Intel�̎�����CPU�ɂ��Č�낤 17�v����
���O�X��
Intel�̎�����CPU�ɂ��Č�낤 16�v����
http://pc7.2ch.net/test/read.cgi/jisaku/1122463712/l50
���ߋ��X��
15 http://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
14 http://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 http://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 http://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 http://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 http://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
9 http://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
8 http://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
7 http://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
6 http://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
5 http://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
4 http://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
3 http://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
2 http://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
1 http://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
Intel�̎�����CPU�ɂ��Č�낤 16�v����
http://pc7.2ch.net/test/read.cgi/jisaku/1122463712/l50
���ߋ��X��
15 http://pc7.2ch.net/test/read.cgi/jisaku/1115570909/
14 http://pc7.2ch.net/test/read.cgi/jisaku/1108228581/
13 http://pc7.2ch.net/test/read.cgi/jisaku/1097947493/
12 http://pc5.2ch.net/test/read.cgi/jisaku/1089896048/
11 http://pc5.2ch.net/test/read.cgi/jisaku/1085287040/
10 http://pc5.2ch.net/test/read.cgi/jisaku/1079371291/
9 http://pc3.2ch.net/test/read.cgi/jisaku/1077935289/
8 http://pc3.2ch.net/test/read.cgi/jisaku/1076749130/
7 http://pc3.2ch.net/test/read.cgi/jisaku/1075729779/
6 http://pc3.2ch.net/test/read.cgi/jisaku/1074656386/
5 http://pc3.2ch.net/test/read.cgi/jisaku/1072672636/
4 http://pc3.2ch.net/test/read.cgi/jisaku/1069899330/
3 http://pc3.2ch.net/test/read.cgi/jisaku/1068220780/
2 http://pc3.2ch.net/test/read.cgi/jisaku/1064098746/
1 http://pc3.2ch.net/test/read.cgi/jisaku/1058361617/
���r�炵�E����E�~�[�E�A���h���͕��u����Ԍ��ʓI�ł��B�ԓ������ɍ폜�˗����o���܂��傤�B
�@���u�ł��Ȃ��l���r�炵�ł��B�}�^�[�����܂��傤�B
|
|
|
�E�f�X�N�g�b�v���[�h�}�b�v
Willamette-478 0.18��m��Pentium 4 2000�N11������
�@�@��0.13�ʉ�
Northwood 0.13��m��Pentium 4 2001�N12������
�@�@��90nm���A64bit�����ASSE3���̑��啝�ȕύX
Prescott 90nm��Pentium 4 2004�N2������
�@�@���L���b�V��2M��
Prescott 2M Pentium 4 6xx 2005�N2������
Smithfield �f���A���R�A Pentium D 2005�N5������
�E���o�C�����[�h�}�b�v
Banias�@0.13��m��Pentium M/Celeron M 2003�N1������
�@�@���L���b�V��2M���A�����̉���
Dothan�@90nm��Pentium M/Celeron M 2004�N5������
�E���㔭���\��H��CPU
CedarMill 65nm�v���Z�XCPU NetBurst�n
Presler�@65nm�Ńf���A���R�ACPU NetBurst�n
Yonah�@65nm�Ńf���A���R�ACPU SSE3
Merom 65nm�ł̃f�X�N�g�b�v&���o�C������CPU�R�A EM64T
Conroe�@65nm�Ńf���A���R�ACPU
Willamette-478 0.18��m��Pentium 4 2000�N11������
�@�@��0.13�ʉ�
Northwood 0.13��m��Pentium 4 2001�N12������
�@�@��90nm���A64bit�����ASSE3���̑��啝�ȕύX
Prescott 90nm��Pentium 4 2004�N2������
�@�@���L���b�V��2M��
Prescott 2M Pentium 4 6xx 2005�N2������
Smithfield �f���A���R�A Pentium D 2005�N5������
�E���o�C�����[�h�}�b�v
Banias�@0.13��m��Pentium M/Celeron M 2003�N1������
�@�@���L���b�V��2M���A�����̉���
Dothan�@90nm��Pentium M/Celeron M 2004�N5������
�E���㔭���\��H��CPU
CedarMill 65nm�v���Z�XCPU NetBurst�n
Presler�@65nm�Ńf���A���R�ACPU NetBurst�n
Yonah�@65nm�Ńf���A���R�ACPU SSE3
Merom 65nm�ł̃f�X�N�g�b�v&���o�C������CPU�R�A EM64T
Conroe�@65nm�Ńf���A���R�ACPU
�֘A�X��
intel�G�k�گ��
http://pc7.2ch.net/test/read.cgi/jisaku/1098932664/
Pentium M - Centrino - 33W
http://pc7.2ch.net/test/read.cgi/jisaku/1123902786/l50
Northwood Pentium4�F�̉� Part15
http://pc7.2ch.net/test/read.cgi/jisaku/1124199111/l50
Smithfield PentiumD�F�̉�
http://pc7.2ch.net/test/read.cgi/jisaku/1117890989/
Prescott Pentium4�F�̉�y�����F�b�z
http://pc7.2ch.net/test/read.cgi/jisaku/1112237419/
Celeron ���� Part6
http://pc7.2ch.net/test/read.cgi/jisaku/1119604058/
CeleronD Prescott Part4
http://pc7.2ch.net/test/read.cgi/jisaku/1106566395/
�ynocona�z�����XEON���I���̏E��yprestonia�z
http://pc7.2ch.net/test/read.cgi/jisaku/1114588731/
�yIA-64�zItanium2��p�X���E����3�y�A�C�e�j�A���z
http://pc7.2ch.net/test/read.cgi/jisaku/1097330852/
Intel uPs Info @�Vmac��
http://pc7.2ch.net/test/read.cgi/mac/1121683774/
intel�G�k�گ��
http://pc7.2ch.net/test/read.cgi/jisaku/1098932664/
Pentium M - Centrino - 33W
http://pc7.2ch.net/test/read.cgi/jisaku/1123902786/l50
Northwood Pentium4�F�̉� Part15
http://pc7.2ch.net/test/read.cgi/jisaku/1124199111/l50
Smithfield PentiumD�F�̉�
http://pc7.2ch.net/test/read.cgi/jisaku/1117890989/
Prescott Pentium4�F�̉�y�����F�b�z
http://pc7.2ch.net/test/read.cgi/jisaku/1112237419/
Celeron ���� Part6
http://pc7.2ch.net/test/read.cgi/jisaku/1119604058/
CeleronD Prescott Part4
http://pc7.2ch.net/test/read.cgi/jisaku/1106566395/
�ynocona�z�����XEON���I���̏E��yprestonia�z
http://pc7.2ch.net/test/read.cgi/jisaku/1114588731/
�yIA-64�zItanium2��p�X���E����3�y�A�C�e�j�A���z
http://pc7.2ch.net/test/read.cgi/jisaku/1097330852/
Intel uPs Info @�Vmac��
http://pc7.2ch.net/test/read.cgi/mac/1121683774/
��m�ꂸ�����Ȑl�X
2���邪�ǂ����폜�H
��������������
7 �FSocket774�F2005/08/29(��) 03:05:10 ID:CtFyN6P4
>>1
��
��
>>�O�X��1000
�K�[���B
Galaxy �͑S�Ĕ��^�u���[�h�T�[�o�Ȃ̂��ƌ�����Ă܂����B
���^�u���[�h�T�[�o���������Ă����������̂��B
�ǂ������肪�ƁB(��
�K�[���B
Galaxy �͑S�Ĕ��^�u���[�h�T�[�o�Ȃ̂��ƌ�����Ă܂����B
���^�u���[�h�T�[�o���������Ă����������̂��B
�ǂ������肪�ƁB(��
intel�ɂ���AMD�ɂ���AHPC�n��Power4+�̎��̂悤�Ƀ������ш摫��Ȃ�����
Dual�R�A�̕Е����E�����Ďg�����ɂȂ�Ȃ��Ɨǂ����ǁB�B�B
Dual�R�A�̕Е����E�����Ďg�����ɂȂ�Ȃ��Ɨǂ����ǁB�B�B
���x�ƃR�X�g�p�t�H�[�}���X���l�����1U 2�\�P�b�g��IB�ڑ��N���X�^���ȁB
RDMA��latency��Opteron > Xeon�ɂȂ�ƕ��������Ƃ�����̂�Opteron��
�K�������D�ʂł͂Ȃ��B�܂�͗p�r����B
>>9
����ȗp�r�ɂ̓x�N�g���}�V�����E�E�E
RDMA��latency��Opteron > Xeon�ɂȂ�ƕ��������Ƃ�����̂�Opteron��
�K�������D�ʂł͂Ȃ��B�܂�͗p�r����B
>>9
����ȗp�r�ɂ̓x�N�g���}�V�����E�E�E
>10
IB�ł�Pathscale�̂悤��HyperTransport�Ƀ_�C���N�g�Ɍq����������
RDMA�ł�Opteron�̕���Low�@Latency�̂悤�ł���B1.32us���������B
IB�ł�Pathscale�̂悤��HyperTransport�Ƀ_�C���N�g�Ɍq����������
RDMA�ł�Opteron�̕���Low�@Latency�̂悤�ł���B1.32us���������B
>>12
PCI-X��PCIe��IB�Ɣ�r����ƃR�X�g�����BIB���j�b�`�ɂȂ�����ȁB
�ŏ��̗\��ʂ�`�b�v�Z�b�g��IB���g�ݍ��܂�Ă���Ȃ��E�E�E
PCI-X��PCIe��IB�Ɣ�r����ƃR�X�g�����BIB���j�b�`�ɂȂ�����ȁB
�ŏ��̗\��ʂ�`�b�v�Z�b�g��IB���g�ݍ��܂�Ă���Ȃ��E�E�E
>12
�܂������ł��ȁBHPC�͎s�ꎩ�̂��j�b�`�����ǁB�B�B
�`�v�Z�g��IB�g�ݍ��܂�Ă�����ATCPoverIB�Ƃ����邩��
�ӂ���PC�Ŏg���Ă����̂�������Ȃ��̂ɁB
QsNet�AInfiniBand�AMyrinet�ǂ��PC���փt�B�[�h�o�b�N���܂���˂�
�܂������ł��ȁBHPC�͎s�ꎩ�̂��j�b�`�����ǁB�B�B
�`�v�Z�g��IB�g�ݍ��܂�Ă�����ATCPoverIB�Ƃ����邩��
�ӂ���PC�Ŏg���Ă����̂�������Ȃ��̂ɁB
QsNet�AInfiniBand�AMyrinet�ǂ��PC���փt�B�[�h�o�b�N���܂���˂�
�������A�Ȃ����Ȃ��Ƃ�3hop���炢�Œm�l�̂悤�ȋC�����Ă������c
HPC�ŁA������IB����Ă�Ƃ����āA���Ȃ�������ˁB
(���Ȃ݂ɉ���IB�́A����ĂȂ��B1hop�̒m�l�ł͉��l�����邯��)
HPC�ŁA������IB����Ă�Ƃ����āA���Ȃ�������ˁB
(���Ȃ݂ɉ���IB�́A����ĂȂ��B1hop�̒m�l�ł͉��l�����邯��)
���̋ƊE�͋����̂ōő�2hop�ł�����܂��ˁB��w-������-���[�J�[
���͂����Ȃ��O���Ȃ̂ŁA����3�ɂ͓���܂���B(w
���������ς�3hop���ȁB
���������ς�3hop���ȁB
>>15-16
�ŋ߂�PC�N���X�^�̃��[�U�������Ă��Ă��邩��2hop�͂�����Ɩ���������܂���B
����HPC�̐l����Ȃ��ł����L���l(M�搶�Ƃ�)�܂�1hop��2hop�ł��ˁB
�����3hop�������I�ł��傤�B
�ŋ߂�PC�N���X�^�̃��[�U�������Ă��Ă��邩��2hop�͂�����Ɩ���������܂���B
����HPC�̐l����Ȃ��ł����L���l(M�搶�Ƃ�)�܂�1hop��2hop�ł��ˁB
�����3hop�������I�ł��傤�B
��ӂ���Ȃɂ��L�тĂ�Ǝv������B
Gk���Ƃ��������Ă����B
Gk���Ƃ��������Ă����B
��m�ꂸ������seRKraHs ��(߁��)!!
Gkf6/42t = �O���Ȃ̂��B
�Ȃ�قǁB�B�B
�Ȃ�قǁB�B�B
Banias�J���҂ɕ����AIntel�̎�����ȓd��CPU�Z�p
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
Mr.�G�f���̋����[���b�B
Yonah�͂��Ȃ�i�����Ă���Ƃ̂��ƁB
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
Mr.�G�f���̋����[���b�B
Yonah�͂��Ȃ�i�����Ă���Ƃ̂��ƁB
�{�c�����A�����Ɠ˂�����ŕ����Ă����[�B
>>22
���uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i��
�����Ă���Ƃ���ƁADothan����Yonah�ւ̐i���͂��̐��{���̑傫��
����������܂��BYonah����Merom�̐i���������ď������͂���܂��A
��Dothan����Yonah�ւ̕ω��قǑ傫�Ȃ��̂ł͂���܂���v
�܂�����́uPenM�n���̃f���A���R�A������ƂĂ��v��J������[�v���Ă��ƂȂ낤�ȁB
���\�ʂł�Yonah��Merom�ŃW�����v�A�b�v���Ă�����ƍ���B
>>22
���uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i��
�����Ă���Ƃ���ƁADothan����Yonah�ւ̐i���͂��̐��{���̑傫��
����������܂��BYonah����Merom�̐i���������ď������͂���܂��A
��Dothan����Yonah�ւ̕ω��قǑ傫�Ȃ��̂ł͂���܂���v
�܂�����́uPenM�n���̃f���A���R�A������ƂĂ��v��J������[�v���Ă��ƂȂ낤�ȁB
���\�ʂł�Yonah��Merom�ŃW�����v�A�b�v���Ă�����ƍ���B
24 �FSocket774�F2005/08/29(��) 15:27:40 ID:4LcaltFX
Dothan����Yonah������ۂǃX�S�C��
������C�ɂȂ�̂�
Conroe�̐v��
�I���S���`�[��(�K���K;)
���w�}������ǂ�����H
���ق��킦�邩(��)
������C�ɂȂ�̂�
Conroe�̐v��
�I���S���`�[��(�K���K;)
���w�}������ǂ�����H
���ق��킦�邩(��)
��������P-M�̌���P6
�������̂̓I���S�������B
�������̂̓I���S�������B
26 �FSocket774�F2005/08/29(��) 15:51:00 ID:4LcaltFX
�ł��l�g�o������̃I���S������(��)
>�}�C�N���A�[�L�e�N�`���͓����ł����A
>�ŏI�I�ȃ`�b�v�̃f�U�C���͔ނ炪�s���Ă��܂�
>�ŏI�I�ȃ`�b�v�̃f�U�C���͔ނ炪�s���Ă��܂�
28 �FSocket774�F2005/08/29(��) 15:55:46 ID:4LcaltFX
������
�Ȃ�����ꂻ��(��)
�Ȃ�����ꂻ��(��)
�����I��肪�����Ă���H
30 �FSocket774�F2005/08/29(��) 18:12:13 ID:4LcaltFX
>>29
�����H
�����H
32 �FSocket774�F2005/08/29(��) 18:51:40 ID:4LcaltFX
>>31
�۽
�۽
33 �FSocket774�F2005/08/29(��) 20:01:39 ID:LrlIg5ik
34 �FSocket774�F2005/08/29(��) 20:03:51 ID:LrlIg5ik
�K�@�@�@�@�@�@�@�@�@���@�@�@�@�K
�@�@�@o�@��@�@ �@ �K߁@�@� �D�@�@�@�@o�@�@�@�@�@�@��o
�@�@�@�@�@�@�@�@���܁R�@�@(�܁�)�@�@���܁R/,
�@�@�@�@ �A�A;(�܁S�@�@�@((�܁�))�@�@/��) ),�@�@, �B
�@�@�A�@�S�@(�܁@�@�@ ̧�ޮ����݁I�܁�);;�j�^.�@,
�@�A�_(�܁T;(�܁S�@�@In�Q��In�Q���܁j�^�j) .,�^ ,,
�i(��-��(;;;(�܁T;;(��(�G�M�t�L)�M�t�L)�@,�܁�);;;;;�j�j)��)
�@(;;;;(��(��;;;(�܁@���@ ���@ |�@�F�@���^�@)�j��)�j;;;;�j-��)�j
�U�@(�܁�=���@�@�@�@(,,�t.�@� (,,�t .Ɂ@�@�@�@��=�܁�)�m;;�m;;;::)
�i(�܁߁����@ �l��;;;;�@���@�@��'�@;;;���l�����߁�)��;;���m
�@�@�@o�@��@�@ �@ �K߁@�@� �D�@�@�@�@o�@�@�@�@�@�@��o
�@�@�@�@�@�@�@�@���܁R�@�@(�܁�)�@�@���܁R/,
�@�@�@�@ �A�A;(�܁S�@�@�@((�܁�))�@�@/��) ),�@�@, �B
�@�@�A�@�S�@(�܁@�@�@ ̧�ޮ����݁I�܁�);;�j�^.�@,
�@�A�_(�܁T;(�܁S�@�@In�Q��In�Q���܁j�^�j) .,�^ ,,
�i(��-��(;;;(�܁T;;(��(�G�M�t�L)�M�t�L)�@,�܁�);;;;;�j�j)��)
�@(;;;;(��(��;;;(�܁@���@ ���@ |�@�F�@���^�@)�j��)�j;;;;�j-��)�j
�U�@(�܁�=���@�@�@�@(,,�t.�@� (,,�t .Ɂ@�@�@�@��=�܁�)�m;;�m;;;::)
�i(�܁߁����@ �l��;;;;�@���@�@��'�@;;;���l�����߁�)��;;���m
35 �FSocket774�F2005/08/29(��) 20:25:38 ID:EnOxpz+m
LrlIg5ik
36 �FSocket774�F2005/08/29(��) 20:56:20 ID:4LcaltFX
�ǂ����̃z�[���y�[�W��
Conroe���ō�2.93GHz�ŏo����ď����Ă�����TDP��65W
�����h�X�u�C�}�K�W����������Woodcrest��2.93GHz��TDP80W�Ə����Ă�����
���Ă���TDP15W�̈Ⴂ�͂Ȃ�ł��傤
Conroe���ō�2.93GHz�ŏo����ď����Ă�����TDP��65W
�����h�X�u�C�}�K�W����������Woodcrest��2.93GHz��TDP80W�Ə����Ă�����
���Ă���TDP15W�̈Ⴂ�͂Ȃ�ł��傤
�����������
38 �FSocket774�F2005/08/29(��) 21:06:57 ID:4LcaltFX
�Ȃ�Ń�������˂�ȃփсV��˃�
���܂�A�L���b�V����
40 �FSocket774�F2005/08/29(��) 21:28:58 ID:4LcaltFX
�L���b�V������Ȃ�
ttp://www.geocities.jp/andosprocinfo/wadai05/20050827.htm
> �ŋ߂̘b�� 2005�N8��27��
> �R�DMerom�CConroe�CWoodcrest
> (����)
> �����āCMutiply��Add���߂���������Multiply Accumulate���߂ɂ���Macro OP Fusion�����邻���ł����C
�}�a�ł����H
> �ŋ߂̘b�� 2005�N8��27��
> �R�DMerom�CConroe�CWoodcrest
> (����)
> �����āCMutiply��Add���߂���������Multiply Accumulate���߂ɂ���Macro OP Fusion�����邻���ł����C
�}�a�ł����H
FB-DIMM�̃R���g���[����CSI���_�C�ɓ������Ă�̂��W�����Ȃ��H
43 �FSocket774�F2005/08/29(��) 22:59:19 ID:4LcaltFX
���Ȃ݂ɃA�X����64�~2��TDP�͍Œ�ł�89W��
Conroe���24W�قǍ����Ȃ��Ă܂�
�A���~�ɂ�
�C���e���Ƃ�TDP�̈Ӗ����Ⴄ�ƌ����l�����܂����X���[���܂��傤
Conroe���24W�قǍ����Ȃ��Ă܂�
�A���~�ɂ�
�C���e���Ƃ�TDP�̈Ӗ����Ⴄ�ƌ����l�����܂����X���[���܂��傤
�o�ĂȂ����i�ƌ��s�i���ׂ鈢�����X���[�ȁE�E�E
AMD�͎�����CPU���������猻�s�i������r�ł��Ȃ��̂˂�
47 �FSocket774�F2005/08/29(��) 23:29:23 ID:4LcaltFX
���������ɂ͉������Ă����ʂ��E�E�E
age�Ƃ����A���̈����J�L�R�Ƃ����c�c�B
�A���`���x��ł���H
�A���`���x��ł���H
>>48
�����Ă�̂ʼn��������Ă����ʂł���B
���]������>>48�l�͂������AMD�̎�����CPU�Ɋւ��đ����Ɍ���ĉ������܂��B
AMD�̎�����CPU�ɂ��Č�낤
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
�����Ă�̂ʼn��������Ă����ʂł���B
���]������>>48�l�͂������AMD�̎�����CPU�Ɋւ��đ����Ɍ���ĉ������܂��B
AMD�̎�����CPU�ɂ��Č�낤
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
51 �FSocket774�F2005/08/29(��) 23:38:17 ID:4LcaltFX
�A���~�X���ɗU�������
52 �FSocket774�F2005/08/30(��) 00:04:02 ID:QdkZ1ERt
�ȂA�Ȃ��̖@�������Ă���Intel���Ė��ƌ����̍����傫������Ǝv��Ȃ����H
�p���m�C������T���N�ւ̕ϐg�H
�p���m�C������T���N�ւ̕ϐg�H
�����AAMD�̘b�ȂS�����ĂȂ����ȁE�E�E
�{���ɕ����Ă�
�{���ɕ����Ă�
54 �FSocket774�F2005/08/30(��) 02:52:14 ID:rhqymNTX
>>43
�������J�L�R�c�c( ߄t�)
�������J�L�R�c�c( ߄t�)
55 �FSocket774�F2005/08/30(��) 05:43:28 ID:YZNNQ7jh
>>43�������Ă鎖���Ė{���H
����ȏ���������H�ꎞ��2006�N�O���Ƃ��������͂������C�����邪�B
�����牽�ł�Intel�����N�x��͖����C������B
�i�ŋ߃g���u���Ă�Ƃ����\�����邯�ǁj���N�㔼����Ȃ����ˁB
�����牽�ł�Intel�����N�x��͖����C������B
�i�ŋ߃g���u���Ă�Ƃ����\�����邯�ǁj���N�㔼����Ȃ����ˁB
58 �FSocket774�F2005/08/30(��) 07:26:53 ID:YZNNQ7jh
06�N�O�����Ēމ�����Ȃ��H
59 �FSocket774�F2005/08/30(��) 07:40:40 ID:9YgS2j/Z
>>57
��N�x�ꂾ
��N�x�ꂾ
�����������Ȃ�PenD���Pen4 6�����̋@�픃���Ƃ��������������ۂ��́H
�������܂߂ė�p�ł��鎩�M������Ȃ�APenD�������͂Ȃ��Ǝv���
>>58
Fab36�ɒ��H�����Ă̍��͗ʎY�J�n��2005�N���Ƃ����b���������B
Intel�������̗\����x��Ă邩�炳�����ɏ������݂��������ǁB
�ꉞFab36�͍��N���ɐ��Y�J�n�ɂȂ��Ă邩��˂��B
�ŏ��̐��i��90nm�����m���65nm�Ή��H����ԗV���Ă����Ƃ��v����B
2007�N���Ղɂ�65nm�ւ̊��S�]�����ʂ����炵������A���̈�N�O����65nm���i���o�Ă�����ɂ�ł�B
SocketM2�Ɉڍs���Đ�������ɂ�65nm���o�Ă��Ȃ����Ɩ����Ɋ��҂��Ă���B
���傤��Socket939��Winchester�̊W�݂����ɁB
Fab36�ɒ��H�����Ă̍��͗ʎY�J�n��2005�N���Ƃ����b���������B
Intel�������̗\����x��Ă邩�炳�����ɏ������݂��������ǁB
�ꉞFab36�͍��N���ɐ��Y�J�n�ɂȂ��Ă邩��˂��B
�ŏ��̐��i��90nm�����m���65nm�Ή��H����ԗV���Ă����Ƃ��v����B
2007�N���Ղɂ�65nm�ւ̊��S�]�����ʂ����炵������A���̈�N�O����65nm���i���o�Ă�����ɂ�ł�B
SocketM2�Ɉڍs���Đ�������ɂ�65nm���o�Ă��Ȃ����Ɩ����Ɋ��҂��Ă���B
���傤��Socket939��Winchester�̊W�݂����ɁB
63 �FSocket774�F2005/08/30(��) 08:19:03 ID:YZNNQ7jh
�C���e���͂����Ƃ�����65nm�����グ�Ă��ȁH
AMD�͍�������ꂮ�炢�̃X�P�W���[�����O�����Ă��Ȃ��́H
Fab 30�͂Ȃ�����Ȃɏ����Ȃ̂�
http://pc.watch.impress.co.jp/docs/article/20001207/kaigai01.htm
Fab 30�͂Ȃ�����Ȃɏ����Ȃ̂�
http://pc.watch.impress.co.jp/docs/article/20001207/kaigai01.htm
���A����Fab30�̃X�P�W���[���Ō�����99�NQ1���炢�̊����ł���
AMD�̎�����CPU�ɂ��Č�낤
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
http://pc7.2ch.net/test/read.cgi/jisaku/1124542812/
Yonah�̓W���A���R�A�ƃW���A���`�����l���ŃI���{�[�h�O���t�B�b�N���L�r�L�r�H
70 �FSocket774�F2005/08/30(��) 20:53:56 ID:YZNNQ7jh
�������������H
71 �FSocket774�F2005/08/30(��) 21:03:01 ID:PKt1wLgz
���ꂪ�C���e���̖{�C���BPenXE�̃��e�[���t�@���̉��������B
ttp://koti.welho.com/pnystro2/Hauskat_videot/PXE840_Cooling.avi
ttp://koti.welho.com/pnystro2/Hauskat_videot/PXE840_Cooling.avi
>>69
CPU�ɂ��ω���VertexShader�̑��x�̌��サ���Ȃ��B���Ƃ�915GM����945GM�ւ̕ύX�_���������B
CPU�ɂ��ω���VertexShader�̑��x�̌��サ���Ȃ��B���Ƃ�915GM����945GM�ւ̕ύX�_���������B
>>71
�|���@����
�|���@����
74 �FSocket774�F2005/08/30(��) 22:22:49 ID:wrZyCJAZ
�A����������ƂƂ���Ƀ��x����������Ȃ��B
���̃X�������낻�뒪�����ˁB
���̃X�������낻�뒪�����ˁB
���������v���X�R�͎������o��܂Ŗk�X��ꊄ����IPC�Ƃ������Ă��ȁB
���~�����̎����A�ʂ̈Ӗ��Ń��x���Ⴂ����
>Yonah�ł�CPU�̃p���[�v���[�����P��ŁA�N���b�N�h���C�����R�A�ŕ�������Ă��Ȃ��B
>���̂��߁A������������ɂȂ��Ă���B2�R�A�̎��g��&�d�����A�����Ă��邱�Ƃ́A����
>����d�͂ɂ�����x�̉e����^����͂����B
>Merom����ł��A�R�A�P�ʂ̓d���Ǝ��g���̃t���L�V�u���Ȑ���͓�����߁A��{�I
>�ɂ�Yonah�Ɠ���̐���ɂȂ�Ɛ��������B
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
>���̂��߁A������������ɂȂ��Ă���B2�R�A�̎��g��&�d�����A�����Ă��邱�Ƃ́A����
>����d�͂ɂ�����x�̉e����^����͂����B
>Merom����ł��A�R�A�P�ʂ̓d���Ǝ��g���̃t���L�V�u���Ȑ���͓�����߁A��{�I
>�ɂ�Yonah�Ɠ���̐���ɂȂ�Ɛ��������B
http://pc.watch.impress.co.jp/docs/2005/0831/kaigai208.htm
IDF Fall 2005 - Merom/Conroe/Woodcrest�̓o��
ttp://pcweb.mycom.co.jp/articles/2005/08/31/idf1/
Yonah�͑S�Ă̐������Z���j�b�g��SSE/SSE2�����s�ł��邱�Ƃ����Ɍ��J����Ă��邩��A
�܂萮�����Z�Ɋւ��Ă̓p�C�v���C����3�{�Ƃ������ƂɂȂ�B
�v�����2�̃R�A�Ԃœ��������ۂɁAL1�L���b�V���̒��g��Snoop�ڍs����Ƃ����b�ł���B
����ɂ��A����v���Z�X�̒���2�̃X���b�h���ʁX�̃R�A�Ŏ��s����Ă���ۂ�
�X���b�h�ԓ��������I�[�o�[�w�b�h�́AYonah��Athlon 64 X2�Ɣ�r���Ă����炩�ɏ������Ȃ��Ă���A
Hyper-Threading�����Ɣ�r���Ă��قƂ�Ǒ��F�Ȃ��ƍl������B
Q: ����4 issue�Ƃ����̂́A���Ƃ��Δ{����Execution Unit��2�Ƃ����Ӗ��ł���?
����Ƃ�����(Regular Speed)��Execution Unit��2�Ƃ����Ӗ��ł��傤��?
�@A: �����̂��̂�4���B
Q: ����EM64T�ɂ��ċ����Ă��������BPrescott�̐���ł́AExecution Unit��32bit���ɂȂ��Ă���A
64bit���߂���������ꍇ�͂����2�ɕ����Ď��s���Ă��܂����B
�ŁAConroe�̐���͂ǂ��Ȃ̂ł��傤��?
�@A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ���(��)�A���ꂾ���͌�����B
�@Conroe�̐����4 issue��64bit�}�V����EM64T���T�|�[�g����B�����Native��64bit�}�V�����B
Q: ����������m�F�������������B
Conroe�̐���ł́A64bit���߂�32bit���߂̏������x�͓����Ȃ̂ł��傤��?
���Z�p�I�ɂ́A1��64bit Execution Unit�͓�����2��32bit���߂��������邱�Ƃ��\���Ǝv���̂ł����A
���̂�����͂ǂ��ł��傤?
�@A: ����ɂ��Ă͍��炩�ɂł��Ȃ��B
Q: �Ƃ������Ƃ́A���Ƃ���Merom��Conroe�ł̓p�C�v���C���̍\�����قȂ�\��������킯�ł���?
�@A: ����������ɂ͓������Ȃ��B
ttp://pcweb.mycom.co.jp/articles/2005/08/31/idf1/
Yonah�͑S�Ă̐������Z���j�b�g��SSE/SSE2�����s�ł��邱�Ƃ����Ɍ��J����Ă��邩��A
�܂萮�����Z�Ɋւ��Ă̓p�C�v���C����3�{�Ƃ������ƂɂȂ�B
�v�����2�̃R�A�Ԃœ��������ۂɁAL1�L���b�V���̒��g��Snoop�ڍs����Ƃ����b�ł���B
����ɂ��A����v���Z�X�̒���2�̃X���b�h���ʁX�̃R�A�Ŏ��s����Ă���ۂ�
�X���b�h�ԓ��������I�[�o�[�w�b�h�́AYonah��Athlon 64 X2�Ɣ�r���Ă����炩�ɏ������Ȃ��Ă���A
Hyper-Threading�����Ɣ�r���Ă��قƂ�Ǒ��F�Ȃ��ƍl������B
Q: ����4 issue�Ƃ����̂́A���Ƃ��Δ{����Execution Unit��2�Ƃ����Ӗ��ł���?
����Ƃ�����(Regular Speed)��Execution Unit��2�Ƃ����Ӗ��ł��傤��?
�@A: �����̂��̂�4���B
Q: ����EM64T�ɂ��ċ����Ă��������BPrescott�̐���ł́AExecution Unit��32bit���ɂȂ��Ă���A
64bit���߂���������ꍇ�͂����2�ɕ����Ď��s���Ă��܂����B
�ŁAConroe�̐���͂ǂ��Ȃ̂ł��傤��?
�@A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ���(��)�A���ꂾ���͌�����B
�@Conroe�̐����4 issue��64bit�}�V����EM64T���T�|�[�g����B�����Native��64bit�}�V�����B
Q: ����������m�F�������������B
Conroe�̐���ł́A64bit���߂�32bit���߂̏������x�͓����Ȃ̂ł��傤��?
���Z�p�I�ɂ́A1��64bit Execution Unit�͓�����2��32bit���߂��������邱�Ƃ��\���Ǝv���̂ł����A
���̂�����͂ǂ��ł��傤?
�@A: ����ɂ��Ă͍��炩�ɂł��Ȃ��B
Q: �Ƃ������Ƃ́A���Ƃ���Merom��Conroe�ł̓p�C�v���C���̍\�����قȂ�\��������킯�ł���?
�@A: ����������ɂ͓������Ȃ��B
Desktop�S�����������������Ȃ�
XE��Presler����Ȃ���Paxville��FSB1066MHz�ł𓊓�����ȁB
������Presler�ƂقڃC�R�[����Dempsey�ł�FSB1066MHz���\�炵������Presler�ɂ��̂܂܍s���낤���B
����Ƃ��Ă�CedarMill��XE691���o���Ăق������E�E�E
������Presler�ƂقڃC�R�[����Dempsey�ł�FSB1066MHz���\�炵������Presler�ɂ��̂܂܍s���낤���B
����Ƃ��Ă�CedarMill��XE691���o���Ăق������E�E�E
>�܂��A4 issue�̃X�[�p�[�X�P�[���ł��邪�A����͌�Ŋm�F�ł����b�����������Z�u�̂݁v�ł���
�ԈႢ��������
>>DDR2-677��2ch����8.4GB/sec�ɒB����̂ɑ�
DDR2-677��2ch����10.8GB/sec�̊ԈႢ�ł���
>>DDR2-677��2ch����8.4GB/sec�ɒB����̂ɑ�
DDR2-677��2ch����10.8GB/sec�̊ԈႢ�ł���
Presler��Dempsey��Paxville�̃V�������N��������B
����������Ƃ͂���2���~���悤������낤���B
����ς�A�Y�Ɠ������g���ׂ������h���B
����������Ƃ͂���2���~���悤������낤���B
����ς�A�Y�Ɠ������g���ׂ������h���B
>>86
90nm��Paxville������āA65nm�ɃV�������N����̂�҂��Ă�����
Merom��Conroe���o�ꂷ�邩��ȁB
�ŏ�����65nm�ō��I���������X�N���l����Ƃ��肦�Ȃ��B
90nm��Paxville������āA65nm�ɃV�������N����̂�҂��Ă�����
Merom��Conroe���o�ꂷ�邩��ȁB
�ŏ�����65nm�ō��I���������X�N���l����Ƃ��肦�Ȃ��B
intel��65nm�v���Z�X��90nm�݂�����
�o�Ă����烊�[�N�т�����Ƃ͂Ȃ�Ȃ��悤�ň���S�ł���?
yonah�̃f�����Ĉ��S�����B
conroe�Amerom�����v���ȁB
�o�Ă����烊�[�N�т�����Ƃ͂Ȃ�Ȃ��悤�ň���S�ł���?
yonah�̃f�����Ĉ��S�����B
conroe�Amerom�����v���ȁB
���݂̂��̂�艺�����Ă�ΊT�˃I�P(w
�����Ĕ���B
�����Ĕ���B
Intel�̃V�������N���̂ɖ�肠��Ȃ�ABanias��Dothan����ς�
���ƂɂȂ��Ă�͂������ȁB
���ƂɂȂ��Ă�͂������ȁB
Banias�n�͌�����ȓd�͐v�����������e����
�y���������������Ǝv���B
���ہA�l�g�o��180nm��130nm�ł͉������Ă�B
�y���������������Ǝv���B
���ہA�l�g�o��180nm��130nm�ł͉������Ă�B
���܂Œʂ�ɃV�������N�ŏ���d�͑啝���ɂȂ�ƌ������
�d�͌����������邯�ǐ��\�͏オ��悤�ȕύX���Ă݂���
�\�z�O�ɉ�����Ȃ���orz
���Ă̂���ڽ�����Ȃ���������
�d�͌����������邯�ǐ��\�͏オ��悤�ȕύX���Ă݂���
�\�z�O�ɉ�����Ȃ���orz
���Ă̂���ڽ�����Ȃ���������
�l�g�o
130nm���N���b�Nage��90nm
PenM
130nm�i�ȓd�́j���N���b�Nage��90nm�i�ȓd�́j
K8
130nm���N���b�N�����u����90nm�i�ȓd�́j
����Ȋ������ƁB
130nm���N���b�Nage��90nm
PenM
130nm�i�ȓd�́j���N���b�Nage��90nm�i�ȓd�́j
K8
130nm���N���b�N�����u����90nm�i�ȓd�́j
����Ȋ������ƁB
Dothan�����N�x�ꂽ�̂͂����Y�ꂽ��
Yonah�������̗\�肩�甼�N�x��Ă܂���Ŋ���
Yonah�ƈ���ăh�^�L�����������낤
X86�ȊO�̎�����͂ǂ��H
>>96
�N���b�N�������̗\��ʂ���M�Œx�ꂽ�\���͒Ⴂ
�N���b�N�������̗\��ʂ���M�Œx�ꂽ�\���͒Ⴂ
101 �FSocket774�F2005/08/31(��) 18:24:57 ID:u2GV7xUd
>>96
�����܂肪�オ��Ȃ�������Ȃ������H
�����܂肪�オ��Ȃ�������Ȃ������H
���o�C����TDP���肪��������ʂ͎��ɂ��������ȁB
90nm�v���Z�X���̂̕����܂�͍ō������B
90nm�v���Z�X���̂̕����܂�͍ō������B
����CPUID�̃t�@�~���[�͂Ȃ�
NT 4.0�Ή��𑱂���Ȃ�23������H
NT 4.0�Ή��𑱂���Ȃ�23������H
�f�X�N�g�b�v�Ɏg�����A�A�A����Ȃ�w
http://pc.watch.impress.co.jp/docs/2003/1010/kaigai031.htm
����90nm��Dothan�̒x��ɂ��ẮA���݁A����d�͂ƔM�������炵�����Ƃ��ق�
���炩�ɂȂ��Ă���B�����āA����90nm�����Prescott�̕�������������ɂ���悤���B
http://pc.watch.impress.co.jp/docs/2003/1027/kaigai038.htm
���݂�B�X�e�b�v�̃�PGA478��Prescott�𓋍ڂ����ꍇ�A�o�X�G���[������
����P�[�X�������������Ƃɂ���Ƃ����B���̌����́A�o�X�C���^�[�t�F�C�X��
�d���U�����A�K�肳�ꂽ�X�y�b�N�ɍ���Ȃ��P�[�X���o�����炾�Ƃ����B
����90nm��Dothan�̒x��ɂ��ẮA���݁A����d�͂ƔM�������炵�����Ƃ��ق�
���炩�ɂȂ��Ă���B�����āA����90nm�����Prescott�̕�������������ɂ���悤���B
http://pc.watch.impress.co.jp/docs/2003/1027/kaigai038.htm
���݂�B�X�e�b�v�̃�PGA478��Prescott�𓋍ڂ����ꍇ�A�o�X�G���[������
����P�[�X�������������Ƃɂ���Ƃ����B���̌����́A�o�X�C���^�[�t�F�C�X��
�d���U�����A�K�肳�ꂽ�X�y�b�N�ɍ���Ȃ��P�[�X���o�����炾�Ƃ����B
>>107
���p�������������L���o����Ă��ȁB
���p�������������L���o����Ă��ȁB
>>103
�m�̎��s���ŏo�א������đ啝�O�|�����s��ꂽ�B
�m�̎��s���ŏo�א������đ啝�O�|�����s��ꂽ�B
>>102
�]�݂������Ă�ȁE�E�E
�]�݂������Ă�ȁE�E�E
111 �FSocket774�F2005/08/31(��) 20:25:03 ID:6AzxRW9a
> ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ���(��)�A���ꂾ���͌�����B
>Conroe�̐����4 issue��64bit�}�V����EM64T���T�|�[�g����B
>�����Native��64bit�}�V�����B
Oh�I�`�l�c����ŁE�E�E�E�E
>Conroe�̐����4 issue��64bit�}�V����EM64T���T�|�[�g����B
>�����Native��64bit�}�V�����B
Oh�I�`�l�c����ŁE�E�E�E�E
>>110
���O�قǂł͂Ȃ���B
�y�]�Ƀ��[�N��{�����`�Ղ���������B
���邢�̓L���b�V���̃Q�[�g���L�����i��C�Á�D�Âł̍X�V�j�̂�������Ȃ����A
�����������̒��x��������Ă��Ȃ��B
���O�قǂł͂Ȃ���B
�y�]�Ƀ��[�N��{�����`�Ղ���������B
���邢�̓L���b�V���̃Q�[�g���L�����i��C�Á�D�Âł̍X�V�j�̂�������Ȃ����A
�����������̒��x��������Ă��Ȃ��B
intel��90nm�v���Z�X���̂Ƀ��[�N�d����̂��߂̃M�~�b�N�͂Ȃ������悤�ȁE�E�E�H
�cSi���p�t�H�[�}���X���グ���Ȃ��ďȓd�͂ɂȂ�悤�Ɏg���B
��������AggressiveClockGating�����邩��ȁB
����������ƍׂ����z�u����Ƃ��ŏ���d�͂��팸�����̂����m���B
ttp://pc.watch.impress.co.jp/docs/2003/1009/ubiq28.htm
�u������600MHz�ŁABanias��������d�͂�������Dothan�v
�ȍ~�������Dothan�ł����[�N�d���ŋ�J�����̂͊m���B
���ƁA�{�����������ǂ����͒m��Ȃ���
ttp://pc.watch.impress.co.jp/docs/2003/0806/ubiq18.htm
> Intel�͂���܂ŁADothan�̔M�v����d�͂�21W���Ɛ������Ă������A
>7�����̃A�b�v�f�[�g��30W�ɋ߂��M�v����d�͂ɂȂ�ƒʒm���Ă����Ƃ����B
�Ȃ�Ęb������B
��������AggressiveClockGating�����邩��ȁB
����������ƍׂ����z�u����Ƃ��ŏ���d�͂��팸�����̂����m���B
ttp://pc.watch.impress.co.jp/docs/2003/1009/ubiq28.htm
�u������600MHz�ŁABanias��������d�͂�������Dothan�v
�ȍ~�������Dothan�ł����[�N�d���ŋ�J�����̂͊m���B
���ƁA�{�����������ǂ����͒m��Ȃ���
ttp://pc.watch.impress.co.jp/docs/2003/0806/ubiq18.htm
> Intel�͂���܂ŁADothan�̔M�v����d�͂�21W���Ɛ������Ă������A
>7�����̃A�b�v�f�[�g��30W�ɋ߂��M�v����d�͂ɂȂ�ƒʒm���Ă����Ƃ����B
�Ȃ�Ęb������B
EIST�̘b�Ȃ�Ă��ĂȂ��킯����
117 �FSocket774�F2005/08/31(��) 22:06:29 ID:bym+ayXD
�C���e���̋Z�p�͐��E�����[�[�[�[�[���I
���[�N�d���̖������N�����ɉ�������B
���[�N�d���̖������N�����ɉ�������B
���[�N�d���̖������E�����[�[�[�[�[�[�[�[�[�[�[���I
�Ɍ������B
�I���A������[����
�Ɍ������B
�I���A������[����
119 �FSocket774�F2005/08/31(��) 22:58:36 ID:u2GV7xUd
>>118
�������O�������L����
�������O�������L����
120 �FSocket774�F2005/08/31(��) 23:30:14 ID:BeqrokC0
>>119
��ӁI�@�҂ސ~�ͷӲ�I
��ӁI�@�҂ސ~�ͷӲ�I
�������ق�1GHz�z���ł̏��܂���
>>121
WHAT?
WHAT?
>>124
THANKS
THANKS
High-k�͂ǂ��������H
High-k�CMetal Gate�CTri-Gate��45nm�B
AMD��High-k��Metal Gate��65nm�œ�������Ƃ����W�������������Ƃ��������Ȃ��B
���S��R�^SOI��������65nm�ō̗p�������悤��
>>99
��d����Itanium 2 1.30GHz/3MB L3�L���b�V��/400MHz FSB 62W 57,240�~
CPU�������ƈ����Ȃ������B������̓v���Z�X���ǂ����̂�XEON���痬��邩���B
��d����Itanium 2 1.30GHz/3MB L3�L���b�V��/400MHz FSB 62W 57,240�~
CPU�������ƈ����Ȃ������B������̓v���Z�X���ǂ����̂�XEON���痬��邩���B
Xeon�ƃv���b�g�t�H�[�������ʉ����ꂽ��C�y�ɍ����ւ��Ďg����悤�ɂȂ�ȁB
�t�@�[���̖������\���肻�������v�Z�p�ɂ͂����Ȃ��B
�t�@�[���̖������\���肻�������v�Z�p�ɂ͂����Ȃ��B
�v���Z�X�Z�p�ł�IBM�AMD�Sony�Toshiba�CSM�A���́A�̐S�v��IBM�̍H�ꂪ���^���^��
�o���o���̍ŐV�Z�p��������Ǝ��ʂ��߁A�O�Ɣ�ׂ�Ɗ��ƐT�d�ɂȂ��Ă��Ă܂B
�B��A���g��łȂ�Intel����Ԑg�y�Ȃ͂������ǁA�����������l�܂�l�����Ă��ێ�I�łˁB
�o���o���̍ŐV�Z�p��������Ǝ��ʂ��߁A�O�Ɣ�ׂ�Ɗ��ƐT�d�ɂȂ��Ă��Ă܂B
�B��A���g��łȂ�Intel����Ԑg�y�Ȃ͂������ǁA�����������l�܂�l�����Ă��ێ�I�łˁB
Centaur�́c
>>133
cell�̂��ƁH
cell�̂��ƁH
>>116
AggressiveClockGating��EIST
AggressiveClockGating��EIST
����͂Ђ���Ƃ��ăM���O�Ō����Ă�̂�!?�iAA��
���ӂƎv�������AAggressiveClockGating�ŏ���d�͂�����̂́A
1.CPU�g�p����100%���Ă��鎞
2.�p�C�v���C���X�g�[�����������Ă��鎞
�Ȗ��A�܂���CedarMill/Presler�ɐςȂ�Ď��́E�E�E
1.CPU�g�p����100%���Ă��鎞
2.�p�C�v���C���X�g�[�����������Ă��鎞
�Ȗ��A�܂���CedarMill/Presler�ɐςȂ�Ď��́E�E�E
�ςރ����b�g�͂����Ă��f�����b�g�͂Ȃ����H
CPU�g�p����100%�ł����Ă��A����d�͂�MAX�ɂȂ�Ƃ͌���Ȃ��B
���ׂẴ��\�[�X��busy�ɂ���悤�ȃv���O�����͒���������B
�ƂȂ�ƁA
���ׂẴ��\�[�X��busy�ɂȂ����Ƃ��̏���d�͂ɍ����āA
�d�͂�p�M�̐v������ƁA�����]�T�������Ă��������Ȃ���ˁB
�Ȃ�A����d�͂≷�x�̘g���Ɏ��܂�悤�ɊǗ����Ȃ���
���I�ɃN���b�N���グ�Ă��A��萫�\���オ���ijϰ����ˁB
���������l�����ō��ꂽ���̂��A
�M�ŃN���b�N��������!
�ƒ@����Ă�̂́A������ƂȂ��B
CPU�ɘA���I�ɕ��ׂ�������A�v�������邯��ǂ��A
���x���K�v�Ȃ̂�10�b�̂���1�b�����Ƃ����A�v���������Ǝv���B
�̂��ƁA�����ϊ��ŕϊ��L�[���������u�ԂƂ��A�ˁB
���ׂẴ��\�[�X��busy�ɂ���悤�ȃv���O�����͒���������B
�ƂȂ�ƁA
���ׂẴ��\�[�X��busy�ɂȂ����Ƃ��̏���d�͂ɍ����āA
�d�͂�p�M�̐v������ƁA�����]�T�������Ă��������Ȃ���ˁB
�Ȃ�A����d�͂≷�x�̘g���Ɏ��܂�悤�ɊǗ����Ȃ���
���I�ɃN���b�N���グ�Ă��A��萫�\���オ���ijϰ����ˁB
���������l�����ō��ꂽ���̂��A
�M�ŃN���b�N��������!
