉��{���炢�̐��\���ł��鎖���B
CPU��GPU����̉������悤�ȃA�[�L�e�N�`������B
P4�Ƃ�CoreDuo�Ƃ�Athlon64x2�������GeForce7800/7900���RADEONx1900������̃V�F�[�_���j�b�g���킹����A
Cell�̉��{���炢�̐��\���ł��鎖���B
�����X2x00��Unified Shader�Ɋ��ҁB
>>807
�������Ƃ��Ă��A������`�ɂ��Ȃ���Ӗ����Ȃ��B
�������Ƃ��Ă��A������`�ɂ��Ȃ���Ӗ����Ȃ��B
>>809
�����Cell���������Ƃł���ˁB
���������AP4��Core Duo��64X2��GF7800�������X1900�����Ɏs��ɏo�Ă��܂����A
Cell�͎����I�ɂ܂��s��ɏo�Ă��Ȃ��B�i�J���L�b�g�Ƃ����t�@�����X�L�b�g�Ƃ������`
�ł͏o�Ă��܂����j
�����Cell���������Ƃł���ˁB
���������AP4��Core Duo��64X2��GF7800�������X1900�����Ɏs��ɏo�Ă��܂����A
Cell�͎����I�ɂ܂��s��ɏo�Ă��Ȃ��B�i�J���L�b�g�Ƃ����t�@�����X�L�b�g�Ƃ������`
�ł͏o�Ă��܂����j
>>810
�������Ⴂ���Ă��B
����Cell�͂��̗l�ȍ\���ō�����ł���B
>>807��
��P4�Ƃ�CoreDuo�Ƃ�Athlon64x2�������
��GeForce7800/7900���RADEONx1900������̃V�F�[�_���j�b�g���킹����A
��Cell�̉��{���炢�̐��\���ł��鎖���B
�ƌ����Ă���̂ɁA
>>810��
��P4��Core Duo��64X2��GF7800�������X1900�����Ɏs��ɏo�Ă��܂���
�ƁB
�e�X���P�̂Ō`�ɂȂ��Ă��鎖�����Ă���ł͂Ȃ��̂ł���B
�������Ⴂ���Ă��B
����Cell�͂��̗l�ȍ\���ō�����ł���B
>>807��
��P4�Ƃ�CoreDuo�Ƃ�Athlon64x2�������
��GeForce7800/7900���RADEONx1900������̃V�F�[�_���j�b�g���킹����A
��Cell�̉��{���炢�̐��\���ł��鎖���B
�ƌ����Ă���̂ɁA
>>810��
��P4��Core Duo��64X2��GF7800�������X1900�����Ɏs��ɏo�Ă��܂���
�ƁB
�e�X���P�̂Ō`�ɂȂ��Ă��鎖�����Ă���ł͂Ȃ��̂ł���B
>>809
�`�ɂ���Ƃ������A�����𓋍ڂ���PC���s��ɗ��ʂ��Ă邾������ʖڂȂ̂����H
GPU�̉��Z���ʂ�CPU�����p�ł��Ȃ���_�����ƁH
���܂̂Ƃ���́AAVIVO�Ƃ�PureVideo�ȊO�ɂ͒m��iPreVideo�͈Ⴄ��)
Vista�ł�GPU����CPU�ւ̃f�[�^�]���̃C���^�t�F�[�X����������āA
�r�f�I�̃G���R�[�h����n�߂ɑ����̗p�r����������Ă���B
�����������ȁAGPU��CPU�́A�ʂɃ����`�b�v�ɂ܂Ƃ߂�K�v�ȂNJF���B
Cell�ł����̋@�\�����Ă���悤�Ȉ����Ȃ̂́A�P�ɃR�X�g�̓s���ł����Ȃ��B
(���������ACell�̂ق��ɁAGPU���ڂ���炵���Ƃ��������ACell�̉��Z���\�������ᑫ��Ȃ��������炾��H
�`�ɂ���Ƃ������A�����𓋍ڂ���PC���s��ɗ��ʂ��Ă邾������ʖڂȂ̂����H
GPU�̉��Z���ʂ�CPU�����p�ł��Ȃ���_�����ƁH
���܂̂Ƃ���́AAVIVO�Ƃ�PureVideo�ȊO�ɂ͒m��iPreVideo�͈Ⴄ��)
Vista�ł�GPU����CPU�ւ̃f�[�^�]���̃C���^�t�F�[�X����������āA
�r�f�I�̃G���R�[�h����n�߂ɑ����̗p�r����������Ă���B
�����������ȁAGPU��CPU�́A�ʂɃ����`�b�v�ɂ܂Ƃ߂�K�v�ȂNJF���B
Cell�ł����̋@�\�����Ă���悤�Ȉ����Ȃ̂́A�P�ɃR�X�g�̓s���ł����Ȃ��B
(���������ACell�̂ق��ɁAGPU���ڂ���炵���Ƃ��������ACell�̉��Z���\�������ᑫ��Ȃ��������炾��H
>>811
������Cell�͂��̗l�ȍ\���ō�����ł���
�R�X�g�̓s���Ń����`�b�v�����Ă邾������B
���e�X���P�̂Ō`�ɂȂ��Ă��鎖�����Ă���ł͂Ȃ��̂ł���B
�Ȃ��P�̂���_���Ȃ̂��H
�I����807�ɏ��������Ƃ́A>810���ɂ͐������`����Ă邪
(�����瓯���l�Ȃ��Ƃ��l���Ă�����t�قȕ��͂ł��ʂ����̂��H)
>811���ɂ̓}�g���ɒʂ��Ă��Ȃ��������B
������Cell�͂��̗l�ȍ\���ō�����ł���
�R�X�g�̓s���Ń����`�b�v�����Ă邾������B
���e�X���P�̂Ō`�ɂȂ��Ă��鎖�����Ă���ł͂Ȃ��̂ł���B
�Ȃ��P�̂���_���Ȃ̂��H
�I����807�ɏ��������Ƃ́A>810���ɂ͐������`����Ă邪
(�����瓯���l�Ȃ��Ƃ��l���Ă�����t�قȕ��͂ł��ʂ����̂��H)
>811���ɂ̓}�g���ɒʂ��Ă��Ȃ��������B
�}���`�R�A�ŕ���x���グ�Đ��\�����}���
�A���_�[�����̂܂�܂ƌ��������\���T�`���āA
�����ǂ����R�A����3��4�őł��~�߂ɂ���킯���ƋC�t����
�ėp�R�v�����̂����܂���\���ɂ������A����ŃO���t�B�b�N����낤�Ƃ�����
�ǂ��̃o�X���{�g���l�b�N�ɂȂ��Ă�̂��A�p�t�H�[�}���X���X�����Ȃ��̂�
NVIDIA�ɐ�p���W�b�N��点���悤�ȗ��ꂾ�����Ǝv���킯�����B
��������Cell���������������̂��A�����o����̂��ǂ��������킯����
�V�F�[�_�����j�t�@�C�h�ɂȂ��Ĕėp�����オ���Ă����Cell�̂悤�ȕ�����
�s�������C�͂��Ȃ��ł��Ȃ��B�܂��s����������ɂ�PS2�݂����ɐi���̗��ꂩ��
���c���ꂽ�َ��ȑ��݂ƂȂ��Ă邾�낤���ǂȁB
�A���_�[�����̂܂�܂ƌ��������\���T�`���āA
�����ǂ����R�A����3��4�őł��~�߂ɂ���킯���ƋC�t����
�ėp�R�v�����̂����܂���\���ɂ������A����ŃO���t�B�b�N����낤�Ƃ�����
�ǂ��̃o�X���{�g���l�b�N�ɂȂ��Ă�̂��A�p�t�H�[�}���X���X�����Ȃ��̂�
NVIDIA�ɐ�p���W�b�N��点���悤�ȗ��ꂾ�����Ǝv���킯�����B
��������Cell���������������̂��A�����o����̂��ǂ��������킯����
�V�F�[�_�����j�t�@�C�h�ɂȂ��Ĕėp�����オ���Ă����Cell�̂悤�ȕ�����
�s�������C�͂��Ȃ��ł��Ȃ��B�܂��s����������ɂ�PS2�݂����ɐi���̗��ꂩ��
���c���ꂽ�َ��ȑ��݂ƂȂ��Ă邾�낤���ǂȁB
>>814
����A�ǂ��̃o�X������̂����ʓI�����Ď������A
����܂�}�g���ɒNj��ł��ĂȂ���������Cell
EE�����l�������ȁB
�J���Ɍ��o������{�X���A�v���Z�b�T�̂��Ƃ����܂藝�����ĂȂ����c�������̂��ȁH
�J���҈�l�̖�肾������A�ӔC�Ƃ��čX�R�ŁA
��_���_��Cell�܂Ŏ����z���Ȃ��͂�������ȁB
���j�t�@�C�h�̃V�F�[�_���o�Ă�����(�{D3D10�j�A
Cell�Ƃقړ������ɂȂ邾�낤���ē_�͓��ӂ����A
����Ȃ�ɗp�r�������Đ����c���Ǝv���B
����A�ǂ��̃o�X������̂����ʓI�����Ď������A
����܂�}�g���ɒNj��ł��ĂȂ���������Cell
EE�����l�������ȁB
�J���Ɍ��o������{�X���A�v���Z�b�T�̂��Ƃ����܂藝�����ĂȂ����c�������̂��ȁH
�J���҈�l�̖�肾������A�ӔC�Ƃ��čX�R�ŁA
��_���_��Cell�܂Ŏ����z���Ȃ��͂�������ȁB
���j�t�@�C�h�̃V�F�[�_���o�Ă�����(�{D3D10�j�A
Cell�Ƃقړ������ɂȂ邾�낤���ē_�͓��ӂ����A
����Ȃ�ɗp�r�������Đ����c���Ǝv���B
��GPU��CPU�́A�ʂɃ����`�b�v�ɂ܂Ƃ߂�K�v�ȂNJF��
�������肻�̂܂ܑS�Ă���ɂ��Ă��Ȃ��ł���B
����ɁA