�ƒ@����Ă�̂́A������ƂȂ��B
CPU�ɘA���I�ɕ��ׂ�������A�v�������邯��ǂ��A
���x���K�v�Ȃ̂�10�b�̂���1�b�����Ƃ����A�v���������Ǝv���B
�̂��ƁA�����ϊ��ŕϊ��L�[���������u�ԂƂ��A�ˁB
>>139
CPU�g�p����100%�ł����Ă�ALU��FPU���S�ĉ���Ă���Ƃ͌���Ȃ��킯����
���������킯�ŁAAggressive Clock Gating�͍ő����d�͂ɂ����ʂ�����ꍇ������
CPU�g�p����100%�ł����Ă�ALU��FPU���S�ĉ���Ă���Ƃ͌���Ȃ��킯����
���������킯�ŁAAggressive Clock Gating�͍ő����d�͂ɂ����ʂ�����ꍇ������
����A���̏ꍇ���ő�Ƃ͌���Ȃ��E�E�E
144 �FSocket774�F2005/09/01(��) 19:52:15 ID:xt95DQSF
>>141
��������܂��������B
3.2G�����ǔM��2.8G�ɂȂ�܂��B
����Ȃ���
2.8G�����lj��x�Ⴏ���3.2G�œ����܂��B
��������N�����匾��Ȃ������낤�B
��������܂��������B
3.2G�����ǔM��2.8G�ɂȂ�܂��B
����Ȃ���
2.8G�����lj��x�Ⴏ���3.2G�œ����܂��B
��������N�����匾��Ȃ������낤�B
��
���ꂾ!(w
���ꂾ!(w
>>145
�ʏ�N���b�N 2.8GHz
���x���Ⴂ�� 3.2GHz�œ��삵�܂��I
���̖���PenD 840 ��6���~
����ŁA�������ł� 2.8GHz
PenD 820 ��3�������낵���ˁB
�E�E�E�Ŕ���o���̂��H
�ʏ�N���b�N 2.8GHz
���x���Ⴂ�� 3.2GHz�œ��삵�܂��I
���̖���PenD 840 ��6���~
����ŁA�������ł� 2.8GHz
PenD 820 ��3�������낵���ˁB
�E�E�E�Ŕ���o���̂��H
>>141
PenD�̓G���R�����敿����������Ȃ��B
���̃G���R��CPU�ɘA���I�ɕ��ׂ�������A�v���Ȃ킯�ŁA
�B��̓��ӕ���ŃN���b�N�_�E������PenD�͒@����ē��R�B
PenD�̓G���R�����敿����������Ȃ��B
���̃G���R��CPU�ɘA���I�ɕ��ׂ�������A�v���Ȃ킯�ŁA
�B��̓��ӕ���ŃN���b�N�_�E������PenD�͒@����ē��R�B
Pen4 630��PrnD 830
�ςނȂ�����Pen4���H
�ςނȂ�����Pen4���H
High-k�AMetal Gate�ATri-Gate�Ƃ����{�ł̊J�����܂������ĂȂ��낤�ȁB
���܂��s���Ă�Ȃ�A����̐V�}�C�N���A�[�L������������ƃp�C�v���C���̒i���傫��
�����͂��B ���㐔�N�́A���[�N���ɉ����̌����݂��Ȃ�����A14�i�ɂȂ�����ł��傤�A�����B
���܂��s���Ă�Ȃ�A����̐V�}�C�N���A�[�L������������ƃp�C�v���C���̒i���傫��
�����͂��B ���㐔�N�́A���[�N���ɉ����̌����݂��Ȃ�����A14�i�ɂȂ�����ł��傤�A�����B
���S�ɐV�A�[�L�Ƃ������Ă邯�ǁANetBurst���������Ƃ͂����ɂ���������
�x�[�X��PenM������14�i�Ə��Ȃ��܂܂Ȃ̂ł�
�x�[�X��PenM������14�i�Ə��Ȃ��܂܂Ȃ̂ł�
>>151
�w�l�g�o���x�[�X�ɍ����PenM�݂����ȃ��m�x�Ȃ킯�����B
�w�l�g�o���x�[�X�ɍ����PenM�݂����ȃ��m�x�Ȃ킯�����B
�܂��̐S�̃g���[�X�L���b�V����f�R�[�_�[�ɂ��ĐG��Ă��Ȃ�����
�ǂ������킩��Ȃ���� >NetBurst��F�Z���c���B
�ǂ������킩��Ȃ���� >NetBurst��F�Z���c���B
156 �FSocket774�F2005/09/02(��) 08:52:53 ID:XTnSk15I
157 �FSocket774�F2005/09/02(��) 09:33:21 ID:P1+swLYk
�p�C�v���C���͒i�����₹�Α��₷�����~�X�̃y�i���e�B���傫���Ȃ��
�g���[�X�L���c�V���̗p�Ȃ�X�e�[�W���͎����{�ȏ�B���ߎ��s���x�������邽�߂̃_�C�i�~�b�N�X�P�W���[�����O�ɂ����悻10�i�g����Ƃ���A�����Ȃ����s�ł���̂����B
4issue��2way�p�C�v���C���~2��OPs�t���[�W���������B
��̓I�ɂ�MMX�~4�AFPU�~4�����ˁB
SSEx��1�N���b�N2���ߎ��s�ł���BAltiVec���^���B
�g���[�X�L���c�V���̗p�Ȃ�X�e�[�W���͎����{�ȏ�B���ߎ��s���x�������邽�߂̃_�C�i�~�b�N�X�P�W���[�����O�ɂ����悻10�i�g����Ƃ���A�����Ȃ����s�ł���̂����B
4issue��2way�p�C�v���C���~2��OPs�t���[�W���������B
��̓I�ɂ�MMX�~4�AFPU�~4�����ˁB
SSEx��1�N���b�N2���ߎ��s�ł���BAltiVec���^���B
158 �FSocket774�F2005/09/02(��) 09:36:21 ID:XTnSk15I
�g���[�X�L���b�V���Ƀf�����b�g�������������H
���Ȃ݂ɃA���~�ł͂���܂���
���Ȃ݂ɃA���~�ł͂���܂���
���ꂾ�ȁB
ttp://pcweb.mycom.co.jp/articles/2005/08/31/idf1/003.html
Q: �VMicroArchitecture�́ANetBurst Architecture��Banias Architecture�������̂ł�����?
A: ��X���������Ă���̂́ANetBurst Architecture��Feature��Conroe��MicroArchitecture�Ɏ�荞�Ƃ������̂��B
NetBurst�̎��������̓����́AConroe����ɂ͌������Ȃ����̂����炾�B
��̓I�Ɍ�����64bit�AQuad Pump Bus(P6�o�X)�AVT�ALaGrande Technology�Ȃǂ��B
���̈���ŁAPower Design��philosophy�Ɋւ��Ă�Banias Architecture���玝���Ă����B
�܂�Philosophy of Design���B�܂�Feature��Philosophy��NetBurst��Banias���玝���Ă�����ŁA
New Architecture���`�����Ƃ������Ƃ��B
ttp://pcweb.mycom.co.jp/articles/2005/08/31/idf1/003.html
Q: �VMicroArchitecture�́ANetBurst Architecture��Banias Architecture�������̂ł�����?
A: ��X���������Ă���̂́ANetBurst Architecture��Feature��Conroe��MicroArchitecture�Ɏ�荞�Ƃ������̂��B
NetBurst�̎��������̓����́AConroe����ɂ͌������Ȃ����̂����炾�B
��̓I�Ɍ�����64bit�AQuad Pump Bus(P6�o�X)�AVT�ALaGrande Technology�Ȃǂ��B
���̈���ŁAPower Design��philosophy�Ɋւ��Ă�Banias Architecture���玝���Ă����B
�܂�Philosophy of Design���B�܂�Feature��Philosophy��NetBurst��Banias���玝���Ă�����ŁA
New Architecture���`�����Ƃ������Ƃ��B
64bit�Ƃ�VT�Ƃ��ʂ�NetBurst�p���Ă킯����ˁ[����
���XHT�����ĂȂ�������
���XHT�����ĂȂ�������
�ǂ����͋Z�Ńf���A���_�C�ɂ���̂Ȃ�PenM��Itanium2�̃f���A���_�C
��������B
��������B
164 �FSocket774�F2005/09/02(��) 11:54:37 ID:XTnSk15I
>>160
������ăl�g�o�x�[�X���Č�����蔼�X����Ȃ��H
������ăl�g�o�x�[�X���Č�����蔼�X����Ȃ��H
>>164
�wFeature���l�g�o����APhilosophy����Ƃ���x�Ƃ킴�킴���������Ă���̂́A
��H�̍\�����̂̓l�g�o�ɋ߂��ƌ����Ӗ��Ȃ킯�����B
�wFeature���l�g�o����APhilosophy����Ƃ���x�Ƃ킴�킴���������Ă���̂́A
��H�̍\�����̂̓l�g�o�ɋ߂��ƌ����Ӗ��Ȃ킯�����B
167 �FSocket774�F2005/09/02(��) 12:07:34 ID:P1+swLYk
�L���b�V���Ƀq�b�g�������t�����g�G���h�̃f�R�[�_���x�܂�����̂ŁA�ȓd�͉��ɂ͂��Ȃ�L�������ǂ�
�t�Ƀg���[�X�L���c�V���Ȃ���4issue�̓f�R�[�_4�t���ғ�������H�ڂɂȂ�A�������f�R�[�h���݂�14�i����4issue�������������I�[�_�����O�͍���B
���ʃp�C�v���C�����X�J�X�J�ł������ēd�͌����𗎂Ƃ��H�ڂɂ��Ȃ�B
Merom�͔{��ALU���Ȃ��Ȃ������A�ɒ[�ɍ��N���b�N��_�����v�łȂ�����A
�L���b�V���̃��C�e���V�傳���邱�ƂȂ��u������x�v�e�ʂ𑝂₹��͂��B
�����͏ȗ����邯�ǁB
���ƁA�~�X�q�b�g���̃y�i���e�B�y���̈Ӗ��Ńf�R�[�_���p�ӂ���������㩁B
����ł��N���b�N�Q�[�e�B���O�����邩�����d�͂ɖw��lje�����Ȃ����B
�t�Ƀg���[�X�L���c�V���Ȃ���4issue�̓f�R�[�_4�t���ғ�������H�ڂɂȂ�A�������f�R�[�h���݂�14�i����4issue�������������I�[�_�����O�͍���B
���ʃp�C�v���C�����X�J�X�J�ł������ēd�͌����𗎂Ƃ��H�ڂɂ��Ȃ�B
Merom�͔{��ALU���Ȃ��Ȃ������A�ɒ[�ɍ��N���b�N��_�����v�łȂ�����A
�L���b�V���̃��C�e���V�傳���邱�ƂȂ��u������x�v�e�ʂ𑝂₹��͂��B
�����͏ȗ����邯�ǁB
���ƁA�~�X�q�b�g���̃y�i���e�B�y���̈Ӗ��Ńf�R�[�_���p�ӂ���������㩁B
����ł��N���b�N�Q�[�e�B���O�����邩�����d�͂ɖw��lje�����Ȃ����B
64bit�AP6�o�X)�AVT(ry�̓l�g�o�������ė���Ί��ɂ������Ă���B
����ŔM�I�ɂ́A�p�C�v���C����Z�����āAALU�������āA�e��ȓd�͋@�\���������A
��ƕ��Ɏd�グ��B
�ȊO�ɂǂ��ǂ߂�낤���H
����ŔM�I�ɂ́A�p�C�v���C����Z�����āAALU�������āA�e��ȓd�͋@�\���������A
��ƕ��Ɏd�グ��B
�ȊO�ɂǂ��ǂ߂�낤���H
�u�l�g�o�̏ȓd�͋Z�p�v�ōł��L���Ȃ��̂��g���[�X�L���c�V�����Ǝv�����B
ttp://pc.watch.impress.co.jp/docs/2005/0825/kaigai206.htm
�����ɂ�
> ���ۂɂ́A������}�C�N���A�[�L�e�N�`���̊J���́ABanias���J������Intel�C�X���G����
> �J���`�[�����S�������B���̂��߁ABanias��Yonah(���i)�̔��W�^�Ƃ��ĊJ������Merom�ɁA
> NetBurst�̃t�B�[�`���ƃo�X����荞�Ɛ��������B
�Ƃ������Ă���ȁB
�����ɂ�
> ���ۂɂ́A������}�C�N���A�[�L�e�N�`���̊J���́ABanias���J������Intel�C�X���G����
> �J���`�[�����S�������B���̂��߁ABanias��Yonah(���i)�̔��W�^�Ƃ��ĊJ������Merom�ɁA
> NetBurst�̃t�B�[�`���ƃo�X����荞�Ɛ��������B
�Ƃ������Ă���ȁB
>>168
Banias�ɂȂ���NetBurst�ɂ���������(4T)��NetBurst����A�v�v�z��Banias���玝���Ă����Ɠǂ߂��B
Banias�ɂȂ���NetBurst�ɂ���������(4T)��NetBurst����A�v�v�z��Banias���玝���Ă����Ɠǂ߂��B
Feature�F�����I
Philosophy�F�_���I
���{��Ɖp�ꂾ���猵���ɂ͈Ӗ��Ⴄ���ǂȁB
Philosophy�F�_���I
���{��Ɖp�ꂾ���猵���ɂ͈Ӗ��Ⴄ���ǂȁB
>>171
Philosophy�̑O�ŁwPower Design�́x�ƌ��肵�Ă�����B
Philosophy�̑O�ŁwPower Design�́x�ƌ��肵�Ă�����B
>>172-173
�����Ȃ���Ⴄ�Ǝv�����E�E�E
�����Ȃ���Ⴄ�Ǝv�����E�E�E
175 �FSocket774�F2005/09/02(��) 13:15:58 ID:XTnSk15I
�����z�t�j�搶�����܂�����
�������炭��NetBurst���p�������A�[�L�e�N�`���ł������ł��낤Tejas/Jayhawk�̃f���A���R�A/�}���`�R�A����A
�����o�C���p�̃R�A�ł�����Banias/Dothan���x�[�X�ɂ����f���A���R�A/�}���`�R�A�֓]�������A�Ƃ������ƂȂ̂��Ǝv����B
�������NetBurst���ƕ��̎��ƕ����́A���ʂƂ��ē�l�������Ŏ��C�������ƂɂȂ�B
�����S��H����
�������炭��NetBurst���p�������A�[�L�e�N�`���ł������ł��낤Tejas/Jayhawk�̃f���A���R�A/�}���`�R�A����A
�����o�C���p�̃R�A�ł�����Banias/Dothan���x�[�X�ɂ����f���A���R�A/�}���`�R�A�֓]�������A�Ƃ������ƂȂ̂��Ǝv����B
�������NetBurst���ƕ��̎��ƕ����́A���ʂƂ��ē�l�������Ŏ��C�������ƂɂȂ�B
�����S��H����
��Feature�F�����I
��Philosophy�F�_���I
�����{��Ɖp�ꂾ���猵���ɂ͈Ӗ��Ⴄ���ǂȁB
�ǂ��ł���������肪���荞�܂ꂽ�̂��A���������C�ɂȂ�̂� ID:Ie1MXSyR ����o�ė��Ă��������B
��Philosophy�F�_���I
�����{��Ɖp�ꂾ���猵���ɂ͈Ӗ��Ⴄ���ǂȁB
�ǂ��ł���������肪���荞�܂ꂽ�̂��A���������C�ɂȂ�̂� ID:Ie1MXSyR ����o�ė��Ă��������B
�g���[�X�L���b�V���̃f�����b�g���āA
�e�ʑ�������ƃN���b�N�������Ȃ��Ƃ��A����ȂƂ���?
����̓N���b�N�u������Ȃ��݂��������A
�f�R�[�_�[�̏���d��(�M)�̂��Ƃ����邩��g���Ă�C�͂��邯�ǁA�ǂ��Ȃ̂��˂��B
���ƃp�C�v���C���̒i����NetBurst�ɉ�����ő�̓��F�ƕ߂炦�Ă�l�ɂ�
Merom Conroe��14�i(Conro�͈Ⴄ��������Ȃ��炵��?)�����w�E����
�ق�PenM���C�N�ł���?�A�Ƃ����]���ɂȂ邩�������ˁB
�e�ʑ�������ƃN���b�N�������Ȃ��Ƃ��A����ȂƂ���?
����̓N���b�N�u������Ȃ��݂��������A
�f�R�[�_�[�̏���d��(�M)�̂��Ƃ����邩��g���Ă�C�͂��邯�ǁA�ǂ��Ȃ̂��˂��B
���ƃp�C�v���C���̒i����NetBurst�ɉ�����ő�̓��F�ƕ߂炦�Ă�l�ɂ�
Merom Conroe��14�i(Conro�͈Ⴄ��������Ȃ��炵��?)�����w�E����
�ق�PenM���C�N�ł���?�A�Ƃ����]���ɂȂ邩�������ˁB
�{��ALU�ƈٗl�ɒ����p�C�v���C���͓������Ǝv����
fea�Eture
���� n. ��̈ꕔ ((�Ђ����E�ځE�@�E���Ȃ�)); �ipl.�j �e�; ����; ���_; ���ҁm��v�n���f�� �ifeature film�j; �i�V���E�G���́j���W�L��; �i�e���r�́j���ʔԑg ((on)); �ڋʏ��i.
���� vt. �c�̓����ɂȂ�; �Ăѕ��ɂ���; ���W����; �o���m�剉�n������; �k�Ęb�l �z������.
���� vi. �d�v�Ȗ����������� ((in)).
http://dictionary.goo.ne.jp/search.php?MT=Feature&kind=ej&kwassist=0&mode=1
phi�Elos�Eo�Ephy
���� n. �N�w; �i����́j�N�w�̌n; ����; �l����; ����; ���; �錍.
http://dictionary.goo.ne.jp/search.php?MT=Philosophy&kind=ej&kwassist=0&mode=1
�v�v�z��P-M�ŃA�[�L�e�N�`���̓����Ƀl�g�o����������Ċ������˂��B
���� n. ��̈ꕔ ((�Ђ����E�ځE�@�E���Ȃ�)); �ipl.�j �e�; ����; ���_; ���ҁm��v�n���f�� �ifeature film�j; �i�V���E�G���́j���W�L��; �i�e���r�́j���ʔԑg ((on)); �ڋʏ��i.
���� vt. �c�̓����ɂȂ�; �Ăѕ��ɂ���; ���W����; �o���m�剉�n������; �k�Ęb�l �z������.
���� vi. �d�v�Ȗ����������� ((in)).
http://dictionary.goo.ne.jp/search.php?MT=Feature&kind=ej&kwassist=0&mode=1
phi�Elos�Eo�Ephy
���� n. �N�w; �i����́j�N�w�̌n; ����; �l����; ����; ���; �錍.
http://dictionary.goo.ne.jp/search.php?MT=Philosophy&kind=ej&kwassist=0&mode=1
�v�v�z��P-M�ŃA�[�L�e�N�`���̓����Ƀl�g�o����������Ċ������˂��B
�܂��Ԃ����Ⴏ�ǂ����ł��ǂ����ǂ�(w
intel�̎���Conroe Merom����̒����d�͂Ɛ��\�������Ȃ�B
intel�̎���Conroe Merom����̒����d�͂Ɛ��\�������Ȃ�B
>>170,175,176
�A�t�H
intel�Ј��̘b�Ɖ������Ɉ����Ȃ�B
>>180
���̒ʂ�B���
>>180�������Ă��A�C�X���G���`�[����1����g�i��Ƃł������j�A�[�L�e�N�`�����Ǝv���̂����B
�A�t�H
intel�Ј��̘b�Ɖ������Ɉ����Ȃ�B
>>180
���̒ʂ�B���
>>180�������Ă��A�C�X���G���`�[����1����g�i��Ƃł������j�A�[�L�e�N�`�����Ǝv���̂����B
�p���t���Ŕ�r�I�N�[����Merom
���\���悭�ď���d��/���M�����Ȃ��Ȃ�劽�}��
>>182
���S�V�K�A�[�L�Ƃ͂�߂�Ȃ�
PenM�����Ċ��S�V�K����ˁ[��
���������PenM�̂��炵�����J���w�ł��b��ɂȂ�
Yona�̌����̗ǂ����x�[�X�ɂ����
�f�X�N�g�b�v�A���o�C���A�T�[�o�[�œ���R�A�ɂł��Ă��W���ł���
�����A�f�X�N�g�b�v��T�[�o�[�Ŏ���邽�߂ɂ�64bit��������낪�K�v�ɂȂ�
���Ă�������ˁ[�́H
������NetBurst�̎��ƕ������J
���S�V�K�A�[�L�Ƃ͂�߂�Ȃ�
PenM�����Ċ��S�V�K����ˁ[��
���������PenM�̂��炵�����J���w�ł��b��ɂȂ�
Yona�̌����̗ǂ����x�[�X�ɂ����
�f�X�N�g�b�v�A���o�C���A�T�[�o�[�œ���R�A�ɂł��Ă��W���ł���
�����A�f�X�N�g�b�v��T�[�o�[�Ŏ���邽�߂ɂ�64bit��������낪�K�v�ɂȂ�
���Ă�������ˁ[�́H
������NetBurst�̎��ƕ������J
�p�a���T����Ȃ����ʂ̎��T����������?
ttp://dictionary.reference.com/search?q=feature
7. An item advertised or offered as particularly attractive or as an inducement: a washing machine with many features.
ttp://dictionary.reference.com/search?q=feature
7. An item advertised or offered as particularly attractive or as an inducement: a washing machine with many features.
>183
����۽
����۽
>>185
���̃C���^�r���[���I���Ă̑匴�̓Z�߁B
�@�@�@�@�@�@�@�@�@�@�@ ~~~~~~~~
���f�U�C���I�ɂ�Yonah����X�^�[�g�����u�̂�������Ȃ��v(���͕M�҂́A���ł͂��ꂷ��^���Ă���)���A
�����ʂƂ��Ă��Ȃ�Ⴄ���̂ɂȂ��Ă���ƍl���Ă��悳�������B
���̃C��(ry������O�̌㓡�A�����z�̐����B
>>170,176�@�@ ~~~~~~~~
���ꂪ�M�p�ɑ���̂��͂܂��A�u���Ă����B
���̃C���^�r���[���I���Ă̑匴�̓Z�߁B
�@�@�@�@�@�@�@�@�@�@�@ ~~~~~~~~
���f�U�C���I�ɂ�Yonah����X�^�[�g�����u�̂�������Ȃ��v(���͕M�҂́A���ł͂��ꂷ��^���Ă���)���A
�����ʂƂ��Ă��Ȃ�Ⴄ���̂ɂȂ��Ă���ƍl���Ă��悳�������B
���̃C��(ry������O�̌㓡�A�����z�̐����B
>>170,176�@�@ ~~~~~~~~
���ꂪ�M�p�ɑ���̂��͂܂��A�u���Ă����B
IDF�֘A�̋L���Ƃ��ǂ�ł�AMerom��Banias�n�ƕ��ʂɑ�����Ǝv�����ǁB
CNET�̌��͂�����ˁB����ōl���Ⴂ�����l�������Ԃ����Ȃ��̂��ȁB
CNET�̌��͂�����ˁB����ōl���Ⴂ�����l�������Ԃ����Ȃ��̂��ȁB
Dightal Health Group�͍��J����ˁ[�́H
�匴���i�R��݂�����orz�j��Ă��Ȃ�����A
�wPower Design�́xphilosophy
�ƌ����������́A���Ɉ��������錾���Ȃ킯�����B
�wPower Design�́xphilosophy
�ƌ����������́A���Ɉ��������錾���Ȃ킯�����B
NetBurst���\�����p�C�v���C���̒i����TraceCache�ゾ����20�i���Ĕ��\���Ă���ȁB
Pen3�݂����ȕ��ʂ�14�i��3GHz�Ƃ��B���o����낤���B
Pen3�݂����ȕ��ʂ�14�i��3GHz�Ƃ��B���o����낤���B
����PenM�łRGH���͂��Ƃ����邱�Ƃ��l�����
�f�X�N�g�b�v��T�[�o�[������TDP�������v���Z�X���[�����������Ă邵
�����Ȃ����Ƃ͂Ȃ��̂ł́H
�f�X�N�g�b�v��T�[�o�[������TDP�������v���Z�X���[�����������Ă邵
�����Ȃ����Ƃ͂Ȃ��̂ł́H
Net-burst���ڰ�������͂��łɃ�Ops�ɂ��Ă邩��܂���킵������
�ڰ���������Č��t���̂�ISA���W
�i������x86�̂܂܂Ŋi�[�����ڰ�������Ȃ�Ă̂��ǂ�������낤�Ǝv���ł���͂��A�قƂ�LjӖ��Ȃ����������ǂ��j
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
���g���[�X�L���b�V���́APentium 4�ł��̗p����Ă��閽�߃L���b�V�������ŁA
���v���O�����̒��̎��ۂɎg����R�[�h�̃g���[�X(���s�����p�X)�ɂ����Ė��߂��L���b�V������B
���v���O�����̖��ߏ����ɏ]���ăL���b�V������]���̖��߃L���b�V�����������������B
http://techon.nikkeibp.co.jp/word/data/ID0517.html
������i�{���́juOps��������ڰ������
�ڰ���������Č��t���̂�ISA���W
�i������x86�̂܂܂Ŋi�[�����ڰ�������Ȃ�Ă̂��ǂ�������낤�Ǝv���ł���͂��A�قƂ�LjӖ��Ȃ����������ǂ��j
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
���g���[�X�L���b�V���́APentium 4�ł��̗p����Ă��閽�߃L���b�V�������ŁA
���v���O�����̒��̎��ۂɎg����R�[�h�̃g���[�X(���s�����p�X)�ɂ����Ė��߂��L���b�V������B
���v���O�����̖��ߏ����ɏ]���ăL���b�V������]���̖��߃L���b�V�����������������B
http://techon.nikkeibp.co.jp/word/data/ID0517.html
������i�{���́juOps��������ڰ������
196 �FSocket774�F2005/09/02(��) 20:56:08 ID:XTnSk15I
�X�}�[�g�L���b�V�����ĉ��H
197 �FSocket774�F2005/09/02(��) 21:18:20 ID:P1+swLYk
���L�L���b�V����Intel���̌Ăі��B
������Athlon�́A���߂�L1�Ƀt�F�b�`����ۂɖ��ߒ���\���r�b�g��擪�ɕt�����Ċi�[����@�\�������͂��B
�v���f�R�[�h�Ă���ˁB
�]���f�R�[�h�����̈ꕔ���������̂��p�C�v���C���̊O�ɒǂ��o���Ă�Ƃ����Ӗ��ł͈ĊO�߂��̂����B
������Athlon�́A���߂�L1�Ƀt�F�b�`����ۂɖ��ߒ���\���r�b�g��擪�ɕt�����Ċi�[����@�\�������͂��B
�v���f�R�[�h�Ă���ˁB
�]���f�R�[�h�����̈ꕔ���������̂��p�C�v���C���̊O�ɒǂ��o���Ă�Ƃ����Ӗ��ł͈ĊO�߂��̂����B
198 �FSocket774�F2005/09/02(��) 21:38:03 ID:P1+swLYk
feature�͓����Ƃ������Ƃ����j���A���X�������Ǝv���B
�^�Ċ�Ƃ̑g�ݍ��ݐ̃}�j���A���|�����Ƃ����������Afeature�����\�ӏ��ɂ킽���ďo�Ă���㩁B
�^�Ċ�Ƃ̑g�ݍ��ݐ̃}�j���A���|�����Ƃ����������Afeature�����\�ӏ��ɂ킽���ďo�Ă���㩁B
�����킯�킩�߂ɂȂ��Ă邯��
�uNetBurst Architecture��Feature��Conroe��MicroArchitecture�Ɏ�荞�Ƃ������̂��v
���Ă̂́CConroe�̃ʃA�[�L���x�[�X�ɂ��ĔM���̓�����t�����������ĈӖ�����
�ŁC���̓����Ƃ��́u��̓I�Ɍ�����64bit�AQuad Pump Bus(P6�o�X)�AVT�ALaGrande Technology�Ȃǂ��v���Ă��Ƃ�
����́i���́j�M���A�[�L�̓����ł͂��邪�C�����Ă��܂��Ύ}�t�ł����Ȃ�
�uNetBurst Architecture��Feature��Conroe��MicroArchitecture�Ɏ�荞�Ƃ������̂��v
���Ă̂́CConroe�̃ʃA�[�L���x�[�X�ɂ��ĔM���̓�����t�����������ĈӖ�����
�ŁC���̓����Ƃ��́u��̓I�Ɍ�����64bit�AQuad Pump Bus(P6�o�X)�AVT�ALaGrande Technology�Ȃǂ��v���Ă��Ƃ�
����́i���́j�M���A�[�L�̓����ł͂��邪�C�����Ă��܂��Ύ}�t�ł����Ȃ�
feature���ē��{��ɂ͖Ȃ��P�ꂾ��ȁB
�p�a���T�ɍڂ��Ă�Ӗ��͖{���̈Ӗ��Ƃ��Ȃ肸��Ă�̂������Ǝv���B
"�����ƂȂ�@�\"�݂����ȃj���A���X���˂��B
VT��64bit�͂��܂��@�\�����炻����������ł��l�g�o�x�[�X�Ƃ͌����Ȃ��ȁB
�܂��A�����܂ŕς�����Ⴄ�ƃt���X�N���b�`�ƌ����Ă����ł��傤�B
�t���X�N���b�`�ƌ����ƁA�S���V�v�ł͂Ȃ��Ƃ�������������z�����邪�A
�����ߋ��̎��Y�g��Ȃ��ʼn�H�v���邱�ƂȂ�Ă܂��Ȃ����B
�p�a���T�ɍڂ��Ă�Ӗ��͖{���̈Ӗ��Ƃ��Ȃ肸��Ă�̂������Ǝv���B
"�����ƂȂ�@�\"�݂����ȃj���A���X���˂��B
VT��64bit�͂��܂��@�\�����炻����������ł��l�g�o�x�[�X�Ƃ͌����Ȃ��ȁB
�܂��A�����܂ŕς�����Ⴄ�ƃt���X�N���b�`�ƌ����Ă����ł��傤�B
�t���X�N���b�`�ƌ����ƁA�S���V�v�ł͂Ȃ��Ƃ�������������z�����邪�A
�����ߋ��̎��Y�g��Ȃ��ʼn�H�v���邱�ƂȂ�Ă܂��Ȃ����B
���b�`��Microcode�w�ŏ_��ɑΉ��\�A�ƌ���NetBurst�̓����������p����Ă���̂��Ȃ�?
>�t���X�N���b�`�ƌ����ƁA�S���V�v�ł͂Ȃ��Ƃ�������������z�����邪�A
>�����ߋ��̎��Y�g��Ȃ��ʼn�H�v���邱�ƂȂ�Ă܂��Ȃ����B
���ԂɈ�l�o�v���Ă����l�q�ł���B
>�t���X�N���b�`�ƌ����ƁA�S���V�v�ł͂Ȃ��Ƃ�������������z�����邪�A
>�����ߋ��̎��Y�g��Ȃ��ʼn�H�v���邱�ƂȂ�Ă܂��Ȃ����B
���ԂɈ�l�o�v���Ă����l�q�ł���B
>>201
Netburst�̓����������p���ƌ����Ă�������AMicrocode�𗘗p�����_��Ȋg�����͈����p���Ǝv���B
Netburst�̓����������p���ƌ����Ă�������AMicrocode�𗘗p�����_��Ȋg�����͈����p���Ǝv���B
>>179
�{��ALU��4���ߕ���͂ǂ������ǂ��̂��ˁH
�{��ALU��4���ߕ���͂ǂ������ǂ��̂��ˁH
>>203
�����������A�����ĂȂ��Ȃ�Ȃ�����
�����������A�����ĂȂ��Ȃ�Ȃ�����
�����Ȃ��������A�������p����Q�l�ɂ���B
�R���s���[�^�ƊE��feature�Ƃ�������A
�@�\�ꗗ�ɏ�����鍀�ڂ̂悤�Ȃ��Ƃ��B
��̓I�Ɍ����A
�E64�r�b�g
�EQuad Pump Bus
�EVT
�ELaGrande Technology
���ƁA���̌�Ō����Ă�ł���B
����ɂ��A
������Conroe��MicroArchitecture�Ɏ�荞��
�Ƃ������͂ɂȂ��Ă���̂ɁA
NetBurst�̃}�C�N���A�[�L�e�N�`���x�[�X���Ȃ�Ď��̂́A���{�ꂷ��ǂ߂Ȃ��ƁE�E�E�B
�R���s���[�^�ƊE��feature�Ƃ�������A
�@�\�ꗗ�ɏ�����鍀�ڂ̂悤�Ȃ��Ƃ��B
��̓I�Ɍ����A
�E64�r�b�g
�EQuad Pump Bus
�EVT
�ELaGrande Technology
���ƁA���̌�Ō����Ă�ł���B
����ɂ��A
������Conroe��MicroArchitecture�Ɏ�荞��
�Ƃ������͂ɂȂ��Ă���̂ɁA
NetBurst�̃}�C�N���A�[�L�e�N�`���x�[�X���Ȃ�Ď��̂́A���{�ꂷ��ǂ߂Ȃ��ƁE�E�E�B
206 �FSocket774�F2005/09/03(�y) 10:23:48 ID:7c7LRpeS
>>205������������
���������U�X�S�g�[�݂Ƃ����O����PenM�̔��W�^ϲ�۱�����Č����Ă�̂ɂȂ�Ńl�g�o�x�[�X���Ďv�������������
���������U�X�S�g�[�݂Ƃ����O����PenM�̔��W�^ϲ�۱�����Č����Ă�̂ɂȂ�Ńl�g�o�x�[�X���Ďv�������������
>>201,202
http://pc.watch.impress.co.jp/docs/2004/0310/kaigai072.htm
�㓡�L���ōl�@���Ă���ǁA
NetBurst�̏_��́ARich�ȃf�R�[�h�w�Ƃ�����x������g���[�X�L���b�V��
�ɂ����̂Ȃ��ǁAMerom�ł͐v�v�z����Ⴄ��ˁB
�ʂ�Netburst��VT,LT,EM64T�Ƃ���Feature��AMD�̎���������悤�ɁANetburst
����Ȃ�������ł��Ȃ����̂���Ȃ��BNetburst�̂ق����e�Ղ��낤����ǁB
�����AYonah�ɑ��ĉ��ǂ����傫�������́A�����ɑΉ����邽�߂Ƀf�R�[�h�w��
�������@�\�ɂ������Ƃ�������Ȃ��B
http://pc.watch.impress.co.jp/docs/2004/0310/kaigai072.htm
�㓡�L���ōl�@���Ă���ǁA
NetBurst�̏_��́ARich�ȃf�R�[�h�w�Ƃ�����x������g���[�X�L���b�V��
�ɂ����̂Ȃ��ǁAMerom�ł͐v�v�z����Ⴄ��ˁB
�ʂ�Netburst��VT,LT,EM64T�Ƃ���Feature��AMD�̎���������悤�ɁANetburst
����Ȃ�������ł��Ȃ����̂���Ȃ��BNetburst�̂ق����e�Ղ��낤����ǁB
�����AYonah�ɑ��ĉ��ǂ����傫�������́A�����ɑΉ����邽�߂Ƀf�R�[�h�w��
�������@�\�ɂ������Ƃ�������Ȃ��B
Merom�ɂ̓g���[�X�L���b�V�����̗p����ĂȂ����Ă���?
"�l�I"�ɂ̓g���[�X�L���b�V�� neary equal Netburst �Ȃ��ǁB
4issue�̎��s���j�b�g�߂�ׂɂ̓f�R�[�_�[�������撣��Ȃ��Ƃ����Ȃ����ŁA
���ł���CPU�̒��ň�Ԃ�hot spot�̓f�R�[�_�[���Ƃ������A
�g���[�X�L���b�V��������A�f�R�[�_�[�x�܂�����Ԃ����d��&�M�I�ɗL���ł�?
�����I�Ɏ������ł��낤Parrot���d�v���Ƃ��̂�������������Ă邵�B
parrot�ƃg���[�X�L���b�V���ɂ��Ă͂�����A����ƌÂ����ǁB
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
�g���[�X�L���b�V���Ȃ[�A�����ł����ł��ˁ[��A�Ƃ�
PentiumM�͊��Ƀg���[�X�L���b�V���̗p���Ă��ް�(�m���ڍׂ��͂�����Ƃ͔��\����ĂȂ��͂�)
�Ƃ����̂Ȃ牴���n���������̂ŕ����Ȃ��������Ƃɂ��Ă��������B
"�l�I"�ɂ̓g���[�X�L���b�V�� neary equal Netburst �Ȃ��ǁB
4issue�̎��s���j�b�g�߂�ׂɂ̓f�R�[�_�[�������撣��Ȃ��Ƃ����Ȃ����ŁA
���ł���CPU�̒��ň�Ԃ�hot spot�̓f�R�[�_�[���Ƃ������A
�g���[�X�L���b�V��������A�f�R�[�_�[�x�܂�����Ԃ����d��&�M�I�ɗL���ł�?
�����I�Ɏ������ł��낤Parrot���d�v���Ƃ��̂�������������Ă邵�B
parrot�ƃg���[�X�L���b�V���ɂ��Ă͂�����A����ƌÂ����ǁB
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
�g���[�X�L���b�V���Ȃ[�A�����ł����ł��ˁ[��A�Ƃ�
PentiumM�͊��Ƀg���[�X�L���b�V���̗p���Ă��ް�(�m���ڍׂ��͂�����Ƃ͔��\����ĂȂ��͂�)
�Ƃ����̂Ȃ牴���n���������̂ŕ����Ȃ��������Ƃɂ��Ă��������B
���߂�Anearly����ցcorz
�g���[�X�L���b�V���͐ς�łȂ����낤�i�͂��j�����ǁA�����������L������̂��ȁH
�匴�����肪������ƕ����Ă�悩�����̂����ǁB
�匴�����肪������ƕ����Ă�悩�����̂����ǁB
>>208
�l�I�ɂ� NetBurst �̓����͂Ȃ�ƌ����Ă��A
�N���b�N�ŏd���ŁA�O��I�ɍו������������p�C�v���C��
�Ȃ̂ŁA���ꂪ�Ȃ����� NetBurst �Ƃ͌����Ȃ��ȁB
�g���[�X�L���b�V���Ȃ�Ă̂͋@�\�̈�ŁA�ǂ�����
�}�C�N���A�[�L�e�N�`���ɂ����čڂ�������̂ł���B
����ɁA�{���� NetBurst �n�̃}�C�N���A�[�L�e�N�`��
�Ȃ�AHyperThreading ���T�|�[�g���Ȃ����R���Ȃ��B
(���͒P���� HyperThreading ���ڂ��Ă��鎞�Ԃ��Ȃ�����
�̂ŃT�|�[�g���ĂȂ��ƍl���Ă���B)
�S�̐v�� PenM �x�[�X�ŁA������ NetBurst ����
�������@�\�������Ă������ĂƂ���ł���B
�l�I�ɂ� NetBurst �̓����͂Ȃ�ƌ����Ă��A
�N���b�N�ŏd���ŁA�O��I�ɍו������������p�C�v���C��
�Ȃ̂ŁA���ꂪ�Ȃ����� NetBurst �Ƃ͌����Ȃ��ȁB
�g���[�X�L���b�V���Ȃ�Ă̂͋@�\�̈�ŁA�ǂ�����
�}�C�N���A�[�L�e�N�`���ɂ����čڂ�������̂ł���B
����ɁA�{���� NetBurst �n�̃}�C�N���A�[�L�e�N�`��
�Ȃ�AHyperThreading ���T�|�[�g���Ȃ����R���Ȃ��B
(���͒P���� HyperThreading ���ڂ��Ă��鎞�Ԃ��Ȃ�����
�̂ŃT�|�[�g���ĂȂ��ƍl���Ă���B)
�S�̐v�� PenM �x�[�X�ŁA������ NetBurst ����
�������@�\�������Ă������ĂƂ���ł���B
>>211
�����_�ł͂��ꂪ�L�͂���ˁB
�����A�ǐ�����Ȃ�ӂ肩�܂킸���X�ɁA���đ̎������炩�ȁ[��ו��܂Ŏ��������Banias����o�����ĂĂ��A�����Ȃ������ɂȂ��Ă�C������B
P6�R�A��Banias�̒���݂����ɁB
�����_�ł͂��ꂪ�L�͂���ˁB
�����A�ǐ�����Ȃ�ӂ肩�܂킸���X�ɁA���đ̎������炩�ȁ[��ו��܂Ŏ��������Banias����o�����ĂĂ��A�����Ȃ������ɂȂ��Ă�C������B
P6�R�A��Banias�̒���݂����ɁB
�� Timna�iKatmai+i810�j��Banias+i85x�̖��i
214 �FSocket774�F2005/09/03(�y) 16:44:05 ID:Dd9TaxJq
4issue���]���^�A�[�L�Ŏ�������̂́A�f�R�[�_�𑝂₷�����Ȃ��A
�_�C�i�~�b�N�X�P�W���[�����O�����G�ɂȂ�A����d�͓��̖�肩�猻��B
���������āA�g���[�X�L���c�V�����̗p����̂͂قڊm��B
�ŁA��OP�̃f�[�^�\����Banias���B
����ł��������B
�l�b�g�o�[�X�g�̓�OPs����������@�\�͂Ȃ������̂ŁA�V�@�\�ɂȂ肤��B
�_�C�i�~�b�N�X�P�W���[�����O�����G�ɂȂ�A����d�͓��̖�肩�猻��B
���������āA�g���[�X�L���c�V�����̗p����̂͂قڊm��B
�ŁA��OP�̃f�[�^�\����Banias���B
����ł��������B
�l�b�g�o�[�X�g�̓�OPs����������@�\�͂Ȃ������̂ŁA�V�@�\�ɂȂ肤��B
>>212
�m���ɂǂ����ɂ��Ă��ŏI�I�ɂłĂ���͎̂��Ă������Ȃ������ɂȂ��Ă����ł͂����
�m���ɂǂ����ɂ��Ă��ŏI�I�ɂłĂ���͎̂��Ă������Ȃ������ɂȂ��Ă����ł͂����
�g���[�X�L���b�V�������Ă邩�Ȃ��H
�匴�̃C���^�r���[����ƃf�R�[�_���₵�Ă�݂������������͎v���Ȃ��̂���
Q: Execution��4 issue�Ƃ������Ƃ́ADecoder��4 issue�Ƃ��������ł悢�ł���?
A: ���̒ʂ肾�B�����A����͕W���I(Standard)�Ȏ��s�̗Ⴞ�B���Ƃ���������
���[�h/�X�g�A�͂�葽���̎��Ԃ��|����B�W���I�Ȗ��߂Ȃ�ADecode /
Execute / Retirement��4 issue�Ŏ��s�ł���B
Q: �Ƃ���ł���issue�ł����A�����Ō����Ă���̂�MicroOps��4 issue�Ŏ��s
�ł���Ƃ����Ӗ��ł��傤��? ����Ƃ�x86���߂�4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ����A�����O�̐���̃A�[�L�e�N�`���ł�
�������悯���3��x86���߂�MicroOps�ɕϊ����ē����Ɏ��s���鎖���ł����B
���Ɍ�����̂͂����܂ł�(��)�B
�匴�̃C���^�r���[����ƃf�R�[�_���₵�Ă�݂������������͎v���Ȃ��̂���
Q: Execution��4 issue�Ƃ������Ƃ́ADecoder��4 issue�Ƃ��������ł悢�ł���?
A: ���̒ʂ肾�B�����A����͕W���I(Standard)�Ȏ��s�̗Ⴞ�B���Ƃ���������
���[�h/�X�g�A�͂�葽���̎��Ԃ��|����B�W���I�Ȗ��߂Ȃ�ADecode /
Execute / Retirement��4 issue�Ŏ��s�ł���B
Q: �Ƃ���ł���issue�ł����A�����Ō����Ă���̂�MicroOps��4 issue�Ŏ��s
�ł���Ƃ����Ӗ��ł��傤��? ����Ƃ�x86���߂�4 issue�Ŏ��s�ł���Ƃ����Ӗ��ł��傤��?
A: ����ȏ�̏ڍׂ͘b�����Ƃ��ł��Ȃ����A�����O�̐���̃A�[�L�e�N�`���ł�
�������悯���3��x86���߂�MicroOps�ɕϊ����ē����Ɏ��s���鎖���ł����B
���Ɍ�����̂͂����܂ł�(��)�B
Whitefield�ACSI �ɖ�肠��Ŕ��N�x���B2007H2?
ttp://www.theinquirer.net/?article=25887
Intel needs this interconnect yesterday, and
each day of delay will hurt. Even if it ends
up being a little less than optimal, it is a
lot better than the current bus.
�Ƃ܂Ō����Ă邵�c orz
ttp://www.theinquirer.net/?article=25887
Intel needs this interconnect yesterday, and
each day of delay will hurt. Even if it ends
up being a little less than optimal, it is a
lot better than the current bus.
�Ƃ܂Ō����Ă邵�c orz
Merom���g���[�X�L���b�V���������Ƃ��āA
C�X�e�C�g�Ǘ��ŕБ�CPU Sleep���̃X�k�[�s���O�͔@�������ˁH
Yonah�Ɠ����l��L2�ɑޔ��H
C�X�e�C�g�Ǘ��ŕБ�CPU Sleep���̃X�k�[�s���O�͔@�������ˁH
Yonah�Ɠ����l��L2�ɑޔ��H
>>216
�����A����ł͒P�Ƀf�R�[�_���₵�Ă�Ƃ������Ƃ��ǂݎ��邾���ŁB
����d�͂̊ϓ_����́A�f�R�[�_�̃p�C�v���C���i���͂���قǑ��₹�Ȃ����A
��������ƁA�킴�킴�i�C�X���G���������j�g���[�X�L���b�V����������K�v���͊������Ȃ��B
Yonah���ς�Ŗ������B
�����A����ł͒P�Ƀf�R�[�_���₵�Ă�Ƃ������Ƃ��ǂݎ��邾���ŁB
����d�͂̊ϓ_����́A�f�R�[�_�̃p�C�v���C���i���͂���قǑ��₹�Ȃ����A
��������ƁA�킴�킴�i�C�X���G���������j�g���[�X�L���b�V����������K�v���͊������Ȃ��B
Yonah���ς�Ŗ������B
220 �FSocket774�F2005/09/03(�y) 21:55:49 ID:Dd9TaxJq
�g���[�X�L���b�V���͊m���Ƀf�R�[�_���������邱�Ƃ��ł��邪�A���t�B���̍��������l����Ȃ�4���j�b�g�������ق��������B
�g���[�X�L���c�V���̏ȓd�͌��ʂ́A�f�R�[�_�̐������点�邱�Ƃ����A���点�邱�Ƃ��ł��邱�Ƃ̂ق����傫���B
�g���[�X�L���c�V���̏ȓd�͌��ʂ́A�f�R�[�_�̐������点�邱�Ƃ����A���点�邱�Ƃ��ł��邱�Ƃ̂ق����傫���B
221 �FSocket774�F2005/09/03(�y) 22:12:35 ID:Dd9TaxJq
�g���[�X�L���b�V���ɂ���������܂��Ă���f�R�[�_���ғ����Ȃ��Ă�������
�p�C�v���C���i���͂���܊W�Ȃ��C�����邪�B
������f�R�[�_���x�܂��邱�Ƃ��ł��Ȃ��]���^�ŁA�X�Ƀ��j�b�g���𑝂₹�Ώ���d�͖ʂŕs�����ȁB
�X�P�W���[�����O��������B
�p�C�v���C���i���͂���܊W�Ȃ��C�����邪�B
������f�R�[�_���x�܂��邱�Ƃ��ł��Ȃ��]���^�ŁA�X�Ƀ��j�b�g���𑝂₹�Ώ���d�͖ʂŕs�����ȁB
�X�P�W���[�����O��������B
�f�R�[�_4�{��2�R�A�ŋ��L�A�g���[�X�L���b�V���t���Ƃ�
Merom���o�����ƁA�m��PenD�݂����Ɍ����܂���悤�ɁB
WhiteField�Ƃ����l�R�~�~�̌��c�Ȃ̍���
225 �FSocket774�F2005/09/03(�y) 22:38:18 ID:q16fxfyd
Merom/Conroe/Woodcrest�̐��i���C���i�b�v�����APhoto11�̗l�Ȍ`�ɂȂ��Ă���B
Mobile�͒P��\���ŁA�����炭��4MB�L���b�V����Dual Core�BMobility TDP Envelope��
�����炭30W�O��(���ꂪ���C���X�g���[��)��15W(���ꂪLow Voltage)�A�����5W�O��
(���ꂪUltra Low Voltage)�ɂȂ邾�낤�B
���Desktop��TDP��65W�ŌŒ肾���APhoto11�̃_�C�̐}��M����Mobile�̃T�C�Y����
��������Ȃ�A�L���b�V����4MB��8MB��2��ށB
Server�͌��݂�Xeon��130W�̃����W�ɒB���Ă��邩��A40%�팸�����78W�ƂȂ�A�ق�
80W �Ƃ������Ƃ��납? �������2�R�A�E8MB�L���b�V����Woodcrest�ƁA4�R�A�E32MB(!)
�L���b�V����Whitefield�Ƃ����\���ɂȂ�B
80W�̃����W�͂����炭4�R�A��Whitefield�ɓK�p�������̂ɂȂ邾�낤�B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
Mobile�͒P��\���ŁA�����炭��4MB�L���b�V����Dual Core�BMobility TDP Envelope��
�����炭30W�O��(���ꂪ���C���X�g���[��)��15W(���ꂪLow Voltage)�A�����5W�O��
(���ꂪUltra Low Voltage)�ɂȂ邾�낤�B
���Desktop��TDP��65W�ŌŒ肾���APhoto11�̃_�C�̐}��M����Mobile�̃T�C�Y����
��������Ȃ�A�L���b�V����4MB��8MB��2��ށB
Server�͌��݂�Xeon��130W�̃����W�ɒB���Ă��邩��A40%�팸�����78W�ƂȂ�A�ق�
80W �Ƃ������Ƃ��납? �������2�R�A�E8MB�L���b�V����Woodcrest�ƁA4�R�A�E32MB(!)
�L���b�V����Whitefield�Ƃ����\���ɂȂ�B
80W�̃����W�͂����炭4�R�A��Whitefield�ɓK�p�������̂ɂȂ邾�낤�B
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/001.html
226 �FSocket774�F2005/09/03(�y) 23:49:39 ID:7c7LRpeS
Q: �ł̓p�C�v���C���̍\����MicroArchitecture�ł���? ����Ƃ�Implementation�ł���?
A: Implementation���B
Q: �Ƃ������Ƃ́A���Ƃ���Merom��Conroe�ł̓p�C�v���C���̍\�����قȂ�\��������킯�ł���?
A: ����������ɂ͓������Ȃ��B
�ւ��[
A: Implementation���B
Q: �Ƃ������Ƃ́A���Ƃ���Merom��Conroe�ł̓p�C�v���C���̍\�����قȂ�\��������킯�ł���?
A: ����������ɂ͓������Ȃ��B
�ւ��[
228 �FSocket774�F2005/09/04(��) 07:50:24 ID:gwf5qsnP
>>227
��
��
>227
������ăp�C�v���C�����ǂ��ł��낤�Ƃ����Micro Architecture����Ȃ��ł���A���Ă��ƂȂ�?
NetBurst�ł��p�C�v���C���i���̕ω����������킯�����A
�J���͂���Ɋւ��Ă�Micro Architecture����Ȃ��Ƒ����Ă�̂��ȁB
���႟�ANetBurst��Micro Architecture���ĉ����B
������ăp�C�v���C�����ǂ��ł��낤�Ƃ����Micro Architecture����Ȃ��ł���A���Ă��ƂȂ�?
NetBurst�ł��p�C�v���C���i���̕ω����������킯�����A
�J���͂���Ɋւ��Ă�Micro Architecture����Ȃ��Ƒ����Ă�̂��ȁB
���႟�ANetBurst��Micro Architecture���ĉ����B
>>229
Q: �����Ō���MicroArchitecture�Ƃ͉��������Ă��܂���?
A: �����Machine Implementation���Bx86�����Ƃ����̂�Architecture�ł���A
MicroArchitecture�͂�����ǂ��C���v�������g���邩�Ƃ������̂��B
���i��MicroArchitecture�ɂ����Drive�����B��������悤�B
MicroArchitecture�̓p�C�v���C���̐��Ƃ��[���Ƃ������x�[�V�b�N�ɂȂ���̂��B
1��̖ⓚ
Q: �����Ō���MicroArchitecture�Ƃ͉��������Ă��܂���?
A: �����Machine Implementation���Bx86�����Ƃ����̂�Architecture�ł���A
MicroArchitecture�͂�����ǂ��C���v�������g���邩�Ƃ������̂��B
���i��MicroArchitecture�ɂ����Drive�����B��������悤�B
MicroArchitecture�̓p�C�v���C���̐��Ƃ��[���Ƃ������x�[�V�b�N�ɂȂ���̂��B
1��̖ⓚ
�܂�ʏ팾����u�A�[�L�e�N�`���v�Ƃ����̂�Intel�̌����Ƃ����
MicroArchitecture�Ƃ������Ƃł����H
MicroArchitecture�Ƃ������Ƃł����H
�Ă��A>>227�Ɉ��p���Ă��鎿�⎩�̂�������������B
�A�Ƃ�MicroArchitecture�Ƃ�Implementation�̎�����
�����Ă�̂ɁA�u�p�C�v���C���̍\����MicroArchi
tecture�ł���? ����Ƃ�Implementation�ł����v
�Ƃ�������́A�ǂ��������������Ă�B
�A�Ƃ�MicroArchitecture�Ƃ�Implementation�̎�����
�����Ă�̂ɁA�u�p�C�v���C���̍\����MicroArchi
tecture�ł���? ����Ƃ�Implementation�ł����v
�Ƃ�������́A�ǂ��������������Ă�B
>>232
"Machine Implementation"�Ƃ�����"Implementation"�͂܂��Ⴄ���ĂƂ����̂��ȁH
"Machine Implementation"�Ƃ�����"Implementation"�͂܂��Ⴄ���ĂƂ����̂��ȁH
���邳����X�V�L�e������
�[����MicroArchitecture
�\����Implementation
����
�\����Implementation
����
>>231
���Ƃ��ƁACPU�W�ŃA�[�L�e�N�`�����Ă�������A���߃Z�b�g
�A�[�L�e�N�`���A���Ȃ킿���߃Z�b�g�̎d�l�̂��Ƃ��w���̂�B
�]���āA���̈Ӗ����ƁAIntel��AMD���A�[�L�e�N�`���͓�����
�Ȃ�킯�B�܂�3DNow�Ƃ������ȈႢ�͂��邪�B
�ŋ߁A�}�C�N���A�[�L�e�N�`���̂��Ƃ��A�[�L�e�N�`���Ə���
��p�������Ă邾���B
>>235
���[��A����>>232�Ɠ����B
���Ƃ��ƁACPU�W�ŃA�[�L�e�N�`�����Ă�������A���߃Z�b�g
�A�[�L�e�N�`���A���Ȃ킿���߃Z�b�g�̎d�l�̂��Ƃ��w���̂�B
�]���āA���̈Ӗ����ƁAIntel��AMD���A�[�L�e�N�`���͓�����
�Ȃ�킯�B�܂�3DNow�Ƃ������ȈႢ�͂��邪�B
�ŋ߁A�}�C�N���A�[�L�e�N�`���̂��Ƃ��A�[�L�e�N�`���Ə���
��p�������Ă邾���B
>>235
���[��A����>>232�Ɠ����B
http://pc.watch.impress.co.jp/docs/2004/1109/kaigai133.htm
�����ł�PentiumM�̐��PARROT������A�Ƃ���Ă���B
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
�C�X���G���̌����`�[�������\����PARROT�_���ɂ�
�g���[�X�L���b�V���O��œ��e�������Ă���B
(�L���ɂ́APentium 4���������ƃX�}�[�g�ȃg���[�X�I���@�\�ɂ���āA�������̂����g���[�X�L���b�V������������悤���A�ƗL��B)
�ӂ肩�玟(Merom Conroe)�ɂ̓g���[�X�L���b�V���̗p�A�Ɩ��z���Ă����ǁB
�����ł�PentiumM�̐��PARROT������A�Ƃ���Ă���B
http://pc.watch.impress.co.jp/docs/2004/1108/kaigai132.htm
�C�X���G���̌����`�[�������\����PARROT�_���ɂ�
�g���[�X�L���b�V���O��œ��e�������Ă���B
(�L���ɂ́APentium 4���������ƃX�}�[�g�ȃg���[�X�I���@�\�ɂ���āA�������̂����g���[�X�L���b�V������������悤���A�ƗL��B)
�ӂ肩�玟(Merom Conroe)�ɂ̓g���[�X�L���b�V���̗p�A�Ɩ��z���Ă����ǁB
>>237
Merom���ゾ��PARROT�͎����܂ł͊Ԃɍ���Ȃ��悤�ȋC�����邴�B
Merom���ゾ��PARROT�͎����܂ł͊Ԃɍ���Ȃ��悤�ȋC�����邴�B
PARROT�����͂Ƃ������A�������̂����g���[�X�L���b�V���Ƃ��͓���Ƃ����l����Ǝv�������ǁB
�f�R�[�_�[�̏���d�͂ƔM�̖����ʂŁB
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/003.html
�����ł�Merom�̃A�[�L�e�B�N�`����10�N��ݶ�ق��Č����Ă��Ȃ��B
PARROT�A10�N�ォ�A���҂������ܲ��
�f�R�[�_�[�̏���d�͂ƔM�̖����ʂŁB
http://pcweb.mycom.co.jp/articles/2005/08/31/idf1/003.html
�����ł�Merom�̃A�[�L�e�B�N�`����10�N��ݶ�ق��Č����Ă��Ȃ��B
PARROT�A10�N�ォ�A���҂������ܲ��
>>238
PARROT���g���[�X�L���b�V�����Ⴀ��܂����H
PARROT���g���[�X�L���b�V�����Ⴀ��܂����H
http://pc.watch.impress.co.jp/docs/2004/1109/kaigai02.jpg
���̐}�����邩��ɂ́AN�iMerom like�j�̓g���[�X�L���b�V�������ȋC���B
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
���uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i��
�����Ă���Ƃ���ƁADothan����Yonah�ւ̐i���͂��̐��{���̑傫��
����������܂��BYonah����Merom�̐i���������ď������͂���܂��A
��Dothan����Yonah�ւ̕ω��قǑ傫�Ȃ��̂ł͂���܂���v
�G�f�����̌��t���炷��ƁA�g���[�X�L���b�V����������̕ω��͂Ȃ��悤�Ɋ�������B
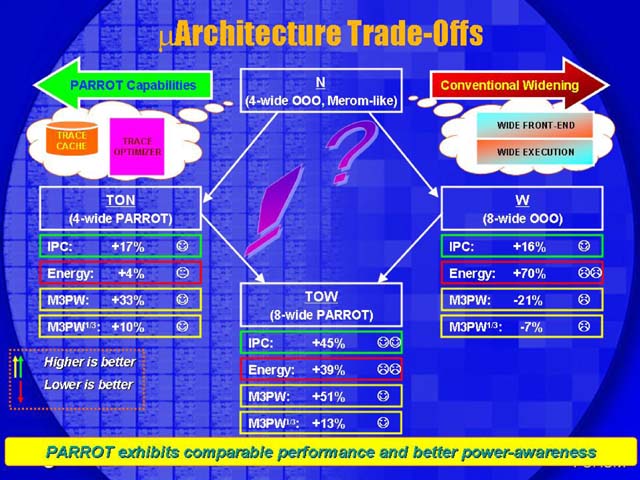{kind=link}
���̐}�����邩��ɂ́AN�iMerom like�j�̓g���[�X�L���b�V�������ȋC���B
http://www.itmedia.co.jp/news/articles/0508/29/news008.html
���uPentium III�ɑ���Banias�̐i���ɑ���Dothan�������x�i��
�����Ă���Ƃ���ƁADothan����Yonah�ւ̐i���͂��̐��{���̑傫��
����������܂��BYonah����Merom�̐i���������ď������͂���܂��A
��Dothan����Yonah�ւ̕ω��قǑ傫�Ȃ��̂ł͂���܂���v
�G�f�����̌��t���炷��ƁA�g���[�X�L���b�V����������̕ω��͂Ȃ��悤�Ɋ�������B
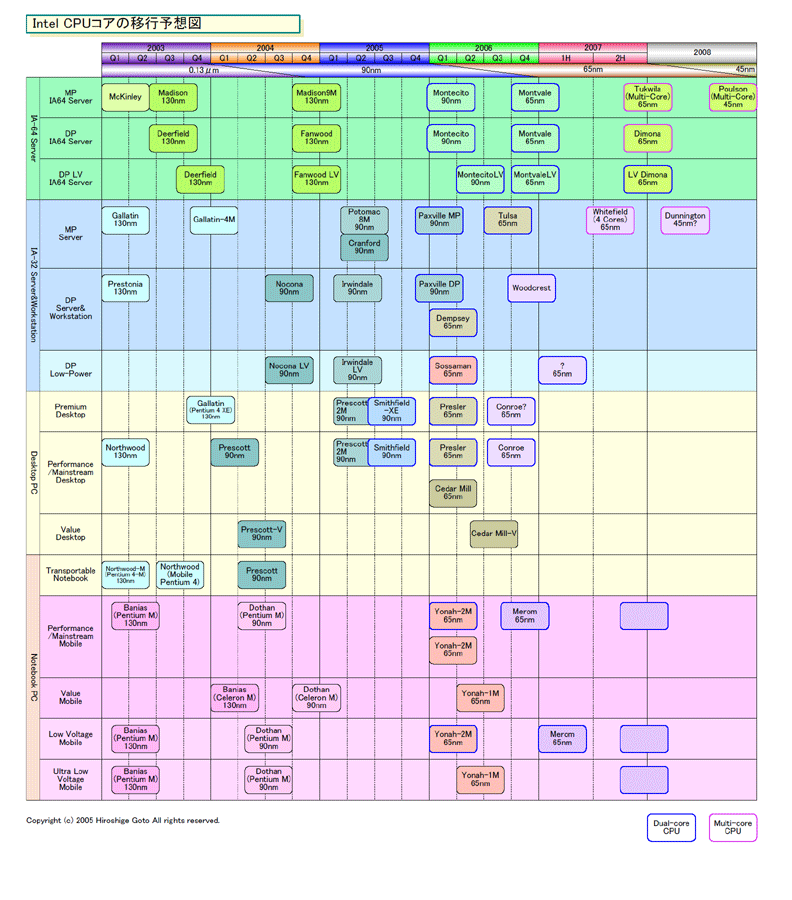
http://pc.watch.impress.co.jp/docs/2005/0826/kaigai207_08l.gif
�㓡�����̃��[�h�}�b�v�ł̓f�X�N�g�b�v�E�m�[�g�̖��������܂��Ă��Ȃ��B
����PARROT�����������ł��낤Merom�̎��͘g�����悢�Ă���B
������ɂ��Ă��܂�Intel�̓��[�N�ł���i�K�ɂȂ��B
�Ƃ������Ƃ�PARROT����������̂͂܂��܂�����������ԁB
���Ƀg���[�X�Z���N�^/�t�B���^/�r���_�i�z�b�g�R�[�h��I�ʂ��g���[�X�\�z�j��
�g���[�X�I�v�e�B�}�C�U�i�o�b�N�O���E���h�ł̃R�[�h�œK���j�̕�������ς������B
{kind=link}
�㓡�����̃��[�h�}�b�v�ł̓f�X�N�g�b�v�E�m�[�g�̖��������܂��Ă��Ȃ��B
����PARROT�����������ł��낤Merom�̎��͘g�����悢�Ă���B
������ɂ��Ă��܂�Intel�̓��[�N�ł���i�K�ɂȂ��B
�Ƃ������Ƃ�PARROT����������̂͂܂��܂�����������ԁB
���Ƀg���[�X�Z���N�^/�t�B���^/�r���_�i�z�b�g�R�[�h��I�ʂ��g���[�X�\�z�j��
�g���[�X�I�v�e�B�}�C�U�i�o�b�N�O���E���h�ł̃R�[�h�œK���j�̕�������ς������B
Merom �̎��́AWhitefield �Ɠ��l�A�������R���g���[��������
�Ȃ�낤���ǁA������������킯�ɂ̓C�J���Ƃ������Ƃł́H
�Ȃ�낤���ǁA������������킯�ɂ̓C�J���Ƃ������Ƃł́H
>>242
PARROT���̂��A�[�L�e�N�`������Ȃ��́H
PARROT���̂��A�[�L�e�N�`������Ȃ��́H
>>243
�������킯�ɂ̓C�J���Ƃ������A�����炭�������C���^�[�t�F�[�X�̃V���A�������������̂ł��낤��
���̋K�i���ǂ��Ȃ邩�s�����Ȃ̂Ŗ������Ȃ��Ƃ�����
�������킯�ɂ̓C�J���Ƃ������A�����炭�������C���^�[�t�F�[�X�̃V���A�������������̂ł��낤��
���̋K�i���ǂ��Ȃ邩�s�����Ȃ̂Ŗ������Ȃ��Ƃ�����
���Ȃ�FB-DIMM���炶���
�I�͂����Ȃ邾�낤���A�R���V���[�}�@�ɂ�
FB-DIMM�̂悤�ȏ璷���͕s�v������B
FB-DIMM��Registered DIMM�̑���ɂȂ�悤��
�l�Ă��ꂽ�\�����[�V����������B
FB-DIMM�̂悤�ȏ璷���͕s�v������B
FB-DIMM��Registered DIMM�̑���ɂȂ�悤��
�l�Ă��ꂽ�\�����[�V����������B
�����̃A�[�L�e�N�`���ł͂����炭�V���O���R�A���̐��\�����(PARROT��������)
���������ŖO�a���邾�낤�Ǝv���B
PARROT�̌��ʂ��������Ȃ��悤����2003Q3�ȍ~��Netburst�̎S��E�E�E�E
�ȏ�̒��Merom�A�[�L�e�N�`�������������ƂɂȂ��Ă��܂��B
�����R���������A���̎���������Ă���̂��ǂ����S�z���B
���������ŖO�a���邾�낤�Ǝv���B
PARROT�̌��ʂ��������Ȃ��悤����2003Q3�ȍ~��Netburst�̎S��E�E�E�E
�ȏ�̒��Merom�A�[�L�e�N�`�������������ƂɂȂ��Ă��܂��B
�����R���������A���̎���������Ă���̂��ǂ����S�z���B
���X���ゾ�Ƃ���Ă���PARROT�A�[�L�e�N�`���͂����炭�A�A�[�L�e�N�`���i������@)�Ƃ��Ă̌��ؒi�K�ŁA�V���R���ւ̎��������͂܂����n�܂������肾�Ǝv���B
����͂܂��A�I�����̈�ɉ߂����A�Ⴄ�I���ɂȂ邩������Ȃ��B�L�͌��̂P�Ƃ����ʒu�Â����Ǝv���B
Intel�ɂ��Ă݂��AMD�ɑ��ē������A���������Ă���Ώ����Ɣ��f���邾�낤����ABanias������Yonah�ł��ꂪ�����\���ƒ��x�ڏ������āA2008�N���o���PARROT��������Ȃ�CPU�Ɍq����S�ς���ł��傤�B
�����APARROT�����Ɋ���H����������Ȃ��̂ŁA�������������̂ɑ�������ɂȂ�\���������Ă���\�����炢�͂��邩������Ȃ��B
����͂܂��A�I�����̈�ɉ߂����A�Ⴄ�I���ɂȂ邩������Ȃ��B�L�͌��̂P�Ƃ����ʒu�Â����Ǝv���B
Intel�ɂ��Ă݂��AMD�ɑ��ē������A���������Ă���Ώ����Ɣ��f���邾�낤����ABanias������Yonah�ł��ꂪ�����\���ƒ��x�ڏ������āA2008�N���o���PARROT��������Ȃ�CPU�Ɍq����S�ς���ł��傤�B
�����APARROT�����Ɋ���H����������Ȃ��̂ŁA�������������̂ɑ�������ɂȂ�\���������Ă���\�����炢�͂��邩������Ȃ��B
���ǂǂ��Ȃ邩�͂킩�����Ď��ł���
251 �FSocket774�F2005/09/05(��) 08:21:09 ID:6JLK9jTi
INTELCPU�ɂ͂����������ɂȂ����烁���R�����̂�H
PARROT���炩�H
PARROT���炩�H
253 �FSocket774�F2005/09/05(��) 14:38:57 ID:6JLK9jTi
>>252
�V���A��������2008�Ƃ��H
�V���A��������2008�Ƃ��H
>>253
45nm�ɂȂ��Ă���B
45nm�ɂȂ��Ă���B
�f�R�[�_���d�͂�H���Ȃ�A���G�ȃf�R�[�_���g���̂���߂�Ⴂ�������B
�܂�x86�̖��߃Z�b�g���l�C�e�B�u�Ɏ��s����̂���߂�����B
���ꂩ��A���j�[�R�A����ɂȂ�A�������A�N�Z�X�̑ш悪�l�b�N�ɂȂ�B
�l�b�N�ɂȂ�̂��������Ƃ���Ȃ��āA�l�b�N�ɂȂ�܂ŃR�A���l�ߍ��ނׂ��B
��������ƁA�e�R�A�ł̓������A�N�Z�X�҂����������邾�낤����A
�p�C�v���C�����X�J�X�J�ŃX�g�[�����܂����Ă��\��Ȃ��Ǝv���B
�܂�x86�̖��߃Z�b�g���l�C�e�B�u�Ɏ��s����̂���߂�����B
���ꂩ��A���j�[�R�A����ɂȂ�A�������A�N�Z�X�̑ш悪�l�b�N�ɂȂ�B
�l�b�N�ɂȂ�̂��������Ƃ���Ȃ��āA�l�b�N�ɂȂ�܂ŃR�A���l�ߍ��ނׂ��B
��������ƁA�e�R�A�ł̓������A�N�Z�X�҂����������邾�낤����A
�p�C�v���C�����X�J�X�J�ŃX�g�[�����܂����Ă��\��Ȃ��Ǝv���B
>>255
���߂�A���������������J����
���߂�A���������������J����
�O����
IA-64 + IA-32EL
Transmeta��CMS
Alpha + FX!32
�F�X�Ȏ�����͂��邯�ǁA�������������ɍs���ׂ����ƁB
�㔼��
VIA��Winchip�n�́A��ΐ��\�͒Ⴂ���g�����W�X�^���̊��ɂ͐��\�̂悢�R�A���A��������l�ߍ��߂ƁB
1���̑��x����̂��߂Ƀg�����W�X�^��1���ȏ㑝�₷�ȁA�ƁB
IA-64 + IA-32EL
Transmeta��CMS
Alpha + FX!32
�F�X�Ȏ�����͂��邯�ǁA�������������ɍs���ׂ����ƁB
�㔼��
VIA��Winchip�n�́A��ΐ��\�͒Ⴂ���g�����W�X�^���̊��ɂ͐��\�̂悢�R�A���A��������l�ߍ��߂ƁB
1���̑��x����̂��߂Ƀg�����W�X�^��1���ȏ㑝�₷�ȁA�ƁB
>>257
���܂�A�A�z�ɂ���������
���܂�A�A�z�ɂ���������
>>257
�܂��A���܂ł̗Ⴉ�炢���ă\�t�g�͏��F�G�~�������B
�ǂ�ȂɊ撣���Ă��A�n�[�h�Ŏ����o����悤��
�����ȃp�t�H�[�}���X��������Ƃ͎v����B
�܂��A���܂ł̗Ⴉ�炢���ă\�t�g�͏��F�G�~�������B
�ǂ�ȂɊ撣���Ă��A�n�[�h�Ŏ����o����悤��
�����ȃp�t�H�[�}���X��������Ƃ͎v����B
>>257
���̎O��A�ǂ��������p�t�H�[�}���X�ɓ�L��B
�X�W�̂����Z�p�Ƃ͎v����B
�������������ɖ����͖������������B
���̎O��A�ǂ��������p�t�H�[�}���X�ɓ�L��B
�X�W�̂����Z�p�Ƃ͎v����B
�������������ɖ����͖������������B
261 �FSocket774�F2005/09/05(��) 17:19:29 ID:6JLK9jTi
�C���e������65nm���������H
>>261
���ǁA�������o�Ă݂Ȃ��Ɖ��Ƃ��������B
��芸�����AYonah�͏����łP�������J��オ���āA
�P�����XCES(5�`8���j�Ŕ��\�����Ƃ��B
���ǁA�������o�Ă݂Ȃ��Ɖ��Ƃ��������B
��芸�����AYonah�͏����łP�������J��オ���āA
�P�����XCES(5�`8���j�Ŕ��\�����Ƃ��B
263 �FSocket774�F2005/09/05(��) 18:12:09 ID:6JLK9jTi
���N��NaPa�v���b�g�t�H�[����CES����Ȃ������H
�����l�����MEROM�̎���������Ȃ����H
��3�l�������Ď���IDF�̒���ӂ�ɔ��\���ȁH
�����l�����MEROM�̎���������Ȃ����H
��3�l�������Ď���IDF�̒���ӂ�ɔ��\���ȁH
�܂��A����ɍS��Ȃ�IDF fal����WPC EXPO�Ƃ��������I�ɋ߂���łȂ������B
265 �FSocket774�F2005/09/05(��) 19:31:09 ID:6JLK9jTi
����A�m��ǂˁB
�悭�l�����獡�܂ł����܂��ē��ɉ����̃C�x���g��
���i���\���Ă��킯�ł��Ȃ��C�����邵�B
�悭�l�����獡�܂ł����܂��ē��ɉ����̃C�x���g��
���i���\���Ă��킯�ł��Ȃ��C�����邵�B
267 �FSocket774�F2005/09/05(��) 21:18:16 ID:6JLK9jTi
�܂���
>>264
���܂ł̗Ⴞ�ƁAPenD�Ƃ��ł͌��Z���\�O��������
���܂ł̗Ⴞ�ƁAPenD�Ƃ��ł͌��Z���\�O��������
269 �FSocket774�F2005/09/05(��) 22:04:55 ID:6JLK9jTi
>>268
���ႠConroe�̔��\�͑�3�l�����̌��Z���\�O���Ď���
���ႠConroe�̔��\�͑�3�l�����̌��Z���\�O���Ď���
http://pc.watch.impress.co.jp/docs/2005/0906/kaigai209.htm
��������㓡����
�u�@�\�g���̊��ɏ�����Yonah�̃R�A�v
��������㓡����
�u�@�\�g���̊��ɏ�����Yonah�̃R�A�v
ttp://techreport.com/etc/2005q3/idf/index.x?pg=4
����Mitosis����ƁAIntel�͂���SMT���CMT��
���\���シ������Ɍ����Ă������ȁB
����Mitosis����ƁAIntel�͂���SMT���CMT��
���\���シ������Ɍ����Ă������ȁB
>>271
�ǂ䂱�ƁH
�ǂ䂱�ƁH
273 �FSocket774�F2005/09/06(��) 08:48:51 ID:BO4TkFAV
.anandtech.com/cpuchipsets/showdoc.aspx?i=2492
��������2�y�[�W�ڂɃg���[�X�L���b�V���̂��Ƃ������Ă��邯��Conroe�ɍ̗p������Ă��ƁH
����3�y�[�W�ڂ̈�ԍŌ��
�A���h��K9�Ɠ������炢������ȏ�݂����Ȃ��Ƃ������Ă���(Conroe)
��������2�y�[�W�ڂɃg���[�X�L���b�V���̂��Ƃ������Ă��邯��Conroe�ɍ̗p������Ă��ƁH
����3�y�[�W�ڂ̈�ԍŌ��
�A���h��K9�Ɠ������炢������ȏ�݂����Ȃ��Ƃ������Ă���(Conroe)
274 �FSocket774�F2005/09/06(��) 08:55:22 ID:DTpCNbiU
http://www.powup.jp/jinken/leaflet/A3_v1.0_OMO.jpg
http://www.powup.jp/jinken/leaflet/A3_v1.0_URA.jpg
{kind=link}
http://www.powup.jp/jinken/leaflet/A3_v1.0_URA.jpg
{kind=link}
���������i�݂����Ȃ���ˁ[��
276 �FSocket774�F2005/09/06(��) 09:49:42 ID:BO4TkFAV
�X���Ⴂ
>>273 ���O���[�f�B���O�͖������@����Ȃ璆�w���ł��ǂ߂�͂�
trace cache �̘b�� Netburst �̐����i���̕ł�3/4�͂���܂ł� Intel ��
�A�[�L�e�N�`���̉���Ŋ̐S�̌��_�́u�܂��ǂ��������v���j
3�Ŗڂ� K9 �� Conroe �̔�r�͌����_�ŕ������Ă���
>but we know even less about K9 than we do about Conroe.
trace cache �̘b�� Netburst �̐����i���̕ł�3/4�͂���܂ł� Intel ��
�A�[�L�e�N�`���̉���Ŋ̐S�̌��_�́u�܂��ǂ��������v���j
3�Ŗڂ� K9 �� Conroe �̔�r�͌����_�ŕ������Ă���
>but we know even less about K9 than we do about Conroe.
279 �FSocket774�F2005/09/06(��) 18:12:27 ID:BO4TkFAV
����H
�A���h��K9���ď�������Ȃ����������H
�A���h��K9���ď�������Ȃ����������H
K9�����������̂�������������Ă��Ȃ��̂�
���lj����ǂ��ς�����̂��͕s��
���lj����ǂ��ς�����̂��͕s��
281 �FSocket774�F2005/09/07(��) 07:25:32 ID:/M0N+DJT
�܂��A���h�����ɉ����o�����������Ƃ肠����Conroe�ŋt�]���Ă��Ƃ�
>>281
�����Â��Ȃ�����orz
�����Â��Ȃ�����orz
intel�̏ꍇ��I/O���]���^�ȕ��A
���ꂾ���ł��傫�ȃw�b�h���[�����c����Ă邩��ˁB
��������k7����k8�̐��\���㕪�͂قƂ�ǃ����R�����������B
�Ă��Aintel��Whitefield�Ń����R�������ƃV���A���o�X�������Ă�����A
AMD�̃A�h�o���e�|�W�����Ȃ�ȁE�E�E
���ꂾ���ł��傫�ȃw�b�h���[�����c����Ă邩��ˁB
��������k7����k8�̐��\���㕪�͂قƂ�ǃ����R�����������B
�Ă��Aintel��Whitefield�Ń����R�������ƃV���A���o�X�������Ă�����A
AMD�̃A�h�o���e�|�W�����Ȃ�ȁE�E�E
http://pcweb.mycom.co.jp/photo/articles/2005/09/06/siggraph2/images/038l.jpg
�Z�p�v�Z�x���`�}�[�N��Brook�x�[�X��Pentium 4 3.0GHz��GeForce 7800 GTX�Ŏ��s�����Ƃ��̃p�t�H�[�}���X��r�B
���̍��͂��Ȃ�傫��
�����GPGPU��
{kind=link}
�Z�p�v�Z�x���`�}�[�N��Brook�x�[�X��Pentium 4 3.0GHz��GeForce 7800 GTX�Ŏ��s�����Ƃ��̃p�t�H�[�}���X��r�B
���̍��͂��Ȃ�傫��
�����GPGPU��
�����R�������`�҂₽��Ƒ����ȁB
K7��K8�̐��\����́A�A�[�L�e�N�`���̉��ǂƃN���b�N�㏸������ł����āA
�����R�������̌��ʂ�"�H"����B
K7��K8�̐��\����́A�A�[�L�e�N�`���̉��ǂƃN���b�N�㏸������ł����āA
�����R�������̌��ʂ�"�H"����B
K7����K8�ɂȂ��āA�N���b�N�͉����������B
�A�z�H
���ꃂ�f���i���o�[�ł́A�N���b�N����������
�܂�
�����N���b�N�ł́A���\���オ����
���\����́A�N���b�N�㏸�ɂ����̂ł͂Ȃ��A���Ă��Ƃ��ˁB
K7�����������g���œ������̂�K8�ɂ���̂́A���V�����Z�p�ō���Ă��邩�炾��ˁB
�܂�
�����N���b�N�ł́A���\���オ����
���\����́A�N���b�N�㏸�ɂ����̂ł͂Ȃ��A���Ă��Ƃ��ˁB
K7�����������g���œ������̂�K8�ɂ���̂́A���V�����Z�p�ō���Ă��邩�炾��ˁB
>>289
��������邾�낤����
K7��K8��荂�N���b�N�ɂȂ�����}�Y�C���Ă����}�[�P�e�B���O�̓s���������Ȃ�
PenM�̃N���b�N���~�܂��Ă�̂����ꂾ�낤��
��������邾�낤����
K7��K8��荂�N���b�N�ɂȂ�����}�Y�C���Ă����}�[�P�e�B���O�̓s���������Ȃ�
PenM�̃N���b�N���~�܂��Ă�̂����ꂾ�낤��
291 �FSocket774�F2005/09/07(��) 12:44:22 ID:/M0N+DJT
PenM��TDP�̖�肾�낤
�������Z�̏�������۸��т��Ɠ����g����K7�̕��������ꍇ���������悤��
FX-51(2.2GHz)�������B3400+(2.2GHz)�͌ゾ�ȁB
����ɂ���>>293���A�t�H
����ɂ���>>293���A�t�H
���܂��炱���̓A���h�̃X������Ȃ��ł����
�ŏ��ɏo�J�n���A�i�E���X����K8�́A
Opteron 244(1.8GHz)�A242(1.6GHz)�A240(1.4GHz)�ŁA
�����2003/4/22�̂��ƁB
����AK7�ōō��N���b�N�ƂȂ�̂́A
AthlonXP 2800+(Thoroughbred 2.25GHz)�ŁA
�����2002/10/1���\
���Ȃ݂ɁA
AthlonMP 2600+(2.133GHz)��2003/2/4���\
AthlonMP 2800+(2.133GHz)��2003/5/6���\
AthlonXP 3200+(2.2GHz)��2003/5/13���\
Opteron 244(1.8GHz)�A242(1.6GHz)�A240(1.4GHz)�ŁA
�����2003/4/22�̂��ƁB
����AK7�ōō��N���b�N�ƂȂ�̂́A
AthlonXP 2800+(Thoroughbred 2.25GHz)�ŁA
�����2002/10/1���\
���Ȃ݂ɁA
AthlonMP 2600+(2.133GHz)��2003/2/4���\
AthlonMP 2800+(2.133GHz)��2003/5/6���\
AthlonXP 3200+(2.2GHz)��2003/5/13���\
�A�t�H�x
XP(64)��MP(��)���ׂ�298��|�z�����Ȃ���|��293
XP(64)��MP(��)���ׂ�298��|�z�����Ȃ���|��293
�Ƃ���ŁA�M2800+(2.25GHz)���Ď��ۂɔ̔����ꂽ�����H
301 �FSocket774�F2005/09/07(��) 14:43:55 ID:/M0N+DJT
���Ă���ɖ��ł�
�����͉��̃X���ł��傤��
�����͉��̃X���ł��傤��
�A�b�[�[�I�I
�܂�Rx028TQe���A�t�H�������Ƃ������ƂŁB
>>299
K7 vs K8�ŃN���b�N�̘b�����Ă���̂ɁA
XP��MP�A64��Opteron�̈Ⴂ�������o���ق����A�A�z���Ǝv�����B
>>301
���܂����B
���J�b�ƂȂ��Ă�����B
���͔��Ȃ��Ă���B
K7 vs K8�ŃN���b�N�̘b�����Ă���̂ɁA
XP��MP�A64��Opteron�̈Ⴂ�������o���ق����A�A�z���Ǝv�����B
>>301
���܂����B
���J�b�ƂȂ��Ă�����B
���͔��Ȃ��Ă���B
305 �FSocket774�F2005/09/07(��) 16:41:24 ID:/M0N+DJT
�ʂɂ�����Ȃ��́B
���\�C���p�N�g�I�ɂ� Dualcore��64bit ���낤����B
���[�J�I�ɂ��t�ď���Yonah�A�H�~����Merom�iVista�j�Ő����邵�B
���\�C���p�N�g�I�ɂ� Dualcore��64bit ���낤����B
���[�J�I�ɂ��t�ď���Yonah�A�H�~����Merom�iVista�j�Ő����邵�B
K8�̎����������������ǁA���ێ�ɂƂ��Ă݂Ȃ��Ɣ���Ȃ�����
�҂�����h�L�h�L����������ˁB
�҂�����h�L�h�L����������ˁB
308 �FSocket774�F2005/09/07(��) 19:08:23 ID:/M0N+DJT
�܂�TDP�������邩��Conroe��҂Ƃ��邩
CPU���ɒ����H�Ƃ�炪�����FSB�����ɂȂ炸�ɍςނ́H
�P�{�͂ǂ�ȂɊ撣���Ă��Q�{�ɂ͂Ȃ�Ȃ�
>>309
���̘b�HPaxville�̎��H
���̘b�HPaxville�̎��H
����̐��i�łȂ��Ĉ�ʓI�Șb�ł́B
CPU���ɒ����H�����ꍇ�A�R�A�Ԃ̒ʐM�́ACPU���ō����ɍs�Ȃ��邪�A
CPU���ɒ����H�������Ȃ��ꍇ���ƁA�ᑬ��FSB���o�R���āA
�m�[�X�u���b�W�����X�̃R�A��FSB����Ē�������A�ʐM���鎖�ɂȂ�B
CPU���ɒ����H�����ꍇ�A�R�A�Ԃ̒ʐM�́ACPU���ō����ɍs�Ȃ��邪�A
CPU���ɒ����H�������Ȃ��ꍇ���ƁA�ᑬ��FSB���o�R���āA
�m�[�X�u���b�W�����X�̃R�A��FSB����Ē�������A�ʐM���鎖�ɂȂ�B
>>311
���i�Ƃ��R�����̘b
���i�Ƃ��R�����̘b
�킴�킴���₵�Ă���Ď��͈�̃o�X�ɂԂ牺�����Ă���Ď�������
���ǎ������ŒʐM���邵���Ȃ��悤�ȁB
���ǎ������ŒʐM���邵���Ȃ��悤�ȁB
�����H��������ɋ��L�L���b�V��������
>>315
�m���ɥ�
�m���ɥ�
�f�l�L������ŃX�}�����A���L�L���b�V���Ƃ����̂�
�Q��CPU���瓯���ɃA�N�Z�X����Ă�����������̂Ȃ̂��H
����Ƃ��Е��͏��ԑ҂��ɂȂ�̂��H
�Q��CPU���瓯���ɃA�N�Z�X����Ă�����������̂Ȃ̂��H
����Ƃ��Е��͏��ԑ҂��ɂȂ�̂��H
>>317
IDF�̋L�����炢�ڂ��Ƃ�������`
IDF�̋L�����炢�ڂ��Ƃ�������`
319 �FSocket774�F2005/09/08(��) 12:30:25 ID:uH7eoNKZ
>>317
���OIDF�̋L�����ĂȂ��̂��H
���OIDF�̋L�����ĂȂ��̂��H
conroe���҂��Ă������ł����H
�E�B�����b�g�A�v���X�R�b�g�̂悤��
�O��萫�\���Ⴂ���Ƃ͂Ȃ��ł����H
�E�B�����b�g�A�v���X�R�b�g�̂悤��
�O��萫�\���Ⴂ���Ƃ͂Ȃ��ł����H
321 �FSocket774�F2005/09/08(��) 16:58:07 ID:uH7eoNKZ
�v���X�R�ȉ��Ȃ���肦��
>>321
�Y
�Y
>>323
����
����
���j�o�[�T���o�C�i���ɋ����������āA���܂���Mac-mini�����Ă݂����ǁA
�������J���ꂽAltiVec��SSE�ڐA�̃h�L�������g�ɂ���
EM64T��IA32e���[�h�iAMD���ɂ�����LONG���[�h�j��FP/MMX�g�����ǂ�������܂�����炵���ˁB
�������J���ꂽAltiVec��SSE�ڐA�̃h�L�������g�ɂ���
EM64T��IA32e���[�h�iAMD���ɂ�����LONG���[�h�j��FP/MMX�g�����ǂ�������܂�����炵���ˁB
Win64�ł�OS��FPU/MMX���W�X�^��ۑ����Ȃ��Ƃ̂��킳
���������Ȃ�AFPU/MMX�������͎̂����㖳��
���������Ȃ�AFPU/MMX�������͎̂����㖳��
FPU/MMX���g�������b�g���ĉ��H
SSE2/3�̕������\�o���H
SSE2/3�̕������\�o���H
�q���g�F���Ð~
329 �FSocket774�F2005/09/09(��) 02:59:23 ID:EcMCytyc
>>328
������H
������H
Windows����Ō����AVC�Ȃǂ�MS�̌�����g�p�������
�����^�C����80bit���x�̉��Z�����Ȃ�����FPU�s�v�B
�ł������̂��Ȃ����Ċ����B
�����^�C����80bit���x�̉��Z�����Ȃ�����FPU�s�v�B
�ł������̂��Ȃ����Ċ����B
331 �FSocket774�F2005/09/09(��) 03:21:22 ID:NFQNmKH2
�@�@�@ In�Q���@ �^�P�P�P�P
�@ In�i�@�M�́L�j���@����
�@�i�L�� �@�Y�@�� �_�Q�Q�Q�Q
�@�i�@�@�m �m
�@�b�i_�Q�j�Q�j
�@�i_�Q�j�Q�j
�@ In�i�@�M�́L�j���@����
�@�i�L�� �@�Y�@�� �_�Q�Q�Q�Q
�@�i�@�@�m �m
�@�b�i_�Q�j�Q�j
�@�i_�Q�j�Q�j
332 �FSocket774�F2005/09/09(��) 04:54:16 ID:EcMCytyc
�����m���ɂ����ł�
>>327
���sPentium M�ł͋t�B
�P�Q�W�r�b�g��SIMD���Z���j�b�g�̔������}�X�N���ė��p���Ă��������Ȃ�
����Ȃ���SSE2/3����
���ۂɂ͂Q��64bitSIMD���j�b�g���g�������Z�ɓW�J���Ă�Ƃ����̂�
�m���Ă�ł���B
Yonah�ł͉�������Ƃ����Ă���i�炵���j��肾���ǁB
�܂��APentium 4�ł���movq�~�Q��movdqu�����A�g���ꏊ��I�ԁB
���Ƃ��Ή���QWORD�����g��Ȃ���ʂ�MMX���j�b�g�Q�g���̂�
���\���ʂ����B
MMX���Z���j�b�g���P�Q�W�r�b�g���Z���j�b�g�̉���QWORD�}�X�N
�݂������ґ�Ȏ����ɂȂ�Ȃ�����A�Q�P�����ł������́A
�����I�ɂł�MMX���g�����ق��������P�[�X�͏o�Ă���̂ł���B
Apple���g�����_�ł�EM64T�̎�����FP�^MMX���W�{���ǂ������^�₾���ˁB
�����������߃Z�b�g�I�ɂP�U�{�Ɋg�����Ă�x64�Ƃ̌݊����͕ۂĂ�Ǝv���B
���sPentium M�ł͋t�B
�P�Q�W�r�b�g��SIMD���Z���j�b�g�̔������}�X�N���ė��p���Ă��������Ȃ�
����Ȃ���SSE2/3����
���ۂɂ͂Q��64bitSIMD���j�b�g���g�������Z�ɓW�J���Ă�Ƃ����̂�
�m���Ă�ł���B
Yonah�ł͉�������Ƃ����Ă���i�炵���j��肾���ǁB
�܂��APentium 4�ł���movq�~�Q��movdqu�����A�g���ꏊ��I�ԁB
���Ƃ��Ή���QWORD�����g��Ȃ���ʂ�MMX���j�b�g�Q�g���̂�
���\���ʂ����B
MMX���Z���j�b�g���P�Q�W�r�b�g���Z���j�b�g�̉���QWORD�}�X�N
�݂������ґ�Ȏ����ɂȂ�Ȃ�����A�Q�P�����ł������́A
�����I�ɂł�MMX���g�����ق��������P�[�X�͏o�Ă���̂ł���B
Apple���g�����_�ł�EM64T�̎�����FP�^MMX���W�{���ǂ������^�₾���ˁB
�����������߃Z�b�g�I�ɂP�U�{�Ɋg�����Ă�x64�Ƃ̌݊����͕ۂĂ�Ǝv���B
334 �FSocket774�F2005/09/09(��) 09:52:56 ID:8bsfjr8V
>>333
���肦��
���肦��
��MM��XMM�͔r������Ȃ���ŁB
�����Ɏg���邵���݂Ƀf�[�^�������閽�߂�����B
����������XMM�Ŏg���Ȃ���MMX�g�����Ƃ����Ăł���B
���Ȃ݂�MS��PSDK2003�ł͂������Ɏg���Ȃ���VS2005�ł�MMX�����̂܂g����B
�Ȃ�ɂ���g���Ȃ����g�������������Ɍ��܂��Ă��邾��B
�����Ȃ��Ƃ�Merom�܂ł�SIMD ALU��128�r�b�g������Ȃ����B
�����Ȃ��2�̉��Z���j�b�g�ɕʁX�̖��߂��s�킹�邱�Ƃ��ł����ق��������B
�����Ɏg���邵���݂Ƀf�[�^�������閽�߂�����B
����������XMM�Ŏg���Ȃ���MMX�g�����Ƃ����Ăł���B
���Ȃ݂�MS��PSDK2003�ł͂������Ɏg���Ȃ���VS2005�ł�MMX�����̂܂g����B
�Ȃ�ɂ���g���Ȃ����g�������������Ɍ��܂��Ă��邾��B
�����Ȃ��Ƃ�Merom�܂ł�SIMD ALU��128�r�b�g������Ȃ����B
�����Ȃ��2�̉��Z���j�b�g�ɕʁX�̖��߂��s�킹�邱�Ƃ��ł����ق��������B
336 �FSocket774�F2005/09/09(��) 13:31:02 ID:q1oFL+ux
Intel��AMD�ɂƂ���x87�⓯�����W�X�^�𗘗p���Ă���MMX�͏�����
�l�������Ɏז��ȑ��݂Ɣ��f���ꂽ�B
�ߎ��I�v�l�͎~�߂���H
�l�������Ɏז��ȑ��݂Ɣ��f���ꂽ�B
�ߎ��I�v�l�͎~�߂���H
338 �FSocket774�F2005/09/09(��) 14:13:30 ID:X1q8aWd2
>>337
����ȓ�����O�̎����������ɘb����Ă��Ȃ��E�E�E
EM64T��AMD64�����y����32bit��Legacy�ƂȂ��x87��MMX��
���W�b�N���蔲���ł���B�蔲����������SSE?�Ɏg���ΑS�̂Ƃ���
happy�ɂȂ��\���������B
����x86�n�̓f�R�[�_���ꂵ���Ƃ����̂ł��̌��ʂ͔n����
�ł��Ȃ��Ǝv���B
����ȓ�����O�̎����������ɘb����Ă��Ȃ��E�E�E
EM64T��AMD64�����y����32bit��Legacy�ƂȂ��x87��MMX��
���W�b�N���蔲���ł���B�蔲����������SSE?�Ɏg���ΑS�̂Ƃ���
happy�ɂȂ��\���������B
����x86�n�̓f�R�[�_���ꂵ���Ƃ����̂ł��̌��ʂ͔n����
�ł��Ȃ��Ǝv���B
>>336
�Z�O�����g���W�X�^�́H�@���A�����[�h�́H�@���z386���[�h�́H
�Z�O�����g���W�X�^�́H�@���A�����[�h�́H�@���z386���[�h�́H
�X�}��
�����̎ז��ł����Ă��܂�����
�����̎ז��ł����Ă��܂�����
341 �FSocket774�F2005/09/09(��) 14:51:17 ID:X1q8aWd2
>>339
���O�n�����낤�B
�Z�O�����g���W�X�^ -> �Z�O�����g�Z���N�^�Ƃ��Ă܂��g���Ă���
���A�����[�h -> �ߋ��݊����̈וK�v
���z386���[�h -> ���z86���[�h�̎����Hwww
64bit native mode��x87��MMX���T�|�[�g���Ȃ����͌݊�����K�v��
���Ȃ����炾�Ƃ������������ł��Ă��Ȃ��ȁB
���O�n�����낤�B
�Z�O�����g���W�X�^ -> �Z�O�����g�Z���N�^�Ƃ��Ă܂��g���Ă���
���A�����[�h -> �ߋ��݊����̈וK�v
���z386���[�h -> ���z86���[�h�̎����Hwww
64bit native mode��x87��MMX���T�|�[�g���Ȃ����͌݊�����K�v��
���Ȃ����炾�Ƃ������������ł��Ă��Ȃ��ȁB
>>341
�i>>326�̉\���{���Ȃ�jMS���K�v�Ƃ��ĂȂ��͕̂����邪�A
�ǂ̃��X���ǂ��ǂނ�Intel��AMD���K�v�Ƃ��Ȃ��Ɠǂ߂�H
�����A>>336��>>341���K�v�Ƃ��ĂȂ��͕̂������Ă�B
���łɌ����ΘR�������ǂȁB
�i>>326�̉\���{���Ȃ�jMS���K�v�Ƃ��ĂȂ��͕̂����邪�A
�ǂ̃��X���ǂ��ǂނ�Intel��AMD���K�v�Ƃ��Ȃ��Ɠǂ߂�H
�����A>>336��>>341���K�v�Ƃ��ĂȂ��͕̂������Ă�B
���łɌ����ΘR�������ǂȁB
343 �FSocket774�F2005/09/09(��) 15:06:38 ID:X1q8aWd2
>>342
> �i>>326�̉\���{���Ȃ�j
�m�F���Ă݂��������Ȃ����B�ȒP�ȃv���O�����������ł��邼�B
> �ǂ̃��X���ǂ��ǂނ�Intel��AMD���K�v�Ƃ��Ȃ��Ɠǂ߂�H
MS���S�Ĉ����݂����Ȕn���Ȏ�������������Ⴄ�Ə������̂ł����H
> �i>>326�̉\���{���Ȃ�j
�m�F���Ă݂��������Ȃ����B�ȒP�ȃv���O�����������ł��邼�B
> �ǂ̃��X���ǂ��ǂނ�Intel��AMD���K�v�Ƃ��Ȃ��Ɠǂ߂�H
MS���S�Ĉ����݂����Ȕn���Ȏ�������������Ⴄ�Ə������̂ł����H
>>343
�����
�uIntel��AMD���K�v�Ƃ��Ă��Ȃ�����AMS�������Č݊��������Ȃ������v
�Ƃ��������́H�@�����v���\�[�X����H�@�E�X�^�[�Ƃ��g���J�c�ȊO�́B
�����
�uIntel��AMD���K�v�Ƃ��Ă��Ȃ�����AMS�������Č݊��������Ȃ������v
�Ƃ��������́H�@�����v���\�[�X����H�@�E�X�^�[�Ƃ��g���J�c�ȊO�́B
345 �FSocket774�F2005/09/09(��) 15:35:16 ID:Sc1VFkon
>>344
�d�l���悭�ǂ�ł���o�����ĂˁB
�d�l���悭�ǂ�ł���o�����ĂˁB
FSB��1066Mhz�ɂȂ�̂͂��H
347 �FSocket774�F2005/09/09(��) 17:51:30 ID:EcMCytyc
>>346
�����炭Conroe
�����炭Conroe
>>326
�̫���B���ʂɂ��肦��B
�݊����ƃv���O�����̏_���������
��������64bit8�{�����̃��W�X�^�ۑ��̃I�[�o�[�w�b�h���Ƃ����C�ɂ���Ƃ͎v���Ȃ��B
�ނ�ꂷ���ł��B
�ȒP�ȃA�Z���u���Ńe�X�g�ł��邩��
64bit�̊J����������ЂƂ̓e�X�g�L�{��
�̫���B���ʂɂ��肦��B
�݊����ƃv���O�����̏_���������
��������64bit8�{�����̃��W�X�^�ۑ��̃I�[�o�[�w�b�h���Ƃ����C�ɂ���Ƃ͎v���Ȃ��B
�ނ�ꂷ���ł��B
�ȒP�ȃA�Z���u���Ńe�X�g�ł��邩��
64bit�̊J����������ЂƂ̓e�X�g�L�{��
>�ȒP�ȃA�Z���u���Ńe�X�g�ł��邩��
�����͏��ׂ��Ƃ��납��
�����͏��ׂ��Ƃ��납��
>>349
���ǂ���̕�����Ȃ��R��̓C�P�e�i�C�̂��낤���B
FPU���W�X�^�̓��e���_���v����v���O�����ƁA
FPU���W�X�^�̓��e��ύX���܂���v���O�������A
�����ɑ��点��Έ�ڗđR�B���ɊȒP�B
�����Ƃ��A�R��̎���ɂ�64bit Windows���Ȃ��̂ŁA
���������Ӗ��ł͔��ɓ���e�X�g�ł͂���B
���ǂ���̕�����Ȃ��R��̓C�P�e�i�C�̂��낤���B
FPU���W�X�^�̓��e���_���v����v���O�����ƁA
FPU���W�X�^�̓��e��ύX���܂���v���O�������A
�����ɑ��点��Έ�ڗđR�B���ɊȒP�B
�����Ƃ��A�R��̎���ɂ�64bit Windows���Ȃ��̂ŁA
���������Ӗ��ł͔��ɓ���e�X�g�ł͂���B
2�̃v���O�������ɋN�����A
���ꂼ�ꂪFPU�X�^�b�N�A��������mm���W�X�^��
�l�̈Ⴄ�f�[�^����������ł݂āA�ǂݎ����
���ꂪ���������̂ƈ�v���邩�m�F��������B
movq mm1, [eax]
//�����ɂȂɂ��E�F�C�g�������B
movq [eax] , mm1
���ꂾ���B
���ꂼ�ꂪFPU�X�^�b�N�A��������mm���W�X�^��
�l�̈Ⴄ�f�[�^����������ł݂āA�ǂݎ����
���ꂪ���������̂ƈ�v���邩�m�F��������B
movq mm1, [eax]
//�����ɂȂɂ��E�F�C�g�������B
movq [eax] , mm1
���ꂾ���B
��̃v���O�����ł͏㏑�����Ă�Ƃ���r���ĂȂ��Ƃ�
���W�X�^�̒l���ǂ��̂����̂Ƃ��A���낢�날�邾�낤���ǁA
�܂��A���̕ӂͷƼŲ�ŸځB
���W�X�^�̒l���ǂ��̂����̂Ƃ��A���낢�날�邾�낤���ǁA
�܂��A���̕ӂͷƼŲ�ŸځB
�A�z���I�I�I
x86 64bit�ł�RegisterCall�ɂ��Ẵh�L�������e�[�V��������Ȃ����B
x86 32bit��stdcall�K��̊��͂ǂ��Ȃ��Ă�Ǝv���H
eax�͊��̌��ʂ̃��^�[���Ɏg����B
edx,ecx�͌Ăяo���������K���ɕύX����̂ŁA�߂����Ƃ��̒l�͕s��ł���B
ebx���̑��̃��W�X�^�͊��Ăяo���̑O��Œl�͕ύX����Ȃ����Ƃ�ۏႷ��B
���ꂾ���̂��Ƃ���Ȃ����B
�v���Z�X���x���A�X���b�h���x���ł̃��W�X�^�̕ۑ����炢�͂���Ă邾��B
x86 64bit�ł�RegisterCall�ɂ��Ẵh�L�������e�[�V��������Ȃ����B
x86 32bit��stdcall�K��̊��͂ǂ��Ȃ��Ă�Ǝv���H
eax�͊��̌��ʂ̃��^�[���Ɏg����B
edx,ecx�͌Ăяo���������K���ɕύX����̂ŁA�߂����Ƃ��̒l�͕s��ł���B
ebx���̑��̃��W�X�^�͊��Ăяo���̑O��Œl�͕ύX����Ȃ����Ƃ�ۏႷ��B
���ꂾ���̂��Ƃ���Ȃ����B
�v���Z�X���x���A�X���b�h���x���ł̃��W�X�^�̕ۑ����炢�͂���Ă邾��B
���܂���A��g���X�⋤���o�ł̃J�[�l���v�̖{��߂�B
TSS���Ȃ邩������B
TSS���Ȃ邩������B
�J�[�l�����[�h����̘b���ۂ��ȁB
>>348 80�r�b�g
358 �FSocket774�F2005/09/10(�y) 11:18:07 ID:sK+dNBCn
>>351
64bit��[eax]����B
>>356
32bit�ł�kernel mode��FP,MMX���g�p����ꍇ�̃��W�X�^�ޔ��͕K�v�ł���B
DDK��document���炢�ǂ�łˁB
�܂��A���_���猾����user mode program��FP,MMX���W�X�^�̑ޔ��͂���B
������web�ɂ���ߋ��̏��l����ƃ����[�X�O�̃o�[�W�����ł͑ޔ���
�Ă��Ȃ��������m�����肻���Bml64�ł�����ȃ��b�Z�[�W���o�����B
x87 and MMX instructions disallowed; legacy FP state not saved in Win64
64bit��[eax]����B
>>356
32bit�ł�kernel mode��FP,MMX���g�p����ꍇ�̃��W�X�^�ޔ��͕K�v�ł���B
DDK��document���炢�ǂ�łˁB
�܂��A���_���猾����user mode program��FP,MMX���W�X�^�̑ޔ��͂���B
������web�ɂ���ߋ��̏��l����ƃ����[�X�O�̃o�[�W�����ł͑ޔ���
�Ă��Ȃ��������m�����肻���Bml64�ł�����ȃ��b�Z�[�W���o�����B
x87 and MMX instructions disallowed; legacy FP state not saved in Win64
360 �FSocket774�F2005/09/10(�y) 12:47:41 ID:4ZKhqN3U
>>359
eax�Ə�������[eax]�Ə��������R���킩��Ȃ��ˁBwww
eax�Ə�������[eax]�Ə��������R���킩��Ȃ��ˁBwww
�Ȃςȃr�p�[�������
�t��
movq mm0, eax
���ʂ�Ƃł��v���Ă�̂��낤���B
�t��
movq mm0, eax
���ʂ�Ƃł��v���Ă�̂��낤���B
362 �FSocket774�F2005/09/10(�y) 14:39:57 ID:+hB8HV0L
>>361
64bit�Ȃ�
movq mm0,[eax]
����Ȃ���
movq mm0,[rax]
���Ǝw�E�������
movq mm0,eax
���ʂ�Ǝv���Ă���H
�Ǝ��₷��n�������鎖�ɋ������B
64bit�Ȃ�
movq mm0,[eax]
����Ȃ���
movq mm0,[rax]
���Ǝw�E�������
movq mm0,eax
���ʂ�Ǝv���Ă���H
�Ǝ��₷��n�������鎖�ɋ������B
32bit�̃R�[�h�Ƃ͂��Ƃ���ĂȂ������킯��
movq mm1,[eax]
��32bit�ł͐������R�[�h�����A�܂���Ȃ�ɂ�XP 64bit Edition�ł͎��s�\�B
������>>361��32bit�p�ł�64bit�p�ł��ʂ�Ȃ��B
������mm1��mm0�ɂ���ւ���Ă邱�ƂɋC�Â��Ȃ��n��������
movq mm1,[eax]
��32bit�ł͐������R�[�h�����A�܂���Ȃ�ɂ�XP 64bit Edition�ł͎��s�\�B
������>>361��32bit�p�ł�64bit�p�ł��ʂ�Ȃ��B
������mm1��mm0�ɂ���ւ���Ă邱�ƂɋC�Â��Ȃ��n��������
364 �FSocket774�F2005/09/10(�y) 15:51:19 ID:sK+dNBCn
365 �FSocket774�F2005/09/10(�y) 15:53:00 ID:u+cYR2vv
>>363
(�E�́E)����
(�E�́E)����
����ID�ς���̂�߂悤�ˁB
>>z8EmdPn0�ɂ�����B
368 �FSocket774�F2005/09/10(�y) 15:57:00 ID:sK+dNBCn
>>z8EmdPn0
�����̋������ɋC�t��
�Ђ���Ƃ��Ę^�����H
�����̋������ɋC�t��
�Ђ���Ƃ��Ę^�����H
370 �FSocket774�F2005/09/10(�y) 16:10:09 ID:sK+dNBCn
�R�[�h�Ƃ��v���O�����Ƃ������ς�킩��Ȃ��̂�CPU�̘b���悤��B
372 �F���������������I���ɍs�����F2005/09/10(�y) 17:04:36 ID:7vmV+YZ4
�v���O�����Ƀo�O�Ȃ���킯�Ȃ�����B
�b�o�t���Ⴀ��܂����B
�b�o�t���Ⴀ��܂����B
373 �F���������������I���ɍs�����F2005/09/10(�y) 17:25:58 ID:rMI5X59j
����������CPU�X������ȁH
374 �F���������������I���ɍs�����F2005/09/10(�y) 17:49:30 ID:rMI5X59j
>>372
CPU�ƃv���O�������E�E�E
CPU�ƃv���O�������E�E�E
375 �F���������������I���ɍs�����F2005/09/10(�y) 19:30:13 ID:M1R68ekj
http://www.digitimes.com/mobos/a20050908A2004.html
Yonah,CedarMill,Presler�͑�����1���̓o��ɂȂ肻�����ƁB
Yonah,CedarMill,Presler�͑�����1���̓o��ɂȂ肻�����ƁB
376 �F���������������I���ɍs�����F2005/09/10(�y) 19:46:05 ID:rMI5X59j
>>375��
377 �F���������������I���ɍs�����F2005/09/10(�y) 20:11:37 ID:yP3h7KXt
>>375
�X���W�������ǁAFab36��10������ʎY���c
�X���W�������ǁAFab36��10������ʎY���c
378 �F���������������I���ɍs�����F2005/09/11(��) 01:23:10 ID:E5HKi+75
��������O�ɍ��̐����CPU�������ق����B
CedarMill����Tejas�̐����c�肾�����H
SSE4�������肷��́H
SSE4�������肷��́H
380 �F���������������I���ɍs�����F2005/09/11(��) 10:39:07 ID:Brpo6BWc
381 �F���������������I���ɍs�����F2005/09/11(��) 11:41:53 ID:j8gfeDiq
��������Ă����̘b���H
vista���o����PC�������悤�Ǝv�����ǂ��̎��͎�����CPU�ɂȂ��Ă�H
vista���o����PC�������悤�Ǝv�����ǂ��̎��͎�����CPU�ɂȂ��Ă�H
382 �F���������������I���ɍs�����F2005/09/11(��) 12:12:52 ID:PQ890e5N
Merom�AConroe���o����B
383 �F���������������I���ɍs�����F2005/09/11(��) 12:17:17 ID:mPbQrjRl
384 �F���������������I���ɍs�����F2005/09/11(��) 14:55:06 ID:WYbyWg/3
CEDEC2005 - �f���A���R�A�v���Z�b�T�̂��߂̃}���`�X���b�h�Ή��Q�[���̊J������
ttp://pcweb.mycom.co.jp/articles/2005/09/10/cedec1/
��������
ttp://pcweb.mycom.co.jp/articles/2005/09/10/cedec1/
��������
385 �F���������������I���ɍs�����F2005/09/11(��) 16:10:58 ID:E5HKi+75
386 �F���������������I���ɍs�����F2005/09/11(��) 16:38:19 ID:c3LOf0ds
�{����"�킩���Ă�"�z�Ȃ�Ĉꈬ�肾�낤�Ɂc
�������Ȃ��̂��A�Ȃ�Č������Ⴄ�ʂ��낤����킩���Ă�l�Ȃ낤���ǁB
�������Ȃ��̂��A�Ȃ�Č������Ⴄ�ʂ��낤����킩���Ă�l�Ȃ낤���ǁB
���Ⴀ�b�o�t�̕��͂ǂ��ł�������ł����H
�܂�OS�̕�������BOS��m����IRQ��MMU���{���I�ɗ����ł��Ȃ��B
��g�Ƌ����o�ł��ȁB
��g�Ƌ����o�ł��ȁB
�m4-8222-8056-X]
Tejas����4��CPU��������HT�����������H
SSE4�͂܂��c���Ă���낤���B
conroe�ɓ��ڂ��ꂽ�肵�āB
SSE4�͂܂��c���Ă���낤���B
conroe�ɓ��ڂ��ꂽ�肵�āB
>>390
CONROE�͉\�������
CONROE�͉\�������
Paper: Intel buys entry-level chipsets from ATI
ttp://www.digitimes.com/mobos/a20050912PR207.html
Intel may purchase a combined volume of 1.5 million chipsets from ATI and SiS per month,
with shipments to start in October this year, the paper said
ttp://www.digitimes.com/mobos/a20050912PR207.html
Intel may purchase a combined volume of 1.5 million chipsets from ATI and SiS per month,
with shipments to start in October this year, the paper said
Server and Workstation Roadmap
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2528&p=3
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2528&p=3
Intel prepares to roll out 65 nano Pentium 4s
ttp://www.theinquirer.net/?article=26071
Intel prices up Yonah microprocessors
ttp://www.theinquirer.net/?article=26062
Yonah��1��6���炵���ȁB
ttp://www.theinquirer.net/?article=26071
Intel prices up Yonah microprocessors
ttp://www.theinquirer.net/?article=26062
Yonah��1��6���炵���ȁB
ttp://arena.nikkeibp.co.jp/winpc/col/02/map_intel.shtml
>Intel�̓f���A���R�ACPU���[�h�}�b�v��ϋɓI�ɓW�J�������A
>����Pentium 4 6xx�V���[�Y�Ƃ��ĊJ�����Ă���uCedar Mill�v�i�V�_�[�~���F�J���R�[�h���j�́A
>�n�[�h�E�G�A�o�[�`�����}�V���@�\�́uVirtualization Technology�iVT�j�v�삳���Ȃ����Ƃɂ����B
�ǂ����Cedar Mill��VT�Adisable�ɂ���炵���ˁB
>Intel�̓f���A���R�ACPU���[�h�}�b�v��ϋɓI�ɓW�J�������A
>����Pentium 4 6xx�V���[�Y�Ƃ��ĊJ�����Ă���uCedar Mill�v�i�V�_�[�~���F�J���R�[�h���j�́A
>�n�[�h�E�G�A�o�[�`�����}�V���@�\�́uVirtualization Technology�iVT�j�v�삳���Ȃ����Ƃɂ����B
�ǂ����Cedar Mill��VT�Adisable�ɂ���炵���ˁB
presler�͂ǂ��Ȃ�낤�B
CederMill��������͂�disable?