���`�ɂ���Ƃ������A�����𓋍ڂ���PC���s��ɗ��ʂ��Ă邾������ʖڂȂ̂����H
���Ȃ��P�̂���_���Ȃ̂��H
�����܂�CPU�͈̔͂ōl���ĉ������B
CPU�̘g�ł̉��Z�\�͂ł���B
�������肻�̂܂ܑS�Ă���ɂ��Ă��Ȃ��ł���B
����ɁA
���`�ɂ���Ƃ������A�����𓋍ڂ���PC���s��ɗ��ʂ��Ă邾������ʖڂȂ̂����H
���Ȃ��P�̂���_���Ȃ̂��H
�����܂�CPU�͈̔͂ōl���ĉ������B
CPU�̘g�ł̉��Z�\�͂ł���B
�K�v�Ȃ̂́A�V�X�e���S�̂̔\�͂���
�ǂ�����CPU�P�̂̔\�͂����Ɍ��肵�Ȃ���Ȃ��̂��H
�ǂ�����CPU�P�̂̔\�͂����Ɍ��肵�Ȃ���Ȃ��̂��H
�b���Ă�̂́ACPU�P�̂ł̘b�ł���B
�����ƂˁA�Ƃ肠���� ID: LP4CTT/S�͕��u�������������Ǝv����B
GPU�p�r�Ŏg�����Z���j�b�g�܂�CPU�ɓ�����������Ƃ����āA
GPU�ȊO�̗p�r�Ɏg���ėp�����������㏸����킯����Ȃ����A
GPU���Z��̔ėp�������߂邾���Ȃ�PC�ł��������悤�Ƃ��Ă�̂ɂ��H
���������A���ꂼ��̃R�A�́A�N���b�N������������IPC�Ⴗ���邾��B
GPU�ȊO�̗p�r�Ɏg���ėp�����������㏸����킯����Ȃ����A
GPU���Z��̔ėp�������߂邾���Ȃ�PC�ł��������悤�Ƃ��Ă�̂ɂ��H
���������A���ꂼ��̃R�A�́A�N���b�N������������IPC�Ⴗ���邾��B
>>819
�X�}���A�G���̎�ɔ@�J�I�Ő���������悤�ȍs�ׂ����Ă��܂����ȁB
����A�����āA�u�b�̎�v�Ƃ��u���|���_�v�Ƃ����������킯����Ȃ����B
�X�}���A�G���̎�ɔ@�J�I�Ő���������悤�ȍs�ׂ����Ă��܂����ȁB
����A�����āA�u�b�̎�v�Ƃ��u���|���_�v�Ƃ����������킯����Ȃ����B
���������Ό���ASCII�ɍڂ��Ă����ǁACell�ɂ��}���f���u���W���̉��Z�͑��������˂��B
Athlon 64 X2�̐��\�{�������H
AMD�̓R�v���Z�b�T�헪��ł��o���Ă����悤�����ǁA�R�v���Z�b�T���������ɂ̓\�t�g�E�F�A
���������Ȃ��Ƃ����Ȃ����낤����A�ǂꂾ�����y������̂��c�B
Athlon 64 X2�̐��\�{�������H
AMD�̓R�v���Z�b�T�헪��ł��o���Ă����悤�����ǁA�R�v���Z�b�T���������ɂ̓\�t�g�E�F�A
���������Ȃ��Ƃ����Ȃ����낤����A�ǂꂾ�����y������̂��c�B
�Ă�Cell�M�҂͂�������Cell�X���A���Ă��B
�͂��H�@Cell�M�҂��ĉ��̂��Ƃ��H
�����ł�Cell�̂��Ƃ�ǂ���������M�ҔF�肩�H
�����ł�Cell�̂��Ƃ�ǂ���������M�ҔF�肩�H
>>822
����͒P���x���ȁB
�}���f���u���W�����������Ǝv������A�{���x�͂ق����Ƃ���B
���ۂɁACell���g�����������p�r�Ȃ猃���������B
GPU�Ɣ�ׂẮA�ėp���ł͂邩�ɏ���B
Athlon64�̂悤��CPU��A���͂�GPU�ɂ�
���R�悳�͂���B
�P�[�X�o�C�P�[�X�Ƃ���������O�̌��_�B
����͒P���x���ȁB
�}���f���u���W�����������Ǝv������A�{���x�͂ق����Ƃ���B
���ۂɁACell���g�����������p�r�Ȃ猃���������B
GPU�Ɣ�ׂẮA�ėp���ł͂邩�ɏ���B
Athlon64�̂悤��CPU��A���͂�GPU�ɂ�
���R�悳�͂���B
�P�[�X�o�C�P�[�X�Ƃ���������O�̌��_�B
GK(sony.co.jp)�����Ă��炷�����蕳�X���ɂȂ����܂���
>>827
�悵�A���Ⴀ���͂��O���uCell�M�ҔF��~�v�ƔF�肵�Ă�낤�B
���O���Ƃ��ɖ��߂���āA�͂������ł����Əo�čs���z�����邩���Ȃ����͕�����ȁH
�悵�A���Ⴀ���͂��O���uCell�M�ҔF��~�v�ƔF�肵�Ă�낤�B
���O���Ƃ��ɖ��߂���āA�͂������ł����Əo�čs���z�����邩���Ȃ����͕�����ȁH
Cell������CPU���Ǝv�����A��ȗp�r��PS3���Ă�����
������Ⴂ���Ȃ����Ď��͂Ȃ�����
������Ⴂ���Ȃ����Ď��͂Ȃ�����
>>828
�킴�ƁHsage��
�킴�ƁHsage��
>>828
�����ŔS�����Ă܂��Ǝ������Ă�͕̂����邩�ȁH��
�����ŔS�����Ă܂��Ǝ������Ă�͕̂����邩�ȁH��
>>815
PS2��GS���AGPU�Ƃ��Ăَ͈��ȑ��݂ɂȂ����悤��
�ėpMPU��Cell�݂����ȕ������ɍs���������Ƃ��āA
Cell�͓���̃v���Z�b�T�Ƃَ͈��ȑ��݂Ȃ낤�B
�c�Ƃ����Ӗ��ŏ��������ǂȁB
�O���t�B�b�N�x���_�[��CPU�x���_�[���_�����z���Ă��܂�����
�O���t�B�b�N�̂ق��͔ėp�����ǂ�ǂ��ĕ������Z�R�v���J�[�h�݂�����
�ʒu�Â��ɂȂ��Ă��邾�낤���ACPU�̂ق��̓O���t�B�b�N��N�H���ă��C��
�v���Z�b�T�ƘA�g����̂ɃV�X�e���o�X���{�g���l�b�N�ɂȂ�܂����݂�����
����ł����Ȃ����Ǝv�������B
�܂�Cell�͂������낤�Ƃ��Ĕ\�͕s���Ŏ��s�����Ǝv�������B
�C���e���͓Ɨ͂ł��邾�낤���AAMD�͈ꎞ���ꂽATi�����̉\�̑_�������ꂩ�Ǝv������B
PS2��GS���AGPU�Ƃ��Ăَ͈��ȑ��݂ɂȂ����悤��
�ėpMPU��Cell�݂����ȕ������ɍs���������Ƃ��āA
Cell�͓���̃v���Z�b�T�Ƃَ͈��ȑ��݂Ȃ낤�B
�c�Ƃ����Ӗ��ŏ��������ǂȁB
�O���t�B�b�N�x���_�[��CPU�x���_�[���_�����z���Ă��܂�����
�O���t�B�b�N�̂ق��͔ėp�����ǂ�ǂ��ĕ������Z�R�v���J�[�h�݂�����
�ʒu�Â��ɂȂ��Ă��邾�낤���ACPU�̂ق��̓O���t�B�b�N��N�H���ă��C��
�v���Z�b�T�ƘA�g����̂ɃV�X�e���o�X���{�g���l�b�N�ɂȂ�܂����݂�����
����ł����Ȃ����Ǝv�������B
�܂�Cell�͂������낤�Ƃ��Ĕ\�͕s���Ŏ��s�����Ǝv�������B
�C���e���͓Ɨ͂ł��邾�낤���AAMD�͈ꎞ���ꂽATi�����̉\�̑_�������ꂩ�Ǝv������B
PS2���āA���ǂ́A�s�[�N���\������������
�펞�^�p�̕��ϑ��x��PC��舳�|�I�ɒx����������
���ȁ`��g�p�����𐧌����Ȃ���PC��荂���Ƃ͂Ȃ炸�A
���̌��PC��PC�pGPU�̍����\��������������A
PS2�����̎��_�ŁA���ł�PC�ȉ��̐��\�ɂȂ��Ă��B
GS��GPU�Ƃ��Ăَ͈����������R�́A
���\�ʂł̕s�����䂦�ɐ^���������Ȃ�Ȃ���������B
�펞�^�p�̕��ϑ��x��PC��舳�|�I�ɒx����������
���ȁ`��g�p�����𐧌����Ȃ���PC��荂���Ƃ͂Ȃ炸�A
���̌��PC��PC�pGPU�̍����\��������������A
PS2�����̎��_�ŁA���ł�PC�ȉ��̐��\�ɂȂ��Ă��B
GS��GPU�Ƃ��Ăَ͈����������R�́A
���\�ʂł̕s�����䂦�ɐ^���������Ȃ�Ȃ���������B
�K����Cell�֘A�l�^�U�葱���Ă邪���̘b���������Q�n�̃e�N�m�X����Cell�X���r�B
����ȃl�^�R�قǏo�Ă邼�i�Ƃ�����100%��������j�B
�L�p�ȏ������W������c�_�������Ȃ炱���ɗ��܂闝�R�͉���Ȃ����B
�ǂ����Ɍق��ĉ������`�������Ė�����藯�܂��Ă�Ȃ�b�͕ʂ����B
����ȃl�^�R�قǏo�Ă邼�i�Ƃ�����100%��������j�B
�L�p�ȏ������W������c�_�������Ȃ炱���ɗ��܂闝�R�͉���Ȃ����B
�ǂ����Ɍق��ĉ������`�������Ė�����藯�܂��Ă�Ȃ�b�͕ʂ����B
���炵�ɔ������������炵���ėǂ������b�����ǂȁB
����AMD�͂ǂ����������ɍs���̂��ȁH
����nVIDIA��CPU������ǂ�ȃA�[�L�ɂȂ邩�\�z����Ƃ킭�킭����̂���...