CederMill��������͂�disable?
�L���ǂ߂u�f���A���R�ACPU�݂̂������\������悤���v�Ə����Ă�����炳
���ʂ�enable���ƍl���Ȃ����H
���ʂ�enable���ƍl���Ȃ����H
���߂�A�L���ǂ�łȂ�������B
http://pc.watch.impress.co.jp/docs/2005/0913/ubiq124.htm
Yonah���X�����f�X�N�g�b�vPC�����s��ɓ�����
Intel�͓�����1�l�����Ƀn�C�G���h���������łȂ��A�V�����v���b�g�t�H�[���Ƃ��ăX����PC�����̐��i���C���𓊓�����B
��̓I�ɂ́AYonah���f�X�N�g�b�vPC�s��ւƓ�������B
Yonah���X�����f�X�N�g�b�vPC�����s��ɓ�����
Intel�͓�����1�l�����Ƀn�C�G���h���������łȂ��A�V�����v���b�g�t�H�[���Ƃ��ăX����PC�����̐��i���C���𓊓�����B
��̓I�ɂ́AYonah���f�X�N�g�b�vPC�s��ւƓ�������B
>Banias�n�R�A�̗��������Conroe��3GHz��̓�����g���ŋ쓮����A
>4MB/2MB��L2�L���b�V��������郂�f�����p�ӂ����Ƃ����B
>�܂��A�uMerom New Instruction(MNI)�v�ƌĂ��V�������߃Z�b�g���lj������\��ŁA
>��Ƀ��f�B�A�t�@�C���������̐��\���啝�Ɍ��シ�邱�ƂɂȂ�Ƃ����B
SSE4������݂������ȁB
>4MB/2MB��L2�L���b�V��������郂�f�����p�ӂ����Ƃ����B
>�܂��A�uMerom New Instruction(MNI)�v�ƌĂ��V�������߃Z�b�g���lj������\��ŁA
>��Ƀ��f�B�A�t�@�C���������̐��\���啝�Ɍ��シ�邱�ƂɂȂ�Ƃ����B
SSE4������݂������ȁB
merom�Aconroe����̃Z�������ɂ��ẮA�����A�i�E���X����Ă�?
>401
����
�ƌ�����
�y���e�B�A���u�����h�ŏo�������番����Ȃ�
����
�ƌ�����
�y���e�B�A���u�����h�ŏo�������番����Ȃ�
>>400
�ǂ��̈��p�H
�ǂ��̈��p�H
�L���ǂ�����
�g�т�����L���ǂ߂Ȃ�
407 �FSocket774�F2005/09/13(��) 23:56:34 ID:jXXdaFWj
�@�@�@�@�@�@�@�@�@�@�@�@In�Q�� �@�@
�@�@�@�@�@�@�@�@�@�@ |||�i�M�D�L#�j�@�ǂ߂Ȃ�
�@�@�@�@�@�@�@�@�@�@ ���@�v ��)
�@�@�@�@�@�@�@�@ �^�U�^�O�^�^|
�@�@�@�@�@�@�@�@|�P�P�P�P�P| .
�@�@�@�@�@�@�@�@�@�@ |||�i�M�D�L#�j�@�ǂ߂Ȃ�
�@�@�@�@�@�@�@�@�@�@ ���@�v ��)
�@�@�@�@�@�@�@�@ �^�U�^�O�^�^|
�@�@�@�@�@�@�@�@|�P�P�P�P�P| .
�S�X��1000�ł��B
�O���̕��܂����Ă邩�ȁH
�M�����N�V�[�o�܂����ˁBOpteron�@8way���o��\��ł��ˁB
�R�����g�ق����Ȃ�
�O���̕��܂����Ă邩�ȁH
�M�����N�V�[�o�܂����ˁBOpteron�@8way���o��\��ł��ˁB
�R�����g�ق����Ȃ�
Intel 975X chipset to support Nvidia�fs SLI and ATI�fs CrossFire
ttp://www.digitimes.com/mobos/a20050913A4012.html
Intel has reached a licensing agreement with both Nvidia and ATI
that will allow Intel users access to drivers to enable SLI or CrossFire, the sources noted.
ttp://www.digitimes.com/mobos/a20050913A4012.html
Intel has reached a licensing agreement with both Nvidia and ATI
that will allow Intel users access to drivers to enable SLI or CrossFire, the sources noted.
>408
�S����߂�B
�w�NJW�Ȃ��b�ŃX���ׂ����W�҂͎���
�S����߂�B
�w�NJW�Ȃ��b�ŃX���ׂ����W�҂͎���
>>410
���O�̔]�����Ⴡ�����C���^�t�F�[�X�̃g�|���W��CPU�ɊW�����b�Ȃ̂��H
���O�̔]�����Ⴡ�����C���^�t�F�[�X�̃g�|���W��CPU�ɊW�����b�Ȃ̂��H
>���O�̔]�����Ⴡ�����C���^�t�F�[�X�̃g�|���W��CPU�ɊW�����b�Ȃ̂��H
�ł�opteron��"intel"�� CPU����Ȃ��ł�����B
�ł�opteron��"intel"�� CPU����Ȃ��ł�����B
413 �FSocket774�F2005/09/14(��) 14:40:40 ID:Hjpu7lwa
>>412
�m����
�m����
�����炭intel��CPU�̈�ʖ����Ȃ�
>>395
INTEL�̐����ł́APen4 6x1�V���[�Y��VT���f�B�Z�[�u���ɂ���̂́A����d�͂�}���邽�߁B
�ƁAWinPC�̖{�ԕ��̋L���ɂ͏����Ă��B
INTEL�̐����ł́APen4 6x1�V���[�Y��VT���f�B�Z�[�u���ɂ���̂́A����d�͂�}���邽�߁B
�ƁAWinPC�̖{�ԕ��̋L���ɂ͏����Ă��B
>>412
�����R�������̃����b�g�E�f�����b�g�̘b����B
Opteron�����Ƀ����R���������̗p���Ă�����Ă����B
����ȋ������삶�����̘b�Ȃ�Ŗ������ȁBwww
�����R�������̃����b�g�E�f�����b�g�̘b����B
Opteron�����Ƀ����R���������̗p���Ă�����Ă����B
����ȋ������삶�����̘b�Ȃ�Ŗ������ȁBwww
>>416���L��������I���Ă���邻���ł�
>>417
�Ȃ�ŃV���O���R�A��VT disable����\��ɂȂ����Ǝv���H
�Ȃ�ŃV���O���R�A��VT disable����\��ɂȂ����Ǝv���H
>>418
�Ȃ�ŁH
�Ȃ�ŁH
FSB�����������̂̂��H
�ʂɊW�Ȃ��Ǝv����B
�@�\�̗L���E�����ō��ʉ����Ĕ���̂͂�����Intel�̏퓅��i������B
�@�\�̗L���E�����ō��ʉ����Ĕ���̂͂�����Intel�̏퓅��i������B
>>422
����
���\��������Ȃ痎����őS�R�\��Ȃ�
�f���A���R�A�ɗU������l�^�ɂł��邩��
�R���e�N�X�g��ւ��Ȃ�ăV���O���R�A�ł�����Ă�킯��
����
���\��������Ȃ痎����őS�R�\��Ȃ�
�f���A���R�A�ɗU������l�^�ɂł��邩��
�R���e�N�X�g��ւ��Ȃ�ăV���O���R�A�ł�����Ă�킯��
�L������܂�?(�L�E�ցE`)
����VMware��Virtual PC/Server������̂�VT�ʼn����ς��H
>>426
����ʼn����ς��H
����ʼn����ς��H
�\�t�g�E�F�A�G�~���ƃn�[�h�E�F�A�G�~���̍��ɂ�鐫�\���B
>>428
�����Ȃ�̂��H
�����Ȃ�̂��H
�����A�e���z�}�V�����n�[�h�E�F�A�ŊǗ��x�����鎖�ɂȂ邩��ˁB
>>430
�c�O�I
VMware�Ђ͏]����direct execution and binary translation������VT-x��
�ǂ��炩��������\�I�ɗL���Ƃ͌��܂�Ȃ��Ƃ����Ă���B
�c�O�I
VMware�Ђ͏]����direct execution and binary translation������VT-x��
�ǂ��炩��������\�I�ɗL���Ƃ͌��܂�Ȃ��Ƃ����Ă���B
>>432
���������\�[�X��IDF�̎������B
�Q�������l�����������Ǐ����up�ł��E�E�E
���ۂ�web����ȒP��password�œ���\������T���Ă���B
�Z�b�V��������Enterprise Virtualization for Intel Platforms
����22�y�[�W���B
���������\�[�X��IDF�̎������B
�Q�������l�����������Ǐ����up�ł��E�E�E
���ۂ�web����ȒP��password�œ���\������T���Ă���B
�Z�b�V��������Enterprise Virtualization for Intel Platforms
����22�y�[�W���B
���z���Z�p�ʼn����ł����ł����H
����IDF��MS�̃��c���畷�����b��
Xen��VT�݂�Pen4�ŁA260%�����Ȃ���ĕ���������
AMD�̂�(�L�[`)��ȰւƂ����Ă���
���Ȃ݂Ɍ��`�݂̂Ȃ̂ŁA�����Ȃǂ͂Ȃ�
Xen��VT�݂�Pen4�ŁA260%�����Ȃ���ĕ���������
AMD�̂�(�L�[`)��ȰւƂ����Ă���
���Ȃ݂Ɍ��`�݂̂Ȃ̂ŁA�����Ȃǂ͂Ȃ�
Xen��user/kernel��ring3/1������ˁB
VMware��ring3/3�Ƃ͎���Ⴄ��B
VMware��ring3/3�Ƃ͎���Ⴄ��B
AMD��intel���z���Z�p�Ɋւ���
�݊������Ȃ��炵�����ǁA
�ǂ��������Ƃ������H
SSE�̂悤��intel�����̂��ȁH
3Dnow���Ă܂��g���Ă�������H
�݊������Ȃ��炵�����ǁA
�ǂ��������Ƃ������H
SSE�̂悤��intel�����̂��ȁH
3Dnow���Ă܂��g���Ă�������H
��������Ƃ����\�Ƃ�����Ȃ̊W������MS���Ή�����ΐ����c��
VT�������c��̂�>>435�ǂނƊm��̂悤�Ɏv����
AMD�̂��Ή�����Ȃ琶���c�邾�낤
VT�������c��̂�>>435�ǂނƊm��̂悤�Ɏv����
AMD�̂��Ή�����Ȃ琶���c�邾�낤
����\�Ɋւ��Ă�VT�̏����o�[�W�����ʼn��������ł��傤�B
440 �FSocket774�F2005/09/15(��) 22:12:23 ID:xYzxhLED
�ǂ��������\���������͕������
���Ȃ��Ƃ���ނ͂܂��u�p�V�t�B�J�H�v���ł��ĂȂ�
VP�͂ł��Ă���(�Ƃ����������ς�)
����č��̂Ƃ���C���e���L��
���Ȃ��Ƃ���ނ͂܂��u�p�V�t�B�J�H�v���ł��ĂȂ�
VP�͂ł��Ă���(�Ƃ����������ς�)
����č��̂Ƃ���C���e���L��
AMD��Pacifica�̎d�l�́AVT����Ɍ��J����Ă邶��Ȃ����������H
>>441
�ł��܂��������͎������炵�ĂȂ�
�ł��܂��������͎������炵�ĂȂ�
443 �FSocket774�F2005/09/15(��) 22:41:07 ID:UbyHyK/6
>>438
MS�̃A�_�����ɂ��ƁAVT�̃T�|�[�g�A�Ȃ�тɁuPacifica�v�iAMD�j�̃T�|�[�g�́A2006�N���܂ł�
�o�ח\���Virtual Server�o�[�W�����Ɋ܂܂�錩���݂��Ƃ����B
http://www.itmedia.co.jp/enterprise/articles/0508/25/news018.html
MS�̃A�_�����ɂ��ƁAVT�̃T�|�[�g�A�Ȃ�тɁuPacifica�v�iAMD�j�̃T�|�[�g�́A2006�N���܂ł�
�o�ח\���Virtual Server�o�[�W�����Ɋ܂܂�錩���݂��Ƃ����B
http://www.itmedia.co.jp/enterprise/articles/0508/25/news018.html
>>442
�^�C�~���O���猩��ƁA����AMD��Op�pEgypt/Italy/Denmark��disable���ۂ����ǂ�
�cSan Diego��Venice�͒m���
�^�C�~���O���猩��ƁA����AMD��Op�pEgypt/Italy/Denmark��disable���ۂ����ǂ�
�cSan Diego��Venice�͒m���
�����āE�E�E�f�o�C�X�̃o�X�}�X�^�]����CPU���ǂ�����Ċ֗^����ƁE�E�E
Intel�̕��j�Ƃ��Ă̓`�b�v�Z�b�g��DMA remapping�@�\��������\��ɂ͂Ȃ��Ă���B
Intel�̕��j�Ƃ��Ă̓`�b�v�Z�b�g��DMA remapping�@�\��������\��ɂ͂Ȃ��Ă���B
>>441
����A���ʂ�intel����B���N��1���Ɋ��Ɏd�l�����J���Ă�B
����A���ʂ�intel����B���N��1���Ɋ��Ɏd�l�����J���Ă�B
>>444
Rev.F�����B
Rev.F�����B
Intel invests $345 million to expand 200-mm U.S. fabs
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=SMASYZIFWO0MUQSNDBESKHA?articleID=170703488
http://www.eetimes.com/news/latest/showArticle.jhtml;jsessionid=SMASYZIFWO0MUQSNDBESKHA?articleID=170703488
����݂̂Ȃ��܂̒��N�̊����炷���
Merom�R�A�͂��Ȃ���҂ł�����̂ɂȂ肻���ł����H
Merom�R�A�͂��Ȃ���҂ł�����̂ɂȂ肻���ł����H
���O�@����̐��ш�����������B
454 �F�傫�����Ƃ͂������Ƃ�!?�F2005/09/16(��) 16:37:43 ID:+QJwvXDv
Intel�A3��4500���h�����������\�͊g��
http://www.itmedia.co.jp/news/articles/0509/16/news022.html
Merom/Conroe������ނ���
��״���т̂����̹������ł߂��Ⴍ���Ꮼ�����Ȃ邩�Ǝv���Ă�����
�ӊO�ƲҰ�ނقǏ������Ȃ��̂����ˁH
http://www.itmedia.co.jp/news/articles/0509/16/news022.html
Merom/Conroe������ނ���
��״���т̂����̹������ł߂��Ⴍ���Ꮼ�����Ȃ邩�Ǝv���Ă�����
�ӊO�ƲҰ�ނقǏ������Ȃ��̂����ˁH
>>456
���ׂ����o���Ȃ��Ă�
���ׂ����o���Ȃ��Ă�
�C�X���G���`�[���ɉߓx�̊��҂͂ǂ����Ǝv��
�l�b�g�o�[�X�g������̂�P6������̂��I���S���`�[��������
PentimM���������Ă���̂�P6�̑f���̗ǂ����������炢����
�l�b�g�o�[�X�g������̂�P6������̂��I���S���`�[��������
PentimM���������Ă���̂�P6�̑f���̗ǂ����������炢����
�E�p�C�v���C���̒i������
�E��e�ʏȓd��2���L���b�V��
�E��ops�t���[�W����
�EP4�o�X���x�[�X�ɏȓd�͉�
�ESSE2����
�ȓd�͂ɂ������Ă̂Ă�����͂��Ȃ�̏C���ӏ����Ǝv����
P6��PenM�̂ق���Yona��Merom���ύX�_�͑����Ǝv��
�E��e�ʏȓd��2���L���b�V��
�E��ops�t���[�W����
�EP4�o�X���x�[�X�ɏȓd�͉�
�ESSE2����
�ȓd�͂ɂ������Ă̂Ă�����͂��Ȃ�̏C���ӏ����Ǝv����
P6��PenM�̂ق���Yona��Merom���ύX�_�͑����Ǝv��
>>460
�g�т�����ǂ����������(P6��PenM)��(Yonah��Merom)��(PenM��Yonah)�̏��Ői���x�������炵����
�g�т�����ǂ����������(P6��PenM)��(Yonah��Merom)��(PenM��Yonah)�̏��Ői���x�������炵����
P6��PenM�@�t���X�N���b�`
Yonah��Merom�@�t���X�N���b�`
Dothan��Yonah�@����
Banias��Dothan�@������
�������v����ňႢ�̑傫�������̏�����
�������͂܂��悾����n�b�L�����Ȃ����ǂ�
�������x�[�X�̃R�����̓I���S���`�[��������
�����̃L�P�������Ȃ��ɂ������炸�E�E�E
Yonah��Merom�@�t���X�N���b�`
Dothan��Yonah�@����
Banias��Dothan�@������
�������v����ňႢ�̑傫�������̏�����
�������͂܂��悾����n�b�L�����Ȃ����ǂ�
�������x�[�X�̃R�����̓I���S���`�[��������
�����̃L�P�������Ȃ��ɂ������炸�E�E�E
���������Ă��A���x�͏���d�͂ɑ��Ă̐��\���ɂ��Ă�������A
TDP��Merom����Ƃ����ȏ�A��ΐ��\��Conroe����ɂȂ炴��Ȃ���c?
Merom��overclocking�œ������x�̒l�i��Conroe�̐��\���A�Ƃ����̂Ȃ�
���������킩��c
TDP��Merom����Ƃ����ȏ�A��ΐ��\��Conroe����ɂȂ炴��Ȃ���c?
Merom��overclocking�œ������x�̒l�i��Conroe�̐��\���A�Ƃ����̂Ȃ�
���������킩��c
465 �FSocket774�F2005/09/17(�y) 14:44:30 ID:0mAhIQLA
>>464
�I���S����������E�E�E��肩�˂�
�I���S����������E�E�E��肩�˂�
466 �FSocket774�F2005/09/17(�y) 15:17:51 ID:rAluEyjv
�@�@In�Q���@�@�@�@In�Q�� �@�@�@�@In�Q���@
�@�i���Á�)�@�i�@�M�́L�j�@�i���̓��j��
�@�i�@��@�@�@�@�i�@��@�@�@�@�i�@���
�@�@�_./ /�A�@�@�@�@�_./ /�A�@�@�@�@�_./ /�A
�@�@�@ ��`�i�@�@�@�@�@ ��`�i�@�@�@�@�@ ��`�i
���B�I���S���`�[���̎����ɐ����̕����͂Ȃ��I
�@�i���Á�)�@�i�@�M�́L�j�@�i���̓��j��
�@�i�@��@�@�@�@�i�@��@�@�@�@�i�@���
�@�@�_./ /�A�@�@�@�@�_./ /�A�@�@�@�@�_./ /�A
�@�@�@ ��`�i�@�@�@�@�@ ��`�i�@�@�@�@�@ ��`�i
���B�I���S���`�[���̎����ɐ����̕����͂Ȃ��I
R520�݂����ɂȂ�����E�E
�R�����͒P�Ƀ�������Vth������Vcore�グ���o�[�W�����ł���
�����A�X�L�[��Yonah 2GHz�̃x���`���ڂ��Ă����B
���̂��Q�[����PenD840�Ɠ����ȏ�A�ł�X2 4800+�ɂ͂��Ȃ�y�Ȃ��݂���
���̂��Q�[����PenD840�Ɠ����ȏ�A�ł�X2 4800+�ɂ͂��Ȃ�y�Ȃ��݂���
������P6���I���S���Ȃ��B
���ꂩ��Conroe���I���S���Ȃ�Ă������͂Ȃ��B
�I���S���`�[�������C�X���G�����ÎQ�Ȃ��ǂˁB
NetBurst�ꔭ�łǂ����������Ă��́A2ch���ɐ��]���ꂷ������B
���ꂩ��Conroe���I���S���Ȃ�Ă������͂Ȃ��B
�I���S���`�[�������C�X���G�����ÎQ�Ȃ��ǂˁB
NetBurst�ꔭ�łǂ����������Ă��́A2ch���ɐ��]���ꂷ������B
���ꂩ��PenM�̃f�R�[�_�����܂�P6�Ƃ������ĕς��Ȃ��Ƃ������ƂɋC�Â���B
Yonah��AMD�Ԃ���������肾�����̂��E�E�E
�����̐~�ǂ���
�����̐~�ǂ���
�܁AConroe�ł͂�������Athlon64�͔��������킯�����B
�G�f�����@�u�����A�����ł͂���܂���B�m����Merom�̓C�X���G���Őv����܂������A
���̃v���Z�b�T�Ɋւ��Ă͕ʂ̃`�[�����v���s���Ă��܂��B�Ⴆ�I���S���̃`�[����
�f���A���^�}���`�v���Z�b�T�̌o���A�T�[�o�����v���Z�b�T�̌o�����L�x�ł��B
�}�C�N���A�[�L�e�N�`���͓����ł����A�ŏI�I�ȃ`�b�v�̃f�U�C���͔ނ炪�s���Ă��܂��v
���ꂩ�B��������Conroe�̓I���S��������Ă���悤���B
���̃v���Z�b�T�Ɋւ��Ă͕ʂ̃`�[�����v���s���Ă��܂��B�Ⴆ�I���S���̃`�[����
�f���A���^�}���`�v���Z�b�T�̌o���A�T�[�o�����v���Z�b�T�̌o�����L�x�ł��B
�}�C�N���A�[�L�e�N�`���͓����ł����A�ŏI�I�ȃ`�b�v�̃f�U�C���͔ނ炪�s���Ă��܂��v
���ꂩ�B��������Conroe�̓I���S��������Ă���悤���B
>Yonah
PenD�����o�Ă��ł��邾���̐��\�͂���͎̂������B
����ɁA�݊p�ȉ��Ƃ͂����A�m�[�g����CPU��Athlon64 X2�Ə����ɂȂ�Ȃ�債�����̂��Ǝv���B
Prescott��Smithfield���쒀�����͎̂��Ԃ̖�肩�ȁB
PenD�����o�Ă��ł��邾���̐��\�͂���͎̂������B
����ɁA�݊p�ȉ��Ƃ͂����A�m�[�g����CPU��Athlon64 X2�Ə����ɂȂ�Ȃ�債�����̂��Ǝv���B
Prescott��Smithfield���쒀�����͎̂��Ԃ̖�肩�ȁB
pin���͑����]���ʂ�478���Ǝv�����ǂȁB�iSocket����479�����j
�Ƌl�܂�Ȃ��c�b�R�~�����Ă݂�B
����ԋC�ɂȂ��Ă���̂�Conroe�o�ꎞ�Ƀ��[�G���h���ǂꂭ�炢�̉��i�ŏo���Ă��邩�Ȃ�ȁB
$500�ȏ�ł�������Ȃ��Ƃ����Ƃǂꂾ�����\�ǂ��Ă��������B
�Ƌl�܂�Ȃ��c�b�R�~�����Ă݂�B
����ԋC�ɂȂ��Ă���̂�Conroe�o�ꎞ�Ƀ��[�G���h���ǂꂭ�炢�̉��i�ŏo���Ă��邩�Ȃ�ȁB
$500�ȏ�ł�������Ȃ��Ƃ����Ƃǂꂾ�����\�ǂ��Ă��������B
�悭�l������
���܂ł�PenM��479�s����
Yonah��478�s������Ȃ��H
���܂ł�PenM��479�s����
Yonah��478�s������Ȃ��H
>>481
Conroe�̓n�C�G���h����̓����ɂȂ�݂����B
�ŁB���炭�̊Ԃ̓n�C�G���h��Conroe�A���C���X�g���[����Presler�ŏZ�ݕ�����͗l�B
Conroe�����C���X�g���[���`���[�G���h�ɍ~��Ă���̔����サ�炭�����Ă��炶��Ȃ�?
Conroe�̓n�C�G���h����̓����ɂȂ�݂����B
�ŁB���炭�̊Ԃ̓n�C�G���h��Conroe�A���C���X�g���[����Presler�ŏZ�ݕ�����͗l�B
Conroe�����C���X�g���[���`���[�G���h�ɍ~��Ă���̔����サ�炭�����Ă��炶��Ȃ�?
Banias�͍ŏ�479pin�œr������478pin�ADothan�͍ŏ�����478pin�������Ǝv���B
�㓡�̋L�q��Conroe�̓n�C�G���h����A�Ƃ����̂͌����悤�ȋL���͊m���ɂ���ȁB
�����AConroe�Ɠ�������Allendale�Ƃ����R�A���ŗ����ł̉\����������B
���ꂪ�{�����ǂ����B
�㓡�̋L�q��Conroe�̓n�C�G���h����A�Ƃ����̂͌����悤�ȋL���͊m���ɂ���ȁB
�����AConroe�Ɠ�������Allendale�Ƃ����R�A���ŗ����ł̉\����������B
���ꂪ�{�����ǂ����B
>>478
Conroe��Merom�̍��ق���FSB�ʂ��������Ǝv���Ă����ǁA���ɂ��L��̂��H
Conroe��Merom�̍��ق���FSB�ʂ��������Ǝv���Ă����ǁA���ɂ��L��̂��H
���Ⴆ�I���S���̃`�[����
���f���A���^�}���`�v���Z�b�T�̌o���A
���T�[�o�����v���Z�b�T�̌o�����L�x�ł��B
�f���A���v���Z�b�T�^�}���`�v���Z�b�T�̌o�����āE�E�E
�I���S����PenM���Q�������������̃R�A�Ƃ��o�����˂Ȃ��v
���f���A���^�}���`�v���Z�b�T�̌o���A
���T�[�o�����v���Z�b�T�̌o�����L�x�ł��B
�f���A���v���Z�b�T�^�}���`�v���Z�b�T�̌o�����āE�E�E
�I���S����PenM���Q�������������̃R�A�Ƃ��o�����˂Ȃ��v
���i�A�R�������o����X2�����Ȃ�܂����B
���i��IPC�ǂꂭ�炢���ȁH
���i��IPC�ǂꂭ�炢���ȁH
{kind=link}
Tr�����������X���[�v������Ƃ������Ă��悤�ȋL�����������
���\�������邩��Merom�ɂ͎g����Conroe�ɂ͎g��Ȃ��Ƃ���肻��
���\�������邩��Merom�ɂ͎g����Conroe�ɂ͎g��Ȃ��Ƃ���肻��
>>490
�ǂ����Ă������p�̊G����B��
�ǂ����Ă������p�̊G����B��
>>485
Pentium PRO�� 16bit�R�[�h���x�����߁A�����������]�����������ǁA
32bit �R�[�h�͌�����������B����Pentium PRO��UNIX�nOS�Ŏg����
������A���]�Ƃ͔��ŁA���ɖ������Ă��ȁB
�ŏ��ɏo�� P4 �́A������ P3 �Ɠ��� 1.4GHz �������̂ŁAP3 ��
7�������炢�̐��\�����o�Ȃ��āA�݂�Ȕ���̂ɍ����ĂȂ�����?
Pentium PRO�� 16bit�R�[�h���x�����߁A�����������]�����������ǁA
32bit �R�[�h�͌�����������B����Pentium PRO��UNIX�nOS�Ŏg����
������A���]�Ƃ͔��ŁA���ɖ������Ă��ȁB
�ŏ��ɏo�� P4 �́A������ P3 �Ɠ��� 1.4GHz �������̂ŁAP3 ��
7�������炢�̐��\�����o�Ȃ��āA�݂�Ȕ���̂ɍ����ĂȂ�����?
> �ŏ��ɏo�� P4 �́A������ P3 �Ɠ��� 1.4GHz �������̂ŁA
����͊ԈႢ���BP3 �͓��� 1GHz ���炢�������̂ˁB
�ł��A1.4GHz �ǂ��납�A1.7GHz �� P4 �ł����AP3 1GHz ��
Athlon 850MHz �ɕ�����Ƃ����]�����c���Ă�ȁB(w
ttp://www.atmarkit.co.jp/fpc/motoazabu/011_2001-04-27/about_bench.html
UNIX �T�[�o���I���\�]�����A���l�������L��������B
����͊ԈႢ���BP3 �͓��� 1GHz ���炢�������̂ˁB
�ł��A1.4GHz �ǂ��납�A1.7GHz �� P4 �ł����AP3 1GHz ��
Athlon 850MHz �ɕ�����Ƃ����]�����c���Ă�ȁB(w
ttp://www.atmarkit.co.jp/fpc/motoazabu/011_2001-04-27/about_bench.html
UNIX �T�[�o���I���\�]�����A���l�������L��������B
�\�t�g�I�Ȗ���������?
SSE2�����ď��߂āA�I�Ȋ��������B
�}���`�R�A���\�t�g�E�F�A�̑Ή����ӂł��傤�Ȃ��B
SSE2�����ď��߂āA�I�Ȋ��������B
�}���`�R�A���\�t�g�E�F�A�̑Ή����ӂł��傤�Ȃ��B
�T�[�o�A�v���ł́AMMX �� SSE ���āA�قڑS�����p�@��Ȃ��̂�B
����ɑ��A�}���`�R�A�͔��ɃT�[�o�����ŁA���Ƀ\�t�g�I�ȑΉ�
�͊������Ă���ƌ����Ă������B
������A�}���`�R�A���N���C�A���g����CPU����n�߂āA���܂���
�T�[�o����CPU�Ń}���`�R�A�̑I�������Ȃ�Intel���āA�헪�I�ɕ�
�Ȃ̂ˁB
����ɑ��A�}���`�R�A�͔��ɃT�[�o�����ŁA���Ƀ\�t�g�I�ȑΉ�
�͊������Ă���ƌ����Ă������B
������A�}���`�R�A���N���C�A���g����CPU����n�߂āA���܂���
�T�[�o����CPU�Ń}���`�R�A�̑I�������Ȃ�Intel���āA�헪�I�ɕ�
�Ȃ̂ˁB
�܂Ƃ��ȎI�͊��Ƀ}���`�v���Z�b�T������Intel��FSB�ł���ȏ�R�A���₵�Ă����\�łȂ����
FSB���R�A�ԃg�|���W�̖��̕����傫���ł���B
�n���T�[�o�p�ɏo���ꂽ�炻�ꂱ����������������Ⴂ�����i���
�܂Ƃ��Ƀ}���`�R�A�Ŏg�������Ȃ̂�Merom�ȍ~�ɂȂ邾�낤����A
���ʂ́u�N���C�A���g���}���`�R�A�Ɂv�̖��ڂŔ��肳���̂�
�헪�Ƃ��Ă͊Ԉ���ĂȂ��Ǝv���B�����̐���͂Ƃ������Ƃ��ĂˁB
�n���T�[�o�p�ɏo���ꂽ�炻�ꂱ����������������Ⴂ�����i���
�܂Ƃ��Ƀ}���`�R�A�Ŏg�������Ȃ̂�Merom�ȍ~�ɂȂ邾�낤����A
���ʂ́u�N���C�A���g���}���`�R�A�Ɂv�̖��ڂŔ��肳���̂�
�헪�Ƃ��Ă͊Ԉ���ĂȂ��Ǝv���B�����̐���͂Ƃ������Ƃ��ĂˁB
XeonDP�ɖn�̗p��2�v���Z�b�T����4�v���Z�b�T�ɂȂ邽��
�@�@�@�@�@�@�@�@�@�@�@�@�@FSB��800����400�Ƃ�533�Ƃ��ɉ�����
XeonMP�ɖn�̗p��L3�t�̖n�łȂ��Ƃ��܂����Ӗ����Ȃ���
�@�@�@�@�@�@�@�@�@�@�@�@�@L3�t�̖n�̓_�C���ł�������
�@�@�@�@�@�@�@�@�@�@�@�@�@FSB��800����400�Ƃ�533�Ƃ��ɉ�����
XeonMP�ɖn�̗p��L3�t�̖n�łȂ��Ƃ��܂����Ӗ����Ȃ���
�@�@�@�@�@�@�@�@�@�@�@�@�@L3�t�̖n�̓_�C���ł�������
>>497
intel�F�N���C�A���g��������
AMD�F�I��������
������B
X2��Yonah�̉��i�ь��Ă��A
X2�F2�ΎI������
Yonah�FHTT�̑���Ƀf���A���R�A�̗p
�ƌ��������������Ď���B
intel�F�N���C�A���g��������
AMD�F�I��������
������B
X2��Yonah�̉��i�ь��Ă��A
X2�F2�ΎI������
Yonah�FHTT�̑���Ƀf���A���R�A�̗p
�ƌ��������������Ď���B
>Yonah�FHTT�̑���Ƀf���A���R�A�̗p
����͂ǂ����炻��ȃC���[�W���c
SMT�ƃf���A���R�A�͂܂������ʂ̂��̂Ȃ̂ɁB
����͂ǂ����炻��ȃC���[�W���c
SMT�ƃf���A���R�A�͂܂������ʂ̂��̂Ȃ̂ɁB
> intel�F�N���C�A���g��������
> AMD�F�I��������
> ������B
���ŋ߂܂ł͋t��������B�ŋ߂� Opteron �̐����܂ł́A
AMD �̃T�[�o�����V�F�A�͂قƂ�ǃ[���������B
�헪�I�ɃN���C�A���g�Ɏ�����u���Ă�킯����Ȃ��āA
���܂��܌���AIntel �̐헪���R�P�Ă邾���ł���B
> AMD�F�I��������
> ������B
���ŋ߂܂ł͋t��������B�ŋ߂� Opteron �̐����܂ł́A
AMD �̃T�[�o�����V�F�A�͂قƂ�ǃ[���������B
�헪�I�ɃN���C�A���g�Ɏ�����u���Ă�킯����Ȃ��āA
���܂��܌���AIntel �̐헪���R�P�Ă邾���ł���B
�ƌ�����intel�̖{���̎I�͒ɂ����B
���̎I�̌�����E�E�E
> Xeon��Pentium�̏�����
> Athlon��MP��Opteron�̋@�\������
Pentium=Xeon�̋@�\������
MP��Opteron=Athlon �̏�����
�Ƃ������邶���B
Xeon�̓L���b�V�����₵��MP�ɂ��������B
Opteron��HT�̐����₵��MP,registered DIMM�Ή��ɂ��������B
Athlon ����� MP ��� Athlon �̕�����ɏo�Ă����B
Athlon 64 ���オ�܂� Opteron ����o���͕̂����܂�ƁA
64bit �Ή����T�[�o�œ��ɏd�v������ł���B
�Ă䂤���N���C�A���g�͂������� OS���Ȃ��������B
> Athlon��MP��Opteron�̋@�\������
Pentium=Xeon�̋@�\������
MP��Opteron=Athlon �̏�����
�Ƃ������邶���B
Xeon�̓L���b�V�����₵��MP�ɂ��������B
Opteron��HT�̐����₵��MP,registered DIMM�Ή��ɂ��������B
Athlon ����� MP ��� Athlon �̕�����ɏo�Ă����B
Athlon 64 ���オ�܂� Opteron ����o���͕̂����܂�ƁA
64bit �Ή����T�[�o�œ��ɏd�v������ł���B
�Ă䂤���N���C�A���g�͂������� OS���Ȃ��������B
>>508
AMD�̕��͍ŋ߂����A
intel���N���C�A���g���������Ƀ����[�X����̂�Pentium�ȑO���炾���B
�IWS�s��𑼎ЂɐȊ������̂����߂Ăł͖������B
AMD�̕��͍ŋ߂����A
intel���N���C�A���g���������Ƀ����[�X����̂�Pentium�ȑO���炾���B
�IWS�s��𑼎ЂɐȊ������̂����߂Ăł͖������B
���Ƃ���PC���ŁA�T�[�o�����Ƃ��Ă͌㔭���[�J�Ȃ̂ŁA
�N���C�A���g����ɏo�邱�Ǝ��̂͂�����܂������ǂˁB
�ł��AP3 �n�A�[�L�̏���ł���APentium PRO �́A
�C���e���I�ɂ̓T�[�o�����̈�������Ȃ�����? �܂�
Win16 ���x���Ă��ꂵ�����H���Ȃ������Ƃ����̂͂��邪�B
����ɁA���[�G���h�T�[�o�����ŃV�F�A���������͍̂���
���߂Ă̊�K�X�B����܂łɂ����������H Crusoe ���o��
����Ƀu���[�h�����ł�����Ƙb��ɂȂ������ǁA�덷��
�͈͂������Ǝv�����B
�N���C�A���g����ɏo�邱�Ǝ��̂͂�����܂������ǂˁB
�ł��AP3 �n�A�[�L�̏���ł���APentium PRO �́A
�C���e���I�ɂ̓T�[�o�����̈�������Ȃ�����? �܂�
Win16 ���x���Ă��ꂵ�����H���Ȃ������Ƃ����̂͂��邪�B
����ɁA���[�G���h�T�[�o�����ŃV�F�A���������͍̂���
���߂Ă̊�K�X�B����܂łɂ����������H Crusoe ���o��
����Ƀu���[�h�����ł�����Ƙb��ɂȂ������ǁA�덷��
�͈͂������Ǝv�����B
>>510
X68000
X68000
�E�E�E�I���ᖳ���Ȃ�w
>>469
�����ǂ݂��Ă�����
�x���`�}�[�N�X�R�A�̂��Ăˁ[�����
PentiumM�����Ƃɂ��ꂭ�炢�ɂȂ�ƃA�X�L�[�ҏW���ŗ\�z�����O���t
���̂��Ă邾��������
�����ǂ݂��Ă�����
�x���`�}�[�N�X�R�A�̂��Ăˁ[�����
PentiumM�����Ƃɂ��ꂭ�炢�ɂȂ�ƃA�X�L�[�ҏW���ŗ\�z�����O���t
���̂��Ă邾��������
>>508
Opteron�͖��炩�Ƀ}���`�v���Z�b�T�d���̐v�����B
���łɁAAth64�o�����_�ł��N���C�A���g����64bitOS�͖����������B
Opteron�͖��炩�Ƀ}���`�v���Z�b�T�d���̐v�����B
���łɁAAth64�o�����_�ł��N���C�A���g����64bitOS�͖����������B
515 �FSocket774�F2005/09/18(��) 15:35:56 ID:/Tpo/AeM
>>513
�\�z�Ȃ́H
�\�z�Ȃ́H
>>515
���Ă���Ƃ�����
PentiumM�̌��ɂ���FSB��666MHz���ƃf���A���R�A�ł̗\�z�O���t������
���L2���L���b�V���Ƃ��͍l������ĂȂ��Ə����Ă���
�p�C�v���C���Ƃ����Z�̍������Ƃ�SSE�̉��ǂƂ��ǂ������\�z�ł��̃O���t�ɂȂ����낤��
���Ă���Ƃ�����
PentiumM�̌��ɂ���FSB��666MHz���ƃf���A���R�A�ł̗\�z�O���t������
���L2���L���b�V���Ƃ��͍l������ĂȂ��Ə����Ă���
�p�C�v���C���Ƃ����Z�̍������Ƃ�SSE�̉��ǂƂ��ǂ������\�z�ł��̃O���t�ɂȂ����낤��
> Opteron�͖��炩�Ƀ}���`�v���Z�b�T�d���̐v�����B
�\�P�b�g���ɔ�Ⴕ�ă������o���h�����オ�邩��A
Intel �� FSB ���������}���`�\�P�b�g�\���Ŗ��炩��
���_������Ƃ����͓̂��������A�������\�d�͔��A������
���C�e���V�̌����1�\�P�b�g�̃N���C�A���gPC�ł��\����
�L��������A>>501�̂悤�Ȉӌ��ɂ͎^���ł���ȁB
NetBurst�̂悤�ȗ�p�@�\�ɕ��S��������v�́A�ނ���
�������C�ɂ����t�@������T�[�o�����ł����āA�ƒ��
�u���N���C�A���gPC�ɂ͓K���Ȃ����čl���������Ăł��邾��B
(�����Ƃ����M�d�l�̓u���[�h�T�[�o�ɂ͌�����)
> ���łɁAAth64�o�����_�ł��N���C�A���g����64bitOS�͖����������B
����� Athlon �� headroom ���Ȃ��Ȃ������߂̒P�Ȃ錩�蔭�Ԃ���B
�\�P�b�g���ɔ�Ⴕ�ă������o���h�����オ�邩��A
Intel �� FSB ���������}���`�\�P�b�g�\���Ŗ��炩��
���_������Ƃ����͓̂��������A�������\�d�͔��A������
���C�e���V�̌����1�\�P�b�g�̃N���C�A���gPC�ł��\����
�L��������A>>501�̂悤�Ȉӌ��ɂ͎^���ł���ȁB
NetBurst�̂悤�ȗ�p�@�\�ɕ��S��������v�́A�ނ���
�������C�ɂ����t�@������T�[�o�����ł����āA�ƒ��
�u���N���C�A���gPC�ɂ͓K���Ȃ����čl���������Ăł��邾��B
(�����Ƃ����M�d�l�̓u���[�h�T�[�o�ɂ͌�����)
> ���łɁAAth64�o�����_�ł��N���C�A���g����64bitOS�͖����������B
����� Athlon �� headroom ���Ȃ��Ȃ������߂̒P�Ȃ錩�蔭�Ԃ���B
�M�������d�v�ȃT�[�o�ɂ͑����͂ꂽ���m���g���ׂ��B
���̕���Ŏ������̂�����AMD���������d�|���ē������������B
���̕���Ŏ������̂�����AMD���������d�|���ē������������B
519 �F�u�c�F2005/09/18(��) 17:26:04 ID:oZEqiT9k
�K�@�@�@�@�@�@�@�@�@���@�@�@�@�K
�@�@�@o�@��@�@ �@ �K߁@�@� �D�@�@�@�@o�@�@�@�@�@�@��o
�@�@�@�@�@�@�@�@���܁R�@�@(�܁�)�@�@���܁R/,
�@�@�@�@ �A�A;(�܁S�@�@�@((�܁�))�@�@/��) ),�@�@, �B
�@�@�A�@�S�@(�܁@�@�@ ̧�ޮ����݁I�܁�);;�j�^.�@,
�@�A�_(�܁T;(�܁S�@�@In�Q��In�Q���܁j�^�j) .,�^ ,,
�i(��-��(;;;(�܁T;;(��(�G�M�t�L)�M�t�L)�@,�܁�);;;;;�j�j)��)
�@(;;;;(��(��;;;(�܁@���@ ���@ |�@�F�@���^�@)�j��)�j;;;;�j-��)�j
�U�@(�܁�=���@�@�@�@(,,�t.�@� (,,�t .Ɂ@�@�@�@��=�܁�)�m;;�m;;;::)
�i(�܁߁����@ �l��;;;;�@���@�@��'�@;;;���l�����߁�)��;;���m
�@�@�@o�@��@�@ �@ �K߁@�@� �D�@�@�@�@o�@�@�@�@�@�@��o
�@�@�@�@�@�@�@�@���܁R�@�@(�܁�)�@�@���܁R/,
�@�@�@�@ �A�A;(�܁S�@�@�@((�܁�))�@�@/��) ),�@�@, �B
�@�@�A�@�S�@(�܁@�@�@ ̧�ޮ����݁I�܁�);;�j�^.�@,
�@�A�_(�܁T;(�܁S�@�@In�Q��In�Q���܁j�^�j) .,�^ ,,
�i(��-��(;;;(�܁T;;(��(�G�M�t�L)�M�t�L)�@,�܁�);;;;;�j�j)��)
�@(;;;;(��(��;;;(�܁@���@ ���@ |�@�F�@���^�@)�j��)�j;;;;�j-��)�j
�U�@(�܁�=���@�@�@�@(,,�t.�@� (,,�t .Ɂ@�@�@�@��=�܁�)�m;;�m;;;::)
�i(�܁߁����@ �l��;;;;�@���@�@��'�@;;;���l�����߁�)��;;���m
��
����AA������o���ɂȂ�Ƃ����Ȃ��A�}�W�ŁB
intel 65nm�Ɋ��҂��Ă��B
�}�Y�̓n�C�G���h����̋������Ď������ǁA
x2�݂����ɍ����������ˁ[��R(`�D�L)ɳܧ��݁A���Č�������͔�����ꂻ�����Ȃ����ǁB
����AA������o���ɂȂ�Ƃ����Ȃ��A�}�W�ŁB
intel 65nm�Ɋ��҂��Ă��B
�}�Y�̓n�C�G���h����̋������Ď������ǁA
x2�݂����ɍ����������ˁ[��R(`�D�L)ɳܧ��݁A���Č�������͔�����ꂻ�����Ȃ����ǁB
CPU�̘b�������[����ł����A�n�R�l�ɂƂ��Ă��܂̃}�U�{���g���邩�ǂ���
�C�ɂȂ�܂��B���̂�����̏��͂ǂ��ł��傤���H
�C�ɂȂ�܂��B���̂�����̏��͂ǂ��ł��傤���H
>>522
���i�Ƃ��������͂ǂ��ł����H
���i�Ƃ��������͂ǂ��ł����H
524 �FSocket774�F2005/09/18(��) 19:05:28 ID:/Tpo/AeM
���̂�����̏���
���A�X�ɍڂ��Ă�
���A�X�ɍڂ��Ă�
���Ƃ��\�P�b�g�݊��ł��ǂ����낤�B
�v���b�g�t�H�[���헪�Ƃ���邭�炢������A
intel�I�ɂ͌Â���݂̂��Ƃ͍l���ĂȂ��C������B
�v���b�g�t�H�[���헪�Ƃ���邭�炢������A
intel�I�ɂ͌Â���݂̂��Ƃ͍l���ĂȂ��C������B
526 �FSocket774�F2005/09/18(��) 20:04:20 ID:/Tpo/AeM
527 �FSocket774�F2005/09/18(��) 20:14:18 ID:/KXNl3OK
>>524
�����A�X�����H
�����A�X�����H
>522
BIOS�őΉ��Ƃ������̂��ȁH
�����̂��Ƃ����z����FSB1066����ݔ��������������C�ɂȂ�B
�܂������������炢�����ǂˁB��������DDR�����B
BIOS�őΉ��Ƃ������̂��ȁH
�����̂��Ƃ����z����FSB1066����ݔ��������������C�ɂȂ�B
�܂������������炢�����ǂˁB��������DDR�����B
529 �FSocket774�F2005/09/18(��) 20:28:19 ID:/KXNl3OK
>>528
���Ԃ͂R�f�g�тȂ̂ɐ�����z���ĉq���g�є��������炢�̐�������
���Ԃ͂R�f�g�тȂ̂ɐ�����z���ĉq���g�є��������炢�̐�������
�C���W�E���̂��Ƃ���������������������������������������������
�C�W���E�����ƂȂG����
532 �FSocket774�F2005/09/18(��) 20:36:19 ID:/Tpo/AeM
>>517
�\�P�b�g���ɔ�Ⴕ�ăo���h������������Ă������Ȃ�����B���L���ɐ��]�����ȁB
���������Ă��ꉞ�ш悪�ێ�����邾�����B���ʂɍl�����킩��ł���B
�\�P�b�g���ɔ�Ⴕ�ăo���h������������Ă������Ȃ�����B���L���ɐ��]�����ȁB
���������Ă��ꉞ�ш悪�ێ�����邾�����B���ʂɍl�����킩��ł���B
>>533�e�\�P�b�g�ɂ��ꂼ�ꃁ�������ڑ�����邩��u�g�[�^���́v�������o���h���́A�\�P�b�g���ɔ�Ⴕ�ďオ���B(�\�P�b�g������̃������o���h���͓��R���)���������āA�����������Ƃ��m��Ȃ���?
>>533-534
�������������Ƃ��������ǂ�
������������r�����p���Ă�Ɖ��肵�Ȃ��Ɓi������ւ�534)
���ǃ��������l�b�N�ɂȂ��Ȃ��̂���(������ւ�533�j
�`�b�v�Z�b�g�ˑ�����Ȃ��̂���
�Ɗۂ������߂Ă݂�e�X�g
�������������Ƃ��������ǂ�
������������r�����p���Ă�Ɖ��肵�Ȃ��Ɓi������ւ�534)
���ǃ��������l�b�N�ɂȂ��Ȃ��̂���(������ւ�533�j
�`�b�v�Z�b�g�ˑ�����Ȃ��̂���
�Ɗۂ������߂Ă݂�e�X�g
�������ȁBOS�ƃv���O�����̏������ɂ�邾�낤�B
�R�����̓o�X�C���^�[�t�F�[�X���ς��Ȃ�������LGA775�̂܂܂��낤�B
����MB���g����Ƃ͂���܂�v����
�R�����̓o�X�C���^�[�t�F�[�X���ς��Ȃ�������LGA775�̂܂܂��낤�B
����MB���g����Ƃ͂���܂�v����
>>536
Merom��Socket M�Ƃ���478�ł�479�ł�775�ł��Ȃ��V�\�P�b�g�ƕ�������
Merom��Socket M�Ƃ���478�ł�479�ł�775�ł��Ȃ��V�\�P�b�g�ƕ�������
Opteron��Xeon����A�T�[�o�[�x���`�Ń_�u���X�R�A�ɂȂ肩�˂炢��
�卷���������̂͂��Y��ł����̂�
�I�p�̃A�[�L�e�N�`����Op�ƌ��̓N���C�A���g�p��Xeon�̍������
�卷���������̂͂��Y��ł����̂�
�I�p�̃A�[�L�e�N�`����Op�ƌ��̓N���C�A���g�p��Xeon�̍������
Pen3Xeon�̂܂܍��N���b�N�����Ă����Ă���Ђǂ�����Ȃ��������낤���ǂȂ�
�܂�PenM�̓������������v��������
�܂�PenM�̓������������v��������
>>517
����i
�����R�������͓e���p�AHT�̓V���O���v���Z�b�T�@�ɖ{���ɕK�v���ǂ����^�₾���B
�����i
������CPU�͎�芸�����u���Ă����Ƃ��āA
�����R�������̗l��1�`�b�v�W�������Ƒ����͑������B�i��Fn�́j
����i
�����R�������͓e���p�AHT�̓V���O���v���Z�b�T�@�ɖ{���ɕK�v���ǂ����^�₾���B
�����i
������CPU�͎�芸�����u���Ă����Ƃ��āA
�����R�������̗l��1�`�b�v�W�������Ƒ����͑������B�i��Fn�́j
���Ղ�athlon64���ǂ������Ȃ͕̂ʃX���ŁB
xeon���ǂ������Ȃ̂́A���̃X���ŁB
xeon���ǂ������Ȃ̂́A���̃X���ŁB
>>537
pin����479pin���Ăǂ����Ō����ȁA������Xeon�n��LGA774����GND��{�����������H
pin����479pin���Ăǂ����Ō����ȁA������Xeon�n��LGA774����GND��{�����������H
Xeon�n��������R�A���Ƃ̓d�����������ɓ���ė~�����ȁ[
>>540
FSB �݂����ȋ��L�o�X����AHT��PCI Express�݂�����P2P�����V���A��
�����N�ւ̈ڍs�͎���̗���ł���B���L�o�X�ł͍��̓]�����x��
���E�ɋ߂����AHT��PCI Express�͍�����\���������̗]�n������킯�ŁB
��������PCI Express�Ŏ��ӂ̓V���A�������Ă�̂ɁACPU�Ƃ̐ڑ���
���܂��ɋ��L�o�X���͂��܂��Ă���Ă̂͂ނ��돇�Ԃ��t�ł���B
�������̕K�v������CPU�̉�肩��V���A��������ق������ɂ��Ȃ��Ă�B
Intel������Whitefield����ł͂����Ȃ�낤���A���܂��ɂ����
���ƌ����Ă���Ă��Ƃ́A�g�����h���ǂ߂ĂȂ��Ǝv����B
FSB �݂����ȋ��L�o�X����AHT��PCI Express�݂�����P2P�����V���A��
�����N�ւ̈ڍs�͎���̗���ł���B���L�o�X�ł͍��̓]�����x��
���E�ɋ߂����AHT��PCI Express�͍�����\���������̗]�n������킯�ŁB
��������PCI Express�Ŏ��ӂ̓V���A�������Ă�̂ɁACPU�Ƃ̐ڑ���
���܂��ɋ��L�o�X���͂��܂��Ă���Ă̂͂ނ��돇�Ԃ��t�ł���B
�������̕K�v������CPU�̉�肩��V���A��������ق������ɂ��Ȃ��Ă�B
Intel������Whitefield����ł͂����Ȃ�낤���A���܂��ɂ����
���ƌ����Ă���Ă��Ƃ́A�g�����h���ǂ߂ĂȂ��Ǝv����B
>HT�̓V���O���v���Z�b�T�@�ɖ{���ɕK�v���ǂ����^�₾���B
�K�v�Ȃ�ˁH�k�t�H�Ȃ��ォ��HT�g���Ă����A�����Ĉ��肵�Ă�
�����Ĕėp���ɕx�o�X�g�����������Ђ��`�b�v�Z�b�g�̊J���Ƃ��y����
�����BPCI-E��Infiniband�Ƃ̐e�a�����������B���XAthlon(�����`)����HT
�ɂ�����Ǝ���EV6(PtoP)�o�X�����B
�t��Intel���Ȃ�ŃV�F�A�[�h�o�X�ɍS��̂������J�����ˁB
�K�v�Ȃ�ˁH�k�t�H�Ȃ��ォ��HT�g���Ă����A�����Ĉ��肵�Ă�
�����Ĕėp���ɕx�o�X�g�����������Ђ��`�b�v�Z�b�g�̊J���Ƃ��y����
�����BPCI-E��Infiniband�Ƃ̐e�a�����������B���XAthlon(�����`)����HT
�ɂ�����Ǝ���EV6(PtoP)�o�X�����B
�t��Intel���Ȃ�ŃV�F�A�[�h�o�X�ɍS��̂������J�����ˁB
�܁A���ǔ�r�Ώۂ������Ă̌����Ȃ��
���ǂ͂��̃X���ł�Op���64�̘b���̂ڂ��ȁB
���ǂ͂��̃X���ł�Op���64�̘b���̂ڂ��ȁB
�b��ɏ��̂͂킩�邯�ǁA���X�����������C���ɂȂ�l�Ԃ̑������Ƒ�������(w
>>544-545
���L�o�X�ƃp�����X�p�X���������Ă���B
�]�����x�̃w�b�h���[���̓V���O���v���Z�b�T�Ȃ�܂����������]�T�����邵�A
���x�����o��ΐ��\�I�ɂ͑債�č��͏o�Ȃ�����ȁB
��������IO�Ƃ̕����Ƃ��͂܂��ʂ̘b�����ȁB
�����Ƃ�Intel�̓A�i���O�n�̐v�Ɋւ��Ă͌����ē��ӂ���Ȃ��悤������A
�Ƃ��ƂƋ����N���b�N�o�X�Ɉڍs���������Ă̂͂��邾�낤�ˁB
�V���A��DRAM�𐄐i���Ă��̂����ꂪ���邵�B
���L�o�X�ƃp�����X�p�X���������Ă���B
�]�����x�̃w�b�h���[���̓V���O���v���Z�b�T�Ȃ�܂����������]�T�����邵�A
���x�����o��ΐ��\�I�ɂ͑債�č��͏o�Ȃ�����ȁB
��������IO�Ƃ̕����Ƃ��͂܂��ʂ̘b�����ȁB
�����Ƃ�Intel�̓A�i���O�n�̐v�Ɋւ��Ă͌����ē��ӂ���Ȃ��悤������A
�Ƃ��ƂƋ����N���b�N�o�X�Ɉڍs���������Ă̂͂��邾�낤�ˁB
�V���A��DRAM�𐄐i���Ă��̂����ꂪ���邵�B
>�]�����x�̃w�b�h���[���̓V���O���v���Z�b�T�Ȃ�܂����������]�T�����邵�A
���邩�HPCI-E�Ƃ�Infiniband�AS-ATA2�A�����̐��\�\���ɔ�������ɂ�
���̃o�X���Ⴂ���ς������ς�����ˁH�f���A���R�A�ɂȂ��čX�Ƀo�X���{�g
���l�b�N�ɂȂ鎖�����邾�낤���B
�����SSE*�A�����o�X�����������Ƃ����Ɛ��\�o�����ȋC������̂����A
�����I�ɂ�256Bit�p�b�N�h���Z�Ƃ��o�Ă��邾�낤���A�t��Pen4�̗l�ȃp�C�v
���C�����[���A�x�N�g��(�n�H)���Z�ӂƂ���CPU�̕����o�X�X�s�[�h�K�v��
�ʂ��Ǝv���Ă�̂����B
������ł���������SiS��4ch-RDRAM�o�Ȃ����ȁE�E�E
���邩�HPCI-E�Ƃ�Infiniband�AS-ATA2�A�����̐��\�\���ɔ�������ɂ�
���̃o�X���Ⴂ���ς������ς�����ˁH�f���A���R�A�ɂȂ��čX�Ƀo�X���{�g
���l�b�N�ɂȂ鎖�����邾�낤���B
�����SSE*�A�����o�X�����������Ƃ����Ɛ��\�o�����ȋC������̂����A
�����I�ɂ�256Bit�p�b�N�h���Z�Ƃ��o�Ă��邾�낤���A�t��Pen4�̗l�ȃp�C�v
���C�����[���A�x�N�g��(�n�H)���Z�ӂƂ���CPU�̕����o�X�X�s�[�h�K�v��
�ʂ��Ǝv���Ă�̂����B
������ł���������SiS��4ch-RDRAM�o�Ȃ����ȁE�E�E
>>549
SSE*�̓L���b�V���ʂ���DRAM�Ƃ̂��Ƃ�͐�ǂ݁E�x���������݂����ق��������B
DRAM���̂��̂��x����ˁB
�Q�[���@�Ȃ̓��C�����������̂��̂�SRAM�Ȃ݂ɑ�������L���b�V�����s�v�B
���̂ւ�͂������������Ȃ�d�v�����B
���₵���瑝�₵���Ń��C�e���V�����傷�邵�A���̂Ԃ�]���ш摝���ŕ₤�Ƃ��B
FSB��166MHz�����Ȃ�G4�ł�AltiVec�͂���ς葬���B
���W�X�^��������L/S���s�p�x�����Ȃ�����ˁB
SSE*�̓L���b�V���ʂ���DRAM�Ƃ̂��Ƃ�͐�ǂ݁E�x���������݂����ق��������B
DRAM���̂��̂��x����ˁB
�Q�[���@�Ȃ̓��C�����������̂��̂�SRAM�Ȃ݂ɑ�������L���b�V�����s�v�B
���̂ւ�͂������������Ȃ�d�v�����B
���₵���瑝�₵���Ń��C�e���V�����傷�邵�A���̂Ԃ�]���ш摝���ŕ₤�Ƃ��B
FSB��166MHz�����Ȃ�G4�ł�AltiVec�͂���ς葬���B
���W�X�^��������L/S���s�p�x�����Ȃ�����ˁB
>>550
�R���G4�����ĂȂ�����A�������AAltiVec���Ė{���ɑ����́H�x���`����
���Ĉ�ۂȂ��E�E
����Ɛ�ǂ݁E�x���������݂͂���ό��x�����邾��HCPU�L���b�V���ɂ��B
�R�ꂪ���������̂�Pen4�݂����ȓ˔��CPU(����)���Ȃ点�߂�1�_����
�ł��ŋ��I���Č�����镔�����L�����������݉��l�������Ă�����ެϲ�
�Ǝv���āE�E
�����炱��RD-RAM�ɂ͐����c���ė~���������B������2����4ch���o�������ˁB
�����o�X�Ƃ��ƂƎ���ł�������RD-RAM��������Ȃ����ȁE�Ew
�R���G4�����ĂȂ�����A�������AAltiVec���Ė{���ɑ����́H�x���`����
���Ĉ�ۂȂ��E�E
����Ɛ�ǂ݁E�x���������݂͂���ό��x�����邾��HCPU�L���b�V���ɂ��B
�R�ꂪ���������̂�Pen4�݂����ȓ˔��CPU(����)���Ȃ点�߂�1�_����
�ł��ŋ��I���Č�����镔�����L�����������݉��l�������Ă�����ެϲ�
�Ǝv���āE�E
�����炱��RD-RAM�ɂ͐����c���ė~���������B������2����4ch���o�������ˁB
�����o�X�Ƃ��ƂƎ���ł�������RD-RAM��������Ȃ����ȁE�Ew
AltiVec��SSE�łǂ�������������r���Ă�T�C�g�Ȃ��̂��H
���_�����ƁA�p�r�ɂ���邪���ӂȏ����Ȃ爳�|�I�ɑ�����B
Pentium4��G4�A�ǂ�����ő�3���߁iPen4�̏ꍇ��OPs�j/clk����
�EG4��128bit�p�b�N�h�����^����������1issue�ň����AL/S�������͐����╂�������ŁA
���ƂQ���߂͕ʌɕ�����s�\�B
�EPentium 4�́i�Ƃ��������sIA32�́jSSE*�̎�����64bit�~2issue�ŁA���Ƃ̓��W�X�^��
���Ȃ������[�h�A�X�g�A���{�g���l�b�N�ɂȂ��Ă���ȏ�͕�����s�ł��Ȃ��B
�����I�Ȗ��ߑш�s���B
�i�����炱�����W�X�^�̑�����EM64T�̓v���X�q��SSE*���Z�ɂ������b�g���������j
����G4��FSB���������ɒǂ����ĂȂ��̂ŁA�X�g���[�~���O�݂����Ȃ��Ƃ���
�߂��ۂ��ア�̂ˁB
G5�ł�FSB�ш悪�悤�₭���C������������
�������A�ǂ��������C�e���V�����債�Ă�B
�i�Ƃ����Ă�����ł��X�P�W���[�����O��MMX/SSE*���͊y�j
�܂��A�����Ƃ�x86/x64�ł�SIMD�����A��128�r�b�g�������ق�������㩁B
Merom��4issue�炵����A�e���Z���j�b�g�EL/S���j�b�g128bit�~2��ڂȂ�A
���S��PowerPC������B
�W���u�Y��Intel�ɉ���������ꂽ���͒m��Ȃ����A���Ȃ��Ƃ�����������
���sPPC�i�����G4��G5���͕s���j�̔{�ȏ�̓d�͓����萫�\�ɂȂ�炵�����B
Pentium4��G4�A�ǂ�����ő�3���߁iPen4�̏ꍇ��OPs�j/clk����
�EG4��128bit�p�b�N�h�����^����������1issue�ň����AL/S�������͐����╂�������ŁA
���ƂQ���߂͕ʌɕ�����s�\�B
�EPentium 4�́i�Ƃ��������sIA32�́jSSE*�̎�����64bit�~2issue�ŁA���Ƃ̓��W�X�^��
���Ȃ������[�h�A�X�g�A���{�g���l�b�N�ɂȂ��Ă���ȏ�͕�����s�ł��Ȃ��B
�����I�Ȗ��ߑш�s���B
�i�����炱�����W�X�^�̑�����EM64T�̓v���X�q��SSE*���Z�ɂ������b�g���������j
����G4��FSB���������ɒǂ����ĂȂ��̂ŁA�X�g���[�~���O�݂����Ȃ��Ƃ���
�߂��ۂ��ア�̂ˁB
G5�ł�FSB�ш悪�悤�₭���C������������
�������A�ǂ��������C�e���V�����債�Ă�B
�i�Ƃ����Ă�����ł��X�P�W���[�����O��MMX/SSE*���͊y�j
�܂��A�����Ƃ�x86/x64�ł�SIMD�����A��128�r�b�g�������ق�������㩁B
Merom��4issue�炵����A�e���Z���j�b�g�EL/S���j�b�g128bit�~2��ڂȂ�A
���S��PowerPC������B
�W���u�Y��Intel�ɉ���������ꂽ���͒m��Ȃ����A���Ȃ��Ƃ�����������
���sPPC�i�����G4��G5���͕s���j�̔{�ȏ�̓d�͓����萫�\�ɂȂ�炵�����B
�ŁAAltiVec�����Ђ��ς���G4�̓N���b�N���オ�炸���ځ[��
�Ƃ����킯���c�B
�[���APen4�̏ꍇ�A
2�T�C�N���������Ă邾���Ŏ�����128bit�Ȃ�Ȃ��́H�B
����NetBurst�̕��������_���Z��̑����͔����ʼn���Ă���Ƃ����b�����邭�炢������ȁB
���Z�̎�ނ�SSE�̕������b�`�Ȃ�Ȃ����������H
�����A�����̃p�b�N�h���Z�Ƃ�AltiVec�͂ǂ��Ȃ�B
�Ƃ����킯���c�B
�[���APen4�̏ꍇ�A
2�T�C�N���������Ă邾���Ŏ�����128bit�Ȃ�Ȃ��́H�B
����NetBurst�̕��������_���Z��̑����͔����ʼn���Ă���Ƃ����b�����邭�炢������ȁB
���Z�̎�ނ�SSE�̕������b�`�Ȃ�Ȃ����������H
�����A�����̃p�b�N�h���Z�Ƃ�AltiVec�͂ǂ��Ȃ�B
>>554
����A������64�r�b�g����B
Pen4�̏ꍇ64bit���A�㉺�ɂ킯��2�{�̃N���b�N�ʼn��Z���Ă�B
�����琮���Ȃ�MMX�ƕς��Ȃ����A�X�P�W���[�����O���������Ėʓ|�B
���Ȃ݂Ƀf�R�[�_��2��64�r�b�gSIMD���߂ɕ������Ă��̂�
PenM��K8�Ȃ̏ꍇ�ˁB
�ǂ����̌��Q�[���n�[�h���[�J�[���ɂ����u128�r�b�g���v�B
����A������64�r�b�g����B
Pen4�̏ꍇ64bit���A�㉺�ɂ킯��2�{�̃N���b�N�ʼn��Z���Ă�B
�����琮���Ȃ�MMX�ƕς��Ȃ����A�X�P�W���[�����O���������Ėʓ|�B
���Ȃ݂Ƀf�R�[�_��2��64�r�b�gSIMD���߂ɕ������Ă��̂�
PenM��K8�Ȃ̏ꍇ�ˁB
�ǂ����̌��Q�[���n�[�h���[�J�[���ɂ����u128�r�b�g���v�B
>>554
���ށBSSE��xmm���W�X�^��128bit���B
�V�F�A�[�h�o�X�̌��͏��Ɖ���ŋ��L���Ă��邽�߁A
����Ӗ��V�F�A�[�h�Ƃ������Ȃ��낤���B
�h���C�o�ƃ��V�[�o�̂��Ƃ��l����Ǝ����͑�����ρH
�����z�����Ȃ���Ȃ�Ȃ��悤�Ȃ炳��ɑ�ς���
���ށBSSE��xmm���W�X�^��128bit���B
�V�F�A�[�h�o�X�̌��͏��Ɖ���ŋ��L���Ă��邽�߁A
����Ӗ��V�F�A�[�h�Ƃ������Ȃ��낤���B
�h���C�o�ƃ��V�[�o�̂��Ƃ��l����Ǝ����͑�����ρH
�����z�����Ȃ���Ȃ�Ȃ��悤�Ȃ炳��ɑ�ς���
>>555
����Șb�͂��߂Ă������ȁB
NetBurst�Ŕ{���œ����Ă���̂͒P����LU��2�������B
MMX_ALU��FP���Z�n�͓���������ȉ��̃X�s�[�h�Ȃ͂������c�B
����Șb�͂��߂Ă������ȁB
NetBurst�Ŕ{���œ����Ă���̂͒P����LU��2�������B
MMX_ALU��FP���Z�n�͓���������ȉ��̃X�s�[�h�Ȃ͂������c�B
>>557
����A������2��ɂ킯�Ă�邩��2�N���b�N������́B
��������ps{r,l}ldq�ȊO�͒P����MMX/3DNOW��2��������������
�ȒP�Ɏ����ł���㕨�����B
���Ƃ��Α����Z�̏ꍇ�AIntel�̍œK���}�j���A���ɂ���
MMX(64bit) Latency 2clk�AThroughput 1clk
SSE2(128bit) Latency 4clk�AThroughput 2clk
�Ȃɂ�����́B
����A������2��ɂ킯�Ă�邩��2�N���b�N������́B
��������ps{r,l}ldq�ȊO�͒P����MMX/3DNOW��2��������������
�ȒP�Ɏ����ł���㕨�����B
���Ƃ��Α����Z�̏ꍇ�AIntel�̍œK���}�j���A���ɂ���
MMX(64bit) Latency 2clk�AThroughput 1clk
SSE2(128bit) Latency 4clk�AThroughput 2clk
�Ȃɂ�����́B
�ŁAAltiVec�����|�I�Ƀn�C�X�R�A�����Ă�x���`�́H
��������Intel��MacOSX���łĂ邱�Ƃ����A��r�ł��Ă��ǂ��Ǝv�����c�B
��������Intel��MacOSX���łĂ邱�Ƃ����A��r�ł��Ă��ǂ��Ǝv�����c�B
John the Ripper��DES�x���`���ȁB
http://todd.dailey.info/archives/2005/07/18/john-the-ripper-1638-benchmarks-on-a-dual-27-powermac/
http://www.anandtech.com/linux/showdoc.aspx?i=2163&p=7
Nocona��Opteron150���f���A���\���ő����Ă邩�ǂ����͉���Ȃ����A
SIMD�Ή��̃x���`�Ń_�u���X�R�A�ȏ�̐��\���o���Ă��ȁB
http://todd.dailey.info/archives/2005/07/18/john-the-ripper-1638-benchmarks-on-a-dual-27-powermac/
http://www.anandtech.com/linux/showdoc.aspx?i=2163&p=7
Nocona��Opteron150���f���A���\���ő����Ă邩�ǂ����͉���Ȃ����A
SIMD�Ή��̃x���`�Ń_�u���X�R�A�ȏ�̐��\���o���Ă��ȁB
���������Ȃ�Ŏ莝���̃}�V���ŃN���b�N�̋߂��̂��B�s���͂��Ă��Ȃ��B
NEC LaVieRX Pentium M (Banias) 1.5GHz, Windows XP SP2 Memory 768MB
MMX�œK����
> john --test
Benchmarking: Standard DES [48/64 4K]... DONE
Many salts: 200583 c/s
Only one salt: 190005 c/s
Benchmarking: BSDI DES (x725) [48/64 4K]... DONE
Many salts: 6125 c/s
Only one salt: 6091 c/s
Benchmarking: FreeBSD MD5 [32/32]... DONE
Raw: 3688 c/s
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 215 c/s
Benchmarking: Kerberos AFS DES [48/64 4K]... DONE
Short: 187602 c/s
Long: 510721 c/s
Benchmarking: NT LM DES [48/64 4K]... DONE
Raw: 728653 c/s
NEC LaVieRX Pentium M (Banias) 1.5GHz, Windows XP SP2 Memory 768MB
MMX�œK����
> john --test
Benchmarking: Standard DES [48/64 4K]... DONE
Many salts: 200583 c/s
Only one salt: 190005 c/s
Benchmarking: BSDI DES (x725) [48/64 4K]... DONE
Many salts: 6125 c/s
Only one salt: 6091 c/s
Benchmarking: FreeBSD MD5 [32/32]... DONE
Raw: 3688 c/s
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 215 c/s
Benchmarking: Kerberos AFS DES [48/64 4K]... DONE
Short: 187602 c/s
Long: 510721 c/s
Benchmarking: NT LM DES [48/64 4K]... DONE
Raw: 728653 c/s
Mac-mini PowerPC G4 1.42GHz, MacOS X Tiger, Memory 512MB,
Altivec�œK����
$ ./john --test
Benchmarking: Traditional DES [128/128 BS AltiVec]... DONE
Many salts: 642227 c/s real, 667595 c/s virtual
Only one salt: 586188 c/s real, 596933 c/s virtual
Benchmarking: BSDI DES (x725) [128/128 BS AltiVec]... DONE
Many salts: 22220 c/s real, 22860 c/s virtual
Only one salt: 21639 c/s real, 22080 c/s virtual
Benchmarking: FreeBSD MD5 [32/32 X2]... DONE
Raw: 3604 c/s real, 3731 c/s virtual
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 269 c/s real, 279 c/s virtual
Benchmarking: Kerberos AFS DES [24/32 4K]... DONE
Short: 96409 c/s real, 99391 c/s virtual
Long: 264089 c/s real, 270583 c/s virtual
Benchmarking: NT LM DES [128/128 BS AltiVec]... DONE
Raw: 4501K c/s real, 4641K c/s virtual
Altivec�œK����
$ ./john --test
Benchmarking: Traditional DES [128/128 BS AltiVec]... DONE
Many salts: 642227 c/s real, 667595 c/s virtual
Only one salt: 586188 c/s real, 596933 c/s virtual
Benchmarking: BSDI DES (x725) [128/128 BS AltiVec]... DONE
Many salts: 22220 c/s real, 22860 c/s virtual
Only one salt: 21639 c/s real, 22080 c/s virtual
Benchmarking: FreeBSD MD5 [32/32 X2]... DONE
Raw: 3604 c/s real, 3731 c/s virtual
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 269 c/s real, 279 c/s virtual
Benchmarking: Kerberos AFS DES [24/32 4K]... DONE
Short: 96409 c/s real, 99391 c/s virtual
Long: 264089 c/s real, 270583 c/s virtual
Benchmarking: NT LM DES [128/128 BS AltiVec]... DONE
Raw: 4501K c/s real, 4641K c/s virtual
������Mac-mini Altivec��g�p�ŁB
x86��MMX��g�p�ł́E�E�E���Ȃ������������ƁB
$ ./john --test
Benchmarking: Traditional DES [32/32 BS]... DONE
Many salts: 185753 c/s real, 191104 c/s virtual
Only one salt: 176908 c/s real, 181259 c/s virtual
Benchmarking: BSDI DES (x725) [32/32 BS]... DONE
Many salts: 6131 c/s real, 6308 c/s virtual
Only one salt: 6099 c/s real, 6249 c/s virtual
Benchmarking: FreeBSD MD5 [32/32 X2]... DONE
Raw: 3484 c/s real, 3599 c/s virtual
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 245 c/s real, 253 c/s virtual
Benchmarking: Kerberos AFS DES [24/32 4K]... DONE
Short: 99481 c/s real, 102347 c/s virtual
Long: 243378 c/s real, 250375 c/s virtual
Benchmarking: NT LM DES [32/32 BS]... DONE
Raw: 2510K c/s real, 2587K c/s virtual
�A�[�L������@��Mac�ɃA�v�����ڐA���悤�Ǝv����Mini�������̂�
�͂����茾���ĒE�͊��ɏP��ꂽ�B
�Ȃ��PPC���߂��܂���ƁB
SIMD�������ĂȂ�Kerberos AFS DES������Pentium M���t�Ƀ_�u���X�R�A
�����A���Ԃ�L/S�̃��j�b�g���iPenM�͂P�{�ɑ�G�S�͂P�{�����Ȃ��j��
��肩�ƁBS-Box���e�[�u�����b�N�A�b�v�ɓW�J���Ă��邩��ˁB
���A���Ƃ��ƃ��g���[��(Freescale)�͒ʐM����p�̐���Ă郁�[�J�[
�Ȃ�ŁA�Í��ɋ����̂͂���Ӗ����R�ł͂���̂����ǂˁB
VPERM�Ȃ�Ă����AES�Ƃ��̃o�C�g�]�u�ɗL�p�ȃ��j�b�g�����A
�t�ɂ���n�ȊO�Ɏg���ɂ̓��b�`������B
x86��MMX��g�p�ł́E�E�E���Ȃ������������ƁB
$ ./john --test
Benchmarking: Traditional DES [32/32 BS]... DONE
Many salts: 185753 c/s real, 191104 c/s virtual
Only one salt: 176908 c/s real, 181259 c/s virtual
Benchmarking: BSDI DES (x725) [32/32 BS]... DONE
Many salts: 6131 c/s real, 6308 c/s virtual
Only one salt: 6099 c/s real, 6249 c/s virtual
Benchmarking: FreeBSD MD5 [32/32 X2]... DONE
Raw: 3484 c/s real, 3599 c/s virtual
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 245 c/s real, 253 c/s virtual
Benchmarking: Kerberos AFS DES [24/32 4K]... DONE
Short: 99481 c/s real, 102347 c/s virtual
Long: 243378 c/s real, 250375 c/s virtual
Benchmarking: NT LM DES [32/32 BS]... DONE
Raw: 2510K c/s real, 2587K c/s virtual
�A�[�L������@��Mac�ɃA�v�����ڐA���悤�Ǝv����Mini�������̂�
�͂����茾���ĒE�͊��ɏP��ꂽ�B
�Ȃ��PPC���߂��܂���ƁB
SIMD�������ĂȂ�Kerberos AFS DES������Pentium M���t�Ƀ_�u���X�R�A
�����A���Ԃ�L/S�̃��j�b�g���iPenM�͂P�{�ɑ�G�S�͂P�{�����Ȃ��j��
��肩�ƁBS-Box���e�[�u�����b�N�A�b�v�ɓW�J���Ă��邩��ˁB
���A���Ƃ��ƃ��g���[��(Freescale)�͒ʐM����p�̐���Ă郁�[�J�[
�Ȃ�ŁA�Í��ɋ����̂͂���Ӗ����R�ł͂���̂����ǂˁB
VPERM�Ȃ�Ă����AES�Ƃ��̃o�C�g�]�u�ɗL�p�ȃ��j�b�g�����A
�t�ɂ���n�ȊO�Ɏg���ɂ̓��b�`������B
���@�iPenM�͂Q�{�ɑ�
���Ԃ�L/S���l�b�N�ɂȂ�₷�������Ɍ����Ă͌��ʓI��
x86�̂ق��������Ȃ邱�Ƃ�����Ǝv���B
�iG�T�͂Q�{�ɂȂ������̂̃��[�h��p�P�{�A�X�g�A��p�P�{�Ȃ�Łj
�t�Ƀ��[�h���Q�{�ɂȂ��x86�����Ă鏈���͂��Ȃ茸���Ă��邩�ƁB
�����Ƃ��A����肪�厖�����ǁB
���Ԃ�L/S���l�b�N�ɂȂ�₷�������Ɍ����Ă͌��ʓI��
x86�̂ق��������Ȃ邱�Ƃ�����Ǝv���B
�iG�T�͂Q�{�ɂȂ������̂̃��[�h��p�P�{�A�X�g�A��p�P�{�Ȃ�Łj
�t�Ƀ��[�h���Q�{�ɂȂ��x86�����Ă鏈���͂��Ȃ茸���Ă��邩�ƁB
�����Ƃ��A����肪�厖�����ǁB
��������
���I
�������ǂ������ǂ��悢�̂����܂����킩���
�O���t�������悤�ňႤ�E�E�E
�������ǂ������ǂ��悢�̂����܂����킩���
�O���t�������悤�ňႤ�E�E�E
cygwin�����1.6.39�̃\�[�X����build���Ă݂��B
$ ./john --test
Benchmarking: Traditional DES [64/64 BS MMX]... DONE
Many salts: 559903 c/s
Only one salt: 515833 c/s
Benchmarking: BSDI DES (x725) [64/64 BS MMX]... DONE
Many salts: 18449 c/s
Only one salt: 18195 c/s
Benchmarking: FreeBSD MD5 [32/32]... DONE
Raw: 3722 c/s
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 250 c/s
Benchmarking: Kerberos AFS DES [48/64 4K MMX]... DONE
Short: 194241 c/s
Long: 488645 c/s
Benchmarking: NT LM DES [64/64 BS MMX]... DONE
Raw: 4739K c/s
�R���p�C���̐i���̂��������A�������܂Ƃ��ȃX�R�A�ɂȂ����B
���A����ł��N���b�N���ł�FSB�ш�ł������Mac-mini�ɕ�����B
SSE*�̓f�R�[�_�l�b�N�Ő��\���o�ɂ����̂ł����炭�͂���Ȃ��낤�B
���������낵�����ƂɁAG4�̃v���t�@�C�����Ƃ��Ă݂�ɁA�܂��p�C�v���C���̔�����
�g����ĂȂ��B
�������Z���j�b�g�����ƂQ�قNj�g���Ă��܂��X�P�W���[�����O����2�C30���̃A�b�v��
�_���邩������Ȃ��B
$ ./john --test
Benchmarking: Traditional DES [64/64 BS MMX]... DONE
Many salts: 559903 c/s
Only one salt: 515833 c/s
Benchmarking: BSDI DES (x725) [64/64 BS MMX]... DONE
Many salts: 18449 c/s
Only one salt: 18195 c/s
Benchmarking: FreeBSD MD5 [32/32]... DONE
Raw: 3722 c/s
Benchmarking: OpenBSD Blowfish (x32) [32/32]... DONE
Raw: 250 c/s
Benchmarking: Kerberos AFS DES [48/64 4K MMX]... DONE
Short: 194241 c/s
Long: 488645 c/s
Benchmarking: NT LM DES [64/64 BS MMX]... DONE
Raw: 4739K c/s
�R���p�C���̐i���̂��������A�������܂Ƃ��ȃX�R�A�ɂȂ����B
���A����ł��N���b�N���ł�FSB�ш�ł������Mac-mini�ɕ�����B
SSE*�̓f�R�[�_�l�b�N�Ő��\���o�ɂ����̂ł����炭�͂���Ȃ��낤�B
���������낵�����ƂɁAG4�̃v���t�@�C�����Ƃ��Ă݂�ɁA�܂��p�C�v���C���̔�����
�g����ĂȂ��B
�������Z���j�b�g�����ƂQ�قNj�g���Ă��܂��X�P�W���[�����O����2�C30���̃A�b�v��
�_���邩������Ȃ��B
Intel debuts low-power 65-nm process
ttp://www.eetimes.com/news/latest/showArticle.jhtml?articleID=170704744&pgno=1
The P1265 process is said to have demonstrated leakages of only 0.01-nA/micron,
as compared to 100-nA/micron for the high-performance process, according to Intel.
To enable the breakthrough, Intel has modified its 1264 process.
These transistor modifications result in reductions in the three major sources of transistor leakage:
sub-threshold leakage, junction leakage and gate oxide leakage.
ttp://www.eetimes.com/news/latest/showArticle.jhtml?articleID=170704744&pgno=1
The P1265 process is said to have demonstrated leakages of only 0.01-nA/micron,
as compared to 100-nA/micron for the high-performance process, according to Intel.
To enable the breakthrough, Intel has modified its 1264 process.
These transistor modifications result in reductions in the three major sources of transistor leakage:
sub-threshold leakage, junction leakage and gate oxide leakage.
�㓡�O��Weekly�C�O�j���[�X
�n�[�h�E�F�A���z���ƃ}���`�R�ACPU�̊W
http://pc.watch.impress.co.jp/docs/2005/0920/kaigai213.htm
�n�[�h�E�F�A���z���ƃ}���`�R�ACPU�̊W
http://pc.watch.impress.co.jp/docs/2005/0920/kaigai213.htm
572 �FSocket774�F2005/09/20(��) 16:36:08 ID:7QxQET1o
>>572
�mWSJ�n Intel�A�d�����[�N��1000����1�ɂ���Z�p���J��
http://www.itmedia.co.jp/news/articles/0509/20/news042.html
�mWSJ�n Intel�A�d�����[�N��1000����1�ɂ���Z�p���J��
http://www.itmedia.co.jp/news/articles/0509/20/news042.html
>>571�E573
�{���Ȃ炷�����ȁB�����Aintel���Ă�������イ�啗�C�~�L���邩�畨���o��܂Ŕ��M���^���B
�{���Ȃ炷�����ȁB�����Aintel���Ă�������イ�啗�C�~�L���邩�畨���o��܂Ŕ��M���^���B
1000���̂P���Ă������ȥ���B
���i�ɂȂ������ɂ͐������x��������Ȃ��낤���ǂ�
���i�ɂȂ������ɂ͐������x��������Ȃ��낤���ǂ�
�㓡���̉��z���̘b�����A
���j�[�R�A����̃L���b�V���R�q�[�����X���{�g���l�b�N�ƂȂ�Ƃ����b�����ǁA
1���[�U�[��1�o�[�`�����}�V�[���ō����ׂȃ^�X�N1�𑖂点��ꍇ�Ȃǂ�
�S�ẴR�A���g�����A�R�q�[�����X�ő�����������Ȃ������̃R�A���������蓖�Ă�
���s���邱�ƂɂȂ����肷��̂��낤��?
���j�[�R�A����̃L���b�V���R�q�[�����X���{�g���l�b�N�ƂȂ�Ƃ����b�����ǁA
1���[�U�[��1�o�[�`�����}�V�[���ō����ׂȃ^�X�N1�𑖂点��ꍇ�Ȃǂ�
�S�ẴR�A���g�����A�R�q�[�����X�ő�����������Ȃ������̃R�A���������蓖�Ă�
���s���邱�ƂɂȂ����肷��̂��낤��?
�܂��A�R�A�������Ȃ�ΐ�����A�i�R�A�ɑ���X���b�h��^�X�N�̊��蓖�ēd�͊Ǘ�����
�n�[�h�E�F�A���x���œ��������p����R�A���K�v�ɂȂ��Ă���͖̂������Ǝv���B
�\�t�g�E�F�A���x������S�����ҏo���Ȃ�����ˁB
�n�[�h�E�F�A���x���œ��������p����R�A���K�v�ɂȂ��Ă���͖̂������Ǝv���B
�\�t�g�E�F�A���x������S�����ҏo���Ȃ�����ˁB
>578
�����Ȃ��Ă���ƁA���x�͒P���ȃR�A�������\�̃s�[�N�ɒ������Ȃ��Ȃ���
�X����������ƂɂȂ肻���ł��ˁB
���������E�܂Ŏ����āA�Ώ���d�͔�̐��\�����E�܂ōs���l������
���x�̓_�C�T�C�Y(�R�A���܂�)�ŋ��������āA
�Ō�͂ǂ��Ȃ�܂����c
�����Ȃ��Ă���ƁA���x�͒P���ȃR�A�������\�̃s�[�N�ɒ������Ȃ��Ȃ���
�X����������ƂɂȂ肻���ł��ˁB
���������E�܂Ŏ����āA�Ώ���d�͔�̐��\�����E�܂ōs���l������
���x�̓_�C�T�C�Y(�R�A���܂�)�ŋ��������āA
�Ō�͂ǂ��Ȃ�܂����c
�����āA�ʎq�R���s���[�^��
582 �FSocket774�F2005/09/20(��) 19:05:17 ID:7QxQET1o
>>573
�d�N�X
�d�N�X
1/1000���Ă�������0.1W�Ȃ킯�ŁE�E�E
�V���N���X������
�V���N���X������
>"�d�����[�N"��1000����1�ɂ���
���[�N�d���̘b����
���i�͂����Ȃ��Ǝv�����ǁC
�R����������Ǝv��H
�R����������Ǝv���l��������Ȃ����D
�R����������Ǝv��H
�R����������Ǝv���l��������Ȃ����D
(presler�ȍ~��)�n�C�G���h���瓊���Ɩ������Ă�ȏ�A
�����舫���Ȃ邱�Ƃ͂Ȃ��Ǝv���B
�T���v���̒i�K�Ŋ��ɒ��q�ǂ��̂ł��傤�B
�����舫���Ȃ邱�Ƃ͂Ȃ��Ǝv���B
�T���v���̒i�K�Ŋ��ɒ��q�ǂ��̂ł��傤�B
���Ă����ƁA���i�[�̃f�X�N�g�b�v�ł̎��g���Ⴂ�̂��悵���B
�R�����ւ̏�芷���̓\�P�b�g�ꏏ���Ƃ����ȁ`
�R�����ւ̏�芷���̓\�P�b�g�ꏏ���Ƃ����ȁ`
Yonah���i65nm�v���Z�X���Ɓj�R�P�Ȃ����Conroe���R�P��\���͖w�ǖ������B
LGA775�͂Ȃ��������ȁB�s���̑唼���d�������p����B
Merom��4issue�Ɋg�����Ă邩��A�킩����B64�r�b�g�g�������邵�B
G5��4�������ȁB
Merom��4issue�Ɋg�����Ă邩��A�킩����B64�r�b�g�g�������邵�B
G5��4�������ȁB
>>588
Yonah�͂����܂Ŋ�{�I�Ƀ��o�C��CPU�i�\�P�b�g���`�v�Z�g���m�[�g�p�j��B
Yonah�̗p�����f�X�N�g�b�v���i�͏o�邩���m��A
����Ƃ��Ă͂��܂���҂��Ȃ������ǂ��Ǝv����B
Yonah�͂����܂Ŋ�{�I�Ƀ��o�C��CPU�i�\�P�b�g���`�v�Z�g���m�[�g�p�j��B
Yonah�̗p�����f�X�N�g�b�v���i�͏o�邩���m��A
����Ƃ��Ă͂��܂���҂��Ȃ������ǂ��Ǝv����B
IDF�ɏo�Ă������^�f�X�N�g�b�v�͌��\�c�{�������ǂȁB
�悭�悭�l����m�[�g��➑̂��c�ɂ��������Ƃ�������B
Yonah�͌��\���҂��Ă���ǂˁBSSE����128�r�b�g�p�b�N�h���Z���ǂ̃f�R�[�_�p�X�ł��P�N���b�N�Ŏ��s�ł���B
�������ߑш悪�������悤�Ȃ��́B
�����Ȃ�ƁA���Z���j�b�g�����Ȃ���ǂ���Ă�C��������ȁB
������Intel�`�b�v�͕����̉��Z���j�b�g�ɑ��|�[�g�����L����`�Ԃ��Ƃ��ĂāA���ꂪ�������ɂȂ��Ă����ǁA
�P���j�b�g�P�|�[�g�ɐU��Ȃ����Ƃ��B
�悭�悭�l����m�[�g��➑̂��c�ɂ��������Ƃ�������B
Yonah�͌��\���҂��Ă���ǂˁBSSE����128�r�b�g�p�b�N�h���Z���ǂ̃f�R�[�_�p�X�ł��P�N���b�N�Ŏ��s�ł���B
�������ߑш悪�������悤�Ȃ��́B
�����Ȃ�ƁA���Z���j�b�g�����Ȃ���ǂ���Ă�C��������ȁB
������Intel�`�b�v�͕����̉��Z���j�b�g�ɑ��|�[�g�����L����`�Ԃ��Ƃ��ĂāA���ꂪ�������ɂȂ��Ă����ǁA
�P���j�b�g�P�|�[�g�ɐU��Ȃ����Ƃ��B
>>590
IDF�̋L���������H
�܂����̂܂܂�������
LGA775�̂܂܂���
>>591
�������
Presler��2.8G���
Yonah�ō��N���b�N�̕���
���\��������K�X
�Ƃ��������
IDF�̋L���������H
�܂����̂܂܂�������
LGA775�̂܂܂���
>>591
�������
Presler��2.8G���
Yonah�ō��N���b�N�̕���
���\��������K�X
�Ƃ��������
�͓����m�A�k�X���߁A�N���X�̈����͓�������\�z����Ă���ꍇ�i�O�ҁj�ƁA
�v���Z�X���[���ύX�ɔ����āi��ҁj�ȊO�ɂ�N����悤���������낤�B
�v���Z�X���[���ύX�ɔ����āi��ҁj�ȊO�ɂ�N����悤���������낤�B
�ǂ����ɂ���R�����[��90W�Ȃ�B
�f�X�N�g�b�v�ł�20W����CPU�͂łȂ����̂��B
�f�X�N�g�b�v�ł�20W����CPU�͂łȂ����̂��B
Conroe��65�����ȁB
�ǂ����uIntel TDP75%�̖@���v�������āA���ۂ�90W�������肷���
������B
Conroe 90W��65W
Merom 45W��35W
�����Ƃ�Typical TDP���낤���ǂȁB
Conroe 90W��65W
Merom 45W��35W
�����Ƃ�Typical TDP���낤���ǂȁB
�}���`�R�A�����zOS�Ŗ��ɗ��Ƃ����͈̂�ʏ���҂����
���̂��������ɓI�ȗ��R�t���ɂ����Ȃ�Ȃ���Ȃ����H
���zOS�����ɗ��Ɩ������݂��邱�Ƃ͎��������p�҂Ƃ���
�g�ɂ��݂Ă�킯����������ʉƒ�ł����p���l�������͂���
�}���`���[�U�[�����͂���قǖ��ɗ����ĂȂ��Ƃ����̂�
���̂��������ɓI�ȗ��R�t���ɂ����Ȃ�Ȃ���Ȃ����H
���zOS�����ɗ��Ɩ������݂��邱�Ƃ͎��������p�҂Ƃ���
�g�ɂ��݂Ă�킯����������ʉƒ�ł����p���l�������͂���
�}���`���[�U�[�����͂���قǖ��ɗ����ĂȂ��Ƃ����̂�
>>595
�c�O�������M�������Ă��x���`���グ��Ƃ����v���̂ق��������ȁB
M���ނ�Geode���T�C���b�N�X���}�C�i�[�����B
>>599
�t�ɃY�A���Ȃ獂���Ă������悤���ȁB
�V���O�����猩��Δ��M��X2���i�������B
�c�O�������M�������Ă��x���`���グ��Ƃ����v���̂ق��������ȁB
M���ނ�Geode���T�C���b�N�X���}�C�i�[�����B
>>599
�t�ɃY�A���Ȃ獂���Ă������悤���ȁB
�V���O�����猩��Δ��M��X2���i�������B
>>599
�\�t�g����Ƃ�������B
�V�F�A�[�h�L���b�V�����I�t�B�X�n�ŗL���Ƃ������AYonah/Merom��MS�ސ���Office�x���`��
�ǂꂾ�����\���L�т邩�����̂��Ǝv�����B
�\�t�g����Ƃ�������B
�V�F�A�[�h�L���b�V�����I�t�B�X�n�ŗL���Ƃ������AYonah/Merom��MS�ސ���Office�x���`��
�ǂꂾ�����\���L�т邩�����̂��Ǝv�����B
>>601
��������Office�n�̓}���`�X���b�h�ɑΉ����ĂȂ����A
����Ӗ����債�ėL��Ƃ͎v���Ȃ�����A
Dualcore��V�F�A�[�h�L���b�V���͈Ӗ��Ȃ��ł���B
�������Z����������Ă镪�͌��シ�邾�낤���ǁB
��������Office�n�̓}���`�X���b�h�ɑΉ����ĂȂ����A
����Ӗ����債�ėL��Ƃ͎v���Ȃ�����A
Dualcore��V�F�A�[�h�L���b�V���͈Ӗ��Ȃ��ł���B
�������Z����������Ă镪�͌��シ�邾�낤���ǁB
�V���O���A�v�����f���A���R�A�ő����Ȃ�Ƃ����Ȃ�킩����ǂˁB
������̉\�����ے肵�Ȃ����B
�����N���b�N����قǂ��̕ω��͂킩��ɂ����B
�P�Ȃ�Z�[���X�g�[�N�p�ŏI���Ă��܂��͔̂߂������Ƃ��B
������̉\�����ے肵�Ȃ����B
�����N���b�N����قǂ��̕ω��͂킩��ɂ����B
�P�Ȃ�Z�[���X�g�[�N�p�ŏI���Ă��܂��͔̂߂������Ƃ��B
>>602
����AOffice�Ȃ�ActiveX��DLL�̉���A�����̃h�L�������g�J���Ă�Ƃ��ł�
�L���b�V���̌����ʂŗL���ɂȂ�炵���B
���ƁA.NET�Ȃ�����ł����(VS2005�ł�.NET��Office�̃A�h�C�����ȒP��
����@�\���[�����Ă���j�ǂ����Ă��}���`�X���b�h������ł���͂��B
����AOffice�Ȃ�ActiveX��DLL�̉���A�����̃h�L�������g�J���Ă�Ƃ��ł�
�L���b�V���̌����ʂŗL���ɂȂ�炵���B
���ƁA.NET�Ȃ�����ł����(VS2005�ł�.NET��Office�̃A�h�C�����ȒP��
����@�\���[�����Ă���j�ǂ����Ă��}���`�X���b�h������ł���͂��B
���zOS��������Ȃ��āA���܂�javaVM�Ƃ�.Net framework�Ƃ���
�A�N�Z�����[�V����?�ɃR�A�I�Ɋ��蓖�Ă�Ȃǂ������Ȃ�?