����AMD�͂ǂ����������ɍs���̂��ȁH
����nVIDIA��CPU������ǂ�ȃA�[�L�ɂȂ邩�\�z����Ƃ킭�킭����̂���...
��������x86�ȊO�̘b�͂��߂Ȃ́H
>>836
����K8�̉��ǂ����Ȃ��A�Ƃ������邯�ǁA
AMD������Ȃ�ɍl���đ��̃v���W�F�N�g���~�߂��͂��Ȃ킯�ŁB
SSE��������邻�������ǁA
��Intel�łԂ�������̃X�s�[�h�A�Ƃ����҂��Ȃ���ΐ��\�o��낤�ȁB
���o�C���E�g�ݍ��݂ł�GeodeNX���ŁA�A���P�~�[���p�AAMD�@Efficeon�͊m��B
>>837
ꌍb��̂悤�ȋC�����邪�A���̃X���ł�OK���ۂ��B
�l�I�ɂ�GS�̐��\�͎��͌��\�������ǁA�o�X�̃X�s�[�h���S�R����Ȃ������Ǝv���B
����K8�̉��ǂ����Ȃ��A�Ƃ������邯�ǁA
AMD������Ȃ�ɍl���đ��̃v���W�F�N�g���~�߂��͂��Ȃ킯�ŁB
SSE��������邻�������ǁA
��Intel�łԂ�������̃X�s�[�h�A�Ƃ����҂��Ȃ���ΐ��\�o��낤�ȁB
���o�C���E�g�ݍ��݂ł�GeodeNX���ŁA�A���P�~�[���p�AAMD�@Efficeon�͊m��B
>>837
ꌍb��̂悤�ȋC�����邪�A���̃X���ł�OK���ۂ��B
�l�I�ɂ�GS�̐��\�͎��͌��\�������ǁA�o�X�̃X�s�[�h���S�R����Ȃ������Ǝv���B
�ق�Ɩ�����肾�Ȃ�
>>839
��������܂��Ă�A�ƌ��������̂����m��Ȃ������͂W�R�V�ȑO�A
���Ȃ��Ƃ��T�O���X�͏�������łȂ��B
�����GS�����ǃo�X���_�����������琫�\���łȂ������A�ƌ����Ă���̂����B
���傢�Ɛ�ɂȂ邪�AAMD�̓A�����J�ɐV�H���炵���B45nm�̃j�N�C�z���B
�v���Z�X�Ō�o��q���Ă��錻�݂̏����P������Core�ƌ�����ׂ邱�ƂɂȂ邾�낤�B
��������܂��Ă�A�ƌ��������̂����m��Ȃ������͂W�R�V�ȑO�A
���Ȃ��Ƃ��T�O���X�͏�������łȂ��B
�����GS�����ǃo�X���_�����������琫�\���łȂ������A�ƌ����Ă���̂����B
���傢�Ɛ�ɂȂ邪�AAMD�̓A�����J�ɐV�H���炵���B45nm�̃j�N�C�z���B
�v���Z�X�Ō�o��q���Ă��錻�݂̏����P������Core�ƌ�����ׂ邱�ƂɂȂ邾�낤�B
32nm�ł���
>>841
���܂�B�����Ԉ���Ă��B
���܂�B�����Ԉ���Ă��B
GS���Ă��͂�CPU�ł���Ȃ��킯����
844 �FSocket774�F2006/06/25(��) 15:52:57 ID:ufqsoiQ/
�����PowerPC���ŋ�����
Intel���������̘b������
Intel���������̘b������
Power PC 603 100MHz�̓q�[�g�V���N����t���ĂȂ��ᔭ�M������B
����603�Ȃ�ăA�b�v���Ƀ_���o���H������w�^��CPU����Ȃ����B
���������Ηǂ����e�}�[�N�ōċN�������ˁB
�������PowerPC�̂����Ȃ́H
����ASystem7�̂������Ǝv���B
�P�UMB�ł��ǂ����������Ǝv�����ǁB
�P�UMB�ł��ǂ����������Ǝv�����ǁB
����Talk�Ƃ��ň���������ł�����
>>846
�m���L���b�V����601�̔�����������ˁB
�ł������������Ƀ_���Ȃ̂�3DO2�ɓ��ڗ\�肾����FPU���X��602���������������ǁH
�m���L���b�V����601�̔�����������ˁB
�ł������������Ƀ_���Ȃ̂�3DO2�ɓ��ڗ\�肾����FPU���X��602���������������ǁH
�Q�e���m�e�N�m���W�����܂�����
>"Reverse(Anti)-Hyper-Threading"�Z�p���āA
>X2��2�̃R�A��������6IPC(3IPCx2��)�̃V���O���R�A���G�~�����[�g����Z�p�Ƃ̂���(CONROE��4IPC)�B
329 ���O�FSocket774[sage] ���e���F2006/06/24(�y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
�p�t�H�[�}���X�����AM2������Ȃ���B
939�ŏo����ΐ_�Ȃ̂ɂ�
336 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:38:21 ID:W3KCOSqT
Intel���������Ƃ�邻���ł���
�P���c��4�R�A��1CPU�ɂ�
98 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:33:05 ID:Utko172H
�Ȃ����悤�Ȃ̂��c
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
>"Reverse(Anti)-Hyper-Threading"�Z�p���āA
>X2��2�̃R�A��������6IPC(3IPCx2��)�̃V���O���R�A���G�~�����[�g����Z�p�Ƃ̂���(CONROE��4IPC)�B
329 ���O�FSocket774[sage] ���e���F2006/06/24(�y) 23:36:08 ID:GbdsoFH3
http://nueda.main.jp/blog/archives/002203.html
�p�t�H�[�}���X�����AM2������Ȃ���B
939�ŏo����ΐ_�Ȃ̂ɂ�
336 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:38:21 ID:W3KCOSqT
Intel���������Ƃ�邻���ł���
�P���c��4�R�A��1CPU�ɂ�
98 ���O�FSocket774[sage] ���e���F2006/06/25(��) 00:33:05 ID:Utko172H
�Ȃ����悤�Ȃ̂��c
CMT (Core Multiplexing Technology)
http://www.xtremesystems.org/forums/showthread.php?t=104178
�o�X�o�R��HT�ɂ��CPU�����ō����o�����B
Quadro���݂����Ȃ���ł��ˁB
�r�f�I�J�[�h�̓z��?