�A�N�Z�����[�V����?�ɃR�A�I�Ɋ��蓖�Ă�Ȃǂ������Ȃ�?
>>605
����
�o�b�N�O���E���h�R���p�C���Ƃ�AWT�X���b�h�AJavaSound�X���b�h�Ƃ�
�v���t�@�C���ł��̂����Ă݂�����킩�邪�X���b�h���\�����オ�����
����GC�g���Ό��ʑ傫������
�X���[�v�b�g�ƃ��X�|���X������������@�Ƃ���2��̕���GC������
�����Ă����̃A�v����64bit���[�Ƃ�32bit���[�Ƃ��W�Ȃ�
64bit�Ή�VM��œ��������W�X�^�����Ă邩�牽�����Ȃ��Ă�����Ȃ�ɑ����Ƃ���
Java�̃_�C�i�~�b�N�R���p�C���̍œK���͏����SSE�g���悤�ɂȂ��Ă����肵�Ă邩��
����R�[�h����葁���A�Ƃ����_�ł��Ȃ�ʔ���
�ÓI�ȃR���p�C����蓝�v���Ȃ���R���p�C�����Ă����ق����L���ɂȂ�ꍇ����������
�ŋ߂�GC��̍Ĕz�u�Ɍ����̂悢�A���S���Y�����̗p��������
�L���b�V���̃q�b�g�����オ�����肵�ĉ����l���Ȃ�C�̃R�[�h��葬�������肵��
����
�o�b�N�O���E���h�R���p�C���Ƃ�AWT�X���b�h�AJavaSound�X���b�h�Ƃ�
�v���t�@�C���ł��̂����Ă݂�����킩�邪�X���b�h���\�����オ�����
����GC�g���Ό��ʑ傫������
�X���[�v�b�g�ƃ��X�|���X������������@�Ƃ���2��̕���GC������
�����Ă����̃A�v����64bit���[�Ƃ�32bit���[�Ƃ��W�Ȃ�
64bit�Ή�VM��œ��������W�X�^�����Ă邩�牽�����Ȃ��Ă�����Ȃ�ɑ����Ƃ���
Java�̃_�C�i�~�b�N�R���p�C���̍œK���͏����SSE�g���悤�ɂȂ��Ă����肵�Ă邩��
����R�[�h����葁���A�Ƃ����_�ł��Ȃ�ʔ���
�ÓI�ȃR���p�C����蓝�v���Ȃ���R���p�C�����Ă����ق����L���ɂȂ�ꍇ����������
�ŋ߂�GC��̍Ĕz�u�Ɍ����̂悢�A���S���Y�����̗p��������
�L���b�V���̃q�b�g�����オ�����肵�ĉ����l���Ȃ�C�̃R�[�h��葬�������肵��
����@���̓����I�ȕ��̂͂�
>>607
���O�����A���B
�������������̓s���̈����A�������͘^���ɂ��Ă͂߂�s�ׂ͂�߂���ǂ����B
���ꂾ������Ȃ��Ȃ��E�E�E
���Ɩn�B
���O�����A���B
�������������̓s���̈����A�������͘^���ɂ��Ă͂߂�s�ׂ͂�߂���ǂ����B
���ꂾ������Ȃ��Ȃ��E�E�E
���Ɩn�B
>>598
����A���C���X�g���[�������̐����B
����A���C���X�g���[�������̐����B
����̕����D�܂���p�t�H�[�}���X�f�X�N�g�b�v��90W�̂܂܂ł���B
>>611
����A�ǂ��ɏ����Ă���́H
����A�ǂ��ɏ����Ă���́H
�T�[�o�[�p�ɂ͊m��90W���Ƃ������\�͂������ˁB
80W�ł�
���ꂻ���������A��ҿ
>>611
XE��FX�����̂͋Ɉꕔ���Ǝv���̂����B
XE��FX�����̂͋Ɉꕔ���Ǝv���̂����B
http://pc.watch.impress.co.jp/docs/2005/0921/intel.htm
�T�u�X���b�V���u�z�[���h�v(��
�T�u�X���b�V���u�z�[���h�v(��
>>618
���ʂɎg���Ă�B
ttp://www.google.co.jp/search?sourceid=navclient&hl=ja&ie=UTF-8&rls=GGLD,GGLD:2005-29,GGLD:ja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%83%83%E3%82%B7%E3%83%A5%E3%83%9B%E3%83%BC%E3%83%AB%E3%83%89
ttp://www.google.co.jp/search?sourceid=navclient&hl=ja&ie=UTF-8&rls=GGLD,GGLD:2005-29,GGLD:ja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%82%B7%E3%83%A7%E3%83%AB%E3%83%89
���ʂɎg���Ă�B
ttp://www.google.co.jp/search?sourceid=navclient&hl=ja&ie=UTF-8&rls=GGLD,GGLD:2005-29,GGLD:ja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%83%83%E3%82%B7%E3%83%A5%E3%83%9B%E3%83%BC%E3%83%AB%E3%83%89
ttp://www.google.co.jp/search?sourceid=navclient&hl=ja&ie=UTF-8&rls=GGLD,GGLD:2005-29,GGLD:ja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%82%B7%E3%83%A7%E3%83%AB%E3%83%89
>>619
http://www.google.co.jp/search?hl=ja&c2coff=1&rls=GGLD%2CGGLD%3A2005-29%2CGGLD%3Aja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%83%83%E3%82%B7%E3%83%A7%E3%83%AB%E3%83%89
�܂��Ӗ��킩�邩�炢�����ǂ�
http://www.google.co.jp/search?hl=ja&c2coff=1&rls=GGLD%2CGGLD%3A2005-29%2CGGLD%3Aja&q=%E3%82%B5%E3%83%96%E3%82%B9%E3%83%AC%E3%83%83%E3%82%B7%E3%83%A7%E3%83%AB%E3%83%89
�܂��Ӗ��킩�邩�炢�����ǂ�
621 �FSocket774�F2005/09/21(��) 15:20:55 ID:CmD2oSb6
>>618
�����L��������Bh���ȗ�����ꍇ�����邪����̂͂��O���B
http://dictionary.goo.ne.jp/search.php?MT=threshold&kind=ej
�����L��������Bh���ȗ�����ꍇ�����邪����̂͂��O���B
http://dictionary.goo.ne.jp/search.php?MT=threshold&kind=ej
�����H
>>622
���۽www
���۽www
��[����ꂽ�[
625 �FSocket774�F2005/09/21(��) 15:30:36 ID:CmD2oSb6
>>622
���w�����蒼���E�E�E����A�����h���H
���w�����蒼���E�E�E����A�����h���H
>>625
�܂��`�����l���ƃ`���l�����C�ɂȂ邨�N�����Ă킯�ł���
�܂��`�����l���ƃ`���l�����C�ɂȂ邨�N�����Ă킯�ł���
627 �FSocket774�F2005/09/21(��) 16:22:48 ID:CftxF+2j
>>626
���Z���H
���Z���H
�X���b�V�����h�����ʂ���
629 �FSocket774�F2005/09/21(��) 17:11:00 ID:T5UYXA7j
yonah���ăf���A���R�A�ɂȂ�ȁB
�o�����c�݂����ɕ��b�o�t�ɂȂ邩����
�o�����c�݂����ɕ��b�o�t�ɂȂ邩����
���i�̓V���O���R�A�̃��f�������邵
PenD�̓x�[�X�ƂȂ�Pen4�����łɖ�肾�����̂ł͂Ȃ�����
PenD�̓x�[�X�ƂȂ�Pen4�����łɖ�肾�����̂ł͂Ȃ�����
Yonah�͍ŏ�����f���A���R�A�O��̃_�C�B
�����s�ǂ̂��̂�ЃR�A�E���ăV���O���R�A�łƂ��ďo���������悗
�����s�ǂ̂��̂�ЃR�A�E���ăV���O���R�A�łƂ��ďo���������悗
K9�L�����Z���ɂȂ������C
���F�ɑR�ł���AMD�̃R�A�iK10?)�͂��o��́H
���F�ɑR�ł���AMD�̃R�A�iK10?)�͂��o��́H
���
������intel������X��
������intel������X��
>>591
�p�C�Ă��Ƃ�����ƁA�ȊO�ɉ邩������Ȃ���
>>632
�ǂ��m��Ȃ��A���̏�'07�炵��
ttp://pcweb.mycom.co.jp/news/2005/06/18/102bl.jpg
�p�C�Ă��Ƃ�����ƁA�ȊO�ɉ邩������Ȃ���
>>632
�ǂ��m��Ȃ��A���̏�'07�炵��
ttp://pcweb.mycom.co.jp/news/2005/06/18/102bl.jpg
{kind=link}
635 �FSocket774�F2005/09/21(��) 20:51:58 ID:CftxF+2j
Yonah��
�j��ō��̃f���A���R�A�v���Z�b�T�ɂȂ邱�ƊԈႢ�����I�I(�����i�т�)
�j��ō��̃f���A���R�A�v���Z�b�T�ɂȂ邱�ƊԈႢ�����I�I(�����i�т�)
���҂����Ă�������
638 �FSocket774�F2005/09/21(��) 21:09:50 ID:0Bp4mKkr
���エ�[
>>635
�}�U�{�̉��i�ő��E���ꂻ���ł�����A���ǂ��Ȃ��C�����܂����ǂˁB
�}�U�{�̉��i�ő��E���ꂻ���ł�����A���ǂ��Ȃ��C�����܂����ǂˁB
�K�x�[�W�E�R���N�V������GC�Ȃ�ė����͈̂�ʓI�Ȃ̂��H>>606
�Ō�̓�s������܂ŁA����͔���Ȃ������B
�Ō�̓�s������܂ŁA����͔���Ȃ������B
>>640
�\�t�g���Ȃ犄�ƈ�ʓI
�K�x�[�W�R���N�^�Ƃ��Ƃ��Ƃ����邩�炠�ꂾ��
�Ƃ肠����Java��.NET�̓����Pen4���PentiumM�����|�I�ɓ���
�����HT���ł���ɂ�������炸��
�[�킯�Ń\�t�g���ɂƂ��Ă�Yona�����傤�ǖ]�܂����ۂ�
�J�����m�[�g�ł��邱�Ƃ����������
�Ȃ�IDE�̂ق��ɃA�v���I��DB�A�����Ċ̐S�̃\�t�g�̃f�o�b�O�ƃv���Z�X�����グ�܂���킯����
�}���`�X���b�h������ĂȂ�C�x�[�X�̃\�t�g�ƃ}���`�X���b�h�����e�ՂȒ��Ԍ���n��
���ɑ��x���肠�����ꍇ�A�J���҂��ǂ������Ƃ邩�A�Ƃ����̂��݂��̂ł�����
�X���b�h�����ꃌ�x���ŃT�|�[�g���Ă�Ƃ���ς肿�������AJava�̃A�g�~�b�N�N���X�݂�����
CPU�̃��x���܂œ��荞���̂��ǂ�ǂ���Ǝv��
�\�t�g���Ȃ犄�ƈ�ʓI
�K�x�[�W�R���N�^�Ƃ��Ƃ��Ƃ����邩�炠�ꂾ��
�Ƃ肠����Java��.NET�̓����Pen4���PentiumM�����|�I�ɓ���
�����HT���ł���ɂ�������炸��
�[�킯�Ń\�t�g���ɂƂ��Ă�Yona�����傤�ǖ]�܂����ۂ�
�J�����m�[�g�ł��邱�Ƃ����������
�Ȃ�IDE�̂ق��ɃA�v���I��DB�A�����Ċ̐S�̃\�t�g�̃f�o�b�O�ƃv���Z�X�����グ�܂���킯����
�}���`�X���b�h������ĂȂ�C�x�[�X�̃\�t�g�ƃ}���`�X���b�h�����e�ՂȒ��Ԍ���n��
���ɑ��x���肠�����ꍇ�A�J���҂��ǂ������Ƃ邩�A�Ƃ����̂��݂��̂ł�����
�X���b�h�����ꃌ�x���ŃT�|�[�g���Ă�Ƃ���ς肿�������AJava�̃A�g�~�b�N�N���X�݂�����
CPU�̃��x���܂œ��荞���̂��ǂ�ǂ���Ǝv��
Lisp���̉��ɂ�GC��GC�ȊO�̉����ł�����
643 �FSocket774�F2005/09/21(��) 23:38:19 ID:o3FxKS8J
�ނ���X���b�h�����p����قǂɐ��\�ɃV�r�A�Ȃ�C++����B
template�̉��p��Generics���i���������̂ŊJ���̂��₷���ł�����B
template�̉��p��Generics���i���������̂ŊJ���̂��₷���ł�����B
>>644
�V�r�A�Ƃ�����Ȃ��āA���ꃌ�x���ŃX���b�h�����Ă���
�}���`�X���b�h�������قLjӎ����Ȃ��Ă��ȒP�ɂ�������Ă��Ƃ���B
�����ăK�`�K�`�ɍœK�����邺�[�Ƃ�������ł��}���`�X���b�h�̋Z�p���Ȃ��Ƃ��悭���邱�ƁB
�����Ă��������œK�������V���O���X���b�h�����قǑ��x�o�ĂȂ��i���͂���Ȃ��ƂȂ����ǁj
���Ԍ���n�̃}���`�X���b�h�Ή��A�v���ɑ��x�ŕ����Ă��ڂ�B
�������ł����͂Ȃɂ���Ă���������ǂˁB
�V�r�A�Ƃ�����Ȃ��āA���ꃌ�x���ŃX���b�h�����Ă���
�}���`�X���b�h�������قLjӎ����Ȃ��Ă��ȒP�ɂ�������Ă��Ƃ���B
�����ăK�`�K�`�ɍœK�����邺�[�Ƃ�������ł��}���`�X���b�h�̋Z�p���Ȃ��Ƃ��悭���邱�ƁB
�����Ă��������œK�������V���O���X���b�h�����قǑ��x�o�ĂȂ��i���͂���Ȃ��ƂȂ����ǁj
���Ԍ���n�̃}���`�X���b�h�Ή��A�v���ɑ��x�ŕ����Ă��ڂ�B
�������ł����͂Ȃɂ���Ă���������ǂˁB
���ƕK����template�̂悳�����Ă�悤������ǂ��Agenerics���ǂ����Ƃ�
����ȃ��x������Ȃ���A�J�������́B
����ȃ��x������Ȃ���A�J�������́B
����A�}���`�X���b�h�̋Z�p���Ȃ��悤�ȘA���̓I�u�W�F�N�g�̎������l���Ȃ��n���R�[�h�Y���邼�B
>>637
CeleronM�͂ǂ���SpeedStep�Ȃ��������
�Е��̃R�A����ł������g�����肵��
�ŁA������̂�����V���O���R�A��p�}�X�N��Yonah�̑I�ʗ������������
CeleronM�͂ǂ���SpeedStep�Ȃ��������
�Е��̃R�A����ł������g�����肵��
�ŁA������̂�����V���O���R�A��p�}�X�N��Yonah�̑I�ʗ������������
�V���O���R�A��p����Ȃ���CeleronM�͉��i�D�悾���炫��������
�ǂ����ɂ���SpeedStep�Ȃ��ƃL���b�V�������A�R�A��������
Pentium�u�����h��Celeron�u�����h�Ƃ͂�����Ƃ������\�����o�邾�낤��
�ǂ����ɂ���SpeedStep�Ȃ��ƃL���b�V�������A�R�A��������
Pentium�u�����h��Celeron�u�����h�Ƃ͂�����Ƃ������\�����o�邾�낤��
Yonah Celeron��EIST Enable���ĉ\�����邯��
�������������ă��i��FSB800�ɂȂ�\���͂���H
>>649
Pen4��ȁA�Z���Ų������ɂ͒���Ă��邾�낤����Ȃ��B
Pen4��ȁA�Z���Ų������ɂ͒���Ă��邾�낤����Ȃ��B
654 �FSocket774�F2005/09/23(��) 17:29:29 ID:wtX8Kql8
���[�N�d�����������Ă��A4issue����ʂ̖ʂŋꂵ���C��
656 �FSocket774�F2005/09/23(��) 17:50:55 ID:YVt7cEPo
Merom��FSB1333
�ŏ���Merom��Napa�v���b�g�t�H�[�������̂܂g������ˁB
658 �FSocket774�F2005/09/23(��) 18:05:56 ID:ob26c3WC
��������FSB667�A���F��FSB1066����H
Napa��FSB667�ASanta Rosa��FSB800�D
660 �FSocket774�F2005/09/23(��) 18:39:43 ID:wtX8Kql8
���H
�T���^���U����
�T���^���U����
���o�C���b�o�t�Ɠ������炢�ȓd�͂ɂȂ�Ǝv�����ǂǂ����Ȃ�Ȃ��ȁE�E�E�E
�U�O�v���炢�ɂȂ��Ă��܂������B
�U�O�v���炢�ɂȂ��Ă��܂������B
>>661
�R�����̂��ƌ����Ă�̂��H
�R�����̂��ƌ����Ă�̂��H
�����͐��S�R�A�ɂȂ�炵�����ǃR�A���ĕ����I�ɉ����́H
�\�A��\�͏�邩������Ȃ����njܕS�Ƃ���S�ł����v�Ȃ́H
�\�A��\�͏�邩������Ȃ����njܕS�Ƃ���S�ł����v�Ȃ́H
>>663
�v���Z�X���[������������͉��ł��ڂ�B
�����ɕ���������MMX/SSE�ɃA�E�g�I�u�I�[�_�ɁE�E�E�ƃt���Z�b�g�������R�A��1��2��
SIMD��O���t�B�b�N�ɓ������������ȃR�A�������ڂ���v�悾�낤�B
�q���g�F�v���Z�X���[����n����i�߂P�R�A������̖ʐς�2^-n�{�ɂȂ�
�Ȃ��A�_�C�̃T�C�Y��80�`200mm²���x�Ɏ��߂邾�낤�B
�v���Z�X���[������������͉��ł��ڂ�B
�����ɕ���������MMX/SSE�ɃA�E�g�I�u�I�[�_�ɁE�E�E�ƃt���Z�b�g�������R�A��1��2��
SIMD��O���t�B�b�N�ɓ������������ȃR�A�������ڂ���v�悾�낤�B
�q���g�F�v���Z�X���[����n����i�߂P�R�A������̖ʐς�2^-n�{�ɂȂ�
�Ȃ��A�_�C�̃T�C�Y��80�`200mm²���x�Ɏ��߂邾�낤�B
����ȂɃR�A���₵�Č������オ��̂�����
>>663
���̓d�g�̔��M���͉������ˁH
���̓d�g�̔��M���͉������ˁH
���ŋ߉��L�̋L������������
�w�e���W�j�A�X�ȃ}���`�R�A�ɂȂ�����ǂ�ǂ�R�A���͑�����������
�n�[�h�E�F�A���z���ƃ}���`�R�ACPU�̊W
ttp://pc.watch.impress.co.jp/docs/2005/0920/kaigai213.htm
�w�e���W�j�A�X�ȃ}���`�R�A�ɂȂ�����ǂ�ǂ�R�A���͑�����������
�n�[�h�E�F�A���z���ƃ}���`�R�ACPU�̊W
ttp://pc.watch.impress.co.jp/docs/2005/0920/kaigai213.htm
ttp://www.ebjapan.com/content/l_news/2005/03/08re_intel050304.html
ttp://www.designnewsjapan.com/news/200503/08etest_intel050308.html
ttp://www.designnewsjapan.com/news/200503/08etest_intel050308.html
���������APARROT�̘_���ɏ����Ă����r�x���`CPU��Merom�Ƃ����邳�����Ă���
Baker���ăG�[�W�F���g�u�����ꂩ��
�u�����w��
�A�v�����}���`�X���b�h�������̂�������O�ɂȂ��Ă��āA
�ʏ�g���A�v�����R���炢�����オ���Ă��Ƃ����8���炢�܂ł�
�f�X�N�g�b�v�ł����b�͂��肻����
�����ăG���R�[�h�͋��낵�����x�ŏI���
�I�͐���100�������Ă��g�����Ǝv���Ύg���Ƃ���������
�T�[�r�X�u���������Ȃ��ď����̑唼�͎I�ł��A�Ƃ����������ɂȂ邩����
PDA�Ƃ��g�ѓd�b�Ƃ��Ɠd�Ƃ����N���C�A���g�̃��C���ɂȂ��Ă�����
�ǂ����ɂ���R���p�C��������R�[�q�[�^�C���Ȏ��ォ��͑z���������
�ʏ�g���A�v�����R���炢�����オ���Ă��Ƃ����8���炢�܂ł�
�f�X�N�g�b�v�ł����b�͂��肻����
�����ăG���R�[�h�͋��낵�����x�ŏI���
�I�͐���100�������Ă��g�����Ǝv���Ύg���Ƃ���������
�T�[�r�X�u���������Ȃ��ď����̑唼�͎I�ł��A�Ƃ����������ɂȂ邩����
PDA�Ƃ��g�ѓd�b�Ƃ��Ɠd�Ƃ����N���C�A���g�̃��C���ɂȂ��Ă�����
�ǂ����ɂ���R���p�C��������R�[�q�[�^�C���Ȏ��ォ��͑z���������
���ɏI�ƑO�Ƀo�b�`�˂�����ŏo�Ў��Ɍ��ʊm�F���Ă����ォ��͑z�������Ȃ��Ȃ��Ă邯�ǂ�
"�p�[�\�i��"�R���s���[�^�łR�R�A�ȏ�͖��ʈȊO�̉����ł��Ȃ�
����͂��O�̃p�[�\�i��
�������Ԕ��Ȑl������ȁB
�}���`�R�A�E���j�C�R�A�ŊF�n�b�s�[�Ȃ�A10�N�O���炻���Ȃ��Ă���B
�}���`�R�A�E���j�C�R�A�ŊF�n�b�s�[�Ȃ�A10�N�O���炻���Ȃ��Ă���B
�������Ԕ��Ȑl������ȁB
�V���O���R�A�Ő��\����ł���Ȃ�A�l�b�g�o�[�X�g�͌��̂Ă��Ȃ�������B
�V���O���R�A�Ő��\����ł���Ȃ�A�l�b�g�o�[�X�g�͌��̂Ă��Ȃ�������B
�A�z�����肾
�̕ω��𗝉��o���Ȃ��ȁB
������\�N�O�Ɠ������������Ȃ��Ǝv������ł邵�B
������\�N�O�Ɠ������������Ȃ��Ǝv������ł邵�B
���ꂩ�������A�N�Z�X�����������Ƃ���
��ʓI�ȃ��C�e���V�������Ă���B
�Ƃ肠���������̊��ł̓������̕����ł̃A�N�Z�X��9�N���b�N�������Ă���悤�����B
�iDDR400�E200MHz�x�[�X�Łj
ras�M��-trcd-cas�M��-tcas-�o�[�X�g�N���b�N(DDR)
����ł����Ă�H
��ʓI�ȃ��C�e���V�������Ă���B
�Ƃ肠���������̊��ł̓������̕����ł̃A�N�Z�X��9�N���b�N�������Ă���悤�����B
�iDDR400�E200MHz�x�[�X�Łj
ras�M��-trcd-cas�M��-tcas-�o�[�X�g�N���b�N(DDR)
����ł����Ă�H
�}���`�R�A�Ȃ�Č����ʁB
�V���O���R�A�{Hyper-Threading���x�X�g�B
http://www.ne.jp/asahi/comp/tarusan/main49.htm
http://www.ne.jp/asahi/comp/tarusan/main72.htm
http://www.ne.jp/asahi/comp/tarusan/main88.htm
http://www.ne.jp/asahi/comp/tarusan/main90.htm
http://www.ne.jp/asahi/comp/tarusan/main96.htm
http://www.ne.jp/asahi/comp/tarusan/main107.htm
http://www.ne.jp/asahi/comp/tarusan/main119.htm
�V���O���R�A�{Hyper-Threading���x�X�g�B
http://www.ne.jp/asahi/comp/tarusan/main49.htm
http://www.ne.jp/asahi/comp/tarusan/main72.htm
http://www.ne.jp/asahi/comp/tarusan/main88.htm
http://www.ne.jp/asahi/comp/tarusan/main90.htm
http://www.ne.jp/asahi/comp/tarusan/main96.htm
http://www.ne.jp/asahi/comp/tarusan/main107.htm
http://www.ne.jp/asahi/comp/tarusan/main119.htm
���������A�V���O���R�A�ƃ}���`�R�A�̃g�����W�X�^���������Ƃ������肪�Ԉ���Ă�B
�A�[�L�e�N�`���̊ϓ_����ł��̂��l����Ƃ��������ԈႢ��Ƃ��B
�A�[�L�e�N�`���̊ϓ_����ł��̂��l����Ƃ��������ԈႢ��Ƃ��B
���邳��̓}�[�P�e�B���O�ʂƃA�[�L�e�N�`���ʂ͂����ƕ����ď����Ă邾��
���W�b�N�ɓ����ʂ̃g�����W�X�^���g���ꍇ�A�V���O���R�A�̕����V���O���X���b�h���\�͂����Ƃ�������ˁB
�����Đ��ɂ���\�t�g�̓V���O���X���b�h�����܂��ɂƂĂ��������A�}���`�X���b�h�������ɂ����v�Z���Ă̂����Ȃ��炸����B
HyperThreading���͂��߂Ƃ�����CPU�R�A�ŕ����̃X���b�h�����Z�p�́A
���\������قNjɒ[�ɐL�тȂ������Ƀg�����W�X�^�����܂�H��Ȃ��B
������A���W�b�N���r�I���b�`�ɕۂ����܂�(�V���O���X���b�h���\�𗎂Ƃ�����)�}���`�X���b�h���\������ł���B
�����Ƃ������PC�p�ɂłĂ�f���A���R�A���x�ł̓}���`�R�A�̃g�����W�X�^�̃R�X�g�p�t�H�[�}���X�̈����͂��܂���ɂȂ��ĂȂ��B
�܂�V���O���R�A�Ɠ����̃��b�`�ȃR�A�����ڂł��邵�A�\�t�g�I�ɂ�2�X���b�h������PC�ł͏\���ȋǖʂ��قƂ�ǂ�����B
�R�X�g�p�t�H�[�}���X�̈��������ɂȂ�̂�4��8�R�A�����肩�炩�ȁB
�����Đ��ɂ���\�t�g�̓V���O���X���b�h�����܂��ɂƂĂ��������A�}���`�X���b�h�������ɂ����v�Z���Ă̂����Ȃ��炸����B
HyperThreading���͂��߂Ƃ�����CPU�R�A�ŕ����̃X���b�h�����Z�p�́A
���\������قNjɒ[�ɐL�тȂ������Ƀg�����W�X�^�����܂�H��Ȃ��B
������A���W�b�N���r�I���b�`�ɕۂ����܂�(�V���O���X���b�h���\�𗎂Ƃ�����)�}���`�X���b�h���\������ł���B
�����Ƃ������PC�p�ɂłĂ�f���A���R�A���x�ł̓}���`�R�A�̃g�����W�X�^�̃R�X�g�p�t�H�[�}���X�̈����͂��܂���ɂȂ��ĂȂ��B
�܂�V���O���R�A�Ɠ����̃��b�`�ȃR�A�����ڂł��邵�A�\�t�g�I�ɂ�2�X���b�h������PC�ł͏\���ȋǖʂ��قƂ�ǂ�����B
�R�X�g�p�t�H�[�}���X�̈��������ɂȂ�̂�4��8�R�A�����肩�炩�ȁB
>>664
�v���Z�X���[���̌��E�͂ǂ��Ȃ́H
�C���e���̃��[�h�}�b�v����45n�����4�R�A���嗬�ɂȂ�݂��������ǁA���̂܂܂ǂ��܂Ŕ����͐i�ނ́H
0.1n�Ƃ����肦�Ȃ��Ǝv���̂����B
�v���Z�X���[���̌��E�͂ǂ��Ȃ́H
�C���e���̃��[�h�}�b�v����45n�����4�R�A���嗬�ɂȂ�݂��������ǁA���̂܂܂ǂ��܂Ŕ����͐i�ނ́H
0.1n�Ƃ����肦�Ȃ��Ǝv���̂����B
���������x���ł͌��q�T�C�Y�܂ł̃��h�͂ł��Ă�����H
�P���q�g�����W�X�^�̎����ɂ͐������Ă���悤���B���p�̃��h�͒m���
>>685
�����ɍ��N���b�N�����Ă������Ƃ����TDP�Ƃ��������E�Ȃ�Ȃ��́H
�\��ł̓v���X�R�͑啝�ɏ���d�͂�������o�ϓI�ȃR�A��
���ە����o�Ă��Ă݂��炱��������
�����ɍ��N���b�N�����Ă������Ƃ����TDP�Ƃ��������E�Ȃ�Ȃ��́H
�\��ł̓v���X�R�͑啝�ɏ���d�͂�������o�ϓI�ȃR�A��
���ە����o�Ă��Ă݂��炱��������
>>692
�����ނȂ����������ƌ������Ə����Ă���
�u�N���e�B�J���p�X�v�Ƃ��u�M���x�v�Ƃ�
TDP������Ɖ����Ă���Ƃ́A�ǂ��������E�����Y���o���Ȃ�ŏ������@�o���Ƃ����
�����ނȂ����������ƌ������Ə����Ă���
�u�N���e�B�J���p�X�v�Ƃ��u�M���x�v�Ƃ�
TDP������Ɖ����Ă���Ƃ́A�ǂ��������E�����Y���o���Ȃ�ŏ������@�o���Ƃ����
�������M���x����ԏd�v���Ǝv���Ă邪�A�킩��₷���A��
�V���O���R�A�ݾ�
http://www.biwa.ne.jp/~yok/838RANK-NEW.htm
http://www.biwa.ne.jp/~yok/838RANK-NEW.htm
>>690
>>691
�v���Z�X���[���ł����Ƃǂꂭ�炢�H0.01n�ʂ��H
���q�T�C�Y�ȉ��͖�������ˁB��������������x�����ƌ��E�ɒB�������Ă��ƁH
����Ƃ������Ɣ����͏o����́H
���������x��������p���܂ʼn��N�ʂȂ́H
>>693
>>694
�M���x�������Ɖ������Ȃ́H������̂͂ǂ�����Ηǂ��́H
>>691
�v���Z�X���[���ł����Ƃǂꂭ�炢�H0.01n�ʂ��H
���q�T�C�Y�ȉ��͖�������ˁB��������������x�����ƌ��E�ɒB�������Ă��ƁH
����Ƃ������Ɣ����͏o����́H
���������x��������p���܂ʼn��N�ʂȂ́H
>>693
>>694
�M���x�������Ɖ������Ȃ́H������̂͂ǂ�����Ηǂ��́H
>>696
���̏�intel�̃��[�h�}�b�v�ł�'11��22nm(�v���Z�X1270)�܂ł͏����Ă��邯�ǁA
�@���Ȃ��ˁH�V���R���̌����\���̍ŏ��T�C�Y��0.54nm������
���Ƃ�����ƌ����Ή��Ƃ����邩������Ȃ����c
���̏�intel�̃��[�h�}�b�v�ł�'11��22nm(�v���Z�X1270)�܂ł͏����Ă��邯�ǁA
�@���Ȃ��ˁH�V���R���̌����\���̍ŏ��T�C�Y��0.54nm������
���Ƃ�����ƌ����Ή��Ƃ����邩������Ȃ����c
>>697
intel�̃��[�h�}�b�v�����d���҂̕ԍόv��
intel�̃��[�h�}�b�v�����d���҂̕ԍόv��
700 �FSocket774�F2005/09/24(�y) 10:39:45 ID:lse1feOB
700
701 �FSocket774�F2005/09/24(�y) 10:40:13 ID:PavCW+Dj
>>699
�@�@ ���Q�Q�Q��
�@�@ | �m�@�@�@�@�@ �R/��)�@�@100mm^2�̕\�ʐς������̃N�}�[
�@ /��) (�)�@�@�@(�)�@|�@.|
�@/�@/�@ �@( _��_)�@ �~/�@�@
.�i�@�@�R�@�@|��|�@�@�^ �@�@
�@�_�@�@�@ �R�m�@/ �@�@�@
�@ /�@�@�@�@�@�@/�@�@ �@�@
�@|�@�@�@�@�@�@ / �@�@ �@�@
�@|�@�@�^�_�@�_ �@�@ �@
�@|�@/�@�@�@ )�@ )�@�@�@
�@���@�@�@ �i�@ �_�@�@�@�@
�@�@�@�@�@�@ �_,,�Q�j
�@�@ ���Q�Q�Q��
�@�@ | �m�@�@�@�@�@ �R/��)�@�@100mm^2�̕\�ʐς������̃N�}�[
�@ /��) (�)�@�@�@(�)�@|�@.|
�@/�@/�@ �@( _��_)�@ �~/�@�@
.�i�@�@�R�@�@|��|�@�@�^ �@�@
�@�_�@�@�@ �R�m�@/ �@�@�@
�@ /�@�@�@�@�@�@/�@�@ �@�@
�@|�@�@�@�@�@�@ / �@�@ �@�@
�@|�@�@�^�_�@�_ �@�@ �@
�@|�@/�@�@�@ )�@ )�@�@�@
�@���@�@�@ �i�@ �_�@�@�@�@
�@�@�@�@�@�@ �_,,�Q�j
702 �FSocket774�F2005/09/24(�y) 11:45:19 ID:Rt5bucNz
���q����
���Ƀ��[�g���H
���Ƀ��[�g���H
�l�����̕����ƁA�W��̕����ƁA�ǂ������G�A�R���̌������ǂ��H
��������l����ƁA�ʐς̏������ق�����₵�₷���B
��������l����ƁA�ʐς̏������ق�����₵�₷���B
���̂����̂܂܂���30nm�����̎���22nm�����ł����ł��~�߂������悤�ȁB
>>703
���Ƃ��Ƃ��ĕs�K���Ǝv���܂��B
�����G�A�R���Ȃ�l�������W������\�ɑ��Ď�����Ԃ͏\���L���ƍl������̂ŁA�����������Ȃ�M�e�ʂ�
�����L�������̂ق������R�s���ł��B
���̗Ⴆ���Ɓu�������x�̑傫���̈Ⴄ�q�[�g�V���N�ǂ�������₵�₷�����v�ɋ߂��ˁB
CPU��p�͔��M�̂��������̂Ńq�[�g�V���N���g�����炢�Ȃ̂ŁA������x�܂ł͑傫���ق����L��(�ő̓��̑Η�
��C�ɂ���p�����҂ł��邵���������t�@���̌`��ɗ]�T������Η�p�\�͂��グ����̂�)�B
>>703
���Ƃ��Ƃ��ĕs�K���Ǝv���܂��B
�����G�A�R���Ȃ�l�������W������\�ɑ��Ď�����Ԃ͏\���L���ƍl������̂ŁA�����������Ȃ�M�e�ʂ�
�����L�������̂ق������R�s���ł��B
���̗Ⴆ���Ɓu�������x�̑傫���̈Ⴄ�q�[�g�V���N�ǂ�������₵�₷�����v�ɋ߂��ˁB
CPU��p�͔��M�̂��������̂Ńq�[�g�V���N���g�����炢�Ȃ̂ŁA������x�܂ł͑傫���ق����L��(�ő̓��̑Η�
��C�ɂ���p�����҂ł��邵���������t�@���̌`��ɗ]�T������Η�p�\�͂��グ����̂�)�B
>>706
���łɂ������̃X���ɂ������������Ă����B
��
VIA C7 �X��
http://pc7.2ch.net/test/read.cgi/jisaku/1117267861/
���łɂ������̃X���ɂ������������Ă����B
��
VIA C7 �X��
http://pc7.2ch.net/test/read.cgi/jisaku/1117267861/
>>705
������āA���e�[���̃I�}�P��Alpha�Ƃǂ������₦��H�̚g���ƈႤ���H
������āA���e�[���̃I�}�P��Alpha�Ƃǂ������₦��H�̚g���ƈႤ���H
>>706
������CPU�̐��\��d�l�ɂ��Č�荇��
�@�@�@�@�@�@�@�@�@�@��
����PC�p�[�c�ɂ��ẮA�����I�ȓW�]��w���v��ɖ𗧂Ă�
(��������i���g�p�ł��邩�E�����ւ��̍D�@�͂���)
�@�@�@�@�@�@�@�@�@�@��
����PC���C�t�̏[���Ɍq����
������ƍl����A�����ɕ����肻���Ȃ��̂����ǁE�E�E
AMD������CPU�X���ł��������Ɛu���Ă鍁��t�����āA
�������ȕԓ����X���t�����Ǝv���đ҂��Ă����ǁA
���ǒN�������Ă��Ȃ������̂��s�v�c�łȂ�Ȃ��B
������CPU�̐��\��d�l�ɂ��Č�荇��
�@�@�@�@�@�@�@�@�@�@��
����PC�p�[�c�ɂ��ẮA�����I�ȓW�]��w���v��ɖ𗧂Ă�
(��������i���g�p�ł��邩�E�����ւ��̍D�@�͂���)
�@�@�@�@�@�@�@�@�@�@��
����PC���C�t�̏[���Ɍq����
������ƍl����A�����ɕ����肻���Ȃ��̂����ǁE�E�E
AMD������CPU�X���ł��������Ɛu���Ă鍁��t�����āA
�������ȕԓ����X���t�����Ǝv���đ҂��Ă����ǁA
���ǒN�������Ă��Ȃ������̂��s�v�c�łȂ�Ȃ��B
�G�A�R���b�́A�G�A�R�����̂��̂��M���ŁA�����͔}�́B
���ۂ̃R�A�́A�R�A�̖ʐς��̂��̂��M���B
��r�Ƃ��đS���؈Ⴂ�B���v���r�O��B
���ۂ̃R�A�́A�R�A�̖ʐς��̂��̂��M���B
��r�Ƃ��đS���؈Ⴂ�B���v���r�O��B
>>669
�����64�v���Z�b�T�T�[�o�[����ă^�X�N�}�l�[�W���[�J�������ς��ȁB
>>702
���q�j��1fm�ʂ�����0.000001nm���ȁB���q���a�͂����Ƒ傫�����ǁB
>>707
�����N��ł����������B>>706��3�X���ڂɍs���Ȃ��̂��ȁB���������Ă����̑O������̂��H
�����64�v���Z�b�T�T�[�o�[����ă^�X�N�}�l�[�W���[�J�������ς��ȁB
>>702
���q�j��1fm�ʂ�����0.000001nm���ȁB���q���a�͂����Ƒ傫�����ǁB
>>707
�����N��ł����������B>>706��3�X���ڂɍs���Ȃ��̂��ȁB���������Ă����̑O������̂��H
�v���Z�X���[���̔����́A�ʎY���A�o�ϐ����l�����Ȃ��Ⴂ���Ȃ��B
32nm�͊��Ƃ���Ȃ�s�����낤���ǁA����ȍ~�A�m������킯����Ȃ��B
�l���Č���A�v���Z�X���[�������E�Ɏ������Ƃ���ŁA���Ɉ�厖
�Ƃ����킯�ł��Ȃ���˂��E�E�A�܂��APC�ƊE�͌����낤���ǁA
����Ȃ���ł�����A�Ǝv���Ă�l�������낤���B
32nm�͊��Ƃ���Ȃ�s�����낤���ǁA����ȍ~�A�m������킯����Ȃ��B
�l���Č���A�v���Z�X���[�������E�Ɏ������Ƃ���ŁA���Ɉ�厖
�Ƃ����킯�ł��Ȃ���˂��E�E�A�܂��APC�ƊE�͌����낤���ǁA
����Ȃ���ł�����A�Ǝv���Ă�l�������낤���B
>>714
�v���Z�X���������E�ɒB������A�ǂ��l���Ă���厖�B
�v���Z�X���������E�ɒB������A�ǂ��l���Ă���厖�B
>>1 ����ł������̃X���́����ƁA
�ǂ������W������̂ł����H �S���W�Ȃ��Ǝv���܂����c
����A�P�Ȃ�R�s�y�r�炵�̃t�H�[�}�b�g����B
�r�炵�Ƀ}�W���X����l�����Ȃ��͓̂�����O�B
�ǂ������W������̂ł����H �S���W�Ȃ��Ǝv���܂����c
����A�P�Ȃ�R�s�y�r�炵�̃t�H�[�}�b�g����B
�r�炵�Ƀ}�W���X����l�����Ȃ��͓̂�����O�B
>>718
�����Ȃ̂��A�X�}�\�B
�����Ȃ̂��A�X�}�\�B
�l�X�ȎY�ƂŁA�i�������܂薳�����ł������Ƒ������Ă�킯�ŁB
�����̎Y�Ƃ̔����I�Ȑi���̂ق����ُ�Ȃ��ǂˁB
�����̎Y�Ƃ̔����I�Ȑi���̂ق����ُ�Ȃ��ǂˁB
>>688
�|���b�N�̖@���ɔj��ăL�����Z�����ꂽ�uTejas�v
http://pc.watch.impress.co.jp/docs/2004/1224/kaigai144.htm
���|���b�N�̖@���́ACPU�̃}�C�N���A�[�L�e�N�`�����g�����ă_�C(�g�����W�X�^��)��2�{�ɑ��₵�Ă��A
�����\��2�̕������̖�1.4�{���x�ɂ����L�тȂ��Ƃ����o�������B
�����}���`�R�A���V���O���X���b�h�𑬂����Ȃ��̂͂قڊm��
�܁[�ߋ��̃\�t�g���ق��Ƃ��Ă������Ȃ������܂ł����b�L�[���������Ă��Ƃł���H
>>704�̂���
���ł�90nm�ŃQ�[�g�_���������q�����܂Ŕ����Ȃ��Ă�炵��
���ꂩ��͗ʎq�͊w�I���ʂŐ≏���Ă�͂��̂Ƃ���ł��d�������R��i���[�N�j���܂��܂��Ђǂ��Ȃ邩��
�v���Z�X���[���k�������
�|���b�N�̖@���ɔj��ăL�����Z�����ꂽ�uTejas�v
http://pc.watch.impress.co.jp/docs/2004/1224/kaigai144.htm
���|���b�N�̖@���́ACPU�̃}�C�N���A�[�L�e�N�`�����g�����ă_�C(�g�����W�X�^��)��2�{�ɑ��₵�Ă��A
�����\��2�̕������̖�1.4�{���x�ɂ����L�тȂ��Ƃ����o�������B
�����}���`�R�A���V���O���X���b�h�𑬂����Ȃ��̂͂قڊm��
�܁[�ߋ��̃\�t�g���ق��Ƃ��Ă������Ȃ������܂ł����b�L�[���������Ă��Ƃł���H
>>704�̂���
���ł�90nm�ŃQ�[�g�_���������q�����܂Ŕ����Ȃ��Ă�炵��
���ꂩ��͗ʎq�͊w�I���ʂŐ≏���Ă�͂��̂Ƃ���ł��d�������R��i���[�N�j���܂��܂��Ђǂ��Ȃ邩��
�v���Z�X���[���k�������
���������v���X�R�R�A�͉��ł���ȂɃf�J�C�H
�L���b�V���������R�A���̃g�����W�X�^���A�k�X��2�{�ʂɂȂ��Ă��悤�ȁB
�L���b�V���������R�A���̃g�����W�X�^���A�k�X��2�{�ʂɂȂ��Ă��悤�ȁB
��ݼ�2�{���\1.4�{�̖@���Ȃ��8086�̂��납�炠��������
���ɂȂ��Ă��[�����[���������ł͂Ȃ�
���ɂȂ��Ă��[�����[���������ł͂Ȃ�
>>668-669
�d�g�L���̌��l�^��T���ɋ�J���܂����B���ꂾ�ȁA
http://www.intel.com/technology/techresearch/idf/platform-2015-keynote.htm
������The Trend to Many-Core
�C���e���ł�10���R�A�̎��������Ă���A���S�R�A��
�\����������Ď���Rattner�������Ă���Ď��ł���B
�����͐��S�R�A�ɂȂ�A���Ęb���Ƃ����Ԃ�j���A���X
���Ⴄ�Ǝv�����ǁB
������������Rattner���Ă�������A���N�O�ɂ�2010�N
�ɂ�15�`20GHz�ɂȂ�Ȃ�ė\�����Ă����킯�Ȃ̂ŁA
�܂��A�M�p�Ȃ���ȁB
�d�g�L���̌��l�^��T���ɋ�J���܂����B���ꂾ�ȁA
http://www.intel.com/technology/techresearch/idf/platform-2015-keynote.htm
������The Trend to Many-Core
�C���e���ł�10���R�A�̎��������Ă���A���S�R�A��
�\����������Ď���Rattner�������Ă���Ď��ł���B
�����͐��S�R�A�ɂȂ�A���Ęb���Ƃ����Ԃ�j���A���X
���Ⴄ�Ǝv�����ǁB
������������Rattner���Ă�������A���N�O�ɂ�2010�N
�ɂ�15�`20GHz�ɂȂ�Ȃ�ė\�����Ă����킯�Ȃ̂ŁA
�܂��A�M�p�Ȃ���ȁB
�ʂɍ������j�[�R�A���́A���������ł��Ȃ���B
���\�`���S�R�A�P�ʂ�MPU�J�����Ă�̂Ȃ��Intel�����ł������i�B
���\�`���S�R�A�P�ʂ�MPU�J�����Ă�̂Ȃ��Intel�����ł������i�B
(�R���V���[�}�ɂ�����)���j�C�R�A�̋P������������M���Ă�l����
���N�O��10�`20GHz�̔M���o�[�X�g��M���Ă��l�B�Ȃ낤�Ȃ�
���N�O��10�`20GHz�̔M���o�[�X�g��M���Ă��l�B�Ȃ낤�Ȃ�
Cell�Ƃ��́A���j�C�R�A���Č����̂��ȁH
Cell�̓w�e���W�j�A�X�ȃ��j�C�R�A�����˂�
�� ���j�C�R�v���Z�b�T
���ق���Ȃ�s�N�Z���V�F�[�_�[���j�b�g��o�[�e�b�N�X�V�F�[�_�[���j�b�g�����ꂼ���̃R�A�Ƃ��������
nVidia��G70��30�ȏ�̃R�A���W�ς������j�C�R�A�ł������܂��Ƃ�
nVidia��G70��30�ȏ�̃R�A���W�ς������j�C�R�A�ł������܂��Ƃ�
ttp://pcweb.mycom.co.jp/news/2005/07/27/002.html
�Q�[���p�ȊO�ł�SUN��Niagara�i8�R�A�j�o�����̂ŁA���ꂪ�ǂ��Ȃ邩��
���������ˁB
httpd�Ƃ��P���ȃv���Z�X����ʂɐ��������Web�T�[�o�[�͓��ӂ݂���
�����ǁA�ʏ�p�r�ł͍��̂Ƃ��낻��قǑ����͂Ȃ�Ȃ��݂������ˁB
�����ǃ��`�����҂��Ă���B
�f�X�N�g�b�v���j�C�R�A�g��������
�Q�[���p�ȊO�ł�SUN��Niagara�i8�R�A�j�o�����̂ŁA���ꂪ�ǂ��Ȃ邩��
���������ˁB
httpd�Ƃ��P���ȃv���Z�X����ʂɐ��������Web�T�[�o�[�͓��ӂ݂���
�����ǁA�ʏ�p�r�ł͍��̂Ƃ��낻��قǑ����͂Ȃ�Ȃ��݂������ˁB
�����ǃ��`�����҂��Ă���B
�f�X�N�g�b�v���j�C�R�A�g��������
����Ȃ烊�R���t�B�M���A���u���n��PU�����ɐ��\�R�A�ł���
�܂��e��R�v������������Ă��Ă邵�����Ƃ��Ă͓����悤�Ȋ���������
�Ή��A�v�����Ȃ��ƍ��������Ȃ��Ƃ������Ƃ�
�t�ɍl����Ɠ����悤�ɕW���ɂȂ邱�Ƃɂ���ē�����O�̂悤�Ɏg����E�E�E�͂�
�Ή��A�v�����Ȃ��ƍ��������Ȃ��Ƃ������Ƃ�
�t�ɍl����Ɠ����悤�ɕW���ɂȂ邱�Ƃɂ���ē�����O�̂悤�Ɏg����E�E�E�͂�
�O�ɂ��������Ǝv�����ǁAIBM��cisco���l�b�g���[�N�p��188��CPU�R�A