����͎g���ĂȂ���H���g���悤�ɂ����Ȃ��������B
�ނ���MAXX����B
����͎g���ĂȂ���H���g���悤�ɂ����Ȃ��������B
�ނ���MAXX����B
MAXX�͈Ⴄ�ȁB
���ꂾ�AVoodoo��2���g�B
���ꂾ�AVoodoo��2���g�B
GPU�͋��������C���ǂ��납�s�N�Z���P�ʂŗe�Ղɕ��ł��邯��
CPU�̃V���O���X���b�h���ǂ�������CPU�ɕ�����̂����������Ȃ��ȁB
CPU�̃V���O���X���b�h���ǂ�������CPU�ɕ�����̂����������Ȃ��ȁB
Kentsfield�ł����ď�����Ă邯�ǁAConroe/Merom�ł͖����Ȃ́H
Intel POWER��ް
�v��ǖƂ������A�t�H��Cell�ŎI�]�X�Ƃ���É]�X�Ƃ�
�����o�����̂����������̌�������ȁB
�Ƃǂ̂܂�A>>834��FA���Ǝv���B
�Ȍ�Cell�̘b�������Ȃ�Q�n�łǂ����B
�����o�����̂����������̌�������ȁB
�Ƃǂ̂܂�A>>834��FA���Ǝv���B
�Ȍ�Cell�̘b�������Ȃ�Q�n�łǂ����B
Cell����Ë@��ɓ��ڂ��āA������k�ɂ����������Ȃ��B
����Ȉ�Ë@��Ō����Ƃ����͂Ƃ����ꂽ���Ȃ���
����Ȉ�Ë@��Ō����Ƃ����͂Ƃ����ꂽ���Ȃ���
�ėpPowerPC�̗p�̈�Ë@��Ȃ�Ē���������Ȃ�����
CT��voxel��SPE�̃l�b�g���[�N�Ō����I�ɏ������悤���Ă̂�
���X�̈��ՂȎv�����Ȃ낤�P�hCell�Ȃ�ĕs�v����
�ǂ����Ă����Z�\�͕K�v�Ȃ�ASIC�g�߂Ηǂ����B
���X�̈��ՂȎv�����Ȃ낤�P�hCell�Ȃ�ĕs�v����
�ǂ����Ă����Z�\�͕K�v�Ȃ�ASIC�g�߂Ηǂ����B
���������ΐ̑咰����������������Ƃ��A
���̓��揈�����u����PowerPC���ڂȂ�ł�����Č����Z�t�������Ă��ȁB
���̂����܂����ٕ����ł���ǂ���ł͂Ȃ��������ǁE�E�E
���̓��揈�����u����PowerPC���ڂȂ�ł�����Č����Z�t�������Ă��ȁB
���̂����܂����ٕ����ł���ǂ���ł͂Ȃ��������ǁE�E�E
�����̔Z�l���l����A�ŗǂ�CPU�\�����Ăǂ�Ȃ̂��낤�B
�F�ǂ�Ȃ̂������Ǝv���Ă�̂������ÁX
�F�ǂ�Ȃ̂������Ǝv���Ă�̂������ÁX
AMD PowerPC
867 �FSocket774�F2006/06/25(��) 23:17:33 ID:rkVRUaDt
��O���}�Ƃ��Ă�Cell�͍ň����ȁB
�V���O���R�A��������ς�ł��̏�f���A���Ȃ猾�����ƂȂ��B
�A�[�L�e�N�`���͐����ǂ��ł������ₗ
�V���O���R�A��������ς�ł��̏�f���A���Ȃ猾�����ƂȂ��B
�A�[�L�e�N�`���͐����ǂ��ł������ₗ
��Ȃ�s�[�L�[��Cell�͖ʔ�����Ȃ��́H
SIMD�n�g��Ȃ���Ȃ炠�ꂾ���ǁB
SIMD�n�g��Ȃ���Ȃ炠�ꂾ���ǁB
�uCore Microarchitecture�v�̑����̔閧�́gCISC�̔��h
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
http://pc.watch.impress.co.jp/docs/2006/0626/kaigai285.htm
PS3��ffmpeg���点�ăG���R��conroe��athlonFX���R�U�炵�܂��B
GK��
>>871
�܂��A���́A�ȂA����ꂗ����
�܂��A���́A�ȂA����ꂗ����
874 �FSocket774�F2006/06/26(��) 21:51:24 ID:eZUkwCJE
����������A�N�^���b�V��(AAry
>>871
�G���R�������Ȃ�\����S�R�z���o���Ȃ��B
4x2 �� 2x4 ������lj��Z�p���[�h�ŃJ�R�J�R�X�g�[������l�������܂�
1������256byte�̃L���b�V���ς�łȂɂ��ł���̂��
�G���R�������Ȃ�\����S�R�z���o���Ȃ��B
4x2 �� 2x4 ������lj��Z�p���[�h�ŃJ�R�J�R�X�g�[������l�������܂�
1������256byte�̃L���b�V���ς�łȂɂ��ł���̂��
����PowerPC���g�����������̘b�Ȃ̂ŁA���Ȃ�
AMD��4�~4�B
http://pc.watch.impress.co.jp/docs/2006/0626/amd.htm
����Ȃ���A����ۂNj��ɗ]�T�����郄�c����Ȃ��Ƃł����Ȃ��c�B
���������A���v�ŏ���d�͂ǂꂮ�炢�ɂȂ�H
http://pc.watch.impress.co.jp/docs/2006/0626/amd.htm
����Ȃ���A����ۂNj��ɗ]�T�����郄�c����Ȃ��Ƃł����Ȃ��c�B
���������A���v�ŏ���d�͂ǂꂮ�炢�ɂȂ�H
�P����2�{�ł���H
�}�U�[��������ƕς�10����������ʂ�
15��+12��x2+9��x2+���X = 60�� Windows�t�����̂�����Ɨǂ��p�\�R���Ȃ畁�ʂ̒l�i
�}�U�[��������ƕς�10����������ʂ�
15��+12��x2+9��x2+���X = 60�� Windows�t�����̂�����Ɨǂ��p�\�R���Ȃ畁�ʂ̒l�i
4�~4��AMD�����s��ȃM���O
SONAR���ĉ��y����\�t�g����Ȃ����������B
�O���t�B�b�N���\�v��̂�?
�O���t�B�b�N���\�v��̂�?
���[�ƁAAM2�Ńf���A���\�P�b�g������Ȃ́H
Opteron 1xxx��Athlon64�V���[�Y�ł��f���A���ł���悤�ɂȂ���Ď����ˁB
Opteron 1xxx��Athlon64�V���[�Y�ł��f���A���ł���悤�ɂȂ���Ď����ˁB
2�䔃������4x4�̕��������d�͂Œቿ�i�Ȃ�B
���̒��p�\�R�������ł͂Ȃ��̂���B
�ǂ����삪�������B
���̒��p�\�R�������ł͂Ȃ��̂���B
�ǂ����삪�������B
����Woodcrest�Ɣ�r���������Ȏq������? >>4x4
AMD��RHT�Ƃ�炪�ǂ̒��x�̃p�t�H�[�}���X���҂���̂��^�ʖڂɌ������Ă݂���
�C�����邯�ǖʓ|�ɂȂ��Ă���
�[���債�����\�o�Ȃ����낤���Ȃ��A���ʂɍl����
�C�����邯�ǖʓ|�ɂȂ��Ă���
�[���債�����\�o�Ȃ����낤���Ȃ��A���ʂɍl����
���������ǂ������d�g�݂�����n�b�L�����ĂȂ����猟�����ł��Ȃ�����B
���҂ł���d�g�݂��Ƃ����Ă������I�ɔz���x���Ƃ������Đ��\�o�Ȃ������m��B
���҂ł���d�g�݂��Ƃ����Ă������I�ɔz���x���Ƃ������Đ��\�o�Ȃ������m��B
>>881
�O���t�B�b�N���\�́A���������}���`�f�B�X�v���C���ł�����x�̂��̂�����Ώ\�������A
CPU�p���[�ׂ͂�ڂ��ɂ���B
�f���A���\�P�b�g�Ńf���A���R�A���AMCM�ŃN�A�b�h�R�A���o���Ă��ꂽ����10�{���炢�ǂ����A
MCM�̃m�E�n�E�����܂莝���ĂȂ��Ƃ��A
�]����FX�Ɠ����N���b�N���������悤�Ƃ���ƒʏ�̃N�[���[�ƃq�[�g�X�v���b�_�ŗ�p�ł���
�M���x�̏����ꡂ��ɒ����Ă��܂��Ƃ��A������������͂���̂��낤�B
�O���t�B�b�N���\�́A���������}���`�f�B�X�v���C���ł�����x�̂��̂�����Ώ\�������A
CPU�p���[�ׂ͂�ڂ��ɂ���B
�f���A���\�P�b�g�Ńf���A���R�A���AMCM�ŃN�A�b�h�R�A���o���Ă��ꂽ����10�{���炢�ǂ����A
MCM�̃m�E�n�E�����܂莝���ĂȂ��Ƃ��A
�]����FX�Ɠ����N���b�N���������悤�Ƃ���ƒʏ�̃N�[���[�ƃq�[�g�X�v���b�_�ŗ�p�ł���
�M���x�̏����ꡂ��ɒ����Ă��܂��Ƃ��A������������͂���̂��낤�B
>>885
�V���O���X���b�h���\�ł�1�N�����ĂقƂ�Ǐオ���ĂȂ���������AX2�o��Ɠ����ɓ������ė~���������˂�
Pentium4/D�̏�����̐��\�ɋ�����������Conroe�Ɏ肱����킯������
�V���O���X���b�h���\�ł�1�N�����ĂقƂ�Ǐオ���ĂȂ���������AX2�o��Ɠ����ɓ������ė~���������˂�
Pentium4/D�̏�����̐��\�ɋ�����������Conroe�Ɏ肱����킯������
�C���e���A�R�~���j�P�[�V�����Y�����6���h���Ŕ��p
http://headlines.yahoo.co.jp/hl?a=20060627-00000015-cnet-sci
http://headlines.yahoo.co.jp/hl?a=20060627-00000015-cnet-sci
462 �F ���������� [sage] �F2006/06/24(�y) 23:29:26
>>460
>>191�̂���ˁB
������ƈˑ��W�����Ď��s������A���Ԓʂ�Ƀ��^�C���������肷��̂��A
��̂ǂ�����Ď�������̂������ɋ^�₾�B
������A�ʃR�A�Ńf�R�[�h���ꂽ���߂Ƃ̈ˑ��W�ׂȂ��Ƃ����Ȃ��̂��B
�X�ɕʃR�A�̌v�Z���ʂ�clk�ň��������Ă����肷��K�v������B
���ꂶ����������1�R�ACPU�̃n�C�p�[�X���b�f�B���O����˂��B
472 �F ���������� [] �F2006/06/26(��) 03:10:08
���ۂɂ͂����������x���ł������Ȃ��C������B
for ( i = 0; i < 10000; i++) a[i] = Foo( b[i] ) ;
��
core0:�@for ( i = 0; i < 5000; i++) a[i] = Foo( b[i] ) ;
core1:�@for ( i = 5000; i < 10000; i++) a[i] = Foo( b[i] ) ;
474 �F ���������� [sage] �F2006/06/26(��) 16:59:25
>>469
�s���̂����U�蕪����CPU���l����ɂ��A�f�R�[�h���Ȃ��Ƃ����Ȃ����A
����ł��ꂾ�����R�A�ւ̎Q�Ƃ���������ƂȂ�ƕ��ʂȂ疳�Ӗ�����Ȃ��B
�܂��AIPC6��_���Ƃ��������A����IPC��1.3�̃P�[�X��1.5���o��Ζ��X�A
�Ƃ����Z�p���Ǝv���B
>>472
���ꂱ���R���p�C�����Ή����ׂ��ł��傤�B
�Ă���������ȋZ�p��������i���Ƃ��Ắj���ҊO��������Ƃ����B
�ł��R�A���m�����ڂɗ��ݍ������ċZ�p�I�ɂ��肦�Ȃ��������Ȃ��E�E�E�B
>>460
>>191�̂���ˁB
������ƈˑ��W�����Ď��s������A���Ԓʂ�Ƀ��^�C���������肷��̂��A
��̂ǂ�����Ď�������̂������ɋ^�₾�B
������A�ʃR�A�Ńf�R�[�h���ꂽ���߂Ƃ̈ˑ��W�ׂȂ��Ƃ����Ȃ��̂��B
�X�ɕʃR�A�̌v�Z���ʂ�clk�ň��������Ă����肷��K�v������B
���ꂶ����������1�R�ACPU�̃n�C�p�[�X���b�f�B���O����˂��B
472 �F ���������� [] �F2006/06/26(��) 03:10:08
���ۂɂ͂����������x���ł������Ȃ��C������B
for ( i = 0; i < 10000; i++) a[i] = Foo( b[i] ) ;
��
core0:�@for ( i = 0; i < 5000; i++) a[i] = Foo( b[i] ) ;
core1:�@for ( i = 5000; i < 10000; i++) a[i] = Foo( b[i] ) ;
474 �F ���������� [sage] �F2006/06/26(��) 16:59:25
>>469
�s���̂����U�蕪����CPU���l����ɂ��A�f�R�[�h���Ȃ��Ƃ����Ȃ����A
����ł��ꂾ�����R�A�ւ̎Q�Ƃ���������ƂȂ�ƕ��ʂȂ疳�Ӗ�����Ȃ��B
�܂��AIPC6��_���Ƃ��������A����IPC��1.3�̃P�[�X��1.5���o��Ζ��X�A
�Ƃ����Z�p���Ǝv���B
>>472
���ꂱ���R���p�C�����Ή����ׂ��ł��傤�B
�Ă���������ȋZ�p��������i���Ƃ��Ắj���ҊO��������Ƃ����B
�ł��R�A���m�����ڂɗ��ݍ������ċZ�p�I�ɂ��肦�Ȃ��������Ȃ��E�E�E�B
479 �F ���������� [sage] �F2006/06/27(��) 00:30:42
>>472
���ꉽ��OpenMP?
��OpenMP��VisualC++�ɂ������Ă�̂ł܂Ƃ��ȋK�i�Ȃ畁�y����ł��傤�B
�N���X�^�̂悤�Ȃ��͕̂��G�Ȃ̂�������܂��A
�P�����[�v���X���b�h�ɕ������邭�炢�Ȃ�ȒP�ɏo����킯�ł�����
��{�I�ɂ�OpenMP�������u���Ă킴�킴��p�\�t�g�������炦��܂ł��Ȃ��ł���
Intel��CPU��ł����l�ɓ����R�[�h���o���オ��̂ŃA�h�o���e�[�W�ɂȂ�܂���B
�t�Ɏ㏬AMD��CPU�ł��������Ȃ��悤�ȑ㕨(uOPs�o�C�i����f���Ƃ�)�ł���A
3DNow!�̓�̕��ł��B
OpenMP���g���ɂ����A�܂Ƃ�����Ȃ��Ƃ����̂�
AMD���Ǝ��̃c�[�������Ƃ����̂̓A���ł����ACPU�̋@�\�Ƃ͌����܂���B
>>472
���ꉽ��OpenMP?
��OpenMP��VisualC++�ɂ������Ă�̂ł܂Ƃ��ȋK�i�Ȃ畁�y����ł��傤�B
�N���X�^�̂悤�Ȃ��͕̂��G�Ȃ̂�������܂��A
�P�����[�v���X���b�h�ɕ������邭�炢�Ȃ�ȒP�ɏo����킯�ł�����
��{�I�ɂ�OpenMP�������u���Ă킴�킴��p�\�t�g�������炦��܂ł��Ȃ��ł���
Intel��CPU��ł����l�ɓ����R�[�h���o���オ��̂ŃA�h�o���e�[�W�ɂȂ�܂���B
�t�Ɏ㏬AMD��CPU�ł��������Ȃ��悤�ȑ㕨(uOPs�o�C�i����f���Ƃ�)�ł���A
3DNow!�̓�̕��ł��B
OpenMP���g���ɂ����A�܂Ƃ�����Ȃ��Ƃ����̂�
AMD���Ǝ��̃c�[�������Ƃ����̂̓A���ł����ACPU�̋@�\�Ƃ͌����܂���B
485 �F ���������� [sage] �F2006/06/27(��) 08:58:15
>>481
����A�f�R�[�h�����u��Łv�U�蕪���Ȃ��Ƃ����Ȃ��Ƃ������Ɓi���߂̓f�R�[�_��I�ׂȂ��j�B
�܂�A�p�C�v���C���̓r���Ŗ��߂��Ⴄ�R�A�ɑ���K�v���o�Ă���B
�R�A�ԒʐM�̐�����������R�X�g�͂������Ǝv�����A�R�A�̐v�����Ȃ�ς���K�v������B
�܂��A�U�蕪�����l����̂���ςȍ�ƂŁA�p�C�v���C���������Ȃ�Ǝv���B
Core1��Core0�̒S����\�����邱�Ƃɂ��ẮACore1�ɓ��������߂�m��K�v������̂�
�\���͕s�\�ł���A�����ʐM�R�X�g��������Core0���狳���Ă��炤�����Ȃ��B
> ���������}���`�R�A�ł�点��̂ł�*����*�Ƃ�����
����A���������̋Z�p�̃L�����Ǝv���B����͖{���Ɋ������B
�������A�����炱������B
�ȑO�i>>191�̂Ƃ��j������FPU�����L�Ƃ����̂͂ǂ����낤�B
6IPC�Ƃ����Ŕ͎��s���j�b�g�����ŁA�f�R�[�h�E���^�C����3IPC�Ɏ~�܂�Ƃ������́B
�����A
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai_5.jpg
���̕ӂ�̃��C�A�E�g������ƁA�e�R�A��SIMD���j�b�g�͕����I�ɗ���܂����Ă���B
����ǂ��납�A��clk�ŃR�A�ԒʐM�Ȃǂ��A�ƂĂ������������B
3GHz�Ȃ�A1clk�Ō���10cm�����i�߂Ȃ����E������˂��B
���������ŏ����ĂĐ�]�I�ȋC���ɂȂ��Ă�����orz
�ˑ��W�̃`�F�b�N������OoO�̃X�P�W���[���Ƃ��A���ԂɃ��^�C���Ƃ��A
�����ł����d�͐H���ƌ�����d�������Ȃ̂ɁA�Ⴄ�R�A�ɂ��閽�߂Ƃł���킯���Ȃ��B
�{����6IPC���\�Ȃ�A�Ƃ����ɃV���O���R�A�ł������Ă�͂��i�f���A���Ȃo�����Ɂj�B
�ł��Ȃ����ǁA�������̂Ă邱�ƂŁA�f���A���R�A��6IPC�̉��zCPU����ꂽ�B
���₠�A�����̂ĂȂ��Ƃł������ɂȂ��ł��B�B
>>481
����A�f�R�[�h�����u��Łv�U�蕪���Ȃ��Ƃ����Ȃ��Ƃ������Ɓi���߂̓f�R�[�_��I�ׂȂ��j�B
�܂�A�p�C�v���C���̓r���Ŗ��߂��Ⴄ�R�A�ɑ���K�v���o�Ă���B
�R�A�ԒʐM�̐�����������R�X�g�͂������Ǝv�����A�R�A�̐v�����Ȃ�ς���K�v������B
�܂��A�U�蕪�����l����̂���ςȍ�ƂŁA�p�C�v���C���������Ȃ�Ǝv���B
Core1��Core0�̒S����\�����邱�Ƃɂ��ẮACore1�ɓ��������߂�m��K�v������̂�
�\���͕s�\�ł���A�����ʐM�R�X�g��������Core0���狳���Ă��炤�����Ȃ��B
> ���������}���`�R�A�ł�点��̂ł�*����*�Ƃ�����
����A���������̋Z�p�̃L�����Ǝv���B����͖{���Ɋ������B
�������A�����炱������B
�ȑO�i>>191�̂Ƃ��j������FPU�����L�Ƃ����̂͂ǂ����낤�B
6IPC�Ƃ����Ŕ͎��s���j�b�g�����ŁA�f�R�[�h�E���^�C����3IPC�Ɏ~�܂�Ƃ������́B
�����A
http://pc.watch.impress.co.jp/docs/2006/0522/kaigai_5.jpg
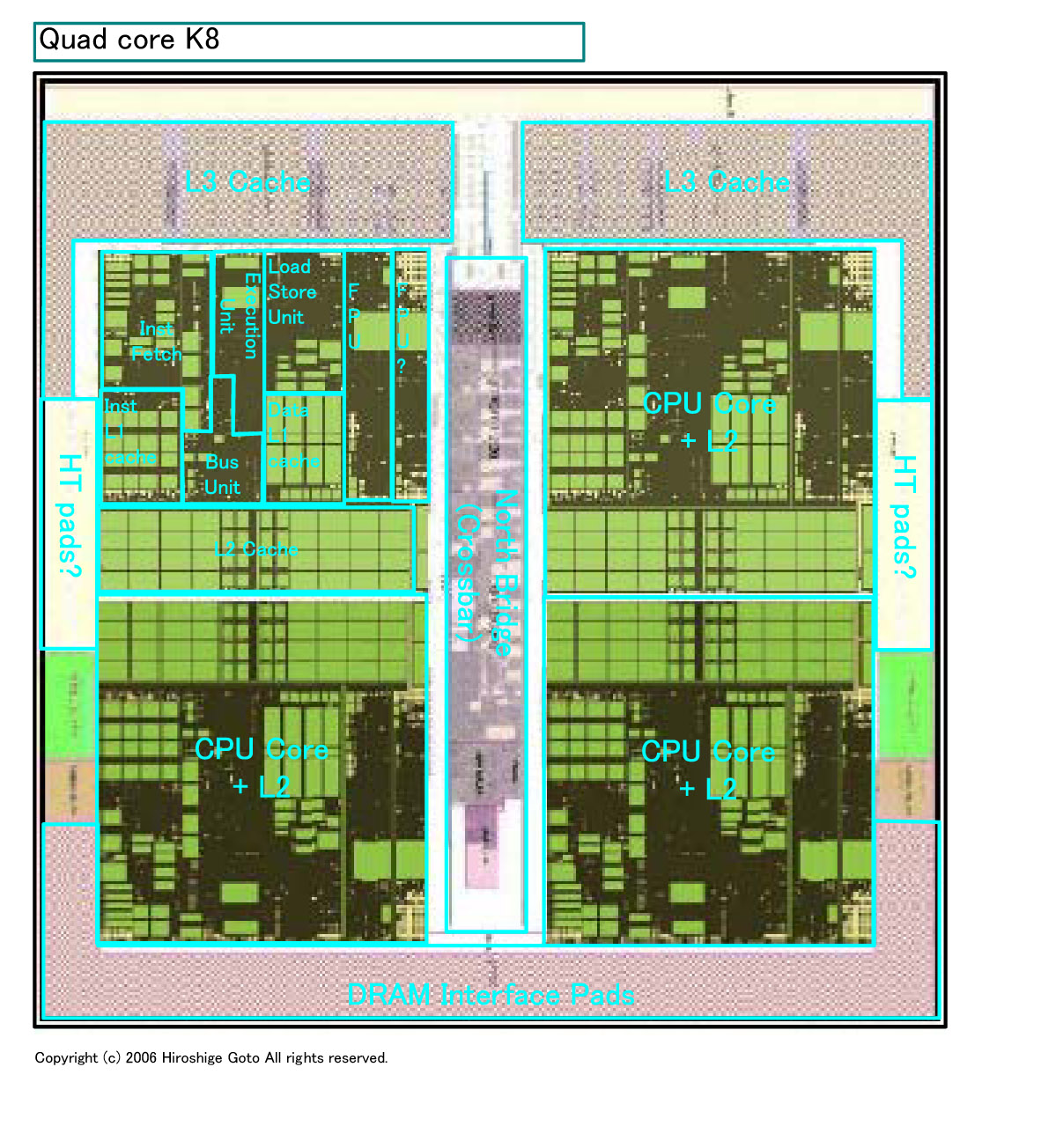{kind=link}
���̕ӂ�̃��C�A�E�g������ƁA�e�R�A��SIMD���j�b�g�͕����I�ɗ���܂����Ă���B
����ǂ��납�A��clk�ŃR�A�ԒʐM�Ȃǂ��A�ƂĂ������������B
3GHz�Ȃ�A1clk�Ō���10cm�����i�߂Ȃ����E������˂��B
���������ŏ����ĂĐ�]�I�ȋC���ɂȂ��Ă�����orz
�ˑ��W�̃`�F�b�N������OoO�̃X�P�W���[���Ƃ��A���ԂɃ��^�C���Ƃ��A
�����ł����d�͐H���ƌ�����d�������Ȃ̂ɁA�Ⴄ�R�A�ɂ��閽�߂Ƃł���킯���Ȃ��B