�W�ς����`�b�v����Ă�Bintel���l�b�g���[�N�����ɊJ�����̃n�Y�B�܂����p�r�����ǂˁB
intel�̃w�e���W�j�A�X�ȃR�A���A�i���̐��Ƃ������j�������ꂽ�A�[�L�e�N�`����
���͂Ƃ����W�J�Ȃ�ʔ������A����p�r�����̃R�A���ς�ł���Ȃ������B
�������ш��\�t�g�E�F�A�I�Ȗ��͑傫�����ǁAintel�����̃X���̏Z�l��
�������Ă邱�Ƃ��낤�B
�W�ς����`�b�v����Ă�Bintel���l�b�g���[�N�����ɊJ�����̃n�Y�B�܂����p�r�����ǂˁB
intel�̃w�e���W�j�A�X�ȃR�A���A�i���̐��Ƃ������j�������ꂽ�A�[�L�e�N�`����
���͂Ƃ����W�J�Ȃ�ʔ������A����p�r�����̃R�A���ς�ł���Ȃ������B
�������ш��\�t�g�E�F�A�I�Ȗ��͑傫�����ǁAintel�����̃X���̏Z�l��
�������Ă邱�Ƃ��낤�B
>>732
�ŁA���̒ʏ�p�r���ĉ���H���Ċ����Ȃ��B
�ŁA���̒ʏ�p�r���ĉ���H���Ċ����Ȃ��B
����p�r�����͂��ꂱ����p�̃`�b�v������
CPU�̃R�A�𑝂₷�K�v�͖���
CPU�̃R�A�𑝂₷�K�v�͖���
CPU���ʂɓ����Ƃ�������DSP��1�`�b�v�ɑg�ݍ����Ċ����Ȃ��
�ł�PC�p�r�̏ꍇCPU�R�A�����ł����Ǝv���
�r�f�I�`�b�v���������邫�Ȃ炩�܂��
�ł�PC�p�r�̏ꍇCPU�R�A�����ł����Ǝv���
�r�f�I�`�b�v���������邫�Ȃ炩�܂��
���j�C�R�A���Č����Ă��������邩��˂��B
�ėpCPU�Ɠ���p�rCPU�����čl����K�v������B
���S�R�A�Ƃ������Ă�̂́A����p�r�ł����ĔėpCPU�̘b�Ŗ�����B
��ʗp�r�̔ėpCPU�͖��������i�V���O���X���b�h���\�]���ɂ����j
�����ɂ���đ��₹����x��10�R�A�O����Ęb��B
�ėpCPU�Ɠ���p�rCPU�����čl����K�v������B
���S�R�A�Ƃ������Ă�̂́A����p�r�ł����ĔėpCPU�̘b�Ŗ�����B
��ʗp�r�̔ėpCPU�͖��������i�V���O���X���b�h���\�]���ɂ����j
�����ɂ���đ��₹����x��10�R�A�O����Ęb��B
���A�z
�A�z����
���͓ǂ߂Ȃ�
���͓ǂ߂Ȃ�
����p�r������MMX/SSE��AltiVec���L��������Ă錻����l�����
���̂Ƃ��ɂȂ��Ă݂�\�t�g����łǂ��ɂ��Ȃ�C������B
���̂Ƃ��ɂȂ��Ă݂�\�t�g����łǂ��ɂ��Ȃ�C������B
>>737�̍l�����ǂ�قǃA�z�Ȏ��Ȃ̂�����Ȃ��Ƃ����̂͒ɂ�����˂��B
�̂�FPU�ł������p�r�����̐�p�̃`�b�v�������Ƃ����̂ɁB
�̂�FPU�ł������p�r�����̐�p�̃`�b�v�������Ƃ����̂ɁB
���W�b�N��H�𑝂₷���ƂƃR�A���𑝂₷���ƂƂ��������Ă�A�t�H
>>745
�q���g�F�w�e��
�q���g�F�w�e��
���̃X���ɂ͔����̋ƊE�̒��́i�s��K�͂̓f�J�C���j�����Ƃ��낵�����ĂȂ��l���풓���Ă�悤��
�����`�b�v�ł��낢��ł����ق����M���x���͏��������ȁB
���������C�e���V���P�̂��߂Ƀ����R��������悤�Ȏ��ゾ
�_�C��ɓ���p�r�ɗL���ȏ����ȃR�A���ڂ���̂����R�ȗ��ꂾ��B
���������C�e���V���P�̂��߂Ƀ����R��������悤�Ȏ��ゾ
�_�C��ɓ���p�r�ɗL���ȏ����ȃR�A���ڂ���̂����R�ȗ��ꂾ��B
Tunt+g7Y�͐����Ȃ��A
�ł͐����̋ƊE���L������ł݂�
����Intel��M���Ƃ���CPU���[�J�[����������Ă��̂��\�����Ă��ꂗ
�N�̘b����Intel�����Ɍ��y���Ă鎖���ے�o����悤�����B
�z���g�����킗
�ł͐����̋ƊE���L������ł݂�
����Intel��M���Ƃ���CPU���[�J�[����������Ă��̂��\�����Ă��ꂗ
�N�̘b����Intel�����Ɍ��y���Ă鎖���ے�o����悤�����B
�z���g�����킗
�܂��A�C���e�������N���b�N�V���O���R�A�̂Ăăf���A���R�A�ɑ������̂́A
���ȏ�̐��\���V���O���ŏo�������b�g�������Ǝv�������炾��B
�����\���K�v�Ȃ̂́A�Q�[���Ɠ���ҏW�̂݁B
���̓�ɓ�������Ȃ�A�f���A���R�A�ɂ������������B
�Q�[���v���O���}�͂��ԂƂ�����A�P�N������f���A���R�A�p�̃v���O�����쐬�m�E�n�E�Q�b�g���邳�B
���ȏ�̐��\���V���O���ŏo�������b�g�������Ǝv�������炾��B
�����\���K�v�Ȃ̂́A�Q�[���Ɠ���ҏW�̂݁B
���̓�ɓ�������Ȃ�A�f���A���R�A�ɂ������������B
�Q�[���v���O���}�͂��ԂƂ�����A�P�N������f���A���R�A�p�̃v���O�����쐬�m�E�n�E�Q�b�g���邳�B
�M�̘b�́A���傤�Ǘǂ�������n�܂�����K�X
ttp://pcweb.mycom.co.jp/column/architecture/001/
ttp://pcweb.mycom.co.jp/column/architecture/001/
�}���`�R�A����ł��V���O���X���b�h���\�͏d�v�B
����A�����獡�ȏ�̐��\�͕K�v�Ȃ̂��A�ƁB
���������A���N���b�N�Ƀ����b�g���Ȃ��Ɣ��f���Ă��Ȃ�
PentiumIII�`Banias�n���������o���Ȃ������낤��
PentiumIII�`Banias�n���������o���Ȃ������낤��
>>754
����}�C�N���A�[�L�e�N�`�������肵���ꍇ�A
2�R�A2GHz�����A1�R�A4GHz�̕����A�قڏ�ɐ��\��������
�l���ėǂ��B�Ȃ��Ȃ�A�A���_�[���̖@���ɂ��A�R�A����
���₵�Ă��A���\�̓��j�A�ɂ͐L�тȂ�����B
������A�V���O���R�A�Ő��\���L�т����́A�R�A���͂ނ�
�돭�Ȃ�����������B
�����A�|���b�N�̖@������A��������g�����W�X�^���ƁA
���\���㗦�̔�ł́A���G�ȃV���O���R�ACPU�����A�P����
�R�A���ς����A�g�[�^���X���[�v�b�g�̓_�ŗL���B
���̕ӂ���������Sun�̃}�[�P�b�e�B���O���[�h���A
�X���[�v�b�g�R���s���[�e�B���O���ȁB
����}�C�N���A�[�L�e�N�`�������肵���ꍇ�A
2�R�A2GHz�����A1�R�A4GHz�̕����A�قڏ�ɐ��\��������
�l���ėǂ��B�Ȃ��Ȃ�A�A���_�[���̖@���ɂ��A�R�A����
���₵�Ă��A���\�̓��j�A�ɂ͐L�тȂ�����B
������A�V���O���R�A�Ő��\���L�т����́A�R�A���͂ނ�
�돭�Ȃ�����������B
�����A�|���b�N�̖@������A��������g�����W�X�^���ƁA
���\���㗦�̔�ł́A���G�ȃV���O���R�ACPU�����A�P����
�R�A���ς����A�g�[�^���X���[�v�b�g�̓_�ŗL���B
���̕ӂ���������Sun�̃}�[�P�b�e�B���O���[�h���A
�X���[�v�b�g�R���s���[�e�B���O���ȁB
�i����d�́E���M��傫�����Ă܂Łj�V���O���X���b�h���\���グ��K�v�͖����ȁB
>>757
�b���t�ŁA�K�v���Ȃ��킯����Ȃ����A����d�́E���M��
�_�Ō��E�ɂԂ����������̂ŁA�V���O���X���b�h���\���グ����
�Ă��グ���Ȃ��Ȃ������Ă��Ƃ���B
�b���t�ŁA�K�v���Ȃ��킯����Ȃ����A����d�́E���M��
�_�Ō��E�ɂԂ����������̂ŁA�V���O���X���b�h���\���グ����
�Ă��グ���Ȃ��Ȃ������Ă��Ƃ���B
����p�r�����Ƃ����̂́A�����ėp���W�b�N���Ԃ��������Ȃ����A
����̂ق���CPU�̍������ɏ]���đ����Ȃ���A�_��A�Ƃ����l������
�O���炠��B�iLisp�`�b�v���ׂꂽ�̂�����ȂƂ��납�j
�ł��A����d�̖͂ʂ��l����ΐ�p���W�b�N�̂ق��������Ƃ����_�ƁA
�c��ȃg�����W�X�^�̎g�����Ƃ��āA�������p�r�̃R�A������Ƃ����̂�
�ȑO���L���ɂȂ��Ȃ����ȂƁB
http://pc.watch.impress.co.jp/docs/2005/0530/spf06.htm
���Tarari�̂悤�Ȃ̂�ʃR�A�ɓ����Ζʔ����ȂƎv�����̂ƁARattner��
XML�����̂��Ƃ͌����Ă�B���Ƃ�Java/.NET�Ƃ��ˁB
Niagara�ɂ͈Í��������W�b�N���i���C���R�A�Ƃ͕ʂɁj����Ƃ��Ȃ�Ƃ��B
������Ƃ����܂��ȋL�������ǁB
����̂ق���CPU�̍������ɏ]���đ����Ȃ���A�_��A�Ƃ����l������
�O���炠��B�iLisp�`�b�v���ׂꂽ�̂�����ȂƂ��납�j
�ł��A����d�̖͂ʂ��l����ΐ�p���W�b�N�̂ق��������Ƃ����_�ƁA
�c��ȃg�����W�X�^�̎g�����Ƃ��āA�������p�r�̃R�A������Ƃ����̂�
�ȑO���L���ɂȂ��Ȃ����ȂƁB
http://pc.watch.impress.co.jp/docs/2005/0530/spf06.htm
���Tarari�̂悤�Ȃ̂�ʃR�A�ɓ����Ζʔ����ȂƎv�����̂ƁARattner��
XML�����̂��Ƃ͌����Ă�B���Ƃ�Java/.NET�Ƃ��ˁB
Niagara�ɂ͈Í��������W�b�N���i���C���R�A�Ƃ͕ʂɁj����Ƃ��Ȃ�Ƃ��B
������Ƃ����܂��ȋL�������ǁB
����PC����x86�nCPU�̏ꍇ�͐�ɃV���O���X���b�h���\��O�̃A�[�L�e�N�`����藎�Ƃ��킯�ɂ͂����Ȃ����˂��B
Conroe�ł�ILP�𑊓��������Ă邵�B���̏�Ń}���`�R�A�����Ă�B
�T�[�o�Ƃ�HPC�A�Q�[���@�Ȃ̓}���`�X���b�h������Ă�\�t�g�������ʂ����ăm�E�n�E�������ς����邵�A
��r�I�e�ՂɃh���X�e�B�b�N�Ƀ\�t�g�E�F�A��u���������邩��A�V���v���ȃR�A�������ς����ׂ���@���y�ɂł���낤���ǂˁB
Intel�͂��̕ӂ̃\�t�g�E�F�A���Y�̂�����݂��������ׂ������^�C���x�[�X�̃\�t�g�E�F�A�J�����𐄐i���Ă��C�����邪�A
Microsoft�����邵���\������낤�Ȃ��B
Conroe�ł�ILP�𑊓��������Ă邵�B���̏�Ń}���`�R�A�����Ă�B
�T�[�o�Ƃ�HPC�A�Q�[���@�Ȃ̓}���`�X���b�h������Ă�\�t�g�������ʂ����ăm�E�n�E�������ς����邵�A
��r�I�e�ՂɃh���X�e�B�b�N�Ƀ\�t�g�E�F�A��u���������邩��A�V���v���ȃR�A�������ς����ׂ���@���y�ɂł���낤���ǂˁB
Intel�͂��̕ӂ̃\�t�g�E�F�A���Y�̂�����݂��������ׂ������^�C���x�[�X�̃\�t�g�E�F�A�J�����𐄐i���Ă��C�����邪�A
Microsoft�����邵���\������낤�Ȃ��B
���Q�[���v���O���}�͂��ԂƂ�����A�P�N������f���A���R�A�p�̃v���O�����쐬�m�E�n�E�Q�b�g���邳�B
( ߄t�)�߶��
( ߄t�)�߶��
�܁A�Q�[���v���O���}���Ă������Q�[���\�t�g���̂��A�ق��̃A�v���ƈႤ����ȁB
�n�[�h�E�G�A�̐��\�������o���Ȃ��ƁA���̂܂܃��C�o���Ɍ��h���̂��Ƃ�\�t�g�Ɏd�オ�邩��A
�}���`�X���b�h�ɂǂꂾ���Ή��ł��邩�����������ˁB
�n�[�h�E�G�A�̐��\�������o���Ȃ��ƁA���̂܂܃��C�o���Ɍ��h���̂��Ƃ�\�t�g�Ɏd�オ�邩��A
�}���`�X���b�h�ɂǂꂾ���Ή��ł��邩�����������ˁB
�}���`�X���b�h�ȃv���O�����́A�o�J�ł��Ƃ͌�����������ł����Ȃ畁�ʂɏ�����B
�����A�R��ׂ��f���A���R�A/�}���`�R�A/���j�C�R�A�̃V�X�e���Ńp�t�H�[���X�������o���邩�͑S�R�ʖ��B
4�X���b�h�Ή��x���`��Pentium XE 840����(�m��`)�����Ȃ��ƂɂȂ邱�Ƃ��������悤�ɁB
�����A�R��ׂ��f���A���R�A/�}���`�R�A/���j�C�R�A�̃V�X�e���Ńp�t�H�[���X�������o���邩�͑S�R�ʖ��B
4�X���b�h�Ή��x���`��Pentium XE 840����(�m��`)�����Ȃ��ƂɂȂ邱�Ƃ��������悤�ɁB
> Niagara�ɂ͈Í��������W�b�N���i���C���R�A�Ƃ͕ʂɁj����Ƃ��Ȃ�Ƃ��B
���̒ʂ�B
Web �t�����g�G���h�T�[�o�́A��ʂ�SSL�R�l�N�V�������������߂�
�Í��������n���ɂȂ�Ȃ��āA���̂��߂� SSL �A�N�Z�����[�^��p
�n�[�h�E�F�A������Ƃ��A�����������Ƃ�������O�ɂȂ��Ă���B
Niagara �́A�܂��� Web �t�����g�G���h�T�[�o�����̃v���Z�b�T�Ȃ̂ŁA
���̂��߂� SSL �������̃��W�b�N��ATCP offload �G���W���� CPU ����
�������Ă��锤�B
TCP offload �G���W���́A������ PC �p Gigabit Ether �J�[�h������
���Ă邯�ǂˁB
���̒ʂ�B
Web �t�����g�G���h�T�[�o�́A��ʂ�SSL�R�l�N�V�������������߂�
�Í��������n���ɂȂ�Ȃ��āA���̂��߂� SSL �A�N�Z�����[�^��p
�n�[�h�E�F�A������Ƃ��A�����������Ƃ�������O�ɂȂ��Ă���B
Niagara �́A�܂��� Web �t�����g�G���h�T�[�o�����̃v���Z�b�T�Ȃ̂ŁA
���̂��߂� SSL �������̃��W�b�N��ATCP offload �G���W���� CPU ����
�������Ă��锤�B
TCP offload �G���W���́A������ PC �p Gigabit Ether �J�[�h������
���Ă邯�ǂˁB
�[���AIntel�̊�]�Ƃ͗����ɁAPC�̓��j�[�R�A���������`�b�v���̕����Ɍ������i�ދC������̂����B
���ہAAMD�Ȃ�I/O�̓����ɂ��ϋɓI�Ȃ킯�����B
���ہAAMD�Ȃ�I/O�̓����ɂ��ϋɓI�Ȃ킯�����B
�́H
AMD��PCIe���USB�o�X�C���^�[�t�F�[�X�̓������l���Ă���悤����B
���j�[�R�A��PC�ł��܂�K�v�Ƃ���Ȃ�������`�b�v���̕����ɐi������\�����������ƁB
���j�[�R�A��PC�ł��܂�K�v�Ƃ���Ȃ�������`�b�v���̕����ɐi������\�����������ƁB
���j�[�R�A���ĉ��̂��Ƃ��������Ă�H
32�R�A�ȏ�̓��j�[�R�A���Ă�����BIntel�p��ł͂ȁB
���܂����g�����W�X�^�̎g�����̘b�����Ă���̂ŁA���j�[�R�Avs�V�X�e�������`�b�v��
���Ă�����r���o���Ă���̂����A�\�t�g������ɂ͂�����������͗����ł��Ȃ��̂��ˁB
���܂����g�����W�X�^�̎g�����̘b�����Ă���̂ŁA���j�[�R�Avs�V�X�e�������`�b�v��
���Ă�����r���o���Ă���̂����A�\�t�g������ɂ͂�����������͗����ł��Ȃ��̂��ˁB
�Ȃ�Ń��j�[�R�A�ƃV�X�e�������`�b�v���������o���Ȃ��悗
8�w��K�{�ɂ��邩�H
���̗\�z�ł́APCI-E���͒P�Ȃ�\�ɂ������A
�����ŕ]���͂���Ă邩������A�����͏o�Ă��Ȃ����낤�B
���R�̓����b�g���قƂ�ǂȂ�����B
CPU��GPU�������悤�ȃ}���`�R�A�͂��Ȃ胁���b�g�傫��������
�i��G�œ��삷��GPU�I�ACPU�Ɩ��ڂɘA�g�ł���I���j
��ʂ̃s�����������o�X�Ɋ����K�v������A
�i�����CPU�I���{�[�h�ƂȂ�����AMB��8�w��ɂȂ�����E�E�E�j������s�\�ɋ߂����낤�B
���̗\�z�ł́APCI-E���͒P�Ȃ�\�ɂ������A
�����ŕ]���͂���Ă邩������A�����͏o�Ă��Ȃ����낤�B
���R�̓����b�g���قƂ�ǂȂ�����B
CPU��GPU�������悤�ȃ}���`�R�A�͂��Ȃ胁���b�g�傫��������
�i��G�œ��삷��GPU�I�ACPU�Ɩ��ڂɘA�g�ł���I���j
��ʂ̃s�����������o�X�Ɋ����K�v������A
�i�����CPU�I���{�[�h�ƂȂ�����AMB��8�w��ɂȂ�����E�E�E�j������s�\�ɋ߂����낤�B
>>770
����˂��BI/O�Ɏg���Ă�g�����W�X�^�Ȃ�đ������ς����Ă�CPU�R�A��ɖ����Ȃ����낤���B
PCIe������R���g���[���݂����Ȕ�r�I��x����I/O�Ȃ�Ƃ������AUSB�Ƃ����̕ӓ������鐫�\�I�����b�g���S���v�����B
�Ă������g�����W�X�^�̎g�����̘b���Ă��B�����������w
����˂��BI/O�Ɏg���Ă�g�����W�X�^�Ȃ�đ������ς����Ă�CPU�R�A��ɖ����Ȃ����낤���B
PCIe������R���g���[���݂����Ȕ�r�I��x����I/O�Ȃ�Ƃ������AUSB�Ƃ����̕ӓ������鐫�\�I�����b�g���S���v�����B
�Ă������g�����W�X�^�̎g�����̘b���Ă��B�����������w
I/O��CPU�_�C�ɐ�߂�ʐς̊����͂ǂ�ǂ����Ă��邵�A
I/O�֘A�̃��W�b�N�̗ʂ͔n���ɂł��Ȃ����B
�����I/O�̕���CPU�R�A��荂�N���b�N�ɂȂ���Ă̂�Intel��AMD���F�߂Ă��邵�A
���͂��Ȃ�d�v�Ȃ��B
I/O�֘A�̃��W�b�N�̗ʂ͔n���ɂł��Ȃ����B
�����I/O�̕���CPU�R�A��荂�N���b�N�ɂȂ���Ă̂�Intel��AMD���F�߂Ă��邵�A
���͂��Ȃ�d�v�Ȃ��B
���������d�g��M�Ȑl�����������C�����܂����A���o�ł��傤��
>>764
��͂肻���ł��ˁBThx
��͂肻���ł��ˁBThx
�R�ꂪ���j�[�R�A�ɔߊϓI�Ȃ̂́APC�ɑ��鐫�\�v�������łɌ��ނ��Ă��Ă���Ǝv������B
����I�^�I�ɂ͖����ł��Ȃ����낤���ǁB
PC�͔N�X�ቿ�i�����Â��Ă��邵�A����A���\�ɑ���v������������A
�����`�b�v���A�ቿ�iPC�A��l����PC�̎���ɓ˓�����\�������肩�ƁB
����I�^�I�ɂ͖����ł��Ȃ����낤���ǁB
PC�͔N�X�ቿ�i�����Â��Ă��邵�A����A���\�ɑ���v������������A
�����`�b�v���A�ቿ�iPC�A��l����PC�̎���ɓ˓�����\�������肩�ƁB
I/O���d�v�Ȃ͕̂����邪���̓R�X�g�Ɍ��������\���オ���邩�ǂ�������B
�����I/O�������L���ȕ�����Ă��܂�v�������Ȃ��Ȃ��B
�Ǝv������ቿ�iPC�̘b����B
�����I/O�������L���ȕ�����Ă��܂�v�������Ȃ��Ȃ��B
�Ǝv������ቿ�iPC�̘b����B
������Ɠǂ߂Η����ł�����e���Ǝv�����ǂȁB
�ʂɃ����`�b�v���̘b�͘R��̑O�ɂ��łĂ��Ă��邵�A
���̂܂��̓v���Z�X�̐i�����K�v�Ȃ��݂����Șb������Ă邵�A
�L��]��g�����W�X�^���ǂ��g�������Ă͍̂��̐�[LSI�Z�p�̏œ_�Ȃ̂����B
�ʂɃ����`�b�v���̘b�͘R��̑O�ɂ��łĂ��Ă��邵�A
���̂܂��̓v���Z�X�̐i�����K�v�Ȃ��݂����Șb������Ă邵�A
�L��]��g�����W�X�^���ǂ��g�������Ă͍̂��̐�[LSI�Z�p�̏œ_�Ȃ̂����B
779 �FSocket774�F2005/09/25(��) 01:50:21 ID:LtBFBHzc
��TCP offload �G���W���́A������ PC �p Gigabit Ether �J�[�h������
�����Ă邯�ǂˁB
�n�@�H
�����Ă邯�ǂˁB
�n�@�H
�����`�b�v���̖��_��CPU�Ƃ��̑��̐i�����x���Ⴄ���Ƃ��ȁB
�������\���グ�Ă������Ǝv���ƊJ�������B
�\�t�g�E�F�A�̐i���ɂ����čs���Ȃ��Ƃ����Ȃ����B
���ǁA���\��Ⴍ�Z�߂��g�ݍ��݂��ۂ��Ȃ肻���BGeodeLX800�݂����ɁB
�ቿ�i�������Ď��̓_�C�ʐς����������Ď����낤���ǁB
���ꂾ�ƍ����\�Ń_�C�ʐς��傫��CPU�͂ǂ��i������́H
�������\���グ�Ă������Ǝv���ƊJ�������B
�\�t�g�E�F�A�̐i���ɂ����čs���Ȃ��Ƃ����Ȃ����B
���ǁA���\��Ⴍ�Z�߂��g�ݍ��݂��ۂ��Ȃ肻���BGeodeLX800�݂����ɁB
�ቿ�i�������Ď��̓_�C�ʐς����������Ď����낤���ǁB
���ꂾ�ƍ����\�Ń_�C�ʐς��傫��CPU�͂ǂ��i������́H
��AMD�����j�[�R�A�u������B
�R�A�����`�b�v���Ƃ܂������������͔����Ȃ��B
�R�A�����`�b�v���Ƃ܂������������͔����Ȃ��B
Intel's new instructions to Rockton round the clock
http://www.theinquirer.net/?article=24781
SO, YESTERDAY WE TOLD you about AMD and integrated PCIe,
and that Intel had a bunch of goodies to compete with. One of them is called RT or Rockton Technology,
another in the long line of *Ts. With clock speeds basically stalled, you have to do something with those
transistors, and Rockton is one of the better ideas.
Inquirer��Rockton Technology�̋L���ł��A�N���b�N���グ��ȊO�̃g�����W�X�^�̎g����
���[���ƂŁARockton��PCIe�̓�������r����Ă���킯�����B
AMD��32�R�A�ȏ�Ɋւ��ĂȂ���Ă������H
�ʂɁAIO�����������瑽���R�A����Ζ����Ƃ͂���Ȃ����ǁB
http://www.theinquirer.net/?article=24781
SO, YESTERDAY WE TOLD you about AMD and integrated PCIe,
and that Intel had a bunch of goodies to compete with. One of them is called RT or Rockton Technology,
another in the long line of *Ts. With clock speeds basically stalled, you have to do something with those
transistors, and Rockton is one of the better ideas.
Inquirer��Rockton Technology�̋L���ł��A�N���b�N���グ��ȊO�̃g�����W�X�^�̎g����
���[���ƂŁARockton��PCIe�̓�������r����Ă���킯�����B
AMD��32�R�A�ȏ�Ɋւ��ĂȂ���Ă������H
�ʂɁAIO�����������瑽���R�A����Ζ����Ƃ͂���Ȃ����ǁB
�I���_�C��L3�L���b�V��64MB�Ƃ�����Ăق���
���j�C�R�A�́��ɂ��Ă��炢����
>>779
����Ȃɋ����b?
Intel ���� i82544 �ȏ�̃��f�� (82547 ������) �Ƃ��A
Realtek 8169 �Ƃ��A�f�[�^�V�[�g��ǂ߂A
TCP segment offloading �̂��Ƃ��ڂ��Ă��B
����̐l�Ԃ͂��������b�͂��܂苻���Ȃ��̂��ȁB
����Ȃɋ����b?
Intel ���� i82544 �ȏ�̃��f�� (82547 ������) �Ƃ��A
Realtek 8169 �Ƃ��A�f�[�^�V�[�g��ǂ߂A
TCP segment offloading �̂��Ƃ��ڂ��Ă��B
����̐l�Ԃ͂��������b�͂��܂苻���Ȃ��̂��ȁB
>>786
�����A���������Ӗ��Ō����Ă��̂��B
�m���Ɋ��S�Ƀ{�[�h���ŏ�������z������ˁBF�ЂƂ��B
I/O ���� CPU���ׂ��l����ƁA�������ɂ����܂ł��̂�
���z�Ȃ��ǁANiagara������TCP offload�G���W�����āA
�����܂ł���?
�����A���������Ӗ��Ō����Ă��̂��B
�m���Ɋ��S�Ƀ{�[�h���ŏ�������z������ˁBF�ЂƂ��B
I/O ���� CPU���ׂ��l����ƁA�������ɂ����܂ł��̂�
���z�Ȃ��ǁANiagara������TCP offload�G���W�����āA
�����܂ł���?
>>787
����Ă����Ƃ��Ă��s�v�c����Ȃ���B
���Ƀ��j�C�R�A�Ȃ�SMP��TCP�v���g�R���X�^�b�N���������������
��Ώ�MP�Ƃ��Đ�C������̂������Ȃ��B
����Ă����Ƃ��Ă��s�v�c����Ȃ���B
���Ƀ��j�C�R�A�Ȃ�SMP��TCP�v���g�R���X�^�b�N���������������
��Ώ�MP�Ƃ��Đ�C������̂������Ȃ��B
>>782
���̋L���͒m���Ă�B
�����A�������Ƃ��Ă�PCI-E�̐�ɉ����q�����H���Ė�肪����B
�I����������GigabitEther���炢�����������낤�Ǝv�����ǁB
���C�e���V���팸���ĈӖ������镨���đ��ɉ����낤�B
����ς���܈Ӗ������C�������ȁB
���ƁA65nm��45nm���x����M����l���Ȃ��Ƃ����Ȃ����g�����W�X�^�͑S�R�L��]��Ȃ��ł���B
�����Ɖ��������̘b���Ǝv���Ă����̂����B
Intel��AMD���߂������ł̓R�A�𑝂₵��������������A�i�g�����W�X�^�g���j
FSB��HT���������ă`�b�v�Z�b�g�Ԃ𑬂��������������v���Ă�B�i�`�b�v�Z�b�g��I/O�����j
����Ƀ}���`�R�A������ƃ������ш�����₳�Ȃ��Ƃ����Ȃ�����A�����R�������Ă�ꍇ�͂������ł��s�����H��ꂻ���B
SocketF�ł�FB-DIMM��4ch�Ƃ�����Ɋ��҂��Ă���B
���Ȃ݂�Intel��AMD��"����ł�"8�R�A���x���L���Ƃ����l���ł͈�v���Ă�B
������Intel��"������"���j�[�R�A�ƂԂ��グ�����B
�\�t�g�E�F�A�̐i���≼�z�����Ă̂��o�Ă�������ǂ��܂ōs�����ȁB
���̋L���͒m���Ă�B
�����A�������Ƃ��Ă�PCI-E�̐�ɉ����q�����H���Ė�肪����B
�I����������GigabitEther���炢�����������낤�Ǝv�����ǁB
���C�e���V���팸���ĈӖ������镨���đ��ɉ����낤�B
����ς���܈Ӗ������C�������ȁB
���ƁA65nm��45nm���x����M����l���Ȃ��Ƃ����Ȃ����g�����W�X�^�͑S�R�L��]��Ȃ��ł���B
�����Ɖ��������̘b���Ǝv���Ă����̂����B
Intel��AMD���߂������ł̓R�A�𑝂₵��������������A�i�g�����W�X�^�g���j
FSB��HT���������ă`�b�v�Z�b�g�Ԃ𑬂��������������v���Ă�B�i�`�b�v�Z�b�g��I/O�����j
����Ƀ}���`�R�A������ƃ������ш�����₳�Ȃ��Ƃ����Ȃ�����A�����R�������Ă�ꍇ�͂������ł��s�����H��ꂻ���B
SocketF�ł�FB-DIMM��4ch�Ƃ�����Ɋ��҂��Ă���B
���Ȃ݂�Intel��AMD��"����ł�"8�R�A���x���L���Ƃ����l���ł͈�v���Ă�B
������Intel��"������"���j�[�R�A�ƂԂ��グ�����B
�\�t�g�E�F�A�̐i���≼�z�����Ă̂��o�Ă�������ǂ��܂ōs�����ȁB
>>788
�Ȃ�قǁB
���� TOE �������āA��{�I�ɃX�g���[�W�p�r���^�[�Q�b�g��
���Ă邩��ATCP �̃I�v�V�����Ƃ��A�����ƃT�|�[�g����
���邩�A�\�t�g���I�ɂ͕s���Ȃ�ˁBWeb �T�[�o�ł���
�����ƁA����͉�����������A�Œ���A�E�B���h�E�T�C�Y�Ƃ�
�͂����ƍL���ė~�������ǁASAN ���Ƃ����܂ʼn�������
�͕��ʋC�ɂ��Ȃ�����c ���������Ӗ��ŁATSO ���x�̕���
���\�͗�邯�ǁA�ނ�����S�Ƃ������B
�܂� F�̂͑����m�z���Ƃ��f�����Ă�����A�����Ǝ�������
���������ǁA���̃x���_�̂͂ǂ��Ȃ��B
�Ȃ�قǁB
���� TOE �������āA��{�I�ɃX�g���[�W�p�r���^�[�Q�b�g��
���Ă邩��ATCP �̃I�v�V�����Ƃ��A�����ƃT�|�[�g����
���邩�A�\�t�g���I�ɂ͕s���Ȃ�ˁBWeb �T�[�o�ł���
�����ƁA����͉�����������A�Œ���A�E�B���h�E�T�C�Y�Ƃ�
�͂����ƍL���ė~�������ǁASAN ���Ƃ����܂ʼn�������
�͕��ʋC�ɂ��Ȃ�����c ���������Ӗ��ŁATSO ���x�̕���
���\�͗�邯�ǁA�ނ�����S�Ƃ������B
�܂� F�̂͑����m�z���Ƃ��f�����Ă�����A�����Ǝ�������
���������ǁA���̃x���_�̂͂ǂ��Ȃ��B
>>558
�����炾���B
��MMX(64bit) Latency 2clk�AThroughput 1clk
��SSE2(128bit) Latency 4clk�AThroughput 2clk
����́A��͐����A���͕��������_�̐�������B
Pen4��SSE2�����̃N���b�N���́ALatency 2clk�AThroughput 2clk ���������B
�������ALatency 2clk�AThroughput 1clk �̖��߂��Q����Ƃ�����A
Latency 3clk�AThroughput 2clk �ƂȂ�i��ʂƉ��ʂ͈ˑ������Ȃ��̂Łj�B
Pen4��SIMD���j�b�g�͔���128bit�i�����64bit��MMX�ɂ͕s�����j�ƍl����̂����R���ƁB
�����炾���B
��MMX(64bit) Latency 2clk�AThroughput 1clk
��SSE2(128bit) Latency 4clk�AThroughput 2clk
����́A��͐����A���͕��������_�̐�������B
Pen4��SSE2�����̃N���b�N���́ALatency 2clk�AThroughput 2clk ���������B
�������ALatency 2clk�AThroughput 1clk �̖��߂��Q����Ƃ�����A
Latency 3clk�AThroughput 2clk �ƂȂ�i��ʂƉ��ʂ͈ˑ������Ȃ��̂Łj�B
Pen4��SIMD���j�b�g�͔���128bit�i�����64bit��MMX�ɂ͕s�����j�ƍl����̂����R���ƁB
�܂�A�����CPU�́A�m�[�X�u���b�W���������j�[�R�A�̕����ɐi��ł����B
celeron���̒ቿ�i����CPU�́A���j�[�R�A�͂�����CPU��Ƀr�f�I�@�\�������i�r�f�I�������[�Ƃ��āA���C������������e�ʂ��P�U���K�قǔ��D�j������B
����Ȋ����H
celeron���̒ቿ�i����CPU�́A���j�[�R�A�͂�����CPU��Ƀr�f�I�@�\�������i�r�f�I�������[�Ƃ��āA���C������������e�ʂ��P�U���K�قǔ��D�j������B
����Ȋ����H
{kind=link}
>>793
MediaGX������������
���A���łɃr�f�I�����`�b�v�Z�b�g���قƂ�ǂ����߂邱�̎���
�������R���g���[������������r�f�I���߂��ɂ��������Ƃ����͓̂�����O������
��ʕ\�����邾����FSB�ɑ�ʂ̃A�N�Z�X���͂���͖̂]�܂����Ȃ�����
>>794
�{���Ƀ}���`�X���b�h�����Ă���Q�C�S�R�A�̐��\�㏸�͏ゾ���炿�Ƃ��Ă͂܂���
�������������Đ��\�L�т���H
MediaGX������������
���A���łɃr�f�I�����`�b�v�Z�b�g���قƂ�ǂ����߂邱�̎���
�������R���g���[������������r�f�I���߂��ɂ��������Ƃ����͓̂�����O������
��ʕ\�����邾����FSB�ɑ�ʂ̃A�N�Z�X���͂���͖̂]�܂����Ȃ�����
>>794
�{���Ƀ}���`�X���b�h�����Ă���Q�C�S�R�A�̐��\�㏸�͏ゾ���炿�Ƃ��Ă͂܂���
�������������Đ��\�L�т���H
{kind=link}
>>789
����ł́APARROT�ł�8�R�A�ȏ�͌��ʂ������炵����
����ł́APARROT�ł�8�R�A�ȏ�͌��ʂ������炵����
������Ƃ�����Yonah�ɂ��Ăł���
Yonah�͊k�t���ł����H�k�����ł����H
Yonah�͊k�t���ł����H�k�����ł����H
>>798
�P��tr��1/2�̐�*2���ׂĂ���́B
�P��tr��1/2�̐�*2���ׂĂ���́B
>>798
�uHyperThreading�ݾ��v
�uHyperThreading�ݾ��v
�O�ɂ����������ǁADual�R�A�ł�Tr���Ƃ������肪�������������ƈ���Ă��B
���ۂɏo�Ă��Ă鐻�i�̍\�������ċc�_���Ȃ��Ɗ���̋�_�ɂȂ����܂��B
�����̌��E���M���x�̌��E�ɑ����Ԃ������܂�������A�����Tr�]��C���Ȃ�B
������L���b�V�����₵����ADual�R�A�ɂ����肵�Ă��ł��傤�B
���ۂɏo�Ă��Ă鐻�i�̍\�������ċc�_���Ȃ��Ɗ���̋�_�ɂȂ����܂��B
�����̌��E���M���x�̌��E�ɑ����Ԃ������܂�������A�����Tr�]��C���Ȃ�B
������L���b�V�����₵����ADual�R�A�ɂ����肵�Ă��ł��傤�B
���̑O�������������Ƃ�������Ă邩��A�����ŋc�_����ɒl���Ȃ��Ǝv���B
������intel�̎�����CPU�����X��������ȁB �����ȋZ�p�_�Ƃ��Ă͊Ԉ���ĂȂ��Ǝv����B
������intel�̎�����CPU�����X��������ȁB �����ȋZ�p�_�Ƃ��Ă͊Ԉ���ĂȂ��Ǝv����B
����
Athlon 64 4000+ (2.4GHz)�@�@�@�@���ω��i*45,976�~
Athlon 64 X2 4800+ (2.4GHz)�@�@���ω��i109,133�~
Athlon 64 4000+ (2.4GHz)�@�@�@�@���ω��i*45,976�~
Athlon 64 X2 4800+ (2.4GHz)�@�@���ω��i109,133�~
>>804
�����炱���A���[�N��肪������Ȃ��c�Ƃ͎v����
�����炱���A���[�N��肪������Ȃ��c�Ƃ͎v����
�M���x��肪����Ȃ�65nm�`45nm�E�E�E��CPU�͂��������o���Ȃ��B
�e�ЂƂ��v�i�K�Ńz�b�g�X�|�b�g���o���Ȃ��悤�ɐv���Ă�B
�N���b�N�㏸�̈�Ԃ̑��g�́A���݂̓��z���ɂ�����u�z���x���v�B
�e�ЂƂ��v�i�K�Ńz�b�g�X�|�b�g���o���Ȃ��悤�ɐv���Ă�B
�N���b�N�㏸�̈�Ԃ̑��g�́A���݂̓��z���ɂ�����u�z���x���v�B
>>807
�Ⴄ�ł���B���׃v���Z�X�ŃX�s�[�h���o�����Ƃ����
���[�N�������B�_�����̔������Ŕ��ɕs����ȓ�����
�o�₷���B����2�_���������Ȃ��Ɛ��i�Ƃ��Đ��藧���Ȃ��B
�Ⴄ�ł���B���׃v���Z�X�ŃX�s�[�h���o�����Ƃ����
���[�N�������B�_�����̔������Ŕ��ɕs����ȓ�����
�o�₷���B����2�_���������Ȃ��Ɛ��i�Ƃ��Đ��藧���Ȃ��B
809 �FSocket774�F2005/09/25(��) 18:52:00 ID:h8cT/rNy
>>808 ���[�N�̓v���Z�X�̉��P�ʼn������邪�z���̒x���͓���A
���z�������[����������̌��ʁA���Ǝc��̂͂R�����ɂ��邾���B
���z�������[����������̌��ʁA���Ǝc��̂͂R�����ɂ��邾���B
http://pcweb.mycom.co.jp/articles/2004/01/01/moore/
�������ł��ˁB����̃p�l���ł́A�z���̕�������ۂǖ�肾��
�������ł��ˁB����̃p�l���ł́A�z���̕�������ۂǖ�肾��
���ق�@
�z���̒x�����傫���e������̂͊e�����̃N���b�N�������邩��B
���̂ւ�悤�l���Ă݁B
�z���̒x�����傫���e������̂͊e�����̃N���b�N�������邩��B
���̂ւ�悤�l���Ă݁B
��ڽ��ł͔z���͂��Ȃ�œK�����i���ǂȁB
�������ł��OC�ł���悤�ɁB
���Ƃ͎ߔz�����g������ɍœK���o���邩�ȁB
�������ł��OC�ł���悤�ɁB
���Ƃ͎ߔz�����g������ɍœK���o���邩�ȁB
>>809
������v���Z�X���P�Ń��[�N�͉����o���Ă��Ȃ��ł���B
��������Ăǂ�����́H
�z���x�����Ȃ�Ă��̐�̘b�����A���C�A�E�g�ł���
���x����ł�����B����ł��������Ă��邵�B
>>810
2003�N�����_�ł́A���[�N�͂����܂ō����Ƃ͐��E���ŔF��
����Ă��Ȃ�����B
> �g�����W�X�^�̃��[�N���傫�Ȗ�肾���A�u�z�������낻��
> �ɂ��Ă����킯�ł͂Ȃ��v�ƁB
���R���낻���ɂ��Ă����킯�Ȃ��ł��ˁB������܂���
���������Ă܂��B
������v���Z�X���P�Ń��[�N�͉����o���Ă��Ȃ��ł���B
��������Ăǂ�����́H
�z���x�����Ȃ�Ă��̐�̘b�����A���C�A�E�g�ł���
���x����ł�����B����ł��������Ă��邵�B
>>810
2003�N�����_�ł́A���[�N�͂����܂ō����Ƃ͐��E���ŔF��
����Ă��Ȃ�����B
> �g�����W�X�^�̃��[�N���傫�Ȗ�肾���A�u�z�������낻��
> �ɂ��Ă����킯�ł͂Ȃ��v�ƁB
���R���낻���ɂ��Ă����킯�Ȃ��ł��ˁB������܂���
���������Ă܂��B
�����łb�m�s�ł���
�����C���e���ȊO�Ȃ�N�̖ڂɂ��v���X�R�̔M�̖��͖��炩�������̂ɁA
�C���e�����܂����j�]�������߂ĂȂ��������ォ�c
�C���e���قǂ̃g�b�v���[�J�ł��A�ڂ̑O�̖�������邱�Ƃ������
�˂��B����A�ނ���g�b�v���[�J�����炱���A�����ł���Ǝ��Ђ̗͂�
�ߐM�����̂��B
�C���e�����܂����j�]�������߂ĂȂ��������ォ�c
�C���e���قǂ̃g�b�v���[�J�ł��A�ڂ̑O�̖�������邱�Ƃ������
�˂��B����A�ނ���g�b�v���[�J�����炱���A�����ł���Ǝ��Ђ̗͂�
�ߐM�����̂��B
��������Z�p�ւ̒��� �`�g���C�E�Q�[�g�E�g�����W�X�^���\�̔w�i�`
http://pcweb.mycom.co.jp/news/2002/09/24/13.html
���̉āAPrescott���M���B���N�͏���d��100W�I�[�o�[��
http://pc.watch.impress.co.jp/docs/2003/0722/kaigai005.htm
140W�ւƂЂ����瑖��? Intel CPU�̏���d��
http://pc.watch.impress.co.jp/docs/2003/0725/kaigai006.htm
��͂���̓��[�N�d���ɋN���������d�͂�TDP�̑傫��
http://pcweb.mycom.co.jp/news/2003/09/19/17.html
�ǂ�ǂ�ς��Prescott FMB�X�y�b�N
http://pc.watch.impress.co.jp/docs/2003/1010/kaigai031.htm
http://pcweb.mycom.co.jp/news/2002/09/24/13.html
���̉āAPrescott���M���B���N�͏���d��100W�I�[�o�[��
http://pc.watch.impress.co.jp/docs/2003/0722/kaigai005.htm
140W�ւƂЂ����瑖��? Intel CPU�̏���d��
http://pc.watch.impress.co.jp/docs/2003/0725/kaigai006.htm
��͂���̓��[�N�d���ɋN���������d�͂�TDP�̑傫��
http://pcweb.mycom.co.jp/news/2003/09/19/17.html
�ǂ�ǂ�ς��Prescott FMB�X�y�b�N
http://pc.watch.impress.co.jp/docs/2003/1010/kaigai031.htm
���łɁAIA64�ł͔�����������Ă邩��˂��B ���g���Ă��܂��v�����
�z���x���͂���قǃ{�g���l�b�N�ɂȂ�Ȃ��Ǝv���Ă邯�ǁA�ǂ��Ȃ��낤���B
�z���x���͂���قǃ{�g���l�b�N�ɂȂ�Ȃ��Ǝv���Ă邯�ǁA�ǂ��Ȃ��낤���B
>>792
padd*�n��latency/throughput���Ă݂��B
�g���Ɩ����̃o���o��
�A���C�������g����Ė����f�[�^�Ɋւ��Ă�MMX�̂ق��������B
padd*�n��latency/throughput���Ă݂��B
�g���Ɩ����̃o���o��
�A���C�������g����Ė����f�[�^�Ɋւ��Ă�MMX�̂ق��������B
Presler��Extreme Edition�ł́A
���ΓI�ɏd��2�̃X���b�h��1�̃R�A��HT�Ɋ����Ă��܂�
�|�J�͋N�����Ȃ��悤�ȉ��ǂ͂���Ă�̂��ȁH
����σo�J�`�����̂܂܂Ȃ̂��ȁH
���ΓI�ɏd��2�̃X���b�h��1�̃R�A��HT�Ɋ����Ă��܂�
�|�J�͋N�����Ȃ��悤�ȉ��ǂ͂���Ă�̂��ȁH
����σo�J�`�����̂܂܂Ȃ̂��ȁH
>>824
����AOS�̎d������Ȃ��́H
����AOS�̎d������Ȃ��́H
latency�͐����u������throuput���Y���2�{
�ꕔ��latency�܂Ŕ{������ȏ�
Throuput���Ă����̂͂��̏ꍇ�e���Z���j�b�g�̃p�C�v���C���ňꖽ�߂̏����ŐH�炤�N���b�N���̂��Ƃ��낤�B
MMX�łłP�N���b�N�ASSE2�����łQ�N���b�N�H�����Ă̂́A�܂�64�r�b�g���������Ă邩��Ȃ�㩁B
�ꕔ��latency�܂Ŕ{������ȏ�
Throuput���Ă����̂͂��̏ꍇ�e���Z���j�b�g�̃p�C�v���C���ňꖽ�߂̏����ŐH�炤�N���b�N���̂��Ƃ��낤�B
MMX�łłP�N���b�N�ASSE2�����łQ�N���b�N�H�����Ă̂́A�܂�64�r�b�g���������Ă邩��Ȃ�㩁B
Presler���ăN���b�N200MHz�ӂ��邾���Ȃ�ˁH
Presler���̂�HTOFF�������������邪
Presler���̂�HTOFF�������������邪
������ʼn�������Ă�X���I�ɂ͖��Ȃ��B
>>827
�Y����ڽׂ�HT�L���Ȃ̂�XE��������
�Y����ڽׂ�HT�L���Ȃ̂�XE��������
�C���e����XE�ł�Ƃ͖������ĂȂ������ƋL�����Ă���
Dempsey��HT����
Dempsey��HT����
Presler����HTTon�ɂ����Ȃ�����?