�{����6IPC���\�Ȃ�A�Ƃ����ɃV���O���R�A�ł������Ă�͂��i�f���A���Ȃo�����Ɂj�B
�ł��Ȃ����ǁA�������̂Ă邱�ƂŁA�f���A���R�A��6IPC�̉��zCPU����ꂽ�B
���₠�A�����̂ĂȂ��Ƃł������ɂȂ��ł��B�B
����l���邩�����B
GPU���Ă݂Ȃ�B
GPU���Ă݂Ȃ�B
������ς���������l���ĂȂ��Ǝv�����ǂ�
�ŁAGPU�̉�����������́H
�ŁAGPU�̉�����������́H
�����ŃN���X�^�̏o�Ԃł�
�A�E�g�I�u�I�[�_�̈Ӗ����킩���ĂȂ�
�R�v���Z�b�T�̈Ӗ����킩���ĂȂ�
��m(ry�@�͏��F���̒��x
�R�v���Z�b�T�̈Ӗ����킩���ĂȂ�
��m(ry�@�͏��F���̒��x
>>753
ttp://www.riken.jp/r-world/info/release/press/2006/060619/index.html
> �C���e���А��̍ŐV�̃f���A���R�A �C���e��R XeonR�v���Z�b�T�[ 5000�ԑ�i�J���R�[�h���F Dempsey�j
> �R�A��256���ڂ�������T�[�o�[64��ƁA�C���e��R XeonR�v���Z�b�T�[ 3.2GHz(2���L���b�V��1MB)�R�A��
> 74���ڂ�������T�[�o�[37���ڑ�������K�͂ȍ\��
(����)
> ���V�X�e���́A����̂���Ȃ鐫�\����Ɍ����A������̃}�C�N���A�[�L�e�N�`���[�A�C���e��R CoreTM �}�C�N��
> �A�[�L�e�N�`���[�Ɋ�Â��f���A���R�A �C���e�� Xeon �v���Z�b�T�[5100�ԑ�i�J���R�[�h���FWoodcrest�j��
> �ڍs����\��ŁA���łɌ��؍�Ƃ��J�n���Ă��܂��B
ttp://pc.watch.impress.co.jp/docs/2006/0626/intel2_13.jpg
�����ɂ�����ƂɂȂ���Dempsey�ܲ��
ttp://www.riken.jp/r-world/info/release/press/2006/060619/index.html
> �C���e���А��̍ŐV�̃f���A���R�A �C���e��R XeonR�v���Z�b�T�[ 5000�ԑ�i�J���R�[�h���F Dempsey�j
> �R�A��256���ڂ�������T�[�o�[64��ƁA�C���e��R XeonR�v���Z�b�T�[ 3.2GHz(2���L���b�V��1MB)�R�A��
> 74���ڂ�������T�[�o�[37���ڑ�������K�͂ȍ\��
(����)
> ���V�X�e���́A����̂���Ȃ鐫�\����Ɍ����A������̃}�C�N���A�[�L�e�N�`���[�A�C���e��R CoreTM �}�C�N��
> �A�[�L�e�N�`���[�Ɋ�Â��f���A���R�A �C���e�� Xeon �v���Z�b�T�[5100�ԑ�i�J���R�[�h���FWoodcrest�j��
> �ڍs����\��ŁA���łɌ��؍�Ƃ��J�n���Ă��܂��B
ttp://pc.watch.impress.co.jp/docs/2006/0626/intel2_13.jpg
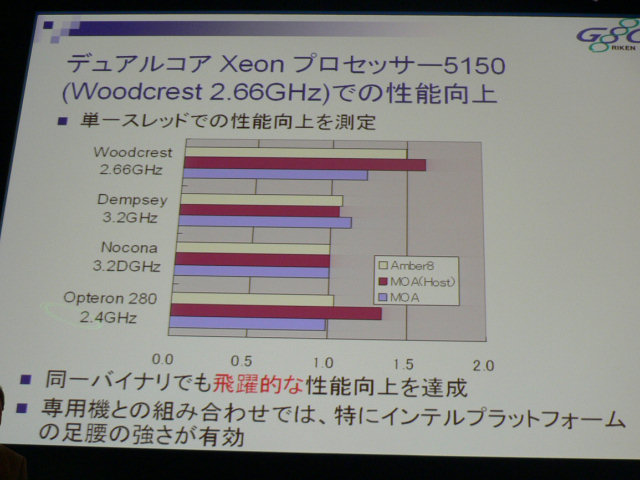{kind=link}
�����ɂ�����ƂɂȂ���Dempsey�ܲ��
80286�Ƃ�V33�Ƃ���32bit���[�h�̕������z
�����Ȃ���͖��������K���Ă鏈���Ȃ炢���R�A�������Ă����p�ł�����Ď��B
����ȊȒP�Ȏ����킩��Ȃ��n�����ɋC�Â��ĂȂ��B
�G���R���l���Ă݂悤�B
4���̃R�A����ĂɃr�f�I�̐擪����G���R���n�߂�Ƒ卬�����B
��ʂ�4�������Ă݂悤��?
������ʓ|�B
�r�f�I��4���ɕ������Ă��ꂼ������ꂼ��̃R�A�ŃG���R�����邭�炢�̒m�b�͂���킯�B
4�{�̃r�f�I���G���R������̂Ɠ����B
�ׂ̃R�A��������Ă邩�Ȃ�ĊW�Ȃ��B
GPU�͍��x�ȉ��Z���s�����s�N�Z���P�ʁA�e�p�C�v���C�����Ɨ����Ďd���ł���B
�����Ȃ�悤�Ƀ}�C�N���\�t�g��DirectX��v���Ă�B
����ȊȒP�Ȏ����킩��Ȃ��n�����ɋC�Â��ĂȂ��B
�G���R���l���Ă݂悤�B
4���̃R�A����ĂɃr�f�I�̐擪����G���R���n�߂�Ƒ卬�����B
��ʂ�4�������Ă݂悤��?
������ʓ|�B
�r�f�I��4���ɕ������Ă��ꂼ������ꂼ��̃R�A�ŃG���R�����邭�炢�̒m�b�͂���킯�B
4�{�̃r�f�I���G���R������̂Ɠ����B
�ׂ̃R�A��������Ă邩�Ȃ�ĊW�Ȃ��B
GPU�͍��x�ȉ��Z���s�����s�N�Z���P�ʁA�e�p�C�v���C�����Ɨ����Ďd���ł���B
�����Ȃ�悤�Ƀ}�C�N���\�t�g��DirectX��v���Ă�B
���[���A�����SF�ɏo�Ă��邢�������Ȗ��̋Z�p�̉����ǂ�ł�C���ł��B
>>900
�c�c�ŁH
�c�c�ŁH
�v���Ԃ�Ƀ��l�T�X�̃z�[���y�[�W������SH5�Ƃ����P�ꂪ��ł��Ă����B
�܂��������B
�܂��������B
>>900
�K���Ă��鏈���ł��V���O���X���b�h�ŏ�����Ă����犈�p�ł��Ȃ��ł���B
���������P�[�X�ł��f���A���R�A�����p�ł����炢���ȂƂ����b�B
�X�ɁA�f���A���R�A�ł͍������ł��Ȃ���������������������
�\������߂Ă���̂ŁA�{���������炷�������ƂȂ킯�B
�K���Ă��鏈���ł��V���O���X���b�h�ŏ�����Ă����犈�p�ł��Ȃ��ł���B
���������P�[�X�ł��f���A���R�A�����p�ł����炢���ȂƂ����b�B
�X�ɁA�f���A���R�A�ł͍������ł��Ȃ���������������������
�\������߂Ă���̂ŁA�{���������炷�������ƂȂ킯�B
>>904
OpenMP���A���_�[���̖@�����낭�ɒm��Ȃ����ӂ��ł���?
OpenMP���A���_�[���̖@�����낭�ɒm��Ȃ����ӂ��ł���?
>>904
���[�ƁA�V���O���X���b�h�ȃR�[�h���畡���̃X���b�h�𒊏o������Ęb�ł����H
���[�ƁA�V���O���X���b�h�ȃR�[�h���畡���̃X���b�h�𒊏o������Ęb�ł����H
>>905
OpenMP���g����̂̓R���p�C���O����B
���ƂȂ��A���_�[���̖@�����o�Ă���B
>>906
���������b����ŏo�Ă����̂ŁB
���ۂǂ����͒m��Ȃ��B
OpenMP���g����̂̓R���p�C���O����B
���ƂȂ��A���_�[���̖@�����o�Ă���B
>>906
���������b����ŏo�Ă����̂ŁB
���ۂǂ����͒m��Ȃ��B
��������Ă����ł��Ȃ�(�������s��)����A���_�[�����Ȃ�Ă��̂�����킯�ŁB
�����I��@�ő�K�͂ȕ��������Ȃ��Ɩ�肪�N���邩��OpenMP��MPI�Ȃ�Ă��̂�����킯�ŁB
�����I��@�ő�K�͂ȕ��������Ȃ��Ɩ�肪�N���邩��OpenMP��MPI�Ȃ�Ă��̂�����킯�ŁB
�v�����>>852�̓f�}���ƁH�܂�����͉����v���B
>>906
�����炻�ꂪ�N���X�^
�����炻�ꂪ�N���X�^
>>910
�͂��H
�͂��H
���̃X����1��2��3�Ɨ��Ē��������x��������������
>>911
clustered microarchitecture�Ō������Ă݂�
clustered microarchitecture�Ō������Ă݂�
������CPU���F
���[�G���h�}�V���F�������R���g���[���APCI Express�A�O���t�B�b�N�X�@�\�����A�̍�IPC�P�R�A�B
�n�C�G���h�}�V���F�������R���g���[���APCI Express�@�\�����A��IPC�P�R�A�A�ȓd�̓R�A����
�ɂȂ�Ɨ\�z���Ă�B
���[�G���h�}�V���F�������R���g���[���APCI Express�A�O���t�B�b�N�X�@�\�����A�̍�IPC�P�R�A�B
�n�C�G���h�}�V���F�������R���g���[���APCI Express�@�\�����A��IPC�P�R�A�A�ȓd�̓R�A����
�ɂȂ�Ɨ\�z���Ă�B
��IPC�R�A2�`4, SIMD�R�A�����@����]�B
����IPC�R�A1��+�L���b�V���������ڂ�
Cell�ɒ������x���LL2�̗p�����悤�Ȃ̂Ƃ܂Ƃ��ȃR���p�C�����ڂ�
�}���`�R�A�A���Ƀw�e����CPU�Ɋւ��Ă�Intel�ɂ�����Ă��炢�����ˁB
ISA�͋��ʂŔėp�R�A�{float/double�����R�A�݂����ȑg�ݍ��킹�ɂȂ��Ă�̂��v�悵�Ă�����B
ISA�͋��ʂŔėp�R�A�{float/double�����R�A�݂����ȑg�ݍ��킹�ɂȂ��Ă�̂��v�悵�Ă�����B
>>918Conroe�Q��Pre�ȗ��łW�Ƃ����Ǝv��
�������������ł��Ȃ��ĕ��d�������Ƃ����̂��A���܂�v�����Ȃ���B
�{���Ƀ��x�����������˂�
�Ȃ�����A�̗����Reverse(Anti)-Hyper-Threading�̎����Ɨ������ĂȂ���������������悤�Ɋ�����킯�Ȃ�ł���
�����A>>921�Ƃ��̂��Ƃ��B
�Ƃ肠����R-HT�͑ʖڂ��Ǝv��
���R�FAMD�܂߂݂�ȁA����Ȃ��Ƃ��Ă����ʂ��Ǝv�������炱���A���̗����
�Ȃ��Ă���̂�
���R�FAMD�܂߂݂�ȁA����Ȃ��Ƃ��Ă����ʂ��Ǝv�������炱���A���̗����
�Ȃ��Ă���̂�
>>914
����Ȃ�Č��sPowerPC G4?
����Ȃ�Č��sPowerPC G4?
>>905
������Ƃ悭�킩���̂����A�V���O���X���b�h���}���`�X���b�h�ɂ��Ď��s�ł���悤�ɂȂ����Ƃ��āA
�A���_�[���̖@���ɂ����E�͓˔j�ł���̂��H
������Ƃ悭�킩���̂����A�V���O���X���b�h���}���`�X���b�h�ɂ��Ď��s�ł���悤�ɂȂ����Ƃ��āA
�A���_�[���̖@���ɂ����E�͓˔j�ł���̂��H
>>926
����Ⴈ�߁A
> �V���O���X���b�h���}���`�X���b�h�ɂ��Ď��s�ł���悤�ɂȂ����Ƃ��āA
���̍���ȑO����ǂ��������悤�ƍl���邩���悾�낤���B
����Ⴈ�߁A
> �V���O���X���b�h���}���`�X���b�h�ɂ��Ď��s�ł���悤�ɂȂ����Ƃ��āA
���̍���ȑO����ǂ��������悤�ƍl���邩���悾�낤���B
�g�ݍ��킹�̘b�Ȃ�ď��w���ł��킩�邱��
>>920
CPU�V�~�����[�V�����Ƃ���www
CPU�V�~�����[�V�����Ƃ���www
cell���t����]��������X�[�p�[�R���s���[�^�̐��\�����L���OTOP500�ɓ����ˁB
(PS3�ł͘b�ɂȂ�Ȃ�����cell���t����]������}�U�[�͉\���Ǝv��)
100�ʈȉ��̓X�[�o�[�R���s���[�^�̏̍��D���ׂ����B
�������Ȃ��ƃX�[�p�[�R���s���[�^�[���́`����ʔ�������B
(PS3�ł͘b�ɂȂ�Ȃ�����cell���t����]������}�U�[�͉\���Ǝv��)
100�ʈȉ��̓X�[�o�[�R���s���[�^�̏̍��D���ׂ����B
�������Ȃ��ƃX�[�p�[�R���s���[�^�[���́`����ʔ�������B
�@�@�܁@���@G�@K�@���@!
933 �FSocket774�F2006/06/29(��) 18:16:09 ID:qW7A/bXf
>>931
�g�т���̃J�L�R�Ȃ�Ŋm�F�ł��Ȃ�����
����top500����4Tflops���炢���炶��Ȃ����������H
�ق��ɂ�PS3��CELL�̐��\���o���Ȃ��Ƃ��˂����݂ǂ��떞��
�g�т���̃J�L�R�Ȃ�Ŋm�F�ł��Ȃ�����
����top500����4Tflops���炢���炶��Ȃ����������H
�ق��ɂ�PS3��CELL�̐��\���o���Ȃ��Ƃ��˂����݂ǂ��떞��
>>931
���悭������Ȃ����ǁACell���āA�{���x���������_���Z�̃X�s�[�h�ǂꂮ�炢�����������H
�Ȃ��A�����Ă����B�Ȃ��B
���悭������Ȃ����ǁACell���āA�{���x���������_���Z�̃X�s�[�h�ǂꂮ�炢�����������H
�Ȃ��A�����Ă����B�Ȃ��B
���̃t�B�j�b�V������������
>934
�{���x���������_���Z�̒�������������ɗp�ӂł��܂���B
���j�b�g�̌����͂܂����������ėe�Ղł��A���������\���B
PS3�ł͕K�v�Ȃ������B
>>933
(PS3�ł͘b�ɂȂ�Ȃ�����cell���t����]������}�U�[�͉\���Ǝv��)
���Ȃ����{����ǂ߂Ȃ��l?
�{���x���������_���Z�̒�������������ɗp�ӂł��܂���B
���j�b�g�̌����͂܂����������ėe�Ղł��A���������\���B
PS3�ł͕K�v�Ȃ������B
>>933
(PS3�ł͘b�ɂȂ�Ȃ�����cell���t����]������}�U�[�͉\���Ǝv��)
���Ȃ����{����ǂ߂Ȃ��l?