�ǂ����œǂC�����邯�ǁA�������̖ϑz�̗\���B
�ǂ����œǂC�����邯�ǁA�������̖ϑz�̗\���B
{kind=link}
�����Ŕ��v�ł���B
Presler�ł�Pentium D�ł�HT�̓I�t�BXE�ł̓I���ɂ���邾�낤���A�R�A���Ȃ�ɂȂ邩�͕������B
Paxville FSB1066�ɂȂ�̂�Dempsy FSB1066�ɂȂ�̂��B�����̉\������������Ă�B
Paxville�Ȃ�FSB1333MHz���\�Ȃ͂��ł͂��邪�E�E�E
Paxville FSB1066�ɂȂ�̂�Dempsy FSB1066�ɂȂ�̂��B�����̉\������������Ă�B
Paxville�Ȃ�FSB1333MHz���\�Ȃ͂��ł͂��邪�E�E�E
�p���͂�߂㓡�݂̂���\�z�Ƃ��������Ƃ��
���̏�Ԃł��M���A�b�v�A�b�v�Ȃ̂ɁAFSB��1066�Ƃ�������܂��܂���ɕ����Ȃ���
�郄�J��
�v���X�������ɂ��܂���������A�v���X�R�Ɠ������炢�̏���d�͂Ɏ��܂�̂��ȁH
����ł��M�����ǁB
�郄�J��
�v���X�������ɂ��܂���������A�v���X�R�Ɠ������炢�̏���d�͂Ɏ��܂�̂��ȁH
����ł��M�����ǁB
>>823
IA-32 Intel Architecture Optimization���������AMMX��2-1�AXMM��2-2���������B
���ʂ́A�Ɨ�����2-1���Q�����3-2�ɂȂ���A����ɂ��Ă͂ǂ��v���H
���ۑg���ƂȂ����Ă̂͂����B���i��PenM�ŁAP4�͐��������G���ĂȂ��B
MMX�̃X���[�v�b�g���P�Ȃ͉̂����Ȃ������킩��Ȃ������̂����A
NetBurst�́AALU��{���ɂ��āA���G�ȂƂ��̓X�s�[�h���Ƃ��Ă�炵������
SSE��FP���j�b�g�͔������Ǝv���Ă����B
SSE�̃N���b�N���͂قƂ�Nj��������B
IA-32 Intel Architecture Optimization���������AMMX��2-1�AXMM��2-2���������B
���ʂ́A�Ɨ�����2-1���Q�����3-2�ɂȂ���A����ɂ��Ă͂ǂ��v���H
���ۑg���ƂȂ����Ă̂͂����B���i��PenM�ŁAP4�͐��������G���ĂȂ��B
MMX�̃X���[�v�b�g���P�Ȃ͉̂����Ȃ������킩��Ȃ������̂����A
NetBurst�́AALU��{���ɂ��āA���G�ȂƂ��̓X�s�[�h���Ƃ��Ă�炵������
SSE��FP���j�b�g�͔������Ǝv���Ă����B
SSE�̃N���b�N���͂قƂ�Nj��������B
���Ⴂ���Ă�悤������128bit���̃f�[�^�u���b�N�������K�v�̂����ʂȂ�ĂقƂ�ǖ����B
���Ƃ��t���J���[��DIB�̃f�[�^�������̂ɂ��Ă��A1�s�N�Z��������8bit�~�S��32�r�b�g
���ݎ嗬��128�r�b�g�u���b�N�Í��̑����̎������A���s���Ԃ̂قƂ�ǂ��߂�S-Box�ł�
64�r�b�g�{64�r�b�g�ɕ����Č��݂Ƀr�b�g�̒u�����s���Ă����B
64�r�b�g�P�ʂň����ƗL���ȃf�[�^�͐��������ǁA128bit�����Ȃ��ƒx���Ȃ�A���S���Y�����Ă̂�
����܂薳����㩁B
���Ⴀ�ǂ���邩�Ƃ����ƁA���[�v���ɂ���2�̃f�[�^�������悤�ɂ��邾���B
�v����ɁA�uMMX�ł�128�r�b�g�̃f�[�^��64�~2�ɕ������Ă���SSE�̗p�ɂ��1�ŏ����ł���v
���ăP�[�X�͋H�ŁA
���ۂɂ́A64�r�b�g�ȉ��̒P�ʂň����Ă����̂��ASSE2�̗̍p�ɂ��
���[�v2�̃f�[�^��1�x�ɂ܂Ƃ߂ď�������Ƃ������Ƃ̂ق��������B
��x�Ɉ����f�[�^�ʂ������Ă��A���̕����C�g�o�b�t�@�̏���{�����A
�������ă��C�e���V�傳���邱�Ƃ������B
���W�X�^�̏��Ȃ�x86�A�[�L�e�N�`���ł́A���C�g�o�b�t�@��Ƀf�[�^�����邩�Ȃ����A
���邢��L1��ɂ��邩�Ȃ����A�̂ق����A���\�ɋ����P�[�X�͑����B
�_���Z�p���Z�̃��C�e���V���A���[�h�E�X�g�A�̃��C�e���V�̂ق����傫������ˁB
���������Ӗ���Pentium4�ł�SSE2�����̓K�p�Ő��\���オ��P�[�X���Ă̂͌���ꂽ�P�[�X�B
John the Ripper�����Ă��܂Ōo���Ă�SSE2�͍̗p����Ȃ����i�Ȃ��Ȃ�MMX��萫�\�����邩��j
Pentium 4��SSE2���g���Ӗ��́A16�o�C�g���E�ɍ��킹���f�[�^���Ƀ��[�h�E�X�g�A�ł��邱�Ƃɂ�������B
�܂�A�قƂ�ǁAmovdqa�ɏW��Ă�B
�i����ł��L���b�V���̃q�b�g���𗎂Ƃ����炢�Ȃ�MMX�ł�����ق��������B�j
�܂��Ax64�Ř_�����W�X�^�̑�����SSE2�̂ق������ʓI�ɑ����P�[�X�͍��㑝���Ă��邾�낤���ǂˁB
���Ƃ��t���J���[��DIB�̃f�[�^�������̂ɂ��Ă��A1�s�N�Z��������8bit�~�S��32�r�b�g
���ݎ嗬��128�r�b�g�u���b�N�Í��̑����̎������A���s���Ԃ̂قƂ�ǂ��߂�S-Box�ł�
64�r�b�g�{64�r�b�g�ɕ����Č��݂Ƀr�b�g�̒u�����s���Ă����B
64�r�b�g�P�ʂň����ƗL���ȃf�[�^�͐��������ǁA128bit�����Ȃ��ƒx���Ȃ�A���S���Y�����Ă̂�
����܂薳����㩁B
���Ⴀ�ǂ���邩�Ƃ����ƁA���[�v���ɂ���2�̃f�[�^�������悤�ɂ��邾���B
�v����ɁA�uMMX�ł�128�r�b�g�̃f�[�^��64�~2�ɕ������Ă���SSE�̗p�ɂ��1�ŏ����ł���v
���ăP�[�X�͋H�ŁA
���ۂɂ́A64�r�b�g�ȉ��̒P�ʂň����Ă����̂��ASSE2�̗̍p�ɂ��
���[�v2�̃f�[�^��1�x�ɂ܂Ƃ߂ď�������Ƃ������Ƃ̂ق��������B
��x�Ɉ����f�[�^�ʂ������Ă��A���̕����C�g�o�b�t�@�̏���{�����A
�������ă��C�e���V�傳���邱�Ƃ������B
���W�X�^�̏��Ȃ�x86�A�[�L�e�N�`���ł́A���C�g�o�b�t�@��Ƀf�[�^�����邩�Ȃ����A
���邢��L1��ɂ��邩�Ȃ����A�̂ق����A���\�ɋ����P�[�X�͑����B
�_���Z�p���Z�̃��C�e���V���A���[�h�E�X�g�A�̃��C�e���V�̂ق����傫������ˁB
���������Ӗ���Pentium4�ł�SSE2�����̓K�p�Ő��\���オ��P�[�X���Ă̂͌���ꂽ�P�[�X�B
John the Ripper�����Ă��܂Ōo���Ă�SSE2�͍̗p����Ȃ����i�Ȃ��Ȃ�MMX��萫�\�����邩��j
Pentium 4��SSE2���g���Ӗ��́A16�o�C�g���E�ɍ��킹���f�[�^���Ƀ��[�h�E�X�g�A�ł��邱�Ƃɂ�������B
�܂�A�قƂ�ǁAmovdqa�ɏW��Ă�B
�i����ł��L���b�V���̃q�b�g���𗎂Ƃ����炢�Ȃ�MMX�ł�����ق��������B�j
�܂��Ax64�Ř_�����W�X�^�̑�����SSE2�̂ق������ʓI�ɑ����P�[�X�͍��㑝���Ă��邾�낤���ǂˁB
>>838
�����Ⴂ���Ă�悤������128bit���̃f�[�^�u���b�N�������K�v�̂����ʂȂ�ĂقƂ�ǖ����B
����͂킩���Ă������B
MMX�����ӂ�PenM�łȂ�ASSE2���g������MMX�������̂��o�����Ă���B
�iP4�ł͌o�����Ȃ����߂킩��Ȃ��BMMX�������P�[�X������̂͒m���Ă���j
>>838�̓��e�Ɋւ��Ă͂قڑS�ʓI�ɓ��ӁB
�ŁA����͂����̂����A����Pen4��SSE���j�b�g��64bit��128bit����m�肽���B
�ȉ�Intel��HP����̈��p�B
Pentium 4 �v���Z�b�T�����ł́A�e�Z�N�V�������قȂ�N���b�N���g���œ��삵�Ă��܂��B
���̂悤�ɁA�e���W�b�N�E�Z�N�V�����̓�����g�����œK���������ʁAPentium 4 �v���Z�b�T��
�����p�t�H�[�}���X���������Ă��܂��B�ł��������g���œ��삵�Ă���̂� ALU �o�C�p�X���s���[�v�ŁA
�v���Z�b�T�E�R�A�E�N���b�N��2�{ (�t�@�X�g�E�N���b�N) �œ��삵�Ă��܂��B����́A�قƂ�ǂ�
�����v���O�����̉��Z���s�����̂ŁA����߂ďd�v�Ȗ������ʂ����Ă��܂��B���̂ق��̂قƂ�ǂ̕�����
�v���Z�b�T�E�R�A�Ɠ����N���b�N (3GHz �t�@�X�g�E�N���b�N��1/2) �œ��삵�Ă��܂����A
����͐v�����G�ɂȂ�̂�h�����߂ł��B�܂��A�t�@�X�g�E�N���b�N��1/4�œ��삷��Z�N�V����������܂����A
������v��e�Ղɂ��邱�Ƃ�ړI�Ƃ��Ă��܂��B�o�X�E���W�b�N��100MHz �œ��삵�A
�V�X�e���E�o�X�ɑ��鍂���j�[�Y�����Ă��܂��B
�����Ⴂ���Ă�悤������128bit���̃f�[�^�u���b�N�������K�v�̂����ʂȂ�ĂقƂ�ǖ����B
����͂킩���Ă������B
MMX�����ӂ�PenM�łȂ�ASSE2���g������MMX�������̂��o�����Ă���B
�iP4�ł͌o�����Ȃ����߂킩��Ȃ��BMMX�������P�[�X������̂͒m���Ă���j
>>838�̓��e�Ɋւ��Ă͂قڑS�ʓI�ɓ��ӁB
�ŁA����͂����̂����A����Pen4��SSE���j�b�g��64bit��128bit����m�肽���B
�ȉ�Intel��HP����̈��p�B
Pentium 4 �v���Z�b�T�����ł́A�e�Z�N�V�������قȂ�N���b�N���g���œ��삵�Ă��܂��B
���̂悤�ɁA�e���W�b�N�E�Z�N�V�����̓�����g�����œK���������ʁAPentium 4 �v���Z�b�T��
�����p�t�H�[�}���X���������Ă��܂��B�ł��������g���œ��삵�Ă���̂� ALU �o�C�p�X���s���[�v�ŁA
�v���Z�b�T�E�R�A�E�N���b�N��2�{ (�t�@�X�g�E�N���b�N) �œ��삵�Ă��܂��B����́A�قƂ�ǂ�
�����v���O�����̉��Z���s�����̂ŁA����߂ďd�v�Ȗ������ʂ����Ă��܂��B���̂ق��̂قƂ�ǂ̕�����
�v���Z�b�T�E�R�A�Ɠ����N���b�N (3GHz �t�@�X�g�E�N���b�N��1/2) �œ��삵�Ă��܂����A
����͐v�����G�ɂȂ�̂�h�����߂ł��B�܂��A�t�@�X�g�E�N���b�N��1/4�œ��삷��Z�N�V����������܂����A
������v��e�Ղɂ��邱�Ƃ�ړI�Ƃ��Ă��܂��B�o�X�E���W�b�N��100MHz �œ��삵�A
�V�X�e���E�o�X�ɑ��鍂���j�[�Y�����Ă��܂��B
�⑫�B
����Pen4��SSE�̎����͔���128bit���Ǝv���Ă���B
64bit���ƌ����Ȃ�Apaddd xmm0,xmm0�����C�e���V3�łȂ�2�Ȃ��Ƃ�A
addps xmm0,xmm0�i���C�e���V4�j��A���Ŏ��s�����Ƃ��P����4clk�ɂȂ邱�Ƃ�
�i���C�e���V4��PenM�ł͂P����3clk�ɂȂ�B�����64bit�����s���邽�߁j
�������邤�܂����R���Ȃ��B
����Pen4��SSE�̎����͔���128bit���Ǝv���Ă���B
64bit���ƌ����Ȃ�Apaddd xmm0,xmm0�����C�e���V3�łȂ�2�Ȃ��Ƃ�A
addps xmm0,xmm0�i���C�e���V4�j��A���Ŏ��s�����Ƃ��P����4clk�ɂȂ邱�Ƃ�
�i���C�e���V4��PenM�ł͂P����3clk�ɂȂ�B�����64bit�����s���邽�߁j
�������邤�܂����R���Ȃ��B
Yonah����945/955���ڃ}�}���ɏ�肻���ł����H
�܂����ʂɖ�������B
�ŋ߂�Intel�͐VCPU�ɂ͐V�`�b�v�Z�b�g�K�{�Ȋ��������B
�ŋ߂�Intel�͐VCPU�ɂ͐V�`�b�v�Z�b�g�K�{�Ȋ��������B
>>841
��������
945�955�͒Y��
�R�A���ʂ̃R�A��L2�ɃA�N�Z�X���鎞�`�b�v�Z�b�g���o�R�������
�܂��ڂ������͕������
��������
945�955�͒Y��
�R�A���ʂ̃R�A��L2�ɃA�N�Z�X���鎞�`�b�v�Z�b�g���o�R�������
�܂��ڂ������͕������
Presler��Conroe��Yonah��Merom�͓����`�b�v�Z�b�g�ł�����݂��������B
Yonah��478PIN�������悤��
������k�X��478�Ƃ͈Ⴄ�\�P�b�g���낤
������k�X��478�Ƃ͈Ⴄ�\�P�b�g���낤
>>844
����945�955
�Ɋւ��Č���������
��
Presler�͊J�����Ԃ�������x����������
�`�b�v�Z�b�g���o�R���Ȃ��Ă����v�ɂȂ����Ƃ�����Ȃ��H
�܂��f�l�����炻�̕ӂ�͂悭�������
����945�955
�Ɋւ��Č���������
��
Presler�͊J�����Ԃ�������x����������
�`�b�v�Z�b�g���o�R���Ȃ��Ă����v�ɂȂ����Ƃ�����Ȃ��H
�܂��f�l�����炻�̕ӂ�͂悭�������
����p��p�`�b�v��ʃ_�C�ŏ悹���Ȃ��̂��H
>>846
�Y/Presler�̍\���́A��2�ɕ�����Ă���ȊO�قƂ�Ǖς��B
���݂ɁA�@�\������Ȃ��ꍇ�͑Ή��ł��Ȃ����ǁA�]�v�ȕ����t���Ă��Ă��Ή��\������A
�ĊO945�955��Conroe���������B
�Y/Presler�̍\���́A��2�ɕ�����Ă���ȊO�قƂ�Ǖς��B
���݂ɁA�@�\������Ȃ��ꍇ�͑Ή��ł��Ȃ����ǁA�]�v�ȕ����t���Ă��Ă��Ή��\������A
�ĊO945�955��Conroe���������B
>>840
SIMD���Z���j�b�g��128bit�����Ȃ�AMMX����64bit���Z�̃X���[�v�b�g��2�ɂȂ�̂ł́H
PUNPCKH** �Ɓ@PUNPCKL**�̃��C�e���V���Ⴄ�͉̂��́H
SIMD���Z���j�b�g��128bit�����Ȃ�AMMX����64bit���Z�̃X���[�v�b�g��2�ɂȂ�̂ł́H
PUNPCKH** �Ɓ@PUNPCKL**�̃��C�e���V���Ⴄ�͉̂��́H
>>850
���ӁB
�����]�X��SSE2��MMX��2�{�̃N���b�N�T�C�N����v���Ă邩��o�Ă������Ⴂ���낤�ȁB
�����Ƃ��L�͂Ȑ��́A64�r�b�g������64bit�P�ʂł�128bit�P�ʂł�1��OP�ň����Ă邾���B
���s���ɂQ�Ԃ�̃f�[�^�ɕ�������2�N���b�N�����ď������Ă�B
�����]�X��SSE2��MMX�Ƃ͕ʂ̐�p���Z���j�b�g������Ɗ��Ⴂ��������t��������������B
���ӁB
�����]�X��SSE2��MMX��2�{�̃N���b�N�T�C�N����v���Ă邩��o�Ă������Ⴂ���낤�ȁB
�����Ƃ��L�͂Ȑ��́A64�r�b�g������64bit�P�ʂł�128bit�P�ʂł�1��OP�ň����Ă邾���B
���s���ɂQ�Ԃ�̃f�[�^�ɕ�������2�N���b�N�����ď������Ă�B
�����]�X��SSE2��MMX�Ƃ͕ʂ̐�p���Z���j�b�g������Ɗ��Ⴂ��������t��������������B
�X���[�v�b�g/���C�e���V�W�́A
http://pc8.2ch.net/test/read.cgi/tech/1103609337/l50
�ł���������ǂ��Ȃ���?
�܂��A��������1��14�����肪�o�����Ă��Ă�݂����Ȋ��������B
http://pc8.2ch.net/test/read.cgi/tech/1103609337/l50
�ł���������ǂ��Ȃ���?
�܂��A��������1��14�����肪�o�����Ă��Ă�݂����Ȋ��������B
Yonah�̃V���O���X���b�h���x���ł̃p�t�H�[�}���X�̉��ǂ͂قƂ��SSE ��OPs�t���[�W����
�ɂ��Ƃ��낪�傫���Ǝv���B
SSEx���P��OP�őΉ��ł��邩��f�R�[�_�̕��S������ǂ̃f�R�[�_�ł��ʂ���悤�ɂȂ�A
���̂Ԃ�SSEx���g�������������̃X���[�v�b�g�����P�����B
�������A���Z���j�b�g�������Ă邩�ǂ����͋^���ˁB
Yonah����̓�OP���t���[�W������XMM���W�X�^�x�[�X�̉��Z��1��OP�ň�����悤�ɂȂ邩��
����SSE���ߑш悪�������悤�Ȃ��̂����A���j�b�g����|�[�g���L�̔��肪���P����ĂȂ����
�L�т͏��Ȃ��ƌ��Ă���B
Merom�ł̓��A���Ŗ��ߑш��4issue�ɑ��₵�Ă邪�A���ꂪ�ǂ��o�邩�ˁB
�ɂ��Ƃ��낪�傫���Ǝv���B
SSEx���P��OP�őΉ��ł��邩��f�R�[�_�̕��S������ǂ̃f�R�[�_�ł��ʂ���悤�ɂȂ�A
���̂Ԃ�SSEx���g�������������̃X���[�v�b�g�����P�����B
�������A���Z���j�b�g�������Ă邩�ǂ����͋^���ˁB
Yonah����̓�OP���t���[�W������XMM���W�X�^�x�[�X�̉��Z��1��OP�ň�����悤�ɂȂ邩��
����SSE���ߑш悪�������悤�Ȃ��̂����A���j�b�g����|�[�g���L�̔��肪���P����ĂȂ����
�L�т͏��Ȃ��ƌ��Ă���B
Merom�ł̓��A���Ŗ��ߑш��4issue�ɑ��₵�Ă邪�A���ꂪ�ǂ��o�邩�ˁB
���ۂ̂Ƃ���PentiumM�̌���̖��_��SSE�Ȃǂ𑽗p�����G���R�[�h�n�����Ȃ�
���ꂪ��C�ɉ��P����āA�f���A���R�A�ł���Ƀu�[�X�g���Ă��Ƃ�
���炭�̓m�[�g�p�ɂ���ɂ͂��������Ȃ��ɂȂ�̂���
����ł�780�������H����͂Ƃ�ł��Ȃ������������Ă邯��
���ꂪ��C�ɉ��P����āA�f���A���R�A�ł���Ƀu�[�X�g���Ă��Ƃ�
���炭�̓m�[�g�p�ɂ���ɂ͂��������Ȃ��ɂȂ�̂���
����ł�780�������H����͂Ƃ�ł��Ȃ������������Ă邯��
>>855
intel�̕��j�Ƃ��ẮA���v���m�[�g�A�X�����Ɉ��������X2�iTDP89W/110W�j�͉��������A
�ƌ����������Ǝv���B
intel�̕��j�Ƃ��ẮA���v���m�[�g�A�X�����Ɉ��������X2�iTDP89W/110W�j�͉��������A
�ƌ����������Ǝv���B
>>793
�� Timna
�� Timna
>>852
�����AMMX��SSE2�͐����n�ȊO�͊�{�I�ɕʂ���B
�����AMMX��SSE2�͐����n�ȊO�͊�{�I�ɕʂ���B
�simna�̓C�X���G���`�[���̍ō�����
�R�������Ė��O�������Ȃ��H
�v���X�R�b�g�݂����ɔ��M�ɂȂ�Ȃ���������B
�v���X�R�b�g�݂����ɔ��M�ɂȂ�Ȃ���������B
����Ȃ�������˂����Ŏv���Y��ŁA�S��ɂ߂Ă���������̂́A
�S���E���ł��O�B��l�������n���B
�S���E���ł��O�B��l�������n���B
>862
�A�����J���Ⴀ�S����薳����
�A�����J���Ⴀ�S����薳����
�A�����J���ᕔ���̏Ɩ���100�h�̃n���Q�������v���{�R�{�R�t���Ă���Ă͖̂{���Ȃ낤���H
�S���Ŗ��Ȃ��B
>>857
���́A�X�Onm�v���Z�X���]�T�Ŏ����o���Ă鍡�̐��̒��Ȃ�ATimna���o�����R�͑傫���Ǝv���B
�ቿ�i�т�������Ȃ��A�����i�тł��ACPU���`�b�v�Z�b�g�����ȃ����b�g�͑傫���͂��B
�̂Ɣ�ׂāA�K�v�ȃ_�C�ʐς͔����ȉ��Ȃ킯�����B
VIA��SiS���爳�͎āA���~�ɂȂ邩������Ȃ����ǂȁB
���́A�X�Onm�v���Z�X���]�T�Ŏ����o���Ă鍡�̐��̒��Ȃ�ATimna���o�����R�͑傫���Ǝv���B
�ቿ�i�т�������Ȃ��A�����i�тł��ACPU���`�b�v�Z�b�g�����ȃ����b�g�͑傫���͂��B
�̂Ɣ�ׂāA�K�v�ȃ_�C�ʐς͔����ȉ��Ȃ킯�����B
VIA��SiS���爳�͎āA���~�ɂȂ邩������Ȃ����ǂȁB
>VIA��SiS���爳�͎āA���~�ɂȂ邩������Ȃ����ǂȁB
������Ƃ���ł���?
������Ƃ���ł���?
>>862
�u�R�����[���R���������F�����M���ۂ����O�����爫�����O�v���[
���z�́A�Ⴆ��
�u�C��Sea���V�[���V���������N��������C�̌Ăѕ��ς����ق����ǂ��Ȃ��H�v
�Ɠ����x�������Ă��ƕ������Ă�H
�u�R�����[���R���������F�����M���ۂ����O�����爫�����O�v���[
���z�́A�Ⴆ��
�u�C��Sea���V�[���V���������N��������C�̌Ăѕ��ς����ق����ǂ��Ȃ��H�v
�Ɠ����x�������Ă��ƕ������Ă�H
�킴�킴���{�̌��t���l������
���O�����邱�Ƃ͂܂��Ȃ���Ȃ���
���{�݂̂��^�[�Q�b�g�ɂȂ��Ă�Ȃ�ʂ�������Ȃ�����
�ǂ����ɂ���A���`�̓}�C�i�X�Ȗ��O�������Ă��邩��W�Ȃ���W���}�C�J
���O�����邱�Ƃ͂܂��Ȃ���Ȃ���
���{�݂̂��^�[�Q�b�g�ɂȂ��Ă�Ȃ�ʂ�������Ȃ�����
�ǂ����ɂ���A���`�̓}�C�i�X�Ȗ��O�������Ă��邩��W�Ȃ���W���}�C�J
�E���R�A�`���R�����ɖ��͖���������v���낗
���B�[���e�N�m���W�Ȃ�ē��{�l�����ĂȂ���\�ł�
���{�l�ɂ͔������ɂ����������ɂ���
���{�l�ɂ͔������ɂ����������ɂ���
>>870
�������m�A�߁A�Y�E�E�E���R�A�������B
�͓��A�L�A�k�X�E�E�E�ǃR�A�B
�����A���A䕁A�^�M�A�U�M�A�A���l�A�V��A���e�A�g�E�E�E�B
AMD�ɂ͊O�ꂪ�Ȃ��B
�������m�A�߁A�Y�E�E�E���R�A�������B
�͓��A�L�A�k�X�E�E�E�ǃR�A�B
�����A���A䕁A�^�M�A�U�M�A�A���l�A�V��A���e�A�g�E�E�E�B
AMD�ɂ͊O�ꂪ�Ȃ��B
AMD�̘b�Ȃ��ĂȂ��킯����
�~�[�͎U��U��
�~�[�͎U��U��
>>873
���R�A���ǃR�A���͕ʂƂ��ăy�j�X�����邾��
���R�A���ǃR�A���͕ʂƂ��ăy�j�X�����邾��
���i���Ȃ�Ƃ������A�ꕔ�̃}�j�������C�ɂ��Ȃ������̊J���R�[�h��
�����ꌗ�ł̋����]�X�Ƃ����ӎ��ߏ�������Ƃ��낾�Ǝv�����B
�����Pentium���Ė��̂��ς��Ă��邩������Ȃ�����A�������̂ق����C���p�N�g��^������B
�����ꌗ�ł̋����]�X�Ƃ����ӎ��ߏ�������Ƃ��낾�Ǝv�����B
�����Pentium���Ė��̂��ς��Ă��邩������Ȃ�����A�������̂ق����C���p�N�g��^������B
�������ɂ��������邼>878
�S��ǂ��ł�����
�m�͊��������Ɏ��Ă���ȁB
���̎���A�N���b�N�ł������ł������邢���Ƃ���Ȃ������ǂȁB
�R�����͂ǂ��Ȃ邱�Ƃ��B
���̎���A�N���b�N�ł������ł������邢���Ƃ���Ȃ������ǂȁB
�R�����͂ǂ��Ȃ邱�Ƃ��B
882 �FSocket774�F2005/09/30(��) 01:39:31 ID:/o/Ok3v2
INTEL�̃��j�[�R�A�́A100�̃R�A�[�Ƃ������Ă��邪�A
5�N���Pentium�S�̂��Ƃ��l����ƁA�R�A��40���炢���H
�R�A�𑝂₷�����A�N���b�N�����������������B
5�N���Pentium�S�̂��Ƃ��l����ƁA�R�A��40���炢���H
�R�A�𑝂₷�����A�N���b�N�����������������B
�͂��H
�t���Z�b�g�������R�A���ڂ���K�v�Ȃ�ĂȂ�����
SIMD��p��������t�ɔڂ�������A�P���ȃR�A�̕��ʂ𑝂₵��
�X���b�h���Ő��\���҂��A�v���[�`����B
����ł��N���b�N��2�{�ɂ�����R�A�������Ƃ��t���Z�b�g�̂܂܂ł�4�{�ɂ���ق����ȒP�B
�t���Z�b�g�������R�A���ڂ���K�v�Ȃ�ĂȂ�����
SIMD��p��������t�ɔڂ�������A�P���ȃR�A�̕��ʂ𑝂₵��
�X���b�h���Ő��\���҂��A�v���[�`����B
����ł��N���b�N��2�{�ɂ�����R�A�������Ƃ��t���Z�b�g�̂܂܂ł�4�{�ɂ���ق����ȒP�B
�m���ɂ��������ASMP�̕������̊ȒP�����Ȃ��BOS�܂߂āB
�R�A���͑����邾�낤�ȁB�X���b�h�͂S�܂łȂ�N���b�N��肠�肪�����B
�R�A���͑����邾�낤�ȁB�X���b�h�͂S�܂łȂ�N���b�N��肠�肪�����B
>>883
�������������������l�b�g�o�[�X�g�������킯�Ō����ʍӂ����킯����
�������������������l�b�g�o�[�X�g�������킯�Ō����ʍӂ����킯����
SIMD��p�R�A�ł��\�t�g���C�Z���X�͕K�v���낤���B��
>>873
�A���[���Ӑ}�I��Intel���i�ɂ͔M�����Ȗ��O��P�o���Ă��邱�ƂɋC�Â���B
��́A���̎�̖��O�����̂�Ŏg���Ă���̂͐~�[����������ȁB
�܂Ƃ��ȏ������݂����͂����Ƃ����\�L�ŏ����Ă�B
�A���[���Ӑ}�I��Intel���i�ɂ͔M�����Ȗ��O��P�o���Ă��邱�ƂɋC�Â���B
��́A���̎�̖��O�����̂�Ŏg���Ă���̂͐~�[����������ȁB
�܂Ƃ��ȏ������݂����͂����Ƃ����\�L�ŏ����Ă�B
>>886
SPE�݂����ȏ����ȃ��[�J���������ő���Oracle�������邩����肾�Ȃ���
SPE�݂����ȏ����ȃ��[�J���������ő���Oracle�������邩����肾�Ȃ���
�u�A���[�v�u�A���~�v�Ƃ����D��Ŏg���Ă���̂��^���~�[����������ȁB
���j�C�R�A����������t���Z�b�g�����\�I�ɕ�̂���R�A�����낢��ς��
�X���b�h�Ǘ��`�b�v�݂����Ȃ����I�ɍœK�ȃR�A�ɃX���b�h������U��悤�ɂ���̂��˂��B
�X���b�h�Ǘ��`�b�v�݂����Ȃ����I�ɍœK�ȃR�A�ɃX���b�h������U��悤�ɂ���̂��˂��B
>>887
�����ɏオ���Ă�̂ŔM�����Ȗ��O���ĒY���������B
�����ɏオ���Ă�̂ŔM�����Ȗ��O���ĒY���������B
CPU�t�@�����~�܂�����O��肵���瑦������Athlon�R�A���ĂȂ��������H
>>894
�Y
�Y
>>891
IRQL���āE�E�E���l���ĂH
IRQL���āE�E�E���l���ĂH
PS3��CELL�Ƃ����̕ӂ݂����ȃw�e���W�j�A�X�}���`�R�A�͖����I�ɂǂ̃R�A���g�����w��ł���낤���ǁA
PC�p�͂����͂����Ȃ���œ��I�X�P�W���[��(?)�����肻�����ˁB
PC�p�͂����͂����Ȃ���œ��I�X�P�W���[��(?)�����肻�����ˁB
���̃R���g���[���܂߂�Cell�iOS�j����
������A���[�U�[�͈ӎ������Ƃ��R�A��������X�P�[���u���ɐ��\��L�����Ƃ��o����
�Ƃ����̂��E��
��360��2�X���b�h3�R�A�̂ق����͂邩�Ɏg���₷���������ǂ�
������A���[�U�[�͈ӎ������Ƃ��R�A��������X�P�[���u���ɐ��\��L�����Ƃ��o����
�Ƃ����̂��E��
��360��2�X���b�h3�R�A�̂ق����͂邩�Ɏg���₷���������ǂ�
AMD�́A���l�����K8�ȑO�͂��ׂĂ͂���݂����Ȃ������낤�Ɂc�B
��͂胁�����R���g���[�������͓`�Ƃ̕B
��ɔ������������Ƃ��B
��ɔ������������Ƃ��B
PPE�̃W���u�X�P�W���[�����O��A���U�^SPE�J�[�l���͌����_�ł͑����E���R�炵��
���炭8��(7��)��SPE�̂��������͕s�Ǎ��Ɖ���
���������J���`�[���͏璷����������ő��߂�6�ƌ������Ă����̂ɁA���̂������]�v�Ȃ��Ƃ�
���炭8��(7��)��SPE�̂��������͕s�Ǎ��Ɖ���
���������J���`�[���͏璷����������ő��߂�6�ƌ������Ă����̂ɁA���̂������]�v�Ȃ��Ƃ�
>>900
����ȋC�����邪�C���e���͈ꐶ�����Ȃ����Ȃ�B
����ȋC�����邪�C���e���͈ꐶ�����Ȃ����Ȃ�B
�ǂ݂̂�NetBurst�H���ł�AES�A�N�Z�����[�^�Ƃ��͍ڂ���\�肾������B
Java��.NET�̃A�N�Z�����[�^�͏�����ė~������
Java��.NET�̃A�N�Z�����[�^�͏�����ė~������
FB-DIMM�̐���ł́A�����Ƃ����b���B
>>904
�m���Ƀi
�m���Ƀi
Whitefield �̐���Ŕ������Ƃ͌���ς݂���Ȃ��́H 2007Q2 ������?
�����ɍs�����Ƃ��āA�f�X�N�g�b�v��m�[�g���� 2007H2 �� 2008H1 ���炢�H
�����ɍs�����Ƃ��āA�f�X�N�g�b�v��m�[�g���� 2007H2 �� 2008H1 ���炢�H
�m�[�g�𒆐S�ɍ��̃}�V���̂قƂ�ǂ͂��ł�UMA�ɂȂ��Ă邩��
�������R���g���[����CPU���ɗ���ƃf�����b�g������Ȃ肾��Ȃ�
�������R���g���[����CPU���ɗ���ƃf�����b�g������Ȃ肾��Ȃ�
������ �� GMCH �� �r�f�I
��
������ �� CPU �� �m�[�X�u���b�W �� �r�f�I
��1hop������킯������A�r�f�I�`�b�v�ɑ��郌�C�e���V��
�]���ɂȂ邾�낤�ˁB
�����A�r�f�I�`�b�v�̎d���̓X�g���[�������Ȃ킯�ŁA
���C�e���V�̉e���͌y���Ȕ�������A�o���h�������������
�m�ۂ��Ă���A���̂Ƃ��눫�e���͂قƂ�ǂȂ���Ȃ��́H
���ɂ��������A�[�L�e�N�`���ֈڍs���Ă��� Athlon 64 �̕����A
Pentium 4 �����Q�[���n�̃x���`�}�[�N�ł͂ނ��덂���Ȃ���
���������Ă��Ƃ́A���̐����𗠕t���Ă��邱�ƂɂȂ�Ǝv����
�����B
���Ԃ�A�������R���g���[�������ʼn��P����� CPU �̃��C�e���V
�̉e���̕����A�����ƌ����Ă���낤�ˁB
��
������ �� CPU �� �m�[�X�u���b�W �� �r�f�I
��1hop������킯������A�r�f�I�`�b�v�ɑ��郌�C�e���V��
�]���ɂȂ邾�낤�ˁB
�����A�r�f�I�`�b�v�̎d���̓X�g���[�������Ȃ킯�ŁA
���C�e���V�̉e���͌y���Ȕ�������A�o���h�������������
�m�ۂ��Ă���A���̂Ƃ��눫�e���͂قƂ�ǂȂ���Ȃ��́H
���ɂ��������A�[�L�e�N�`���ֈڍs���Ă��� Athlon 64 �̕����A
Pentium 4 �����Q�[���n�̃x���`�}�[�N�ł͂ނ��덂���Ȃ���
���������Ă��Ƃ́A���̐����𗠕t���Ă��邱�ƂɂȂ�Ǝv����
�����B
���Ԃ�A�������R���g���[�������ʼn��P����� CPU �̃��C�e���V
�̉e���̕����A�����ƌ����Ă���낤�ˁB
����̃f�����b�g���Ă̂͏]���ƈႤ�������K�v�ɂȂ�Ƃ���
�`�b�v�Z�b�g�v���̎�Ԃ̖��Ő��\�I���ł͂Ȃ��B
�`�b�v�Z�b�g�v���̎�Ԃ̖��Ő��\�I���ł͂Ȃ��B
>>908
����f�B�X�N���[�g��3D�O���t�B�b�N�X�̘b�ł����āAUMA�ȃV�X�e���ł͂�����Ǝ���Ⴄ���낤�B
�Ȃg���郁�����ш悪Intel�p�Ȃ�ő�800MHz/128bit(DDR2-800 DualChannel)�Ȃ̂ɑ��A
K8�ł͍ő�ł����16bit(1GHz)+����16bit(1GHz)�ł����Ȃ�����ˁB
UMA�V�X�e���ł̓������ш�͂������قǂ�������A�_��ɍ����ȃ��������̗p�ł���ق��������B
���C�e���V�͑債�Ė��ɂȂ��悤���B
����f�B�X�N���[�g��3D�O���t�B�b�N�X�̘b�ł����āAUMA�ȃV�X�e���ł͂�����Ǝ���Ⴄ���낤�B
�Ȃg���郁�����ш悪Intel�p�Ȃ�ő�800MHz/128bit(DDR2-800 DualChannel)�Ȃ̂ɑ��A
K8�ł͍ő�ł����16bit(1GHz)+����16bit(1GHz)�ł����Ȃ�����ˁB
UMA�V�X�e���ł̓������ш�͂������قǂ�������A�_��ɍ����ȃ��������̗p�ł���ق��������B
���C�e���V�͑債�Ė��ɂȂ��悤���B
���C�e���V��p�t�H�[�}���X�̖��ł͂Ȃ��āA
�Ȃɂ������Ƃ����DAC�ǂݏo���̂��߂Ƀo�X�����������邱�Ƃ��ʂ�����
����d�͓I�ɂ��������ƂȂ̂��킩���
���Ă��Ƃ�
�Ȃɂ������Ƃ����DAC�ǂݏo���̂��߂Ƀo�X�����������邱�Ƃ��ʂ�����
����d�͓I�ɂ��������ƂȂ̂��킩���
���Ă��Ƃ�
�@�k����VRAM�����ڂ�������̂ł́H
>>910
�Ȃ��낢�늨�Ⴂ������C������ȁB
�܂� K8�� HyperTransport�̕Е����̑��x�� 16bit�~1GHz=2GB/s
�ł͂Ȃ��āA16bit�~ 2(DDR) �~800MHz=3.2GB/s ���낤�H
����� Intel�ōő�800MHz/128bit(DDR2-800 DualChannel)�Ƃ������A
����AIntel ���`�b�v�Z�b�g�ŃT�|�[�g����Ă���̂� DDR2-533
�܂ł��낤? �����̘b�ł��� DDR2-800 �ƈ������ɏo���̂ɁA�����
K8 �̃������o���h���Ɣ�ׂ�͕̂ς���B
AMD �́A���N���� Socket M �Ɉڍs���āADDR2 ���T�|�[�g����B
����Ɠ����� HyperTransport �� 2.0 �Ƀo�[�W�����A�b�v���A
�N���b�N�� 800MHz ���� 1.0�`1.4GHz �Ɍ��シ��B�܂� 16bit ��
�Ƃ����̂͌Œ�ł͂Ȃ��A2bit �` 32bit �܂ł̕���I���ł��邩��A
2.0 �� 32bit ����I�ׂΕЕ��� 11.2GB/s �܂ŃT�|�[�g�ł���B
���̐���ɂȂ�ƁA�Е����݂̂̏ꍇ�� DDR2-800 DualChannel ��
�قړ����A�g���t�B�b�N���o��������ꍇ�͔{�̐��\�ƂȂ�B
�Ƃ����킯�ŁA�܂��������F�Ȃ��l�Ȃ��H
�Ȃ��낢�늨�Ⴂ������C������ȁB
�܂� K8�� HyperTransport�̕Е����̑��x�� 16bit�~1GHz=2GB/s
�ł͂Ȃ��āA16bit�~ 2(DDR) �~800MHz=3.2GB/s ���낤�H
����� Intel�ōő�800MHz/128bit(DDR2-800 DualChannel)�Ƃ������A
����AIntel ���`�b�v�Z�b�g�ŃT�|�[�g����Ă���̂� DDR2-533
�܂ł��낤? �����̘b�ł��� DDR2-800 �ƈ������ɏo���̂ɁA�����
K8 �̃������o���h���Ɣ�ׂ�͕̂ς���B
AMD �́A���N���� Socket M �Ɉڍs���āADDR2 ���T�|�[�g����B
����Ɠ����� HyperTransport �� 2.0 �Ƀo�[�W�����A�b�v���A
�N���b�N�� 800MHz ���� 1.0�`1.4GHz �Ɍ��シ��B�܂� 16bit ��
�Ƃ����̂͌Œ�ł͂Ȃ��A2bit �` 32bit �܂ł̕���I���ł��邩��A
2.0 �� 32bit ����I�ׂΕЕ��� 11.2GB/s �܂ŃT�|�[�g�ł���B
���̐���ɂȂ�ƁA�Е����݂̂̏ꍇ�� DDR2-800 DualChannel ��
�قړ����A�g���t�B�b�N���o��������ꍇ�͔{�̐��\�ƂȂ�B
�Ƃ����킯�ŁA�܂��������F�Ȃ��l�Ȃ��H
>>913
�����AHyperTransport�ɂ��Ă͊Ԉ���Ă��悤���BUp1GHz/Dl1GHz DDR��8GB/s���ȁB
�ł��������͂��܂���DDR400��Dual������6.4GB/s���ˁB�����@����3.2GB/s���B
��̘b�͂Ƃ������Ƃ��āA����Ń������R���g���[��������K8�p�`�b�v�Z�b�g�ł͍L�ш�̃�������ł��ĂȂ����Ƃ͎����ł���H
DDR2-800�����ʐ�ɂȂ��Ă��܂����A���炭�̓������ш�ɍ��킹�ē����O���t�B�b�N�X������Ȃ�Ƀ`�[�v�Ȃ��̂ɂ�����Ȃ��B
����DDR2-800�͂������������ADDR2-667�����S�ɋO���ɏ���Ă邩��ˁB
�����AHyperTransport�ɂ��Ă͊Ԉ���Ă��悤���BUp1GHz/Dl1GHz DDR��8GB/s���ȁB
�ł��������͂��܂���DDR400��Dual������6.4GB/s���ˁB�����@����3.2GB/s���B
��̘b�͂Ƃ������Ƃ��āA����Ń������R���g���[��������K8�p�`�b�v�Z�b�g�ł͍L�ш�̃�������ł��ĂȂ����Ƃ͎����ł���H
DDR2-800�����ʐ�ɂȂ��Ă��܂����A���炭�̓������ш�ɍ��킹�ē����O���t�B�b�N�X������Ȃ�Ƀ`�[�v�Ȃ��̂ɂ�����Ȃ��B
����DDR2-800�͂������������ADDR2-667�����S�ɋO���ɏ���Ă邩��ˁB
> HyperTransport�ɂ��Ă͊Ԉ���Ă��悤���BUp1GHz/Dl1GHz DDR��8GB/s���ȁB
���� 1GHz, 8GB/s ���Ēl�͂ǂ�����E���Ă����H
����AAthlon 64 �� Opteron �� CPU�ԃ����N�Ɏg���Ă��� HyperTransport
�̃o���h���́APC3200 �f���A���`���l���Ɠ����Е��� 6.4GB/s ����B
ttp://pc.watch.impress.co.jp/docs/2003/0916/kaigai023.htm
�����Ƃ� Opteron �� HyperTranport �����N�� 3�{�ς�ł���̂ŁA
���̈Ӗ��ł́A����ɂ��� 3�{�̃o���h��������킯�����B
> ��̘b�͂Ƃ������Ƃ��āA����Ń������R���g���[��������K8�p�`�b�v�Z�b
> �g�ł͍L�ш�̃�������ł��ĂȂ����Ƃ͎����ł���H
DDR2 ���T�|�[�g���Ă��Ȃ��ȏ�A�n�C�G���h�ł̃������ш�ł͌�����
����̂͊m���ɂ��̒ʂ肾�ȁB
�����AUMA �̎�p�r�̓O���t�B�b�N�����^�`�b�v�Z�b�g�Ȃ̂ŁA�����_��
����͑S�����ɂȂ��ĂȂ��Ǝv�����ǂ���H
�O���t�B�b�N���\��������Ƃł��C�ɂ���ꍇ�ɁA�`�b�v�Z�b�g������
�O���t�B�b�N�@�\���g���z�͂��炸�A�K���r�f�I�J�[�h���Ƀ������𓋍�
���邩��ȁB
�`�b�v�Z�b�g�����O���t�B�b�N�̂悤�ɁA�v�A�[�Ȑ��\�����Ȃ��ꍇ�ɂ́A
6.4GB/s �ł��ނ���]�邮�炢�Ȃ�Ȃ��̂��H
> DDR2-800�����ʐ�ɂȂ��Ă��܂����A���炭�̓������ш�ɍ��킹��
> �����O���t�B�b�N�X������Ȃ�Ƀ`�[�v�Ȃ��̂ɂ�����Ȃ��B
> ����DDR2-800�͂������������ADDR2-667�����S�ɋO���ɏ���Ă邩��ˁB
DDR2-667 �� 800 ���A�O���t�B�b�N�����`�b�v�Z�b�g�̎�^�[�Q�b�g�ł���
�����ȃ}�V���Ŏg���鎞��ɂ́ASocket M �����y���Ă��邩��S�����
�Ȃ��낤�B�o�����Ō���ƃC���e���n�̔{�̃o���h���ɂȂ邩��A�ނ���
�C���e���̕������o����Ȃ��̂��H
���� 1GHz, 8GB/s ���Ēl�͂ǂ�����E���Ă����H
����AAthlon 64 �� Opteron �� CPU�ԃ����N�Ɏg���Ă��� HyperTransport
�̃o���h���́APC3200 �f���A���`���l���Ɠ����Е��� 6.4GB/s ����B
ttp://pc.watch.impress.co.jp/docs/2003/0916/kaigai023.htm
�����Ƃ� Opteron �� HyperTranport �����N�� 3�{�ς�ł���̂ŁA
���̈Ӗ��ł́A����ɂ��� 3�{�̃o���h��������킯�����B
> ��̘b�͂Ƃ������Ƃ��āA����Ń������R���g���[��������K8�p�`�b�v�Z�b
> �g�ł͍L�ш�̃�������ł��ĂȂ����Ƃ͎����ł���H
DDR2 ���T�|�[�g���Ă��Ȃ��ȏ�A�n�C�G���h�ł̃������ш�ł͌�����
����̂͊m���ɂ��̒ʂ肾�ȁB
�����AUMA �̎�p�r�̓O���t�B�b�N�����^�`�b�v�Z�b�g�Ȃ̂ŁA�����_��
����͑S�����ɂȂ��ĂȂ��Ǝv�����ǂ���H
�O���t�B�b�N���\��������Ƃł��C�ɂ���ꍇ�ɁA�`�b�v�Z�b�g������
�O���t�B�b�N�@�\���g���z�͂��炸�A�K���r�f�I�J�[�h���Ƀ������𓋍�
���邩��ȁB
�`�b�v�Z�b�g�����O���t�B�b�N�̂悤�ɁA�v�A�[�Ȑ��\�����Ȃ��ꍇ�ɂ́A
6.4GB/s �ł��ނ���]�邮�炢�Ȃ�Ȃ��̂��H
> DDR2-800�����ʐ�ɂȂ��Ă��܂����A���炭�̓������ш�ɍ��킹��
> �����O���t�B�b�N�X������Ȃ�Ƀ`�[�v�Ȃ��̂ɂ�����Ȃ��B
> ����DDR2-800�͂������������ADDR2-667�����S�ɋO���ɏ���Ă邩��ˁB
DDR2-667 �� 800 ���A�O���t�B�b�N�����`�b�v�Z�b�g�̎�^�[�Q�b�g�ł���
�����ȃ}�V���Ŏg���鎞��ɂ́ASocket M �����y���Ă��邩��S�����
�Ȃ��낤�B�o�����Ō���ƃC���e���n�̔{�̃o���h���ɂȂ邩��A�ނ���
�C���e���̕������o����Ȃ��̂��H
�����Ƃ��ƁA���N�ɓ����Ă��� 1GHz 8GB/s �ł��o�Ă��̂��B
���炵���B
���炵���B
���N�ɓ����Ă���Ƃ����̂��ꕾ�������āAAthlon 64 �̕���
���N���炾�����ȁB������Ɩڂ𗣂��Ă�Ƃ�������x��
�ɂȂ��Ă�����ȁB
���ƁA�C�ɂȂ��Ă�����x���ׂĂ݂����A
HyperTransport �̃o���h���Ƃ��� >>915 �ɋ������㓡����
�L���͌��ŁA��͂艴���ŏ��ɏ����� >>913 �������������B
�N���b�N�� 1GHz �ɏオ���Ă��邩��A�Е��� 4GB/s �Ƃ���
���ƂɂȂ�ȁB
�Ⴆ��
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/33425.pdf
������A
One 16-bit link supporting speeds up to 1 GHz (2000 MT/s)
or 4 Gigabytes/s in each direction
�Ƃ͂����菑���Ă���B
DDR-400 �������ł��f���A���`�����l�����ƃo���h��������Ȃ�
�v�Z�ɂȂ邪�A���ɂȂ��Ă���Ęb����ɕ����Ȃ��̂́A
��͂� UMA �Ŏg����O���t�B�b�N�X�����^�`�b�v�Z�b�g��
���\���v�A�[�Ȃ�������Ȃ��̂��ȁB
���N���炾�����ȁB������Ɩڂ𗣂��Ă�Ƃ�������x��
�ɂȂ��Ă�����ȁB
���ƁA�C�ɂȂ��Ă�����x���ׂĂ݂����A
HyperTransport �̃o���h���Ƃ��� >>915 �ɋ������㓡����
�L���͌��ŁA��͂艴���ŏ��ɏ����� >>913 �������������B
�N���b�N�� 1GHz �ɏオ���Ă��邩��A�Е��� 4GB/s �Ƃ���
���ƂɂȂ�ȁB
�Ⴆ��
ttp://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/33425.pdf
������A
One 16-bit link supporting speeds up to 1 GHz (2000 MT/s)
or 4 Gigabytes/s in each direction
�Ƃ͂����菑���Ă���B
DDR-400 �������ł��f���A���`�����l�����ƃo���h��������Ȃ�
�v�Z�ɂȂ邪�A���ɂȂ��Ă���Ęb����ɕ����Ȃ��̂́A
��͂� UMA �Ŏg����O���t�B�b�N�X�����^�`�b�v�Z�b�g��
���\���v�A�[�Ȃ�������Ȃ��̂��ȁB
>>908
CPU�R�A�A�[�L�e�N�`�����S�R�ʕ�������A�����R���̎����̍��ق��p�t�H�[�}���X�����߂Ă�Ƃ���
�_���͂��������B
CPU�R�A�A�[�L�e�N�`�����S�R�ʕ�������A�����R���̎����̍��ق��p�t�H�[�}���X�����߂Ă�Ƃ���
�_���͂��������B