>>936
�\�z�ʂ�ނ�܂������H
�\�z�ʂ�ނ�܂������H
���X���̓V�n����͂����
���O�炢�������A���\��AMD�[�EIntel�[�EGK�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
������Cell�֘A�͈�؋֎~�Ƃ��܂��B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
���O�炢�������A���\��AMD�[�EIntel�[�EGK�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
������Cell�֘A�͈�؋֎~�Ƃ��܂��B
�����A�s�тȑ������~�߂�CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�܂��߂�Cell����肽���l�ɂ͂������A
��������������܂��B
��������������܂��B
Cell�͐�p�X���������Ă邩��Ȃ̂��B
�������ACPU��CPU�����ACell�݂̂͂Ԃ�̂͌l�I�����Ƃ����v���Ȃ����B
�������ACPU��CPU�����ACell�݂̂͂Ԃ�̂͌l�I�����Ƃ����v���Ȃ����B
Cell�l�^���̂͂Ȃ�����Ȃ��Ƃ͎v������
�ϑz100%�̂������̕��X���������Ă��邩��ȁE�E�E
�u�c���łĎ��������肵�Ď����x�[�X�Řb������Ȃ��Ȃ�܂ł�
�������ł�������Ȃ��́B�������U���Ȃ����f�����b�g�͂قƂ�ǂȂ��B
�ϑz100%�̂������̕��X���������Ă��邩��ȁE�E�E
�u�c���łĎ��������肵�Ď����x�[�X�Řb������Ȃ��Ȃ�܂ł�
�������ł�������Ȃ��́B�������U���Ȃ����f�����b�g�͂قƂ�ǂȂ��B
>>939
�t���b�v�t���b�v
�Ă��������ACell�̘b�̓n�[�h�E�F�A�ł�낤��B
����Ȃ���A����ɊW�̂���CPU�ɏœ_���i�낤��B
�t���b�v�t���b�v
�Ă��������ACell�̘b�̓n�[�h�E�F�A�ł�낤��B
����Ȃ���A����ɊW�̂���CPU�ɏœ_���i�낤��B
944 �FSocket774�F2006/06/29(��) 23:14:58 ID:5XAdfgpg
�����X�����Ǝv���Ă��̂ɂȁE�E�E
���̃X���ł�x86�̐��E�ɂ������Ĉ�̒��̊^������������킯��
���̃X���ł�x86�̐��E�ɂ������Ĉ�̒��̊^������������킯��
Cell�~�i�܁EGK�j���Cell�܂�
>>945
���������ӁB
���������ӁB
cell���Ėʔ������ƂȂ�����
3.2Ghz���ăN���b�N�͂���������
3.2Ghz���ăN���b�N�͂���������
>>939
���������A���\�ŊQ���ȃQ�n�~�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�Q�n�̐~�[�̓X���[����CPU�A�[�L�e�N�`���ɂ��Č�낤�I
���������A���\�ŊQ���ȃQ�n�~�ɐU��܂킳�ꂸ�A
�G���R���Ԃ��ǂ��Ƃ�PI���ǂ��Ƃ�����Ȃ��A
CPU�R�A�̃A�[�L�e�N�`���ɂ��Č��܂��傤�B
x86/RISC/CISC/�X�[�p�[�X�J��/VLIW/MIMD/SIMD
���ɂ��Č���Ă��悵�A
�t���b�v�t���b�v��H��������Pentium M�}���Z�[�A
CISC�Ȃ̂ɓ�����RISC��Pentium 4�}���Z�[�A
x86�Ȃ̂�32/64bit�R���p�`��Opteron�}���Z�[�A
�́X8086�̎����(�ȉ����E�E�E�����悵�B
�����A�Q�n�̐~�[�̓X���[����CPU�A�[�L�e�N�`���ɂ��Č�낤�I
�Ƃ����IA-32�̐������Z���\�������̂��ĂȂ�ł��낤?
�ƍl���Ă݂�
����Ă邩������Ȃ����A������O�̂��ƂȂ̂�������Ȃ����ǁA
IA-32��ALU�̑��ɃA�h���X�v�Z�p��AGU�������Ă�
���Ă��ƂŐ������Z��͎���2�{
����̂�������Ȃ���?��
�ƍl���Ă݂�
����Ă邩������Ȃ����A������O�̂��ƂȂ̂�������Ȃ����ǁA
IA-32��ALU�̑��ɃA�h���X�v�Z�p��AGU�������Ă�
���Ă��ƂŐ������Z��͎���2�{
����̂�������Ȃ���?��
SPARC���ARM���POWER���PA-RISC���EPIC�������ʂɌ���Ă���X���ł���
GK�ɂ͂��ꂪ�킩���̂ł�
Cell�ʂɌ��Ȃ����͋C��������̂�GK
�����A�����̂�GK
GK�ɂ͂��ꂪ�킩���̂ł�
Cell�ʂɌ��Ȃ����͋C��������̂�GK
�����A�����̂�GK
>>949
IA32�}�V���̐������Z���\�������̂ł͂Ȃ��āA���������_���Z���\���Ⴂ�����B
�Ȃ̂œ������炢�̕��������_���Z���\�̂ق��̃}�V���������Ă���ΐ������Z���\��
����������B
IA32�}�V���̐������Z���\�������̂ł͂Ȃ��āA���������_���Z���\���Ⴂ�����B
�Ȃ̂œ������炢�̕��������_���Z���\�̂ق��̃}�V���������Ă���ΐ������Z���\��
����������B
Cell�֎~�͖����������ق����������낤�ȁB
�����瓪����������B
Cell 64
http://game10.2ch.net/test/read.cgi/ghard/1151116507/
�����瓪����������B
Cell 64
http://game10.2ch.net/test/read.cgi/ghard/1151116507/
Cell��GPU�Ƃ��Ďg�����Ƃ��Ăł���H
�ł���Ƃ�����ANVIDIA��ATi��GPU�Ō�������ǂꂮ�炢�ɑ������鐫�\�ɂȂ�H
�ł���Ƃ�����ANVIDIA��ATi��GPU�Ō�������ǂꂮ�炢�ɑ������鐫�\�ɂȂ�H
�Q�n�~�̍D���ȔB
1.�����
2.AV��
3.�n�[�h��
���̂�����̔ł��ނ�͌����Ă���܂��B
1.�����
2.AV��
3.�n�[�h��
���̂�����̔ł��ނ�͌����Ă���܂��B
>>953
�v���O���}�u���ȃv���Z�b�T�Ȃ�A���_��ǂ�ȉ��Z�ł��ł���
�t�@�~�R����CPU�����Ė����ȃo���N��ւ�(�_����Ԉȏ�
���������ɃA�N�Z�X���邽�߂̋@�\�̈��)�����
GPU�Ɠ������Z�ł����
�v���O���}�u���ȃv���Z�b�T�Ȃ�A���_��ǂ�ȉ��Z�ł��ł���
�t�@�~�R����CPU�����Ė����ȃo���N��ւ�(�_����Ԉȏ�
���������ɃA�N�Z�X���邽�߂̋@�\�̈��)�����
GPU�Ɠ������Z�ł����
>>956
Cell��GPU�Ƃ��Ďg������A�p�t�H�[�}���X�͂ǂꂮ�炢�o����ˁH
Cell��GPU�Ƃ��Ďg������A�p�t�H�[�}���X�͂ǂꂮ�炢�o����ˁH
>>951
SPECint2000�ł�IA32�ɏ��Ă���̂Ȃ�
SPECint2000�ł�IA32�ɏ��Ă���̂Ȃ�
959 �FSocket774�F2006/06/30(��) 01:24:56 ID:s7rlq+CV
>>944
�����炳�A�����͎���PC�Ȃ́B
����PC�Ɏg���Ȃ�CPU�͔Ⴂ�B
��r�ΏۂƂ��ċ�����̂͂������ǁA���C���Ɍ���Ă̓_���Ȃ́B
x86�ȊO�̘b���������Ȃ��̂ł͂Ȃ��A
�n�[�h�E�F�A��x86�ȊO�̘b���������́B
����Ŏ���PC�Ɏg����CPU��x86�n�ȊO�ƂȂ��IA-64���炢�����Ȃ����ǂȁB
Windows�łȂ��Ă�Linux�ł����������ƂȂ�AuCLinux������H8�}�C�R�������e�ɓ��邯�ǁA�������PC�Ȃ̂�? �ƁB
�����炳�A�����͎���PC�Ȃ́B
����PC�Ɏg���Ȃ�CPU�͔Ⴂ�B
��r�ΏۂƂ��ċ�����̂͂������ǁA���C���Ɍ���Ă̓_���Ȃ́B
x86�ȊO�̘b���������Ȃ��̂ł͂Ȃ��A
�n�[�h�E�F�A��x86�ȊO�̘b���������́B
����Ŏ���PC�Ɏg����CPU��x86�n�ȊO�ƂȂ��IA-64���炢�����Ȃ����ǂȁB
Windows�łȂ��Ă�Linux�ł����������ƂȂ�AuCLinux������H8�}�C�R�������e�ɓ��邯�ǁA�������PC�Ȃ̂�? �ƁB
���쁁�����Ă�M/B��CPU�̑g�ݗ��Ă��� or �����ʂ莩��(�����Őv/����)
PC��AT�݊��@ or �p�[�\�i���R���s���[�^�I�H
����ɂ����x86�ȊO�����C���ɂȂ��Ă�OK���Ǝv�����c
���̕ӂǂ����ɒ�`���Ă�H
PC��AT�݊��@ or �p�[�\�i���R���s���[�^�I�H
����ɂ����x86�ȊO�����C���ɂȂ��Ă�OK���Ǝv�����c
���̕ӂǂ����ɒ�`���Ă�H
>>960
�Q����1�X��/2�X�������Ă���ɂ��ĂˁB
�Q����1�X��/2�X�������Ă���ɂ��ĂˁB
�Z�[���X���f����x�ɓ���Ƃ��Ⴂ������B
��r��PowerPC���Cell��炪�o�镪�ɂ͒N�����匾��Ȃ���B
�K���ɂȂ��Ă�̂͒��ߏo�����GK��������B
��r��PowerPC���Cell��炪�o�镪�ɂ͒N�����匾��Ȃ���B
�K���ɂȂ��Ă�̂͒��ߏo�����GK��������B
�܂��A���̃A�[�L�e�N�`���[�ɒE���㓙�A���Ă��Ƃɂ��Ă���������Ȃ��B
�E�U�C�̂��o�Ă�����X���Ⴂ������A���Ēǂ��Ԃ��āB
�E�U�C�̂��o�Ă�����X���Ⴂ������A���Ēǂ��Ԃ��āB